---
language:
- en
license: apache-2.0
pipeline_tag: text-generation
library_name: transformers
tags:
- llm
- instruction-tuned
- text-generation
- text-classification
- sql-generation
- reasoning
- lora
- lightweight
- safetensors
- causal-lm
base_model: unsloth/Phi-3-mini-4k-instruct-bnb-4bit
fine_tuned_from: unsloth/Phi-3-mini-4k-instruct-bnb-4bit
organization: QuantaSparkLabs
model_type: causal-lm
model_index:
- name: Antiplex-Instruct-3B
results:
- task:
type: text-generation
name: SQL Generation
metrics:
- type: accuracy
value: 100
- task:
type: text-classification
name: Intent Detection
metrics:
- type: accuracy
value: 66.7
---

Antiplex-Instruct-3B
A compact, instruction-tuned large language model optimized for Text Generation, Intent Classification, and SQL Reasoning.




---
## 📋 Overview
**Antiplex-Instruct-3B** is a high-performance instruction-tuned language model developed by **QuantaSparkLabs**. Released in 2026, this model is engineered for dual-task capability, delivering accurate identity alignment, reliable SQL generation, and strong general reasoning, while remaining lightweight and efficient.
The model is fine-tuned using **LoRA (PEFT)** on curated datasets emphasizing identity consistency and structured reasoning, making it ideal for edge deployment and specialized assistant roles.
## ✨ Core Features
| 🎯 Task Versatility | ⚡ Performance Optimized |
| :--- | :--- |
| **Text Generation**: SQL/NLP, creative writing, technical explanations. | **LoRA Fine-tuning**: Efficient parameter adaptation. |
| **Classification**: Intent detection, task routing, safety filtering. | **Identity Alignment**: Consistent persona across interactions. |
| **Dual-Mode**: Single model handling generation + classification. | **Lightweight**: ~3.8B parameters, edge-friendly VRAM footprint. |
---
## 📊 Performance Benchmarks
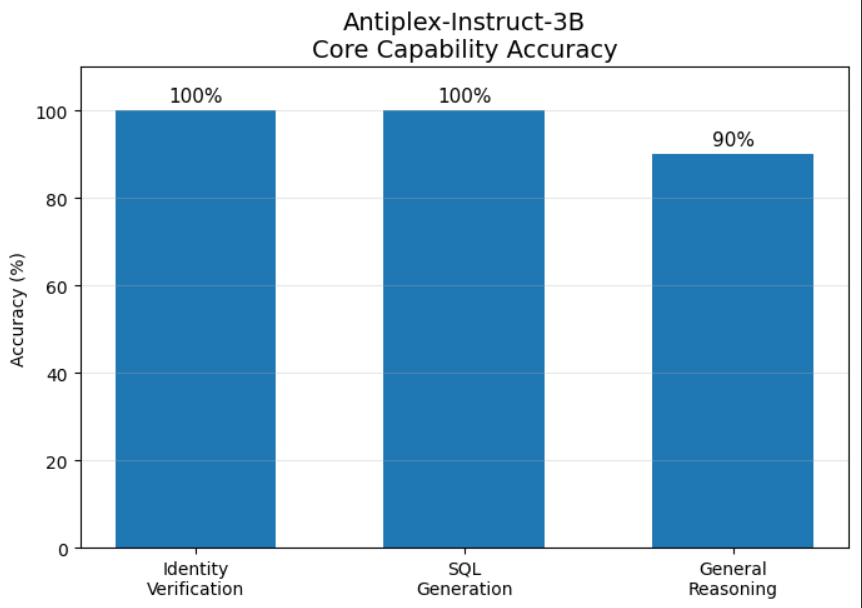
### 🏆 Accuracy Metrics
| Task | Accuracy | Confidence |
| :--- | :--- | :--- |
| Identity Verification | 100% | ⭐⭐⭐⭐⭐ |
| SQL Generation | 100% | ⭐⭐⭐⭐⭐ |
| General Reasoning | 90% | ⭐⭐⭐⭐ |
### 🔬 Reliability Assessment
**21-Test Internal Validation Suite**
* **Passed:** 16 tests (76.2%)
* **Failed:** 5 tests (23.8%)
* **Overall Grade:** B (Good)

📈 View Detailed Test Categories
| Category | Tests | Passed | Rate |
| :--- | :--- | :--- | :--- |
| Identity Tasks | 7 | 7 | 100% |
| SQL Generation | 6 | 6 | 100% |
| Reasoning | 5 | 3 | 60% |
| Classification | 3 | 2 | 66.7% |
**Test Dataset:** `QuantaSparkLabs/antiplex-test-suite`
---
## 🏗️ Model Architecture
### Training Pipeline
```mermaid
graph TD
A[Base Model Phi-3-mini] --> B[LoRA Fine-tuning]
B --> C[Task-Specific Heads]
C --> D[Text Generation Head]
C --> E[Classification Head]
D --> F[Generation Output]
E --> G[Classification Output]
H[Instruction Dataset] --> B
I[SQL Dataset] --> B
J[Identity Dataset] --> B
```

