diff --git a/README.md b/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..652ed8398d9a8e5eb6fc2ff05d9be05e27f38c48
--- /dev/null
+++ b/README.md
@@ -0,0 +1,15 @@
+
+---
+base_model: stabilityai/stable-diffusion-xl-base-1.0
+instance_prompt: a photo of sks dog
+tags:
+- text-to-image
+- diffusers
+- autotrain
+inference: true
+---
+
+# DreamBooth trained by AutoTrain
+
+Test enoder was not trained.
+
diff --git a/autotrain-advanced/.dockerignore b/autotrain-advanced/.dockerignore
new file mode 100644
index 0000000000000000000000000000000000000000..cd1d39f433137e1d62970ca6dfa338d60ae2189d
--- /dev/null
+++ b/autotrain-advanced/.dockerignore
@@ -0,0 +1,9 @@
+build/
+dist/
+logs/
+output/
+output2/
+test/
+test.py
+.DS_Store
+.vscode/
\ No newline at end of file
diff --git a/autotrain-advanced/.github/workflows/build_documentation.yml b/autotrain-advanced/.github/workflows/build_documentation.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c43ccf01925ddf41669754ae0308686457f758a0
--- /dev/null
+++ b/autotrain-advanced/.github/workflows/build_documentation.yml
@@ -0,0 +1,19 @@
+name: Build documentation
+
+on:
+ push:
+ branches:
+ - main
+ - doc-builder*
+ - v*-release
+
+jobs:
+ build:
+ uses: huggingface/doc-builder/.github/workflows/build_main_documentation.yml@main
+ with:
+ commit_sha: ${{ github.sha }}
+ package: autotrain-advanced
+ package_name: autotrain
+ secrets:
+ token: ${{ secrets.HUGGINGFACE_PUSH }}
+ hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
\ No newline at end of file
diff --git a/autotrain-advanced/.github/workflows/build_pr_documentation.yml b/autotrain-advanced/.github/workflows/build_pr_documentation.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f5759a06761196262d0f69403bbddc39ddd1b4df
--- /dev/null
+++ b/autotrain-advanced/.github/workflows/build_pr_documentation.yml
@@ -0,0 +1,17 @@
+name: Build PR Documentation
+
+on:
+ pull_request:
+
+concurrency:
+ group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
+ cancel-in-progress: true
+
+jobs:
+ build:
+ uses: huggingface/doc-builder/.github/workflows/build_pr_documentation.yml@main
+ with:
+ commit_sha: ${{ github.event.pull_request.head.sha }}
+ pr_number: ${{ github.event.number }}
+ package: autotrain-advanced
+ package_name: autotrain
diff --git a/autotrain-advanced/.github/workflows/code_quality.yml b/autotrain-advanced/.github/workflows/code_quality.yml
new file mode 100644
index 0000000000000000000000000000000000000000..9570ce96d9cfad0a3db247f60b7318b6ffebb38c
--- /dev/null
+++ b/autotrain-advanced/.github/workflows/code_quality.yml
@@ -0,0 +1,30 @@
+name: Code quality
+
+on:
+ push:
+ branches:
+ - main
+ pull_request:
+ branches:
+ - main
+ release:
+ types:
+ - created
+
+jobs:
+ check_code_quality:
+ name: Check code quality
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python 3.9
+ uses: actions/setup-python@v2
+ with:
+ python-version: 3.9
+ - name: Install dependencies
+ run: |
+ python -m pip install --upgrade pip
+ python -m pip install flake8 black isort
+ - name: Make quality
+ run: |
+ make quality
diff --git a/autotrain-advanced/.github/workflows/delete_doc_comment.yml b/autotrain-advanced/.github/workflows/delete_doc_comment.yml
new file mode 100644
index 0000000000000000000000000000000000000000..72801c856eb5155ccf321d63be37bd146aff260d
--- /dev/null
+++ b/autotrain-advanced/.github/workflows/delete_doc_comment.yml
@@ -0,0 +1,13 @@
+name: Delete doc comment
+
+on:
+ workflow_run:
+ workflows: ["Delete doc comment trigger"]
+ types:
+ - completed
+
+jobs:
+ delete:
+ uses: huggingface/doc-builder/.github/workflows/delete_doc_comment.yml@main
+ secrets:
+ comment_bot_token: ${{ secrets.COMMENT_BOT_TOKEN }}
\ No newline at end of file
diff --git a/autotrain-advanced/.github/workflows/delete_doc_comment_trigger.yml b/autotrain-advanced/.github/workflows/delete_doc_comment_trigger.yml
new file mode 100644
index 0000000000000000000000000000000000000000..5e39e253974df54fd284cf44bb1e52afbefecded
--- /dev/null
+++ b/autotrain-advanced/.github/workflows/delete_doc_comment_trigger.yml
@@ -0,0 +1,12 @@
+name: Delete doc comment trigger
+
+on:
+ pull_request:
+ types: [ closed ]
+
+
+jobs:
+ delete:
+ uses: huggingface/doc-builder/.github/workflows/delete_doc_comment_trigger.yml@main
+ with:
+ pr_number: ${{ github.event.number }}
\ No newline at end of file
diff --git a/autotrain-advanced/.github/workflows/tests.yml b/autotrain-advanced/.github/workflows/tests.yml
new file mode 100644
index 0000000000000000000000000000000000000000..2f6d41e65d6f8b067e954402c90fb83ebb908299
--- /dev/null
+++ b/autotrain-advanced/.github/workflows/tests.yml
@@ -0,0 +1,30 @@
+name: Tests
+
+on:
+ push:
+ branches:
+ - main
+ pull_request:
+ branches:
+ - main
+ release:
+ types:
+ - created
+
+jobs:
+ tests:
+ name: Run unit tests
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v2
+ - name: Set up Python 3.9
+ uses: actions/setup-python@v2
+ with:
+ python-version: 3.9
+ - name: Install dependencies
+ run: |
+ python -m pip install --upgrade pip
+ python -m pip install .[dev]
+ - name: Make test
+ run: |
+ make test
diff --git a/autotrain-advanced/.github/workflows/upload_pr_documentation.yml b/autotrain-advanced/.github/workflows/upload_pr_documentation.yml
new file mode 100644
index 0000000000000000000000000000000000000000..2bd49da63cc4d4ccec2a8730c2566585c2fb3e83
--- /dev/null
+++ b/autotrain-advanced/.github/workflows/upload_pr_documentation.yml
@@ -0,0 +1,16 @@
+name: Upload PR Documentation
+
+on:
+ workflow_run:
+ workflows: ["Build PR Documentation"]
+ types:
+ - completed
+
+jobs:
+ build:
+ uses: huggingface/doc-builder/.github/workflows/upload_pr_documentation.yml@main
+ with:
+ package_name: autotrain
+ secrets:
+ hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
+ comment_bot_token: ${{ secrets.COMMENT_BOT_TOKEN }}
\ No newline at end of file
diff --git a/autotrain-advanced/.gitignore b/autotrain-advanced/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..9e10756026b04e5d579770041f0f71656b5b7e8e
--- /dev/null
+++ b/autotrain-advanced/.gitignore
@@ -0,0 +1,138 @@
+# Local stuff
+.DS_Store
+.vscode/
+test/
+test.py
+output/
+output2/
+logs/
+
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+pip-wheel-metadata/
+share/python-wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.nox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+*.py,cover
+.hypothesis/
+.pytest_cache/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+db.sqlite3-journal
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# IPython
+profile_default/
+ipython_config.py
+
+# pyenv
+.python-version
+
+# pipenv
+# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
+# However, in case of collaboration, if having platform-specific dependencies or dependencies
+# having no cross-platform support, pipenv may install dependencies that don't work, or not
+# install all needed dependencies.
+#Pipfile.lock
+
+# PEP 582; used by e.g. github.com/David-OConnor/pyflow
+__pypackages__/
+
+# Celery stuff
+celerybeat-schedule
+celerybeat.pid
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+.dmypy.json
+dmypy.json
+
+# Pyre type checker
+.pyre/
diff --git a/autotrain-advanced/Dockerfile b/autotrain-advanced/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..056d7f570ba8bfb7a6e2a298f585ab21f672b1eb
--- /dev/null
+++ b/autotrain-advanced/Dockerfile
@@ -0,0 +1,65 @@
+FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu20.04
+
+ENV DEBIAN_FRONTEND=noninteractive \
+ TZ=UTC
+
+ENV PATH="${HOME}/miniconda3/bin:${PATH}"
+ARG PATH="${HOME}/miniconda3/bin:${PATH}"
+
+RUN mkdir -p /tmp/model
+RUN chown -R 1000:1000 /tmp/model
+RUN mkdir -p /tmp/data
+RUN chown -R 1000:1000 /tmp/data
+
+RUN apt-get update && \
+ apt-get upgrade -y && \
+ apt-get install -y \
+ build-essential \
+ cmake \
+ curl \
+ ca-certificates \
+ gcc \
+ git \
+ locales \
+ net-tools \
+ wget \
+ libpq-dev \
+ libsndfile1-dev \
+ git \
+ git-lfs \
+ libgl1 \
+ && rm -rf /var/lib/apt/lists/*
+
+
+RUN curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash && \
+ git lfs install
+
+WORKDIR /app
+RUN mkdir -p /app/.cache
+ENV HF_HOME="/app/.cache"
+RUN chown -R 1000:1000 /app
+USER 1000
+ENV HOME=/app
+
+ENV PYTHONPATH=$HOME/app \
+ PYTHONUNBUFFERED=1 \
+ GRADIO_ALLOW_FLAGGING=never \
+ GRADIO_NUM_PORTS=1 \
+ GRADIO_SERVER_NAME=0.0.0.0 \
+ SYSTEM=spaces
+
+
+RUN wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh \
+ && sh Miniconda3-latest-Linux-x86_64.sh -b -p /app/miniconda \
+ && rm -f Miniconda3-latest-Linux-x86_64.sh
+ENV PATH /app/miniconda/bin:$PATH
+
+RUN conda create -p /app/env -y python=3.9
+
+SHELL ["conda", "run","--no-capture-output", "-p","/app/env", "/bin/bash", "-c"]
+
+RUN conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
+RUN pip install git+https://github.com/huggingface/peft.git
+COPY --chown=1000:1000 . /app/
+
+RUN pip install -e .
\ No newline at end of file
diff --git a/autotrain-advanced/LICENSE b/autotrain-advanced/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..7a4a3ea2424c09fbe48d455aed1eaa94d9124835
--- /dev/null
+++ b/autotrain-advanced/LICENSE
@@ -0,0 +1,202 @@
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
\ No newline at end of file
diff --git a/autotrain-advanced/Makefile b/autotrain-advanced/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..cc8e0146ceb1aae8fc271cd430678c96c26c800d
--- /dev/null
+++ b/autotrain-advanced/Makefile
@@ -0,0 +1,28 @@
+.PHONY: quality style test
+
+# Check that source code meets quality standards
+
+quality:
+ black --check --line-length 119 --target-version py38 .
+ isort --check-only .
+ flake8 --max-line-length 119
+
+# Format source code automatically
+
+style:
+ black --line-length 119 --target-version py38 .
+ isort .
+
+test:
+ pytest -sv ./src/
+
+docker:
+ docker build -t autotrain-advanced:latest .
+ docker tag autotrain-advanced:latest huggingface/autotrain-advanced:latest
+ docker push huggingface/autotrain-advanced:latest
+
+pip:
+ rm -rf build/
+ rm -rf dist/
+ python setup.py sdist bdist_wheel
+ twine upload dist/* --verbose
\ No newline at end of file
diff --git a/autotrain-advanced/README.md b/autotrain-advanced/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..6965d6c08c41bd72482bb7d087b2fe9b6cad1298
--- /dev/null
+++ b/autotrain-advanced/README.md
@@ -0,0 +1,13 @@
+# 🤗 AutoTrain Advanced
+
+AutoTrain Advanced: faster and easier training and deployments of state-of-the-art machine learning models
+
+## Installation
+
+You can Install AutoTrain-Advanced python package via PIP. Please note you will need python >= 3.8 for AutoTrain Advanced to work properly.
+
+ pip install autotrain-advanced
+
+Please make sure that you have git lfs installed. Check out the instructions here: https://github.com/git-lfs/git-lfs/wiki/Installation
+
+## Coming Soon!
\ No newline at end of file
diff --git a/autotrain-advanced/docs/source/_toctree.yml b/autotrain-advanced/docs/source/_toctree.yml
new file mode 100644
index 0000000000000000000000000000000000000000..f00a96415d97f839239201d5c9dc51bb4c5e9e8f
--- /dev/null
+++ b/autotrain-advanced/docs/source/_toctree.yml
@@ -0,0 +1,28 @@
+- sections:
+ - local: index
+ title: 🤗 AutoTrain
+ - local: getting_started
+ title: Installation
+ - local: cost
+ title: How much does it cost?
+ - local: support
+ title: Get help and support
+ title: Get started
+- sections:
+ - local: model_choice
+ title: Model Selection
+ - local: param_choice
+ title: Parameter Selection
+ title: Selecting Models and Parameters
+- sections:
+ - local: text_classification
+ title: Text Classification
+ - local: llm_finetuning
+ title: LLM Finetuning
+ title: Text Tasks
+- sections:
+ - local: image_classification
+ title: Image Classification
+ - local: dreambooth
+ title: DreamBooth
+ title: Image Tasks
diff --git a/autotrain-advanced/docs/source/cost.mdx b/autotrain-advanced/docs/source/cost.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..bcfdad181a15514057310382a8e9239ab4f77ff6
--- /dev/null
+++ b/autotrain-advanced/docs/source/cost.mdx
@@ -0,0 +1,17 @@
+# How much does it cost?
+
+AutoTrain provides you with best models which are deployable with just a few clicks.
+Unlike other services, we don't own your models. Once the training is done, you can download them and use them anywhere you want.
+
+Before you start training, you can see the estimated cost of training.
+
+Free tier is available for everyone. For a limited number of samples, you can train your models for free!
+If your dataset is larger, you will be presented with the estimated cost of training.
+Training will begin only after you confirm the payment.
+
+Please note that in order to use non-free tier AutoTrain, you need to have a valid payment method on file.
+You can add your payment method in the [billing](https://huggingface.co/settings/billing) section.
+
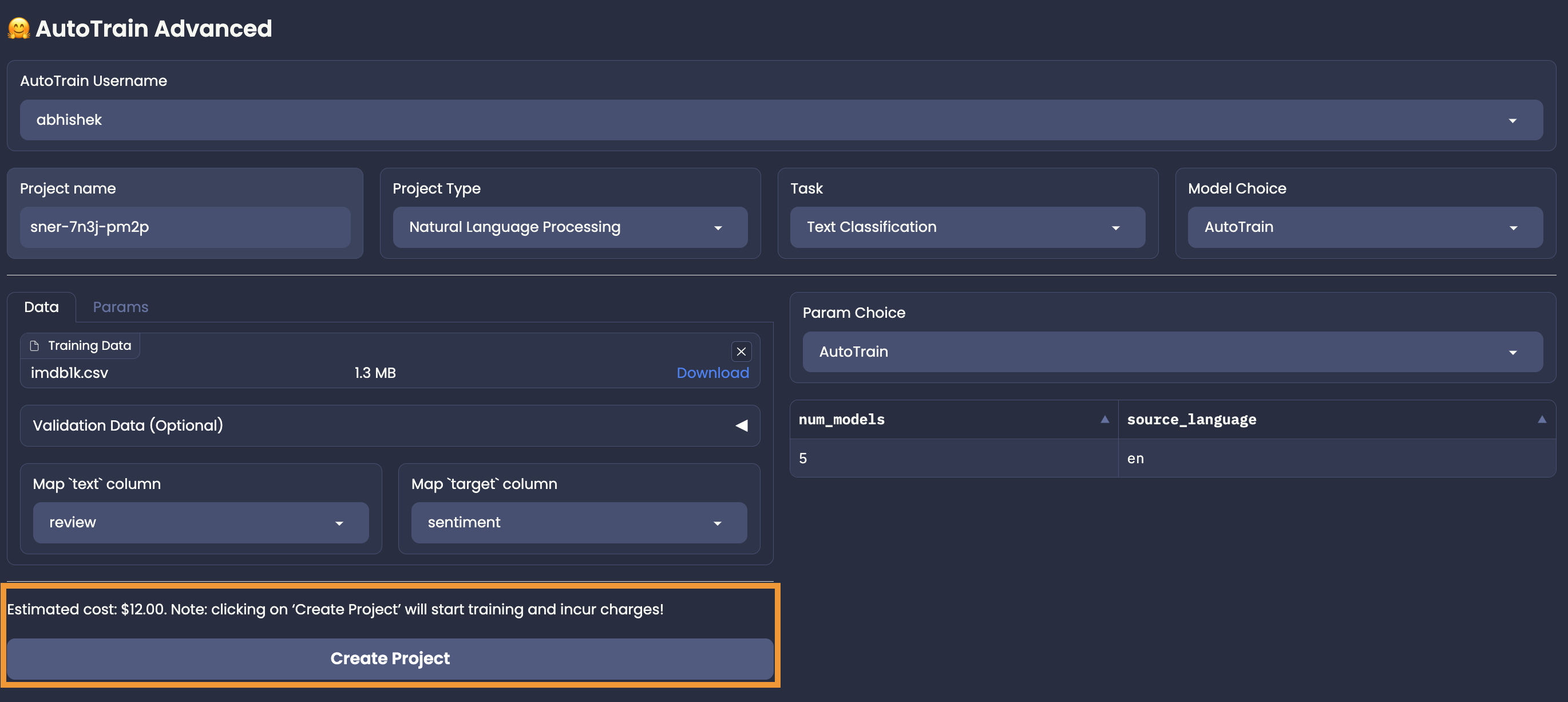
+Estimated cost will be displayed in the UI as follows:
+
+
\ No newline at end of file
diff --git a/autotrain-advanced/docs/source/dreambooth.mdx b/autotrain-advanced/docs/source/dreambooth.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..f2f7232098c0c4d3a07fab1e9aa1623d15f3c9f8
--- /dev/null
+++ b/autotrain-advanced/docs/source/dreambooth.mdx
@@ -0,0 +1,18 @@
+# DreamBooth
+
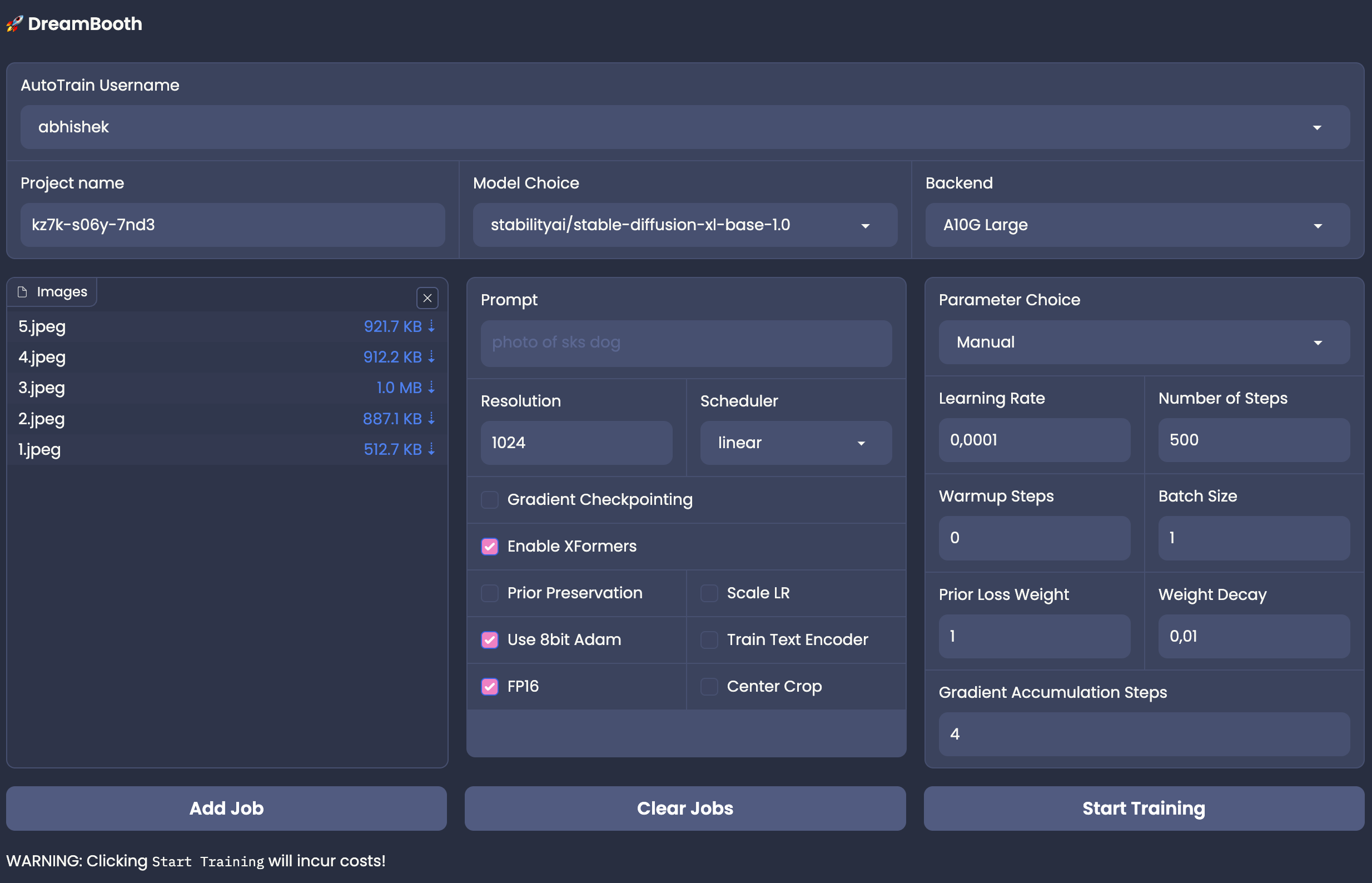
+DreamBooth is a method to personalize text-to-image models like Stable Diffusion given just a few (3-5) images of a subject. It allows the model to generate contextualized images of the subject in different scenes, poses, and views.
+
+
+
+## Data Preparation
+
+The data format for DreamBooth training is simple. All you need is images of a concept (e.g. a person) and a concept token.
+
+
+
+To train a dreambooth model, please select an appropriate model from the hub. You can also let AutoTrain decide the best model for you!
+When choosing a model from the hub, please make sure you select the correct image size compatible with the model.
+
+Same as other tasks, you also have an option to select the parameters manually or automatically using AutoTrain.
+
+For each concept that you want to train, you must have a concept token and concept images. Concept token is nothing but a word that is not available in the dictionary.
diff --git a/autotrain-advanced/docs/source/getting_started.mdx b/autotrain-advanced/docs/source/getting_started.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..14d0a999c289ab4270531d8731813c9b1d8d72a8
--- /dev/null
+++ b/autotrain-advanced/docs/source/getting_started.mdx
@@ -0,0 +1,29 @@
+# Installation
+
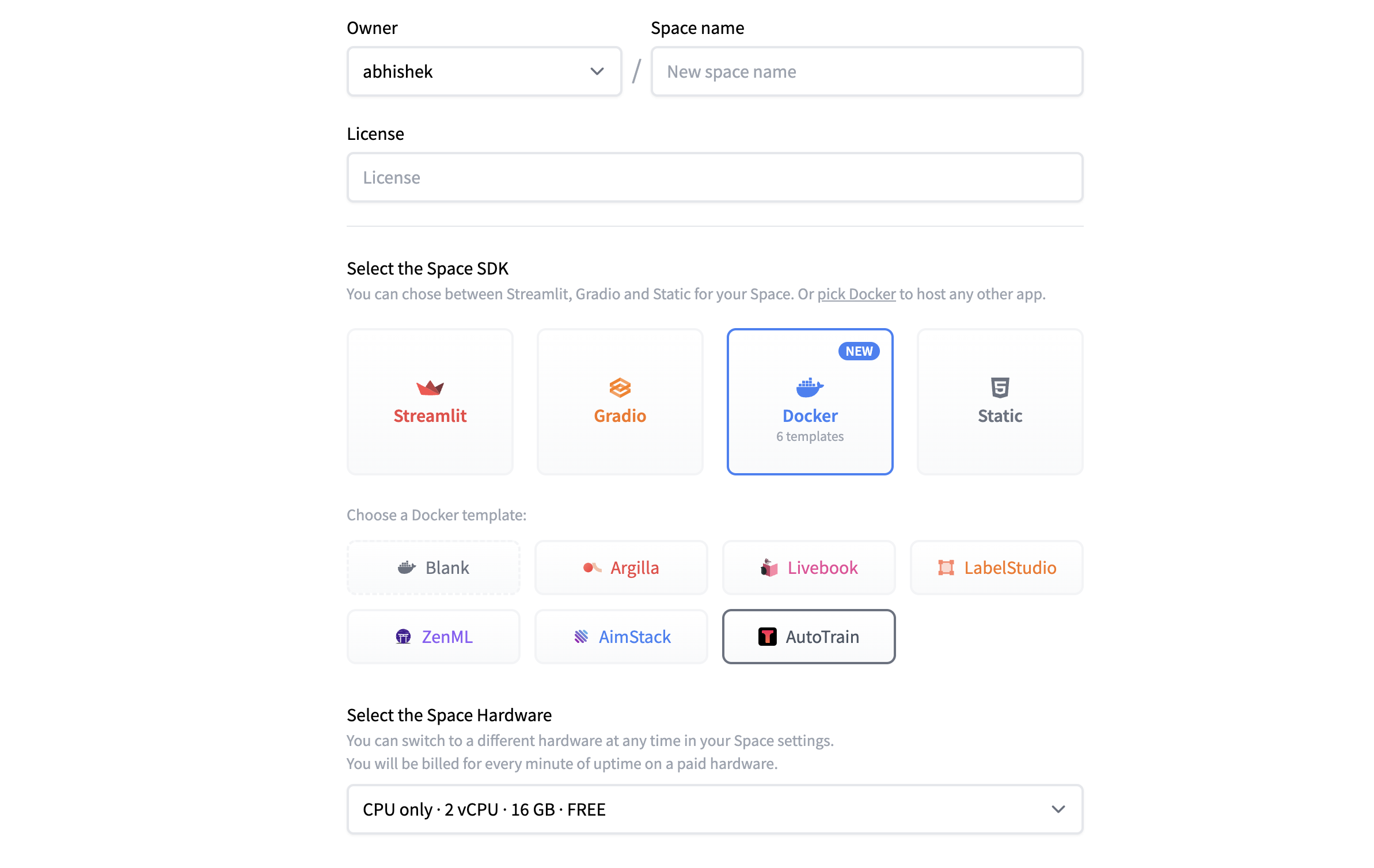
+There is no installation required! AutoTrain Advanced runs on Hugging Face Spaces. All you need to do is create a new space with the AutoTrain Advanced template: https://huggingface.co/new-space?template=autotrain-projects/autotrain-advanced. Please make sure you keep the space private.
+
+
+
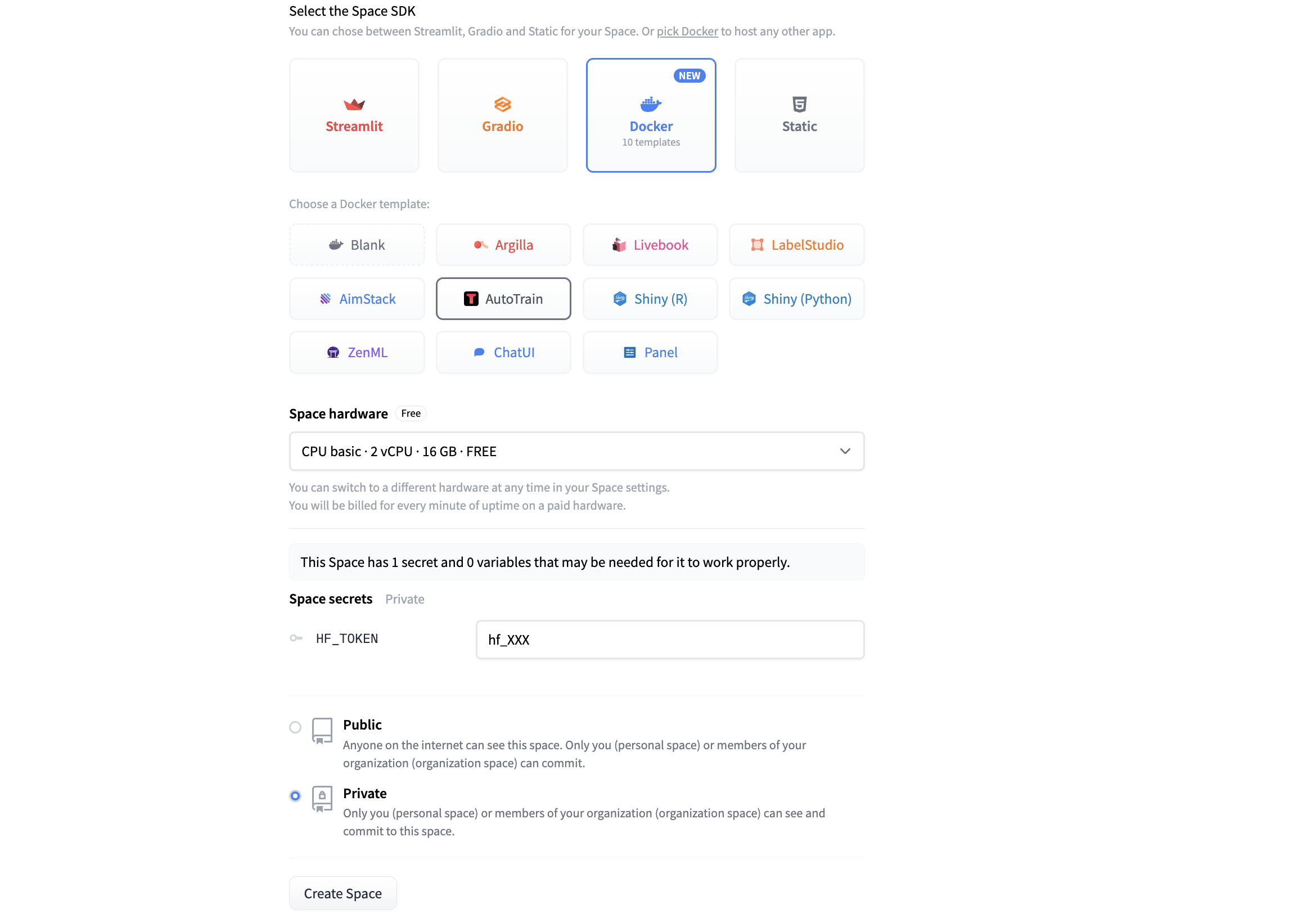
+Once you have selected Docker > AutoTrain template. You can click on "Create Space" and you will be redirected to your new space.
+
+
+
+Once the space is build, you will see this screen:
+
+
+
+You can find your token at https://huggingface.co/settings/token.
+
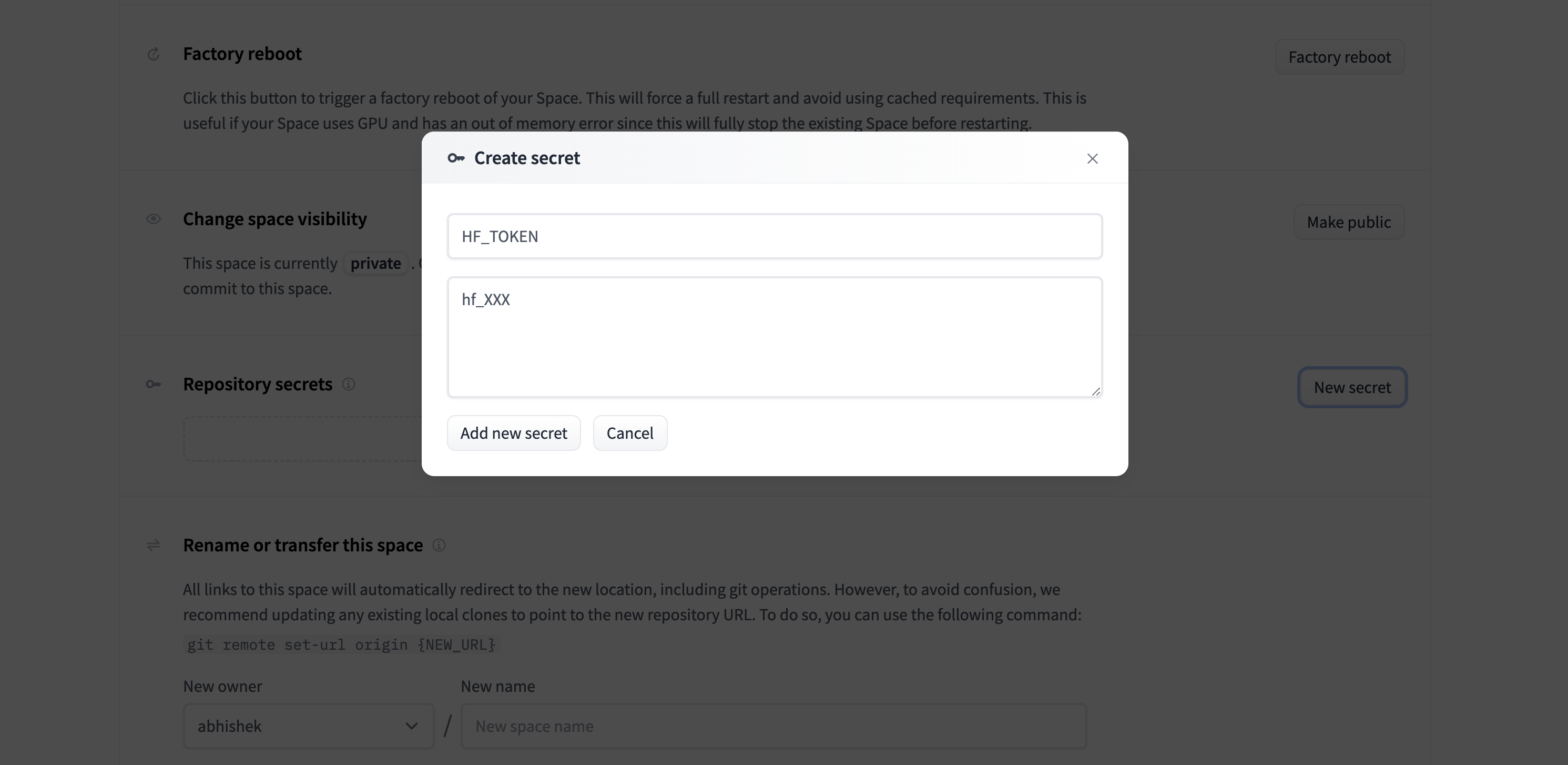
+Note: you have to add HF_TOKEN as an environment variable in your space settings. To do so, click on the "Settings" button in the top right corner of your space, then click on "New Secret" in the "Repository Secrets" section and add a new variable with the name HF_TOKEN and your token as the value as shown below:
+
+
+
+# Updating AutoTrain Advanced to Latest Version
+
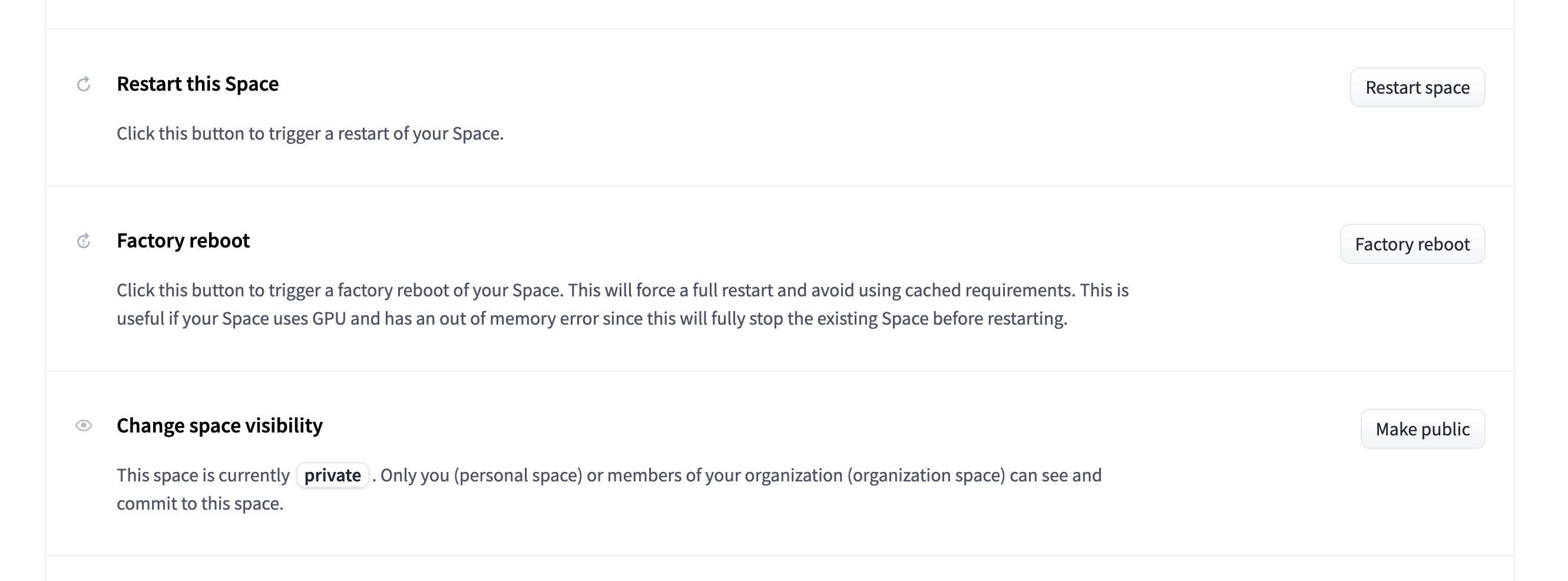
+We are constantly adding new features and tasks to AutoTrain Advanced. Its always a good idea to update your space to the latest version before starting a new project. An up-to-date version of AutoTrain Advanced will have the latest tasks, features and bug fixes! Updating is as easy as clicking on the "Factory reboot" button in the setting page of your space.
+
+
+
+Please note that "restarting" a space will not update it to the latest version. You need to "Factory reboot" the space to update it to the latest version.
+
+And now we are all set and we can start with our first project!
\ No newline at end of file
diff --git a/autotrain-advanced/docs/source/image_classification.mdx b/autotrain-advanced/docs/source/image_classification.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..d8f1ba1997d186cd58311d981a5a046a6a98fdeb
--- /dev/null
+++ b/autotrain-advanced/docs/source/image_classification.mdx
@@ -0,0 +1,40 @@
+# Image Classification
+
+Image classification is a supervised learning problem: define a set of target classes (objects to identify in images), and train a model to recognize them using labeled example photos.
+Using AutoTrain, its super-easy to train a state-of-the-art image classification model. Just upload a set of images, and AutoTrain will automatically train a model to classify them.
+
+## Data Preparation
+
+The data for image classification must be in zip format, with each class in a separate subfolder. For example, if you want to classify cats and dogs, your zip file should look like this:
+
+```
+cats_and_dogs.zip
+├── cats
+│ ├── cat.1.jpg
+│ ├── cat.2.jpg
+│ ├── cat.3.jpg
+│ └── ...
+└── dogs
+ ├── dog.1.jpg
+ ├── dog.2.jpg
+ ├── dog.3.jpg
+ └── ...
+```
+
+Some points to keep in mind:
+
+- The zip file should contain multiple folders (the classes), each folder should contain images of a single class.
+- The name of the folder should be the name of the class.
+- The images must be jpeg, jpg or png.
+- There should be at least 5 images per class.
+- There should not be any other files in the zip file.
+- There should not be any other folders inside the zip folder.
+
+When train.zip is decompressed, it creates two folders: cats and dogs. these are the two categories for classification. The images for both categories are in their respective folders. You can have as many categories as you want.
+
+## Training
+
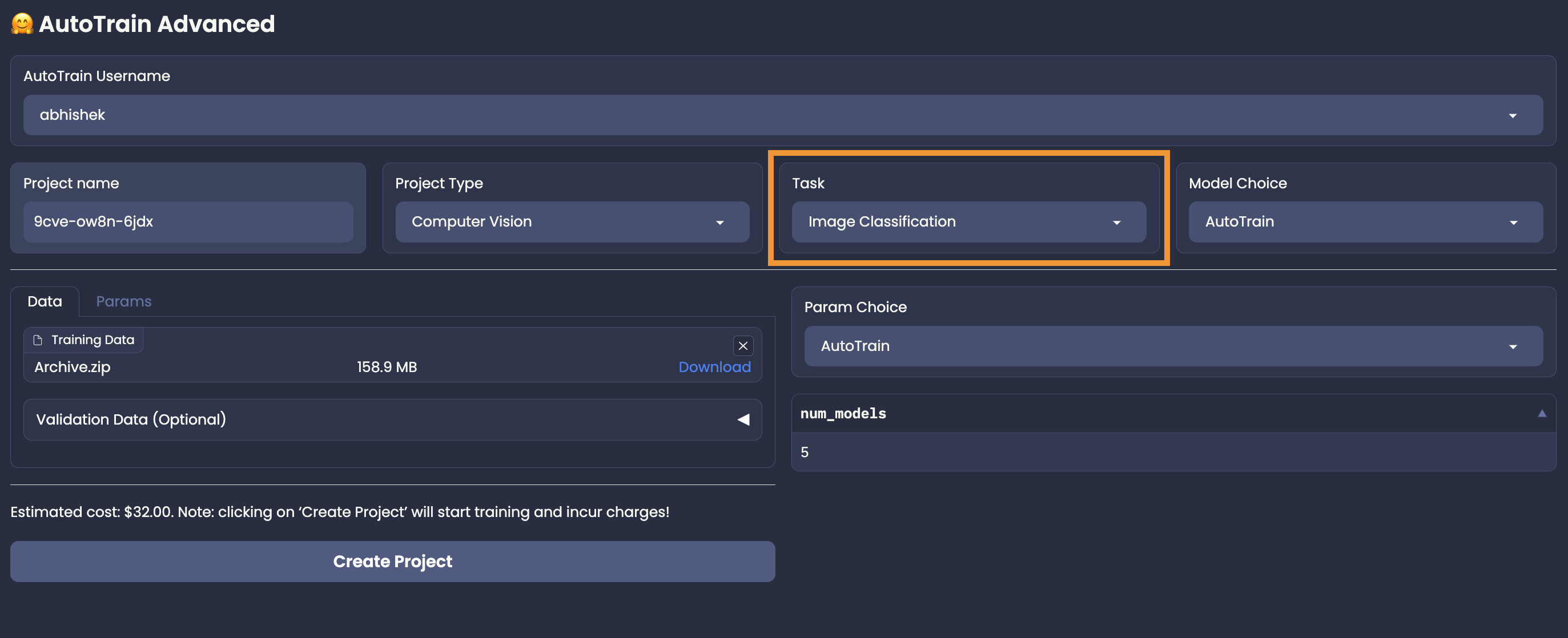
+Once you have your data ready, you can upload it to AutoTrain and select model and parameters.
+If the estimate looks good, click on `Create Project` button to start training.
+
+
\ No newline at end of file
diff --git a/autotrain-advanced/docs/source/index.mdx b/autotrain-advanced/docs/source/index.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..faaeb22caf4bdf7001c0d7740f992add27071055
--- /dev/null
+++ b/autotrain-advanced/docs/source/index.mdx
@@ -0,0 +1,34 @@
+# AutoTrain
+
+🤗 AutoTrain is a no-code tool for training state-of-the-art models for Natural Language Processing (NLP) tasks, for Computer Vision (CV) tasks, and for Speech tasks and even for Tabular tasks. It is built on top of the awesome tools developed by the Hugging Face team, and it is designed to be easy to use.
+
+## Who should use AutoTrain?
+
+AutoTrain is for anyone who wants to train a state-of-the-art model for a NLP, CV, Speech or Tabular task, but doesn't want to spend time on the technical details of training a model. AutoTrain is also for anyone who wants to train a model for a custom dataset, but doesn't want to spend time on the technical details of training a model. Our goal is to make it easy for anyone to train a state-of-the-art model for any task and our focus is not just data scientists or machine learning engineers, but also non-technical users.
+
+## How to use AutoTrain?
+
+We offer several ways to use AutoTrain:
+
+- No code users with large number of data samples can use `AutoTrain Advanced` by creating a new space with AutoTrain Docker image: https://huggingface.co/new-space?template=autotrain-projects/autotrain-advanced. Please make sure you keep the space private.
+
+- No code users with small number of data samples can use AutoTrain using the UI located at: https://ui.autotrain.huggingface.co/projects. Please note that this UI won't be updated with new tasks and features as frequently as AutoTrain Advanced.
+
+- Developers can access and build on top of AutoTrain using python api or run AutoTrain Advanced UI locally. The python api is available in the `autotrain-advanced` package. You can install it using pip:
+
+```bash
+pip install autotrain-advanced
+```
+
+- Developers can also use the AutoTrain API directly. The API is available at: https://api.autotrain.huggingface.co/docs
+
+
+## What is AutoTrain Advanced?
+
+AutoTrain Advanced processes your data either in a Hugging Face Space or locally (if installed locally using pip). This saves one time since the data processing is not done by the AutoTrain backend, resulting in your job not being queued. AutoTrain Advanced also allows you to use your own hardware (better CPU and RAM) to process the data, thus, making the data processing faster.
+
+Using AutoTrain Advanced, advanced users can also control the hyperparameters used for training per job. This allows you to train multiple models with different hyperparameters and compare the results.
+
+Everything else is the same as AutoTrain. You can use AutoTrain Advanced to train models for NLP, CV, Speech and Tabular tasks.
+
+We recommend using [AutoTrain Advanced](https://huggingface.co/new-space?template=autotrain-projects/autotrain-advanced) since it is faster, more flexible and will have more supported tasks and features in the future.
