
File size: 14,081 Bytes
1f9bc58 | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 | ---
library_name: vllm
language:
- en
- fr
- es
- de
- ru
- zh
- ja
- it
- pt
- nl
- ar
- hi
- ko
license: apache-2.0
inference: false
base_model:
- mistralai/Ministral-3-3B-Base-2512
extra_gated_description: >-
If you want to learn more about how we process your personal data, please read
our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
pipeline_tag: automatic-speech-recognition
tags:
- mistral-common
---
# Voxtral Mini 4B Realtime 2602
Voxtral Mini 4B Realtime 2602 is a **multilingual, realtime speech-transcription model** and among the first open-source solutions to achieve accuracy comparable to offline systems with a delay of **<500ms**.
It supports **13 languages** and outperforms existing open-source baselines across a range of tasks, making it ideal for applications like voice assistants and live subtitling.
Built with a **natively streaming architecture** and a custom causal audio encoder - it allows configurable transcription delays (240ms to 2.4s), enabling users to balance **latency and accuracy** based on their needs.
At a **480ms delay**, it matches the performance of leading offline open-source transcription models, as well as realtime APIs.
As a **4B-parameter model**, is optimized for **on-device deployment**, requiring minimal hardware resources.
It runs in realtime with on devices minimal hardware with throughput exceeding 12.5 tokens/second.
This model is released in **BF16** under the **Apache-2 license**, ensuring flexibility for both research and commercial use.
For more details, see our:
- [Blog post](https://mistral.ai/news/voxtral-transcribe-2)
- [Demo](https://huggingface.co/spaces/mistralai/Voxtral-Mini-Realtime)
- [Technical report](https://arxiv.org/abs/2602.11298)
- [vLLM's blog on streaming input](https://blog.vllm.ai/2026/01/31/streaming-realtime.html)
## Key Features
Voxtral Mini 4B Realtime consists of two main architectural components:
- **≈3.4B Language Model**
- **≈970M Audio Encoder**
- The audio encoder was trained from scratch with causal attention enabling streaming capability
- Both the audio encoder as well as the LLM backbone use sliding window attention allowing for "infinite" streaming
