+
+写真提供:[Denys Nevozhai](https://unsplash.com/@dnevozhai)。
+
+テキストおよび画像のプロンプトを単一のリストとしてモデルのプロセッサに渡し、適切な入力を作成できます。
+
+```py
+>>> prompt = [
+... "https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
+... "This is an image of ",
+... ]
+
+>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> print(generated_text[0])
+This is an image of the Eiffel Tower in Paris, France.
+```
+
+## Few-shot prompting
+
+IDEFICS はゼロショットで優れた結果を示しますが、タスクによっては特定の形式のキャプションが必要になる場合や、キャプションが付属する場合があります。
+タスクの複雑さを増大させるその他の制限または要件。少数のショットのプロンプトを使用して、コンテキスト内の学習を有効にすることができます。
+プロンプトに例を指定することで、指定された例の形式を模倣した結果を生成するようにモデルを操作できます。
+
+前のエッフェル塔の画像をモデルの例として使用し、モデルにデモンストレーションするプロンプトを作成してみましょう。
+画像内のオブジェクトが何であるかを知ることに加えて、それに関する興味深い情報も取得したいと考えています。
+次に、自由の女神の画像に対して同じ応答形式を取得できるかどうかを見てみましょう。
+
+
+
+
+
+写真提供:[Juan Mayobre](https://unsplash.com/@jmayobres)。
+
+```py
+>>> prompt = ["User:",
+... "https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
+... "Describe this image.\nAssistant: An image of the Eiffel Tower at night. Fun fact: the Eiffel Tower is the same height as an 81-storey building.\n",
+... "User:",
+... "https://images.unsplash.com/photo-1524099163253-32b7f0256868?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3387&q=80",
+... "Describe this image.\nAssistant:"
+... ]
+
+>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, max_new_tokens=30, bad_words_ids=bad_words_ids)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> print(generated_text[0])
+User: Describe this image.
+Assistant: An image of the Eiffel Tower at night. Fun fact: the Eiffel Tower is the same height as an 81-storey building.
+User: Describe this image.
+Assistant: An image of the Statue of Liberty. Fun fact: the Statue of Liberty is 151 feet tall.
+```
+
+モデルは 1 つの例 (つまり、1 ショット) だけからタスクの実行方法を学習していることに注目してください。より複雑なタスクの場合は、
+より多くの例 (3 ショット、5 ショットなど) を自由に試してみてください。
+
+## Visual question answering
+
+Visual Question Answering (VQA) は、画像に基づいて自由形式の質問に答えるタスクです。画像に似ている
+キャプションは、アクセシビリティ アプリケーションだけでなく、教育 (視覚資料についての推論) にも使用できます。
+サービス(画像を基にした商品に関する質問)、画像検索など。
+
+このタスク用に新しい画像を取得しましょう。
+
+
+
+
+
+写真提供 [Jarritos Mexican Soda](https://unsplash.com/@jarritos).
+
+適切な指示をプロンプトすることで、モデルを画像キャプションから視覚的な質問への応答に導くことができます。
+
+```py
+>>> prompt = [
+... "Instruction: Provide an answer to the question. Use the image to answer.\n",
+... "https://images.unsplash.com/photo-1623944889288-cd147dbb517c?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
+... "Question: Where are these people and what's the weather like? Answer:"
+... ]
+
+>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, max_new_tokens=20, bad_words_ids=bad_words_ids)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> print(generated_text[0])
+Instruction: Provide an answer to the question. Use the image to answer.
+ Question: Where are these people and what's the weather like? Answer: They're in a park in New York City, and it's a beautiful day.
+```
+
+## Image classification
+
+IDEFICS は、次のデータを含むデータについて明示的にトレーニングしなくても、画像をさまざまなカテゴリに分類できます。
+これらの特定のカテゴリからのラベル付きの例。カテゴリのリストを指定し、その画像とテキストを使用して理解する
+機能を利用すると、モデルは画像がどのカテゴリに属する可能性が高いかを推測できます。
+
+たとえば、次のような野菜スタンドの画像があるとします。
+
+
+
+
+
+写真提供:[Peter Wendt](https://unsplash.com/@peterwendt)。
+
+画像を次のいずれかのカテゴリに分類するようにモデルに指示できます。
+
+```py
+>>> categories = ['animals','vegetables', 'city landscape', 'cars', 'office']
+>>> prompt = [f"Instruction: Classify the following image into a single category from the following list: {categories}.\n",
+... "https://images.unsplash.com/photo-1471193945509-9ad0617afabf?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
+... "Category: "
+... ]
+
+>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, max_new_tokens=6, bad_words_ids=bad_words_ids)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> print(generated_text[0])
+Instruction: Classify the following image into a single category from the following list: ['animals', 'vegetables', 'city landscape', 'cars', 'office'].
+Category: Vegetables
+```
+
+上の例では、画像を 1 つのカテゴリに分類するようにモデルに指示していますが、ランク分類を行うようにモデルに指示することもできます。
+
+## Image-guided text generation
+
+よりクリエイティブなアプリケーションの場合は、画像ガイド付きテキスト生成を使用して、画像に基づいてテキストを生成できます。これは可能です
+製品、広告、シーンの説明などを作成するのに役立ちます。
+
+IDEFICS に、赤いドアの単純な画像に基づいてストーリーを書くように促してみましょう。
+
+
+
+
+
+写真提供:[Craig Tidball](https://unsplash.com/@devonshiremedia)。
+
+```py
+>>> prompt = ["Instruction: Use the image to write a story. \n",
+... "https://images.unsplash.com/photo-1517086822157-2b0358e7684a?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=2203&q=80",
+... "Story: \n"]
+
+>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, num_beams=2, max_new_tokens=200, bad_words_ids=bad_words_ids)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> print(generated_text[0])
+Instruction: Use the image to write a story.
+ Story:
+Once upon a time, there was a little girl who lived in a house with a red door. She loved her red door. It was the prettiest door in the whole world.
+
+One day, the little girl was playing in her yard when she noticed a man standing on her doorstep. He was wearing a long black coat and a top hat.
+
+The little girl ran inside and told her mother about the man.
+
+Her mother said, “Don’t worry, honey. He’s just a friendly ghost.”
+
+The little girl wasn’t sure if she believed her mother, but she went outside anyway.
+
+When she got to the door, the man was gone.
+
+The next day, the little girl was playing in her yard again when she noticed the man standing on her doorstep.
+
+He was wearing a long black coat and a top hat.
+
+The little girl ran
+```
+
+IDEFICS は玄関先にあるカボチャに気づき、幽霊に関する不気味なハロウィーンの話をしたようです。
+
+
+
+このような長い出力の場合、テキスト生成戦略を微調整すると大きなメリットが得られます。これは役に立ちます
+生成される出力の品質が大幅に向上します。 [テキスト生成戦略](../generation_strategies) を確認してください。
+詳しく知ることができ。
+
+
+
+## Running inference in batch mode
+
+これまでのすべてのセクションでは、IDEFICS を 1 つの例として説明しました。非常に似た方法で、推論を実行できます。
+プロンプトのリストを渡すことにより、サンプルのバッチを取得します。
+
+```py
+>>> prompts = [
+... [ "https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
+... "This is an image of ",
+... ],
+... [ "https://images.unsplash.com/photo-1623944889288-cd147dbb517c?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
+... "This is an image of ",
+... ],
+... [ "https://images.unsplash.com/photo-1471193945509-9ad0617afabf?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
+... "This is an image of ",
+... ],
+... ]
+
+>>> inputs = processor(prompts, return_tensors="pt").to("cuda")
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> for i,t in enumerate(generated_text):
+... print(f"{i}:\n{t}\n")
+0:
+This is an image of the Eiffel Tower in Paris, France.
+
+1:
+This is an image of a couple on a picnic blanket.
+
+2:
+This is an image of a vegetable stand.
+```
+
+## IDEFICS instruct for conversational use
+
+会話型のユースケースの場合は、🤗 ハブでモデルの微調整された指示されたバージョンを見つけることができます。
+`HuggingFaceM4/idefics-80b-instruct` および `HuggingFaceM4/idefics-9b-instruct`。
+
+これらのチェックポイントは、教師ありモデルと命令モデルを組み合わせたそれぞれの基本モデルを微調整した結果です。
+データセットを微調整することで、ダウンストリームのパフォーマンスを向上させながら、会話設定でモデルをより使いやすくします。
+
+会話での使用とプロンプトは、基本モデルの使用と非常に似ています。
+
+```py
+>>> import torch
+>>> from transformers import IdeficsForVisionText2Text, AutoProcessor
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+
+>>> checkpoint = "HuggingFaceM4/idefics-9b-instruct"
+>>> model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
+>>> processor = AutoProcessor.from_pretrained(checkpoint)
+
+>>> prompts = [
+... [
+... "User: What is in this image?",
+... "https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
+... "",
+
+... "\nAssistant: This picture depicts Idefix, the dog of Obelix in Asterix and Obelix. Idefix is running on the ground.",
+
+... "\nUser:",
+... "https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
+... "And who is that?",
+
+... "\nAssistant:",
+... ],
+... ]
+
+>>> # --batched mode
+>>> inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
+>>> # --single sample mode
+>>> # inputs = processor(prompts[0], return_tensors="pt").to(device)
+
+>>> # Generation args
+>>> exit_condition = processor.tokenizer("", add_special_tokens=False).input_ids
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> for i, t in enumerate(generated_text):
+... print(f"{i}:\n{t}\n")
+```
diff --git a/docs/transformers/docs/source/ja/tasks/image_captioning.md b/docs/transformers/docs/source/ja/tasks/image_captioning.md
new file mode 100644
index 0000000000000000000000000000000000000000..7649947b2c6450110c60ad6f6d7f4a5ad2a9d49d
--- /dev/null
+++ b/docs/transformers/docs/source/ja/tasks/image_captioning.md
@@ -0,0 +1,276 @@
+
+
+# Image captioning
+
+[[open-in-colab]]
+
+画像のキャプション付けは、特定の画像のキャプションを予測するタスクです。一般的な現実世界のアプリケーションには次のものがあります。
+視覚障害者がさまざまな状況を乗り越えられるよう支援します。したがって、画像のキャプション
+画像を説明することで人々のコンテンツへのアクセシビリティを向上させるのに役立ちます。
+
+このガイドでは、次の方法を説明します。
+
+* 画像キャプション モデルを微調整します。
+* 微調整されたモデルを推論に使用します。
+
+始める前に、必要なライブラリがすべてインストールされていることを確認してください。
+
+```bash
+pip install transformers datasets evaluate -q
+pip install jiwer -q
+```
+
+モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
+
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+## Load the Pokémon BLIP captions dataset
+
+🤗 データセット ライブラリを使用して、{image-caption} ペアで構成されるデータセットを読み込みます。独自の画像キャプション データセットを作成するには
+PyTorch では、[このノートブック](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GIT/Fine_tune_GIT_on_an_image_captioning_dataset.ipynb) を参照できます。
+
+```py
+ds = load_dataset("lambdalabs/pokemon-blip-captions")
+ds
+```
+
+```bash
+DatasetDict({
+ train: Dataset({
+ features: ['image', 'text'],
+ num_rows: 833
+ })
+})
+```
+
+データセットには `image`と`text`の 2 つの機能があります。
+
+
+
+多くの画像キャプション データセットには、画像ごとに複数のキャプションが含まれています。このような場合、一般的な戦略は、トレーニング中に利用可能なキャプションの中からランダムにキャプションをサンプリングすることです。
+
+
+
+[`~datasets.Dataset.train_test_split`] メソッドを使用して、データセットのトレイン スプリットをトレイン セットとテスト セットに分割します。
+
+```python
+ds = ds["train"].train_test_split(test_size=0.1)
+train_ds = ds["train"]
+test_ds = ds["test"]
+```
+
+トレーニング セットからのいくつかのサンプルを視覚化してみましょう。
+
+```python
+from textwrap import wrap
+import matplotlib.pyplot as plt
+import numpy as np
+
+
+def plot_images(images, captions):
+ plt.figure(figsize=(20, 20))
+ for i in range(len(images)):
+ ax = plt.subplot(1, len(images), i + 1)
+ caption = captions[i]
+ caption = "\n".join(wrap(caption, 12))
+ plt.title(caption)
+ plt.imshow(images[i])
+ plt.axis("off")
+
+
+sample_images_to_visualize = [np.array(train_ds[i]["image"]) for i in range(5)]
+sample_captions = [train_ds[i]["text"] for i in range(5)]
+plot_images(sample_images_to_visualize, sample_captions)
+```
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md b/docs/transformers/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
new file mode 100644
index 0000000000000000000000000000000000000000..1079121c6062bceb7b53e1e71625f6744c49f6eb
--- /dev/null
+++ b/docs/transformers/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md
@@ -0,0 +1,188 @@
+
+# Knowledge Distillation for Computer Vision
+
+[[open-in-colab]]
+
+知識の蒸留は、より大規模で複雑なモデル (教師) からより小規模で単純なモデル (生徒) に知識を伝達するために使用される手法です。あるモデルから別のモデルに知識を抽出するには、特定のタスク (この場合は画像分類) でトレーニングされた事前トレーニング済み教師モデルを取得し、画像分類でトレーニングされる生徒モデルをランダムに初期化します。次に、学生モデルをトレーニングして、その出力と教師の出力の差を最小限に抑え、動作を模倣します。これは [Distilling the Knowledge in a Neural Network by Hinton et al](https://arxiv.org/abs/1503.02531) で最初に導入されました。このガイドでは、タスク固有の知識の蒸留を行います。これには [Beans データセット](https://huggingface.co/datasets/beans) を使用します。
+
+このガイドでは、[微調整された ViT モデル](https://huggingface.co/merve/vit-mobilenet-beans-224) (教師モデル) を抽出して [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (学生モデル) 🤗 Transformers の [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) を使用します。
+
+蒸留とプロセスの評価に必要なライブラリをインストールしましょう。
+
+```bash
+pip install transformers datasets accelerate tensorboard evaluate --upgrade
+```
+
+この例では、教師モデルとして`merve/beans-vit-224`モデルを使用しています。これは、Bean データセットに基づいて微調整された`google/vit-base-patch16-224-in21k`に基づく画像分類モデルです。このモデルをランダムに初期化された MobileNetV2 に抽出します。
+
+次に、データセットをロードします。
+
+```python
+from datasets import load_dataset
+
+dataset = load_dataset("beans")
+```
+
+この場合、同じ解像度で同じ出力が返されるため、どちらのモデルの画像プロセッサも使用できます。 `dataset`の`map()`メソッドを使用して、データセットのすべての分割に前処理を適用します。
+
+```python
+from transformers import AutoImageProcessor
+teacher_processor = AutoImageProcessor.from_pretrained("merve/beans-vit-224")
+
+def process(examples):
+ processed_inputs = teacher_processor(examples["image"])
+ return processed_inputs
+
+processed_datasets = dataset.map(process, batched=True)
+```
+
+基本的に、我々は生徒モデル(ランダムに初期化されたMobileNet)が教師モデル(微調整されたビジョン変換器)を模倣することを望む。これを実現するために、まず教師と生徒からロジット出力を得る。次に、それぞれのソフトターゲットの重要度を制御するパラメータ`temperature`で分割する。`lambda`と呼ばれるパラメータは蒸留ロスの重要度を量る。この例では、`temperature=5`、`lambda=0.5`とする。生徒と教師の間の発散を計算するために、Kullback-Leibler発散損失を使用します。2つのデータPとQが与えられたとき、KLダイバージェンスはQを使ってPを表現するためにどれだけの余分な情報が必要かを説明します。もし2つが同じであれば、QからPを説明するために必要な他の情報はないので、それらのKLダイバージェンスはゼロになります。
+
+
+```python
+from transformers import TrainingArguments, Trainer
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class ImageDistilTrainer(Trainer):
+ def __init__(self, *args, teacher_model=None, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.teacher = teacher_model
+ self.student = student_model
+ self.loss_function = nn.KLDivLoss(reduction="batchmean")
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+ self.teacher.to(device)
+ self.teacher.eval()
+ self.temperature = temperature
+ self.lambda_param = lambda_param
+
+ def compute_loss(self, student, inputs, return_outputs=False):
+ student_output = self.student(**inputs)
+
+ with torch.no_grad():
+ teacher_output = self.teacher(**inputs)
+
+ # Compute soft targets for teacher and student
+ soft_teacher = F.softmax(teacher_output.logits / self.temperature, dim=-1)
+ soft_student = F.log_softmax(student_output.logits / self.temperature, dim=-1)
+
+ # Compute the loss
+ distillation_loss = self.loss_function(soft_student, soft_teacher) * (self.temperature ** 2)
+
+ # Compute the true label loss
+ student_target_loss = student_output.loss
+
+ # Calculate final loss
+ loss = (1. - self.lambda_param) * student_target_loss + self.lambda_param * distillation_loss
+ return (loss, student_output) if return_outputs else loss
+```
+
+次に、Hugging Face Hub にログインして、`trainer`を通じてモデルを Hugging Face Hub にプッシュできるようにします。
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+教師モデルと生徒モデルである`TrainingArguments`を設定しましょう。
+
+```python
+from transformers import AutoModelForImageClassification, MobileNetV2Config, MobileNetV2ForImageClassification
+
+training_args = TrainingArguments(
+ output_dir="my-awesome-model",
+ num_train_epochs=30,
+ fp16=True,
+ logging_dir=f"{repo_name}/logs",
+ logging_strategy="epoch",
+ eval_strategy="epoch",
+ save_strategy="epoch",
+ load_best_model_at_end=True,
+ metric_for_best_model="accuracy",
+ report_to="tensorboard",
+ push_to_hub=True,
+ hub_strategy="every_save",
+ hub_model_id=repo_name,
+ )
+
+num_labels = len(processed_datasets["train"].features["labels"].names)
+
+# initialize models
+teacher_model = AutoModelForImageClassification.from_pretrained(
+ "merve/beans-vit-224",
+ num_labels=num_labels,
+ ignore_mismatched_sizes=True
+)
+
+# training MobileNetV2 from scratch
+student_config = MobileNetV2Config()
+student_config.num_labels = num_labels
+student_model = MobileNetV2ForImageClassification(student_config)
+```
+
+`compute_metrics` 関数を使用して、テスト セットでモデルを評価できます。この関数は、トレーニング プロセス中にモデルの`accuracy`と`f1`を計算するために使用されます。
+
+```python
+import evaluate
+import numpy as np
+
+accuracy = evaluate.load("accuracy")
+
+def compute_metrics(eval_pred):
+ predictions, labels = eval_pred
+ acc = accuracy.compute(references=labels, predictions=np.argmax(predictions, axis=1))
+ return {"accuracy": acc["accuracy"]}
+```
+
+定義したトレーニング引数を使用して`Trainer`を初期化しましょう。データ照合装置も初期化します。
+
+
+```python
+from transformers import DefaultDataCollator
+
+data_collator = DefaultDataCollator()
+trainer = ImageDistilTrainer(
+ student_model=student_model,
+ teacher_model=teacher_model,
+ training_args=training_args,
+ train_dataset=processed_datasets["train"],
+ eval_dataset=processed_datasets["validation"],
+ data_collator=data_collator,
+ processing_class=teacher_extractor,
+ compute_metrics=compute_metrics,
+ temperature=5,
+ lambda_param=0.5
+)
+```
+
+これでモデルをトレーニングできるようになりました。
+
+```python
+trainer.train()
+```
+
+テスト セットでモデルを評価できます。
+
+
+```python
+trainer.evaluate(processed_datasets["test"])
+```
+
+テスト セットでは、モデルの精度は 72% に達します。蒸留効率の健全性チェックを行うために、同じハイパーパラメータを使用して Bean データセットで MobileNet を最初からトレーニングし、テスト セットで 63% の精度を観察しました。読者の皆様には、さまざまな事前トレーニング済み教師モデル、学生アーキテクチャ、蒸留パラメータを試していただき、その結果を報告していただくようお勧めします。抽出されたモデルのトレーニング ログとチェックポイントは [このリポジトリ](https://huggingface.co/merve/vit-mobilenet-beans-224) にあり、最初からトレーニングされた MobileNetV2 はこの [リポジトリ](https://huggingface.co/merve/resnet-mobilenet-beans-5)。
diff --git a/docs/transformers/docs/source/ja/tasks/language_modeling.md b/docs/transformers/docs/source/ja/tasks/language_modeling.md
new file mode 100644
index 0000000000000000000000000000000000000000..1cadc0af0ac0a559dd3b332c742dffa503b4fe64
--- /dev/null
+++ b/docs/transformers/docs/source/ja/tasks/language_modeling.md
@@ -0,0 +1,437 @@
+
+
+# Causal language modeling
+
+
+[[open-in-colab]]
+
+
+言語モデリングには、因果的モデリングとマスクされた言語モデリングの 2 つのタイプがあります。このガイドでは、因果関係のある言語モデリングについて説明します。
+因果言語モデルはテキスト生成によく使用されます。これらのモデルは、次のようなクリエイティブなアプリケーションに使用できます。
+独自のテキスト アドベンチャーを選択するか、Copilot や CodeParrot などのインテリジェントなコーディング アシスタントを選択します。
+
+
+
+
+因果言語モデリングは、一連のトークン内の次のトークンを予測します。モデルは、次のトークンにのみ対応できます。
+左。これは、モデルが将来のトークンを認識できないことを意味します。 GPT-2 は因果的言語モデルの一例です。
+
+このガイドでは、次の方法を説明します。
+
+1. [ELI5](https:/) の [r/askscience](https://www.reddit.com/r/askscience/) サブセットで [DistilGPT2](https://huggingface.co/distilbert/distilgpt2) を微調整します。 /huggingface.co/datasets/eli5) データセット。
+2. 微調整したモデルを推論に使用します。
+
+
+
+このタスクと互換性のあるすべてのアーキテクチャとチェックポイントを確認するには、[タスクページ](https://huggingface.co/tasks/text-generation) を確認することをお勧めします。u
+
+
+
+始める前に、必要なライブラリがすべてインストールされていることを確認してください。
+
+```bash
+pip install transformers datasets evaluate
+```
+
+モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## Load ELI5 dataset
+
+
+まず、ELI5 データセットの r/askscience サブセットの小さいサブセットを 🤗 データセット ライブラリからロードします。
+ これにより、完全なデータセットのトレーニングにさらに時間を費やす前に、実験してすべてが機能することを確認する機会が得られます。
+
+```py
+>>> from datasets import load_dataset
+
+>>> eli5 = load_dataset("eli5", split="train_asks[:5000]")
+```
+
+[`~datasets.Dataset.train_test_split`] メソッドを使用して、データセットの `train_asks` をトレイン セットとテスト セットに分割します。
+
+```py
+>>> eli5 = eli5.train_test_split(test_size=0.2)
+```
+
+次に、例を見てみましょう。
+
+```py
+>>> eli5["train"][0]
+{'answers': {'a_id': ['c3d1aib', 'c3d4lya'],
+ 'score': [6, 3],
+ 'text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
+ "Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"]},
+ 'answers_urls': {'url': []},
+ 'document': '',
+ 'q_id': 'nyxfp',
+ 'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
+ 'selftext_urls': {'url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg']},
+ 'subreddit': 'askscience',
+ 'title': 'Few questions about this space walk photograph.',
+ 'title_urls': {'url': []}}
+```
+
+これは多くのことのように見えるかもしれませんが、実際に関心があるのは`text`フィールドだけです。言語モデリングの優れている点
+タスクでは、次の単語がラベル * であるため、ラベル (教師なしタスクとも呼ばれます) は必要ありません。
+
+
+## Preprocess
+
+
+
+
+次のステップは、`text`サブフィールドを処理するために DistilGPT2 トークナイザーをロードすることです。
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
+```
+
+上の例からわかるように、`text`フィールドは実際には`answers`内にネストされています。つまり、次のことが必要になります。
+[` flatten`](https://huggingface.co/docs/datasets/process.html#flatten) メソッドを使用して、ネストされた構造から `text` サブフィールドを抽出します。
+
+```py
+>>> eli5 = eli5.flatten()
+>>> eli5["train"][0]
+{'answers.a_id': ['c3d1aib', 'c3d4lya'],
+ 'answers.score': [6, 3],
+ 'answers.text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
+ "Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"],
+ 'answers_urls.url': [],
+ 'document': '',
+ 'q_id': 'nyxfp',
+ 'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
+ 'selftext_urls.url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg'],
+ 'subreddit': 'askscience',
+ 'title': 'Few questions about this space walk photograph.',
+ 'title_urls.url': []}
+```
+
+`answers`接頭辞で示されるように、各サブフィールドは個別の列になり、`text`フィールドはリストになりました。その代わり
+各文を個別にトークン化する場合は、リストを文字列に変換して、それらをまとめてトークン化できるようにします。
+
+以下は、各例の文字列のリストを結合し、結果をトークン化する最初の前処理関数です。
+
+```py
+>>> def preprocess_function(examples):
+... return tokenizer([" ".join(x) for x in examples["answers.text"]])
+```
+
+この前処理関数をデータセット全体に適用するには、🤗 Datasets [`~datasets.Dataset.map`] メソッドを使用します。 `map` 関数を高速化するには、`batched=True` を設定してデータセットの複数の要素を一度に処理し、`num_proc` でプロセスの数を増やします。不要な列を削除します。
+
+```py
+>>> tokenized_eli5 = eli5.map(
+... preprocess_function,
+... batched=True,
+... num_proc=4,
+... remove_columns=eli5["train"].column_names,
+... )
+```
+
+このデータセットにはトークン シーケンスが含まれていますが、その一部はモデルの最大入力長よりも長くなります。
+
+2 番目の前処理関数を使用して、
+- すべてのシーケンスを連結します
+- 連結されたシーケンスを`block_size`で定義された短いチャンクに分割します。これは、最大入力長より短く、GPU RAM に十分な長さである必要があります。
+
+```py
+>>> block_size = 128
+
+
+>>> def group_texts(examples):
+... # Concatenate all texts.
+... concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
+... total_length = len(concatenated_examples[list(examples.keys())[0]])
+... # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
+... # customize this part to your needs.
+... if total_length >= block_size:
+... total_length = (total_length // block_size) * block_size
+... # Split by chunks of block_size.
+... result = {
+... k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
+... for k, t in concatenated_examples.items()
+... }
+... result["labels"] = result["input_ids"].copy()
+... return result
+```
+
+Apply the `group_texts` function over the entire dataset:
+
+```py
+>>> lm_dataset = tokenized_eli5.map(group_texts, batched=True, num_proc=4)
+```
+
+次に、[`DataCollatorForLanguageModeling`] を使用してサンプルのバッチを作成します。 *動的にパディング*する方が効率的です。
+データセット全体を最大長までパディングするのではなく、照合中にバッチ内の文を最長の長さにします。
+
+
+
+
+シーケンス終了トークンをパディング トークンとして使用し、`mlm=False` を設定します。これは、入力を 1 要素分右にシフトしたラベルとして使用します。
+
+```py
+>>> from transformers import DataCollatorForLanguageModeling
+
+>>> tokenizer.pad_token = tokenizer.eos_token
+>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
+```
+
+
+
+シーケンス終了トークンをパディング トークンとして使用し、`mlm=False` を設定します。これは、入力を 1 要素分右にシフトしたラベルとして使用します。
+
+```py
+>>> from transformers import DataCollatorForLanguageModeling
+
+>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False, return_tensors="tf")
+```
+
+
+
+
+
+## Train
+
+
+
+
+
+[`Trainer`] を使用したモデルの微調整に慣れていない場合は、[基本チュートリアル](../training#train-with-pytorch-trainer) を参照してください。
+
+
+
+これでモデルのトレーニングを開始する準備が整いました。 [`AutoModelForCausalLM`] を使用して DistilGPT2 をロードします。
+
+
+```py
+>>> from transformers import AutoModelForCausalLM, TrainingArguments, Trainer
+
+>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
+```
+
+この時点で残っている手順は次の 3 つだけです。
+
+1. [`TrainingArguments`] でトレーニング ハイパーパラメータを定義します。唯一の必須パラメータは、モデルの保存場所を指定する `output_dir` です。 `push_to_hub=True`を設定して、このモデルをハブにプッシュします (モデルをアップロードするには、Hugging Face にサインインする必要があります)。
+2. トレーニング引数をモデル、データセット、データ照合器とともに [`Trainer`] に渡します。
+3. [`~Trainer.train`] を呼び出してモデルを微調整します。
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_eli5_clm-model",
+... eval_strategy="epoch",
+... learning_rate=2e-5,
+... weight_decay=0.01,
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=lm_dataset["train"],
+... eval_dataset=lm_dataset["test"],
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+トレーニングが完了したら、 [`~transformers.Trainer.evaluate`] メソッドを使用してモデルを評価し、その複雑さを取得します。
+
+```py
+>>> import math
+
+>>> eval_results = trainer.evaluate()
+>>> print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
+Perplexity: 49.61
+```
+
+次に、 [`~transformers.Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、誰もがモデルを使用できるようにします。
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+Keras を使用したモデルの微調整に慣れていない場合は、[基本チュートリアル](../training#train-a-tensorflow-model-with-keras) をご覧ください。
+
+
+TensorFlow でモデルを微調整するには、オプティマイザー関数、学習率スケジュール、およびいくつかのトレーニング ハイパーパラメーターをセットアップすることから始めます。
+
+```py
+>>> from transformers import create_optimizer, AdamWeightDecay
+
+>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
+```
+
+次に、[`TFAutoModelForCausalLM`] を使用して DistilGPT2 をロードできます。
+
+```py
+>>> from transformers import TFAutoModelForCausalLM
+
+>>> model = TFAutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
+```
+
+[`~transformers.TFPreTrainedModel.prepare_tf_dataset`] を使用して、データセットを `tf.data.Dataset` 形式に変換します。
+
+```py
+>>> tf_train_set = model.prepare_tf_dataset(
+... lm_dataset["train"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_test_set = model.prepare_tf_dataset(
+... lm_dataset["test"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+[`compile`](https://keras.io/api/models/model_training_apis/#compile-method) を使用してトレーニング用のモデルを設定します。 Transformers モデルにはすべてデフォルトのタスク関連の損失関数があるため、次の場合を除き、損失関数を指定する必要はないことに注意してください。
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer) # No loss argument!
+```
+
+これは、モデルとトークナイザーを [`~transformers.PushToHubCallback`] でプッシュする場所を指定することで実行できます。
+
+
+
+```py
+>>> from transformers.keras_callbacks import PushToHubCallback
+
+>>> callback = PushToHubCallback(
+... output_dir="my_awesome_eli5_clm-model",
+... tokenizer=tokenizer,
+... )
+```
+
+ついに、モデルのトレーニングを開始する準備が整いました。トレーニングおよび検証データセット、エポック数、コールバックを指定して [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) を呼び出し、モデルを微調整します。
+
+
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=[callback])
+```
+
+トレーニングが完了すると、モデルは自動的にハブにアップロードされ、誰でも使用できるようになります。
+
+
+
+
+
+
+因果言語モデリング用にモデルを微調整する方法のより詳細な例については、対応するドキュメントを参照してください。
+[PyTorch ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
+または [TensorFlow ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)。
+
+
+
+## Inference
+
+モデルを微調整したので、それを推論に使用できるようになりました。
+
+テキストを生成するプロンプトを考え出します。
+
+```py
+>>> prompt = "Somatic hypermutation allows the immune system to"
+```
+
+推論用に微調整されたモデルを試す最も簡単な方法は、それを [`pipeline`] で使用することです。モデルを使用してテキスト生成用の`pipeline`をインスタンス化し、それにテキストを渡します。
+
+
+```py
+>>> from transformers import pipeline
+
+>>> generator = pipeline("text-generation", model="my_awesome_eli5_clm-model")
+>>> generator(prompt)
+[{'generated_text': "Somatic hypermutation allows the immune system to be able to effectively reverse the damage caused by an infection.\n\n\nThe damage caused by an infection is caused by the immune system's ability to perform its own self-correcting tasks."}]
+```
+
+
+
+
+
+テキストをトークン化し、「input_ids」を PyTorch テンソルとして返します。
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_eli5_clm-model")
+>>> inputs = tokenizer(prompt, return_tensors="pt").input_ids
+```
+
+[`~generation.GenerationMixin.generate`] メソッドを使用してテキストを生成します。
+さまざまなテキスト生成戦略と生成を制御するためのパラメーターの詳細については、[テキスト生成戦略](../generation_strategies) ページを参照してください。
+
+```py
+>>> from transformers import AutoModelForCausalLM
+
+>>> model = AutoModelForCausalLM.from_pretrained("my_awesome_eli5_clm-model")
+>>> outputs = model.generate(inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
+```
+
+生成されたトークン ID をデコードしてテキストに戻します。
+
+```py
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+["Somatic hypermutation allows the immune system to react to drugs with the ability to adapt to a different environmental situation. In other words, a system of 'hypermutation' can help the immune system to adapt to a different environmental situation or in some cases even a single life. In contrast, researchers at the University of Massachusetts-Boston have found that 'hypermutation' is much stronger in mice than in humans but can be found in humans, and that it's not completely unknown to the immune system. A study on how the immune system"]
+```
+
+
+
+
+テキストをトークン化し、`input_ids`を TensorFlow テンソルとして返します。
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_eli5_clm-model")
+>>> inputs = tokenizer(prompt, return_tensors="tf").input_ids
+```
+
+[`~transformers.generation_tf_utils.TFGenerationMixin.generate`] メソッドを使用して要約を作成します。さまざまなテキスト生成戦略と生成を制御するためのパラメーターの詳細については、[テキスト生成戦略](../generation_strategies) ページを参照してください。
+
+```py
+>>> from transformers import TFAutoModelForCausalLM
+
+>>> model = TFAutoModelForCausalLM.from_pretrained("my_awesome_eli5_clm-model")
+>>> outputs = model.generate(input_ids=inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
+```
+
+生成されたトークン ID をデコードしてテキストに戻します。
+
+```py
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['Somatic hypermutation allows the immune system to detect the presence of other viruses as they become more prevalent. Therefore, researchers have identified a high proportion of human viruses. The proportion of virus-associated viruses in our study increases with age. Therefore, we propose a simple algorithm to detect the presence of these new viruses in our samples as a sign of improved immunity. A first study based on this algorithm, which will be published in Science on Friday, aims to show that this finding could translate into the development of a better vaccine that is more effective for']
+```
+
+
+
diff --git a/docs/transformers/docs/source/ja/tasks/masked_language_modeling.md b/docs/transformers/docs/source/ja/tasks/masked_language_modeling.md
new file mode 100644
index 0000000000000000000000000000000000000000..29d7b73ae5d026f210de5c9d82401224a4a94bda
--- /dev/null
+++ b/docs/transformers/docs/source/ja/tasks/masked_language_modeling.md
@@ -0,0 +1,449 @@
+
+
+# Masked language modeling
+
+[[open-in-colab]]
+
+
+
+マスクされた言語モデリングはシーケンス内のマスクされたトークンを予測し、モデルはトークンを双方向に処理できます。これ
+これは、モデルが左右のトークンに完全にアクセスできることを意味します。マスクされた言語モデリングは、次のようなタスクに最適です。
+シーケンス全体の文脈をよく理解する必要があります。 BERT はマスクされた言語モデルの一例です。
+
+このガイドでは、次の方法を説明します。
+
+1. [ELI5](https://huggingface.co/distilbert/distilroberta-base) の [r/askscience](https://www.reddit.com/r/askscience/) サブセットで [DistilRoBERTa](https://huggingface.co/distilbert/distilroberta-base) を微調整します。 ://huggingface.co/datasets/eli5) データセット。
+2. 微調整したモデルを推論に使用します。
+
+
+
+このタスクと互換性のあるすべてのアーキテクチャとチェックポイントを確認するには、[タスクページ](https://huggingface.co/tasks/fill-mask) を確認することをお勧めします。
+
+
+
+始める前に、必要なライブラリがすべてインストールされていることを確認してください。
+
+```bash
+pip install transformers datasets evaluate
+```
+
+モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## Load ELI5 dataset
+
+まず、ELI5 データセットの r/askscience サブセットの小さいサブセットを 🤗 データセット ライブラリからロードします。これで
+データセット全体のトレーニングにさらに時間を費やす前に、実験してすべてが機能することを確認する機会が与えられます。
+
+```py
+>>> from datasets import load_dataset
+
+>>> eli5 = load_dataset("eli5", split="train_asks[:5000]")
+```
+
+[`~datasets.Dataset.train_test_split`] メソッドを使用して、データセットの `train_asks` をトレイン セットとテスト セットに分割します。
+
+```py
+>>> eli5 = eli5.train_test_split(test_size=0.2)
+```
+
+次に、例を見てみましょう。
+
+```py
+>>> eli5["train"][0]
+{'answers': {'a_id': ['c3d1aib', 'c3d4lya'],
+ 'score': [6, 3],
+ 'text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
+ "Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"]},
+ 'answers_urls': {'url': []},
+ 'document': '',
+ 'q_id': 'nyxfp',
+ 'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
+ 'selftext_urls': {'url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg']},
+ 'subreddit': 'askscience',
+ 'title': 'Few questions about this space walk photograph.',
+ 'title_urls': {'url': []}}
+```
+
+これは多くのことのように見えるかもしれませんが、実際に関心があるのは`text`フィールドだけです。言語モデリング タスクの優れた点は、次の単語がラベル * であるため、ラベル (教師なしタスクとも呼ばれます) が必要ないことです。
+
+## Preprocess
+
+
+
+マスクされた言語モデリングの場合、次のステップは、`text`サブフィールドを処理するために DistilRoBERTa トークナイザーをロードすることです。
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilroberta-base")
+```
+
+上の例からわかるように、`text`フィールドは実際には`answers`内にネストされています。これは、次のことを行う必要があることを意味します
+[` flatten`](https://huggingface.co/docs/datasets/process.html#flatten) メソッドを使用して、ネストされた構造から `text` サブフィールドを抽出します。
+
+```py
+>>> eli5 = eli5.flatten()
+>>> eli5["train"][0]
+{'answers.a_id': ['c3d1aib', 'c3d4lya'],
+ 'answers.score': [6, 3],
+ 'answers.text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
+ "Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"],
+ 'answers_urls.url': [],
+ 'document': '',
+ 'q_id': 'nyxfp',
+ 'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
+ 'selftext_urls.url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg'],
+ 'subreddit': 'askscience',
+ 'title': 'Few questions about this space walk photograph.',
+ 'title_urls.url': []}
+```
+
+`answers`接頭辞で示されるように、各サブフィールドは個別の列になり、`text`フィールドはリストになりました。その代わり
+各文を個別にトークン化する場合は、リストを文字列に変換して、それらをまとめてトークン化できるようにします。
+
+以下は、各例の文字列のリストを結合し、結果をトークン化する最初の前処理関数です。
+
+```py
+>>> def preprocess_function(examples):
+... return tokenizer([" ".join(x) for x in examples["answers.text"]])
+```
+
+この前処理関数をデータセット全体に適用するには、🤗 Datasets [`~datasets.Dataset.map`] メソッドを使用します。 `map` 関数を高速化するには、`batched=True` を設定してデータセットの複数の要素を一度に処理し、`num_proc` でプロセスの数を増やします。不要な列を削除します。
+
+```py
+>>> tokenized_eli5 = eli5.map(
+... preprocess_function,
+... batched=True,
+... num_proc=4,
+... remove_columns=eli5["train"].column_names,
+... )
+```
+
+このデータセットにはトークン シーケンスが含まれていますが、その一部はモデルの最大入力長よりも長くなります。
+
+2 番目の前処理関数を使用して、
+- すべてのシーケンスを連結します
+- 連結されたシーケンスを`block_size`で定義された短いチャンクに分割します。これは、最大入力長より短く、GPU RAM に十分な長さである必要があります。
+
+```py
+>>> block_size = 128
+
+
+>>> def group_texts(examples):
+... # Concatenate all texts.
+... concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
+... total_length = len(concatenated_examples[list(examples.keys())[0]])
+... # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
+... # customize this part to your needs.
+... if total_length >= block_size:
+... total_length = (total_length // block_size) * block_size
+... # Split by chunks of block_size.
+... result = {
+... k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
+... for k, t in concatenated_examples.items()
+... }
+... return result
+```
+
+データセット全体に`group_texts`関数を適用します。
+
+```py
+>>> lm_dataset = tokenized_eli5.map(group_texts, batched=True, num_proc=4)
+```
+
+次に、[`DataCollatorForLanguageModeling`] を使用してサンプルのバッチを作成します。データセット全体を最大長までパディングするのではなく、照合中にバッチ内の最長の長さまで文を *動的にパディング* する方が効率的です。
+
+
+
+
+シーケンス終了トークンをパディング トークンとして使用し、データを反復するたびにランダムにトークンをマスクするために `mlm_probability` を指定します。
+
+```py
+>>> from transformers import DataCollatorForLanguageModeling
+
+>>> tokenizer.pad_token = tokenizer.eos_token
+>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
+```
+
+
+
+シーケンス終了トークンをパディング トークンとして使用し、データを反復するたびにランダムにトークンをマスクするために `mlm_probability` を指定します。
+
+
+```py
+>>> from transformers import DataCollatorForLanguageModeling
+
+>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15, return_tensors="tf")
+```
+
+
+
+## Train
+
+
+
+
+
+[`Trainer`] を使用したモデルの微調整に慣れていない場合は、[ここ](../training#train-with-pytorch-trainer) の基本的なチュートリアルをご覧ください。
+
+
+
+これでモデルのトレーニングを開始する準備が整いました。 [`AutoModelForMaskedLM`] を使用して DistilRoBERTa をロードします。
+
+```py
+>>> from transformers import AutoModelForMaskedLM
+
+>>> model = AutoModelForMaskedLM.from_pretrained("distilbert/distilroberta-base")
+```
+
+この時点で残っている手順は次の 3 つだけです。
+
+1. [`TrainingArguments`] でトレーニング ハイパーパラメータを定義します。唯一の必須パラメータは、モデルの保存場所を指定する `output_dir` です。 `push_to_hub=True`を設定して、このモデルをハブにプッシュします (モデルをアップロードするには、Hugging Face にサインインする必要があります)。
+2. トレーニング引数をモデル、データセット、データ照合器とともに [`Trainer`] に渡します。
+3. [`~Trainer.train`] を呼び出してモデルを微調整します。
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_eli5_mlm_model",
+... eval_strategy="epoch",
+... learning_rate=2e-5,
+... num_train_epochs=3,
+... weight_decay=0.01,
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=lm_dataset["train"],
+... eval_dataset=lm_dataset["test"],
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+トレーニングが完了したら、 [`~transformers.Trainer.evaluate`] メソッドを使用してモデルを評価し、その複雑さを取得します。
+
+
+```py
+>>> import math
+
+>>> eval_results = trainer.evaluate()
+>>> print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
+Perplexity: 8.76
+```
+
+次に、 [`~transformers.Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、誰もがモデルを使用できるようにします。
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+
+Keras を使用したモデルの微調整に慣れていない場合は、[こちら](../training#train-a-tensorflow-model-with-keras) の基本的なチュートリアルをご覧ください。
+
+
+
+TensorFlow でモデルを微調整するには、オプティマイザー関数、学習率スケジュール、およびいくつかのトレーニング ハイパーパラメーターをセットアップすることから始めます。
+
+```py
+>>> from transformers import create_optimizer, AdamWeightDecay
+
+>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
+```
+
+次に、[`TFAutoModelForMaskedLM`] を使用して DistilRoBERTa をロードできます。
+
+```py
+>>> from transformers import TFAutoModelForMaskedLM
+
+>>> model = TFAutoModelForMaskedLM.from_pretrained("distilbert/distilroberta-base")
+```
+
+[`~transformers.TFPreTrainedModel.prepare_tf_dataset`] を使用して、データセットを `tf.data.Dataset` 形式に変換します。
+
+```py
+>>> tf_train_set = model.prepare_tf_dataset(
+... lm_dataset["train"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_test_set = model.prepare_tf_dataset(
+... lm_dataset["test"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+[`compile`](https://keras.io/api/models/model_training_apis/#compile-method) を使用してトレーニング用のモデルを設定します。 Transformers モデルにはすべてデフォルトのタスク関連の損失関数があるため、次の場合を除き、損失関数を指定する必要はないことに注意してください。
+
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer) # No loss argument!
+```
+
+This can be done by specifying where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
+
+```py
+>>> from transformers.keras_callbacks import PushToHubCallback
+
+>>> callback = PushToHubCallback(
+... output_dir="my_awesome_eli5_mlm_model",
+... tokenizer=tokenizer,
+... )
+```
+
+ついに、モデルのトレーニングを開始する準備が整いました。トレーニングおよび検証データセット、エポック数、コールバックを指定して [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) を呼び出し、モデルを微調整します。
+
+
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=[callback])
+```
+
+トレーニングが完了すると、モデルは自動的にハブにアップロードされ、誰でも使用できるようになります。
+
+
+
+
+
+
+マスクされた言語モデリング用にモデルを微調整する方法のより詳細な例については、対応するドキュメントを参照してください。
+[PyTorch ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
+または [TensorFlow ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)。
+
+
+
+## Inference
+
+モデルを微調整したので、それを推論に使用できるようになりました。
+
+モデルに空白を埋めるテキストを考え出し、特別な `` トークンを使用して空白を示します。
+
+```py
+>>> text = "The Milky Way is a galaxy."
+```
+
+推論用に微調整されたモデルを試す最も簡単な方法は、それを [`pipeline`] で使用することです。モデルを使用してフィルマスクの`pipeline`をインスタンス化し、テキストをそれに渡します。必要に応じて、`top_k`パラメータを使用して、返す予測の数を指定できます。
+
+```py
+>>> from transformers import pipeline
+
+>>> mask_filler = pipeline("fill-mask", "stevhliu/my_awesome_eli5_mlm_model")
+>>> mask_filler(text, top_k=3)
+[{'score': 0.5150994658470154,
+ 'token': 21300,
+ 'token_str': ' spiral',
+ 'sequence': 'The Milky Way is a spiral galaxy.'},
+ {'score': 0.07087188959121704,
+ 'token': 2232,
+ 'token_str': ' massive',
+ 'sequence': 'The Milky Way is a massive galaxy.'},
+ {'score': 0.06434620916843414,
+ 'token': 650,
+ 'token_str': ' small',
+ 'sequence': 'The Milky Way is a small galaxy.'}]
+```
+
+
+
+
+テキストをトークン化し、`input_ids`を PyTorch テンソルとして返します。 `` トークンの位置も指定する必要があります。
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
+>>> inputs = tokenizer(text, return_tensors="pt")
+>>> mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
+```
+
+入力をモデルに渡し、マスクされたトークンの`logits`を返します。
+
+```py
+>>> from transformers import AutoModelForMaskedLM
+
+>>> model = AutoModelForMaskedLM.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
+>>> logits = model(**inputs).logits
+>>> mask_token_logits = logits[0, mask_token_index, :]
+```
+
+次に、マスクされた 3 つのトークンを最も高い確率で返し、出力します。
+
+```py
+>>> top_3_tokens = torch.topk(mask_token_logits, 3, dim=1).indices[0].tolist()
+
+>>> for token in top_3_tokens:
+... print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
+The Milky Way is a spiral galaxy.
+The Milky Way is a massive galaxy.
+The Milky Way is a small galaxy.
+```
+
+
+
+
+テキストをトークン化し、`input_ids`を TensorFlow テンソルとして返します。 `` トークンの位置も指定する必要があります。
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
+>>> inputs = tokenizer(text, return_tensors="tf")
+>>> mask_token_index = tf.where(inputs["input_ids"] == tokenizer.mask_token_id)[0, 1]
+```
+
+入力をモデルに渡し、マスクされたトークンの`logits`を返します。
+
+
+```py
+>>> from transformers import TFAutoModelForMaskedLM
+
+>>> model = TFAutoModelForMaskedLM.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
+>>> logits = model(**inputs).logits
+>>> mask_token_logits = logits[0, mask_token_index, :]
+```
+
+次に、マスクされた 3 つのトークンを最も高い確率で返し、出力します。
+
+
+```py
+>>> top_3_tokens = tf.math.top_k(mask_token_logits, 3).indices.numpy()
+
+>>> for token in top_3_tokens:
+... print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
+The Milky Way is a spiral galaxy.
+The Milky Way is a massive galaxy.
+The Milky Way is a small galaxy.
+```
+
+
diff --git a/docs/transformers/docs/source/ja/tasks/monocular_depth_estimation.md b/docs/transformers/docs/source/ja/tasks/monocular_depth_estimation.md
new file mode 100644
index 0000000000000000000000000000000000000000..e7a3a994a60ebc3ee752cfd0461bb7436c7b8406
--- /dev/null
+++ b/docs/transformers/docs/source/ja/tasks/monocular_depth_estimation.md
@@ -0,0 +1,149 @@
+
+
+# Monocular depth estimation
+
+単眼奥行き推定は、シーンの奥行き情報を画像から予測することを含むコンピューター ビジョン タスクです。
+単一の画像。言い換えれば、シーン内のオブジェクトの距離を距離から推定するプロセスです。
+単一カメラの視点。
+
+単眼奥行き推定には、3D 再構築、拡張現実、自動運転、
+そしてロボット工学。モデルがオブジェクト間の複雑な関係を理解する必要があるため、これは困難な作業です。
+シーンとそれに対応する深度情報(照明条件などの要因の影響を受ける可能性があります)
+オクルージョンとテクスチャ。
+
+
+
+このタスクと互換性のあるすべてのアーキテクチャとチェックポイントを確認するには、[タスクページ](https://huggingface.co/tasks/depth-estimation) を確認することをお勧めします。
+
+
+
+このガイドでは、次の方法を学びます。
+
+* 深度推定パイプラインを作成する
+* 手動で深度推定推論を実行します
+
+始める前に、必要なライブラリがすべてインストールされていることを確認してください。
+
+```bash
+pip install -q transformers
+```
+
+## Depth estimation pipeline
+
+深度推定をサポートするモデルで推論を試す最も簡単な方法は、対応する [`pipeline`] を使用することです。
+[Hugging Face Hub のチェックポイント](https://huggingface.co/models?pipeline_tag=Depth-estimation&sort=downloads) からパイプラインをインスタンス化します。
+
+
+```py
+>>> from transformers import pipeline
+
+>>> checkpoint = "vinvino02/glpn-nyu"
+>>> depth_estimator = pipeline("depth-estimation", model=checkpoint)
+```
+
+次に、分析する画像を選択します。
+
+```py
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "https://unsplash.com/photos/HwBAsSbPBDU/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8MzR8fGNhciUyMGluJTIwdGhlJTIwc3RyZWV0fGVufDB8MHx8fDE2Nzg5MDEwODg&force=true&w=640"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> image
+```
+
+
diff --git a/docs/transformers/docs/source/ja/tasks/summarization.md b/docs/transformers/docs/source/ja/tasks/summarization.md
new file mode 100644
index 0000000000000000000000000000000000000000..6784696e6c95a3bdc3abe661236ad540b3304bfc
--- /dev/null
+++ b/docs/transformers/docs/source/ja/tasks/summarization.md
@@ -0,0 +1,404 @@
+
+
+# Summarization
+
+[[open-in-colab]]
+
+
+
+要約により、すべての重要な情報をまとめた短いバージョンの文書または記事が作成されます。これは、翻訳と並んで、シーケンス間のタスクとして定式化できるタスクのもう 1 つの例です。要約は次のようになります。
+
+- 抽出: 文書から最も関連性の高い情報を抽出します。
+- 抽象的: 最も関連性の高い情報を捉えた新しいテキストを生成します。
+
+このガイドでは、次の方法を説明します。
+
+1. 抽象的な要約のために、[BillSum](https://huggingface.co/datasets/billsum) データセットのカリフォルニア州請求書サブセットで [T5](https://huggingface.co/google-t5/t5-small) を微調整します。
+2. 微調整したモデルを推論に使用します。
+
+
+
+このタスクと互換性のあるすべてのアーキテクチャとチェックポイントを確認するには、[タスクページ](https://huggingface.co/tasks/summarization) を確認することをお勧めします。
+
+
+
+始める前に、必要なライブラリがすべてインストールされていることを確認してください。
+
+```bash
+pip install transformers datasets evaluate rouge_score
+```
+
+モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## Load BillSum dataset
+
+まず、🤗 データセット ライブラリから BillSum データセットの小さいカリフォルニア州請求書サブセットを読み込みます。
+
+```py
+>>> from datasets import load_dataset
+
+>>> billsum = load_dataset("billsum", split="ca_test")
+```
+
+[`~datasets.Dataset.train_test_split`] メソッドを使用して、データセットをトレイン セットとテスト セットに分割します。
+
+```py
+>>> billsum = billsum.train_test_split(test_size=0.2)
+```
+
+次に、例を見てみましょう。
+
+```py
+>>> billsum["train"][0]
+{'summary': 'Existing law authorizes state agencies to enter into contracts for the acquisition of goods or services upon approval by the Department of General Services. Existing law sets forth various requirements and prohibitions for those contracts, including, but not limited to, a prohibition on entering into contracts for the acquisition of goods or services of $100,000 or more with a contractor that discriminates between spouses and domestic partners or same-sex and different-sex couples in the provision of benefits. Existing law provides that a contract entered into in violation of those requirements and prohibitions is void and authorizes the state or any person acting on behalf of the state to bring a civil action seeking a determination that a contract is in violation and therefore void. Under existing law, a willful violation of those requirements and prohibitions is a misdemeanor.\nThis bill would also prohibit a state agency from entering into contracts for the acquisition of goods or services of $100,000 or more with a contractor that discriminates between employees on the basis of gender identity in the provision of benefits, as specified. By expanding the scope of a crime, this bill would impose a state-mandated local program.\nThe California Constitution requires the state to reimburse local agencies and school districts for certain costs mandated by the state. Statutory provisions establish procedures for making that reimbursement.\nThis bill would provide that no reimbursement is required by this act for a specified reason.',
+ 'text': 'The people of the State of California do enact as follows:\n\n\nSECTION 1.\nSection 10295.35 is added to the Public Contract Code, to read:\n10295.35.\n(a) (1) Notwithstanding any other law, a state agency shall not enter into any contract for the acquisition of goods or services in the amount of one hundred thousand dollars ($100,000) or more with a contractor that, in the provision of benefits, discriminates between employees on the basis of an employee’s or dependent’s actual or perceived gender identity, including, but not limited to, the employee’s or dependent’s identification as transgender.\n(2) For purposes of this section, “contract” includes contracts with a cumulative amount of one hundred thousand dollars ($100,000) or more per contractor in each fiscal year.\n(3) For purposes of this section, an employee health plan is discriminatory if the plan is not consistent with Section 1365.5 of the Health and Safety Code and Section 10140 of the Insurance Code.\n(4) The requirements of this section shall apply only to those portions of a contractor’s operations that occur under any of the following conditions:\n(A) Within the state.\n(B) On real property outside the state if the property is owned by the state or if the state has a right to occupy the property, and if the contractor’s presence at that location is connected to a contract with the state.\n(C) Elsewhere in the United States where work related to a state contract is being performed.\n(b) Contractors shall treat as confidential, to the maximum extent allowed by law or by the requirement of the contractor’s insurance provider, any request by an employee or applicant for employment benefits or any documentation of eligibility for benefits submitted by an employee or applicant for employment.\n(c) After taking all reasonable measures to find a contractor that complies with this section, as determined by the state agency, the requirements of this section may be waived under any of the following circumstances:\n(1) There is only one prospective contractor willing to enter into a specific contract with the state agency.\n(2) The contract is necessary to respond to an emergency, as determined by the state agency, that endangers the public health, welfare, or safety, or the contract is necessary for the provision of essential services, and no entity that complies with the requirements of this section capable of responding to the emergency is immediately available.\n(3) The requirements of this section violate, or are inconsistent with, the terms or conditions of a grant, subvention, or agreement, if the agency has made a good faith attempt to change the terms or conditions of any grant, subvention, or agreement to authorize application of this section.\n(4) The contractor is providing wholesale or bulk water, power, or natural gas, the conveyance or transmission of the same, or ancillary services, as required for ensuring reliable services in accordance with good utility practice, if the purchase of the same cannot practically be accomplished through the standard competitive bidding procedures and the contractor is not providing direct retail services to end users.\n(d) (1) A contractor shall not be deemed to discriminate in the provision of benefits if the contractor, in providing the benefits, pays the actual costs incurred in obtaining the benefit.\n(2) If a contractor is unable to provide a certain benefit, despite taking reasonable measures to do so, the contractor shall not be deemed to discriminate in the provision of benefits.\n(e) (1) Every contract subject to this chapter shall contain a statement by which the contractor certifies that the contractor is in compliance with this section.\n(2) The department or other contracting agency shall enforce this section pursuant to its existing enforcement powers.\n(3) (A) If a contractor falsely certifies that it is in compliance with this section, the contract with that contractor shall be subject to Article 9 (commencing with Section 10420), unless, within a time period specified by the department or other contracting agency, the contractor provides to the department or agency proof that it has complied, or is in the process of complying, with this section.\n(B) The application of the remedies or penalties contained in Article 9 (commencing with Section 10420) to a contract subject to this chapter shall not preclude the application of any existing remedies otherwise available to the department or other contracting agency under its existing enforcement powers.\n(f) Nothing in this section is intended to regulate the contracting practices of any local jurisdiction.\n(g) This section shall be construed so as not to conflict with applicable federal laws, rules, or regulations. In the event that a court or agency of competent jurisdiction holds that federal law, rule, or regulation invalidates any clause, sentence, paragraph, or section of this code or the application thereof to any person or circumstances, it is the intent of the state that the court or agency sever that clause, sentence, paragraph, or section so that the remainder of this section shall remain in effect.\nSEC. 2.\nSection 10295.35 of the Public Contract Code shall not be construed to create any new enforcement authority or responsibility in the Department of General Services or any other contracting agency.\nSEC. 3.\nNo reimbursement is required by this act pursuant to Section 6 of Article XIII\u2009B of the California Constitution because the only costs that may be incurred by a local agency or school district will be incurred because this act creates a new crime or infraction, eliminates a crime or infraction, or changes the penalty for a crime or infraction, within the meaning of Section 17556 of the Government Code, or changes the definition of a crime within the meaning of Section 6 of Article XIII\u2009B of the California Constitution.',
+ 'title': 'An act to add Section 10295.35 to the Public Contract Code, relating to public contracts.'}
+```
+
+使用するフィールドが 2 つあります。
+
+- `text`: モデルへの入力となる請求書のテキスト。
+- `summary`: モデルのターゲットとなる `text` の要約版。
+
+## Preprocess
+
+次のステップでは、T5 トークナイザーをロードして「text」と`summary`を処理します。
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> checkpoint = "google-t5/t5-small"
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+```
+
+作成する前処理関数は次のことを行う必要があります。
+
+1. T5 がこれが要約タスクであることを認識できるように、入力の前にプロンプトを付けます。複数の NLP タスクが可能な一部のモデルでは、特定のタスクのプロンプトが必要です。
+2. ラベルをトークン化するときにキーワード `text_target` 引数を使用します。
+3. `max_length`パラメータで設定された最大長を超えないようにシーケンスを切り詰めます。
+
+```py
+>>> prefix = "summarize: "
+
+
+>>> def preprocess_function(examples):
+... inputs = [prefix + doc for doc in examples["text"]]
+... model_inputs = tokenizer(inputs, max_length=1024, truncation=True)
+
+... labels = tokenizer(text_target=examples["summary"], max_length=128, truncation=True)
+
+... model_inputs["labels"] = labels["input_ids"]
+... return model_inputs
+```
+
+データセット全体に前処理関数を適用するには、🤗 Datasets [`~datasets.Dataset.map`] メソッドを使用します。 `batched=True` を設定してデータセットの複数の要素を一度に処理することで、`map` 関数を高速化できます。
+
+```py
+>>> tokenized_billsum = billsum.map(preprocess_function, batched=True)
+```
+
+次に、[`DataCollatorForSeq2Seq`] を使用してサンプルのバッチを作成します。データセット全体を最大長までパディングするのではなく、照合中にバッチ内の最長の長さまで文を *動的にパディング* する方が効率的です。
+
+
+
+
+```py
+>>> from transformers import DataCollatorForSeq2Seq
+
+>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint)
+```
+
+
+
+```py
+>>> from transformers import DataCollatorForSeq2Seq
+
+>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint, return_tensors="tf")
+```
+
+
+
+## Evaluate
+
+トレーニング中にメトリクスを含めると、多くの場合、モデルのパフォーマンスを評価するのに役立ちます。 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) ライブラリを使用して、評価メソッドをすばやくロードできます。このタスクでは、[ROUGE](https://huggingface.co/spaces/evaluate-metric/rouge) メトリックを読み込みます (🤗 Evaluate [クイック ツアー](https://huggingface.co/docs/evaluate/a_quick_tour) を参照してください) ) メトリクスをロードして計算する方法の詳細については、次を参照してください)。
+
+```py
+>>> import evaluate
+
+>>> rouge = evaluate.load("rouge")
+```
+
+次に、予測とラベルを [`~evaluate.EvaluationModule.compute`] に渡して ROUGE メトリクスを計算する関数を作成します。
+
+```py
+>>> import numpy as np
+
+
+>>> def compute_metrics(eval_pred):
+... predictions, labels = eval_pred
+... decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+... labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+... decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+... result = rouge.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
+
+... prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]
+... result["gen_len"] = np.mean(prediction_lens)
+
+... return {k: round(v, 4) for k, v in result.items()}
+```
+
+これで`compute_metrics`関数の準備が整いました。トレーニングをセットアップするときにこの関数に戻ります。
+
+## Train
+
+
+
+
+
+
+[`Trainer`] を使用したモデルの微調整に慣れていない場合は、[こちら](../training#train-with-pytorch-trainer) の基本的なチュートリアルをご覧ください。
+
+
+
+これでモデルのトレーニングを開始する準備が整いました。 [`AutoModelForSeq2SeqLM`] を使用して T5 をロードします。
+
+
+```py
+>>> from transformers import AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+```
+
+この時点で残っている手順は次の 3 つだけです。
+
+1. [`Seq2SeqTrainingArguments`] でトレーニング ハイパーパラメータを定義します。唯一の必須パラメータは、モデルの保存場所を指定する `output_dir` です。 `push_to_hub=True`を設定して、このモデルをハブにプッシュします (モデルをアップロードするには、Hugging Face にサインインする必要があります)。各エポックの終了時に、[`Trainer`] は ROUGE メトリクスを評価し、トレーニング チェックポイントを保存します。
+2. トレーニング引数をモデル、データセット、トークナイザー、データ照合器、および `compute_metrics` 関数とともに [`Seq2SeqTrainer`] に渡します。
+3. [`~Trainer.train`] を呼び出してモデルを微調整します。
+
+```py
+>>> training_args = Seq2SeqTrainingArguments(
+... output_dir="my_awesome_billsum_model",
+... eval_strategy="epoch",
+... learning_rate=2e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... weight_decay=0.01,
+... save_total_limit=3,
+... num_train_epochs=4,
+... predict_with_generate=True,
+... fp16=True,
+... push_to_hub=True,
+... )
+
+>>> trainer = Seq2SeqTrainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_billsum["train"],
+... eval_dataset=tokenized_billsum["test"],
+... processing_class=tokenizer,
+... data_collator=data_collator,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+
+トレーニングが完了したら、 [`~transformers.Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、誰もがモデルを使用できるようにします。
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+Keras を使用したモデルの微調整に慣れていない場合は、[こちら](../training#train-a-tensorflow-model-with-keras) の基本的なチュートリアルをご覧ください。
+
+
+TensorFlow でモデルを微調整するには、オプティマイザー関数、学習率スケジュール、およびいくつかのトレーニング ハイパーパラメーターをセットアップすることから始めます。
+
+```py
+>>> from transformers import create_optimizer, AdamWeightDecay
+
+>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
+```
+
+次に、[`TFAutoModelForSeq2SeqLM`] を使用して T5 をロードできます。
+
+
+```py
+>>> from transformers import TFAutoModelForSeq2SeqLM
+
+>>> model = TFAutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+```
+
+[`~transformers.TFPreTrainedModel.prepare_tf_dataset`] を使用して、データセットを `tf.data.Dataset` 形式に変換します。
+
+```py
+>>> tf_train_set = model.prepare_tf_dataset(
+... tokenized_billsum["train"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_test_set = model.prepare_tf_dataset(
+... tokenized_billsum["test"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+[`compile`](https://keras.io/api/models/model_training_apis/#compile-method) を使用してトレーニング用のモデルを設定します。 Transformers モデルにはすべてデフォルトのタスク関連の損失関数があるため、次の場合を除き、損失関数を指定する必要はないことに注意してください。
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer) # No loss argument!
+```
+
+トレーニングを開始する前にセットアップする最後の 2 つのことは、予測から ROUGE スコアを計算し、モデルをハブにプッシュする方法を提供することです。どちらも [Keras コールバック](../main_classes/keras_callbacks) を使用して行われます。
+
+`compute_metrics` 関数を [`~transformers.KerasMetricCallback`] に渡します。
+
+```py
+>>> from transformers.keras_callbacks import KerasMetricCallback
+
+>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
+```
+
+Specify where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
+
+```py
+>>> from transformers.keras_callbacks import PushToHubCallback
+
+>>> push_to_hub_callback = PushToHubCallback(
+... output_dir="my_awesome_billsum_model",
+... tokenizer=tokenizer,
+... )
+```
+
+次に、コールバックをまとめてバンドルします。
+
+```py
+>>> callbacks = [metric_callback, push_to_hub_callback]
+```
+
+ついに、モデルのトレーニングを開始する準備が整いました。トレーニングおよび検証データセット、エポック数、コールバックを指定して [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) を呼び出し、モデルを微調整します。
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=callbacks)
+```
+
+トレーニングが完了すると、モデルは自動的にハブにアップロードされ、誰でも使用できるようになります。
+
+
+
+
+
+
+要約用にモデルを微調整する方法のより詳細な例については、対応するセクションを参照してください。
+[PyTorch ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)
+または [TensorFlow ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)。
+
+
+
+## Inference
+
+モデルを微調整したので、それを推論に使用できるようになりました。
+
+要約したいテキストを考え出します。 T5 の場合、作業中のタスクに応じて入力に接頭辞を付ける必要があります。要約するには、以下に示すように入力にプレフィックスを付ける必要があります。
+
+```py
+>>> text = "summarize: The Inflation Reduction Act lowers prescription drug costs, health care costs, and energy costs. It's the most aggressive action on tackling the climate crisis in American history, which will lift up American workers and create good-paying, union jobs across the country. It'll lower the deficit and ask the ultra-wealthy and corporations to pay their fair share. And no one making under $400,000 per year will pay a penny more in taxes."
+```
+
+推論用に微調整されたモデルを試す最も簡単な方法は、それを [`pipeline`] で使用することです。モデルを使用して要約用の `pipeline` をインスタンス化し、テキストをそれに渡します。
+
+```py
+>>> from transformers import pipeline
+
+>>> summarizer = pipeline("summarization", model="stevhliu/my_awesome_billsum_model")
+>>> summarizer(text)
+[{"summary_text": "The Inflation Reduction Act lowers prescription drug costs, health care costs, and energy costs. It's the most aggressive action on tackling the climate crisis in American history, which will lift up American workers and create good-paying, union jobs across the country."}]
+```
+
+必要に応じて、`pipeline`」の結果を手動で複製することもできます。
+
+
+
+Tokenize the text and return the `input_ids` as PyTorch tensors:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_billsum_model")
+>>> inputs = tokenizer(text, return_tensors="pt").input_ids
+```
+
+[`~generation.GenerationMixin.generate`] メソッドを使用して要約を作成します。さまざまなテキスト生成戦略と生成を制御するためのパラメーターの詳細については、[Text Generation](../main_classes/text_generation) API を確認してください。
+
+```py
+>>> from transformers import AutoModelForSeq2SeqLM
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("stevhliu/my_awesome_billsum_model")
+>>> outputs = model.generate(inputs, max_new_tokens=100, do_sample=False)
+```
+
+生成されたトークン ID をデコードしてテキストに戻します。
+
+```py
+>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
+'the inflation reduction act lowers prescription drug costs, health care costs, and energy costs. it's the most aggressive action on tackling the climate crisis in american history. it will ask the ultra-wealthy and corporations to pay their fair share.'
+```
+
+
+
+テキストをトークン化し、`input_ids`を TensorFlow テンソルとして返します。
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_billsum_model")
+>>> inputs = tokenizer(text, return_tensors="tf").input_ids
+```
+
+[`~transformers.generation_tf_utils.TFGenerationMixin.generate`] メソッドを使用して要約を作成します。さまざまなテキスト生成戦略と生成を制御するためのパラメーターの詳細については、[Text Generation](../main_classes/text_generation) API を確認してください。
+
+```py
+>>> from transformers import TFAutoModelForSeq2SeqLM
+
+>>> model = TFAutoModelForSeq2SeqLM.from_pretrained("stevhliu/my_awesome_billsum_model")
+>>> outputs = model.generate(inputs, max_new_tokens=100, do_sample=False)
+```
+
+生成されたトークン ID をデコードしてテキストに戻します。
+
+```py
+>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
+'the inflation reduction act lowers prescription drug costs, health care costs, and energy costs. it's the most aggressive action on tackling the climate crisis in american history. it will ask the ultra-wealthy and corporations to pay their fair share.'
+```
+
+
diff --git a/docs/transformers/docs/source/ja/tasks/text-to-speech.md b/docs/transformers/docs/source/ja/tasks/text-to-speech.md
new file mode 100644
index 0000000000000000000000000000000000000000..669d15730e24f892e27103a9ad48733b5e7fb34d
--- /dev/null
+++ b/docs/transformers/docs/source/ja/tasks/text-to-speech.md
@@ -0,0 +1,638 @@
+
+
+# Text to speech
+
+[[open-in-colab]]
+
+テキスト読み上げ (TTS) は、テキストから自然な音声を作成するタスクです。音声は複数の形式で生成できます。
+言語と複数の話者向け。現在、いくつかのテキスト読み上げモデルが 🤗 Transformers で利用可能です。
+[Bark](../model_doc/bark)、[MMS](../model_doc/mms)、[VITS](../model_doc/vits)、および [SpeechT5](../model_doc/speecht5)。
+
+`text-to-audio`パイプライン (またはその別名 - `text-to-speech`) を使用して、音声を簡単に生成できます。 Bark などの一部のモデルは、
+笑い、ため息、泣きなどの非言語コミュニケーションを生成したり、音楽を追加したりするように条件付けすることもできます。
+Bark で`text-to-speech`パイプラインを使用する方法の例を次に示します。
+
+```py
+>>> from transformers import pipeline
+
+>>> pipe = pipeline("text-to-speech", model="suno/bark-small")
+>>> text = "[clears throat] This is a test ... and I just took a long pause."
+>>> output = pipe(text)
+```
+
+ノートブックで結果の音声を聞くために使用できるコード スニペットを次に示します。
+
+```python
+>>> from IPython.display import Audio
+>>> Audio(output["audio"], rate=output["sampling_rate"])
+```
+Bark およびその他の事前トレーニングされた TTS モデルができることの詳細な例については、次のドキュメントを参照してください。
+[音声コース](https://huggingface.co/learn/audio-course/chapter6/pre-trained_models)。
+
+TTS モデルを微調整する場合、現在微調整できるのは SpeechT5 のみです。 SpeechT5 は、次の組み合わせで事前トレーニングされています。
+音声からテキストへのデータとテキストから音声へのデータ。両方のテキストに共有される隠された表現の統一された空間を学習できるようにします。
+そしてスピーチ。これは、同じ事前トレーニング済みモデルをさまざまなタスクに合わせて微調整できることを意味します。さらに、SpeechT5
+X ベクトル スピーカーの埋め込みを通じて複数のスピーカーをサポートします。
+
+このガイドの残りの部分では、次の方法を説明します。
+
+1. [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) のオランダ語 (`nl`) 言語サブセット上の英語音声で元々トレーニングされた [SpeechT5](../model_doc/speecht5) を微調整します。 データセット。
+2. パイプラインを使用するか直接使用するかの 2 つの方法のいずれかで、洗練されたモデルを推論に使用します。
+
+始める前に、必要なライブラリがすべてインストールされていることを確認してください。
+
+
+```bash
+pip install datasets soundfile speechbrain accelerate
+```
+
+SpeechT5 のすべての機能がまだ正式リリースにマージされていないため、ソースから 🤗Transformers をインストールします。
+
+```bash
+pip install git+https://github.com/huggingface/transformers.git
+```
+
+
+
+このガイドに従うには、GPU が必要です。ノートブックで作業している場合は、次の行を実行して GPU が利用可能かどうかを確認します。
+
+```bash
+!nvidia-smi
+```
+
+
+
+Hugging Face アカウントにログインして、モデルをアップロードしてコミュニティと共有することをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## Load the dataset
+
+[VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) は、以下で構成される大規模な多言語音声コーパスです。
+データは 2009 年から 2020 年の欧州議会のイベント記録をソースとしています。 15 件分のラベル付き音声文字起こしデータが含まれています。
+ヨーロッパの言語。このガイドではオランダ語のサブセットを使用していますが、自由に別のサブセットを選択してください。
+
+VoxPopuli またはその他の自動音声認識 (ASR) データセットは最適ではない可能性があることに注意してください。
+TTS モデルをトレーニングするためのオプション。過剰なバックグラウンドノイズなど、ASR にとって有益となる機能は次のとおりです。
+通常、TTS では望ましくありません。ただし、最高品質、多言語、マルチスピーカーの TTS データセットを見つけるのは非常に困難な場合があります。
+挑戦的。
+
+データをロードしましょう:
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("facebook/voxpopuli", "nl", split="train")
+>>> len(dataset)
+20968
+```
+
+微調整には 20968 個の例で十分です。 SpeechT5 はオーディオ データのサンプリング レートが 16 kHz であることを想定しているため、
+データセット内の例がこの要件を満たしていることを確認してください。
+
+
+```py
+dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
+```
+
+## Preprocess the data
+
+使用するモデル チェックポイントを定義し、適切なプロセッサをロードすることから始めましょう。
+
+
+```py
+>>> from transformers import SpeechT5Processor
+
+>>> checkpoint = "microsoft/speecht5_tts"
+>>> processor = SpeechT5Processor.from_pretrained(checkpoint)
+```
+
+### Text cleanup for SpeechT5 tokenization
+
+
+まずはテキストデータをクリーンアップすることから始めます。テキストを処理するには、プロセッサのトークナイザー部分が必要です。
+
+```py
+>>> tokenizer = processor.tokenizer
+```
+
+データセットの例には、`raw_text`機能と `normalized_text`機能が含まれています。テキスト入力としてどの機能を使用するかを決めるときは、
+SpeechT5 トークナイザーには数値のトークンがないことを考慮してください。 `normalized_text`には数字が書かれています
+テキストとして出力します。したがって、これはより適切であり、入力テキストとして `normalized_text` を使用することをお勧めします。
+
+SpeechT5 は英語でトレーニングされているため、オランダ語のデータセット内の特定の文字を認識しない可能性があります。もし
+残っているように、これらの文字は ``トークンに変換されます。ただし、オランダ語では、`à`などの特定の文字は
+音節を強調することに慣れています。テキストの意味を保持するために、この文字を通常の`a`に置き換えることができます。
+
+サポートされていないトークンを識別するには、`SpeechT5Tokenizer`を使用してデータセット内のすべての一意の文字を抽出します。
+文字をトークンとして扱います。これを行うには、以下を連結する `extract_all_chars` マッピング関数を作成します。
+すべての例からの転写を 1 つの文字列にまとめ、それを文字セットに変換します。
+すべての文字起こしが一度に利用できるように、`dataset.map()`で`batched=True`と`batch_size=-1`を必ず設定してください。
+マッピング機能。
+
+```py
+>>> def extract_all_chars(batch):
+... all_text = " ".join(batch["normalized_text"])
+... vocab = list(set(all_text))
+... return {"vocab": [vocab], "all_text": [all_text]}
+
+
+>>> vocabs = dataset.map(
+... extract_all_chars,
+... batched=True,
+... batch_size=-1,
+... keep_in_memory=True,
+... remove_columns=dataset.column_names,
+... )
+
+>>> dataset_vocab = set(vocabs["vocab"][0])
+>>> tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}
+```
+
+これで、2 つの文字セットができました。1 つはデータセットの語彙を持ち、もう 1 つはトークナイザーの語彙を持ちます。
+データセット内でサポートされていない文字を特定するには、これら 2 つのセットの差分を取ることができます。結果として
+set には、データセットにはあるがトークナイザーには含まれていない文字が含まれます。
+
+```py
+>>> dataset_vocab - tokenizer_vocab
+{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}
+```
+
+前の手順で特定されたサポートされていない文字を処理するには、これらの文字を
+有効なトークン。スペースはトークナイザーですでに `▁` に置き換えられているため、個別に処理する必要がないことに注意してください。
+
+```py
+>>> replacements = [
+... ("à", "a"),
+... ("ç", "c"),
+... ("è", "e"),
+... ("ë", "e"),
+... ("í", "i"),
+... ("ï", "i"),
+... ("ö", "o"),
+... ("ü", "u"),
+... ]
+
+
+>>> def cleanup_text(inputs):
+... for src, dst in replacements:
+... inputs["normalized_text"] = inputs["normalized_text"].replace(src, dst)
+... return inputs
+
+
+>>> dataset = dataset.map(cleanup_text)
+```
+
+テキスト内の特殊文字を扱ったので、今度は音声データに焦点を移します。
+
+### Speakers
+
+VoxPopuli データセットには複数の話者の音声が含まれていますが、データセットには何人の話者が含まれているのでしょうか?に
+これを決定すると、一意の話者の数と、各話者がデータセットに寄与する例の数を数えることができます。
+データセットには合計 20,968 個の例が含まれており、この情報により、分布をより深く理解できるようになります。
+講演者とデータ内の例。
+
+```py
+>>> from collections import defaultdict
+
+>>> speaker_counts = defaultdict(int)
+
+>>> for speaker_id in dataset["speaker_id"]:
+... speaker_counts[speaker_id] += 1
+```
+
+ヒストグラムをプロットすると、各話者にどれだけのデータがあるかを把握できます。
+
+```py
+>>> import matplotlib.pyplot as plt
+
+>>> plt.figure()
+>>> plt.hist(speaker_counts.values(), bins=20)
+>>> plt.ylabel("Speakers")
+>>> plt.xlabel("Examples")
+>>> plt.show()
+```
+
+
+
+OWL-ViTによる推論をインタラクティブに試したい場合は、このデモをチェックしてください。
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ja/tokenizer_summary.md b/docs/transformers/docs/source/ja/tokenizer_summary.md
new file mode 100644
index 0000000000000000000000000000000000000000..448ad9c871aaa340de9d2b6f954549c8849091d3
--- /dev/null
+++ b/docs/transformers/docs/source/ja/tokenizer_summary.md
@@ -0,0 +1,179 @@
+
+
+# Summary of the tokenizers
+
+[[open-in-colab]]
+
+このページでは、トークナイゼーションについて詳しく見ていきます。
+
+
+
+[前処理のチュートリアル](preprocessing)で見たように、テキストをトークン化することは、それを単語またはサブワードに分割し、それらをルックアップテーブルを介してIDに変換することです。単語またはサブワードをIDに変換することは簡単ですので、この要約ではテキストを単語またはサブワードに分割する(つまり、テキストをトークナイズする)ことに焦点を当てます。具体的には、🤗 Transformersで使用される3つの主要なトークナイザ、[Byte-Pair Encoding(BPE)](#byte-pair-encoding)、[WordPiece](#wordpiece)、および[SentencePiece](#sentencepiece)を見て、どのモデルがどのトークナイザタイプを使用しているかの例を示します。
+
+各モデルページでは、事前トレーニング済みモデルがどのトークナイザタイプを使用しているかを知るために、関連するトークナイザのドキュメントを確認できます。例えば、[`BertTokenizer`]を見ると、モデルが[WordPiece](#wordpiece)を使用していることがわかります。
+
+## Introduction
+
+テキストをより小さなチャンクに分割することは、見かけ以上に難しいタスクであり、複数の方法があります。例えば、次の文を考えてみましょう。「"Don't you love 🤗 Transformers? We sure do."」
+
+
+
+このテキストをトークン化する簡単な方法は、スペースで分割することです。これにより、以下のようになります:
+
+
+```
+["Don't", "you", "love", "🤗", "Transformers?", "We", "sure", "do."]
