
File size: 8,457 Bytes
184eb6e 86abc1e 0ca3b47 86abc1e 0ca3b47 86abc1e 0ca3b47 184eb6e 544f01e 184eb6e 86abc1e 184eb6e 9092183 86abc1e 184eb6e 9080fea 88e58b1 9080fea 9092183 184eb6e 9d21133 184eb6e 9092183 184eb6e 9092183 184eb6e 9092183 184eb6e 9092183 29e0d39 184eb6e 29e0d39 184eb6e 29e0d39 184eb6e |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 |
---
license: cc-by-4.0
datasets:
- MultiBridge/LnNor
- speech31/timit_english_ipa
language:
- en
metrics:
- cer
base_model:
- facebook/wav2vec2-base
pipeline_tag: automatic-speech-recognition
tags:
- phoneme_recognition
- IPA
model-index:
- name: MultiBridge/wav2vec-LnNor-IPA-ft
results:
- task:
type: phoneme-recognition
name: Phoneme Recognition
dataset:
name: TIMIT
type: speech31/timit_english_ipa
metrics:
- type: cer
value: 0.0416
name: CER
---
# Model Card for MultiBridge/wav2vec-LnNor-IPA-ft
<!-- Provide a quick summary of what the model is/does. -->
This model is built for phoneme recognition tasks. It was developed by fine-tuning the wav2vec2 base model on TIMIT and LnNor datasets. The predictions are in IPA.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Multibridge
- **Funded by [optional]:** EEA Financial Mechanism and Norwegian Financial Mechanism
- **Shared by [optional]:** Multibridge
- **Model type:** Transformer
- **Language(s) (NLP):** English
- **License:** cc-by-4.0
- **Finetuned from model [optional]:** facebook/wav2vec2-base
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
- Automatic phonetic transcription: Converting raw speech into phoneme sequences.
- Speech processing applications: Serving as a component in speech processing pipelines or prototyping.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
- data specificity: By excluding recordings shorter than 2 seconds or longer than 30 seconds, and labels with fewer than 5 phonemes, some natural speech variations are ignored. This might affect the model's performance in real-world applications. The model's performance is influenced by the characteristics of TIMIT and LnNor datasets. This can lead to potential biases, especially if the target application involves speakers or dialects not well-represented in these datasets. LnNor contains non-native speech and automaticly generated annotations that don't reflect true pronunciation rather canonical pronunciation. This could result in a model that fails to accurately predict non-native speech.
- frozen encoder: Freezing the encoder retains useful pre-learned features but also prevents the model from adapting fully to the new datasets.
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Evaluate the model's performance for your specific use case.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("MultiBridge/wav2vec-LnNor-IPA-ft")
model = Wav2Vec2ForCTC.from_pretrained("MultiBridge/wav2vec-LnNor-IPA-ft")
# load dummy dataset and read soundfiles
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values
# retrieve logits
with torch.no_grad():
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
# => should give ['mɪstɝkwɪltɝɪzðəəpɑslʌvðəmɪdəlklæsəzændwiɑəɡlædtəwɛlkəmhɪzɡɑspəl'] for MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL
```
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
The training data comes from two key sources:
- [TIMIT](https://huggingface.co/datasets/speech31/timit_english_ipa): A widely-used dataset for phonetic transcription, providing a standard benchmark in speech research.
- [LnNor](https://huggingface.co/datasets/MultiBridge/LnNor): A multilingual dataset of high-quality speech recordings in Norwegian, English, and Polish. The dataset compiled from non-native speakers with various language proficiencies. The phoneme annotations in LnNor were generated using the WebMAUS tool, meaning they represent canonical phonemes rather than the true pronunciations typical of spontaneous speech or non native pronunciation.
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
The original, pre-trained encoder representations were preserved - the encoder was kept frozen during fine-tuning in order to minimizes training time and resource consumption. The model was trained with CTC loss and AdamW optimizer, with no learning rate scheduler.
#### Preprocessing [optional]
The training dataset was filtered. Recordings shorter than 2 seconds or longer than 30 seconds were removed. Any labels consisting of fewer than 5 phonemes were discarded.
