Step 1 - Exploring the Credit Card Font
NOTE: Download all code in resources
Open the file titled: Credit Card Reader.ipynb
Unfortunately, there isn't an official standard credit card number font - some of the fonts used go by the names Farrington 7B, OCR-B, SecurePay, OCR-A and MICR E13B. However, in my experience there seem to be two main font variations used in credit cards:

and

Note the differences, especially in the 1, 7 and 8.
Let's open these images in Python using OpenCV
import cv2
+
+cc1 = cv2.imread('creditcard_digits1.jpg', 0)
+cv2.imshow("Digits 1", cc1)
+cv2.waitKey(0)
+cc2 = cv2.imread('creditcard_digits2.jpg', 0)
+cv2.imshow("Digits 2", cc2)
+cv2.waitKey(0)
+cv2.destroyAllWindows()Let's experiment with testing OTSU Binarization. Remember binarization converts a grayscale image to two colors, black and white. Values under a certain threshold (typically 127 out of 255) are clipped to 0, while the values greater than 127 are clipped to 255. It looks like this below.

The code to perform this is:
cc1 = cv2.imread('creditcard_digits2.jpg', 0)
+_, th2 = cv2.threshold(cc1, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
+cv2.imshow("Digits 2 Thresholded", th2)
+cv2.waitKey(0)
+
+cv2.destroyAllWindows()Step 2 - Creating our Dataset Directories
This sets up our training and test directories for the digits (0 to 9).
#Create our dataset directories + +import os + +def makedir(directory): + """Creates a new directory if it does not exist""" + if not os.path.exists(directory): + os.makedirs(directory) + return None, 0 + +for i in range(0,10): + directory_name = "./credit_card/train/"+str(i) + print(directory_name) + makedir(directory_name) + +for i in range(0,10): + directory_name = "./credit_card/test/"+str(i) + print(directory_name) + makedir(directory_name)
Step 3 - Creating our Data Augmentation Functions
Let's now create some functions to create more data. What we're doing here is taking the two samples of each digit we saw above, and adding small variations to the digit. This is very similar to Keras's Data Augmentation, however, we're using OpenCV to create an augmented dataset instead. We will further use Keras to Augment this even further.
We've created 5 functions here, let's discuss each:
DigitAugmentation() - This one simply uses the other image manipulating functions, but calls them randomly. Examine to code to see how it's done.
add_noise() - This function introduces some noise elements to the image
pixelate() - This function re-sizes the image then upscales/upsamples it. This degrades the quality and is meant to simulate blur to the image from either a shakey or poor quality camera.
stretch() - This simulates some variation in re-sizing where it stretches the image to a small random amount
pre_process() - This is a simple function that applies OTSU Binarization to the image and re-sizes it. We use this on the extracted digits. To create a clean dataset akin to the MNIST style format.
import cv2 +import numpy as np +import random +import cv2 +from scipy.ndimage import convolve + +def DigitAugmentation(frame, dim = 32): + """Randomly alters the image using noise, pixelation and streching image functions""" + frame = cv2.resize(frame, None, fx=2, fy=2, interpolation = cv2.INTER_CUBIC) + frame = cv2.cvtColor(frame, cv2.COLOR_GRAY2RGB) + random_num = np.random.randint(0,9) + + if (random_num % 2 == 0): + frame = add_noise(frame) + if(random_num % 3 == 0): + frame = pixelate(frame) + if(random_num % 2 == 0): + frame = stretch(frame) + frame = cv2.resize(frame, (dim, dim), interpolation = cv2.INTER_AREA) + + return frame + +def add_noise(image): + """Addings noise to image""" + prob = random.uniform(0.01, 0.05) + rnd = np.random.rand(image.shape[0], image.shape[1]) + noisy = image.copy() + noisy[rnd < prob] = 0 + noisy[rnd > 1 - prob] = 1 + return noisy + +def pixelate(image): + "Pixelates an image by reducing the resolution then upscaling it" + dim = np.random.randint(8,12) + image = cv2.resize(image, (dim, dim), interpolation = cv2.INTER_AREA) + image = cv2.resize(image, (16, 16), interpolation = cv2.INTER_AREA) + return image + +def stretch(image): + "Randomly applies different degrees of stretch to image" + ran = np.random.randint(0,3)*2 + if np.random.randint(0,2) == 0: + frame = cv2.resize(image, (32, ran+32), interpolation = cv2.INTER_AREA) + return frame[int(ran/2):int(ran+32)-int(ran/2), 0:32] + else: + frame = cv2.resize(image, (ran+32, 32), interpolation = cv2.INTER_AREA) + return frame[0:32, int(ran/2):int(ran+32)-int(ran/2)] + +def pre_process(image, inv = False): + """Uses OTSU binarization on an image""" + try: + gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) + except: + gray_image = image + pass + + if inv == False: + _, th2 = cv2.threshold(gray_image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU) + else: + _, th2 = cv2.threshold(gray_image, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU) + resized = cv2.resize(th2, (32,32), interpolation = cv2.INTER_AREA) + return resized +
We can test our augmentation by using this bit of code:
cc1 = cv2.imread('creditcard_digits2.jpg', 0)
+_, th2 = cv2.threshold(cc1, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
+cv2.imshow("cc1", th2)
+cv2.waitKey(0)
+cv2.destroyAllWindows()
+
+# This is the coordinates of the region enclosing the first digit
+# This is preset and was done manually based on this specific image
+region = [(0, 0), (35, 48)]
+
+# Assigns values to each region for ease of interpretation
+top_left_y = region[0][1]
+bottom_right_y = region[1][1]
+top_left_x = region[0][0]
+bottom_right_x = region[1][0]
+
+for i in range(0,1): #We only look at the first digit in testing out augmentation functions
+ roi = cc1[top_left_y:bottom_right_y, top_left_x:bottom_right_x]
+ for j in range(0,10):
+ roi2 = DigitAugmentation(roi)
+ roi_otsu = pre_process(roi2, inv = False)
+ cv2.imshow("otsu", roi_otsu)
+ cv2.waitKey(0)
+
+cv2.destroyAllWindows()Typically it looks like this:

You can try more adventurous forms of varying the original image. My suggestion would be to try dilation and erosion on these.
Step 4 - Creating our dataset
Let's create 1000 variations of the first font we're sampling (note 1000 is perhaps way too much, but the data sizes were small and quick to train so why not use the arbitrary number of 1000).
# Creating 2000 Images for each digit in creditcard_digits1 - TRAINING DATA
+
+# Load our first image
+cc1 = cv2.imread('creditcard_digits1.jpg', 0)
+
+_, th2 = cv2.threshold(cc1, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
+cv2.imshow("cc1", th2)
+cv2.imshow("creditcard_digits1", cc1)
+cv2.waitKey(0)
+cv2.destroyAllWindows()
+
+region = [(2, 19), (50, 72)]
+
+top_left_y = region[0][1]
+bottom_right_y = region[1][1]
+top_left_x = region[0][0]
+bottom_right_x = region[1][0]
+
+for i in range(0,10):
+ # We jump the next digit each time we loop
+ if i > 0:
+ top_left_x = top_left_x + 59
+ bottom_right_x = bottom_right_x + 59
+
+ roi = cc1[top_left_y:bottom_right_y, top_left_x:bottom_right_x]
+ print("Augmenting Digit - ", str(i))
+ # We create 200 versions of each image for our dataset
+ for j in range(0,2000):
+ roi2 = DigitAugmentation(roi)
+ roi_otsu = pre_process(roi2, inv = True)
+ cv2.imwrite("./credit_card/train/"+str(i)+"./_1_"+str(j)+".jpg", roi_otsu)
+cv2.destroyAllWindows()
+
+Next, let's make 1000 variations to each digit of the second font type.
# Creating 2000 Images for each digit in creditcard_digits2 - TRAINING DATA
+
+cc1 = cv2.imread('creditcard_digits2.jpg', 0)
+_, th2 = cv2.threshold(cc1, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
+cv2.imshow("cc1", th2)
+cv2.waitKey(0)
+cv2.destroyAllWindows()
+
+region = [(0, 0), (35, 48)]
+
+top_left_y = region[0][1]
+bottom_right_y = region[1][1]
+top_left_x = region[0][0]
+bottom_right_x = region[1][0]
+
+for i in range(0,10):
+ if i > 0:
+ # We jump the next digit each time we loop
+ top_left_x = top_left_x + 35
+ bottom_right_x = bottom_right_x + 35
+
+ roi = cc1[top_left_y:bottom_right_y, top_left_x:bottom_right_x]
+ print("Augmenting Digit - ", str(i))
+ # We create 200 versions of each image for our dataset
+ for j in range(0,2000):
+ roi2 = DigitAugmentation(roi)
+ roi_otsu = pre_process(roi2, inv = False)
+ cv2.imwrite("./credit_card/train/"+str(i)+"./_2_"+str(j)+".jpg", roi_otsu)
+ cv2.imshow("otsu", roi_otsu)
+ print("-")
+ cv2.waitKey(0)
+
+cv2.destroyAllWindows()Making our Test Data
- Note is a VERY bad practice to create a test dataset like this. Even though we're adding random variations, our test data here is too similar to our training data. Ideally, you'd want to use some real life unseen data from another source. In our case, we're sampling for the same dataset.
# Creating 200 Images for each digit in creditcard_digits1 - TEST DATA
+
+# Load our first image
+cc1 = cv2.imread('creditcard_digits1.jpg', 0)
+
+_, th2 = cv2.threshold(cc1, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
+cv2.imshow("cc1", th2)
+cv2.imshow("creditcard_digits1", cc1)
+cv2.waitKey(0)
+cv2.destroyAllWindows()
+
+region = [(2, 19), (50, 72)]
+
+top_left_y = region[0][1]
+bottom_right_y = region[1][1]
+top_left_x = region[0][0]
+bottom_right_x = region[1][0]
+
+for i in range(0,10):
+ # We jump the next digit each time we loop
+ if i > 0:
+ top_left_x = top_left_x + 59
+ bottom_right_x = bottom_right_x + 59
+
+ roi = cc1[top_left_y:bottom_right_y, top_left_x:bottom_right_x]
+ print("Augmenting Digit - ", str(i))
+ # We create 200 versions of each image for our dataset
+ for j in range(0,2000):
+ roi2 = DigitAugmentation(roi)
+ roi_otsu = pre_process(roi2, inv = True)
+ cv2.imwrite("./credit_card/test/"+str(i)+"./_1_"+str(j)+".jpg", roi_otsu)
+cv2.destroyAllWindows()# Creating 200 Images for each digit in creditcard_digits2 - TEST DATA
+
+cc1 = cv2.imread('creditcard_digits2.jpg', 0)
+_, th2 = cv2.threshold(cc1, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
+cv2.imshow("cc1", th2)
+cv2.waitKey(0)
+cv2.destroyAllWindows()
+
+region = [(0, 0), (35, 48)]
+
+top_left_y = region[0][1]
+bottom_right_y = region[1][1]
+top_left_x = region[0][0]
+bottom_right_x = region[1][0]
+
+for i in range(0,10):
+ if i > 0:
+ # We jump the next digit each time we loop
+ top_left_x = top_left_x + 35
+ bottom_right_x = bottom_right_x + 35
+
+ roi = cc1[top_left_y:bottom_right_y, top_left_x:bottom_right_x]
+ print("Augmenting Digit - ", str(i))
+ # We create 200 versions of each image for our dataset
+ for j in range(0,2000):
+ roi2 = DigitAugmentation(roi)
+ roi_otsu = pre_process(roi2, inv = False)
+ cv2.imwrite("./credit_card/test/"+str(i)+"./_2_"+str(j)+".jpg", roi_otsu)
+ cv2.imshow("otsu", roi_otsu)
+ print("-")
+ cv2.waitKey(0)
+cv2.destroyAllWindows()
+Creating our Classifier in Keras
Now that we have our dataset we can dive in your using the Keras code you're now so familiar with :)
Let's now take advantage of Keras's Data Augmentation and apply some small rotations, shifts, shearing and zooming.
import os +import numpy as np +from keras.models import Sequential +from keras.layers import Activation, Dropout, Flatten, Dense +from keras.preprocessing.image import ImageDataGenerator +from keras.layers import Conv2D, MaxPooling2D, ZeroPadding2D +from keras import optimizers +import keras + +input_shape = (32, 32, 3) +img_width = 32 +img_height = 32 +num_classes = 10 +nb_train_samples = 10000 +nb_validation_samples = 2000 +batch_size = 16 +epochs = 1 + +train_data_dir = './credit_card/train' +validation_data_dir = './credit_card/test' + +# Creating our data generator for our test data +validation_datagen = ImageDataGenerator( + # used to rescale the pixel values from [0, 255] to [0, 1] interval + rescale = 1./255) + +# Creating our data generator for our training data +train_datagen = ImageDataGenerator( + rescale = 1./255, # normalize pixel values to [0,1] + rotation_range = 10, # randomly applies rotations + width_shift_range = 0.25, # randomly applies width shifting + height_shift_range = 0.25, # randomly applies height shifting + shear_range=0.5, + zoom_range=0.5, + horizontal_flip = False, # randonly flips the image + fill_mode = 'nearest') # uses the fill mode nearest to fill gaps created by the above + +# Specify criteria about our training data, such as the directory, image size, batch size and type +# automagically retrieve images and their classes for train and validation sets +train_generator = train_datagen.flow_from_directory( + train_data_dir, + target_size = (img_width, img_height), + batch_size = batch_size, + class_mode = 'categorical') + +validation_generator = validation_datagen.flow_from_directory( + validation_data_dir, + target_size = (img_width, img_height), + batch_size = batch_size, + class_mode = 'categorical', + shuffle = False)
Let's use the effective and famous (on MNIST) LeNET Convolutional Neural Network Architecture
# create model
+model = Sequential()
+
+# 2 sets of CRP (Convolution, RELU, Pooling)
+model.add(Conv2D(20, (5, 5),
+ padding = "same",
+ input_shape = input_shape))
+model.add(Activation("relu"))
+model.add(MaxPooling2D(pool_size = (2, 2), strides = (2, 2)))
+
+model.add(Conv2D(50, (5, 5),
+ padding = "same"))
+model.add(Activation("relu"))
+model.add(MaxPooling2D(pool_size = (2, 2), strides = (2, 2)))
+
+# Fully connected layers (w/ RELU)
+model.add(Flatten())
+model.add(Dense(500))
+model.add(Activation("relu"))
+
+# Softmax (for classification)
+model.add(Dense(num_classes))
+model.add(Activation("softmax"))
+
+model.compile(loss = 'categorical_crossentropy',
+ optimizer = keras.optimizers.Adadelta(),
+ metrics = ['accuracy'])
+
+print(model.summary())
+And now let's train our model for 5 EPOCHS.
from keras.optimizers import RMSprop
+from keras.callbacks import ModelCheckpoint, EarlyStopping
+
+checkpoint = ModelCheckpoint("/home/deeplearningcv/DeepLearningCV/Trained Models/creditcard.h5",
+ monitor="val_loss",
+ mode="min",
+ save_best_only = True,
+ verbose=1)
+
+earlystop = EarlyStopping(monitor = 'val_loss',
+ min_delta = 0,
+ patience = 3,
+ verbose = 1,
+ restore_best_weights = True)
+
+# we put our call backs into a callback list
+callbacks = [earlystop, checkpoint]
+
+# Note we use a very small learning rate
+model.compile(loss = 'categorical_crossentropy',
+ optimizer = RMSprop(lr = 0.001),
+ metrics = ['accuracy'])
+
+nb_train_samples = 20000
+nb_validation_samples = 4000
+epochs = 5
+batch_size = 16
+
+history = model.fit_generator(
+ train_generator,
+ steps_per_epoch = nb_train_samples // batch_size,
+ epochs = epochs,
+ callbacks = callbacks,
+ validation_data = validation_generator,
+ validation_steps = nb_validation_samples // batch_size)
+
+model.save("/home/deeplearningcv/DeepLearningCV/Trained Models/creditcard.h5")Perfect, now you have an extremely accurate (on our limited test data) model.
In the next section we will build a Credit Card Extractor using OpenCV
\ No newline at end of file diff --git a/27. BONUS - Build a Credit Card Number Reader/3. Step 3 - Extracting A Credit Card from the Background.html b/27. BONUS - Build a Credit Card Number Reader/3. Step 3 - Extracting A Credit Card from the Background.html new file mode 100644 index 0000000000000000000000000000000000000000..270b3017d152f81db73fc494c5836c891c27c7e6 --- /dev/null +++ b/27. BONUS - Build a Credit Card Number Reader/3. Step 3 - Extracting A Credit Card from the Background.html @@ -0,0 +1,139 @@ +Extracting a Credit Card
NOTE: This example extracts only 12 of the 16 digits because, this is a working credit card :)
The code below does contains the functions we use to do the following:
1. It loads the image, image we're using our mobile phone camera to take this picture. (Note: ideally place the card on a contrasting background)

2. We use Canny Edge detection to identify the edges of card

3. We using cv2.findContours() to extract the largest contour (which we assume will be the credit card)

4. This is where we use the function four_point_transform() and order_points() to adjust the perspective of the card. It creates a top-down type view that is useful because:
It standardizes the view of the card so that the credit card digits are always roughly in the same area.
It removes/reduces skew and warped perspectives from the image when taken from a camera. All cameras unless taken exactly top down, will introduce some skew to text/digits. This is why scanners always produce more realistic looking images.


import cv2
+import numpy as np
+import imutils
+from skimage.filters import threshold_adaptive
+import os
+
+def order_points(pts):
+ # initialize a list of coordinates that will be ordered
+ # such that the first entry in the list is the top-left,
+ # the second entry is the top-right, the third is the
+ # bottom-right, and the fourth is the bottom-left
+ rect = np.zeros((4, 2), dtype = "float32")
+
+ # the top-left point will have the smallest sum, whereas
+ # the bottom-right point will have the largest sum
+ s = pts.sum(axis = 1)
+ rect[0] = pts[np.argmin(s)]
+ rect[2] = pts[np.argmax(s)]
+
+ # now, compute the difference between the points, the
+ # top-right point will have the smallest difference,
+ # whereas the bottom-left will have the largest difference
+ diff = np.diff(pts, axis = 1)
+ rect[1] = pts[np.argmin(diff)]
+ rect[3] = pts[np.argmax(diff)]
+
+ # return the ordered coordinates
+ return rect
+
+def four_point_transform(image, pts):
+ # obtain a consistent order of the points and unpack them
+ # individually
+ rect = order_points(pts)
+ (tl, tr, br, bl) = rect
+
+ # compute the width of the new image, which will be the
+ # maximum distance between bottom-right and bottom-left
+ # x-coordinates or the top-right and top-left x-coordinates
+ widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
+ widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
+ maxWidth = max(int(widthA), int(widthB))
+
+ # compute the height of the new image, which will be the
+ # maximum distance between the top-right and bottom-right
+ # y-coordinates or the top-left and bottom-left y-coordinates
+ heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
+ heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
+ maxHeight = max(int(heightA), int(heightB))
+
+ # now that we have the dimensions of the new image, construct
+ # the set of destination points to obtain a "birds eye view",
+ # (i.e. top-down view) of the image, again specifying points
+ # in the top-left, top-right, bottom-right, and bottom-left
+ # order
+ dst = np.array([
+ [0, 0],
+ [maxWidth - 1, 0],
+ [maxWidth - 1, maxHeight - 1],
+ [0, maxHeight - 1]], dtype = "float32")
+
+ # compute the perspective transform matrix and then apply it
+ M = cv2.getPerspectiveTransform(rect, dst)
+ warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
+
+ # return the warped image
+ return warped
+
+def doc_Scan(image):
+ orig_height, orig_width = image.shape[:2]
+ ratio = image.shape[0] / 500.0
+
+ orig = image.copy()
+ image = imutils.resize(image, height = 500)
+ orig_height, orig_width = image.shape[:2]
+ Original_Area = orig_height * orig_width
+
+ # convert the image to grayscale, blur it, and find edges
+ # in the image
+ gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
+ gray = cv2.GaussianBlur(gray, (5, 5), 0)
+ edged = cv2.Canny(gray, 75, 200)
+
+ cv2.imshow("Image", image)
+ cv2.imshow("Edged", edged)
+ cv2.waitKey(0)
+ # show the original image and the edge detected image
+
+ # find the contours in the edged image, keeping only the
+ # largest ones, and initialize the screen contour
+ _, contours, hierarchy = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
+ contours = sorted(contours, key = cv2.contourArea, reverse = True)[:5]
+
+ # loop over the contours
+ for c in contours:
+
+ # approximate the contour
+ area = cv2.contourArea(c)
+ if area < (Original_Area/3):
+ print("Error Image Invalid")
+ return("ERROR")
+ peri = cv2.arcLength(c, True)
+ approx = cv2.approxPolyDP(c, 0.02 * peri, True)
+
+ # if our approximated contour has four points, then we
+ # can assume that we have found our screen
+ if len(approx) == 4:
+ screenCnt = approx
+ break
+
+ # show the contour (outline) of the piece of paper
+ cv2.drawContours(image, [screenCnt], -1, (0, 255, 0), 2)
+ cv2.imshow("Outline", image)
+
+ warped = four_point_transform(orig, screenCnt.reshape(4, 2) * ratio)
+ # convert the warped image to grayscale, then threshold it
+ # to give it that 'black and white' paper effect
+ cv2.resize(warped, (640,403), interpolation = cv2.INTER_AREA)
+ cv2.imwrite("credit_card_color.jpg", warped)
+ warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
+ warped = warped.astype("uint8") * 255
+ cv2.imshow("Extracted Credit Card", warped)
+ cv2.waitKey(0)
+ cv2.destroyAllWindows()
+ return warpedWe now need to extract the credit card number region. If you looked at the code in the above example we are always re-sizing our extracted credit card image to a size of 640 x 403. The odd choice of 403 was chosen because 640:403 is the actual ratio of a credit card. We are trying to maintain as accurate as possible the length and width dimensions so that we don't necessarily warp the image too much.
NOTE: I know we're re-sizing all extracted digits to 32 x 32, but even still keeping the initial ratio correct will only help our classifier accuracy.
As such, because of the fixed size, we can now extract the region ([(55, 210), (640, 290)]) easily from our image.
image = cv2.imread('test_card.jpg')
+image = doc_Scan(image)
+
+region = [(55, 210), (640, 290)]
+
+top_left_y = region[0][1]
+bottom_right_y = region[1][1]
+top_left_x = region[0][0]
+bottom_right_x = region[1][0]
+
+# Extracting the area were the credit numbers are located
+roi = image[top_left_y:bottom_right_y, top_left_x:bottom_right_x]
+cv2.imshow("Region", roi)
+cv2.imwrite("credit_card_extracted_digits.jpg", roi)
+cv2.waitKey(0)
+cv2.destroyAllWindows()This is what our extracted region looks like.

In the next section, we're going to using some OpenCV techniques to extract each digit and pass it to our classifier for identification.
\ No newline at end of file diff --git a/27. BONUS - Build a Credit Card Number Reader/4. Step 4 - Use our Model to Identify the Digits & Display it onto our Credit Card.html b/27. BONUS - Build a Credit Card Number Reader/4. Step 4 - Use our Model to Identify the Digits & Display it onto our Credit Card.html new file mode 100644 index 0000000000000000000000000000000000000000..5d5c17d86a4c5a7719fcba17c8a3d06630fded04 --- /dev/null +++ b/27. BONUS - Build a Credit Card Number Reader/4. Step 4 - Use our Model to Identify the Digits & Display it onto our Credit Card.html @@ -0,0 +1,60 @@ +Classifying Digits on a real Credit Card

In this section we're going to write the code to make the above!
Firstly, let's load the model we created by:
from keras.models import load_model
+import keras
+
+classifier = load_model('/home/deeplearningcv/DeepLearningCV/Trained Models/creditcard.h5')Now let's do some OpenCV magic and extract the digits from the image below:

The algorithm we follow to do this is really quite simple:
We first load our grayscale extracted image and the original color (note we could have just loaded the color and grayscaled it)
We apply the Canny Edge algorithm (typically we apply blur first to reduce noise in finding the edges).
We then use findCountours to isolate the digits
We sort the contours by size (so that smaller irrelevant contours aren't used)
We then sort it left to right by creating a function that returns the x-cordinate of a contour.
Once we have our cleaned up contours, we find the bounding rectange of the contour which gives us an enclosed rectangle around the digit. (To ensure these contours are valid we do extract only contours meeting the minimum width and height expectations). Also because I've created a black square around the last 4 digits, we discard contours of large area so that it isn't fed into our classifier.
We then take each extracted digit, use our pre_processing function (which applies OTSU Binarization and re-sizes it) then breakdown that image array so that it can be loaded into our classifier.
The full code to do this is shown below:
def x_cord_contour(contours):
+ #Returns the X cordinate for the contour centroid
+ if cv2.contourArea(contours) > 10:
+ M = cv2.moments(contours)
+ return (int(M['m10']/M['m00']))
+ else:
+ pass
+
+img = cv2.imread('credit_card_extracted_digits.jpg')
+orig_img = cv2.imread('credit_card_color.jpg')
+gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
+cv2.imshow("image", img)
+cv2.waitKey(0)
+
+# Blur image then find edges using Canny
+blurred = cv2.GaussianBlur(gray, (5, 5), 0)
+#cv2.imshow("blurred", blurred)
+#cv2.waitKey(0)
+
+edged = cv2.Canny(blurred, 30, 150)
+#cv2.imshow("edged", edged)
+#cv2.waitKey(0)
+
+# Find Contours
+_, contours, _ = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
+
+#Sort out contours left to right by using their x cordinates
+contours = sorted(contours, key=cv2.contourArea, reverse=True)[:13] #Change this to 16 to get all digits
+contours = sorted(contours, key = x_cord_contour, reverse = False)
+
+# Create empty array to store entire number
+full_number = []
+
+# loop over the contours
+for c in contours:
+ # compute the bounding box for the rectangle
+ (x, y, w, h) = cv2.boundingRect(c)
+ if w >= 5 and h >= 25 and cv2.contourArea(c) < 1000:
+ roi = blurred[y:y + h, x:x + w]
+ #ret, roi = cv2.threshold(roi, 20, 255,cv2.THRESH_BINARY_INV)
+ cv2.imshow("ROI1", roi)
+ roi_otsu = pre_process(roi, True)
+ cv2.imshow("ROI2", roi_otsu)
+ roi_otsu = cv2.cvtColor(roi_otsu, cv2.COLOR_GRAY2RGB)
+ roi_otsu = keras.preprocessing.image.img_to_array(roi_otsu)
+ roi_otsu = roi_otsu * 1./255
+ roi_otsu = np.expand_dims(roi_otsu, axis=0)
+ image = np.vstack([roi_otsu])
+ label = str(classifier.predict_classes(image, batch_size = 10))[1]
+ print(label)
+ (x, y, w, h) = (x+region[0][0], y+region[0][1], w, h)
+ cv2.rectangle(orig_img, (x, y), (x + w, y + h), (0, 255, 0), 2)
+ cv2.putText(orig_img, label, (x , y + 90), cv2.FONT_HERSHEY_COMPLEX, 2, (255, 0, 0), 2)
+ cv2.imshow("image", orig_img)
+ cv2.waitKey(0)
+
+cv2.destroyAllWindows()
\ No newline at end of file
diff --git a/28. BONUS - Use Cloud GPUs on PaperSpace/1. Why use Cloud GPUs and How to Setup a PaperSpace Gradient Notebook.html b/28. BONUS - Use Cloud GPUs on PaperSpace/1. Why use Cloud GPUs and How to Setup a PaperSpace Gradient Notebook.html
new file mode 100644
index 0000000000000000000000000000000000000000..0f660c6770bf22a1339fae7814a246e89e02ca79
--- /dev/null
+++ b/28. BONUS - Use Cloud GPUs on PaperSpace/1. Why use Cloud GPUs and How to Setup a PaperSpace Gradient Notebook.html
@@ -0,0 +1 @@
+Why GPU's are better for Deep Learning
https://www.quora.com/Why-are-GPUs-well-suited-to-deep-learning
As many have said GPUs are so fast because they are so efficient for matrix multiplication and convolution, but nobody gave a real explanation for why this is so. The real reason for this is memory bandwidth and not necessarily parallelism.
First of all, you have to understand that CPUs are latency optimized while GPUs are bandwidth optimized. You can visualize this as a CPU being a Ferrari and a GPU being a big truck. The task of both is to pick up packages from a random location A and to transport those packages to another random location B. The CPU (Ferrari) can fetch some memory (packages) in your RAM quickly while the GPU (big truck) is slower in doing that (much higher latency). However, the CPU (Ferrari) needs to go back and forth many times to do its job (location A $\rightarrow$ pick up 2 packages $\rightarrow$ location B ... repeat) while the GPU can fetch much more memory at once (location A $\rightarrow$ pick up 100 packages $\rightarrow$ location B ... repeat).
So, in other words, the CPU is good at fetching small amounts of memory quickly (5 * 3 * 7) while the GPU is good at fetching large amounts of memory (Matrix multiplication: (A*B)*C). The best CPUs have about 50GB/s while the best GPUs have 750GB/s memory bandwidth. So the more memory your computational operations require, the more significant the advantage of GPUs over CPUs. But there is still the latency that may hurt performance in the case of the GPU. A big truck may be able to pick up a lot of packages with each tour, but the problem is that you are waiting a long time until the next set of packages arrives. Without solving this problem, GPUs would be very slow even for large amounts of data. So how is this solved?
If you ask a big truck to make many tours to fetch packages you will always wait for a long time for the next load of packages once the truck has departed to do the next tour — the truck is just slow. However, if you now use a fleet of either Ferraris and big trucks (thread parallelism), and you have a big job with many packages (large chunks of memory such as matrices) then you will wait for the first truck a bit, but after that you will have no waiting time at all — unloading the packages takes so much time that all the trucks will queue in unloading location B so that you always have direct access to your packages (memory). This effectively hides latency so that GPUs offer high bandwidth while hiding their latency under thread parallelism — so for large chunks of memory GPUs provide the best memory bandwidth while having almost no drawback due to latency via thread parallelism. This is the second reason why GPUs are faster than CPUs for deep learning. As a side note, you will also see why more threads do not make sense for CPUs: A fleet of Ferraris has no real benefit in any scenario.
But the advantages for the GPU do not end here. This is the first step where the memory is fetched from the main memory (RAM) to the local memory on the chip (L1 cache and registers). This second step is less critical for performance but still adds to the lead for GPUs. All computation that ever is executed happens in registers which are directly attached to the execution unit (a core for CPUs, a stream processor for GPUs). Usually, you have the fast L1 and register memory very close to the execution engine, and you want to keep these memories small so that access is fast. Increased distance to the execution engine dramatically reduces memory access speed, so the larger the distance to access it the slower it gets. If you make your memory larger and larger, then, in turn, it gets slower to access its memory (on average, finding what you want to buy in a small store is faster than finding what you want to buy in a huge store, even if you know where that item is). So the size is limited for register files - we are just at the limits of physics here and every nanometer counts, we want to keep them small.
The advantage of the GPU is here that it can have a small pack of registers for every processing unit (stream processor, or SM), of which it has many. Thus we can have in total a lot of register memory, which is very small and thus very fast. This leads to the aggregate GPU registers size being more than 30 times larger compared to CPUs and still twice as fast which translates to up to 14MB register memory that operates at a whopping 80TB/s. As a comparison, the CPU L1 cache only operates at about 5TB/s which is quite slow and has the size of roughly 1MB; CPU registers usually have sizes of around 64-128KB and operate at 10-20TB/s. Of course, this comparison of numbers is a bit flawed because registers operate a bit differently than GPU registers (a bit like apples and oranges), but the difference in size here is more crucial than the difference in speed, and it does make a difference.
As a side note, full register utilization in GPUs seems to be difficult to achieve at first because it is the smallest unit of computation which needs to be fine-tuned by hand for good performance. However, NVIDIA has developed helpful compiler tools which indicate when you are using too much or too few registers per stream processor. It is easy to tweak your GPU code to make use of the right amount of registers and L1 cache for fast performance. This gives GPUs an advantage over other architectures like Xeon Phis where this utilization is complicated to achieve and painful to debug which in the end makes it difficult to maximize performance on a Xeon Phi.
What this means, in the end, is that you can store a lot of data in your L1 caches and register files on GPUs to reuse convolutional and matrix multiplication tiles. For example the best matrix multiplication algorithms use 2 tiles of 64x32 to 96x64 numbers for 2 matrices in L1 cache, and a 16x16 to 32x32 number register tile for the outputs sums per thread block (1 thread block = up to 1024 threads; you have 8 thread blocks per stream processor, there are 60 stream processors in total for the entire GPU). If you have a 100MB matrix, you can split it up in smaller matrices that fit into your cache and registers, and then do matrix multiplication with three matrix tiles at speeds of 10-80TB/s — that is fast! This is the third reason why GPUs are so much faster than CPUs, and why they are so well suited for deep learning.
Keep in mind that the slower memory always dominates performance bottlenecks. If 95% of your memory movements take place in registers (80TB/s), and 5% in your main memory (0.75TB/s), then you still spend most of the time on memory access of main memory (about six times as much).
Thus in order of importance: (1) High bandwidth main memory, (2) hiding memory access latency under thread parallelism, and (3) large and fast register and L1 memory which is easily programmable are the components which make GPUs so well suited for deep learning.
However, building your own deep learning rig is a pricey affair. Factor in costs of a fast and powerful GPU, CPU, SSD, compatible motherboard and power supply, air-conditioning bills, maintenance and damage to components. On top of it, you run the risk of falling behind on the latest hardware in this rapidly advancing industry.
Moreover, just assembling the components is not enough. You need to setup all the required libraries and compatible drivers before you can start training your first model. People still go along this route, and if you plan to use deep learning extensively (>150 hrs/mo), building your own deep learning workstation might be the right move.
A better and cheaper alternative is to use cloud-based GPU servers provided by the likes of Amazon, Google, Microsoft and others, especially if you are just breaking into this domain and plan to use the computing power for learning and experimenting. I have been using AWS, Paperspace and FloydHub for the past 4–5 months. Google Cloud Platform and Microsoft Azure were similar to AWS in their pricing and offerings, hence, I stuck to the previously mentioned three.
However, the reason you WANT to use Cloud GPUs is because GPU Architecture

Source - https://www.nvidia.com/en-us/data-center/tesla-v100/
Now that we know we want to use GPUs - Sign up and Create a Gradient Notebook with Keras and TensorFlow pre-installed
In my opinion PaperSpace's Gradient containers are some of quickest and simplest ways to started using a cloud GPU. In a matter of minutes you'll be training a CNN!
Of course you're free to use other Cloud GPU services, AWS, Azure, Floydhub, Google Cloud (GPUs and TPUs), Vast.AI and many others.
Here's an entite list of Cloud GPU providers - https://towardsdatascience.com/list-of-deep-learning-cloud-service-providers-579f2c769ed6
Using PaperSpace's GPU and Gradient Notebooks
Step 1
Go to www.paperspace.com
Step 2
Sign up using your GitHub account or a regular email and password:

Step 3A - Adding Credit Card and using my Referral Code to get $10 Free Credit
Verify your email and sign in to PaperSpace, you'll be greeted by this page. It may not immediately appear, but notice Error Alert box in pink below (see yellow box I drew over it).

STEP 3B - Go to the Billing Page

Step 3C - Enter Credit Card Info and Referral code
Get $5 Free Credit by using Referral Code - 2DSSNCI
or click below
https://paperspace.io/&R=2DSSNCI
This gives you ~10 hours of usage on a P4000 GPU
After the user must enter their credit card information, otherwise you won't be able to launch a gradient machine
Step 4A - Creating a Gradient Notebook
Go back to the Home landing page and click on the Gradient Box shown below.

Step 4B - Click on box in yellow to create your first notebook

Step 4C -Under the Public Containers Tab (should be shown by default), click on the ufoym/deepo:all-py36-jupyter container box (shown in the yellow box below).
This container contains many essential Deep Learning Libraries including Keras and TensorFlow. The main libraries included are:
darknet latest (git)
python 3.6 (apt)
torch latest (git)
chainer latest (pip)
jupyter latest (pip)
mxnet latest (pip)
onnx latest (pip)
pytorch latest (pip)
tensorflow latest (pip)
theano latest (git)
keras latest (pip)
lasagne latest (git)
opencv 4.0.1 (git)
sonnet latest (pip)
caffe latest (git)
cntk latest (pip)

Step 4D - Select the following instance, the P4000. Note feel free to select other more expensive GPUs, but as a cost per value system, the P4000 is excellent.

Step 4E - Name your Notebook (or keep the default name, it's your choice). I chose "DL CV P4000".
Next you should see the Create Notebook button below in green, click that to create your notebook!
Note: You can ignore the 04. Auto-Shutdown are for now, but remember to shutdown your notebook after use (will show you how soon) so that your credit does not run down.

Step 5 - Launching your notebook
Your notebook will now show up in the Notebook section shown below.
Click the greyed out Start button (located in the Actions column) to boot it up.

This window will now appear, click Start Notebook below.

Status will change from Stopped to Pending -> Provisioned -> Running
Once it's running you'll be able to launch it by pressing Open

Training AlexNet on the CIFAR10 Dataset
Upon clicking start from our previous section, we'll now be greeted with this screen:

Looks a fairly harmless Notebook, but this cloud system will allow us to training AlexNet almost 100X faster!
But first, let's explore our new PaperSpace Gradient Notebook.
Observe the two directories that are setup (see above) by the PaperSpace Gradient system:
datasets - contains some common datasets some of which you'd recognize from earlier in our course, these are there as test data to check performance of new CNNs or even to aid in transfer learning etc. (See below for a screenshot)
storage - This is where you'd preferably want to keep files (ipynb notebooks and data) (see below)
Datasets

Storage

Note: data stored in the storage folder is persistent across all gradient machines in your account.
Data saved in the main workspace area (i.e. the default directory which is /home/paperspace) will be lost when your terminate the session - do not save important files there or they will be lost!
lost+found can be ignored as it's a directory created in Unix systems where corrupted data is temporarily stored (if you do lose files it's possible they maybe stored there)
There are two easy ways to use PaperSpace Gradients
1. Go to the storage directory Click on New and....

Start a new Python3 notebook

This launches a new python3 notebook where you can import Keras, TensorFlow etc and use just like you do on your local machine or Virtual Machine. Except we're now taking advantage of their lightening quick GPUs! Feel free to copy and paste your existing code into these notebooks.

OR
2. Upload your existing notebooks and datasets by using the Upload button. (see resources for AlexNet CIFAR10 .ipynb)

It's that simple!
Now let's try our AlexNet CIFAR10 CNN
Either upload the notebook in the attached resources or copy and paste this code into
#Keras Imports and Loading Our CIFAR10 Dataset
+from __future__ import print_function
+import keras
+from keras.datasets import cifar10
+from keras.preprocessing.image import ImageDataGenerator
+from keras.models import Sequential
+from keras.layers import Dense, Dropout, Activation, Flatten
+from keras.layers import Conv2D, MaxPooling2D, ZeroPadding2D
+from keras.layers.normalization import BatchNormalization
+from keras.regularizers import l2
+
+# Loads the CIFAR dataset
+(x_train, y_train), (x_test, y_test) = cifar10.load_data()
+
+# Display our data shape/dimensions
+print('x_train shape:', x_train.shape)
+print(x_train.shape[0], 'train samples')
+print(x_test.shape[0], 'test samples')
+
+# Now we one hot encode outputs
+num_classes = 10
+y_train = keras.utils.to_categorical(y_train, num_classes)
+y_test = keras.utils.to_categorical(y_test, num_classes)#Defining our AlexNet Convolutional Neural Network
+l2_reg = 0
+
+
+# Initialize model
+model = Sequential()
+
+# 1st Conv Layer
+model.add(Conv2D(96, (11, 11), input_shape=x_train.shape[1:],
+ padding='same', kernel_regularizer=l2(l2_reg)))
+model.add(BatchNormalization())
+model.add(Activation('relu'))
+model.add(MaxPooling2D(pool_size=(2, 2)))
+
+# 2nd Conv Layer
+model.add(Conv2D(256, (5, 5), padding='same'))
+model.add(BatchNormalization())
+model.add(Activation('relu'))
+model.add(MaxPooling2D(pool_size=(2, 2)))
+
+# 3rd Conv Layer
+model.add(ZeroPadding2D((1, 1)))
+model.add(Conv2D(512, (3, 3), padding='same'))
+model.add(BatchNormalization())
+model.add(Activation('relu'))
+model.add(MaxPooling2D(pool_size=(2, 2)))
+
+# 4th Conv Layer
+model.add(ZeroPadding2D((1, 1)))
+model.add(Conv2D(1024, (3, 3), padding='same'))
+model.add(BatchNormalization())
+model.add(Activation('relu'))
+
+# 5th Conv Layer
+model.add(ZeroPadding2D((1, 1)))
+model.add(Conv2D(1024, (3, 3), padding='same'))
+model.add(BatchNormalization())
+model.add(Activation('relu'))
+model.add(MaxPooling2D(pool_size=(2, 2)))
+
+# 1st FC Layer
+model.add(Flatten())
+model.add(Dense(3072))
+model.add(BatchNormalization())
+model.add(Activation('relu'))
+model.add(Dropout(0.5))
+
+# 2nd FC Layer
+model.add(Dense(4096))
+model.add(BatchNormalization())
+model.add(Activation('relu'))
+model.add(Dropout(0.5))
+
+# 3rd FC Layer
+model.add(Dense(num_classes))
+model.add(BatchNormalization())
+model.add(Activation('softmax'))
+
+print(model.summary())
+
+model.compile(loss = 'categorical_crossentropy',
+ optimizer = keras.optimizers.Adadelta(),
+ metrics = ['accuracy'])# Training Parameters
+batch_size = 32
+epochs = 10
+
+history = model.fit(x_train, y_train,
+ batch_size=batch_size,
+ epochs=epochs,
+ validation_data=(x_test, y_test),
+ shuffle=True)
+
+model.save("./Models/CIFAR10_AlexNet_10_Epoch.h5")
+
+# Evaluate the performance of our trained model
+scores = model.evaluate(x_test, y_test, verbose=1)
+print('Test loss:', scores[0])
+print('Test accuracy:', scores[1])Our Cloud GPU as trained almost 60-100X faster than our CPU!

We've trained 10 EPOCHs are 80% Accuracy in just bout 45 minutes. A CPU only system that would have taken over well over 24 hours.
Our Training Loss and Accuracy Graphs


Introduction
We're about to create a Computer Vision (CV) API and Web App. But first, why would we want to do this?
Ever wanted to share your Computer Vision App on the web to show a friend using their PC or Phone?
Want to sell or commercialize your python computer vision code, but not sure how to distribute Python?
Well if you want to make your CV code available to the world you need to make it accessible from the web. There are three main ways you can do this:
1. Create an API, which allows any other application (whether it's an iOS, Android or within any other software) to access it via the API protocol. APIs are Application Programming Interfaces that facilitate access to complex external applications via a simplified interface. In our example, we'll be using the RESTful API protocol which allows us to run our Python CV via the web.
2. Create a Web App, this is basically the same as an API, except we'll be allowing users to access or run our CV app via any web browser.
3. Run the CV code natively on another platform. This is the more difficult option is it requires you to re-code your Python CV code into another language. This is far more difficult and requires you learning an entirely new language e.g. Java if making an Android App. But the local access reduces the need to send data over the web and can perform real-time operations. This method won't be shown in this tutorial.
Introducing Flask
Before we begin installing Flask and setting up everything on AWS, let me first explain what exactly is Flask, and why we need it.

Flask is a micro web framework written in Python. It is classified as a microframework because it does not require particular tools or libraries. It has no database abstraction layer, form validation, or any other components where pre-existing third-party libraries provide common functions. This allows us to easily build simple APIs without much effort.
Step 1: Installing Flask
If using your VM, activate your environment (so that we can use OpenCV and Keras).
source activate cv or whatever your environment is named
pip install flask
That's it, Flask is ready to go!
Let's run a simple Flask test.
Step 2: Installing a code editor since we won't be using Ipython Notebooks. I recommend Sublime, but VSCode, Atom, Spyder, and PyCharm are all great!
If using Windows or Mac, visit the Sublime website to get the download link - https://www.sublimetext.com/download
Ubuntu/VM users can bring up the Ubuntu Software app, search for Sublime and install it from there.

Open up your chosen Text/Code Editor and copy the code below into it and save it in an easy to find directory, e.g.
/home/deeplearningcv/MyFlaskProjects

This is code for your first simple Flask app, the 'hello world' app.
Also, see Resources to download all code required for this section
from flask import Flask
+app = Flask(__name__)
+
+@app.route("/")
+def hello():
+ return "Hello World!"
+
+if __name__ == "__main__":
+ app.run()Once your code is saved in the path, use Terminal or Command Prompt and navigate to the folder where you saved your helloworld.py file.

Upon executing this code, you'll see the following:
This means your server is running successfully and you can now go to your web browser and view your hello world project!

You should see this if you enter 127.0.0.1:5000 in your browser. This means you Flask server is pushing/serving the text "Hello World!" to your localhost on Port 5000.

Remember to press CTRL+C to exit (when in Terminal).
Congratulations! Now you're ready to start testing your Computer Vision API locally, which we'll do in the next chapter!
\ No newline at end of file diff --git a/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/1.1 Download CV API Files.html b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/1.1 Download CV API Files.html new file mode 100644 index 0000000000000000000000000000000000000000..c7b25fc5b8881c3944fd7705fb1a393be185eb80 --- /dev/null +++ b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/1.1 Download CV API Files.html @@ -0,0 +1 @@ + \ No newline at end of file diff --git a/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/2. Running Your Computer Vision Web App on Flask Locally.html b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/2. Running Your Computer Vision Web App on Flask Locally.html new file mode 100644 index 0000000000000000000000000000000000000000..1bf6d7bbb1894f8fb0383a22658053a6237e4585 --- /dev/null +++ b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/2. Running Your Computer Vision Web App on Flask Locally.html @@ -0,0 +1,86 @@ +Our Flask WebApp Template Code
In the previous chapter, we created a simple Hello World app. We're now going create a simple App that does the following:
Allows you to upload an image
Uses OpenCV and Keras to do some operations on the image
Returns the outputs of our operations to the user
We'll be making a simple App that users OpenCV to find the dominant color (Red vs Green vs Blue) and determines whether the animal in the picture is a Cat or Dog.
Our Web App 1:

Our Web App 2:

Our Web App 3:

Our Web App 4:

NOTE: Download the code in the resources section
The code for our web app is as follows:
import os
+from flask import Flask, flash, request, redirect, url_for, jsonify
+from werkzeug.utils import secure_filename
+import cv2
+import keras
+import numpy as np
+from keras.models import load_model
+from keras import backend as K
+
+UPLOAD_FOLDER = './uploads/'
+ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg'])
+DEBUG = True
+app = Flask(__name__)
+app.config.from_object(__name__)
+app.config['SECRET_KEY'] = '7d441f27d441f27567d441f2b6176a'
+app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
+
+def allowed_file(filename):
+ return '.' in filename and \
+ filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
+
+@app.route('/', methods=['GET', 'POST'])
+def upload_file():
+ if request.method == 'POST':
+ # check if the post request has the file part
+ if 'file' not in request.files:
+ flash('No file part')
+ return redirect(request.url)
+ file = request.files['file']
+ if file.filename == '':
+ flash('No selected file')
+ return redirect(request.url)
+ if file and allowed_file(file.filename):
+ filename = secure_filename(file.filename)
+ file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
+ image = cv2.imread(os.path.dirname(os.path.realpath(__file__))+"/uploads/"+filename)
+ color_result = getDominantColor(image)
+ result = catOrDog(image)
+ redirect(url_for('upload_file',filename=filename))
+ return '''
+ <!doctype html>
+ <title>Results</title>
+ <h1>Image contains a - '''+result+'''</h1>
+ <h2>Dominant color is - '''+color_result+'''</h2>
+ <form method=post enctype=multipart/form-data>
+ <input type=file name=file>
+ <input type=submit value=Upload>
+ </form>
+ '''
+ return '''
+ <!doctype html>
+ <title>Upload new File</title>
+ <h1>Upload new File</h1>
+ <form method=post enctype=multipart/form-data>
+ <input type=file name=file>
+ <input type=submit value=Upload>
+ </form>
+ '''
+
+def catOrDog(image):
+ '''Determines if the image contains a cat or dog'''
+ classifier = load_model('./models/cats_vs_dogs_V1.h5')
+ image = cv2.resize(image, (150,150), interpolation = cv2.INTER_AREA)
+ image = image.reshape(1,150,150,3)
+ res = str(classifier.predict_classes(image, 1, verbose = 0)[0][0])
+ print(res)
+ print(type(res))
+ if res == "0":
+ res = "Cat"
+ else:
+ res = "Dog"
+ K.clear_session()
+ return res
+
+def getDominantColor(image):
+ '''returns the dominate color among Blue, Green and Reds in the image '''
+ B, G, R = cv2.split(image)
+ B, G, R = np.sum(B), np.sum(G), np.sum(R)
+ color_sums = [B,G,R]
+ color_values = {"0": "Blue", "1":"Green", "2": "Red"}
+ return color_values[str(np.argmax(color_sums))]
+
+if __name__ == "__main__":
+ app.run()
+
+Running our web app in Terminal (or Command Prompt, it should be exactly the same).

