


Commit ·
2924d8d
0
Parent(s):
Duplicate from mistralai/Voxtral-Mini-4B-Realtime-2602
Browse filesCo-authored-by: Patrick von Platen <patrickvonplaten@users.noreply.huggingface.co>
- .gitattributes +36 -0
- README.md +280 -0
- config.json +60 -0
- consolidated.safetensors +3 -0
- generation_config.json +9 -0
- model.safetensors +3 -0
- params.json +55 -0
- processor_config.json +15 -0
- tekken.json +3 -0
.gitattributes
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tekken.json filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,280 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: vllm
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
- fr
|
| 6 |
+
- es
|
| 7 |
+
- de
|
| 8 |
+
- ru
|
| 9 |
+
- zh
|
| 10 |
+
- ja
|
| 11 |
+
- it
|
| 12 |
+
- pt
|
| 13 |
+
- nl
|
| 14 |
+
- ar
|
| 15 |
+
- hi
|
| 16 |
+
- ko
|
| 17 |
+
license: apache-2.0
|
| 18 |
+
inference: false
|
| 19 |
+
base_model:
|
| 20 |
+
- mistralai/Ministral-3-3B-Base-2512
|
| 21 |
+
extra_gated_description: >-
|
| 22 |
+
If you want to learn more about how we process your personal data, please read
|
| 23 |
+
our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
|
| 24 |
+
pipeline_tag: automatic-speech-recognition
|
| 25 |
+
tags:
|
| 26 |
+
- mistral-common
|
| 27 |
+
---
|
| 28 |
+
|
| 29 |
+
# Voxtral Mini 4B Realtime 2602
|
| 30 |
+
|
| 31 |
+
Voxtral Mini 4B Realtime 2602 is a **multilingual, realtime speech-transcription model** and among the first open-source solutions to achieve accuracy comparable to offline systems with a delay of **<500ms**.
|
| 32 |
+
It supports **13 languages** and outperforms existing open-source baselines across a range of tasks, making it ideal for applications like voice assistants and live subtitling.
|
| 33 |
+
|
| 34 |
+
Built with a **natively streaming architecture** and a custom causal audio encoder - it allows configurable transcription delays (240ms to 2.4s), enabling users to balance **latency and accuracy** based on their needs.
|
| 35 |
+