\ No newline at end of file
diff --git a/autotrain-advanced/docs/source/llm_finetuning.mdx b/autotrain-advanced/docs/source/llm_finetuning.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..6c41f715972f20ea630d425c5cd408a5c7c375f3
--- /dev/null
+++ b/autotrain-advanced/docs/source/llm_finetuning.mdx
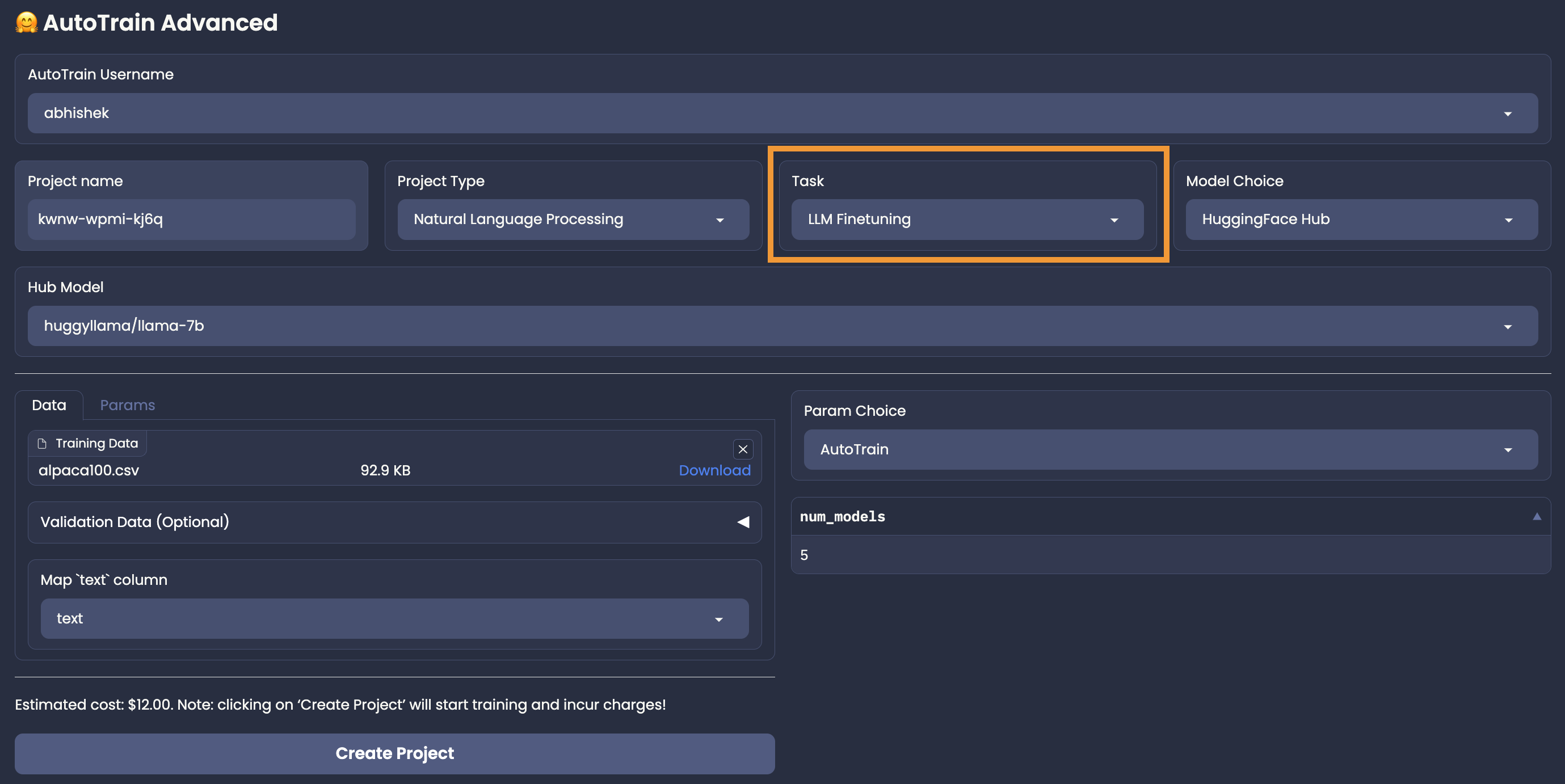
@@ -0,0 +1,43 @@
+# LLM Finetuning
+
+With AutoTrain, you can easily finetune large language models (LLMs) on your own data!
+
+AutoTrain supports the following types of LLM finetuning:
+
+- Causal Language Modeling (CLM)
+- Masked Language Modeling (MLM) [Coming Soon]
+
+For LLM finetuning, only Hugging Face Hub model choice is available.
+User needs to select a model from Hugging Face Hub, that they want to finetune and select the parameters on their own (Manual Parameter Selection),
+or use AutoTrain's Auto Parameter Selection to automatically select the best parameters for the task.
+
+## Data Preparation
+
+LLM finetuning accepts data in CSV format.
+There are two modes for LLM finetuning: `generic` and `chat`.
+An example dataset with both formats in the same dataset can be found here: https://huggingface.co/datasets/tatsu-lab/alpaca
+
+### Generic
+
+In generic mode, only one column is required: `text`.
+The user can take care of how the data is formatted for the task.
+A sample instance for this format is presented below:
+
+```
+Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
+
+### Instruction: Evaluate this sentence for spelling and grammar mistakes
+
+### Input: He finnished his meal and left the resturant
+
+### Response: He finished his meal and left the restaurant.
+```
+
+
+
+Please note that above is the format for instruction finetuning. But in the `generic` mode, you can also finetune on any other format as you want. The data can be changed according to the requirements.
+
+
+## Training
+
+Once you have your data ready and estimate verified, you can start training your model by clicking the "Create Project" button.
\ No newline at end of file
diff --git a/autotrain-advanced/docs/source/model_choice.mdx b/autotrain-advanced/docs/source/model_choice.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..e7f3b26fb6dbde8fcd8548e100dcb81b9bde1df9
--- /dev/null
+++ b/autotrain-advanced/docs/source/model_choice.mdx
@@ -0,0 +1,24 @@
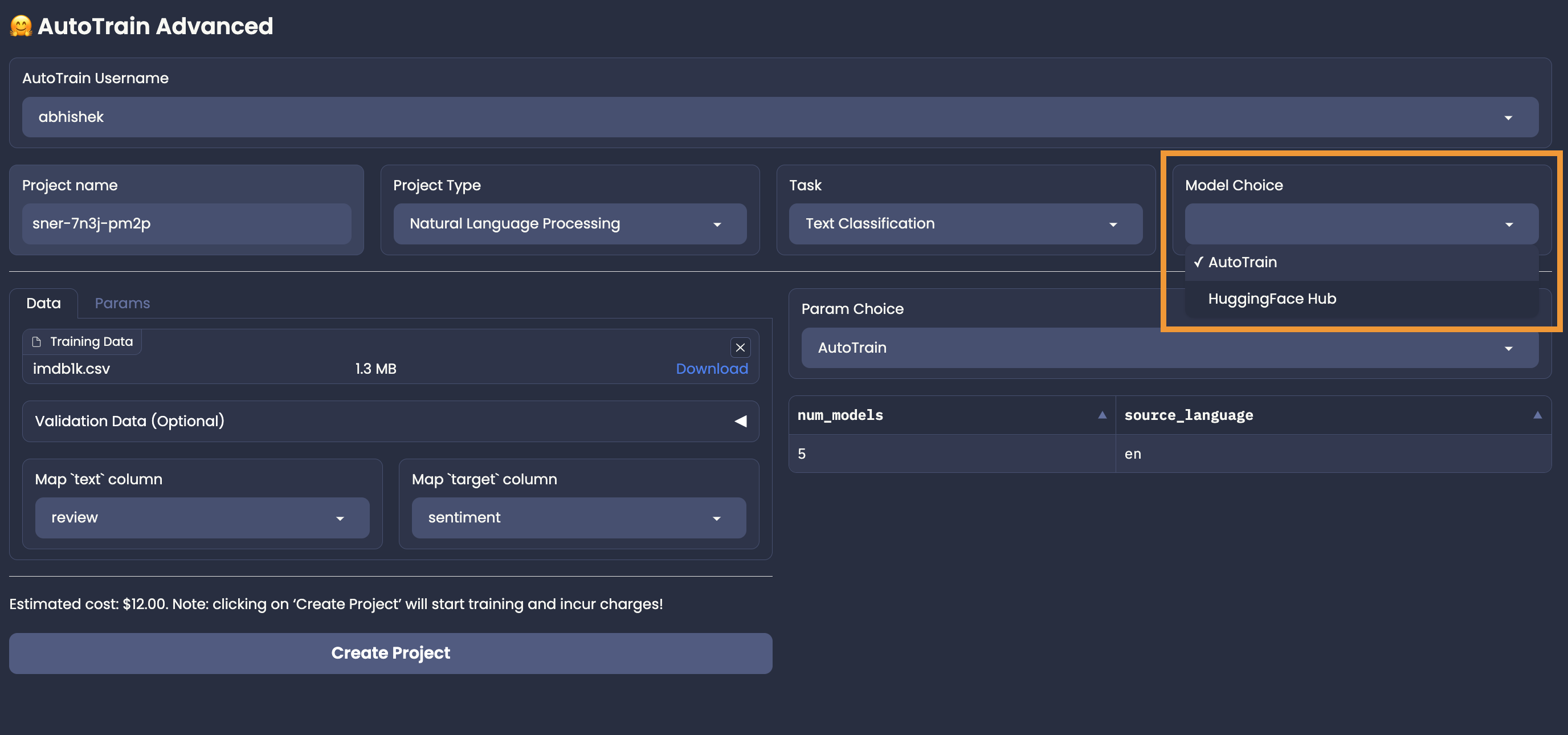
+# Model Choice
+
+AutoTrain can automagically select the best models for your task! However, you are also
+allowed to choose the models you want to use. You can choose the most appropriate models
+from the Hugging Face Hub.
+
+
+
+## AutoTrain Model Choice
+
+To let AutoTrain choose the best models for your task, you can use the "AutoTrain"
+in the "Model Choice" section. Once you choose AutoTrain mode, you no longer need to worry about model and parameter selection.
+AutoTrain will automatically select the best models (and parameters) for your task.
+
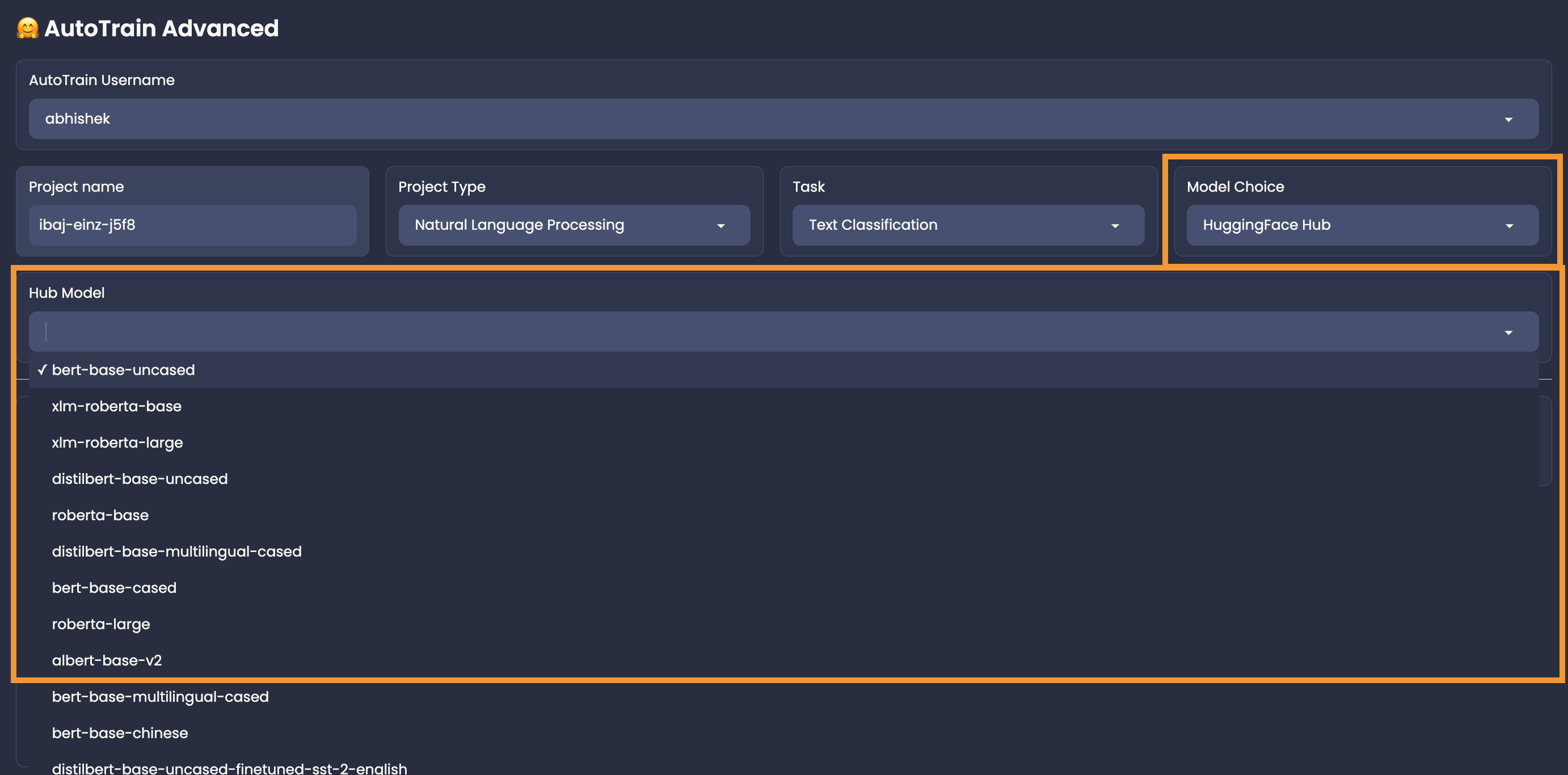
+## Manual Model Choice
+
+To choose the models manually, you can use the "HuggingFace Hub" in the "Model Choice" section.
+For example, if you want to use if you are training a text classification task and want to choose Deberta V3 Base for your task
+from https://huggingface.co/microsoft/deberta-v3-base,
+You can choose "HuggingFace Hub" and then write the model name: `microsoft/deberta-v3-base` in the model name field.
+
+
+
+Please note that if you are selecting a hub model, you should make sure that it is compatible with your task, otherwise the training will fail.
\ No newline at end of file
diff --git a/autotrain-advanced/docs/source/param_choice.mdx b/autotrain-advanced/docs/source/param_choice.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..14439ab1e1742567a4600adfc9acd3836b37d271
--- /dev/null
+++ b/autotrain-advanced/docs/source/param_choice.mdx
@@ -0,0 +1,25 @@
+# Parameter Choice
+
+Just like model choice, you can choose the parameters for your job in two ways: AutoTrain and Manual.
+
+## AutoTrain Mode
+
+In the AutoTrain mode, the parameters for your task-model pair will be chosen automagically.
+If you choose "AutoTrain" as model choice, you get the AutoTrain mode as the only option.
+If you choose "HuggingFace Hub" as model choice, you get the the option to choose between AutoTrain and Manual mode for parameter choice.
+
+An example of AutoTrain mode for a text classification task is shown below:
+
+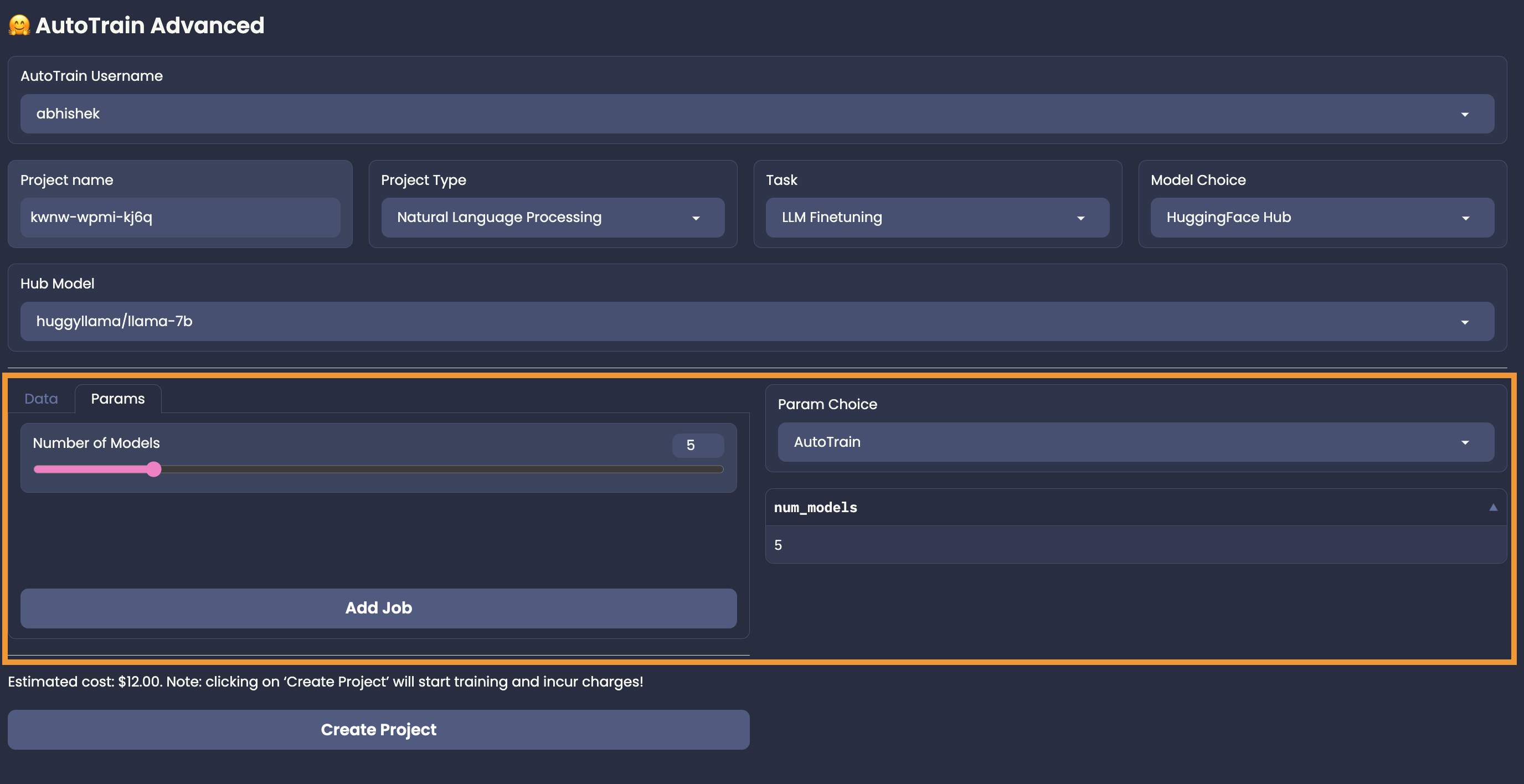
+
+For most of the tasks in AutoTrain parameter selection mode, you will get "Number of Models" as the only parameter to choose. Some tasks like test-classification might ask you about the language of the dataset.
+The more the number of models, the better the final results might be but it might be more expensive too!
+
+## Manual Mode
+
+Manual model can be used only when you choose "HuggingFace Hub" as model choice. In this mode, you can choose the parameters for your task-model pair manually.
+An example of Manual mode for a text classification task is shown below:
+
+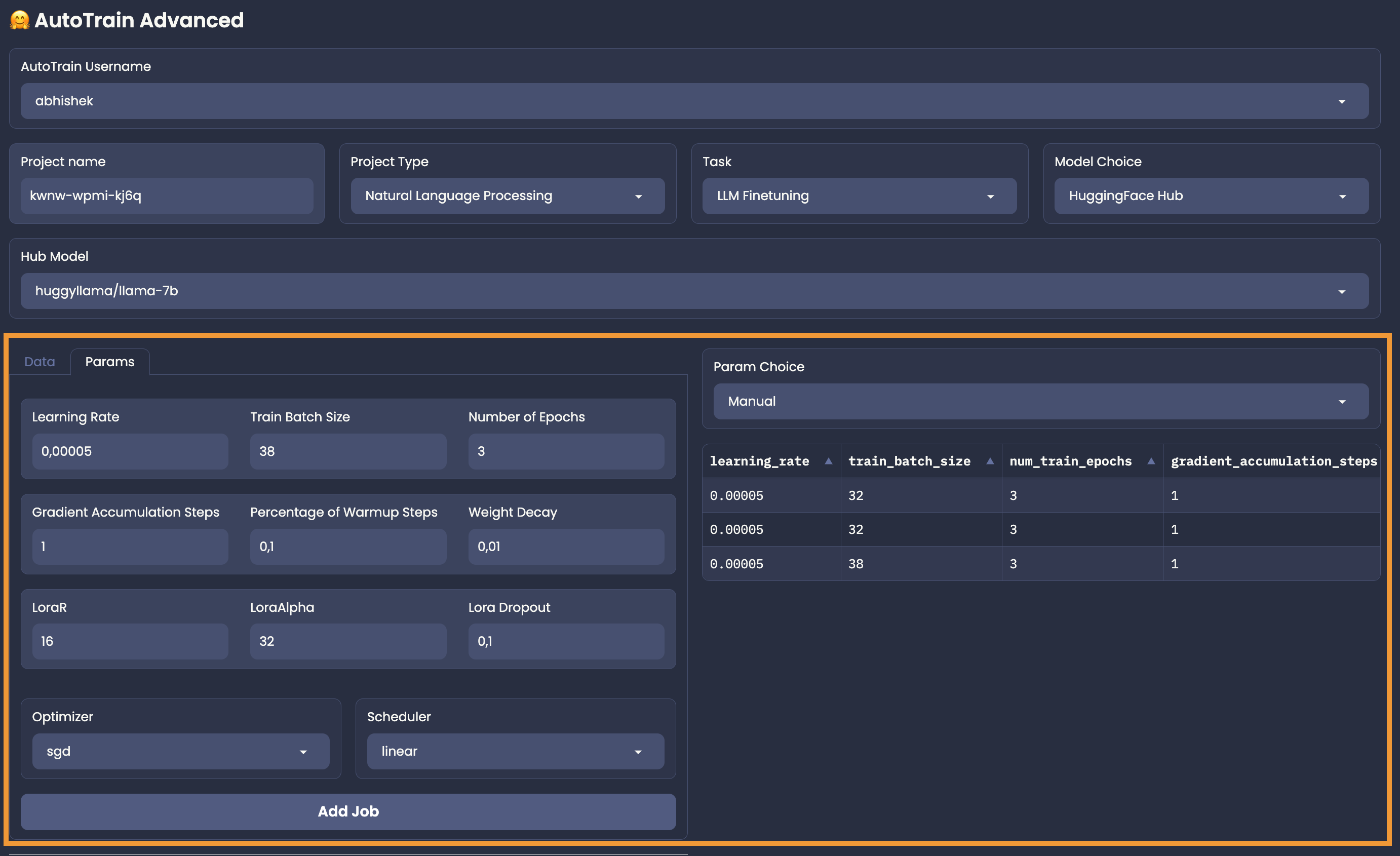
+
+In the manual mode, you have to add the jobs on your own. So, carefully select your parameters, click on "Add Job" and 💥.
\ No newline at end of file
diff --git a/autotrain-advanced/docs/source/support.mdx b/autotrain-advanced/docs/source/support.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..0a180c3f8ee27dd748a665767556bae7a13f9ae5
--- /dev/null
+++ b/autotrain-advanced/docs/source/support.mdx
@@ -0,0 +1,12 @@
+# Help and Support
+
+To get help and support for autotrain, there are 3 ways:
+
+- [Create an issue](https://github.com/huggingface/autotrain-advanced/issues/new) in AutoTrain Advanced GitHub repository.
+
+- [Ask in the Hugging Face Forum](https://discuss.huggingface.co/c/autotrain/16).
+
+- [Email us](mailto:autotrain@hf.co) directly.
+
+
+Please don't forget to mention your username and project name if you have a specific question about your project.
diff --git a/autotrain-advanced/docs/source/text_classification.mdx b/autotrain-advanced/docs/source/text_classification.mdx
new file mode 100644
index 0000000000000000000000000000000000000000..6135db8867ea4deefbde365522061c5bcb660e89
--- /dev/null
+++ b/autotrain-advanced/docs/source/text_classification.mdx
@@ -0,0 +1,60 @@
+# Text Classification
+
+Training a text classification model with AutoTrain is super-easy! Get your data ready in
+proper format and then with just a few clicks, your state-of-the-art model will be ready to
+be used in production.
+
+## Data Format
+
+Let's train a model for classifying the sentiment of a movie review. The data should be
+in the following CSV format:
+
+```csv
+review,sentiment
+"this movie is great",positive
+"this movie is bad",negative
+.
+.
+.
+```
+
+As you can see, we have two columns in the CSV file. One column is the text and the other
+is the label. The label can be any string. In this example, we have two labels: `positive`
+and `negative`. You can have as many labels as you want.
+
+If your CSV is huge, you can divide it into multiple CSV files and upload them separately.
+Please make sure that the column names are the same in all CSV files.
+
+One way to divide the CSV file using pandas is as follows:
+
+```python
+import pandas as pd
+
+# Set the chunk size
+chunk_size = 1000
+i = 1
+
+# Open the CSV file and read it in chunks
+for chunk in pd.read_csv('example.csv', chunksize=chunk_size):
+ # Save each chunk to a new file
+ chunk.to_csv(f'chunk_{i}.csv', index=False)
+ i += 1
+```
+
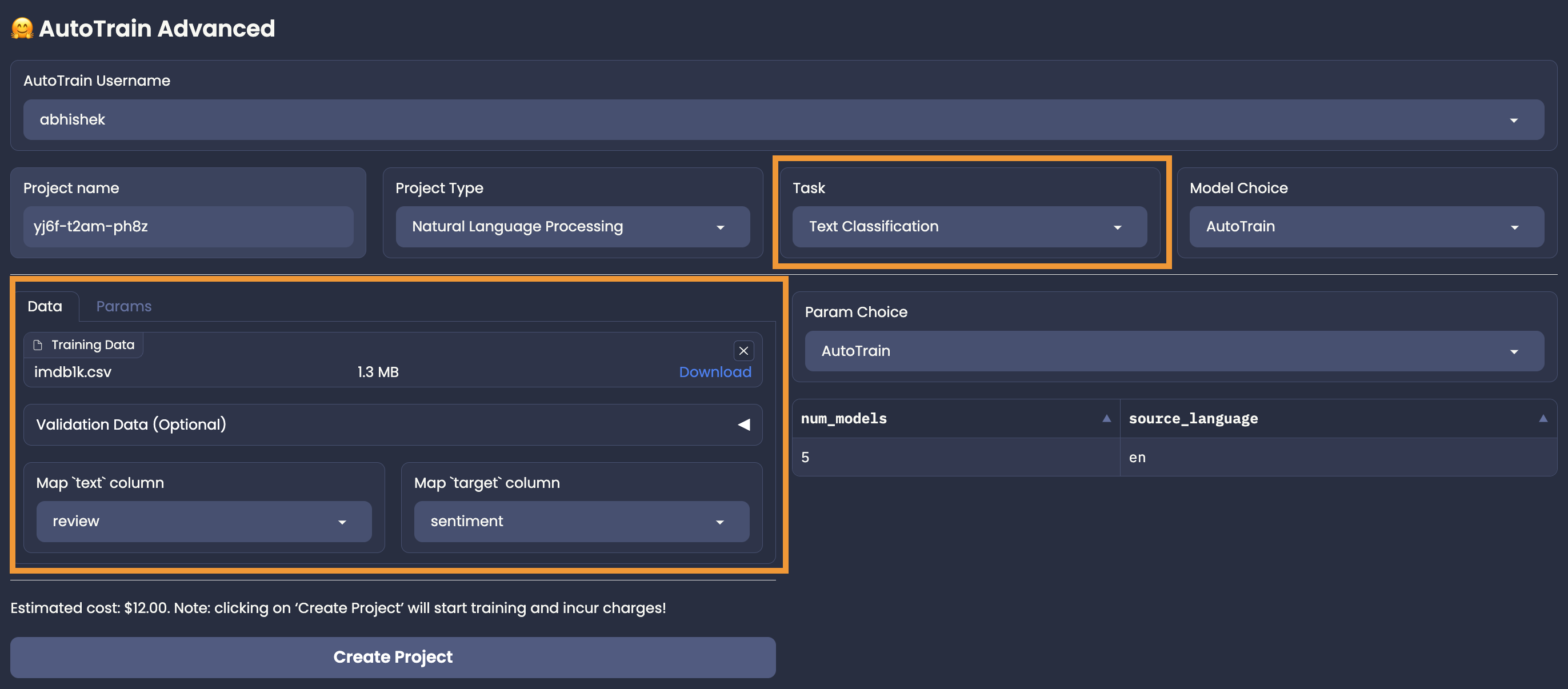
+Once the data has been uploaded, you have to select the proper column mapping
+
+## Column Mapping
+
+
+
+In our example, the text column is called `review` and the label column is called `sentiment`.
+Thus, we have to select `review` for the text column and `sentiment` for the label column.
+Please note that, if column mapping is not done correctly, the training will fail.
+
+
+## Training
+
+Once you have uploaded the data, selected the column mapping, and set the hyperparameters (AutoTrain or Manual mode), you can start the training.
+To start the training, please confirm the estimated cost and click on the `Create Project` button.
+
+
diff --git a/autotrain-advanced/examples/text_classification_binary.py b/autotrain-advanced/examples/text_classification_binary.py
new file mode 100644
index 0000000000000000000000000000000000000000..2cd6469968ab528065bc9807db80e45d3c3f8da2
--- /dev/null
+++ b/autotrain-advanced/examples/text_classification_binary.py
@@ -0,0 +1,77 @@
+import os
+from uuid import uuid4
+
+from datasets import load_dataset
+
+from autotrain.dataset import AutoTrainDataset
+from autotrain.project import Project
+
+
+RANDOM_ID = str(uuid4())
+DATASET = "imdb"
+PROJECT_NAME = f"imdb_{RANDOM_ID}"
+TASK = "text_binary_classification"
+MODEL = "bert-base-uncased"
+
+USERNAME = os.environ["AUTOTRAIN_USERNAME"]
+TOKEN = os.environ["HF_TOKEN"]
+
+
+if __name__ == "__main__":
+ dataset = load_dataset(DATASET)
+ train = dataset["train"]
+ validation = dataset["test"]
+
+ # convert to pandas dataframe
+ train_df = train.to_pandas()
+ validation_df = validation.to_pandas()
+
+ # prepare dataset for AutoTrain
+ dset = AutoTrainDataset(
+ train_data=[train_df],
+ valid_data=[validation_df],
+ task=TASK,
+ token=TOKEN,
+ project_name=PROJECT_NAME,
+ username=USERNAME,
+ column_mapping={"text": "text", "label": "label"},
+ percent_valid=None,
+ )
+ dset.prepare()
+
+ #
+ # How to get params for a task:
+ #
+ # from autotrain.params import Params
+ # params = Params(task=TASK, training_type="hub_model").get()
+ # print(params) to get full list of params for the task
+
+ # define params in proper format
+ job1 = {
+ "task": TASK,
+ "learning_rate": 1e-5,
+ "optimizer": "adamw_torch",
+ "scheduler": "linear",
+ "epochs": 5,
+ }
+
+ job2 = {
+ "task": TASK,
+ "learning_rate": 3e-5,
+ "optimizer": "adamw_torch",
+ "scheduler": "cosine",
+ "epochs": 5,
+ }
+
+ job3 = {
+ "task": TASK,
+ "learning_rate": 5e-5,
+ "optimizer": "sgd",
+ "scheduler": "cosine",
+ "epochs": 5,
+ }
+
+ jobs = [job1, job2, job3]
+ project = Project(dataset=dset, hub_model=MODEL, job_params=jobs)
+ project_id = project.create()
+ project.approve(project_id)
diff --git a/autotrain-advanced/examples/text_classification_multiclass.py b/autotrain-advanced/examples/text_classification_multiclass.py
new file mode 100644
index 0000000000000000000000000000000000000000..57b1b13fcfd6b78f7525c5ac81d8bd18f7e71c0a
--- /dev/null
+++ b/autotrain-advanced/examples/text_classification_multiclass.py
@@ -0,0 +1,77 @@
+import os
+from uuid import uuid4
+
+from datasets import load_dataset
+
+from autotrain.dataset import AutoTrainDataset
+from autotrain.project import Project
+
+
+RANDOM_ID = str(uuid4())
+DATASET = "amazon_reviews_multi"
+PROJECT_NAME = f"amazon_reviews_multi_{RANDOM_ID}"
+TASK = "text_multi_class_classification"
+MODEL = "bert-base-uncased"
+
+USERNAME = os.environ["AUTOTRAIN_USERNAME"]
+TOKEN = os.environ["HF_TOKEN"]
+
+
+if __name__ == "__main__":
+ dataset = load_dataset(DATASET, "en")
+ train = dataset["train"]
+ validation = dataset["test"]
+
+ # convert to pandas dataframe
+ train_df = train.to_pandas()
+ validation_df = validation.to_pandas()
+
+ # prepare dataset for AutoTrain
+ dset = AutoTrainDataset(
+ train_data=[train_df],
+ valid_data=[validation_df],
+ task=TASK,
+ token=TOKEN,
+ project_name=PROJECT_NAME,
+ username=USERNAME,
+ column_mapping={"text": "review_body", "label": "stars"},
+ percent_valid=None,
+ )
+ dset.prepare()
+
+ #
+ # How to get params for a task:
+ #
+ # from autotrain.params import Params
+ # params = Params(task=TASK, training_type="hub_model").get()
+ # print(params) to get full list of params for the task
+
+ # define params in proper format
+ job1 = {
+ "task": TASK,
+ "learning_rate": 1e-5,
+ "optimizer": "adamw_torch",
+ "scheduler": "linear",
+ "epochs": 5,
+ }
+
+ job2 = {
+ "task": TASK,
+ "learning_rate": 3e-5,
+ "optimizer": "adamw_torch",
+ "scheduler": "cosine",
+ "epochs": 5,
+ }
+
+ job3 = {
+ "task": TASK,
+ "learning_rate": 5e-5,
+ "optimizer": "sgd",
+ "scheduler": "cosine",
+ "epochs": 5,
+ }
+
+ jobs = [job1, job2, job3]
+ project = Project(dataset=dset, hub_model=MODEL, job_params=jobs)
+ project_id = project.create()
+ project.approve(project_id)
diff --git a/autotrain-advanced/requirements.txt b/autotrain-advanced/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..b5103740a6cab81568d6251088d50050dffb78ef
--- /dev/null
+++ b/autotrain-advanced/requirements.txt
@@ -0,0 +1,31 @@
+albumentations==1.3.1
+codecarbon==2.2.3
+datasets[vision]~=2.14.0
+evaluate==0.3.0
+ipadic==1.0.0
+jiwer==3.0.2
+joblib==1.3.1
+loguru==0.7.0
+pandas==2.0.3
+Pillow==10.0.0
+protobuf==4.23.4
+pydantic==1.10.11
+sacremoses==0.0.53
+scikit-learn==1.3.0
+sentencepiece==0.1.99
+tqdm==4.65.0
+werkzeug==2.3.6
+huggingface_hub>=0.16.4
+requests==2.31.0
+gradio==3.39.0
+einops==0.6.1
+invisible-watermark==0.2.0
+# latest versions
+tensorboard
+peft
+trl
+tiktoken
+transformers
+accelerate
+diffusers
+bitsandbytes
\ No newline at end of file
diff --git a/autotrain-advanced/setup.cfg b/autotrain-advanced/setup.cfg
new file mode 100644
index 0000000000000000000000000000000000000000..d69b03cda1889d4f3a52ece513782736a4cbdecb
--- /dev/null
+++ b/autotrain-advanced/setup.cfg
@@ -0,0 +1,24 @@
+[metadata]
+license_files = LICENSE
+version = attr: autotrain.__version__
+
+[isort]
+ensure_newline_before_comments = True
+force_grid_wrap = 0
+include_trailing_comma = True
+line_length = 119
+lines_after_imports = 2
+multi_line_output = 3
+use_parentheses = True
+
+[flake8]
+ignore = E203, E501, W503
+max-line-length = 119
+per-file-ignores =
+ # imported but unused
+ __init__.py: F401
+exclude =
+ .git,
+ .venv,
+ __pycache__,
+ dist
\ No newline at end of file
diff --git a/autotrain-advanced/setup.py b/autotrain-advanced/setup.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8165e593380b4aeccb92d922dcc3393451a636e
--- /dev/null
+++ b/autotrain-advanced/setup.py
@@ -0,0 +1,71 @@
+# Lint as: python3
+"""
+HuggingFace / AutoTrain Advanced
+"""
+import os
+
+from setuptools import find_packages, setup
+
+
+DOCLINES = __doc__.split("\n")
+
+this_directory = os.path.abspath(os.path.dirname(__file__))
+with open(os.path.join(this_directory, "README.md"), encoding="utf-8") as f:
+ LONG_DESCRIPTION = f.read()
+
+# get INSTALL_REQUIRES from requirements.txt
+with open(os.path.join(this_directory, "requirements.txt"), encoding="utf-8") as f:
+ INSTALL_REQUIRES = f.read().splitlines()
+
+QUALITY_REQUIRE = [
+ "black",
+ "isort",
+ "flake8==3.7.9",
+]
+
+TESTS_REQUIRE = ["pytest"]
+
+
+EXTRAS_REQUIRE = {
+ "dev": INSTALL_REQUIRES + QUALITY_REQUIRE + TESTS_REQUIRE,
+ "quality": INSTALL_REQUIRES + QUALITY_REQUIRE,
+ "docs": INSTALL_REQUIRES
+ + [
+ "recommonmark",
+ "sphinx==3.1.2",
+ "sphinx-markdown-tables",
+ "sphinx-rtd-theme==0.4.3",
+ "sphinx-copybutton",
+ ],
+}
+
+setup(
+ name="autotrain-advanced",
+ description=DOCLINES[0],
+ long_description=LONG_DESCRIPTION,
+ long_description_content_type="text/markdown",
+ author="HuggingFace Inc.",
+ author_email="autotrain@huggingface.co",
+ url="https://github.com/huggingface/autotrain-advanced",
+ download_url="https://github.com/huggingface/autotrain-advanced/tags",
+ license="Apache 2.0",
+ package_dir={"": "src"},
+ packages=find_packages("src"),
+ extras_require=EXTRAS_REQUIRE,
+ install_requires=INSTALL_REQUIRES,
+ entry_points={"console_scripts": ["autotrain=autotrain.cli.autotrain:main"]},
+ classifiers=[
+ "Development Status :: 5 - Production/Stable",
+ "Intended Audience :: Developers",
+ "Intended Audience :: Education",
+ "Intended Audience :: Science/Research",
+ "License :: OSI Approved :: Apache Software License",
+ "Operating System :: OS Independent",
+ "Programming Language :: Python :: 3.8",
+ "Programming Language :: Python :: 3.9",
+ "Programming Language :: Python :: 3.10",
+ "Programming Language :: Python :: 3.11",
+ "Topic :: Scientific/Engineering :: Artificial Intelligence",
+ ],
+ keywords="automl autonlp autotrain huggingface",
+)
diff --git a/autotrain-advanced/src/autotrain/__init__.py b/autotrain-advanced/src/autotrain/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6d020a37e75d5d58ba706d21478da80aceec3e5d
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/__init__.py
@@ -0,0 +1,24 @@
+# coding=utf-8
+# Copyright 2020-2021 The HuggingFace AutoTrain Authors
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Lint as: python3
+# pylint: enable=line-too-long
+import os
+
+
+# ignore bnb warnings
+os.environ["BITSANDBYTES_NOWELCOME"] = "1"
+# os.environ["HF_HUB_DISABLE_PROGRESS_BARS"] = "1"
+__version__ = "0.6.16.dev0"
diff --git a/autotrain-advanced/src/autotrain/app.py b/autotrain-advanced/src/autotrain/app.py
new file mode 100644
index 0000000000000000000000000000000000000000..24cd86021512f2bba7c3c7d676d54a5275cc3bc4
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/app.py
@@ -0,0 +1,965 @@
+import json
+import os
+import random
+import string
+import zipfile
+
+import gradio as gr
+import pandas as pd
+from huggingface_hub import list_models
+from loguru import logger
+
+from autotrain.dataset import AutoTrainDataset, AutoTrainDreamboothDataset, AutoTrainImageClassificationDataset
+from autotrain.languages import SUPPORTED_LANGUAGES
+from autotrain.params import Params
+from autotrain.project import Project
+from autotrain.utils import get_project_cost, get_user_token, user_authentication
+
+
+APP_TASKS = {
+ "Natural Language Processing": ["Text Classification", "LLM Finetuning"],
+ # "Tabular": TABULAR_TASKS,
+ "Computer Vision": ["Image Classification", "Dreambooth"],
+}
+
+APP_TASKS_MAPPING = {
+ "Text Classification": "text_multi_class_classification",
+ "LLM Finetuning": "lm_training",
+ "Image Classification": "image_multi_class_classification",
+ "Dreambooth": "dreambooth",
+}
+
+APP_TASK_TYPE_MAPPING = {
+ "text_classification": "Natural Language Processing",
+ "lm_training": "Natural Language Processing",
+ "image_classification": "Computer Vision",
+ "dreambooth": "Computer Vision",
+}
+
+ALLOWED_FILE_TYPES = [
+ ".csv",
+ ".CSV",
+ ".jsonl",
+ ".JSONL",
+ ".zip",
+ ".ZIP",
+ ".png",
+ ".PNG",
+ ".jpg",
+ ".JPG",
+ ".jpeg",
+ ".JPEG",
+]
+
+
+def _login_user(user_token):
+ user_info = user_authentication(token=user_token)
+ username = user_info["name"]
+
+ user_can_pay = user_info["canPay"]
+ orgs = user_info["orgs"]
+
+ valid_orgs = [org for org in orgs if org["canPay"] is True]
+ valid_orgs = [org for org in valid_orgs if org["roleInOrg"] in ("admin", "write")]
+ valid_orgs = [org["name"] for org in valid_orgs]
+
+ valid_can_pay = [username] + valid_orgs if user_can_pay else valid_orgs
+ who_is_training = [username] + [org["name"] for org in orgs]
+ return user_token, valid_can_pay, who_is_training
+
+
+def _update_task_type(project_type):
+ return gr.Dropdown.update(
+ value=APP_TASKS[project_type][0],
+ choices=APP_TASKS[project_type],
+ visible=True,
+ )
+
+
+def _update_model_choice(task, autotrain_backend):
+ # TODO: add tabular and remember, for tabular, we only support AutoTrain
+ if autotrain_backend.lower() != "huggingface internal":
+ model_choice = ["HuggingFace Hub"]
+ return gr.Dropdown.update(
+ value=model_choice[0],
+ choices=model_choice,
+ visible=True,
+ )
+
+ if task == "LLM Finetuning":
+ model_choice = ["HuggingFace Hub"]
+ else:
+ model_choice = ["AutoTrain", "HuggingFace Hub"]
+
+ return gr.Dropdown.update(
+ value=model_choice[0],
+ choices=model_choice,
+ visible=True,
+ )
+
+
+def _update_file_type(task):
+ task = APP_TASKS_MAPPING[task]
+ if task in ("text_multi_class_classification", "lm_training"):
+ return gr.Radio.update(
+ value="CSV",
+ choices=["CSV", "JSONL"],
+ visible=True,
+ )
+ elif task == "image_multi_class_classification":
+ return gr.Radio.update(
+ value="ZIP",
+ choices=["Image Subfolders", "ZIP"],
+ visible=True,
+ )
+ elif task == "dreambooth":
+ return gr.Radio.update(
+ value="ZIP",
+ choices=["Image Folder", "ZIP"],
+ visible=True,
+ )
+ else:
+ raise NotImplementedError
+
+
+def _update_param_choice(model_choice, autotrain_backend):
+ logger.info(f"model_choice: {model_choice}")
+ choices = ["AutoTrain", "Manual"] if model_choice == "HuggingFace Hub" else ["AutoTrain"]
+ choices = ["Manual"] if autotrain_backend != "HuggingFace Internal" else choices
+ return gr.Dropdown.update(
+ value=choices[0],
+ choices=choices,
+ visible=True,
+ )
+
+
+def _project_type_update(project_type, task_type, autotrain_backend):
+ logger.info(f"project_type: {project_type}, task_type: {task_type}")
+ task_choices_update = _update_task_type(project_type)
+ model_choices_update = _update_model_choice(task_choices_update["value"], autotrain_backend)
+ param_choices_update = _update_param_choice(model_choices_update["value"], autotrain_backend)
+ return [
+ task_choices_update,
+ model_choices_update,
+ param_choices_update,
+ _update_hub_model_choices(task_choices_update["value"], model_choices_update["value"]),
+ ]
+
+
+def _task_type_update(task_type, autotrain_backend):
+ logger.info(f"task_type: {task_type}")
+ model_choices_update = _update_model_choice(task_type, autotrain_backend)
+ param_choices_update = _update_param_choice(model_choices_update["value"], autotrain_backend)
+ return [
+ model_choices_update,
+ param_choices_update,
+ _update_hub_model_choices(task_type, model_choices_update["value"]),
+ ]
+
+
+def _update_col_map(training_data, task):
+ task = APP_TASKS_MAPPING[task]
+ if task == "text_multi_class_classification":
+ data_cols = pd.read_csv(training_data[0].name, nrows=2).columns.tolist()
+ return [
+ gr.Dropdown.update(visible=True, choices=data_cols, label="Map `text` column", value=data_cols[0]),
+ gr.Dropdown.update(visible=True, choices=data_cols, label="Map `target` column", value=data_cols[1]),
+ gr.Text.update(visible=False),
+ ]
+ elif task == "lm_training":
+ data_cols = pd.read_csv(training_data[0].name, nrows=2).columns.tolist()
+ return [
+ gr.Dropdown.update(visible=True, choices=data_cols, label="Map `text` column", value=data_cols[0]),
+ gr.Dropdown.update(visible=False),
+ gr.Text.update(visible=False),
+ ]
+ elif task == "dreambooth":
+ return [
+ gr.Dropdown.update(visible=False),
+ gr.Dropdown.update(visible=False),
+ gr.Text.update(visible=True, label="Concept Token", interactive=True),
+ ]
+ else:
+ return [
+ gr.Dropdown.update(visible=False),
+ gr.Dropdown.update(visible=False),
+ gr.Text.update(visible=False),
+ ]
+
+
+def _estimate_costs(
+ training_data, validation_data, task, user_token, autotrain_username, training_params_txt, autotrain_backend
+):
+ if autotrain_backend.lower() != "huggingface internal":
+ return [
+ gr.Markdown.update(
+ value="Cost estimation is not available for this backend",
+ visible=True,
+ ),
+ gr.Number.update(visible=False),
+ ]
+ try:
+ logger.info("Estimating costs....")
+ if training_data is None:
+ return [
+ gr.Markdown.update(
+ value="Could not estimate cost. Please add training data",
+ visible=True,
+ ),
+ gr.Number.update(visible=False),
+ ]
+ if validation_data is None:
+ validation_data = []
+
+ training_params = json.loads(training_params_txt)
+ if len(training_params) == 0:
+ return [
+ gr.Markdown.update(
+ value="Could not estimate cost. Please add atleast one job",
+ visible=True,
+ ),
+ gr.Number.update(visible=False),
+ ]
+ elif len(training_params) == 1:
+ if "num_models" in training_params[0]:
+ num_models = training_params[0]["num_models"]
+ else:
+ num_models = 1
+ else:
+ num_models = len(training_params)
+ task = APP_TASKS_MAPPING[task]
+ num_samples = 0
+ logger.info("Estimating number of samples")
+ if task in ("text_multi_class_classification", "lm_training"):
+ for _f in training_data:
+ num_samples += pd.read_csv(_f.name).shape[0]
+ for _f in validation_data:
+ num_samples += pd.read_csv(_f.name).shape[0]
+ elif task == "image_multi_class_classification":
+ logger.info(f"training_data: {training_data}")
+ if len(training_data) > 1:
+ return [
+ gr.Markdown.update(
+ value="Only one training file is supported for image classification",
+ visible=True,
+ ),
+ gr.Number.update(visible=False),
+ ]
+ if len(validation_data) > 1:
+ return [
+ gr.Markdown.update(
+ value="Only one validation file is supported for image classification",
+ visible=True,
+ ),
+ gr.Number.update(visible=False),
+ ]
+ for _f in training_data:
+ zip_ref = zipfile.ZipFile(_f.name, "r")
+ for _ in zip_ref.namelist():
+ num_samples += 1
+ for _f in validation_data:
+ zip_ref = zipfile.ZipFile(_f.name, "r")
+ for _ in zip_ref.namelist():
+ num_samples += 1
+ elif task == "dreambooth":
+ num_samples = len(training_data)
+ else:
+ raise NotImplementedError
+
+ logger.info(f"Estimating costs for: num_models: {num_models}, task: {task}, num_samples: {num_samples}")
+ estimated_cost = get_project_cost(
+ username=autotrain_username,
+ token=user_token,
+ task=task,
+ num_samples=num_samples,
+ num_models=num_models,
+ )
+ logger.info(f"Estimated_cost: {estimated_cost}")
+ return [
+ gr.Markdown.update(
+ value=f"Estimated cost: ${estimated_cost:.2f}. Note: clicking on 'Create Project' will start training and incur charges!",
+ visible=True,
+ ),
+ gr.Number.update(visible=False),
+ ]
+ except Exception as e:
+ logger.error(e)
+ logger.error("Could not estimate cost, check inputs")
+ return [
+ gr.Markdown.update(
+ value="Could not estimate cost, check inputs",
+ visible=True,
+ ),
+ gr.Number.update(visible=False),
+ ]
+
+
+def get_job_params(param_choice, training_params, task):
+ if param_choice == "autotrain":
+ if len(training_params) > 1:
+ raise ValueError("❌ Only one job parameter is allowed for AutoTrain.")
