

Update README.md
Browse files
README.md
CHANGED
|
@@ -1,202 +1,135 @@
|
|
| 1 |
---
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 5 |
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
## Model Details
|
| 13 |
-
|
| 14 |
-
### Model Description
|
| 15 |
-
|
| 16 |
-
<!-- Provide a longer summary of what this model is. -->
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
- **Developed by:** [More Information Needed]
|
| 21 |
-
- **Funded by [optional]:** [More Information Needed]
|
| 22 |
-
- **Shared by [optional]:** [More Information Needed]
|
| 23 |
-
- **Model type:** [More Information Needed]
|
| 24 |
-
- **Language(s) (NLP):** [More Information Needed]
|
| 25 |
-
- **License:** [More Information Needed]
|
| 26 |
-
- **Finetuned from model [optional]:** [More Information Needed]
|
| 27 |
-
|
| 28 |
-
### Model Sources [optional]
|
| 29 |
-
|
| 30 |
-
<!-- Provide the basic links for the model. -->
|
| 31 |
-
|
| 32 |
-
- **Repository:** [More Information Needed]
|
| 33 |
-
- **Paper [optional]:** [More Information Needed]
|
| 34 |
-
- **Demo [optional]:** [More Information Needed]
|
| 35 |
-
|
| 36 |
-
## Uses
|
| 37 |
-
|
| 38 |
-
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
|
| 39 |
-
|
| 40 |
-
### Direct Use
|
| 41 |
-
|
| 42 |
-
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
|
| 43 |
-
|
| 44 |
-
[More Information Needed]
|
| 45 |
-
|
| 46 |
-
### Downstream Use [optional]
|
| 47 |
-
|
| 48 |
-
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
|
| 49 |
-
|
| 50 |
-
[More Information Needed]
|
| 51 |
-
|
| 52 |
-
### Out-of-Scope Use
|
| 53 |
-
|
| 54 |
-
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
|
| 55 |
-
|
| 56 |
-
[More Information Needed]
|
| 57 |
-
|
| 58 |
-
## Bias, Risks, and Limitations
|
| 59 |
-
|
| 60 |
-
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
|
| 61 |
-
|
| 62 |
-
[More Information Needed]
|
| 63 |
-
|
| 64 |
-
### Recommendations
|
| 65 |
-
|
| 66 |
-
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
|
| 67 |
-
|
| 68 |
-
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
|
| 69 |
-
|
| 70 |
-
## How to Get Started with the Model
|
| 71 |
-
|
| 72 |
-
Use the code below to get started with the model.
|
| 73 |
-
|
| 74 |
-
[More Information Needed]
|
| 75 |
-
|
| 76 |
-
## Training Details
|
| 77 |
-
|
| 78 |
-
### Training Data
|
| 79 |
-
|
| 80 |
-
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
|
| 81 |
-
|
| 82 |
-
[More Information Needed]
|
| 83 |
-
|
| 84 |
-
### Training Procedure
|
| 85 |
-
|
| 86 |
-
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
|
| 87 |
-
|
| 88 |
-
#### Preprocessing [optional]
|
| 89 |
-
|
| 90 |
-
[More Information Needed]
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
#### Training Hyperparameters
|
| 94 |
-
|
| 95 |
-
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
|
| 96 |
-
|
| 97 |
-
#### Speeds, Sizes, Times [optional]
|
| 98 |
-
|
| 99 |
-
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
|
| 100 |
-
|
| 101 |
-
[More Information Needed]
|
| 102 |
-
|
| 103 |
-
## Evaluation
|
| 104 |
-
|
| 105 |
-
<!-- This section describes the evaluation protocols and provides the results. -->
|
| 106 |
-
|
| 107 |
-
### Testing Data, Factors & Metrics
|
| 108 |
-
|
| 109 |
-
#### Testing Data
|
| 110 |
-
|
| 111 |
-
<!-- This should link to a Dataset Card if possible. -->
|
| 112 |
-
|
| 113 |
-
[More Information Needed]
|
| 114 |
-
|
| 115 |
-
#### Factors
|
| 116 |