Brief Code Description:
Lines 1 to 8: Importing our flask functions and other relevant functions/Libraries we'll be using in this program such as werkzeug, keras, numpy and opencv
Line 10 to 16: Defining our paths, allowed files and setting our Flask Parameters. Look up the Flask documentation to better understand
Line 18 to 10: Our 'allowed files function', it simply checks the extension of the selected file to ensure only images are uploaded.
Line 22: The route() function of Flask. It is a decorator that tells the Application which URL should call the associated function.
Line 23 to 58: Our main function, it results to both GET or POST Requests. These are HTTP methods that form the basis of data communication over the internet. GET Sends data in unencrypted form to the server. Most common method. POS is used to send HTML form data to the server. Data received by POST method is not cached by the server. We're using an unconventional method of serving the HTML to our client Typically Flask apps used templates stored in a Templates folder which contains our HTML. However, this is a simple web app and it's better for your understanding if we server the HTML like this. Note we have two blocks of code, one is the default HTML used prompting the user to upload an image. The second block sends the response to the user.
Line 60 to 73: This is our Cats vs Dogs function that takes an image and outputs a string stating which animal is found in the image, either "Cat" or "Dog".
Line 75 to 81: This function sums all the Blue, Green and Red color components of an image and returns the color with the largest sum.
Line 83 to 84: Our main code that runs the Flask app by calling the app.run() function.
Our Folder Setup:
MyFlaskProjects/
------Models/ (where our Keras catsvsdogs.h5 is stored)
------Uploads/ (where our uploaded files are stored)
------webapp.py
Feel free to experiment with different images! Let's now move on to a variation of this code that acts as a standalone API.
\ No newline at end of file diff --git a/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/3. Running Your Computer Vision API.html b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/3. Running Your Computer Vision API.html new file mode 100644 index 0000000000000000000000000000000000000000..f585bab2433b2cf64c3cf24f1f43475461436d3f --- /dev/null +++ b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/3. Running Your Computer Vision API.html @@ -0,0 +1,76 @@ +Our Flask API Template Code
In the previous chapter, we created a Web App that's accessible via the web browser. Pretty cool! but what if we wanted to call this API from different Apps e.g. a Native Android or iOS App?
Let's turn it into RESTful API that returns simple JSON responses encapsulating the results.
NOTE: A RESTful API is an application program interface (API) that uses HTTP requests to GET, PUT, POST and DELETE data.
Step 1: Firstly, install Postman to test our API
Windows/Max - Download and install here
Ubuntu Users - Launch Ubuntu Software and Install

Step 2: Our Flask API Code
import os
+from flask import Flask, flash, request, redirect, url_for, jsonify
+from werkzeug.utils import secure_filename
+import cv2
+import numpy as np
+import keras
+from keras.models import load_model
+from keras import backend as K
+
+UPLOAD_FOLDER = './uploads/'
+ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg'])
+DEBUG = True
+app = Flask(__name__)
+app.config.from_object(__name__)
+app.config['SECRET_KEY'] = '7d441f27d441f27567d441f2b6176a'
+app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
+
+def allowed_file(filename):
+ return '.' in filename and \
+ filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
+
+@app.route('/', methods=['GET', 'POST'])
+def upload_file():
+ if request.method == 'POST':
+ # check if the post request has the file part
+ if 'file' not in request.files:
+ flash('No file part')
+ return redirect(request.url)
+ file = request.files['file']
+ # if user does not select file, browser also
+ # submit an empty part without filename
+ if file.filename == '':
+ flash('No selected file')
+ return redirect(request.url)
+ if file and allowed_file(file.filename):
+ filename = secure_filename(file.filename)
+ file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
+ image = cv2.imread(os.path.dirname(os.path.realpath(__file__))+"/uploads/"+filename)
+ color_result = getDominantColor(image)
+ dogOrCat = catOrDog(image)
+ #return redirect(url_for('upload_file',filename=filename)), jsonify({"key":
+ return jsonify({"MainColor": color_result, "catOrDog": dogOrCat} )
+ return '''
+ <!doctype html>
+ <title>API</title>
+ <h1>API Running Successfully</h1>'''
+
+def catOrDog(image):
+ '''Determines if the image contains a cat or dog'''
+ classifier = load_model('./models/cats_vs_dogs_V1.h5')
+ image = cv2.resize(image, (150,150), interpolation = cv2.INTER_AREA)
+ image = image.reshape(1,150,150,3)
+ res = str(classifier.predict_classes(image, 1, verbose = 0)[0][0])
+ print(res)
+ print(type(res))
+ if res == "0":
+ res = "Cat"
+ else:
+ res = "Dog"
+ K.clear_session()
+ return res
+
+def getDominantColor(image):
+ '''returns the dominate color among Blue, Green and Reds in the image '''
+ B, G, R = cv2.split(image)
+ B, G, R = np.sum(B), np.sum(G), np.sum(R)
+ color_sums = [B,G,R]
+ color_values = {"0": "Blue", "1":"Green", "2": "Red"}
+ return color_values[str(np.argmax(color_sums))]
+
+
+if __name__ == "__main__":
+ app.run()
Using Postman (see image above and the corresponding numbered steps below:
Change the protocol to POST
Enter the local host address: http://127.0.0.1:5000/
Change Tab to Body
Select the form-data radio button
From the drop-down, select Key type to be file
For Value, select one of our test images
Click send to send our image to our API
Our response will be shown in the window below.
The output is JSON file containing:
{
+ "MainColor": "Red",
+ "catOrDog": "Cat"
+}The cool thing about using Postman is that we can generate the code to call this API in several different languages:
See blue box to bring up the code box:

Code Generator

Now that you've got your Flask API and Web App working, let's look at deploying this on AWS using an EC2 Instance.
\ No newline at end of file diff --git a/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/4. Setting Up An AWS Account.html b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/4. Setting Up An AWS Account.html new file mode 100644 index 0000000000000000000000000000000000000000..a60f8129f7443de9c2ac815e3e1215d204d15d00 --- /dev/null +++ b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/4. Setting Up An AWS Account.html @@ -0,0 +1 @@ +Setting up AWS
Step 1: Go to https://aws.amazon.com/ and click on Complete Sign Up

Step 2: Create New Account

Step 3: Enter your main account details

Step 4: Enter Contact Info

Step 5: Enter your verification code

Step 6: Select the Free Basic Plan

Step 7: Sign up is now complete! Sign in to your account now.


Your AWS Account is Complete!
Let's now create our EC2 Instance.
\ No newline at end of file diff --git a/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/5. Setting Up Your AWS EC2 Instance & Installing Keras, TensorFlow, OpenCV & Flask.html b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/5. Setting Up Your AWS EC2 Instance & Installing Keras, TensorFlow, OpenCV & Flask.html new file mode 100644 index 0000000000000000000000000000000000000000..5a26cd0b4bcf484a023599ad4c2ca30b5dec5697 --- /dev/null +++ b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/5. Setting Up Your AWS EC2 Instance & Installing Keras, TensorFlow, OpenCV & Flask.html @@ -0,0 +1,9 @@ +Launching Your E2C Instance
Step 1: Your landing page upon logging in should be the AWS Management Console (see below). Click on the area highlighted in yellow that says "Launch a virtual Machine" with EC2.
What is EC2? Amazon Elastic Compute Cloud (Amazon EC2) provides scalable computing capacity in the Amazon Web Services (AWS) cloud. Using Amazon EC2 eliminates your need to invest in hardware up front, so you can develop and deploy applications faster.
 .
.Step 2: As a Basic Plan (FREE) User, you're eligible to launch and use any of the "Free tier" AMIs. The one we'll be using in this project is the Ubuntu Server 18.04 LTS (HVM), SSD Volume Type. See image below, you'll have to scroll down a bit to find it amongst the many AMIs. We use this image as it's quite easy to get everything up and running.


Step 3: Choosing an Instance Type - We already have chosen the type of OS we want to use (Ubuntu 18.04), now we have to choose a hardware configuration. We aren't given much of a choice due to our Free Tier limitations. The t2.micro will suffice for our application needs for now. Click Review and Launch (highlighted in yellow)

Step 4: Reviewing and launching. No need to change anything here, the defaults are fine. Click Launch (highlighted in yellow)

Step 5A: Creating a new Key Pair. If this is your first time you will need to create a new Key Pair. Click on the drop-down highlighted in yellow below.

Step 5B: GIve you key a name e.g. my_aws_key and Download Key Pair (please don't lose this file otherwise you won't be able to log in to your EC2 instance).

Step 5C: Your Instance has been launched, it will take a few mins for AWS to create and have your instance up and running

Step 6A: Clicking View instances brings up the EC2 Dashboard.

Step 6B: To view the details of the individual instance you just launched, click on Instances under Instances on the left panel.

Step 7: Viewing your Instance public IP. Note your IP as you'll need it later when connecting to your instance.

Step 8: Assuming you're using Ubuntu on the VM (if not it's highly recommended as I find using Putty and SSH keys over windows to be sometimes problematic). Note Windows isn't always, so you're welcome to try using the guide here: https://docs.aws.amazon.com/codedeploy/latest/userguide/tutorials-windows-launch-instance.html)
Mac instructions would be the same as the Ubuntu instructions.
Let's chmod your downloaded key to protect it from overwriting. If you've never used ssh on your VM, create a ./ssh folder in the home director. The following commands also assume your key is in the downloaded directory.
mkdir ${HOME}/.ssh
+cp ~/Downloads/my_aws_key.pem ~/.ssh
+chmod 400 ~/.ssh/my_aws_key.pem
+
Step 9: Connecting to your EC2 instance via Terminal, by running this:
ssh -i ~/.ssh/my_aws_key.pem ubuntu@18.224.96.38
You'll be prompted by the following, type yes and hit Enter.

You'll now be greeted by this! Congratulations, you've connected to your EC2 Instance successfully!

Step 10: Installing the necessary packages by executing the following commands:
sudo apt update +sudo apt install python3-pip +sudo pip3 install tensorflow +sudo pip3 install keras +sudo pip3 install flask
Note: As of April 2019, sudo pip3 install opencv-python appears to be broken, if importing cv2 fails, run sudo apt install python3-opencv
sudo pip3 install opencv-python +sudo apt install python3-opencv
Screenshots of the TensorFlow install:

Screenshots of the Keras install:

Screenshots of the Flask install:

We've successfully installed all libraries needed for our API and Web App on our EC2 Instance!
In the next chapters, we'll:
Setup Filezilla to transfer our code to your EC2
Setup our Security Group on AWS to allow TCP traffic.
Changing your EC2 Security Group to allow HTTP traffic
Step 1: Go to Instances on the left panel of your AWS EC2 Console and click on Instances. Then click on the blue text under the Security Groups column. It may either be named 'default' or 'launch-wizard-1'. This brings up the Security Group Page.

Step 2A: Changing the Security Group Inbound Rules. Right click on the security group shown below.

Step 2B: Click on Edit Inbound Rules

Step 2C: Change the Rules to as shown below.
Type - All Traffic (Protocol will be automatically set to All and Port Range to 0-65535)
Source - Custom which should autofill the box the right to, 0.0.0.0/0 (this indicates we are accepting traffic from all IPs).
Click Save and that's it, your Security Group settings are now set.

Using FileZilla to Connect to Your EC2 Instance to Allow Transferring of Files
Step 1: Install FileZilla
Windows and Mac Users can go here and download and install - https://filezilla-project.org/
Ubuntu users can open the Terminal and install as follows:
sudo apt-get update +sudo apt-get install filezilla

Step 2: Let's load our SSH Key into FileZilla. Open FileZilla, and click Preferences in the main toolbar (should be the same for Windows and Mac users)

Step 3A: In the left panel, select SFTP and then click Add key file...

Step 3B: To find your ssh key, navigate to your "./ssh" directory, as it is a hidden directory, in Ubuntu, you can hit CTRL+L which changes the Location bar to an address bar. Simply type ".ssh/" as shown below to find your ssh key directory.


Step 4A: Connecting to your EC2. Now that you've added your key we can create a new connection.
On the main toolbar again, click File and Site Manager

Step 4B: This brings up the Site Manager window. Click New Site as shown below

Step 4C: Enter the IP (IPv4 Public IP) of your EC2 Instance (can be found under Instances in your AWS Console Manager).

Step 4D: Change the Protocol to SFTP

Step 4E: Change the Logon Type to Normal

Step 4F: Put the Username as ubuntu. Leave the password field alone.

Step 4G: Check the "Always trust this host, add the key to the cache box" and click on OK.

Step 5: We've Connected!
The numbered boxes below show the main windows we'll be using in FileZilla.
1. Is the connection status box that shows the logs as the system connects to your EC2 instance.
2. These are your local files on your system
3. These are the files on your EC2 VM. By default both these

Step 6: Navigate to your Flask python files you downloaded in the previous resource section and drag them accross to your EC2 home directory (default directory).

Great! You're almost ready to have a fully working CV API live on the web!
Next, we need to change the security group of our EC2 to allow HTTP inbound traffic.
\ No newline at end of file diff --git a/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/8. Running your CV Web App on EC2.html b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/8. Running your CV Web App on EC2.html new file mode 100644 index 0000000000000000000000000000000000000000..2f23da3bef53f3c040ffd8b456e020930931de4e --- /dev/null +++ b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/8. Running your CV Web App on EC2.html @@ -0,0 +1 @@ +Running Our CV Web App
Step 1: Let's go back to your terminal in our VM or local OS and connect to our EC2 system
ssh -i ~/.ssh/my_aws_key.pem ubuntu@18.224.96.38

Step 2: Check to see if the files we transferred using FileZilla are indeed located on our EC2 Instance. Running ls should display the following files:

Step 3: Launch our Web App by running this line:
sudo python3 webapp.py

If you see the above, Flask is running our CV Web App! Let's go the our web browser and access it:
Step 4: Enter the EC2 IP in your web browser and your should see the following.
Congratulations! You've just launched a simple Computer Vision API for anyone in the world to use! Let's upload some test images to see our Web App in action!




Awesome!
Note:
This isn't a production grade Web App, there are many things needed to make this ready for public consumption (mainly in terms of security, scalability and appearance), however as of now, it's perfect to demo friends, colleagues, potential investors etc.
To keep our API running constantly launch the python code using this instead:
sudo nohup python3 forms.py & screen
Finally, let's deploy our API version of this App and test using Postman.
\ No newline at end of file diff --git a/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/9. Running your CV API on EC2.html b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/9. Running your CV API on EC2.html new file mode 100644 index 0000000000000000000000000000000000000000..49926da8c6e5f63a2d848cdfbe318d4ad54bb810 --- /dev/null +++ b/29. BONUS - Create a Computer Vision API & Web App Using Flask and AWS/9. Running your CV API on EC2.html @@ -0,0 +1,4 @@ +Running your CV API on EC2
Postman is an extremely useful app used to test APIs. We'll be using it to demonstrate our CV API
Step 1: Install Postman
Windows/Mac Users - https://www.getpostman.com/downloads/
Ubuntu - Open Ubuntu Software, search for Postman and install

Step 2: Setting up Postman for testing your EC2 API

Using Postman (see image above and the corresponding numbered steps below:
Change the protocol to POST
Enter the Public IP Address of your EC2 Instance: http://18.224.96.38
Change Tab to Body
Select the form-data radio button
From the drop down, select Key type to be file
For Value, select one of our test images
Click send to send our image to our API
Our response will be shown in the window below.
The output is JSON file containing:
{
+ "MainColor": "Red",
+ "catOrDog": "Cat"
+}The cool thing about using Postman is that we can generate the code to call this API in several different languages:
See blue box to bring up the code box:

Code Generator
Note: To keep our API running constantly launch the python code using this instead:
sudo nohup python3 forms.py & screen
Conclusion
So you've just successfully deployed a Computer Vision Web App and API that can be used by users anywhere in the world! This facilitates many possibilities from developing Mobile Apps, startup products and research tools. However, it should be noted there are many improvements that can be made:
Saving our uploaded image to as S3 Bucket. We don't want to store all these images on our API server and it wasn't designed for mass storage. It's quite easy to configure and S3 bucket and store all uploaded images there. If privacy is a concern we can forget that entirely and use Python to delete the image after it's been processed.
Using Nginx or Gunicorn or something similar to be the main server for our API
Using a more scalable design (this far from my expertise, but if you ever wanted to support simultaneous users, you'll need to make some adjustments.
Troubleshooting guide
If you get any issues (happens on various systems and configurations, please look at the guide below for the possible solutions). If not, please post a screenshot of your error in the class forum and we'll try to assist.
Summary of this document.
ERROR # 1: Failed to Import Appliance
ERROR # 2: Failed to open a session for the virtual machine Deep Learning CV Ubuntu
ERROR # 3 - (May appear as Warnings) Broken links to shared folder found?
ERROR # 4 - On Macs it's advised you install the feature the feature pack for virtualbox
ERROR # 5 (Common) - VirtualBox fails with “Implementation of the USB 2.0 controller not found” after upgrading
MAC OS Guide - Installing VirtualBox Extension Pack on MacOS (required to access webcam)
NOTE 2019 Update:
With newer versions of windows there are more Virtualbox issues.
The following need to be turned off in windows features for VM to run:
<any> Guard
Containers
Hyper-V
Virtual Machine Platform
Windows Hypervisor Platform
Windows Sandbox
Windows Subsystem for Linux (WSL)
ERROR # 1: Failed to Import Appliance
If you get the following error:

1. Move the .vmdk file to your second (bigger) disk. To do this click on "Global tools", choose the correct vmdk file and select move. It requires few minutes to do it.
2. Create a new virtual machine clicking on the new button.
3. Select Linux -> Ubuntu 64 bit.
4. Choose either 8192 or 4096 megabytes of RAM. Rule of thumb is half of your installed RAM.
5. On the next screen choose "Use an existing fixed virtual disk" and selected the just created .vmdk file
If for some reason this doesn't work. Try this:
1. Go the properties:

2. Click on remove to delete your virtual hard disk
3. Do the procedure of importing the virtual machine again from the start (only once) and you will get the error again.
4. Then try the above procedure again
Thanks to student PierLuigi for this guide!
Alternative option:
Import OVA using VMWare
ERROR # 2: Failed to open a session for the virtual machine Deep Learning CV Ubuntu
Implementation of the USB 2.0 controller not found!
Because the USB 2.0 controller state is part of the saved VM state, the VM cannot be started. To fix this problem, either install the 'Oracle VM VirtualBox Extension Pack' or disable USB 2.0 support in the VM settings.
Note! This error could also mean that an incompatible version of the 'Oracle VM VirtualBox Extension Pack' is installed (VERR_NOT_FOUND).
Result Code: E_FAIL (0x80004005)Component: ConsoleWrapInterface: IConsole {872da645-4a9b-1727-bee2-5585105b9eed}
SOLUTION HERE - https://www.virtualbox.org/ticket/8182
Simply:
Right click on the vm image > USB > USB 1.1
ERROR # 3 - Broken links to shared folder
Ignore those messages and if needed setup your own shared folder (see Lecture 9).
ERROR # 4 - On Macs it's advised you install the feature the feature pack for virtualbox
ERROR # 5 (Common) - VirtualBox fails with “Implementation of the USB 2.0 controller not found” after upgrading
Disable USB Controller when first loading if USB Error. Uncheck the Enable USB Controller box.

Then after loaded up, install the Guest Additions by finding it here from the top toolbar menu.
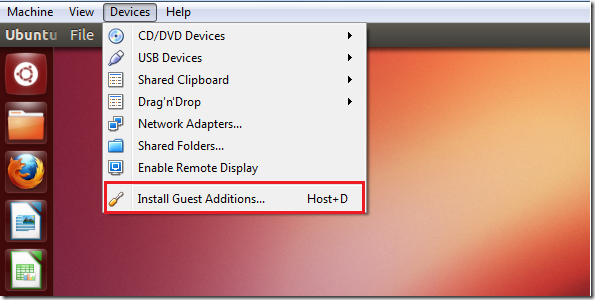
ERROR 6: E_FAIL(0x8004005)

Solution: youtube.com/watch?reload=9&v=u0AWnCr80Ws
Installing VirtualBox Extension Pack on MacOS (required to access webcam)
Credit for these steps goes to one of your yellow students, Erwin.








Model: \"sequential_3\"\n",
+ "\n"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ },
+ {
+ "data": {
+ "text/plain": [
+ "┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓\n",
+ "┃\u001B[1m \u001B[0m\u001B[1mLayer (type) \u001B[0m\u001B[1m \u001B[0m┃\u001B[1m \u001B[0m\u001B[1mOutput Shape \u001B[0m\u001B[1m \u001B[0m┃\u001B[1m \u001B[0m\u001B[1m Param #\u001B[0m\u001B[1m \u001B[0m┃\n",
+ "┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩\n",
+ "│ conv2d_2 (\u001B[38;5;33mConv2D\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m26\u001B[0m, \u001B[38;5;34m26\u001B[0m, \u001B[38;5;34m32\u001B[0m) │ \u001B[38;5;34m320\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ conv2d_3 (\u001B[38;5;33mConv2D\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m24\u001B[0m, \u001B[38;5;34m24\u001B[0m, \u001B[38;5;34m64\u001B[0m) │ \u001B[38;5;34m18,496\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ max_pooling2d_1 (\u001B[38;5;33mMaxPooling2D\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m12\u001B[0m, \u001B[38;5;34m12\u001B[0m, \u001B[38;5;34m64\u001B[0m) │ \u001B[38;5;34m0\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ dropout_2 (\u001B[38;5;33mDropout\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m12\u001B[0m, \u001B[38;5;34m12\u001B[0m, \u001B[38;5;34m64\u001B[0m) │ \u001B[38;5;34m0\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ flatten_1 (\u001B[38;5;33mFlatten\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m9216\u001B[0m) │ \u001B[38;5;34m0\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ dense_2 (\u001B[38;5;33mDense\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m128\u001B[0m) │ \u001B[38;5;34m1,179,776\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ dropout_3 (\u001B[38;5;33mDropout\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m128\u001B[0m) │ \u001B[38;5;34m0\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ dense_3 (\u001B[38;5;33mDense\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m10\u001B[0m) │ \u001B[38;5;34m1,290\u001B[0m │\n",
+ "└─────────────────────────────────┴────────────────────────┴───────────────┘\n"
+ ],
+ "text/html": [
+ "┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓\n", + "┃ Layer (type) ┃ Output Shape ┃ Param # ┃\n", + "┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩\n", + "│ conv2d_2 (Conv2D) │ (None, 26, 26, 32) │ 320 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ conv2d_3 (Conv2D) │ (None, 24, 24, 64) │ 18,496 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ max_pooling2d_1 (MaxPooling2D) │ (None, 12, 12, 64) │ 0 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ dropout_2 (Dropout) │ (None, 12, 12, 64) │ 0 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ flatten_1 (Flatten) │ (None, 9216) │ 0 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ dense_2 (Dense) │ (None, 128) │ 1,179,776 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ dropout_3 (Dropout) │ (None, 128) │ 0 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ dense_3 (Dense) │ (None, 10) │ 1,290 │\n", + "└─────────────────────────────────┴────────────────────────┴───────────────┘\n", + "\n" + ] + }, + "metadata": {}, + "output_type": "display_data" + }, + { + "data": { + "text/plain": [ + "\u001B[1m Total params: \u001B[0m\u001B[38;5;34m1,199,884\u001B[0m (4.58 MB)\n" + ], + "text/html": [ + "
Total params: 1,199,884 (4.58 MB)\n", + "\n" + ] + }, + "metadata": {}, + "output_type": "display_data" + }, + { + "data": { + "text/plain": [ + "\u001B[1m Trainable params: \u001B[0m\u001B[38;5;34m1,199,882\u001B[0m (4.58 MB)\n" + ], + "text/html": [ + "
Trainable params: 1,199,882 (4.58 MB)\n", + "\n" + ] + }, + "metadata": {}, + "output_type": "display_data" + }, + { + "data": { + "text/plain": [ + "\u001B[1m Non-trainable params: \u001B[0m\u001B[38;5;34m0\u001B[0m (0.00 B)\n" + ], + "text/html": [ + "
Non-trainable params: 0 (0.00 B)\n", + "\n" + ] + }, + "metadata": {}, + "output_type": "display_data" + }, + { + "data": { + "text/plain": [ + "\u001B[1m Optimizer params: \u001B[0m\u001B[38;5;34m2\u001B[0m (12.00 B)\n" + ], + "text/html": [ + "
Optimizer params: 2 (12.00 B)\n", + "\n" + ] + }, + "metadata": {}, + "output_type": "display_data" + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "None\n" + ] + } + ], + "execution_count": null + }, + { + "metadata": { + "ExecuteTime": { + "end_time": "2025-03-13T16:05:45.557030Z", + "start_time": "2025-03-13T16:05:45.541940Z" + } + }, + "cell_type": "code", + "source": "import numpy", + "outputs": [], + "execution_count": 2 + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### Testing our classifier on a real image" + ] + }, + { + "cell_type": "code", + "metadata": { + "jupyter": { + "is_executing": true + }, + "ExecuteTime": { + "start_time": "2025-03-13T16:05:47.832541Z" + } + }, + "source": [ + "import numpy as np\n", + "import cv2\n", + "from preprocessors import x_cord_contour, makeSquare, resize_to_pixel\n", + " \n", + "image = cv2.imread('images/numbers.jpg')\n", + "gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)\n", + "cv2.imshow(\"image\", image)\n", + "cv2.waitKey(0)\n", + "\n", + "# Blur image then find edges using Canny \n", + "blurred = cv2.GaussianBlur(gray, (5, 5), 0)\n", + "#cv2.imshow(\"blurred\", blurred)\n", + "#cv2.waitKey(0)\n", + "\n", + "edged = cv2.Canny(blurred, 30, 150)\n", + "#cv2.imshow(\"edged\", edged)\n", + "#cv2.waitKey(0)\n", + "\n", + "# Find Contours\n", + "contours, _ = cv2.findContours(edged.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)\n", + "\n", + "#Sort out contours left to right by using their x cordinates\n", + "contours = sorted(contours, key = x_cord_contour, reverse = False)\n", + "\n", + "# Create empty array to store entire number\n", + "full_number = []\n", + "\n", + "# loop over the contours\n", + "for c in contours:\n", + " # compute the bounding box for the rectangle\n", + " (x, y, w, h) = cv2.boundingRect(c) \n", + "\n", + " if w >= 5 and h >= 25:\n", + " roi = blurred[y:y + h, x:x + w]\n", + " ret, roi = cv2.threshold(roi, 127, 255,cv2.THRESH_BINARY_INV)\n", + " roi = makeSquare(roi)\n", + " roi = resize_to_pixel(28, roi)\n", + " cv2.imshow(\"ROI\", roi)\n", + " roi = roi / 255.0 \n", + " roi = roi.reshape(1,28,28,1) \n", + "\n", + " ## Get Prediction\n", + " res = str(classifier.predict_classes(roi, 1, verbose = 0)[0])\n", + " full_number.append(res)\n", + " cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)\n", + " cv2.putText(image, res, (x , y + 155), cv2.FONT_HERSHEY_COMPLEX, 2, (255, 0, 0), 2)\n", + " cv2.imshow(\"image\", image)\n", + " cv2.waitKey(0) \n", + " \n", + "cv2.destroyAllWindows()\n", + "print (\"The number is: \" + ''.join(full_number))" + ], + "outputs": [], + "execution_count": null + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### Training this Model" + ] + }, + { + "cell_type": "code", + "metadata": { + "ExecuteTime": { + "end_time": "2025-03-13T13:12:31.511869Z", + "start_time": "2025-03-13T12:29:08.572403Z" + } + }, + "source": [ + "from tensorflow.keras.datasets import mnist\n", + "from tensorflow.keras.utils import to_categorical\n", + "from tensorflow.keras.optimizers import Adadelta\n", + "from tensorflow.keras.datasets import mnist\n", + "from tensorflow.keras.models import Sequential\n", + "from tensorflow.keras.layers import Dense, Dropout, Flatten\n", + "from tensorflow.keras.layers import Conv2D, MaxPooling2D ,Input\n", + "from tensorflow.keras import backend as K\n", + "\n", + "# Training Parameters\n", + "batch_size = 128\n", + "epochs = 20\n", + "\n", + "# loads the MNIST dataset\n", + "(x_train, y_train), (x_test, y_test) = mnist.load_data()\n", + "\n", + "# Lets store the number of rows and columns\n", + "img_rows = x_train[0].shape[0]\n", + "img_cols = x_train[1].shape[0]\n", + "\n", + "# Getting our date in the right 'shape' needed for Keras\n", + "# We need to add a 4th dimenion to our date thereby changing our\n", + "# Our original image shape of (60000,28,28) to (60000,28,28,1)\n", + "x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)\n", + "x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)\n", + "\n", + "# store the shape of a single image \n", + "input_shape = (img_rows, img_cols, 1)\n", + "\n", + "# change our image type to float32 data type\n", + "x_train = x_train.astype('float32')\n", + "x_test = x_test.astype('float32')\n", + "\n", + "# Normalize our data by changing the range from (0 to 255) to (0 to 1)\n", + "x_train /= 255\n", + "x_test /= 255\n", + "\n", + "print('x_train shape:', x_train.shape)\n", + "print(x_train.shape[0], 'train samples')\n", + "print(x_test.shape[0], 'test samples')\n", + "\n", + "# Now we one hot encode outputs\n", + "y_train = to_categorical(y_train)\n", + "y_test = to_categorical(y_test)\n", + "\n", + "# Let's count the number columns in our hot encoded matrix \n", + "print (\"Number of Classes: \" + str(y_test.shape[1]))\n", + "\n", + "num_classes = y_test.shape[1]\n", + "num_pixels = x_train.shape[1] * x_train.shape[2]\n", + "\n", + "# create model\n", + "model = Sequential()\n", + "\n", + "model.add(Input(shape=(28,28,1)))\n", + "model.add(Conv2D(32, kernel_size=(3, 3),\n", + " activation='relu',\n", + " input_shape=input_shape))\n", + "model.add(Conv2D(64, (3, 3), activation='relu'))\n", + "model.add(MaxPooling2D(pool_size=(2, 2)))\n", + "model.add(Dropout(0.25))\n", + "model.add(Flatten())\n", + "model.add(Dense(128, activation='relu'))\n", + "model.add(Dropout(0.5))\n", + "model.add(Dense(num_classes, activation='softmax'))\n", + "\n", + "model.compile(loss = 'categorical_crossentropy',\n", + " optimizer = Adadelta(),\n", + " metrics = ['accuracy'])\n", + "\n", + "print(model.summary())\n", + "\n", + "history = model.fit(x_train, y_train,\n", + " batch_size=batch_size,\n", + " epochs=epochs,\n", + " verbose=1,\n", + " validation_data=(x_test, y_test))\n", + "\n", + "score = model.evaluate(x_test, y_test, verbose=0)\n", + "print('Test loss:', score[0])\n", + "print('Test accuracy:', score[1])" + ], + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "x_train shape: (60000, 28, 28, 1)\n", + "60000 train samples\n", + "10000 test samples\n", + "Number of Classes: 10\n" + ] + }, + { + "data": { + "text/plain": [ + "\u001B[1mModel: \"sequential_3\"\u001B[0m\n" + ], + "text/html": [ + "
Model: \"sequential_3\"\n",
+ "\n"
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ },
+ {
+ "data": {
+ "text/plain": [
+ "┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓\n",
+ "┃\u001B[1m \u001B[0m\u001B[1mLayer (type) \u001B[0m\u001B[1m \u001B[0m┃\u001B[1m \u001B[0m\u001B[1mOutput Shape \u001B[0m\u001B[1m \u001B[0m┃\u001B[1m \u001B[0m\u001B[1m Param #\u001B[0m\u001B[1m \u001B[0m┃\n",
+ "┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩\n",
+ "│ conv2d_2 (\u001B[38;5;33mConv2D\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m26\u001B[0m, \u001B[38;5;34m26\u001B[0m, \u001B[38;5;34m32\u001B[0m) │ \u001B[38;5;34m320\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ conv2d_3 (\u001B[38;5;33mConv2D\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m24\u001B[0m, \u001B[38;5;34m24\u001B[0m, \u001B[38;5;34m64\u001B[0m) │ \u001B[38;5;34m18,496\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ max_pooling2d_1 (\u001B[38;5;33mMaxPooling2D\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m12\u001B[0m, \u001B[38;5;34m12\u001B[0m, \u001B[38;5;34m64\u001B[0m) │ \u001B[38;5;34m0\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ dropout_2 (\u001B[38;5;33mDropout\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m12\u001B[0m, \u001B[38;5;34m12\u001B[0m, \u001B[38;5;34m64\u001B[0m) │ \u001B[38;5;34m0\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ flatten_1 (\u001B[38;5;33mFlatten\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m9216\u001B[0m) │ \u001B[38;5;34m0\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ dense_2 (\u001B[38;5;33mDense\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m128\u001B[0m) │ \u001B[38;5;34m1,179,776\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ dropout_3 (\u001B[38;5;33mDropout\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m128\u001B[0m) │ \u001B[38;5;34m0\u001B[0m │\n",
+ "├─────────────────────────────────┼────────────────────────┼───────────────┤\n",
+ "│ dense_3 (\u001B[38;5;33mDense\u001B[0m) │ (\u001B[38;5;45mNone\u001B[0m, \u001B[38;5;34m10\u001B[0m) │ \u001B[38;5;34m1,290\u001B[0m │\n",
+ "└─────────────────────────────────┴────────────────────────┴───────────────┘\n"
+ ],
+ "text/html": [
+ "┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓\n", + "┃ Layer (type) ┃ Output Shape ┃ Param # ┃\n", + "┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩\n", + "│ conv2d_2 (Conv2D) │ (None, 26, 26, 32) │ 320 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ conv2d_3 (Conv2D) │ (None, 24, 24, 64) │ 18,496 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ max_pooling2d_1 (MaxPooling2D) │ (None, 12, 12, 64) │ 0 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ dropout_2 (Dropout) │ (None, 12, 12, 64) │ 0 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ flatten_1 (Flatten) │ (None, 9216) │ 0 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ dense_2 (Dense) │ (None, 128) │ 1,179,776 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ dropout_3 (Dropout) │ (None, 128) │ 0 │\n", + "├─────────────────────────────────┼────────────────────────┼───────────────┤\n", + "│ dense_3 (Dense) │ (None, 10) │ 1,290 │\n", + "└─────────────────────────────────┴────────────────────────┴───────────────┘\n", + "\n" + ] + }, + "metadata": {}, + "output_type": "display_data" + }, + { + "data": { + "text/plain": [ + "\u001B[1m Total params: \u001B[0m\u001B[38;5;34m1,199,882\u001B[0m (4.58 MB)\n" + ], + "text/html": [ + "
Total params: 1,199,882 (4.58 MB)\n", + "\n" + ] + }, + "metadata": {}, + "output_type": "display_data" + }, + { + "data": { + "text/plain": [ + "\u001B[1m Trainable params: \u001B[0m\u001B[38;5;34m1,199,882\u001B[0m (4.58 MB)\n" + ], + "text/html": [ + "
Trainable params: 1,199,882 (4.58 MB)\n", + "\n" + ] + }, + "metadata": {}, + "output_type": "display_data" + }, + { + "data": { + "text/plain": [ + "\u001B[1m Non-trainable params: \u001B[0m\u001B[38;5;34m0\u001B[0m (0.00 B)\n" + ], + "text/html": [ + "
Non-trainable params: 0 (0.00 B)\n", + "\n" + ] + }, + "metadata": {}, + "output_type": "display_data" + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "None\n", + "Epoch 1/20\n" + ] + }, + { + "name": "stderr", + "output_type": "stream", + "text": [ + "2025-03-13 17:59:09.869544: W external/local_xla/xla/tsl/framework/cpu_allocator_impl.cc:83] Allocation of 188160000 exceeds 10% of free system memory.\n" + ] + }, + { + "name": "stdout", + "output_type": "stream", + "text": [ + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m110s\u001B[0m 229ms/step - accuracy: 0.1052 - loss: 2.3000 - val_accuracy: 0.2693 - val_loss: 2.2488\n", + "Epoch 2/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m162s\u001B[0m 271ms/step - accuracy: 0.2265 - loss: 2.2399 - val_accuracy: 0.4505 - val_loss: 2.1755\n", + "Epoch 3/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m101s\u001B[0m 215ms/step - accuracy: 0.3401 - loss: 2.1674 - val_accuracy: 0.5460 - val_loss: 2.0756\n", + "Epoch 4/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m98s\u001B[0m 208ms/step - accuracy: 0.4168 - loss: 2.0707 - val_accuracy: 0.6309 - val_loss: 1.9400\n", + "Epoch 5/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m101s\u001B[0m 216ms/step - accuracy: 0.4859 - loss: 1.9388 - val_accuracy: 0.7004 - val_loss: 1.7650\n", + "Epoch 6/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m148s\u001B[0m 228ms/step - accuracy: 0.5514 - loss: 1.7740 - val_accuracy: 0.7517 - val_loss: 1.5543\n", + "Epoch 7/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m106s\u001B[0m 225ms/step - accuracy: 0.5989 - loss: 1.5901 - val_accuracy: 0.7860 - val_loss: 1.3342\n", + "Epoch 8/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m141s\u001B[0m 224ms/step - accuracy: 0.6395 - loss: 1.4047 - val_accuracy: 0.8053 - val_loss: 1.1347\n", + "Epoch 9/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m106s\u001B[0m 226ms/step - accuracy: 0.6621 - loss: 1.2518 - val_accuracy: 0.8213 - val_loss: 0.9769\n", + "Epoch 10/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m118s\u001B[0m 252ms/step - accuracy: 0.6848 - loss: 1.1299 - val_accuracy: 0.8310 - val_loss: 0.8569\n", + "Epoch 11/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m140s\u001B[0m 298ms/step - accuracy: 0.7070 - loss: 1.0295 - val_accuracy: 0.8393 - val_loss: 0.7659\n", + "Epoch 12/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m139s\u001B[0m 297ms/step - accuracy: 0.7191 - loss: 0.9594 - val_accuracy: 0.8467 - val_loss: 0.6961\n", + "Epoch 13/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m139s\u001B[0m 297ms/step - accuracy: 0.7353 - loss: 0.8954 - val_accuracy: 0.8541 - val_loss: 0.6418\n", + "Epoch 14/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m141s\u001B[0m 301ms/step - accuracy: 0.7501 - loss: 0.8407 - val_accuracy: 0.8598 - val_loss: 0.5981\n", + "Epoch 15/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m145s\u001B[0m 309ms/step - accuracy: 0.7608 - loss: 0.8010 - val_accuracy: 0.8637 - val_loss: 0.5631\n", + "Epoch 16/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m140s\u001B[0m 299ms/step - accuracy: 0.7708 - loss: 0.7630 - val_accuracy: 0.8675 - val_loss: 0.5345\n", + "Epoch 17/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m140s\u001B[0m 294ms/step - accuracy: 0.7818 - loss: 0.7294 - val_accuracy: 0.8720 - val_loss: 0.5091\n", + "Epoch 18/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m136s\u001B[0m 290ms/step - accuracy: 0.7874 - loss: 0.7058 - val_accuracy: 0.8745 - val_loss: 0.4890\n", + "Epoch 19/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m141s\u001B[0m 301ms/step - accuracy: 0.7911 - loss: 0.6918 - val_accuracy: 0.8777 - val_loss: 0.4711\n", + "Epoch 20/20\n", + "\u001B[1m469/469\u001B[0m \u001B[32m━━━━━━━━━━━━━━━━━━━━\u001B[0m\u001B[37m\u001B[0m \u001B[1m144s\u001B[0m 306ms/step - accuracy: 0.7922 - loss: 0.6763 - val_accuracy: 0.8803 - val_loss: 0.4562\n", + "Test loss: 0.4561978578567505\n", + "Test accuracy: 0.880299985408783\n" + ] + } + ], + "execution_count": 19 + }, + { + "metadata": {}, + "cell_type": "code", + "outputs": [], + "execution_count": null, + "source": "" + }, + { + "metadata": { + "ExecuteTime": { + "end_time": "2025-03-13T13:19:19.771353Z", + "start_time": "2025-03-13T13:19:19.412004Z" + } + }, + "cell_type": "code", + "source": "model.save(\"mnist_simple_cnn.h5\")", + "outputs": [ + { + "name": "stderr", + "output_type": "stream", + "text": [ + "WARNING:absl:You are saving your model as an HDF5 file via `model.save()` or `keras.saving.save_model(model)`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')` or `keras.saving.save_model(model, 'my_model.keras')`. \n" + ] + } + ], + "execution_count": 20 + }, + { + "metadata": { + "ExecuteTime": { + "end_time": "2025-03-13T13:20:22.752001Z", + "start_time": "2025-03-13T13:20:14.810410Z" + } + }, + "cell_type": "code", + "source": "score = model.evaluate(x_test, y_test, verbose=0)\n", + "outputs": [], + "execution_count": 22 + }, + { + "metadata": {}, + "cell_type": "code", + "outputs": [], + "execution_count": null, + "source": "" + } + ], + "metadata": { + "kernelspec": { + "display_name": "Python 3 (ipykernel)", + "language": "python", + "name": "python3" + }, + "language_info": { + "codemirror_mode": { + "name": "ipython", + "version": 3 + }, + "file_extension": ".py", + "mimetype": "text/x-python", + "name": "python", + "nbconvert_exporter": "python", + "pygments_lexer": "ipython3", + "version": "3.10.11" + } + }, + "nbformat": 4, + "nbformat_minor": 2 +} diff --git a/4. Get Started! Handwritting Recognition, Simple Object Classification & OpenCV Demo/4.2 - Image Classifier - CIFAR10.ipynb b/4. Get Started! Handwritting Recognition, Simple Object Classification & OpenCV Demo/4.2 - Image Classifier - CIFAR10.ipynb new file mode 100644 index 0000000000000000000000000000000000000000..8e4b20658ec3c3bbadb7a0d1fd70598dad6e1b06 --- /dev/null +++ b/4. Get Started! Handwritting Recognition, Simple Object Classification & OpenCV Demo/4.2 - Image Classifier - CIFAR10.ipynb @@ -0,0 +1,167 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### Let's run a simple image classifier, using the CIFAR 10 dataset of 10 image categories\n", + "* CIFAR's 10 categories:\n", + " * airplane\n", + " * automobile\n", + " * bird\n", + " * cat\n", + " * deer\n", + " * dog\n", + " * frog\n", + " * horse\n", + " * ship\n", + " * truck" + ] + }, + { + "cell_type": "code", + "metadata": { + "ExecuteTime": { + "end_time": "2025-03-13T16:11:52.999533Z", + "start_time": "2025-03-13T16:11:47.171043Z" + } + }, + "source": [ + "import cv2\n", + "import numpy as np\n", + "from tensorflow.keras.models import load_model\n", + "from tensorflow.keras.datasets import cifar10 \n", + "\n", + "img_row, img_height, img_depth = 32,32,3\n", + "\n", + "classifier = load_model('cifar_simple_cnn.h5')\n", + "\n", + "# Loads the CIFAR dataset\n", + "(x_train, y_train), (x_test, y_test) = cifar10.load_data()\n", + "color = True \n", + "scale = 8\n", + "\n", + "def draw_test(name, res, input_im, scale, img_row, img_height):\n", + " BLACK = [0,0,0]\n", + " res = int(res)\n", + " if res == 0:\n", + " pred = \"airplane\"\n", + " if res == 1:\n", + " pred = \"automobile\"\n", + " if res == 2:\n", + " pred = \"bird\"\n", + " if res == 3:\n", + " pred = \"cat\"\n", + " if res == 4:\n", + " pred = \"deer\"\n", + " if res == 5:\n", + " pred = \"dog\"\n", + " if res == 6:\n", + " pred = \"frog\"\n", + " if res == 7:\n", + " pred = \"horse\"\n", + " if res == 8:\n", + " pred = \"ship\"\n", + " if res == 9:\n", + " pred = \"truck\"\n", + " \n", + " expanded_image = cv2.copyMakeBorder(input_im, 0, 0, 0, imageL.shape[0]*2 ,cv2.BORDER_CONSTANT,value=BLACK)\n", + " if color == False:\n", + " expanded_image = cv2.cvtColor(expanded_image, cv2.COLOR_GRAY2BGR)\n", + " cv2.putText(expanded_image, str(pred), (300, 80) , cv2.FONT_HERSHEY_COMPLEX_SMALL,4, (0,255,0), 2)\n", + " cv2.imshow(name, expanded_image)\n", + "\n", + "\n", + "for i in range(0,10):\n", + " rand = np.random.randint(0,len(x_test))\n", + " input_im = x_test[rand]\n", + " imageL = cv2.resize(input_im, None, fx=scale, fy=scale, interpolation = cv2.INTER_CUBIC) \n", + " input_im = input_im.reshape(1,img_row, img_height, img_depth) \n", + " \n", + " ## Get Prediction\n", + " res = str(classifier.predict_classes(input_im, 1, verbose = 0)[0])\n", + " \n", + " draw_test(\"Prediction\", res, imageL, scale, img_row, img_height) \n", + " cv2.waitKey(0)\n", + "\n", + "cv2.destroyAllWindows()" + ], + "outputs": [ + { + "name": "stderr", + "output_type": "stream", + "text": [ + "2025-03-13 21:41:47.742478: I external/local_xla/xla/tsl/cuda/cudart_stub.cc:32] Could not find cuda drivers on your machine, GPU will not be used.\n", + "2025-03-13 21:41:47.746738: I external/local_xla/xla/tsl/cuda/cudart_stub.cc:32] Could not find cuda drivers on your machine, GPU will not be used.\n", + "2025-03-13 21:41:47.759288: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:477] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered\n", + "WARNING: All log messages before absl::InitializeLog() is called are written to STDERR\n", + "E0000 00:00:1741882307.783990 24522 cuda_dnn.cc:8310] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered\n", + "E0000 00:00:1741882307.790137 24522 cuda_blas.cc:1418] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered\n", + "2025-03-13 21:41:47.814207: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.\n", + "To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.\n", + "/home/newton/miniconda3/envs/dl/lib/python3.12/site-packages/keras/src/layers/convolutional/base_conv.py:107: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead.\n", + " super().__init__(activity_regularizer=activity_regularizer, **kwargs)\n" + ] + }, + { + "ename": "ValueError", + "evalue": "Kernel shape must have the same length as input, but received kernel of shape (3, 3, 3, 32) and input of shape (None, None, 32, 32, 3).", + "output_type": "error", + "traceback": [ + "\u001B[0;31m---------------------------------------------------------------------------\u001B[0m", + "\u001B[0;31mValueError\u001B[0m Traceback (most recent call last)", + "Cell \u001B[0;32mIn[1], line 8\u001B[0m\n\u001B[1;32m 4\u001B[0m \u001B[38;5;28;01mfrom\u001B[39;00m \u001B[38;5;21;01mtensorflow\u001B[39;00m\u001B[38;5;21;01m.\u001B[39;00m\u001B[38;5;21;01mkeras\u001B[39;00m\u001B[38;5;21;01m.\u001B[39;00m\u001B[38;5;21;01mdatasets\u001B[39;00m \u001B[38;5;28;01mimport\u001B[39;00m cifar10 \n\u001B[1;32m 6\u001B[0m img_row, img_height, img_depth \u001B[38;5;241m=\u001B[39m \u001B[38;5;241m32\u001B[39m,\u001B[38;5;241m32\u001B[39m,\u001B[38;5;241m3\u001B[39m\n\u001B[0;32m----> 8\u001B[0m classifier \u001B[38;5;241m=\u001B[39m load_model(\u001B[38;5;124m'\u001B[39m\u001B[38;5;124mcifar_simple_cnn.h5\u001B[39m\u001B[38;5;124m'\u001B[39m)\n\u001B[1;32m 10\u001B[0m \u001B[38;5;66;03m# Loads the CIFAR dataset\u001B[39;00m\n\u001B[1;32m 11\u001B[0m (x_train, y_train), (x_test, y_test) \u001B[38;5;241m=\u001B[39m cifar10\u001B[38;5;241m.\u001B[39mload_data()\n", + "File \u001B[0;32m~/miniconda3/envs/dl/lib/python3.12/site-packages/keras/src/saving/saving_api.py:196\u001B[0m, in \u001B[0;36mload_model\u001B[0;34m(filepath, custom_objects, compile, safe_mode)\u001B[0m\n\u001B[1;32m 189\u001B[0m \u001B[38;5;28;01mreturn\u001B[39;00m saving_lib\u001B[38;5;241m.\u001B[39mload_model(\n\u001B[1;32m 190\u001B[0m filepath,\n\u001B[1;32m 191\u001B[0m custom_objects\u001B[38;5;241m=\u001B[39mcustom_objects,\n\u001B[1;32m 192\u001B[0m \u001B[38;5;28mcompile\u001B[39m\u001B[38;5;241m=\u001B[39m\u001B[38;5;28mcompile\u001B[39m,\n\u001B[1;32m 193\u001B[0m safe_mode\u001B[38;5;241m=\u001B[39msafe_mode,\n\u001B[1;32m 194\u001B[0m )\n\u001B[1;32m 195\u001B[0m \u001B[38;5;28;01mif\u001B[39;00m \u001B[38;5;28mstr\u001B[39m(filepath)\u001B[38;5;241m.\u001B[39mendswith((\u001B[38;5;124m\"\u001B[39m\u001B[38;5;124m.h5\u001B[39m\u001B[38;5;124m\"\u001B[39m, \u001B[38;5;124m\"\u001B[39m\u001B[38;5;124m.hdf5\u001B[39m\u001B[38;5;124m\"\u001B[39m)):\n\u001B[0;32m--> 196\u001B[0m \u001B[38;5;28;01mreturn\u001B[39;00m legacy_h5_format\u001B[38;5;241m.\u001B[39mload_model_from_hdf5(\n\u001B[1;32m 197\u001B[0m filepath, custom_objects\u001B[38;5;241m=\u001B[39mcustom_objects, \u001B[38;5;28mcompile\u001B[39m\u001B[38;5;241m=\u001B[39m\u001B[38;5;28mcompile\u001B[39m\n\u001B[1;32m 198\u001B[0m )\n\u001B[1;32m 199\u001B[0m \u001B[38;5;28;01melif\u001B[39;00m \u001B[38;5;28mstr\u001B[39m(filepath)\u001B[38;5;241m.\u001B[39mendswith(\u001B[38;5;124m\"\u001B[39m\u001B[38;5;124m.keras\u001B[39m\u001B[38;5;124m\"\u001B[39m):\n\u001B[1;32m 200\u001B[0m \u001B[38;5;28;01mraise\u001B[39;00m \u001B[38;5;167;01mValueError\u001B[39;00m(\n\u001B[1;32m 201\u001B[0m \u001B[38;5;124mf\u001B[39m\u001B[38;5;124m\"\u001B[39m\u001B[38;5;124mFile not found: filepath=\u001B[39m\u001B[38;5;132;01m{\u001B[39;00mfilepath\u001B[38;5;132;01m}\u001B[39;00m\u001B[38;5;124m. \u001B[39m\u001B[38;5;124m\"\u001B[39m\n\u001B[1;32m 202\u001B[0m \u001B[38;5;124m\"\u001B[39m\u001B[38;5;124mPlease ensure the file is an accessible `.keras` \u001B[39m\u001B[38;5;124m\"\u001B[39m\n\u001B[1;32m 203\u001B[0m \u001B[38;5;124m\"\u001B[39m\u001B[38;5;124mzip file.\u001B[39m\u001B[38;5;124m\"\u001B[39m\n\u001B[1;32m 204\u001B[0m )\n", + "File \u001B[0;32m~/miniconda3/envs/dl/lib/python3.12/site-packages/keras/src/legacy/saving/legacy_h5_format.py:133\u001B[0m, in \u001B[0;36mload_model_from_hdf5\u001B[0;34m(filepath, custom_objects, compile)\u001B[0m\n\u001B[1;32m 130\u001B[0m model_config \u001B[38;5;241m=\u001B[39m json_utils\u001B[38;5;241m.\u001B[39mdecode(model_config)\n\u001B[1;32m 132\u001B[0m \u001B[38;5;28;01mwith\u001B[39;00m saving_options\u001B[38;5;241m.\u001B[39mkeras_option_scope(use_legacy_config\u001B[38;5;241m=\u001B[39m\u001B[38;5;28;01mTrue\u001B[39;00m):\n\u001B[0;32m--> 133\u001B[0m model \u001B[38;5;241m=\u001B[39m saving_utils\u001B[38;5;241m.\u001B[39mmodel_from_config(\n\u001B[1;32m 134\u001B[0m model_config, custom_objects\u001B[38;5;241m=\u001B[39mcustom_objects\n\u001B[1;32m 135\u001B[0m )\n\u001B[1;32m 137\u001B[0m \u001B[38;5;66;03m# set weights\u001B[39;00m\n\u001B[1;32m 138\u001B[0m load_weights_from_hdf5_group(f[\u001B[38;5;124m\"\u001B[39m\u001B[38;5;124mmodel_weights\u001B[39m\u001B[38;5;124m\"\u001B[39m], model)\n", + "File \u001B[0;32m~/miniconda3/envs/dl/lib/python3.12/site-packages/keras/src/legacy/saving/saving_utils.py:85\u001B[0m, in \u001B[0;36mmodel_from_config\u001B[0;34m(config, custom_objects)\u001B[0m\n\u001B[1;32m 81\u001B[0m \u001B[38;5;66;03m# TODO(nkovela): Swap find and replace args during Keras 3.0 release\u001B[39;00m\n\u001B[1;32m 82\u001B[0m \u001B[38;5;66;03m# Replace keras refs with keras\u001B[39;00m\n\u001B[1;32m 83\u001B[0m config \u001B[38;5;241m=\u001B[39m _find_replace_nested_dict(config, \u001B[38;5;124m\"\u001B[39m\u001B[38;5;124mkeras.\u001B[39m\u001B[38;5;124m\"\u001B[39m, \u001B[38;5;124m\"\u001B[39m\u001B[38;5;124mkeras.\u001B[39m\u001B[38;5;124m\"\u001B[39m)\n\u001B[0;32m---> 85\u001B[0m \u001B[38;5;28;01mreturn\u001B[39;00m serialization\u001B[38;5;241m.\u001B[39mdeserialize_keras_object(\n\u001B[1;32m 86\u001B[0m config,\n\u001B[1;32m 87\u001B[0m module_objects\u001B[38;5;241m=\u001B[39mMODULE_OBJECTS\u001B[38;5;241m.\u001B[39mALL_OBJECTS,\n\u001B[1;32m 88\u001B[0m custom_objects\u001B[38;5;241m=\u001B[39mcustom_objects,\n\u001B[1;32m 89\u001B[0m printable_module_name\u001B[38;5;241m=\u001B[39m\u001B[38;5;124m\"\u001B[39m\u001B[38;5;124mlayer\u001B[39m\u001B[38;5;124m\"\u001B[39m,\n\u001B[1;32m 90\u001B[0m )\n", + "File \u001B[0;32m~/miniconda3/envs/dl/lib/python3.12/site-packages/keras/src/legacy/saving/serialization.py:495\u001B[0m, in \u001B[0;36mdeserialize_keras_object\u001B[0;34m(identifier, module_objects, custom_objects, printable_module_name)\u001B[0m\n\u001B[1;32m 490\u001B[0m cls_config \u001B[38;5;241m=\u001B[39m _find_replace_nested_dict(\n\u001B[1;32m 491\u001B[0m cls_config, \u001B[38;5;124m\"\u001B[39m\u001B[38;5;124mkeras.\u001B[39m\u001B[38;5;124m\"\u001B[39m, \u001B[38;5;124m\"\u001B[39m\u001B[38;5;124mkeras.\u001B[39m\u001B[38;5;124m\"\u001B[39m\n\u001B[1;32m 492\u001B[0m )\n\u001B[1;32m 494\u001B[0m \u001B[38;5;28;01mif\u001B[39;00m \u001B[38;5;124m\"\u001B[39m\u001B[38;5;124mcustom_objects\u001B[39m\u001B[38;5;124m\"\u001B[39m \u001B[38;5;129;01min\u001B[39;00m arg_spec\u001B[38;5;241m.\u001B[39margs:\n\u001B[0;32m--> 495\u001B[0m deserialized_obj \u001B[38;5;241m=\u001B[39m \u001B[38;5;28mcls\u001B[39m\u001B[38;5;241m.\u001B[39mfrom_config(\n\u001B[1;32m 496\u001B[0m cls_config,\n\u001B[1;32m 497\u001B[0m custom_objects\u001B[38;5;241m=\u001B[39m{\n\u001B[1;32m 498\u001B[0m \u001B[38;5;241m*\u001B[39m\u001B[38;5;241m*\u001B[39mobject_registration\u001B[38;5;241m.\u001B[39mGLOBAL_CUSTOM_OBJECTS,\n\u001B[1;32m 499\u001B[0m \u001B[38;5;241m*\u001B[39m\u001B[38;5;241m*\u001B[39mcustom_objects,\n\u001B[1;32m 500\u001B[0m },\n\u001B[1;32m 501\u001B[0m )\n\u001B[1;32m 502\u001B[0m \u001B[38;5;28;01melse\u001B[39;00m:\n\u001B[1;32m 503\u001B[0m \u001B[38;5;28;01mwith\u001B[39;00m object_registration\u001B[38;5;241m.\u001B[39mCustomObjectScope(custom_objects):\n", + "File \u001B[0;32m~/miniconda3/envs/dl/lib/python3.12/site-packages/keras/src/models/sequential.py:359\u001B[0m, in \u001B[0;36mSequential.from_config\u001B[0;34m(cls, config, custom_objects)\u001B[0m\n\u001B[1;32m 354\u001B[0m \u001B[38;5;28;01melse\u001B[39;00m:\n\u001B[1;32m 355\u001B[0m layer \u001B[38;5;241m=\u001B[39m serialization_lib\u001B[38;5;241m.\u001B[39mdeserialize_keras_object(\n\u001B[1;32m 356\u001B[0m layer_config,\n\u001B[1;32m 357\u001B[0m custom_objects\u001B[38;5;241m=\u001B[39mcustom_objects,\n\u001B[1;32m 358\u001B[0m )\n\u001B[0;32m--> 359\u001B[0m model\u001B[38;5;241m.\u001B[39madd(layer)\n\u001B[1;32m 360\u001B[0m \u001B[38;5;28;01mif\u001B[39;00m (\n\u001B[1;32m 361\u001B[0m \u001B[38;5;129;01mnot\u001B[39;00m model\u001B[38;5;241m.\u001B[39m_functional\n\u001B[1;32m 362\u001B[0m \u001B[38;5;129;01mand\u001B[39;00m \u001B[38;5;124m\"\u001B[39m\u001B[38;5;124mbuild_input_shape\u001B[39m\u001B[38;5;124m\"\u001B[39m \u001B[38;5;129;01min\u001B[39;00m \u001B[38;5;28mlocals\u001B[39m()\n\u001B[1;32m 363\u001B[0m \u001B[38;5;129;01mand\u001B[39;00m build_input_shape\n\u001B[1;32m 364\u001B[0m \u001B[38;5;129;01mand\u001B[39;00m \u001B[38;5;28misinstance\u001B[39m(build_input_shape, (\u001B[38;5;28mtuple\u001B[39m, \u001B[38;5;28mlist\u001B[39m))\n\u001B[1;32m 365\u001B[0m ):\n\u001B[1;32m 366\u001B[0m model\u001B[38;5;241m.\u001B[39mbuild(build_input_shape)\n", + "File \u001B[0;32m~/miniconda3/envs/dl/lib/python3.12/site-packages/keras/src/models/sequential.py:122\u001B[0m, in \u001B[0;36mSequential.add\u001B[0;34m(self, layer, rebuild)\u001B[0m\n\u001B[1;32m 120\u001B[0m \u001B[38;5;28mself\u001B[39m\u001B[38;5;241m.\u001B[39m_layers\u001B[38;5;241m.\u001B[39mappend(layer)\n\u001B[1;32m 121\u001B[0m \u001B[38;5;28;01mif\u001B[39;00m rebuild:\n\u001B[0;32m--> 122\u001B[0m \u001B[38;5;28mself\u001B[39m\u001B[38;5;241m.\u001B[39m_maybe_rebuild()\n\u001B[1;32m 123\u001B[0m \u001B[38;5;28;01melse\u001B[39;00m:\n\u001B[1;32m 124\u001B[0m \u001B[38;5;28mself\u001B[39m\u001B[38;5;241m.\u001B[39mbuilt \u001B[38;5;241m=\u001B[39m \u001B[38;5;28;01mFalse\u001B[39;00m\n", + "File \u001B[0;32m~/miniconda3/envs/dl/lib/python3.12/site-packages/keras/src/models/sequential.py:141\u001B[0m, in \u001B[0;36mSequential._maybe_rebuild\u001B[0;34m(self)\u001B[0m\n\u001B[1;32m 139\u001B[0m \u001B[38;5;28;01mif\u001B[39;00m \u001B[38;5;28misinstance\u001B[39m(\u001B[38;5;28mself\u001B[39m\u001B[38;5;241m.\u001B[39m_layers[\u001B[38;5;241m0\u001B[39m], InputLayer) \u001B[38;5;129;01mand\u001B[39;00m \u001B[38;5;28mlen\u001B[39m(\u001B[38;5;28mself\u001B[39m\u001B[38;5;241m.\u001B[39m_layers) \u001B[38;5;241m>\u001B[39m \u001B[38;5;241m1\u001B[39m:\n\u001B[1;32m 140\u001B[0m input_shape \u001B[38;5;241m=\u001B[39m \u001B[38;5;28mself\u001B[39m\u001B[38;5;241m.\u001B[39m_layers[\u001B[38;5;241m0\u001B[39m]\u001B[38;5;241m.\u001B[39mbatch_shape\n\u001B[0;32m--> 141\u001B[0m \u001B[38;5;28mself\u001B[39m\u001B[38;5;241m.\u001B[39mbuild(input_shape)\n\u001B[1;32m 142\u001B[0m \u001B[38;5;28;01melif\u001B[39;00m \u001B[38;5;28mhasattr\u001B[39m(\u001B[38;5;28mself\u001B[39m\u001B[38;5;241m.\u001B[39m_layers[\u001B[38;5;241m0\u001B[39m], \u001B[38;5;124m\"\u001B[39m\u001B[38;5;124minput_shape\u001B[39m\u001B[38;5;124m\"\u001B[39m) \u001B[38;5;129;01mand\u001B[39;00m \u001B[38;5;28mlen\u001B[39m(\u001B[38;5;28mself\u001B[39m\u001B[38;5;241m.\u001B[39m_layers) \u001B[38;5;241m>\u001B[39m \u001B[38;5;241m1\u001B[39m:\n\u001B[1;32m 143\u001B[0m \u001B[38;5;66;03m# We can build the Sequential model if the first layer has the\u001B[39;00m\n\u001B[1;32m 144\u001B[0m \u001B[38;5;66;03m# `input_shape` property. This is most commonly found in Functional\u001B[39;00m\n\u001B[1;32m 145\u001B[0m \u001B[38;5;66;03m# model.\u001B[39;00m\n\u001B[1;32m 146\u001B[0m input_shape \u001B[38;5;241m=\u001B[39m \u001B[38;5;28mself\u001B[39m\u001B[38;5;241m.\u001B[39m_layers[\u001B[38;5;241m0\u001B[39m]\u001B[38;5;241m.\u001B[39minput_shape\n", + "File \u001B[0;32m~/miniconda3/envs/dl/lib/python3.12/site-packages/keras/src/layers/layer.py:228\u001B[0m, in \u001B[0;36mLayer.__new__.
Circle Detection with Hough Cirlces
cv2.HoughCircles(image, method, dp, MinDist, param1, param2, minRadius, MaxRadius)