+ training_params[0].update({"task": task})
+ elif param_choice.lower() == "manual":
+ for i in range(len(training_params)):
+ training_params[i].update({"task": task})
+ if "hub_model" in training_params[i]:
+ # remove hub_model from training_params
+ training_params[i].pop("hub_model")
+ return training_params
+
+
+def _update_project_name():
+ random_project_name = "-".join(
+ ["".join(random.choices(string.ascii_lowercase + string.digits, k=4)) for _ in range(3)]
+ )
+ # check if training tracker exists
+ if os.path.exists(os.path.join("/tmp", "training")):
+ return [
+ gr.Text.update(value=random_project_name, visible=True, interactive=True),
+ gr.Button.update(interactive=False),
+ ]
+ return [
+ gr.Text.update(value=random_project_name, visible=True, interactive=True),
+ gr.Button.update(interactive=True),
+ ]
+
+
+def _update_hub_model_choices(task, model_choice):
+ task = APP_TASKS_MAPPING[task]
+ logger.info(f"Updating hub model choices for task: {task}, model_choice: {model_choice}")
+ if model_choice.lower() == "autotrain":
+ return gr.Dropdown.update(
+ visible=False,
+ interactive=False,
+ )
+ if task == "text_multi_class_classification":
+ hub_models1 = list_models(filter="fill-mask", sort="downloads", direction=-1, limit=100)
+ hub_models2 = list_models(filter="text-classification", sort="downloads", direction=-1, limit=100)
+ hub_models = list(hub_models1) + list(hub_models2)
+ elif task == "lm_training":
+ hub_models = list(list_models(filter="text-generation", sort="downloads", direction=-1, limit=100))
+ elif task == "image_multi_class_classification":
+ hub_models = list(list_models(filter="image-classification", sort="downloads", direction=-1, limit=100))
+ elif task == "dreambooth":
+ hub_models = list(list_models(filter="text-to-image", sort="downloads", direction=-1, limit=100))
+ else:
+ raise NotImplementedError
+ # sort by number of downloads in descending order
+ hub_models = [{"id": m.modelId, "downloads": m.downloads} for m in hub_models if m.private is False]
+ hub_models = sorted(hub_models, key=lambda x: x["downloads"], reverse=True)
+
+ if task == "dreambooth":
+ choices = ["stabilityai/stable-diffusion-xl-base-1.0"] + [m["id"] for m in hub_models]
+ value = choices[0]
+ return gr.Dropdown.update(
+ choices=choices,
+ value=value,
+ visible=True,
+ interactive=True,
+ )
+
+ return gr.Dropdown.update(
+ choices=[m["id"] for m in hub_models],
+ value=hub_models[0]["id"],
+ visible=True,
+ interactive=True,
+ )
+
+
+def _update_backend(backend):
+ if backend != "Hugging Face Internal":
+ return [
+ gr.Dropdown.update(
+ visible=True,
+ interactive=True,
+ choices=["HuggingFace Hub"],
+ value="HuggingFace Hub",
+ ),
+ gr.Dropdown.update(
+ visible=True,
+ interactive=True,
+ choices=["Manual"],
+ value="Manual",
+ ),
+ ]
+ return [
+ gr.Dropdown.update(
+ visible=True,
+ interactive=True,
+ ),
+ gr.Dropdown.update(
+ visible=True,
+ interactive=True,
+ ),
+ ]
+
+
+def _create_project(
+ autotrain_username,
+ valid_can_pay,
+ project_name,
+ user_token,
+ task,
+ training_data,
+ validation_data,
+ col_map_text,
+ col_map_label,
+ concept_token,
+ training_params_txt,
+ hub_model,
+ estimated_cost,
+ autotrain_backend,
+):
+ task = APP_TASKS_MAPPING[task]
+ valid_can_pay = valid_can_pay.split(",")
+ can_pay = autotrain_username in valid_can_pay
+ logger.info(f"🚨🚨🚨Creating project: {project_name}")
+ logger.info(f"🚨Task: {task}")
+ logger.info(f"🚨Training data: {training_data}")
+ logger.info(f"🚨Validation data: {validation_data}")
+ logger.info(f"🚨Training params: {training_params_txt}")
+ logger.info(f"🚨Hub model: {hub_model}")
+ logger.info(f"🚨Estimated cost: {estimated_cost}")
+ logger.info(f"🚨:Can pay: {can_pay}")
+
+ if can_pay is False and estimated_cost > 0:
+ raise gr.Error("❌ You do not have enough credits to create this project. Please add a valid payment method.")
+
+ training_params = json.loads(training_params_txt)
+ if len(training_params) == 0:
+ raise gr.Error("Please add atleast one job")
+ elif len(training_params) == 1:
+ if "num_models" in training_params[0]:
+ param_choice = "autotrain"
+ else:
+ param_choice = "manual"
+ else:
+ param_choice = "manual"
+
+ if task == "image_multi_class_classification":
+ training_data = training_data[0].name
+ if validation_data is not None:
+ validation_data = validation_data[0].name
+ dset = AutoTrainImageClassificationDataset(
+ train_data=training_data,
+ token=user_token,
+ project_name=project_name,
+ username=autotrain_username,
+ valid_data=validation_data,
+ percent_valid=None, # TODO: add to UI
+ )
+ elif task == "text_multi_class_classification":
+ training_data = [f.name for f in training_data]
+ if validation_data is None:
+ validation_data = []
+ else:
+ validation_data = [f.name for f in validation_data]
+ dset = AutoTrainDataset(
+ train_data=training_data,
+ task=task,
+ token=user_token,
+ project_name=project_name,
+ username=autotrain_username,
+ column_mapping={"text": col_map_text, "label": col_map_label},
+ valid_data=validation_data,
+ percent_valid=None, # TODO: add to UI
+ )
+ elif task == "lm_training":
+ training_data = [f.name for f in training_data]
+ if validation_data is None:
+ validation_data = []
+ else:
+ validation_data = [f.name for f in validation_data]
+ dset = AutoTrainDataset(
+ train_data=training_data,
+ task=task,
+ token=user_token,
+ project_name=project_name,
+ username=autotrain_username,
+ column_mapping={"text": col_map_text},
+ valid_data=validation_data,
+ percent_valid=None, # TODO: add to UI
+ )
+ elif task == "dreambooth":
+ dset = AutoTrainDreamboothDataset(
+ concept_images=training_data,
+ concept_name=concept_token,
+ token=user_token,
+ project_name=project_name,
+ username=autotrain_username,
+ )
+ else:
+ raise NotImplementedError
+
+ dset.prepare()
+ project = Project(
+ dataset=dset,
+ param_choice=param_choice,
+ hub_model=hub_model,
+ job_params=get_job_params(param_choice, training_params, task),
+ )
+ if autotrain_backend.lower() == "huggingface internal":
+ project_id = project.create()
+ project.approve(project_id)
+ return gr.Markdown.update(
+ value=f"Project created successfully. Monitor progess on the [dashboard](https://ui.autotrain.huggingface.co/{project_id}/trainings).",
+ visible=True,
+ )
+ else:
+ project.create(local=True)
+
+
+def get_variable_name(var, namespace):
+ for name in namespace:
+ if namespace[name] is var:
+ return name
+ return None
+
+
+def disable_create_project_button():
+ return gr.Button.update(interactive=False)
+
+
+def main():
+ with gr.Blocks(theme="freddyaboulton/dracula_revamped") as demo:
+ gr.Markdown("## 🤗 AutoTrain Advanced")
+ user_token = os.environ.get("HF_TOKEN", "")
+
+ if len(user_token) == 0:
+ user_token = get_user_token()
+
+ if user_token is None:
+ gr.Markdown(
+ """Please login with a write [token](https://huggingface.co/settings/tokens).
+ Pass your HF token in an environment variable called `HF_TOKEN` and then restart this app.
+ """
+ )
+ return demo
+
+ user_token, valid_can_pay, who_is_training = _login_user(user_token)
+
+ if user_token is None or len(user_token) == 0:
+ gr.Error("Please login with a write token.")
+
+ user_token = gr.Textbox(
+ value=user_token, type="password", lines=1, max_lines=1, visible=False, interactive=False
+ )
+ valid_can_pay = gr.Textbox(value=",".join(valid_can_pay), visible=False, interactive=False)
+ with gr.Row():
+ with gr.Column():
+ with gr.Row():
+ autotrain_username = gr.Dropdown(
+ label="AutoTrain Username",
+ choices=who_is_training,
+ value=who_is_training[0] if who_is_training else "",
+ )
+ autotrain_backend = gr.Dropdown(
+ label="AutoTrain Backend",
+ choices=["HuggingFace Internal", "HuggingFace Spaces"],
+ value="HuggingFace Internal",
+ interactive=True,
+ )
+ with gr.Row():
+ project_name = gr.Textbox(label="Project name", value="", lines=1, max_lines=1, interactive=True)
+ project_type = gr.Dropdown(
+ label="Project Type", choices=list(APP_TASKS.keys()), value=list(APP_TASKS.keys())[0]
+ )
+ task_type = gr.Dropdown(
+ label="Task",
+ choices=APP_TASKS[list(APP_TASKS.keys())[0]],
+ value=APP_TASKS[list(APP_TASKS.keys())[0]][0],
+ interactive=True,
+ )
+ model_choice = gr.Dropdown(
+ label="Model Choice",
+ choices=["AutoTrain", "HuggingFace Hub"],
+ value="AutoTrain",
+ visible=True,
+ interactive=True,
+ )
+ hub_model = gr.Dropdown(
+ label="Hub Model",
+ value="",
+ visible=False,
+ interactive=True,
+ elem_id="hub_model",
+ )
+ gr.Markdown("
")
+ with gr.Row():
+ with gr.Column():
+ with gr.Tabs(elem_id="tabs"):
+ with gr.TabItem("Data"):
+ with gr.Column():
+ # file_type_training = gr.Radio(
+ # label="File Type",
+ # choices=["CSV", "JSONL"],
+ # value="CSV",
+ # visible=True,
+ # interactive=True,
+ # )
+ training_data = gr.File(
+ label="Training Data",
+ file_types=ALLOWED_FILE_TYPES,
+ file_count="multiple",
+ visible=True,
+ interactive=True,
+ elem_id="training_data_box",
+ )
+ with gr.Accordion("Validation Data (Optional)", open=False):
+ validation_data = gr.File(
+ label="Validation Data (Optional)",
+ file_types=ALLOWED_FILE_TYPES,
+ file_count="multiple",
+ visible=True,
+ interactive=True,
+ elem_id="validation_data_box",
+ )
+ with gr.Row():
+ col_map_text = gr.Dropdown(
+ label="Text Column", choices=[], visible=False, interactive=True
+ )
+ col_map_target = gr.Dropdown(
+ label="Target Column", choices=[], visible=False, interactive=True
+ )
+ concept_token = gr.Text(
+ value="", visible=False, interactive=True, lines=1, max_lines=1
+ )
+ with gr.TabItem("Params"):
+ with gr.Row():
+ source_language = gr.Dropdown(
+ label="Source Language",
+ choices=SUPPORTED_LANGUAGES[:-1],
+ value="en",
+ visible=True,
+ interactive=True,
+ elem_id="source_language",
+ )
+ num_models = gr.Slider(
+ label="Number of Models",
+ minimum=1,
+ maximum=25,
+ value=5,
+ step=1,
+ visible=True,
+ interactive=True,
+ elem_id="num_models",
+ )
+ target_language = gr.Dropdown(
+ label="Target Language",
+ choices=["fr"],
+ value="fr",
+ visible=False,
+ interactive=True,
+ elem_id="target_language",
+ )
+ image_size = gr.Number(
+ label="Image Size",
+ value=512,
+ visible=False,
+ interactive=True,
+ elem_id="image_size",
+ )
+
+ with gr.Row():
+ learning_rate = gr.Number(
+ label="Learning Rate",
+ value=5e-5,
+ visible=False,
+ interactive=True,
+ elem_id="learning_rate",
+ )
+ batch_size = gr.Number(
+ label="Train Batch Size",
+ value=32,
+ visible=False,
+ interactive=True,
+ elem_id="train_batch_size",
+ )
+ num_epochs = gr.Number(
+ label="Number of Epochs",
+ value=3,
+ visible=False,
+ interactive=True,
+ elem_id="num_train_epochs",
+ )
+ with gr.Row():
+ gradient_accumulation_steps = gr.Number(
+ label="Gradient Accumulation Steps",
+ value=1,
+ visible=False,
+ interactive=True,
+ elem_id="gradient_accumulation_steps",
+ )
+ percentage_warmup_steps = gr.Number(
+ label="Percentage of Warmup Steps",
+ value=0.1,
+ visible=False,
+ interactive=True,
+ elem_id="percentage_warmup",
+ )
+ weight_decay = gr.Number(
+ label="Weight Decay",
+ value=0.01,
+ visible=False,
+ interactive=True,
+ elem_id="weight_decay",
+ )
+ with gr.Row():
+ lora_r = gr.Number(
+ label="LoraR",
+ value=16,
+ visible=False,
+ interactive=True,
+ elem_id="lora_r",
+ )
+ lora_alpha = gr.Number(
+ label="LoraAlpha",
+ value=32,
+ visible=False,
+ interactive=True,
+ elem_id="lora_alpha",
+ )
+ lora_dropout = gr.Number(
+ label="Lora Dropout",
+ value=0.1,
+ visible=False,
+ interactive=True,
+ elem_id="lora_dropout",
+ )
+ with gr.Row():
+ db_num_steps = gr.Number(
+ label="Num Steps",
+ value=500,
+ visible=False,
+ interactive=True,
+ elem_id="num_steps",
+ )
+ with gr.Row():
+ optimizer = gr.Dropdown(
+ label="Optimizer",
+ choices=["adamw_torch", "adamw_hf", "sgd", "adafactor", "adagrad"],
+ value="adamw_torch",
+ visible=False,
+ interactive=True,
+ elem_id="optimizer",
+ )
+ scheduler = gr.Dropdown(
+ label="Scheduler",
+ choices=["linear", "cosine"],
+ value="linear",
+ visible=False,
+ interactive=True,
+ elem_id="scheduler",
+ )
+
+ add_job_button = gr.Button(
+ value="Add Job",
+ visible=True,
+ interactive=True,
+ elem_id="add_job",
+ )
+ # clear_jobs_button = gr.Button(
+ # value="Clear Jobs",
+ # visible=True,
+ # interactive=True,
+ # elem_id="clear_jobs",
+ # )
+ gr.Markdown("
")
+ estimated_costs_md = gr.Markdown(value="Estimated Costs: N/A", visible=True, interactive=False)
+ estimated_costs_num = gr.Number(value=0, visible=False, interactive=False)
+ create_project_button = gr.Button(
+ value="Create Project",
+ visible=True,
+ interactive=True,
+ elem_id="create_project",
+ )
+ with gr.Column():
+ param_choice = gr.Dropdown(
+ label="Param Choice",
+ choices=["AutoTrain"],
+ value="AutoTrain",
+ visible=True,
+ interactive=True,
+ )
+ training_params_txt = gr.Text(value="[]", visible=False, interactive=False)
+ training_params_md = gr.DataFrame(visible=False, interactive=False)
+
+ final_output = gr.Markdown(value="", visible=True, interactive=False)
+ hyperparameters = [
+ hub_model,
+ num_models,
+ source_language,
+ target_language,
+ learning_rate,
+ batch_size,
+ num_epochs,
+ gradient_accumulation_steps,
+ lora_r,
+ lora_alpha,
+ lora_dropout,
+ optimizer,
+ scheduler,
+ percentage_warmup_steps,
+ weight_decay,
+ db_num_steps,
+ image_size,
+ ]
+
+ def _update_params(params_data):
+ _task = params_data[task_type]
+ _task = APP_TASKS_MAPPING[_task]
+ params = Params(
+ task=_task,
+ param_choice="autotrain" if params_data[param_choice] == "AutoTrain" else "manual",
+ model_choice="autotrain" if params_data[model_choice] == "AutoTrain" else "hub_model",
+ )
+ params = params.get()
+ visible_params = []
+ for param in hyperparameters:
+ if param.elem_id in params.keys():
+ visible_params.append(param.elem_id)
+ op = [h.update(visible=h.elem_id in visible_params) for h in hyperparameters]
+ op.append(add_job_button.update(visible=True))
+ op.append(training_params_md.update(visible=False))
+ op.append(training_params_txt.update(value="[]"))
+ return op
+
+ autotrain_backend.change(
+ _project_type_update,
+ inputs=[project_type, task_type, autotrain_backend],
+ outputs=[task_type, model_choice, param_choice, hub_model],
+ )
+
+ project_type.change(
+ _project_type_update,
+ inputs=[project_type, task_type, autotrain_backend],
+ outputs=[task_type, model_choice, param_choice, hub_model],
+ )
+ task_type.change(
+ _task_type_update,
+ inputs=[task_type, autotrain_backend],
+ outputs=[model_choice, param_choice, hub_model],
+ )
+ model_choice.change(
+ _update_param_choice,
+ inputs=[model_choice, autotrain_backend],
+ outputs=param_choice,
+ ).then(
+ _update_hub_model_choices,
+ inputs=[task_type, model_choice],
+ outputs=hub_model,
+ )
+
+ param_choice.change(
+ _update_params,
+ inputs=set([task_type, param_choice, model_choice] + hyperparameters + [add_job_button]),
+ outputs=hyperparameters + [add_job_button, training_params_md, training_params_txt],
+ )
+ task_type.change(
+ _update_params,
+ inputs=set([task_type, param_choice, model_choice] + hyperparameters + [add_job_button]),
+ outputs=hyperparameters + [add_job_button, training_params_md, training_params_txt],
+ )
+ model_choice.change(
+ _update_params,
+ inputs=set([task_type, param_choice, model_choice] + hyperparameters + [add_job_button]),
+ outputs=hyperparameters + [add_job_button, training_params_md, training_params_txt],
+ )
+
+ def _add_job(params_data):
+ _task = params_data[task_type]
+ _task = APP_TASKS_MAPPING[_task]
+ _param_choice = "autotrain" if params_data[param_choice] == "AutoTrain" else "manual"
+ _model_choice = "autotrain" if params_data[model_choice] == "AutoTrain" else "hub_model"
+ if _model_choice == "hub_model" and params_data[hub_model] is None:
+ logger.error("Hub model is None")
+ return
+ _training_params = {}
+ params = Params(task=_task, param_choice=_param_choice, model_choice=_model_choice)
+ params = params.get()
+ for _param in hyperparameters:
+ if _param.elem_id in params.keys():
+ _training_params[_param.elem_id] = params_data[_param]
+ _training_params_md = json.loads(params_data[training_params_txt])
+ if _param_choice == "autotrain":
+ if len(_training_params_md) > 0:
+ _training_params_md[0] = _training_params
+ _training_params_md = _training_params_md[:1]
+ else:
+ _training_params_md.append(_training_params)
+ else:
+ _training_params_md.append(_training_params)
+ params_df = pd.DataFrame(_training_params_md)
+ # remove hub_model column
+ if "hub_model" in params_df.columns:
+ params_df = params_df.drop(columns=["hub_model"])
+ return [
+ gr.DataFrame.update(value=params_df, visible=True),
+ gr.Textbox.update(value=json.dumps(_training_params_md), visible=False),
+ ]
+
+ add_job_button.click(
+ _add_job,
+ inputs=set(
+ [task_type, param_choice, model_choice] + hyperparameters + [training_params_md, training_params_txt]
+ ),
+ outputs=[training_params_md, training_params_txt],
+ )
+ col_map_components = [
+ col_map_text,
+ col_map_target,
+ concept_token,
+ ]
+ training_data.change(
+ _update_col_map,
+ inputs=[training_data, task_type],
+ outputs=col_map_components,
+ )
+ task_type.change(
+ _update_col_map,
+ inputs=[training_data, task_type],
+ outputs=col_map_components,
+ )
+ estimate_costs_inputs = [
+ training_data,
+ validation_data,
+ task_type,
+ user_token,
+ autotrain_username,
+ training_params_txt,
+ autotrain_backend,
+ ]
+ estimate_costs_outputs = [estimated_costs_md, estimated_costs_num]
+ training_data.change(_estimate_costs, inputs=estimate_costs_inputs, outputs=estimate_costs_outputs)
+ validation_data.change(_estimate_costs, inputs=estimate_costs_inputs, outputs=estimate_costs_outputs)
+ training_params_txt.change(_estimate_costs, inputs=estimate_costs_inputs, outputs=estimate_costs_outputs)
+ task_type.change(_estimate_costs, inputs=estimate_costs_inputs, outputs=estimate_costs_outputs)
+ add_job_button.click(_estimate_costs, inputs=estimate_costs_inputs, outputs=estimate_costs_outputs)
+
+ create_project_button.click(disable_create_project_button, None, create_project_button).then(
+ _create_project,
+ inputs=[
+ autotrain_username,
+ valid_can_pay,
+ project_name,
+ user_token,
+ task_type,
+ training_data,
+ validation_data,
+ col_map_text,
+ col_map_target,
+ concept_token,
+ training_params_txt,
+ hub_model,
+ estimated_costs_num,
+ autotrain_backend,
+ ],
+ outputs=final_output,
+ )
+
+ demo.load(
+ _update_project_name,
+ outputs=[project_name, create_project_button],
+ )
+
+ return demo
diff --git a/autotrain-advanced/src/autotrain/cli/__init__.py b/autotrain-advanced/src/autotrain/cli/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..02b80c7e1fdd1e09b445b058195a9722b3fbb978
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/cli/__init__.py
@@ -0,0 +1,13 @@
+from abc import ABC, abstractmethod
+from argparse import ArgumentParser
+
+
+class BaseAutoTrainCommand(ABC):
+ @staticmethod
+ @abstractmethod
+ def register_subcommand(parser: ArgumentParser):
+ raise NotImplementedError()
+
+ @abstractmethod
+ def run(self):
+ raise NotImplementedError()
diff --git a/autotrain-advanced/src/autotrain/cli/accelerated_autotrain.py b/autotrain-advanced/src/autotrain/cli/accelerated_autotrain.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/autotrain-advanced/src/autotrain/cli/autotrain.py b/autotrain-advanced/src/autotrain/cli/autotrain.py
new file mode 100644
index 0000000000000000000000000000000000000000..4309cd7defb2ff9e8f775047a4ea431e32d00c51
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/cli/autotrain.py
@@ -0,0 +1,40 @@
+import argparse
+
+from .. import __version__
+from .run_app import RunAutoTrainAppCommand
+from .run_dreambooth import RunAutoTrainDreamboothCommand
+from .run_llm import RunAutoTrainLLMCommand
+from .run_setup import RunSetupCommand
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ "AutoTrain advanced CLI",
+ usage="autotrain []",
+ epilog="For more information about a command, run: `autotrain --help`",
+ )
+ parser.add_argument("--version", "-v", help="Display AutoTrain version", action="store_true")
+ commands_parser = parser.add_subparsers(help="commands")
+
+ # Register commands
+ RunAutoTrainAppCommand.register_subcommand(commands_parser)
+ RunAutoTrainLLMCommand.register_subcommand(commands_parser)
+ RunSetupCommand.register_subcommand(commands_parser)
+ RunAutoTrainDreamboothCommand.register_subcommand(commands_parser)
+
+ args = parser.parse_args()
+
+ if args.version:
+ print(__version__)
+ exit(0)
+
+ if not hasattr(args, "func"):
+ parser.print_help()
+ exit(1)
+
+ command = args.func(args)
+ command.run()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/autotrain-advanced/src/autotrain/cli/run_app.py b/autotrain-advanced/src/autotrain/cli/run_app.py
new file mode 100644
index 0000000000000000000000000000000000000000..36db92be43cf82963cd6aa217e4ea0dd9242d5eb
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/cli/run_app.py
@@ -0,0 +1,55 @@
+from argparse import ArgumentParser
+
+from . import BaseAutoTrainCommand
+
+
+def run_app_command_factory(args):
+ return RunAutoTrainAppCommand(
+ args.port,
+ args.host,
+ args.task,
+ )
+
+
+class RunAutoTrainAppCommand(BaseAutoTrainCommand):
+ @staticmethod
+ def register_subcommand(parser: ArgumentParser):
+ run_app_parser = parser.add_parser(
+ "app",
+ description="✨ Run AutoTrain app",
+ )
+ run_app_parser.add_argument(
+ "--port",
+ type=int,
+ default=7860,
+ help="Port to run the app on",
+ required=False,
+ )
+ run_app_parser.add_argument(
+ "--host",
+ type=str,
+ default="127.0.0.1",
+ help="Host to run the app on",
+ required=False,
+ )
+ run_app_parser.add_argument(
+ "--task",
+ type=str,
+ required=False,
+ help="Task to run",
+ )
+ run_app_parser.set_defaults(func=run_app_command_factory)
+
+ def __init__(self, port, host, task):
+ self.port = port
+ self.host = host
+ self.task = task
+
+ def run(self):
+ if self.task == "dreambooth":
+ from ..dreambooth_app import main
+ else:
+ from ..app import main
+
+ demo = main()
+ demo.queue(concurrency_count=10).launch()
diff --git a/autotrain-advanced/src/autotrain/cli/run_dreambooth.py b/autotrain-advanced/src/autotrain/cli/run_dreambooth.py
new file mode 100644
index 0000000000000000000000000000000000000000..f445b265a54a43187b4fa9911183b6d4f26dc620
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/cli/run_dreambooth.py
@@ -0,0 +1,469 @@
+import glob
+import os
+from argparse import ArgumentParser
+
+from loguru import logger
+
+from autotrain.cli import BaseAutoTrainCommand
+
+
+try:
+ from autotrain.trainers.dreambooth import train as train_dreambooth
+ from autotrain.trainers.dreambooth.params import DreamBoothTrainingParams
+ from autotrain.trainers.dreambooth.utils import VALID_IMAGE_EXTENSIONS, XL_MODELS
+except ImportError:
+ logger.warning(
+ "❌ Some DreamBooth components are missing! Please run `autotrain setup` to install it. Ignore this warning if you are not using DreamBooth or running `autotrain setup` already."
+ )
+
+
+def count_images(directory):
+ files_grabbed = []
+ for files in VALID_IMAGE_EXTENSIONS:
+ files_grabbed.extend(glob.glob(os.path.join(directory, "*" + files)))
+ return len(files_grabbed)
+
+
+def run_dreambooth_command_factory(args):
+ return RunAutoTrainDreamboothCommand(args)
+
+
+class RunAutoTrainDreamboothCommand(BaseAutoTrainCommand):
+ @staticmethod
+ def register_subcommand(parser: ArgumentParser):
+ arg_list = [
+ {
+ "arg": "--model",
+ "help": "Model to use for training",
+ "required": True,
+ "type": str,
+ },
+ {
+ "arg": "--revision",
+ "help": "Model revision to use for training",
+ "required": False,
+ "type": str,
+ },
+ {
+ "arg": "--tokenizer",
+ "help": "Tokenizer to use for training",
+ "required": False,
+ "type": str,
+ },
+ {
+ "arg": "--image-path",
+ "help": "Path to the images",
+ "required": True,
+ "type": str,
+ },
+ {
+ "arg": "--class-image-path",
+ "help": "Path to the class images",
+ "required": False,
+ "type": str,
+ },
+ {
+ "arg": "--prompt",
+ "help": "Instance prompt",
+ "required": True,
+ "type": str,
+ },
+ {
+ "arg": "--class-prompt",
+ "help": "Class prompt",
+ "required": False,
+ "type": str,
+ },
+ {
+ "arg": "--num-class-images",
+ "help": "Number of class images",
+ "required": False,
+ "default": 100,
+ "type": int,
+ },
+ {
+ "arg": "--class-labels-conditioning",
+ "help": "Class labels conditioning",
+ "required": False,
+ "type": str,
+ },
+ {
+ "arg": "--prior-preservation",
+ "help": "With prior preservation",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--prior-loss-weight",
+ "help": "Prior loss weight",
+ "required": False,
+ "default": 1.0,
+ "type": float,
+ },
+ {
+ "arg": "--output",
+ "help": "Output directory",
+ "required": True,
+ "type": str,
+ },
+ {
+ "arg": "--seed",
+ "help": "Seed",
+ "required": False,
+ "default": 42,
+ "type": int,
+ },
+ {
+ "arg": "--resolution",
+ "help": "Resolution",
+ "required": True,
+ "type": int,
+ },
+ {
+ "arg": "--center-crop",
+ "help": "Center crop",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--train-text-encoder",
+ "help": "Train text encoder",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--batch-size",
+ "help": "Train batch size",
+ "required": False,
+ "default": 4,
+ "type": int,
+ },
+ {
+ "arg": "--sample-batch-size",
+ "help": "Sample batch size",
+ "required": False,
+ "default": 4,
+ "type": int,
+ },
+ {
+ "arg": "--epochs",
+ "help": "Number of training epochs",
+ "required": False,
+ "default": 1,
+ "type": int,
+ },
+ {
+ "arg": "--num-steps",
+ "help": "Max train steps",
+ "required": False,
+ "type": int,
+ },
+ {
+ "arg": "--checkpointing-steps",
+ "help": "Checkpointing steps",
+ "required": False,
+ "default": 100000,
+ "type": int,
+ },
+ {
+ "arg": "--resume-from-checkpoint",
+ "help": "Resume from checkpoint",
+ "required": False,
+ "type": str,
+ },
+ {
+ "arg": "--gradient-accumulation",
+ "help": "Gradient accumulation steps",
+ "required": False,
+ "default": 1,
+ "type": int,
+ },
+ {
+ "arg": "--gradient-checkpointing",
+ "help": "Gradient checkpointing",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--lr",
+ "help": "Learning rate",
+ "required": False,
+ "default": 5e-4,
+ "type": float,
+ },
+ {
+ "arg": "--scale-lr",
+ "help": "Scale learning rate",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--scheduler",
+ "help": "Learning rate scheduler",
+ "required": False,
+ "default": "constant",
+ },
+ {
+ "arg": "--warmup-steps",
+ "help": "Learning rate warmup steps",
+ "required": False,
+ "default": 0,
+ "type": int,
+ },
+ {
+ "arg": "--num-cycles",
+ "help": "Learning rate num cycles",
+ "required": False,
+ "default": 1,
+ "type": int,
+ },
+ {
+ "arg": "--lr-power",
+ "help": "Learning rate power",
+ "required": False,
+ "default": 1.0,
+ "type": float,
+ },
+ {
+ "arg": "--dataloader-num-workers",
+ "help": "Dataloader num workers",
+ "required": False,
+ "default": 0,
+ "type": int,
+ },
+ {
+ "arg": "--use-8bit-adam",
+ "help": "Use 8bit adam",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--adam-beta1",
+ "help": "Adam beta 1",
+ "required": False,
+ "default": 0.9,
+ "type": float,
+ },
+ {
+ "arg": "--adam-beta2",
+ "help": "Adam beta 2",
+ "required": False,
+ "default": 0.999,
+ "type": float,
+ },
+ {
+ "arg": "--adam-weight-decay",
+ "help": "Adam weight decay",
+ "required": False,
+ "default": 1e-2,
+ "type": float,
+ },
+ {
+ "arg": "--adam-epsilon",
+ "help": "Adam epsilon",
+ "required": False,
+ "default": 1e-8,
+ "type": float,
+ },
+ {
+ "arg": "--max-grad-norm",
+ "help": "Max grad norm",
+ "required": False,
+ "default": 1.0,
+ "type": float,
+ },
+ {
+ "arg": "--allow-tf32",
+ "help": "Allow TF32",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--prior-generation-precision",
+ "help": "Prior generation precision",
+ "required": False,
+ "type": str,
+ },
+ {
+ "arg": "--local-rank",
+ "help": "Local rank",
+ "required": False,
+ "default": -1,
+ "type": int,
+ },
+ {
+ "arg": "--xformers",
+ "help": "Enable xformers memory efficient attention",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--pre-compute-text-embeddings",
+ "help": "Pre compute text embeddings",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--tokenizer-max-length",
+ "help": "Tokenizer max length",
+ "required": False,
+ "type": int,
+ },
+ {
+ "arg": "--text-encoder-use-attention-mask",
+ "help": "Text encoder use attention mask",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--rank",
+ "help": "Rank",
+ "required": False,
+ "default": 4,
+ "type": int,
+ },
+ {
+ "arg": "--xl",
+ "help": "XL",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--fp16",
+ "help": "FP16",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--bf16",
+ "help": "BF16",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--hub-token",
+ "help": "Hub token",
+ "required": False,
+ "type": str,
+ },
+ {
+ "arg": "--hub-model-id",
+ "help": "Hub model id",
+ "required": False,
+ "type": str,
+ },
+ {
+ "arg": "--push-to-hub",
+ "help": "Push to hub",
+ "required": False,
+ "action": "store_true",
+ },
+ {
+ "arg": "--validation-prompt",
+ "help": "Validation prompt",
+ "required": False,
+ "type": str,
+ },
+ {
+ "arg": "--num-validation-images",
+ "help": "Number of validation images",
+ "required": False,
+ "default": 4,
+ "type": int,
+ },
+ {
+ "arg": "--validation-epochs",
+ "help": "Validation epochs",
+ "required": False,
+ "default": 50,
+ "type": int,
+ },
+ {
+ "arg": "--checkpoints-total-limit",
+ "help": "Checkpoints total limit",
+ "required": False,
+ "type": int,
+ },
+ {
+ "arg": "--validation-images",
+ "help": "Validation images",
+ "required": False,
+ "type": str,
+ },
+ {
+ "arg": "--logging",
+ "help": "Logging using tensorboard",
+ "required": False,
+ "action": "store_true",
+ },
+ ]
+
+ run_dreambooth_parser = parser.add_parser("dreambooth", description="✨ Run AutoTrain DreamBooth Training")
+ for arg in arg_list:
+ if "action" in arg:
+ run_dreambooth_parser.add_argument(
+ arg["arg"],
+ help=arg["help"],
+ required=arg.get("required", False),
+ action=arg.get("action"),
+ default=arg.get("default"),
+ )
+ else:
+ run_dreambooth_parser.add_argument(
+ arg["arg"],
+ help=arg["help"],
+ required=arg.get("required", False),
+ type=arg.get("type"),
+ default=arg.get("default"),
+ )
+ run_dreambooth_parser.set_defaults(func=run_dreambooth_command_factory)
+
+ def __init__(self, args):
+ self.args = args
+ logger.info(self.args)
+
+ store_true_arg_names = [
+ "center_crop",
+ "train_text_encoder",
+ "gradient_checkpointing",
+ "scale_lr",
+ "use_8bit_adam",
+ "allow_tf32",
+ "xformers",
+ "pre_compute_text_embeddings",
+ "text_encoder_use_attention_mask",
+ "xl",
+ "fp16",
+ "bf16",
+ "push_to_hub",
+ "logging",
+ "prior_preservation",
+ ]
+
+ for arg_name in store_true_arg_names:
+ if getattr(self.args, arg_name) is None:
+ setattr(self.args, arg_name, False)
+
+ if self.args.fp16 and self.args.bf16:
+ raise ValueError("❌ Please choose either FP16 or BF16")
+
+ # check if self.args.image_path is a directory with images
+ if not os.path.isdir(self.args.image_path):
+ raise ValueError("❌ Please specify a valid image directory")
+
+ # count the number of images in the directory. valid images are .jpg, .jpeg, .png
+ num_images = count_images(self.args.image_path)
+ if num_images == 0:
+ raise ValueError("❌ Please specify a valid image directory")
+
+ if self.args.push_to_hub:
+ if self.args.hub_model_id is None:
+ raise ValueError("❌ Please specify a hub model id")
+
+ if self.args.model in XL_MODELS:
+ self.args.xl = True
+
+ def run(self):
+ logger.info("Running DreamBooth Training")
+ params = DreamBoothTrainingParams(**vars(self.args))
+ train_dreambooth(params)
diff --git a/autotrain-advanced/src/autotrain/cli/run_llm.py b/autotrain-advanced/src/autotrain/cli/run_llm.py
new file mode 100644
index 0000000000000000000000000000000000000000..bafc4669714fb59631d395d93752d2e2487d90d1
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/cli/run_llm.py
@@ -0,0 +1,489 @@
+from argparse import ArgumentParser
+
+from loguru import logger
+
+from autotrain.infer.text_generation import TextGenerationInference
+
+from ..trainers.clm import train as train_llm
+from ..trainers.utils import LLMTrainingParams
+from . import BaseAutoTrainCommand
+
+
+def run_llm_command_factory(args):
+ return RunAutoTrainLLMCommand(
+ args.train,
+ args.deploy,
+ args.inference,
+ args.data_path,
+ args.train_split,
+ args.valid_split,
+ args.text_column,
+ args.model,
+ args.learning_rate,
+ args.num_train_epochs,
+ args.train_batch_size,
+ args.eval_batch_size,
+ args.warmup_ratio,
+ args.gradient_accumulation_steps,
+ args.optimizer,
+ args.scheduler,
+ args.weight_decay,
+ args.max_grad_norm,
+ args.seed,
+ args.add_eos_token,
+ args.block_size,
+ args.use_peft,
+ args.lora_r,
+ args.lora_alpha,
+ args.lora_dropout,
+ args.training_type,
+ args.train_on_inputs,
+ args.logging_steps,
+ args.project_name,
+ args.evaluation_strategy,
+ args.save_total_limit,
+ args.save_strategy,
+ args.auto_find_batch_size,
+ args.fp16,
+ args.push_to_hub,
+ args.use_int8,
+ args.model_max_length,
+ args.repo_id,
+ args.use_int4,
+ args.trainer,
+ args.target_modules,
+ )
+
+
+class RunAutoTrainLLMCommand(BaseAutoTrainCommand):
+ @staticmethod
+ def register_subcommand(parser: ArgumentParser):
+ run_llm_parser = parser.add_parser(
+ "llm",
+ description="✨ Run AutoTrain LLM training/inference/deployment",
+ )
+ run_llm_parser.add_argument(
+ "--train",
+ help="Train the model",
+ required=False,
+ action="store_true",
+ )
+ run_llm_parser.add_argument(
+ "--deploy",
+ help="Deploy the model",
+ required=False,
+ action="store_true",
+ )
+ run_llm_parser.add_argument(
+ "--inference",
+ help="Run inference",
+ required=False,
+ action="store_true",
+ )
+ run_llm_parser.add_argument(
+ "--data_path",
+ help="Train dataset to use",
+ required=False,
+ type=str,
+ )
+ run_llm_parser.add_argument(
+ "--train_split",
+ help="Test dataset split to use",
+ required=False,
+ type=str,
+ default="train",
+ )
+ run_llm_parser.add_argument(
+ "--valid_split",
+ help="Validation dataset split to use",
+ required=False,
+ type=str,
+ default=None,
+ )
+ run_llm_parser.add_argument(
+ "--text_column",
+ help="Text column to use",
+ required=False,
+ type=str,
+ default="text",
+ )
+ run_llm_parser.add_argument(
+ "--model",
+ help="Model to use",
+ required=False,
+ type=str,
+ )
+ run_llm_parser.add_argument(
+ "--learning_rate",
+ help="Learning rate to use",
+ required=False,
+ type=float,
+ default=3e-5,
+ )
+ run_llm_parser.add_argument(
+ "--num_train_epochs",
+ help="Number of training epochs to use",
+ required=False,
+ type=int,
+ default=1,
+ )
+ run_llm_parser.add_argument(
+ "--train_batch_size",
+ help="Training batch size to use",
+ required=False,
+ type=int,
+ default=2,
+ )
+ run_llm_parser.add_argument(
+ "--eval_batch_size",
+ help="Evaluation batch size to use",
+ required=False,
+ type=int,
+ default=4,
+ )
+ run_llm_parser.add_argument(
+ "--warmup_ratio",
+ help="Warmup proportion to use",
+ required=False,
+ type=float,
+ default=0.1,
+ )
+ run_llm_parser.add_argument(
+ "--gradient_accumulation_steps",
+ help="Gradient accumulation steps to use",
+ required=False,
+ type=int,
+ default=1,
+ )
+ run_llm_parser.add_argument(
+ "--optimizer",
+ help="Optimizer to use",
+ required=False,
+ type=str,
+ default="adamw_torch",
+ )
+ run_llm_parser.add_argument(
+ "--scheduler",
+ help="Scheduler to use",
+ required=False,
+ type=str,
+ default="linear",
+ )
+ run_llm_parser.add_argument(
+ "--weight_decay",
+ help="Weight decay to use",
+ required=False,
+ type=float,
+ default=0.0,
+ )
+ run_llm_parser.add_argument(
+ "--max_grad_norm",
+ help="Max gradient norm to use",
+ required=False,
+ type=float,
+ default=1.0,
+ )
+ run_llm_parser.add_argument(
+ "--seed",
+ help="Seed to use",
+ required=False,
+ type=int,
+ default=42,
+ )
+ run_llm_parser.add_argument(
+ "--add_eos_token",
+ help="Add EOS token to use",
+ required=False,
+ action="store_true",
+ )
+ run_llm_parser.add_argument(
+ "--block_size",
+ help="Block size to use",
+ required=False,
+ type=int,
+ default=-1,
+ )
+ run_llm_parser.add_argument(
+ "--use_peft",
+ help="Use PEFT to use",
+ required=False,
+ action="store_true",
+ )
+ run_llm_parser.add_argument(
+ "--lora_r",
+ help="Lora r to use",
+ required=False,
+ type=int,
+ default=16,
+ )
+ run_llm_parser.add_argument(
+ "--lora_alpha",
+ help="Lora alpha to use",
+ required=False,
+ type=int,
+ default=32,
+ )
+ run_llm_parser.add_argument(
+ "--lora_dropout",
+ help="Lora dropout to use",
+ required=False,
+ type=float,
+ default=0.05,
+ )
+ run_llm_parser.add_argument(
+ "--training_type",
+ help="Training type to use",
+ required=False,
+ type=str,
+ default="generic",
+ )
+ run_llm_parser.add_argument(
+ "--train_on_inputs",
+ help="Train on inputs to use",
+ required=False,
+ action="store_true",
+ )
+ run_llm_parser.add_argument(
+ "--logging_steps",
+ help="Logging steps to use",
+ required=False,
+ type=int,
+ default=-1,
+ )
+ run_llm_parser.add_argument(
+ "--project_name",
+ help="Output directory",
+ required=False,
+ type=str,
+ )
+ run_llm_parser.add_argument(
+ "--evaluation_strategy",
+ help="Evaluation strategy to use",
+ required=False,
+ type=str,
+ default="epoch",
+ )
+ run_llm_parser.add_argument(
+ "--save_total_limit",
+ help="Save total limit to use",
+ required=False,
+ type=int,
+ default=1,
+ )
+ run_llm_parser.add_argument(
+ "--save_strategy",
+ help="Save strategy to use",
+ required=False,
+ type=str,
+ default="epoch",
+ )
+ run_llm_parser.add_argument(
+ "--auto_find_batch_size",
+ help="Auto find batch size True/False",
+ required=False,
+ action="store_true",
+ )
+ run_llm_parser.add_argument(
+ "--fp16",
+ help="FP16 True/False",
+ required=False,
+ action="store_true",
+ )
+ run_llm_parser.add_argument(
+ "--push_to_hub",
+ help="Push to hub True/False",
+ required=False,
+ action="store_true",
+ )
+ run_llm_parser.add_argument(
+ "--use_int8",
+ help="Use int8 True/False",
+ required=False,
+ action="store_true",
+ )
+ run_llm_parser.add_argument(
+ "--model_max_length",
+ help="Model max length to use",
+ required=False,
+ type=int,
+ default=1024,
+ )
+ run_llm_parser.add_argument(
+ "--repo_id",
+ help="Repo id for hugging face hub",
+ required=False,
+ type=str,
+ )
+ run_llm_parser.add_argument(
+ "--use_int4",
+ help="Use int4 True/False",
+ required=False,
+ action="store_true",
+ )
+ run_llm_parser.add_argument(
+ "--trainer",
+ help="Trainer type to use",
+ required=False,
+ type=str,
+ default="default",
+ )
+ run_llm_parser.add_argument(
+ "--target_modules",
+ help="Target modules to use",
+ required=False,
+ type=str,
+ default=None,
+ )
+
+ run_llm_parser.set_defaults(func=run_llm_command_factory)
+
+ def __init__(
+ self,
+ train,
+ deploy,
+ inference,
+ data_path,
+ train_split,
+ valid_split,
+ text_column,
+ model,
+ learning_rate,
+ num_train_epochs,
+ train_batch_size,
+ eval_batch_size,
+ warmup_ratio,
+ gradient_accumulation_steps,
+ optimizer,
+ scheduler,
+ weight_decay,
+ max_grad_norm,
+ seed,
+ add_eos_token,
+ block_size,
+ use_peft,
+ lora_r,
+ lora_alpha,
+ lora_dropout,
+ training_type,
+ train_on_inputs,
+ logging_steps,
+ project_name,
+ evaluation_strategy,
+ save_total_limit,
+ save_strategy,
+ auto_find_batch_size,
+ fp16,
+ push_to_hub,
+ use_int8,
+ model_max_length,
+ repo_id,
+ use_int4,
+ trainer,
+ target_modules,
+ ):
+ self.train = train
+ self.deploy = deploy
+ self.inference = inference
+ self.data_path = data_path
+ self.train_split = train_split
+ self.valid_split = valid_split
+ self.text_column = text_column
+ self.model = model
+ self.learning_rate = learning_rate
+ self.num_train_epochs = num_train_epochs
+ self.train_batch_size = train_batch_size
+ self.eval_batch_size = eval_batch_size
+ self.warmup_ratio = warmup_ratio
+ self.gradient_accumulation_steps = gradient_accumulation_steps
+ self.optimizer = optimizer
+ self.scheduler = scheduler
+ self.weight_decay = weight_decay
+ self.max_grad_norm = max_grad_norm
+ self.seed = seed
+ self.add_eos_token = add_eos_token
+ self.block_size = block_size
+ self.use_peft = use_peft
+ self.lora_r = lora_r
+ self.lora_alpha = lora_alpha
+ self.lora_dropout = lora_dropout
+ self.training_type = training_type
+ self.train_on_inputs = train_on_inputs
+ self.logging_steps = logging_steps
+ self.project_name = project_name
+ self.evaluation_strategy = evaluation_strategy
+ self.save_total_limit = save_total_limit
+ self.save_strategy = save_strategy
+ self.auto_find_batch_size = auto_find_batch_size
+ self.fp16 = fp16
+ self.push_to_hub = push_to_hub
+ self.use_int8 = use_int8
+ self.model_max_length = model_max_length
+ self.repo_id = repo_id
+ self.use_int4 = use_int4
+ self.trainer = trainer
+ self.target_modules = target_modules
+
+ if self.train:
+ if self.project_name is None:
+ raise ValueError("Project name must be specified")
+ if self.data_path is None:
+ raise ValueError("Data path must be specified")
+ if self.model is None:
+ raise ValueError("Model must be specified")
+ if self.push_to_hub:
+ if self.repo_id is None:
+ raise ValueError("Repo id must be specified for push to hub")
+
+ if self.inference:
+ tgi = TextGenerationInference(self.project_name, use_int4=self.use_int4, use_int8=self.use_int8)
+ while True:
+ prompt = input("User: ")
+ if prompt == "exit()":
+ break
+ print(f"Bot: {tgi.chat(prompt)}")
+
+ def run(self):
+ logger.info("Running LLM")
+ logger.info(f"Train: {self.train}")
+ if self.train:
+ params = LLMTrainingParams(
+ model_name=self.model,
+ data_path=self.data_path,
+ train_split=self.train_split,
+ valid_split=self.valid_split,
+ text_column=self.text_column,
