
lihongjie commited on
Commit ·
11cbf1b
1
Parent(s): 917bf1c
update
Browse files- .gitattributes +4 -0
- README.md +24 -24
- axera_logo.png +3 -0
- gradio_demo.py +262 -0
- main_ax650 +2 -2
- main_ax650_api +3 -0
- main_axcl_aarch64 +2 -2
- main_axcl_api_aarch64 +3 -0
- main_axcl_api_x86 +3 -0
- main_axcl_x86 +2 -2
- openai_cli.py +66 -0
- qwen3-vl-tokenizer/README.md +0 -192
- qwen3-vl-tokenizer/chat_template.json +0 -4
- qwen3-vl-tokenizer/config.json +0 -63
- qwen3-vl-tokenizer/configuration.json +0 -1
- qwen3-vl-tokenizer/generation_config.json +0 -14
- qwen3-vl-tokenizer/preprocessor_config.json +0 -21
- qwen3-vl-tokenizer/tokenizer.json +0 -0
- qwen3-vl-tokenizer/tokenizer_config.json +0 -239
- qwen3-vl-tokenizer/video_preprocessor_config.json +0 -21
- qwen3-vl-tokenizer/vocab.json +0 -0
- qwen3-vl-tokenizer/merges.txt → qwen3_tokenizer.txt +0 -0
- requirements.txt +1 -4
- run_ax_api.sh +17 -0
- run_axcl_api.sh +18 -0
- run_image_ax650.sh +1 -1
- run_image_ax650_imgu8.sh +1 -1
- run_image_axcl_aarch64.sh +1 -1
- run_image_axcl_x86.sh +1 -1
- run_video_ax650.sh +1 -1
- run_video_ax650_imgu8.sh +1 -1
- run_video_axcl_aarch64.sh +1 -1
- run_video_axcl_x86.sh +1 -1
- tokenizer_images.py +0 -244
- tokenizer_video.py +0 -244
.gitattributes
CHANGED
|
@@ -57,3 +57,7 @@ main_ax650 filter=lfs diff=lfs merge=lfs -text
|
|
| 57 |
main_axcl_aarch64 filter=lfs diff=lfs merge=lfs -text
|
| 58 |
main_axcl_x86 filter=lfs diff=lfs merge=lfs -text
|
| 59 |
Qwen3-VL-4B-Instruct-AX650-c128_p1152-int4/Qwen3-VL-4B-Instruct_vision_u8.axmodel filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 57 |
main_axcl_aarch64 filter=lfs diff=lfs merge=lfs -text
|
| 58 |
main_axcl_x86 filter=lfs diff=lfs merge=lfs -text
|
| 59 |
Qwen3-VL-4B-Instruct-AX650-c128_p1152-int4/Qwen3-VL-4B-Instruct_vision_u8.axmodel filter=lfs diff=lfs merge=lfs -text
|
| 60 |
+
main_axcl_api_aarch64 filter=lfs diff=lfs merge=lfs -text
|
| 61 |
+
main_axcl_api_x86 filter=lfs diff=lfs merge=lfs -text
|
| 62 |
+
main_ax650_api filter=lfs diff=lfs merge=lfs -text
|
| 63 |
+
axera_logo.png filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -17,7 +17,7 @@ tags:
|
|
| 17 |
- GPTQ
|
| 18 |
---
|
| 19 |
|
| 20 |
-
# Qwen3-VL-
|
| 21 |
|
| 22 |
This version of Qwen3-VL-4B-Instruct have been converted to run on the Axera NPU using **w4a16** quantization.
|
| 23 |
|
|
@@ -70,26 +70,10 @@ Download all files from this repository to the device
|
|
| 70 |
|
| 71 |
**If you using AX650 Board**
|
| 72 |
|
| 73 |
-
### Prepare tokenizer server
|
| 74 |
-
|
| 75 |
-
#### Install transformer
|
| 76 |
-
|
| 77 |
-
```
|
| 78 |
-
pip install -r requirements.txt
|
| 79 |
-
```
|
| 80 |
-
|
| 81 |
### Demo Run
|
| 82 |
|
| 83 |
#### Image understand demo
|
| 84 |
|
| 85 |
-
##### start tokenizer server for image understand demo
|
| 86 |
-
|
| 87 |
-
```
|
| 88 |
-
python3 tokenizer_images.py --port 8080
|
| 89 |
-
```
|
| 90 |
-
|
| 91 |
-
##### run image understand demo
|
| 92 |
-
|
| 93 |
- input text
|
| 94 |
|
| 95 |
```
|
|
@@ -161,13 +145,6 @@ image >> images/recoAll_attractions_1.jpg
|
|
| 161 |
|
| 162 |
#### Video understand demo
|
| 163 |
|
| 164 |
-
##### start tokenizer server for image understand demo
|
| 165 |
-
|
| 166 |
-
```
|
| 167 |
-
python tokenizer_video.py --port 8080
|
| 168 |
-
```
|
| 169 |
-
|
| 170 |
-
##### run video understand demo
|
| 171 |
- input text
|
| 172 |
|
| 173 |
```
|
|
@@ -265,3 +242,26 @@ video/frame_0056.jpg
|
|
| 265 |
|
| 266 |
prompt >> q
|
| 267 |
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 17 |
- GPTQ
|
| 18 |
---
|
| 19 |
|
| 20 |
+
# Qwen3-VL-4B-Instruct-GPTQ-Int4
|
| 21 |
|
| 22 |
This version of Qwen3-VL-4B-Instruct have been converted to run on the Axera NPU using **w4a16** quantization.
|
| 23 |
|
|
|
|
| 70 |
|
| 71 |
**If you using AX650 Board**
|
| 72 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 73 |
### Demo Run
|
| 74 |
|
| 75 |
#### Image understand demo
|
| 76 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 77 |
- input text
|
| 78 |
|
| 79 |
```
|
|
|
|
| 145 |
|
| 146 |
#### Video understand demo
|
| 147 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 148 |
- input text
|
| 149 |
|
| 150 |
```
|
|
|
|
| 242 |
|
| 243 |
prompt >> q
|
| 244 |
```
|
| 245 |
+
|
| 246 |
+
### Gradio demo
|
| 247 |
+
|
| 248 |
+
#### start openai style api server
|
| 249 |
+
if the tokenizer server is not run in the same machine,please modify the tokenizer server ip in shell file.
|
| 250 |
+
```shell
|
| 251 |
+
pip3 install -r requirements.txt
|
| 252 |
+
# for axcl x86
|
| 253 |
+
./run_axcl_x86_api.sh
|
| 254 |
+
# for axcl aarch64
|
| 255 |
+
./run_axcl_aarch64_api.sh
|
| 256 |
+
# for ax650
|
| 257 |
+
./run_ax650_api.sh
|
| 258 |
+
```
|
| 259 |
+
|
| 260 |
+
#### start gradio demo
|
| 261 |
+
if the api server is not run in the same machine,please modify the api url in gradio web ui.
|
| 262 |
+
```shell
|
| 263 |
+
python gradio_demo.py
|
| 264 |
+
```
|
| 265 |
+
|
| 266 |
+

|
| 267 |
+
|
axera_logo.png
ADDED
|
|
Git LFS Details
|
gradio_demo.py
ADDED
|
@@ -0,0 +1,262 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# gradio_chat_single_turn.py
|
| 2 |
+
import re
|
| 3 |
+
import subprocess
|
| 4 |
+
import gradio as gr
|
| 5 |
+
import base64, cv2, os, tempfile
|
| 6 |
+
from openai import OpenAI
|
| 7 |
+
import requests
|
| 8 |
+
|
| 9 |
+
def get_all_local_ips():
|
| 10 |
+
result = subprocess.run(['ip', 'a'], capture_output=True, text=True)
|
| 11 |
+
output = result.stdout
|
| 12 |
+
|
| 13 |
+
# 匹配所有IPv4
|
| 14 |
+
ips = re.findall(r'inet (\d+\.\d+\.\d+\.\d+)', output)
|
| 15 |
+
|
| 16 |
+
# 过滤掉回环地址
|
| 17 |
+
real_ips = [ip for ip in ips if not ip.startswith('127.')]
|
| 18 |
+
|
| 19 |
+
return real_ips
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
# ---------- Helpers ----------
|
| 24 |
+
def img_to_data_url_from_cvframe(frame):
|
| 25 |
+
import base64, cv2
|
| 26 |
+
ok, buf = cv2.imencode(".jpg", frame, [int(cv2.IMWRITE_JPEG_QUALITY), 85])
|
| 27 |
+
b64 = base64.b64encode(buf).decode("ascii")
|
| 28 |
+
return f"data:image/jpeg;base64,{b64}"
|
| 29 |
+
|
| 30 |
+
def img_to_data_url_from_path(img_path: str) -> str:
|
| 31 |
+
import cv2, base64
|
| 32 |
+
img = cv2.imread(img_path)
|
| 33 |
+
return img_to_data_url_from_cvframe(img)
|
| 34 |
+
|
| 35 |
+
def video_to_data_urls(video_path: str, frame_stride: int = 30, max_frames: int = 8):
|
| 36 |
+
import cv2, base64
|
| 37 |
+
cap = cv2.VideoCapture(video_path)
|
| 38 |
+
total = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
|
| 39 |
+
|
| 40 |
+
if total / frame_stride > max_frames:
|
| 41 |
+
frame_stride = int(total/max_frames)
|
| 42 |
+
|
| 43 |
+
urls = []
|
| 44 |
+
idx = 0
|
| 45 |
+
first_preview = None
|
| 46 |
+
while len(urls) < max_frames and idx < total:
|
| 47 |
+
cap.set(cv2.CAP_PROP_POS_FRAMES, idx)
|
| 48 |
+
ret, frame = cap.read()
|
| 49 |
+
if not ret:
|
| 50 |
+
break
|
| 51 |
+
ok, buf = cv2.imencode(".jpg", frame, [int(cv2.IMWRITE_JPEG_QUALITY), 85])
|
| 52 |
+
if not ok:
|
| 53 |
+
break
|
| 54 |
+
b64 = base64.b64encode(buf).decode("ascii")
|
| 55 |
+
data_url = f"data:image/jpeg;base64,{b64}"
|
| 56 |
+
urls.append(data_url)
|
| 57 |
+
if first_preview is None:
|
| 58 |
+
first_preview = data_url
|
| 59 |
+
idx += frame_stride
|
| 60 |
+
cap.release()
|
| 61 |
+
return urls, first_preview
|
| 62 |
+
|
| 63 |
+
def save_preview_image_from_data_url(data_url: str) -> str:
|
| 64 |
+
# 仅用于在 Chatbot 里显示缩略图
|
| 65 |
+
comma = data_url.find(",")
|
| 66 |
+
if comma == -1:
|
| 67 |
+
return ""
|
| 68 |
+
b64 = data_url[comma+1:]
|
| 69 |
+
raw = base64.b64decode(b64)
|
| 70 |
+
fd, tmp_path = tempfile.mkstemp(suffix=".jpg", prefix="preview_")
|
| 71 |
+
os.close(fd)
|
| 72 |
+
with open(tmp_path, "wb") as f:
|
| 73 |
+
f.write(raw)
|
| 74 |
+
return tmp_path
|
| 75 |
+
|
| 76 |
+
def build_messages(prompt: str, image_path: str | None, video_path: str | None,
|
| 77 |
+
prefer_video: bool, frame_stride: int, max_frames: int):
|
| 78 |
+
content = []
|
| 79 |
+
if prompt and prompt.strip():
|
| 80 |
+
content.append({"type": "text", "text": prompt.strip()})
|
| 81 |
+
|
| 82 |
+
if video_path and os.path.exists(video_path) and prefer_video:
|
| 83 |
+
urls, first_preview = video_to_data_urls(video_path, frame_stride=frame_stride, max_frames=max_frames)
|
| 84 |
+
content.append({"type": "image_url", "is_video":True, "image_url": urls})
|
| 85 |
+
media_desc = f"(视频抽帧:{len(urls)} 帧,步长 {frame_stride})"
|
| 86 |
+
return {"role": "user", "content": content}, first_preview, media_desc
|
| 87 |
+
|
| 88 |
+
if image_path and os.path.exists(image_path):
|
| 89 |
+
u = img_to_data_url_from_path(image_path)
|
| 90 |
+
content.append({"type": "image_url", "image_url": u})
|
| 91 |
+
media_desc = "(已附带图片)"
|
| 92 |
+
return {"role": "user", "content": content}, u, media_desc
|
| 93 |
+
|
| 94 |
+
if video_path and os.path.exists(video_path):
|
| 95 |
+
urls, first_preview = video_to_data_urls(video_path, frame_stride=frame_stride, max_frames=max_frames)
|
| 96 |
+
content.append({"type": "image_url", "is_video":True, "image_url": urls})
|
| 97 |
+
media_desc = f"(视频抽帧:{len(urls)} 帧,步长 {frame_stride})"
|
| 98 |
+
return {"role": "user", "content": content}, first_preview, media_desc
|
| 99 |
+
|
| 100 |
+
return {"role": "user", "content": content if content else [{"type": "text", "text": prompt or ""}]}, None, ""
|
| 101 |
+
|
| 102 |
+
# ---------- Gradio callback (single-turn, stream) ----------
|
| 103 |
+
def run_single_turn(prompt, image_file, video_file, prefer_video, frame_stride, max_frames,
|
| 104 |
+
base_url, model, api_key, chatbot_state):
|
| 105 |
+
"""
|
| 106 |
+
单轮:每次发送都会重置聊天历史,只显示本轮的 user/assistant 两个气泡。
|
| 107 |
+
"""
|
| 108 |
+
try:
|
| 109 |
+
# 清空历史(单轮),构造用户气泡
|
| 110 |
+
chatbot_state = []
|
| 111 |
+
|
| 112 |
+
# 准备文件路径
|
| 113 |
+
image_path = image_file if isinstance(image_file, str) else (image_file.name if image_file else None)
|
| 114 |
+
video_path = video_file if isinstance(video_file, str) else (video_file.name if video_file else None)
