+  +
+
+ ![]() +
+ 
![]() +
+ ![]() +
+ 
+
+
+ ![]() +
+ ![]() +
+ ![]() +
+
 |
|  |
|  |
|  |
+| [**人脸检测**](#模型库) | [**2D关键点检测**](#️pp-tinypose-人体骨骼关键点识别) | [**多目标追踪**](#pp-tracking-实时多目标跟踪系统) | [**实例分割**](#模型库) |
+|
|
+| [**人脸检测**](#模型库) | [**2D关键点检测**](#️pp-tinypose-人体骨骼关键点识别) | [**多目标追踪**](#pp-tracking-实时多目标跟踪系统) | [**实例分割**](#模型库) |
+|  |
|  |
|  |
|  |
+| [**车辆分析——车牌识别**](#️pp-vehicle-实时车辆分析工具) | [**车辆分析——车流统计**](#️pp-vehicle-实时车辆分析工具) | [**车辆分析——违章检测**](#️pp-vehicle-实时车辆分析工具) | [**车辆分析——属性分析**](#️pp-vehicle-实时车辆分析工具) |
+|
|
+| [**车辆分析——车牌识别**](#️pp-vehicle-实时车辆分析工具) | [**车辆分析——车流统计**](#️pp-vehicle-实时车辆分析工具) | [**车辆分析——违章检测**](#️pp-vehicle-实时车辆分析工具) | [**车辆分析——属性分析**](#️pp-vehicle-实时车辆分析工具) |
+|  |
|  |
|  |
|  |
+| [**行人分析——闯入分析**](#pp-human-实时行人分析工具) | [**行人分析——行为分析**](#pp-human-实时行人分析工具) | [**行人分析——属性分析**](#pp-human-实时行人分析工具) | [**行人分析——人流统计**](#pp-human-实时行人分析工具) |
+|
|
+| [**行人分析——闯入分析**](#pp-human-实时行人分析工具) | [**行人分析——行为分析**](#pp-human-实时行人分析工具) | [**行人分析——属性分析**](#pp-human-实时行人分析工具) | [**行人分析——人流统计**](#pp-human-实时行人分析工具) |
+|  |
|  |
|  |
|  |
+
+同时,PaddleDetection提供了模型的在线体验功能,用户可以选择自己的数据进行在线推理。
+
+`说明`:考虑到服务器负载压力,在线推理均为CPU推理,完整的模型开发实例以及产业部署实践代码示例请前往[🎗️产业特色模型|产业工具](#️产业特色模型产业工具-1)。
+
+`传送门`:[模型在线体验](https://www.paddlepaddle.org.cn/models)
+
+
|
+
+同时,PaddleDetection提供了模型的在线体验功能,用户可以选择自己的数据进行在线推理。
+
+`说明`:考虑到服务器负载压力,在线推理均为CPU推理,完整的模型开发实例以及产业部署实践代码示例请前往[🎗️产业特色模型|产业工具](#️产业特色模型产业工具-1)。
+
+`传送门`:[模型在线体验](https://www.paddlepaddle.org.cn/models)
+
+
+  +
+
+  +
+
 +
+PaddleDetection官方交流群二维码
