
Update README.md
Browse files
README.md
CHANGED
|
@@ -11,13 +11,10 @@ tags:
|
|
| 11 |
- agent
|
| 12 |
---
|
| 13 |
|
| 14 |
-
<h1 align="center">
|
| 15 |
-
OffSeeker: Online Reinforcement Learning Is Not All You Need for Deep Research Agents
|
| 16 |
-
</h1>
|
| 17 |
|
| 18 |
-
|
| 19 |
|
| 20 |
-
-
|
| 21 |
|
| 22 |
<!-- [](https://arxiv.org/abs/2601.18467) [](https://huggingface.co/OffSeeker/OffSeeker-8B-DPO) [](https://huggingface.co/datasets/OffSeeker/DeepForge) [](LICENSE) -->
|
| 23 |
|
|
@@ -27,8 +24,6 @@ We introduce a fully open-source suite designed for effective offline training.
|
|
| 27 |
|
| 28 |
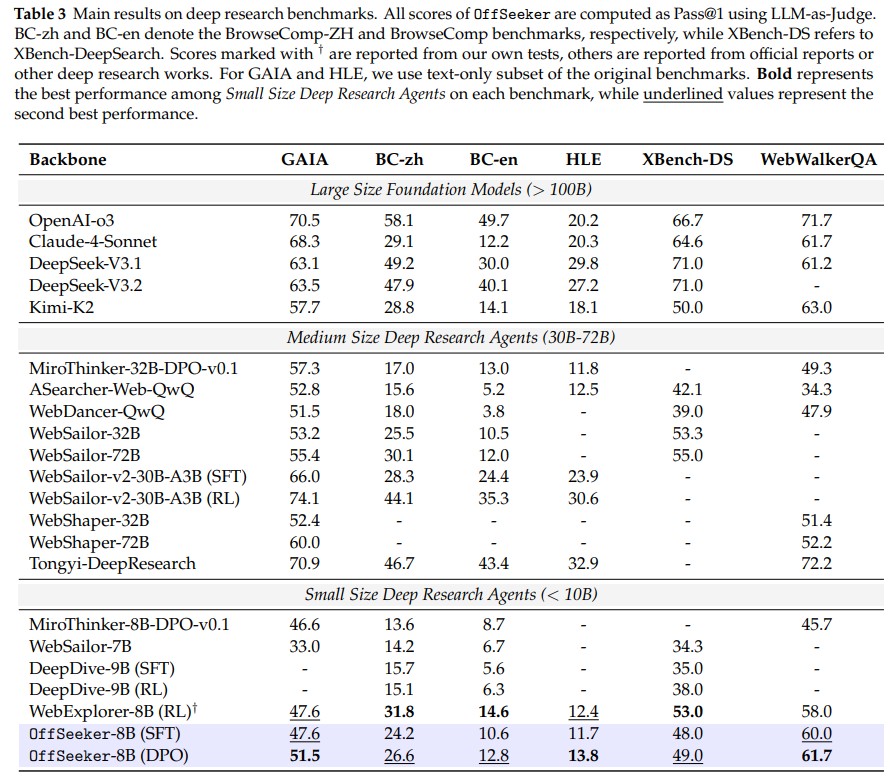
|
| 29 |
|
| 30 |
-
---
|
| 31 |
-
|
| 32 |
|
| 33 |
## 📊 Resources & Datasets
|
| 34 |
|
|
@@ -42,8 +37,6 @@ We are releasing our complete dataset to support the research community in offli
|
|
| 42 |
| **DPO Pairs** | 21,000 | Preference pairs for refining agent behavior |
|
| 43 |
| **OffSeeker Model** | 8B | Competitive with 30B-parameter online RL models |
|
| 44 |
|
| 45 |
-
---
|
| 46 |
-
|
| 47 |
## 📖 Citation
|
| 48 |
|
| 49 |
If you find this work useful for your research, please cite our paper:
|
|
|
|
| 11 |
- agent
|
| 12 |
---
|
| 13 |
|
|
|
|
|
|
|
|
|
|
| 14 |
|
| 15 |
+
# OffSeeker: Online Reinforcement Learning Is Not All You Need for Deep Research Agents
|
| 16 |
|
| 17 |
+
<a href="https://arxiv.org/abs/2601.18467"><b>Paper</b></a> | <a href="https://github.com/Ralph-Zhou/OffSeeker/tree/main"><b>Github</b></a>
|
| 18 |
|
| 19 |
<!-- [](https://arxiv.org/abs/2601.18467) [](https://huggingface.co/OffSeeker/OffSeeker-8B-DPO) [](https://huggingface.co/datasets/OffSeeker/DeepForge) [](LICENSE) -->
|
| 20 |
|
|
|
|
| 24 |
|
| 25 |

|
| 26 |
|
|
|
|
|
|
|
| 27 |
|
| 28 |
## 📊 Resources & Datasets
|
| 29 |
|
|
|
|
| 37 |
| **DPO Pairs** | 21,000 | Preference pairs for refining agent behavior |
|
| 38 |
| **OffSeeker Model** | 8B | Competitive with 30B-parameter online RL models |
|
| 39 |
|
|
|
|
|
|
|
| 40 |
## 📖 Citation
|
| 41 |
|
| 42 |
If you find this work useful for your research, please cite our paper:
|