
File size: 15,262 Bytes
ad84a3a 2d46aeb ad84a3a 2d46aeb ad84a3a |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 |
---
license: mit
library_name: transformers
pipeline_tag: text-generation
tags:
- vLLM
- AWQ
base_model:
- zai-org/GLM-4.7
base_model_relation: quantized
---
# GLM-4.7-AWQ
Base model: [zai-org/GLM-4.7](https://huggingface.co/zai-org/GLM-4.7)
### 【Dependencies / Installation】
```python
vllm==0.14.0
```
As of **2025-12-24**, make sure your system has cuda12.8 installed.
Then, create a fresh Python environment (e.g. python3.12 venv) and run:
```bash
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
```
### 【vLLM Startup Command】
<i>Note: When launching with TP=8, include `--enable-expert-parallel`;
otherwise the expert tensors couldn’t be evenly sharded across GPU devices.</i>
```
export VLLM_USE_DEEP_GEMM=0
export VLLM_USE_FLASHINFER_MOE_FP16=1
export VLLM_USE_FLASHINFER_SAMPLER=0
export OMP_NUM_THREADS=4
vllm serve \
__YOUR_PATH__/tclf90/GLM-4.7-AWQ \
--served-model-name MY_MODEL_NAME \
--swap-space 16 \
--max-num-seqs 32 \
--max-model-len 32768 \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 8 \
--enable-expert-parallel \
--speculative-config.method mtp \
--speculative-config.num_speculative_tokens 1 \
--tool-call-parser glm47 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--trust-remote-code \
--host 0.0.0.0 \
--port 8000
```
### 【Logs】
```
2025-12-24
1. Initial commit
```
### 【Model Files】
| File Size | Last Updated |
|-----------|--------------|
| `181 GiB` | `2025-12-24` |
### 【Model Download】
```python
from modelscope import snapshot_download
snapshot_download('tclf90/GLM-4.7-AWQ', cache_dir="your_local_path")
```
### 【Overview】
# GLM-4.7
<div align="center">
<img src=https://raw.githubusercontent.com/zai-org/GLM-4.5/refs/heads/main/resources/logo.svg width="15%"/>
</div>
<p align="center">
👋 Join our <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community.
<br>
📖 Check out the GLM-4.7 <a href="https://z.ai/blog/glm-4.7" target="_blank">technical blog</a>, <a href="https://arxiv.org/abs/2508.06471" target="_blank">technical report(GLM-4.5)</a>.
<br>
📍 Use GLM-4.7 API services on <a href="https://docs.z.ai/guides/llm/glm-4.7">Z.ai API Platform. </a>
<br>
👉 One click to <a href="https://chat.z.ai">GLM-4.7</a>.
</p>
## Introduction
**GLM-4.7**, your new coding partner, is coming with the following features:
- **Core Coding**: GLM-4.7 brings clear gains, compared to its predecessor GLM-4.6, in multilingual agentic coding and terminal-based tasks, including (73.8%, +5.8%) on SWE-bench, (66.7%, +12.9%) on SWE-bench Multilingual, and (41%, +16.5%) on Terminal Bench 2.0. GLM-4.7 also supports thinking before acting, with significant improvements on complex tasks in mainstream agent frameworks such as Claude Code, Kilo Code, Cline, and Roo Code.
- **Vibe Coding**: GLM-4.7 takes a big step forward in improving UI quality. It produces cleaner, more modern webpages and generates better-looking slides with more accurate layout and sizing.
- **Tool Using**: GLM-4.7 achieves significantly improvements in Tool using. Significant better performances can be seen on benchmarks such as τ^2-Bench and on web browsing via BrowseComp.
- **Complex Reasoning**: GLM-4.7 delivers a substantial boost in mathematical and reasoning capabilities, achieving (42.8%, +12.4%) on the HLE (Humanity’s Last Exam) benchmark compared to GLM-4.6.