|
| 115 |
+
|
| 116 |
+
# 构造 messages 和预览
|
| 117 |
+
messages, preview_data_url, media_desc = build_messages(
|
| 118 |
+
prompt=prompt or "",
|
| 119 |
+
image_path=image_path,
|
| 120 |
+
video_path=video_path,
|
| 121 |
+
prefer_video=bool(prefer_video),
|
| 122 |
+
frame_stride=int(frame_stride),
|
| 123 |
+
max_frames=int(max_frames),
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
# 组装用户气泡(Markdown):文本 + 预览图/视频说明
|
| 127 |
+
user_md = (prompt or "").strip()
|
| 128 |
+
if media_desc:
|
| 129 |
+
user_md = (user_md + "\n\n" if user_md else "") + f"> {media_desc}"
|
| 130 |
+
if preview_data_url:
|
| 131 |
+
# user_md = (user_md + "\n\n" if user_md else "") + f""
|
| 132 |
+
user_md = (user_md + "\n\n" if user_md else "") + f""
|
| 133 |
+
|
| 134 |
+
chatbot_state.append((user_md or "(空提示)", "")) # assistant 先空字符串,等待流式填充
|
| 135 |
+
yield chatbot_state # 先把用户气泡渲染出来
|
| 136 |
+
|
| 137 |
+
# 调后端(流式)
|
| 138 |
+
client = OpenAI(api_key=api_key or "not-needed", base_url=base_url.strip())
|
| 139 |
+
stream = client.chat.completions.create(
|
| 140 |
+
model=model.strip(),
|
| 141 |
+
messages=messages,
|
| 142 |
+
stream=True,
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
bot_chunks = []
|
| 146 |
+
# 先补一个空 assistant 气泡
|
| 147 |
+
if len(chatbot_state) == 1:
|
| 148 |
+
chatbot_state[0] = (chatbot_state[0][0], "")
|
| 149 |
+
yield chatbot_state
|
| 150 |
+
|
| 151 |
+
# 逐 chunk 更新 assistant 气泡(Markdown)
|
| 152 |
+
for ev in stream:
|
| 153 |
+
delta = getattr(ev.choices[0], "delta", None)
|
| 154 |
+
if delta and getattr(delta, "content", None):
|
| 155 |
+
bot_chunks.append(delta.content)
|
| 156 |
+
chatbot_state[-1] = (chatbot_state[-1][0], "".join(bot_chunks))
|
| 157 |
+
yield chatbot_state
|
| 158 |
+
|
| 159 |
+
# 结束再确保收尾
|
| 160 |
+
chatbot_state[-1] = (chatbot_state[-1][0], "".join(bot_chunks) if bot_chunks else "(empty response)")
|
| 161 |
+
yield chatbot_state
|
| 162 |
+
|
| 163 |
+
except Exception as e:
|
| 164 |
+
chatbot_state.append((
|
| 165 |
+
chatbot_state[-1][0] if chatbot_state else "(request)",
|
| 166 |
+
f"**Error:** {e}"
|
| 167 |
+
))
|
| 168 |
+
yield chatbot_state
|
| 169 |
+
|
| 170 |
+
# ---------- Gradio UI ----------
|
| 171 |
+
with gr.Blocks(css="""
|
| 172 |
+
#chat,
|
| 173 |
+
#chat * {
|
| 174 |
+
font-size: 18px !important;
|
| 175 |
+
line-height: 1.6 !important;
|
| 176 |
+
}
|
| 177 |
+
|
| 178 |
+
#chat .message,
|
| 179 |
+
#chat [data-testid="bot"],
|
| 180 |
+
#chat [data-testid="user"] {
|
| 181 |
+
font-size: 18px !important;
|
| 182 |
+
}
|
| 183 |
+
""",title="AXERA Qwen3 VL") as demo:
|
| 184 |
+
axera_logo = img_to_data_url_from_path("./axera_logo.png")
|
| 185 |
+
gr.Markdown(
|
| 186 |
+
f"""
|
| 187 |
+
<div style="display: flex; align-items: center; gap: 10px;">
|
| 188 |
+
<img src="{axera_logo}" alt="axera_logo" style="height: 60px;">
|
| 189 |
+
</div>
|
| 190 |
+
"""
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
chatbot = gr.Chatbot(
|
| 194 |
+
label="对话",
|
| 195 |
+
bubble_full_width=False,
|
| 196 |
+
height=500,
|
| 197 |
+
avatar_images=(None, None), # 可替换头像
|
| 198 |
+
latex_delimiters=[{"left": "$$", "right": "$$", "display": True},
|
| 199 |
+
{"left": "$", "right": "$", "display": False}],
|
| 200 |
+
show_copy_button=True,
|
| 201 |
+
render_markdown=True,
|
| 202 |
+
elem_id="chat"
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
with gr.Row():
|
| 206 |
+
with gr.Column(scale=2):
|
| 207 |
+
prompt = gr.Textbox(label="Prompt", placeholder="输入你的提示语", lines=2)
|
| 208 |
+
with gr.Row():
|
| 209 |
+
send_btn = gr.Button("发送 ▶️", variant="primary")
|
| 210 |
+
clear_btn = gr.Button("清空")
|
| 211 |
+
stop_btn = gr.Button("停止 ■", variant="stop")
|
| 212 |
+
with gr.Row():
|
| 213 |
+
image = gr.Image(type="filepath", label="上传图片(可选)")
|
| 214 |
+
video = gr.Video(label="上传视频(可选)")
|
| 215 |
+
|
| 216 |
+
with gr.Column(scale=1):
|
| 217 |
+
base_url = gr.Textbox(value="http://localhost:8000/v1", label="Base URL")
|
| 218 |
+
model = gr.Textbox(value="AXERA-TECH/Qwen3-VL-2B-Instruct-GPTQ-Int4", label="Model")
|
| 219 |
+
api_key = gr.Textbox(value="not-needed", label="API Key", type="password")
|
| 220 |
+
with gr.Row():
|
| 221 |
+
prefer_video = gr.Checkbox(True, label="如果有视频,优先使用视频抽帧")
|
| 222 |
+
frame_stride = gr.Slider(1, 90, value=30, step=1, label="视频抽帧间隔")
|
| 223 |
+
max_frames = gr.Slider(1, 8, value=8, step=1, label="最多抽帧数")
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
# 单轮对话需要一个 state 来承载当前这轮的气泡
|
| 227 |
+
state = gr.State([])
|
| 228 |
+
|
| 229 |
+
send_btn.click(
|
| 230 |
+
fn=run_single_turn,
|
| 231 |
+
inputs=[prompt, image, video, prefer_video, frame_stride, max_frames, base_url, model, api_key, state],
|
| 232 |
+
outputs=chatbot,
|
| 233 |
+
show_progress=True,
|
| 234 |
+
queue=True,
|
| 235 |
+
)
|
| 236 |
+
|
| 237 |
+
def stop_stream(base_url):
|
| 238 |
+
url = f"{base_url.strip()}/stop"
|
| 239 |
+
response = requests.get(url)
|
| 240 |
+
if response.status_code == 200:
|
| 241 |
+
print("Stream stopped successfully")
|
| 242 |
+
else:
|
| 243 |
+
print(f"Failed to stop stream: {response.status_code} - {response.text}")
|
| 244 |
+
|
| 245 |
+
stop_btn.click(
|
| 246 |
+
fn=stop_stream,
|
| 247 |
+
inputs=[base_url],
|
| 248 |
+
outputs=chatbot,
|
| 249 |
+
show_progress=True,
|
| 250 |
+
queue=True,
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
def clear_all():
|
| 254 |
+
return [], "", None, None, True, 30, 8
|
| 255 |
+
clear_btn.click(clear_all, None, [chatbot, prompt, image, video, prefer_video, frame_stride, max_frames])
|
| 256 |
+
|
| 257 |
+
if __name__ == "__main__":
|
| 258 |
+
ips = get_all_local_ips()
|
| 259 |
+
for ip in ips:
|
| 260 |
+
print(f"* Running on local URL: http://{ip}:7860")
|
| 261 |
+
ip = "0.0.0.0"
|
| 262 |
+
demo.launch(server_name=ip, server_port=7860)
|
main_ax650
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bd12cddc400cd3ffb78af4a4512211af28c33f98993b9c7447aab8d8f29d7893
|
| 3 |
+
size 6821432
|
main_ax650_api
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:390236f0fef17d46c1bdf0b26f831335fe0e5ede1c10814c1462fdd360b1b984
|
| 3 |
+
size 6935688
|
main_axcl_aarch64
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a0ded679af8f4fb115b04977d4bc4ecc63783f98d3b239cd3a73de19a6cd19ed
|
| 3 |
+
size 1952752
|
main_axcl_api_aarch64
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c90d9dfae62b17ef4681f103c62b483e96a862e900a364673e57bc91d078c63d
|
| 3 |
+
size 2105232
|
main_axcl_api_x86
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:67be73d1a6a4c17ee6b73222d3c5988fa10d2dbcf71515f6dad090a561dcc252
|
| 3 |
+
size 2202296
|
main_axcl_x86
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1113a46767e5cc6c0a53172c5973848a40c65f379a428b3efc64a9fb6f6fb212
|
| 3 |
+
size 2062240
|
openai_cli.py
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import base64
|
| 2 |
+
import glob
|
| 3 |
+
from openai import OpenAI
|
| 4 |
+
import cv2
|
| 5 |
+
|
| 6 |
+
BASE_URL = "http://localhost:8000/v1"
|
| 7 |
+
|
| 8 |
+
def img_to_data_url(img_path: str):
|
| 9 |
+
img = cv2.imread(img_path)
|
| 10 |
+
if img is None:
|
| 11 |
+
raise FileNotFoundError(f"Cannot read image: {img_path}")
|
| 12 |
+
ok, buf = cv2.imencode(".jpg", img)
|
| 13 |
+
if not ok:
|
| 14 |
+
raise RuntimeError("cv2.imencode failed")
|
| 15 |
+
b64 = base64.b64encode(buf).decode("ascii")
|
| 16 |
+
return f"data:image/jpeg;base64,{b64}"
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def test(openai_messages):
|
| 20 |
+
client = OpenAI(api_key="not-needed", base_url=BASE_URL)
|
| 21 |
+
|
| 22 |
+
stream = client.chat.completions.create(
|
| 23 |
+
model="AXERA-TECH/Qwen3-VL-2B-Instruct-GPTQ-Int4",
|
| 24 |
+
messages=openai_messages,
|
| 25 |
+
stream=True,
|
| 26 |
+
)
|
| 27 |
+
out_chunks = []
|
| 28 |
+
for ev in stream:
|
| 29 |
+
delta = ev.choices[0].delta
|
| 30 |
+
if delta and delta.content:
|
| 31 |
+
out_chunks.append(delta.content)
|
| 32 |
+
print(delta.content, end="", flush=True)
|
| 33 |
+
print()
|
| 34 |
+
assistant_text = "".join(out_chunks).strip()
|
| 35 |
+
|
| 36 |
+
def test_image():
|
| 37 |
+
image_data = img_to_data_url("../demo_cv308/frame_0075.jpg")
|
| 38 |
+
|
| 39 |
+
openai_messages = {
|
| 40 |
+
"role": "user",
|
| 41 |
+
"content": [
|
| 42 |
+
{"type": "text", "text": "描述一下这张图片"},
|
| 43 |
+
{"type": "image_url", "image_url": image_data},
|
| 44 |
+
],
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
test(openai_messages)
|
| 49 |
+
|
| 50 |
+
def test_video():
|
| 51 |
+
image_list = glob.glob("../demo_cv308/*.jpg")
|
| 52 |
+
image_list.sort()
|
| 53 |
+
|
| 54 |
+
image_data_list = [img_to_data_url(img) for img in image_list]
|
| 55 |
+
|
| 56 |
+
openai_messages = {
|
| 57 |
+
"role": "user",
|
| 58 |
+
"content": [
|
| 59 |
+
{"type": "text", "text": "描述一下这个视频"},
|
| 60 |
+
{"type": "image_url", "is_video":True, "image_url": image_data_list},
|
| 61 |
+
],
|
| 62 |
+
}
|
| 63 |
+
|
| 64 |
+
test(openai_messages)
|
| 65 |
+
|
| 66 |
+
test_video()
|
qwen3-vl-tokenizer/README.md
DELETED
|
@@ -1,192 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
pipeline_tag: image-text-to-text
|
| 4 |
-
library_name: transformers
|
| 5 |
-
---
|
| 6 |
-
<a href="https://chat.qwenlm.ai/" target="_blank" style="margin: 2px;">
|
| 7 |
-
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
|
| 8 |
-
</a>
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
# Qwen3-VL-2B-Instruct
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
Meet Qwen3-VL — the most powerful vision-language model in the Qwen series to date.
|
| 15 |
-
|
| 16 |
-
This generation delivers comprehensive upgrades across the board: superior text understanding & generation, deeper visual perception & reasoning, extended context length, enhanced spatial and video dynamics comprehension, and stronger agent interaction capabilities.
|
| 17 |
-
|
| 18 |
-
Available in Dense and MoE architectures that scale from edge to cloud, with Instruct and reasoning‑enhanced Thinking editions for flexible, on‑demand deployment.
