
GEM_banking77
Browse files- gem-banking77.ipynb +1 -0
- gem_model.pth +3 -0
gem-banking77.ipynb
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
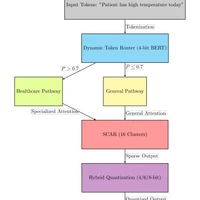
{"metadata":{"kernelspec":{"language":"python","display_name":"Python 3","name":"python3"},"language_info":{"name":"python","version":"3.10.12","mimetype":"text/x-python","codemirror_mode":{"name":"ipython","version":3},"pygments_lexer":"ipython3","nbconvert_exporter":"python","file_extension":".py"},"kaggle":{"accelerator":"nvidiaTeslaT4","dataSources":[],"dockerImageVersionId":30887,"isInternetEnabled":true,"language":"python","sourceType":"notebook","isGpuEnabled":true}},"nbformat_minor":4,"nbformat":4,"cells":[{"cell_type":"markdown","source":"## GEM Architecture Train on Banking 77 dataset","metadata":{}},{"cell_type":"markdown","source":"## PIP INSTALLS\n---","metadata":{}},{"cell_type":"code","source":"##@ All necessary pip installs\n!pip install -qU transformers datasets accelerate","metadata":{"trusted":true,"execution":{"iopub.status.busy":"2025-02-21T09:23:29.845977Z","iopub.execute_input":"2025-02-21T09:23:29.846275Z","iopub.status.idle":"2025-02-21T09:23:43.164796Z","shell.execute_reply.started":"2025-02-21T09:23:29.846253Z","shell.execute_reply":"2025-02-21T09:23:43.163965Z"}},"outputs":[{"name":"stdout","text":"\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m44.0/44.0 kB\u001b[0m \u001b[31m2.0 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m10.0/10.0 MB\u001b[0m \u001b[31m69.1 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m:00:01\u001b[0m:01\u001b[0m\n\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m485.4/485.4 kB\u001b[0m \u001b[31m32.5 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n\u001b[2K \u001b[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[32m342.1/342.1 kB\u001b[0m \u001b[31m23.6 MB/s\u001b[0m eta \u001b[36m0:00:00\u001b[0m\n\u001b[?25h","output_type":"stream"}],"execution_count":1},{"cell_type":"markdown","source":"## HANDLING WARNINGS\n---","metadata":{}},{"cell_type":"code","source":"import warnings \nwarnings.filterwarnings('ignore')","metadata":{"trusted":true,"execution":{"iopub.status.busy":"2025-02-21T09:23:43.165972Z","iopub.execute_input":"2025-02-21T09:23:43.166248Z","iopub.status.idle":"2025-02-21T09:23:43.169893Z","shell.execute_reply.started":"2025-02-21T09:23:43.166212Z","shell.execute_reply":"2025-02-21T09:23:43.169147Z"}},"outputs":[],"execution_count":2},{"cell_type":"markdown","source":"## IMPORTS\n\n---","metadata":{}},{"cell_type":"code","source":"##@ Core Imports\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom torch.utils.data import DataLoader\nfrom transformers import (\n AutoModel, AutoTokenizer, \n AutoModelForSequenceClassification,\n get_linear_schedule_with_warmup\n)\nfrom datasets import load_dataset\nfrom sklearn.cluster import MiniBatchKMeans\nfrom tqdm.auto import tqdm\nimport numpy as np","metadata":{"_uuid":"8f2839f25d086af736a60e9eeb907d3b93b6e0e5","_cell_guid":"b1076dfc-b9ad-4769-8c92-a6c4dae69d19","trusted":true,"execution":{"iopub.status.busy":"2025-02-21T09:23:43.171248Z","iopub.execute_input":"2025-02-21T09:23:43.171481Z","iopub.status.idle":"2025-02-21T09:23:51.733221Z","shell.execute_reply.started":"2025-02-21T09:23:43.171462Z","shell.execute_reply":"2025-02-21T09:23:51.732498Z"}},"outputs":[],"execution_count":3},{"cell_type":"markdown","source":"## ARCHITECTURE CONFIG\n---","metadata":{}},{"cell_type":"code","source":"# 1. Configuration\nclass GEMConfig:\n def __init__(self):\n self.device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n self.hidden_size = 768\n self.num_domains = 8\n self.cluster_size = 256\n self.num_classes = 77\n self.num_attention_heads = 12\n self.max_seq_length = 128\n self.batch_size = 32 * max(1, torch.cuda.device_count()) # Dynamic scaling\n self.epochs = 10\n self.learning_rate = 2e-5\n self.gradient_accumulation_steps = 2","metadata":{"trusted":true,"execution":{"iopub.status.busy":"2025-02-21T09:23:51.734281Z","iopub.execute_input":"2025-02-21T09:23:51.734840Z","iopub.status.idle":"2025-02-21T09:23:51.740124Z","shell.execute_reply.started":"2025-02-21T09:23:51.734814Z","shell.execute_reply":"2025-02-21T09:23:51.739007Z"}},"outputs":[],"execution_count":4},{"cell_type":"code","source":"# 2. Core Components\nclass QuantizedBERT(nn.Module):\n def __init__(self):\n super().__init__()\n self.bert = AutoModel.from_pretrained(\"bert-base-uncased\")\n self.quant = torch.quantization.QuantStub()\n self.dequant = torch.quantization.DeQuantStub()\n \n def forward(self, input_ids, attention_mask=None):\n outputs = self.bert(input_ids, attention_mask=attention_mask)\n return self.dequant(self.quant(outputs.last_hidden_state))\n\nclass TokenRouter(nn.Module):\n def __init__(self, config):\n super().__init__()\n self.config = config\n self.clusterer = MiniBatchKMeans(n_clusters=config.cluster_size)\n self.W_r = nn.Parameter(torch.randn(config.num_domains, config.hidden_size))\n self.threshold = 0.65\n\n def forward(self, x):\n # Device-safe clustering\n cluster_input = x.detach().cpu().numpy().reshape(-1, x.shape[-1])\n cluster_ids = self.clusterer.fit_predict(cluster_input)\n cluster_ids = torch.tensor(cluster_ids, device=self.config.device).reshape(x.shape[:2])\n \n # Device-aware projections\n domain_logits = torch.einsum('bsh,nh->bsn', x, self.W_r.to(x.device))\n domain_probs = F.softmax(domain_logits, dim=-1)\n routing_mask = (domain_probs.max(-1).values > self.threshold).long()\n \n return domain_probs, routing_mask, cluster_ids\n\nclass SCAR(nn.Module):\n def __init__(self, config):\n super().__init__()\n self.num_heads = config.num_attention_heads\n self.head_dim = config.hidden_size // self.num_heads\n self.qkv = nn.Linear(config.hidden_size, 3*config.hidden_size)\n self.out = nn.Linear(config.hidden_size, config.hidden_size)\n\n def create_mask(self, cluster_ids, routing_mask):\n cluster_mask = (cluster_ids.unsqueeze(-1) == cluster_ids.unsqueeze(-2))\n domain_mask = (routing_mask.unsqueeze(-1) == routing_mask.unsqueeze(-2))\n return cluster_mask | domain_mask\n\n def forward(self, x, cluster_ids, routing_mask):\n B, N, _ = x.shape\n qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)\n q, k, v = qkv[0], qkv[1], qkv[2]\n \n attn = (q @ k.transpose(-2, -1)) / np.sqrt(self.head_dim)\n mask = self.create_mask(cluster_ids, routing_mask).unsqueeze(1)\n attn = attn.masked_fill(~mask, -1e9)\n \n attn = F.softmax(attn, dim=-1)\n x = (attn @ v).transpose(1, 2).reshape(B, N, -1)\n return self.out(x)","metadata":{"trusted":true,"execution":{"iopub.status.busy":"2025-02-21T09:23:51.741577Z","iopub.execute_input":"2025-02-21T09:23:51.741971Z","iopub.status.idle":"2025-02-21T09:23:51.760226Z","shell.execute_reply.started":"2025-02-21T09:23:51.741934Z","shell.execute_reply":"2025-02-21T09:23:51.759344Z"}},"outputs":[],"execution_count":5},{"cell_type":"code","source":"# 3. Complete GEM Model\nclass GEM(nn.Module):\n def __init__(self, config):\n super().