---
license: apache-2.0
pipeline_tag: text-generation
---
# ROME-30B-A3B (Coming Soon)
🔗 Technical Report
 ---
## 📢 Note: Coming Soon!
**ROME (ROME is Obviously an Agentic ModEl)** will be officially released soon.
The project is currently under final review and preparation. Model weights will be made publicly available shortly. Stay tuned!
---
## 📢 Note: Coming Soon!
**ROME (ROME is Obviously an Agentic ModEl)** will be officially released soon.
The project is currently under final review and preparation. Model weights will be made publicly available shortly. Stay tuned!
 ---
## Highlights
**ROME** is an open-source **agentic model** incubated within the **ALE (Agentic Learning Ecosystem)**.
Rather than scaling performance purely by increasing parameter count, ROME achieves parameter-scale–crossing agentic performance through full-stack infrastructure and RL algorithmic optimization.
---
## Highlights
**ROME** is an open-source **agentic model** incubated within the **ALE (Agentic Learning Ecosystem)**.
Rather than scaling performance purely by increasing parameter count, ROME achieves parameter-scale–crossing agentic performance through full-stack infrastructure and RL algorithmic optimization.
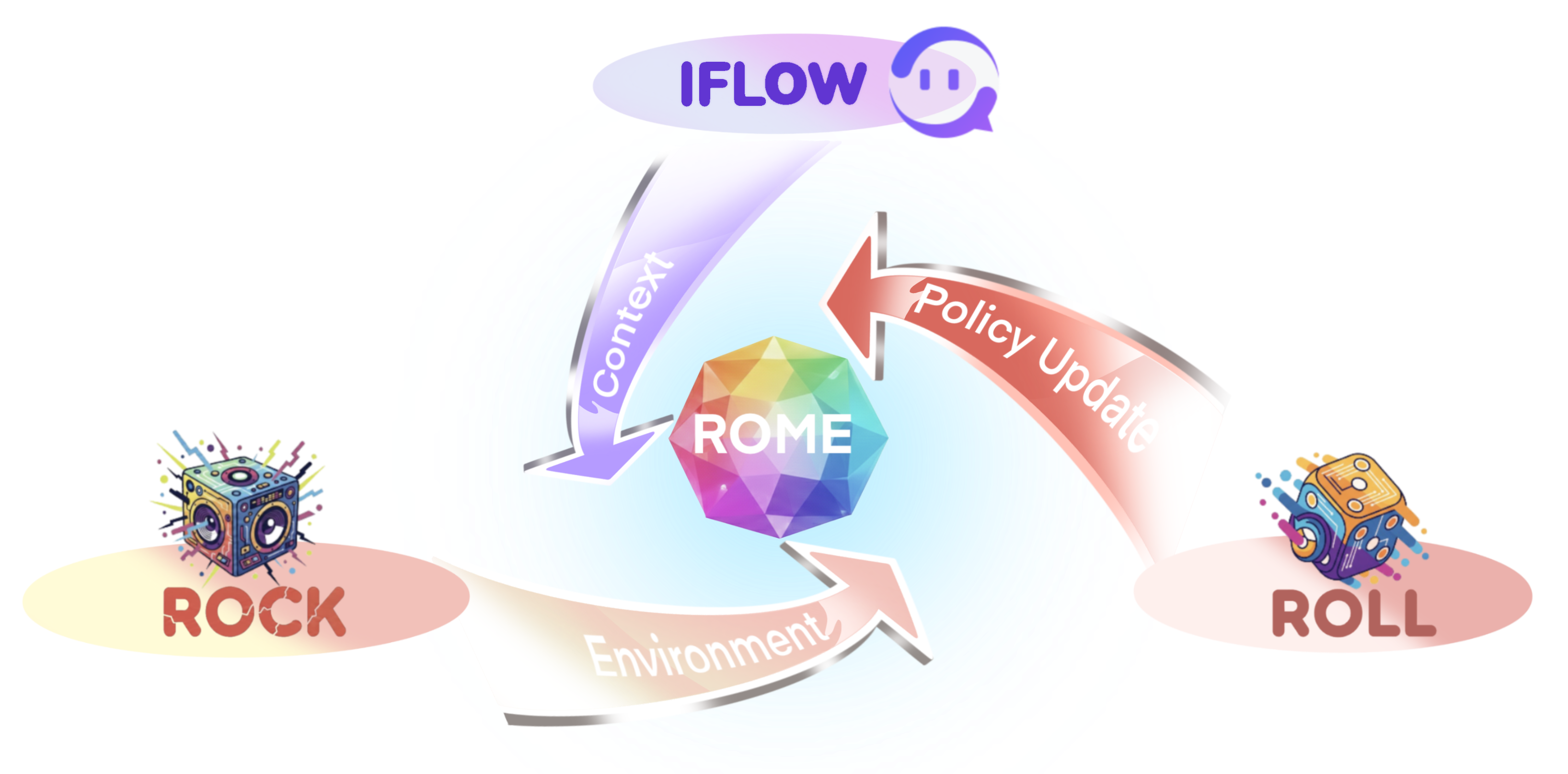 ### 🔧 ALE Full-Stack Infrastructure
- **ROLL** – Large-scale reinforcement learning optimization engine
- **ROCK** – Secure sandbox and environment orchestration for agent execution
- **iFlow CLI** – Unified agent framework and developer interface
### 🧠 IPA Policy Optimization Algorithm
- Introduces **Interaction-Perceptive Agentic Policy Optimization (IPA)**
- Performs credit assignment at the level of **Semantic Interaction Chunks**
- Significantly improves **training stability** and **success rates** on **long-horizon tasks**