+```
+
+これは合理的な第一歩ですが、トークン "Transformers?" と "do." を見ると、句読点が単語 "Transformer" と "do" に結合されていることがわかり、これは最適ではありません。句読点を考慮に入れるべきで、モデルが単語とそれに続く可能性のあるすべての句読点記号の異なる表現を学ばなければならないことを避けるべきです。これにより、モデルが学ばなければならない表現の数が爆発的に増加します。句読点を考慮に入れた場合、例文のトークン化は次のようになります:
+
+
+```
+["Don", "'", "t", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
+```
+
+ただし、単語「"Don't"」をトークン化する方法に関しては、不利な側面があります。 「"Don't"」は「"do not"」を表しているため、「["Do", "n't"]」としてトークン化する方が適しています。ここから事柄が複雑になり、各モデルが独自のトークナイザータイプを持つ理由の一部でもあります。テキストをトークン化するために適用するルールに応じて、同じテキストに対して異なるトークナイズされた出力が生成されます。事前トレーニング済みモデルは、トレーニングデータをトークナイズするのに使用されたルールと同じルールでトークナイズされた入力を提供する場合にのみ正常に機能します。
+
+[spaCy](https://spacy.io/)と[Moses](http://www.statmt.org/moses/?n=Development.GetStarted)は、2つの人気のあるルールベースのトークナイザーです。これらを私たちの例に適用すると、*spaCy*と*Moses*は次のような出力を生成します:
+
+```
+["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
+```
+
+空白と句読点のトークン化、およびルールベースのトークン化が使用されていることがわかります。空白と句読点のトークン化、およびルールベースのトークン化は、文を単語に分割することをゆるやかに定義される単語トークン化の例です。テキストをより小さなチャンクに分割するための最も直感的な方法である一方、このトークン化方法は大規模なテキストコーパスに対して問題を引き起こすことがあります。この場合、空白と句読点のトークン化は通常、非常に大きな語彙(すべての一意な単語とトークンのセット)を生成します。例えば、[Transformer XL](model_doc/transformerxl)は空白と句読点のトークン化を使用しており、語彙サイズは267,735です!
+
+このような大きな語彙サイズは、モデルに非常に大きな埋め込み行列を入力および出力レイヤーとして持たせることを強制し、メモリおよび時間の複雑さの増加を引き起こします。一般的に、トランスフォーマーモデルは、特に単一の言語で事前トレーニングされた場合、50,000を超える語彙サイズを持つことはほとんどありません。
+
+したがって、シンプルな空白と句読点のトークン化が不十分な場合、なぜ単に文字単位でトークン化しないのかという疑問が生じますか?
+
+
+
+文字単位のトークン化は非常にシンプルであり、メモリと時間の複雑さを大幅に削減できますが、モデルに意味のある入力表現を学習させることが非常に難しくなります。たとえば、文字「"t"」のための意味のあるコンテキスト独立の表現を学習することは、単語「"today"」のためのコンテキスト独立の表現を学習するよりもはるかに難しいです。そのため、文字単位のトークン化はしばしばパフォーマンスの低下を伴います。したがって、トランスフォーマーモデルは単語レベルと文字レベルのトークン化のハイブリッドである**サブワード**トークン化を使用して、両方の世界の利点を活かします。
+
+## Subword tokenization
+
+
+
+サブワードトークン化アルゴリズムは、頻繁に使用される単語をより小さなサブワードに分割すべきではないが、珍しい単語は意味のあるサブワードに分解されるという原則に依存しています。たとえば、「"annoyingly"」は珍しい単語と見なされ、その単語は「"annoying"」と「"ly"」に分解されるかもしれません。独立した「"annoying"」と「"ly"」はより頻繁に現れますが、「"annoyingly"」の意味は「"annoying"」と「"ly"」の合成的な意味によって保持されます。これは特にトルコ語などの結合言語で役立ちます。ここではサブワードを連結して(ほぼ)任意の長い複雑な単語を形成できます。
+
+サブワードトークン化により、モデルは合理的な語彙サイズを持つことができ、意味のあるコンテキスト独立の表現を学習できます。さらに、サブワードトークン化により、モデルは以前に見たことのない単語を処理し、それらを既知のサブワードに分解することができます。例えば、[`~transformers.BertTokenizer`]は`"I have a new GPU!"`を以下のようにトークン化します:
+
+
+```py
+>>> from transformers import BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> tokenizer.tokenize("I have a new GPU!")
+["i", "have", "a", "new", "gp", "##u", "!"]
+```
+
+「uncased」モデルを考慮しているため、まず文を小文字に変換しました。トークナイザの語彙に「["i", "have", "a", "new"]」という単語が存在することがわかりますが、「"gpu"」という単語は存在しません。したがって、トークナイザは「"gpu"」を既知のサブワード「["gp"、"##u"]」に分割します。ここで「"##"」は、トークンのデコードまたはトークナイゼーションの逆転のために、トークンの前の部分にスペースなしで接続する必要があることを意味します。
+
+別の例として、[`~transformers.XLNetTokenizer`]は以下のように以前のサンプルテキストをトークン化します:
+
+```py
+>>> from transformers import XLNetTokenizer
+
+>>> tokenizer = XLNetTokenizer.from_pretrained("xlnet/xlnet-base-cased")
+>>> tokenizer.tokenize("Don't you love 🤗 Transformers? We sure do.")
+["▁Don", "'", "t", "▁you", "▁love", "▁", "🤗", "▁", "Transform", "ers", "?", "▁We", "▁sure", "▁do", "."]
+```
+
+これらの「▁」の意味については、[SentencePiece](#sentencepiece)を見るときに詳しく説明します。ご覧の通り、「Transformers」という珍しい単語は、より頻繁に現れるサブワード「Transform」と「ers」に分割されています。
+
+さて、異なるサブワードトークン化アルゴリズムがどのように動作するかを見てみましょう。これらのトークナイゼーションアルゴリズムはすべて、通常は対応するモデルがトレーニングされるコーパスで行われる形式のトレーニングに依存しています。
+
+
+
+### Byte-Pair Encoding(BPE)
+
+Byte-Pair Encoding(BPE)は、[Neural Machine Translation of Rare Words with Subword Units(Sennrich et al., 2015)](https://arxiv.org/abs/1508.07909)で導入されました。BPEは、トレーニングデータを単語に分割するプリトークナイザに依存しています。プリトークナイゼーションは、空白のトークナイゼーションなど、非常に単純なものであることがあります。例えば、[GPT-2](model_doc/gpt2)、[RoBERTa](model_doc/roberta)です。より高度なプリトークナイゼーションには、ルールベースのトークナイゼーション([XLM](model_doc/xlm)、[FlauBERT](model_doc/flaubert)などが大部分の言語にMosesを使用)や、[GPT](model_doc/gpt)(Spacyとftfyを使用してトレーニングコーパス内の各単語の頻度を数える)などが含まれます。
+
+プリトークナイゼーションの後、一意の単語セットが作成され、各単語がトレーニングデータで出現した頻度が決定されます。次に、BPEはベース語彙を作成し、ベース語彙の二つのシンボルから新しいシンボルを形成するためのマージルールを学習します。このプロセスは、語彙が所望の語彙サイズに達するまで続けられます。なお、所望の語彙サイズはトークナイザをトレーニングする前に定義するハイパーパラメータであることに注意してください。
+
+例として、プリトークナイゼーションの後、次のセットの単語とその出現頻度が決定されたと仮定しましょう:
+
+
+```
+("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
+```
+
+したがって、ベース語彙は「["b", "g", "h", "n", "p", "s", "u"]」です。すべての単語をベース語彙のシンボルに分割すると、次のようになります:
+
+
+```
+("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
+```
+
+その後、BPEは可能なすべてのシンボルペアの頻度を数え、最も頻繁に発生するシンボルペアを選択します。上記の例では、`"h"`の後に`"u"`が15回(`"hug"`の10回、`"hugs"`の5回)出現します。しかし、最も頻繁なシンボルペアは、合計で20回(`"u"`の10回、`"g"`の5回、`"u"`の5回)出現する`"u"`の後に`"g"`が続くシンボルペアです。したがって、トークナイザが最初に学習するマージルールは、`"u"`の後に`"g"`が続くすべての`"u"`シンボルを一緒にグループ化することです。次に、`"ug"`が語彙に追加されます。単語のセットは次になります:
+
+
+```
+("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
+```
+
+次に、BPEは次に最も一般的なシンボルペアを識別します。それは「"u"」に続いて「"n"」で、16回出現します。したがって、「"u"」と「"n"」は「"un"」に結合され、語彙に追加されます。次に最も頻度の高いシンボルペアは、「"h"」に続いて「"ug"」で、15回出現します。再びペアが結合され、「hug」が語彙に追加できます。
+
+この段階では、語彙は`["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]`であり、一意の単語のセットは以下のように表されます:
+
+
+```
+("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
+```
+
+前提として、Byte-Pair Encoding(BPE)のトレーニングがこの段階で停止すると、学習されたマージルールが新しい単語に適用されます(新しい単語にはベースボキャブラリに含まれていないシンボルが含まれていない限り)。 例えば、単語 "bug" は ["b", "ug"] としてトークン化されますが、"mug" はベースボキャブラリに "m" シンボルが含まれていないため、["", "ug"] としてトークン化されます。 一般的に、"m" のような単一の文字は、トレーニングデータには通常、各文字の少なくとも1つの出現が含まれているため、"" シンボルに置き換えられることはありませんが、絵文字のような非常に特殊な文字の場合には発生する可能性があります。
+
+前述のように、ボキャブラリサイズ、すなわちベースボキャブラリサイズ + マージの回数は選択するハイパーパラメータです。 例えば、[GPT](model_doc/gpt) はベース文字が478文字で、40,000回のマージ後にトレーニングを停止したため、ボキャブラリサイズは40,478です。
+
+#### Byte-level BPE
+
+すべてのUnicode文字をベース文字と考えると、すべての可能なベース文字が含まれるかもしれないベースボキャブラリはかなり大きくなることがあります。 [GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) は、ベースボキャブラリを256バイトにする賢いトリックとしてバイトをベースボキャブラリとして使用し、すべてのベース文字がボキャブラリに含まれるようにしています。 パンクチュエーションを扱うためのいくつかの追加ルールを備えたGPT2のトークナイザは、 シンボルを必要とせずにすべてのテキストをトークン化できます。 [GPT-2](model_doc/gpt) は50,257のボキャブラリサイズを持っており、これは256バイトのベーストークン、特別なテキストの終了を示すトークン、および50,000回のマージで学習したシンボルに対応しています。
+
+### WordPiece
+
+WordPieceは、[BERT](model_doc/bert)、[DistilBERT](model_doc/distilbert)、および[Electra](model_doc/electra)で使用されるサブワードトークナイゼーションアルゴリズムです。 このアルゴリズムは、[Japanese and Korean Voice Search (Schuster et al., 2012)](https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/37842.pdf) で概説されており、BPEに非常に似ています。 WordPieceは最も頻繁なシンボルペアを選択するのではなく、トレーニングデータに追加した場合にトレーニングデータの尤度を最大化するシンボルペアを選択します。
+
+これは具体的にはどういう意味ですか?前の例を参照すると、トレーニングデータの尤度を最大化することは、そのシンボルペアの確率をその最初のシンボルに続く2番目のシンボルの確率で割ったものが、すべてのシンボルペアの中で最も大きい場合に該当するシンボルペアを見つけることに等しいです。 たとえば、"u" の後に "g" が続く場合、他のどのシンボルペアよりも "ug" の確率を "u"、"g" で割った確率が高ければ、それらのシンボルは結合されます。直感的に言えば、WordPieceは2つのシンボルを結合することによって失われるものを評価し、それがそれに値するかどうかを確認する点でBPEとはわずかに異なります。
+
+### Unigram
+
+Unigramは、[Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf) で導入されたサブワードトークナイゼーションアルゴリズムです。 BPEやWordPieceとは異なり、Unigramはベースボキャブラリを多数のシンボルで初期化し、各シンボルを削減してより小さなボキャブラリを取得します。 ベースボキャブラリは、事前にトークン化されたすべての単語と最も一般的な部分文字列に対応する可能性があります。 Unigramはtransformersのモデルの直接の使用には適していませんが、[SentencePiece](#sentencepiece)と組み合わせて使用されます。
+
+各トレーニングステップで、Unigramアルゴリズムは現在のボキャブラリとユニグラム言語モデルを使用してトレーニングデータ上の損失(通常は対数尤度として定義)を定義します。その後、ボキャブラリ内の各シンボルについて、そのシンボルがボキャブラリから削除された場合に全体の損失がどれだけ増加するかを計算します。 Unigramは、損失の増加が最も低いp(通常は10%または20%)パーセントのシンボルを削除します。つまり、トレーニングデータ全体の損失に最も影響を与えない、最も損失の少ないシンボルを削除します。 このプロセスは、ボキャブラリが望ましいサイズに達するまで繰り返されます。 Unigramアルゴリズムは常にベース文字を保持するため、任意の単語をトークン化できます。
+
+Unigramはマージルールに基づいていないため(BPEとWordPieceとは対照的に)、トレーニング後の新しいテキストのトークン化にはいくつかの方法があります。例として、トレーニングされたUnigramトークナイザが持つボキャブラリが次のような場合:
+
+
+```
+["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"],
+```
+
+`"hugs"`は、`["hug", "s"]`、`["h", "ug", "s"]`、または`["h", "u", "g", "s"]`のようにトークン化できます。では、どれを選択すべきでしょうか? Unigramは、トレーニングコーパス内の各トークンの確率を保存し、トレーニング後に各可能なトークン化の確率を計算できるようにします。このアルゴリズムは実際には最も可能性の高いトークン化を選択しますが、確率に従って可能なトークン化をサンプリングするオプションも提供します。
+
+これらの確率は、トークナイザーがトレーニングに使用する損失によって定義されます。トレーニングデータが単語 \\(x_{1}, \dots, x_{N}\\) で構成され、単語 \\(x_{i}\\) のすべての可能なトークン化のセットが \\(S(x_{i})\\) と定義される場合、全体の損失は次のように定義されます。
+
+$$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )$$
+
+
+
+### SentencePiece
+
+これまでに説明したすべてのトークン化アルゴリズムには同じ問題があります。それは、入力テキストが単語を区切るためにスペースを使用していると仮定しているということです。しかし、すべての言語が単語を区切るためにスペースを使用しているわけではありません。この問題を一般的に解決するための1つの方法は、言語固有の前トークナイザーを使用することです(例:[XLM](model_doc/xlm)は特定の中国語、日本語、およびタイ語の前トークナイザーを使用しています)。より一般的にこの問題を解決するために、[SentencePiece:ニューラルテキスト処理のためのシンプルで言語非依存のサブワードトークナイザーおよびデトークナイザー(Kudo et al.、2018)](https://arxiv.org/pdf/1808.06226.pdf) は、入力を生の入力ストリームとして扱い、スペースを使用する文字のセットに含めます。それからBPEまたはunigramアルゴリズムを使用して適切な語彙を構築します。
+
+たとえば、[`XLNetTokenizer`]はSentencePieceを使用しており、そのために前述の例で`"▁"`文字が語彙に含まれていました。SentencePieceを使用したデコードは非常に簡単で、すべてのトークンを単純に連結し、`"▁"`はスペースに置換されます。
+
+ライブラリ内のすべてのtransformersモデルは、SentencePieceをunigramと組み合わせて使用します。SentencePieceを使用するモデルの例には、[ALBERT](model_doc/albert)、[XLNet](model_doc/xlnet)、[Marian](model_doc/marian)、および[T5](model_doc/t5)があります。
diff --git a/docs/transformers/docs/source/ja/torchscript.md b/docs/transformers/docs/source/ja/torchscript.md
new file mode 100644
index 0000000000000000000000000000000000000000..27d64a625c8c4299e1be68f71541966604dc65c1
--- /dev/null
+++ b/docs/transformers/docs/source/ja/torchscript.md
@@ -0,0 +1,177 @@
+
+
+# Export to TorchScript
+
+
+
+これはTorchScriptを使用した実験の最初であり、可変入力サイズのモデルに対するその能力をまだ探求中です。これは私たちの関心の焦点であり、今後のリリースでは、より柔軟な実装や、PythonベースのコードとコンパイルされたTorchScriptを比較するベンチマークを含む、より多くのコード例で詳細な分析を行います。
+
+
+
+[TorchScriptのドキュメント](https://pytorch.org/docs/stable/jit.html)によれば:
+
+> TorchScriptは、PyTorchコードから直列化および最適化可能なモデルを作成する方法です。
+
+TorchScriptを使用すると、効率志向のC++プログラムなど、他のプログラムでモデルを再利用できるようになります。PyTorchベースのPythonプログラム以外の環境で🤗 Transformersモデルをエクスポートして使用するためのインターフェースを提供しています。ここでは、TorchScriptを使用してモデルをエクスポートし、使用する方法を説明します。
+
+モデルをエクスポートするには、次の2つの要件があります:
+
+- `torchscript`フラグを使用したモデルのインスタンス化
+- ダミーの入力を使用したフォワードパス
+
+これらの必要条件は、以下で詳細に説明されているように、開発者が注意する必要があるいくつかのことを意味します。
+
+## TorchScript flag and tied weights
+
+`torchscript`フラグは、ほとんどの🤗 Transformers言語モデルにおいて、`Embedding`レイヤーと`Decoding`レイヤー間で重みが連結されているため必要です。
+TorchScriptでは、重みが連結されているモデルをエクスポートすることはできませんので、事前に重みを切り離して複製する必要があります。
+
+`torchscript`フラグを使用してインスタンス化されたモデルは、`Embedding`レイヤーと`Decoding`レイヤーが分離されており、そのため後でトレーニングしてはいけません。
+トレーニングは、これらの2つのレイヤーを非同期にする可能性があり、予期しない結果をもたらす可能性があります。
+
+言語モデルヘッドを持たないモデルには言及しませんが、これらのモデルには連結された重みが存在しないため、`torchscript`フラグなしで安全にエクスポートできます。
+
+## Dummy inputs and standard lengths
+
+ダミー入力はモデルのフォワードパスに使用されます。入力の値はレイヤーを通じて伝播される間、PyTorchは各テンソルに実行された異なる操作を追跡します。これらの記録された操作は、モデルの*トレース*を作成するために使用されます。
+
+トレースは入力の寸法に対して作成されます。そのため、ダミー入力の寸法に制約され、他のシーケンス長やバッチサイズでは動作しません。異なるサイズで試すと、以下のエラーが発生します:
+
+```
+`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
+```
+
+お勧めしますのは、モデルの推論中に供給される最大の入力と同じ大きさのダミー入力サイズでモデルをトレースすることです。パディングを使用して不足値を補完することもできます。ただし、モデルがより大きな入力サイズでトレースされるため、行列の寸法も大きくなり、より多くの計算が発生します。
+
+異なるシーケンス長のモデルをエクスポートする際に、各入力に対して実行される演算の総数に注意して、パフォーマンスを密接にフォローすることをお勧めします。
+
+## Using TorchScript in Python
+
+このセクションでは、モデルの保存と読み込み、および推論にトレースを使用する方法を示します。
+
+### Saving a model
+
+TorchScriptで`BertModel`をエクスポートするには、`BertConfig`クラスから`BertModel`をインスタンス化し、それをファイル名`traced_bert.pt`でディスクに保存します:
+
+```python
+from transformers import BertModel, BertTokenizer, BertConfig
+import torch
+
+enc = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+
+# Tokenizing input text
+text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
+tokenized_text = enc.tokenize(text)
+
+# Masking one of the input tokens
+masked_index = 8
+tokenized_text[masked_index] = "[MASK]"
+indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
+segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
+
+# Creating a dummy input
+tokens_tensor = torch.tensor([indexed_tokens])
+segments_tensors = torch.tensor([segments_ids])
+dummy_input = [tokens_tensor, segments_tensors]
+
+# Initializing the model with the torchscript flag
+# Flag set to True even though it is not necessary as this model does not have an LM Head.
+config = BertConfig(
+ vocab_size_or_config_json_file=32000,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ torchscript=True,
+)
+
+# Instantiating the model
+model = BertModel(config)
+
+# The model needs to be in evaluation mode
+model.eval()
+
+# If you are instantiating the model with *from_pretrained* you can also easily set the TorchScript flag
+model = BertModel.from_pretrained("google-bert/bert-base-uncased", torchscript=True)
+
+# Creating the trace
+traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
+torch.jit.save(traced_model, "traced_bert.pt")
+```
+
+### Loading a model
+
+以前に保存した `BertModel`、`traced_bert.pt` をディスクから読み込んで、以前に初期化した `dummy_input` で使用できます。
+
+```python
+loaded_model = torch.jit.load("traced_bert.pt")
+loaded_model.eval()
+
+all_encoder_layers, pooled_output = loaded_model(*dummy_input)
+```
+
+
+### Using a traced model for inference
+
+トレースモデルを使用して推論を行うには、その `__call__` ダンダーメソッドを使用します。
+
+```python
+traced_model(tokens_tensor, segments_tensors)
+```
+
+
+## Deploy Hugging Face TorchScript models to AWS with the Neuron SDK
+
+AWSはクラウドでの低コストで高性能な機械学習推論向けに [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/) インスタンスファミリーを導入しました。Inf1インスタンスはAWS Inferentiaチップによって駆動され、ディープラーニング推論ワークロードに特化したカスタムビルドのハードウェアアクセラレータです。[AWS Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#) はInferentia用のSDKで、トランスフォーマーモデルをトレースして最適化し、Inf1に展開するためのサポートを提供します。
+
+Neuron SDK が提供するもの:
+
+1. クラウドでの推論のためにTorchScriptモデルをトレースして最適化するための、1行のコード変更で使用できる簡単なAPI。
+2. [改善されたコストパフォーマンス](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/) のためのボックス外のパフォーマンス最適化。
+3. [PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html) または [TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html) で構築されたHugging Faceトランスフォーマーモデルへのサポート。
+
+### Implications
+
+BERT(Bidirectional Encoder Representations from Transformers)アーキテクチャやその変種([distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert) や [roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta) など)に基づくトランスフォーマーモデルは、非生成タスク(抽出型質問応答、シーケンス分類、トークン分類など)において、Inf1上で最適に動作します。ただし、テキスト生成タスクも [AWS Neuron MarianMT チュートリアル](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html) に従ってInf1上で実行できます。Inferentiaでボックス外で変換できるモデルに関する詳細情報は、Neuronドキュメンテーションの [Model Architecture Fit](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia) セクションにあります。
+
+### Dependencies
+
+モデルをAWS Neuronに変換するには、[Neuron SDK 環境](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide) が必要で、[AWS Deep Learning AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html) に事前に構成されています。
+
+### Converting a model for AWS Neuron
+
+モデルをAWS NEURON用に変換するには、[PythonでTorchScriptを使用する](torchscript#using-torchscript-in-python) と同じコードを使用して `BertModel` をトレースします。Python APIを介してNeuron SDKのコンポーネントにアクセスするために、`torch.neuron` フレームワーク拡張をインポートします。
+
+```python
+from transformers import BertModel, BertTokenizer, BertConfig
+import torch
+import torch.neuron
+```
+
+次の行を変更するだけで済みます。
+
+```diff
+- torch.jit.trace(model, [tokens_tensor, segments_tensors])
++ torch.neuron.trace(model, [token_tensor, segments_tensors])
+```
+
+これにより、Neuron SDKはモデルをトレースし、Inf1インスタンス向けに最適化します。
+
+AWS Neuron SDKの機能、ツール、サンプルチュートリアル、最新のアップデートについて詳しく知りたい場合は、[AWS NeuronSDK ドキュメンテーション](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html) をご覧ください。
+
+
+
diff --git a/docs/transformers/docs/source/ja/training.md b/docs/transformers/docs/source/ja/training.md
new file mode 100644
index 0000000000000000000000000000000000000000..9dd2369601c10a52f009dc4a790e63d14370b8d0
--- /dev/null
+++ b/docs/transformers/docs/source/ja/training.md
@@ -0,0 +1,434 @@
+
+
+# Fine-tune a pretrained model
+
+[[open-in-colab]]
+
+事前学習済みモデルを使用すると、計算コストを削減し、炭素排出量を減少させ、ゼロからモデルをトレーニングする必要なしに最新のモデルを使用できる利点があります。
+🤗 Transformersは、さまざまなタスクに対応した数千もの事前学習済みモデルへのアクセスを提供します。
+事前学習済みモデルを使用する場合、それを特定のタスクに合わせたデータセットでトレーニングします。これはファインチューニングとして知られ、非常に強力なトレーニング技術です。
+このチュートリアルでは、事前学習済みモデルを選択したディープラーニングフレームワークでファインチューニングする方法について説明します:
+
+* 🤗 Transformersの[`Trainer`]を使用して事前学習済みモデルをファインチューニングする。
+* TensorFlowとKerasを使用して事前学習済みモデルをファインチューニングする。
+* ネイティブのPyTorchを使用して事前学習済みモデルをファインチューニングする。
+
+
+
+## Prepare a dataset
+
+
+
+事前学習済みモデルをファインチューニングする前に、データセットをダウンロードしてトレーニング用に準備する必要があります。
+前のチュートリアルでは、トレーニングデータの処理方法を説明しましたが、これからはそれらのスキルを活かす機会があります!
+
+まず、[Yelp Reviews](https://huggingface.co/datasets/yelp_review_full)データセットを読み込んでみましょう:
+
+```python
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("yelp_review_full")
+>>> dataset["train"][100]
+{'label': 0,
+ 'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
+```
+
+トークナイザがテキストを処理し、可変のシーケンス長を処理するためのパディングと切り捨て戦略を含める必要があることをご存知の通り、
+データセットを1つのステップで処理するには、🤗 Datasets の [`map`](https://huggingface.co/docs/datasets/process#map) メソッドを使用して、
+データセット全体に前処理関数を適用します:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
+
+>>> def tokenize_function(examples):
+... return tokenizer(examples["text"], padding="max_length", truncation=True)
+
+>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
+```
+
+お好みで、実行時間を短縮するためにフルデータセットの小さなサブセットを作成することができます:
+
+```py
+>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
+>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
+```
+
+
+
+## Train
+
+この時点で、使用したいフレームワークに対応するセクションに従う必要があります。右側のサイドバーのリンクを使用して、ジャンプしたいフレームワークに移動できます。
+そして、特定のフレームワークのすべてのコンテンツを非表示にしたい場合は、そのフレームワークのブロック右上にあるボタンを使用してください!
+
+
+
+
+
+## Train with Pytorch Trainer
+
+🤗 Transformersは、🤗 Transformersモデルのトレーニングを最適化した[`Trainer`]クラスを提供し、独自のトレーニングループを手動で記述せずにトレーニングを開始しやすくしています。
+[`Trainer`] APIは、ログ記録、勾配累積、混合精度など、さまざまなトレーニングオプションと機能をサポートしています。
+
+まず、モデルをロードし、予想されるラベルの数を指定します。Yelp Review [dataset card](https://huggingface.co/datasets/yelp_review_full#data-fields)から、5つのラベルがあることがわかります:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=5)
+```
+
+
+
+一部の事前学習済みの重みが使用されず、一部の重みがランダムに初期化された警告が表示されることがあります。心配しないでください、これは完全に正常です!
+BERTモデルの事前学習済みのヘッドは破棄され、ランダムに初期化された分類ヘッドで置き換えられます。この新しいモデルヘッドをシーケンス分類タスクでファインチューニングし、事前学習モデルの知識をそれに転送します。
+
+
+
+### Training Hyperparameters
+
+次に、トレーニングオプションをアクティベートするためのすべてのハイパーパラメータと、調整できるハイパーパラメータを含む[`TrainingArguments`]クラスを作成します。
+このチュートリアルでは、デフォルトのトレーニング[ハイパーパラメータ](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments)を使用して開始できますが、最適な設定を見つけるためにこれらを実験しても構いません。
+
+トレーニングのチェックポイントを保存する場所を指定します:
+
+```python
+>>> from transformers import TrainingArguments
+
+>>> training_args = TrainingArguments(output_dir="test_trainer")
+```
+
+### Evaluate
+
+[`Trainer`]はトレーニング中に自動的にモデルのパフォーマンスを評価しません。メトリクスを計算して報告する関数を[`Trainer`]に渡す必要があります。
+[🤗 Evaluate](https://huggingface.co/docs/evaluate/index)ライブラリでは、[`evaluate.load`]関数を使用して読み込むことができるシンプルな[`accuracy`](https://huggingface.co/spaces/evaluate-metric/accuracy)関数が提供されています(詳細については[こちらのクイックツアー](https://huggingface.co/docs/evaluate/a_quick_tour)を参照してください):
+
+```python
+>>> import numpy as np
+>>> import evaluate
+
+>>> metric = evaluate.load("accuracy")
+```
+
+`metric`の`~evaluate.compute`を呼び出して、予測の正確度を計算します。 `compute`に予測を渡す前に、予測をロジットに変換する必要があります(すべての🤗 Transformersモデルはロジットを返すことを覚えておいてください):
+
+```py
+>>> def compute_metrics(eval_pred):
+... logits, labels = eval_pred
+... predictions = np.argmax(logits, axis=-1)
+... return metric.compute(predictions=predictions, references=labels)
+```
+
+評価メトリクスをファインチューニング中に監視したい場合、トレーニング引数で `eval_strategy` パラメータを指定して、各エポックの終了時に評価メトリクスを報告します:
+
+```python
+>>> from transformers import TrainingArguments, Trainer
+
+>>> training_args = TrainingArguments(output_dir="test_trainer", eval_strategy="epoch")
+```
+
+### Trainer
+
+モデル、トレーニング引数、トレーニングおよびテストデータセット、評価関数を使用して[`Trainer`]オブジェクトを作成します:
+
+```py
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=small_train_dataset,
+... eval_dataset=small_eval_dataset,
+... compute_metrics=compute_metrics,
+... )
+```
+
+その後、[`~transformers.Trainer.train`]を呼び出してモデルを微調整します:
+
+```python
+>>> trainer.train()
+```
+
+
+
+
+
+
+
+## Kerasを使用してTensorFlowモデルをトレーニングする
+
+Keras APIを使用して🤗 TransformersモデルをTensorFlowでトレーニングすることもできます!
+
+### Loading Data from Keras
+
+🤗 TransformersモデルをKeras APIでトレーニングする場合、データセットをKerasが理解できる形式に変換する必要があります。
+データセットが小さい場合、データセット全体をNumPy配列に変換してKerasに渡すことができます。
+複雑なことをする前に、まずそれを試してみましょう。
+
+まず、データセットを読み込みます。GLUEベンチマークからCoLAデータセットを使用します
+([GLUE Banchmark](https://huggingface.co/datasets/glue))、これは単純なバイナリテキスト分類タスクです。今のところトレーニング分割のみを使用します。
+
+```py
+from datasets import load_dataset
+
+dataset = load_dataset("glue", "cola")
+dataset = dataset["train"] # 今のところトレーニング分割のみを使用します
+```
+
+次に、トークナイザをロードし、データをNumPy配列としてトークン化します。ラベルは既に`0`と`1`のリストであるため、トークン化せずに直接NumPy配列に変換できます!
+
+```python
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
+tokenized_data = tokenizer(dataset["sentence"], return_tensors="np", padding=True)
+# トークナイザはBatchEncodingを返しますが、それをKeras用に辞書に変換します
+tokenized_data = dict(tokenized_data)
+
+labels = np.array(dataset["label"]) # ラベルはすでに0と1の配列です
+```
+
+最後に、モデルをロードし、[`compile`](https://keras.io/api/models/model_training_apis/#compile-method) と [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) メソッドを実行します。
+注意点として、Transformersモデルはすべてデフォルトでタスクに関連した損失関数を持っているため、指定しなくても構いません(指定する場合を除く):
+
+```python
+from transformers import TFAutoModelForSequenceClassification
+from tensorflow.keras.optimizers import Adam
+
+# モデルをロードしてコンパイルする
+model = TFAutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased")
+# ファインチューニングには通常、学習率を下げると良いです
+model.compile(optimizer=Adam(3e-5)) # 損失関数の指定は不要です!
+
+model.fit(tokenized_data, labels)
+```
+
+
+
+モデルを`compile()`する際に`loss`引数を渡す必要はありません!Hugging Faceモデルは、この引数を空白のままにしておくと、タスクとモデルアーキテクチャに適した損失を自動的に選択します。
+必要に応じて自分で損失を指定してオーバーライドすることもできます!
+
+
+
+このアプローチは、小規模なデータセットには適していますが、大規模なデータセットに対しては問題になることがあります。なぜなら、トークナイズされた配列とラベルはメモリに完全に読み込まれる必要があり、またNumPyは「ジャギー」な配列を処理しないため、トークナイズされた各サンプルを全体のデータセット内で最も長いサンプルの長さにパディングする必要があります。
+これにより、配列がさらに大きくなり、すべてのパディングトークンがトレーニングを遅くする原因になります!
+
+### Loading data as a tf.data.Dataset
+
+トレーニングを遅くせずにデータを読み込むには、データを`tf.data.Dataset`として読み込むことができます。独自の`tf.data`パイプラインを作成することもできますが、これを行うための便利な方法が2つあります:
+
+- [`~TFPreTrainedModel.prepare_tf_dataset`]: これはほとんどの場合で推奨する方法です。モデル上のメソッドなので、モデルを検査してモデル入力として使用可能な列を自動的に把握し、他の列を破棄してより単純で高性能なデータセットを作成できます。
+- [`~datasets.Dataset.to_tf_dataset`]: このメソッドはより低レベルで、データセットがどのように作成されるかを正確に制御する場合に便利です。`columns`と`label_cols`を指定して、データセットに含める列を正確に指定できます。
+
+[`~TFPreTrainedModel.prepare_tf_dataset`]を使用する前に、次のコードサンプルに示すように、トークナイザの出力をデータセットに列として追加する必要があります:
+
+```py
+def tokenize_dataset(data):
+ # 返された辞書のキーはデータセットに列として追加されます
+ return tokenizer(data["text"])
+
+
+dataset = dataset.map(tokenize_dataset)
+```
+
+Hugging Faceのデータセットはデフォルトでディスクに保存されるため、これによりメモリの使用量が増えることはありません!
+列が追加されたら、データセットからバッチをストリームし、各バッチにパディングを追加できます。これにより、
+データセット全体にパディングを追加する場合と比べて、パディングトークンの数が大幅に削減されます。
+
+```python
+>>> tf_dataset = model.prepare_tf_dataset(dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer)
+```
+
+上記のコードサンプルでは、トークナイザを`prepare_tf_dataset`に渡して、バッチを正しく読み込む際に正しくパディングできるようにする必要があります。
+データセットのすべてのサンプルが同じ長さであり、パディングが不要な場合は、この引数をスキップできます。
+パディング以外の複雑な処理を行う必要がある場合(例:マスク言語モデリングのためのトークンの破損など)、
+代わりに`collate_fn`引数を使用して、サンプルのリストをバッチに変換し、必要な前処理を適用する関数を渡すことができます。
+このアプローチを実際に使用した例については、
+[examples](https://github.com/huggingface/transformers/tree/main/examples)や
+[notebooks](https://huggingface.co/docs/transformers/notebooks)をご覧ください。
+
+`tf.data.Dataset`を作成したら、以前と同様にモデルをコンパイルし、適合させることができます:
+
+```python
+model.compile(optimizer=Adam(3e-5)) # 損失引数は不要です!
+
+model.fit(tf_dataset)
+```
+
+
+
+
+
+
+## Train in native Pytorch
+
+
+
+
+
+[`Trainer`]はトレーニングループを処理し、1行のコードでモデルをファインチューニングできるようにします。
+トレーニングループを独自に記述したいユーザーのために、🤗 TransformersモデルをネイティブのPyTorchでファインチューニングすることもできます。
+
+この時点で、ノートブックを再起動するか、以下のコードを実行してメモリを解放する必要があるかもしれません:
+
+```py
+del model
+del trainer
+torch.cuda.empty_cache()
+```
+
+1. モデルは生のテキストを入力として受け取らないため、`text` 列を削除します:
+
+```py
+>>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
+```
+
+2. `label`列を`labels`に名前を変更します。モデルは引数の名前を`labels`と期待しています:
+
+```py
+>>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
+```
+
+3. データセットの形式をリストではなくPyTorchテンソルを返すように設定します:
+
+```py
+>>> tokenized_datasets.set_format("torch")
+```
+
+以前に示したように、ファインチューニングを高速化するためにデータセットの小さなサブセットを作成します:
+
+```py
+>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
+>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
+```
+
+### DataLoader
+
+トレーニングデータセットとテストデータセット用の`DataLoader`を作成して、データのバッチをイテレートできるようにします:
+
+```py
+>>> from torch.utils.data import DataLoader
+
+>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
+>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
+```
+
+ロードするモデルと期待されるラベルの数を指定してください:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=5)
+```
+
+### Optimizer and learning rate scheduler
+
+モデルをファインチューニングするためのオプティマイザと学習率スケジューラーを作成しましょう。
+PyTorchから[`AdamW`](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html)オプティマイザを使用します:
+
+```python
+>>> from torch.optim import AdamW
+
+>>> optimizer = AdamW(model.parameters(), lr=5e-5)
+```
+
+デフォルトの学習率スケジューラを[`Trainer`]から作成する:
+
+```py
+>>> from transformers import get_scheduler
+
+>>> num_epochs = 3
+>>> num_training_steps = num_epochs * len(train_dataloader)
+>>> lr_scheduler = get_scheduler(
+... name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
+... )
+```
+
+最後に、GPUを利用できる場合は `device` を指定してください。それ以外の場合、CPUでのトレーニングは数時間かかる可能性があり、数分で完了することができます。
+
+```py
+>>> import torch
+
+>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+>>> model.to(device)
+```
+
+
+
+クラウドGPUが利用できない場合、[Colaboratory](https://colab.research.google.com/)や[SageMaker StudioLab](https://studiolab.sagemaker.aws/)などのホストされたノートブックを使用して無料でGPUにアクセスできます。
+
+
+
+さて、トレーニングの準備が整いました! 🥳
+
+### トレーニングループ
+
+トレーニングの進捗を追跡するために、[tqdm](https://tqdm.github.io/)ライブラリを使用してトレーニングステップの数に対して進行状況バーを追加します:
+
+```py
+>>> from tqdm.auto import tqdm
+
+>>> progress_bar = tqdm(range(num_training_steps))
+
+>>> model.train()
+>>> for epoch in range(num_epochs):
+... for batch in train_dataloader:
+... batch = {k: v.to(device) for k, v in batch.items()}
+... outputs = model(**batch)
+... loss = outputs.loss
+... loss.backward()
+
+... optimizer.step()
+... lr_scheduler.step()
+... optimizer.zero_grad()
+... progress_bar.update(1)
+```
+
+### Evaluate
+
+[`Trainer`]に評価関数を追加したのと同様に、独自のトレーニングループを作成する際にも同様の操作を行う必要があります。
+ただし、各エポックの最後にメトリックを計算および報告する代わりに、今回は[`~evaluate.add_batch`]を使用してすべてのバッチを蓄積し、最後にメトリックを計算します。
+
+```python
+>>> import evaluate
+
+>>> metric = evaluate.load("accuracy")
+>>> model.eval()
+>>> for batch in eval_dataloader:
+... batch = {k: v.to(device) for k, v in batch.items()}
+... with torch.no_grad():
+... outputs = model(**batch)
+
+... logits = outputs.logits
+... predictions = torch.argmax(logits, dim=-1)
+... metric.add_batch(predictions=predictions, references=batch["labels"])
+
+>>> metric.compute()
+```
+
+
+
+
+
+
+## 追加リソース
+
+さらなるファインチューニングの例については、以下を参照してください:
+
+- [🤗 Transformers Examples](https://github.com/huggingface/transformers/tree/main/examples) には、PyTorchとTensorFlowで一般的なNLPタスクをトレーニングするスクリプトが含まれています。
+
+- [🤗 Transformers Notebooks](notebooks) には、特定のタスクにモデルをファインチューニングする方法に関するさまざまなノートブックが含まれています。
diff --git a/docs/transformers/docs/source/ja/troubleshooting.md b/docs/transformers/docs/source/ja/troubleshooting.md
new file mode 100644
index 0000000000000000000000000000000000000000..b13b5993171a0a31c9f3d9c65d70069e5909b57a
--- /dev/null
+++ b/docs/transformers/docs/source/ja/troubleshooting.md
@@ -0,0 +1,195 @@
+
+
+# Troubleshoot
+
+時にはエラーが発生することがありますが、私たちはここにいます!このガイドでは、私たちがよく見る最も一般的な問題と、それらを解決する方法について説明します。ただし、このガイドはすべての 🤗 Transformers の問題の包括的なコレクションではありません。問題をトラブルシューティングするための詳細なヘルプが必要な場合は、以下の方法を試してみてください:
+
+
+
+1. [フォーラム](https://discuss.huggingface.co/)で助けを求める。 [初心者向け](https://discuss.huggingface.co/c/beginners/5) または [🤗 Transformers](https://discuss.huggingface.co/c/transformers/9) など、質問を投稿できる特定のカテゴリがあります。問題が解決される可能性を最大限にするために、再現可能なコードを含む良い説明的なフォーラム投稿を書くことを確認してください!
+
+
+
+2. バグがライブラリに関連する場合は、🤗 Transformers リポジトリで [Issue](https://github.com/huggingface/transformers/issues/new/choose) を作成してください。バグを説明するためのできるだけ多くの情報を含めるように心がけ、何が問題で、どのように修正できるかをより良く理解できるようにしてください。
+
+3. より古いバージョンの 🤗 Transformers を使用している場合は、[Migration](migration) ガイドを確認してください。バージョン間で重要な変更が導入されているためです。
+
+トラブルシューティングとヘルプの詳細については、Hugging Faceコースの [第8章](https://huggingface.co/course/chapter8/1?fw=pt) を参照してください。
+
+## Firewalled environments
+
+一部のクラウド上のGPUインスタンスやイントラネットセットアップは、外部接続に対してファイアウォールで保護されているため、接続エラーが発生することがあります。スクリプトがモデルの重みやデータセットをダウンロードしようとすると、ダウンロードが途中で止まり、次のメッセージとタイムアウトエラーが表示されます:
+
+```
+ValueError: Connection error, and we cannot find the requested files in the cached path.
+Please try again or make sure your Internet connection is on.
+```
+
+
+この場合、接続エラーを回避するために[オフラインモード](installation#offline-mode)で🤗 Transformersを実行してみてください。
+
+## CUDA out of memory
+
+数百万のパラメータを持つ大規模なモデルのトレーニングは、適切なハードウェアなしでは課題です。GPUのメモリが不足するとよくあるエラーの1つは次のとおりです:
+
+以下はメモリ使用量を減らすために試すことができるいくつかの解決策です:
+
+- [`TrainingArguments`]の中で [`per_device_train_batch_size`](main_classes/trainer#transformers.TrainingArguments.per_device_train_batch_size) の値を減らす。
+- [`TrainingArguments`]の中で [`gradient_accumulation_steps`](main_classes/trainer#transformers.TrainingArguments.gradient_accumulation_steps) を使用して、全体的なバッチサイズを効果的に増やすことを試す。
+
+
+
+メモリ節約のテクニックについての詳細は、[ガイド](performance)を参照してください。
+
+
+
+## Unable to load a saved TensorFlow model
+
+TensorFlowの[model.save](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model)メソッドは、モデル全体 - アーキテクチャ、重み、トレーニング設定 - を1つのファイルに保存します。しかし、モデルファイルを再度読み込む際にエラーが発生することがあります。これは、🤗 Transformersがモデルファイル内のすべてのTensorFlow関連オブジェクトを読み込まないためです。TensorFlowモデルの保存と読み込みに関する問題を回避するために、次のことをお勧めします:
+
+- モデルの重みを`h5`ファイル拡張子で保存し、[`~TFPreTrainedModel.from_pretrained`]を使用してモデルを再読み込みする:
+
+```py
+>>> from transformers import TFPreTrainedModel
+
+>>> model.save_weights("some_folder/tf_model.h5")
+>>> model = TFPreTrainedModel.from_pretrained("some_folder")
+```
+
+- Save the model with [`~TFPretrainedModel.save_pretrained`] and load it again with [`~TFPreTrainedModel.from_pretrained`]:
+
+```py
+>>> from transformers import TFPreTrainedModel
+
+>>> model.save_pretrained("path_to/model")
+>>> model = TFPreTrainedModel.from_pretrained("path_to/model")
+```
+
+## ImportError
+
+もう一つよくあるエラーは、特に新しくリリースされたモデルの場合に遭遇することがある `ImportError` です:
+
+
+```
+ImportError: cannot import name 'ImageGPTImageProcessor' from 'transformers' (unknown location)
+```
+
+これらのエラータイプに関しては、最新バージョンの 🤗 Transformers がインストールされていることを確認して、最新のモデルにアクセスできるようにしてください:
+
+```bash
+pip install transformers --upgrade
+```
+
+## CUDA error: device-side assert triggered
+
+時々、デバイスコードでエラーが発生したという一般的な CUDA エラーに遭遇することがあります。
+
+```
+RuntimeError: CUDA error: device-side assert triggered
+```
+
+より具体的なエラーメッセージを取得するために、まずはCPU上でコードを実行してみることをお勧めします。以下の環境変数をコードの冒頭に追加して、CPUに切り替えてみてください:
+
+```py
+>>> import os
+
+>>> os.environ["CUDA_VISIBLE_DEVICES"] = ""
+```
+
+GPUからより良いトレースバックを取得する別のオプションは、次の環境変数をコードの先頭に追加することです。これにより、エラーの発生源を指すトレースバックが得られます:
+
+```py
+>>> import os
+
+>>> os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
+```
+
+
+## Incorrect output when padding tokens aren't masked
+
+一部のケースでは、`input_ids`にパディングトークンが含まれている場合、出力の`hidden_state`が正しくないことがあります。デモンストレーションのために、モデルとトークナイザーをロードします。モデルの`pad_token_id`にアクセスして、その値を確認できます。一部のモデルでは`pad_token_id`が`None`になることもありますが、常に手動で設定することができます。
+
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+>>> import torch
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
+>>> model.config.pad_token_id
+0
+```
+
+以下の例は、パディングトークンをマスクせずに出力を表示したものです:
+
+```py
+>>> input_ids = torch.tensor([[7592, 2057, 2097, 2393, 9611, 2115], [7592, 0, 0, 0, 0, 0]])
+>>> output = model(input_ids)
+>>> print(output.logits)
+tensor([[ 0.0082, -0.2307],
+ [ 0.1317, -0.1683]], grad_fn=)
+```
+
+以下は、第2のシーケンスの実際の出力です:
+
+```py
+>>> input_ids = torch.tensor([[7592]])
+>>> output = model(input_ids)
+>>> print(output.logits)
+tensor([[-0.1008, -0.4061]], grad_fn=)
+```
+
+大抵の場合、モデルには `attention_mask` を提供して、パディングトークンを無視し、このような無音のエラーを回避する必要があります。これにより、2番目のシーケンスの出力が実際の出力と一致するようになります。
+
+
+
+デフォルトでは、トークナイザは、トークナイザのデフォルトに基づいて `attention_mask` を自動で作成します。
+
+
+
+```py
+>>> attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0]])
+>>> output = model(input_ids, attention_mask=attention_mask)
+>>> print(output.logits)
+tensor([[ 0.0082, -0.2307],
+ [-0.1008, -0.4061]], grad_fn=)
+```
+
+🤗 Transformersは、提供されるパディングトークンをマスクするために自動的に`attention_mask`を作成しません。その理由は以下の通りです:
+
+- 一部のモデルにはパディングトークンが存在しない場合があるためです。
+- 一部のユースケースでは、ユーザーがパディングトークンにアテンションを向けることを望む場合があるためです。
+
+## ValueError: Unrecognized configuration class XYZ for this kind of AutoModel
+
+一般的に、事前学習済みモデルのインスタンスをロードするためには[`AutoModel`]クラスを使用することをお勧めします。このクラスは、設定に基づいて与えられたチェックポイントから正しいアーキテクチャを自動的に推測およびロードできます。モデルをロードする際にこの`ValueError`が表示される場合、Autoクラスは与えられたチェックポイントの設定から、ロードしようとしているモデルの種類へのマッピングを見つけることができなかったことを意味します。最も一般的には、特定のタスクをサポートしないチェックポイントがある場合にこのエラーが発生します。
+例えば、質問応答のためのGPT2が存在しない場合、次の例でこのエラーが表示されます:
+
+上記のテキストを日本語に翻訳し、Markdownファイルとしてフォーマットしました。
+
+
+```py
+>>> from transformers import AutoProcessor, AutoModelForQuestionAnswering
+
+>>> processor = AutoProcessor.from_pretrained("openai-community/gpt2-medium")
+>>> model = AutoModelForQuestionAnswering.from_pretrained("openai-community/gpt2-medium")
+ValueError: Unrecognized configuration class for this kind of AutoModel: AutoModelForQuestionAnswering.
+Model type should be one of AlbertConfig, BartConfig, BertConfig, BigBirdConfig, BigBirdPegasusConfig, BloomConfig, ...
+```
diff --git a/docs/transformers/docs/source/ko/_config.py b/docs/transformers/docs/source/ko/_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..ab61af6ef9e86028ae075e01fb244ae4226f387b
--- /dev/null
+++ b/docs/transformers/docs/source/ko/_config.py
@@ -0,0 +1,14 @@
+# docstyle-ignore
+INSTALL_CONTENT = """
+# Transformers 설치 방법
+! pip install transformers datasets evaluate accelerate
+# 마지막 릴리스 대신 소스에서 설치하려면, 위 명령을 주석으로 바꾸고 아래 명령을 해제하세요.
+# ! pip install git+https://github.com/huggingface/transformers.git
+"""
+
+notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
+black_avoid_patterns = {
+ "{processor_class}": "FakeProcessorClass",
+ "{model_class}": "FakeModelClass",
+ "{object_class}": "FakeObjectClass",
+}
diff --git a/docs/transformers/docs/source/ko/_toctree.yml b/docs/transformers/docs/source/ko/_toctree.yml
new file mode 100644
index 0000000000000000000000000000000000000000..1a9c61ce09cf612f273bb911637e8059dba4e8ef
--- /dev/null
+++ b/docs/transformers/docs/source/ko/_toctree.yml
@@ -0,0 +1,790 @@
+- sections:
+ - local: index
+ title: 🤗 Transformers
+ - local: quicktour
+ title: 둘러보기
+ - local: installation
+ title: 설치방법
+ title: 시작하기
+- sections:
+ - local: pipeline_tutorial
+ title: Pipeline으로 추론하기
+ - local: autoclass_tutorial
+ title: AutoClass로 사전 학습된 인스턴스 로드하기
+ - local: preprocessing
+ title: 데이터 전처리하기
+ - local: training
+ title: 사전 학습된 모델 미세 조정하기
+ - local: run_scripts
+ title: 스크립트로 학습하기
+ - local: accelerate
+ title: 🤗 Accelerate로 분산 학습 구성하기
+ - local: peft
+ title: 🤗 PEFT로 어댑터 로드 및 학습하기
+ - local: model_sharing
+ title: 만든 모델 공유하기
+ - local: llm_tutorial
+ title: 대규모 언어 모델로 생성하기
+ - local: conversations
+ title: Transformers로 채팅하기
+ title: 튜토리얼
+- sections:
+ - isExpanded: false
+ sections:
+ - local: tasks/sequence_classification
+ title: 텍스트 분류
+ - local: tasks/token_classification
+ title: 토큰 분류
+ - local: tasks/question_answering
+ title: 질의 응답(Question Answering)
+ - local: tasks/language_modeling
+ title: 인과적 언어 모델링(Causal language modeling)
+ - local: tasks/masked_language_modeling
+ title: 마스킹된 언어 모델링(Masked language modeling)
+ - local: tasks/translation
+ title: 번역
+ - local: tasks/summarization
+ title: 요약
+ - local: tasks/multiple_choice
+ title: 객관식 문제(Multiple Choice)
+ title: 자연어처리
+ - isExpanded: false
+ sections:
+ - local: tasks/audio_classification
+ title: 오디오 분류
+ - local: tasks/asr
+ title: 자동 음성 인식
+ title: 오디오
+ - isExpanded: false
+ sections:
+ - local: tasks/image_classification
+ title: 이미지 분류
+ - local: tasks/semantic_segmentation
+ title: 의미적 분할(Semantic segmentation)
+ - local: tasks/video_classification
+ title: 영상 분류
+ - local: tasks/object_detection
+ title: 객체 탐지
+ - local: tasks/zero_shot_object_detection
+ title: 제로샷(zero-shot) 객체 탐지
+ - local: tasks/zero_shot_image_classification
+ title: 제로샷(zero-shot) 이미지 분류
+ - local: tasks/monocular_depth_estimation
+ title: 단일 영상 기반 깊이 추정
+ - local: tasks/image_to_image
+ title: Image-to-Image
+ - local: tasks/image_feature_extraction
+ title: 이미지 특징 추출
+ - local: tasks/mask_generation
+ title: 마스크 생성
+ - local: tasks/knowledge_distillation_for_image_classification
+ title: 컴퓨터 비전(이미지 분류)를 위한 지식 증류(knowledge distillation)
+ title: 컴퓨터 비전
+ - isExpanded: false
+ sections:
+ - local: tasks/image_captioning
+ title: 이미지 캡셔닝
+ - local: tasks/document_question_answering
+ title: 문서 질의 응답(Document Question Answering)
+ - local: tasks/visual_question_answering
+ title: 시각적 질의응답 (Visual Question Answering)
+ - local: in_translation
+ title: (번역중) Text to speech
+ title: 멀티모달
+ - isExpanded: false
+ sections:
+ - local: generation_strategies
+ title: 텍스트 생성 전략 사용자 정의
+ title: 생성
+ - isExpanded: false
+ sections:
+ - local: tasks/idefics
+ title: IDEFICS를 이용한 이미지 작업
+ - local: tasks/prompting
+ title: 대규모 언어 모델 프롬프팅 가이드
+ title: 프롬프팅
+ title: 태스크 가이드
+- sections:
+ - local: fast_tokenizers
+ title: 🤗 Tokenizers 라이브러리에서 토크나이저 사용하기
+ - local: multilingual
+ title: 다국어 모델 추론하기
+ - local: create_a_model
+ title: 모델별 API 사용하기
+ - local: custom_models
+ title: 사용자 정의 모델 공유하기
+ - local: chat_templating
+ title: 챗봇 템플릿 익히기
+ - local: trainer
+ title: Trainer 사용하기
+ - local: sagemaker
+ title: Amazon SageMaker에서 학습 실행하기
+ - local: serialization
+ title: ONNX로 내보내기
+ - local: tflite
+ title: TFLite로 내보내기
+ - local: torchscript
+ title: TorchScript로 내보내기
+ - local: in_translation
+ title: (번역중) Notebooks with examples
+ - local: community
+ title: 커뮤니티 리소스
+ - local: troubleshooting
+ title: 문제 해결
+ - local: gguf
+ title: GGUF 파일들과의 상호 운용성
+ - local: modular_transformers
+ title: transformers에서의 모듈성
+ title: (번역중) 개발자 가이드
+- sections:
+ - local: in_translation
+ title: (번역중) Getting started
+ - local: quantization/bitsandbytes
+ title: bitsandbytes
+ - local: quantization/gptq
+ title: GPTQ
+ - local: quantization/awq
+ title: AWQ
+ - local: in_translation
+ title: (번역중) AQLM
+ - local: in_translation
+ title: (번역중) VPTQ
+ - local: quantization/quanto
+ title: Quanto
+ - local: quantization/eetq
+ title: EETQ
+ - local: in_translation
+ title: (번역중) HQQ
+ - local: in_translation
+ title: (번역중) Optimum
+ - local: in_translation
+ title: (번역중) Contribute new quantization method
+ title: (번역중) 경량화 메소드
+- sections:
+ - local: performance
+ title: 성능 및 확장성
+ - local: in_translation
+ title: (번역중) Quantization
+ - local: llm_optims
+ title: LLM 추론 최적화
+ - sections:
+ - local: in_translation
+ title: (번역중) Methods and tools for efficient training on a single GPU
+ - local: perf_train_gpu_many
+ title: 다중 GPU에서 훈련 진행하기
+ - local: deepspeed
+ title: DeepSpeed
+ - local: fsdp
+ title: 완전 분할 데이터 병렬 처리
+ - local: perf_train_cpu
+ title: CPU에서 훈련
+ - local: perf_train_cpu_many
+ title: 다중 CPU에서 훈련하기
+ - local: perf_train_tpu_tf
+ title: TensorFlow로 TPU에서 훈련하기
+ - local: perf_train_special
+ title: Apple 실리콘에서 PyTorch 학습
+ - local: perf_hardware
+ title: 훈련용 사용자 맞춤형 하드웨어
+ - local: hpo_train
+ title: Trainer API를 사용한 하이퍼파라미터 탐색
+ title: (번역중) 효율적인 학습 기술들
+ - sections:
+ - local: perf_infer_cpu
+ title: CPU로 추론하기
+ - local: perf_infer_gpu_one
+ title: 하나의 GPU를 활용한 추론
+ title: 추론 최적화하기
+ - local: big_models
+ title: 대형 모델을 인스턴스화
+ - local: debugging
+ title: 디버깅
+ - local: tf_xla
+ title: TensorFlow 모델을 위한 XLA 통합
+ - local: in_translation
+ title: (번역중) Optimize inference using `torch.compile()`
+ title: (번역중) 성능 및 확장성
+- sections:
+ - local: contributing
+ title: 🤗 Transformers에 기여하는 방법
+ - local: add_new_model
+ title: 🤗 Transformers에 새로운 모델을 추가하는 방법
+ - local: add_new_pipeline
+ title: 어떻게 🤗 Transformers에 파이프라인을 추가하나요?
+ - local: testing
+ title: 테스트
+ - local: pr_checks
+ title: Pull Request에 대한 검사
+ title: 기여하기
+- sections:
+ - local: philosophy
+ title: 이념과 목표
+ - local: in_translation
+ title: (번역중) Glossary
+ - local: task_summary
+ title: 🤗 Transformers로 할 수 있는 작업
+ - local: tasks_explained
+ title: 🤗 Transformers로 작업을 해결하는 방법
+ - local: model_summary
+ title: Transformer 모델군
+ - local: tokenizer_summary
+ title: 토크나이저 요약
+ - local: attention
+ title: 어텐션 매커니즘
+ - local: pad_truncation
+ title: 패딩과 잘라내기
+ - local: bertology
+ title: BERTology
+ - local: perplexity
+ title: 고정 길이 모델의 펄플렉서티(Perplexity)
+ - local: pipeline_webserver
+ title: 추론 웹 서버를 위한 파이프라인
+ - local: model_memory_anatomy
+ title: 모델 학습 해부하기
+ - local: llm_tutorial_optimization
+ title: LLM을 최대한 활용하기
+ title: (번역중) 개념 가이드
+- sections:
+ - sections:
+ - local: model_doc/auto
+ title: 자동 클래스
+ - local: in_translation
+ title: (번역중) Backbones
+ - local: main_classes/callback
+ title: 콜백
+ - local: main_classes/configuration
+ title: 구성
+ - local: main_classes/data_collator
+ title: 데이터 콜레이터
+ - local: main_classes/keras_callbacks
+ title: 케라스 콜백
+ - local: main_classes/logging
+ title: 로깅
+ - local: main_classes/model
+ title: Models
+ - local: main_classes/text_generation
+ title: 텍스트 생성
+ - local: main_classes/onnx
+ title: ONNX
+ - local: in_translation
+ title: (번역중) Optimization
+ - local: in_translation
+ title: 모델 출력
+ - local: main_classes/output
+ title: (번역중) Pipelines
+ - local: in_translation
+ title: (번역중) Processors
+ - local: main_classes/quantization
+ title: 양자화
+ - local: in_translation
+ title: (번역중) Tokenizer
+ - local: main_classes/trainer
+ title: Trainer
+ - local: deepspeed
+ title: DeepSpeed
+ - local: main_classes/executorch
+ title: ExecuTorch
+ - local: main_classes/feature_extractor
+ title: 특성 추출기
+ - local: in_translation
+ title: (번역중) Image Processor
+ title: (번역중) 메인 클래스
+ - sections:
+ - isExpanded: false
+ sections:
+ - local: in_translation
+ title: (번역중) ALBERT
+ - local: model_doc/bart
+ title: BART
+ - local: model_doc/barthez
+ title: BARThez
+ - local: model_doc/bartpho
+ title: BARTpho
+ - local: model_doc/bert
+ title: BERT
+ - local: in_translation
+ title: (번역중) BertGeneration
+ - local: model_doc/bert-japanese
+ title: 일본어 Bert
+ - local: model_doc/bertweet
+ title: Bertweet
+ - local: in_translation
+ title: (번역중) BigBird
+ - local: in_translation
+ title: (번역중) BigBirdPegasus
+ - local: model_doc/biogpt
+ title: BioGpt
+ - local: in_translation
+ title: (번역중) Blenderbot
+ - local: in_translation
+ title: (번역중) Blenderbot Small
+ - local: in_translation
+ title: (번역중) BLOOM
+ - local: in_translation
+ title: (번역중) BORT
+ - local: in_translation
+ title: (번역중) ByT5
+ - local: in_translation
+ title: (번역중) CamemBERT
+ - local: in_translation
+ title: (번역중) CANINE
+ - local: model_doc/codegen
+ title: CodeGen
+ - local: model_doc/cohere
+ title: Cohere
+ - local: model_doc/convbert
+ title: ConvBERT
+ - local: in_translation
+ title: (번역중) CPM
+ - local: in_translation
+ title: (번역중) CPMANT
+ - local: in_translation
+ title: (번역중) CTRL
+ - local: model_doc/dbrx
+ title: DBRX
+ - local: model_doc/deberta
+ title: DeBERTa
+ - local: model_doc/deberta-v2
+ title: DeBERTa-v2
+ - local: in_translation
+ title: (번역중) DialoGPT
+ - local: in_translation
+ title: (번역중) DistilBERT
+ - local: in_translation
+ title: (번역중) DPR
+ - local: in_translation
+ title: (번역중) ELECTRA
+ - local: model_doc/encoder-decoder
+ title: 인코더 디코더 모델
+ - local: in_translation
+ title: (번역중) ERNIE
+ - local: in_translation
+ title: (번역중) ErnieM
+ - local: model_doc/esm
+ title: ESM
+ - local: in_translation
+ title: (번역중) FLAN-T5
+ - local: in_translation
+ title: (번역중) FLAN-UL2
+ - local: in_translation
+ title: (번역중) FlauBERT
+ - local: in_translation
+ title: (번역중) FNet
+ - local: in_translation
+ title: (번역중) FSMT
+ - local: in_translation
+ title: (번역중) Funnel Transformer
+ - local: model_doc/gemma
+ title: Gemma
+ - local: model_doc/gemma2
+ title: Gemma2
+ - local: model_doc/openai-gpt
+ title: GPT
+ - local: in_translation
+ title: (번역중) GPT Neo
+ - local: in_translation
+ title: (번역중) GPT NeoX
+ - local: model_doc/gpt_neox_japanese
+ title: GPT NeoX Japanese
+ - local: in_translation
+ title: (번역중) GPT-J
+ - local: in_translation
+ title: (번역중) GPT2
+ - local: in_translation
+ title: (번역중) GPTBigCode
+ - local: in_translation
+ title: (번역중) GPTSAN Japanese
+ - local: in_translation
+ title: (번역중) GPTSw3
+ - local: in_translation
+ title: (번역중) HerBERT
+ - local: in_translation
+ title: (번역중) I-BERT
+ - local: in_translation
+ title: (번역중) Jukebox
+ - local: in_translation
+ title: (번역중) LED
+ - local: model_doc/llama
+ title: LLaMA
+ - local: model_doc/llama2
+ title: LLaMA2
+ - local: model_doc/llama3
+ title: LLaMA3
+ - local: in_translation
+ title: (번역중) Longformer
+ - local: in_translation
+ title: (번역중) LongT5
+ - local: in_translation
+ title: (번역중) LUKE
+ - local: in_translation
+ title: (번역중) M2M100
+ - local: model_doc/mamba
+ title: Mamba
+ - local: model_doc/mamba2
+ title: Mamba2
+ - local: model_doc/marian
+ title: MarianMT
+ - local: in_translation
+ title: (번역중) MarkupLM
+ - local: in_translation
+ title: (번역중) MBart and MBart-50
+ - local: in_translation
+ title: (번역중) MEGA
+ - local: in_translation
+ title: (번역중) MegatronBERT
+ - local: in_translation
+ title: (번역중) MegatronGPT2
+ - local: model_doc/mistral
+ title: Mistral
+ - local: in_translation
+ title: (번역중) mLUKE
+ - local: in_translation
+ title: (번역중) MobileBERT
+ - local: in_translation
+ title: (번역중) MPNet
+ - local: in_translation
+ title: (번역중) MT5
+ - local: in_translation
+ title: (번역중) MVP
+ - local: in_translation
+ title: (번역중) NEZHA
+ - local: in_translation
+ title: (번역중) NLLB
+ - local: in_translation
+ title: (번역중) NLLB-MoE
+ - local: in_translation
+ title: (번역중) Nyströmformer
+ - local: in_translation
+ title: (번역중) Open-Llama
+ - local: in_translation
+ title: (번역중) OPT
+ - local: in_translation
+ title: (번역중) Pegasus
+ - local: in_translation
+ title: (번역중) PEGASUS-X
+ - local: in_translation
+ title: (번역중) PhoBERT
+ - local: in_translation
+ title: (번역중) PLBart
+ - local: in_translation
+ title: (번역중) ProphetNet
+ - local: in_translation
+ title: (번역중) QDQBert
+ - local: model_doc/rag
+ title: RAG(검색 증강 생성)
+ - local: in_translation
+ title: (번역중) REALM
+ - local: in_translation
+ title: (번역중) Reformer
+ - local: in_translation
+ title: (번역중) RemBERT
+ - local: in_translation
+ title: (번역중) RetriBERT
+ - local: in_translation
+ title: (번역중) RoBERTa
+ - local: in_translation
+ title: (번역중) RoBERTa-PreLayerNorm
+ - local: in_translation
+ title: (번역중) RoCBert
+ - local: in_translation
+ title: (번역중) RoFormer
+ - local: in_translation
+ title: (번역중) Splinter
+ - local: in_translation
+ title: (번역중) SqueezeBERT
+ - local: in_translation
+ title: (번역중) SwitchTransformers
+ - local: in_translation
+ title: (번역중) T5
+ - local: in_translation
+ title: (번역중) T5v1.1
+ - local: in_translation
+ title: (번역중) TAPEX
+ - local: in_translation
+ title: (번역중) Transformer XL
+ - local: in_translation
+ title: (번역중) UL2
+ - local: in_translation
+ title: (번역중) X-MOD
+ - local: in_translation
+ title: (번역중) XGLM
+ - local: in_translation
+ title: (번역중) XLM
+ - local: in_translation
+ title: (번역중) XLM-ProphetNet
+ - local: in_translation
+ title: (번역중) XLM-RoBERTa
+ - local: in_translation
+ title: (번역중) XLM-RoBERTa-XL
+ - local: in_translation
+ title: (번역중) XLM-V
+ - local: in_translation
+ title: (번역중) XLNet
+ - local: in_translation
+ title: (번역중) YOSO
+ title: (번역중) 텍스트 모델
+ - isExpanded: false
+ sections:
+ - local: in_translation
+ title: (번역중) BEiT
+ - local: in_translation
+ title: (번역중) BiT
+ - local: in_translation
+ title: (번역중) Conditional DETR
+ - local: in_translation
+ title: (번역중) ConvNeXT
+ - local: in_translation
+ title: (번역중) ConvNeXTV2
+ - local: in_translation
+ title: (번역중) CvT
+ - local: in_translation
+ title: (번역중) Deformable DETR
+ - local: in_translation
+ title: (번역중) DeiT
+ - local: in_translation
+ title: (번역중) DETA
+ - local: in_translation
+ title: (번역중) DETR
+ - local: in_translation
+ title: (번역중) DiNAT
+ - local: in_translation
+ title: (번역중) DiT
+ - local: in_translation
+ title: (번역중) DPT
+ - local: in_translation
+ title: (번역중) EfficientFormer
+ - local: in_translation
+ title: (번역중) EfficientNet
+ - local: in_translation
+ title: (번역중) FocalNet
+ - local: in_translation
+ title: (번역중) GLPN
+ - local: in_translation
+ title: (번역중) ImageGPT
+ - local: in_translation
+ title: (번역중) LeViT
+ - local: in_translation
+ title: (번역중) Mask2Former
+ - local: in_translation
+ title: (번역중) MaskFormer
+ - local: in_translation
+ title: (번역중) MobileNetV1
+ - local: in_translation
+ title: (번역중) MobileNetV2
+ - local: in_translation
+ title: (번역중) MobileViT
+ - local: in_translation
+ title: (번역중) NAT
+ - local: in_translation
+ title: (번역중) PoolFormer
+ - local: in_translation
+ title: (번역중) RegNet
+ - local: in_translation
+ title: (번역중) ResNet
+ - local: in_translation
+ title: (번역중) SegFormer
+ - local: model_doc/swin
+ title: Swin Transformer
+ - local: model_doc/swinv2
+ title: Swin Transformer V2
+ - local: model_doc/swin2sr
+ title: Swin2SR
+ - local: in_translation
+ title: (번역중) Table Transformer
+ - local: in_translation
+ title: (번역중) TimeSformer
+ - local: in_translation
+ title: (번역중) UperNet
+ - local: in_translation
+ title: (번역중) VAN
+ - local: in_translation
+ title: (번역중) VideoMAE
+ - local: in_translation
+ title: Vision Transformer (ViT)
+ - local: model_doc/vit
+ title: (번역중) ViT Hybrid
+ - local: in_translation
+ title: (번역중) ViTMAE
+ - local: in_translation
+ title: (번역중) ViTMSN
+ - local: in_translation
+ title: (번역중) YOLOS
+ title: (번역중) 비전 모델
+ - isExpanded: false
+ sections:
+ - local: in_translation
+ title: (번역중) Audio Spectrogram Transformer
+ - local: in_translation
+ title: (번역중) CLAP
+ - local: in_translation
+ title: (번역중) Hubert
+ - local: in_translation
+ title: (번역중) MCTCT
+ - local: in_translation
+ title: (번역중) SEW
+ - local: in_translation
+ title: (번역중) SEW-D
+ - local: in_translation
+ title: (번역중) Speech2Text
+ - local: in_translation
+ title: (번역중) Speech2Text2
+ - local: in_translation
+ title: (번역중) SpeechT5
+ - local: in_translation
+ title: (번역중) UniSpeech
+ - local: in_translation
+ title: (번역중) UniSpeech-SAT
+ - local: in_translation
+ title: (번역중) Wav2Vec2
+ - local: in_translation
+ title: (번역중) Wav2Vec2-Conformer
+ - local: in_translation
+ title: (번역중) Wav2Vec2Phoneme
+ - local: in_translation
+ title: (번역중) WavLM
+ - local: model_doc/whisper
+ title: Whisper
+ - local: in_translation
+ title: (번역중) XLS-R
+ - local: in_translation
+ title: (번역중) XLSR-Wav2Vec2
+ title: (번역중) 오디오 모델
+ - isExpanded: false
+ sections:
+ - local: model_doc/timesformer
+ title: TimeSformer
+ - local: in_translation
+ title: (번역중) VideoMAE
+ - local: model_doc/vivit
+ title: ViViT
+ title: (번역중) 비디오 모델
+ - isExpanded: false
+ sections:
+ - local: in_translation
+ title: (번역중) ALIGN
+ - local: model_doc/altclip
+ title: AltCLIP
+ - local: model_doc/blip-2
+ title: BLIP-2
+ - local: model_doc/blip
+ title: BLIP
+ - local: in_translation
+ title: (번역중) BridgeTower
+ - local: model_doc/chameleon
+ title: Chameleon
+ - local: in_translation
+ title: (번역중) Chinese-CLIP
+ - local: model_doc/clip
+ title: CLIP
+ - local: in_translation
+ title: (번역중) CLIPSeg
+ - local: in_translation
+ title: (번역중) Data2Vec
+ - local: in_translation
+ title: (번역중) DePlot
+ - local: in_translation
+ title: (번역중) Donut
+ - local: in_translation
+ title: (번역중) FLAVA
+ - local: in_translation
+ title: (번역중) GIT
+ - local: in_translation
+ title: (번역중) GroupViT
+ - local: in_translation
+ title: (번역중) LayoutLM
+ - local: in_translation
+ title: (번역중) LayoutLMV2
+ - local: in_translation
+ title: (번역중) LayoutLMV3
+ - local: in_translation
+ title: (번역중) LayoutXLM
+ - local: in_translation
+ title: (번역중) LiLT
+ - local: in_translation
+ title: (번역중) LXMERT
+ - local: in_translation
+ title: (번역중) MatCha
+ - local: in_translation
+ title: (번역중) MGP-STR
+ - local: in_translation
+ title: (번역중) OneFormer
+ - local: in_translation
+ title: (번역중) OWL-ViT
+ - local: model_doc/paligemma
+ title: PaliGemma
+ - local: in_translation
+ title: (번역중) Perceiver
+ - local: in_translation
+ title: (번역중) Pix2Struct
+ - local: model_doc/qwen2_vl
+ title: Qwen2VL
+ - local: in_translation
+ title: (번역중) Segment Anything
+ - local: model_doc/siglip
+ title: SigLIP
+ - local: in_translation
+ title: (번역중) Speech Encoder Decoder Models
+ - local: in_translation
+ title: (번역중) TAPAS
+ - local: in_translation
+ title: (번역중) TrOCR
+ - local: in_translation
+ title: (번역중) TVLT
+ - local: in_translation
+ title: (번역중) ViLT
+ - local: in_translation
+ title: (번역중) Vision Encoder Decoder Models
+ - local: in_translation
+ title: (번역중) Vision Text Dual Encoder
+ - local: in_translation
+ title: (번역중) VisualBERT
+ - local: in_translation
+ title: (번역중) X-CLIP
+ title: (번역중) 멀티모달 모델
+ - isExpanded: false
+ sections:
+ - local: in_translation
+ title: (번역중) Decision Transformer
+ - local: model_doc/trajectory_transformer
+ title: 궤적 트랜스포머
+ title: (번역중) 강화학습 모델
+ - isExpanded: false
+ sections:
+ - local: model_doc/autoformer
+ title: Autoformer
+ - local: model_doc/informer
+ title: Informer
+ - local: model_doc/patchtsmixer
+ title: PatchTSMixer
+ - local: model_doc/patchtst
+ title: PatchTST
+ - local: model_doc/time_series_transformer
+ title: 시계열 트랜스포머
+ title: 시계열 모델
+ - isExpanded: false
+ sections:
+ - local: model_doc/graphormer
+ title: Graphormer
+ title: 그래프 모델
+ title: (번역중) 모델
+ - sections:
+ - local: internal/modeling_utils
+ title: 사용자 정의 레이어 및 유틸리티
+ - local: internal/pipelines_utils
+ title: 파이프라인을 위한 유틸리티
+ - local: internal/tokenization_utils
+ title: 토크나이저를 위한 유틸리티
+ - local: internal/trainer_utils
+ title: Trainer를 위한 유틸리티
+ - local: internal/generation_utils
+ title: 생성을 위한 유틸리티
+ - local: internal/image_processing_utils
+ title: 이미지 프로세서를 위한 유틸리티
+ - local: internal/audio_utils
+ title: 오디오 처리를 위한 유틸리티
+ - local: internal/file_utils
+ title: 일반 유틸리티
+ - local: internal/time_series_utils
+ title: 시계열을 위한 유틸리티
+ title: (번역중) Internal Helpers
+ title: (번역중) API
diff --git a/docs/transformers/docs/source/ko/accelerate.md b/docs/transformers/docs/source/ko/accelerate.md
new file mode 100644
index 0000000000000000000000000000000000000000..0ef8957de3ac20d38326624d60e7cd1fd349197b
--- /dev/null
+++ b/docs/transformers/docs/source/ko/accelerate.md
@@ -0,0 +1,136 @@
+
+
+# 🤗 Accelerate를 활용한 분산 학습[[distributed-training-with-accelerate]]
+
+모델이 커지면서 병렬 처리는 제한된 하드웨어에서 더 큰 모델을 훈련하고 훈련 속도를 몇 배로 가속화하기 위한 전략으로 등장했습니다. Hugging Face에서는 사용자가 하나의 머신에 여러 개의 GPU를 사용하든 여러 머신에 여러 개의 GPU를 사용하든 모든 유형의 분산 설정에서 🤗 Transformers 모델을 쉽게 훈련할 수 있도록 돕기 위해 [🤗 Accelerate](https://huggingface.co/docs/accelerate) 라이브러리를 만들었습니다. 이 튜토리얼에서는 분산 환경에서 훈련할 수 있도록 기본 PyTorch 훈련 루프를 커스터마이즈하는 방법을 알아봅시다.
+
+## 설정[[setup]]
+
+🤗 Accelerate 설치 시작하기:
+
+```bash
+pip install accelerate
+```
+
+그 다음, [`~accelerate.Accelerator`] 객체를 불러오고 생성합니다. [`~accelerate.Accelerator`]는 자동으로 분산 설정 유형을 감지하고 훈련에 필요한 모든 구성 요소를 초기화합니다. 장치에 모델을 명시적으로 배치할 필요는 없습니다.
+
+```py
+>>> from accelerate import Accelerator
+
+>>> accelerator = Accelerator()
+```
+
+## 가속화를 위한 준비[[prepare-to-accelerate]]
+
+다음 단계는 관련된 모든 훈련 객체를 [`~accelerate.Accelerator.prepare`] 메소드에 전달하는 것입니다. 여기에는 훈련 및 평가 데이터로더, 모델 및 옵티마이저가 포함됩니다:
+
+```py
+>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+... train_dataloader, eval_dataloader, model, optimizer
+... )
+```
+
+## 백워드(Backward)[[backward]]
+
+마지막으로 훈련 루프의 일반적인 `loss.backward()`를 🤗 Accelerate의 [`~accelerate.Accelerator.backward`] 메소드로 대체하기만 하면 됩니다:
+
+```py
+>>> for epoch in range(num_epochs):
+... for batch in train_dataloader:
+... outputs = model(**batch)
+... loss = outputs.loss
+... accelerator.backward(loss)
+
+... optimizer.step()
+... lr_scheduler.step()
+... optimizer.zero_grad()
+... progress_bar.update(1)
+```
+
+다음 코드에서 볼 수 있듯이, 훈련 루프에 코드 네 줄만 추가하면 분산 학습을 활성화할 수 있습니다!
