

Update README.md
Browse files
README.md
CHANGED
|
@@ -37,7 +37,7 @@ We achieved this through machine-generated task vectors that optimize thinking p
|
|
| 37 |
- **🎯 Focused Reasoning**: Machine-generated task vectors optimize thinking processes for search tasks
|
| 38 |
|
| 39 |
## Evaluation
|
| 40 |
-
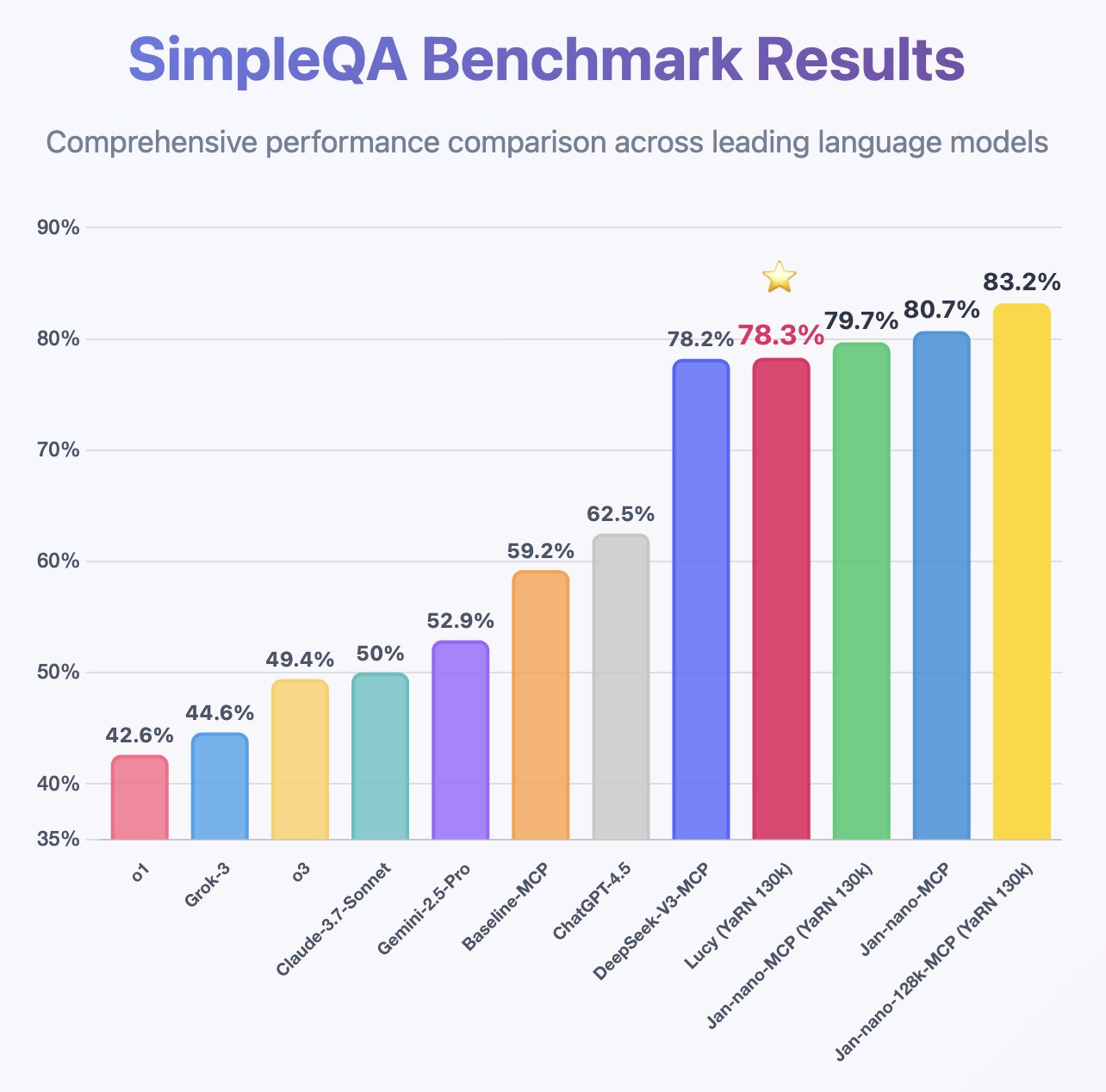
Following the same MCP benchmark methodology used for [Jan-Nano](https://huggingface.co/Menlo/Jan-nano) and [Jan-Nano-128k](https://huggingface.co/Menlo/Jan-nano-128k), Lucy demonstrates impressive performance despite being only a 1.7B model, achieving higher accuracy than DeepSeek-v3 on
|
| 41 |
|
| 42 |
|
| 43 |
|
|
|
|
| 37 |
- **🎯 Focused Reasoning**: Machine-generated task vectors optimize thinking processes for search tasks
|
| 38 |
|
| 39 |
## Evaluation
|
| 40 |
+
Following the same MCP benchmark methodology used for [Jan-Nano](https://huggingface.co/Menlo/Jan-nano) and [Jan-Nano-128k](https://huggingface.co/Menlo/Jan-nano-128k), Lucy demonstrates impressive performance despite being only a 1.7B model, achieving higher accuracy than DeepSeek-v3 on [SimpleQA](https://openai.com/index/introducing-simpleqa/).
|
| 41 |
|
| 42 |

|
| 43 |
|