

Update README.md
Browse files
README.md
CHANGED
|
@@ -18,7 +18,7 @@ This model doesn't dramatically improve on the base model's general task perform
|
|
| 18 |
|
| 19 |
# Evaluations
|
| 20 |
|
| 21 |
-
We've only done
|
| 22 |
|
| 23 |
## HuggingFaceH4 Open LLM Leaderboard Performance
|
| 24 |
|
|
@@ -29,6 +29,9 @@ The only significant improvement was with TruthfulQA.
|
|
| 29 |
|
| 30 |
## MT-bench Performance
|
| 31 |
|
|
|
|
|
|
|
|
|
|
| 32 |
| Epoch | Average | Turn 1 | Turn 2 |
|
| 33 |
|:----------|:----------|:----------|:----------|
|
| 34 |
| 3 | 4.85 | 5.69 | 4.01 |
|
|
|
|
| 18 |
|
| 19 |
# Evaluations
|
| 20 |
|
| 21 |
+
We've only done limited testing as yet. The [epoch 3.5 checkpoint](https://huggingface.co/Open-Orca/oo-phi-1_5/commit/f7754d8b8b4c3e0748eaf47be4cf5aac1f80a401) scores above 5.1 on MT-Bench (better than Alpaca-13B, worse than Llama2-7b-chat), while preliminary benchmarks suggest peak average performance was achieved roughly at epoch 4.
|
| 22 |
|
| 23 |
## HuggingFaceH4 Open LLM Leaderboard Performance
|
| 24 |
|
|
|
|
| 29 |
|
| 30 |
## MT-bench Performance
|
| 31 |
|
| 32 |
+
|
| 33 |
+
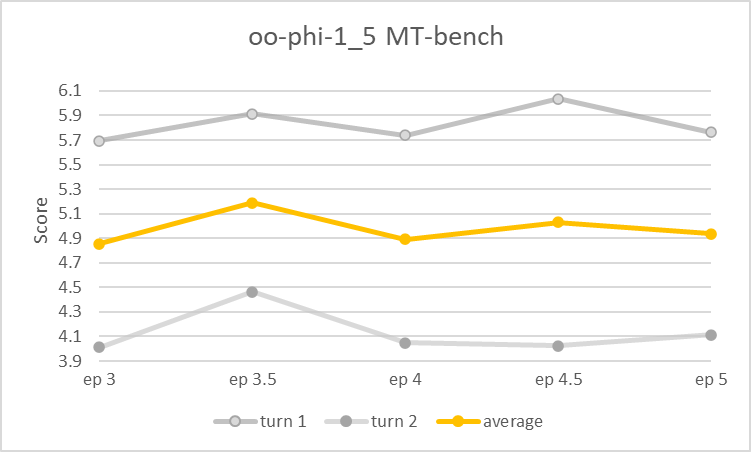
|
| 34 |
+
|
| 35 |
| Epoch | Average | Turn 1 | Turn 2 |
|
| 36 |
|:----------|:----------|:----------|:----------|
|
| 37 |
| 3 | 4.85 | 5.69 | 4.01 |
|