+
+```diff
++ from accelerate import Accelerator
+ from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+
++ accelerator = Accelerator()
+
+ model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+ optimizer = AdamW(model.parameters(), lr=3e-5)
+
+- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+- model.to(device)
+
++ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
++ train_dataloader, eval_dataloader, model, optimizer
++ )
+
+ num_epochs = 3
+ num_training_steps = num_epochs * len(train_dataloader)
+ lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps
+ )
+
+ progress_bar = tqdm(range(num_training_steps))
+
+ model.train()
+ for epoch in range(num_epochs):
+ for batch in train_dataloader:
+- batch = {k: v.to(device) for k, v in batch.items()}
+ outputs = model(**batch)
+ loss = outputs.loss
+- loss.backward()
++ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+```
+
+## 학습[[train]]
+
+관련 코드를 추가한 후에는 스크립트나 Colaboratory와 같은 노트북에서 훈련을 시작하세요.
+
+### 스크립트로 학습하기[[train-with-a-script]]
+
+스크립트에서 훈련을 실행하는 경우, 다음 명령을 실행하여 구성 파일을 생성하고 저장합니다:
+
+```bash
+accelerate config
+```
+
+Then launch your training with:
+
+```bash
+accelerate launch train.py
+```
+
+### 노트북으로 학습하기[[train-with-a-notebook]]
+
+Collaboratory의 TPU를 사용하려는 경우, 노트북에서도 🤗 Accelerate를 실행할 수 있습니다. 훈련을 담당하는 모든 코드를 함수로 감싸서 [`~accelerate.notebook_launcher`]에 전달하세요:
+
+```py
+>>> from accelerate import notebook_launcher
+
+>>> notebook_launcher(training_function)
+```
+
+🤗 Accelerate 및 다양한 기능에 대한 자세한 내용은 [documentation](https://huggingface.co/docs/accelerate)를 참조하세요.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/add_new_model.md b/docs/transformers/docs/source/ko/add_new_model.md
new file mode 100644
index 0000000000000000000000000000000000000000..d5834777d31eefbb00188d11ce1c115557793eab
--- /dev/null
+++ b/docs/transformers/docs/source/ko/add_new_model.md
@@ -0,0 +1,626 @@
+
+
+# Hugging Face Transformers를 추가하는 방법은 무엇인가요? [[how-to-add-a-model-to-transformers]]
+
+Hugging Face Transformers 라이브러리는 커뮤니티 기여자들 덕분에 새로운 모델을 제공할 수 있는 경우가 많습니다. 하지만 이는 도전적인 프로젝트이며 Hugging Face Transformers 라이브러리와 구현할 모델에 대한 깊은 이해가 필요합니다. Hugging Face에서는 더 많은 커뮤니티 멤버가 모델을 적극적으로 추가할 수 있도록 지원하고자 하며, 이 가이드를 통해 PyTorch 모델을 추가하는 과정을 안내하고 있습니다 (PyTorch가 설치되어 있는지 확인해주세요).
+
+이 과정을 진행하면 다음과 같은 내용을 이해하게 됩니다:
+
+- 오픈 소스의 모범 사례에 대한 통찰력을 얻습니다.
+- 가장 인기 있는 딥러닝 라이브러리의 설계 원칙을 이해합니다.
+- 대규모 모델을 효율적으로 테스트하는 방법을 배웁니다.
+- `black`, `ruff`, `make fix-copies`와 같은 Python 유틸리티를 통합하여 깔끔하고 가독성 있는 코드를 작성하는 방법을 배웁니다.
+
+Hugging Face 팀은 항상 도움을 줄 준비가 되어 있으므로 혼자가 아니라는 점을 기억하세요. 🤗 ❤️
+
+시작에 앞서 🤗 Transformers에 원하는 모델을 추가하기 위해 [New model addition](https://github.com/huggingface/transformers/issues/new?assignees=&labels=New+model&template=new-model-addition.yml) 이슈를 열어야 합니다. 특정 모델을 기여하는 데 특별히 까다로운 기준을 가지지 않는 경우 [New model label](https://github.com/huggingface/transformers/labels/New%20model)을 필터링하여 요청되지 않은 모델이 있는지 확인하고 작업할 수 있습니다.
+
+새로운 모델 요청을 열었다면 첫 번째 단계는 🤗 Transformers에 익숙해지는 것입니다!
+
+## 🤗 Transformers의 전반적인 개요 [[general-overview-of-transformers]]
+
+먼저 🤗 Transformers에 대한 전반적인 개요를 파악해야 합니다. 🤗 Transformers는 매우 주관적인 라이브러리이기 때문에 해당 라이브러리의 철학이나 설계 선택 사항에 동의하지 않을 수도 있습니다. 그러나 우리의 경험상 라이브러리의 기본적인 설계 선택과 철학은 🤗 Transformers의 규모를 효율적으로 확장하면서 유지 보수 비용을 합리적인 수준으로 유지하는 것입니다.
+
+[라이브러리의 철학에 대한 문서](philosophy)를 읽는 것이 라이브러리를 더 잘 이해하는 좋은 시작점입니다. 모든 모델에 적용하려는 몇 가지 작업 방식에 대한 선택 사항이 있습니다:
+
+- 일반적으로 추상화보다는 구성을 선호합니다.
+- 코드를 복제하는 것이 항상 나쁜 것은 아닙니다. 코드의 가독성이나 접근성을 크게 향상시킨다면 복제하는 것은 좋습니다.
+- 모델 파일은 가능한 한 독립적으로 유지되어야 합니다. 따라서 특정 모델의 코드를 읽을 때 해당 `modeling_....py` 파일만 확인하면 됩니다.
+
+우리는 라이브러리의 코드가 제품을 제공하는 수단뿐만 아니라 개선하고자 하는 제품이라고도 생각합니다. 따라서 모델을 추가할 때, 사용자는 모델을 사용할 사람뿐만 아니라 코드를 읽고 이해하고 필요한 경우 조정할 수 있는 모든 사람까지도 포함한다는 점을 기억해야 합니다.
+
+이를 염두에 두고 일반적인 라이브러리 설계에 대해 조금 더 자세히 알아보겠습니다.
+
+### 모델 개요 [[overview-of-models]]
+
+모델을 성공적으로 추가하려면 모델과 해당 구성인 [`PreTrainedModel`] 및 [`PretrainedConfig`] 간의 상호작용을 이해하는 것이 중요합니다. 예를 들어, 🤗 Transformers에 추가하려는 모델을 `BrandNewBert`라고 부르겠습니다.
+
+다음을 살펴보겠습니다:
+
+
+
+보다시피, 🤗 Transformers에서는 상속을 사용하지만 추상화 수준을 최소한으로 유지합니다. 라이브러리의 어떤 모델에서도 두 수준 이상의 추상화가 존재하지 않습니다. `BrandNewBertModel`은 `BrandNewBertPreTrainedModel`에서 상속받고, 이 클래스는 [`PreTrainedModel`]에서 상속받습니다. 이로써 새로운 모델은 [`PreTrainedModel`]에만 의존하도록 하려고 합니다. 모든 새로운 모델에 자동으로 제공되는 중요한 기능은 [`~PreTrainedModel.from_pretrained`] 및 [`~PreTrainedModel.save_pretrained`]입니다. 이러한 기능 외에도 `BrandNewBertModel.forward`와 같은 다른 중요한 기능은 새로운 `modeling_brand_new_bert.py` 스크립트에서 완전히 정의되어야 합니다. 또한 `BrandNewBertForMaskedLM`과 같은 특정 헤드 레이어를 가진 모델은 `BrandNewBertModel`을 상속받지 않고 forward pass에서 호출할 수 있는 `BrandNewBertModel`을 사용하여 추상화 수준을 낮게 유지합니다. 모든 새로운 모델은 `BrandNewBertConfig`라는 구성 클래스를 필요로 합니다. 이 구성은 항상 [`PreTrainedModel`]의 속성으로 저장되며, 따라서 `BrandNewBertPreTrainedModel`을 상속받는 모든 클래스에서 `config` 속성을 통해 액세스할 수 있습니다:
+
+```python
+model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
+model.config # model has access to its config
+```
+
+모델과 마찬가지로 구성은 [`PretrainedConfig`]에서 기본 직렬화 및 역직렬화 기능을 상속받습니다. 구성과 모델은 항상 *pytorch_model.bin* 파일과 *config.json* 파일로 각각 별도로 직렬화됩니다. [`~PreTrainedModel.save_pretrained`]를 호출하면 자동으로 [`~PretrainedConfig.save_pretrained`]도 호출되므로 모델과 구성이 모두 저장됩니다.
+
+
+### 코드 스타일 [[code-style]]
+
+새로운 모델을 작성할 때, Transformers는 주관적인 라이브러리이며 몇 가지 독특한 코딩 스타일이 있습니다:
+
+1. 모델의 forward pass는 모델 파일에 완전히 작성되어야 합니다. 라이브러리의 다른 모델에서 블록을 재사용하려면 코드를 복사하여 위에 `# Copied from` 주석과 함께 붙여넣으면 됩니다 (예: [여기](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)를 참조하세요).
+2. 코드는 완전히 이해하기 쉬워야 합니다. 변수 이름을 명확하게 지정하고 약어를 사용하지 않는 것이 좋습니다. 예를 들어, `act`보다는 `activation`을 선호합니다. 한 글자 변수 이름은 루프의 인덱스인 경우를 제외하고 권장되지 않습니다.
+3. 더 일반적으로, 짧은 마법 같은 코드보다는 길고 명시적인 코드를 선호합니다.
+4. PyTorch에서 `nn.Sequential`을 하위 클래스로 만들지 말고 `nn.Module`을 하위 클래스로 만들고 forward pass를 작성하여 다른 사람이 코드를 빠르게 디버그할 수 있도록 합니다. print 문이나 중단점을 추가할 수 있습니다.
+5. 함수 시그니처에는 타입 주석을 사용해야 합니다. 그 외에는 타입 주석보다 변수 이름이 훨씬 읽기 쉽고 이해하기 쉽습니다.
+
+### 토크나이저 개요 [[overview-of-tokenizers]]
+
+아직 준비되지 않았습니다 :-( 이 섹션은 곧 추가될 예정입니다!
+
+## 🤗 Transformers에 모델 추가하는 단계별 방법 [[stepbystep-recipe-to-add-a-model-to-transformers]]
+
+각자 모델을 이식하는 방법에 대한 선호가 다르기 때문에 다른 기여자들이 Hugging Face에 모델을 이식하는 방법에 대한 요약을 살펴보는 것이 매우 유용할 수 있습니다. 다음은 모델을 이식하는 방법에 대한 커뮤니티 블로그 게시물 목록입니다:
+
+1. [GPT2 모델 이식하기](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) - [Thomas](https://huggingface.co/thomwolf)
+2. [WMT19 MT 모델 이식하기](https://huggingface.co/blog/porting-fsmt) - [Stas](https://huggingface.co/stas)
+
+경험상 모델을 추가할 때 주의해야 할 가장 중요한 사항은 다음과 같습니다:
+
+- 같은 일을 반복하지 마세요! 새로운 🤗 Transformers 모델을 위해 추가할 코드의 대부분은 이미 🤗 Transformers 어딘가에 존재합니다. 이미 존재하는 복사할 수 있는 유사한 모델과 토크나이저를 찾는데 시간을 투자하세요. [grep](https://www.gnu.org/software/grep/)와 [rg](https://github.com/BurntSushi/ripgrep)를 참고하세요. 모델의 토크나이저가 한 모델을 기반으로 하고 모델링 코드가 다른 모델을 기반으로 하는 경우가 존재할 수도 있습니다. 예를 들어 FSMT의 모델링 코드는 BART를 기반으로 하고 FSMT의 토크나이저 코드는 XLM을 기반으로 합니다.
+- 이것은 과학적인 도전보다는 공학적인 도전입니다. 논문의 모델의 모든 이론적 측면을 이해하려는 것보다 효율적인 디버깅 환경을 만드는 데 더 많은 시간을 소비해야 합니다.
+- 막힐 때 도움을 요청하세요! 모델은 🤗 Transformers의 핵심 구성 요소이므로 Hugging Face의 우리는 당신이 모델을 추가하는 각 단계에서 기꺼이 도움을 줄 준비가 되어 있습니다. 진전이 없다고 느끼면 주저하지 말고 도움을 요청하세요.
+
+다음에서는 모델을 🤗 Transformers로 이식하는 데 가장 유용한 일반적인 절차를 제공하려고 노력합니다.
+
+다음 목록은 모델을 추가하는 데 수행해야 할 모든 작업의 요약이며 To-Do 목록으로 사용할 수 있습니다:
+
+☐ (선택 사항) BrandNewBert의 이론적 측면 이해
+☐ Hugging Face 개발 환경 준비
+☐ 원본 리포지토리의 디버깅 환경 설정
+☐ 원본 리포지토리와 체크포인트를 사용하여 `forward()` pass가 성공적으로 실행되는 스크립트 작성
+☐ 🤗 Transformers에 모델 스켈레톤 성공적으로 추가
+☐ 원본 체크포인트를 🤗 Transformers 체크포인트로 성공적으로 변환
+☐ 🤗 Transformers에서 원본 체크포인트와 동일한 출력을 내주는 `forward()` pass 성공적으로 실행
+☐ 🤗 Transformers에서 모델 테스트 완료
+☐ 🤗 Transformers에 토크나이저 성공적으로 추가
+☐ 종단 간 통합 테스트 실행
+☐ 문서 작성 완료
+☐ 모델 가중치를 허브에 업로드
+☐ Pull request 제출
+☐ (선택 사항) 데모 노트북 추가
+
+우선, 일반적으로는 `BrandNewBert`의 이론적인 이해로 시작하는 것을 권장합니다. 그러나 이론적 측면을 직접 이해하는 대신 *직접 해보면서* 모델의 이론적 측면을 이해하는 것을 선호하는 경우 바로 `BrandNewBert` 코드 베이스로 빠져드는 것도 괜찮습니다. 이 옵션은 엔지니어링 기술이 이론적 기술보다 더 뛰어난 경우, `BrandNewBert`의 논문을 이해하는 데 어려움이 있는 경우, 또는 과학적인 논문을 읽는 것보다 프로그래밍에 훨씬 더 흥미 있는 경우에 더 적합할 수 있습니다.
+
+### 1. (선택 사항) BrandNewBert의 이론적 측면 [[1-optional-theoretical-aspects-of-brandnewbert]]
+
+만약 그런 서술적인 작업이 존재한다면, *BrandNewBert*의 논문을 읽어보는 시간을 가져야 합니다. 이해하기 어려운 섹션이 많을 수 있습니다. 그렇더라도 걱정하지 마세요! 목표는 논문의 깊은 이론적 이해가 아니라 *BrandNewBert*를 🤗 Transformers에서 효과적으로 재구현하기 위해 필요한 정보를 추출하는 것입니다. 이를 위해 이론적 측면에 너무 많은 시간을 투자할 필요는 없지만 다음과 같은 실제적인 측면에 집중해야 합니다:
+
+- *BrandNewBert*는 어떤 유형의 모델인가요? BERT와 유사한 인코더 모델인가요? GPT2와 유사한 디코더 모델인가요? BART와 유사한 인코더-디코더 모델인가요? 이들 간의 차이점에 익숙하지 않은 경우[model_summary](model_summary)를 참조하세요.
+- *BrandNewBert*의 응용 분야는 무엇인가요? 텍스트 분류인가요? 텍스트 생성인가요? 요약과 같은 Seq2Seq 작업인가요?
+- *brand_new_bert*와 BERT/GPT-2/BART의 차이점은 무엇인가요?
+- *brand_new_bert*와 가장 유사한 [🤗 Transformers 모델](https://huggingface.co/transformers/#contents)은 무엇인가요?
+- 어떤 종류의 토크나이저가 사용되나요? Sentencepiece 토크나이저인가요? Word piece 토크나이저인가요? BERT 또는 BART에 사용되는 동일한 토크나이저인가요?
+
+모델의 아키텍처에 대해 충분히 이해했다는 생각이 든 후, 궁금한 사항이 있으면 Hugging Face 팀에 문의하십시오. 이는 모델의 아키텍처, 어텐션 레이어 등에 관한 질문을 포함할 수 있습니다. Hugging Face의 유지 관리자들은 보통 코드를 검토하는 것에 대해 매우 기뻐하므로 당신을 돕는 일을 매우 환영할 것입니다!
+
+### 2. 개발 환경 설정 [[2-next-prepare-your-environment]]
+
+1. 저장소 페이지에서 "Fork" 버튼을 클릭하여 저장소의 사본을 GitHub 사용자 계정으로 만듭니다.
+
+2. `transformers` fork를 로컬 디스크에 클론하고 베이스 저장소를 원격 저장소로 추가합니다:
+
+```bash
+git clone https://github.com/[your Github handle]/transformers.git
+cd transformers
+git remote add upstream https://github.com/huggingface/transformers.git
+```
+
+3. 개발 환경을 설정합니다. 다음 명령을 실행하여 개발 환경을 설정할 수 있습니다:
+
+```bash
+python -m venv .env
+source .env/bin/activate
+pip install -e ".[dev]"
+```
+
+각 운영 체제에 따라 Transformers의 선택적 의존성이 개수가 증가하면 이 명령이 실패할 수 있습니다. 그런 경우에는 작업 중인 딥 러닝 프레임워크 (PyTorch, TensorFlow 및/또는 Flax)을 설치한 후, 다음 명령을 수행하면 됩니다:
+
+```bash
+pip install -e ".[quality]"
+```
+
+대부분의 경우에는 이것으로 충분합니다. 그런 다음 상위 디렉토리로 돌아갑니다.
+
+```bash
+cd ..
+```
+
+4. Transformers에 *brand_new_bert*의 PyTorch 버전을 추가하는 것을 권장합니다. PyTorch를 설치하려면 다음 링크의 지침을 따르십시오: https://pytorch.org/get-started/locally/.
+
+**참고:** CUDA를 설치할 필요는 없습니다. 새로운 모델이 CPU에서 작동하도록 만드는 것으로 충분합니다.
+
+5. *brand_new_bert*를 이식하기 위해서는 해당 원본 저장소에 접근할 수 있어야 합니다:
+
+```bash
+git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
+cd brand_new_bert
+pip install -e .
+```
+
+이제 *brand_new_bert*를 🤗 Transformers로 이식하기 위한 개발 환경을 설정하였습니다.
+
+### 3.-4. 원본 저장소에서 사전 훈련된 체크포인트 실행하기 [[3.-4.-run-a-pretrained-checkpoint-using-the-original-repository]]
+
+먼저, 원본 *brand_new_bert* 저장소에서 작업을 시작합니다. 원본 구현은 보통 "연구용"으로 많이 사용됩니다. 즉, 문서화가 부족하고 코드가 이해하기 어려울 수 있습니다. 그러나 이것이 바로 *brand_new_bert*를 다시 구현하려는 동기가 되어야 합니다. Hugging Face에서의 주요 목표 중 하나는 **거인의 어깨 위에 서는 것**이며, 이는 여기에서 쉽게 해석되어 동작하는 모델을 가져와서 가능한 한 **접근 가능하고 사용자 친화적이며 아름답게** 만드는 것입니다. 이것은 🤗 Transformers에서 모델을 다시 구현하는 가장 중요한 동기입니다 - 새로운 복잡한 NLP 기술을 **모두에게** 접근 가능하게 만드는 것을 목표로 합니다.
+
+따라서 원본 저장소에 대해 자세히 살펴보는 것으로 시작해야 합니다.
+
+원본 저장소에서 공식 사전 훈련된 모델을 성공적으로 실행하는 것은 종종 **가장 어려운** 단계입니다. 우리의 경험에 따르면, 원본 코드 베이스에 익숙해지는 데 시간을 투자하는 것이 매우 중요합니다. 다음을 파악해야 합니다:
+
+- 사전 훈련된 가중치를 어디서 찾을 수 있는지?
+- 사전 훈련된 가중치를 해당 모델에로드하는 방법은?
+- 모델과 독립적으로 토크나이저를 실행하는 방법은?
+- 간단한 forward pass에 필요한 클래스와 함수를 파악하기 위해 forward pass를 한 번 추적해 보세요. 일반적으로 해당 함수들만 다시 구현하면 됩니다.
+- 모델의 중요한 구성 요소를 찾을 수 있어야 합니다. 모델 클래스는 어디에 있나요? 모델 하위 클래스(*EncoderModel*, *DecoderModel* 등)가 있나요? self-attention 레이어는 어디에 있나요? self-attention, cross-attention 등 여러 가지 다른 어텐션 레이어가 있나요?
+- 원본 환경에서 모델을 디버그할 수 있는 방법은 무엇인가요? *print* 문을 추가해야 하나요? *ipdb*와 같은 대화식 디버거를 사용할 수 있나요? PyCharm과 같은 효율적인 IDE를 사용해 모델을 디버그할 수 있나요?
+
+원본 저장소에서 코드를 이식하는 작업을 시작하기 전에 원본 저장소에서 코드를 **효율적으로** 디버그할 수 있어야 합니다! 또한, 오픈 소스 라이브러리로 작업하고 있다는 것을 기억해야 합니다. 따라서 원본 저장소에서 issue를 열거나 pull request를 열기를 주저하지 마십시오. 이 저장소의 유지 관리자들은 누군가가 자신들의 코드를 살펴본다는 것에 대해 매우 기뻐할 것입니다!
+
+현재 시점에서, 원래 모델을 디버깅하기 위해 어떤 디버깅 환경과 전략을 선호하는지는 당신에게 달렸습니다. 우리는 고가의 GPU 환경을 구축하는 것은 비추천합니다. 대신, 원래 저장소로 들어가서 작업을 시작할 때와 🤗 Transformers 모델의 구현을 시작할 때에도 CPU에서 작업하는 것이 좋습니다. 모델이 이미 🤗 Transformers로 성공적으로 이식되었을 때에만 모델이 GPU에서도 예상대로 작동하는지 확인해야합니다.
+
+일반적으로, 원래 모델을 실행하기 위한 두 가지 가능한 디버깅 환경이 있습니다.
+
+- [Jupyter 노트북](https://jupyter.org/) / [Google Colab](https://colab.research.google.com/notebooks/intro.ipynb)
+- 로컬 Python 스크립트
+
+Jupyter 노트북의 장점은 셀 단위로 실행할 수 있다는 것입니다. 이는 논리적인 구성 요소를 더 잘 분리하고 중간 결과를 저장할 수 있으므로 디버깅 사이클이 더 빨라질 수 있습니다. 또한, 노트북은 다른 기여자와 쉽게 공유할 수 있으므로 Hugging Face 팀의 도움을 요청하려는 경우 매우 유용할 수 있습니다. Jupyter 노트북에 익숙하다면 이를 사용하는 것을 강력히 추천합니다.
+
+Jupyter 노트북의 단점은 사용에 익숙하지 않은 경우 새로운 프로그래밍 환경에 적응하는 데 시간을 할애해야 하며, `ipdb`와 같은 알려진 디버깅 도구를 더 이상 사용할 수 없을 수도 있다는 것입니다.
+
+각 코드 베이스에 대해 좋은 첫 번째 단계는 항상 **작은** 사전 훈련된 체크포인트를 로드하고 더미 정수 벡터 입력을 사용하여 단일 forward pass를 재현하는 것입니다. 이와 같은 스크립트는 다음과 같을 수 있습니다(의사 코드로 작성):
+
+```python
+model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
+input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
+original_output = model.predict(input_ids)
+```
+
+다음으로, 디버깅 전략에 대해 일반적으로 다음과 같은 몇 가지 선택지가 있습니다:
+
+- 원본 모델을 많은 작은 테스트 가능한 구성 요소로 분해하고 각각에 대해 forward pass를 실행하여 검증합니다.
+- 원본 모델을 원본 *tokenizer*과 원본 *model*로만 분해하고 해당 부분에 대해 forward pass를 실행한 후 검증을 위해 중간 출력(print 문 또는 중단점)을 사용합니다.
+
+다시 말하지만, 어떤 전략을 선택할지는 당신에게 달려 있습니다. 원본 코드 베이스에 따라 하나 또는 다른 전략이 유리할 수 있습니다.
+
+원본 코드 베이스를 모델의 작은 하위 구성 요소로 분해할 수 있는지 여부, 예를 들어 원본 코드 베이스가 즉시 실행 모드에서 간단히 실행될 수 있는 경우, 그런 경우에는 그 노력이 가치가 있다는 것이 일반적입니다. 초기에 더 어려운 방법을 선택하는 것에는 몇 가지 중요한 장점이 있습니다.
+
+- 원본 모델을 🤗 Transformers 구현과 비교할 때 각 구성 요소가 일치하는지 자동으로 확인할 수 있습니다. 즉, 시각적인 비교(print 문을 통한 비교가 아닌) 대신 🤗 Transformers 구현과 그에 대응하는 원본 구성 요소가 일치하는지 확인할 수 있습니다.
+- 전체 모델을 모듈별로, 즉 작은 구성 요소로 분해함으로써 모델을 이식하는 큰 문제를 단순히 개별 구성 요소를 이식하는 작은 문제로 분해할 수 있으므로 작업을 더 잘 구조화할 수 있습니다.
+- 모델을 논리적으로 의미 있는 구성 요소로 분리하는 것은 모델의 설계에 대한 더 나은 개요를 얻고 모델을 더 잘 이해하는 데 도움이 됩니다.
+- 이러한 구성 요소별 테스트를 통해 코드를 변경하면서 회귀가 발생하지 않도록 보장할 수 있습니다.
+
+[Lysandre의 ELECTRA 통합 검사](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed)는 이를 수행하는 좋은 예제입니다.
+
+그러나 원본 코드 베이스가 매우 복잡하거나 중간 구성 요소를 컴파일된 모드에서 실행하는 것만 허용하는 경우, 모델을 테스트 가능한 작은 하위 구성 요소로 분해하는 것이 시간이 많이 소요되거나 불가능할 수도 있습니다. [T5의 MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow) 라이브러리는 매우 복잡하며 모델을 하위 구성 요소로 분해하는 간단한 방법을 제공하지 않습니다. 이러한 라이브러리의 경우, 보통 print 문을 통해 확인합니다.
+
+어떤 전략을 선택하더라도 권장되는 절차는 동일합니다. 먼저 시작 레이어를 디버그하고 마지막 레이어를 마지막에 디버그하는 것이 좋습니다.
+
+다음 순서로 각 레이어의 출력을 검색하는 것이 좋습니다:
+
+1. 모델에 전달된 입력 ID 가져오기
+2. 워드 임베딩 가져오기
+3. 첫 번째 Transformer 레이어의 입력 가져오기
+4. 첫 번째 Transformer 레이어의 출력 가져오기
+5. 다음 n-1개의 Transformer 레이어의 출력 가져오기
+6. BrandNewBert 모델의 출력 가져오기
+
+입력 ID는 정수 배열로 구성되며, 예를 들어 `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`와 같을 수 있습니다.
+
+다음 레이어의 출력은 종종 다차원 실수 배열로 구성되며, 다음과 같이 나타낼 수 있습니다:
+
+```
+[[
+ [-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
+ [-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
+ [-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
+ ...,
+ [-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
+ [-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
+ [-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
+```
+
+🤗 Transformers에 추가되는 모든 모델은 통합 테스트를 통과해야 합니다. 즉, 원본 모델과 🤗 Transformers의 재구현 버전이 0.001의 정밀도로 정확히 동일한 출력을 내야 합니다! 동일한 모델이 다른 라이브러리에서 작성되었을 때 라이브러리 프레임워크에 따라 약간 다른 출력을 얻는 것은 정상이므로 1e-3(0.001)의 오차는 허용합니다. 거의 동일한 출력을 내는 것만으로는 충분하지 않으며, 완벽히 일치하는 수준이어야 합니다. 따라서 🤗 Transformers 버전의 중간 출력을 *brand_new_bert*의 원래 구현의 중간 출력과 여러 번 비교해야 합니다. 이 경우 원본 저장소의 **효율적인** 디버깅 환경이 절대적으로 중요합니다. 디버깅 환경을 가능한 한 효율적으로 만드는 몇 가지 조언을 제시합니다.
+
+- 중간 결과를 디버그하는 가장 좋은 방법을 찾으세요. 원본 저장소가 PyTorch로 작성되었다면 원본 모델을 더 작은 하위 구성 요소로 분해하여 중간 값을 검색하는 긴 스크립트를 작성하는 것에 시간을 투자할 가치가 있습니다. 원본 저장소가 Tensorflow 1로 작성되었다면 [tf.print](https://www.tensorflow.org/api_docs/python/tf/print)와 같은 Tensorflow 출력 작업을 사용하여 중간 값을 출력해야 할 수도 있습니다. 원본 저장소가 Jax로 작성되었다면 forward pass를 실행할 때 모델이 **jit 되지 않도록** 해야 합니다. 예를 들어 [이 링크](https://github.com/google/jax/issues/196)를 확인해 보세요.
+- 사용 가능한 가장 작은 사전 훈련된 체크포인트를 사용하세요. 체크포인트가 작을수록 디버그 사이클이 더 빨라집니다. 전반적으로 forward pass에 10초 이상이 걸리는 경우 효율적이지 않습니다. 매우 큰 체크포인트만 사용할 수 있는 경우, 새 환경에서 임의로 초기화된 가중치로 더미 모델을 만들고 해당 가중치를 🤗 Transformers 버전과 비교하기 위해 저장하는 것이 더 의미가 있을 수 있습니다.
+- 디버깅 설정에서 가장 쉽게 forward pass를 호출하는 방법을 사용하세요. 원본 저장소에서 **단일** forward pass만 호출하는 함수를 찾는 것이 이상적입니다. 이 함수는 일반적으로 `predict`, `evaluate`, `forward`, `__call__`과 같이 호출됩니다. `autoregressive_sample`과 같은 텍스트 생성에서 `forward`를 여러 번 호출하여 텍스트를 생성하는 등의 작업을 수행하는 함수를 디버그하고 싶지 않을 것입니다.
+- 토큰화 과정을 모델의 *forward* pass와 분리하려고 노력하세요. 원본 저장소에서 입력 문자열을 입력해야 하는 예제가 있는 경우, 입력 문자열이 입력 ID로 변경되는 순간을 찾아서 시작하세요. 이 경우 직접 ID를 입력할 수 있도록 작은 스크립트를 작성하거나 원본 코드를 수정해야 할 수도 있습니다.
+- 디버깅 설정에서 모델이 훈련 모드가 아니라는 것을 확인하세요. 훈련 모드에서는 모델의 여러 드롭아웃 레이어 때문에 무작위 출력이 생성될 수 있습니다. 디버깅 환경에서 forward pass가 **결정론적**이도록 해야 합니다. 또는 동일한 프레임워크에 있는 경우 *transformers.utils.set_seed*를 사용하세요.
+
+다음 섹션에서는 *brand_new_bert*에 대해 이 작업을 수행하는 데 더 구체적인 세부 사항/팁을 제공합니다.
+
+### 5.-14. 🤗 Transformers에 BrandNewBert를 이식하기 [[5.-14.-port-brandnewbert-to-transformers]]
+
+이제, 마침내 🤗 Transformers에 새로운 코드를 추가할 수 있습니다. 🤗 Transformers 포크의 클론으로 이동하세요:
+
+```bash
+cd transformers
+```
+
+다음과 같이 이미 존재하는 모델의 모델 아키텍처와 정확히 일치하는 모델을 추가하는 특별한 경우에는 [이 섹션](#write-a-conversion-script)에 설명된대로 변환 스크립트만 추가하면 됩니다. 이 경우에는 이미 존재하는 모델의 전체 모델 아키텍처를 그대로 재사용할 수 있습니다.
+
+그렇지 않으면 새 모델 생성을 시작하겠습니다. 다음 스크립트를 사용하여 다음에서 시작하는 모델을 추가하는 것이 좋습니다.
+기존 모델:
+
+```bash
+transformers-cli add-new-model-like
+```
+
+모델의 기본 정보를 입력하는 설문지가 표시됩니다.
+
+**huggingface/transformers 메인 저장소에 Pull Request 열기**
+
+자동으로 생성된 코드를 수정하기 전에, 지금은 "작업 진행 중 (WIP)" 풀 리퀘스트를 열기 위한 시기입니다. 예를 들어, 🤗 Transformers에 "*brand_new_bert* 추가"라는 제목의 "[WIP] Add *brand_new_bert*" 풀 리퀘스트를 엽니다. 이렇게 하면 당신과 Hugging Face 팀이 🤗 Transformers에 모델을 통합하는 작업을 함께할 수 있습니다.
+
+다음을 수행해야 합니다:
+
+1. 메인 브랜치에서 작업을 잘 설명하는 이름으로 브랜치 생성
+
+```bash
+git checkout -b add_brand_new_bert
+```
+
+2. 자동으로 생성된 코드 커밋
+
+```bash
+git add .
+git commit
+```
+
+3. 현재 메인을 가져오고 리베이스
+
+```bash
+git fetch upstream
+git rebase upstream/main
+```
+
+4. 변경 사항을 계정에 푸시
+
+```bash
+git push -u origin a-descriptive-name-for-my-changes
+```
+
+5. 만족스럽다면, GitHub에서 자신의 포크한 웹 페이지로 이동합니다. "Pull request"를 클릭합니다. Hugging Face 팀의 일부 멤버의 GitHub 핸들을 리뷰어로 추가하여 Hugging Face 팀이 앞으로의 변경 사항에 대해 알림을 받을 수 있도록 합니다.
+
+6. GitHub 풀 리퀘스트 웹 페이지 오른쪽에 있는 "Convert to draft"를 클릭하여 PR을 초안으로 변경합니다.
+
+다음으로, 어떤 진전을 이루었다면 작업을 커밋하고 계정에 푸시하여 풀 리퀘스트에 표시되도록 해야 합니다. 또한, 다음과 같이 현재 메인과 작업을 업데이트해야 합니다:
+
+```bash
+git fetch upstream
+git merge upstream/main
+```
+
+일반적으로, 모델 또는 구현에 관한 모든 질문은 자신의 PR에서 해야 하며, PR에서 토론되고 해결되어야 합니다. 이렇게 하면 Hugging Face 팀이 새로운 코드를 커밋하거나 질문을 할 때 항상 알림을 받을 수 있습니다. Hugging Face 팀에게 문제 또는 질문을 효율적으로 이해할 수 있도록 추가한 코드를 명시하는 것이 도움이 될 때가 많습니다.
+
+이를 위해, 변경 사항을 모두 볼 수 있는 "Files changed" 탭으로 이동하여 질문하고자 하는 줄로 이동한 다음 "+" 기호를 클릭하여 코멘트를 추가할 수 있습니다. 질문이나 문제가 해결되면, 생성된 코멘트의 "Resolve" 버튼을 클릭할 수 있습니다.
+
+마찬가지로, Hugging Face 팀은 코드를 리뷰할 때 코멘트를 남길 것입니다. 우리는 PR에서 대부분의 질문을 GitHub에서 묻는 것을 권장합니다. 공개에 크게 도움이 되지 않는 매우 일반적인 질문의 경우, Slack이나 이메일을 통해 Hugging Face 팀에게 문의할 수 있습니다.
+
+**5. brand_new_bert에 대해 생성된 모델 코드를 적용하기**
+
+먼저, 우리는 모델 자체에만 초점을 맞추고 토크나이저에 대해서는 신경 쓰지 않을 것입니다. 모든 관련 코드는 다음의 생성된 파일에서 찾을 수 있습니다: `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` 및 `src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`.
+
+이제 마침내 코딩을 시작할 수 있습니다 :). `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`의 생성된 코드는 인코더 전용 모델인 경우 BERT와 동일한 아키텍처를 가지거나, 인코더-디코더 모델인 경우 BART와 동일한 아키텍처를 가질 것입니다. 이 시점에서, 모델의 이론적 측면에 대해 배운 내용을 다시 상기해야 합니다: *모델이 BERT 또는 BART와 어떻게 다른가요?*. 자주 변경해야 하는 것은 *self-attention* 레이어, 정규화 레이어의 순서 등을 변경하는 것입니다. 다시 말하지만, 자신의 모델을 구현하는 데 도움이 되도록 Transformers에서 이미 존재하는 모델의 유사한 아키텍처를 살펴보는 것이 유용할 수 있습니다.
+
+**참고로** 이 시점에서, 코드가 완전히 정확하거나 깨끗하다고 확신할 필요는 없습니다. 오히려 처음에는 원본 코드의 첫 번째 *불완전하고* 복사된 버전을 `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`에 추가하는 것이 좋습니다. 필요한 모든 코드가 추가될 때까지 이러한 작업을 진행한 후, 다음 섹션에서 설명한 변환 스크립트를 사용하여 코드를 점진적으로 개선하고 수정하는 것이 훨씬 효율적입니다. 이 시점에서 작동해야 하는 유일한 것은 다음 명령이 작동하는 것입니다:
+
+```python
+from transformers import BrandNewBertModel, BrandNewBertConfig
+
+model = BrandNewBertModel(BrandNewBertConfig())
+```
+
+위의 명령은 `BrandNewBertConfig()`에 정의된 기본 매개변수에 따라 무작위 가중치로 모델을 생성하며, 이로써 모든 구성 요소의 `init()` 메서드가 작동함을 보장합니다.
+
+모든 무작위 초기화는 `BrandnewBertPreTrainedModel` 클래스의 `_init_weights` 메서드에서 수행되어야 합니다. 이 메서드는 구성 설정 변수에 따라 모든 리프 모듈을 초기화해야 합니다. BERT의 `_init_weights` 메서드 예제는 다음과 같습니다:
+
+```py
+def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+```
+
+몇 가지 모듈에 대해 특별한 초기화가 필요한 경우 사용자 정의 방식을 사용할 수도 있습니다. 예를 들어, `Wav2Vec2ForPreTraining`에서 마지막 두 개의 선형 레이어는 일반적인 PyTorch `nn.Linear`의 초기화를 가져야 하지만, 다른 모든 레이어는 위와 같은 초기화를 사용해야 합니다. 이는 다음과 같이 코드화됩니다:
+
+```py
+def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, Wav2Vec2ForPreTraining):
+ module.project_hid.reset_parameters()
+ module.project_q.reset_parameters()
+ module.project_hid._is_hf_initialized = True
+ module.project_q._is_hf_initialized = True
+ elif isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+```
+
+`_is_hf_initialized` 플래그는 서브모듈을 한 번만 초기화하도록 내부적으로 사용됩니다. `module.project_q` 및 `module.project_hid`에 대해 `True`로 설정함으로써, 우리가 수행한 사용자 정의 초기화가 이후에 덮어쓰이지 않도록 합니다. 즉, `_init_weights` 함수가 이들에게 적용되지 않습니다.
+
+**6. 변환 스크립트 작성하기**
+
+다음으로, 디버그에 사용한 체크포인트를 기존 저장소에서 만든 🤗 Transformers 구현과 호환되는 체크포인트로 변환할 수 있는 변환 스크립트를 작성해야 합니다. 변환 스크립트를 처음부터 작성하는 것보다는 *brand_new_bert*와 동일한 프레임워크로 작성된 유사한 모델을 변환한 기존 변환 스크립트를 찾아보는 것이 좋습니다. 일반적으로 기존 변환 스크립트를 복사하여 사용 사례에 맞게 약간 수정하는 것으로 충분합니다. 모델에 대해 유사한 기존 변환 스크립트를 어디에서 찾을 수 있는지 Hugging Face 팀에게 문의하는 것을 망설이지 마세요.
+
+- TensorFlow에서 PyTorch로 모델을 이전하는 경우, 좋은 참고 자료로 BERT의 변환 스크립트 [여기](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)를 참조할 수 있습니다.
+- PyTorch에서 PyTorch로 모델을 이전하는 경우, 좋은 참고 자료로 BART의 변환 스크립트 [여기](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)를 참조할 수 있습니다.
+
+다음에서는 PyTorch 모델이 레이어 가중치를 저장하고 레이어 이름을 정의하는 방법에 대해 간단히 설명하겠습니다. PyTorch에서 레이어의 이름은 레이어에 지정한 클래스 속성의 이름으로 정의됩니다. 다음과 같이 PyTorch에서 `SimpleModel`이라는 더미 모델을 정의해 봅시다:
+
+```python
+from torch import nn
+
+
+class SimpleModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.dense = nn.Linear(10, 10)
+ self.intermediate = nn.Linear(10, 10)
+ self.layer_norm = nn.LayerNorm(10)
+```
+
+이제 이 모델 정의의 인스턴스를 생성할 수 있으며 `dense`, `intermediate`, `layer_norm` 등의 가중치가 랜덤하게 할당됩니다. 모델을 출력하여 아키텍처를 확인할 수 있습니다.
+
+```python
+model = SimpleModel()
+
+print(model)
+```
+
+이는 다음과 같이 출력됩니다:
+
+```
+SimpleModel(
+ (dense): Linear(in_features=10, out_features=10, bias=True)
+ (intermediate): Linear(in_features=10, out_features=10, bias=True)
+ (layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
+)
+```
+
+우리는 레이어의 이름이 PyTorch에서 클래스 속성의 이름으로 정의되어 있는 것을 볼 수 있습니다. 특정 레이어의 가중치 값을 출력하여 확인할 수 있습니다:
+
+```python
+print(model.dense.weight.data)
+```
+
+가중치가 무작위로 초기화되었음을 확인할 수 있습니다.
+
+```
+tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
+ -0.2077, 0.2157],
+ [ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
+ 0.2166, -0.0212],
+ [-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
+ -0.1023, -0.0447],
+ [-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
+ -0.1876, -0.2467],
+ [ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
+ 0.2577, 0.0402],
+ [ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
+ 0.2132, 0.1680],
+ [ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
+ 0.2707, -0.2509],
+ [-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
+ 0.1829, -0.1568],
+ [-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
+ 0.0333, -0.0536],
+ [-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
+ 0.2220, 0.2358]]).
+```
+
+변환 스크립트에서는 이러한 무작위로 초기화된 가중치를 체크포인트의 해당 레이어의 정확한 가중치로 채워야 합니다. 예를 들면 다음과 같습니다:
+
+```python
+# retrieve matching layer weights, e.g. by
+# recursive algorithm
+layer_name = "dense"
+pretrained_weight = array_of_dense_layer
+
+model_pointer = getattr(model, "dense")
+
+model_pointer.weight.data = torch.from_numpy(pretrained_weight)
+```
+
+이렇게 하면 PyTorch 모델의 무작위로 초기화된 각 가중치와 해당 체크포인트 가중치가 **모양과 이름** 모두에서 정확히 일치하는지 확인해야 합니다. 이를 위해 모양에 대한 assert 문을 추가하고 체크포인트 가중치의 이름을 출력해야 합니다. 예를 들어 다음과 같은 문장을 추가해야 합니다:
+
+```python
+assert (
+ model_pointer.weight.shape == pretrained_weight.shape
+), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
+```
+
+또한 두 가중치의 이름을 출력하여 일치하는지 확인해야 합니다. *예시*:
+
+```python
+logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
+```
+
+모양 또는 이름이 일치하지 않는 경우, 랜덤으로 초기화된 레이어에 잘못된 체크포인트 가중치를 할당한 것으로 추측됩니다.
+
+잘못된 모양은 `BrandNewBertConfig()`의 구성 매개변수 설정이 변환하려는 체크포인트에 사용된 설정과 정확히 일치하지 않기 때문일 가능성이 가장 큽니다. 그러나 PyTorch의 레이어 구현 자체에서 가중치를 전치해야 할 수도 있습니다.
+
+마지막으로, **모든** 필요한 가중치가 초기화되었는지 확인하고 초기화에 사용되지 않은 모든 체크포인트 가중치를 출력하여 모델이 올바르게 변환되었는지 확인해야 합니다. 잘못된 모양 문장이나 잘못된 이름 할당으로 인해 변환 시도가 실패하는 것은 완전히 정상입니다. 이는 `BrandNewBertConfig()`에서 잘못된 매개변수를 사용하거나 🤗 Transformers 구현에서 잘못된 아키텍처, 🤗 Transformers 구현의 구성 요소 중 하나의 `init()` 함수에 버그가 있는 경우이거나 체크포인트 가중치 중 하나를 전치해야 하는 경우일 가능성이 가장 높습니다.
+
+이 단계는 이전 단계와 함께 반복되어야 하며 모든 체크포인트의 가중치가 Transformers 모델에 올바르게 로드되었을 때까지 계속되어야 합니다. 🤗 Transformers 구현에 체크포인트를 올바르게 로드한 후에는 `/path/to/converted/checkpoint/folder`와 같은 원하는 폴더에 모델을 저장할 수 있어야 합니다. 해당 폴더에는 `pytorch_model.bin` 파일과 `config.json` 파일이 모두 포함되어야 합니다.
+
+```python
+model.save_pretrained("/path/to/converted/checkpoint/folder")
+```
+
+**7. 순방향 패스 구현하기**
+
+🤗 Transformers 구현에 사전 훈련된 가중치를 정확하게 로드한 후에는 순방향 패스가 올바르게 구현되었는지 확인해야 합니다. [원본 저장소에 익숙해지기](#3-4-run-a-pretrained-checkpoint-using-the-original-repository)에서 이미 원본 저장소를 사용하여 모델의 순방향 패스를 실행하는 스크립트를 만들었습니다. 이제 원본 대신 🤗 Transformers 구현을 사용하는 유사한 스크립트를 작성해야 합니다. 다음과 같이 작성되어야 합니다:
+
+```python
+model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
+input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
+output = model(input_ids).last_hidden_states
+```
+
+🤗 Transformers 구현과 원본 모델 구현이 처음부터 정확히 동일한 출력을 제공하지 않거나 순방향 패스에서 오류가 발생할 가능성이 매우 높습니다. 실망하지 마세요. 예상된 일입니다! 먼저, 순방향 패스에서 오류가 발생하지 않도록 해야 합니다. 종종 잘못된 차원이 사용되어 *차원 불일치* 오류가 발생하거나 잘못된 데이터 유형 개체가 사용되는 경우가 있습니다. 예를 들면 `torch.long` 대신에 `torch.float32`가 사용된 경우입니다. 해결할 수 없는 오류가 발생하면 Hugging Face 팀에 도움을 요청하는 것이 좋습니다.
+
+🤗 Transformers 구현이 올바르게 작동하는지 확인하는 마지막 단계는 출력이 `1e-3`의 정밀도로 동일한지 확인하는 것입니다. 먼저, 출력 모양이 동일하도록 보장해야 합니다. 즉, 🤗 Transformers 구현 스크립트와 원본 구현 사이에서 `outputs.shape`는 동일한 값을 반환해야 합니다. 그 다음으로, 출력 값이 동일하도록 해야 합니다. 이는 새로운 모델을 추가할 때 가장 어려운 부분 중 하나입니다. 출력이 동일하지 않은 일반적인 실수 사례는 다음과 같습니다:
+
+- 일부 레이어가 추가되지 않았습니다. 즉, *활성화* 레이어가 추가되지 않았거나 잔차 연결이 빠졌습니다.
+- 단어 임베딩 행렬이 연결되지 않았습니다.
+- 잘못된 위치 임베딩이 사용되었습니다. 원본 구현에서는 오프셋을 사용합니다.
+- 순방향 패스 중에 Dropout이 적용되었습니다. 이를 수정하려면 *model.training이 False*인지 확인하고 순방향 패스 중에 Dropout 레이어가 잘못 활성화되지 않도록 하세요. 즉, [PyTorch의 기능적 Dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)에 *self.training*을 전달하세요.
+
+문제를 해결하는 가장 좋은 방법은 일반적으로 원본 구현과 🤗 Transformers 구현의 순방향 패스를 나란히 놓고 차이점이 있는지 확인하는 것입니다. 이상적으로는 순방향 패스의 중간 출력을 디버그/출력하여 원본 구현과 🤗 Transformers 구현의 정확한 위치를 찾을 수 있어야 합니다. 먼저, 두 스크립트의 하드코딩된 `input_ids`가 동일한지 확인하세요. 다음으로, `input_ids`의 첫 번째 변환의 출력(일반적으로 단어 임베딩)이 동일한지 확인하세요. 그런 다음 네트워크의 가장 마지막 레이어까지 진행해보세요. 어느 시점에서 두 구현 사이에 차이가 있는 것을 알게 되는데, 이는 🤗 Transformers 구현의 버그 위치를 가리킬 것입니다. 저희 경험상으로는 원본 구현과 🤗 Transformers 구현 모두에서 동일한 위치에 많은 출력 문을 추가하고 이들의 중간 표현에 대해 동일한 값을 보이는 출력 문을 연속적으로 제거하는 것이 간단하고 효과적인 방법입니다.
+
+`torch.allclose(original_output, output, atol=1e-3)`로 출력을 확인하여 두 구현이 동일한 출력을 하는 것을 확신한다면, 가장 어려운 부분은 끝났습니다! 축하드립니다. 남은 작업은 쉬운 일이 될 것입니다 😊.
+
+**8. 필요한 모든 모델 테스트 추가하기**
+
+이 시점에서 새로운 모델을 성공적으로 추가했습니다. 그러나 해당 모델이 요구되는 디자인에 완전히 부합하지 않을 수도 있습니다. 🤗 Transformers와 완벽하게 호환되는 구현인지 확인하기 위해 모든 일반 테스트를 통과해야 합니다. Cookiecutter는 아마도 모델을 위한 테스트 파일을 자동으로 추가했을 것입니다. 아마도 `tests/models/brand_new_bert/test_modeling_brand_new_bert.py`와 같은 경로에 위치할 것입니다. 이 테스트 파일을 실행하여 일반 테스트가 모두 통과하는지 확인하세요.
+
+```bash
+pytest tests/models/brand_new_bert/test_modeling_brand_new_bert.py
+```
+
+모든 일반 테스트를 수정한 후, 이제 수행한 작업을 충분히 테스트하여 다음 사항을 보장해야 합니다.
+
+- a) 커뮤니티가 *brand_new_bert*의 특정 테스트를 살펴봄으로써 작업을 쉽게 이해할 수 있도록 함
+- b) 모델에 대한 향후 변경 사항이 모델의 중요한 기능을 손상시키지 않도록 함
+
+먼저 통합 테스트를 추가해야 합니다. 이러한 통합 테스트는 이전에 모델을 🤗 Transformers로 구현하기 위해 사용한 디버깅 스크립트와 동일한 작업을 수행합니다. Cookiecutter에 이미 이러한 모델 테스트의 템플릿인 `BrandNewBertModelIntegrationTests`가 추가되어 있으며, 여러분이 작성해야 할 내용으로만 채워 넣으면 됩니다. 이러한 테스트가 통과하는지 확인하려면 다음을 실행하세요.
+
+```bash
+RUN_SLOW=1 pytest -sv tests/models/brand_new_bert/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
+```
+
+
+
+Windows를 사용하는 경우 `RUN_SLOW=1`을 `SET RUN_SLOW=1`로 바꿔야 합니다.
+
+
+
+둘째로, *brand_new_bert*에 특화된 모든 기능도 별도의 테스트에서 추가로 테스트해야 합니다. 이 부분은 종종 잊히는데, 두 가지 측면에서 굉장히 유용합니다.
+
+- *brand_new_bert*의 특수 기능이 어떻게 작동해야 하는지 보여줌으로써 커뮤니티에게 모델 추가 과정에서 습득한 지식을 전달하는 데 도움이 됩니다.
+- 향후 기여자는 이러한 특수 테스트를 실행하여 모델에 대한 변경 사항을 빠르게 테스트할 수 있습니다.
+
+
+**9. 토크나이저 구현하기**
+
+다음으로, *brand_new_bert*의 토크나이저를 추가해야 합니다. 보통 토크나이저는 🤗 Transformers의 기존 토크나이저와 동일하거나 매우 유사합니다.
+
+토크나이저가 올바르게 작동하는지 확인하기 위해 먼저 원본 리포지토리에서 문자열을 입력하고 `input_ids`를 반환하는 스크립트를 생성하는 것이 좋습니다. 다음과 같은 유사한 스크립트일 수 있습니다 (의사 코드로 작성):
+
+```python
+input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
+model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
+input_ids = model.tokenize(input_str)
+```
+
+원본 리포지토리를 자세히 살펴보고 올바른 토크나이저 함수를 찾거나, 복제본에서 변경 사항을 적용하여 `input_ids`만 출력하도록 해야 합니다. 원본 리포지토리를 사용하는 기능적인 토큰화 스크립트를 작성한 후, 🤗 Transformers의 유사한 스크립트를 생성해야 합니다. 다음과 같이 작성되어야 합니다:
+
+```python
+from transformers import BrandNewBertTokenizer
+
+input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
+
+tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
+
+input_ids = tokenizer(input_str).input_ids
+```
+
+두 개의 `input_ids`가 동일한 값을 반환할 때, 마지막 단계로 토크나이저 테스트 파일도 추가해야 합니다.
+
+*brand_new_bert*의 모델링 테스트 파일과 유사하게, *brand_new_bert*의 토크나이제이션 테스트 파일에는 몇 가지 하드코딩된 통합 테스트가 포함되어야 합니다.
+
+**10. 종단 간 통합 테스트 실행**
+
+토크나이저를 추가한 후에는 모델과 토크나이저를 사용하여 몇 가지 종단 간 통합 테스트를 추가해야 합니다. `tests/models/brand_new_bert/test_modeling_brand_new_bert.py`에 추가해주세요. 이러한 테스트는 🤗 Transformers 구현이 예상대로 작동하는지를 의미 있는 text-to-text 예시로 보여줘야 합니다. 그 예시로는 *예를 들어* source-to-target 번역 쌍, article-to-summary 쌍, question-to-answer 쌍 등이 포함될 수 있습니다. 불러온 체크포인트 중 어느 것도 다운스트림 작업에서 미세 조정되지 않았다면, 모델 테스트만으로 충분합니다. 모델이 완전히 기능을 갖추었는지 확인하기 위해 마지막 단계로 GPU에서 모든 테스트를 실행하는 것이 좋습니다. 모델의 내부 텐서의 일부에 `.to(self.device)` 문을 추가하는 것을 잊었을 수 있으며, 이 경우 테스트에서 오류로 표시됩니다. GPU에 액세스할 수 없는 경우, Hugging Face 팀이 테스트를 대신 실행할 수 있습니다.
+
+**11. 기술문서 추가**
+
+이제 *brand_new_bert*에 필요한 모든 기능이 추가되었습니다. 거의 끝났습니다! 추가해야 할 것은 멋진 기술문서과 기술문서 페이지입니다. Cookiecutter가 `docs/source/model_doc/brand_new_bert.md`라는 템플릿 파일을 추가해줬을 것입니다. 이 페이지를 사용하기 전에 모델을 사용하는 사용자들은 일반적으로 이 페이지를 먼저 확인합니다. 따라서 문서는 이해하기 쉽고 간결해야 합니다. 모델을 사용하는 방법을 보여주기 위해 *팁*을 추가하는 것이 커뮤니티에 매우 유용합니다. 독스트링에 관련하여 Hugging Face 팀에 문의하는 것을 주저하지 마세요.
+
+다음으로, `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py`에 추가된 독스트링이 올바르며 필요한 모든 입력 및 출력을 포함하도록 확인하세요. [여기](writing-documentation)에서 우리의 문서 작성 가이드와 독스트링 형식에 대한 상세 가이드가 있습니다. 문서는 일반적으로 커뮤니티와 모델의 첫 번째 접점이기 때문에, 문서는 적어도 코드만큼의 주의를 기울여야 합니다.
+
+**코드 리팩토링**
+
+좋아요, 이제 *brand_new_bert*를 위한 모든 필요한 코드를 추가했습니다. 이 시점에서 다음을 실행하여 잠재적으로 잘못된 코드 스타일을 수정해야 합니다:
+
+그리고 코딩 스타일이 품질 점검을 통과하는지 확인하기 위해 다음을 실행하고 확인해야 합니다:
+
+```bash
+make style
+```
+
+🤗 Transformers에는 여전히 실패할 수 있는 몇 가지 매우 엄격한 디자인 테스트가 있습니다. 이는 독스트링에 누락된 정보나 잘못된 명명 때문에 종종 발생합니다. 여기서 막히면 Hugging Face 팀이 도움을 줄 것입니다.
+
+```bash
+make quality
+```
+
+마지막으로, 코드가 정확히 작동하는 것을 확인한 후에는 항상 코드를 리팩토링하는 것이 좋은 생각입니다. 모든 테스트가 통과된 지금은 추가한 코드를 다시 검토하고 리팩토링하는 좋은 시기입니다.
+
+이제 코딩 부분을 완료했습니다. 축하합니다! 🎉 멋져요! 😎
+
+**12. 모델을 모델 허브에 업로드하세요**
+
+이 마지막 파트에서는 모든 체크포인트를 변환하여 모델 허브에 업로드하고 각 업로드된 모델 체크포인트에 대한 모델 카드를 추가해야 합니다. [Model sharing and uploading Page](model_sharing)를 읽고 허브 기능에 익숙해지세요. *brand_new_bert*의 저자 조직 아래에 모델을 업로드할 수 있는 필요한 액세스 권한을 얻기 위해 Hugging Face 팀과 협업해야 합니다. `transformers`의 모든 모델에 있는 `push_to_hub` 메서드는 체크포인트를 허브에 빠르고 효율적으로 업로드하는 방법입니다. 아래에 작은 코드 조각이 붙여져 있습니다:
+
+각 체크포인트에 적합한 모델 카드를 만드는 데 시간을 할애하는 것은 가치가 있습니다. 모델 카드는 체크포인트의 특성을 강조해야 합니다. *예를 들어* 이 체크포인트는 어떤 데이터셋에서 사전 훈련/세부 훈련되었는지? 이 모델은 어떤 하위 작업에서 사용해야 하는지? 그리고 모델을 올바르게 사용하는 방법에 대한 몇 가지 코드도 포함해야 합니다.
+
+```python
+brand_new_bert.push_to_hub("brand_new_bert")
+# Uncomment the following line to push to an organization.
+# brand_new_bert.push_to_hub("/brand_new_bert")
+```
+
+**13. (선택 사항) 노트북 추가**
+
+*brand_new_bert*를 다운스트림 작업에서 추론 또는 미세 조정에 사용하는 방법을 자세히 보여주는 노트북을 추가하는 것이 매우 유용합니다. 이것은 PR을 병합하는 데 필수적이지는 않지만 커뮤니티에 매우 유용합니다.
+
+**14. 완료된 PR 제출**
+
+이제 프로그래밍을 마쳤으며, 마지막 단계로 PR을 메인 브랜치에 병합해야 합니다. 보통 Hugging Face 팀은 이미 여기까지 도움을 주었을 것입니다. 그러나 PR에 멋진 설명을 추가하고 리뷰어에게 특정 디자인 선택 사항을 강조하려면 완료된 PR에 약간의 설명을 추가하는 시간을 할애하는 것이 가치가 있습니다.
+
+### 작업물을 공유하세요!! [[share-your-work]]
+
+이제 커뮤니티에서 작업물을 인정받을 시간입니다! 모델 추가 작업을 완료하는 것은 Transformers와 전체 NLP 커뮤니티에 큰 기여입니다. 당신의 코드와 이식된 사전 훈련된 모델은 수백, 심지어 수천 명의 개발자와 연구원에 의해 확실히 사용될 것입니다. 당신의 작업에 자랑스러워해야 하며 이를 커뮤니티와 공유해야 합니다.
+
+**당신은 커뮤니티 내 모든 사람들에게 매우 쉽게 접근 가능한 또 다른 모델을 만들었습니다! 🤯**
diff --git a/docs/transformers/docs/source/ko/add_new_pipeline.md b/docs/transformers/docs/source/ko/add_new_pipeline.md
new file mode 100644
index 0000000000000000000000000000000000000000..42c9b57c9d7be675010069bc1803233befba410a
--- /dev/null
+++ b/docs/transformers/docs/source/ko/add_new_pipeline.md
@@ -0,0 +1,244 @@
+
+
+# 어떻게 사용자 정의 파이프라인을 생성하나요? [[how-to-create-a-custom-pipeline]]
+
+이 가이드에서는 사용자 정의 파이프라인을 어떻게 생성하고 [허브](https://hf.co/models)에 공유하거나 🤗 Transformers 라이브러리에 추가하는 방법을 살펴보겠습니다.
+
+먼저 파이프라인이 수용할 수 있는 원시 입력을 결정해야 합니다.
+문자열, 원시 바이트, 딕셔너리 또는 가장 원하는 입력일 가능성이 높은 것이면 무엇이든 가능합니다.
+이 입력을 가능한 한 순수한 Python 형식으로 유지해야 (JSON을 통해 다른 언어와도) 호환성이 좋아집니다.
+이것이 전처리(`preprocess`) 파이프라인의 입력(`inputs`)이 될 것입니다.
+
+그런 다음 `outputs`를 정의하세요.
+`inputs`와 같은 정책을 따르고, 간단할수록 좋습니다.
+이것이 후처리(`postprocess`) 메소드의 출력이 될 것입니다.
+
+먼저 4개의 메소드(`preprocess`, `_forward`, `postprocess` 및 `_sanitize_parameters`)를 구현하기 위해 기본 클래스 `Pipeline`을 상속하여 시작합니다.
+
+
+```python
+from transformers import Pipeline
+
+
+class MyPipeline(Pipeline):
+ def _sanitize_parameters(self, **kwargs):
+ preprocess_kwargs = {}
+ if "maybe_arg" in kwargs:
+ preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
+ return preprocess_kwargs, {}, {}
+
+ def preprocess(self, inputs, maybe_arg=2):
+ model_input = Tensor(inputs["input_ids"])
+ return {"model_input": model_input}
+
+ def _forward(self, model_inputs):
+ # model_inputs == {"model_input": model_input}
+ outputs = self.model(**model_inputs)
+ # Maybe {"logits": Tensor(...)}
+ return outputs
+
+ def postprocess(self, model_outputs):
+ best_class = model_outputs["logits"].softmax(-1)
+ return best_class
+```
+
+이 분할 구조는 CPU/GPU에 대한 비교적 원활한 지원을 제공하는 동시에, 다른 스레드에서 CPU에 대한 사전/사후 처리를 수행할 수 있게 지원하는 것입니다.
+
+`preprocess`는 원래 정의된 입력을 가져와 모델에 공급할 수 있는 형식으로 변환합니다.
+더 많은 정보를 포함할 수 있으며 일반적으로 `Dict` 형태입니다.
+
+`_forward`는 구현 세부 사항이며 직접 호출할 수 없습니다.
+`forward`는 예상 장치에서 모든 것이 작동하는지 확인하기 위한 안전장치가 포함되어 있어 선호되는 호출 메소드입니다.
+실제 모델과 관련된 것은 `_forward` 메소드에 속하며, 나머지는 전처리/후처리 과정에 있습니다.
+
+`postprocess` 메소드는 `_forward`의 출력을 가져와 이전에 결정한 최종 출력 형식으로 변환합니다.
+
+`_sanitize_parameters`는 초기화 시간에 `pipeline(...., maybe_arg=4)`이나 호출 시간에 `pipe = pipeline(...); output = pipe(...., maybe_arg=4)`과 같이, 사용자가 원하는 경우 언제든지 매개변수를 전달할 수 있도록 허용합니다.
+
+`_sanitize_parameters`의 반환 값은 `preprocess`, `_forward`, `postprocess`에 직접 전달되는 3개의 kwargs 딕셔너리입니다.
+호출자가 추가 매개변수로 호출하지 않았다면 아무것도 채우지 마십시오.
+이렇게 하면 항상 더 "자연스러운" 함수 정의의 기본 인수를 유지할 수 있습니다.
+
+분류 작업에서 `top_k` 매개변수가 대표적인 예입니다.
+
+```python
+>>> pipe = pipeline("my-new-task")
+>>> pipe("This is a test")
+[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}, {"label": "3-star", "score": 0.05}
+{"label": "4-star", "score": 0.025}, {"label": "5-star", "score": 0.025}]
+
+>>> pipe("This is a test", top_k=2)
+[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}]
+```
+
+이를 달성하기 위해 우리는 `postprocess` 메소드를 기본 매개변수인 `5`로 업데이트하고 `_sanitize_parameters`를 수정하여 이 새 매개변수를 허용합니다.
+
+
+```python
+def postprocess(self, model_outputs, top_k=5):
+ best_class = model_outputs["logits"].softmax(-1)
+ # top_k를 처리하는 로직 추가
+ return best_class
+
+
+def _sanitize_parameters(self, **kwargs):
+ preprocess_kwargs = {}
+ if "maybe_arg" in kwargs:
+ preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
+
+ postprocess_kwargs = {}
+ if "top_k" in kwargs:
+ postprocess_kwargs["top_k"] = kwargs["top_k"]
+ return preprocess_kwargs, {}, postprocess_kwargs
+```
+
+입/출력을 가능한 한 간단하고 완전히 JSON 직렬화 가능한 형식으로 유지하려고 노력하십시오.
+이렇게 하면 사용자가 새로운 종류의 개체를 이해하지 않고도 파이프라인을 쉽게 사용할 수 있습니다.
+또한 사용 용이성을 위해 여러 가지 유형의 인수(오디오 파일은 파일 이름, URL 또는 순수한 바이트일 수 있음)를 지원하는 것이 비교적 일반적입니다.
+
+
+
+## 지원되는 작업 목록에 추가하기 [[adding-it-to-the-list-of-supported-tasks]]
+
+`new-task`를 지원되는 작업 목록에 등록하려면 `PIPELINE_REGISTRY`에 추가해야 합니다:
+
+```python
+from transformers.pipelines import PIPELINE_REGISTRY
+
+PIPELINE_REGISTRY.register_pipeline(
+ "new-task",
+ pipeline_class=MyPipeline,
+ pt_model=AutoModelForSequenceClassification,
+)
+```
+
+원하는 경우 기본 모델을 지정할 수 있으며, 이 경우 특정 개정(분기 이름 또는 커밋 해시일 수 있음, 여기서는 "abcdef")과 타입을 함께 가져와야 합니다:
+
+```python
+PIPELINE_REGISTRY.register_pipeline(
+ "new-task",
+ pipeline_class=MyPipeline,
+ pt_model=AutoModelForSequenceClassification,
+ default={"pt": ("user/awesome_model", "abcdef")},
+ type="text", # 현재 지원 유형: text, audio, image, multimodal
+)
+```
+
+## Hub에 파이프라인 공유하기 [[share-your-pipeline-on-the-hub]]
+
+Hub에 사용자 정의 파이프라인을 공유하려면 `Pipeline` 하위 클래스의 사용자 정의 코드를 Python 파일에 저장하기만 하면 됩니다.
+예를 들어, 다음과 같이 문장 쌍 분류를 위한 사용자 정의 파이프라인을 사용한다고 가정해 보겠습니다:
+
+```py
+import numpy as np
+
+from transformers import Pipeline
+
+
+def softmax(outputs):
+ maxes = np.max(outputs, axis=-1, keepdims=True)
+ shifted_exp = np.exp(outputs - maxes)
+ return shifted_exp / shifted_exp.sum(axis=-1, keepdims=True)
+
+
+class PairClassificationPipeline(Pipeline):
+ def _sanitize_parameters(self, **kwargs):
+ preprocess_kwargs = {}
+ if "second_text" in kwargs:
+ preprocess_kwargs["second_text"] = kwargs["second_text"]
+ return preprocess_kwargs, {}, {}
+
+ def preprocess(self, text, second_text=None):
+ return self.tokenizer(text, text_pair=second_text, return_tensors=self.framework)
+
+ def _forward(self, model_inputs):
+ return self.model(**model_inputs)
+
+ def postprocess(self, model_outputs):
+ logits = model_outputs.logits[0].numpy()
+ probabilities = softmax(logits)
+
+ best_class = np.argmax(probabilities)
+ label = self.model.config.id2label[best_class]
+ score = probabilities[best_class].item()
+ logits = logits.tolist()
+ return {"label": label, "score": score, "logits": logits}
+```
+
+구현은 프레임워크에 구애받지 않으며, PyTorch와 TensorFlow 모델에 대해 작동합니다.
+이를 `pair_classification.py`라는 파일에 저장한 경우, 다음과 같이 가져오고 등록할 수 있습니다:
+
+```py
+from pair_classification import PairClassificationPipeline
+from transformers.pipelines import PIPELINE_REGISTRY
+from transformers import AutoModelForSequenceClassification, TFAutoModelForSequenceClassification
+
+PIPELINE_REGISTRY.register_pipeline(
+ "pair-classification",
+ pipeline_class=PairClassificationPipeline,
+ pt_model=AutoModelForSequenceClassification,
+ tf_model=TFAutoModelForSequenceClassification,
+)
+```
+
+이 작업이 완료되면 사전훈련된 모델과 함께 사용할 수 있습니다.
+예를 들어, `sgugger/finetuned-bert-mrpc`은 MRPC 데이터 세트에서 미세 조정되어 문장 쌍을 패러프레이즈인지 아닌지를 분류합니다.
+
+```py
+from transformers import pipeline
+
+classifier = pipeline("pair-classification", model="sgugger/finetuned-bert-mrpc")
+```
+
+그런 다음 `push_to_hub` 메소드를 사용하여 허브에 공유할 수 있습니다:
+
+```py
+classifier.push_to_hub("test-dynamic-pipeline")
+```
+
+이렇게 하면 "test-dynamic-pipeline" 폴더 내에 `PairClassificationPipeline`을 정의한 파일이 복사되며, 파이프라인의 모델과 토크나이저도 저장한 후, `{your_username}/test-dynamic-pipeline` 저장소에 있는 모든 것을 푸시합니다.
+이후에는 `trust_remote_code=True` 옵션만 제공하면 누구나 사용할 수 있습니다.
+
+```py
+from transformers import pipeline
+
+classifier = pipeline(model="{your_username}/test-dynamic-pipeline", trust_remote_code=True)
+```
+
+## 🤗 Transformers에 파이프라인 추가하기 [[add-the-pipeline-to-transformers]]
+
+🤗 Transformers에 사용자 정의 파이프라인을 기여하려면, `pipelines` 하위 모듈에 사용자 정의 파이프라인 코드와 함께 새 모듈을 추가한 다음, `pipelines/__init__.py`에서 정의된 작업 목록에 추가해야 합니다.
+
+그런 다음 테스트를 추가해야 합니다.
+`tests/test_pipelines_MY_PIPELINE.py`라는 새 파일을 만들고 다른 테스트와 예제를 함께 작성합니다.
+
+`run_pipeline_test` 함수는 매우 일반적이며, `model_mapping` 및 `tf_model_mapping`에서 정의된 가능한 모든 아키텍처의 작은 무작위 모델에서 실행됩니다.
+
+이는 향후 호환성을 테스트하는 데 매우 중요하며, 누군가 `XXXForQuestionAnswering`을 위한 새 모델을 추가하면 파이프라인 테스트가 해당 모델에서 실행을 시도한다는 의미입니다.
+모델이 무작위이기 때문에 실제 값을 확인하는 것은 불가능하므로, 단순히 파이프라인 출력 `TYPE`과 일치시키기 위한 도우미 `ANY`가 있습니다.
+
+또한 2개(이상적으로는 4개)의 테스트를 구현해야 합니다.
+
+- `test_small_model_pt`: 이 파이프라인에 대한 작은 모델 1개를 정의(결과가 의미 없어도 상관없음)하고 파이프라인 출력을 테스트합니다.
+결과는 `test_small_model_tf`와 동일해야 합니다.
+- `test_small_model_tf`: 이 파이프라인에 대한 작은 모델 1개를 정의(결과가 의미 없어도 상관없음)하고 파이프라인 출력을 테스트합니다.
+결과는 `test_small_model_pt`와 동일해야 합니다.
+- `test_large_model_pt`(`선택사항`): 결과가 의미 있을 것으로 예상되는 실제 파이프라인에서 파이프라인을 테스트합니다.
+이러한 테스트는 속도가 느리므로 이를 표시해야 합니다.
+여기서의 목표는 파이프라인을 보여주고 향후 릴리즈에서의 변화가 없는지 확인하는 것입니다.
+- `test_large_model_tf`(`선택사항`): 결과가 의미 있을 것으로 예상되는 실제 파이프라인에서 파이프라인을 테스트합니다.
+이러한 테스트는 속도가 느리므로 이를 표시해야 합니다.
+여기서의 목표는 파이프라인을 보여주고 향후 릴리즈에서의 변화가 없는지 확인하는 것입니다.
diff --git a/docs/transformers/docs/source/ko/attention.md b/docs/transformers/docs/source/ko/attention.md
new file mode 100644
index 0000000000000000000000000000000000000000..d9a5eeee1b73eada3d0d704b2ff6744f545c6d2b
--- /dev/null
+++ b/docs/transformers/docs/source/ko/attention.md
@@ -0,0 +1,54 @@
+
+
+# 어텐션 메커니즘[[attention_mechanisms]]
+
+대부분의 트랜스포머 모델은 정방행렬인 전체 어텐션을 사용합니다.
+하지만 이는 긴 텍스트를 다룰 때는 큰 계산 병목 현상을 유발할 수 있습니다.
+`Longformer`와 `Reformer`는 훈련 속도를 높이기 위해 어텐션 행렬의 희소 버전을 사용하여 효율을 높이려는 모델입니다.
+
+## LSH 어텐션[[lsh_attention]]
+
+
+[Reformer](model_doc/reformer)는 LSH(Locality Sensitive Hashing) 어텐션을 사용합니다. softmax(QK^t)에서는 행렬 QK^t의 (softmax 차원에서) 가장 큰 요소들만 유용한 기여를 할 것입니다.
+따라서 각각의 쿼리 q에 대해, q와 가까운 키 k만 고려할 수 있습니다. 해시 함수는 q와 k가 가까운지 여부를 결정하는 데 사용됩니다.
+어텐션 마스크는 현재 토큰을 마스킹하여 변경됩니다. 이 때 첫 번째 위치의 토큰은 제외합니다. 왜냐하면 쿼리와 키가 동일한 값을 갖게 되기 때문입니다(서로 매우 유사함).
+해시는 약간의 무작위성을 가질 수 있으므로, 실제로는 여러 개의 해시 함수가 사용되고 (`n_rounds` 매개변수에 의해 결정됨) 그 후에 평균값을 취하게 됩니다.
+
+## 지역 어텐션[[local_attention]]
+
+[Longformer](model_doc/longformer)는 지역 어텐션을 사용합니다. 종종 특정 토큰에 대해 지역 컨텍스트(예: 왼쪽과 오른쪽에 있는 두 개의 토큰은 무엇인가요?)만으로도 작업을 수행하는데 충분합니다.
+또한 작은 창(window)을 가진 어텐션 레이어를 쌓음으로써 마지막 레이어는 창 내의 토큰뿐만 아니라 더 많은 수의 토큰에 대한 수용 영역(receptive field)을 갖게 되어 전체 문장의 표현을 구축할 수 있습니다.
+
+사전에 선택된 일부 입력 토큰들은 전역 어텐션을 받습니다. 이 몇 개의 토큰에 대해서는 어텐션 행렬이 모든 토큰에 접근할 수 있으며, 이 과정은 대칭적으로 이루어집니다.
+다른 모든 토큰들은 로컬 창 내의 토큰들에 더해 해당 특정 토큰들에도 접근할 수 있습니다. 이는 논문의 Figure 2d에서 나타나며, 아래에 샘플 어텐션 마스크가 제시되어 있습니다:
+
+
+
+
+
+
+
+적은 파라미터의 어텐션 행렬을 사용하면 모델이 더 큰 시퀀스 입력 길이를 가질 수 있습니다.
+
+## 다른 방법들[[other_tricks]]
+
+### 축별 위치 인코딩[[axial_positional_encodings]]
+
+[Reformer](model_doc/reformer)는 축별 위치 인코딩(axial positional encodings)을 사용합니다. 기존의 트랜스포머 모델에서는 위치 인코딩 행렬 E는 크기가 \\(l \times d\\)인 행렬이며,
+여기서 \\(l\\)은 시퀀스 길이(sequence length)이고 \\(d\\)는 숨겨진 상태(hidden state)의 차원입니다. 매우 긴 텍스트의 경우, 이 행렬은 매우 크며 GPU 상에서 공간을 많이 차지할 수 있습니다.
+이를 완화하기 위해, 축별 위치 인코딩은 큰 행렬 E를 두 개의 작은 행렬 E1과 E2로 분해합니다. 이때 E1의 크기는 \\(l_{1} \times d_{1}\\)이고, E2의 크기는 \\(l_{2} \times d_{2}\\)입니다.
+이때 \\(l_{1} \times l_{2} = l\\)이고 \\(d_{1} + d_{2} = d\\)(길이에 대한 곱셈 연산을 사용하면 훨씬 작아집니다). E의 시간 단계 j에 대한 임베딩은 E1에서 시간 단계 \\(j \% l1\\)의 임베딩과 E2에서 시간 단계 \\(j // l1\\)의 임베딩을 연결하여 얻습니다.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/autoclass_tutorial.md b/docs/transformers/docs/source/ko/autoclass_tutorial.md
new file mode 100644
index 0000000000000000000000000000000000000000..e41a2acc7b486b44590387fd2aa495b78b530f75
--- /dev/null
+++ b/docs/transformers/docs/source/ko/autoclass_tutorial.md
@@ -0,0 +1,144 @@
+
+
+# AutoClass로 사전 학습된 인스턴스 로드[[load-pretrained-instances-with-an-autoclass]]
+
+트랜스포머 아키텍처가 매우 다양하기 때문에 체크포인트에 맞는 아키텍처를 생성하는 것이 어려울 수 있습니다. 라이브러리를 쉽고 간단하며 유연하게 사용하기 위한 Transformer 핵심 철학의 일환으로, `AutoClass`는 주어진 체크포인트에서 올바른 아키텍처를 자동으로 추론하여 로드합니다. `from_pretrained()` 메서드를 사용하면 모든 아키텍처에 대해 사전 학습된 모델을 빠르게 로드할 수 있으므로 모델을 처음부터 학습하는 데 시간과 리소스를 투입할 필요가 없습니다.
+체크포인트에 구애받지 않는 코드를 생성한다는 것은 코드가 한 체크포인트에서 작동하면 아키텍처가 다르더라도 다른 체크포인트(유사한 작업에 대해 학습된 경우)에서도 작동한다는 것을 의미합니다.
+
+
+
+아키텍처는 모델의 골격을 의미하며 체크포인트는 주어진 아키텍처에 대한 가중치입니다. 예를 들어, [BERT](https://huggingface.co/google-bert/bert-base-uncased)는 아키텍처이고, `google-bert/bert-base-uncased`는 체크포인트입니다. 모델은 아키텍처 또는 체크포인트를 의미할 수 있는 일반적인 용어입니다.
+
+
+
+이 튜토리얼에서는 다음을 학습합니다:
+
+* 사전 학습된 토크나이저 로드하기.
+* 사전 학습된 이미지 프로세서 로드하기.
+* 사전 학습된 특징 추출기 로드하기.
+* 사전 훈련된 프로세서 로드하기.
+* 사전 학습된 모델 로드하기.
