

Create README.md
Browse files# SmolLM3 Checkpoints
We are releasing intermediate checkpoints of SmolLM3 to enable further research.
## Pre-training
We release checkpoints every 40,000 steps, which equals 94.4B tokens.
The GBS (Global Batch Size) in tokens for SmolLM3-3B is 2,359,296. To calculate the number of tokens from a given step:
```python
nb_tokens = nb_step * GBS
```
### Training Stages
**Stage 1:** Steps 0 to 3,450,000 (86 checkpoints)
[config](https://huggingface.co/datasets/HuggingFaceTB/smollm3-configs/blob/main/stage1_8T.yaml)
**Stage 2:** Steps 3,450,000 to 4,200,000 (19 checkpoints)
[config](https://huggingface.co/datasets/HuggingFaceTB/smollm3-configs/blob/main/stage2_8T_9T.yaml)
**Stage 3:** Steps 4,200,000 to 4,720,000 (13 checkpoints)
[config](https://huggingface.co/datasets/HuggingFaceTB/smollm3-configs/blob/main/stage3_9T_11T.yaml)

### Long Context Extension
For the additional 2 stages that extend the context length to 64k, we sample checkpoints every 4,000 steps (9.4B tokens) for a total of 10 checkpoints:
**Long Context 4k to 32k**
[config](https://huggingface.co/datasets/HuggingFaceTB/smollm3-configs/blob/main/long_context_4k_to_32k.yaml)
**Long Context 32k to 64k**
[config](https://huggingface.co/datasets/HuggingFaceTB/smollm3-configs/blob/main/long_context_32k_to_64k.yaml)

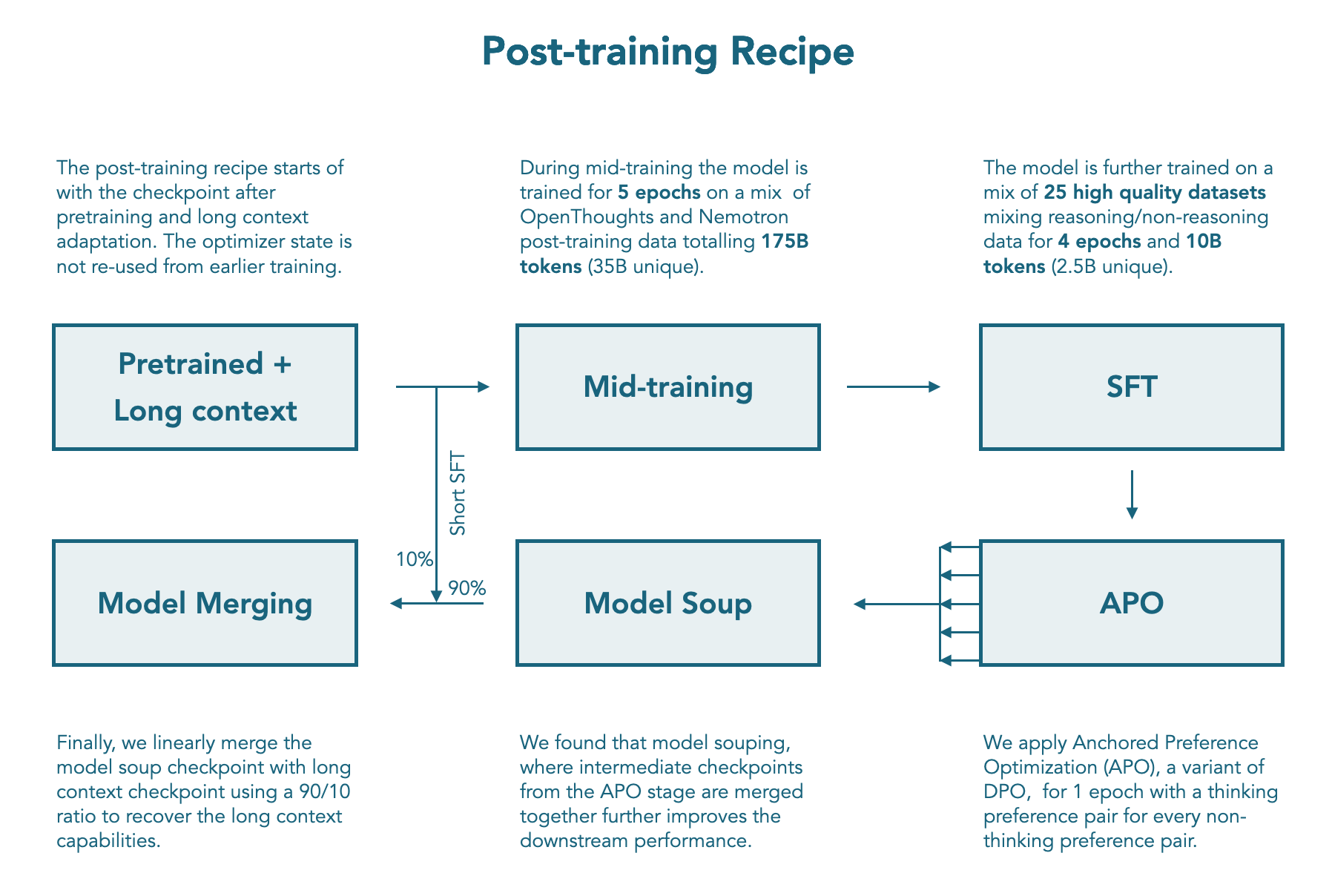
## Post-training
We release checkpoints at every step of our post-training recipe: Mid training, SFT, APO soup, and LC expert.
## How to Load a Checkpoint
```python
# pip install transformers
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceTB/SmolLM3-3B-checkpoints"
revision = "stage1-step-40000" # replace by the revision you want
device = torch.device("cuda" if torch.cuda.is_available() else "mps" if hasattr(torch, 'mps') and torch.mps.is_available() else "cpu")
tokenizer = AutoTokenizer.from_pretrained(checkpoint, revision=revision)
model = AutoModelForCausalLM.from_pretrained(checkpoint, revision=revision).to(device)
inputs = tokenizer.encode("Gravity is", return_tensors="pt").to(device)
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
## License
[Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)