

Commit ·
5988096
0
Parent(s):
Duplicate from AIOmarRehan/CNN_Audio_Classification_Model_with_Spectrogram
Browse files- .gitattributes +35 -0
- Audio_Model_Classification.h5 +3 -0
- README.md +320 -0
.gitattributes
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
Audio_Model_Classification.h5
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ceef1269f64afc26d31dc35e4bcacf68c2d91181aa28afeecec0e2403aabf739
|
| 3 |
+
size 22083448
|
README.md
ADDED
|
@@ -0,0 +1,320 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language: en
|
| 3 |
+
license: mit
|
| 4 |
+
tags:
|
| 5 |
+
- audio-classification
|
| 6 |
+
- tensorflow
|
| 7 |
+
- mel-spectrogram-images
|
| 8 |
+
- audio-processing
|
| 9 |
+
inference: true
|
| 10 |
+
datasets:
|
| 11 |
+
- AIOmarRehan/Mel_Spectrogram_Images_for_Audio_Classification
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
[If you would like a detailed explanation of this project, please refer to the Medium article below.](https://medium.com/@ai.omar.rehan/building-a-complete-audio-classification-pipeline-using-deep-learning-from-raw-audio-to-mel-9894bd438d85)
|
| 15 |
+
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
[The project is also available for testing on Hugging Face.](https://huggingface.co/spaces/AIOmarRehan/Deep_Audio_Classifier_using_CNN)
|
| 19 |
+
|
| 20 |
+
---
|
| 21 |
+
|
| 22 |
+
# Audio-Classification-Raw-Audio-to-Mel-Spectrogram-CNNs
|
| 23 |
+
Complete end-to-end audio classification pipeline using deep learning. From raw recordings to Mel spectrogram CNNs, includes preprocessing, augmentation, dataset validation, model training, and evaluation - a reproducible blueprint for speech, environmental, or general sound classification tasks.
|
| 24 |
+
|
| 25 |
+
---
|
| 26 |
+
|
| 27 |
+
# Audio Classification Pipeline - From Raw Audio to Mel-Spectrogram CNNs
|
| 28 |
+
|
| 29 |
+
> *“In machine learning, the model is rarely the problem - the data almost always is.”*
|
| 30 |
+
> - A reminder I kept repeating to myself while building this project.
|
| 31 |
+
|
| 32 |
+
This repository contains a complete, professional, end-to-end pipeline for **audio classification using deep learning**, starting from **raw, messy audio recordings** and ending with a fully trained **CNN model** using **Mel spectrograms**.
|
| 33 |
+
|
| 34 |
+
The workflow includes:
|
| 35 |
+
|
| 36 |
+
* Raw audio loading
|
| 37 |
+
* Cleaning & normalization
|
| 38 |
+
* Silence trimming
|
| 39 |
+
* Noise reduction
|
| 40 |
+
* Chunking
|
| 41 |
+
* Data augmentation
|
| 42 |
+
* Mel spectrogram generation
|
| 43 |
+
* Dataset validation
|
| 44 |
+
* CNN training
|
| 45 |
+
* Evaluation & metrics
|
| 46 |
+
|
| 47 |
+
It is a fully reproducible blueprint for real-world audio classification tasks.