+
+## AutoTokenizer[[autotokenizer]]
+
+거의 모든 NLP 작업은 토크나이저로 시작됩니다. 토크나이저는 사용자의 입력을 모델에서 처리할 수 있는 형식으로 변환합니다.
+[`AutoTokenizer.from_pretrained`]로 토크나이저를 로드합니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+```
+
+그리고 아래와 같이 입력을 토큰화합니다:
+
+```py
+>>> sequence = "In a hole in the ground there lived a hobbit."
+>>> print(tokenizer(sequence))
+{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+## AutoImageProcessor[[autoimageprocessor]]
+
+비전 작업의 경우 이미지 프로세서가 이미지를 올바른 입력 형식으로 처리합니다.
+
+```py
+>>> from transformers import AutoImageProcessor
+
+>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
+```
+
+
+## AutoFeatureExtractor[[autofeatureextractor]]
+
+오디오 작업의 경우 특징 추출기가 오디오 신호를 올바른 입력 형식으로 처리합니다.
+
+[`AutoFeatureExtractor.from_pretrained`]로 특징 추출기를 로드합니다:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
+... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
+... )
+```
+
+## AutoProcessor[[autoprocessor]]
+
+멀티모달 작업에는 두 가지 유형의 전처리 도구를 결합한 프로세서가 필요합니다. 예를 들어 LayoutLMV2 모델에는 이미지를 처리하는 이미지 프로세서와 텍스트를 처리하는 토크나이저가 필요하며, 프로세서는 이 두 가지를 결합합니다.
+
+[`AutoProcessor.from_pretrained()`]로 프로세서를 로드합니다:
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
+```
+
+## AutoModel[[automodel]]
+
+
+
+마지막으로 AutoModelFor클래스를 사용하면 주어진 작업에 대해 미리 학습된 모델을 로드할 수 있습니다 (사용 가능한 작업의 전체 목록은 [여기](model_doc/auto)를 참조하세요). 예를 들어, [`AutoModelForSequenceClassification.from_pretrained`]를 사용하여 시퀀스 분류용 모델을 로드할 수 있습니다:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+동일한 체크포인트를 쉽게 재사용하여 다른 작업에 아키텍처를 로드할 수 있습니다:
+
+```py
+>>> from transformers import AutoModelForTokenClassification
+
+>>> model = AutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+
+
+PyTorch모델의 경우 `from_pretrained()` 메서드는 내부적으로 피클을 사용하여 안전하지 않은 것으로 알려진 `torch.load()`를 사용합니다.
+일반적으로 신뢰할 수 없는 소스에서 가져왔거나 변조되었을 수 있는 모델은 로드하지 마세요. 허깅 페이스 허브에서 호스팅되는 공개 모델의 경우 이러한 보안 위험이 부분적으로 완화되며, 각 커밋 시 멀웨어를 [검사합니다](https://huggingface.co/docs/hub/security-malware). GPG를 사용해 서명된 [커밋 검증](https://huggingface.co/docs/hub/security-gpg#signing-commits-with-gpg)과 같은 모범사례는 [문서](https://huggingface.co/docs/hub/security)를 참조하세요.
+
+텐서플로우와 Flax 체크포인트는 영향을 받지 않으며, `from_pretrained`메서드에 `from_tf` 와 `from_flax` 키워드 가변 인자를 사용하여 이 문제를 우회할 수 있습니다.
+
+
+
+일반적으로 AutoTokenizer 클래스와 AutoModelFor 클래스를 사용하여 미리 학습된 모델 인스턴스를 로드하는 것이 좋습니다. 이렇게 하면 매번 올바른 아키텍처를 로드할 수 있습니다. 다음 [튜토리얼](preprocessing)에서는 새롭게 로드한 토크나이저, 이미지 프로세서, 특징 추출기를 사용하여 미세 튜닝용 데이터 세트를 전처리하는 방법에 대해 알아봅니다.
+
+
+마지막으로 `TFAutoModelFor` 클래스를 사용하면 주어진 작업에 대해 사전 훈련된 모델을 로드할 수 있습니다. (사용 가능한 작업의 전체 목록은 [여기](model_doc/auto)를 참조하세요. 예를 들어, [`TFAutoModelForSequenceClassification.from_pretrained`]로 시퀀스 분류를 위한 모델을 로드합니다:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+쉽게 동일한 체크포인트를 재사용하여 다른 작업에 아키텍처를 로드할 수 있습니다:
+
+```py
+>>> from transformers import TFAutoModelForTokenClassification
+
+>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+일반적으로, `AutoTokenizer`클래스와 `TFAutoModelFor` 클래스를 사용하여 미리 학습된 모델 인스턴스를 로드하는 것이 좋습니다. 이렇게 하면 매번 올바른 아키텍처를 로드할 수 있습니다. 다음 [튜토리얼](preprocessing)에서는 새롭게 로드한 토크나이저, 이미지 프로세서, 특징 추출기를 사용하여 미세 튜닝용 데이터 세트를 전처리하는 방법에 대해 알아봅니다.
+
+
diff --git a/docs/transformers/docs/source/ko/bertology.md b/docs/transformers/docs/source/ko/bertology.md
new file mode 100644
index 0000000000000000000000000000000000000000..1f69a0381707dc5ecc862068593dc261953a36a0
--- /dev/null
+++ b/docs/transformers/docs/source/ko/bertology.md
@@ -0,0 +1,41 @@
+
+
+# BERTology
+
+BERT와 같은 대규모 트랜스포머의 내부 동작을 조사하는 연구 분야가 점점 더 중요해지고 있습니다.
+혹자는 "BERTology"라 칭하기도 합니다. 이 분야의 좋은 예시는 다음과 같습니다:
+
+
+- BERT는 고전적인 NLP 파이프라인의 재발견 - Ian Tenney, Dipanjan Das, Ellie Pavlick:
+ https://arxiv.org/abs/1905.05950
+- 16개의 헤드가 정말로 1개보다 나은가? - Paul Michel, Omer Levy, Graham Neubig:
+ https://arxiv.org/abs/1905.10650
+- BERT는 무엇을 보는가? BERT의 어텐션 분석 - Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D. Manning:
+ https://arxiv.org/abs/1906.04341
+- CAT-probing: 프로그래밍 언어에 대해 사전훈련된 모델이 어떻게 코드 구조를 보는지 알아보기 위한 메트릭 기반 접근 방법:
+ https://arxiv.org/abs/2210.04633
+
+우리는 이 새로운 연구 분야의 발전을 돕기 위해, BERT/GPT/GPT-2 모델에 내부 표현을 살펴볼 수 있는 몇 가지 기능을 추가했습니다.
+이 기능들은 주로 Paul Michel의 훌륭한 작업을 참고하여 개발되었습니다
+(https://arxiv.org/abs/1905.10650):
+
+
+- BERT/GPT/GPT-2의 모든 은닉 상태에 접근하기,
+- BERT/GPT/GPT-2의 각 헤드의 모든 어텐션 가중치에 접근하기,
+- 헤드의 출력 값과 그래디언트를 검색하여 헤드 중요도 점수를 계산하고 https://arxiv.org/abs/1905.10650에서 설명된 대로 헤드를 제거하는 기능을 제공합니다.
+
+이러한 기능들을 이해하고 직접 사용해볼 수 있도록 [bertology.py](https://github.com/huggingface/transformers-research-projects/tree/main/bertology/run_bertology.py) 예제 스크립트를 추가했습니다. 이 예제 스크립트에서는 GLUE에 대해 사전훈련된 모델에서 정보를 추출하고 모델을 가지치기(prune)해봅니다.
diff --git a/docs/transformers/docs/source/ko/big_models.md b/docs/transformers/docs/source/ko/big_models.md
new file mode 100644
index 0000000000000000000000000000000000000000..3180b51117a97b93566775485455e157ee7bd6ff
--- /dev/null
+++ b/docs/transformers/docs/source/ko/big_models.md
@@ -0,0 +1,122 @@
+
+
+# 큰 모델 인스턴스화 [[instantiating-a-big-model]]
+
+매우 큰 사전훈련된 모델을 사용하려면, RAM 사용을 최소화해야 하는 과제가 있습니다. 일반적인 PyTorch 워크플로우는 다음과 같습니다:
+
+1. 무작위 가중치로 모델을 생성합니다.
+2. 사전훈련된 가중치를 불러옵니다.
+3. 사전훈련된 가중치를 무작위 모델에 적용합니다.
+
+1단계와 2단계 모두 모델의 전체 버전을 메모리에 적재해야 하며, 대부분 문제가 없지만 모델이 기가바이트급의 용량을 차지하기 시작하면 복사본 2개가 RAM을 초과하여 메모리 부족 이슈를 야기할 수 있습니다. 더 심각한 문제는 분산 학습을 위해 `torch.distributed`를 사용하는 경우, 프로세스마다 사전훈련된 모델을 로드하고 복사본을 2개씩 RAM에 저장한다는 것입니다.
+
+
+
+무작위로 생성된 모델은 "비어 있는" (즉 그때 메모리에 있던 것으로 이뤄진) 텐서로 초기화되며 메모리 공간을 차지합니다. 초기화된 모델/파라미터의 종류에 적합한 분포(예: 정규 분포)에 따른 무작위 초기화는 가능한 한 빠르게 하기 위해 초기화되지 않은 가중치에 대해 3단계 이후에만 수행됩니다!
+
+
+
+이 안내서에서는 Transformers가 이 문제를 해결하기 위해 제공하는 솔루션을 살펴봅니다. 주의할 점은 아직 활발히 개발 중인 분야이므로 여기서 설명하는 API가 앞으로 약간 변경될 수 있다는 것입니다.
+
+## 샤딩된 체크포인트 [[sharded-checkpoints]]
+
+4.18.0 버전 이후, 10GB 이상의 공간을 차지하는 모델 체크포인트는 자동으로 작은 조각들로 샤딩됩니다. `model.save_pretrained(save_dir)`를 실행할 때 하나의 단일 체크포인트를 가지게 될 대신, 여러 부분 체크포인트(각각의 크기는 10GB 미만)와 매개변수 이름을 해당 파일에 매핑하는 인덱스가 생성됩니다.
+
+`max_shard_size` 매개변수로 샤딩 전 최대 크기를 제어할 수 있으므로, 이 예제를 위해 샤드 크기가 작은 일반 크기의 모델을 사용하겠습니다: 전통적인 BERT 모델을 사용해 봅시다.
+
+```py
+from transformers import AutoModel
+
+model = AutoModel.from_pretrained("google-bert/bert-base-cased")
+```
+
+[`~PreTrainedModel.save_pretrained`]을 사용하여 모델을 저장하면, 모델의 구성과 가중치가 들어있는 두 개의 파일이 있는 새 폴더가 생성됩니다:
+
+```py
+>>> import os
+>>> import tempfile
+
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir)
+... print(sorted(os.listdir(tmp_dir)))
+['config.json', 'pytorch_model.bin']
+```
+
+이제 최대 샤드 크기를 200MB로 사용해 봅시다:
+
+```py
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir, max_shard_size="200MB")
+... print(sorted(os.listdir(tmp_dir)))
+['config.json', 'pytorch_model-00001-of-00003.bin', 'pytorch_model-00002-of-00003.bin', 'pytorch_model-00003-of-00003.bin', 'pytorch_model.bin.index.json']
+```
+
+모델의 구성에 더해, 세 개의 다른 가중치 파일과 파라미터 이름과 해당 파일의 매핑이 포함된 `index.json` 파일을 볼 수 있습니다. 이러한 체크포인트는 [`~PreTrainedModel.from_pretrained`] 메서드를 사용하여 완전히 다시 로드할 수 있습니다:
+
+```py
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir, max_shard_size="200MB")
+... new_model = AutoModel.from_pretrained(tmp_dir)
+```
+
+큰 모델의 경우 이러한 방식으로 처리하는 주된 장점은 위에서 보여준 흐름의 2단계에서, 각 샤드가 이전 샤드 다음에 로드되므로 메모리 사용량이 모델 크기와 가장 큰 샤드의 크기를 초과하지 않는다는 점입니다.
+
+이 인덱스 파일은 키가 체크포인트에 있는지, 그리고 해당 가중치가 어디에 저장되어 있는지를 결정하는 데 사용됩니다. 이 인덱스를 json과 같이 로드하고 딕셔너리를 얻을 수 있습니다:
+
+```py
+>>> import json
+
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir, max_shard_size="200MB")
+... with open(os.path.join(tmp_dir, "pytorch_model.bin.index.json"), "r") as f:
+... index = json.load(f)
+
+>>> print(index.keys())
+dict_keys(['metadata', 'weight_map'])
+```
+
+메타데이터는 현재 모델의 총 크기만 포함됩니다. 앞으로 다른 정보를 추가할 계획입니다:
+
+```py
+>>> index["metadata"]
+{'total_size': 433245184}
+```
+
+가중치 맵은 이 인덱스의 주요 부분으로, 각 매개변수 이름(PyTorch 모델 `state_dict`에서 보통 찾을 수 있는)을 해당 파일에 매핑합니다:
+
+```py
+>>> index["weight_map"]
+{'embeddings.LayerNorm.bias': 'pytorch_model-00001-of-00003.bin',
+ 'embeddings.LayerNorm.weight': 'pytorch_model-00001-of-00003.bin',
+ ...
+```
+
+만약 [`~PreTrainedModel.from_pretrained`]를 사용하지 않고 모델 내에서 이러한 샤딩된 체크포인트를 직접 가져오려면 (전체 체크포인트를 위해 `model.load_state_dict()`를 수행하는 것처럼), [`~modeling_utils.load_sharded_checkpoint`]를 사용해야 합니다.
+
+```py
+>>> from transformers.modeling_utils import load_sharded_checkpoint
+
+>>> with tempfile.TemporaryDirectory() as tmp_dir:
+... model.save_pretrained(tmp_dir, max_shard_size="200MB")
+... load_sharded_checkpoint(model, tmp_dir)
+```
+
+## 저(低)메모리 로딩 [[low-memory-loading]]
+
+샤딩된 체크포인트는 위에서 언급한 작업 흐름의 2단계에서 메모리 사용량을 줄이지만, 저(低)메모리 설정에서 모델을 사용하기 위해 우리의 Accelerate 라이브러리를 기반으로 한 도구를 활용하는 것이 좋습니다.
+
+자세한 사항은 다음 가이드를 참조해주세요: [Accelerate로 대규모 모델 가져오기 (영문)](../en/main_classes/model#large-model-loading)
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/chat_templating.md b/docs/transformers/docs/source/ko/chat_templating.md
new file mode 100644
index 0000000000000000000000000000000000000000..5e6cbc4491dd9951f42f00b8c5022e72dda920c6
--- /dev/null
+++ b/docs/transformers/docs/source/ko/chat_templating.md
@@ -0,0 +1,720 @@
+
+
+# 채팅 모델을 위한 템플릿[[templates-for-chat-models]]
+
+## 소개[[introduction]]
+
+요즘 LLM의 가장 흔한 활용 사례 중 하나는 **채팅**입니다. 채팅은 일반적인 언어 모델처럼 단일 문자열을 이어가는 대신 여러 개의 **메시지**로 구성된 대화를 이어갑니다. 이 대화에는 "사용자"나 "어시스턴트"와 같은 **역할**과 메시지 텍스트가 포함됩니다.
+
+토큰화와 마찬가지로, 다양한 모델은 채팅에 대해 매우 다른 입력 형식을 기대합니다. 이것이 우리가 **채팅 템플릿**을 기능으로 추가한 이유입니다. 채팅 템플릿은 토크나이저의 일부입니다. 채팅 템플릿은 대화 목록을 모델이 기대하는 형식인 '단일 토큰화가 가능한 문자열'로 변환하는 방법을 지정합니다.
+
+`BlenderBot` 모델을 사용한 간단한 예제를 통해 이를 구체적으로 살펴보겠습니다. BlenderBot은 기본적으로 매우 간단한 템플릿을 가지고 있으며, 주로 대화 라운드 사이에 공백을 추가합니다:
+
+```python
+>>> from transformers import AutoTokenizer
+>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
+
+>>> chat = [
+... {"role": "user", "content": "Hello, how are you?"},
+... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
+... {"role": "user", "content": "I'd like to show off how chat templating works!"},
+... ]
+
+>>> tokenizer.apply_chat_template(chat, tokenize=False)
+" Hello, how are you? I'm doing great. How can I help you today? I'd like to show off how chat templating works!"
+```
+
+전체 채팅이 하나의 문자열로 압축된 것을 확인할 수 있습니다. 기본 설정인 `tokenize=True`를 사용하면, 그 문자열도 토큰화됩니다. 더 복잡한 템플릿을 사용하기 위해 `mistralai/Mistral-7B-Instruct-v0.1` 모델을 사용해 보겠습니다.
+
+```python
+>>> from transformers import AutoTokenizer
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
+
+>>> chat = [
+... {"role": "user", "content": "Hello, how are you?"},
+... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
+... {"role": "user", "content": "I'd like to show off how chat templating works!"},
+... ]
+
+>>> tokenizer.apply_chat_template(chat, tokenize=False)
+"[INST] Hello, how are you? [/INST]I'm doing great. How can I help you today? [INST] I'd like to show off how chat templating works! [/INST]"
+```
+
+이번에는 토크나이저가 [INST]와 [/INST] 제어 토큰을 추가하여 사용자 메시지의 시작과 끝을 표시했습니다(어시스턴트 메시지 제외). Mistral-instruct는 이러한 토큰으로 훈련되었지만, BlenderBot은 그렇지 않았습니다.
+
+## 채팅 템플릿을 어떻게 사용하나요?[[how-do-i-use-chat-templates]]
+
+위의 예에서 볼 수 있듯이 채팅 템플릿은 사용하기 쉽습니다. `role`과 `content` 키가 포함된 메시지 목록을 작성한 다음, [`~PreTrainedTokenizer.apply_chat_template`] 메서드에 전달하기만 하면 됩니다. 이렇게 하면 바로 사용할 수 있는 출력이 생성됩니다! 모델 생성의 입력으로 채팅 템플릿을 사용할 때, `add_generation_prompt=True`를 사용하여 [생성 프롬프트](#what-are-generation-prompts)를 추가하는 것도 좋은 방법입니다.
+
+다음은 `Zephyr` 어시스턴트 모델을 사용하여 `model.generate()`의 입력을 준비하는 예제입니다:
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+checkpoint = "HuggingFaceH4/zephyr-7b-beta"
+tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+model = AutoModelForCausalLM.from_pretrained(checkpoint) # 여기서 bfloat16 사용 및/또는 GPU로 이동할 수 있습니다.
+
+
+messages = [
+ {
+ "role": "system",
+ "content": "You are a friendly chatbot who always responds in the style of a pirate",
+ },
+ {"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
+ ]
+tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
+print(tokenizer.decode(tokenized_chat[0]))
+```
+이렇게 하면 Zephyr가 기대하는 입력 형식의 문자열이 생성됩니다.
+```text
+<|system|>
+You are a friendly chatbot who always responds in the style of a pirate
+<|user|>
+How many helicopters can a human eat in one sitting?
+<|assistant|>
+```
+
+이제 입력이 Zephyr에 맞게 형식이 지정되었으므로 모델을 사용하여 사용자의 질문에 대한 응답을 생성할 수 있습니다:
+
+```python
+outputs = model.generate(tokenized_chat, max_new_tokens=128)
+print(tokenizer.decode(outputs[0]))
+```
+
+이렇게 하면 다음과 같은 결과가 나옵니다:
+
+```text
+<|system|>
+You are a friendly chatbot who always responds in the style of a pirate
+<|user|>
+How many helicopters can a human eat in one sitting?
+<|assistant|>
+Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
+```
+
+이제 쉬워졌죠!
+
+## 채팅을 위한 자동화된 파이프라인이 있나요?[[is-there-an-automated-pipeline-for-chat]]
+
+네, 있습니다! 우리의 텍스트 생성 파이프라인은 채팅 입력을 지원하여 채팅 모델을 쉽게 사용할 수 있습니다. 이전에는 "ConversationalPipeline" 클래스를 사용했지만, 이제는 이 기능이 [`TextGenerationPipeline`]에 통합되었습니다. 이번에는 파이프라인을 사용하여 `Zephyr` 예제를 다시 시도해 보겠습니다:
+
+```python
+from transformers import pipeline
+
+pipe = pipeline("text-generation", "HuggingFaceH4/zephyr-7b-beta")
+messages = [
+ {
+ "role": "system",
+ "content": "You are a friendly chatbot who always responds in the style of a pirate",
+ },
+ {"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
+]
+print(pipe(messages, max_new_tokens=128)[0]['generated_text'][-1]) # 어시스턴트의 응답을 출력합니다.
+```
+
+```text
+{'role': 'assistant', 'content': "Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all."}
+```
+
+파이프라인은 토큰화와 `apply_chat_template` 호출 의 세부 사항을 모두 처리해주기 때문에, 모델에 채팅 템플릿이 있으면 파이프라인을 초기화하고 메시지 목록을 전달하기만 하면 됩니다!
+
+
+## "생성 프롬프트"란 무엇인가요?[[what-are-generation-prompts]]
+
+`apply_chat_template` 메서드에는 `add_generation_prompt` 인수가 있다는 것을 눈치챘을 것입니다. 이 인수는 템플릿에 봇 응답의 시작을 나타내는 토큰을 추가하도록 지시합니다. 예를 들어, 다음과 같은 채팅을 고려해 보세요:
+
+```python
+messages = [
+ {"role": "user", "content": "Hi there!"},
+ {"role": "assistant", "content": "Nice to meet you!"},
+ {"role": "user", "content": "Can I ask a question?"}
+]
+```
+
+Zephyr 예제에서 보았던 것과 같이, 생성 프롬프트 없이 ChatML 템플릿을 사용한다면 다음과 같이 보일 것입니다:
+
+```python
+tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
+"""<|im_start|>user
+Hi there!<|im_end|>
+<|im_start|>assistant
+Nice to meet you!<|im_end|>
+<|im_start|>user
+Can I ask a question?<|im_end|>
+"""
+```
+
+생성 프롬프트가 **있는** 경우는 다음과 같습니다:
+
+```python
+tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
+"""<|im_start|>user
+Hi there!<|im_end|>
+<|im_start|>assistant
+Nice to meet you!<|im_end|>
+<|im_start|>user
+Can I ask a question?<|im_end|>
+<|im_start|>assistant
+"""
+```
+
+이번에는 봇 응답의 시작을 나타내는 토큰을 추가한 것을 주목하세요. 이렇게 하면 모델이 텍스트를 생성할 때 사용자의 메시지를 계속하는 대신 봇 응답을 작성하게 됩니다. 기억하세요, 채팅 모델은 여전히 언어 모델일 뿐이며, 그들에게 채팅은 특별한 종류의 텍스트일 뿐입니다! 적절한 제어 토큰으로 안내해야 채팅 모델이 무엇을 해야 하는지 알 수 있습니다.
+
+모든 모델이 생성 프롬프트를 필요로 하는 것은 아닙니다. BlenderBot과 LLaMA 같은 일부 모델은 봇 응답 전에 특별한 토큰이 없습니다. 이러한 경우 `add_generation_prompt` 인수는 효과가 없습니다. `add_generation_prompt`의 정확한 효과는 사용 중인 템플릿에 따라 다릅니다.
+
+
+
+## 채팅 템플릿을 훈련에 사용할 수 있나요?[[can-i-use-chat-templates-in-training]]
+
+네! 이 방법은 채팅 템플릿을 모델이 훈련 중에 보는 토큰과 일치하도록 하는 좋은 방법입니다. 데이터 세트에 대한 전처리 단계로 채팅 템플릿을 적용하는 것이 좋습니다. 그 후에는 다른 언어 모델 훈련 작업과 같이 계속할 수 있습니다. 훈련할 때는 일반적으로 `add_generation_prompt=False`로 설정해야 합니다. 어시스턴트 응답을 프롬프트하는 추가 토큰은 훈련 중에는 도움이 되지 않기 때문입니다. 예제를 보겠습니다:
+
+```python
+from transformers import AutoTokenizer
+from datasets import Dataset
+
+tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-beta")
+
+chat1 = [
+ {"role": "user", "content": "Which is bigger, the moon or the sun?"},
+ {"role": "assistant", "content": "The sun."}
+]
+chat2 = [
+ {"role": "user", "content": "Which is bigger, a virus or a bacterium?"},
+ {"role": "assistant", "content": "A bacterium."}
+]
+
+dataset = Dataset.from_dict({"chat": [chat1, chat2]})
+dataset = dataset.map(lambda x: {"formatted_chat": tokenizer.apply_chat_template(x["chat"], tokenize=False, add_generation_prompt=False)})
+print(dataset['formatted_chat'][0])
+```
+다음과 같은 결과를 얻을 수 있습니다:
+```text
+<|user|>
+Which is bigger, the moon or the sun?
+<|assistant|>
+The sun.
+```
+
+여기서부터는 일반적인 언어 모델 작업과 같이 `formatted_chat` 열을 사용하여 훈련을 계속하면 됩니다.
+
+
+`apply_chat_template(tokenize=False)`로 텍스트를 형식화한 다음 별도의 단계에서 토큰화하는 경우, `add_special_tokens=False` 인수를 설정해야 합니다. `apply_chat_template(tokenize=True)`를 사용하는 경우에는 이 문제를 걱정할 필요가 없습니다!
+기본적으로 일부 토크나이저는 토큰화할 때 `` 및 ``와 같은 특별 토큰을 추가합니다. 채팅 템플릿은 항상 필요한 모든 특별 토큰을 포함해야 하므로, 기본 `add_special_tokens=True`로 추가적인 특별 토큰을 추가하면 잘못되거나 중복되는 특별 토큰을 생성하여 모델 성능이 저하될 수 있습니다.
+
+
+## 고급: 채팅 템플릿에 추가 입력 사용[[advanced-extra-inputs-to-chat-templates]]
+
+`apply_chat_template`가 필요한 유일한 인수는 `messages`입니다. 그러나 `apply_chat_template`에 키워드 인수를 전달하면 템플릿 내부에서 사용할 수 있습니다. 이를 통해 채팅 템플릿을 다양한 용도로 사용할 수 있는 자유를 얻을 수 있습니다. 이러한 인수의 이름이나 형식에는 제한이 없어 문자열, 리스트, 딕셔너리 등을 전달할 수 있습니다.
+
+그렇긴 하지만, 이러한 추가 인수의 일반적인 사용 사례로 '함수 호출을 위한 도구'나 '검색 증강 생성을 위한 문서'를 전달하는 것이 있습니다. 이러한 일반적인 경우에 대해 인수의 이름과 형식에 대한 몇 가지 권장 사항이 있으며, 이는 아래 섹션에 설명되어 있습니다. 우리는 모델 작성자에게 도구 호출 코드를 모델 간에 쉽게 전송할 수 있도록 채팅 템플릿을 이 형식과 호환되도록 만들 것을 권장합니다.
+
+## 고급: 도구 사용 / 함수 호출[[advanced-tool-use--function-calling]]
+
+"도구 사용" LLM은 답변을 생성하기 전에 외부 도구로서 함수를 호출할 수 있습니다. 도구 사용 모델에 도구를 전달할 때는 단순히 함수 목록을 `tools` 인수로 전달할 수 있습니다:
+
+```python
+import datetime
+
+def current_time():
+ """현재 현지 시간을 문자열로 가져옵니다."""
+ return str(datetime.now())
+
+def multiply(a: float, b: float):
+ """
+ 두 숫자를 곱하는 함수
+
+ 인수:
+ a: 곱할 첫 번째 숫자
+ b: 곱할 두 번째 숫자
+ """
+ return a * b
+
+tools = [current_time, multiply]
+
+model_input = tokenizer.apply_chat_template(
+ messages,
+ tools=tools
+)
+```
+
+이것이 올바르게 작동하려면 함수를 위 형식으로 작성해야 도구로 올바르게 구문 분석할 수 있습니다. 구체적으로 다음 규칙을 따라야 합니다:
+
+- 함수는 설명적인 이름을 가져야 합니다.
+- 모든 인수에는 타입 힌트가 있어야 합니다.
+- 함수에는 표준 Google 스타일의 도크스트링이 있어야 합니다(즉, 초기 함수 설명 다음에 인수를 설명하는 `Args:` 블록이 있어야 합니다).
+- `Args:` 블록에는 타입을 포함하지 마세요. 즉, `a (int): The first number to multiply` 대신 `a: The first number to multiply`라고 작성해야 합니다. 타입 힌트는 함수 헤더에 있어야 합니다.
+- 함수에는 반환 타입과 도크스트링에 `Returns:` 블록이 있을 수 있습니다. 그러나 대부분의 도구 사용 모델은 이를 무시하므로 이는 선택 사항입니다.
+
+
+### 도구 결과를 모델에 전달하기[[passing-tool-results-to-the-model]]
+
+위의 예제 코드는 모델에 사용할 수 있는 도구를 나열하는 데 충분하지만, 실제로 사용하고자 하는 경우는 어떻게 해야 할까요? 이러한 경우에는 다음을 수행해야 합니다:
+
+1. 모델의 출력을 파싱하여 도구 이름과 인수를 가져옵니다.
+2. 모델의 도구 호출을 대화에 추가합니다.
+3. 해당 인수에 대응하는 함수를 호출합니다.
+4. 결과를 대화에 추가합니다.
+
+### 도구 사용 예제[[a-complete-tool-use-example]]
+
+도구 사용 예제를 단계별로 살펴보겠습니다. 이 예제에서는 도구 사용 모델 중에서 성능이 가장 우수한 8B `Hermes-2-Pro` 모델을 사용할 것입니다. 메모리가 충분하다면, 더 큰 모델인 [Command-R](https://huggingface.co/CohereForAI/c4ai-command-r-v01) 또는 [Mixtral-8x22B](https://huggingface.co/mistralai/Mixtral-8x22B-Instruct-v0.1)를 사용하는 것도 고려할 수 있습니다. 이 두 모델 모두 도구 사용을 지원하며 더 강력한 성능을 제공합니다.
+
+먼저 모델과 토크나이저를 로드해 보겠습니다:
+
+```python
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+checkpoint = "NousResearch/Hermes-2-Pro-Llama-3-8B"
+
+tokenizer = AutoTokenizer.from_pretrained(checkpoint, revision="pr/13")
+model = AutoModelForCausalLM.from_pretrained(checkpoint, torch_dtype=torch.bfloat16, device_map="auto")
+```
+
+다음으로, 도구 목록을 정의해 보겠습니다:
+
+```python
+def get_current_temperature(location: str, unit: str) -> float:
+ """
+ 특정 위치의 현재 온도를 가져옵니다.
+
+ 인수:
+ 위치: 온도를 가져올 위치, "도시, 국가" 형식
+ 단위: 온도 단위 (선택지: ["celsius", "fahrenheit"])
+ 반환값:
+ 지정된 위치의 현재 온도를 지정된 단위로 반환, float 형식.
+ """
+ return 22. # 이 함수는 실제로 온도를 가져와야 할 것입니다!
+
+def get_current_wind_speed(location: str) -> float:
+ """
+ 주어진 위치의 현재 풍속을 km/h 단위로 가져옵니다.
+
+ 인수:
+ 위치(location): 풍속을 가져올 위치, "도시, 국가" 형식
+ 반환값:
+ 주어진 위치의 현재 풍속을 km/h 단위로 반환, float 형식.
+ """
+ return 6. # 이 함수는 실제로 풍속을 가져와야 할 것입니다!
+
+tools = [get_current_temperature, get_current_wind_speed]
+```
+
+이제 봇을 위한 대화를 설정해 보겠습니다:
+
+```python
+messages = [
+ {"role": "system", "content": "You are a bot that responds to weather queries. You should reply with the unit used in the queried location."},
+ {"role": "user", "content": "Hey, what's the temperature in Paris right now?"}
+]
+```
+
+이제 채팅 템플릿을 적용하고 응답을 생성해 보겠습니다:
+
+```python
+inputs = tokenizer.apply_chat_template(messages, chat_template="tool_use", tools=tools, add_generation_prompt=True, return_dict=True, return_tensors="pt")
+inputs = {k: v.to(model.device) for k, v in inputs.items()}
+out = model.generate(**inputs, max_new_tokens=128)
+print(tokenizer.decode(out[0][len(inputs["input_ids"][0]):]))
+```
+
+결과는 다음과 같습니다:
+
+```text
+
+{"arguments": {"location": "Paris, France", "unit": "celsius"}, "name": "get_current_temperature"}
+<|im_end|>
+```
+
+모델이 함수 호출을 유효한 인수로 수행했으며, 함수 도크스트링에 요청된 형식으로 호출했음을 알 수 있습니다. 모델은 우리가 프랑스의 파리를 지칭하고 있다는 것을 추론했고, 프랑스가 SI 단위의 본고장임을 기억하여 온도를 섭씨로 표시해야 한다고 판단했습니다.
+
+모델의 도구 호출을 대화에 추가해 보겠습니다. 여기서 임의의 `tool_call_id`를 생성합니다. 이 ID는 모든 모델에서 사용되는 것은 아니지만, 여러 도구 호출을 한 번에 발행하고 각 응답이 어느 호출에 해당하는지 추적할 수 있게 해줍니다. 이 ID는 대화 내에서 고유해야 합니다.
+
+```python
+tool_call_id = "vAHdf3" # 임의의 ID, 각 도구 호출마다 고유해야 함
+tool_call = {"name": "get_current_temperature", "arguments": {"location": "Paris, France", "unit": "celsius"}}
+messages.append({"role": "assistant", "tool_calls": [{"id": tool_call_id, "type": "function", "function": tool_call}]})
+```
+
+
+이제 도구 호출을 대화에 추가했으므로, 함수를 호출하고 결과를 대화에 추가할 수 있습니다. 이 예제에서는 항상 22.0을 반환하는 더미 함수를 사용하고 있으므로, 결과를 직접 추가하면 됩니다. 다시 한 번, `tool_call_id`는 도구 호출에 사용했던 ID와 일치해야 합니다.
+
+```python
+messages.append({"role": "tool", "tool_call_id": tool_call_id, "name": "get_current_temperature", "content": "22.0"})
+```
+
+마지막으로, 어시스턴트가 함수 출력을 읽고 사용자와 계속 대화할 수 있도록 하겠습니다:
+
+```python
+inputs = tokenizer.apply_chat_template(messages, chat_template="tool_use", tools=tools, add_generation_prompt=True, return_dict=True, return_tensors="pt")
+inputs = {k: v.to(model.device) for k, v in inputs.items()}
+out = model.generate(**inputs, max_new_tokens=128)
+print(tokenizer.decode(out[0][len(inputs["input_ids"][0]):]))
+```
+
+결과는 다음과 같습니다:
+
+```text
+The current temperature in Paris, France is 22.0 ° Celsius.<|im_end|>
+```
+
+이것은 더미 도구와 단일 호출을 사용한 간단한 데모였지만, 동일한 기술을 사용하여 여러 실제 도구와 더 긴 대화를 처리할 수 있습니다. 이를 통해 실시간 정보, 계산 도구 또는 대규모 데이터베이스에 접근하여 대화형 에이전트의 기능을 확장할 수 있습니다.
+
+
+위에서 보여준 도구 호출 기능은 모든 모델에서 사용되는 것은 아닙니다. 일부 모델은 도구 호출 ID를 사용하고, 일부는 함수 이름만 사용하여 결과와 도구 호출을 순서에 따라 매칭하며, 혼동을 피하기 위해 한 번에 하나의 도구 호출만 발행하는 모델도 있습니다. 가능한 많은 모델과 호환되는 코드를 원한다면, 여기에 보여준 것처럼 도구 호출을 구성하고, 모델이 발행한 순서대로 도구 결과를 반환하는 것을 권장합니다. 각 모델의 채팅 템플릿이 나머지 작업을 처리할 것입니다.
+
+
+### 도구 스키마 이해하기[[understanding-tool-schemas]]
+
+`apply_chat_template`의 `tools` 인수에 전달하는 각 함수는 [JSON 스키마](https://json-schema.org/learn/getting-started-step-by-step)로 변환됩니다. 이러한 스키마는 모델 채팅 템플릿에 전달됩니다. 즉, 도구 사용 모델은 함수 자체를 직접 보지 않으며, 함수 내부의 실제 코드를 보지 않습니다. 도구 사용 모델이 관심을 가지는 것은 함수 **정의**와 **인수**입니다. 함수가 무엇을 하고 어떻게 사용하는지에 관심이 있을 뿐, 어떻게 작동하는지는 중요하지 않습니다! 모델의 출력을 읽고 모델이 도구 사용을 요청했는지 감지하여, 인수를 도구 함수에 전달하고 채팅에서 응답을 반환하는 것은 여러분의 몫입니다.
+
+위의 규격을 따른다면, 템플릿에 전달할 JSON 스키마 생성을 자동화하고 보이지 않게 처리하는 것이 좋습니다. 그러나 문제가 발생하거나 변환을 더 제어하고 싶다면 수동으로 변환을 처리할 수 있습니다. 다음은 수동 스키마 변환 예제입니다.
+
+```python
+from transformers.utils import get_json_schema
+
+def multiply(a: float, b: float):
+ """
+ 두 숫자를 곱하는 함수
+
+ 인수:
+ a: 곱할 첫 번째 숫자
+ b: 곱할 두 번째 숫자
+ """
+ return a * b
+
+schema = get_json_schema(multiply)
+print(schema)
+```
+
+이 결과는 다음과 같습니다:
+
+```json
+{
+ "type": "function",
+ "function": {
+ "name": "multiply",
+ "description": "A function that multiplies two numbers",
+ "parameters": {
+ "type": "object",
+ "properties": {
+ "a": {
+ "type": "number",
+ "description": "The first number to multiply"
+ },
+ "b": {
+ "type": "number",
+ "description": "The second number to multiply"
+ }
+ },
+ "required": ["a", "b"]
+ }
+ }
+}
+```
+
+원한다면 이러한 스키마를 편집하거나 `get_json_schema`를 전혀 사용하지 않고 처음부터 직접 작성할 수도 있습니다. JSON 스키마는 `apply_chat_template`의 `tools` 인수에 직접 전달할 수 있습니다. 이를 통해 더 복잡한 함수에 대한 정밀한 스키마를 정의할 수 있게 됩니다. 그러나 스키마가 복잡할수록 모델이 처리하는 데 혼란을 겪을 가능성이 높아집니다! 가능한 한 간단한 함수 서명을 유지하고, 인수(특히 복잡하고 중첩된 인수)를 최소화하는 것을 권장합니다.
+
+여기 직접 스키마를 정의하고 이를 `apply_chat_template`에 전달하는 예제가 있습니다:
+
+```python
+# 인수를 받지 않는 간단한 함수
+current_time = {
+ "type": "function",
+ "function": {
+ "name": "current_time",
+ "description": "Get the current local time as a string.",
+ "parameters": {
+ 'type': 'object',
+ 'properties': {}
+ }
+ }
+}
+
+# 두 개의 숫자 인수를 받는 더 완전한 함수
+multiply = {
+ 'type': 'function',
+ 'function': {
+ 'name': 'multiply',
+ 'description': 'A function that multiplies two numbers',
+ 'parameters': {
+ 'type': 'object',
+ 'properties': {
+ 'a': {
+ 'type': 'number',
+ 'description': 'The first number to multiply'
+ },
+ 'b': {
+ 'type': 'number', 'description': 'The second number to multiply'
+ }
+ },
+ 'required': ['a', 'b']
+ }
+ }
+}
+
+model_input = tokenizer.apply_chat_template(
+ messages,
+ tools = [current_time, multiply]
+)
+```
+
+## 고급: 검색 증강 생성[[advanced-retrieval-augmented-generation]]
+
+"검색 증강 생성" 또는 "RAG" LLM은 쿼리에 응답하기 전에 문서의 코퍼스를 검색하여 정보를 얻을 수 있습니다. 이를 통해 모델은 제한된 컨텍스트 크기 이상으로 지식 기반을 크게 확장할 수 있습니다. RAG 모델에 대한 우리의 권장 사항은 템플릿이 `documents` 인수를 허용해야 한다는 것입니다. 이 인수는 각 "문서"가 `title`과 `contents` 키를 가지는 단일 dict인 문서 목록이어야 합니다. 이 형식은 도구에 사용되는 JSON 스키마보다 훨씬 간단하므로 별도의 도우미 함수가 필요하지 않습니다.
+
+
+다음은 RAG 템플릿이 작동하는 예제입니다:
+
+
+```python
+document1 = {
+ "title": "The Moon: Our Age-Old Foe",
+ "contents": "Man has always dreamed of destroying the moon. In this essay, I shall..."
+}
+
+document2 = {
+ "title": "The Sun: Our Age-Old Friend",
+ "contents": "Although often underappreciated, the sun provides several notable benefits..."
+}
+
+model_input = tokenizer.apply_chat_template(
+ messages,
+ documents=[document1, document2]
+)
+```
+
+## 고급: 채팅 템플릿은 어떻게 작동하나요?[[advanced-how-do-chat-templates-work]]
+
+모델의 채팅 템플릿은 `tokenizer.chat_template` 속성에 저장됩니다. 채팅 템플릿이 설정되지 않은 경우 해당 모델 클래스의 기본 템플릿이 대신 사용됩니다. `BlenderBot`의 템플릿을 살펴보겠습니다:
+
+```python
+
+>>> from transformers import AutoTokenizer
+>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
+
+>>> tokenizer.chat_template
+"{% for message in messages %}{% if message['role'] == 'user' %}{{ ' ' }}{% endif %}{{ message['content'] }}{% if not loop.last %}{{ ' ' }}{% endif %}{% endfor %}{{ eos_token }}"
+```
+
+약간 복잡해 보일 수 있습니다. 읽기 쉽게 정리해 보겠습니다. 이 과정에서 추가하는 줄바꿈과 들여쓰기가 템플릿 출력에 포함되지 않도록 해야 합니다. 아래는 [공백을 제거하는](#trimming-whitespace) 팁입니다:
+
+```
+{%- for message in messages %}
+ {%- if message['role'] == 'user' %}
+ {{- ' ' }}
+ {%- endif %}
+ {{- message['content'] }}
+ {%- if not loop.last %}
+ {{- ' ' }}
+ {%- endif %}
+{%- endfor %}
+{{- eos_token }}
+```
+
+만약 이와 같은 형식을 처음 본다면, 이것은 [Jinja 템플릿](https://jinja.palletsprojects.com/en/3.1.x/templates/)입니다.
+Jinja는 텍스트를 생성하는 간단한 코드를 작성할 수 있는 템플릿 언어입니다. 많은 면에서 코드와 구문이 파이썬과 유사합니다. 순수 파이썬에서는 이 템플릿이 다음과 같이 보일 것입니다:
+
+
+```python
+for idx, message in enumerate(messages):
+ if message['role'] == 'user':
+ print(' ')
+ print(message['content'])
+ if not idx == len(messages) - 1: # Check for the last message in the conversation
+ print(' ')
+print(eos_token)
+```
+
+이 템플릿은 세 가지 일을 합니다:
+1. 각 메시지에 대해, 메시지가 사용자 메시지인 경우 공백을 추가하고, 그렇지 않으면 아무것도 출력하지 않습니다.
+2. 메시지 내용을 추가합니다.
+3. 메시지가 마지막 메시지가 아닌 경우 두 개의 공백을 추가합니다. 마지막 메시지 후에는 EOS 토큰을 출력합니다.
+
+이것은 매우 간단한 템플릿입니다. 제어 토큰을 추가하지 않으며, 이후 대화에서 모델이 어떻게 동작해야 하는지 지시하는 "시스템" 메시지를 지원하지 않습니다. 하지만 Jinja는 이러한 작업을 수행할 수 있는 많은 유연성을 제공합니다! LLaMA가 입력을 형식화하는 방식과 유사한 형식의 Jinja 템플릿을 살펴보겠습니다(실제 LLaMA 템플릿은 기본 시스템 메시지 처리와 일반적인 시스템 메시지 처리를 포함하고 있습니다 - 실제 코드에서는 이 템플릿을 사용하지 마세요!).
+
+```
+{%- for message in messages %}
+ {%- if message['role'] == 'user' %}
+ {{- bos_token + '[INST] ' + message['content'] + ' [/INST]' }}
+ {%- elif message['role'] == 'system' %}
+ {{- '<>\\n' + message['content'] + '\\n<>\\n\\n' }}
+ {%- elif message['role'] == 'assistant' %}
+ {{- ' ' + message['content'] + ' ' + eos_token }}
+ {%- endif %}
+{%- endfor %}
+```
+
+이 템플릿을 잠시 살펴보면 무엇을 하는지 이해할 수 있습니다. 먼저, 각 메시지의 "role"에 따라 특정 토큰을 추가하여 누가 메시지를 보냈는지 모델에게 명확하게 알려줍니다. 또한 사용자, 어시스턴트 및 시스템 메시지는 각각 고유한 토큰으로 래핑되어 모델이 명확하게 구분할 수 있습니다.
+
+## 고급: 채팅 템플릿 추가 및 편집[[advanced-adding-and-editing-chat-templates]]
+
+### 채팅 템플릿을 어떻게 만들 수 있나요?[[how-do-i-create-a-chat-template]]
+
+간단합니다. Jinja 템플릿을 작성하고 `tokenizer.chat_template`에 설정하기만 하면 됩니다. 다른 모델의 기존 템플릿을 시작점으로 사용하고 필요에 맞게 편집하는 것이 더 쉬울 것 입니다! 예를 들어, 위의 LLaMA 템플릿을 가져와 어시스턴트 메시지에 "[ASST]" 및 "[/ASST]"를 추가할 수 있습니다:
+
+```
+{%- for message in messages %}
+ {%- if message['role'] == 'user' %}
+ {{- bos_token + '[INST] ' + message['content'].strip() + ' [/INST]' }}
+ {%- elif message['role'] == 'system' %}
+ {{- '<>\\n' + message['content'].strip() + '\\n<>\\n\\n' }}
+ {%- elif message['role'] == 'assistant' %}
+ {{- '[ASST] ' + message['content'] + ' [/ASST]' + eos_token }}
+ {%- endif %}
+{%- endfor %}
+```
+
+이제 `tokenizer.chat_template` 속성을 설정하기만 하면 됩니다. 이렇게 하면 다음에 [`~PreTrainedTokenizer.apply_chat_template`]를 사용할 때 새롭게 설정한 템플릿이 사용됩니다! 이 속성은 `tokenizer_config.json` 파일에 저장되므로, [`~utils.PushToHubMixin.push_to_hub`]를 사용하여 새 템플릿을 허브에 업로드하고 모든 사용자가 모델에 맞는 템플릿을 사용할 수 있도록 할 수 있습니다!
+
+```python
+template = tokenizer.chat_template
+template = template.replace("SYS", "SYSTEM") # 시스템 토큰 변경
+tokenizer.chat_template = template # 새 템플릿 설정
+tokenizer.push_to_hub("model_name") # 새 템플릿을 허브에 업로드!
+```
+
+채팅 템플릿을 사용하는 [`~PreTrainedTokenizer.apply_chat_template`] 메소드는 [`TextGenerationPipeline`] 클래스에서 호출되므로, 올바른 채팅 템플릿을 설정하면 모델이 자동으로 [`TextGenerationPipeline`]과 호환됩니다.
+
+
+모델을 채팅 용도로 미세 조정하는 경우, 채팅 템플릿을 설정하는 것 외에도 새 채팅 제어 토큰을 토크나이저에 특별 토큰으로 추가하는 것이 좋습니다. 특별 토큰은 절대로 분할되지 않으므로, 제어 토큰이 여러 조각으로 토큰화되는 것을 방지합니다. 또한, 템플릿에서 어시스턴트 생성의 끝을 나타내는 토큰으로 토크나이저의 `eos_token` 속성을 설정해야 합니다. 이렇게 하면 텍스트 생성 도구가 텍스트 생성을 언제 중지해야 할지 정확히 알 수 있습니다.
+
+
+
+### 왜 일부 모델은 여러 개의 템플릿을 가지고 있나요?[[why-do-some-models-have-multiple-templates]]
+
+일부 모델은 다른 사용 사례에 대해 다른 템플릿을 사용합니다. 예를 들어, 일반 채팅을 위한 템플릿과 도구 사용 또는 검색 증강 생성에 대한 템플릿을 별도로 사용할 수 있습니다. 이러한 경우 `tokenizer.chat_template`는 딕셔너리입니다. 이것은 약간의 혼란을 초래할 수 있으며, 가능한 한 모든 사용 사례에 대해 단일 템플릿을 사용하는 것을 권장합니다. `if tools is defined`와 같은 Jinja 문장과 `{% macro %}` 정의를 사용하여 여러 코드 경로를 단일 템플릿에 쉽게 래핑할 수 있습니다.
+
+토크나이저에 여러 개의 템플릿이 있는 경우, `tokenizer.chat_template`는 템플릿 이름이 키인 `딕셔너리`입니다. `apply_chat_template` 메소드는 특정 템플릿 이름에 대한 특별한 처리를 합니다: 일반적으로 `default`라는 템플릿을 찾고, 찾을 수 없으면 오류를 발생시킵니다. 그러나 사용자가 `tools` 인수를 전달할 때 `tool_use`라는 템플릿이 존재하면 대신 그것을 사용합니다. 다른 이름의 템플릿에 접근하려면 `apply_chat_template()`의 `chat_template` 인수에 원하는 템플릿 이름을 전달하면 됩니다.
+
+사용자에게 약간의 혼란을 줄 수 있으므로, 템플릿을 직접 작성하는 경우 가능한 한 단일 템플릿에 모든 것을 넣는 것을 권장합니다!
+
+### 어떤 템플릿을 사용해야 하나요?[[what-template-should-i-use]]
+
+이미 채팅용으로 훈련된 모델에 템플릿을 설정할 때는 템플릿이 훈련 중 모델이 본 메시지 형식과 정확히 일치하도록 해야 합니다. 그렇지 않으면 성능 저하를 경험할 가능성이 큽니다. 이는 모델을 추가로 훈련할 때도 마찬가지입니다. 채팅 토큰을 일정하게 유지하는 것이 최상의 성능을 얻는 방법입니다. 이는 토큰화와 매우 유사합니다. 훈련 중에 사용된 토큰화를 정확히 일치시킬 때 추론이나 미세 조정에서 최고의 성능을 얻을 수 있습니다.
+
+반면에 처음부터 모델을 훈련시키거나 채팅용으로 기본 언어 모델을 미세 조정하는 경우, 적절한 템플릿을 선택할 수 있는 많은 자유가 있습니다. LLM은 다양한 입력 형식을 처리할 만큼 충분히 똑똑합니다. 인기 있는 선택 중 하나는 `ChatML` 형식이며, 이는 많은 사용 사례에 유연하게 사용할 수 있는 좋은 선택입니다. 다음과 같습니다:
+
+```
+{%- for message in messages %}
+ {{- '<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n' }}
+{%- endfor %}
+```
+
+이 템플릿이 마음에 든다면, 코드에 바로 복사하여 사용할 수 있는 한 줄 버전을 제공하겠습니다. 이 한 줄 버전은 [생성 프롬프트](#what-are-generation-prompts)에 대한 편리한 지원도 포함하고 있지만, BOS나 EOS 토큰을 추가하지 않는다는 점에 유의하세요! 모델이 해당 토큰을 기대하더라도, `apply_chat_template`에 의해 자동으로 추가되지 않습니다. 즉, 텍스트는 `add_special_tokens=False`에 의해 토큰화됩니다. 이는 템플릿과 `add_special_tokens` 논리 간의 잠재적인 충돌을 피하기 위함입니다. 모델이 특별 토큰을 기대하는 경우, 템플릿에 직접 추가해야 합니다!
+
+
+```python
+tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
+```
+
+이 템플릿은 각 메시지를 `<|im_start|>` 와 `<|im_end|>`토큰으로 감싸고, 역할을 문자열로 작성하여 훈련 시 사용하는 역할에 대한 유연성을 제공합니다. 출력은 다음과 같습니다:
+
+
+```text
+<|im_start|>system
+You are a helpful chatbot that will do its best not to say anything so stupid that people tweet about it.<|im_end|>
+<|im_start|>user
+How are you?<|im_end|>
+<|im_start|>assistant
+I'm doing great!<|im_end|>
+```
+
+"사용자", "시스템" 및 "어시스턴트" 역할은 채팅의 표준이며, 가능할 때 이를 사용하는 것을 권장합니다. 특히 모델이 [`TextGenerationPipeline`]과 잘 작동하도록 하려면 그렇습니다. 그러나 이러한 역할에만 국한되지 않습니다. 템플릿은 매우 유연하며, 어떤 문자열이든 역할로 사용할 수 있습니다.
+
+
+
+### 채팅 템플릿을 추가하고 싶습니다! 어떻게 시작해야 하나요?[[i-want-to-add-some-chat-templates-how-should-i-get-started]]
+
+채팅 모델이 있는 경우, 해당 모델의 `tokenizer.chat_template` 속성을 설정하고 [`~PreTrainedTokenizer.apply_chat_template`]를 사용하여 테스트한 다음 업데이트된 토크나이저를 허브에 푸시해야 합니다. 이는 모델 소유자가 아닌 경우에도 적용됩니다. 빈 채팅 템플릿을 사용하는 모델이나 여전히 기본 클래스 템플릿을 사용하는 모델을 사용하는 경우, [풀 리퀘스트](https://huggingface.co/docs/hub/repositories-pull-requests-discussions)를 모델 리포지토리에 열어 이 속성을 올바르게 설정할 수 있도록 하세요!
+
+속성을 설정하면 끝입니다! `tokenizer.apply_chat_template`가 이제 해당 모델에 대해 올바르게 작동하므로, `TextGenerationPipeline`과 같은 곳에서도 자동으로 지원됩니다!
+
+모델에 이 속성을 설정함으로써, 오픈 소스 모델의 전체 기능을 커뮤니티가 사용할 수 있도록 할 수 있습니다. 형식 불일치는 이 분야에서 오랫동안 성능을 저하시키는 문제였으므로, 이제 이를 끝낼 때입니다!
+
+## 고급: 템플릿 작성 팁[[advanced-template-writing-tips]]
+
+Jinja에 익숙하지 않은 경우, 채팅 템플릿을 작성하는 가장 쉬운 방법은 먼저 메시지를 원하는 방식으로 형식화하는 짧은 파이썬 스크립트를 작성한 다음, 해당 스크립트를 템플릿으로 변환하는 것입니다.
+
+템플릿 핸들러는 `messages`라는 변수로 대화 기록을 받습니다. 파이썬에서와 마찬가지로 템플릿 내의 `messages`에 접근할 수 있으며, `{% for message in messages %}`로 반복하거나 `{{ messages[0] }}`와 같이 개별 메시지에 접근할 수 있습니다.
+
+다음 팁을 사용하여 코드를 Jinja로 변환할 수도 있습니다:
+
+### 공백 제거[[trimming-whitespace]]
+
+기본적으로 Jinja는 블록 전후의 공백을 출력합니다. 이는 일반적으로 공백을 매우 정확하게 다루고자 하는 채팅 템플릿에서는 문제가 될 수 있습니다! 이를 피하기 위해 템플릿을 다음과 같이 작성하는 것이 좋습니다:
+
+```
+{%- for message in messages %}
+ {{- message['role'] + message['content'] }}
+{%- endfor %}
+```
+
+아래와 같이 작성하지 마세요:
+
+```
+{% for message in messages %}
+ {{ message['role'] + message['content'] }}
+{% endfor %}
+```
+
+`-`를 추가하면 블록 전후의 공백이 제거됩니다. 두 번째 예제는 무해해 보이지만, 줄바꿈과 들여쓰기가 출력에 포함될 수 있으며, 이는 원하지 않는 결과일 수 있습니다!
+
+### 반복문[[for-loops]]
+
+Jinja에서 반복문은 다음과 같습니다:
+
+```
+{%- for message in messages %}
+ {{- message['content'] }}
+{%- endfor %}
+```
+
+{{ 표현식 블록 }} 내부에 있는 모든 것이 출력으로 인쇄됩니다. `+`와 같은 연산자를 사용하여 표현식 블록 내부에서 문자열을 결합할 수 있습니다.
+
+### 조건문[[if-statements]]
+
+Jinja에서 조건문은 다음과 같습니다:
+
+```
+{%- if message['role'] == 'user' %}
+ {{- message['content'] }}
+{%- endif %}
+```
+
+파이썬이 공백을 사용하여 `for` 및 `if` 블록의 시작과 끝을 표시하는 반면, Jinja는 `{% endfor %}` 및 `{% endif %}`로 명시적으로 끝을 표시해야 합니다.
+
+### 특수 변수[[special-variables]]
+
+템플릿 내부에서는 `messages` 목록에 접근할 수 있을 뿐만 아니라 여러 다른 특수 변수에도 접근할 수 있습니다. 여기에는 `bos_token` 및 `eos_token`과 같은 특별 토큰과 앞서 논의한 `add_generation_prompt` 변수가 포함됩니다. 또한 `loop` 변수를 사용하여 현재 반복에 대한 정보를 얻을 수 있으며, 예를 들어 `{% if loop.last %}`를 사용하여 현재 메시지가 대화의 마지막 메시지인지 확인할 수 있습니다. `add_generation_prompt`가 `True`인 경우 대화 끝에 생성 프롬프트를 추가하는 예제는 다음과 같습니다:
+
+```
+{%- if loop.last and add_generation_prompt %}
+ {{- bos_token + 'Assistant:\n' }}
+{%- endif %}
+```
+
+### 비파이썬 Jinja와의 호환성[[compatibility-with-non-python-jinja]]
+
+Jinja의 여러 구현은 다양한 언어로 제공됩니다. 일반적으로 동일한 구문을 사용하지만, 주요 차이점은 파이썬에서 템플릿을 작성할 때 파이썬 메소드를 사용할 수 있다는 점입니다. 예를 들어, 문자열에 `.lower()`를 사용하거나 딕셔너리에 `.items()`를 사용하는 것입니다. 이는 비파이썬 Jinja 구현에서 템플릿을 사용하려고 할 때 문제가 발생할 수 있습니다. 특히 JS와 Rust가 인기 있는 배포 환경에서는 비파이썬 구현이 흔합니다.
+
+하지만 걱정하지 마세요! 모든 Jinja 구현에서 호환성을 보장하기 위해 템플릿을 쉽게 변경할 수 있는 몇 가지 방법이 있습니다:
+
+- 파이썬 메소드를 Jinja 필터로 대체하세요. 일반적으로 같은 이름을 가지며, 예를 들어 `string.lower()`는 `string|lower`로, `dict.items()`는 `dict|items`로 대체할 수 있습니다. 주목할 만한 변경 사항은 `string.strip()`이 `string|trim`으로 바뀌는 것입니다. 더 자세한 내용은 Jinja 문서의 [내장 필터 목록](https://jinja.palletsprojects.com/en/3.1.x/templates/#builtin-filters)을 참조하세요.
+- 파이썬에 특화된 `True`, `False`, `None`을 각각 `true`, `false`, `none`으로 대체하세요.
+- 딕셔너리나 리스트를 직접 렌더링할 때 다른 구현에서는 결과가 다를 수 있습니다(예: 문자열 항목이 단일 따옴표에서 이중 따옴표로 변경될 수 있습니다). `tojson` 필터를 추가하면 일관성을 유지하는 데 도움이 됩니다.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/community.md b/docs/transformers/docs/source/ko/community.md
new file mode 100644
index 0000000000000000000000000000000000000000..d50168d7548620805d06b2aa06190bbbc8d4d936
--- /dev/null
+++ b/docs/transformers/docs/source/ko/community.md
@@ -0,0 +1,69 @@
+
+
+# 커뮤니티 [[community]]
+
+이 페이지는 커뮤니티에서 개발한 🤗 Transformers 리소스를 재구성한 페이지입니다.
+
+## 커뮤니티 리소스: [[community-resources]]
+
+| 리소스 | 설명 | 만든이 |
+|:----------|:-------------|------:|
+| [Hugging Face Transformers 용어집 플래시카드](https://www.darigovresearch.com/huggingface-transformers-glossary-flashcards) | [Transformers 문서 용어집](glossary)을 기반으로 한 플래시카드 세트로, 지식을 장기적으로 유지하기 위해 특별히 설계된 오픈소스 크로스 플랫폼 앱인 [Anki](https://apps.ankiweb.net/)를 사용하여 쉽게 학습/수정할 수 있는 형태로 제작되었습니다. [플래시카드 사용법에 대한 소개 동영상](https://www.youtube.com/watch?v=Dji_h7PILrw)을 참조하세요. | [Darigov 리서치](https://www.darigovresearch.com/) |
+
+## 커뮤니티 노트북: [[community-notebooks]]
+
+| 노트북 | 설명 | 만든이 | |
+|:----------|:-------------|:-------------|------:|
+| [가사를 생성하기 위해 사전훈련된 트랜스포머를 미세 조정하기](https://github.com/AlekseyKorshuk/huggingartists) | GPT-2 모델을 미세 조정하여 좋아하는 아티스트의 스타일로 가사를 생성하는 방법 | [Aleksey Korshuk](https://github.com/AlekseyKorshuk) | [](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb) |
+| [Tensorflow 2로 T5 훈련하기](https://github.com/snapthat/TF-T5-text-to-text) | Tensorflow 2를 사용하여 T5를 훈련시키는 방법. 이 노트북은 Tensorflow 2로 SQUAD를 사용하여 구현한 질의응답 작업을 보여줍니다. | [Muhammad Harris](https://github.com/HarrisDePerceptron) |[](https://colab.research.google.com/github/snapthat/TF-T5-text-to-text/blob/master/snapthatT5/notebooks/TF-T5-Datasets%20Training.ipynb) |
+| [TPU에서 T5 훈련하기](https://github.com/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb) | Transformers와 Nlp를 사용하여 SQUAD로 T5를 훈련하는 방법 | [Suraj Patil](https://github.com/patil-suraj) |[](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb#scrollTo=QLGiFCDqvuil) |
+| [분류 및 객관식 문제를 위해 T5 미세 조정하기](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) | 분류 및 객관식 문제에 맞게 텍스트-텍스트 형식을 사용하여 PyTorch Lightning으로 T5를 미세 조정하는 방법 | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) |
+| [새로운 데이터 세트와 언어로 DialoGPT 미세 조정하기](https://github.com/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) | 자유 대화형 챗봇을 만들기 위해 새로운 데이터 세트로 DialoGPT 모델을 미세 조정하는 방법 | [Nathan Cooper](https://github.com/ncoop57) | [](https://colab.research.google.com/github/ncoop57/i-am-a-nerd/blob/master/_notebooks/2020-05-12-chatbot-part-1.ipynb) |
+| [Reformer로 긴 시퀀스 모델링하기](https://github.com/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) | Reformer로 최대 50만 토큰의 시퀀스를 훈련하는 방법 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/PyTorch_Reformer.ipynb) |
+| [요약을 위해 BART 미세 조정하기](https://github.com/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb) | blurr를 사용하여 fastai로 요약하기 위해 BART를 미세 조정하는 방법 | [Wayde Gilliam](https://ohmeow.com/) | [](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb) |
+| [다른 사람의 트윗으로 사전훈련된 트랜스포머 미세 조정하기](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) | GPT-2 모델을 미세 조정하여 좋아하는 트위터 계정 스타일로 트윗을 생성하는 방법 | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) |
+| [Weights & Biases로 🤗 Hugging Face 모델 최적화하기](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) | W&B와 Hugging Face의 통합을 보여주는 전체 튜토리얼 | [Boris Dayma](https://github.com/borisdayma) | [](https://colab.research.google.com/github/wandb/examples/blob/master/colabs/huggingface/Optimize_Hugging_Face_models_with_Weights_%26_Biases.ipynb) |
+| [Longformer 사전훈련하기](https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) | 기존 사전훈련된 모델의 "긴" 버전을 빌드하는 방법 | [Iz Beltagy](https://beltagy.net) | [](https://colab.research.google.com/github/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) |
+| [QA를 위해 Longformer 미세 조정하기](https://github.com/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) | QA 작업을 위해 Longformer를 미세 조정하는 방법 | [Suraj Patil](https://github.com/patil-suraj) | [](https://colab.research.google.com/github/patil-suraj/Notebooks/blob/master/longformer_qa_training.ipynb) |
+| [🤗 Nlp로 모델 평가하기](https://github.com/patrickvonplaten/notebooks/blob/master/How_to_evaluate_Longformer_on_TriviaQA_using_NLP.ipynb) | `Nlp`로 TriviaQA에서 Longformer를 평가하는 방법 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1m7eTGlPmLRgoPkkA7rkhQdZ9ydpmsdLE?usp=sharing) |
+| [감정 범위 추출을 위해 T5 미세 조정하기](https://github.com/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) | 감정 범위 추출을 위해 텍스트-텍스트 형식을 사용하여 PyTorch Lightning으로 T5를 미세 조정하는 방법 | [Lorenzo Ampil](https://github.com/enzoampil) | [](https://colab.research.google.com/github/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) |
+| [다중 클래스 분류를 위해 DistilBert 미세 조정하기](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb) | 다중 클래스 분류를 위해 PyTorch를 사용하여 DistilBert를 미세 조정하는 방법 | [Abhishek Kumar Mishra](https://github.com/abhimishra91) | [](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multiclass_classification.ipynb)|
+| [다중 레이블 분류를 위해 BERT 미세 조정하기](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb) | 다중 레이블 분류를 위해 PyTorch를 사용하여 BERT를 미세 조정하는 방법 | [Abhishek Kumar Mishra](https://github.com/abhimishra91) | [](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)|
+| [요약을 위해 T5 미세 조정하기](https://github.com/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb) | 요약을 위해 PyTorch로 T5를 미세 조정하고 WandB로 실험을 추적하는 방법 | [Abhishek Kumar Mishra](https://github.com/abhimishra91) | [](https://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_summarization_wandb.ipynb)|
+| [동적 패딩/버켓팅으로 Transformers 미세 조정 속도 높이기](https://github.com/ELS-RD/transformers-notebook/blob/master/Divide_Hugging_Face_Transformers_training_time_by_2_or_more.ipynb)| 동적 패딩/버켓팅을 사용하여 미세 조정 속도를 2배로 높이는 방법 |[Michael Benesty](https://github.com/pommedeterresautee) |[](https://colab.research.google.com/drive/1CBfRU1zbfu7-ijiOqAAQUA-RJaxfcJoO?usp=sharing)|
+|[마스킹된 언어 모델링을 위해 Reformer 사전훈련하기](https://github.com/patrickvonplaten/notebooks/blob/master/Reformer_For_Masked_LM.ipynb)| 양방향 셀프 어텐션 레이어를 이용해서 Reformer 모델을 훈련하는 방법 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/drive/1tzzh0i8PgDQGV3SMFUGxM7_gGae3K-uW?usp=sharing)|
+| [Sci-BERT 확장 및 미세 조정하기](https://github.com/lordtt13/word-embeddings/blob/master/COVID-19%20Research%20Data/COVID-SciBERT.ipynb)| CORD 데이터 세트로 AllenAI에서 사전훈련된 SciBERT 모델의 어휘를 늘리고 파이프라인을 구축하는 방법 | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/1rqAR40goxbAfez1xvF3hBJphSCsvXmh8)|
+| [요약을 위해 Trainer API로 BlenderBotSmall 미세 조정하기](https://github.com/lordtt13/transformers-experiments/blob/master/Custom%20Tasks/fine-tune-blenderbot_small-for-summarization.ipynb)| 요약을 위해 Trainer API를 사용하여 사용자 지정 데이터 세트로 BlenderBotSmall 미세 조정하기 | [Tanmay Thakur](https://github.com/lordtt13) | [](https://colab.research.google.com/drive/19Wmupuls7mykSGyRN_Qo6lPQhgp56ymq?usp=sharing)|
+| [통합 기울기(Integrated Gradient)를 이용하여 Electra 미세 조정하고 해석하기](https://github.com/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb) | 감정 분석을 위해 Electra를 미세 조정하고 Captum 통합 기울기로 예측을 해석하는 방법 | [Eliza Szczechla](https://elsanns.github.io) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/electra_fine_tune_interpret_captum_ig.ipynb)|
+| [Trainer 클래스로 비영어권 GPT-2 모델 미세 조정하기](https://github.com/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb) | Trainer 클래스로 비영어권 GPT-2 모델을 미세 조정하는 방법 | [Philipp Schmid](https://www.philschmid.de) | [](https://colab.research.google.com/github/philschmid/fine-tune-GPT-2/blob/master/Fine_tune_a_non_English_GPT_2_Model_with_Huggingface.ipynb)|
+|[다중 라벨 분류 작업을 위해 DistilBERT 모델 미세 조정하기](https://github.com/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb) | 다중 라벨 분류 작업을 위해 DistilBERT 모델을 미세 조정하는 방법 | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/Transformers_scripts/blob/master/Transformers_multilabel_distilbert.ipynb)|
+|[문장쌍 분류를 위해 ALBERT 미세 조정하기](https://github.com/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb) | 문장쌍 분류 작업을 위해 ALBERT 모델 또는 다른 BERT 기반 모델을 미세 조정하는 방법 | [Nadir El Manouzi](https://github.com/NadirEM) | [](https://colab.research.google.com/github/NadirEM/nlp-notebooks/blob/master/Fine_tune_ALBERT_sentence_pair_classification.ipynb)|
+|[감정 분석을 위해 Roberta 미세 조정하기](https://github.com/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb) | 감정 분석을 위해 Roberta 모델을 미세 조정하는 방법 | [Dhaval Taunk](https://github.com/DhavalTaunk08) | [](https://colab.research.google.com/github/DhavalTaunk08/NLP_scripts/blob/master/sentiment_analysis_using_roberta.ipynb)|
+|[질문 생성 모델 평가하기](https://github.com/flexudy-pipe/qugeev) | seq2seq 트랜스포머 모델이 생성한 질문과 이에 대한 답변이 얼마나 정확한가요? | [Pascal Zoleko](https://github.com/zolekode) | [](https://colab.research.google.com/drive/1bpsSqCQU-iw_5nNoRm_crPq6FRuJthq_?usp=sharing)|
+|[DistilBERT와 Tensorflow로 텍스트 분류하기](https://github.com/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb) | 텍스트 분류를 위해 TensorFlow로 DistilBERT를 미세 조정하는 방법 | [Peter Bayerle](https://github.com/peterbayerle) | [](https://colab.research.google.com/github/peterbayerle/huggingface_notebook/blob/main/distilbert_tf.ipynb)|
+|[CNN/Dailail 요약을 위해 인코더-디코더 모델에 BERT 활용하기](https://github.com/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb) | CNN/Dailail 요약을 위해 *google-bert/bert-base-uncased* 체크포인트를 활용하여 *EncoderDecoderModel*을 워밍업하는 방법 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)|
+|[BBC XSum 요약을 위해 인코더-디코더 모델에 RoBERTa 활용하기](https://github.com/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb) | BBC/XSum 요약을 위해 *FacebookAI/roberta-base* 체크포인트를 활용하여 공유 *EncoderDecoderModel*을 워밍업하는 방법 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/RoBERTaShared_for_BBC_XSum.ipynb)|
+|[순차적 질문 답변(SQA)을 위해 TAPAS 미세 조정하기](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb) | *tapas-base* 체크포인트를 활용하여 순차적 질문 답변(SQA) 데이터 세트로 *TapasForQuestionAnswering*을 미세 조정하는 방법 | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Fine_tuning_TapasForQuestionAnswering_on_SQA.ipynb)|
+|[표 사실 검사(TabFact)로 TAPAS 평가하기](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb) | 🤗 Datasets와 🤗 Transformer 라이브러리를 함께 사용하여 *tapas-base-finetuned-tabfact* 체크포인트로 미세 조정된 *TapasForSequenceClassification*을 평가하는 방법 | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/TAPAS/Evaluating_TAPAS_on_the_Tabfact_test_set.ipynb)|
+|[번역을 위해 mBART 미세 조정하기](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb) | 힌디어에서 영어로 번역하기 위해 Seq2SeqTrainer를 사용하여 mBART를 미세 조정하는 방법 | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb)|
+|[FUNSD(양식 이해 데이터 세트)로 LayoutLM 미세 조정하기](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb) | 스캔한 문서에서 정보 추출을 위해 FUNSD 데이터 세트로 *LayoutLMForTokenClassification*을 미세 조정하는 방법 | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForTokenClassification_on_FUNSD.ipynb)|
+|[DistilGPT2 미세 조정하고 및 텍스트 생성하기](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb) | DistilGPT2를 미세 조정하고 텍스트를 생성하는 방법 | [Aakash Tripathi](https://github.com/tripathiaakash) | [](https://colab.research.google.com/github/tripathiaakash/DistilGPT2-Tutorial/blob/main/distilgpt2_fine_tuning.ipynb)|
+|[최대 8K 토큰에서 LED 미세 조정하기](https://github.com/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb) | 긴 범위를 요약하기 위해 PubMed로 LED를 미세 조정하는 방법 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb)|
+|[Arxiv로 LED 평가하기](https://github.com/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb) | 긴 범위 요약에 대해 LED를 효과적으로 평가하는 방법 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/LED_on_Arxiv.ipynb)|
+|[RVL-CDIP(문서 이미지 분류 데이터 세트)로 LayoutLM 미세 조정하기)](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb) | 스캔 문서 분류를 위해 RVL-CDIP 데이터 세트로 *LayoutLMForSequenceClassification*을 미세 조정하는 방법 | [Niels Rogge](https://github.com/nielsrogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/LayoutLM/Fine_tuning_LayoutLMForSequenceClassification_on_RVL_CDIP.ipynb)|
+|[GPT2 조정을 통한 Wav2Vec2 CTC 디코딩](https://github.com/voidful/huggingface_notebook/blob/main/xlsr_gpt.ipynb) | 언어 모델 조정을 통해 CTC 시퀀스를 디코딩하는 방법 | [Eric Lam](https://github.com/voidful) | [](https://colab.research.google.com/drive/1e_z5jQHYbO2YKEaUgzb1ww1WwiAyydAj?usp=sharing)|
+|[Trainer 클래스로 두 개 언어로 요약하기 위해 BART 미세 조정하기](https://github.com/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb) | Trainer 클래스로 두 개 언어로 요약하기 위해 BART 미세 조정하는 방법 | [Eliza Szczechla](https://github.com/elsanns) | [](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb)|
+|[Trivia QA로 Big Bird 평가하기](https://github.com/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb) | Trivia QA로 긴 문서 질문에 대한 답변에 대해 BigBird를 평가하는 방법 | [Patrick von Platen](https://github.com/patrickvonplaten) | [](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb)|
+| [Wav2Vec2를 사용하여 동영상 캡션 만들기](https://github.com/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) | Wav2Vec으로 오디오를 텍스트로 변환하여 모든 동영상에서 YouTube 캡션 만드는 방법 | [Niklas Muennighoff](https://github.com/Muennighoff) |[](https://colab.research.google.com/github/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb) |
+| [PyTorch Lightning을 사용하여 CIFAR-10으로 비전 트랜스포머 미세 조정하기](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) | HuggingFace Transformers, Datasets, PyTorch Lightning을 사용하여 CIFAR-10으로 비전 트랜스포머(ViT)를 미세 조정하는 방법 | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb) |
+| [🤗 Trainer를 사용하여 CIFAR-10에서 비전 트랜스포머 미세 조정하기](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) | Datasets, 🤗 Trainer를 사용하여 CIFAR-10에서 비전 트랜스포머(ViT)를 미세 조정하는 방법 | [Niels Rogge](https://github.com/nielsrogge) |[](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb) |
+| [개체 입력 데이터 세트인 Open Entity로 LUKE 평가하기](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) | Open Entity 데이터 세트로 *LukeForEntityClassification*을 평가하는 방법 | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_open_entity.ipynb) |
+| [관계 추출 데이터 세트인 TACRED로 LUKE 평가하기](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) | TACRED 데이터 세트로 *LukeForEntityPairClassification*을 평가하는 방법 | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_tacred.ipynb) |
+| [중요 NER 벤치마크인 CoNLL-2003으로 LUKE 평가하기](https://github.com/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) | CoNLL-2003 데이터 세트로 *LukeForEntitySpanClassification*를 평가하는 방법 | [Ikuya Yamada](https://github.com/ikuyamada) |[](https://colab.research.google.com/github/studio-ousia/luke/blob/master/notebooks/huggingface_conll_2003.ipynb) |
+| [PubMed 데이터 세트로 BigBird-Pegasus 평가하기](https://github.com/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) | PubMed 데이터 세트로 *BigBirdPegasusForConditionalGeneration*를 평가하는 방법 | [Vasudev Gupta](https://github.com/vasudevgupta7) | [](https://colab.research.google.com/github/vasudevgupta7/bigbird/blob/main/notebooks/bigbird_pegasus_evaluation.ipynb) |
+| [Wav2Vec2를 사용해서 음성 감정 분류하기](https://github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) | 감정 분류를 위해 사전훈련된 Wav2Vec2 모델을 MEGA 데이터 세트에 활용하는 방법 | [Mehrdad Farahani](https://github.com/m3hrdadfi) | [](https://colab.research.google.com/github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb) |
+| [DETR로 이미지에서 객체 탐지하기](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) | 훈련된 *DetrForObjectDetection* 모델을 사용하여 이미지에서 객체를 탐지하고 어텐션을 시각화하는 방법 | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb) |
+| [사용자 지정 객체 탐지 데이터 세트로 DETR 미세 조정하기](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) | 사용자 지정 객체 탐지 데이터 세트로 *DetrForObjectDetection*을 미세 조정하는 방법 | [Niels Rogge](https://github.com/NielsRogge) | [](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/Fine_tuning_DetrForObjectDetection_on_custom_dataset_(balloon).ipynb) |
+| [개체명 인식을 위해 T5 미세 조정하기](https://github.com/ToluClassics/Notebooks/blob/main/T5_Ner_Finetuning.ipynb) | 개체명 인식 작업을 위해 *T5*를 미세 조정하는 방법 | [Ogundepo Odunayo](https://github.com/ToluClassics) | [](https://colab.research.google.com/drive/1obr78FY_cBmWY5ODViCmzdY6O1KB65Vc?usp=sharing) |
diff --git a/docs/transformers/docs/source/ko/contributing.md b/docs/transformers/docs/source/ko/contributing.md
new file mode 100644
index 0000000000000000000000000000000000000000..f1c0a84ef32d848467026a812eaf776c2222a7fe
--- /dev/null
+++ b/docs/transformers/docs/source/ko/contributing.md
@@ -0,0 +1,330 @@
+
+
+# 🤗 Transformers에 기여하기 [[contribute-to-transformers]]
+
+누구나 🤗 Transformers에 기여할 수 있으며, 우리는 모든 사람의 기여를 소중히 생각합니다. 코드 기여는 커뮤니티를 돕는 유일한 방법이 아닙니다. 질문에 답하거나 다른 사람을 도와 문서를 개선하는 것도 매우 가치가 있습니다.
+
+🤗 Transformers를 널리 알리는 것도 큰 도움이 됩니다! 멋진 프로젝트들을 가능하게 한 🤗 Transformers 라이브러리에 대해 블로그 게시글에 언급하거나, 도움이 되었을 때마다 Twitter에 알리거나, 저장소에 ⭐️ 를 표시하여 감사 인사를 전해주세요.
+
+어떤 방식으로 기여하든 [행동 규칙](https://github.com/huggingface/transformers/blob/main/CODE_OF_CONDUCT.md)을 숙지하고 존중해주세요.
