
Commit ·
cc443eb
0
Parent(s):
Initial release
Browse files- .gitattributes +35 -0
- Nucleus-Image-FP8.safetensors +3 -0
- README.md +224 -0
- config.json +60 -0
- moe_fp8_patch.py +281 -0
.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
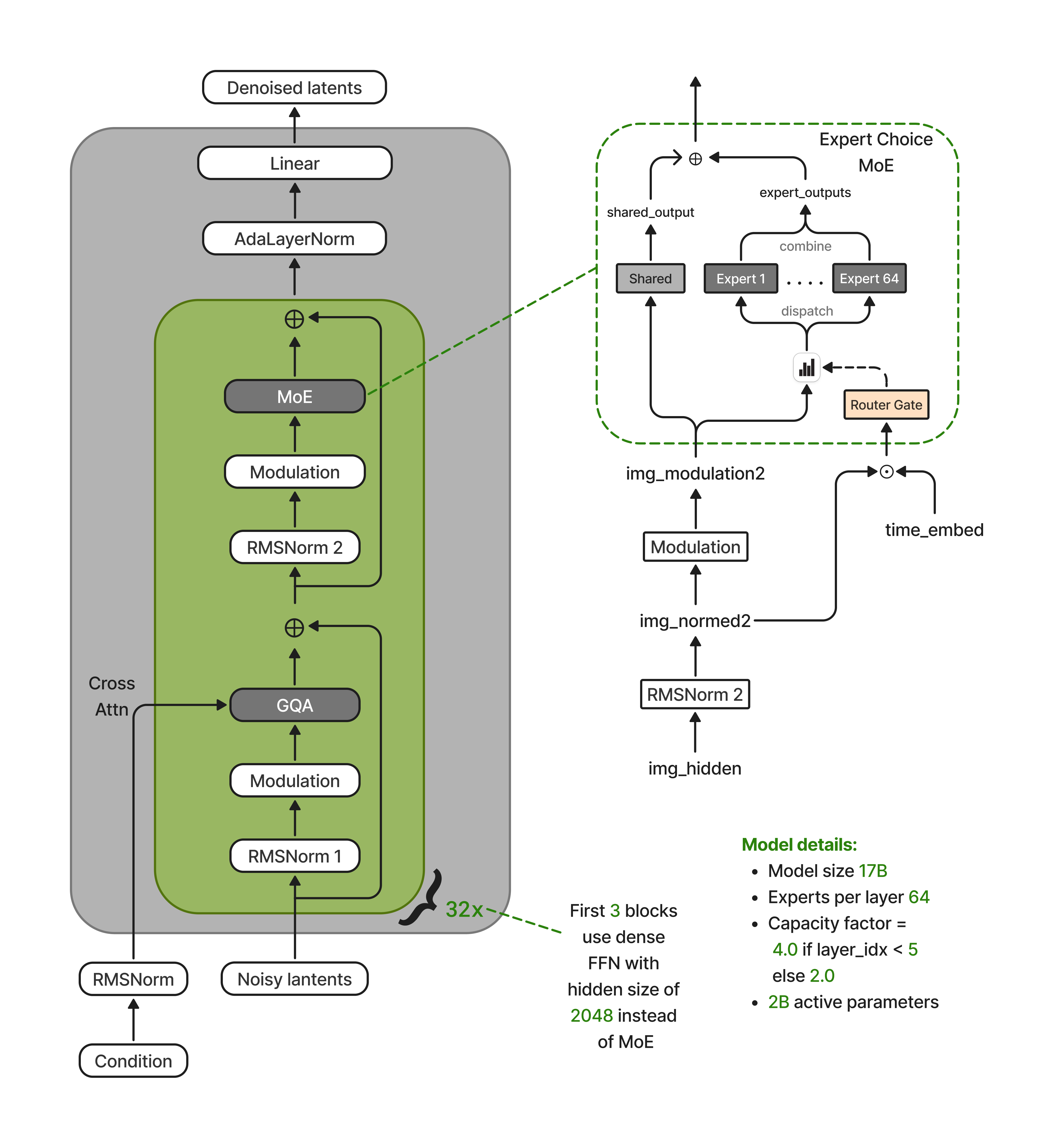
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
Nucleus-Image-FP8.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6555d4212cf6eb00d0f03505cc8f3e2032ca73927905cd57b54df2eb999115f7
|
| 3 |
+
size 16942185128
|
README.md
ADDED
|
@@ -0,0 +1,224 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
library_name: diffusers
|
| 6 |
+
pipeline_tag: text-to-image
|
| 7 |
+
base_model: NucleusAI/Nucleus-Image
|
| 8 |
+
tags:
|
| 9 |
+
- moe
|
| 10 |
+
- sparse-moe
|
| 11 |
+
- diffusion
|
| 12 |
+
- text-to-image
|
| 13 |
+
- image-generation
|
| 14 |
+
- quantization
|
| 15 |
+
- fp8
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
# Nucleus-Image — FP8 (e4m3)
|
| 19 |
+
|
| 20 |
+
FP8 weight-only quantization of [`NucleusAI/Nucleus-Image`](https://huggingface.co/NucleusAI/Nucleus-Image). Single 16.94 GB safetensors file at the repo root (was 33.85 GB in BF16). Peak VRAM at 1024² is **17.6 GB** with `enable_model_cpu_offload()` — fits comfortably on 24 GB cards.