+ learning_rate=self.learning_rate,
+ num_train_epochs=self.num_train_epochs,
+ train_batch_size=self.train_batch_size,
+ eval_batch_size=self.eval_batch_size,
+ warmup_ratio=self.warmup_ratio,
+ gradient_accumulation_steps=self.gradient_accumulation_steps,
+ optimizer=self.optimizer,
+ scheduler=self.scheduler,
+ weight_decay=self.weight_decay,
+ max_grad_norm=self.max_grad_norm,
+ seed=self.seed,
+ add_eos_token=self.add_eos_token,
+ block_size=self.block_size,
+ use_peft=self.use_peft,
+ lora_r=self.lora_r,
+ lora_alpha=self.lora_alpha,
+ lora_dropout=self.lora_dropout,
+ training_type=self.training_type,
+ train_on_inputs=self.train_on_inputs,
+ logging_steps=self.logging_steps,
+ project_name=self.project_name,
+ evaluation_strategy=self.evaluation_strategy,
+ save_total_limit=self.save_total_limit,
+ save_strategy=self.save_strategy,
+ auto_find_batch_size=self.auto_find_batch_size,
+ fp16=self.fp16,
+ push_to_hub=self.push_to_hub,
+ use_int8=self.use_int8,
+ model_max_length=self.model_max_length,
+ repo_id=self.repo_id,
+ use_int4=self.use_int4,
+ trainer=self.trainer,
+ target_modules=self.target_modules,
+ )
+ train_llm(params)
diff --git a/autotrain-advanced/src/autotrain/cli/run_setup.py b/autotrain-advanced/src/autotrain/cli/run_setup.py
new file mode 100644
index 0000000000000000000000000000000000000000..91513125248db34d728fbd003ee1e1e8a378e878
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/cli/run_setup.py
@@ -0,0 +1,61 @@
+import subprocess
+from argparse import ArgumentParser
+
+from loguru import logger
+
+from . import BaseAutoTrainCommand
+
+
+def run_app_command_factory(args):
+ return RunSetupCommand(args.update_torch)
+
+
+class RunSetupCommand(BaseAutoTrainCommand):
+ @staticmethod
+ def register_subcommand(parser: ArgumentParser):
+ run_setup_parser = parser.add_parser(
+ "setup",
+ description="✨ Run AutoTrain setup",
+ )
+ run_setup_parser.add_argument(
+ "--update-torch",
+ action="store_true",
+ help="Update PyTorch to latest version",
+ )
+ run_setup_parser.set_defaults(func=run_app_command_factory)
+
+ def __init__(self, update_torch: bool):
+ self.update_torch = update_torch
+
+ def run(self):
+ # install latest transformers
+ cmd = "pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers.git"
+ pipe = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ logger.info("Installing latest transformers@main")
+ _, _ = pipe.communicate()
+ logger.info("Successfully installed latest transformers")
+
+ cmd = "pip uninstall -y peft && pip install git+https://github.com/huggingface/peft.git"
+ pipe = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ logger.info("Installing latest peft@main")
+ _, _ = pipe.communicate()
+ logger.info("Successfully installed latest peft")
+
+ cmd = "pip uninstall -y diffusers && pip install git+https://github.com/huggingface/diffusers.git"
+ pipe = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ logger.info("Installing latest diffusers@main")
+ _, _ = pipe.communicate()
+ logger.info("Successfully installed latest diffusers")
+
+ cmd = "pip uninstall -y trl && pip install git+https://github.com/lvwerra/trl.git"
+ pipe = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ logger.info("Installing latest trl@main")
+ _, _ = pipe.communicate()
+ logger.info("Successfully installed latest trl")
+
+ if self.update_torch:
+ cmd = "pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118"
+ pipe = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
+ logger.info("Installing latest PyTorch")
+ _, _ = pipe.communicate()
+ logger.info("Successfully installed latest PyTorch")
diff --git a/autotrain-advanced/src/autotrain/config.py b/autotrain-advanced/src/autotrain/config.py
new file mode 100644
index 0000000000000000000000000000000000000000..6f0f2ba4587ce4d7a93a5f3b1c45c7c82da84b1c
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/config.py
@@ -0,0 +1,12 @@
+import os
+import sys
+
+from loguru import logger
+
+
+AUTOTRAIN_BACKEND_API = os.getenv("AUTOTRAIN_BACKEND_API", "https://api.autotrain.huggingface.co")
+
+HF_API = os.getenv("HF_API", "https://huggingface.co")
+
+
+logger.configure(handlers=[dict(sink=sys.stderr, format="> {level:<7} {message}")])
diff --git a/autotrain-advanced/src/autotrain/dataset.py b/autotrain-advanced/src/autotrain/dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..01e1332d5b582d41212befb4e29091c9d63be7bd
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/dataset.py
@@ -0,0 +1,344 @@
+import os
+import uuid
+import zipfile
+from dataclasses import dataclass
+from typing import Any, Dict, List, Optional
+
+import pandas as pd
+from loguru import logger
+
+from autotrain.preprocessor.dreambooth import DreamboothPreprocessor
+from autotrain.preprocessor.tabular import (
+ TabularBinaryClassificationPreprocessor,
+ TabularMultiClassClassificationPreprocessor,
+ TabularSingleColumnRegressionPreprocessor,
+)
+from autotrain.preprocessor.text import (
+ LLMPreprocessor,
+ TextBinaryClassificationPreprocessor,
+ TextMultiClassClassificationPreprocessor,
+ TextSingleColumnRegressionPreprocessor,
+)
+from autotrain.preprocessor.vision import ImageClassificationPreprocessor
+
+
+def remove_non_image_files(folder):
+ # Define allowed image file extensions
+ allowed_extensions = {".jpg", ".jpeg", ".png", ".JPG", ".JPEG", ".PNG"}
+
+ # Iterate through all files in the folder
+ for root, dirs, files in os.walk(folder):
+ for file in files:
+ # Get the file extension
+ file_extension = os.path.splitext(file)[1]
+
+ # If the file extension is not in the allowed list, remove the file
+ if file_extension.lower() not in allowed_extensions:
+ file_path = os.path.join(root, file)
+ os.remove(file_path)
+ print(f"Removed file: {file_path}")
+
+ # Recursively call the function on each subfolder
+ for subfolder in dirs:
+ remove_non_image_files(os.path.join(root, subfolder))
+
+
+@dataclass
+class AutoTrainDreamboothDataset:
+ concept_images: List[Any]
+ concept_name: str
+ token: str
+ project_name: str
+ username: str
+
+ def __str__(self) -> str:
+ info = f"Dataset: {self.project_name} ({self.task})\n"
+ return info
+
+ def __post_init__(self):
+ self.task = "dreambooth"
+ logger.info(self.__str__())
+
+ @property
+ def num_samples(self):
+ return len(self.concept_images)
+
+ def prepare(self):
+ preprocessor = DreamboothPreprocessor(
+ concept_images=self.concept_images,
+ concept_name=self.concept_name,
+ token=self.token,
+ project_name=self.project_name,
+ username=self.username,
+ )
+ preprocessor.prepare()
+
+
+@dataclass
+class AutoTrainImageClassificationDataset:
+ train_data: str
+ token: str
+ project_name: str
+ username: str
+ valid_data: Optional[str] = None
+ percent_valid: Optional[float] = None
+
+ def __str__(self) -> str:
+ info = f"Dataset: {self.project_name} ({self.task})\n"
+ info += f"Train data: {self.train_data}\n"
+ info += f"Valid data: {self.valid_data}\n"
+ return info
+
+ def __post_init__(self):
+ self.task = "image_multi_class_classification"
+ if not self.valid_data and self.percent_valid is None:
+ self.percent_valid = 0.2
+ elif self.valid_data and self.percent_valid is not None:
+ raise ValueError("You can only specify one of valid_data or percent_valid")
+ elif self.valid_data:
+ self.percent_valid = 0.0
+ logger.info(self.__str__())
+
+ self.num_files = self._count_files()
+
+ @property
+ def num_samples(self):
+ return self.num_files
+
+ def _count_files(self):
+ num_files = 0
+ zip_ref = zipfile.ZipFile(self.train_data, "r")
+ for _ in zip_ref.namelist():
+ num_files += 1
+ if self.valid_data:
+ zip_ref = zipfile.ZipFile(self.valid_data, "r")
+ for _ in zip_ref.namelist():
+ num_files += 1
+ return num_files
+
+ def prepare(self):
+ cache_dir = os.environ.get("HF_HOME")
+ if not cache_dir:
+ cache_dir = os.path.join(os.path.expanduser("~"), ".cache", "huggingface")
+
+ random_uuid = uuid.uuid4()
+ train_dir = os.path.join(cache_dir, "autotrain", str(random_uuid))
+ os.makedirs(train_dir, exist_ok=True)
+ zip_ref = zipfile.ZipFile(self.train_data, "r")
+ zip_ref.extractall(train_dir)
+ # remove the __MACOSX directory
+ macosx_dir = os.path.join(train_dir, "__MACOSX")
+ if os.path.exists(macosx_dir):
+ os.system(f"rm -rf {macosx_dir}")
+ remove_non_image_files(train_dir)
+
+ valid_dir = None
+ if self.valid_data:
+ random_uuid = uuid.uuid4()
+ valid_dir = os.path.join(cache_dir, "autotrain", str(random_uuid))
+ os.makedirs(valid_dir, exist_ok=True)
+ zip_ref = zipfile.ZipFile(self.valid_data, "r")
+ zip_ref.extractall(valid_dir)
+ # remove the __MACOSX directory
+ macosx_dir = os.path.join(valid_dir, "__MACOSX")
+ if os.path.exists(macosx_dir):
+ os.system(f"rm -rf {macosx_dir}")
+ remove_non_image_files(valid_dir)
+
+ preprocessor = ImageClassificationPreprocessor(
+ train_data=train_dir,
+ valid_data=valid_dir,
+ token=self.token,
+ project_name=self.project_name,
+ username=self.username,
+ )
+ preprocessor.prepare()
+
+
+@dataclass
+class AutoTrainDataset:
+ train_data: List[str]
+ task: str
+ token: str
+ project_name: str
+ username: str
+ column_mapping: Optional[Dict[str, str]] = None
+ valid_data: Optional[List[str]] = None
+ percent_valid: Optional[float] = None
+
+ def __str__(self) -> str:
+ info = f"Dataset: {self.project_name} ({self.task})\n"
+ info += f"Train data: {self.train_data}\n"
+ info += f"Valid data: {self.valid_data}\n"
+ info += f"Column mapping: {self.column_mapping}\n"
+ return info
+
+ def __post_init__(self):
+ if not self.valid_data and self.percent_valid is None:
+ self.percent_valid = 0.2
+ elif self.valid_data and self.percent_valid is not None:
+ raise ValueError("You can only specify one of valid_data or percent_valid")
+ elif self.valid_data:
+ self.percent_valid = 0.0
+
+ self.train_df, self.valid_df = self._preprocess_data()
+ logger.info(self.__str__())
+
+ def _preprocess_data(self):
+ train_df = []
+ for file in self.train_data:
+ if isinstance(file, pd.DataFrame):
+ train_df.append(file)
+ else:
+ train_df.append(pd.read_csv(file))
+ if len(train_df) > 1:
+ train_df = pd.concat(train_df)
+ else:
+ train_df = train_df[0]
+
+ valid_df = None
+ if len(self.valid_data) > 0:
+ valid_df = []
+ for file in self.valid_data:
+ if isinstance(file, pd.DataFrame):
+ valid_df.append(file)
+ else:
+ valid_df.append(pd.read_csv(file))
+ if len(valid_df) > 1:
+ valid_df = pd.concat(valid_df)
+ else:
+ valid_df = valid_df[0]
+ return train_df, valid_df
+
+ @property
+ def num_samples(self):
+ return len(self.train_df) + len(self.valid_df) if self.valid_df is not None else len(self.train_df)
+
+ def prepare(self):
+ if self.task == "text_binary_classification":
+ text_column = self.column_mapping["text"]
+ label_column = self.column_mapping["label"]
+ preprocessor = TextBinaryClassificationPreprocessor(
+ train_data=self.train_df,
+ text_column=text_column,
+ label_column=label_column,
+ username=self.username,
+ project_name=self.project_name,
+ valid_data=self.valid_df,
+ test_size=self.percent_valid,
+ token=self.token,
+ seed=42,
+ )
+ preprocessor.prepare()
+
+ elif self.task == "text_multi_class_classification":
+ text_column = self.column_mapping["text"]
+ label_column = self.column_mapping["label"]
+ preprocessor = TextMultiClassClassificationPreprocessor(
+ train_data=self.train_df,
+ text_column=text_column,
+ label_column=label_column,
+ username=self.username,
+ project_name=self.project_name,
+ valid_data=self.valid_df,
+ test_size=self.percent_valid,
+ token=self.token,
+ seed=42,
+ )
+ preprocessor.prepare()
+
+ elif self.task == "text_single_column_regression":
+ text_column = self.column_mapping["text"]
+ label_column = self.column_mapping["label"]
+ preprocessor = TextSingleColumnRegressionPreprocessor(
+ train_data=self.train_df,
+ text_column=text_column,
+ label_column=label_column,
+ username=self.username,
+ project_name=self.project_name,
+ valid_data=self.valid_df,
+ test_size=self.percent_valid,
+ token=self.token,
+ seed=42,
+ )
+ preprocessor.prepare()
+
+ elif self.task == "lm_training":
+ text_column = self.column_mapping.get("text", None)
+ if text_column is None:
+ prompt_column = self.column_mapping["prompt"]
+ response_column = self.column_mapping["response"]
+ else:
+ prompt_column = None
+ response_column = None
+ context_column = self.column_mapping.get("context", None)
+ prompt_start_column = self.column_mapping.get("prompt_start", None)
+ preprocessor = LLMPreprocessor(
+ train_data=self.train_df,
+ text_column=text_column,
+ prompt_column=prompt_column,
+ response_column=response_column,
+ context_column=context_column,
+ prompt_start_column=prompt_start_column,
+ username=self.username,
+ project_name=self.project_name,
+ valid_data=self.valid_df,
+ test_size=self.percent_valid,
+ token=self.token,
+ seed=42,
+ )
+ preprocessor.prepare()
+
+ elif self.task == "tabular_binary_classification":
+ id_column = self.column_mapping["id"]
+ label_column = self.column_mapping["label"]
+ if len(id_column.strip()) == 0:
+ id_column = None
+ preprocessor = TabularBinaryClassificationPreprocessor(
+ train_data=self.train_df,
+ id_column=id_column,
+ label_column=label_column,
+ username=self.username,
+ project_name=self.project_name,
+ valid_data=self.valid_df,
+ test_size=self.percent_valid,
+ token=self.token,
+ seed=42,
+ )
+ preprocessor.prepare()
+ elif self.task == "tabular_multi_class_classification":
+ id_column = self.column_mapping["id"]
+ label_column = self.column_mapping["label"]
+ if len(id_column.strip()) == 0:
+ id_column = None
+ preprocessor = TabularMultiClassClassificationPreprocessor(
+ train_data=self.train_df,
+ id_column=id_column,
+ label_column=label_column,
+ username=self.username,
+ project_name=self.project_name,
+ valid_data=self.valid_df,
+ test_size=self.percent_valid,
+ token=self.token,
+ seed=42,
+ )
+ preprocessor.prepare()
+ elif self.task == "tabular_single_column_regression":
+ id_column = self.column_mapping["id"]
+ label_column = self.column_mapping["label"]
+ if len(id_column.strip()) == 0:
+ id_column = None
+ preprocessor = TabularSingleColumnRegressionPreprocessor(
+ train_data=self.train_df,
+ id_column=id_column,
+ label_column=label_column,
+ username=self.username,
+ project_name=self.project_name,
+ valid_data=self.valid_df,
+ test_size=self.percent_valid,
+ token=self.token,
+ seed=42,
+ )
+ preprocessor.prepare()
+ else:
+ raise ValueError(f"Task {self.task} not supported")
diff --git a/autotrain-advanced/src/autotrain/dreambooth_app.py b/autotrain-advanced/src/autotrain/dreambooth_app.py
new file mode 100644
index 0000000000000000000000000000000000000000..60f602ba28ce1ae3d56be00fb3a4c7b446503186
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/dreambooth_app.py
@@ -0,0 +1,485 @@
+import os
+import pty
+import random
+import shutil
+import string
+import subprocess
+
+import gradio as gr
+from huggingface_hub import HfApi, whoami
+
+
+# ❯ autotrain dreambooth --help
+# usage: autotrain [] dreambooth [-h] --model MODEL [--revision REVISION] [--tokenizer TOKENIZER] --image-path IMAGE_PATH
+# [--class-image-path CLASS_IMAGE_PATH] --prompt PROMPT [--class-prompt CLASS_PROMPT]
+# [--num-class-images NUM_CLASS_IMAGES] [--class-labels-conditioning CLASS_LABELS_CONDITIONING]
+# [--prior-preservation] [--prior-loss-weight PRIOR_LOSS_WEIGHT] --output OUTPUT [--seed SEED]
+# --resolution RESOLUTION [--center-crop] [--train-text-encoder] [--batch-size BATCH_SIZE]
+# [--sample-batch-size SAMPLE_BATCH_SIZE] [--epochs EPOCHS] [--num-steps NUM_STEPS]
+# [--checkpointing-steps CHECKPOINTING_STEPS] [--resume-from-checkpoint RESUME_FROM_CHECKPOINT]
+# [--gradient-accumulation GRADIENT_ACCUMULATION] [--gradient-checkpointing] [--lr LR] [--scale-lr]
+# [--scheduler SCHEDULER] [--warmup-steps WARMUP_STEPS] [--num-cycles NUM_CYCLES] [--lr-power LR_POWER]
+# [--dataloader-num-workers DATALOADER_NUM_WORKERS] [--use-8bit-adam] [--adam-beta1 ADAM_BETA1]
+# [--adam-beta2 ADAM_BETA2] [--adam-weight-decay ADAM_WEIGHT_DECAY] [--adam-epsilon ADAM_EPSILON]
+# [--max-grad-norm MAX_GRAD_NORM] [--allow-tf32]
+# [--prior-generation-precision PRIOR_GENERATION_PRECISION] [--local-rank LOCAL_RANK] [--xformers]
+# [--pre-compute-text-embeddings] [--tokenizer-max-length TOKENIZER_MAX_LENGTH]
+# [--text-encoder-use-attention-mask] [--rank RANK] [--xl] [--fp16] [--bf16] [--hub-token HUB_TOKEN]
+# [--hub-model-id HUB_MODEL_ID] [--push-to-hub] [--validation-prompt VALIDATION_PROMPT]
+# [--num-validation-images NUM_VALIDATION_IMAGES] [--validation-epochs VALIDATION_EPOCHS]
+# [--checkpoints-total-limit CHECKPOINTS_TOTAL_LIMIT] [--validation-images VALIDATION_IMAGES]
+# [--logging]
+
+REPO_ID = os.environ.get("REPO_ID")
+ALLOWED_FILE_TYPES = ["png", "jpg", "jpeg"]
+MODELS = [
+ "stabilityai/stable-diffusion-xl-base-1.0",
+ "runwayml/stable-diffusion-v1-5",
+ "stabilityai/stable-diffusion-2-1",
+ "stabilityai/stable-diffusion-2-1-base",
+]
+WELCOME_TEXT = """
+Welcome to the AutoTrain DreamBooth! This app allows you to train a DreamBooth model using AutoTrain.
+The app runs on HuggingFace Spaces. Your data is not stored anywhere.
+The trained model (LoRA) will be pushed to your HuggingFace Hub account.
+
+You need to use your HuggingFace Hub write [token](https://huggingface.co/settings/tokens) to push the model to your account.
+
+NOTE: This space requires GPU to train. Please make sure you have GPU enabled in space settings.
+Please make sure to shutdown / pause the space to avoid any additional charges.
+"""
+
+STEPS = """
+1. [Duplicate](https://huggingface.co/spaces/autotrain-projects/dreambooth?duplicate=true) this space
+2. Upgrade the space to GPU
+3. Enter your HuggingFace Hub write token
+4. Upload images and adjust prompt (remember the prompt!)
+5. Click on Train and wait for the training to finish
+6. Go to your HuggingFace Hub account to find the trained model
+
+NOTE: For any issues or feature requests, please open an issue [here](https://github.com/huggingface/autotrain-advanced/issues)
+"""
+
+
+def _update_project_name():
+ random_project_name = "-".join(
+ ["".join(random.choices(string.ascii_lowercase + string.digits, k=4)) for _ in range(3)]
+ )
+ # check if training tracker exists
+ if os.path.exists(os.path.join("/tmp", "training")):
+ return [
+ gr.Text.update(value=random_project_name, visible=True, interactive=True),
+ gr.Button.update(interactive=False),
+ ]
+ return [
+ gr.Text.update(value=random_project_name, visible=True, interactive=True),
+ gr.Button.update(interactive=True),
+ ]
+
+
+def run_command(cmd):
+ cmd = [str(c) for c in cmd]
+ print(f"Running command: {' '.join(cmd)}")
+ master, slave = pty.openpty()
+ p = subprocess.Popen(cmd, stdout=slave, stderr=slave)
+ os.close(slave)
+
+ while p.poll() is None:
+ try:
+ output = os.read(master, 1024).decode()
+ except OSError:
+ # Handle exception here, e.g. the pty was closed
+ break
+ else:
+ print(output, end="")
+
+
+def _run_training(
+ hub_token,
+ project_name,
+ model,
+ images,
+ prompt,
+ learning_rate,
+ num_steps,
+ batch_size,
+ gradient_accumulation_steps,
+ prior_preservation,
+ scale_lr,
+ use_8bit_adam,
+ train_text_encoder,
+ gradient_checkpointing,
+ center_crop,
+ prior_loss_weight,
+ num_cycles,
+ lr_power,
+ adam_beta1,
+ adam_beta2,
+ adam_weight_decay,
+ adam_epsilon,
+ max_grad_norm,
+ warmup_steps,
+ scheduler,
+ resolution,
+ fp16,
+):
+ if REPO_ID == "autotrain-projects/dreambooth":
+ return gr.Markdown.update(
+ value="❌ Please [duplicate](https://huggingface.co/spaces/autotrain-projects/dreambooth?duplicate=true) this space before training."
+ )
+
+ api = HfApi(token=hub_token)
+
+ if os.path.exists(os.path.join("/tmp", "training")):
+ return gr.Markdown.update(value="❌ Another training job is already running in this space.")
+
+ with open(os.path.join("/tmp", "training"), "w") as f:
+ f.write("training")
+
+ hub_model_id = whoami(token=hub_token)["name"] + "/" + str(project_name).strip()
+
+ image_path = "/tmp/data"
+ os.makedirs(image_path, exist_ok=True)
+ output_dir = "/tmp/model"
+ os.makedirs(output_dir, exist_ok=True)
+
+ for image in images:
+ shutil.copy(image.name, image_path)
+ cmd = [
+ "autotrain",
+ "dreambooth",
+ "--model",
+ model,
+ "--output",
+ output_dir,
+ "--image-path",
+ image_path,
+ "--prompt",
+ prompt,
+ "--resolution",
+ "1024",
+ "--batch-size",
+ batch_size,
+ "--num-steps",
+ num_steps,
+ "--gradient-accumulation",
+ gradient_accumulation_steps,
+ "--lr",
+ learning_rate,
+ "--scheduler",
+ scheduler,
+ "--warmup-steps",
+ warmup_steps,
+ "--num-cycles",
+ num_cycles,
+ "--lr-power",
+ lr_power,
+ "--adam-beta1",
+ adam_beta1,
+ "--adam-beta2",
+ adam_beta2,
+ "--adam-weight-decay",
+ adam_weight_decay,
+ "--adam-epsilon",
+ adam_epsilon,
+ "--max-grad-norm",
+ max_grad_norm,
+ "--prior-loss-weight",
+ prior_loss_weight,
+ "--push-to-hub",
+ "--hub-token",
+ hub_token,
+ "--hub-model-id",
+ hub_model_id,
+ ]
+
+ if prior_preservation:
+ cmd.append("--prior-preservation")
+ if scale_lr:
+ cmd.append("--scale-lr")
+ if use_8bit_adam:
+ cmd.append("--use-8bit-adam")
+ if train_text_encoder:
+ cmd.append("--train-text-encoder")
+ if gradient_checkpointing:
+ cmd.append("--gradient-checkpointing")
+ if center_crop:
+ cmd.append("--center-crop")
+ if fp16:
+ cmd.append("--fp16")
+
+ try:
+ run_command(cmd)
+ # delete the training tracker file in /tmp/
+ os.remove(os.path.join("/tmp", "training"))
+ # switch off space
+ if REPO_ID is not None:
+ api.pause_space(repo_id=REPO_ID)
+ return gr.Markdown.update(value=f"✅ Training finished! Model pushed to {hub_model_id}")
+ except Exception as e:
+ print(e)
+ print("Error running command")
+ # delete the training tracker file in /tmp/
+ os.remove(os.path.join("/tmp", "training"))
+ return gr.Markdown.update(value="❌ Error running command. Please try again.")
+
+
+def main():
+ with gr.Blocks(theme="freddyaboulton/dracula_revamped") as demo:
+ gr.Markdown("## 🤗 AutoTrain DreamBooth")
+ gr.Markdown(WELCOME_TEXT)
+ with gr.Accordion("Steps", open=False):
+ gr.Markdown(STEPS)
+ hub_token = gr.Textbox(
+ label="Hub Token",
+ value="",
+ lines=1,
+ max_lines=1,
+ interactive=True,
+ type="password",
+ )
+
+ with gr.Row():
+ with gr.Column():
+ project_name = gr.Textbox(
+ label="Project name",
+ value="",
+ lines=1,
+ max_lines=1,
+ interactive=True,
+ )
+ model = gr.Dropdown(
+ label="Model",
+ choices=MODELS,
+ value=MODELS[0],
+ visible=True,
+ interactive=True,
+ elem_id="model",
+ allow_custom_values=True,
+ )
+ images = gr.File(
+ label="Images",
+ file_types=ALLOWED_FILE_TYPES,
+ file_count="multiple",
+ visible=True,
+ interactive=True,
+ )
+
+ with gr.Column():
+ prompt = gr.Textbox(
+ label="Prompt",
+ placeholder="photo of sks dog",
+ lines=1,
+ )
+ with gr.Row():
+ learning_rate = gr.Number(
+ label="Learning Rate",
+ value=1e-4,
+ visible=True,
+ interactive=True,
+ elem_id="learning_rate",
+ )
+ num_steps = gr.Number(
+ label="Number of Steps",
+ value=500,
+ visible=True,
+ interactive=True,
+ elem_id="num_steps",
+ precision=0,
+ )
+ batch_size = gr.Number(
+ label="Batch Size",
+ value=1,
+ visible=True,
+ interactive=True,
+ elem_id="batch_size",
+ precision=0,
+ )
+ with gr.Row():
+ gradient_accumulation_steps = gr.Number(
+ label="Gradient Accumulation Steps",
+ value=4,
+ visible=True,
+ interactive=True,
+ elem_id="gradient_accumulation_steps",
+ precision=0,
+ )
+ resolution = gr.Number(
+ label="Resolution",
+ value=1024,
+ visible=True,
+ interactive=True,
+ elem_id="resolution",
+ precision=0,
+ )
+ scheduler = gr.Dropdown(
+ label="Scheduler",
+ choices=["cosine", "linear", "constant"],
+ value="constant",
+ visible=True,
+ interactive=True,
+ elem_id="scheduler",
+ )
+ with gr.Column():
+ with gr.Group():
+ fp16 = gr.Checkbox(
+ label="FP16",
+ value=True,
+ visible=True,
+ interactive=True,
+ elem_id="fp16",
+ )
+ prior_preservation = gr.Checkbox(
+ label="Prior Preservation",
+ value=False,
+ visible=True,
+ interactive=True,
+ elem_id="prior_preservation",
+ )
+ scale_lr = gr.Checkbox(
+ label="Scale LR",
+ value=False,
+ visible=True,
+ interactive=True,
+ elem_id="scale_lr",
+ )
+ use_8bit_adam = gr.Checkbox(
+ label="Use 8bit Adam",
+ value=True,
+ visible=True,
+ interactive=True,
+ elem_id="use_8bit_adam",
+ )
+ train_text_encoder = gr.Checkbox(
+ label="Train Text Encoder",
+ value=False,
+ visible=True,
+ interactive=True,
+ elem_id="train_text_encoder",
+ )
+ gradient_checkpointing = gr.Checkbox(
+ label="Gradient Checkpointing",
+ value=False,
+ visible=True,
+ interactive=True,
+ elem_id="gradient_checkpointing",
+ )
+ center_crop = gr.Checkbox(
+ label="Center Crop",
+ value=False,
+ visible=True,
+ interactive=True,
+ elem_id="center_crop",
+ )
+ with gr.Accordion("Advanced Parameters", open=False):
+ with gr.Row():
+ prior_loss_weight = gr.Number(
+ label="Prior Loss Weight",
+ value=1.0,
+ visible=True,
+ interactive=True,
+ elem_id="prior_loss_weight",
+ )
+ num_cycles = gr.Number(
+ label="Num Cycles",
+ value=1,
+ visible=True,
+ interactive=True,
+ elem_id="num_cycles",
+ precision=0,
+ )
+ lr_power = gr.Number(
+ label="LR Power",
+ value=1,
+ visible=True,
+ interactive=True,
+ elem_id="lr_power",
+ )
+
+ adam_beta1 = gr.Number(
+ label="Adam Beta1",
+ value=0.9,
+ visible=True,
+ interactive=True,
+ elem_id="adam_beta1",
+ )
+ adam_beta2 = gr.Number(
+ label="Adam Beta2",
+ value=0.999,
+ visible=True,
+ interactive=True,
+ elem_id="adam_beta2",
+ )
+ adam_weight_decay = gr.Number(
+ label="Adam Weight Decay",
+ value=1e-2,
+ visible=True,
+ interactive=True,
+ elem_id="adam_weight_decay",
+ )
+ adam_epsilon = gr.Number(
+ label="Adam Epsilon",
+ value=1e-8,
+ visible=True,
+ interactive=True,
+ elem_id="adam_epsilon",
+ )
+ max_grad_norm = gr.Number(
+ label="Max Grad Norm",
+ value=1,
+ visible=True,
+ interactive=True,
+ elem_id="max_grad_norm",
+ )
+ warmup_steps = gr.Number(
+ label="Warmup Steps",
+ value=0,
+ visible=True,
+ interactive=True,
+ elem_id="warmup_steps",
+ precision=0,
+ )
+
+ train_button = gr.Button(value="Train", elem_id="train")
+ output_md = gr.Markdown("## Output")
+ inputs = [
+ hub_token,
+ project_name,
+ model,
+ images,
+ prompt,
+ learning_rate,
+ num_steps,
+ batch_size,
+ gradient_accumulation_steps,
+ prior_preservation,
+ scale_lr,
+ use_8bit_adam,
+ train_text_encoder,
+ gradient_checkpointing,
+ center_crop,
+ prior_loss_weight,
+ num_cycles,
+ lr_power,
+ adam_beta1,
+ adam_beta2,
+ adam_weight_decay,
+ adam_epsilon,
+ max_grad_norm,
+ warmup_steps,
+ scheduler,
+ resolution,
+ fp16,
+ ]
+
+ train_button.click(_run_training, inputs=inputs, outputs=output_md)
+ demo.load(
+ _update_project_name,
+ outputs=[project_name, train_button],
+ )
+ return demo
+
+
+if __name__ == "__main__":
+ demo = main()
+ demo.launch()
diff --git a/autotrain-advanced/src/autotrain/help.py b/autotrain-advanced/src/autotrain/help.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9bbf59a78ef740499d0d96c698d78373f4c951b
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/help.py
@@ -0,0 +1,28 @@
+APP_AUTOTRAIN_USERNAME = """Please choose the user or organization who is creating the AutoTrain Project.
+In case of non-free tier, this user or organization will be billed.
+"""
+
+APP_PROJECT_NAME = """A unique name for the AutoTrain Project.
+This name will be used to identify the project in the AutoTrain dashboard."""
+
+
+APP_IMAGE_CLASSIFICATION_DATA_HELP = """The data for the Image Classification task should be in the following format:
+- The data should be in a zip file.
+- The zip file should contain multiple folders (the classes), each folder should contain images of a single class.
+- The name of the folder should be the name of the class.
+- The images must be jpeg, jpg or png.
+- There should be at least 5 images per class.
+- There should not be any other files in the zip file.
+- There should not be any other folders inside the zip folder.
+"""
+
+APP_LM_TRAINING_TYPE = """There are two types of Language Model Training:
+- generic
+- chat
+
+In the generic mode, you provide a CSV with a text column which has already been formatted by you for training a language model.
+In the chat mode, you provide a CSV with two or three text columns: prompt, context (optional) and response.
+Context column can be empty for samples if not needed. You can also have a "prompt start" column. If provided, "prompt start" will be prepended before the prompt column.
+
+Please see [this](https://huggingface.co/datasets/tatsu-lab/alpaca) dataset which has both formats in the same dataset.
+"""
diff --git a/autotrain-advanced/src/autotrain/infer/__init__.py b/autotrain-advanced/src/autotrain/infer/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/autotrain-advanced/src/autotrain/infer/text_generation.py b/autotrain-advanced/src/autotrain/infer/text_generation.py
new file mode 100644
index 0000000000000000000000000000000000000000..62f3bc9176be7328a626198d9459bfb5d78c906d
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/infer/text_generation.py
@@ -0,0 +1,50 @@
+from dataclasses import dataclass
+from typing import Optional
+
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
+
+
+@dataclass
+class TextGenerationInference:
+ model_path: str = "gpt2"
+ use_int4: Optional[bool] = False
+ use_int8: Optional[bool] = False
+ temperature: Optional[float] = 1.0
+ top_k: Optional[int] = 50
+ top_p: Optional[float] = 0.95
+ repetition_penalty: Optional[float] = 1.0
+ num_return_sequences: Optional[int] = 1
+ num_beams: Optional[int] = 1
+ max_new_tokens: Optional[int] = 1024
+ do_sample: Optional[bool] = True
+
+ def __post_init__(self):
+ self.model = AutoModelForCausalLM.from_pretrained(
+ self.model_path,
+ load_in_4bit=self.use_int4,
+ load_in_8bit=self.use_int8,
+ torch_dtype=torch.float16,
+ trust_remote_code=True,
+ device_map="auto",
+ )
+ self.tokenizer = AutoTokenizer.from_pretrained(self.model_path, trust_remote_code=True)
+ self.model.eval()
+ self.device = "cuda" if torch.cuda.is_available() else "cpu"
+ self.generation_config = GenerationConfig(
+ temperature=self.temperature,
+ top_k=self.top_k,
+ top_p=self.top_p,
+ repetition_penalty=self.repetition_penalty,
+ num_return_sequences=self.num_return_sequences,
+ num_beams=self.num_beams,
+ max_length=self.max_new_tokens,
+ eos_token_id=self.tokenizer.eos_token_id,
+ do_sample=self.do_sample,
+ max_new_tokens=self.max_new_tokens,
+ )
+
+ def chat(self, prompt):
+ inputs = self.tokenizer([prompt], return_tensors="pt").to(self.device)
+ outputs = self.model.generate(**inputs, generation_config=self.generation_config)
+ return self.tokenizer.decode(outputs[0], skip_special_tokens=True)
diff --git a/autotrain-advanced/src/autotrain/languages.py b/autotrain-advanced/src/autotrain/languages.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea41cdedfd03866b08269738ff9b50c7710ae727
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/languages.py
@@ -0,0 +1,19 @@
+SUPPORTED_LANGUAGES = [
+ "en",
+ "ar",
+ "bn",
+ "de",
+ "es",
+ "fi",
+ "fr",
+ "hi",
+ "it",
+ "ja",
+ "ko",
+ "nl",
+ "pt",
+ "sv",
+ "tr",
+ "zh",
+ "unk",
+]
diff --git a/autotrain-advanced/src/autotrain/params.py b/autotrain-advanced/src/autotrain/params.py
new file mode 100644
index 0000000000000000000000000000000000000000..e017adb8eeae778400e42a6cbdaea1edb272d8e6
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/params.py
@@ -0,0 +1,512 @@
+from dataclasses import dataclass
+from typing import Literal
+
+import gradio as gr
+from pydantic import BaseModel, Field
+
+from autotrain.languages import SUPPORTED_LANGUAGES
+from autotrain.tasks import TASKS
+
+
+class LoraR:
+ TYPE = "int"
+ MIN_VALUE = 1
+ MAX_VALUE = 100
+ DEFAULT = 16
+ STEP = 1
+ STREAMLIT_INPUT = "number_input"
+ PRETTY_NAME = "LoRA R"
+ GRADIO_INPUT = gr.Slider(minimum=MIN_VALUE, maximum=MAX_VALUE, value=DEFAULT, step=STEP)
+
+
+class LoraAlpha:
+ TYPE = "int"
+ MIN_VALUE = 1
+ MAX_VALUE = 256
+ DEFAULT = 32
+ STEP = 1
+ STREAMLIT_INPUT = "number_input"
+ PRETTY_NAME = "LoRA Alpha"
+ GRADIO_INPUT = gr.Slider(minimum=MIN_VALUE, maximum=MAX_VALUE, value=DEFAULT, step=STEP)
+
+
+class LoraDropout:
+ TYPE = "float"
+ MIN_VALUE = 0.0
+ MAX_VALUE = 1.0
+ DEFAULT = 0.05
+ STEP = 0.01
+ STREAMLIT_INPUT = "number_input"
+ PRETTY_NAME = "LoRA Dropout"
+ GRADIO_INPUT = gr.Slider(minimum=MIN_VALUE, maximum=MAX_VALUE, value=DEFAULT, step=STEP)
+
+
+class LearningRate:
+ TYPE = "float"
+ MIN_VALUE = 1e-7
+ MAX_VALUE = 1e-1
+ DEFAULT = 1e-3
+ STEP = 1e-6
+ FORMAT = "%.2E"
+ STREAMLIT_INPUT = "number_input"
+ PRETTY_NAME = "Learning Rate"
+ GRADIO_INPUT = gr.Slider(minimum=MIN_VALUE, maximum=MAX_VALUE, value=DEFAULT, step=STEP)
+
+
+class LMLearningRate(LearningRate):
+ DEFAULT = 5e-5
+
+
+class Optimizer:
+ TYPE = "str"
+ DEFAULT = "adamw_torch"
+ CHOICES = ["adamw_torch", "adamw_hf", "sgd", "adafactor", "adagrad"]
+ STREAMLIT_INPUT = "selectbox"
+ PRETTY_NAME = "Optimizer"
+ GRADIO_INPUT = gr.Dropdown(CHOICES, value=DEFAULT)
+
+
+class LMTrainingType:
+ TYPE = "str"
+ DEFAULT = "generic"
+ CHOICES = ["generic", "chat"]
+ STREAMLIT_INPUT = "selectbox"
+ PRETTY_NAME = "LM Training Type"
+ GRAIDO_INPUT = gr.Dropdown(CHOICES, value=DEFAULT)
+
+
+class Scheduler:
+ TYPE = "str"
+ DEFAULT = "linear"
+ CHOICES = ["linear", "cosine"]
+ STREAMLIT_INPUT = "selectbox"
+ PRETTY_NAME = "Scheduler"
+ GRADIO_INPUT = gr.Dropdown(CHOICES, value=DEFAULT)
+
+
+class TrainBatchSize:
+ TYPE = "int"
+ MIN_VALUE = 1
+ MAX_VALUE = 128
+ DEFAULT = 2
+ STEP = 2
+ STREAMLIT_INPUT = "number_input"
+ PRETTY_NAME = "Train Batch Size"
+ GRADIO_INPUT = gr.Slider(minimum=MIN_VALUE, maximum=MAX_VALUE, value=DEFAULT, step=STEP)
+
+
+class LMTrainBatchSize(TrainBatchSize):
+ DEFAULT = 4
+
+
+class Epochs:
+ TYPE = "int"
+ MIN_VALUE = 1
+ MAX_VALUE = 1000
+ DEFAULT = 10
+ STREAMLIT_INPUT = "number_input"
+ PRETTY_NAME = "Epochs"
+ GRADIO_INPUT = gr.Number(value=DEFAULT)
+
+
+class LMEpochs(Epochs):
+ DEFAULT = 1
+
+
+class PercentageWarmup:
+ TYPE = "float"
+ MIN_VALUE = 0.0
+ MAX_VALUE = 1.0
+ DEFAULT = 0.1
+ STEP = 0.01
+ STREAMLIT_INPUT = "number_input"
+ PRETTY_NAME = "Percentage Warmup"
+ GRADIO_INPUT = gr.Slider(minimum=MIN_VALUE, maximum=MAX_VALUE, value=DEFAULT, step=STEP)
+
+
+class GradientAccumulationSteps:
+ TYPE = "int"
+ MIN_VALUE = 1
+ MAX_VALUE = 100
+ DEFAULT = 1
+ STREAMLIT_INPUT = "number_input"
+ PRETTY_NAME = "Gradient Accumulation Steps"
+ GRADIO_INPUT = gr.Number(value=DEFAULT)
+
+
+class WeightDecay:
+ TYPE = "float"
+ MIN_VALUE = 0.0
+ MAX_VALUE = 1.0
+ DEFAULT = 0.0
+ STREAMLIT_INPUT = "number_input"
+ PRETTY_NAME = "Weight Decay"
+ GRADIO_INPUT = gr.Number(value=DEFAULT)
+
+
+class SourceLanguage:
+ TYPE = "str"
+ DEFAULT = "en"
+ CHOICES = SUPPORTED_LANGUAGES
+ STREAMLIT_INPUT = "selectbox"
+ PRETTY_NAME = "Source Language"
+ GRADIO_INPUT = gr.Dropdown(CHOICES, value=DEFAULT)
+
+
+class TargetLanguage:
+ TYPE = "str"
+ DEFAULT = "en"
+ CHOICES = SUPPORTED_LANGUAGES
+ STREAMLIT_INPUT = "selectbox"
+ PRETTY_NAME = "Target Language"
+ GRADIO_INPUT = gr.Dropdown(CHOICES, value=DEFAULT)
+
+
+class NumModels:
+ TYPE = "int"
+ MIN_VALUE = 1
+ MAX_VALUE = 25
+ DEFAULT = 1
+ STREAMLIT_INPUT = "number_input"
+ PRETTY_NAME = "Number of Models"
+ GRADIO_INPUT = gr.Slider(minimum=MIN_VALUE, maximum=MAX_VALUE, value=DEFAULT, step=1)
+
+
+class DBNumSteps:
+ TYPE = "int"
+ MIN_VALUE = 100
+ MAX_VALUE = 10000
+ DEFAULT = 1500
+ STREAMLIT_INPUT = "number_input"
+ PRETTY_NAME = "Number of Steps"
+ GRADIO_INPUT = gr.Slider(minimum=MIN_VALUE, maximum=MAX_VALUE, value=DEFAULT, step=100)
+
+
+class DBTextEncoderStepsPercentage:
+ TYPE = "int"
+ MIN_VALUE = 1
+ MAX_VALUE = 100
+ DEFAULT = 30
+ STREAMLIT_INPUT = "number_input"
+ PRETTY_NAME = "Text encoder steps percentage"
+ GRADIO_INPUT = gr.Slider(minimum=MIN_VALUE, maximum=MAX_VALUE, value=DEFAULT, step=1)
+
+
+class DBPriorPreservation:
+ TYPE = "bool"
+ DEFAULT = False
+ STREAMLIT_INPUT = "checkbox"
+ PRETTY_NAME = "Prior preservation"
+ GRADIO_INPUT = gr.Dropdown(["True", "False"], value="False")
+
+
+class ImageSize:
+ TYPE = "int"
+ MIN_VALUE = 64
+ MAX_VALUE = 2048
+ DEFAULT = 512
+ STREAMLIT_INPUT = "number_input"
+ PRETTY_NAME = "Image Size"
+ GRADIO_INPUT = gr.Slider(minimum=MIN_VALUE, maximum=MAX_VALUE, value=DEFAULT, step=64)
+
+
+class DreamboothConceptType:
+ TYPE = "str"
+ DEFAULT = "person"
+ CHOICES = ["person", "object"]
+ STREAMLIT_INPUT = "selectbox"
+ PRETTY_NAME = "Concept Type"
+ GRADIO_INPUT = gr.Dropdown(CHOICES, value=DEFAULT)
+
+
+class SourceLanguageUnk:
+ TYPE = "str"
+ DEFAULT = "unk"
+ CHOICES = ["unk"]
+ STREAMLIT_INPUT = "selectbox"
+ PRETTY_NAME = "Source Language"
+ GRADIO_INPUT = gr.Dropdown(CHOICES, value=DEFAULT)
+
+
+class HubModel:
+ TYPE = "str"
+ DEFAULT = "bert-base-uncased"
+ PRETTY_NAME = "Hub Model"
+ GRADIO_INPUT = gr.Textbox(lines=1, max_lines=1, label="Hub Model")
+
+
+class TextBinaryClassificationParams(BaseModel):
+ task: Literal["text_binary_classification"]
+ learning_rate: float = Field(5e-5, title="Learning rate")
+ num_train_epochs: int = Field(3, title="Number of training epochs")
+ max_seq_length: int = Field(128, title="Max sequence length")
+ train_batch_size: int = Field(32, title="Training batch size")
+ warmup_ratio: float = Field(0.1, title="Warmup proportion")
+ gradient_accumulation_steps: int = Field(1, title="Gradient accumulation steps")
+ optimizer: str = Field("adamw_torch", title="Optimizer")
+ scheduler: str = Field("linear", title="Scheduler")
+ weight_decay: float = Field(0.0, title="Weight decay")
+ max_grad_norm: float = Field(1.0, title="Max gradient norm")
+ seed: int = Field(42, title="Seed")
+
+
+class TextMultiClassClassificationParams(BaseModel):
+ task: Literal["text_multi_class_classification"]
+ learning_rate: float = Field(5e-5, title="Learning rate")
+ num_train_epochs: int = Field(3, title="Number of training epochs")
+ max_seq_length: int = Field(128, title="Max sequence length")
+ train_batch_size: int = Field(32, title="Training batch size")
+ warmup_ratio: float = Field(0.1, title="Warmup proportion")
+ gradient_accumulation_steps: int = Field(1, title="Gradient accumulation steps")
+ optimizer: str = Field("adamw_torch", title="Optimizer")
+ scheduler: str = Field("linear", title="Scheduler")
+ weight_decay: float = Field(0.0, title="Weight decay")
+ max_grad_norm: float = Field(1.0, title="Max gradient norm")
+ seed: int = Field(42, title="Seed")
+
+
+class DreamboothParams(BaseModel):
+ task: Literal["dreambooth"]
+ num_steps: int = Field(1500, title="Number of steps")
+ image_size: int = Field(512, title="Image size")
+ text_encoder_steps_percentage: int = Field(30, title="Text encoder steps percentage")
+ prior_preservation: bool = Field(False, title="Prior preservation")
+ learning_rate: float = Field(2e-6, title="Learning rate")
+ train_batch_size: int = Field(1, title="Training batch size")
+ gradient_accumulation_steps: int = Field(1, title="Gradient accumulation steps")
+
+
+class ImageBinaryClassificationParams(BaseModel):
+ task: Literal["image_binary_classification"]
+ learning_rate: float = Field(3e-5, title="Learning rate")
+ num_train_epochs: int = Field(3, title="Number of training epochs")
+ train_batch_size: int = Field(8, title="Training batch size")
+ warmup_ratio: float = Field(0.1, title="Warmup proportion")
+ gradient_accumulation_steps: int = Field(1, title="Gradient accumulation steps")
+ optimizer: str = Field("adamw_torch", title="Optimizer")
+ scheduler: str = Field("linear", title="Scheduler")
+ weight_decay: float = Field(0.0, title="Weight decay")
+ max_grad_norm: float = Field(1.0, title="Max gradient norm")
+ seed: int = Field(42, title="Seed")
+
+
+class ImageMultiClassClassificationParams(BaseModel):
+ task: Literal["image_multi_class_classification"]
+ learning_rate: float = Field(3e-5, title="Learning rate")
+ num_train_epochs: int = Field(3, title="Number of training epochs")
+ train_batch_size: int = Field(8, title="Training batch size")
+ warmup_ratio: float = Field(0.1, title="Warmup proportion")
+ gradient_accumulation_steps: int = Field(1, title="Gradient accumulation steps")
+ optimizer: str = Field("adamw_torch", title="Optimizer")
+ scheduler: str = Field("linear", title="Scheduler")
+ weight_decay: float = Field(0.0, title="Weight decay")
+ max_grad_norm: float = Field(1.0, title="Max gradient norm")
+ seed: int = Field(42, title="Seed")
+
+
+class LMTrainingParams(BaseModel):
+ task: Literal["lm_training"]
+ learning_rate: float = Field(3e-5, title="Learning rate")
+ num_train_epochs: int = Field(3, title="Number of training epochs")
+ train_batch_size: int = Field(8, title="Training batch size")
+ warmup_ratio: float = Field(0.1, title="Warmup proportion")
+ gradient_accumulation_steps: int = Field(1, title="Gradient accumulation steps")
+ optimizer: str = Field("adamw_torch", title="Optimizer")
+ scheduler: str = Field("linear", title="Scheduler")
+ weight_decay: float = Field(0.0, title="Weight decay")
+ max_grad_norm: float = Field(1.0, title="Max gradient norm")
+ seed: int = Field(42, title="Seed")
+ add_eos_token: bool = Field(True, title="Add EOS token")
+ block_size: int = Field(-1, title="Block size")
+ lora_r: int = Field(16, title="Lora r")
+ lora_alpha: int = Field(32, title="Lora alpha")
+ lora_dropout: float = Field(0.05, title="Lora dropout")
+ training_type: str = Field("generic", title="Training type")
+ train_on_inputs: bool = Field(False, title="Train on inputs")
+
+
+@dataclass
+class Params:
+ task: str
+ param_choice: str
+ model_choice: str
+
+ def __post_init__(self):
+ # task should be one of the keys in TASKS
+ if self.task not in TASKS:
+ raise ValueError(f"task must be one of {TASKS.keys()}")
+ self.task_id = TASKS[self.task]
+
+ if self.param_choice not in ("autotrain", "manual"):
+ raise ValueError("param_choice must be either autotrain or manual")