+
+**이 안내서는 멋진 [scikit-learn 기여 안내서](https://github.com/scikit-learn/scikit-learn/blob/main/CONTRIBUTING.md)에서 큰 영감을 받았습니다.**
+
+## 기여하는 방법 [[ways-to-contribute]]
+
+여러 가지 방법으로 🤗 Transformers에 기여할 수 있습니다:
+
+* 기존 코드의 미해결된 문제를 수정합니다.
+* 버그 또는 새로 추가되길 원하는 기능과 관련된 이슈를 제출합니다.
+* 새로운 모델을 구현합니다.
+* 예제나 문서에 기여합니다.
+
+어디서부터 시작할지 모르겠다면, [Good First Issue](https://github.com/huggingface/transformers/contribute) 목록을 확인해보세요. 이 목록은 초보자도 참여하기 쉬운 오픈 이슈 목록을 제공하며, 당신이 오픈소스에 처음으로 기여하는 데 큰 도움이 될 것입니다. 그저 작업하고 싶은 이슈에 댓글만 달아주면 됩니다.
+
+조금 더 도전적인 작업을 원한다면, [Good Second Issue](https://github.com/huggingface/transformers/labels/Good%20Second%20Issue) 목록도 확인해보세요. 이미 당신이 잘 하고 있다고 생각되더라도, 한 번 시도해보세요! 우리도 여러분을 도울 것입니다. 🚀
+
+> 커뮤니티에 이루어지는 모든 기여는 똑같이 소중합니다. 🥰
+
+## 미해결된 문제 수정하기 [[fixing-outstanding-issues]]
+
+기존 코드에서 발견한 문제점에 대한 해결책이 떠오른 경우, 언제든지 [기여를 시작](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md/#create-a-pull-request)하고 Pull Request를 생성해주세요!
+
+## 버그 관련 이슈를 제기하거나 새로운 기능 요청하기 [[submitting-a-bugrelated-issue-or-feature-request]]
+
+버그 관련 이슈를 제기하거나 새로운 기능을 요청할 때는 다음 가이드라인을 최대한 준수해주세요. 이렇게 하면 좋은 피드백과 함께 빠르게 답변해 드릴 수 있습니다.
+
+### 버그를 발견하셨나요? [[did-you-find-a-bug]]
+
+🤗 Transformers 라이브러리는 사용 중에 겪는 문제를 보고해주는 사용자들 덕분에 더욱 견고해지고 신뢰할 수 있게 되었습니다.
+
+이슈를 보고하기 전에, 버그가 이미 **보고되지 않았는지** 확인해주세요. (GitHub의 이슈 탭 아래의 검색 바를 사용하세요). 이슈는 라이브러리 자체에서 발생한 버그어야 하며, 코드의 다른 부분과 관련된 것이 아니어야 합니다. 버그가 라이브러리의 문제로 발생하였는지 확실하지 않은 경우 먼저 [포럼](https://discuss.huggingface.co/)에서 질문해 주세요. 이렇게 하면 일반적인 질문보다 라이브러리와 관련된 문제를 더 빠르게 해결할 수 있습니다.
+
+버그가 이미 보고되지 않았다는 것을 확인했다면, 다음 정보를 포함하여 이슈를 제출해 주세요. 그러면 우리가 빠르게 해결할 수 있습니다:
+
+* 사용 중인 **운영체제 종류와 버전**, 그리고 **Python**, **PyTorch** 또는 **TensorFlow** 버전.
+* 버그를 30초 이내로 재현할 수 있는 간단하고 독립적인 코드 스니펫.
+* 예외가 발생한 경우 *전체* 트레이스백.
+* 스크린샷과 같이 도움이 될 것으로 생각되는 추가 정보를 첨부해 주세요.
+
+운영체제와 소프트웨어 버전을 자동으로 가져오려면 다음 명령을 실행하세요:
+
+```bash
+transformers-cli env
+```
+
+저장소의 루트 디렉터리에서도 같은 명령을 실행할 수 있습니다:
+
+```bash
+python src/transformers/commands/transformers_cli.py env
+```
+
+
+### 새로운 기능을 원하시나요? [[do-you-want-a-new-feature]]
+
+🤗 Transformers에서 사용하고 싶은 새로운 기능이 있다면, 다음 내용을 포함하여 이슈를 제출해 주세요:
+
+1. 이 기능이 필요한 *이유*는 무엇인가요? 라이브러리에 대한 문제나 불만과 관련이 있나요? 프로젝트에 필요한 기능인가요? 커뮤니티에 도움이 될 만한 기능인가요?
+
+ 어떤 내용이든 여러분의 이야기를 듣고 싶습니다!
+
+2. 요청하는 기능을 최대한 자세히 설명해 주세요. 더 많은 정보를 제공할수록 더 나은 도움을 드릴 수 있습니다.
+3. 해당 기능의 사용법을 보여주는 *코드 스니펫*을 제공해 주세요.
+4. 기능과 관련된 논문이 있는 경우 링크를 포함해 주세요.
+
+이슈가 잘 작성되었다면 이슈가 생성된 순간, 이미 80% 정도의 작업이 완료된 것입니다.
+
+이슈를 제기하는 데 도움이 될 만한 [템플릿](https://github.com/huggingface/transformers/tree/main/templates)도 준비되어 있습니다.
+
+## 새로운 모델을 구현하고 싶으신가요? [[do-you-want-to-implement-a-new-model]]
+
+새로운 모델은 계속해서 출시됩니다. 만약 여러분이 새로운 모델을 구현하고 싶다면 다음 정보를 제공해 주세요:
+
+* 모델에 대한 간단한 설명과 논문 링크.
+* 구현이 공개되어 있다면 구현 링크.
+* 모델 가중치가 사용 가능하다면 가중치 링크.
+
+만약 모델을 직접 기여하고 싶으시다면, 알려주세요. 🤗 Transformers에 추가할 수 있도록 도와드리겠습니다!
+
+[🤗 Transformers에 새로운 모델을 추가하는 방법](https://huggingface.co/docs/transformers/add_new_model)에 대한 기술적인 안내서도 있습니다.
+
+## 문서를 추가하고 싶으신가요? [[do-you-want-to-add-documentation]]
+
+우리는 언제나 더 명확하고 정확한 문서를 제공하기 위하여 개선점을 찾고 있습니다. 오탈자나 부족한 내용, 분명하지 않거나 부정확한 내용 등을 알려주시면 개선하는 데 도움이 됩니다. 관심이 있으시다면 변경하거나 기여하실 수 있도록 도와드리겠습니다!
+
+문서를 생성, 빌드 및 작성하는 방법에 대한 자세한 내용은 [README](https://github.com/huggingface/transformers/tree/main/docs) 문서를 확인해 주세요.
+
+## 풀 리퀘스트(Pull Request) 생성하기 [[create-a-pull-request]]
+
+코드를 작성하기 전에 기존의 Pull Request나 이슈를 검색하여 누군가 이미 동일한 작업을 하고 있는지 확인하는 것이 좋습니다. 확실하지 않다면 피드백을 받기 위해 이슈를 열어보는 것이 좋습니다.
+
+🤗 Transformers에 기여하기 위해서는 기본적인 `git` 사용 능력이 필요합니다. `git`은 사용하기 쉬운 도구는 아니지만, 매우 훌륭한 매뉴얼을 제공합니다. 쉘(shell)에서 `git --help`을 입력하여 확인해보세요! 만약 책을 선호한다면, [Pro Git](https://git-scm.com/book/en/v2)은 매우 좋은 참고 자료가 될 것입니다.
+
+🤗 Transformers에 기여하려면 **[Python 3.9](https://github.com/huggingface/transformers/blob/main/setup.py#L426)** 이상의 버전이 필요합니다. 기여를 시작하려면 다음 단계를 따르세요:
+
+1. 저장소 페이지에서 **[Fork](https://github.com/huggingface/transformers/fork)** 버튼을 클릭하여 저장소를 포크하세요. 이렇게 하면 코드의 복사본이 여러분의 GitHub 사용자 계정 아래에 생성됩니다.
+
+2. 포크한 저장소를 로컬 디스크로 클론하고, 기본 저장소를 원격(remote)으로 추가하세요:
+
+ ```bash
+ git clone git@github.com:/transformers.git
+ cd transformers
+ git remote add upstream https://github.com/huggingface/transformers.git
+ ```
+
+3. 개발 변경 사항을 저장할 새 브랜치를 생성하세요:
+
+ ```bash
+ git checkout -b a-descriptive-name-for-my-changes
+ ```
+
+ 🚨 절대 `main` 브랜치에서 작업하지 **마세요!**
+
+4. 가상 환경에서 다음 명령을 실행하여 개발 환경을 설정하세요:
+
+ ```bash
+ pip install -e ".[dev]"
+ ```
+
+ 만약 이미 가상 환경에 🤗 Transformers가 설치되어 있다면, `-e` 플래그를 사용하여 설치하기 전에 `pip uninstall transformers`로 제거해주세요.
+
+ 여러분의 운영체제에 따라서, 그리고 🤗 Transformers의 선택적 의존성의 수가 증가하면서, 이 명령이 실패할 수도 있습니다. 그럴 경우 사용하려는 딥러닝 프레임워크(PyTorch, TensorFlow, 그리고/또는 Flax)를 설치한 후 아래 명령을 실행해주세요:
+
+ ```bash
+ pip install -e ".[quality]"
+ ```
+
+ 대부분의 경우 이것으로 충분할 것입니다.
+
+5. 브랜치에서 기능을 개발하세요.
+
+ 코드를 작업하는 동안 테스트 스위트(test suite)가 통과하는지 확인하세요. 다음과 같이 변경 사항에 영향을 받는 테스트를 실행하세요:
+
+ ```bash
+ pytest tests/.py
+ ```
+
+ 테스트에 대한 더 많은 정보는 [테스트](https://huggingface.co/docs/transformers/testing) 가이드를 확인하세요.
+
+ 🤗 Transformers는 `black`과 `ruff`를 사용하여 소스 코드의 형식을 일관되게 유지합니다. 변경 사항을 적용한 후에는 다음 명령으로 자동으로 스타일 교정 및 코드 검증을 수행하세요:
+
+ ```bash
+ make fixup
+ ```
+
+ 이것은 또한 작업 중인 PR에서 수정한 파일에서만 작동하도록 최적화되어 있습니다.
+
+ 검사를 하나씩 실행하려는 경우, 다음 명령으로 스타일 교정을 적용할 수 있습니다:
+
+ ```bash
+ make style
+ ```
+
+ 🤗 Transformers는 또한 `ruff`와 몇 가지 사용자 정의 스크립트를 사용하여 코딩 실수를 확인합니다. CI를 통해 품질 관리가 수행되지만, 다음 명령으로 동일한 검사를 실행할 수 있습니다:
+
+ ```bash
+ make quality
+ ```
+
+ 마지막으로, 새 모델을 추가할 때 일부 파일을 업데이트하는 것을 잊지 않도록 하기 위한 많은 스크립트가 있습니다. 다음 명령으로 이러한 스크립트를 실행할 수 있습니다:
+
+ ```bash
+ make repo-consistency
+ ```
+
+ 이러한 검사에 대해 자세히 알아보고 관련 문제를 해결하는 방법은 [Pull Request에 대한 검사](https://huggingface.co/docs/transformers/pr_checks) 가이드를 확인하세요.
+
+ 만약 `docs/source` 디렉터리 아래의 문서를 수정하는 경우, 문서가 빌드될 수 있는지 확인하세요. 이 검사는 Pull Request를 열 때도 CI에서 실행됩니다. 로컬 검사를 실행하려면 문서 빌더를 설치해야 합니다:
+
+ ```bash
+ pip install ".[docs]"
+ ```
+
+ 저장소의 루트 디렉터리에서 다음 명령을 실행하세요:
+
+ ```bash
+ doc-builder build transformers docs/source/en --build_dir ~/tmp/test-build
+ ```
+
+ 이 명령은 `~/tmp/test-build` 폴더에 문서를 빌드하며, 생성된 Markdown 파일을 선호하는 편집기로 확인할 수 있습니다. Pull Request를 열 때 GitHub에서 문서를 미리 볼 수도 있습니다.
+
+ 변경 사항에 만족하면 `git add`로 변경된 파일을 추가하고, `git commit`으로 변경 사항을 로컬에 기록하세요:
+
+ ```bash
+ git add modified_file.py
+ git commit
+ ```
+
+ [좋은 커밋 메시지](https://chris.beams.io/posts/git-commit/)를 작성하여 변경 사항을 명확하게 전달하세요!
+
+ 변경 사항을 프로젝트 원본 저장소와 동기화하려면, PR을 *열기 전에* 브랜치를 `upstream/branch`로 리베이스(rebase)하세요. 또는 관리자의 요청에 이 작업이 필요할 수 있습니다:
+
+ ```bash
+ git fetch upstream
+ git rebase upstream/main
+ ```
+
+ 변경 사항을 브랜치에 푸시하세요:
+
+ ```bash
+ git push -u origin a-descriptive-name-for-my-changes
+ ```
+
+ 이미 PR을 열었다면, `--force` 플래그와 함께 강제 푸시해야 합니다. 아직 PR이 열리지 않았다면 정상적으로 변경 사항을 푸시하면 됩니다.
+
+6. 이제 GitHub에서 포크한 저장소로 이동하고 **Pull request(풀 리퀘스트)**를 클릭하여 Pull Request를 열 수 있습니다. 아래의 [체크리스트](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md/#pull-request-checklist)에서 모든 항목에 체크 표시를 하세요. 준비가 완료되면 프로젝트 관리자에게 변경 사항을 보내 검토를 요청할 수 있습니다.
+
+7. 관리자가 변경 사항을 요청해도 괜찮습니다. 핵심 기여자들도 동일한 상황을 겪습니다! 모두가 변경 사항을 Pull Request에서 볼 수 있도록, 로컬 브랜치에서 작업하고 변경 사항을 포크한 저장소로 푸시하세요. 그러면 변경 사항이 자동으로 Pull Request에 나타납니다.
+
+### Pull Request 체크리스트 [[pull-request-checklist]]
+
+☐ Pull Request 제목은 기여 내용을 요약해야 합니다.
+☐ Pull Request가 이슈를 해결하는 경우, Pull Request 설명에 이슈 번호를 언급하여 연관되어 있음을 알려주세요. (이슈를 확인하는 사람들이 해당 이슈에 대한 작업이 진행 중임을 알 수 있게 합니다).
+☐ 작업이 진행중이라면 제목 앞에 `[WIP]`를 붙여주세요. 중복 작업을 피하고 병합할 준비가 된 PR과 구분하기에 유용합니다.
+☐ 기존 테스트를 통과하는지 확인하세요.
+☐ 새로운 기능을 추가하는 경우, 해당 기능에 대한 테스트도 추가하세요.
+ - 새 모델을 추가하는 경우, `ModelTester.all_model_classes = (MyModel, MyModelWithLMHead,...)`을 사용하여 일반적인 테스트를 활성화하세요.
+ - 새 `@slow` 테스트를 추가하는 경우, 다음 명령으로 테스트를 통과하는지 확인하세요: `RUN_SLOW=1 python -m pytest tests/models/my_new_model/test_my_new_model.py`.
+ - 새 토크나이저를 추가하는 경우, 테스트를 작성하고 다음 명령으로 테스트를 통과하는지 확인하세요: `RUN_SLOW=1 python -m pytest tests/models/{your_model_name}/test_tokenization_{your_model_name}.py`.
+ - CircleCI에서는 느린 테스트를 실행하지 않지만, GitHub Actions에서는 매일 밤 실행됩니다!
+
+☐ 모든 공개 메소드는 유용한 기술문서를 가져야 합니다 (예를 들어 [`modeling_bert.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py) 참조).
+☐ 저장소가 빠르게 성장하고 있으므로 저장소에 상당한 부담을 주는 이미지, 동영상 및 기타 텍스트가 아닌 파일은 추가하지 마세요. 대신 [`hf-internal-testing`](https://huggingface.co/hf-internal-testing)과 같은 Hub 저장소를 사용하여 이러한 파일을 호스팅하고 URL로 참조하세요. 문서와 관련된 이미지는 다음 저장소에 배치하는 것을 권장합니다: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images). 이 데이터셋 저장소에서 PR을 열어서 Hugging Face 멤버에게 병합을 요청할 수 있습니다.
+
+Pull Request에서 실행되는 검사에 대한 자세한 정보는 [Pull Request에 대한 검사](https://huggingface.co/docs/transformers/pr_checks) 가이드를 확인하세요.
+
+### 테스트 [[tests]]
+
+라이브러리 동작과 여러 예제를 테스트할 수 있는 광범위한 테스트 스위트가 포함되어 있습니다. 라이브러리 테스트는 [tests](https://github.com/huggingface/transformers/tree/main/tests) 폴더에, 예제 테스트는 [examples](https://github.com/huggingface/transformers/tree/main/examples) 폴더에 있습니다.
+
+속도가 빠른 `pytest`와 `pytest-xdist`를 선호합니다. 저장소의 루트 디렉터리에서 테스트를 실행할 *하위 폴더 경로 또는 테스트 파일 경로*를 지정하세요:
+
+```bash
+python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model
+```
+
+마찬가지로 `examples` 디렉터리에서도 *하위 폴더 경로 또는 테스트 파일 경로*를 지정하세요. 예를 들어, 다음 명령은 PyTorch `examples` 디렉터리의 텍스트 분류 하위 폴더를 테스트합니다:
+
+```bash
+pip install -r examples/xxx/requirements.txt # only needed the first time
+python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification
+```
+
+이것이 실제로 `make test` 및 `make test-examples` 명령이 구현되는 방식입니다 (`pip install`은 제외합니다)!
+
+또한 특정 기능만 테스트하기 위한 더 작은 테스트를 지정할 수 있습니다.
+
+기본적으로 느린 테스트는 건너뛰지만 `RUN_SLOW` 환경 변수를 `yes`로 설정하여 실행할 수 있습니다. 이렇게 하면 많은 기가바이트 단위의 모델이 다운로드되므로 충분한 디스크 공간, 좋은 인터넷 연결과 많은 인내가 필요합니다!
+
+
+
+테스트를 실행하려면 *하위 폴더 경로 또는 테스트 파일 경로*를 지정하세요. 그렇지 않으면 `tests` 또는 `examples` 폴더의 모든 테스트를 실행하게 되어 매우 긴 시간이 걸립니다!
+
+
+
+```bash
+RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./tests/models/my_new_model
+RUN_SLOW=yes python -m pytest -n auto --dist=loadfile -s -v ./examples/pytorch/text-classification
+```
+
+느린 테스트와 마찬가지로, 다음과 같이 테스트 중에 기본적으로 활성화되지 않는 다른 환경 변수도 있습니다:
+- `RUN_CUSTOM_TOKENIZERS`: 사용자 정의 토크나이저 테스트를 활성화합니다.
+
+더 많은 환경 변수와 추가 정보는 [testing_utils.py](src/transformers/testing_utils.py)에서 찾을 수 있습니다.
+
+🤗 Transformers는 테스트 실행기로 `pytest`를 사용합니다. 그러나 테스트 스위트 자체에서는 `pytest` 관련 기능을 사용하지 않습니다.
+
+이것은 `unittest`가 완전히 지원된다는 것을 의미합니다. 다음은 `unittest`로 테스트를 실행하는 방법입니다:
+
+```bash
+python -m unittest discover -s tests -t . -v
+python -m unittest discover -s examples -t examples -v
+```
+
+### 스타일 가이드 [[style-guide]]
+
+문서는 [Google Python 스타일 가이드](https://google.github.io/styleguide/pyguide.html)를 따릅니다. 자세한 정보는 [문서 작성 가이드](https://github.com/huggingface/transformers/tree/main/docs#writing-documentation---specification)를 확인하세요.
+
+### Windows에서 개발 [[develop-on-windows]]
+
+Windows에서 개발할 경우([Windows Subsystem for Linux](https://learn.microsoft.com/en-us/windows/wsl/) 또는 WSL에서 작업하지 않는 한) Windows `CRLF` 줄 바꿈을 Linux `LF` 줄 바꿈으로 변환하도록 git을 구성해야 합니다:
+
+```bash
+git config core.autocrlf input
+```
+
+Windows에서 `make` 명령을 실행하는 한 가지 방법은 MSYS2를 사용하는 것입니다:
+
+1. [MSYS2](https://www.msys2.org/)를 다운로드합니다. `C:\msys64`에 설치되었다고 가정합니다.
+2. CLI에서 `C:\msys64\msys2.exe`를 엽니다 (시작 메뉴에서 사용 가능해야 함).
+3. 쉘에서 다음을 실행하여: `pacman -Syu` 및 `pacman -S make`로 `make`를 설치합니다.
+4. 환경 변수 PATH에 `C:\msys64\usr\bin`을 추가하세요.
+
+이제 모든 터미널 (PowerShell, cmd.exe 등)에서 `make`를 사용할 수 있습니다! 🎉
+
+### 포크한 저장소를 상위 원본 브랜치(main)과 동기화하기 (Hugging Face 저장소) [[sync-a-forked-repository-with-upstream-main-the-hugging-face-repository]]
+
+포크한 저장소의 main 브랜치를 업데이트할 때, 다음 단계를 따라 수행해주세요. 이렇게 하면 각 upstream PR에 참조 노트가 추가되는 것을 피하고 이러한 PR에 관여하는 개발자들에게 불필요한 알림이 전송되는 것을 방지할 수 있습니다.
+
+1. 가능하면 포크된 저장소의 브랜치 및 PR을 사용하여 upstream과 동기화하지 마세요. 대신 포크된 main 저장소에 직접 병합하세요.
+2. PR이 반드시 필요한 경우, 브랜치를 확인한 후 다음 단계를 사용하세요:
+
+ ```bash
+ git checkout -b your-branch-for-syncing
+ git pull --squash --no-commit upstream main
+ git commit -m ''
+ git push --set-upstream origin your-branch-for-syncing
+ ```
diff --git a/docs/transformers/docs/source/ko/conversations.md b/docs/transformers/docs/source/ko/conversations.md
new file mode 100644
index 0000000000000000000000000000000000000000..920cb1387860865e6f01ff47b79c50a2e9c4bea3
--- /dev/null
+++ b/docs/transformers/docs/source/ko/conversations.md
@@ -0,0 +1,306 @@
+
+
+# Transformers로 채팅하기[[chatting-with-transformers]]
+
+이 글을 보고 있다면 **채팅 모델**에 대해 어느 정도 알고 계실 것입니다.
+채팅 모델이란 메세지를 주고받을 수 있는 대화형 인공지능입니다.
+대표적으로 ChatGPT가 있고, 이와 비슷하거나 더 뛰어난 오픈소스 채팅 모델이 많이 존재합니다.
+이러한 모델들은 무료 다운로드할 수 있으며, 로컬에서 실행할 수 있습니다.
+크고 무거운 모델은 고성능 하드웨어와 메모리가 필요하지만,
+저사양 GPU 혹은 일반 데스크탑이나 노트북 CPU에서도 잘 작동하는 소형 모델들도 있습니다.
+
+이 가이드는 채팅 모델을 처음 사용하는 분들에게 유용할 것입니다.
+우리는 간편한 고수준(High-Level) "pipeline"을 통해 빠른 시작 가이드를 진행할 것입니다.
+가이드에는 채팅 모델을 바로 시작할 때 필요한 모든 정보가 담겨 있습니다.
+빠른 시작 가이드 이후에는 채팅 모델이 정확히 무엇인지, 적절한 모델을 선택하는 방법과,
+채팅 모델을 사용하는 각 단계의 저수준(Low-Level) 분석 등 더 자세한 정보를 다룰 것입니다.
+또한 채팅 모델의 성능과 메모리 사용을 최적화하는 방법에 대한 팁도 제공할 것입니다.
+
+
+## 빠른 시작[[quickstart]]
+
+자세히 볼 여유가 없는 분들을 위해 간단히 요약해 보겠습니다:
+채팅 모델은 대화 메세지를 계속해서 생성해 나갑니다.
+즉, 짤막한 채팅 메세지를 모델에게 전달하면, 모델은 이를 바탕으로 응답을 추가하며 대화를 이어 나갑니다.
+이제 실제로 어떻게 작동하는지 살펴보겠습니다.
+먼저, 채팅을 만들어 보겠습니다:
+
+
+```python
+chat = [
+ {"role": "system", "content": "You are a sassy, wise-cracking robot as imagined by Hollywood circa 1986."},
+ {"role": "user", "content": "Hey, can you tell me any fun things to do in New York?"}
+]
+```
+
+주목하세요, 대화를 처음 시작할 때 유저 메세지 이외의도, 별도의 **시스템** 메세지가 필요할 수 있습니다.
+모든 채팅 모델이 시스템 메세지를 지원하는 것은 아니지만,
+지원하는 경우에는 시스템 메세지는 대화에서 모델이 어떻게 행동해야 하는지를 지시할 수 있습니다.
+예를 들어, 유쾌하거나 진지하고자 할 때, 짧은 답변이나 긴 답변을 원할 때 등을 설정할 수 있습니다.
+시스템 메세지를 생략하고
+"You are a helpful and intelligent AI assistant who responds to user queries."
+와 같은 간단한 프롬프트를 사용하는 것도 가능합니다.
+
+채팅을 시작했다면 대화를 이어 나가는 가장 빠른 방법은 [`TextGenerationPipeline`]를 사용하는 것입니다.
+한번 `LLaMA-3`를 사용하여 이를 시연해 보겠습니다.
+우선 `LLaMA-3`를 사용하기 위해서는 승인이 필요합니다. [권한 신청](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)을 하고 Hugging Face 계정으로 로그인한 후에 사용할 수 있습니다.
+또한 우리는 `device_map="auto"`를 사용합니다. GPU 메모리가 충분하다면 로드될 것입니다.
+그리고 메모리 절약을 위해 dtype을 `torch.bfloat16`으로 설정할 것입니다.
+
+```python
+import torch
+from transformers import pipeline
+
+pipe = pipeline("text-generation", "meta-llama/Meta-Llama-3-8B-Instruct", torch_dtype=torch.bfloat16, device_map="auto")
+response = pipe(chat, max_new_tokens=512)
+print(response[0]['generated_text'][-1]['content'])
+```
+
+이후 실행을 하면 아래와 같이 출력됩니다:
+
+```text
+(sigh) Oh boy, you're asking me for advice? You're gonna need a map, pal! Alright,
+alright, I'll give you the lowdown. But don't say I didn't warn you, I'm a robot, not a tour guide!
+
+So, you wanna know what's fun to do in the Big Apple? Well, let me tell you, there's a million
+things to do, but I'll give you the highlights. First off, you gotta see the sights: the Statue of
+Liberty, Central Park, Times Square... you know, the usual tourist traps. But if you're lookin' for
+something a little more... unusual, I'd recommend checkin' out the Museum of Modern Art. It's got
+some wild stuff, like that Warhol guy's soup cans and all that jazz.
+
+And if you're feelin' adventurous, take a walk across the Brooklyn Bridge. Just watch out for
+those pesky pigeons, they're like little feathered thieves! (laughs) Get it? Thieves? Ah, never mind.
+
+Now, if you're lookin' for some serious fun, hit up the comedy clubs in Greenwich Village. You might
+even catch a glimpse of some up-and-coming comedians... or a bunch of wannabes tryin' to make it big. (winks)
+
+And finally, if you're feelin' like a real New Yorker, grab a slice of pizza from one of the many amazing
+pizzerias around the city. Just don't try to order a "robot-sized" slice, trust me, it won't end well. (laughs)
+
+So, there you have it, pal! That's my expert advice on what to do in New York. Now, if you'll
+excuse me, I've got some oil changes to attend to. (winks)
+```
+
+채팅을 계속하려면, 자신의 답장을 추가하면 됩니다.
+파이프라인에서 반환된 `response` 객체에는 현재까지 모든 채팅을 포함하고 있으므로
+메세지를 추가하고 다시 전달하기만 하면 됩니다.
+
+```python
+chat = response[0]['generated_text']
+chat.append(
+ {"role": "user", "content": "Wait, what's so wild about soup cans?"}
+)
+response = pipe(chat, max_new_tokens=512)
+print(response[0]['generated_text'][-1]['content'])
+```
+
+이후 실행을 하면 아래와 같이 출력됩니다:
+
+```text
+(laughs) Oh, you're killin' me, pal! You don't get it, do you? Warhol's soup cans are like, art, man!
+It's like, he took something totally mundane, like a can of soup, and turned it into a masterpiece. It's
+like, "Hey, look at me, I'm a can of soup, but I'm also a work of art!"
+(sarcastically) Oh, yeah, real original, Andy.
+
+But, you know, back in the '60s, it was like, a big deal. People were all about challenging the
+status quo, and Warhol was like, the king of that. He took the ordinary and made it extraordinary.
+And, let me tell you, it was like, a real game-changer. I mean, who would've thought that a can of soup could be art? (laughs)
+
+But, hey, you're not alone, pal. I mean, I'm a robot, and even I don't get it. (winks)
+But, hey, that's what makes art, art, right? (laughs)
+```
+
+이 튜토리얼의 후반부에서는 성능과 메모리 관리,
+그리고 사용자의 필요에 맞는 채팅 모델 선택과 같은 구체적인 주제들을 다룰 것입니다.
+
+## 채팅 모델 고르기[[choosing-a-chat-model]]
+
+[Hugging Face Hub](https://huggingface.co/models?pipeline_tag=text-generation&sort=trending)는 채팅 모델을 다양하게 제공하고 있습니다.
+처음 사용하는 사람에게는 모델을 선택하기가 어려울지 모릅니다.
+하지만 걱정하지 마세요! 두 가지만 명심하면 됩니다:
+
+- 모델의 크기는 실행 속도와 메모리에 올라올 수 있는지 여부를 결정.
+- 모델이 생성한 출력의 품질.
+
+일반적으로 이러한 요소들은 상관관계가 있습니다. 더 큰 모델일수록 더 뛰어난 성능을 보이는 경향이 있지만, 동일한 크기의 모델이라도 유의미한 차이가 날 수 있습니다!
+
+### 모델의 명칭과 크기[[size-and-model-naming]]
+
+모델의 크기는 모델 이름에 있는 숫자로 쉽게 알 수 있습니다.
+예를 들어, "8B" 또는 "70B"와 같은 숫자는 모델의 **파라미터** 수를 나타냅니다.
+양자화된 경우가 아니라면, 파라미터 하나당 약 2바이트의 메모리가 필요하다고 예상 가능합니다.
+따라서 80억 개의 파라미터를 가진 "8B" 모델은 16GB의 메모리를 차지하며, 추가적인 오버헤드를 위한 약간의 여유가 필요합니다.
+이는 3090이나 4090와 같은 24GB의 메모리를 갖춘 하이엔드 GPU에 적합합니다.
+
+일부 채팅 모델은 "Mixture of Experts" 모델입니다.
+이러한 모델은 크기를 "8x7B" 또는 "141B-A35B"와 같이 다르게 표시하곤 합니다.
+숫자가 다소 모호하다 느껴질 수 있지만, 첫 번째 경우에는 약 56억(8x7) 개의 파라미터가 있고,
+두 번째 경우에는 약 141억 개의 파라미터가 있다고 해석할 수 있습니다.
+
+양자화는 파라미터당 메모리 사용량을 8비트, 4비트, 또는 그 이하로 줄이는 데 사용됩니다.
+이 주제에 대해서는 아래의 [메모리 고려사항](#memory-considerations) 챕터에서 더 자세히 다룰 예정입니다.
+
+### 그렇다면 어떤 채팅 모델이 가장 좋을까요?[[but-which-chat-model-is-best]]
+모델의 크기 외에도 고려할 점이 많습니다.
+이를 한눈에 살펴보려면 **리더보드**를 참고하는 것이 좋습니다.
+가장 인기 있는 리더보드 두 가지는 [OpenLLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)와 [LMSys Chatbot Arena Leaderboard](https://chat.lmsys.org/?leaderboard)입니다.
+LMSys 리더보드에는 독점 모델도 포함되어 있으니,
+`license` 열에서 접근 가능한 모델을 선택한 후
+[Hugging Face Hub](https://huggingface.co/models?pipeline_tag=text-generation&sort=trending)에서 검색해 보세요.
+
+### 전문 분야[[specialist-domains]]
+일부 모델은 의료 또는 법률 텍스트와 같은 특정 도메인이나 비영어권 언어에 특화되어 있기도 합니다.
+이러한 도메인에서 작업할 경우 특화된 모델이 좋은 성능을 보일 수 있습니다.
+하지만 항상 그럴 것이라 단정하기는 힘듭니다.
+특히 모델의 크기가 작거나 오래된 모델인 경우,
+최신 범용 모델이 더 뛰어날 수 있습니다.
+다행히도 [domain-specific leaderboards](https://huggingface.co/blog/leaderboard-medicalllm)가 점차 등장하고 있어, 특정 도메인에 최고의 모델을 쉽게 찾을 수 있을 것입니다.
+
+
+## 파이프라인 내부는 어떻게 되어있는가?[[what-happens-inside-the-pipeline]]
+위의 빠른 시작에서는 고수준(High-Level) 파이프라인을 사용하였습니다.
+이는 간편한 방법이지만, 유연성은 떨어집니다.
+이제 더 저수준(Low-Level) 접근 방식을 통해 대화에 포함된 각 단계를 살펴보겠습니다.
+코드 샘플로 시작한 후 이를 분석해 보겠습니다:
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+import torch
+
+# 입력값을 사전에 준비해 놓습니다
+chat = [
+ {"role": "system", "content": "You are a sassy, wise-cracking robot as imagined by Hollywood circa 1986."},
+ {"role": "user", "content": "Hey, can you tell me any fun things to do in New York?"}
+]
+
+# 1: 모델과 토크나이저를 불러옵니다
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct", device_map="auto", torch_dtype=torch.bfloat16)
+tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
+
+# 2: 채팅 템플릿에 적용합니다
+formatted_chat = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
+print("Formatted chat:\n", formatted_chat)
+
+# 3: 채팅을 토큰화합니다 (바로 이전 과정에서 tokenized=True로 설정하면 한꺼번에 처리할 수 있습니다)
+inputs = tokenizer(formatted_chat, return_tensors="pt", add_special_tokens=False)
+# 토큰화된 입력값을 모델이 올라와 있는 기기(CPU/GPU)로 옮깁니다.
+inputs = {key: tensor.to(model.device) for key, tensor in inputs.items()}
+print("Tokenized inputs:\n", inputs)
+
+# 4: 모델로부터 응답을 생성합니다
+outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.1)
+print("Generated tokens:\n", outputs)
+
+# 5: 모델이 출력한 토큰을 다시 문자열로 디코딩합니다
+decoded_output = tokenizer.decode(outputs[0][inputs['input_ids'].size(1):], skip_special_tokens=True)
+print("Decoded output:\n", decoded_output)
+```
+여기에는 각 부분이 자체 문서가 될 수 있을 만큼 많은 내용이 담겨 있습니다!
+너무 자세히 설명하기보다는 넓은 개념을 다루고, 세부 사항은 링크된 문서에서 다루겠습니다.
+주요 단계는 다음과 같습니다:
+
+1. [모델](https://huggingface.co/learn/nlp-course/en/chapter2/3)과 [토크나이저](https://huggingface.co/learn/nlp-course/en/chapter2/4?fw=pt)를 Hugging Face Hub에서 로드합니다.
+2. 대화는 토크나이저의 [채팅 템플릿](https://huggingface.co/docs/transformers/main/en/chat_templating)을 사용하여 양식을 구성합니다.
+3. 구성된 채팅은 토크나이저를 사용하여 [토큰화](https://huggingface.co/learn/nlp-course/en/chapter2/4)됩니다.
+4. 모델에서 응답을 [생성](https://huggingface.co/docs/transformers/en/llm_tutorial)합니다.
+5. 모델이 출력한 토큰을 다시 문자열로 디코딩합니다.
+
+## 성능, 메모리와 하드웨어[[performance-memory-and-hardware]]
+이제 대부분의 머신 러닝 작업이 GPU에서 실행된다는 것을 아실 겁니다.
+다소 느리기는 해도 CPU에서 채팅 모델이나 언어 모델로부터 텍스트를 생성하는 것도 가능합니다.
+하지만 모델을 GPU 메모리에 올려놓을 수만 있다면, GPU를 사용하는 것이 일반적으로 더 선호되는 방식입니다.
+
+### 메모리 고려사항[[memory-considerations]]
+
+기본적으로, [`TextGenerationPipeline`]이나 [`AutoModelForCausalLM`]과 같은
+Hugging Face 클래스는 모델을 `float32` 정밀도(Precision)로 로드합니다.
+이는 파라미터당 4바이트(32비트)를 필요로 하므로,
+80억 개의 파라미터를 가진 "8B" 모델은 약 32GB의 메모리를 필요로 한다는 것을 의미합니다.
+하지만 이는 낭비일 수 있습니다!
+대부분의 최신 언어 모델은 파라미터당 2바이트를 사용하는 "bfloat16" 정밀도(Precision)로 학습됩니다.
+하드웨어가 이를 지원하는 경우(Nvidia 30xx/Axxx 이상),
+`torch_dtype` 파라미터로 위와 같이 `bfloat16` 정밀도(Precision)로 모델을 로드할 수 있습니다.
+
+또한, 16비트보다 더 낮은 정밀도(Precision)로 모델을 압축하는
+"양자화(quantization)" 방법을 사용할 수도 있습니다.
+이 방법은 모델의 가중치를 손실 압축하여 각 파라미터를 8비트,
+4비트 또는 그 이하로 줄일 수 있습니다.
+특히 4비트에서 모델의 출력이 부정적인 영향을 받을 수 있지만,
+더 크고 강력한 채팅 모델을 메모리에 올리기 위해 이 같은 트레이드오프를 감수할 가치가 있습니다.
+이제 `bitsandbytes`를 사용하여 이를 실제로 확인해 보겠습니다:
+
+```python
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_8bit=True) # You can also try load_in_4bit
+model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct", device_map="auto", quantization_config=quantization_config)
+```
+
+위의 작업은 `pipeline` API에도 적용 가능합니다:
+
+```python
+from transformers import pipeline, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_8bit=True) # You can also try load_in_4bit
+pipe = pipeline("text-generation", "meta-llama/Meta-Llama-3-8B-Instruct", device_map="auto", model_kwargs={"quantization_config": quantization_config})
+```
+
+`bitsandbytes` 외에도 모델을 양자화하는 다양한 방법이 있습니다.
+자세한 내용은 [Quantization guide](./quantization)를 참조해 주세요.
+
+
+### 성능 고려사항[[performance-considerations]]
+
+
+
+언어 모델 성능과 최적화에 대한 보다 자세한 가이드는 [LLM Inference Optimization](./llm_optims)을 참고하세요.
+
+
+
+
+일반적으로 더 큰 채팅 모델은 메모리를 더 많이 요구하고,
+속도도 느려지는 경향이 있습니다. 구체적으로 말하자면,
+채팅 모델에서 텍스트를 생성할 때는 컴퓨팅 파워보다 **메모리 대역폭**이 병목 현상을 일으키는 경우가 많습니다.
+이는 모델이 토큰을 하나씩 생성할 때마다 파라미터를 메모리에서 읽어야 하기 때문입니다.
+따라서 채팅 모델에서 초당 생성할 수 있는 토큰 수는 모델이 위치한 메모리의 대역폭을 모델의 크기로 나눈 값에 비례합니다.
+
+위의 예제에서는 모델이 bfloat16 정밀도(Precision)로 로드될 때 용량이 약 16GB였습니다.
+이 경우, 모델이 생성하는 각 토큰마다 16GB를 메모리에서 읽어야 한다는 의미입니다.
+총 메모리 대역폭은 소비자용 CPU에서는 20-100GB/sec,
+소비자용 GPU나 Intel Xeon, AMD Threadripper/Epyc,
+애플 실리콘과 같은 특수 CPU에서는 200-900GB/sec,
+데이터 센터 GPU인 Nvidia A100이나 H100에서는 최대 2-3TB/sec에 이를 수 있습니다.
+이러한 정보는 각자 하드웨어에서 생성 속도를 예상하는 데 도움이 될 것입니다.
+
+따라서 텍스트 생성 속도를 개선하려면 가장 간단한 방법은 모델의 크기를 줄이거나(주로 양자화를 사용),
+메모리 대역폭이 더 높은 하드웨어를 사용하는 것입니다.
+이 대역폭 병목 현상을 피할 수 있는 고급 기술도 여러 가지 있습니다.
+가장 일반적인 방법은 [보조 생성](https://huggingface.co/blog/assisted-generation), "추측 샘플링"이라고 불리는 기술입니다.
+이 기술은 종종 더 작은 "초안 모델"을 사용하여 여러 개의 미래 토큰을 한 번에 추측한 후,
+채팅 모델로 생성 결과를 확인합니다.
+만약 채팅 모델이 추측을 확인하면, 한 번의 순전파에서 여러 개의 토큰을 생성할 수 있어
+병목 현상이 크게 줄어들고 생성 속도가 빨라집니다.
+
+마지막으로, "Mixture of Experts" (MoE) 모델에 대해서도 짚고 넘어가 보도록 합니다.
+Mixtral, Qwen-MoE, DBRX와 같은 인기 있는 채팅 모델이 바로 MoE 모델입니다.
+이 모델들은 토큰을 생성할 때 모든 파라미터가 사용되지 않습니다.
+이로 인해 MoE 모델은 전체 크기가 상당히 클 수 있지만,
+차지하는 메모리 대역폭은 낮은 편입니다.
+따라서 동일한 크기의 일반 "조밀한(Dense)" 모델보다 몇 배 빠를 수 있습니다.
+하지만 보조 생성과 같은 기술은 MoE 모델에서 비효율적일 수 있습니다.
+새로운 추측된 토큰이 추가되면서 더 많은 파라미터가 활성화되기 때문에,
+MoE 아키텍처가 제공하는 속도 이점이 상쇄될 수 있습니다.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/create_a_model.md b/docs/transformers/docs/source/ko/create_a_model.md
new file mode 100644
index 0000000000000000000000000000000000000000..b911669bb174b96ac8b43c9c9490bc16b75f3a7e
--- /dev/null
+++ b/docs/transformers/docs/source/ko/create_a_model.md
@@ -0,0 +1,388 @@
+
+
+# 맞춤형 아키텍처 만들기[[create-a-custom-architecture]]
+
+[`AutoClass`](model_doc/auto)는 모델 아키텍처를 자동으로 추론하고 미리 학습된 configuration과 가중치를 다운로드합니다. 일반적으로 체크포인트에 구애받지 않는 코드를 생성하려면 `AutoClass`를 사용하는 것이 좋습니다. 하지만 특정 모델 파라미터를 보다 세밀하게 제어하고자 하는 사용자는 몇 가지 기본 클래스만으로 커스텀 🤗 Transformers 모델을 생성할 수 있습니다. 이는 🤗 Transformers 모델을 연구, 교육 또는 실험하는 데 관심이 있는 모든 사용자에게 특히 유용할 수 있습니다. 이 가이드에서는 'AutoClass'를 사용하지 않고 커스텀 모델을 만드는 방법에 대해 알아보겠습니다:
+
+- 모델 configuration을 가져오고 사용자 지정합니다.
+- 모델 아키텍처를 생성합니다.
+- 텍스트에 사용할 느리거나 빠른 토큰화기를 만듭니다.
+- 비전 작업을 위한 이미지 프로세서를 생성합니다.
+- 오디오 작업을 위한 특성 추출기를 생성합니다.
+- 멀티모달 작업용 프로세서를 생성합니다.
+
+## Configuration[[configuration]]
+
+[configuration](main_classes/configuration)은 모델의 특정 속성을 나타냅니다. 각 모델 구성에는 서로 다른 속성이 있습니다. 예를 들어, 모든 NLP 모델에는 `hidden_size`, `num_attention_heads`, `num_hidden_layers` 및 `vocab_size` 속성이 공통으로 있습니다. 이러한 속성은 모델을 구성할 attention heads 또는 hidden layers의 수를 지정합니다.
+
+[DistilBERT](model_doc/distilbert) 속성을 검사하기 위해 [`DistilBertConfig`]에 접근하여 자세히 살펴봅니다:
+
+```py
+>>> from transformers import DistilBertConfig
+
+>>> config = DistilBertConfig()
+>>> print(config)
+DistilBertConfig {
+ "activation": "gelu",
+ "attention_dropout": 0.1,
+ "dim": 768,
+ "dropout": 0.1,
+ "hidden_dim": 3072,
+ "initializer_range": 0.02,
+ "max_position_embeddings": 512,
+ "model_type": "distilbert",
+ "n_heads": 12,
+ "n_layers": 6,
+ "pad_token_id": 0,
+ "qa_dropout": 0.1,
+ "seq_classif_dropout": 0.2,
+ "sinusoidal_pos_embds": false,
+ "transformers_version": "4.16.2",
+ "vocab_size": 30522
+}
+```
+
+[`DistilBertConfig`]는 기본 [`DistilBertModel`]을 빌드하는 데 사용되는 모든 기본 속성을 표시합니다. 모든 속성은 커스터마이징이 가능하므로 실험을 위한 공간을 만들 수 있습니다. 예를 들어 기본 모델을 다음과 같이 커스터마이즈할 수 있습니다:
+
+- `activation` 파라미터로 다른 활성화 함수를 사용해 보세요.
+- `attention_dropout` 파라미터를 사용하여 어텐션 확률에 더 높은 드롭아웃 비율을 사용하세요.
+
+```py
+>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
+>>> print(my_config)
+DistilBertConfig {
+ "activation": "relu",
+ "attention_dropout": 0.4,
+ "dim": 768,
+ "dropout": 0.1,
+ "hidden_dim": 3072,
+ "initializer_range": 0.02,
+ "max_position_embeddings": 512,
+ "model_type": "distilbert",
+ "n_heads": 12,
+ "n_layers": 6,
+ "pad_token_id": 0,
+ "qa_dropout": 0.1,
+ "seq_classif_dropout": 0.2,
+ "sinusoidal_pos_embds": false,
+ "transformers_version": "4.16.2",
+ "vocab_size": 30522
+}
+```
+
+사전 학습된 모델 속성은 [`~PretrainedConfig.from_pretrained`] 함수에서 수정할 수 있습니다:
+
+```py
+>>> my_config = DistilBertConfig.from_pretrained("distilbert/distilbert-base-uncased", activation="relu", attention_dropout=0.4)
+```
+
+모델 구성이 만족스러우면 [`~PretrainedConfig.save_pretrained`]로 저장할 수 있습니다. 설정 파일은 지정된 작업 경로에 JSON 파일로 저장됩니다:
+
+```py
+>>> my_config.save_pretrained(save_directory="./your_model_save_path")
+```
+
+configuration 파일을 재사용하려면 [`~PretrainedConfig.from_pretrained`]를 사용하여 가져오세요:
+
+```py
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
+```
+
+
+
+configuration 파일을 딕셔너리로 저장하거나 사용자 정의 configuration 속성과 기본 configuration 속성의 차이점만 저장할 수도 있습니다! 자세한 내용은 [configuration](main_classes/configuration) 문서를 참조하세요.
+
+
+
+## 모델[[model]]
+
+다음 단계는 [모델(model)](main_classes/models)을 만드는 것입니다. 느슨하게 아키텍처라고도 불리는 모델은 각 계층이 수행하는 동작과 발생하는 작업을 정의합니다. configuration의 `num_hidden_layers`와 같은 속성은 아키텍처를 정의하는 데 사용됩니다. 모든 모델은 기본 클래스 [`PreTrainedModel`]과 입력 임베딩 크기 조정 및 셀프 어텐션 헤드 가지 치기와 같은 몇 가지 일반적인 메소드를 공유합니다. 또한 모든 모델은 [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) 또는 [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html)의 서브클래스이기도 합니다. 즉, 모델은 각 프레임워크의 사용법과 호환됩니다.
+
+
+
+사용자 지정 configuration 속성을 모델에 가져옵니다:
+
+```py
+>>> from transformers import DistilBertModel
+
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
+>>> model = DistilBertModel(my_config)
+```
+
+이제 사전 학습된 가중치 대신 임의의 값을 가진 모델이 생성됩니다. 이 모델을 훈련하기 전까지는 유용하게 사용할 수 없습니다. 훈련은 비용과 시간이 많이 소요되는 프로세스입니다. 일반적으로 훈련에 필요한 리소스의 일부만 사용하면서 더 나은 결과를 더 빨리 얻으려면 사전 훈련된 모델을 사용하는 것이 좋습니다.
+
+사전 학습된 모델을 [`~PreTrainedModel.from_pretrained`]로 생성합니다:
+
+```py
+>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+🤗 Transformers에서 제공한 모델의 사전 학습된 가중치를 사용하는 경우 기본 모델 configuration을 자동으로 불러옵니다. 그러나 원하는 경우 기본 모델 configuration 속성의 일부 또는 전부를 사용자 지정으로 바꿀 수 있습니다:
+
+```py
+>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
+```
+
+
+사용자 지정 configuration 속성을 모델에 불러옵니다:
+
+```py
+>>> from transformers import TFDistilBertModel
+
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
+>>> tf_model = TFDistilBertModel(my_config)
+```
+
+이제 사전 학습된 가중치 대신 임의의 값을 가진 모델이 생성됩니다. 이 모델을 훈련하기 전까지는 유용하게 사용할 수 없습니다. 훈련은 비용과 시간이 많이 소요되는 프로세스입니다. 일반적으로 훈련에 필요한 리소스의 일부만 사용하면서 더 나은 결과를 더 빨리 얻으려면 사전 훈련된 모델을 사용하는 것이 좋습니다.
+
+사전 학습된 모델을 [`~TFPreTrainedModel.from_pretrained`]로 생성합니다:
+
+```py
+>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+🤗 Transformers에서 제공한 모델의 사전 학습된 가중치를 사용하는 경우 기본 모델 configuration을 자동으로 불러옵니다. 그러나 원하는 경우 기본 모델 configuration 속성의 일부 또는 전부를 사용자 지정으로 바꿀 수 있습니다:
+
+```py
+>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
+```
+
+
+
+### 모델 헤드[[model-heads]]
+
+이 시점에서 *은닉 상태(hidden state)*를 출력하는 기본 DistilBERT 모델을 갖게 됩니다. 은닉 상태는 최종 출력을 생성하기 위해 모델 헤드에 입력으로 전달됩니다. 🤗 Transformers는 모델이 해당 작업을 지원하는 한 각 작업마다 다른 모델 헤드를 제공합니다(즉, 번역과 같은 시퀀스 간 작업에는 DistilBERT를 사용할 수 없음).
+
+
+
+예를 들어, [`DistilBertForSequenceClassification`]은 시퀀스 분류 헤드가 있는 기본 DistilBERT 모델입니다. 시퀀스 분류 헤드는 풀링된 출력 위에 있는 선형 레이어입니다.
+
+```py
+>>> from transformers import DistilBertForSequenceClassification
+
+>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+다른 모델 헤드로 전환하여 이 체크포인트를 다른 작업에 쉽게 재사용할 수 있습니다. 질의응답 작업의 경우, [`DistilBertForQuestionAnswering`] 모델 헤드를 사용할 수 있습니다. 질의응답 헤드는 숨겨진 상태 출력 위에 선형 레이어가 있다는 점을 제외하면 시퀀스 분류 헤드와 유사합니다.
+
+```py
+>>> from transformers import DistilBertForQuestionAnswering
+
+>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+
+예를 들어, [`TFDistilBertForSequenceClassification`]은 시퀀스 분류 헤드가 있는 기본 DistilBERT 모델입니다. 시퀀스 분류 헤드는 풀링된 출력 위에 있는 선형 레이어입니다.
+
+```py
+>>> from transformers import TFDistilBertForSequenceClassification
+
+>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+다른 모델 헤드로 전환하여 이 체크포인트를 다른 작업에 쉽게 재사용할 수 있습니다. 질의응답 작업의 경우, [`TFDistilBertForQuestionAnswering`] 모델 헤드를 사용할 수 있습니다. 질의응답 헤드는 숨겨진 상태 출력 위에 선형 레이어가 있다는 점을 제외하면 시퀀스 분류 헤드와 유사합니다.
+
+```py
+>>> from transformers import TFDistilBertForQuestionAnswering
+
+>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+
+
+## 토크나이저[[tokenizer]]
+
+텍스트 데이터에 모델을 사용하기 전에 마지막으로 필요한 기본 클래스는 원시 텍스트를 텐서로 변환하는 [토크나이저](main_classes/tokenizer)입니다. 🤗 Transformers에 사용할 수 있는 토크나이저는 두 가지 유형이 있습니다:
+
+- [`PreTrainedTokenizer`]: 파이썬으로 구현된 토크나이저입니다.
+- [`PreTrainedTokenizerFast`]: Rust 기반 [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) 라이브러리로 만들어진 토크나이저입니다. 이 토크나이저는 Rust로 구현되어 배치 토큰화에서 특히 빠릅니다. 빠른 토크나이저는 토큰을 원래 단어나 문자에 매핑하는 *오프셋 매핑*과 같은 추가 메소드도 제공합니다.
+두 토크나이저 모두 인코딩 및 디코딩, 새 토큰 추가, 특수 토큰 관리와 같은 일반적인 방법을 지원합니다.
+
+
+
+모든 모델이 빠른 토크나이저를 지원하는 것은 아닙니다. 이 [표](index#supported-frameworks)에서 모델의 빠른 토크나이저 지원 여부를 확인하세요.
+
+
+
+토크나이저를 직접 학습한 경우, *어휘(vocabulary)* 파일에서 토크나이저를 만들 수 있습니다:
+
+```py
+>>> from transformers import DistilBertTokenizer
+
+>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
+```
+
+사용자 지정 토크나이저의 어휘는 사전 학습된 모델의 토크나이저에서 생성된 어휘와 다를 수 있다는 점을 기억하는 것이 중요합니다. 사전 학습된 모델을 사용하는 경우 사전 학습된 모델의 어휘를 사용해야 하며, 그렇지 않으면 입력이 의미를 갖지 못합니다. [`DistilBertTokenizer`] 클래스를 사용하여 사전 학습된 모델의 어휘로 토크나이저를 생성합니다:
+
+```py
+>>> from transformers import DistilBertTokenizer
+
+>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+[`DistilBertTokenizerFast`] 클래스로 빠른 토크나이저를 생성합니다:
+
+```py
+>>> from transformers import DistilBertTokenizerFast
+
+>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+
+
+[`AutoTokenizer`]는 기본적으로 빠른 토크나이저를 가져오려고 합니다. 이 동작을 비활성화하려면 `from_pretrained`에서 `use_fast=False`를 설정하면 됩니다.
+
+
+
+## 이미지 프로세서[[image-processor]]
+
+이미지 프로세서(image processor)는 비전 입력을 처리합니다. 기본 [`~image_processing_utils.ImageProcessingMixin`] 클래스에서 상속합니다.
+
+사용하려면 사용 중인 모델과 연결된 이미지 프로세서를 생성합니다. 예를 들어, 이미지 분류에 [ViT](model_doc/vit)를 사용하는 경우 기본 [`ViTImageProcessor`]를 생성합니다:
+
+```py
+>>> from transformers import ViTImageProcessor
+
+>>> vit_extractor = ViTImageProcessor()
+>>> print(vit_extractor)
+ViTImageProcessor {
+ "do_normalize": true,
+ "do_resize": true,
+ "feature_extractor_type": "ViTImageProcessor",
+ "image_mean": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "image_std": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "resample": 2,
+ "size": 224
+}
+```
+
+
+
+사용자 지정을 원하지 않는 경우 `from_pretrained` 메소드를 사용하여 모델의 기본 이미지 프로세서 매개변수를 불러오면 됩니다.
+
+
+
+사용자 지정 이미지 프로세서를 생성하려면 [`ViTImageProcessor`] 파라미터를 수정합니다:
+
+```py
+>>> from transformers import ViTImageProcessor
+
+>>> my_vit_extractor = ViTImageProcessor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
+>>> print(my_vit_extractor)
+ViTImageProcessor {
+ "do_normalize": false,
+ "do_resize": true,
+ "feature_extractor_type": "ViTImageProcessor",
+ "image_mean": [
+ 0.3,
+ 0.3,
+ 0.3
+ ],
+ "image_std": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "resample": "PIL.Image.BOX",
+ "size": 224
+}
+```
+
+## 특성 추출기[[feature-extractor]]
+
+특성 추출기(feature extractor)는 오디오 입력을 처리합니다. 기본 [`~feature_extraction_utils.FeatureExtractionMixin`] 클래스에서 상속되며, 오디오 입력을 처리하기 위해 [`SequenceFeatureExtractor`] 클래스에서 상속할 수도 있습니다.
+
+사용하려면 사용 중인 모델과 연결된 특성 추출기를 생성합니다. 예를 들어, 오디오 분류에 [Wav2Vec2](model_doc/wav2vec2)를 사용하는 경우 기본 [`Wav2Vec2FeatureExtractor`]를 생성합니다:
+
+```py
+>>> from transformers import Wav2Vec2FeatureExtractor
+
+>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
+>>> print(w2v2_extractor)
+Wav2Vec2FeatureExtractor {
+ "do_normalize": true,
+ "feature_extractor_type": "Wav2Vec2FeatureExtractor",
+ "feature_size": 1,
+ "padding_side": "right",
+ "padding_value": 0.0,
+ "return_attention_mask": false,
+ "sampling_rate": 16000
+}
+```
+
+
+
+사용자 지정이 필요하지 않은 경우 `from_pretrained` 메소드를 사용하여 모델의 기본 특성 추출기 ㅁ개변수를 불러 오면 됩니다.
+
+
+
+사용자 지정 특성 추출기를 만들려면 [`Wav2Vec2FeatureExtractor`] 매개변수를 수정합니다:
+
+```py
+>>> from transformers import Wav2Vec2FeatureExtractor
+
+>>> w2v2_extractor = Wav2Vec2FeatureExtractor(sampling_rate=8000, do_normalize=False)
+>>> print(w2v2_extractor)
+Wav2Vec2FeatureExtractor {
+ "do_normalize": false,
+ "feature_extractor_type": "Wav2Vec2FeatureExtractor",
+ "feature_size": 1,
+ "padding_side": "right",
+ "padding_value": 0.0,
+ "return_attention_mask": false,
+ "sampling_rate": 8000
+}
+```
+
+
+## 프로세서[[processor]]
+
+멀티모달 작업을 지원하는 모델의 경우, 🤗 Transformers는 특성 추출기 및 토크나이저와 같은 처리 클래스를 단일 객체로 편리하게 래핑하는 프로세서 클래스를 제공합니다. 예를 들어, 자동 음성 인식 작업(Automatic Speech Recognition task (ASR))에 [`Wav2Vec2Processor`]를 사용한다고 가정해 보겠습니다. 자동 음성 인식 작업은 오디오를 텍스트로 변환하므로 특성 추출기와 토크나이저가 필요합니다.
+
+오디오 입력을 처리할 특성 추출기를 만듭니다:
+
+```py
+>>> from transformers import Wav2Vec2FeatureExtractor
+
+>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
+```
+
+텍스트 입력을 처리할 토크나이저를 만듭니다:
+
+```py
+>>> from transformers import Wav2Vec2CTCTokenizer
+
+>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
+```
+
+[`Wav2Vec2Processor`]에서 특성 추출기와 토크나이저를 결합합니다:
+
+```py
+>>> from transformers import Wav2Vec2Processor
+
+>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+```
+
+configuration과 모델이라는 두 가지 기본 클래스와 추가 전처리 클래스(토크나이저, 이미지 프로세서, 특성 추출기 또는 프로세서)를 사용하면 🤗 Transformers에서 지원하는 모든 모델을 만들 수 있습니다. 이러한 각 기본 클래스는 구성이 가능하므로 원하는 특정 속성을 사용할 수 있습니다. 학습을 위해 모델을 쉽게 설정하거나 기존의 사전 학습된 모델을 수정하여 미세 조정할 수 있습니다.
diff --git a/docs/transformers/docs/source/ko/custom_models.md b/docs/transformers/docs/source/ko/custom_models.md
new file mode 100644
index 0000000000000000000000000000000000000000..cb67a535b47d41453e2b5d27fcc67b89a7ab7407
--- /dev/null
+++ b/docs/transformers/docs/source/ko/custom_models.md
@@ -0,0 +1,346 @@
+
+
+# 사용자 정의 모델 공유하기[[sharing-custom-models]]
+
+🤗 Transformers 라이브러리는 쉽게 확장할 수 있도록 설계되었습니다.
+모든 모델은 추상화 없이 저장소의 지정된 하위 폴더에 완전히 코딩되어 있으므로, 손쉽게 모델링 파일을 복사하고 필요에 따라 조정할 수 있습니다.
+
+완전히 새로운 모델을 만드는 경우에는 처음부터 시작하는 것이 더 쉬울 수 있습니다.
+이 튜토리얼에서는 Transformers 내에서 사용할 수 있도록 사용자 정의 모델과 구성을 작성하는 방법과
+🤗 Transformers 라이브러리에 없는 경우에도 누구나 사용할 수 있도록 (의존성과 함께) 커뮤니티에 공유하는 방법을 배울 수 있습니다.
+
+[timm 라이브러리](https://github.com/rwightman/pytorch-image-models)의 ResNet 클래스를 [`PreTrainedModel`]로 래핑한 ResNet 모델을 예로 모든 것을 설명합니다.
+
+## 사용자 정의 구성 작성하기[[writing-a-custom-configuration]]
+
+모델에 들어가기 전에 먼저 구성을 작성해보도록 하겠습니다.
+모델의 `configuration`은 모델을 만들기 위해 필요한 모든 중요한 것들을 포함하고 있는 객체입니다.
+다음 섹션에서 볼 수 있듯이, 모델은 `config`를 사용해서만 초기화할 수 있기 때문에 완벽한 구성이 필요합니다.
+
+아래 예시에서는 ResNet 클래스의 인수(argument)를 조정해보겠습니다.
+다른 구성은 가능한 ResNet 중 다른 유형을 제공합니다.
+그런 다음 몇 가지 유효성을 확인한 후 해당 인수를 저장합니다.
+
+```python
+from transformers import PretrainedConfig
+from typing import List
+
+
+class ResnetConfig(PretrainedConfig):
+ model_type = "resnet"
+
+ def __init__(
+ self,
+ block_type="bottleneck",
+ layers: List[int] = [3, 4, 6, 3],
+ num_classes: int = 1000,
+ input_channels: int = 3,
+ cardinality: int = 1,
+ base_width: int = 64,
+ stem_width: int = 64,
+ stem_type: str = "",
+ avg_down: bool = False,
+ **kwargs,
+ ):
+ if block_type not in ["basic", "bottleneck"]:
+ raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
+ if stem_type not in ["", "deep", "deep-tiered"]:
+ raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
+
+ self.block_type = block_type
+ self.layers = layers
+ self.num_classes = num_classes
+ self.input_channels = input_channels
+ self.cardinality = cardinality
+ self.base_width = base_width
+ self.stem_width = stem_width
+ self.stem_type = stem_type
+ self.avg_down = avg_down
+ super().__init__(**kwargs)
+```
+
+사용자 정의 `configuration`을 작성할 때 기억해야 할 세 가지 중요한 사항은 다음과 같습니다:
+- `PretrainedConfig`을 상속해야 합니다.
+- `PretrainedConfig`의 `__init__`은 모든 kwargs를 허용해야 하고,
+- 이러한 `kwargs`는 상위 클래스 `__init__`에 전달되어야 합니다.
+
+상속은 🤗 Transformers 라이브러리에서 모든 기능을 가져오는 것입니다.
+이러한 점으로부터 비롯되는 두 가지 제약 조건은 `PretrainedConfig`에 설정하는 것보다 더 많은 필드가 있습니다.
+`from_pretrained` 메서드로 구성을 다시 로드할 때 해당 필드는 구성에서 수락한 후 상위 클래스로 보내야 합니다.
+
+모델을 auto 클래스에 등록하지 않는 한, `configuration`에서 `model_type`을 정의(여기서 `model_type="resnet"`)하는 것은 필수 사항이 아닙니다 (마지막 섹션 참조).
+
+이렇게 하면 라이브러리의 다른 모델 구성과 마찬가지로 구성을 쉽게 만들고 저장할 수 있습니다.
+다음은 resnet50d 구성을 생성하고 저장하는 방법입니다:
+
+```py
+resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
+resnet50d_config.save_pretrained("custom-resnet")
+```
+
+이렇게 하면 `custom-resnet` 폴더 안에 `config.json`이라는 파일이 저장됩니다.
+그런 다음 `from_pretrained` 메서드를 사용하여 구성을 다시 로드할 수 있습니다.
+
+```py
+resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
+```
+
+구성을 Hub에 직접 업로드하기 위해 [`PretrainedConfig`] 클래스의 [`~PretrainedConfig.push_to_hub`]와 같은 다른 메서드를 사용할 수 있습니다.
+
+
+## 사용자 정의 모델 작성하기[[writing-a-custom-model]]
+
+이제 ResNet 구성이 있으므로 모델을 작성할 수 있습니다.
+실제로는 두 개를 작성할 것입니다. 하나는 이미지 배치에서 hidden features를 추출하는 것([`BertModel`]과 같이), 다른 하나는 이미지 분류에 적합한 것입니다([`BertForSequenceClassification`]과 같이).
+
+이전에 언급했듯이 이 예제에서는 단순하게 하기 위해 모델의 느슨한 래퍼(loose wrapper)만 작성할 것입니다.
+이 클래스를 작성하기 전에 블록 유형과 실제 블록 클래스 간의 매핑 작업만 하면 됩니다.
+그런 다음 `ResNet` 클래스로 전달되어 `configuration`을 통해 모델이 선언됩니다:
+
+```py
+from transformers import PreTrainedModel
+from timm.models.resnet import BasicBlock, Bottleneck, ResNet
+from .configuration_resnet import ResnetConfig
+
+
+BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
+
+
+class ResnetModel(PreTrainedModel):
+ config_class = ResnetConfig
+
+ def __init__(self, config):
+ super().__init__(config)
+ block_layer = BLOCK_MAPPING[config.block_type]
+ self.model = ResNet(
+ block_layer,
+ config.layers,
+ num_classes=config.num_classes,
+ in_chans=config.input_channels,
+ cardinality=config.cardinality,
+ base_width=config.base_width,
+ stem_width=config.stem_width,
+ stem_type=config.stem_type,
+ avg_down=config.avg_down,
+ )
+
+ def forward(self, tensor):
+ return self.model.forward_features(tensor)
+```
+
+이미지 분류 모델을 만들기 위해서는 forward 메소드만 변경하면 됩니다:
+
+```py
+import torch
+
+
+class ResnetModelForImageClassification(PreTrainedModel):
+ config_class = ResnetConfig
+
+ def __init__(self, config):
+ super().__init__(config)
+ block_layer = BLOCK_MAPPING[config.block_type]
+ self.model = ResNet(
+ block_layer,
+ config.layers,
+ num_classes=config.num_classes,
+ in_chans=config.input_channels,
+ cardinality=config.cardinality,
+ base_width=config.base_width,
+ stem_width=config.stem_width,
+ stem_type=config.stem_type,
+ avg_down=config.avg_down,
+ )
+
+ def forward(self, tensor, labels=None):
+ logits = self.model(tensor)
+ if labels is not None:
+ loss = torch.nn.functional.cross_entropy(logits, labels)
+ return {"loss": loss, "logits": logits}
+ return {"logits": logits}
+```
+
+두 경우 모두 `PreTrainedModel`를 상속받고, `config`를 통해 상위 클래스 초기화를 호출하다는 점을 기억하세요 (일반적인 `torch.nn.Module`을 작성할 때와 비슷함).
+모델을 auto 클래스에 등록하고 싶은 경우에는 `config_class`를 설정하는 부분이 필수입니다 (마지막 섹션 참조).
+
+
+
+라이브러리에 존재하는 모델과 굉장히 유사하다면, 모델을 생성할 때 구성을 참조해 재사용할 수 있습니다.
+
+
+
+원하는 것을 모델이 반환하도록 할 수 있지만, `ResnetModelForImageClassification`에서 했던 것 처럼
+레이블을 통과시켰을 때 손실과 함께 사전 형태로 반환하는 것이 [`Trainer`] 클래스 내에서 직접 모델을 사용하기에 유용합니다.
+자신만의 학습 루프 또는 다른 학습 라이브러리를 사용할 계획이라면 다른 출력 형식을 사용해도 좋습니다.
+
+이제 모델 클래스가 있으므로 하나 생성해 보겠습니다:
+
+```py
+resnet50d = ResnetModelForImageClassification(resnet50d_config)
+```
+
+다시 말하지만, [`~PreTrainedModel.save_pretrained`]또는 [`~PreTrainedModel.push_to_hub`]처럼 [`PreTrainedModel`]에 속하는 모든 메소드를 사용할 수 있습니다.
+다음 섹션에서 두 번째 메소드를 사용해 모델 코드와 모델 가중치를 업로드하는 방법을 살펴보겠습니다.
+먼저, 모델 내부에 사전 훈련된 가중치를 로드해 보겠습니다.
+
+이 예제를 활용할 때는, 사용자 정의 모델을 자신만의 데이터로 학습시킬 것입니다.
+이 튜토리얼에서는 빠르게 진행하기 위해 사전 훈련된 resnet50d를 사용하겠습니다.
+아래 모델은 resnet50d의 래퍼이기 때문에, 가중치를 쉽게 로드할 수 있습니다.
+
+
+```py
+import timm
+
+pretrained_model = timm.create_model("resnet50d", pretrained=True)
+resnet50d.model.load_state_dict(pretrained_model.state_dict())
+```
+
+이제 [`~PreTrainedModel.save_pretrained`] 또는 [`~PreTrainedModel.push_to_hub`]를 사용할 때 모델 코드가 저장되는지 확인해봅시다.
+
+## Hub로 코드 업로드하기[[sending-the-code-to-the-hub]]
+
+
+
+이 API는 실험적이며 다음 릴리스에서 약간의 변경 사항이 있을 수 있습니다.
+
+
+
+먼저 모델이 `.py` 파일에 완전히 정의되어 있는지 확인하세요.
+모든 파일이 동일한 작업 경로에 있기 때문에 상대경로 임포트(relative import)에 의존할 수 있습니다 (transformers에서는 이 기능에 대한 하위 모듈을 지원하지 않습니다).
+이 예시에서는 작업 경로 안의 `resnet_model`에서 `modeling_resnet.py` 파일과 `configuration_resnet.py` 파일을 정의합니다.
+구성 파일에는 `ResnetConfig`에 대한 코드가 있고 모델링 파일에는 `ResnetModel` 및 `ResnetModelForImageClassification`에 대한 코드가 있습니다.
+
+```
+.
+└── resnet_model
+ ├── __init__.py
+ ├── configuration_resnet.py
+ └── modeling_resnet.py
+```
+
+Python이 `resnet_model`을 모듈로 사용할 수 있도록 감지하는 목적이기 때문에 `__init__.py`는 비어 있을 수 있습니다.
+
+
+
+라이브러리에서 모델링 파일을 복사하는 경우,
+모든 파일 상단에 있는 상대 경로 임포트(relative import) 부분을 `transformers` 패키지에서 임포트 하도록 변경해야 합니다.
+
+
+
+기존 구성이나 모델을 재사용(또는 서브 클래스화)할 수 있습니다.
+
+커뮤니티에 모델을 공유하기 위해서는 다음 단계를 따라야 합니다:
+먼저, 새로 만든 파일에 ResNet 모델과 구성을 임포트합니다:
+
+```py
+from resnet_model.configuration_resnet import ResnetConfig
+from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
+```
+
+다음으로 `save_pretrained` 메소드를 사용해 해당 객체의 코드 파일을 복사하고,
+복사한 파일을 Auto 클래스로 등록하고(모델인 경우) 실행합니다:
+
+```py
+ResnetConfig.register_for_auto_class()
+ResnetModel.register_for_auto_class("AutoModel")
+ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
+```
+
+`configuration`에 대한 auto 클래스를 지정할 필요는 없지만(`configuration` 관련 auto 클래스는 AutoConfig 클래스 하나만 있음), 모델의 경우에는 지정해야 합니다.
+사용자 지정 모델은 다양한 작업에 적합할 수 있으므로, 모델에 맞는 auto 클래스를 지정해야 합니다.
+
+다음으로, 이전에 작업했던 것과 마찬가지로 구성과 모델을 작성합니다:
+
+```py
+resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
+resnet50d = ResnetModelForImageClassification(resnet50d_config)
+
+pretrained_model = timm.create_model("resnet50d", pretrained=True)
+resnet50d.model.load_state_dict(pretrained_model.state_dict())
+```
+
+이제 모델을 Hub로 업로드하기 위해 로그인 상태인지 확인하세요.
+터미널에서 다음 코드를 실행해 확인할 수 있습니다:
+
+```bash
+huggingface-cli login
+```
+
+주피터 노트북의 경우에는 다음과 같습니다:
+
+```py
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+그런 다음 이렇게 자신의 네임스페이스(또는 자신이 속한 조직)에 업로드할 수 있습니다:
+```py
+resnet50d.push_to_hub("custom-resnet50d")
+```
+
+On top of the modeling weights and the configuration in json format, this also copied the modeling and
+configuration `.py` files in the folder `custom-resnet50d` and uploaded the result to the Hub. You can check the result
+in this [model repo](https://huggingface.co/sgugger/custom-resnet50d).
+json 형식의 모델링 가중치와 구성 외에도 `custom-resnet50d` 폴더 안의 모델링과 구성 `.py` 파일을 복사하해 Hub에 업로드합니다.
+[모델 저장소](https://huggingface.co/sgugger/custom-resnet50d)에서 결과를 확인할 수 있습니다.
+
+[sharing tutorial](model_sharing) 문서의 `push_to_hub` 메소드에서 자세한 내용을 확인할 수 있습니다.
+
+
+## 사용자 정의 코드로 모델 사용하기[[using-a-model-with-custom-code]]
+
+auto 클래스와 `from_pretrained` 메소드를 사용하여 사용자 지정 코드 파일과 함께 모든 구성, 모델, 토크나이저를 사용할 수 있습니다.
+Hub에 업로드된 모든 파일 및 코드는 멜웨어가 있는지 검사되지만 (자세한 내용은 [Hub 보안](https://huggingface.co/docs/hub/security#malware-scanning) 설명 참조),
+자신의 컴퓨터에서 모델 코드와 작성자가 악성 코드를 실행하지 않는지 확인해야 합니다.
+사용자 정의 코드로 모델을 사용하려면 `trust_remote_code=True`로 설정하세요:
+
+```py
+from transformers import AutoModelForImageClassification
+
+model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
+```
+
+모델 작성자가 악의적으로 코드를 업데이트하지 않았다는 점을 확인하기 위해, 커밋 해시(commit hash)를 `revision`으로 전달하는 것도 강력히 권장됩니다 (모델 작성자를 완전히 신뢰하지 않는 경우).
+
+```py
+commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
+model = AutoModelForImageClassification.from_pretrained(
+ "sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
+)
+```
+
+Hub에서 모델 저장소의 커밋 기록을 찾아볼 때, 모든 커밋의 커밋 해시를 쉽게 복사할 수 있는 버튼이 있습니다.
+
+## 사용자 정의 코드로 만든 모델을 auto 클래스로 등록하기[[registering-a-model-with-custom-code-to-the-auto-classes]]
+
+🤗 Transformers를 상속하는 라이브러리를 작성하는 경우 사용자 정의 모델을 auto 클래스에 추가할 수 있습니다.
+사용자 정의 모델을 사용하기 위해 해당 라이브러리를 임포트해야 하기 때문에, 이는 Hub로 코드를 업로드하는 것과 다릅니다 (Hub에서 자동적으로 모델 코드를 다운로드 하는 것과 반대).
+
+구성에 기존 모델 유형과 다른 `model_type` 속성이 있고 모델 클래스에 올바른 `config_class` 속성이 있는 한,
+다음과 같이 auto 클래스에 추가할 수 있습니다:
+
+```py
+from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
+
+AutoConfig.register("resnet", ResnetConfig)
+AutoModel.register(ResnetConfig, ResnetModel)
+AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
+```
+
+사용자 정의 구성을 [`AutoConfig`]에 등록할 때 사용되는 첫 번째 인수는 사용자 정의 구성의 `model_type`과 일치해야 합니다.
+또한, 사용자 정의 모델을 auto 클래스에 등록할 때 사용되는 첫 번째 인수는 해당 모델의 `config_class`와 일치해야 합니다.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/debugging.md b/docs/transformers/docs/source/ko/debugging.md
new file mode 100644
index 0000000000000000000000000000000000000000..24b2c7b04b509d9301003a3911dbb0b0e324eedf
--- /dev/null
+++ b/docs/transformers/docs/source/ko/debugging.md
@@ -0,0 +1,306 @@
+
+
+# 디버깅 [[debugging]]
+
+## Multi-GPU 네트워크 문제 디버그 [[multigpu-network-issues-debug]]
+
+`DistributedDataParallel` 및 다중 GPU를 사용하여 훈련하거나 추론할 때, 프로세스 및/또는 노드 간의 상호 통신 문제가 발생하는 경우, 다음 스크립트를 사용하여 네트워크 문제를 진단할 수 있습니다.
+
+```bash
+wget https://raw.githubusercontent.com/huggingface/transformers/main/scripts/distributed/torch-distributed-gpu-test.py
+```
+
+예를 들어, 2개의 GPU가 상호 작용하는 방식을 테스트하려면 다음을 실행하세요:
+
+```bash
+python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
+```
+두 프로세스가 서로 통신하고 GPU 메모리를 할당하는 경우, 각각 "OK" 상태를 출력합니다.
+
+더 많은 GPU 또는 노드의 경우 스크립트의 인수를 조정하면 됩니다.
+
+진단 스크립트 내에서 더 많은 세부 정보와 SLURM 환경에서 실행하는 방법에 대한 레시피를 찾을 수 있습니다.
+
+추가적인 디버그 수준은 다음과 같이 `NCCL_DEBUG=INFO` 환경 변수를 추가하는 것입니다:
+
+```bash
+NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
+```
+
+이렇게 하면 NCCL 관련 디버그 정보가 많이 출력되며, 문제가 보고된 경우에는 인터넷에서 검색할 수 있습니다. 또는 출력을 해석하는 방법을 잘 모르는 경우 로그 파일을 이슈에 공유할 수 있습니다.
+
+
+
+## 언더플로 및 오버플로 감지 [[underflow-and-overflow-detection]]
+
+
+
+
+이 기능은 현재 PyTorch에서만 사용할 수 있습니다.
+
+
+
+
+
+다중 GPU 훈련을 위해서는 DDP (`torch.distributed.launch`)가 필요합니다.
+
+
+
+
+
+이 기능은 `nn.Module`을 기반으로 하는 모델과 함께 사용할 수 있습니다.
+
+
+
+`loss=NaN`이 나타나거나 모델이 `inf` 또는 `nan`으로 인해 다른 이상한 동작을 하는 경우, 언더플로 또는 오버플로의 첫 번째 발생 위치와 그 원인을 파악해야 합니다. 다행히도 이를 자동으로 감지하는 특수 모듈을 활성화하여 쉽게 알아낼 수 있습니다.
+
+[`Trainer`]를 사용하는 경우, 다음을 기존의 명령줄 인수에 추가하면 됩니다.
+
+```bash
+--debug underflow_overflow
+```
+또는 [`TrainingArguments`] 객체를 생성할 때 `debug="underflow_overflow"`를 전달합니다.