Method - currently only cv2.HOUGH_GRADIENT available
dp - Inverse ratio of accumulator resolution
MinDist - the minimum distance between the center of detected circles
param1 - Gradient value used in the edge detection
param2 - Accumulator threshold for the HOUGH_GRADIENT method, lower allows more circles to be detected (false positives)
minRadius - limits the smallest circle to this size (via radius)
MaxRadius - similarly sets the limit for the largest circles
import cv2
+import numpy as np
+import cv2.cv as cv
+
+image = cv2.imread('images/bottlecaps.jpg')
+gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
+
+blur = cv2.medianBlur(gray, 5)
+circles = cv2.HoughCircles(blur, cv.CV_HOUGH_GRADIENT, 1.5, 10)
+
+for i in circles[0,:]:
+ # draw the outer circle
+ cv2.circle(image,(i[0], i[1]), i[2], (255, 0, 0), 2)
+
+ # draw the center of the circle
+ cv2.circle(image, (i[0], i[1]), 2, (0, 255, 0), 5)
+
+cv2.imshow('detected circles', image)
+cv2.waitKey(0)
+cv2.destroyAllWindows()
+
\ No newline at end of file
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/32. Blob Detection - Detect The Center of Flowers.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/32. Blob Detection - Detect The Center of Flowers.srt
new file mode 100644
index 0000000000000000000000000000000000000000..9d84fc3aa36aef85c68bd15b0bffcd24f07f76fd
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/32. Blob Detection - Detect The Center of Flowers.srt
@@ -0,0 +1,231 @@
+1
+00:00:02,310 --> 00:00:06,980
+OK so let's talk about blubbed detection so blood production songs but where.
+
+2
+00:00:07,200 --> 00:00:11,100
+However if you've been into Computer Vision world for some time you would have bound to come across
+
+3
+00:00:11,100 --> 00:00:12,250
+it by now.
+
+4
+00:00:12,300 --> 00:00:14,110
+So what exactly is a blob.
+
+5
+00:00:14,400 --> 00:00:17,200
+Well a blob just like a real life blob.
+
+6
+00:00:17,220 --> 00:00:22,350
+I guess it's just a group of connected pixels that share similar property.
+
+7
+00:00:22,350 --> 00:00:27,210
+So in this example of the sunflowers here you can see the sense of flowers some flowers all have similar
+
+8
+00:00:27,270 --> 00:00:28,860
+green tinge here.
+
+9
+00:00:29,220 --> 00:00:34,590
+That's basically what blubbed ejection has picked up now no properties can be size it can be shape and
+
+10
+00:00:34,590 --> 00:00:36,970
+we actually get to that shortly.
+
+11
+00:00:36,990 --> 00:00:40,310
+So in general how do we use open of his simple blood test.
+
+12
+00:00:40,470 --> 00:00:43,630
+That's demitted what we call in Bigham.
+
+13
+00:00:43,710 --> 00:00:50,070
+So what do we do first we create or initialize the detector object we input an image into detector.
+
+14
+00:00:50,070 --> 00:00:54,170
+We then optin the key points and then we draw those key points like we do here.
+
+15
+00:00:54,180 --> 00:00:56,870
+So let's actually get into the code and do this.
+
+16
+00:00:57,340 --> 00:00:57,680
+OK.
+
+17
+00:00:57,720 --> 00:01:02,520
+So let's open a simple blob detector file here selects you for point it.
+
+18
+00:01:03,000 --> 00:01:04,720
+So here's a code for it here.
+
+19
+00:01:04,750 --> 00:01:05,760
+Doesn't look too scary.
+
+20
+00:01:05,760 --> 00:01:07,850
+It's pretty basic actually.
+
+21
+00:01:07,860 --> 00:01:10,680
+So let's run this could see what's happening here.
+
+22
+00:01:10,710 --> 00:01:15,810
+So we've loaded up a great skill image of sunflowers that you saw previously and we've identified blobs
+
+23
+00:01:15,810 --> 00:01:17,360
+in the center of the fellows here.
+
+24
+00:01:18,210 --> 00:01:19,510
+Quite nice.
+
+25
+00:01:19,530 --> 00:01:20,970
+So let's see how we do this.
+
+26
+00:01:20,970 --> 00:01:23,530
+So first if we RIDO imagen and previously.
+
+27
+00:01:23,520 --> 00:01:28,540
+So if I just putting a zero here we can actually call grayscale image.
+
+28
+00:01:28,590 --> 00:01:30,500
+I mean at a critical image in here.
+
+29
+00:01:30,640 --> 00:01:36,000
+However this is zero actually signifies you're writing in this line of function here so you may have
+
+30
+00:01:36,000 --> 00:01:40,950
+seen some open Sivy functions where we have numbers instead of the actual words here.
+
+31
+00:01:40,950 --> 00:01:42,180
+That's just shorthand
+
+32
+00:01:44,910 --> 00:01:45,970
+so I'm moving on.
+
+33
+00:01:46,240 --> 00:01:50,060
+So the first part of this here is that we need to initialize the doctor.
+
+34
+00:01:50,290 --> 00:01:52,040
+So we call this function here.
+
+35
+00:01:52,130 --> 00:01:58,850
+Well this class actually and we create to detect the object and using this object now we actually pass.
+
+36
+00:01:58,870 --> 00:02:01,980
+We run the detect method within this object here.
+
+37
+00:02:02,350 --> 00:02:08,380
+We pass the image the input image into it here and this gives us several key points key points being
+
+38
+00:02:08,380 --> 00:02:09,950
+all blubs detected.
+
+39
+00:02:10,060 --> 00:02:12,140
+So it is no tuning of parameters here.
+
+40
+00:02:12,520 --> 00:02:17,460
+What is some tuning up from now is basically here where we draw the key points and image.
+
+41
+00:02:17,480 --> 00:02:24,190
+Now however these parameters don't affect the number of blobs that were identified they just affect
+
+42
+00:02:24,220 --> 00:02:27,250
+how would a ball blubbers looked like on the image itself.
+
+43
+00:02:29,170 --> 00:02:32,100
+So this is pretty self-explanatory here.
+
+44
+00:02:32,120 --> 00:02:39,330
+In that image the key points we identified so blank actually here as well as open Zeevi type Quick's.
+
+45
+00:02:39,400 --> 00:02:41,950
+It's just a one by one matrix of zeroes here.
+
+46
+00:02:41,950 --> 00:02:44,840
+So pretty much ignore it and just use this going forward.
+
+47
+00:02:44,920 --> 00:02:51,430
+This here's a color which we use yellow is green and red here and this is how we draw the points here.
+
+48
+00:02:51,430 --> 00:02:54,600
+So it actually just changed this just now to reach key points.
+
+49
+00:02:54,650 --> 00:02:56,760
+We can see it's actually yellow now.
+
+50
+00:02:56,860 --> 00:03:01,710
+However Initially we used the default one which I believe was this dude.
+
+51
+00:03:02,290 --> 00:03:04,510
+The fold there just looks a bit smaller.
+
+52
+00:03:04,520 --> 00:03:06,190
+So it is no big difference.
+
+53
+00:03:06,940 --> 00:03:07,310
+OK.
+
+54
+00:03:07,360 --> 00:03:08,380
+So let's move on to it.
+
+55
+00:03:08,390 --> 00:03:14,590
+Too many projects where we actually filter different types of blobs because as you saw here in simple
+
+56
+00:03:14,590 --> 00:03:17,660
+blood detect and detect there's no problem to here.
+
+57
+00:03:17,830 --> 00:03:18,990
+Well actually there is.
+
+58
+00:03:19,060 --> 00:03:20,220
+We'll get to it shortly.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/33. Mini Project 3 - Counting Circles and Ellipses.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/33. Mini Project 3 - Counting Circles and Ellipses.srt
new file mode 100644
index 0000000000000000000000000000000000000000..baf5add12efb146ba495b5ea31d274dbaed2cefa
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/33. Mini Project 3 - Counting Circles and Ellipses.srt
@@ -0,0 +1,375 @@
+1
+00:00:00,720 --> 00:00:01,310
+All right.
+
+2
+00:00:01,380 --> 00:00:05,370
+So you reached out to the many projec counting circles and ellipses.
+
+3
+00:00:05,370 --> 00:00:08,700
+So this is actually what our little mini project here is going to produce.
+
+4
+00:00:08,700 --> 00:00:13,440
+We're going to count a number of ellipses and cycles together here and then count singles separately
+
+5
+00:00:13,440 --> 00:00:17,920
+here and we do this by filtering Blob's which you mentioned previously.
+
+6
+00:00:17,940 --> 00:00:19,660
+So let's get to it.
+
+7
+00:00:19,730 --> 00:00:22,010
+Okay let's open a good fit as did many project.
+
+8
+00:00:22,050 --> 00:00:30,440
+That's a four point nine.
+
+9
+00:00:30,570 --> 00:00:31,620
+And here we are.
+
+10
+00:00:31,620 --> 00:00:33,980
+So this is actually run this code and see what's going on.
+
+11
+00:00:35,760 --> 00:00:37,130
+So here we have a image here.
+
+12
+00:00:37,260 --> 00:00:40,760
+We have some circles and some levels or ellipses here.
+
+13
+00:00:42,120 --> 00:00:47,360
+This we count all the blobs all the objects in the image that we have to the two.
+
+14
+00:00:47,400 --> 00:00:50,520
+And now we count to cicle separately and we have it.
+
+15
+00:00:50,550 --> 00:00:52,860
+So let's see how we do that.
+
+16
+00:00:52,950 --> 00:00:53,370
+All right.
+
+17
+00:00:53,400 --> 00:00:57,550
+Let me first show you how we actually count the number of blobs and put it in image.
+
+18
+00:00:57,570 --> 00:01:00,630
+This one is quite simple and you should be able to do this by now.
+
+19
+00:01:01,320 --> 00:01:07,860
+So we fiercly initialize a simple blob it's like to hear the Passo input image here to the detector.
+
+20
+00:01:07,860 --> 00:01:12,810
+We get the key points and we actually show the key points and bring it up on the image here.
+
+21
+00:01:13,020 --> 00:01:14,270
+But what's going on here.
+
+22
+00:01:14,460 --> 00:01:16,290
+Well here's a very simple function.
+
+23
+00:01:16,290 --> 00:01:21,780
+We just find the length of the key points that was generated by a detector here and we just create a
+
+24
+00:01:21,780 --> 00:01:22,700
+string here.
+
+25
+00:01:22,770 --> 00:01:24,930
+We passed a string to put Tex here.
+
+26
+00:01:24,930 --> 00:01:28,450
+That's the text variable here and that's all there is to it.
+
+27
+00:01:28,470 --> 00:01:30,230
+That's pretty much how we.
+
+28
+00:01:30,270 --> 00:01:31,950
+All the blobs that were detected here.
+
+29
+00:01:33,090 --> 00:01:37,680
+But how do we distinguish between ellipses and circles like how did we actually go into the key points
+
+30
+00:01:37,740 --> 00:01:39,440
+and determine which was which.
+
+31
+00:01:39,810 --> 00:01:41,720
+That's actually what we do over here.
+
+32
+00:01:42,120 --> 00:01:44,370
+So here's something I haven't showed you before.
+
+33
+00:01:44,550 --> 00:01:50,100
+We can actually pass parameters to a simple love detector by recalling diskless here.
+
+34
+00:01:50,550 --> 00:01:54,240
+It's a simple Babadook to underscore prom's.
+
+35
+00:01:54,390 --> 00:01:57,590
+And as you can see here is a number of parameters here to filter on.
+
+36
+00:01:57,870 --> 00:02:02,700
+So let me go back to the presentation and we'll discuss what these parameters are and how do we distinguish
+
+37
+00:02:02,700 --> 00:02:03,500
+between them.
+
+38
+00:02:03,840 --> 00:02:06,070
+OK so these are the parameters we're actually setting.
+
+39
+00:02:06,070 --> 00:02:12,490
+What we call a simple blood test to underscore a premise forming the parameters we filter on here.
+
+40
+00:02:12,580 --> 00:02:18,700
+Area similarity convexity and issue and we can each contain each of it on or off by something isn't
+
+41
+00:02:18,720 --> 00:02:19,610
+Decoud here.
+
+42
+00:02:19,920 --> 00:02:25,650
+So just by sitting per Armstead filter by area equal true means we're actually going to say or you can
+
+43
+00:02:25,650 --> 00:02:29,580
+set minimum areas or maximum areas and vice versa.
+
+44
+00:02:29,610 --> 00:02:30,710
+So let's look at it here.
+
+45
+00:02:30,900 --> 00:02:37,230
+So by setting that area and areas measured in pixels the minimum size and giving it to maximum.
+
+46
+00:02:37,230 --> 00:02:41,370
+If we do instead is maximum demark it's not going to actually stop then the maximum is just going to
+
+47
+00:02:41,370 --> 00:02:44,320
+give you the maximum of all Blob's day.
+
+48
+00:02:44,790 --> 00:02:49,890
+So setting the threshold between here and something is true means that we're only going to be seeing
+
+49
+00:02:49,890 --> 00:02:53,840
+blobs that are between these two values here in area.
+
+50
+00:02:54,360 --> 00:02:59,390
+Similarly for secularity singularity is a measure of being circular.
+
+51
+00:02:59,520 --> 00:03:01,300
+It's probably the best way I can put it.
+
+52
+00:03:01,470 --> 00:03:07,440
+One being a perfect circle which means that it really is as consistent as you rotate around the circle
+
+53
+00:03:08,010 --> 00:03:10,650
+and 0 is being the opposite.
+
+54
+00:03:10,650 --> 00:03:12,840
+So what about convexity.
+
+55
+00:03:12,840 --> 00:03:20,430
+Convexity here measures measures basically the convexity of the object itself.
+
+56
+00:03:20,460 --> 00:03:22,390
+So that's a pretty bad way to phrase it.
+
+57
+00:03:22,460 --> 00:03:25,240
+But this diagram illustrates that quite nicely.
+
+58
+00:03:25,530 --> 00:03:27,720
+So look at the ship here the convex shape.
+
+59
+00:03:27,990 --> 00:03:30,650
+There's no real Conkey of parts of the ship here.
+
+60
+00:03:30,660 --> 00:03:33,190
+I mean yes there is but it's not much.
+
+61
+00:03:33,210 --> 00:03:37,350
+However in this ship here it is a definite concave thing going on right here.
+
+62
+00:03:37,540 --> 00:03:43,560
+So if it was a jaw convex hull or on this image you'd realize that the ratio of this area here to this
+
+63
+00:03:43,560 --> 00:03:47,630
+area here would actually be pretty similar.
+
+64
+00:03:47,820 --> 00:03:53,070
+Whereas if you draw convicts hold on this image here the issue of Syria to Syria here is actually going
+
+65
+00:03:53,070 --> 00:03:54,180
+to be quite high.
+
+66
+00:03:54,570 --> 00:03:56,840
+So that's how we filter by convexity here.
+
+67
+00:03:59,580 --> 00:04:05,900
+Now this value should actually be some value between 0 2 1 and that is basically what we consider the
+
+68
+00:04:06,080 --> 00:04:09,160
+convexity values that we set.
+
+69
+00:04:09,170 --> 00:04:10,360
+Sorry.
+
+70
+00:04:10,400 --> 00:04:14,240
+So what about inertia now inertia is a weird concept to think about.
+
+71
+00:04:14,240 --> 00:04:17,220
+However it's actually very well explained in this image here.
+
+72
+00:04:18,740 --> 00:04:23,840
+So simply put in issues a measure of elliptical ness which probably isn't a word but it probably best
+
+73
+00:04:23,840 --> 00:04:29,360
+describes what you're measuring here little being more elliptical high being more secular.
+
+74
+00:04:29,420 --> 00:04:33,130
+So it's also falls back into this secularity setting here.
+
+75
+00:04:36,430 --> 00:04:43,910
+So we can actually set the minimum inertia to be 0.01 with zero being basically almost like a straight
+
+76
+00:04:43,910 --> 00:04:48,490
+line and one being roughly a circle.
+
+77
+00:04:48,520 --> 00:04:55,000
+So let's go back to the court and see how so no having understood those parameters.
+
+78
+00:04:55,000 --> 00:05:00,250
+These are the settings we actually use when we're filtering on ellipses in oil example file.
+
+79
+00:05:00,410 --> 00:05:04,370
+So you can play around with these and play along with your own images as well I encourage you to do
+
+80
+00:05:04,370 --> 00:05:06,690
+that because what works here for me.
+
+81
+00:05:06,740 --> 00:05:11,150
+Well not all of us look for the images which is why I tend to use very simple images here.
+
+82
+00:05:11,180 --> 00:05:16,670
+This is just to illustrate a concept not to do anything too fancy just yet the fancy stuff is coming
+
+83
+00:05:16,670 --> 00:05:17,210
+later on.
+
+84
+00:05:17,210 --> 00:05:20,680
+So don't worry about it.
+
+85
+00:05:20,730 --> 00:05:22,430
+And similarly what happens now.
+
+86
+00:05:22,770 --> 00:05:28,730
+Once we set the premises here we didn't create or simple but protect it after setting those parameters.
+
+87
+00:05:28,730 --> 00:05:34,400
+So remember that said parameters first then call simple love to here.
+
+88
+00:05:34,740 --> 00:05:37,670
+And this actually pulls the problems that were created right here.
+
+89
+00:05:38,620 --> 00:05:45,160
+And then what we do we actually just use the detector again to detect our key points.
+
+90
+00:05:45,340 --> 00:05:50,950
+And having gotten those points now we actually do the same thing we did appear before where we just
+
+91
+00:05:50,950 --> 00:05:55,050
+find a link to create a string and use text to put it on the image.
+
+92
+00:05:55,060 --> 00:05:56,620
+So again that's quite simple here.
+
+93
+00:05:56,830 --> 00:06:04,120
+And let's just run it one more time in partimage all Blob's counted and not only or similar but Blob's
+
+94
+00:06:04,120 --> 00:06:05,690
+counted.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/34. Object Detection Overview.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/34. Object Detection Overview.srt
new file mode 100644
index 0000000000000000000000000000000000000000..6d70f56ef893a867dd77ae873c53f375e9cefbe8
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/34. Object Detection Overview.srt
@@ -0,0 +1,171 @@
+1
+00:00:00,570 --> 00:00:06,350
+Welcome to Section 5 where we talk about object detection Now object detection is what makes competing
+
+2
+00:00:06,350 --> 00:00:11,460
+visions so powerful and it's in this arena where there's so much cutting edge research currently taking
+
+3
+00:00:11,460 --> 00:00:12,630
+place.
+
+4
+00:00:12,660 --> 00:00:18,030
+So in dissection we sort of doing some simple object detection using template matching which then leads
+
+5
+00:00:18,030 --> 00:00:24,170
+us to have this mini project where we actually have to find walde you can see it here quickly finding
+
+6
+00:00:24,170 --> 00:00:27,200
+Waldo and this means was a mess of a picture here.
+
+7
+00:00:27,620 --> 00:00:32,510
+We didn't describe the features or features of very important features consist of corners and other
+
+8
+00:00:32,510 --> 00:00:34,690
+attributes associated with the image.
+
+9
+00:00:34,880 --> 00:00:41,120
+And then we looked at some common and popular feature algorithms such as sift fast brief and orb.
+
+10
+00:00:41,160 --> 00:00:43,620
+And you're a couple that is like freek'n Breske as well.
+
+11
+00:00:44,770 --> 00:00:50,470
+I mean didn't utilize these features actual algorithms in our second mini project where we do some actual
+
+12
+00:00:50,470 --> 00:00:56,900
+object detection using these features and then we get we describe a bit of bit more and histogram of
+
+13
+00:00:56,900 --> 00:01:01,220
+gradients which is one of the best descriptors used to describe optics and pictures.
+
+14
+00:01:01,300 --> 00:01:02,680
+So let's get started.
+
+15
+00:01:03,100 --> 00:01:06,240
+So why do we need to detect objects and images.
+
+16
+00:01:06,520 --> 00:01:12,230
+Well object detection and object recognition deform perhaps probably probably the most important use
+
+17
+00:01:12,240 --> 00:01:13,830
+case for a division.
+
+18
+00:01:13,840 --> 00:01:18,370
+You can do so many powerful things like labeling scenes such as labeling this as a digital billboard
+
+19
+00:01:18,720 --> 00:01:19,490
+bus.
+
+20
+00:01:19,630 --> 00:01:26,290
+People on the sidewalk storefronts oil also applies to robotic navigation and V-Strom algorithms self-driving
+
+21
+00:01:26,290 --> 00:01:32,440
+cars which are actually a form of robotic navigation body recognition through Microsoft Knecht disease
+
+22
+00:01:32,440 --> 00:01:38,550
+and cancer detection things like looking at malaria slides or pictures of skin cancer face recognition
+
+23
+00:01:38,560 --> 00:01:44,230
+handwriting recognition even military use cases like detecting objects and satellite images and the
+
+24
+00:01:44,230 --> 00:01:49,660
+list goes on and on literally so many use cases for object detection and recognition.
+
+25
+00:01:52,090 --> 00:01:56,200
+So it is a key difference between object detection and recognition.
+
+26
+00:01:56,200 --> 00:01:59,890
+Recognition is basically the second level of object detection.
+
+27
+00:01:59,890 --> 00:02:05,440
+It allows the computer to actually recognize multiple objects within an image.
+
+28
+00:02:05,560 --> 00:02:11,890
+Take example this picture of Hillary Clinton an object recognition algorithm probably a Fistric admission
+
+29
+00:02:11,890 --> 00:02:17,410
+algorithm would detect that firstly it is a human fetus in this picture and then tries to match it to
+
+30
+00:02:17,410 --> 00:02:19,320
+a person in the database.
+
+31
+00:02:19,320 --> 00:02:24,050
+This being Hillary Clinton now in this case here this is one of many projects which we'll do in the
+
+32
+00:02:24,050 --> 00:02:28,730
+section later on we were just doing a simple object detection method here.
+
+33
+00:02:28,810 --> 00:02:33,430
+So as soon as this object is held up in this little box here it says object is found.
+
+34
+00:02:33,550 --> 00:02:38,330
+This one only looks at one particular object and does not try to recognize exactly what it seeing.
+
+35
+00:02:38,500 --> 00:02:42,950
+It just waits for this image to be there and then it tells you yes object has been found.
+
+36
+00:02:46,140 --> 00:02:50,210
+So let's look at our first object detection algorithm that we're going to investigate.
+
+37
+00:02:50,310 --> 00:02:54,090
+This one is called template matching it and it's actually a very basic algorithm.
+
+38
+00:02:54,230 --> 00:02:58,400
+What it does it slides a picture that it's looking for in a larger picture here.
+
+39
+00:02:58,680 --> 00:03:04,050
+So the picture we're looking for is a picture of Waldo here can kind of see him slightly blurred.
+
+40
+00:03:04,530 --> 00:03:09,260
+That's bringing back down to this similar skilless this image and what template matching does.
+
+41
+00:03:09,360 --> 00:03:13,550
+It actually slides this picture across the image back in for it waiting for a match.
+
+42
+00:03:13,560 --> 00:03:18,990
+And as soon as the match is found it actually tells you yes that much has been found in this point here.
+
+43
+00:03:19,350 --> 00:03:20,450
+So let's get to it.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/35. Mini Project # 4 - Finding Waldo (Quickly Find A Specific Pattern In An Image).srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/35. Mini Project # 4 - Finding Waldo (Quickly Find A Specific Pattern In An Image).srt
new file mode 100644
index 0000000000000000000000000000000000000000..1b90c0fdd383f855cdcdb38877f15dbc8a15b9ef
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/35. Mini Project # 4 - Finding Waldo (Quickly Find A Specific Pattern In An Image).srt
@@ -0,0 +1,175 @@
+1
+00:00:01,050 --> 00:00:04,680
+It's welcome to our 420 project which is finding Waldo.
+
+2
+00:00:04,720 --> 00:00:09,820
+Now if you're familiar with those wallaroo children's books you basically have to find Waldo who is
+
+3
+00:00:09,820 --> 00:00:14,020
+this little character in this messy maze of image here.
+
+4
+00:00:14,470 --> 00:00:19,330
+So we're going to know we use template matching which we just discussed to actually find Waldo.
+
+5
+00:00:19,330 --> 00:00:20,950
+So this is the input image we're giving it.
+
+6
+00:00:20,980 --> 00:00:21,920
+And this is output.
+
+7
+00:00:22,030 --> 00:00:25,930
+We're going to get so let's see how we do this in our code.
+
+8
+00:00:26,380 --> 00:00:26,820
+All right.
+
+9
+00:00:26,860 --> 00:00:29,880
+So let's load up a code foot miff what Mindy Project.
+
+10
+00:00:29,970 --> 00:00:33,480
+That's here letter 5.2.
+
+11
+00:00:33,610 --> 00:00:35,440
+And here we are.
+
+12
+00:00:35,510 --> 00:00:37,920
+So let's see what's going on let's actually run this could quickly.
+
+13
+00:00:37,970 --> 00:00:39,820
+So she looks very short.
+
+14
+00:00:40,090 --> 00:00:42,350
+So his image of well being on a beach.
+
+15
+00:00:42,350 --> 00:00:46,480
+Well we don't know where Waldo is yet although he may have wanted to do it before.
+
+16
+00:00:47,000 --> 00:00:47,740
+There he is.
+
+17
+00:00:47,870 --> 00:00:50,170
+So we found them and that was really quick.
+
+18
+00:00:50,180 --> 00:00:53,260
+So let's see what's actually going on here on the hood.
+
+19
+00:00:53,360 --> 00:00:58,370
+So what's happening here is that we're using the matched template function from open C.V that is function
+
+20
+00:00:58,370 --> 00:01:00,390
+is pretty cool and pretty easy to use.
+
+21
+00:01:00,640 --> 00:01:05,510
+What's happening here is that we have an image here that's we all do the beach the one that we couldn't
+
+22
+00:01:05,510 --> 00:01:10,720
+find Waldo in and we have a smaller template image which is the one we're looking for in the larger
+
+23
+00:01:10,730 --> 00:01:13,490
+image and this is a matching method here.
+
+24
+00:01:13,820 --> 00:01:20,150
+And what it does is to enter in very cold results and what result has in it is the results of Daschle
+
+25
+00:01:20,270 --> 00:01:21,900
+simply matching procedure.
+
+26
+00:01:22,250 --> 00:01:26,340
+And then we just use this other CB2 to function minimax location.
+
+27
+00:01:26,450 --> 00:01:32,000
+What is does is gives us basically to coordinates sort of bounding box that Walder was found in and
+
+28
+00:01:32,000 --> 00:01:37,900
+after we get that box we basically just use those points to actually draw tangle over.
+
+29
+00:01:38,070 --> 00:01:40,600
+Well what I have done here you may wonder.
+
+30
+00:01:40,750 --> 00:01:46,340
+I have some little little odd things here such as Plus 50 plus 50 I miss making the box slightly bigger
+
+31
+00:01:46,340 --> 00:01:47,240
+than the image itself.
+
+32
+00:01:47,270 --> 00:01:54,780
+So we actually can highlight wallaroo properly on the larger image so it is one thing I just casually
+
+33
+00:01:54,780 --> 00:01:57,900
+brush over here and thats a matching method being used.
+
+34
+00:01:58,100 --> 00:02:01,560
+Now there are a few methods available in open C.v.
+
+35
+00:02:01,560 --> 00:02:05,840
+This one is called a correlation coefficient and you can learn more about it here.
+
+36
+00:02:05,850 --> 00:02:08,870
+I have a link at the bottom of this item book file.
+
+37
+00:02:08,880 --> 00:02:10,550
+Just quickly visit the site here.
+
+38
+00:02:10,650 --> 00:02:17,010
+This tells you the differences mathematically of what the different matching methods are doing exactly.
+
+39
+00:02:17,010 --> 00:02:23,190
+So I actually use all of these in this example and others before I don't see much difference between
+
+40
+00:02:23,190 --> 00:02:26,020
+them although some of them do seem to work better than others.
+
+41
+00:02:26,280 --> 00:02:30,780
+So if you're using template matching for an application just experiment with these different methods
+
+42
+00:02:30,780 --> 00:02:33,900
+here and just choose one that works best.
+
+43
+00:02:34,410 --> 00:02:40,950
+If you really want to learn about the Tieri maybe actually explore what's going on in his mathematical
+
+44
+00:02:40,950 --> 00:02:45,360
+formulas here and you may actually have one that's more suited for your application right there.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/36. Feature Description Theory - How We Digitally Represent Objects.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/36. Feature Description Theory - How We Digitally Represent Objects.srt
new file mode 100644
index 0000000000000000000000000000000000000000..994191294e2082e6afa72031eb6bc25325de17ab
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/36. Feature Description Theory - How We Digitally Represent Objects.srt
@@ -0,0 +1,291 @@
+1
+00:00:00,510 --> 00:00:05,880
+Let's take a step back from the code for a minute and think about what we just did we basically cropped
+
+2
+00:00:06,150 --> 00:00:11,430
+an image from this here to me in that image and was able to match it back to the same spots in this
+
+3
+00:00:11,430 --> 00:00:12,520
+image again.
+
+4
+00:00:12,630 --> 00:00:16,100
+No that has severe limitations if you think about it one.
+
+5
+00:00:16,230 --> 00:00:19,590
+This image here has to be very similar to the image here.
+
+6
+00:00:19,590 --> 00:00:21,590
+Otherwise it's not going to get matched.
+
+7
+00:00:21,630 --> 00:00:22,860
+And then what about skill.
+
+8
+00:00:22,890 --> 00:00:26,870
+What about tradition what about taking a different angles or different perspectives.
+
+9
+00:00:27,610 --> 00:00:32,890
+As you can see here all those things I mentioned are problems with template matching rotation and renders
+
+10
+00:00:32,890 --> 00:00:34,720
+this method pretty much ineffective.
+
+11
+00:00:34,960 --> 00:00:36,300
+Skilling as well.
+
+12
+00:00:36,370 --> 00:00:39,470
+What about changes in brightness contrast and hue.
+
+13
+00:00:39,650 --> 00:00:44,930
+What about distortions so tempered matching isn't ideal in most cases.
+
+14
+00:00:45,000 --> 00:00:46,530
+So how do we solve this problem.
+
+15
+00:00:47,560 --> 00:00:52,760
+So one technique that helps us solve a problem is by looking at image features and what image features
+
+16
+00:00:52,780 --> 00:00:58,670
+are there basically summaries of pictures we can formally defined them as interesting areas of an image
+
+17
+00:00:59,150 --> 00:01:02,190
+that are somewhat unique and specific to that image.
+
+18
+00:01:02,330 --> 00:01:05,800
+Also they are popularly called keypoint features or interest points.
+
+19
+00:01:05,960 --> 00:01:09,350
+So they may have come across in textbooks or other online classes.
+
+20
+00:01:09,680 --> 00:01:14,850
+So in this picture of London Bridge here we can clearly see that the sky is all one color and it's an
+
+21
+00:01:14,930 --> 00:01:20,560
+interesting is no way in the sky here summarizes image except maybe in the amount of skaters exposed.
+
+22
+00:01:20,600 --> 00:01:23,600
+But then again that's not that unique to most pictures.
+
+23
+00:01:23,690 --> 00:01:29,780
+However looking a little points along the bridge here we can see it does feature detection or image
+
+24
+00:01:29,780 --> 00:01:34,630
+features here is actually looking at key points that are interesting to the image and unique to it.
+
+25
+00:01:34,670 --> 00:01:40,590
+All these lighting conditions tiles Newbridge peaks here as well.
+
+26
+00:01:40,700 --> 00:01:44,910
+There were VDM interesting and we can use this to summarize this image quite nicely.
+
+27
+00:01:45,890 --> 00:01:51,230
+So maybe in future if we have an image of the London Bridge a lot of these points here will be common
+
+28
+00:01:51,230 --> 00:01:55,470
+to both images and that's exactly how we can detect and matched these images together.
+
+29
+00:01:56,500 --> 00:01:58,870
+So why is Fuji detection so important.
+
+30
+00:01:59,110 --> 00:02:03,030
+Well going back to object detection we have a lot of these similar use cases here.
+
+31
+00:02:03,100 --> 00:02:07,500
+And one key example we can look at is image alignment or Piner on the stitching.
+
+32
+00:02:07,540 --> 00:02:11,560
+So looking at these live pictures here we can see that these two points are similar in both pictures
+
+33
+00:02:11,560 --> 00:02:12,340
+here.
+
+34
+00:02:12,340 --> 00:02:17,320
+And by doing some perspective warping and stuff we can actually match and overlay these images correctly
+
+35
+00:02:17,320 --> 00:02:18,330
+together.
+
+36
+00:02:18,460 --> 00:02:20,730
+Similarly look at this image here.
+
+37
+00:02:20,830 --> 00:02:25,850
+There are only four key points we can use here and we can detect that a seam object is in images here.
+
+38
+00:02:27,510 --> 00:02:32,460
+Well I previously said that image features have to be interesting points we should be interesting points
+
+39
+00:02:33,030 --> 00:02:34,770
+but what defines interesting.
+
+40
+00:02:35,100 --> 00:02:39,370
+Well an interesting point is a point that carries a lot of information about that image.
+
+41
+00:02:39,540 --> 00:02:45,150
+And typically the areas of high intensity of change corners or edges and what happens or what it means
+
+42
+00:02:45,150 --> 00:02:47,550
+is that these areas are distinct and unique.
+
+43
+00:02:47,550 --> 00:02:50,970
+That image itself however we should be careful.
+
+44
+00:02:50,970 --> 00:02:53,420
+Noise can also be informative when it's not.
+
+45
+00:02:53,560 --> 00:02:57,970
+So before we actually use feature detection algorithm on an image.
+
+46
+00:02:57,990 --> 00:03:01,050
+Maybe we should clean it up reduce noise at some blue.
+
+47
+00:03:01,050 --> 00:03:07,790
+Just keep in mind as we work as we go along for the this is a summary of the characteristics of good
+
+48
+00:03:07,790 --> 00:03:09,130
+and interesting features.
+
+49
+00:03:09,130 --> 00:03:13,530
+This should be repeatable meaning that they should be found in multiple pitches of the same scene.
+
+50
+00:03:13,780 --> 00:03:15,730
+They should be distinctive and unique.
+
+51
+00:03:15,830 --> 00:03:17,590
+They also should be compact and efficient.
+
+52
+00:03:17,600 --> 00:03:23,330
+We don't want an image that has a ton of features we wanted to have at least a minimal amount of features
+
+53
+00:03:23,330 --> 00:03:26,620
+I can describe that scene accurately and locality.
+
+54
+00:03:26,720 --> 00:03:33,490
+Again that pertains to last point so having just learnt a little bit about features.
+
+55
+00:03:33,670 --> 00:03:37,660
+Let's start using some of open civies feature extraction algorithms.
+
+56
+00:03:37,660 --> 00:03:42,840
+So if this image features that we're going to take a brief look at is using corner's as features no
+
+57
+00:03:42,850 --> 00:03:46,480
+corners on the best to images in terms of image matching.
+
+58
+00:03:46,660 --> 00:03:50,300
+However they do have special use cases and make them quite handy to know.
+
+59
+00:03:50,680 --> 00:03:54,820
+So how exactly do we identify corners in an image so quickly.
+
+60
+00:03:54,830 --> 00:04:00,100
+Just imagine this is a window that you're looking at here and this black box here is on a bigger image
+
+61
+00:04:00,100 --> 00:04:00,950
+here.
+
+62
+00:04:01,050 --> 00:04:07,570
+Removing this window across this black box because there's no change in intensity in this blocks in
+
+63
+00:04:07,570 --> 00:04:08,610
+his box sorry.
+
+64
+00:04:08,680 --> 00:04:11,760
+We know that there's no edge or corner found in this box.
+
+65
+00:04:11,800 --> 00:04:13,630
+So this is deemed as flat.
+
+66
+00:04:13,960 --> 00:04:19,000
+But what if we move this box horizontally across this edge here there is a change but it changes only
+
+67
+00:04:19,000 --> 00:04:20,350
+in one direction.
+
+68
+00:04:20,350 --> 00:04:22,140
+So that's an edge not a corner.
+
+69
+00:04:22,420 --> 00:04:24,490
+However let's come to the coin over here.
+
+70
+00:04:24,760 --> 00:04:28,990
+I mean moving this in all directions here no matter what direction we move it in.
+
+71
+00:04:28,990 --> 00:04:33,000
+Similarly we in all the actions here there are changes in intensity.
+
+72
+00:04:33,010 --> 00:04:34,720
+Previously there were none over here.
+
+73
+00:04:34,720 --> 00:04:36,520
+So this spot is deemed a corner.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/37. Finding Corners - Why Corners In Images Are Important to Object Detection.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/37. Finding Corners - Why Corners In Images Are Important to Object Detection.srt
new file mode 100644
index 0000000000000000000000000000000000000000..098fe9845f57e12c1ce48454fc8b97bca2688b1a
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/37. Finding Corners - Why Corners In Images Are Important to Object Detection.srt
@@ -0,0 +1,423 @@
+1
+00:00:00,680 --> 00:00:06,020
+Sort of this image features that we're going to take a brief look at is using corners as features no
+
+2
+00:00:06,110 --> 00:00:09,790
+corners on the best summaries images in terms of image matching.
+
+3
+00:00:09,840 --> 00:00:13,820
+However they do have special use cases and make them quite handy to know.
+
+4
+00:00:13,860 --> 00:00:17,970
+So how exactly do we identify corners in an image so quickly.
+
+5
+00:00:17,970 --> 00:00:23,490
+Just imagine this is a window that you're looking at here and this black box here's a bigger image here
+
+6
+00:00:23,810 --> 00:00:29,640
+of removing this window across this black box because there's no change in intensity in this blocks
+
+7
+00:00:30,570 --> 00:00:31,750
+in his box sorry.
+
+8
+00:00:31,860 --> 00:00:34,940
+We know that there's no edge or corner found in this box.
+
+9
+00:00:34,980 --> 00:00:36,810
+So this is deemed as flat.
+
+10
+00:00:37,110 --> 00:00:42,270
+But what if we moved this box horizontally across this edge here there is a change but it is only in
+
+11
+00:00:42,270 --> 00:00:43,440
+one direction.
+
+12
+00:00:43,500 --> 00:00:45,320
+So that's an edge not a corner.
+
+13
+00:00:45,570 --> 00:00:47,850
+However let's come to the corner over here.
+
+14
+00:00:47,900 --> 00:00:50,010
+I mean moving this in all directions here.
+
+15
+00:00:50,520 --> 00:00:52,140
+No matter what direction we move it in.
+
+16
+00:00:52,140 --> 00:00:54,650
+Similarly we did all the actions here.
+
+17
+00:00:54,660 --> 00:00:56,150
+They are changes in intensity.
+
+18
+00:00:56,160 --> 00:00:57,610
+Previously there were none over here.
+
+19
+00:00:57,900 --> 00:01:00,090
+So this spot is deemed a corner.
+
+20
+00:01:01,500 --> 00:01:07,290
+So let's actually take a look at the Open see if we could that we can use to find quantus says bring
+
+21
+00:01:07,290 --> 00:01:07,560
+a ball.
+
+22
+00:01:07,560 --> 00:01:13,440
+I put on that book manager here lecture 5.4 finding corners.
+
+23
+00:01:13,570 --> 00:01:15,430
+And here we are.
+
+24
+00:01:15,630 --> 00:01:19,240
+We're going to explore using two different methods of detection.
+
+25
+00:01:19,240 --> 00:01:23,730
+First we're going to use this called Harris scorners and that comes out of some work done by Steven
+
+26
+00:01:23,730 --> 00:01:25,820
+Harris and Nathan can it to people.
+
+27
+00:01:25,830 --> 00:01:28,530
+Here is a link right here to it.
+
+28
+00:01:28,700 --> 00:01:34,290
+It actually defines the algorithm used in the corner as well as scorners which is what is typically
+
+29
+00:01:34,440 --> 00:01:35,720
+called.
+
+30
+00:01:35,730 --> 00:01:38,100
+So let's take a look at this code and see what's going on here.
+
+31
+00:01:38,370 --> 00:01:42,420
+So first we look at this image and this image is of a chessboard which you'll see shortly.
+
+32
+00:01:42,720 --> 00:01:47,670
+Then we grayscale this image converted to float to the do because this is what co-winner Harris actually
+
+33
+00:01:47,670 --> 00:01:50,190
+requires as input for function.
+
+34
+00:01:50,190 --> 00:01:54,680
+So this is a this is a nado open C-v quick that's not straightforward.
+
+35
+00:01:54,690 --> 00:01:57,460
+However just keep this in mind when you're using this function.
+
+36
+00:01:57,900 --> 00:02:06,700
+And no we actually used a higher squint function right here so we put the image here which is gry and
+
+37
+00:02:06,700 --> 00:02:09,190
+then we put some tweaking parameters here.
+
+38
+00:02:09,350 --> 00:02:14,820
+DS You can see here these are block and aperture size for the sole builder derivative that's used.
+
+39
+00:02:14,860 --> 00:02:20,170
+I don't expect you to know exactly what these are because they are defined properly here and the people.
+
+40
+00:02:20,280 --> 00:02:25,440
+So if you want to play around and toy with these values see if it gets the results that you actually
+
+41
+00:02:25,440 --> 00:02:31,140
+want and then there's a free parameter here which again I don't recommend you play with too much unless
+
+42
+00:02:31,140 --> 00:02:34,770
+you actually unless it improves your results significantly.
+
+43
+00:02:34,770 --> 00:02:39,790
+So once we run this corner Harris function it returns an array of corner locations.
+
+44
+00:02:42,020 --> 00:02:46,590
+However to actually visualize is called coiners because they're given as tiny locations.
+
+45
+00:02:46,820 --> 00:02:48,590
+We can actually do a couple of things to do it here.
+
+46
+00:02:48,650 --> 00:02:55,660
+So one technique we can use is by using dilution to actually add pixels to the edges of those corners.
+
+47
+00:02:55,940 --> 00:03:02,180
+So we run the corners here in dilations here run it twice and then we actually do some thresholding
+
+48
+00:03:02,180 --> 00:03:02,660
+here.
+
+49
+00:03:04,050 --> 00:03:09,180
+Just a chin story change the color of the coin is that we that we are drawing an image here and let's
+
+50
+00:03:09,180 --> 00:03:10,000
+run this function.
+
+51
+00:03:10,020 --> 00:03:11,300
+And here we are.
+
+52
+00:03:11,310 --> 00:03:15,260
+So these are the corners hard scorners defined and these are the corners dilated.
+
+53
+00:03:15,300 --> 00:03:21,420
+Here you can actually see that you're not perfectly aligned totally It is actually on my screen it looks
+
+54
+00:03:21,420 --> 00:03:23,190
+like a tiny optical illusion.
+
+55
+00:03:23,190 --> 00:03:25,310
+I don't know how it looks and who knows.
+
+56
+00:03:25,470 --> 00:03:29,340
+And those are the hardest going as we detected on our chessboard.
+
+57
+00:03:29,450 --> 00:03:34,730
+So let's take a look at a second Quintard detection method called good features to track no good features.
+
+58
+00:03:34,730 --> 00:03:40,890
+The track is actually an improvement on the work done by Steven Harris in 1998 and his algorithm all
+
+59
+00:03:41,060 --> 00:03:43,080
+the to be function here.
+
+60
+00:03:43,310 --> 00:03:47,500
+So let's run this code and here we go we've got some co-winners.
+
+61
+00:03:47,530 --> 00:03:50,290
+No are some key differences in this algorithm.
+
+62
+00:03:50,300 --> 00:03:52,120
+And I'll discuss this quickly.
+
+63
+00:03:52,160 --> 00:03:55,990
+So again we have a grayscale image here that we use as a input file.
+
+64
+00:03:56,150 --> 00:03:59,030
+Then there's a valuable 50 here and what 50 is.
+
+65
+00:03:59,150 --> 00:04:03,520
+These are the max quitter's you want to read to and you know image we could set this to 10.
+
+66
+00:04:03,610 --> 00:04:09,050
+Look what happens we get to 10 strongest ones and we can set it to 100.
+
+67
+00:04:09,080 --> 00:04:11,500
+We basically just get all the corners it could have possibly found.
+
+68
+00:04:11,510 --> 00:04:14,960
+So it's finding some co-winners some possible corners on the edges here.
+
+69
+00:04:16,640 --> 00:04:21,870
+Then we've got some promises here that as tweaks to corner detection sensitivity.
+
+70
+00:04:22,040 --> 00:04:28,520
+So quality level here is a parameter characterising the minimal accepted quality of the image coiners
+
+71
+00:04:30,430 --> 00:04:32,880
+it actually is a bit complicated to explain.
+
+72
+00:04:32,900 --> 00:04:38,420
+However DMax value we can set it as a 5100 and Louis valued point 0 1.
+
+73
+00:04:38,650 --> 00:04:41,620
+Now mid-distance is similar to another algorithm that we looked at.
+
+74
+00:04:41,620 --> 00:04:45,220
+I think that was in probabilistic HOV lanes.
+
+75
+00:04:45,220 --> 00:04:48,390
+This is the minimum distance between us that we were seeing here.
+
+76
+00:04:48,560 --> 00:04:54,920
+So if we said this to one 50 seconds or two and a lot less scorners as you can see the coin is a more
+
+77
+00:04:54,920 --> 00:04:55,830
+spaced out.
+
+78
+00:04:56,110 --> 00:05:01,210
+So using Goodrich's the truck you can actually tweak recorded detection method is quite good.
+
+79
+00:05:01,270 --> 00:05:07,890
+And similarly just like Harris Quinlan's did it returns an array of x y locations.
+
+80
+00:05:07,910 --> 00:05:10,060
+So what we do here is a bit different.
+
+81
+00:05:10,060 --> 00:05:13,870
+What we did previously but this is actually easier to understand.
+
+82
+00:05:14,110 --> 00:05:21,010
+All we do is we reach through each corner in the corners Zuri get an x y locations and then plot a rectangle.
+
+83
+00:05:21,010 --> 00:05:24,410
+But what I'm doing here is I'm actually adding some dimensions.
+
+84
+00:05:24,790 --> 00:05:31,100
