
File size: 7,832 Bytes
1f31f70 1d65120 1f31f70 1d65120 1f31f70 4c5d673 1d65120 4fc3624 1d65120 648489e 1d65120 648489e 1d65120 648489e 1d65120 5a2a1a3 50a96d6 5a2a1a3 648489e 5a2a1a3 1d65120 1f31f70 1d65120 1f31f70 50a96d6 1d65120 1f31f70 1d65120 aae9948 1f31f70 1d65120 1f31f70 1d65120 1f31f70 1d65120 1f31f70 1d65120 1f31f70 5e963db 1d65120 1f31f70 1d65120 1f31f70 648489e 1d65120 648489e 1d65120 50a96d6 1d65120 50a96d6 1d65120 648489e 1d65120 50a96d6 1d65120 f90cedf 1d65120 | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 | ---
license: apache-2.0
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- moe
- sparse-moe
- diffusion
- text-to-image
- image-generation
---
<p align="center"> <a href="https://withnucleus.ai/image" target="_blank" rel="noopener noreferrer"><img src="https://i.imgur.com/s6taicv.jpeg" width="400"/></a></p>
<p align="center">
🌐 <a href="https://withnucleus.ai/image"><b>Website</b></a> | 🖥️ <a href="https://github.com/WithNucleusAI/Nucleus-Image"><b>GitHub</b></a> | 🤗 <a href="https://huggingface.co/NucleusAI/NucleusMoE-Image"><b>Hugging Face</b></a> | 📑 <a href="https://arxiv.org/abs/2604.12163"><b>Tech Report</b></a>
</p>
## Introduction
**Nucleus-Image** is a text-to-image generation model built on a sparse mixture-of-experts (MoE) diffusion transformer architecture. It scales to **17B total parameters** across 64 routed experts per layer while activating only **~2B parameters** per forward pass, establishing a new Pareto frontier in quality-versus-efficiency. Nucleus-Image matches or exceeds leading models including Qwen-Image, GPT Image 1, Seedream 3.0, and Imagen4 on GenEval, DPG-Bench, and OneIG-Bench. This is a **base model** released without any post-training optimization (no DPO, no reinforcement learning, no human preference tuning). All reported results reflect pre-training performance only. We release the full model weights, training code, and dataset, making Nucleus-Image the first fully open-source MoE diffusion model at this quality tier.
## Key Features
- **Sparse MoE efficiency**: 17B total capacity with only ~2B active parameters per forward pass, enabling high-quality generation at a fraction of the inference cost of dense models
- **Expert-Choice Routing**: Guarantees balanced expert utilization without auxiliary load-balancing losses, with a decoupled routing design that separates timestep-aware assignment from timestep-conditioned computation
- **Base model, no post-training**: This is a base model. All benchmark results are from pre-training alone, without DPO, reinforcement learning, or human preference tuning
- **Multi-aspect-ratio support**: Trained with aspect-ratio bucketing from the outset at every resolution stage, supporting a range of output dimensions
- **Text KV caching via diffusers**: Text tokens are excluded from the transformer backbone entirely and their KV projections are cached across all denoising steps. This caching is natively integrated into the `diffusers` pipeline. Simply enable it with `TextKVCacheConfig` for automatic speedup with no code changes to the inference loop
- **Progressive resolution training**: Three-stage curriculum (256 → 512 → 1024) with progressive sparsification of expert capacity
## Architecture
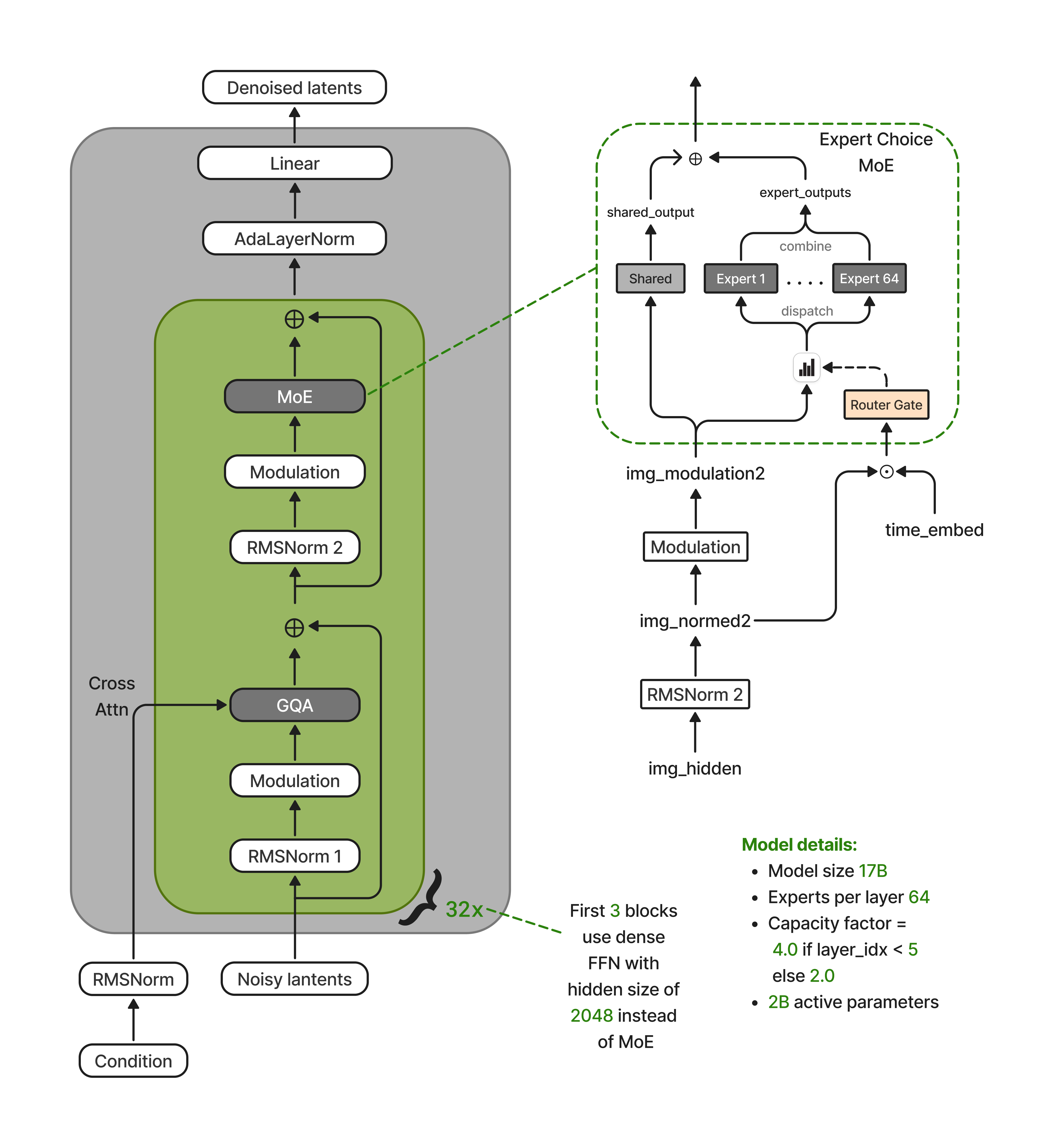
Nucleus-Image is a 32-layer diffusion transformer where 29 of the 32 blocks replace the dense FFN with a sparse MoE layer containing 64 routed experts and one shared expert (the first 3 layers use dense FFN for training stability). Image queries attend to concatenated image and text key-value pairs via joint attention. Text tokens are excluded from the transformer backbone entirely, participating only as KV contributors. This eliminates MoE routing overhead for text and enables full text KV caching across denoising steps.
Routing uses **Expert-Choice** with a **decoupled design**: the router receives the unmodulated token representation concatenated with the timestep embedding, while expert MLPs receive the fully modulated representation. This prevents the adaptive modulation scale — which varies by an order of magnitude across timesteps — from collapsing expert selection into timestep-dependent routing, preserving spatial and semantic expert specialization.
## Model Specifications
| Specification | Value |
|---|---|
| Total parameters | 17B |
| Active parameters | ~2B |
| Architecture | Sparse MoE Diffusion Transformer |
| Layers | 32 |
| Hidden dimension | 2048 |
| Attention heads (Q / KV) | 16 / 4 (GQA) |
| Experts per MoE layer | 64 routed + 1 shared |
| Expert hidden dimension | 1344 |
| Text encoder | Qwen3-VL-8B-Instruct |
| Image tokenizer | Qwen-Image VAE (16ch) |
| Training data | 700M images, 1.5B caption pairs |
| Training curriculum | Progressive resolution (256 → 512 → 1024) |
| Total training steps | 1.7M |
## Benchmark Results