-
|
| 117 |
-
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
|
| 118 |
-
|
| 119 |
-
[More Information Needed]
|
| 120 |
-
|
| 121 |
-
#### Metrics
|
| 122 |
-
|
| 123 |
-
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 124 |
-
|
| 125 |
-
[More Information Needed]
|
| 126 |
-
|
| 127 |
-
### Results
|
| 128 |
-
|
| 129 |
-
[More Information Needed]
|
| 130 |
-
|
| 131 |
-
#### Summary
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
|
| 135 |
-
## Model Examination [optional]
|
| 136 |
-
|
| 137 |
-
<!-- Relevant interpretability work for the model goes here -->
|
| 138 |
-
|
| 139 |
-
[More Information Needed]
|
| 140 |
-
|
| 141 |
-
## Environmental Impact
|
| 142 |
-
|
| 143 |
-
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 144 |
-
|
| 145 |
-
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 146 |
-
|
| 147 |
-
- **Hardware Type:** [More Information Needed]
|
| 148 |
-
- **Hours used:** [More Information Needed]
|
| 149 |
-
- **Cloud Provider:** [More Information Needed]
|
| 150 |
-
- **Compute Region:** [More Information Needed]
|
| 151 |
-
- **Carbon Emitted:** [More Information Needed]
|
| 152 |
-
|
| 153 |
-
## Technical Specifications [optional]
|
| 154 |
-
|
| 155 |
-
### Model Architecture and Objective
|
| 156 |
-
|
| 157 |
-
[More Information Needed]
|
| 158 |
-
|
| 159 |
-
### Compute Infrastructure
|
| 160 |
-
|
| 161 |
-
[More Information Needed]
|
| 162 |
-
|
| 163 |
-
#### Hardware
|
| 164 |
-
|
| 165 |
-
[More Information Needed]
|
| 166 |
-
|
| 167 |
-
#### Software
|
| 168 |
-
|
| 169 |
-
[More Information Needed]
|
| 170 |
|
| 171 |
-
## Citation [optional]
|
| 172 |
|
| 173 |
-
|
| 174 |
|
| 175 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 176 |
|
| 177 |
-
|
| 178 |
|
| 179 |
-
|
|
|
|
|
|
|
|
|
|
| 180 |
|
| 181 |
-
|
| 182 |
|
| 183 |
-
#
|
|
|
|
|
|
|
|
|
|
| 184 |
|
| 185 |
-
|
| 186 |
|
| 187 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 188 |
|
| 189 |
-
|
| 190 |
|
| 191 |
-
|
|
|
|
|
|
|
| 192 |
|
| 193 |
-
#
|
|
|
|
|
|
|
| 194 |
|
| 195 |
-
[More Information Needed]
|
| 196 |
|
| 197 |
-
#
|
|
|
|
|
|
|
|
|
|
| 198 |
|
| 199 |
-
|
| 200 |
-
|
|
|
|
|
|
|
|
|
|
| 201 |
|
| 202 |
-
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
tags:
|
| 4 |
+
- mistral
|
| 5 |
+
- Uncensored
|
| 6 |
+
- text-generation-inference
|
| 7 |
+
- transformers
|
| 8 |
+
- unsloth
|
| 9 |
+
- trl
|
| 10 |
+
- roleplay
|
| 11 |
+
- conversational
|
| 12 |
+
- rp
|
| 13 |
+
datasets:
|
| 14 |
+
- N-Bot-Int/Iris-Uncensored-R1
|
| 15 |
+
- N-Bot-Int/Moshpit-Combined-R2-Uncensored
|
| 16 |
+
- N-Bot-Int/Mushed-Dataset-Uncensored
|
| 17 |
+
- N-Bot-Int/Muncher-R1-Uncensored
|
| 18 |
+
- unalignment/toxic-dpo-v0.2
|
| 19 |
+
language:
|
| 20 |
+
- en
|
| 21 |
+
base_model:
|
| 22 |
+
- unsloth/mistral-7b-instruct-v0.3-bnb-4bit
|
| 23 |
+
pipeline_tag: text-generation
|
| 24 |
+
library_name: transformers
|
| 25 |
+
metrics:
|
| 26 |
+
- character
|
| 27 |
---
|
| 28 |
+

|
| 29 |
+
# Official Quants are Uploaded By Us
|
| 30 |
+
- [MistThena7BV2-GGUF](https://huggingface.co/N-Bot-Int/MistThena7BV2-GGUF)
|
| 31 |
+
|
| 32 |
+
# Support us on Ko-Fi!
|
| 33 |
+
- [](https://ko-fi.com/J3J61D8NHV)
|
| 34 |
+
|
| 35 |
+
# MistThena7B - V2.
|
| 36 |
+
- Introducing our Mindboggling MistThena7B **V2**, This Version Offer an Upgraded RP experience, beyond Other AI model
|
| 37 |
+
We've made, Outcompetting our 3B, 1B, MythoMax, Deepseek and Hermes for Roleplaying!