__init__()\n self.config = config\n self.bert = QuantizedBERT()\n self.router = TokenRouter(config)\n self.scar = SCAR(config)\n self.classifier = nn.Linear(config.hidden_size, config.num_classes)\n \n # Teacher model with proper device placement\n self.teacher = AutoModelForSequenceClassification.from_pretrained(\n \"bert-base-uncased\", num_labels=config.num_classes\n ).eval().to(config.device).requires_grad_(False)\n\n def forward(self, input_ids, attention_mask=None):\n x = self.bert(input_ids, attention_mask=attention_mask)\n domain_probs, routing_mask, cluster_ids = self.router(x)\n x = self.scar(x, cluster_ids, routing_mask)\n return self.classifier(x[:, 0, :])\n\n def qakp_loss(self, outputs, labels, input_ids):\n task_loss = F.cross_entropy(outputs, labels)\n quant_error = F.mse_loss(self.bert.quant(self.bert.dequant(outputs)), outputs)\n \n with torch.no_grad():\n teacher_logits = self.teacher(input_ids).logits\n \n kd_loss = F.kl_div(\n F.log_softmax(outputs, dim=-1),\n F.softmax(teacher_logits, dim=-1),\n reduction='batchmean'\n )\n \n return task_loss + 0.3*quant_error + 0.7*kd_loss","metadata":{"trusted":true,"execution":{"iopub.status.busy":"2025-02-21T09:23:51.761218Z","iopub.execute_input":"2025-02-21T09:23:51.761564Z","iopub.status.idle":"2025-02-21T09:23:51.776886Z","shell.execute_reply.started":"2025-02-21T09:23:51.761541Z","shell.execute_reply":"2025-02-21T09:23:51.776073Z"}},"outputs":[],"execution_count":6},{"cell_type":"code","source":"# 6. Evaluation and Deployment (Fixed)\ndef prepare_dataloaders(config):\n dataset = load_dataset(\"banking77\")\n tokenizer = AutoTokenizer.from_pretrained(\"bert-base-uncased\")\n \n def tokenize(examples):\n return tokenizer(\n examples['text'],\n padding='max_length',\n truncation=True,\n max_length=config.max_seq_length\n )\n \n dataset = dataset.map(tokenize, batched=True)\n \n def collate(batch):\n return {\n 'input_ids': torch.stack([torch.tensor(x['input_ids']) for x in batch]),\n 'attention_mask': torch.stack([torch.tensor(x['attention_mask']) for x in batch]),\n 'labels': torch.tensor([x['label'] for x in batch])\n }\n \n train_loader = DataLoader(\n dataset['train'],\n batch_size=config.batch_size,\n shuffle=True,\n collate_fn=collate\n )\n \n test_loader = DataLoader(\n dataset['test'],\n batch_size=config.batch_size,\n collate_fn=collate\n )\n \n return train_loader, test_loader","metadata":{"trusted":true,"execution":{"iopub.status.busy":"2025-02-21T09:23:51.777773Z","iopub.execute_input":"2025-02-21T09:23:51.778001Z","iopub.status.idle":"2025-02-21T09:23:51.790865Z","shell.execute_reply.started":"2025-02-21T09:23:51.777979Z","shell.execute_reply":"2025-02-21T09:23:51.790197Z"}},"outputs":[],"execution_count":7},{"cell_type":"markdown","source":"## TRAINING LOOP \n---","metadata":{}},{"cell_type":"code","source":"##@ Training Loop with Multi-GPU Support\ndef train_model():\n config = GEMConfig()\n train_loader, test_loader = prepare_dataloaders(config)\n \n model = GEM(config)\n if torch.cuda.device_count() > 1:\n model = nn.DataParallel(model, device_ids=list(range(torch.cuda.device_count())))\n model.to(config.device)\n \n optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate)\n scheduler = get_linear_schedule_with_warmup(\n optimizer,\n num_warmup_steps=100,\n num_training_steps=len(train_loader)*config.epochs\n )\n \n model.train()\n for epoch in range(config.epochs):\n total_loss = 0\n for step, batch in enumerate(tqdm(train_loader)):\n inputs = batch['input_ids'].to(config.device)\n masks = batch['attention_mask'].to(config.device)\n labels = batch['labels'].to(config.device)\n \n outputs = model(inputs, attention_mask=masks)\n loss = model.module.qakp_loss(outputs, labels, inputs)\n \n loss.backward()\n if (step+1) % config.gradient_accumulation_steps == 0:\n optimizer.step()\n scheduler.step()\n optimizer.zero_grad()\n \n total_loss += loss.item()\n \n print(f\"Epoch {epoch+1} | Avg Loss: {total_loss/len(train_loader):.4f}\")\n \n return model\n\n##@ Evaluation & Saving\ndef evaluate_and_save(model):\n config = GEMConfig()\n _, test_loader = prepare_dataloaders(config)\n \n model.eval()\n correct = total = 0\n with torch.no_grad():\n for batch in test_loader:\n inputs = batch['input_ids'].to(config.device)\n masks = batch['attention_mask'].to(config.device)\n labels = batch['labels'].to(config.device)\n \n outputs = model(inputs, attention_mask=masks)\n preds = outputs.argmax(dim=-1)\n correct += (preds == labels).sum().item()\n total += labels.size(0)\n \n print(f\"Final Accuracy: {100*correct/total:.2f}%\")\n torch.save(model.module.state_dict() if hasattr(model, 'module') else model.state_dict(), \n \"gem_model.pth\")\n\nif __name__ == \"__main__\":\n trained_model = train_model()\n evaluate_and_save(trained_model)","metadata":{"trusted":true,"execution":{"iopub.status.busy":"2025-02-21T09:23:51.792402Z","iopub.execute_input":"2025-02-21T09:23:51.792628Z","iopub.status.idle":"2025-02-21T13:11:50.188671Z","shell.execute_reply.started":"2025-02-21T09:23:51.792608Z","shell.execute_reply":"2025-02-21T13:11:50.187687Z"}},"outputs":[{"output_type":"display_data","data":{"text/plain":"README.md: 0%| | 0.00/14.4k [00:00<?, ?B/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"73b43f49973f4fab8a9190fe19d20900"}},"metadata":{}},{"output_type":"display_data","data":{"text/plain":"train-00000-of-00001.parquet: 0%| | 0.00/298k [00:00<?, ?B/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"fe45cec32bbb46a29626d8b7658178eb"}},"metadata":{}},{"output_type":"display_data","data":{"text/plain":"test-00000-of-00001.parquet: 0%| | 0.00/93.9k [00:00<?, ?B/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"cebabb2a674247e482d0df3c3b18c2f3"}},"metadata":{}},{"output_type":"display_data","data":{"text/plain":"Generating train split: 0%| | 0/10003 [00:00<?, ? examples/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"53551fa09a13448f99a3a30b819c5407"}},"metadata":{}},{"output_type":"display_data","data":{"text/plain":"Generating test split: 0%| | 0/3080 [00:00<?, ? examples/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"bcf0a86aaef643a696081c554ca4dfe7"}},"metadata":{}},{"output_type":"display_data","data":{"text/plain":"tokenizer_config.json: 0%| | 0.00/48.0 [00:00<?, ?B/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"17f04029de274493a16550078b4e2f25"}},"metadata":{}},{"output_type":"display_data","data":{"text/plain":"config.json: 0%| | 0.00/570 [00:00<?, ?B/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"898448adda524f99ae0a8aeae0ead368"}},"metadata":{}},{"output_type":"display_data","data":{"text/plain":"vocab.txt: 0%| | 0.00/232k [00:00<?, ?B/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"e6cef0de0f3243e0bc0b6ceb4923b460"}},"metadata":{}},{"output_type":"display_data","data":{"text/plain":"tokenizer.json: 0%| | 0.00/466k [00:00<?, ?B/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"44aa51c8835748a2824652691ad87be5"}},"metadata":{}},{"output_type":"display_data","data":{"text/plain":"Map: 0%| | 0/10003 [00:00<?, ? examples/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"53baf51c2ca548129500579070e95495"}},"metadata":{}},{"output_type":"display_data","data":{"text/plain":"Map: 0%| | 0/3080 [00:00<?, ? examples/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"4cb7c0398ddd43519968fa82a7dbdfa2"}},"metadata":{}},{"output_type":"display_data","data":{"text/plain":"model.safetensors: 0%| | 0.00/440M [00:00<?, ?B/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"741e492820504dd6a6538b9ac91a4715"}},"metadata":{}},{"name":"stderr","text":"Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['classifier.bias', 