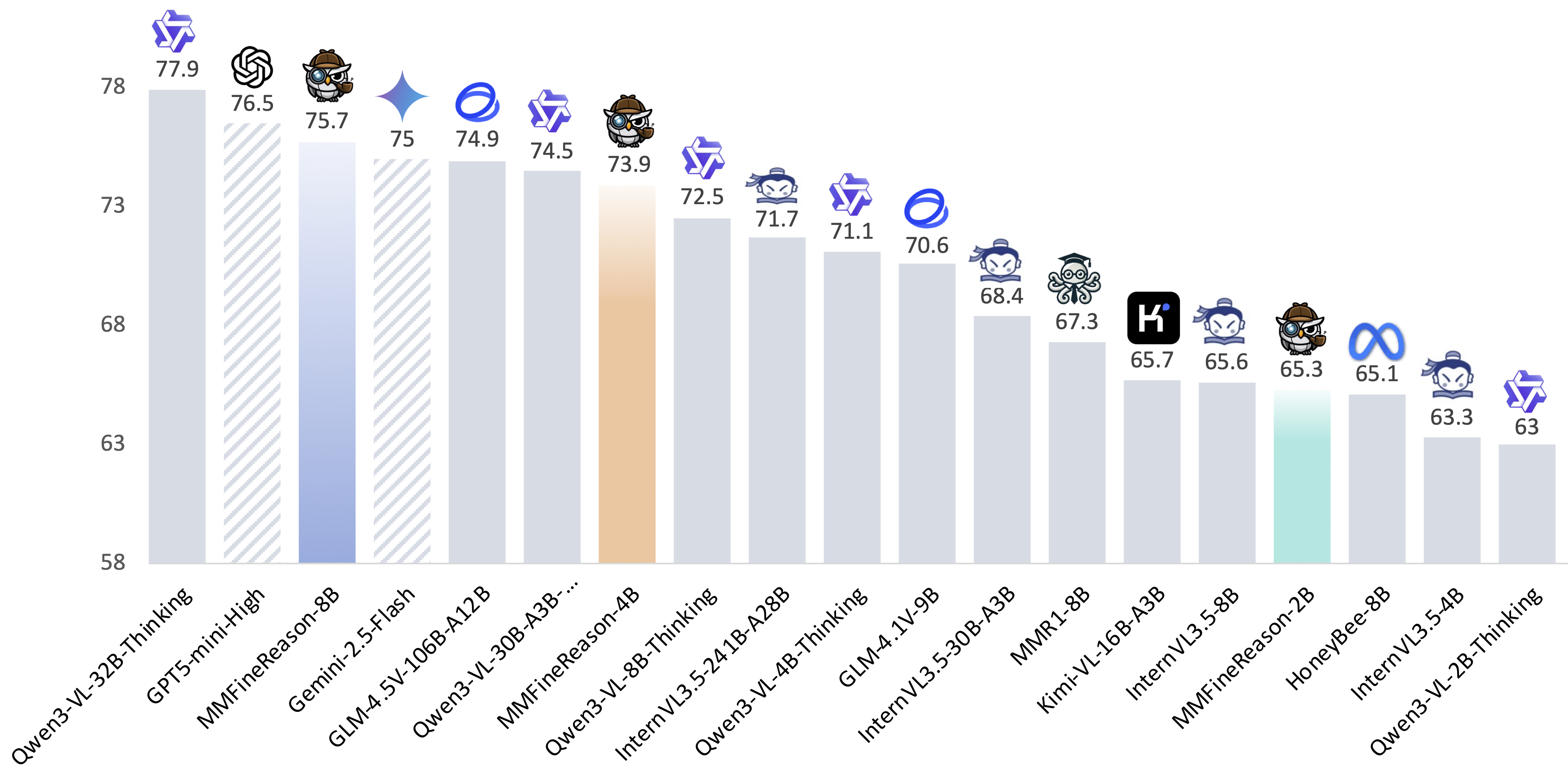
Average score across mathematical reasoning and multimodal understanding benchmarks.