- For more details, refer to the [technical report](https://arxiv.org/abs/2602.11298)
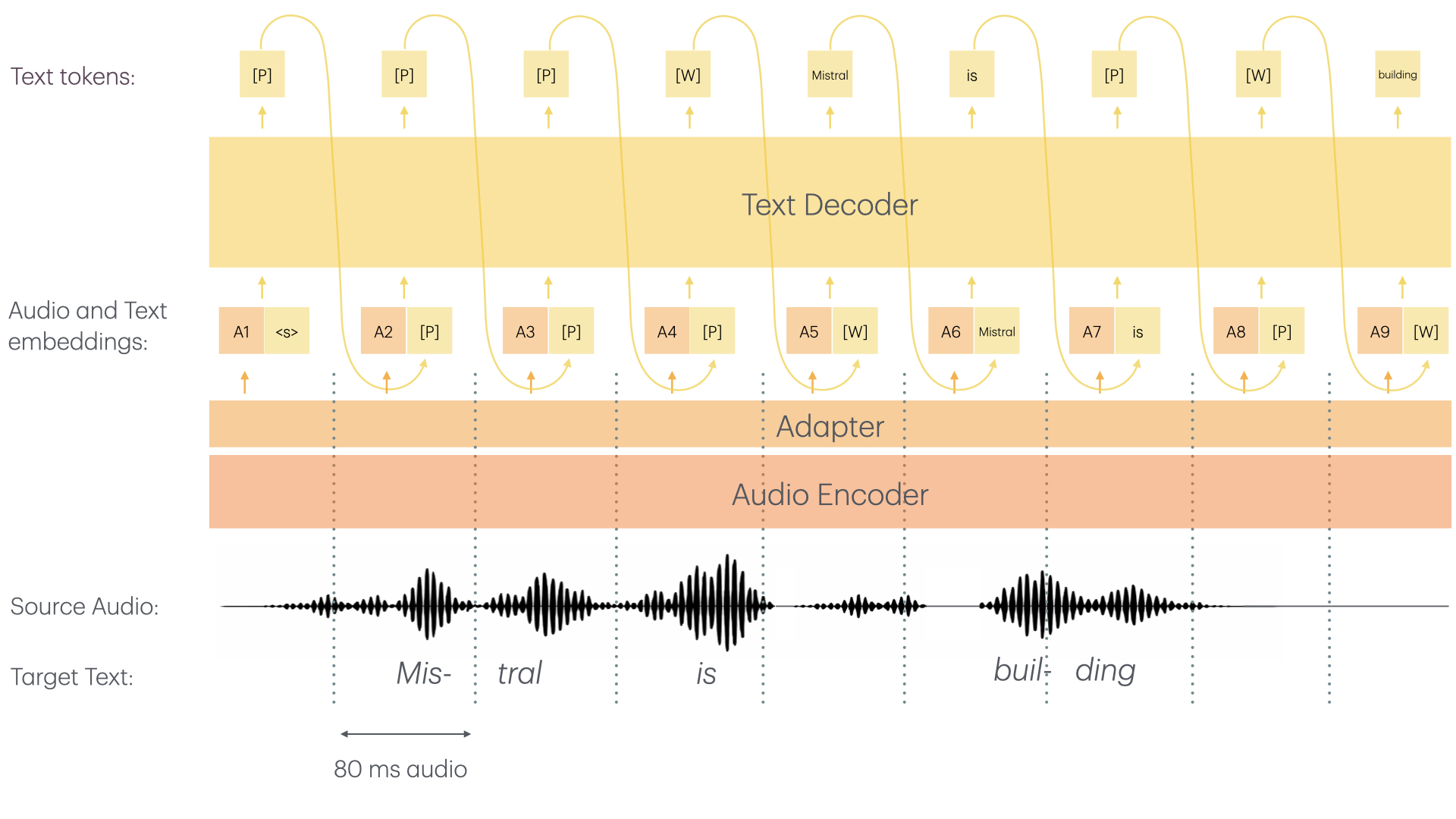
The Voxtral Mini 4B Realtime model offers the following capabilities:
- **High-Quality Transcription**: Transcribe audio to text with confidence.
- **Multilingual**: Supports dozens of languages, making it perfect for multilingual transcription tasks.
- **Real-Time**: Fast streaming ASR model, enabling real-time transcription use cases.
- **Configurable Transcription Delays**: Customize the transcription delay to balance quality and latency, from 80ms to 2.4s.
### Use Cases
**Real-Time Transcription Purposes:**
- Private meeting transcriptions
- Live subtitle creation
- Real-time assistants with speech understanding
- And more
Bringing real-time transcription capabilities to all.
### Recommended Settings
We recommend deploying with the following best practices:
- Always set the temperature to 0.0
- A single text-token is worth 80ms. Hence, make sure to set your `--max-model-len` accordingly. To live-record a 1h meeting, you need to set `--max-model-len >= 3600 / 0.8 = 45000`.
In theory, you should be able to record with no limit; in practice, pre-allocations of RoPE parameters among other things limits `--max-model-len`.
For the best user experience, we recommend to simply instantiate vLLM with the default parameters which will automatically set a maximum model length of 131072 (~ca. 3h).
- We strongly recommend using websockets to set up audio streaming sessions. For more info on how to do so, check [Usage](#usage).
- We recommend using a delay of 480ms as we found it to be the sweet spot of performance and low latency. If, however, you want to adapt the delay, you can change the `"transcription_delay_ms": 480` parameter
in the [tekken.json](https://huggingface.co/mistralai/Voxtral-Mini-4B-Realtime-2602/blob/main/params.json) file to any multiple of 80ms between 80 and 1200, as well as 2400 as a standalone value.
## Benchmark Results
We compare Voxtral Mini 4B Realtime to similar models - both offline models and realtime.
Voxtral Mini 4B Realtime is competitive to leading offline models and shows significant gains over existing open-source realtime solutions.