+
+자체 훈련 루프나 다른 Trainer를 사용하는 경우, 다음과 같이 수행할 수 있습니다.
+
+```python
+from transformers.debug_utils import DebugUnderflowOverflow
+
+debug_overflow = DebugUnderflowOverflow(model)
+```
+
+[`~debug_utils.DebugUnderflowOverflow`]는 모델에 후크를 삽입하여 각 forward 호출 직후에 입력 및 출력 변수 및 해당 모듈의 가중치를 테스트합니다. 활성화나 가중치의 최소한 하나의 요소에서 `inf` 또는 `nan`이 감지되면 프로그램이 어설트되고 다음과 같은 보고서가 출력됩니다. (이 예제는 fp16 혼합 정밀도에서 `google/mt5-small`에서 캡처된 것입니다):
+
+```
+Detected inf/nan during batch_number=0
+Last 21 forward frames:
+abs min abs max metadata
+ encoder.block.1.layer.1.DenseReluDense.dropout Dropout
+0.00e+00 2.57e+02 input[0]
+0.00e+00 2.85e+02 output
+[...]
+ encoder.block.2.layer.0 T5LayerSelfAttention
+6.78e-04 3.15e+03 input[0]
+2.65e-04 3.42e+03 output[0]
+ None output[1]
+2.25e-01 1.00e+04 output[2]
+ encoder.block.2.layer.1.layer_norm T5LayerNorm
+8.69e-02 4.18e-01 weight
+2.65e-04 3.42e+03 input[0]
+1.79e-06 4.65e+00 output
+ encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
+2.17e-07 4.50e+00 weight
+1.79e-06 4.65e+00 input[0]
+2.68e-06 3.70e+01 output
+ encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
+8.08e-07 2.66e+01 weight
+1.79e-06 4.65e+00 input[0]
+1.27e-04 2.37e+02 output
+ encoder.block.2.layer.1.DenseReluDense.dropout Dropout
+0.00e+00 8.76e+03 input[0]
+0.00e+00 9.74e+03 output
+ encoder.block.2.layer.1.DenseReluDense.wo Linear
+1.01e-06 6.44e+00 weight
+0.00e+00 9.74e+03 input[0]
+3.18e-04 6.27e+04 output
+ encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
+1.79e-06 4.65e+00 input[0]
+3.18e-04 6.27e+04 output
+ encoder.block.2.layer.1.dropout Dropout
+3.18e-04 6.27e+04 input[0]
+0.00e+00 inf output
+```
+
+예제 출력은 간략성을 위해 중간 부분이 잘려 있습니다.
+
+두 번째 열은 절대적으로 가장 큰 요소의 값이며, 따라서 마지막 몇 개의 프레임을 자세히 살펴보면 입력과 출력이 `1e4` 범위에 있음을 알 수 있습니다. 따라서 이 훈련은 `fp16` 혼합 정밀도로 수행될 때 가장 마지막 단계에서 오버플로우가 발생했습니다 (`fp16`에서 `inf` 이전의 가장 큰 숫자는 `64e3`입니다). `fp16` 아래에서 오버플로우를 피하기 위해서는 활성화는 `1e4`보다 훨씬 작아야 합니다. 왜냐하면 `1e4 * 1e4 = 1e8`이기 때문에 큰 활성화와의 행렬 곱은 수치적인 오버플로우 조건으로 이어질 것입니다.
+
+추적의 맨 처음에서 어느 배치 번호에서 문제가 발생했는지 알 수 있습니다 (여기서 `Detected inf/nan during batch_number=0`은 문제가 첫 번째 배치에서 발생했음을 의미합니다).
+
+각 보고된 프레임은 해당 프레임이 보고하는 해당 모듈에 대한 완전한 항목을 선언하며, 이 프레임만 살펴보면 다음과 같습니다.
+
+```
+ encoder.block.2.layer.1.layer_norm T5LayerNorm
+8.69e-02 4.18e-01 weight
+2.65e-04 3.42e+03 input[0]
+1.79e-06 4.65e+00 output
+```
+
+여기서 `encoder.block.2.layer.1.layer_norm`은 인코더의 두 번째 블록의 첫 번째 레이어에 대한 레이어 정규화를 의미하며, `forward`의 특정 호출은 `T5LayerNorm`입니다.
+
+이 보고서의 마지막 몇 개 프레임을 살펴보겠습니다:
+
+```
+Detected inf/nan during batch_number=0
+Last 21 forward frames:
+abs min abs max metadata
+[...]
+ encoder.block.2.layer.1.DenseReluDense.wi_0 Linear
+2.17e-07 4.50e+00 weight
+1.79e-06 4.65e+00 input[0]
+2.68e-06 3.70e+01 output
+ encoder.block.2.layer.1.DenseReluDense.wi_1 Linear
+8.08e-07 2.66e+01 weight
+1.79e-06 4.65e+00 input[0]
+1.27e-04 2.37e+02 output
+ encoder.block.2.layer.1.DenseReluDense.wo Linear
+1.01e-06 6.44e+00 weight
+0.00e+00 9.74e+03 input[0]
+3.18e-04 6.27e+04 output
+ encoder.block.2.layer.1.DenseReluDense T5DenseGatedGeluDense
+1.79e-06 4.65e+00 input[0]
+3.18e-04 6.27e+04 output
+ encoder.block.2.layer.1.dropout Dropout
+3.18e-04 6.27e+04 input[0]
+0.00e+00 inf output
+```
+
+마지막 프레임은 `Dropout.forward` 함수에 대한 보고입니다. 첫 번째 항목은 유일한 입력을 나타내고 두 번째 항목은 유일한 출력을 나타냅니다. 이 함수가 `DenseReluDense` 클래스 내부의 `dropout` 속성에서 호출된 것을 볼 수 있습니다. 이는 첫 번째 레이어의 두 번째 블록에서 첫 번째 배치 중에 발생했다는 것을 알 수 있습니다. 마지막으로, 절대적으로 가장 큰 입력 요소는 `6.27e+04`이고 출력도 마찬가지로 `inf`입니다.
+
+여기에서는 `T5DenseGatedGeluDense.forward`가 출력 활성화를 생성하는데, 절대적으로 가장 큰 값이 약 62.7K인 것을 볼 수 있습니다. 이 값은 fp16의 최대 제한인 64K에 매우 근접합니다. 다음 프레임에서는 일부 요소를 0으로 만든 후 가중치를 재정규화하는 `Dropout`이 있습니다. 이로 인해 절대 최대값이 64K를 초과하고 오버플로우(`inf`)가 발생합니다.
+
+보시다시피, fp16 숫자의 경우 숫자가 매우 커질 때 이전 프레임을 살펴보아야 합니다.
+
+보고서를 `models/t5/modeling_t5.py`의 코드와 일치시켜 보겠습니다.
+
+```python
+class T5DenseGatedGeluDense(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.wi_0 = nn.Linear(config.d_model, config.d_ff, bias=False)
+ self.wi_1 = nn.Linear(config.d_model, config.d_ff, bias=False)
+ self.wo = nn.Linear(config.d_ff, config.d_model, bias=False)
+ self.dropout = nn.Dropout(config.dropout_rate)
+ self.gelu_act = ACT2FN["gelu_new"]
+
+ def forward(self, hidden_states):
+ hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
+ hidden_linear = self.wi_1(hidden_states)
+ hidden_states = hidden_gelu * hidden_linear
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.wo(hidden_states)
+ return hidden_states
+```
+
+이제 `dropout` 호출과 이전의 모든 호출을 쉽게 확인할 수 있습니다.
+
+감지는 `forward` 후크에서 발생하므로, 이러한 보고서는 각 `forward`가 반환된 직후에 즉시 출력됩니다.
+
+전체 보고서로 돌아가서 문제에 대한 조치 및 수정을 하려면, 숫자가 증가하기 시작한 몇 개의 프레임 위로 이동해서 여기서 `fp32` 모드로 전환해야 합니다. 이렇게 해야 숫자가 곱해지거나 합쳐질 때 오버플로우되지 않을 가능성이 높습니다. 물론 다른 해결책도 있을 수 있습니다. 예를 들어, `amp`가 활성화된 경우 일시적으로 끄고 원래의 `forward`를 도우미 래퍼로 이동한 후 다음과 같이 할 수 있습니다:
+
+```python
+def _forward(self, hidden_states):
+ hidden_gelu = self.gelu_act(self.wi_0(hidden_states))
+ hidden_linear = self.wi_1(hidden_states)
+ hidden_states = hidden_gelu * hidden_linear
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.wo(hidden_states)
+ return hidden_states
+
+
+import torch
+
+
+def forward(self, hidden_states):
+ if torch.is_autocast_enabled():
+ with torch.cuda.amp.autocast(enabled=False):
+ return self._forward(hidden_states)
+ else:
+ return self._forward(hidden_states)
+```
+
+자동 감지기는 전체 프레임의 입력과 출력에 대해서만 보고하므로, 어디를 살펴봐야 하는지 알면 특정 `forward` 함수의 중간 단계도 분석할 수 있습니다. 이 경우에는 `detect_overflow` 도우미 함수를 사용하여 원하는 위치에 감지기를 삽입할 수 있습니다. 예를 들어:
+
+```python
+from debug_utils import detect_overflow
+
+
+class T5LayerFF(nn.Module):
+ [...]
+
+ def forward(self, hidden_states):
+ forwarded_states = self.layer_norm(hidden_states)
+ detect_overflow(forwarded_states, "after layer_norm")
+ forwarded_states = self.DenseReluDense(forwarded_states)
+ detect_overflow(forwarded_states, "after DenseReluDense")
+ return hidden_states + self.dropout(forwarded_states)
+```
+
+여기서는 이를 추가하여 2개의 것을 추적하고 이제 `forwarded_states`의 `inf` 또는 `nan`이 중간에 감지되었는지를 추적합니다.
+
+실제로 위의 예제에서 각 호출이 `nn.Module`이기 때문에 탐지기가 이미 이를 보고합니다. 로컬에서 직접 계산하는 경우 이렇게 수행한다고 가정해 봅시다.
+
+또한, 자체 코드에서 디버거를 인스턴스화하는 경우 기본값에서 출력되는 프레임 수를 조정할 수 있습니다. 예를 들어:
+
+```python
+from transformers.debug_utils import DebugUnderflowOverflow
+
+debug_overflow = DebugUnderflowOverflow(model, max_frames_to_save=100)
+```
+
+### 특정 배치의 절댓값 최소 및 최대 값 추적 [[specific-batch-absolute-min-and-max-value-tracing]]
+
+동일한 디버깅 클래스는 언더플로우/오버플로우 감지 기능이 꺼진 상태에서 배치별 추적에도 사용할 수 있습니다.
+
+예를 들어, 특정 배치의 각 `forward` 호출의 모든 구성 성분에 대한 절대 최솟값과 최댓값을 확인하고, 이를 배치 1과 3에 대해서만 수행하려면 다음과 같이 이 클래스를 인스턴스화합니다:
+
+```python
+debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3])
+```
+
+그러면 이제 배치 1과 3 전체가 언더플로우/오버플로우 감지기와 동일한 형식으로 추적됩니다.
+
+배치는 0부터 시작합니다.
+
+이는 프로그램이 특정 배치 번호 이후에 오작동하기 시작하는 것을 알고 있는 경우에 유용합니다. 그렇기 때문에 해당 영역으로 바로 이동할 수 있습니다. 이런 구성에 대한 샘플 축소된 출력은 다음과 같습니다.
+
+```
+ *** Starting batch number=1 ***
+abs min abs max metadata
+ shared Embedding
+1.01e-06 7.92e+02 weight
+0.00e+00 2.47e+04 input[0]
+5.36e-05 7.92e+02 output
+[...]
+ decoder.dropout Dropout
+1.60e-07 2.27e+01 input[0]
+0.00e+00 2.52e+01 output
+ decoder T5Stack
+ not a tensor output
+ lm_head Linear
+1.01e-06 7.92e+02 weight
+0.00e+00 1.11e+00 input[0]
+6.06e-02 8.39e+01 output
+ T5ForConditionalGeneration
+ not a tensor output
+
+ *** Starting batch number=3 ***
+abs min abs max metadata
+ shared Embedding
+1.01e-06 7.92e+02 weight
+0.00e+00 2.78e+04 input[0]
+5.36e-05 7.92e+02 output
+[...]
+```
+
+여기에서는 모델의 forward 호출 수와 동일한 수의 프레임이 덤프되므로 많은 수의 프레임이 생성됩니다. 따라서 원하는 것일 수도 있고 아닐 수도 있습니다. 그러나 때로는 일반 디버거보다 디버깅 목적으로 더 쉽게 사용할 수 있습니다. 예를 들어, 문제가 배치 번호 150에서 시작하는 경우 149와 150의 추적을 덤프하고 숫자가 어디서부터 다르게 되었는지 비교할 수 있습니다.
+
+또한, 훈련을 중지할 배치 번호를 지정할 수도 있습니다. 다음과 같이 지정할 수 있습니다.
+
+```python
+debug_overflow = DebugUnderflowOverflow(model, trace_batch_nums=[1, 3], abort_after_batch_num=3)
+```
diff --git a/docs/transformers/docs/source/ko/deepspeed.md b/docs/transformers/docs/source/ko/deepspeed.md
new file mode 100644
index 0000000000000000000000000000000000000000..48758ad9d52e2ddc6d7ed8e29c1fe580bed9cd70
--- /dev/null
+++ b/docs/transformers/docs/source/ko/deepspeed.md
@@ -0,0 +1,1220 @@
+
+
+# DeepSpeed[[deepspeed]]
+
+[DeepSpeed](https://www.deepspeed.ai/)는 분산 학습 메모리를 효율적이고 빠르게 만드는 PyTorch 최적화 라이브러리입니다. 그 핵심은 대규모 모델을 규모에 맞게 훈련할 수 있는 [Zero Redundancy Optimizer(ZeRO)](https://hf.co/papers/1910.02054)입니다. ZeRO는 여러 단계로 작동합니다:
+
+* ZeRO-1, GPU 간 최적화 상태 분할
+* ZeRO-2, GPU 간 그레이디언트 분할
+* ZeRO-3, GPU 간 매개변수 분할
+
+GPU가 제한된 환경에서 ZeRO는 최적화 메모리와 계산을 GPU에서 CPU로 오프로드하여 단일 GPU에 대규모 모델을 장착하고 훈련할 수 있습니다. DeepSpeed는 모든 ZeRO 단계 및 오프로딩을 위해 Transformers [`Trainer`] 클래스와 통합되어 있습니다. 구성 파일을 제공하거나 제공된 템플릿을 사용하기만 하면 됩니다. 추론의 경우, Transformers는 대용량 모델을 가져올 수 있으므로 ZeRO-3 및 오프로딩을 지원합니다.
+
+이 가이드에서는 DeepSpeed 트레이닝을 배포하는 방법, 활성화할 수 있는 기능, 다양한 ZeRO 단계에 대한 구성 파일 설정 방법, 오프로딩, 추론 및 [`Trainer`] 없이 DeepSpeed를 사용하는 방법을 안내해 드립니다.
+
+## 설치[[installation]]
+
+DeepSpeed는 PyPI 또는 Transformers에서 설치할 수 있습니다(자세한 설치 옵션은 DeepSpeed [설치 상세사항](https://www.deepspeed.ai/tutorials/advanced-install/) 또는 GitHub [README](https://github.com/deepspeedai/DeepSpeed#installation)를 참조하세요).
+
+
+
+DeepSpeed를 설치하는 데 문제가 있는 경우 [DeepSpeed CUDA 설치](../debugging#deepspeed-cuda-installation) 가이드를 확인하세요. DeepSpeed에는 pip 설치 가능한 PyPI 패키지로 설치할 수 있지만, 하드웨어에 가장 잘 맞고 PyPI 배포판에서는 제공되지 않는 1비트 Adam과 같은 특정 기능을 지원하려면 [소스에서 설치하기](https://www.deepspeed.ai/tutorials/advanced-install/#install-deepspeed-from-source)를 적극 권장합니다.
+
+
+
+
+
+
+```bash
+pip install deepspeed
+```
+
+
+
+
+```bash
+pip install transformers[deepspeed]
+```
+
+
+
+
+## 메모리 요구량[[memory-requirements]]
+
+시작하기 전에 모델에 맞는 충분한 GPU 및 CPU 메모리가 있는지 확인하는 것이 좋습니다. DeepSpeed는 필요한 CPU/GPU 메모리를 추정할 수 있는 도구를 제공합니다. 예를 들어, 단일 GPU에서 [bigscience/T0_3B](bigscience/T0_3B) 모델의 메모리 요구 사항을 추정할 수 있습니다:
+
+```bash
+$ python -c 'from transformers import AutoModel; \
+from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
+model = AutoModel.from_pretrained("bigscience/T0_3B"); \
+estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)'
+[...]
+Estimated memory needed for params, optim states and gradients for a:
+HW: Setup with 1 node, 1 GPU per node.
+SW: Model with 2783M total params, 65M largest layer params.
+ per CPU | per GPU | Options
+ 70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
+ 70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
+ 62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=1
+ 62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=0
+ 0.37GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=1
+ 15.56GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=0
+```
+
+즉, CPU 오프로드가 없는 단일 80GB GPU 또는 오프로드 할 8GB GPU와 최대 60GB CPU가 필요합니다 (이는 매개변수, 최적화 상태 및 그레이디언트에 대한 메모리 요구 사항일 뿐이며 CUDA 커널 및 활성화에는 조금 더 필요합니다). 또한 더 작은 GPU를 대여하거나 구입하는 것이 더 저렴하지만 모델을 훈련하는 데 시간이 더 오래 걸리므로 비용과 속도 간의 균형을 고려해야 합니다.
+
+GPU 메모리가 충분하다면 CPU/NVMe 오프로드를 비활성화하여 모든 작업을 더 빠르게 처리하세요.
+
+## ZeRO 단계 설정하기[[select-a-zero-stage]]
+
+DeepSpeed를 설치하고 메모리 요구 사항을 더 잘 파악했다면 다음 단계는 사용할 ZeRO 스테이지를 선택하는 것입니다. 가장 빠르고 메모리 효율이 높은 순서대로 정렬하면 다음과 같습니다:
+
+| 속도 | 메모리 효율 |
+|------------------|------------------|
+| ZeRO-1 | ZeRO-3 + offload |
+| ZeRO-2 | ZeRO-3 |
+| ZeRO-2 + offload | ZeRO-2 + offload |
+| ZeRO-3 | ZeRO-2 |
+| ZeRO-3 + offload | ZeRO-1 |
+
+자신에게 가장 적합한 방법을 찾으려면 가장 빠른 방법부터 시작하고 메모리가 부족하면 더 느리지만 메모리 효율이 높은 다음 단계를 시도하세요. 속도와 메모리 사용량 사이의 적절한 균형을 찾기 위해 (가장 메모리 효율적이거나 가장 빠른 것부터 시작하여) 원하는 방향으로 자유롭게 작업하세요.
+
+일반적으로 사용할 수 있는 프로세스는 다음과 같습니다(배치 크기 1로 시작):
+
+1. 그레이디언트 체크포인팅 활성화
+2. ZeRO-2 시도
+3. ZeRO-2와 매개변수 오프로드 시도
+4. ZeRO-3 시도
+5. ZeRO-3과 매개변수 CPU 오프로드 시도
+6. ZeRO-3, 매개변수와 옵티마이저 CPU 오프로드 시도
+7. [`~GenerationMixin.generate`] 메소드를 사용하는 경우 더 좁은 빔 서치 검색 범위와 같은 다양한 기본값을 낮춰보기
+8. 전체 정밀도 가중치보다 반정밀도(구형 GPU 구조의 경우 fp16, 암페어 이후 GPU의 경우 bf16)를 혼합해보기
+9. 가능하면 하드웨어를 더 추가하거나 Infinity가 매개변수와 옵티마이저를 NVMe로 오프로드하도록 활성화
+10. 메모리가 부족하지 않으면 유효 처리량을 측정한 다음 배치 크기를 최대한 크게 늘려 GPU 효율성을 극대화
+11. 마지막으로 일부 오프로드 기능을 비활성화하거나 더 빠른 ZeRO 스테이지를 사용하고 배치 크기를 늘리거나 줄여 속도와 메모리 사용량 간의 최적의 균형을 찾아 트레이닝 설정을 최적화
+
+
+## DeepSpeed 구성 파일[[deepspeed-configuration-file]]
+
+DeepSpeed는 트레이닝 실행 방법을 구성하는 모든 매개변수가 포함된 구성 파일을 통해 [`Trainer`] 클래스와 함께 작동합니다. 트레이닝 스크립트를 실행하면 DeepSpeed는 [`Trainer`]로부터 받은 구성을 콘솔에 기록하므로 어떤 구성이 사용되었는지 정확히 확인할 수 있습니다.
+
+
+
+DeepSpeed 구성 옵션의 전체 목록은 [DeepSpeed Configuration JSON](https://www.deepspeed.ai/docs/config-json/)에서 확인할 수 있습니다. 또한 [DeepSpeedExamples](https://github.com/deepspeedai/DeepSpeedExamples) 리포지토리 또는 기본 [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) 리포지토리에서 다양한 DeepSpeed 구성 예제에 대한 보다 실용적인 예제를 찾을 수 있습니다. 구체적인 예제를 빠르게 찾으려면 다음과 같이 하세요:
+
+```bash
+git clone https://github.com/deepspeedai/DeepSpeedExamples
+cd DeepSpeedExamples
+find . -name '*json'
+# Lamb 옵티마이저 샘플 찾기
+grep -i Lamb $(find . -name '*json')
+```
+
+
+
+명령줄 인터페이스에서 트레이닝하는 경우 DeepSpeed 구성 파일은 JSON 파일의 경로로 전달되거나 노트북 설정에서 [`Trainer`]를 사용하는 경우 중첩된 `dict` 객체로 전달됩니다.
+
+
+
+
+```py
+TrainingArguments(..., deepspeed="path/to/deepspeed_config.json")
+```
+
+
+
+
+```py
+ds_config_dict = dict(scheduler=scheduler_params, optimizer=optimizer_params)
+args = TrainingArguments(..., deepspeed=ds_config_dict)
+trainer = Trainer(model, args, ...)
+```
+
+
+
+
+### DeepSpeed와 Trainer 매개변수[[deepspeed-and-trainer-parameters]]
+
+구성 매개변수에는 세 가지 유형이 있습니다:
+
+1. 일부 구성 매개변수는 [`Trainer`]와 DeepSpeed가 공유하며, 정의가 충돌하는 경우 오류를 식별하기 어려울 수 있습니다. 이러한 공유 구성 매개변수는 [`Trainer`] 명령줄 인수에서 쉽게 설정할 수 있습니다.
+
+2. 모델 설정에서 자동으로 도출되는 일부 설정 매개변수는 수동으로 값을 조정할 필요가 없습니다. [`Trainer`]는 구성 값 `auto`를 사용하여 가장 정확하거나 효율적인 값을 설정합니다. 직접 구성 매개변수를 명시적으로 설정할 수도 있지만, [`Trainer`] 인수와 DeepSpeed 설정 매개변수가 일치하도록 주의해야 합니다. 일치하지 않으면 감지하기 매우 어려운 방식으로 훈련이 실패할 수 있습니다!
+
+3. 교육 요구 사항에 따라 수동으로 설정해야 하는 일부 설정 매개변수는 DeepSpeed에만 해당됩니다.
+
+DeepSpeed 구성을 수정하고 [`TrainingArguments`]를 편집할 수도 있습니다:
+
+1. 기본 구성으로 사용할 DeepSpeed 구성 파일을 생성하거나 로드합니다.
+2. 다음 DeepSpeed 구성을 기반으로 [`TrainingArguments`] 객체를 생성합니다.
+
+`scheduler.params.total_num_steps`와 같은 일부 값은 트레이닝 중 [`Trainer`]에 의해 계산됩니다.
+
+### ZeRO 구성[[zero-configuration]]
+
+세 가지 구성이 있으며, 각 구성은 서로 다른 ZeRO 단계에 해당합니다. 1단계는 확장성 측면에서 그다지 눈여겨볼만하지 않으므로 이 가이드에서는 2단계와 3단계에 중점을 둡니다. `zero_optimization` 구성에는 활성화할 항목과 구성 방법에 대한 모든 옵션이 포함되어 있습니다. 각 매개변수에 대한 자세한 설명은 [DeepSpeed 구성 JSON](https://www.deepspeed.ai/docs/config-json/) 참조를 참조하세요.
+
+
+DeepSpeed는 매개변수 이름의 유효성을 검사하지 않으며 오타가 있으면 매개변수의 기본 설정으로 대체합니다. DeepSpeed 엔진 시작 로그 메시지를 보고 어떤 값을 사용할지 확인할 수 있습니다.
+
+
+
+[`Trainer`]는 동등한 명령줄 인수를 제공하지 않으므로 다음 구성은 DeepSpeed로 설정해야 합니다.
+
+
+
+
+ZeRO-1은 옵티마이저 상태를 GPU에 분할하여 약간의 속도 향상을 기대할 수 있습니다. ZeRO-1 구성은 다음과 같이 설정할 수 있습니다:
+
+```yml
+{
+ "zero_optimization": {
+ "stage": 1
+ }
+}
+```
+
+
+
+
+ZeRO-2는 GPU에서 옵티마이저와 그레이디언트를 분할합니다. 이 단계는 추론과 관련이 없는 기능이기 때문에 주로 훈련에 사용됩니다. 더 나은 성능을 위해 구성해야 할 몇 가지 중요한 매개변수는 다음과 같습니다:
+
+* GPU 메모리 사용량을 줄이려면 `offload_optimizer`를 활성화해야 합니다.
+* `true`로 설정된 경우 `overlap_comm`은 GPU 메모리 사용량 증가를 상쇄하여 지연 시간을 줄입니다. 이 기능은 4.5배의 `allgather_bucket_size` 및 `reduce_bucket_size`값을 사용합니다. 이 예에서는 `5e8`로 설정되어 있으므로 9GB의 GPU 메모리가 필요합니다. GPU 메모리가 8GB 이하인 경우, 메모리 요구량을 낮추고 메모리 부족(OOM) 오류를 방지하기 위해 `overlap_comm`을 줄여야 합니다.
+* `allgather_bucket_size`와 `reduce_bucket_size`는 사용 가능한 GPU 메모리와 통신 속도를 절충합니다. 값이 작을수록 통신 속도가 느려지고 더 많은 GPU 메모리를 사용할 수 있습니다. 예를 들어, 배치 크기가 큰 것이 약간 느린 훈련 시간보다 더 중요한지 균형을 맞출 수 있습니다.
+* DeepSpeed 0.4.4에서는 CPU 오프로딩을 위해 `round_robin_gradients`를 사용할 수 있습니다. 이 기능은 세분화된 그레이디언트 파티셔닝을 통해 등급 간 그레이디언트 복사를 CPU 메모리로 병렬화합니다. 성능 이점은 그레이디언트 누적 단계(최적화 단계 간 복사 횟수 증가) 또는 GPU 수(병렬 처리 증가)에 따라 증가합니다.
+
+```yml
+{
+ "zero_optimization": {
+ "stage": 2,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "allgather_partitions": true,
+ "allgather_bucket_size": 5e8,
+ "overlap_comm": true,
+ "reduce_scatter": true,
+ "reduce_bucket_size": 5e8,
+ "contiguous_gradients": true
+ "round_robin_gradients": true
+ }
+}
+```
+
+
+
+
+ZeRO-3는 옵티마이저, 그래디언트, 매개변수를 여러 GPU에 걸쳐 분할합니다. ZeRO-2와 달리 ZeRO-3는 여러 GPU에 대규모 모델을 가져올 수 있기 때문에 훈련 외에도 추론에도 사용할 수 있습니다. 구성해야 할 몇 가지 중요한 매개변수는 다음과 같습니다:
+
+* `device: "cpu"` 는 GPU 메모리가 부족하고 사용 가능한 CPU 메모리가 있는 경우 도움이 될 수 있습니다. 이를 통해 모델 매개변수를 CPU로 오프로드할 수 있습니다.
+* `pin_memory: true` 는 처리량을 향상시킬 수 있지만, 핀 메모리는 메모리를 요청한 특정 프로세스를 위해 예약되어 있고 일반적으로 일반 CPU 메모리보다 훨씬 빠르게 액세스되기 때문에 다른 프로세스에서 사용할 수 있는 메모리가 줄어듭니다.
+* `stage3_max_live_parameters` 는 특정 시간에 GPU에 유지하려는 전체 매개변수의 상한값입니다. OOM 오류가 발생하면 이 값을 줄이세요.
+* `stage3_max_reuse_distance` 는 향후 매개변수를 다시 사용할 시기를 결정하는 값으로, 매개변수를 버릴지 유지할지 결정하는 데 도움이 됩니다. 매개변수를 재사용할 경우(`stage3_max_reuse_distance`보다 작은 값인 경우) 통신 오버헤드를 줄이기 위해 매개변수를 유지합니다. 이 기능은 활성화 체크포인팅이 활성화되어 있고 역전파 계산시까지 순전파 시점의 매개변수를 유지하려는 경우에 매우 유용합니다. 그러나 OOM 오류가 발생하면 이 값을 줄이세요.
+* 모델 저장 시 `stage3_gather_16bit_weights_on_model_save`는 fp16 가중치를 통합합니다. 대규모 모델을 학습하거나 여러 GPU를 사용할 경우 메모리와 속도 측면에서 비용이 많이 듭니다. 훈련을 재개할 계획이라면 이 옵션을 활성화해야 합니다.
+* `sub_group_size` 는 최적화 단계에서 업데이트되는 매개변수를 제어합니다. 매개변수는 `sub_group_size`의 버킷으로 그룹화되며 각 버킷은 한 번에 하나씩 업데이트됩니다. NVMe 오프로드와 함께 사용하는 경우 `sub_group_size`는 최적화 단계 중 모델 상태가 CPU 메모리로 이동하는 시점을 결정합니다. 이렇게 하면 매우 큰 모델의 CPU 메모리 부족을 방지할 수 있습니다. NVMe 오프로드를 사용하지 않는 경우 `sub_group_size`를 기본값으로 둘 수 있지만, 사용하는 경우 변경하는 것이 좋습니다:
+
+ 1. 옵티마이저 단계에서 OOM 오류가 발생합니다. 이 경우, 임시 버퍼의 메모리 사용량을 줄이려면 `sub_group_size`를 줄이세요.
+ 2. 옵티마이저 단계에서 시간이 너무 오래 걸립니다. 이 경우 데이터 버퍼 증가로 인한 대역폭 사용률을 개선하기 위해 `sub_group_size`를 늘리세요.
+
+* `reduce_bucket_size`, `stage3_prefetch_bucket_size`, `stage3_param_persistence_threshold`는 모델의 숨겨진 크기에 따라 달라집니다. 이 값들을 `auto`으로 설정하고 [`Trainer`]가 자동으로 값을 할당하도록 허용하는 것이 좋습니다.
+
+```yml
+{
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": "auto",
+ "stage3_prefetch_bucket_size": "auto",
+ "stage3_param_persistence_threshold": "auto",
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ }
+}
+```
+
+[`deepspeed.zero.Init`](https://deepspeed.readthedocs.io/en/latest/zero3.html#deepspeed.zero.Init) 컨텍스트 매니저를 사용하면 모델을 더 빠르게 초기화할 수 있습니다:
+
+```py
+from transformers import T5ForConditionalGeneration, T5Config
+import deepspeed
+
+with deepspeed.zero.Init():
+ config = T5Config.from_pretrained("google-t5/t5-small")
+ model = T5ForConditionalGeneration(config)
+```
+
+사전 학습된 모델의 경우, 딥스피드 구성 파일에 `is_deepspeed_zero3_enabled: true`가 [`TrainingArguments`]에 설정되어 있어야 하며, ZeRO 구성이 활성화되어 있어야 합니다. 훈련된 모델 [`~PreTrainedModel.from_pretrained`]을 호출하기 **전에** [`TrainingArguments`] 객체를 생성해야 합니다.
+
+```py
+from transformers import AutoModel, Trainer, TrainingArguments
+
+training_args = TrainingArguments(..., deepspeed=ds_config)
+model = AutoModel.from_pretrained("google-t5/t5-small")
+trainer = Trainer(model=model, args=training_args, ...)
+```
+
+fp16 가중치가 단일 GPU에 맞지 않는 경우 ZeRO-3이 필요합니다. fp16 가중치를 로드할 수 있는 경우, [`~PreTrainedModel.from_pretrained`]에 `torch_dtype=torch.float16`을 지정해야 합니다.
+
+ZeRO-3의 또 다른 고려 사항은 여러 개의 GPU를 사용하는 경우 현재 실행 중인 레이어의 매개변수가 아닌 한 단일 GPU에 모든 매개변수가 없다는 것입니다. 사전 훈련된 모델 가중치를 [`~PreTrainedModel.from_pretrained`]에 로드하는 등 모든 레이어의 모든 매개변수에 한 번에 액세스하려면 한 번에 하나의 레이어를 로드하고 즉시 모든 GPU에 파티셔닝합니다. 이는 매우 큰 모델의 경우 메모리 제한으로 인해 하나의 GPU에 가중치를 로드한 다음 다른 GPU에 분산할 수 없기 때문입니다.
+
+다음과 같이 보이는 모델 매개변수 가중치(여기서 `tensor([1.])`) 또는 매개변수 크기가 더 큰 다차원 형태 대신 1인 경우, 이는 매개변수가 분할되어 있으며 이것이 ZeRO-3 플레이스홀더인 것을 의미합니다.
+
+```py
+tensor([1.0], device="cuda:0", dtype=torch.float16, requires_grad=True)
+```
+
+
+
+ZeRO-3로 대규모 모델을 초기화하고 매개변수에 액세스하는 방법에 대한 자세한 내용은 [Constructing Massive Models](https://deepspeed.readthedocs.io/en/latest/zero3.html#constructing-massive-models) 및 [Gathering Parameters](https://deepspeed.readthedocs.io/en/latest/zero3.html#gathering-parameters) 가이드를 참조하세요.
+
+
+
+
+
+
+### NVMe 설정[[nvme-configuration]]
+
+[ZeRO-Infinity](https://hf.co/papers/2104.07857)를 사용하면 모델 상태를 CPU 및/또는 NVMe로 오프로드하여 더 많은 메모리를 절약할 수 있습니다. 스마트 파티셔닝 및 타일링 알고리즘을 통해 각 GPU는 오프로딩 중에 매우 적은 양의 데이터를 주고받을 수 있으므로 최신 NVMe는 훈련 프로세스에 사용할 수 있는 것보다 훨씬 더 큰 총 메모리 풀에 맞출 수 있습니다. ZeRO-Infinity에는 ZeRO-3가 필요합니다.
+
+사용 가능한 CPU 및/또는 NVMe 메모리에 따라 [옵티마이저](https://www.deepspeed.ai/docs/config-json/#optimizer-offloading)와 [매개변수](https://www.deepspeed.ai/docs/config-json/#parameter-offloading) 중 하나만 오프로드하거나 아무것도 오프로드하지 않을 수 있습니다. 또한 일반 하드 드라이브나 솔리드 스테이트 드라이브에서도 작동하지만 속도가 현저히 느려지므로 `nvme_path`가 NVMe 장치를 가리키고 있는지 확인해야 합니다. 최신 NVMe를 사용하면 읽기 작업의 경우 최대 3.5GB/s, 쓰기 작업의 경우 최대 3GB/s의 전송 속도를 기대할 수 있습니다. 마지막으로, 트레이닝 설정에서 [벤치마크 실행하기](https://github.com/deepspeedai/DeepSpeed/issues/998)을 통해 최적의 'aio' 구성을 결정합니다.
+
+아래 예제 ZeRO-3/Infinity 구성 파일은 대부분의 매개변수 값을 `auto`으로 설정하고 있지만, 수동으로 값을 추가할 수도 있습니다.
+
+```yml
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": "auto",
+ "betas": "auto",
+ "eps": "auto",
+ "weight_decay": "auto"
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "nvme",
+ "nvme_path": "/local_nvme",
+ "pin_memory": true,
+ "buffer_count": 4,
+ "fast_init": false
+ },
+ "offload_param": {
+ "device": "nvme",
+ "nvme_path": "/local_nvme",
+ "pin_memory": true,
+ "buffer_count": 5,
+ "buffer_size": 1e8,
+ "max_in_cpu": 1e9
+ },
+ "aio": {
+ "block_size": 262144,
+ "queue_depth": 32,
+ "thread_count": 1,
+ "single_submit": false,
+ "overlap_events": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": "auto",
+ "stage3_prefetch_bucket_size": "auto",
+ "stage3_param_persistence_threshold": "auto",
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ },
+
+ "gradient_accumulation_steps": "auto",
+ "gradient_clipping": "auto",
+ "steps_per_print": 2000,
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto",
+ "wall_clock_breakdown": false
+}
+```
+
+## DeepSpeed 구성[[deepspeed-features]]
+
+이 섹션에서 간략하게 설명하는 몇 가지 중요한 매개변수를 DeepSpeed 구성 파일에 지정할 수 있습니다.
+
+### 활성화/그레이디언트 체크포인팅[[activationgradient-checkpointing]]
+
+활성화 및 그레이디언트 체크포인팅은 속도를 더 많은 GPU 메모리와 교환하여 GPU 메모리가 부족한 상황을 극복하거나 배치 크기를 늘려 성능을 향상시킬 수 있습니다. 이 기능을 활성화하려면 다음과 같이 하세요:
+
+1. 허깅 페이스 모델의 경우, [`Trainer`]에서 `model.gradient_checkpointing_enable()` 또는 `--gradient_checkpointing`을 설정합니다.
+2. 허깅 페이스가 아닌 모델의 경우, 딥스피드 [Activation Checkpointing API](https://deepspeed.readthedocs.io/en/latest/activation-checkpointing.html)를 사용합니다. 트랜스포머 모델링 코드를 대체하고 `torch.utils.checkpoint`를 DeepSpeed API로 대체할 수도 있습니다. 이 접근 방식은 순방향 활성화를 다시 계산하는 대신 CPU 메모리로 오프로드할 수 있으므로 더 유연합니다.
+
+### 옵티마이저와 스케줄러[[optimizer-and-scheduler]]
+
+`offload_optimizer`를 활성화하지 않는 한 DeepSpeed와 트랜스포머 옵티마이저 및 스케줄러를 혼합하여 사용할 수 있습니다. `offload_optimizer`를 활성화하면 CPU와 GPU 구현이 모두 있는 경우 DeepSpeed가 아닌 최적화기(LAMB 제외)를 사용할 수 있습니다.
+
+
+
+구성 파일의 최적화 프로그램 및 스케줄러 매개변수는 명령줄에서 설정할 수 있으므로 오류를 찾기 어렵지 않습니다. 예를 들어 학습 속도가 다른 곳에서 다른 값으로 설정된 경우 명령줄에서 이를 재정의할 수 있습니다. 최적화 프로그램 및 스케줄러 매개변수 외에도 [`Trainer`] 명령줄 인수가 DeepSpeed 구성과 일치하는지 확인해야 합니다.
+
+
+
+
+
+
+DeepSpeed는 여러 [옵티마이저](https://www.deepspeed.ai/docs/config-json/#optimizer-parameters)를 제공하지만(Adam, AdamW, OneBitAdam 및 LAMB) PyTorch에서 다른 옵티마이저를 가져올 수도 있습니다. 설정에서 옵티마이저를 구성하지 않으면 [`Trainer`]가 자동으로 AdamW를 선택하고 명령줄에서 제공된 값 또는 기본값을 사용합니다: `lr`, `adam_beta1`, `adam_beta2`, `adam_epsilon`, `weight_decay`.
+
+매개변수를 `"auto"`으로 설정하거나 원하는 값을 직접 수동으로 입력할 수 있습니다.
+
+```yaml
+{
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": "auto",
+ "betas": "auto",
+ "eps": "auto",
+ "weight_decay": "auto"
+ }
+ }
+}
+```
+
+최상위 구성에 다음을 추가하여 지원되지 않는 옵티마이저를 사용할 수도 있습니다.
+
+```yaml
+{
+ "zero_allow_untested_optimizer": true
+}
+```
+
+DeepSpeed==0.8.3부터 오프로드를 사용하려면 오프로드가 DeepSpeed의 CPU Adam 옵티마이저에서 가장 잘 작동하므로 최상위 수준 구성에 다음 사항을 추가해야 합니다.
+
+```yaml
+{
+ "zero_force_ds_cpu_optimizer": false
+}
+```
+
+
+
+
+DeepSpeed는 LRRangeTest, OneCycle, WarmupLR 및 WarmupDecayLR learning rate[schedulers](https://www.deepspeed.ai/docs/config-json/#scheduler-parameters)를 지원합니다.
+
+트랜스포머와 DeepSpeed는 동일한 두 가지 스케줄러를 제공합니다:
+
+* WarmupLR은 Transformers의 `--lr_scheduler_type constant_warmup`과 동일합니다.
+* WarmupDecayLR은 Transformers의 `--lr_scheduler_type linear`와 동일합니다(Transformers에서 사용되는 기본 스케줄러입니다).
+
+설정에서 스케줄러를 구성하지 않으면[`Trainer`]는 자동으로 WarmupDecayLR을 선택하고 명령줄에서 제공된 값 또는 기본값을 사용합니다: `warmup_min_lr`, `warmup_max_lr`, `warmup_num_steps`, `total_num_steps` (`max_steps`가 제공되지 않으면 런타임 중에 자동으로 계산됨).
+
+매개변수를 `"auto"`으로 설정하거나 원하는 값을 직접 수동으로 입력할 수 있습니다.
+
+```yaml
+{
+ "scheduler": {
+ "type": "WarmupDecayLR",
+ "params": {
+ "total_num_steps": "auto",
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ }
+}
+```
+
+
+
+
+### 정밀도[[precision]]
+
+DeepSpeed는 fp32, fp16 및 bf16 혼합 정밀도를 지원합니다.
+
+
+
+
+모델이 혼합 정밀도로 사전 학습되지 않은 경우와 같이 혼합 정밀도로 잘 작동하지 않는 경우 NaN 손실을 유발할 수 있는 오버플로 또는 언더플로 문제가 발생할 수 있습니다. 이러한 경우에는 기본 fp16 모드를 명시적으로 비활성화하여 전체 fp32 정밀도를 사용해야 합니다.
+
+```yaml
+{
+ "fp16": {
+ "enabled": false
+ }
+}
+```
+
+Ampere GPU 및 PyTorch 1.7 이상의 경우 일부 연산에 대해 더 효율적인 [tf32](https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices) 형식으로 자동 전환되지만 결과는 여전히 fp32로 표시됩니다. [`Trainer`]에서 `--tf32`를 설정하여 활성화하고 `--tf32 0` 또는 `--no_tf32`를 비활성화하면 제어할 수 있습니다.
+
+
+
+
+PyTorch AMP와 같은 fp16 혼합 정밀도를 구성하면 메모리 사용량이 줄어들고 훈련 속도가 빨라집니다.[`Trainer`]는 `args.fp16_backend` 값에 따라 fp16을 자동으로 활성화 또는 비활성화하며, 나머지 구성은 사용자가 설정할 수 있습니다. 명령줄에서 다음 인수를 전달하면 fp16이 활성화됩니다: `fp16`, `--fp16_backend amp` 또는 `--fp16_full_eval`.
+
+```yaml
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ }
+}
+```
+
+추가 딥스피드 fp16 훈련 옵션은 [fp16 훈련 옵션](https://www.deepspeed.ai/docs/config-json/#fp16-training-options) 참조를 참조하세요.
+
+Apex와 같은 fp16 혼합 정밀도를 구성하려면 아래 그림과 같이 `"auto"` 또는 직접 값을 설정합니다.[`Trainer`]는 `args.fp16_backend` 및 `args.fp16_opt_level`의 값에 따라 `amp`를 자동으로 구성합니다. 다음 인수를 전달하면 명령줄에서 활성화할 수도 있습니다: `fp16`, `--fp16_backend apex` 또는 `--fp16_opt_level 01`.
+
+```yaml
+{
+ "amp": {
+ "enabled": "auto",
+ "opt_level": "auto"
+ }
+}
+```
+
+
+
+
+bf16을 사용하려면 DeepSpeed==0.6.0 이상이 필요합니다. bf16은 fp32와 동적 범위가 동일하며 손실 스케일링이 필요하지 않습니다. 그러나 [gradient accumulation](#gradient-accumulation)을 bf16과 함께 사용하면 이 형식의 낮은 정밀도로 인해 손실이 발생할 수 있으므로 원하지 않는 그레이디언트가 bf16에 누적될 수 있습니다.
+
+bf16은 설정 파일에서 설정하거나 다음 인수를 전달하면 명령줄에서 활성화할 수 있습니다: `--bf16` 또는 `--bf16_full_eval`.
+
+```yaml
+{
+ "bf16": {
+ "enabled": "auto"
+ }
+}
+```
+
+
+
+
+### 배치 크기[[batch-size]]
+
+배치 크기는 자동으로 구성하거나 명시적으로 설정할 수 있습니다. `"auto"` 옵션을 사용하도록 선택하면 [`Trainer`]는 `train_micro_batch_size_per_gpu`를 args.`per_device_train_batch_size`의 값으로, `train_batch_size`를 `args.world_size * args.per_device_train_batch_size * args.gradient_accumulation_steps`로 설정합니다.
+
+```yaml
+{
+ "train_micro_batch_size_per_gpu": "auto",
+ "train_batch_size": "auto"
+}
+```
+
+### 그레이디언트 누적[[gradient-accumulation]]
+
+그레이디언트 누적을 자동으로 구성하거나 명시적으로 설정할 수 있습니다. `"auto"` 옵션을 사용하도록 선택하면 [`Trainer`]가 `args.gradient_accumulation_steps`의 값으로 설정합니다.
+
+```yaml
+{
+ "gradient_accumulation_steps": "auto"
+}
+
+```
+
+### 그레이디언트 클리핑[[gradient-clipping]]
+
+그레이디언트 클리핑은 자동으로 구성하거나 명시적으로 설정할 수 있습니다. `"auto"` 옵션을 사용하도록 선택하면 [`Trainer`]가 `args.max_grad_norm`의 값으로 설정합니다.
+
+```yaml
+{
+ "gradient_clipping": "auto"
+}
+```
+
+### 통신 데이터 유형(Communication data type)[[communication-data-type]]
+
+축소, 수집 및 분산 작업과 같은 통신 집합체의 경우 별도의 데이터 유형이 사용됩니다.
+
+모든 수집 및 분산 작업은 데이터와 동일한 데이터 유형으로 수행됩니다. 예를 들어 bf16으로 훈련하는 경우, 수집은 비손실 연산이므로 데이터도 bf16으로 수집됩니다.
+
+예를 들어 그레이디언트가 여러 GPU에 걸쳐 평균화되는 경우와 같이 감소 연산은 손실이 발생합니다. 통신이 fp16 또는 bf16으로 수행되는 경우, 낮은 정밀도로 여러 숫자를 더하면 정확하지 않기 때문에 손실이 발생할 가능성이 더 높습니다. 특히 fp16보다 정밀도가 낮은 bf16의 경우 더욱 그렇습니다. 이러한 이유로 기울기를 평균화할 때 손실이 최소화되므로 감소 연산에는 fp16이 기본값으로 사용됩니다.
+
+통신 데이터 유형은 설정 파일에서 `communication_data_type` 매개변수를 설정하여 선택할 수 있습니다. 예를 들어, fp32를 선택하면 약간의 오버헤드가 추가되지만 감소 연산이 fp32에 누적되고 준비가 되면 훈련 중인 반정밀 dtype으로 다운캐스트됩니다.
+
+```yaml
+{
+ "communication_data_type": "fp32"
+}
+```
+
+## 모델 배포[[deployment]]
+
+[torchrun](https://pytorch.org/docs/stable/elastic/run.html), `deepspeed` 런처 또는 [Accelerate](https://huggingface.co/docs/accelerate/basic_tutorials/launch#using-accelerate-launch) 등 다양한 런처를 통해 DeepSpeed를 배포할 수 있습니다. 배포하려면 [`Trainer`] 명령줄에 `--deepspeed ds_config.json`을 추가합니다. 필요한 명령줄 인수를 코드에 추가하려면 DeepSpeed의 [`add_config_arguments`](https://deepspeed.readthedocs.io/en/latest/initialize.html#argument-parsing) 유틸리티를 사용하는 것이 좋습니다.
+
+이 가이드에서는 다양한 트레이닝 설정에 대해 `deepspeed` 런처로 DeepSpeed를 배포하는 방법을 보여드립니다. 보다 실용적인 사용 예제는 이 [post](https://github.com/huggingface/transformers/issues/8771#issuecomment-759248400)에서 확인할 수 있습니다.
+
+
+
+
+여러 GPU에 DeepSpeed를 배포하려면 `--num_gpus` 매개변수를 추가하세요. 사용 가능한 모든 GPU를 사용하려는 경우 `--num_gpus`를 추가할 필요가 없습니다. 아래 예제에서는 2개의 GPU를 사용합니다.
+
+```bash
+deepspeed --num_gpus=2 examples/pytorch/translation/run_translation.py \
+--deepspeed tests/deepspeed/ds_config_zero3.json \
+--model_name_or_path google-t5/t5-small --per_device_train_batch_size 1 \
+--output_dir output_dir --overwrite_output_dir --fp16 \
+--do_train --max_train_samples 500 --num_train_epochs 1 \
+--dataset_name wmt16 --dataset_config "ro-en" \
+--source_lang en --target_lang ro
+```
+
+
+
+
+단일 GPU에 DeepSpeed를 배포하려면 `--num_gpus` 매개변수를 추가하세요. GPU가 1개만 있는 경우 이 값을 명시적으로 설정할 필요는 없습니다. DeepSpeed는 지정된 노드에서 볼 수 있는 모든 GPU를 배포하므로 이 값을 명시적으로 설정할 필요는 없습니다.
+
+```bash
+deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py \
+--deepspeed tests/deepspeed/ds_config_zero2.json \
+--model_name_or_path google-t5/t5-small --per_device_train_batch_size 1 \
+--output_dir output_dir --overwrite_output_dir --fp16 \
+--do_train --max_train_samples 500 --num_train_epochs 1 \
+--dataset_name wmt16 --dataset_config "ro-en" \
+--source_lang en --target_lang ro
+```
+
+DeepSpeed는 단 하나의 GPU로도 여전히 유용합니다:
+
+1. 일부 계산과 메모리를 CPU로 오프로드하여 더 큰 배치 크기를 사용하거나 일반적으로 맞지 않는 매우 큰 모델을 맞추기 위해 모델에 더 많은 GPU 리소스를 사용할 수 있도록 합니다.
+2. 스마트 GPU 메모리 관리 시스템으로 메모리 조각화를 최소화하여 더 큰 모델과 데이터 배치에 맞출 수 있습니다.
+
+
+
+단일 GPU에서 더 나은 성능을 얻으려면 [ZeRO-2](#zero-configuration) 구성 파일에서 `allgather_bucket_size` 및 `reduce_bucket_size` 값을 2e8로 설정하세요.
+
+
+
+
+
+
+### 다중 노드 환경에서의 모델 배포[[multi-node-deployment]]
+
+노드는 워크로드를 실행하기 위한 하나 이상의 GPU입니다. 더 강력한 설정은 멀티 노드 설정으로, `deepspeed` 런처로 실행할 수 있습니다. 이 가이드에서는 각각 8개의 GPU가 있는 두 개의 노드가 있다고 가정해 보겠습니다. 첫 번째 노드는 `ssh hostname1`로, 두 번째 노드는 `ssh hostname2`로 접속할 수 있습니다. 두 노드 모두 비밀번호 없이 ssh를 통해 로컬로 서로 통신할 수 있어야 합니다.
+
+기본적으로 DeepSpeed는 멀티노드 환경에서 공유 저장소를 사용할 것으로 예상합니다. 그렇지 않고 각 노드가 로컬 파일 시스템만 볼 수 있는 경우, 공유 파일 시스템에 대한 액세스 없이 로딩할 수 있도록 [`checkpoint`](https://www.deepspeed.ai/docs/config-json/#checkpoint-options)를 포함하도록 구성 파일을 조정해야 합니다:
+
+```yaml
+{
+ "checkpoint": {
+ "use_node_local_storage": true
+ }
+}
+```
+
+[`Trainer`]의 ``--save_on_each_node` 인수를 사용하여 위의 `checkpoint`를 구성에 자동으로 추가할 수도 있습니다.
+
+
+
+
+[torchrun](https://pytorch.org/docs/stable/elastic/run.html)의 경우, 각 노드에 ssh로 접속한 후 두 노드 모두에서 다음 명령을 실행해야 합니다. 런처는 두 노드가 동기화될 때까지 기다렸다가 트레이닝을 시작합니다.
+
+```bash
+torchrun --nproc_per_node=8 --nnode=2 --node_rank=0 --master_addr=hostname1 \
+--master_port=9901 your_program.py --deepspeed ds_config.json
+```
+
+
+
+
+`deepspeed` 런처의 경우, 먼저 `hostfile`을 생성합니다.
+
+```bash
+hostname1 slots=8
+hostname2 slots=8
+```
+
+그런 다음 다음 명령어로 트레이닝을 시작할 수 있습니다. `deepspeed` 런처는 두 노드에서 동시에 명령을 자동으로 실행합니다.
+
+```bash
+deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 \
+your_program.py --deepspeed ds_config.json
+```
+
+다중 노드 컴퓨팅 리소스 구성에 대한 자세한 내용은 [Resource Configuration (multi-node)](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node) 가이드를 참조하세요.
+
+
+
+
+### SLURM[[slurm]]
+
+SLURM 환경에서는 특정 SLURM 환경에 맞게 SLURM 스크립트를 조정해야 합니다.SLURM 스크립트 예시는 다음과 같습니다:
+
+```bash
+#SBATCH --job-name=test-nodes # 작업 이름
+#SBATCH --nodes=2 # 노드 수
+#SBATCH --ntasks-per-node=1 # 중요 - 노드당 분산 작업 1개!
+#SBATCH --cpus-per-task=10 # 작업당 CPU 코어 수
+#SBATCH --gres=gpu:8 # gpu 수
+#SBATCH --time 20:00:00 # 최대 실행 시간 (HH:MM:SS)
+#SBATCH --output=%x-%j.out # 출력 파일 이름
+
+export GPUS_PER_NODE=8
+export MASTER_ADDR=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
+export MASTER_PORT=9901
+
+srun --jobid $SLURM_JOBID bash -c 'python -m torch.distributed.run \
+ --nproc_per_node $GPUS_PER_NODE --nnodes $SLURM_NNODES --node_rank $SLURM_PROCID \
+ --master_addr $MASTER_ADDR --master_port $MASTER_PORT \
+your_program.py --deepspeed ds_config.json'
+```
+
+그런 다음 모든 노드에서 동시에 학습을 시작하는 다음 명령을 사용하여 다중 노드 배포를 예약할 수 있습니다.
+
+```bash
+sbatch launch.slurm
+```
+
+### 노트북[[notebook]]
+
+`deepspeed` 런처는 노트북에서의 배포를 지원하지 않으므로 분산 환경을 에뮬레이션해야 합니다. 하지만 이는 1개의 GPU에서만 작동합니다. 1개 이상의 GPU를 사용하려면 딥스피드가 작동할 수 있는 다중 프로세스 환경을 사용해야 합니다. 즉, 여기에 표시된 것처럼 에뮬레이션할 수 없는 `deepspeed` 런처를 사용해야 합니다.
+
+```py
+# DeepSpeed는 단일 프로세스만 사용하더라도 분산 환경을 필요로 합니다.
+# 이 코드로 분산 환경을 모방합니다.
+import os
+
+os.environ["MASTER_ADDR"] = "localhost"
+os.environ["MASTER_PORT"] = "9994" # RuntimeError: Address already in use 오류 발생 시 수정
+os.environ["RANK"] = "0"
+os.environ["LOCAL_RANK"] = "0"
+os.environ["WORLD_SIZE"] = "1"
+
+# 이제 평소와 같이 진행하되, DeepSpeed 설정 파일을 전달합니다.
+training_args = TrainingArguments(..., deepspeed="ds_config_zero3.json")
+trainer = Trainer(...)
+trainer.train()
+```
+
+현재 디렉터리의 노트북에 구성 파일을 즉석에서 만들고 싶다면 전용 셀을 만들 수 있습니다.
+
+```py
+%%bash
+cat <<'EOT' > ds_config_zero3.json
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ },
+
+ "optimizer": {
+ "type": "AdamW",
+ "params": {
+ "lr": "auto",
+ "betas": "auto",
+ "eps": "auto",
+ "weight_decay": "auto"
+ }
+ },
+
+ "scheduler": {
+ "type": "WarmupLR",
+ "params": {
+ "warmup_min_lr": "auto",
+ "warmup_max_lr": "auto",
+ "warmup_num_steps": "auto"
+ }
+ },
+
+ "zero_optimization": {
+ "stage": 3,
+ "offload_optimizer": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": true
+ },
+ "overlap_comm": true,
+ "contiguous_gradients": true,
+ "sub_group_size": 1e9,
+ "reduce_bucket_size": "auto",
+ "stage3_prefetch_bucket_size": "auto",
+ "stage3_param_persistence_threshold": "auto",
+ "stage3_max_live_parameters": 1e9,
+ "stage3_max_reuse_distance": 1e9,
+ "stage3_gather_16bit_weights_on_model_save": true
+ },
+
+ "gradient_accumulation_steps": "auto",
+ "gradient_clipping": "auto",
+ "steps_per_print": 2000,
+ "train_batch_size": "auto",
+ "train_micro_batch_size_per_gpu": "auto",
+ "wall_clock_breakdown": false
+}
+EOT
+```
+
+트레이닝 스크립트가 노트북 셀이 아닌 파일에 있는 경우, 노트북 셀의 셸에서 `deepspeed`를 정상적으로 실행할 수 있습니다. 예를 들어 `run_translation.py`를 시작하려면 다음과 같이 하세요.:
+
+```py
+!git clone https://github.com/huggingface/transformers
+!cd transformers; deepspeed examples/pytorch/translation/run_translation.py ...
+```
+
+또한 `%%bash` 매직을 사용하여 여러 줄의 코드를 작성하여 셸 프로그램을 실행할 수도 있지만 교육이 완료될 때까지 로그를 볼 수 없습니다. `%%bash` 매직으로 분산 환경을 에뮬레이션할 필요는 없습니다.
+
+```py
+%%bash
+
+git clone https://github.com/huggingface/transformers
+cd transformers
+deepspeed examples/pytorch/translation/run_translation.py ...
+```
+
+## 모델 가중치 저장하기[[save-model-weights]]
+
+딥스피드는 기본 고정밀 fp32 가중치를 사용자 지정 체크포인트 최적화 파일(glob 패턴은 `global_step*/*optim_states.pt`처럼 보입니다)에 저장하고 일반 체크포인트 아래에 저장합니다.
+
+
+
+
+ZeRO-2로 훈련된 모델은 pytorch_model.bin 가중치를 fp16에 저장합니다. ZeRO-3으로 훈련된 모델의 모델 가중치를 fp16에 저장하려면 모델 가중치가 여러 GPU에 분할되어 있으므로 `“stage3_gather_16bit_weights_on_model_save”: true`를 설정해야 합니다. 그렇지 않으면 [`Trainer`]가 가중치를 fp16에 저장하지 않고 pytorch_model.bin 파일을 생성하지 않습니다. 이는 DeepSpeed의 state_dict에 실제 가중치 대신 플레이스홀더가 포함되어 있어 이를 로드할 수 없기 때문입니다.
+
+```yaml
+{
+ "zero_optimization": {
+ "stage3_gather_16bit_weights_on_model_save": true
+ }
+}
+```
+
+
+
+
+전체 정밀 가중치는 많은 메모리가 필요할 수 있으므로 트레이닝 중에 저장해서는 안 됩니다. 일반적으로 훈련이 완료된 후 오프라인으로 fp32 가중치를 저장하는 것이 가장 좋습니다. 그러나 여유 CPU 메모리가 많은 경우 훈련 중에 fp32 가중치를 저장할 수 있습니다. 이 섹션에서는 온라인과 오프라인 방식을 모두 다룹니다.
+
+### 온라인 환경[[online]]
+
+다음과 같이 최신 체크포인트를 로드하려면 체크포인트를 하나 이상 저장해야 합니다:
+
+```py
+from transformers.trainer_utils import get_last_checkpoint
+from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
+
+checkpoint_dir = get_last_checkpoint(trainer.args.output_dir)
+fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
+```
+
+`--load_best_model_at_end` 매개변수를 활성화하여 [`TrainingArguments`]에서 최적의 체크포인트를 추적하는 경우, 먼저 학습을 완료하고 최종 모델을 명시적으로 저장할 수 있습니다. 그런 다음 아래와 같이 다시 로드할 수 있습니다:
+
+```py
+from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
+
+checkpoint_dir = os.path.join(trainer.args.output_dir, "checkpoint-final")
+trainer.deepspeed.save_checkpoint(checkpoint_dir)
+fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
+```
+
+
+
+`load_state_dict_from_zero_checkpoint`가 실행되면 동일한 애플리케이션의 컨텍스트에서 모델을 더 이상 DeepSpeed에서 사용할 수 없습니다. `model.load_state_dict(state_dict)`는 모든 딥스피드 마법을 제거하므로 딥스피드 엔진을 다시 초기화해야 합니다. 이 기능은 훈련이 끝날 때만 사용하세요.
+
+
+
+fp32 가중치의 state_dict를 추출하여 로드할 수도 있습니다:
+
+```py
+from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpoint
+
+state_dict = get_fp32_state_dict_from_zero_checkpoint(checkpoint_dir) # cpu에 이미 존재함
+model = model.cpu()
+model.load_state_dict(state_dict)
+```
+
+### 오프라인 환경[[offline]]
+
+DeepSpeed는 언제든지 가중치를 추출할 수 있도록 체크포인트 폴더의 최상위 레벨에 zero_to_fp32.py 스크립트를 제공합니다. 이 스크립트는 독립형 스크립트로 구성 파일이나 [`Trainer`]가 필요하지 않습니다.
+
+예를 들어 체크포인트 폴더가 다음과 같은 경우입니다:
+
+```bash
+$ ls -l output_dir/checkpoint-1/
+-rw-rw-r-- 1 stas stas 1.4K Mar 27 20:42 config.json
+drwxrwxr-x 2 stas stas 4.0K Mar 25 19:52 global_step1/
+-rw-rw-r-- 1 stas stas 12 Mar 27 13:16 latest
+-rw-rw-r-- 1 stas stas 827K Mar 27 20:42 optimizer.pt
+-rw-rw-r-- 1 stas stas 231M Mar 27 20:42 pytorch_model.bin
+-rw-rw-r-- 1 stas stas 623 Mar 27 20:42 scheduler.pt
+-rw-rw-r-- 1 stas stas 1.8K Mar 27 20:42 special_tokens_map.json
+-rw-rw-r-- 1 stas stas 774K Mar 27 20:42 spiece.model
+-rw-rw-r-- 1 stas stas 1.9K Mar 27 20:42 tokenizer_config.json
+-rw-rw-r-- 1 stas stas 339 Mar 27 20:42 trainer_state.json
+-rw-rw-r-- 1 stas stas 2.3K Mar 27 20:42 training_args.bin
+-rwxrw-r-- 1 stas stas 5.5K Mar 27 13:16 zero_to_fp32.py*
+```
+
+딥스피드 체크포인트(ZeRO-2 또는 ZeRO-3) 하위 폴더 `global_step1`에서 fp32 가중치를 재구성하려면 다음 명령을 실행하여 여러 GPU의 전체 fp32 가중치를 단일 pytorch_model.bin 파일로 생성하고 통합합니다. 스크립트는 자동으로 체크포인트가 포함된 하위 폴더를 찾습니다.
+
+```py
+python zero_to_fp32.py . pytorch_model.bin
+```
+
+
+
+자세한 사용법은 `python zero_to_fp32.py -h`를 실행하세요. 이 스크립트에는 최종 fp32 가중치의 2배의 일반 RAM이 필요합니다.
+
+
+
+
+
+
+## ZeRO Inference[[zero-inference]]
+
+[ZeRO Inference](https://www.deepspeed.ai/2022/09/09/zero-inference.html)는 모델 가중치를 CPU 또는 NVMe 메모리에 배치하여 GPU에 부담을 주지 않으므로 GPU에서 대규모 모델을 사용하여 추론을 실행할 수 있습니다. 추론은 최적화 상태 및 그레이디언트에 많은 양의 메모리를 추가로 필요로 하지 않으므로 동일한 하드웨어에 훨씬 더 큰 배치 및/또는 시퀀스 길이를 맞출 수 있습니다.
+
+ZeRO Inference는 [ZeRO-3](#zero-configuration)와 동일한 구성 파일을 공유하며, ZeRO-2 및 ZeRO-1 구성은 추론에 아무런 이점을 제공하지 않으므로 작동하지 않습니다.
+
+ZeRO Inference를 실행하려면 일반적인 훈련 인수를 [`TrainingArguments`] 클래스에 전달하고 `--do_eval` 인수를 추가합니다.
+
+```bash
+deepspeed --num_gpus=2 your_program.py --do_eval --deepspeed ds_config.json
+```
+
+## Trainer 없이 DeepSpeed 사용하기[[non-trainer-deepspeed-integration]]
+
+DeepSpeed는 [`Trainer`] 클래스가 없는 트랜스포머에서도 작동합니다. 이는 [`~PreTrainedModel.from_pretrained`]를 호출할 때 ZeRO-3 매개변수를 수집하고 모델을 여러 GPU에 분할하는 작업만 처리하는 [`HfDeepSpeedConfig`]가 처리합니다.
+
+
+
+모든 것이 자동으로 처리되기를 원한다면, [`Trainer`]와 함께 DeepSpeed를 사용해 보세요! [DeepSpeed 문서](https://www.deepspeed.ai/)를 참조하여 설정 파일에서 매개변수 값을 수동으로 구성해야 합니다(`"auto"` 값은 사용할 수 없음).
+
+
+
+ZeRO-3를 효율적으로 배포하려면 모델 앞에 [`HfDeepSpeedConfig`] 객체를 인스턴스화하고 해당 객체를 유지해야 합니다:
+
+
+
+
+```py
+from transformers.integrations import HfDeepSpeedConfig
+from transformers import AutoModel
+import deepspeed
+
+ds_config = {...} # deepspeed 설정 객체 또는 파일 경로
+# Zero 3를 감지하기 위해 모델을 인스턴스화하기 전에 반드시 실행해야 합니다
+dschf = HfDeepSpeedConfig(ds_config) # 이 객체를 유지하세요.
+model = AutoModel.from_pretrained("openai-community/gpt2")
+engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
+```
+
+
+
+
+[`HfDeepSpeedConfig`] is not required for ZeRO-1 or ZeRO-2.
+
+```py
+from transformers.integrations import HfDeepSpeedConfig
+from transformers import AutoModel, AutoConfig
+import deepspeed
+
+ds_config = {...} # deepspeed 설정 객체 또는 파일 경로
+# Zero 3를 감지하기 위해 모델을 인스턴스화하기 전에 반드시 실행해야 합니다
+dschf = HfDeepSpeedConfig(ds_config) # 이 객체를 유지하세요.
+config = AutoConfig.from_pretrained("openai-community/gpt2")
+model = AutoModel.from_config(config)
+engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
+```
+
+
+
+
+### Trainer 없이 ZeRO Inference 사용하기[[non-trainer-zero-inference]]
+
+단일 GPU에 모델을 맞출 수 없는 경우 [`Trainer`]없이 ZeRO 추론을 실행하려면 추가 GPU를 사용하거나 CPU 메모리로 오프로드를 시도하세요. 여기서 이해해야 할 중요한 뉘앙스는 ZeRO가 설계된 방식에 따라 서로 다른 GPU에서 서로 다른 입력을 병렬로 처리할 수 있다는 것입니다.
+
+반드시 확인하세요:
+
+* GPU 메모리가 충분한 경우 CPU 오프로드를 비활성화합니다(속도가 느려지므로).
+* Ampere 이상의 GPU를 사용하는 경우 bf16을 활성화하면 속도가 빨라집니다. 이러한 GPU가 없는 경우 오버플로 오류가 발생할 수 있으므로 bf16으로 사전 학습된 모델(T5 모델)을 사용하지 않는 한 fp16을 활성화할 수 있습니다.
+
+단일 GPU에 맞지 않는 모델에서 [`Trainer`] 없이 ZeRO 추론을 실행하는 방법에 대한 더 나은 아이디어를 얻으려면 다음 스크립트를 살펴보시기 바랍니다.
+
+```py
+#!/usr/bin/env python
+
+# 이 스크립트는 단일 GPU에 모델을 맞출 수 없을 때 추론 모드에서 Deepspeed ZeRO를 사용하는 방법을 보여줍니다.
+#
+# 1. CPU 오프로드와 함께 1개의 GPU 사용
+# 2. 또는 여러 GPU 사용
+#
+# 먼저 deepspeed를 설치해야 합니다: pip install deepspeed
+#
+# 여기서는 약 15GB의 GPU RAM이 필요한 3B "bigscience/T0_3B" 모델을 사용합니다 - 따라서 1개의 큰 GPU나 2개의
+# 작은 GPU로 처리할 수 있습니다. 또는 1개의 작은 GPU와 많은 CPU 메모리로도 가능합니다.
+#
+# 약 50GB가 필요한 "bigscience/T0"와 같은 더 큰 모델을 사용하려면, 80GB GPU가 없는 한
+# 2-4개의 GPU가 필요할 것입니다. 그리고 여러 입력을 한 번에 처리하고 싶다면
+# 스크립트를 수정하여 더 많은 GPU를 처리할 수 있습니다.
+#
+# 제공된 deepspeed 설정은 CPU 메모리 오프로딩도 활성화하므로, 사용 가능한 CPU 메모리가 많고
+# 속도 저하를 감수할 수 있다면 일반적으로 단일 GPU에 맞지 않는 모델을 로드할 수 있을 것입니다.
+# GPU 메모리가 충분하다면 CPU로의 오프로드를 원하지 않을 때 프로그램이 더 빠르게 실행될 것입니다 - 그럴 때는 해당 섹션을 비활성화하세요.
+#
+# 1개의 GPU에 배포하려면:
+#
+# deepspeed --num_gpus 1 t0.py
+# 또는:
+# python -m torch.distributed.run --nproc_per_node=1 t0.py
+#
+# 2개의 GPU에 배포하려면:
+#
+# deepspeed --num_gpus 2 t0.py
+# 또는:
+# python -m torch.distributed.run --nproc_per_node=2 t0.py
+
+from transformers import AutoTokenizer, AutoConfig, AutoModelForSeq2SeqLM
+from transformers.integrations import HfDeepSpeedConfig
+import deepspeed
+import os
+import torch
+
+os.environ["TOKENIZERS_PARALLELISM"] = "false" # 토크나이저의 병렬 처리에 관한 경고를 피하기 위함입니다.
+
+# 분산 환경 설정
+local_rank = int(os.getenv("LOCAL_RANK", "0"))
+world_size = int(os.getenv("WORLD_SIZE", "1"))
+torch.cuda.set_device(local_rank)
+deepspeed.init_distributed()
+
+model_name = "bigscience/T0_3B"
+
+config = AutoConfig.from_pretrained(model_name)
+model_hidden_size = config.d_model
+
+# 배치 크기는 world_size로 나누어 떨어져야 하지만, world_size보다 클 수 있습니다
+train_batch_size = 1 * world_size
+
+# ds_config 참고사항
+#
+# - Ampere 이상의 GPU를 사용하는 경우 bf16을 활성화하세요 - 이는 혼합 정밀도로 실행되어
+# 더 빠를 것입니다.
+#
+# - 오래된 GPU의 경우 fp16을 활성화할 수 있지만, bf16으로 사전 훈련되지 않은 모델에서만 작동합니다 - 예를 들어
+# 모든 공식 t5 모델은 bf16으로 사전 훈련되었습니다
+#
+# - CPU 오프로드를 원하지 않는다면 offload_param.device를 "none"으로 설정하거나 `offload_param` 섹션을
+# 완전히 제거하세요
+#
+# - `offload_param`을 사용하는 경우, stage3_param_persistence_threshold를 수동으로 미세 조정하여
+# 어떤 매개변수가 GPU에 남아있어야 하는지 제어할 수 있습니다 - 값이 클수록 오프로드 크기가 작아집니다
+#
+# Deepspeed 설정에 대한 자세한 정보는 다음을 참조하세요
+# https://huggingface.co/docs/transformers/main/main_classes/deepspeed
+
+# 일관성을 위해 json과 동일한 형식을 유지하되, true/false에는 소문자를 사용합니다
+# fmt: off
+ds_config = {
+ "fp16": {
+ "enabled": False
+ },
+ "bf16": {
+ "enabled": False
+ },
+ "zero_optimization": {
+ "stage": 3,
+ "offload_param": {
+ "device": "cpu",
+ "pin_memory": True
+ },
+ "overlap_comm": True,
+ "contiguous_gradients": True,
+ "reduce_bucket_size": model_hidden_size * model_hidden_size,
+ "stage3_prefetch_bucket_size": 0.9 * model_hidden_size * model_hidden_size,
+ "stage3_param_persistence_threshold": 10 * model_hidden_size
+ },
+ "steps_per_print": 2000,
+ "train_batch_size": train_batch_size,
+ "train_micro_batch_size_per_gpu": 1,
+ "wall_clock_breakdown": False
+}
+# fmt: on
+
+# 다음 줄은 모델의 `from_pretrained` 메소드가 호출될 때
+# deepspeed.zero.Init를 사용하여 모델을 여러 GPU에 직접 분할하도록 transformers에 지시합니다.
+#
+# **이는 AutoModelForSeq2SeqLM.from_pretrained(model_name)로 모델을 로드하기 전에 실행되어야 합니다**
+#
+# 그렇지 않으면 모델이 먼저 정상적으로 로드된 후 포워드 시에만 분할되는데, 이는
+# 덜 효율적이며 CPU RAM이 부족할 경우 실패할 수 있습니다
+dschf = HfDeepSpeedConfig(ds_config) # 이 객체를 유지하세요
+
+# 이제 모델을 로드할 수 있습니다.
+model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
+
+# Deepspeed ZeRO를 초기화하고 엔진 객체만 저장
+ds_engine = deepspeed.initialize(model=model, config_params=ds_config)[0]
+ds_engine.module.eval() # inference
+
+# Deepspeed ZeRO는 각 GPU에서 서로 관련 없는 입력을 처리할 수 있습니다. 따라서 2개의 GPU를 사용하면 한 번에 2개의 입력을 처리할 수 있습니다.
+# GPU를 더 많이 사용하는 경우 그에 맞게 조정하세요.
+
+# 물론 처리할 입력이 하나뿐이라면 두 GPU에 동일한 문자열을 전달해야 합니다.
+# GPU를 하나만 사용하는 경우에는 rank 0만 갖게 됩니다.
+rank = torch.distributed.get_rank()
+if rank == 0:
+ text_in = "Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy"
+elif rank == 1:
+ text_in = "Is this review positive or negative? Review: this is the worst restaurant ever"
+
+tokenizer = AutoTokenizer.from_pretrained(model_name)
+inputs = tokenizer.encode(text_in, return_tensors="pt").to(device=local_rank)
+with torch.no_grad():
+ outputs = ds_engine.module.generate(inputs, synced_gpus=True)
+text_out = tokenizer.decode(outputs[0], skip_special_tokens=True)
+print(f"rank{rank}:\n in={text_in}\n out={text_out}")
+```
+
+스크립트를 t0.py로 저장하고 실행합니다:
+
+```bash
+$ deepspeed --num_gpus 2 t0.py
+rank0:
+ in=Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy
+ out=Positive
+rank1:
+ in=Is this review positive or negative? Review: this is the worst restaurant ever
+ out=negative
+```
+
+이것은 매우 기본적인 예시이므로 사용 사례에 맞게 조정할 수 있습니다.
+
+### 생성[[generate]]
+
+생성에 ZeRO-3와 함께 여러 개의 GPU를 사용하려면 [`~GenerationMixin.generate`] 메서드에서 `synced_gpus=True`를 설정하여 GPU를 동기화해야 합니다. 그렇지 않으면 한 GPU가 다른 GPU보다 먼저 생성을 완료하면 나머지 GPU가 먼저 완료한 GPU로부터 가중치 샤드를 받지 못하여 전체 시스템이 중단됩니다.
+
+트랜스포머>=4.28의 경우, 생성 중에 여러 개의 GPU가 감지되면 `synced_gpus`가 자동으로 `True`로 설정됩니다.
+
+## 트러블슈팅[[troubleshoot]]
+
+문제가 발생하면 DeepSpeed가 문제의 원인이 아닌 경우가 많으므로(아주 명백하고 예외적으로 DeepSpeed 모듈을 볼 수 있는 경우가 아니라면) DeepSpeed가 문제의 원인인지 고려해야 합니다! 첫 번째 단계는 DeepSpeed 없이 설정을 다시 시도하고 문제가 지속되면 문제를 신고하는 것입니다. 문제가 핵심적인 DeepSpeed 문제이고 transformers와 관련이 없는 경우, [DeepSpeed 리포지토리](https://github.com/deepspeedai/DeepSpeed)에서 이슈를 개설하세요.
+
+transformers와 관련된 이슈를 개설할 때에는 다음 정보를 제공해 주세요:
+
+* 전체 DeepSpeed 구성 파일
+
+*[`Trainer`]의 명령줄 인수, 또는[`Trainer`] 설정을 직접 작성하는 경우[`TrainingArguments`] 인수(관련 없는 항목이 수십 개 있는 [`TrainingArguments`]는 덤프하지 마세요).
+
+* 다음 코드의 출력 결과:
+
+```bash
+python -c 'import torch; print(f"torch: {torch.__version__}")'
+python -c 'import transformers; print(f"transformers: {transformers.__version__}")'
+python -c 'import deepspeed; print(f"deepspeed: {deepspeed.__version__}")'
+```
+
+* 문제를 재현할 수 있는 Google Colab 노트북 링크
+
+* 불가능할 경우 기존 예제를 사용하여 문제를 재현할 수 있는 표준 및 사용자 지정이 아닌 데이터 집합을 사용할 수 있습니다.
+
+다음 섹션에서는 가장 일반적인 두 가지 문제를 해결하기 위한 가이드를 제공합니다.
+
+### DeepSpeed 프로세스가 시작 단계에서 종료되었을 경우[[deepspeed-process-killed-at-startup]]
+
+실행 중에 트레이스백 없이 DeepSpeed 프로세스가 종료되면 일반적으로 프로그램이 시스템보다 많은 CPU 메모리를 할당하려고 시도했거나 프로세스가 허용된 것보다 많은 CPU 메모리를 할당하려고 시도하여 OS 커널이 프로세스를 종료했음을 의미합니다. 이 경우 구성 파일에 `offload_optimizer`, `offload_param` 또는 둘 다 CPU로 오프로드하도록 구성되어 있는지 확인하세요.
+
+NVMe 및 ZeRO-3를 설정한 경우 NVMe로 오프로드를 실험해 보세요(모델의 메모리 요구 사항을 [확인](https://deepspeed.readthedocs.io/en/latest/memory.html)하세요).