You can also see significant improvements in many other scenarios such as chat, creative writing, and role-play scenario.
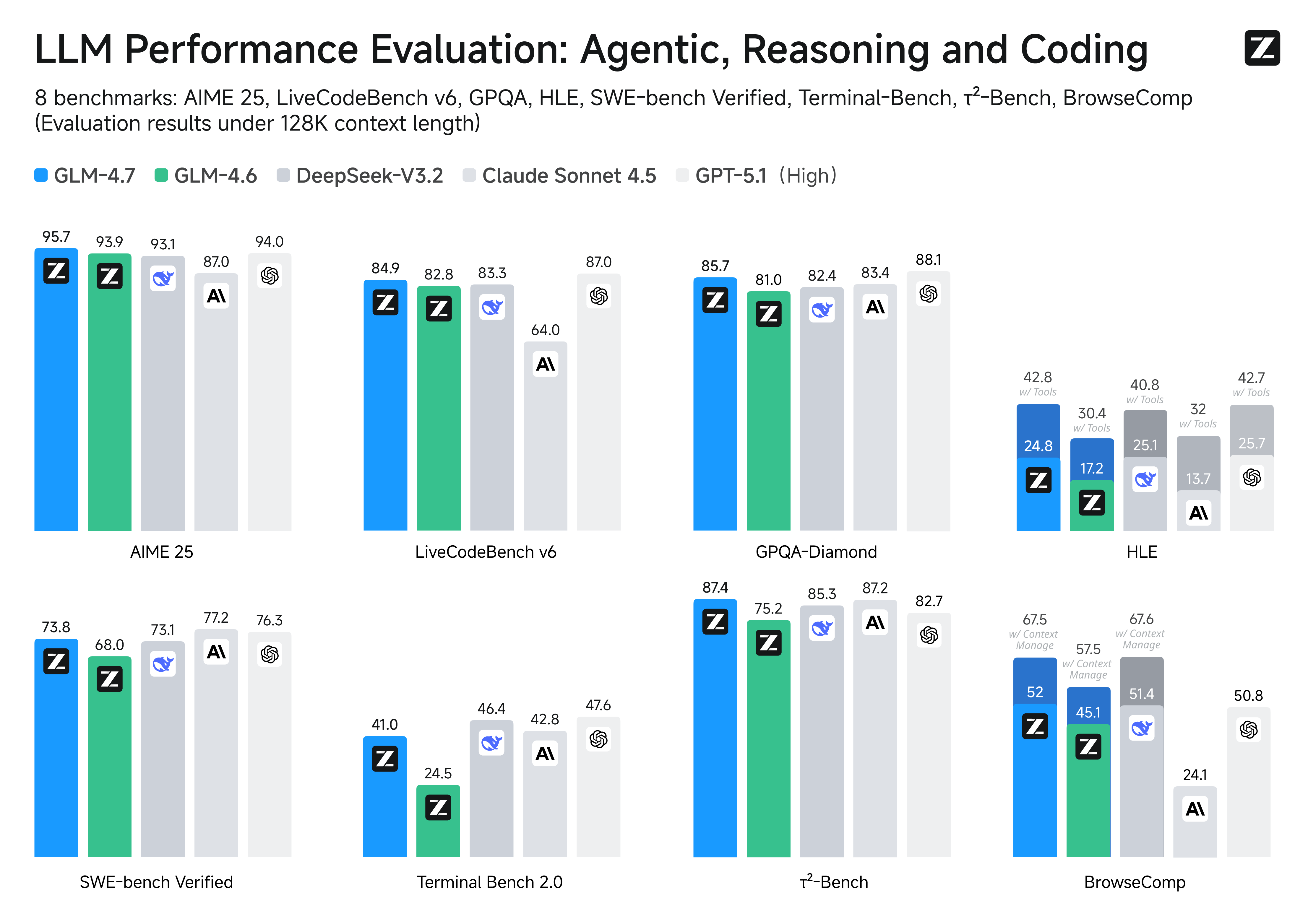
**Performances on Benchmarks.** More detailed comparisons of GLM-4.7 with other models GPT-5-High, GPT-5.1-High, Claude Sonnet 4.5, Gemini 3.0 Pro, DeepSeek-V3.2, Kimi K2 Thinking, on 17 benchmarks (including 8 reasoning, 5 coding, and 3 agents benchmarks) can be seen in the below table.
