
File size: 4,634 Bytes
9b3e3f8 371f855 9b3e3f8 c1c5bef 9b3e3f8 da24a73 f51368a da24a73 c1c5bef da24a73 9b3e3f8 c1c5bef da24a73 c1c5bef da24a73 c1c5bef da24a73 9b3e3f8 da24a73 c1c5bef da24a73 c1c5bef da24a73 c1c5bef 9b3e3f8 | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 | ---
license: apache-2.0
pipeline_tag: automatic-speech-recognition
language: multilingual
---
# Dolphin
[Paper](https://arxiv.org/abs/2503.20212)
[Github](https://github.com/DataoceanAI/Dolphin)
[Huggingface](https://huggingface.co/DataoceanAI)
[Modelscope](https://www.modelscope.cn/organization/DataoceanAI)
# Repository Notice
This model is officially maintained by **Dataocean AI**.
To ensure compatibility with existing user code and download links, we keep two official repositories for the same model:
- Original / legacy repository: DataoceanAI
- Organization / enterprise repository: DataoceanAI1
Both repositories are maintained by the same team and contain the same model files.
DataoceanAI1 is the newly created enterprise organization account, while DataoceanAI is kept to avoid breaking existing user download scripts and links.
Please do not regard either repository as an unofficial copy or unauthorized redistribution.
Dolphin is a multilingual, multitask ASR model developed through a collaboration between Dataocean AI and Tsinghua University. It supports 40 Eastern languages across East Asia, South Asia, Southeast Asia, and the Middle East, while also supporting 22 Chinese dialects. It is trained on over 210,000 hours of data, which includes both DataoceanAI's proprietary datasets and open-source datasets. The model can perform speech recognition, voice activity detection (VAD), segmentation, and language identification (LID).
## Approach
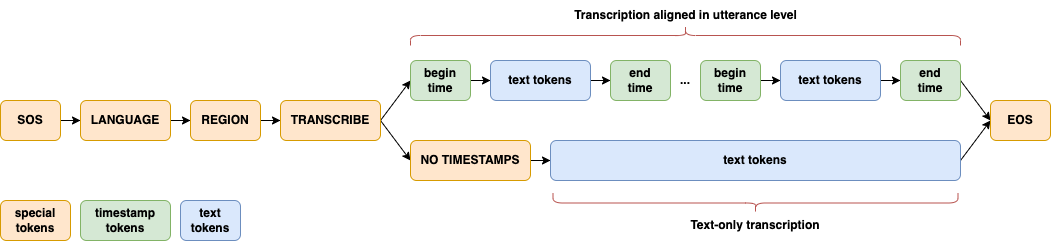
Dolphin largely follows the innovative design approach of [Whisper](https://github.com/openai/whisper) and [OWSM](https://github.com/espnet/espnet/tree/master/egs2/owsm_v3.1/s2t1). A joint CTC-Attention architecture is adopted, with encoder based on E-Branchformer and decoder based on standard Transformer. Several key modifications are introduced for its specific focus on ASR. Dolphin does not support translation tasks, and eliminates the use of previous text and its related tokens.
A significant enhancement in Dolphin is the introduction of a two-level language token system to better handle linguistic and regional diversity, especially in Dataocean AI dataset. The first token specifies the language (e.g., `<zh>`, `<ja>`), while the second token indicates the region (e.g., `<CN>`, `<JP>`). See details in [paper](https://arxiv.org/abs/2503.20212).
## Setup
Dolphin requires FFmpeg to convert audio file to WAV format. If FFmpeg is not installed on your system, please install it first:
```shell
# Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# MacOS
brew install ffmpeg
# Windows
choco install ffmpeg
```
You can install the latest version of Dolphin using the following command:
```shell
pip install -U dataoceanai-dolphin
```
Alternatively, it can also be installed from the source:
```shell
pip install git+https://github.com/SpeechOceanTech/Dolphin.git
```
## Available Models and Languages
### Models
There are 4 models in Dolphin, and 2 of them are available now. See details in [paper](https://arxiv.org/abs/2503.20212).
| Model | Parameters | Average WER | Publicly Available |
|:------:|:----------:|:------------------:|:------------------:|
| base | 140 M | 33.3 | ✅ |
| small | 372 M | 25.2 | ✅ |
| medium | 910 M | 23.1 | |
| large | 1679 M | 21.6 | |
### Languages
Dolphin supports 40 Eastern languages and 22 Chinese dialects. For a complete list of supported languages, see [languages.md](https://github.com/DataoceanAI/Dolphin/blob/main/languages.md).
## Usage
### Command-line usage
```shell
dolphin audio.wav
# Download model and specify the model path
dolphin audio.wav --model small --model_dir /data/models/dolphin/
# Specify language and region
dolphin audio.wav --model small --model_dir /data/models/dolphin/ --lang_sym "zh" --region_sym "CN"
# padding speech to 30 seconds
dolphin audio.wav --model small --model_dir /data/models/dolphin/ --lang_sym "zh" --region_sym "CN" --padding_speech true
```
### Python usage
```python
import dolphin
waveform = dolphin.load_audio("audio.wav")
model = dolphin.load_model("small", "/data/models/dolphin", "cuda")
result = model(waveform)
# Specify language and region
result = model(waveform, lang_sym="zh", region_sym="CN")
print(result.text)
```
## License
Dolphin's code and model weights are released under the [Apache 2.0 License](https://github.com/DataoceanAI/Dolphin/blob/main/LICENSE). |