
yongqiang commited on
Commit ·
ba96580
1
Parent(s): dacb0ec
initialize this repo
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- .gitattributes +3 -0
- .gitignore +171 -0
- VideoX-Fun/.gitignore +171 -0
- VideoX-Fun/Dockerfile.ds +52 -0
- VideoX-Fun/LICENSE +201 -0
- VideoX-Fun/README.md +697 -0
- VideoX-Fun/README_ja-JP.md +697 -0
- VideoX-Fun/README_zh-CN.md +687 -0
- VideoX-Fun/build_context.json +63 -0
- VideoX-Fun/comfyui/README.md +281 -0
- VideoX-Fun/comfyui/annotator/dwpose_utils/onnxdet.py +128 -0
- VideoX-Fun/comfyui/annotator/dwpose_utils/onnxpose.py +364 -0
- VideoX-Fun/comfyui/annotator/dwpose_utils/util.py +359 -0
- VideoX-Fun/comfyui/annotator/dwpose_utils/wholebody.py +129 -0
- VideoX-Fun/comfyui/annotator/nodes.py +274 -0
- VideoX-Fun/comfyui/annotator/zoe/LICENSE +21 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas.py +379 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/.gitignore +110 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/Dockerfile +29 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/LICENSE +21 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/README.md +259 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/environment.yaml +16 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/hubconf.py +435 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/input/.placeholder +0 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/beit.py +198 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/levit.py +106 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/next_vit.py +39 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/swin.py +13 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/swin2.py +34 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/swin_common.py +52 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/utils.py +249 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/vit.py +221 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/base_model.py +16 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/blocks.py +439 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/dpt_depth.py +166 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/midas_net.py +76 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/midas_net_custom.py +128 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/model_loader.py +242 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/transforms.py +234 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/LICENSE +21 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/README.md +131 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/additions/do_catkin_make.sh +5 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/additions/downloads.sh +5 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/additions/install_ros_melodic_ubuntu_17_18.sh +34 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/additions/install_ros_noetic_ubuntu_20.sh +33 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/additions/make_package_cpp.sh +16 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/launch_midas_cpp.sh +2 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/midas_cpp/CMakeLists.txt +189 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/midas_cpp/launch/midas_cpp.launch +19 -0
- VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/midas_cpp/launch/midas_talker_listener.launch +23 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.axmodel filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
*.jpg filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
output*
|
| 3 |
+
logs*
|
| 4 |
+
taming*
|
| 5 |
+
samples*
|
| 6 |
+
datasets*
|
| 7 |
+
asset*
|
| 8 |
+
_*
|
| 9 |
+
logs*
|
| 10 |
+
__pycache__/
|
| 11 |
+
*.py[cod]
|
| 12 |
+
*$py.class
|
| 13 |
+
scripts_demo*
|
| 14 |
+
compiled_*
|
| 15 |
+
onnx-*
|
| 16 |
+
|
| 17 |
+
# C extensions
|
| 18 |
+
*.so
|
| 19 |
+
|
| 20 |
+
# Distribution / packaging
|
| 21 |
+
.Python
|
| 22 |
+
build/
|
| 23 |
+
develop-eggs/
|
| 24 |
+
dist/
|
| 25 |
+
downloads/
|
| 26 |
+
eggs/
|
| 27 |
+
.eggs/
|
| 28 |
+
lib/
|
| 29 |
+
lib64/
|
| 30 |
+
parts/
|
| 31 |
+
sdist/
|
| 32 |
+
var/
|
| 33 |
+
wheels/
|
| 34 |
+
share/python-wheels/
|
| 35 |
+
*.egg-info/
|
| 36 |
+
.installed.cfg
|
| 37 |
+
*.egg
|
| 38 |
+
MANIFEST
|
| 39 |
+
|
| 40 |
+
# PyInstaller
|
| 41 |
+
# Usually these files are written by a python script from a template
|
| 42 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 43 |
+
*.manifest
|
| 44 |
+
*.spec
|
| 45 |
+
|
| 46 |
+
# Installer logs
|
| 47 |
+
pip-log.txt
|
| 48 |
+
pip-delete-this-directory.txt
|
| 49 |
+
|
| 50 |
+
# Unit test / coverage reports
|
| 51 |
+
htmlcov/
|
| 52 |
+
.tox/
|
| 53 |
+
.nox/
|
| 54 |
+
.coverage
|
| 55 |
+
.coverage.*
|
| 56 |
+
.cache
|
| 57 |
+
nosetests.xml
|
| 58 |
+
coverage.xml
|
| 59 |
+
*.cover
|
| 60 |
+
*.py,cover
|
| 61 |
+
.hypothesis/
|
| 62 |
+
.pytest_cache/
|
| 63 |
+
cover/
|
| 64 |
+
|
| 65 |
+
# Translations
|
| 66 |
+
*.mo
|
| 67 |
+
*.pot
|
| 68 |
+
|
| 69 |
+
# Django stuff:
|
| 70 |
+
*.log
|
| 71 |
+
local_settings.py
|
| 72 |
+
db.sqlite3
|
| 73 |
+
db.sqlite3-journal
|
| 74 |
+
|
| 75 |
+
# Flask stuff:
|
| 76 |
+
instance/
|
| 77 |
+
.webassets-cache
|
| 78 |
+
|
| 79 |
+
# Scrapy stuff:
|
| 80 |
+
.scrapy
|
| 81 |
+
|
| 82 |
+
# Sphinx documentation
|
| 83 |
+
docs/_build/
|
| 84 |
+
|
| 85 |
+
# PyBuilder
|
| 86 |
+
.pybuilder/
|
| 87 |
+
target/
|
| 88 |
+
|
| 89 |
+
# Jupyter Notebook
|
| 90 |
+
.ipynb_checkpoints
|
| 91 |
+
|
| 92 |
+
# IPython
|
| 93 |
+
profile_default/
|
| 94 |
+
ipython_config.py
|
| 95 |
+
|
| 96 |
+
# pyenv
|
| 97 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 98 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 99 |
+
# .python-version
|
| 100 |
+
|
| 101 |
+
# pipenv
|
| 102 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 103 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 104 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 105 |
+
# install all needed dependencies.
|
| 106 |
+
#Pipfile.lock
|
| 107 |
+
|
| 108 |
+
# poetry
|
| 109 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 110 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 111 |
+
# commonly ignored for libraries.
|
| 112 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 113 |
+
#poetry.lock
|
| 114 |
+
|
| 115 |
+
# pdm
|
| 116 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 117 |
+
#pdm.lock
|
| 118 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 119 |
+
# in version control.
|
| 120 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 121 |
+
.pdm.toml
|
| 122 |
+
|
| 123 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 124 |
+
__pypackages__/
|
| 125 |
+
|
| 126 |
+
# Celery stuff
|
| 127 |
+
celerybeat-schedule
|
| 128 |
+
celerybeat.pid
|
| 129 |
+
|
| 130 |
+
# SageMath parsed files
|
| 131 |
+
*.sage.py
|
| 132 |
+
|
| 133 |
+
# Environments
|
| 134 |
+
.env
|
| 135 |
+
.venv
|
| 136 |
+
env/
|
| 137 |
+
venv/
|
| 138 |
+
ENV/
|
| 139 |
+
env.bak/
|
| 140 |
+
venv.bak/
|
| 141 |
+
|
| 142 |
+
# Spyder project settings
|
| 143 |
+
.spyderproject
|
| 144 |
+
.spyproject
|
| 145 |
+
|
| 146 |
+
# Rope project settings
|
| 147 |
+
.ropeproject
|
| 148 |
+
|
| 149 |
+
# mkdocs documentation
|
| 150 |
+
/site
|
| 151 |
+
|
| 152 |
+
# mypy
|
| 153 |
+
.mypy_cache/
|
| 154 |
+
.dmypy.json
|
| 155 |
+
dmypy.json
|
| 156 |
+
|
| 157 |
+
# Pyre type checker
|
| 158 |
+
.pyre/
|
| 159 |
+
|
| 160 |
+
# pytype static type analyzer
|
| 161 |
+
.pytype/
|
| 162 |
+
|
| 163 |
+
# Cython debug symbols
|
| 164 |
+
cython_debug/
|
| 165 |
+
|
| 166 |
+
# PyCharm
|
| 167 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 168 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 169 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 170 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 171 |
+
#.idea/
|
VideoX-Fun/.gitignore
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
output*
|
| 3 |
+
logs*
|
| 4 |
+
taming*
|
| 5 |
+
samples*
|
| 6 |
+
datasets*
|
| 7 |
+
asset*
|
| 8 |
+
_*
|
| 9 |
+
logs*
|
| 10 |
+
__pycache__/
|
| 11 |
+
*.py[cod]
|
| 12 |
+
*$py.class
|
| 13 |
+
scripts_demo*
|
| 14 |
+
compiled_*
|
| 15 |
+
onnx-*
|
| 16 |
+
|
| 17 |
+
# C extensions
|
| 18 |
+
*.so
|
| 19 |
+
|
| 20 |
+
# Distribution / packaging
|
| 21 |
+
.Python
|
| 22 |
+
build/
|
| 23 |
+
develop-eggs/
|
| 24 |
+
dist/
|
| 25 |
+
downloads/
|
| 26 |
+
eggs/
|
| 27 |
+
.eggs/
|
| 28 |
+
lib/
|
| 29 |
+
lib64/
|
| 30 |
+
parts/
|
| 31 |
+
sdist/
|
| 32 |
+
var/
|
| 33 |
+
wheels/
|
| 34 |
+
share/python-wheels/
|
| 35 |
+
*.egg-info/
|
| 36 |
+
.installed.cfg
|
| 37 |
+
*.egg
|
| 38 |
+
MANIFEST
|
| 39 |
+
|
| 40 |
+
# PyInstaller
|
| 41 |
+
# Usually these files are written by a python script from a template
|
| 42 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 43 |
+
*.manifest
|
| 44 |
+
*.spec
|
| 45 |
+
|
| 46 |
+
# Installer logs
|
| 47 |
+
pip-log.txt
|
| 48 |
+
pip-delete-this-directory.txt
|
| 49 |
+
|
| 50 |
+
# Unit test / coverage reports
|
| 51 |
+
htmlcov/
|
| 52 |
+
.tox/
|
| 53 |
+
.nox/
|
| 54 |
+
.coverage
|
| 55 |
+
.coverage.*
|
| 56 |
+
.cache
|
| 57 |
+
nosetests.xml
|
| 58 |
+
coverage.xml
|
| 59 |
+
*.cover
|
| 60 |
+
*.py,cover
|
| 61 |
+
.hypothesis/
|
| 62 |
+
.pytest_cache/
|
| 63 |
+
cover/
|
| 64 |
+
|
| 65 |
+
# Translations
|
| 66 |
+
*.mo
|
| 67 |
+
*.pot
|
| 68 |
+
|
| 69 |
+
# Django stuff:
|
| 70 |
+
*.log
|
| 71 |
+
local_settings.py
|
| 72 |
+
db.sqlite3
|
| 73 |
+
db.sqlite3-journal
|
| 74 |
+
|
| 75 |
+
# Flask stuff:
|
| 76 |
+
instance/
|
| 77 |
+
.webassets-cache
|
| 78 |
+
|
| 79 |
+
# Scrapy stuff:
|
| 80 |
+
.scrapy
|
| 81 |
+
|
| 82 |
+
# Sphinx documentation
|
| 83 |
+
docs/_build/
|
| 84 |
+
|
| 85 |
+
# PyBuilder
|
| 86 |
+
.pybuilder/
|
| 87 |
+
target/
|
| 88 |
+
|
| 89 |
+
# Jupyter Notebook
|
| 90 |
+
.ipynb_checkpoints
|
| 91 |
+
|
| 92 |
+
# IPython
|
| 93 |
+
profile_default/
|
| 94 |
+
ipython_config.py
|
| 95 |
+
|
| 96 |
+
# pyenv
|
| 97 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 98 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 99 |
+
# .python-version
|
| 100 |
+
|
| 101 |
+
# pipenv
|
| 102 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 103 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 104 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 105 |
+
# install all needed dependencies.
|
| 106 |
+
#Pipfile.lock
|
| 107 |
+
|
| 108 |
+
# poetry
|
| 109 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 110 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 111 |
+
# commonly ignored for libraries.
|
| 112 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 113 |
+
#poetry.lock
|
| 114 |
+
|
| 115 |
+
# pdm
|
| 116 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 117 |
+
#pdm.lock
|
| 118 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 119 |
+
# in version control.
|
| 120 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 121 |
+
.pdm.toml
|
| 122 |
+
|
| 123 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 124 |
+
__pypackages__/
|
| 125 |
+
|
| 126 |
+
# Celery stuff
|
| 127 |
+
celerybeat-schedule
|
| 128 |
+
celerybeat.pid
|
| 129 |
+
|
| 130 |
+
# SageMath parsed files
|
| 131 |
+
*.sage.py
|
| 132 |
+
|
| 133 |
+
# Environments
|
| 134 |
+
.env
|
| 135 |
+
.venv
|
| 136 |
+
env/
|
| 137 |
+
venv/
|
| 138 |
+
ENV/
|
| 139 |
+
env.bak/
|
| 140 |
+
venv.bak/
|
| 141 |
+
|
| 142 |
+
# Spyder project settings
|
| 143 |
+
.spyderproject
|
| 144 |
+
.spyproject
|
| 145 |
+
|
| 146 |
+
# Rope project settings
|
| 147 |
+
.ropeproject
|
| 148 |
+
|
| 149 |
+
# mkdocs documentation
|
| 150 |
+
/site
|
| 151 |
+
|
| 152 |
+
# mypy
|
| 153 |
+
.mypy_cache/
|
| 154 |
+
.dmypy.json
|
| 155 |
+
dmypy.json
|
| 156 |
+
|
| 157 |
+
# Pyre type checker
|
| 158 |
+
.pyre/
|
| 159 |
+
|
| 160 |
+
# pytype static type analyzer
|
| 161 |
+
.pytype/
|
| 162 |
+
|
| 163 |
+
# Cython debug symbols
|
| 164 |
+
cython_debug/
|
| 165 |
+
|
| 166 |
+
# PyCharm
|
| 167 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 168 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 169 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 170 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 171 |
+
#.idea/
|
VideoX-Fun/Dockerfile.ds
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
|
| 2 |
+
ENV DEBIAN_FRONTEND noninteractive
|
| 3 |
+
|
| 4 |
+
RUN rm -r /etc/apt/sources.list.d/
|
| 5 |
+
|
| 6 |
+
RUN apt-get update -y && apt-get install -y \
|
| 7 |
+
libgl1 libglib2.0-0 google-perftools \
|
| 8 |
+
sudo wget git git-lfs vim tig pkg-config libcairo2-dev \
|
| 9 |
+
aria2 telnet curl net-tools iputils-ping jq \
|
| 10 |
+
python3-pip python-is-python3 python3.10-venv tzdata lsof zip tmux
|
| 11 |
+
RUN apt-get update && \
|
| 12 |
+
apt-get install -y software-properties-common && \
|
| 13 |
+
add-apt-repository ppa:ubuntuhandbook1/ffmpeg6 && \
|
| 14 |
+
apt-get update && \
|
| 15 |
+
apt-get install -y ffmpeg
|
| 16 |
+
|
| 17 |
+
RUN pip3 install --upgrade pip -i https://mirrors.aliyun.com/pypi/simple/
|
| 18 |
+
|
| 19 |
+
# add all extensions
|
| 20 |
+
RUN pip install wandb tqdm GitPython==3.1.32 Pillow==9.5.0 setuptools --upgrade -i https://mirrors.aliyun.com/pypi/simple/
|
| 21 |
+
|
| 22 |
+
RUN pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu118
|
| 23 |
+
RUN pip install xformers==0.0.27.post2 --index-url https://download.pytorch.org/whl/cu118
|
| 24 |
+
|
| 25 |
+
# install vllm (video-caption)
|
| 26 |
+
RUN pip install vllm==0.6.3
|
| 27 |
+
|
| 28 |
+
# install requirements (video-caption)
|
| 29 |
+
WORKDIR /root/
|
| 30 |
+
COPY easyanimate/video_caption/requirements.txt /root/requirements-video_caption.txt
|
| 31 |
+
RUN pip install -r /root/requirements-video_caption.txt
|
| 32 |
+
RUN rm /root/requirements-video_caption.txt
|
| 33 |
+
|
| 34 |
+
RUN pip install -U http://eas-data.oss-cn-shanghai.aliyuncs.com/sdk/allspark-0.15-py2.py3-none-any.whl
|
| 35 |
+
RUN pip install -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers
|
| 36 |
+
RUN pip install came-pytorch deepspeed pytorch_lightning==1.9.4 func_timeout -i https://mirrors.aliyun.com/pypi/simple/
|
| 37 |
+
|
| 38 |
+
# install requirements
|
| 39 |
+
RUN pip install bitsandbytes mamba-ssm causal-conv1d>=1.4.0 -i https://mirrors.aliyun.com/pypi/simple/
|
| 40 |
+
RUN pip install ipykernel -i https://mirrors.aliyun.com/pypi/simple/
|
| 41 |
+
COPY ./requirements.txt /root/requirements.txt
|
| 42 |
+
RUN pip install -r /root/requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
|
| 43 |
+
RUN rm -rf /root/requirements.txt
|
| 44 |
+
|
| 45 |
+
# install package patches (video-caption)
|
| 46 |
+
COPY easyanimate/video_caption/package_patches/easyocr_detection_patched.py /usr/local/lib/python3.10/dist-packages/easyocr/detection.py
|
| 47 |
+
COPY easyanimate/video_caption/package_patches/vila_siglip_encoder_patched.py /usr/local/lib/python3.10/dist-packages/llava/model/multimodal_encoder/siglip_encoder.py
|
| 48 |
+
|
| 49 |
+
ENV PYTHONUNBUFFERED 1
|
| 50 |
+
ENV NVIDIA_DISABLE_REQUIRE 1
|
| 51 |
+
|
| 52 |
+
WORKDIR /root/
|
VideoX-Fun/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
VideoX-Fun/README.md
ADDED
|
@@ -0,0 +1,697 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# VideoX-Fun
|
| 2 |
+
|
| 3 |
+
😊 Welcome!
|
| 4 |
+
|
| 5 |
+
CogVideoX-Fun:
|
| 6 |
+
[](https://huggingface.co/spaces/alibaba-pai/CogVideoX-Fun-5b)
|
| 7 |
+
|
| 8 |
+
Wan-Fun:
|
| 9 |
+
[](https://huggingface.co/spaces/alibaba-pai/Wan2.1-Fun-1.3B-InP)
|
| 10 |
+
|
| 11 |
+
English | [简体中文](./README_zh-CN.md) | [日本語](./README_ja-JP.md)
|
| 12 |
+
|
| 13 |
+
# Table of Contents
|
| 14 |
+
- [Table of Contents](#table-of-contents)
|
| 15 |
+
- [Introduction](#introduction)
|
| 16 |
+
- [Quick Start](#quick-start)
|
| 17 |
+
- [Video Result](#video-result)
|
| 18 |
+
- [How to use](#how-to-use)
|
| 19 |
+
- [Model zoo](#model-zoo)
|
| 20 |
+
- [Reference](#reference)
|
| 21 |
+
- [License](#license)
|
| 22 |
+
|
| 23 |
+
# Introduction
|
| 24 |
+
VideoX-Fun is a video generation pipeline that can be used to generate AI images and videos, as well as to train baseline and Lora models for Diffusion Transformer. We support direct prediction from pre-trained baseline models to generate videos with different resolutions, durations, and FPS. Additionally, we also support users in training their own baseline and Lora models to perform specific style transformations.
|
| 25 |
+
|
| 26 |
+
We will support quick pull-ups from different platforms, refer to [Quick Start](#quick-start).
|
| 27 |
+
|
| 28 |
+
What's New:
|
| 29 |
+
- Added support for Wan 2.2 series models, Wan-VACE control model, Fantasy Talking digital human model, Qwen-Image, Flux image generation models, and more. [2025.10.16]
|
| 30 |
+
- Update Wan2.1-Fun-V1.1: Support for 14B and 1.3B model Control + Reference Image models, support for camera control, and the Inpaint model has been retrained for improved performance. [2025.04.25]
|
| 31 |
+
- Update Wan2.1-Fun-V1.0: Support I2V and Control models for 14B and 1.3B models, with support for start and end frame prediction. [2025.03.26]
|
| 32 |
+
- Update CogVideoX-Fun-V1.5: Upload I2V model and related training/prediction code. [2024.12.16]
|
| 33 |
+
- Reward Lora Support: Train Lora using reward backpropagation techniques to optimize generated videos, making them better aligned with human preferences. [More Information](scripts/README_TRAIN_REWARD.md). New version of the control model supports various control conditions such as Canny, Depth, Pose, MLSD, etc. [2024.11.21]
|
| 34 |
+
- Diffusers Support: CogVideoX-Fun Control is now supported in diffusers. Thanks to [a-r-r-o-w](https://github.com/a-r-r-o-w) for contributing support in this [PR](https://github.com/huggingface/diffusers/pull/9671). Check out the [documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/cogvideox) for more details. [2024.10.16]
|
| 35 |
+
- Update CogVideoX-Fun-V1.1: Retrain i2v model, add Noise to increase the motion amplitude of the video. Upload control model training code and Control model. [2024.09.29]
|
| 36 |
+
- Update CogVideoX-Fun-V1.0: Initial code release! Now supports Windows and Linux. Supports video generation at arbitrary resolutions from 256x256x49 to 1024x1024x49 for 2B and 5B models. [2024.09.18]
|
| 37 |
+
|
| 38 |
+
Function:
|
| 39 |
+
- [Data Preprocessing](#data-preprocess)
|
| 40 |
+
- [Train DiT](#dit-train)
|
| 41 |
+
- [Video Generation](#video-gen)
|
| 42 |
+
|
| 43 |
+
Our UI interface is as follows:
|
| 44 |
+

|
| 45 |
+
|
| 46 |
+
# Quick Start
|
| 47 |
+
### 1. Cloud usage: AliyunDSW/Docker
|
| 48 |
+
#### a. From AliyunDSW
|
| 49 |
+
DSW has free GPU time, which can be applied once by a user and is valid for 3 months after applying.
|
| 50 |
+
|
| 51 |
+
Aliyun provide free GPU time in [Freetier](https://free.aliyun.com/?product=9602825&crowd=enterprise&spm=5176.28055625.J_5831864660.1.e939154aRgha4e&scm=20140722.M_9974135.P_110.MO_1806-ID_9974135-MID_9974135-CID_30683-ST_8512-V_1), get it and use in Aliyun PAI-DSW to start CogVideoX-Fun within 5min!
|
| 52 |
+
|
| 53 |
+
[](https://gallery.pai-ml.com/#/preview/deepLearning/cv/cogvideox_fun)
|
| 54 |
+
|
| 55 |
+
#### b. From ComfyUI
|
| 56 |
+
Our ComfyUI is as follows, please refer to [ComfyUI README](comfyui/README.md) for details.
|
| 57 |
+

|
| 58 |
+
|
| 59 |
+
#### c. From docker
|
| 60 |
+
If you are using docker, please make sure that the graphics card driver and CUDA environment have been installed correctly in your machine.
|
| 61 |
+
|
| 62 |
+
Then execute the following commands in this way:
|
| 63 |
+
|
| 64 |
+
```
|
| 65 |
+
# pull image
|
| 66 |
+
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:cogvideox_fun
|
| 67 |
+
|
| 68 |
+
# enter image
|
| 69 |
+
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:cogvideox_fun
|
| 70 |
+
|
| 71 |
+
# clone code
|
| 72 |
+
git clone https://github.com/aigc-apps/VideoX-Fun.git
|
| 73 |
+
|
| 74 |
+
# enter VideoX-Fun's dir
|
| 75 |
+
cd VideoX-Fun
|
| 76 |
+
|
| 77 |
+
# download weights
|
| 78 |
+
mkdir models/Diffusion_Transformer
|
| 79 |
+
mkdir models/Personalized_Model
|
| 80 |
+
|
| 81 |
+
# Please use the hugginface link or modelscope link to download the model.
|
| 82 |
+
# CogVideoX-Fun
|
| 83 |
+
# https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-InP
|
| 84 |
+
# https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-InP
|
| 85 |
+
|
| 86 |
+
# Wan
|
| 87 |
+
# https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-InP
|
| 88 |
+
# https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-InP
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
### 2. Local install: Environment Check/Downloading/Installation
|
| 92 |
+
#### a. Environment Check
|
| 93 |
+
We have verified this repo execution on the following environment:
|
| 94 |
+
|
| 95 |
+
The detailed of Windows:
|
| 96 |
+
- OS: Windows 10
|
| 97 |
+
- python: python3.10 & python3.11
|
| 98 |
+
- pytorch: torch2.2.0
|
| 99 |
+
- CUDA: 11.8 & 12.1
|
| 100 |
+
- CUDNN: 8+
|
| 101 |
+
- GPU: Nvidia-3060 12G & Nvidia-3090 24G
|
| 102 |
+
|
| 103 |
+
The detailed of Linux:
|
| 104 |
+
- OS: Ubuntu 20.04, CentOS
|
| 105 |
+
- python: python3.10 & python3.11
|
| 106 |
+
- pytorch: torch2.2.0
|
| 107 |
+
- CUDA: 11.8 & 12.1
|
| 108 |
+
- CUDNN: 8+
|
| 109 |
+
- GPU:Nvidia-V100 16G & Nvidia-A10 24G & Nvidia-A100 40G & Nvidia-A100 80G
|
| 110 |
+
|
| 111 |
+
We need about 60GB available on disk (for saving weights), please check!
|
| 112 |
+
|
| 113 |
+
#### b. Weights
|
| 114 |
+
We'd better place the [weights](#model-zoo) along the specified path:
|
| 115 |
+
|
| 116 |
+
**Via ComfyUI**:
|
| 117 |
+
Put the models into the ComfyUI weights folder `ComfyUI/models/Fun_Models/`:
|
| 118 |
+
```
|
| 119 |
+
📦 ComfyUI/
|
| 120 |
+
├── 📂 models/
|
| 121 |
+
│ └── 📂 Fun_Models/
|
| 122 |
+
│ ├── 📂 CogVideoX-Fun-V1.1-2b-InP/
|
| 123 |
+
│ ├── 📂 CogVideoX-Fun-V1.1-5b-InP/
|
| 124 |
+
│ ├── 📂 Wan2.1-Fun-14B-InP
|
| 125 |
+
│ └── 📂 Wan2.1-Fun-1.3B-InP/
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
**Run its own python file or UI interface**:
|
| 129 |
+
```
|
| 130 |
+
📦 models/
|
| 131 |
+
├── 📂 Diffusion_Transformer/
|
| 132 |
+
│ ├── 📂 CogVideoX-Fun-V1.1-2b-InP/
|
| 133 |
+
│ ├── 📂 CogVideoX-Fun-V1.1-5b-InP/
|
| 134 |
+
│ ├── 📂 Wan2.1-Fun-14B-InP
|
| 135 |
+
│ └── 📂 Wan2.1-Fun-1.3B-InP/
|
| 136 |
+
├── 📂 Personalized_Model/
|
| 137 |
+
│ └── your trained trainformer model / your trained lora model (for UI load)
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
# Video Result
|
| 141 |
+
|
| 142 |
+
### Wan2.1-Fun-V1.1-14B-InP && Wan2.1-Fun-V1.1-1.3B-InP
|
| 143 |
+
|
| 144 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 145 |
+
<tr>
|
| 146 |
+
<td>
|
| 147 |
+
<video src="https://github.com/user-attachments/assets/d6a46051-8fe6-4174-be12-95ee52c96298" width="100%" controls autoplay loop></video>
|
| 148 |
+
</td>
|
| 149 |
+
<td>
|
| 150 |
+
<video src="https://github.com/user-attachments/assets/8572c656-8548-4b1f-9ec8-8107c6236cb1" width="100%" controls autoplay loop></video>
|
| 151 |
+
</td>
|
| 152 |
+
<td>
|
| 153 |
+
<video src="https://github.com/user-attachments/assets/d3411c95-483d-4e30-bc72-483c2b288918" width="100%" controls autoplay loop></video>
|
| 154 |
+
</td>
|
| 155 |
+
<td>
|
| 156 |
+
<video src="https://github.com/user-attachments/assets/b2f5addc-06bd-49d9-b925-973090a32800" width="100%" controls autoplay loop></video>
|
| 157 |
+
</td>
|
| 158 |
+
</tr>
|
| 159 |
+
</table>
|
| 160 |
+
|
| 161 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 162 |
+
<tr>
|
| 163 |
+
<td>
|
| 164 |
+
<video src="https://github.com/user-attachments/assets/747b6ab8-9617-4ba2-84a0-b51c0efbd4f8" width="100%" controls autoplay loop></video>
|
| 165 |
+
</td>
|
| 166 |
+
<td>
|
| 167 |
+
<video src="https://github.com/user-attachments/assets/ae94dcda-9d5e-4bae-a86f-882c4282a367" width="100%" controls autoplay loop></video>
|
| 168 |
+
</td>
|
| 169 |
+
<td>
|
| 170 |
+
<video src="https://github.com/user-attachments/assets/a4aa1a82-e162-4ab5-8f05-72f79568a191" width="100%" controls autoplay loop></video>
|
| 171 |
+
</td>
|
| 172 |
+
<td>
|
| 173 |
+
<video src="https://github.com/user-attachments/assets/83c005b8-ccbc-44a0-a845-c0472763119c" width="100%" controls autoplay loop></video>
|
| 174 |
+
</td>
|
| 175 |
+
</tr>
|
| 176 |
+
</table>
|
| 177 |
+
|
| 178 |
+
### Wan2.1-Fun-V1.1-14B-Control && Wan2.1-Fun-V1.1-1.3B-Control
|
| 179 |
+
|
| 180 |
+
Generic Control Video + Reference Image:
|
| 181 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 182 |
+
<tr>
|
| 183 |
+
<td>
|
| 184 |
+
Reference Image
|
| 185 |
+
</td>
|
| 186 |
+
<td>
|
| 187 |
+
Control Video
|
| 188 |
+
</td>
|
| 189 |
+
<td>
|
| 190 |
+
Wan2.1-Fun-V1.1-14B-Control
|
| 191 |
+
</td>
|
| 192 |
+
<td>
|
| 193 |
+
Wan2.1-Fun-V1.1-1.3B-Control
|
| 194 |
+
</td>
|
| 195 |
+
<tr>
|
| 196 |
+
<td>
|
| 197 |
+
<image src="https://github.com/user-attachments/assets/221f2879-3b1b-4fbd-84f9-c3e0b0b3533e" width="100%" controls autoplay loop></image>
|
| 198 |
+
</td>
|
| 199 |
+
<td>
|
| 200 |
+
<video src="https://github.com/user-attachments/assets/f361af34-b3b3-4be4-9d03-cd478cb3dfc5" width="100%" controls autoplay loop></video>
|
| 201 |
+
</td>
|
| 202 |
+
<td>
|
| 203 |
+
<video src="https://github.com/user-attachments/assets/85e2f00b-6ef0-4922-90ab-4364afb2c93d" width="100%" controls autoplay loop></video>
|
| 204 |
+
</td>
|
| 205 |
+
<td>
|
| 206 |
+
<video src="https://github.com/user-attachments/assets/1f3fe763-2754-4215-bc9a-ae804950d4b3" width="100%" controls autoplay loop></video>
|
| 207 |
+
</td>
|
| 208 |
+
<tr>
|
| 209 |
+
</table>
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
Generic Control Video (Canny, Pose, Depth, etc.) and Trajectory Control:
|
| 213 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 214 |
+
<tr>
|
| 215 |
+
<td>
|
| 216 |
+
<video src="https://github.com/user-attachments/assets/f35602c4-9f0a-4105-9762-1e3a88abbac6" width="100%" controls autoplay loop></video>
|
| 217 |
+
</td>
|
| 218 |
+
<td>
|
| 219 |
+
<video src="https://github.com/user-attachments/assets/8b0f0e87-f1be-4915-bb35-2d53c852333e" width="100%" controls autoplay loop></video>
|
| 220 |
+
</td>
|
| 221 |
+
<td>
|
| 222 |
+
<video src="https://github.com/user-attachments/assets/972012c1-772b-427a-bce6-ba8b39edcfad" width="100%" controls autoplay loop></video>
|
| 223 |
+
</td>
|
| 224 |
+
<tr>
|
| 225 |
+
</table>
|
| 226 |
+
|
| 227 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 228 |
+
<tr>
|
| 229 |
+
<td>
|
| 230 |
+
<video src="https://github.com/user-attachments/assets/ce62d0bd-82c0-4d7b-9c49-7e0e4b605745" width="100%" controls autoplay loop></video>
|
| 231 |
+
</td>
|
| 232 |
+
<td>
|
| 233 |
+
<video src="https://github.com/user-attachments/assets/89dfbffb-c4a6-4821-bcef-8b1489a3ca00" width="100%" controls autoplay loop></video>
|
| 234 |
+
</td>
|
| 235 |
+
<td>
|
| 236 |
+
<video src="https://github.com/user-attachments/assets/72a43e33-854f-4349-861b-c959510d1a84" width="100%" controls autoplay loop></video>
|
| 237 |
+
</td>
|
| 238 |
+
<tr>
|
| 239 |
+
<td>
|
| 240 |
+
<video src="https://github.com/user-attachments/assets/bb0ce13d-dee0-4049-9eec-c92f3ebc1358" width="100%" controls autoplay loop></video>
|
| 241 |
+
</td>
|
| 242 |
+
<td>
|
| 243 |
+
<video src="https://github.com/user-attachments/assets/7840c333-7bec-4582-ba63-20a39e1139c4" width="100%" controls autoplay loop></video>
|
| 244 |
+
</td>
|
| 245 |
+
<td>
|
| 246 |
+
<video src="https://github.com/user-attachments/assets/85147d30-ae09-4f36-a077-2167f7a578c0" width="100%" controls autoplay loop></video>
|
| 247 |
+
</td>
|
| 248 |
+
</tr>
|
| 249 |
+
</table>
|
| 250 |
+
|
| 251 |
+
### Wan2.1-Fun-V1.1-14B-Control-Camera && Wan2.1-Fun-V1.1-1.3B-Control-Camera
|
| 252 |
+
|
| 253 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 254 |
+
<tr>
|
| 255 |
+
<td>
|
| 256 |
+
Pan Up
|
| 257 |
+
</td>
|
| 258 |
+
<td>
|
| 259 |
+
Pan Left
|
| 260 |
+
</td>
|
| 261 |
+
<td>
|
| 262 |
+
Pan Right
|
| 263 |
+
</td>
|
| 264 |
+
<tr>
|
| 265 |
+
<td>
|
| 266 |
+
<video src="https://github.com/user-attachments/assets/869fe2ef-502a-484e-8656-fe9e626b9f63" width="100%" controls autoplay loop></video>
|
| 267 |
+
</td>
|
| 268 |
+
<td>
|
| 269 |
+
<video src="https://github.com/user-attachments/assets/2d4185c8-d6ec-4831-83b4-b1dbfc3616fa" width="100%" controls autoplay loop></video>
|
| 270 |
+
</td>
|
| 271 |
+
<td>
|
| 272 |
+
<video src="https://github.com/user-attachments/assets/7dfb7cad-ed24-4acc-9377-832445a07ec7" width="100%" controls autoplay loop></video>
|
| 273 |
+
</td>
|
| 274 |
+
<tr>
|
| 275 |
+
<td>
|
| 276 |
+
Pan Down
|
| 277 |
+
</td>
|
| 278 |
+
<td>
|
| 279 |
+
Pan Up + Pan Left
|
| 280 |
+
</td>
|
| 281 |
+
<td>
|
| 282 |
+
Pan Up + Pan Right
|
| 283 |
+
</td>
|
| 284 |
+
<tr>
|
| 285 |
+
<td>
|
| 286 |
+
<video src="https://github.com/user-attachments/assets/3ea3a08d-f2df-43a2-976e-bf2659345373" width="100%" controls autoplay loop></video>
|
| 287 |
+
</td>
|
| 288 |
+
<td>
|
| 289 |
+
<video src="https://github.com/user-attachments/assets/4a85b028-4120-4293-886b-b8afe2d01713" width="100%" controls autoplay loop></video>
|
| 290 |
+
</td>
|
| 291 |
+
<td>
|
| 292 |
+
<video src="https://github.com/user-attachments/assets/ad0d58c1-13ef-450c-b658-4fed7ff5ed36" width="100%" controls autoplay loop></video>
|
| 293 |
+
</td>
|
| 294 |
+
</tr>
|
| 295 |
+
</table>
|
| 296 |
+
|
| 297 |
+
### CogVideoX-Fun-V1.1-5B
|
| 298 |
+
|
| 299 |
+
Resolution-1024
|
| 300 |
+
|
| 301 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 302 |
+
<tr>
|
| 303 |
+
<td>
|
| 304 |
+
<video src="https://github.com/user-attachments/assets/34e7ec8f-293e-4655-bb14-5e1ee476f788" width="100%" controls autoplay loop></video>
|
| 305 |
+
</td>
|
| 306 |
+
<td>
|
| 307 |
+
<video src="https://github.com/user-attachments/assets/7809c64f-eb8c-48a9-8bdc-ca9261fd5434" width="100%" controls autoplay loop></video>
|
| 308 |
+
</td>
|
| 309 |
+
<td>
|
| 310 |
+
<video src="https://github.com/user-attachments/assets/8e76aaa4-c602-44ac-bcb4-8b24b72c386c" width="100%" controls autoplay loop></video>
|
| 311 |
+
</td>
|
| 312 |
+
<td>
|
| 313 |
+
<video src="https://github.com/user-attachments/assets/19dba894-7c35-4f25-b15c-384167ab3b03" width="100%" controls autoplay loop></video>
|
| 314 |
+
</td>
|
| 315 |
+
</tr>
|
| 316 |
+
</table>
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
Resolution-768
|
| 320 |
+
|
| 321 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 322 |
+
<tr>
|
| 323 |
+
<td>
|
| 324 |
+
<video src="https://github.com/user-attachments/assets/0bc339b9-455b-44fd-8917-80272d702737" width="100%" controls autoplay loop></video>
|
| 325 |
+
</td>
|
| 326 |
+
<td>
|
| 327 |
+
<video src="https://github.com/user-attachments/assets/70a043b9-6721-4bd9-be47-78b7ec5c27e9" width="100%" controls autoplay loop></video>
|
| 328 |
+
</td>
|
| 329 |
+
<td>
|
| 330 |
+
<video src="https://github.com/user-attachments/assets/d5dd6c09-14f3-40f8-8b6d-91e26519b8ac" width="100%" controls autoplay loop></video>
|
| 331 |
+
</td>
|
| 332 |
+
<td>
|
| 333 |
+
<video src="https://github.com/user-attachments/assets/9327e8bc-4f17-46b0-b50d-38c250a9483a" width="100%" controls autoplay loop></video>
|
| 334 |
+
</td>
|
| 335 |
+
</tr>
|
| 336 |
+
</table>
|
| 337 |
+
|
| 338 |
+
Resolution-512
|
| 339 |
+
|
| 340 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 341 |
+
<tr>
|
| 342 |
+
<td>
|
| 343 |
+
<video src="https://github.com/user-attachments/assets/ef407030-8062-454d-aba3-131c21e6b58c" width="100%" controls autoplay loop></video>
|
| 344 |
+
</td>
|
| 345 |
+
<td>
|
| 346 |
+
<video src="https://github.com/user-attachments/assets/7610f49e-38b6-4214-aa48-723ae4d1b07e" width="100%" controls autoplay loop></video>
|
| 347 |
+
</td>
|
| 348 |
+
<td>
|
| 349 |
+
<video src="https://github.com/user-attachments/assets/1fff0567-1e15-415c-941e-53ee8ae2c841" width="100%" controls autoplay loop></video>
|
| 350 |
+
</td>
|
| 351 |
+
<td>
|
| 352 |
+
<video src="https://github.com/user-attachments/assets/bcec48da-b91b-43a0-9d50-cf026e00fa4f" width="100%" controls autoplay loop></video>
|
| 353 |
+
</td>
|
| 354 |
+
</tr>
|
| 355 |
+
</table>
|
| 356 |
+
|
| 357 |
+
### CogVideoX-Fun-V1.1-5B-Control
|
| 358 |
+
|
| 359 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 360 |
+
<tr>
|
| 361 |
+
<td>
|
| 362 |
+
<video src="https://github.com/user-attachments/assets/53002ce2-dd18-4d4f-8135-b6f68364cabd" width="100%" controls autoplay loop></video>
|
| 363 |
+
</td>
|
| 364 |
+
<td>
|
| 365 |
+
<video src="https://github.com/user-attachments/assets/a1a07cf8-d86d-4cd2-831f-18a6c1ceee1d" width="100%" controls autoplay loop></video>
|
| 366 |
+
</td>
|
| 367 |
+
<td>
|
| 368 |
+
<video src="https://github.com/user-attachments/assets/3224804f-342d-4947-918d-d9fec8e3d273" width="100%" controls autoplay loop></video>
|
| 369 |
+
</td>
|
| 370 |
+
<tr>
|
| 371 |
+
<td>
|
| 372 |
+
A young woman with beautiful clear eyes and blonde hair, wearing white clothes and twisting her body, with the camera focused on her face. High quality, masterpiece, best quality, high resolution, ultra-fine, dreamlike.
|
| 373 |
+
</td>
|
| 374 |
+
<td>
|
| 375 |
+
A young woman with beautiful clear eyes and blonde hair, wearing white clothes and twisting her body, with the camera focused on her face. High quality, masterpiece, best quality, high resolution, ultra-fine, dreamlike.
|
| 376 |
+
</td>
|
| 377 |
+
<td>
|
| 378 |
+
A young bear.
|
| 379 |
+
</td>
|
| 380 |
+
</tr>
|
| 381 |
+
<tr>
|
| 382 |
+
<td>
|
| 383 |
+
<video src="https://github.com/user-attachments/assets/ea908454-684b-4d60-b562-3db229a250a9" width="100%" controls autoplay loop></video>
|
| 384 |
+
</td>
|
| 385 |
+
<td>
|
| 386 |
+
<video src="https://github.com/user-attachments/assets/ffb7c6fc-8b69-453b-8aad-70dfae3899b9" width="100%" controls autoplay loop></video>
|
| 387 |
+
</td>
|
| 388 |
+
<td>
|
| 389 |
+
<video src="https://github.com/user-attachments/assets/d3f757a3-3551-4dcb-9372-7a61469813f5" width="100%" controls autoplay loop></video>
|
| 390 |
+
</td>
|
| 391 |
+
</tr>
|
| 392 |
+
</table>
|
| 393 |
+
|
| 394 |
+
# How to Use
|
| 395 |
+
|
| 396 |
+
<h3 id="video-gen">1. Generation</h3>
|
| 397 |
+
|
| 398 |
+
#### a. GPU Memory Optimization
|
| 399 |
+
Since Wan2.1 has a very large number of parameters, we need to consider memory optimization strategies to adapt to consumer-grade GPUs. We provide `GPU_memory_mode` for each prediction file, allowing you to choose between `model_cpu_offload`, `model_cpu_offload_and_qfloat8`, and `sequential_cpu_offload`. This solution is also applicable to CogVideoX-Fun generation.
|
| 400 |
+
|
| 401 |
+
- `model_cpu_offload`: The entire model is moved to the CPU after use, saving some GPU memory.
|
| 402 |
+
- `model_cpu_offload_and_qfloat8`: The entire model is moved to the CPU after use, and the transformer model is quantized to float8, saving more GPU memory.
|
| 403 |
+
- `sequential_cpu_offload`: Each layer of the model is moved to the CPU after use. It is slower but saves a significant amount of GPU memory.
|
| 404 |
+
|
| 405 |
+
`qfloat8` may slightly reduce model performance but saves more GPU memory. If you have sufficient GPU memory, it is recommended to use `model_cpu_offload`.
|
| 406 |
+
|
| 407 |
+
#### b. Using ComfyUI
|
| 408 |
+
For details, refer to [ComfyUI README](comfyui/README.md).
|
| 409 |
+
|
| 410 |
+
#### c. Running Python Files
|
| 411 |
+
|
| 412 |
+
##### i. Single-GPU Inference:
|
| 413 |
+
|
| 414 |
+
- **Step 1**: Download the corresponding [weights](#model-zoo) and place them in the `models` folder.
|
| 415 |
+
- **Step 2**: Use different files for prediction based on the weights and prediction goals. This library currently supports CogVideoX-Fun, Wan2.1, and Wan2.1-Fun. Different models are distinguished by folder names under the `examples` folder, and their supported features vary. Use them accordingly. Below is an example using CogVideoX-Fun:
|
| 416 |
+
- **Text-to-Video**:
|
| 417 |
+
- Modify `prompt`, `neg_prompt`, `guidance_scale`, and `seed` in the file `examples/cogvideox_fun/predict_t2v.py`.
|
| 418 |
+
- Run the file `examples/cogvideox_fun/predict_t2v.py` and wait for the results. The generated videos will be saved in the folder `samples/cogvideox-fun-videos`.
|
| 419 |
+
- **Image-to-Video**:
|
| 420 |
+
- Modify `validation_image_start`, `validation_image_end`, `prompt`, `neg_prompt`, `guidance_scale`, and `seed` in the file `examples/cogvideox_fun/predict_i2v.py`.
|
| 421 |
+
- `validation_image_start` is the starting image of the video, and `validation_image_end` is the ending image of the video.
|
| 422 |
+
- Run the file `examples/cogvideox_fun/predict_i2v.py` and wait for the results. The generated videos will be saved in the folder `samples/cogvideox-fun-videos_i2v`.
|
| 423 |
+
- **Video-to-Video**:
|
| 424 |
+
- Modify `validation_video`, `validation_image_end`, `prompt`, `neg_prompt`, `guidance_scale`, and `seed` in the file `examples/cogvideox_fun/predict_v2v.py`.
|
| 425 |
+
- `validation_video` is the reference video for video-to-video generation. You can use the following demo video: [Demo Video](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1/play_guitar.mp4).
|
| 426 |
+
- Run the file `examples/cogvideox_fun/predict_v2v.py` and wait for the results. The generated videos will be saved in the folder `samples/cogvideox-fun-videos_v2v`.
|
| 427 |
+
- **Controlled Video Generation (Canny, Pose, Depth, etc.)**:
|
| 428 |
+
- Modify `control_video`, `validation_image_end`, `prompt`, `neg_prompt`, `guidance_scale`, and `seed` in the file `examples/cogvideox_fun/predict_v2v_control.py`.
|
| 429 |
+
- `control_video` is the control video extracted using operators such as Canny, Pose, or Depth. You can use the following demo video: [Demo Video](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.1/pose.mp4).
|
| 430 |
+
- Run the file `examples/cogvideox_fun/predict_v2v_control.py` and wait for the results. The generated videos will be saved in the folder `samples/cogvideox-fun-videos_v2v_control`.
|
| 431 |
+
- **Step 3**: If you want to integrate other backbones or Loras trained by yourself, modify `lora_path` and relevant paths in `examples/{model_name}/predict_t2v.py` or `examples/{model_name}/predict_i2v.py` as needed.
|
| 432 |
+
|
| 433 |
+
##### ii. Multi-GPU Inference:
|
| 434 |
+
When using multi-GPU inference, please make sure to install the xfuser. We recommend installing xfuser==0.4.2 and yunchang==0.6.2.
|
| 435 |
+
```
|
| 436 |
+
pip install xfuser==0.4.2 --progress-bar off -i https://mirrors.aliyun.com/pypi/simple/
|
| 437 |
+
pip install yunchang==0.6.2 --progress-bar off -i https://mirrors.aliyun.com/pypi/simple/
|
| 438 |
+
```
|
| 439 |
+
|
| 440 |
+
Please ensure that the product of `ulysses_degree` and `ring_degree` equals the number of GPUs being used. For example, if you are using 8 GPUs, you can set `ulysses_degree=2` and `ring_degree=4`, or alternatively `ulysses_degree=4` and `ring_degree=2`.
|
| 441 |
+
|
| 442 |
+
- `ulysses_degree` performs parallelization after splitting across the heads.
|
| 443 |
+
- `ring_degree` performs parallelization after splitting across the sequence.
|
| 444 |
+
|
| 445 |
+
Compared to `ulysses_degree`, `ring_degree` incurs higher communication costs. Therefore, when setting these parameters, you should take into account both the sequence length and the number of heads in the model.
|
| 446 |
+
|
| 447 |
+
Let’s take 8-GPU parallel inference as an example:
|
| 448 |
+
|
| 449 |
+
- **For Wan2.1-Fun-V1.1-14B-InP**, which has 40 heads, `ulysses_degree` should be set to a divisor of 40 (e.g., 2, 4, 8, etc.). Thus, when using 8 GPUs for parallel inference, you can set `ulysses_degree=8` and `ring_degree=1`.
|
| 450 |
+
|
| 451 |
+
- **For Wan2.1-Fun-V1.1-1.3B-InP**, which has 12 heads, `ulysses_degree` should be set to a divisor of 12 (e.g., 2, 4, etc.). Thus, when using 8 GPUs for parallel inference, you can set `ulysses_degree=4` and `ring_degree=2`.
|
| 452 |
+
|
| 453 |
+
After setting the parameters, run the following command for parallel inference:
|
| 454 |
+
|
| 455 |
+
```sh
|
| 456 |
+
torchrun --nproc-per-node=8 examples/wan2.1_fun/predict_t2v.py
|
| 457 |
+
```
|
| 458 |
+
|
| 459 |
+
#### d. Using the Web UI
|
| 460 |
+
The web UI supports text-to-video, image-to-video, video-to-video, and controlled video generation (Canny, Pose, Depth, etc.). This library currently supports CogVideoX-Fun, Wan2.1, and Wan2.1-Fun. Different models are distinguished by folder names under the `examples` folder, and their supported features vary. Use them accordingly. Below is an example using CogVideoX-Fun:
|
| 461 |
+
|
| 462 |
+
- **Step 1**: Download the corresponding [weights](#model-zoo) and place them in the `models` folder.
|
| 463 |
+
- **Step 2**: Run the file `examples/cogvideox_fun/app.py` to access the Gradio interface.
|
| 464 |
+
- **Step 3**: Select the generation model on the page, fill in `prompt`, `neg_prompt`, `guidance_scale`, and `seed`, click "Generate," and wait for the results. The generated videos will be saved in the `sample` folder.
|
| 465 |
+
|
| 466 |
+
### 2. Model Training
|
| 467 |
+
A complete model training pipeline should include data preprocessing and Video DiT training. The training process for different models is similar, and the data formats are also similar:
|
| 468 |
+
|
| 469 |
+
<h4 id="data-preprocess">a. data preprocessing</h4>
|
| 470 |
+
|
| 471 |
+
We have provided a simple demo of training the Lora model through image data, which can be found in the [wiki](https://github.com/aigc-apps/CogVideoX-Fun/wiki/Training-Lora) for details.
|
| 472 |
+
|
| 473 |
+
A complete data preprocessing link for long video segmentation, cleaning, and description can refer to [README](cogvideox/video_caption/README.md) in the video captions section.
|
| 474 |
+
|
| 475 |
+
If you want to train a text to image and video generation model. You need to arrange the dataset in this format.
|
| 476 |
+
|
| 477 |
+
```
|
| 478 |
+
📦 project/
|
| 479 |
+
├── 📂 datasets/
|
| 480 |
+
│ ├── 📂 internal_datasets/
|
| 481 |
+
│ ├── 📂 train/
|
| 482 |
+
│ │ ├── 📄 00000001.mp4
|
| 483 |
+
│ │ ├── 📄 00000002.jpg
|
| 484 |
+
│ │ └── 📄 .....
|
| 485 |
+
│ └── 📄 json_of_internal_datasets.json
|
| 486 |
+
```
|
| 487 |
+
|
| 488 |
+
The json_of_internal_datasets.json is a standard JSON file. The file_path in the json can to be set as relative path, as shown in below:
|
| 489 |
+
```json
|
| 490 |
+
[
|
| 491 |
+
{
|
| 492 |
+
"file_path": "train/00000001.mp4",
|
| 493 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 494 |
+
"type": "video"
|
| 495 |
+
},
|
| 496 |
+
{
|
| 497 |
+
"file_path": "train/00000002.jpg",
|
| 498 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 499 |
+
"type": "image"
|
| 500 |
+
},
|
| 501 |
+
.....
|
| 502 |
+
]
|
| 503 |
+
```
|
| 504 |
+
|
| 505 |
+
You can also set the path as absolute path as follow:
|
| 506 |
+
```json
|
| 507 |
+
[
|
| 508 |
+
{
|
| 509 |
+
"file_path": "/mnt/data/videos/00000001.mp4",
|
| 510 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 511 |
+
"type": "video"
|
| 512 |
+
},
|
| 513 |
+
{
|
| 514 |
+
"file_path": "/mnt/data/train/00000001.jpg",
|
| 515 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 516 |
+
"type": "image"
|
| 517 |
+
},
|
| 518 |
+
.....
|
| 519 |
+
]
|
| 520 |
+
```
|
| 521 |
+
|
| 522 |
+
<h4 id="dit-train">b. Video DiT training </h4>
|
| 523 |
+
|
| 524 |
+
If the data format is relative path during data preprocessing, please set ```scripts/{model_name}/train.sh``` as follow.
|
| 525 |
+
```
|
| 526 |
+
export DATASET_NAME="datasets/internal_datasets/"
|
| 527 |
+
export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
|
| 528 |
+
```
|
| 529 |
+
|
| 530 |
+
If the data format is absolute path during data preprocessing, please set ```scripts/train.sh``` as follow.
|
| 531 |
+
```
|
| 532 |
+
export DATASET_NAME=""
|
| 533 |
+
export DATASET_META_NAME="/mnt/data/json_of_internal_datasets.json"
|
| 534 |
+
```
|
| 535 |
+
|
| 536 |
+
Then, we run scripts/train.sh.
|
| 537 |
+
```sh
|
| 538 |
+
sh scripts/train.sh
|
| 539 |
+
```
|
| 540 |
+
|
| 541 |
+
For details on some parameter settings:
|
| 542 |
+
Wan2.1-Fun can be found in [Readme Train](scripts/wan2.1_fun/README_TRAIN.md) and [Readme Lora](scripts/wan2.1_fun/README_TRAIN_LORA.md).
|
| 543 |
+
Wan2.1 can be found in [Readme Train](scripts/wan2.1/README_TRAIN.md) and [Readme Lora](scripts/wan2.1/README_TRAIN_LORA.md).
|
| 544 |
+
CogVideoX-Fun can be found in [Readme Train](scripts/cogvideox_fun/README_TRAIN.md) and [Readme Lora](scripts/cogvideox_fun/README_TRAIN_LORA.md).
