---
license: apache-2.0
datasets:
- WeiChow/merit
language:
- en
- id
- ms
- th
- vn
base_model:
- Qwen/Qwen2.5-3B-Instruct
---
MERIT: Multilingual Semantic Retrieval with Interleaved Multi-Condition Query
[](https://arxiv.org/abs/2506.03144)
[](https://huggingface.co/datasets/WeiChow/merit)
[](https://huggingface.co/Bia/CORAL)
[](https://github.com/weichow23/merit)
[](https://merit-2025.github.io/)
## Model Details
We introduce CORAL, a multi-modal embedding model built upon Qwen2.5-3B-Instruct. CORAL enables interleaved multi-condition semantic retrieval queries, and was trained using MERIT, a novel dataset proposed in our paper, [MERIT: Multilingual Semantic Retrieval with Interleaved Multi-Condition Query](http://arxiv.org/abs/2506.03144).
CORAL is short for Contrastive Reconstruction for Multimodal Retrieval. The loss function of CORAL consists of three components: Contrastive Learning Loss, Vision Reconstruction Loss, and Masked Language Modeling Loss. During training, we reconstruct both the query and its corresponding positive sample.
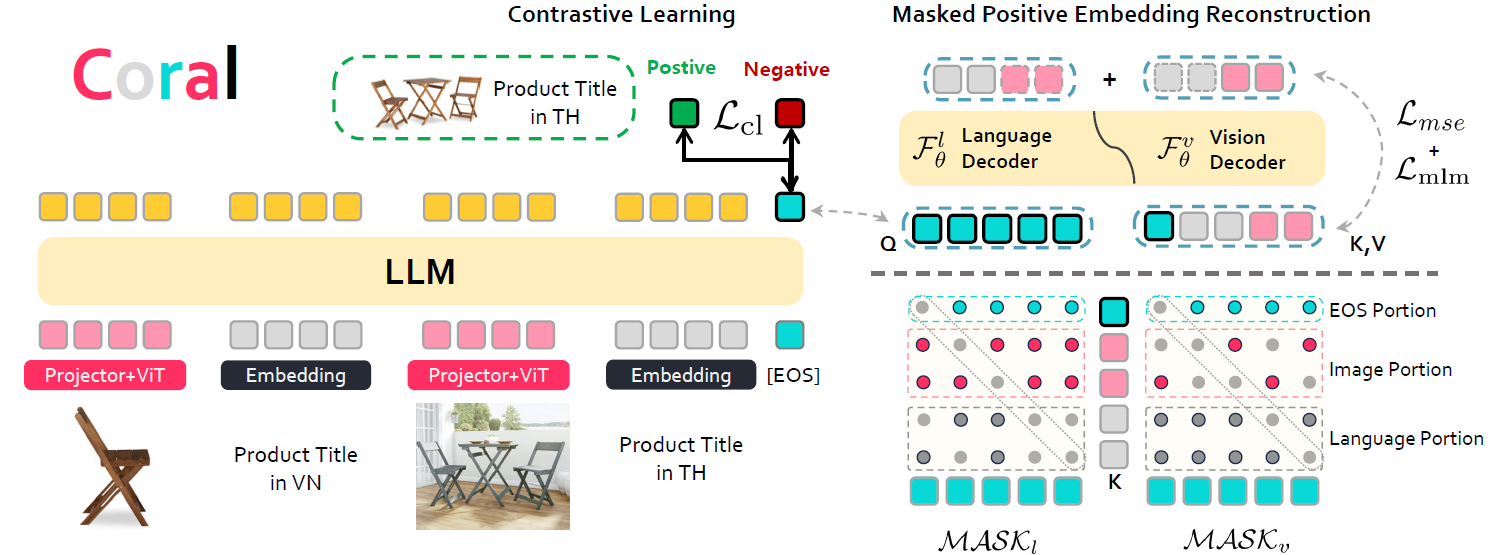
Overview for CORAL

Example Query and Ground Truth
## Usage
**Transformers**
We provide the checkpoint of CORAL on Huggingface. You can load the model using the following code:
```python
import torch
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
## Initialize Model and Processor
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Bia/CORAL", torch_dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained("Bia/CORAL")
## Prepare Inputs
query = [
{
"role": "user",
"content": [
{"type": "text", "text": "Find a product of backpack that have the same brand with \n "},
{
"type": "image",
"image": "CORAL/images/product_1.png",
},
{"type": "text", "text": "\n Ransel MOSSDOOM Polyester dengan Ruang Komputer dan Penyimpanan Besar, Ukuran $30 \times 12 \times 38$ cm , Berat 0.32 kg. and the same fashion style with "},
{
"type": "image",
"image": "CORAL/images/product_2.png",
},
{"type": "text", "text": "\n Elegant Pink Flats with Low Heel and Buckle Closure for Stylish Party Wear with a quilted texture and a chain strap."}
],
}
]
candidate = [
{
"role": "user",
"content": [
{"type": "text", "text": "Represent the given product: "},
{
"type": "image",
"image": "CORAL/images/product_3.png",