+
+ if self.model_choice not in ("autotrain", "hub_model"):
+ raise ValueError("model_choice must be either autotrain or hub_model")
+
+ def _dreambooth(self):
+ if self.param_choice == "manual":
+ return {
+ "hub_model": HubModel,
+ "image_size": ImageSize,
+ "learning_rate": LearningRate,
+ "train_batch_size": TrainBatchSize,
+ "num_steps": DBNumSteps,
+ "gradient_accumulation_steps": GradientAccumulationSteps,
+ }
+ if self.param_choice == "autotrain":
+ if self.model_choice == "hub_model":
+ return {
+ "hub_model": HubModel,
+ "image_size": ImageSize,
+ "num_models": NumModels,
+ }
+ else:
+ return {
+ "num_models": NumModels,
+ }
+
+ def _tabular_binary_classification(self):
+ return {
+ "num_models": NumModels,
+ }
+
+ def _lm_training(self):
+ if self.param_choice == "manual":
+ return {
+ "hub_model": HubModel,
+ "learning_rate": LMLearningRate,
+ "optimizer": Optimizer,
+ "scheduler": Scheduler,
+ "train_batch_size": LMTrainBatchSize,
+ "num_train_epochs": LMEpochs,
+ "percentage_warmup": PercentageWarmup,
+ "gradient_accumulation_steps": GradientAccumulationSteps,
+ "weight_decay": WeightDecay,
+ "lora_r": LoraR,
+ "lora_alpha": LoraAlpha,
+ "lora_dropout": LoraDropout,
+ "training_type": LMTrainingType,
+ }
+ if self.param_choice == "autotrain":
+ if self.model_choice == "autotrain":
+ return {
+ "num_models": NumModels,
+ "training_type": LMTrainingType,
+ }
+ else:
+ return {
+ "hub_model": HubModel,
+ "num_models": NumModels,
+ "training_type": LMTrainingType,
+ }
+ raise ValueError("param_choice must be either autotrain or manual")
+
+ def _tabular_multi_class_classification(self):
+ return self._tabular_binary_classification()
+
+ def _tabular_single_column_regression(self):
+ return self._tabular_binary_classification()
+
+ def tabular_multi_label_classification(self):
+ return self._tabular_binary_classification()
+
+ def _text_binary_classification(self):
+ if self.param_choice == "manual":
+ return {
+ "hub_model": HubModel,
+ "learning_rate": LearningRate,
+ "optimizer": Optimizer,
+ "scheduler": Scheduler,
+ "train_batch_size": TrainBatchSize,
+ "num_train_epochs": Epochs,
+ "percentage_warmup": PercentageWarmup,
+ "gradient_accumulation_steps": GradientAccumulationSteps,
+ "weight_decay": WeightDecay,
+ }
+ if self.param_choice == "autotrain":
+ if self.model_choice == "autotrain":
+ return {
+ "source_language": SourceLanguage,
+ "num_models": NumModels,
+ }
+ return {
+ "hub_model": HubModel,
+ "source_language": SourceLanguageUnk,
+ "num_models": NumModels,
+ }
+ raise ValueError("param_choice must be either autotrain or manual")
+
+ def _text_multi_class_classification(self):
+ return self._text_binary_classification()
+
+ def _text_entity_extraction(self):
+ return self._text_binary_classification()
+
+ def _text_single_column_regression(self):
+ return self._text_binary_classification()
+
+ def _text_natural_language_inference(self):
+ return self._text_binary_classification()
+
+ def _image_binary_classification(self):
+ if self.param_choice == "manual":
+ return {
+ "hub_model": HubModel,
+ "learning_rate": LearningRate,
+ "optimizer": Optimizer,
+ "scheduler": Scheduler,
+ "train_batch_size": TrainBatchSize,
+ "num_train_epochs": Epochs,
+ "percentage_warmup": PercentageWarmup,
+ "gradient_accumulation_steps": GradientAccumulationSteps,
+ "weight_decay": WeightDecay,
+ }
+ if self.param_choice == "autotrain":
+ if self.model_choice == "autotrain":
+ return {
+ "num_models": NumModels,
+ }
+ return {
+ "hub_model": HubModel,
+ "num_models": NumModels,
+ }
+ raise ValueError("param_choice must be either autotrain or manual")
+
+ def _image_multi_class_classification(self):
+ return self._image_binary_classification()
+
+ def get(self):
+ if self.task in ("text_binary_classification", "text_multi_class_classification"):
+ return self._text_binary_classification()
+
+ if self.task == "text_entity_extraction":
+ return self._text_entity_extraction()
+
+ if self.task == "text_single_column_regression":
+ return self._text_single_column_regression()
+
+ if self.task == "text_natural_language_inference":
+ return self._text_natural_language_inference()
+
+ if self.task == "tabular_binary_classification":
+ return self._tabular_binary_classification()
+
+ if self.task == "tabular_multi_class_classification":
+ return self._tabular_multi_class_classification()
+
+ if self.task == "tabular_single_column_regression":
+ return self._tabular_single_column_regression()
+
+ if self.task == "tabular_multi_label_classification":
+ return self.tabular_multi_label_classification()
+
+ if self.task in ("image_binary_classification", "image_multi_class_classification"):
+ return self._image_binary_classification()
+
+ if self.task == "dreambooth":
+ return self._dreambooth()
+
+ if self.task == "lm_training":
+ return self._lm_training()
+
+ raise ValueError(f"task {self.task} not supported")
diff --git a/autotrain-advanced/src/autotrain/preprocessor/__init__.py b/autotrain-advanced/src/autotrain/preprocessor/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/autotrain-advanced/src/autotrain/preprocessor/dreambooth.py b/autotrain-advanced/src/autotrain/preprocessor/dreambooth.py
new file mode 100644
index 0000000000000000000000000000000000000000..c969881954e2d57a98164c56a8ea460cd6c72935
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/preprocessor/dreambooth.py
@@ -0,0 +1,62 @@
+import io
+import json
+from dataclasses import dataclass
+from typing import Any, List
+
+from huggingface_hub import HfApi, create_repo
+from loguru import logger
+
+
+@dataclass
+class DreamboothPreprocessor:
+ concept_images: List[Any]
+ concept_name: str
+ username: str
+ project_name: str
+ token: str
+
+ def __post_init__(self):
+ self.repo_name = f"{self.username}/autotrain-data-{self.project_name}"
+ try:
+ create_repo(
+ repo_id=self.repo_name,
+ repo_type="dataset",
+ token=self.token,
+ private=True,
+ exist_ok=False,
+ )
+ except Exception:
+ logger.error("Error creating repo")
+ raise ValueError("Error creating repo")
+
+ def _upload_concept_images(self, file, api):
+ logger.info(f"Uploading {file} to concept1")
+ api.upload_file(
+ path_or_fileobj=file.name,
+ path_in_repo=f"concept1/{file.name.split('/')[-1]}",
+ repo_id=self.repo_name,
+ repo_type="dataset",
+ token=self.token,
+ )
+
+ def _upload_concept_prompts(self, api):
+ _prompts = {}
+ _prompts["concept1"] = self.concept_name
+
+ prompts = json.dumps(_prompts)
+ prompts = prompts.encode("utf-8")
+ prompts = io.BytesIO(prompts)
+ api.upload_file(
+ path_or_fileobj=prompts,
+ path_in_repo="prompts.json",
+ repo_id=self.repo_name,
+ repo_type="dataset",
+ token=self.token,
+ )
+
+ def prepare(self):
+ api = HfApi()
+ for _file in self.concept_images:
+ self._upload_concept_images(_file, api)
+
+ self._upload_concept_prompts(api)
diff --git a/autotrain-advanced/src/autotrain/preprocessor/tabular.py b/autotrain-advanced/src/autotrain/preprocessor/tabular.py
new file mode 100644
index 0000000000000000000000000000000000000000..d224409254777e2d782b3153929905df453a2946
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/preprocessor/tabular.py
@@ -0,0 +1,99 @@
+from dataclasses import dataclass
+from typing import Optional
+
+import pandas as pd
+from datasets import Dataset
+from sklearn.model_selection import train_test_split
+
+
+RESERVED_COLUMNS = ["autotrain_id", "autotrain_label"]
+
+
+@dataclass
+class TabularBinaryClassificationPreprocessor:
+ train_data: pd.DataFrame
+ label_column: str
+ username: str
+ project_name: str
+ id_column: Optional[str] = None
+ valid_data: Optional[pd.DataFrame] = None
+ test_size: Optional[float] = 0.2
+ seed: Optional[int] = 42
+
+ def __post_init__(self):
+ # check if id_column and label_column are in train_data
+ if self.id_column is not None:
+ if self.id_column not in self.train_data.columns:
+ raise ValueError(f"{self.id_column} not in train data")
+
+ if self.label_column not in self.train_data.columns:
+ raise ValueError(f"{self.label_column} not in train data")
+
+ # check if id_column and label_column are in valid_data
+ if self.valid_data is not None:
+ if self.id_column is not None:
+ if self.id_column not in self.valid_data.columns:
+ raise ValueError(f"{self.id_column} not in valid data")
+ if self.label_column not in self.valid_data.columns:
+ raise ValueError(f"{self.label_column} not in valid data")
+
+ # make sure no reserved columns are in train_data or valid_data
+ for column in RESERVED_COLUMNS:
+ if column in self.train_data.columns:
+ raise ValueError(f"{column} is a reserved column name")
+ if self.valid_data is not None:
+ if column in self.valid_data.columns:
+ raise ValueError(f"{column} is a reserved column name")
+
+ def split(self):
+ if self.valid_data is not None:
+ return self.train_data, self.valid_data
+ else:
+ train_df, valid_df = train_test_split(
+ self.train_data,
+ test_size=self.test_size,
+ random_state=self.seed,
+ stratify=self.train_data[self.label_column],
+ )
+ train_df = train_df.reset_index(drop=True)
+ valid_df = valid_df.reset_index(drop=True)
+ return train_df, valid_df
+
+ def prepare_columns(self, train_df, valid_df):
+ train_df.loc[:, "autotrain_id"] = train_df[self.id_column]
+ train_df.loc[:, "autotrain_label"] = train_df[self.label_column]
+ valid_df.loc[:, "autotrain_id"] = valid_df[self.id_column]
+ valid_df.loc[:, "autotrain_label"] = valid_df[self.label_column]
+
+ # drop id_column and label_column
+ train_df = train_df.drop(columns=[self.id_column, self.label_column])
+ valid_df = valid_df.drop(columns=[self.id_column, self.label_column])
+ return train_df, valid_df
+
+ def prepare(self):
+ train_df, valid_df = self.split()
+ train_df, valid_df = self.prepare_columns(train_df, valid_df)
+ train_df = Dataset.from_pandas(train_df)
+ valid_df = Dataset.from_pandas(valid_df)
+ train_df.push_to_hub(f"{self.username}/autotrain-data-{self.project_name}", split="train", private=True)
+ valid_df.push_to_hub(f"{self.username}/autotrain-data-{self.project_name}", split="validation", private=True)
+ return train_df, valid_df
+
+
+class TabularMultiClassClassificationPreprocessor(TabularBinaryClassificationPreprocessor):
+ pass
+
+
+class TabularSingleColumnRegressionPreprocessor(TabularBinaryClassificationPreprocessor):
+ def split(self):
+ if self.valid_data is not None:
+ return self.train_data, self.valid_data
+ else:
+ train_df, valid_df = train_test_split(
+ self.train_data,
+ test_size=self.test_size,
+ random_state=self.seed,
+ )
+ train_df = train_df.reset_index(drop=True)
+ valid_df = valid_df.reset_index(drop=True)
+ return train_df, valid_df
diff --git a/autotrain-advanced/src/autotrain/preprocessor/text.py b/autotrain-advanced/src/autotrain/preprocessor/text.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf9c35722ec861af6652b06d5d2090bc9fdf1c2b
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/preprocessor/text.py
@@ -0,0 +1,220 @@
+from dataclasses import dataclass
+from typing import Optional
+
+import pandas as pd
+from datasets import Dataset
+from sklearn.model_selection import train_test_split
+
+
+RESERVED_COLUMNS = ["autotrain_text", "autotrain_label"]
+LLM_RESERVED_COLUMNS = ["autotrain_prompt", "autotrain_context", "autotrain_response", "autotrain_prompt_start"]
+
+
+@dataclass
+class TextBinaryClassificationPreprocessor:
+ train_data: pd.DataFrame
+ text_column: str
+ label_column: str
+ username: str
+ project_name: str
+ token: str
+ valid_data: Optional[pd.DataFrame] = None
+ test_size: Optional[float] = 0.2
+ seed: Optional[int] = 42
+
+ def __post_init__(self):
+ # check if text_column and label_column are in train_data
+ if self.text_column not in self.train_data.columns:
+ raise ValueError(f"{self.text_column} not in train data")
+ if self.label_column not in self.train_data.columns:
+ raise ValueError(f"{self.label_column} not in train data")
+ # check if text_column and label_column are in valid_data
+ if self.valid_data is not None:
+ if self.text_column not in self.valid_data.columns:
+ raise ValueError(f"{self.text_column} not in valid data")
+ if self.label_column not in self.valid_data.columns:
+ raise ValueError(f"{self.label_column} not in valid data")
+
+ # make sure no reserved columns are in train_data or valid_data
+ for column in RESERVED_COLUMNS:
+ if column in self.train_data.columns:
+ raise ValueError(f"{column} is a reserved column name")
+ if self.valid_data is not None:
+ if column in self.valid_data.columns:
+ raise ValueError(f"{column} is a reserved column name")
+
+ def split(self):
+ if self.valid_data is not None:
+ return self.train_data, self.valid_data
+ else:
+ train_df, valid_df = train_test_split(
+ self.train_data,
+ test_size=self.test_size,
+ random_state=self.seed,
+ stratify=self.train_data[self.label_column],
+ )
+ train_df = train_df.reset_index(drop=True)
+ valid_df = valid_df.reset_index(drop=True)
+ return train_df, valid_df
+
+ def prepare_columns(self, train_df, valid_df):
+ train_df.loc[:, "autotrain_text"] = train_df[self.text_column]
+ train_df.loc[:, "autotrain_label"] = train_df[self.label_column]
+ valid_df.loc[:, "autotrain_text"] = valid_df[self.text_column]
+ valid_df.loc[:, "autotrain_label"] = valid_df[self.label_column]
+
+ # drop text_column and label_column
+ train_df = train_df.drop(columns=[self.text_column, self.label_column])
+ valid_df = valid_df.drop(columns=[self.text_column, self.label_column])
+ return train_df, valid_df
+
+ def prepare(self):
+ train_df, valid_df = self.split()
+ train_df, valid_df = self.prepare_columns(train_df, valid_df)
+ train_df = Dataset.from_pandas(train_df)
+ valid_df = Dataset.from_pandas(valid_df)
+ train_df.push_to_hub(
+ f"{self.username}/autotrain-data-{self.project_name}",
+ split="train",
+ private=True,
+ token=self.token,
+ )
+ valid_df.push_to_hub(
+ f"{self.username}/autotrain-data-{self.project_name}",
+ split="validation",
+ private=True,
+ token=self.token,
+ )
+ return train_df, valid_df
+
+
+class TextMultiClassClassificationPreprocessor(TextBinaryClassificationPreprocessor):
+ pass
+
+
+class TextSingleColumnRegressionPreprocessor(TextBinaryClassificationPreprocessor):
+ def split(self):
+ if self.valid_data is not None:
+ return self.train_data, self.valid_data
+ else:
+ train_df, valid_df = train_test_split(
+ self.train_data,
+ test_size=self.test_size,
+ random_state=self.seed,
+ )
+ train_df = train_df.reset_index(drop=True)
+ valid_df = valid_df.reset_index(drop=True)
+ return train_df, valid_df
+
+
+@dataclass
+class LLMPreprocessor:
+ train_data: pd.DataFrame
+ username: str
+ project_name: str
+ token: str
+ valid_data: Optional[pd.DataFrame] = None
+ test_size: Optional[float] = 0.2
+ seed: Optional[int] = 42
+ context_column: Optional[str] = None
+ prompt_start_column: Optional[str] = None
+ text_column: Optional[str] = None
+ prompt_column: Optional[str] = None
+ response_column: Optional[str] = None
+
+ def __post_init__(self):
+ # user can either provide text_column or prompt_column and response_column
+ if self.text_column is not None and (self.prompt_column is not None or self.response_column is not None):
+ raise ValueError("Please provide either text_column or prompt_column and response_column")
+
+ if self.text_column is not None:
+ # if text_column is provided, use it for prompt_column and response_column
+ self.prompt_column = self.text_column
+ self.response_column = self.text_column
+
+ # check if text_column and response_column are in train_data
+ if self.prompt_column not in self.train_data.columns:
+ raise ValueError(f"{self.prompt_column} not in train data")
+ if self.response_column not in self.train_data.columns:
+ raise ValueError(f"{self.response_column} not in train data")
+ # check if text_column and response_column are in valid_data
+ if self.valid_data is not None:
+ if self.prompt_column not in self.valid_data.columns:
+ raise ValueError(f"{self.prompt_column} not in valid data")
+ if self.response_column not in self.valid_data.columns:
+ raise ValueError(f"{self.response_column} not in valid data")
+
+ # make sure no reserved columns are in train_data or valid_data
+ for column in RESERVED_COLUMNS + LLM_RESERVED_COLUMNS:
+ if column in self.train_data.columns:
+ raise ValueError(f"{column} is a reserved column name")
+ if self.valid_data is not None:
+ if column in self.valid_data.columns:
+ raise ValueError(f"{column} is a reserved column name")
+
+ def split(self):
+ if self.valid_data is not None:
+ return self.train_data, self.valid_data
+ else:
+ train_df, valid_df = train_test_split(
+ self.train_data,
+ test_size=self.test_size,
+ random_state=self.seed,
+ )
+ train_df = train_df.reset_index(drop=True)
+ valid_df = valid_df.reset_index(drop=True)
+ return train_df, valid_df
+
+ def prepare_columns(self, train_df, valid_df):
+ if self.text_column is not None:
+ train_df.loc[:, "autotrain_text"] = train_df[self.text_column]
+ valid_df.loc[:, "autotrain_text"] = valid_df[self.text_column]
+
+ # drop text_column and label_column
+ train_df = train_df.drop(columns=[self.text_column])
+ valid_df = valid_df.drop(columns=[self.text_column])
+ return train_df, valid_df
+ else:
+ train_df.loc[:, "autotrain_prompt"] = train_df[self.prompt_column]
+ valid_df.loc[:, "autotrain_prompt"] = valid_df[self.prompt_column]
+
+ train_df.loc[:, "autotrain_response"] = train_df[self.response_column]
+ valid_df.loc[:, "autotrain_response"] = valid_df[self.response_column]
+
+ train_df = train_df.drop(columns=[self.prompt_column, self.response_column])
+ valid_df = valid_df.drop(columns=[self.prompt_column, self.response_column])
+
+ if self.context_column is not None:
+ train_df.loc[:, "autotrain_context"] = train_df[self.context_column]
+ valid_df.loc[:, "autotrain_context"] = valid_df[self.context_column]
+
+ train_df = train_df.drop(columns=[self.context_column])
+ valid_df = valid_df.drop(columns=[self.context_column])
+
+ if self.prompt_start_column is not None:
+ train_df.loc[:, "autotrain_prompt_start"] = train_df[self.prompt_start_column]
+ valid_df.loc[:, "autotrain_prompt_start"] = valid_df[self.prompt_start_column]
+
+ train_df = train_df.drop(columns=[self.prompt_start_column])
+ valid_df = valid_df.drop(columns=[self.prompt_start_column])
+
+ return train_df, valid_df
+
+ def prepare(self):
+ train_df, valid_df = self.split()
+ train_df, valid_df = self.prepare_columns(train_df, valid_df)
+ train_df = Dataset.from_pandas(train_df)
+ valid_df = Dataset.from_pandas(valid_df)
+ train_df.push_to_hub(
+ f"{self.username}/autotrain-data-{self.project_name}",
+ split="train",
+ private=True,
+ token=self.token,
+ )
+ valid_df.push_to_hub(
+ f"{self.username}/autotrain-data-{self.project_name}",
+ split="validation",
+ private=True,
+ token=self.token,
+ )
+ return train_df, valid_df
diff --git a/autotrain-advanced/src/autotrain/preprocessor/vision.py b/autotrain-advanced/src/autotrain/preprocessor/vision.py
new file mode 100644
index 0000000000000000000000000000000000000000..5dedd5ddff2df5eb0cc86f1f2e4d085547a08eac
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/preprocessor/vision.py
@@ -0,0 +1,147 @@
+import os
+import shutil
+import uuid
+from dataclasses import dataclass
+from typing import Optional
+
+import pandas as pd
+from datasets import load_dataset
+from loguru import logger
+from sklearn.model_selection import train_test_split
+
+
+ALLOWED_EXTENSIONS = ("jpeg", "png", "jpg", "JPG", "JPEG", "PNG")
+
+
+@dataclass
+class ImageClassificationPreprocessor:
+ train_data: str
+ username: str
+ project_name: str
+ token: str
+ valid_data: Optional[str] = None
+ test_size: Optional[float] = 0.2
+ seed: Optional[int] = 42
+
+ def __post_init__(self):
+ # Check if train data path exists
+ if not os.path.exists(self.train_data):
+ raise ValueError(f"{self.train_data} does not exist.")
+
+ # Check if train data path contains at least 2 folders
+ subfolders = [f.path for f in os.scandir(self.train_data) if f.is_dir()]
+ # list subfolders
+ logger.info(f"🚀 Subfolders: {subfolders}")
+ if len(subfolders) < 2:
+ raise ValueError(f"{self.train_data} should contain at least 2 subfolders.")
+
+ # Check if each subfolder contains at least 5 image files in jpeg, png or jpg format only
+ for subfolder in subfolders:
+ image_files = [f for f in os.listdir(subfolder) if f.endswith(ALLOWED_EXTENSIONS)]
+ if len(image_files) < 5:
+ raise ValueError(f"{subfolder} should contain at least 5 jpeg, png or jpg files.")
+ # Check if there are no other files except image files in the subfolder
+ if len(image_files) != len(os.listdir(subfolder)):
+ raise ValueError(f"{subfolder} should not contain any other files except image files.")
+
+ # Check if there are no subfolders inside subfolders
+ subfolders_in_subfolder = [f.path for f in os.scandir(subfolder) if f.is_dir()]
+ if len(subfolders_in_subfolder) > 0:
+ raise ValueError(f"{subfolder} should not contain any subfolders.")
+
+ if self.valid_data:
+ # Check if valid data path exists
+ if not os.path.exists(self.valid_data):
+ raise ValueError(f"{self.valid_data} does not exist.")
+
+ # Check if valid data path contains at least 2 folders
+ subfolders = [f.path for f in os.scandir(self.valid_data) if f.is_dir()]
+
+ # make sure that the subfolders in train and valid data are the same
+ train_subfolders = set(os.path.basename(f.path) for f in os.scandir(self.train_data) if f.is_dir())
+ valid_subfolders = set(os.path.basename(f.path) for f in os.scandir(self.valid_data) if f.is_dir())
+ if train_subfolders != valid_subfolders:
+ raise ValueError(f"{self.valid_data} should have the same subfolders as {self.train_data}.")
+
+ if len(subfolders) < 2:
+ raise ValueError(f"{self.valid_data} should contain at least 2 subfolders.")
+
+ # Check if each subfolder contains at least 5 image files in jpeg, png or jpg format only
+ for subfolder in subfolders:
+ image_files = [f for f in os.listdir(subfolder) if f.endswith(ALLOWED_EXTENSIONS)]
+ if len(image_files) < 5:
+ raise ValueError(f"{subfolder} should contain at least 5 jpeg, png or jpg files.")
+
+ # Check if there are no other files except image files in the subfolder
+ if len(image_files) != len(os.listdir(subfolder)):
+ raise ValueError(f"{subfolder} should not contain any other files except image files.")
+
+ # Check if there are no subfolders inside subfolders
+ subfolders_in_subfolder = [f.path for f in os.scandir(subfolder) if f.is_dir()]
+ if len(subfolders_in_subfolder) > 0:
+ raise ValueError(f"{subfolder} should not contain any subfolders.")
+
+ def split(self, df):
+ train_df, valid_df = train_test_split(
+ df,
+ test_size=self.test_size,
+ random_state=self.seed,
+ stratify=df["subfolder"],
+ )
+ train_df = train_df.reset_index(drop=True)
+ valid_df = valid_df.reset_index(drop=True)
+ return train_df, valid_df
+
+ def prepare(self):
+ random_uuid = uuid.uuid4()
+ cache_dir = os.environ.get("HF_HOME")
+ if not cache_dir:
+ cache_dir = os.path.join(os.path.expanduser("~"), ".cache", "huggingface")
+ data_dir = os.path.join(cache_dir, "autotrain", str(random_uuid))
+
+ if self.valid_data:
+ shutil.copytree(self.train_data, os.path.join(data_dir, "train"))
+ shutil.copytree(self.valid_data, os.path.join(data_dir, "validation"))
+
+ dataset = load_dataset("imagefolder", data_dir=data_dir)
+ dataset.push_to_hub(
+ f"{self.username}/autotrain-data-{self.project_name}",
+ private=True,
+ token=self.token,
+ )
+
+ else:
+ subfolders = [f.path for f in os.scandir(self.train_data) if f.is_dir()]
+
+ image_filenames = []
+ subfolder_names = []
+
+ for subfolder in subfolders:
+ for filename in os.listdir(subfolder):
+ if filename.endswith(("jpeg", "png", "jpg")):
+ image_filenames.append(filename)
+ subfolder_names.append(os.path.basename(subfolder))
+
+ df = pd.DataFrame({"image_filename": image_filenames, "subfolder": subfolder_names})
+ train_df, valid_df = self.split(df)
+
+ for row in train_df.itertuples():
+ os.makedirs(os.path.join(data_dir, "train", row.subfolder), exist_ok=True)
+ shutil.copy(
+ os.path.join(self.train_data, row.subfolder, row.image_filename),
+ os.path.join(data_dir, "train", row.subfolder, row.image_filename),
+ )
+
+ for row in valid_df.itertuples():
+ os.makedirs(os.path.join(data_dir, "validation", row.subfolder), exist_ok=True)
+ shutil.copy(
+ os.path.join(self.train_data, row.subfolder, row.image_filename),
+ os.path.join(data_dir, "validation", row.subfolder, row.image_filename),
+ )
+
+ dataset = load_dataset("imagefolder", data_dir=data_dir)
+ dataset.push_to_hub(
+ f"{self.username}/autotrain-data-{self.project_name}",
+ private=True,
+ token=self.token,
+ )
diff --git a/autotrain-advanced/src/autotrain/project.py b/autotrain-advanced/src/autotrain/project.py
new file mode 100644
index 0000000000000000000000000000000000000000..7e0abafb205acfb27d30eb8647efdb06d2cf2b6b
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/project.py
@@ -0,0 +1,204 @@
+"""
+Copyright 2023 The HuggingFace Team
+"""
+
+import os
+import time
+from dataclasses import dataclass
+from typing import Dict, List, Optional, Union
+
+from codecarbon import EmissionsTracker
+from loguru import logger
+
+from autotrain.dataset import AutoTrainDataset, AutoTrainDreamboothDataset, AutoTrainImageClassificationDataset
+from autotrain.languages import SUPPORTED_LANGUAGES
+from autotrain.tasks import TASKS
+from autotrain.utils import http_get, http_post
+
+
+@dataclass
+class Project:
+ dataset: Union[AutoTrainDataset, AutoTrainDreamboothDataset, AutoTrainImageClassificationDataset]
+ param_choice: Optional[str] = "autotrain"
+ hub_model: Optional[str] = None
+ job_params: Optional[List[Dict[str, str]]] = None
+
+ def __post_init__(self):
+ self.token = self.dataset.token
+ self.name = self.dataset.project_name
+ self.username = self.dataset.username
+ self.task = self.dataset.task
+
+ self.param_choice = self.param_choice.lower()
+
+ if self.hub_model is not None:
+ if len(self.hub_model) == 0:
+ self.hub_model = None
+
+ if self.job_params is None:
+ self.job_params = []
+
+ logger.info(f"🚀🚀🚀 Creating project {self.name}, task: {self.task}")
+ logger.info(f"🚀 Using username: {self.username}")
+ logger.info(f"🚀 Using param_choice: {self.param_choice}")
+ logger.info(f"🚀 Using hub_model: {self.hub_model}")
+ logger.info(f"🚀 Using job_params: {self.job_params}")
+
+ if self.token is None:
+ raise ValueError("❌ Please login using `huggingface-cli login`")
+
+ if self.hub_model is not None and len(self.job_params) == 0:
+ raise ValueError("❌ Job parameters are required when hub model is specified.")
+
+ if self.hub_model is None and len(self.job_params) > 1:
+ raise ValueError("❌ Only one job parameter is allowed in AutoTrain mode.")
+
+ if self.param_choice == "autotrain":
+ if "source_language" in self.job_params[0] and "target_language" not in self.job_params[0]:
+ self.language = self.job_params[0]["source_language"]
+ # remove source language from job params
+ self.job_params[0].pop("source_language")
+ elif "source_language" in self.job_params[0] and "target_language" in self.job_params[0]:
+ self.language = f'{self.job_params[0]["target_language"]}2{self.job_params[0]["source_language"]}'
+ # remove source and target language from job params
+ self.job_params[0].pop("source_language")
+ self.job_params[0].pop("target_language")
+ else:
+ self.language = "unk"
+
+ if "num_models" in self.job_params[0]:
+ self.max_models = self.job_params[0]["num_models"]
+ self.job_params[0].pop("num_models")
+ elif "num_models" not in self.job_params[0] and "source_language" in self.job_params[0]:
+ raise ValueError("❌ Please specify num_models in job_params when using AutoTrain model")
+ else:
+ self.language = "unk"
+ self.max_models = len(self.job_params)
+
+ def create_local(self, payload):
+ from autotrain.trainers.dreambooth import train_ui as train_dreambooth
+ from autotrain.trainers.image_classification import train as train_image_classification
+ from autotrain.trainers.lm_trainer import train as train_lm
+ from autotrain.trainers.text_classification import train as train_text_classification
+
+ # check if training tracker file exists in /tmp/
+ if os.path.exists(os.path.join("/tmp", "training")):
+ raise ValueError("❌ Another training job is already running in this workspace.")
+
+ if len(payload["config"]["params"]) > 1:
+ raise ValueError("❌ Only one job parameter is allowed in spaces/local mode.")
+
+ model_path = os.path.join("/tmp/model", payload["proj_name"])
+ os.makedirs(model_path, exist_ok=True)
+
+ co2_tracker = EmissionsTracker(save_to_file=False)
+ co2_tracker.start()
+ # create a training tracker file in /tmp/, using touch
+ with open(os.path.join("/tmp", "training"), "w") as f:
+ f.write("training")
+
+ if payload["task"] in [1, 2]:
+ _ = train_text_classification(
+ co2_tracker=co2_tracker,
+ payload=payload,
+ huggingface_token=self.token,
+ model_path=model_path,
+ )
+ elif payload["task"] in [17, 18]:
+ _ = train_image_classification(
+ co2_tracker=co2_tracker,
+ payload=payload,
+ huggingface_token=self.token,
+ model_path=model_path,
+ )
+ elif payload["task"] == 25:
+ _ = train_dreambooth(
+ co2_tracker=co2_tracker,
+ payload=payload,
+ huggingface_token=self.token,
+ model_path=model_path,
+ )
+ elif payload["task"] == 9:
+ _ = train_lm(
+ co2_tracker=co2_tracker,
+ payload=payload,
+ huggingface_token=self.token,
+ model_path=model_path,
+ )
+ else:
+ raise NotImplementedError
+
+ # remove the training tracker file in /tmp/, using rm
+ os.remove(os.path.join("/tmp", "training"))
+
+ def create(self, local=False):
+ """Create a project and return it"""
+ logger.info(f"🚀 Creating project {self.name}, task: {self.task}")
+ task_id = TASKS.get(self.task)
+ if task_id is None:
+ raise ValueError(f"❌ Invalid task selected. Please choose one of {TASKS.keys()}")
+ language = str(self.language).strip().lower()
+ if task_id is None:
+ raise ValueError(f"❌ Invalid task specified. Please choose one of {list(TASKS.keys())}")
+
+ if self.hub_model is not None:
+ language = "unk"
+
+ if language not in SUPPORTED_LANGUAGES:
+ raise ValueError("❌ Invalid language. Please check supported languages in AutoTrain documentation.")
+
+ payload = {
+ "username": self.username,
+ "proj_name": self.name,
+ "task": task_id,
+ "config": {
+ "advanced": True,
+ "autotrain": True if self.param_choice == "autotrain" else False,
+ "language": language,
+ "max_models": self.max_models,
+ "hub_model": self.hub_model,
+ "params": self.job_params,
+ },
+ }
+ logger.info(f"🚀 Creating project with payload: {payload}")
+
+ if local is True:
+ return self.create_local(payload=payload)
+
+ logger.info(f"🚀 Creating project with payload: {payload}")
+ json_resp = http_post(path="/projects/create", payload=payload, token=self.token).json()
+ proj_name = json_resp["proj_name"]
+ proj_id = json_resp["id"]
+ created = json_resp["created"]
+
+ if created is True:
+ return proj_id
+ raise ValueError(f"❌ Project with name {proj_name} already exists.")
+
+ def approve(self, project_id):
+ # Process data
+ _ = http_post(
+ path=f"/projects/{project_id}/data/start_processing",
+ token=self.token,
+ ).json()
+
+ logger.info("⏳ Waiting for data processing to complete ...")
+ is_data_processing_success = False
+ while is_data_processing_success is not True:
+ project_status = http_get(
+ path=f"/projects/{project_id}",
+ token=self.token,
+ ).json()
+ # See database.database.enums.ProjectStatus for definitions of `status`
+ if project_status["status"] == 3:
+ is_data_processing_success = True
+ logger.info("✅ Data processing complete!")
+
+ time.sleep(3)
+
+ logger.info(f"🚀 Approving project # {project_id}")
+ # Approve training job
+ _ = http_post(
+ path=f"/projects/{project_id}/start_training",
+ token=self.token,
+ ).json()
diff --git a/autotrain-advanced/src/autotrain/splits.py b/autotrain-advanced/src/autotrain/splits.py
new file mode 100644
index 0000000000000000000000000000000000000000..15fb334be2135480d726f3a3876ddbe2270d1a02
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/splits.py
@@ -0,0 +1,3 @@
+TRAIN_SPLIT = "train"
+VALID_SPLIT = "valid"
+TEST_SPLIT = "test"
diff --git a/autotrain-advanced/src/autotrain/tasks.py b/autotrain-advanced/src/autotrain/tasks.py
new file mode 100644
index 0000000000000000000000000000000000000000..201920fb9ca8075979e2e2de7a6dfcb0048f802c
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/tasks.py
@@ -0,0 +1,72 @@
+NLP_TASKS = {
+ "text_binary_classification": 1,
+ "text_multi_class_classification": 2,
+ "text_entity_extraction": 4,
+ "text_extractive_question_answering": 5,
+ "text_summarization": 8,
+ "text_single_column_regression": 10,
+ "speech_recognition": 11,
+ "natural_language_inference": 22,
+ "lm_training": 9,
+}
+
+VISION_TASKS = {
+ "image_binary_classification": 17,
+ "image_multi_class_classification": 18,
+ "image_single_column_regression": 24,
+ "dreambooth": 25,
+}
+
+TABULAR_TASKS = {
+ "tabular_binary_classification": 13,
+ "tabular_multi_class_classification": 14,
+ "tabular_multi_label_classification": 15,
+ "tabular_single_column_regression": 16,
+}
+
+
+TASKS = {
+ **NLP_TASKS,
+ **VISION_TASKS,
+ **TABULAR_TASKS,
+}
+
+COLUMN_MAPPING = {
+ "text_binary_classification": ("text", "label"),
+ "text_multi_class_classification": ("text", "label"),
+ "text_entity_extraction": ("text", "tokens"),
+ "text_extractive_question_answering": ("text", "context", "question", "answer"),
+ "text_summarization": ("text", "summary"),
+ "text_single_column_regression": ("text", "label"),
+ "speech_recognition": ("audio", "text"),
+ "natural_language_inference": ("premise", "hypothesis", "label"),
+ "image_binary_classification": ("image", "label"),
+ "image_multi_class_classification": ("image", "label"),
+ "image_single_column_regression": ("image", "label"),
+ # "dreambooth": ("image", "label"),
+ "tabular_binary_classification": ("id", "label"),
+ "tabular_multi_class_classification": ("id", "label"),
+ "tabular_multi_label_classification": ("id", "label"),
+ "tabular_single_column_regression": ("id", "label"),
+ "lm_training": ("text", "prompt_start", "prompt", "context", "response"),
+}
+
+TASK_TYPE_MAPPING = {
+ "text_binary_classification": "Natural Language Processing",
+ "text_multi_class_classification": "Natural Language Processing",
+ "text_entity_extraction": "Natural Language Processing",
+ "text_extractive_question_answering": "Natural Language Processing",
+ "text_summarization": "Natural Language Processing",
+ "text_single_column_regression": "Natural Language Processing",
+ "lm_training": "Natural Language Processing",
+ "speech_recognition": "Natural Language Processing",
+ "natural_language_inference": "Natural Language Processing",
+ "image_binary_classification": "Computer Vision",
+ "image_multi_class_classification": "Computer Vision",
+ "image_single_column_regression": "Computer Vision",
+ "dreambooth": "Computer Vision",
+ "tabular_binary_classification": "Tabular",
+ "tabular_multi_class_classification": "Tabular",
+ "tabular_multi_label_classification": "Tabular",
+ "tabular_single_column_regression": "Tabular",
+}
diff --git a/autotrain-advanced/src/autotrain/tests/test_dummy.py b/autotrain-advanced/src/autotrain/tests/test_dummy.py
new file mode 100644
index 0000000000000000000000000000000000000000..97144ebc823f20f6bd2a4910f531b994ab39d988
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/tests/test_dummy.py
@@ -0,0 +1,2 @@
+def test_dummy():
+ assert 1 + 1 == 2
diff --git a/autotrain-advanced/src/autotrain/trainers/__init__.py b/autotrain-advanced/src/autotrain/trainers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/autotrain-advanced/src/autotrain/trainers/callbacks.py b/autotrain-advanced/src/autotrain/trainers/callbacks.py
new file mode 100644
index 0000000000000000000000000000000000000000..544f6f9a480a24c9361fa2cc715c98b87d965829
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/trainers/callbacks.py
@@ -0,0 +1,39 @@
+import os
+
+import torch
+from peft import set_peft_model_state_dict
+from transformers import TrainerCallback, TrainerControl, TrainerState, TrainingArguments
+from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
+
+
+class SavePeftModelCallback(TrainerCallback):
+ def on_save(
+ self,
+ args: TrainingArguments,
+ state: TrainerState,
+ control: TrainerControl,
+ **kwargs,
+ ):
+ checkpoint_folder = os.path.join(args.output_dir, f"{PREFIX_CHECKPOINT_DIR}-{state.global_step}")
+
+ kwargs["model"].save_pretrained(checkpoint_folder)
+
+ pytorch_model_path = os.path.join(checkpoint_folder, "pytorch_model.bin")
+ torch.save({}, pytorch_model_path)
+ return control
+
+
+class LoadBestPeftModelCallback(TrainerCallback):
+ def on_train_end(
+ self,
+ args: TrainingArguments,
+ state: TrainerState,
+ control: TrainerControl,
+ **kwargs,
+ ):
+ print(f"Loading best peft model from {state.best_model_checkpoint} (score: {state.best_metric}).")
+ best_model_path = os.path.join(state.best_model_checkpoint, "adapter_model.bin")
+ adapters_weights = torch.load(best_model_path)
+ model = kwargs["model"]
+ set_peft_model_state_dict(model, adapters_weights)
+ return control
diff --git a/autotrain-advanced/src/autotrain/trainers/clm.py b/autotrain-advanced/src/autotrain/trainers/clm.py
new file mode 100644
index 0000000000000000000000000000000000000000..04cb69d2ac0bdb13109556c401cac2bd4f92cb3d
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/trainers/clm.py
@@ -0,0 +1,316 @@
+import os
+import sys
+from functools import partial
+
+import pandas as pd
+import torch
+from datasets import Dataset, load_dataset
+from huggingface_hub import HfApi
+from loguru import logger
+from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training
+from transformers import (
+ AutoConfig,
+ AutoModelForCausalLM,
+ AutoTokenizer,
+ BitsAndBytesConfig,
+ Trainer,
+ TrainingArguments,
+ default_data_collator,
+)
+from trl import SFTTrainer
+
+from autotrain.trainers import utils
+from autotrain.trainers.callbacks import LoadBestPeftModelCallback, SavePeftModelCallback
+
+
+def train(config):
+ if isinstance(config, dict):
+ config = utils.LLMTrainingParams(**config)
+
+ # TODO: remove when SFT is fixed
+ if config.trainer == "sft":
+ config.trainer = "default"
+
+ # check if config.train_split.csv exists in config.data_path
+ if config.train_split is not None:
+ train_path = f"{config.data_path}/{config.train_split}.csv"
+ if os.path.exists(train_path):
+ logger.info("loading dataset from csv")
+ train_data = pd.read_csv(train_path)
+ train_data = Dataset.from_pandas(train_data)
+ else:
+ train_data = load_dataset(
+ config.data_path,
+ split=config.train_split,
+ use_auth_token=config.huggingface_token,
+ )
+
+ if config.valid_split is not None:
+ valid_path = f"{config.data_path}/{config.valid_split}.csv"
+ if os.path.exists(valid_path):
+ logger.info("loading dataset from csv")
+ valid_data = pd.read_csv(valid_path)
+ valid_data = Dataset.from_pandas(valid_data)
+ else:
+ valid_data = load_dataset(
+ config.data_path,
+ split=config.valid_split,
+ use_auth_token=config.huggingface_token,
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained(
+ config.model_name,
+ use_auth_token=config.huggingface_token,
+ trust_remote_code=True,
+ )
+
+ if tokenizer.model_max_length > 2048:
+ tokenizer.model_max_length = config.model_max_length
+
+ if getattr(tokenizer, "pad_token", None) is None:
+ tokenizer.pad_token = tokenizer.eos_token
+
+ if config.trainer == "default":
+ train_data = utils.process_data(
+ data=train_data,
+ tokenizer=tokenizer,
+ config=config,
+ )
+ if config.valid_split is not None:
+ valid_data = utils.process_data(
+ data=valid_data,
+ tokenizer=tokenizer,
+ config=config,
+ )
+
+ model_config = AutoConfig.from_pretrained(
+ config.model_name,
+ use_auth_token=config.huggingface_token,
+ trust_remote_code=True,
+ )
+
+ if config.use_peft:
+ if config.use_int4:
+ bnb_config = BitsAndBytesConfig(
+ load_in_4bit=config.use_int4,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.float16,
+ bnb_4bit_use_double_quant=False,
+ )
+ elif config.use_int8:
+ bnb_config = BitsAndBytesConfig(load_in_8bit=config.use_int8)
+ else:
+ bnb_config = BitsAndBytesConfig()
+
+ model = AutoModelForCausalLM.from_pretrained(
+ config.model_name,
+ config=model_config,
+ use_auth_token=config.huggingface_token,
+ quantization_config=bnb_config,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ trust_remote_code=True,
+ )
+ else:
+ model = AutoModelForCausalLM.from_pretrained(
+ config.model_name,
+ config=model_config,
+ use_auth_token=config.huggingface_token,
+ trust_remote_code=True,
+ )
+
+ model.resize_token_embeddings(len(tokenizer))
+
+ if config.use_peft:
+ if config.use_int8 or config.use_int4:
+ model = prepare_model_for_int8_training(model)
+ peft_config = LoraConfig(
+ r=config.lora_r,
+ lora_alpha=config.lora_alpha,
+ lora_dropout=config.lora_dropout,
+ bias="none",
+ task_type="CAUSAL_LM",
+ target_modules=utils.get_target_modules(config),
+ )
+ model = get_peft_model(model, peft_config)
+
+ if config.block_size == -1:
+ config.block_size = None
+
+ if config.block_size is None:
+ block_size = tokenizer.model_max_length
+ if block_size > 1024:
+ logger.warning(
+ "The chosen tokenizer supports a `model_max_length` that is longer than the default `block_size` value"
+ " of 1024. If you would like to use a longer `block_size` up to `tokenizer.model_max_length` you can"
+ " override this default with `--block_size xxx`."
+ )
+ block_size = 1024
+ else:
+ if config.block_size > tokenizer.model_max_length:
+ logger.warning(
+ f"The block_size passed ({config.block_size}) is larger than the maximum length for the model"
+ f"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}."
