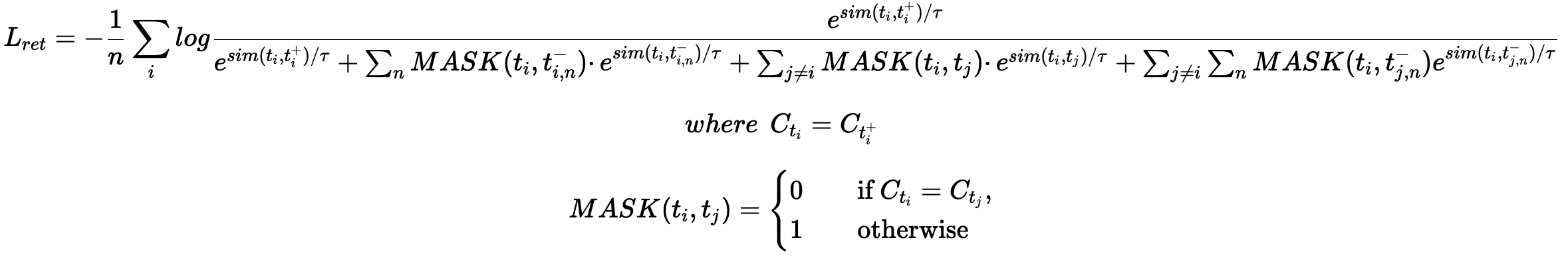---
license: apache-2.0
tags:
- sentence-transformers
- sentence-similarity
- mteb
- retriever
- text-embeddings-inference
---
# QZhou-Embedding
## Introduction
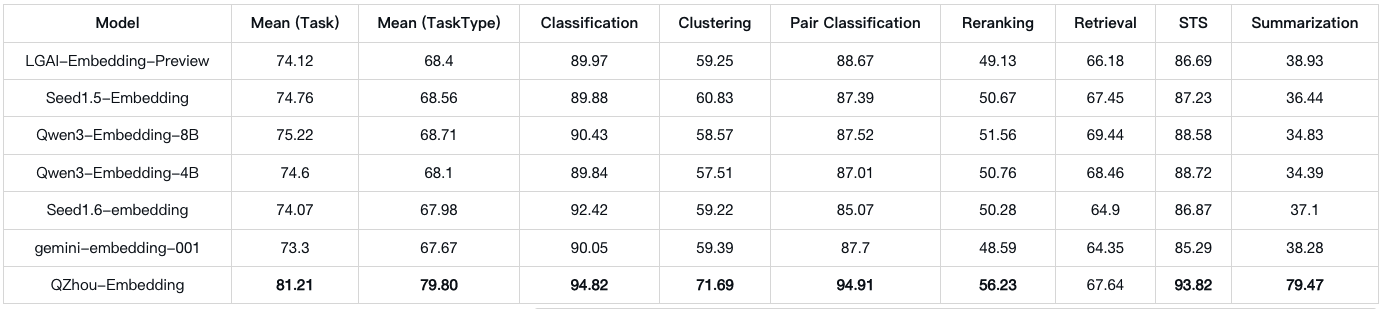
We have released QZhou-Embedding (called "Qingzhou Embedding"), a large-scale text embedding model designed for general use,excelling at various text embedding tasks (retrieval, re-ranking, sentence similarity, and classification). We modified the model structure based on Qwen2Model by changing the causal attention mechanism to bidirectional attention, so that each token can capture the global context semantics. The new module is named QZhouModel.Leveraging the general language capabilities of its underlying model, and pre-trained on massive amounts of text, QZhou-Embedding achieves even more powerful text embedding representations. QZhou-Embedding is continuously trained using millions of high-quality open-source embedding datasets and over 5 million high-quality synthetic data (using two synthetic techniques: rewriting and expansion). Initial retrieval training provides the model with a foundation for query-doc semantic matching capabilities. Later, multi-dimensional training such as STS and clustering, helps the model achieve continuous breakthroughs in various tasks. QZhou-Embedding is a 7B model and can embed long text vectors up to 8k in size. It achieved the highest average score on the mteb/cmteb evaluation benchmarks. In terms of various task scores, its clustering, sentence pair classification, rearrangement, and STS task achieved the highest average scores.
## Basic Features
- Powerful text embedding capabilities;
- Long context: up to 8k context length;
- 7B parameter size
## Technical Introduction
### Unified Task Modeling Framework
We unify the text embedding objectives into three major modeling optimization issues and propose a unified training data structured solution and corresponding training mechanism. This approach can integrate most open source data as retrieval training sets. The structured data can be as follows:
- Retrieval
- title-body
- title-abstract
- Question Answering Dataset
- Reading comprehension
- ...
- STS
- text pair + label in {true, false}、{yes, no}
- text pair + score(such as 0.2, 3.1. 4.8, etc.)
- NLI dataset:text pair + label in {'entailment', 'neutral', 'contradiction'}
- CLS
- text+CLS label
### Training Objectives
- Retrieval: Apply InfoNCE contrastive loss function, and follow the gte/qwen3-embedding to add the query-query negative as part of the denominator.
- STS:Apply Cosent loss:
- CLS: Apply the same InfoNCE loss as retrieval, but for In-Batch Negative, due to the high probability of same-class conflicts, a mask mechanism is used to cover up similar samples in negative examples shared by different samples.
Where $C_{t_i}$ represents the class label of sample $t_i$ , and $n$ is the number of negative samples for a single data point.
### Feature Enhancement Data Synthesis Technology
In the context of powerful languages and writing capabilities in LLMs, we've fully leveraged the LLMs API to propose a data synthesis technology. To address issues like limited data and narrow topics/features in training sets, we've proposed rewriting and expanding synthesis techniques. Furthermore, to increase the difficulty of negative examples during training, we've designed a hard negative example synthesis technology based on big models, combined with existing strong retriever-based hard negative examples sampling. Several of these technologies are described below:
For more details, including reproduction of evaluation results, Instruction content and adding method, please refer to our GitHub repo, thanks!
## Evaluation Results
### mteb details
### cmteb details
## Usage
### Completely reproduce the benchmark results
We provide detailed parameters and environment configurations so that you can run results that are completely consistent with the mteb leaderboard on your own machine, including configurations such as environment dependencies and model arguments.
#### Requirements
- Python: 3.10.12
- Sentence Transformers: 3.4.1
- Transformers: 4.51.1
- PyTorch: 2.7.1
- Accelerate: 1.3.0
- Datasets: 3.2.0
- Tokenizers: 0.21.2
- mteb: 1.38.30
#### Transformers model load arguments
torch_dtype=torch.bfloat16
attn_implementation='sdpa'
**NOTE:** The ranking results use the sdpa mode. Other modes ('eager', 'flash_attention_2') may have deviations in results, but still keep the overall performance consistent.
#### Instruction Adding Rules
Details can be found on our GitHub.
#### Evaluation code usage
Find our benchmark evaluation code on GitHub. The mteb benchmark script is **run_mteb_all_v2.py**, and the cmteb benchmark script is **run_cmteb_all.py**. Run the following command:
```bash
POOLING_MODE=mean
normalize=true
use_instruction=true
export TOKENIZERS_PARALLELISM=true
model_name_or_path=
python3 ./run_cmteb_all.py \
--model_name_or_path ${model_name_or_path} \
--pooling_mode ${POOLING_MODE} \
--normalize ${normalize} \
--use_instruction ${use_instruction} \
--output_dir