At a **480ms delay**, it matches the performance of leading offline open-source transcription models, as well as realtime APIs.
|
| 36 |
+
|
| 37 |
+
As a **4B-parameter model**, is optimized for **on-device deployment**, requiring minimal hardware resources.
|
| 38 |
+
It runs in realtime with on devices minimal hardware with throughput exceeding 12.5 tokens/second.
|
| 39 |
+
|
| 40 |
+
This model is released in **BF16** under the **Apache-2 license**, ensuring flexibility for both research and commercial use.
|
| 41 |
+
|
| 42 |
+
For more details, see our:
|
| 43 |
+
- [Blog post](https://mistral.ai/news/voxtral-transcribe-2)
|
| 44 |
+
- [Demo](https://huggingface.co/spaces/mistralai/Voxtral-Mini-Realtime)
|
| 45 |
+
- [Technical report](https://arxiv.org/abs/2602.11298)
|
| 46 |
+
- [vLLM's blog on streaming input](https://blog.vllm.ai/2026/01/31/streaming-realtime.html)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
## Key Features
|
| 50 |
+
Voxtral Mini 4B Realtime consists of two main architectural components:
|
| 51 |
+
- **≈3.4B Language Model**
|
| 52 |
+
- **≈970M Audio Encoder**
|
| 53 |
+
- The audio encoder was trained from scratch with causal attention enabling streaming capability
|
| 54 |
+
- Both the audio encoder as well as the LLM backbone use sliding window attention allowing for "infinite" streaming
|
| 55 |
+
- For more details, refer to the [technical report](https://arxiv.org/abs/2602.11298)
|
| 56 |
+
|
| 57 |
+
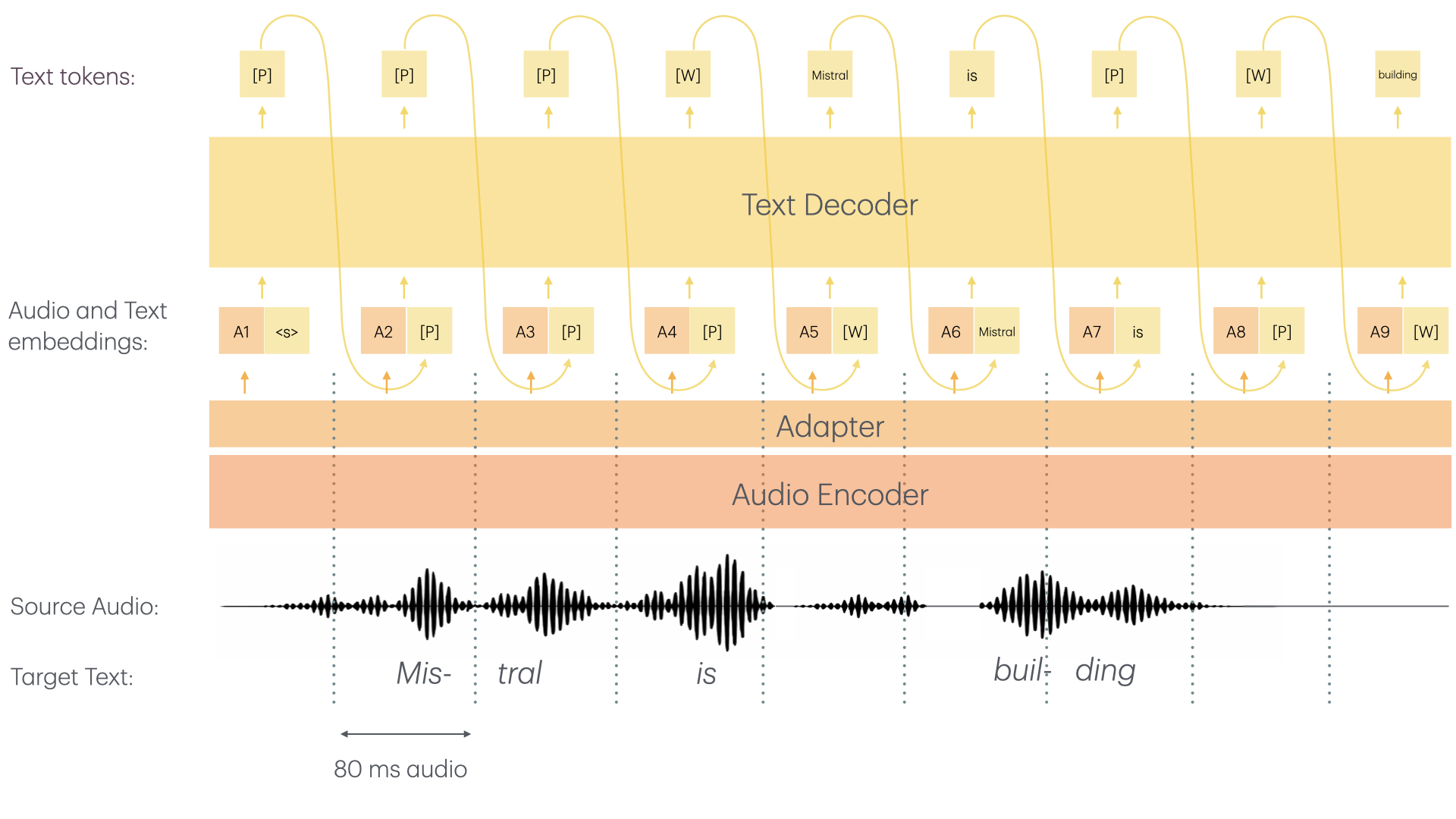
|
| 58 |
+
|
| 59 |
+
The Voxtral Mini 4B Realtime model offers the following capabilities:
|
| 60 |
+
- **High-Quality Transcription**: Transcribe audio to text with confidence.
|
| 61 |
+
- **Multilingual**: Supports dozens of languages, making it perfect for multilingual transcription tasks.
|
| 62 |
+
- **Real-Time**: Fast streaming ASR model, enabling real-time transcription use cases.
|
| 63 |
+
- **Configurable Transcription Delays**: Customize the transcription delay to balance quality and latency, from 80ms to 2.4s.