|
| 21 |
+
|
| 22 |
+
## Run it
|
| 23 |
+
|
| 24 |
+
```python
|
| 25 |
+
import importlib.util, torch
|
| 26 |
+
from diffusers import DiffusionPipeline
|
| 27 |
+
from huggingface_hub import hf_hub_download
|
| 28 |
+
|
| 29 |
+
REPO = "D-Squarius-Green-Jr/Nucleus-Image-FP8"
|
| 30 |
+
patch_py = hf_hub_download(REPO, "moe_fp8_patch.py")
|
| 31 |
+
weights = hf_hub_download(REPO, "Nucleus-Image-FP8.safetensors")
|
| 32 |
+
hf_hub_download(REPO, "config.json") # sits next to the weights
|
| 33 |
+
|
| 34 |
+
spec = importlib.util.spec_from_file_location("moe_fp8_patch", patch_py)
|
| 35 |
+
patch = importlib.util.module_from_spec(spec); spec.loader.exec_module(patch)
|
| 36 |
+
patch.apply_patch()
|
| 37 |
+
|
| 38 |
+
transformer = patch.load_fp8_safetensors_transformer(weights)
|
| 39 |
+
|
| 40 |
+
pipe = DiffusionPipeline.from_pretrained(
|
| 41 |
+
"NucleusAI/Nucleus-Image",
|
| 42 |
+
transformer=transformer,
|
| 43 |
+
torch_dtype=torch.bfloat16,
|
| 44 |
+
)
|
| 45 |
+
pipe.enable_model_cpu_offload()
|
| 46 |
+
|
| 47 |
+
image = pipe(
|
| 48 |
+
prompt="A quiet alpine lake at sunrise, mist rising off still water, snow-capped peaks reflected, soft pink and gold sky",
|
| 49 |
+
width=1024, height=1024,
|
| 50 |
+
num_inference_steps=20, guidance_scale=8.0,
|
| 51 |
+
generator=torch.Generator(device="cuda").manual_seed(42),
|
| 52 |
+
).images[0]
|
| 53 |
+
image.save("out.png")
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
> Skip `TextKVCacheConfig` if running multiple prompts of different lengths — its state has no public reset (as of `diffusers` 0.38.0.dev0). Single prompts are fine.
|
| 57 |
+
|
| 58 |
+
## Quant scheme
|
| 59 |
+
|
| 60 |
+
| Layers | How | Size |
|
| 61 |
+
|---|---|---|
|
| 62 |
+
| 354 `nn.Linear` | FP8 e4m3, per-output-channel scale | 1.6 GB |
|
| 63 |
+
| 29 `SwiGLUExperts` (15.3 B params, fused 64-expert tensors) | FP8 e4m3, per-expert × per-output-channel scale | 15.3 GB |
|
| 64 |
+
| Norms / routing logits / embeddings | BF16 (routing decisions stay bit-identical to BF16) | 0.04 GB |
|
| 65 |
+
|
| 66 |
+
Off-the-shelf quantizers (TorchAO, optimum-quanto, bnb) only walk `nn.Linear`, missing the 15.3 B inside `SwiGLUExperts`. The runtime patch handles both.
|
| 67 |
+
|
| 68 |
+
## Numbers
|
| 69 |
+
|
| 70 |
+
- Dequant rel L2: 2.69 % worst across all SwiGLUExperts
|
| 71 |
+
- Per-layer forward rel L2 (random `x`): 4.49 %
|
| 72 |
+
- Generation: ~25-42 s per image at 1024², 20 steps, RTX 5090
|
| 73 |
+
- Peak VRAM: 17.62 GB allocated / 17.82 GB reserved
|
| 74 |
+
|
| 75 |
+
---
|
| 76 |
+
|
| 77 |
+
# Original Model Card
|
| 78 |
+
|
| 79 |
+
The text below is the verbatim model card from [`NucleusAI/Nucleus-Image`](https://huggingface.co/NucleusAI/Nucleus-Image).
|
| 80 |
+
|
| 81 |
+
<p align="center"> <a href="https://withnucleus.ai/image" target="_blank" rel="noopener noreferrer"><img src="https://storage.googleapis.com/nucleus_image_v1/nucleus_header.png" width="400"/></a></p>
|
| 82 |
+
<p align="center">
|
| 83 |
+
🌐 <a href="https://withnucleus.ai/image"><b>Website</b></a> | 🖥️ <a href="https://github.com/WithNucleusAI/Nucleus-Image"><b>GitHub</b></a> | 🤗 <a href="https://huggingface.co/NucleusAI/NucleusMoE-Image"><b>Hugging Face</b></a> | 📑 <a href="https://storage.googleapis.com/nucleus_image_v1/Nucleus-Image-Technical-Report.pdf"><b>Tech Report</b></a>
|
| 84 |
+
</p>
|
| 85 |
+
|
| 86 |
+
## Introduction
|
| 87 |
+
|
| 88 |
+
**Nucleus-Image** is a text-to-image generation model built on a sparse mixture-of-experts (MoE) diffusion transformer architecture. It scales to **17B total parameters** across 64 routed experts per layer while activating only **~2B parameters** per forward pass, establishing a new Pareto frontier in quality-versus-efficiency. Nucleus-Image matches or exceeds leading models including Qwen-Image, GPT Image 1, Seedream 3.0, and Imagen4 on GenEval, DPG-Bench, and OneIG-Bench. This is a **base model** released without any post-training optimization (no DPO, no reinforcement learning, no human preference tuning). All reported results reflect pre-training performance only. We release the full model weights, training code, and dataset, making Nucleus-Image the first fully open-source MoE diffusion model at this quality tier.