+I'm decreasing and pulling back sort of speak direct angular bunji here and adding 10 here.
+
+85
+00:05:31,360 --> 00:05:35,640
+So that gives us a slightly larger rectangle to visualize O'Connors image here.
+
+86
+00:05:35,770 --> 00:05:39,770
+Otherwise it would have been a bit too small but that's just purely for static reasons.
+
+87
+00:05:40,210 --> 00:05:46,250
+So as I mentioned initially in the introduction slide to corner Kinesis features there are some problems
+
+88
+00:05:46,250 --> 00:05:47,680
+with using coiners.
+
+89
+00:05:47,710 --> 00:05:51,060
+One corner has not tolerant intensity issues here.
+
+90
+00:05:51,280 --> 00:05:54,700
+As you can see we had detected corners at these points here in this image.
+
+91
+00:05:54,730 --> 00:05:57,240
+However when you brightened image do all go under.
+
+92
+00:05:57,310 --> 00:05:58,650
+No longer visible.
+
+93
+00:05:58,930 --> 00:06:03,310
+So also corners intolerant scaling as well.
+
+94
+00:06:03,340 --> 00:06:06,890
+Look at this image here this image it's normal size here.
+
+95
+00:06:06,910 --> 00:06:11,890
+However when it's when it's reduced in scale or resize to a smaller image possibly the coin detection
+
+96
+00:06:11,920 --> 00:06:14,830
+augured will only detect one corner.
+
+97
+00:06:14,830 --> 00:06:16,010
+So that's not very good.
+
+98
+00:06:16,300 --> 00:06:19,530
+And here's an illustration of what happens when we enlarge an image here.
+
+99
+00:06:19,570 --> 00:06:23,050
+So this was a corner that still bonding bácsi I found.
+
+100
+00:06:23,230 --> 00:06:28,570
+But what about when this bone box is moving over an enlarged image here is no longer going to detect
+
+101
+00:06:28,780 --> 00:06:31,150
+it it's actually going to detect edges.
+
+102
+00:06:31,330 --> 00:06:35,520
+If the recycling box would have to resize automatically in this case to compensate.
+
+103
+00:06:35,590 --> 00:06:37,040
+However that's not being done.
+
+104
+00:06:37,330 --> 00:06:39,890
+So how do we get around some of these issues here.
+
+105
+00:06:40,270 --> 00:06:45,190
+Well that brings us to the other sort of image feature detection algorithms that were Know About to
+
+106
+00:06:45,190 --> 00:06:45,850
+discuss.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/38. Histogram of Oriented Gradients - Another Novel Way Of Representing Images.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/38. Histogram of Oriented Gradients - Another Novel Way Of Representing Images.srt
new file mode 100644
index 0000000000000000000000000000000000000000..f9ec496061c8b595152b7692e098ea3f12b4f4ba
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/38. Histogram of Oriented Gradients - Another Novel Way Of Representing Images.srt
@@ -0,0 +1,487 @@
+1
+00:00:00,750 --> 00:00:06,570
+So let's talk about a different descriptor and that's histogram of oriented Graydon's short for hogs.
+
+2
+00:00:06,570 --> 00:00:09,080
+Hogs are short for history oriented gradients.
+
+3
+00:00:09,540 --> 00:00:13,790
+So hogs are actually very cool and very useful image descriptor.
+
+4
+00:00:14,130 --> 00:00:19,000
+So you saw previously using Sifton or we had to compute key points then compute descriptors altered
+
+5
+00:00:19,030 --> 00:00:20,010
+as key points.
+
+6
+00:00:20,280 --> 00:00:25,770
+Well hugs do it a bit differently Hogg's actually represented as a single vector as opposed to a set
+
+7
+00:00:25,770 --> 00:00:30,010
+of feature vectors where each represents a segment of the image.
+
+8
+00:00:30,100 --> 00:00:31,470
+Hopefully that's been clear to you.
+
+9
+00:00:31,470 --> 00:00:38,490
+But what this means exactly is that we have a single feature vector for the entire image that's computed.
+
+10
+00:00:38,490 --> 00:00:43,980
+And this is how it's computed computed by sliding a window detector over the image and we generate a
+
+11
+00:00:43,980 --> 00:00:49,260
+hog descriptor which is computed for each position in the image and that position each position is and
+
+12
+00:00:49,260 --> 00:00:51,080
+combined into a single feature vector.
+
+13
+00:00:51,120 --> 00:00:58,640
+Later on and again we do use permitting as a technique for generating this feature of etic I should
+
+14
+00:00:58,640 --> 00:00:59,370
+say.
+
+15
+00:00:59,930 --> 00:01:02,020
+So how do we use Hock's.
+
+16
+00:01:02,090 --> 00:01:07,490
+Because previously we had matches like Flon and V.F. much of all hugs are actually traditionally best
+
+17
+00:01:07,490 --> 00:01:12,680
+used with SVM with Suns for support vector machines which is a machine learning classifier and a very
+
+18
+00:01:12,680 --> 00:01:15,260
+good one and ADAT.
+
+19
+00:01:15,350 --> 00:01:20,930
+So each traditionally again how we do it is that each Hogge descriptor for that image is computed and
+
+20
+00:01:20,930 --> 00:01:25,460
+then fed into the classifier to determine whether the object was found and where it was found in that
+
+21
+00:01:25,460 --> 00:01:27,080
+image.
+
+22
+00:01:27,080 --> 00:01:31,040
+So let's get to a brief explanation of Hogg's
+
+23
+00:01:34,410 --> 00:01:37,370
+so understanding Hoag's can be a bit complicated for a beginner.
+
+24
+00:01:37,440 --> 00:01:41,700
+So I'm going to try to break it down as simple as I can without going into the hardcore mathematics
+
+25
+00:01:41,730 --> 00:01:42,910
+of it.
+
+26
+00:01:42,960 --> 00:01:48,930
+So here's a picture i use of my wife and I've sort of pixilated it a bit so we can sort of see that
+
+27
+00:01:48,930 --> 00:01:49,580
+this isn't it.
+
+28
+00:01:49,580 --> 00:01:51,540
+But it pixel box it's actually not it.
+
+29
+00:01:51,590 --> 00:01:53,640
+It's probably a lot more in reality.
+
+30
+00:01:53,880 --> 00:01:56,260
+However just defining the boxes here.
+
+31
+00:01:56,280 --> 00:02:01,790
+So what we do in this box we compute degree and vector or edge orientations.
+
+32
+00:02:01,830 --> 00:02:06,420
+So what that means here is that in this pixel box you remember what image Grilli and will sort of the
+
+33
+00:02:06,420 --> 00:02:10,060
+directions of the flow of the image is intensity itself.
+
+34
+00:02:10,290 --> 00:02:12,690
+Well that's what we compute inside this box.
+
+35
+00:02:12,960 --> 00:02:19,080
+And this generates 64 where we generate 64 trillion factors which are represented done in a histogram.
+
+36
+00:02:19,110 --> 00:02:22,330
+So imagine a histogram that distributes each Grilli and vector.
+
+37
+00:02:22,500 --> 00:02:28,180
+So if all the points of intensity is light in one direction the histogram for that direction.
+
+38
+00:02:28,200 --> 00:02:30,810
+Let's say that was 45 degrees.
+
+39
+00:02:30,810 --> 00:02:35,290
+So I think if this was zero then it would have a peak at 45 degrees here.
+
+40
+00:02:35,760 --> 00:02:43,860
+So what we don't do is as I just mentioned we split does this angles of orientations into angular bends
+
+41
+00:02:44,430 --> 00:02:50,580
+and into the Lalan tricks people who initially pappooses histogram for integrity and they use nine bins
+
+42
+00:02:50,700 --> 00:02:53,050
+20 degrees each from zero to one easy.
+
+43
+00:02:53,460 --> 00:02:58,960
+So what we've done day we've effectively reduce the 64 vectors into just nine values.
+
+44
+00:02:58,970 --> 00:03:02,750
+So we've reduced the size and yet kept basically all information that we needed.
+
+45
+00:03:02,790 --> 00:03:03,720
+All the key information
+
+46
+00:03:06,620 --> 00:03:13,560
+is a key note here as it stores in magnitudes is relatively immune to image defamations So moving on
+
+47
+00:03:13,560 --> 00:03:14,550
+to the next slide.
+
+48
+00:03:15,730 --> 00:03:19,370
+So the next step in beating Hogg's is actually called normalization.
+
+49
+00:03:19,630 --> 00:03:25,480
+And we do a normalization just to make it in variant illumination changes such as brightness and contrast.
+
+50
+00:03:25,480 --> 00:03:30,070
+So with that I'm going to quickly describe the mathematics here to show you how we actually find the
+
+51
+00:03:30,070 --> 00:03:31,460
+normalization factor.
+
+52
+00:03:31,810 --> 00:03:35,750
+So in this original image here you can see his colors.
+
+53
+00:03:35,770 --> 00:03:38,160
+So this is one to one top half of that here.
+
+54
+00:03:38,580 --> 00:03:44,940
+61 91 and 51 says distance of 50 and oil horizontal and vertical directions.
+
+55
+00:03:44,980 --> 00:03:48,580
+So we get a normalization constant here at 70.
+
+56
+00:03:48,580 --> 00:03:54,350
+Similarly if the image increased in brightness we can actually compute and see to see seventy point
+
+57
+00:03:54,350 --> 00:03:55,780
+seventy two.
+
+58
+00:03:55,780 --> 00:04:01,240
+However if that contrast increased contrast means that the bright areas got brighter and dark areas
+
+59
+00:04:01,240 --> 00:04:05,940
+got darker sort of we actually cede distance has increased.
+
+60
+00:04:05,960 --> 00:04:09,130
+However we can still compute the normalization factor here.
+
+61
+00:04:09,500 --> 00:04:14,580
+So by doing that we divide the vectors by degree in magnitudes which we get.
+
+62
+00:04:15,290 --> 00:04:18,780
+This is distance divided by a hundred seven point seven.
+
+63
+00:04:19,160 --> 00:04:20,810
+And that's a normalization constant.
+
+64
+00:04:20,810 --> 00:04:23,830
+Similarly for here when we do it with the contrasts.
+
+65
+00:04:24,410 --> 00:04:31,900
+So so normalization doesn't take place on a set level it actually takes place on a block level itself
+
+66
+00:04:32,320 --> 00:04:36,960
+so blocks are basically groups of four cells here.
+
+67
+00:04:37,030 --> 00:04:43,360
+So what we do we just take into consideration our neighboring blocks or cells I should say when computing
+
+68
+00:04:43,440 --> 00:04:44,950
+a normalization constant.
+
+69
+00:04:45,040 --> 00:04:50,050
+So the normalization factor is completed for each year and then averaged out and then divided by it
+
+70
+00:04:50,050 --> 00:04:50,780
+here.
+
+71
+00:04:51,340 --> 00:04:52,600
+So that's it for hugs.
+
+72
+00:04:52,600 --> 00:04:53,510
+Let's take a look.
+
+73
+00:04:53,570 --> 00:04:55,150
+That's the expedition for hugs.
+
+74
+00:04:55,150 --> 00:04:58,480
+Take a look at computing hogs in our code.
+
+75
+00:04:58,480 --> 00:05:05,750
+OK so let's load up all we could such a five point seven for histogram oriented gradients.
+
+76
+00:05:06,080 --> 00:05:06,570
+All right.
+
+77
+00:05:06,590 --> 00:05:12,120
+So firstly you can see code looks a bit complicated and I'm actually not go into the details of this.
+
+78
+00:05:12,890 --> 00:05:17,900
+This exercise is just going to be a very high level explanation if you do want to learn more about it.
+
+79
+00:05:17,940 --> 00:05:21,730
+Some links you can click here just to understand how the script a bit more.
+
+80
+00:05:22,070 --> 00:05:25,290
+There's also a lot of cool things being done and how descript doesn't SVM.
+
+81
+00:05:25,280 --> 00:05:26,990
+So I encourage you to look into that.
+
+82
+00:05:26,990 --> 00:05:30,490
+You can just search google and you'll find tons of resources.
+
+83
+00:05:30,500 --> 00:05:35,570
+So what I'm going to do here I'm going to load the image of a white elephant that we used previously
+
+84
+00:05:35,630 --> 00:05:38,610
+I believe is Guillot image.
+
+85
+00:05:38,630 --> 00:05:39,610
+Sure image here.
+
+86
+00:05:39,650 --> 00:05:46,460
+And then we define the parameters or remember we're defining the cell size as it by 8 pixels or block
+
+87
+00:05:46,460 --> 00:05:50,730
+size is too big to remember the block size was what we normalize to here.
+
+88
+00:05:52,680 --> 00:05:57,050
+Number of bins which was nine previously each 120 degrees.
+
+89
+00:05:57,390 --> 00:05:59,800
+And this is where we find open civies here.
+
+90
+00:05:59,890 --> 00:06:01,690
+CB2 hold descriptor.
+
+91
+00:06:01,890 --> 00:06:06,410
+This is what we use to define that descriptive right here.
+
+92
+00:06:07,050 --> 00:06:09,030
+So this maybe it's confusing.
+
+93
+00:06:09,120 --> 00:06:14,120
+It was to me at first however when size is just the size of an image cropped in multiple sizes here
+
+94
+00:06:14,210 --> 00:06:18,150
+and you'll see when size somewhere inside of here right here.
+
+95
+00:06:20,070 --> 00:06:28,290
+And then later on we compute shibari for the hog reaches and gets called and sells then we get over
+
+96
+00:06:28,440 --> 00:06:34,400
+and features from hogback compute and we get our agreements.
+
+97
+00:06:34,440 --> 00:06:37,220
+So then we compete on a gradient orientations here.
+
+98
+00:06:37,440 --> 00:06:40,250
+Well it does something up already for it here.
+
+99
+00:06:40,680 --> 00:06:44,720
+And then we actually create the tree for the cell dimensions here cell account.
+
+100
+00:06:44,970 --> 00:06:47,600
+Then we implement a block normalization.
+
+101
+00:06:47,880 --> 00:06:49,750
+I'm sorry from going going over this pretty quickly.
+
+102
+00:06:49,750 --> 00:06:53,750
+It will take very long to actually go through each line properly for you guys.
+
+103
+00:06:54,000 --> 00:06:55,990
+And then we average brilliance here.
+
+104
+00:06:56,200 --> 00:07:03,450
+He's the most elegant and then we just plot all our hog or his general gram of Grilli unsorry using
+
+105
+00:07:03,450 --> 00:07:07,820
+matplotlib which is why we wanted initially here just take note of that.
+
+106
+00:07:07,830 --> 00:07:11,790
+So let's run this code and create a visual for Hogg's.
+
+107
+00:07:11,850 --> 00:07:13,180
+So let's run it here.
+
+108
+00:07:13,200 --> 00:07:15,740
+This is the elephant in that image.
+
+109
+00:07:15,750 --> 00:07:17,840
+And these are the hogs for that image.
+
+110
+00:07:17,850 --> 00:07:18,540
+So these are.
+
+111
+00:07:18,630 --> 00:07:20,570
+Let me explain quickly what this is.
+
+112
+00:07:20,730 --> 00:07:25,290
+So you can see it's a bit granular here and you can sort of Micko the shape of an elephant here.
+
+113
+00:07:25,600 --> 00:07:30,210
+But what's happening here is that each of these blocks here is by pixels here.
+
+114
+00:07:30,210 --> 00:07:33,300
+And basically these are the Grilli and directions that we give here.
+
+115
+00:07:33,600 --> 00:07:39,390
+So you can see this is actually how we actually store hogs are called descriptors for images here.
+
+116
+00:07:39,750 --> 00:07:46,620
+So all of these values here basically are essentially formatted or descriptor or descriptive of this
+
+117
+00:07:46,620 --> 00:07:48,330
+image.
+
+118
+00:07:48,390 --> 00:07:48,690
+OK.
+
+119
+00:07:48,810 --> 00:07:56,660
+So that's it for hugs you use hugs essentially is once you have does the Scriptures that we create we
+
+120
+00:07:56,660 --> 00:08:02,870
+just created and as we just visualize right there you can then feed that information into SVM classifier
+
+121
+00:08:03,470 --> 00:08:08,800
+and compute well or do some object recognition or Object object detection using it.
+
+122
+00:08:08,810 --> 00:08:09,230
+OK.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/39. HAAR Cascade Classifiers - Learn How Classifiers Work And Why They're Amazing.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/39. HAAR Cascade Classifiers - Learn How Classifiers Work And Why They're Amazing.srt
new file mode 100644
index 0000000000000000000000000000000000000000..bc65b81c4f61553af504699c6db436847671aa37
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/39. HAAR Cascade Classifiers - Learn How Classifiers Work And Why They're Amazing.srt
@@ -0,0 +1,275 @@
+1
+00:00:00,510 --> 00:00:06,030
+Hi and welcome to Section 6 we are going to learn to implement fierce people and detection.
+
+2
+00:00:06,290 --> 00:00:11,280
+So let's take a look at a section in more detail so fiercely before we implement these detectors we're
+
+3
+00:00:11,280 --> 00:00:14,110
+going to learn how we build these classify as themselves.
+
+4
+00:00:14,340 --> 00:00:19,620
+So you're going to understand our KOSKY classifiers then we're going to use those classifiers in doing
+
+5
+00:00:19,620 --> 00:00:21,140
+thius in either direction.
+
+6
+00:00:21,360 --> 00:00:27,710
+And then that brings us to our sixth many projects where we detect cars and pedestrians and video frames.
+
+7
+00:00:28,000 --> 00:00:31,490
+So let's begin with understanding what custom classifiers are.
+
+8
+00:00:31,690 --> 00:00:33,650
+And then you get into how they work.
+
+9
+00:00:33,660 --> 00:00:38,260
+So in the previous section we sort of we can extract features from images and then use those features
+
+10
+00:00:38,260 --> 00:00:45,100
+to classify or detect objects so hard KOSKY classify as essentially the same thing except the they have
+
+11
+00:00:45,100 --> 00:00:49,480
+a different way of storing those features and whose feature is called hard features which we get into
+
+12
+00:00:49,480 --> 00:00:50,640
+in a moment.
+
+13
+00:00:50,680 --> 00:00:56,410
+So what we do know we feed her features into a series of cascade or a series of classifiers which is
+
+14
+00:00:56,410 --> 00:01:01,960
+called a cascade of gas advise and then we used that to basically detect whether that image is present
+
+15
+00:01:02,110 --> 00:01:03,960
+in the image or not where the objects are.
+
+16
+00:01:04,000 --> 00:01:05,640
+Is present an image or not.
+
+17
+00:01:05,940 --> 00:01:10,490
+So Harakah ossify is very good at detecting one particular object.
+
+18
+00:01:10,540 --> 00:01:17,500
+Example of this however we can use them in Pardoel to detect faces and eyes maybe Moat's etc. so I'm
+
+19
+00:01:17,500 --> 00:01:22,300
+going to try to explain the theory behind her Caskie classify as it can be a bit tricky.
+
+20
+00:01:22,460 --> 00:01:24,370
+It's actually very good to know.
+
+21
+00:01:24,430 --> 00:01:30,860
+So let's start so firstly we train to declassify it by giving it a bunch of images and a bunch and when
+
+22
+00:01:30,890 --> 00:01:34,900
+you say a bunch I mean like sometimes thousands or hundreds at least.
+
+23
+00:01:34,900 --> 00:01:39,350
+So we give it some positive images and those actually can be less than the negative images.
+
+24
+00:01:39,670 --> 00:01:44,370
+So let's see if we get that 500 positive images and those could be images with a fierce.
+
+25
+00:01:44,380 --> 00:01:50,830
+If we building a face classify and then we give it maybe Towson's of images with no faeces present.
+
+26
+00:01:50,830 --> 00:01:59,750
+So that's the first part of basically treating a haircut you classify as guttering and those images.
+
+27
+00:01:59,780 --> 00:02:04,420
+So once we have those images we now have to extract or her features out of it.
+
+28
+00:02:04,430 --> 00:02:10,700
+So explain to you what car features are there basically the sum of in pixel intensities under rectangular
+
+29
+00:02:10,700 --> 00:02:11,780
+windows here.
+
+30
+00:02:11,810 --> 00:02:14,620
+So these are examples of different windows that are used.
+
+31
+00:02:14,870 --> 00:02:19,890
+So in the first proposal for Horncastle classifiers I believe that was in the violet jeunes people or
+
+32
+00:02:19,890 --> 00:02:24,690
+it could have been something before they use these different rectangular features here.
+
+33
+00:02:24,950 --> 00:02:29,240
+And what we did we recorded some Fich intensities under each rectangle here.
+
+34
+00:02:29,540 --> 00:02:35,120
+However doing so for an entire image even if the image is resized and we use a larger window it results
+
+35
+00:02:35,120 --> 00:02:41,780
+in literally thousands and thousands so enthused people here I think it was 180000 features were generated.
+
+36
+00:02:41,870 --> 00:02:47,130
+And that's a very slow process to actually calculate the intensities under all these different windows.
+
+37
+00:02:47,130 --> 00:02:52,700
+So what the researchers did developed a method called into images that actually computed the some intensity
+
+38
+00:02:52,700 --> 00:02:57,170
+is using for real references and it was much much faster.
+
+39
+00:02:57,180 --> 00:03:01,330
+These are some other rectangle features that could be used as well just in case you want to create a
+
+40
+00:03:01,340 --> 00:03:08,450
+one horror classic classify you and future so even do the researchers find a way to calculate the sum
+
+41
+00:03:08,460 --> 00:03:11,340
+intensities much faster using integral images.
+
+42
+00:03:11,340 --> 00:03:16,470
+They still ended up with quite a large number of features one needed to be exact and the majority a
+
+43
+00:03:16,560 --> 00:03:21,140
+majority of them added no value because they were landing on areas that didn't have a fetus.
+
+44
+00:03:21,540 --> 00:03:26,190
+So what they do what they did was they used a technique called Wisting and then used an algorithm called
+
+45
+00:03:26,220 --> 00:03:31,480
+it abuse which actually found the most informative features in them.
+
+46
+00:03:31,830 --> 00:03:34,210
+So it is actually a really cool algorithm.
+
+47
+00:03:34,440 --> 00:03:40,650
+What it does actually makes uses weak classifiers to build strong classifiers and it does that by assigning
+
+48
+00:03:40,650 --> 00:03:43,980
+heavy awaited penalties on incorrect classifications.
+
+49
+00:03:43,980 --> 00:03:52,350
+So what they ended up doing was reducing these 180000 features which to 6000 which is a huge reduction.
+
+50
+00:03:52,350 --> 00:03:57,720
+So now if you think about it intuitively even if we have 6000 features that's still a lot to process
+
+51
+00:03:57,720 --> 00:03:58,770
+at once.
+
+52
+00:03:58,890 --> 00:04:03,740
+And obviously in those 6000 features some are definitely going to be more informative than others.
+
+53
+00:04:03,810 --> 00:04:05,190
+So what the researchers did.
+
+54
+00:04:05,280 --> 00:04:10,580
+They developed a system called a cascade of classifiers and that's where Nim originates from obviously.
+
+55
+00:04:10,950 --> 00:04:11,730
+So what this does.
+
+56
+00:04:11,760 --> 00:04:16,550
+It actually looks at the most important feature of this and what it does as well.
+
+57
+00:04:16,770 --> 00:04:20,820
+It sort of get tuned to what classifying faces easily.
+
+58
+00:04:20,850 --> 00:04:25,370
+So let's assume this Fu's region here it classify this as a face.
+
+59
+00:04:25,380 --> 00:04:27,360
+So that's a false positive.
+
+60
+00:04:27,380 --> 00:04:33,000
+However typically what happens is that as it moves moves to stage 2 and it detects 10 more features.
+
+61
+00:04:33,000 --> 00:04:38,450
+This area may be eliminated as offis So as you can see by sliding this window across we're actually
+
+62
+00:04:38,480 --> 00:04:44,490
+discomforting based on one or 10 or even 20 features sometimes until it reaches a fixed region and then
+
+63
+00:04:44,490 --> 00:04:49,140
+it's actually going to go through all €60 before it actually says it's a feast.
+
+64
+00:04:49,290 --> 00:04:52,550
+That's why Caskie classify is actually so good and so fast.
+
+65
+00:04:52,670 --> 00:04:56,190
+Deducting faeces and rejecting everything else that doesn't AFIS.
+
+66
+00:04:56,220 --> 00:05:01,370
+So this was basically the system of the violet jeunes face detection method.
+
+67
+00:05:01,680 --> 00:05:05,550
+You should actually give people read up the link and I fight on the book file.
+
+68
+00:05:05,550 --> 00:05:10,170
+So we're not about to implement actually does this detection algorithm an either direction algorithm
+
+69
+00:05:10,370 --> 00:05:10,800
+or code.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/4. Storing Images on Computers.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/4. Storing Images on Computers.srt
new file mode 100644
index 0000000000000000000000000000000000000000..b59f0f91719914504f9aa9acd465cfb4595ff3e5
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/4. Storing Images on Computers.srt
@@ -0,0 +1,283 @@
+1
+00:00:01,340 --> 00:00:07,160
+So how it can be distorted which it's not in many ways this can be done or whether we're going to look
+
+2
+00:00:07,160 --> 00:00:11,680
+into that default method utilized by NCB which is r.g.
+
+3
+00:00:11,940 --> 00:00:14,170
+RGV stands for red green and blue.
+
+4
+00:00:14,570 --> 00:00:24,020
+So imagine this 10 by 10 grid I have here represented an image and each pixel point which is what these
+
+5
+00:00:24,020 --> 00:00:25,060
+cells are.
+
+6
+00:00:25,310 --> 00:00:30,610
+We have tree values one for red one for green one from Blue.
+
+7
+00:00:30,700 --> 00:00:31,270
+Now Open.
+
+8
+00:00:31,270 --> 00:00:32,960
+See these stories these values in it.
+
+9
+00:00:33,050 --> 00:00:35,700
+It as that integer.
+
+10
+00:00:35,720 --> 00:00:38,550
+This allows us to go from zero to 255.
+
+11
+00:00:38,560 --> 00:00:41,790
+Giving us 256 values.
+
+12
+00:00:42,220 --> 00:00:47,910
+So no we represent colors here by mixing different intensities of red green and blue.
+
+13
+00:00:48,400 --> 00:00:54,450
+So as we can see in this pretty child destroying here all these values here are going to be white.
+
+14
+00:00:54,490 --> 00:00:58,170
+White is represented by 255 in each color.
+
+15
+00:00:58,340 --> 00:01:00,880
+So that's 255 for red green and blue.
+
+16
+00:01:01,180 --> 00:01:03,070
+Next if we have a green over here.
+
+17
+00:01:03,450 --> 00:01:13,210
+So 0 4 is going to be have zero red zero blue but filigree wholeheartedly colors light brown and yellow.
+
+18
+00:01:13,210 --> 00:01:20,770
+Now if we mix colors as you may have done in kindergarten I guess you can see that they're mixing red
+
+19
+00:01:20,770 --> 00:01:21,530
+and green.
+
+20
+00:01:21,550 --> 00:01:23,730
+You actually create yellow.
+
+21
+00:01:24,040 --> 00:01:30,640
+Now that's actually how we represent color spectrum using RGV by mixing different combinations of colors
+
+22
+00:01:30,730 --> 00:01:32,290
+of different intensities.
+
+23
+00:01:32,500 --> 00:01:36,400
+And that's what is vollies by the way they are called intensities.
+
+24
+00:01:36,460 --> 00:01:43,000
+So the value of red that's low is going to be a condensed dark value and one that's two fifty five was
+
+25
+00:01:43,000 --> 00:01:45,490
+going to be a bright red similar the shade.
+
+26
+00:01:46,700 --> 00:01:54,280
+Now this picture of the Eiffel Tower which blue actually resize we actually have a very low green pixel
+
+27
+00:01:54,280 --> 00:01:55,160
+count.
+
+28
+00:01:55,330 --> 00:02:00,850
+You can see the individual pixels here and you can actually see that there are different shades of yellow
+
+29
+00:02:00,850 --> 00:02:02,610
+and brown and black.
+
+30
+00:02:02,710 --> 00:02:07,380
+So that's exactly how we use RGV to represent images.
+
+31
+00:02:07,400 --> 00:02:13,550
+Now I've talked a lot about how R&B is used but I haven't talked a lot about how it's stored in a computer.
+
+32
+00:02:14,110 --> 00:02:16,070
+So that's what we're going to look at next.
+
+33
+00:02:17,470 --> 00:02:21,540
+So this scary looking thing here is actually hope to store images.
+
+34
+00:02:21,640 --> 00:02:29,210
+This mess basically represents by a hundred pixel image where each point goes from zero to fifty five
+
+35
+00:02:29,230 --> 00:02:30,810
+as we saw previously.
+
+36
+00:02:31,150 --> 00:02:37,150
+And these are the colors for any color intensities for blue green and red.
+
+37
+00:02:37,400 --> 00:02:42,090
+If you're familiar with programming you'd quickly realize that this data can be easily stored in areas.
+
+38
+00:02:42,230 --> 00:02:49,750
+And that's exactly open C-v stores images if you're unfamiliar with RIAs give you a quick introduction
+
+39
+00:02:49,750 --> 00:02:56,110
+before we go into any coding first think of Finerty as a table which is so that if I had best location
+
+40
+00:02:56,260 --> 00:03:03,490
+which is called its index in a one dimensional array you have one row of information and each so is
+
+41
+00:03:03,550 --> 00:03:07,560
+identified by the index number which is 0 1 2 and so on.
+
+42
+00:03:08,510 --> 00:03:12,560
+In a two dimensional array we have multiple rows now.
+
+43
+00:03:12,900 --> 00:03:16,370
+So no we need two numbers to identify individual cells.
+
+44
+00:03:16,370 --> 00:03:19,710
+So imagine this cell right here with midmost this is over.
+
+45
+00:03:19,730 --> 00:03:23,130
+It's going to be identified by position 1 1.
+
+46
+00:03:23,150 --> 00:03:26,400
+Think of it like an x y coordinate system.
+
+47
+00:03:26,570 --> 00:03:34,130
+So now we move on to treat dimensional arrays which is what we use is an open city to store images.
+
+48
+00:03:34,130 --> 00:03:35,990
+So in a two dimensional array.
+
+49
+00:03:36,230 --> 00:03:41,860
+Think of this seman two dimensional array but these are stacks behind them.
+
+50
+00:03:42,080 --> 00:03:45,240
+So as you can see in this field is stuck here.
+
+51
+00:03:45,260 --> 00:03:46,700
+We have to read values.
+
+52
+00:03:46,700 --> 00:03:51,270
+Then behind it degree values and certain values and so on.
+
+53
+00:03:51,900 --> 00:03:56,280
+So what this means now is that each cell is not defined by tree numbers.
+
+54
+00:03:56,300 --> 00:04:02,850
+Now we have 0 0 and 0 here 0 1 and 0 to represent a red.
+
+55
+00:04:03,140 --> 00:04:08,730
+If you wanted to find a green value it would be 0 1 1.
+
+56
+00:04:08,760 --> 00:04:16,440
+So that's essentially how RGV images are stored in an array is an open C.v.
+
+57
+00:04:16,490 --> 00:04:19,210
+So what about black and white or grayscale images.
+
+58
+00:04:19,220 --> 00:04:20,630
+Now these are actually simpler.
+
+59
+00:04:20,720 --> 00:04:22,860
+These two end of a two dimension.
+
+60
+00:04:22,880 --> 00:04:26,120
+In fact they're just stored in a two dimensional array.
+
+61
+00:04:26,510 --> 00:04:31,640
+So instead of having multiple layers you just have a single layer like this.
+
+62
+00:04:31,790 --> 00:04:38,400
+And with each image each co-ordinate position is a value associated with it.
+
+63
+00:04:38,570 --> 00:04:47,750
+And that value in a greyscale image basically represents sheets of three under 256 sheets not 50 and
+
+64
+00:04:51,540 --> 00:04:56,420
+as you can see here darker colors are represented by lower values.
+
+65
+00:04:56,590 --> 00:05:00,830
+Previously we saw white being or presence represented by high values.
+
+66
+00:05:00,880 --> 00:05:03,530
+And that follows suit here.
+
+67
+00:05:03,730 --> 00:05:07,330
+So now we have a full spectrum of green for an image.
+
+68
+00:05:07,390 --> 00:05:10,490
+This is an image of a number one by the way.
+
+69
+00:05:10,540 --> 00:05:15,670
+So what about binary images binary images can also be called black and white images.
+
+70
+00:05:15,700 --> 00:05:21,270
+However they're just two values use 255 and 0 binary meaning 2.
+
+71
+00:05:21,460 --> 00:05:23,890
+So it's either Maximin type system.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/40. Face and Eye Detection - Detect Human Faces and Eyes In Any Image.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/40. Face and Eye Detection - Detect Human Faces and Eyes In Any Image.srt
new file mode 100644
index 0000000000000000000000000000000000000000..9f8036f620ac37f75a98d4788b478473a21467a9
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/40. Face and Eye Detection - Detect Human Faces and Eyes In Any Image.srt
@@ -0,0 +1,691 @@
+1
+00:00:00,480 --> 00:00:04,280
+Hi and welcome to our lesson on fees and detection.
+
+2
+00:00:04,680 --> 00:00:09,880
+So we're finally going to use some Caskie classifiers to detect Buddh faces and eyes and pictures and
+
+3
+00:00:09,880 --> 00:00:11,750
+an even video streams.
+
+4
+00:00:12,000 --> 00:00:16,800
+So we're going to use some preachy and classifiers that have been provided by open C-v and you can access
+
+5
+00:00:16,800 --> 00:00:18,050
+them to this link here.
+
+6
+00:00:18,060 --> 00:00:23,710
+Although I have given given them to you on the course files there are supposed to be in your excuse
+
+7
+00:00:23,790 --> 00:00:25,020
+folder.
+
+8
+00:00:25,920 --> 00:00:29,920
+So anyway we can take a look at open see if you like to see to classify as the provider.
+
+9
+00:00:30,180 --> 00:00:31,730
+It's actually quite quite a few of them.
+
+10
+00:00:31,800 --> 00:00:38,360
+And today we're going to use a hair cascade and full frontal vs default I believe which is here.
+
+11
+00:00:38,420 --> 00:00:39,390
+Yes.
+
+12
+00:00:40,290 --> 00:00:43,050
+So you may have just notice actually go by quickly.
+
+13
+00:00:43,140 --> 00:00:48,960
+That is classify as XML files and SML stands for basically Extensible Markup Language.
+
+14
+00:00:48,960 --> 00:00:54,860
+It's basically a language we use to store vast amounts of data could even store data be and XML file.
+
+15
+00:00:54,930 --> 00:00:57,000
+However it's designed to be human readable.
+
+16
+00:00:57,000 --> 00:01:01,440
+So it's not too much you need to know about this format when using Harke ASCII classifiers just need
+
+17
+00:01:01,440 --> 00:01:02,260
+to know what it's doing.
+
+18
+00:01:02,310 --> 00:01:10,200
+As an XML file and I'll give you a simple overview of the flow of how we actually use these Kusiak classify
+
+19
+00:01:10,210 --> 00:01:11,860
+as an open CV.
+
+20
+00:01:11,990 --> 00:01:18,090
+So simply like using Sifton some of these other algorithms before we load or initialize our classifier
+
+21
+00:01:18,870 --> 00:01:25,980
+and then we pass the image or video frame to detect or classify a method and that method typically returns
+
+22
+00:01:25,980 --> 00:01:32,580
+and our way or region of interests which is location of the face here or eyes perhaps and then simply
+
+23
+00:01:32,580 --> 00:01:37,530
+Once we have that region we can actually draw a rectangle over it feels like we have done in this sample
+
+24
+00:01:37,530 --> 00:01:42,720
+image here or you can actually use the fiest you can crop it and maybe apply some sort of face mask
+
+25
+00:01:42,720 --> 00:01:43,440
+or filter.
+
+26
+00:01:43,630 --> 00:01:44,620
+So that's pretty cool.
+
+27
+00:01:46,460 --> 00:01:51,050
+So let's actually look at implementing this and detection using open Zeevi.
+
+28
+00:01:51,050 --> 00:01:55,690
+All right let's go ahead and open our code section 6.2 face and eye detection.
+
+29
+00:01:55,910 --> 00:01:57,030
+Bring it up here.
+
+30
+00:01:57,500 --> 00:01:57,860
+OK.
+
+31
+00:01:57,880 --> 00:01:59,350
+And we have a few blocks of code.
+
+32
+00:01:59,420 --> 00:02:01,470
+So let's look at the first block here.
+
+33
+00:02:01,490 --> 00:02:03,300
+This one is just doing this detection.
+
+34
+00:02:03,320 --> 00:02:05,270
+So let's quickly run this.
+
+35
+00:02:05,690 --> 00:02:07,960
+And there we go it successfully successfully run.
+
+36
+00:02:07,970 --> 00:02:12,550
+We have a pink square or rectangle around Donald Trump's face.
+
+37
+00:02:12,590 --> 00:02:13,560
+That's pretty cool.
+
+38
+00:02:13,940 --> 00:02:15,690
+So let's see exactly what's happening here.
+
+39
+00:02:16,900 --> 00:02:19,570
+So let's look at the first line of this code here.
+
+40
+00:02:19,570 --> 00:02:26,250
+So we're using the to cascade classifier dysfunction which we point to a cascade ossified.
+
+41
+00:02:26,260 --> 00:02:28,590
+We would be using here for detection.
+
+42
+00:02:28,810 --> 00:02:31,430
+That's a cascade frontal thius default.
+
+43
+00:02:31,660 --> 00:02:36,200
+And that would have been one to classify as a give you in the IG files for discourse.
+
+44
+00:02:36,210 --> 00:02:38,440
+It's in the Cascades folder under a tree.
+
+45
+00:02:38,470 --> 00:02:41,200
+Other classify as C as well.
+
+46
+00:02:41,200 --> 00:02:44,900
+So what this does this creates our fears classify object here.
+
+47
+00:02:45,460 --> 00:02:49,480
+And then what we do know is we LoDo image.
+
+48
+00:02:49,480 --> 00:02:53,620
+So this is the image of Donald Trump that we just that you just saw actually.
+
+49
+00:02:53,620 --> 00:02:57,100
+And then we find a grayscale of an image which is pretty much standard right.
+
+50
+00:02:57,110 --> 00:03:02,710
+Now you may have noticed a lot of open C-v functions required images to be in grayscale and then we
+
+51
+00:03:02,710 --> 00:03:10,290
+use this method that's in the classify object detect multi-skilled and you see the tree parameters here
+
+52
+00:03:10,620 --> 00:03:14,330
+in that image and I'll get to these two parameters right after.
+
+53
+00:03:14,770 --> 00:03:19,860
+And what does this actually gives us the region of interests that for each of the tasks.
+
+54
+00:03:20,000 --> 00:03:21,870
+So this faces files actually Inori.
+
+55
+00:03:21,940 --> 00:03:26,020
+It's not the not the location of one fiest but the location of many faces.
+
+56
+00:03:26,080 --> 00:03:32,860
+So similarly you saw previously how we had a list of this to give it as that as basically locations
+
+57
+00:03:32,860 --> 00:03:39,690
+for different offices would have located or detected it in the file so similarly if the file is empty
+
+58
+00:03:39,780 --> 00:03:41,470
+that means no visas have been found.
+
+59
+00:03:41,520 --> 00:03:43,190
+So we actually print that here.
+
+60
+00:03:43,420 --> 00:03:51,310
+So if you're using pite on point all this website entry point for actually skip it's done.
+
+61
+00:03:51,870 --> 00:03:53,730
+OK.
+
+62
+00:03:53,830 --> 00:03:58,420
+So then we simply have to draw offices over that image and that's what this loop is about.
+
+63
+00:03:58,420 --> 00:04:02,300
+So as you can see we have four values here in our offices.
+
+64
+00:04:02,630 --> 00:04:07,360
+So what we're doing we're stepping through each of these four values in this industry by using a for
+
+65
+00:04:07,360 --> 00:04:07,930
+loop.
+
+66
+00:04:08,350 --> 00:04:12,100
+And what we're doing we're plotting or drawing I should see a rectangle.
+
+67
+00:04:12,340 --> 00:04:13,870
+And this is the color pink here.
+
+68
+00:04:14,030 --> 00:04:19,740
+I guess you're wondering just plugging it here is in your tangle function and then issuing it here.
+
+69
+00:04:19,780 --> 00:04:20,470
+So it's simple.
+
+70
+00:04:20,500 --> 00:04:22,180
+Let's run this one more time.
+
+71
+00:04:22,180 --> 00:04:23,030
+There we go.
+
+72
+00:04:23,410 --> 00:04:25,390
+Let's go combining this in either direction.
+
+73
+00:04:25,510 --> 00:04:28,420
+So let's move on to the second block of code here.
+
+74
+00:04:28,480 --> 00:04:33,670
+So what's different here is no we're not we're looking to classify as we're Firstly loading thius classify
+
+75
+00:04:33,670 --> 00:04:38,220
+as we did before but now we're also creating an I classify object here.
+
+76
+00:04:38,230 --> 00:04:45,350
+So again we LoDo image default image here greyscale image and initialize all of these classifier here.
+
+77
+00:04:47,260 --> 00:04:53,650
+So similarly as well if no faces have been found we print notices found actually just changes quickly
+
+78
+00:04:53,650 --> 00:04:56,580
+to be compatible with two and three point four.
+
+79
+00:04:57,100 --> 00:05:02,140
+So what happens when faeces are found is that we're actually drawing rectangles again over the face
+
+80
+00:05:02,350 --> 00:05:08,530
+showing that image waiting for a key to be pressed and once a key is pressed we cropped that fierce.
+
+81
+00:05:08,560 --> 00:05:13,180
+So remember how we cropped images using umpires array indexing.
+
+82
+00:05:13,180 --> 00:05:14,960
+So we have cropped the fees out of it.
+
+83
+00:05:14,970 --> 00:05:19,450
+These are from to co-ordinate the locations of the feast that was stored in faeces here.
+
+84
+00:05:19,990 --> 00:05:21,520
+And we actually feed that image.
+
+85
+00:05:21,520 --> 00:05:22,290
+No.
+
+86
+00:05:22,450 --> 00:05:22,880
+2 0.
+
+87
+00:05:22,900 --> 00:05:26,650
+I classify you what we actually feed degree image in here.
+
+88
+00:05:27,070 --> 00:05:30,970
+So we feed it to gasifier and then we have eyes.
+
+89
+00:05:31,080 --> 00:05:36,260
+It eyes that were stored in image and you know most humans should have two eyes.
+
+90
+00:05:36,280 --> 00:05:39,100
+So we'll see if Donald Trump has two eyes just now.
+
+91
+00:05:39,550 --> 00:05:41,620
+And we actually draw his eyes over here.
+
+92
+00:05:41,620 --> 00:05:48,110
+So each time someone clicks key here and he on the image it plots each eye at a time.
+
+93
+00:05:48,610 --> 00:05:50,890
+So let's go ahead and run this school.
+
+94
+00:05:50,890 --> 00:05:51,850
+There we go.
+
+95
+00:05:52,000 --> 00:05:52,730
+It reads.
+
+96
+00:05:52,810 --> 00:05:54,220
+Let's see if it picks up the ice.
+
+97
+00:05:54,340 --> 00:05:56,270
+Yep first has been found.
+
+98
+00:05:56,290 --> 00:05:57,580
+Second day has been found.
+
+99
+00:05:57,820 --> 00:05:58,600
+Excellent.
+
+100
+00:05:59,470 --> 00:06:00,050
+All right.
+
+101
+00:06:00,080 --> 00:06:04,000
+So we've actually made a fierce and I did action successfully here.
+
+102
+00:06:04,390 --> 00:06:10,180
+Let's see if we can do it with a live video stream from a webcam so let's scroll down to that block
+
+103
+00:06:10,180 --> 00:06:11,200
+of code here.
+
+104
+00:06:11,710 --> 00:06:15,670
+And this is where we actually do to see him face an eye detection.
+
+105
+00:06:15,670 --> 00:06:20,840
+However we're doing it now from a video stream from a webcam and would have done differently here.
+
+106
+00:06:20,860 --> 00:06:27,220
+Usually in most applications you actually find you fill a rectangle of the fierce highlighted image.
+
+107
+00:06:27,220 --> 00:06:30,830
+However what I've done I've actually cropped my face of the image.
+
+108
+00:06:30,850 --> 00:06:34,000
+So let's run the code and I'll give you an idea what's going on.
+
+109
+00:06:34,030 --> 00:06:34,760
+So there we go.
+
+110
+00:06:34,810 --> 00:06:40,210
+My fears cropped out of the image and only my face so you can run this good I mean it's just the novelty
+
+111
+00:06:40,210 --> 00:06:40,720
+effects.
+
+112
+00:06:40,720 --> 00:06:41,810
+No big deal.
+
+113
+00:06:42,070 --> 00:06:46,990
+If you wanted differently like if you actually showed a Bactrim with a face you can actually try something
+
+114
+00:06:47,200 --> 00:06:50,860
+different to anyone but editing this into the same code here.
+
+115
+00:06:50,860 --> 00:06:57,520
+So what's going on here is that again reloading our classify has however created a function that we
+
+116
+00:06:57,520 --> 00:07:03,520
+feed the webcam image in and dysfunction basically takes the webcam image finds forces using the similar
+
+117
+00:07:03,520 --> 00:07:05,110
+crude that we did before.
+
+118
+00:07:05,170 --> 00:07:09,830
+Krups So it does this and finds that I again as we did previously here.
+
+119
+00:07:10,210 --> 00:07:15,460
+But instead of drawing a rectangle for the face although it is being done here we actually just crop
+
+120
+00:07:15,550 --> 00:07:23,010
+that rectangle out and once we have cropped that image of all of this we detect eyes in that image right
+
+121
+00:07:23,010 --> 00:07:27,620
+here and we draw the rectangle colored rectangle over each of your eyes.
+
+122
+00:07:27,630 --> 00:07:31,190
+We don't have any weird keys here because we wanted to do it at the same time.
+
+123
+00:07:31,680 --> 00:07:33,840
+And then we simply flip that image here.
+
+124
+00:07:33,840 --> 00:07:39,390
+So it's you know in sync like a mirror image for yourself and read in that image.
+
+125
+00:07:39,390 --> 00:07:40,900
+So let's roll it one more time.
+
+126
+00:07:41,910 --> 00:07:42,650
+There we go.
+
+127
+00:07:43,020 --> 00:07:44,700
+It's pretty simple.
+
+128
+00:07:44,700 --> 00:07:49,260
+So I invite you to actually keep playing and tuning does all the things you can make some cool little
+
+129
+00:07:49,290 --> 00:07:52,640
+apps with these images with his fist and detections.
+
+130
+00:07:52,650 --> 00:07:54,410
+So have fun.
+
+131
+00:07:54,450 --> 00:07:58,700
+So what am actually know about to do though is actually show you what these parameters indetectable