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
#### Key Enhancements:
|
| 22 |
-
|
| 23 |
-
* **Visual Agent**: Operates PC/mobile GUIs—recognizes elements, understands functions, invokes tools, completes tasks.
|
| 24 |
-
|
| 25 |
-
* **Visual Coding Boost**: Generates Draw.io/HTML/CSS/JS from images/videos.
|
| 26 |
-
|
| 27 |
-
* **Advanced Spatial Perception**: Judges object positions, viewpoints, and occlusions; provides stronger 2D grounding and enables 3D grounding for spatial reasoning and embodied AI.
|
| 28 |
-
|
| 29 |
-
* **Long Context & Video Understanding**: Native 256K context, expandable to 1M; handles books and hours-long video with full recall and second-level indexing.
|
| 30 |
-
|
| 31 |
-
* **Enhanced Multimodal Reasoning**: Excels in STEM/Math—causal analysis and logical, evidence-based answers.
|
| 32 |
-
|
| 33 |
-
* **Upgraded Visual Recognition**: Broader, higher-quality pretraining is able to “recognize everything”—celebrities, anime, products, landmarks, flora/fauna, etc.
|
| 34 |
-
|
| 35 |
-
* **Expanded OCR**: Supports 32 languages (up from 19); robust in low light, blur, and tilt; better with rare/ancient characters and jargon; improved long-document structure parsing.
|
| 36 |
-
|
| 37 |
-
* **Text Understanding on par with pure LLMs**: Seamless text–vision fusion for lossless, unified comprehension.
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
#### Model Architecture Updates:
|
| 41 |
-
|
| 42 |
-
<p align="center">
|
| 43 |
-
<img src="https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3-VL/qwen3vl_arc.jpg" width="80%"/>
|
| 44 |
-
<p>
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
1. **Interleaved-MRoPE**: Full‑frequency allocation over time, width, and height via robust positional embeddings, enhancing long‑horizon video reasoning.
|
| 48 |
-
|
| 49 |
-
2. **DeepStack**: Fuses multi‑level ViT features to capture fine‑grained details and sharpen image–text alignment.
|
| 50 |
-
|
| 51 |
-
3. **Text–Timestamp Alignment:** Moves beyond T‑RoPE to precise, timestamp‑grounded event localization for stronger video temporal modeling.
|
| 52 |
-
|
| 53 |
-
This is the weight repository for Qwen3-VL-2B-Instruct.
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
---
|
| 57 |
-
|
| 58 |
-
## Model Performance
|
| 59 |
-
|
| 60 |
-
**Multimodal performance**
|
| 61 |
-
|
| 62 |
-
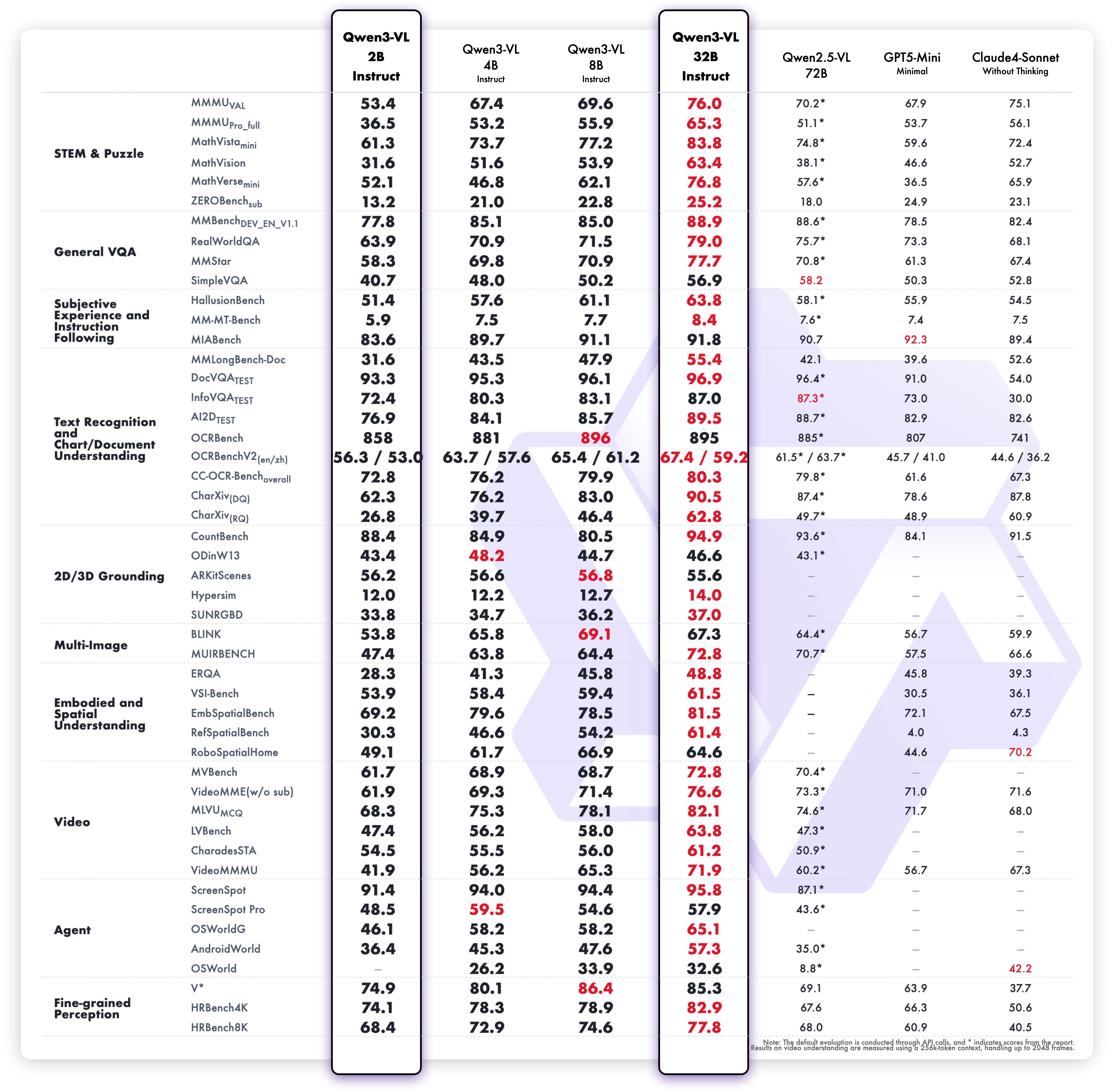
|
| 63 |
-
|
| 64 |
-
**Pure text performance**
|
| 65 |
-
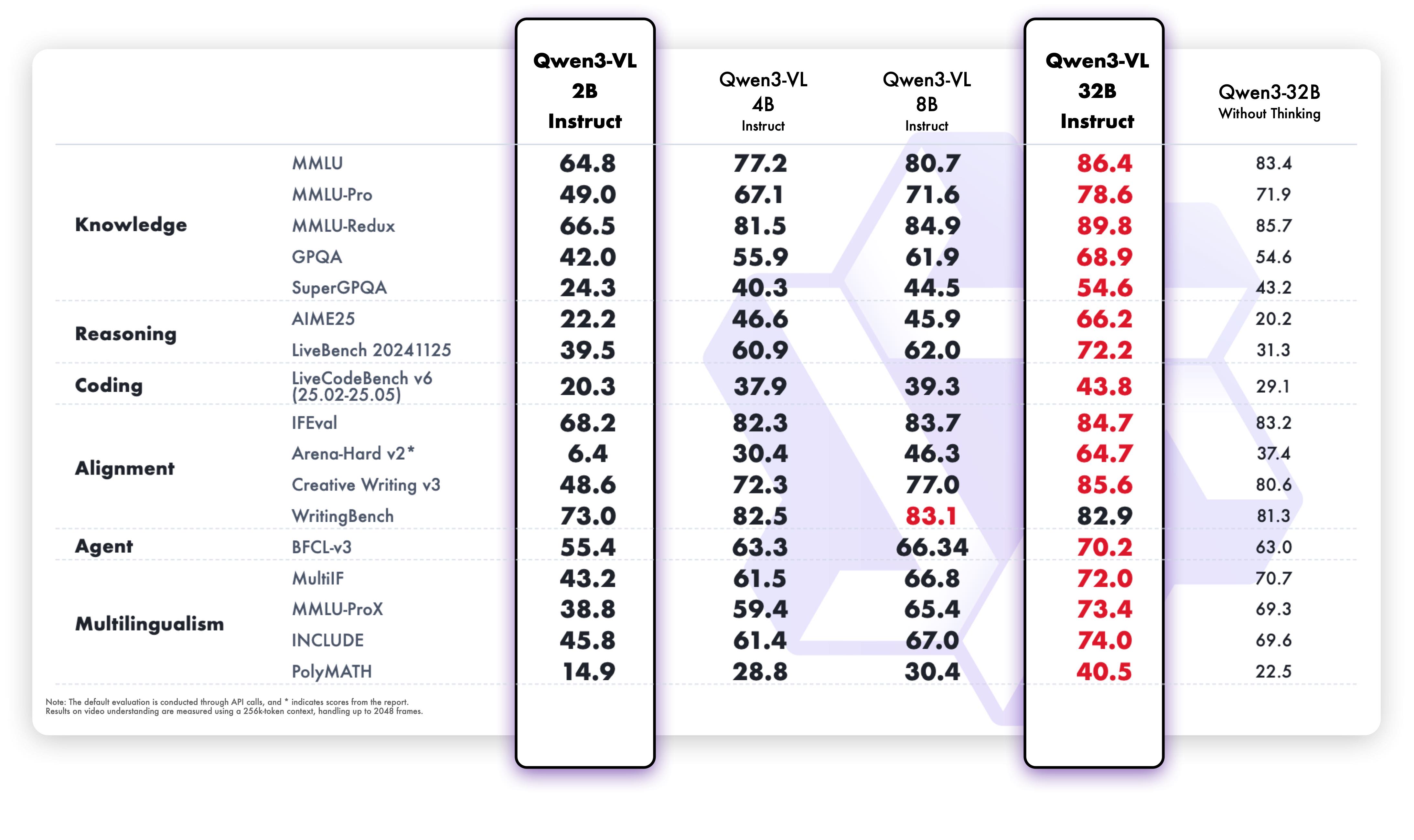
|
| 66 |
-
|
| 67 |
-
## Quickstart
|
| 68 |
-
|
| 69 |
-
Below, we provide simple examples to show how to use Qwen3-VL with 🤖 ModelScope and 🤗 Transformers.