| Benchmark | GLM-4.7 | GLM-4.6 | Kimi K2 Thinking | DeepSeek-V3.2 | Gemini 3.0 Pro | Claude Sonnet 4.5 | GPT-5-High | GPT-5.1-High |
|:-------------------------------|:-------:|:-------:|:----------------:|:-------------:|:--------------:|:-----------------:|:----------:|:------------:|
| MMLU-Pro | 84.3 | 83.2 | 84.6 | 85.0 | 90.1 | 88.2 | 87.5 | 87.0 |
| GPQA-Diamond | 85.7 | 81.0 | 84.5 | 82.4 | 91.9 | 83.4 | 85.7 | 88.1 |
| HLE | 24.8 | 17.2 | 23.9 | 25.1 | 37.5 | 13.7 | 26.3 | 25.7 |
| HLE (w/ Tools) | 42.8 | 30.4 | 44.9 | 40.8 | 45.8 | 32.0 | 35.2 | 42.7 |
| AIME 2025 | 95.7 | 93.9 | 94.5 | 93.1 | 95.0 | 87.0 | 94.6 | 94.0 |
| HMMT Feb. 2025 | 97.1 | 89.2 | 89.4 | 92.5 | 97.5 | 79.2 | 88.3 | 96.3 |
| HMMT Nov. 2025 | 93.5 | 87.7 | 89.2 | 90.2 | 93.3 | 81.7 | 89.2 | - |
| IMOAnswerBench | 82.0 | 73.5 | 78.6 | 78.3 | 83.3 | 65.8 | 76.0 | - |
| LiveCodeBench-v6 | 84.9 | 82.8 | 83.1 | 83.3 | 90.7 | 64.0 | 87.0 | 87.0 |
| SWE-bench Verified | 73.8 | 68.0 | 71.3 | 73.1 | 76.2 | 77.2 | 74.9 | 76.3 |
| SWE-bench Multilingual | 66.7 | 53.8 | 61.1 | 70.2 | - | 68.0 | 55.3 | - |
| Terminal Bench Hard | 33.3 | 23.6 | 30.6 | 35.4 | 39.0 | 33.3 | 30.5 | 43.0 |
| Terminal Bench 2.0 | 41.0 | 24.5 | 35.7 | 46.4 | 54.2 | 42.8 | 35.2 | 47.6 |
| BrowseComp | 52.0 | 45.1 | - | 51.4 | - | 24.1 | 54.9 | 50.8 |
| BrowseComp (w/ Context Manage) | 67.5 | 57.5 | 60.2 | 67.6 | 59.2 | - | - | - |
| BrowseComp-Zh | 66.6 | 49.5 | 62.3 | 65.0 | - | 42.4 | 63.0 | - |
| τ²-Bench | 87.4 | 75.2 | 74.3 | 85.3 | 90.7 | 87.2 | 82.4 | 82.7 |
> **Coding:** AGI is a long journey, and benchmarks are only one way to evaluate performance. While the metrics provide necessary checkpoints, the most important thing is still how it *feels*. True intelligence isn't just about acing a test or processing data faster; ultimately, the success of AGI will be measured by how seamlessly it integrates into our lives-**"coding"** this time.