### Fleurs
| Model | Delay | AVG | Arabic | German | English | Spanish | French | Hindi | Italian | Dutch | Portuguese | Chinese | Japanese | Korean | Russian |
|-----------------------------------------|-------------|---------|--------|--------|---------|---------|--------|--------|---------|-------|------------|---------|----------|--------|---------|
| Voxtral Mini Transcribe 2.0 | Offline | 5.90% | 13.54% | 3.54% | 3.32% | 2.63% | 4.32% | 10.33% | 2.17% | 4.78% | 3.56% | 7.30% | 4.14% | 12.29% | 4.75% |
| **Voxtral Mini 4B Realtime 2602** | 480 ms | 8.72% | 22.53% | 6.19% | 4.90% | 3.31% | 6.42% | 12.88% | 3.27% | 7.07% | 5.03% | 10.45% | 9.59% | 15.74% | 6.02% |
| | | | | | | | | | | | | | | | |
| | 160 ms | 12.60% | 24.33% | 9.50% | 6.46% | 5.34% | 9.75% | 15.28% | 5.59% | 11.39%| 10.01% | 17.67% | 19.17% | 19.81% | 9.53% |
| | 240 ms | 10.80% | 23.95% | 8.15% | 5.91% | 4.59% | 8.00% | 14.26% | 4.41% | 9.23% | 7.51% | 13.84% | 15.17% | 17.56% | 7.87% |
| | 960 ms | 7.70% | 20.32% | 4.87% | 4.34% | 2.98% | 5.68% | 11.82% | 2.46% | 6.76% | 4.57% | 8.99% | 6.80% | 14.90% | 5.56% |
| | 2400 ms | 6.73% | 14.71% | 4.15% | 4.05% | 2.71% | 5.23% | 10.73% | 2.37% | 5.91% | 3.93% | 8.48% | 5.50% | 14.30% | 5.41% |
### Long-form English
| Model | Delay | Meanwhile (<10m) | E-21 (<10m) | E-22 (<10m) | TEDLIUM (<20m) |
| ---------------------------------- | ------ | ---------------- | ----------- | ----------- | -------------- |
| Voxtral Mini Transcribe 2.0 | Offline| 4.08% | 9.81% | 11.69% | 2.86% |
| **Voxtral Mini 4B Realtime 2602** | 480ms | 5.05% | 10.23% | 12.30% | 3.17% |
### Short-form English
| Model | Delay | CHiME-4 | GigaSpeech 2k Subset | AMI IHM | SwitchBoard | CHiME-4 SP | GISpeech 2k Subset |
| ---------------------------------- | ------ | ------- | -------------------- | ------- | ----------- | ---------- | ------------------ |
| Voxtral Mini Transcribe 2.0 | Offline | 10.39% | 6.81% | 14.43% | 11.54% | 10.42% | 1.74% |
| **Voxtral Mini 4B Realtime 2602** | 480ms | 10.50% | 7.35% | 15.05% | 11.65% | 12.41% | 1.73% |
## Usage
The model can also be deployed with the following libraries:
- [`vllm (recommended)`](https://github.com/vllm-project/vllm): See [here](#vllm-recommended)
- [`transformers`](https://github.com/huggingface/transformers): See [here](#transformers)
- *Community Contributions*: See [here](#community-contributions-untested)
### vLLM (recommended)
> [!Tip]
> We've worked hand-in-hand with the vLLM team to have production-grade support for Voxtral Mini 4B Realtime 2602 with vLLM.
> Special thanks goes out to [Joshua Deng](https://github.com/joshuadeng), [Yu Luo](https://github.com/ErickLuo90), [Chen Zhang](https://github.com/heheda12345), [Nick Hill](https://github.com/njhill), [Nicolò Lucchesi](https://github.com/NickLucche), [Roger Wang](https://github.com/ywang96), and [Cyrus Leung](https://github.com/DarkLight1337)
> for the amazing work and help on building a production-ready audio streaming and realtime system in vLLM.
> [!Warning]
> Due to its novel architecture, Voxtral Realtime is currently only support in vLLM. We very much welcome community contributions
> to add the architecture to [Transformers](https://github.com/huggingface/transformers) and [Llama.cpp](https://github.com/ggml-org/llama.cpp).
We've worked hand-in-hand with the vLLM team to have production-grade support for Voxtral Mini 4B Realtime 2602 with vLLM.
[vLLM](https://github.com/vllm-project/vllm)'s [new Realtime API](https://docs.vllm.ai/en/latest/serving/openai_compatible_server/?h=realtime#realtime-api) is perfectly suited to
run audio streaming sessions with the model.
#### Installation
Make sure to install [vllm](https://github.com/vllm-project/vllm) from the nightly pypi package.
See [here](https://docs.vllm.ai/en/latest/getting_started/installation/) for a full installation guide.
```
uv pip install -U vllm \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly # add variant subdirectory here if needed
```
Doing so should automatically install [`mistral_common >= 1.9.0`](https://github.com/mistralai/mistral-common/releases/tag/v1.9.0).
To check:
```
python -c "import mistral_common; print(mistral_common.__version__)"
```
You can also make use of a ready-to-go [docker image](https://github.com/vllm-project/vllm/blob/main/docker/Dockerfile) or on the [docker hub](https://hub.docker.com/layers/vllm/vllm-openai/nightly/images/sha256-6ae33f5001ab9d32346ce2c82c660fe57021c4f0c162ed0c60b843319829b810).
