---
tags:
- image-to-image
- reflection-removal
- highlight-removal
- computer-vision
- dinov3
- surgical-imaging
license: mit
pipeline_tag: image-to-image
---
# UnReflectAnything
[](https://alberto-rota.github.io/UnReflectAnything/)
[](https://pypi.org/project/unreflectanything/)
[](https://arxiv.org/abs/2512.09583)
[](https://huggingface.co/spaces/AlbeRota/UnReflectAnything)
[](https://github.com/alberto-rota/UnReflectAnything/wiki)
[](https://mit-license.org/)
UnReflectAnything inputs any RGB image and removes specular highlights, returning a clean diffuse-only outputs. We trained UnReflectAnything by synthetizing specularities and supervising in DINOv3 feature space.
UnReflectAnything works on both natural indoor and surgical/endoscopic domain data.
## Architecture
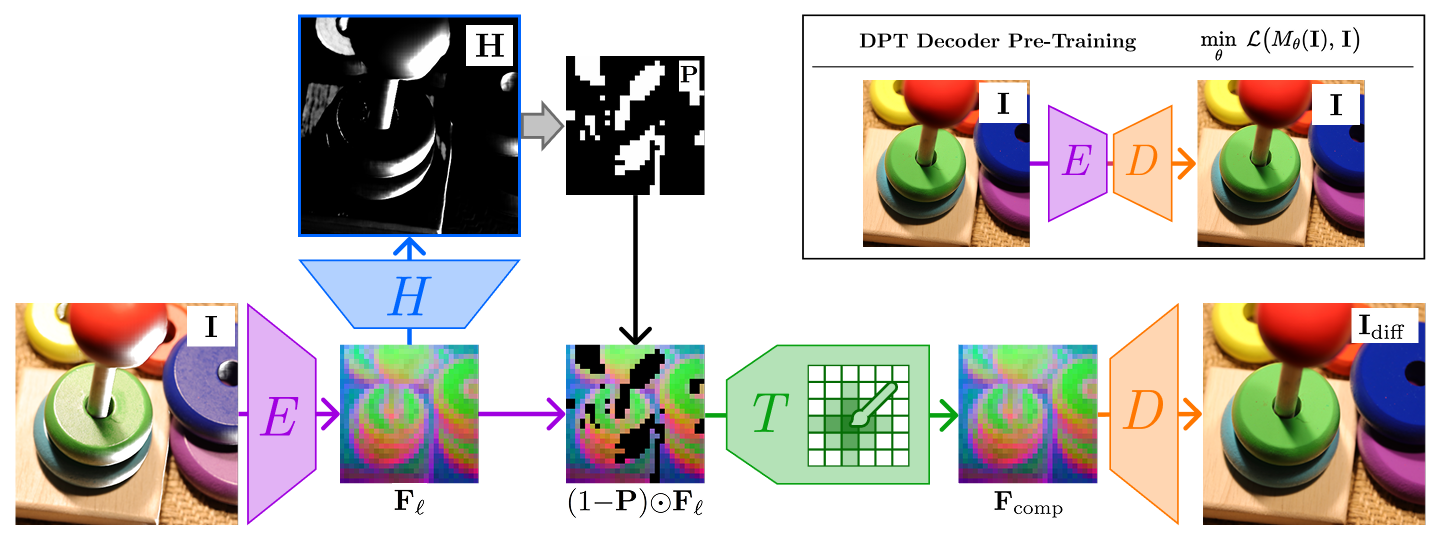
* **Encoder E **: Processes the input image to extract a rich latent representation. This is the off-the-shelf pretrained [DINOv3-large](https://huggingface.co/facebook/dinov3-vitl16-pretrain-lvd1689m)
* **Reflection Predictor H**: Predicts a soft highlight mask (**H**), identifying areas of specular highlights.
* **Masking Operation**: A binary mask **P** is derived from the prediction and applied to the feature map: This removes features contaminated by reflections, leaving "holes" in the data.
* **Token Inpainter T**: Acts as a neural in-painter. It processes the masked features and uses the surrounding clean context prior and a learned mask token to synthesize the missing information in embedding space, producing the completed feature map $\mathbf{F}_{\text{comp}}$.
* **Decoder D **: Project the completed features back into the pixel space to generate the final, reflection-free image
---
## Training Strategy
We train UnReflectAnything with **Synthetic Specular Supervision** by inferring 3D geometry from [MoGe-2](https://wangrc.site/MoGe2Page/) and rendering highlights with a Blinn-Phong reflection model. We randomly sample the light source position in 3D space at every training iteration enhance etherogeneity.