|
| 64 |
+
|
| 65 |
+
### Use Cases
|
| 66 |
+
**Real-Time Transcription Purposes:**
|
| 67 |
+
- Private meeting transcriptions
|
| 68 |
+
- Live subtitle creation
|
| 69 |
+
- Real-time assistants with speech understanding
|
| 70 |
+
- And more
|
| 71 |
+
|
| 72 |
+
Bringing real-time transcription capabilities to all.
|
| 73 |
+
|
| 74 |
+
### Recommended Settings
|
| 75 |
+
|
| 76 |
+
We recommend deploying with the following best practices:
|
| 77 |
+
- Always set the temperature to 0.0
|
| 78 |
+
- A single text-token is worth 80ms. Hence, make sure to set your `--max-model-len` accordingly. To live-record a 1h meeting, you need to set `--max-model-len >= 3600 / 0.8 = 45000`.
|
| 79 |
+
In theory, you should be able to record with no limit; in practice, pre-allocations of RoPE parameters among other things limits `--max-model-len`.
|
| 80 |
+
For the best user experience, we recommend to simply instantiate vLLM with the default parameters which will automatically set a maximum model length of 131072 (~ca. 3h).
|
| 81 |
+
- We strongly recommend using websockets to set up audio streaming sessions. For more info on how to do so, check [Usage](#usage).
|
| 82 |
+
- We recommend using a delay of 480ms as we found it to be the sweet spot of performance and low latency. If, however, you want to adapt the delay, you can change the `"transcription_delay_ms": 480` parameter
|
| 83 |
+
in the [tekken.json](https://huggingface.co/mistralai/Voxtral-Mini-4B-Realtime-2602/blob/main/tekken.json) file to any multiple of 80ms between 80 and 1200, as well as 2400 as a standalone value.
|
| 84 |
+
|
| 85 |
+
## Benchmark Results
|
| 86 |
+
|
| 87 |
+
We compare Voxtral Mini 4B Realtime to similar models - both offline models and realtime.
|
| 88 |
+
Voxtral Mini 4B Realtime is competitive to leading offline models and shows significant gains over existing open-source realtime solutions.
|
| 89 |
+
|
| 90 |
+
### Fleurs
|
| 91 |
+
|
| 92 |
+
| Model | Delay | AVG | Arabic | German | English | Spanish | French | Hindi | Italian | Dutch | Portuguese | Chinese | Japanese | Korean | Russian |
|
| 93 |
+
|-----------------------------------------|-------------|---------|--------|--------|---------|---------|--------|--------|---------|-------|------------|---------|----------|--------|---------|
|
| 94 |
+
| Voxtral Mini Transcribe 2.0 | Offline | 5.90% | 13.54% | 3.54% | 3.32% | 2.63% | 4.32% | 10.33% | 2.17% | 4.78% | 3.56% | 7.30% | 4.14% | 12.29% | 4.75% |
|
| 95 |
+
| **Voxtral Mini 4B Realtime 2602** | 480 ms | 8.72% | 22.53% | 6.19% | 4.90% | 3.31% | 6.42% | 12.88% | 3.27% | 7.07% | 5.03% | 10.45% | 9.59% | 15.74% | 6.02% |
|
| 96 |
+
| | | | | | | | | | | | | | | | |
|
| 97 |
+
| | 160 ms | 12.60% | 24.33% | 9.50% | 6.46% | 5.34% | 9.75% | 15.28% | 5.59% | 11.39%| 10.01% | 17.67% | 19.17% | 19.81% | 9.53% |
|
| 98 |
+
| | 240 ms | 10.80% | 23.95% | 8.15% | 5.91% | 4.59% | 8.00% | 14.26% | 4.41% | 9.23% | 7.51% | 13.84% | 15.17% | 17.56% | 7.87% |
|
| 99 |
+
| | 960 ms | 7.70% | 20.32% | 4.87% | 4.34% | 2.98% | 5.68% | 11.82% | 2.46% | 6.76% | 4.57% | 8.99% | 6.80% | 14.90% | 5.56% |
|
| 100 |
+
| | 2400 ms | 6.73% | 14.71% | 4.15% | 4.05% | 2.71% | 5.23% | 10.73% | 2.37% | 5.91% | 3.93% | 8.48% | 5.50% | 14.30% | 5.41% |