},
{"type": "text", "text": "\n MOSSDOOM Elegant Pink PU Leather Handbag with Chain Strap and Large Capacity, Compact Size $18 \times 9.5 \times 15 \mathrm{~cm}$."},
],
}
]
query_text = processor.apply_chat_template(
query, tokenize=False, add_generation_prompt=True
)
candidate_text = processor.apply_chat_template(
candidate, tokenize=False, add_generation_prompt=True
)
query_image_inputs, query_video_inputs = process_vision_info(query)
candidate_image_inputs, candidate_video_inputs = process_vision_info(candidate)
query_inputs = processor(
text=[query_text],
images=query_image_inputs,
videos=query_video_inputs,
padding=True,
return_tensors="pt",
).to("cuda")
candidate_inputs = processor(
text=[candidate_text],
images=candidate_image_inputs,
videos=candidate_video_inputs,
padding=True,
return_tensors="pt",
).to("cuda")
# Encode Embeddings
with torch.inference_mode():
query_outputs = model(**query_inputs, return_dict=True, output_hidden_states=True)
query_embedding = query_outputs.hidden_states[-1][:,-1,:]
query_embedding = torch.nn.functional.normalize(query_embedding, dim=-1)
print(query_embedding.shape) # torch.Size([1, 2048])
candidate_outputs = model(**candidate_inputs, return_dict=True, output_hidden_states=True)
candidate_embedding = candidate_outputs.hidden_states[-1][:,-1,:]
candidate_embedding = torch.nn.functional.normalize(candidate_embedding, dim=-1)
print(candidate_embedding.shape) # torch.Size([1, 2048])
# Compute Similarity
similarity = torch.matmul(query_embedding, candidate_embedding.T)
print(similarity) # tensor([[0.6992]], device='cuda:0', dtype=torch.bfloat16)
```
## Evaluation
We provide the experiment results of CORAL on the MERIT dataset.
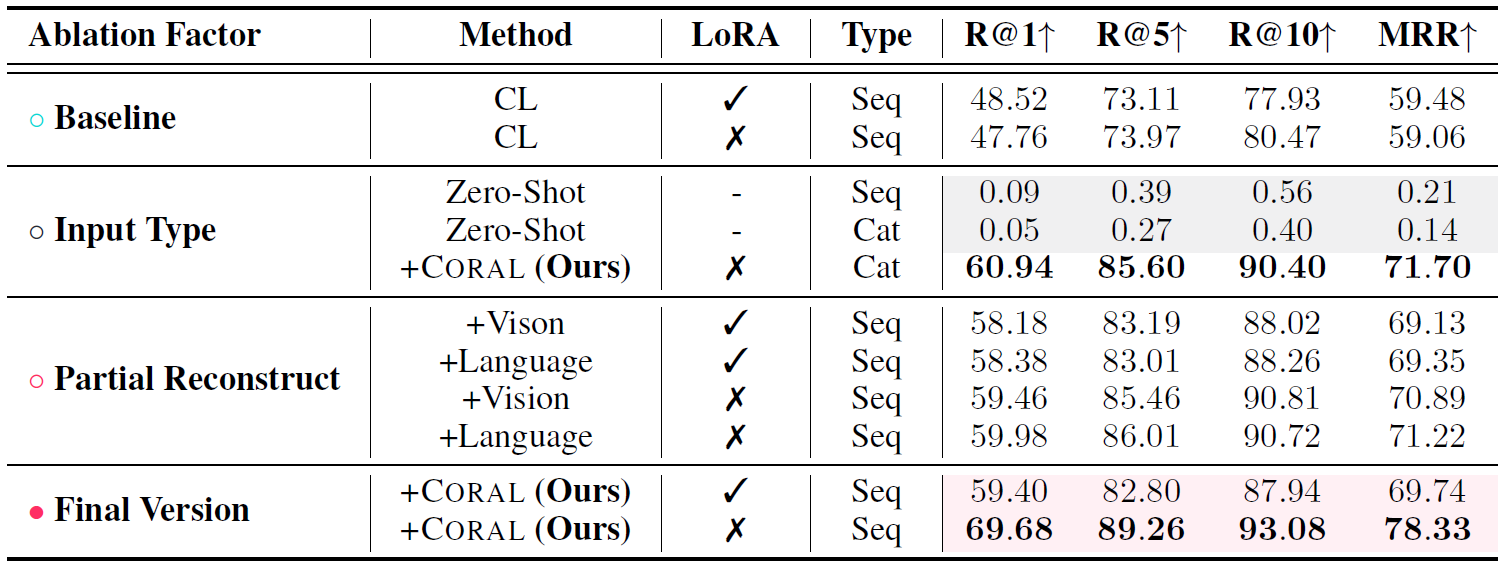
Performance of CORAL on MERIT
## Citation
Chow W, Gao Y, Li L, et al. MERIT: Multilingual Semantic Retrieval with Interleaved Multi-Condition Query[J]. arXiv preprint arXiv:2506.03144, 2025.
**BibTeX:**
```bibtex
@article{chow2025merit,
title={MERIT: Multilingual Semantic Retrieval with Interleaved Multi-Condition Query},
author={Chow, Wei and Gao, Yuan and Li, Linfeng and Wang, Xian and Xu, Qi and Song, Hang and Kong, Lingdong and Zhou, Ran and Zeng, Yi and Cai, Yidong and others},
journal={arXiv preprint arXiv:2506.03144},
year={2025}
}