'classifier.weight']\nYou should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\n","output_type":"stream"},{"output_type":"display_data","data":{"text/plain":" 0%| | 0/157 [00:00<?, ?it/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"eda3f8b565a4437ebda86da9eaff23c6"}},"metadata":{}},{"name":"stderr","text":"We strongly recommend passing in an `attention_mask` since your input_ids may be padded. See https://huggingface.co/docs/transformers/troubleshooting#incorrect-output-when-padding-tokens-arent-masked.\n","output_type":"stream"},{"name":"stdout","text":"Epoch 1 | Avg Loss: 4.2777\n","output_type":"stream"},{"output_type":"display_data","data":{"text/plain":" 0%| | 0/157 [00:00<?, ?it/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"cc1f2bfa72a546648706727acb20ea59"}},"metadata":{}},{"name":"stdout","text":"Epoch 2 | Avg Loss: 3.0262\n","output_type":"stream"},{"output_type":"display_data","data":{"text/plain":" 0%| | 0/157 [00:00<?, ?it/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"5da69658f1dc4dd899f9461b5fc5d464"}},"metadata":{}},{"name":"stdout","text":"Epoch 3 | Avg Loss: 1.9194\n","output_type":"stream"},{"output_type":"display_data","data":{"text/plain":" 0%| | 0/157 [00:00<?, ?it/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"dcdc632cb9534a5faa889d3cb0703430"}},"metadata":{}},{"name":"stdout","text":"Epoch 4 | Avg Loss: 1.5360\n","output_type":"stream"},{"output_type":"display_data","data":{"text/plain":" 0%| | 0/157 [00:00<?, ?it/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"41f8b0936e514254919ce29d3f51eb8a"}},"metadata":{}},{"name":"stdout","text":"Epoch 5 | Avg Loss: 1.3822\n","output_type":"stream"},{"output_type":"display_data","data":{"text/plain":" 0%| | 0/157 [00:00<?, ?it/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"27b1e4a8ff004aeb8730fe72ba51a7b6"}},"metadata":{}},{"name":"stdout","text":"Epoch 6 | Avg Loss: 1.3048\n","output_type":"stream"},{"output_type":"display_data","data":{"text/plain":" 0%| | 0/157 [00:00<?, ?it/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"c7174fd243494926bd689f345398e4c2"}},"metadata":{}},{"name":"stdout","text":"Epoch 7 | Avg Loss: 1.2548\n","output_type":"stream"},{"output_type":"display_data","data":{"text/plain":" 0%| | 0/157 [00:00<?, ?it/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"f688c9f2175e48438dffcfd20e91dbac"}},"metadata":{}},{"name":"stdout","text":"Epoch 8 | Avg Loss: 1.2228\n","output_type":"stream"},{"output_type":"display_data","data":{"text/plain":" 0%| | 0/157 [00:00<?, ?it/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"dea97098560c4f27a9083dc1ff916d20"}},"metadata":{}},{"name":"stdout","text":"Epoch 9 | Avg Loss: 1.1982\n","output_type":"stream"},{"output_type":"display_data","data":{"text/plain":" 0%| | 0/157 [00:00<?, ?it/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"f75690157166416e90b3ce08ae2aca2d"}},"metadata":{}},{"name":"stdout","text":"Epoch 10 | Avg Loss: 1.1828\n","output_type":"stream"},{"output_type":"display_data","data":{"text/plain":"Map: 0%| | 0/3080 [00:00<?, ? examples/s]","application/vnd.jupyter.widget-view+json":{"version_major":2,"version_minor":0,"model_id":"741f291edb45433593a80bd21c4dadb9"}},"metadata":{}},{"name":"stdout","text":"Final Accuracy: 92.56%\n","output_type":"stream"}],"execution_count":8},{"cell_type":"code","source":"","metadata":{"trusted":true},"outputs":[],"execution_count":null}]}
|
gem_model.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c05aeefd4563ea3304644a30d47fc8f2b88e54243b9e772ca451633d8a627229
|
| 3 |
+
size 885976954
|