

Update README.md
Browse files
README.md
CHANGED
|
@@ -43,7 +43,8 @@ Our model is based on Mixtral-8x7B-v0.1-Instruct, a generic English LLM with 13
|
|
| 43 |
### Training Data
|
| 44 |
|
| 45 |
The training data combines diverse datasets from medical consultations, rationale QA, and knowledge graphs to ensure comprehensive medical knowledge coverage and reasoning ability.
|
| 46 |
-
|
|
|
|
| 47 |
## Model Sources
|
| 48 |
|
| 49 |
**Repository:** [https://huggingface.co/SNOWTEAM/sft_medico-mistral](https://huggingface.co/SNOWTEAM/sft_medico-mistral)
|
|
|
|
| 43 |
### Training Data
|
| 44 |
|
| 45 |
The training data combines diverse datasets from medical consultations, rationale QA, and knowledge graphs to ensure comprehensive medical knowledge coverage and reasoning ability.
|
| 46 |
+
### Result
|
| 47 |
+
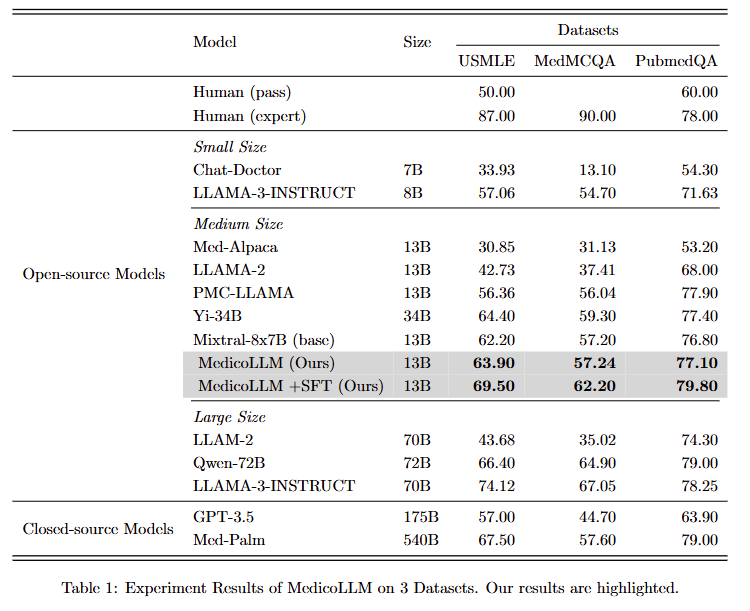
|
| 48 |
## Model Sources
|
| 49 |
|
| 50 |
**Repository:** [https://huggingface.co/SNOWTEAM/sft_medico-mistral](https://huggingface.co/SNOWTEAM/sft_medico-mistral)
|