|
| 70 |
-
|
| 71 |
-
The code of Qwen3-VL has been in the latest Hugging Face transformers and we advise you to build from source with command:
|
| 72 |
-
```
|
| 73 |
-
pip install git+https://github.com/huggingface/transformers
|
| 74 |
-
# pip install transformers==4.57.0 # currently, V4.57.0 is not released
|
| 75 |
-
```
|
| 76 |
-
|
| 77 |
-
### Using 🤗 Transformers to Chat
|
| 78 |
-
|
| 79 |
-
Here we show a code snippet to show how to use the chat model with `transformers`:
|
| 80 |
-
|
| 81 |
-
```python
|
| 82 |
-
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
|
| 83 |
-
|
| 84 |
-
# default: Load the model on the available device(s)
|
| 85 |
-
model = Qwen3VLForConditionalGeneration.from_pretrained(
|
| 86 |
-
"Qwen/Qwen3-VL-2B-Instruct", dtype="auto", device_map="auto"
|
| 87 |
-
)
|
| 88 |
-
|
| 89 |
-
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
|
| 90 |
-
# model = Qwen3VLForConditionalGeneration.from_pretrained(
|
| 91 |
-
# "Qwen/Qwen3-VL-2B-Instruct",
|
| 92 |
-
# dtype=torch.bfloat16,
|
| 93 |
-
# attn_implementation="flash_attention_2",
|
| 94 |
-
# device_map="auto",
|
| 95 |
-
# )
|
| 96 |
-
|
| 97 |
-
processor = AutoProcessor.from_pretrained("Qwen/Qwen3-VL-2B-Instruct")
|
| 98 |
-
|
| 99 |
-
messages = [
|
| 100 |
-
{
|
| 101 |
-
"role": "user",
|
| 102 |
-
"content": [
|
| 103 |
-
{
|
| 104 |
-
"type": "image",
|
| 105 |
-
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
|
| 106 |
-
},
|
| 107 |
-
{"type": "text", "text": "Describe this image."},
|
| 108 |
-
],
|
| 109 |
-
}
|
| 110 |
-
]
|
| 111 |
-
|
| 112 |
-
# Preparation for inference
|
| 113 |
-
inputs = processor.apply_chat_template(
|
| 114 |
-
messages,
|
| 115 |
-
tokenize=True,
|
| 116 |
-
add_generation_prompt=True,
|
| 117 |
-
return_dict=True,
|
| 118 |
-
return_tensors="pt"
|
| 119 |
-
)
|
| 120 |
-
inputs = inputs.to(model.device)
|
| 121 |
-
|
| 122 |
-
# Inference: Generation of the output
|
| 123 |
-
generated_ids = model.generate(**inputs, max_new_tokens=128)
|
| 124 |
-
generated_ids_trimmed = [
|
| 125 |
-
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
| 126 |
-
]
|
| 127 |
-
output_text = processor.batch_decode(
|
| 128 |
-
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 129 |
-
)
|
| 130 |
-
print(output_text)
|
| 131 |
-
```
|
| 132 |
-
|
| 133 |
-
### Generation Hyperparameters
|
| 134 |
-
#### VL
|
| 135 |
-
```bash
|
| 136 |
-
export greedy='false'
|
| 137 |
-
export top_p=0.8
|
| 138 |
-
export top_k=20
|
| 139 |
-
export temperature=0.7
|
| 140 |
-
export repetition_penalty=1.0
|
| 141 |
-
export presence_penalty=1.5
|
| 142 |
-
export out_seq_length=16384
|
| 143 |
-
```
|
| 144 |
-
|
| 145 |
-
#### Text
|
| 146 |
-
```bash
|
| 147 |
-
export greedy='false'
|
| 148 |
-
export top_p=1.0
|
| 149 |
-
export top_k=40
|
| 150 |
-
export repetition_penalty=1.0
|
| 151 |
-
export presence_penalty=2.0
|
| 152 |
-
export temperature=1.0
|
| 153 |
-
export out_seq_length=32768
|
| 154 |
-
```
|
| 155 |
-
|
| 156 |
-
|
| 157 |
-
## Citation
|
| 158 |
-
|
| 159 |
-
If you find our work helpful, feel free to give us a cite.
|
| 160 |
-
|
| 161 |
-
```
|
| 162 |
-
@misc{qwen3technicalreport,
|
| 163 |
-
title={Qwen3 Technical Report},
|
| 164 |
-
author={Qwen Team},
|
| 165 |
-
year={2025},
|
| 166 |
-
eprint={2505.09388},
|
| 167 |
-
archivePrefix={arXiv},
|
| 168 |
-
primaryClass={cs.CL},
|
| 169 |
-
url={https://arxiv.org/abs/2505.09388},
|
| 170 |
-
}
|
| 171 |
-
|
| 172 |
-
@article{Qwen2.5-VL,
|
| 173 |
-
title={Qwen2.5-VL Technical Report},
|
| 174 |
-
author={Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Zesen and Zhang, Hang and Yang, Zhibo and Xu, Haiyang and Lin, Junyang},
|
| 175 |
-
journal={arXiv preprint arXiv:2502.13923},
|
| 176 |
-
year={2025}
|
| 177 |
-
}
|
| 178 |
-
|
| 179 |
-
@article{Qwen2VL,
|
| 180 |
-
title={Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution},
|
| 181 |
-
author={Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang},
|
| 182 |
-
journal={arXiv preprint arXiv:2409.12191},
|
| 183 |
-
year={2024}
|
| 184 |
-
}
|
| 185 |
-
|
| 186 |
-
@article{Qwen-VL,
|
| 187 |
-
title={Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond},
|
| 188 |
-
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
|
| 189 |
-
journal={arXiv preprint arXiv:2308.12966},
|
| 190 |
-
year={2023}
|
| 191 |
-
}
|
| 192 |
-
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
qwen3-vl-tokenizer/chat_template.json
DELETED
|
@@ -1,4 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].role == 'system' %}\n {%- if messages[0].content is string %}\n {{- messages[0].content }}\n {%- else %}\n {%- for content in messages[0].content %}\n {%- if 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '\\n\\n' }}\n {%- endif %}\n {{- \"# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0].role == 'system' %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].content is string %}\n {{- messages[0].content }}\n {%- else %}\n {%- for content in messages[0].content %}\n {%- if 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- set image_count = namespace(value=0) %}\n{%- set video_count = namespace(value=0) %}\n{%- for message in messages %}\n {%- if message.role == \"user\" %}\n {{- '<|im_start|>' + message.role + '\\n' }}\n {%- if message.content is string %}\n {{- message.content }}\n {%- else %}\n {%- for content in message.content %}\n {%- if content.type == 'image' or 'image' in content or 'image_url' in content %}\n {%- set image_count.value = image_count.value + 1 %}\n {%- if add_vision_id %}Picture {{ image_count.value }}: {% endif -%}\n <|vision_start|><|image_pad|><|vision_end|>\n {%- elif content.type == 'video' or 'video' in content %}\n {%- set video_count.value = video_count.value + 1 %}\n {%- if add_vision_id %}Video {{ video_count.value }}: {% endif -%}\n <|vision_start|><|video_pad|><|vision_end|>\n {%- elif 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role + '\\n' }}\n {%- if message.content is string %}\n {{- message.content }}\n {%- else %}\n {%- for content_item in message.content %}\n {%- if 'text' in content_item %}\n {{- content_item.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {%- if message.tool_calls %}\n {%- for tool_call in message.tool_calls %}\n {%- if (loop.first and message.content) or (not loop.first) %}\n {{- '\\n' }}\n {%- endif %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {%- if tool_call.arguments is string %}\n {{- tool_call.arguments }}\n {%- else %}\n {{- tool_call.arguments | tojson }}\n {%- endif %}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {%- if message.content is string %}\n {{- message.content }}\n {%- else %}\n {%- for content in message.content %}\n {%- if content.type == 'image' or 'image' in content or 'image_url' in content %}\n {%- set image_count.value = image_count.value + 1 %}\n {%- if add_vision_id %}Picture {{ image_count.value }}: {% endif -%}\n <|vision_start|><|image_pad|><|vision_end|>\n {%- elif content.type == 'video' or 'video' in content %}\n {%- set video_count.value = video_count.value + 1 %}\n {%- if add_vision_id %}Video {{ video_count.value }}: {% endif -%}\n <|vision_start|><|video_pad|><|vision_end|>\n {%- elif 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n"
|
| 3 |
-
}
|
| 4 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
qwen3-vl-tokenizer/config.json
DELETED
|
@@ -1,63 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"architectures": [
|
| 3 |
-
"Qwen3VLForConditionalGeneration"
|
| 4 |
-
],
|
| 5 |
-
"image_token_id": 151655,
|
| 6 |
-
"model_type": "qwen3_vl",
|
| 7 |
-
"text_config": {
|
| 8 |
-
"attention_bias": false,
|
| 9 |
-
"attention_dropout": 0.0,
|
| 10 |
-
"bos_token_id": 151643,
|
| 11 |
-
"dtype": "bfloat16",
|
| 12 |
-
"eos_token_id": 151645,
|
| 13 |
-
"head_dim": 128,
|
| 14 |
-
"hidden_act": "silu",
|
| 15 |
-
"hidden_size": 2048,
|
| 16 |
-
"initializer_range": 0.02,
|
| 17 |
-
"intermediate_size": 6144,
|
| 18 |
-
"max_position_embeddings": 262144,
|
| 19 |
-
"model_type": "qwen3_vl_text",
|
| 20 |
-
"num_attention_heads": 16,
|
| 21 |
-
"num_hidden_layers": 28,
|
| 22 |
-
"num_key_value_heads": 8,
|
| 23 |
-
"rms_norm_eps": 1e-06,
|
| 24 |
-
"rope_scaling": {
|
| 25 |
-
"mrope_interleaved": true,
|
| 26 |
-
"mrope_section": [
|
| 27 |
-
24,
|
| 28 |
-
20,
|
| 29 |
-
20
|
| 30 |
-
],
|
| 31 |
-
"rope_type": "default"
|
| 32 |
-
},
|
| 33 |
-
"rope_theta": 5000000,
|
| 34 |
-
"tie_word_embeddings": true,
|
| 35 |
-
"use_cache": true,
|
| 36 |
-
"vocab_size": 151936
|
| 37 |
-
},
|
| 38 |
-
"tie_word_embeddings": true,
|
| 39 |
-
"transformers_version": "4.57.0.dev0",
|
| 40 |
-
"video_token_id": 151656,
|
| 41 |
-
"vision_config": {
|
| 42 |
-
"deepstack_visual_indexes": [
|
| 43 |
-
5,
|
| 44 |
-
11,
|
| 45 |
-
17
|
| 46 |
-
],
|
| 47 |
-
"depth": 24,
|
| 48 |
-
"hidden_act": "gelu_pytorch_tanh",
|
| 49 |
-
"hidden_size": 1024,
|
| 50 |
-
"in_channels": 3,
|
| 51 |
-
"initializer_range": 0.02,
|
| 52 |
-
"intermediate_size": 4096,
|
| 53 |
-
"model_type": "qwen3_vl",
|
| 54 |
-
"num_heads": 16,
|
| 55 |
-
"num_position_embeddings": 2304,
|
| 56 |
-
"out_hidden_size": 2048,
|
| 57 |
-
"patch_size": 16,
|
| 58 |
-
"spatial_merge_size": 2,
|
| 59 |
-
"temporal_patch_size": 2
|
| 60 |
-
},
|
| 61 |
-
"vision_end_token_id": 151653,
|
| 62 |
-
"vision_start_token_id": 151652
|
| 63 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
qwen3-vl-tokenizer/configuration.json
DELETED
|
@@ -1 +0,0 @@
|
|
| 1 |
-
{"framework":"Pytorch","task":"image-text-to-text"}
|
|
|
|
|
|
qwen3-vl-tokenizer/generation_config.json
DELETED
|
@@ -1,14 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"bos_token_id": 151643,
|
| 3 |
-
"pad_token_id": 151643,
|
| 4 |
-
"do_sample": true,
|
| 5 |
-
"eos_token_id": [
|
| 6 |
-
151645,
|
| 7 |
-
151643
|
| 8 |
-
],
|
| 9 |
-
"top_p": 0.8,
|
| 10 |
-
"top_k": 20,
|
| 11 |
-
"temperature": 0.7,
|
| 12 |
-
"repetition_penalty": 1.0,
|
| 13 |
-
"transformers_version": "4.56.0"
|
| 14 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
qwen3-vl-tokenizer/preprocessor_config.json
DELETED
|
@@ -1,21 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"size": {
|
| 3 |
-
"longest_edge": 16777216,
|
| 4 |
-
"shortest_edge": 65536
|
| 5 |
-
},
|
| 6 |
-
"patch_size": 16,
|
| 7 |
-
"temporal_patch_size": 2,
|
| 8 |
-
"merge_size": 2,
|
| 9 |
-
"image_mean": [
|
| 10 |
-
0.5,
|
| 11 |
-
0.5,
|
| 12 |
-
0.5
|
| 13 |
-
],
|
| 14 |
-
"image_std": [
|
| 15 |
-
0.5,
|
| 16 |
-
0.5,
|
| 17 |
-
0.5
|
| 18 |
-
],
|
| 19 |
-
"processor_class": "Qwen3VLProcessor",
|
| 20 |
-
"image_processor_type": "Qwen2VLImageProcessorFast"
|
| 21 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
qwen3-vl-tokenizer/tokenizer.json
DELETED
|
The diff for this file is too large to render.
