---
license: apache-2.0
---
# Diagram Formalizer
Model Structure:
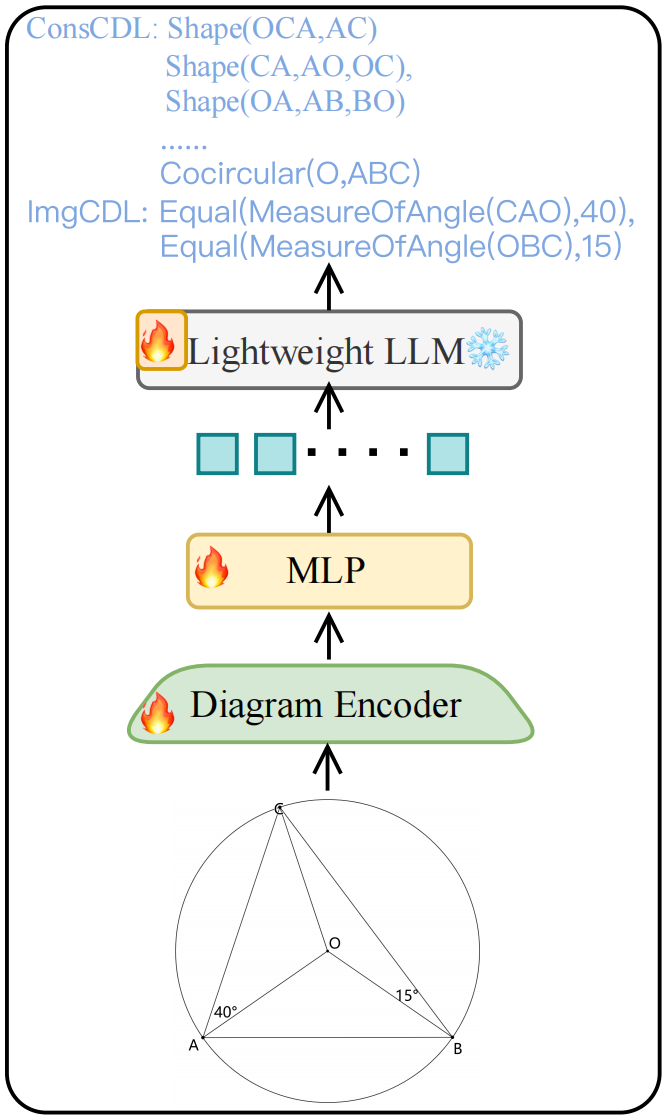
- **Diagram Encoder**: [siglip-so400m-patch14-384](https://huggingface.co/google/siglip-so400m-patch14-384)
- **Lightweight LLM**: [Qwen2-0.5B-Instruct](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct)
## Quick Start
Before running the script, install the following necessary dependencies.
```shell
pip install torch==2.4.0 transformers==4.40.0 accelerate pillow sentencepiece
```
You can use the following script to predict the ConsCDL and ImgCDL for geometric diagram.
```python
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
import warnings
import numpy as np
# set device
device = 'cuda' # or cpu
torch.set_default_device(device)
# create model
model = AutoModelForCausalLM.from_pretrained(
'NaughtyDog97/DiagramFormalizer',
torch_dtype=torch.float16, # float32 for cpu
device_map='auto',
trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(
'NaughtyDog97/DiagramFormalizer',
use_fast=True,
padding_side="right",
trust_remote_code=True)
# text prompt
img_path = 'sample/4927.png'
prompt = 'Based on the image, first describe what you see in the figure, then predict the construction_cdl and image_cdl and calibrate it.'
text = f'<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n\n{prompt}<|im_end|>\n<|im_start|>assistant\n'
def tokenizer_image_token(prompt, tokenizer, image_token_index, return_tensors=None):
prompt_chunks = [tokenizer(chunk).input_ids for chunk in prompt.split('')]
def insert_separator(X, sep):
return [ele for sublist in zip(X, [sep] * len(X)) for ele in sublist][:-1]
input_ids = []
offset = 0
if len(prompt_chunks) > 0 and len(prompt_chunks[0]) > 0 and prompt_chunks[0][0] == tokenizer.bos_token_id:
offset = 1
input_ids.append(prompt_chunks[0][0])
for x in insert_separator(prompt_chunks, [image_token_index] * (offset + 1)):
input_ids.extend(x[offset:])
if return_tensors is not None:
if return_tensors == 'pt':
return torch.tensor(input_ids, dtype=torch.long)
raise ValueError(f'Unsupported tensor type: {return_tensors}')
return input_ids
input_ids = tokenizer_image_token(text, tokenizer, -200, return_tensors='pt').unsqueeze(0).cuda()
# image, sample images can be found in images folder
image = Image.open(img_path).convert('RGB')
image_tensor = model.process_images([image], model.config).to(dtype=model.dtype, device=device)
# generate
with torch.inference_mode():
output_ids = model.generate(
input_ids,
images=image_tensor,
do_sample=False,
temperature=None,
top_p=None,
top_k=None,
num_beams=1,
max_new_tokens=3500,
eos_token_id=tokenizer.eos_token_id,
repetition_penalty=None,
use_cache=True
)[0]
respones = tokenizer.decode(output_ids[input_ids.shape[1]:], skip_special_tokens=True).strip()
print(respones)
```
Our model supports the following recognition instrutions:
- Natural Language Description:
- Describe what you see in the figure.
- Tell me what you observe in the image.
- Predicting ConsCDL only
- Based on the image, predict the construction_cdl.
- Based on the image, predict the construction_cdl and calibrate it.
- Based on the image, first describe what you see in the figure, then predict the construction_cdl.
- Based on the image, first describe what you see in the figure, then predict the construction_cdl and calibrate it.
- Predicting ImgCDL only:
- Based on the image, predict the image_cdl.
- Based on the image, predict the image_cdl and calibrate it.
- Based on the image, first describe what you see in the figure, then predict the image_cdl.
- Based on the image, first describe what you see in the figure, then predict the image_cdl and calibrate it.
- Predicting construction_cdl and image_cdl simultaneously:
- Based on the image, predict the construction_cdl and image_cdl.
- Based on the image, first predict the construction_cdl and image_cdl and calibrate it.
- Based on the image, first describe what you see in the figure, then predict the construction_cdl and image_cdl.
- Based on the image, first describe what you see in the figure, then predict the construction_cdl and image_cdl and calibrate it.
## Performance of Diagram Formalizer on formalgeo7k test set
| Model | ConsCdlAcc | ConsCdlPerfect | ImgCdlAcc | ImgCdlPerfect | BothPerfect |
|-----|----------------|---------------------|---------------|-------------------|------------------|
| Diagram Formalizer | 90.25 | 72.29 | 92.88 | 84.38 | 65.05 |