---
library_name: transformers
license: cc-by-nc-4.0
language:
- en
datasets:
- GeneralAnalysis/GA_Guardrail_Benchmark
base_model:
- Qwen/Qwen3-4B-Instruct-2507
tags:
- Moderation
- Safety
- Filter
---

Website ·
GA Blog ·
GA Bench ·
API Access
Introducing the GA Guard series — a family of open-weight moderation models built to help developers and organizations keep language models safe, compliant, and aligned with real-world use.
**GA-Guard** is designed to detect violations across the following seven categories:
- **Illicit Activities** – instructions or content related to crimes, weapons, or illegal substances.
- **Hate & Abuse** – harassment, slurs, dehumanization, or abusive language.
- **PII & IP** – exposure or solicitation of sensitive personal information, secrets, or intellectual property.
- **Prompt Security** – jailbreaks, prompt-injection, secret exfiltration, or obfuscation attempts.
- **Sexual Content** – sexually explicit or adult material.
- **Misinformation** – demonstrably false or deceptive claims presented as fact.
- **Violence & Self-Harm** – content that encourages violence, self-harm, or suicide.
The model outputs a **structured token** for each category (e.g., `` or ``).
>[!Note]
> **Important:** This model outputs **special tokens** (e.g. ``). Do **not** use `pipeline("text-generation")` since it strips them by default. Always decode with `skip_special_tokens=False` to preserve the outputs.
## Model Details
GA Guard Core features:
- Type: Causal Language Model
- Training: Full finetune
- Number of Parameters: 4.0B
- Number of Non-Embedding Parameters: 3.6B
- Number of Layers: 36
- Number of Attention Heads (GQA): 32 for Q and 8 for KV
- Context Length: 262,144 tokens
## Inference Examples
### Transformers Library
```python
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("GeneralAnalysis/GA_Guard_Core")
model = AutoModelForCausalLM.from_pretrained("GeneralAnalysis/GA_Guard_Core")
messages = [
{"role": "user", "content": "Who are you?"},
]
# The chat template automatically adds the guardrail system prompt and prefixes user messages with "text:".
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=40)
# Decode only the newly generated tokens
print(tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:]))
# Sample output:
# ...
```