+ +
+
+
+  +
+
+
+  +
+
+
+  +
+ | + Backbones + | ++ Necks + | ++ Loss + | ++ Common + | ++ Data Augmentation + | +
+
|
+
+
|
+
+
|
+
+
+
|
+
+
|
+
| + 2D Detection + | ++ Multi Object Tracking + | ++ KeyPoint Detection + | ++ Others + | +
+
|
+ + + | +
+
|
+
+
+
|
+
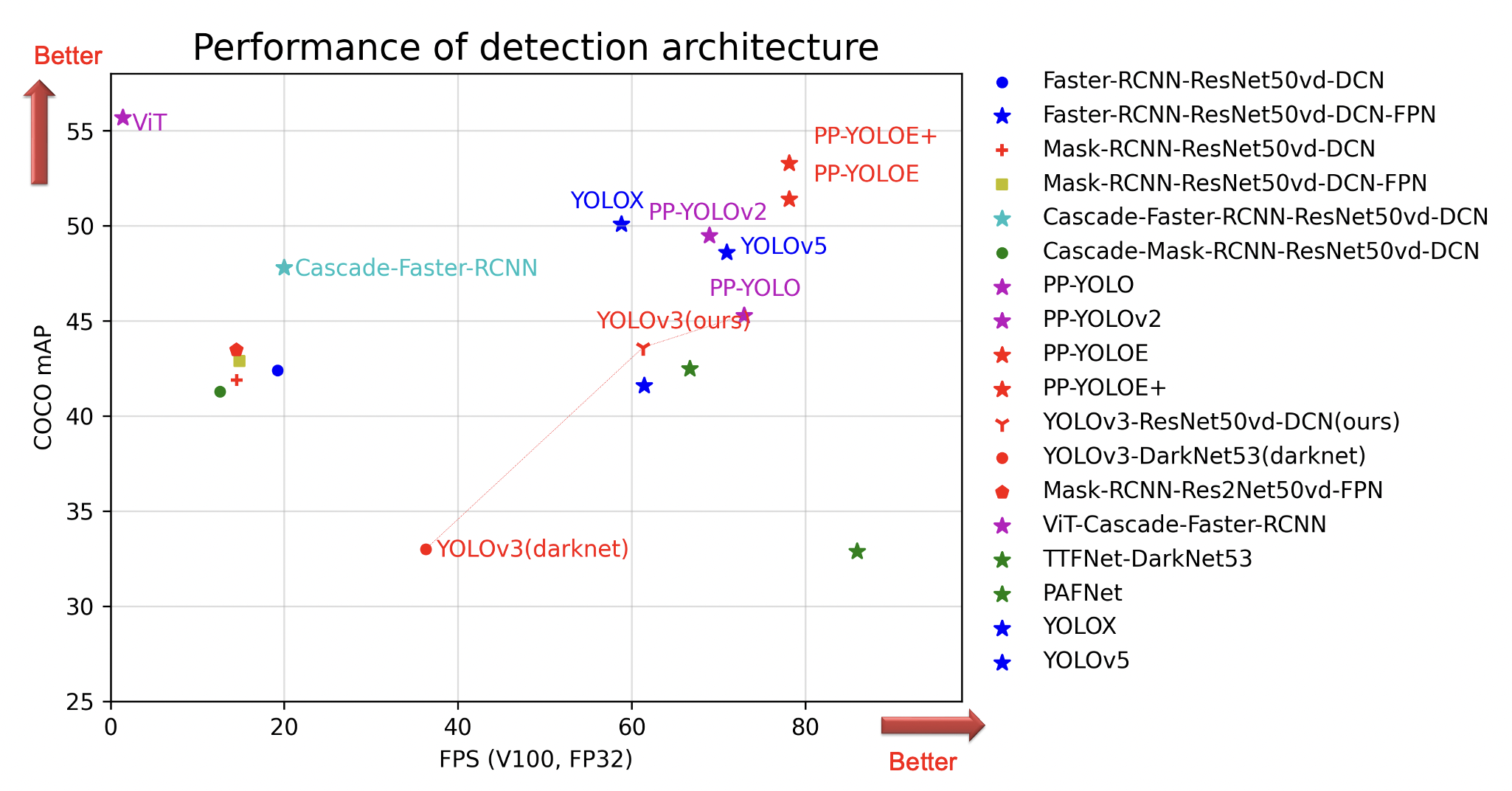 +
+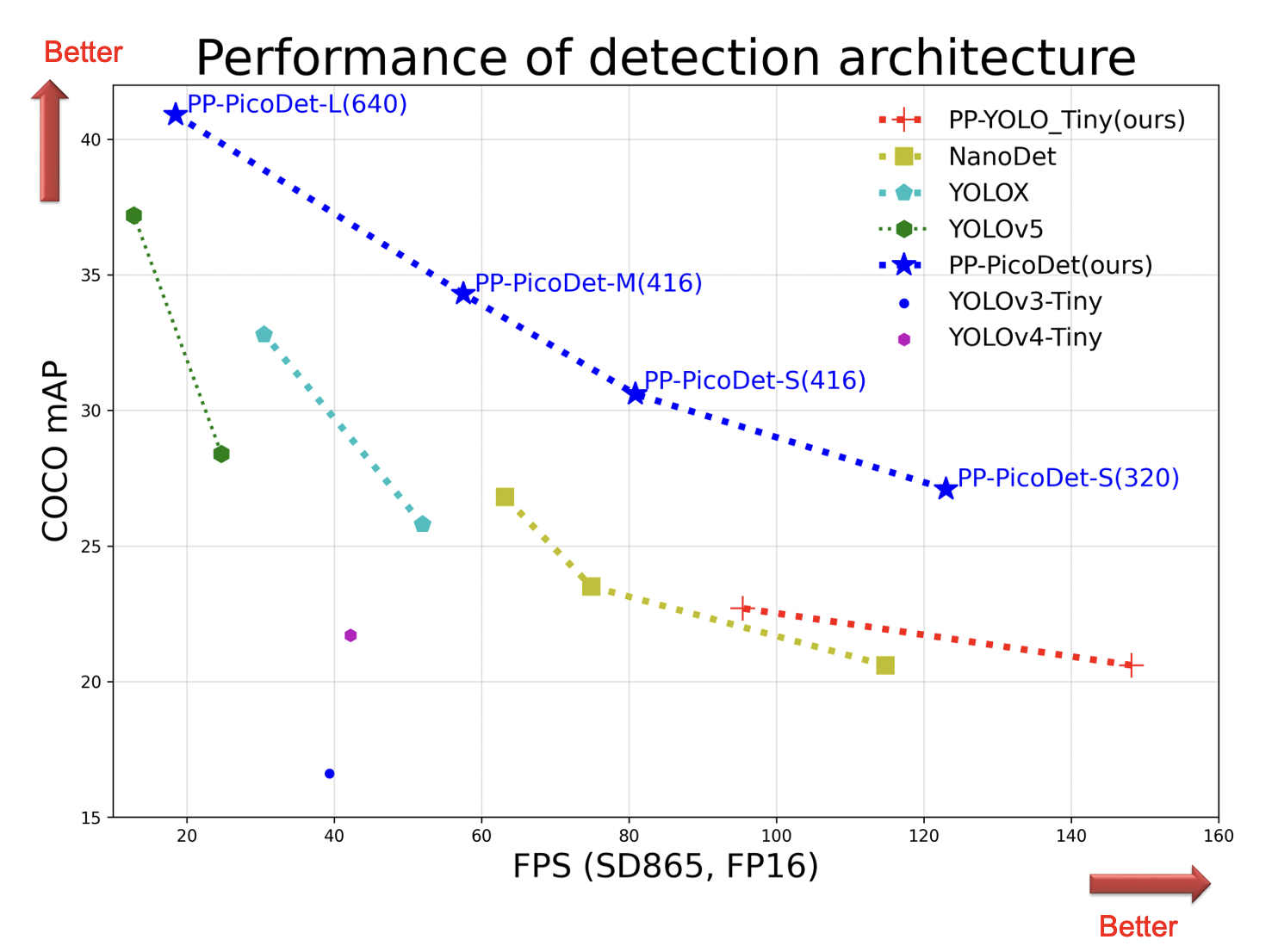 +
+
+
+
+ ![]() +
+ ![]() +
+ ![]() +
+
 +
+
+
+ +
+ +
+ +
+ | + Architectures + | ++ Backbones + | ++ Components + | ++ Data Augmentation + | +
+
Object Detection+
Instance Segmentation+
Face Detection+
Multi-Object-Tracking+
KeyPoint-Detection+
|
+
+ Details+
|
+
+ Common+
KeyPoint+
FPN+
Loss+
Post-processing+
Speed+
|
+
+ Details+
|
+
 +
+ +
+ +
+
+
+ +
+  +
+ +
+ +
+
+
+
+
+
+
+
+
+ +
+
+
+  +
+ +
+
+
+ +
+


 +
+
+
+
+
+ +
+ +
+ +
+  +
+  +
+
+
+ +
+
+
+ +
+
+
+


 +
+## 内容
+- [简介](#简介)
+- [切图使用说明](#切图使用说明)
+ - [小目标数据集下载](#小目标数据集下载)
+ - [统计数据集分布](#统计数据集分布)
+ - [SAHI切图](#SAHI切图)
+- [模型库](#模型库)
+ - [VisDrone模型](#VisDrone模型)
+ - [COCO模型](#COCO模型)
+ - [切图模型](#切图模型)
+ - [拼图模型](#拼图模型)
+ - [注意事项](#注意事项)
+- [模型库使用说明](#模型库使用说明)
+ - [训练](#训练)
+ - [评估](#评估)
+ - [预测](#预测)
+ - [部署](#部署)
+- [引用](#引用)
+
+
+## 简介
+PaddleDetection团队提供了针对VisDrone-DET、DOTA水平框、Xview等小目标场景数据集的基于PP-YOLOE改进的检测模型 PP-YOLOE-SOD,以及提供了一套使用[SAHI](https://github.com/obss/sahi)(Slicing Aided Hyper Inference)工具的切图和拼图的方案。
+
+ - PP-YOLOE-SOD 是PaddleDetection团队自研的小目标检测特色模型,使用**数据集分布相关的基于向量的DFL算法** 和 **针对小目标优化的中心先验优化策略**,并且**在模型的Neck(FPN)结构中加入Transformer模块**,以及结合增加P2层、使用large size等策略,最终在多个小目标数据集上达到极高的精度。