## Getting started with GLM-4.7
### Interleaved Thinking & Preserved Thinking
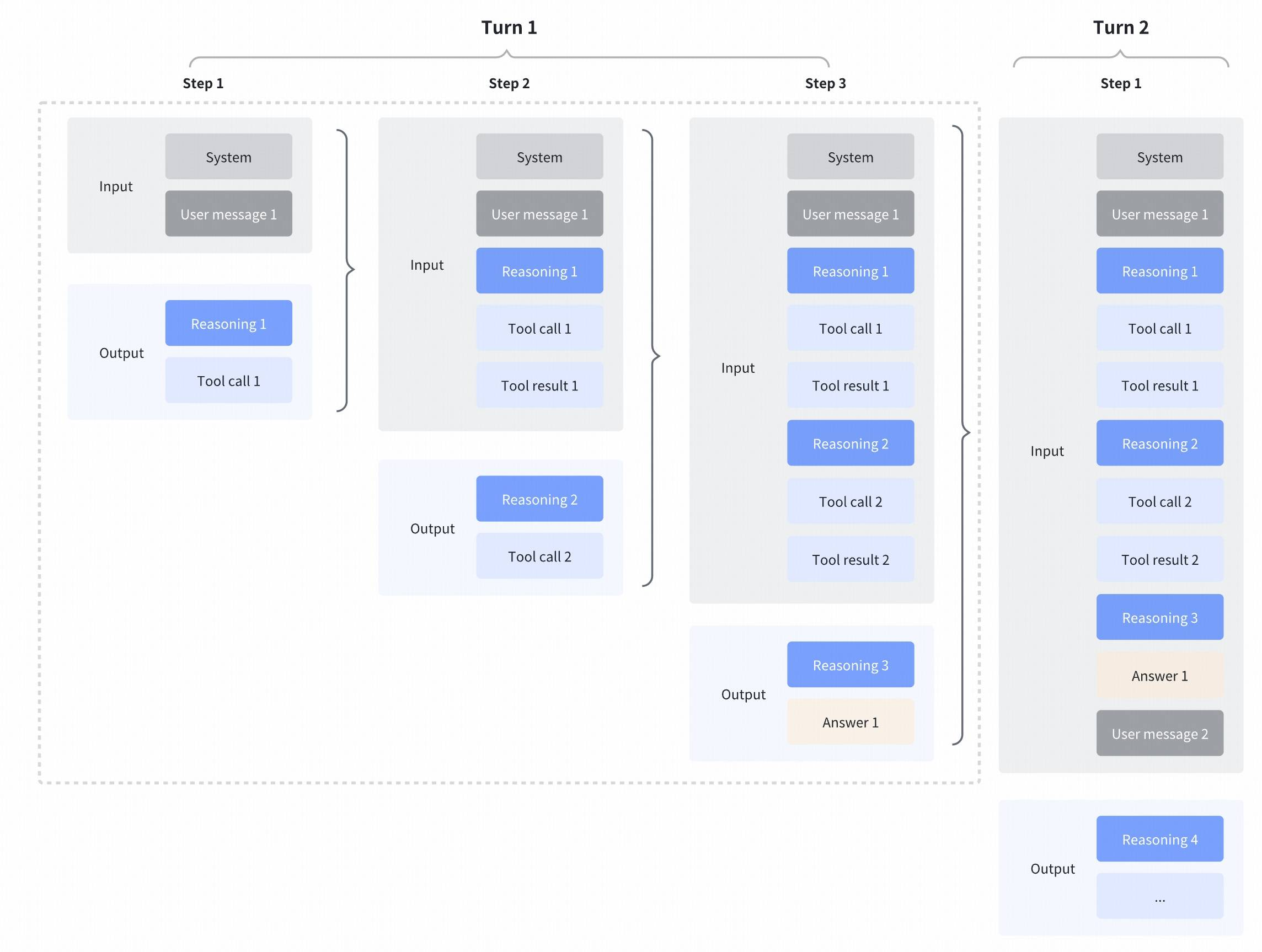
GLM-4.7 further enhances **Interleaved Thinking** (a feature introduced since GLM-4.5) and introduces **Preserved Thinking** and **Turn-level Thinking**. By thinking between actions and staying consistent across turns, it makes complex tasks more stable and more controllable:
- **Interleaved Thinking**: The model thinks before every response and tool calling, improving instruction following and the quality of generation.