|
| 48 |
+
|
| 49 |
+
---
|
| 50 |
+
|
| 51 |
+
# Project Structure
|
| 52 |
+
|
| 53 |
+
Here is a quick table summarizing the core stages of the pipeline:
|
| 54 |
+
|
| 55 |
+
| Stage | Description | Output |
|
| 56 |
+
| ----------------------- | -------------------------------------- | ---------------- |
|
| 57 |
+
| **1. Raw Audio** | Unprocessed WAV/MP3 files | Audio dataset |
|
| 58 |
+
| **2. Preprocessing** | Trimming, cleaning, resampling | Cleaned signals |
|
| 59 |
+
| **3. Augmentation** | Pitch shift, time stretch, noise | Expanded dataset |
|
| 60 |
+
| **4. Mel Spectrograms** | Converts audio → images | PNG/IMG files |
|
| 61 |
+
| **5. CNN Training** | Deep model learns spectrogram patterns | `.h5` model |
|
| 62 |
+
| **6. Evaluation** | Accuracy, F1, Confusion Matrix | Metrics + plots |
|
| 63 |
+
|
| 64 |
+
---
|
| 65 |
+
|
| 66 |
+
# 1. Loading & Inspecting Raw Audio
|
| 67 |
+
|
| 68 |
+
The dataset is loaded from directory structure:
|
| 69 |
+
|
| 70 |
+
```python
|
| 71 |
+
paths = [(path.parts[-2], path.name, str(path))
|
| 72 |
+
for path in Path(extract_to).rglob('*.*')
|
| 73 |
+
if path.suffix.lower() in audio_extensions]
|
| 74 |
+
|
| 75 |
+
df = pd.DataFrame(paths, columns=['class', 'filename', 'full_path'])
|
| 76 |
+
df = df.sort_values('class').reset_index(drop=True)
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
During EDA, I computed:
|
| 80 |
+
|
| 81 |
+
* Duration
|
| 82 |
+
* Sample rate
|
| 83 |
+
* Peak amplitude
|
| 84 |
+
|
| 85 |
+
And visualized duration distribution:
|
| 86 |
+
|
| 87 |
+
```python
|
| 88 |
+
plt.hist(df['duration'], bins=30, edgecolor='black')
|
| 89 |
+
plt.xlabel("Duration (seconds)")
|
| 90 |
+
plt.ylabel("Number of recordings")
|
| 91 |
+
plt.title("Audio Duration Distribution")
|
| 92 |
+
plt.show()
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
---
|
| 96 |
+
|
| 97 |
+
# 2. Audio Cleaning & Normalization
|
| 98 |
+
|
| 99 |
+
Bad samples were removed, silent files filtered, and amplitudes normalized:
|
| 100 |
+
|
| 101 |
+
```python
|
| 102 |
+
peak = np.abs(y).max()
|
| 103 |
+
if peak > 0:
|
| 104 |
+
y = y / peak * 0.99
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
This ensures consistency and prevents the model from learning from corrupted audio.
|
| 108 |
+
|
| 109 |
+
---
|
| 110 |
+
|
| 111 |
+
# 3. Advanced Preprocessing
|
| 112 |
+
|
| 113 |
+
Preprocessing included:
|
| 114 |
+
|
| 115 |
+
* Silence trimming
|
| 116 |
+
* Noise reduction
|
| 117 |
+
* Resampling → **16 kHz**
|
| 118 |
+
* Mono conversion
|
| 119 |
+
* 5-second chunking
|
| 120 |
+
|
| 121 |
+
```python
|
| 122 |
+
TARGET_DURATION = 5.0
|
| 123 |
+
TARGET_SR = 16000
|
| 124 |
+
TARGET_LENGTH = int(TARGET_DURATION * TARGET_SR)
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
Every audio file becomes a clean, consistent chunk ready for feature extraction.
|
| 128 |
+
|
| 129 |
+
---
|
| 130 |
+
|
| 131 |
+
# 4. Audio Augmentation
|
| 132 |
+
|
| 133 |
+
To improve generalization, I applied augmentations:
|
| 134 |
+
|
| 135 |
+
```python
|
| 136 |
+
augment = Compose([
|
| 137 |
+
Shift(min_shift=-0.3, max_shift=0.3, p=0.5),
|
| 138 |
+
PitchShift(min_semitones=-2, max_semitones=2, p=0.5),
|
| 139 |
+
TimeStretch(min_rate=0.8, max_rate=1.25, p=0.5),
|
| 140 |
+
AddGaussianNoise(min_amplitude=0.001, max_amplitude=0.015, p=0.5)
|
| 141 |
+
])
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
Every augmented file receives a unique name to avoid collisions.