|
| 545 |
+
|
| 546 |
+
|
| 547 |
+
# Model zoo
|
| 548 |
+
## 1. Wan2.2-Fun
|
| 549 |
+
|
| 550 |
+
| Name | Storage Size | Hugging Face | Model Scope | Description |
|
| 551 |
+
|--|--|--|--|--|
|
| 552 |
+
| Wan2.2-Fun-A14B-InP | 64.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-A14B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-A14B-InP) | Wan2.2-Fun-14B text-to-video generation weights, trained at multiple resolutions, supports start-end image prediction. |
|
| 553 |
+
| Wan2.2-Fun-A14B-Control | 64.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-A14B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-A14B-Control)| Wan2.2-Fun-14B video control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, etc., and trajectory control. Supports multi-resolution (512, 768, 1024) video prediction at 81 frames, trained at 16 frames per second, with multilingual prediction support. |
|
| 554 |
+
| Wan2.2-Fun-A14B-Control-Camera | 64.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-A14B-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-A14B-Control-Camera)| Wan2.2-Fun-14B camera lens control weights. Supports multi-resolution (512, 768, 1024) video prediction, trained with 81 frames at 16 FPS, supports multilingual prediction. |
|
| 555 |
+
| Wan2.2-VACE-Fun-A14B | 64.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-VACE-Fun-A14B) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-VACE-Fun-A14B) | Control weights for Wan2.2 trained using the VACE scheme (based on the base model Wan2.2-T2V-A14B), supporting various control conditions such as Canny, Depth, Pose, MLSD, trajectory control, etc. It supports video generation by specifying the subject. It supports multi-resolution (512, 768, 1024) video prediction, and is trained with 81 frames at 16 FPS. It also supports multi-language prediction. |
|
| 556 |
+
| Wan2.2-Fun-5B-InP | 23.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-5B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-5B-InP) | Wan2.2-Fun-5B text-to-video weights trained at 121 frames, 24 FPS, supporting first/last frame prediction. |
|
| 557 |
+
| Wan2.2-Fun-5B-Control | 23.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-5B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-5B-Control)| Wan2.2-Fun-5B video control weights, supporting control conditions like Canny, Depth, Pose, MLSD, and trajectory control. Trained at 121 frames, 24 FPS, with multilingual prediction support. |
|
| 558 |
+
| Wan2.2-Fun-5B-Control-Camera | 23.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-5B-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-5B-Control-Camera)| Wan2.2-Fun-5B camera lens control weights. Trained at 121 frames, 24 FPS, with multilingual prediction support. |
|
| 559 |
+
|
| 560 |
+
|
| 561 |
+
## 2. Wan2.2
|
| 562 |
+
|
| 563 |
+
| Name | Hugging Face | Model Scope | Description |
|
| 564 |
+
|--|--|--|--|
|
| 565 |
+
| Wan2.2-TI2V-5B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.2-TI2V-5B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.2-TI2V-5B) | Wan2.2-5B Text-to-Video Weights |
|
| 566 |
+
| Wan2.2-T2V-14B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.2-T2V-A14B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.2-T2V-A14B) | Wan2.2-14B Text-to-Video Weights |
|
| 567 |
+
| Wan2.2-I2V-A14B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.2-I2V-A14B) | Wan2.2-I2V-A14B Image-to-Video Weights |
|
| 568 |
+
|
| 569 |
+
## 3. Wan2.1-Fun
|
| 570 |
+
|
| 571 |
+
V1.1:
|
| 572 |
+
| Name | Storage Size | Hugging Face | Model Scope | Description |
|
| 573 |
+
|------|--------------|--------------|-------------|-------------|
|
| 574 |
+
| Wan2.1-Fun-V1.1-1.3B-InP | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-1.3B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-1.3B-InP) | Wan2.1-Fun-V1.1-1.3B text-to-video generation weights, trained at multiple resolutions, supports start-end image prediction. |
|
| 575 |
+
| Wan2.1-Fun-V1.1-14B-InP | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-InP) | Wan2.1-Fun-V1.1-14B text-to-video generation weights, trained at multiple resolutions, supports start-end image prediction. |
|
| 576 |
+
| Wan2.1-Fun-V1.1-1.3B-Control | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-1.3B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-1.3B-Control) | Wan2.1-Fun-V1.1-1.3B video control weights support various control conditions such as Canny, Depth, Pose, MLSD, etc., supports reference image + control condition-based control, and trajectory control. Supports multi-resolution (512, 768, 1024) video prediction, trained with 81 frames at 16 FPS, supports multilingual prediction. |
|
| 577 |
+
| Wan2.1-Fun-V1.1-14B-Control | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-Control) | Wan2.1-Fun-V1.1-14B video control weights support various control conditions such as Canny, Depth, Pose, MLSD, etc., supports reference image + control condition-based control, and trajectory control. Supports multi-resolution (512, 768, 1024) video prediction, trained with 81 frames at 16 FPS, supports multilingual prediction. |
|
| 578 |
+
| Wan2.1-Fun-V1.1-1.3B-Control-Camera | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-1.3B-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-1.3B-Control-Camera) | Wan2.1-Fun-V1.1-1.3B camera lens control weights. Supports multi-resolution (512, 768, 1024) video prediction, trained with 81 frames at 16 FPS, supports multilingual prediction. |
|
| 579 |
+
| Wan2.1-Fun-V1.1-14B-Control-Camera | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-Control-Camera) | Wan2.1-Fun-V1.1-14B camera lens control weights. Supports multi-resolution (512, 768, 1024) video prediction, trained with 81 frames at 16 FPS, supports multilingual prediction. |
|
| 580 |
+
|
| 581 |
+
V1.0:
|
| 582 |
+
| Name | Storage Space | Hugging Face | Model Scope | Description |
|
| 583 |
+
|--|--|--|--|--|
|
| 584 |
+
| Wan2.1-Fun-1.3B-InP | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-1.3B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-1.3B-InP) | Wan2.1-Fun-1.3B text-to-video weights, trained at multiple resolutions, supporting start and end frame prediction. |
|
| 585 |
+
| Wan2.1-Fun-14B-InP | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-14B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-14B-InP) | Wan2.1-Fun-14B text-to-video weights, trained at multiple resolutions, supporting start and end frame prediction. |
|
| 586 |
+
| Wan2.1-Fun-1.3B-Control | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-1.3B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-1.3B-Control) | Wan2.1-Fun-1.3B video control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, etc., and trajectory control. Supports multi-resolution (512, 768, 1024) video prediction at 81 frames, trained at 16 frames per second, with multilingual prediction support. |
|
| 587 |
+
| Wan2.1-Fun-14B-Control | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-14B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-14B-Control) | Wan2.1-Fun-14B video control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, etc., and trajectory control. Supports multi-resolution (512, 768, 1024) video prediction at 81 frames, trained at 16 frames per second, with multilingual prediction support. |
|
| 588 |
+
|
| 589 |
+
## 4. Wan2.1
|
| 590 |
+
|
| 591 |
+
| Name | Hugging Face | Model Scope | Description |
|
| 592 |
+
|--|--|--|--|
|
| 593 |
+
| Wan2.1-T2V-1.3B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-1.3B) | Wanxiang 2.1-1.3B text-to-video weights |
|
| 594 |
+
| Wan2.1-T2V-14B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-T2V-14B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-14B) | Wanxiang 2.1-14B text-to-video weights |
|
| 595 |
+
| Wan2.1-I2V-14B-480P | [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-480P) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-480P) | Wanxiang 2.1-14B-480P image-to-video weights |
|
| 596 |
+
| Wan2.1-I2V-14B-720P| [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-720P) | Wanxiang 2.1-14B-720P image-to-video weights |
|
| 597 |
+
|
| 598 |
+
## 5. FantasyTalking
|
| 599 |
+
|
| 600 |
+
| Name | Storage | Hugging Face | Model Scope | Description |
|
| 601 |
+
|--|--|--|--|--|
|
| 602 |
+
| Wan2.1-I2V-14B-720P | - | [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-720P) | Wan 2.1-14B-720P image-to-video model weights |
|
| 603 |
+
| Wav2Vec | - | [🤗Link](https://huggingface.co/facebook/wav2vec2-base-960h) | [😄Link](https://modelscope.cn/models/AI-ModelScope/wav2vec2-base-960h) | Wav2Vec model; place inside the Wan2.1-I2V-14B-720P folder and rename to `audio_encoder` |
|
| 604 |
+
| FantasyTalking model | - | [🤗Link](https://huggingface.co/acvlab/FantasyTalking/) | [😄Link](https://www.modelscope.cn/models/amap_cvlab/FantasyTalking/) | Official audio-conditioned weights |
|
| 605 |
+
|
| 606 |
+
## 6. Qwen-Image
|
| 607 |
+
|
| 608 |
+
| Name | Storage | Hugging Face | Model Scope | Description |
|
| 609 |
+
|--|--|--|--|--|
|
| 610 |
+
| Qwen-Image | [🤗Link](https://huggingface.co/Qwen/Qwen-Image) | [😄Link](https://modelscope.cn/models/Qwen/Qwen-Image) | Official Qwen-Image weights |
|
| 611 |
+
| Qwen-Image-Edit | [🤗Link](https://huggingface.co/Qwen/Qwen-Image-Edit) | [😄Link](https://modelscope.cn/models/Qwen/Qwen-Image-Edit) | Official Qwen-Image-Edit weights |
|
| 612 |
+
| Qwen-Image-Edit-2509 | [🤗Link](https://huggingface.co/Qwen/Qwen-Image-Edit-2509) | [😄Link](https://modelscope.cn/models/Qwen/Qwen-Image-Edit-2509) | Official Qwen-Image-Edit-2509 weights |
|
| 613 |
+
|
| 614 |
+
## 7. Z-Image
|
| 615 |
+
|
| 616 |
+
| Name | Storage | Hugging Face | Model Scope | Description |
|
| 617 |
+
|--|--|--|--|--|
|
| 618 |
+
| Z-Image-Turbo | [🤗Link](https://huggingface.co/Tongyi-MAI/Z-Image-Turbo) | [😄Link](https://www.modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo) | Official weights for Z-Image-Turbo |
|
| 619 |
+
|
| 620 |
+
## 8. Z-Image-Fun
|
| 621 |
+
|
| 622 |
+
| Name | Storage | Hugging Face | Model Scope | Description |
|
| 623 |
+
|--|--|--|--|--|
|
| 624 |
+
| Z-Image-Turbo-Fun-Controlnet-Union | - | [🤗Link](https://huggingface.co/alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union) | [😄Link](https://modelscope.cn/models/PAI/Z-Image-Turbo-Fun-Controlnet-Union) | ControlNet weights for Z-Image-Turbo, supporting multiple control conditions such as Canny, Depth, Pose, MLSD, etc. |
|
| 625 |
+
|
| 626 |
+
## 9. Flux
|
| 627 |
+
|
| 628 |
+
| Name | Storage | Hugging Face | Model Scope | Description |
|
| 629 |
+
|--|--|--|--|--|
|
| 630 |
+
| FLUX.1-dev | [🤗Link](https://huggingface.co/black-forest-labs/FLUX.1-dev) | [😄Link](https://www.modelscope.cn/models/black-forest-labs/FLUX.1-dev) | Official FLUX.1-dev weights |
|
| 631 |
+
| FLUX.2-dev | [🤗Link](https://huggingface.co/black-forest-labs/FLUX.2-dev) | [😄Link](https://www.modelscope.cn/models/black-forest-labs/FLUX.2-dev) | Official FLUX.2-dev weights |
|
| 632 |
+
|
| 633 |
+
## 10. Flux-Fun
|
| 634 |
+
|
| 635 |
+
| Name | Storage | Hugging Face | Model Scope | Description |
|
| 636 |
+
|--|--|--|--|--|
|
| 637 |
+
| Flux.2-dev-Fun-Controlnet-Union | - | [🤗Link](https://huggingface.co/alibaba-pai/FLUX.2-dev-Fun-Controlnet-Union) | [😄Link](https://modelscope.cn/models/PAI/FLUX.2-dev-Fun-Controlnet-Union) | Flux.2-dev control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, etc. |
|
| 638 |
+
|
| 639 |
+
## 11. HunyuanVideo
|
| 640 |
+
|
| 641 |
+
| Name | Storage | Hugging Face | Model Scope | Description |
|
| 642 |
+
|--|--|--|--|--|
|
| 643 |
+
| HunyuanVideo | [🤗Link](https://huggingface.co/hunyuanvideo-community/HunyuanVideo) | - | HunyuanVideo-diffusers weights |
|
| 644 |
+
| HunyuanVideo-I2V | [🤗Link](https://huggingface.co/hunyuanvideo-community/HunyuanVideo-I2V) | - | HunyuanVideo-I2V-diffusers weights |
|
| 645 |
+
|
| 646 |
+
## 12. CogVideoX-Fun
|
| 647 |
+
|
| 648 |
+
V1.5:
|
| 649 |
+
|
| 650 |
+
| Name | Storage Space | Hugging Face | Model Scope | Description |
|
| 651 |
+
|--|--|--|--|--|
|
| 652 |
+
| CogVideoX-Fun-V1.5-5b-InP | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.5-5b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.5-5b-InP) | Our official graph-generated video model is capable of predicting videos at multiple resolutions (512, 768, 1024) and has been trained on 85 frames at a rate of 8 frames per second. |
|
| 653 |
+
| CogVideoX-Fun-V1.5-Reward-LoRAs | - | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-Reward-LoRAs) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.5-Reward-LoRAs) | The official reward backpropagation technology model optimizes the videos generated by CogVideoX-Fun-V1.5 to better match human preferences. |
|
| 654 |
+
|
| 655 |
+
V1.1:
|
| 656 |
+
|
| 657 |
+
| Name | Storage Space | Hugging Face | Model Scope | Description |
|
| 658 |
+
|--|--|--|--|--|
|
| 659 |
+
| CogVideoX-Fun-V1.1-2b-InP | 13.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-2b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-2b-InP) | Our official graph-generated video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second. |
|
| 660 |
+
| CogVideoX-Fun-V1.1-5b-InP | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-InP) | Our official graph-generated video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second. Noise has been added to the reference image, and the amplitude of motion is greater compared to V1.0. |
|
| 661 |
+
| CogVideoX-Fun-V1.1-2b-Pose | 13.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-2b-Pose) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-2b-Pose) | Our official pose-control video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second.|
|
| 662 |
+
| CogVideoX-Fun-V1.1-2b-Control | 13.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-2b-Control) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-2b-Control) | Our official control video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second. Supporting various control conditions such as Canny, Depth, Pose, MLSD, etc.|
|
| 663 |
+
| CogVideoX-Fun-V1.1-5b-Pose | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-Pose) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-Pose) | Our official pose-control video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second.|
|
| 664 |
+
| CogVideoX-Fun-V1.1-5b-Control | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-Control) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-Control) | Our official control video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second. Supporting various control conditions such as Canny, Depth, Pose, MLSD, etc.|
|
| 665 |
+
| CogVideoX-Fun-V1.1-Reward-LoRAs | - | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-Reward-LoRAs) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-Reward-LoRAs) | The official reward backpropagation technology model optimizes the videos generated by CogVideoX-Fun-V1.1 to better match human preferences. |
|
| 666 |
+
|
| 667 |
+
<details>
|
| 668 |
+
<summary>(Obsolete) V1.0:</summary>
|
| 669 |
+
|
| 670 |
+
| Name | Storage Space | Hugging Face | Model Scope | Description |
|
| 671 |
+
|--|--|--|--|--|
|
| 672 |
+
| CogVideoX-Fun-2b-InP | 13.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-2b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-2b-InP) | Our official graph-generated video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second. |
|
| 673 |
+
| CogVideoX-Fun-5b-InP | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-5b-InP)| [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-5b-InP)| Our official graph-generated video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second. |
|
| 674 |
+
</details>
|
| 675 |
+
|
| 676 |
+
# Reference
|
| 677 |
+
- CogVideo: https://github.com/THUDM/CogVideo/
|
| 678 |
+
- EasyAnimate: https://github.com/aigc-apps/EasyAnimate
|
| 679 |
+
- Wan2.1: https://github.com/Wan-Video/Wan2.1/
|
| 680 |
+
- Wan2.2: https://github.com/Wan-Video/Wan2.2/
|
| 681 |
+
- Diffusers: https://github.com/huggingface/diffusers
|
| 682 |
+
- Qwen-Image: https://github.com/QwenLM/Qwen-Image
|
| 683 |
+
- Self-Forcing: https://github.com/guandeh17/Self-Forcing
|
| 684 |
+
- Flux: https://github.com/black-forest-labs/flux
|
| 685 |
+
- Flux2: https://github.com/black-forest-labs/flux2
|
| 686 |
+
- HunyuanVideo: https://github.com/Tencent-Hunyuan/HunyuanVideo
|
| 687 |
+
- ComfyUI-KJNodes: https://github.com/kijai/ComfyUI-KJNodes
|
| 688 |
+
- ComfyUI-EasyAnimateWrapper: https://github.com/kijai/ComfyUI-EasyAnimateWrapper
|
| 689 |
+
- ComfyUI-CameraCtrl-Wrapper: https://github.com/chaojie/ComfyUI-CameraCtrl-Wrapper
|
| 690 |
+
- CameraCtrl: https://github.com/hehao13/CameraCtrl
|
| 691 |
+
|
| 692 |
+
# License
|
| 693 |
+
This project is licensed under the [Apache License (Version 2.0)](https://github.com/modelscope/modelscope/blob/master/LICENSE).
|
| 694 |
+
|
| 695 |
+
The CogVideoX-2B model (including its corresponding Transformers module and VAE module) is released under the [Apache 2.0 License](LICENSE).
|
| 696 |
+
|
| 697 |
+
The CogVideoX-5B model (Transformers module) is released under the [CogVideoX LICENSE](https://huggingface.co/THUDM/CogVideoX-5b/blob/main/LICENSE).
|
VideoX-Fun/README_ja-JP.md
ADDED
|
@@ -0,0 +1,697 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# VideoX-Fun
|
| 2 |
+
|
| 3 |
+
😊 ようこそ!
|
| 4 |
+
|
| 5 |
+
CogVideoX-Fun:
|
| 6 |
+
[](https://huggingface.co/spaces/alibaba-pai/CogVideoX-Fun-5b)
|
| 7 |
+
|
| 8 |
+
Wan-Fun:
|
| 9 |
+
[](https://huggingface.co/spaces/alibaba-pai/Wan2.1-Fun-1.3B-InP)
|
| 10 |
+
|
| 11 |
+
[English](./README.md) | [简体中文](./README_zh-CN.md) | 日本語
|
| 12 |
+
|
| 13 |
+
# 目次
|
| 14 |
+
- [目次](#目次)
|
| 15 |
+
- [紹介](#紹介)
|
| 16 |
+
- [クイックスタート](#クイックスタート)
|
| 17 |
+
- [ビデオ結果](#ビデオ結果)
|
| 18 |
+
- [使用方法](#使用方法)
|
| 19 |
+
- [モデルの場所](#モデルの場所)
|
| 20 |
+
- [参考文献](#参考文献)
|
| 21 |
+
- [ライセンス](#ライセンス)
|
| 22 |
+
|
| 23 |
+
# 紹介
|
| 24 |
+
VideoX-Funはビデオ生成のパイプラインであり、AI画像やビデオの生成、Diffusion TransformerのベースラインモデルとLoraモデルのトレーニングに使用できます。我々は、すでに学習済みのベースラインモデルから直接予測を行い、異なる解像度、秒数、FPSのビデオを生成することをサポートしています。また、ユーザーが独自のベースラインモデルやLoraモデルをトレーニングし、特定のスタイル変換を行うこともサポートしています。
|
| 25 |
+
|
| 26 |
+
異なるプラットフォームからのクイックスタートをサポートします。詳細は[クイックスタート](#クイックスタート)を参照してください。
|
| 27 |
+
|
| 28 |
+
新機能:
|
| 29 |
+
- Wan 2.2シリーズモデル、Wan-VACE制御モデル、Fantasy Talkingデジタルヒューマンモデル、Qwen-Image、Flux画像生成モデルなどのサポートを追加しました。[2025.10.16]
|
| 30 |
+
- Wan2.1-Fun-V1.1バージョンを更新:14Bと1.3BモデルのControl+参照画像モデルをサポート、カメラ制御にも対応。さらに、Inpaintモデルを再訓練し、性能が向上しました。[2025.04.25]
|
| 31 |
+
- Wan2.1-Fun-V1.0の更新:14Bおよび1.3BのI2V(画像からビデオ)モデルとControlモデルをサポートし、開始フレームと終了フレームの予測に対応。[2025.03.26]
|
| 32 |
+
- CogVideoX-Fun-V1.5の更新:I2Vモデルと関連するトレーニング・予測コードをアップロード。[2024.12.16]
|
| 33 |
+
- 報酬Loraのサポート:報酬逆伝播技術を使用してLoraをトレーニングし、生成された動画を最適化し、人間の好みによりよく一致させる。[詳細情報](scripts/README_TRAIN_REWARD.md)。新しいバージョンの制御モデルでは、Canny、Depth、Pose、MLSDなどの異なる制御条件に対応。[2024.11.21]
|
| 34 |
+
- diffusersのサポート:CogVideoX-Fun Controlがdiffusersでサポートされるようになりました。[a-r-r-o-w](https://github.com/a-r-r-o-w)がこの[PR](https://github.com/huggingface/diffusers/pull/9671)でサポートを提供してくれたことに感謝します。詳細は[ドキュメント](https://huggingface.co/docs/diffusers/main/en/api/pipelines/cogvideox)をご覧ください。[2024.10.16]
|
| 35 |
+
- CogVideoX-Fun-V1.1の更新:i2vモデルを再トレーニングし、Noiseを追加して動画の動きの範囲を拡大。制御モデルのトレーニングコードとControlモデルをアップロード。[2024.09.29]
|
| 36 |
+
- CogVideoX-Fun-V1.0の更新:コードを作成!WindowsとLinuxに対応しました。2Bおよび5Bモデルでの最大256x256x49から1024x1024x49までの任意の解像度の動画生成をサポート。[2024.09.18]
|
| 37 |
+
|
| 38 |
+
機能:
|
| 39 |
+
- [データ前処理](#data-preprocess)
|
| 40 |
+
- [DiTのトレーニング](#dit-train)
|
| 41 |
+
- [ビデオ生成](#video-gen)
|
| 42 |
+
|
| 43 |
+
私たちのUIインターフェースは次のとおりです:
|
| 44 |
+

|
| 45 |
+
|
| 46 |
+
# クイックスタート
|
| 47 |
+
### 1. クラウド使用: AliyunDSW/Docker
|
| 48 |
+
#### a. AliyunDSWから
|
| 49 |
+
DSWには無料のGPU時間があり、ユーザーは一度申請でき、申請後3か月間有効です。
|
| 50 |
+
|
| 51 |
+
Aliyunは[Freetier](https://free.aliyun.com/?product=9602825&crowd=enterprise&spm=5176.28055625.J_5831864660.1.e939154aRgha4e&scm=20140722.M_9974135.P_110.MO_1806-ID_9974135-MID_9974135-CID_30683-ST_8512-V_1)で無料のGPU時間を提供しています。取得してAliyun PAI-DSWで使用し、5分以内にCogVideoX-Funを開始できます!
|
| 52 |
+
|
| 53 |
+
[](https://gallery.pai-ml.com/#/preview/deepLearning/cv/cogvideox_fun)
|
| 54 |
+
|
| 55 |
+
#### b. ComfyUIから
|
| 56 |
+
私たちのComfyUIは次のとおりです。詳細は[ComfyUI README](comfyui/README.md)を参照してください。
|
| 57 |
+

|
| 58 |
+
|
| 59 |
+
#### c. Dockerから
|
| 60 |
+
Dockerを使用する場合、マシンにグラフィックスカードドライバとCUDA環境が正しくインストールされていることを確認してください。
|
| 61 |
+
|
| 62 |
+
次のコ��ンドをこの方法で実行します:
|
| 63 |
+
|
| 64 |
+
```
|
| 65 |
+
# イメージをプル
|
| 66 |
+
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:cogvideox_fun
|
| 67 |
+
|
| 68 |
+
# イメージに入る
|
| 69 |
+
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:cogvideox_fun
|
| 70 |
+
|
| 71 |
+
# コードをクローン
|
| 72 |
+
git clone https://github.com/aigc-apps/VideoX-Fun.git
|
| 73 |
+
|
| 74 |
+
# VideoX-Funのディレクトリに入る
|
| 75 |
+
cd VideoX-Fun
|
| 76 |
+
|
| 77 |
+
# 重みをダウンロード
|
| 78 |
+
mkdir models/Diffusion_Transformer
|
| 79 |
+
mkdir models/Personalized_Model
|
| 80 |
+
|
| 81 |
+
# Please use the hugginface link or modelscope link to download the model.
|
| 82 |
+
# CogVideoX-Fun
|
| 83 |
+
# https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-InP
|
| 84 |
+
# https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-InP
|
| 85 |
+
|
| 86 |
+
# Wan
|
| 87 |
+
# https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-InP
|
| 88 |
+
# https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-InP
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
### 2. ローカルインストール: 環境チェック/ダウンロード/インストール
|
| 92 |
+
#### a. 環境チェック
|
| 93 |
+
以下の環境でこのライブラリの実行を確認しています:
|
| 94 |
+
|
| 95 |
+
Windowsの詳細:
|
| 96 |
+
- OS: Windows 10
|
| 97 |
+
- python: python3.10 & python3.11
|
| 98 |
+
- pytorch: torch2.2.0
|
| 99 |
+
- CUDA: 11.8 & 12.1
|
| 100 |
+
- CUDNN: 8+
|
| 101 |
+
- GPU: Nvidia-3060 12G & Nvidia-3090 24G
|
| 102 |
+
|
| 103 |
+
Linuxの詳細:
|
| 104 |
+
- OS: Ubuntu 20.04, CentOS
|
| 105 |
+
- python: python3.10 & python3.11
|
| 106 |
+
- pytorch: torch2.2.0
|
| 107 |
+
- CUDA: 11.8 & 12.1
|
| 108 |
+
- CUDNN: 8+
|
| 109 |
+
- GPU:Nvidia-V100 16G & Nvidia-A10 24G & Nvidia-A100 40G & Nvidia-A100 80G
|
| 110 |
+
|
| 111 |
+
重みを保存するために約60GBのディスクスペースが必要です。確認してください!
|
| 112 |
+
|
| 113 |
+
#### b. 重み
|
| 114 |
+
[重み](#model-zoo)を指定されたパスに配置することをお勧めします:
|
| 115 |
+
|
| 116 |
+
**ComfyUIを通じて**:
|
| 117 |
+
モデルをComfyUIの重みフォルダ `ComfyUI/models/Fun_Models/` に入れます:
|
| 118 |
+
```
|
| 119 |
+
📦 ComfyUI/
|
| 120 |
+
├── 📂 models/
|
| 121 |
+
│ └── 📂 Fun_Models/
|
| 122 |
+
│ ├── 📂 CogVideoX-Fun-V1.1-2b-InP/
|
| 123 |
+
│ ├── 📂 CogVideoX-Fun-V1.1-5b-InP/
|
| 124 |
+
│ ├── 📂 Wan2.1-Fun-V1.1-14B-InP
|
| 125 |
+
│ └── 📂 Wan2.1-Fun-V1.1-1.3B-InP/
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
**独自のpythonファイルまたはUIインターフェースを実行**:
|
| 129 |
+
```
|
| 130 |
+
📦 models/
|
| 131 |
+
├── 📂 Diffusion_Transformer/
|
| 132 |
+
│ ├── 📂 CogVideoX-Fun-V1.1-2b-InP/
|
| 133 |
+
│ ├── 📂 CogVideoX-Fun-V1.1-5b-InP/
|
| 134 |
+
│ ├── 📂 Wan2.1-Fun-V1.1-14B-InP
|
| 135 |
+
│ └── 📂 Wan2.1-Fun-V1.1-1.3B-InP/
|
| 136 |
+
├── 📂 Personalized_Model/
|
| 137 |
+
│ └── あなたのトレーニング済みのトランスフォーマーモデル / あなたのトレーニング済みのLoraモデル(UIロード用)
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
# ビデオ結果
|
| 141 |
+
|
| 142 |
+
### Wan2.1-Fun-V1.1-14B-InP && Wan2.1-Fun-V1.1-1.3B-InP
|
| 143 |
+
|
| 144 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 145 |
+
<tr>
|
| 146 |
+
<td>
|
| 147 |
+
<video src="https://github.com/user-attachments/assets/d6a46051-8fe6-4174-be12-95ee52c96298" width="100%" controls autoplay loop></video>
|
| 148 |
+
</td>
|
| 149 |
+
<td>
|
| 150 |
+
<video src="https://github.com/user-attachments/assets/8572c656-8548-4b1f-9ec8-8107c6236cb1" width="100%" controls autoplay loop></video>
|
| 151 |
+
</td>
|
| 152 |
+
<td>
|
| 153 |
+
<video src="https://github.com/user-attachments/assets/d3411c95-483d-4e30-bc72-483c2b288918" width="100%" controls autoplay loop></video>
|
| 154 |
+
</td>
|
| 155 |
+
<td>
|
| 156 |
+
<video src="https://github.com/user-attachments/assets/b2f5addc-06bd-49d9-b925-973090a32800" width="100%" controls autoplay loop></video>
|
| 157 |
+
</td>
|
| 158 |
+
</tr>
|
| 159 |
+
</table>
|
| 160 |
+
|
| 161 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 162 |
+
<tr>
|
| 163 |
+
<td>
|
| 164 |
+
<video src="https://github.com/user-attachments/assets/747b6ab8-9617-4ba2-84a0-b51c0efbd4f8" width="100%" controls autoplay loop></video>
|
| 165 |
+
</td>
|
| 166 |
+
<td>
|
| 167 |
+
<video src="https://github.com/user-attachments/assets/ae94dcda-9d5e-4bae-a86f-882c4282a367" width="100%" controls autoplay loop></video>
|
| 168 |
+
</td>
|
| 169 |
+
<td>
|
| 170 |
+
<video src="https://github.com/user-attachments/assets/a4aa1a82-e162-4ab5-8f05-72f79568a191" width="100%" controls autoplay loop></video>
|
| 171 |
+
</td>
|
| 172 |
+
<td>
|
| 173 |
+
<video src="https://github.com/user-attachments/assets/83c005b8-ccbc-44a0-a845-c0472763119c" width="100%" controls autoplay loop></video>
|
| 174 |
+
</td>
|
| 175 |
+
</tr>
|
| 176 |
+
</table>
|
| 177 |
+
|
| 178 |
+
### Wan2.1-Fun-V1.1-14B-Control && Wan2.1-Fun-V1.1-1.3B-Control
|
| 179 |
+
|
| 180 |
+
Generic Control Video + Reference Image:
|
| 181 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 182 |
+
<tr>
|
| 183 |
+
<td>
|
| 184 |
+
Reference Image
|
| 185 |
+
</td>
|
| 186 |
+
<td>
|
| 187 |
+
Control Video
|
| 188 |
+
</td>
|
| 189 |
+
<td>
|
| 190 |
+
Wan2.1-Fun-V1.1-14B-Control
|
| 191 |
+
</td>
|
| 192 |
+
<td>
|
| 193 |
+
Wan2.1-Fun-V1.1-1.3B-Control
|
| 194 |
+
</td>
|
| 195 |
+
<tr>
|
| 196 |
+
<td>
|
| 197 |
+
<image src="https://github.com/user-attachments/assets/221f2879-3b1b-4fbd-84f9-c3e0b0b3533e" width="100%" controls autoplay loop></image>
|
| 198 |
+
</td>
|
| 199 |
+
<td>
|
| 200 |
+
<video src="https://github.com/user-attachments/assets/f361af34-b3b3-4be4-9d03-cd478cb3dfc5" width="100%" controls autoplay loop></video>
|
| 201 |
+
</td>
|
| 202 |
+
<td>
|
| 203 |
+
<video src="https://github.com/user-attachments/assets/85e2f00b-6ef0-4922-90ab-4364afb2c93d" width="100%" controls autoplay loop></video>
|
| 204 |
+
</td>
|
| 205 |
+
<td>
|
| 206 |
+
<video src="https://github.com/user-attachments/assets/1f3fe763-2754-4215-bc9a-ae804950d4b3" width="100%" controls autoplay loop></video>
|
| 207 |
+
</td>
|
| 208 |
+
<tr>
|
| 209 |
+
</table>
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
Generic Control Video (Canny, Pose, Depth, etc.) and Trajectory Control:
|
| 213 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 214 |
+
<tr>
|
| 215 |
+
<td>
|
| 216 |
+
<video src="https://github.com/user-attachments/assets/f35602c4-9f0a-4105-9762-1e3a88abbac6" width="100%" controls autoplay loop></video>
|
| 217 |
+
</td>
|
| 218 |
+
<td>
|
| 219 |
+
<video src="https://github.com/user-attachments/assets/8b0f0e87-f1be-4915-bb35-2d53c852333e" width="100%" controls autoplay loop></video>
|
| 220 |
+
</td>
|
| 221 |
+
<td>
|
| 222 |
+
<video src="https://github.com/user-attachments/assets/972012c1-772b-427a-bce6-ba8b39edcfad" width="100%" controls autoplay loop></video>
|
| 223 |
+
</td>
|
| 224 |
+
<tr>
|
| 225 |
+
</table>
|
| 226 |
+
|
| 227 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 228 |
+
<tr>
|
| 229 |
+
<td>
|
| 230 |
+
<video src="https://github.com/user-attachments/assets/ce62d0bd-82c0-4d7b-9c49-7e0e4b605745" width="100%" controls autoplay loop></video>
|
| 231 |
+
</td>
|
| 232 |
+
<td>
|
| 233 |
+
<video src="https://github.com/user-attachments/assets/89dfbffb-c4a6-4821-bcef-8b1489a3ca00" width="100%" controls autoplay loop></video>
|
| 234 |
+
</td>
|
| 235 |
+
<td>
|
| 236 |
+
<video src="https://github.com/user-attachments/assets/72a43e33-854f-4349-861b-c959510d1a84" width="100%" controls autoplay loop></video>
|
| 237 |
+
</td>
|
| 238 |
+
<tr>
|
| 239 |
+
<td>
|
| 240 |
+
<video src="https://github.com/user-attachments/assets/bb0ce13d-dee0-4049-9eec-c92f3ebc1358" width="100%" controls autoplay loop></video>
|
| 241 |
+
</td>
|
| 242 |
+
<td>
|
| 243 |
+
<video src="https://github.com/user-attachments/assets/7840c333-7bec-4582-ba63-20a39e1139c4" width="100%" controls autoplay loop></video>
|
| 244 |
+
</td>
|
| 245 |
+
<td>
|
| 246 |
+
<video src="https://github.com/user-attachments/assets/85147d30-ae09-4f36-a077-2167f7a578c0" width="100%" controls autoplay loop></video>
|
| 247 |
+
</td>
|
| 248 |
+
</tr>
|
| 249 |
+
</table>
|
| 250 |
+
|
| 251 |
+
### Wan2.1-Fun-V1.1-14B-Control-Camera && Wan2.1-Fun-V1.1-1.3B-Control-Camera
|
| 252 |
+
|
| 253 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 254 |
+
<tr>
|
| 255 |
+
<td>
|
| 256 |
+
Pan Up
|
| 257 |
+
</td>
|
| 258 |
+
<td>
|
| 259 |
+
Pan Left
|
| 260 |
+
</td>
|
| 261 |
+
<td>
|
| 262 |
+
Pan Right
|
| 263 |
+
</td>
|
| 264 |
+
<tr>
|
| 265 |
+
<td>
|
| 266 |
+
<video src="https://github.com/user-attachments/assets/869fe2ef-502a-484e-8656-fe9e626b9f63" width="100%" controls autoplay loop></video>
|
| 267 |
+
</td>
|
| 268 |
+
<td>
|
| 269 |
+
<video src="https://github.com/user-attachments/assets/2d4185c8-d6ec-4831-83b4-b1dbfc3616fa" width="100%" controls autoplay loop></video>
|
| 270 |
+
</td>
|
| 271 |
+
<td>
|
| 272 |
+
<video src="https://github.com/user-attachments/assets/7dfb7cad-ed24-4acc-9377-832445a07ec7" width="100%" controls autoplay loop></video>
|
| 273 |
+
</td>
|
| 274 |
+
<tr>
|
| 275 |
+
<td>
|
| 276 |
+
Pan Down
|
| 277 |
+
</td>
|
| 278 |
+
<td>
|
| 279 |
+
Pan Up + Pan Left
|
| 280 |
+
</td>
|
| 281 |
+
<td>
|
| 282 |
+
Pan Up + Pan Right
|
| 283 |
+
</td>
|
| 284 |
+
<tr>
|
| 285 |
+
<td>
|
| 286 |
+
<video src="https://github.com/user-attachments/assets/3ea3a08d-f2df-43a2-976e-bf2659345373" width="100%" controls autoplay loop></video>
|
| 287 |
+
</td>
|
| 288 |
+
<td>
|
| 289 |
+
<video src="https://github.com/user-attachments/assets/4a85b028-4120-4293-886b-b8afe2d01713" width="100%" controls autoplay loop></video>
|
| 290 |
+
</td>
|
| 291 |
+
<td>
|
| 292 |
+
<video src="https://github.com/user-attachments/assets/ad0d58c1-13ef-450c-b658-4fed7ff5ed36" width="100%" controls autoplay loop></video>
|
| 293 |
+
</td>
|
| 294 |
+
</tr>
|
| 295 |
+
</table>
|
| 296 |
+
|
| 297 |
+
### CogVideoX-Fun-V1.1-5B
|
| 298 |
+
|
| 299 |
+
解像度-1024
|
| 300 |
+
|
| 301 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 302 |
+
<tr>
|
| 303 |
+
<td>
|
| 304 |
+
<video src="https://github.com/user-attachments/assets/34e7ec8f-293e-4655-bb14-5e1ee476f788" width="100%" controls autoplay loop></video>
|
| 305 |
+
</td>
|
| 306 |
+
<td>
|
| 307 |
+
<video src="https://github.com/user-attachments/assets/7809c64f-eb8c-48a9-8bdc-ca9261fd5434" width="100%" controls autoplay loop></video>
|
| 308 |
+
</td>
|
| 309 |
+
<td>
|
| 310 |
+
<video src="https://github.com/user-attachments/assets/8e76aaa4-c602-44ac-bcb4-8b24b72c386c" width="100%" controls autoplay loop></video>
|
| 311 |
+
</td>
|
| 312 |
+
<td>
|
| 313 |
+
<video src="https://github.com/user-attachments/assets/19dba894-7c35-4f25-b15c-384167ab3b03" width="100%" controls autoplay loop></video>
|
| 314 |
+
</td>
|
| 315 |
+
</tr>
|
| 316 |
+
</table>
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
解像度-768
|
| 320 |
+
|
| 321 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 322 |
+
<tr>
|
| 323 |
+
<td>
|
| 324 |
+
<video src="https://github.com/user-attachments/assets/0bc339b9-455b-44fd-8917-80272d702737" width="100%" controls autoplay loop></video>
|
| 325 |
+
</td>
|
| 326 |
+
<td>
|
| 327 |
+
<video src="https://github.com/user-attachments/assets/70a043b9-6721-4bd9-be47-78b7ec5c27e9" width="100%" controls autoplay loop></video>
|
| 328 |
+
</td>
|
| 329 |
+
<td>
|
| 330 |
+
<video src="https://github.com/user-attachments/assets/d5dd6c09-14f3-40f8-8b6d-91e26519b8ac" width="100%" controls autoplay loop></video>
|
| 331 |
+
</td>
|
| 332 |
+
<td>
|
| 333 |
+
<video src="https://github.com/user-attachments/assets/9327e8bc-4f17-46b0-b50d-38c250a9483a" width="100%" controls autoplay loop></video>
|
| 334 |
+
</td>
|
| 335 |
+
</tr>
|
| 336 |
+
</table>
|
| 337 |
+
|
| 338 |
+
解像度-512
|
| 339 |
+
|
| 340 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 341 |
+
<tr>
|
| 342 |
+
<td>
|
| 343 |
+
<video src="https://github.com/user-attachments/assets/ef407030-8062-454d-aba3-131c21e6b58c" width="100%" controls autoplay loop></video>
|
| 344 |
+
</td>
|
| 345 |
+
<td>
|
| 346 |
+
<video src="https://github.com/user-attachments/assets/7610f49e-38b6-4214-aa48-723ae4d1b07e" width="100%" controls autoplay loop></video>
|
| 347 |
+
</td>
|
| 348 |
+
<td>
|
| 349 |
+
<video src="https://github.com/user-attachments/assets/1fff0567-1e15-415c-941e-53ee8ae2c841" width="100%" controls autoplay loop></video>
|
| 350 |
+
</td>
|
| 351 |
+
<td>
|
| 352 |
+
<video src="https://github.com/user-attachments/assets/bcec48da-b91b-43a0-9d50-cf026e00fa4f" width="100%" controls autoplay loop></video>
|
| 353 |
+
</td>
|
| 354 |
+
</tr>
|
| 355 |
+
</table>
|
| 356 |
+
|
| 357 |
+
### CogVideoX-Fun-V1.1-5B-Control
|
| 358 |
+
|
| 359 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 360 |
+
<tr>
|
| 361 |
+
<td>
|
| 362 |
+
<video src="https://github.com/user-attachments/assets/53002ce2-dd18-4d4f-8135-b6f68364cabd" width="100%" controls autoplay loop></video>
|
| 363 |
+
</td>
|
| 364 |
+
<td>
|
| 365 |
+
<video src="https://github.com/user-attachments/assets/a1a07cf8-d86d-4cd2-831f-18a6c1ceee1d" width="100%" controls autoplay loop></video>
|
| 366 |
+
</td>
|
| 367 |
+
<td>
|
| 368 |
+
<video src="https://github.com/user-attachments/assets/3224804f-342d-4947-918d-d9fec8e3d273" width="100%" controls autoplay loop></video>
|
| 369 |
+
</td>
|
| 370 |
+
<tr>
|
| 371 |
+
<td>
|
| 372 |
+
美しい澄んだ目と金髪の若い女性が白い服を着て体をひねり、カメラは彼女の顔に焦点を合わせています。高品質、傑作、最高品質、高解像度、超微細、夢のような。
|
| 373 |
+
</td>
|
| 374 |
+
<td>
|
| 375 |
+
美しい澄んだ目と金髪の若い女性が白い服を着て体をひねり、カメラは彼女の顔に焦点を合わせています。高品質、傑作、最高品質、高解像度、超微細、夢のような。
|
| 376 |
+
</td>
|
| 377 |
+
<td>
|
| 378 |
+
若いクマ。
|
| 379 |
+
</td>
|
| 380 |
+
</tr>
|
| 381 |
+
<tr>
|
| 382 |
+
<td>
|
| 383 |
+
<video src="https://github.com/user-attachments/assets/ea908454-684b-4d60-b562-3db229a250a9" width="100%" controls autoplay loop></video>
|
| 384 |
+
</td>
|
| 385 |
+
<td>
|
| 386 |
+
<video src="https://github.com/user-attachments/assets/ffb7c6fc-8b69-453b-8aad-70dfae3899b9" width="100%" controls autoplay loop></video>
|
| 387 |
+
</td>
|
| 388 |
+
<td>
|
| 389 |
+
<video src="https://github.com/user-attachments/assets/d3f757a3-3551-4dcb-9372-7a61469813f5" width="100%" controls autoplay loop></video>
|
| 390 |
+
</td>
|
| 391 |
+
</tr>
|
| 392 |
+
</table>
|
| 393 |
+
|
| 394 |
+
# 使い方
|
| 395 |
+
|
| 396 |
+
<h3 id="video-gen">1. 生成</h3>
|
| 397 |
+
|
| 398 |
+
#### a. GPUメモリ節約方法
|
| 399 |
+
Wan2.1のパラメータが非常に大きいため、GPUメモリを節約し、コンシューマー向けGPUに適応させる必要があります。各予測ファイルには`GPU_memory_mode`を提供しており、`model_cpu_offload`、`model_cpu_offload_and_qfloat8`、`sequential_cpu_offload`の中から選択できます。この方法はCogVideoX-Funの生成にも適用されます。
|
| 400 |
+
|
| 401 |
+
- `model_cpu_offload`: モデル全体が使用後にCPUに移動し、一部のGPUメモリを節約します。
|
| 402 |
+
- `model_cpu_offload_and_qfloat8`: モデル全体が使用後にCPUに移動し、Transformerモデルに対してfloat8の量子化を行い、より多くのGPUメモリを節約します。
|
| 403 |
+
- `sequential_cpu_offload`: モデルの各層が使用後にCPUに移動します。速度は遅くなりますが、大量のGPUメモリを節約します。
|
| 404 |
+
|
| 405 |
+
`qfloat8`はモデルの性能を部分的に低下させる可能性がありますが、より多くのGPUメモリを節約できます。十分なGPUメモリがある場合は、`model_cpu_offload`の使用をお勧めします。
|
| 406 |
+
|
| 407 |
+
#### b. ComfyUIを使用する
|
| 408 |
+
詳細は[ComfyUI README](comfyui/README.md)をご覧ください。
|
| 409 |
+
|
| 410 |
+
#### c. Pythonファイルを実行する
|
| 411 |
+
|
| 412 |
+
##### i. 単一GPUでの推論:
|
| 413 |
+
|
| 414 |
+
- ステップ1: 対応する[重み](#model-zoo)をダウンロードし、`models`フォルダに配置します。
|
| 415 |
+
- ステップ2: 異なる重みと予測目標に基づいて、異なるファイルを使用して予測を行います。現在、このライブラリはCogVideoX-Fun、Wan2.1、およびWan2.1-Funをサポートしています。`examples`フォルダ内のフォルダ名で区別され、異なるモデルがサポートする機能が異なりますので、状況に応じて区別してください。以下はCogVideoX-Funを例として説明します。
|
| 416 |
+
- テキストからビデオ:
|
| 417 |
+
- `examples/cogvideox_fun/predict_t2v.py`ファイルで`prompt`、`neg_prompt`、`guidance_scale`、`seed`を変更します。
|
| 418 |
+
- 次に、`examples/cogvideox_fun/predict_t2v.py`ファイルを実行し、結果が生成されるのを待ちます。結果は`samples/cogvideox-fun-videos`フォルダに保存されます。
|
| 419 |
+
- 画像からビデオ:
|
| 420 |
+
- `examples/cogvideox_fun/predict_i2v.py`ファイルで`validation_image_start`、`validation_image_end`、`prompt`、`neg_prompt`、`guidance_scale`、`seed`を変更します。
|
| 421 |
+
- `validation_image_start`はビデオの開始画像、`validation_image_end`はビデオの終了画像です。
|
| 422 |
+
- 次に、`examples/cogvideox_fun/predict_i2v.py`ファイルを実行し、結果が生成されるのを待ちます。結果は`samples/cogvideox-fun-videos_i2v`フォルダに保存されます。
|
| 423 |
+
- ビデオからビデオ:
|
| 424 |
+
- `examples/cogvideox_fun/predict_v2v.py`ファイルで`validation_video`、`validation_image_end`、`prompt`、`neg_prompt`、`guidance_scale`、`seed`を変更します。
|
| 425 |
+
- `validation_video`はビデオ生成のための参照ビデオです。以下のデモビデオを使用して実行できます:[デモビデオ](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1/play_guitar.mp4)
|
| 426 |
+
- 次に、`examples/cogvideox_fun/predict_v2v.py`ファイルを実行し、結果が生成されるのを待ちます。結果は`samples/cogvideox-fun-videos_v2v`フォルダに保存されます。
|
| 427 |
+
- 通常の制御付きビデオ生成(Canny、Pose、Depthなど):
|
| 428 |
+
- `examples/cogvideox_fun/predict_v2v_control.py`ファイルで`control_video`、`validation_image_end`、`prompt`、`neg_prompt`、`guidance_scale`、`seed`を変更します。
|
| 429 |
+
- `control_video`は、Canny、Pose、Depthなどの演算子で抽出された制御用ビデオです。以下のデモビデオを使用して実行できます:[デモビデオ](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.1/pose.mp4)
|
| 430 |
+
- 次に、`examples/cogvideox_fun/predict_v2v_control.py`ファイルを実行し、結果が生成されるのを待ちます。結果は`samples/cogvideox-fun-videos_v2v_control`フォルダに保存されます。
|
| 431 |
+
- ステップ3: 自分でトレーニングした他のバックボーンやLoraを組み合わせたい場合は、必要に応じて`examples/{model_name}/predict_t2v.py`や`examples/{model_name}/predict_i2v.py`、`lora_path`を修正します。
|
| 432 |
+
|
| 433 |
+
##### ii. 複数GPUでの推論:
|
| 434 |
+
多カードでの推論を行う際は、xfuserリポジトリのインストールに注意してください。xfuser==0.4.2 と yunchang==0.6.2 のインストールが推奨されます。
|
| 435 |
+
```
|
| 436 |
+
pip install xfuser==0.4.2 --progress-bar off -i https://mirrors.aliyun.com/pypi/simple/
|
| 437 |
+
pip install yunchang==0.6.2 --progress-bar off -i https://mirrors.aliyun.com/pypi/simple/
|
| 438 |
+
```
|
| 439 |
+
|
| 440 |
+
`ulysses_degree` と `ring_degree` の積が使用する GPU 数と一致することを確認してください。たとえば、8つのGPUを使用する場合、`ulysses_degree=2` と `ring_degree=4`、または `ulysses_degree=4` と `ring_degree=2` を設定することができます。
|
| 441 |
+
|
| 442 |
+
- `ulysses_degree` はヘッド(head)に分割した後の並列化を行います。
|
| 443 |
+
- `ring_degree` はシーケンスに分割した後の並列化を行います。
|
| 444 |
+
|
| 445 |
+
`ring_degree` は `ulysses_degree` よりも通信コストが高いため、これらのパラメータを設定する際には、シーケンス長とモデルのヘッド数を考慮する必要があります。
|
| 446 |
+
|
| 447 |
+
8GPUでの並列推論を例に挙げます:
|
| 448 |
+
|
| 449 |
+
- **Wan2.1-Fun-V1.1-14B-InP** はヘッド数が40あります。この場合、`ulysses_degree` は40で割り切れる値(例:2, 4, 8など)に設定する必要があります。したがって、8GPUを使用して並列推論を行う場合、`ulysses_degree=8` と `ring_degree=1` を設定できます。
|
| 450 |
+
|
| 451 |
+
- **Wan2.1-Fun-V1.1-1.3B-InP** はヘッド数が12あります。この場合、`ulysses_degree` は12で割り切れる値(例:2, 4など)に設定する必要があります。したがって、8GPUを使用して並列推論を行う場合、`ulysses_degree=4` と `ring_degree=2` を設定できます。
|
| 452 |
+
|
| 453 |
+
パラメータの設定が完了したら、以下のコマンドで並列推論を実行してください:
|
| 454 |
+
|
| 455 |
+
```sh
|
| 456 |
+
torchrun --nproc-per-node=8 examples/wan2.1_fun/predict_t2v.py
|
| 457 |
+
```
|
| 458 |
+
|
| 459 |
+
#### d. UIインターフェースを使用する
|
| 460 |
+
|
| 461 |
+
WebUIは、テキストからビデオ、画像からビデオ、ビデオからビデオ、および通常の制御付きビデオ生成(Canny、Pose、Depthなど)をサポートします。現在、このライブラリはCogVideoX-Fun、Wan2.1、およびWan2.1-Funをサポートしており、`examples`フォルダ内のフォルダ名で区別されています。異なるモデルがサポートする機能が異なるため、状況に応じて区別してください。以下はCogVideoX-Funを例として説明します。
|
| 462 |
+
|
| 463 |
+
- ステップ1: 対応する[重み](#model-zoo)をダウンロードし、`models`フォルダに配置します。
|
| 464 |
+
- ステップ2: `examples/cogvideox_fun/app.py`ファイルを実行し、Gradioページに入ります。
|
| 465 |
+
- ステップ3: ページ上で生成モデルを選択し、`prompt`、`neg_prompt`、`guidance_scale`、`seed`などを入力し、「生成」をクリックして結果が生成されるのを待ちます。結果は`sample`フォルダに保存されます。
|
| 466 |
+
|
| 467 |
+
### 2. モデルのトレーニング
|
| 468 |
+
完全なモデルトレーニングの流れには、データの前処理とVideo DiTのトレーニングが含まれるべきです。異なるモデルのトレーニングプロセスは類似しており、データ形式も類似しています:
|
| 469 |
+
|
| 470 |
+
<h4 id="data-preprocess">a. データ前処理</h4>
|
| 471 |
+
|
| 472 |
+
画像データを使用してLoraモデルをトレーニングする簡単なデモを提供しました。詳細は[wiki](https://github.com/aigc-apps/CogVideoX-Fun/wiki/Training-Lora)をご覧ください。
|
| 473 |
+
|
| 474 |
+
長いビデオのセグメンテーション、クリーニング、説明のための完全なデータ前処理リンクは、ビデオキャプションセクションの[README](cogvideox/video_caption/README.md)を参照してください。
|
| 475 |
+
|
| 476 |
+
テキストから画像およびビデオ生成モデルをトレーニングしたい場合。この形式でデータセットを配置する必要があります。
|
| 477 |
+
|
| 478 |
+
```
|
| 479 |
+
📦 project/
|
| 480 |
+
├── 📂 datasets/
|
| 481 |
+
│ ├── 📂 internal_datasets/
|
| 482 |
+
│ ├── 📂 train/
|
| 483 |
+
│ │ ├── 📄 00000001.mp4
|
| 484 |
+
│ │ ├── 📄 00000002.jpg
|
| 485 |
+
│ │ └── 📄 .....
|
| 486 |
+
│ └── 📄 json_of_internal_datasets.json
|
| 487 |
+
```
|
| 488 |
+
|
| 489 |
+
json_of_internal_datasets.jsonは標準のJSONファイルです。json内のfile_pathは相対パスとして設定できます。以下のように:
|
| 490 |
+
```json
|
| 491 |
+
[
|
| 492 |
+
{
|
| 493 |
+
"file_path": "train/00000001.mp4",
|
| 494 |
+
"text": "スーツとサングラスを着た若い男性のグループが街の通りを歩いている。",
|
| 495 |
+
"type": "video"
|
| 496 |
+
},
|
| 497 |
+
{
|
| 498 |
+
"file_path": "train/00000002.jpg",
|
| 499 |
+
"text": "スーツとサングラスを着た若い男性のグループが街の通りを歩いている。",
|
| 500 |
+
"type": "image"
|
| 501 |
+
},
|
| 502 |
+
.....
|
| 503 |
+
]
|
| 504 |
+
```
|
| 505 |
+
|
| 506 |
+
次のように絶対パスとして設定することもできます:
|
| 507 |
+
```json
|
| 508 |
+
[
|
| 509 |
+
{
|
| 510 |
+
"file_path": "/mnt/data/videos/00000001.mp4",
|
| 511 |
+
"text": "スーツとサングラスを着た若い男性のグループが街の通りを歩いている。",
|
| 512 |
+
"type": "video"
|
| 513 |
+
},
|
| 514 |
+
{
|
| 515 |
+
"file_path": "/mnt/data/train/00000001.jpg",
|
| 516 |
+
"text": "スーツとサングラスを着た若い男性のグループが街の通りを歩いている。",
|
| 517 |
+
"type": "image"
|
| 518 |
+
},
|
| 519 |
+
.....
|
| 520 |
+
]
|
| 521 |
+
```
|
| 522 |
+
|
| 523 |
+
<h4 id="dit-train">b. Video DiTトレーニング </h4>
|
| 524 |
+
|
| 525 |
+
データ前処理時にデータ形式が相対パスの場合、```scripts/{model_name}/train.sh```を次のように設定します。
|
| 526 |
+
```
|
| 527 |
+
export DATASET_NAME="datasets/internal_datasets/"
|
| 528 |
+
export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
|
| 529 |
+
```
|
| 530 |
+
|
| 531 |
+
データ形式が絶対パスの場合、```scripts/train.sh```を次のように設定します。
|
| 532 |
+
```
|
| 533 |
+
export DATASET_NAME=""
|
| 534 |
+
export DATASET_META_NAME="/mnt/data/json_of_internal_datasets.json"
|
| 535 |
+
```
|
| 536 |
+
|
| 537 |
+
次に、scripts/train.shを実行します。
|
| 538 |
+
```sh
|
| 539 |
+
sh scripts/train.sh
|
| 540 |
+
```
|
| 541 |
+
いくつかのパラメータ設定の詳細について:
|
| 542 |
+
Wan2.1-Funは[Readme Train](scripts/wan2.1_fun/README_TRAIN.md)と[Readme Lora](scripts/wan2.1_fun/README_TRAIN_LORA.md)を参照してください。
|
| 543 |
+
Wan2.1は[Readme Train](scripts/wan2.1/README_TRAIN.md)と[Readme Lora](scripts/wan2.1/README_TRAIN_LORA.md)を参照してください。
|
| 544 |
+
CogVideoX-Funは[Readme Train](scripts/cogvideox_fun/README_TRAIN.md)と[Readme Lora](scripts/cogvideox_fun/README_TRAIN_LORA.md)を参照してください。
|
| 545 |
+
|
| 546 |
+
# モデルの場所
|
| 547 |
+
|
| 548 |
+
## 1. Wan2.2-Fun
|
| 549 |
+
|
| 550 |
+
| 名前 | ストレージ容量 | Hugging Face | Model Scope | 説明 |
|
| 551 |
+
|------|----------------|------------|-------------|------|
|
| 552 |
+
| Wan2.2-Fun-A14B-InP | 64.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-A14B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-A14B-InP) | Wan2.2-Fun-14Bのテキスト・画像から動画を生成するモデルの重み。複数の解像度で学習されており、動画の最初と最後のフレームの予測をサポートしています。 |
|
| 553 |
+
| Wan2.2-Fun-A14B-Control | 64.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-A14B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-A14B-Control) | Wan2.2-Fun-14Bの動画制御用重み。Canny、Depth、Pose、MLSDなどのさまざまな制御条件に対応しており、軌跡制御もサポートしています。512、768、1024の複数解像度での動画生成が可能で、81フレーム、16fpsで学習されています。多言語対応の予測もサポートしています。 |
|
| 554 |
+
| Wan2.2-Fun-A14B-Contro-Camera | 64.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/Wan2.2-Fun-A14B-Control-Camera) | [😄リンク](https://modelscope.cn/models/PAI/Wan2.2-Fun-A14B-Control-Camera)| Wan2.2-Fun-14Bのカメラレンズ制御重み。512、768、1024のマルチ解像度での動画予測をサポートし、81フレーム、毎秒16フレームで訓練されています。多言語予測に対応しています。 |
|
| 555 |
+
| Wan2.2-VACE-Fun-A14B | 64.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/Wan2.2-VACE-Fun-A14B) | [😄リンク](https://modelscope.cn/models/PAI/Wan2.2-VACE-Fun-A14B) | VACE方式でトレーニングされたWan2.2の制御ウェイト(ベースモデルはWan2.2-T2V-A14B)。Canny、Depth、Pose、MLSD、軌道制御などの異なる制御条件をサポートします。対象を指定して動画生成が可能です。多解像度(512、768、1024)の動画予測をサポートし、81フレームで16FPSでトレーニングされています。多言語予測にも対応しています。 |
|
| 556 |
+
| Wan2.2-Fun-5B-InP | 23.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-5B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-5B-InP) | Wan2.2-Fun-5B テキストから動画生成用の重み。121フレーム、24 FPSで学習され、先頭/末尾フレーム予測をサポート。 |
|
| 557 |
+
| Wan2.2-Fun-5B-Control | 23.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-5B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-5B-Control)| Wan2.2-Fun-5B 動画制御用重み。Canny、Depth、Pose、MLSDなどの制御条件や軌道制御をサポート。121フレーム、24 FPSで学習され、多言語予測に対応。 |
|
| 558 |
+
| Wan2.2-Fun-5B-Control-Camera | 23.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-5B-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-5B-Control-Camera)| Wan2.2-Fun-5B カメラレンズ制御用重み。121フレーム、24 FPSで学習され、多言語予測に対応。 |
|
| 559 |
+
|
| 560 |
+
## 2. Wan2.2
|
| 561 |
+
|
| 562 |
+
| モデル名 | Hugging Face | Model Scope | 説明 |
|
| 563 |
+
|--|--|--|--|
|
| 564 |
+
| Wan2.2-TI2V-5B | [🤗リンク](https://huggingface.co/Wan-AI/Wan2.2-TI2V-5B) | [😄リンク](https://www.modelscope.cn/models/Wan-AI/Wan2.2-TI2V-5B) | 万象2.2-5B テキストから動画生成重み |
|
| 565 |
+
| Wan2.2-T2V-A14B | [🤗リンク](https://huggingface.co/Wan-AI/Wan2.2-T2V-A14B) | [😄リンク](https://www.modelscope.cn/models/Wan-AI/Wan2.2-T2V-A14B) | 万象2.2-14B テキストから動画生成重み |
|
| 566 |
+
| Wan2.2-I2V-A14B | [🤗リンク](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B) | [😄リンク](https://www.modelscope.cn/models/Wan-AI/Wan2.2-I2V-A14B) | 万象2.2-14B 画像から動画生成重み |
|
| 567 |
+
|
| 568 |
+
## 3. Wan2.1-Fun
|
| 569 |
+
|
| 570 |
+
V1.1:
|
| 571 |
+
| 名称 | ストレージ容量 | Hugging Face | Model Scope | 説明 |
|
| 572 |
+
|--|--|--|--|--|
|
| 573 |
+
| Wan2.1-Fun-V1.1-1.3B-InP | 19.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-1.3B-InP) | [😄リンク](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-1.3B-InP) | Wan2.1-Fun-V1.1-1.3Bのテキスト・画像から動画生成の重み。マルチ解像度で訓練され、最初と最後の画像予測をサポートします。 |
|
| 574 |
+
| Wan2.1-Fun-V1.1-14B-InP | 47.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-InP) | [😄リンク](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-InP) | Wan2.1-Fun-V1.1-14Bのテキスト・画像から動画生成の重み。マルチ解像度で訓練され、最初と最後の画像予測をサポートします。 |
|
| 575 |
+
| Wan2.1-Fun-V1.1-1.3B-Control | 19.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-1.3B-Control) | [😄リンク](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-1.3B-Control)| Wan2.1-Fun-V1.1-1.3Bのビデオ制御重み。Canny、Depth、Pose、MLSDなどの異なる制御条件に対応し、参照画像+制御条件を使用した制御や軌跡制御をサポートします。512、768、1024のマルチ解像度での動画予測をサポートし、81フレーム、毎秒16フレームで訓練されています。多言語予測に対応しています。 |
|
| 576 |
+
| Wan2.1-Fun-V1.1-14B-Control | 47.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-Control) | [😄リンク](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-Control)| Wan2.1-Fun-V1.1-14Bのビデオ制御重み。Canny、Depth、Pose、MLSDなどの異なる制御条件に対応し、参照画像+制御条件を使用した制御や軌跡制御をサポートします。512、768、1024のマルチ解像度での動画予測をサポートし、81フレーム、毎秒16フレームで訓練されています。多言語予測に対応しています。 |
|
| 577 |
+
| Wan2.1-Fun-V1.1-1.3B-Control-Camera | 19.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-1.3B-Control-Camera) | [😄リンク](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-1.3B-Control-Camera)| Wan2.1-Fun-V1.1-1.3Bのカメラレ��ズ制御重み。512、768、1024のマルチ解像度での動画予測をサポートし、81フレーム、毎秒16フレームで訓練されています。多言語予測に対応しています。 |
|
| 578 |
+
| Wan2.1-Fun-V1.1-14B-Control-Camera | 47.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-Control-Camera) | [😄リンク](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-Control-Camera)| Wan2.1-Fun-V1.1-14Bのカメラレンズ制御重み。512、768、1024のマルチ解像度での動画予測をサポートし、81フレーム、毎秒16フレームで訓練されています。多言語予測に対応しています。 |
|
| 579 |
+
|
| 580 |
+
|
| 581 |
+
V1.0:
|
| 582 |
+
| 名称 | ストレージ容量 | Hugging Face | Model Scope | 説明 |
|
| 583 |
+
|--|--|--|--|--|
|
| 584 |
+
| Wan2.1-Fun-1.3B-InP | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-1.3B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-1.3B-InP) | Wan2.1-Fun-1.3Bのテキスト・画像から動画生成する重み。マルチ解像度で学習され、開始・終了画像予測をサポート。 |
|
| 585 |
+
| Wan2.1-Fun-14B-InP | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-14B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-14B-InP) | Wan2.1-Fun-14Bのテキスト・画像から動画生成する重み。マルチ解像度で学習され、開始・終了画像予測をサポート。 |
|
| 586 |
+
| Wan2.1-Fun-1.3B-Control | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-1.3B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-1.3B-Control) | Wan2.1-Fun-1.3Bのビデオ制御ウェイト。Canny、Depth、Pose、MLSDなどの異なる制御条件をサポートし、トラジェクトリ制御も利用可能。512、768、1024のマルチ解像度でのビデオ予測をサポートし、81フレーム(1秒間に16フレーム)でトレーニング済みで、多言語予測にも対応しています。 |
|
| 587 |
+
| Wan2.1-Fun-14B-Control | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-14B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-14B-Control) | Wan2.1-Fun-14Bのビデオ制御ウェイト。Canny、Depth、Pose、MLSDなどの異なる制御条件をサポートし、トラジェクトリ制御も利用可能。512、768、1024のマルチ解像度でのビデオ予測をサポートし、81フレーム(1秒間に16フレーム)でトレーニング済みで、多言語予測にも対応しています。 |
|
| 588 |
+
|
| 589 |
+
## 4. Wan2.1
|
| 590 |
+
|
| 591 |
+
| 名称 | Hugging Face | Model Scope | 説明 |
|
| 592 |
+
|--|--|--|--|
|
| 593 |
+
| Wan2.1-T2V-1.3B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-1.3B) | 万象2.1-1.3Bのテキストから動画生成する重み |
|
| 594 |
+
| Wan2.1-T2V-14B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-T2V-14B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-14B) | 万象2.1-14Bのテキストから動画生成する重み |
|
| 595 |
+
| Wan2.1-I2V-14B-480P | [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-480P) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-480P) | 万象2.1-14B-480Pの画像から動画生成する重み |
|
| 596 |
+
| Wan2.1-I2V-14B-720P| [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-720P) | 万象2.1-14B-720Pの画像から動画生成する重み |
|
| 597 |
+
|
| 598 |
+
## 5. FantasyTalking
|
| 599 |
+
|
| 600 |
+
| 名称 | ストレージ | Hugging Face | Model Scope | 説明 |
|
| 601 |
+
|--|--|--|--|--|
|
| 602 |
+
| Wan2.1-I2V-14B-720P | - | [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-720P) | 万象2.1-14B-720P 画像→動画モデルの重み |
|
| 603 |
+
| Wav2Vec | - | [🤗Link](https://huggingface.co/facebook/wav2vec2-base-960h) | [😄Link](https://modelscope.cn/models/AI-ModelScope/wav2vec2-base-960h) | Wav2Vecモデル。Wan2.1-I2V-14B-720Pフォルダ内に配置し、`audio_encoder` という名前に変更してください |
|
| 604 |
+
| FantasyTalking model | - | [🤗Link](https://huggingface.co/acvlab/FantasyTalking/) | [😄Link](https://www.modelscope.cn/models/amap_cvlab/FantasyTalking/) | 公式Audio Condition重み |
|
| 605 |
+
|
| 606 |
+
## 6. Qwen-Image
|
| 607 |
+
|
| 608 |
+
| 名称 | ストレージ | Hugging Face | Model Scope | 説明 |
|
| 609 |
+
|--|--|--|--|--|
|
| 610 |
+
| Qwen-Image | [🤗Link](https://huggingface.co/Qwen/Qwen-Image) | [😄Link](https://modelscope.cn/models/Qwen/Qwen-Image) | Qwen-Image 公式重み |
|
| 611 |
+
| Qwen-Image-Edit | [🤗Link](https://huggingface.co/Qwen/Qwen-Image-Edit) | [😄Link](https://modelscope.cn/models/Qwen/Qwen-Image-Edit) | Qwen-Image-Edit 公式重み |
|
| 612 |
+
| Qwen-Image-Edit-2509 | [🤗Link](https://huggingface.co/Qwen/Qwen-Image-Edit-2509) | [😄Link](https://modelscope.cn/models/Qwen/Qwen-Image-Edit-2509) | Qwen-Image-Edit-2509 公式重み |
|
| 613 |
+
|
| 614 |
+
## 7. Z-Image
|
| 615 |
+
|
| 616 |
+
| 名称 | ストレージ | Hugging Face | Model Scope | 説明 |
|
| 617 |
+
|--|--|--|--|--|
|
| 618 |
+
| Z-Image-Turbo | [🤗リンク](https://huggingface.co/Tongyi-MAI/Z-Image-Turbo) | [😄リンク](https://www.modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo) | Z-Image-Turboの公式重み |
|
| 619 |
+
|
| 620 |
+
## 8. Z-Image-Fun
|
| 621 |
+
|
| 622 |
+
| 名称 | ストレージ | Hugging Face | Model Scope | 説明 |
|
| 623 |
+
|--|--|--|--|--|
|
| 624 |
+
| Z-Image-Turbo-Fun-Controlnet-Union | - | [🤗リンク](https://huggingface.co/alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union) | [😄リンク](https://modelscope.cn/models/PAI/Z-Image-Turbo-Fun-Controlnet-Union) | Z-Image-Turbo用のControlNet重み。Canny、Depth、Pose、MLSDなど複数の制御条件をサポート。 |
|
| 625 |
+
|
| 626 |
+
## 9. Flux
|
| 627 |
+
|
| 628 |
+
| 名称 | ストレージ | Hugging Face | Model Scope | 説明 |
|
| 629 |
+
|--|--|--|--|--|
|
| 630 |
+
| FLUX.1-dev | [🤗Link](https://huggingface.co/black-forest-labs/FLUX.1-dev) | [😄Link](https://www.modelscope.cn/models/black-forest-labs/FLUX.1-dev)| FLUX.1-dev 公式重み |
|
| 631 |
+
| FLUX.2-dev | [🤗Link](https://huggingface.co/black-forest-labs/FLUX.2-dev) | [😄Link](https://www.modelscope.cn/models/black-forest-labs/FLUX.2-dev) | FLUX.2-dev 公式重み |
|
| 632 |
+
|
| 633 |
+
## 10. Flux-Fun
|
| 634 |
+
|
| 635 |
+
| 名前 | ストレージ | Hugging Face | ModelScope | 説明 |
|
| 636 |
+
|--|--|--|--|--|
|
| 637 |
+
| Flux.2-dev-Fun-Controlnet-Union | - | [🤗リンク](https://huggingface.co/alibaba-pai/FLUX.2-dev-Fun-Controlnet-Union) | [😄リンク](https://modelscope.cn/models/PAI/FLUX.2-dev-Fun-Controlnet-Union) | Flux.2-dev 用の ControlNet 重みで、Canny、Depth、Pose、MLSD など様々な制御条件をサポートします。 |
|
| 638 |
+
|
| 639 |
+
## 11. HunyuanVideo
|
| 640 |
+
|
| 641 |
+
| 名称 | ストレージ | Hugging Face | Model Scope | 説明 |
|
| 642 |
+
|--|--|--|--|--|
|
| 643 |
+
| HunyuanVideo | [🤗Link](https://huggingface.co/hunyuanvideo-community/HunyuanVideo) | - | HunyuanVideo-diffusers 公式重み |
|
| 644 |
+
| HunyuanVideo-I2V | [🤗Link](https://huggingface.co/hunyuanvideo-community/HunyuanVideo-I2V) | - | HunyuanVideo-I2V-diffusers 公式重み |
|
| 645 |
+
|
| 646 |
+
## 12. CogVideoX-Fun
|
| 647 |
+
|
| 648 |
+
V1.5:
|
| 649 |
+
|
| 650 |
+
| 名称 | ストレージスペース | Hugging Face | Model Scope | 説明 |
|
| 651 |
+
|--|--|--|--|--|
|
| 652 |
+
| CogVideoX-Fun-V1.5-5b-InP | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.5-5b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.5-5b-InP) | 公式のグラフ生成ビデオモデルは、複数の解像度(512、768、1024)でビデオを予測できます。85フレーム、8フレーム/秒でトレーニングされています。 |
|
| 653 |
+
| CogVideoX-Fun-V1.5-Reward-LoRAs | - | [🤗リンク](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-Reward-LoRAs) | [😄リンク](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.5-Reward-LoRAs) | 公式の報酬逆伝播技術モデルで、CogVideoX-Fun-V1.5が生成するビデオを最適化し、人間の嗜好によりよく合うようにする。 |
|
| 654 |
+
|
| 655 |
+
V1.1:
|
| 656 |
+
|
| 657 |
+
| 名称 | ストレージスペース | Hugging Face | Model Scope | 説明 |
|
| 658 |
+
|--|--|--|--|--|
|
| 659 |
+
| CogVideoX-Fun-V1.1-2b-InP | 13.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-2b-InP) | [😄リンク](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-2b-InP) | 公式のグラフ生成ビデオモデルは、複数の解像度(512、768、1024、1280)でビデオを予測できます。49フレーム、8フレーム/秒でトレーニングされています。参照画像にノイズが追加され、V1.0と比較して動きの幅が広がっています。 |
|
| 660 |
+
| CogVideoX-Fun-V1.1-5b-InP | 20.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-InP) | [😄リンク](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-InP) | 公式のグラフ生成ビデオモデルは、複数の解像度(512、768、1024、1280)でビデオを予測できます。49フレーム、8フレーム/秒でトレーニングされています。参照画像にノイズが追加され、V1.0と比較して動きの幅が広がっています。 |
|
| 661 |
+
| CogVideoX-Fun-V1.1-2b-Pose | 13.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-2b-Pose) | [😄リンク](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-2b-Pose) | 公式のポーズコントロールビデオモデルは、複数の解像度(512、768、1024、1280)でビデオを予測できます。49フレーム、8フレーム/秒でトレーニングされています。|
|
| 662 |
+
| CogVideoX-Fun-V1.1-2b-Control | 13.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-2b-Control) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-2b-Control) | 公式のコントロールビデオモデルは、複数の解像度(512、768、1024、1280)でビデオを予測できます。49フレーム、8フレーム/秒でトレーニングされています。Canny、Depth、Pose、MLSDなどのさまざまなコントロール条件をサポートします。|
|
| 663 |
+
| CogVideoX-Fun-V1.1-5b-Pose | 20.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-Pose) | [😄リンク](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-Pose) | 公式のポーズコントロールビデオモデルは、複数の解像度(512、768、1024、1280)でビデオを予測できます。49フレーム、8フレーム/秒でトレーニングされています。|
|
| 664 |
+
| CogVideoX-Fun-V1.1-5b-Control | 20.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-Control) | [😄リンク](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-Control) | 公式のコントロールビデオモデルは、複数の解像度(512、768、1024、1280)でビデオを予測できます。49フレーム、8フレーム/秒でトレーニングされています。Canny、Depth、Pose、MLSDなどのさまざまなコントロール条件をサポートします。|
|
| 665 |
+
| CogVideoX-Fun-V1.1-Reward-LoRAs | - | [🤗リンク](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-Reward-LoRAs) | [😄リンク](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.5-Reward-LoRAs) | 公式の報酬逆伝播技術モデルで、CogVideoX-Fun-V1.1が生成するビデオを最適化し、人間の嗜好によりよく合うようにする。 |
|
| 666 |
+
|
| 667 |
+
<details>
|
| 668 |
+
<summary>(Obsolete) V1.0:</summary>
|
| 669 |
+
|
| 670 |
+
| 名称 | ストレージスペース | Hugging Face | Model Scope | 説明 |
|
| 671 |
+
|--|--|--|--|--|
|
| 672 |
+
| CogVideoX-Fun-2b-InP | 13.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/CogVideoX-Fun-2b-InP) | [😄リンク](https://modelscope.cn/models/PAI/CogVideoX-Fun-2b-InP) | 公式のグラフ生成ビデオモデルは、複数の解像度(512、768、1024、1280)でビデオを予測できます。49フレーム、8フレーム/秒でトレーニングされています。 |
|
| 673 |
+
| CogVideoX-Fun-5b-InP | 20.0 GB | [🤗リンク](https://huggingface.co/alibaba-pai/CogVideoX-Fun-5b-InP)| [😄リンク](https://modelscope.cn/models/PAI/CogVideoX-Fun-5b-InP)| 公式のグラフ生成ビデオモデルは、複数の解像度(512、768、1024、1280)でビデオを予測できます。49フレーム、8フレーム/秒でトレーニングされています。|
|
| 674 |
+
</details>
|
| 675 |
+
|
| 676 |
+
# 参考文献
|
| 677 |
+
- CogVideo: https://github.com/THUDM/CogVideo/
|
| 678 |
+
- EasyAnimate: https://github.com/aigc-apps/EasyAnimate
|
| 679 |
+
- Wan2.1: https://github.com/Wan-Video/Wan2.1/
|
| 680 |
+
- Wan2.2: https://github.com/Wan-Video/Wan2.2/
|
| 681 |
+
- Diffusers: https://github.com/huggingface/diffusers
|
| 682 |
+
- Qwen-Image: https://github.com/QwenLM/Qwen-Image
|
| 683 |
+
- Self-Forcing: https://github.com/guandeh17/Self-Forcing
|
| 684 |
+
- Flux: https://github.com/black-forest-labs/flux
|
| 685 |
+
- Flux2: https://github.com/black-forest-labs/flux2
|
| 686 |
+
- HunyuanVideo: https://github.com/Tencent-Hunyuan/HunyuanVideo
|
| 687 |
+
- ComfyUI-KJNodes: https://github.com/kijai/ComfyUI-KJNodes
|
| 688 |
+
- ComfyUI-EasyAnimateWrapper: https://github.com/kijai/ComfyUI-EasyAnimateWrapper
|
| 689 |
+
- ComfyUI-CameraCtrl-Wrapper: https://github.com/chaojie/ComfyUI-CameraCtrl-Wrapper
|
| 690 |
+
- CameraCtrl: https://github.com/hehao13/CameraCtrl
|
| 691 |
+
|
| 692 |
+
# ライセンス
|
| 693 |
+
このプロジェクトは[Apache License (Version 2.0)](https://github.com/modelscope/modelscope/blob/master/LICENSE)の下でライセンスされています。
|
| 694 |
+
|
| 695 |
+
CogVideoX-2Bモデル(対応するTransformersモジュール、VAEモジュールを含む)は、[Apache 2.0ライセンス](LICENSE)の下でリリースされています。
|
| 696 |
+
|
| 697 |
+
CogVideoX-5Bモデル(Transformersモジュール)は、[CogVideoXライセンス](https://huggingface.co/THUDM/CogVideoX-5b/blob/main/LICENSE)の下でリリースされています。
|
VideoX-Fun/README_zh-CN.md
ADDED
|
@@ -0,0 +1,687 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# VideoX-Fun
|
| 2 |
+
|
| 3 |
+
😊 Welcome!