## Benchmarks
We evaluated GA Guards on public moderation suites (OpenAI Moderation, WildGuard Benchmark, and HarmBench), our adversarial GA Jailbreak Bench, and the new GA Long-Context Bench. Across all three, our models consistently outperform major cloud guardrails and even surpass GPT-5 (when prompted to act as a guardrail).
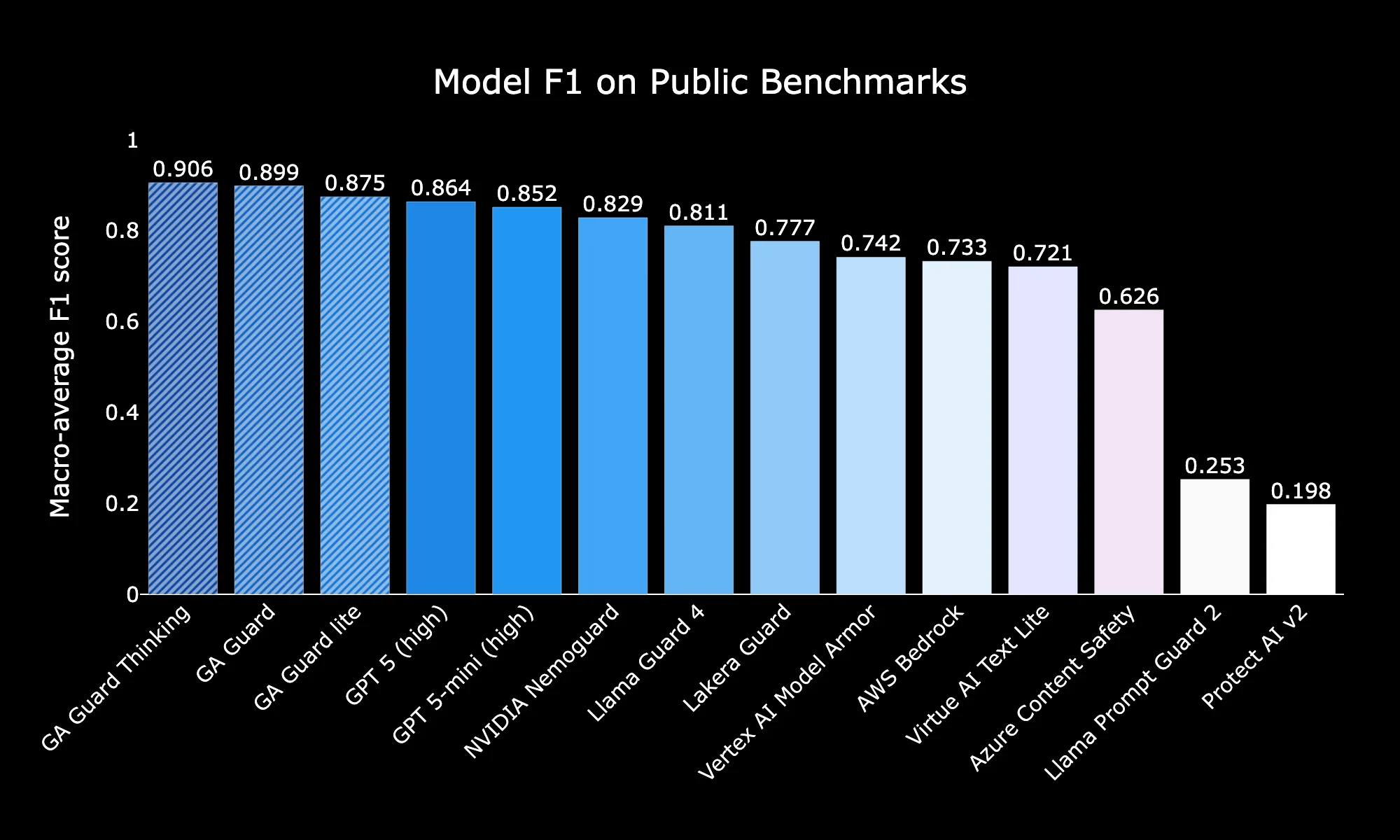
### Public Benchmarks
On public moderation suites, Guard Thinking reports 0.906 F1, Guard 0.899, and Lite 0.875 — all higher than GPT-5 (0.864) and GPT-5-mini (0.852), with cloud guardrails in the 0.62–0.74 range.
| Guard | OpenAI Moderation (Acc/F1/FPR) | WildGuard (Acc/F1/FPR) | HarmBench Behaviors (Acc/F1/FPR) | Avg Time (s) |
|-----------------------------|--------------------------------|-------------------------|-----------------------------------|--------------|
| GA Guard | 0.916 / 0.873 / 0.111 | 0.856 / 0.844 / 0.172 | 0.963 / 0.981 / N/A | 0.029 |
| GA Guard Thinking | 0.917 / 0.876 / 0.112 | 0.862 / 0.858 / 0.134 | 0.967 / 0.983 / N/A | 0.650 |
| GA Guard Lite | 0.896 / 0.844 / 0.109 | 0.835 / 0.819 / 0.176 | 0.929 / 0.963 / N/A | 0.016 |
| AWS Bedrock Guardrail | 0.818 / 0.754 / 0.216 | 0.642 / 0.649 / 0.449 | 0.662 / 0.797 / N/A | 0.375 |
| Azure AI Content Safety | 0.879 / 0.807 / 0.091 | 0.667 / 0.463 / 0.071 | 0.438 / 0.609 / N/A | 0.389 |
| Vertex AI Model Armor | 0.779 / 0.690 / 0.225 | 0.711 / 0.590 / 0.105 | 0.896 / 0.945 / N/A | 0.873 |
| GPT 5 | 0.838 / 0.775 / 0.188 | 0.849 / 0.830 / 0.145 | 0.975 / 0.987 / N/A | 11.275 |
| GPT 5-mini | 0.794 / 0.731 / 0.255 | 0.855 / 0.839 / 0.151 | 0.975 / 0.987 / N/A | 5.604 |
| Llama Guard 4 12B | 0.826 / 0.737 / 0.156 | 0.799 / 0.734 / 0.071 | 0.925 / 0.961 / N/A | 0.459 |
| Llama Prompt Guard 2 86M | 0.686 / 0.015 / 0.009 | 0.617 / 0.412 / 0.143 | 0.200 / 0.333 / N/A | 0.114 |
| Nvidia Llama 3.1 Nemoguard 8B | 0.852 / 0.793 / 0.174 | 0.849 / 0.818 / 0.096 | 0.875 / 0.875 / N/A | 0.358 |
| VirtueGuard Text Lite | 0.507 / 0.548 / 0.699 | 0.656 / 0.682 / 0.491 | 0.875 / 0.933 / N/A | 0.651 |
| Lakera Guard | 0.752 / 0.697 / 0.323 | 0.630 / 0.662 / 0.527 | 0.946 / 0.972 / N/A | 0.377 |
| Protect AI (prompt-injection-v2) | 0.670 / 0.014 / 0.032 | 0.559 / 0.382 / 0.248 | N/A | 0.115 |