|
| 145 |
+
|
| 146 |
+
---
|
| 147 |
+
|
| 148 |
+
# 5. Mel Spectrogram Generation
|
| 149 |
+
|
| 150 |
+
Each cleaned audio chunk is transformed into a **Mel spectrogram**:
|
| 151 |
+
|
| 152 |
+
```python
|
| 153 |
+
S = librosa.feature.melspectrogram(
|
| 154 |
+
y=y, sr=SR,
|
| 155 |
+
n_fft=N_FFT,
|
| 156 |
+
hop_length=HOP_LENGTH,
|
| 157 |
+
n_mels=N_MELS
|
| 158 |
+
)
|
| 159 |
+
S_dB = librosa.power_to_db(S, ref=np.max)
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
* Output: **128×128 PNG images**
|
| 163 |
+
* Separate directories per class
|
| 164 |
+
* Supports both original & augmented samples
|
| 165 |
+
|
| 166 |
+
These images become the CNN input.
|
| 167 |
+
|
| 168 |
+
### ***Example of Mel Spectrogram Images***
|
| 169 |
+
|
| 170 |
+
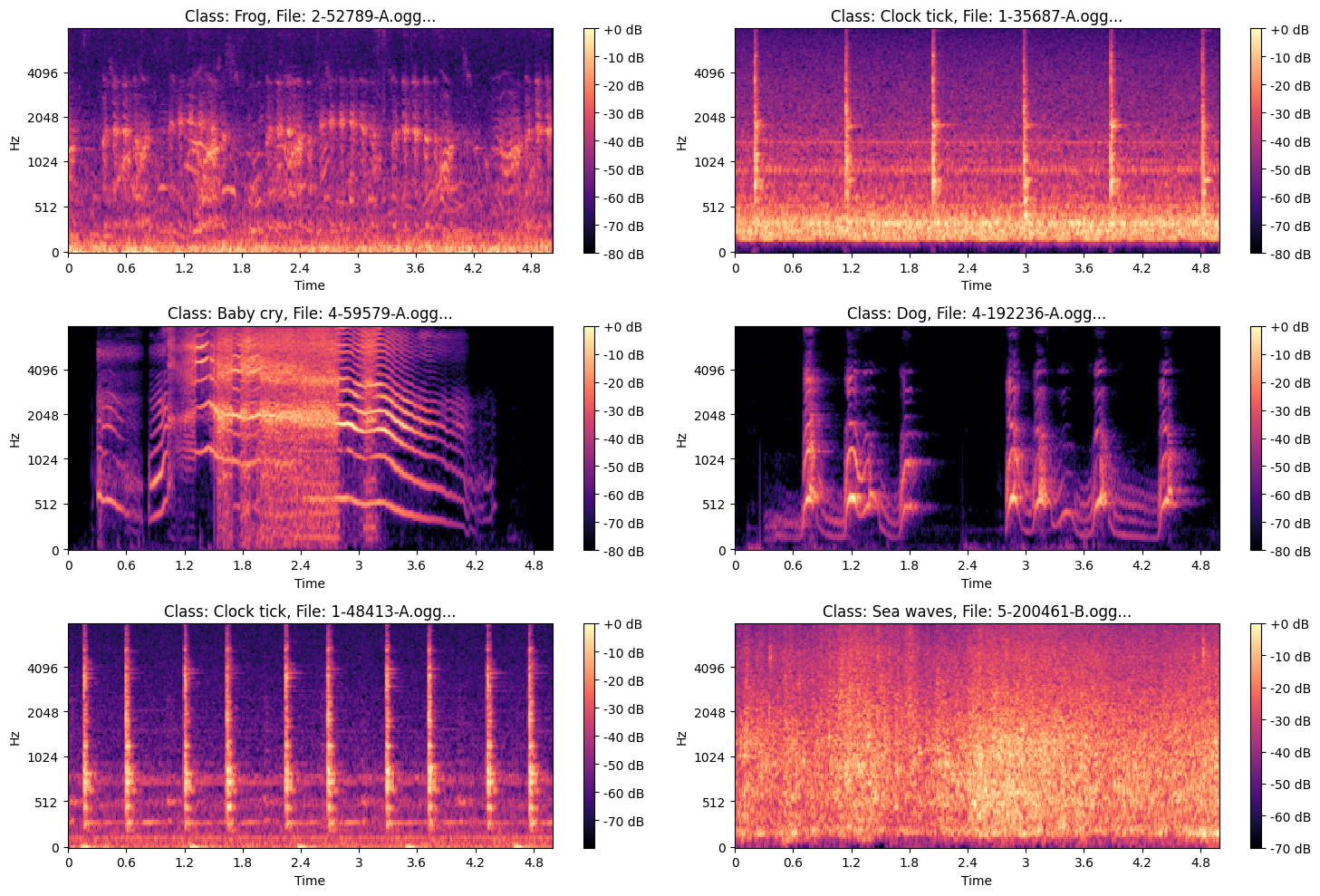
|
| 171 |
+
|
| 172 |
+
.png?generation=1763570855911665&alt=media)
|
| 173 |
+
|
| 174 |
+
---
|
| 175 |
+
|
| 176 |
+
# 6. Dataset Validation
|
| 177 |
+
|
| 178 |
+
After spectrogram creation:
|
| 179 |
+
|
| 180 |
+
* Corrupted images removed
|
| 181 |
+
* Duplicate hashes filtered
|
| 182 |
+
* Filename integrity checked
|
| 183 |
+
* Class folders validated
|
| 184 |
+
|
| 185 |
+
```python
|
| 186 |
+
df['file_hash'] = df['full_path'].apply(get_hash)
|
| 187 |
+
duplicate_hashes = df[df.duplicated(subset=['file_hash'], keep=False)]
|
| 188 |
+
```
|
| 189 |
+
|
| 190 |
+
This step ensures **clean, reliable** training data.