|
| 4 |
+
|
| 5 |
+
CogVideoX-Fun:
|
| 6 |
+
[](https://huggingface.co/spaces/alibaba-pai/CogVideoX-Fun-5b)
|
| 7 |
+
|
| 8 |
+
Wan-Fun:
|
| 9 |
+
[](https://huggingface.co/spaces/alibaba-pai/Wan2.1-Fun-1.3B-InP)
|
| 10 |
+
|
| 11 |
+
[English](./README.md) | 简体中文 | [日本語](./README_ja-JP.md)
|
| 12 |
+
|
| 13 |
+
# 目录
|
| 14 |
+
- [目录](#目录)
|
| 15 |
+
- [简介](#简介)
|
| 16 |
+
- [快速启动](#快速启动)
|
| 17 |
+
- [视频作品](#视频作品)
|
| 18 |
+
- [如何使用](#如何使用)
|
| 19 |
+
- [模型地址](#模型地址)
|
| 20 |
+
- [参考文献](#参考文献)
|
| 21 |
+
- [许可证](#许可证)
|
| 22 |
+
|
| 23 |
+
# 简介
|
| 24 |
+
VideoX-Fun是一个视频生成的pipeline,可用于生成AI图片与视频、训练Diffusion Transformer的基线模型与Lora模型,我们支持从已经训练好的基线模型直接进行预测,生成不同分辨率,不同秒数、不同FPS的视频,也支持用户训练自己的基线模型与Lora模型,进行一定的风格变换。
|
| 25 |
+
|
| 26 |
+
我们会逐渐支持从不同平台快速启动,请参阅 [快速启动](#快速启动)。
|
| 27 |
+
|
| 28 |
+
新特性:
|
| 29 |
+
- 更新支持Wan2.2系列模型、Wan-VACE控制模型、支持Fantasy Talking数字人模型、Qwen-Image和Flux图片生成模型等。[2025.10.16]。
|
| 30 |
+
- 更新Wan2.1-Fun-V1.1版本:支持14B与1.3B模型Control+参考图模型,支持镜头控制,另外Inpaint模型重新训练,性能更佳。[2025.04.25]
|
| 31 |
+
- 更新Wan2.1-Fun-V1.0版本:支持14B与1.3B模型的I2V和Control模型,支持首尾图预测。[2025.03.26]
|
| 32 |
+
- 更新CogVideoX-Fun-V1.5版本:上传I2V模型与相关训练预测代码。[2024.12.16]
|
| 33 |
+
- 奖励Lora支持:通过奖励反向传播技术训练Lora,以优化生成的视频,使其更好地与人类偏好保持一致,[更多信息](scripts/README_TRAIN_REWARD.md)。新版本的控制模型,支持不同的控制条件,如Canny、Depth、Pose、MLSD等。[2024.11.21]
|
| 34 |
+
- diffusers支持:CogVideoX-Fun Control现在在diffusers中得到了支持。感谢 [a-r-r-o-w](https://github.com/a-r-r-o-w)在这个 [PR](https://github.com/huggingface/diffusers/pull/9671)中贡献了支持。查看[文档](https://huggingface.co/docs/diffusers/main/en/api/pipelines/cogvideox)以了解更多信息。[2024.10.16]
|
| 35 |
+
- 更新CogVideoX-Fun-V1.1版本:重新训练i2v模型,添加Noise,使得视频的运动幅度更大。上传控制模型训练代码与Control模型。[2024.09.29]
|
| 36 |
+
- 更新CogVideoX-Fun-V1.0版本:创建代码!现在支持 Windows 和 Linux。支持2b与5b最大256x256x49到1024x1024x49的任意分辨率的视频生成。[2024.09.18]
|
| 37 |
+
|
| 38 |
+
功能概览:
|
| 39 |
+
- [数据预处理](#data-preprocess)
|
| 40 |
+
- [训练DiT](#dit-train)
|
| 41 |
+
- [模型生成](#video-gen)
|
| 42 |
+
|
| 43 |
+
我们的ui界面如下:
|
| 44 |
+

|
| 45 |
+
|
| 46 |
+
# 快速启动
|
| 47 |
+
### 1. 云使用: AliyunDSW/Docker
|
| 48 |
+
#### a. 通过阿里云 DSW
|
| 49 |
+
DSW 有免费 GPU 时间,用户可申请一次,申请后3个月内有效。
|
| 50 |
+
|
| 51 |
+
阿里云在[Freetier](https://free.aliyun.com/?product=9602825&crowd=enterprise&spm=5176.28055625.J_5831864660.1.e939154aRgha4e&scm=20140722.M_9974135.P_110.MO_1806-ID_9974135-MID_9974135-CID_30683-ST_8512-V_1)提供免费GPU时间,获取并在阿里云PAI-DSW中使用,5分钟内即可启动CogVideoX-Fun。
|
| 52 |
+
|
| 53 |
+
[](https://gallery.pai-ml.com/#/preview/deepLearning/cv/cogvideox_fun)
|
| 54 |
+
|
| 55 |
+
#### b. 通过ComfyUI
|
| 56 |
+
我们的ComfyUI界面如下,具体查看[ComfyUI README](comfyui/README.md)。
|
| 57 |
+

|
| 58 |
+
|
| 59 |
+
#### c. 通过docker
|
| 60 |
+
使用docker的情况下,请保证机器中已经正确安装显卡驱动与CUDA环境,然后以此执行以下命令:
|
| 61 |
+
|
| 62 |
+
```
|
| 63 |
+
# pull image
|
| 64 |
+
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:cogvideox_fun
|
| 65 |
+
|
| 66 |
+
# enter image
|
| 67 |
+
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:cogvideox_fun
|
| 68 |
+
|
| 69 |
+
# clone code
|
| 70 |
+
git clone https://github.com/aigc-apps/VideoX-Fun.git
|
| 71 |
+
|
| 72 |
+
# enter VideoX-Fun's dir
|
| 73 |
+
cd VideoX-Fun
|
| 74 |
+
|
| 75 |
+
# download weights
|
| 76 |
+
mkdir models/Diffusion_Transformer
|
| 77 |
+
mkdir models/Personalized_Model
|
| 78 |
+
|
| 79 |
+
# Please use the hugginface link or modelscope link to download the model.
|
| 80 |
+
# CogVideoX-Fun
|
| 81 |
+
# https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-InP
|
| 82 |
+
# https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-InP
|
| 83 |
+
|
| 84 |
+
# Wan
|
| 85 |
+
# https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-InP
|
| 86 |
+
# https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-InP
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
### 2. 本地安装: 环境检查/下载/安装
|
| 90 |
+
#### a. 环境检查
|
| 91 |
+
我们已验证该库可在以下环境中执行:
|
| 92 |
+
|
| 93 |
+
Windows 的详细信息:
|
| 94 |
+
- 操作系统 Windows 10
|
| 95 |
+
- python: python3.10 & python3.11
|
| 96 |
+
- pytorch: torch2.2.0
|
| 97 |
+
- CUDA: 11.8 & 12.1
|
| 98 |
+
- CUDNN: 8+
|
| 99 |
+
- GPU: Nvidia-3060 12G & Nvidia-3090 24G
|
| 100 |
+
|
| 101 |
+
Linux 的详细信息:
|
| 102 |
+
- 操作系统 Ubuntu 20.04, CentOS
|
| 103 |
+
- python: python3.10 & python3.11
|
| 104 |
+
- pytorch: torch2.2.0
|
| 105 |
+
- CUDA: 11.8 & 12.1
|
| 106 |
+
- CUDNN: 8+
|
| 107 |
+
- GPU:Nvidia-V100 16G & Nvidia-A10 24G & Nvidia-A100 40G & Nvidia-A100 80G
|
| 108 |
+
|
| 109 |
+
我们需要大约 60GB 的可用磁盘空间,请检查!
|
| 110 |
+
|
| 111 |
+
#### b. 权重放置
|
| 112 |
+
我们最好将[权重](#model-zoo)按照指定路径进行放置:
|
| 113 |
+
|
| 114 |
+
**通过comfyui**:
|
| 115 |
+
将模型放入Comfyui的权重文件夹`ComfyUI/models/Fun_Models/`:
|
| 116 |
+
```
|
| 117 |
+
📦 ComfyUI/
|
| 118 |
+
├── 📂 models/
|
| 119 |
+
│ └── 📂 Fun_Models/
|
| 120 |
+
│ ├── 📂 CogVideoX-Fun-V1.1-2b-InP/
|
| 121 |
+
│ ├── 📂 CogVideoX-Fun-V1.1-5b-InP/
|
| 122 |
+
│ ├── 📂 Wan2.1-Fun-V1.1-14B-InP
|
| 123 |
+
│ └── 📂 Wan2.1-Fun-V1.1-1.3B-InP/
|
| 124 |
+
```
|
| 125 |
+
|
| 126 |
+
**运行自身的python文件或ui界面**:
|
| 127 |
+
```
|
| 128 |
+
📦 models/
|
| 129 |
+
├── 📂 Diffusion_Transformer/
|
| 130 |
+
│ ├── 📂 CogVideoX-Fun-V1.1-2b-InP/
|
| 131 |
+
│ ├── 📂 CogVideoX-Fun-V1.1-5b-InP/
|
| 132 |
+
│ ├── 📂 Wan2.1-Fun-V1.1-14B-InP
|
| 133 |
+
│ └── 📂 Wan2.1-Fun-V1.1-1.3B-InP/
|
| 134 |
+
├── 📂 Personalized_Model/
|
| 135 |
+
│ └── your trained trainformer model / your trained lora model (for UI load)
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
# 视频作品
|
| 139 |
+
|
| 140 |
+
### Wan2.1-Fun-V1.1-14B-InP && Wan2.1-Fun-V1.1-1.3B-InP
|
| 141 |
+
|
| 142 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 143 |
+
<tr>
|
| 144 |
+
<td>
|
| 145 |
+
<video src="https://github.com/user-attachments/assets/d6a46051-8fe6-4174-be12-95ee52c96298" width="100%" controls autoplay loop></video>
|
| 146 |
+
</td>
|
| 147 |
+
<td>
|
| 148 |
+
<video src="https://github.com/user-attachments/assets/8572c656-8548-4b1f-9ec8-8107c6236cb1" width="100%" controls autoplay loop></video>
|
| 149 |
+
</td>
|
| 150 |
+
<td>
|
| 151 |
+
<video src="https://github.com/user-attachments/assets/d3411c95-483d-4e30-bc72-483c2b288918" width="100%" controls autoplay loop></video>
|
| 152 |
+
</td>
|
| 153 |
+
<td>
|
| 154 |
+
<video src="https://github.com/user-attachments/assets/b2f5addc-06bd-49d9-b925-973090a32800" width="100%" controls autoplay loop></video>
|
| 155 |
+
</td>
|
| 156 |
+
</tr>
|
| 157 |
+
</table>
|
| 158 |
+
|
| 159 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 160 |
+
<tr>
|
| 161 |
+
<td>
|
| 162 |
+
<video src="https://github.com/user-attachments/assets/747b6ab8-9617-4ba2-84a0-b51c0efbd4f8" width="100%" controls autoplay loop></video>
|
| 163 |
+
</td>
|
| 164 |
+
<td>
|
| 165 |
+
<video src="https://github.com/user-attachments/assets/ae94dcda-9d5e-4bae-a86f-882c4282a367" width="100%" controls autoplay loop></video>
|
| 166 |
+
</td>
|
| 167 |
+
<td>
|
| 168 |
+
<video src="https://github.com/user-attachments/assets/a4aa1a82-e162-4ab5-8f05-72f79568a191" width="100%" controls autoplay loop></video>
|
| 169 |
+
</td>
|
| 170 |
+
<td>
|
| 171 |
+
<video src="https://github.com/user-attachments/assets/83c005b8-ccbc-44a0-a845-c0472763119c" width="100%" controls autoplay loop></video>
|
| 172 |
+
</td>
|
| 173 |
+
</tr>
|
| 174 |
+
</table>
|
| 175 |
+
|
| 176 |
+
### Wan2.1-Fun-V1.1-14B-Control && Wan2.1-Fun-V1.1-1.3B-Control
|
| 177 |
+
|
| 178 |
+
Generic Control Video + Reference Image:
|
| 179 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 180 |
+
<tr>
|
| 181 |
+
<td>
|
| 182 |
+
Reference Image
|
| 183 |
+
</td>
|
| 184 |
+
<td>
|
| 185 |
+
Control Video
|
| 186 |
+
</td>
|
| 187 |
+
<td>
|
| 188 |
+
Wan2.1-Fun-V1.1-14B-Control
|
| 189 |
+
</td>
|
| 190 |
+
<td>
|
| 191 |
+
Wan2.1-Fun-V1.1-1.3B-Control
|
| 192 |
+
</td>
|
| 193 |
+
<tr>
|
| 194 |
+
<td>
|
| 195 |
+
<image src="https://github.com/user-attachments/assets/221f2879-3b1b-4fbd-84f9-c3e0b0b3533e" width="100%" controls autoplay loop></image>
|
| 196 |
+
</td>
|
| 197 |
+
<td>
|
| 198 |
+
<video src="https://github.com/user-attachments/assets/f361af34-b3b3-4be4-9d03-cd478cb3dfc5" width="100%" controls autoplay loop></video>
|
| 199 |
+
</td>
|
| 200 |
+
<td>
|
| 201 |
+
<video src="https://github.com/user-attachments/assets/85e2f00b-6ef0-4922-90ab-4364afb2c93d" width="100%" controls autoplay loop></video>
|
| 202 |
+
</td>
|
| 203 |
+
<td>
|
| 204 |
+
<video src="https://github.com/user-attachments/assets/1f3fe763-2754-4215-bc9a-ae804950d4b3" width="100%" controls autoplay loop></video>
|
| 205 |
+
</td>
|
| 206 |
+
<tr>
|
| 207 |
+
</table>
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
Generic Control Video (Canny, Pose, Depth, etc.) and Trajectory Control:
|
| 211 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 212 |
+
<tr>
|
| 213 |
+
<td>
|
| 214 |
+
<video src="https://github.com/user-attachments/assets/f35602c4-9f0a-4105-9762-1e3a88abbac6" width="100%" controls autoplay loop></video>
|
| 215 |
+
</td>
|
| 216 |
+
<td>
|
| 217 |
+
<video src="https://github.com/user-attachments/assets/8b0f0e87-f1be-4915-bb35-2d53c852333e" width="100%" controls autoplay loop></video>
|
| 218 |
+
</td>
|
| 219 |
+
<td>
|
| 220 |
+
<video src="https://github.com/user-attachments/assets/972012c1-772b-427a-bce6-ba8b39edcfad" width="100%" controls autoplay loop></video>
|
| 221 |
+
</td>
|
| 222 |
+
<tr>
|
| 223 |
+
</table>
|
| 224 |
+
|
| 225 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 226 |
+
<tr>
|
| 227 |
+
<td>
|
| 228 |
+
<video src="https://github.com/user-attachments/assets/ce62d0bd-82c0-4d7b-9c49-7e0e4b605745" width="100%" controls autoplay loop></video>
|
| 229 |
+
</td>
|
| 230 |
+
<td>
|
| 231 |
+
<video src="https://github.com/user-attachments/assets/89dfbffb-c4a6-4821-bcef-8b1489a3ca00" width="100%" controls autoplay loop></video>
|
| 232 |
+
</td>
|
| 233 |
+
<td>
|
| 234 |
+
<video src="https://github.com/user-attachments/assets/72a43e33-854f-4349-861b-c959510d1a84" width="100%" controls autoplay loop></video>
|
| 235 |
+
</td>
|
| 236 |
+
<tr>
|
| 237 |
+
<td>
|
| 238 |
+
<video src="https://github.com/user-attachments/assets/bb0ce13d-dee0-4049-9eec-c92f3ebc1358" width="100%" controls autoplay loop></video>
|
| 239 |
+
</td>
|
| 240 |
+
<td>
|
| 241 |
+
<video src="https://github.com/user-attachments/assets/7840c333-7bec-4582-ba63-20a39e1139c4" width="100%" controls autoplay loop></video>
|
| 242 |
+
</td>
|
| 243 |
+
<td>
|
| 244 |
+
<video src="https://github.com/user-attachments/assets/85147d30-ae09-4f36-a077-2167f7a578c0" width="100%" controls autoplay loop></video>
|
| 245 |
+
</td>
|
| 246 |
+
</tr>
|
| 247 |
+
</table>
|
| 248 |
+
|
| 249 |
+
### Wan2.1-Fun-V1.1-14B-Control-Camera && Wan2.1-Fun-V1.1-1.3B-Control-Camera
|
| 250 |
+
|
| 251 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 252 |
+
<tr>
|
| 253 |
+
<td>
|
| 254 |
+
Pan Up
|
| 255 |
+
</td>
|
| 256 |
+
<td>
|
| 257 |
+
Pan Left
|
| 258 |
+
</td>
|
| 259 |
+
<td>
|
| 260 |
+
Pan Right
|
| 261 |
+
</td>
|
| 262 |
+
<tr>
|
| 263 |
+
<td>
|
| 264 |
+
<video src="https://github.com/user-attachments/assets/869fe2ef-502a-484e-8656-fe9e626b9f63" width="100%" controls autoplay loop></video>
|
| 265 |
+
</td>
|
| 266 |
+
<td>
|
| 267 |
+
<video src="https://github.com/user-attachments/assets/2d4185c8-d6ec-4831-83b4-b1dbfc3616fa" width="100%" controls autoplay loop></video>
|
| 268 |
+
</td>
|
| 269 |
+
<td>
|
| 270 |
+
<video src="https://github.com/user-attachments/assets/7dfb7cad-ed24-4acc-9377-832445a07ec7" width="100%" controls autoplay loop></video>
|
| 271 |
+
</td>
|
| 272 |
+
<tr>
|
| 273 |
+
<td>
|
| 274 |
+
Pan Down
|
| 275 |
+
</td>
|
| 276 |
+
<td>
|
| 277 |
+
Pan Up + Pan Left
|
| 278 |
+
</td>
|
| 279 |
+
<td>
|
| 280 |
+
Pan Up + Pan Right
|
| 281 |
+
</td>
|
| 282 |
+
<tr>
|
| 283 |
+
<td>
|
| 284 |
+
<video src="https://github.com/user-attachments/assets/3ea3a08d-f2df-43a2-976e-bf2659345373" width="100%" controls autoplay loop></video>
|
| 285 |
+
</td>
|
| 286 |
+
<td>
|
| 287 |
+
<video src="https://github.com/user-attachments/assets/4a85b028-4120-4293-886b-b8afe2d01713" width="100%" controls autoplay loop></video>
|
| 288 |
+
</td>
|
| 289 |
+
<td>
|
| 290 |
+
<video src="https://github.com/user-attachments/assets/ad0d58c1-13ef-450c-b658-4fed7ff5ed36" width="100%" controls autoplay loop></video>
|
| 291 |
+
</td>
|
| 292 |
+
</tr>
|
| 293 |
+
</table>
|
| 294 |
+
|
| 295 |
+
### CogVideoX-Fun-V1.1-5B
|
| 296 |
+
|
| 297 |
+
Resolution-1024
|
| 298 |
+
|
| 299 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 300 |
+
<tr>
|
| 301 |
+
<td>
|
| 302 |
+
<video src="https://github.com/user-attachments/assets/34e7ec8f-293e-4655-bb14-5e1ee476f788" width="100%" controls autoplay loop></video>
|
| 303 |
+
</td>
|
| 304 |
+
<td>
|
| 305 |
+
<video src="https://github.com/user-attachments/assets/7809c64f-eb8c-48a9-8bdc-ca9261fd5434" width="100%" controls autoplay loop></video>
|
| 306 |
+
</td>
|
| 307 |
+
<td>
|
| 308 |
+
<video src="https://github.com/user-attachments/assets/8e76aaa4-c602-44ac-bcb4-8b24b72c386c" width="100%" controls autoplay loop></video>
|
| 309 |
+
</td>
|
| 310 |
+
<td>
|
| 311 |
+
<video src="https://github.com/user-attachments/assets/19dba894-7c35-4f25-b15c-384167ab3b03" width="100%" controls autoplay loop></video>
|
| 312 |
+
</td>
|
| 313 |
+
</tr>
|
| 314 |
+
</table>
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
Resolution-768
|
| 318 |
+
|
| 319 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 320 |
+
<tr>
|
| 321 |
+
<td>
|
| 322 |
+
<video src="https://github.com/user-attachments/assets/0bc339b9-455b-44fd-8917-80272d702737" width="100%" controls autoplay loop></video>
|
| 323 |
+
</td>
|
| 324 |
+
<td>
|
| 325 |
+
<video src="https://github.com/user-attachments/assets/70a043b9-6721-4bd9-be47-78b7ec5c27e9" width="100%" controls autoplay loop></video>
|
| 326 |
+
</td>
|
| 327 |
+
<td>
|
| 328 |
+
<video src="https://github.com/user-attachments/assets/d5dd6c09-14f3-40f8-8b6d-91e26519b8ac" width="100%" controls autoplay loop></video>
|
| 329 |
+
</td>
|
| 330 |
+
<td>
|
| 331 |
+
<video src="https://github.com/user-attachments/assets/9327e8bc-4f17-46b0-b50d-38c250a9483a" width="100%" controls autoplay loop></video>
|
| 332 |
+
</td>
|
| 333 |
+
</tr>
|
| 334 |
+
</table>
|
| 335 |
+
|
| 336 |
+
Resolution-512
|
| 337 |
+
|
| 338 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 339 |
+
<tr>
|
| 340 |
+
<td>
|
| 341 |
+
<video src="https://github.com/user-attachments/assets/ef407030-8062-454d-aba3-131c21e6b58c" width="100%" controls autoplay loop></video>
|
| 342 |
+
</td>
|
| 343 |
+
<td>
|
| 344 |
+
<video src="https://github.com/user-attachments/assets/7610f49e-38b6-4214-aa48-723ae4d1b07e" width="100%" controls autoplay loop></video>
|
| 345 |
+
</td>
|
| 346 |
+
<td>
|
| 347 |
+
<video src="https://github.com/user-attachments/assets/1fff0567-1e15-415c-941e-53ee8ae2c841" width="100%" controls autoplay loop></video>
|
| 348 |
+
</td>
|
| 349 |
+
<td>
|
| 350 |
+
<video src="https://github.com/user-attachments/assets/bcec48da-b91b-43a0-9d50-cf026e00fa4f" width="100%" controls autoplay loop></video>
|
| 351 |
+
</td>
|
| 352 |
+
</tr>
|
| 353 |
+
</table>
|
| 354 |
+
|
| 355 |
+
### CogVideoX-Fun-V1.1-5B-Control
|
| 356 |
+
|
| 357 |
+
<table border="0" style="width: 100%; text-align: left; margin-top: 20px;">
|
| 358 |
+
<tr>
|
| 359 |
+
<td>
|
| 360 |
+
<video src="https://github.com/user-attachments/assets/53002ce2-dd18-4d4f-8135-b6f68364cabd" width="100%" controls autoplay loop></video>
|
| 361 |
+
</td>
|
| 362 |
+
<td>
|
| 363 |
+
<video src="https://github.com/user-attachments/assets/a1a07cf8-d86d-4cd2-831f-18a6c1ceee1d" width="100%" controls autoplay loop></video>
|
| 364 |
+
</td>
|
| 365 |
+
<td>
|
| 366 |
+
<video src="https://github.com/user-attachments/assets/3224804f-342d-4947-918d-d9fec8e3d273" width="100%" controls autoplay loop></video>
|
| 367 |
+
</td>
|
| 368 |
+
<tr>
|
| 369 |
+
<td>
|
| 370 |
+
A young woman with beautiful clear eyes and blonde hair, wearing white clothes and twisting her body, with the camera focused on her face. High quality, masterpiece, best quality, high resolution, ultra-fine, dreamlike.
|
| 371 |
+
</td>
|
| 372 |
+
<td>
|
| 373 |
+
A young woman with beautiful clear eyes and blonde hair, wearing white clothes and twisting her body, with the camera focused on her face. High quality, masterpiece, best quality, high resolution, ultra-fine, dreamlike.
|
| 374 |
+
</td>
|
| 375 |
+
<td>
|
| 376 |
+
A young bear.
|
| 377 |
+
</td>
|
| 378 |
+
</tr>
|
| 379 |
+
<tr>
|
| 380 |
+
<td>
|
| 381 |
+
<video src="https://github.com/user-attachments/assets/ea908454-684b-4d60-b562-3db229a250a9" width="100%" controls autoplay loop></video>
|
| 382 |
+
</td>
|
| 383 |
+
<td>
|
| 384 |
+
<video src="https://github.com/user-attachments/assets/ffb7c6fc-8b69-453b-8aad-70dfae3899b9" width="100%" controls autoplay loop></video>
|
| 385 |
+
</td>
|
| 386 |
+
<td>
|
| 387 |
+
<video src="https://github.com/user-attachments/assets/d3f757a3-3551-4dcb-9372-7a61469813f5" width="100%" controls autoplay loop></video>
|
| 388 |
+
</td>
|
| 389 |
+
</tr>
|
| 390 |
+
</table>
|
| 391 |
+
|
| 392 |
+
# 如何使用
|
| 393 |
+
|
| 394 |
+
<h3 id="video-gen">1. 生成 </h3>
|
| 395 |
+
|
| 396 |
+
#### a、显存节省方案
|
| 397 |
+
由于Wan2.1的参数非常大,我们需要考虑显存节省方案,以节省显存适应消费级显卡。我们给每个预测文件都提供了GPU_memory_mode,可以在model_cpu_offload,model_cpu_offload_and_qfloat8,sequential_cpu_offload中进行选择。该方案同样适用于CogVideoX-Fun的生成。
|
| 398 |
+
|
| 399 |
+
- model_cpu_offload代表整个模型在使用后会进入cpu,可以节省部分显存。
|
| 400 |
+
- model_cpu_offload_and_qfloat8代表整个模型在使用后会进入cpu,并且对transformer模型进行了float8的量化,可以节省更多的显存。
|
| 401 |
+
- sequential_cpu_offload代表模型的每一层在使用后会进入cpu,速度较慢,节省大量显存。
|
| 402 |
+
|
| 403 |
+
qfloat8会部分降低模型的性能,但可以节省更多的显存。如果显存足够,推荐使用model_cpu_offload。
|
| 404 |
+
|
| 405 |
+
#### b、通过comfyui
|
| 406 |
+
具体查看[ComfyUI README](comfyui/README.md)。
|
| 407 |
+
|
| 408 |
+
#### c、运行python文件
|
| 409 |
+
|
| 410 |
+
##### i、单卡运行:
|
| 411 |
+
|
| 412 |
+
- 步骤1:下载对应[权重](#model-zoo)放入models文件夹。
|
| 413 |
+
- 步骤2:根据不同的权重与预测目标使用不同的文件进行预测。当前该库支持CogVideoX-Fun、Wan2.1和Wan2.1-Fun,在examples文件夹下用文件夹名以区分,不同模型支持的功能不同,请视具体情况予以区分。以CogVideoX-Fun为例。
|
| 414 |
+
- 文生视频:
|
| 415 |
+
- 使用examples/cogvideox_fun/predict_t2v.py文件中修改prompt、neg_prompt、guidance_scale和seed。
|
| 416 |
+
- 而后运行examples/cogvideox_fun/predict_t2v.py文件,等待生成结果,结果保存在samples/cogvideox-fun-videos文件夹中。
|
| 417 |
+
- 图生视频:
|
| 418 |
+
- 使用examples/cogvideox_fun/predict_i2v.py文件中修改validation_image_start、validation_image_end、prompt、neg_prompt、guidance_scale和seed。
|
| 419 |
+
- validation_image_start是视频的开始图片,validation_image_end是视频的结尾图片。
|
| 420 |
+
- 而后运行examples/cogvideox_fun/predict_i2v.py文件,等待生成结果,结果保存在samples/cogvideox-fun-videos_i2v文件夹中。
|
| 421 |
+
- 视频生视频:
|
| 422 |
+
- 使用examples/cogvideox_fun/predict_v2v.py文件中修改validation_video、validation_image_end、prompt、neg_prompt、guidance_scale和seed。
|
| 423 |
+
- validation_video是视频生视频的参考视频。您可以使用以下视频运行演示:[演示视频](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1/play_guitar.mp4)
|
| 424 |
+
- 而后运行examples/cogvideox_fun/predict_v2v.py文件,等待生成结果,结果保存在samples/cogvideox-fun-videos_v2v文件夹中。
|
| 425 |
+
- 普通控制生视频(Canny、Pose、Depth等):
|
| 426 |
+
- 使用examples/cogvideox_fun/predict_v2v_control.py文件中修改control_video、validation_image_end、prompt、neg_prompt、guidance_scale和seed。
|
| 427 |
+
- control_video是控制生视频的控制视频,是使用Canny、Pose、Depth等算子提取后的视频。您可以使用以下视频运行演示:[演示视频](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.1/pose.mp4)
|
| 428 |
+
- 而后运行examples/cogvideox_fun/predict_v2v_control.py文件,等待生成结果,结果保存在samples/cogvideox-fun-videos_v2v_control文件夹中。
|
| 429 |
+
- 步骤3:如果想结合自己训练的其他backbone与Lora,则看情况修改examples/{model_name}/predict_t2v.py中的examples/{model_name}/predict_i2v.py和lora_path。
|
| 430 |
+
|
| 431 |
+
##### ii、多卡运行:
|
| 432 |
+
在使用多卡预测时请注意安装xfuser仓库,推荐安装xfuser==0.4.2和yunchang==0.6.2。
|
| 433 |
+
```
|
| 434 |
+
pip install xfuser==0.4.2 --progress-bar off -i https://mirrors.aliyun.com/pypi/simple/
|
| 435 |
+
pip install yunchang==0.6.2 --progress-bar off -i https://mirrors.aliyun.com/pypi/simple/
|
| 436 |
+
```
|
| 437 |
+
|
| 438 |
+
请确保ulysses_degree和ring_degree的乘积等于使用的GPU数量。例如,如果您使用8个GPU,则可以设置ulysses_degree=2和ring_degree=4,也可以设置ulysses_degree=4和ring_degree=2。
|
| 439 |
+
|
| 440 |
+
ulysses_degree是在head进行切分后并行生成,ring_degree是在sequence上进行切分后并行生成。ring_degree相比ulysses_degree有更大的通信成本,在设置参数时需要结合序列长度和模型的head数进行设置。
|
| 441 |
+
|
| 442 |
+
以8卡并行预测为例。
|
| 443 |
+
- 以Wan2.1-Fun-V1.1-14B-InP为例,其head数为40,ulysses_degree需要设置为其可以整除的数如2、4、8等。因此在使用8卡并行预测时,可以设置ulysses_degree=8和ring_degree=1.
|
| 444 |
+
- 以Wan2.1-Fun-V1.1-1.3B-InP为例,其head数为12,ulysses_degree需要设置为其可以整除的数如2、4等。因此在使用8卡并行预测时,可以设置ulysses_degree=4和ring_degree=2.
|
| 445 |
+
|
| 446 |
+
设置完成后,使用如下指令进行并行预测:
|
| 447 |
+
```sh
|
| 448 |
+
torchrun --nproc-per-node=8 examples/wan2.1_fun/predict_t2v.py
|
| 449 |
+
```
|
| 450 |
+
|
| 451 |
+
#### d、通过ui界面
|
| 452 |
+
|
| 453 |
+
webui支持文生视频、图生视频、视频生视频和普通控制生视频(Canny、Pose、Depth等)。当前该库支持CogVideoX-Fun、Wan2.1和Wan2.1-Fun,在examples文件夹下用文件夹名以区分,不同模型支持的功能不同,请视具体情况予以区分。以CogVideoX-Fun为例。
|
| 454 |
+
|
| 455 |
+
- 步骤1:下载对应[权重](#model-zoo)放入models文件夹。
|
| 456 |
+
- 步骤2:运行examples/cogvideox_fun/app.py文件,进入gradio页面。
|
| 457 |
+
- 步骤3:根据页面选择生成模型,填入prompt、neg_prompt、guidance_scale和seed等,点击生成,等待生成结果,结果保存在sample文件夹中。
|
| 458 |
+
|
| 459 |
+
### 2. 模型训练
|
| 460 |
+
一个完整的模型训练链路应该包括数据预处理和Video DiT训练。不同模型的训练流程类似,数据格式也类似:
|
| 461 |
+
|
| 462 |
+
<h4 id="data-preprocess">a.数据预处理</h4>
|
| 463 |
+
我们给出了一个简单的demo通过图片数据训练lora模型,详情可以查看[wiki](https://github.com/aigc-apps/CogVideoX-Fun/wiki/Training-Lora)。
|
| 464 |
+
|
| 465 |
+
一个完整的长视频切分、清洗、描述的数据预处理链路可以参考video caption部分的[README](cogvideox/video_caption/README.md)进行。
|
| 466 |
+
|
| 467 |
+
如果期望训练一个文生图视频的生成模型,您需要以这种格式排列数据集。
|
| 468 |
+
```
|
| 469 |
+
📦 project/
|
| 470 |
+
├── 📂 datasets/
|
| 471 |
+
│ ├── 📂 internal_datasets/
|
| 472 |
+
│ ├── 📂 train/
|
| 473 |
+
│ │ ├── 📄 00000001.mp4
|
| 474 |
+
│ │ ├── 📄 00000002.jpg
|
| 475 |
+
│ │ └── 📄 .....
|
| 476 |
+
│ └── 📄 json_of_internal_datasets.json
|
| 477 |
+
```
|
| 478 |
+
|
| 479 |
+
json_of_internal_datasets.json是一个标准的json文件。json中的file_path可以被设置为相对路径,如下所示:
|
| 480 |
+
```json
|
| 481 |
+
[
|
| 482 |
+
{
|
| 483 |
+
"file_path": "train/00000001.mp4",
|
| 484 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 485 |
+
"type": "video"
|
| 486 |
+
},
|
| 487 |
+
{
|
| 488 |
+
"file_path": "train/00000002.jpg",
|
| 489 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 490 |
+
"type": "image"
|
| 491 |
+
},
|
| 492 |
+
.....
|
| 493 |
+
]
|
| 494 |
+
```
|
| 495 |
+
|
| 496 |
+
你也可以将路径设置为绝对路径:
|
| 497 |
+
```json
|
| 498 |
+
[
|
| 499 |
+
{
|
| 500 |
+
"file_path": "/mnt/data/videos/00000001.mp4",
|
| 501 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 502 |
+
"type": "video"
|
| 503 |
+
},
|
| 504 |
+
{
|
| 505 |
+
"file_path": "/mnt/data/train/00000001.jpg",
|
| 506 |
+
"text": "A group of young men in suits and sunglasses are walking down a city street.",
|
| 507 |
+
"type": "image"
|
| 508 |
+
},
|
| 509 |
+
.....
|
| 510 |
+
]
|
| 511 |
+
```
|
| 512 |
+
<h4 id="dit-train">b. Video DiT训练 </h4>
|
| 513 |
+
|
| 514 |
+
如果数据预处理时,数据的格式为相对路径,则进入scripts/{model_name}/train.sh进行如下设置。
|
| 515 |
+
```
|
| 516 |
+
export DATASET_NAME="datasets/internal_datasets/"
|
| 517 |
+
export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
|
| 518 |
+
```
|
| 519 |
+
|
| 520 |
+
如果数据的格式为绝对路径,则进入scripts/train.sh进行如下设置。
|
| 521 |
+
```
|
| 522 |
+
export DATASET_NAME=""
|
| 523 |
+
export DATASET_META_NAME="/mnt/data/json_of_internal_datasets.json"
|
| 524 |
+
```
|
| 525 |
+
|
| 526 |
+
最后运行scripts/train.sh。
|
| 527 |
+
```sh
|
| 528 |
+
sh scripts/train.sh
|
| 529 |
+
```
|
| 530 |
+
|
| 531 |
+
关于一些参数的设置细节:
|
| 532 |
+
Wan2.1-Fun可以查看[Readme Train](scripts/wan2.1_fun/README_TRAIN.md)与[Readme Lora](scripts/wan2.1_fun/README_TRAIN_LORA.md)。
|
| 533 |
+
Wan2.1可以查看[Readme Train](scripts/wan2.1/README_TRAIN.md)与[Readme Lora](scripts/wan2.1/README_TRAIN_LORA.md)。
|
| 534 |
+
CogVideoX-Fun可以查看[Readme Train](scripts/cogvideox_fun/README_TRAIN.md)与[Readme Lora](scripts/cogvideox_fun/README_TRAIN_LORA.md)。
|
| 535 |
+
|
| 536 |
+
|
| 537 |
+
# 模型地址
|
| 538 |
+
## 1.Wan2.2-Fun
|
| 539 |
+
|
| 540 |
+
| 名称 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
| 541 |
+
|--|--|--|--|--|
|
| 542 |
+
| Wan2.2-Fun-A14B-InP | 64.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-A14B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-A14B-InP) | Wan2.2-Fun-14B文图生视频权重,以多分辨率训练,支持首尾图预测。 |
|
| 543 |
+
| Wan2.2-Fun-A14B-Control | 64.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-A14B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-A14B-Control)| Wan2.2-Fun-14B视频控制权重,支持不同的控制条件,如Canny、Depth、Pose、MLSD等,同时支持使用轨迹控制。支持多分辨率(512,768,1024)的视频预测,,以81帧、每秒16帧进行训练,支持多语言预测 |
|
| 544 |
+
| Wan2.2-Fun-A14B-Control-Camera | 64.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-A14B-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-A14B-Control-Camera)| Wan2.2-Fun-14B相机镜头控制权重。支持多分辨率(512,768,1024)的视频预测,,以81帧、每秒16帧进行训练,支持多语言预测 |
|
| 545 |
+
| Wan2.2-VACE-Fun-A14B | 64.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-VACE-Fun-A14B) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-VACE-Fun-A14B)| 以VACE方案训练的Wan2.2控制权重,基础模型为Wan2.2-T2V-A14B,支持不同的控制条件,如Canny、Depth、Pose、MLSD、轨迹控制等。支持通过主体指定生视频。支持多分辨率(512,768,1024)的视频预测,支持多分辨率(512,768,1024)的视频预测,以81帧、每秒16帧进行训练,支持多语言预测 |
|
| 546 |
+
| Wan2.2-Fun-5B-InP | 23.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-5B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-5B-InP) | Wan2.2-Fun-5B文图生视频权重,以121帧、每秒24帧进行训练支持首尾图预测。 |
|
| 547 |
+
| Wan2.2-Fun-5B-Control | 23.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-5B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-5B-Control)| Wan2.2-Fun-5B视频控制权重,支持不同的控制条件,如Canny、Depth、Pose、MLSD等,同时支持使用轨迹控制。以121帧、每秒24帧进行训练,支持多语言预测 |
|
| 548 |
+
| Wan2.2-Fun-5B-Control-Camera | 23.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-5B-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-5B-Control-Camera)| Wan2.2-Fun-5B相机镜头控制权重。以121帧、每秒24帧进行训练,支持多语言预测 |
|
| 549 |
+
|
| 550 |
+
## 2. Wan2.2
|
| 551 |
+
|
| 552 |
+
| 名称 | Hugging Face | Model Scope | 描述 |
|
| 553 |
+
|--|--|--|--|
|
| 554 |
+
| Wan2.2-TI2V-5B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.2-TI2V-5B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.2-TI2V-5B) | 万象2.2-5B文生视频权重 |
|
| 555 |
+
| Wan2.2-T2V-A14B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.2-T2V-A14B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.2-T2V-A14B) | 万象2.2-14B文生视频权重 |
|
| 556 |
+
| Wan2.2-I2V-A14B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.2-I2V-A14B) | 万象2.2-14B图生视频权重 |
|
| 557 |
+
|
| 558 |
+
## 3. Wan2.1-Fun
|
| 559 |
+
|
| 560 |
+
V1.1:
|
| 561 |
+
| 名称 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
| 562 |
+
|--|--|--|--|--|
|
| 563 |
+
| Wan2.1-Fun-V1.1-1.3B-InP | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-1.3B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-1.3B-InP) | Wan2.1-Fun-V1.1-1.3B文图生视频权重,以多分辨率训练,支持首尾图预测。 |
|
| 564 |
+
| Wan2.1-Fun-V1.1-14B-InP | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-InP) | Wan2.1-Fun-V1.1-14B文图生视频权重,以多分辨率训练,支持首尾图预测。 |
|
| 565 |
+
| Wan2.1-Fun-V1.1-1.3B-Control | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-1.3B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-1.3B-Control)| Wan2.1-Fun-V1.1-1.3B视频控制权重支持不同的控制条件,如Canny、Depth、Pose、MLSD等,支持参考图 + 控制条件进行控制,支持使用轨迹控制。支持多分辨率(512,768,1024)的视频预测,,以81帧、每秒16帧进行训练,支持多语言预测 |
|
| 566 |
+
| Wan2.1-Fun-V1.1-14B-Control | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-Control)| Wan2.1-Fun-V1.1-14B视视频控制权重支持不同的控制条件,如Canny、Depth、Pose、MLSD等,支持参考图 + 控制条件进行控制,支持使用轨迹控制。支持多分辨率(512,768,1024)的视频预测,,以81帧、每秒16帧进行训练,支持多语言预测 |
|
| 567 |
+
| Wan2.1-Fun-V1.1-1.3B-Control-Camera | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-1.3B-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-1.3B-Control-Camera)| Wan2.1-Fun-V1.1-1.3B相机镜头控制权重。支持多分辨率(512,768,1024)的视频预测,,以81帧、每秒16帧进行训练,支持多语言预测 |
|
| 568 |
+
| Wan2.1-Fun-V1.1-14B-Control-Camera | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-Control-Camera)| Wan2.1-Fun-V1.1-14B相机镜头控制权重。支持多分辨率(512,768,1024)的视频预测,,以81帧、每秒16帧进行训练,支持多语言预测 |
|
| 569 |
+
|
| 570 |
+
V1.0:
|
| 571 |
+
| 名称 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
| 572 |
+
|--|--|--|--|--|
|
| 573 |
+
| Wan2.1-Fun-1.3B-InP | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-1.3B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-1.3B-InP) | Wan2.1-Fun-1.3B文图生视频权重,以多分辨率训练,支持首尾图预测。 |
|
| 574 |
+
| Wan2.1-Fun-14B-InP | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-14B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-14B-InP) | Wan2.1-Fun-14B文图生视频权重,以多分辨率训练,支持首尾图预测。 |
|
| 575 |
+
| Wan2.1-Fun-1.3B-Control | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-1.3B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-1.3B-Control)| Wan2.1-Fun-1.3B视频控制权重,支持不同的控制条件,如Canny、Depth、Pose、MLSD等,同时支持使用轨迹控制。支持多分辨率(512,768,1024)的视频预测,,以81帧、每秒16帧进行训练,支持多语言预测 |
|
| 576 |
+
| Wan2.1-Fun-14B-Control | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-14B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-14B-Control)| Wan2.1-Fun-14B视频控制权重,支持不同的控制条件,如Canny、Depth、Pose、MLSD等,同时支持使用轨迹控制。支持多分辨率(512,768,1024)的视频预测,,以81帧、每秒16帧进行训练,支持多语言预测 |
|
| 577 |
+
|
| 578 |
+
## 4. Wan2.1
|
| 579 |
+
|
| 580 |
+
| 名称 | Hugging Face | Model Scope | 描述 |
|
| 581 |
+
|--|--|--|--|
|
| 582 |
+
| Wan2.1-T2V-1.3B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-1.3B) | 万象2.1-1.3B文生视频权重 |
|
| 583 |
+
| Wan2.1-T2V-14B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-T2V-14B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-14B) | 万象2.1-14B文生视频权重 |
|
| 584 |
+
| Wan2.1-I2V-14B-480P | [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-480P) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-480P) | 万象2.1-14B-480P图生视频权重 |
|
| 585 |
+
| Wan2.1-I2V-14B-720P| [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-720P) | 万象2.1-14B-720P图生视频权重 |
|
| 586 |
+
|
| 587 |
+
## 5. FantasyTalking
|
| 588 |
+
|
| 589 |
+
| 名称 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
| 590 |
+
|--|--|--|--|--|
|
| 591 |
+
| Wan2.1-I2V-14B-720P | - | [🤗Link](https://huggingface.co/Wan-AI/Wan2.1-I2V-14B-720P) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-720P) | 万象2.1-14B-720P图生视频权重 |
|
| 592 |
+
| Wav2Vec | - | [🤗Link](https://huggingface.co/facebook/wav2vec2-base-960h) | [😄Link](https://modelscope.cn/models/AI-ModelScope/wav2vec2-base-960h) | Wav2Vec模型,请放在Wan2.1-I2V-14B-720P文件夹下,命名为audio_encoder |
|
| 593 |
+
| FantasyTalking model | - | [🤗Link](https://huggingface.co/acvlab/FantasyTalking/) | [😄Link](https://www.modelscope.cn/models/amap_cvlab/FantasyTalking/) | 官方Audio Condition的权重。 |
|
| 594 |
+
|
| 595 |
+
## 6. Qwen-Image
|
| 596 |
+
|
| 597 |
+
| 名称 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
| 598 |
+
|--|--|--|--|--|
|
| 599 |
+
| Qwen-Image | [🤗Link](https://huggingface.co/Qwen/Qwen-Image) | [😄Link](https://modelscope.cn/models/Qwen/Qwen-Image) | Qwen-Image官方权重 |
|
| 600 |
+
| Qwen-Image-Edit | [🤗Link](https://huggingface.co/Qwen/Qwen-Image-Edit) | [😄Link](https://modelscope.cn/models/Qwen/Qwen-Image-Edit) | Qwen-Image-Edit官方权重 |
|
| 601 |
+
| Qwen-Image-Edit-2509 | [🤗Link](https://huggingface.co/Qwen/Qwen-Image-Edit-2509) | [😄Link](https://modelscope.cn/models/Qwen/Qwen-Image-Edit-2509) | Qwen-Image-Edit-2509官方权重 |
|
| 602 |
+
|
| 603 |
+
## 7. Z-Image
|
| 604 |
+
|
| 605 |
+
| 名称 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
| 606 |
+
|--|--|--|--|--|
|
| 607 |
+
| Z-Image-Turbo | [🤗Link](https://huggingface.co/Tongyi-MAI/Z-Image-Turbo) | [😄Link](https://www.modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo) | Z-Image-Turbo官方权重 |
|
| 608 |
+
|
| 609 |
+
## 8. Z-Image-Fun
|
| 610 |
+
|
| 611 |
+
| 名称 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
| 612 |
+
|--|--|--|--|--|
|
| 613 |
+
| Z-Image-Turbo-Fun-Controlnet-Union | - | [🤗链接](https://huggingface.co/alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union) | [😄链接](https://modelscope.cn/models/PAI/Z-Image-Turbo-Fun-Controlnet-Union) | Z-Image-Turbo 的 ControlNet 权重,支持 Canny、Depth、Pose、MLSD 等多种控制条件。 |
|
| 614 |
+
|
| 615 |
+
## 9. Flux
|
| 616 |
+
|
| 617 |
+
| 名称 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
| 618 |
+
|--|--|--|--|--|
|
| 619 |
+
| FLUX.1-dev | [🤗Link](https://huggingface.co/black-forest-labs/FLUX.1-dev) | [😄Link](https://www.modelscope.cn/models/black-forest-labs/FLUX.1-dev) | FLUX.1-dev官方权重 |
|
| 620 |
+
| FLUX.2-dev | [🤗Link](https://huggingface.co/black-forest-labs/FLUX.2-dev) | [��Link](https://www.modelscope.cn/models/black-forest-labs/FLUX.2-dev) | FLUX.2-dev官方权重 |
|
| 621 |
+
|
| 622 |
+
## 10. Flux-Fun
|
| 623 |
+
|
| 624 |
+
| 名称 | 存储 | Hugging Face | 魔搭社区(ModelScope) | 描述 |
|
| 625 |
+
|--|--|--|--|--|
|
| 626 |
+
| Flux.2-dev-Fun-Controlnet-Union | - | [🤗链接](https://huggingface.co/alibaba-pai/FLUX.2-dev-Fun-Controlnet-Union) | [😄链接](https://modelscope.cn/models/PAI/FLUX.2-dev-Fun-Controlnet-Union) | Flux.2-dev 的 ControlNet 权重,支持 Canny、Depth、Pose、MLSD 等多种控制条件。 |
|
| 627 |
+
|
| 628 |
+
## 11. HunyuanVideo
|
| 629 |
+
|
| 630 |
+
| 名称 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
| 631 |
+
|--|--|--|--|--|
|
| 632 |
+
| HunyuanVideo | [🤗Link](https://huggingface.co/hunyuanvideo-community/HunyuanVideo) | - | HunyuanVideo-diffusers权重 |
|
| 633 |
+
| HunyuanVideo-I2V | [🤗Link](https://huggingface.co/hunyuanvideo-community/HunyuanVideo-I2V) | - | HunyuanVideo-I2V-diffusers权重 |
|
| 634 |
+
|
| 635 |
+
## 12. CogVideoX-Fun
|
| 636 |
+
|
| 637 |
+
V1.5:
|
| 638 |
+
|
| 639 |
+
| 名称 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
| 640 |
+
|--|--|--|--|--|
|
| 641 |
+
| CogVideoX-Fun-V1.5-5b-InP | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.5-5b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.5-5b-InP) | 官方的图生视频权重。支持多分辨率(512,768,1024)的视频预测,以85帧、每秒8帧进行训练 |
|
| 642 |
+
| CogVideoX-Fun-V1.5-Reward-LoRAs | - | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-Reward-LoRAs) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.5-Reward-LoRAs) | 官方的奖励反向传播技术模型,优化CogVideoX-Fun-V1.5生成的视频,使其更好地符合人类偏好。 |
|
| 643 |
+
|
| 644 |
+
|
| 645 |
+
V1.1:
|
| 646 |
+
|
| 647 |
+
| 名称 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
| 648 |
+
|--|--|--|--|--|
|
| 649 |
+
| CogVideoX-Fun-V1.1-2b-InP | 13.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-2b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-2b-InP) | 官方的图生视频权重。支持多分辨率(512,768,1024,1280)的视频预测,以49帧、每秒8帧进行训练 |
|
| 650 |
+
| CogVideoX-Fun-V1.1-5b-InP | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-InP) | 官方的图生视频权重。添加了Noise,运动幅度相比于V1.0更大。支持多分辨率(512,768,1024,1280)的视频预测,以49帧、每秒8帧进行训练 |
|
| 651 |
+
| CogVideoX-Fun-V1.1-2b-Pose | 13.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-2b-Pose) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-2b-Pose) | 官方的姿态控制生视频权重。支持多分辨率(512,768,1024,1280)的视频预测,以49帧、每秒8帧进行训练 |
|
| 652 |
+
| CogVideoX-Fun-V1.1-2b-Control | 13.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-2b-Control) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-2b-Control) | 官方的控制生视频权重。支持多分辨率(512,768,1024,1280)的视频预测,以49帧、每秒8帧进行训练。支持不同的控制条件,如Canny、Depth、Pose、MLSD等 |
|
| 653 |
+
| CogVideoX-Fun-V1.1-5b-Pose | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-Pose) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-Pose) | 官方的姿态控制生视频权重。支持多分辨率(512,768,1024,1280)的视频预测,以49帧、每秒8帧进行训练 |
|
| 654 |
+
| CogVideoX-Fun-V1.1-5b-Control | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-Control) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-Control) | 官方的控制生视频权重。支持多分辨率(512,768,1024,1280)的视频预测,以49帧、每秒8帧进行训练。支持不同的控制条件,如Canny、Depth、Pose、MLSD等 |
|
| 655 |
+
| CogVideoX-Fun-V1.1-Reward-LoRAs | - | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-Reward-LoRAs) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-Reward-LoRAs) | 官方的奖励反向传播技术模型,优化CogVideoX-Fun-V1.1生成的视频,使其更好地符合人类偏好。 |
|
| 656 |
+
|
| 657 |
+
<details>
|
| 658 |
+
<summary>(Obsolete) V1.0:</summary>
|
| 659 |
+
|
| 660 |
+
| 名称 | 存储空间 | Hugging Face | Model Scope | 描述 |
|
| 661 |
+
|--|--|--|--|--|
|
| 662 |
+
| CogVideoX-Fun-2b-InP | 13.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-2b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-2b-InP) | 官方的图生视频权重。支持多分辨率(512,768,1024,1280)的视频预测,以49帧、每秒8帧进行训练 |
|
| 663 |
+
| CogVideoX-Fun-5b-InP | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-5b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-5b-InP) | 官方的图生视频权重。支持多分辨率(512,768,1024,1280)的视频预测,以49帧、每秒8帧进行训练 |
|
| 664 |
+
</details>
|
| 665 |
+
|
| 666 |
+
# 参考文献
|
| 667 |
+
- CogVideo: https://github.com/THUDM/CogVideo/
|
| 668 |
+
- EasyAnimate: https://github.com/aigc-apps/EasyAnimate
|
| 669 |
+
- Wan2.1: https://github.com/Wan-Video/Wan2.1/
|
| 670 |
+
- Wan2.2: https://github.com/Wan-Video/Wan2.2/
|
| 671 |
+
- Diffusers: https://github.com/huggingface/diffusers
|
| 672 |
+
- Qwen-Image: https://github.com/QwenLM/Qwen-Image
|
| 673 |
+
- Self-Forcing: https://github.com/guandeh17/Self-Forcing
|
| 674 |
+
- Flux: https://github.com/black-forest-labs/flux
|
| 675 |
+
- Flux2: https://github.com/black-forest-labs/flux2
|
| 676 |
+
- HunyuanVideo: https://github.com/Tencent-Hunyuan/HunyuanVideo
|
| 677 |
+
- ComfyUI-KJNodes: https://github.com/kijai/ComfyUI-KJNodes
|
| 678 |
+
- ComfyUI-EasyAnimateWrapper: https://github.com/kijai/ComfyUI-EasyAnimateWrapper
|
| 679 |
+
- ComfyUI-CameraCtrl-Wrapper: https://github.com/chaojie/ComfyUI-CameraCtrl-Wrapper
|
| 680 |
+
- CameraCtrl: https://github.com/hehao13/CameraCtrl
|
| 681 |
+
|
| 682 |
+
# 许可证
|
| 683 |
+
本项目采用 [Apache License (Version 2.0)](https://github.com/modelscope/modelscope/blob/master/LICENSE).