---
This repository provides **MMFineReason-8B**; detailed dataset information is available at https://huggingface.co/datasets/OpenDataArena/MMFineReason-1.8M.
## 📖 Overview
**MMFineReason** is a large-scale, high-quality multimodal reasoning dataset comprising **1.8M samples** and **5.1B solution tokens**, featuring detailed reasoning annotations distilled from **Qwen3-VL-235B-A22B-Thinking**.
### 🎯 Key Highlights
- **1.8M High-Quality Samples** with **5.1B Solution Tokens**
- **Long-Form CoT**: Average reasoning length of **2,910 tokens** (2.7× HoneyBee, 4.3× OpenMMReasoner)
- **100% Caption Coverage**: Dense visual descriptions averaging 609 tokens
- **Multi-Domain**: Mathematics (79.4%), Science (13.8%), Puzzle/Game (4.6%), General/OCR (2.2%)
- **State-of-the-Art**: Models trained on this dataset achieve SOTA performance in their size class
## 🧠 Model Training
Based on the MMFineReason dataset, we train a family of multimodal reasoning models at 2B / 4B / 8B scales, all initialized from the corresponding Qwen3-VL-Instruct backbones and fine-tuned using a unified data-centric training recipe.
Each MMFineReason model is trained in two stages:
- **Supervised Fine-Tuning (SFT)** on MMFineReason-1.8M-SFT, leveraging long-form, visually grounded Chain-of-Thought (CoT) annotations with an average length of 2,910 tokens.
- **Reinforcement Learning (RL)** using GSPO, applied on MMFineReason-1.8M-RL to further improve reasoning reliability and generalization.
---
## 📊 Model Performance
### Main Results
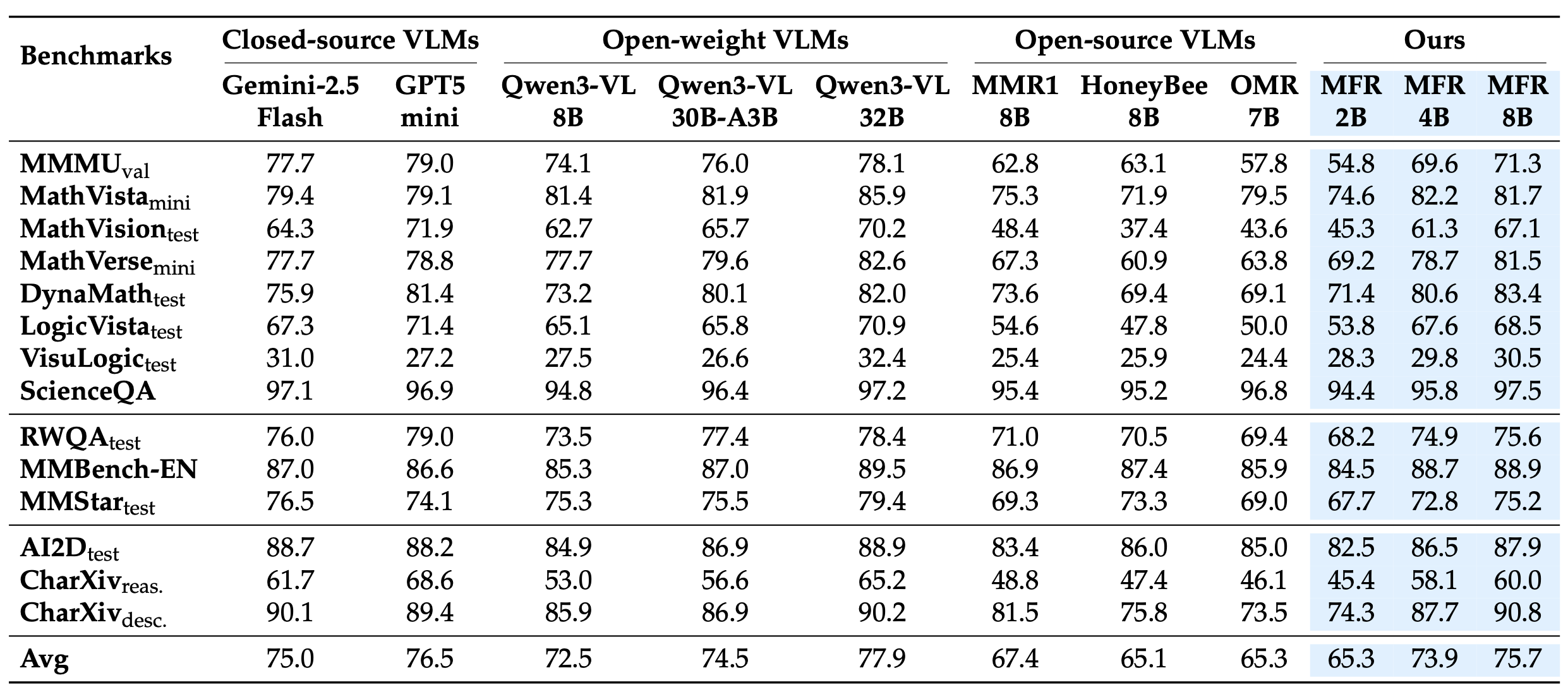
Comparison of MMFineReason models with state-of-the-art models.
MMFineReason-4B surpasses Qwen3-VL-8B-Thinking (73.9 vs 72.5), while MMFineReason-8B outperforms the larger Qwen3-VL-30B-A3B-Thinking (75.7 vs 74.5) and exceeds Gemini-2.5-Flash. On mathematical benchmarks, MFR-8B achieves 83.4% on DynaMath (vs Qwen3-VL-32B-Thinking's 82.0%) and 67.1% on MathVision, outperforming HoneyBee-8B and OMR-7B by 23-30 points. Despite minimal chart training data, MFR-8B generalizes well to CharXiv (90.8%) and RealWorldQA (75.6%).
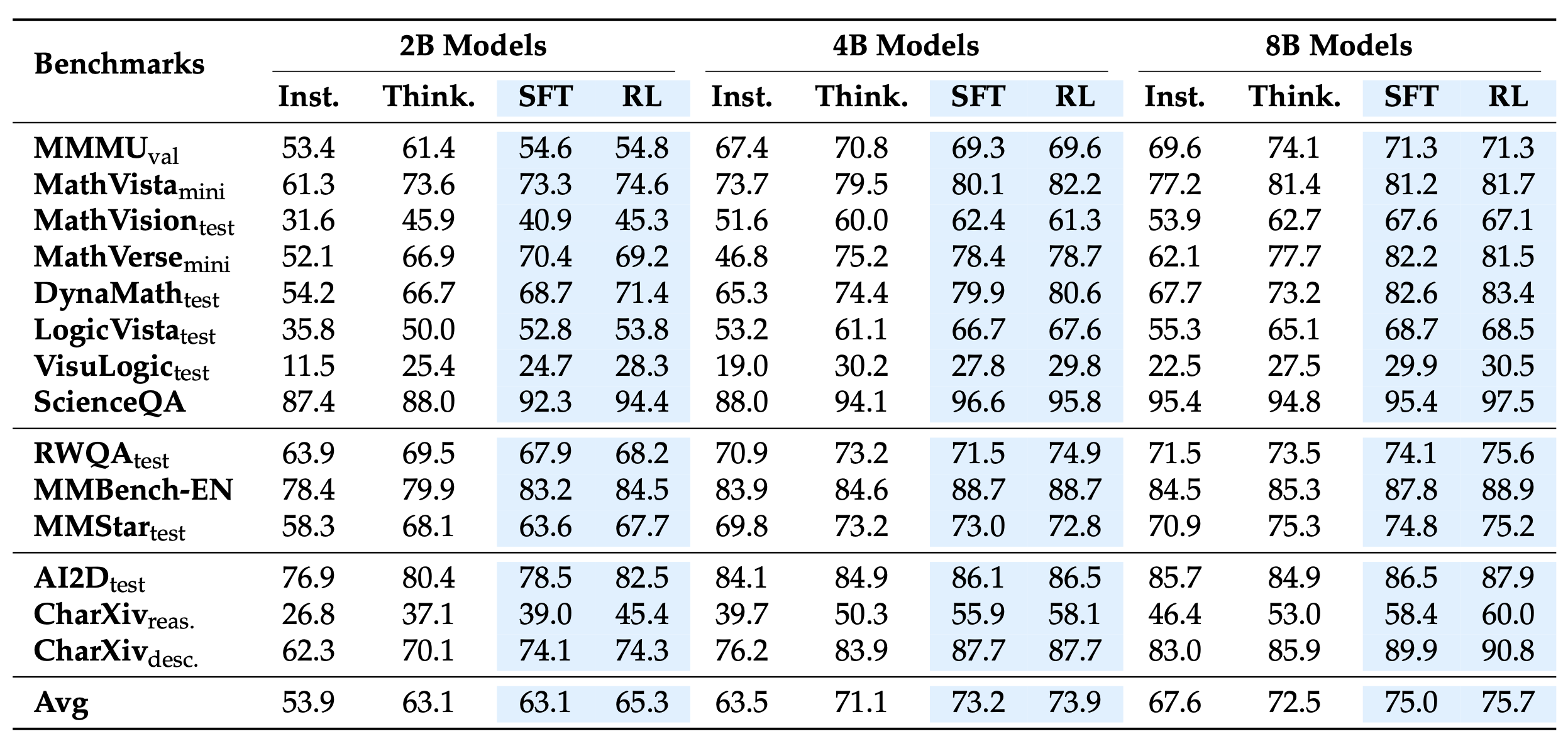
### SFT vs RL Training Analysis
Results comparing MFR-SFT and MFR-Thinking models against base Qwen3-VL variants.
SFT drives major gains in mathematical reasoning (e.g., MathVision: 53.9% → 67.6% for 8B). RL enhances generalization on understanding benchmarks (e.g., AI2D: 78.5% → 82.5% for 2B) while showing variance on math benchmarks.