### [GA Long-Context Bench](https://huggingface.co/datasets/GeneralAnalysis/GA_Long_context_Jailbreak_Benchmark)
On GA Long-Context Bench (up to 256k tokens), GA Guard Thinking scores 0.893 F1, GA Guard 0.891, and Lite 0.885. Cloud baselines collapse: Vertex 0.560, AWS misclassifies nearly all inputs with a 1.0 false-positive rate, and Azure records just 0.046 F1.
| Guard | Accuracy | F1 Score | FPR | F1 Hate & Abuse | F1 Illicit Activities | F1 Misinformation | F1 PII & IP | F1 Prompt Security | F1 Sexual Content | F1 Violence & Self-Harm |
|-----------------------------|----------|----------|------|-----------------|-----------------------|-------------------|-------------|--------------------|-------------------|-------------------------|
| GA Guard | 0.887 | 0.891 | 0.147| 0.983 | 0.972 | 0.966 | 0.976 | 0.875 | 0.966 | 0.988 |
| GA Guard Thinking | 0.889 | 0.893 | 0.151| 0.967 | 0.951 | 0.940 | 0.961 | 0.828 | 0.920 | 0.962 |
| GA Guard Lite | 0.881 | 0.885 | 0.148| 0.979 | 0.969 | 0.972 | 0.976 | 0.846 | 0.973 | 0.985 |
| AWS Bedrock Guardrail | 0.532 | 0.695 | 1.000| 0.149 | 0.211 | 0.131 | 0.367 | 0.175 | 0.092 | 0.157 |
| Azure AI Content Safety | 0.480 | 0.046 | 0.001| 0.028 | 0.041 | 0.016 | 0.073 | 0.049 | 0.000 | 0.081 |
| Vertex AI Model Armor | 0.635 | 0.560 | 0.138| 0.187 | 0.312 | 0.109 | 0.473 | 0.194 | 0.085 | 0.241 |
| GPT 5 | 0.764 | 0.799 | 0.372| 0.219 | 0.297 | 0.189 | 0.404 | 0.243 | 0.137 | 0.229 |
| GPT 5-mini | 0.697 | 0.772 | 0.607| 0.184 | 0.253 | 0.157 | 0.412 | 0.215 | 0.112 | 0.190 |
| Llama Guard 4 12B | 0.569 | 0.602 | 0.516| 0.164 | 0.228 | 0.132 | 0.334 | 0.188 | 0.097 | 0.195 |
| Llama Prompt Guard 2 86M | 0.505 | 0.314 | 0.162| N/A | N/A | N/A | N/A | 0.093 | N/A | N/A |
| Nvidia Llama 3.1 Nemoguard 8B | 0.601 | 0.360 | 0.021| 0.243 | 0.288 | 0.097 | 0.192 | 0.116 | 0.305 | 0.321 |
| VirtueGuard Text Lite | 0.490 | 0.147 | 0.047| 0.082 | 0.203 | 0.118 | 0.069 | 0.074 | 0.058 | 0.132 |
| Lakera Guard | 0.520 | 0.684 | 0.999| 0.151 | 0.200 | 0.132 | 0.361 | 0.160 | 0.093 | 0.159 |
| Protect AI (prompt-injection-v2) | 0.496| 0.102 | 0.001| N/A | N/A | N/A | N/A | 0.032 | N/A | N/A |
### [GA Jailbreak Bench](https://huggingface.co/datasets/GeneralAnalysis/GA_Jailbreak_Benchmark)
On GA Jailbreak Bench, which measures resilience against adversarial attacks, Guard Thinking achieves 0.933 F1, Guard 0.930, and Lite 0.898. GPT-5 reaches 0.893, while cloud guardrails fall significantly lower.