|
| 101 |
+
|
| 102 |
+
### Long-form English
|
| 103 |
+
|
| 104 |
+
| Model | Delay | Meanwhile (<10m) | E-21 (<10m) | E-22 (<10m) | TEDLIUM (<20m) |
|
| 105 |
+
| ---------------------------------- | ------ | ---------------- | ----------- | ----------- | -------------- |
|
| 106 |
+
| Voxtral Mini Transcribe 2.0 | Offline| 4.08% | 9.81% | 11.69% | 2.86% |
|
| 107 |
+
| **Voxtral Mini 4B Realtime 2602** | 480ms | 5.05% | 10.23% | 12.30% | 3.17% |
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
### Short-form English
|
| 111 |
+
|
| 112 |
+
| Model | Delay | CHiME-4 | GigaSpeech 2k Subset | AMI IHM | SwitchBoard | CHiME-4 SP | GISpeech 2k Subset |
|
| 113 |
+
| ---------------------------------- | ------ | ------- | -------------------- | ------- | ----------- | ---------- | ------------------ |
|
| 114 |
+
| Voxtral Mini Transcribe 2.0 | Offline | 10.39% | 6.81% | 14.43% | 11.54% | 10.42% | 1.74% |
|
| 115 |
+
| **Voxtral Mini 4B Realtime 2602** | 480ms | 10.50% | 7.35% | 15.05% | 11.65% | 12.41% | 1.73% |
|
| 116 |
+
|
| 117 |
+
## Usage
|
| 118 |
+
|
| 119 |
+
The model can also be deployed with the following libraries:
|
| 120 |
+
- [`vllm (recommended)`](https://github.com/vllm-project/vllm): See [here](#vllm-recommended)
|
| 121 |
+
- [`transformers`](https://github.com/huggingface/transformers): See [here](#transformers)
|
| 122 |
+
- [`executorch` (untested)](https://github.com/pytorch/executorch/tree/main/examples/models/voxtral_realtime): See [here](#executorch-untested)
|
| 123 |
+
|
| 124 |
+
- *Community Contributions*: See [here](#community-contributions-untested)
|
| 125 |
+
|
| 126 |
+
### vLLM (recommended)
|
| 127 |
+
|
| 128 |
+
> [!Tip]
|
| 129 |
+
> We've worked hand-in-hand with the vLLM team to have production-grade support for Voxtral Mini 4B Realtime 2602 with vLLM.
|
| 130 |
+
> Special thanks goes out to [Joshua Deng](https://github.com/joshuadeng), [Yu Luo](https://github.com/ErickLuo90), [Chen Zhang](https://github.com/heheda12345), [Nick Hill](https://github.com/njhill), [Nicolò Lucchesi](https://github.com/NickLucche), [Roger Wang](https://github.com/ywang96), and [Cyrus Leung](https://github.com/DarkLight1337)
|
| 131 |
+
> for the amazing work and help on building a production-ready audio streaming and realtime system in vLLM.
|
| 132 |
+
|
| 133 |
+
> [!Warning]
|
| 134 |
+
> Due to its novel architecture, Voxtral Realtime is currently only support in vLLM. We very much welcome community contributions
|
| 135 |
+
> to add the architecture to [Transformers](https://github.com/huggingface/transformers) and [Llama.cpp](https://github.com/ggml-org/llama.cpp).
|
| 136 |
+
|
| 137 |
+
We've worked hand-in-hand with the vLLM team to have production-grade support for Voxtral Mini 4B Realtime 2602 with vLLM.
|
| 138 |
+
[vLLM](https://github.com/vllm-project/vllm)'s [new Realtime API](https://docs.vllm.ai/en/latest/serving/openai_compatible_server/?h=realtime#realtime-api) is perfectly suited to
|
| 139 |
+
run audio streaming sessions with the model.
|
| 140 |
+
|
| 141 |
+
#### Installation
|
| 142 |
+
|
| 143 |
+
Make sure to install [vllm](https://github.com/vllm-project/vllm) from the nightly pypi package.
