
Update README.md
Browse files
README.md
CHANGED
|
@@ -17,11 +17,6 @@ pipeline_tag: text-to-image
|
|
| 17 |
|
| 18 |
<strong style="color: rosybrown; font-size: 18px">Text-to-Image Generation with Fine-Tuned SDXL [QLoRA]</strong>
|
| 19 |
|
| 20 |
-
<strong>Goal of this project:</strong> This project focuses on building an advanced text-to-image generation system using the Stable Diffusion XL (SDXL) model, a state-of-the-art deep learning architecture. The goal is to transform natural language text descriptions into visually coherent and high-quality images, unlocking creative possibilities in areas like art generation, design prototyping, and multimedia applications.
|
| 21 |
-
|
| 22 |
-
To enhance performance and tailor the model to specific use cases, SDXL is fine-tuned using <strong>QLoRA (Quantized Low-Rank Adaptation)</strong>. This approach leverages efficient parameter fine-tuning and memory optimization techniques, enabling high-quality adaptations with reduced computational overhead. Fine-tuning with QLoRA ensures that the model is optimized for domain-specific text-to-image tasks, delivering even more precise and creative outputs.
|
| 23 |
-
|
| 24 |
-
Simplified Architecture: 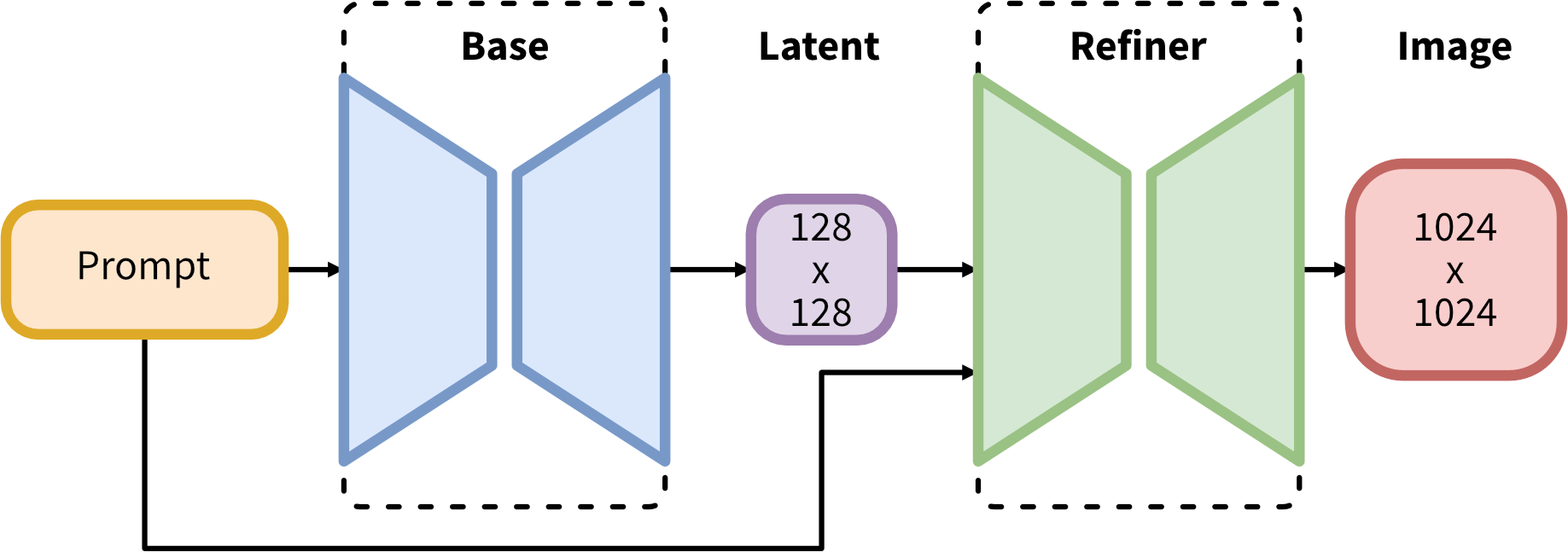
|
| 25 |
|
| 26 |
<strong style="text-decoration: underline">Example Prompts: </strong>
|
| 27 |
<p style="color: orangered">1. A young, attractive female with arched eyebrows and a pointy nose. She has wavy brown hair, wears heavy makeup with lipstick, and exudes a confident, stylish look. The scene features soft, flattering lighting that enhances her youthful features and glamorous appearance.</p>
|
|
@@ -29,6 +24,13 @@ Simplified Architecture: .</p>
|
| 33 |
|
| 34 |
<p style="font-family: Lucida Sans ;font-size:15px;">The CelebA dataset is a widely-used, large-scale dataset in the field of computer vision, particularly for tasks related to faces. It consists of over 200,000 celebrity face images annotated with a rich set of attributes. The dataset offers diverse visual content with variations in pose, facial expressions, and backgrounds, making it suitable for a range of face-related applications.</p>
|
|
|
|
| 17 |
|
| 18 |
<strong style="color: rosybrown; font-size: 18px">Text-to-Image Generation with Fine-Tuned SDXL [QLoRA]</strong>
|
| 19 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 20 |
|
| 21 |
<strong style="text-decoration: underline">Example Prompts: </strong>
|
| 22 |
<p style="color: orangered">1. A young, attractive female with arched eyebrows and a pointy nose. She has wavy brown hair, wears heavy makeup with lipstick, and exudes a confident, stylish look. The scene features soft, flattering lighting that enhances her youthful features and glamorous appearance.</p>
|
|
|
|
| 24 |
<p style="color: orangered">3. Male with a big nose, black hair, bushy eyebrows, high cheekbones, and a receding hairline. He has an oval face, a mouth slightly open in a smile, and is clean-shaven with no beard.</p>
|
| 25 |
|
| 26 |
|
| 27 |
+
<strong>Goal of this project:</strong> This project focuses on building an advanced text-to-image generation system using the Stable Diffusion XL (SDXL) model, a state-of-the-art deep learning architecture. The goal is to transform natural language text descriptions into visually coherent and high-quality images, unlocking creative possibilities in areas like art generation, design prototyping, and multimedia applications.
|
| 28 |
+
|
| 29 |
+
To enhance performance and tailor the model to specific use cases, SDXL is fine-tuned using <strong>QLoRA (Quantized Low-Rank Adaptation)</strong>. This approach leverages efficient parameter fine-tuning and memory optimization techniques, enabling high-quality adaptations with reduced computational overhead. Fine-tuning with QLoRA ensures that the model is optimized for domain-specific text-to-image tasks, delivering even more precise and creative outputs.
|
| 30 |
+
|
| 31 |
+
Simplified Architecture: 
|
| 32 |
+
|
| 33 |
+
|
| 34 |
<p style="font-family:Lucida Sans ;font-size:15px;">Dataset Description: CelebFaces Attributes Dataset (CelebA).</p>
|
| 35 |
|
| 36 |
<p style="font-family: Lucida Sans ;font-size:15px;">The CelebA dataset is a widely-used, large-scale dataset in the field of computer vision, particularly for tasks related to faces. It consists of over 200,000 celebrity face images annotated with a rich set of attributes. The dataset offers diverse visual content with variations in pose, facial expressions, and backgrounds, making it suitable for a range of face-related applications.</p>
|