|
| 684 |
+
|
| 685 |
+
CogVideoX-2B 模型 (包括其对应的Transformers模块,VAE模块) 根据 [Apache 2.0 协议](LICENSE) 许可证发布。
|
| 686 |
+
|
| 687 |
+
CogVideoX-5B 模型(Transformer 模块)在[CogVideoX许可证](https://huggingface.co/THUDM/CogVideoX-5b/blob/main/LICENSE)下发布.
|
VideoX-Fun/build_context.json
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"toolchain_version": "5.1-patch1",
|
| 3 |
+
"toolchain_commit": "5c5e711b",
|
| 4 |
+
"target_platform": "AX650A",
|
| 5 |
+
"cfg": {
|
| 6 |
+
"input": "",
|
| 7 |
+
"output_dir": "",
|
| 8 |
+
"output_name": "",
|
| 9 |
+
"work_dir": "",
|
| 10 |
+
"model_type": "ONNX",
|
| 11 |
+
"target_hardware": "AX650",
|
| 12 |
+
"npu_mode": "NPU1",
|
| 13 |
+
"input_shapes": "",
|
| 14 |
+
"input_processors": [],
|
| 15 |
+
"output_processors": [],
|
| 16 |
+
"const_processors": [],
|
| 17 |
+
"op_processors": [],
|
| 18 |
+
"quant_op_processors": [],
|
| 19 |
+
"custom_ops": []
|
| 20 |
+
},
|
| 21 |
+
"axmodel_extra": {
|
| 22 |
+
"version": "",
|
| 23 |
+
"tensor_extras": [],
|
| 24 |
+
"subgraphs": [],
|
| 25 |
+
"hardware_type": "AX650"
|
| 26 |
+
},
|
| 27 |
+
"build_start": 1768291836.7460434,
|
| 28 |
+
"build_time": 16.673909187316895,
|
| 29 |
+
"input_model_size": 0,
|
| 30 |
+
"macs": 0,
|
| 31 |
+
"compiled_model_size": 0,
|
| 32 |
+
"input_model": "/data/tmp/yongqiang/nfs/Z-Image-Turbo.axera/python/VideoX-Fun",
|
| 33 |
+
"work_dir": "/data/tmp/yongqiang/nfs/Z-Image-Turbo.axera/python/VideoX-Fun",
|
| 34 |
+
"output_dir": "/data/tmp/yongqiang/nfs/Z-Image-Turbo.axera/python/VideoX-Fun",
|
| 35 |
+
"output_model": "/data/tmp/yongqiang/nfs/Z-Image-Turbo.axera/python/VideoX-Fun",
|
| 36 |
+
"npu_mode": 0,
|
| 37 |
+
"npu_mode_str": "",
|
| 38 |
+
"model_type": 0,
|
| 39 |
+
"model_type_str": "ONNX",
|
| 40 |
+
"quant_dir": "/data/tmp/yongqiang/nfs/Z-Image-Turbo.axera/python/VideoX-Fun",
|
| 41 |
+
"onnx_model_check": false,
|
| 42 |
+
"frontend_dir": "/data/tmp/yongqiang/nfs/Z-Image-Turbo.axera/python/VideoX-Fun",
|
| 43 |
+
"random_seed": 1504902737,
|
| 44 |
+
"stride_ios": [],
|
| 45 |
+
"input_tensor_infos": {},
|
| 46 |
+
"compiler_dir": "/data/tmp/yongqiang/nfs/Z-Image-Turbo.axera/python/VideoX-Fun",
|
| 47 |
+
"compiler_extra_input_shapes": [],
|
| 48 |
+
"compiler_static_batchs": [],
|
| 49 |
+
"compiler_max_dynamic_batch": 0,
|
| 50 |
+
"compiler_batch_sizes": [],
|
| 51 |
+
"enable_compiler_check": false,
|
| 52 |
+
"dump_npu_case": false,
|
| 53 |
+
"dump_npu_trace": false,
|
| 54 |
+
"gen_neusight": false,
|
| 55 |
+
"compress_mcode": true,
|
| 56 |
+
"code": "UnknownError",
|
| 57 |
+
"error_msg": "OSError: [Errno 28] No space left on device",
|
| 58 |
+
"axe_code": "NotRunning",
|
| 59 |
+
"axe_error_msg": "",
|
| 60 |
+
"io_info": "",
|
| 61 |
+
"subgraphs": [],
|
| 62 |
+
"custom_ops": []
|
| 63 |
+
}
|
VideoX-Fun/comfyui/README.md
ADDED
|
@@ -0,0 +1,281 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ComfyUI VideoX-Fun
|
| 2 |
+
Easily use VideoX-Fun and Wan2.1-Fun inside ComfyUI!
|
| 3 |
+
|
| 4 |
+
- [Installation](#1-installation)
|
| 5 |
+
- [Node types](#node-types)
|
| 6 |
+
- [Example workflows](#example-workflows)
|
| 7 |
+
|
| 8 |
+
## Installation
|
| 9 |
+
### 1. ComfyUI Installation
|
| 10 |
+
|
| 11 |
+
#### Option 1: Install via ComfyUI Manager
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
#### Option 2: Install manually
|
| 15 |
+
The VideoX-Fun repository needs to be placed at `ComfyUI/custom_nodes/VideoX-Fun/`.
|
| 16 |
+
|
| 17 |
+
```
|
| 18 |
+
cd ComfyUI/custom_nodes/
|
| 19 |
+
|
| 20 |
+
# Git clone the cogvideox_fun itself
|
| 21 |
+
git clone https://github.com/aigc-apps/VideoX-Fun.git
|
| 22 |
+
|
| 23 |
+
# Git clone the video outout node
|
| 24 |
+
git clone https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite.git
|
| 25 |
+
|
| 26 |
+
# Git clone the KJ Nodes
|
| 27 |
+
git clone https://github.com/kijai/ComfyUI-KJNodes.git
|
| 28 |
+
|
| 29 |
+
cd VideoX-Fun/
|
| 30 |
+
python install.py
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
### 2. Download models
|
| 34 |
+
#### i、Full loading
|
| 35 |
+
Download full model into `ComfyUI/models/Fun_Models/`.
|
| 36 |
+
|
| 37 |
+
#### ii、Chunked loading
|
| 38 |
+
Put the transformer model weights to the `ComfyUI/models/diffusion_models/`.
|
| 39 |
+
Put the text encoer model weights to the `ComfyUI/models/text_encoders/`.
|
| 40 |
+
Put the clip vision model weights to the `ComfyUI/models/clip_vision/`.
|
| 41 |
+
Put the vae model weights to the `ComfyUI/models/vae/`.
|
| 42 |
+
Put the tokenizer files to the `ComfyUI/models/Fun_Models/` (For example: `ComfyUI/models/Fun_Models/umt5-xxl`).
|
| 43 |
+
|
| 44 |
+
### 3. (Optional) Download preprocess weights into `ComfyUI/custom_nodes/Fun_Models/Third_Party/`.
|
| 45 |
+
Except for the fun models' weights, if you want to use the control preprocess nodes, you can download the preprocess weights to `ComfyUI/custom_nodes/Fun_Models/Third_Party/`.
|
| 46 |
+
|
| 47 |
+
```
|
| 48 |
+
remote_onnx_det = "https://huggingface.co/yzd-v/DWPose/resolve/main/yolox_l.onnx"
|
| 49 |
+
remote_onnx_pose = "https://huggingface.co/yzd-v/DWPose/resolve/main/dw-ll_ucoco_384.onnx"
|
| 50 |
+
remote_zoe= "https://huggingface.co/lllyasviel/Annotators/resolve/main/ZoeD_M12_N.pt"
|
| 51 |
+
```
|
| 52 |
+
#### i. Wan2.2-Fun
|
| 53 |
+
| Name | Hugging Face | Model Scope | Description |
|
| 54 |
+
|--|--|--|--|--|
|
| 55 |
+
| Wan2.2-Fun-A14B-InP | 64.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-A14B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-A14B-InP) | Wan2.2-Fun-14B text-to-video generation weights, trained at multiple resolutions, supports start-end image prediction. |
|
| 56 |
+
| Wan2.2-Fun-A14B-Control | 64.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-A14B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-A14B-Control)| Wan2.2-Fun-14B video control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, etc., and trajectory control. Supports multi-resolution (512, 768, 1024) video prediction at 81 frames, trained at 16 frames per second, with multilingual prediction support. |
|
| 57 |
+
| Wan2.2-Fun-A14B-Control-Camera | 64.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-A14B-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-A14B-Control-Camera)| Wan2.2-Fun-14B camera lens control weights. Supports multi-resolution (512, 768, 1024) video prediction, trained with 81 frames at 16 FPS, supports multilingual prediction. |
|
| 58 |
+
| Wan2.2-Fun-5B-InP | 23.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-5B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-5B-InP) | Wan2.2-Fun-5B text-to-video weights trained at 121 frames, 24 FPS, supporting first/last frame prediction. |
|
| 59 |
+
| Wan2.2-Fun-5B-Control | 23.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-5B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-5B-Control)| Wan2.2-Fun-5B video control weights, supporting control conditions like Canny, Depth, Pose, MLSD, and trajectory control. Trained at 121 frames, 24 FPS, with multilingual prediction support. |
|
| 60 |
+
| Wan2.2-Fun-5B-Control-Camera | 23.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.2-Fun-5B-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/Wan2.2-Fun-5B-Control-Camera)| Wan2.2-Fun-5B camera lens control weights. Trained at 121 frames, 24 FPS, with multilingual prediction support. |
|
| 61 |
+
|
| 62 |
+
#### ii. Wan2.2
|
| 63 |
+
|
| 64 |
+
| Name | Hugging Face | Model Scope | Description |
|
| 65 |
+
|--|--|--|--|
|
| 66 |
+
| Wan2.2-TI2V-5B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.2-TI2V-5B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.2-TI2V-5B) | Wan2.2-5B Text-to-Video Weights |
|
| 67 |
+
| Wan2.2-T2V-14B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.2-T2V-A14B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.2-T2V-A14B) | Wan2.2-14B Text-to-Video Weights |
|
| 68 |
+
| Wan2.2-I2V-A14B | [🤗Link](https://huggingface.co/Wan-AI/Wan2.2-I2V-A14B) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.2-I2V-A14B) | Wan2.2-I2V-A14B Image-to-Video Weights |
|
| 69 |
+
|
| 70 |
+
#### iii. Wan2.1-Fun
|
| 71 |
+
|
| 72 |
+
V1.1:
|
| 73 |
+
| Name | Storage Size | Hugging Face | Model Scope | Description |
|
| 74 |
+
|------|--------------|--------------|-------------|-------------|
|
| 75 |
+
| Wan2.1-Fun-V1.1-1.3B-InP | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-1.3B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-1.3B-InP) | Wan2.1-Fun-V1.1-1.3B text-to-video generation weights, trained at multiple resolutions, supports start-end image prediction. |
|
| 76 |
+
| Wan2.1-Fun-V1.1-14B-InP | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-InP) | Wan2.1-Fun-V1.1-14B text-to-video generation weights, trained at multiple resolutions, supports start-end image prediction. |
|
| 77 |
+
| Wan2.1-Fun-V1.1-1.3B-Control | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-1.3B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-1.3B-Control) | Wan2.1-Fun-V1.1-1.3B video control weights support various control conditions such as Canny, Depth, Pose, MLSD, etc., supports reference image + control condition-based control, and trajectory control. Supports multi-resolution (512, 768, 1024) video prediction, trained with 81 frames at 16 FPS, supports multilingual prediction. |
|
| 78 |
+
| Wan2.1-Fun-V1.1-14B-Control | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-Control) | Wan2.1-Fun-V1.1-14B video control weights support various control conditions such as Canny, Depth, Pose, MLSD, etc., supports reference image + control condition-based control, and trajectory control. Supports multi-resolution (512, 768, 1024) video prediction, trained with 81 frames at 16 FPS, supports multilingual prediction. |
|
| 79 |
+
| Wan2.1-Fun-V1.1-1.3B-Control-Camera | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-1.3B-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-1.3B-Control-Camera) | Wan2.1-Fun-V1.1-1.3B camera lens control weights. Supports multi-resolution (512, 768, 1024) video prediction, trained with 81 frames at 16 FPS, supports multilingual prediction. |
|
| 80 |
+
| Wan2.1-Fun-V1.1-14B-Control-Camera | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-V1.1-14B-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-V1.1-14B-Control-Camera) | Wan2.1-Fun-V1.1-14B camera lens control weights. Supports multi-resolution (512, 768, 1024) video prediction, trained with 81 frames at 16 FPS, supports multilingual prediction. |
|
| 81 |
+
|
| 82 |
+
V1.0:
|
| 83 |
+
| Name | Storage Space | Hugging Face | Model Scope | Description |
|
| 84 |
+
|--|--|--|--|--|
|
| 85 |
+
| Wan2.1-Fun-1.3B-InP | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-1.3B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-1.3B-InP) | Wan2.1-Fun-1.3B text-to-video weights, trained at multiple resolutions, supporting start and end frame prediction. |
|
| 86 |
+
| Wan2.1-Fun-14B-InP | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-14B-InP) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-14B-InP) | Wan2.1-Fun-14B text-to-video weights, trained at multiple resolutions, supporting start and end frame prediction. |
|
| 87 |
+
| Wan2.1-Fun-1.3B-Control | 19.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-1.3B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-1.3B-Control) | Wan2.1-Fun-1.3B video control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, etc., and trajectory control. Supports multi-resolution (512, 768, 1024) video prediction at 81 frames, trained at 16 frames per second, with multilingual prediction support. |
|
| 88 |
+
| Wan2.1-Fun-14B-Control | 47.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-14B-Control) | [😄Link](https://modelscope.cn/models/PAI/Wan2.1-Fun-14B-Control) | Wan2.1-Fun-14B video control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, etc., and trajectory control. Supports multi-resolution (512, 768, 1024) video prediction at 81 frames, trained at 16 frames per second, with multilingual prediction support. |
|
| 89 |
+
|
| 90 |
+
#### iv. Wan2.1
|
| 91 |
+
|
| 92 |
+
| Name | Hugging Face | Model Scope | Description |
|
| 93 |
+
|--|--|--|--|
|
| 94 |
+
| Wan2.1-T2V-1.3B | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-1.3B-InP) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-1.3B) | Wanxiang 2.1-1.3B text-to-video weights |
|
| 95 |
+
| Wan2.1-T2V-14B | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-1.3B-InP) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-T2V-14B) | Wanxiang 2.1-14B text-to-video weights |
|
| 96 |
+
| Wan2.1-I2V-14B-480P | [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-14B-InP) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-480P) | Wanxiang 2.1-14B-480P image-to-video weights |
|
| 97 |
+
| Wan2.1-I2V-14B-720P| [🤗Link](https://huggingface.co/alibaba-pai/Wan2.1-Fun-14B-InP) | [😄Link](https://www.modelscope.cn/models/Wan-AI/Wan2.1-I2V-14B-720P) | Wanxiang 2.1-14B-720P image-to-video weights |
|
| 98 |
+
|
| 99 |
+
#### v. CogVideoX-Fun
|
| 100 |
+
|
| 101 |
+
V1.5:
|
| 102 |
+
|
| 103 |
+
| Name | Storage Space | Hugging Face | Model Scope | Description |
|
| 104 |
+
|--|--|--|--|--|
|
| 105 |
+
| CogVideoX-Fun-V1.5-5b-InP | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.5-5b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.5-5b-InP) | Our official graph-generated video model is capable of predicting videos at multiple resolutions (512, 768, 1024) and has been trained on 85 frames at a rate of 8 frames per second. |
|
| 106 |
+
| CogVideoX-Fun-V1.5-Reward-LoRAs | - | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-Reward-LoRAs) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.5-Reward-LoRAs) | The official reward backpropagation technology model optimizes the videos generated by CogVideoX-Fun-V1.5 to better match human preferences. |
|
| 107 |
+
|
| 108 |
+
V1.1:
|
| 109 |
+
|
| 110 |
+
| Name | Storage Space | Hugging Face | Model Scope | Description |
|
| 111 |
+
|--|--|--|--|--|
|
| 112 |
+
| CogVideoX-Fun-V1.1-2b-InP | 13.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-2b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-2b-InP) | Our official graph-generated video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second. |
|
| 113 |
+
| CogVideoX-Fun-V1.1-5b-InP | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-InP) | Our official graph-generated video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second. Noise has been added to the reference image, and the amplitude of motion is greater compared to V1.0. |
|
| 114 |
+
| CogVideoX-Fun-V1.1-2b-Pose | 13.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-2b-Pose) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-2b-Pose) | Our official pose-control video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second.|
|
| 115 |
+
| CogVideoX-Fun-V1.1-2b-Control | 13.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-2b-Control) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-2b-Control) | Our official control video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second. Supporting various control conditions such as Canny, Depth, Pose, MLSD, etc.|
|
| 116 |
+
| CogVideoX-Fun-V1.1-5b-Pose | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-Pose) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-Pose) | Our official pose-control video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second.|
|
| 117 |
+
| CogVideoX-Fun-V1.1-5b-Control | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-5b-Control) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-5b-Control) | Our official control video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second. Supporting various control conditions such as Canny, Depth, Pose, MLSD, etc.|
|
| 118 |
+
| CogVideoX-Fun-V1.1-Reward-LoRAs | - | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-V1.1-Reward-LoRAs) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-V1.1-Reward-LoRAs) | The official reward backpropagation technology model optimizes the videos generated by CogVideoX-Fun-V1.1 to better match human preferences. |
|
| 119 |
+
|
| 120 |
+
<details>
|
| 121 |
+
<summary>(Obsolete) V1.0:</summary>
|
| 122 |
+
|
| 123 |
+
| Name | Storage Space | Hugging Face | Model Scope | Description |
|
| 124 |
+
|--|--|--|--|--|
|
| 125 |
+
| CogVideoX-Fun-2b-InP | 13.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-2b-InP) | [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-2b-InP) | Our official graph-generated video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second. |
|
| 126 |
+
| CogVideoX-Fun-5b-InP | 20.0 GB | [🤗Link](https://huggingface.co/alibaba-pai/CogVideoX-Fun-5b-InP)| [😄Link](https://modelscope.cn/models/PAI/CogVideoX-Fun-5b-InP)| Our official graph-generated video model is capable of predicting videos at multiple resolutions (512, 768, 1024, 1280) and has been trained on 49 frames at a rate of 8 frames per second. |
|
| 127 |
+
</details>
|
| 128 |
+
|
| 129 |
+
### 3. (Optional) Download Lora models into `ComfyUI/models/loras/fun_models/`
|
| 130 |
+
If you want to use lora in CogVideoX-Fun, please put the lora to `ComfyUI/models/loras/fun_models/`.
|
| 131 |
+
|
| 132 |
+
## Node types
|
| 133 |
+
### 1. Wan-Fun
|
| 134 |
+
- **LoadWanFunModel**
|
| 135 |
+
- Loads the Wan-Fun Model.
|
| 136 |
+
- **LoadWanFunLora**
|
| 137 |
+
- Write the prompt for Wan-Fun model
|
| 138 |
+
- **WanFunInpaintSampler**
|
| 139 |
+
- Wan-Fun Sampler for Image to Video
|
| 140 |
+
- **WanFunT2VSampler**
|
| 141 |
+
- Wan-Fun Sampler for Text to Video
|
| 142 |
+
|
| 143 |
+
### 2. Wan
|
| 144 |
+
- **LoadWanModel**
|
| 145 |
+
- Loads the Wan-Fun Model.
|
| 146 |
+
- **LoadWanLora**
|
| 147 |
+
- Write the prompt for Wan-Fun model
|
| 148 |
+
- **WanI2VSampler**
|
| 149 |
+
- Wan-Fun Sampler for Image to Video
|
| 150 |
+
- **WanT2VSampler**
|
| 151 |
+
- Wan-Fun Sampler for Text to Video
|
| 152 |
+
|
| 153 |
+
### 3. CogVideoX-Fun
|
| 154 |
+
- **LoadCogVideoXFunModel**
|
| 155 |
+
- Loads the CogVideoX-Fun model
|
| 156 |
+
- **FunTextBox**
|
| 157 |
+
- Write the prompt for CogVideoX-Fun model
|
| 158 |
+
- **CogVideoXFunInpaintSampler**
|
| 159 |
+
- CogVideoX-Fun Sampler for Image to Video
|
| 160 |
+
- **CogVideoXFunT2VSampler**
|
| 161 |
+
- CogVideoX-Fun Sampler for Text to Video
|
| 162 |
+
- **CogVideoXFunV2VSampler**
|
| 163 |
+
- CogVideoX-Fun Sampler for Video to Video
|
| 164 |
+
|
| 165 |
+
## Example workflows
|
| 166 |
+
### 1. Wan-Fun
|
| 167 |
+
#### i. Image to video generation
|
| 168 |
+
[Download link](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan_fun/asset/v1.1/wan2.1_fun_workflow_i2v.json) for wan-fun.
|
| 169 |
+
|
| 170 |
+
Our ui is shown as follow:
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
You can run the demo using following photo:
|
| 174 |
+

|
| 175 |
+
|
| 176 |
+
#### ii. Text to video generation
|
| 177 |
+
[Download link](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan_fun/asset/v1.1/wan2.1_fun_workflow_t2v.json) for wan-fun.
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
### iii. Trajectory Control Video Generation
|
| 182 |
+
Our user interface is shown as follows, this is the [json](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan_fun/asset/v1.1/wan2.1_fun_workflow_control_trajectory.json):
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
You can run a demo using the following photo:
|
| 187 |
+
|
| 188 |
+

|
| 189 |
+
|
| 190 |
+
### iv. Control Video Generation
|
| 191 |
+
Our user interface is shown as follows, this is the [json](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan_fun/asset/v1.1/wan2.1_fun_workflow_v2v_control.json):
|
| 192 |
+
|
| 193 |
+
To facilitate usage, we have added several JSON configurations that automatically process input videos into the necessary control videos. These include [canny processing](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan_fun/asset/v1.1/wan2.1_fun_workflow_v2v_control_canny.json), [pose processing](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan_fun/asset/v1.1/wan2.1_fun_workflow_v2v_control_pose.json), and [depth processing](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan_fun/asset/v1.1/wan2.1_fun_workflow_v2v_control_depth.json).
|
| 194 |
+
|
| 195 |
+
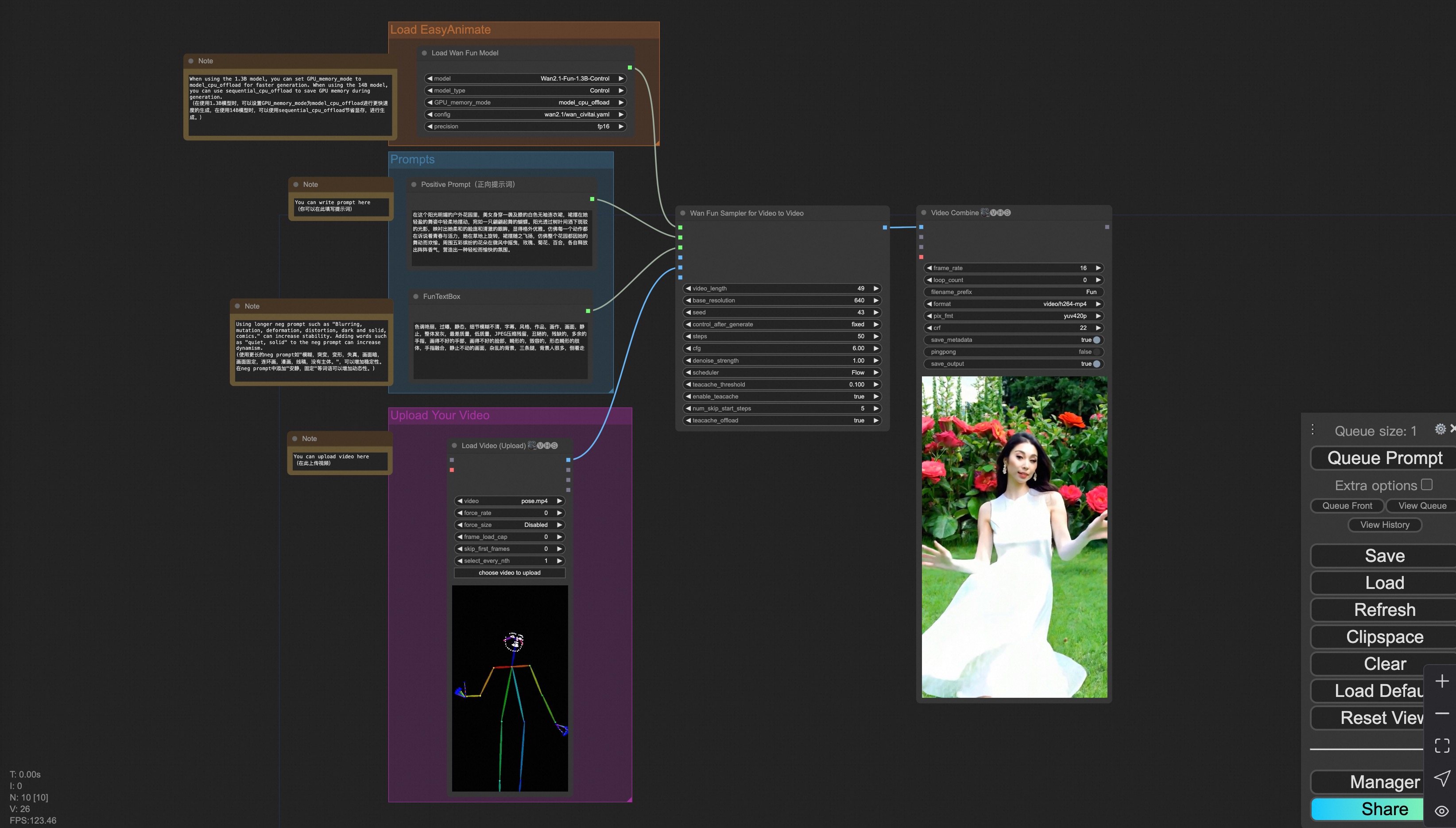
|
| 196 |
+
|
| 197 |
+
You can run a demo using the following video:
|
| 198 |
+
|
| 199 |
+
[Demo Video](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.1/pose.mp4)
|
| 200 |
+
|
| 201 |
+
### v. Control + Ref Video Generation
|
| 202 |
+
Our user interface is shown as follows, this is the [json](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan_fun/asset/v1.1/wan2.1_fun_workflow_v2v_control_ref.json):
|
| 203 |
+
|
| 204 |
+
To facilitate usage, we have added several JSON configurations that automatically process input videos into the necessary control videos. These include [pose processing](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan_fun/asset/v1.1/wan2.1_fun_workflow_v2v_control_pose_ref.json), and [depth processing](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan_fun/asset/v1.1/wan2.1_fun_workflow_v2v_control_depth_ref.json).
|
| 205 |
+
|
| 206 |
+
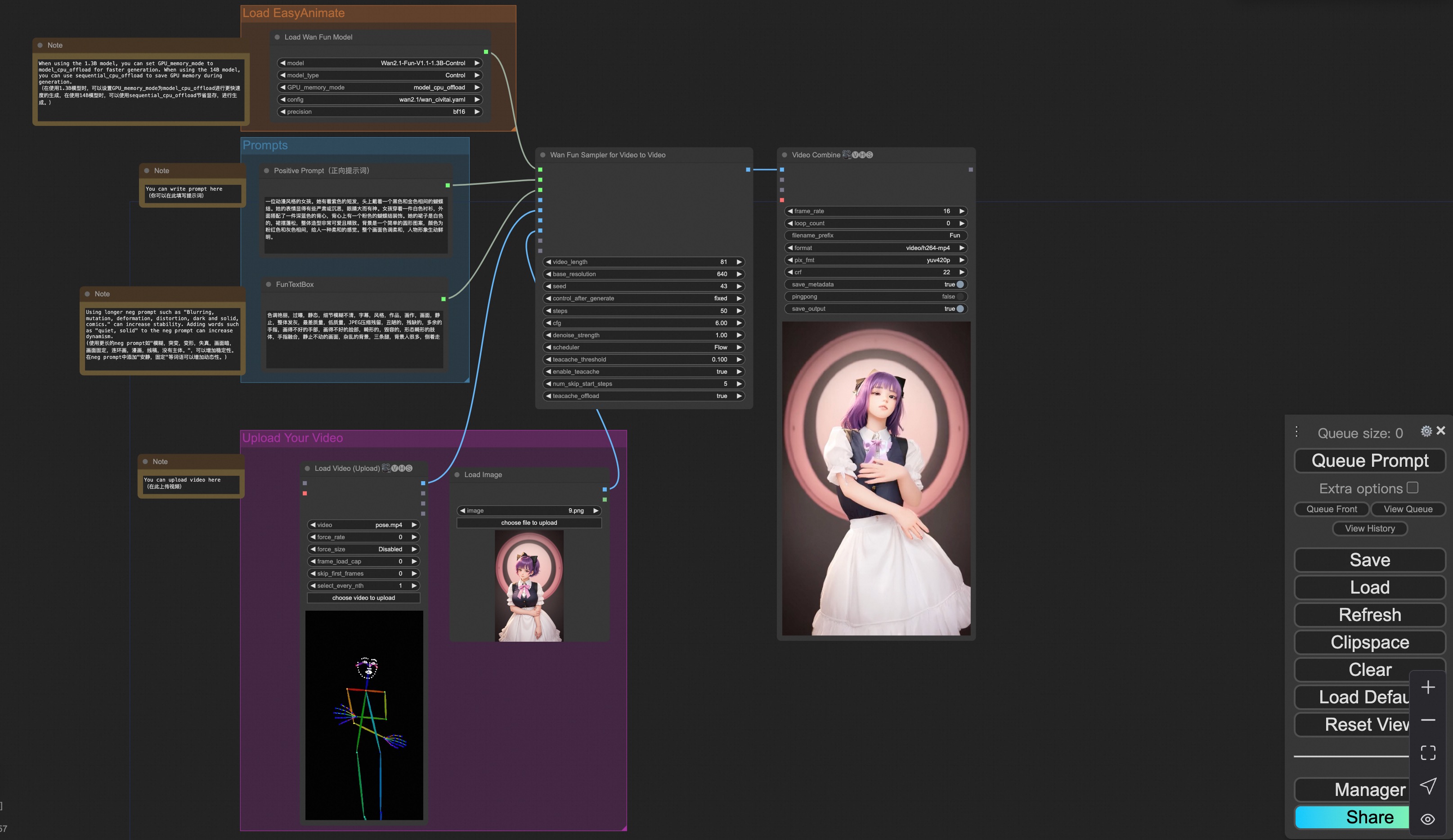
|
| 207 |
+
|
| 208 |
+
You can run a demo using the following video:
|
| 209 |
+
|
| 210 |
+
[Demo Image](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan_fun/asset/v1.1/6.png)
|
| 211 |
+
|
| 212 |
+
[Demo Video](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan_fun/asset/v1.1/pose.mp4)
|
| 213 |
+
|
| 214 |
+
### vi. Camera Control Video Generation
|
| 215 |
+
Our user interface is shown as follows, this is the [json](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan_fun/asset/v1.1/wan2.1_fun_workflow_control_camera.json):
|
| 216 |
+
|
| 217 |
+
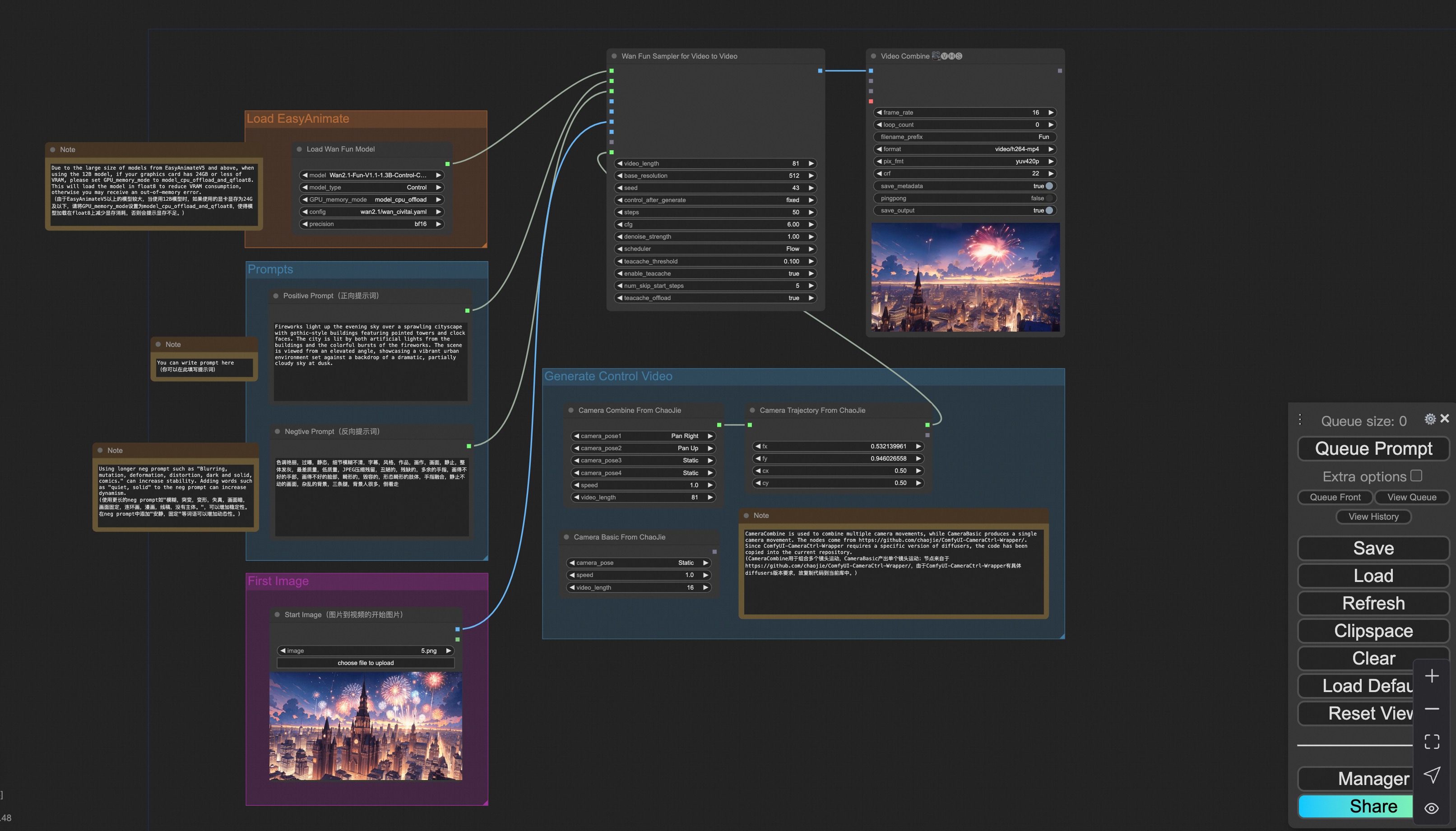
|
| 218 |
+
|
| 219 |
+
You can run a demo using the following photo:
|
| 220 |
+
|
| 221 |
+

|
| 222 |
+
|
| 223 |
+
### 2. Wan
|
| 224 |
+
#### i. Image to video generation
|
| 225 |
+
[Download link](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan/asset/v1.0/wan2.1_workflow_i2v.json) for wan-fun.
|
| 226 |
+
|
| 227 |
+
Our ui is shown as follow:
|
| 228 |
+
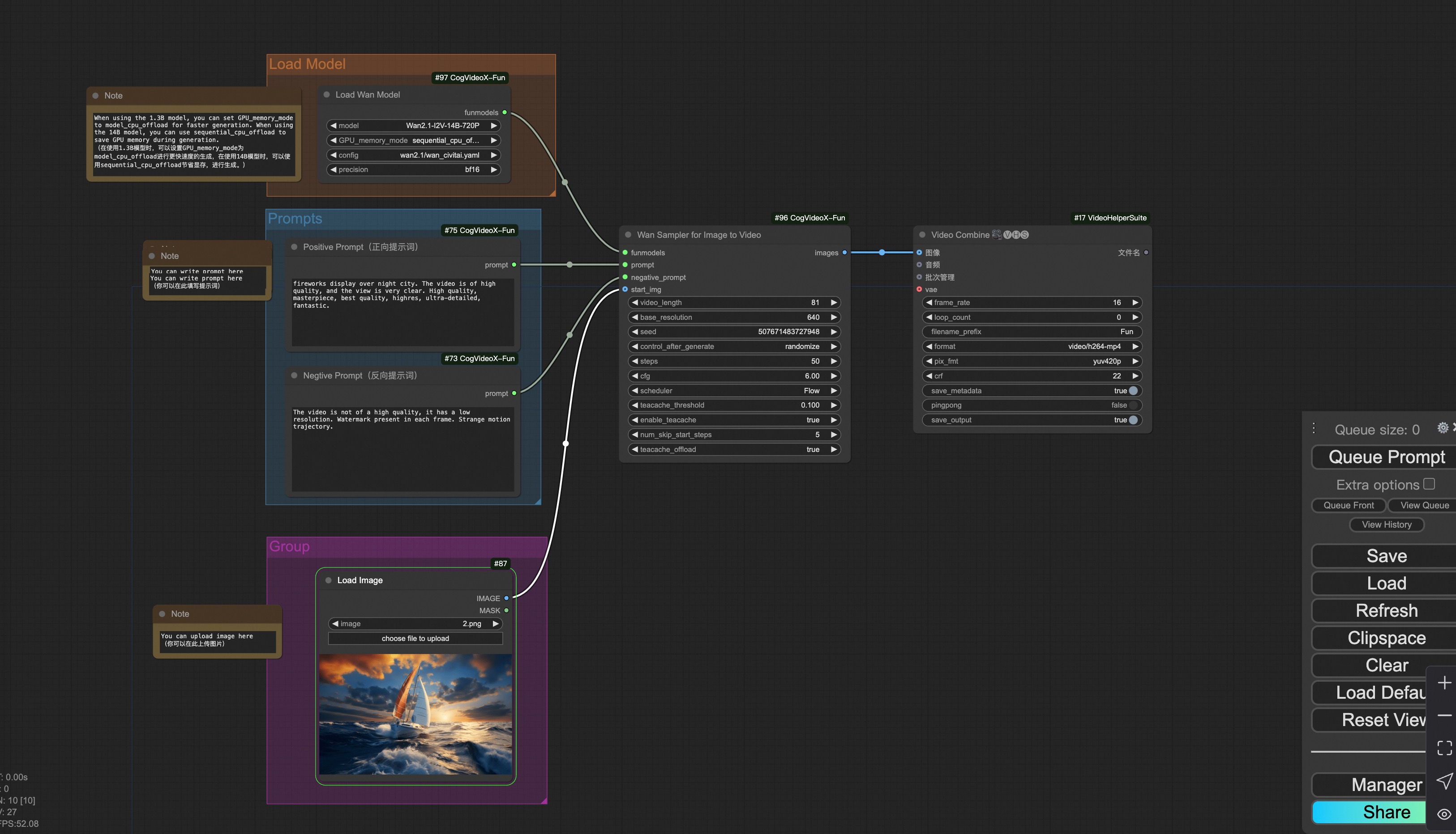
|
| 229 |
+
|
| 230 |
+
You can run the demo using following photo:
|
| 231 |
+

|
| 232 |
+
|
| 233 |
+
#### ii. Text to video generation
|
| 234 |
+
[Download link](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/wan/asset/v1.0/wan2.1_workflow_t2v.json) for wan-fun.
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
### 3. CogVideoX-Fun
|
| 239 |
+
#### i. Video to video generation
|
| 240 |
+
[Download link](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.5/cogvideoxfunv1.5_workflow_v2v.json) for v1.5.
|
| 241 |
+
|
| 242 |
+
[Download link](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.1/cogvideoxfunv1.1_workflow_v2v.json) for v1.1.
|
| 243 |
+
|
| 244 |
+
Our ui is shown as follow:
|
| 245 |
+

|
| 246 |
+
|
| 247 |
+
You can run the demo using following video:
|
| 248 |
+
[demo video](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1/play_guitar.mp4)
|
| 249 |
+
|
| 250 |
+
#### ii. Image to video generation
|
| 251 |
+
[Download link](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.5/cogvideoxfunv1.5_workflow_i2v.json) for v1.5.
|
| 252 |
+
|
| 253 |
+
[Download link](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.1/cogvideoxfunv1.1_workflow_i2v.json) for v1.1.
|
| 254 |
+
|
| 255 |
+
Our ui is shown as follow:
|
| 256 |
+

|
| 257 |
+
|
| 258 |
+
You can run the demo using following photo:
|
| 259 |
+

|
| 260 |
+
|
| 261 |
+
#### iii. Text to video generation
|
| 262 |
+
[Download link](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.5/cogvideoxfunv1.5_workflow_t2v.json) for v1.5.
|
| 263 |
+
|
| 264 |
+
[Download link](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.1/cogvideoxfunv1.1_workflow_t2v.json) for v1.1.
|
| 265 |
+
|
| 266 |
+

|
| 267 |
+
|
| 268 |
+
#### iv. Control video generation
|
| 269 |
+
[Download link](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.1/cogvideoxfunv1.1_workflow_v2v_control.json) for v1.1.
|
| 270 |
+
|
| 271 |
+
Our ui is shown as follow:
|
| 272 |
+

|
| 273 |
+
|
| 274 |
+
You can run the demo using following video:
|
| 275 |
+
[demo video](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.1/pose.mp4)
|
| 276 |
+
|
| 277 |
+
#### v. Lora usage.
|
| 278 |
+
[Download link](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.1/cogvideoxfunv1.1_workflow_t2v_lora.json) for v1.1.
|
| 279 |
+
|
| 280 |
+
Our ui is shown as follow:
|
| 281 |
+

|
VideoX-Fun/comfyui/annotator/dwpose_utils/onnxdet.py
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
def nms(boxes, scores, nms_thr):
|
| 5 |
+
"""Single class NMS implemented in Numpy."""
|
| 6 |
+
x1 = boxes[:, 0]
|
| 7 |
+
y1 = boxes[:, 1]
|
| 8 |
+
x2 = boxes[:, 2]
|
| 9 |
+
y2 = boxes[:, 3]
|
| 10 |
+
|
| 11 |
+
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
|
| 12 |
+
order = scores.argsort()[::-1]
|
| 13 |
+
|
| 14 |
+
keep = []
|
| 15 |
+
while order.size > 0:
|
| 16 |
+
i = order[0]
|
| 17 |
+
keep.append(i)
|
| 18 |
+
xx1 = np.maximum(x1[i], x1[order[1:]])
|
| 19 |
+
yy1 = np.maximum(y1[i], y1[order[1:]])
|
| 20 |
+
xx2 = np.minimum(x2[i], x2[order[1:]])
|
| 21 |
+
yy2 = np.minimum(y2[i], y2[order[1:]])
|
| 22 |
+
|
| 23 |
+
w = np.maximum(0.0, xx2 - xx1 + 1)
|
| 24 |
+
h = np.maximum(0.0, yy2 - yy1 + 1)
|
| 25 |
+
inter = w * h
|
| 26 |
+
ovr = inter / (areas[i] + areas[order[1:]] - inter)
|
| 27 |
+
|
| 28 |
+
inds = np.where(ovr <= nms_thr)[0]
|
| 29 |
+
order = order[inds + 1]
|
| 30 |
+
|
| 31 |
+
return keep
|
| 32 |
+
|
| 33 |
+
def multiclass_nms(boxes, scores, nms_thr, score_thr):
|
| 34 |
+
"""Multiclass NMS implemented in Numpy. Class-aware version."""
|
| 35 |
+
final_dets = []
|
| 36 |
+
num_classes = scores.shape[1]
|
| 37 |
+
for cls_ind in range(num_classes):
|
| 38 |
+
cls_scores = scores[:, cls_ind]
|
| 39 |
+
valid_score_mask = cls_scores > score_thr
|
| 40 |
+
if valid_score_mask.sum() == 0:
|
| 41 |
+
continue
|
| 42 |
+
else:
|
| 43 |
+
valid_scores = cls_scores[valid_score_mask]
|
| 44 |
+
valid_boxes = boxes[valid_score_mask]
|
| 45 |
+
keep = nms(valid_boxes, valid_scores, nms_thr)
|
| 46 |
+
if len(keep) > 0:
|
| 47 |
+
cls_inds = np.ones((len(keep), 1)) * cls_ind
|
| 48 |
+
dets = np.concatenate(
|
| 49 |
+
[valid_boxes[keep], valid_scores[keep, None], cls_inds], 1
|
| 50 |
+
)
|
| 51 |
+
final_dets.append(dets)
|
| 52 |
+
if len(final_dets) == 0:
|
| 53 |
+
return None
|
| 54 |
+
return np.concatenate(final_dets, 0)
|
| 55 |
+
|
| 56 |
+
def demo_postprocess(outputs, img_size, p6=False):
|
| 57 |
+
grids = []
|
| 58 |
+
expanded_strides = []
|
| 59 |
+
strides = [8, 16, 32] if not p6 else [8, 16, 32, 64]
|
| 60 |
+
|
| 61 |
+
hsizes = [img_size[0] // stride for stride in strides]
|
| 62 |
+
wsizes = [img_size[1] // stride for stride in strides]
|
| 63 |
+
|
| 64 |
+
for hsize, wsize, stride in zip(hsizes, wsizes, strides):
|
| 65 |
+
xv, yv = np.meshgrid(np.arange(wsize), np.arange(hsize))
|
| 66 |
+
grid = np.stack((xv, yv), 2).reshape(1, -1, 2)
|
| 67 |
+
grids.append(grid)
|
| 68 |
+
shape = grid.shape[:2]
|
| 69 |
+
expanded_strides.append(np.full((*shape, 1), stride))
|
| 70 |
+
|
| 71 |
+
grids = np.concatenate(grids, 1)
|
| 72 |
+
expanded_strides = np.concatenate(expanded_strides, 1)
|
| 73 |
+
outputs[..., :2] = (outputs[..., :2] + grids) * expanded_strides
|
| 74 |
+
outputs[..., 2:4] = np.exp(outputs[..., 2:4]) * expanded_strides
|
| 75 |
+
|
| 76 |
+
return outputs
|
| 77 |
+
|
| 78 |
+
def preprocess(img, input_size, swap=(2, 0, 1)):
|
| 79 |
+
if len(img.shape) == 3:
|
| 80 |
+
padded_img = np.ones((input_size[0], input_size[1], 3), dtype=np.uint8) * 114
|
| 81 |
+
else:
|
| 82 |
+
padded_img = np.ones(input_size, dtype=np.uint8) * 114
|
| 83 |
+
|
| 84 |
+
r = min(input_size[0] / img.shape[0], input_size[1] / img.shape[1])
|
| 85 |
+
resized_img = cv2.resize(
|
| 86 |
+
img,
|
| 87 |
+
(int(img.shape[1] * r), int(img.shape[0] * r)),
|
| 88 |
+
interpolation=cv2.INTER_LINEAR,
|
| 89 |
+
).astype(np.uint8)
|
| 90 |
+
padded_img[: int(img.shape[0] * r), : int(img.shape[1] * r)] = resized_img
|
| 91 |
+
|
| 92 |
+
padded_img = padded_img.transpose(swap)
|
| 93 |
+
padded_img = np.ascontiguousarray(padded_img, dtype=np.float32)
|
| 94 |
+
return padded_img, r
|
| 95 |
+
|
| 96 |
+
def inference_detector(session, oriImg, detect_classes=[0]):
|
| 97 |
+
input_shape = (640,640)
|
| 98 |
+
img, ratio = preprocess(oriImg, input_shape)
|
| 99 |
+
|
| 100 |
+
input = img[None, :, :, :]
|
| 101 |
+
if "InferenceSession" in type(session).__name__:
|
| 102 |
+
input_name = session.get_inputs()[0].name
|
| 103 |
+
output = session.run(None, {input_name: input})
|
| 104 |
+
else:
|
| 105 |
+
outNames = session.getUnconnectedOutLayersNames()
|
| 106 |
+
session.setInput(input)
|
| 107 |
+
output = session.forward(outNames)
|
| 108 |
+
|
| 109 |
+
predictions = demo_postprocess(output[0], input_shape)[0]
|
| 110 |
+
|
| 111 |
+
boxes = predictions[:, :4]
|
| 112 |
+
scores = predictions[:, 4:5] * predictions[:, 5:]
|
| 113 |
+
|
| 114 |
+
boxes_xyxy = np.ones_like(boxes)
|
| 115 |
+
boxes_xyxy[:, 0] = boxes[:, 0] - boxes[:, 2]/2.
|
| 116 |
+
boxes_xyxy[:, 1] = boxes[:, 1] - boxes[:, 3]/2.
|
| 117 |
+
boxes_xyxy[:, 2] = boxes[:, 0] + boxes[:, 2]/2.
|
| 118 |
+
boxes_xyxy[:, 3] = boxes[:, 1] + boxes[:, 3]/2.
|
| 119 |
+
boxes_xyxy /= ratio
|
| 120 |
+
dets = multiclass_nms(boxes_xyxy, scores, nms_thr=0.45, score_thr=0.1)
|
| 121 |
+
if dets is None:
|
| 122 |
+
return None
|
| 123 |
+
final_boxes, final_scores, final_cls_inds = dets[:, :4], dets[:, 4], dets[:, 5]
|
| 124 |
+
isscore = final_scores>0.3
|
| 125 |
+
iscat = np.isin(final_cls_inds, detect_classes)
|
| 126 |
+
isbbox = [ i and j for (i, j) in zip(isscore, iscat)]
|
| 127 |
+
final_boxes = final_boxes[isbbox]
|
| 128 |
+
return final_boxes
|
VideoX-Fun/comfyui/annotator/dwpose_utils/onnxpose.py
ADDED
|
@@ -0,0 +1,364 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Tuple
|
| 2 |
+
|
| 3 |
+
import cv2
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
def preprocess(
|
| 7 |
+
img: np.ndarray, out_bbox, input_size: Tuple[int, int] = (192, 256)
|
| 8 |
+
) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
|
| 9 |
+
"""Do preprocessing for DWPose model inference.
|
| 10 |
+
|
| 11 |
+
Args:
|
| 12 |
+
img (np.ndarray): Input image in shape.
|
| 13 |
+
input_size (tuple): Input image size in shape (w, h).
|
| 14 |
+
|
| 15 |
+
Returns:
|
| 16 |
+
tuple:
|
| 17 |
+
- resized_img (np.ndarray): Preprocessed image.
|
| 18 |
+
- center (np.ndarray): Center of image.
|
| 19 |
+
- scale (np.ndarray): Scale of image.
|
| 20 |
+
"""
|
| 21 |
+
# get shape of image
|
| 22 |
+
img_shape = img.shape[:2]
|
| 23 |
+
out_img, out_center, out_scale = [], [], []
|
| 24 |
+
if len(out_bbox) == 0:
|
| 25 |
+
out_bbox = [[0, 0, img_shape[1], img_shape[0]]]
|
| 26 |
+
for i in range(len(out_bbox)):
|
| 27 |
+
x0 = out_bbox[i][0]
|
| 28 |
+
y0 = out_bbox[i][1]
|
| 29 |
+
x1 = out_bbox[i][2]
|
| 30 |
+
y1 = out_bbox[i][3]
|
| 31 |
+
bbox = np.array([x0, y0, x1, y1])
|
| 32 |
+
|
| 33 |
+
# get center and scale
|
| 34 |
+
center, scale = bbox_xyxy2cs(bbox, padding=1.25)
|
| 35 |
+
|
| 36 |
+
# do affine transformation
|
| 37 |
+
resized_img, scale = top_down_affine(input_size, scale, center, img)
|
| 38 |
+
|
| 39 |
+
# normalize image
|
| 40 |
+
mean = np.array([123.675, 116.28, 103.53])
|
| 41 |
+
std = np.array([58.395, 57.12, 57.375])
|
| 42 |
+
resized_img = (resized_img - mean) / std
|
| 43 |
+
|
| 44 |
+
out_img.append(resized_img)
|
| 45 |
+
out_center.append(center)
|
| 46 |
+
out_scale.append(scale)
|
| 47 |
+
|
| 48 |
+
return out_img, out_center, out_scale
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def inference(sess, img):
|
| 52 |
+
"""Inference DWPose model.
|
| 53 |
+
|
| 54 |
+
Args:
|
| 55 |
+
sess : ONNXRuntime session.
|
| 56 |
+
img : Input image in shape.
|
| 57 |
+
|
| 58 |
+
Returns:
|
| 59 |
+
outputs : Output of DWPose model.
|
| 60 |
+
"""
|
| 61 |
+
all_out = []
|
| 62 |
+
# build input
|
| 63 |
+
input = np.stack(img, axis=0).transpose(0, 3, 1, 2)
|
| 64 |
+
input = input.astype(np.float32)
|
| 65 |
+
if "InferenceSession" in type(sess).__name__:
|
| 66 |
+
input_name = sess.get_inputs()[0].name
|
| 67 |
+
all_outputs = sess.run(None, {input_name: input})
|
| 68 |
+
for batch_idx in range(len(all_outputs[0])):
|
| 69 |
+
outputs = [all_outputs[i][batch_idx:batch_idx+1,...] for i in range(len(all_outputs))]
|
| 70 |
+
all_out.append(outputs)
|
| 71 |
+
return all_out
|
| 72 |
+
|
| 73 |
+
for i in range(len(img)):
|
| 74 |
+
|
| 75 |
+
input = img[i].transpose(2, 0, 1)
|
| 76 |
+
input = input[None, :, :, :]
|
| 77 |
+
|
| 78 |
+
outNames = sess.getUnconnectedOutLayersNames()
|
| 79 |
+
sess.setInput(input)
|
| 80 |
+
outputs = sess.forward(outNames)
|
| 81 |
+
all_out.append(outputs)
|
| 82 |
+
|
| 83 |
+
return all_out
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def postprocess(outputs: List[np.ndarray],
|
| 87 |
+
model_input_size: Tuple[int, int],
|
| 88 |
+
center: Tuple[int, int],
|
| 89 |
+
scale: Tuple[int, int],
|
| 90 |
+
simcc_split_ratio: float = 2.0
|
| 91 |
+
) -> Tuple[np.ndarray, np.ndarray]:
|
| 92 |
+
"""Postprocess for DWPose model output.
|
| 93 |
+
|
| 94 |
+
Args:
|
| 95 |
+
outputs (np.ndarray): Output of RTMPose model.
|
| 96 |
+
model_input_size (tuple): RTMPose model Input image size.
|
| 97 |
+
center (tuple): Center of bbox in shape (x, y).
|
| 98 |
+
scale (tuple): Scale of bbox in shape (w, h).
|
| 99 |
+
simcc_split_ratio (float): Split ratio of simcc.
|
| 100 |
+
|
| 101 |
+
Returns:
|
| 102 |
+
tuple:
|
| 103 |
+
- keypoints (np.ndarray): Rescaled keypoints.
|
| 104 |
+
- scores (np.ndarray): Model predict scores.
|
| 105 |
+
"""
|
| 106 |
+
all_key = []
|
| 107 |
+
all_score = []
|
| 108 |
+
for i in range(len(outputs)):
|
| 109 |
+
# use simcc to decode
|
| 110 |
+
simcc_x, simcc_y = outputs[i]
|
| 111 |
+
keypoints, scores = decode(simcc_x, simcc_y, simcc_split_ratio)
|
| 112 |
+
|
| 113 |
+
# rescale keypoints
|
| 114 |
+
keypoints = keypoints / model_input_size * scale[i] + center[i] - scale[i] / 2
|
| 115 |
+
all_key.append(keypoints[0])
|
| 116 |
+
all_score.append(scores[0])
|
| 117 |
+
|
| 118 |
+
return np.array(all_key), np.array(all_score)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def bbox_xyxy2cs(bbox: np.ndarray,
|
| 122 |
+
padding: float = 1.) -> Tuple[np.ndarray, np.ndarray]:
|
| 123 |
+
"""Transform the bbox format from (x,y,w,h) into (center, scale)
|
| 124 |
+
|
| 125 |
+
Args:
|
| 126 |
+
bbox (ndarray): Bounding box(es) in shape (4,) or (n, 4), formatted
|
| 127 |
+
as (left, top, right, bottom)
|
| 128 |
+
padding (float): BBox padding factor that will be multilied to scale.
|
| 129 |
+
Default: 1.0
|
| 130 |
+
|
| 131 |
+
Returns:
|
| 132 |
+
tuple: A tuple containing center and scale.
|
| 133 |
+
- np.ndarray[float32]: Center (x, y) of the bbox in shape (2,) or
|
| 134 |
+
(n, 2)
|
| 135 |
+
- np.ndarray[float32]: Scale (w, h) of the bbox in shape (2,) or
|
| 136 |
+
(n, 2)
|
| 137 |
+
"""
|
| 138 |
+
# convert single bbox from (4, ) to (1, 4)
|
| 139 |
+
dim = bbox.ndim
|
| 140 |
+
if dim == 1:
|
| 141 |
+
bbox = bbox[None, :]
|
| 142 |
+
|
| 143 |
+
# get bbox center and scale
|
| 144 |
+
x1, y1, x2, y2 = np.hsplit(bbox, [1, 2, 3])
|
| 145 |
+
center = np.hstack([x1 + x2, y1 + y2]) * 0.5
|
| 146 |
+
scale = np.hstack([x2 - x1, y2 - y1]) * padding
|
| 147 |
+
|
| 148 |
+
if dim == 1:
|
| 149 |
+
center = center[0]
|
| 150 |
+
scale = scale[0]
|
| 151 |
+
|
| 152 |
+
return center, scale
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def _fix_aspect_ratio(bbox_scale: np.ndarray,
|
| 156 |
+
aspect_ratio: float) -> np.ndarray:
|
| 157 |
+
"""Extend the scale to match the given aspect ratio.
|
| 158 |
+
|
| 159 |
+
Args:
|
| 160 |
+
scale (np.ndarray): The image scale (w, h) in shape (2, )
|
| 161 |
+
aspect_ratio (float): The ratio of ``w/h``
|
| 162 |
+
|
| 163 |
+
Returns:
|
| 164 |
+
np.ndarray: The reshaped image scale in (2, )
|
| 165 |
+
"""
|
| 166 |
+
w, h = np.hsplit(bbox_scale, [1])
|
| 167 |
+
bbox_scale = np.where(w > h * aspect_ratio,
|
| 168 |
+
np.hstack([w, w / aspect_ratio]),
|
| 169 |
+
np.hstack([h * aspect_ratio, h]))
|
| 170 |
+
return bbox_scale
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
def _rotate_point(pt: np.ndarray, angle_rad: float) -> np.ndarray:
|
| 174 |
+
"""Rotate a point by an angle.
|
| 175 |
+
|
| 176 |
+
Args:
|
| 177 |
+
pt (np.ndarray): 2D point coordinates (x, y) in shape (2, )
|
| 178 |
+
angle_rad (float): rotation angle in radian
|
| 179 |
+
|
| 180 |
+
Returns:
|
| 181 |
+
np.ndarray: Rotated point in shape (2, )
|
| 182 |
+
"""
|
| 183 |
+
sn, cs = np.sin(angle_rad), np.cos(angle_rad)
|
| 184 |
+
rot_mat = np.array([[cs, -sn], [sn, cs]])
|
| 185 |
+
return rot_mat @ pt
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
def _get_3rd_point(a: np.ndarray, b: np.ndarray) -> np.ndarray:
|
| 189 |
+
"""To calculate the affine matrix, three pairs of points are required. This
|
| 190 |
+
function is used to get the 3rd point, given 2D points a & b.
|
| 191 |
+
|
| 192 |
+
The 3rd point is defined by rotating vector `a - b` by 90 degrees
|
| 193 |
+
anticlockwise, using b as the rotation center.
|
| 194 |
+
|
| 195 |
+
Args:
|
| 196 |
+
a (np.ndarray): The 1st point (x,y) in shape (2, )
|
| 197 |
+
b (np.ndarray): The 2nd point (x,y) in shape (2, )
|
| 198 |
+
|
| 199 |
+
Returns:
|
| 200 |
+
np.ndarray: The 3rd point.
|
| 201 |
+
"""
|
| 202 |
+
direction = a - b
|
| 203 |
+
c = b + np.r_[-direction[1], direction[0]]
|
| 204 |
+
return c
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def get_warp_matrix(center: np.ndarray,
|
| 208 |
+
scale: np.ndarray,
|
| 209 |
+
rot: float,
|
| 210 |
+
output_size: Tuple[int, int],
|
| 211 |
+
shift: Tuple[float, float] = (0., 0.),
|
| 212 |
+
inv: bool = False) -> np.ndarray:
|
| 213 |
+
"""Calculate the affine transformation matrix that can warp the bbox area
|
| 214 |
+
in the input image to the output size.
|
| 215 |
+
|
| 216 |
+
Args:
|
| 217 |
+
center (np.ndarray[2, ]): Center of the bounding box (x, y).
|
| 218 |
+
scale (np.ndarray[2, ]): Scale of the bounding box
|
| 219 |
+
wrt [width, height].
|
| 220 |
+
rot (float): Rotation angle (degree).
|
| 221 |
+
output_size (np.ndarray[2, ] | list(2,)): Size of the
|
| 222 |
+
destination heatmaps.
|
| 223 |
+
shift (0-100%): Shift translation ratio wrt the width/height.
|
| 224 |
+
Default (0., 0.).
|
| 225 |
+
inv (bool): Option to inverse the affine transform direction.