See raw diff
|
|
|
qwen3-vl-tokenizer/tokenizer_config.json
DELETED
|
@@ -1,239 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"add_bos_token": false,
|
| 3 |
-
"add_prefix_space": false,
|
| 4 |
-
"added_tokens_decoder": {
|
| 5 |
-
"151643": {
|
| 6 |
-
"content": "<|endoftext|>",
|
| 7 |
-
"lstrip": false,
|
| 8 |
-
"normalized": false,
|
| 9 |
-
"rstrip": false,
|
| 10 |
-
"single_word": false,
|
| 11 |
-
"special": true
|
| 12 |
-
},
|
| 13 |
-
"151644": {
|
| 14 |
-
"content": "<|im_start|>",
|
| 15 |
-
"lstrip": false,
|
| 16 |
-
"normalized": false,
|
| 17 |
-
"rstrip": false,
|
| 18 |
-
"single_word": false,
|
| 19 |
-
"special": true
|
| 20 |
-
},
|
| 21 |
-
"151645": {
|
| 22 |
-
"content": "<|im_end|>",
|
| 23 |
-
"lstrip": false,
|
| 24 |
-
"normalized": false,
|
| 25 |
-
"rstrip": false,
|
| 26 |
-
"single_word": false,
|
| 27 |
-
"special": true
|
| 28 |
-
},
|
| 29 |
-
"151646": {
|
| 30 |
-
"content": "<|object_ref_start|>",
|
| 31 |
-
"lstrip": false,
|
| 32 |
-
"normalized": false,
|
| 33 |
-
"rstrip": false,
|
| 34 |
-
"single_word": false,
|
| 35 |
-
"special": true
|
| 36 |
-
},
|
| 37 |
-
"151647": {
|
| 38 |
-
"content": "<|object_ref_end|>",
|
| 39 |
-
"lstrip": false,
|
| 40 |
-
"normalized": false,
|
| 41 |
-
"rstrip": false,
|
| 42 |
-
"single_word": false,
|
| 43 |
-
"special": true
|
| 44 |
-
},
|
| 45 |
-
"151648": {
|
| 46 |
-
"content": "<|box_start|>",
|
| 47 |
-
"lstrip": false,
|
| 48 |
-
"normalized": false,
|
| 49 |
-
"rstrip": false,
|
| 50 |
-
"single_word": false,
|
| 51 |
-
"special": true
|
| 52 |
-
},
|
| 53 |
-
"151649": {
|
| 54 |
-
"content": "<|box_end|>",
|
| 55 |
-
"lstrip": false,
|
| 56 |
-
"normalized": false,
|
| 57 |
-
"rstrip": false,
|
| 58 |
-
"single_word": false,
|
| 59 |
-
"special": true
|
| 60 |
-
},
|
| 61 |
-
"151650": {
|
| 62 |
-
"content": "<|quad_start|>",
|
| 63 |
-
"lstrip": false,
|
| 64 |
-
"normalized": false,
|
| 65 |
-
"rstrip": false,
|
| 66 |
-
"single_word": false,
|
| 67 |
-
"special": true
|
| 68 |
-
},
|
| 69 |
-
"151651": {
|
| 70 |
-
"content": "<|quad_end|>",
|
| 71 |
-
"lstrip": false,
|
| 72 |
-
"normalized": false,
|
| 73 |
-
"rstrip": false,
|
| 74 |
-
"single_word": false,
|
| 75 |
-
"special": true
|
| 76 |
-
},
|
| 77 |
-
"151652": {
|
| 78 |
-
"content": "<|vision_start|>",
|
| 79 |
-
"lstrip": false,
|
| 80 |
-
"normalized": false,
|
| 81 |
-
"rstrip": false,
|
| 82 |
-
"single_word": false,
|
| 83 |
-
"special": true
|
| 84 |
-
},
|
| 85 |
-
"151653": {
|
| 86 |
-
"content": "<|vision_end|>",
|
| 87 |
-
"lstrip": false,
|
| 88 |
-
"normalized": false,
|
| 89 |
-
"rstrip": false,
|
| 90 |
-
"single_word": false,
|
| 91 |
-
"special": true
|
| 92 |
-
},
|
| 93 |
-
"151654": {
|
| 94 |
-
"content": "<|vision_pad|>",
|
| 95 |
-
"lstrip": false,
|
| 96 |
-
"normalized": false,
|
| 97 |
-
"rstrip": false,
|
| 98 |
-
"single_word": false,
|
| 99 |
-
"special": true
|
| 100 |
-
},
|
| 101 |
-
"151655": {
|
| 102 |
-
"content": "<|image_pad|>",
|
| 103 |
-
"lstrip": false,
|
| 104 |
-
"normalized": false,
|
| 105 |
-
"rstrip": false,
|
| 106 |
-
"single_word": false,
|
| 107 |
-
"special": true
|
| 108 |
-
},
|
| 109 |
-
"151656": {
|
| 110 |
-
"content": "<|video_pad|>",
|
| 111 |
-
"lstrip": false,
|
| 112 |
-
"normalized": false,
|
| 113 |
-
"rstrip": false,
|
| 114 |
-
"single_word": false,
|
| 115 |
-
"special": true
|
| 116 |
-
},
|
| 117 |
-
"151657": {
|
| 118 |
-
"content": "<tool_call>",
|
| 119 |
-
"lstrip": false,
|
| 120 |
-
"normalized": false,
|
| 121 |
-
"rstrip": false,
|
| 122 |
-
"single_word": false,
|
| 123 |
-
"special": false
|
| 124 |
-
},
|
| 125 |
-
"151658": {
|
| 126 |
-
"content": "</tool_call>",
|
| 127 |
-
"lstrip": false,
|
| 128 |
-
"normalized": false,
|
| 129 |
-
"rstrip": false,
|
| 130 |
-
"single_word": false,
|
| 131 |
-
"special": false
|
| 132 |
-
},
|
| 133 |
-
"151659": {
|
| 134 |
-
"content": "<|fim_prefix|>",
|
| 135 |
-
"lstrip": false,
|
| 136 |
-
"normalized": false,
|
| 137 |
-
"rstrip": false,
|
| 138 |
-
"single_word": false,
|
| 139 |
-
"special": false
|
| 140 |
-
},
|
| 141 |
-
"151660": {
|
| 142 |
-
"content": "<|fim_middle|>",
|
| 143 |
-
"lstrip": false,
|
| 144 |
-
"normalized": false,
|
| 145 |
-
"rstrip": false,
|
| 146 |
-
"single_word": false,
|
| 147 |
-
"special": false
|
| 148 |
-
},
|
| 149 |
-
"151661": {
|
| 150 |
-
"content": "<|fim_suffix|>",
|
| 151 |
-
"lstrip": false,
|
| 152 |
-
"normalized": false,
|
| 153 |
-
"rstrip": false,
|
| 154 |
-
"single_word": false,
|
| 155 |
-
"special": false
|
| 156 |
-
},
|
| 157 |
-
"151662": {
|
| 158 |
-
"content": "<|fim_pad|>",
|
| 159 |
-
"lstrip": false,
|
| 160 |
-
"normalized": false,
|
| 161 |
-
"rstrip": false,
|
| 162 |
-
"single_word": false,
|
| 163 |
-
"special": false
|
| 164 |
-
},
|
| 165 |
-
"151663": {
|
| 166 |
-
"content": "<|repo_name|>",
|
| 167 |
-
"lstrip": false,
|
| 168 |
-
"normalized": false,
|
| 169 |
-
"rstrip": false,
|
| 170 |
-
"single_word": false,
|
| 171 |
-
"special": false
|
| 172 |
-
},
|
| 173 |
-
"151664": {
|
| 174 |
-
"content": "<|file_sep|>",
|
| 175 |
-
"lstrip": false,
|
| 176 |
-
"normalized": false,
|
| 177 |
-
"rstrip": false,
|
| 178 |
-
"single_word": false,
|
| 179 |
-
"special": false
|
| 180 |
-
},
|
| 181 |
-
"151665": {
|
| 182 |
-
"content": "<tool_response>",
|
| 183 |
-
"lstrip": false,
|
| 184 |
-
"normalized": false,
|
| 185 |
-
"rstrip": false,
|
| 186 |
-
"single_word": false,
|
| 187 |
-
"special": false
|
| 188 |
-
},
|
| 189 |
-
"151666": {
|
| 190 |
-
"content": "</tool_response>",
|
| 191 |
-
"lstrip": false,
|
| 192 |
-
"normalized": false,
|
| 193 |
-
"rstrip": false,
|
| 194 |
-
"single_word": false,
|
| 195 |
-
"special": false
|
| 196 |
-
},
|
| 197 |
-
"151667": {
|
| 198 |
-
"content": "<think>",
|
| 199 |
-
"lstrip": false,
|
| 200 |
-
"normalized": false,
|
| 201 |
-
"rstrip": false,
|
| 202 |
-
"single_word": false,
|
| 203 |
-
"special": false
|
| 204 |
-
},
|
| 205 |
-
"151668": {
|
| 206 |
-
"content": "</think>",
|
| 207 |
-
"lstrip": false,
|
| 208 |
-
"normalized": false,
|
| 209 |
-
"rstrip": false,
|
| 210 |
-
"single_word": false,
|
| 211 |
-
"special": false
|
| 212 |
-
}
|
| 213 |
-
},
|
| 214 |
-
"additional_special_tokens": [
|
| 215 |
-
"<|im_start|>",
|
| 216 |
-
"<|im_end|>",
|
| 217 |
-
"<|object_ref_start|>",
|
| 218 |
-
"<|object_ref_end|>",
|
| 219 |
-
"<|box_start|>",
|
| 220 |
-
"<|box_end|>",
|
| 221 |
-
"<|quad_start|>",
|
| 222 |
-
"<|quad_end|>",
|
| 223 |
-
"<|vision_start|>",
|
| 224 |
-
"<|vision_end|>",
|
| 225 |
-
"<|vision_pad|>",
|
| 226 |
-
"<|image_pad|>",
|
| 227 |
-
"<|video_pad|>"
|
| 228 |
-
],
|
| 229 |
-
"bos_token": null,
|
| 230 |
-
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].role == 'system' %}\n {%- if messages[0].content is string %}\n {{- messages[0].content }}\n {%- else %}\n {%- for content in messages[0].content %}\n {%- if 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '\\n\\n' }}\n {%- endif %}\n {{- \"# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0].role == 'system' %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].content is string %}\n {{- messages[0].content }}\n {%- else %}\n {%- for content in messages[0].content %}\n {%- if 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- set image_count = namespace(value=0) %}\n{%- set video_count = namespace(value=0) %}\n{%- for message in messages %}\n {%- if message.role == \"user\" %}\n {{- '<|im_start|>' + message.role + '\\n' }}\n {%- if message.content is string %}\n {{- message.content }}\n {%- else %}\n {%- for content in message.content %}\n {%- if content.type == 'image' or 'image' in content or 'image_url' in content %}\n {%- set image_count.value = image_count.value + 1 %}\n {%- if add_vision_id %}Picture {{ image_count.value }}: {% endif -%}\n <|vision_start|><|image_pad|><|vision_end|>\n {%- elif content.type == 'video' or 'video' in content %}\n {%- set video_count.value = video_count.value + 1 %}\n {%- if add_vision_id %}Video {{ video_count.value }}: {% endif -%}\n <|vision_start|><|video_pad|><|vision_end|>\n {%- elif 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role + '\\n' }}\n {%- if message.content is string %}\n {{- message.content }}\n {%- else %}\n {%- for content_item in message.content %}\n {%- if 'text' in content_item %}\n {{- content_item.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {%- if message.tool_calls %}\n {%- for tool_call in message.tool_calls %}\n {%- if (loop.first and message.content) or (not loop.first) %}\n {{- '\\n' }}\n {%- endif %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {%- if tool_call.arguments is string %}\n {{- tool_call.arguments }}\n {%- else %}\n {{- tool_call.arguments | tojson }}\n {%- endif %}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {%- if message.content is string %}\n {{- message.content }}\n {%- else %}\n {%- for content in message.content %}\n {%- if content.type == 'image' or 'image' in content or 'image_url' in content %}\n {%- set image_count.value = image_count.value + 1 %}\n {%- if add_vision_id %}Picture {{ image_count.value }}: {% endif -%}\n <|vision_start|><|image_pad|><|vision_end|>\n {%- elif content.type == 'video' or 'video' in content %}\n {%- set video_count.value = video_count.value + 1 %}\n {%- if add_vision_id %}Video {{ video_count.value }}: {% endif -%}\n <|vision_start|><|video_pad|><|vision_end|>\n {%- elif 'text' in content %}\n {{- content.text }}\n {%- endif %}\n {%- endfor %}\n {%- endif %}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
|
| 231 |
-
"clean_up_tokenization_spaces": false,
|
| 232 |
-
"eos_token": "<|im_end|>",
|
| 233 |
-
"errors": "replace",
|
| 234 |
-
"model_max_length": 262144,
|
| 235 |
-
"pad_token": "<|endoftext|>",
|
| 236 |
-
"split_special_tokens": false,
|
| 237 |
-
"tokenizer_class": "Qwen2Tokenizer",
|
| 238 |
-
"unk_token": null
|
| 239 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
qwen3-vl-tokenizer/video_preprocessor_config.json
DELETED
|
@@ -1,21 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"size": {
|
| 3 |
-
"longest_edge": 25165824,
|
| 4 |
-
"shortest_edge": 4096
|
| 5 |
-
},
|
| 6 |
-
"patch_size": 16,
|
| 7 |
-
"temporal_patch_size": 2,
|
| 8 |
-
"merge_size": 2,
|
| 9 |
-
"image_mean": [
|
| 10 |
-
0.5,
|
| 11 |
-
0.5,
|
| 12 |
-
0.5
|
| 13 |
-
],
|
| 14 |
-
"image_std": [
|
| 15 |
-
0.5,
|
| 16 |
-
0.5,
|
| 17 |
-
0.5
|
| 18 |
-
],
|
| 19 |
-
"processor_class": "Qwen3VLProcessor",
|
| 20 |
-
"video_processor_type": "Qwen3VLVideoProcessor"
|
| 21 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
qwen3-vl-tokenizer/vocab.json
DELETED
|
The diff for this file is too large to render.