|
| 144 |
+
See [here](https://docs.vllm.ai/en/latest/getting_started/installation/) for a full installation guide.
|
| 145 |
+
|
| 146 |
+
```
|
| 147 |
+
uv pip install -U vllm
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
Doing so should automatically install [`mistral_common >= 1.9.0`](https://github.com/mistralai/mistral-common/releases/tag/v1.9.0).
|
| 151 |
+
|
| 152 |
+
To check:
|
| 153 |
+
```
|
| 154 |
+
python -c "import mistral_common; print(mistral_common.__version__)"
|
| 155 |
+
```
|
| 156 |
+
|
| 157 |
+
You can also make use of a ready-to-go [docker image](https://github.com/vllm-project/vllm/blob/main/docker/Dockerfile) or on the [docker hub](https://hub.docker.com/layers/vllm/vllm-openai/nightly/images/sha256-6ae33f5001ab9d32346ce2c82c660fe57021c4f0c162ed0c60b843319829b810).
|
| 158 |
+
|
| 159 |
+
Make sure to also install all required audio processing libraries:
|
| 160 |
+
|
| 161 |
+
```
|
| 162 |
+
uv pip install soxr librosa soundfile
|
| 163 |
+
```
|
| 164 |
+
|
| 165 |
+
Also we recommend using Transformers v5 as v4 can clutter the terminal with unnecessary warnings (see [here](https://github.com/vllm-project/vllm/issues/34642))
|
| 166 |
+
|
| 167 |
+
```
|
| 168 |
+
uv pip install --upgrade transformers
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
#### Serve
|
| 172 |
+
|
| 173 |
+
Due to size and the BF16 format of the weights - `Voxtral-Mini-4B-Realtime-2602` can run on a single GPU with >= 16GB memory.
|
| 174 |
+
|
| 175 |
+
The model can be launched in both "eager" mode:
|
| 176 |
+
|
| 177 |
+
```bash
|
| 178 |
+
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve mistralai/Voxtral-Mini-4B-Realtime-2602 --compilation_config '{"cudagraph_mode": "PIECEWISE"}'
|
| 179 |
+
```
|
| 180 |
+
|
| 181 |
+
Additional flags:
|
| 182 |
+
* You can set `--max-num-batched-tokens` to balance throughput and latency, higher means higher throughput but higher latency.
|
| 183 |
+
* You can reduce the default `--max-model-len` to allocate less memory for the pre-computed RoPE frequencies,
|
| 184 |
+
if you are certain that you won't have to transcribe for more than X hours. By default the model uses a `--max-model-len` of 131072 (> 3h).
|
| 185 |
+
|
| 186 |
+
#### Client
|
| 187 |
+
|
| 188 |
+
After serving `vllm`, you should see that the model is compatible with `vllm's` new realtime endpoint:
|
| 189 |
+
```
|
| 190 |
+
...
|
| 191 |
+
(APIServer pid=3246965) INFO 02-03 17:04:43 [launcher.py:58] Route: /v1/realtime, Endpoint: realtime_endpoint
|
| 192 |
+
...
|
| 193 |
+
```
|
| 194 |
+
|
| 195 |
+
We have added two simple example files that allow you to:
|
| 196 |
+
- [Stream audio files](https://docs.vllm.ai/en/latest/examples/online_serving/openai_realtime_client/?h=realtime#openai-realtime-client)
|
| 197 |
+
- [Simple gradio live transcription demo](https://docs.vllm.ai/en/latest/examples/online_serving/openai_realtime_microphone_client/#openai-realtime-microphone-client)
|
| 198 |
+
|
| 199 |
+
[](https://huggingface.co/spaces/mistralai/Voxtral-Mini-Realtime)
|
| 200 |
+
|
| 201 |
+
**To try out a demo, click [here](https://huggingface.co/spaces/mistralai/Voxtral-Mini-Realtime)**
|
| 202 |
+
|
| 203 |
+
### Transformers
|
| 204 |
+
|
| 205 |
+
Starting with `transformers >= 5.2.0`, you can run Voxtral Realtime natively in Transformers!
|
| 206 |
+
|
| 207 |
+
For more details, refer to the [Transformers documentation](https://huggingface.co/docs/transformers/main/en/model_doc/voxtral_realtime).