+
+ - 切图拼图方案**适用于任何检测模型**,建议**使用 PP-YOLOE-SOD 结合切图拼图方案**一起使用以达到最佳的效果。
+
+ - 官方 AI Studio 教程案例请参考 [基于PP-YOLOE-SOD的无人机航拍图像检测案例全流程实操](https://aistudio.baidu.com/aistudio/projectdetail/5036782),欢迎一起动手实践学习。
+
+ - 第三方 AI Studio 教程案例可参考 [PPYOLOE:遥感场景下的小目标检测与部署(切图版)](https://aistudio.baidu.com/aistudio/projectdetail/4493701) 和 [涨分神器!基于PPYOLOE的切图和拼图解决方案](https://aistudio.baidu.com/aistudio/projectdetail/4438275),欢迎一起动手实践学习。
+
+**注意:**
+ - **不通过切图拼图而直接使用原图或子图**去训练评估预测,推荐使用 PP-YOLOE-SOD 模型,更多细节和消融实验可参照[COCO模型](#COCO模型)和[VisDrone模型](./visdrone)。
+ - 是否需要切图然后使用子图去**训练**,建议首先参照[切图使用说明](#切图使用说明)中的[统计数据集分布](#统计数据集分布)分析一下数据集再确定,一般数据集中**所有的目标均极小**的情况下推荐切图去训练。
+ - 是否需要切图然后使用子图去**预测**,建议在切图训练的情况下,配合着**同样操作的切图策略和参数**去预测(inference)效果更佳。但其实即便不切图训练,也可进行切图预测(inference),只需**在常规的预测命令最后加上`--slice_infer`以及相关子图参数**即可。
+ - 是否需要切图然后使用子图去**评估**,建议首先确保制作生成了合适的子图验证集,以及确保对应的标注框制作无误,并需要参照[模型库使用说明-评估](#评估)去**改动配置文件中的验证集(EvalDataset)的相关配置**,然后**在常规的评估命令最后加上`--slice_infer`以及相关子图参数**即可。
+ - `--slice_infer`的操作在PaddleDetection中默认**子图预测框会自动组合并拼回原图**,默认返回的是原图上的预测框,此方法也**适用于任何训好的检测模型**,无论是否切图训练。
+
+
+## 切图使用说明
+
+### 小目标数据集下载
+PaddleDetection团队整理提供的VisDrone-DET、DOTA水平框、Xview等小目标场景数据集的下载链接可以参照 [DataDownload.md](./DataDownload.md)。
+
+### 统计数据集分布
+
+对于待训的数据集(默认已处理为COCO格式,参照 [COCO格式数据集准备](../../docs/tutorials/data/PrepareDetDataSet.md#用户数据转成COCO数据),首先统计**标注框的平均宽高占图片真实宽高的比例**分布:
+
+以DOTA水平框数据集的train数据集为例:
+
+```bash
+python tools/box_distribution.py --json_path dataset/DOTA/annotations/train.json --out_img box_distribution.jpg --eval_size 640 --small_stride 8