Nucleus-Image achieves state-of-the-art or near state-of-the-art results on all three benchmarks despite activating only ~2B of its 17B parameters per forward pass. All results are from the base model at 1024x1024, 50 inference steps, CFG scale 8.0.
| Benchmark | Score | Highlights |
|---|---|---|
| **GenEval** | **0.87** | Matches Qwen-Image; leads all models on spatial position (0.85) |
| **DPG-Bench** | **88.79** | #1 overall; leads in entity (93.08), attribute (92.20), and other (93.62) |
| **OneIG-Bench** | **0.522** | Surpasses Imagen4 (0.515) and Recraft V3 (0.502); strong style (0.430) |
## Quick Start
Install the latest version of diffusers:
```
pip install git+https://github.com/huggingface/diffusers
```
Generate images with Nucleus-Image:
```python
import torch
from diffusers import DiffusionPipeline
from diffusers import TextKVCacheConfig
model_name = "NucleusAI/Nucleus-Image"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch.bfloat16)
pipe.to("cuda")
# Enable Text KV caching across denoising steps (integrated into diffusers)
config = TextKVCacheConfig()
pipe.transformer.enable_cache(config)
# Supported aspect ratios
aspect_ratios = {
"1:1": (1024, 1024),
"16:9": (1344, 768),
"9:16": (768, 1344),
"4:3": (1184, 896),
"3:4": (896, 1184),
"3:2": (1248, 832),
"2:3": (832, 1248),
}
prompt = "A weathered lighthouse on a rocky coastline at golden hour, waves crashing against the rocks below, seagulls circling overhead, dramatic clouds painted in shades of amber and violet"
width, height = aspect_ratios["16:9"]
image = pipe(
prompt=prompt,
width=width,
height=height,
num_inference_steps=50,
guidance_scale=4.0,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("nucleus_output.png")
```
## Highlights
### Portraits & People
Nucleus-Image generations of human subjects and portraits, spanning diverse cultures, ages, and artistic styles. From expressive character studies to fine-grained close-ups with intricate skin texture and detail.


### Fantasy, Surrealism & Nature
Nucleus-Image generations spanning fantasy, surrealism, animation, and the natural world.


### Commercial & Everyday Imagery
Nucleus-Image generations across product photography, architecture, typography, food, and world culture, demonstrating versatility in commercial, conceptual, and everyday imagery.


## License
Nucleus-Image is licensed under [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0).
## Citation
```bibtex
@misc{nucleusimage2026,
title={Nucleus-Image: Sparse MoE for Image Generation},
author={Nucleus AI Team},
year={2026},
eprint={2604.12163},
archivePrefix={arXiv},
primaryClass={cs.CV},
}
```
|