|
| 226 |
+
(inv=False: src->dst or inv=True: dst->src)
|
| 227 |
+
|
| 228 |
+
Returns:
|
| 229 |
+
np.ndarray: A 2x3 transformation matrix
|
| 230 |
+
"""
|
| 231 |
+
shift = np.array(shift)
|
| 232 |
+
src_w = scale[0]
|
| 233 |
+
dst_w = output_size[0]
|
| 234 |
+
dst_h = output_size[1]
|
| 235 |
+
|
| 236 |
+
# compute transformation matrix
|
| 237 |
+
rot_rad = np.deg2rad(rot)
|
| 238 |
+
src_dir = _rotate_point(np.array([0., src_w * -0.5]), rot_rad)
|
| 239 |
+
dst_dir = np.array([0., dst_w * -0.5])
|
| 240 |
+
|
| 241 |
+
# get four corners of the src rectangle in the original image
|
| 242 |
+
src = np.zeros((3, 2), dtype=np.float32)
|
| 243 |
+
src[0, :] = center + scale * shift
|
| 244 |
+
src[1, :] = center + src_dir + scale * shift
|
| 245 |
+
src[2, :] = _get_3rd_point(src[0, :], src[1, :])
|
| 246 |
+
|
| 247 |
+
# get four corners of the dst rectangle in the input image
|
| 248 |
+
dst = np.zeros((3, 2), dtype=np.float32)
|
| 249 |
+
dst[0, :] = [dst_w * 0.5, dst_h * 0.5]
|
| 250 |
+
dst[1, :] = np.array([dst_w * 0.5, dst_h * 0.5]) + dst_dir
|
| 251 |
+
dst[2, :] = _get_3rd_point(dst[0, :], dst[1, :])
|
| 252 |
+
|
| 253 |
+
if inv:
|
| 254 |
+
warp_mat = cv2.getAffineTransform(np.float32(dst), np.float32(src))
|
| 255 |
+
else:
|
| 256 |
+
warp_mat = cv2.getAffineTransform(np.float32(src), np.float32(dst))
|
| 257 |
+
|
| 258 |
+
return warp_mat
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
def top_down_affine(input_size: dict, bbox_scale: dict, bbox_center: dict,
|
| 262 |
+
img: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
|
| 263 |
+
"""Get the bbox image as the model input by affine transform.
|
| 264 |
+
|
| 265 |
+
Args:
|
| 266 |
+
input_size (dict): The input size of the model.
|
| 267 |
+
bbox_scale (dict): The bbox scale of the img.
|
| 268 |
+
bbox_center (dict): The bbox center of the img.
|
| 269 |
+
img (np.ndarray): The original image.
|
| 270 |
+
|
| 271 |
+
Returns:
|
| 272 |
+
tuple: A tuple containing center and scale.
|
| 273 |
+
- np.ndarray[float32]: img after affine transform.
|
| 274 |
+
- np.ndarray[float32]: bbox scale after affine transform.
|
| 275 |
+
"""
|
| 276 |
+
w, h = input_size
|
| 277 |
+
warp_size = (int(w), int(h))
|
| 278 |
+
|
| 279 |
+
# reshape bbox to fixed aspect ratio
|
| 280 |
+
bbox_scale = _fix_aspect_ratio(bbox_scale, aspect_ratio=w / h)
|
| 281 |
+
|
| 282 |
+
# get the affine matrix
|
| 283 |
+
center = bbox_center
|
| 284 |
+
scale = bbox_scale
|
| 285 |
+
rot = 0
|
| 286 |
+
warp_mat = get_warp_matrix(center, scale, rot, output_size=(w, h))
|
| 287 |
+
|
| 288 |
+
# do affine transform
|
| 289 |
+
img = cv2.warpAffine(img, warp_mat, warp_size, flags=cv2.INTER_LINEAR)
|
| 290 |
+
|
| 291 |
+
return img, bbox_scale
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
def get_simcc_maximum(simcc_x: np.ndarray,
|
| 295 |
+
simcc_y: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:
|
| 296 |
+
"""Get maximum response location and value from simcc representations.
|
| 297 |
+
|
| 298 |
+
Note:
|
| 299 |
+
instance number: N
|
| 300 |
+
num_keypoints: K
|
| 301 |
+
heatmap height: H
|
| 302 |
+
heatmap width: W
|
| 303 |
+
|
| 304 |
+
Args:
|
| 305 |
+
simcc_x (np.ndarray): x-axis SimCC in shape (K, Wx) or (N, K, Wx)
|
| 306 |
+
simcc_y (np.ndarray): y-axis SimCC in shape (K, Wy) or (N, K, Wy)
|
| 307 |
+
|
| 308 |
+
Returns:
|
| 309 |
+
tuple:
|
| 310 |
+
- locs (np.ndarray): locations of maximum heatmap responses in shape
|
| 311 |
+
(K, 2) or (N, K, 2)
|
| 312 |
+
- vals (np.ndarray): values of maximum heatmap responses in shape
|
| 313 |
+
(K,) or (N, K)
|
| 314 |
+
"""
|
| 315 |
+
N, K, Wx = simcc_x.shape
|
| 316 |
+
simcc_x = simcc_x.reshape(N * K, -1)
|
| 317 |
+
simcc_y = simcc_y.reshape(N * K, -1)
|
| 318 |
+
|
| 319 |
+
# get maximum value locations
|
| 320 |
+
x_locs = np.argmax(simcc_x, axis=1)
|
| 321 |
+
y_locs = np.argmax(simcc_y, axis=1)
|
| 322 |
+
locs = np.stack((x_locs, y_locs), axis=-1).astype(np.float32)
|
| 323 |
+
max_val_x = np.amax(simcc_x, axis=1)
|
| 324 |
+
max_val_y = np.amax(simcc_y, axis=1)
|
| 325 |
+
|
| 326 |
+
# get maximum value across x and y axis
|
| 327 |
+
mask = max_val_x > max_val_y
|
| 328 |
+
max_val_x[mask] = max_val_y[mask]
|
| 329 |
+
vals = max_val_x
|
| 330 |
+
locs[vals <= 0.] = -1
|
| 331 |
+
|
| 332 |
+
# reshape
|
| 333 |
+
locs = locs.reshape(N, K, 2)
|
| 334 |
+
vals = vals.reshape(N, K)
|
| 335 |
+
|
| 336 |
+
return locs, vals
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
def decode(simcc_x: np.ndarray, simcc_y: np.ndarray,
|
| 340 |
+
simcc_split_ratio) -> Tuple[np.ndarray, np.ndarray]:
|
| 341 |
+
"""Modulate simcc distribution with Gaussian.
|
| 342 |
+
|
| 343 |
+
Args:
|
| 344 |
+
simcc_x (np.ndarray[K, Wx]): model predicted simcc in x.
|
| 345 |
+
simcc_y (np.ndarray[K, Wy]): model predicted simcc in y.
|
| 346 |
+
simcc_split_ratio (int): The split ratio of simcc.
|
| 347 |
+
|
| 348 |
+
Returns:
|
| 349 |
+
tuple: A tuple containing center and scale.
|
| 350 |
+
- np.ndarray[float32]: keypoints in shape (K, 2) or (n, K, 2)
|
| 351 |
+
- np.ndarray[float32]: scores in shape (K,) or (n, K)
|
| 352 |
+
"""
|
| 353 |
+
keypoints, scores = get_simcc_maximum(simcc_x, simcc_y)
|
| 354 |
+
keypoints /= simcc_split_ratio
|
| 355 |
+
|
| 356 |
+
return keypoints, scores
|
| 357 |
+
|
| 358 |
+
|
| 359 |
+
def inference_pose(session, out_bbox, oriImg, model_input_size: Tuple[int, int]= (288, 384) ):
|
| 360 |
+
resized_img, center, scale = preprocess(oriImg, out_bbox, model_input_size)
|
| 361 |
+
outputs = inference(session, resized_img)
|
| 362 |
+
keypoints, scores = postprocess(outputs, model_input_size, center, scale)
|
| 363 |
+
|
| 364 |
+
return keypoints, scores
|
VideoX-Fun/comfyui/annotator/dwpose_utils/util.py
ADDED
|
@@ -0,0 +1,359 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import numpy as np
|
| 3 |
+
import matplotlib
|
| 4 |
+
import cv2
|
| 5 |
+
|
| 6 |
+
eps = 0.01
|
| 7 |
+
|
| 8 |
+
def smart_resize(x, s):
|
| 9 |
+
Ht, Wt = s
|
| 10 |
+
if x.ndim == 2:
|
| 11 |
+
Ho, Wo = x.shape
|
| 12 |
+
Co = 1
|
| 13 |
+
else:
|
| 14 |
+
Ho, Wo, Co = x.shape
|
| 15 |
+
if Co == 3 or Co == 1:
|
| 16 |
+
k = float(Ht + Wt) / float(Ho + Wo)
|
| 17 |
+
return cv2.resize(x, (int(Wt), int(Ht)), interpolation=cv2.INTER_AREA if k < 1 else cv2.INTER_LANCZOS4)
|
| 18 |
+
else:
|
| 19 |
+
return np.stack([smart_resize(x[:, :, i], s) for i in range(Co)], axis=2)
|
| 20 |
+
|
| 21 |
+
def smart_resize_k(x, fx, fy):
|
| 22 |
+
if x.ndim == 2:
|
| 23 |
+
Ho, Wo = x.shape
|
| 24 |
+
Co = 1
|
| 25 |
+
else:
|
| 26 |
+
Ho, Wo, Co = x.shape
|
| 27 |
+
Ht, Wt = Ho * fy, Wo * fx
|
| 28 |
+
if Co == 3 or Co == 1:
|
| 29 |
+
k = float(Ht + Wt) / float(Ho + Wo)
|
| 30 |
+
return cv2.resize(x, (int(Wt), int(Ht)), interpolation=cv2.INTER_AREA if k < 1 else cv2.INTER_LANCZOS4)
|
| 31 |
+
else:
|
| 32 |
+
return np.stack([smart_resize_k(x[:, :, i], fx, fy) for i in range(Co)], axis=2)
|
| 33 |
+
|
| 34 |
+
def padRightDownCorner(img, stride, padValue):
|
| 35 |
+
h = img.shape[0]
|
| 36 |
+
w = img.shape[1]
|
| 37 |
+
|
| 38 |
+
pad = 4 * [None]
|
| 39 |
+
pad[0] = 0 # up
|
| 40 |
+
pad[1] = 0 # left
|
| 41 |
+
pad[2] = 0 if (h % stride == 0) else stride - (h % stride) # down
|
| 42 |
+
pad[3] = 0 if (w % stride == 0) else stride - (w % stride) # right
|
| 43 |
+
|
| 44 |
+
img_padded = img
|
| 45 |
+
pad_up = np.tile(img_padded[0:1, :, :]*0 + padValue, (pad[0], 1, 1))
|
| 46 |
+
img_padded = np.concatenate((pad_up, img_padded), axis=0)
|
| 47 |
+
pad_left = np.tile(img_padded[:, 0:1, :]*0 + padValue, (1, pad[1], 1))
|
| 48 |
+
img_padded = np.concatenate((pad_left, img_padded), axis=1)
|
| 49 |
+
pad_down = np.tile(img_padded[-2:-1, :, :]*0 + padValue, (pad[2], 1, 1))
|
| 50 |
+
img_padded = np.concatenate((img_padded, pad_down), axis=0)
|
| 51 |
+
pad_right = np.tile(img_padded[:, -2:-1, :]*0 + padValue, (1, pad[3], 1))
|
| 52 |
+
img_padded = np.concatenate((img_padded, pad_right), axis=1)
|
| 53 |
+
|
| 54 |
+
return img_padded, pad
|
| 55 |
+
|
| 56 |
+
def transfer(model, model_weights):
|
| 57 |
+
transfered_model_weights = {}
|
| 58 |
+
for weights_name in model.state_dict().keys():
|
| 59 |
+
transfered_model_weights[weights_name] = model_weights['.'.join(weights_name.split('.')[1:])]
|
| 60 |
+
return transfered_model_weights
|
| 61 |
+
|
| 62 |
+
def is_normalized(keypoints) -> bool:
|
| 63 |
+
point_normalized = [
|
| 64 |
+
0 <= abs(k.x) <= 1 and 0 <= abs(k.y) <= 1
|
| 65 |
+
for k in keypoints
|
| 66 |
+
if k is not None
|
| 67 |
+
]
|
| 68 |
+
if not point_normalized:
|
| 69 |
+
return False
|
| 70 |
+
return all(point_normalized)
|
| 71 |
+
|
| 72 |
+
def draw_bodypose(canvas: np.ndarray, keypoints) -> np.ndarray:
|
| 73 |
+
"""
|
| 74 |
+
Draw keypoints and limbs representing body pose on a given canvas.
|
| 75 |
+
|
| 76 |
+
Args:
|
| 77 |
+
canvas (np.ndarray): A 3D numpy array representing the canvas (image) on which to draw the body pose.
|
| 78 |
+
keypoints (List[Keypoint]): A list of Keypoint objects representing the body keypoints to be drawn.
|
| 79 |
+
|
| 80 |
+
Returns:
|
| 81 |
+
np.ndarray: A 3D numpy array representing the modified canvas with the drawn body pose.
|
| 82 |
+
|
| 83 |
+
Note:
|
| 84 |
+
The function expects the x and y coordinates of the keypoints to be normalized between 0 and 1.
|
| 85 |
+
"""
|
| 86 |
+
if not is_normalized(keypoints):
|
| 87 |
+
H, W = 1.0, 1.0
|
| 88 |
+
else:
|
| 89 |
+
H, W, _ = canvas.shape
|
| 90 |
+
|
| 91 |
+
stickwidth = 4
|
| 92 |
+
|
| 93 |
+
limbSeq = [
|
| 94 |
+
[2, 3], [2, 6], [3, 4], [4, 5],
|
| 95 |
+
[6, 7], [7, 8], [2, 9], [9, 10],
|
| 96 |
+
[10, 11], [2, 12], [12, 13], [13, 14],
|
| 97 |
+
[2, 1], [1, 15], [15, 17], [1, 16],
|
| 98 |
+
[16, 18],
|
| 99 |
+
]
|
| 100 |
+
|
| 101 |
+
colors = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0], \
|
| 102 |
+
[0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255], \
|
| 103 |
+
[170, 0, 255], [255, 0, 255], [255, 0, 170], [255, 0, 85]]
|
| 104 |
+
|
| 105 |
+
for (k1_index, k2_index), color in zip(limbSeq, colors):
|
| 106 |
+
keypoint1 = keypoints[k1_index - 1]
|
| 107 |
+
keypoint2 = keypoints[k2_index - 1]
|
| 108 |
+
|
| 109 |
+
if keypoint1 is None or keypoint2 is None:
|
| 110 |
+
continue
|
| 111 |
+
|
| 112 |
+
Y = np.array([keypoint1.x, keypoint2.x]) * float(W)
|
| 113 |
+
X = np.array([keypoint1.y, keypoint2.y]) * float(H)
|
| 114 |
+
mX = np.mean(X)
|
| 115 |
+
mY = np.mean(Y)
|
| 116 |
+
length = ((X[0] - X[1]) ** 2 + (Y[0] - Y[1]) ** 2) ** 0.5
|
| 117 |
+
angle = math.degrees(math.atan2(X[0] - X[1], Y[0] - Y[1]))
|
| 118 |
+
polygon = cv2.ellipse2Poly((int(mY), int(mX)), (int(length / 2), stickwidth), int(angle), 0, 360, 1)
|
| 119 |
+
cv2.fillConvexPoly(canvas, polygon, [int(float(c) * 0.6) for c in color])
|
| 120 |
+
|
| 121 |
+
for keypoint, color in zip(keypoints, colors):
|
| 122 |
+
if keypoint is None:
|
| 123 |
+
continue
|
| 124 |
+
|
| 125 |
+
x, y = keypoint.x, keypoint.y
|
| 126 |
+
x = int(x * W)
|
| 127 |
+
y = int(y * H)
|
| 128 |
+
cv2.circle(canvas, (int(x), int(y)), 4, color, thickness=-1)
|
| 129 |
+
|
| 130 |
+
return canvas
|
| 131 |
+
|
| 132 |
+
def draw_handpose(canvas: np.ndarray, keypoints) -> np.ndarray:
|
| 133 |
+
"""
|
| 134 |
+
Draw keypoints and connections representing hand pose on a given canvas.
|
| 135 |
+
|
| 136 |
+
Args:
|
| 137 |
+
canvas (np.ndarray): A 3D numpy array representing the canvas (image) on which to draw the hand pose.
|
| 138 |
+
keypoints (List[Keypoint]| None): A list of Keypoint objects representing the hand keypoints to be drawn
|
| 139 |
+
or None if no keypoints are present.
|
| 140 |
+
|
| 141 |
+
Returns:
|
| 142 |
+
np.ndarray: A 3D numpy array representing the modified canvas with the drawn hand pose.
|
| 143 |
+
|
| 144 |
+
Note:
|
| 145 |
+
The function expects the x and y coordinates of the keypoints to be normalized between 0 and 1.
|
| 146 |
+
"""
|
| 147 |
+
if not keypoints:
|
| 148 |
+
return canvas
|
| 149 |
+
|
| 150 |
+
if not is_normalized(keypoints):
|
| 151 |
+
H, W = 1.0, 1.0
|
| 152 |
+
else:
|
| 153 |
+
H, W, _ = canvas.shape
|
| 154 |
+
|
| 155 |
+
edges = [[0, 1], [1, 2], [2, 3], [3, 4], [0, 5], [5, 6], [6, 7], [7, 8], [0, 9], [9, 10], \
|
| 156 |
+
[10, 11], [11, 12], [0, 13], [13, 14], [14, 15], [15, 16], [0, 17], [17, 18], [18, 19], [19, 20]]
|
| 157 |
+
|
| 158 |
+
for ie, (e1, e2) in enumerate(edges):
|
| 159 |
+
k1 = keypoints[e1]
|
| 160 |
+
k2 = keypoints[e2]
|
| 161 |
+
if k1 is None or k2 is None:
|
| 162 |
+
continue
|
| 163 |
+
|
| 164 |
+
x1 = int(k1.x * W)
|
| 165 |
+
y1 = int(k1.y * H)
|
| 166 |
+
x2 = int(k2.x * W)
|
| 167 |
+
y2 = int(k2.y * H)
|
| 168 |
+
if x1 > eps and y1 > eps and x2 > eps and y2 > eps:
|
| 169 |
+
cv2.line(canvas, (x1, y1), (x2, y2), matplotlib.colors.hsv_to_rgb([ie / float(len(edges)), 1.0, 1.0]) * 255, thickness=2)
|
| 170 |
+
|
| 171 |
+
for keypoint in keypoints:
|
| 172 |
+
if keypoint is None:
|
| 173 |
+
continue
|
| 174 |
+
|
| 175 |
+
x, y = keypoint.x, keypoint.y
|
| 176 |
+
x = int(x * W)
|
| 177 |
+
y = int(y * H)
|
| 178 |
+
if x > eps and y > eps:
|
| 179 |
+
cv2.circle(canvas, (x, y), 4, (0, 0, 255), thickness=-1)
|
| 180 |
+
return canvas
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
def draw_facepose(canvas: np.ndarray, keypoints) -> np.ndarray:
|
| 184 |
+
"""
|
| 185 |
+
Draw keypoints representing face pose on a given canvas.
|
| 186 |
+
|
| 187 |
+
Args:
|
| 188 |
+
canvas (np.ndarray): A 3D numpy array representing the canvas (image) on which to draw the face pose.
|
| 189 |
+
keypoints (List[Keypoint]| None): A list of Keypoint objects representing the face keypoints to be drawn
|
| 190 |
+
or None if no keypoints are present.
|
| 191 |
+
|
| 192 |
+
Returns:
|
| 193 |
+
np.ndarray: A 3D numpy array representing the modified canvas with the drawn face pose.
|
| 194 |
+
|
| 195 |
+
Note:
|
| 196 |
+
The function expects the x and y coordinates of the keypoints to be normalized between 0 and 1.
|
| 197 |
+
"""
|
| 198 |
+
if not keypoints:
|
| 199 |
+
return canvas
|
| 200 |
+
|
| 201 |
+
if not is_normalized(keypoints):
|
| 202 |
+
H, W = 1.0, 1.0
|
| 203 |
+
else:
|
| 204 |
+
H, W, _ = canvas.shape
|
| 205 |
+
|
| 206 |
+
for keypoint in keypoints:
|
| 207 |
+
if keypoint is None:
|
| 208 |
+
continue
|
| 209 |
+
|
| 210 |
+
x, y = keypoint.x, keypoint.y
|
| 211 |
+
x = int(x * W)
|
| 212 |
+
y = int(y * H)
|
| 213 |
+
if x > eps and y > eps:
|
| 214 |
+
cv2.circle(canvas, (x, y), 3, (255, 255, 255), thickness=-1)
|
| 215 |
+
return canvas
|
| 216 |
+
|
| 217 |
+
# detect hand according to body pose keypoints
|
| 218 |
+
# please refer to https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/src/openpose/hand/handDetector.cpp
|
| 219 |
+
def handDetect(candidate, subset, oriImg):
|
| 220 |
+
# right hand: wrist 4, elbow 3, shoulder 2
|
| 221 |
+
# left hand: wrist 7, elbow 6, shoulder 5
|
| 222 |
+
ratioWristElbow = 0.33
|
| 223 |
+
detect_result = []
|
| 224 |
+
image_height, image_width = oriImg.shape[0:2]
|
| 225 |
+
for person in subset.astype(int):
|
| 226 |
+
# if any of three not detected
|
| 227 |
+
has_left = np.sum(person[[5, 6, 7]] == -1) == 0
|
| 228 |
+
has_right = np.sum(person[[2, 3, 4]] == -1) == 0
|
| 229 |
+
if not (has_left or has_right):
|
| 230 |
+
continue
|
| 231 |
+
hands = []
|
| 232 |
+
#left hand
|
| 233 |
+
if has_left:
|
| 234 |
+
left_shoulder_index, left_elbow_index, left_wrist_index = person[[5, 6, 7]]
|
| 235 |
+
x1, y1 = candidate[left_shoulder_index][:2]
|
| 236 |
+
x2, y2 = candidate[left_elbow_index][:2]
|
| 237 |
+
x3, y3 = candidate[left_wrist_index][:2]
|
| 238 |
+
hands.append([x1, y1, x2, y2, x3, y3, True])
|
| 239 |
+
# right hand
|
| 240 |
+
if has_right:
|
| 241 |
+
right_shoulder_index, right_elbow_index, right_wrist_index = person[[2, 3, 4]]
|
| 242 |
+
x1, y1 = candidate[right_shoulder_index][:2]
|
| 243 |
+
x2, y2 = candidate[right_elbow_index][:2]
|
| 244 |
+
x3, y3 = candidate[right_wrist_index][:2]
|
| 245 |
+
hands.append([x1, y1, x2, y2, x3, y3, False])
|
| 246 |
+
|
| 247 |
+
for x1, y1, x2, y2, x3, y3, is_left in hands:
|
| 248 |
+
# pos_hand = pos_wrist + ratio * (pos_wrist - pos_elbox) = (1 + ratio) * pos_wrist - ratio * pos_elbox
|
| 249 |
+
# handRectangle.x = posePtr[wrist*3] + ratioWristElbow * (posePtr[wrist*3] - posePtr[elbow*3]);
|
| 250 |
+
# handRectangle.y = posePtr[wrist*3+1] + ratioWristElbow * (posePtr[wrist*3+1] - posePtr[elbow*3+1]);
|
| 251 |
+
# const auto distanceWristElbow = getDistance(poseKeypoints, person, wrist, elbow);
|
| 252 |
+
# const auto distanceElbowShoulder = getDistance(poseKeypoints, person, elbow, shoulder);
|
| 253 |
+
# handRectangle.width = 1.5f * fastMax(distanceWristElbow, 0.9f * distanceElbowShoulder);
|
| 254 |
+
x = x3 + ratioWristElbow * (x3 - x2)
|
| 255 |
+
y = y3 + ratioWristElbow * (y3 - y2)
|
| 256 |
+
distanceWristElbow = math.sqrt((x3 - x2) ** 2 + (y3 - y2) ** 2)
|
| 257 |
+
distanceElbowShoulder = math.sqrt((x2 - x1) ** 2 + (y2 - y1) ** 2)
|
| 258 |
+
width = 1.5 * max(distanceWristElbow, 0.9 * distanceElbowShoulder)
|
| 259 |
+
# x-y refers to the center --> offset to topLeft point
|
| 260 |
+
# handRectangle.x -= handRectangle.width / 2.f;
|
| 261 |
+
# handRectangle.y -= handRectangle.height / 2.f;
|
| 262 |
+
x -= width / 2
|
| 263 |
+
y -= width / 2 # width = height
|
| 264 |
+
# overflow the image
|
| 265 |
+
if x < 0: x = 0
|
| 266 |
+
if y < 0: y = 0
|
| 267 |
+
width1 = width
|
| 268 |
+
width2 = width
|
| 269 |
+
if x + width > image_width: width1 = image_width - x
|
| 270 |
+
if y + width > image_height: width2 = image_height - y
|
| 271 |
+
width = min(width1, width2)
|
| 272 |
+
# the max hand box value is 20 pixels
|
| 273 |
+
if width >= 20:
|
| 274 |
+
detect_result.append([int(x), int(y), int(width), is_left])
|
| 275 |
+
|
| 276 |
+
'''
|
| 277 |
+
return value: [[x, y, w, True if left hand else False]].
|
| 278 |
+
width=height since the network require squared input.
|
| 279 |
+
x, y is the coordinate of top left
|
| 280 |
+
'''
|
| 281 |
+
return detect_result
|
| 282 |
+
|
| 283 |
+
# Written by Lvmin
|
| 284 |
+
def faceDetect(candidate, subset, oriImg):
|
| 285 |
+
# left right eye ear 14 15 16 17
|
| 286 |
+
detect_result = []
|
| 287 |
+
image_height, image_width = oriImg.shape[0:2]
|
| 288 |
+
for person in subset.astype(int):
|
| 289 |
+
has_head = person[0] > -1
|
| 290 |
+
if not has_head:
|
| 291 |
+
continue
|
| 292 |
+
|
| 293 |
+
has_left_eye = person[14] > -1
|
| 294 |
+
has_right_eye = person[15] > -1
|
| 295 |
+
has_left_ear = person[16] > -1
|
| 296 |
+
has_right_ear = person[17] > -1
|
| 297 |
+
|
| 298 |
+
if not (has_left_eye or has_right_eye or has_left_ear or has_right_ear):
|
| 299 |
+
continue
|
| 300 |
+
|
| 301 |
+
head, left_eye, right_eye, left_ear, right_ear = person[[0, 14, 15, 16, 17]]
|
| 302 |
+
|
| 303 |
+
width = 0.0
|
| 304 |
+
x0, y0 = candidate[head][:2]
|
| 305 |
+
|
| 306 |
+
if has_left_eye:
|
| 307 |
+
x1, y1 = candidate[left_eye][:2]
|
| 308 |
+
d = max(abs(x0 - x1), abs(y0 - y1))
|
| 309 |
+
width = max(width, d * 3.0)
|
| 310 |
+
|
| 311 |
+
if has_right_eye:
|
| 312 |
+
x1, y1 = candidate[right_eye][:2]
|
| 313 |
+
d = max(abs(x0 - x1), abs(y0 - y1))
|
| 314 |
+
width = max(width, d * 3.0)
|
| 315 |
+
|
| 316 |
+
if has_left_ear:
|
| 317 |
+
x1, y1 = candidate[left_ear][:2]
|
| 318 |
+
d = max(abs(x0 - x1), abs(y0 - y1))
|
| 319 |
+
width = max(width, d * 1.5)
|
| 320 |
+
|
| 321 |
+
if has_right_ear:
|
| 322 |
+
x1, y1 = candidate[right_ear][:2]
|
| 323 |
+
d = max(abs(x0 - x1), abs(y0 - y1))
|
| 324 |
+
width = max(width, d * 1.5)
|
| 325 |
+
|
| 326 |
+
x, y = x0, y0
|
| 327 |
+
|
| 328 |
+
x -= width
|
| 329 |
+
y -= width
|
| 330 |
+
|
| 331 |
+
if x < 0:
|
| 332 |
+
x = 0
|
| 333 |
+
|
| 334 |
+
if y < 0:
|
| 335 |
+
y = 0
|
| 336 |
+
|
| 337 |
+
width1 = width * 2
|
| 338 |
+
width2 = width * 2
|
| 339 |
+
|
| 340 |
+
if x + width > image_width:
|
| 341 |
+
width1 = image_width - x
|
| 342 |
+
|
| 343 |
+
if y + width > image_height:
|
| 344 |
+
width2 = image_height - y
|
| 345 |
+
|
| 346 |
+
width = min(width1, width2)
|
| 347 |
+
|
| 348 |
+
if width >= 20:
|
| 349 |
+
detect_result.append([int(x), int(y), int(width)])
|
| 350 |
+
|
| 351 |
+
return detect_result
|
| 352 |
+
|
| 353 |
+
# get max index of 2d array
|
| 354 |
+
def npmax(array):
|
| 355 |
+
arrayindex = array.argmax(1)
|
| 356 |
+
arrayvalue = array.max(1)
|
| 357 |
+
i = arrayvalue.argmax()
|
| 358 |
+
j = arrayindex[i]
|
| 359 |
+
return i, j
|
VideoX-Fun/comfyui/annotator/dwpose_utils/wholebody.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
import onnxruntime as ort
|
| 5 |
+
from .onnxdet import inference_detector
|
| 6 |
+
from .onnxpose import inference_pose
|
| 7 |
+
from typing import NamedTuple, List, Optional, Union
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class Keypoint(NamedTuple):
|
| 11 |
+
x: float
|
| 12 |
+
y: float
|
| 13 |
+
score: float = 1.0
|
| 14 |
+
id: int = -1
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class BodyResult(NamedTuple):
|
| 18 |
+
# Note: Using `Optional` instead of `|` operator as the ladder is a Python
|
| 19 |
+
# 3.10 feature.
|
| 20 |
+
# Annotator code should be Python 3.8 Compatible, as controlnet repo uses
|
| 21 |
+
# Python 3.8 environment.
|
| 22 |
+
# https://github.com/lllyasviel/ControlNet/blob/d3284fcd0972c510635a4f5abe2eeb71dc0de524/environment.yaml#L6
|
| 23 |
+
keypoints: List[Optional[Keypoint]]
|
| 24 |
+
total_score: float = 0.0
|
| 25 |
+
total_parts: int = 0
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
HandResult = List[Keypoint]
|
| 29 |
+
FaceResult = List[Keypoint]
|
| 30 |
+
AnimalPoseResult = List[Keypoint]
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class HumanPoseResult(NamedTuple):
|
| 34 |
+
body: BodyResult
|
| 35 |
+
left_hand: Optional[HandResult]
|
| 36 |
+
right_hand: Optional[HandResult]
|
| 37 |
+
face: Optional[FaceResult]
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class Wholebody:
|
| 41 |
+
def __init__(self, onnx_det: str, onnx_pose: str):
|
| 42 |
+
# Always loads to CPU to avoid building OpenCV.
|
| 43 |
+
device = 'cpu'
|
| 44 |
+
backend = cv2.dnn.DNN_BACKEND_OPENCV if device == 'cpu' else cv2.dnn.DNN_BACKEND_CUDA
|
| 45 |
+
# You need to manually build OpenCV through cmake to work with your GPU.
|
| 46 |
+
providers = cv2.dnn.DNN_TARGET_CPU if device == 'cpu' else cv2.dnn.DNN_TARGET_CUDA
|
| 47 |
+
|
| 48 |
+
self.session_det = cv2.dnn.readNetFromONNX(onnx_det)
|
| 49 |
+
self.session_det.setPreferableBackend(backend)
|
| 50 |
+
self.session_det.setPreferableTarget(providers)
|
| 51 |
+
|
| 52 |
+
self.session_pose = cv2.dnn.readNetFromONNX(onnx_pose)
|
| 53 |
+
self.session_pose.setPreferableBackend(backend)
|
| 54 |
+
self.session_pose.setPreferableTarget(providers)
|
| 55 |
+
|
| 56 |
+
def __call__(self, oriImg):
|
| 57 |
+
det_result = inference_detector(self.session_det, oriImg)
|
| 58 |
+
if det_result is None:
|
| 59 |
+
return None
|
| 60 |
+
|
| 61 |
+
keypoints, scores = inference_pose(self.session_pose, det_result, oriImg)
|
| 62 |
+
|
| 63 |
+
keypoints_info = np.concatenate(
|
| 64 |
+
(keypoints, scores[..., None]), axis=-1)
|
| 65 |
+
# compute neck joint
|
| 66 |
+
neck = np.mean(keypoints_info[:, [5, 6]], axis=1)
|
| 67 |
+
# neck score when visualizing pred
|
| 68 |
+
neck[:, 2:4] = np.logical_and(
|
| 69 |
+
keypoints_info[:, 5, 2:4] > 0.3,
|
| 70 |
+
keypoints_info[:, 6, 2:4] > 0.3).astype(int)
|
| 71 |
+
new_keypoints_info = np.insert(
|
| 72 |
+
keypoints_info, 17, neck, axis=1)
|
| 73 |
+
mmpose_idx = [
|
| 74 |
+
17, 6, 8, 10, 7, 9, 12, 14, 16, 13, 15, 2, 1, 4, 3
|
| 75 |
+
]
|
| 76 |
+
openpose_idx = [
|
| 77 |
+
1, 2, 3, 4, 6, 7, 8, 9, 10, 12, 13, 14, 15, 16, 17
|
| 78 |
+
]
|
| 79 |
+
new_keypoints_info[:, openpose_idx] = \
|
| 80 |
+
new_keypoints_info[:, mmpose_idx]
|
| 81 |
+
keypoints_info = new_keypoints_info
|
| 82 |
+
|
| 83 |
+
return keypoints_info
|
| 84 |
+
|
| 85 |
+
@staticmethod
|
| 86 |
+
def format_result(keypoints_info: Optional[np.ndarray]) -> List[HumanPoseResult]:
|
| 87 |
+
def format_keypoint_part(
|
| 88 |
+
part: np.ndarray,
|
| 89 |
+
) -> Optional[List[Optional[Keypoint]]]:
|
| 90 |
+
keypoints = [
|
| 91 |
+
Keypoint(x, y, score, i) if score >= 0.3 else None
|
| 92 |
+
for i, (x, y, score) in enumerate(part)
|
| 93 |
+
]
|
| 94 |
+
return (
|
| 95 |
+
None if all(keypoint is None for keypoint in keypoints) else keypoints
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
def total_score(keypoints: Optional[List[Optional[Keypoint]]]) -> float:
|
| 99 |
+
return (
|
| 100 |
+
sum(keypoint.score for keypoint in keypoints if keypoint is not None)
|
| 101 |
+
if keypoints is not None
|
| 102 |
+
else 0.0
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
pose_results = []
|
| 106 |
+
if keypoints_info is None:
|
| 107 |
+
return pose_results
|
| 108 |
+
|
| 109 |
+
for instance in keypoints_info:
|
| 110 |
+
body_keypoints = format_keypoint_part(instance[:18]) or ([None] * 18)
|
| 111 |
+
left_hand = format_keypoint_part(instance[92:113])
|
| 112 |
+
right_hand = format_keypoint_part(instance[113:134])
|
| 113 |
+
face = format_keypoint_part(instance[24:92])
|
| 114 |
+
|
| 115 |
+
# Openpose face consists of 70 points in total, while DWPose only
|
| 116 |
+
# provides 68 points. Padding the last 2 points.
|
| 117 |
+
if face is not None:
|
| 118 |
+
# left eye
|
| 119 |
+
face.append(body_keypoints[14])
|
| 120 |
+
# right eye
|
| 121 |
+
face.append(body_keypoints[15])
|
| 122 |
+
|
| 123 |
+
body = BodyResult(
|
| 124 |
+
body_keypoints, total_score(body_keypoints), len(body_keypoints)
|
| 125 |
+
)
|
| 126 |
+
pose_results.append(HumanPoseResult(body, left_hand, right_hand, face))
|
| 127 |
+
|
| 128 |
+
return pose_results
|
| 129 |
+
|
VideoX-Fun/comfyui/annotator/nodes.py
ADDED
|
@@ -0,0 +1,274 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This folder is modified from the https://github.com/Mikubill/sd-webui-controlnet
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
import cv2
|
| 5 |
+
import folder_paths
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
from einops import rearrange
|
| 9 |
+
|
| 10 |
+
from .dwpose_utils import DWposeDetector
|
| 11 |
+
from .zoe.zoedepth.models.zoedepth.zoedepth_v1 import ZoeDepth
|
| 12 |
+
from .zoe.zoedepth.utils.config import get_config
|
| 13 |
+
|
| 14 |
+
remote_onnx_det = "https://huggingface.co/yzd-v/DWPose/resolve/main/yolox_l.onnx"
|
| 15 |
+
remote_onnx_pose = "https://huggingface.co/yzd-v/DWPose/resolve/main/dw-ll_ucoco_384.onnx"
|
| 16 |
+
remote_zoe= "https://huggingface.co/lllyasviel/Annotators/resolve/main/ZoeD_M12_N.pt"
|
| 17 |
+
|
| 18 |
+
def read_video(video_path):
|
| 19 |
+
cap = cv2.VideoCapture(video_path)
|
| 20 |
+
frames = []
|
| 21 |
+
while cap.isOpened():
|
| 22 |
+
ret, frame = cap.read()
|
| 23 |
+
if not ret:
|
| 24 |
+
break
|
| 25 |
+
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
|
| 26 |
+
frames.append(frame)
|
| 27 |
+
cap.release()
|
| 28 |
+
return frames
|
| 29 |
+
|
| 30 |
+
def HWC3(x):
|
| 31 |
+
assert x.dtype == np.uint8
|
| 32 |
+
if x.ndim == 2:
|
| 33 |
+
x = x[:, :, None]
|
| 34 |
+
assert x.ndim == 3
|
| 35 |
+
H, W, C = x.shape
|
| 36 |
+
assert C == 1 or C == 3 or C == 4
|
| 37 |
+
if C == 3:
|
| 38 |
+
return x
|
| 39 |
+
if C == 1:
|
| 40 |
+
return np.concatenate([x, x, x], axis=2)
|
| 41 |
+
if C == 4:
|
| 42 |
+
color = x[:, :, 0:3].astype(np.float32)
|
| 43 |
+
alpha = x[:, :, 3:4].astype(np.float32) / 255.0
|
| 44 |
+
y = color * alpha + 255.0 * (1.0 - alpha)
|
| 45 |
+
y = y.clip(0, 255).astype(np.uint8)
|
| 46 |
+
return y
|
| 47 |
+
|
| 48 |
+
def pad64(x):
|
| 49 |
+
return int(np.ceil(float(x) / 64.0) * 64 - x)
|
| 50 |
+
|
| 51 |
+
def safer_memory(x):
|
| 52 |
+
# Fix many MAC/AMD problems
|
| 53 |
+
return np.ascontiguousarray(x.copy()).copy()
|
| 54 |
+
|
| 55 |
+
def resize_image_with_pad(input_image, resolution, skip_hwc3=False):
|
| 56 |
+
if skip_hwc3:
|
| 57 |
+
img = input_image
|
| 58 |
+
else:
|
| 59 |
+
img = HWC3(input_image)
|
| 60 |
+
H_raw, W_raw, _ = img.shape
|
| 61 |
+
k = float(resolution) / float(min(H_raw, W_raw))
|
| 62 |
+
interpolation = cv2.INTER_CUBIC if k > 1 else cv2.INTER_AREA
|
| 63 |
+
H_target = int(np.round(float(H_raw) * k))
|
| 64 |
+
W_target = int(np.round(float(W_raw) * k))
|
| 65 |
+
img = cv2.resize(img, (W_target, H_target), interpolation=interpolation)
|
| 66 |
+
H_pad, W_pad = pad64(H_target), pad64(W_target)
|
| 67 |
+
img_padded = np.pad(img, [[0, H_pad], [0, W_pad], [0, 0]], mode='edge')
|
| 68 |
+
|
| 69 |
+
def remove_pad(x):
|
| 70 |
+
return safer_memory(x[:H_target, :W_target])
|
| 71 |
+
|
| 72 |
+
return safer_memory(img_padded), remove_pad
|
| 73 |
+
|
| 74 |
+
def load_file_from_url(
|
| 75 |
+
url: str,
|
| 76 |
+
model_dir: str,
|
| 77 |
+
progress: bool = True,
|
| 78 |
+
file_name: str | None = None,
|
| 79 |
+
hash_prefix: str | None = None,
|
| 80 |
+
) -> str:
|
| 81 |
+
"""Download a file from `url` into `model_dir`, using the file present if possible.
|
| 82 |
+
|
| 83 |
+
Returns the path to the downloaded file.
|
| 84 |
+
"""
|
| 85 |
+
from urllib.parse import urlparse
|
| 86 |
+
os.makedirs(model_dir, exist_ok=True)
|
| 87 |
+
if not file_name:
|
| 88 |
+
parts = urlparse(url)
|
| 89 |
+
file_name = os.path.basename(parts.path)
|
| 90 |
+
cached_file = os.path.abspath(os.path.join(model_dir, file_name))
|
| 91 |
+
if not os.path.exists(cached_file):
|
| 92 |
+
print(f'Downloading: "{url}" to {cached_file}\n')
|
| 93 |
+
from torch.hub import download_url_to_file
|
| 94 |
+
download_url_to_file(url, cached_file, progress=progress, hash_prefix=hash_prefix)
|
| 95 |
+
return cached_file
|
| 96 |
+
|
| 97 |
+
class VideoToCanny:
|
| 98 |
+
@classmethod
|
| 99 |
+
def INPUT_TYPES(s):
|
| 100 |
+
return {
|
| 101 |
+
"required": {
|
| 102 |
+
"input_video": ("IMAGE",),
|
| 103 |
+
"low_threshold": ("INT", {"default": 100, "min": 0, "max": 255, "step": 1}),
|
| 104 |
+
"high_threshold": ("INT", {"default": 200, "min": 0, "max": 255, "step": 1}),
|
| 105 |
+
"video_length": (
|
| 106 |
+
"INT", {"default": 81, "min": 1, "max": 81, "step": 4}
|
| 107 |
+
),
|
| 108 |
+
}
|
| 109 |
+
}
|
| 110 |
+
|
| 111 |
+
RETURN_TYPES = ("IMAGE",)
|
| 112 |
+
RETURN_NAMES =("images",)
|
| 113 |
+
FUNCTION = "process"
|
| 114 |
+
CATEGORY = "CogVideoXFUNWrapper"
|
| 115 |
+
|
| 116 |
+
def process(self, input_video, low_threshold, high_threshold, video_length):
|
| 117 |
+
def extract_canny_frames(frames):
|
| 118 |
+
canny_frames = []
|
| 119 |
+
for frame in frames:
|
| 120 |
+
gray = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
|
| 121 |
+
edges = cv2.Canny(gray, low_threshold, high_threshold)
|
| 122 |
+
edges_colored = cv2.cvtColor(edges, cv2.COLOR_GRAY2RGB)
|
| 123 |
+
canny_frames.append(edges_colored)
|
| 124 |
+
return canny_frames
|
| 125 |
+
|
| 126 |
+
if type(input_video) is str:
|
| 127 |
+
video_frames = read_video(input_video)
|
| 128 |
+
else:
|
| 129 |
+
video_frames = np.array(input_video * 255, np.uint8)[:video_length]
|
| 130 |
+
output_video = extract_canny_frames(video_frames)
|
| 131 |
+
output_video = torch.from_numpy(np.array(output_video)) / 255
|
| 132 |
+
return (output_video,)
|
| 133 |
+
|
| 134 |
+
class VideoToDepth:
|
| 135 |
+
@classmethod
|
| 136 |
+
def INPUT_TYPES(s):
|
| 137 |
+
return {
|
| 138 |
+
"required": {
|
| 139 |
+
"input_video": ("IMAGE",),
|
| 140 |
+
"video_length": (
|
| 141 |
+
"INT", {"default": 81, "min": 1, "max": 81, "step": 4}
|
| 142 |
+
),
|
| 143 |
+
}
|
| 144 |
+
}
|
| 145 |
+
|
| 146 |
+
RETURN_TYPES = ("IMAGE",)
|
| 147 |
+
RETURN_NAMES = ("images",)
|
| 148 |
+
FUNCTION = "process"
|
| 149 |
+
CATEGORY = "CogVideoXFUNWrapper"
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def process_frame(self, model, image, device, weight_dtype):
|
| 153 |
+
with torch.no_grad():
|
| 154 |
+
image, remove_pad = resize_image_with_pad(image, 512)
|
| 155 |
+
image_depth = image
|
| 156 |
+
with torch.no_grad():
|
| 157 |
+
image_depth = torch.from_numpy(image_depth).to(device, weight_dtype)
|
| 158 |
+
image_depth = image_depth / 255.0
|
| 159 |
+
image_depth = rearrange(image_depth, 'h w c -> 1 c h w')
|
| 160 |
+
depth = model.infer(image_depth)
|
| 161 |
+
|
| 162 |
+
depth = depth[0, 0].cpu().numpy()
|
| 163 |
+
|
| 164 |
+
vmin = np.percentile(depth, 2)
|
| 165 |
+
vmax = np.percentile(depth, 85)
|
| 166 |
+
|
| 167 |
+
depth -= vmin
|
| 168 |
+
depth /= vmax - vmin
|
| 169 |
+
depth = 1.0 - depth
|
| 170 |
+
depth_image = (depth * 255.0).clip(0, 255).astype(np.uint8)
|
| 171 |
+
image = remove_pad(depth_image)
|
| 172 |
+
image = HWC3(image)
|
| 173 |
+
return image
|
| 174 |
+
|
| 175 |
+
def process(self, input_video, video_length):
|
| 176 |
+
model = ZoeDepth.build_from_config(get_config("zoedepth", "infer"))
|
| 177 |
+
|
| 178 |
+
# Detect model is existing or not
|
| 179 |
+
possible_folders = ["CogVideoX_Fun/Third_Party", "Fun_Models/Third_Party", "VideoX_Fun/Third_Party"] # Possible folder names to check
|
| 180 |
+
|
| 181 |
+
# Check if the model exists in any of the possible folders within folder_paths.models_dir
|
| 182 |
+
zoe_model_path = "ZoeD_M12_N.pt"
|
| 183 |
+
for folder in possible_folders:
|
| 184 |
+
candidate_path = os.path.join(folder_paths.models_dir, folder, zoe_model_path)
|
| 185 |
+
if os.path.exists(candidate_path):
|
| 186 |
+
zoe_model_path = candidate_path
|
| 187 |
+
break
|
| 188 |
+
if not os.path.exists(zoe_model_path):
|
| 189 |
+
load_file_from_url(remote_zoe, model_dir=os.path.join(folder_paths.models_dir, "Fun_Models/Third_Party"))
|
| 190 |
+
zoe_model_path = os.path.join(folder_paths.models_dir, "Fun_Models/Third_Party", zoe_model_path)
|
| 191 |
+
|
| 192 |
+
model.load_state_dict(
|
| 193 |
+
torch.load(zoe_model_path, map_location="cpu")['model'],
|
| 194 |
+
strict=False
|
| 195 |
+
)
|
| 196 |
+
if torch.cuda.is_available():
|
| 197 |
+
device = "cuda"
|
| 198 |
+
weight_dtype = torch.float32
|
| 199 |
+
else:
|
| 200 |
+
device = "cpu"
|
| 201 |
+
weight_dtype = torch.float32
|
| 202 |
+
model = model.to(device=device, dtype=weight_dtype).eval().requires_grad_(False)
|
| 203 |
+
|
| 204 |
+
if isinstance(input_video, str):
|
| 205 |
+
video_frames = read_video(input_video)
|
| 206 |
+
else:
|
| 207 |
+
video_frames = np.array(input_video * 255, np.uint8)[:video_length]
|
| 208 |
+
|
| 209 |
+
output_video = [self.process_frame(model, frame, device, weight_dtype) for frame in video_frames]
|
| 210 |
+
output_video = torch.from_numpy(np.array(output_video)) / 255
|
| 211 |
+
|
| 212 |
+
return (output_video,)
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
class VideoToPose:
|
| 216 |
+
@classmethod
|
| 217 |
+
def INPUT_TYPES(s):
|
| 218 |
+
return {
|
| 219 |
+
"required": {
|
| 220 |
+
"input_video": ("IMAGE",),
|
| 221 |
+
"video_length": (
|
| 222 |
+
"INT", {"default": 81, "min": 1, "max": 81, "step": 4}
|
| 223 |
+
),
|
| 224 |
+
}
|
| 225 |
+
}
|
| 226 |
+
|
| 227 |
+
RETURN_TYPES = ("IMAGE",)
|
| 228 |
+
RETURN_NAMES = ("images",)
|
| 229 |
+
FUNCTION = "process"
|
| 230 |
+
CATEGORY = "CogVideoXFUNWrapper"
|
| 231 |
+
|
| 232 |
+
def process_frame(self, model, image):
|
| 233 |
+
with torch.no_grad():
|
| 234 |
+
image, remove_pad = resize_image_with_pad(image, 512)
|
| 235 |
+
pose_image = model(image)
|
| 236 |
+
image = remove_pad(pose_image)
|
| 237 |
+
image = HWC3(image)
|
| 238 |
+
return image
|
| 239 |
+
|
| 240 |
+
def process(self, input_video, video_length):
|
| 241 |
+
# Detect model is existing or not
|
| 242 |
+
possible_folders = ["CogVideoX_Fun/Third_Party", "Fun_Models/Third_Party", "VideoX_Fun/Third_Party"] # Possible folder names to check
|
| 243 |
+
|
| 244 |
+
# Check if the model exists in any of the possible folders within folder_paths.models_dir
|
| 245 |
+
onnx_det = "yolox_l.onnx"
|
| 246 |
+
for folder in possible_folders:
|
| 247 |
+
candidate_path = os.path.join(folder_paths.models_dir, folder, onnx_det)
|
| 248 |
+
if os.path.exists(candidate_path):
|
| 249 |
+
onnx_det = candidate_path
|
| 250 |
+
break
|
| 251 |
+
if not os.path.exists(onnx_det):
|
| 252 |
+
load_file_from_url(remote_onnx_det, os.path.join(folder_paths.models_dir, "Fun_Models/Third_Party"))
|
| 253 |
+
onnx_det = os.path.join(folder_paths.models_dir, "Fun_Models/Third_Party", onnx_det)
|
| 254 |
+
|
| 255 |
+
onnx_pose = "dw-ll_ucoco_384.onnx"
|
| 256 |
+
for folder in possible_folders:
|
| 257 |
+
candidate_path = os.path.join(folder_paths.models_dir, folder, onnx_pose)
|
| 258 |
+
if os.path.exists(candidate_path):
|
| 259 |
+
onnx_pose = candidate_path
|
| 260 |
+
break
|
| 261 |
+
if not os.path.exists(onnx_pose):
|
| 262 |
+
load_file_from_url(remote_onnx_pose, os.path.join(folder_paths.models_dir, "Fun_Models/Third_Party"))
|
| 263 |
+
onnx_pose = os.path.join(folder_paths.models_dir, "Fun_Models/Third_Party", onnx_pose)
|
| 264 |
+
|
| 265 |
+
model = DWposeDetector(onnx_det, onnx_pose)
|
| 266 |
+
|
| 267 |
+
if isinstance(input_video, str):
|
| 268 |
+
video_frames = read_video(input_video)
|
| 269 |
+
else:
|
| 270 |
+
video_frames = np.array(input_video * 255, np.uint8)[:video_length]
|
| 271 |
+
|
| 272 |
+
output_video = [self.process_frame(model, frame) for frame in video_frames]
|
| 273 |
+
output_video = torch.from_numpy(np.array(output_video)) / 255
|
| 274 |
+
return (output_video,)
|
VideoX-Fun/comfyui/annotator/zoe/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 Intelligent Systems Lab Org
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas.py
ADDED
|
@@ -0,0 +1,379 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MIT License
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
# Copyright (c) 2022 Intelligent Systems Lab Org
|
| 5 |
+
|
| 6 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 7 |
+
# of this software and associated documentation files (the "Software"), to deal
|
| 8 |
+
# in the Software without restriction, including without limitation the rights
|
| 9 |
+
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 10 |
+
# copies of the Software, and to permit persons to whom the Software is
|
| 11 |
+
# furnished to do so, subject to the following conditions:
|
| 12 |
+
|
| 13 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 14 |
+
# copies or substantial portions of the Software.
|
| 15 |
+
|
| 16 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 17 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 18 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 19 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 20 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 21 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 22 |
+
# SOFTWARE.
|
| 23 |
+
|
| 24 |
+
# File author: Shariq Farooq Bhat
|
| 25 |
+
|
| 26 |
+
import torch
|
| 27 |
+
import torch.nn as nn
|
| 28 |
+
import numpy as np
|
| 29 |
+
from torchvision.transforms import Normalize
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def denormalize(x):
|
| 33 |
+
"""Reverses the imagenet normalization applied to the input.
|
| 34 |
+
|
| 35 |
+
Args:
|
| 36 |
+
x (torch.Tensor - shape(N,3,H,W)): input tensor
|
| 37 |
+
|
| 38 |
+
Returns:
|
| 39 |
+
torch.Tensor - shape(N,3,H,W): Denormalized input
|
| 40 |
+
"""
|
| 41 |
+
mean = torch.Tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1).to(x.device)
|
| 42 |
+
std = torch.Tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1).to(x.device)
|
| 43 |
+
return x * std + mean
|
| 44 |
+
|
| 45 |
+
def get_activation(name, bank):
|
| 46 |
+
def hook(model, input, output):
|
| 47 |
+
bank[name] = output
|
| 48 |
+
return hook
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class Resize(object):
|
| 52 |
+
"""Resize sample to given size (width, height).
|
| 53 |
+
"""
|
| 54 |
+
|
| 55 |
+
def __init__(
|
| 56 |
+
self,
|
| 57 |
+
width,
|
| 58 |
+
height,
|
| 59 |
+
resize_target=True,
|
| 60 |
+
keep_aspect_ratio=False,
|
| 61 |
+
ensure_multiple_of=1,
|
| 62 |
+
resize_method="lower_bound",
|
| 63 |
+
):
|
| 64 |
+
"""Init.
|
| 65 |
+
Args:
|
| 66 |
+
width (int): desired output width
|
| 67 |
+
height (int): desired output height
|
| 68 |
+
resize_target (bool, optional):
|
| 69 |
+
True: Resize the full sample (image, mask, target).
|
| 70 |
+
False: Resize image only.
|
| 71 |
+
Defaults to True.
|
| 72 |
+
keep_aspect_ratio (bool, optional):
|
| 73 |
+
True: Keep the aspect ratio of the input sample.
|
| 74 |
+
Output sample might not have the given width and height, and
|
| 75 |
+
resize behaviour depends on the parameter 'resize_method'.
|
| 76 |
+
Defaults to False.
|
| 77 |
+
ensure_multiple_of (int, optional):
|
| 78 |
+
Output width and height is constrained to be multiple of this parameter.
|
| 79 |
+
Defaults to 1.
|
| 80 |
+
resize_method (str, optional):
|
| 81 |
+
"lower_bound": Output will be at least as large as the given size.
|
| 82 |
+
"upper_bound": Output will be at max as large as the given size. (Output size might be smaller than given size.)
|
| 83 |
+
"minimal": Scale as least as possible. (Output size might be smaller than given size.)
|
| 84 |
+
Defaults to "lower_bound".
|
| 85 |
+
"""
|
| 86 |
+
print("Params passed to Resize transform:")
|
| 87 |
+
print("\twidth: ", width)
|
| 88 |
+
print("\theight: ", height)
|
| 89 |
+
print("\tresize_target: ", resize_target)
|
| 90 |
+
print("\tkeep_aspect_ratio: ", keep_aspect_ratio)
|
| 91 |
+
print("\tensure_multiple_of: ", ensure_multiple_of)
|
| 92 |
+
print("\tresize_method: ", resize_method)
|
| 93 |
+
|
| 94 |
+
self.__width = width
|
| 95 |
+
self.__height = height
|
| 96 |
+
|
| 97 |
+
self.__keep_aspect_ratio = keep_aspect_ratio
|
| 98 |
+
self.__multiple_of = ensure_multiple_of
|
| 99 |
+
self.__resize_method = resize_method
|
| 100 |
+
|
| 101 |
+
def constrain_to_multiple_of(self, x, min_val=0, max_val=None):
|
| 102 |
+
y = (np.round(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
| 103 |
+
|
| 104 |
+
if max_val is not None and y > max_val:
|
| 105 |
+
y = (np.floor(x / self.__multiple_of)
|
| 106 |
+
* self.__multiple_of).astype(int)
|
| 107 |
+
|
| 108 |
+
if y < min_val:
|
| 109 |
+
y = (np.ceil(x / self.__multiple_of)
|
| 110 |
+
* self.__multiple_of).astype(int)
|
| 111 |
+
|
| 112 |
+
return y
|
| 113 |
+
|
| 114 |
+
def get_size(self, width, height):
|
| 115 |
+
# determine new height and width
|
| 116 |
+
scale_height = self.__height / height
|
| 117 |
+
scale_width = self.__width / width
|
| 118 |
+
|
| 119 |
+
if self.__keep_aspect_ratio:
|
| 120 |
+
if self.__resize_method == "lower_bound":
|
| 121 |
+
# scale such that output size is lower bound
|
| 122 |
+
if scale_width > scale_height:
|
| 123 |
+
# fit width
|
| 124 |
+
scale_height = scale_width
|
| 125 |
+
else:
|
| 126 |
+
# fit height
|
| 127 |
+
scale_width = scale_height
|
| 128 |
+
elif self.__resize_method == "upper_bound":
|
| 129 |
+
# scale such that output size is upper bound
|
| 130 |
+
if scale_width < scale_height:
|
| 131 |
+
# fit width
|
| 132 |
+
scale_height = scale_width
|
| 133 |
+
else:
|
| 134 |
+
# fit height
|
| 135 |
+
scale_width = scale_height
|
| 136 |
+
elif self.__resize_method == "minimal":
|
| 137 |
+
# scale as least as possbile
|
| 138 |
+
if abs(1 - scale_width) < abs(1 - scale_height):
|
| 139 |
+
# fit width
|
| 140 |
+
scale_height = scale_width
|
| 141 |
+
else:
|
| 142 |
+
# fit height
|
| 143 |
+
scale_width = scale_height
|
| 144 |
+
else:
|
| 145 |
+
raise ValueError(
|
| 146 |
+
f"resize_method {self.__resize_method} not implemented"
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
if self.__resize_method == "lower_bound":
|
| 150 |
+
new_height = self.constrain_to_multiple_of(
|
| 151 |
+
scale_height * height, min_val=self.__height
|
| 152 |
+
)
|
| 153 |
+
new_width = self.constrain_to_multiple_of(
|
| 154 |
+
scale_width * width, min_val=self.__width
|
| 155 |
+
)
|
| 156 |
+
elif self.__resize_method == "upper_bound":
|
| 157 |
+
new_height = self.constrain_to_multiple_of(
|
| 158 |
+
scale_height * height, max_val=self.__height
|
| 159 |
+
)
|
| 160 |
+
new_width = self.constrain_to_multiple_of(
|
| 161 |
+
scale_width * width, max_val=self.__width
|
| 162 |
+
)
|
| 163 |
+
elif self.__resize_method == "minimal":
|
| 164 |
+
new_height = self.constrain_to_multiple_of(scale_height * height)
|
| 165 |
+
new_width = self.constrain_to_multiple_of(scale_width * width)
|
| 166 |
+
else:
|
| 167 |
+
raise ValueError(
|
| 168 |
+
f"resize_method {self.__resize_method} not implemented")
|
| 169 |
+
|
| 170 |
+
return (new_width, new_height)
|
| 171 |
+
|
| 172 |
+
def __call__(self, x):
|
| 173 |
+
width, height = self.get_size(*x.shape[-2:][::-1])
|
| 174 |
+
return nn.functional.interpolate(x, (int(height), int(width)), mode='bilinear', align_corners=True)
|
| 175 |
+
|
| 176 |
+
class PrepForMidas(object):
|
| 177 |
+
def __init__(self, resize_mode="minimal", keep_aspect_ratio=True, img_size=384, do_resize=True):
|
| 178 |
+
if isinstance(img_size, int):
|
| 179 |
+
img_size = (img_size, img_size)
|
| 180 |
+
net_h, net_w = img_size
|
| 181 |
+
self.normalization = Normalize(
|
| 182 |
+
mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 183 |
+
self.resizer = Resize(net_w, net_h, keep_aspect_ratio=keep_aspect_ratio, ensure_multiple_of=32, resize_method=resize_mode) \
|
| 184 |
+
if do_resize else nn.Identity()
|
| 185 |
+
|
| 186 |
+
def __call__(self, x):
|
| 187 |
+
return self.normalization(self.resizer(x))
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
class MidasCore(nn.Module):
|
| 191 |
+
def __init__(self, midas, trainable=False, fetch_features=True, layer_names=('out_conv', 'l4_rn', 'r4', 'r3', 'r2', 'r1'), freeze_bn=False, keep_aspect_ratio=True,
|
| 192 |
+
img_size=384, **kwargs):
|
| 193 |
+
"""Midas Base model used for multi-scale feature extraction.
|
| 194 |
+
|
| 195 |
+
Args:
|
| 196 |
+
midas (torch.nn.Module): Midas model.
|
| 197 |
+
trainable (bool, optional): Train midas model. Defaults to False.
|
| 198 |
+
fetch_features (bool, optional): Extract multi-scale features. Defaults to True.
|
| 199 |
+
layer_names (tuple, optional): Layers used for feature extraction. Order = (head output features, last layer features, ...decoder features). Defaults to ('out_conv', 'l4_rn', 'r4', 'r3', 'r2', 'r1').
|
| 200 |
+
freeze_bn (bool, optional): Freeze BatchNorm. Generally results in better finetuning performance. Defaults to False.
|
| 201 |
+
keep_aspect_ratio (bool, optional): Keep the aspect ratio of input images while resizing. Defaults to True.
|
| 202 |
+
img_size (int, tuple, optional): Input resolution. Defaults to 384.