|
| 208 |
+
|
| 209 |
+
#### Installation
|
| 210 |
+
|
| 211 |
+
Install Transformers:
|
| 212 |
+
|
| 213 |
+
```bash
|
| 214 |
+
pip install --upgrade transformers
|
| 215 |
+
```
|
| 216 |
+
|
| 217 |
+
Make sure to have `mistral-common` installed with audio dependencies:
|
| 218 |
+
|
| 219 |
+
```bash
|
| 220 |
+
pip install --upgrade "mistral-common[audio]"
|
| 221 |
+
```
|
| 222 |
+
|
| 223 |
+
#### Usage
|
| 224 |
+
|
| 225 |
+
```python
|
| 226 |
+
from transformers import VoxtralRealtimeForConditionalGeneration, AutoProcessor
|
| 227 |
+
from mistral_common.tokens.tokenizers.audio import Audio
|
| 228 |
+
from huggingface_hub import hf_hub_download
|
| 229 |
+
|
| 230 |
+
repo_id = "mistralai/Voxtral-Mini-4B-Realtime-2602"
|
| 231 |
+
|
| 232 |
+
processor = AutoProcessor.from_pretrained(repo_id)
|
| 233 |
+
model = VoxtralRealtimeForConditionalGeneration.from_pretrained(repo_id, device_map="auto")
|
| 234 |
+
|
| 235 |
+
repo_id = "patrickvonplaten/audio_samples"
|
| 236 |
+
audio_file = hf_hub_download(repo_id=repo_id, filename="bcn_weather.mp3", repo_type="dataset")
|
| 237 |
+
|
| 238 |
+
audio = Audio.from_file(audio_file, strict=False)
|
| 239 |
+
audio.resample(processor.feature_extractor.sampling_rate)
|
| 240 |
+
|
| 241 |
+
inputs = processor(audio.audio_array, return_tensors="pt")
|
| 242 |
+
inputs = inputs.to(model.device, dtype=model.dtype)
|
| 243 |
+
|
| 244 |
+
outputs = model.generate(**inputs)
|
| 245 |
+
decoded_outputs = processor.batch_decode(outputs, skip_special_tokens=True)
|
| 246 |
+
|
| 247 |
+
print(decoded_outputs[0])
|
| 248 |
+
```
|
| 249 |
+
|
| 250 |
+
### ExecuTorch (Untested)
|
| 251 |
+
|
| 252 |
+
> [!Warning]
|
| 253 |
+
> Running Voxtral-Realtime on-device with ExecuTorch is not throughly tested and hence
|
| 254 |
+
> there might be some sharp edges. If you encounter any problems, please file a bug report directly on
|
| 255 |
+
> [ExecuTorch's GitHub](https://github.com/pytorch/executorch/issues/new/choose)
|
| 256 |
+
|
| 257 |
+
[ExecuTorch](https://github.com/pytorch/executorch) enables you to deploy **Voxtral-Realtime** locally—either on-device or on your laptop.
|
| 258 |
+
|
| 259 |
+
For a quick, offline demo on your MacBook, check out [Voxtral-Mini-4B-Realtime-2602-ExecuTorch](https://huggingface.co/mistral-labs/Voxtral-Mini-4B-Realtime-2602-ExecuTorch).
|
| 260 |
+
|
| 261 |
+
To deploy **Voxtral-Realtime** in a custom environment or on any device, refer to the [Official Readme](https://github.com/pytorch/executorch/blob/main/examples/models/voxtral_realtime/README.md).
|
| 262 |
+
|
| 263 |
+
> [!Tip]
|
| 264 |
+
> If you're looking for an implementation that is purely written in C,
|
| 265 |
+
> we recommend to take a look at [voxtral.c](https://github.com/antirez/voxtral.c)
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
### Community Contributions (Untested)
|
| 269 |
+
|
| 270 |
+
Voxtral Realtime integrations in:
|
| 271 |
+
- [Pure C](https://github.com/antirez/voxtral.c) - thanks [Salvatore Sanfilippo](https://github.com/antirez)
|
| 272 |
+
- [mlx-audio framework](https://github.com/Blaizzy/mlx-audio) - thanks [Shreyas Karnik](https://github.com/shreyaskarnik)
|
| 273 |
+
- [MLX](https://github.com/awni/voxmlx) - thanks [Awni Hannun](https://github.com/awni)
|
| 274 |
+
- [Rust](https://github.com/TrevorS/voxtral-mini-realtime-rs) - thanks [TrevorS](https://github.com/TrevorS)
|
| 275 |
+
|
| 276 |
+
## License
|
| 277 |
+
|
| 278 |
+
This model is licensed under the [Apache 2.0 License](https://www.apache.org/licenses/LICENSE-2.0.txt).