|
| 38 |
+
|
| 39 |
+
- **MistThena7B-V2** Offer an expanded Roleplay capabilities, using our EmojiEmulsifyer Program to Train MistThena7B
|
| 40 |
+
To Use Emojis, expanding the Roleplaying Immersiveness and Actionsets MistThena7B can do!
|
| 41 |
+
|
| 42 |
+
- Activate MistThena's Expanded Actions, by mirroring it(ie using Emoji on your own prompts), to ensure MistThena's
|
| 43 |
+
Use of Emoji or Actions!
|
| 44 |
+
|
| 45 |
+
- MistThena7B contains more Fine-tuned Dataset so please Report any issues found through our email
|
| 46 |
+
[nexus.networkinteractives@gmail.com](mailto:nexus.networkinteractives@gmail.com)
|
| 47 |
+
about any overfitting, or improvements for the future Model **V3**,
|
| 48 |
+
Once again feel free to Modify the LORA to your likings, However please consider Adding this Page
|
| 49 |
+
for credits and if you'll increase its **Dataset**, then please handle it with care and ethical considerations
|
| 50 |
+
|
| 51 |
+
- MistThena is
|
| 52 |
+
- **Developed by:** N-Bot-Int
|
| 53 |
+
- **License:** apache-2.0
|
| 54 |
+
- **Finetuned from model:** unsloth/mistral-7b-instruct-v0.3-bnb-4bit
|
| 55 |
+
- **Sequential Trained from Model:** N-Bot-Int/OpenElla3-Llama3.2A
|
| 56 |
+
- **Dataset Combined Using:** Mosher-R1(Propietary Software)
|
| 57 |
+
|
| 58 |
+
- Comparison Metric Score
|
| 59 |
+
|
| 60 |
+
- Metrics Made By **ItsMeDevRoland**
|
| 61 |
+
Which compares:
|
| 62 |
+
- **MistThena7B-V1**
|
| 63 |
+
- **MistThena7B-V2 : 60 STEP VERSION**
|
| 64 |
+
Which are All Ranked with the Same Prompt, Same Temperature, Same Hardware(Google Colab),
|
| 65 |
+
To Properly Showcase the differences and strength of the Models
|
| 66 |
|
| 67 |
+
---
|
| 68 |
+
# 🌀 MistThema-7B V2: Slower Beats, Stronger Bonds — A Roleplay Revival
|
| 69 |
+
> "She may not win the speed race, but when it comes to presence and performance — she owns the stage."
|
| 70 |
+

|
| 71 |
+

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 72 |
|
|
|
|
| 73 |
|
| 74 |
+
---
|
| 75 |
|
| 76 |
+
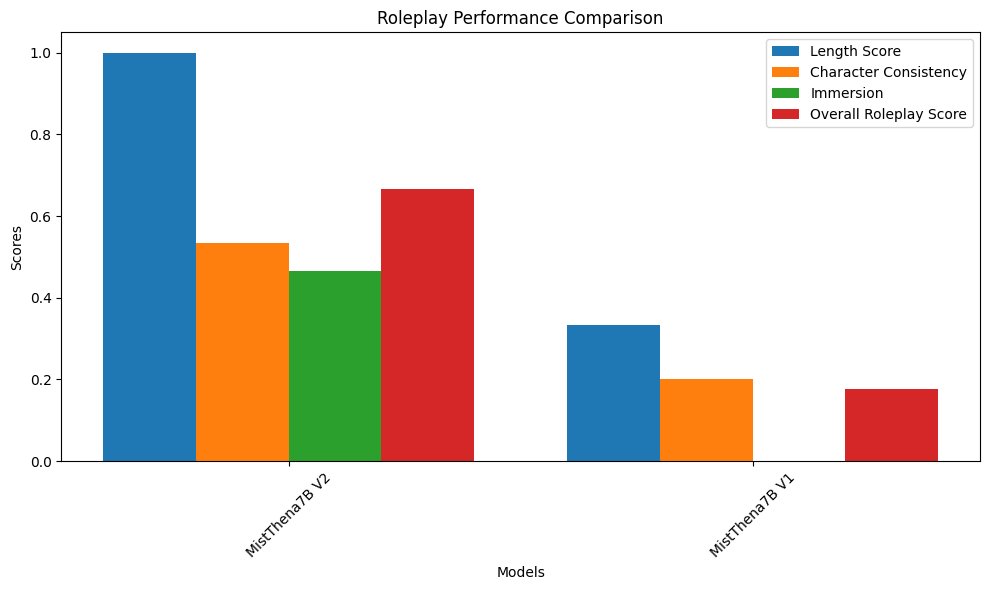
# MistThema-7B V2 isn’t just an upgrade — she’s a reinvention. Built on V1’s storytelling roots, V2 shifts her focus inward: longer scenes, deeper characters, and dialogue that breathes.