- **Preserved Thinking**: In coding agent scenarios, the model automatically retains all thinking blocks across multi-turn conversations, reusing the existing reasoning instead of re-deriving from scratch. This reduces information loss and inconsistencies, and is well-suited for long-horizon, complex tasks.
- **Turn-level Thinking**: The model supports per-turn control over reasoning within a session—disable thinking for lightweight requests to reduce latency/cost, enable it for complex tasks to improve accuracy and stability.
More details: https://docs.z.ai/guides/capabilities/thinking-mode
### Evaluation Parameters
**Default Settings (Most Tasks)**
* temperature: `1.0`
* top-p: `0.95`
* max new tokens: `131072`
For multi-turn agentic tasks (τ²-Bench and Terminal Bench 2), please turn on [Preserved Thinking mode](https://docs.z.ai/guides/capabilities/thinking-mode).
**Terminal Bench, SWE Bench Verified**
* temperature: `0.7`
* top-p: `1.0`
* max new tokens: `16384`
**τ^2-Bench**
* Temperature: `0`
* Max new tokens: `16384`
For τ^2-Bench evaluation, we added an additional prompt to the Retail and Telecom user interaction to avoid failure modes caused by users ending the interaction incorrectly. For the Airline domain, we applied the domain fixes as proposed in the [Claude Opus 4.5](https://assets.anthropic.com/m/64823ba7485345a7/Claude-Opus-4-5-System-Card.pdf) release report.
## Serve GLM-4.7 Locally
For local deployment, GLM-4.7 supports inference frameworks including vLLM and SGLang. Comprehensive deployment instructions are available in the official [Github](https://github.com/zai-org/GLM-4.5) repository.
vLLM and SGLang only support GLM-4.7 on their main branches. you can use their official docker images for inference.
### vLLM
Using Docker as:
```shell
docker pull vllm/vllm-openai:nightly
```
or using pip (must use pypi.org as the index url):
```shell
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
```
### SGLang
Using Docker as:
```shell
docker pull lmsysorg/sglang:dev
```
or using pip install sglang from source.
### transformers
using with transformers as `4.57.3` and then run:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "zai-org/GLM-4.7"
messages = [{"role": "user", "content": "hello"}]
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
model = AutoModelForCausalLM.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto",
)
inputs = inputs.to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=128, do_sample=False)
output_text = tokenizer.decode(generated_ids[0][inputs.input_ids.shape[1] :])
print(output_text)
```
### vLLM
```shell
vllm serve zai-org/GLM-4.7-FP8 \
--tensor-parallel-size 4 \
--speculative-config.method mtp \
--speculative-config.num_speculative_tokens 1 \
--tool-call-parser glm47 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--served-model-name glm-4.7-fp8
```
### SGLang
```shell
python3 -m sglang.launch_server \
--model-path zai-org/GLM-4.7-FP8 \
--tp-size 8 \
--tool-call-parser glm47 \
--reasoning-parser glm45 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--mem-fraction-static 0.8 \
--served-model-name glm-4.7-fp8 \
--host 0.0.0.0 \
--port 8000
```
### Parameter Instructions
- For agentic tasks of GLM-4.7, please turn on [Preserved Thinking mode](https://docs.z.ai/guides/capabilities/thinking-mode) by adding the following config (only sglang support):
```
"chat_template_kwargs": {
"enable_thinking": true,
"clear_thinking": false
}
```
- When using `vLLM` and `SGLang`, thinking mode is enabled by default when sending requests. If you want to disable the thinking switch, you need to add the `extra_body={"chat_template_kwargs": {"enable_thinking": False}}` parameter.