+
+132
+00:07:58,720 --> 00:07:59,990
+the scale here.
+
+133
+00:08:00,090 --> 00:08:06,240
+So you may have noticed we use detect multi-skilled in our eye and fiefs classify your radio and your
+
+134
+00:08:06,240 --> 00:08:11,870
+two parameters here 1.3 and five which is what we used we use typically for physics.
+
+135
+00:08:12,210 --> 00:08:17,270
+But I'll explain why and explain the effects of increasing and decreasing numbers.
+
+136
+00:08:17,370 --> 00:08:19,540
+So let's go along to some notes I left here.
+
+137
+00:08:20,010 --> 00:08:28,350
+So as I said detectability skill as tree input parameters your input image a scale factor and minimum
+
+138
+00:08:28,350 --> 00:08:29,420
+neighbors.
+
+139
+00:08:29,490 --> 00:08:31,140
+So what does skill factor do.
+
+140
+00:08:31,220 --> 00:08:36,140
+First the skill factor specifies how much we want to reduce the image is shown with skill.
+
+141
+00:08:36,390 --> 00:08:41,100
+So what that means is that when you're pyramiding how many times like by what factor are we increasing
+
+142
+00:08:41,100 --> 00:08:46,440
+or decreasing to permit image by setting it at one point means we're increasing or decreasing the image
+
+143
+00:08:46,470 --> 00:08:48,760
+by 80 percent each time it's killed.
+
+144
+00:08:49,140 --> 00:08:54,930
+So you know if you're doing if you're bigger value smaller live closer to 1.0 of five or valiance close
+
+145
+00:08:54,930 --> 00:08:58,310
+to one but not exactly one because one is not going to do anything.
+
+146
+00:08:58,380 --> 00:09:02,520
+You actually have a lot more competitions to do because you're actually scaling a smaller and smaller
+
+147
+00:09:02,520 --> 00:09:04,020
+increments.
+
+148
+00:09:04,890 --> 00:09:07,930
+So now let's discuss the minimum neighbors setting.
+
+149
+00:09:07,980 --> 00:09:09,390
+So quickly let's read this here.
+
+150
+00:09:09,390 --> 00:09:11,110
+It specifies a number of numbers.
+
+151
+00:09:11,130 --> 00:09:17,310
+Each potential window as her mother's heart cascaded windows should have in order to be considered positive
+
+152
+00:09:17,310 --> 00:09:18,400
+detection.
+
+153
+00:09:18,990 --> 00:09:20,960
+So typically we set a tree in six.
+
+154
+00:09:20,970 --> 00:09:26,940
+What this means if you think about it is that let's run this first first ossify of Trump.
+
+155
+00:09:26,970 --> 00:09:31,530
+So what's going to happen here is that usually when there's a window the size the window that's right
+
+156
+00:09:31,530 --> 00:09:35,720
+next it like if we draw an image right here is also going to fix.
+
+157
+00:09:35,730 --> 00:09:36,900
+And similarly again.
+
+158
+00:09:36,900 --> 00:09:39,770
+So you may have multiple windows over to see him face.
+
+159
+00:09:40,080 --> 00:09:43,410
+So how do we know that's one piece and not many faces.
+
+160
+00:09:43,410 --> 00:09:44,260
+Well we don't.
+
+161
+00:09:44,280 --> 00:09:46,960
+But what we do is actually set this value here.
+
+162
+00:09:47,220 --> 00:09:54,680
+So if we got a minimum of say tree faces in that same region then we know that's one fix that's there
+
+163
+00:09:54,700 --> 00:09:56,560
+with minimum neighbors indicates.
+
+164
+00:09:56,760 --> 00:10:05,130
+So a low value will actually detect multiple pieces of a single thius and a high is actually reduce
+
+165
+00:10:05,130 --> 00:10:09,810
+the sensitivity of our detection units or algorithm.
+
+166
+00:10:09,870 --> 00:10:12,470
+So typical ranges are between 3 and 6.
+
+167
+00:10:12,480 --> 00:10:18,540
+If you want to reduce your false false positive I suggest you said this value may be higher maybe even
+
+168
+00:10:19,170 --> 00:10:20,660
+10 if you want.
+
+169
+00:10:20,940 --> 00:10:25,900
+And if you wanted to be very sensitive in picking up this is that something that maybe one or even two.
+
+170
+00:10:25,950 --> 00:10:29,060
+So that brings us to the end of season detection.
+
+171
+00:10:29,070 --> 00:10:33,040
+Hope you learned a art in this lesson and you're not ready to implement.
+
+172
+00:10:33,090 --> 00:10:34,910
+Pretty cool and actually very simple.
+
+173
+00:10:34,920 --> 00:10:38,940
+Many projects on pedestrian and car detection.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/40.1 Download - Lecture 6.2 and Lecture 6.3.html b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/40.1 Download - Lecture 6.2 and Lecture 6.3.html
new file mode 100644
index 0000000000000000000000000000000000000000..b2800f4b989cc4204a8dc61acf95814a2c10ffb4
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/40.1 Download - Lecture 6.2 and Lecture 6.3.html
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/41. Mini Project 6 - Car and Pedestrian Detection in Videos.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/41. Mini Project 6 - Car and Pedestrian Detection in Videos.srt
new file mode 100644
index 0000000000000000000000000000000000000000..87e9c4f9de17e5db8ed5a19c4f7ec0707d4b22e9
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/41. Mini Project 6 - Car and Pedestrian Detection in Videos.srt
@@ -0,0 +1,431 @@
+1
+00:00:01,260 --> 00:00:06,370
+All right let's start with a six minute project which is on call and pedestrian detection.
+
+2
+00:00:06,390 --> 00:00:09,510
+Let's take a look at code and see how we implement this.
+
+3
+00:00:09,510 --> 00:00:09,900
+All right.
+
+4
+00:00:09,940 --> 00:00:15,610
+Let's go ahead and open up with six to many project that's lecture's 6.3.
+
+5
+00:00:15,700 --> 00:00:17,140
+And here we go.
+
+6
+00:00:17,170 --> 00:00:20,000
+So I actually want you to run just run a test.
+
+7
+00:00:20,000 --> 00:00:25,050
+Just make sure open TV is installed properly on your machine because it's a very common issue that prevents
+
+8
+00:00:25,050 --> 00:00:27,440
+openness even from actually playing videos.
+
+9
+00:00:27,460 --> 00:00:30,550
+So let's run the code and this is how it's supposed to work.
+
+10
+00:00:30,550 --> 00:00:34,380
+So that's actually all petition action going on right there.
+
+11
+00:00:34,420 --> 00:00:40,330
+So let's close it off and know if nothing happened the kid just could run and execute it successfully.
+
+12
+00:00:40,330 --> 00:00:44,190
+However it didn't look at any video and didn't even show an error.
+
+13
+00:00:44,260 --> 00:00:50,600
+That means that your parts for this file open CVF MPEG audio hasn't been found.
+
+14
+00:00:50,950 --> 00:00:52,300
+So what you need to do now.
+
+15
+00:00:52,390 --> 00:00:54,790
+You'll need to actually find where this file is.
+
+16
+00:00:54,830 --> 00:00:57,580
+This is it stored in your open C-v directory.
+
+17
+00:00:57,620 --> 00:01:00,870
+So let us get it here.
+
+18
+00:01:00,910 --> 00:01:06,680
+So this is OPEN CVS's stolen my machine is really in the directory here.
+
+19
+00:01:06,940 --> 00:01:07,400
+So good.
+
+20
+00:01:07,430 --> 00:01:10,250
+Open C-v Buddhist sources good too.
+
+21
+00:01:10,260 --> 00:01:12,250
+Party F-F MPEG.
+
+22
+00:01:12,250 --> 00:01:17,000
+And this is a file here of we're actually going to copy.
+
+23
+00:01:17,030 --> 00:01:20,870
+So we actually copy that file to where your Python is installed.
+
+24
+00:01:20,870 --> 00:01:24,930
+So this is where my Python is installed and Anaconda too apparently.
+
+25
+00:01:25,010 --> 00:01:30,680
+So to find a directory pythoness install your machine just run these two lines of code and it tells
+
+26
+00:01:30,680 --> 00:01:32,220
+you where to put and store it.
+
+27
+00:01:32,240 --> 00:01:37,590
+So what you need to do you need to drag or copy this file to design on the two directory.
+
+28
+00:01:37,610 --> 00:01:40,440
+At least that's in my machine where it's installed.
+
+29
+00:01:40,490 --> 00:01:42,800
+So let's quickly do that.
+
+30
+00:01:43,490 --> 00:01:48,860
+So I'm in the biz directly with my Python on xes installed and you can see I have the files here.
+
+31
+00:01:49,160 --> 00:01:50,850
+However there is one important thing to note.
+
+32
+00:01:50,870 --> 00:01:56,450
+You are going to have to rename the file service kept the original here and you can just copy make a
+
+33
+00:01:56,450 --> 00:02:03,680
+copy of it and rename that copy with division of full of open TV that you have as you're currently using.
+
+34
+00:02:03,680 --> 00:02:06,610
+So I'm using 2.4 one tree.
+
+35
+00:02:06,860 --> 00:02:09,270
+So that's a version of called here in the name.
+
+36
+00:02:09,590 --> 00:02:10,170
+So simple.
+
+37
+00:02:10,190 --> 00:02:14,340
+Similarly if you're using 3.1 you can just put tree 1 0.
+
+38
+00:02:14,420 --> 00:02:19,280
+No no decimal points either and underscore 64 if you're using a 64 bit machine.
+
+39
+00:02:19,280 --> 00:02:24,920
+If not if it is going to ex-city ex-city 6 3 to the tablet machine which most of you shouldn't be.
+
+40
+00:02:25,250 --> 00:02:29,380
+You just leave out the underscore 64.
+
+41
+00:02:29,380 --> 00:02:31,060
+OK so that's it.
+
+42
+00:02:31,060 --> 00:02:35,290
+So once you've done that successfully and the instructions are here in case you didn't follow it properly
+
+43
+00:02:35,290 --> 00:02:40,680
+in my view you can just executed and try this again and hopefully it should work.
+
+44
+00:02:40,690 --> 00:02:43,570
+So now let's go about explaining what the school is doing here.
+
+45
+00:02:45,760 --> 00:02:50,600
+So this could is actually pretty simple and it follows a similar method that we've actually just done
+
+46
+00:02:50,600 --> 00:02:52,630
+for fees and classification.
+
+47
+00:02:52,700 --> 00:02:54,800
+So we're using a different classifier now.
+
+48
+00:02:54,800 --> 00:03:00,230
+This is a full body classifier and this is what we're using to to basically classify pedestrians so
+
+49
+00:03:00,230 --> 00:03:02,700
+let's create a body classify object.
+
+50
+00:03:02,910 --> 00:03:08,000
+And what we're doing differently here though is that instead of actually covering this argument as zero
+
+51
+00:03:08,300 --> 00:03:11,830
+as we did for video capture with a webcam we're actually pointing at.
+
+52
+00:03:11,850 --> 00:03:17,760
+And even if that's the walking Felis a file with the pedestrians walking is actually a standard file
+
+53
+00:03:17,880 --> 00:03:19,510
+is actually using a lot of research.
+
+54
+00:03:19,520 --> 00:03:22,170
+So that's why I'm using it here for you guys.
+
+55
+00:03:22,820 --> 00:03:27,650
+So again while a cap is opened or you can have while truth and have a breeks Edmund here it's up to
+
+56
+00:03:27,650 --> 00:03:28,850
+you.
+
+57
+00:03:28,850 --> 00:03:31,420
+We're reading each frame of video.
+
+58
+00:03:31,430 --> 00:03:32,620
+Video file here.
+
+59
+00:03:33,110 --> 00:03:35,360
+And we're also resizing the frame to half its size.
+
+60
+00:03:35,360 --> 00:03:41,270
+And the reason we're doing that is actually to speed up our classification method because large images
+
+61
+00:03:41,330 --> 00:03:46,290
+obviously have a lot more windows to slide over a lot more pixels I should see the slide over.
+
+62
+00:03:46,580 --> 00:03:48,310
+So it's actually going to slow it down quite a bit.
+
+63
+00:03:48,350 --> 00:03:51,290
+So we're decreasing the resolution of that video by half.
+
+64
+00:03:51,500 --> 00:03:53,340
+That's what 0.5 indicates here.
+
+65
+00:03:54,580 --> 00:03:58,480
+And also using one of the quickly into politian methods into linear.
+
+66
+00:03:58,890 --> 00:03:59,260
+Okay.
+
+67
+00:03:59,280 --> 00:04:04,780
+So then we also have to grease Guillot image as we had done previously and we fit that image until we
+
+68
+00:04:04,780 --> 00:04:09,190
+detect multi-skilled which is overclassify and set the parameters here.
+
+69
+00:04:09,190 --> 00:04:14,770
+And as you remember this was a scaling parameter of larger values Meeke makes it classify the detection
+
+70
+00:04:14,770 --> 00:04:15,360
+faster.
+
+71
+00:04:15,360 --> 00:04:16,110
+I should say.
+
+72
+00:04:16,540 --> 00:04:19,330
+And this value is basically a sensitivity factor.
+
+73
+00:04:19,330 --> 00:04:24,670
+So by reducing it actually becomes more sensitive but it also produces a lot of false positives.
+
+74
+00:04:24,680 --> 00:04:28,190
+So these parameters work well and you'll see shortly.
+
+75
+00:04:28,570 --> 00:04:35,350
+And what it does again it returns bodies being an array of points and then we can just plot those points
+
+76
+00:04:35,350 --> 00:04:37,820
+here using a CVT rectangle function.
+
+77
+00:04:38,080 --> 00:04:42,570
+So this is how we actually draw the little boxes of petitions that we've identified.
+
+78
+00:04:42,940 --> 00:04:48,160
+And we just exit is running this loop here by pressing Enter key.
+
+79
+00:04:48,250 --> 00:04:50,710
+So let's run this and quickly look at it.
+
+80
+00:04:50,710 --> 00:04:56,170
+So let's bring it up and there we go we see it's actually it's acting most of the pedestrians here sometimes
+
+81
+00:04:56,170 --> 00:05:00,360
+it misses it sometimes it doesn't but it's actually fairly accurate and fairly good.
+
+82
+00:05:00,980 --> 00:05:04,420
+OK so let's move on to car detection now.
+
+83
+00:05:04,780 --> 00:05:08,890
+So this could actually is pretty much very similar to the previous code.
+
+84
+00:05:08,900 --> 00:05:15,010
+The only differences here that we're pointing at now to car classify classify here and pretty much the
+
+85
+00:05:15,010 --> 00:05:16,210
+same thing is going on here.
+
+86
+00:05:16,210 --> 00:05:20,730
+So let's just run this code and let's take a look at what's going on.
+
+87
+00:05:20,730 --> 00:05:25,080
+So again we see is actually pretty accurate actually picking up a lot of the cause is not all that very
+
+88
+00:05:25,080 --> 00:05:28,260
+accurate especially would cause in the distance here and miss the truck.
+
+89
+00:05:28,270 --> 00:05:31,490
+And also Mr. bicyclist's here but it's pretty good.
+
+90
+00:05:31,560 --> 00:05:36,450
+So I encourage you again to play with these parameters see if it is not of one and any of the better
+
+91
+00:05:36,450 --> 00:05:37,840
+options you have here.
+
+92
+00:05:38,160 --> 00:05:43,460
+So a line here maybe I was experimenting at some parameters you can delete it for these purposes here.
+
+93
+00:05:43,740 --> 00:05:48,970
+You also may have noticed I actually have this time comment that sleep come out here.
+
+94
+00:05:49,270 --> 00:05:54,730
+Now what this does actually you may have noticed that the frame rates in this video is a bit fast.
+
+95
+00:05:55,050 --> 00:05:58,880
+So what time does it's a way just to add some pauses in our code.
+
+96
+00:05:58,890 --> 00:06:02,420
+So you need to import time and then actually execute it.
+
+97
+00:06:02,430 --> 00:06:07,100
+Yes at this point one adds a delay of point one before executing the rest of the code.
+
+98
+00:06:07,560 --> 00:06:10,220
+So you can see it's definitely much slower.
+
+99
+00:06:10,260 --> 00:06:13,740
+You can actually use this for testing if you want to just make sure you're testing it correctly and
+
+100
+00:06:13,740 --> 00:06:19,310
+getting all the cars you want to see by making it smaller just in case you're wondering.
+
+101
+00:06:19,350 --> 00:06:22,370
+It actually speeds up to frame it does wrong.
+
+102
+00:06:25,790 --> 00:06:26,700
+So there we go.
+
+103
+00:06:26,730 --> 00:06:30,980
+You can keep experimenting with it to actually get a more natural free Mid or something you like.
+
+104
+00:06:31,340 --> 00:06:33,120
+So that's it for car and.
+
+105
+00:06:33,200 --> 00:06:35,210
+Action is actually pretty simple.
+
+106
+00:06:35,540 --> 00:06:41,840
+So I hope you actually find this stuff useful and maybe later on in the course like an idea of lecture
+
+107
+00:06:41,870 --> 00:06:45,230
+and how to actually create these KOSKY classifiers.
+
+108
+00:06:45,380 --> 00:06:45,830
+Thanks.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/41.2 Download - Lecture 6.2 and Lecture 6.3.html b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/41.2 Download - Lecture 6.2 and Lecture 6.3.html
new file mode 100644
index 0000000000000000000000000000000000000000..b2800f4b989cc4204a8dc61acf95814a2c10ffb4
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/41.2 Download - Lecture 6.2 and Lecture 6.3.html
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/5. Getting Started with OpenCV - A Brief OpenCV Intro.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/5. Getting Started with OpenCV - A Brief OpenCV Intro.srt
new file mode 100644
index 0000000000000000000000000000000000000000..4e09c8ca4fa59501ad04caddd6fc90a0ac661207
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/5. Getting Started with OpenCV - A Brief OpenCV Intro.srt
@@ -0,0 +1,509 @@
+1
+00:00:00,740 --> 00:00:06,910
+So what exactly is opens even opens in the sense of open source computer vision and was an Intel initiative
+
+2
+00:00:06,970 --> 00:00:08,730
+launched in 1989.
+
+3
+00:00:08,970 --> 00:00:14,890
+Now the primary purpose of NCB was to consolidate a lot of the completed mission research that was being
+
+4
+00:00:14,890 --> 00:00:21,490
+done and on a lot of this research was written in C++ which is why we've been is actually written in
+
+5
+00:00:21,580 --> 00:00:22,920
+C++.
+
+6
+00:00:22,930 --> 00:00:29,290
+However there are several bindings that exist that Locy use Open's you keep an eye on Java Matlab and
+
+7
+00:00:29,320 --> 00:00:31,030
+mobile applications as well.
+
+8
+00:00:31,820 --> 00:00:33,560
+These findings are quite useful.
+
+9
+00:00:33,560 --> 00:00:38,010
+However they do tend to slow down the open operation.
+
+10
+00:00:38,060 --> 00:00:41,850
+So if you want speed use open SEE be in C++.
+
+11
+00:00:42,020 --> 00:00:49,570
+However using it in item allows us to do easily grasp complex concepts and use them by.
+
+12
+00:00:49,610 --> 00:00:53,040
+Which is a powerful data read too.
+
+13
+00:00:54,050 --> 00:01:00,580
+So the first major release of openness to me was actually in 2006 and is second to those nine and two
+
+14
+00:01:00,580 --> 00:01:03,130
+and just last year in 2015.
+
+15
+00:01:03,770 --> 00:01:06,370
+Now in this course we actually use.
+
+16
+00:01:06,440 --> 00:01:14,090
+I actually encourage you to use 2.4 one tree is actually very new latest release I think was just last
+
+17
+00:01:14,090 --> 00:01:14,660
+year.
+
+18
+00:01:14,770 --> 00:01:20,390
+You can check the Web sites maybe the latest version by the time you read this to us and it's quite
+
+19
+00:01:20,390 --> 00:01:22,190
+stable and it's widely deployed.
+
+20
+00:01:22,190 --> 00:01:27,570
+I remember seeing stuff seeing that people still eats up to 60 percent of researchers to use and see
+
+21
+00:01:27,570 --> 00:01:29,460
+the 2.4 1 tree.
+
+22
+00:01:30,080 --> 00:01:36,910
+Now if you think you need for you to use open see victory point X you can go out an install.
+
+23
+00:01:36,950 --> 00:01:44,330
+However they actually are some disadvantages to using 2.0 plus now some important algorithms such as
+
+24
+00:01:44,330 --> 00:01:47,050
+swift and safe have actually been removed.
+
+25
+00:01:47,300 --> 00:01:50,200
+You can actually manually add them back in.
+
+26
+00:01:50,220 --> 00:01:55,880
+Well it's a bit tedious and I'm not going to actually encourage that during this course you output links
+
+27
+00:01:55,880 --> 00:01:56,460
+up.
+
+28
+00:01:56,510 --> 00:01:58,480
+You're free to do as you please.
+
+29
+00:01:58,760 --> 00:02:05,470
+If you want to learn more about conceiving you can go to NCB or check or with TPD page.
+
+30
+00:02:05,560 --> 00:02:12,140
+I should also say it opens any point X actually has a love of the modern research built into it as well.
+
+31
+00:02:12,200 --> 00:02:13,720
+And bug fixes.
+
+32
+00:02:13,880 --> 00:02:19,310
+However if you don't think you're going to use those maybe just stick with 2.4 2.40.
+
+33
+00:02:19,350 --> 00:02:24,110
+So I think you're about ready to get out of the programming that opens in the end Python.
+
+34
+00:02:24,390 --> 00:02:30,430
+So let's begin by and we'll continue this cool long session and discourse.
+
+35
+00:02:30,440 --> 00:02:33,120
+So we're finally here using a principii.
+
+36
+00:02:33,140 --> 00:02:37,700
+So this question as I like to not book is actually going to teach you to read write and display images
+
+37
+00:02:37,700 --> 00:02:38,920
+at open C.v.
+
+38
+00:02:39,140 --> 00:02:45,350
+Notice what is heavily commented at least by my standards and it is going to teach you how to do the
+
+39
+00:02:45,350 --> 00:02:47,790
+functions I described above.
+
+40
+00:02:47,840 --> 00:02:53,260
+So to run it each block of code you press control and so on.
+
+41
+00:02:53,300 --> 00:02:55,950
+Matchbooks I believe that's command.
+
+42
+00:02:56,630 --> 00:02:58,700
+And we run it and we go.
+
+43
+00:02:59,160 --> 00:03:04,640
+So you should see me having a second or two or one comes up here and that means that the it was run
+
+44
+00:03:04,640 --> 00:03:05,760
+successfully.
+
+45
+00:03:06,440 --> 00:03:10,630
+So to import open C-v into Python if you're familiar with Python you would know it.
+
+46
+00:03:10,640 --> 00:03:17,900
+You'd have to import a lot of different use and libraries into Python so we can use less advanced functions
+
+47
+00:03:18,800 --> 00:03:26,600
+open civies call C.V to maybe because the first version was we'll see the one so important and C.V too.
+
+48
+00:03:27,200 --> 00:03:34,490
+Secondly we don't necessarily need to import NUMP buy into this Swiss causation here.
+
+49
+00:03:34,850 --> 00:03:39,350
+But it's also a good habit because you never know when you actually need to use it.
+
+50
+00:03:39,410 --> 00:03:48,740
+Imageries we import some by as mainly because it needed to write it using any sort of number.
+
+51
+00:03:49,340 --> 00:03:51,610
+We get it pretty much call this anything difficult.
+
+52
+00:03:51,630 --> 00:03:56,350
+X however the convention in place is to use the whole number.
+
+53
+00:03:56,780 --> 00:03:59,340
+So let's run this block of code as well.
+
+54
+00:03:59,350 --> 00:03:59,920
+There we go.
+
+55
+00:04:00,940 --> 00:04:03,130
+So now that's a lot of this image.
+
+56
+00:04:03,190 --> 00:04:09,360
+No you do if you have a one notebook open you don't necessarily need to import CB2 again.
+
+57
+00:04:09,610 --> 00:04:16,360
+Well that's a good habit of wait's you know missing libraries and allows you to run lots of code independently.
+
+58
+00:04:16,480 --> 00:04:20,890
+So do it to get into the habit.
+
+59
+00:04:20,920 --> 00:04:26,660
+So no we don't use to seek CB2 that Emerita function to load images.
+
+60
+00:04:26,660 --> 00:04:33,160
+Now I would have given you full of images that we use in this course.
+
+61
+00:04:33,370 --> 00:04:41,110
+So by using the argument we enter into Embree function is a part of that image directory and image file
+
+62
+00:04:41,860 --> 00:04:45,640
+actually and that returns the image here.
+
+63
+00:04:45,700 --> 00:04:48,160
+So we're storing the first image here as input
+
+64
+00:04:53,690 --> 00:04:55,410
+and not in display this image.
+
+65
+00:04:55,460 --> 00:04:59,480
+We actually call on the CB to do it in show function.
+
+66
+00:04:59,480 --> 00:05:01,250
+This function takes two arguments.
+
+67
+00:05:01,250 --> 00:05:05,150
+I've put all the notes in the comments in case you want to go over this one you're on.
+
+68
+00:05:05,150 --> 00:05:07,280
+However I will talk it out to you.
+
+69
+00:05:07,280 --> 00:05:11,170
+So the first argument is a title that's going to be displayed on the window.
+
+70
+00:05:11,210 --> 00:05:18,500
+So since this is your first division you're going to make an item that's called Say Hello World Vision
+
+71
+00:05:19,280 --> 00:05:21,260
+and image file that we want to open.
+
+72
+00:05:21,260 --> 00:05:25,020
+It's going to be an input file that we previously loaded into here.
+
+73
+00:05:26,620 --> 00:05:29,970
+Now you would see it as we'd key and destroy all Windows keys.
+
+74
+00:05:30,000 --> 00:05:32,160
+Those are not necessarily important.
+
+75
+00:05:32,170 --> 00:05:36,210
+However you should always use them when you're loading images.
+
+76
+00:05:36,310 --> 00:05:45,160
+The key words for you to press any key to and then it was this window that destroy windows destroy all
+
+77
+00:05:45,160 --> 00:05:47,450
+Windows function actually is very important.
+
+78
+00:05:47,500 --> 00:05:51,960
+Otherwise it leaves your window hanging on this function.
+
+79
+00:05:51,970 --> 00:05:57,620
+You would wish me to crash your pipes on it and restart it to kernel restart here.
+
+80
+00:05:59,180 --> 00:06:00,400
+So let's not do that.
+
+81
+00:06:00,800 --> 00:06:02,510
+So let's run through this code.
+
+82
+00:06:02,510 --> 00:06:02,870
+Yeah.
+
+83
+00:06:04,660 --> 00:06:10,370
+Well here's the imprint image it's a picture of the love that I took in Paris when I was here a couple
+
+84
+00:06:10,390 --> 00:06:11,570
+years ago.
+
+85
+00:06:11,930 --> 00:06:19,960
+And Dirigo so you wouldn't your first image into Concini notices a qubit that all the comments much
+
+86
+00:06:19,960 --> 00:06:26,350
+neater and of course I probably will run record books like this some something that will come in like
+
+87
+00:06:26,620 --> 00:06:27,640
+image here.
+
+88
+00:06:27,950 --> 00:06:30,170
+Well it's not too difficult to understand.
+
+89
+00:06:30,190 --> 00:06:32,320
+I hope you guys are following as well.
+
+90
+00:06:35,120 --> 00:06:41,640
+If there's anything that's unclear in my class please it be a message and I'll get back to you as soon
+
+91
+00:06:41,640 --> 00:06:44,270
+as possible within 24 hours.
+
+92
+00:06:44,700 --> 00:06:47,270
+So let's take a closer look at how images are stored.
+
+93
+00:06:47,370 --> 00:06:49,950
+So no that's important.
+
+94
+00:06:50,200 --> 00:06:51,290
+Yes indeed.
+
+95
+00:06:51,580 --> 00:06:57,390
+And using non-place duct sheep function use duct tape is actually very useful when you're looking at
+
+96
+00:06:57,390 --> 00:07:04,530
+the dimensions of injury you entity every dot shape and it returns a tuple which gives you the dimensions
+
+97
+00:07:04,620 --> 00:07:05,680
+of an image.
+
+98
+00:07:05,770 --> 00:07:14,550
+So it took five group represented to them and listen to the X Y dimensions of the image being the height
+
+99
+00:07:14,570 --> 00:07:21,540
+
+100
+12:45 the tree being the RSGB values of the image.
+
+101
+00:07:21,550 --> 00:07:27,460
+So let's take a look at looking at the height and width of image by actually displaying it using a print
+
+102
+00:07:27,460 --> 00:07:28,030
+function.
+
+103
+00:07:29,700 --> 00:07:33,010
+What is what we're showing here is that we can get.
+
+104
+00:07:33,050 --> 00:07:40,660
+We can isolate the height and width of this tree which you would you see will be useful later on.
+
+105
+00:07:41,000 --> 00:07:46,320
+We use it just to convert it into simple volume because otherwise it comes up with Oh yeah.
+
+106
+00:07:46,770 --> 00:07:48,000
+And we put pixels here.
+
+107
+00:07:48,020 --> 00:07:53,440
+This is just simple a string concatenation very basic bytes on a hoop it's not too difficult for you
+
+108
+00:07:53,480 --> 00:07:54,960
+if you're unfamiliar.
+
+109
+00:07:55,370 --> 00:07:57,660
+And that's it there.
+
+110
+00:07:58,190 --> 00:08:01,770
+So no let's go into saving images in open sea.
+
+111
+00:08:01,820 --> 00:08:08,420
+We use a CD to imitate function which is very similar to that as you can see the Emerita function over
+
+112
+00:08:08,420 --> 00:08:10,670
+this one has two arguments.
+
+113
+00:08:10,670 --> 00:08:15,280
+First argument is the name of the file that we're going to see with us.
+
+114
+00:08:15,740 --> 00:08:24,350
+Now anytime you're opening files or writing files in frequency of functions use these inverted commas
+
+115
+00:08:24,350 --> 00:08:27,530
+to indicate that it's a string.
+
+116
+00:08:28,070 --> 00:08:32,820
+Secondly this second argument is going to be the filing of the image.
+
+117
+00:08:33,050 --> 00:08:40,010
+So as we previously loaded image as input using every function we can then put inputs here and that
+
+118
+00:08:40,010 --> 00:08:41,270
+writes a file.
+
+119
+00:08:41,270 --> 00:08:46,400
+Now one cool thing about open CD is that it actually is stored in multiple formats gaeshi read it multiple
+
+120
+00:08:46,400 --> 00:08:52,370
+formats to keep XP and these are the most common types but it believe they can do BMTC and a few image
+
+121
+00:08:52,370 --> 00:08:54,110
+types as well.
+
+122
+00:08:54,110 --> 00:09:00,910
+So we run this and this should be written to your working directory and on you if you can just take
+
+123
+00:09:00,910 --> 00:09:03,430
+a look at new file explorer and you'll see it there.
+
+124
+00:09:04,060 --> 00:09:10,190
+If it didn't run if it didn't exist we run for some reason it would be two folds in the above statements.
+
+125
+00:09:11,840 --> 00:09:13,400
+Bookcase and that's it for your office.
+
+126
+00:09:13,490 --> 00:09:15,200
+Basic lesson in open seamier.
+
+127
+00:09:15,200 --> 00:09:16,960
+Hope you guys had fun.
+
+128
+00:09:17,140 --> 00:09:19,610
+We're going to move one now integrate skewing images.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/6. Grayscaling - Converting Color Images To Shades of Gray.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/6. Grayscaling - Converting Color Images To Shades of Gray.srt
new file mode 100644
index 0000000000000000000000000000000000000000..60ee8483df220e26e073b7d8acffaa04315481e7
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/6. Grayscaling - Converting Color Images To Shades of Gray.srt
@@ -0,0 +1,107 @@
+1
+00:00:01,100 --> 00:00:03,310
+So let's talk a bit about Skilling.
+
+2
+00:00:03,620 --> 00:00:08,380
+So Grace Skilling has a process by which we can vote for a color image into shades of gray.
+
+3
+00:00:08,660 --> 00:00:11,280
+Essentially what we call a black and white image.
+
+4
+00:00:11,780 --> 00:00:19,370
+So in open C-v we use do the CVT color function here that takes away image that we look at here and
+
+5
+00:00:19,370 --> 00:00:25,820
+then impasses this C-v to color BGR to the command or function here.
+
+6
+00:00:26,180 --> 00:00:32,750
+Now what this does it tells the CVT color function to convert the image which was a full BGR full color
+
+7
+00:00:32,840 --> 00:00:38,170
+R.G. image to get the image and store the output as Ikari scale image here.
+
+8
+00:00:38,660 --> 00:00:43,750
+So let's run this code and you'll see the gristly image of all full color image.
+
+9
+00:00:43,910 --> 00:00:44,580
+Sokolow.
+
+10
+00:00:44,860 --> 00:00:45,980
+That's a great skill.
+
+11
+00:00:45,980 --> 00:00:46,780
+Pretty cool.
+
+12
+00:00:47,660 --> 00:00:53,120
+So no it isn't actually easier or faster method of doing this faster in the sense that it actually takes
+
+13
+00:00:53,120 --> 00:00:54,360
+less time to type.
+
+14
+00:00:54,380 --> 00:00:56,580
+We actually do need to take this line of code anymore.
+
+15
+00:00:56,840 --> 00:01:02,850
+All we need to do is when we're loading the image using Emerita is to put comma and argument zero Embree
+
+16
+00:01:02,870 --> 00:01:08,870
+takes on several little arguments and this is one of them that automatically converts image to rescue.
+
+17
+00:01:08,870 --> 00:01:15,230
+It doesn't seem any time and could start processing time but it is a sea of sand and typing or decode.
+
+18
+00:01:15,320 --> 00:01:16,640
+So we run this school here.
+
+19
+00:01:16,710 --> 00:01:23,870
+We get Krissie of the mage automatically is wanting to not support Greece scaling images is done a lot
+
+20
+00:01:23,870 --> 00:01:29,180
+of open Sivy functions actually require you to convert an image to grayscale before it actually operates
+
+21
+00:01:29,240 --> 00:01:30,320
+on the image.
+
+22
+00:01:30,500 --> 00:01:35,630
+And that's because greyscale images are actually much easier to process mainly because they have less
+
+23
+00:01:35,630 --> 00:01:39,370
+information but yet still important segments of the image.
+
+24
+00:01:40,130 --> 00:01:45,010
+This is actually kind of why the way in TV actually looks fine to our eyes.
+
+25
+00:01:45,140 --> 00:01:47,840
+We can sort of visually process and analyze everything.
+
+26
+00:01:48,080 --> 00:01:54,260
+Color information is a bonus but it's not all that is necessary and a lot of these open TV functions
+
+27
+00:01:54,260 --> 00:01:58,470
+that use grayscale images operate much quicker than if they were to use a full color image.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/7. Understanding Color Spaces - The Many Ways Color Images Are Stored Digitally.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/7. Understanding Color Spaces - The Many Ways Color Images Are Stored Digitally.srt
new file mode 100644
index 0000000000000000000000000000000000000000..93c2cc93e70fd22003efddd5346ea5e828246f02
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/7. Understanding Color Spaces - The Many Ways Color Images Are Stored Digitally.srt
@@ -0,0 +1,667 @@
+1
+00:00:01,200 --> 00:00:04,850
+So you may have to Tim's R.G. be HSV or see same way.
+
+2
+00:00:05,390 --> 00:00:10,680
+These are names of different color spaces and what color spaces are there are different methods by which
+
+3
+00:00:10,680 --> 00:00:12,750
+we store images on computers.
+
+4
+00:00:12,750 --> 00:00:18,270
+So you may be familiar with RG B which is how we store colors and various intensities of red green and
+
+5
+00:00:18,270 --> 00:00:18,760
+blue.
+
+6
+00:00:19,230 --> 00:00:26,100
+But there's also HSV which is huge saturation and value or intensity and then we see him waky which
+
+7
+00:00:26,100 --> 00:00:33,130
+is actually commonly used in printers so inkjet printers keep being black by the way.
+
+8
+00:00:33,190 --> 00:00:36,100
+So let's talk a bit about the RG Because it's a piece of it.
+
+9
+00:00:36,190 --> 00:00:42,640
+Is it to BGR a color space that can be a bit confusing because well happens if he uses R.G. as its default
+
+10
+00:00:42,670 --> 00:00:48,370
+color speech something the actual order in Erie is BGR of the colors.
+
+11
+00:00:48,370 --> 00:00:53,720
+Now there's a reason for that and that reason has to do with how computers store memory.
+
+12
+00:00:53,770 --> 00:01:00,010
+So as you can see here even though we're storing it in BGR format it actually is stored in our shabby
+
+13
+00:01:00,130 --> 00:01:01,230
+format.
+
+14
+00:01:01,360 --> 00:01:05,940
+It's a little bit complex and maybe you can dig into it on your own time doing some research.
+
+15
+00:01:06,040 --> 00:01:12,190
+All of it is a cool factor though and disk heading back into R.G. which I may have already mentioned
+
+16
+00:01:12,560 --> 00:01:19,030
+is an additive color model which means that we mix different intensities of red green and blue to generate
+
+17
+00:01:19,030 --> 00:01:19,780
+different colors.
+
+18
+00:01:19,780 --> 00:01:26,960
+And it's quite useful we can perhaps generate any color we can see with our eyes using the small.
+
+19
+00:01:26,980 --> 00:01:31,970
+So let's take a look at the not very important color space which is HSV color space.
+
+20
+00:01:32,110 --> 00:01:38,020
+It's just the sensor hue saturation value slash braveness intensity.
+
+21
+00:01:38,030 --> 00:01:43,040
+Now this color space attempts to represent colors the way we perceive it and it stores information in
+
+22
+00:01:43,040 --> 00:01:47,530
+a cylindrical model which actually maps directly to R.G. B color points.
+
+23
+00:01:47,690 --> 00:01:51,930
+Now an open SAVVIDES it arranges that the HSV scale goes up to you.
+
+24
+00:01:52,220 --> 00:02:00,560
+So the first value is from 0 to 179 second goes to zero to 55 and value goes to zero to do 55.
+
+25
+00:02:00,620 --> 00:02:04,790
+You may remember that in R.G. B they all go up to 275 to 55.
+
+26
+00:02:04,790 --> 00:02:05,710
+Sorry.
+
+27
+00:02:05,750 --> 00:02:11,820
+So you may be wondering if it is v actually generates as much colors as RGV and that's a good question
+
+28
+00:02:12,080 --> 00:02:19,250
+and the answer is in open C-v No because we're actually not getting all the colors matched here because
+
+29
+00:02:19,340 --> 00:02:25,850
+how does represents colors is that you go tree 60 degree circle around the cylinder but in open C-v
+
+30
+00:02:25,850 --> 00:02:28,210
+we only go in one degree.
+
+31
+00:02:28,220 --> 00:02:31,310
+Sorry two degree increments because it's divided by two.
+
+32
+00:02:31,430 --> 00:02:36,370
+So which means we don't have the same granularity or Anytus V as RG B.
+
+33
+00:02:36,490 --> 00:02:41,020
+However that's OK we didn't actually lose much in real will of division.
+
+34
+00:02:41,090 --> 00:02:43,270
+This is more for high fidelity photography.
+
+35
+00:02:43,560 --> 00:02:43,970
+Me.
+
+36
+00:02:44,000 --> 00:02:46,230
+It may matter more to them now.
+
+37
+00:02:46,260 --> 00:02:51,090
+HSV is actually very very useful and it comes in very useful and colorful.
+
+38
+00:02:51,500 --> 00:02:57,320
+If you want to learn more about it just V H S L which is another similar color space.
+
+39
+00:02:57,320 --> 00:02:58,890
+You can look at these links here.
+
+40
+00:02:58,910 --> 00:03:02,890
+They have some very useful information.
+
+41
+00:03:02,920 --> 00:03:06,790
+Now color filtering is actually way HSV is so useful.
+
+42
+00:03:06,790 --> 00:03:11,660
+This is actually a representation of FACIL in the open C-v itself.
+
+43
+00:03:11,680 --> 00:03:17,940
+So when you're actually filtering on color we're actually filtering on the hue part of the HSV.
+
+44
+00:03:17,940 --> 00:03:25,090
+So which I didn't mention before was that Hue is essentially color saturation is vibrancy of the color.
+
+45
+00:03:25,180 --> 00:03:30,160
+So as you can see in the cylinder here it everything kind of tends to white at the center.
+
+46
+00:03:30,160 --> 00:03:35,260
+So at low saturation everything is white and that high saturation that's when you start getting rich
+
+47
+00:03:35,380 --> 00:03:39,490
+colors here and value as well as brightness.
+
+48
+00:03:39,490 --> 00:03:45,970
+So as you can see value here at the ends of the value you get dark or black colors and then going all
+
+49
+00:03:45,970 --> 00:03:48,250
+the way up you so getting bright colors.
+
+50
+00:03:48,280 --> 00:03:54,040
+So this is how each year represents colors and does it almost as good as R.G. be even given this limited
+
+51
+00:03:54,040 --> 00:03:54,680
+range here.
+
+52
+00:03:56,260 --> 00:04:01,140
+So now back to color filtering so well here goes from zero to 180.
+
+53
+00:04:01,150 --> 00:04:03,360
+You can see that intruder's circle here.
+
+54
+00:04:04,810 --> 00:04:12,630
+If you would like to filter different branches this this diagram gives us a lot of useful information
+
+55
+00:04:12,630 --> 00:04:13,500
+to filter.
+
+56
+00:04:13,920 --> 00:04:20,270
+So by sitting here from 165 to 15 you can filter on the red colors here.
+
+57
+00:04:20,520 --> 00:04:24,220
+And then something at 45 or 75 you're getting the greens.
+
+58
+00:04:24,360 --> 00:04:28,440
+And similarly for blue 90 to 120 and get the blues here.
+
+59
+00:04:29,350 --> 00:04:32,330
+We're actually going to do some real color filtering in the school us later on.
+
+60
+00:04:32,530 --> 00:04:39,200
+But just remember this diagram which I created here is very very useful for color filtering so let's
+
+61
+00:04:39,200 --> 00:04:42,040
+actually explore these color spaces using some code.
+
+62
+00:04:42,500 --> 00:04:49,620
+So let's load an image here and that image was actually the live picture we looked at previously.
+
+63
+00:04:49,650 --> 00:04:53,700
+So now let's look at it BGR or R.G. be values of that image.
+
+64
+00:04:53,700 --> 00:04:58,200
+So by doing this indexing here for an image array.
+
+65
+00:04:58,500 --> 00:05:03,900
+What we're actually doing is accessing the values the values that are stored in the first pixel location
+
+66
+00:05:04,290 --> 00:05:07,480
+which is 0 0 so let's run that.
+
+67
+00:05:07,480 --> 00:05:09,660
+And this is actually the values here.
+
+68
+00:05:09,670 --> 00:05:12,210
+So we can see the blue which is be here.
+
+69
+00:05:12,460 --> 00:05:18,510
+Of course one a value of 12 green and red tiddy one.
+
+70
+00:05:18,640 --> 00:05:19,660
+So that's pretty cool.
+
+71
+00:05:19,690 --> 00:05:21,460
+So we can actually play with this a little more.
+
+72
+00:05:21,520 --> 00:05:23,970
+You can actually look at more pixels here.
+
+73
+00:05:24,220 --> 00:05:25,420
+That one didn't change much.
+
+74
+00:05:25,430 --> 00:05:27,750
+Surprisingly good to hear.
+
+75
+00:05:27,820 --> 00:05:29,610
+And we get some new values.
+
+76
+00:05:29,680 --> 00:05:33,220
+Remember this image wasn't a highly very and image like a very colorful image.
+
+77
+00:05:33,220 --> 00:05:36,830
+So that's why you probably seeing small changes if you're playing with you and values here.
+
+78
+00:05:37,780 --> 00:05:42,840
+So now let's see what happens to these be values when we converted into grayscale.
+
+79
+00:05:42,940 --> 00:05:49,340
+So let's run the first line as you remember previously This converts an image to grayscale BGR to gray
+
+80
+00:05:50,170 --> 00:05:52,400
+and that's the shape we get.
+
+81
+00:05:52,420 --> 00:05:56,800
+So previously actually we should print the shape for the last image file.
+
+82
+00:05:57,190 --> 00:06:00,340
+Let's take a look at what this looks like.
+
+83
+00:06:01,680 --> 00:06:05,050
+We see it at 12:45 and trio.
+
+84
+00:06:05,280 --> 00:06:06,500
+Wonder what we're going to get now.
+
+85
+00:06:07,280 --> 00:06:08,910
+Just two dimensions.
+
+86
+00:06:09,200 --> 00:06:15,110
+And as you may remember a tool you and when you store an image in green scaly are essentially converting
+
+87
+00:06:15,110 --> 00:06:16,770
+it into two dimensional array.
+
+88
+00:06:17,060 --> 00:06:22,870
+So each pixel point no and we can look at it by doing something similar here.
+
+89
+00:06:23,070 --> 00:06:30,790
+That's Prince this is actually going to get one value you know which is 22.
+
+90
+00:06:31,300 --> 00:06:32,750
+So that's actually quite cool.
+
+91
+00:06:32,980 --> 00:06:35,790
+And we can does it get more points here.
+
+92
+00:06:36,940 --> 00:06:38,560
+Similarly this is actually the same thing
+
+93
+00:06:42,060 --> 00:06:46,110
+so now you've just seen the effect Grace Skilling has on images.
+
+94
+00:06:46,180 --> 00:06:49,050
+So let's take a look at another useful color space.
+
+95
+00:06:49,150 --> 00:06:54,390
+Well actually it just feels extremely useful in terms of color filtering.
+
+96
+00:06:54,480 --> 00:06:57,810
+So this coverage is for you here's a reminder.
+
+97
+00:06:57,870 --> 00:07:04,950
+Now rumble before previously one of the arguments of the CVT color function was color and the score
+
+98
+00:07:05,200 --> 00:07:06,680
+BGR to great.
+
+99
+00:07:06,780 --> 00:07:09,120
+Now we can see it's BGR to each his feet.
+
+100
+00:07:09,530 --> 00:07:15,020
+So we've created an ESV image here and then ruthlessly go to show this HSV image.
+
+101
+00:07:15,180 --> 00:07:22,020
+Then separately we're going to show the HSV huge channel such action now and then value or intensity
+
+102
+00:07:22,020 --> 00:07:23,530
+or brightness channel.
+
+103
+00:07:23,930 --> 00:07:28,340
+Oh we're doing this by indexing dustups specific value in theory.
+
+104
+00:07:28,410 --> 00:07:37,150
+So by putting the semi-colon here actually call I'm sorry this is saying we want all values of the first
+
+105
+00:07:37,450 --> 00:07:41,900
+and second dimensions so these are the widths the heights and width sorry.
+
+106
+00:07:42,190 --> 00:07:48,240