#### Training Hyperparameters
**Training regime:**
- learning rate: 1e-5
- optimizer: AdamW
- batch size: 64
- weight decay: 0.001
- epochs: 40
#### Speeds, Sizes, Times [optional]
- Avg epoch training time: 650s
- Number of updates: ~25k
- Final training loss: 0.09713
- Final validation loss: 0.2142
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
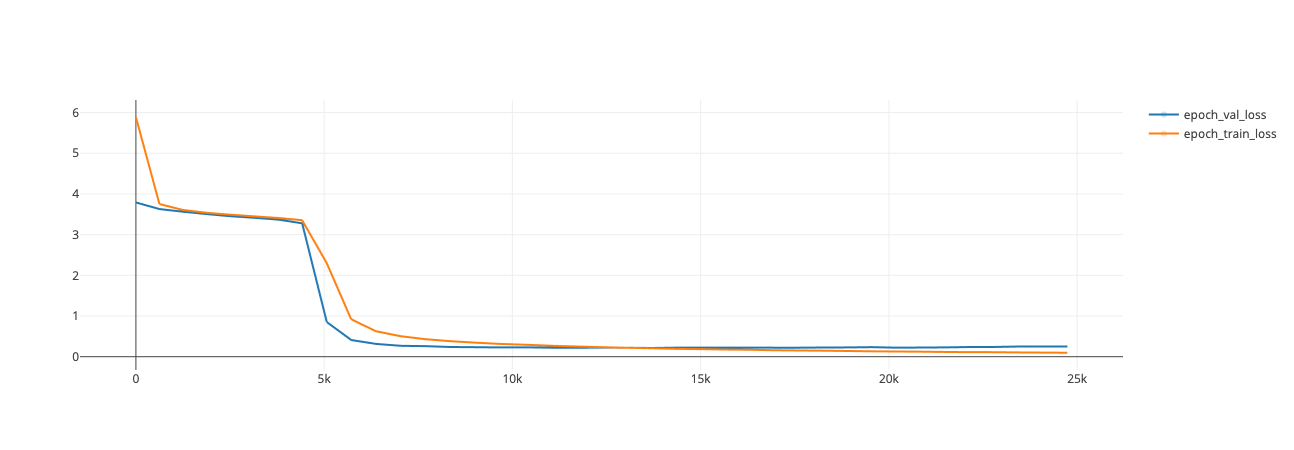
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
The model was evaluated on TIMIT's test split.
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
CER/PER (Phoneme Error Rate)
### Results
PER (Phoneme Error Rate) on TIMIT's test split: 0.0416
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Nvidia A100-80
- **Hours used:** [More Information Needed]
- **Cloud Provider:** Poznan University of Technology
- **Compute Region:** Poland
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
Transformer model + CTC loss
### Compute Infrastructure
#### Hardware
2 x Nvidia A100-80
#### Software
python 3.12
transformers 4.50.0
torch 2.6.0
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
I you use the LnNor dataset for research, cite these papers:
```
@article{magdalena2024lnnor,
title={The LnNor Corpus: A spoken multilingual corpus of non-native and native Norwegian, English and Polish (Part 1)},
author={Magdalena, Wrembel and Hwaszcz, Krzysztof and Agnieszka, Pludra and Ska{\l}ba, Anna and Weckwerth, Jaros{\l}aw and Walczak, Angelika and Sypia{\'n}ska, Jolanta and {\.Z}ychli{\'n}ski, Sylwiusz and Malarski, Kamil and K{\k{e}}dzierska, Hanna and others},
year={2024},
publisher={Adam Mickiewicz University}
}
@article{wrembel2024lnnor,
title={The LnNor Corpus: A spoken multilingual corpus of non-native and native Norwegian, English and Polish--Part 2},
author={Wrembel, Magdalena and Hwaszcz, Krzysztof and Pludra, Agnieszka and Ska{\l}ba, Anna and Weckwerth, Jaros{\l}aw and Malarski, Kamil and Cal, Zuzanna Ewa and K{\k{e}}dzierska, Hanna and Czarnecki-Verner, Tristan and Balas, Anna and others},
year={2024},
publisher={Adam Mickiewicz University}
}
```
## Model Card Authors [optional]
Agnieszka Pludra
Izabela Krysińska
Piotr Kabaciński
## Model Card Contact
agnieszka.pludra@pearson.com
izabela.krysinska@pearson.com
piotr.kabacinski@pearson.com |