+```
+ - `--json_path` :待统计数据集 COCO 格式 annotation 的json标注文件路径
+ - `--out_img` :输出的统计分布图的路径
+ - `--eval_size` :推理尺度(默认640)
+ - `--small_stride` :模型最小步长(默认8)
+
+统计结果打印如下:
+```bash
+Suggested reg_range[1] is 13 # DFL算法中推荐值,在 PP-YOLOE-SOD 模型的配置文件的head中设置为此值,效果最佳
+Mean of all img_w is 2304.3981547196595 # 原图宽的平均值
+Mean of all img_h is 2180.9354151880766 # 原图高的平均值
+Median of ratio_w is 0.03799439775910364 # 标注框的宽与原图宽的比例的中位数
+Median of ratio_h is 0.04074914637387802 # 标注框的高与原图高的比例的中位数
+all_img with box: 1409 # 数据集图片总数(排除无框或空标注的图片)
+all_ann: 98905 # 数据集标注框总数
+Distribution saved as box_distribution.jpg
+```
+
+**注意:**
+- 一般情况下,在原始数据集全部有标注框的图片中,**原图宽高的平均值大于1500像素,且有1/2以上的图片标注框的平均宽高与原图宽高比例小于0.04时(通过打印中位数得到该值)**,建议进行切图训练。
+- `Suggested reg_range[1]` 为数据集在优化后DFL算法中推荐的`reg_range`上限,即`reg_max + 1`,在 PP-YOLOE-SOD 模型的配置文件的head中设置这个值。
+
+
+### SAHI切图
+
+针对需要切图的数据集,使用[SAHI](https://github.com/obss/sahi)库进行切图:
+
+#### 安装SAHI库:
+
+参考[SAHI installation](https://github.com/obss/sahi/blob/main/README.md#installation)进行安装,`pip install sahi`,参考[installation](https://github.com/obss/sahi/blob/main/README.md#installation)。
+
+#### 基于SAHI切图
+
+以DOTA水平框数据集的train数据集为例,切分后的**子图文件夹**与**子图json标注文件**共同保存在`dota_sliced`文件夹下,分别命名为`train_images_500_025`、`train_500_025.json`:
+
+```bash
+python tools/slice_image.py --image_dir dataset/DOTA/train/ --json_path dataset/DOTA/annotations/train.json --output_dir dataset/dota_sliced --slice_size 500 --overlap_ratio 0.25
+```
+ - `--image_dir`:原始数据集图片文件夹的路径