+And then this is actually telling us we wanted him that we wanted a huge channel only here.
+
+107
+00:07:48,410 --> 00:07:54,650
+And similarly this is something else we wanted saturation tile which is the second volume of this index
+
+108
+00:07:55,220 --> 00:07:56,930
+and to channel its value channel.
+
+109
+00:07:56,960 --> 00:08:03,150
+So let's run this code and we can actually see individual components coming out right here.
+
+110
+00:08:03,410 --> 00:08:08,390
+No this isn't terribly useful for anything other than just a visualizes exercise.
+
+111
+00:08:08,750 --> 00:08:10,560
+So we can see a huge channel a new channel.
+
+112
+00:08:10,560 --> 00:08:14,960
+It's quite dark because it only goes from zero to 180.
+
+113
+00:08:15,020 --> 00:08:20,180
+One thing you should note that's important here is that anytime you use the show function it's trying
+
+114
+00:08:20,180 --> 00:08:24,000
+to shoot the image as a BGR or R.G. image.
+
+115
+00:08:24,290 --> 00:08:28,760
+So it doesn't actually display it just view images because look what happens when we try to display
+
+116
+00:08:28,930 --> 00:08:32,090
+and each as we can with that image everything is totally messed up.
+
+117
+00:08:32,090 --> 00:08:38,450
+I mean general image is here but it colors out of whack and it's not terribly useful if anything at
+
+118
+00:08:38,450 --> 00:08:39,920
+least not to my knowledge.
+
+119
+00:08:40,190 --> 00:08:43,600
+So we can look at the value channel and this actually looks like a great skill of them.
+
+120
+00:08:43,640 --> 00:08:49,640
+And in fact it actually is because there's a brightness and saturation type also looks a bit messed
+
+121
+00:08:49,640 --> 00:08:53,460
+up but it's good to visualize each component separately.
+
+122
+00:08:53,480 --> 00:08:55,860
+So we have an idea of what we're looking at.
+
+123
+00:08:56,240 --> 00:08:57,520
+So we actually can do that today.
+
+124
+00:08:57,530 --> 00:08:58,720
+RG channel too.
+
+125
+00:08:59,050 --> 00:09:01,600
+So we're using Open series split function.
+
+126
+00:09:01,730 --> 00:09:05,600
+Quick way to do it we can actually separate the components into BGR.
+
+127
+00:09:05,600 --> 00:09:12,860
+Once an image is loaded as a RGV BGR already and then we're going to print the ship just so we can see
+
+128
+00:09:12,860 --> 00:09:17,570
+what it looks like and then we're actually going to shoot the individual components here.
+
+129
+00:09:17,570 --> 00:09:23,390
+One thing to note is that because we're splitting the image here it's going to show as a greyscale image
+
+130
+00:09:23,570 --> 00:09:28,290
+in open C-v because it's only going to have one dimension of color.
+
+131
+00:09:28,310 --> 00:09:29,590
+Previously we had all three.
+
+132
+00:09:29,630 --> 00:09:34,600
+But no it's only going to take the red green and blue and show them as various grayscale images.
+
+133
+00:09:34,850 --> 00:09:41,030
+However if we used image function we can actually compile and combine all of them sorry and get back
+
+134
+00:09:41,030 --> 00:09:42,980
+to the original image.
+
+135
+00:09:42,980 --> 00:09:49,400
+And what about if we wanted to actually add or amplify certain colors in an image we can do that by
+
+136
+00:09:49,610 --> 00:09:55,510
+adding plus 100 here it adds 100 to every value in the blue matrix.
+
+137
+00:09:55,700 --> 00:10:01,800
+If the value was close to 255 that's going to Max that 255 we can go past that in open CV.
+
+138
+00:10:01,820 --> 00:10:05,310
+So let's take a look at it and see how it appears.
+
+139
+00:10:06,340 --> 00:10:12,190
+So as we can see here these are the visual image holes this is blue over the way Green.
+
+140
+00:10:12,520 --> 00:10:17,080
+Not much to look at and read again not much difference to look at.
+
+141
+00:10:17,080 --> 00:10:23,050
+Now you should know if I had an image that had separate green blue and red significantly that you would
+
+142
+00:10:23,170 --> 00:10:26,980
+the series separately you would actually see a drastic difference.
+
+143
+00:10:26,980 --> 00:10:29,600
+So now let's look at imaged image here.
+
+144
+00:10:30,410 --> 00:10:34,890
+So we get back to our original image by imaging all Trico the space is quite nice.
+
+145
+00:10:35,930 --> 00:10:38,920
+Now what about adding the 100 to blue.
+
+146
+00:10:39,190 --> 00:10:41,660
+Now as you can see the image has a very much a blue.
+
+147
+00:10:41,690 --> 00:10:44,490
+Well actually almost a pupil ish dentist.
+
+148
+00:10:44,750 --> 00:10:49,410
+So this is actually how color filters and colors are created.
+
+149
+00:10:49,700 --> 00:10:54,400
+You may have noticed movies like The Matrix sort of have a green and blue tinge in different scenes.
+
+150
+00:10:54,890 --> 00:10:56,580
+That's sort of how that's done.
+
+151
+00:10:59,930 --> 00:11:05,570
+But what if we wanted to see these red green red and blue is actual colors as opposed to just grayscale
+
+152
+00:11:05,570 --> 00:11:06,430
+images.
+
+153
+00:11:06,650 --> 00:11:08,560
+We can use a seam split function.
+
+154
+00:11:08,630 --> 00:11:13,490
+However let's create using non-pay let's create a matrix called zeroes.
+
+155
+00:11:13,580 --> 00:11:20,300
+And this may be confusing to non-pay newbies here but what we're doing right now is that so what exactly
+
+156
+00:11:20,300 --> 00:11:27,100
+we're doing here is creating an array of zeros that are the same shape as the original image.
+
+157
+00:11:27,110 --> 00:11:34,190
+So if you can see if you run this line here which is in theory you get this it tity by 2045 dimensions
+
+158
+00:11:34,910 --> 00:11:40,440
+and everything using zeroes just makes everything every element in the series zeroes.
+
+159
+00:11:40,820 --> 00:11:44,410
+So why does it useful for us when we were actually using the zeros.
+
+160
+00:11:44,450 --> 00:11:45,260
+Here.
+
+161
+00:11:45,770 --> 00:11:53,660
+Dispiritedly gives a list of all zeros all zeroes that fit to the same high dimensions of R G and B.
+
+162
+00:11:54,260 --> 00:11:57,790
+So let's run this code and this is pretty cool.
+
+163
+00:11:57,790 --> 00:12:04,330
+We can see that we have no individual components with the red blue and green tints that make up the
+
+164
+00:12:04,330 --> 00:12:05,010
+image.
+
+165
+00:12:05,020 --> 00:12:08,830
+So this is actually a pretty nice thing to see.
+
+166
+00:12:08,900 --> 00:12:11,310
+So that's it for color spaces.
+
+167
+00:12:11,330 --> 00:12:12,550
+Hope you enjoyed the section.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/8. Histogram representation of Images - Visualizing the Components of Images.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/8. Histogram representation of Images - Visualizing the Components of Images.srt
new file mode 100644
index 0000000000000000000000000000000000000000..2d07cd12c4a00e50b54d2012bc4505b754c997b6
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/8. Histogram representation of Images - Visualizing the Components of Images.srt
@@ -0,0 +1,239 @@
+1
+00:00:01,130 --> 00:00:04,980
+So no we're going to take a look at histograms which actually create division.
+
+2
+00:00:05,100 --> 00:00:09,440
+Visualise individual color components of an image and to do so.
+
+3
+00:00:09,460 --> 00:00:13,900
+We need to import Pipelet as Piazzi from the mudflat lab library.
+
+4
+00:00:13,970 --> 00:00:17,320
+Now this should have come to bundled with your anaconda solution.
+
+5
+00:00:17,330 --> 00:00:25,970
+However if it isn't you can run a Pipp install of Pi plot and my portal up separately so we LoDo imagen
+
+6
+00:00:26,120 --> 00:00:28,940
+as we have done previously so many times.
+
+7
+00:00:28,940 --> 00:00:32,430
+But no we're using this C-v to calque function.
+
+8
+00:00:32,760 --> 00:00:36,350
+So I've actually put whether what that Stansel here
+
+9
+00:00:41,310 --> 00:00:46,890
+so you can see what calc is actually the function actually does what it does.
+
+10
+00:00:46,890 --> 00:00:49,340
+It generates a histogram of the image we look at here.
+
+11
+00:00:49,350 --> 00:00:54,360
+Now image needs to be in a reform which it already is but has to be in to second level array.
+
+12
+00:00:54,570 --> 00:00:57,050
+So that's why we need to square brackets here.
+
+13
+00:00:57,300 --> 00:01:01,440
+Then we actually have the number of channels so we can use for color images.
+
+14
+00:01:01,440 --> 00:01:07,460
+You can pass 0 1 or 2 to get it colors respectively and then none.
+
+15
+00:01:07,530 --> 00:01:13,690
+If you want to use a mask or not and 256 for full histogram size.
+
+16
+00:01:13,830 --> 00:01:15,360
+So we actually want to see the full size.
+
+17
+00:01:15,360 --> 00:01:20,490
+We use a full scale of 256 and then we put the reinsure and all that needs to be in square brackets
+
+18
+00:01:20,490 --> 00:01:21,070
+as well.
+
+19
+00:01:22,650 --> 00:01:29,660
+So now to visualize histogram we use or Ravel Ravel function which actually flattens imagery.
+
+20
+00:01:29,670 --> 00:01:37,740
+No that may be it alien concept to those of you who don't know too much data analysis type stuff but
+
+21
+00:01:37,890 --> 00:01:44,840
+imagine it essentially takes a two by two sorry a two dimensional array actually makes it into one dimension.
+
+22
+00:01:44,880 --> 00:01:49,470
+That's sort of what ravelled us so we use to plot his function.
+
+23
+00:01:49,470 --> 00:01:54,900
+I'm not going to go into my plot libs function here too much but these things that correspond to reinjure
+
+24
+00:01:54,900 --> 00:01:57,090
+and bin size as well.
+
+25
+00:01:57,090 --> 00:02:02,110
+And then penalty's sure which actually shows so histogram itself and then we can.
+
+26
+00:02:02,190 --> 00:02:05,660
+This one actually looked at viewing the blue alone.
+
+27
+00:02:05,970 --> 00:02:12,600
+We could have done one or two to get to red or green separately but to do that we actually have to run
+
+28
+00:02:12,690 --> 00:02:20,590
+a loop that we actually put I hear in place of the 0 and actually generates all tree on this image here.
+
+29
+00:02:20,820 --> 00:02:26,770
+So let's take a look at this this here is the blue components of grim image.
+
+30
+00:02:27,050 --> 00:02:33,370
+What this means is that we have a lot of importance here and maybe the tity reading starts.
+
+31
+00:02:33,440 --> 00:02:38,600
+That means the bulk of all Bleus are basically dull blues or dim colored blues.
+
+32
+00:02:38,600 --> 00:02:41,990
+Those are two peaks and blues although that's not that significant.
+
+33
+00:02:41,990 --> 00:02:43,730
+Maybe it could be for other images.
+
+34
+00:02:44,090 --> 00:02:45,900
+So now let's take a look at all the tree.
+
+35
+00:02:46,160 --> 00:02:48,410
+So this is all tree colors here.
+
+36
+00:02:48,410 --> 00:02:52,050
+No image and this shows the distribution of them here.
+
+37
+00:02:52,340 --> 00:02:57,770
+So we can see this image has the most amount of reds dotted Reds are Sartori at the highest intensity
+
+38
+00:02:57,830 --> 00:02:59,300
+in the image.
+
+39
+00:02:59,300 --> 00:03:03,510
+Also the Greens are second highest and then the blues are the adults and image.
+
+40
+00:03:03,540 --> 00:03:08,790
+Now most importantly here we actually can see it is very little bright colors no image.
+
+41
+00:03:08,810 --> 00:03:13,510
+In fact there's a peak of red hair which may correspond to some either some noise perhaps even noise
+
+42
+00:03:13,520 --> 00:03:20,250
+with some odd small discrepancies in image and the bulk of it is actually pretty dark.
+
+43
+00:03:20,540 --> 00:03:26,000
+Usually you would find for bright delayed scenes a lot of them to be peaking early here so that's pretty
+
+44
+00:03:26,000 --> 00:03:26,590
+interesting.
+
+45
+00:03:26,780 --> 00:03:28,680
+So let's take a look at another image now.
+
+46
+00:03:30,180 --> 00:03:35,570
+So let's take a look at another image as I just said zoomed image going good use is of what I took into
+
+47
+00:03:35,580 --> 00:03:40,360
+Biegel which is another island which is the island of Trinidad and Tobago.
+
+48
+00:03:40,430 --> 00:03:46,730
+It's actually the far more beautiful pretty island Welsh and that is the industrial ugly island.
+
+49
+00:03:46,850 --> 00:03:48,220
+Sorry to say so.
+
+50
+00:03:48,620 --> 00:03:51,000
+So let's take a look at this image.
+
+51
+00:03:51,020 --> 00:03:59,170
+These are the blues in the image here and clues in this off these alleged full calls here.
+
+52
+00:03:59,190 --> 00:04:00,900
+So this is actually quite interesting.
+
+53
+00:04:01,060 --> 00:04:07,980
+You actually see it is actually some dim dark colors here then is a slow decrease and quite even distribution
+
+54
+00:04:08,430 --> 00:04:10,680
+then is a spike of green and red.
+
+55
+00:04:10,710 --> 00:04:14,150
+No actually should be showing what the image is.
+
+56
+00:04:14,700 --> 00:04:19,540
+So this is the image that we just thought it up as you can see it's quite pretty.
+
+57
+00:04:19,540 --> 00:04:27,310
+Some nice Greenhills some reds and yellows quite wide nice even the distribution of colors here so.
+
+58
+00:04:27,370 --> 00:04:33,380
+And then once again we can look at a separate color components that's blue and these are the colors
+
+59
+00:04:33,380 --> 00:04:33,790
+here.
+
+60
+00:04:33,810 --> 00:04:35,260
+So quite cool.
diff --git a/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/9. Creating Images & Drawing on Images - Make Squares, Circles, Polygons & Add Text.srt b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/9. Creating Images & Drawing on Images - Make Squares, Circles, Polygons & Add Text.srt
new file mode 100644
index 0000000000000000000000000000000000000000..2416d6e391c729087937e052c8399cd555ecf76a
--- /dev/null
+++ b/5. OpenCV Tutorial - Learn Classic Computer Vision & Face Detection (OPTIONAL)/9. Creating Images & Drawing on Images - Make Squares, Circles, Polygons & Add Text.srt
@@ -0,0 +1,245 @@
+1
+00:00:01,570 --> 00:00:06,600
+So let's take a look at drawing it in open C-v so fiercely we're going to create a very simple image.
+
+2
+00:00:06,610 --> 00:00:08,360
+It's going to be a black square.
+
+3
+00:00:08,680 --> 00:00:14,500
+And to create a black square we actually use non-payers zero's function to create an area that's 12
+
+4
+00:00:14,760 --> 00:00:20,240
+
+5
+5:12 height dimensions and has truly is for the BGR RGV colors.
+
+6
+00:00:20,740 --> 00:00:24,420
+And this is actually going to be blank or black square.
+
+7
+00:00:24,430 --> 00:00:25,780
+Similarly we can actually do this.
+
+8
+00:00:25,780 --> 00:00:31,180
+What are the three dimensions to create a grayscale image that's also black what you're going to look
+
+9
+00:00:31,180 --> 00:00:33,420
+identical as we can see here.
+
+10
+00:00:36,430 --> 00:00:42,310
+So now let's draw a line across cellblocks black square and to do this we actually use DCV to line function
+
+11
+00:00:42,910 --> 00:00:45,250
+so we can see the sticks in several arguments here.
+
+12
+00:00:45,310 --> 00:00:48,990
+Image which is a blank square image shoeblack square image we created.
+
+13
+00:00:49,480 --> 00:00:52,750
+And then it takes into these a tuple of two coordinates here.
+
+14
+00:00:52,810 --> 00:00:54,970
+This is the start position of the line.
+
+15
+00:00:55,000 --> 00:00:56,470
+Then this is the end position of the line.
+
+16
+00:00:56,470 --> 00:01:00,120
+Similarly Noddy's tree values here represent colors.
+
+17
+00:01:00,160 --> 00:01:01,240
+B g r.
+
+18
+00:01:01,360 --> 00:01:06,970
+So this is actually going to be the color line and the last argument five is a thickness which we use
+
+19
+00:01:06,970 --> 00:01:08,010
+5 pixels here.
+
+20
+00:01:08,200 --> 00:01:12,420
+So let's take a look at this amazing.
+
+21
+00:01:12,670 --> 00:01:14,280
+So no know this rectangle.
+
+22
+00:01:14,280 --> 00:01:15,060
+No image.
+
+23
+00:01:15,340 --> 00:01:20,340
+So similarly rectangles are very similar to a line function in that we have an input image.
+
+24
+00:01:20,380 --> 00:01:27,370
+We have a start position and position color and pixels thickness of line.
+
+25
+00:01:28,150 --> 00:01:29,450
+So that's the deal.
+
+26
+00:01:29,890 --> 00:01:37,290
+So what if we put minus one here that actually fills all rectangle with this image.
+
+27
+00:01:38,530 --> 00:01:39,670
+So that's pretty cool.
+
+28
+00:01:39,670 --> 00:01:41,250
+So how about circles.
+
+29
+00:01:41,380 --> 00:01:43,390
+Let's create a circle here.
+
+30
+00:01:43,660 --> 00:01:47,730
+Now the circle arguments are slightly different as it does no start an end.
+
+31
+00:01:47,740 --> 00:01:52,310
+However it is a center and a radius that gives the dimensions of the circle.
+
+32
+00:01:52,660 --> 00:01:58,840
+Then a color and then similarly hecticness here we use minus one to have a full fill of the single image
+
+33
+00:01:58,850 --> 00:01:59,490
+here.
+
+34
+00:02:00,010 --> 00:02:01,810
+So that's all the green simple.
+
+35
+00:02:01,840 --> 00:02:05,700
+We created and what about polygons.
+
+36
+00:02:05,800 --> 00:02:12,320
+So no polygons basically are basically points points of each end of the polygon.
+
+37
+00:02:12,670 --> 00:02:14,800
+So let's create a wide array of points here.
+
+38
+00:02:14,830 --> 00:02:16,570
+So these are four points here.
+
+39
+00:02:17,050 --> 00:02:19,230
+And we actually used reshape function.
+
+40
+00:02:19,240 --> 00:02:25,840
+This is some non-pay function here so I'm not going to get too much into this reship function here.
+
+41
+00:02:25,870 --> 00:02:32,560
+Just remember this is this do we we require polyline requires the points to be stored.
+
+42
+00:02:32,630 --> 00:02:36,430
+So not a polyline function which is a CV to function here open C V function.
+
+43
+00:02:36,430 --> 00:02:40,110
+I mean takes the image takes two points and does form.
+
+44
+00:02:40,370 --> 00:02:43,860
+True is what is the image the polygon is closed or not.
+
+45
+00:02:44,200 --> 00:02:48,120
+Color of the polygon and the thickness of line.
+
+46
+00:02:48,130 --> 00:02:50,680
+So again let's run this.
+
+47
+00:02:50,830 --> 00:02:53,810
+We have a weird boomerang shaped polygon that I created.
+
+48
+00:02:58,220 --> 00:03:00,770
+So what about adding text images.
+
+49
+00:03:01,100 --> 00:03:04,820
+Well open C-v luckily has done two as well with Tex.
+
+50
+00:03:04,850 --> 00:03:10,730
+So politics is another simple function takes the image again Oblak black square that we created the
+
+51
+00:03:10,730 --> 00:03:13,230
+text in the string form.
+
+52
+00:03:13,340 --> 00:03:18,470
+These are the coordinates of the bottom left STARTING POINT the front and this is a list of all the
+
+53
+00:03:18,470 --> 00:03:23,690
+fun stuff I believe in CV has they may have added some others but these are the ones that are actually
+
+54
+00:03:23,690 --> 00:03:26,080
+shouldn and documentation.
+
+55
+00:03:26,070 --> 00:03:30,890
+This is the thickness sorry the fun site is to color and thickness of the font.
+
+56
+00:03:30,890 --> 00:03:33,350
+So now let's run this and see how it looks.
+
+57
+00:03:33,350 --> 00:03:33,960
+There we go.
+
+58
+00:03:34,040 --> 00:03:35,040
+Hello world.
+
+59
+00:03:35,150 --> 00:03:39,210
+Office it'll open C-v putting text function.
+
+60
+00:03:39,290 --> 00:03:44,200
+So that's the basics of drawing images on open C-v is actually pretty easy.
+
+61
+00:03:44,540 --> 00:03:46,100
+And we will actually be doing it a lot.
+
+62
+00:03:46,100 --> 00:03:47,120
+JUDITH TROETH discourse.
diff --git a/6. Neural Networks Explained/1. Neural Networks Chapter Overview.srt b/6. Neural Networks Explained/1. Neural Networks Chapter Overview.srt
new file mode 100644
index 0000000000000000000000000000000000000000..9bd23741396ff19b0ce9d547ea832fd8eb736ff6
--- /dev/null
+++ b/6. Neural Networks Explained/1. Neural Networks Chapter Overview.srt
@@ -0,0 +1,79 @@
+1
+00:00:00,690 --> 00:00:07,230
+Hi and welcome to chapter 6 which is probably the most important chapter or maybe second most important
+
+2
+00:00:07,230 --> 00:00:09,150
+chapter in discourse.
+
+3
+00:00:09,150 --> 00:00:16,100
+And that's basically a very good and detailed explanation about neural networks.
+
+4
+00:00:16,190 --> 00:00:19,590
+So let's see what this chapter comprises of.
+
+5
+00:00:19,670 --> 00:00:26,270
+So the neural networks explain chapter fiercly I given machine learning of a view because deepening
+
+6
+00:00:26,300 --> 00:00:29,650
+and neural networks are essentially a machine learning algorithm.
+
+7
+00:00:29,660 --> 00:00:32,750
+Perhaps one of the best ones ever.
+
+8
+00:00:32,870 --> 00:00:38,450
+Next they go into Follette propagation which you you'll hear about shortly activation functions training
+
+9
+00:00:38,960 --> 00:00:44,860
+part 1 which is last function and training Patu which talks about back propagation and gradient descent
+
+10
+00:00:45,620 --> 00:00:48,650
+then actually go to back propagation in detail.
+
+11
+00:00:48,710 --> 00:00:55,940
+Actually true an example with the mathematics mainly because back propagation is critical for treating
+
+12
+00:00:56,270 --> 00:00:59,900
+neural networks and convolutional neural networks.
+
+13
+00:00:59,900 --> 00:01:06,460
+And then I go into regularisation overfitting generalization and understanding test data sets.
+
+14
+00:01:06,530 --> 00:01:12,380
+And I talk about sometimes you will probably see a lot in future in this course which talks iterations
+
+15
+00:01:12,380 --> 00:01:13,820
+and bat sizes.
+
+16
+00:01:13,990 --> 00:01:18,950
+Then I talk about how to measure performance and how to analyze a performance with the confusion matrix.
+
+17
+00:01:19,370 --> 00:01:24,860
+And basically then I go do a recap of the entire chapter mainly because there are so many moving bits
+
+18
+00:01:24,940 --> 00:01:29,870
+and let's talk about the best practices involved in training neural nets.
+
+19
+00:01:30,200 --> 00:01:31,160
+So stay tuned.
+
+20
+00:01:31,190 --> 00:01:34,230
+6.1 is coming up which is the machine learning overview.
diff --git a/6. Neural Networks Explained/10. Epochs, Iterations and Batch Sizes.srt b/6. Neural Networks Explained/10. Epochs, Iterations and Batch Sizes.srt
new file mode 100644
index 0000000000000000000000000000000000000000..14d96f66ee0d612ec0cb4bb7f48fead85c28d07b
--- /dev/null
+++ b/6. Neural Networks Explained/10. Epochs, Iterations and Batch Sizes.srt
@@ -0,0 +1,191 @@
+1
+00:00:00,510 --> 00:00:08,340
+So in this section 6.9 I discuss some Tooms of use before him such as e-books iterations and bed sizes.
+
+2
+00:00:08,400 --> 00:00:13,320
+I'll discuss it a bit because a lot of games and tutorials and in lectures you'll hear these sims being
+
+3
+00:00:13,320 --> 00:00:17,070
+used and sometimes you'll be mixed up and I'll tell you why.
+
+4
+00:00:17,090 --> 00:00:17,480
+Afterward
+
+5
+00:00:21,210 --> 00:00:24,550
+ebox sure you've heard me mention it quite a few times before.
+
+6
+00:00:24,810 --> 00:00:26,440
+So what exactly is in the book.
+
+7
+00:00:26,470 --> 00:00:32,640
+And he took a kids when the full set of training data is passed or propagated and then back propagated
+
+8
+00:00:32,760 --> 00:00:34,290
+show a neural network.
+
+9
+00:00:34,470 --> 00:00:41,220
+So the process of Wanni book means that we've trained on your own network on a full data set an idea
+
+10
+00:00:41,220 --> 00:00:44,010
+that all the weights after difference.
+
+11
+00:00:44,060 --> 00:00:47,530
+But generally we will have a decent set of weights.
+
+12
+00:00:47,550 --> 00:00:49,110
+However it's never enough.
+
+13
+00:00:49,140 --> 00:00:54,300
+You need to train for several ebox over and over and over to continuously updating the weights that
+
+14
+00:00:54,330 --> 00:00:56,560
+we converge and converge.
+
+15
+00:00:56,570 --> 00:01:00,450
+I mean GET TO LOUIS we it's got Lewis last possible.
+
+16
+00:01:00,450 --> 00:01:06,380
+We do a set of weights no batches no.
+
+17
+00:01:06,540 --> 00:01:13,110
+Every time we train in Paris or any any CNN or the neural net you'll see to specify how much batches
+
+18
+00:01:13,110 --> 00:01:14,170
+do you want.
+
+19
+00:01:14,260 --> 00:01:18,060
+No that is on supercritical like that size.
+
+20
+00:01:18,260 --> 00:01:21,810
+It doesn't affect generally affect your results that much.
+
+21
+00:01:22,020 --> 00:01:29,600
+Well what you need to do to get a batch generally better however you're limited by around vigor and
+
+22
+00:01:29,670 --> 00:01:34,640
+if using GP use you can put all the data at once into a batch.
+
+23
+00:01:34,680 --> 00:01:35,980
+So you need to split that up.
+
+24
+00:01:35,970 --> 00:01:38,680
+So generally if using image data.
+
+25
+00:01:38,850 --> 00:01:42,750
+And it's basically resized to something like say 100 by 100 pixels.
+
+26
+00:01:42,750 --> 00:01:48,270
+You can use about say as of maybe 16 to the two depending on how much RAM you have.
+
+27
+00:01:48,570 --> 00:01:55,390
+I'm assuming you maybe maybe using at least 48 eggs from 16 but 16 is generally quite good.
+
+28
+00:01:58,190 --> 00:02:02,990
+So I actually have to feel to mention one thing though if your about size is one you're effectively
+
+29
+00:02:02,990 --> 00:02:08,990
+just doing stochastic really in descent which is not a very effective way of doing really and doesn't
+
+30
+00:02:09,800 --> 00:02:14,410
+many Bache many Bachche couldn't I believe that's an end of it.
+
+31
+00:02:14,450 --> 00:02:21,330
+But using many matches is basically the best process to actually train and implement really indecent.
+
+32
+00:02:21,330 --> 00:02:22,950
+So what about iterations.
+
+33
+00:02:23,840 --> 00:02:27,530
+I used to get confused between iterations and ebox quite a bit.
+
+34
+00:02:27,530 --> 00:02:32,870
+However the difference is quite simple durations are just simply how many batches we need to complete
+
+35
+00:02:33,080 --> 00:02:34,130
+one epoch.
+
+36
+00:02:34,520 --> 00:02:40,100
+No the reason I use to get confused was because I had a professor who would say you train your neural
+
+37
+00:02:40,100 --> 00:02:47,420
+net for 10 or 100 durations and that was because I think he was using matlab to train and in Matlab
+
+38
+00:02:47,420 --> 00:02:54,110
+at least maybe in a library he was using iterations were actually meant as ebox and I didn't even know
+
+39
+00:02:54,110 --> 00:02:56,710
+what ebox actually were at that point.
+
+40
+00:02:56,810 --> 00:03:00,350
+There were just iterations but I mean I don't even know what iterations were called.
+
+41
+00:03:00,620 --> 00:03:05,480
+Maybe they were called batches or mini batches perhaps.
+
+42
+00:03:05,540 --> 00:03:11,870
+So in our previous example which had undisputed and actually discuss but let's say we had a Tozan samples
+
+43
+00:03:11,900 --> 00:03:15,900
+of data and we specified about size of 100.
+
+44
+00:03:15,920 --> 00:03:22,950
+That means if we take in a hundred samples of that data in each pass in the network to update over its.
+
+45
+00:03:23,140 --> 00:03:28,790
+So we have 10 basically durations to complete one batch.
+
+46
+00:03:29,200 --> 00:03:32,250
+As I said right here.
+
+47
+00:03:32,320 --> 00:03:33,030
+So that's it.
+
+48
+00:03:33,030 --> 00:03:37,790
+So now let's move on to how we actually measure performance and understanding the confusion matrix.
diff --git a/6. Neural Networks Explained/11. Measuring Performance and the Confusion Matrix.srt b/6. Neural Networks Explained/11. Measuring Performance and the Confusion Matrix.srt
new file mode 100644
index 0000000000000000000000000000000000000000..800fd032d1ebd625fba5334a05f540fd42f366d7
--- /dev/null
+++ b/6. Neural Networks Explained/11. Measuring Performance and the Confusion Matrix.srt
@@ -0,0 +1,391 @@
+1
+00:00:00,480 --> 00:00:07,230
+So welcome to up to six point one zero chapter 6.10 where I basically explained how we assess and measure
+
+2
+00:00:07,230 --> 00:00:09,210
+performance of all tree in the water.
+
+3
+00:00:09,630 --> 00:00:14,660
+As you will learn is a lot more than accuracy to determine the models performance.
+
+4
+00:00:17,190 --> 00:00:18,610
+So we've seen this graph before.
+
+5
+00:00:18,640 --> 00:00:25,250
+We've said this is basically the graph the shooting overfitting and it was a pretty bad model here with
+
+6
+00:00:25,390 --> 00:00:30,970
+vidit quite a bit but it was very good and interesting data but that's not what we want at all.
+
+7
+00:00:32,500 --> 00:00:35,020
+So let's talk about loss and accuracy.
+
+8
+00:00:35,020 --> 00:00:39,160
+It's important to realize well loss and accuracy represent different things.
+
+9
+00:00:39,160 --> 00:00:40,760
+They are highly correlated.
+
+10
+00:00:40,960 --> 00:00:46,120
+So they are essentially measuring the same thing for months of our neural nets on overtreating data.
+
+11
+00:00:47,680 --> 00:00:53,680
+Accuracy basically is just a simple measure of how many correct classifications we got over the total
+
+12
+00:00:53,680 --> 00:00:56,320
+number of plastic with classifications overall.
+
+13
+00:00:56,350 --> 00:00:59,940
+So let's say we were predicting whether something was a cat or dog.
+
+14
+00:01:00,250 --> 00:01:02,630
+And let's see if we got it we got it right.
+
+15
+00:01:02,650 --> 00:01:04,490
+Ninety nine times out of 100.
+
+16
+00:01:04,660 --> 00:01:07,510
+That would be a 99 percent accuracy.
+
+17
+00:01:08,630 --> 00:01:15,470
+No last values tend to go up tend to they will go up when classifications are incorrect.
+
+18
+00:01:15,530 --> 00:01:18,280
+That is different to the expected target values.
+
+19
+00:01:18,290 --> 00:01:26,140
+So basically as I said before they are corelated says accuracy to only beat us as a model.
+
+20
+00:01:26,160 --> 00:01:29,810
+No there are actually other ways and I'll discuss it too here.
+
+21
+00:01:30,150 --> 00:01:32,220
+So accuracy is important to us.
+
+22
+00:01:32,220 --> 00:01:34,360
+They didn't tell us the full story.
+
+23
+00:01:34,650 --> 00:01:36,780
+So let's look at this example here.
+
+24
+00:01:36,840 --> 00:01:43,020
+Let's see if we're using the neural net to predict whether a person had a life threatening disease based
+
+25
+00:01:43,020 --> 00:01:44,100
+on a blood test.
+
+26
+00:01:44,100 --> 00:01:46,150
+Now they are.
+
+27
+00:01:46,230 --> 00:01:49,890
+You would think they are yes or no are the basically possible answers.
+
+28
+00:01:50,160 --> 00:01:55,840
+However those are the answers is yes but not the actual scenarios that happen in real life in real life.
+
+29
+00:01:55,890 --> 00:01:59,220
+In reality I should say these are the four scenarios that can happen.
+
+30
+00:01:59,310 --> 00:02:05,370
+It can be a true positive which means that the test predicts positive for the disease and the person
+
+31
+00:02:05,370 --> 00:02:06,390
+has the disease.
+
+32
+00:02:06,420 --> 00:02:12,390
+So that's good can be a true negative which is the opposite test predicts negative and it doesn't have
+
+33
+00:02:12,390 --> 00:02:13,900
+the disease get it.
+
+34
+00:02:14,320 --> 00:02:21,890
+However it can be a false positive test predicts Yes for disease but it didn't actually have the disease.
+
+35
+00:02:22,060 --> 00:02:27,660
+So it's not good but not as bad as this one where it predicts negative for that disease.
+
+36
+00:02:27,900 --> 00:02:30,870
+But a person actually had the disease.
+
+37
+00:02:30,870 --> 00:02:40,480
+So let's take a look and see how we use these four scenarios to assess the accuracy of a model so I'm
+
+38
+00:02:40,660 --> 00:02:47,380
+not sure if you've ever heard of The Sims but is recall precision and school now is defined as this
+
+39
+00:02:47,440 --> 00:02:53,440
+number of true positives over a number of true positives Plus the false negatives.
+
+40
+00:02:53,440 --> 00:02:58,120
+If you remember correctly false negative is decir and true positive is dis here.
+
+41
+00:02:58,120 --> 00:03:03,320
+So what we call telling us is that how many true positives did we get.
+
+42
+00:03:03,530 --> 00:03:08,540
+So how many times did we accurately predict that a person has a disease over how many times a person
+
+43
+00:03:08,620 --> 00:03:10,370
+actually had the disease.
+
+44
+00:03:10,390 --> 00:03:12,600
+So that's what the denominator in this is.
+
+45
+00:03:12,850 --> 00:03:17,730
+How many cases of the diseases were there and how many times did we get it right.
+
+46
+00:03:17,740 --> 00:03:24,010
+That is effectively what a recall is now precision of all our samples here.
+
+47
+00:03:24,340 --> 00:03:27,490
+How much did you declassify get right.
+
+48
+00:03:27,520 --> 00:03:28,980
+That's what precision measures here.
+
+49
+00:03:28,990 --> 00:03:35,610
+So we have again true positives here over true positives plus false positives.
+
+50
+00:03:35,930 --> 00:03:44,350
+So let's go back sorry to false positives here false positive here is basically the test predicted positive.
+
+51
+00:03:44,440 --> 00:03:46,760
+But the person didn't have the disease.
+
+52
+00:03:46,900 --> 00:03:48,600
+So that's the denominator here.
+
+53
+00:03:48,610 --> 00:03:53,620
+So how many times did he be on you samples.
+
+54
+00:03:53,620 --> 00:03:55,650
+How much did declassify get right.
+
+55
+00:03:56,290 --> 00:03:57,170
+And F school.
+
+56
+00:03:57,170 --> 00:04:03,460
+It is an attempt to actually measure boat recall and position in one OK.
+
+57
+00:04:03,460 --> 00:04:06,800
+So let's take a look at the actual example here.
+
+58
+00:04:07,840 --> 00:04:14,350
+So let's say we have built to classify to identify gender male this female in an image where in this
+
+59
+00:04:14,350 --> 00:04:19,530
+image there were 10 male faces and 15 and five female faces.
+
+60
+00:04:19,600 --> 00:04:24,390
+So we run our classify on this image and it picks up six male faces.
+
+61
+00:04:25,970 --> 00:04:31,370
+No other 6 Malthus's full were actually male to female.
+
+62
+00:04:31,410 --> 00:04:33,440
+So how do we look at a position.
+
+63
+00:04:33,510 --> 00:04:39,450
+Now go back to the form of the opposition position is number of true positives which was four.
+
+64
+00:04:39,540 --> 00:04:47,110
+In this case because we got formula here right other than sex and how many do see him two positives
+
+65
+00:04:47,140 --> 00:04:48,740
+plus false positives.
+
+66
+00:04:48,970 --> 00:04:51,100
+So how many false positives were there.
+
+67
+00:04:51,280 --> 00:04:56,080
+There were actually two false positives because it picked up two females here but two two listed were
+
+68
+00:04:56,080 --> 00:04:57,040
+males.
+
+69
+00:04:57,040 --> 00:04:58,660
+So those were false positives.
+
+70
+00:04:58,690 --> 00:05:02,190
+So there's four of us six or six or six percent two point six six.
+
+71
+00:05:02,230 --> 00:05:03,520
+So let's we've got a recall.
+
+72
+00:05:03,550 --> 00:05:10,150
+Now recall is the same true positives over true positives plus false negatives.
+
+73
+00:05:10,150 --> 00:05:12,250
+Now what's the false negatives here.
+
+74
+00:05:12,540 --> 00:05:18,250
+The false negatives here with the fact that six male faces rumbo false negative.
+
+75
+00:05:18,250 --> 00:05:24,370
+In our other example was how much diseases how much test for disease that missed.
+
+76
+00:05:24,550 --> 00:05:25,040
+OK.
+
+77
+00:05:25,330 --> 00:05:28,880
+So in this case there were six male faces that were missed.
+
+78
+00:05:28,900 --> 00:05:35,740
+So it's true positives of a true positives plus false negatives which is 0.4 40 percent.
+
+79
+00:05:35,740 --> 00:05:43,300
+So now playing with one formula this year two times we called him precision ovoid recall plus the position
+
+80
+00:05:43,840 --> 00:05:49,060
+that gives estus and that gives us his final value which is close to 0.5 which is point 4 9 8.
+
+81
+00:05:49,060 --> 00:05:57,150
+So that's a good example of how recall an EF 1 and precision I use to actually assess model accuracy.
+
+82
+00:05:57,160 --> 00:06:05,290
+Now this isn't actually used debt often in CNN's but it actually I actually do use it quite a bit and
+
+83
+00:06:05,290 --> 00:06:07,400
+some models I shouldn't say it's not that much use.
+
+84
+00:06:07,420 --> 00:06:11,390
+I just don't see it used that often in a lot of other researchers.
+
+85
+00:06:11,390 --> 00:06:15,490
+Not entirely sure why but to me it depends on the application.
+
+86
+00:06:15,490 --> 00:06:21,400
+So if you're if you're predicting something very important you need to use this to understand your performance.
+
+87
+00:06:21,430 --> 00:06:27,280
+How well is or model actually picking up stuff and what is it what kind of mistakes is making.
+
+88
+00:06:27,630 --> 00:06:28,040
+OK.
+
+89
+00:06:28,300 --> 00:06:32,370
+So it all depends on the domain.
+
+90
+00:06:32,410 --> 00:06:35,150
+So this is a good example here from Wikipedia.
+
+91
+00:06:35,440 --> 00:06:41,440
+It actually illustrates the true negatives false positives true positives false negatives in a little
+
+92
+00:06:41,440 --> 00:06:43,010
+Venn diagram here.
+
+93
+00:06:43,190 --> 00:06:48,160
+The elements so you can actually see the formulas applied here visually.
+
+94
+00:06:48,520 --> 00:06:49,980
+So you can take a look this line.
+
+95
+00:06:49,990 --> 00:06:53,360
+Take a look and try to understand it conceptually as well.
+
+96
+00:06:53,400 --> 00:06:59,080
+So hopefully this helps that point of this chapter was actually show you that accuracy and loss are
+
+97
+00:06:59,080 --> 00:07:05,360
+not the sort of metrics we use to assess performance so now let's go into a review of everything we've
+
+98
+00:07:05,360 --> 00:07:05,900
+just learnt.
diff --git a/6. Neural Networks Explained/12. Review and Best Practices.srt b/6. Neural Networks Explained/12. Review and Best Practices.srt
new file mode 100644
index 0000000000000000000000000000000000000000..d80b850528df382d9d8d2e3eec93f923f2961f16
--- /dev/null
+++ b/6. Neural Networks Explained/12. Review and Best Practices.srt
@@ -0,0 +1,239 @@
+1
+00:00:00,480 --> 00:00:05,190
+So you've spent over an hour basically going to on your own that's in some detail.
+
+2
+00:00:05,190 --> 00:00:10,290
+So I think it's about time we actually do a review and basically try to reiterate everything we've just
+
+3
+00:00:10,290 --> 00:00:10,880
+learned.
+
+4
+00:00:11,220 --> 00:00:13,520
+So let's move on.
+
+5
+00:00:13,620 --> 00:00:15,330
+So let's go overtreating again.
+
+6
+00:00:15,360 --> 00:00:22,740
+So just to reiterate the steps we initialize some random values for weights and biases we input a single
+
+7
+00:00:22,740 --> 00:00:25,780
+sample or batch perhaps of samples of data.
+
+8
+00:00:25,950 --> 00:00:29,170
+We then compare our outputs with the actual target values.
+
+9
+00:00:29,460 --> 00:00:35,090
+We use those last values we use those values now to calculate our loss values based on a loss function
+
+10
+00:00:35,090 --> 00:00:35,890
+here.
+
+11
+00:00:36,240 --> 00:00:41,520
+We didn't use back propagation to basically before many about secretly and dissent to update.
+
+12
+00:00:41,570 --> 00:00:42,280
+Wait.
+
+13
+00:00:42,430 --> 00:00:47,270
+It doesn't have to be made about security and the center can be suggested in the sense when naïve really
+
+14
+00:00:47,310 --> 00:00:47,970
+doesn't.
+
+15
+00:00:48,120 --> 00:00:54,300
+But many batches perhaps the best and and we keep doing this for each batch of data in our dataset and
+
+16
+00:00:54,300 --> 00:01:01,710
+each time we process a batch cycle and I tradition until we complete one epical an epoch which means
+
+17
+00:01:01,710 --> 00:01:09,660
+that all trining data was fed into our model and we use by propagation to update the weights.
+
+18
+00:01:09,690 --> 00:01:15,140
+And then we just keep completing we keep performing more and more ebox and stop treating.
+
+19
+00:01:15,190 --> 00:01:21,320
+When accuracy or whatever it is that stops decreasing.
+
+20
+00:01:21,700 --> 00:01:24,570
+So again this is a training process visualized.
+
+21
+00:01:24,880 --> 00:01:29,260
+I think we went through this before but this again will do it quickly in buddied it comes in a whole
+
+22
+00:01:29,260 --> 00:01:30,280
+batch of input data.
+
+23
+00:01:30,370 --> 00:01:33,340
+We get the predictions compare them to the true targets.
+
+24
+00:01:33,340 --> 00:01:39,460
+We do use a loss function to assess how different they are and we get an optimizer and we use back propagation
+
+25
+00:01:39,720 --> 00:01:46,160
+to cast a gradient which basically forms to stick really innocent of any other form of data.
+
+26
+00:01:46,210 --> 00:01:50,020
+And then we get Gibbs doing this again and again more and more ebox.
+
+27
+00:01:50,420 --> 00:01:50,700
+OK.
+
+28
+00:01:50,710 --> 00:01:55,930
+So these are some general best practices I find that are quite useful to use when training.
+
+29
+00:01:55,930 --> 00:02:02,350
+Neural nets definitely use real who are like you really explain what Licky really is and later sleights
+
+30
+00:02:03,040 --> 00:02:09,610
+loss functions are definitely should all this use MSE or some variation like an absolute URL when you're
+
+31
+00:02:09,610 --> 00:02:10,950
+doing regularisation.
+
+32
+00:02:11,020 --> 00:02:14,410
+I always recommend you try to use at least L2.
+
+33
+00:02:14,590 --> 00:02:20,410
+Definitely use drop out and it's not stated here because this is for neural nets but generally all of
+
+34
+00:02:20,410 --> 00:02:27,490
+these use data augmentation If you're treating CNN's Living rates should be low point 0 0 1 is a good
+
+35
+00:02:27,490 --> 00:02:28,620
+value to use.
+
+36
+00:02:28,720 --> 00:02:30,550
+We talk more about living rates in later slide.
+
+37
+00:02:30,560 --> 00:02:37,270
+So for now remember 20 years or one a good leading rate start of that number if any is depends on the
+
+38
+00:02:37,270 --> 00:02:38,630
+performance of your machine.
+
+39
+00:02:38,860 --> 00:02:41,900
+Honestly I mean I would go as deep as you can go.
+
+40
+00:02:41,920 --> 00:02:46,810
+However that can exacerbate and lengthen your training time so much.
+
+41
+00:02:46,850 --> 00:02:49,820
+So don't try to be too adventurous.
+
+42
+00:02:49,900 --> 00:02:55,420
+Keep a model that you can train fairly quickly on your machine and that will allow you to experiment
+
+43
+00:02:55,510 --> 00:03:01,930
+a lot as opposed to training for days and then realizing something is set badly and you're not getting
+
+44
+00:03:01,930 --> 00:03:03,420
+performance you want to.
+
+45
+00:03:04,240 --> 00:03:11,020
+And the number of ebox you should all this strategy and train for at least 10 to 100 ebox after generally
+
+46
+00:03:11,020 --> 00:03:15,050
+20 bucks you can kind of get an idea of how the model is performing.
+
+47
+00:03:15,340 --> 00:03:22,900
+So once you can start of training maybe 20 boxed ebox at first and adjust the parameters to suit and
+
+48
+00:03:22,900 --> 00:03:30,140
+then your final model one you want to actually make the best transfer at least 50 ebox.
+
+49
+00:03:30,160 --> 00:03:33,610
+So that brings us to the end of a neural network section.
+
+50
+00:03:33,640 --> 00:03:39,790
+Now a lot of the courses and textbooks and blogs will talk about different types of neural nets and
+
+51
+00:03:40,310 --> 00:03:44,920
+all sorts of exotic stuff but to be honest you need to understand a core which is what I just showed
+
+52
+00:03:44,920 --> 00:03:45,350
+you.
+
+53
+00:03:45,530 --> 00:03:48,090
+Decore being gritty and descend back propagation.
+
+54
+00:03:48,190 --> 00:03:54,400
+How training is done and how to assess the performance effectively how to avoid overfitting in the sun
+
+55
+00:03:54,400 --> 00:03:55,880
+when you overfit as well.
+
+56
+00:03:56,200 --> 00:04:02,830
+So you know have a very good core understanding of neural nets and now we can begin moving onto chapter