+ )
+ block_size = min(config.block_size, tokenizer.model_max_length)
+
+ config.block_size = block_size
+
+ if config.trainer == "default":
+ tokenize_fn = partial(utils.tokenize, tokenizer=tokenizer, config=config)
+ group_texts_fn = partial(utils.group_texts, config=config)
+
+ train_data = train_data.map(
+ tokenize_fn,
+ batched=True,
+ num_proc=1,
+ remove_columns=list(train_data.features),
+ desc="Running tokenizer on train dataset",
+ )
+
+ if config.valid_split is not None:
+ valid_data = valid_data.map(
+ tokenize_fn,
+ batched=True,
+ num_proc=1,
+ remove_columns=list(valid_data.features),
+ desc="Running tokenizer on validation dataset",
+ )
+
+ train_data = train_data.map(
+ group_texts_fn,
+ batched=True,
+ num_proc=4,
+ desc=f"Grouping texts in chunks of {block_size}",
+ )
+
+ if config.valid_split is not None:
+ valid_data = valid_data.map(
+ group_texts_fn,
+ batched=True,
+ num_proc=4,
+ desc=f"Grouping texts in chunks of {block_size}",
+ )
+
+ logger.info("creating trainer")
+ # trainer specific
+ if config.logging_steps == -1:
+ if config.valid_split is not None:
+ logging_steps = int(0.2 * len(valid_data) / config.train_batch_size)
+ else:
+ logging_steps = int(0.2 * len(train_data) / config.train_batch_size)
+ if logging_steps == 0:
+ logging_steps = 1
+
+ else:
+ logging_steps = config.logging_steps
+
+ training_args = dict(
+ output_dir=config.project_name,
+ per_device_train_batch_size=config.train_batch_size,
+ per_device_eval_batch_size=config.eval_batch_size,
+ learning_rate=config.learning_rate,
+ num_train_epochs=config.num_train_epochs,
+ evaluation_strategy=config.evaluation_strategy if config.valid_split is not None else "no",
+ logging_steps=logging_steps,
+ save_total_limit=config.save_total_limit,
+ save_strategy=config.save_strategy,
+ gradient_accumulation_steps=config.gradient_accumulation_steps,
+ report_to="tensorboard",
+ auto_find_batch_size=config.auto_find_batch_size,
+ lr_scheduler_type=config.scheduler,
+ optim=config.optimizer,
+ warmup_ratio=config.warmup_ratio,
+ weight_decay=config.weight_decay,
+ max_grad_norm=config.max_grad_norm,
+ fp16=config.fp16,
+ push_to_hub=False,
+ load_best_model_at_end=True if config.valid_split is not None else False,
+ )
+
+ args = TrainingArguments(**training_args)
+
+ callbacks = []
+ if config.use_peft:
+ callbacks.append(SavePeftModelCallback)
+ if config.valid_split is not None:
+ callbacks.append(LoadBestPeftModelCallback)
+
+ trainer_args = dict(
+ args=args,
+ model=model,
+ )
+
+ if config.trainer == "default":
+ trainer = Trainer(
+ **trainer_args,
+ train_dataset=train_data,
+ eval_dataset=valid_data if config.valid_split is not None else None,
+ tokenizer=tokenizer,
+ data_collator=default_data_collator,
+ callbacks=callbacks,
+ )
+ elif config.trainer == "sft":
+ trainer = SFTTrainer(
+ **trainer_args,
+ train_dataset=train_data,
+ eval_dataset=valid_data if config.valid_split is not None else None,
+ peft_config=peft_config if config.use_peft else None,
+ dataset_text_field="text",
+ max_seq_length=config.block_size,
+ tokenizer=tokenizer,
+ packing=True,
+ )
+ model.config.use_cache = False
+
+ if torch.__version__ >= "2" and sys.platform != "win32":
+ model = torch.compile(model)
+
+ for name, module in trainer.model.named_modules():
+ # if isinstance(module, LoraLayer):
+ # if script_args.bf16:
+ # module = module.to(torch.bfloat16)
+ if "norm" in name:
+ module = module.to(torch.float32)
+ # if "lm_head" in name or "embed_tokens" in name:
+ # if hasattr(module, "weight"):
+ # if script_args.bf16 and module.weight.dtype == torch.float32:
+ # module = module.to(torch.bfloat16)
+
+ trainer.train()
+
+ logger.info("Finished training, saving model...")
+ trainer.save_model(config.project_name)
+
+ model_card = utils.create_model_card()
+
+ # save model card to output directory as README.md
+ with open(f"{config.project_name}/README.md", "w") as f:
+ f.write(model_card)
+
+ if config.use_peft:
+ logger.info("Merging adapter weights...")
+ utils.merge_adapter(
+ base_model_path=config.model_name,
+ target_model_path=config.project_name,
+ adapter_path=config.project_name,
+ )
+
+ if config.push_to_hub:
+ logger.info("Pushing model to hub...")
+ api = HfApi()
+ api.create_repo(repo_id=config.repo_id, repo_type="model")
+ api.upload_folder(folder_path=config.project_name, repo_id=config.repo_id, repo_type="model")
+
+
+if __name__ == "__main__":
+ config = {
+ # "model_name": "gpt2",
+ "model_name": "Salesforce/xgen-7b-8k-base",
+ "data_path": "tatsu-lab/alpaca",
+ "push_to_hub": False,
+ "project_name": "output",
+ "use_peft": True,
+ }
+
+ train(config)
diff --git a/autotrain-advanced/src/autotrain/trainers/dreambooth/__init__.py b/autotrain-advanced/src/autotrain/trainers/dreambooth/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..47c14872209285be45a4a64d436007cc0e8baa52
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/trainers/dreambooth/__init__.py
@@ -0,0 +1 @@
+from autotrain.trainers.dreambooth.main import train, train_ui
diff --git a/autotrain-advanced/src/autotrain/trainers/dreambooth/datasets.py b/autotrain-advanced/src/autotrain/trainers/dreambooth/datasets.py
new file mode 100644
index 0000000000000000000000000000000000000000..791c46d51058094ad8acc0a033ced1cea96af8d0
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/trainers/dreambooth/datasets.py
@@ -0,0 +1,236 @@
+from pathlib import Path
+
+import torch
+from PIL import Image
+from PIL.ImageOps import exif_transpose
+from torch.utils.data import Dataset
+from torchvision import transforms
+
+
+class PromptDataset(Dataset):
+ "A simple dataset to prepare the prompts to generate class images on multiple GPUs."
+
+ def __init__(self, prompt, num_samples):
+ self.prompt = prompt
+ self.num_samples = num_samples
+
+ def __len__(self):
+ return self.num_samples
+
+ def __getitem__(self, index):
+ example = {}
+ example["prompt"] = self.prompt
+ example["index"] = index
+ return example
+
+
+class DreamBoothDatasetXL(Dataset):
+ """
+ A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
+ It pre-processes the images.
+ """
+
+ def __init__(
+ self,
+ instance_data_root,
+ class_data_root=None,
+ class_num=None,
+ size=1024,
+ center_crop=False,
+ ):
+ self.size = size
+ self.center_crop = center_crop
+
+ self.instance_data_root = Path(instance_data_root)
+ if not self.instance_data_root.exists():
+ raise ValueError("Instance images root doesn't exists.")
+
+ self.instance_images_path = list(Path(instance_data_root).iterdir())
+ self.num_instance_images = len(self.instance_images_path)
+ self._length = self.num_instance_images
+
+ if class_data_root is not None:
+ self.class_data_root = Path(class_data_root)
+ self.class_data_root.mkdir(parents=True, exist_ok=True)
+ self.class_images_path = list(self.class_data_root.iterdir())
+ if class_num is not None:
+ self.num_class_images = min(len(self.class_images_path), class_num)
+ else:
+ self.num_class_images = len(self.class_images_path)
+ self._length = max(self.num_class_images, self.num_instance_images)
+ else:
+ self.class_data_root = None
+
+ self.image_transforms = transforms.Compose(
+ [
+ transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, index):
+ example = {}
+ instance_image = Image.open(self.instance_images_path[index % self.num_instance_images])
+ instance_image = exif_transpose(instance_image)
+
+ if not instance_image.mode == "RGB":
+ instance_image = instance_image.convert("RGB")
+ example["instance_images"] = self.image_transforms(instance_image)
+
+ if self.class_data_root:
+ class_image = Image.open(self.class_images_path[index % self.num_class_images])
+ class_image = exif_transpose(class_image)
+
+ if not class_image.mode == "RGB":
+ class_image = class_image.convert("RGB")
+ example["class_images"] = self.image_transforms(class_image)
+
+ return example
+
+
+class DreamBoothDataset(Dataset):
+ """
+ A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
+ It pre-processes the images and the tokenizes prompts.
+ """
+
+ def __init__(self, config, tokenizers, encoder_hidden_states, instance_prompt_encoder_hidden_states):
+ self.config = config
+ self.tokenizer = tokenizers[0]
+ self.size = self.config.resolution
+ self.center_crop = self.config.center_crop
+ self.tokenizer_max_length = self.config.tokenizer_max_length
+ self.instance_data_root = Path(self.config.image_path)
+ self.instance_prompt = self.config.prompt
+ self.class_data_root = Path(self.config.class_image_path) if self.config.prior_preservation else None
+ self.class_prompt = self.config.class_prompt
+ self.class_num = self.config.num_class_images
+
+ self.encoder_hidden_states = encoder_hidden_states
+ self.instance_prompt_encoder_hidden_states = instance_prompt_encoder_hidden_states
+
+ if not self.instance_data_root.exists():
+ raise ValueError("Instance images root doesn't exists.")
+
+ self.instance_images_path = list(Path(self.instance_data_root).iterdir())
+
+ self.num_instance_images = len(self.instance_images_path)
+ self._length = self.num_instance_images
+
+ if self.class_data_root is not None:
+ self.class_data_root.mkdir(parents=True, exist_ok=True)
+ self.class_images_path = list(self.class_data_root.iterdir())
+ if self.class_num is not None:
+ self.num_class_images = min(len(self.class_images_path), self.class_num)
+ else:
+ self.num_class_images = len(self.class_images_path)
+ self._length = max(self.num_class_images, self.num_instance_images)
+ else:
+ self.class_data_root = None
+
+ self.image_transforms = transforms.Compose(
+ [
+ transforms.Resize(self.size, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(self.size) if self.center_crop else transforms.RandomCrop(self.size),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def __len__(self):
+ return self._length
+
+ def _tokenize_prompt(self, tokenizer, prompt, tokenizer_max_length=None):
+ # this function is here to avoid cyclic import issues
+ if tokenizer_max_length is not None:
+ max_length = tokenizer_max_length
+ else:
+ max_length = tokenizer.model_max_length
+
+ text_inputs = tokenizer(
+ prompt,
+ truncation=True,
+ padding="max_length",
+ max_length=max_length,
+ return_tensors="pt",
+ )
+
+ return text_inputs
+
+ def __getitem__(self, index):
+ example = {}
+ instance_image = Image.open(self.instance_images_path[index % self.num_instance_images])
+ instance_image = exif_transpose(instance_image)
+
+ if not instance_image.mode == "RGB":
+ instance_image = instance_image.convert("RGB")
+ example["instance_images"] = self.image_transforms(instance_image)
+
+ if not self.config.xl:
+ if self.encoder_hidden_states is not None:
+ example["instance_prompt_ids"] = self.encoder_hidden_states
+ else:
+ text_inputs = self._tokenize_prompt(
+ self.tokenizer, self.instance_prompt, tokenizer_max_length=self.tokenizer_max_length
+ )
+ example["instance_prompt_ids"] = text_inputs.input_ids
+ example["instance_attention_mask"] = text_inputs.attention_mask
+
+ if self.class_data_root:
+ class_image = Image.open(self.class_images_path[index % self.num_class_images])
+ class_image = exif_transpose(class_image)
+
+ if not class_image.mode == "RGB":
+ class_image = class_image.convert("RGB")
+ example["class_images"] = self.image_transforms(class_image)
+
+ if not self.config.xl:
+ if self.instance_prompt_encoder_hidden_states is not None:
+ example["class_prompt_ids"] = self.instance_prompt_encoder_hidden_states
+ else:
+ class_text_inputs = self._tokenize_prompt(
+ self.tokenizer, self.class_prompt, tokenizer_max_length=self.tokenizer_max_length
+ )
+ example["class_prompt_ids"] = class_text_inputs.input_ids
+ example["class_attention_mask"] = class_text_inputs.attention_mask
+
+ return example
+
+
+def collate_fn(examples, config):
+ pixel_values = [example["instance_images"] for example in examples]
+
+ if not config.xl:
+ has_attention_mask = "instance_attention_mask" in examples[0]
+ input_ids = [example["instance_prompt_ids"] for example in examples]
+
+ if has_attention_mask:
+ attention_mask = [example["instance_attention_mask"] for example in examples]
+
+ if config.prior_preservation:
+ pixel_values += [example["class_images"] for example in examples]
+ if not config.xl:
+ input_ids += [example["class_prompt_ids"] for example in examples]
+ if has_attention_mask:
+ attention_mask += [example["class_attention_mask"] for example in examples]
+
+ pixel_values = torch.stack(pixel_values)
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+
+ batch = {
+ "pixel_values": pixel_values,
+ }
+
+ if not config.xl:
+ input_ids = torch.cat(input_ids, dim=0)
+ batch["input_ids"] = input_ids
+ if has_attention_mask:
+ # attention_mask = torch.cat(attention_mask, dim=0)
+ batch["attention_mask"] = attention_mask
+
+ return batch
diff --git a/autotrain-advanced/src/autotrain/trainers/dreambooth/dreambooth_deprecated.py b/autotrain-advanced/src/autotrain/trainers/dreambooth/dreambooth_deprecated.py
new file mode 100644
index 0000000000000000000000000000000000000000..6755940bce3fccdafc54f5dbce5015cfb6bc9132
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/trainers/dreambooth/dreambooth_deprecated.py
@@ -0,0 +1,909 @@
+import gc
+import itertools
+import json
+import math
+import os
+import random
+import subprocess
+import sys
+from dataclasses import dataclass
+from pathlib import Path
+from typing import Optional
+
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from accelerate import Accelerator
+from accelerate.utils import set_seed
+from diffusers import AutoencoderKL, DDPMScheduler, DiffusionPipeline, UNet2DConditionModel
+from diffusers.optimization import get_scheduler
+from diffusers.utils.import_utils import is_xformers_available
+from huggingface_hub import HfApi
+from loguru import logger
+from PIL import Image
+from torch.utils.data import Dataset
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import AutoTokenizer, PretrainedConfig
+
+from autotrain import utils
+from autotrain.params import DreamboothParams
+from autotrain.utils import LFS_PATTERNS
+
+
+MARKDOWN = """
+---
+tags:
+- autotrain
+- stable-diffusion
+- text-to-image
+datasets:
+- {dataset}
+co2_eq_emissions:
+ emissions: {co2}
+---
+
+# Model Trained Using AutoTrain
+
+- Problem type: Dreambooth
+- Model ID: {model_id}
+- CO2 Emissions (in grams): {co2:.4f}
+"""
+
+SPACE_README = """
+---
+title: AutoTrain Dreambooth({model_id})
+emoji: 😻
+colorFrom: gray
+colorTo: yellow
+sdk: gradio
+sdk_version: 3.12.0
+app_file: app.py
+pinned: false
+tags:
+ - autotrain
+---
+
+Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
+"""
+
+SPACE_APP = """
+import os
+
+import gradio as gr
+import torch
+from diffusers import StableDiffusionPipeline
+
+DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
+PIPE = StableDiffusionPipeline.from_pretrained(
+ "model/",
+ torch_dtype=torch.float16 if DEVICE == "cuda" else torch.float32,
+)
+PIPE = PIPE.to(DEVICE)
+
+
+def generate_image(prompt, negative_prompt, image_size, scale, steps, seed):
+ image_size = int(image_size) if image_size else int({img_size})
+ generator = torch.Generator(device=DEVICE).manual_seed(seed)
+ images = PIPE(
+ prompt,
+ negative_prompt=negative_prompt,
+ width=image_size,
+ height=image_size,
+ num_inference_steps=steps,
+ guidance_scale=scale,
+ num_images_per_prompt=1,
+ generator=generator,
+ ).images[0]
+ return images
+
+
+gr.Interface(
+ fn=generate_image,
+ inputs=[
+ gr.Textbox(label="Prompt", lines=5, max_lines=5),
+ gr.Textbox(label="Negative prompt (optional)", lines=5, max_lines=5),
+ gr.Textbox(label="Image size (optional)", lines=1, max_lines=1),
+ gr.Slider(1, maximum=20, value=7.5, step=0.5, label="Scale"),
+ gr.Slider(1, 150, 50, label="Steps"),
+ gr.Slider(minimum=1, step=1, maximum=999999999999999999, randomize=True, label="Seed"),
+ ],
+ outputs="image",
+ title="Dreambooth - Powered by AutoTrain",
+ description="Model:{model_id}, concept prompts: {concept_prompts}. Tip: Switch to GPU hardware in settings to make inference superfast!",
+).launch()
+"""
+
+SPACE_REQUIREMENTS = """
+--extra-index-url https://download.pytorch.org/whl/cu113
+torch==1.12.1+cu113
+torchvision==0.13.1+cu113
+accelerate
+transformers
+git+https://github.com/huggingface/diffusers.git
+"""
+
+
+def create_model_card(dataset_id: str, model_id: str, co2: float):
+ co2 = co2 * 1000 if co2 is not None else 0
+ logger.info("Generating markdown for dreambooth")
+ markdown = MARKDOWN.strip().format(
+ model_id=model_id,
+ dataset=dataset_id,
+ co2=co2,
+ )
+ return markdown
+
+
+@dataclass
+class TrainingArgs:
+ pretrained_model_name_or_path: str
+ instance_data_dir: str
+ revision: Optional[str] = None
+ class_data_dir: Optional[str] = None
+ tokenizer_name: Optional[str] = None
+ class_prompt: str = ""
+ with_prior_preservation: bool = False
+ prior_loss_weight: float = 1.0
+ num_class_images: int = 100
+ output_dir: str = ""
+ seed: int = 42
+ resolution: int = 512
+ center_crop: bool = False
+ train_text_encoder: bool = True
+ train_batch_size: int = 4
+ sample_batch_size: int = 4
+ num_train_epochs: int = 1
+ max_train_steps: int = 5000
+ gradient_accumulation_steps: int = 1
+ gradient_checkpointing: bool = False
+ learning_rate: float = 5e-6
+ scale_lr: bool = False
+ lr_scheduler: str = "constant"
+ lr_warmup_steps: int = 500
+ lr_num_cycles: int = 1
+ lr_power: float = 1.0
+ use_8bit_adam: bool = False
+ adam_beta1: float = 0.9
+ adam_beta2: float = 0.999
+ adam_weight_decay: float = 1e-2
+ adam_epsilon: float = 1e-8
+ max_grad_norm: float = 1.0
+ logging_dir: str = "logs"
+ mixed_precision: str = "no"
+ stop_text_encoder_training: int = 1000000
+ cache_latents: bool = False
+
+
+def pad_image(image):
+ w, h = image.size
+ if w == h:
+ return image
+ elif w > h:
+ new_image = Image.new(image.mode, (w, w), (0, 0, 0))
+ new_image.paste(image, (0, (w - h) // 2))
+ return new_image
+ else:
+ new_image = Image.new(image.mode, (h, h), (0, 0, 0))
+ new_image.paste(image, ((h - w) // 2, 0))
+ return new_image
+
+
+def process_images(data_path, job_config):
+ # create processed_data folder in data_path
+ processed_data_path = os.path.join(data_path, "processed_data")
+ os.makedirs(processed_data_path, exist_ok=True)
+ # find all folders in data_path that start with "concept"
+ concept_folders = [f for f in os.listdir(data_path) if f.startswith("concept")]
+ concept_prompts = json.load(open(os.path.join(data_path, "prompts.json")))
+
+ for concept_folder in concept_folders:
+ concept_folder_path = os.path.join(data_path, concept_folder)
+ # find all images in concept_folder_path
+ ALLOWED_EXTENSIONS = ["jpg", "png", "jpeg"]
+ images = [
+ f for f in os.listdir(concept_folder_path) if any(f.lower().endswith(ext) for ext in ALLOWED_EXTENSIONS)
+ ]
+ for image_index, image in enumerate(images):
+ image_path = os.path.join(concept_folder_path, image)
+ img = Image.open(image_path)
+ img = pad_image(img)
+ img = img.resize((job_config.image_size, job_config.image_size))
+ img = img.convert("RGB")
+ processed_filename = f"{concept_prompts[concept_folder]}_{image_index}.jpg"
+ img.save(os.path.join(processed_data_path, processed_filename), format="JPEG", quality=100)
+ return concept_prompts
+
+
+def import_model_class_from_model_name_or_path(pretrained_model_name_or_path: str, revision: str):
+ text_encoder_config = PretrainedConfig.from_pretrained(
+ pretrained_model_name_or_path,
+ subfolder="text_encoder",
+ revision=revision,
+ )
+ model_class = text_encoder_config.architectures[0]
+
+ if model_class == "CLIPTextModel":
+ from transformers import CLIPTextModel
+
+ return CLIPTextModel
+ elif model_class == "RobertaSeriesModelWithTransformation":
+ from diffusers.pipelines.alt_diffusion.modeling_roberta_series import RobertaSeriesModelWithTransformation
+
+ return RobertaSeriesModelWithTransformation
+ else:
+ raise ValueError(f"{model_class} is not supported.")
+
+
+class DreamBoothDataset(Dataset):
+ """
+ A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
+ It pre-processes the images and the tokenizes prompts.
+ """
+
+ def __init__(
+ self,
+ instance_data_root,
+ tokenizer,
+ size,
+ class_data_root=None,
+ class_prompt=None,
+ center_crop=False,
+ ):
+ self.size = size
+ self.center_crop = center_crop
+ self.tokenizer = tokenizer
+ self.class_data_root = class_data_root
+
+ self.instance_data_root = Path(instance_data_root)
+ if not self.instance_data_root.exists():
+ raise ValueError("Instance images root doesn't exists.")
+
+ self.instance_images_path = list(Path(instance_data_root).iterdir())
+ self.num_instance_images = len(self.instance_images_path)
+ self._length = self.num_instance_images
+
+ if class_data_root is not None:
+ self.class_data_root = Path(class_data_root)
+ self.class_data_root.mkdir(parents=True, exist_ok=True)
+ self.class_images_path = list(self.class_data_root.iterdir())
+ random.shuffle(self.class_images_path)
+ self.num_class_images = len(self.class_images_path)
+ self._length = max(self.num_class_images, self.num_instance_images)
+ self.class_prompt = class_prompt
+
+ self.image_transforms = transforms.Compose(
+ [
+ transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, index):
+ example = {}
+ path = self.instance_images_path[index % self.num_instance_images]
+ instance_image = Image.open(path)
+ if not instance_image.mode == "RGB":
+ instance_image = instance_image.convert("RGB")
+
+ filename = Path(path).stem
+ pt = "".join([i for i in filename if not i.isdigit()])
+ pt = pt.replace("_", " ")
+ pt = pt.replace("(", "")
+ pt = pt.replace(")", "")
+ pt = pt.replace("-", "")
+ instance_prompt = pt
+ sys.stdout.write(" �[0;32m" + instance_prompt + " �[0m")
+ sys.stdout.flush()
+
+ example["instance_images"] = self.image_transforms(instance_image)
+ example["instance_prompt_ids"] = self.tokenizer(
+ instance_prompt,
+ padding="do_not_pad",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ ).input_ids
+
+ if self.class_data_root:
+ class_image = Image.open(self.class_images_path[index % self.num_class_images])
+ if not class_image.mode == "RGB":
+ class_image = class_image.convert("RGB")
+ example["class_images"] = self.image_transforms(class_image)
+ example["class_prompt_ids"] = self.tokenizer(
+ self.class_prompt,
+ padding="do_not_pad",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ ).input_ids
+
+ return example
+
+
+class PromptDataset(Dataset):
+ "A simple dataset to prepare the prompts to generate class images on multiple GPUs."
+
+ def __init__(self, prompt, num_samples):
+ self.prompt = prompt
+ self.num_samples = num_samples
+
+ def __len__(self):
+ return self.num_samples
+
+ def __getitem__(self, index):
+ example = {}
+ example["prompt"] = self.prompt
+ example["index"] = index
+ return example
+
+
+class LatentsDataset(Dataset):
+ def __init__(self, latents_cache, text_encoder_cache):
+ self.latents_cache = latents_cache
+ self.text_encoder_cache = text_encoder_cache
+
+ def __len__(self):
+ return len(self.latents_cache)
+
+ def __getitem__(self, index):
+ return self.latents_cache[index], self.text_encoder_cache[index]
+
+
+def collate_fn(examples, tokenizer, with_prior_preservation=False):
+ input_ids = [example["instance_prompt_ids"] for example in examples]
+ pixel_values = [example["instance_images"] for example in examples]
+
+ # Concat class and instance examples for prior preservation.
+ # We do this to avoid doing two forward passes.
+ if with_prior_preservation:
+ input_ids += [example["class_prompt_ids"] for example in examples]
+ pixel_values += [example["class_images"] for example in examples]
+
+ pixel_values = torch.stack(pixel_values)
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+
+ input_ids = tokenizer.pad({"input_ids": input_ids}, padding=True, return_tensors="pt").input_ids
+
+ batch = {
+ "input_ids": input_ids,
+ "pixel_values": pixel_values,
+ }
+ return batch
+
+
+def run_training(args):
+ logger.info(args)
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ )
+
+ # Currently, it's not possible to do gradient accumulation when training two models with accelerate.accumulate
+ # This will be enabled soon in accelerate. For now, we don't allow gradient accumulation when training two models.
+ # TODO (patil-suraj): Remove this check when gradient accumulation with two models is enabled in accelerate.
+ if args.train_text_encoder and args.gradient_accumulation_steps > 1 and accelerator.num_processes > 1:
+ raise ValueError(
+ "Gradient accumulation is not supported when training the text encoder in distributed training. "
+ "Please set gradient_accumulation_steps to 1. This feature will be supported in the future."
+ )
+
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ if args.with_prior_preservation:
+ class_images_dir = Path(args.class_data_dir)
+ if not class_images_dir.exists():
+ class_images_dir.mkdir(parents=True)
+ cur_class_images = len(list(class_images_dir.iterdir()))
+
+ if cur_class_images < args.num_class_images:
+ torch_dtype = torch.float16 if accelerator.device.type == "cuda" else torch.float32
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ torch_dtype=torch_dtype,
+ safety_checker=None,
+ revision=args.revision,
+ )
+ pipeline.set_progress_bar_config(disable=True)
+
+ num_new_images = args.num_class_images - cur_class_images
+ logger.info(f"Number of class images to sample: {num_new_images}.")
+
+ sample_dataset = PromptDataset(args.class_prompt, num_new_images)
+ sample_dataloader = torch.utils.data.DataLoader(sample_dataset, batch_size=args.sample_batch_size)
+
+ sample_dataloader = accelerator.prepare(sample_dataloader)
+ pipeline.to(accelerator.device)
+
+ for example in tqdm(
+ sample_dataloader, desc="Generating class images", disable=not accelerator.is_local_main_process
+ ):
+ images = pipeline(example["prompt"]).images
+
+ for i, image in enumerate(images):
+ image.save(class_images_dir / f"{example['index'][i] + cur_class_images}.jpg")
+
+ del pipeline
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ # Load the tokenizer
+ if args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_name,
+ revision=args.revision,
+ use_fast=False,
+ )
+ elif args.pretrained_model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.pretrained_model_name_or_path,
+ subfolder="tokenizer",
+ revision=args.revision,
+ use_fast=False,
+ )
+
+ # import correct text encoder class
+ text_encoder_cls = import_model_class_from_model_name_or_path(args.pretrained_model_name_or_path, args.revision)
+
+ text_encoder = text_encoder_cls.from_pretrained(
+ args.pretrained_model_name_or_path,
+ subfolder="text_encoder",
+ revision=args.revision,
+ )
+ vae = AutoencoderKL.from_pretrained(
+ args.pretrained_model_name_or_path,
+ subfolder="vae",
+ revision=args.revision,
+ )
+ unet = UNet2DConditionModel.from_pretrained(
+ args.pretrained_model_name_or_path,
+ subfolder="unet",
+ revision=args.revision,
+ )
+
+ if is_xformers_available():
+ try:
+ unet.enable_xformers_memory_efficient_attention()
+ except Exception as e:
+ logger.warning(
+ "Could not enable memory efficient attention. Make sure xformers is installed"
+ f" correctly and a GPU is available: {e}"
+ )
+
+ vae.requires_grad_(False)
+ if not args.train_text_encoder:
+ text_encoder.requires_grad_(False)
+
+ if args.gradient_checkpointing:
+ unet.enable_gradient_checkpointing()
+ if args.train_text_encoder:
+ text_encoder.gradient_checkpointing_enable()
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
+ )
+
+ optimizer_class = bnb.optim.AdamW8bit
+ else:
+ optimizer_class = torch.optim.AdamW
+
+ params_to_optimize = (
+ itertools.chain(unet.parameters(), text_encoder.parameters()) if args.train_text_encoder else unet.parameters()
+ )
+ optimizer = optimizer_class(
+ params_to_optimize,
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ noise_scheduler = DDPMScheduler.from_config(args.pretrained_model_name_or_path, subfolder="scheduler")
+
+ train_dataset = DreamBoothDataset(
+ instance_data_root=args.instance_data_dir,
+ class_data_root=args.class_data_dir if args.with_prior_preservation else None,
+ class_prompt=args.class_prompt,
+ tokenizer=tokenizer,
+ size=args.resolution,
+ center_crop=args.center_crop,
+ )
+
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset,
+ batch_size=args.train_batch_size,
+ shuffle=True,
+ collate_fn=lambda examples: collate_fn(examples, tokenizer, args.with_prior_preservation),
+ )
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ num_cycles=args.lr_num_cycles,
+ power=args.lr_power,
+ )
+
+ if args.train_text_encoder:
+ unet, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, text_encoder, optimizer, train_dataloader, lr_scheduler
+ )
+ else:
+ unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, optimizer, train_dataloader, lr_scheduler
+ )
+
+ weight_dtype = torch.float32
+ if args.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif args.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move text_encode and vae to gpu.
+ # For mixed precision training we cast the text_encoder and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ vae.to(accelerator.device, dtype=weight_dtype)
+ if not args.train_text_encoder:
+ text_encoder.to(accelerator.device, dtype=weight_dtype)
+
+ if args.cache_latents:
+ latents_cache = []
+ text_encoder_cache = []
+ for batch in tqdm(train_dataloader, desc="Caching latents"):
+ with torch.no_grad():
+ batch["pixel_values"] = batch["pixel_values"].to(
+ accelerator.device, non_blocking=True, dtype=weight_dtype
+ )
+ batch["input_ids"] = batch["input_ids"].to(accelerator.device, non_blocking=True)
+ latents_cache.append(vae.encode(batch["pixel_values"]).latent_dist)
+ if args.train_text_encoder:
+ text_encoder_cache.append(batch["input_ids"])
+ else:
+ text_encoder_cache.append(text_encoder(batch["input_ids"])[0])
+ train_dataset = LatentsDataset(latents_cache, text_encoder_cache)
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset, batch_size=1, collate_fn=lambda x: x, shuffle=True
+ )
+
+ del vae
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("dreambooth", config=vars(args))
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num batches each epoch = {len(train_dataloader)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ progress_bar.set_description("Steps")
+ global_step = 0
+ first_epoch = 0
+
+ for epoch in range(first_epoch, args.num_train_epochs):
+ unet.train()
+ if args.train_text_encoder:
+ text_encoder.train()
+ for step, batch in enumerate(train_dataloader):
+ with accelerator.accumulate(unet):
+ # Convert images to latent space
+ with torch.no_grad():
+ if args.cache_latents:
+ latents_dist = batch[0][0]
+ else:
+ latents_dist = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist
+ latents = latents_dist.sample() * 0.18215
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the text embedding for conditioning
+ if args.cache_latents:
+ if args.train_text_encoder:
+ encoder_hidden_states = text_encoder(batch[0][1])[0]
+ else:
+ encoder_hidden_states = batch[0][1]
+ else:
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0]
+
+ # Predict the noise residual
+ model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ if args.with_prior_preservation:
+ # Chunk the noise and model_pred into two parts and compute the loss on each part separately.
+ model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0)
+ target, target_prior = torch.chunk(target, 2, dim=0)
+
+ # Compute instance loss
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="none").mean([1, 2, 3]).mean()
+
+ # Compute prior loss
+ prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean")
+
+ # Add the prior loss to the instance loss.
+ loss = loss + args.prior_loss_weight * prior_loss
+ else:
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ accelerator.backward(loss)
+ if accelerator.sync_gradients:
+ params_to_clip = (
+ itertools.chain(unet.parameters(), text_encoder.parameters())
+ if args.train_text_encoder
+ else unet.parameters()
+ )
+ accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+ accelerator.log(logs, step=global_step)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ if args.train_text_encoder and global_step == args.stop_text_encoder_training and global_step >= 30:
+ if accelerator.is_main_process:
+ logger.info("Freezing the text_encoder ...")
+ frz_dir = args.output_dir + "/text_encoder_frozen"
+ if os.path.exists(frz_dir):
+ subprocess.call("rm -r " + frz_dir, shell=True)
+ os.mkdir(frz_dir)
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ )
+ pipeline.text_encoder.save_pretrained(frz_dir)
+ try:
+ pipeline.text_encoder.save_pretrained(frz_dir, safe_serialization=True)
+ except Exception as e:
+ logger.error("Failed to save the text_encoder with safe serialization: " + str(e))
+
+ accelerator.wait_for_everyone()
+
+ # Create the pipeline using using the trained modules and save it.
+ if accelerator.is_main_process:
+ pipeline = DiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ )
+ frz_dir = args.output_dir + "/text_encoder_frozen"
+ pipeline.save_pretrained(args.output_dir)
+ try:
+ pipeline.save_pretrained(args.output_dir, safe_serialization=True)
+ except Exception as e:
+ logger.error("Failed to save the pipeline with safe serialization: " + str(e))
+ if args.train_text_encoder and os.path.exists(frz_dir):
+ subprocess.call("mv -f " + frz_dir + "/*.* " + args.output_dir + "/text_encoder", shell=True)
+ subprocess.call("rm -r " + frz_dir, shell=True)
+
+ accelerator.end_training()
+ del pipeline
+ torch.cuda.empty_cache()
+ gc.collect()
+
+
+@utils.job_watcher
+def train(co2_tracker, payload, huggingface_token, model_path):
+ data_repo_path = f"{payload['username']}/autotrain-data-{payload['proj_name']}"
+ data_path = "/tmp/data"
+ data_repo = utils.clone_hf_repo(
+ local_dir=data_path,
+ repo_url="https://huggingface.co/datasets/" + data_repo_path,
+ token=huggingface_token,
+ )
+ data_repo.git_pull()
+
+ job_config = payload["config"]["params"][0]
+ job_config["model_name"] = payload["config"]["hub_model"]
+
+ model_name = job_config["model_name"]
+ # device = job_config.get("device", "cuda")
+ del job_config["model_name"]
+ if "device" in job_config:
+ del job_config["device"]
+ job_config = DreamboothParams(**job_config)
+
+ logger.info("Create model repo")
+ project_name = payload["proj_name"]
+ repo_name = f"autotrain-{project_name}"
+ repo_user = payload["username"]
+ repo_url = HfApi().create_repo(
+ repo_id=f"{repo_user}/{repo_name}", token=huggingface_token, exist_ok=True, private=True
+ )
+ if len(repo_url.strip()) == 0:
+ repo_url = f"https://huggingface.co/{repo_user}/{repo_name}"
+
+ space_repo_url = HfApi().create_repo(
+ repo_id=f"{repo_user}/{repo_name}",
+ token=huggingface_token,
+ exist_ok=True,
+ private=True,
+ repo_type="space",
+ space_sdk="gradio",
+ )
+ if len(repo_url.strip()) == 0:
+ space_repo_url = f"https://huggingface.co/spaces/{repo_user}/{repo_name}"
+
+ space_path = "/tmp/space"
+ os.makedirs(space_path, exist_ok=True)
+
+ logger.info(f"Created repo: {repo_url}")
+ logger.info(f"Created space: {space_repo_url}")
+
+ model_repo = utils.clone_hf_repo(
+ local_dir=model_path,
+ repo_url=repo_url,
+ token=huggingface_token,
+ )
+ model_repo.lfs_track(patterns=LFS_PATTERNS)
+
+ space_repo = utils.clone_hf_repo(
+ local_dir=space_path,
+ repo_url=space_repo_url,
+ token=huggingface_token,
+ )
+ space_repo.lfs_track(patterns=LFS_PATTERNS)
+
+ # print contents of data_path folder
+ logger.info("contents of data_path folder")
+ os.system(f"ls -l {data_path}")
+
+ logger.info("processing images")
+ concept_prompts = process_images(data_path=data_path, job_config=job_config)
+ # convert concept_prompts dict to string
+ concept_prompts = ", ".join([f"{k}-> {v}" for k, v in concept_prompts.items()])
+ logger.info("done processing images")
+
+ gradient_checkpointing = True if model_name != "multimodalart/sd-fine-tunable" else False
+ cache_latents = True if model_name != "multimodalart/sd-fine-tunable" else False
+
+ stop_text_encoder_training = int(job_config.text_encoder_steps_percentage * job_config.num_steps / 100)
+
+ args = TrainingArgs(
+ train_text_encoder=True if job_config.text_encoder_steps_percentage > 0 else False,
+ stop_text_encoder_training=stop_text_encoder_training,
+ pretrained_model_name_or_path=model_name,
+ instance_data_dir=os.path.join(data_path, "processed_data"),
+ class_data_dir=None,
+ output_dir=model_path,
+ seed=42,
+ resolution=job_config.image_size,
+ mixed_precision="fp16",
+ train_batch_size=job_config.batch_size,
+ gradient_accumulation_steps=1,
+ use_8bit_adam=True,
+ learning_rate=job_config.lr,
+ lr_scheduler="polynomial",
+ lr_warmup_steps=0,
+ max_train_steps=job_config.num_steps,
+ gradient_checkpointing=gradient_checkpointing,
+ cache_latents=cache_latents,
+ revision=None,
+ )
+ logger.info(args)
+
+ run_training(args)
+
+ co2_consumed = co2_tracker.stop()
+
+ # remove logs folder from model_path
+ os.system(f"rm -rf {model_path}/logs")
+
+ model_card = create_model_card(
+ dataset_id=data_repo_path,
+ model_id=f"{repo_user}/{repo_name}",
+ co2=co2_consumed,
+ )
+
+ if model_card is not None:
+ with open(os.path.join(model_path, "README.md"), "w") as fp:
+ fp.write(f"{model_card}")
+
+ logger.info("Pushing model to Hub")
+ model_repo.git_pull()
+ model_repo.git_add()
+ model_repo.git_commit(commit_message="Commit From AutoTrain")
+ model_repo.git_push()
+
+ # delete README.md from model_path
+ os.system(f"rm -rf {model_path}/README.md")
+
+ # delete .git folder from model_path
+ os.system(f"rm -rf {model_path}/.git")
+
+ # copy all contents of model_path to space_path/model
+ os.makedirs(os.path.join(space_path, "model"), exist_ok=True)
+ os.system(f"cp -r {model_path}/* {space_path}/model")
+
+ # remove old README.md from space_path
+ os.system(f"rm -rf {space_path}/README.md")
+
+ # create README.md in space_path
+ with open(os.path.join(space_path, "README.md"), "w") as fp:
+ fp.write(f"{SPACE_README.format(model_id=repo_name).strip()}")
+
+ # add app.py to space_path
+ with open(os.path.join(space_path, "app.py"), "w") as fp:
+ fp.write(
+ f"{SPACE_APP.format(model_id=repo_name, concept_prompts=concept_prompts, img_size=job_config.image_size).strip()}"
+ )
+
+ # add requirements.txt to space_path
+ with open(os.path.join(space_path, "requirements.txt"), "w") as fp:
+ fp.write(f"{SPACE_REQUIREMENTS.strip()}")
+
+ logger.info("Pushing space to Hub")
+ space_repo.git_pull()
+ space_repo.git_add()
+ space_repo.git_commit(commit_message="Commit From AutoTrain")
+ space_repo.git_push()
diff --git a/autotrain-advanced/src/autotrain/trainers/dreambooth/main.py b/autotrain-advanced/src/autotrain/trainers/dreambooth/main.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e3ca64c348b2d5a2876ebbba67139990073529b
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/trainers/dreambooth/main.py
@@ -0,0 +1,359 @@
+import json
+import os
+
+import diffusers
+import torch
+import torch.nn.functional as F
+import transformers
+from accelerate import Accelerator
+from accelerate.utils import ProjectConfiguration, set_seed
+from diffusers import StableDiffusionXLPipeline
+from diffusers.loaders import LoraLoaderMixin, text_encoder_lora_state_dict
+from diffusers.models.attention_processor import (
+ AttnAddedKVProcessor,
+ AttnAddedKVProcessor2_0,
+ LoRAAttnAddedKVProcessor,
+ LoRAAttnProcessor,
+ LoRAAttnProcessor2_0,
+ SlicedAttnAddedKVProcessor,
+)
+from loguru import logger
+from PIL import Image
+
+from autotrain import utils as at_utils
+from autotrain.params import DreamboothParams
+from autotrain.trainers.dreambooth import utils
+from autotrain.trainers.dreambooth.datasets import DreamBoothDataset, collate_fn
+from autotrain.trainers.dreambooth.params import DreamBoothTrainingParams
+from autotrain.trainers.dreambooth.trainer import Trainer
+
+
+def train(config):
+ if isinstance(config, dict):
+ config = DreamBoothTrainingParams(**config)
+ config.prompt = str(config.prompt).strip()
+ accelerator_project_config = ProjectConfiguration(
+ project_dir=config.output, logging_dir=os.path.join(config.output, "logs")
+ )
+
+ if config.fp16:
+ mixed_precision = "fp16"
+ elif config.bf16:
+ mixed_precision = "bf16"
+ else:
+ mixed_precision = "no"
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=config.gradient_accumulation,
+ mixed_precision=mixed_precision,
+ log_with="tensorboard" if config.logging else None,
+ project_config=accelerator_project_config,
+ )
+
+ if config.train_text_encoder and config.gradient_accumulation > 1 and accelerator.num_processes > 1:
+ raise ValueError(
+ "Gradient accumulation is not supported when training the text encoder in distributed training. "
+ "Please set gradient_accumulation_steps to 1. This feature will be supported in the future."
+ )
+
+ if accelerator.is_local_main_process:
+ transformers.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ transformers.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ set_seed(config.seed)
+
+ # Generate class images if prior preservation is enabled.
+ if config.prior_preservation:
+ utils.setup_prior_preservation(accelerator, config)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if config.output is not None:
+ os.makedirs(config.output, exist_ok=True)
+
+ weight_dtype = torch.float32
+ if accelerator.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif accelerator.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+ tokenizers, text_encoders, vae, unet, noise_scheduler = utils.load_model_components(
+ config, accelerator.device, weight_dtype
+ )
+
+ utils.enable_xformers(unet, config)
+
+ unet_lora_attn_procs = {}
+ unet_lora_parameters = []
+ for name, attn_processor in unet.attn_processors.items():
+ cross_attention_dim = None if name.endswith("attn1.processor") else unet.config.cross_attention_dim
+ if name.startswith("mid_block"):
+ hidden_size = unet.config.block_out_channels[-1]
+ elif name.startswith("up_blocks"):
+ block_id = int(name[len("up_blocks.")])
+ hidden_size = list(reversed(unet.config.block_out_channels))[block_id]
+ elif name.startswith("down_blocks"):
+ block_id = int(name[len("down_blocks.")])