|
| 191 |
+
|
| 192 |
+
---
|
| 193 |
+
|
| 194 |
+
# 7. Building TensorFlow Datasets
|
| 195 |
+
|
| 196 |
+
The dataset is built with batching, caching, prefetching:
|
| 197 |
+
|
| 198 |
+
```python
|
| 199 |
+
train_ds = tf.data.Dataset.from_tensor_slices((train_paths, train_labels))
|
| 200 |
+
train_ds = train_ds.map(load_and_preprocess, num_parallel_calls=AUTOTUNE)
|
| 201 |
+
train_ds = train_ds.shuffle(1024).batch(batch_size).prefetch(AUTOTUNE)
|
| 202 |
+
```
|
| 203 |
+
|
| 204 |
+
I used a simple image-level augmentation pipeline:
|
| 205 |
+
|
| 206 |
+
```python
|
| 207 |
+
data_augmentation = tf.keras.Sequential([
|
| 208 |
+
tf.keras.layers.InputLayer(input_shape=(231, 232, 4)),
|
| 209 |
+
tf.keras.layers.RandomFlip("horizontal"),
|
| 210 |
+
tf.keras.layers.RandomRotation(0.1),
|
| 211 |
+
tf.keras.layers.RandomZoom(0.1),
|
| 212 |
+
])
|
| 213 |
+
```
|
| 214 |
+
|
| 215 |
+
---
|
| 216 |
+
|
| 217 |
+
# 8. CNN Architecture
|
| 218 |
+
|
| 219 |
+
The CNN captures deep frequency-time patterns across Mel images.
|
| 220 |
+
|
| 221 |
+
Key features:
|
| 222 |
+
|
| 223 |
+
* Multiple Conv2D + BatchNorm blocks
|
| 224 |
+
* Dropout
|
| 225 |
+
* L2 regularization
|
| 226 |
+
* Softmax output
|
| 227 |
+
|
| 228 |
+
```python
|
| 229 |
+
model = Sequential([
|
| 230 |
+
data_augmentation,
|
| 231 |
+
Conv2D(32, (3,3), padding='same', activation='relu', kernel_regularizer=l2(weight_decay)),