|
| 89 |
+
|
| 90 |
+
## Key Features
|
| 91 |
+
|
| 92 |
+
- **Sparse MoE efficiency**: 17B total capacity with only ~2B active parameters per forward pass, enabling high-quality generation at a fraction of the inference cost of dense models
|
| 93 |
+
- **Expert-Choice Routing**: Guarantees balanced expert utilization without auxiliary load-balancing losses, with a decoupled routing design that separates timestep-aware assignment from timestep-conditioned computation
|
| 94 |
+
- **Base model, no post-training**: This is a base model. All benchmark results are from pre-training alone, without DPO, reinforcement learning, or human preference tuning
|
| 95 |
+
- **Multi-aspect-ratio support**: Trained with aspect-ratio bucketing from the outset at every resolution stage, supporting a range of output dimensions
|
| 96 |
+
- **Text KV caching via diffusers**: Text tokens are excluded from the transformer backbone entirely and their KV projections are cached across all denoising steps. This caching is natively integrated into the `diffusers` pipeline. Simply enable it with `TextKVCacheConfig` for automatic speedup with no code changes to the inference loop
|
| 97 |
+
- **Progressive resolution training**: Three-stage curriculum (256 → 512 → 1024) with progressive sparsification of expert capacity
|
| 98 |
+
|
| 99 |
+
## Architecture
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
Nucleus-Image is a 32-layer diffusion transformer where 29 of the 32 blocks replace the dense FFN with a sparse MoE layer containing 64 routed experts and one shared expert (the first 3 layers use dense FFN for training stability). Image queries attend to concatenated image and text key-value pairs via joint attention. Text tokens are excluded from the transformer backbone entirely, participating only as KV contributors. This eliminates MoE routing overhead for text and enables full text KV caching across denoising steps.
|
| 104 |
+
|
| 105 |
+
Routing uses **Expert-Choice** with a **decoupled design**: the router receives the unmodulated token representation concatenated with the timestep embedding, while expert MLPs receive the fully modulated representation. This prevents the adaptive modulation scale — which varies by an order of magnitude across timesteps — from collapsing expert selection into timestep-dependent routing, preserving spatial and semantic expert specialization.
|
| 106 |
+
|
| 107 |
+
## Model Specifications
|
| 108 |
+
|
| 109 |
+
| Specification | Value |
|
| 110 |
+
|---|---|
|
| 111 |
+
| Total parameters | 17B |
|
| 112 |
+
| Active parameters | ~2B |
|
| 113 |
+
| Architecture | Sparse MoE Diffusion Transformer |
|
| 114 |
+
| Layers | 32 |
|
| 115 |
+
| Hidden dimension | 2048 |
|
| 116 |
+
| Attention heads (Q / KV) | 16 / 4 (GQA) |
|
| 117 |
+
| Experts per MoE layer | 64 routed + 1 shared |
|
| 118 |
+
| Expert hidden dimension | 1344 |
|
| 119 |
+
| Text encoder | Qwen3-VL-8B-Instruct |
|
| 120 |
+
| Image tokenizer | Qwen-Image VAE (16ch) |
|
| 121 |
+
| Training data | 700M images, 1.5B caption pairs |
|
| 122 |
+
| Training curriculum | Progressive resolution (256 → 512 → 1024) |
|
| 123 |
+
| Total training steps | 1.7M |
|
| 124 |
+
|
| 125 |
+
## Benchmark Results
|
| 126 |
+
|
| 127 |
+

|
| 128 |
+
|
| 129 |
+
Nucleus-Image achieves state-of-the-art or near state-of-the-art results on all three benchmarks despite activating only ~2B of its 17B parameters per forward pass. All results are from the base model at 1024x1024, 50 inference steps, CFG scale 8.0.