## 🏆 Model Zoo
| Model | Parameters | Avg Score | HuggingFace |
|-------|------------|-----------|-------------|
| MMFineReason-2B | 2B | 65.3 | [🤗 Link](https://huggingface.co/OpenDataArena/MMFineReason-2B) |
| MMFineReason-4B | 4B | 73.9 | [🤗 Link](https://huggingface.co/OpenDataArena/MMFineReason-4B) |
| MMFineReason-8B | 8B | 75.7 | [🤗 Link](https://huggingface.co/OpenDataArena/MMFineReason-8B) |
---
## 📚 Citation
```bibtex
@article{lin2026mmfinereason,
title={MMFineReason: Closing the Multimodal Reasoning Gap via Open Data-Centric Methods},
author={Lin, Honglin and Liu, Zheng and Zhu, Yun and Qin, Chonghan and Lin, Juekai and Shang, Xiaoran and He, Conghui and Zhang, Wentao and Wu, Lijun},
journal={arXiv preprint arXiv:2601.21821},
year={2026},
url={https://mmfinereason.github.io/}
}
```
---
## 📄 License
This dataset is released under the [Apache 2.0 License](https://opensource.org/licenses/Apache-2.0). Individual source datasets may have their own licenses.
---
## 🤝 Acknowledgments
We thank the creators of FineVision, MMR1, BMMR, Euclid30K, GameQA-140K, LLaVA-CoT, WeMath, ViRL39K, and others. We also thank the Qwen team for the powerful Qwen3-VL series models.