[](https://mbadran2000.github.io/DiffuDETR/)
[](https://openreview.net/pdf?id=nkp4LdWDOr)
[](https://github.com/MBadran2000/DiffuDETR)
# DiffuDETR: Rethinking Detection Transformers with Denoising Diffusion Process
### [ICLR 2026](https://iclr.cc/virtual/2026/poster/10007459)
**[Youssef Nawar](https://scholar.google.com/citations?hl=en&user=HQWsM2gAAAAJ)\* [Mohamed Badran](https://scholar.google.com/citations?hl=en&user=HkQmlHoAAAAJ)\* [Marwan Torki](https://scholar.google.com/citations?hl=en&user=aYLNZT4AAAAJ)**
Alexandria University · Technical University of Munich · Applied Innovation Center
* Equal Contribution
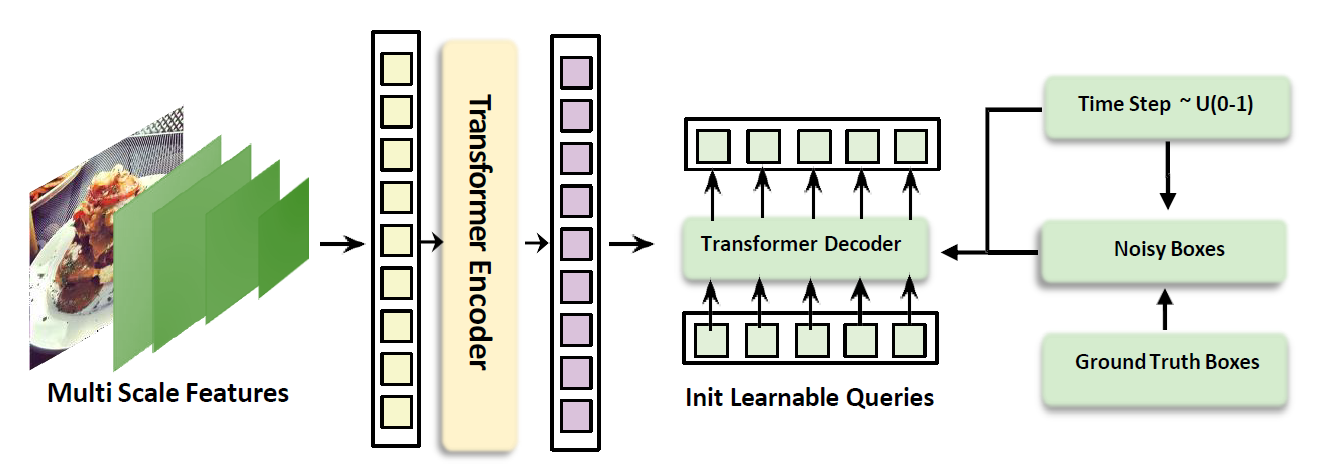
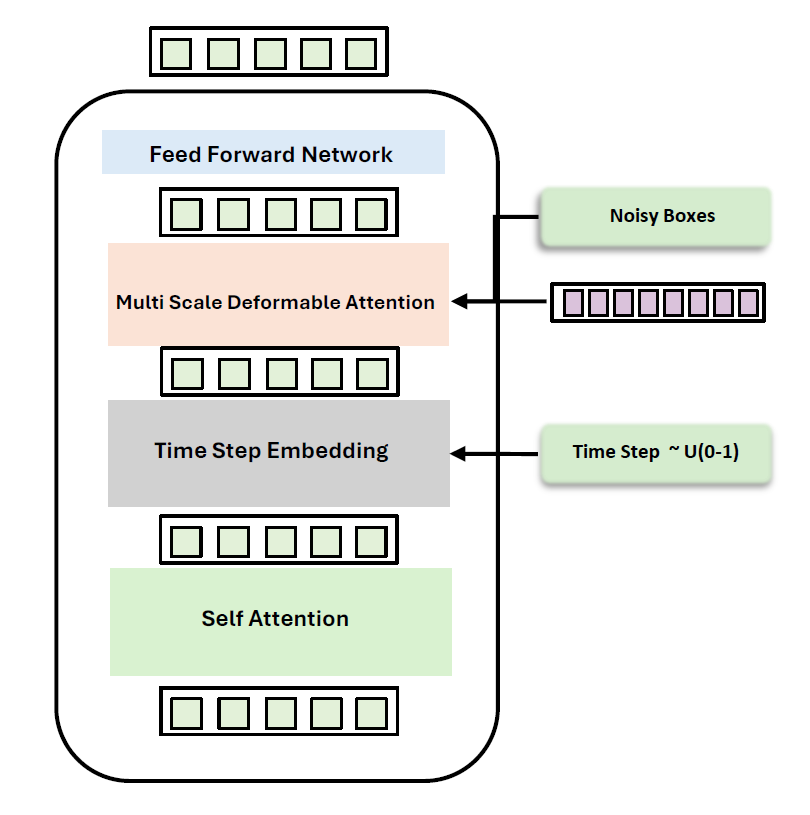
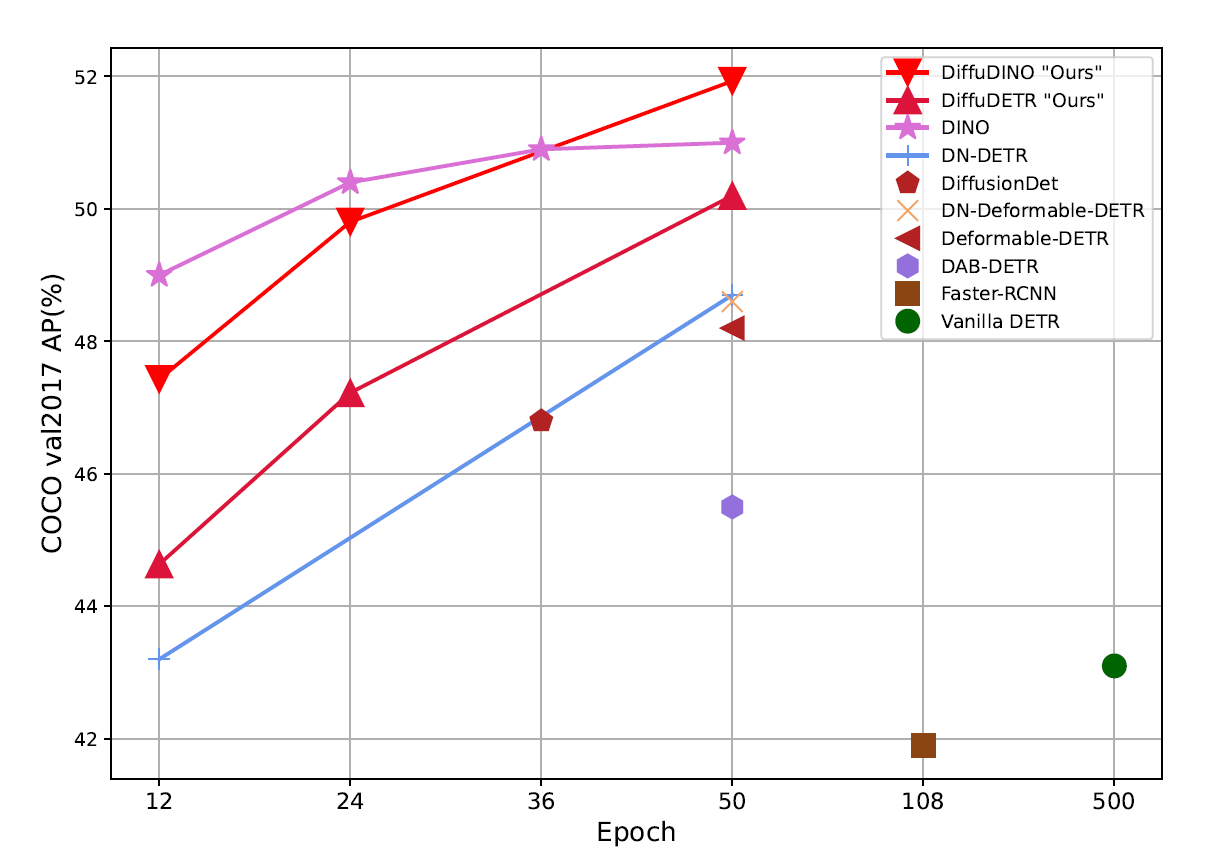
DiffuDETR reformulates object detection as a conditional query generation task using denoising diffusion, improving strong baselines on COCO, LVIS, and V3Det.
---
## 🔥 Highlights