+ - `--json_path`:原始数据集COCO格式的json标注文件的路径
+ - `--output_dir`:切分后的子图及其json标注文件保存的路径
+ - `--slice_size`:切分以后子图的边长尺度大小(默认切图后为正方形)
+ - `--overlap_ratio`:切分时的子图之间的重叠率
+
+**注意:**
+- 如果切图然后使用子图去**训练**,则只能**离线切图**,即切完图后保存成子图,存放在内存空间中。
+- 如果切图然后使用子图去**评估或预测**,则既可以**离线切图**,也可以**在线切图**,PaddleDetection中支持切图并自动拼图组合结果到原图上。
+
+
+## 模型库
+
+### [VisDrone模型](visdrone/)
+
+| 模型 | COCOAPI mAPval
+
+## 内容
+- [简介](#简介)
+- [切图使用说明](#切图使用说明)
+ - [小目标数据集下载](#小目标数据集下载)
+ - [统计数据集分布](#统计数据集分布)
+ - [SAHI切图](#SAHI切图)
+- [模型库](#模型库)
+ - [VisDrone模型](#VisDrone模型)
+ - [COCO模型](#COCO模型)
+ - [切图模型](#切图模型)
+ - [拼图模型](#拼图模型)
+ - [注意事项](#注意事项)
+- [模型库使用说明](#模型库使用说明)
+ - [训练](#训练)
+ - [评估](#评估)
+ - [预测](#预测)
+ - [部署](#部署)
+- [引用](#引用)
+
+
+## 简介
+PaddleDetection团队提供了针对VisDrone-DET、DOTA水平框、Xview等小目标场景数据集的基于PP-YOLOE改进的检测模型 PP-YOLOE-SOD,以及提供了一套使用[SAHI](https://github.com/obss/sahi)(Slicing Aided Hyper Inference)工具的切图和拼图的方案。
+
+ - PP-YOLOE-SOD 是PaddleDetection团队自研的小目标检测特色模型,使用**数据集分布相关的基于向量的DFL算法** 和 **针对小目标优化的中心先验优化策略**,并且**在模型的Neck(FPN)结构中加入Transformer模块**,以及结合增加P2层、使用large size等策略,最终在多个小目标数据集上达到极高的精度。
+
+ - 切图拼图方案**适用于任何检测模型**,建议**使用 PP-YOLOE-SOD 结合切图拼图方案**一起使用以达到最佳的效果。
+
+ - 官方 AI Studio 教程案例请参考 [基于PP-YOLOE-SOD的无人机航拍图像检测案例全流程实操](https://aistudio.baidu.com/aistudio/projectdetail/5036782),欢迎一起动手实践学习。
+
+ - 第三方 AI Studio 教程案例可参考 [PPYOLOE:遥感场景下的小目标检测与部署(切图版)](https://aistudio.baidu.com/aistudio/projectdetail/4493701) 和 [涨分神器!基于PPYOLOE的切图和拼图解决方案](https://aistudio.baidu.com/aistudio/projectdetail/4438275),欢迎一起动手实践学习。
+
+**注意:**