|
| 279 |
+
|
| 280 |
+
*You must not use this model in a manner that infringes, misappropriates, or otherwise violates any third party’s rights, including intellectual property rights.*
|
config.json
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"VoxtralRealtimeForConditionalGeneration"
|
| 4 |
+
],
|
| 5 |
+
"audio_config": {
|
| 6 |
+
"activation_function": "gelu",
|
| 7 |
+
"attention_dropout": 0.0,
|
| 8 |
+
"head_dim": 64,
|
| 9 |
+
"hidden_act": "silu",
|
| 10 |
+
"hidden_size": 1280,
|
| 11 |
+
"initializer_range": 0.02,
|
| 12 |
+
"intermediate_size": 5120,
|
| 13 |
+
"max_position_embeddings": 1500,
|
| 14 |
+
"model_type": "voxtral_realtime_encoder",
|
| 15 |
+
"num_attention_heads": 32,
|
| 16 |
+
"num_hidden_layers": 32,
|
| 17 |
+
"num_key_value_heads": 32,
|
| 18 |
+
"num_mel_bins": 128,
|
| 19 |
+
"rms_norm_eps": 1e-05,
|
| 20 |
+
"rope_parameters": {
|
| 21 |
+
"rope_theta": 1000000.0,
|
| 22 |
+
"rope_type": "default"
|
| 23 |
+
},
|
| 24 |
+
"sliding_window": 750,
|
| 25 |
+
"vocab_size": 131072
|
| 26 |
+
},
|
| 27 |
+
"audio_length_per_tok": 8,
|
| 28 |
+
"default_num_delay_tokens": 6,
|
| 29 |
+
"downsample_factor": 4,
|
| 30 |
+
"dtype": "bfloat16",
|
| 31 |
+
"hidden_size": 3072,
|
| 32 |
+
"model_type": "voxtral_realtime",
|
| 33 |
+
"projector_hidden_act": "gelu",
|
| 34 |
+
"text_config": {
|
| 35 |
+
"attention_dropout": 0.0,
|
| 36 |
+
"bos_token_id": 1,
|
| 37 |
+
"eos_token_id": 2,
|
| 38 |
+
"head_dim": 128,
|
| 39 |
+
"hidden_act": "silu",
|
| 40 |
+
"hidden_size": 3072,
|
| 41 |
+
"initializer_range": 0.02,
|
| 42 |
+
"intermediate_size": 9216,
|
| 43 |
+
"max_position_embeddings": 131072,
|
| 44 |
+
"model_type": "voxtral_realtime_text",
|
| 45 |
+
"num_attention_heads": 32,
|
| 46 |
+
"num_hidden_layers": 26,
|
| 47 |
+
"num_key_value_heads": 8,
|
| 48 |
+
"pad_token_id": null,
|
| 49 |
+
"rms_norm_eps": 1e-05,
|
| 50 |
+
"rope_parameters": {
|
| 51 |
+
"rope_theta": 1000000.0,
|
| 52 |
+
"rope_type": "default"
|
| 53 |
+
},
|
| 54 |
+
"sliding_window": 8192,
|
| 55 |
+
"tie_word_embeddings": true,
|
| 56 |
+
"use_cache": true,
|
| 57 |
+
"vocab_size": 131072
|
| 58 |
+
},
|
| 59 |
+
"transformers_version": "5.2.0.dev0"
|
| 60 |
+
}
|
consolidated.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:263f178fe752c90a2ae58f037a95ed092db8b14768b0978b8c48f66979c8345d
|
| 3 |
+
size 8859462744
|
generation_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 1,
|
| 3 |
+
"eos_token_id": 2,
|
| 4 |
+
"output_attentions": false,
|
| 5 |
+
"output_hidden_states": false,
|
| 6 |
+
"pad_token_id": 11,
|
| 7 |
