---
base_model:
- Qwen2.5-VL
datasets:
- COCO
- ReasonSeg
- CountBench
- Ricky06662/refCOCOg_9k_840
- Ricky06662/VisionReasoner_multi_object_7k_840
language:
- en
library_name: transformers
license: apache-2.0
metrics:
- accuracy
pipeline_tag: image-segmentation
---
# VisionReasoner-7B from the Seg-Zero Framework
This repository contains the **VisionReasoner-7B** model, developed as part of the novel **Seg-Zero** framework, presented in the paper [Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement](https://huggingface.co/papers/2503.06520). This model is also associated with the paper [VisionReasoner: Unified Visual Perception and Reasoning via Reinforcement Learning](https://huggingface.co/papers/2505.12081).
Code: [https://github.com/dvlab-research/Seg-Zero](https://github.com/dvlab-research/Seg-Zero)
Project page: [https://github.com/dvlab-research/Seg-Zero](https://github.com/dvlab-research/Seg-Zero)
## Description
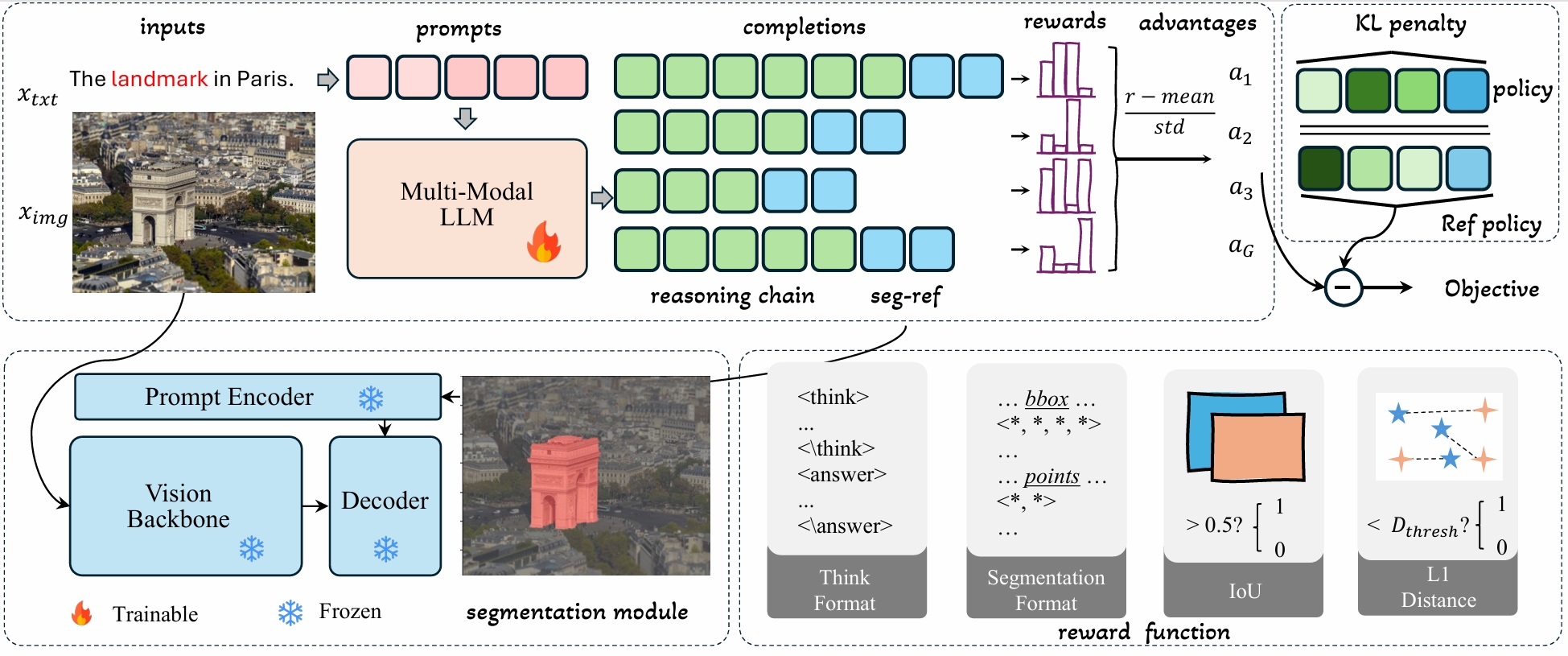
**Seg-Zero** is a novel framework that demonstrates remarkable generalizability and derives explicit chain-of-thought reasoning through cognitive reinforcement for reasoning segmentation. This **VisionReasoner-7B** model employs a decoupled architecture consisting of a reasoning model and a segmentation model. The reasoning model interprets user intentions, generates explicit reasoning chains, and produces positional prompts, which are subsequently used by the segmentation model to generate precise pixel-level masks.
Trained exclusively via reinforcement learning with GRPO and without explicit reasoning data, Seg-Zero achieves robust zero-shot generalization and exhibits emergent test-time reasoning capabilities. Experiments show that Seg-Zero-7B achieves a zero-shot performance of 57.5 on the ReasonSeg benchmark, surpassing the prior LISA-7B by 18%. This significant improvement highlights Seg-Zero's ability to generalize across domains while presenting an explicit reasoning process.
## Usage
You can load and use this model with the `transformers` library:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# load model
model = AutoModelForCausalLM.from_pretrained("Ricky06662/VisionReasoner-7B")
tokenizer = AutoTokenizer.from_pretrained("Ricky06662/VisionReasoner-7B")
```
For full inference examples, including image processing and input formatting, please refer to the project's GitHub repository.
## Citation
If you find our work helpful or inspiring, please feel free to cite our papers:
```bibtex
@article{liu2025segzero,
title = {Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement},
author = {Liu, Yuqi and Peng, Bohao and Zhong, Zhisheng and Yue, Zihao and Lu, Fanbin and Yu, Bei and Jia, Jiaya},
journal = {arXiv preprint arXiv:2503.06520},
year = {2025}
}
@article{liu2025visionreasoner,
title = {VisionReasoner: Unified Visual Perception and Reasoning via Reinforcement Learning},
author = {Liu, Yuqi and Qu, Tianyuan and Zhong, Zhisheng and Peng, Bohao and Liu, Shu and Yu, Bei and Jia, Jiaya},
journal = {arXiv preprint arXiv:2505.12081},
year = {2025}
}
```