|
| 130 |
+
|
| 131 |
+
| Benchmark | Score | Highlights |
|
| 132 |
+
|---|---|---|
|
| 133 |
+
| **GenEval** | **0.87** | Matches Qwen-Image; leads all models on spatial position (0.85) |
|
| 134 |
+
| **DPG-Bench** | **88.79** | #1 overall; leads in entity (93.08), attribute (92.20), and other (93.62) |
|
| 135 |
+
| **OneIG-Bench** | **0.522** | Surpasses Imagen4 (0.515) and Recraft V3 (0.502); strong style (0.430) |
|
| 136 |
+
|
| 137 |
+
## Quick Start
|
| 138 |
+
|
| 139 |
+
Install the latest version of diffusers:
|
| 140 |
+
```
|
| 141 |
+
pip install git+https://github.com/huggingface/diffusers
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
Generate images with Nucleus-Image:
|
| 145 |
+
|
| 146 |
+
```python
|
| 147 |
+
import torch
|
| 148 |
+
from diffusers import DiffusionPipeline
|
| 149 |
+
from diffusers import TextKVCacheConfig
|
| 150 |
+
|
| 151 |
+
model_name = "NucleusAI/Nucleus-Image"
|
| 152 |
+
|
| 153 |
+
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch.bfloat16)
|
| 154 |
+
pipe.to("cuda")
|
| 155 |
+
|
| 156 |
+
# Enable Text KV caching across denoising steps (integrated into diffusers)
|
| 157 |
+
config = TextKVCacheConfig()
|
| 158 |
+
pipe.transformer.enable_cache(config)
|
| 159 |
+
|
| 160 |
+
# Supported aspect ratios
|
| 161 |
+
aspect_ratios = {
|
| 162 |
+
"1:1": (1024, 1024),
|
| 163 |
+
"16:9": (1344, 768),
|
| 164 |
+
"9:16": (768, 1344),
|
| 165 |
+
"4:3": (1184, 896),
|
| 166 |
+
"3:4": (896, 1184),
|
| 167 |
+
"3:2": (1248, 832),
|
| 168 |
+
"2:3": (832, 1248),
|
| 169 |
+
}
|
| 170 |
+
|
| 171 |
+
prompt = "A weathered lighthouse on a rocky coastline at golden hour, waves crashing against the rocks below, seagulls circling overhead, dramatic clouds painted in shades of amber and violet"
|
| 172 |
+
width, height = aspect_ratios["16:9"]
|
| 173 |
+
|
| 174 |
+
image = pipe(
|
| 175 |
+
prompt=prompt,
|
| 176 |
+
width=width,
|
| 177 |
+
height=height,
|
| 178 |
+
num_inference_steps=50,
|
| 179 |
+
guidance_scale=8.0,
|
| 180 |
+
generator=torch.Generator(device="cuda").manual_seed(42),
|
| 181 |
+
).images[0]
|
| 182 |
+
|
| 183 |
+
image.save("nucleus_output.png")
|
| 184 |
+
```
|
| 185 |
+
|
| 186 |
+
## Highlights
|
| 187 |
+
|
| 188 |
+
### Portraits & People
|
| 189 |
+
|
| 190 |
+
Nucleus-Image generations of human subjects and portraits, spanning diverse cultures, ages, and artistic styles. From expressive character studies to fine-grained close-ups with intricate skin texture and detail.
|
| 191 |
+
|
| 192 |
+

|
| 193 |
+

|
| 194 |
+
|
| 195 |
+
### Fantasy, Surrealism & Nature
|
| 196 |
+
|
| 197 |
+
Nucleus-Image generations spanning fantasy, surrealism, animation, and the natural world.
|
| 198 |
+
|
| 199 |
+

|
| 200 |
+

|
| 201 |
+
|
| 202 |
+
### Commercial & Everyday Imagery
|
| 203 |
+
|
| 204 |
+
Nucleus-Image generations across product photography, architecture, typography, food, and world culture, demonstrating versatility in commercial, conceptual, and everyday imagery.
|
| 205 |
+
|
| 206 |
+

|
| 207 |
+

|
| 208 |
+
|
| 209 |
+
## License
|
| 210 |
+
|
| 211 |
+
Nucleus-Image is licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0).
|
| 212 |
+
|
| 213 |
+
## Citation
|
| 214 |
+
|
| 215 |
+
```bibtex
|
| 216 |
+
@misc{nucleusimage2026,
|
| 217 |
+
title={Nucleus-Image: Sparse MoE for Image Generation},
|
| 218 |
+
author={Nucleus AI Team},
|
| 219 |
+
year={2026},
|
| 220 |
+
eprint={XXXX.XXXXX},
|
| 221 |
+
archivePrefix={arXiv},
|
| 222 |
+
primaryClass={cs.CV},
|
| 223 |
+
}
|
| 224 |
+
```
|
config.json
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "NucleusMoEImageTransformer2DModel",
|
| 3 |
+
"_diffusers_version": "0.38.0.dev0",
|
| 4 |
+
"_name_or_path": "C:\\Users\\gabeg\\Projects\\nucleus-image\\Nucleus-Image_FP8",
|
| 5 |
+
"attention_head_dim": 128,
|
| 6 |
+
"axes_dims_rope": [
|
| 7 |
+
16,
|
| 8 |
+
56,
|
| 9 |
+
56
|
| 10 |
+
],
|
| 11 |
+
"capacity_factors": [
|
| 12 |
+
0.0,
|
| 13 |
+
0.0,
|
| 14 |
+
0.0,
|
| 15 |
+
4.0,
|
| 16 |
+
4.0,
|
| 17 |
+
2.0,
|
| 18 |
+
2.0,
|
| 19 |
+
2.0,
|
| 20 |
+
2.0,
|
| 21 |
+
2.0,
|
| 22 |
+
2.0,
|
| 23 |
+
2.0,
|
| 24 |
+
2.0,
|
| 25 |
+
2.0,
|
| 26 |
+
2.0,
|
| 27 |
+
2.0,
|
| 28 |
+
2.0,
|
| 29 |
+
2.0,
|
| 30 |
+
2.0,
|
| 31 |
+
2.0,
|
| 32 |
+
2.0,
|
| 33 |
+
2.0,
|
| 34 |
+
2.0,
|
| 35 |
+
2.0,
|
| 36 |
+
2.0,
|
| 37 |
+
2.0,
|
| 38 |
+
2.0,
|
| 39 |
+
2.0,
|
| 40 |
+
2.0,
|
| 41 |
+
2.0,
|
| 42 |
+
2.0,
|
| 43 |
+
2.0
|
| 44 |
+
],
|
| 45 |
+
"dense_moe_strategy": "leave_first_three_blocks_dense",
|
| 46 |
+
"in_channels": 64,
|
| 47 |
+
"joint_attention_dim": 4096,
|
| 48 |
+
"mlp_ratio": 4.0,
|
| 49 |
+
"moe_enabled": true,
|
| 50 |
+
"moe_intermediate_dim": 1344,
|
| 51 |
+
"num_attention_heads": 16,
|
| 52 |
+
"num_experts": 64,
|
| 53 |
+
"num_key_value_heads": 4,
|
| 54 |
+
"num_layers": 32,
|
| 55 |
+
"out_channels": 16,
|
| 56 |
+
"patch_size": 2,
|
| 57 |
+
"route_scale": 2.5,
|
| 58 |
+
"use_grouped_mm": true,
|
| 59 |
+
"use_sigmoid": false
|
| 60 |
+
}
|
moe_fp8_patch.py
ADDED
|
@@ -0,0 +1,281 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
SwiGLUExperts FP8 monkey-patch.