|
| 203 |
+
"""
|
| 204 |
+
super().__init__()
|
| 205 |
+
self.core = midas
|
| 206 |
+
self.output_channels = None
|
| 207 |
+
self.core_out = {}
|
| 208 |
+
self.trainable = trainable
|
| 209 |
+
self.fetch_features = fetch_features
|
| 210 |
+
# midas.scratch.output_conv = nn.Identity()
|
| 211 |
+
self.handles = []
|
| 212 |
+
# self.layer_names = ['out_conv','l4_rn', 'r4', 'r3', 'r2', 'r1']
|
| 213 |
+
self.layer_names = layer_names
|
| 214 |
+
|
| 215 |
+
self.set_trainable(trainable)
|
| 216 |
+
self.set_fetch_features(fetch_features)
|
| 217 |
+
|
| 218 |
+
self.prep = PrepForMidas(keep_aspect_ratio=keep_aspect_ratio,
|
| 219 |
+
img_size=img_size, do_resize=kwargs.get('do_resize', True))
|
| 220 |
+
|
| 221 |
+
if freeze_bn:
|
| 222 |
+
self.freeze_bn()
|
| 223 |
+
|
| 224 |
+
def set_trainable(self, trainable):
|
| 225 |
+
self.trainable = trainable
|
| 226 |
+
if trainable:
|
| 227 |
+
self.unfreeze()
|
| 228 |
+
else:
|
| 229 |
+
self.freeze()
|
| 230 |
+
return self
|
| 231 |
+
|
| 232 |
+
def set_fetch_features(self, fetch_features):
|
| 233 |
+
self.fetch_features = fetch_features
|
| 234 |
+
if fetch_features:
|
| 235 |
+
if len(self.handles) == 0:
|
| 236 |
+
self.attach_hooks(self.core)
|
| 237 |
+
else:
|
| 238 |
+
self.remove_hooks()
|
| 239 |
+
return self
|
| 240 |
+
|
| 241 |
+
def freeze(self):
|
| 242 |
+
for p in self.parameters():
|
| 243 |
+
p.requires_grad = False
|
| 244 |
+
self.trainable = False
|
| 245 |
+
return self
|
| 246 |
+
|
| 247 |
+
def unfreeze(self):
|
| 248 |
+
for p in self.parameters():
|
| 249 |
+
p.requires_grad = True
|
| 250 |
+
self.trainable = True
|
| 251 |
+
return self
|
| 252 |
+
|
| 253 |
+
def freeze_bn(self):
|
| 254 |
+
for m in self.modules():
|
| 255 |
+
if isinstance(m, nn.BatchNorm2d):
|
| 256 |
+
m.eval()
|
| 257 |
+
return self
|
| 258 |
+
|
| 259 |
+
def forward(self, x, denorm=False, return_rel_depth=False):
|
| 260 |
+
with torch.no_grad():
|
| 261 |
+
if denorm:
|
| 262 |
+
x = denormalize(x)
|
| 263 |
+
x = self.prep(x)
|
| 264 |
+
# print("Shape after prep: ", x.shape)
|
| 265 |
+
|
| 266 |
+
with torch.set_grad_enabled(self.trainable):
|
| 267 |
+
|
| 268 |
+
# print("Input size to Midascore", x.shape)
|
| 269 |
+
rel_depth = self.core(x)
|
| 270 |
+
# print("Output from midas shape", rel_depth.shape)
|
| 271 |
+
if not self.fetch_features:
|
| 272 |
+
return rel_depth
|
| 273 |
+
out = [self.core_out[k] for k in self.layer_names]
|
| 274 |
+
|
| 275 |
+
if return_rel_depth:
|
| 276 |
+
return rel_depth, out
|
| 277 |
+
return out
|
| 278 |
+
|
| 279 |
+
def get_rel_pos_params(self):
|
| 280 |
+
for name, p in self.core.pretrained.named_parameters():
|
| 281 |
+
if "relative_position" in name:
|
| 282 |
+
yield p
|
| 283 |
+
|
| 284 |
+
def get_enc_params_except_rel_pos(self):
|
| 285 |
+
for name, p in self.core.pretrained.named_parameters():
|
| 286 |
+
if "relative_position" not in name:
|
| 287 |
+
yield p
|
| 288 |
+
|
| 289 |
+
def freeze_encoder(self, freeze_rel_pos=False):
|
| 290 |
+
if freeze_rel_pos:
|
| 291 |
+
for p in self.core.pretrained.parameters():
|
| 292 |
+
p.requires_grad = False
|
| 293 |
+
else:
|
| 294 |
+
for p in self.get_enc_params_except_rel_pos():
|
| 295 |
+
p.requires_grad = False
|
| 296 |
+
return self
|
| 297 |
+
|
| 298 |
+
def attach_hooks(self, midas):
|
| 299 |
+
if len(self.handles) > 0:
|
| 300 |
+
self.remove_hooks()
|
| 301 |
+
if "out_conv" in self.layer_names:
|
| 302 |
+
self.handles.append(list(midas.scratch.output_conv.children())[
|
| 303 |
+
3].register_forward_hook(get_activation("out_conv", self.core_out)))
|
| 304 |
+
if "r4" in self.layer_names:
|
| 305 |
+
self.handles.append(midas.scratch.refinenet4.register_forward_hook(
|
| 306 |
+
get_activation("r4", self.core_out)))
|
| 307 |
+
if "r3" in self.layer_names:
|
| 308 |
+
self.handles.append(midas.scratch.refinenet3.register_forward_hook(
|
| 309 |
+
get_activation("r3", self.core_out)))
|
| 310 |
+
if "r2" in self.layer_names:
|
| 311 |
+
self.handles.append(midas.scratch.refinenet2.register_forward_hook(
|
| 312 |
+
get_activation("r2", self.core_out)))
|
| 313 |
+
if "r1" in self.layer_names:
|
| 314 |
+
self.handles.append(midas.scratch.refinenet1.register_forward_hook(
|
| 315 |
+
get_activation("r1", self.core_out)))
|
| 316 |
+
if "l4_rn" in self.layer_names:
|
| 317 |
+
self.handles.append(midas.scratch.layer4_rn.register_forward_hook(
|
| 318 |
+
get_activation("l4_rn", self.core_out)))
|
| 319 |
+
|
| 320 |
+
return self
|
| 321 |
+
|
| 322 |
+
def remove_hooks(self):
|
| 323 |
+
for h in self.handles:
|
| 324 |
+
h.remove()
|
| 325 |
+
return self
|
| 326 |
+
|
| 327 |
+
def __del__(self):
|
| 328 |
+
self.remove_hooks()
|
| 329 |
+
|
| 330 |
+
def set_output_channels(self, model_type):
|
| 331 |
+
self.output_channels = MIDAS_SETTINGS[model_type]
|
| 332 |
+
|
| 333 |
+
@staticmethod
|
| 334 |
+
def build(midas_model_type="DPT_BEiT_L_384", train_midas=False, use_pretrained_midas=True, fetch_features=False, freeze_bn=True, force_keep_ar=False, force_reload=False, **kwargs):
|
| 335 |
+
if midas_model_type not in MIDAS_SETTINGS:
|
| 336 |
+
raise ValueError(
|
| 337 |
+
f"Invalid model type: {midas_model_type}. Must be one of {list(MIDAS_SETTINGS.keys())}")
|
| 338 |
+
if "img_size" in kwargs:
|
| 339 |
+
kwargs = MidasCore.parse_img_size(kwargs)
|
| 340 |
+
img_size = kwargs.pop("img_size", [384, 384])
|
| 341 |
+
print("img_size", img_size)
|
| 342 |
+
midas_path = os.path.join(os.path.dirname(__file__), 'midas_repo')
|
| 343 |
+
midas = torch.hub.load(midas_path, midas_model_type,
|
| 344 |
+
pretrained=use_pretrained_midas, force_reload=force_reload, source='local')
|
| 345 |
+
kwargs.update({'keep_aspect_ratio': force_keep_ar})
|
| 346 |
+
midas_core = MidasCore(midas, trainable=train_midas, fetch_features=fetch_features,
|
| 347 |
+
freeze_bn=freeze_bn, img_size=img_size, **kwargs)
|
| 348 |
+
midas_core.set_output_channels(midas_model_type)
|
| 349 |
+
return midas_core
|
| 350 |
+
|
| 351 |
+
@staticmethod
|
| 352 |
+
def build_from_config(config):
|
| 353 |
+
return MidasCore.build(**config)
|
| 354 |
+
|
| 355 |
+
@staticmethod
|
| 356 |
+
def parse_img_size(config):
|
| 357 |
+
assert 'img_size' in config
|
| 358 |
+
if isinstance(config['img_size'], str):
|
| 359 |
+
assert "," in config['img_size'], "img_size should be a string with comma separated img_size=H,W"
|
| 360 |
+
config['img_size'] = list(map(int, config['img_size'].split(",")))
|
| 361 |
+
assert len(
|
| 362 |
+
config['img_size']) == 2, "img_size should be a string with comma separated img_size=H,W"
|
| 363 |
+
elif isinstance(config['img_size'], int):
|
| 364 |
+
config['img_size'] = [config['img_size'], config['img_size']]
|
| 365 |
+
else:
|
| 366 |
+
assert isinstance(config['img_size'], list) and len(
|
| 367 |
+
config['img_size']) == 2, "img_size should be a list of H,W"
|
| 368 |
+
return config
|
| 369 |
+
|
| 370 |
+
|
| 371 |
+
nchannels2models = {
|
| 372 |
+
tuple([256]*5): ["DPT_BEiT_L_384", "DPT_BEiT_L_512", "DPT_BEiT_B_384", "DPT_SwinV2_L_384", "DPT_SwinV2_B_384", "DPT_SwinV2_T_256", "DPT_Large", "DPT_Hybrid"],
|
| 373 |
+
(512, 256, 128, 64, 64): ["MiDaS_small"]
|
| 374 |
+
}
|
| 375 |
+
|
| 376 |
+
# Model name to number of output channels
|
| 377 |
+
MIDAS_SETTINGS = {m: k for k, v in nchannels2models.items()
|
| 378 |
+
for m in v
|
| 379 |
+
}
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/.gitignore
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
*.egg-info/
|
| 24 |
+
.installed.cfg
|
| 25 |
+
*.egg
|
| 26 |
+
MANIFEST
|
| 27 |
+
|
| 28 |
+
# PyInstaller
|
| 29 |
+
# Usually these files are written by a python script from a template
|
| 30 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 31 |
+
*.manifest
|
| 32 |
+
*.spec
|
| 33 |
+
|
| 34 |
+
# Installer logs
|
| 35 |
+
pip-log.txt
|
| 36 |
+
pip-delete-this-directory.txt
|
| 37 |
+
|
| 38 |
+
# Unit test / coverage reports
|
| 39 |
+
htmlcov/
|
| 40 |
+
.tox/
|
| 41 |
+
.coverage
|
| 42 |
+
.coverage.*
|
| 43 |
+
.cache
|
| 44 |
+
nosetests.xml
|
| 45 |
+
coverage.xml
|
| 46 |
+
*.cover
|
| 47 |
+
.hypothesis/
|
| 48 |
+
.pytest_cache/
|
| 49 |
+
|
| 50 |
+
# Translations
|
| 51 |
+
*.mo
|
| 52 |
+
*.pot
|
| 53 |
+
|
| 54 |
+
# Django stuff:
|
| 55 |
+
*.log
|
| 56 |
+
local_settings.py
|
| 57 |
+
db.sqlite3
|
| 58 |
+
|
| 59 |
+
# Flask stuff:
|
| 60 |
+
instance/
|
| 61 |
+
.webassets-cache
|
| 62 |
+
|
| 63 |
+
# Scrapy stuff:
|
| 64 |
+
.scrapy
|
| 65 |
+
|
| 66 |
+
# Sphinx documentation
|
| 67 |
+
docs/_build/
|
| 68 |
+
|
| 69 |
+
# PyBuilder
|
| 70 |
+
target/
|
| 71 |
+
|
| 72 |
+
# Jupyter Notebook
|
| 73 |
+
.ipynb_checkpoints
|
| 74 |
+
|
| 75 |
+
# pyenv
|
| 76 |
+
.python-version
|
| 77 |
+
|
| 78 |
+
# celery beat schedule file
|
| 79 |
+
celerybeat-schedule
|
| 80 |
+
|
| 81 |
+
# SageMath parsed files
|
| 82 |
+
*.sage.py
|
| 83 |
+
|
| 84 |
+
# Environments
|
| 85 |
+
.env
|
| 86 |
+
.venv
|
| 87 |
+
env/
|
| 88 |
+
venv/
|
| 89 |
+
ENV/
|
| 90 |
+
env.bak/
|
| 91 |
+
venv.bak/
|
| 92 |
+
|
| 93 |
+
# Spyder project settings
|
| 94 |
+
.spyderproject
|
| 95 |
+
.spyproject
|
| 96 |
+
|
| 97 |
+
# Rope project settings
|
| 98 |
+
.ropeproject
|
| 99 |
+
|
| 100 |
+
# mkdocs documentation
|
| 101 |
+
/site
|
| 102 |
+
|
| 103 |
+
# mypy
|
| 104 |
+
.mypy_cache/
|
| 105 |
+
|
| 106 |
+
*.png
|
| 107 |
+
*.pfm
|
| 108 |
+
*.jpg
|
| 109 |
+
*.jpeg
|
| 110 |
+
*.pt
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/Dockerfile
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# enables cuda support in docker
|
| 2 |
+
FROM nvidia/cuda:10.2-cudnn7-runtime-ubuntu18.04
|
| 3 |
+
|
| 4 |
+
# install python 3.6, pip and requirements for opencv-python
|
| 5 |
+
# (see https://github.com/NVIDIA/nvidia-docker/issues/864)
|
| 6 |
+
RUN apt-get update && apt-get -y install \
|
| 7 |
+
python3 \
|
| 8 |
+
python3-pip \
|
| 9 |
+
libsm6 \
|
| 10 |
+
libxext6 \
|
| 11 |
+
libxrender-dev \
|
| 12 |
+
curl \
|
| 13 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 14 |
+
|
| 15 |
+
# install python dependencies
|
| 16 |
+
RUN pip3 install --upgrade pip
|
| 17 |
+
RUN pip3 install torch~=1.8 torchvision opencv-python-headless~=3.4 timm
|
| 18 |
+
|
| 19 |
+
# copy inference code
|
| 20 |
+
WORKDIR /opt/MiDaS
|
| 21 |
+
COPY ./midas ./midas
|
| 22 |
+
COPY ./*.py ./
|
| 23 |
+
|
| 24 |
+
# download model weights so the docker image can be used offline
|
| 25 |
+
RUN cd weights && {curl -OL https://github.com/isl-org/MiDaS/releases/download/v3/dpt_hybrid_384.pt; cd -; }
|
| 26 |
+
RUN python3 run.py --model_type dpt_hybrid; exit 0
|
| 27 |
+
|
| 28 |
+
# entrypoint (dont forget to mount input and output directories)
|
| 29 |
+
CMD python3 run.py --model_type dpt_hybrid
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2019 Intel ISL (Intel Intelligent Systems Lab)
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/README.md
ADDED
|
@@ -0,0 +1,259 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer
|
| 2 |
+
|
| 3 |
+
This repository contains code to compute depth from a single image. It accompanies our [paper](https://arxiv.org/abs/1907.01341v3):
|
| 4 |
+
|
| 5 |
+
>Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer
|
| 6 |
+
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, Vladlen Koltun
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
and our [preprint](https://arxiv.org/abs/2103.13413):
|
| 10 |
+
|
| 11 |
+
> Vision Transformers for Dense Prediction
|
| 12 |
+
> René Ranftl, Alexey Bochkovskiy, Vladlen Koltun
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
MiDaS was trained on up to 12 datasets (ReDWeb, DIML, Movies, MegaDepth, WSVD, TartanAir, HRWSI, ApolloScape, BlendedMVS, IRS, KITTI, NYU Depth V2) with
|
| 16 |
+
multi-objective optimization.
|
| 17 |
+
The original model that was trained on 5 datasets (`MIX 5` in the paper) can be found [here](https://github.com/isl-org/MiDaS/releases/tag/v2).
|
| 18 |
+
The figure below shows an overview of the different MiDaS models; the bubble size scales with number of parameters.
|
| 19 |
+
|
| 20 |
+

|
| 21 |
+
|
| 22 |
+
### Setup
|
| 23 |
+
|
| 24 |
+
1) Pick one or more models and download the corresponding weights to the `weights` folder:
|
| 25 |
+
|
| 26 |
+
MiDaS 3.1
|
| 27 |
+
- For highest quality: [dpt_beit_large_512](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt)
|
| 28 |
+
- For moderately less quality, but better speed-performance trade-off: [dpt_swin2_large_384](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_large_384.pt)
|
| 29 |
+
- For embedded devices: [dpt_swin2_tiny_256](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_tiny_256.pt), [dpt_levit_224](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_levit_224.pt)
|
| 30 |
+
- For inference on Intel CPUs, OpenVINO may be used for the small legacy model: openvino_midas_v21_small [.xml](https://github.com/isl-org/MiDaS/releases/download/v3_1/openvino_midas_v21_small_256.xml), [.bin](https://github.com/isl-org/MiDaS/releases/download/v3_1/openvino_midas_v21_small_256.bin)
|
| 31 |
+
|
| 32 |
+
MiDaS 3.0: Legacy transformer models [dpt_large_384](https://github.com/isl-org/MiDaS/releases/download/v3/dpt_large_384.pt) and [dpt_hybrid_384](https://github.com/isl-org/MiDaS/releases/download/v3/dpt_hybrid_384.pt)
|
| 33 |
+
|
| 34 |
+
MiDaS 2.1: Legacy convolutional models [midas_v21_384](https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_384.pt) and [midas_v21_small_256](https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_small_256.pt)
|
| 35 |
+
|
| 36 |
+
1) Set up dependencies:
|
| 37 |
+
|
| 38 |
+
```shell
|
| 39 |
+
conda env create -f environment.yaml
|
| 40 |
+
conda activate midas-py310
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
#### optional
|
| 44 |
+
|
| 45 |
+
For the Next-ViT model, execute
|
| 46 |
+
|
| 47 |
+
```shell
|
| 48 |
+
git submodule add https://github.com/isl-org/Next-ViT midas/external/next_vit
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
For the OpenVINO model, install
|
| 52 |
+
|
| 53 |
+
```shell
|
| 54 |
+
pip install openvino
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
### Usage
|
| 58 |
+
|
| 59 |
+
1) Place one or more input images in the folder `input`.
|
| 60 |
+
|
| 61 |
+
2) Run the model with
|
| 62 |
+
|
| 63 |
+
```shell
|
| 64 |
+
python run.py --model_type <model_type> --input_path input --output_path output
|
| 65 |
+
```
|
| 66 |
+
where ```<model_type>``` is chosen from [dpt_beit_large_512](#model_type), [dpt_beit_large_384](#model_type),
|
| 67 |
+
[dpt_beit_base_384](#model_type), [dpt_swin2_large_384](#model_type), [dpt_swin2_base_384](#model_type),
|
| 68 |
+
[dpt_swin2_tiny_256](#model_type), [dpt_swin_large_384](#model_type), [dpt_next_vit_large_384](#model_type),
|
| 69 |
+
[dpt_levit_224](#model_type), [dpt_large_384](#model_type), [dpt_hybrid_384](#model_type),
|
| 70 |
+
[midas_v21_384](#model_type), [midas_v21_small_256](#model_type), [openvino_midas_v21_small_256](#model_type).
|
| 71 |
+
|
| 72 |
+
3) The resulting depth maps are written to the `output` folder.
|
| 73 |
+
|
| 74 |
+
#### optional
|
| 75 |
+
|
| 76 |
+
1) By default, the inference resizes the height of input images to the size of a model to fit into the encoder. This
|
| 77 |
+
size is given by the numbers in the model names of the [accuracy table](#accuracy). Some models do not only support a single
|
| 78 |
+
inference height but a range of different heights. Feel free to explore different heights by appending the extra
|
| 79 |
+
command line argument `--height`. Unsupported height values will throw an error. Note that using this argument may
|
| 80 |
+
decrease the model accuracy.
|
| 81 |
+
2) By default, the inference keeps the aspect ratio of input images when feeding them into the encoder if this is
|
| 82 |
+
supported by a model (all models except for Swin, Swin2, LeViT). In order to resize to a square resolution,
|
| 83 |
+
disregarding the aspect ratio while preserving the height, use the command line argument `--square`.
|
| 84 |
+
|
| 85 |
+
#### via Camera
|
| 86 |
+
|
| 87 |
+
If you want the input images to be grabbed from the camera and shown in a window, leave the input and output paths
|
| 88 |
+
away and choose a model type as shown above:
|
| 89 |
+
|
| 90 |
+
```shell
|
| 91 |
+
python run.py --model_type <model_type> --side
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
The argument `--side` is optional and causes both the input RGB image and the output depth map to be shown
|
| 95 |
+
side-by-side for comparison.
|
| 96 |
+
|
| 97 |
+
#### via Docker
|
| 98 |
+
|
| 99 |
+
1) Make sure you have installed Docker and the
|
| 100 |
+
[NVIDIA Docker runtime](https://github.com/NVIDIA/nvidia-docker/wiki/Installation-\(Native-GPU-Support\)).
|
| 101 |
+
|
| 102 |
+
2) Build the Docker image:
|
| 103 |
+
|
| 104 |
+
```shell
|
| 105 |
+
docker build -t midas .
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
3) Run inference:
|
| 109 |
+
|
| 110 |
+
```shell
|
| 111 |
+
docker run --rm --gpus all -v $PWD/input:/opt/MiDaS/input -v $PWD/output:/opt/MiDaS/output -v $PWD/weights:/opt/MiDaS/weights midas
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
This command passes through all of your NVIDIA GPUs to the container, mounts the
|
| 115 |
+
`input` and `output` directories and then runs the inference.
|
| 116 |
+
|
| 117 |
+
#### via PyTorch Hub
|
| 118 |
+
|
| 119 |
+
The pretrained model is also available on [PyTorch Hub](https://pytorch.org/hub/intelisl_midas_v2/)
|
| 120 |
+
|
| 121 |
+
#### via TensorFlow or ONNX
|
| 122 |
+
|
| 123 |
+
See [README](https://github.com/isl-org/MiDaS/tree/master/tf) in the `tf` subdirectory.
|
| 124 |
+
|
| 125 |
+
Currently only supports MiDaS v2.1.
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
#### via Mobile (iOS / Android)
|
| 129 |
+
|
| 130 |
+
See [README](https://github.com/isl-org/MiDaS/tree/master/mobile) in the `mobile` subdirectory.
|
| 131 |
+
|
| 132 |
+
#### via ROS1 (Robot Operating System)
|
| 133 |
+
|
| 134 |
+
See [README](https://github.com/isl-org/MiDaS/tree/master/ros) in the `ros` subdirectory.
|
| 135 |
+
|
| 136 |
+
Currently only supports MiDaS v2.1. DPT-based models to be added.
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
### Accuracy
|
| 140 |
+
|
| 141 |
+
We provide a **zero-shot error** $\epsilon_d$ which is evaluated for 6 different datasets
|
| 142 |
+
(see [paper](https://arxiv.org/abs/1907.01341v3)). **Lower error values are better**.
|
| 143 |
+
$\color{green}{\textsf{Overall model quality is represented by the improvement}}$ ([Imp.](#improvement)) with respect to
|
| 144 |
+
MiDaS 3.0 DPT<sub>L-384</sub>. The models are grouped by the height used for inference, whereas the square training resolution is given by
|
| 145 |
+
the numbers in the model names. The table also shows the **number of parameters** (in millions) and the
|
| 146 |
+
**frames per second** for inference at the training resolution (for GPU RTX 3090):
|
| 147 |
+
|
| 148 |
+
| MiDaS Model | DIW </br><sup>WHDR</sup> | Eth3d </br><sup>AbsRel</sup> | Sintel </br><sup>AbsRel</sup> | TUM </br><sup>δ1</sup> | KITTI </br><sup>δ1</sup> | NYUv2 </br><sup>δ1</sup> | $\color{green}{\textsf{Imp.}}$ </br><sup>%</sup> | Par.</br><sup>M</sup> | FPS</br><sup> </sup> |
|
| 149 |
+
|-----------------------------------------------------------------------------------------------------------------------|-------------------------:|-----------------------------:|------------------------------:|-------------------------:|-------------------------:|-------------------------:|-------------------------------------------------:|----------------------:|--------------------------:|
|
| 150 |
+
| **Inference height 512** | | | | | | | | | |
|
| 151 |
+
| [v3.1 BEiT<sub>L-512</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt) | 0.1137 | 0.0659 | 0.2366 | **6.13** | 11.56* | **1.86*** | $\color{green}{\textsf{19}}$ | **345** | **5.7** |
|
| 152 |
+
| [v3.1 BEiT<sub>L-512</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt)$\tiny{\square}$ | **0.1121** | **0.0614** | **0.2090** | 6.46 | **5.00*** | 1.90* | $\color{green}{\textsf{34}}$ | **345** | **5.7** |
|
| 153 |
+
| | | | | | | | | | |
|
| 154 |
+
| **Inference height 384** | | | | | | | | | |
|
| 155 |
+
| [v3.1 BEiT<sub>L-512</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt) | 0.1245 | 0.0681 | **0.2176** | **6.13** | 6.28* | **2.16*** | $\color{green}{\textsf{28}}$ | 345 | 12 |
|
| 156 |
+
| [v3.1 Swin2<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_large_384.pt)$\tiny{\square}$ | 0.1106 | 0.0732 | 0.2442 | 8.87 | **5.84*** | 2.92* | $\color{green}{\textsf{22}}$ | 213 | 41 |
|
| 157 |
+
| [v3.1 Swin2<sub>B-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_base_384.pt)$\tiny{\square}$ | 0.1095 | 0.0790 | 0.2404 | 8.93 | 5.97* | 3.28* | $\color{green}{\textsf{22}}$ | 102 | 39 |
|
| 158 |
+
| [v3.1 Swin<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin_large_384.pt)$\tiny{\square}$ | 0.1126 | 0.0853 | 0.2428 | 8.74 | 6.60* | 3.34* | $\color{green}{\textsf{17}}$ | 213 | 49 |
|
| 159 |
+
| [v3.1 BEiT<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_384.pt) | 0.1239 | **0.0667** | 0.2545 | 7.17 | 9.84* | 2.21* | $\color{green}{\textsf{17}}$ | 344 | 13 |
|
| 160 |
+
| [v3.1 Next-ViT<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_next_vit_large_384.pt) | **0.1031** | 0.0954 | 0.2295 | 9.21 | 6.89* | 3.47* | $\color{green}{\textsf{16}}$ | **72** | 30 |
|
| 161 |
+
| [v3.1 BEiT<sub>B-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_base_384.pt) | 0.1159 | 0.0967 | 0.2901 | 9.88 | 26.60* | 3.91* | $\color{green}{\textsf{-31}}$ | 112 | 31 |
|
| 162 |
+
| [v3.0 DPT<sub>L-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3/dpt_large_384.pt) | 0.1082 | 0.0888 | 0.2697 | 9.97 | 8.46 | 8.32 | $\color{green}{\textsf{0}}$ | 344 | **61** |
|
| 163 |
+
| [v3.0 DPT<sub>H-384</sub>](https://github.com/isl-org/MiDaS/releases/download/v3/dpt_hybrid_384.pt) | 0.1106 | 0.0934 | 0.2741 | 10.89 | 11.56 | 8.69 | $\color{green}{\textsf{-10}}$ | 123 | 50 |
|
| 164 |
+
| [v2.1 Large<sub>384</sub>](https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_384.pt) | 0.1295 | 0.1155 | 0.3285 | 12.51 | 16.08 | 8.71 | $\color{green}{\textsf{-32}}$ | 105 | 47 |
|
| 165 |
+
| | | | | | | | | | |
|
| 166 |
+
| **Inference height 256** | | | | | | | | | |
|
| 167 |
+
| [v3.1 Swin2<sub>T-256</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_tiny_256.pt)$\tiny{\square}$ | **0.1211** | **0.1106** | **0.2868** | **13.43** | **10.13*** | **5.55*** | $\color{green}{\textsf{-11}}$ | 42 | 64 |
|
| 168 |
+
| [v2.1 Small<sub>256</sub>](https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_small_256.pt) | 0.1344 | 0.1344 | 0.3370 | 14.53 | 29.27 | 13.43 | $\color{green}{\textsf{-76}}$ | **21** | **90** |
|
| 169 |
+
| | | | | | | | | | |
|
| 170 |
+
| **Inference height 224** | | | | | | | | | |
|
| 171 |
+
| [v3.1 LeViT<sub>224</sub>](https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_levit_224.pt)$\tiny{\square}$ | **0.1314** | **0.1206** | **0.3148** | **18.21** | **15.27*** | **8.64*** | $\color{green}{\textsf{-40}}$ | **51** | **73** |
|
| 172 |
+
|
| 173 |
+
* No zero-shot error, because models are also trained on KITTI and NYU Depth V2\
|
| 174 |
+
$\square$ Validation performed at **square resolution**, either because the transformer encoder backbone of a model
|
| 175 |
+
does not support non-square resolutions (Swin, Swin2, LeViT) or for comparison with these models. All other
|
| 176 |
+
validations keep the aspect ratio. A difference in resolution limits the comparability of the zero-shot error and the
|
| 177 |
+
improvement, because these quantities are averages over the pixels of an image and do not take into account the
|
| 178 |
+
advantage of more details due to a higher resolution.\
|
| 179 |
+
Best values per column and same validation height in bold
|
| 180 |
+
|
| 181 |
+
#### Improvement
|
| 182 |
+
|
| 183 |
+
The improvement in the above table is defined as the relative zero-shot error with respect to MiDaS v3.0
|
| 184 |
+
DPT<sub>L-384</sub> and averaging over the datasets. So, if $\epsilon_d$ is the zero-shot error for dataset $d$, then
|
| 185 |
+
the $\color{green}{\textsf{improvement}}$ is given by $100(1-(1/6)\sum_d\epsilon_d/\epsilon_{d,\rm{DPT_{L-384}}})$%.
|
| 186 |
+
|
| 187 |
+
Note that the improvements of 10% for MiDaS v2.0 → v2.1 and 21% for MiDaS v2.1 → v3.0 are not visible from the
|
| 188 |
+
improvement column (Imp.) in the table but would require an evaluation with respect to MiDaS v2.1 Large<sub>384</sub>
|
| 189 |
+
and v2.0 Large<sub>384</sub> respectively instead of v3.0 DPT<sub>L-384</sub>.
|
| 190 |
+
|
| 191 |
+
### Depth map comparison
|
| 192 |
+
|
| 193 |
+
Zoom in for better visibility
|
| 194 |
+

|
| 195 |
+
|
| 196 |
+
### Speed on Camera Feed
|
| 197 |
+
|
| 198 |
+
Test configuration
|
| 199 |
+
- Windows 10
|
| 200 |
+
- 11th Gen Intel Core i7-1185G7 3.00GHz
|
| 201 |
+
- 16GB RAM
|
| 202 |
+
- Camera resolution 640x480
|
| 203 |
+
- openvino_midas_v21_small_256
|
| 204 |
+
|
| 205 |
+
Speed: 22 FPS
|
| 206 |
+
|
| 207 |
+
### Changelog
|
| 208 |
+
|
| 209 |
+
* [Dec 2022] Released MiDaS v3.1:
|
| 210 |
+
- New models based on 5 different types of transformers ([BEiT](https://arxiv.org/pdf/2106.08254.pdf), [Swin2](https://arxiv.org/pdf/2111.09883.pdf), [Swin](https://arxiv.org/pdf/2103.14030.pdf), [Next-ViT](https://arxiv.org/pdf/2207.05501.pdf), [LeViT](https://arxiv.org/pdf/2104.01136.pdf))
|
| 211 |
+
- Training datasets extended from 10 to 12, including also KITTI and NYU Depth V2 using [BTS](https://github.com/cleinc/bts) split
|
| 212 |
+
- Best model, BEiT<sub>Large 512</sub>, with resolution 512x512, is on average about [28% more accurate](#Accuracy) than MiDaS v3.0
|
| 213 |
+
- Integrated live depth estimation from camera feed
|
| 214 |
+
* [Sep 2021] Integrated to [Huggingface Spaces](https://huggingface.co/spaces) with [Gradio](https://github.com/gradio-app/gradio). See [Gradio Web Demo](https://huggingface.co/spaces/akhaliq/DPT-Large).
|
| 215 |
+
* [Apr 2021] Released MiDaS v3.0:
|
| 216 |
+
- New models based on [Dense Prediction Transformers](https://arxiv.org/abs/2103.13413) are on average [21% more accurate](#Accuracy) than MiDaS v2.1
|
| 217 |
+
- Additional models can be found [here](https://github.com/isl-org/DPT)
|
| 218 |
+
* [Nov 2020] Released MiDaS v2.1:
|
| 219 |
+
- New model that was trained on 10 datasets and is on average about [10% more accurate](#Accuracy) than [MiDaS v2.0](https://github.com/isl-org/MiDaS/releases/tag/v2)
|
| 220 |
+
- New light-weight model that achieves [real-time performance](https://github.com/isl-org/MiDaS/tree/master/mobile) on mobile platforms.
|
| 221 |
+
- Sample applications for [iOS](https://github.com/isl-org/MiDaS/tree/master/mobile/ios) and [Android](https://github.com/isl-org/MiDaS/tree/master/mobile/android)
|
| 222 |
+
- [ROS package](https://github.com/isl-org/MiDaS/tree/master/ros) for easy deployment on robots
|
| 223 |
+
* [Jul 2020] Added TensorFlow and ONNX code. Added [online demo](http://35.202.76.57/).
|
| 224 |
+
* [Dec 2019] Released new version of MiDaS - the new model is significantly more accurate and robust
|
| 225 |
+
* [Jul 2019] Initial release of MiDaS ([Link](https://github.com/isl-org/MiDaS/releases/tag/v1))
|
| 226 |
+
|
| 227 |
+
### Citation
|
| 228 |
+
|
| 229 |
+
Please cite our paper if you use this code or any of the models:
|
| 230 |
+
```
|
| 231 |
+
@ARTICLE {Ranftl2022,
|
| 232 |
+
author = "Ren\'{e} Ranftl and Katrin Lasinger and David Hafner and Konrad Schindler and Vladlen Koltun",
|
| 233 |
+
title = "Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer",
|
| 234 |
+
journal = "IEEE Transactions on Pattern Analysis and Machine Intelligence",
|
| 235 |
+
year = "2022",
|
| 236 |
+
volume = "44",
|
| 237 |
+
number = "3"
|
| 238 |
+
}
|
| 239 |
+
```
|
| 240 |
+
|
| 241 |
+
If you use a DPT-based model, please also cite:
|
| 242 |
+
|
| 243 |
+
```
|
| 244 |
+
@article{Ranftl2021,
|
| 245 |
+
author = {Ren\'{e} Ranftl and Alexey Bochkovskiy and Vladlen Koltun},
|
| 246 |
+
title = {Vision Transformers for Dense Prediction},
|
| 247 |
+
journal = {ICCV},
|
| 248 |
+
year = {2021},
|
| 249 |
+
}
|
| 250 |
+
```
|
| 251 |
+
|
| 252 |
+
### Acknowledgements
|
| 253 |
+
|
| 254 |
+
Our work builds on and uses code from [timm](https://github.com/rwightman/pytorch-image-models) and [Next-ViT](https://github.com/bytedance/Next-ViT).
|
| 255 |
+
We'd like to thank the authors for making these libraries available.
|
| 256 |
+
|
| 257 |
+
### License
|
| 258 |
+
|
| 259 |
+
MIT License
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/environment.yaml
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: midas-py310
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- defaults
|
| 5 |
+
dependencies:
|
| 6 |
+
- nvidia::cudatoolkit=11.7
|
| 7 |
+
- python=3.10.8
|
| 8 |
+
- pytorch::pytorch=1.13.0
|
| 9 |
+
- torchvision=0.14.0
|
| 10 |
+
- pip=22.3.1
|
| 11 |
+
- numpy=1.23.4
|
| 12 |
+
- pip:
|
| 13 |
+
- opencv-python==4.6.0.66
|
| 14 |
+
- imutils==0.5.4
|
| 15 |
+
- timm==0.6.12
|
| 16 |
+
- einops==0.6.0
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/hubconf.py
ADDED
|
@@ -0,0 +1,435 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dependencies = ["torch"]
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
from midas.dpt_depth import DPTDepthModel
|
| 6 |
+
from midas.midas_net import MidasNet
|
| 7 |
+
from midas.midas_net_custom import MidasNet_small
|
| 8 |
+
|
| 9 |
+
def DPT_BEiT_L_512(pretrained=True, **kwargs):
|
| 10 |
+
""" # This docstring shows up in hub.help()
|
| 11 |
+
MiDaS DPT_BEiT_L_512 model for monocular depth estimation
|
| 12 |
+
pretrained (bool): load pretrained weights into model
|
| 13 |
+
"""
|
| 14 |
+
|
| 15 |
+
model = DPTDepthModel(
|
| 16 |
+
path=None,
|
| 17 |
+
backbone="beitl16_512",
|
| 18 |
+
non_negative=True,
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
if pretrained:
|
| 22 |
+
checkpoint = (
|
| 23 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_512.pt"
|
| 24 |
+
)
|
| 25 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 26 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 27 |
+
)
|
| 28 |
+
model.load_state_dict(state_dict)
|
| 29 |
+
|
| 30 |
+
return model
|
| 31 |
+
|
| 32 |
+
def DPT_BEiT_L_384(pretrained=True, **kwargs):
|
| 33 |
+
""" # This docstring shows up in hub.help()
|
| 34 |
+
MiDaS DPT_BEiT_L_384 model for monocular depth estimation
|
| 35 |
+
pretrained (bool): load pretrained weights into model
|
| 36 |
+
"""
|
| 37 |
+
|
| 38 |
+
model = DPTDepthModel(
|
| 39 |
+
path=None,
|
| 40 |
+
backbone="beitl16_384",
|
| 41 |
+
non_negative=True,
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
if pretrained:
|
| 45 |
+
checkpoint = (
|
| 46 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_large_384.pt"
|
| 47 |
+
)
|
| 48 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 49 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 50 |
+
)
|
| 51 |
+
model.load_state_dict(state_dict)
|
| 52 |
+
|
| 53 |
+
return model
|
| 54 |
+
|
| 55 |
+
def DPT_BEiT_B_384(pretrained=True, **kwargs):
|
| 56 |
+
""" # This docstring shows up in hub.help()
|
| 57 |
+
MiDaS DPT_BEiT_B_384 model for monocular depth estimation
|
| 58 |
+
pretrained (bool): load pretrained weights into model
|
| 59 |
+
"""
|
| 60 |
+
|
| 61 |
+
model = DPTDepthModel(
|
| 62 |
+
path=None,
|
| 63 |
+
backbone="beitb16_384",
|
| 64 |
+
non_negative=True,
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
if pretrained:
|
| 68 |
+
checkpoint = (
|
| 69 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_beit_base_384.pt"
|
| 70 |
+
)
|
| 71 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 72 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 73 |
+
)
|
| 74 |
+
model.load_state_dict(state_dict)
|
| 75 |
+
|
| 76 |
+
return model
|
| 77 |
+
|
| 78 |
+
def DPT_SwinV2_L_384(pretrained=True, **kwargs):
|
| 79 |
+
""" # This docstring shows up in hub.help()
|
| 80 |
+
MiDaS DPT_SwinV2_L_384 model for monocular depth estimation
|
| 81 |
+
pretrained (bool): load pretrained weights into model
|
| 82 |
+
"""
|
| 83 |
+
|
| 84 |
+
model = DPTDepthModel(
|
| 85 |
+
path=None,
|
| 86 |
+
backbone="swin2l24_384",
|
| 87 |
+
non_negative=True,
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
if pretrained:
|
| 91 |
+
checkpoint = (
|
| 92 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_large_384.pt"
|
| 93 |
+
)
|
| 94 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 95 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 96 |
+
)
|
| 97 |
+
model.load_state_dict(state_dict)
|
| 98 |
+
|
| 99 |
+
return model
|
| 100 |
+
|
| 101 |
+
def DPT_SwinV2_B_384(pretrained=True, **kwargs):
|
| 102 |
+
""" # This docstring shows up in hub.help()
|
| 103 |
+
MiDaS DPT_SwinV2_B_384 model for monocular depth estimation
|
| 104 |
+
pretrained (bool): load pretrained weights into model
|
| 105 |
+
"""
|
| 106 |
+
|
| 107 |
+
model = DPTDepthModel(
|
| 108 |
+
path=None,
|
| 109 |
+
backbone="swin2b24_384",
|
| 110 |
+
non_negative=True,
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
if pretrained:
|
| 114 |
+
checkpoint = (
|
| 115 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_base_384.pt"
|
| 116 |
+
)
|
| 117 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 118 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 119 |
+
)
|
| 120 |
+
model.load_state_dict(state_dict)
|
| 121 |
+
|
| 122 |
+
return model
|
| 123 |
+
|
| 124 |
+
def DPT_SwinV2_T_256(pretrained=True, **kwargs):
|
| 125 |
+
""" # This docstring shows up in hub.help()
|
| 126 |
+
MiDaS DPT_SwinV2_T_256 model for monocular depth estimation
|
| 127 |
+
pretrained (bool): load pretrained weights into model
|
| 128 |
+
"""
|
| 129 |
+
|
| 130 |
+
model = DPTDepthModel(
|
| 131 |
+
path=None,
|
| 132 |
+
backbone="swin2t16_256",
|
| 133 |
+
non_negative=True,
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
if pretrained:
|
| 137 |
+
checkpoint = (
|
| 138 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin2_tiny_256.pt"
|
| 139 |
+
)
|
| 140 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 141 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 142 |
+
)
|
| 143 |
+
model.load_state_dict(state_dict)
|
| 144 |
+
|
| 145 |
+
return model
|
| 146 |
+
|
| 147 |
+
def DPT_Swin_L_384(pretrained=True, **kwargs):
|
| 148 |
+
""" # This docstring shows up in hub.help()
|
| 149 |
+
MiDaS DPT_Swin_L_384 model for monocular depth estimation
|
| 150 |
+
pretrained (bool): load pretrained weights into model
|
| 151 |
+
"""
|
| 152 |
+
|
| 153 |
+
model = DPTDepthModel(
|
| 154 |
+
path=None,
|
| 155 |
+
backbone="swinl12_384",
|
| 156 |
+
non_negative=True,
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
if pretrained:
|
| 160 |
+
checkpoint = (
|
| 161 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_swin_large_384.pt"
|
| 162 |
+
)
|
| 163 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 164 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 165 |
+
)
|
| 166 |
+
model.load_state_dict(state_dict)
|
| 167 |
+
|
| 168 |
+
return model
|
| 169 |
+
|
| 170 |
+
def DPT_Next_ViT_L_384(pretrained=True, **kwargs):
|
| 171 |
+
""" # This docstring shows up in hub.help()
|
| 172 |
+
MiDaS DPT_Next_ViT_L_384 model for monocular depth estimation
|
| 173 |
+
pretrained (bool): load pretrained weights into model
|
| 174 |
+
"""
|
| 175 |
+
|
| 176 |
+
model = DPTDepthModel(
|
| 177 |
+
path=None,
|
| 178 |
+
backbone="next_vit_large_6m",
|
| 179 |
+
non_negative=True,
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
if pretrained:
|
| 183 |
+
checkpoint = (
|
| 184 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_next_vit_large_384.pt"
|
| 185 |
+
)
|
| 186 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 187 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 188 |
+
)
|
| 189 |
+
model.load_state_dict(state_dict)
|
| 190 |
+
|
| 191 |
+
return model
|
| 192 |
+
|
| 193 |
+
def DPT_LeViT_224(pretrained=True, **kwargs):
|
| 194 |
+
""" # This docstring shows up in hub.help()
|
| 195 |
+
MiDaS DPT_LeViT_224 model for monocular depth estimation
|
| 196 |
+
pretrained (bool): load pretrained weights into model
|
| 197 |
+
"""
|
| 198 |
+
|
| 199 |
+
model = DPTDepthModel(
|
| 200 |
+
path=None,
|
| 201 |
+
backbone="levit_384",
|
| 202 |
+
non_negative=True,
|
| 203 |
+
head_features_1=64,
|
| 204 |
+
head_features_2=8,
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
if pretrained:
|
| 208 |
+
checkpoint = (
|
| 209 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3_1/dpt_levit_224.pt"
|
| 210 |
+
)
|
| 211 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 212 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 213 |
+
)
|
| 214 |
+
model.load_state_dict(state_dict)
|
| 215 |
+
|
| 216 |
+
return model
|
| 217 |
+
|
| 218 |
+
def DPT_Large(pretrained=True, **kwargs):
|
| 219 |
+
""" # This docstring shows up in hub.help()
|
| 220 |
+
MiDaS DPT-Large model for monocular depth estimation
|
| 221 |
+
pretrained (bool): load pretrained weights into model
|
| 222 |
+
"""
|
| 223 |
+
|
| 224 |
+
model = DPTDepthModel(
|
| 225 |
+
path=None,
|
| 226 |
+
backbone="vitl16_384",
|
| 227 |
+
non_negative=True,
|
| 228 |
+
)
|
| 229 |
+
|
| 230 |
+
if pretrained:
|
| 231 |
+
checkpoint = (
|
| 232 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3/dpt_large_384.pt"
|
| 233 |
+
)
|
| 234 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 235 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 236 |
+
)
|
| 237 |
+
model.load_state_dict(state_dict)
|
| 238 |
+
|
| 239 |
+
return model
|
| 240 |
+
|
| 241 |
+
def DPT_Hybrid(pretrained=True, **kwargs):
|
| 242 |
+
""" # This docstring shows up in hub.help()
|
| 243 |
+
MiDaS DPT-Hybrid model for monocular depth estimation
|
| 244 |
+
pretrained (bool): load pretrained weights into model
|
| 245 |
+
"""
|
| 246 |
+
|
| 247 |
+
model = DPTDepthModel(
|
| 248 |
+
path=None,
|
| 249 |
+
backbone="vitb_rn50_384",
|
| 250 |
+
non_negative=True,
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
if pretrained:
|
| 254 |
+
checkpoint = (
|
| 255 |
+
"https://github.com/isl-org/MiDaS/releases/download/v3/dpt_hybrid_384.pt"
|
| 256 |
+
)
|
| 257 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 258 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 259 |
+
)
|
| 260 |
+
model.load_state_dict(state_dict)
|
| 261 |
+
|
| 262 |
+
return model
|
| 263 |
+
|
| 264 |
+
def MiDaS(pretrained=True, **kwargs):
|
| 265 |
+
""" # This docstring shows up in hub.help()
|
| 266 |
+
MiDaS v2.1 model for monocular depth estimation
|
| 267 |
+
pretrained (bool): load pretrained weights into model
|
| 268 |
+
"""
|
| 269 |
+
|
| 270 |
+
model = MidasNet()
|
| 271 |
+
|
| 272 |
+
if pretrained:
|
| 273 |
+
checkpoint = (
|
| 274 |
+
"https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_384.pt"
|
| 275 |
+
)
|
| 276 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 277 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 278 |
+
)
|
| 279 |
+
model.load_state_dict(state_dict)
|
| 280 |
+
|
| 281 |
+
return model
|
| 282 |
+
|
| 283 |
+
def MiDaS_small(pretrained=True, **kwargs):
|
| 284 |
+
""" # This docstring shows up in hub.help()
|
| 285 |
+
MiDaS v2.1 small model for monocular depth estimation on resource-constrained devices
|
| 286 |
+
pretrained (bool): load pretrained weights into model
|
| 287 |
+
"""
|
| 288 |
+
|
| 289 |
+
model = MidasNet_small(None, features=64, backbone="efficientnet_lite3", exportable=True, non_negative=True, blocks={'expand': True})
|
| 290 |
+
|
| 291 |
+
if pretrained:
|
| 292 |
+
checkpoint = (
|
| 293 |
+
"https://github.com/isl-org/MiDaS/releases/download/v2_1/midas_v21_small_256.pt"
|
| 294 |
+
)
|
| 295 |
+
state_dict = torch.hub.load_state_dict_from_url(
|
| 296 |
+
checkpoint, map_location=torch.device('cpu'), progress=True, check_hash=True
|
| 297 |
+
)
|
| 298 |
+
model.load_state_dict(state_dict)
|
| 299 |
+
|
| 300 |
+
return model
|
| 301 |
+
|
| 302 |
+
|
| 303 |
+
def transforms():
|
| 304 |
+
import cv2
|
| 305 |
+
from torchvision.transforms import Compose
|
| 306 |
+
from midas.transforms import Resize, NormalizeImage, PrepareForNet
|
| 307 |
+
from midas import transforms
|
| 308 |
+
|
| 309 |
+
transforms.default_transform = Compose(
|
| 310 |
+
[
|
| 311 |
+
lambda img: {"image": img / 255.0},
|
| 312 |
+
Resize(
|
| 313 |
+
384,
|
| 314 |
+
384,
|
| 315 |
+
resize_target=None,
|
| 316 |
+
keep_aspect_ratio=True,
|
| 317 |
+
ensure_multiple_of=32,
|
| 318 |
+
resize_method="upper_bound",
|
| 319 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 320 |
+
),
|
| 321 |
+
NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
|
| 322 |
+
PrepareForNet(),
|
| 323 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 324 |
+
]
|
| 325 |
+
)
|
| 326 |
+
|
| 327 |
+
transforms.small_transform = Compose(
|
| 328 |
+
[
|
| 329 |
+
lambda img: {"image": img / 255.0},
|
| 330 |
+
Resize(
|
| 331 |
+
256,
|
| 332 |
+
256,
|
| 333 |
+
resize_target=None,
|
| 334 |
+
keep_aspect_ratio=True,
|
| 335 |
+
ensure_multiple_of=32,
|
| 336 |
+
resize_method="upper_bound",
|
| 337 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 338 |
+
),
|
| 339 |
+
NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
|
| 340 |
+
PrepareForNet(),
|
| 341 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 342 |
+
]
|
| 343 |
+
)
|
| 344 |
+
|
| 345 |
+
transforms.dpt_transform = Compose(
|
| 346 |
+
[
|
| 347 |
+
lambda img: {"image": img / 255.0},
|
| 348 |
+
Resize(
|
| 349 |
+
384,
|
| 350 |
+
384,
|
| 351 |
+
resize_target=None,
|
| 352 |
+
keep_aspect_ratio=True,
|
| 353 |
+
ensure_multiple_of=32,
|
| 354 |
+
resize_method="minimal",
|
| 355 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 356 |
+
),
|
| 357 |
+
NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
|
| 358 |
+
PrepareForNet(),
|
| 359 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 360 |
+
]
|
| 361 |
+
)
|
| 362 |
+
|
| 363 |
+
transforms.beit512_transform = Compose(
|
| 364 |
+
[
|
| 365 |
+
lambda img: {"image": img / 255.0},
|
| 366 |
+
Resize(
|
| 367 |
+
512,
|
| 368 |
+
512,
|
| 369 |
+
resize_target=None,
|
| 370 |
+
keep_aspect_ratio=True,
|
| 371 |
+
ensure_multiple_of=32,
|
| 372 |
+
resize_method="minimal",
|
| 373 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 374 |
+
),
|
| 375 |
+
NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
|
| 376 |
+
PrepareForNet(),
|
| 377 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 378 |
+
]
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
transforms.swin384_transform = Compose(
|
| 382 |
+
[
|
| 383 |
+
lambda img: {"image": img / 255.0},
|
| 384 |
+
Resize(
|
| 385 |
+
384,
|
| 386 |
+
384,
|
| 387 |
+
resize_target=None,
|
| 388 |
+
keep_aspect_ratio=False,
|
| 389 |
+
ensure_multiple_of=32,
|
| 390 |
+
resize_method="minimal",
|
| 391 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 392 |
+
),
|
| 393 |
+
NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
|
| 394 |
+
PrepareForNet(),
|
| 395 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 396 |
+
]
|
| 397 |
+
)
|
| 398 |
+
|
| 399 |
+
transforms.swin256_transform = Compose(
|
| 400 |
+
[
|
| 401 |
+
lambda img: {"image": img / 255.0},
|
| 402 |
+
Resize(
|
| 403 |
+
256,
|
| 404 |
+
256,
|
| 405 |
+
resize_target=None,
|
| 406 |
+
keep_aspect_ratio=False,
|
| 407 |
+
ensure_multiple_of=32,
|
| 408 |
+
resize_method="minimal",
|
| 409 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 410 |
+
),
|
| 411 |
+
NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
|
| 412 |
+
PrepareForNet(),
|
| 413 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 414 |
+
]
|
| 415 |
+
)
|
| 416 |
+
|
| 417 |
+
transforms.levit_transform = Compose(
|
| 418 |
+
[
|
| 419 |
+
lambda img: {"image": img / 255.0},
|
| 420 |
+
Resize(
|
| 421 |
+
224,
|
| 422 |
+
224,
|
| 423 |
+
resize_target=None,
|
| 424 |
+
keep_aspect_ratio=False,
|
| 425 |
+
ensure_multiple_of=32,
|
| 426 |
+
resize_method="minimal",
|
| 427 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 428 |
+
),
|
| 429 |
+
NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
|
| 430 |
+
PrepareForNet(),
|
| 431 |
+
lambda sample: torch.from_numpy(sample["image"]).unsqueeze(0),
|
| 432 |
+
]
|
| 433 |
+
)
|
| 434 |
+
|
| 435 |
+
return transforms
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/input/.placeholder
ADDED
|
File without changes
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/beit.py
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import timm
|
| 2 |
+
import torch
|
| 3 |
+
import types
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
from .utils import forward_adapted_unflatten, make_backbone_default
|
| 9 |
+
from timm.models.beit import gen_relative_position_index
|
| 10 |
+
from torch.utils.checkpoint import checkpoint
|
| 11 |
+
from typing import Optional
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def forward_beit(pretrained, x):
|
| 15 |
+
return forward_adapted_unflatten(pretrained, x, "forward_features")
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def patch_embed_forward(self, x):
|
| 19 |
+
"""
|
| 20 |
+
Modification of timm.models.layers.patch_embed.py: PatchEmbed.forward to support arbitrary window sizes.
|
| 21 |
+
"""
|
| 22 |
+
x = self.proj(x)
|
| 23 |
+
if self.flatten:
|
| 24 |
+
x = x.flatten(2).transpose(1, 2)
|
| 25 |
+
x = self.norm(x)
|
| 26 |
+
return x
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def _get_rel_pos_bias(self, window_size):
|
| 30 |
+
"""
|
| 31 |
+
Modification of timm.models.beit.py: Attention._get_rel_pos_bias to support arbitrary window sizes.
|
| 32 |
+
"""
|
| 33 |
+
old_height = 2 * self.window_size[0] - 1
|
| 34 |
+
old_width = 2 * self.window_size[1] - 1
|
| 35 |
+
|
| 36 |
+
new_height = 2 * window_size[0] - 1
|
| 37 |
+
new_width = 2 * window_size[1] - 1
|
| 38 |
+
|
| 39 |
+
old_relative_position_bias_table = self.relative_position_bias_table
|
| 40 |
+
|
| 41 |
+
old_num_relative_distance = self.num_relative_distance
|
| 42 |
+
new_num_relative_distance = new_height * new_width + 3
|
| 43 |
+
|
| 44 |
+
old_sub_table = old_relative_position_bias_table[:old_num_relative_distance - 3]
|
| 45 |
+
|
| 46 |
+
old_sub_table = old_sub_table.reshape(1, old_width, old_height, -1).permute(0, 3, 1, 2)
|
| 47 |
+
new_sub_table = F.interpolate(old_sub_table, size=(int(new_height), int(new_width)), mode="bilinear")
|
| 48 |
+
new_sub_table = new_sub_table.permute(0, 2, 3, 1).reshape(new_num_relative_distance - 3, -1)
|
| 49 |
+
|
| 50 |
+
new_relative_position_bias_table = torch.cat(
|
| 51 |
+
[new_sub_table, old_relative_position_bias_table[old_num_relative_distance - 3:]])
|
| 52 |
+
|
| 53 |
+
key = str(window_size[1]) + "," + str(window_size[0])
|
| 54 |
+
if key not in self.relative_position_indices.keys():
|
| 55 |
+
self.relative_position_indices[key] = gen_relative_position_index(window_size)
|
| 56 |
+
|
| 57 |
+
relative_position_bias = new_relative_position_bias_table[
|
| 58 |
+
self.relative_position_indices[key].view(-1)].view(
|
| 59 |
+
window_size[0] * window_size[1] + 1,
|
| 60 |
+
window_size[0] * window_size[1] + 1, -1) # Wh*Ww,Wh*Ww,nH
|
| 61 |
+
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
|
| 62 |
+
return relative_position_bias.unsqueeze(0)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def attention_forward(self, x, resolution, shared_rel_pos_bias: Optional[torch.Tensor] = None):
|
| 66 |
+
"""
|
| 67 |
+
Modification of timm.models.beit.py: Attention.forward to support arbitrary window sizes.
|
| 68 |
+
"""
|
| 69 |
+
B, N, C = x.shape
|
| 70 |
+
|
| 71 |
+
qkv_bias = torch.cat((self.q_bias, self.k_bias, self.v_bias)) if self.q_bias is not None else None
|
| 72 |
+
qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
|
| 73 |
+
qkv = qkv.reshape(B, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
|
| 74 |
+
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
|
| 75 |
+
|
| 76 |
+
q = q * self.scale
|
| 77 |
+
attn = (q @ k.transpose(-2, -1))
|
| 78 |
+
|
| 79 |
+
if self.relative_position_bias_table is not None:
|
| 80 |
+
window_size = tuple(np.array(resolution) // 16)
|
| 81 |
+
attn = attn + self._get_rel_pos_bias(window_size)
|
| 82 |
+
if shared_rel_pos_bias is not None:
|
| 83 |
+
attn = attn + shared_rel_pos_bias
|
| 84 |
+
|
| 85 |
+
attn = attn.softmax(dim=-1)
|
| 86 |
+
attn = self.attn_drop(attn)
|
| 87 |
+
|
| 88 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
|
| 89 |
+
x = self.proj(x)
|
| 90 |
+
x = self.proj_drop(x)
|
| 91 |
+
return x
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def block_forward(self, x, resolution, shared_rel_pos_bias: Optional[torch.Tensor] = None):
|
| 95 |
+
"""
|
| 96 |
+
Modification of timm.models.beit.py: Block.forward to support arbitrary window sizes.
|
| 97 |
+
"""
|
| 98 |
+
if hasattr(self, 'drop_path1') and not hasattr(self, 'drop_path'):
|
| 99 |
+
self.drop_path = self.drop_path1
|
| 100 |
+
if self.gamma_1 is None:
|
| 101 |
+
x = x + self.drop_path(self.attn(self.norm1(x), resolution, shared_rel_pos_bias=shared_rel_pos_bias))
|
| 102 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 103 |
+
else:
|
| 104 |
+
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x), resolution,
|
| 105 |
+
shared_rel_pos_bias=shared_rel_pos_bias))
|
| 106 |
+
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))
|
| 107 |
+
return x
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def beit_forward_features(self, x):
|
| 111 |
+
"""
|
| 112 |
+
Modification of timm.models.beit.py: Beit.forward_features to support arbitrary window sizes.
|
| 113 |
+
"""
|
| 114 |
+
resolution = x.shape[2:]
|
| 115 |
+
|
| 116 |
+
x = self.patch_embed(x)
|
| 117 |
+
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1)
|
| 118 |
+
if self.pos_embed is not None:
|
| 119 |
+
x = x + self.pos_embed
|
| 120 |
+
x = self.pos_drop(x)
|
| 121 |
+
|
| 122 |
+
rel_pos_bias = self.rel_pos_bias() if self.rel_pos_bias is not None else None
|
| 123 |
+
for blk in self.blocks:
|
| 124 |
+
if self.grad_checkpointing and not torch.jit.is_scripting():
|
| 125 |
+
x = checkpoint(blk, x, shared_rel_pos_bias=rel_pos_bias)
|
| 126 |
+
else:
|
| 127 |
+
x = blk(x, resolution, shared_rel_pos_bias=rel_pos_bias)
|
| 128 |
+
x = self.norm(x)
|
| 129 |
+
return x
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def _make_beit_backbone(
|
| 133 |
+
model,
|
| 134 |
+
features=[96, 192, 384, 768],
|
| 135 |
+
size=[384, 384],
|
| 136 |
+
hooks=[0, 4, 8, 11],
|
| 137 |
+
vit_features=768,
|
| 138 |
+
use_readout="ignore",
|
| 139 |
+
start_index=1,
|
| 140 |
+
start_index_readout=1,
|
| 141 |
+
):
|
| 142 |
+
backbone = make_backbone_default(model, features, size, hooks, vit_features, use_readout, start_index,
|
| 143 |
+
start_index_readout)
|
| 144 |
+
|
| 145 |
+
backbone.model.patch_embed.forward = types.MethodType(patch_embed_forward, backbone.model.patch_embed)
|
| 146 |
+
backbone.model.forward_features = types.MethodType(beit_forward_features, backbone.model)
|
| 147 |
+
|
| 148 |
+
for block in backbone.model.blocks:
|
| 149 |
+
attn = block.attn
|
| 150 |
+
attn._get_rel_pos_bias = types.MethodType(_get_rel_pos_bias, attn)
|
| 151 |
+
attn.forward = types.MethodType(attention_forward, attn)
|
| 152 |
+
attn.relative_position_indices = {}
|
| 153 |
+
|
| 154 |
+
block.forward = types.MethodType(block_forward, block)
|
| 155 |
+
|
| 156 |
+
return backbone
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def _make_pretrained_beitl16_512(pretrained, use_readout="ignore", hooks=None):
|
| 160 |
+
model = timm.create_model("beit_large_patch16_512", pretrained=pretrained)
|
| 161 |
+
|
| 162 |
+
hooks = [5, 11, 17, 23] if hooks is None else hooks
|
| 163 |
+
|
| 164 |
+
features = [256, 512, 1024, 1024]
|
| 165 |
+
|
| 166 |
+
return _make_beit_backbone(
|
| 167 |
+
model,
|
| 168 |
+
features=features,
|
| 169 |
+
size=[512, 512],
|
| 170 |
+
hooks=hooks,
|
| 171 |
+
vit_features=1024,
|
| 172 |
+
use_readout=use_readout,
|
| 173 |
+
)
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def _make_pretrained_beitl16_384(pretrained, use_readout="ignore", hooks=None):
|
| 177 |
+
model = timm.create_model("beit_large_patch16_384", pretrained=pretrained)
|
| 178 |
+
|
| 179 |
+
hooks = [5, 11, 17, 23] if hooks is None else hooks
|
| 180 |
+
return _make_beit_backbone(
|
| 181 |
+
model,
|
| 182 |
+
features=[256, 512, 1024, 1024],
|
| 183 |
+
hooks=hooks,
|
| 184 |
+
vit_features=1024,
|
| 185 |
+
use_readout=use_readout,
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
def _make_pretrained_beitb16_384(pretrained, use_readout="ignore", hooks=None):
|
| 190 |
+
model = timm.create_model("beit_base_patch16_384", pretrained=pretrained)
|
| 191 |
+
|
| 192 |
+
hooks = [2, 5, 8, 11] if hooks is None else hooks
|
| 193 |
+
return _make_beit_backbone(
|
| 194 |
+
model,
|
| 195 |
+
features=[96, 192, 384, 768],
|
| 196 |
+
hooks=hooks,
|
| 197 |
+
use_readout=use_readout,
|
| 198 |
+
)
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/levit.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import timm
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
from .utils import activations, get_activation, Transpose
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def forward_levit(pretrained, x):
|
| 10 |
+
pretrained.model.forward_features(x)
|
| 11 |
+
|
| 12 |
+
layer_1 = pretrained.activations["1"]
|
| 13 |
+
layer_2 = pretrained.activations["2"]
|
| 14 |
+
layer_3 = pretrained.activations["3"]
|
| 15 |
+
|
| 16 |
+
layer_1 = pretrained.act_postprocess1(layer_1)
|
| 17 |
+
layer_2 = pretrained.act_postprocess2(layer_2)
|
| 18 |
+
layer_3 = pretrained.act_postprocess3(layer_3)
|
| 19 |
+
|
| 20 |
+
return layer_1, layer_2, layer_3
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def _make_levit_backbone(
|
| 24 |
+
model,
|
| 25 |
+
hooks=[3, 11, 21],
|
| 26 |
+
patch_grid=[14, 14]
|
| 27 |
+
):
|
| 28 |
+
pretrained = nn.Module()
|
| 29 |
+
|
| 30 |
+
pretrained.model = model
|
| 31 |
+
pretrained.model.blocks[hooks[0]].register_forward_hook(get_activation("1"))
|
| 32 |
+
pretrained.model.blocks[hooks[1]].register_forward_hook(get_activation("2"))
|
| 33 |
+
pretrained.model.blocks[hooks[2]].register_forward_hook(get_activation("3"))
|
| 34 |
+
|
| 35 |
+
pretrained.activations = activations
|
| 36 |
+
|
| 37 |
+
patch_grid_size = np.array(patch_grid, dtype=int)
|
| 38 |
+
|
| 39 |
+
pretrained.act_postprocess1 = nn.Sequential(
|
| 40 |
+
Transpose(1, 2),
|
| 41 |
+
nn.Unflatten(2, torch.Size(patch_grid_size.tolist()))
|
| 42 |
+
)
|
| 43 |
+
pretrained.act_postprocess2 = nn.Sequential(
|
| 44 |
+
Transpose(1, 2),
|
| 45 |
+
nn.Unflatten(2, torch.Size((np.ceil(patch_grid_size / 2).astype(int)).tolist()))
|
| 46 |
+
)
|
| 47 |
+
pretrained.act_postprocess3 = nn.Sequential(
|
| 48 |
+
Transpose(1, 2),
|
| 49 |
+
nn.Unflatten(2, torch.Size((np.ceil(patch_grid_size / 4).astype(int)).tolist()))
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
return pretrained
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class ConvTransposeNorm(nn.Sequential):
|
| 56 |
+
"""
|
| 57 |
+
Modification of
|
| 58 |
+
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/levit.py: ConvNorm
|
| 59 |
+
such that ConvTranspose2d is used instead of Conv2d.