+
+57
+00:04:02,920 --> 00:04:05,220
+7 which is unconstitutional.
+
+58
+00:04:05,290 --> 00:04:07,470
+And that's the real deal.
+
+59
+00:04:07,480 --> 00:04:13,150
+But this course is actually Klon convolutional you're on that's Which is what we'll be treating many
+
+60
+00:04:13,330 --> 00:04:14,690
+in Paris going forward.
diff --git a/6. Neural Networks Explained/2. Machine Learning Overview.srt b/6. Neural Networks Explained/2. Machine Learning Overview.srt
new file mode 100644
index 0000000000000000000000000000000000000000..62dc58ce291658ca639fcf13f723540844f79e5f
--- /dev/null
+++ b/6. Neural Networks Explained/2. Machine Learning Overview.srt
@@ -0,0 +1,427 @@
+1
+00:00:00,570 --> 00:00:06,360
+I welcome to chapter 6.1 which is basically a machine learning crash course overview.
+
+2
+00:00:06,390 --> 00:00:06,690
+All right.
+
+3
+00:00:06,690 --> 00:00:09,980
+So let's get started into this so what is machine learning now.
+
+4
+00:00:10,050 --> 00:00:14,910
+Machine learning has been synonymous to artificial intelligence because basically it's a field of study
+
+5
+00:00:15,030 --> 00:00:21,620
+that basically studies how algorithms or software actually learns from data.
+
+6
+00:00:21,620 --> 00:00:27,920
+So basically as I said some field or field in artificial intelligence that uses statistical techniques
+
+7
+00:00:27,920 --> 00:00:33,050
+to give computers the ability to learn from data without being explicitly programmed and explicitly
+
+8
+00:00:33,050 --> 00:00:39,440
+means like if this is dad and that is that basically a hard look up table of criteria machine learning
+
+9
+00:00:39,440 --> 00:00:40,180
+does not do that.
+
+10
+00:00:40,190 --> 00:00:46,890
+It learns from the data learns it's one model of how it should be answered and basically over the last
+
+11
+00:00:46,890 --> 00:00:52,010
+five to 10 years maybe even 15 years or so machine learning has exploded there.
+
+12
+00:00:52,110 --> 00:00:58,860
+Basically a number of masters and BSD programs all over the world have specializations in machine learning
+
+13
+00:00:58,860 --> 00:01:05,430
+now it is and this has mainly been brought brought born because processing power and also from GPS use
+
+14
+00:01:05,910 --> 00:01:12,280
+has basically caught up to the process of intensive intensity required for machine learning.
+
+15
+00:01:13,830 --> 00:01:19,320
+So there are four types of machine learning with neural networks being basically one type belonging
+
+16
+00:01:19,320 --> 00:01:20,010
+to us.
+
+17
+00:01:20,190 --> 00:01:27,630
+A subtype belonging to one type of DS for these four are basically supervised unsupervised self supervised
+
+18
+00:01:27,680 --> 00:01:29,640
+and reinforcement learning.
+
+19
+00:01:29,640 --> 00:01:36,350
+And I'm going to talk a little bit about each one so fiercely supervised living now supervised living
+
+20
+00:01:36,350 --> 00:01:39,660
+is by far the most popular form of E.I. and well used today.
+
+21
+00:01:39,800 --> 00:01:48,060
+And they'll being machine learning basically because it's relatively easy compared to other things to
+
+22
+00:01:48,070 --> 00:01:48,910
+implement.
+
+23
+00:01:49,150 --> 00:01:56,230
+All they need is labelled data set and we feed this data set into machine learning model algorithm and
+
+24
+00:01:56,230 --> 00:01:59,330
+it develops a model to fit this data to some outputs.
+
+25
+00:01:59,380 --> 00:02:06,910
+So basically it's like an example here is let's see if we have 10000 emails that are labeled spam 10000
+
+26
+00:02:06,910 --> 00:02:10,120
+that are not spam and we give this to a model.
+
+27
+00:02:10,120 --> 00:02:17,520
+Basically we get the text and Miss riskless subjects and from the sender of the email and now the e-mail
+
+28
+00:02:17,860 --> 00:02:23,910
+story the machine learning algorithm is now going to figure out what is spam based on that.
+
+29
+00:02:23,960 --> 00:02:31,870
+So we have input data being an e-mail model that we just trained and it outputs but it's or not.
+
+30
+00:02:31,930 --> 00:02:38,480
+So that in a nutshell is supervised learning.
+
+31
+00:02:38,620 --> 00:02:42,260
+And here are some examples of supervised living in crappy division.
+
+32
+00:02:42,640 --> 00:02:48,160
+Basically it's used heavily in image justification even object detection and segmentation.
+
+33
+00:02:48,220 --> 00:02:54,310
+Basically all of these involve feeding some label data into our depleting model and treating it and
+
+34
+00:02:54,310 --> 00:03:00,420
+getting a model that is accurate enough to take unseen data and classified them correctly.
+
+35
+00:03:01,650 --> 00:03:07,500
+So what about unsupervised learning now unsupervised learning learning is concerned with finding interesting
+
+36
+00:03:07,500 --> 00:03:12,030
+clusters Indian data and it does so without any hope of data labeling.
+
+37
+00:03:12,030 --> 00:03:18,630
+So you just feed some data into it and the unsupervised learning algorithm basically finds interesting
+
+38
+00:03:18,630 --> 00:03:21,240
+patterns and clusters in the information
+
+39
+00:03:24,510 --> 00:03:29,520
+it is actually very important in data analytics when you're trying to understand vast amounts of data
+
+40
+00:03:29,520 --> 00:03:31,320
+of that data.
+
+41
+00:03:31,410 --> 00:03:37,350
+Basically when you have huge data sets with huge number of columns and rows and different information
+
+42
+00:03:37,770 --> 00:03:43,430
+using unsupervised learning can help you understand very quickly what is important in your data.
+
+43
+00:03:44,130 --> 00:03:46,720
+This is a best example of it here.
+
+44
+00:03:47,190 --> 00:03:48,970
+Go back to it.
+
+45
+00:03:48,980 --> 00:03:54,010
+So now imagine we have basically meats of food items here.
+
+46
+00:03:54,770 --> 00:04:00,500
+And we give it as a seamstress pictures here and we'll give it to an unsupervised machine learning algorithm
+
+47
+00:04:01,070 --> 00:04:05,270
+and it's going to actually pick it close to what interests you and I'm willing to bet close to what
+
+48
+00:04:05,270 --> 00:04:13,150
+is going to be the first tree I trusted to baby does it's a meets it's that is interesting pattern unsupervised
+
+49
+00:04:13,220 --> 00:04:17,190
+machine learning algorithms help us pick out.
+
+50
+00:04:17,190 --> 00:04:19,460
+So what about self supervised learning.
+
+51
+00:04:19,870 --> 00:04:23,880
+Now sylphs revised learning is the same concept as supervised learning.
+
+52
+00:04:23,920 --> 00:04:31,650
+However that data is not labeled by humans which is pretty interesting so how it is level is generated.
+
+53
+00:04:31,690 --> 00:04:34,100
+Basically it's done using heuristic algorithms.
+
+54
+00:04:34,180 --> 00:04:40,030
+Example also includes an A good example of that is basically trying to predict the next Freman a video
+
+55
+00:04:40,240 --> 00:04:42,130
+given the previous frames.
+
+56
+00:04:42,130 --> 00:04:44,980
+That's a very good example of self supervised learning.
+
+57
+00:04:44,980 --> 00:04:49,660
+We're not going to deal with any self-sacrifice or unsupervised learning in this class but it's good
+
+58
+00:04:49,660 --> 00:04:50,070
+to know.
+
+59
+00:04:50,140 --> 00:04:54,570
+If you want to have an overview of machine learning what they're about.
+
+60
+00:04:54,610 --> 00:04:59,890
+And lastly we have reinforcement learning that reinforcement learning is potentially very interesting.
+
+61
+00:04:59,960 --> 00:05:05,190
+However it's still in its infancy and it's still a bit tricky to actually do.
+
+62
+00:05:05,200 --> 00:05:11,500
+I actually did a couple of courses classes on this in my university in Edinburgh and it wasn't that
+
+63
+00:05:11,500 --> 00:05:11,790
+fun.
+
+64
+00:05:11,800 --> 00:05:17,220
+Was actually very challenging but once I got it working it was actually quite fun quite cool.
+
+65
+00:05:18,980 --> 00:05:20,730
+So the concept is pretty simple.
+
+66
+00:05:21,050 --> 00:05:23,280
+However it's that simple to implement.
+
+67
+00:05:23,660 --> 00:05:30,850
+But we basically teach the algorithm something by giving it bad examples or penalties against something.
+
+68
+00:05:31,060 --> 00:05:32,800
+So it's of like learning to play games.
+
+69
+00:05:32,840 --> 00:05:35,370
+It's a very good example of reinforcement learning.
+
+70
+00:05:36,050 --> 00:05:40,880
+You're basically trying different things and getting punished or dying or losing points for something
+
+71
+00:05:41,420 --> 00:05:45,500
+until you come up with a strategy where you're basically minimizing your loss.
+
+72
+00:05:45,500 --> 00:05:49,530
+That is what reinforcement learning technically is.
+
+73
+00:05:49,540 --> 00:05:55,810
+So in machine learning it and machining in supervised machine learning is a basic tenet process which
+
+74
+00:05:55,810 --> 00:06:02,320
+you follow in every basically every using of every algorithm whether it be deplaning convolutional and
+
+75
+00:06:02,350 --> 00:06:04,080
+that's SVM.
+
+76
+00:06:04,120 --> 00:06:04,910
+Blah blah blah.
+
+77
+00:06:05,110 --> 00:06:06,650
+They all follow this pattern.
+
+78
+00:06:06,700 --> 00:06:12,070
+So in step one you obtain a label dataset.
+
+79
+00:06:12,170 --> 00:06:13,970
+Step two is split to say the set.
+
+80
+00:06:13,970 --> 00:06:20,840
+This is very important into a trining portion and the validation or test portion noted is technically
+
+81
+00:06:20,840 --> 00:06:24,400
+a little difference between the validation and test portion.
+
+82
+00:06:24,590 --> 00:06:30,620
+However for all intents and purposes which is about Free's I shouldn't be using but whatever.
+
+83
+00:06:31,050 --> 00:06:36,430
+Basically validation and test push is basically the unseen data.
+
+84
+00:06:36,430 --> 00:06:43,130
+Your model never sees this data model only sees the training data and we test performance on the validation
+
+85
+00:06:43,160 --> 00:06:45,700
+or test push and test tested assets.
+
+86
+00:06:46,240 --> 00:06:47,790
+So this in step 3.
+
+87
+00:06:47,990 --> 00:06:51,380
+We take this training data set that we split from the original.
+
+88
+00:06:51,860 --> 00:06:54,280
+And we feel it's our model.
+
+89
+00:06:54,370 --> 00:06:59,990
+So model takes us still and isn't inputs all labels and basically loon's tries to figure out patterns
+
+90
+00:07:00,320 --> 00:07:01,270
+how do we predict this.
+
+91
+00:07:01,280 --> 00:07:07,670
+How do we know what this is after some time it develops a fully trained model and so forth.
+
+92
+00:07:07,670 --> 00:07:12,700
+Basically we run this model in our test validation dataset to see how effective it is.
+
+93
+00:07:14,380 --> 00:07:19,710
+So here's some machine learning terminology that you're probably going to hear in this course and it
+
+94
+00:07:19,720 --> 00:07:27,280
+will basically target data with all this if we is to the ground troop levels technically in programming
+
+95
+00:07:27,280 --> 00:07:27,780
+languages.
+
+96
+00:07:27,790 --> 00:07:37,010
+You'll see that refer to as the y o In mathematics the Y labels X being the training data set.
+
+97
+00:07:37,030 --> 00:07:37,990
+Sorry about that.
+
+98
+00:07:38,620 --> 00:07:45,250
+And prediction basically being what all models predicted from some input data classes will be basically
+
+99
+00:07:45,250 --> 00:07:47,170
+the categories of your data.
+
+100
+00:07:47,400 --> 00:07:53,770
+So if you were talking about the hand-written digit amnesty the set there were 10 classes there would
+
+101
+00:07:53,770 --> 00:08:02,810
+be zero 1 2 3 4 5 6 7 8 9 aggression or phrase do when you're in classes we are operating basically.
+
+102
+00:08:02,880 --> 00:08:05,560
+This image belongs to this last regression.
+
+103
+00:08:05,610 --> 00:08:09,980
+We're putting basically a continuous value digit number.
+
+104
+00:08:10,290 --> 00:08:15,450
+So that's say we taking some inputs and trying to predict someone's height or weight that would be a
+
+105
+00:08:15,450 --> 00:08:16,820
+regression model.
+
+106
+00:08:17,340 --> 00:08:21,290
+And as I mentioned before invalidations last tests yes to can be different.
+
+107
+00:08:21,300 --> 00:08:25,950
+But in early Christou unseen data that we test our tree and model on.
diff --git a/6. Neural Networks Explained/3. Neural Networks Explained.srt b/6. Neural Networks Explained/3. Neural Networks Explained.srt
new file mode 100644
index 0000000000000000000000000000000000000000..eded604c79265c85c69b06594083a80ed3ed29f0
--- /dev/null
+++ b/6. Neural Networks Explained/3. Neural Networks Explained.srt
@@ -0,0 +1,227 @@
+1
+00:00:00,670 --> 00:00:07,650
+OK so finally let's get down to it and let's get into neural networks and I'll show you this is probably
+
+2
+00:00:07,650 --> 00:00:11,860
+the best explanation you'll ever see on your books online.
+
+3
+00:00:12,030 --> 00:00:17,690
+So let's get to it so fiercely why is this a best explanation.
+
+4
+00:00:18,050 --> 00:00:21,170
+I start off at a very high level explanation first.
+
+5
+00:00:21,440 --> 00:00:23,020
+I don't use much math.
+
+6
+00:00:23,030 --> 00:00:29,510
+And when I do it introduce it slowly and gradually I understand until you make you understand what makes
+
+7
+00:00:29,510 --> 00:00:31,040
+your life work so important.
+
+8
+00:00:31,390 --> 00:00:37,160
+Break down key elements in neural networks would back propagation which is something it's actually rare
+
+9
+00:00:37,220 --> 00:00:37,700
+to find.
+
+10
+00:00:37,700 --> 00:00:44,330
+And when you do find that online it is bit tricky to understand and I walked you really into descent
+
+11
+00:00:44,390 --> 00:00:50,990
+last functions activation functions all of which are very important to neural networks and I make you
+
+12
+00:00:50,990 --> 00:00:56,690
+understand what is actually going on in the training process something I rarely see taught in any tutorial
+
+13
+00:00:58,510 --> 00:01:05,710
+so fiercely What are neural networks neural networks technically because it's just a big bunch of weights
+
+14
+00:01:05,770 --> 00:01:11,560
+which are just matrices with numbers tend to be like a black box and we don't actually know how they
+
+15
+00:01:11,590 --> 00:01:12,300
+work.
+
+16
+00:01:12,310 --> 00:01:13,430
+Now that's kind of a lie.
+
+17
+00:01:13,540 --> 00:01:15,820
+We do know how they work conceptually.
+
+18
+00:01:15,820 --> 00:01:19,530
+We just it is so much information sometimes stored in a neural network.
+
+19
+00:01:19,540 --> 00:01:21,950
+We doing actually know what it knows.
+
+20
+00:01:21,980 --> 00:01:29,080
+Sometimes but essentially it takes inputs and predicts an output just like any other machine learning
+
+21
+00:01:29,200 --> 00:01:30,120
+algorithm.
+
+22
+00:01:31,160 --> 00:01:36,420
+However it's different and better than most traditional algorithms mainly because it can learn complex
+
+23
+00:01:36,440 --> 00:01:43,070
+non-linear and I'll describe what non-linear is soon mappings to former and produced far more accurate
+
+24
+00:01:43,070 --> 00:01:43,730
+model.
+
+25
+00:01:44,240 --> 00:01:47,420
+So you get better results from neural networks by far.
+
+26
+00:01:48,980 --> 00:01:55,590
+So this isn't mysterious but books will give it a picture of a cat and a nose as a cat how Same with
+
+27
+00:01:55,590 --> 00:01:57,000
+a gorilla.
+
+28
+00:01:57,000 --> 00:01:58,450
+Same with a dog.
+
+29
+00:01:59,190 --> 00:02:02,640
+So let's actually see what neuroethics actually do.
+
+30
+00:02:03,030 --> 00:02:07,650
+So this is a very very simplistic model of a neural network.
+
+31
+00:02:07,830 --> 00:02:12,350
+It has two inputs and these inputs are basically like pixels in an image.
+
+32
+00:02:12,360 --> 00:02:14,300
+You can consider them to be.
+
+33
+00:02:14,460 --> 00:02:15,410
+These are the hidden nodes.
+
+34
+00:02:15,420 --> 00:02:19,050
+These are basically what actually is a black box information.
+
+35
+00:02:19,050 --> 00:02:22,400
+The hidden area we don't actually know what these values are.
+
+36
+00:02:22,410 --> 00:02:23,930
+I mean we do know what is not is.
+
+37
+00:02:24,270 --> 00:02:28,810
+But there are so many of them we actually don't know how to actually interpret them as human.
+
+38
+00:02:28,950 --> 00:02:34,050
+And basically it does all these calculations in here and then upwards to categories.
+
+39
+00:02:34,240 --> 00:02:37,160
+This can be cat or dog.
+
+40
+00:02:37,170 --> 00:02:43,360
+So as I said this is basically the input layer here the hidden layer and output layer.
+
+41
+00:02:43,650 --> 00:02:49,480
+So in a very high level example we can have an input layer where we're giving the neural nets cut off
+
+42
+00:02:49,530 --> 00:02:53,950
+a blitz Fedder the weight of the bid and tells you the species and the sex of Tibet.
+
+43
+00:02:54,240 --> 00:02:55,490
+I mean that would be pretty cool.
+
+44
+00:02:55,500 --> 00:02:57,440
+I don't think it exists but it would be pretty cool.
+
+45
+00:02:59,300 --> 00:03:01,950
+So how exactly do we get a prediction.
+
+46
+00:03:01,950 --> 00:03:05,390
+We passed the inputs into a neural net and received an output.
+
+47
+00:03:05,430 --> 00:03:09,560
+So this is an example of how we actually how we actually can pass data.
+
+48
+00:03:09,930 --> 00:03:11,820
+Let's say it's a dark brown with white head.
+
+49
+00:03:11,940 --> 00:03:17,820
+That's a fair description DeWitt's and we get what it actually is a female.
+
+50
+00:03:17,850 --> 00:03:21,790
+So here's another example of neural nets that does handwritten The declassification.
+
+51
+00:03:21,860 --> 00:03:23,360
+So let's move onto it.
+
+52
+00:03:23,400 --> 00:03:29,280
+This is the original input right here and we have some hidden layers that we will talk about very soon.
+
+53
+00:03:29,640 --> 00:03:36,020
+So basically we feed this image input here and we get an output classification it being 4.
+
+54
+00:03:36,460 --> 00:03:39,170
+So this is an example of a neural net.
+
+55
+00:03:39,460 --> 00:03:42,020
+We're going to learn a lot more later on this.
+
+56
+00:03:42,150 --> 00:03:46,690
+This is at a high level it's conceptually how neural networks work.
+
+57
+00:03:46,780 --> 00:03:47,230
+OK.
diff --git a/6. Neural Networks Explained/4. Forward Propagation.srt b/6. Neural Networks Explained/4. Forward Propagation.srt
new file mode 100644
index 0000000000000000000000000000000000000000..dcefcb22e1ff8acb5857f72ceec4545b2b43bea7
--- /dev/null
+++ b/6. Neural Networks Explained/4. Forward Propagation.srt
@@ -0,0 +1,495 @@
+1
+00:00:00,830 --> 00:00:08,500
+Hi and welcome back to chapter six point three where I discuss what exactly is for propagation and distils
+
+2
+00:00:08,490 --> 00:00:13,320
+would hope neural networks actually process the inputs and produce an output.
+
+3
+00:00:13,340 --> 00:00:16,530
+So let's take a look.
+
+4
+00:00:16,670 --> 00:00:21,260
+OK so you may have been familiar with this diagram but now we have values assigned.
+
+5
+00:00:21,670 --> 00:00:26,990
+And this may seem a bit confusing at first but let me go through it step by step.
+
+6
+00:00:27,040 --> 00:00:33,610
+So looking at the input as only we have a value point for going into Input 1 and a value of point to
+
+7
+00:00:33,610 --> 00:00:35,550
+5 going into input 2.
+
+8
+00:00:35,820 --> 00:00:38,060
+Now in neural nets and CNN's.
+
+9
+00:00:38,080 --> 00:00:41,980
+And pretty much all machine learning algorithms.
+
+10
+00:00:42,160 --> 00:00:48,940
+Your inputs are numerical values are categorical values in neural nets are almost always or exclusively
+
+11
+00:00:49,620 --> 00:00:52,800
+input I mean numerical values here.
+
+12
+00:00:52,840 --> 00:00:56,080
+So now let's take a look at the hidden nodes here.
+
+13
+00:00:56,080 --> 00:00:58,030
+Each one H2.
+
+14
+00:00:58,030 --> 00:01:00,550
+Now you see each connection to the input.
+
+15
+00:01:00,730 --> 00:01:02,650
+Each one has a connection from input.
+
+16
+00:01:02,650 --> 00:01:08,440
+One also has a connection from input to and you see the two weights connected to it.
+
+17
+00:01:08,530 --> 00:01:09,580
+What these are.
+
+18
+00:01:09,640 --> 00:01:12,080
+You'll see the actual formula in the next line.
+
+19
+00:01:12,520 --> 00:01:16,190
+But imagine these are the wits that neural network learns.
+
+20
+00:01:16,420 --> 00:01:23,540
+And this is actually how these values matter quite a bit because actually how it produces its output.
+
+21
+00:01:23,710 --> 00:01:29,530
+So for now just remember each connection has a wait and you'll see this floating be one here.
+
+22
+00:01:29,730 --> 00:01:35,930
+No I mean this image is for simplicity one constant for all the way it's here.
+
+23
+00:01:36,220 --> 00:01:39,200
+In reality each It has its own constants.
+
+24
+00:01:39,220 --> 00:01:42,950
+But for now let's assume everyone has him constantly.
+
+25
+00:01:43,420 --> 00:01:48,170
+What is is this is a bias constant that's added to the weights calculation here.
+
+26
+00:01:48,560 --> 00:01:49,880
+Again you'll see this formula.
+
+27
+00:01:49,870 --> 00:01:55,810
+So don't be too confused yet but just remember these are the values weights that a neural net uses when
+
+28
+00:01:55,810 --> 00:01:57,190
+processing its input.
+
+29
+00:01:57,730 --> 00:02:00,980
+And likewise going into the output node they also weights.
+
+30
+00:02:01,150 --> 00:02:07,290
+So each node has two connections in this diagram one to each one one to each do their associated with
+
+31
+00:02:07,310 --> 00:02:14,520
+Stubley 5 6 7 8 for our partner and also a beta constant here as well.
+
+32
+00:02:14,980 --> 00:02:20,290
+And you see some values here named target or put point 1 and point nine.
+
+33
+00:02:20,380 --> 00:02:25,440
+These targets are basically the values that we want to get on your own to produce.
+
+34
+00:02:25,450 --> 00:02:30,030
+However in actual fact we use We're using some random values here.
+
+35
+00:02:30,310 --> 00:02:32,460
+So we're actually going to see what the outputs actually are.
+
+36
+00:02:32,500 --> 00:02:35,780
+So let's calculate these values.
+
+37
+00:02:35,860 --> 00:02:43,090
+So looking at each one each one Rambla as that had two input values here one from and put one one from
+
+38
+00:02:43,090 --> 00:02:46,420
+and Patou and associated with it's here as well.
+
+39
+00:02:46,840 --> 00:02:49,690
+So how do we get the output of each one.
+
+40
+00:02:50,050 --> 00:02:50,800
+That's simple.
+
+41
+00:02:50,800 --> 00:02:52,180
+That's this formula right here.
+
+42
+00:02:52,330 --> 00:02:53,900
+And it's quite easy to understand.
+
+43
+00:02:54,160 --> 00:03:01,900
+It's doubly one multiplied by one which is point for double-D to multiply by two plus B one which is
+
+44
+00:03:01,900 --> 00:03:10,210
+this constant at all the here and in calculating calculating this you end up getting point six of five
+
+45
+00:03:10,900 --> 00:03:17,220
+point four point two plus point to five point five plus points of them gives you this.
+
+46
+00:03:17,710 --> 00:03:19,520
+So that's each one's out.
+
+47
+00:03:20,350 --> 00:03:24,450
+What we can do now is look at the formulas for each one here.
+
+48
+00:03:24,700 --> 00:03:28,810
+Each one is this H2 is this and likewise output.
+
+49
+00:03:29,080 --> 00:03:34,200
+Note here its value is going to be a similar in similar form here as well.
+
+50
+00:03:34,390 --> 00:03:37,100
+It's going to be H-1 rumbler.
+
+51
+00:03:37,120 --> 00:03:41,960
+This is each one now the opposite of each one is not put in to here.
+
+52
+00:03:42,640 --> 00:03:48,490
+So that's w five times each one out w six times each.
+
+53
+00:03:48,490 --> 00:03:50,700
+Two outs plus B2.
+
+54
+00:03:51,430 --> 00:04:02,070
+And similarly for upper two it's going to be H-1 times w 7 h to start H 2 times we ate here.
+
+55
+00:04:02,120 --> 00:04:04,350
+This beat better too.
+
+56
+00:04:04,360 --> 00:04:07,110
+This is a general formula here for every output node.
+
+57
+00:04:07,300 --> 00:04:14,360
+So we can have multiple layers here going and it's always going to be some of the weights cost inputs
+
+58
+00:04:14,500 --> 00:04:19,210
+plus to do constant.
+
+59
+00:04:19,230 --> 00:04:20,610
+So we actually have the formulas.
+
+60
+00:04:20,610 --> 00:04:25,190
+Now what this means so you can actually see it's a little bit more explicitly here.
+
+61
+00:04:26,040 --> 00:04:26,350
+OK.
+
+62
+00:04:26,410 --> 00:04:28,350
+So moving onto the next slide.
+
+63
+00:04:29,590 --> 00:04:30,910
+This is how we get H2.
+
+64
+00:04:31,240 --> 00:04:33,860
+If you wanted to get on your own you could have.
+
+65
+00:04:34,090 --> 00:04:36,050
+But I did it for you right here.
+
+66
+00:04:36,460 --> 00:04:43,420
+And each do with these values here which was point four by point sorry.
+
+67
+00:04:43,650 --> 00:04:44,450
+What was it.
+
+68
+00:04:45,820 --> 00:04:54,510
+Point four times point one five do so point for them to one five point two five times point five yeah.
+
+69
+00:04:54,880 --> 00:04:56,430
+Plus when some kids do this
+
+70
+00:04:59,350 --> 00:05:00,450
+great.
+
+71
+00:05:00,580 --> 00:05:09,400
+Why have a twice a year to fix a slate Ledo and for us to know let's get a final update here if I can.
+
+72
+00:05:09,450 --> 00:05:16,900
+But no but one is this we think devalues basically mumble we've got point eight six seven five and point
+
+73
+00:05:16,940 --> 00:05:22,130
+eight eight five point eighty five is here and point 8 6 7 5.
+
+74
+00:05:22,350 --> 00:05:25,960
+If you remember was this one H-1.
+
+75
+00:05:26,280 --> 00:05:33,180
+So we have each one H-2 in now and we just multiply by the way it's going with here.
+
+76
+00:05:33,210 --> 00:05:35,890
+So you get up at 1 and 0 2.
+
+77
+00:05:36,450 --> 00:05:38,370
+So these are the actual outputs we get now.
+
+78
+00:05:38,620 --> 00:05:46,650
+However you see I had a target in green but one we wanted it to be point one wanted it to be point nine.
+
+79
+00:05:46,740 --> 00:05:47,600
+What does that mean.
+
+80
+00:05:47,670 --> 00:05:48,020
+What is it.
+
+81
+00:05:48,020 --> 00:05:50,410
+What do we mean by say we wanted it to be these things.
+
+82
+00:05:50,700 --> 00:05:56,880
+Well this is very important neural nets because imagine we're training some data and remember when we
+
+83
+00:05:56,880 --> 00:06:03,270
+use it when we use training examples we have basically we have the inputs and we have the outputs and
+
+84
+00:06:03,270 --> 00:06:04,830
+we're giving it to a neural net.
+
+85
+00:06:05,000 --> 00:06:08,320
+So you were telling the neural that this is an example.
+
+86
+00:06:08,520 --> 00:06:12,810
+So we have point for point to five period without an example here.
+
+87
+00:06:12,810 --> 00:06:14,050
+Point 1 this is the output.
+
+88
+00:06:14,070 --> 00:06:17,000
+It's supposed to be and point nine.
+
+89
+00:06:18,010 --> 00:06:24,090
+And now but in reality when we initialize this with running values this is what we got pretty far off
+
+90
+00:06:24,210 --> 00:06:25,970
+the actual values.
+
+91
+00:06:26,040 --> 00:06:27,180
+So what does this tell us.
+
+92
+00:06:27,180 --> 00:06:33,480
+It tells us that the initial random weights we used for W can be produced very incorrect results.
+
+93
+00:06:33,990 --> 00:06:38,300
+Feeding them is true and your and that is a matter of simple matrix multiplication as you saw.
+
+94
+00:06:38,640 --> 00:06:42,360
+And when you on that as you know it's just a series of linear equations.
+
+95
+00:06:42,360 --> 00:06:43,850
+These equations here.
+
+96
+00:06:44,450 --> 00:06:50,070
+So this is the basis of what Follette propagation is you're going to see very shortly how important
+
+97
+00:06:50,700 --> 00:06:53,530
+Basically this is let's go back to it here.
+
+98
+00:06:53,730 --> 00:06:58,890
+These values knowing these values and cafetiere thing the difference between our actual values and these
+
+99
+00:06:58,890 --> 00:06:59,820
+values are.
+
+100
+00:07:00,250 --> 00:07:00,730
+OK.
+
+101
+00:07:03,640 --> 00:07:06,520
+So no this is a good time to actually talk about the bias trick.
+
+102
+00:07:06,670 --> 00:07:13,990
+Now it may confuse you and I hope I don't get confused too much but by a strict basically tells you
+
+103
+00:07:13,990 --> 00:07:19,830
+that it's basically a multiplication to show you this is how you will do it much quicker.
+
+104
+00:07:19,830 --> 00:07:25,150
+So remember I said we have weights coming in this way it's the sushi that we have to inputs here.
+
+105
+00:07:25,270 --> 00:07:25,960
+OK.
+
+106
+00:07:26,420 --> 00:07:28,760
+So imagine we have these weights coming in here.
+
+107
+00:07:28,840 --> 00:07:30,110
+This is the x i.
+
+108
+00:07:30,130 --> 00:07:32,500
+These are also the inputs as well.
+
+109
+00:07:32,590 --> 00:07:36,960
+Sorry it is it puts the weight in but to embed values it awaits.
+
+110
+00:07:37,060 --> 00:07:38,950
+And these are the better constants.
+
+111
+00:07:38,960 --> 00:07:42,740
+Now how do neural nets actually do this calculation quickly.
+
+112
+00:07:43,030 --> 00:07:45,960
+Well is something called a by a strict now the bias trick.
+
+113
+00:07:45,970 --> 00:07:51,860
+Basically what it does because this is not the same dimensions is this where does the pens.
+
+114
+00:07:51,870 --> 00:07:54,480
+One here Joines better.
+
+115
+00:07:54,850 --> 00:07:57,350
+Constance to the WHCA.
+
+116
+00:07:57,730 --> 00:08:01,280
+And if we can do a simple multiplication like this.
+
+117
+00:08:01,420 --> 00:08:09,100
+So what it means is that now that vector is larger by a factor of 1 because initially as you can see
+
+118
+00:08:09,100 --> 00:08:11,560
+here we had four input values.
+
+119
+00:08:11,560 --> 00:08:12,970
+Now we have five five.
+
+120
+00:08:12,970 --> 00:08:19,060
+Basically the first one the last one being a bit constant and allows this to be multiplied by this quite
+
+121
+00:08:19,060 --> 00:08:19,710
+easily.
+
+122
+00:08:19,720 --> 00:08:19,990
+All right
+
+123
+00:08:24,830 --> 00:08:29,330
+OK so now we're going to move on to chapter 6 plane tree which talks about the activation functions
+
+124
+00:08:29,360 --> 00:08:31,190
+and what dip really means.
diff --git a/6. Neural Networks Explained/5. Activation Functions.srt b/6. Neural Networks Explained/5. Activation Functions.srt
new file mode 100644
index 0000000000000000000000000000000000000000..db03bce58c6e92dab63540fb6c09e42b90b74701
--- /dev/null
+++ b/6. Neural Networks Explained/5. Activation Functions.srt
@@ -0,0 +1,499 @@
+1
+00:00:00,900 --> 00:00:04,640
+So just do a quick recap on the last section.
+
+2
+00:00:05,070 --> 00:00:05,520
+All right.
+
+3
+00:00:05,580 --> 00:00:11,550
+We saw basically that we learned the bias trick in how we actually make this matrix calculation much
+
+4
+00:00:11,550 --> 00:00:12,850
+simpler and faster.
+
+5
+00:00:12,890 --> 00:00:16,630
+And that's we talked about how we got to wait's calculations here.
+
+6
+00:00:17,010 --> 00:00:23,190
+And we talked about basically it being a series of linear equations now know that Q With it is linear.
+
+7
+00:00:23,240 --> 00:00:30,390
+Now if you come from a machine learning background you're wondering what makes us different to regressions
+
+8
+00:00:30,450 --> 00:00:35,430
+or logistic directions as Reems which also a series of linear equations.
+
+9
+00:00:35,430 --> 00:00:38,450
+Well let's get into that in this chapter right now.
+
+10
+00:00:40,230 --> 00:00:42,940
+So now let's talk about activation functions.
+
+11
+00:00:43,230 --> 00:00:51,350
+So should you Enric in India but notice that it was just input value multiplied by the weights Plus
+
+12
+00:00:51,360 --> 00:00:52,480
+the biased.
+
+13
+00:00:52,500 --> 00:00:56,370
+And some of those that goes into the node is what produces the output.
+
+14
+00:00:56,370 --> 00:01:06,180
+However in reality yes that is true but it's these w x y plus beta and Pitsea actually passed into an
+
+15
+00:01:06,180 --> 00:01:07,670
+activation function.
+
+16
+00:01:07,980 --> 00:01:14,190
+And basically the simplest an activation function is that simple this type of activation function is
+
+17
+00:01:14,190 --> 00:01:16,740
+that this one here Max zero.
+
+18
+00:01:16,830 --> 00:01:17,560
+Excellent.
+
+19
+00:01:17,940 --> 00:01:23,460
+What this means is that any value over Zero is going to be passed.
+
+20
+00:01:23,550 --> 00:01:24,470
+Right.
+
+21
+00:01:24,870 --> 00:01:26,660
+Now I'll tell you why this is important later.
+
+22
+00:01:26,700 --> 00:01:29,000
+But just imagine we have a function a max function here.
+
+23
+00:01:29,410 --> 00:01:31,590
+And we have this way it's going into it.
+
+24
+00:01:31,620 --> 00:01:34,480
+So let's see where we it's what we got point eight eight five.
+
+25
+00:01:34,490 --> 00:01:35,880
+What each do believe.
+
+26
+00:01:36,320 --> 00:01:41,520
+That's a CMO we had six of us point seventy five this next election because it's crucial that again
+
+27
+00:01:41,520 --> 00:01:46,090
+zero which means that anything below zero will be negated.
+
+28
+00:01:46,470 --> 00:01:47,570
+And you see that here.
+
+29
+00:01:47,670 --> 00:01:49,610
+However anything above you will be allowed.
+
+30
+00:01:49,710 --> 00:01:53,250
+So in this example here point 75 is allowed.
+
+31
+00:01:53,250 --> 00:02:00,420
+However if the weeds give us a negative value which can happen easily then ethics is clamped and zero.
+
+32
+00:02:00,750 --> 00:02:01,760
+It isn't 6.5.
+
+33
+00:02:01,770 --> 00:02:03,310
+It doesn't take any positive value.
+
+34
+00:02:03,440 --> 00:02:04,790
+It just just becomes zero.
+
+35
+00:02:05,010 --> 00:02:08,430
+With this activation function.
+
+36
+00:02:08,530 --> 00:02:11,320
+So let's talk about the real activation function.
+
+37
+00:02:11,580 --> 00:02:17,780
+Reduced handsful rectified ling a unit and it probably is the most common activation function used in
+
+38
+00:02:17,800 --> 00:02:21,370
+CNN's and your own that's now the appearance is quite simple.
+
+39
+00:02:21,410 --> 00:02:23,360
+You just take a look at it.
+
+40
+00:02:23,420 --> 00:02:24,840
+Basically it's this.
+
+41
+00:02:24,970 --> 00:02:27,180
+It clamps a negative value to zero.
+
+42
+00:02:27,560 --> 00:02:32,950
+So there's no negative value is being passed going forward and what value is basically left alone.
+
+43
+00:02:33,410 --> 00:02:37,200
+So default value is X which is always positive.
+
+44
+00:02:37,200 --> 00:02:42,660
+So it's basically this really.
+
+45
+00:02:42,730 --> 00:02:45,520
+So why do we need these activation functions.
+
+46
+00:02:45,580 --> 00:02:47,550
+Remember I said if you come from.
+
+47
+00:02:47,650 --> 00:02:54,040
+Coming from a machine learning Becchio you're thinking so far with activation functions and that's basically
+
+48
+00:02:54,190 --> 00:02:58,880
+just another form of basically not a model linear model.
+
+49
+00:02:59,000 --> 00:03:06,820
+However having activation functions allows us to basically expressed the linearity relationships in
+
+50
+00:03:06,820 --> 00:03:07,700
+this data.
+
+51
+00:03:08,200 --> 00:03:11,580
+Most of my models have a tough time dealing with this.
+
+52
+00:03:11,650 --> 00:03:12,070
+All right.
+
+53
+00:03:12,070 --> 00:03:18,870
+So the whole huge advantage of deepening is its ability to understand nonlinear models.
+
+54
+00:03:19,480 --> 00:03:21,360
+And what do we mean by linear.
+
+55
+00:03:21,360 --> 00:03:24,100
+Now imagine we have two categories of data.
+
+56
+00:03:24,140 --> 00:03:33,980
+Imagine just for expressions like this is cats dogs and no linear separate Rubell data will be easily.
+
+57
+00:03:34,110 --> 00:03:40,970
+This is called The Decision boundary will be easily separated here however the non linear is linearly.
+
+58
+00:03:40,990 --> 00:03:42,020
+Sorry about that.
+
+59
+00:03:42,550 --> 00:03:48,100
+None linearly separable little is going to require a much more complicated function to do.
+
+60
+00:03:48,490 --> 00:03:49,360
+Now we can use.
+
+61
+00:03:49,360 --> 00:03:55,420
+You may have been thinking we can use complicated polynomial decision about your type functions to get
+
+62
+00:03:55,420 --> 00:03:58,440
+this but what about if it was more than two dimensions.
+
+63
+00:03:58,450 --> 00:04:01,520
+Imagine how complicated that function is going to be.
+
+64
+00:04:01,840 --> 00:04:09,100
+That's going to separate us data and introducing activation functions which allows us to basically expressed
+
+65
+00:04:09,100 --> 00:04:13,810
+a non linear relationship and data is what makes that so powerful.
+
+66
+00:04:14,440 --> 00:04:15,590
+So there are a few other types.
+
+67
+00:04:15,600 --> 00:04:21,390
+Activation functions some of which we may use in the source we definitely use rectify Lyndie and it's
+
+68
+00:04:21,400 --> 00:04:22,530
+quite a bit.
+
+69
+00:04:22,610 --> 00:04:29,230
+Sometimes we use sigmoid sometimes use hyperbolic tangent but rarely ever use those and we use those
+
+70
+00:04:29,560 --> 00:04:32,040
+in specialized cases which you'll see later on.
+
+71
+00:04:35,180 --> 00:04:42,930
+So as before mentioned in the previous chapter we have be obeyed of course by its functions.
+
+72
+00:04:42,930 --> 00:04:45,640
+So why do we need by assumptions.
+
+73
+00:04:45,770 --> 00:04:52,670
+You know you know training right now because you may be thinking we can pretty much make it anything.
+
+74
+00:04:53,040 --> 00:04:54,940
+However that doesn't change much.
+
+75
+00:04:55,110 --> 00:04:57,600
+It's simply changed a gradient.
+
+76
+00:04:57,600 --> 00:05:04,260
+If you're from a mathematical background he would know any value multiplied by x increases the steepness
+
+77
+00:05:04,380 --> 00:05:05,940
+of the values going in.
+
+78
+00:05:06,000 --> 00:05:07,170
+That's what this is here.
+
+79
+00:05:07,230 --> 00:05:13,280
+So you can see that it seemed this way it was point 5 1 2 and the sigmoid function here.
+
+80
+00:05:13,770 --> 00:05:16,100
+So you can actually see point five.
+
+81
+00:05:16,100 --> 00:05:17,510
+It's not that steep.
+
+82
+00:05:17,750 --> 00:05:21,620
+One gets deeper and definitely had to it's super steep here.
+
+83
+00:05:22,230 --> 00:05:30,280
+However what if we wanted to shift left and right we can do that without changing by changing the way
+
+84
+00:05:30,420 --> 00:05:31,530
+in front of the Exa.
+
+85
+00:05:31,800 --> 00:05:37,320
+But we can do it by adding a value to it adding a value actually shifts at the left and right here as
+
+86
+00:05:37,320 --> 00:05:38,550
+you can see.
+
+87
+00:05:39,210 --> 00:05:46,830
+So now we have the weights here constant weights going into X plus a constant value here 5 minus 1 0
+
+88
+00:05:47,190 --> 00:05:48,070
+5.
+
+89
+00:05:48,180 --> 00:05:54,280
+So we can actually used we it's about sort of bias values to actually shifted left and right.
+
+90
+00:05:55,740 --> 00:06:01,990
+So let's talk a bit about in your own inspiration behind your own that's why the way.
+
+91
+00:06:02,000 --> 00:06:03,680
+Why is it called you and that's in the first place.
+
+92
+00:06:03,690 --> 00:06:05,960
+Is it a replication of a brain.
+
+93
+00:06:05,970 --> 00:06:06,840
+Not quite.
+
+94
+00:06:06,840 --> 00:06:15,360
+However activation units basically act make these hidden units these notes act like neurons because
+
+95
+00:06:16,020 --> 00:06:22,950
+if you know how neurons work neurons receive inputs along these lines here believe dical dendrites I
+
+96
+00:06:22,950 --> 00:06:23,500
+think.
+
+97
+00:06:23,940 --> 00:06:29,550
+And basically when these we just sit and value trouble the neuron fires and neurons connected to many
+
+98
+00:06:29,700 --> 00:06:35,250
+different neurons who then received these inputs from this hearing that is a very similar analogy to
+
+99
+00:06:35,250 --> 00:06:40,980
+how neural nets work when a value input value crosses that threshold it fails.
+
+100
+00:06:43,510 --> 00:06:48,300
+And let's talk about how deep in deep learning what do we mean by deep.
+
+101
+00:06:48,640 --> 00:06:53,770
+Everyone says deep listening but no one actually tells you what deep this deep is actually the number
+
+102
+00:06:53,770 --> 00:06:55,290
+of hidden layers here.
+
+103
+00:06:55,750 --> 00:07:00,710
+So this is a nice example illustration of neuro that here.
+
+104
+00:07:01,210 --> 00:07:03,970
+These are the connections with our heads and biases.
+
+105
+00:07:03,970 --> 00:07:10,540
+These are the nodes here and this one has one two three four five six seven eight hidden layers here.
+
+106
+00:07:10,940 --> 00:07:12,800
+As you can probably count this one do as well.
+
+107
+00:07:12,850 --> 00:07:14,320
+Sometimes they do.
+
+108
+00:07:14,410 --> 00:07:17,530
+So this isn't all the hidden layers here that we don't see.
+
+109
+00:07:17,530 --> 00:07:23,650
+And I imagine now we have millions millions of thousands of these like parameters and all the stuff
+
+110
+00:07:23,650 --> 00:07:29,850
+here that gives you an example of how complicated your own skin actually get especially deep neural
+
+111
+00:07:29,870 --> 00:07:31,660
+nets.
+
+112
+00:07:31,990 --> 00:07:40,210
+Now when do we need to be deep deep actually helped to represent non-linear representations in the data
+
+113
+00:07:40,270 --> 00:07:41,390
+quite well.
+
+114
+00:07:41,800 --> 00:07:49,070
+So if you want to actually train a complicated network it's always better to go deep rather than shallow.
+
+115
+00:07:49,600 --> 00:07:55,780
+However deeper it is not always easier and better to work with deeper networks require a lot more training
+
+116
+00:07:55,780 --> 00:07:56,430
+time.
+
+117
+00:07:56,680 --> 00:07:59,700
+And sometimes it tend to fit the input data.
+
+118
+00:07:59,710 --> 00:08:02,720
+No I haven't introduced the concept of overfitting yet.
+
+119
+00:08:02,950 --> 00:08:05,320
+However we will deal with it very shortly.
+
+120
+00:08:07,690 --> 00:08:13,300
+So like I said your real magic of your own that happens during training because we see that it's very
+
+121
+00:08:13,300 --> 00:08:18,280
+simple to execute a tree and you know that when you don't it but when it's when I mean execute I mean
+
+122
+00:08:18,670 --> 00:08:19,810
+pasand but do it and get it.
+
+123
+00:08:19,840 --> 00:08:23,440
+But but how exactly do we get these weights and biases.
+
+124
+00:08:23,440 --> 00:08:25,630
+This is exactly what we want to do.
+
+125
+00:08:26,020 --> 00:08:28,820
+And I haven't told you about it yet so let's find out.
diff --git "a/6. Neural Networks Explained/6. Training Part 1 \342\200\223 Loss Functions.srt" "b/6. Neural Networks Explained/6. Training Part 1 \342\200\223 Loss Functions.srt"
new file mode 100644
index 0000000000000000000000000000000000000000..efbb72786334d957ccc903d1a89ad2cba229941e
--- /dev/null
+++ "b/6. Neural Networks Explained/6. Training Part 1 \342\200\223 Loss Functions.srt"
@@ -0,0 +1,483 @@
+1
+00:00:00,600 --> 00:00:03,070
+OK welcome to chapter 6.4.
+
+2
+00:00:03,470 --> 00:00:09,400
+And this is a very important chapter because we know getting into how we actually train and that's.
+
+3
+00:00:09,620 --> 00:00:11,630
+And now we're looking at lost functions first.
+
+4
+00:00:11,660 --> 00:00:12,740
+So let's begin.
+
+5
+00:00:12,740 --> 00:00:13,690
+All right.
+
+6
+00:00:13,700 --> 00:00:19,080
+Those functions are essential and how we actually train and ghetto with values and by Assayas.
+
+7
+00:00:19,130 --> 00:00:20,920
+So let's move onto it.
+
+8
+00:00:21,850 --> 00:00:22,410
+OK.
+
+9
+00:00:22,430 --> 00:00:28,760
+So first of all near-religious have to learn the weights but how exactly do we learn those weights as
+
+10
+00:00:28,760 --> 00:00:30,980
+you saw previously or random default.
+
+11
+00:00:30,990 --> 00:00:35,490
+We said we assigned produce some very bad results.