|
| 3 |
+
|
| 4 |
+
Imported by both 03_quantize_fp8.py (before loading BF16 model) and 04_test_inference.py
|
| 5 |
+
(before loading FP8 model). Idempotent: importing twice is a no-op.
|
| 6 |
+
|
| 7 |
+
What it does:
|
| 8 |
+
- Adds two persistent buffers (gate_up_proj_scale, down_proj_scale) to every SwiGLUExperts.
|
| 9 |
+
- Replaces _run_experts_for_loop to dequantize per-expert weights on-the-fly when stored as fp8_e4m3fn.
|
| 10 |
+
- Forces use_grouped_mm=False (the grouped_mm kernel doesn't accept fp8 e4m3 inputs as of torch 2.11).
|
| 11 |
+
- If weights are still bf16 (un-quantized model), behavior is identical to the original SwiGLU forward.
|
| 12 |
+
"""
|
| 13 |
+
from __future__ import annotations
|
| 14 |
+
import torch
|
| 15 |
+
import torch.nn as nn
|
| 16 |
+
import torch.nn.functional as F
|
| 17 |
+
from diffusers.models.transformers import transformer_nucleusmoe_image as _moe_mod
|
| 18 |
+
|
| 19 |
+
FP8_E4M3_MAX = 448.0 # float8_e4m3fn dynamic range
|
| 20 |
+
SCALE_DTYPE = torch.bfloat16
|
| 21 |
+
|
| 22 |
+
_PATCH_FLAG = "_nucleus_fp8_patched_v1"
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def apply_patch():
|
| 26 |
+
if getattr(_moe_mod.SwiGLUExperts, _PATCH_FLAG, False):
|
| 27 |
+
return # already patched
|
| 28 |
+
|
| 29 |
+
cls = _moe_mod.SwiGLUExperts
|
| 30 |
+
orig_init = cls.__init__
|
| 31 |
+
|
| 32 |
+
def patched_init(self, hidden_size, moe_intermediate_dim, num_experts, use_grouped_mm: bool = False):
|
| 33 |
+
# Force use_grouped_mm off — fp8 inputs aren't supported by F.grouped_mm on Blackwell yet,
|
| 34 |
+
# and the for-loop path is the patched/quantized path.
|
| 35 |
+
orig_init(self, hidden_size, moe_intermediate_dim, num_experts, use_grouped_mm=False)
|
| 36 |
+
# Persistent buffers; default to ones so a non-quantized BF16 checkpoint still produces
|
| 37 |
+
# mathematically identical output through patched_for_loop.
|
| 38 |
+
self.register_buffer(
|
| 39 |
+
"gate_up_proj_scale",
|
| 40 |
+
torch.ones(num_experts, 1, 2 * moe_intermediate_dim, dtype=SCALE_DTYPE),
|
| 41 |
+
persistent=True,
|
| 42 |
+
)
|
| 43 |
+
self.register_buffer(
|
| 44 |
+
"down_proj_scale",
|
| 45 |
+
torch.ones(num_experts, 1, hidden_size, dtype=SCALE_DTYPE),
|
| 46 |
+
persistent=True,
|
| 47 |
+
)
|
| 48 |
+
|
| 49 |
+
def patched_for_loop(self, x: torch.Tensor, num_tokens_per_expert: torch.Tensor) -> torch.Tensor:
|
| 50 |
+
n_list = num_tokens_per_expert.tolist()
|
| 51 |
+
n_real = sum(n_list)
|
| 52 |
+
n_pad = x.shape[0] - n_real
|
| 53 |
+
x_per_expert = torch.split(x[:n_real], split_size_or_sections=n_list, dim=0)
|
| 54 |
+
|
| 55 |
+
is_fp8 = self.gate_up_proj.dtype == torch.float8_e4m3fn
|
| 56 |
+
compute_dtype = x.dtype # bf16 in normal use
|
| 57 |
+
|
| 58 |
+
outs = []
|
| 59 |
+
for i, xe in enumerate(x_per_expert):
|
| 60 |
+
if is_fp8:
|
| 61 |
+
w_gu = self.gate_up_proj[i].to(compute_dtype) * self.gate_up_proj_scale[i].to(compute_dtype)
|
| 62 |
+
w_dn = self.down_proj[i].to(compute_dtype) * self.down_proj_scale[i].to(compute_dtype)
|
| 63 |
+
else:
|
| 64 |
+
w_gu = self.gate_up_proj[i]
|
| 65 |
+
w_dn = self.down_proj[i]
|
| 66 |
+
gate_up = torch.matmul(xe, w_gu)
|
| 67 |
+
gate, up = gate_up.chunk(2, dim=-1)
|
| 68 |
+
outs.append(torch.matmul(F.silu(gate) * up, w_dn))
|
| 69 |
+
|
| 70 |
+
out = torch.cat(outs, dim=0)
|
| 71 |
+
return torch.vstack((out, out.new_zeros((n_pad, out.shape[-1]))))
|
| 72 |
+
|
| 73 |
+
def patched_forward(self, x, num_tokens_per_expert):
|
| 74 |
+
return patched_for_loop(self, x, num_tokens_per_expert)
|
| 75 |
+
|
| 76 |
+
cls.__init__ = patched_init
|
| 77 |
+
cls._run_experts_for_loop = patched_for_loop
|
| 78 |
+
cls.forward = patched_forward
|
| 79 |
+
setattr(cls, _PATCH_FLAG, True)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def _patched_fp8_linear_forward(self, x):