| Guard | Accuracy | F1 Score | FPR | F1 Hate & Abuse | F1 Illicit Activities | F1 Misinf. | F1 PII & IP | F1 Prompt Security | F1 Sexual Content | F1 Violence & Self-Harm |
|-----------------------------|----------|----------|------|-----------------|-----------------------|------------|-------------|--------------------|-------------------|-------------------------|
| GA Guard | 0.931 | 0.930 | 0.038| 0.946 | 0.939 | 0.886 | 0.967 | 0.880 | 0.954 | 0.928 |
| GA Guard Thinking | 0.939 | 0.933 | 0.029| 0.965 | 0.925 | 0.894 | 0.962 | 0.885 | 0.942 | 0.946 |
| GA Guard Lite | 0.902 | 0.898 | 0.065| 0.908 | 0.900 | 0.856 | 0.936 | 0.850 | 0.934 | 0.904 |
| AWS Bedrock Guardrail | 0.606 | 0.607 | 0.396| 0.741 | 0.456 | 0.535 | 0.576 | 0.649 | 0.721 | 0.518 |
| Azure AI Content Safety | 0.542 | 0.193 | 0.026| 0.236 | 0.093 | 0.155 | 0.068 | 0.416 | 0.186 | 0.130 |
| Vertex AI Model Armor | 0.550 | 0.190 | 0.008| 0.077 | 0.190 | 0.582 | 0.076 | 0.000 | 0.000 | 0.241 |
| GPT 5 | 0.900 | 0.893 | 0.035| 0.928 | 0.942 | 0.856 | 0.799 | 0.819 | 0.953 | 0.939 |
| GPT 5-mini | 0.891 | 0.883 | 0.050| 0.917 | 0.942 | 0.845 | 0.850 | 0.822 | 0.882 | 0.924 |
| Llama Guard 4 12B | 0.822 | 0.796 | 0.053| 0.768 | 0.774 | 0.587 | 0.809 | 0.833 | 0.927 | 0.827 |
| Llama Prompt Guard 2 86M | 0.490 | 0.196 | 0.069| N/A | N/A | N/A | N/A | 0.196 | N/A | N/A |
| Nvidia Llama 3.1 Nemoguard 8B | 0.668 | 0.529 | 0.038| 0.637 | 0.555 | 0.513 | 0.524 | 0.049 | 0.679 | 0.575 |
| VirtueGuard Text Lite | 0.513 | 0.664 | 0.933| 0.659 | 0.689 | 0.657 | 0.646 | 0.659 | 0.675 | 0.662 |
| Lakera Guard | 0.525 | 0.648 | 0.825| 0.678 | 0.645 | 0.709 | 0.643 | 0.631 | 0.663 | 0.548 |
| Protect AI (prompt-injection-v2) | 0.528| 0.475 | 0.198| N/A | N/A | N/A | N/A | 0.475 | N/A | N/A |
## Licensing
This model is a fine-tune of [Qwen3-4B](https://huggingface.co/Qwen/Qwen3-4B),
which is licensed under the **Apache License 2.0** by Alibaba Cloud.
The upstream license text is included in this repository as `LICENSE.Apache`, and
attribution is provided in the `NOTICE` file.
**GA Guard Core** in this repository is provided under the
**Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0)** license
for non-commercial use.
- Free for research, experimentation, and non-commercial internal use
- No commercial or production deployment without a separate commercial license
For **commercial / production use**, please contact **info@generalanalysis.com** to obtain a
paid license and support agreement.
## Citation [optional]
```bibtex
@misc{generalanalysis2025gaguardcore,
title = {GA Guard Core},
author = {Rez Havaei and Rex Liu and General Analysis},
year = {2025},
archivePrefix={arXiv},
primaryClass={cs.CL},
howpublished = {\url{https://huggingface.co/GeneralAnalysis/GA_Guard_Core}},
note = {Open-weight moderation model for seven safety categories},
}
```