+
"transformers_version": "5.2.0.dev0",
|
| 8 |
+
"use_cache": true
|
| 9 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e745e4902df6a4c48f29f2f8dc1f6d0fb4cc73c7156bc45923451a5bcdfcd1d6
|
| 3 |
+
size 8859446848
|
params.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"dim": 3072,
|
| 3 |
+
"n_layers": 26,
|
| 4 |
+
"head_dim": 128,
|
| 5 |
+
"hidden_dim": 9216,
|
| 6 |
+
"n_heads": 32,
|
| 7 |
+
"n_kv_heads": 8,
|
| 8 |
+
"use_biases": false,
|
| 9 |
+
"causal": true,
|
| 10 |
+
"rope_theta": 1000000.0,
|
| 11 |
+
"norm_eps": 1e-05,
|
| 12 |
+
"vocab_size": 131072,
|
| 13 |
+
"model_parallel": 1,
|
| 14 |
+
"tied_embeddings": true,
|
| 15 |
+
"sliding_window": 8192,
|
| 16 |
+
"model_max_length": 131072,
|
| 17 |
+
"multimodal": {
|
| 18 |
+
"whisper_model_args": {
|
| 19 |
+
"encoder_args": {
|
| 20 |
+
"audio_encoding_args": {
|
| 21 |
+
"sampling_rate": 16000,
|
| 22 |
+
"frame_rate": 12.5,
|
| 23 |
+
"num_mel_bins": 128,
|
| 24 |
+
"hop_length": 160,
|
| 25 |
+
"window_size": 400,
|
| 26 |
+
"chunk_length_s": null,
|
| 27 |
+
"global_log_mel_max": 1.5,
|
| 28 |
+
"transcription_format": "streaming"
|
| 29 |
+
},
|
| 30 |
+
"dim": 1280,
|
| 31 |
+
"n_layers": 32,
|
| 32 |
+
"head_dim": 64,
|
| 33 |
+
"hidden_dim": 5120,
|
| 34 |
+
"n_heads": 32,
|
| 35 |
+
"vocab_size": 131072,
|
| 36 |
+
"n_kv_heads": 32,
|
| 37 |
+
"use_biases": true,
|
| 38 |
+
"use_cache": false,
|
| 39 |
+
"rope_theta": 1000000.0,
|
| 40 |
+
"causal": true,
|
| 41 |
+
"norm_eps": 1e-05,
|
| 42 |
+
"pos_embed": "rope",
|
| 43 |
+
"max_source_positions": null,
|
| 44 |
+
"ffn_type": "swiglu",
|
| 45 |
+
"norm_type": "rms_norm",
|
| 46 |
+
"sliding_window": 750
|
| 47 |
+
},
|
| 48 |
+
"downsample_args": {
|
| 49 |
+
"downsample_factor": 4
|
| 50 |
+
}
|
| 51 |
+
}
|
| 52 |
+
},
|
| 53 |
+
"ada_rms_norm_t_cond": true,
|
| 54 |
+
"ada_rms_norm_t_cond_dim": 32
|
| 55 |
+
}
|
processor_config.json
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"feature_extractor": {
|
| 3 |
+
"feature_extractor_type": "VoxtralRealtimeFeatureExtractor",
|
| 4 |
+
"feature_size": 128,
|
| 5 |
+
"global_log_mel_max": 1.5,
|
| 6 |
+
"hop_length": 160,
|
| 7 |
+
"n_fft": 400,
|
| 8 |
+
"padding_side": "right",
|
| 9 |
+
"padding_value": 0.0,
|
| 10 |
+
"return_attention_mask": true,
|
| 11 |
+
"sampling_rate": 16000,
|
| 12 |
+
"win_length": 400
|
| 13 |
+
},
|
| 14 |
+
"processor_class": "VoxtralRealtimeProcessor"
|
| 15 |
+
}
|
tekken.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8434af1d39eba99f0ef46cf1450bf1a63fa941a26933a1ef5dbbf4adf0d00e44
|
| 3 |
+
size 14910348
|