Make sure to also install all required audio processing libraries:
```
uv pip install soxr librosa soundfile
```
Also we recommend using Transformers v5 as v4 can clutter the terminal with unnecessary warnings (see [here](https://github.com/vllm-project/vllm/issues/34642))
```
uv pip install --upgrade transformers
```
#### Serve
Due to size and the BF16 format of the weights - `Voxtral-Mini-4B-Realtime-2602` can run on a single GPU with >= 16GB memory.
The model can be launched in both "eager" mode:
```bash
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve mistralai/Voxtral-Mini-4B-Realtime-2602 --compilation_config '{"cudagraph_mode": "PIECEWISE"}'
```
Additional flags:
* You can set `--max-num-batched-tokens` to balance throughput and latency, higher means higher throughput but higher latency.
* You can reduce the default `--max-model-len` to allocate less memory for the pre-computed RoPE frequencies,
if you are certain that you won't have to transcribe for more than X hours. By default the model uses a `--max-model-len` of 131072 (> 3h).
#### Client
After serving `vllm`, you should see that the model is compatible with `vllm's` new realtime endpoint:
```
...
(APIServer pid=3246965) INFO 02-03 17:04:43 [launcher.py:58] Route: /v1/realtime, Endpoint: realtime_endpoint
...
```
We have added two simple example files that allow you to:
- [Stream audio files](https://docs.vllm.ai/en/latest/examples/online_serving/openai_realtime_client/?h=realtime#openai-realtime-client)
- [Simple gradio live transcription demo](https://docs.vllm.ai/en/latest/examples/online_serving/openai_realtime_microphone_client/#openai-realtime-microphone-client)
[](https://huggingface.co/spaces/mistralai/Voxtral-Mini-Realtime)
**To try out a demo, click [here](https://huggingface.co/spaces/mistralai/Voxtral-Mini-Realtime)**
### Transformers
Starting with `transformers >= 5.2.0`, you can run Voxtral Realtime natively in Transformers!
For more details, refer to the [Transformers documentation](https://huggingface.co/docs/transformers/main/en/model_doc/voxtral_realtime).
#### Installation
Install Transformers:
```bash
pip install --upgrade transformers
```
Make sure to have `mistral-common` installed with audio dependencies:
```bash
pip install --upgrade "mistral-common[audio]"
```
#### Usage
```python
from transformers import VoxtralRealtimeForConditionalGeneration, AutoProcessor
from mistral_common.tokens.tokenizers.audio import Audio
from huggingface_hub import hf_hub_download
repo_id = "mistralai/Voxtral-Mini-4B-Realtime-2602"
processor = AutoProcessor.from_pretrained(repo_id)
model = VoxtralRealtimeForConditionalGeneration.from_pretrained(repo_id, device_map="auto")
repo_id = "patrickvonplaten/audio_samples"
audio_file = hf_hub_download(repo_id=repo_id, filename="bcn_weather.mp3", repo_type="dataset")
audio = Audio.from_file(audio_file, strict=False)
audio.resample(processor.feature_extractor.sampling_rate)
inputs = processor(audio.audio_array, return_tensors="pt")
inputs = inputs.to(model.device, dtype=model.dtype)
outputs = model.generate(**inputs)
decoded_outputs = processor.batch_decode(outputs, skip_special_tokens=True)
print(decoded_outputs[0])
```
### Community Contributions (Untested)
Voxtral Realtime integrations in:
- [Executorch](https://github.com/pytorch/executorch/tree/main/examples/models/voxtral_realtime) - thanks [Mergen Nachin](https://github.com/mergennachin)
- [Pure C](https://github.com/antirez/voxtral.c) - thanks [Salvatore Sanfilippo](https://github.com/antirez)
- [mlx-audio framework](https://github.com/Blaizzy/mlx-audio) - thanks [Shreyas Karnik](https://github.com/shreyaskarnik)
- [MLX](https://github.com/awni/voxmlx) - thanks [Awni Hannun](https://github.com/awni)
- [Rust](https://github.com/TrevorS/voxtral-mini-realtime-rs) - thanks [TrevorS](https://github.com/TrevorS)
## License
This model is licensed under the [Apache 2.0 License](https://www.apache.org/licenses/LICENSE-2.0.txt).
*You must not use this model in a manner that infringes, misappropriates, or otherwise violates any third party’s rights, including intellectual property rights.* |