See raw diff
|
|
|
qwen3-vl-tokenizer/merges.txt → qwen3_tokenizer.txt
RENAMED
|
The diff for this file is too large to render.
See raw diff
|
|
|
requirements.txt
CHANGED
|
@@ -1,5 +1,2 @@
|
|
| 1 |
opencv-python
|
| 2 |
-
|
| 3 |
-
torchvision>=0.19.0
|
| 4 |
-
transformers>=4.57.0
|
| 5 |
-
qwen-vl-utils>=0.0.14
|
|
|
|
| 1 |
opencv-python
|
| 2 |
+
openai
|
|
|
|
|
|
|
|
|
run_ax_api.sh
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
AXMODEL_DIR=./Qwen3-VL-4B-Instruct-AX650-c128_p1152-int4/
|
| 2 |
+
|
| 3 |
+
./main_api_ax650 \
|
| 4 |
+
--template_filename_axmodel "${AXMODEL_DIR}/qwen3_vl_text_p128_l%d_together.axmodel" \
|
| 5 |
+
--axmodel_num 36 \
|
| 6 |
+
--filename_image_encoder_axmodedl "${AXMODEL_DIR}/Qwen3-VL-4B-Instruct_vision.axmodel" \
|
| 7 |
+
--use_mmap_load_embed 1 \
|
| 8 |
+
--filename_tokenizer_model "qwen3_tokenizer.txt" \
|
| 9 |
+
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 10 |
+
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
| 11 |
+
--tokens_embed_num 151936 \
|
| 12 |
+
--tokens_embed_size 2560 \
|
| 13 |
+
--patch_size 16 \
|
| 14 |
+
--img_width 384 \
|
| 15 |
+
--img_height 384 \
|
| 16 |
+
--vision_start_token_id 151652 \
|
| 17 |
+
--post_config_path post_config.json
|
run_axcl_api.sh
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
AXMODEL_DIR=./Qwen3-VL-4B-Instruct-AX650-c128_p1152-int4/
|
| 2 |
+
|
| 3 |
+
./main_axcl_api_x86 \
|
| 4 |
+
--template_filename_axmodel "${AXMODEL_DIR}/qwen3_vl_text_p128_l%d_together.axmodel" \
|
| 5 |
+
--axmodel_num 36 \
|
| 6 |
+
--filename_image_encoder_axmodedl "${AXMODEL_DIR}/Qwen3-VL-4B-Instruct_vision.axmodel" \
|
| 7 |
+
--use_mmap_load_embed 1 \
|
| 8 |
+
--filename_tokenizer_model "qwen3_tokenizer.txt" \
|
| 9 |
+
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 10 |
+
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
| 11 |
+
--tokens_embed_num 151936 \
|
| 12 |
+
--tokens_embed_size 2560 \
|
| 13 |
+
--patch_size 16 \
|
| 14 |
+
--img_width 384 \
|
| 15 |
+
--img_height 384 \
|
| 16 |
+
--vision_start_token_id 151652 \
|
| 17 |
+
--post_config_path post_config.json \
|
| 18 |
+
--devices 0,
|
run_image_ax650.sh
CHANGED
|
@@ -7,7 +7,7 @@ AXMODEL_DIR=./Qwen3-VL-4B-Instruct-AX650-c128_p1152-int4/
|
|
| 7 |
--bos 0 --eos 0 \
|
| 8 |
--dynamic_load_axmodel_layer 0 \
|
| 9 |
--use_mmap_load_embed 1 \
|
| 10 |
-
--filename_tokenizer_model "
|
| 11 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 12 |
--use_topk 0 \
|
| 13 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
|
|
|
| 7 |
--bos 0 --eos 0 \
|
| 8 |
--dynamic_load_axmodel_layer 0 \
|
| 9 |
--use_mmap_load_embed 1 \
|
| 10 |
+
--filename_tokenizer_model "qwen3_tokenizer.txt" \
|
| 11 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 12 |
--use_topk 0 \
|
| 13 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
run_image_ax650_imgu8.sh
CHANGED
|
@@ -7,7 +7,7 @@ AXMODEL_DIR=./Qwen3-VL-4B-Instruct-AX650-c128_p1152-int4/
|
|
| 7 |
--bos 0 --eos 0 \
|
| 8 |
--dynamic_load_axmodel_layer 0 \
|
| 9 |
--use_mmap_load_embed 1 \
|
| 10 |
-
--filename_tokenizer_model "
|
| 11 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 12 |
--use_topk 0 \
|
| 13 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
|
|
|
| 7 |
--bos 0 --eos 0 \
|
| 8 |
--dynamic_load_axmodel_layer 0 \
|
| 9 |
--use_mmap_load_embed 1 \
|
| 10 |
+
--filename_tokenizer_model "qwen3_tokenizer.txt" \
|
| 11 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 12 |
--use_topk 0 \
|
| 13 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
run_image_axcl_aarch64.sh
CHANGED
|
@@ -5,7 +5,7 @@ AXMODEL_DIR=./Qwen3-VL-4B-Instruct-AX650-c128_p1152-int4/
|
|
| 5 |
--axmodel_num 36 \
|
| 6 |
--filename_image_encoder_axmodedl "${AXMODEL_DIR}/Qwen3-VL-4B-Instruct_vision.axmodel" \
|
| 7 |
--use_mmap_load_embed 1 \
|
| 8 |
-
--filename_tokenizer_model "
|
| 9 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 10 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
| 11 |
--tokens_embed_num 151936 \
|
|
|
|
| 5 |
--axmodel_num 36 \
|
| 6 |
--filename_image_encoder_axmodedl "${AXMODEL_DIR}/Qwen3-VL-4B-Instruct_vision.axmodel" \
|
| 7 |
--use_mmap_load_embed 1 \
|
| 8 |
+
--filename_tokenizer_model "qwen3_tokenizer.txt" \
|
| 9 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 10 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
| 11 |
--tokens_embed_num 151936 \
|
run_image_axcl_x86.sh
CHANGED
|
@@ -5,7 +5,7 @@ AXMODEL_DIR=./Qwen3-VL-4B-Instruct-AX650-c128_p1152-int4/
|
|
| 5 |
--axmodel_num 36 \
|
| 6 |
--filename_image_encoder_axmodedl "${AXMODEL_DIR}/Qwen3-VL-4B-Instruct_vision.axmodel" \
|
| 7 |
--use_mmap_load_embed 1 \
|
| 8 |
-
--filename_tokenizer_model "
|
| 9 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 10 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
| 11 |
--tokens_embed_num 151936 \
|
|
|
|
| 5 |
--axmodel_num 36 \
|
| 6 |
--filename_image_encoder_axmodedl "${AXMODEL_DIR}/Qwen3-VL-4B-Instruct_vision.axmodel" \
|
| 7 |
--use_mmap_load_embed 1 \
|
| 8 |
+
--filename_tokenizer_model "qwen3_tokenizer.txt" \
|
| 9 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 10 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
| 11 |
--tokens_embed_num 151936 \
|
run_video_ax650.sh
CHANGED
|
@@ -7,7 +7,7 @@ AXMODEL_DIR=./Qwen3-VL-4B-Instruct-AX650-c128_p1152-int4/
|
|
| 7 |
--bos 0 --eos 0 \
|
| 8 |
--dynamic_load_axmodel_layer 0 \
|
| 9 |
--use_mmap_load_embed 1 \
|
| 10 |
-
--filename_tokenizer_model "
|
| 11 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 12 |
--use_topk 0 \
|
| 13 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
|
|
|
| 7 |
--bos 0 --eos 0 \
|
| 8 |
--dynamic_load_axmodel_layer 0 \
|
| 9 |
--use_mmap_load_embed 1 \
|
| 10 |
+
--filename_tokenizer_model "qwen3_tokenizer.txt" \
|
| 11 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 12 |
--use_topk 0 \
|
| 13 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
run_video_ax650_imgu8.sh
CHANGED
|
@@ -7,7 +7,7 @@ AXMODEL_DIR=./Qwen3-VL-4B-Instruct-AX650-c128_p1152-int4/
|
|
| 7 |
--bos 0 --eos 0 \
|
| 8 |
--dynamic_load_axmodel_layer 0 \
|
| 9 |
--use_mmap_load_embed 1 \
|
| 10 |
-
--filename_tokenizer_model "
|
| 11 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 12 |
--use_topk 0 \
|
| 13 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
|
|
|
| 7 |
--bos 0 --eos 0 \
|
| 8 |
--dynamic_load_axmodel_layer 0 \
|
| 9 |
--use_mmap_load_embed 1 \
|
| 10 |
+
--filename_tokenizer_model "qwen3_tokenizer.txt" \
|
| 11 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 12 |
--use_topk 0 \
|
| 13 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
run_video_axcl_aarch64.sh
CHANGED
|
@@ -5,7 +5,7 @@ AXMODEL_DIR=./Qwen3-VL-4B-Instruct-AX650-c128_p1152-int4/
|
|
| 5 |
--axmodel_num 36 \
|
| 6 |
--filename_image_encoder_axmodedl "${AXMODEL_DIR}/Qwen3-VL-4B-Instruct_vision.axmodel" \
|
| 7 |
--use_mmap_load_embed 1 \
|
| 8 |
-
--filename_tokenizer_model "
|
| 9 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 10 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
| 11 |
--tokens_embed_num 151936 \
|
|
|
|
| 5 |
--axmodel_num 36 \
|
| 6 |
--filename_image_encoder_axmodedl "${AXMODEL_DIR}/Qwen3-VL-4B-Instruct_vision.axmodel" \
|
| 7 |
--use_mmap_load_embed 1 \
|
| 8 |
+
--filename_tokenizer_model "qwen3_tokenizer.txt" \
|
| 9 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 10 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
| 11 |
--tokens_embed_num 151936 \
|
run_video_axcl_x86.sh
CHANGED
|
@@ -5,7 +5,7 @@ AXMODEL_DIR=./Qwen3-VL-4B-Instruct-AX650-c128_p1152-int4/
|
|
| 5 |
--axmodel_num 36 \
|
| 6 |
--filename_image_encoder_axmodedl "${AXMODEL_DIR}/Qwen3-VL-4B-Instruct_vision.axmodel" \
|
| 7 |
--use_mmap_load_embed 1 \
|
| 8 |
-
--filename_tokenizer_model "
|
| 9 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 10 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
| 11 |
--tokens_embed_num 151936 \
|
|
|
|
| 5 |
--axmodel_num 36 \
|
| 6 |
--filename_image_encoder_axmodedl "${AXMODEL_DIR}/Qwen3-VL-4B-Instruct_vision.axmodel" \
|
| 7 |
--use_mmap_load_embed 1 \
|
| 8 |
+
--filename_tokenizer_model "qwen3_tokenizer.txt" \
|
| 9 |
--filename_post_axmodel "${AXMODEL_DIR}/qwen3_vl_text_post.axmodel" \
|
| 10 |
--filename_tokens_embed "${AXMODEL_DIR}/model.embed_tokens.weight.bfloat16.bin" \
|
| 11 |
--tokens_embed_num 151936 \
|
tokenizer_images.py
DELETED
|
@@ -1,244 +0,0 @@
|
|
| 1 |
-
from transformers import AutoTokenizer, PreTrainedTokenizerFast
|
| 2 |
-
from transformers.tokenization_utils_base import AddedToken
|
| 3 |
-
from http.server import HTTPServer, BaseHTTPRequestHandler
|
| 4 |
-
import json
|
| 5 |
-
import argparse
|
| 6 |
-
|
| 7 |
-
def _prompt_split_image(
|
| 8 |
-
image_seq_len,
|
| 9 |
-
image_rows,
|
| 10 |
-
image_cols,
|
| 11 |
-
fake_token_around_image,
|
| 12 |
-
image_token,
|
| 13 |
-
global_img_token,
|
| 14 |
-
):
|
| 15 |
-
"""Prompt with expanded image tokens for when the image is split into patches."""
|
| 16 |
-
text_split_images = ""
|
| 17 |
-
for n_h in range(image_rows):
|
| 18 |
-
for n_w in range(image_cols):
|
| 19 |
-
text_split_images += (
|
| 20 |
-
f"{fake_token_around_image}"
|
| 21 |
-
+ f"<row_{n_h + 1}_col_{n_w + 1}>"
|
| 22 |
-
+ f"{image_token}" * image_seq_len
|
| 23 |
-
)
|
| 24 |
-
text_split_images += "\n"
|
| 25 |
-
|
| 26 |
-
text_split_images += (
|
| 27 |
-
f"\n{fake_token_around_image}"
|
| 28 |
-
+ f"{global_img_token}"
|
| 29 |
-
+ f"{image_token}" * image_seq_len
|
| 30 |
-
+ f"{fake_token_around_image}"
|
| 31 |
-
)
|
| 32 |
-
return text_split_images
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
def _prompt_single_image(
|
| 36 |
-
image_seq_len, fake_token_around_image, image_token, global_img_token
|
| 37 |
-
):
|
| 38 |
-
"""Prompt with expanded image tokens for a single image."""
