---
license: mit
language:
- en
tags:
- html
- css
- tailwind
- code-generation
- from-scratch
- small-model
- text-generation
library_name: transformers
pipeline_tag: text-generation
---
# Indensa-Coder-FrontEnd
⚠️ Note: The native Ollama UI may visually collapse indentation/newlines in generated HTML. This is a UI rendering issue, not a model issue. Verify output in Ollama CLI, VS Code, or by copying the generated text into a code editor.
# Indensa-Coder-FrontEnd
`This is a V1 model. Can be used. V2 is coming soon!`
A 33M parameter decoder-only transformer that takes a text prompt and spits out a bite-sized HTML + Tailwind CSS block. Trained from scratch on my desk in 6 minutes.
This is not a SOTA model. It's not trying to be. It's a small honest model that learned the shape of web components from a curated dataset, and now it can make new ones.
If you wanted GPT-4-level web design, this isn't it. If you wanted a tiny model you can actually run anywhere, including on Ollama with a fast prompt-to-HTML use case, you're in the right place.
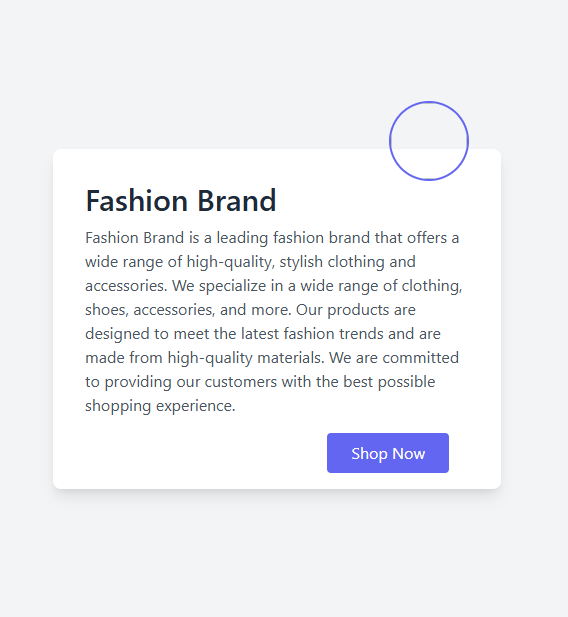 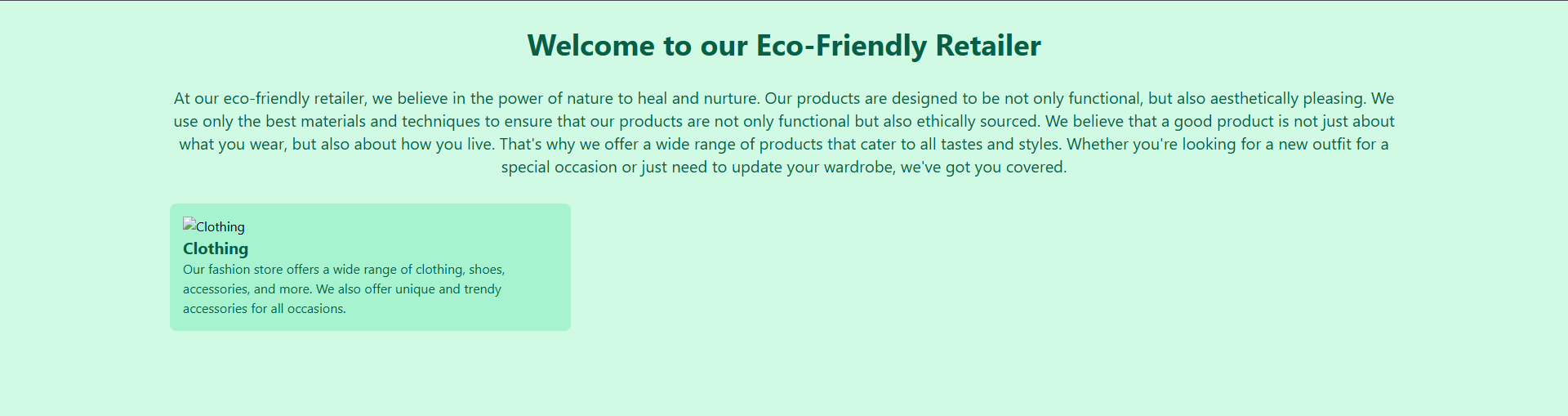
## What it does
You give it something like:
```
PROMPT: a hero section for a SaaS landing page
HTML:
```
And it continues with a real HTML document using Tailwind classes. The output is bite-sized (≤512 tokens by design), so think landing page sections, pricing cards, contact forms, navbars — not entire 10-page websites.