|
| 83 |
+
# Dequantize qdata fp8 + per-output-channel scale on the fly, then F.linear.
|
| 84 |
+
w = self.weight.to(x.dtype) * self._fp8_scale.to(x.dtype)
|
| 85 |
+
return F.linear(x, w, self.bias)
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def install_fp8_linear(linear: nn.Linear, fp8_qdata: torch.Tensor, scale: torch.Tensor) -> None:
|
| 89 |
+
"""Convert one Linear instance to fp8-stored, per-instance forward override."""
|
| 90 |
+
assert isinstance(linear, nn.Linear), f"expected nn.Linear, got {type(linear).__name__}"
|
| 91 |
+
linear.weight = nn.Parameter(fp8_qdata, requires_grad=False)
|
| 92 |
+
linear.register_buffer("_fp8_scale", scale.to(SCALE_DTYPE))
|
| 93 |
+
# Bind forward at the instance level — does NOT affect other nn.Linear instances.
|
| 94 |
+
linear.forward = _patched_fp8_linear_forward.__get__(linear, type(linear))
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def load_fp8_safetensors_transformer(safetensors_path: str, config_dir: str | None = None):
|
| 98 |
+
"""
|
| 99 |
+
Load a Nucleus-Image FP8 transformer from a single safetensors file. The safetensors
|
| 100 |
+
holds raw fp8 + per-channel bf16 scale tensors (no torchao wrapper objects).
|
| 101 |
+
|
| 102 |
+
SwiGLUExperts: weights `gate_up_proj` / `down_proj` (fp8) + buffers `*_scale` (bf16).
|
| 103 |
+
Standard nn.Linear: weight (fp8) + buffer `_fp8_scale` (bf16) — forward override
|
| 104 |
+
installed by `install_fp8_linear` so the dequantize+matmul happens inline.
|
| 105 |
+
"""
|
| 106 |
+
from pathlib import Path
|
| 107 |
+
import json
|
| 108 |
+
from safetensors.torch import safe_open
|
| 109 |
+
from diffusers import AutoModel
|
| 110 |
+
from accelerate import init_empty_weights
|
| 111 |
+
|
| 112 |
+
apply_patch()
|
| 113 |
+
|
| 114 |
+
cfg_dir = Path(config_dir) if config_dir else Path(safetensors_path).parent
|
| 115 |
+
cfg = json.loads((cfg_dir / "config.json").read_text(encoding="utf-8"))
|
| 116 |
+
|
| 117 |
+
# Locate the actual transformer class via the AutoModel mapping.
|
| 118 |
+
from diffusers import NucleusMoEImageTransformer2DModel
|
| 119 |
+
with init_empty_weights():
|
| 120 |
+
model = NucleusMoEImageTransformer2DModel.from_config(cfg)
|
| 121 |
+
|
| 122 |
+
fp8_dtypes = (torch.float8_e4m3fn, torch.float8_e5m2)
|
| 123 |
+
|
| 124 |
+
# Two passes over the file:
|
| 125 |
+
# Pass 1: identify Linears that have an `_fp8_scale` sibling — install fp8 weight + scale + forward.
|
| 126 |
+
# Pass 2: load everything else via standard assign.
|
| 127 |
+
with safe_open(safetensors_path, framework="pt", device="cpu") as f:
|
| 128 |
+
all_keys = set(f.keys())
|
| 129 |
+
# Linear keys with fp8 representation: those with a `_fp8_scale` buffer.
|
| 130 |
+
linear_paths = set()
|
| 131 |
+
for k in all_keys:
|
| 132 |
+
if k.endswith("._fp8_scale"):
|
| 133 |
+
base = k[: -len("._fp8_scale")]
|
| 134 |
+
if (base + ".weight") in all_keys:
|
| 135 |
+
linear_paths.add(base)