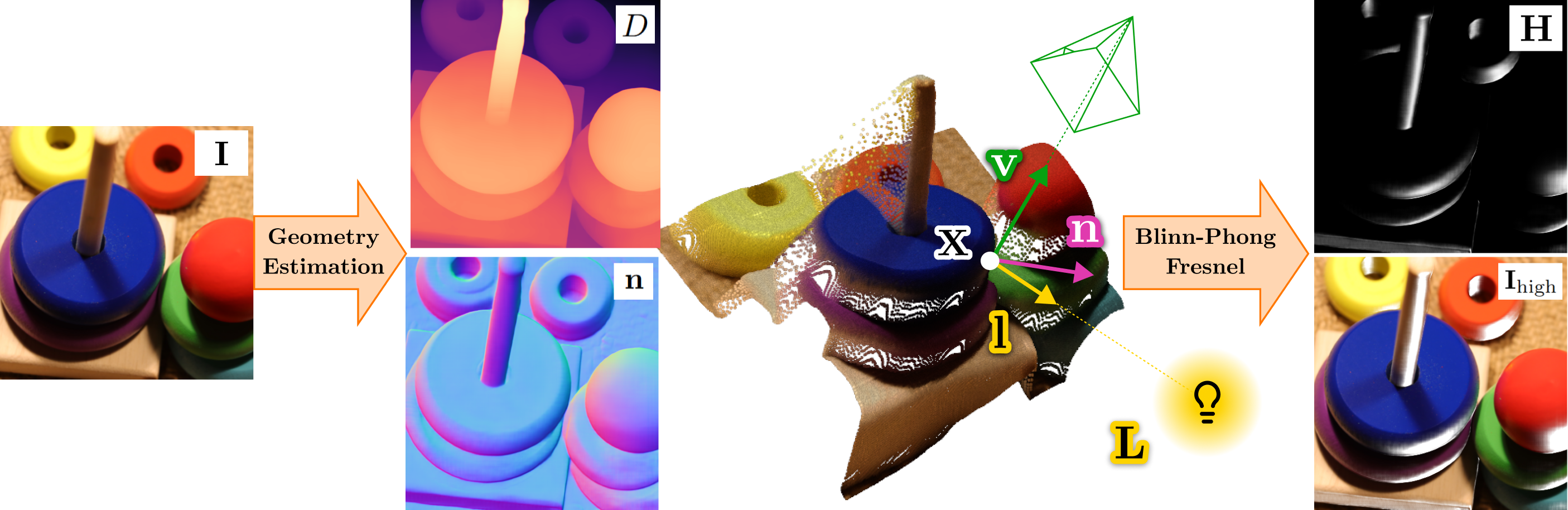
We train the model in two stages
1. **DPT Decoder Pre-Training**: The **Decoder** is first pre-trained in an autoencoder configuration to ensure it can reconstruct realistic RGB textures from the DINOV3 latent space.
2. **End-to-End Refinement**: The full pipeline is then trained to predict reflection masks and fill them using the **Token Inpainter**, ensuring the final output is both visually consistent and physically accurate. We utilize the Synthetic Specular Supervision to generate ground-truth signals in feature space. The decoder is also fine-tuned at this stage
## Weights
Install the API and CLI on a **Python>=3.11** environment with
```bash
pip install unreflectanything
```
then run
```bash
unreflectanything download --weights
```
to download the `.pth` weights in the package cache dir. The cache dir is usually at `.cache/unreflectanything`
---
### Basic Python Usage
```python
import unreflectanything
import torch
# Load the pretrained model (uses cached weights)
unreflect_model = unreflectanything.model()
# Run inference on a tensor [B, 3, H, W] in range [0, 1]
images = torch.rand(2, 3, 448, 448).cuda()
diffuse_output = unreflect_model(images)
# Simple file-based inference
unreflectanything.inference("input_with_highlights.png", output="diffuse_result.png")
```
Refer to the [Wiki](https://github.com/alberto-rota/UnReflectAnything/wiki) for all details on the API endpoints
---
### CLI Overview
The package provides a comprehensive command-line interface via `ura`, `unreflect`, or `unreflectanything`.
* **Inference**: `ura inference --input /path/to/images --output /path/to/output`
* **Evaluation**: `ura evaluate --output /path/to/results --gt /path/to/groundtruth`
* **Verification**: `ura verify --dataset /path/to/dataset`
Refer to the [Wiki](https://github.com/alberto-rota/UnReflectAnything/wiki) for all details on the CLI endpoints
---
## Citation
If you use UnReflectAnything in your research or pipeline, please cite our paper:
```bibtex
@misc{rota2025unreflectanythingrgbonlyhighlightremoval,
title={UnReflectAnything: RGB-Only Highlight Removal by Rendering Synthetic Specular Supervision},
author={Alberto Rota and Mert Kiray and Mert Asim Karaoglu and Patrick Ruhkamp and Elena De Momi and Nassir Navab and Benjamin Busam},
year={2025},
eprint={2512.09583},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={[https://arxiv.org/abs/2512.09583](https://arxiv.org/abs/2512.09583)},
}
```
---