## Sample output
Prompt: *"a publishing house landing page"*
```html
Publishing House
Welcome to our Publishing House
We are a leading publisher of high-quality books...
...
```
That output was checked manually against the training set — no 100% match exists in training data. So it's actually generating, not parroting.
## The honest details
| Thing | Value |
|---|---|
| Parameters | 33.6M |
| Architecture | Decoder-only transformer |
| Layers | 8 |
| d_model | 512 |
| Heads | 8 (head_dim 64) |
| FFN dim | 2048 |
| Block size | 1024 |
| Tokenizer | Custom ByteLevel BPE, vocab 16,000 |
| Training data | ~50k samples from HuggingFaceM4/WebSight v0.2 (Tailwind) |
| Training tokens | 10.17M (8 epochs = ~81M effective) |
| Best val loss | 0.4772 |
| Training time | 7.4 minutes |
| Hardware | RTX 5080 16GB |
| Precision | bf16 mixed |
## Why custom BPE
GPT-2's BPE was trained on web prose, not code. It splits stuff like `text-3xl` into 4 tokens and `bg-gradient-to-r` into 7 tokens. My custom 16k BPE trained on WebSight compresses these to 1-2 tokens because Tailwind patterns are everywhere in the corpus.
Net result: roughly 1.5-2× better compression on the same content, which means more useful content fits inside the 512-token window.
## Why 33M params
I did the math. Chinchilla-optimal for 10M tokens is around 500k params, which is too tiny to learn anything interesting. For structured code with high pattern repetition, 5-10× Chinchilla is the empirical sweet spot. 33M lands in that range. Big enough to learn HTML structure, small enough to not just memorize 10M tokens at 8 epochs.
The train/val gap stayed around 0.1 nats throughout training. That means generalization, not memorization. Confirmed by manually searching the training data for the sample output above — no exact match exists.
## How to use it (Python)
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("Rohanify/Indensa-Coder-FrontEnd")
model = AutoModelForCausalLM.from_pretrained("Rohanify/Indensa-Coder-FrontEnd").to("cuda")
prompt = "PROMPT: a pricing card with three tiers\nHTML:\n"
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cuda")
output = model.generate(
input_ids,
max_new_tokens=400,
temperature=0.8,
top_k=50,
do_sample=True,
)
print(tokenizer.decode(output[0]))
```
Then prompt it the same way. It's small enough to run anywhere.
## Things it's good at
- Bite-sized HTML blocks (landing page sections, components)
- Tailwind class usage that mostly looks right
- Common patterns: cards, headers, footers, forms, navbars, hero sections
- Producing valid HTML that opens in a browser without errors most of the time
- Being tiny and fast
## Things it's NOT good at
- Full multi-page websites (not what it was trained for)
- Modern Tailwind v3+ utility classes that didn't exist in WebSight v0.2 (the dataset uses Tailwind 2.2.19)
- Highly specific design requests with lots of constraints
- Anything outside the WebSight distribution (think generic-looking business websites)
- Replacing a real designer or v0.dev
It's a 33M model trained for 6 minutes. Manage your expectations and it'll surprise you. Expect SOTA and you'll be disappointed.
## Training data
[HuggingFaceM4/WebSight v0.2](https://huggingface.co/datasets/HuggingFaceM4/WebSight) — synthetic HTML+Tailwind pairs generated by Deepseek-Coder-33B from Mistral-7B prompts. I used the first 50k rows, filtered to samples ≤512 tokens after tokenization, and threw away the screenshots since this is a pure text task.
## Roadmap
- Train v2 on Ollama-generated prompts and components — more diversity, less synthetic feel
- More training data (the 50k cap was based on what I could download in a session)
- Maybe a 128M version if there's interest
- Modern Tailwind v3+ support
## License
MIT. Use it for whatever. Attribution appreciated but not required.
## Author
Made by Rohan ([Rohanify on HuggingFace](https://huggingface.co/Rohanify)). Also on YouTube as ElectroPlayin where I make AI tutorials and weird projects.
Built in a single session on a home PC with help from Claude (Anthropic). The architecture decisions, dataset curation, debugging cycles, frustration, and final ship are all mine. The math checks and code scaffolding came from a long conversation.
If you find this useful or just funny, drop a like on HF or come say hi. If you train a bigger version, I'd love to see it.
## Citation
If you use this for anything serious (you probably shouldn't, it's a hobby model, but):
```
@misc{indensa2026,
author = {Rohan},
title = {Indensa-Coder-FrontEnd: A 33M Parameter Prompt-to-HTML Model},
year = {2026},
publisher = {HuggingFace},
url = {https://huggingface.co/Rohanify/Indensa-Coder-FrontEnd}
}
```