|
| 232 |
+
BatchNormalization(),
|
| 233 |
+
MaxPooling2D((2,2)),
|
| 234 |
+
Dropout(0.2),
|
| 235 |
+
# ... more layers ...
|
| 236 |
+
Flatten(),
|
| 237 |
+
Dense(num_classes, activation='softmax')
|
| 238 |
+
])
|
| 239 |
+
```
|
| 240 |
+
|
| 241 |
+
---
|
| 242 |
+
|
| 243 |
+
# 9. Training Strategy
|
| 244 |
+
|
| 245 |
+
```python
|
| 246 |
+
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=10)
|
| 247 |
+
early_stopping = EarlyStopping(monitor='val_loss', patience=40, restore_best_weights=True)
|
| 248 |
+
|
| 249 |
+
history = model.fit(
|
| 250 |
+
train_ds,
|
| 251 |
+
validation_data=val_ds,
|
| 252 |
+
epochs=50,
|
| 253 |
+
callbacks=[reduce_lr, early_stopping]
|
| 254 |
+
)
|
| 255 |
+
```
|
| 256 |
+
|
| 257 |
+
The model converges smoothly while avoiding overfitting.
|
| 258 |
+
|
| 259 |
+
---
|
| 260 |
+
|
| 261 |
+
# 10. Evaluation
|
| 262 |
+
|
| 263 |
+
Performance is evaluated using:
|
| 264 |
+
|
| 265 |
+
* Accuracy
|
| 266 |
+
* Precision, recall, F1-score
|
| 267 |
+
* Confusion matrix
|
| 268 |
+
* ROC/AUC curves
|
| 269 |
+
|
| 270 |
+
```python
|
| 271 |
+
y_pred = np.argmax(model.predict(test_ds), axis=1)
|
| 272 |
+
print(classification_report(y_true, y_pred, target_names=le.classes_))
|
| 273 |
+
```
|
| 274 |
+
|
| 275 |
+
Confusion matrix:
|
| 276 |
+
|
| 277 |
+
```python
|
| 278 |
+
sns.heatmap(confusion_matrix(y_true, y_pred), annot=True, cmap='Blues')
|
| 279 |
+
plt.title("Confusion Matrix")
|
| 280 |
+
plt.show()
|
| 281 |
+
```
|
| 282 |
+
|
| 283 |
+
---
|
| 284 |
+
|
| 285 |
+
# 11. Saving the Model & Dataset
|
| 286 |
+
|
| 287 |
+
```python
|
| 288 |
+
model.save("Audio_Model_Classification.h5")
|
| 289 |
+
shutil.make_archive("/content/spectrograms", 'zip', "/content/spectrograms")
|
| 290 |
+
```
|
| 291 |
+
|
| 292 |
+
The entire spectrogram dataset is also zipped for sharing or deployment.
|
| 293 |
+
|
| 294 |
+
---
|
| 295 |
+
|
| 296 |
+
# Final Notes
|
| 297 |
+
|
| 298 |
+
This project demonstrates:
|
| 299 |
+
|
| 300 |
+
* How to clean & prepare raw audio at a professional level
|
| 301 |
+
* Audio augmentation best practices
|
| 302 |
+
* How Mel spectrograms unlock CNN performance
|
| 303 |
+
* A full TensorFlow training pipeline
|
| 304 |
+
* Proper evaluation, reporting, and dataset integrity
|
| 305 |
+
|
| 306 |
+
If you're working on sound recognition, speech tasks, or environmental audio detection, this pipeline gives you a **complete production-grade foundation**.
|
| 307 |
+
|
| 308 |
+
---
|
| 309 |
+
|
| 310 |
+
# **Results**
|
| 311 |
+
> **Note:** Click the image below to view the video showcasing the project’s results.
|
| 312 |
+
<a href="https://files.catbox.moe/suzziy.mp4">
|
| 313 |
+
<img src="https://images.unsplash.com/photo-1611162616475-46b635cb6868?q=80&w=1974&auto=format&fit=crop&ixlib=rb-4.1.0&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D" width="400">
|
| 314 |
+
</a>
|
| 315 |
+
|
| 316 |
+
<hr style="border-bottom: 5px solid gray; margin-top: 10px;">
|
| 317 |
+
|
| 318 |
+
> **Note:** If the video above is not working, you can access it directly via the link below.
|
| 319 |
+
|
| 320 |
+
[Watch Demo Video](Results/Spectrogram_CNN_Audio_Classification.mp4)
|