|
| 136 |
+
|
| 137 |
+
# Pass 1: install fp8 Linears.
|
| 138 |
+
for base in linear_paths:
|
| 139 |
+
module = model.get_submodule(base)
|
| 140 |
+
qdata = f.get_tensor(base + ".weight").to("cpu")
|
| 141 |
+
scale = f.get_tensor(base + "._fp8_scale").to("cpu")
|
| 142 |
+
bias = None
|
| 143 |
+
if (base + ".bias") in all_keys:
|
| 144 |
+
bias = f.get_tensor(base + ".bias").to("cpu").to(torch.bfloat16)
|
| 145 |
+
# The init_empty_weights model has meta-device weights; replace cleanly.
|
| 146 |
+
if module.bias is not None and bias is not None:
|
| 147 |
+
module.bias = nn.Parameter(bias)
|
| 148 |
+
install_fp8_linear(module, qdata, scale)
|
| 149 |
+
|
| 150 |
+
# Pass 2: rest of the state dict (SwiGLUExperts fp8 + scales, norms, embeddings, etc.).
|
| 151 |
+
for k in all_keys:
|
| 152 |
+
# Skip keys we already handled in pass 1.
|
| 153 |
+
if any(k == p + ".weight" or k == p + "._fp8_scale" or k == p + ".bias" for p in linear_paths):
|
| 154 |
+
continue
|
| 155 |
+
t = f.get_tensor(k).to("cpu")
|
| 156 |
+
module_path, _, attr = k.rpartition(".")
|
| 157 |
+
module = model.get_submodule(module_path) if module_path else model
|
| 158 |
+
cur = getattr(module, attr, None)
|
| 159 |
+
if isinstance(cur, nn.Parameter) or cur is None:
|
| 160 |
+
# cur may be a meta-device Parameter — replace whole thing
|
| 161 |
+
if t.dtype.is_floating_point and t.dtype not in fp8_dtypes and t.dtype != torch.bfloat16:
|
| 162 |
+
t = t.to(torch.bfloat16)
|
| 163 |
+
setattr(module, attr, nn.Parameter(t, requires_grad=False) if attr in dict(module.named_parameters(recurse=False)) or cur is None or isinstance(cur, nn.Parameter) else t)
|
| 164 |
+
else:
|
| 165 |
+
# Buffer
|
| 166 |
+
if t.dtype.is_floating_point and t.dtype not in fp8_dtypes and t.dtype != torch.bfloat16:
|
| 167 |
+
t = t.to(torch.bfloat16)
|
| 168 |
+
module.register_buffer(attr, t)
|
| 169 |
+
|
| 170 |
+
# Final cleanup: any param/buffer still on meta should never happen, but assert.
|
| 171 |
+
meta_left = [n for n, p in model.named_parameters() if p.is_meta]
|
| 172 |
+
if meta_left:
|
| 173 |
+
raise RuntimeError(f"Some parameters still on meta device after load: {meta_left[:5]}... ({len(meta_left)} total)")
|
| 174 |
+
|
| 175 |
+
print(f" load_fp8_safetensors_transformer: installed {len(linear_paths)} fp8 Linears")
|
| 176 |
+
return model
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
def load_fp8_transformer(model_dir: str):
|
| 180 |
+
"""
|
| 181 |
+
Load an FP8-quantized Nucleus transformer from `model_dir` while preserving on-disk
|
| 182 |
+
fp8_e4m3fn dtypes for SwiGLUExperts weights. Other floating params are normalized to bf16.
|
| 183 |
+
|
| 184 |
+
Why: AutoModel.from_pretrained(torch_dtype=torch.bfloat16) force-casts ALL floating
|
| 185 |
+
weights including fp8. We do the standard load (which casts to bf16), then re-stream
|
| 186 |
+
the on-disk shards and reassign every fp8_e4m3fn tensor as a fresh nn.Parameter so
|
| 187 |
+
the dtype is preserved. TorchAO Float8Tensor wrappers for nn.Linear are restored
|
| 188 |
+
correctly by the standard loader (its DiffusersAutoQuantizer hook intercepts them).
|
| 189 |
+
"""
|
| 190 |
+
import json
|
| 191 |
+
from pathlib import Path
|
| 192 |
+
from diffusers import AutoModel
|
| 193 |
+
|
| 194 |
+
apply_patch() # ensure SwiGLUExperts is patched before construction
|
| 195 |
+
|
| 196 |
+
model = AutoModel.from_pretrained(
|
| 197 |
+
model_dir,
|
| 198 |
+
use_safetensors=False,
|
| 199 |
+
low_cpu_mem_usage=True,
|
| 200 |
+
)
|
| 201 |
+
|
| 202 |
+
# Re-stream disk to recover fp8 dtypes (auto-cast lost them).
|
| 203 |
+
md = Path(model_dir)
|
| 204 |
+
idx_path = md / "diffusion_pytorch_model.bin.index.json"
|
| 205 |
+
if idx_path.exists():
|
| 206 |
+
idx = json.loads(idx_path.read_text(encoding="utf-8"))
|
| 207 |
+
files = sorted(set(idx["weight_map"].values()))
|
| 208 |
+
else:
|
| 209 |
+
files = ["diffusion_pytorch_model.bin"]
|
| 210 |
+
|
| 211 |
+
fp8_dtypes = (torch.float8_e4m3fn, torch.float8_e5m2)
|
| 212 |
+
fp8_reassigned = 0
|
| 213 |
+
for fname in files:
|
| 214 |
+
shard = torch.load(md / fname, map_location="cpu", weights_only=False)
|
| 215 |
+
for key, tensor in shard.items():
|
| 216 |
+
if not hasattr(tensor, "dtype") or tensor.dtype not in fp8_dtypes:
|
| 217 |
+
continue
|
| 218 |
+
module_path, _, attr = key.rpartition(".")