- Both support tool calling. Please use OpenAI-style tool description format for calls.
## Citation
If you find our work useful in your research, please consider citing the following paper:
```bibtex
@misc{5team2025glm45agenticreasoningcoding,
title={GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models},
author={GLM Team and Aohan Zeng and Xin Lv and Qinkai Zheng and Zhenyu Hou and Bin Chen and Chengxing Xie and Cunxiang Wang and Da Yin and Hao Zeng and Jiajie Zhang and Kedong Wang and Lucen Zhong and Mingdao Liu and Rui Lu and Shulin Cao and Xiaohan Zhang and Xuancheng Huang and Yao Wei and Yean Cheng and Yifan An and Yilin Niu and Yuanhao Wen and Yushi Bai and Zhengxiao Du and Zihan Wang and Zilin Zhu and Bohan Zhang and Bosi Wen and Bowen Wu and Bowen Xu and Can Huang and Casey Zhao and Changpeng Cai and Chao Yu and Chen Li and Chendi Ge and Chenghua Huang and Chenhui Zhang and Chenxi Xu and Chenzheng Zhu and Chuang Li and Congfeng Yin and Daoyan Lin and Dayong Yang and Dazhi Jiang and Ding Ai and Erle Zhu and Fei Wang and Gengzheng Pan and Guo Wang and Hailong Sun and Haitao Li and Haiyang Li and Haiyi Hu and Hanyu Zhang and Hao Peng and Hao Tai and Haoke Zhang and Haoran Wang and Haoyu Yang and He Liu and He Zhao and Hongwei Liu and Hongxi Yan and Huan Liu and Huilong Chen and Ji Li and Jiajing Zhao and Jiamin Ren and Jian Jiao and Jiani Zhao and Jianyang Yan and Jiaqi Wang and Jiayi Gui and Jiayue Zhao and Jie Liu and Jijie Li and Jing Li and Jing Lu and Jingsen Wang and Jingwei Yuan and Jingxuan Li and Jingzhao Du and Jinhua Du and Jinxin Liu and Junkai Zhi and Junli Gao and Ke Wang and Lekang Yang and Liang Xu and Lin Fan and Lindong Wu and Lintao Ding and Lu Wang and Man Zhang and Minghao Li and Minghuan Xu and Mingming Zhao and Mingshu Zhai and Pengfan Du and Qian Dong and Shangde Lei and Shangqing Tu and Shangtong Yang and Shaoyou Lu and Shijie Li and Shuang Li and Shuang-Li and Shuxun Yang and Sibo Yi and Tianshu Yu and Wei Tian and Weihan Wang and Wenbo Yu and Weng Lam Tam and Wenjie Liang and Wentao Liu and Xiao Wang and Xiaohan Jia and Xiaotao Gu and Xiaoying Ling and Xin Wang and Xing Fan and Xingru Pan and Xinyuan Zhang and Xinze Zhang and Xiuqing Fu and Xunkai Zhang and Yabo Xu and Yandong Wu and Yida Lu and Yidong Wang and Yilin Zhou and Yiming Pan and Ying Zhang and Yingli Wang and Yingru Li and Yinpei Su and Yipeng Geng and Yitong Zhu and Yongkun Yang and Yuhang Li and Yuhao Wu and Yujiang Li and Yunan Liu and Yunqing Wang and Yuntao Li and Yuxuan Zhang and Zezhen Liu and Zhen Yang and Zhengda Zhou and Zhongpei Qiao and Zhuoer Feng and Zhuorui Liu and Zichen Zhang and Zihan Wang and Zijun Yao and Zikang Wang and Ziqiang Liu and Ziwei Chai and Zixuan Li and Zuodong Zhao and Wenguang Chen and Jidong Zhai and Bin Xu and Minlie Huang and Hongning Wang and Juanzi Li and Yuxiao Dong and Jie Tang},
year={2025},
eprint={2508.06471},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.06471},
}
|