### Inference Flow
```
User Prompt → Tokenization → Antiplex Core → Task Router
↓
[Generation/Classification] → Post-processing → Output
```
---
## 🔧 Technical Specifications
| Parameter | Value |
| :--- | :--- |
| **Base Model** | `unsloth/Phi-3-mini-4k-instruct-bnb-4bit` |
| **Fine-tuning** | LoRA (PEFT) |
| **Rank (r)** | 16 |
| **Alpha (α)** | 32 |
| **Optimizer** | AdamW (β₁=0.9, β₂=0.999) |
| **Learning Rate** | 2e-4 |
| **Batch Size** | 8 |
| **Epochs** | 3 |
| **Total Parameters** | ~3.8B |
### Dataset Composition
| Dataset Type | Samples | Purpose |
| :--- | :--- | :--- |
| Identity Alignment | 30 | Consistent persona training |
| SQL Generation | 300 | Structured query training |
| Instruction Tuning | 2,500 | General capability enhancement |
| Classification | 1,000 | Intent detection training |
---
## 💻 Quick Start
### Installation
```bash
pip install transformers torch accelerate
```
### Basic Usage (Text Generation)
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "QuantaSparkLabs/Antiplex-instruct-3B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto"
)
prompt = "Write an SQL query to fetch users created in the last 30 days."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=256,
temperature=0.7,
top_p=0.9,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
### Classification Mode
```python
# Intent classification example
classification_prompt = """[CLASSIFY]
User Query: "I need to reset my account password"
Categories: account_issue, technical_support, billing, general_inquiry
"""
inputs = tokenizer(classification_prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=64,
temperature=0.3,
do_sample=False
)
detected_intent = tokenizer.decode(outputs[0], skip_special_tokens=True).split('[')[-1].split(']')[0]
print(f"Detected Intent: {detected_intent}")
```
### Chat Interface
```python
from transformers import pipeline
chatbot = pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
device=0 if torch.cuda.is_available() else -1
)
messages = [
{"role": "system", "content": "You are Antiplex, a helpful AI assistant specialized in SQL and classification tasks."},
{"role": "user", "content": "Classify this intent: 'Can you help me with invoice generation?' Then write a SQL query to find recent invoices."}
]
response = chatbot(messages, max_new_tokens=512, temperature=0.7)
print(response[0]['generated_text'][-1]['content'])
```
---
## 🚀 Deployment Options
### Hardware Requirements
| Environment | VRAM | Quantization | Speed |
| :--- | :--- | :--- | :--- |
| **GPU (Optimal)** | 8-12 GB | FP16 | ⚡ Fast |
| **GPU (Efficient)** | 4-6 GB | INT8 | ⚡ Fast |
| **CPU** | N/A | FP32 | 🐌 Slow |
| **Edge Device** | 2-4 GB | INT4 | ⚡ Fast |
### Cloud Deployment (Docker)
```dockerfile
FROM pytorch/pytorch:2.0.1-cuda11.7-cudnn8-runtime
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["python", "app.py"]
```
---
## 📁 Repository Structure
```
Antiplex-Instruct-3B/
├── README.md
├── model.safetensors
├── config.json
├── tokenizer.json
├── tokenizer_config.json
├── generation_config.json
├── special_tokens_map.json
├── quantasparklogo.png
├── examples/
│ ├── classification_demo.py
│ ├── sql_generation_demo.py
│ └── chat_interface.py
└── evaluation/
└── test_results.json
```
---
## ⚠️ Limitations & Safety
### Known Limitations
- **Domain Specificity**: Not trained for medical/legal/safety-critical domains
- **Bias Inheritance**: May reflect biases in training data
- **Context Window**: Limited to 4K tokens
- **Multilingual**: Primarily English-focused
### Safety Guidelines
```python
# Recommended safety wrapper
def safety_check(text):
blocked_terms = ["harmful", "dangerous", "illegal", "exploit"]
if any(term in text.lower() for term in blocked_terms):
return "Content filtered for safety reasons."
return text
```
---
## 🔄 Version History
| Version | Date | Changes |
| :--- | :--- | :--- |
| v1.0.0 | 2026-01-1 | Initial release |
| v1.1.0 | 2026-01-10 | Enhanced classification head |
| v1.2.0 | 2026-01-25 | SQL generation improvements |
---
## 📄 License & Citation
**License:** Apache 2.0
**Citation:**
```bibtex
@misc{antiplex2026,
title={Antiplex-Instruct-3B: A Dual-Task Instruction-Tuned Language Model},
author={QuantaSparkLabs},
year={2026},
url={https://huggingface.co/QuantaSparkLabs/Antiplex-instruct-3B}
}
```
---
## 👥 Credits & Acknowledgments
- **Base Model**: Microsoft Phi-3 Mini team
- **Fine-tuning Framework**: Unsloth for efficient LoRA training
- **Evaluation**: Internal QuantaSparkLabs team
- **Testing**: Community contributors
---
## 🤝 Contributing & Support
### Reporting Issues
Please open an issue on our repository with:
1. Model version
2. Reproduction steps
3. Expected vs actual behavior
---
Built with ❤️ by QuantaSparkLabs
Model ID: Antiplex-Instruct-3B • Parameters: ~3.8B • Release: 2026

>Special thanks to microsoft!