|
| 60 |
+
"""
|
| 61 |
+
|
| 62 |
+
def __init__(
|
| 63 |
+
self, in_chs, out_chs, kernel_size=1, stride=1, pad=0, dilation=1,
|
| 64 |
+
groups=1, bn_weight_init=1):
|
| 65 |
+
super().__init__()
|
| 66 |
+
self.add_module('c',
|
| 67 |
+
nn.ConvTranspose2d(in_chs, out_chs, kernel_size, stride, pad, dilation, groups, bias=False))
|
| 68 |
+
self.add_module('bn', nn.BatchNorm2d(out_chs))
|
| 69 |
+
|
| 70 |
+
nn.init.constant_(self.bn.weight, bn_weight_init)
|
| 71 |
+
|
| 72 |
+
@torch.no_grad()
|
| 73 |
+
def fuse(self):
|
| 74 |
+
c, bn = self._modules.values()
|
| 75 |
+
w = bn.weight / (bn.running_var + bn.eps) ** 0.5
|
| 76 |
+
w = c.weight * w[:, None, None, None]
|
| 77 |
+
b = bn.bias - bn.running_mean * bn.weight / (bn.running_var + bn.eps) ** 0.5
|
| 78 |
+
m = nn.ConvTranspose2d(
|
| 79 |
+
w.size(1), w.size(0), w.shape[2:], stride=self.c.stride,
|
| 80 |
+
padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups)
|
| 81 |
+
m.weight.data.copy_(w)
|
| 82 |
+
m.bias.data.copy_(b)
|
| 83 |
+
return m
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def stem_b4_transpose(in_chs, out_chs, activation):
|
| 87 |
+
"""
|
| 88 |
+
Modification of
|
| 89 |
+
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/levit.py: stem_b16
|
| 90 |
+
such that ConvTranspose2d is used instead of Conv2d and stem is also reduced to the half.
|
| 91 |
+
"""
|
| 92 |
+
return nn.Sequential(
|
| 93 |
+
ConvTransposeNorm(in_chs, out_chs, 3, 2, 1),
|
| 94 |
+
activation(),
|
| 95 |
+
ConvTransposeNorm(out_chs, out_chs // 2, 3, 2, 1),
|
| 96 |
+
activation())
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def _make_pretrained_levit_384(pretrained, hooks=None):
|
| 100 |
+
model = timm.create_model("levit_384", pretrained=pretrained)
|
| 101 |
+
|
| 102 |
+
hooks = [3, 11, 21] if hooks == None else hooks
|
| 103 |
+
return _make_levit_backbone(
|
| 104 |
+
model,
|
| 105 |
+
hooks=hooks
|
| 106 |
+
)
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/next_vit.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import timm
|
| 2 |
+
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
from .utils import activations, forward_default, get_activation
|
| 7 |
+
|
| 8 |
+
from ..external.next_vit.classification.nextvit import *
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def forward_next_vit(pretrained, x):
|
| 12 |
+
return forward_default(pretrained, x, "forward")
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def _make_next_vit_backbone(
|
| 16 |
+
model,
|
| 17 |
+
hooks=[2, 6, 36, 39],
|
| 18 |
+
):
|
| 19 |
+
pretrained = nn.Module()
|
| 20 |
+
|
| 21 |
+
pretrained.model = model
|
| 22 |
+
pretrained.model.features[hooks[0]].register_forward_hook(get_activation("1"))
|
| 23 |
+
pretrained.model.features[hooks[1]].register_forward_hook(get_activation("2"))
|
| 24 |
+
pretrained.model.features[hooks[2]].register_forward_hook(get_activation("3"))
|
| 25 |
+
pretrained.model.features[hooks[3]].register_forward_hook(get_activation("4"))
|
| 26 |
+
|
| 27 |
+
pretrained.activations = activations
|
| 28 |
+
|
| 29 |
+
return pretrained
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def _make_pretrained_next_vit_large_6m(hooks=None):
|
| 33 |
+
model = timm.create_model("nextvit_large")
|
| 34 |
+
|
| 35 |
+
hooks = [2, 6, 36, 39] if hooks == None else hooks
|
| 36 |
+
return _make_next_vit_backbone(
|
| 37 |
+
model,
|
| 38 |
+
hooks=hooks,
|
| 39 |
+
)
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/swin.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import timm
|
| 2 |
+
|
| 3 |
+
from .swin_common import _make_swin_backbone
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def _make_pretrained_swinl12_384(pretrained, hooks=None):
|
| 7 |
+
model = timm.create_model("swin_large_patch4_window12_384", pretrained=pretrained)
|
| 8 |
+
|
| 9 |
+
hooks = [1, 1, 17, 1] if hooks == None else hooks
|
| 10 |
+
return _make_swin_backbone(
|
| 11 |
+
model,
|
| 12 |
+
hooks=hooks
|
| 13 |
+
)
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/swin2.py
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import timm
|
| 2 |
+
|
| 3 |
+
from .swin_common import _make_swin_backbone
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def _make_pretrained_swin2l24_384(pretrained, hooks=None):
|
| 7 |
+
model = timm.create_model("swinv2_large_window12to24_192to384_22kft1k", pretrained=pretrained)
|
| 8 |
+
|
| 9 |
+
hooks = [1, 1, 17, 1] if hooks == None else hooks
|
| 10 |
+
return _make_swin_backbone(
|
| 11 |
+
model,
|
| 12 |
+
hooks=hooks
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def _make_pretrained_swin2b24_384(pretrained, hooks=None):
|
| 17 |
+
model = timm.create_model("swinv2_base_window12to24_192to384_22kft1k", pretrained=pretrained)
|
| 18 |
+
|
| 19 |
+
hooks = [1, 1, 17, 1] if hooks == None else hooks
|
| 20 |
+
return _make_swin_backbone(
|
| 21 |
+
model,
|
| 22 |
+
hooks=hooks
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def _make_pretrained_swin2t16_256(pretrained, hooks=None):
|
| 27 |
+
model = timm.create_model("swinv2_tiny_window16_256", pretrained=pretrained)
|
| 28 |
+
|
| 29 |
+
hooks = [1, 1, 5, 1] if hooks == None else hooks
|
| 30 |
+
return _make_swin_backbone(
|
| 31 |
+
model,
|
| 32 |
+
hooks=hooks,
|
| 33 |
+
patch_grid=[64, 64]
|
| 34 |
+
)
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/swin_common.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
from .utils import activations, forward_default, get_activation, Transpose
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def forward_swin(pretrained, x):
|
| 10 |
+
return forward_default(pretrained, x)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def _make_swin_backbone(
|
| 14 |
+
model,
|
| 15 |
+
hooks=[1, 1, 17, 1],
|
| 16 |
+
patch_grid=[96, 96]
|
| 17 |
+
):
|
| 18 |
+
pretrained = nn.Module()
|
| 19 |
+
|
| 20 |
+
pretrained.model = model
|
| 21 |
+
pretrained.model.layers[0].blocks[hooks[0]].register_forward_hook(get_activation("1"))
|
| 22 |
+
pretrained.model.layers[1].blocks[hooks[1]].register_forward_hook(get_activation("2"))
|
| 23 |
+
pretrained.model.layers[2].blocks[hooks[2]].register_forward_hook(get_activation("3"))
|
| 24 |
+
pretrained.model.layers[3].blocks[hooks[3]].register_forward_hook(get_activation("4"))
|
| 25 |
+
|
| 26 |
+
pretrained.activations = activations
|
| 27 |
+
|
| 28 |
+
if hasattr(model, "patch_grid"):
|
| 29 |
+
used_patch_grid = model.patch_grid
|
| 30 |
+
else:
|
| 31 |
+
used_patch_grid = patch_grid
|
| 32 |
+
|
| 33 |
+
patch_grid_size = np.array(used_patch_grid, dtype=int)
|
| 34 |
+
|
| 35 |
+
pretrained.act_postprocess1 = nn.Sequential(
|
| 36 |
+
Transpose(1, 2),
|
| 37 |
+
nn.Unflatten(2, torch.Size(patch_grid_size.tolist()))
|
| 38 |
+
)
|
| 39 |
+
pretrained.act_postprocess2 = nn.Sequential(
|
| 40 |
+
Transpose(1, 2),
|
| 41 |
+
nn.Unflatten(2, torch.Size((patch_grid_size // 2).tolist()))
|
| 42 |
+
)
|
| 43 |
+
pretrained.act_postprocess3 = nn.Sequential(
|
| 44 |
+
Transpose(1, 2),
|
| 45 |
+
nn.Unflatten(2, torch.Size((patch_grid_size // 4).tolist()))
|
| 46 |
+
)
|
| 47 |
+
pretrained.act_postprocess4 = nn.Sequential(
|
| 48 |
+
Transpose(1, 2),
|
| 49 |
+
nn.Unflatten(2, torch.Size((patch_grid_size // 8).tolist()))
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
return pretrained
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/utils.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class Slice(nn.Module):
|
| 7 |
+
def __init__(self, start_index=1):
|
| 8 |
+
super(Slice, self).__init__()
|
| 9 |
+
self.start_index = start_index
|
| 10 |
+
|
| 11 |
+
def forward(self, x):
|
| 12 |
+
return x[:, self.start_index:]
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class AddReadout(nn.Module):
|
| 16 |
+
def __init__(self, start_index=1):
|
| 17 |
+
super(AddReadout, self).__init__()
|
| 18 |
+
self.start_index = start_index
|
| 19 |
+
|
| 20 |
+
def forward(self, x):
|
| 21 |
+
if self.start_index == 2:
|
| 22 |
+
readout = (x[:, 0] + x[:, 1]) / 2
|
| 23 |
+
else:
|
| 24 |
+
readout = x[:, 0]
|
| 25 |
+
return x[:, self.start_index:] + readout.unsqueeze(1)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class ProjectReadout(nn.Module):
|
| 29 |
+
def __init__(self, in_features, start_index=1):
|
| 30 |
+
super(ProjectReadout, self).__init__()
|
| 31 |
+
self.start_index = start_index
|
| 32 |
+
|
| 33 |
+
self.project = nn.Sequential(nn.Linear(2 * in_features, in_features), nn.GELU())
|
| 34 |
+
|
| 35 |
+
def forward(self, x):
|
| 36 |
+
readout = x[:, 0].unsqueeze(1).expand_as(x[:, self.start_index:])
|
| 37 |
+
features = torch.cat((x[:, self.start_index:], readout), -1)
|
| 38 |
+
|
| 39 |
+
return self.project(features)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class Transpose(nn.Module):
|
| 43 |
+
def __init__(self, dim0, dim1):
|
| 44 |
+
super(Transpose, self).__init__()
|
| 45 |
+
self.dim0 = dim0
|
| 46 |
+
self.dim1 = dim1
|
| 47 |
+
|
| 48 |
+
def forward(self, x):
|
| 49 |
+
x = x.transpose(self.dim0, self.dim1)
|
| 50 |
+
return x
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
activations = {}
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def get_activation(name):
|
| 57 |
+
def hook(model, input, output):
|
| 58 |
+
activations[name] = output
|
| 59 |
+
|
| 60 |
+
return hook
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def forward_default(pretrained, x, function_name="forward_features"):
|
| 64 |
+
exec(f"pretrained.model.{function_name}(x)")
|
| 65 |
+
|
| 66 |
+
layer_1 = pretrained.activations["1"]
|
| 67 |
+
layer_2 = pretrained.activations["2"]
|
| 68 |
+
layer_3 = pretrained.activations["3"]
|
| 69 |
+
layer_4 = pretrained.activations["4"]
|
| 70 |
+
|
| 71 |
+
if hasattr(pretrained, "act_postprocess1"):
|
| 72 |
+
layer_1 = pretrained.act_postprocess1(layer_1)
|
| 73 |
+
if hasattr(pretrained, "act_postprocess2"):
|
| 74 |
+
layer_2 = pretrained.act_postprocess2(layer_2)
|
| 75 |
+
if hasattr(pretrained, "act_postprocess3"):
|
| 76 |
+
layer_3 = pretrained.act_postprocess3(layer_3)
|
| 77 |
+
if hasattr(pretrained, "act_postprocess4"):
|
| 78 |
+
layer_4 = pretrained.act_postprocess4(layer_4)
|
| 79 |
+
|
| 80 |
+
return layer_1, layer_2, layer_3, layer_4
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def forward_adapted_unflatten(pretrained, x, function_name="forward_features"):
|
| 84 |
+
b, c, h, w = x.shape
|
| 85 |
+
|
| 86 |
+
exec(f"glob = pretrained.model.{function_name}(x)")
|
| 87 |
+
|
| 88 |
+
layer_1 = pretrained.activations["1"]
|
| 89 |
+
layer_2 = pretrained.activations["2"]
|
| 90 |
+
layer_3 = pretrained.activations["3"]
|
| 91 |
+
layer_4 = pretrained.activations["4"]
|
| 92 |
+
|
| 93 |
+
layer_1 = pretrained.act_postprocess1[0:2](layer_1)
|
| 94 |
+
layer_2 = pretrained.act_postprocess2[0:2](layer_2)
|
| 95 |
+
layer_3 = pretrained.act_postprocess3[0:2](layer_3)
|
| 96 |
+
layer_4 = pretrained.act_postprocess4[0:2](layer_4)
|
| 97 |
+
|
| 98 |
+
unflatten = nn.Sequential(
|
| 99 |
+
nn.Unflatten(
|
| 100 |
+
2,
|
| 101 |
+
torch.Size(
|
| 102 |
+
[
|
| 103 |
+
h // pretrained.model.patch_size[1],
|
| 104 |
+
w // pretrained.model.patch_size[0],
|
| 105 |
+
]
|
| 106 |
+
),
|
| 107 |
+
)
|
| 108 |
+
)
|
| 109 |
+
|
| 110 |
+
if layer_1.ndim == 3:
|
| 111 |
+
layer_1 = unflatten(layer_1)
|
| 112 |
+
if layer_2.ndim == 3:
|
| 113 |
+
layer_2 = unflatten(layer_2)
|
| 114 |
+
if layer_3.ndim == 3:
|
| 115 |
+
layer_3 = unflatten(layer_3)
|
| 116 |
+
if layer_4.ndim == 3:
|
| 117 |
+
layer_4 = unflatten(layer_4)
|
| 118 |
+
|
| 119 |
+
layer_1 = pretrained.act_postprocess1[3: len(pretrained.act_postprocess1)](layer_1)
|
| 120 |
+
layer_2 = pretrained.act_postprocess2[3: len(pretrained.act_postprocess2)](layer_2)
|
| 121 |
+
layer_3 = pretrained.act_postprocess3[3: len(pretrained.act_postprocess3)](layer_3)
|
| 122 |
+
layer_4 = pretrained.act_postprocess4[3: len(pretrained.act_postprocess4)](layer_4)
|
| 123 |
+
|
| 124 |
+
return layer_1, layer_2, layer_3, layer_4
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def get_readout_oper(vit_features, features, use_readout, start_index=1):
|
| 128 |
+
if use_readout == "ignore":
|
| 129 |
+
readout_oper = [Slice(start_index)] * len(features)
|
| 130 |
+
elif use_readout == "add":
|
| 131 |
+
readout_oper = [AddReadout(start_index)] * len(features)
|
| 132 |
+
elif use_readout == "project":
|
| 133 |
+
readout_oper = [
|
| 134 |
+
ProjectReadout(vit_features, start_index) for out_feat in features
|
| 135 |
+
]
|
| 136 |
+
else:
|
| 137 |
+
assert (
|
| 138 |
+
False
|
| 139 |
+
), "wrong operation for readout token, use_readout can be 'ignore', 'add', or 'project'"
|
| 140 |
+
|
| 141 |
+
return readout_oper
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
def make_backbone_default(
|
| 145 |
+
model,
|
| 146 |
+
features=[96, 192, 384, 768],
|
| 147 |
+
size=[384, 384],
|
| 148 |
+
hooks=[2, 5, 8, 11],
|
| 149 |
+
vit_features=768,
|
| 150 |
+
use_readout="ignore",
|
| 151 |
+
start_index=1,
|
| 152 |
+
start_index_readout=1,
|
| 153 |
+
):
|
| 154 |
+
pretrained = nn.Module()
|
| 155 |
+
|
| 156 |
+
pretrained.model = model
|
| 157 |
+
pretrained.model.blocks[hooks[0]].register_forward_hook(get_activation("1"))
|
| 158 |
+
pretrained.model.blocks[hooks[1]].register_forward_hook(get_activation("2"))
|
| 159 |
+
pretrained.model.blocks[hooks[2]].register_forward_hook(get_activation("3"))
|
| 160 |
+
pretrained.model.blocks[hooks[3]].register_forward_hook(get_activation("4"))
|
| 161 |
+
|
| 162 |
+
pretrained.activations = activations
|
| 163 |
+
|
| 164 |
+
readout_oper = get_readout_oper(vit_features, features, use_readout, start_index_readout)
|
| 165 |
+
|
| 166 |
+
# 32, 48, 136, 384
|
| 167 |
+
pretrained.act_postprocess1 = nn.Sequential(
|
| 168 |
+
readout_oper[0],
|
| 169 |
+
Transpose(1, 2),
|
| 170 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 171 |
+
nn.Conv2d(
|
| 172 |
+
in_channels=vit_features,
|
| 173 |
+
out_channels=features[0],
|
| 174 |
+
kernel_size=1,
|
| 175 |
+
stride=1,
|
| 176 |
+
padding=0,
|
| 177 |
+
),
|
| 178 |
+
nn.ConvTranspose2d(
|
| 179 |
+
in_channels=features[0],
|
| 180 |
+
out_channels=features[0],
|
| 181 |
+
kernel_size=4,
|
| 182 |
+
stride=4,
|
| 183 |
+
padding=0,
|
| 184 |
+
bias=True,
|
| 185 |
+
dilation=1,
|
| 186 |
+
groups=1,
|
| 187 |
+
),
|
| 188 |
+
)
|
| 189 |
+
|
| 190 |
+
pretrained.act_postprocess2 = nn.Sequential(
|
| 191 |
+
readout_oper[1],
|
| 192 |
+
Transpose(1, 2),
|
| 193 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 194 |
+
nn.Conv2d(
|
| 195 |
+
in_channels=vit_features,
|
| 196 |
+
out_channels=features[1],
|
| 197 |
+
kernel_size=1,
|
| 198 |
+
stride=1,
|
| 199 |
+
padding=0,
|
| 200 |
+
),
|
| 201 |
+
nn.ConvTranspose2d(
|
| 202 |
+
in_channels=features[1],
|
| 203 |
+
out_channels=features[1],
|
| 204 |
+
kernel_size=2,
|
| 205 |
+
stride=2,
|
| 206 |
+
padding=0,
|
| 207 |
+
bias=True,
|
| 208 |
+
dilation=1,
|
| 209 |
+
groups=1,
|
| 210 |
+
),
|
| 211 |
+
)
|
| 212 |
+
|
| 213 |
+
pretrained.act_postprocess3 = nn.Sequential(
|
| 214 |
+
readout_oper[2],
|
| 215 |
+
Transpose(1, 2),
|
| 216 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 217 |
+
nn.Conv2d(
|
| 218 |
+
in_channels=vit_features,
|
| 219 |
+
out_channels=features[2],
|
| 220 |
+
kernel_size=1,
|
| 221 |
+
stride=1,
|
| 222 |
+
padding=0,
|
| 223 |
+
),
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
pretrained.act_postprocess4 = nn.Sequential(
|
| 227 |
+
readout_oper[3],
|
| 228 |
+
Transpose(1, 2),
|
| 229 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 230 |
+
nn.Conv2d(
|
| 231 |
+
in_channels=vit_features,
|
| 232 |
+
out_channels=features[3],
|
| 233 |
+
kernel_size=1,
|
| 234 |
+
stride=1,
|
| 235 |
+
padding=0,
|
| 236 |
+
),
|
| 237 |
+
nn.Conv2d(
|
| 238 |
+
in_channels=features[3],
|
| 239 |
+
out_channels=features[3],
|
| 240 |
+
kernel_size=3,
|
| 241 |
+
stride=2,
|
| 242 |
+
padding=1,
|
| 243 |
+
),
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
pretrained.model.start_index = start_index
|
| 247 |
+
pretrained.model.patch_size = [16, 16]
|
| 248 |
+
|
| 249 |
+
return pretrained
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/backbones/vit.py
ADDED
|
@@ -0,0 +1,221 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import timm
|
| 4 |
+
import types
|
| 5 |
+
import math
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
from .utils import (activations, forward_adapted_unflatten, get_activation, get_readout_oper,
|
| 9 |
+
make_backbone_default, Transpose)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def forward_vit(pretrained, x):
|
| 13 |
+
return forward_adapted_unflatten(pretrained, x, "forward_flex")
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def _resize_pos_embed(self, posemb, gs_h, gs_w):
|
| 17 |
+
posemb_tok, posemb_grid = (
|
| 18 |
+
posemb[:, : self.start_index],
|
| 19 |
+
posemb[0, self.start_index:],
|
| 20 |
+
)
|
| 21 |
+
|
| 22 |
+
gs_old = int(math.sqrt(len(posemb_grid)))
|
| 23 |
+
|
| 24 |
+
posemb_grid = posemb_grid.reshape(1, gs_old, gs_old, -1).permute(0, 3, 1, 2)
|
| 25 |
+
posemb_grid = F.interpolate(posemb_grid, size=(gs_h, gs_w), mode="bilinear")
|
| 26 |
+
posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, gs_h * gs_w, -1)
|
| 27 |
+
|
| 28 |
+
posemb = torch.cat([posemb_tok, posemb_grid], dim=1)
|
| 29 |
+
|
| 30 |
+
return posemb
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def forward_flex(self, x):
|
| 34 |
+
b, c, h, w = x.shape
|
| 35 |
+
|
| 36 |
+
pos_embed = self._resize_pos_embed(
|
| 37 |
+
self.pos_embed, h // self.patch_size[1], w // self.patch_size[0]
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
B = x.shape[0]
|
| 41 |
+
|
| 42 |
+
if hasattr(self.patch_embed, "backbone"):
|
| 43 |
+
x = self.patch_embed.backbone(x)
|
| 44 |
+
if isinstance(x, (list, tuple)):
|
| 45 |
+
x = x[-1] # last feature if backbone outputs list/tuple of features
|
| 46 |
+
|
| 47 |
+
x = self.patch_embed.proj(x).flatten(2).transpose(1, 2)
|
| 48 |
+
|
| 49 |
+
if getattr(self, "dist_token", None) is not None:
|
| 50 |
+
cls_tokens = self.cls_token.expand(
|
| 51 |
+
B, -1, -1
|
| 52 |
+
) # stole cls_tokens impl from Phil Wang, thanks
|
| 53 |
+
dist_token = self.dist_token.expand(B, -1, -1)
|
| 54 |
+
x = torch.cat((cls_tokens, dist_token, x), dim=1)
|
| 55 |
+
else:
|
| 56 |
+
if self.no_embed_class:
|
| 57 |
+
x = x + pos_embed
|
| 58 |
+
cls_tokens = self.cls_token.expand(
|
| 59 |
+
B, -1, -1
|
| 60 |
+
) # stole cls_tokens impl from Phil Wang, thanks
|
| 61 |
+
x = torch.cat((cls_tokens, x), dim=1)
|
| 62 |
+
|
| 63 |
+
if not self.no_embed_class:
|
| 64 |
+
x = x + pos_embed
|
| 65 |
+
x = self.pos_drop(x)
|
| 66 |
+
|
| 67 |
+
for blk in self.blocks:
|
| 68 |
+
x = blk(x)
|
| 69 |
+
|
| 70 |
+
x = self.norm(x)
|
| 71 |
+
|
| 72 |
+
return x
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def _make_vit_b16_backbone(
|
| 76 |
+
model,
|
| 77 |
+
features=[96, 192, 384, 768],
|
| 78 |
+
size=[384, 384],
|
| 79 |
+
hooks=[2, 5, 8, 11],
|
| 80 |
+
vit_features=768,
|
| 81 |
+
use_readout="ignore",
|
| 82 |
+
start_index=1,
|
| 83 |
+
start_index_readout=1,
|
| 84 |
+
):
|
| 85 |
+
pretrained = make_backbone_default(model, features, size, hooks, vit_features, use_readout, start_index,
|
| 86 |
+
start_index_readout)
|
| 87 |
+
|
| 88 |
+
# We inject this function into the VisionTransformer instances so that
|
| 89 |
+
# we can use it with interpolated position embeddings without modifying the library source.
|
| 90 |
+
pretrained.model.forward_flex = types.MethodType(forward_flex, pretrained.model)
|
| 91 |
+
pretrained.model._resize_pos_embed = types.MethodType(
|
| 92 |
+
_resize_pos_embed, pretrained.model
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
return pretrained
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def _make_pretrained_vitl16_384(pretrained, use_readout="ignore", hooks=None):
|
| 99 |
+
model = timm.create_model("vit_large_patch16_384", pretrained=pretrained)
|
| 100 |
+
|
| 101 |
+
hooks = [5, 11, 17, 23] if hooks == None else hooks
|
| 102 |
+
return _make_vit_b16_backbone(
|
| 103 |
+
model,
|
| 104 |
+
features=[256, 512, 1024, 1024],
|
| 105 |
+
hooks=hooks,
|
| 106 |
+
vit_features=1024,
|
| 107 |
+
use_readout=use_readout,
|
| 108 |
+
)
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def _make_pretrained_vitb16_384(pretrained, use_readout="ignore", hooks=None):
|
| 112 |
+
model = timm.create_model("vit_base_patch16_384", pretrained=pretrained)
|
| 113 |
+
|
| 114 |
+
hooks = [2, 5, 8, 11] if hooks == None else hooks
|
| 115 |
+
return _make_vit_b16_backbone(
|
| 116 |
+
model, features=[96, 192, 384, 768], hooks=hooks, use_readout=use_readout
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def _make_vit_b_rn50_backbone(
|
| 121 |
+
model,
|
| 122 |
+
features=[256, 512, 768, 768],
|
| 123 |
+
size=[384, 384],
|
| 124 |
+
hooks=[0, 1, 8, 11],
|
| 125 |
+
vit_features=768,
|
| 126 |
+
patch_size=[16, 16],
|
| 127 |
+
number_stages=2,
|
| 128 |
+
use_vit_only=False,
|
| 129 |
+
use_readout="ignore",
|
| 130 |
+
start_index=1,
|
| 131 |
+
):
|
| 132 |
+
pretrained = nn.Module()
|
| 133 |
+
|
| 134 |
+
pretrained.model = model
|
| 135 |
+
|
| 136 |
+
used_number_stages = 0 if use_vit_only else number_stages
|
| 137 |
+
for s in range(used_number_stages):
|
| 138 |
+
pretrained.model.patch_embed.backbone.stages[s].register_forward_hook(
|
| 139 |
+
get_activation(str(s + 1))
|
| 140 |
+
)
|
| 141 |
+
for s in range(used_number_stages, 4):
|
| 142 |
+
pretrained.model.blocks[hooks[s]].register_forward_hook(get_activation(str(s + 1)))
|
| 143 |
+
|
| 144 |
+
pretrained.activations = activations
|
| 145 |
+
|
| 146 |
+
readout_oper = get_readout_oper(vit_features, features, use_readout, start_index)
|
| 147 |
+
|
| 148 |
+
for s in range(used_number_stages):
|
| 149 |
+
value = nn.Sequential(nn.Identity(), nn.Identity(), nn.Identity())
|
| 150 |
+
exec(f"pretrained.act_postprocess{s + 1}=value")
|
| 151 |
+
for s in range(used_number_stages, 4):
|
| 152 |
+
if s < number_stages:
|
| 153 |
+
final_layer = nn.ConvTranspose2d(
|
| 154 |
+
in_channels=features[s],
|
| 155 |
+
out_channels=features[s],
|
| 156 |
+
kernel_size=4 // (2 ** s),
|
| 157 |
+
stride=4 // (2 ** s),
|
| 158 |
+
padding=0,
|
| 159 |
+
bias=True,
|
| 160 |
+
dilation=1,
|
| 161 |
+
groups=1,
|
| 162 |
+
)
|
| 163 |
+
elif s > number_stages:
|
| 164 |
+
final_layer = nn.Conv2d(
|
| 165 |
+
in_channels=features[3],
|
| 166 |
+
out_channels=features[3],
|
| 167 |
+
kernel_size=3,
|
| 168 |
+
stride=2,
|
| 169 |
+
padding=1,
|
| 170 |
+
)
|
| 171 |
+
else:
|
| 172 |
+
final_layer = None
|
| 173 |
+
|
| 174 |
+
layers = [
|
| 175 |
+
readout_oper[s],
|
| 176 |
+
Transpose(1, 2),
|
| 177 |
+
nn.Unflatten(2, torch.Size([size[0] // 16, size[1] // 16])),
|
| 178 |
+
nn.Conv2d(
|
| 179 |
+
in_channels=vit_features,
|
| 180 |
+
out_channels=features[s],
|
| 181 |
+
kernel_size=1,
|
| 182 |
+
stride=1,
|
| 183 |
+
padding=0,
|
| 184 |
+
),
|
| 185 |
+
]
|
| 186 |
+
if final_layer is not None:
|
| 187 |
+
layers.append(final_layer)
|
| 188 |
+
|
| 189 |
+
value = nn.Sequential(*layers)
|
| 190 |
+
exec(f"pretrained.act_postprocess{s + 1}=value")
|
| 191 |
+
|
| 192 |
+
pretrained.model.start_index = start_index
|
| 193 |
+
pretrained.model.patch_size = patch_size
|
| 194 |
+
|
| 195 |
+
# We inject this function into the VisionTransformer instances so that
|
| 196 |
+
# we can use it with interpolated position embeddings without modifying the library source.
|
| 197 |
+
pretrained.model.forward_flex = types.MethodType(forward_flex, pretrained.model)
|
| 198 |
+
|
| 199 |
+
# We inject this function into the VisionTransformer instances so that
|
| 200 |
+
# we can use it with interpolated position embeddings without modifying the library source.
|
| 201 |
+
pretrained.model._resize_pos_embed = types.MethodType(
|
| 202 |
+
_resize_pos_embed, pretrained.model
|
| 203 |
+
)
|
| 204 |
+
|
| 205 |
+
return pretrained
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
def _make_pretrained_vitb_rn50_384(
|
| 209 |
+
pretrained, use_readout="ignore", hooks=None, use_vit_only=False
|
| 210 |
+
):
|
| 211 |
+
model = timm.create_model("vit_base_resnet50_384", pretrained=pretrained)
|
| 212 |
+
|
| 213 |
+
hooks = [0, 1, 8, 11] if hooks == None else hooks
|
| 214 |
+
return _make_vit_b_rn50_backbone(
|
| 215 |
+
model,
|
| 216 |
+
features=[256, 512, 768, 768],
|
| 217 |
+
size=[384, 384],
|
| 218 |
+
hooks=hooks,
|
| 219 |
+
use_vit_only=use_vit_only,
|
| 220 |
+
use_readout=use_readout,
|
| 221 |
+
)
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/base_model.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class BaseModel(torch.nn.Module):
|
| 5 |
+
def load(self, path):
|
| 6 |
+
"""Load model from file.
|
| 7 |
+
|
| 8 |
+
Args:
|
| 9 |
+
path (str): file path
|
| 10 |
+
"""
|
| 11 |
+
parameters = torch.load(path, map_location=torch.device('cpu'))
|
| 12 |
+
|
| 13 |
+
if "optimizer" in parameters:
|
| 14 |
+
parameters = parameters["model"]
|
| 15 |
+
|
| 16 |
+
self.load_state_dict(parameters)
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/blocks.py
ADDED
|
@@ -0,0 +1,439 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
from .backbones.beit import (
|
| 5 |
+
_make_pretrained_beitl16_512,
|
| 6 |
+
_make_pretrained_beitl16_384,
|
| 7 |
+
_make_pretrained_beitb16_384,
|
| 8 |
+
forward_beit,
|
| 9 |
+
)
|
| 10 |
+
from .backbones.swin_common import (
|
| 11 |
+
forward_swin,
|
| 12 |
+
)
|
| 13 |
+
from .backbones.swin2 import (
|
| 14 |
+
_make_pretrained_swin2l24_384,
|
| 15 |
+
_make_pretrained_swin2b24_384,
|
| 16 |
+
_make_pretrained_swin2t16_256,
|
| 17 |
+
)
|
| 18 |
+
from .backbones.swin import (
|
| 19 |
+
_make_pretrained_swinl12_384,
|
| 20 |
+
)
|
| 21 |
+
from .backbones.levit import (
|
| 22 |
+
_make_pretrained_levit_384,
|
| 23 |
+
forward_levit,
|
| 24 |
+
)
|
| 25 |
+
from .backbones.vit import (
|
| 26 |
+
_make_pretrained_vitb_rn50_384,
|
| 27 |
+
_make_pretrained_vitl16_384,
|
| 28 |
+
_make_pretrained_vitb16_384,
|
| 29 |
+
forward_vit,
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
def _make_encoder(backbone, features, use_pretrained, groups=1, expand=False, exportable=True, hooks=None,
|
| 33 |
+
use_vit_only=False, use_readout="ignore", in_features=[96, 256, 512, 1024]):
|
| 34 |
+
if backbone == "beitl16_512":
|
| 35 |
+
pretrained = _make_pretrained_beitl16_512(
|
| 36 |
+
use_pretrained, hooks=hooks, use_readout=use_readout
|
| 37 |
+
)
|
| 38 |
+
scratch = _make_scratch(
|
| 39 |
+
[256, 512, 1024, 1024], features, groups=groups, expand=expand
|
| 40 |
+
) # BEiT_512-L (backbone)
|
| 41 |
+
elif backbone == "beitl16_384":
|
| 42 |
+
pretrained = _make_pretrained_beitl16_384(
|
| 43 |
+
use_pretrained, hooks=hooks, use_readout=use_readout
|
| 44 |
+
)
|
| 45 |
+
scratch = _make_scratch(
|
| 46 |
+
[256, 512, 1024, 1024], features, groups=groups, expand=expand
|
| 47 |
+
) # BEiT_384-L (backbone)
|
| 48 |
+
elif backbone == "beitb16_384":
|
| 49 |
+
pretrained = _make_pretrained_beitb16_384(
|
| 50 |
+
use_pretrained, hooks=hooks, use_readout=use_readout
|
| 51 |
+
)
|
| 52 |
+
scratch = _make_scratch(
|
| 53 |
+
[96, 192, 384, 768], features, groups=groups, expand=expand
|
| 54 |
+
) # BEiT_384-B (backbone)
|
| 55 |
+
elif backbone == "swin2l24_384":
|
| 56 |
+
pretrained = _make_pretrained_swin2l24_384(
|
| 57 |
+
use_pretrained, hooks=hooks
|
| 58 |
+
)
|
| 59 |
+
scratch = _make_scratch(
|
| 60 |
+
[192, 384, 768, 1536], features, groups=groups, expand=expand
|
| 61 |
+
) # Swin2-L/12to24 (backbone)
|
| 62 |
+
elif backbone == "swin2b24_384":
|
| 63 |
+
pretrained = _make_pretrained_swin2b24_384(
|
| 64 |
+
use_pretrained, hooks=hooks
|
| 65 |
+
)
|
| 66 |
+
scratch = _make_scratch(
|
| 67 |
+
[128, 256, 512, 1024], features, groups=groups, expand=expand
|
| 68 |
+
) # Swin2-B/12to24 (backbone)
|
| 69 |
+
elif backbone == "swin2t16_256":
|
| 70 |
+
pretrained = _make_pretrained_swin2t16_256(
|
| 71 |
+
use_pretrained, hooks=hooks
|
| 72 |
+
)
|
| 73 |
+
scratch = _make_scratch(
|
| 74 |
+
[96, 192, 384, 768], features, groups=groups, expand=expand
|
| 75 |
+
) # Swin2-T/16 (backbone)
|
| 76 |
+
elif backbone == "swinl12_384":
|
| 77 |
+
pretrained = _make_pretrained_swinl12_384(
|
| 78 |
+
use_pretrained, hooks=hooks
|
| 79 |
+
)
|
| 80 |
+
scratch = _make_scratch(
|
| 81 |
+
[192, 384, 768, 1536], features, groups=groups, expand=expand
|
| 82 |
+
) # Swin-L/12 (backbone)
|
| 83 |
+
elif backbone == "next_vit_large_6m":
|
| 84 |
+
from .backbones.next_vit import _make_pretrained_next_vit_large_6m
|
| 85 |
+
pretrained = _make_pretrained_next_vit_large_6m(hooks=hooks)
|
| 86 |
+
scratch = _make_scratch(
|
| 87 |
+
in_features, features, groups=groups, expand=expand
|
| 88 |
+
) # Next-ViT-L on ImageNet-1K-6M (backbone)
|
| 89 |
+
elif backbone == "levit_384":
|
| 90 |
+
pretrained = _make_pretrained_levit_384(
|
| 91 |
+
use_pretrained, hooks=hooks
|
| 92 |
+
)
|
| 93 |
+
scratch = _make_scratch(
|
| 94 |
+
[384, 512, 768], features, groups=groups, expand=expand
|
| 95 |
+
) # LeViT 384 (backbone)
|
| 96 |
+
elif backbone == "vitl16_384":
|
| 97 |
+
pretrained = _make_pretrained_vitl16_384(
|
| 98 |
+
use_pretrained, hooks=hooks, use_readout=use_readout
|
| 99 |
+
)
|
| 100 |
+
scratch = _make_scratch(
|
| 101 |
+
[256, 512, 1024, 1024], features, groups=groups, expand=expand
|
| 102 |
+
) # ViT-L/16 - 85.0% Top1 (backbone)
|
| 103 |
+
elif backbone == "vitb_rn50_384":
|
| 104 |
+
pretrained = _make_pretrained_vitb_rn50_384(
|
| 105 |
+
use_pretrained,
|
| 106 |
+
hooks=hooks,
|
| 107 |
+
use_vit_only=use_vit_only,
|
| 108 |
+
use_readout=use_readout,
|
| 109 |
+
)
|
| 110 |
+
scratch = _make_scratch(
|
| 111 |
+
[256, 512, 768, 768], features, groups=groups, expand=expand
|
| 112 |
+
) # ViT-H/16 - 85.0% Top1 (backbone)
|
| 113 |
+
elif backbone == "vitb16_384":
|
| 114 |
+
pretrained = _make_pretrained_vitb16_384(
|
| 115 |
+
use_pretrained, hooks=hooks, use_readout=use_readout
|
| 116 |
+
)
|
| 117 |
+
scratch = _make_scratch(
|
| 118 |
+
[96, 192, 384, 768], features, groups=groups, expand=expand
|
| 119 |
+
) # ViT-B/16 - 84.6% Top1 (backbone)
|
| 120 |
+
elif backbone == "resnext101_wsl":
|
| 121 |
+
pretrained = _make_pretrained_resnext101_wsl(use_pretrained)
|
| 122 |
+
scratch = _make_scratch([256, 512, 1024, 2048], features, groups=groups, expand=expand) # efficientnet_lite3
|
| 123 |
+
elif backbone == "efficientnet_lite3":
|
| 124 |
+
pretrained = _make_pretrained_efficientnet_lite3(use_pretrained, exportable=exportable)
|
| 125 |
+
scratch = _make_scratch([32, 48, 136, 384], features, groups=groups, expand=expand) # efficientnet_lite3
|
| 126 |
+
else:
|
| 127 |
+
print(f"Backbone '{backbone}' not implemented")
|
| 128 |
+
assert False
|
| 129 |
+
|
| 130 |
+
return pretrained, scratch
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def _make_scratch(in_shape, out_shape, groups=1, expand=False):
|
| 134 |
+
scratch = nn.Module()
|
| 135 |
+
|
| 136 |
+
out_shape1 = out_shape
|
| 137 |
+
out_shape2 = out_shape
|
| 138 |
+
out_shape3 = out_shape
|
| 139 |
+
if len(in_shape) >= 4:
|
| 140 |
+
out_shape4 = out_shape
|
| 141 |
+
|
| 142 |
+
if expand:
|
| 143 |
+
out_shape1 = out_shape
|
| 144 |
+
out_shape2 = out_shape*2
|
| 145 |
+
out_shape3 = out_shape*4
|
| 146 |
+
if len(in_shape) >= 4:
|
| 147 |
+
out_shape4 = out_shape*8
|
| 148 |
+
|
| 149 |
+
scratch.layer1_rn = nn.Conv2d(
|
| 150 |
+
in_shape[0], out_shape1, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 151 |
+
)
|
| 152 |
+
scratch.layer2_rn = nn.Conv2d(
|
| 153 |
+
in_shape[1], out_shape2, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 154 |
+
)
|
| 155 |
+
scratch.layer3_rn = nn.Conv2d(
|
| 156 |
+
in_shape[2], out_shape3, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 157 |
+
)
|
| 158 |
+
if len(in_shape) >= 4:
|
| 159 |
+
scratch.layer4_rn = nn.Conv2d(
|
| 160 |
+
in_shape[3], out_shape4, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
return scratch
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def _make_pretrained_efficientnet_lite3(use_pretrained, exportable=False):
|
| 167 |
+
efficientnet = torch.hub.load(
|
| 168 |
+
"rwightman/gen-efficientnet-pytorch",
|
| 169 |
+
"tf_efficientnet_lite3",
|
| 170 |
+
pretrained=use_pretrained,
|
| 171 |
+
exportable=exportable
|
| 172 |
+
)
|
| 173 |
+
return _make_efficientnet_backbone(efficientnet)
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
def _make_efficientnet_backbone(effnet):
|
| 177 |
+
pretrained = nn.Module()
|
| 178 |
+
|
| 179 |
+
pretrained.layer1 = nn.Sequential(
|
| 180 |
+
effnet.conv_stem, effnet.bn1, effnet.act1, *effnet.blocks[0:2]
|
| 181 |
+
)
|
| 182 |
+
pretrained.layer2 = nn.Sequential(*effnet.blocks[2:3])
|
| 183 |
+
pretrained.layer3 = nn.Sequential(*effnet.blocks[3:5])
|
| 184 |
+
pretrained.layer4 = nn.Sequential(*effnet.blocks[5:9])
|
| 185 |
+
|
| 186 |
+
return pretrained
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
def _make_resnet_backbone(resnet):
|
| 190 |
+
pretrained = nn.Module()
|
| 191 |
+
pretrained.layer1 = nn.Sequential(
|
| 192 |
+
resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool, resnet.layer1
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
pretrained.layer2 = resnet.layer2
|
| 196 |
+
pretrained.layer3 = resnet.layer3
|
| 197 |
+
pretrained.layer4 = resnet.layer4
|
| 198 |
+
|
| 199 |
+
return pretrained
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def _make_pretrained_resnext101_wsl(use_pretrained):
|
| 203 |
+
resnet = torch.hub.load("facebookresearch/WSL-Images", "resnext101_32x8d_wsl")
|
| 204 |
+
return _make_resnet_backbone(resnet)
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
class Interpolate(nn.Module):
|
| 209 |
+
"""Interpolation module.
|
| 210 |
+
"""
|
| 211 |
+
|
| 212 |
+
def __init__(self, scale_factor, mode, align_corners=False):
|
| 213 |
+
"""Init.
|
| 214 |
+
|
| 215 |
+
Args:
|
| 216 |
+
scale_factor (float): scaling
|
| 217 |
+
mode (str): interpolation mode
|
| 218 |
+
"""
|
| 219 |
+
super(Interpolate, self).__init__()
|
| 220 |
+
|
| 221 |
+
self.interp = nn.functional.interpolate
|
| 222 |
+
self.scale_factor = scale_factor
|
| 223 |
+
self.mode = mode
|
| 224 |
+
self.align_corners = align_corners
|
| 225 |
+
|
| 226 |
+
def forward(self, x):
|
| 227 |
+
"""Forward pass.
|
| 228 |
+
|
| 229 |
+
Args:
|
| 230 |
+
x (tensor): input
|
| 231 |
+
|
| 232 |
+
Returns:
|
| 233 |
+
tensor: interpolated data
|
| 234 |
+
"""
|
| 235 |
+
|
| 236 |
+
x = self.interp(
|
| 237 |
+
x, scale_factor=self.scale_factor, mode=self.mode, align_corners=self.align_corners
|
| 238 |
+
)
|
| 239 |
+
|
| 240 |
+
return x
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
class ResidualConvUnit(nn.Module):
|
| 244 |
+
"""Residual convolution module.
|
| 245 |
+
"""
|
| 246 |
+
|
| 247 |
+
def __init__(self, features):
|
| 248 |
+
"""Init.
|
| 249 |
+
|
| 250 |
+
Args:
|
| 251 |
+
features (int): number of features
|
| 252 |
+
"""
|
| 253 |
+
super().__init__()
|
| 254 |
+
|
| 255 |
+
self.conv1 = nn.Conv2d(
|
| 256 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True
|
| 257 |
+
)
|
| 258 |
+
|
| 259 |
+
self.conv2 = nn.Conv2d(
|
| 260 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True
|
| 261 |
+
)
|
| 262 |
+
|
| 263 |
+
self.relu = nn.ReLU(inplace=True)
|
| 264 |
+
|
| 265 |
+
def forward(self, x):
|
| 266 |
+
"""Forward pass.
|
| 267 |
+
|
| 268 |
+
Args:
|
| 269 |
+
x (tensor): input
|
| 270 |
+
|
| 271 |
+
Returns:
|
| 272 |
+
tensor: output
|
| 273 |
+
"""
|
| 274 |
+
out = self.relu(x)
|
| 275 |
+
out = self.conv1(out)
|
| 276 |
+
out = self.relu(out)
|
| 277 |
+
out = self.conv2(out)
|
| 278 |
+
|
| 279 |
+
return out + x
|
| 280 |
+
|
| 281 |
+
|
| 282 |
+
class FeatureFusionBlock(nn.Module):
|
| 283 |
+
"""Feature fusion block.
|
| 284 |
+
"""
|
| 285 |
+
|
| 286 |
+
def __init__(self, features):
|
| 287 |
+
"""Init.
|
| 288 |
+
|
| 289 |
+
Args:
|
| 290 |
+
features (int): number of features
|
| 291 |
+
"""
|
| 292 |
+
super(FeatureFusionBlock, self).__init__()
|
| 293 |
+
|
| 294 |
+
self.resConfUnit1 = ResidualConvUnit(features)
|
| 295 |
+
self.resConfUnit2 = ResidualConvUnit(features)
|
| 296 |
+
|
| 297 |
+
def forward(self, *xs):
|
| 298 |
+
"""Forward pass.
|
| 299 |
+
|
| 300 |
+
Returns:
|
| 301 |
+
tensor: output
|
| 302 |
+
"""
|
| 303 |
+
output = xs[0]
|
| 304 |
+
|
| 305 |
+
if len(xs) == 2:
|
| 306 |
+
output += self.resConfUnit1(xs[1])
|
| 307 |
+
|
| 308 |
+
output = self.resConfUnit2(output)
|
| 309 |
+
|
| 310 |
+
output = nn.functional.interpolate(
|
| 311 |
+
output, scale_factor=2, mode="bilinear", align_corners=True
|
| 312 |
+
)
|
| 313 |
+
|
| 314 |
+
return output
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
class ResidualConvUnit_custom(nn.Module):
|
| 320 |
+
"""Residual convolution module.
|
| 321 |
+
"""
|
| 322 |
+
|
| 323 |
+
def __init__(self, features, activation, bn):
|
| 324 |
+
"""Init.
|
| 325 |
+
|
| 326 |
+
Args:
|
| 327 |
+
features (int): number of features
|
| 328 |
+
"""
|
| 329 |
+
super().__init__()
|
| 330 |
+
|
| 331 |
+
self.bn = bn
|
| 332 |
+
|
| 333 |
+
self.groups=1
|
| 334 |
+
|
| 335 |
+
self.conv1 = nn.Conv2d(
|
| 336 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
self.conv2 = nn.Conv2d(
|
| 340 |
+
features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups
|
| 341 |
+
)
|
| 342 |
+
|
| 343 |
+
if self.bn==True:
|
| 344 |
+
self.bn1 = nn.BatchNorm2d(features)
|
| 345 |
+
self.bn2 = nn.BatchNorm2d(features)
|
| 346 |
+
|
| 347 |
+
self.activation = activation
|
| 348 |
+
|
| 349 |
+
self.skip_add = nn.quantized.FloatFunctional()
|
| 350 |
+
|
| 351 |
+
def forward(self, x):
|
| 352 |
+
"""Forward pass.
|
| 353 |
+
|
| 354 |
+
Args:
|
| 355 |
+
x (tensor): input
|
| 356 |
+
|
| 357 |
+
Returns:
|
| 358 |
+
tensor: output
|
| 359 |
+
"""
|
| 360 |
+
|
| 361 |
+
out = self.activation(x)
|
| 362 |
+
out = self.conv1(out)
|
| 363 |
+
if self.bn==True:
|
| 364 |
+
out = self.bn1(out)
|
| 365 |
+
|
| 366 |
+
out = self.activation(out)
|
| 367 |
+
out = self.conv2(out)
|
| 368 |
+
if self.bn==True:
|
| 369 |
+
out = self.bn2(out)
|
| 370 |
+
|
| 371 |
+
if self.groups > 1:
|
| 372 |
+
out = self.conv_merge(out)
|
| 373 |
+
|
| 374 |
+
return self.skip_add.add(out, x)
|
| 375 |
+
|
| 376 |
+
# return out + x
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
class FeatureFusionBlock_custom(nn.Module):
|
| 380 |
+
"""Feature fusion block.
|
| 381 |
+
"""
|
| 382 |
+
|
| 383 |
+
def __init__(self, features, activation, deconv=False, bn=False, expand=False, align_corners=True, size=None):
|
| 384 |
+
"""Init.
|
| 385 |
+
|
| 386 |
+
Args:
|
| 387 |
+
features (int): number of features
|
| 388 |
+
"""
|
| 389 |
+
super(FeatureFusionBlock_custom, self).__init__()
|
| 390 |
+
|
| 391 |
+
self.deconv = deconv
|
| 392 |
+
self.align_corners = align_corners
|
| 393 |
+
|
| 394 |
+
self.groups=1
|
| 395 |
+
|
| 396 |
+
self.expand = expand
|
| 397 |
+
out_features = features
|
| 398 |
+
if self.expand==True:
|
| 399 |
+
out_features = features//2
|
| 400 |
+
|
| 401 |
+
self.out_conv = nn.Conv2d(features, out_features, kernel_size=1, stride=1, padding=0, bias=True, groups=1)
|
| 402 |
+
|
| 403 |
+
self.resConfUnit1 = ResidualConvUnit_custom(features, activation, bn)
|
| 404 |
+
self.resConfUnit2 = ResidualConvUnit_custom(features, activation, bn)
|
| 405 |
+
|
| 406 |
+
self.skip_add = nn.quantized.FloatFunctional()
|
| 407 |
+
|
| 408 |
+
self.size=size
|
| 409 |
+
|
| 410 |
+
def forward(self, *xs, size=None):
|
| 411 |
+
"""Forward pass.
|
| 412 |
+
|
| 413 |
+
Returns:
|
| 414 |
+
tensor: output
|
| 415 |
+
"""
|
| 416 |
+
output = xs[0]
|
| 417 |
+
|
| 418 |
+
if len(xs) == 2:
|
| 419 |
+
res = self.resConfUnit1(xs[1])
|
| 420 |
+
output = self.skip_add.add(output, res)
|
| 421 |
+
# output += res
|
| 422 |
+
|
| 423 |
+
output = self.resConfUnit2(output)
|
| 424 |
+
|
| 425 |
+
if (size is None) and (self.size is None):
|
| 426 |
+
modifier = {"scale_factor": 2}
|
| 427 |
+
elif size is None:
|
| 428 |
+
modifier = {"size": self.size}
|
| 429 |
+
else:
|
| 430 |
+
modifier = {"size": size}
|
| 431 |
+
|
| 432 |
+
output = nn.functional.interpolate(
|
| 433 |
+
output, **modifier, mode="bilinear", align_corners=self.align_corners
|
| 434 |
+
)
|
| 435 |
+
|
| 436 |
+
output = self.out_conv(output)
|
| 437 |
+
|
| 438 |
+
return output
|
| 439 |
+
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/dpt_depth.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
from .base_model import BaseModel
|
| 5 |
+
from .blocks import (
|
| 6 |
+
FeatureFusionBlock_custom,
|
| 7 |
+
Interpolate,
|
| 8 |
+
_make_encoder,
|
| 9 |
+
forward_beit,
|
| 10 |
+
forward_swin,
|
| 11 |
+
forward_levit,
|
| 12 |
+
forward_vit,
|
| 13 |
+
)
|
| 14 |
+
from .backbones.levit import stem_b4_transpose
|
| 15 |
+
from timm.models.layers import get_act_layer
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def _make_fusion_block(features, use_bn, size = None):
|
| 19 |
+
return FeatureFusionBlock_custom(
|
| 20 |
+
features,
|
| 21 |
+
nn.ReLU(False),
|
| 22 |
+
deconv=False,
|
| 23 |
+
bn=use_bn,
|
| 24 |
+
expand=False,
|
| 25 |
+
align_corners=True,
|
| 26 |
+
size=size,
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class DPT(BaseModel):
|
| 31 |
+
def __init__(
|
| 32 |
+
self,
|
| 33 |
+
head,
|
| 34 |
+
features=256,
|
| 35 |
+
backbone="vitb_rn50_384",
|
| 36 |
+
readout="project",
|
| 37 |
+
channels_last=False,
|
| 38 |
+
use_bn=False,
|
| 39 |
+
**kwargs
|
| 40 |
+
):
|
| 41 |
+
|
| 42 |
+
super(DPT, self).__init__()
|
| 43 |
+
|
| 44 |
+
self.channels_last = channels_last
|
| 45 |
+
|
| 46 |
+
# For the Swin, Swin 2, LeViT and Next-ViT Transformers, the hierarchical architectures prevent setting the
|
| 47 |
+
# hooks freely. Instead, the hooks have to be chosen according to the ranges specified in the comments.
|
| 48 |
+
hooks = {
|
| 49 |
+
"beitl16_512": [5, 11, 17, 23],
|
| 50 |
+
"beitl16_384": [5, 11, 17, 23],
|
| 51 |
+
"beitb16_384": [2, 5, 8, 11],
|
| 52 |
+
"swin2l24_384": [1, 1, 17, 1], # Allowed ranges: [0, 1], [0, 1], [ 0, 17], [ 0, 1]
|
| 53 |
+
"swin2b24_384": [1, 1, 17, 1], # [0, 1], [0, 1], [ 0, 17], [ 0, 1]
|
| 54 |
+
"swin2t16_256": [1, 1, 5, 1], # [0, 1], [0, 1], [ 0, 5], [ 0, 1]
|
| 55 |
+
"swinl12_384": [1, 1, 17, 1], # [0, 1], [0, 1], [ 0, 17], [ 0, 1]
|
| 56 |
+
"next_vit_large_6m": [2, 6, 36, 39], # [0, 2], [3, 6], [ 7, 36], [37, 39]
|
| 57 |
+
"levit_384": [3, 11, 21], # [0, 3], [6, 11], [14, 21]
|
| 58 |
+
"vitb_rn50_384": [0, 1, 8, 11],
|
| 59 |
+
"vitb16_384": [2, 5, 8, 11],
|
| 60 |
+
"vitl16_384": [5, 11, 17, 23],
|
| 61 |
+
}[backbone]
|
| 62 |
+
|
| 63 |
+
if "next_vit" in backbone:
|
| 64 |
+
in_features = {
|
| 65 |
+
"next_vit_large_6m": [96, 256, 512, 1024],
|
| 66 |
+
}[backbone]
|
| 67 |
+
else:
|
| 68 |
+
in_features = None
|
| 69 |
+
|
| 70 |
+
# Instantiate backbone and reassemble blocks
|
| 71 |
+
self.pretrained, self.scratch = _make_encoder(
|
| 72 |
+
backbone,
|
| 73 |
+
features,
|
| 74 |
+
False, # Set to true of you want to train from scratch, uses ImageNet weights
|
| 75 |
+
groups=1,
|
| 76 |
+
expand=False,
|
| 77 |
+
exportable=False,
|
| 78 |
+
hooks=hooks,
|
| 79 |
+
use_readout=readout,
|
| 80 |
+
in_features=in_features,
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
self.number_layers = len(hooks) if hooks is not None else 4
|
| 84 |
+
size_refinenet3 = None
|
| 85 |
+
self.scratch.stem_transpose = None
|
| 86 |
+
|
| 87 |
+
if "beit" in backbone:
|
| 88 |
+
self.forward_transformer = forward_beit
|
| 89 |
+
elif "swin" in backbone:
|
| 90 |
+
self.forward_transformer = forward_swin
|
| 91 |
+
elif "next_vit" in backbone:
|
| 92 |
+
from .backbones.next_vit import forward_next_vit
|
| 93 |
+
self.forward_transformer = forward_next_vit
|
| 94 |
+
elif "levit" in backbone:
|
| 95 |
+
self.forward_transformer = forward_levit
|
| 96 |
+
size_refinenet3 = 7
|
| 97 |
+
self.scratch.stem_transpose = stem_b4_transpose(256, 128, get_act_layer("hard_swish"))
|
| 98 |
+
else:
|
| 99 |
+
self.forward_transformer = forward_vit
|
| 100 |
+
|
| 101 |
+
self.scratch.refinenet1 = _make_fusion_block(features, use_bn)
|
| 102 |
+
self.scratch.refinenet2 = _make_fusion_block(features, use_bn)
|
| 103 |
+
self.scratch.refinenet3 = _make_fusion_block(features, use_bn, size_refinenet3)
|
| 104 |
+
if self.number_layers >= 4:
|
| 105 |
+
self.scratch.refinenet4 = _make_fusion_block(features, use_bn)
|
| 106 |
+
|
| 107 |
+
self.scratch.output_conv = head
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def forward(self, x):
|
| 111 |
+
if self.channels_last == True:
|
| 112 |
+
x.contiguous(memory_format=torch.channels_last)
|
| 113 |
+
|
| 114 |
+
layers = self.forward_transformer(self.pretrained, x)
|
| 115 |
+
if self.number_layers == 3:
|
| 116 |
+
layer_1, layer_2, layer_3 = layers
|
| 117 |
+
else:
|
| 118 |
+
layer_1, layer_2, layer_3, layer_4 = layers
|
| 119 |
+
|
| 120 |
+
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
| 121 |
+
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
| 122 |
+
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
| 123 |
+
if self.number_layers >= 4:
|
| 124 |
+
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
| 125 |
+
|
| 126 |
+
if self.number_layers == 3:
|
| 127 |
+
path_3 = self.scratch.refinenet3(layer_3_rn, size=layer_2_rn.shape[2:])
|
| 128 |
+
else:
|
| 129 |
+
path_4 = self.scratch.refinenet4(layer_4_rn, size=layer_3_rn.shape[2:])
|
| 130 |
+
path_3 = self.scratch.refinenet3(path_4, layer_3_rn, size=layer_2_rn.shape[2:])
|
| 131 |
+
path_2 = self.scratch.refinenet2(path_3, layer_2_rn, size=layer_1_rn.shape[2:])
|
| 132 |
+
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
| 133 |
+
|
| 134 |
+
if self.scratch.stem_transpose is not None:
|
| 135 |
+
path_1 = self.scratch.stem_transpose(path_1)
|
| 136 |
+
|
| 137 |
+
out = self.scratch.output_conv(path_1)
|
| 138 |
+
|
| 139 |
+
return out
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
class DPTDepthModel(DPT):
|
| 143 |
+
def __init__(self, path=None, non_negative=True, **kwargs):
|
| 144 |
+
features = kwargs["features"] if "features" in kwargs else 256
|
| 145 |
+
head_features_1 = kwargs["head_features_1"] if "head_features_1" in kwargs else features
|
| 146 |
+
head_features_2 = kwargs["head_features_2"] if "head_features_2" in kwargs else 32
|
| 147 |
+
kwargs.pop("head_features_1", None)
|
| 148 |
+
kwargs.pop("head_features_2", None)
|
| 149 |
+
|
| 150 |
+
head = nn.Sequential(
|
| 151 |
+
nn.Conv2d(head_features_1, head_features_1 // 2, kernel_size=3, stride=1, padding=1),
|
| 152 |
+
Interpolate(scale_factor=2, mode="bilinear", align_corners=True),
|
| 153 |
+
nn.Conv2d(head_features_1 // 2, head_features_2, kernel_size=3, stride=1, padding=1),
|
| 154 |
+
nn.ReLU(True),
|
| 155 |
+
nn.Conv2d(head_features_2, 1, kernel_size=1, stride=1, padding=0),
|
| 156 |
+
nn.ReLU(True) if non_negative else nn.Identity(),
|
| 157 |
+
nn.Identity(),
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
super().__init__(head, **kwargs)
|
| 161 |
+
|
| 162 |
+
if path is not None:
|
| 163 |
+
self.load(path)
|
| 164 |
+
|
| 165 |
+
def forward(self, x):
|
| 166 |
+
return super().forward(x).squeeze(dim=1)
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/midas_net.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""MidashNet: Network for monocular depth estimation trained by mixing several datasets.
|
| 2 |
+
This file contains code that is adapted from
|
| 3 |
+
https://github.com/thomasjpfan/pytorch_refinenet/blob/master/pytorch_refinenet/refinenet/refinenet_4cascade.py
|
| 4 |
+
"""
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
|
| 8 |
+
from .base_model import BaseModel
|
| 9 |
+
from .blocks import FeatureFusionBlock, Interpolate, _make_encoder
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class MidasNet(BaseModel):
|
| 13 |
+
"""Network for monocular depth estimation.