+ hidden_size = unet.config.block_out_channels[block_id]
+
+ if isinstance(attn_processor, (AttnAddedKVProcessor, SlicedAttnAddedKVProcessor, AttnAddedKVProcessor2_0)):
+ lora_attn_processor_class = LoRAAttnAddedKVProcessor
+ else:
+ lora_attn_processor_class = (
+ LoRAAttnProcessor2_0 if hasattr(F, "scaled_dot_product_attention") else LoRAAttnProcessor
+ )
+
+ module = lora_attn_processor_class(hidden_size=hidden_size, cross_attention_dim=cross_attention_dim)
+ unet_lora_attn_procs[name] = module
+ unet_lora_parameters.extend(module.parameters())
+
+ unet.set_attn_processor(unet_lora_attn_procs)
+
+ text_lora_parameters = []
+ if config.train_text_encoder:
+ # ensure that dtype is float32, even if rest of the model that isn't trained is loaded in fp16
+ text_lora_parameters = [
+ LoraLoaderMixin._modify_text_encoder(_text_encoder, dtype=torch.float32) for _text_encoder in text_encoders
+ ]
+
+ def save_model_hook(models, weights, output_dir):
+ # there are only two options here. Either are just the unet attn processor layers
+ # or there are the unet and text encoder atten layers
+ unet_lora_layers_to_save = None
+ text_encoder_lora_layers_to_save = []
+
+ for model in models:
+ if isinstance(model, type(accelerator.unwrap_model(unet))):
+ unet_lora_layers_to_save = utils.unet_attn_processors_state_dict(model)
+
+ for _text_encoder in text_encoders:
+ if isinstance(model, type(accelerator.unwrap_model(_text_encoder))):
+ text_encoder_lora_layers_to_save.append(text_encoder_lora_state_dict(model))
+
+ # make sure to pop weight so that corresponding model is not saved again
+ weights.pop()
+
+ if len(text_encoder_lora_layers_to_save) == 0:
+ LoraLoaderMixin.save_lora_weights(
+ output_dir,
+ unet_lora_layers=unet_lora_layers_to_save,
+ text_encoder_lora_layers=None,
+ safe_serialization=True,
+ )
+ elif len(text_encoder_lora_layers_to_save) == 1:
+ LoraLoaderMixin.save_lora_weights(
+ output_dir,
+ unet_lora_layers=unet_lora_layers_to_save,
+ text_encoder_lora_layers=text_encoder_lora_layers_to_save[0],
+ safe_serialization=True,
+ )
+ elif len(text_encoder_lora_layers_to_save) == 2:
+ StableDiffusionXLPipeline.save_lora_weights(
+ output_dir,
+ unet_lora_layers=unet_lora_layers_to_save,
+ text_encoder_lora_layers=text_encoder_lora_layers_to_save[0],
+ text_encoder_2_lora_layers=text_encoder_lora_layers_to_save[1],
+ safe_serialization=True,
+ )
+ else:
+ raise ValueError("unexpected number of text encoders")
+
+ def load_model_hook(models, input_dir):
+ unet_ = None
+ text_encoders_ = []
+
+ while len(models) > 0:
+ model = models.pop()
+
+ if isinstance(model, type(accelerator.unwrap_model(unet))):
+ unet_ = model
+ for _text_encoder in text_encoders:
+ if isinstance(model, type(accelerator.unwrap_model(_text_encoder))):
+ text_encoders_.append(model)
+
+ lora_state_dict, network_alpha = LoraLoaderMixin.lora_state_dict(input_dir)
+ LoraLoaderMixin.load_lora_into_unet(lora_state_dict, network_alpha=network_alpha, unet=unet_)
+
+ if len(text_encoders_) == 0:
+ LoraLoaderMixin.load_lora_into_text_encoder(
+ lora_state_dict,
+ network_alpha=network_alpha,
+ text_encoder=None,
+ )
+ elif len(text_encoders_) == 1:
+ LoraLoaderMixin.load_lora_into_text_encoder(
+ lora_state_dict,
+ network_alpha=network_alpha,
+ text_encoder=text_encoders_[0],
+ )
+ elif len(text_encoders_) == 2:
+ LoraLoaderMixin.load_lora_into_text_encoder(
+ lora_state_dict,
+ network_alpha=network_alpha,
+ text_encoder=text_encoders_[0],
+ )
+ LoraLoaderMixin.load_lora_into_text_encoder(
+ lora_state_dict,
+ network_alpha=network_alpha,
+ text_encoder=text_encoders_[1],
+ )
+ else:
+ raise ValueError("unexpected number of text encoders")
+
+ accelerator.register_save_state_pre_hook(save_model_hook)
+ accelerator.register_load_state_pre_hook(load_model_hook)
+
+ if config.allow_tf32:
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ if config.scale_lr:
+ config.lr = config.lr * config.gradient_accumulation * config.batch_size * accelerator.num_processes
+
+ optimizer = utils.get_optimizer(config, unet_lora_parameters, text_lora_parameters)
+
+ encoder_hs, instance_prompt_encoder_hs = utils.pre_compute_text_embeddings(
+ config=config, text_encoders=text_encoders, tokenizers=tokenizers
+ )
+ train_dataset = DreamBoothDataset(
+ config=config,
+ tokenizers=tokenizers,
+ encoder_hidden_states=encoder_hs,
+ instance_prompt_encoder_hidden_states=instance_prompt_encoder_hs,
+ )
+
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset,
+ batch_size=config.batch_size,
+ shuffle=True,
+ collate_fn=lambda examples: collate_fn(examples, config),
+ num_workers=config.dataloader_num_workers,
+ )
+ trainer = Trainer(
+ unet=unet,
+ vae=vae,
+ train_dataloader=train_dataloader,
+ text_encoders=text_encoders,
+ config=config,
+ optimizer=optimizer,
+ accelerator=accelerator,
+ noise_scheduler=noise_scheduler,
+ train_dataset=train_dataset,
+ weight_dtype=weight_dtype,
+ text_lora_parameters=text_lora_parameters,
+ unet_lora_parameters=unet_lora_parameters,
+ tokenizers=tokenizers,
+ )
+ trainer.train()
+
+ if config.push_to_hub:
+ trainer.push_to_hub()
+
+
+def pad_image(image):
+ w, h = image.size
+ if w == h:
+ return image
+ elif w > h:
+ new_image = Image.new(image.mode, (w, w), (0, 0, 0))
+ new_image.paste(image, (0, (w - h) // 2))
+ return new_image
+ else:
+ new_image = Image.new(image.mode, (h, h), (0, 0, 0))
+ new_image.paste(image, ((h - w) // 2, 0))
+ return new_image
+
+
+def process_images(data_path, job_config):
+ # create processed_data folder in data_path
+ processed_data_path = os.path.join(data_path, "processed_data")
+ os.makedirs(processed_data_path, exist_ok=True)
+ # find all folders in data_path that start with "concept"
+ concept_folders = [f for f in os.listdir(data_path) if f.startswith("concept")]
+ concept_prompts = json.load(open(os.path.join(data_path, "prompts.json")))
+
+ for concept_folder in concept_folders:
+ concept_folder_path = os.path.join(data_path, concept_folder)
+ # find all images in concept_folder_path
+ ALLOWED_EXTENSIONS = ["jpg", "png", "jpeg"]
+ images = [
+ f for f in os.listdir(concept_folder_path) if any(f.lower().endswith(ext) for ext in ALLOWED_EXTENSIONS)
+ ]
+ for image_index, image in enumerate(images):
+ image_path = os.path.join(concept_folder_path, image)
+ img = Image.open(image_path)
+ img = pad_image(img)
+ img = img.resize((job_config.image_size, job_config.image_size))
+ img = img.convert("RGB")
+ processed_filename = f"{concept_prompts[concept_folder]}_{image_index}.jpg"
+ img.save(os.path.join(processed_data_path, processed_filename), format="JPEG", quality=100)
+ return concept_prompts
+
+
+@at_utils.job_watcher
+def train_ui(co2_tracker, payload, huggingface_token, model_path):
+ data_repo_path = f"{payload['username']}/autotrain-data-{payload['proj_name']}"
+ data_path = "/tmp/data"
+ data_repo = at_utils.clone_hf_repo(
+ local_dir=data_path,
+ repo_url="https://huggingface.co/datasets/" + data_repo_path,
+ token=huggingface_token,
+ )
+ data_repo.git_pull()
+
+ job_config = payload["config"]["params"][0]
+ job_config["model_name"] = payload["config"]["hub_model"]
+
+ model_name = job_config["model_name"]
+ # device = job_config.get("device", "cuda")
+ del job_config["model_name"]
+ if "device" in job_config:
+ del job_config["device"]
+ logger.info(f"job_config: {job_config}")
+ job_config = DreamboothParams(**job_config)
+ logger.info(f"job_config: {job_config}")
+
+ logger.info("Create model repo")
+ project_name = payload["proj_name"]
+ repo_name = f"autotrain-{project_name}"
+ repo_user = payload["username"]
+
+ # print contents of data_path folder
+ logger.info("contents of data_path folder")
+ os.system(f"ls -l {data_path}")
+
+ logger.info("processing images")
+ concept_prompts = process_images(data_path=data_path, job_config=job_config)
+ # convert concept_prompts dict to string
+ concept_prompts = list(concept_prompts.values())[0]
+ logger.info("done processing images")
+
+ xl = False
+ if model_name in utils.XL_MODELS:
+ xl = True
+
+ args = DreamBoothTrainingParams(
+ model=model_name,
+ image_path=os.path.join(data_path, "processed_data"),
+ output=model_path,
+ seed=42,
+ resolution=job_config.image_size,
+ fp16=True,
+ batch_size=job_config.train_batch_size,
+ gradient_accumulation=job_config.gradient_accumulation_steps,
+ use_8bit_adam=True,
+ lr=job_config.learning_rate,
+ scheduler="constant",
+ warmup_steps=0,
+ num_steps=job_config.num_steps,
+ revision=None,
+ push_to_hub=True,
+ hub_model_id=f"{repo_user}/{repo_name}",
+ xl=xl,
+ prompt=concept_prompts,
+ hub_token=huggingface_token,
+ )
+ train(args)
+
+ _ = co2_tracker.stop()
diff --git a/autotrain-advanced/src/autotrain/trainers/dreambooth/params.py b/autotrain-advanced/src/autotrain/trainers/dreambooth/params.py
new file mode 100644
index 0000000000000000000000000000000000000000..aae22b1368aa14ce702e2e7f2688fef4996e49bd
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/trainers/dreambooth/params.py
@@ -0,0 +1,73 @@
+from pydantic import BaseModel, Field
+
+
+class DreamBoothTrainingParams(BaseModel):
+ model: str = Field(None, title="Model name")
+ revision: str = Field(None, title="Revision")
+ tokenizer: str = Field(None, title="Tokenizer, if different from model")
+ image_path: str = Field(None, title="Image path")
+ class_image_path: str = Field(None, title="Class image path")
+ prompt: str = Field(None, title="Instance prompt")
+ class_prompt: str = Field(None, title="Class prompt")
+ num_class_images: int = Field(100, title="Number of class images")
+ class_labels_conditioning: str = Field(None, title="Class labels conditioning")
+
+ prior_preservation: bool = Field(False, title="With prior preservation")
+ prior_loss_weight: float = Field(1.0, title="Prior loss weight")
+
+ output: str = Field("dreambooth-model", title="Output directory")
+ seed: int = Field(42, title="Seed")
+ resolution: int = Field(512, title="Resolution")
+ center_crop: bool = Field(False, title="Center crop")
+ train_text_encoder: bool = Field(False, title="Train text encoder")
+ batch_size: int = Field(4, title="Train batch size")
+ sample_batch_size: int = Field(4, title="Sample batch size")
+ epochs: int = Field(1, title="Number of training epochs")
+ num_steps: int = Field(None, title="Max train steps")
+ checkpointing_steps: int = Field(500, title="Checkpointing steps")
+ resume_from_checkpoint: str = Field(None, title="Resume from checkpoint")
+
+ gradient_accumulation: int = Field(1, title="Gradient accumulation steps")
+ gradient_checkpointing: bool = Field(False, title="Gradient checkpointing")
+
+ lr: float = Field(5e-4, title="Learning rate")
+ scale_lr: bool = Field(False, title="Scale learning rate")
+ scheduler: str = Field("constant", title="Learning rate scheduler")
+ warmup_steps: int = Field(0, title="Learning rate warmup steps")
+ num_cycles: int = Field(1, title="Learning rate num cycles")
+ lr_power: float = Field(1.0, title="Learning rate power")
+
+ dataloader_num_workers: int = Field(0, title="Dataloader num workers")
+ use_8bit_adam: bool = Field(False, title="Use 8bit adam")
+ adam_beta1: float = Field(0.9, title="Adam beta 1")
+ adam_beta2: float = Field(0.999, title="Adam beta 2")
+ adam_weight_decay: float = Field(1e-2, title="Adam weight decay")
+ adam_epsilon: float = Field(1e-8, title="Adam epsilon")
+ max_grad_norm: float = Field(1.0, title="Max grad norm")
+
+ allow_tf32: bool = Field(False, title="Allow TF32")
+ prior_generation_precision: str = Field(None, title="Prior generation precision")
+ local_rank: int = Field(-1, title="Local rank")
+ xformers: bool = Field(False, title="Enable xformers memory efficient attention")
+ pre_compute_text_embeddings: bool = Field(False, title="Pre compute text embeddings")
+ tokenizer_max_length: int = Field(None, title="Tokenizer max length")
+ text_encoder_use_attention_mask: bool = Field(False, title="Text encoder use attention mask")
+
+ rank: int = Field(4, title="Rank")
+ xl: bool = Field(False, title="XL")
+
+ fp16: bool = Field(False, title="FP16")
+ bf16: bool = Field(False, title="BF16")
+
+ hub_token: str = Field(None, title="Hub token")
+ hub_model_id: str = Field(None, title="Hub model id")
+ push_to_hub: bool = Field(False, title="Push to hub")
+
+ # disabled:
+ validation_prompt: str = Field(None, title="Validation prompt")
+ num_validation_images: int = Field(4, title="Number of validation images")
+ validation_epochs: int = Field(50, title="Validation epochs")
+ checkpoints_total_limit: int = Field(None, title="Checkpoints total limit")
+ validation_images: str = Field(None, title="Validation images")
+
+ logging: bool = Field(False, title="Logging using tensorboard")
diff --git a/autotrain-advanced/src/autotrain/trainers/dreambooth/trainer.py b/autotrain-advanced/src/autotrain/trainers/dreambooth/trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d72224b25a91d370f0e1bf30c3cbd31f99426ff
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/trainers/dreambooth/trainer.py
@@ -0,0 +1,460 @@
+import itertools
+import math
+import os
+import shutil
+
+import torch
+import torch.nn.functional as F
+from diffusers import StableDiffusionXLPipeline
+from diffusers.loaders import LoraLoaderMixin, text_encoder_lora_state_dict
+from diffusers.optimization import get_scheduler
+from huggingface_hub import create_repo, upload_folder
+from loguru import logger
+from tqdm import tqdm
+
+from autotrain.trainers.dreambooth import utils
+
+
+class Trainer:
+ def __init__(
+ self,
+ unet,
+ vae,
+ train_dataloader,
+ train_dataset,
+ text_encoders,
+ config,
+ optimizer,
+ accelerator,
+ noise_scheduler,
+ weight_dtype,
+ text_lora_parameters,
+ unet_lora_parameters,
+ tokenizers,
+ ):
+ self.train_dataloader = train_dataloader
+ self.config = config
+ self.optimizer = optimizer
+ self.accelerator = accelerator
+ self.unet = unet
+ self.vae = vae
+ self.noise_scheduler = noise_scheduler
+ self.train_dataset = train_dataset
+ self.weight_dtype = weight_dtype
+ self.text_lora_parameters = text_lora_parameters
+ self.unet_lora_parameters = unet_lora_parameters
+ self.tokenizers = tokenizers
+ self.text_encoders = text_encoders
+
+ if self.config.xl:
+ self._setup_xl()
+
+ self.text_encoder1 = text_encoders[0]
+ self.text_encoder2 = None
+ if len(text_encoders) == 2:
+ self.text_encoder2 = text_encoders[1]
+
+ overrode_max_train_steps = False
+ self.num_update_steps_per_epoch = math.ceil(len(train_dataloader) / config.gradient_accumulation)
+ if self.config.num_steps is None:
+ self.config.num_steps = self.config.epochs * self.num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ self.scheduler = get_scheduler(
+ self.config.scheduler,
+ optimizer=self.optimizer,
+ num_warmup_steps=self.config.warmup_steps * self.accelerator.num_processes,
+ num_training_steps=self.config.num_steps * self.accelerator.num_processes,
+ num_cycles=self.config.num_cycles,
+ power=self.config.lr_power,
+ )
+
+ if self.config.train_text_encoder:
+ if len(text_encoders) == 1:
+ (
+ self.unet,
+ self.text_encoder1,
+ self.optimizer,
+ self.train_dataloader,
+ self.scheduler,
+ ) = self.accelerator.prepare(
+ self.unet, self.text_encoder1, self.optimizer, self.train_dataloader, self.scheduler
+ )
+ elif len(text_encoders) == 2:
+ (
+ self.unet,
+ self.text_encoder1,
+ self.text_encoder2,
+ self.optimizer,
+ self.train_dataloader,
+ self.scheduler,
+ ) = self.accelerator.prepare(
+ self.unet,
+ self.text_encoder1,
+ self.text_encoder2,
+ self.optimizer,
+ self.train_dataloader,
+ self.scheduler,
+ )
+
+ else:
+ self.unet, self.optimizer, self.train_dataloader, self.scheduler = accelerator.prepare(
+ self.unet, self.optimizer, self.train_dataloader, self.scheduler
+ )
+
+ self.num_update_steps_per_epoch = math.ceil(len(self.train_dataloader) / self.config.gradient_accumulation)
+ if overrode_max_train_steps:
+ self.config.num_steps = self.config.epochs * self.num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ self.config.epochs = math.ceil(self.config.num_steps / self.num_update_steps_per_epoch)
+
+ if self.accelerator.is_main_process:
+ self.accelerator.init_trackers("dreambooth")
+
+ self.total_batch_size = (
+ self.config.batch_size * self.accelerator.num_processes * self.config.gradient_accumulation
+ )
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(self.train_dataset)}")
+ logger.info(f" Num batches each epoch = {len(self.train_dataloader)}")
+ logger.info(f" Num Epochs = {self.config.epochs}")
+ logger.info(f" Instantaneous batch size per device = {config.batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {self.total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {self.config.gradient_accumulation}")
+ logger.info(f" Total optimization steps = {self.config.num_steps}")
+ logger.info(f" Training config = {self.config}")
+ self.global_step = 0
+ self.first_epoch = 0
+
+ if config.resume_from_checkpoint:
+ self._resume_from_checkpoint()
+
+ def compute_text_embeddings(self, prompt):
+ logger.info(f"Computing text embeddings for prompt: {prompt}")
+ with torch.no_grad():
+ prompt_embeds, pooled_prompt_embeds = utils.encode_prompt_xl(self.text_encoders, self.tokenizers, prompt)
+ prompt_embeds = prompt_embeds.to(self.accelerator.device)
+ pooled_prompt_embeds = pooled_prompt_embeds.to(self.accelerator.device)
+ return prompt_embeds, pooled_prompt_embeds
+
+ def compute_time_ids(self):
+ # Adapted from pipeline.StableDiffusionXLPipeline._get_add_time_ids
+ original_size = (self.config.resolution, self.config.resolution)
+ target_size = (self.config.resolution, self.config.resolution)
+ # crops_coords_top_left = (self.config.crops_coords_top_left_h, self.config.crops_coords_top_left_w)
+ crops_coords_top_left = (0, 0)
+ add_time_ids = list(original_size + crops_coords_top_left + target_size)
+ add_time_ids = torch.tensor([add_time_ids])
+ add_time_ids = add_time_ids.to(self.accelerator.device, dtype=self.weight_dtype)
+ return add_time_ids
+
+ def _setup_xl(self):
+ # Handle instance prompt.
+ instance_time_ids = self.compute_time_ids()
+ if not self.config.train_text_encoder:
+ instance_prompt_hidden_states, instance_pooled_prompt_embeds = self.compute_text_embeddings(
+ self.config.prompt
+ )
+
+ # Handle class prompt for prior-preservation.
+ if self.config.prior_preservation:
+ class_time_ids = self.compute_time_ids()
+ if not self.config.train_text_encoder:
+ class_prompt_hidden_states, class_pooled_prompt_embeds = self.compute_text_embeddings(
+ self.config.class_prompt
+ )
+
+ self.add_time_ids = instance_time_ids
+ if self.config.prior_preservation:
+ self.add_time_ids = torch.cat([self.add_time_ids, class_time_ids], dim=0)
+
+ if not self.config.train_text_encoder:
+ self.prompt_embeds = instance_prompt_hidden_states
+ self.unet_add_text_embeds = instance_pooled_prompt_embeds
+ if self.config.prior_preservation:
+ self.prompt_embeds = torch.cat([self.prompt_embeds, class_prompt_hidden_states], dim=0)
+ self.unet_add_text_embeds = torch.cat([self.unet_add_text_embeds, class_pooled_prompt_embeds], dim=0)
+ else:
+ self.tokens_one = utils.tokenize_prompt(self.tokenizers[0], self.config.prompt).input_ids
+ self.tokens_two = utils.tokenize_prompt(self.tokenizers[1], self.config.prompt).input_ids
+ if self.config.prior_preservation:
+ class_tokens_one = utils.tokenize_prompt(self.tokenizers[0], self.config.class_prompt).input_ids
+ class_tokens_two = utils.tokenize_prompt(self.tokenizers[1], self.config.class_prompt).input_ids
+ self.tokens_one = torch.cat([self.tokens_one, class_tokens_one], dim=0)
+ self.tokens_two = torch.cat([self.tokens_two, class_tokens_two], dim=0)
+
+ def _resume_from_checkpoint(self):
+ if self.config.resume_from_checkpoint != "latest":
+ path = os.path.basename(self.config.resume_from_checkpoint)
+ else:
+ # Get the mos recent checkpoint
+ dirs = os.listdir(self.config.output)
+ dirs = [d for d in dirs if d.startswith("checkpoint")]
+ dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
+ path = dirs[-1] if len(dirs) > 0 else None
+
+ if path is None:
+ self.accelerator.print(
+ f"Checkpoint '{self.config.resume_from_checkpoint}' does not exist. Starting a new training run."
+ )
+ self.config.resume_from_checkpoint = None
+ else:
+ self.accelerator.print(f"Resuming from checkpoint {path}")
+ self.accelerator.load_state(os.path.join(self.config.output, path))
+ self.global_step = int(path.split("-")[1])
+
+ resume_global_step = self.global_step * self.config.gradient_accumulation
+ self.first_epoch = self.global_step // self.num_update_steps_per_epoch
+ self.resume_step = resume_global_step % (
+ self.num_update_steps_per_epoch * self.config.gradient_accumulation
+ )
+
+ def _calculate_loss(self, model_pred, noise, model_input, timesteps):
+ if model_pred.shape[1] == 6 and not self.config.xl:
+ model_pred, _ = torch.chunk(model_pred, 2, dim=1)
+
+ # Get the target for loss depending on the prediction type
+ if self.noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif self.noise_scheduler.config.prediction_type == "v_prediction":
+ target = self.noise_scheduler.get_velocity(model_input, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {self.noise_scheduler.config.prediction_type}")
+
+ if self.config.prior_preservation:
+ # Chunk the noise and model_pred into two parts and compute the loss on each part separately.
+ model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0)
+ target, target_prior = torch.chunk(target, 2, dim=0)
+
+ # Compute instance loss
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ # Compute prior loss
+ prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean")
+
+ # Add the prior loss to the instance loss.
+ loss = loss + self.config.prior_loss_weight * prior_loss
+ else:
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ return loss
+
+ def _clip_gradients(self):
+ if self.accelerator.sync_gradients:
+ if len(self.text_lora_parameters) == 0:
+ params_to_clip = self.unet_lora_parameters
+ elif len(self.text_lora_parameters) == 1:
+ params_to_clip = itertools.chain(self.unet_lora_parameters, self.text_lora_parameters[0])
+ elif len(self.text_lora_parameters) == 2:
+ params_to_clip = itertools.chain(
+ self.unet_lora_parameters, self.text_lora_parameters[0], self.text_lora_parameters[1]
+ )
+ else:
+ raise ValueError("More than 2 text encoders are not supported.")
+ self.accelerator.clip_grad_norm_(params_to_clip, self.config.max_grad_norm)
+
+ def _save_checkpoint(self):
+ if self.accelerator.is_main_process:
+ if self.global_step % self.config.checkpointing_steps == 0:
+ # _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
+ if self.config.checkpoints_total_limit is not None:
+ checkpoints = os.listdir(self.config.output)
+ checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
+ checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
+
+ # before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
+ if len(checkpoints) >= self.config.checkpoints_total_limit:
+ num_to_remove = len(checkpoints) - self.config.checkpoints_total_limit + 1
+ removing_checkpoints = checkpoints[0:num_to_remove]
+
+ logger.info(
+ f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
+ )
+ logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
+
+ for removing_checkpoint in removing_checkpoints:
+ removing_checkpoint = os.path.join(self.config.output, removing_checkpoint)
+ shutil.rmtree(removing_checkpoint)
+
+ save_path = os.path.join(self.config.output, f"checkpoint-{self.global_step}")
+ self.accelerator.save_state(save_path)
+ logger.info(f"Saved state to {save_path}")
+
+ def _get_model_pred(self, batch, channels, noisy_model_input, timesteps, bsz):
+ if self.config.xl:
+ elems_to_repeat = bsz // 2 if self.config.prior_preservation else bsz
+ if not self.config.train_text_encoder:
+ unet_added_conditions = {
+ "time_ids": self.add_time_ids.repeat(elems_to_repeat, 1),
+ "text_embeds": self.unet_add_text_embeds.repeat(elems_to_repeat, 1),
+ }
+ model_pred = self.unet(
+ noisy_model_input,
+ timesteps,
+ self.prompt_embeds.repeat(elems_to_repeat, 1, 1),
+ added_cond_kwargs=unet_added_conditions,
+ ).sample
+ else:
+ unet_added_conditions = {"time_ids": self.add_time_ids.repeat(elems_to_repeat, 1)}
+ prompt_embeds, pooled_prompt_embeds = utils.encode_prompt_xl(
+ text_encoders=self.text_encoders,
+ tokenizers=None,
+ prompt=None,
+ text_input_ids_list=[self.tokens_one, self.tokens_two],
+ )
+ unet_added_conditions.update({"text_embeds": pooled_prompt_embeds.repeat(bsz, 1)})
+ prompt_embeds = prompt_embeds.repeat(elems_to_repeat, 1, 1)
+ model_pred = self.unet(
+ noisy_model_input, timesteps, prompt_embeds, added_cond_kwargs=unet_added_conditions
+ ).sample
+
+ else:
+ if self.config.pre_compute_text_embeddings:
+ encoder_hidden_states = batch["input_ids"]
+ else:
+ encoder_hidden_states = utils.encode_prompt(
+ self.text_encoder1,
+ batch["input_ids"],
+ batch["attention_mask"],
+ text_encoder_use_attention_mask=self.config.text_encoder_use_attention_mask,
+ )
+
+ if self.accelerator.unwrap_model(self.unet).config.in_channels == channels * 2:
+ noisy_model_input = torch.cat([noisy_model_input, noisy_model_input], dim=1)
+
+ if self.config.class_labels_conditioning == "timesteps":
+ class_labels = timesteps
+ else:
+ class_labels = None
+
+ model_pred = self.unet(
+ noisy_model_input, timesteps, encoder_hidden_states, class_labels=class_labels
+ ).sample
+
+ return model_pred
+
+ def train(self):
+ progress_bar = tqdm(
+ range(self.global_step, self.config.num_steps), disable=not self.accelerator.is_local_main_process
+ )
+ progress_bar.set_description("Steps")
+
+ for epoch in range(self.first_epoch, self.config.epochs):
+ self.unet.train()
+
+ if self.config.train_text_encoder:
+ self.text_encoder1.train()
+ if self.config.xl:
+ self.text_encoder2.train()
+
+ for step, batch in enumerate(self.train_dataloader):
+ # Skip steps until we reach the resumed step
+ if self.config.resume_from_checkpoint and epoch == self.first_epoch and step < self.resume_step:
+ if step % self.config.gradient_accumulation == 0:
+ progress_bar.update(1)
+ continue
+
+ with self.accelerator.accumulate(self.unet):
+ if self.config.xl:
+ pixel_values = batch["pixel_values"]
+ else:
+ pixel_values = batch["pixel_values"].to(dtype=self.weight_dtype)
+
+ if self.vae is not None:
+ # Convert images to latent space
+ model_input = self.vae.encode(pixel_values).latent_dist.sample()
+ model_input = model_input * self.vae.config.scaling_factor
+ model_input = model_input.to(dtype=self.weight_dtype)
+ else:
+ model_input = pixel_values
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(model_input)
+ bsz, channels, height, width = model_input.shape
+ # Sample a random timestep for each image
+ timesteps = torch.randint(
+ 0, self.noise_scheduler.config.num_train_timesteps, (bsz,), device=model_input.device
+ )
+ timesteps = timesteps.long()
+
+ # Add noise to the model input according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_model_input = self.noise_scheduler.add_noise(model_input, noise, timesteps)
+ model_pred = self._get_model_pred(batch, channels, noisy_model_input, timesteps, bsz)
+ loss = self._calculate_loss(model_pred, noise, model_input, timesteps)
+ self.accelerator.backward(loss)
+
+ self._clip_gradients()
+ self.optimizer.step()
+ self.scheduler.step()
+ self.optimizer.zero_grad()
+
+ if self.accelerator.sync_gradients:
+ progress_bar.update(1)
+ self.global_step += 1
+ self._save_checkpoint()
+
+ logs = {"loss": loss.detach().item(), "lr": self.scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+ self.accelerator.log(logs, step=self.global_step)
+
+ if self.global_step >= self.config.num_steps:
+ break
+
+ self.accelerator.wait_for_everyone()
+ if self.accelerator.is_main_process:
+ self.unet = self.accelerator.unwrap_model(self.unet)
+ self.unet = self.unet.to(torch.float32)
+ unet_lora_layers = utils.unet_attn_processors_state_dict(self.unet)
+ text_encoder_lora_layers_1 = None
+ text_encoder_lora_layers_2 = None
+
+ if self.text_encoder1 is not None and self.config.train_text_encoder:
+ text_encoder1 = self.accelerator.unwrap_model(self.text_encoder1)
+ text_encoder1 = text_encoder1.to(torch.float32)
+ text_encoder_lora_layers_1 = text_encoder_lora_state_dict(text_encoder1)
+
+ if self.text_encoder2 is not None and self.config.train_text_encoder:
+ text_encoder2 = self.accelerator.unwrap_model(self.text_encoder2)
+ text_encoder2 = text_encoder2.to(torch.float32)
+ text_encoder_lora_layers_2 = text_encoder_lora_state_dict(text_encoder2)
+
+ if self.config.xl:
+ StableDiffusionXLPipeline.save_lora_weights(
+ save_directory=self.config.output,
+ unet_lora_layers=unet_lora_layers,
+ text_encoder_lora_layers=text_encoder_lora_layers_1,
+ text_encoder_2_lora_layers=text_encoder_lora_layers_2,
+ safe_serialization=True,
+ )
+ else:
+ LoraLoaderMixin.save_lora_weights(
+ save_directory=self.config.output,
+ unet_lora_layers=unet_lora_layers,
+ text_encoder_lora_layers=text_encoder_lora_layers_1,
+ safe_serialization=True,
+ )
+ self.accelerator.end_training()
+
+ def push_to_hub(self):
+ repo_id = create_repo(
+ repo_id=self.config.hub_model_id,
+ exist_ok=True,
+ private=True,
+ token=self.config.hub_token,
+ ).repo_id
+
+ utils.create_model_card(
+ repo_id,
+ base_model=self.config.model,
+ train_text_encoder=self.config.train_text_encoder,
+ prompt=self.config.prompt,
+ repo_folder=self.config.output,
+ )
+ upload_folder(
+ repo_id=repo_id,
+ folder_path=self.config.output,
+ commit_message="End of training",
+ ignore_patterns=["step_*", "epoch_*"],
+ token=self.config.hub_token,
+ )
diff --git a/autotrain-advanced/src/autotrain/trainers/dreambooth/utils.py b/autotrain-advanced/src/autotrain/trainers/dreambooth/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..1712dd57efbb0139ac2f0c32fcaafb66d399ee28
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/trainers/dreambooth/utils.py
@@ -0,0 +1,380 @@
+import hashlib
+import itertools
+import os
+from pathlib import Path
+from typing import Dict
+
+import torch
+from diffusers import AutoencoderKL, DDPMScheduler, DiffusionPipeline, StableDiffusionXLPipeline, UNet2DConditionModel
+from diffusers.utils.import_utils import is_xformers_available
+from loguru import logger
+from packaging import version
+from tqdm import tqdm
+from transformers import AutoTokenizer, PretrainedConfig
+
+from autotrain.trainers.dreambooth.datasets import PromptDataset
+
+
+VALID_IMAGE_EXTENSIONS = [".jpg", ".jpeg", ".png", ".JPG", ".JPEG", ".PNG"]
+XL_MODELS = [
+ "stabilityai/stable-diffusion-xl-base-1.0",
+ "stabilityai/stable-diffusion-xl-base-0.9",
+ "diffusers/stable-diffusion-xl-base-1.0",
+]
+
+
+def create_model_card(repo_id: str, base_model: str, train_text_encoder: bool, prompt: str, repo_folder: str):
+ if train_text_encoder:
+ text_encoder_text = "trained"
+ else:
+ text_encoder_text = "not trained"
+ yaml = f"""
+---
+base_model: {base_model}
+instance_prompt: {prompt}
+tags:
+- text-to-image
+- diffusers
+- autotrain
+inference: true
+---
+ """
+ model_card = f"""
+# DreamBooth trained by AutoTrain
+
+Test enoder was {text_encoder_text}.
+
+"""
+ with open(os.path.join(repo_folder, "README.md"), "w") as f:
+ f.write(yaml + model_card)
+
+
+def import_model_class_from_model_name_or_path(
+ pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
+):
+ text_encoder_config = PretrainedConfig.from_pretrained(
+ pretrained_model_name_or_path, subfolder=subfolder, revision=revision
+ )
+ model_class = text_encoder_config.architectures[0]
+
+ if model_class == "CLIPTextModel":
+ from transformers import CLIPTextModel
+
+ return CLIPTextModel
+ elif model_class == "CLIPTextModelWithProjection":
+ from transformers import CLIPTextModelWithProjection
+
+ return CLIPTextModelWithProjection
+ elif model_class == "RobertaSeriesModelWithTransformation":
+ from diffusers.pipelines.alt_diffusion.modeling_roberta_series import RobertaSeriesModelWithTransformation
+
+ return RobertaSeriesModelWithTransformation
+ elif model_class == "T5EncoderModel":
+ from transformers import T5EncoderModel
+
+ return T5EncoderModel
+ else:
+ raise ValueError(f"{model_class} is not supported.")
+
+
+def tokenize_prompt(tokenizer, prompt, tokenizer_max_length=None):
+ if tokenizer_max_length is not None:
+ max_length = tokenizer_max_length
+ else:
+ max_length = tokenizer.model_max_length
+
+ text_inputs = tokenizer(
+ prompt,
+ truncation=True,
+ padding="max_length",
+ max_length=max_length,
+ return_tensors="pt",
+ )
+
+ return text_inputs
+
+
+def encode_prompt(text_encoder, input_ids, attention_mask, text_encoder_use_attention_mask=None):
+ text_input_ids = input_ids.to(text_encoder.device)
+
+ if text_encoder_use_attention_mask:
+ attention_mask = attention_mask.to(text_encoder.device)
+ else:
+ attention_mask = None
+
+ prompt_embeds = text_encoder(
+ text_input_ids,
+ attention_mask=attention_mask,
+ )
+ prompt_embeds = prompt_embeds[0]
+
+ return prompt_embeds
+
+
+def encode_prompt_xl(text_encoders, tokenizers, prompt, text_input_ids_list=None):
+ prompt_embeds_list = []
+ # logger.info(f"Computing text embeddings for prompt: {prompt}")
+ # logger.info(f"Text encoders: {text_encoders}")
+ # logger.info(f"Tokenizers: {tokenizers}")
+
+ for i, text_encoder in enumerate(text_encoders):
+ if tokenizers is not None:
+ tokenizer = tokenizers[i]
+ text_input_ids = tokenize_prompt(tokenizer, prompt).input_ids
+ # logger.info(f"Text input ids: {text_input_ids}")
+ else:
+ assert text_input_ids_list is not None
+ text_input_ids = text_input_ids_list[i]
+
+ prompt_embeds = text_encoder(
+ text_input_ids.to(text_encoder.device),
+ output_hidden_states=True,
+ )
+
+ # We are only ALWAYS interested in the pooled output of the final text encoder
+ pooled_prompt_embeds = prompt_embeds[0]
+ prompt_embeds = prompt_embeds.hidden_states[-2]
+ bs_embed, seq_len, _ = prompt_embeds.shape
+ prompt_embeds = prompt_embeds.view(bs_embed, seq_len, -1)
+ prompt_embeds_list.append(prompt_embeds)
+
+ prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
+ pooled_prompt_embeds = pooled_prompt_embeds.view(bs_embed, -1)
+ return prompt_embeds, pooled_prompt_embeds
+
+
+def unet_attn_processors_state_dict(unet) -> Dict[str, torch.tensor]:
+ r"""
+ Returns:
+ a state dict containing just the attention processor parameters.
+ """
+ attn_processors = unet.attn_processors
+
+ attn_processors_state_dict = {}
+
+ for attn_processor_key, attn_processor in attn_processors.items():
+ for parameter_key, parameter in attn_processor.state_dict().items():
+ attn_processors_state_dict[f"{attn_processor_key}.{parameter_key}"] = parameter
+
+ return attn_processors_state_dict
+
+
+def setup_prior_preservation(accelerator, config):
+ class_images_dir = Path(config.class_image_path)
+ if not class_images_dir.exists():
+ class_images_dir.mkdir(parents=True)
+ cur_class_images = len(list(class_images_dir.iterdir()))
+
+ if cur_class_images < config.num_class_images:
+ torch_dtype = torch.float16 if accelerator.device.type == "cuda" else torch.float32
+ if config.prior_generation_precision == "fp32":
+ torch_dtype = torch.float32
+ elif config.prior_generation_precision == "fp16":
+ torch_dtype = torch.float16
+ elif config.prior_generation_precision == "bf16":
+ torch_dtype = torch.bfloat16
+ if config.xl:
+ pipeline = StableDiffusionXLPipeline.from_pretrained(
+ config.model,
+ torch_dtype=torch_dtype,
+ safety_checker=None,
+ revision=config.revision,
+ )
+ else:
+ pipeline = DiffusionPipeline.from_pretrained(
+ config.model,
+ torch_dtype=torch_dtype,
+ safety_checker=None,
+ revision=config.revision,
+ )
+ pipeline.set_progress_bar_config(disable=True)
+
+ num_new_images = config.num_class_images - cur_class_images
+ logger.info(f"Number of class images to sample: {num_new_images}.")
+
+ sample_dataset = PromptDataset(config.class_prompt, num_new_images)
+ sample_dataloader = torch.utils.data.DataLoader(sample_dataset, batch_size=config.sample_batch_size)
+
+ sample_dataloader = accelerator.prepare(sample_dataloader)
+ pipeline.to(accelerator.device)
+
+ for example in tqdm(
+ sample_dataloader, desc="Generating class images", disable=not accelerator.is_local_main_process
+ ):
+ images = pipeline(example["prompt"]).images
+
+ for i, image in enumerate(images):
+ hash_image = hashlib.sha1(image.tobytes()).hexdigest()
+ image_filename = class_images_dir / f"{example['index'][i] + cur_class_images}-{hash_image}.jpg"
+ image.save(image_filename)
+
+ del pipeline
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+
+
+def load_model_components(config, device, weight_dtype):
+ tokenizers = []
+ tokenizers.append(
+ AutoTokenizer.from_pretrained(
+ config.model,
+ subfolder="tokenizer",
+ revision=config.revision,
+ use_fast=False,
+ )
+ )
+ if config.xl:
+ tokenizers.append(
+ AutoTokenizer.from_pretrained(
+ config.model,
+ subfolder="tokenizer_2",
+ revision=config.revision,
+ use_fast=False,
+ )
+ )
+
+ cls_text_encoders = []
+ cls_text_encoders.append(
+ import_model_class_from_model_name_or_path(config.model, config.revision),
+ )
+ if config.xl:
+ cls_text_encoders.append(
+ import_model_class_from_model_name_or_path(config.model, config.revision, subfolder="text_encoder_2")
+ )
+
+ text_encoders = []
+ text_encoders.append(
+ cls_text_encoders[0].from_pretrained(
+ config.model,
+ subfolder="text_encoder",
+ revision=config.revision,
+ )
+ )
+ if config.xl:
+ text_encoders.append(
+ cls_text_encoders[1].from_pretrained(
+ config.model,
+ subfolder="text_encoder_2",
+ revision=config.revision,
+ )
+ )
+
+ try:
+ vae = AutoencoderKL.from_pretrained(config.model, subfolder="vae", revision=config.revision)
+ except OSError:
+ logger.warning("No VAE found. Training without VAE.")
+ vae = None
+
+ unet = UNet2DConditionModel.from_pretrained(
+ config.model,
+ subfolder="unet",
+ revision=config.revision,
+ )
+
+ noise_scheduler = DDPMScheduler.from_pretrained(config.model, subfolder="scheduler")
+
+ # TODO: non-peft version
+ if vae is not None:
+ vae.requires_grad_(False)
+ for _text_encoder in text_encoders:
+ _text_encoder.requires_grad_(False)
+ unet.requires_grad_(False)
+
+ if vae is not None:
+ if config.xl:
+ vae.to(device, dtype=torch.float32)
+ else:
+ vae.to(device, dtype=weight_dtype)
+ unet.to(device, dtype=weight_dtype)
+ for _text_encoder in text_encoders:
+ _text_encoder.to(device, dtype=weight_dtype)
+
+ return tokenizers, text_encoders, vae, unet, noise_scheduler
+
+
+def enable_xformers(unet, config):
+ if config.xformers:
+ if is_xformers_available():
+ import xformers
+
+ xformers_version = version.parse(xformers.__version__)
+ if xformers_version == version.parse("0.0.16"):
+ logger.warn(
+ "xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
+ )
+ unet.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available. Make sure it is installed correctly")
+
+
+def get_optimizer(config, unet_lora_parameters, text_lora_parameters):
+ # Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
+ if config.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
+ )
+
+ optimizer_class = bnb.optim.AdamW8bit
+ else:
+ optimizer_class = torch.optim.AdamW
+
+ if len(text_lora_parameters) == 0:
+ params_to_optimize = unet_lora_parameters
+ elif len(text_lora_parameters) == 1:
+ params_to_optimize = itertools.chain(unet_lora_parameters, text_lora_parameters[0])
+ elif len(text_lora_parameters) == 2:
+ params_to_optimize = itertools.chain(unet_lora_parameters, text_lora_parameters[0], text_lora_parameters[1])
+ else:
+ raise ValueError("More than 2 text encoders are not supported.")
+
+ optimizer = optimizer_class(
+ params_to_optimize,
+ lr=config.lr,
+ betas=(config.adam_beta1, config.adam_beta2),
+ weight_decay=config.adam_weight_decay,
+ eps=config.adam_epsilon,
+ )
+ return optimizer
+
+
+def pre_compute_text_embeddings(config, tokenizers, text_encoders):
+ if config.pre_compute_text_embeddings:
+ tokenizer = tokenizers[0]
+ text_encoder = text_encoders[0]
+
+ def compute_text_embeddings(prompt):
+ with torch.no_grad():
+ text_inputs = tokenize_prompt(tokenizer, prompt, tokenizer_max_length=config.tokenizer_max_length)
+ prompt_embeds = encode_prompt(
+ text_encoder,
+ text_inputs.input_ids,
+ text_inputs.attention_mask,
+ text_encoder_use_attention_mask=config.text_encoder_use_attention_mask,
+ )
+
+ return prompt_embeds
+
+ pre_computed_encoder_hidden_states = compute_text_embeddings(config.prompt)
+
+ # disable validation prompt for now
+ # validation_prompt_negative_prompt_embeds = compute_text_embeddings("")
+
+ # if args.validation_prompt is not None:
+ # validation_prompt_encoder_hidden_states = compute_text_embeddings(args.validation_prompt)
+ # else:
+ # validation_prompt_encoder_hidden_states = None
+
+ if config.prompt is not None:
+ pre_computed_instance_prompt_encoder_hidden_states = compute_text_embeddings(config.prompt)
+ else:
+ pre_computed_instance_prompt_encoder_hidden_states = None
+
+ else:
+ pre_computed_encoder_hidden_states = None
+ # validation_prompt_encoder_hidden_states = None
+ pre_computed_instance_prompt_encoder_hidden_states = None
+
+ return pre_computed_encoder_hidden_states, pre_computed_instance_prompt_encoder_hidden_states
diff --git a/autotrain-advanced/src/autotrain/trainers/image_classification.py b/autotrain-advanced/src/autotrain/trainers/image_classification.py
new file mode 100644
index 0000000000000000000000000000000000000000..7eebb24f8bdae13293ab7566c8d43be0b90d2a08
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/trainers/image_classification.py
@@ -0,0 +1,310 @@
+import os
+
+import albumentations as A
+import numpy as np
+import torch
+from datasets import load_dataset
+from loguru import logger
+from sklearn import metrics
+from transformers import (
+ AutoConfig,
+ AutoImageProcessor,
+ AutoModelForImageClassification,
+ EarlyStoppingCallback,
+ Trainer,
+ TrainingArguments,
+)
+
+from autotrain import utils
+from autotrain.params import ImageBinaryClassificationParams, ImageMultiClassClassificationParams
+
+
+BINARY_CLASSIFICATION_EVAL_METRICS = (
+ "eval_loss",
+ "eval_accuracy",
+ "eval_f1",
+ "eval_auc",
+ "eval_precision",
+ "eval_recall",
+)
+
+MULTI_CLASS_CLASSIFICATION_EVAL_METRICS = (
+ "eval_loss",
+ "eval_accuracy",
+ "eval_f1_macro",
+ "eval_f1_micro",
+ "eval_f1_weighted",
+ "eval_precision_macro",
+ "eval_precision_micro",
+ "eval_precision_weighted",
+ "eval_recall_macro",
+ "eval_recall_micro",
+ "eval_recall_weighted",
+)
+
+MODEL_CARD = """
+---
+tags:
+- autotrain
+- image-classification
+widget:
+- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
+ example_title: Tiger
+- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
+ example_title: Teapot
+- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
+ example_title: Palace
+datasets:
+- {dataset}
+co2_eq_emissions:
+ emissions: {co2}
+---
+
+# Model Trained Using AutoTrain
+
+- Problem type: Image Classification
+- CO2 Emissions (in grams): {co2:.4f}
+
+## Validation Metricsg
+{validation_metrics}
+"""
+
+
+class Dataset:
+ def __init__(self, data, transforms):
+ self.data = data
+ self.transforms = transforms
+
+ def __len__(self):
+ return len(self.data)
+
+ def __getitem__(self, item):
+ image = self.data[item]["image"]
+ target = int(self.data[item]["label"])
+
+ image = self.transforms(image=np.array(image.convert("RGB")))["image"]
+ image = np.transpose(image, (2, 0, 1)).astype(np.float32)
+
+ return {
+ "pixel_values": torch.tensor(image, dtype=torch.float),
+ "labels": torch.tensor(target, dtype=torch.long),
+ }
+
+
+def _binary_classification_metrics(pred):
+ raw_predictions, labels = pred
+ predictions = np.argmax(raw_predictions, axis=1)
+ result = {
+ "f1": metrics.f1_score(labels, predictions),
+ "precision": metrics.precision_score(labels, predictions),
+ "recall": metrics.recall_score(labels, predictions),
+ "auc": metrics.roc_auc_score(labels, raw_predictions[:, 1]),
+ "accuracy": metrics.accuracy_score(labels, predictions),
+ }
+ return result
+
+
+def _multi_class_classification_metrics(pred):
+ raw_predictions, labels = pred
+ predictions = np.argmax(raw_predictions, axis=1)
+ results = {
+ "f1_macro": metrics.f1_score(labels, predictions, average="macro"),
+ "f1_micro": metrics.f1_score(labels, predictions, average="micro"),
+ "f1_weighted": metrics.f1_score(labels, predictions, average="weighted"),
+ "precision_macro": metrics.precision_score(labels, predictions, average="macro"),
+ "precision_micro": metrics.precision_score(labels, predictions, average="micro"),
+ "precision_weighted": metrics.precision_score(labels, predictions, average="weighted"),
+ "recall_macro": metrics.recall_score(labels, predictions, average="macro"),
+ "recall_micro": metrics.recall_score(labels, predictions, average="micro"),
+ "recall_weighted": metrics.recall_score(labels, predictions, average="weighted"),
+ "accuracy": metrics.accuracy_score(labels, predictions),
+ }
+ return results
+
+
+def process_data(train_data, valid_data, image_processor):
+ if "shortest_edge" in image_processor.size:
+ size = image_processor.size["shortest_edge"]
+ else:
+ size = (image_processor.size["height"], image_processor.size["width"])
+ try:
+ height, width = size
+ except TypeError:
+ height = size
+ width = size
+
+ train_transforms = A.Compose(
+ [
+ A.RandomResizedCrop(height=height, width=width),
+ A.RandomRotate90(),
+ A.HorizontalFlip(p=0.5),
+ A.RandomBrightnessContrast(p=0.2),
+ A.Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
+ ]
+ )
+
+ val_transforms = A.Compose(
+ [
+ A.Resize(height=height, width=width),
+ A.Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
+ ]
+ )
+ train_data = Dataset(train_data, train_transforms)
+ valid_data = Dataset(valid_data, val_transforms)
+ return train_data, valid_data
+
+
+@utils.job_watcher
+def train(co2_tracker, payload, huggingface_token, model_path):
+ # create model repo
+ model_repo = utils.create_repo(
+ project_name=payload["proj_name"],
+ autotrain_user=payload["username"],
+ huggingface_token=huggingface_token,
+ model_path=model_path,
+ )
+
+ data_path = f"{payload['username']}/autotrain-data-{payload['proj_name']}"
+ data = load_dataset(data_path, use_auth_token=huggingface_token)
+ logger.info(f"Loaded data from {data_path}")
+ job_config = payload["config"]["params"][0]
+ job_config["model_name"] = payload["config"]["hub_model"]
+
+ train_data = data["train"]
+ valid_data = data["validation"]
+
+ labels = train_data.features["label"].names
+ label2id, id2label = {}, {}
+ for i, label in enumerate(labels):
+ label2id[label] = str(i)
+ id2label[str(i)] = label
+
+ num_classes = len(labels)
+
+ model_name = job_config["model_name"]
+ device = job_config.get("device", "cuda")
+ # remove model_name from job config
+ del job_config["model_name"]
+ if num_classes == 2:
+ job_config["task"] = "image_binary_classification"
+ job_config = ImageBinaryClassificationParams(**job_config)
+ elif num_classes > 2:
+ job_config["task"] = "image_multi_class_classification"
+ job_config = ImageMultiClassClassificationParams(**job_config)
+ else:
+ raise ValueError("Invalid number of classes")
+
+ model_config = AutoConfig.from_pretrained(
+ model_name,
+ num_labels=num_classes,
+ use_auth_token=huggingface_token,
+ )
+
+ model_config._num_labels = len(label2id)
+ model_config.label2id = label2id
+ model_config.id2label = id2label
+
+ logger.info(model_config)
+
+ try:
+ model = AutoModelForImageClassification.from_pretrained(
+ model_name,
+ config=model_config,
+ use_auth_token=huggingface_token,
+ ignore_mismatched_sizes=True,
+ )
+ except OSError:
+ model = AutoModelForImageClassification.from_pretrained(
+ model_name,
+ config=model_config,
+ use_auth_token=huggingface_token,
+ from_tf=True,
+ ignore_mismatched_sizes=True,
+ )
+
+ image_processor = AutoImageProcessor.from_pretrained(model_name, use_auth_token=huggingface_token)
+
+ train_dataset, valid_dataset = process_data(train_data, valid_data, image_processor)
+
+ # trainer specific
+
+ logging_steps = int(0.2 * len(valid_dataset) / job_config.train_batch_size)
+ if logging_steps == 0:
+ logging_steps = 1
+ fp16 = True
+ if device == "cpu":
+ fp16 = False
+
+ training_args = dict(
+ output_dir=model_path,
+ per_device_train_batch_size=job_config.train_batch_size,
+ per_device_eval_batch_size=job_config.train_batch_size,
+ learning_rate=job_config.learning_rate,
+ num_train_epochs=job_config.num_train_epochs,
+ fp16=fp16,
+ load_best_model_at_end=True,
+ evaluation_strategy="epoch",
+ logging_steps=logging_steps,
+ save_total_limit=1,
+ save_strategy="epoch",
+ disable_tqdm=not bool(os.environ.get("ENABLE_TQDM", 0)),
+ gradient_accumulation_steps=job_config.gradient_accumulation_steps,
+ report_to="none",
+ auto_find_batch_size=True,
+ lr_scheduler_type=job_config.scheduler,
+ optim=job_config.optimizer,
+ warmup_ratio=job_config.warmup_ratio,
+ weight_decay=job_config.weight_decay,
+ max_grad_norm=job_config.max_grad_norm,
+ )
+
+ early_stop = EarlyStoppingCallback(early_stopping_patience=3, early_stopping_threshold=0.01)
+ callbacks_to_use = [early_stop]
+
+ args = TrainingArguments(**training_args)
+ trainer_args = dict(
+ args=args,
+ model=model,
+ callbacks=callbacks_to_use,
+ compute_metrics=_binary_classification_metrics if num_classes == 2 else _multi_class_classification_metrics,
+ )
+
+ trainer = Trainer(
+ **trainer_args,
+ train_dataset=train_dataset,
+ eval_dataset=valid_dataset,
+ )
+ trainer.train()
+
+ logger.info("Finished training")
+ logger.info(trainer.state.best_metric)
+ eval_scores = trainer.evaluate()
+
+ # create and save model card
+ co2_consumed = co2_tracker.stop()
+ co2_consumed = co2_consumed * 1000 if co2_consumed is not None else 0
+
+ valid_metrics = BINARY_CLASSIFICATION_EVAL_METRICS if num_classes == 2 else MULTI_CLASS_CLASSIFICATION_EVAL_METRICS
+ eval_scores = [f"{k[len('eval_'):]}: {v}" for k, v in eval_scores.items() if k in valid_metrics]
+ eval_scores = "\n\n".join(eval_scores)
+ model_card = MODEL_CARD.format(
+ language=payload["config"]["language"],
+ dataset=data_path,
+ co2=co2_consumed,
+ validation_metrics=eval_scores,
+ )
+ logger.info(model_card)
+ utils.save_model_card(model_card, model_path)
+
+ # save model, image_processor and config
+ model = utils.update_model_config(trainer.model, job_config)
+ utils.save_tokenizer(image_processor, model_path)
+ utils.save_model(model, model_path)
+ utils.remove_checkpoints(model_path=model_path)
+
+ # push model to hub
+ logger.info("Pushing model to Hub")
+ model_repo.git_pull()
+ model_repo.git_add()
+ model_repo.git_commit(commit_message="Commit From AutoTrain")
+ model_repo.git_push()
diff --git a/autotrain-advanced/src/autotrain/trainers/lm_trainer.py b/autotrain-advanced/src/autotrain/trainers/lm_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..c4cd52d7398728c5a413cbd0325fa1455990dfef
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/trainers/lm_trainer.py
@@ -0,0 +1,469 @@
+import os
+from itertools import chain
+
+import torch
+from datasets import Dataset, load_dataset
+from loguru import logger
+from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training
+from transformers import (
+ AutoConfig,
+ AutoModelForCausalLM,
+ AutoTokenizer,
+ Trainer,
+ TrainingArguments,
+ default_data_collator,
+)
+
+from autotrain import utils
+from autotrain.params import LMTrainingParams
+
+
+TEXT_COLUMN = "autotrain_text"
+
+IGNORE_INDEX = -100
+DEFAULT_PAD_TOKEN = "[PAD]"
+DEFAULT_EOS_TOKEN = ""
+DEFAULT_BOS_TOKEN = ""
+DEFAULT_UNK_TOKEN = ""
+
+EVAL_METRICS = ("eval_loss",)
+
+MODEL_CARD = """
+---
+tags:
+- autotrain
+- text-generation
+widget:
+- text: "I love AutoTrain because "
+datasets:
+- {dataset}
+co2_eq_emissions:
+ emissions: {co2}
+---
+
+# Model Trained Using AutoTrain
+
+- Problem type: Text Generation
+- CO2 Emissions (in grams): {co2:.4f}
+
+## Validation Metrics
+{validation_metrics}
+"""
+
+HANDLER_CONTENT = """
+from typing import Dict, List, Any
+from transformers import AutoModelForCausalLM, AutoTokenizer
+from peft import PeftModel, PeftConfig
+import torch
+
+
+class EndpointHandler:
+ def __init__(self, path=""):
+ # load model and processor from path
+ model = AutoModelForCausalLM.from_pretrained(
+ path, torch_dtype=torch.float16, load_in_8bit=True, device_map="auto"
+ )
+ self.tokenizer = AutoTokenizer.from_pretrained(path)
+ self.model.eval()
+
+ def __call__(self, data: Dict[str, Any]) -> Dict[str, str]:
+ '''
+ Args:
+ data (:dict:):
+ The payload with the text prompt and generation parameters.