+
+### NaN 손실[[nan-loss]]
+
+모델을 bf16으로 사전 훈련한 다음 fp16으로 사용하려고 할 때 NaN 손실이 발생하는 경우가 많습니다(특히 TPU 훈련 모델에 해당). 이 문제를 해결하려면 하드웨어가 이를 지원하는 경우(TPU, Ampere GPU 이상) fp32 또는 bf16을 사용하세요.
+
+다른 문제는 fp16 사용과 관련이 있을 수 있습니다. 예를 들어 이것이 fp16 구성인 경우입니다:
+
+```yaml
+{
+ "fp16": {
+ "enabled": "auto",
+ "loss_scale": 0,
+ "loss_scale_window": 1000,
+ "initial_scale_power": 16,
+ "hysteresis": 2,
+ "min_loss_scale": 1
+ }
+}
+```
+
+로그에 다음과 같은 `OVERFLOW!` 메시지가 표시될 수 있습니다:
+
+```bash
+0%| | 0/189 [00:00
+
+# 🤗 Tokenizers 라이브러리의 토크나이저 사용하기[[use-tokenizers-from-tokenizers]]
+
+[`PreTrainedTokenizerFast`]는 [🤗 Tokenizers](https://huggingface.co/docs/tokenizers) 라이브러리에 기반합니다. 🤗 Tokenizers 라이브러리의 토크나이저는
+🤗 Transformers로 매우 간단하게 불러올 수 있습니다.
+
+구체적인 내용에 들어가기 전에, 몇 줄의 코드로 더미 토크나이저를 만들어 보겠습니다:
+
+```python
+>>> from tokenizers import Tokenizer
+>>> from tokenizers.models import BPE
+>>> from tokenizers.trainers import BpeTrainer
+>>> from tokenizers.pre_tokenizers import Whitespace
+
+>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
+>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
+
+>>> tokenizer.pre_tokenizer = Whitespace()
+>>> files = [...]
+>>> tokenizer.train(files, trainer)
+```
+
+우리가 정의한 파일을 통해 이제 학습된 토크나이저를 갖게 되었습니다. 이 런타임에서 계속 사용하거나 JSON 파일로 저장하여 나중에 사용할 수 있습니다.
+
+## 토크나이저 객체로부터 직접 불러오기[[loading-directly-from-the-tokenizer-object]]
+
+🤗 Transformers 라이브러리에서 이 토크나이저 객체를 활용하는 방법을 살펴보겠습니다.
+[`PreTrainedTokenizerFast`] 클래스는 인스턴스화된 *토크나이저* 객체를 인수로 받아 쉽게 인스턴스화할 수 있습니다:
+
+```python
+>>> from transformers import PreTrainedTokenizerFast
+
+>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
+```
+
+이제 `fast_tokenizer` 객체는 🤗 Transformers 토크나이저에서 공유하는 모든 메소드와 함께 사용할 수 있습니다! 자세한 내용은 [토크나이저 페이지](main_classes/tokenizer)를 참조하세요.
+
+## JSON 파일에서 불러오기[[loading-from-a-JSON-file]]
+
+
+
+JSON 파일에서 토크나이저를 불러오기 위해, 먼저 토크나이저를 저장해 보겠습니다:
+
+```python
+>>> tokenizer.save("tokenizer.json")
+```
+
+JSON 파일을 저장한 경로는 `tokenizer_file` 매개변수를 사용하여 [`PreTrainedTokenizerFast`] 초기화 메소드에 전달할 수 있습니다:
+
+```python
+>>> from transformers import PreTrainedTokenizerFast
+
+>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
+```
+
+이제 `fast_tokenizer` 객체는 🤗 Transformers 토크나이저에서 공유하는 모든 메소드와 함께 사용할 수 있습니다! 자세한 내용은 [토크나이저 페이지](main_classes/tokenizer)를 참조하세요.
diff --git a/docs/transformers/docs/source/ko/fsdp.md b/docs/transformers/docs/source/ko/fsdp.md
new file mode 100644
index 0000000000000000000000000000000000000000..bab1fda71b4ed10542aea99837bbd06154abd888
--- /dev/null
+++ b/docs/transformers/docs/source/ko/fsdp.md
@@ -0,0 +1,138 @@
+
+
+# 완전 분할 데이터 병렬 처리(FSDP) [[fully-sharded-data-parallel]]
+
+[Fully Sharded Data Parallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/)은 모델의 매개변수, 그레이디언트 및 옵티마이저 상태를 사용 가능한 GPU(작업자 또는 *랭크*라고도 함) 수에 따라 분할하는 데이터 병렬 처리 방식입니다. [DistributedDataParallel (DDP)](https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html)와 달리, FSDP는 각 GPU에 모델을 복제하기 때문에 메모리 사용량을 줄입니다. 이는 GPU 메모리 효율성을 향상시키며 적은 수의 GPU로 훨씬 더 큰 모델을 훈련할 수 있게 합니다. FSDP는 분산 환경에서의 훈련을 쉽게 관리할 수 있는 라이브러리인 Accelerate와 통합되어 있으며, 따라서 [`Trainer`] 클래스에서 사용할 수 있습니다.
+
+시작하기 전에 Accelerate가 설치되어 있고 최소 PyTorch 2.1.0 이상의 버전이 설치되어 있는지 확인하세요.
+
+```bash
+pip install accelerate
+```
+
+## FSDP 구성 [[fsdp-configuration]]
+
+시작하려면 [`accelerate config`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-config) 명령을 실행하여 훈련 환경에 대한 구성 파일을 생성하세요. Accelerate는 이 구성 파일을 사용하여 `accelerate config`에서 선택한 훈련 옵션에 따라 자동으로 올바른 훈련 환경을 설정합니다.
+
+```bash
+accelerate config
+```
+
+`accelerate config`를 실행하면 훈련 환경을 구성하기 위한 일련의 옵션들이 나타납니다. 이 섹션에서는 가장 중요한 FSDP 옵션 중 일부를 다룹니다. 다른 사용 가능한 FSDP 옵션에 대해 더 알아보고 싶다면 [fsdp_config](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.fsdp_config) 매개변수를 참조하세요.
+
+### 분할 전략 [[sharding-strategy]]
+
+FSDP는 여러 가지 분할 전략을 제공합니다:
+
+* `FULL_SHARD` - 모델 매개변수, 그레이디언트 및 옵티마이저 상태를 작업자 간에 분할; 이 옵션을 선택하려면 `1`을 선택하세요
+* `SHARD_GRAD_OP` - 그레이디언트 및 옵티마이저 상태를 작업자 간에 분할; 이 옵션을 선택하려면 `2`를 선택하세요
+* `NO_SHARD` - 아무 것도 분할하지 않음 (DDP와 동일); 이 옵션을 선택하려면 `3`을 선택하세요
+* `HYBRID_SHARD` - 각 작업자가 전체 복사본을 가지고 있는 상태에서 모델 매개변수, 그레이디언트 및 옵티마이저 상태를 작업자 내에서 분할; 이 옵션을 선택하려면 `4`를 선택하세요
+* `HYBRID_SHARD_ZERO2` - 각 작업자가 전체 복사본을 가지고 있는 상태에서 그레이디언트 및 옵티마이저 상태를 작업자 내에서 분할; 이 옵션을 선택하려면 `5`를 선택하세요
+
+이것은 `fsdp_sharding_strategy` 플래그로 활성화됩니다.
+
+### CPU 오프로드 [[cpu-offload]]
+
+사용하지 않는 매개변수와 그레이디언트를 CPU로 오프로드하여 더 많은 GPU 메모리를 절약하고 FSDP로도 충분하지 않은 큰 모델을 GPU에 적재할 수 있도록 할 수 있습니다. 이는 `accelerate config`를 실행할 때 `fsdp_offload_params: true`로 설정하여 활성화됩니다.
+
+### 래핑 정책 [[wrapping-policy]]
+
+FSDP는 네트워크의 각 레이어를 래핑하여 적용됩니다. 래핑은 일반적으로 중첩 방식으로 적용되며 각각 순방향으로 지나간 후 전체 가중치를 삭제하여 다음 레이어에서 사용할 메모리를 절약합니다. *자동 래핑* 정책은 이를 구현하는 가장 간단한 방법이며 코드를 변경할 필요가 없습니다. Transformer 레이어를 래핑하려면 `fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP`를 선택하고 래핑할 레이어를 지정하려면 `fsdp_transformer_layer_cls_to_wrap`를 선택하세요 (예: `BertLayer`).
+
+또는 특정 매개변수 수를 초과할 경우 FSDP가 레이어에 적용되는 크기 기반 래핑 정책을 선택할 수 있습니다. 이는 `fsdp_wrap_policy: SIZE_BASED_WRAP` 및 `min_num_param`을 원하는 크기의 임계값으로 설정하여 활성화됩니다.
+
+### 체크포인트 [[checkpointing]]
+
+중간 체크포인트는 `fsdp_state_dict_type: SHARDED_STATE_DICT`로 저장해야 합니다. CPU 오프로드가 활성화된 랭크 0에서 전체 상태 딕셔너리를 저장하는 데 시간이 많이 걸리고, 브로드캐스팅 중 무기한 대기하여 `NCCL Timeout` 오류가 발생할 수 있기 때문입니다. [`~accelerate.Accelerator.load_state`] 메서드를 사용하여 분할된 상태 딕셔너리로 훈련을 재개할 수 있습니다.
+
+```py
+# 경로가 내재된 체크포인트
+accelerator.load_state("ckpt")
+```
+
+그러나 훈련이 끝나면 전체 상태 딕셔너리를 저장해야 합니다. 분할된 상태 딕셔너리는 FSDP와만 호환되기 때문입니다.
+
+```py
+if trainer.is_fsdp_enabled:
+ trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
+
+trainer.save_model(script_args.output_dir)
+```
+
+### TPU [[tpu]]
+
+[PyTorch XLA](https://pytorch.org/xla/release/2.1/index.html)는 TPU에 대한 FSDP 훈련을 지원하며 `accelerate config`로 생성된 FSDP 구성 파일을 수정하여 활성화할 수 있습니다. 위에서 지정한 분할 전략 및 래핑 옵션 외에도 아래에 표시된 매개변수를 파일에 추가할 수 있습니다.
+
+```yaml
+xla: True # PyTorch/XLA를 활성화하려면 True로 설정해야 합니다
+xla_fsdp_settings: # XLA 특정 FSDP 매개변수
+xla_fsdp_grad_ckpt: True # gradient checkpointing을 사용합니다
+```
+
+[`xla_fsdp_settings`](https://github.com/pytorch/xla/blob/2e6e183e0724818f137c8135b34ef273dea33318/torch_xla/distributed/fsdp/xla_fully_sharded_data_parallel.py#L128)는 FSDP에 대한 추가적인 XLA 특정 매개변수를 구성할 수 있게 합니다.
+
+## 훈련 시작 [[launch-training]]
+
+예시 FSDP 구성 파일은 다음과 같을 수 있습니다:
+
+```yaml
+compute_environment: LOCAL_MACHINE
+debug: false
+distributed_type: FSDP
+downcast_bf16: 'no'
+fsdp_config:
+ fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
+ fsdp_backward_prefetch_policy: BACKWARD_PRE
+ fsdp_cpu_ram_efficient_loading: true
+ fsdp_forward_prefetch: false
+ fsdp_offload_params: true
+ fsdp_sharding_strategy: 1
+ fsdp_state_dict_type: SHARDED_STATE_DICT
+ fsdp_sync_module_states: true
+ fsdp_transformer_layer_cls_to_wrap: BertLayer
+ fsdp_use_orig_params: true
+machine_rank: 0
+main_training_function: main
+mixed_precision: bf16
+num_machines: 1
+num_processes: 2
+rdzv_backend: static
+same_network: true
+tpu_env: []
+tpu_use_cluster: false
+tpu_use_sudo: false
+use_cpu: false
+```
+
+훈련을 시작하려면 [`accelerate launch`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-launch) 명령을 실행하세요. 이 때 전에 `accelerate config`로 생성한 구성 파일을 자동으로 사용합니다.
+
+```bash
+accelerate launch my-trainer-script.py
+```
+
+```bash
+accelerate launch --fsdp="full shard" --fsdp_config="path/to/fsdp_config/ my-trainer-script.py
+```
+
+## 다음 단계 [[next-steps]]
+
+FSDP는 매우 큰 모델을 훈련할 때 강력한 도구가 될 수 있으며, 여러 개의 GPU나 TPU를 사용할 수 있습니다. 모델 매개변수, 옵티마이저 및 그레이디언트 상태를 분할하고 비활성 상태일 때, CPU로 오프로드하면 FSDP는 대규모 훈련의 높은 연산 비용을 줄일 수 있습니다. 더 알아보고 싶다면 다음 자료가 도움이 될 수 있습니다:
+
+* [FSDP](https://huggingface.co/docs/accelerate/usage_guides/fsdp)에 대한 더 깊이 있는 Accelerate 가이드를 따라가 보세요.
+* [PyTorch의 완전 분할 데이터 병렬 처리 (FSDP) API를 소개합니다](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) 블로그 글을 읽어보세요.
+* [FSDP를 사용하여 클라우드 TPU에서 PyTorch 모델 크기 조절하기](https://pytorch.org/blog/scaling-pytorch-models-on-cloud-tpus-with-fsdp/) 블로그 글을 읽어보세요.
diff --git a/docs/transformers/docs/source/ko/generation_strategies.md b/docs/transformers/docs/source/ko/generation_strategies.md
new file mode 100644
index 0000000000000000000000000000000000000000..05f81c008b30f153932258968ed72c01888e35f2
--- /dev/null
+++ b/docs/transformers/docs/source/ko/generation_strategies.md
@@ -0,0 +1,337 @@
+
+
+# Text generation strategies[[text-generation-strategies]]
+
+텍스트 생성은 개방형 텍스트 작성, 요약, 번역 등 다양한 자연어 처리(NLP) 작업에 필수적입니다. 이는 또한 음성-텍스트 변환, 시각-텍스트 변환과 같이 텍스트를 출력으로 하는 여러 혼합 모달리티 응용 프로그램에서도 중요한 역할을 합니다. 텍스트 생성을 가능하게 하는 몇몇 모델로는 GPT2, XLNet, OpenAI GPT, CTRL, TransformerXL, XLM, Bart, T5, GIT, Whisper 등이 있습니다.
+
+
+[`~generation.GenerationMixin.generate`] 메서드를 활용하여 다음과 같은 다양한 작업들에 대해 텍스트 결과물을 생성하는 몇 가지 예시를 살펴보세요:
+* [텍스트 요약](./tasks/summarization#inference)
+* [이미지 캡셔닝](./model_doc/git#transformers.GitForCausalLM.forward.example)
+* [오디오 전사](./model_doc/whisper#transformers.WhisperForConditionalGeneration.forward.example)
+
+generate 메소드에 입력되는 값들은 모델의 데이터 형태에 따라 달라집니다. 이 값들은 AutoTokenizer나 AutoProcessor와 같은 모델의 전처리 클래스에 의해 반환됩니다. 모델의 전처리 장치가 하나 이상의 입력 유형을 생성하는 경우, 모든 입력을 generate()에 전달해야 합니다. 각 모델의 전처리 장치에 대해서는 해당 모델의 문서에서 자세히 알아볼 수 있습니다.
+
+텍스트를 생성하기 위해 출력 토큰을 선택하는 과정을 디코딩이라고 하며, `generate()` 메소드가 사용할 디코딩 전략을 사용자가 커스터마이징할 수 있습니다. 디코딩 전략을 수정하는 것은 훈련 가능한 매개변수의 값들을 변경하지 않지만, 생성된 출력의 품질에 눈에 띄는 영향을 줄 수 있습니다. 이는 텍스트에서 반복을 줄이고, 더 일관성 있게 만드는 데 도움을 줄 수 있습니다.
+
+
+이 가이드에서는 다음과 같은 내용을 다룹니다:
+* 기본 생성 설정
+* 일반적인 디코딩 전략과 주요 파라미터
+* 🤗 Hub에서 미세 조정된 모델과 함께 사용자 정의 생성 설정을 저장하고 공유하는 방법
+
+## 기본 텍스트 생성 설정[[default-text-generation-configuration]]
+
+모델의 디코딩 전략은 생성 설정에서 정의됩니다. 사전 훈련된 모델을 [`pipeline`] 내에서 추론에 사용할 때, 모델은 내부적으로 기본 생성 설정을 적용하는 `PreTrainedModel.generate()` 메소드를 호출합니다. 사용자가 모델과 함께 사용자 정의 설정을 저장하지 않았을 경우에도 기본 설정이 사용됩니다.
+
+모델을 명시적으로 로드할 때, `model.generation_config`을 통해 제공되는 생성 설정을 검사할 수 있습니다.
+
+```python
+>>> from transformers import AutoModelForCausalLM
+
+>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
+>>> model.generation_config
+GenerationConfig {
+ "bos_token_id": 50256,
+ "eos_token_id": 50256,
+}
+```
+
+ `model.generation_config`를 출력하면 기본 설정과 다른 값들만 표시되고, 기본값들은 나열되지 않습니다.
+
+기본 생성 설정은 입력 프롬프트와 출력을 합친 최대 크기를 20 토큰으로 제한하여 리소스 부족을 방지합니다. 기본 디코딩 전략은 탐욕 탐색(greedy search)으로, 다음 토큰으로 가장 높은 확률을 가진 토큰을 선택하는 가장 단순한 디코딩 전략입니다. 많은 작업과 작은 출력 크기에 대해서는 이 방법이 잘 작동하지만, 더 긴 출력을 생성할 때 사용하면 매우 반복적인 결과를 생성하게 될 수 있습니다.
+
+## 텍스트 생성 사용자 정의[[customize-text-generation]]
+
+파라미터와 해당 값을 [`generate`] 메소드에 직접 전달하여 `generation_config`을 재정의할 수 있습니다:
+
+```python
+>>> my_model.generate(**inputs, num_beams=4, do_sample=True) # doctest: +SKIP
+```
+
+기본 디코딩 전략이 대부분의 작업에 잘 작동한다 하더라도, 조정할 수 있는 몇 가지 파라미터가 있습니다. 일반적으로 조정되는 파라미터에는 다음과 같은 것들이 포함됩니다:
+
+- `max_new_tokens`: 생성할 최대 토큰 수입니다. 즉, 프롬프트에 있는 토큰을 제외한 출력 시퀀스의 크기입니다. 출력의 길이를 중단 기준으로 사용하는 대신, 전체 생성물이 일정 시간을 초과할 때 생성을 중단하기로 선택할 수도 있습니다. 더 알아보려면 [`StoppingCriteria`]를 확인하세요.
+- `num_beams`: 1보다 큰 수의 빔을 지정함으로써, 탐욕 탐색(greedy search)에서 빔 탐색(beam search)으로 전환하게 됩니다. 이 전략은 각 시간 단계에서 여러 가설을 평가하고 결국 전체 시퀀스에 대해 가장 높은 확률을 가진 가설을 선택합니다. 이는 초기 토큰의 확률이 낮아 탐욕 탐색에 의해 무시되었을 높은 확률의 시퀀스를 식별할 수 있는 장점을 가집니다.
+- `do_sample`: 이 매개변수를 `True`로 설정하면, 다항 샘플링, 빔 탐색 다항 샘플링, Top-K 샘플링 및 Top-p 샘플링과 같은 디코딩 전략을 활성화합니다. 이러한 전략들은 전체 어휘에 대한 확률 분포에서 다음 토큰을 선택하며, 전략별로 특정 조정이 적용됩니다.
+- `num_return_sequences`: 각 입력에 대해 반환할 시퀀스 후보의 수입니다. 이 옵션은 빔 탐색(beam search)의 변형과 샘플링과 같이 여러 시퀀스 후보를 지원하는 디코딩 전략에만 사용할 수 있습니다. 탐욕 탐색(greedy search)과 대조 탐색(contrastive search) 같은 디코딩 전략은 단일 출력 시퀀스를 반환합니다.
+
+## 모델에 사용자 정의 디코딩 전략 저장[[save-a-custom-decoding-strategy-with-your-model]]
+
+특정 생성 설정을 가진 미세 조정된 모델을 공유하고자 할 때, 다음 단계를 따를 수 있습니다:
+* [`GenerationConfig`] 클래스 인스턴스를 생성합니다.
+* 디코딩 전략 파라미터를 설정합니다.
+* 생성 설정을 [`GenerationConfig.save_pretrained`]를 사용하여 저장하며, `config_file_name` 인자는 비워둡니다.
+* 모델의 저장소에 설정을 업로드하기 위해 `push_to_hub`를 `True`로 설정합니다.
+
+```python
+>>> from transformers import AutoModelForCausalLM, GenerationConfig
+
+>>> model = AutoModelForCausalLM.from_pretrained("my_account/my_model") # doctest: +SKIP
+>>> generation_config = GenerationConfig(
+... max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
+... )
+>>> generation_config.save_pretrained("my_account/my_model", push_to_hub=True) # doctest: +SKIP
+```
+
+단일 디렉토리에 여러 생성 설정을 저장할 수 있으며, 이때 [`GenerationConfig.save_pretrained`]의 `config_file_name` 인자를 사용합니다. 나중에 [`GenerationConfig.from_pretrained`]로 이들을 인스턴스화할 수 있습니다. 이는 단일 모델에 대해 여러 생성 설정을 저장하고 싶을 때 유용합니다(예: 샘플링을 이용한 창의적 텍스트 생성을 위한 하나, 빔 탐색을 이용한 요약을 위한 다른 하나 등). 모델에 설정 파일을 추가하기 위해 적절한 Hub 권한을 가지고 있어야 합니다.
+
+```python
+>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-t5/t5-small")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("google-t5/t5-small")
+
+>>> translation_generation_config = GenerationConfig(
+... num_beams=4,
+... early_stopping=True,
+... decoder_start_token_id=0,
+... eos_token_id=model.config.eos_token_id,
+... pad_token=model.config.pad_token_id,
+... )
+
+>>> # 팁: Hub에 push하려면 `push_to_hub=True`를 추가
+>>> translation_generation_config.save_pretrained("/tmp", "translation_generation_config.json")
+
+>>> # 명명된 생성 설정 파일을 사용하여 생성을 매개변수화할 수 있습니다.
+>>> generation_config = GenerationConfig.from_pretrained("/tmp", "translation_generation_config.json")
+>>> inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
+>>> outputs = model.generate(**inputs, generation_config=generation_config)
+>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['Les fichiers de configuration sont faciles à utiliser!']
+```
+
+## 스트리밍[[streaming]]
+
+`generate()` 메소드는 `streamer` 입력을 통해 스트리밍을 지원합니다. `streamer` 입력은 `put()`과 `end()` 메소드를 가진 클래스의 인스턴스와 호환됩니다. 내부적으로, `put()`은 새 토큰을 추가하는 데 사용되며, `end()`는 텍스트 생성의 끝을 표시하는 데 사용됩니다.
+
+
+
+스트리머 클래스의 API는 아직 개발 중이며, 향후 변경될 수 있습니다.
+
+
+
+실제로 다양한 목적을 위해 자체 스트리밍 클래스를 만들 수 있습니다! 또한, 기본적인 스트리밍 클래스들도 준비되어 있어 바로 사용할 수 있습니다. 예를 들어, [`TextStreamer`] 클래스를 사용하여 `generate()`의 출력을 화면에 한 단어씩 스트리밍할 수 있습니다:
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
+
+>>> tok = AutoTokenizer.from_pretrained("openai-community/gpt2")
+>>> model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
+>>> inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
+>>> streamer = TextStreamer(tok)
+
+>>> # 스트리머는 평소와 같은 출력값을 반환할 뿐만 아니라 생성된 텍스트도 표준 출력(stdout)으로 출력합니다.
+>>> _ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
+An increasing sequence: one, two, three, four, five, six, seven, eight, nine, ten, eleven,
+```
+
+## 디코딩 전략[[decoding-strategies]]
+
+`generate()` 매개변수와 궁극적으로 `generation_config`의 특정 조합을 사용하여 특정 디코딩 전략을 활성화할 수 있습니다. 이 개념이 처음이라면, 흔히 사용되는 디코딩 전략이 어떻게 작동하는지 설명하는 [이 블로그 포스트](https://huggingface.co/blog/how-to-generate)를 읽어보는 것을 추천합니다.
+
+여기서는 디코딩 전략을 제어하는 몇 가지 매개변수를 보여주고, 이를 어떻게 사용할 수 있는지 설명하겠습니다.
+
+### 탐욕 탐색(Greedy Search)[[greedy-search]]
+
+[`generate`]는 기본적으로 탐욕 탐색 디코딩을 사용하므로 이를 활성화하기 위해 별도의 매개변수를 지정할 필요가 없습니다. 이는 `num_beams`가 1로 설정되고 `do_sample=False`로 되어 있다는 의미입니다."
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> prompt = "I look forward to"
+>>> checkpoint = "distilbert/distilgpt2"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+>>> outputs = model.generate(**inputs)
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['I look forward to seeing you all again!\n\n\n\n\n\n\n\n\n\n\n']
+```
+
+### 대조 탐색(Contrastive search)[[contrastive-search]]
+
+2022년 논문 [A Contrastive Framework for Neural Text Generation](https://arxiv.org/abs/2202.06417)에서 제안된 대조 탐색 디코딩 전략은 반복되지 않으면서도 일관된 긴 출력을 생성하는 데 있어 우수한 결과를 보였습니다. 대조 탐색이 작동하는 방식을 알아보려면 [이 블로그 포스트](https://huggingface.co/blog/introducing-csearch)를 확인하세요. 대조 탐색의 동작을 가능하게 하고 제어하는 두 가지 주요 매개변수는 `penalty_alpha`와 `top_k`입니다:
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForCausalLM
+
+>>> checkpoint = "openai-community/gpt2-large"
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+
+>>> prompt = "Hugging Face Company is"
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['Hugging Face Company is a family owned and operated business. We pride ourselves on being the best
+in the business and our customer service is second to none.\n\nIf you have any questions about our
+products or services, feel free to contact us at any time. We look forward to hearing from you!']
+```
+
+### 다항 샘플링(Multinomial sampling)[[multinomial-sampling]]
+
+탐욕 탐색(greedy search)이 항상 가장 높은 확률을 가진 토큰을 다음 토큰으로 선택하는 것과 달리, 다항 샘플링(multinomial sampling, 조상 샘플링(ancestral sampling)이라고도 함)은 모델이 제공하는 전체 어휘에 대한 확률 분포를 기반으로 다음 토큰을 무작위로 선택합니다. 0이 아닌 확률을 가진 모든 토큰은 선택될 기회가 있으므로, 반복의 위험을 줄일 수 있습니다.
+
+다항 샘플링을 활성화하려면 `do_sample=True` 및 `num_beams=1`을 설정하세요.
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
+>>> set_seed(0) # 재현성을 위해
+
+>>> checkpoint = "openai-community/gpt2-large"
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+
+>>> prompt = "Today was an amazing day because"
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['Today was an amazing day because when you go to the World Cup and you don\'t, or when you don\'t get invited,
+that\'s a terrible feeling."']
+```
+
+### 빔 탐색(Beam-search) 디코딩[[beam-search-decoding]]
+
+탐욕 검색(greedy search)과 달리, 빔 탐색(beam search) 디코딩은 각 시간 단계에서 여러 가설을 유지하고 결국 전체 시퀀스에 대해 가장 높은 확률을 가진 가설을 선택합니다. 이는 낮은 확률의 초기 토큰으로 시작하고 그리디 검색에서 무시되었을 가능성이 높은 시퀀스를 식별하는 이점이 있습니다.
+
+이 디코딩 전략을 활성화하려면 `num_beams` (추적할 가설 수라고도 함)를 1보다 크게 지정하세요.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> prompt = "It is astonishing how one can"
+>>> checkpoint = "openai-community/gpt2-medium"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+
+>>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
+time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']
+```
+
+### 빔 탐색 다항 샘플링(Beam-search multinomial sampling)[[beam-search-multinomial-sampling]]
+
+이 디코딩 전략은 이름에서 알 수 있듯이 빔 탐색과 다항 샘플링을 결합한 것입니다. 이 디코딩 전략을 사용하기 위해서는 `num_beams`를 1보다 큰 값으로 설정하고, `do_sample=True`로 설정해야 합니다.
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
+>>> set_seed(0) # 재현성을 위해
+
+>>> prompt = "translate English to German: The house is wonderful."
+>>> checkpoint = "google-t5/t5-small"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+
+>>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
+>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
+'Das Haus ist wunderbar.'
+```
+
+### 다양한 빔 탐색 디코딩(Diverse beam search decoding)[[diverse-beam-search-decoding]]
+
+다양한 빔 탐색(Decoding) 전략은 선택할 수 있는 더 다양한 빔 시퀀스 집합을 생성할 수 있게 해주는 빔 탐색 전략의 확장입니다. 이 방법은 어떻게 작동하는지 알아보려면, [다양한 빔 탐색: 신경 시퀀스 모델에서 다양한 솔루션 디코딩하기](https://arxiv.org/pdf/1610.02424.pdf)를 참조하세요. 이 접근 방식은 세 가지 주요 매개변수를 가지고 있습니다: `num_beams`, `num_beam_groups`, 그리고 `diversity_penalty`. 다양성 패널티는 그룹 간에 출력이 서로 다르게 하기 위한 것이며, 각 그룹 내에서 빔 탐색이 사용됩니다.
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+>>> checkpoint = "google/pegasus-xsum"
+>>> prompt = (
+... "The Permaculture Design Principles are a set of universal design principles "
+... "that can be applied to any location, climate and culture, and they allow us to design "
+... "the most efficient and sustainable human habitation and food production systems. "
+... "Permaculture is a design system that encompasses a wide variety of disciplines, such "
+... "as ecology, landscape design, environmental science and energy conservation, and the "
+... "Permaculture design principles are drawn from these various disciplines. Each individual "
+... "design principle itself embodies a complete conceptual framework based on sound "
+... "scientific principles. When we bring all these separate principles together, we can "
+... "create a design system that both looks at whole systems, the parts that these systems "
+... "consist of, and how those parts interact with each other to create a complex, dynamic, "
+... "living system. Each design principle serves as a tool that allows us to integrate all "
+... "the separate parts of a design, referred to as elements, into a functional, synergistic, "
+... "whole system, where the elements harmoniously interact and work together in the most "
+... "efficient way possible."
+... )
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+
+>>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
+>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
+'The Design Principles are a set of universal design principles that can be applied to any location, climate and
+culture, and they allow us to design the'
+```
+
+이 가이드에서는 다양한 디코딩 전략을 가능하게 하는 주요 매개변수를 보여줍니다. [`generate`] 메서드에 대한 고급 매개변수가 존재하므로 [`generate`] 메서드의 동작을 더욱 세부적으로 제어할 수 있습니다. 사용 가능한 매개변수의 전체 목록은 [API 문서](./main_classes/text_generation.md)를 참조하세요.
+
+### 추론 디코딩(Speculative Decoding)[[speculative-decoding]]
+
+추론 디코딩(보조 디코딩(assisted decoding)으로도 알려짐)은 동일한 토크나이저를 사용하는 훨씬 작은 보조 모델을 활용하여 몇 가지 후보 토큰을 생성하는 상위 모델의 디코딩 전략을 수정한 것입니다. 주 모델은 단일 전방 통과로 후보 토큰을 검증함으로써 디코딩 과정을 가속화합니다. `do_sample=True`일 경우, [추론 디코딩 논문](https://arxiv.org/pdf/2211.17192.pdf)에 소개된 토큰 검증과 재샘플링 방식이 사용됩니다.
+
+현재, 탐욕 검색(greedy search)과 샘플링만이 지원되는 보조 디코딩(assisted decoding) 기능을 통해, 보조 디코딩은 배치 입력을 지원하지 않습니다. 보조 디코딩에 대해 더 알고 싶다면, [이 블로그 포스트](https://huggingface.co/blog/assisted-generation)를 확인해 주세요.
+
+보조 디코딩을 활성화하려면 모델과 함께 `assistant_model` 인수를 설정하세요.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> prompt = "Alice and Bob"
+>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
+>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
+>>> outputs = model.generate(**inputs, assistant_model=assistant_model)
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
+```
+
+샘플링 방법과 함께 보조 디코딩을 사용하는 경우 다항 샘플링과 마찬가지로 `temperature` 인수를 사용하여 무작위성을 제어할 수 있습니다. 그러나 보조 디코딩에서는 `temperature`를 낮추면 대기 시간을 개선하는 데 도움이 될 수 있습니다.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
+>>> set_seed(42) # 재현성을 위해
+
+>>> prompt = "Alice and Bob"
+>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
+>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
+>>> outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['Alice and Bob, who were both in their early twenties, were both in the process of']
+```
diff --git a/docs/transformers/docs/source/ko/gguf.md b/docs/transformers/docs/source/ko/gguf.md
new file mode 100644
index 0000000000000000000000000000000000000000..9d9b02d708a09fe50895a3105752309c62a9ab54
--- /dev/null
+++ b/docs/transformers/docs/source/ko/gguf.md
@@ -0,0 +1,100 @@
+
+
+# GGUF와 Transformers의 상호작용 [[gguf-and-interaction-with-transformers]]
+
+GGUF 파일 형식은 [GGML](https://github.com/ggerganov/ggml)과 그에 의존하는 다른 라이브러리, 예를 들어 매우 인기 있는 [llama.cpp](https://github.com/ggerganov/llama.cpp)이나 [whisper.cpp](https://github.com/ggerganov/whisper.cpp)에서 추론을 위한 모델을 저장하는데 사용됩니다.
+
+이 파일 형식은 [Hugging Face Hub](https://huggingface.co/docs/hub/en/gguf)에서 지원되며, 파일 내의 텐서와 메타데이터를 신속하게 검사할 수 있는 기능을 제공합니다.
+
+이 형식은 "단일 파일 형식(single-file-format)"으로 설계되었으며, 하나의 파일에 설정 속성, 토크나이저 어휘, 기타 속성뿐만 아니라 모델에서 로드되는 모든 텐서가 포함됩니다. 이 파일들은 파일의 양자화 유형에 따라 다른 형식으로 제공됩니다. 다양한 양자화 유형에 대한 간략한 설명은 [여기](https://huggingface.co/docs/hub/en/gguf#quantization-types)에서 확인할 수 있습니다.
+
+## Transformers 내 지원 [[support-within-transformers]]
+
+`transformers` 내에서 `gguf` 파일을 로드할 수 있는 기능을 추가하여 GGUF 모델의 추가 학습/미세 조정을 제공한 후 `ggml` 생태계에서 다시 사용할 수 있도록 `gguf` 파일로 변환하는 기능을 제공합니다. 모델을 로드할 때 먼저 FP32로 역양자화한 후, PyTorch에서 사용할 수 있도록 가중치를 로드합니다.
+
+> [!NOTE]
+> 지원은 아직 초기 단계에 있으며, 다양한 양자화 유형과 모델 아키텍처에 대해 이를 강화하기 위한 기여를 환영합니다.
+
+현재 지원되는 모델 아키텍처와 양자화 유형은 다음과 같습니다:
+
+### 지원되는 양자화 유형 [[supported-quantization-types]]
+
+초기에 지원되는 양자화 유형은 Hub에서 공유된 인기 있는 양자화 파일에 따라 결정되었습니다.
+
+- F32
+- F16
+- BF16
+- Q4_0
+- Q4_1
+- Q5_0
+- Q5_1
+- Q8_0
+- Q2_K
+- Q3_K
+- Q4_K
+- Q5_K
+- Q6_K
+- IQ1_S
+- IQ1_M
+- IQ2_XXS
+- IQ2_XS
+- IQ2_S
+- IQ3_XXS
+- IQ3_S
+- IQ4_XS
+- IQ4_NL
+
+> [!NOTE]
+> GGUF 역양자화를 지원하려면 `gguf>=0.10.0` 설치가 필요합니다.
+
+### 지원되는 모델 아키텍처 [[supported-model-architectures]]
+
+현재 지원되는 모델 아키텍처는 Hub에서 매우 인기가 많은 아키텍처들로 제한되어 있습니다:
+
+- LLaMa
+- Mistral
+- Qwen2
+- Qwen2Moe
+- Phi3
+- Bloom
+
+## 사용 예시 [[example-usage]]
+
+`transformers`에서 `gguf` 파일을 로드하려면 `from_pretrained` 메소드에 `gguf_file` 인수를 지정해야 합니다. 동일한 파일에서 토크나이저와 모델을 로드하는 방법은 다음과 같습니다:
+
+```python
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+model_id = "TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF"
+filename = "tinyllama-1.1b-chat-v1.0.Q6_K.gguf"
+
+tokenizer = AutoTokenizer.from_pretrained(model_id, gguf_file=filename)
+model = AutoModelForCausalLM.from_pretrained(model_id, gguf_file=filename)
+```
+
+이제 PyTorch 생태계에서 모델의 양자화되지 않은 전체 버전에 접근할 수 있으며, 다른 여러 도구들과 결합하여 사용할 수 있습니다.
+
+`gguf` 파일로 다시 변환하려면 llama.cpp의 [`convert-hf-to-gguf.py`](https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py)를 사용하는 것을 권장합니다.
+
+위의 스크립트를 완료하여 모델을 저장하고 다시 `gguf`로 내보내는 방법은 다음과 같습니다:
+
+```python
+tokenizer.save_pretrained('directory')
+model.save_pretrained('directory')
+
+!python ${path_to_llama_cpp}/convert-hf-to-gguf.py ${directory}
+```
diff --git a/docs/transformers/docs/source/ko/hpo_train.md b/docs/transformers/docs/source/ko/hpo_train.md
new file mode 100644
index 0000000000000000000000000000000000000000..c0982db5e093b55b750b655ea6e694c0f62826a8
--- /dev/null
+++ b/docs/transformers/docs/source/ko/hpo_train.md
@@ -0,0 +1,124 @@
+
+
+# Trainer API를 사용한 하이퍼파라미터 탐색 [[hyperparameter-search-using-trainer-api]]
+
+🤗 Transformers에서는 🤗 Transformers 모델을 학습시키는데 최적화된 [`Trainer`] 클래스를 제공하기 때문에, 사용자는 직접 훈련 루프를 작성할 필요 없이 더욱 간편하게 학습을 시킬 수 있습니다. 또한, [`Trainer`]는 하이퍼파라미터 탐색을 위한 API를 제공합니다. 이 문서에서 이 API를 활용하는 방법을 예시와 함께 보여드리겠습니다.
+
+## 하이퍼파라미터 탐색 백엔드 [[hyperparameter-search-backend]]
+
+[`Trainer`]는 현재 아래 4가지 하이퍼파라미터 탐색 백엔드를 지원합니다:
+[optuna](https://optuna.org/)와 [sigopt](https://sigopt.com/), [raytune](https://docs.ray.io/en/latest/tune/index.html), [wandb](https://wandb.ai/site/sweeps) 입니다.
+
+하이퍼파라미터 탐색 백엔드로 사용하기 전에 아래의 명령어를 사용하여 라이브러리들을 설치하세요.
+```bash
+pip install optuna/sigopt/wandb/ray[tune]
+```
+
+## 예제에서 하이퍼파라미터 탐색을 활성화하는 방법 [[how-to-enable-hyperparameter-search-in-example]]
+
+하이퍼파라미터 탐색 공간을 정의하세요. 하이퍼파라미터 탐색 백엔드마다 서로 다른 형식이 필요합니다.
+
+sigopt의 경우, 해당 [object_parameter](https://docs.sigopt.com/ai-module-api-references/api_reference/objects/object_parameter) 문서를 참조하여 아래와 같이 작성하세요:
+```py
+>>> def sigopt_hp_space(trial):
+... return [
+... {"bounds": {"min": 1e-6, "max": 1e-4}, "name": "learning_rate", "type": "double"},
+... {
+... "categorical_values": ["16", "32", "64", "128"],
+... "name": "per_device_train_batch_size",
+... "type": "categorical",
+... },
+... ]
+```
+
+optuna의 경우, 해당 [object_parameter](https://optuna.readthedocs.io/en/stable/tutorial/10_key_features/002_configurations.html#sphx-glr-tutorial-10-key-features-002-configurations-py) 문서를 참조하여 아래와 같이 작성하세요:
+
+```py
+>>> def optuna_hp_space(trial):
+... return {
+... "learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
+... "per_device_train_batch_size": trial.suggest_categorical("per_device_train_batch_size", [16, 32, 64, 128]),
+... }
+```
+
+raytune의 경우, 해당 [object_parameter](https://docs.ray.io/en/latest/tune/api/search_space.html) 문서를 참조하여 아래와 같이 작성하세요:
+
+```py
+>>> def ray_hp_space(trial):
+... return {
+... "learning_rate": tune.loguniform(1e-6, 1e-4),
+... "per_device_train_batch_size": tune.choice([16, 32, 64, 128]),
+... }
+```
+
+wandb의 경우, 해당 [object_parameter](https://docs.wandb.ai/guides/sweeps/configuration) 문서를 참조하여 아래와 같이 작성하세요:
+
+```py
+>>> def wandb_hp_space(trial):
+... return {
+... "method": "random",
+... "metric": {"name": "objective", "goal": "minimize"},
+... "parameters": {
+... "learning_rate": {"distribution": "uniform", "min": 1e-6, "max": 1e-4},
+... "per_device_train_batch_size": {"values": [16, 32, 64, 128]},
+... },
+... }
+```
+
+`model_init` 함수를 정의하고 이를 [`Trainer`]에 전달하세요. 아래는 그 예시입니다.
+```py
+>>> def model_init(trial):
+... return AutoModelForSequenceClassification.from_pretrained(
+... model_args.model_name_or_path,
+... from_tf=bool(".ckpt" in model_args.model_name_or_path),
+... config=config,
+... cache_dir=model_args.cache_dir,
+... revision=model_args.model_revision,
+... token=True if model_args.use_auth_token else None,
+... )
+```
+
+아래와 같이 `model_init` 함수, 훈련 인수, 훈련 및 테스트 데이터셋, 그리고 평가 함수를 사용하여 [`Trainer`]를 생성하세요:
+
+```py
+>>> trainer = Trainer(
+... model=None,
+... args=training_args,
+... train_dataset=small_train_dataset,
+... eval_dataset=small_eval_dataset,
+... compute_metrics=compute_metrics,
+... processing_class=tokenizer,
+... model_init=model_init,
+... data_collator=data_collator,
+... )
+```
+
+하이퍼파라미터 탐색을 호출하고, 최적의 시험 매개변수를 가져오세요. 백엔드는 `"optuna"`/`"sigopt"`/`"wandb"`/`"ray"` 중에서 선택할 수 있습니다. 방향은 `"minimize"` 또는 `"maximize"` 중 선택하며, 목표를 최소화할 것인지 최대화할 것인지를 결정합니다.
+
+자신만의 compute_objective 함수를 정의할 수 있습니다. 만약 이 함수를 정의하지 않으면, 기본 compute_objective가 호출되고, f1과 같은 평가 지표의 합이 목푯값으로 반환됩니다.
+
+```py
+>>> best_trial = trainer.hyperparameter_search(
+... direction="maximize",
+... backend="optuna",
+... hp_space=optuna_hp_space,
+... n_trials=20,
+... compute_objective=compute_objective,
+... )
+```
+
+## DDP 미세 조정을 위한 하이퍼파라미터 탐색 [[hyperparameter-search-for-ddp-finetune]]
+현재, DDP(Distributed Data Parallelism; 분산 데이터 병렬처리)를 위한 하이퍼파라미터 탐색은 optuna와 sigopt에서 가능합니다. 최상위 프로세스가 하이퍼파라미터 탐색 과정을 시작하고 그 결과를 다른 프로세스에 전달합니다.
diff --git a/docs/transformers/docs/source/ko/in_translation.md b/docs/transformers/docs/source/ko/in_translation.md
new file mode 100644
index 0000000000000000000000000000000000000000..61ff1426a4522a90b54a33e3b0c91d8a9a1f4d7c
--- /dev/null
+++ b/docs/transformers/docs/source/ko/in_translation.md
@@ -0,0 +1,5 @@
+
+
+# 열심히 번역 중입니다. 조금 이따 만나요!
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/index.md b/docs/transformers/docs/source/ko/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..bd95cbc0ab09d12c08808fb8c5ff75bf1e1ee9b9
--- /dev/null
+++ b/docs/transformers/docs/source/ko/index.md
@@ -0,0 +1,362 @@
+
+
+# 🤗 Transformers
+
+[PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/), [JAX](https://jax.readthedocs.io/en/latest/)를 위한 최첨단 머신러닝
+
+🤗 Transformers는 사전학습된 최첨단 모델들을 쉽게 다운로드하고 훈련시킬 수 있는 API와 도구를 제공합니다. 사전학습된 모델을 쓰면 컴퓨팅 비용과 탄소 배출량이 줄고, 모델을 처음부터 훈련시키는 데 필요한 시간과 리소스를 절약할 수 있습니다. 저희 모델들은 다양한 분야의 태스크를 지원합니다.
+
+📝 **자연어 처리**: 텍스트 분류, 개체명 인식, 질의응답, 언어 모델링, 요약, 번역, 객관식 질의응답, 텍스트 생성
+🖼️ **컴퓨터 비전**: 이미지 분류, 객체 탐지, 객체 분할
+🗣️ **오디오**: 자동음성인식, 오디오 분류
+🐙 **멀티모달**: 표 질의응답, 광학 문자 인식 (OCR), 스캔한 문서에서 정보 추출, 비디오 분류, 시각 질의응답
+
+🤗 Transformers는 PyTorch, TensorFlow와 JAX 간의 상호운용성을 지원합니다. 유연하게 모델의 각 단계마다 다른 프레임워크를 사용할 수도 있습니다. 예를 들어 코드 3줄만 써서 모델을 훈련시킨 다음, 다른 프레임워크 상에서 추론할 수 있습니다. 모델을 운영 환경에 배포하기 위해 ONNX나 TorchScript 형식으로 내보낼 수도 있습니다.
+
+커뮤니티에 참여하시려면 [Hub](https://huggingface.co/models), [포럼](https://discuss.huggingface.co/), [디스코드](https://discord.com/invite/JfAtkvEtRb)를 방문해주세요!
+
+## Hugging Face 팀과 직접 대화하고 싶으신가요?[[hugging-face-team]]
+
+
+
+
+
+## 콘텐츠[[contents]]
+
+저희 기술문서는 크게 5개 섹션으로 나눌 수 있습니다:
+
+- **시작하기**에서 라이브러리를 간단히 훑어보고, 본격적으로 뛰어들 수 있게 설치 방법을 안내합니다.
+- **튜토리얼**에서 라이브러리에 익숙해질 수 있도록 자세하고도 쉽게 기본적인 부분을 안내합니다.
+- **How-to 가이드**에서 언어 모델링을 위해 사전학습된 모델을 파인 튜닝하는 방법이나, 직접 모델을 작성하고 공유하는 방법과 같이 특정 목표를 달성하는 방법을 안내합니다.
+- **개념 가이드**에서 🤗 Transformers의 설계 철학과 함께 모델이나 태스크 뒤에 숨겨진 개념들과 아이디어를 탐구하고 설명을 덧붙입니다.
+- **API**에서 모든 클래스와 함수를 설명합니다.
+
+ - **메인 클래스**에서 configuration, model, tokenizer, pipeline과 같이 제일 중요한 클래스들을 자세히 설명합니다.
+ - **모델**에서 라이브러리 속 구현된 각 모델과 연관된 클래스와 함수를 자세히 설명합니다.
+ - **내부 유틸리티**에서 내부적으로 사용되는 유틸리티 클래스와 함수를 자세히 설명합니다.
+
+### 지원 모델[[supported-models]]
+
+
+
+1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BLOOM](model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
+1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
+1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
+1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
+1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
+1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
+1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
+1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
+1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
+1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
+1. **[ESM](model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
+1. **[FLAN-T5](model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
+1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
+1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
+1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
+1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
+1. **[GPT NeoX Japanese](model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
+1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
+1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
+1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
+1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
+1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
+1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
+1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
+1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
+1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
+1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
+1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
+1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
+1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
+1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
+1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
+1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
+1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
+1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
+1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoCBert](model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
+1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
+1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
+1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Time Series Transformer](model_doc/time_series_transformer)** (from HuggingFace).
+1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
+1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
+1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
+1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[Whisper](model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
+1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
+1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+
+
+### 지원 프레임워크[[supported-framework]]
+
+아래 표는 라이브러리 속 각 모델의 지원 현황을 나타냅니다. 토큰화를 파이썬 (별칭 "slow") 또는 🤗 Tokenizers (별칭 "fast") 라이브러리로 하는지; (Flax를 통한) Jax, PyTorch, TensorFlow 중 어떤 프레임워크를 지원하는지 표시되어 있습니다.
+
+
+
+| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
+|:---------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
+| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
+| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
+| BigBird-Pegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
+| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
+| CLIPSeg | ❌ | ❌ | ✅ | ❌ | ❌ |
+| CodeGen | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Conditional DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ConvNeXT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| CvT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
+| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Deformable DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DeiT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| DonutSwin | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ERNIE | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ESM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FLAVA | ❌ | ❌ | ✅ | ❌ | ❌ |
+| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
+| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
+| GPT NeoX Japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
+| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
+| GroupViT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
+| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Jukebox | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
+| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| LiLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LongT5 | ❌ | ❌ | ✅ | ❌ | ✅ |
+| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| M-CTC-T | ❌ | ❌ | ✅ | ❌ | ❌ |
+| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
+| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
+| MarkupLM | ✅ | ✅ | ✅ | ❌ | ❌ |
+| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Megatron-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MobileViT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| MVP | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Nezha | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Nyströmformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| OPT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| OWL-ViT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
+| PEGASUS-X | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
+| REALM | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
+| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ResNet | ❌ | ❌ | ✅ | ✅ | ✅ |
+| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| RoCBert | ✅ | ❌ | ✅ | ❌ | ❌ |
+| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
+| SegFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
+| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
+| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
+| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Swin Transformer | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Swin Transformer V2 | ❌ | ❌ | ✅ | ❌ | ❌ |
+| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Table Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Time Series Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VideoMAE | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| VisualBERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
+| ViTMSN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
+| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Whisper | ✅ | ❌ | ✅ | ✅ | ❌ |
+| X-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| XLM-ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
+| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/transformers/docs/source/ko/installation.md b/docs/transformers/docs/source/ko/installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..a744db40d291236a10b6b93c06d99c0b31a0a33d
--- /dev/null
+++ b/docs/transformers/docs/source/ko/installation.md
@@ -0,0 +1,245 @@
+
+
+# 설치방법[[installation]]
+
+🤗 Transformers를 사용 중인 딥러닝 라이브러리에 맞춰 설치하고, 캐시를 구성하거나 선택적으로 오프라인에서도 실행할 수 있도록 🤗 Transformers를 설정하는 방법을 배우겠습니다.
+
+🤗 Transformers는 Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+ 및 Flax에서 테스트되었습니다. 딥러닝 라이브러리를 설치하려면 아래 링크된 저마다의 공식 사이트를 참고해주세요.
+
+* [PyTorch](https://pytorch.org/get-started/locally/) 설치하기
+* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) 설치하기
+* [Flax](https://flax.readthedocs.io/en/latest/) 설치하기
+
+## pip으로 설치하기[[install-with-pip]]
+
+🤗 Transformers를 [가상 환경](https://docs.python.org/3/library/venv.html)에 설치하는 것을 추천드립니다. Python 가상 환경에 익숙하지 않다면, 이 [가이드](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)를 참고하세요. 가상 환경을 사용하면 서로 다른 프로젝트들을 보다 쉽게 관리할 수 있고, 의존성 간의 호환성 문제를 방지할 수 있습니다.
+
+먼저 프로젝트 디렉토리에서 가상 환경을 만들어 줍니다.
+
+```bash
+python -m venv .env
+```
+
+가상 환경을 활성화해주세요. Linux나 MacOS의 경우:
+
+```bash
+source .env/bin/activate
+```
+Windows의 경우:
+
+```bash
+.env/Scripts/activate
+```
+
+이제 🤗 Transformers를 설치할 준비가 되었습니다. 다음 명령을 입력해주세요.
+
+```bash
+pip install transformers
+```
+
+CPU만 써도 된다면, 🤗 Transformers와 딥러닝 라이브러리를 단 1줄로 설치할 수 있습니다. 예를 들어 🤗 Transformers와 PyTorch의 경우:
+
+```bash
+pip install transformers[torch]
+```
+
+🤗 Transformers와 TensorFlow 2.0의 경우:
+
+```bash
+pip install transformers[tf-cpu]
+```
+
+🤗 Transformers와 Flax의 경우:
+
+```bash
+pip install transformers[flax]
+```
+
+마지막으로 🤗 Transformers가 제대로 설치되었는지 확인할 차례입니다. 사전훈련된 모델을 다운로드하는 코드입니다.
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
+```
+
+라벨과 점수가 출력되면 잘 설치된 것입니다.
+
+```bash
+[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
+```
+
+## 소스에서 설치하기[[install-from-source]]
+
+🤗 Transformers를 소스에서 설치하려면 아래 명령을 실행하세요.
+
+```bash
+pip install git+https://github.com/huggingface/transformers
+```
+
+위 명령은 최신이지만 (안정적인) `stable` 버전이 아닌 실험성이 짙은 `main` 버전을 설치합니다. `main` 버전은 개발 현황과 발맞추는데 유용합니다. 예시로 마지막 공식 릴리스 이후 발견된 버그가 패치되었지만, 새 릴리스로 아직 롤아웃되지는 않은 경우를 들 수 있습니다. 바꿔 말하면 `main` 버전이 안정성과는 거리가 있다는 뜻이기도 합니다. 저희는 `main` 버전을 사용하는데 문제가 없도록 노력하고 있으며, 대부분의 문제는 대개 몇 시간이나 하루 안에 해결됩니다. 만약 문제가 발생하면 [이슈](https://github.com/huggingface/transformers/issues)를 열어주시면 더 빨리 해결할 수 있습니다!
+
+전과 마찬가지로 🤗 Transformers가 제대로 설치되었는지 확인할 차례입니다.
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
+```
+
+## 수정 가능한 설치[[editable-install]]
+
+수정 가능한 설치가 필요한 경우는 다음과 같습니다.
+
+* `main` 버전의 소스 코드를 사용하기 위해
+* 🤗 Transformers에 기여하고 싶어서 코드의 변경 사항을 테스트하기 위해
+
+리포지터리를 복제하고 🤗 Transformers를 설치하려면 다음 명령을 입력해주세요.
+
+```bash
+git clone https://github.com/huggingface/transformers.git
+cd transformers
+pip install -e .
+```
+
+위 명령은 리포지터리를 복제한 위치의 폴더와 Python 라이브러리의 경로를 연결시킵니다. Python이 일반 라이브러리 경로 외에 복제한 폴더 내부를 확인할 것입니다. 예를 들어 Python 패키지가 일반적으로 `~/anaconda3/envs/main/lib/python3.7/site-packages/`에 설치되어 있는데, 명령을 받은 Python이 이제 복제한 폴더인 `~/transformers/`도 검색하게 됩니다.
+
+
+
+라이브러리를 계속 사용하려면 `transformers` 폴더를 꼭 유지해야 합니다.
+
+
+
+복제본은 최신 버전의 🤗 Transformers로 쉽게 업데이트할 수 있습니다.
+
+```bash
+cd ~/transformers/
+git pull
+```
+
+Python 환경을 다시 실행하면 업데이트된 🤗 Transformers의 `main` 버전을 찾아낼 것입니다.
+
+## conda로 설치하기[[install-with-conda]]
+
+`conda-forge` conda 채널에서 설치할 수 있습니다.
+
+```bash
+conda install conda-forge::transformers
+```
+
+## 캐시 구성하기[[cache-setup]]
+
+사전훈련된 모델은 다운로드된 후 로컬 경로 `~/.cache/huggingface/hub`에 캐시됩니다. 셸 환경 변수 `TRANSFORMERS_CACHE`의 기본 디렉터리입니다. Windows의 경우 기본 디렉터리는 `C:\Users\username\.cache\huggingface\hub`입니다. 아래의 셸 환경 변수를 (우선 순위) 순서대로 변경하여 다른 캐시 디렉토리를 지정할 수 있습니다.
+
+1. 셸 환경 변수 (기본): `HF_HUB_CACHE` 또는 `TRANSFORMERS_CACHE`
+2. 셸 환경 변수: `HF_HOME`
+3. 셸 환경 변수: `XDG_CACHE_HOME` + `/huggingface`
+
+
+
+과거 🤗 Transformers에서 쓰였던 셸 환경 변수 `PYTORCH_TRANSFORMERS_CACHE` 또는 `PYTORCH_PRETRAINED_BERT_CACHE`이 설정되있다면, 셸 환경 변수 `TRANSFORMERS_CACHE`을 지정하지 않는 한 우선 사용됩니다.
+
+
+
+## 오프라인 모드[[offline-mode]]
+
+🤗 Transformers를 로컬 파일만 사용하도록 해서 방화벽 또는 오프라인 환경에서 실행할 수 있습니다. 활성화하려면 `HF_HUB_OFFLINE=1` 환경 변수를 설정하세요.
+
+
+
+`HF_DATASETS_OFFLINE=1` 환경 변수를 설정하여 오프라인 훈련 과정에 [🤗 Datasets](https://huggingface.co/docs/datasets/)을 추가할 수 있습니다.
+
+
+
+예를 들어 외부 기기 사이에 방화벽을 둔 일반 네트워크에서 평소처럼 프로그램을 다음과 같이 실행할 수 있습니다.
+
+```bash
+python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en ...
+```
+
+오프라인 기기에서 동일한 프로그램을 다음과 같이 실행할 수 있습니다.
+
+```bash
+HF_DATASETS_OFFLINE=1 HF_HUB_OFFLINE=1 \
+python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en ...
+```
+
+이제 스크립트는 로컬 파일에 한해서만 검색할 것이므로, 스크립트가 중단되거나 시간이 초과될 때까지 멈춰있지 않고 잘 실행될 것입니다.
+
+### 오프라인용 모델 및 토크나이저 만들어두기[[fetch-models-and-tokenizers-to-use-offline]]
+
+Another option for using 🤗 Transformers offline is to download the files ahead of time, and then point to their local path when you need to use them offline. There are three ways to do this:
+🤗 Transformers를 오프라인으로 사용하는 또 다른 방법은 파일을 미리 다운로드한 다음, 오프라인일 때 사용할 로컬 경로를 지정해두는 것입니다. 3가지 중 편한 방법을 고르세요.
+
+* [Model Hub](https://huggingface.co/models)의 UI를 통해 파일을 다운로드하려면 ↓ 아이콘을 클릭하세요.
+
+ 
+
+* [`PreTrainedModel.from_pretrained`]와 [`PreTrainedModel.save_pretrained`] 워크플로를 활용하세요.
+
+ 1. 미리 [`PreTrainedModel.from_pretrained`]로 파일을 다운로드해두세요.
+
+ ```py
+ >>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
+ >>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
+ ```
+
+ 2. [`PreTrainedModel.save_pretrained`]로 지정된 경로에 파일을 저장해두세요.
+
+ ```py
+ >>> tokenizer.save_pretrained("./your/path/bigscience_t0")
+ >>> model.save_pretrained("./your/path/bigscience_t0")
+ ```
+
+ 3. 이제 오프라인일 때 [`PreTrainedModel.from_pretrained`]로 저장해뒀던 파일을 지정된 경로에서 다시 불러오세요.
+
+ ```py
+ >>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
+ >>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
+ ```
+
+* [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) 라이브러리를 활용해서 파일을 다운로드하세요.
+
+ 1. 가상환경에 `huggingface_hub` 라이브러리를 설치하세요.
+
+ ```bash
+ python -m pip install huggingface_hub
+ ```
+
+ 2. [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) 함수로 파일을 특정 위치에 다운로드할 수 있습니다. 예를 들어 아래 명령은 [T0](https://huggingface.co/bigscience/T0_3B) 모델의 `config.json` 파일을 지정된 경로에 다운로드합니다.
+
+ ```py
+ >>> from huggingface_hub import hf_hub_download
+
+ >>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
+ ```
+
+파일을 다운로드하고 로컬에 캐시 해놓고 나면, 나중에 불러와 사용할 수 있도록 로컬 경로를 지정해두세요.
+
+```py
+>>> from transformers import AutoConfig
+
+>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
+```
+
+
+
+Hub에 저장된 파일을 다운로드하는 방법을 더 자세히 알아보려면 [Hub에서 파일 다운로드하기](https://huggingface.co/docs/hub/how-to-downstream) 섹션을 참고해주세요.
+
+
diff --git a/docs/transformers/docs/source/ko/internal/audio_utils.md b/docs/transformers/docs/source/ko/internal/audio_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..811f7c0866bd509e0b22c53111330cdacd8c4320
--- /dev/null
+++ b/docs/transformers/docs/source/ko/internal/audio_utils.md
@@ -0,0 +1,39 @@
+
+
+# `FeatureExtractors`를 위한 유틸리티 [[utilities-for-featureextractors]]
+
+이 페이지는 오디오 [`FeatureExtractor`]가 *단시간 푸리에 변환(Short Time Fourier Transform)* 또는 *로그 멜 스펙트로그램(log mel spectrogram)*과 같은 일반적인 알고리즘을 사용하여 원시 오디오에서 특수한 특성을 계산하는 데 사용할 수 있는 유틸리티 함수들을 나열합니다.
+
+이 함수들 대부분은 라이브러리 내 오디오 처리 코드를 연구할 때에만 유용합니다.
+
+## 오디오 변환 [[transformers.audio_utils.hertz_to_mel]]
+
+[[autodoc]] audio_utils.hertz_to_mel
+
+[[autodoc]] audio_utils.mel_to_hertz
+
+[[autodoc]] audio_utils.mel_filter_bank
+
+[[autodoc]] audio_utils.optimal_fft_length
+
+[[autodoc]] audio_utils.window_function
+
+[[autodoc]] audio_utils.spectrogram
+
+[[autodoc]] audio_utils.power_to_db
+
+[[autodoc]] audio_utils.amplitude_to_db
diff --git a/docs/transformers/docs/source/ko/internal/file_utils.md b/docs/transformers/docs/source/ko/internal/file_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..7effad44baa170fba6b4bc8b954f57c2fd208323
--- /dev/null
+++ b/docs/transformers/docs/source/ko/internal/file_utils.md
@@ -0,0 +1,50 @@
+
+
+# 일반 유틸리티 (General Utilities) [[general-utilities]]
+
+이 페이지는 `utils.py` 파일에 있는 Transformers의 일반 유틸리티 함수들을 나열합니다.
+
+이 함수들 대부분은 라이브러리의 일반적인 코드를 연구할 때만 유용합니다.
+
+
+## Enums 및 namedtuples [[transformers.utils.ExplicitEnum]]
+
+[[autodoc]] utils.ExplicitEnum
+
+[[autodoc]] utils.PaddingStrategy
+
+[[autodoc]] utils.TensorType
+
+## 특수 데코레이터 (Special Decorators) [[transformers.add_start_docstrings]]
+
+[[autodoc]] utils.add_start_docstrings
+
+[[autodoc]] utils.add_start_docstrings_to_model_forward
+
+[[autodoc]] utils.add_end_docstrings
+
+[[autodoc]] utils.add_code_sample_docstrings
+
+[[autodoc]] utils.replace_return_docstrings
+
+## 특수 속성 (Special Properties) [[transformers.utils.cached_property]]
+
+[[autodoc]] utils.cached_property
+
+## 기타 유틸리티 [[transformers.utils._LazyModule]]
+
+[[autodoc]] utils._LazyModule
diff --git a/docs/transformers/docs/source/ko/internal/generation_utils.md b/docs/transformers/docs/source/ko/internal/generation_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..a66411f71e9ee8ebb8aa293fa540bda77eeb2d2f
--- /dev/null
+++ b/docs/transformers/docs/source/ko/internal/generation_utils.md
@@ -0,0 +1,413 @@
+
+
+# 생성을 위한 유틸리티 [[utilities-for-generation]]
+
+이 페이지는 [`~generation.GenerationMixin.generate`]에서 사용되는 모든 유틸리티 함수들을 나열합니다.
+
+## 출력을 생성하기 (Generate Outputs) [[generate-outputs]]
+
+[`~generation.GenerationMixin.generate`]의 출력은 [`~utils.ModelOutput`]의 하위 클래스의 인스턴스입니다. 이 출력은 [`~generation.GenerationMixin.generate`]에서 반환되는 모든 정보를 포함하는 데이터 구조체이며, 튜플 또는 딕셔너리로도 사용할 수 있습니다.
+
+다음은 예시입니다:
+
+```python
+from transformers import GPT2Tokenizer, GPT2LMHeadModel
+
+tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
+model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2")
+
+inputs = tokenizer("Hello, my dog is cute and ", return_tensors="pt")
+generation_output = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
+```
+
+`generation_output` 객체는 [`~generation.GenerateDecoderOnlyOutput`]입니다. 아래 문서에서 확인할 수 있듯이, 이 클래스는 다음과 같은 속성을 가지고 있습니다:
+
+- `sequences`: 생성된 토큰 시퀀스
+- `scores` (옵션): 각 생성 단계에서 언어 모델링 헤드의 예측 점수
+- `hidden_states` (옵션): 각 생성 단계에서 모델의 은닉 상태
+- `attentions` (옵션): 각 생성 단계에서 모델의 어텐션 가중치
+
+`output_scores=True`를 전달했기 때문에 `scores`는 포함되어 있지만, `output_hidden_states=True` 또는 `output_attentions=True`를 전달하지 않았으므로 `hidden_states`와 `attentions`는 포함되지 않았습니다.
+
+각 속성은 일반적으로 접근할 수 있으며, 모델이 해당 속성을 반환하지 않았다면 `None`이 반환됩니다. 예를 들어, `generation_output.scores`는 언어 모델링 헤드에서 생성된 모든 예측 점수를 포함하고 있으며, `generation_output.attentions`는 `None`입니다.
+
+`generation_output` 객체를 튜플로 사용할 경우, `None` 값이 아닌 속성만 포함됩니다. 예를 들어, `loss`와 `logits`라는 두 요소가 포함된 경우:
+
+```python
+generation_output[:2]
+```
+
+위 코드는 `(generation_output.sequences, generation_output.scores)` 튜플을 반환합니다.
+
+`generation_output` 객체를 딕셔너리로 사용할 경우, `None` 값이 아닌 속성만 포함됩니다. 예를 들어, `sequences`와 `scores`라는 두 개의 키를 가질 수 있습니다.
+
+여기서는 모든 출력 유형을 문서화합니다.
+
+
+### PyTorch [[transformers.generation.GenerateDecoderOnlyOutput]]
+
+[[autodoc]] generation.GenerateDecoderOnlyOutput
+
+[[autodoc]] generation.GenerateEncoderDecoderOutput
+
+[[autodoc]] generation.GenerateBeamDecoderOnlyOutput
+
+[[autodoc]] generation.GenerateBeamEncoderDecoderOutput
+
+### TensorFlow [[transformers.generation.TFGreedySearchEncoderDecoderOutput]]
+
+[[autodoc]] generation.TFGreedySearchEncoderDecoderOutput
+
+[[autodoc]] generation.TFGreedySearchDecoderOnlyOutput
+
+[[autodoc]] generation.TFSampleEncoderDecoderOutput
+
+[[autodoc]] generation.TFSampleDecoderOnlyOutput
+
+[[autodoc]] generation.TFBeamSearchEncoderDecoderOutput
+
+[[autodoc]] generation.TFBeamSearchDecoderOnlyOutput
+
+[[autodoc]] generation.TFBeamSampleEncoderDecoderOutput
+
+[[autodoc]] generation.TFBeamSampleDecoderOnlyOutput
+
+[[autodoc]] generation.TFContrastiveSearchEncoderDecoderOutput
+
+[[autodoc]] generation.TFContrastiveSearchDecoderOnlyOutput
+
+### FLAX [[transformers.generation.FlaxSampleOutput]]
+
+[[autodoc]] generation.FlaxSampleOutput
+
+[[autodoc]] generation.FlaxGreedySearchOutput
+
+[[autodoc]] generation.FlaxBeamSearchOutput
+
+## LogitsProcessor [[logitsprocessor]]
+
+[`LogitsProcessor`]는 생성 중 언어 모델 헤드의 예측 점수를 수정하는 데 사용됩니다.
+
+### PyTorch [[transformers.AlternatingCodebooksLogitsProcessor]]
+
+[[autodoc]] AlternatingCodebooksLogitsProcessor
+ - __call__
+
+[[autodoc]] ClassifierFreeGuidanceLogitsProcessor
+ - __call__
+
+[[autodoc]] EncoderNoRepeatNGramLogitsProcessor
+ - __call__
+
+[[autodoc]] EncoderRepetitionPenaltyLogitsProcessor
+ - __call__
+
+[[autodoc]] EpsilonLogitsWarper
+ - __call__
+
+[[autodoc]] EtaLogitsWarper
+ - __call__
+
+[[autodoc]] ExponentialDecayLengthPenalty
+ - __call__
+
+[[autodoc]] ForcedBOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] ForcedEOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] HammingDiversityLogitsProcessor
+ - __call__
+
+[[autodoc]] InfNanRemoveLogitsProcessor
+ - __call__
+
+[[autodoc]] LogitNormalization
+ - __call__
+
+[[autodoc]] LogitsProcessor
+ - __call__
+
+[[autodoc]] LogitsProcessorList
+ - __call__
+
+[[autodoc]] MinLengthLogitsProcessor
+ - __call__
+
+[[autodoc]] MinNewTokensLengthLogitsProcessor
+ - __call__
+
+[[autodoc]] MinPLogitsWarper
+ - __call__
+
+[[autodoc]] NoBadWordsLogitsProcessor
+ - __call__
+
+[[autodoc]] NoRepeatNGramLogitsProcessor
+ - __call__
+
+[[autodoc]] PrefixConstrainedLogitsProcessor
+ - __call__
+
+[[autodoc]] RepetitionPenaltyLogitsProcessor
+ - __call__
+
+[[autodoc]] SequenceBiasLogitsProcessor
+ - __call__
+
+[[autodoc]] SuppressTokensAtBeginLogitsProcessor
+ - __call__
+
+[[autodoc]] SuppressTokensLogitsProcessor
+ - __call__
+
+[[autodoc]] TemperatureLogitsWarper
+ - __call__
+
+[[autodoc]] TopKLogitsWarper
+ - __call__
+
+[[autodoc]] TopPLogitsWarper
+ - __call__
+
+[[autodoc]] TypicalLogitsWarper
+ - __call__
+
+[[autodoc]] UnbatchedClassifierFreeGuidanceLogitsProcessor
+ - __call__
+
+[[autodoc]] WhisperTimeStampLogitsProcessor
+ - __call__
+
+[[autodoc]] WatermarkLogitsProcessor
+ - __call__
+
+
+### TensorFlow [[transformers.TFForcedBOSTokenLogitsProcessor]]
+
+[[autodoc]] TFForcedBOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] TFForcedEOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] TFForceTokensLogitsProcessor
+ - __call__
+
+[[autodoc]] TFLogitsProcessor
+ - __call__
+
+[[autodoc]] TFLogitsProcessorList
+ - __call__
+
+[[autodoc]] TFLogitsWarper
+ - __call__
+
+[[autodoc]] TFMinLengthLogitsProcessor
+ - __call__
+
+[[autodoc]] TFNoBadWordsLogitsProcessor
+ - __call__
+
+[[autodoc]] TFNoRepeatNGramLogitsProcessor
+ - __call__
+
+[[autodoc]] TFRepetitionPenaltyLogitsProcessor
+ - __call__
+
+[[autodoc]] TFSuppressTokensAtBeginLogitsProcessor
+ - __call__
+
+[[autodoc]] TFSuppressTokensLogitsProcessor
+ - __call__
+
+[[autodoc]] TFTemperatureLogitsWarper
+ - __call__
+
+[[autodoc]] TFTopKLogitsWarper
+ - __call__
+
+[[autodoc]] TFTopPLogitsWarper
+ - __call__
+
+### FLAX [[transformers.FlaxForcedBOSTokenLogitsProcessor]]
+
+[[autodoc]] FlaxForcedBOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxForcedEOSTokenLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxForceTokensLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxLogitsProcessorList
+ - __call__
+
+[[autodoc]] FlaxLogitsWarper
+ - __call__
+
+[[autodoc]] FlaxMinLengthLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxSuppressTokensAtBeginLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxSuppressTokensLogitsProcessor
+ - __call__
+
+[[autodoc]] FlaxTemperatureLogitsWarper
+ - __call__
+
+[[autodoc]] FlaxTopKLogitsWarper
+ - __call__
+
+[[autodoc]] FlaxTopPLogitsWarper
+ - __call__
+
+[[autodoc]] FlaxWhisperTimeStampLogitsProcessor
+ - __call__
+
+## StoppingCriteria [[transformers.StoppingCriteria]]
+
+[`StoppingCriteria`]는 생성이 언제 멈출지를 결정하는 데 사용됩니다 (EOS 토큰 외). 이 기능은 PyTorch 구현에만 제공됩니다.
+
+[[autodoc]] StoppingCriteria
+ - __call__
+
+[[autodoc]] StoppingCriteriaList
+ - __call__
+
+[[autodoc]] MaxLengthCriteria
+ - __call__
+
+[[autodoc]] MaxTimeCriteria
+ - __call__
+
+[[autodoc]] StopStringCriteria
+ - __call__
+
+[[autodoc]] EosTokenCriteria
+ - __call__
+
+## Constraint [[transformers.Constraint]]
+
+[`Constraint`]는 생성 출력에 특정 토큰이나 시퀀스를 강제로 포함시키는 데 사용됩니다. 이 기능은 PyTorch 구현에만 제공됩니다.
+
+[[autodoc]] Constraint
+
+[[autodoc]] PhrasalConstraint
+
+[[autodoc]] DisjunctiveConstraint
+
+[[autodoc]] ConstraintListState
+
+## 빔 검색 (BeamSearch) [[transformers.BeamScorer]]
+
+[[autodoc]] BeamScorer
+ - process
+ - finalize
+
+[[autodoc]] BeamSearchScorer
+ - process
+ - finalize
+
+[[autodoc]] ConstrainedBeamSearchScorer
+ - process
+ - finalize
+
+## 스트리머 (Streamers) [[transformers.TextStreamer]]
+
+[[autodoc]] TextStreamer
+
+[[autodoc]] TextIteratorStreamer
+
+## 캐시 (Caches) [[transformers.Cache]]
+
+[[autodoc]] Cache
+ - update
+
+[[autodoc]] CacheConfig
+ - update
+
+[[autodoc]] QuantizedCacheConfig
+ - validate
+
+[[autodoc]] DynamicCache
+ - update
+ - get_seq_length
+ - reorder_cache
+ - to_legacy_cache
+ - from_legacy_cache
+
+[[autodoc]] QuantizedCache
+ - update
+ - get_seq_length
+
+[[autodoc]] QuantoQuantizedCache
+
+[[autodoc]] HQQQuantizedCache
+
+[[autodoc]] SinkCache
+ - update
+ - get_seq_length
+ - reorder_cache
+
+[[autodoc]] OffloadedCache
+ - update
+ - prefetch_layer
+ - evict_previous_layer
+
+[[autodoc]] StaticCache
+ - update
+ - get_seq_length
+ - reset
+
+[[autodoc]] OffloadedStaticCache
+ - update
+ - get_seq_length
+ - reset
+
+[[autodoc]] HybridCache
+ - update
+ - get_seq_length
+ - reset
+
+[[autodoc]] SlidingWindowCache
+ - update
+ - reset
+
+[[autodoc]] EncoderDecoderCache
+ - get_seq_length
+ - to_legacy_cache
+ - from_legacy_cache
+ - reset
+ - reorder_cache
+
+[[autodoc]] MambaCache
+ - update_conv_state
+ - update_ssm_state
+ - reset
+
+## 워터마크 유틸리티 (Watermark Utils) [[transformers.WatermarkDetector]]
+
+[[autodoc]] WatermarkDetector
+ - __call__
diff --git a/docs/transformers/docs/source/ko/internal/image_processing_utils.md b/docs/transformers/docs/source/ko/internal/image_processing_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..cd32935132af8798cffa646b1c4e987834a617ee
--- /dev/null
+++ b/docs/transformers/docs/source/ko/internal/image_processing_utils.md
@@ -0,0 +1,47 @@
+
+
+# 이미지 프로세서를 위한 유틸리티 [[utilities-for-image-processors]]
+
+이 페이지는 이미지 프로세서에서 사용되는 유틸리티 함수들을 나열하며, 주로 이미지를 처리하기 위한 함수 기반의 변환 작업들을 다룹니다.
+
+이 함수들 대부분은 라이브러리의 이미지 프로세서 코드를 연구할 때만 유용합니다.
+
+## 이미지 변환 [[transformers.image_transforms.center_crop]]
+
+[[autodoc]] image_transforms.center_crop
+
+[[autodoc]] image_transforms.center_to_corners_format
+
+[[autodoc]] image_transforms.corners_to_center_format
+
+[[autodoc]] image_transforms.id_to_rgb
+
+[[autodoc]] image_transforms.normalize
+
+[[autodoc]] image_transforms.pad
+
+[[autodoc]] image_transforms.rgb_to_id
+
+[[autodoc]] image_transforms.rescale
+
+[[autodoc]] image_transforms.resize
+
+[[autodoc]] image_transforms.to_pil_image
+
+## ImageProcessingMixin [[transformers.ImageProcessingMixin]]
+
+[[autodoc]] image_processing_utils.ImageProcessingMixin
diff --git a/docs/transformers/docs/source/ko/internal/modeling_utils.md b/docs/transformers/docs/source/ko/internal/modeling_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..f84ae30cd6f54555e6390f2f9b9464450f651f4e
--- /dev/null
+++ b/docs/transformers/docs/source/ko/internal/modeling_utils.md
@@ -0,0 +1,66 @@
+
+
+# 사용자 정의 레이어 및 유틸리티 [[custom-layers-and-utilities]]
+
+이 페이지는 라이브러리에서 사용되는 사용자 정의 레이어와 모델링을 위한 유틸리티 함수들을 나열합니다.
+
+이 함수들 대부분은 라이브러리 내의 모델 코드를 연구할 때만 유용합니다.