+ - **不通过切图拼图而直接使用原图或子图**去训练评估预测,推荐使用 PP-YOLOE-SOD 模型,更多细节和消融实验可参照[COCO模型](#COCO模型)和[VisDrone模型](./visdrone)。
+ - 是否需要切图然后使用子图去**训练**,建议首先参照[切图使用说明](#切图使用说明)中的[统计数据集分布](#统计数据集分布)分析一下数据集再确定,一般数据集中**所有的目标均极小**的情况下推荐切图去训练。
+ - 是否需要切图然后使用子图去**预测**,建议在切图训练的情况下,配合着**同样操作的切图策略和参数**去预测(inference)效果更佳。但其实即便不切图训练,也可进行切图预测(inference),只需**在常规的预测命令最后加上`--slice_infer`以及相关子图参数**即可。
+ - 是否需要切图然后使用子图去**评估**,建议首先确保制作生成了合适的子图验证集,以及确保对应的标注框制作无误,并需要参照[模型库使用说明-评估](#评估)去**改动配置文件中的验证集(EvalDataset)的相关配置**,然后**在常规的评估命令最后加上`--slice_infer`以及相关子图参数**即可。
+ - `--slice_infer`的操作在PaddleDetection中默认**子图预测框会自动组合并拼回原图**,默认返回的是原图上的预测框,此方法也**适用于任何训好的检测模型**,无论是否切图训练。
+
+
+## 切图使用说明
+
+### 小目标数据集下载
+PaddleDetection团队整理提供的VisDrone-DET、DOTA水平框、Xview等小目标场景数据集的下载链接可以参照 [DataDownload.md](./DataDownload.md)。
+
+### 统计数据集分布
+
+对于待训的数据集(默认已处理为COCO格式,参照 [COCO格式数据集准备](../../docs/tutorials/data/PrepareDetDataSet.md#用户数据转成COCO数据),首先统计**标注框的平均宽高占图片真实宽高的比例**分布:
+
+以DOTA水平框数据集的train数据集为例:
+
+```bash
+python tools/box_distribution.py --json_path dataset/DOTA/annotations/train.json --out_img box_distribution.jpg --eval_size 640 --small_stride 8
+```
+ - `--json_path` :待统计数据集 COCO 格式 annotation 的json标注文件路径
+ - `--out_img` :输出的统计分布图的路径
+ - `--eval_size` :推理尺度(默认640)
+ - `--small_stride` :模型最小步长(默认8)
+
+统计结果打印如下:
+```bash
+Suggested reg_range[1] is 13 # DFL算法中推荐值,在 PP-YOLOE-SOD 模型的配置文件的head中设置为此值,效果最佳
+Mean of all img_w is 2304.3981547196595 # 原图宽的平均值
+Mean of all img_h is 2180.9354151880766 # 原图高的平均值
+Median of ratio_w is 0.03799439775910364 # 标注框的宽与原图宽的比例的中位数