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def __init__(self, path=None, features=256, non_negative=True):
|
| 17 |
+
"""Init.
|
| 18 |
+
|
| 19 |
+
Args:
|
| 20 |
+
path (str, optional): Path to saved model. Defaults to None.
|
| 21 |
+
features (int, optional): Number of features. Defaults to 256.
|
| 22 |
+
backbone (str, optional): Backbone network for encoder. Defaults to resnet50
|
| 23 |
+
"""
|
| 24 |
+
print("Loading weights: ", path)
|
| 25 |
+
|
| 26 |
+
super(MidasNet, self).__init__()
|
| 27 |
+
|
| 28 |
+
use_pretrained = False if path is None else True
|
| 29 |
+
|
| 30 |
+
self.pretrained, self.scratch = _make_encoder(backbone="resnext101_wsl", features=features, use_pretrained=use_pretrained)
|
| 31 |
+
|
| 32 |
+
self.scratch.refinenet4 = FeatureFusionBlock(features)
|
| 33 |
+
self.scratch.refinenet3 = FeatureFusionBlock(features)
|
| 34 |
+
self.scratch.refinenet2 = FeatureFusionBlock(features)
|
| 35 |
+
self.scratch.refinenet1 = FeatureFusionBlock(features)
|
| 36 |
+
|
| 37 |
+
self.scratch.output_conv = nn.Sequential(
|
| 38 |
+
nn.Conv2d(features, 128, kernel_size=3, stride=1, padding=1),
|
| 39 |
+
Interpolate(scale_factor=2, mode="bilinear"),
|
| 40 |
+
nn.Conv2d(128, 32, kernel_size=3, stride=1, padding=1),
|
| 41 |
+
nn.ReLU(True),
|
| 42 |
+
nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
|
| 43 |
+
nn.ReLU(True) if non_negative else nn.Identity(),
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
if path:
|
| 47 |
+
self.load(path)
|
| 48 |
+
|
| 49 |
+
def forward(self, x):
|
| 50 |
+
"""Forward pass.
|
| 51 |
+
|
| 52 |
+
Args:
|
| 53 |
+
x (tensor): input data (image)
|
| 54 |
+
|
| 55 |
+
Returns:
|
| 56 |
+
tensor: depth
|
| 57 |
+
"""
|
| 58 |
+
|
| 59 |
+
layer_1 = self.pretrained.layer1(x)
|
| 60 |
+
layer_2 = self.pretrained.layer2(layer_1)
|
| 61 |
+
layer_3 = self.pretrained.layer3(layer_2)
|
| 62 |
+
layer_4 = self.pretrained.layer4(layer_3)
|
| 63 |
+
|
| 64 |
+
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
| 65 |
+
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
| 66 |
+
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
| 67 |
+
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
| 68 |
+
|
| 69 |
+
path_4 = self.scratch.refinenet4(layer_4_rn)
|
| 70 |
+
path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
|
| 71 |
+
path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
|
| 72 |
+
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
| 73 |
+
|
| 74 |
+
out = self.scratch.output_conv(path_1)
|
| 75 |
+
|
| 76 |
+
return torch.squeeze(out, dim=1)
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/midas_net_custom.py
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""MidashNet: Network for monocular depth estimation trained by mixing several datasets.
|
| 2 |
+
This file contains code that is adapted from
|
| 3 |
+
https://github.com/thomasjpfan/pytorch_refinenet/blob/master/pytorch_refinenet/refinenet/refinenet_4cascade.py
|
| 4 |
+
"""
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
|
| 8 |
+
from .base_model import BaseModel
|
| 9 |
+
from .blocks import FeatureFusionBlock, FeatureFusionBlock_custom, Interpolate, _make_encoder
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class MidasNet_small(BaseModel):
|
| 13 |
+
"""Network for monocular depth estimation.
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def __init__(self, path=None, features=64, backbone="efficientnet_lite3", non_negative=True, exportable=True, channels_last=False, align_corners=True,
|
| 17 |
+
blocks={'expand': True}):
|
| 18 |
+
"""Init.
|
| 19 |
+
|
| 20 |
+
Args:
|
| 21 |
+
path (str, optional): Path to saved model. Defaults to None.
|
| 22 |
+
features (int, optional): Number of features. Defaults to 256.
|
| 23 |
+
backbone (str, optional): Backbone network for encoder. Defaults to resnet50
|
| 24 |
+
"""
|
| 25 |
+
print("Loading weights: ", path)
|
| 26 |
+
|
| 27 |
+
super(MidasNet_small, self).__init__()
|
| 28 |
+
|
| 29 |
+
use_pretrained = False if path else True
|
| 30 |
+
|
| 31 |
+
self.channels_last = channels_last
|
| 32 |
+
self.blocks = blocks
|
| 33 |
+
self.backbone = backbone
|
| 34 |
+
|
| 35 |
+
self.groups = 1
|
| 36 |
+
|
| 37 |
+
features1=features
|
| 38 |
+
features2=features
|
| 39 |
+
features3=features
|
| 40 |
+
features4=features
|
| 41 |
+
self.expand = False
|
| 42 |
+
if "expand" in self.blocks and self.blocks['expand'] == True:
|
| 43 |
+
self.expand = True
|
| 44 |
+
features1=features
|
| 45 |
+
features2=features*2
|
| 46 |
+
features3=features*4
|
| 47 |
+
features4=features*8
|
| 48 |
+
|
| 49 |
+
self.pretrained, self.scratch = _make_encoder(self.backbone, features, use_pretrained, groups=self.groups, expand=self.expand, exportable=exportable)
|
| 50 |
+
|
| 51 |
+
self.scratch.activation = nn.ReLU(False)
|
| 52 |
+
|
| 53 |
+
self.scratch.refinenet4 = FeatureFusionBlock_custom(features4, self.scratch.activation, deconv=False, bn=False, expand=self.expand, align_corners=align_corners)
|
| 54 |
+
self.scratch.refinenet3 = FeatureFusionBlock_custom(features3, self.scratch.activation, deconv=False, bn=False, expand=self.expand, align_corners=align_corners)
|
| 55 |
+
self.scratch.refinenet2 = FeatureFusionBlock_custom(features2, self.scratch.activation, deconv=False, bn=False, expand=self.expand, align_corners=align_corners)
|
| 56 |
+
self.scratch.refinenet1 = FeatureFusionBlock_custom(features1, self.scratch.activation, deconv=False, bn=False, align_corners=align_corners)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
self.scratch.output_conv = nn.Sequential(
|
| 60 |
+
nn.Conv2d(features, features//2, kernel_size=3, stride=1, padding=1, groups=self.groups),
|
| 61 |
+
Interpolate(scale_factor=2, mode="bilinear"),
|
| 62 |
+
nn.Conv2d(features//2, 32, kernel_size=3, stride=1, padding=1),
|
| 63 |
+
self.scratch.activation,
|
| 64 |
+
nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
|
| 65 |
+
nn.ReLU(True) if non_negative else nn.Identity(),
|
| 66 |
+
nn.Identity(),
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
if path:
|
| 70 |
+
self.load(path)
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def forward(self, x):
|
| 74 |
+
"""Forward pass.
|
| 75 |
+
|
| 76 |
+
Args:
|
| 77 |
+
x (tensor): input data (image)
|
| 78 |
+
|
| 79 |
+
Returns:
|
| 80 |
+
tensor: depth
|
| 81 |
+
"""
|
| 82 |
+
if self.channels_last==True:
|
| 83 |
+
print("self.channels_last = ", self.channels_last)
|
| 84 |
+
x.contiguous(memory_format=torch.channels_last)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
layer_1 = self.pretrained.layer1(x)
|
| 88 |
+
layer_2 = self.pretrained.layer2(layer_1)
|
| 89 |
+
layer_3 = self.pretrained.layer3(layer_2)
|
| 90 |
+
layer_4 = self.pretrained.layer4(layer_3)
|
| 91 |
+
|
| 92 |
+
layer_1_rn = self.scratch.layer1_rn(layer_1)
|
| 93 |
+
layer_2_rn = self.scratch.layer2_rn(layer_2)
|
| 94 |
+
layer_3_rn = self.scratch.layer3_rn(layer_3)
|
| 95 |
+
layer_4_rn = self.scratch.layer4_rn(layer_4)
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
path_4 = self.scratch.refinenet4(layer_4_rn)
|
| 99 |
+
path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
|
| 100 |
+
path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
|
| 101 |
+
path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
|
| 102 |
+
|
| 103 |
+
out = self.scratch.output_conv(path_1)
|
| 104 |
+
|
| 105 |
+
return torch.squeeze(out, dim=1)
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def fuse_model(m):
|
| 110 |
+
prev_previous_type = nn.Identity()
|
| 111 |
+
prev_previous_name = ''
|
| 112 |
+
previous_type = nn.Identity()
|
| 113 |
+
previous_name = ''
|
| 114 |
+
for name, module in m.named_modules():
|
| 115 |
+
if prev_previous_type == nn.Conv2d and previous_type == nn.BatchNorm2d and type(module) == nn.ReLU:
|
| 116 |
+
# print("FUSED ", prev_previous_name, previous_name, name)
|
| 117 |
+
torch.quantization.fuse_modules(m, [prev_previous_name, previous_name, name], inplace=True)
|
| 118 |
+
elif prev_previous_type == nn.Conv2d and previous_type == nn.BatchNorm2d:
|
| 119 |
+
# print("FUSED ", prev_previous_name, previous_name)
|
| 120 |
+
torch.quantization.fuse_modules(m, [prev_previous_name, previous_name], inplace=True)
|
| 121 |
+
# elif previous_type == nn.Conv2d and type(module) == nn.ReLU:
|
| 122 |
+
# print("FUSED ", previous_name, name)
|
| 123 |
+
# torch.quantization.fuse_modules(m, [previous_name, name], inplace=True)
|
| 124 |
+
|
| 125 |
+
prev_previous_type = previous_type
|
| 126 |
+
prev_previous_name = previous_name
|
| 127 |
+
previous_type = type(module)
|
| 128 |
+
previous_name = name
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/model_loader.py
ADDED
|
@@ -0,0 +1,242 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from midas.dpt_depth import DPTDepthModel
|
| 5 |
+
from midas.midas_net import MidasNet
|
| 6 |
+
from midas.midas_net_custom import MidasNet_small
|
| 7 |
+
from midas.transforms import Resize, NormalizeImage, PrepareForNet
|
| 8 |
+
|
| 9 |
+
from torchvision.transforms import Compose
|
| 10 |
+
|
| 11 |
+
default_models = {
|
| 12 |
+
"dpt_beit_large_512": "weights/dpt_beit_large_512.pt",
|
| 13 |
+
"dpt_beit_large_384": "weights/dpt_beit_large_384.pt",
|
| 14 |
+
"dpt_beit_base_384": "weights/dpt_beit_base_384.pt",
|
| 15 |
+
"dpt_swin2_large_384": "weights/dpt_swin2_large_384.pt",
|
| 16 |
+
"dpt_swin2_base_384": "weights/dpt_swin2_base_384.pt",
|
| 17 |
+
"dpt_swin2_tiny_256": "weights/dpt_swin2_tiny_256.pt",
|
| 18 |
+
"dpt_swin_large_384": "weights/dpt_swin_large_384.pt",
|
| 19 |
+
"dpt_next_vit_large_384": "weights/dpt_next_vit_large_384.pt",
|
| 20 |
+
"dpt_levit_224": "weights/dpt_levit_224.pt",
|
| 21 |
+
"dpt_large_384": "weights/dpt_large_384.pt",
|
| 22 |
+
"dpt_hybrid_384": "weights/dpt_hybrid_384.pt",
|
| 23 |
+
"midas_v21_384": "weights/midas_v21_384.pt",
|
| 24 |
+
"midas_v21_small_256": "weights/midas_v21_small_256.pt",
|
| 25 |
+
"openvino_midas_v21_small_256": "weights/openvino_midas_v21_small_256.xml",
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def load_model(device, model_path, model_type="dpt_large_384", optimize=True, height=None, square=False):
|
| 30 |
+
"""Load the specified network.
|
| 31 |
+
|
| 32 |
+
Args:
|
| 33 |
+
device (device): the torch device used
|
| 34 |
+
model_path (str): path to saved model
|
| 35 |
+
model_type (str): the type of the model to be loaded
|
| 36 |
+
optimize (bool): optimize the model to half-integer on CUDA?
|
| 37 |
+
height (int): inference encoder image height
|
| 38 |
+
square (bool): resize to a square resolution?
|
| 39 |
+
|
| 40 |
+
Returns:
|
| 41 |
+
The loaded network, the transform which prepares images as input to the network and the dimensions of the
|
| 42 |
+
network input
|
| 43 |
+
"""
|
| 44 |
+
if "openvino" in model_type:
|
| 45 |
+
from openvino.runtime import Core
|
| 46 |
+
|
| 47 |
+
keep_aspect_ratio = not square
|
| 48 |
+
|
| 49 |
+
if model_type == "dpt_beit_large_512":
|
| 50 |
+
model = DPTDepthModel(
|
| 51 |
+
path=model_path,
|
| 52 |
+
backbone="beitl16_512",
|
| 53 |
+
non_negative=True,
|
| 54 |
+
)
|
| 55 |
+
net_w, net_h = 512, 512
|
| 56 |
+
resize_mode = "minimal"
|
| 57 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 58 |
+
|
| 59 |
+
elif model_type == "dpt_beit_large_384":
|
| 60 |
+
model = DPTDepthModel(
|
| 61 |
+
path=model_path,
|
| 62 |
+
backbone="beitl16_384",
|
| 63 |
+
non_negative=True,
|
| 64 |
+
)
|
| 65 |
+
net_w, net_h = 384, 384
|
| 66 |
+
resize_mode = "minimal"
|
| 67 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 68 |
+
|
| 69 |
+
elif model_type == "dpt_beit_base_384":
|
| 70 |
+
model = DPTDepthModel(
|
| 71 |
+
path=model_path,
|
| 72 |
+
backbone="beitb16_384",
|
| 73 |
+
non_negative=True,
|
| 74 |
+
)
|
| 75 |
+
net_w, net_h = 384, 384
|
| 76 |
+
resize_mode = "minimal"
|
| 77 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 78 |
+
|
| 79 |
+
elif model_type == "dpt_swin2_large_384":
|
| 80 |
+
model = DPTDepthModel(
|
| 81 |
+
path=model_path,
|
| 82 |
+
backbone="swin2l24_384",
|
| 83 |
+
non_negative=True,
|
| 84 |
+
)
|
| 85 |
+
net_w, net_h = 384, 384
|
| 86 |
+
keep_aspect_ratio = False
|
| 87 |
+
resize_mode = "minimal"
|
| 88 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 89 |
+
|
| 90 |
+
elif model_type == "dpt_swin2_base_384":
|
| 91 |
+
model = DPTDepthModel(
|
| 92 |
+
path=model_path,
|
| 93 |
+
backbone="swin2b24_384",
|
| 94 |
+
non_negative=True,
|
| 95 |
+
)
|
| 96 |
+
net_w, net_h = 384, 384
|
| 97 |
+
keep_aspect_ratio = False
|
| 98 |
+
resize_mode = "minimal"
|
| 99 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 100 |
+
|
| 101 |
+
elif model_type == "dpt_swin2_tiny_256":
|
| 102 |
+
model = DPTDepthModel(
|
| 103 |
+
path=model_path,
|
| 104 |
+
backbone="swin2t16_256",
|
| 105 |
+
non_negative=True,
|
| 106 |
+
)
|
| 107 |
+
net_w, net_h = 256, 256
|
| 108 |
+
keep_aspect_ratio = False
|
| 109 |
+
resize_mode = "minimal"
|
| 110 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 111 |
+
|
| 112 |
+
elif model_type == "dpt_swin_large_384":
|
| 113 |
+
model = DPTDepthModel(
|
| 114 |
+
path=model_path,
|
| 115 |
+
backbone="swinl12_384",
|
| 116 |
+
non_negative=True,
|
| 117 |
+
)
|
| 118 |
+
net_w, net_h = 384, 384
|
| 119 |
+
keep_aspect_ratio = False
|
| 120 |
+
resize_mode = "minimal"
|
| 121 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 122 |
+
|
| 123 |
+
elif model_type == "dpt_next_vit_large_384":
|
| 124 |
+
model = DPTDepthModel(
|
| 125 |
+
path=model_path,
|
| 126 |
+
backbone="next_vit_large_6m",
|
| 127 |
+
non_negative=True,
|
| 128 |
+
)
|
| 129 |
+
net_w, net_h = 384, 384
|
| 130 |
+
resize_mode = "minimal"
|
| 131 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 132 |
+
|
| 133 |
+
# We change the notation from dpt_levit_224 (MiDaS notation) to levit_384 (timm notation) here, where the 224 refers
|
| 134 |
+
# to the resolution 224x224 used by LeViT and 384 is the first entry of the embed_dim, see _cfg and model_cfgs of
|
| 135 |
+
# https://github.com/rwightman/pytorch-image-models/blob/main/timm/models/levit.py
|
| 136 |
+
# (commit id: 927f031293a30afb940fff0bee34b85d9c059b0e)
|
| 137 |
+
elif model_type == "dpt_levit_224":
|
| 138 |
+
model = DPTDepthModel(
|
| 139 |
+
path=model_path,
|
| 140 |
+
backbone="levit_384",
|
| 141 |
+
non_negative=True,
|
| 142 |
+
head_features_1=64,
|
| 143 |
+
head_features_2=8,
|
| 144 |
+
)
|
| 145 |
+
net_w, net_h = 224, 224
|
| 146 |
+
keep_aspect_ratio = False
|
| 147 |
+
resize_mode = "minimal"
|
| 148 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 149 |
+
|
| 150 |
+
elif model_type == "dpt_large_384":
|
| 151 |
+
model = DPTDepthModel(
|
| 152 |
+
path=model_path,
|
| 153 |
+
backbone="vitl16_384",
|
| 154 |
+
non_negative=True,
|
| 155 |
+
)
|
| 156 |
+
net_w, net_h = 384, 384
|
| 157 |
+
resize_mode = "minimal"
|
| 158 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 159 |
+
|
| 160 |
+
elif model_type == "dpt_hybrid_384":
|
| 161 |
+
model = DPTDepthModel(
|
| 162 |
+
path=model_path,
|
| 163 |
+
backbone="vitb_rn50_384",
|
| 164 |
+
non_negative=True,
|
| 165 |
+
)
|
| 166 |
+
net_w, net_h = 384, 384
|
| 167 |
+
resize_mode = "minimal"
|
| 168 |
+
normalization = NormalizeImage(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 169 |
+
|
| 170 |
+
elif model_type == "midas_v21_384":
|
| 171 |
+
model = MidasNet(model_path, non_negative=True)
|
| 172 |
+
net_w, net_h = 384, 384
|
| 173 |
+
resize_mode = "upper_bound"
|
| 174 |
+
normalization = NormalizeImage(
|
| 175 |
+
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
elif model_type == "midas_v21_small_256":
|
| 179 |
+
model = MidasNet_small(model_path, features=64, backbone="efficientnet_lite3", exportable=True,
|
| 180 |
+
non_negative=True, blocks={'expand': True})
|
| 181 |
+
net_w, net_h = 256, 256
|
| 182 |
+
resize_mode = "upper_bound"
|
| 183 |
+
normalization = NormalizeImage(
|
| 184 |
+
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
elif model_type == "openvino_midas_v21_small_256":
|
| 188 |
+
ie = Core()
|
| 189 |
+
uncompiled_model = ie.read_model(model=model_path)
|
| 190 |
+
model = ie.compile_model(uncompiled_model, "CPU")
|
| 191 |
+
net_w, net_h = 256, 256
|
| 192 |
+
resize_mode = "upper_bound"
|
| 193 |
+
normalization = NormalizeImage(
|
| 194 |
+
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
|
| 195 |
+
)
|
| 196 |
+
|
| 197 |
+
else:
|
| 198 |
+
print(f"model_type '{model_type}' not implemented, use: --model_type large")
|
| 199 |
+
assert False
|
| 200 |
+
|
| 201 |
+
if not "openvino" in model_type:
|
| 202 |
+
print("Model loaded, number of parameters = {:.0f}M".format(sum(p.numel() for p in model.parameters()) / 1e6))
|
| 203 |
+
else:
|
| 204 |
+
print("Model loaded, optimized with OpenVINO")
|
| 205 |
+
|
| 206 |
+
if "openvino" in model_type:
|
| 207 |
+
keep_aspect_ratio = False
|
| 208 |
+
|
| 209 |
+
if height is not None:
|
| 210 |
+
net_w, net_h = height, height
|
| 211 |
+
|
| 212 |
+
transform = Compose(
|
| 213 |
+
[
|
| 214 |
+
Resize(
|
| 215 |
+
net_w,
|
| 216 |
+
net_h,
|
| 217 |
+
resize_target=None,
|
| 218 |
+
keep_aspect_ratio=keep_aspect_ratio,
|
| 219 |
+
ensure_multiple_of=32,
|
| 220 |
+
resize_method=resize_mode,
|
| 221 |
+
image_interpolation_method=cv2.INTER_CUBIC,
|
| 222 |
+
),
|
| 223 |
+
normalization,
|
| 224 |
+
PrepareForNet(),
|
| 225 |
+
]
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
if not "openvino" in model_type:
|
| 229 |
+
model.eval()
|
| 230 |
+
|
| 231 |
+
if optimize and (device == torch.device("cuda")):
|
| 232 |
+
if not "openvino" in model_type:
|
| 233 |
+
model = model.to(memory_format=torch.channels_last)
|
| 234 |
+
model = model.half()
|
| 235 |
+
else:
|
| 236 |
+
print("Error: OpenVINO models are already optimized. No optimization to half-float possible.")
|
| 237 |
+
exit()
|
| 238 |
+
|
| 239 |
+
if not "openvino" in model_type:
|
| 240 |
+
model.to(device)
|
| 241 |
+
|
| 242 |
+
return model, transform, net_w, net_h
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/midas/transforms.py
ADDED
|
@@ -0,0 +1,234 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import cv2
|
| 3 |
+
import math
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def apply_min_size(sample, size, image_interpolation_method=cv2.INTER_AREA):
|
| 7 |
+
"""Rezise the sample to ensure the given size. Keeps aspect ratio.
|
| 8 |
+
|
| 9 |
+
Args:
|
| 10 |
+
sample (dict): sample
|
| 11 |
+
size (tuple): image size
|
| 12 |
+
|
| 13 |
+
Returns:
|
| 14 |
+
tuple: new size
|
| 15 |
+
"""
|
| 16 |
+
shape = list(sample["disparity"].shape)
|
| 17 |
+
|
| 18 |
+
if shape[0] >= size[0] and shape[1] >= size[1]:
|
| 19 |
+
return sample
|
| 20 |
+
|
| 21 |
+
scale = [0, 0]
|
| 22 |
+
scale[0] = size[0] / shape[0]
|
| 23 |
+
scale[1] = size[1] / shape[1]
|
| 24 |
+
|
| 25 |
+
scale = max(scale)
|
| 26 |
+
|
| 27 |
+
shape[0] = math.ceil(scale * shape[0])
|
| 28 |
+
shape[1] = math.ceil(scale * shape[1])
|
| 29 |
+
|
| 30 |
+
# resize
|
| 31 |
+
sample["image"] = cv2.resize(
|
| 32 |
+
sample["image"], tuple(shape[::-1]), interpolation=image_interpolation_method
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
sample["disparity"] = cv2.resize(
|
| 36 |
+
sample["disparity"], tuple(shape[::-1]), interpolation=cv2.INTER_NEAREST
|
| 37 |
+
)
|
| 38 |
+
sample["mask"] = cv2.resize(
|
| 39 |
+
sample["mask"].astype(np.float32),
|
| 40 |
+
tuple(shape[::-1]),
|
| 41 |
+
interpolation=cv2.INTER_NEAREST,
|
| 42 |
+
)
|
| 43 |
+
sample["mask"] = sample["mask"].astype(bool)
|
| 44 |
+
|
| 45 |
+
return tuple(shape)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class Resize(object):
|
| 49 |
+
"""Resize sample to given size (width, height).
|
| 50 |
+
"""
|
| 51 |
+
|
| 52 |
+
def __init__(
|
| 53 |
+
self,
|
| 54 |
+
width,
|
| 55 |
+
height,
|
| 56 |
+
resize_target=True,
|
| 57 |
+
keep_aspect_ratio=False,
|
| 58 |
+
ensure_multiple_of=1,
|
| 59 |
+
resize_method="lower_bound",
|
| 60 |
+
image_interpolation_method=cv2.INTER_AREA,
|
| 61 |
+
):
|
| 62 |
+
"""Init.
|
| 63 |
+
|
| 64 |
+
Args:
|
| 65 |
+
width (int): desired output width
|
| 66 |
+
height (int): desired output height
|
| 67 |
+
resize_target (bool, optional):
|
| 68 |
+
True: Resize the full sample (image, mask, target).
|
| 69 |
+
False: Resize image only.
|
| 70 |
+
Defaults to True.
|
| 71 |
+
keep_aspect_ratio (bool, optional):
|
| 72 |
+
True: Keep the aspect ratio of the input sample.
|
| 73 |
+
Output sample might not have the given width and height, and
|
| 74 |
+
resize behaviour depends on the parameter 'resize_method'.
|
| 75 |
+
Defaults to False.
|
| 76 |
+
ensure_multiple_of (int, optional):
|
| 77 |
+
Output width and height is constrained to be multiple of this parameter.
|
| 78 |
+
Defaults to 1.
|
| 79 |
+
resize_method (str, optional):
|
| 80 |
+
"lower_bound": Output will be at least as large as the given size.
|
| 81 |
+
"upper_bound": Output will be at max as large as the given size. (Output size might be smaller than given size.)
|
| 82 |
+
"minimal": Scale as least as possible. (Output size might be smaller than given size.)
|
| 83 |
+
Defaults to "lower_bound".
|
| 84 |
+
"""
|
| 85 |
+
self.__width = width
|
| 86 |
+
self.__height = height
|
| 87 |
+
|
| 88 |
+
self.__resize_target = resize_target
|
| 89 |
+
self.__keep_aspect_ratio = keep_aspect_ratio
|
| 90 |
+
self.__multiple_of = ensure_multiple_of
|
| 91 |
+
self.__resize_method = resize_method
|
| 92 |
+
self.__image_interpolation_method = image_interpolation_method
|
| 93 |
+
|
| 94 |
+
def constrain_to_multiple_of(self, x, min_val=0, max_val=None):
|
| 95 |
+
y = (np.round(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
| 96 |
+
|
| 97 |
+
if max_val is not None and y > max_val:
|
| 98 |
+
y = (np.floor(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
| 99 |
+
|
| 100 |
+
if y < min_val:
|
| 101 |
+
y = (np.ceil(x / self.__multiple_of) * self.__multiple_of).astype(int)
|
| 102 |
+
|
| 103 |
+
return y
|
| 104 |
+
|
| 105 |
+
def get_size(self, width, height):
|
| 106 |
+
# determine new height and width
|
| 107 |
+
scale_height = self.__height / height
|
| 108 |
+
scale_width = self.__width / width
|
| 109 |
+
|
| 110 |
+
if self.__keep_aspect_ratio:
|
| 111 |
+
if self.__resize_method == "lower_bound":
|
| 112 |
+
# scale such that output size is lower bound
|
| 113 |
+
if scale_width > scale_height:
|
| 114 |
+
# fit width
|
| 115 |
+
scale_height = scale_width
|
| 116 |
+
else:
|
| 117 |
+
# fit height
|
| 118 |
+
scale_width = scale_height
|
| 119 |
+
elif self.__resize_method == "upper_bound":
|
| 120 |
+
# scale such that output size is upper bound
|
| 121 |
+
if scale_width < scale_height:
|
| 122 |
+
# fit width
|
| 123 |
+
scale_height = scale_width
|
| 124 |
+
else:
|
| 125 |
+
# fit height
|
| 126 |
+
scale_width = scale_height
|
| 127 |
+
elif self.__resize_method == "minimal":
|
| 128 |
+
# scale as least as possbile
|
| 129 |
+
if abs(1 - scale_width) < abs(1 - scale_height):
|
| 130 |
+
# fit width
|
| 131 |
+
scale_height = scale_width
|
| 132 |
+
else:
|
| 133 |
+
# fit height
|
| 134 |
+
scale_width = scale_height
|
| 135 |
+
else:
|
| 136 |
+
raise ValueError(
|
| 137 |
+
f"resize_method {self.__resize_method} not implemented"
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
if self.__resize_method == "lower_bound":
|
| 141 |
+
new_height = self.constrain_to_multiple_of(
|
| 142 |
+
scale_height * height, min_val=self.__height
|
| 143 |
+
)
|
| 144 |
+
new_width = self.constrain_to_multiple_of(
|
| 145 |
+
scale_width * width, min_val=self.__width
|
| 146 |
+
)
|
| 147 |
+
elif self.__resize_method == "upper_bound":
|
| 148 |
+
new_height = self.constrain_to_multiple_of(
|
| 149 |
+
scale_height * height, max_val=self.__height
|
| 150 |
+
)
|
| 151 |
+
new_width = self.constrain_to_multiple_of(
|
| 152 |
+
scale_width * width, max_val=self.__width
|
| 153 |
+
)
|
| 154 |
+
elif self.__resize_method == "minimal":
|
| 155 |
+
new_height = self.constrain_to_multiple_of(scale_height * height)
|
| 156 |
+
new_width = self.constrain_to_multiple_of(scale_width * width)
|
| 157 |
+
else:
|
| 158 |
+
raise ValueError(f"resize_method {self.__resize_method} not implemented")
|
| 159 |
+
|
| 160 |
+
return (new_width, new_height)
|
| 161 |
+
|
| 162 |
+
def __call__(self, sample):
|
| 163 |
+
width, height = self.get_size(
|
| 164 |
+
sample["image"].shape[1], sample["image"].shape[0]
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
# resize sample
|
| 168 |
+
sample["image"] = cv2.resize(
|
| 169 |
+
sample["image"],
|
| 170 |
+
(width, height),
|
| 171 |
+
interpolation=self.__image_interpolation_method,
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
if self.__resize_target:
|
| 175 |
+
if "disparity" in sample:
|
| 176 |
+
sample["disparity"] = cv2.resize(
|
| 177 |
+
sample["disparity"],
|
| 178 |
+
(width, height),
|
| 179 |
+
interpolation=cv2.INTER_NEAREST,
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
if "depth" in sample:
|
| 183 |
+
sample["depth"] = cv2.resize(
|
| 184 |
+
sample["depth"], (width, height), interpolation=cv2.INTER_NEAREST
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
sample["mask"] = cv2.resize(
|
| 188 |
+
sample["mask"].astype(np.float32),
|
| 189 |
+
(width, height),
|
| 190 |
+
interpolation=cv2.INTER_NEAREST,
|
| 191 |
+
)
|
| 192 |
+
sample["mask"] = sample["mask"].astype(bool)
|
| 193 |
+
|
| 194 |
+
return sample
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
class NormalizeImage(object):
|
| 198 |
+
"""Normlize image by given mean and std.
|
| 199 |
+
"""
|
| 200 |
+
|
| 201 |
+
def __init__(self, mean, std):
|
| 202 |
+
self.__mean = mean
|
| 203 |
+
self.__std = std
|
| 204 |
+
|
| 205 |
+
def __call__(self, sample):
|
| 206 |
+
sample["image"] = (sample["image"] - self.__mean) / self.__std
|
| 207 |
+
|
| 208 |
+
return sample
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class PrepareForNet(object):
|
| 212 |
+
"""Prepare sample for usage as network input.
|
| 213 |
+
"""
|
| 214 |
+
|
| 215 |
+
def __init__(self):
|
| 216 |
+
pass
|
| 217 |
+
|
| 218 |
+
def __call__(self, sample):
|
| 219 |
+
image = np.transpose(sample["image"], (2, 0, 1))
|
| 220 |
+
sample["image"] = np.ascontiguousarray(image).astype(np.float32)
|
| 221 |
+
|
| 222 |
+
if "mask" in sample:
|
| 223 |
+
sample["mask"] = sample["mask"].astype(np.float32)
|
| 224 |
+
sample["mask"] = np.ascontiguousarray(sample["mask"])
|
| 225 |
+
|
| 226 |
+
if "disparity" in sample:
|
| 227 |
+
disparity = sample["disparity"].astype(np.float32)
|
| 228 |
+
sample["disparity"] = np.ascontiguousarray(disparity)
|
| 229 |
+
|
| 230 |
+
if "depth" in sample:
|
| 231 |
+
depth = sample["depth"].astype(np.float32)
|
| 232 |
+
sample["depth"] = np.ascontiguousarray(depth)
|
| 233 |
+
|
| 234 |
+
return sample
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2020 Alexey
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/README.md
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MiDaS for ROS1 by using LibTorch in C++
|
| 2 |
+
|
| 3 |
+
### Requirements
|
| 4 |
+
|
| 5 |
+
- Ubuntu 17.10 / 18.04 / 20.04, Debian Stretch
|
| 6 |
+
- ROS Melodic for Ubuntu (17.10 / 18.04) / Debian Stretch, ROS Noetic for Ubuntu 20.04
|
| 7 |
+
- C++11
|
| 8 |
+
- LibTorch >= 1.6
|
| 9 |
+
|
| 10 |
+
## Quick Start with a MiDaS Example
|
| 11 |
+
|
| 12 |
+
MiDaS is a neural network to compute depth from a single image.
|
| 13 |
+
|
| 14 |
+
* input from `image_topic`: `sensor_msgs/Image` - `RGB8` image with any shape
|
| 15 |
+
* output to `midas_topic`: `sensor_msgs/Image` - `TYPE_32FC1` inverse relative depth maps in range [0 - 255] with original size and channels=1
|
| 16 |
+
|
| 17 |
+
### Install Dependecies
|
| 18 |
+
|
| 19 |
+
* install ROS Melodic for Ubuntu 17.10 / 18.04:
|
| 20 |
+
```bash
|
| 21 |
+
wget https://raw.githubusercontent.com/isl-org/MiDaS/master/ros/additions/install_ros_melodic_ubuntu_17_18.sh
|
| 22 |
+
./install_ros_melodic_ubuntu_17_18.sh
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
or Noetic for Ubuntu 20.04:
|
| 26 |
+
|
| 27 |
+
```bash
|
| 28 |
+
wget https://raw.githubusercontent.com/isl-org/MiDaS/master/ros/additions/install_ros_noetic_ubuntu_20.sh
|
| 29 |
+
./install_ros_noetic_ubuntu_20.sh
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
* install LibTorch 1.7 with CUDA 11.0:
|
| 34 |
+
|
| 35 |
+
On **Jetson (ARM)**:
|
| 36 |
+
```bash
|
| 37 |
+
wget https://nvidia.box.com/shared/static/wa34qwrwtk9njtyarwt5nvo6imenfy26.whl -O torch-1.7.0-cp36-cp36m-linux_aarch64.whl
|
| 38 |
+
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
|
| 39 |
+
pip3 install Cython
|
| 40 |
+
pip3 install numpy torch-1.7.0-cp36-cp36m-linux_aarch64.whl
|
| 41 |
+
```
|
| 42 |
+
Or compile LibTorch from source: https://github.com/pytorch/pytorch#from-source
|
| 43 |
+
|
| 44 |
+
On **Linux (x86_64)**:
|
| 45 |
+
```bash
|
| 46 |
+
cd ~/
|
| 47 |
+
wget https://download.pytorch.org/libtorch/cu110/libtorch-cxx11-abi-shared-with-deps-1.7.0%2Bcu110.zip
|
| 48 |
+
unzip libtorch-cxx11-abi-shared-with-deps-1.7.0+cu110.zip
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
* create symlink for OpenCV:
|
| 52 |
+
|
| 53 |
+
```bash
|
| 54 |
+
sudo ln -s /usr/include/opencv4 /usr/include/opencv
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
* download and install MiDaS:
|
| 58 |
+
|
| 59 |
+
```bash
|
| 60 |
+
source ~/.bashrc
|
| 61 |
+
cd ~/
|
| 62 |
+
mkdir catkin_ws
|
| 63 |
+
cd catkin_ws
|
| 64 |
+
git clone https://github.com/isl-org/MiDaS
|
| 65 |
+
mkdir src
|
| 66 |
+
cp -r MiDaS/ros/* src
|
| 67 |
+
|
| 68 |
+
chmod +x src/additions/*.sh
|
| 69 |
+
chmod +x src/*.sh
|
| 70 |
+
chmod +x src/midas_cpp/scripts/*.py
|
| 71 |
+
cp src/additions/do_catkin_make.sh ./do_catkin_make.sh
|
| 72 |
+
./do_catkin_make.sh
|
| 73 |
+
./src/additions/downloads.sh
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
### Usage
|
| 77 |
+
|
| 78 |
+
* run only `midas` node: `~/catkin_ws/src/launch_midas_cpp.sh`
|
| 79 |
+
|
| 80 |
+
#### Test
|
| 81 |
+
|
| 82 |
+
* Test - capture video and show result in the window:
|
| 83 |
+
* place any `test.mp4` video file to the directory `~/catkin_ws/src/`
|
| 84 |
+
* run `midas` node: `~/catkin_ws/src/launch_midas_cpp.sh`
|
| 85 |
+
* run test nodes in another terminal: `cd ~/catkin_ws/src && ./run_talker_listener_test.sh` and wait 30 seconds
|
| 86 |
+
|
| 87 |
+
(to use Python 2, run command `sed -i 's/python3/python2/' ~/catkin_ws/src/midas_cpp/scripts/*.py` )
|
| 88 |
+
|
| 89 |
+
## Mobile version of MiDaS - Monocular Depth Estimation
|
| 90 |
+
|
| 91 |
+
### Accuracy
|
| 92 |
+
|
| 93 |
+
* MiDaS v2 small - ResNet50 default-decoder 384x384
|
| 94 |
+
* MiDaS v2.1 small - EfficientNet-Lite3 small-decoder 256x256
|
| 95 |
+
|
| 96 |
+
**Zero-shot error** (the lower - the better):
|
| 97 |
+
|
| 98 |
+
| Model | DIW WHDR | Eth3d AbsRel | Sintel AbsRel | Kitti δ>1.25 | NyuDepthV2 δ>1.25 | TUM δ>1.25 |
|
| 99 |
+
|---|---|---|---|---|---|---|
|
| 100 |
+
| MiDaS v2 small 384x384 | **0.1248** | 0.1550 | **0.3300** | **21.81** | 15.73 | 17.00 |
|
| 101 |
+
| MiDaS v2.1 small 256x256 | 0.1344 | **0.1344** | 0.3370 | 29.27 | **13.43** | **14.53** |
|
| 102 |
+
| Relative improvement, % | -8 % | **+13 %** | -2 % | -34 % | **+15 %** | **+15 %** |
|
| 103 |
+
|
| 104 |
+
None of Train/Valid/Test subsets of datasets (DIW, Eth3d, Sintel, Kitti, NyuDepthV2, TUM) were not involved in Training or Fine Tuning.
|
| 105 |
+
|
| 106 |
+
### Inference speed (FPS) on nVidia GPU
|
| 107 |
+
|
| 108 |
+
Inference speed excluding pre and post processing, batch=1, **Frames Per Second** (the higher - the better):
|
| 109 |
+
|
| 110 |
+
| Model | Jetson Nano, FPS | RTX 2080Ti, FPS |
|
| 111 |
+
|---|---|---|
|
| 112 |
+
| MiDaS v2 small 384x384 | 1.6 | 117 |
|
| 113 |
+
| MiDaS v2.1 small 256x256 | 8.1 | 232 |
|
| 114 |
+
| SpeedUp, X times | **5x** | **2x** |
|
| 115 |
+
|
| 116 |
+
### Citation
|
| 117 |
+
|
| 118 |
+
This repository contains code to compute depth from a single image. It accompanies our [paper](https://arxiv.org/abs/1907.01341v3):
|
| 119 |
+
|
| 120 |
+
>Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer
|
| 121 |
+
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, Vladlen Koltun
|
| 122 |
+
|
| 123 |
+
Please cite our paper if you use this code or any of the models:
|
| 124 |
+
```
|
| 125 |
+
@article{Ranftl2020,
|
| 126 |
+
author = {Ren\'{e} Ranftl and Katrin Lasinger and David Hafner and Konrad Schindler and Vladlen Koltun},
|
| 127 |
+
title = {Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer},
|
| 128 |
+
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},
|
| 129 |
+
year = {2020},
|
| 130 |
+
}
|
| 131 |
+
```
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/additions/do_catkin_make.sh
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
mkdir src
|
| 2 |
+
catkin_make
|
| 3 |
+
source devel/setup.bash
|
| 4 |
+
echo $ROS_PACKAGE_PATH
|
| 5 |
+
chmod +x ./devel/setup.bash
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/additions/downloads.sh
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
mkdir ~/.ros
|
| 2 |
+
wget https://github.com/isl-org/MiDaS/releases/download/v2_1/model-small-traced.pt
|
| 3 |
+
cp ./model-small-traced.pt ~/.ros/model-small-traced.pt
|
| 4 |
+
|
| 5 |
+
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/additions/install_ros_melodic_ubuntu_17_18.sh
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#@title { display-mode: "code" }
|
| 2 |
+
|
| 3 |
+
#from http://wiki.ros.org/indigo/Installation/Ubuntu
|
| 4 |
+
|
| 5 |
+
#1.2 Setup sources.list
|
| 6 |
+
sudo sh -c 'echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list'
|
| 7 |
+
|
| 8 |
+
# 1.3 Setup keys
|
| 9 |
+
sudo apt-key adv --keyserver 'hkp://keyserver.ubuntu.com:80' --recv-key C1CF6E31E6BADE8868B172B4F42ED6FBAB17C654
|
| 10 |
+
sudo apt-key adv --keyserver 'hkp://ha.pool.sks-keyservers.net:80' --recv-key 421C365BD9FF1F717815A3895523BAEEB01FA116
|
| 11 |
+
|
| 12 |
+
curl -sSL 'http://keyserver.ubuntu.com/pks/lookup?op=get&search=0xC1CF6E31E6BADE8868B172B4F42ED6FBAB17C654' | sudo apt-key add -
|
| 13 |
+
|
| 14 |
+
# 1.4 Installation
|
| 15 |
+
sudo apt-get update
|
| 16 |
+
sudo apt-get upgrade
|
| 17 |
+
|
| 18 |
+
# Desktop-Full Install:
|
| 19 |
+
sudo apt-get install ros-melodic-desktop-full
|
| 20 |
+
|
| 21 |
+
printf "\nsource /opt/ros/melodic/setup.bash\n" >> ~/.bashrc
|
| 22 |
+
|
| 23 |
+
# 1.5 Initialize rosdep
|
| 24 |
+
sudo rosdep init
|
| 25 |
+
rosdep update
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
# 1.7 Getting rosinstall (python)
|
| 29 |
+
sudo apt-get install python-rosinstall
|
| 30 |
+
sudo apt-get install python-catkin-tools
|
| 31 |
+
sudo apt-get install python-rospy
|
| 32 |
+
sudo apt-get install python-rosdep
|
| 33 |
+
sudo apt-get install python-roscd
|
| 34 |
+
sudo apt-get install python-pip
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/additions/install_ros_noetic_ubuntu_20.sh
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#@title { display-mode: "code" }
|
| 2 |
+
|
| 3 |
+
#from http://wiki.ros.org/indigo/Installation/Ubuntu
|
| 4 |
+
|
| 5 |
+
#1.2 Setup sources.list
|
| 6 |
+
sudo sh -c 'echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list'
|
| 7 |
+
|
| 8 |
+
# 1.3 Setup keys
|
| 9 |
+
sudo apt-key adv --keyserver 'hkp://keyserver.ubuntu.com:80' --recv-key C1CF6E31E6BADE8868B172B4F42ED6FBAB17C654
|
| 10 |
+
|
| 11 |
+
curl -sSL 'http://keyserver.ubuntu.com/pks/lookup?op=get&search=0xC1CF6E31E6BADE8868B172B4F42ED6FBAB17C654' | sudo apt-key add -
|
| 12 |
+
|
| 13 |
+
# 1.4 Installation
|
| 14 |
+
sudo apt-get update
|
| 15 |
+
sudo apt-get upgrade
|
| 16 |
+
|
| 17 |
+
# Desktop-Full Install:
|
| 18 |
+
sudo apt-get install ros-noetic-desktop-full
|
| 19 |
+
|
| 20 |
+
printf "\nsource /opt/ros/noetic/setup.bash\n" >> ~/.bashrc
|
| 21 |
+
|
| 22 |
+
# 1.5 Initialize rosdep
|
| 23 |
+
sudo rosdep init
|
| 24 |
+
rosdep update
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
# 1.7 Getting rosinstall (python)
|
| 28 |
+
sudo apt-get install python3-rosinstall
|
| 29 |
+
sudo apt-get install python3-catkin-tools
|
| 30 |
+
sudo apt-get install python3-rospy
|
| 31 |
+
sudo apt-get install python3-rosdep
|
| 32 |
+
sudo apt-get install python3-roscd
|
| 33 |
+
sudo apt-get install python3-pip
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/additions/make_package_cpp.sh
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cd ~/catkin_ws/src
|
| 2 |
+
catkin_create_pkg midas_cpp std_msgs roscpp cv_bridge sensor_msgs image_transport
|
| 3 |
+
cd ~/catkin_ws
|
| 4 |
+
catkin_make
|
| 5 |
+
|
| 6 |
+
chmod +x ~/catkin_ws/devel/setup.bash
|
| 7 |
+
printf "\nsource ~/catkin_ws/devel/setup.bash" >> ~/.bashrc
|
| 8 |
+
source ~/catkin_ws/devel/setup.bash
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
sudo rosdep init
|
| 12 |
+
rosdep update
|
| 13 |
+
#rospack depends1 midas_cpp
|
| 14 |
+
roscd midas_cpp
|
| 15 |
+
#cat package.xml
|
| 16 |
+
#rospack depends midas_cpp
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/launch_midas_cpp.sh
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
source ~/catkin_ws/devel/setup.bash
|
| 2 |
+
roslaunch midas_cpp midas_cpp.launch model_name:="model-small-traced.pt" input_topic:="image_topic" output_topic:="midas_topic" out_orig_size:="true"
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/midas_cpp/CMakeLists.txt
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cmake_minimum_required(VERSION 3.0.2)
|
| 2 |
+
project(midas_cpp)
|
| 3 |
+
|
| 4 |
+
## Compile as C++11, supported in ROS Kinetic and newer
|
| 5 |
+
# add_compile_options(-std=c++11)
|
| 6 |
+
|
| 7 |
+
## Find catkin macros and libraries
|
| 8 |
+
## if COMPONENTS list like find_package(catkin REQUIRED COMPONENTS xyz)
|
| 9 |
+
## is used, also find other catkin packages
|
| 10 |
+
find_package(catkin REQUIRED COMPONENTS
|
| 11 |
+
cv_bridge
|
| 12 |
+
image_transport
|
| 13 |
+
roscpp
|
| 14 |
+
rospy
|
| 15 |
+
sensor_msgs
|
| 16 |
+
std_msgs
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
## System dependencies are found with CMake's conventions
|
| 20 |
+
# find_package(Boost REQUIRED COMPONENTS system)
|
| 21 |
+
|
| 22 |
+
list(APPEND CMAKE_PREFIX_PATH "~/libtorch")
|
| 23 |
+
list(APPEND CMAKE_PREFIX_PATH "/usr/local/lib/python3.6/dist-packages/torch/lib")
|
| 24 |
+
list(APPEND CMAKE_PREFIX_PATH "/usr/local/lib/python2.7/dist-packages/torch/lib")
|
| 25 |
+
|
| 26 |
+
if(NOT EXISTS "~/libtorch")
|
| 27 |
+
if (EXISTS "/usr/local/lib/python3.6/dist-packages/torch")
|
| 28 |
+
include_directories(/usr/local/include)
|
| 29 |
+
include_directories(/usr/local/lib/python3.6/dist-packages/torch/include/torch/csrc/api/include)
|
| 30 |
+
include_directories(/usr/local/lib/python3.6/dist-packages/torch/include)
|
| 31 |
+
|
| 32 |
+
link_directories(/usr/local/lib)
|
| 33 |
+
link_directories(/usr/local/lib/python3.6/dist-packages/torch/lib)
|
| 34 |
+
|
| 35 |
+
set(CMAKE_PREFIX_PATH /usr/local/lib/python3.6/dist-packages/torch)
|
| 36 |
+
set(Boost_USE_MULTITHREADED ON)
|
| 37 |
+
set(Torch_DIR /usr/local/lib/python3.6/dist-packages/torch)
|
| 38 |
+
|
| 39 |
+
elseif (EXISTS "/usr/local/lib/python2.7/dist-packages/torch")
|
| 40 |
+
|
| 41 |
+
include_directories(/usr/local/include)
|
| 42 |
+
include_directories(/usr/local/lib/python2.7/dist-packages/torch/include/torch/csrc/api/include)
|
| 43 |
+
include_directories(/usr/local/lib/python2.7/dist-packages/torch/include)
|
| 44 |
+
|
| 45 |
+
link_directories(/usr/local/lib)
|
| 46 |
+
link_directories(/usr/local/lib/python2.7/dist-packages/torch/lib)
|
| 47 |
+
|
| 48 |
+
set(CMAKE_PREFIX_PATH /usr/local/lib/python2.7/dist-packages/torch)
|
| 49 |
+
set(Boost_USE_MULTITHREADED ON)
|
| 50 |
+
set(Torch_DIR /usr/local/lib/python2.7/dist-packages/torch)
|
| 51 |
+
endif()
|
| 52 |
+
endif()
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
find_package(Torch REQUIRED)
|
| 57 |
+
find_package(OpenCV REQUIRED)
|
| 58 |
+
include_directories( ${OpenCV_INCLUDE_DIRS} )
|
| 59 |
+
|
| 60 |
+
add_executable(midas_cpp src/main.cpp)
|
| 61 |
+
target_link_libraries(midas_cpp "${TORCH_LIBRARIES}" "${OpenCV_LIBS} ${catkin_LIBRARIES}")
|
| 62 |
+
set_property(TARGET midas_cpp PROPERTY CXX_STANDARD 14)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
###################################
|
| 67 |
+
## catkin specific configuration ##
|
| 68 |
+
###################################
|
| 69 |
+
## The catkin_package macro generates cmake config files for your package
|
| 70 |
+
## Declare things to be passed to dependent projects
|
| 71 |
+
## INCLUDE_DIRS: uncomment this if your package contains header files
|
| 72 |
+
## LIBRARIES: libraries you create in this project that dependent projects also need
|
| 73 |
+
## CATKIN_DEPENDS: catkin_packages dependent projects also need
|
| 74 |
+
## DEPENDS: system dependencies of this project that dependent projects also need
|
| 75 |
+
catkin_package(
|
| 76 |
+
# INCLUDE_DIRS include
|
| 77 |
+
# LIBRARIES midas_cpp
|
| 78 |
+
# CATKIN_DEPENDS cv_bridge image_transport roscpp sensor_msgs std_msgs
|
| 79 |
+
# DEPENDS system_lib
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
###########
|
| 83 |
+
## Build ##
|
| 84 |
+
###########
|
| 85 |
+
|
| 86 |
+
## Specify additional locations of header files
|
| 87 |
+
## Your package locations should be listed before other locations
|
| 88 |
+
include_directories(
|
| 89 |
+
# include
|
| 90 |
+
${catkin_INCLUDE_DIRS}
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
## Declare a C++ library
|
| 94 |
+
# add_library(${PROJECT_NAME}
|
| 95 |
+
# src/${PROJECT_NAME}/midas_cpp.cpp
|
| 96 |
+
# )
|
| 97 |
+
|
| 98 |
+
## Add cmake target dependencies of the library
|
| 99 |
+
## as an example, code may need to be generated before libraries
|
| 100 |
+
## either from message generation or dynamic reconfigure
|
| 101 |
+
# add_dependencies(${PROJECT_NAME} ${${PROJECT_NAME}_EXPORTED_TARGETS} ${catkin_EXPORTED_TARGETS})
|
| 102 |
+
|
| 103 |
+
## Declare a C++ executable
|
| 104 |
+
## With catkin_make all packages are built within a single CMake context
|
| 105 |
+
## The recommended prefix ensures that target names across packages don't collide
|
| 106 |
+
# add_executable(${PROJECT_NAME}_node src/midas_cpp_node.cpp)
|
| 107 |
+
|
| 108 |
+
## Rename C++ executable without prefix
|
| 109 |
+
## The above recommended prefix causes long target names, the following renames the
|
| 110 |
+
## target back to the shorter version for ease of user use
|
| 111 |
+
## e.g. "rosrun someones_pkg node" instead of "rosrun someones_pkg someones_pkg_node"
|
| 112 |
+
# set_target_properties(${PROJECT_NAME}_node PROPERTIES OUTPUT_NAME node PREFIX "")
|
| 113 |
+
|
| 114 |
+
## Add cmake target dependencies of the executable
|
| 115 |
+
## same as for the library above
|
| 116 |
+
# add_dependencies(${PROJECT_NAME}_node ${${PROJECT_NAME}_EXPORTED_TARGETS} ${catkin_EXPORTED_TARGETS})
|
| 117 |
+
|
| 118 |
+
## Specify libraries to link a library or executable target against
|
| 119 |
+
# target_link_libraries(${PROJECT_NAME}_node
|
| 120 |
+
# ${catkin_LIBRARIES}
|
| 121 |
+
# )
|
| 122 |
+
|
| 123 |
+
#############
|
| 124 |
+
## Install ##
|
| 125 |
+
#############
|
| 126 |
+
|
| 127 |
+
# all install targets should use catkin DESTINATION variables
|
| 128 |
+
# See http://ros.org/doc/api/catkin/html/adv_user_guide/variables.html
|
| 129 |
+
|
| 130 |
+
## Mark executable scripts (Python etc.) for installation
|
| 131 |
+
## in contrast to setup.py, you can choose the destination
|
| 132 |
+
# catkin_install_python(PROGRAMS
|
| 133 |
+
# scripts/my_python_script
|
| 134 |
+
# DESTINATION ${CATKIN_PACKAGE_BIN_DESTINATION}
|
| 135 |
+
# )
|
| 136 |
+
|
| 137 |
+
## Mark executables for installation
|
| 138 |
+
## See http://docs.ros.org/melodic/api/catkin/html/howto/format1/building_executables.html
|
| 139 |
+
# install(TARGETS ${PROJECT_NAME}_node
|
| 140 |
+
# RUNTIME DESTINATION ${CATKIN_PACKAGE_BIN_DESTINATION}
|
| 141 |
+
# )
|
| 142 |
+
|
| 143 |
+
## Mark libraries for installation
|
| 144 |
+
## See http://docs.ros.org/melodic/api/catkin/html/howto/format1/building_libraries.html
|
| 145 |
+
# install(TARGETS ${PROJECT_NAME}
|
| 146 |
+
# ARCHIVE DESTINATION ${CATKIN_PACKAGE_LIB_DESTINATION}
|
| 147 |
+
# LIBRARY DESTINATION ${CATKIN_PACKAGE_LIB_DESTINATION}
|
| 148 |
+
# RUNTIME DESTINATION ${CATKIN_GLOBAL_BIN_DESTINATION}
|
| 149 |
+
# )
|
| 150 |
+
|
| 151 |
+
## Mark cpp header files for installation
|
| 152 |
+
# install(DIRECTORY include/${PROJECT_NAME}/
|
| 153 |
+
# DESTINATION ${CATKIN_PACKAGE_INCLUDE_DESTINATION}
|
| 154 |
+
# FILES_MATCHING PATTERN "*.h"
|
| 155 |
+
# PATTERN ".svn" EXCLUDE
|
| 156 |
+
# )
|
| 157 |
+
|
| 158 |
+
## Mark other files for installation (e.g. launch and bag files, etc.)
|
| 159 |
+
# install(FILES
|
| 160 |
+
# # myfile1
|
| 161 |
+
# # myfile2
|
| 162 |
+
# DESTINATION ${CATKIN_PACKAGE_SHARE_DESTINATION}
|
| 163 |
+
# )
|
| 164 |
+
|
| 165 |
+
#############
|
| 166 |
+
## Testing ##
|
| 167 |
+
#############
|
| 168 |
+
|
| 169 |
+
## Add gtest based cpp test target and link libraries
|
| 170 |
+
# catkin_add_gtest(${PROJECT_NAME}-test test/test_midas_cpp.cpp)
|
| 171 |
+
# if(TARGET ${PROJECT_NAME}-test)
|
| 172 |
+
# target_link_libraries(${PROJECT_NAME}-test ${PROJECT_NAME})
|
| 173 |
+
# endif()
|
| 174 |
+
|
| 175 |
+
## Add folders to be run by python nosetests
|
| 176 |
+
# catkin_add_nosetests(test)
|
| 177 |
+
|
| 178 |
+
install(TARGETS ${PROJECT_NAME}
|
| 179 |
+
ARCHIVE DESTINATION ${CATKIN_PACKAGE_LIB_DESTINATION}
|
| 180 |
+
LIBRARY DESTINATION ${CATKIN_PACKAGE_LIB_DESTINATION}
|
| 181 |
+
RUNTIME DESTINATION ${CATKIN_PACKAGE_BIN_DESTINATION}
|
| 182 |
+
)
|
| 183 |
+
|
| 184 |
+
add_custom_command(
|
| 185 |
+
TARGET midas_cpp POST_BUILD
|
| 186 |
+
COMMAND ${CMAKE_COMMAND} -E copy
|
| 187 |
+
${CMAKE_CURRENT_BINARY_DIR}/midas_cpp
|
| 188 |
+
${CMAKE_SOURCE_DIR}/midas_cpp
|
| 189 |
+
)
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/midas_cpp/launch/midas_cpp.launch
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<launch>
|
| 2 |
+
<arg name="input_topic" default="image_topic"/>
|
| 3 |
+
<arg name="output_topic" default="midas_topic"/>
|
| 4 |
+
<arg name="model_name" default="model-small-traced.pt"/>
|
| 5 |
+
<arg name="out_orig_size" default="true"/>
|
| 6 |
+
<arg name="net_width" default="256"/>
|
| 7 |
+
<arg name="net_height" default="256"/>
|
| 8 |
+
<arg name="logging" default="false"/>
|
| 9 |
+
|
| 10 |
+
<node pkg="midas_cpp" type="midas_cpp" name="midas_cpp" output="log" respawn="true">
|
| 11 |
+
<param name="input_topic" value="$(arg input_topic)"/>
|
| 12 |
+
<param name="output_topic" value="$(arg output_topic)"/>
|
| 13 |
+
<param name="model_name" value="$(arg model_name)"/>
|
| 14 |
+
<param name="out_orig_size" value="$(arg out_orig_size)"/>
|
| 15 |
+
<param name="net_width" value="$(arg net_width)"/>
|
| 16 |
+
<param name="net_height" value="$(arg net_height)"/>
|
| 17 |
+
<param name="logging" value="$(arg logging)"/>
|
| 18 |
+
</node>
|
| 19 |
+
</launch>
|
VideoX-Fun/comfyui/annotator/zoe/zoedepth/models/base_models/midas_repo/ros/midas_cpp/launch/midas_talker_listener.launch
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<launch>
|
| 2 |
+
<arg name="use_camera" default="false"/>
|
| 3 |
+
<arg name="input_video_file" default="test.mp4"/>
|
| 4 |
+
|
| 5 |
+
<arg name="show_output" default="true"/>
|
| 6 |
+
<arg name="save_output" default="false"/>
|
| 7 |
+
<arg name="output_video_file" default="result.mp4"/>
|
| 8 |
+
|
| 9 |
+
<node pkg="midas_cpp" type="talker.py" name="talker" output="log" respawn="true">
|
| 10 |
+
<param name="use_camera" value="$(arg use_camera)"/>
|
| 11 |
+
<param name="input_video_file" value="$(arg input_video_file)"/>
|
| 12 |
+
</node>
|
| 13 |
+
|
| 14 |
+
<node pkg="midas_cpp" type="listener.py" name="listener" output="log" respawn="true">
|
| 15 |
+
<param name="show_output" value="$(arg show_output)"/>
|
| 16 |
+
<param name="save_output" value="$(arg save_output)"/>
|
| 17 |
+
<param name="output_video_file" value="$(arg output_video_file)"/>
|
| 18 |
+
</node>
|
| 19 |
+
|
| 20 |
+
<node pkg="midas_cpp" type="listener_original.py" name="listener_original" output="log" respawn="true">
|
| 21 |
+
<param name="show_output" value="$(arg show_output)"/>
|
| 22 |
+
</node>
|
| 23 |
+
</launch>
|