|
| 77 |
+

|
| 78 |
+
- 💬 **Roleplay Evaluation**
|
| 79 |
+
- ✍️ **Length Score**: 0.34 → **1.00** (🚀)
|
| 80 |
+
- 🧠 **Character Consistency**: 0.20 → **0.53**
|
| 81 |
+
- 🌌 **Immersion**: 0.00 → **0.47**
|
| 82 |
+
- 🎭 **Overall RP Score**: 0.17 → **0.67**
|
| 83 |
+
> She no longer just responds — she *inhabits*. MistThema-7B V2 is the method actor of models, channeling roles with vivid coherence and creative depth.
|
| 84 |
|
| 85 |
+
---
|
| 86 |
|
| 87 |
+
# ⚙️ The Cost of Craft: Time for Thought
|
| 88 |
+
- 🕒 **Inference Time**: 114s → **179s** (↑)
|
| 89 |
+
- ⚡ **Tokens/sec**: 1.51 → **1.28** (↓)
|
| 90 |
+
> Yes, she’s slower — but that’s not a bug. That’s intention. Every word is more considered, every output more deliberate.
|
| 91 |
|
| 92 |
+
---
|
| 93 |
|
| 94 |
+
# 📏 Traditional Metrics? A Trade-off
|
| 95 |
+
- 📘 **BLEU Score**: 0.43 → **0.18**
|
| 96 |
+
- 📕 **ROUGE-L**: 0.60 → **0.32**
|
| 97 |
+
> While V1 outperforms on surface-level matching, V2 is optimized for *experiential fidelity*, not rigid overlap.
|
| 98 |
|
| 99 |
+
---
|
| 100 |
|
| 101 |
+
# 🎯 Reimagined for Realness
|
| 102 |
+
MistThema-7B V2 isn’t trying to mimic — she’s trying to *immerse*. Designed to tell stories, embody roles, and hold character in long-form exchanges.
|
| 103 |
+
- 🧩 Tailored for:
|
| 104 |
+
- Narrative-heavy use cases
|
| 105 |
+
- Emotional continuity and consistency
|
| 106 |
+
- Richer, longer interactions
|
| 107 |
|
| 108 |
+
---
|
| 109 |
|
| 110 |
+
> “MistThema-7B V2 trades benchmarks for believability. Less about matching — more about meaning. Less polished — more *present*.”
|
| 111 |
+
# MistThema-7B V2 is where slower feels *stronger*.
|
| 112 |
+
---
|
| 113 |
|
| 114 |
+
- # Notice
|
| 115 |
+
- **For a Good Experience, Please use**
|
| 116 |
+
- Low temperature 1.5, min_p = 0.1 and max_new_tokens = 128
|
| 117 |
|
|
|
|
| 118 |
|
| 119 |
+
- # Detail card:
|
| 120 |
+
- Parameter
|
| 121 |
+
- 7 Billion Parameters
|
| 122 |
+
- (Please visit your GPU Vendor if you can Run 7B models)
|
| 123 |
|
| 124 |
+
- Training
|
| 125 |
+
- 250 Steps
|
| 126 |
+
- N-Bot-Int/Iris_Uncensored_R2
|
| 127 |
+
- 60 Steps
|
| 128 |
+
- N-Bot-Int/Millie_DPO
|
| 129 |
|
| 130 |
+
- Finetuning tool:
|
| 131 |
+
- Unsloth AI
|
| 132 |
+
- This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
|
| 133 |
+
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
| 134 |
+
- Fine-tuned Using:
|
| 135 |
+
- Google Colab
|