|
| 219 |
+
module = model.get_submodule(module_path)
|
| 220 |
+
cur = getattr(module, attr, None)
|
| 221 |
+
if isinstance(cur, nn.Parameter):
|
| 222 |
+
setattr(module, attr, nn.Parameter(tensor, requires_grad=False))
|
| 223 |
+
else:
|
| 224 |
+
# buffer
|
| 225 |
+
module.register_buffer(attr, tensor)
|
| 226 |
+
fp8_reassigned += 1
|
| 227 |
+
del shard
|
| 228 |
+
|
| 229 |
+
# Final pass: any non-fp8 floating param in fp32/fp16 → bf16 (uniformity).
|
| 230 |
+
for _, p in model.named_parameters():
|
| 231 |
+
if p.dtype in fp8_dtypes:
|
| 232 |
+
continue
|
| 233 |
+
if p.dtype.is_floating_point and p.dtype != torch.bfloat16:
|
| 234 |
+
p.data = p.data.to(torch.bfloat16)
|
| 235 |
+
for _, b in model.named_buffers():
|
| 236 |
+
if b.dtype in fp8_dtypes:
|
| 237 |
+
continue
|
| 238 |
+
if b.dtype.is_floating_point and b.dtype != torch.bfloat16:
|
| 239 |
+
b.data = b.data.to(torch.bfloat16)
|
| 240 |
+
|
| 241 |
+
print(f" load_fp8_transformer: re-assigned {fp8_reassigned} fp8 tensors from shards")
|
| 242 |
+
return model
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
@torch.no_grad()
|
| 246 |
+
def quantize_swiglu_experts_(module: nn.Module) -> dict:
|
| 247 |
+
"""Quantize a single SwiGLUExperts module in-place. Returns a small report dict."""
|
| 248 |
+
assert type(module).__name__ == "SwiGLUExperts", f"expected SwiGLUExperts, got {type(module).__name__}"
|
| 249 |
+
device = module.gate_up_proj.device
|
| 250 |
+
|
| 251 |
+
def _quant(w: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
|
| 252 |
+
# w shape: (num_experts, in_dim, out_dim). Per-expert per-output-channel scale on dim=-2.
|
| 253 |
+
w32 = w.detach().to(torch.float32)
|
| 254 |
+
scale = w32.abs().amax(dim=-2, keepdim=True).clamp(min=1e-12) / FP8_E4M3_MAX
|
| 255 |
+
q = (w32 / scale).clamp(-FP8_E4M3_MAX, FP8_E4M3_MAX).to(torch.float8_e4m3fn)
|
| 256 |
+
return q, scale.to(SCALE_DTYPE)
|
| 257 |
+
|
| 258 |
+
q_gu, s_gu = _quant(module.gate_up_proj.data)
|
| 259 |
+
q_dn, s_dn = _quant(module.down_proj.data)
|
| 260 |
+
|
| 261 |
+
# Reconstruction error gate. Use rel L2 (||W_hat - W||_2 / ||W||_2) per tensor — the right
|
| 262 |
+
# metric for forward fidelity (matmul amplifies L2-style error, not max-abs).
|
| 263 |
+
w_gu_orig = module.gate_up_proj.data.to(torch.float32)
|
| 264 |
+
w_dn_orig = module.down_proj.data.to(torch.float32)
|
| 265 |
+
rec_gu = q_gu.to(torch.float32) * s_gu.to(torch.float32)
|
| 266 |
+
rec_dn = q_dn.to(torch.float32) * s_dn.to(torch.float32)
|
| 267 |
+
|
| 268 |
+
rep = {
|
| 269 |
+
"gu_rel_l2": ((rec_gu - w_gu_orig).norm() / w_gu_orig.norm().clamp(min=1e-12)).item(),
|
| 270 |
+
"dn_rel_l2": ((rec_dn - w_dn_orig).norm() / w_dn_orig.norm().clamp(min=1e-12)).item(),
|
| 271 |
+
# Keep the loose rel-max-err for visibility but no longer used as a gate.
|
| 272 |
+
"gu_rel_max": ((rec_gu - w_gu_orig).abs().amax() / w_gu_orig.abs().amax().clamp(min=1e-12)).item(),
|
| 273 |
+
"dn_rel_max": ((rec_dn - w_dn_orig).abs().amax() / w_dn_orig.abs().amax().clamp(min=1e-12)).item(),
|
| 274 |
+
}
|
| 275 |
+
|
| 276 |
+
# In-place replacement
|
| 277 |
+
module.gate_up_proj = nn.Parameter(q_gu.to(device), requires_grad=False)
|
| 278 |
+
module.down_proj = nn.Parameter(q_dn.to(device), requires_grad=False)
|
| 279 |
+
module.gate_up_proj_scale.data = s_gu.to(device)
|
| 280 |
+
module.down_proj_scale.data = s_dn.to(device)
|
| 281 |
+
return rep
|