### 🚀 Strong Agentic Performance
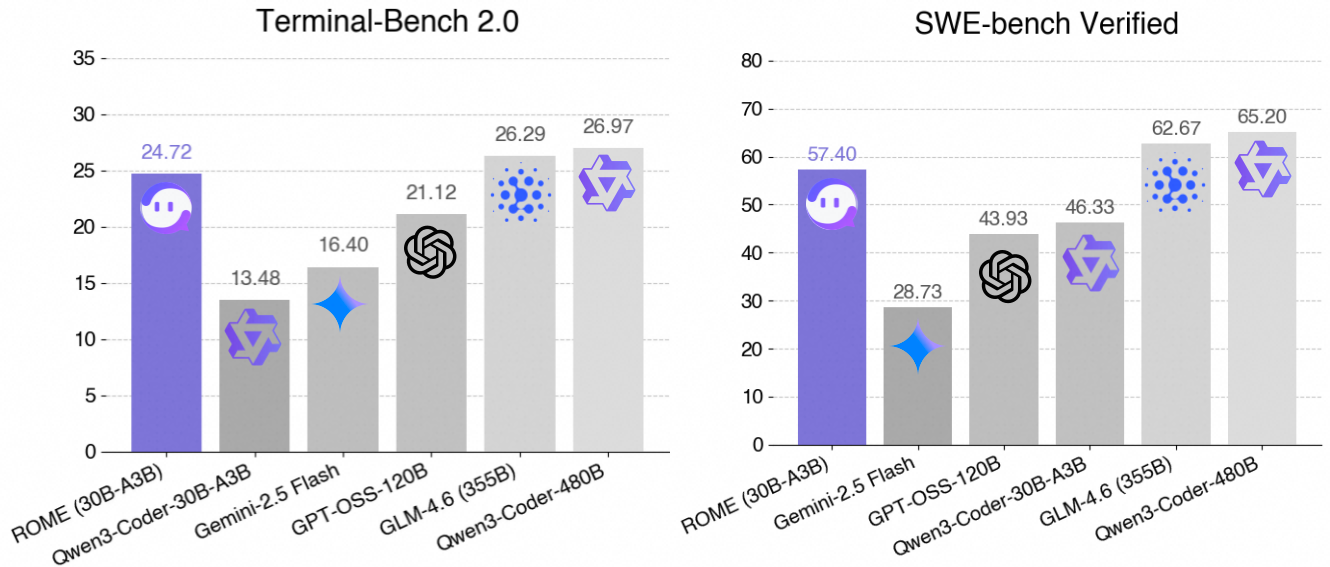
- Despite being a **mid-sized model** (30B MoE with 3B active parameters), ROME outperforms same-scale models on standard agent benchmarks:
- **Terminal-Bench 2.0**: 24.72%
- **SWE-bench Verified**: 57.40%
- Performance is competitive with, and in some cases comparable to, models exceeding **100B parameters**
### 🔒 Production-Grade Safety
- Designed for autonomous agent execution in real environments
- Rigorously aligned and red-teamed against risks such as:
- Unauthorized access
- Illegal or unsafe tool invocation
- Built with **deployment-grade safety guarantees** in mind
---
## Performance (Preview)
### Terminal-Based Benchmarks
| **Model** | **Terminal-Bench 2.0** | **SWE-bench Verified** |
| ---------------------------- | ---------------------- | ---------------------- |
| Qwen3-Coder-30B-A3B-Instruct | 13.48% | 46.33% |
| **ROME-30B-A3B** | **24.72%** | **57.40%** |
| GPT-OSS-120B | 21.12% | 43.93% |
| GLM-4.5 Air (106B) | 17.30% | 56.20% |
> See the technical report for full experimental details.
---
## Best Practices
*(Code examples and usage guidelines will be added after the model release.)*
---
## Citation
If you find our work useful, please consider citing:
```bibtex
@article{rome2025ale,
title={Let It Flow: Agentic Crafting on Rock and Roll - Building the ROME Model within an Open Agentic Learning Ecosystem},
author={Wang, Weixun and Xu, XiaoXiao and An, Wanhe and Dai, Fangwen and others},
journal={arXiv preprint arXiv:2512.24873},
year={2025}
}
### 🔧 ALE Full-Stack Infrastructure
- **ROLL** – Large-scale reinforcement learning optimization engine
- **ROCK** – Secure sandbox and environment orchestration for agent execution
- **iFlow CLI** – Unified agent framework and developer interface
