---
base_model:
- Qwen/Qwen2.5-VL-7B-Instruct
datasets:
- Senqiao/VisionThink-Smart-Train
- Senqiao/VisionThink-Smart-Val
license: apache-2.0
pipeline_tag: image-text-to-text
library_name: transformers
---
# VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning
This repository contains the official model for **VisionThink**, a novel vision-language model (VLM) that dynamically processes images with varying resolutions to optimize efficiency without sacrificing performance. It intelligently decides whether a downsampled image is sufficient for problem-solving, requesting higher-resolution images only when necessary. This approach distinguishes it from existing efficient VLM methods that rely on fixed compression ratios or thresholds.
VisionThink demonstrates strong fine-grained visual understanding capability on OCR-related tasks, while also saving substantial visual tokens on simpler tasks. It achieves this by adopting reinforcement learning and proposing the LLM-as-Judge strategy for general VQA tasks, coupled with a carefully designed reward function and penalty mechanism to achieve a stable and reasonable image resize call ratio.
**Paper:** [VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning](https://huggingface.co/papers/2507.13348)
**Code:** [dvlab-research/VisionThink](https://github.com/dvlab-research/VisionThink)
## ✨ Highlights
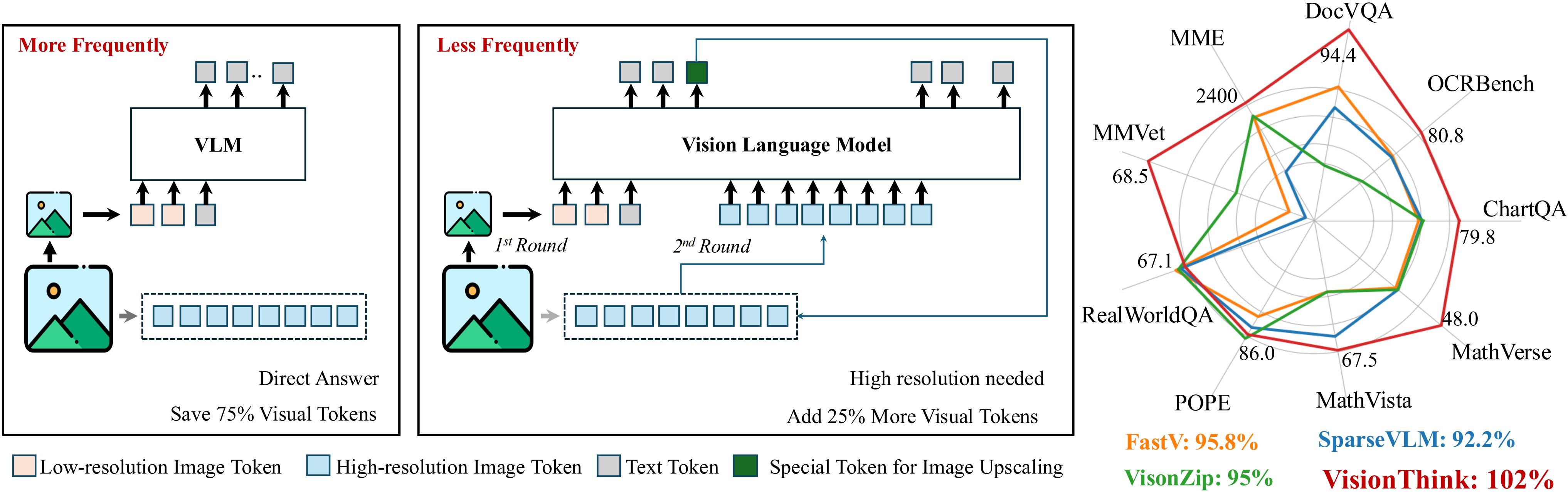
1. Our VisionThink leverages reinforcement learning to **autonomously** learn whether to reduce visual tokens. Compared to traditional efficient VLM approaches, our method achieves significant improvements on **fine-grained** benchmarks, such as those involving OCR-related tasks.
2. VisionThink improves performance on **General VQA** tasks while reducing visual tokens by **50%**, achieving **102%** of the original model’s performance across nine benchmarks.
3. VisionThink achieves strong performance and efficiency by simply resizing input images to reduce visual tokens. We hope this inspires further research into **Efficient Reasoning Vision Language Models**.
## 🚀 Usage
You can use VisionThink with the Hugging Face `transformers` library. This model (Senqiao/VisionThink-Efficient) is based on `Qwen2.5-VL-7B-Instruct`.
First, ensure you have the `transformers` library and `Pillow` installed:
```bash
pip install transformers Pillow requests
```
Here's an example of how to use the model for inference:
```python
from transformers import AutoProcessor, AutoModelForCausalLM
from PIL import Image
import requests
# Load the model and processor
# This repository corresponds to "Senqiao/VisionThink-Efficient".
# You might also find "Senqiao/VisionThink-General" on the Hub.
model_id = "Senqiao/VisionThink-Efficient"
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", trust_remote_code=True)
# Load an example image (using an image from the project's GitHub for consistency)
image_url = "https://raw.githubusercontent.com/dvlab-research/VisionThink/main/files/VisionThink.jpg"
image = Image.open(requests.get(image_url, stream=True).raw).convert("RGB")
# Define your text prompt
text_input = "Describe the image in detail. What is the title?"
# Prepare messages in chat format
# VisionThink can dynamically request higher resolution, but for basic usage,
# you interact with it like a standard VLM.
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": text_input},
],
}
]
# Apply chat template and process inputs
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
inputs = processor(text=[text], images=[image], return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
# Generate response
generated_ids = model.generate(**inputs, max_new_tokens=512)
# Decode the response
response = processor.batch_decode(generated_ids[:, inputs["input_ids"].shape[1]:], skip_special_tokens=True)[0]
print(response)
```
## 📝 Citation
If you find this project useful in your research, please consider citing:
```bibtex
@article{yang2025visionthink,
author={Yang, Senqiao and Li, Junyi and Lai, Xin and Yu, Bei and Zhao, Hengshuang and Jia, Jiaya},
title={VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning},
journal={arXiv preprint arXiv:2507.13348},
year={2025}
}
```