+Median of ratio_h is 0.04074914637387802 # 标注框的高与原图高的比例的中位数
+all_img with box: 1409 # 数据集图片总数(排除无框或空标注的图片)
+all_ann: 98905 # 数据集标注框总数
+Distribution saved as box_distribution.jpg
+```
+
+**注意:**
+- 一般情况下,在原始数据集全部有标注框的图片中,**原图宽高的平均值大于1500像素,且有1/2以上的图片标注框的平均宽高与原图宽高比例小于0.04时(通过打印中位数得到该值)**,建议进行切图训练。
+- `Suggested reg_range[1]` 为数据集在优化后DFL算法中推荐的`reg_range`上限,即`reg_max + 1`,在 PP-YOLOE-SOD 模型的配置文件的head中设置这个值。
+
+
+### SAHI切图
+
+针对需要切图的数据集,使用[SAHI](https://github.com/obss/sahi)库进行切图:
+
+#### 安装SAHI库:
+
+参考[SAHI installation](https://github.com/obss/sahi/blob/main/README.md#installation)进行安装,`pip install sahi`,参考[installation](https://github.com/obss/sahi/blob/main/README.md#installation)。
+
+#### 基于SAHI切图
+
+以DOTA水平框数据集的train数据集为例,切分后的**子图文件夹**与**子图json标注文件**共同保存在`dota_sliced`文件夹下,分别命名为`train_images_500_025`、`train_500_025.json`:
+
+```bash
+python tools/slice_image.py --image_dir dataset/DOTA/train/ --json_path dataset/DOTA/annotations/train.json --output_dir dataset/dota_sliced --slice_size 500 --overlap_ratio 0.25
+```
+ - `--image_dir`:原始数据集图片文件夹的路径
+ - `--json_path`:原始数据集COCO格式的json标注文件的路径
+ - `--output_dir`:切分后的子图及其json标注文件保存的路径
+ - `--slice_size`:切分以后子图的边长尺度大小(默认切图后为正方形)
+ - `--overlap_ratio`:切分时的子图之间的重叠率
+
+**注意:**
+- 如果切图然后使用子图去**训练**,则只能**离线切图**,即切完图后保存成子图,存放在内存空间中。
+- 如果切图然后使用子图去**评估或预测**,则既可以**离线切图**,也可以**在线切图**,PaddleDetection中支持切图并自动拼图组合结果到原图上。
+
+
+## 模型库
+
+### [VisDrone模型](visdrone/)
+
+| 模型 | COCOAPI mAPval +
+
+
+ +
+
+
+ +
+ +
+ +
+  +
+ +
+  +
+ +
+  +
+ +
+ +
+ +
+