### 🧠 IPA Policy Optimization Algorithm
- Introduces **Interaction-Perceptive Agentic Policy Optimization (IPA)**
- Performs credit assignment at the level of **Semantic Interaction Chunks**
- Significantly improves **training stability** and **success rates** on **long-horizon tasks**
### 🚀 Strong Agentic Performance
- Despite being a **mid-sized model** (30B MoE with 3B active parameters), ROME outperforms same-scale models on standard agent benchmarks:
- **Terminal-Bench 2.0**: 24.72%
- **SWE-bench Verified**: 57.40%
- Performance is competitive with, and in some cases comparable to, models exceeding **100B parameters**
### 🔒 Production-Grade Safety
- Designed for autonomous agent execution in real environments
- Rigorously aligned and red-teamed against risks such as:
- Unauthorized access
- Illegal or unsafe tool invocation
- Built with **deployment-grade safety guarantees** in mind
---
## Performance (Preview)
### Terminal-Based Benchmarks
| **Model** | **Terminal-Bench 2.0** | **SWE-bench Verified** |
| ---------------------------- | ---------------------- | ---------------------- |
| Qwen3-Coder-30B-A3B-Instruct | 13.48% | 46.33% |
| **ROME-30B-A3B** | **24.72%** | **57.40%** |
| GPT-OSS-120B | 21.12% | 43.93% |
| GLM-4.5 Air (106B) | 17.30% | 56.20% |
> See the technical report for full experimental details.
---
## Best Practices
*(Code examples and usage guidelines will be added after the model release.)*
---
## Citation
If you find our work useful, please consider citing:
```bibtex
@article{rome2025ale,
title={Let It Flow: Agentic Crafting on Rock and Roll - Building the ROME Model within an Open Agentic Learning Ecosystem},
author={Wang, Weixun and Xu, XiaoXiao and An, Wanhe and Dai, Fangwen and others},
journal={arXiv preprint arXiv:2512.24873},
year={2025}
}