|
| 39 |
-
return (
|
| 40 |
-
f"{fake_token_around_image}"
|
| 41 |
-
+ f"{global_img_token}"
|
| 42 |
-
+ f"{image_token}" * image_seq_len
|
| 43 |
-
+ f"{fake_token_around_image}"
|
| 44 |
-
)
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
def get_image_prompt_string(
|
| 48 |
-
image_rows,
|
| 49 |
-
image_cols,
|
| 50 |
-
image_seq_len,
|
| 51 |
-
fake_token_around_image,
|
| 52 |
-
image_token,
|
| 53 |
-
global_img_token,
|
| 54 |
-
):
|
| 55 |
-
if image_rows == 0 and image_cols == 0:
|
| 56 |
-
return _prompt_single_image(
|
| 57 |
-
image_seq_len,
|
| 58 |
-
fake_token_around_image=fake_token_around_image,
|
| 59 |
-
image_token=image_token,
|
| 60 |
-
global_img_token=global_img_token,
|
| 61 |
-
)
|
| 62 |
-
return _prompt_split_image(
|
| 63 |
-
image_seq_len,
|
| 64 |
-
image_rows,
|
| 65 |
-
image_cols,
|
| 66 |
-
fake_token_around_image,
|
| 67 |
-
image_token,
|
| 68 |
-
global_img_token,
|
| 69 |
-
)
|
| 70 |
-
|
| 71 |
-
class Tokenizer_Http():
|
| 72 |
-
|
| 73 |
-
def __init__(self):
|
| 74 |
-
|
| 75 |
-
path = 'qwen3-vl-tokenizer'
|
| 76 |
-
self.tokenizer = AutoTokenizer.from_pretrained(path,
|
| 77 |
-
trust_remote_code=True,
|
| 78 |
-
use_fast=False)
|
| 79 |
-
|
| 80 |
-
def encode(self, content):
|
| 81 |
-
text = [f'<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n{content}<|im_end|>\n<|im_start|>assistant\n']
|
| 82 |
-
input_ids = self.tokenizer(text)
|
| 83 |
-
return input_ids["input_ids"][0]
|
| 84 |
-
|
| 85 |
-
def encode_vpm(self, content="Describe this image.", num_img=1, img_token_num=256):
|
| 86 |
-
|
| 87 |
-
# official implementation
|
| 88 |
-
imgs_token = '<|vision_start|>' + '<|image_pad|>'*img_token_num + '<|vision_end|>'
|
| 89 |
-
imgs_token *= num_img
|
| 90 |
-
text = f'<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n{imgs_token}{content}<|im_end|>\n<|im_start|>assistant\n'
|
| 91 |
-
|
| 92 |
-
output_kwargs = {'text_kwargs': {'padding': True, 'return_tensors': 'pt'}, 'images_kwargs': {'return_tensors': 'pt'}, 'audio_kwargs': {'padding': True, 'return_tensors': 'pt'}, 'videos_kwargs': {'fps': 2.0, 'return_tensors': 'pt'}, 'common_kwargs': {'return_tensors': 'pt'}}
|
| 93 |
-
|
| 94 |
-
text_inputs = self.tokenizer(text, **output_kwargs["text_kwargs"])
|
| 95 |
-
return text_inputs["input_ids"].tolist()[0]
|
| 96 |
-
|
| 97 |
-
def decode(self, token_ids):
|
| 98 |
-
return self.tokenizer.decode(token_ids,
|
| 99 |
-
clean_up_tokenization_spaces=False)
|
| 100 |
-
|
| 101 |
-
@property
|
| 102 |
-
def bos_id(self):
|
| 103 |
-
return self.tokenizer.bos_token_id
|
| 104 |
-
|
| 105 |
-
@property
|
| 106 |
-
def eos_id(self):
|
| 107 |
-
return self.tokenizer.eos_token_id
|
| 108 |
-
|
| 109 |
-
@property
|
| 110 |
-
def bos_token(self):
|
| 111 |
-
return self.tokenizer.bos_token
|
| 112 |
-
|
| 113 |
-
@property
|
| 114 |
-
def eos_token(self):
|
| 115 |
-
return self.tokenizer.eos_token
|
| 116 |
-
|
| 117 |
-
@property
|
| 118 |
-
def img_start_token(self):
|
| 119 |
-
return self.tokenizer.encode("<|vision_start|>")[0]
|
| 120 |
-
|
| 121 |
-
@property
|
| 122 |
-
def img_context_token(self):
|
| 123 |
-
return self.tokenizer.encode("<|image_pad|>")[0]
|
| 124 |
-
|
| 125 |
-
tokenizer = Tokenizer_Http()
|
| 126 |
-
|
| 127 |
-
print(tokenizer.bos_id, tokenizer.bos_token, tokenizer.eos_id,
|
| 128 |
-
tokenizer.eos_token)
|
| 129 |
-
token_ids = tokenizer.encode_vpm()
|
| 130 |
-
# [151644, 8948, 198, 56568, 104625, 100633, 104455, 104800, 101101, 32022, 102022, 99602, 100013, 9370, 90286, 21287, 42140, 53772, 35243, 26288, 104949, 3837, 105205, 109641, 67916, 30698, 11, 54851, 46944, 115404, 42192, 99441, 100623, 48692, 100168, 110498, 1773, 151645, 151644, 872, 198,
|
| 131 |
-
# 151646,
|
| 132 |
-
# 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648,
|
| 133 |
-
# 151647,
|
| 134 |
-
# 198, 5501, 7512, 279, 2168, 19620, 13, 151645, 151644, 77091, 198]
|
| 135 |
-
# 118
|
| 136 |
-
print(token_ids)
|
| 137 |
-
print(len(token_ids))
|
| 138 |
-
token_ids = tokenizer.encode("hello world")
|
| 139 |
-
# [151644, 8948, 198, 56568, 104625, 100633, 104455, 104800, 101101, 32022, 102022, 99602, 100013, 9370, 90286, 21287, 42140, 53772, 35243, 26288, 104949, 3837, 105205, 109641, 67916, 30698, 11, 54851, 46944, 115404, 42192, 99441, 100623, 48692, 100168, 110498, 1773, 151645, 151644, 872, 198, 14990, 1879, 151645, 151644, 77091, 198]
|
| 140 |
-
# 47
|
| 141 |
-
print(token_ids)
|
| 142 |
-
print(len(token_ids))
|
| 143 |
-
|
| 144 |
-
|
| 145 |
-
class Request(BaseHTTPRequestHandler):
|
| 146 |
-
#通过类继承,新定义类
|
| 147 |
-
timeout = 5
|
| 148 |
-
server_version = 'Apache'
|
| 149 |
-
|
| 150 |
-
def do_GET(self):
|
| 151 |
-
print(self.path)
|
| 152 |
-
#在新类中定义get的内容(当客户端向该服务端使用get请求时,本服务端将如下运行)
|
| 153 |
-
self.send_response(200)
|
| 154 |
-
self.send_header("type", "get") #设置响应头,可省略或设置多个
|
| 155 |
-
self.end_headers()
|
| 156 |
-
|
| 157 |
-
if self.path == '/bos_id':
|
| 158 |
-
bos_id = tokenizer.bos_id
|
| 159 |
-
# print(bos_id)
|
| 160 |
-
# to json
|
| 161 |
-
if bos_id is None:
|
| 162 |
-
msg = json.dumps({'bos_id': -1})
|
| 163 |
-
else:
|
| 164 |
-
msg = json.dumps({'bos_id': bos_id})
|
| 165 |
-
elif self.path == '/eos_id':
|
| 166 |
-
eos_id = tokenizer.eos_id
|
| 167 |
-
if eos_id is None:
|
| 168 |
-
msg = json.dumps({'eos_id': -1})
|
| 169 |
-
else:
|
| 170 |
-
msg = json.dumps({'eos_id': eos_id})
|
| 171 |
-
elif self.path == '/img_start_token':
|
| 172 |
-
img_start_token = tokenizer.img_start_token
|
| 173 |
-
if img_start_token is None:
|
| 174 |
-
msg = json.dumps({'img_start_token': -1})
|
| 175 |
-
else:
|
| 176 |
-
msg = json.dumps({'img_start_token': img_start_token})
|
| 177 |
-
elif self.path == '/img_context_token':
|
| 178 |
-
img_context_token = tokenizer.img_context_token
|
| 179 |
-
if img_context_token is None:
|
| 180 |
-
msg = json.dumps({'img_context_token': -1})
|
| 181 |
-
else:
|
| 182 |
-
msg = json.dumps({'img_context_token': img_context_token})
|
| 183 |
-
else:
|
| 184 |
-
msg = 'error'
|
| 185 |
-
|
| 186 |
-
print(msg)
|
| 187 |
-
msg = str(msg).encode() #转为str再转为byte格式
|
| 188 |
-
|
| 189 |
-
self.wfile.write(msg) #将byte格式的信息返回给客户端
|
| 190 |
-
|
| 191 |
-
def do_POST(self):
|
| 192 |
-
#在新类中定义post的内容(当客户端向该服务端使用post请求时,本服务端将如下运行)
|
| 193 |
-
data = self.rfile.read(int(
|
| 194 |
-
self.headers['content-length'])) #获取从客户端传入的参数(byte格式)
|
| 195 |
-
data = data.decode() #将byte格式转为str格式
|
| 196 |
-
|
| 197 |
-
self.send_response(200)
|
| 198 |
-
self.send_header("type", "post") #设置响应头,可省略或设置多个
|
| 199 |
-
self.end_headers()
|
| 200 |
-
|
| 201 |
-
if self.path == '/encode':
|
| 202 |
-
req = json.loads(data)
|
| 203 |
-
print(req)
|
| 204 |
-
prompt = req['text']
|
| 205 |
-
b_img_prompt = False
|
| 206 |
-
if 'img_prompt' in req:
|
| 207 |
-
b_img_prompt = req['img_prompt']
|
| 208 |
-
if b_img_prompt:
|
| 209 |
-
token_ids = tokenizer.encode_vpm(prompt, req["num_img"], req["img_token_num"])
|
| 210 |
-
else:
|
| 211 |
-
token_ids = tokenizer.encode(prompt)
|
| 212 |
-
|
| 213 |
-
if token_ids is None:
|
| 214 |
-
msg = json.dumps({'token_ids': -1})
|
| 215 |
-
else:
|
| 216 |
-
msg = json.dumps({'token_ids': token_ids})
|
| 217 |
-
|
| 218 |
-
elif self.path == '/decode':
|
| 219 |
-
req = json.loads(data)
|
| 220 |
-
token_ids = req['token_ids']
|
| 221 |
-
text = tokenizer.decode(token_ids)
|
| 222 |
-
if text is None:
|
| 223 |
-
msg = json.dumps({'text': ""})
|
| 224 |
-
else:
|
| 225 |
-
msg = json.dumps({'text': text})
|
| 226 |
-
else:
|
| 227 |
-
msg = 'error'
|
| 228 |
-
print(msg)
|
| 229 |
-
msg = str(msg).encode() #转为str再转为byte格式
|
| 230 |
-
|
| 231 |
-
self.wfile.write(msg) #将byte格式的信息返回给客户端
|
| 232 |
-
|
| 233 |
-
|
| 234 |
-
if __name__ == "__main__":
|
| 235 |
-
|
| 236 |
-
args = argparse.ArgumentParser()
|
| 237 |
-
args.add_argument('--host', type=str, default='localhost')
|
| 238 |
-
args.add_argument('--port', type=int, default=8080)
|
| 239 |
-
args = args.parse_args()
|
| 240 |
-
|
| 241 |
-
host = (args.host, args.port) #设定地址与端口号,'localhost'等价于'127.0.0.1'
|
| 242 |
-
print('http://%s:%s' % host)
|
| 243 |
-
server = HTTPServer(host, Request) #根据地址端口号和新定义的类,创建服务器实例
|
| 244 |
-
server.serve_forever() #开启服务
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
tokenizer_video.py
DELETED
|
@@ -1,244 +0,0 @@
|
|
| 1 |
-
from transformers import AutoTokenizer, PreTrainedTokenizerFast
|
| 2 |
-
from transformers.tokenization_utils_base import AddedToken
|
| 3 |
-
from http.server import HTTPServer, BaseHTTPRequestHandler
|
| 4 |
-
import json
|
| 5 |
-
import argparse
|
| 6 |
-
|
| 7 |
-
def _prompt_split_image(
|
| 8 |
-
image_seq_len,
|
| 9 |
-
image_rows,
|
| 10 |
-
image_cols,
|
| 11 |
-
fake_token_around_image,
|
| 12 |
-
image_token,
|
| 13 |
-
global_img_token,
|
| 14 |
-
):
|
| 15 |
-
"""Prompt with expanded image tokens for when the image is split into patches."""
