
Update README.md
Browse files
README.md
CHANGED
|
@@ -3,7 +3,7 @@ license: apache-2.0
|
|
| 3 |
tags:
|
| 4 |
- generated_from_trainer
|
| 5 |
datasets:
|
| 6 |
-
-
|
| 7 |
metrics:
|
| 8 |
- precision
|
| 9 |
- recall
|
|
@@ -12,6 +12,9 @@ metrics:
|
|
| 12 |
model-index:
|
| 13 |
- name: bert-large-cased-lora-finetuned-ner-EMBO-SourceData
|
| 14 |
results: []
|
|
|
|
|
|
|
|
|
|
| 15 |
---
|
| 16 |
|
| 17 |
# bert-large-cased-lora-finetuned-ner-EMBO-SourceData
|
|
@@ -27,7 +30,7 @@ It achieves the following results on the evaluation set:
|
|
| 27 |
|
| 28 |
## Model description
|
| 29 |
|
| 30 |
-
For more information on how it was created, check out the following link: https://github.com/DunnBC22/NLP_Projects/blob/main/Token%20Classification/Monolingual/EMBO-SourceData%20with%20LoRA/NER%20Project%20Using%20EMBO-SourceData%20with%20LoRA.ipynb
|
| 31 |
|
| 32 |
## Intended uses & limitations
|
| 33 |
|
|
@@ -35,7 +38,7 @@ This model is intended to demonstrate my ability to solve a complex problem usin
|
|
| 35 |
|
| 36 |
## Training and evaluation data
|
| 37 |
|
| 38 |
-
Dataset Source: https://huggingface.co/datasets/EMBO/BLURB
|
| 39 |
|
| 40 |
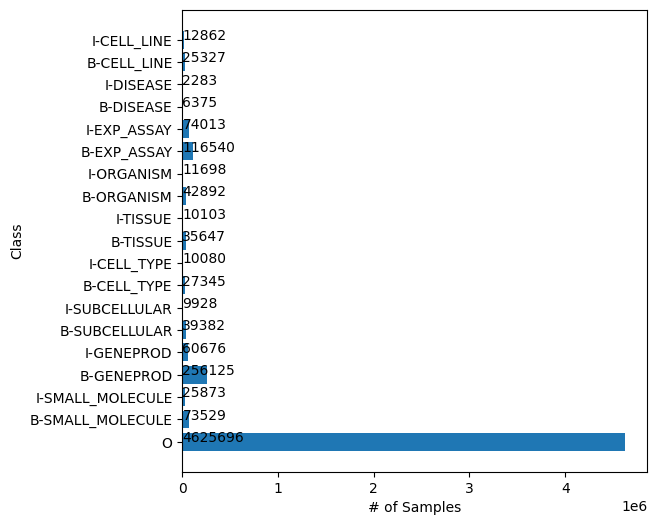
**Token Distribution**
|
| 41 |
|
|
@@ -74,4 +77,4 @@ The following hyperparameters were used during training:
|
|
| 74 |
- Transformers 4.26.1
|
| 75 |
- Pytorch 2.0.1
|
| 76 |
- Datasets 2.13.1
|
| 77 |
-
- Tokenizers 0.13.3
|
|
|
|
| 3 |
tags:
|
| 4 |
- generated_from_trainer
|
| 5 |
datasets:
|
| 6 |
+
- EMBO/BLURB
|
| 7 |
metrics:
|
| 8 |
- precision
|
| 9 |
- recall
|
|
|
|
| 12 |
model-index:
|
| 13 |
- name: bert-large-cased-lora-finetuned-ner-EMBO-SourceData
|
| 14 |
results: []
|
| 15 |
+
language:
|
| 16 |
+
- en
|
| 17 |
+
pipeline_tag: token-classification
|
| 18 |
---
|
| 19 |
|
| 20 |
# bert-large-cased-lora-finetuned-ner-EMBO-SourceData
|
|
|
|
| 30 |
|
| 31 |
## Model description
|
| 32 |
|
| 33 |
+
For more information on how it was created, check out the following link: [https://github.com/DunnBC22/NLP_Projects/blob/main/Token%20Classification/Monolingual/EMBO-SourceData%20with%20LoRA/NER%20Project%20Using%20EMBO-SourceData%20with%20LoRA.ipynb](https://github.com/DunnBC22/NLP_Projects/blob/main/Token%20Classification/Monolingual/EMBO-SourceData%20with%20LoRA/NER%20Project%20Using%20EMBO-SourceData%20with%20LoRA.ipynb)
|
| 34 |
|
| 35 |
## Intended uses & limitations
|
| 36 |
|
|
|
|
| 38 |
|
| 39 |
## Training and evaluation data
|
| 40 |
|
| 41 |
+
Dataset Source: [https://huggingface.co/datasets/EMBO/BLURB](https://huggingface.co/datasets/EMBO/BLURB)
|
| 42 |
|
| 43 |
**Token Distribution**
|
| 44 |

|
|
|
|
| 77 |
- Transformers 4.26.1
|
| 78 |
- Pytorch 2.0.1
|
| 79 |
- Datasets 2.13.1
|
| 80 |
+
- Tokenizers 0.13.3
|