---
base_model:
- Qwen/Qwen2.5-VL-7B-Instruct
datasets:
- Senqiao/VisionThink-General-Train
- Senqiao/VisionThink-General-Val
license: apache-2.0
pipeline_tag: image-text-to-text
library_name: transformers
tags:
- vision-language-model
- multimodal
- qwen
---
# VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning
This repository contains the `VisionThink-General` model, a smart and efficient vision-language model. VisionThink introduces a new paradigm for visual token compression in Vision-Language Models (VLMs). It starts with a downsampled image and smartly decides whether it is sufficient for problem solving. Otherwise, the model could output a special token to request the higher-resolution image. Unlike existing Efficient VLM methods that compress tokens using fixed pruning ratios or thresholds, VisionThink autonomously decides whether to compress tokens case by case.
The model was presented in the paper [**VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning**](https://huggingface.co/papers/2507.13348).
The official code and more details can be found on the [**VisionThink GitHub repository**](https://github.com/dvlab-research/VisionThink).
## Highlights
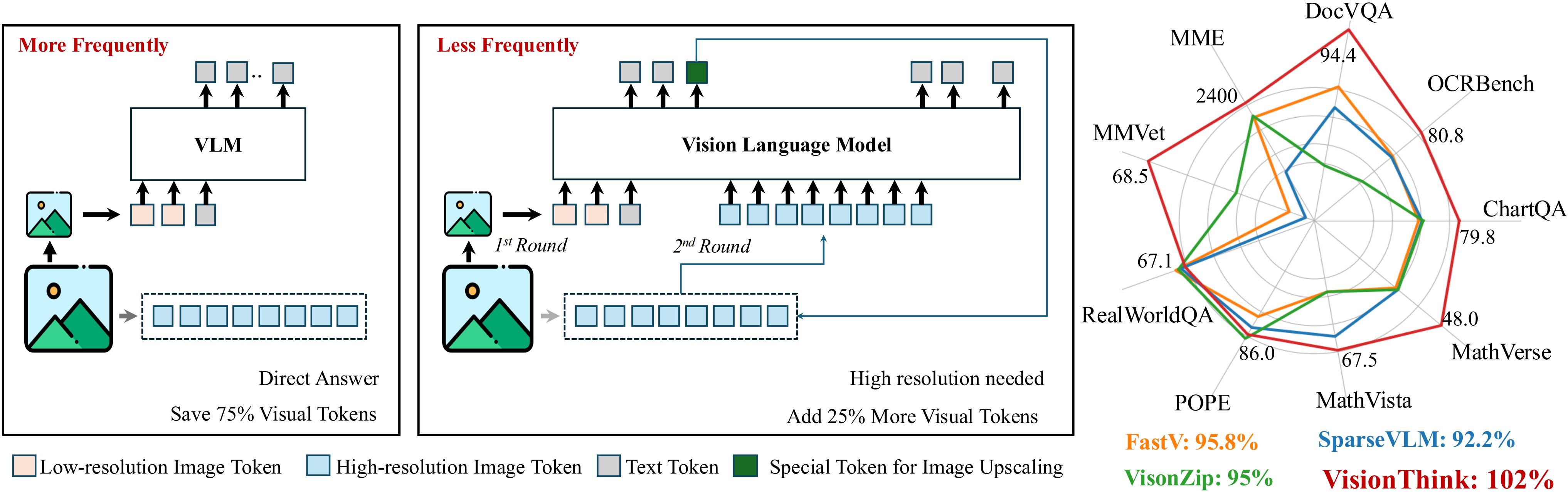
1. Our VisionThink leverages reinforcement learning to **autonomously** learn whether to reduce visual tokens. Compared to traditional efficient VLM approaches, our method achieves significant improvements on **fine-grained** benchmarks, such as those involving OCR-related tasks.
2. VisionThink improves performance on **General VQA** tasks while reducing visual tokens by **50%**, achieving **102%** of the original model’s performance across nine benchmarks.
3. VisionThink achieves strong performance and efficiency by simply resizing input images to reduce visual tokens. We hope this inspires further research into **Efficient Reasoning Vision Language Models**.
## Installation
The environment follows the [Verl](https://github.com/volcengine/verl).
```bash
git clone https://github.com/dvlab-research/VisionThink.git
conda create -n visionthink python=3.11 -y
conda activate visionthink
# veRL
pip3 install -e .
# flash-attn
pip3 install flash-attn --no-build-isolation
```
If you want to use the Qwen3 as the Judge Model.
```bash
pip install -U tensordict
pip install transformers==4.51.0
```
## Usage
You can easily load and use VisionThink with the Hugging Face `transformers` library. Below is a quick example demonstrating how to load the `VisionThink-General` model and perform inference.
```python
from transformers import AutoProcessor, AutoModelForCausalLM
from PIL import Image
# Load model and processor
model_id = "Senqiao/VisionThink-General" # Or "Senqiao/VisionThink-Efficient"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True
)
# Prepare input image and text
# Replace with your image path
image = Image.open("./path/to/your/image.jpg").convert("RGB")
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": "Describe this image in detail."},
],
}
]
# Apply chat template and process inputs
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
inputs = processor(text=text, images=image, return_tensors="pt")
inputs = inputs.to(model.device)
# Generate response
generated_ids = model.generate(**inputs, max_new_tokens=512)
# Decode and print the output
generated_ids = generated_ids[:, inputs["input_ids"].shape[1]:]
response = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
```
## Citation
If you find this project useful in your research, please consider citing:
```bibtex
@article{yang2025visionthink,
title={VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning},
author={Yang, Senqiao and Li, Junyi and Lai, Xin and Yu, Bei and Zhao, Hengshuang and Jia, Jiaya},
journal={arXiv preprint arXiv:2507.13348},
year={2025},
}
```
## Acknowledgement
- This work is built upon [Verl](https://github.com/volcengine/verl), [EasyR1](https://github.com/hiyouga/EasyR1), [Lmms-Eval](https://github.com/EvolvingLMMs-Lab/lmms-eval), and [MMSearch-R1](https://github.com/EvolvingLMMs-Lab/multimodal-search-r1). We thank them for their excellent open-source contributions.
- We also thank [Qwen](https://github.com/QwenLM/Qwen2.5-VL), [DeepSeek-R1](https://github.com/deepseek-ai/DeepSeek-R1), [VisionZip](https://github.com/dvlab-research/VisionZip), [FastV](https://github.com/pkunlp-icler/FastV), [SparseVLM](https://github.com/Gumpest/SparseVLMs), and others for their contributions, which have provided valuable insights.