|
| 16 |
-
text_split_images = ""
|
| 17 |
-
for n_h in range(image_rows):
|
| 18 |
-
for n_w in range(image_cols):
|
| 19 |
-
text_split_images += (
|
| 20 |
-
f"{fake_token_around_image}"
|
| 21 |
-
+ f"<row_{n_h + 1}_col_{n_w + 1}>"
|
| 22 |
-
+ f"{image_token}" * image_seq_len
|
| 23 |
-
)
|
| 24 |
-
text_split_images += "\n"
|
| 25 |
-
|
| 26 |
-
text_split_images += (
|
| 27 |
-
f"\n{fake_token_around_image}"
|
| 28 |
-
+ f"{global_img_token}"
|
| 29 |
-
+ f"{image_token}" * image_seq_len
|
| 30 |
-
+ f"{fake_token_around_image}"
|
| 31 |
-
)
|
| 32 |
-
return text_split_images
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
def _prompt_single_image(
|
| 36 |
-
image_seq_len, fake_token_around_image, image_token, global_img_token
|
| 37 |
-
):
|
| 38 |
-
"""Prompt with expanded image tokens for a single image."""
|
| 39 |
-
return (
|
| 40 |
-
f"{fake_token_around_image}"
|
| 41 |
-
+ f"{global_img_token}"
|
| 42 |
-
+ f"{image_token}" * image_seq_len
|
| 43 |
-
+ f"{fake_token_around_image}"
|
| 44 |
-
)
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
def get_image_prompt_string(
|
| 48 |
-
image_rows,
|
| 49 |
-
image_cols,
|
| 50 |
-
image_seq_len,
|
| 51 |
-
fake_token_around_image,
|
| 52 |
-
image_token,
|
| 53 |
-
global_img_token,
|
| 54 |
-
):
|
| 55 |
-
if image_rows == 0 and image_cols == 0:
|
| 56 |
-
return _prompt_single_image(
|
| 57 |
-
image_seq_len,
|
| 58 |
-
fake_token_around_image=fake_token_around_image,
|
| 59 |
-
image_token=image_token,
|
| 60 |
-
global_img_token=global_img_token,
|
| 61 |
-
)
|
| 62 |
-
return _prompt_split_image(
|
| 63 |
-
image_seq_len,
|
| 64 |
-
image_rows,
|
| 65 |
-
image_cols,
|
| 66 |
-
fake_token_around_image,
|
| 67 |
-
image_token,
|
| 68 |
-
global_img_token,
|
| 69 |
-
)
|
| 70 |
-
|
| 71 |
-
class Tokenizer_Http():
|
| 72 |
-
|
| 73 |
-
def __init__(self):
|
| 74 |
-
|
| 75 |
-
path = 'qwen3-vl-tokenizer'
|
| 76 |
-
self.tokenizer = AutoTokenizer.from_pretrained(path,
|
| 77 |
-
trust_remote_code=True,
|
| 78 |
-
use_fast=False)
|
| 79 |
-
|
| 80 |
-
def encode(self, content):
|
| 81 |
-
text = [f'<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n{content}<|im_end|>\n<|im_start|>assistant\n']
|
| 82 |
-
input_ids = self.tokenizer(text)
|
| 83 |
-
return input_ids["input_ids"][0]
|
| 84 |
-
|
| 85 |
-
def encode_vpm(self, content="Describe this image.", num_img=1, img_token_num=256):
|
| 86 |
-
|
| 87 |
-
# official implementation
|
| 88 |
-
imgs_token = '<|vision_start|>' + '<|video_pad|>'*img_token_num*num_img + '<|vision_end|>'
|
| 89 |
-
|
| 90 |
-
text = f'<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n{imgs_token}{content}<|im_end|>\n<|im_start|>assistant\n'
|
| 91 |
-
|
| 92 |
-
output_kwargs = {'text_kwargs': {'padding': True, 'return_tensors': 'pt'}, 'images_kwargs': {'return_tensors': 'pt'}, 'audio_kwargs': {'padding': True, 'return_tensors': 'pt'}, 'videos_kwargs': {'fps': 2.0, 'return_tensors': 'pt'}, 'common_kwargs': {'return_tensors': 'pt'}}
|
| 93 |
-
|
| 94 |
-
text_inputs = self.tokenizer(text, **output_kwargs["text_kwargs"])
|
| 95 |
-
return text_inputs["input_ids"].tolist()[0]
|
| 96 |
-
|
| 97 |
-
def decode(self, token_ids):
|
| 98 |
-
return self.tokenizer.decode(token_ids,
|
| 99 |
-
clean_up_tokenization_spaces=False)
|
| 100 |
-
|
| 101 |
-
@property
|
| 102 |
-
def bos_id(self):
|
| 103 |
-
return self.tokenizer.bos_token_id
|
| 104 |
-
|
| 105 |
-
@property
|
| 106 |
-
def eos_id(self):
|
| 107 |
-
return self.tokenizer.eos_token_id
|
| 108 |
-
|
| 109 |
-
@property
|
| 110 |
-
def bos_token(self):
|
| 111 |
-
return self.tokenizer.bos_token
|
| 112 |
-
|
| 113 |
-
@property
|
| 114 |
-
def eos_token(self):
|
| 115 |
-
return self.tokenizer.eos_token
|
| 116 |
-
|
| 117 |
-
@property
|
| 118 |
-
def img_start_token(self):
|
| 119 |
-
return self.tokenizer.encode("<|vision_start|>")[0]
|
| 120 |
-
|
| 121 |
-
@property
|
| 122 |
-
def img_context_token(self):
|
| 123 |
-
return self.tokenizer.encode("<|video_pad|>")[0]
|
| 124 |
-
|
| 125 |
-
tokenizer = Tokenizer_Http()
|
| 126 |
-
|
| 127 |
-
print(tokenizer.bos_id, tokenizer.bos_token, tokenizer.eos_id,
|
| 128 |
-
tokenizer.eos_token)
|
| 129 |
-
token_ids = tokenizer.encode_vpm()
|
| 130 |
-
# [151644, 8948, 198, 56568, 104625, 100633, 104455, 104800, 101101, 32022, 102022, 99602, 100013, 9370, 90286, 21287, 42140, 53772, 35243, 26288, 104949, 3837, 105205, 109641, 67916, 30698, 11, 54851, 46944, 115404, 42192, 99441, 100623, 48692, 100168, 110498, 1773, 151645, 151644, 872, 198,
|
| 131 |
-
# 151646,
|
| 132 |
-
# 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648, 151648,
|
| 133 |
-
# 151647,
|
| 134 |
-
# 198, 5501, 7512, 279, 2168, 19620, 13, 151645, 151644, 77091, 198]
|
| 135 |
-
# 118
|
| 136 |
-
print(token_ids)
|
| 137 |
-
print(len(token_ids))
|
| 138 |
-
token_ids = tokenizer.encode("hello world")
|
| 139 |
-
# [151644, 8948, 198, 56568, 104625, 100633, 104455, 104800, 101101, 32022, 102022, 99602, 100013, 9370, 90286, 21287, 42140, 53772, 35243, 26288, 104949, 3837, 105205, 109641, 67916, 30698, 11, 54851, 46944, 115404, 42192, 99441, 100623, 48692, 100168, 110498, 1773, 151645, 151644, 872, 198, 14990, 1879, 151645, 151644, 77091, 198]
|
| 140 |
-
# 47
|
| 141 |
-
print(token_ids)
|
| 142 |
-
print(len(token_ids))
|
| 143 |
-
|
| 144 |
-
|
| 145 |
-
class Request(BaseHTTPRequestHandler):
|
| 146 |
-
#通过类继承,新定义类
|
| 147 |
-
timeout = 5
|
| 148 |
-
server_version = 'Apache'
|
| 149 |
-
|
| 150 |
-
def do_GET(self):
|
| 151 |
-
print(self.path)
|
| 152 |
-
#在新类中定义get的内容(当客户端向该服务端使用get请求时,本服务端将如下运行)
|
| 153 |
-
self.send_response(200)
|
| 154 |
-
self.send_header("type", "get") #设置响应头,可省略或设置多个
|
| 155 |
-
self.end_headers()
|
| 156 |
-
|
| 157 |
-
if self.path == '/bos_id':
|
| 158 |
-
bos_id = tokenizer.bos_id
|
| 159 |
-
# print(bos_id)
|
| 160 |
-
# to json
|
| 161 |
-
if bos_id is None:
|
| 162 |
-
msg = json.dumps({'bos_id': -1})
|
| 163 |
-
else:
|
| 164 |
-
msg = json.dumps({'bos_id': bos_id})
|
| 165 |
-
elif self.path == '/eos_id':
|
| 166 |
-
eos_id = tokenizer.eos_id
|
| 167 |
-
if eos_id is None:
|
| 168 |
-
msg = json.dumps({'eos_id': -1})
|
| 169 |
-
else:
|
| 170 |
-
msg = json.dumps({'eos_id': eos_id})
|
| 171 |
-
elif self.path == '/img_start_token':
|
| 172 |
-
img_start_token = tokenizer.img_start_token
|
| 173 |
-
if img_start_token is None:
|
| 174 |
-
msg = json.dumps({'img_start_token': -1})
|
| 175 |
-
else:
|
| 176 |
-
msg = json.dumps({'img_start_token': img_start_token})
|
| 177 |
-
elif self.path == '/img_context_token':
|
| 178 |
-
img_context_token = tokenizer.img_context_token
|
| 179 |
-
if img_context_token is None:
|
| 180 |
-
msg = json.dumps({'img_context_token': -1})
|
| 181 |
-
else:
|
| 182 |
-
msg = json.dumps({'img_context_token': img_context_token})
|
| 183 |
-
else:
|
| 184 |
-
msg = 'error'
|
| 185 |
-
|
| 186 |
-
print(msg)
|
| 187 |
-
msg = str(msg).encode() #转为str再转为byte格式
|
| 188 |
-
|
| 189 |
-
self.wfile.write(msg) #将byte格式的信息返回给客户端
|
| 190 |
-
|
| 191 |
-
def do_POST(self):
|
| 192 |
-
#在新类中定义post的内容(当客户端向该服务端使用post请求时,本服务端将如下运行)
|
| 193 |
-
data = self.rfile.read(int(
|
| 194 |
-
self.headers['content-length'])) #获取从客户端传入的参数(byte格式)
|
| 195 |
-
data = data.decode() #将byte格式转为str格式
|
| 196 |
-
|
| 197 |
-
self.send_response(200)
|
| 198 |
-
self.send_header("type", "post") #设置响应头,可省略或设置多个
|
| 199 |
-
self.end_headers()
|
| 200 |
-
|
| 201 |
-
if self.path == '/encode':
|
| 202 |
-
req = json.loads(data)
|
| 203 |
-
print(req)
|
| 204 |
-
prompt = req['text']
|
| 205 |
-
b_img_prompt = False
|
| 206 |
-
if 'img_prompt' in req:
|
| 207 |
-
b_img_prompt = req['img_prompt']
|
| 208 |
-
if b_img_prompt:
|
| 209 |
-
token_ids = tokenizer.encode_vpm(prompt, req["num_img"], req["img_token_num"])
|
| 210 |
-
else:
|
| 211 |
-
token_ids = tokenizer.encode(prompt)
|
| 212 |
-
|
| 213 |
-
if token_ids is None:
|
| 214 |
-
msg = json.dumps({'token_ids': -1})
|
| 215 |
-
else:
|
| 216 |
-
msg = json.dumps({'token_ids': token_ids})
|
| 217 |
-
|
| 218 |
-
elif self.path == '/decode':
|
| 219 |
-
req = json.loads(data)
|
| 220 |
-
token_ids = req['token_ids']
|
| 221 |
-
text = tokenizer.decode(token_ids)
|
| 222 |
-
if text is None:
|
| 223 |
-
msg = json.dumps({'text': ""})
|
| 224 |
-
else:
|
| 225 |
-
msg = json.dumps({'text': text})
|
| 226 |
-
else:
|
| 227 |
-
msg = 'error'
|
| 228 |
-
print(msg)
|
| 229 |
-
msg = str(msg).encode() #转为str再转为byte格式
|
| 230 |
-
|
| 231 |
-
self.wfile.write(msg) #将byte格式的信息返回给客户端
|
| 232 |
-
|
| 233 |
-
|
| 234 |
-
if __name__ == "__main__":
|
| 235 |
-
|
| 236 |
-
args = argparse.ArgumentParser()
|
| 237 |
-
args.add_argument('--host', type=str, default='localhost')
|
| 238 |
-
args.add_argument('--port', type=int, default=8080)
|
| 239 |
-
args = args.parse_args()
|
| 240 |
-
|
| 241 |
-
host = (args.host, args.port) #设定地址与端口号,'localhost'等价于'127.0.0.1'
|
| 242 |
-
print('http://%s:%s' % host)
|
| 243 |
-
server = HTTPServer(host, Request) #根据地址端口号和新定义的类,创建服务器实例
|
| 244 |
-
server.serve_forever() #开启服务
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|