+
+12
+00:00:35,570 --> 00:00:40,970
+What we need now is a way to figure out how to change the way it so that our results are more accurate.
+
+13
+00:00:40,970 --> 00:00:47,240
+So imagine we just passed those weights those random values and we got the output values we saw wrong
+
+14
+00:00:47,240 --> 00:00:47,890
+they were.
+
+15
+00:00:48,200 --> 00:00:54,700
+If only we could figure out a way to use basically how wrong our values were to correct the weights
+
+16
+00:00:54,740 --> 00:01:02,670
+inside and that's exactly how we use loss functions and really in the center back propagation.
+
+17
+00:01:02,780 --> 00:01:07,440
+That's how they actually showed it which is a brilliant algorithms that are very very useful in training
+
+18
+00:01:07,600 --> 00:01:08,140
+that's.
+
+19
+00:01:08,180 --> 00:01:13,080
+So it's very important that you understand these.
+
+20
+00:01:13,140 --> 00:01:15,260
+So how exactly do we begin training in Iran.
+
+21
+00:01:15,330 --> 00:01:16,580
+What do we need.
+
+22
+00:01:17,220 --> 00:01:20,410
+Ok so first of all we need some level data obviously.
+
+23
+00:01:20,420 --> 00:01:22,550
+And that's called a data set.
+
+24
+00:01:23,010 --> 00:01:29,840
+And it is more than some sometimes in 2000s but let's see some large data sets a neural network live
+
+25
+00:01:29,910 --> 00:01:32,840
+from look the Karris which is built into a tensor flow.
+
+26
+00:01:32,870 --> 00:01:33,780
+Well Tiano.
+
+27
+00:01:34,170 --> 00:01:39,510
+Alternatively if you want to be adventurous you can actually use platens PI and make all of this on
+
+28
+00:01:39,510 --> 00:01:40,640
+your own.
+
+29
+00:01:40,710 --> 00:01:45,780
+It's a really fun exercise but kind of difficult so I don't recommend it unless you want to challenge
+
+30
+00:01:45,780 --> 00:01:48,360
+yourself and patience.
+
+31
+00:01:48,380 --> 00:01:53,170
+Because training of your own that almost always takes quite a while.
+
+32
+00:01:53,360 --> 00:02:02,030
+And when I mean quite a well I mean simple one that can take you out to a PC on your home PC but a more
+
+33
+00:02:02,030 --> 00:02:09,790
+complicated one you'd definitely need to go use a multiple abuse and sometimes trining time of weeks.
+
+34
+00:02:09,830 --> 00:02:13,340
+So let's look at the training steps in the neural nets step by step.
+
+35
+00:02:13,580 --> 00:02:17,070
+Pay attention to the slide because it's critical you understand this concept.
+
+36
+00:02:18,420 --> 00:02:22,530
+First we initialize some random weights and values for biases.
+
+37
+00:02:22,570 --> 00:02:30,210
+Now technically step 0 would be have a data set assuming we have all data sets we would labeled data
+
+38
+00:02:30,220 --> 00:02:36,680
+set I should say we start training by initializing random values for weights and biases.
+
+39
+00:02:36,690 --> 00:02:40,650
+Step two we input a single sample of all data into it.
+
+40
+00:02:40,950 --> 00:02:43,070
+And that's called Follet propagation stage.
+
+41
+00:02:43,230 --> 00:02:50,970
+So we pass this and put and get an output and once we get an output we compare a output to the actual
+
+42
+00:02:50,970 --> 00:02:53,550
+target value that it was supposed to be.
+
+43
+00:02:53,550 --> 00:02:57,650
+So remember previously we had target values of point 1 and point nine.
+
+44
+00:02:57,960 --> 00:03:03,570
+But the actual outputs will if I remember correctly were 1 point something and one point something again
+
+45
+00:03:04,050 --> 00:03:06,930
+which were very off.
+
+46
+00:03:06,930 --> 00:03:14,110
+So we need a way to quantify how bad these output values coming from these random weights were.
+
+47
+00:03:14,580 --> 00:03:19,040
+And we called this which are at an age and hair loss.
+
+48
+00:03:19,410 --> 00:03:23,280
+We didn't adjust the weights so that all loss is law.
+
+49
+00:03:23,310 --> 00:03:30,930
+And the next iteration would mean the next iteration basically the next time we pass an input data into
+
+50
+00:03:30,970 --> 00:03:38,790
+and knowing that we want the weights to be adjusted so that our final last is low and we keep doing
+
+51
+00:03:38,790 --> 00:03:42,350
+this for samples no data or batches of samples in our data.
+
+52
+00:03:43,330 --> 00:03:50,680
+And then eventually basically we send the entire That is a true weight optimization program and we keep
+
+53
+00:03:50,680 --> 00:03:53,130
+seeing if we can lower a loss.
+
+54
+00:03:53,260 --> 00:03:57,370
+So and basically we just stopped using one last decreases.
+
+55
+00:03:57,370 --> 00:04:03,790
+So if you if you're wondering what this all means here the key thing here is we pass values to and you'll
+
+56
+00:04:03,810 --> 00:04:13,090
+Let's get our loss of just overweights African law lost and process by which we label of a loss is called
+
+57
+00:04:13,090 --> 00:04:16,990
+weight optimization.
+
+58
+00:04:17,010 --> 00:04:21,110
+So this is a good diagram that basically illustrates what I just said.
+
+59
+00:04:21,270 --> 00:04:23,190
+We have it in the data here.
+
+60
+00:04:23,220 --> 00:04:24,430
+This is a neural net here.
+
+61
+00:04:24,460 --> 00:04:30,080
+Layer one layer two we have the ultra protections and we have two targets.
+
+62
+00:04:30,080 --> 00:04:38,040
+So now we passed our actual outputs and compared them with the values that were supposed to be now this
+
+63
+00:04:38,190 --> 00:04:45,030
+optimized this green box here which basically does back propagation he thinks does less value.
+
+64
+00:04:45,360 --> 00:04:50,940
+And basically he recommends new weights goes back into neural nets and the cycle repeats itself continuously
+
+65
+00:04:50,940 --> 00:04:53,120
+for more and more data.
+
+66
+00:04:54,920 --> 00:04:58,550
+So let's see how we actually quantify this loss.
+
+67
+00:04:58,550 --> 00:05:05,840
+As I said before this was the predicted results from a 1 year old that previously unless it's up it's
+
+68
+00:05:05,840 --> 00:05:08,990
+went up it's do these with a target value is that it was supposed to be.
+
+69
+00:05:08,990 --> 00:05:12,250
+And these were the actual results we got from our random values.
+
+70
+00:05:12,680 --> 00:05:18,530
+As you can see a difference between predicted and Target is quite a bit 1.1 6 is nowhere close to 1
+
+71
+00:05:18,590 --> 00:05:19,490
+to 1 1.
+
+72
+00:05:19,670 --> 00:05:22,590
+And likewise although this is closer.
+
+73
+00:05:23,570 --> 00:05:30,150
+So let's talk about loss functions now loss functions integral in training neural nets as the measure
+
+74
+00:05:30,150 --> 00:05:37,150
+of the inconsistency or difference between the predicted results and the actual targeted results are
+
+75
+00:05:37,160 --> 00:05:41,760
+always positive and they tend to try to penalize bigger as well.
+
+76
+00:05:42,350 --> 00:05:44,670
+The lower the loss the better the model.
+
+77
+00:05:44,750 --> 00:05:48,800
+Of remember that there are many different types of loss options.
+
+78
+00:05:48,800 --> 00:05:54,640
+However MSCE called mean squared error is quite useful and perhaps the most popular.
+
+79
+00:05:55,580 --> 00:05:56,800
+And this is a simple formula.
+
+80
+00:05:56,810 --> 00:06:03,120
+MSE OK so no let's actually use the MSE here to actually calculate the TIMOCI formula.
+
+81
+00:06:03,140 --> 00:06:03,750
+Decathlete.
+
+82
+00:06:03,780 --> 00:06:06,140
+Oh erro using just arithmetic.
+
+83
+00:06:06,200 --> 00:06:14,480
+So we had a one point 1 6 4 7 5 1 point 2 9 9 to 5 and basically applying it.
+
+84
+00:06:14,590 --> 00:06:16,410
+This is the A.E. values we get here.
+
+85
+00:06:17,540 --> 00:06:21,280
+So that is actually quite simple to execute.
+
+86
+00:06:21,290 --> 00:06:22,700
+Important to understand.
+
+87
+00:06:22,700 --> 00:06:27,050
+Note that we too in our ERs into positive values by scoring them here.
+
+88
+00:06:32,010 --> 00:06:37,410
+So there are many other types of loss options L1 L2 cross entropy says using binary classifications
+
+89
+00:06:37,820 --> 00:06:43,830
+hinge loss and mean absolute URL which is similar to mean square all other means.
+
+90
+00:06:43,830 --> 00:06:48,000
+But as I said it's quite popular because it's always a good safe choice.
+
+91
+00:06:50,120 --> 00:06:53,850
+Note Elul loss goes hand in hand with accuracy yes.
+
+92
+00:06:54,080 --> 00:06:58,550
+However that doesn't necessarily mean good Thalys on treating data.
+
+93
+00:06:59,000 --> 00:07:05,090
+We always have to assess a loss and accuracy on the test data which we will get some hands on experience
+
+94
+00:07:05,090 --> 00:07:08,440
+with later and discuss.
+
+95
+00:07:08,540 --> 00:07:15,070
+So let's see how we used the last to correct way it's getting the best weed's for classifying data isn't
+
+96
+00:07:15,070 --> 00:07:20,860
+a trivial task especially when we have large image data which has tons of inputs for a single image
+
+97
+00:07:22,150 --> 00:07:25,780
+so no simple neural net.
+
+98
+00:07:25,780 --> 00:07:30,460
+Here we just have two inputs two hidden nodes and two outputs.
+
+99
+00:07:30,490 --> 00:07:33,670
+How many parameters are there in this.
+
+100
+00:07:33,730 --> 00:07:39,450
+Now this is a business is a formula for determining the number of parameters in a neural net.
+
+101
+00:07:39,460 --> 00:07:44,910
+It's quite simple it's input nodes multiplied by the number of hidden nodes Plus the hidden layers.
+
+102
+00:07:44,950 --> 00:07:47,290
+Multiply that outputs plus Tobias's.
+
+103
+00:07:47,710 --> 00:07:55,900
+So the hidden It's here with two input nodes with two hidden layers with two as hidden nodes I should
+
+104
+00:07:55,900 --> 00:08:05,560
+say plus 4 which was a hidden layer plus two by two which is also two here plus two here plus four which
+
+105
+00:08:05,560 --> 00:08:07,850
+is about the bias's here.
+
+106
+00:08:08,020 --> 00:08:14,670
+Remember each time to each node here has a bias going into it.
+
+107
+00:08:14,980 --> 00:08:17,350
+So that's how we get 12 parameters for this here.
+
+108
+00:08:19,160 --> 00:08:21,650
+Hope that's understandable for you guys.
+
+109
+00:08:21,650 --> 00:08:23,250
+Let's look at some more experiments here.
+
+110
+00:08:23,330 --> 00:08:29,150
+K we have tree in protégées here for hidden nodes here.
+
+111
+00:08:29,400 --> 00:08:31,630
+Three by four plus four here.
+
+112
+00:08:31,840 --> 00:08:34,870
+While the above two upwardly Assia the six.
+
+113
+00:08:35,080 --> 00:08:36,340
+OK those are.
+
+114
+00:08:36,400 --> 00:08:39,840
+How much weight by as Brehm's is we going to have here.
+
+115
+00:08:39,890 --> 00:08:42,430
+So one two three four five six.
+
+116
+00:08:42,540 --> 00:08:49,780
+Similarly here we have eight eight plus one for blissful plus 1 it is a bias's here will have tree names
+
+117
+00:08:49,780 --> 00:08:57,490
+for here four times for here and then four times one here Sidus one to two.
+
+118
+00:08:57,700 --> 00:08:59,330
+That is simple.
+
+119
+00:08:59,340 --> 00:09:02,560
+You will not get to it only as here with just four nodes.
+
+120
+00:09:02,560 --> 00:09:06,020
+Each has 41 loanable promises.
+
+121
+00:09:06,220 --> 00:09:10,120
+So now let's get into training Patu which is about propagation and Grilli and descent.
diff --git "a/6. Neural Networks Explained/7. Training Part 2 \342\200\223 Backpropagation and Gradient Descent.srt" "b/6. Neural Networks Explained/7. Training Part 2 \342\200\223 Backpropagation and Gradient Descent.srt"
new file mode 100644
index 0000000000000000000000000000000000000000..8b1f0273ffcb46ad52fe59dc6be7e2038a9b18b9
--- /dev/null
+++ "b/6. Neural Networks Explained/7. Training Part 2 \342\200\223 Backpropagation and Gradient Descent.srt"
@@ -0,0 +1,519 @@
+1
+00:00:00,390 --> 00:00:07,410
+OK so on to treating part 2 where I discuss back propagation and gritty and dissent this is basically
+
+2
+00:00:07,410 --> 00:00:10,480
+how we did two minute waits in an efficient and effective manner.
+
+3
+00:00:11,340 --> 00:00:11,970
+During training
+
+4
+00:00:14,850 --> 00:00:17,450
+so what exactly is back propagation.
+
+5
+00:00:17,730 --> 00:00:23,670
+So what if there was a way we could use those lost values we just saw in the previous section to determine
+
+6
+00:00:23,670 --> 00:00:25,140
+how to adjust the weights.
+
+7
+00:00:25,170 --> 00:00:30,290
+And that is the brilliance of back propagation BRAC back propagation.
+
+8
+00:00:30,330 --> 00:00:36,360
+It's a bit tricky to say sometimes back propagation tells us how much we would how much we need to change
+
+9
+00:00:36,830 --> 00:00:41,950
+our weights in order to change the loss defect or for a loss.
+
+10
+00:00:41,970 --> 00:00:43,390
+So let's see how that works.
+
+11
+00:00:43,440 --> 00:00:50,000
+Revisiting our previous example here remember this diagram of targets of values and stuff.
+
+12
+00:00:50,000 --> 00:00:58,770
+So using the MSE obtained from the OP one back propagation allows us to know if changing W5 from Point
+
+13
+00:00:58,770 --> 00:01:08,760
+6 by a small amount to let's see Point 6 0 0 1 0.5 999 does basically a point 0 0 0 or 1 additional
+
+14
+00:01:08,760 --> 00:01:13,380
+plus 2 this way it will how would that affect the overall loss.
+
+15
+00:01:13,530 --> 00:01:14,660
+We're changing.
+
+16
+00:01:14,690 --> 00:01:18,700
+W5 increase my loss or decrease by loss.
+
+17
+00:01:18,780 --> 00:01:21,490
+That is essentially what propagation tells us.
+
+18
+00:01:25,030 --> 00:01:30,720
+So no we didn't back propagate this loss to each node.
+
+19
+00:01:31,180 --> 00:01:31,920
+Right to left.
+
+20
+00:01:31,920 --> 00:01:36,670
+So we keep moving backwards through time and direction that we should move negative or positive.
+
+21
+00:01:36,670 --> 00:01:43,990
+So imagine we come with it back propagation tells us W5 maybe should have been positive and then we
+
+22
+00:01:43,990 --> 00:01:50,710
+go back then we did w 7 8 W6 and we go back again working backwards right to laugh.
+
+23
+00:01:50,800 --> 00:01:51,930
+So how much should we adjust.
+
+24
+00:01:51,940 --> 00:02:00,430
+This this this and this to all of us and that process basically looking backward from the output is
+
+25
+00:02:00,430 --> 00:02:05,720
+called back propagation So that's a difficult cycle.
+
+26
+00:02:06,040 --> 00:02:12,940
+Therefore by simply passing one set of inputs of a single piece treating data we can know just all the
+
+27
+00:02:12,940 --> 00:02:14,680
+weed steroid use this early loss.
+
+28
+00:02:14,770 --> 00:02:16,120
+What I mean by this.
+
+29
+00:02:16,210 --> 00:02:22,600
+So go back to the previous slide by passing one input data here point 4.5 and getting the last values
+
+30
+00:02:22,630 --> 00:02:23,110
+here.
+
+31
+00:02:23,500 --> 00:02:28,840
+We can now use back propagation now to adjust all the way going back so that the next time we have an
+
+32
+00:02:28,840 --> 00:02:33,780
+input data coming in last should be less.
+
+33
+00:02:34,050 --> 00:02:38,200
+However this tune's tweets for or for that specific input data.
+
+34
+00:02:38,580 --> 00:02:40,930
+But how does that make you and you on that Gen-X.
+
+35
+00:02:41,010 --> 00:02:47,170
+So I'm pretty sure you were thinking that was due reduction in weeks for that particular piece of input
+
+36
+00:02:47,260 --> 00:02:54,240
+data for these values here but what it will and next in PERDIDA is point five point seven and the targets
+
+37
+00:02:54,240 --> 00:02:55,120
+are different.
+
+38
+00:02:55,200 --> 00:02:57,660
+Will those words be better or not.
+
+39
+00:02:57,660 --> 00:02:58,930
+That's a very good question.
+
+40
+00:03:01,140 --> 00:03:07,900
+But however doing this all the treating samples and no data we effectively by just keep giving it more
+
+41
+00:03:07,900 --> 00:03:09,100
+and more examples.
+
+42
+00:03:09,400 --> 00:03:13,100
+And remember this data basically has some sort of structure to it.
+
+43
+00:03:13,120 --> 00:03:20,050
+So essentially by just keep passing more inputs into and you're not using back propagation to keep adjusting
+
+44
+00:03:20,050 --> 00:03:27,090
+the way it's eventually will we keep getting better and better and by better I mean our last value is
+
+45
+00:03:27,100 --> 00:03:33,530
+coming out of the other modes here and missing from the target Opitz is becoming less what is will be
+
+46
+00:03:33,760 --> 00:03:42,700
+becoming less and less so every time we send a full batch of altering data into this it's called the
+
+47
+00:03:42,700 --> 00:03:43,820
+ebook iteration.
+
+48
+00:03:43,930 --> 00:03:47,650
+Now this is a difference here and we'll discuss it soon.
+
+49
+00:03:47,740 --> 00:03:50,150
+An e-book essentially I shall tell you right now.
+
+50
+00:03:50,380 --> 00:03:59,040
+And the book is when we pass the full data set or filtering the data into a neuron that that's one epoch.
+
+51
+00:03:59,530 --> 00:04:03,020
+And it sort of means the same thing but it could be different.
+
+52
+00:04:03,040 --> 00:04:05,480
+But remember IPAC is what's important to you.
+
+53
+00:04:07,690 --> 00:04:12,880
+So we just went through essentially what back propagation is in a very high level.
+
+54
+00:04:12,880 --> 00:04:14,650
+Now what about Grilli and dissent.
+
+55
+00:04:14,710 --> 00:04:22,700
+What exactly is gradient descent now by adjusting the way it's using by propagation to lower the last
+
+56
+00:04:23,260 --> 00:04:29,080
+we are performing gradient descent and gradient descent is essentially an optimization solution.
+
+57
+00:04:29,300 --> 00:04:34,040
+This just in to weeds to look at a loss is essentially an optimization problem.
+
+58
+00:04:34,170 --> 00:04:34,750
+OK.
+
+59
+00:04:35,230 --> 00:04:40,130
+So back propagation is simply a method by which we execute gritty and descent.
+
+60
+00:04:40,180 --> 00:04:45,430
+So always remember that people say we're doing gradient descent what are we doing where optimizing are
+
+61
+00:04:45,430 --> 00:04:47,850
+we it's to reduce our loss.
+
+62
+00:04:47,880 --> 00:04:52,180
+So why is it called really it isn't what even our brilliance.
+
+63
+00:04:52,240 --> 00:04:57,640
+Now if you remember correctly from your high school that's brilliance represent a slope at a point on
+
+64
+00:04:57,640 --> 00:04:58,510
+a function.
+
+65
+00:04:58,900 --> 00:05:02,530
+So and actually tells you the direction function is moving.
+
+66
+00:05:02,560 --> 00:05:05,040
+So disappointed appositive brilliant.
+
+67
+00:05:05,250 --> 00:05:10,120
+This point is still going down what is negative really and at this point is no change.
+
+68
+00:05:10,150 --> 00:05:12,270
+So it's a zero gradient.
+
+69
+00:05:12,310 --> 00:05:17,860
+So by adjusting the way it's little loss we are performing gradient descent which I previously said
+
+70
+00:05:18,580 --> 00:05:23,320
+and gradients as I just said points of direction on the curve here.
+
+71
+00:05:28,360 --> 00:05:35,800
+So a bit more of what gradient descent now forming really and spent on these functions here could be
+
+72
+00:05:35,800 --> 00:05:37,810
+a bit tricky sometimes.
+
+73
+00:05:37,870 --> 00:05:39,230
+And why is that.
+
+74
+00:05:39,310 --> 00:05:41,510
+Imagine a function looks like this.
+
+75
+00:05:42,130 --> 00:05:45,820
+And we're trying to find this this is actually a real function like that.
+
+76
+00:05:45,820 --> 00:05:47,920
+Let's just see this is a real representation.
+
+77
+00:05:47,980 --> 00:05:54,880
+I know it's a 2D thing but if you try to visualize it that is what neural net is basically we have this
+
+78
+00:05:54,940 --> 00:06:00,770
+multidimensional function ever trying to get and by getting what I mean is that we're trying to adjust
+
+79
+00:06:00,770 --> 00:06:03,910
+the way it's so that we get below it.
+
+80
+00:06:04,270 --> 00:06:08,790
+We basically tried to adjust the way we looked at a loss to get dysfunction.
+
+81
+00:06:08,890 --> 00:06:09,860
+So what if.
+
+82
+00:06:09,860 --> 00:06:16,240
+Now these are points here where they'll minimize maximum and minimum points if you remember from your
+
+83
+00:06:16,240 --> 00:06:17,420
+math class.
+
+84
+00:06:17,620 --> 00:06:19,680
+These are called local minimums.
+
+85
+00:06:19,720 --> 00:06:24,190
+Why are the local minimums because they're just in this section of the curve.
+
+86
+00:06:24,580 --> 00:06:26,940
+They're basically the lowest point ingredient.
+
+87
+00:06:26,980 --> 00:06:32,810
+However the global minimum which is actual minimum gradient minimum point here is here.
+
+88
+00:06:33,040 --> 00:06:39,310
+So often times when training we you hear that term we can we tend to get stuck in local minimums that
+
+89
+00:06:39,310 --> 00:06:40,220
+is this here.
+
+90
+00:06:40,570 --> 00:06:41,850
+That is when we're adjusting.
+
+91
+00:06:41,900 --> 00:06:48,930
+We sometimes buy two large values and that you'll see that parameter called lending rates afterward
+
+92
+00:06:49,450 --> 00:06:55,390
+which is how much we adjust these things by all of this will be explained in the next chapter when we
+
+93
+00:06:55,390 --> 00:06:58,320
+actually do a good example of back propagation.
+
+94
+00:06:58,420 --> 00:07:01,300
+But essentially what we're trying to do is find a global minima.
+
+95
+00:07:01,470 --> 00:07:06,110
+This is a true point representation that gives you the lowest loss.
+
+96
+00:07:06,730 --> 00:07:10,370
+So a good example is imagine a bull and we're trying.
+
+97
+00:07:10,390 --> 00:07:17,200
+We're moving in random directions along the spool traversing it and just as rough as you can see and
+
+98
+00:07:17,200 --> 00:07:22,780
+we're trying to find a local sort of global minimum point which would be at a bottom here.
+
+99
+00:07:22,780 --> 00:07:28,420
+However in moving around as if we keep jumping jumping and we don't find it so we mean we need to jump
+
+100
+00:07:28,420 --> 00:07:33,880
+in small steps to actually find this point.
+
+101
+00:07:33,930 --> 00:07:41,660
+So let but brings us to the caustic gray and dissent so naive innocent is traditionally very expensive
+
+102
+00:07:41,660 --> 00:07:48,590
+and slow and it requires exposure to the entire dataset then add up the security and that is if you
+
+103
+00:07:48,600 --> 00:07:51,870
+actually do that and right Rillette that is superslow don't do that.
+
+104
+00:07:52,290 --> 00:07:56,270
+Stochastic really in the sense does updates after every input of a sample.
+
+105
+00:07:56,270 --> 00:08:02,360
+So like I said we put one sample of data and we adjusted gradients immediately using back propagation
+
+106
+00:08:02,450 --> 00:08:05,870
+started with us immediately using back propagation.
+
+107
+00:08:05,870 --> 00:08:07,130
+Now what would this do.
+
+108
+00:08:07,220 --> 00:08:12,170
+This would produce very noisy fluctuating loss outputs in reality.
+
+109
+00:08:12,170 --> 00:08:13,760
+And again this can be slow.
+
+110
+00:08:14,000 --> 00:08:19,100
+You'll probably see changes quickly but you'll almost appear random.
+
+111
+00:08:19,100 --> 00:08:23,840
+That brings us Duminy batch gradient descent which is effectively a combination of the two.
+
+112
+00:08:24,380 --> 00:08:29,720
+Instead of passing you entire data sets like a naive gradient descent we basically take batches of the
+
+113
+00:08:29,720 --> 00:08:37,050
+inputs and we pass a batch during that work then we use the back propagation to adjust it.
+
+114
+00:08:37,340 --> 00:08:41,180
+And basically that is actually how we update OHC.
+
+115
+00:08:41,630 --> 00:08:45,000
+Now there's no specific rule in how big batches can be.
+
+116
+00:08:45,020 --> 00:08:46,770
+They can actually be less than 20.
+
+117
+00:08:46,790 --> 00:08:53,660
+I tend to use 16 sometimes but generally botches depends on how much data you can fit into or I'm at
+
+118
+00:08:53,660 --> 00:09:01,190
+a point where if you're I'm using Gibbins and basically this leads to a faster training time faster
+
+119
+00:09:01,190 --> 00:09:06,480
+convergence due to global minima whenever you hated that convergence we're basically trying to find
+
+120
+00:09:06,840 --> 00:09:15,320
+the basically the ideal number of weights well last stops decreasing.
+
+121
+00:09:15,690 --> 00:09:21,280
+So in this section this is to a quick overview we've learned that last functions such as MSE means squit
+
+122
+00:09:21,280 --> 00:09:21,770
+error.
+
+123
+00:09:22,060 --> 00:09:23,960
+Tell us how much earlier we have.
+
+124
+00:09:23,970 --> 00:09:30,560
+We will wait pretty fast that we didn't used that error to perform back propagation which is only used
+
+125
+00:09:30,560 --> 00:09:37,480
+a little it's in the next cycle an X input but next time we input data and this process of optimizing
+
+126
+00:09:37,480 --> 00:09:42,550
+a little when the weights is called Grilli descent and an efficient method of doing Grilli and descent
+
+127
+00:09:42,670 --> 00:09:46,310
+is called mini batch really and doesn't.
+
+128
+00:09:46,380 --> 00:09:52,970
+OK so now in the next section we're going to actually do a worked example doing some actual matter of
+
+129
+00:09:53,030 --> 00:09:54,500
+back propagation.
+
+130
+00:09:54,500 --> 00:09:56,280
+So stay tuned.
diff --git "a/6. Neural Networks Explained/8. Backpropagation & Learning Rates \342\200\223 A Worked Example.srt" "b/6. Neural Networks Explained/8. Backpropagation & Learning Rates \342\200\223 A Worked Example.srt"
new file mode 100644
index 0000000000000000000000000000000000000000..707b4bd2e6795cde0a65952c9aa0a57f99c08d1b
--- /dev/null
+++ "b/6. Neural Networks Explained/8. Backpropagation & Learning Rates \342\200\223 A Worked Example.srt"
@@ -0,0 +1,771 @@
+1
+00:00:01,100 --> 00:00:06,140
+OK so now this brings us to back propagation an actual example.
+
+2
+00:00:06,140 --> 00:00:07,590
+So let's get to it.
+
+3
+00:00:07,640 --> 00:00:11,680
+And you actually get to understand exactly what pap propagation is doing.
+
+4
+00:00:11,720 --> 00:00:16,850
+So from the previous section we have a good idea of what back propagation is at least at a high level.
+
+5
+00:00:16,850 --> 00:00:23,300
+And to reiterate it's a method of executing Karelian in dissent or with optimization so that we have
+
+6
+00:00:23,300 --> 00:00:26,330
+an efficient method of getting the lowest possible loss.
+
+7
+00:00:26,660 --> 00:00:30,910
+So how does this black magic of black propagation actually work.
+
+8
+00:00:31,700 --> 00:00:35,560
+OK so let's do a simplified explanation again.
+
+9
+00:00:35,870 --> 00:00:43,160
+So we obtain a Twichell arrow that was the last imune squid era of notes and then propagate these errors
+
+10
+00:00:43,240 --> 00:00:49,660
+back to you that were using back propagation to obtain a new and hopefully better gradients or Waites.
+
+11
+00:00:49,670 --> 00:00:57,620
+So what happens is that we get a loss and then we send the loss back in here and when I mean send it
+
+12
+00:00:57,620 --> 00:00:58,160
+back in.
+
+13
+00:00:58,160 --> 00:01:00,870
+Basically we're applying back propagation to this loss.
+
+14
+00:01:01,070 --> 00:01:03,510
+And now it's going back here.
+
+15
+00:01:03,650 --> 00:01:13,010
+We're collecting and updating the so we'd weeds here and then doing it again these notes so backwardation
+
+16
+00:01:13,070 --> 00:01:16,950
+it is simple and it's made possible by the channel.
+
+17
+00:01:16,990 --> 00:01:18,430
+So what is the chain rule.
+
+18
+00:01:18,490 --> 00:01:23,030
+So without making this too complicated essentially this is a general here.
+
+19
+00:01:23,050 --> 00:01:27,400
+We have two functions why Ezekial to f a few and use the G of X.
+
+20
+00:01:27,460 --> 00:01:27,860
+OK.
+
+21
+00:01:28,060 --> 00:01:28,960
+Just two functions.
+
+22
+00:01:28,960 --> 00:01:31,690
+I know it's going to be confusing it's this if you don't know much about.
+
+23
+00:01:31,840 --> 00:01:38,500
+However basically it is a differential of the whole wide changes with respect to ex-CEO rate of change
+
+24
+00:01:39,040 --> 00:01:42,310
+is given by this these canso these two to use.
+
+25
+00:01:42,580 --> 00:01:47,520
+So we end up with this that is effectively the Chanterelle.
+
+26
+00:01:47,560 --> 00:01:53,190
+Now if you really want it in the Senate and rule properly you can go back to some lots of websites that
+
+27
+00:01:53,190 --> 00:01:54,650
+explain it in more detail.
+
+28
+00:01:54,780 --> 00:02:00,480
+I'm not trying to get into too much detail here I'm just giving it a general defined as it is here.
+
+29
+00:02:01,790 --> 00:02:08,820
+So let's look at this as our previous And in here with all the confusing values and formulas we use
+
+30
+00:02:08,820 --> 00:02:11,580
+in general to determine the direction that we should take.
+
+31
+00:02:11,580 --> 00:02:13,360
+So let's see how it's actually done.
+
+32
+00:02:13,720 --> 00:02:21,010
+So remember each one we just cut it out from this point here going into one of his notes.
+
+33
+00:02:21,420 --> 00:02:22,650
+So we have to know it.
+
+34
+00:02:22,740 --> 00:02:23,910
+But when we're looking at.
+
+35
+00:02:24,030 --> 00:02:29,900
+So this is the bias constant here going in the weeds here.
+
+36
+00:02:30,270 --> 00:02:35,390
+And this is basically how we get up with one here from the Disfarmer though from this.
+
+37
+00:02:35,400 --> 00:02:38,630
+So again let's take a look at W5 and I've highlighted it here.
+
+38
+00:02:39,060 --> 00:02:43,570
+How do we change W5 so that we cheat we affect the area.
+
+39
+00:02:43,690 --> 00:02:48,250
+And this note here should be increased or decreased.
+
+40
+00:02:48,660 --> 00:02:50,620
+Well let's find out.
+
+41
+00:02:50,670 --> 00:02:56,170
+So our capital of calculated for what propagation and loss values here.
+
+42
+00:02:56,430 --> 00:03:00,110
+Just to reiterate what they were from the previous section.
+
+43
+00:03:00,390 --> 00:03:07,220
+This is it here if you want to operate one or put two and I haven't mentioned this before.
+
+44
+00:03:07,440 --> 00:03:15,650
+But basically overvalues values here we apply a logistic function that squashes them between 0 and 1.
+
+45
+00:03:15,660 --> 00:03:21,570
+So what it means is we have outputs previously being do I have them here.
+
+46
+00:03:23,090 --> 00:03:29,720
+No but remember they were points one point one something and one point to something I believe.
+
+47
+00:03:29,780 --> 00:03:34,850
+And basically when we apply a logistic function to hear these it devalues it we actually get here.
+
+48
+00:03:35,000 --> 00:03:43,540
+So we took that one point something and we squash it to a value between 0 and 1 using dysfunction.
+
+49
+00:03:43,940 --> 00:03:45,470
+That's the actual outputs here.
+
+50
+00:03:47,230 --> 00:03:49,120
+Case I'm moving onto the next slide.
+
+51
+00:03:51,180 --> 00:03:56,670
+So now we do a slight change in the MSCE function and that change basically just adding a half constant
+
+52
+00:03:57,150 --> 00:04:00,150
+multiplying it by the error means greater here.
+
+53
+00:04:00,210 --> 00:04:03,550
+And that basically is just to make it look a little bit nicer when we differentiate.
+
+54
+00:04:03,560 --> 00:04:08,380
+It doesn't really impact the overall MSCE much because it's a constant.
+
+55
+00:04:08,520 --> 00:04:16,590
+And so a building of values previously this is our new embassy loss playing book dealer joystick squashing
+
+56
+00:04:16,590 --> 00:04:20,230
+function here and MSE as well.
+
+57
+00:04:20,530 --> 00:04:26,170
+OK MC So let's explore.
+
+58
+00:04:26,170 --> 00:04:29,870
+W5 How much do we change w 5 by 2.
+
+59
+00:04:29,890 --> 00:04:36,430
+Basically law the entire loss and that's what this form is here we want to know how much changing w
+
+60
+00:04:36,430 --> 00:04:40,920
+W5 here impacts the total area where it is a sum of error from.
+
+61
+00:04:40,930 --> 00:04:42,910
+I'll put one up two.
+
+62
+00:04:43,900 --> 00:04:51,310
+So I'm not going to get into exactly how we get this equation here but this is basically using the channel
+
+63
+00:04:51,340 --> 00:04:58,750
+to calculate the W5 see how much the total error here changes respectively 5 is given by the differential
+
+64
+00:04:58,810 --> 00:05:04,860
+differential of Itote all over the output one multiplied by the opposite one over the net.
+
+65
+00:05:04,920 --> 00:05:09,160
+But here differential if Sorry it's partial differential.
+
+66
+00:05:09,550 --> 00:05:11,220
+And this is well here.
+
+67
+00:05:11,320 --> 00:05:13,270
+How much does it want to hear changes.
+
+68
+00:05:13,270 --> 00:05:17,460
+And then I'll put one with respect to the change in the five.
+
+69
+00:05:17,500 --> 00:05:23,400
+So these are the tree pieces we need of the general to get this.
+
+70
+00:05:23,460 --> 00:05:25,210
+Now let's look at this here.
+
+71
+00:05:25,290 --> 00:05:29,270
+The total total is basically half.
+
+72
+00:05:29,340 --> 00:05:32,880
+I'll put one up here and I'll put two Patou here.
+
+73
+00:05:33,220 --> 00:05:39,460
+That is how we actually get the total because remember going back to the slide we want to get we know
+
+74
+00:05:39,610 --> 00:05:46,300
+they'll add one here what is predictive value what are random values with predictive value with something
+
+75
+00:05:46,300 --> 00:05:48,150
+his target value is something else.
+
+76
+00:05:48,160 --> 00:05:56,910
+So we just basically apply what output one hears for open node 1 and added to this means we are up to
+
+77
+00:05:57,230 --> 00:05:59,050
+that so we get to it all.
+
+78
+00:05:59,160 --> 00:06:04,030
+So now let's differentiate each hurdle here with respect to that one.
+
+79
+00:06:04,360 --> 00:06:05,120
+Okay.
+
+80
+00:06:05,130 --> 00:06:08,000
+Because that's what the first Dimino chain rule here is.
+
+81
+00:06:08,400 --> 00:06:15,720
+So this gives us two by a half which councils have to be one to minus the exponent 1 and since the this
+
+82
+00:06:15,800 --> 00:06:17,720
+has no one here.
+
+83
+00:06:17,820 --> 00:06:21,960
+This basically is treated the constants are differential if a constant is zero.
+
+84
+00:06:22,620 --> 00:06:25,130
+So simplifying this we get this.
+
+85
+00:06:25,170 --> 00:06:26,700
+And we actually have the values of this.
+
+86
+00:06:26,730 --> 00:06:32,530
+We have the opposite one which was this go back to it 0.7
+
+87
+00:06:36,060 --> 00:06:38,720
+and we have the actual target value which was point 1.
+
+88
+00:06:38,780 --> 00:06:41,990
+So it will add up at one point six four.
+
+89
+00:06:42,330 --> 00:06:43,620
+Brilliant.
+
+90
+00:06:43,620 --> 00:06:49,820
+So now let's get this second team here which is differential up put one over a net up at 1.
+
+91
+00:06:49,890 --> 00:06:52,350
+That's exactly it and see what it exactly means here.
+
+92
+00:06:52,800 --> 00:06:58,860
+So you get up at 1 is basically the application of the sigmoid function for a day.
+
+93
+00:06:59,210 --> 00:07:02,190
+But on that one note remember we apply
+
+94
+00:07:04,700 --> 00:07:05,850
+sigmoid function here.
+
+95
+00:07:05,900 --> 00:07:08,900
+It outputs.
+
+96
+00:07:08,930 --> 00:07:10,230
+So let's go back to it now.
+
+97
+00:07:11,450 --> 00:07:13,880
+So how do we differentiate this.
+
+98
+00:07:13,880 --> 00:07:20,630
+Now fortunately the partial derivative of a logistic function is the output multiplied by 1 minus the
+
+99
+00:07:20,630 --> 00:07:23,170
+output which is the simple thing here.
+
+100
+00:07:23,630 --> 00:07:26,060
+So there we have disvalue 27:14.
+
+101
+00:07:26,480 --> 00:07:28,260
+Let's go back to see how we got it.
+
+102
+00:07:28,310 --> 00:07:29,270
+I'll put one.
+
+103
+00:07:29,360 --> 00:07:32,800
+Just to reiterate that came from here.
+
+104
+00:07:32,930 --> 00:07:33,440
+I'll put one
+
+105
+00:07:36,250 --> 00:07:40,370
+oh I know I'm going a bit too fast for most of you guys to keep up.
+
+106
+00:07:40,500 --> 00:07:45,760
+This actually took me a couple hours embarrassingly to get through to hours.
+
+107
+00:07:45,840 --> 00:07:48,060
+So take some time if you want.
+
+108
+00:07:48,060 --> 00:07:52,680
+Print all these slides I'll have them up and it would treat them if you really want to get a proper
+
+109
+00:07:52,680 --> 00:07:53,890
+understanding of this.
+
+110
+00:07:53,910 --> 00:07:55,380
+Just treat them on your own.
+
+111
+00:07:55,650 --> 00:08:03,730
+OK so that gives us this point seven full one minus one minus puts in full which gives us negative 1
+
+112
+00:08:03,780 --> 00:08:05,730
+1 9 1 2 9 3.
+
+113
+00:08:05,880 --> 00:08:08,540
+So that's no second to him in the general.
+
+114
+00:08:08,860 --> 00:08:11,770
+So let's go forward get it to now.
+
+115
+00:08:11,840 --> 00:08:19,370
+Did Tim was differential in that of output one of the differentiated introspective D-W five.
+
+116
+00:08:19,410 --> 00:08:20,550
+All right.
+
+117
+00:08:20,550 --> 00:08:24,690
+So net of up at one is this year.
+
+118
+00:08:24,830 --> 00:08:28,690
+W5 that was input if you can visualize it here.
+
+119
+00:08:28,760 --> 00:08:32,490
+Terms of what of each one plus W6 to him the opposite of each two.
+
+120
+00:08:32,680 --> 00:08:34,110
+Should've probably had a drawing of it here.
+
+121
+00:08:34,140 --> 00:08:37,640
+But we can just go back to it quickly if you want to just see it.
+
+122
+00:08:38,280 --> 00:08:41,440
+That's decir this formula right here
+
+123
+00:08:45,070 --> 00:08:48,430
+so that's differentiated which respected W5.
+
+124
+00:08:48,640 --> 00:08:55,150
+So differentiating it here we just get this team here one by this because this differential of this
+
+125
+00:08:55,150 --> 00:08:58,610
+would be one plus this is a constant.
+
+126
+00:08:58,750 --> 00:09:00,430
+It's also constant here.
+
+127
+00:09:00,670 --> 00:09:08,060
+So we just end up with a simple output H-1 which points of view which we know from.
+
+128
+00:09:08,080 --> 00:09:09,400
+Let's go back to it here.
+
+129
+00:09:12,150 --> 00:09:14,200
+Where is it when this is hit here.
+
+130
+00:09:14,420 --> 00:09:14,870
+Each one
+
+131
+00:09:20,500 --> 00:09:25,580
+OK but if each one is 1 7 7 0 4 2 2 5 2 3 4.
+
+132
+00:09:25,920 --> 00:09:33,580
+So no as we can clearly see we have the treaty aims for how much each total said was a change with respect
+
+133
+00:09:33,580 --> 00:09:34,570
+to the.
+
+134
+00:09:34,570 --> 00:09:35,110
+All right.
+
+135
+00:09:35,470 --> 00:09:41,260
+So that's this from the here to play auditory items and we get this.
+
+136
+00:09:41,260 --> 00:09:43,950
+Now what exactly does this tell us.
+
+137
+00:09:43,960 --> 00:09:56,700
+We've got put 0 6 5 2 6 Well what does that tell us is that the new five is going to be that minus this.
+
+138
+00:09:56,760 --> 00:10:03,730
+Now you see we introduced this new constant here is new parameter and this prompt is called linning
+
+139
+00:10:03,730 --> 00:10:04,340
+rate.
+
+140
+00:10:04,400 --> 00:10:09,690
+Now before I get into learning it let's just assume that this wasn't here.
+
+141
+00:10:10,040 --> 00:10:14,680
+So the new W 5 would just be W5 to him minus the here.
+
+142
+00:10:15,230 --> 00:10:18,490
+It's a minus point sixty five here.
+
+143
+00:10:18,850 --> 00:10:24,080
+So if it would be that straight away it would just be point six miners 23 at something which would give
+
+144
+00:10:24,080 --> 00:10:25,720
+you point five to you.
+
+145
+00:10:25,950 --> 00:10:32,070
+However we have a constant here cleaning rate now that is a very important constant.
+
+146
+00:10:32,090 --> 00:10:33,210
+I'll tell you why.
+
+147
+00:10:33,920 --> 00:10:35,320
+If we settle it here.
+
+148
+00:10:35,320 --> 00:10:39,070
+Point Five which is actually quite large for living as living rates go.
+
+149
+00:10:39,300 --> 00:10:40,130
+OK.
+
+150
+00:10:40,490 --> 00:10:43,350
+But the reason for that is we don't want to do it.
+
+151
+00:10:43,450 --> 00:10:46,110
+It's too big a jumps.
+
+152
+00:10:46,220 --> 00:10:48,950
+We don't know the direction it's supposed to go.
+
+153
+00:10:49,220 --> 00:10:53,460
+So in this case the direction was supposed to be less than 0.6.
+
+154
+00:10:53,510 --> 00:10:55,200
+So we get point 5:5 here.
+
+155
+00:10:55,500 --> 00:10:58,570
+But well that's playing after paying a living it.
+
+156
+00:10:58,580 --> 00:11:02,540
+However in reality we don't actually want to change it even by that much.
+
+157
+00:11:02,570 --> 00:11:09,480
+This is just an example of a use for you guys but in reality we live in Reidsville a point 0 0 0 1.
+
+158
+00:11:09,590 --> 00:11:15,790
+So we want to just go and smidgens the tiny bit about in the direction of the five is supposed to go.
+
+159
+00:11:16,370 --> 00:11:18,150
+And there's a reason for that.
+
+160
+00:11:18,280 --> 00:11:24,020
+The reason for that for is because if we are changing over it's by such large amounts we tend to skip
+
+161
+00:11:24,020 --> 00:11:26,370
+over the actual global minimum.
+
+162
+00:11:26,690 --> 00:11:28,050
+That's why I mentioned it down here.
+
+163
+00:11:28,050 --> 00:11:29,560
+We've issued a global minimum.
+
+164
+00:11:29,840 --> 00:11:36,560
+So instead of getting trapped in a local minima or just jumping around Tiley we adjust we it's by very
+
+165
+00:11:36,560 --> 00:11:41,300
+tiny amounts so that we could converge exactly to global minima.
+
+166
+00:11:41,420 --> 00:11:48,440
+It makes trining much longer but we always get a much better model out of it.
+
+167
+00:11:48,440 --> 00:11:50,450
+So it is permitted linning or it.
+
+168
+00:11:50,510 --> 00:11:58,170
+Now look carefully at this formula it controls it by a big magnitude here which is why I said we always
+
+169
+00:11:58,190 --> 00:12:05,570
+use a very tiny value so that explains linning rates to you and back propagation to you.
+
+170
+00:12:05,680 --> 00:12:09,300
+This was a bit tricky to understand.
+
+171
+00:12:10,420 --> 00:12:18,830
+Sorry but I think this was this is a very helpful the intuition behind back propagation and how we adjust
+
+172
+00:12:18,840 --> 00:12:19,350
+to it.
+
+173
+00:12:19,390 --> 00:12:25,600
+And if you want to do some homework on your own you can use the same formulas to calculate the 6:54
+
+174
+00:12:25,610 --> 00:12:30,060
+that we ate either them manually myself to quite some time.
+
+175
+00:12:30,070 --> 00:12:36,570
+But you can check it out and see if these are correct.
+
+176
+00:12:36,580 --> 00:12:39,690
+So just to give you a bit a heads up.
+
+177
+00:12:39,790 --> 00:12:44,050
+W1 WTW tree which had didn't it prior to the other nodes.
+
+178
+00:12:44,200 --> 00:12:46,630
+Basically the second stage of back propagation.
+
+179
+00:12:46,870 --> 00:12:49,910
+This is a form of the hair fits going forward.
+
+180
+00:12:50,340 --> 00:12:50,880
+OK.
+
+181
+00:12:50,950 --> 00:12:57,590
+Similarly you can actually calculate w 1 2 3 and 4 using the same method I just showed you.
+
+182
+00:12:57,640 --> 00:12:59,720
+However they are slightly different.
+
+183
+00:12:59,720 --> 00:13:01,760
+They involve a bit more work.
+
+184
+00:13:01,780 --> 00:13:03,940
+So I'll leave this as an exercise for you.
+
+185
+00:13:03,970 --> 00:13:05,410
+You don't necessarily have to do it.
+
+186
+00:13:05,410 --> 00:13:07,780
+To be fair just understand what you're doing.
+
+187
+00:13:07,780 --> 00:13:09,960
+This is the actual formula for it.
+
+188
+00:13:10,000 --> 00:13:14,710
+So play around if you want and go get into it.
+
+189
+00:13:15,210 --> 00:13:15,540
+OK.
+
+190
+00:13:15,610 --> 00:13:20,270
+So that concludes this chapter on back propagation worked example.
+
+191
+00:13:20,270 --> 00:13:22,260
+I hope you find it very useful for you.
+
+192
+00:13:22,450 --> 00:13:30,800
+So let's move on to regularisation overfitting and generalization and then deciding what test tested
+
+193
+00:13:30,800 --> 00:13:33,490
+assets are and how do we know if our model is actually good.