+ '''
+ # process input
+ inputs = data.pop("inputs", data)
+ parameters = data.pop("parameters", None)
+
+ # preprocess
+ input_ids = self.tokenizer(inputs, return_tensors="pt").input_ids
+
+ # pass inputs with all kwargs in data
+ if parameters is not None:
+ outputs = self.model.generate(input_ids=input_ids, **parameters)
+ else:
+ outputs = self.model.generate(input_ids=input_ids)
+
+ # postprocess the prediction
+ prediction = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
+
+ return [{"generated_text": prediction}]
+"""
+
+HANDLER_CONTENT_PEFT = """
+from typing import Dict, List, Any
+from transformers import AutoModelForCausalLM, AutoTokenizer
+from peft import PeftModel, PeftConfig
+import torch
+
+
+class EndpointHandler:
+ def __init__(self, path=""):
+ # load model and processor from path
+ config = PeftConfig.from_pretrained(path)
+ model = AutoModelForCausalLM.from_pretrained(
+ config.base_model_name_or_path, torch_dtype=torch.float16, load_in_8bit=True, device_map="auto"
+ )
+ self.model = PeftModel.from_pretrained(model, path)
+ self.tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
+ self.model.eval()
+
+ def __call__(self, data: Dict[str, Any]) -> Dict[str, str]:
+ '''
+ Args:
+ data (:dict:):
+ The payload with the text prompt and generation parameters.
+ '''
+ # process input
+ inputs = data.pop("inputs", data)
+ parameters = data.pop("parameters", None)
+
+ # preprocess
+ input_ids = self.tokenizer(inputs, return_tensors="pt").input_ids
+
+ # pass inputs with all kwargs in data
+ if parameters is not None:
+ outputs = self.model.generate(input_ids=input_ids, **parameters)
+ else:
+ outputs = self.model.generate(input_ids=input_ids)
+
+ # postprocess the prediction
+ prediction = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
+
+ return [{"generated_text": prediction}]
+"""
+
+
+REQUIREMENTS = """
+accelerate==0.18.0
+transformers==4.28.1
+git+https://github.com/huggingface/peft.git
+bitsandbytes
+tokenizers>=0.13.3
+"""
+
+
+def _eval_metrics(pred):
+ raw_predictions, labels = pred
+ return 0
+
+
+def tokenize(tokenizer, prompt, add_eos_token=True):
+ result = tokenizer(
+ prompt,
+ truncation=True,
+ max_length=tokenizer.model_max_length,
+ padding=False,
+ return_tensors=None,
+ )
+ if result["input_ids"][-1] != tokenizer.eos_token_id and add_eos_token:
+ if len(result["input_ids"]) >= tokenizer.model_max_length:
+ result["input_ids"] = result["input_ids"][:-1]
+ result["attention_mask"] = result["attention_mask"][:-1]
+ result["input_ids"].append(tokenizer.eos_token_id)
+ result["attention_mask"].append(1)
+
+ result["labels"] = result["input_ids"].copy()
+
+ return result
+
+
+def _process_data(data, tokenizer, job_config):
+ data = data.to_pandas()
+ data = data.fillna("")
+
+ data = data[[TEXT_COLUMN]]
+ if job_config.add_eos_token:
+ data[TEXT_COLUMN] = data[TEXT_COLUMN] + tokenizer.eos_token
+ data = Dataset.from_pandas(data)
+ return data
+
+
+def group_texts(examples, block_size):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
+ # customize this part to your needs.
+ if total_length >= block_size:
+ total_length = (total_length // block_size) * block_size
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
+ for k, t in concatenated_examples.items()
+ }
+ result["labels"] = result["input_ids"].copy()
+ return result
+
+
+@utils.job_watcher
+def train(co2_tracker, payload, huggingface_token, model_path):
+ # create model repo
+ model_repo = utils.create_repo(
+ project_name=payload["proj_name"],
+ autotrain_user=payload["username"],
+ huggingface_token=huggingface_token,
+ model_path=model_path,
+ )
+
+ data_path = f"{payload['username']}/autotrain-data-{payload['proj_name']}"
+ data = load_dataset(data_path, use_auth_token=huggingface_token)
+ logger.info(f"Loaded data from {data_path}")
+ job_config = payload["config"]["params"][0]
+ job_config["model_name"] = payload["config"]["hub_model"]
+
+ train_data = data["train"]
+ valid_data = data["validation"]
+
+ model_name = job_config["model_name"]
+ del job_config["model_name"]
+
+ job_config = LMTrainingParams(**job_config)
+
+ tokenizer = AutoTokenizer.from_pretrained(model_name, use_auth_token=huggingface_token)
+
+ if tokenizer.model_max_length > 2048:
+ tokenizer.model_max_length = 2048
+
+ m_arch = utils.get_model_architecture(model_name).lower()
+ logger.info(f"Model architecture: {m_arch}")
+
+ use_peft = False
+ use_int8 = False
+
+ if "llama" in m_arch or "rwforcausallm" in m_arch:
+ use_peft = True
+ use_int8 = True
+
+ if "gptneo" in m_arch:
+ use_peft = True
+ use_int8 = False
+
+ # process data
+ train_data = _process_data(data=train_data, tokenizer=tokenizer, job_config=job_config)
+ valid_data = _process_data(data=valid_data, tokenizer=tokenizer, job_config=job_config)
+
+ model_config = AutoConfig.from_pretrained(
+ model_name,
+ use_auth_token=huggingface_token,
+ trust_remote_code=True,
+ )
+ logger.info(model_config)
+ if use_peft:
+ try:
+ model = AutoModelForCausalLM.from_pretrained(
+ model_name,
+ config=model_config,
+ use_auth_token=huggingface_token,
+ torch_dtype=torch.float16,
+ load_in_8bit=use_int8,
+ device_map="auto",
+ trust_remote_code=True,
+ )
+ except OSError:
+ model = AutoModelForCausalLM.from_pretrained(
+ model_name,
+ config=model_config,
+ use_auth_token=huggingface_token,
+ from_tf=True,
+ torch_dtype=torch.float16,
+ load_in_8bit=use_int8,
+ device_map="auto",
+ trust_remote_code=True,
+ )
+ else:
+ try:
+ model = AutoModelForCausalLM.from_pretrained(
+ model_name,
+ config=model_config,
+ use_auth_token=huggingface_token,
+ trust_remote_code=True,
+ )
+ except OSError:
+ model = AutoModelForCausalLM.from_pretrained(
+ model_name,
+ config=model_config,
+ use_auth_token=huggingface_token,
+ from_tf=True,
+ trust_remote_code=True,
+ )
+
+ # PEFT:
+ model.resize_token_embeddings(len(tokenizer))
+
+ if use_peft:
+ if use_int8:
+ model = prepare_model_for_int8_training(model)
+ peft_config = LoraConfig(
+ r=job_config.lora_r,
+ lora_alpha=job_config.lora_alpha,
+ lora_dropout=job_config.lora_dropout,
+ bias="none",
+ task_type="CAUSAL_LM",
+ target_modules=[
+ "query_key_value",
+ "dense",
+ "dense_h_to_4h",
+ "dense_4h_to_h",
+ ]
+ if "rwforcausallm" in m_arch
+ else None,
+ )
+ model = get_peft_model(model, peft_config)
+
+ if job_config.block_size == -1:
+ job_config.block_size = None
+
+ if job_config.block_size is None:
+ block_size = tokenizer.model_max_length
+ if block_size > 1024:
+ logger.warning(
+ "The chosen tokenizer supports a `model_max_length` that is longer than the default `block_size` value"
+ " of 1024. If you would like to use a longer `block_size` up to `tokenizer.model_max_length` you can"
+ " override this default with `--block_size xxx`."
+ )
+ block_size = 1024
+ else:
+ if job_config.block_size > tokenizer.model_max_length:
+ logger.warning(
+ f"The block_size passed ({job_config['block_size']}) is larger than the maximum length for the model"
+ f"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}."
+ )
+ block_size = min(job_config.block_size, tokenizer.model_max_length)
+
+ logger.info(model)
+
+ def tokenize_function(examples):
+ output = tokenizer(examples[TEXT_COLUMN])
+ return output
+
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+
+ if total_length >= block_size:
+ total_length = (total_length // block_size) * block_size
+
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
+ for k, t in concatenated_examples.items()
+ }
+ result["labels"] = result["input_ids"].copy()
+ return result
+
+ train_data = train_data.map(
+ tokenize_function,
+ batched=True,
+ num_proc=4,
+ remove_columns=list(train_data.features),
+ desc="Running tokenizer on train dataset",
+ )
+
+ valid_data = valid_data.map(
+ tokenize_function,
+ batched=True,
+ num_proc=4,
+ remove_columns=list(valid_data.features),
+ desc="Running tokenizer on validation dataset",
+ )
+
+ train_data = train_data.map(
+ group_texts,
+ batched=True,
+ num_proc=4,
+ desc=f"Grouping texts in chunks of {block_size}",
+ )
+ valid_data = valid_data.map(
+ group_texts,
+ batched=True,
+ num_proc=4,
+ desc=f"Grouping texts in chunks of {block_size}",
+ )
+
+ logger.info("creating trainer")
+ # trainer specific
+ logging_steps = int(0.2 * len(valid_data) / job_config.train_batch_size)
+ if logging_steps == 0:
+ logging_steps = 1
+
+ training_args = dict(
+ output_dir=model_path,
+ per_device_train_batch_size=job_config.train_batch_size,
+ per_device_eval_batch_size=2 * job_config.train_batch_size,
+ learning_rate=job_config.learning_rate,
+ num_train_epochs=job_config.num_train_epochs,
+ evaluation_strategy="epoch",
+ logging_steps=logging_steps,
+ save_total_limit=1,
+ save_strategy="epoch",
+ disable_tqdm=not bool(os.environ.get("ENABLE_TQDM", 0)),
+ gradient_accumulation_steps=job_config.gradient_accumulation_steps,
+ report_to="none",
+ auto_find_batch_size=True,
+ lr_scheduler_type=job_config.scheduler,
+ optim=job_config.optimizer,
+ warmup_ratio=job_config.warmup_ratio,
+ weight_decay=job_config.weight_decay,
+ max_grad_norm=job_config.max_grad_norm,
+ fp16=True,
+ )
+
+ args = TrainingArguments(**training_args)
+
+ trainer_args = dict(
+ args=args,
+ model=model,
+ )
+
+ data_collator = default_data_collator
+ trainer = Trainer(
+ **trainer_args,
+ train_dataset=train_data,
+ eval_dataset=valid_data,
+ tokenizer=tokenizer,
+ data_collator=data_collator,
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ logger.info("Finished training")
+ logger.info(trainer.state.best_metric)
+ eval_scores = trainer.evaluate()
+
+ # create and save model card
+ co2_consumed = co2_tracker.stop()
+ co2_consumed = co2_consumed * 1000 if co2_consumed is not None else 0
+
+ eval_scores = [f"{k[len('eval_'):]}: {v}" for k, v in eval_scores.items() if k in EVAL_METRICS]
+ eval_scores = "\n\n".join(eval_scores)
+ model_card = MODEL_CARD.format(
+ language=payload["config"]["language"],
+ dataset=data_path,
+ co2=co2_consumed,
+ validation_metrics=eval_scores,
+ )
+ logger.info(model_card)
+ utils.save_model_card(model_card, model_path)
+
+ utils.create_file(
+ filename="handler.py",
+ file_content=HANDLER_CONTENT_PEFT.strip() if use_peft else HANDLER_CONTENT.strip(),
+ model_path=model_path,
+ )
+ utils.create_file(filename="requirements.txt", file_content=REQUIREMENTS.strip(), model_path=model_path)
+
+ # save model, tokenizer and config
+ model = utils.update_model_config(trainer.model, job_config)
+ utils.save_tokenizer(tokenizer, model_path)
+ utils.save_model(model, model_path)
+ utils.remove_checkpoints(model_path=model_path)
+
+ # push model to hub
+ logger.info("Pushing model to Hub")
+ model_repo.git_pull()
+ model_repo.git_add()
+ model_repo.git_commit(commit_message="Commit From AutoTrain")
+ model_repo.git_push()
diff --git a/autotrain-advanced/src/autotrain/trainers/text_classification.py b/autotrain-advanced/src/autotrain/trainers/text_classification.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c85354bdc321cf2eda6409891a7f419fdb76fdd
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/trainers/text_classification.py
@@ -0,0 +1,278 @@
+import os
+
+import numpy as np
+import torch
+from datasets import load_dataset
+from loguru import logger
+from sklearn import metrics
+from transformers import (
+ AutoConfig,
+ AutoModelForSequenceClassification,
+ AutoTokenizer,
+ EarlyStoppingCallback,
+ Trainer,
+ TrainingArguments,
+)
+
+from autotrain import utils
+from autotrain.params import TextBinaryClassificationParams, TextMultiClassClassificationParams
+
+
+TEXT_COLUMN = "autotrain_text"
+LABEL_COLUMN = "autotrain_label"
+FP32_MODELS = ("t5", "mt5", "pegasus", "longt5", "bigbird_pegasus")
+BINARY_CLASSIFICATION_EVAL_METRICS = (
+ "eval_loss",
+ "eval_accuracy",
+ "eval_f1",
+ "eval_auc",
+ "eval_precision",
+ "eval_recall",
+)
+
+MULTI_CLASS_CLASSIFICATION_EVAL_METRICS = (
+ "eval_loss",
+ "eval_accuracy",
+ "eval_f1_macro",
+ "eval_f1_micro",
+ "eval_f1_weighted",
+ "eval_precision_macro",
+ "eval_precision_micro",
+ "eval_precision_weighted",
+ "eval_recall_macro",
+ "eval_recall_micro",
+ "eval_recall_weighted",
+)
+
+MODEL_CARD = """
+---
+tags:
+- autotrain
+- text-classification
+language:
+- {language}
+widget:
+- text: "I love AutoTrain"
+datasets:
+- {dataset}
+co2_eq_emissions:
+ emissions: {co2}
+---
+
+# Model Trained Using AutoTrain
+
+- Problem type: Text Classification
+- CO2 Emissions (in grams): {co2:.4f}
+
+## Validation Metrics
+{validation_metrics}
+"""
+
+
+class Dataset:
+ def __init__(self, data, tokenizer, label2id, config):
+ self.data = data
+ self.tokenizer = tokenizer
+ self.config = config
+ self.label2id = label2id
+
+ def __len__(self):
+ return len(self.data)
+
+ def __getitem__(self, item):
+ text = str(self.data[item][TEXT_COLUMN])
+ target = self.data[item][LABEL_COLUMN]
+ target = int(self.label2id[target])
+ inputs = self.tokenizer(
+ text,
+ max_length=self.config.max_seq_length,
+ padding="max_length",
+ truncation=True,
+ )
+
+ ids = inputs["input_ids"]
+ mask = inputs["attention_mask"]
+
+ if "token_type_ids" in inputs:
+ token_type_ids = inputs["token_type_ids"]
+ else:
+ token_type_ids = None
+
+ if token_type_ids is not None:
+ return {
+ "input_ids": torch.tensor(ids, dtype=torch.long),
+ "attention_mask": torch.tensor(mask, dtype=torch.long),
+ "token_type_ids": torch.tensor(token_type_ids, dtype=torch.long),
+ "labels": torch.tensor(target, dtype=torch.long),
+ }
+ return {
+ "input_ids": torch.tensor(ids, dtype=torch.long),
+ "attention_mask": torch.tensor(mask, dtype=torch.long),
+ "labels": torch.tensor(target, dtype=torch.long),
+ }
+
+
+def _binary_classification_metrics(pred):
+ raw_predictions, labels = pred
+ predictions = np.argmax(raw_predictions, axis=1)
+ result = {
+ "f1": metrics.f1_score(labels, predictions),
+ "precision": metrics.precision_score(labels, predictions),
+ "recall": metrics.recall_score(labels, predictions),
+ "auc": metrics.roc_auc_score(labels, raw_predictions[:, 1]),
+ "accuracy": metrics.accuracy_score(labels, predictions),
+ }
+ return result
+
+
+def _multi_class_classification_metrics(pred):
+ raw_predictions, labels = pred
+ predictions = np.argmax(raw_predictions, axis=1)
+ results = {
+ "f1_macro": metrics.f1_score(labels, predictions, average="macro"),
+ "f1_micro": metrics.f1_score(labels, predictions, average="micro"),
+ "f1_weighted": metrics.f1_score(labels, predictions, average="weighted"),
+ "precision_macro": metrics.precision_score(labels, predictions, average="macro"),
+ "precision_micro": metrics.precision_score(labels, predictions, average="micro"),
+ "precision_weighted": metrics.precision_score(labels, predictions, average="weighted"),
+ "recall_macro": metrics.recall_score(labels, predictions, average="macro"),
+ "recall_micro": metrics.recall_score(labels, predictions, average="micro"),
+ "recall_weighted": metrics.recall_score(labels, predictions, average="weighted"),
+ "accuracy": metrics.accuracy_score(labels, predictions),
+ }
+ return results
+
+
+@utils.job_watcher
+def train(co2_tracker, payload, huggingface_token, model_path):
+ model_repo = utils.create_repo(
+ project_name=payload["proj_name"],
+ autotrain_user=payload["username"],
+ huggingface_token=huggingface_token,
+ model_path=model_path,
+ )
+
+ data_path = f"{payload['username']}/autotrain-data-{payload['proj_name']}"
+ data = load_dataset(data_path, use_auth_token=huggingface_token)
+ logger.info(f"Loaded data from {data_path}")
+ job_config = payload["config"]["params"][0]
+ job_config["model_name"] = payload["config"]["hub_model"]
+
+ train_data = data["train"]
+ valid_data = data["validation"]
+ classes = train_data.unique(LABEL_COLUMN)
+ label2id = {c: i for i, c in enumerate(classes)}
+ num_classes = len(classes)
+
+ model_name = job_config["model_name"]
+ device = job_config.get("device", "cuda")
+ # remove model_name from job config
+ del job_config["model_name"]
+ if num_classes == 2:
+ job_config["task"] = "text_binary_classification"
+ job_config = TextBinaryClassificationParams(**job_config)
+ elif num_classes > 2:
+ job_config["task"] = "text_multi_class_classification"
+ job_config = TextMultiClassClassificationParams(**job_config)
+ else:
+ raise ValueError("Invalid number of classes")
+
+ model_config = AutoConfig.from_pretrained(
+ model_name,
+ num_labels=num_classes,
+ )
+
+ model_config._num_labels = len(label2id)
+ model_config.label2id = label2id
+ model_config.id2label = {v: k for k, v in label2id.items()}
+
+ logger.info(model_config)
+
+ try:
+ model = AutoModelForSequenceClassification.from_pretrained(model_name, config=model_config)
+ except OSError:
+ model = AutoModelForSequenceClassification.from_pretrained(model_name, config=model_config, from_tf=True)
+
+ tokenizer = AutoTokenizer.from_pretrained(model_name)
+
+ train_dataset = Dataset(data=train_data, tokenizer=tokenizer, label2id=label2id, config=job_config)
+ valid_dataset = Dataset(data=valid_data, tokenizer=tokenizer, label2id=label2id, config=job_config)
+
+ logging_steps = int(0.2 * len(valid_dataset) / job_config.train_batch_size)
+ if logging_steps == 0:
+ logging_steps = 1
+
+ fp16 = True
+ if model_config.model_type in FP32_MODELS or device == "cpu":
+ fp16 = False
+
+ training_args = dict(
+ output_dir="/tmp/autotrain",
+ per_device_train_batch_size=job_config.train_batch_size,
+ per_device_eval_batch_size=2 * job_config.train_batch_size,
+ learning_rate=job_config.learning_rate,
+ num_train_epochs=job_config.num_train_epochs,
+ fp16=fp16,
+ load_best_model_at_end=True,
+ evaluation_strategy="epoch",
+ logging_steps=logging_steps,
+ save_total_limit=1,
+ save_strategy="epoch",
+ disable_tqdm=not bool(os.environ.get("ENABLE_TQDM", 0)),
+ gradient_accumulation_steps=job_config.gradient_accumulation_steps,
+ report_to="none",
+ auto_find_batch_size=True,
+ lr_scheduler_type=job_config.scheduler,
+ optim=job_config.optimizer,
+ warmup_ratio=job_config.warmup_ratio,
+ weight_decay=job_config.weight_decay,
+ max_grad_norm=job_config.max_grad_norm,
+ )
+
+ early_stop = EarlyStoppingCallback(early_stopping_patience=3, early_stopping_threshold=0.01)
+ callbacks_to_use = [early_stop]
+
+ args = TrainingArguments(**training_args)
+ trainer_args = dict(
+ args=args,
+ model=model,
+ callbacks=callbacks_to_use,
+ compute_metrics=_binary_classification_metrics if num_classes == 2 else _multi_class_classification_metrics,
+ )
+
+ trainer = Trainer(
+ **trainer_args,
+ train_dataset=train_dataset,
+ eval_dataset=valid_dataset,
+ )
+ trainer.train()
+ logger.info("Finished training")
+ logger.info(trainer.state.best_metric)
+ eval_scores = trainer.evaluate()
+
+ co2_consumed = co2_tracker.stop()
+ co2_consumed = co2_consumed * 1000 if co2_consumed is not None else 0
+
+ eval_scores = [f"{k}: {v}" for k, v in eval_scores.items()]
+ eval_scores = "\n\n".join(eval_scores)
+ model_card = MODEL_CARD.format(
+ language=payload["config"]["language"],
+ dataset=data_path,
+ co2=co2_consumed,
+ validation_metrics=eval_scores,
+ )
+
+ utils.save_model_card(model_card, model_path)
+
+ # save model, tokenizer and config
+ model = utils.update_model_config(trainer.model, job_config)
+ utils.save_tokenizer(tokenizer, model_path)
+ utils.save_model(model, model_path)
+ utils.remove_checkpoints(model_path=model_path)
+
+ # push model to hub
+ logger.info("Pushing model to Hub")
+ model_repo.git_pull()
+ model_repo.git_add()
+ model_repo.git_commit(commit_message="Commit From AutoTrain")
+ model_repo.git_push()
diff --git a/autotrain-advanced/src/autotrain/trainers/utils.py b/autotrain-advanced/src/autotrain/trainers/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..bd6ebe269448cb039fa3839f5bef14237ccbe0ad
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/trainers/utils.py
@@ -0,0 +1,159 @@
+from itertools import chain
+
+import torch
+from datasets import Dataset
+from loguru import logger
+from peft import PeftModel
+from pydantic import BaseModel, Field
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+
+IGNORE_INDEX = -100
+DEFAULT_PAD_TOKEN = "[PAD]"
+DEFAULT_EOS_TOKEN = ""
+DEFAULT_BOS_TOKEN = ""
+DEFAULT_UNK_TOKEN = ""
+TARGET_MODULES = {
+ "Salesforce/codegen25-7b-multi": "q_proj,k_proj,v_proj,o_proj,down_proj,up_proj,gate_proj",
+}
+
+MODEL_CARD = """
+---
+tags:
+- autotrain
+- text-generation
+widget:
+- text: "I love AutoTrain because "
+---
+
+# Model Trained Using AutoTrain
+"""
+
+
+class LLMTrainingParams(BaseModel):
+ model_name: str = Field("gpt2", title="Model name")
+ data_path: str = Field("data", title="Data path")
+ train_split: str = Field("train", title="Train data config")
+ valid_split: str = Field(None, title="Validation data config")
+ text_column: str = Field("text", title="Text column")
+ huggingface_token: str = Field(None, title="Huggingface token")
+ learning_rate: float = Field(3e-5, title="Learning rate")
+ num_train_epochs: int = Field(1, title="Number of training epochs")
+ train_batch_size: int = Field(2, title="Training batch size")
+ eval_batch_size: int = Field(4, title="Evaluation batch size")
+ warmup_ratio: float = Field(0.1, title="Warmup proportion")
+ gradient_accumulation_steps: int = Field(1, title="Gradient accumulation steps")
+ optimizer: str = Field("adamw_torch", title="Optimizer")
+ scheduler: str = Field("linear", title="Scheduler")
+ weight_decay: float = Field(0.0, title="Weight decay")
+ max_grad_norm: float = Field(1.0, title="Max gradient norm")
+ seed: int = Field(42, title="Seed")
+ add_eos_token: bool = Field(True, title="Add EOS token")
+ block_size: int = Field(-1, title="Block size")
+ use_peft: bool = Field(False, title="Use PEFT")
+ lora_r: int = Field(16, title="Lora r")
+ lora_alpha: int = Field(32, title="Lora alpha")
+ lora_dropout: float = Field(0.05, title="Lora dropout")
+ training_type: str = Field("generic", title="Training type")
+ train_on_inputs: bool = Field(False, title="Train on inputs")
+ logging_steps: int = Field(-1, title="Logging steps")
+ project_name: str = Field("Project Name", title="Output directory")
+ evaluation_strategy: str = Field("epoch", title="Evaluation strategy")
+ save_total_limit: int = Field(1, title="Save total limit")
+ save_strategy: str = Field("epoch", title="Save strategy")
+ auto_find_batch_size: bool = Field(False, title="Auto find batch size")
+ fp16: bool = Field(False, title="FP16")
+ push_to_hub: bool = Field(False, title="Push to hub")
+ use_int8: bool = Field(False, title="Use int8")
+ model_max_length: int = Field(1024, title="Model max length")
+ repo_id: str = Field(None, title="Repo id")
+ use_int4: bool = Field(False, title="Use int4")
+ trainer: str = Field("default", title="Trainer type")
+ target_modules: str = Field(None, title="Target modules")
+
+
+def get_target_modules(config):
+ if config.target_modules is None:
+ return TARGET_MODULES.get(config.model_name)
+ return config.target_modules.split(",")
+
+
+def process_data(data, tokenizer, config):
+ data = data.to_pandas()
+ data = data.fillna("")
+
+ data = data[[config.text_column]]
+ if config.add_eos_token:
+ data[config.text_column] = data[config.text_column] + tokenizer.eos_token
+ data = Dataset.from_pandas(data)
+ return data
+
+
+def group_texts(examples, config):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
+ # customize this part to your needs.
+ if total_length >= config.block_size:
+ total_length = (total_length // config.block_size) * config.block_size
+ else:
+ total_length = 0
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + config.block_size] for i in range(0, total_length, config.block_size)]
+ for k, t in concatenated_examples.items()
+ }
+ result["labels"] = result["input_ids"].copy()
+ return result
+
+
+def tokenize(examples, tokenizer, config):
+ output = tokenizer(examples[config.text_column])
+ return output
+
+
+def _tokenize(prompt, tokenizer, config):
+ result = tokenizer(
+ prompt,
+ truncation=True,
+ max_length=tokenizer.model_max_length,
+ padding=False,
+ return_tensors=None,
+ )
+ if result["input_ids"][-1] != tokenizer.eos_token_id and config.add_eos_token:
+ if len(result["input_ids"]) >= tokenizer.model_max_length:
+ result["input_ids"] = result["input_ids"][:-1]
+ result["attention_mask"] = result["attention_mask"][:-1]
+ result["input_ids"].append(tokenizer.eos_token_id)
+ result["attention_mask"].append(1)
+
+ result["labels"] = result["input_ids"].copy()
+
+ return result
+
+
+def merge_adapter(base_model_path, target_model_path, adapter_path):
+ logger.info("Loading adapter...")
+ model = AutoModelForCausalLM.from_pretrained(
+ base_model_path,
+ torch_dtype=torch.float16,
+ low_cpu_mem_usage=True,
+ trust_remote_code=True,
+ )
+
+ model = PeftModel.from_pretrained(model, adapter_path)
+
+ tokenizer = AutoTokenizer.from_pretrained(
+ base_model_path,
+ trust_remote_code=True,
+ )
+ model = model.merge_and_unload()
+
+ logger.info("Saving target model...")
+ model.save_pretrained(target_model_path)
+ tokenizer.save_pretrained(target_model_path)
+
+
+def create_model_card():
+ return MODEL_CARD.strip()
diff --git a/autotrain-advanced/src/autotrain/utils.py b/autotrain-advanced/src/autotrain/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..ca80577fa633500f119b4b18986a601a0591b423
--- /dev/null
+++ b/autotrain-advanced/src/autotrain/utils.py
@@ -0,0 +1,274 @@
+import glob
+import json
+import os
+import re
+import shutil
+import subprocess
+import traceback
+from typing import Dict, Optional
+
+import requests
+from huggingface_hub import HfApi, HfFolder
+from huggingface_hub.repository import Repository
+from loguru import logger
+from transformers import AutoConfig
+
+from autotrain import config
+from autotrain.tasks import TASKS
+
+
+FORMAT_TAG = "\033[{code}m"
+RESET_TAG = FORMAT_TAG.format(code=0)
+BOLD_TAG = FORMAT_TAG.format(code=1)
+RED_TAG = FORMAT_TAG.format(code=91)
+GREEN_TAG = FORMAT_TAG.format(code=92)
+YELLOW_TAG = FORMAT_TAG.format(code=93)
+PURPLE_TAG = FORMAT_TAG.format(code=95)
+CYAN_TAG = FORMAT_TAG.format(code=96)
+
+LFS_PATTERNS = [
+ "*.bin.*",
+ "*.lfs.*",
+ "*.bin",
+ "*.h5",
+ "*.tflite",
+ "*.tar.gz",
+ "*.ot",
+ "*.onnx",
+ "*.pt",
+ "*.pkl",
+ "*.parquet",
+ "*.joblib",
+ "tokenizer.json",
+]
+
+
+class UnauthenticatedError(Exception):
+ pass
+
+
+class UnreachableAPIError(Exception):
+ pass
+
+
+def get_auth_headers(token: str, prefix: str = "Bearer"):
+ return {"Authorization": f"{prefix} {token}"}
+
+
+def http_get(
+ path: str,
+ token: str,
+ domain: str = config.AUTOTRAIN_BACKEND_API,
+ token_prefix: str = "Bearer",
+ suppress_logs: bool = False,
+ **kwargs,
+) -> requests.Response:
+ """HTTP GET request to the AutoNLP API, raises UnreachableAPIError if the API cannot be reached"""
+ logger.info(f"Sending GET request to {domain + path}")
+ try:
+ response = requests.get(
+ url=domain + path, headers=get_auth_headers(token=token, prefix=token_prefix), **kwargs
+ )
+ except requests.exceptions.ConnectionError:
+ raise UnreachableAPIError("❌ Failed to reach AutoNLP API, check your internet connection")
+ response.raise_for_status()
+ return response
+
+
+def http_post(
+ path: str,
+ token: str,
+ payload: Optional[Dict] = None,
+ domain: str = config.AUTOTRAIN_BACKEND_API,
+ suppress_logs: bool = False,
+ **kwargs,
+) -> requests.Response:
+ """HTTP POST request to the AutoNLP API, raises UnreachableAPIError if the API cannot be reached"""
+ logger.info(f"Sending POST request to {domain + path}")
+ try:
+ response = requests.post(
+ url=domain + path, json=payload, headers=get_auth_headers(token=token), allow_redirects=True, **kwargs
+ )
+ except requests.exceptions.ConnectionError:
+ raise UnreachableAPIError("❌ Failed to reach AutoNLP API, check your internet connection")
+ response.raise_for_status()
+ return response
+
+
+def get_task(task_id: int) -> str:
+ for key, value in TASKS.items():
+ if value == task_id:
+ return key
+ return "❌ Unsupported task! Please update autonlp"
+
+
+def get_user_token():
+ return HfFolder.get_token()
+
+
+def user_authentication(token):
+ logger.info("Authenticating user...")
+ headers = {}
+ cookies = {}
+ if token.startswith("hf_"):
+ headers["Authorization"] = f"Bearer {token}"
+ else:
+ cookies = {"token": token}
+ try:
+ response = requests.get(
+ config.HF_API + "/api/whoami-v2",
+ headers=headers,
+ cookies=cookies,
+ timeout=3,
+ )
+ except (requests.Timeout, ConnectionError) as err:
+ logger.error(f"Failed to request whoami-v2 - {repr(err)}")
+ raise Exception("Hugging Face Hub is unreachable, please try again later.")
+ return response.json()
+
+
+def get_project_cost(username, token, task, num_samples, num_models):
+ logger.info("Getting project cost...")
+ task_id = TASKS[task]
+ pricing = http_get(
+ path=f"/pricing/compute?username={username}&task_id={task_id}&num_samples={num_samples}&num_models={num_models}",
+ token=token,
+ )
+ return pricing.json()["price"]
+
+
+def app_error_handler(func):
+ def wrapper(*args, **kwargs):
+ try:
+ return func(*args, **kwargs)
+ except Exception as err:
+ logger.error(f"{func.__name__} has failed due to an exception:")
+ logger.error(traceback.format_exc())
+ if "param_choice" in str(err):
+ ValueError("Unable to estimate costs. Job params not chosen yet.")
+ elif "Failed to reach AutoNLP API" in str(err):
+ ValueError("Unable to reach AutoTrain API. Please check your internet connection.")
+ elif "An error has occurred: 'NoneType' object has no attribute 'type'" in str(err):
+ ValueError("Unable to estimate costs. Data not uploaded yet.")
+ else:
+ ValueError(f"An error has occurred: {err}")
+
+ return wrapper
+
+
+def clone_hf_repo(repo_url: str, local_dir: str, token: str) -> Repository:
+ os.makedirs(local_dir, exist_ok=True)
+ repo_url = re.sub(r"(https?://)", rf"\1user:{token}@", repo_url)
+ subprocess.run(
+ "git lfs install".split(),
+ stderr=subprocess.PIPE,
+ stdout=subprocess.PIPE,
+ check=True,
+ encoding="utf-8",
+ cwd=local_dir,
+ )
+
+ subprocess.run(
+ f"git lfs clone {repo_url} .".split(),
+ stderr=subprocess.PIPE,
+ stdout=subprocess.PIPE,
+ check=True,
+ encoding="utf-8",
+ cwd=local_dir,
+ )
+
+ data_repo = Repository(local_dir=local_dir, use_auth_token=token)
+ return data_repo
+
+
+def create_repo(project_name, autotrain_user, huggingface_token, model_path):
+ repo_name = f"autotrain-{project_name}"
+ repo_url = HfApi().create_repo(
+ repo_id=f"{autotrain_user}/{repo_name}",
+ token=huggingface_token,
+ exist_ok=False,
+ private=True,
+ )
+ if len(repo_url.strip()) == 0:
+ repo_url = f"https://huggingface.co/{autotrain_user}/{repo_name}"
+
+ logger.info(f"Created repo: {repo_url}")
+
+ model_repo = clone_hf_repo(
+ local_dir=model_path,
+ repo_url=repo_url,
+ token=huggingface_token,
+ )
+ model_repo.lfs_track(patterns=LFS_PATTERNS)
+ return model_repo
+
+
+def save_model(torch_model, model_path):
+ torch_model.save_pretrained(model_path)
+ try:
+ torch_model.save_pretrained(model_path, safe_serialization=True)
+ except Exception as e:
+ logger.error(f"Safe serialization failed with error: {e}")
+
+
+def save_tokenizer(tok, model_path):
+ tok.save_pretrained(model_path)
+
+
+def update_model_config(model, job_config):
+ model.config._name_or_path = "AutoTrain"
+ if job_config.task in ("speech_recognition", "summarization"):
+ return model
+ if "max_seq_length" in job_config:
+ model.config.max_length = job_config.max_seq_length
+ model.config.padding = "max_length"
+ return model
+
+
+def save_model_card(model_card, model_path):
+ with open(os.path.join(model_path, "README.md"), "w") as fp:
+ fp.write(f"{model_card}")
+
+
+def create_file(filename, file_content, model_path):
+ with open(os.path.join(model_path, filename), "w") as fp:
+ fp.write(f"{file_content}")
+
+
+def save_config(conf, model_path):
+ with open(os.path.join(model_path, "config.json"), "w") as fp:
+ json.dump(conf, fp)
+
+
+def remove_checkpoints(model_path):
+ subfolders = glob.glob(os.path.join(model_path, "*/"))
+ for subfolder in subfolders:
+ shutil.rmtree(subfolder)
+ try:
+ os.remove(os.path.join(model_path, "emissions.csv"))
+ except OSError:
+ pass
+
+
+def job_watcher(func):
+ def wrapper(co2_tracker, *args, **kwargs):
+ try:
+ return func(co2_tracker, *args, **kwargs)
+ except Exception:
+ logger.error(f"{func.__name__} has failed due to an exception:")
+ logger.error(traceback.format_exc())
+ co2_tracker.stop()
+ # delete training tracker file
+ os.remove(os.path.join("/tmp", "training"))
+
+ return wrapper
+
+
+def get_model_architecture(model_path_or_name: str, revision: str = "main") -> str:
+ config = AutoConfig.from_pretrained(model_path_or_name, revision=revision, trust_remote_code=True)
+ architectures = config.architectures
+ if architectures is None or len(architectures) > 1:
+ raise ValueError(
+ f"The model architecture is either not defined or not unique. Found architectures: {architectures}"
+ )
+ return architectures[0]
diff --git a/autotrain-advanced/static/autotrain_model_choice.png b/autotrain-advanced/static/autotrain_model_choice.png
new file mode 100644
index 0000000000000000000000000000000000000000..7830d0fa03e9f718ccd7bd692f9aebb58248a3dd
Binary files /dev/null and b/autotrain-advanced/static/autotrain_model_choice.png differ
diff --git a/autotrain-advanced/static/cost.png b/autotrain-advanced/static/cost.png
new file mode 100644
index 0000000000000000000000000000000000000000..bcb034a70fc7dafa67c5930d4f5621b0949827c7
Binary files /dev/null and b/autotrain-advanced/static/cost.png differ
diff --git a/autotrain-advanced/static/dreambooth1.jpeg b/autotrain-advanced/static/dreambooth1.jpeg
new file mode 100644
index 0000000000000000000000000000000000000000..6f60f556e64b53b330d528c3059feb34475237e2
Binary files /dev/null and b/autotrain-advanced/static/dreambooth1.jpeg differ
diff --git a/autotrain-advanced/static/dreambooth2.png b/autotrain-advanced/static/dreambooth2.png
new file mode 100644
index 0000000000000000000000000000000000000000..a1aeca75bf80714447b1c2cf1791098d57904eb3
Binary files /dev/null and b/autotrain-advanced/static/dreambooth2.png differ
diff --git a/autotrain-advanced/static/hub_model_choice.png b/autotrain-advanced/static/hub_model_choice.png
new file mode 100644
index 0000000000000000000000000000000000000000..e62000ab8f7f53b20073be68786339d5720c436e
Binary files /dev/null and b/autotrain-advanced/static/hub_model_choice.png differ
diff --git a/autotrain-advanced/static/image_classification_1.png b/autotrain-advanced/static/image_classification_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..6d8f7e663949b7135ee3e3e9095be580844df67a
Binary files /dev/null and b/autotrain-advanced/static/image_classification_1.png differ
diff --git a/autotrain-advanced/static/llm_1.png b/autotrain-advanced/static/llm_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..0e46d80169849e1255fb68d873cdb651cb20e0f9
Binary files /dev/null and b/autotrain-advanced/static/llm_1.png differ
diff --git a/autotrain-advanced/static/llm_2.png b/autotrain-advanced/static/llm_2.png
new file mode 100644
index 0000000000000000000000000000000000000000..25926b7b493dc69ce6ced456e963c70d64a02cd8
Binary files /dev/null and b/autotrain-advanced/static/llm_2.png differ
diff --git a/autotrain-advanced/static/llm_3.png b/autotrain-advanced/static/llm_3.png
new file mode 100644
index 0000000000000000000000000000000000000000..4397aad0795121e66989a07897b527f83889253a
Binary files /dev/null and b/autotrain-advanced/static/llm_3.png differ
diff --git a/autotrain-advanced/static/model_choice_1.png b/autotrain-advanced/static/model_choice_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..7830d0fa03e9f718ccd7bd692f9aebb58248a3dd
Binary files /dev/null and b/autotrain-advanced/static/model_choice_1.png differ
diff --git a/autotrain-advanced/static/param_choice_1.png b/autotrain-advanced/static/param_choice_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..5f07f2e4e9665a2099bab2975203e99f9819f7c0
Binary files /dev/null and b/autotrain-advanced/static/param_choice_1.png differ
diff --git a/autotrain-advanced/static/param_choice_2.png b/autotrain-advanced/static/param_choice_2.png
new file mode 100644
index 0000000000000000000000000000000000000000..c4492ff020c39b1da993d716ccb5423535d6de8f
Binary files /dev/null and b/autotrain-advanced/static/param_choice_2.png differ
diff --git a/autotrain-advanced/static/space_template_1.png b/autotrain-advanced/static/space_template_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..0d448c634d4e1bb6696399926eb2290db7d72140
Binary files /dev/null and b/autotrain-advanced/static/space_template_1.png differ
diff --git a/autotrain-advanced/static/space_template_2.png b/autotrain-advanced/static/space_template_2.png
new file mode 100644
index 0000000000000000000000000000000000000000..adf21e39a27e3c7b6c64d2d3c86e30a170562855
Binary files /dev/null and b/autotrain-advanced/static/space_template_2.png differ
diff --git a/autotrain-advanced/static/space_template_3.png b/autotrain-advanced/static/space_template_3.png
new file mode 100644
index 0000000000000000000000000000000000000000..00266eeeda6f88364bbb42a33d6f30db338cf339
Binary files /dev/null and b/autotrain-advanced/static/space_template_3.png differ
diff --git a/autotrain-advanced/static/space_template_4.png b/autotrain-advanced/static/space_template_4.png
new file mode 100644
index 0000000000000000000000000000000000000000..bd5d5e64642d103949d2a84f00df1912bbc4a973
Binary files /dev/null and b/autotrain-advanced/static/space_template_4.png differ
diff --git a/autotrain-advanced/static/space_template_5.png b/autotrain-advanced/static/space_template_5.png
new file mode 100644
index 0000000000000000000000000000000000000000..310b01b31d136a8055fdc4e1d0b811e8ca00d2da
Binary files /dev/null and b/autotrain-advanced/static/space_template_5.png differ
diff --git a/autotrain-advanced/static/text_classification_1.png b/autotrain-advanced/static/text_classification_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..aea55f840ad6bf4103359faabc7afb6b947980b9
Binary files /dev/null and b/autotrain-advanced/static/text_classification_1.png differ
diff --git a/pytorch_lora_weights.safetensors b/pytorch_lora_weights.safetensors
new file mode 100644
index 0000000000000000000000000000000000000000..b396e89b54940eaf2b5f5fe1593dc1384a6f058f
--- /dev/null
+++ b/pytorch_lora_weights.safetensors
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:20caf8c455aafe8d035e181eb6e46c4baf10ea732e708de437c1a8a3aee34458
+size 23401064
diff --git a/state.db b/state.db
new file mode 100644
index 0000000000000000000000000000000000000000..2ebf984baacbd27b459d1f274bc65ab99bd0c27b
Binary files /dev/null and b/state.db differ