# 🌐 SpatialStack-Qwen3.5-4B
### Layered Geometry-Language Fusion for 3D VLM Spatial Reasoning
**CVPR 2026**
---
## 📋 Overview
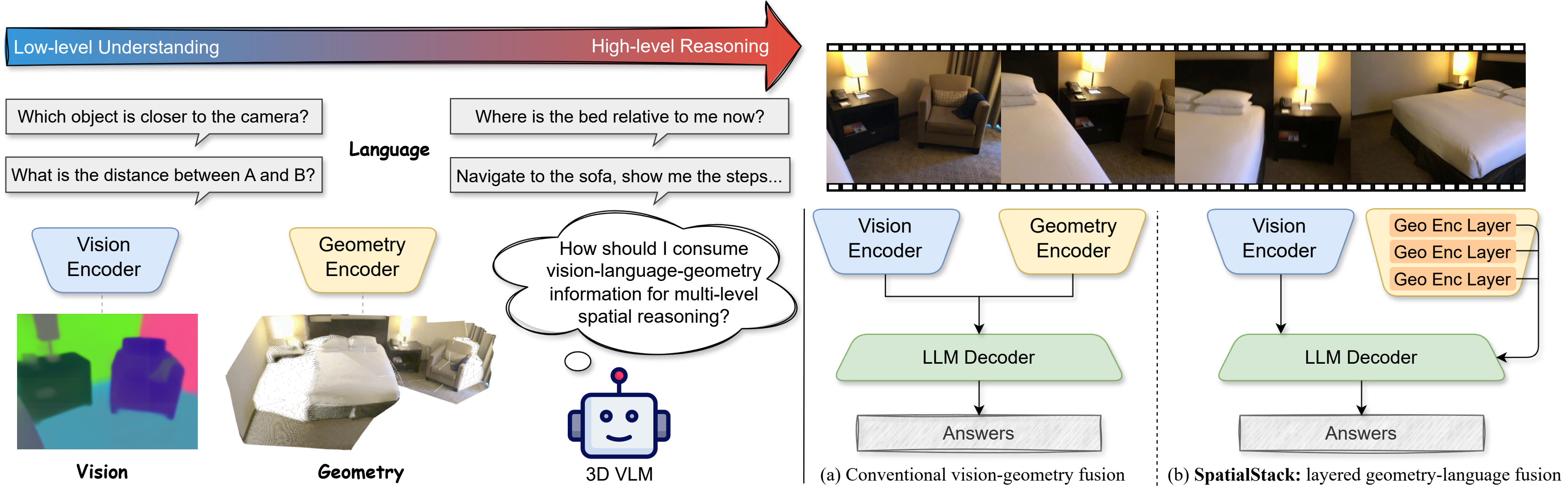
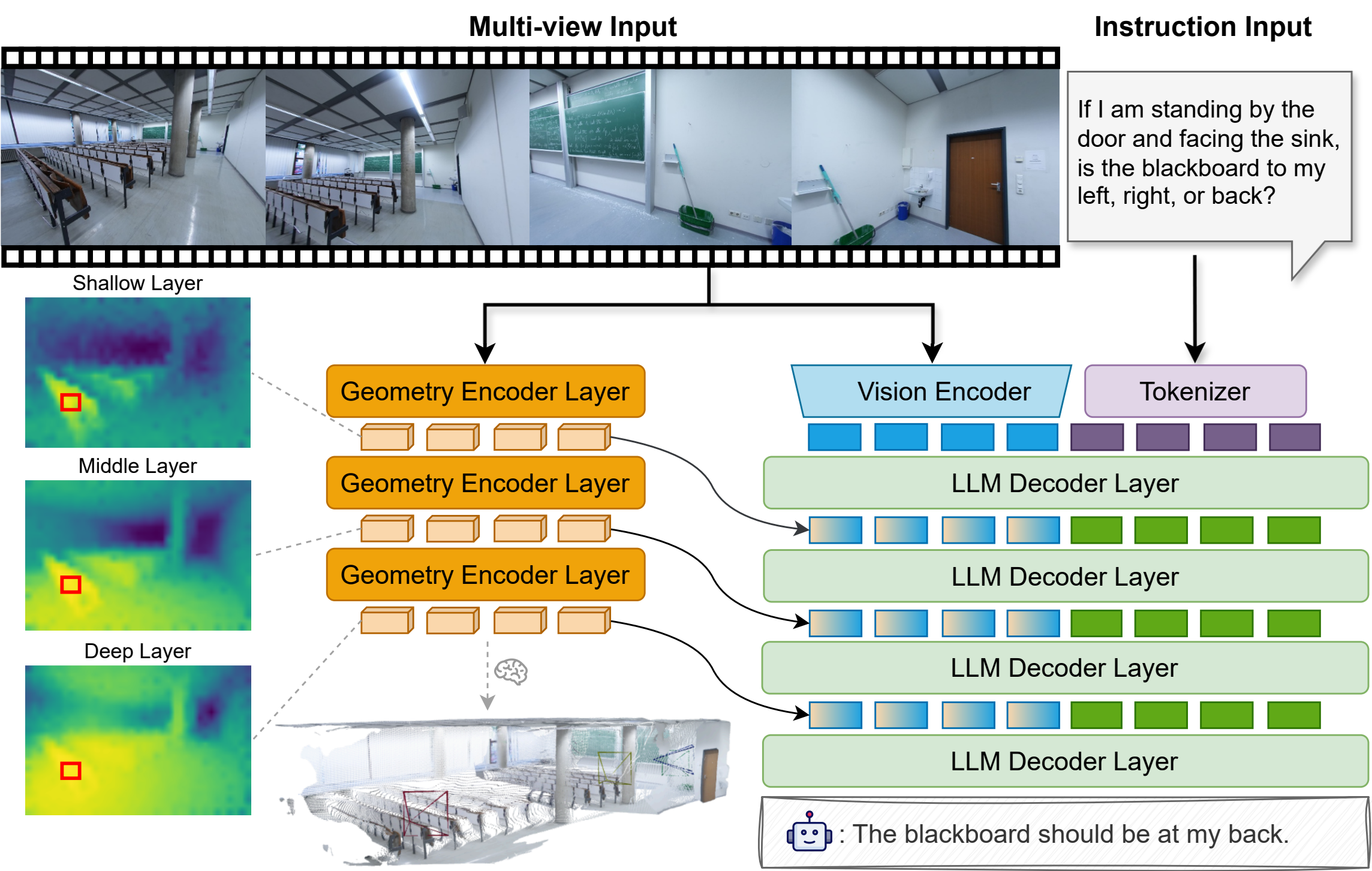
**SpatialStack-Qwen3.5-4B** is a geometry-augmented vision-language model designed for **3D spatial reasoning**. It extends [Qwen3.5-4B](https://huggingface.co/Qwen/Qwen3.5-4B) with a parallel [VGGT-1B](https://huggingface.co/facebook/VGGT-1B) geometry stream, using a novel **layered geometry-language fusion** mechanism that progressively aligns multi-level geometric and language features across model layers.
> Geometry features from encoder layers **[11, 17, 23]** are projected and injected into decoder layers **[0, 1, 2]**, preserving both fine local structure and higher-level spatial context.
## 🏗️ Architecture