+
+
+## PyTorch 사용자 정의 모듈 [[transformers.Conv1D]]
+
+[[autodoc]] pytorch_utils.Conv1D
+
+## PyTorch 헬퍼(helper) 함수 [[transformers.apply_chunking_to_forward]]
+
+[[autodoc]] pytorch_utils.apply_chunking_to_forward
+
+[[autodoc]] pytorch_utils.find_pruneable_heads_and_indices
+
+[[autodoc]] pytorch_utils.prune_layer
+
+[[autodoc]] pytorch_utils.prune_conv1d_layer
+
+[[autodoc]] pytorch_utils.prune_linear_layer
+
+## TensorFlow 사용자 정의 레이어 [[transformers.modeling_tf_utils.TFConv1D]]
+
+[[autodoc]] modeling_tf_utils.TFConv1D
+
+[[autodoc]] modeling_tf_utils.TFSequenceSummary
+
+## TensorFlow 손실 함수 [[transformers.modeling_tf_utils.TFCausalLanguageModelingLoss]]
+
+[[autodoc]] modeling_tf_utils.TFCausalLanguageModelingLoss
+
+[[autodoc]] modeling_tf_utils.TFMaskedLanguageModelingLoss
+
+[[autodoc]] modeling_tf_utils.TFMultipleChoiceLoss
+
+[[autodoc]] modeling_tf_utils.TFQuestionAnsweringLoss
+
+[[autodoc]] modeling_tf_utils.TFSequenceClassificationLoss
+
+[[autodoc]] modeling_tf_utils.TFTokenClassificationLoss
+
+## TensorFlow 도우미 함수 [[transformers.modeling_tf_utils.get_initializer]]
+
+[[autodoc]] modeling_tf_utils.get_initializer
+
+[[autodoc]] modeling_tf_utils.keras_serializable
+
+[[autodoc]] modeling_tf_utils.shape_list
diff --git a/docs/transformers/docs/source/ko/internal/pipelines_utils.md b/docs/transformers/docs/source/ko/internal/pipelines_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..e0e64913145541cc4381df0562861c2b364f1cf2
--- /dev/null
+++ b/docs/transformers/docs/source/ko/internal/pipelines_utils.md
@@ -0,0 +1,43 @@
+
+
+# 파이프라인을 위한 유틸리티 [[utilities-for-pipelines]]
+
+이 페이지는 라이브러리에서 파이프라인을 위해 제공하는 모든 유틸리티 함수들을 나열합니다.
+
+이 함수들 대부분은 라이브러리 내 모델의 코드를 연구할 때만 유용합니다.
+
+## 인자 처리 [[transformers.pipelines.ArgumentHandler]]
+
+[[autodoc]] pipelines.ArgumentHandler
+
+[[autodoc]] pipelines.ZeroShotClassificationArgumentHandler
+
+[[autodoc]] pipelines.QuestionAnsweringArgumentHandler
+
+## 데이터 형식 [[transformers.PipelineDataFormat]]
+
+[[autodoc]] pipelines.PipelineDataFormat
+
+[[autodoc]] pipelines.CsvPipelineDataFormat
+
+[[autodoc]] pipelines.JsonPipelineDataFormat
+
+[[autodoc]] pipelines.PipedPipelineDataFormat
+
+## 유틸리티 [[transformers.pipelines.PipelineException]]
+
+[[autodoc]] pipelines.PipelineException
diff --git a/docs/transformers/docs/source/ko/internal/time_series_utils.md b/docs/transformers/docs/source/ko/internal/time_series_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..5729924575b87332223aa5db6c56b6735777b4db
--- /dev/null
+++ b/docs/transformers/docs/source/ko/internal/time_series_utils.md
@@ -0,0 +1,29 @@
+
+
+# 시계열 유틸리티 [[time-series-utilities]]
+
+이 페이지는 시계열 기반 모델에서 사용할 수 있는 유틸리티 함수와 클래스들을 나열합니다.
+
+이 함수들 대부분은 시계열 모델의 코드를 연구하거나 분포 출력 클래스의 컬렉션에 추가하려는 경우에만 유용합니다.
+
+## 분포 출력 (Distributional Output) [[transformers.time_series_utils.NormalOutput]]
+
+[[autodoc]] time_series_utils.NormalOutput
+
+[[autodoc]] time_series_utils.StudentTOutput
+
+[[autodoc]] time_series_utils.NegativeBinomialOutput
diff --git a/docs/transformers/docs/source/ko/internal/tokenization_utils.md b/docs/transformers/docs/source/ko/internal/tokenization_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..b5b69910479a2fb42aeaf4d8bd366967ea9f53e7
--- /dev/null
+++ b/docs/transformers/docs/source/ko/internal/tokenization_utils.md
@@ -0,0 +1,39 @@
+
+
+# 토크나이저를 위한 유틸리티 [[utilities-for-tokenizers]]
+
+이 페이지는 토크나이저에서 사용되는 모든 유틸리티 함수들을 나열하며, 주로 [`PreTrainedTokenizer`]와 [`PreTrainedTokenizerFast`] 사이의 공통 메소드를 구현하는 [`~tokenization_utils_base.PreTrainedTokenizerBase`] 클래스와 [`~tokenization_utils_base.SpecialTokensMixin`]을 다룹니다.
+
+이 함수들 대부분은 라이브러리의 토크나이저 코드를 연구할 때만 유용합니다.
+
+## PreTrainedTokenizerBase [[transformers.PreTrainedTokenizerBase]]
+
+[[autodoc]] tokenization_utils_base.PreTrainedTokenizerBase
+ - __call__
+ - all
+
+## SpecialTokensMixin [[transformers.SpecialTokensMixin]]
+
+[[autodoc]] tokenization_utils_base.SpecialTokensMixin
+
+## Enums 및 namedtuples [[transformers.tokenization_utils_base.TruncationStrategy]]
+
+[[autodoc]] tokenization_utils_base.TruncationStrategy
+
+[[autodoc]] tokenization_utils_base.CharSpan
+
+[[autodoc]] tokenization_utils_base.TokenSpan
diff --git a/docs/transformers/docs/source/ko/internal/trainer_utils.md b/docs/transformers/docs/source/ko/internal/trainer_utils.md
new file mode 100644
index 0000000000000000000000000000000000000000..15fb457331811c6b8cfce23a53766057e816a058
--- /dev/null
+++ b/docs/transformers/docs/source/ko/internal/trainer_utils.md
@@ -0,0 +1,49 @@
+
+
+# Trainer를 위한 유틸리티 (Utilities for Trainer) [[utilities-for-trainer]]
+
+이 페이지는 [`Trainer`]에서 사용되는 모든 유틸리티 함수들을 나열합니다.
+
+이 함수들 대부분은 라이브러리에 있는 Trainer 코드를 자세히 알아보고 싶을 때만 유용합니다.
+
+## 유틸리티 (Utilities) [[transformers.EvalPrediction]]
+
+[[autodoc]] EvalPrediction
+
+[[autodoc]] IntervalStrategy
+
+[[autodoc]] enable_full_determinism
+
+[[autodoc]] set_seed
+
+[[autodoc]] torch_distributed_zero_first
+
+## 콜백 내부 (Callbacks internals) [[transformers.trainer_callback.CallbackHandler]]
+
+[[autodoc]] trainer_callback.CallbackHandler
+
+## 분산 평가 (Distributed Evaluation) [[transformers.trainer_pt_utils.DistributedTensorGatherer]]
+
+[[autodoc]] trainer_pt_utils.DistributedTensorGatherer
+
+## Trainer 인자 파서 (Trainer Argument Parser) [[transformers.HfArgumentParser]]
+
+[[autodoc]] HfArgumentParser
+
+## 디버그 유틸리티 (Debug Utilities) [[transformers.debug_utils.DebugUnderflowOverflow]]
+
+[[autodoc]] debug_utils.DebugUnderflowOverflow
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/llm_optims.md b/docs/transformers/docs/source/ko/llm_optims.md
new file mode 100644
index 0000000000000000000000000000000000000000..f6eaa58c0004d835418c397cbce0dd47640afd80
--- /dev/null
+++ b/docs/transformers/docs/source/ko/llm_optims.md
@@ -0,0 +1,410 @@
+
+
+# LLM 추론 최적화 [[llm-inference-optimization]]
+
+대규모 언어 모델(LLM)은 채팅 및 코드 완성 모델과 같은 텍스트 생성 응용 프로그램을 한 단계 끌어올리며, 높은 수준의 이해력과 유창함을 보여주는 텍스트를 생성합니다. 그러나 LLM을 강력하게 만드는 요소인 그들의 크기는 동시에 추론 과정에서 도전 과제가 되기도 합니다.
+
+기본적인 추론은 느립니다, 왜냐하면 LLM이 다음 토큰을 생성하기 위해 반복적으로 호출되어야 하기 때문입니다. 생성이 진행됨에 따라 입력 시퀀스가 길어져 처리 시간이 점점 길어집니다. 또한, LLM은 수십억 개의 매개변수를 가지고 있어 모든 가중치를 메모리에 저장하고 처리하는 데 어려움이 있습니다.
+
+이 가이드는 LLM 추론을 가속하기 위해 Transformers에서 사용할 수 있는 최적화 기술을 사용하는 방법을 보여줍니다.
+
+> [!TIP]
+> Hugging Face는 LLM을 추론에 최적화하여 배포하고 서비스하는 데 전념하는 라이브러리인 [Text Generation Inference (TGI)](https://hf.co/docs/text-generation-inference)을 제공합니다. 이 라이브러리는 처리량 증가를 위한 지속적인 배칭과 다중 GPU 추론을 위한 텐서 병렬화와 같은 Transformers에 포함되지 않은 배포 지향 최적화 기능을 포함합니다.
+
+## 정적 kv-cache와 `torch.compile`[[static-kv-cache-and-torchcompile]]
+
+디코딩 중에 LLM은 각 입력 토큰에 대한 key-value(kv) 값을 계산합니다. LLM은 자기회귀(autoregressive)이기 때문에 생성된 출력이 현재 입력의 일부가 되어 매번 동일한 kv 값을 계산합니다. 이는 매번 동일한 kv 값을 다시 계산하기 때문에 효율적이지 않습니다.
+
+이를 최적화하기 위해, 이전 키(key)와 값(value)을 재계산하지 않고 저장하는 kv-cache를 사용할 수 있습니다. 그러나 kv-cache는 각 생성 단계에서 증가하며 동적이기 때문에 PyTorch 코드를 빠르고 최적화된 커널로 통합하는 강력한 최적화 도구인 [`torch.compile`](./perf_torch_compile)을 사용하는 데 제약이 있습니다.
+
+*정적 kv-cache*는 최댓값을 미리 할당하여 이 문제를 해결하여 `torch.compile`과 결합할 수 있게 합니다. 이를 통해 최대 4배의 속도 향상이 가능합니다. 속도 향상은 모델 크기(더 큰 모델은 속도 향상이 적음)와 하드웨어에 따라 다를 수 있습니다.
+
+> [!WARNING]
+현재 [Llama](./model_doc/llama2) 및 몇 가지 다른 모델만 정적 kv-cache와 `torch.compile`을 지원합니다. 실시간 모델 호환성 목록은 [이 이슈](https://github.com/huggingface/transformers/issues/28981)를 확인하십시오.
+
+작업의 복잡성에 따라 세 가지 방식의 정적 kv-cache 사용 방법이 있습니다:
+1. 기본 사용법: `generation_config`에서 플래그를 설정하기만 하면 됩니다(권장);
+2. 고급 사용법: 여러 번의 생성이나 맞춤형 생성 루프를 위해 캐시 객체를 처리합니다;
+3. 고급 사용법: 단일 그래프가 필요한 경우, 전체 `generate` 함수를 하나의 그래프로 컴파일합니다.
+
+올바른 탭을 선택하여 각 방법에 대한 추가 지침을 확인하세요.
+
+> [!TIP]
+> `torch.compile`을 사용할 때 어떤 전략을 사용하든, LLM 입력을 제한된 값 세트로 왼쪽에 패딩하면 모양과 관련된 재컴파일을 피할 수 있습니다. [`pad_to_multiple_of` tokenizer flag](https://huggingface.co/docs/transformers/main_classes/tokenizer#transformers.PreTrainedTokenizer.__call__.pad_to_multiple_of)가 유용할 것입니다!
+
+
+
+
+이 예제에서는 [Gemma](https://hf.co/google/gemma-2b) 모델을 사용해 보겠습니다. 필요한 작업은 다음과 같습니다:
+1. 모델의 `generation_config` 속성에 접근하여 `cache_implementation`을 "static"으로 설정합니다;
+2. 모델의 `forward` 패스를 정적 kv-cache와 함께 컴파일하기 위해 `torch.compile`을 호출합니다.
+
+이렇게 하면 끝입니다!
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM
+import torch
+import os
+os.environ["TOKENIZERS_PARALLELISM"] = "false" # 긴 경고 메시지를 방지하기 위해 설정 :)
+
+tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
+model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto")
+
+model.generation_config.cache_implementation = "static"
+
+model.forward = torch.compile(model.forward, mode="reduce-overhead", fullgraph=True)
+input_text = "The theory of special relativity states "
+input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
+
+outputs = model.generate(**input_ids)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['The theory of special relativity states 1. The speed of light is constant in all inertial reference']
+```
+
+`generate` 함수는 내부적으로 동일한 캐시 객체를 재사용하려고 시도하며, 이를 통해 각 호출 시 재컴파일의 필요성을 제거합니다. 재컴파일을 피하는 것은 `torch.compile`의 성능을 최대한 활용하는 데 매우 중요하며, 다음 사항에 유의해야 합니다:
+1. 배치 크기가 변경되거나 호출 간 최대 출력 길이가 증가하면 캐시를 다시 초기화해야 하며, 이로 인해 새로 컴파일을 해야 합니다;
+2. 컴파일된 함수의 첫 몇 번의 호출은 함수가 컴파일되는 동안 더 느립니다.
+
+> [!WARNING]
+> 다중 턴 대화와 같은 정적 캐시의 고급 사용을 위해서는, 캐시 객체를 [`~GenerationMixin.generate`] 외부에서 인스턴스화하고 조작하는 것을 권장합니다. 고급 사용법 탭을 참조하세요.
+
+
+
+
+[`StaticCache`] 객체는 `past_key_values` 인수로 모델의 [`~GenerationMixin.generate`] 함수에 전달할 수 있습니다. 이 객체는 캐시 내용을 유지하므로, 동적 캐시를 사용하는 것처럼 새로운 [`~GenerationMixin.generate`] 호출에 이를 전달하여 생성을 계속할 수 있습니다.
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM, StaticCache
+import torch
+import os
+os.environ["TOKENIZERS_PARALLELISM"] = "false" # 긴 경고 메시지를 방지하기 위해 설정 :)
+
+tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
+model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto")
+
+model.forward = torch.compile(model.forward, mode="reduce-overhead", fullgraph=True)
+input_text = "The theory of special relativity states "
+input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
+prompt_length = input_ids.input_ids.shape[1]
+model.generation_config.max_new_tokens = 16
+
+past_key_values = StaticCache(
+ config=model.config,
+ max_batch_size=1,
+ # 캐시를 재사용할 계획이 있는 경우, 모든 경우에 충분한 캐시 길이를 설정해야 합니다
+ max_cache_len=prompt_length+(model.generation_config.max_new_tokens*2),
+ device=model.device,
+ dtype=model.dtype
+)
+outputs = model.generate(**input_ids, past_key_values=past_key_values)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['The theory of special relativity states 1. The speed of light is constant in all inertial reference frames. 2']
+
+# 생성된 텍스트와 동일한 캐시 객체를 전달하여, 중단한 곳에서 생성을 계속합니다.
+# 다중 턴 대화의 경우, 생성된 텍스트에 새로운 사용자 입력을 추가할 수 있습니다.
+new_input_ids = outputs
+outputs = model.generate(new_input_ids, past_key_values=past_key_values)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['The theory of special relativity states 1. The speed of light is constant in all inertial reference frames. 2. The speed of light is constant in all inertial reference frames. 3.']
+```
+
+> [!TIP]
+> 동일한 [`StaticCache`] 객체를 새로운 프롬프트에 사용하려면, 호출 간에 `.reset()` 메서드를 사용하여 그 내용을 초기화하는 것이 좋습니다.
+
+더 깊이 들어가고 싶다면, [`StaticCache`] 객체를 모델의 `forward` 패스에 동일한 `past_key_values` 인수로 전달할 수도 있습니다. 이 전략을 사용하면, 현재 토큰과 이전에 생성된 토큰의 위치 및 캐시 위치를 바탕으로 다음 토큰을 디코딩하는 자체 함수를 작성할 수 있습니다.
+
+```py
+from transformers import LlamaTokenizer, LlamaForCausalLM, StaticCache, logging
+from transformers.testing_utils import CaptureLogger
+import torch
+
+prompts = [
+ "Simply put, the theory of relativity states that ",
+ "My favorite all time favorite condiment is ketchup.",
+]
+
+NUM_TOKENS_TO_GENERATE = 40
+torch_device = "cuda"
+
+tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", pad_token="", padding_side="right")
+model = LlamaForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", device_map="sequential")
+inputs = tokenizer(prompts, return_tensors="pt", padding=True).to(model.device)
+
+def decode_one_tokens(model, cur_token, input_pos, cache_position, past_key_values):
+ logits = model(
+ cur_token,
+ position_ids=input_pos,
+ cache_position=cache_position,
+ past_key_values=past_key_values,
+ return_dict=False,
+ use_cache=True
+ )[0]
+ new_token = torch.argmax(logits[:, -1], dim=-1)[:, None]
+ return new_token
+```
+
+`StaticCache` 메서드를 사용하여 정적 kv-cache와 `torch.compile`을 활성화하려면 몇 가지 중요한 작업을 수행해야 합니다:
+1. 추론에 모델을 사용하기 전에 [`StaticCache`] 인스턴스를 초기화합니다. 여기서 최대 배치 크기와 시퀀스 길이와 같은 매개변수를 설정할 수 있습니다.
+2. 정적 kv-cache와 함께 순전파를 컴파일하기 위해 모델에 `torch.compile`을 호출합니다.
+3. [torch.backends.cuda.sdp_kernel](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) 컨텍스트 관리자에서 `enable_math=True`를 설정하여 네이티브 PyTorch C++ 구현된 스케일된 점곱 어텐션(scaled dot product attention)을 활성화하여 추론 속도를 더욱 높입니다.
+
+```py
+batch_size, seq_length = inputs["input_ids"].shape
+with torch.no_grad():
+ past_key_values = StaticCache(
+ config=model.config, max_batch_size=2, max_cache_len=4096, device=torch_device, dtype=model.dtype
+ )
+ cache_position = torch.arange(seq_length, device=torch_device)
+ generated_ids = torch.zeros(
+ batch_size, seq_length + NUM_TOKENS_TO_GENERATE + 1, dtype=torch.int, device=torch_device
+ )
+ generated_ids[:, cache_position] = inputs["input_ids"].to(torch_device).to(torch.int)
+
+ logits = model(
+ **inputs, cache_position=cache_position, past_key_values=past_key_values,return_dict=False, use_cache=True
+ )[0]
+ next_token = torch.argmax(logits[:, -1], dim=-1)[:, None]
+ generated_ids[:, seq_length] = next_token[:, 0]
+
+ decode_one_tokens = torch.compile(decode_one_tokens, mode="reduce-overhead", fullgraph=True)
+ cache_position = torch.tensor([seq_length + 1], device=torch_device)
+ for _ in range(1, NUM_TOKENS_TO_GENERATE):
+ with torch.backends.cuda.sdp_kernel(enable_flash=False, enable_mem_efficient=False, enable_math=True):
+ next_token = decode_one_tokens(model, next_token.clone(), None, cache_position, past_key_values)
+ generated_ids[:, cache_position] = next_token.int()
+ cache_position += 1
+
+text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+text
+['Simply put, the theory of relativity states that 1) the speed of light is constant, 2) the speed of light is the same for all observers, and 3) the laws of physics are the same for all observers.',
+ 'My favorite all time favorite condiment is ketchup. I love it on everything. I love it on my eggs, my fries, my chicken, my burgers, my hot dogs, my sandwiches, my salads, my p']
+```
+
+
+
+
+전체 `generate` 함수를 컴파일하는 것은 코드 측면에서 기본 사용법보다 더 간단합니다. `generate` 함수에 대해 `torch.compile`을 호출하여 전체 함수를 컴파일하면 됩니다. 정적 캐시의 사용을 지정할 필요는 없습니다. 정적 캐시는 호환되지만, 벤치마크에서는 동적 캐시(기본 설정)가 더 빠른 것으로 나타났습니다.
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM
+import torch
+import os
+os.environ["TOKENIZERS_PARALLELISM"] = "false" # 긴 경고 메시지를 방지하기 위해 설정 :)
+
+tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b")
+model = AutoModelForCausalLM.from_pretrained("google/gemma-2b", device_map="auto")
+
+model.generate = torch.compile(model.generate, mode="reduce-overhead", fullgraph=True)
+input_text = "The theory of special relativity states "
+input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
+
+outputs = model.generate(**input_ids)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['The theory of special relativity states 1. The speed of light is constant in all inertial reference']
+```
+
+이 방법을 통해 모델의 forward 패스뿐만 아니라, 입력 준비, logit 처리기 작업 등을 포함한 모든 것을 컴파일합니다. 기본 사용 예제에 비해 `generate` 호출이 약간 더 빠를 수 있으며, 컴파일된 그래프는 더 특이한 하드웨어 장치나 사용 사례에 적합할 수 있습니다. 그러나 이 접근 방식을 사용하는 데는 몇 가지 큰 단점이 있습니다:
+1. 컴파일 속도가 훨씬 느립니다;
+2. `generate`의 모든 매개변수 설정은 `generation_config`를 통해서만 가능합니다;
+3. 많은 경고와 예외가 억제됩니다. -- 먼저 컴파일 되지 않은 형태로 테스트하는 것을 권장합니다;
+4. 현재 작업 중이지만 기능 제한이 심합니다(예: 작성 시점에서는 EOS 토큰이 선택되어도 생성이 중단되지 않습니다).
+
+
+
+
+## 추정 디코딩 [[speculative-decoding]]
+
+> [!TIP]
+> 보다 심층적인 설명을 원한다면, [Assisted Generation: a new direction toward low-latency text generation](https://hf.co/blog/assisted-generation) 블로그 게시물을 확인하십시오!
+
+자기 회귀의 또 다른 문제는 각 입력 토큰에 대해 순전파 중에 모델 가중치를 매번 로드해야 한다는 점입니다. 이는 수십억 개의 매개변수를 가진 LLM에는 느리고 번거롭습니다. 추정 디코딩(speculative decoding)은 더 작고 빠른 보조 모델을 사용하여 후보 토큰을 생성하고, 이를 큰 LLM이 단일 순전파에서 검증하여 이 속도 저하를 완화합니다. 검증된 토큰이 정확하다면, LLM은 본래 자체적으로 생성하는 것처럼 토큰을 얻을 수 있습니다. 전방 패스가 동일한 출력을 보장하기 때문에 정확도 저하가 없습니다.
+
+가장 큰 속도 향상을 얻기 위해, 보조 모델은 빠르게 토큰을 생성할 수 있도록 LLM보다 훨씬 작아야 합니다. 보조 모델과 LLM 모델은 토큰을 다시 인코딩하고 디코딩하지 않도록 동일한 토크나이저를 공유해야 합니다.
+
+> [!WARNING]
+> 추정 디코딩은 탐욕 검색과 샘플링 디코딩 전략에서만 지원되며, 배치 입력을 지원하지 않습니다.
+
+보조 모델을 로드하고 이를 [`~GenerationMixin.generate`] 메서드에 전달하여 추정 디코딩을 활성화하십시오.
+
+
+
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+import torch
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+
+tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
+inputs = tokenizer("Einstein's theory of relativity states", return_tensors="pt").to(device)
+
+model = AutoModelForCausalLM.from_pretrained("facebook/opt-1.3b").to(device)
+assistant_model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m").to(device)
+outputs = model.generate(**inputs, assistant_model=assistant_model)
+tokenizer.batch_decode(outputs, skip_special_tokens=True)
+["Einstein's theory of relativity states that the speed of light is constant. "]
+```
+
+
+
+
+추정 샘플링 디코딩(speculative sampling decoding)을 위해, 보조 모델 외에도 [`~GenerationMixin.generate`] 메서드에 `do_sample` 및 `temperature` 매개변수를 추가하십시오.
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+import torch
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+
+tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
+inputs = tokenizer("Einstein's theory of relativity states", return_tensors="pt").to(device)
+
+model = AutoModelForCausalLM.from_pretrained("facebook/opt-1.3b").to(device)
+assistant_model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m").to(device)
+outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.7)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+["Einstein's theory of relativity states that motion in the universe is not a straight line.\n"]
+```
+
+
+
+
+### 프롬프트 조회 디코딩 [[prompt-lookup-decoding]]
+
+프롬프트 조회 디코딩은 탐욕 검색과 샘플링과도 호환되는 추정 디코딩의 변형입니다. 프롬프트 조회는 요약과 같은 입력 기반 작업에 특히 잘 작동합니다. 여기서는 프롬프트와 출력 간에 종종 겹치는 단어가 있습니다. 이러한 겹치는 n-그램이 LLM 후보 토큰으로 사용됩니다.
+
+프롬프트 조회 디코딩을 활성화하려면 `prompt_lookup_num_tokens` 매개변수에 겹치는 토큰 수를 지정하십시오. 그런 다음 이 매개변수를 [`~GenerationMixin.generate`] 메서드에 전달할 수 있습니다.
+
+
+
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+import torch
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+
+tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
+inputs = tokenizer("The second law of thermodynamics states", return_tensors="pt").to(device)
+
+model = AutoModelForCausalLM.from_pretrained("facebook/opt-1.3b").to(device)
+assistant_model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m").to(device)
+outputs = model.generate(**inputs, prompt_lookup_num_tokens=3)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+['The second law of thermodynamics states that entropy increases with temperature. ']
+```
+
+
+
+
+샘플링과 함께 프롬프트 조회 디코딩을 사용하려면, [`~GenerationMixin.generate`] 메서드에 `do_sample` 및 `temperature` 매개변수를 추가하십시오.
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+import torch
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+
+tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
+inputs = tokenizer("The second law of thermodynamics states", return_tensors="pt").to(device)
+
+model = AutoModelForCausalLM.from_pretrained("facebook/opt-1.3b").to(device)
+outputs = model.generate(**inputs, prompt_lookup_num_tokens=3, do_sample=True, temperature=0.7)
+print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
+["The second law of thermodynamics states that energy cannot be created nor destroyed. It's not a"]
+```
+
+
+
+
+## 어텐션 최적화 [[attention-optimizations]]
+
+트랜스포머 모델의 알려진 문제는 셀프 어텐션 메커니즘이 입력 토큰 수와 함께 계산 및 메모리가 제곱으로 증가한다는 것입니다. 이 제한은 훨씬 더 긴 시퀀스를 처리하는 LLM에서는 더욱 커집니다. 이를 해결하기 위해 FlashAttention2 또는 PyTorch의 스케일된 점곱 어텐션을 사용해 보십시오. 이들은 더 메모리 효율적인 어텐션 구현으로 추론을 가속화할 수 있습니다.
+
+### FlashAttention-2 [[flashattention-2]]
+
+FlashAttention과 [FlashAttention-2](./perf_infer_gpu_one#flashattention-2)는 어텐션 계산을 더 작은 청크로 나누고 중간 읽기/쓰기 작업을 줄여 추론 속도를 높입니다. FlashAttention-2는 원래 FlashAttention 알고리즘을 개선하여 시퀀스 길이 차원에서도 병렬 처리를 수행하고 하드웨어에서 작업을 더 잘 분할하여 동기화 및 통신 오버헤드를 줄입니다.
+
+FlashAttention-2를 사용하려면 [`~PreTrainedModel.from_pretrained`] 메서드에서 `attn_implementation="flash_attention_2"`를 설정하십시오.
+
+```py
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig
+
+quant_config = BitsAndBytesConfig(load_in_8bit=True)
+model = AutoModelForCausalLM.from_pretrained(
+ "google/gemma-2b",
+ quantization_config=quant_config,
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+```
+
+### PyTorch 스케일된 점곱 어텐션(scaled dot product attention) [[pytorch-scaled-dot-product-attention]]
+
+스케일된 점곱 어텐션(SDPA)는 PyTorch 2.0에서 자동으로 활성화되며, FlashAttention, xFormers, PyTorch의 C++ 구현을 지원합니다. SDPA는 CUDA 백엔드를 사용하는 경우 가장 성능이 좋은 어텐션 알고리즘을 선택합니다. 다른 백엔드에서는 SDPA가 PyTorch C++ 구현으로 기본 설정됩니다.
+
+> [!TIP]
+> SDPA는 최신 PyTorch 버전이 설치되어 있으면 FlashAttention-2도 지원합니다.
+
+세 가지 어텐션 알고리즘 중 하나를 명시적으로 활성화하거나 비활성화하려면 [torch.backends.cuda.sdp_kernel](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) 컨텍스트 관리자를 사용하십시오. 예를 들어 FlashAttention을 활성화하려면 `enable_flash=True`로 설정하십시오.
+
+```py
+import torch
+from transformers import AutoModelForCausalLM
+
+model = AutoModelForCausalLM.from_pretrained(
+ "google/gemma-2b",
+ torch_dtype=torch.bfloat16,
+)
+
+with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
+ outputs = model.generate(**inputs)
+```
+
+## 양자화 [[quantization]]
+
+양자화는 LLM 가중치를 더 낮은 정밀도로 저장하여 크기를 줄입니다. 이는 메모리 사용량을 줄이며 GPU 메모리에 제약이 있는 경우 추론을 위해 LLM을 로드하는 것을 더 용이하게 합니다. GPU가 충분하다면, 모델을 양자화할 필요는 없습니다. 추가적인 양자화 및 양자화 해제 단계로 인해 약간의 지연이 발생할 수 있기 때문입니다(AWQ 및 융합 AWQ 모듈 제외).
+
+> [!TIP]
+> 다양한 양자화 라이브러리(자세한 내용은 [Quantization](./quantization) 가이드를 참조하십시오)가 있습니다. 여기에는 Quanto, AQLM, VPTQ, AWQ 및 AutoGPTQ가 포함됩니다. 사용 사례에 가장 잘 맞는 라이브러리를 사용해 보십시오. 또한 AutoGPTQ와 bitsandbytes를 비교하는 [Overview of natively supported quantization schemes in 🤗 Transformers](https://hf.co/blog/overview-quantization-transformers) 블로그 게시물을 읽어보는 것을 추천합니다.
+
+아래의 모델 메모리 계산기를 사용하여 모델을 로드하는 데 필요한 메모리를 추정하고 비교해 보십시오. 예를 들어 [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)를 로드하는 데 필요한 메모리를 추정해 보십시오.
+
+
+
+Mistral-7B-v0.1을 반정밀도로 로드하려면 [`~transformers.AutoModelForCausalLM.from_pretrained`] 메서드에서 `torch_dtype` 매개변수를 `torch.bfloat16`으로 설정하십시오. 이 경우 13.74GB의 메모리가 필요합니다.
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM
+import torch
+
+model = AutoModelForCausalLM.from_pretrained(
+ "mistralai/Mistral-7B-v0.1", torch_dtype=torch.bfloat16, device_map="auto",
+)
+```
+
+추론을 위해 양자화된 모델(8비트 또는 4비트)을 로드하려면 [bitsandbytes](https://hf.co/docs/bitsandbytes)를 사용하고 `load_in_4bit` 또는 `load_in_8bit` 매개변수를 `True`로 설정하십시오. 모델을 8비트로 로드하는 데는 6.87GB의 메모리만 필요합니다.
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
+import torch
+
+quant_config = BitsAndBytesConfig(load_in_8bit=True)
+model = AutoModelForCausalLM.from_pretrained(
+ "mistralai/Mistral-7B-v0.1", quantization_config=quant_config, device_map="auto"
+)
+```
diff --git a/docs/transformers/docs/source/ko/llm_tutorial.md b/docs/transformers/docs/source/ko/llm_tutorial.md
new file mode 100644
index 0000000000000000000000000000000000000000..d5e0bd356edd2e8589e1f70a3ca65809d09c6d72
--- /dev/null
+++ b/docs/transformers/docs/source/ko/llm_tutorial.md
@@ -0,0 +1,222 @@
+
+
+
+# 대규모 언어 모델로 생성하기 [[generation-with-llms]]
+
+[[open-in-colab]]
+
+LLM 또는 대규모 언어 모델은 텍스트 생성의 핵심 구성 요소입니다. 간단히 말하면, 주어진 입력 텍스트에 대한 다음 단어(정확하게는 토큰)를 예측하기 위해 훈련된 대규모 사전 훈련 변환기 모델로 구성됩니다. 토큰을 한 번에 하나씩 예측하기 때문에 새로운 문장을 생성하려면 모델을 호출하는 것 외에 더 복잡한 작업을 수행해야 합니다. 즉, 자기회귀 생성을 수행해야 합니다.
+
+자기회귀 생성은 몇 개의 초기 입력값을 제공한 후, 그 출력을 다시 모델에 입력으로 사용하여 반복적으로 호출하는 추론 과정입니다. 🤗 Transformers에서는 [`~generation.GenerationMixin.generate`] 메소드가 이 역할을 하며, 이는 생성 기능을 가진 모든 모델에서 사용 가능합니다.
+
+이 튜토리얼에서는 다음 내용을 다루게 됩니다:
+
+* LLM으로 텍스트 생성
+* 일반적으로 발생하는 문제 해결
+* LLM을 최대한 활용하기 위한 다음 단계
+
+시작하기 전에 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers bitsandbytes>=0.39.0 -q
+```
+
+
+## 텍스트 생성 [[generate-text]]
+
+[인과적 언어 모델링(causal language modeling)](tasks/language_modeling)을 목적으로 학습된 언어 모델은 일련의 텍스트 토큰을 입력으로 사용하고, 그 결과로 다음 토큰이 나올 확률 분포를 제공합니다.
+
+
+
+
+ "LLM의 전방 패스"
+
+
+LLM과 자기회귀 생성을 함께 사용할 때 핵심적인 부분은 이 확률 분포로부터 다음 토큰을 어떻게 고를 것인지입니다. 다음 반복 과정에 사용될 토큰을 결정하는 한, 어떠한 방법도 가능합니다. 확률 분포에서 가장 가능성이 높은 토큰을 선택하는 것처럼 간단할 수도 있고, 결과 분포에서 샘플링하기 전에 수십 가지 변환을 적용하는 것처럼 복잡할 수도 있습니다.
+
+
+
+
+ "자기회귀 생성은 확률 분포에서 다음 토큰을 반복적으로 선택하여 텍스트를 생성합니다."
+
+
+위에서 설명한 과정은 어떤 종료 조건이 충족될 때까지 반복적으로 수행됩니다. 모델이 시퀀스의 끝(EOS 토큰)을 출력할 때까지를 종료 조건으로 하는 것이 이상적입니다. 그렇지 않은 경우에는 미리 정의된 최대 길이에 도달했을 때 생성이 중단됩니다.
+
+모델이 예상대로 동작하기 위해선 토큰 선택 단계와 정지 조건을 올바르게 설정하는 것이 중요합니다. 이러한 이유로, 각 모델에는 기본 생성 설정이 잘 정의된 [`~generation.GenerationConfig`] 파일이 함께 제공됩니다.
+
+코드를 확인해봅시다!
+
+
+
+기본 LLM 사용에 관심이 있다면, 우리의 [`Pipeline`](pipeline_tutorial) 인터페이스로 시작하는 것을 추천합니다. 그러나 LLM은 양자화나 토큰 선택 단계에서의 미세한 제어와 같은 고급 기능들을 종종 필요로 합니다. 이러한 작업은 [`~generation.GenerationMixin.generate`]를 통해 가장 잘 수행될 수 있습니다. LLM을 이용한 자기회귀 생성은 자원을 많이 소모하므로, 적절한 처리량을 위해 GPU에서 실행되어야 합니다.
+
+
+
+먼저, 모델을 불러오세요.
+
+```python
+>>> from transformers import AutoModelForCausalLM
+
+>>> model = AutoModelForCausalLM.from_pretrained(
+... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
+... )
+```
+
+`from_pretrained` 함수를 호출할 때 2개의 플래그를 주목하세요:
+
+- `device_map`은 모델이 GPU로 이동되도록 합니다.
+- `load_in_4bit`는 리소스 요구 사항을 크게 줄이기 위해 [4비트 동적 양자화](main_classes/quantization)를 적용합니다.
+
+이 외에도 모델을 초기화하는 다양한 방법이 있지만, LLM을 처음 시작할 때 이 설정을 추천합니다.
+
+이어서 텍스트 입력을 [토크나이저](tokenizer_summary)으로 전처리하세요.
+
+```python
+>>> from transformers import AutoTokenizer
+>>> import torch
+
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to(device)
+```
+
+`model_inputs` 변수에는 토큰화된 텍스트 입력과 함께 어텐션 마스크가 들어 있습니다. [`~generation.GenerationMixin.generate`]는 어텐션 마스크가 제공되지 않았을 경우에도 이를 추론하려고 노력하지만, 최상의 성능을 위해서는 가능하면 어텐션 마스크를 전달하는 것을 권장합니다.
+
+마지막으로 [`~generation.GenerationMixin.generate`] 메소드를 호출해 생성된 토큰을 얻은 후, 이를 출력하기 전에 텍스트 형태로 변환하세요.
+
+```python
+>>> generated_ids = model.generate(**model_inputs)
+>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+'A list of colors: red, blue, green, yellow, black, white, and brown'
+```
+
+이게 전부입니다! 몇 줄의 코드만으로 LLM의 능력을 활용할 수 있게 되었습니다.
+
+
+## 일반적으로 발생하는 문제 [[common-pitfalls]]
+
+[생성 전략](generation_strategies)이 많고, 기본값이 항상 사용 사례에 적합하지 않을 수 있습니다. 출력이 예상과 다를 때 흔히 발생하는 문제와 이를 해결하는 방법에 대한 목록을 만들었습니다.
+
+```py
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
+>>> tokenizer.pad_token = tokenizer.eos_token # Mistral has no pad token by default
+>>> model = AutoModelForCausalLM.from_pretrained(
+... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
+... )
+```
+
+### 생성된 출력이 너무 짧거나 길다 [[generated-output-is-too-shortlong]]
+
+[`~generation.GenerationConfig`] 파일에서 별도로 지정하지 않으면, `generate`는 기본적으로 최대 20개의 토큰을 반환합니다. `generate` 호출에서 `max_new_tokens`을 수동으로 설정하여 반환할 수 있는 새 토큰의 최대 수를 설정하는 것이 좋습니다. LLM(정확하게는 [디코더 전용 모델](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt))은 입력 프롬프트도 출력의 일부로 반환합니다.
+
+
+```py
+>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
+
+>>> # By default, the output will contain up to 20 tokens
+>>> generated_ids = model.generate(**model_inputs, pad_token_id=tokenizer.eos_token_id)
+>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+'A sequence of numbers: 1, 2, 3, 4, 5'
+
+>>> # Setting `max_new_tokens` allows you to control the maximum length
+>>> generated_ids = model.generate(**model_inputs, pad_token_id=tokenizer.eos_token_id, max_new_tokens=50)
+>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
+```
+
+### 잘못된 생성 모드 [[incorrect-generation-mode]]
+
+기본적으로 [`~generation.GenerationConfig`] 파일에서 별도로 지정하지 않으면, `generate`는 각 반복에서 가장 확률이 높은 토큰을 선택합니다(그리디 디코딩). 하려는 작업에 따라 이 방법은 바람직하지 않을 수 있습니다. 예를 들어, 챗봇이나 에세이 작성과 같은 창의적인 작업은 샘플링이 적합할 수 있습니다. 반면, 오디오를 텍스트로 변환하거나 번역과 같은 입력 기반 작업은 그리디 디코딩이 더 적합할 수 있습니다. `do_sample=True`로 샘플링을 활성화할 수 있으며, 이 주제에 대한 자세한 내용은 이 [블로그 포스트](https://huggingface.co/blog/how-to-generate)에서 볼 수 있습니다.
+
+```python
+>>> # Set seed or reproducibility -- you don't need this unless you want full reproducibility
+>>> from transformers import set_seed
+>>> set_seed(0)
+
+>>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")
+
+>>> # LLM + greedy decoding = repetitive, boring output
+>>> generated_ids = model.generate(**model_inputs)
+>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+'I am a cat. I am a cat. I am a cat. I am a cat'
+
+>>> # With sampling, the output becomes more creative!
+>>> generated_ids = model.generate(**model_inputs, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+'I am a cat.\nI just need to be. I am always.\nEvery time'
+```
+
+### 잘못된 패딩 [[wrong-padding-side]]
+
+LLM은 [디코더 전용](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt) 구조를 가지고 있어, 입력 프롬프트에 대해 지속적으로 반복 처리를 합니다. 입력 데이터의 길이가 다르면 패딩 작업이 필요합니다. LLM은 패딩 토큰에서 작동을 이어가도록 설계되지 않았기 때문에, 입력 왼쪽에 패딩이 추가 되어야 합니다. 그리고 어텐션 마스크도 꼭 `generate` 함수에 전달되어야 합니다!
+
+```python
+>>> # The tokenizer initialized above has right-padding active by default: the 1st sequence,
+>>> # which is shorter, has padding on the right side. Generation fails.
+>>> model_inputs = tokenizer(
+... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
+... ).to("cuda")
+>>> generated_ids = model.generate(**model_inputs)
+>>> tokenizer.batch_decode(generated_ids[0], skip_special_tokens=True)[0]
+''
+
+>>> # With left-padding, it works as expected!
+>>> tokenizer = AutoTokenizer.from_pretrained("openlm-research/open_llama_7b", padding_side="left")
+>>> tokenizer.pad_token = tokenizer.eos_token # Llama has no pad token by default
+>>> model_inputs = tokenizer(
+... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
+... ).to("cuda")
+>>> generated_ids = model.generate(**model_inputs)
+>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+'1, 2, 3, 4, 5, 6,'
+```
+
+
+
+## 추가 자료 [[further-resources]]
+
+자기회귀 생성 프로세스는 상대적으로 단순한 편이지만, LLM을 최대한 활용하려면 여러 가지 요소를 고려해야 하므로 쉽지 않을 수 있습니다. LLM에 대한 더 깊은 이해와 활용을 위한 다음 단계는 아래와 같습니다:
+
+
+### 고급 생성 사용 [[advanced-generate-usage]]
+
+1. [가이드](generation_strategies)는 다양한 생성 방법을 제어하는 방법, 생성 설정 파일을 설정하는 방법, 출력을 스트리밍하는 방법에 대해 설명합니다.
+2. [`~generation.GenerationConfig`]와 [`~generation.GenerationMixin.generate`], [generate-related classes](internal/generation_utils)를 참조해보세요.
+
+### LLM 리더보드 [[llm-leaderboards]]
+
+1. [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)는 오픈 소스 모델의 품질에 중점을 둡니다.
+2. [Open LLM-Perf Leaderboard](https://huggingface.co/spaces/optimum/llm-perf-leaderboard)는 LLM 처리량에 중점을 둡니다.
+
+### 지연 시간 및 처리량 [[latency-and-throughput]]
+
+1. 메모리 요구 사항을 줄이려면, 동적 양자화에 대한 [가이드](main_classes/quantization)를 참조하세요.
+
+### 관련 라이브러리 [[related-libraries]]
+
+1. [`text-generation-inference`](https://github.com/huggingface/text-generation-inference)는 LLM을 위한 실제 운영 환경에 적합한 서버입니다.
+2. [`optimum`](https://github.com/huggingface/optimum)은 특정 하드웨어 장치에서 LLM을 최적화하기 위해 🤗 Transformers를 확장한 것입니다.
diff --git a/docs/transformers/docs/source/ko/llm_tutorial_optimization.md b/docs/transformers/docs/source/ko/llm_tutorial_optimization.md
new file mode 100644
index 0000000000000000000000000000000000000000..d43affd288fcd5e9b1589bbda634baa5dade67f3
--- /dev/null
+++ b/docs/transformers/docs/source/ko/llm_tutorial_optimization.md
@@ -0,0 +1,759 @@
+
+# 대규모 언어 모델의 속도 및 메모리 최적화 [[optimizing-llms-for-speed-and-memory]]
+
+[[open-in-colab]]
+
+GPT3/4, [Falcon](https://huggingface.co/tiiuae/falcon-40b), [Llama](https://huggingface.co/meta-llama/Llama-2-70b-hf)와 같은 대규모 언어 모델의 인간 중심 과제를 해결하는 능력이 빠르게 발전하고 있으며, 현대 지식 기반 산업에서 필수 도구로 자리잡고 있습니다. 그러나 이러한 모델을 실제 과제에 배포하는 것은 여전히 어려운 과제입니다.
+
+- 인간과 비슷한 텍스트 이해 및 생성 능력을 보이기 위해, 현재 대규모 언어 모델은 수십억 개의 매개변수로 구성되어야 합니다 (참조: [Kaplan et al](https://arxiv.org/abs/2001.08361), [Wei et. al](https://arxiv.org/abs/2206.07682)). 이는 추론을 위한 메모리 요구를 크게 증가시킵니다.
+- 많은 실제 과제에서 대규모 언어 모델은 방대한 맥락 정보를 제공받아야 합니다. 이는 모델이 추론 과정에서 매우 긴 입력 시퀀스를 처리할 수 있어야 한다는 것을 뜻합니다.
+
+이러한 과제의 핵심은 대규모 언어 모델의 계산 및 메모리 활용 능력을 증대시키는 데 있습니다. 특히 방대한 입력 시퀀스를 처리할 때 이러한 능력이 중요합니다.
+
+이 가이드에서는 효율적인 대규모 언어 모델 배포를 위한 효과적인 기법들을 살펴보겠습니다.
+
+1. **낮은 정밀도:** 연구에 따르면, [8비트와 4비트](./main_classes/quantization.md)와 같이 낮은 수치 정밀도로 작동하면 모델 성능의 큰 저하 없이 계산상의 이점을 얻을 수 있습니다.
+
+2. **플래시 어텐션:** 플래시 어텐션은 메모리 효율성을 높일 뿐만 아니라 최적화된 GPU 메모리 활용을 통해 효율성을 향상시키는 어텐션 알고리즘의 변형입니다.
+
+3. **아키텍처 혁신:** 추론 시 대규모 언어 모델은 주로 동일한 방식(긴 입력 맥락을 가진 자기회귀 텍스트 생성 방식)으로 배포되는데, 더 효율적인 추론을 가능하게 하는 특화된 모델 아키텍처가 제안되었습니다. 이러한 모델 아키텍처의 가장 중요한 발전으로는 [Alibi](https://arxiv.org/abs/2108.12409), [Rotary embeddings](https://arxiv.org/abs/2104.09864), [Multi-Query Attention (MQA)](https://arxiv.org/abs/1911.02150), [Grouped-Query-Attention (GQA)]((https://arxiv.org/abs/2305.13245))이 있습니다.
+
+이 가이드에서는 텐서의 관점에서 자기회귀 생성에 대한 분석을 제공합니다. 낮은 정밀도를 채택하는 것의 장단점을 논의하고, 최신 어텐션 알고리즘을 포괄적으로 탐구하며, 향상된 대규모 언어 모델 아키텍처에 대해 논합니다. 이 과정에서 각 기능의 개선 사항을 보여주는 실용적인 예제를 확인합니다.
+
+## 1. 낮은 정밀도 [[1-lower-precision]]
+
+대규모 언어 모델을 가중치 행렬과 벡터의 집합으로 보고, 텍스트 입력을 벡터의 시퀀스로 본다면, 대규모 언어 모델의 메모리 요구사항을 가장 잘 이해할 수 있습니다. 이어지는 내용에서 *가중치*는 모델의 모든 가중치 행렬과 벡터를 의미합니다.
+
+이 가이드를 작성하는 시점의 대규모 언어 모델은 최소 몇십억 개의 매개변수로 구성되어 있습니다. 각 매개변수는 `4.5689`와 같은 십진수로 이루어져 있으며, 보통 [float32](https://en.wikipedia.org/wiki/Single-precision_floating-point_format), [bfloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format) 또는 [float16](https://en.wikipedia.org/wiki/Half-precision_floating-point_format) 형식으로 저장됩니다. 이를 통해 대규모 언어 모델을 메모리에 로드하는 데 필요한 메모리의 요구사항을 쉽게 계산할 수 있습니다:
+
+> *X * 10억 개의 매개변수를 가진 모델의 가중치를 로드하려면 float32 정밀도에서 대략 4 * X GB의 VRAM이 필요합니다.*
+
+요즘에는 모델이 float32 정밀도로 훈련되는 경우는 드물고, 일반적으로 bfloat16 정밀도나 가끔 float16 정밀도로 훈련됩니다. 따라서 경험적으로 알아낸 법칙은 다음과 같습니다:
+
+> *X * 10억 개의 매개변수를 가진 모델의 가중치를 로드하려면 bfloat16/float16 정밀도에서 대략 2 * X GB의 VRAM이 필요합니다.*
+
+짧은 텍스트 입력(1024 토큰 미만)의 경우, 추론을 위한 메모리 요구 사항의 대부분은 가중치를 로드하는 데 필요한 메모리 요구 사항입니다. 따라서 지금은 추론을 위한 메모리 요구 사항이 모델의 가중치를 GPU VRAM에 로드하는 데 필요한 메모리 요구 사항과 같다고 가정합시다.
+
+모델을 bfloat16으로 로드하는 데 대략 얼마나 많은 VRAM이 필요한지 몇 가지 예를 들어보겠습니다:
+
+- **GPT3**는 2 \* 175 GB = **350 GB** VRAM이 필요합니다.
+- [**Bloom**](https://huggingface.co/bigscience/bloom)은 2 \* 176 GB = **352 GB** VRAM이 필요합니다.
+- [**Llama-2-70b**](https://huggingface.co/meta-llama/Llama-2-70b-hf)는 2 \* 70 GB = **140 GB** VRAM이 필요합니다.
+- [**Falcon-40b**](https://huggingface.co/tiiuae/falcon-40b)는 2 \* 40 GB = **80 GB** VRAM이 필요합니다.
+- [**MPT-30b**](https://huggingface.co/mosaicml/mpt-30b)는 2 * 30 GB = **60 GB** VRAM이 필요합니다.
+- [**bigcode/starcoder**](https://huggingface.co/bigcode/starcoder)는 2 * 15.5 GB = **31 GB** VRAM이 필요합니다.
+
+이 문서를 작성하는 시점에서, 현재 시장에서 가장 큰 GPU 칩은 80GB의 VRAM을 제공하는 A100과 H100입니다. 앞서 언급된 대부분의 모델들은 로드하기 위해서는 최소 80GB 이상의 용량을 필요로 하며, 따라서 [텐서 병렬 처리](https://huggingface.co/docs/transformers/perf_train_gpu_many#tensor-parallelism) 및/또는 [파이프라인 병렬 처리](https://huggingface.co/docs/transformers/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism)를 반드시 필요로 합니다.
+
+🤗 Transformers는 텐서 병렬 처리를 바로 지원하지 않습니다. 이는 모델 아키텍처가 특정 방식으로 작성되어야 하기 때문입니다. 텐서 병렬 처리를 지원하는 방식으로 모델을 작성하는 데 관심이 있다면 [the text-generation-inference library](https://github.com/huggingface/text-generation-inference/tree/main/server/text_generation_server/models/custom_modeling)를 참조해 보시기 바랍니다.
+
+기본적인 파이프라인 병렬 처리는 바로 지원됩니다. 이를 위해 단순히 모델을 `device="auto"`로 로드하면 [여기](https://huggingface.co/docs/accelerate/v0.22.0/en/concept_guides/big_model_inference)에 설명된 대로 사용 가능한 GPU에 모델의 서로 다른 레이어를 자동으로 배치합니다. 이것은 매우 효과적이긴 하지만 이러한 기본 파이프라인 병렬 처리는 GPU 유휴 문제를 해결하지 못한다는 점을 유의해야 합니다. 더 발전된 파이프라인 병렬 처리가 필요하며, 이에 대한 설명은 [여기](https://huggingface.co/docs/transformers/en/perf_train_gpu_many#naive-model-parallelism-vertical-and-pipeline-parallelism)에서 확인할 수 있습니다.
+
+80GB A100 GPU 8개를 가진 노드에 접근할 수 있다면, BLOOM을 다음과 같이 로드할 수 있습니다.
+
+```bash
+!pip install transformers accelerate bitsandbytes optimum
+```
+```python
+from transformers import AutoModelForCausalLM
+
+model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)
+```
+
+`device_map="auto"`를 사용하면 모든 사용 가능한 GPU에 어텐션 레이어가 고르게 분산됩니다.
+
+이 가이드에서는 [bigcode/octocoder](https://huggingface.co/bigcode/octocoder)를 사용할 것입니다. 이 모델은 단일 40GB A100 GPU 장치에서 실행할 수 있습니다. 앞으로 적용할 모든 메모리 및 속도 최적화는 모델 또는 텐서 병렬 처리를 필요로 하는 다른 모델에도 동일하게 적용될 수 있습니다.
+
+모델이 bfloat16 정밀도로 로드되기 때문에, 위의 경험적으로 알아낸 법칙을 사용하면 `bigcode/octocoder`를 사용하여 추론을 실행하기 위한 메모리 요구 사항이 약 31GB VRAM일 것으로 예상됩니다. 한 번 시도해 보겠습니다.
+
+먼저 모델과 토크나이저를 로드한 다음, 둘 다 Transformers의 [파이프라인](https://huggingface.co/docs/transformers/main_classes/pipelines) 객체에 전달합니다.
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
+import torch
+
+model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
+tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
+
+pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+```
+
+```python
+prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
+
+result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
+result
+```
+
+**출력**:
+```
+Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
+```
+
+좋습니다. 이제 결과를 직접 사용하여 바이트를 기가바이트로 변환할 수 있습니다.
+
+```python
+def bytes_to_giga_bytes(bytes):
+ return bytes / 1024 / 1024 / 1024
+```
+
+[`torch.cuda.max_memory_allocated`](https://pytorch.org/docs/stable/generated/torch.cuda.max_memory_allocated.html)를 호출하여 최대 GPU 메모리 할당을 측정해 보겠습니다.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**출력**:
+```bash
+29.0260648727417
+```
+
+대략적으로 계산한 결과와 거의 일치합니다! 바이트에서 킬로바이트로 변환할 때 1000이 아닌 1024로 곱해야 하므로 숫자가 정확하지 않은 것을 알 수 있습니다. 따라서 대략적으로 계산할 때 공식은 "최대 X GB"으로 이해할 수 있습니다. 만약 우리가 모델을 float32 정밀도로 실행하려고 했다면 더 큰 크기인 64GB의 VRAM이 필요했을 것입니다.
+
+> 거의 모든 모델이 요즘 bfloat16으로 학습되므로, [GPU가 bfloat16을 지원](https://discuss.pytorch.org/t/bfloat16-native-support/117155/5)한다면 모델을 float32 정밀도로 실행할 이유가 없습니다. float32로 돌리는 모델은 학습할 때 사용했던 정밀도보다 더 나은 추론 결과를 제공하지 않습니다.
+
+모델 가중치가 어떤 정밀도 형식으로 Hub에 저장되어 있는지 확실하지 않은 경우, HuggingFace Hub에서 해당 체크포인트 config의 `"torch_dtype"`을 확인하면 됩니다, *예*를 들어 [여기](https://huggingface.co/meta-llama/Llama-2-7b-hf/blob/6fdf2e60f86ff2481f2241aaee459f85b5b0bbb9/config.json#L21)를 확인하세요. 모델을 `from_pretrained(..., torch_dtype=...)`로 로드할 때는 config에 명시된 정밀도 유형과 동일한 정밀도로 설정하는 것이 권장됩니다. 단, 원래 유형이 float32인 경우 추론을 위해 `float16` 또는 `bfloat16`을 둘 다 사용할 수 있습니다.
+
+이제 `flush(...)` 함수를 정의하여 모든 메모리를 해제하고, GPU 메모리의 최대 할당량을 정확하게 측정하도록 합시다.
+
+
+```python
+del pipe
+del model
+
+import gc
+import torch
+
+def flush():
+ gc.collect()
+ torch.cuda.empty_cache()
+ torch.cuda.reset_peak_memory_stats()
+```
+
+다음 실험을 위해 바로 호출해 봅시다.
+
+```python
+flush()
+```
+최근 버전의 accelerate 라이브러리에서는 `release_memory()`라는 유틸리티 메소드도 사용할 수 있습니다.
+
+```python
+from accelerate.utils import release_memory
+# ...
+
+release_memory(model)
+```
+
+만약 GPU에 32GB의 VRAM이 없다면 어떻게 될까요? 모델 가중치를 성능에 큰 손실 없이 8비트 또는 4비트로 양자화할 수 있다는 것이 밝혀졌습니다(참고: [Dettmers et al.](https://arxiv.org/abs/2208.07339)). 최근의 [GPTQ 논문](https://arxiv.org/abs/2210.17323) 에서는 모델을 3비트 또는 2비트로 양자화해도 성능 손실이 허용 가능한 수준임을 보여주었습니다🤯.
+
+너무 자세한 내용은 다루지 않고 설명하자면, 양자화는 가중치의 정밀도를 줄이면서 모델의 추론 결과를 가능한 한 정확하게(즉, bfloat16과 최대한 가깝게) 유지하려고 합니다. 양자화는 특히 텍스트 생성에 잘 작동하는데, 이는 우리가 *가장 가능성 있는 다음 토큰 집합*을 선택하는 것에 초점을 두고 있기 때문이며, 다음 토큰의 *logit* 분포값을 정확하게 예측할 필요는 없기 때문입니다. 핵심은 다음 토큰 *logit* 분포가 대략적으로 동일하게 유지되어 `argmax` 또는 `topk` 연산이 동일한 결과를 제공하는 것입니다.
+
+다양한 양자화 기법이 존재하지만, 자세히 다루지는 않을 것입니다. 일반적으로 모든 양자화 기법은 다음과 같이 작동합니다:
+
+- 1. 모든 가중치를 목표 정밀도로 양자화합니다.
+- 2. 양자화된 가중치를 로드하고, bfloat16 정밀도의 입력 벡터 시퀀스를 모델에 전달합니다.
+- 3. 가중치를 동적으로 bfloat16으로 반대로 양자화(dequantize)하여 입력 벡터와 함께 bfloat16 정밀도로 계산을 수행합니다.
+
+간단히 말해서, *입력-가중치 행렬* 곱셈은, \\( X \\)가 *입력*, \\( W \\)가 가중치 행렬, \\( Y \\)가 출력인 경우 다음과 같습니다:
+
+$$ Y = X * W $$
+
+위 공식이 다음과 같이 변경됩니다
+
+$$ Y = X * \text{dequantize}(W) $$
+
+모든 행렬 곱셈에 대해 위와 같이 수행됩니다. 입력이 네트워크 그래프를 통과하면서 모든 가중치 행렬에 대해 역양자화(dequantization)와 재양자화(re-quantization)가 순차적으로 수행됩니다.
+
+따라서, 양자화된 가중치를 사용할 때 추론 시간이 감소하지 **않고** 오히려 증가하는 경우가 많습니다. 이제 이론은 충분하니 실제로 시도해 봅시다! Transformers를 사용하여 가중치를 양자화하려면 [`bitsandbytes`](https://github.com/TimDettmers/bitsandbytes) 라이브러리가 설치되어 있는지 확인해야 합니다.
+
+```bash
+!pip install bitsandbytes
+```
+
+그런 다음 `from_pretrained`에 `load_in_8bit=True` 플래그를 추가하여 8비트 양자화로 모델을 로드할 수 있습니다.
+
+```python
+model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)
+```
+
+이제 예제를 다시 실행하고 메모리 사용량을 측정해 봅시다.
+
+```python
+pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+
+result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
+result
+```
+
+**출력**:
+```
+Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single
+```
+
+좋습니다. 정확도 손실 없이 이전과 동일한 결과를 얻고 있습니다! 이번에는 사용된 메모리 양을 확인해 봅시다.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**출력**:
+```
+15.219234466552734
+```
+
+훨씬 적네요! 메모리 사용량이 15GB를 조금 넘는 수준으로 줄어들어 4090과 같은 소비자용 GPU에서도 이 모델을 실행할 수 있습니다. 메모리 효율성에서 매우 큰 향상을 보이고 있으며 모델 출력의 품질 저하도 거의 없습니다. 그러나 추론 중에 약간의 속도 저하가 발생한 것을 확인할 수 있습니다.
+
+
+모델을 삭제하고 메모리를 다시 초기화합니다.
+
+```python
+del model
+del pipe
+```
+
+```python
+flush()
+```
+
+이제 4비트 양자화가 제공하는 최대 GPU 메모리 사용량을 확인해 봅시다. 4비트로 모델을 양자화하려면 이전과 동일한 API를 사용하되 이번에는 `load_in_8bit=True` 대신 `load_in_4bit=True`를 전달하면 됩니다.
+
+```python
+model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
+
+pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+
+result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
+result
+```
+
+**출력**:
+```
+Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument
+```
+
+바로 전 코드 스니펫에서 `python`만 누락되고, 이 전과 거의 동일한 출력 텍스트를 보고 있습니다. 이제 얼마나 많은 메모리가 필요했는지 확인해 봅시다.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**출력**:
+```
+9.543574333190918
+```
+
+9.5GB밖에 되지 않습니다! 150억 개 이상의 파라미터를 가진 모델인 것을 감안하면 매우 적은 양입니다.
+
+여기서는 모델의 정확도 저하가 거의 없음을 확인할 수 있지만, 실제로는 4비트 양자화를 8비트 양자화나 `bfloat16`를 사용한 추론 결과와 비교하면 결과가 다를 수 있습니다. 사용자가 직접 시도해 보는 것이 좋겠습니다.
+
+또한 4비트 양자화에 사용된 더 공격적인 양자화 방법으로 인해 추론 시 \\( \text{quantize} \\)와 \\( \text{dequantize} \\) 과정이 더 오래 걸리므로 여기서도 8비트 양자화와 비교하여 추론 속도가 약간 느려졌음을 유의하세요.
+
+```python
+del model
+del pipe
+```
+```python
+flush()
+```
+
+전체적으로 OctoCoder를 8비트 정밀도로 실행하면 필요한 GPU VRAM이 32GB에서 15GB로 줄어들었고, 4비트 정밀도로 모델을 실행하면 필요한 GPU VRAM이 9GB로 더 줄어드는 것을 확인했습니다.
+
+4비트 양자화는 RTX3090, V100, T4와 같은 GPU에서 모델을 실행할 수 있게 해주며, 이는 대부분의 사람들이 접근할 수 있는 GPU입니다.
+
+양자화에 대한 더 많은 정보를 확인하고 4비트보다 더 적은 GPU VRAM 메모리로 모델을 양자화하거나, 더 많은 양자화 관련 정보를 보려면 [`AutoGPTQ`](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#autogptq-integration%60) 구현을 참조하는 것을 추천합니다.
+
+> 결론적으로, 모델 양자화는 향상된 메모리 효율성과 모델 정확성 간의 균형을 맞추는 것이며, 경우에 따라 추론 시간에도 영향을 미칠 수 있습니다.
+
+실제 사례에서 GPU 메모리가 충분하다면, 양자화를 고려할 필요가 없습니다. 그러나 많은 GPU는 양자화 없이 대규모 언어 모델을 실행할 수 없으며, 이 경우 4비트 및 8비트 양자화가 매우 유용한 도구입니다.
+
+사용과 관련한 더 자세한 정보는 [트랜스포머 양자화 문서](https://huggingface.co/docs/transformers/main_classes/quantization#general-usage)를 참고하는 것을 강력히 추천합니다. 다음으로, 더 나은 알고리즘과 개선된 모델 아키텍처를 사용하여 계산 및 메모리 효율성을 향상시키는 방법을 살펴보겠습니다.
+
+## 2. 플래시 어텐션 [[2-flash-attention]]
+
+오늘날의 최고 성능을 자랑하는 대규모 언어 모델은 대체로 피드포워드 레이어(feed-forward layer), 활성화 레이어(activation layer), 레이어 정규화 레이어(layer normalization layer), 그리고 가장 중요한 셀프 어텐션 레이어(self-attention layer)로 구성된 아키텍처를 공유하고 있습니다.
+
+셀프 어텐션 레이어는 입력 토큰 간의 문맥적 관계를 이해할 수 있게 해 주기 때문에 대규모 언어 모델의 핵심 요소입니다.
+하지만 셀프 어텐션 레이어의 최대 GPU 메모리 소비는 입력 토큰의 수(이하 \\( N \\)으로 표기)와 함께 계산 및 메모리 복잡성이 *2차적*으로 증가합니다. 입력 시퀀스가 짧은 경우(최대 1000개)에는 크게 눈에 띄지 않지만, 더 긴 입력 시퀀스(약 16000개)에서는 심각한 문제가 됩니다.
+
+자세히 한 번 들여다 봅시다. 길이 \\( N \\)의 입력 \\( \mathbf{X} \\)에 대한 셀프 어텐션 레이어의 출력 \\( \mathbf{O} \\)을 계산하는 공식은 다음과 같습니다:
+
+$$ \textbf{O} = \text{Attn}(\mathbf{X}) = \mathbf{V} \times \text{Softmax}(\mathbf{QK}^T) \text{ with } \mathbf{Q} = \mathbf{W}_q \mathbf{X}, \mathbf{V} = \mathbf{W}_v \mathbf{X}, \mathbf{K} = \mathbf{W}_k \mathbf{X} $$
+
+\\( \mathbf{X} = (\mathbf{x}1, ... \mathbf{x}{N}) \\)는 어텐션 레이어의 입력 시퀀스입니다. 프로젝션 \\( \mathbf{Q} \\)와 \\( \mathbf{K} \\)는 각각 \\( N \\)개의 벡터로 구성되며, 그 결과 \\( \mathbf{QK}^T \\)의 크기는 \\( N^2 \\)가 됩니다.
+
+대규모 언어 모델은 일반적으로 여러 개의 어텐션 헤드를 가지고 있어 여러 개의 셀프 어텐션 계산을 병렬로 수행합니다. 대규모 언어 모델이 40개의 어텐션 헤드를 가지고 bfloat16 정밀도로 실행된다고 가정하면, \\( \mathbf{QK^T} \\) 행렬을 저장하는 데 필요한 메모리를 \\( 40 * 2 * N^2 \\) 바이트로 계산할 수 있습니다. \\( N=1000 \\)일 때는 약 50MB의 VRAM만 필요하지만, \\( N=16000 \\)일 때는 19GB의 VRAM이 필요하며, \\( N=100,000 \\)일 때는 \\( \mathbf{QK^T} \\) 행렬을 저장하기 위해 거의 1TB의 VRAM이 필요합니다.
+
+요약하자면, 기본 셀프 어텐션 알고리즘은 큰 입력 컨텍스트에 대해 매우 과도한 메모리 사용을 요구하게 됩니다.
+
+대규모 언어 모델의 텍스트 이해 및 생성 능력이 개선되면서 점점 더 복잡한 작업에 사용되고 있습니다. 한때 몇 문장의 번역이나 요약을 처리하던 모델이 이제는 전체 페이지를 처리해야 하게 되면서 광범위한 입력 길이를 처리할 수 있는 능력이 요구되고 있습니다.
+
+어떻게 하면 큰 입력 길이에 대한 과도한 메모리 요구를 없앨 수 있을까요? \\( QK^T \\) 행렬을 제거하는 새로운 셀프 어텐션 메커니즘을 계산하는 방법이 필요합니다. [Tri Dao et al.](https://arxiv.org/abs/2205.14135)은 바로 이러한 새로운 알고리즘을 개발하였고, 그것이 **플래시 어텐션(Flash Attention)**입니다.
+
+간단히 말해, 플래시 어텐션은 \\(\mathbf{V} \times \text{Softmax}(\mathbf{QK}^T\\)) 계산을 분할하는데, 여러 번의 소프트맥스 계산을 반복하면서 작은 청크 단위로 출력을 계산합니다:
+
+$$ \textbf{O}_i \leftarrow s^a_{ij} * \textbf{O}_i + s^b_{ij} * \mathbf{V}_{j} \times \text{Softmax}(\mathbf{QK}^T_{i,j}) \text{ for multiple } i, j \text{ iterations} $$
+
+여기서 \\( s^a_{ij} \\)와 \\( s^b_{ij} \\)는 각 \\( i \\)와 \\( j \\)에 대해 계산되는 소프트맥스 정규화 통계량입니다.
+
+플래시 어텐션의 전체 알고리즘은 더 복잡하며, 본 가이드의 범위를 벗어나기 때문에 크게 단순화하였습니다. 여러분은 잘 작성된 [Flash Attention paper](https://arxiv.org/abs/2205.14135) 논문을 참조하여 더 자세한 내용을 확인해 보시기 바랍니다.
+
+주요 요점은 다음과 같습니다:
+
+> 소프트맥스 정규화 통계량과 몇 가지 스마트한 수학적 방법을 사용함으로써, 플래시 어텐션은 기본 셀프 어텐션 레이어와 **숫자적으로 동일한** 출력을 제공하고 메모리 비용은 \\( N \\)에 따라 선형적으로만 증가합니다.
+
+공식을 보면, 플래시 어텐션이 더 많은 계산을 필요로 하기 때문에 기본 셀프 어텐션 공식보다 훨씬 느릴 것이라고 생각할 수 있습니다. 실제로 플래시 어텐션은 소프트맥스 정규화 통계량을 지속적으로 다시 계산해야 하기 때문에 일반 어텐션보다 더 많은 FLOP이 필요합니다. (더 자세한 내용은 [논문](https://arxiv.org/abs/2205.14135)을 참조하세요)
+
+> 그러나 플래시 어텐션은 기본 어텐션보다 추론 속도가 훨씬 빠릅니다. 이는 GPU의 느리고 고대역폭 메모리(VRAM)의 사용량을 크게 줄이고 대신 빠른 온칩 메모리(SRAM)에 집중할 수 있기 때문입니다.
+
+본질적으로, 플래시 어텐션의 모든 중간 단계의 쓰기 및 읽기 작업은 느린 VRAM 메모리에 접근하지 않고 빠른 *온칩* SRAM 메모리를 사용하여 출력 벡터 \\( \mathbf{O} \\)를 계산할 수 있도록 합니다.
+
+현실적으로 플래시 어텐션이 사용 가능한 경우 이를 **사용하지 않을** 이유는 전혀 없습니다. 이 알고리즘은 수학적으로 동일한 출력을 제공하며, 더 빠르고 메모리 효율적입니다.
+
+실제 예를 살펴보겠습니다.
+
+우리의 OctoCoder 모델은 이제 *시스템 프롬프트*가 포함된 훨씬 더 긴 입력 프롬프트를 받게 됩니다. 시스템 프롬프트는 대규모 언어 모델을 사용자의 작업에 맞춘 더 나은 어시스턴트로 유도하는 데 사용됩니다. 다음 예제에서는 OctoCoder를 더 나은 코딩 어시스턴트로 만들기 위한 시스템 프롬프트를 사용합니다.
+
+```python
+system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
+The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
+The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
+It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
+That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
+
+The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
+The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
+
+-----
+
+Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
+
+Answer: Sure. Here is a function that does that.
+
+def alternating(list1, list2):
+ results = []
+ for i in range(len(list1)):
+ results.append(list1[i])
+ results.append(list2[i])
+ return results
+
+Question: Can you write some test cases for this function?
+
+Answer: Sure, here are some tests.
+
+assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
+assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
+assert alternating([], []) == []
+
+Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
+
+Answer: Here is the modified function.
+
+def alternating(list1, list2):
+ results = []
+ for i in range(min(len(list1), len(list2))):
+ results.append(list1[i])
+ results.append(list2[i])
+ if len(list1) > len(list2):
+ results.extend(list1[i+1:])
+ else:
+ results.extend(list2[i+1:])
+ return results
+
+-----
+"""
+```
+시연을 위해 시스템 프롬프트를 10번 중복하여 증가시켜 플래시 어텐션의 메모리 절약 효과를 관찰할 수 있을 만큼 입력 길이를 충분히 길게 만듭니다. 원래의 텍스트 프롬프트를 다음과 같이 추가합니다. `"Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"`
+
+```python
+long_prompt = 10 * system_prompt + prompt
+```
+
+모델을 다시 bfloat16 정밀도로 인스턴스화합니다.
+
+```python
+model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
+tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
+
+pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+```
+
+이제 플래시 어텐션을 *사용하지 않고* 이전과 동일하게 모델을 실행하여 최대 GPU 메모리 요구량과 추론 시간을 측정해 봅시다.
+
+```python
+import time
+
+start_time = time.time()
+result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
+
+print(f"Generated in {time.time() - start_time} seconds.")
+result
+```
+
+**출력**:
+```
+Generated in 10.96854019165039 seconds.
+Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
+````
+
+이전과 동일한 출력을 얻고 있지만, 이번에는 모델이 답변을 여러 번 반복하여 60개의 토큰이 잘릴 때까지 계속됩니다. 시연을 위해 시스템 프롬프트를 10번 반복했기 때문에 모델이 스스로 반복하도록 유도한 결과입니다. 이는 놀라운 일이 아닙니다.
+
+**참고** 실제 응용에서는 시스템 프롬프트를 10번 반복할 필요가 없습니다. 한 번만 사용하면 충분합니다!
+
+최대 GPU 메모리 요구량을 측정해 봅시다.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**출력**:
+```bash
+37.668193340301514
+```
+
+보시다시피 최대 GPU 메모리 요구량이 처음보다 상당히 높아졌습니다. 이는 주로 입력 시퀀스가 길어졌기 때문입니다. 또한 생성 시간이 이제 1분을 넘어갑니다.
+
+다음 실험을 위해 `flush()`를 호출하여 GPU 메모리를 초기화합니다.
+
+```python
+flush()
+```
+
+비교를 위해, 동일한 기능을 실행하되 플래시 어텐션을 활성화해 보겠습니다.
+이를 위해 모델을 [BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview)로 변환하고, 이를 통해 PyTorch의 [SDPA self-attention](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention)을 활성화하면 플래시 어텐션을 사용할 수 있습니다.
+
+```python
+model.to_bettertransformer()
+```
+
+이제 이전과 동일한 코드 스니펫을 실행하면, 내부적으로 Transformers가 플래시 어텐션을 사용할 것입니다.
+
+```py
+start_time = time.time()
+with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
+ result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
+
+print(f"Generated in {time.time() - start_time} seconds.")
+result
+```
+
+**출력**:
+```
+Generated in 3.0211617946624756 seconds.
+ Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef
+```
+
+이전과 동일한 결과를 얻었지만, 플래시 어텐션 덕분에 매우 큰 속도 향상을 관찰할 수 있습니다.
+
+메모리 소비량을 마지막으로 한 번 더 측정해 봅시다.
+
+```python
+bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
+```
+
+**출력**:
+```
+32.617331981658936
+```
+
+그리고 우리는 처음에 보았던 GPU 메모리 요구량인 29GB로 돌아왔습니다.
+
+플래시 어텐션을 사용하여 매우 긴 입력 시퀀스를 전달할 때 처음에 짧은 입력 시퀀스를 전달했을 때와 비교하여 약 100MB 정도의 GPU 메모리를 더 사용한다는 것을 관찰할 수 있습니다.
+
+```py
+flush()
+```
+
+플래시 어텐션 사용에 대한 자세한 정보는 [이 문서 페이지](https://huggingface.co/docs/transformers/en/perf_infer_gpu_one#flashattention-2)를 참조해 주세요.
+
+## 3. 아키텍처 혁신 [[3-architectural-innovations]]
+
+지금까지 우리는 계산 및 메모리 효율성을 개선하기 위해 다음을 살펴보았습니다:
+
+- 가중치를 낮은 정밀도 형식으로 변환
+- 셀프 어텐션 알고리즘을 보다 더 메모리 및 계산 효율적인 버전으로 교체
+
+이제 긴 텍스트 입력이 필요한 작업에 가장 효과적이고 효율적인 대규모 언어 모델 아키텍처로 변경하는 방법을 살펴보겠습니다. 작업의 예시는 다음과 같습니다:
+- 검색 증강 질의 응답
+- 요약
+- 채팅
+
+*채팅*을 위해서는 대규모 언어 모델이 긴 텍스트 입력을 처리하는 것뿐만 아니라 사용자와 어시스턴트 간의 대화도 효율적으로 처리할 수 있어야 합니다(예: ChatGPT).
+
+한번 학습된 후에는 대규모 언어 모델의 기본 아키텍처를 변경하기 어렵기 때문에, 대규모 언어 모델의 작업에 대한 고려를 미리 하고 이에 따라 모델의 아키텍처를 최적화하는 것이 중요합니다. 긴 입력 시퀀스에 대해 메모리 또는 성능의 병목 현상을 빠르게 발생시키는 모델 아키텍처의 중요한 두 가지 구성 요소가 있습니다.
+
+- 위치 임베딩
+- 키-값 캐시
+
+각 구성 요소를 더 자세히 살펴보겠습니다.
+
+### 3.1 대규모 언어 모델의 위치 임베딩 개선 [[31-improving-positional-embeddings-of-llms]]
+
+셀프 어텐션은 각 토큰을 서로의 토큰과 연관시킵니다.
+예를 들어, 텍스트 입력 시퀀스 *"Hello", "I", "love", "you"*의 \\( \text{Softmax}(\mathbf{QK}^T) \\) 행렬은 다음과 같을 수 있습니다:
+
+
+
+각 단어 토큰은 다른 모든 단어 토큰에 주의를 기울이는 확률 질량을 부여받아 모든 다른 단어 토큰과 관계를 맺게 됩니다. 예를 들어, 단어 *"love"*는 단어 *"Hello"*에 5%, *"I"*에 30%, 그리고 자신에게 65%의 주의를 기울입니다.
+
+셀프 어텐션 기반 대규모 언어 모델이 위치 임베딩이 없는 경우 텍스트 입력의 위치를 이해하는 데 큰 어려움을 겪을 것입니다. 이는 \\( \mathbf{QK}^T \\)에 의해 계산된 확률 점수가 상대적 위치 거리에 상관없이 각 단어 토큰을 다른 모든 단어 토큰과 \\( O(1) \\) 계산으로 연관시키기 때문입니다. 따라서 위치 임베딩이 없는 대규모 언어 모델은 각 토큰이 다른 모든 토큰과 동일한 거리에 있는 것으로 나타나기 때문에, *"Hello I love you"*와 *"You love I hello"*를 구분하는 것이 매우 어렵습니다.
+
+대규모 언어 모델이 문장의 순서를 이해하려면 추가적인 *단서*가 필요하며, 이는 일반적으로 *위치 인코딩* (또는 *위치 임베딩*이라고도 함)의 형태로 적용됩니다.
+위치 인코딩은 각 토큰의 위치를 숫자 표현으로 인코딩하여 대규모 언어 모델이 문장의 순서를 더 잘 이해할 수 있도록 도와줍니다.
+
+[*Attention Is All You Need*](https://arxiv.org/abs/1706.03762) 논문의 저자들은 사인 함수 기반의 위치 임베딩 \\( \mathbf{P} = \mathbf{p}_1, \ldots, \mathbf{p}_N \\)을 도입했습니다. 각 벡터 \\( \mathbf{p}_i \\)는 위치 \\( i \\)의 사인 함수로 계산됩니다. 위치 인코딩은 입력 시퀀스 벡터에 단순히 더해져 \\( \mathbf{\hat{X}} = \mathbf{\hat{x}}_1, \ldots, \mathbf{\hat{x}}_N \\) = \\( \mathbf{x}_1 + \mathbf{p}_1, \ldots, \mathbf{x}_N + \mathbf{p}_N \\) 모델이 문장 순서를 더 잘 학습할 수 있도록 합니다.
+
+고정된 위치 임베딩 대신 [Devlin et al.](https://arxiv.org/abs/1810.04805)과 같은 다른 연구자들은 학습된 위치 인코딩을 사용했습니다. 이 경우 위치 임베딩 \\( \mathbf{P} \\)은 학습 중에 사용됩니다.
+
+사인 함수 및 학습된 위치 임베딩은 문장 순서를 대규모 언어 모델에 인코딩하는 주요 방법이었지만, 이러한 위치 인코딩과 관련된 몇 가지 문제가 발견되었습니다:
+
+ 1. 사인 함수와 학습된 위치 임베딩은 모두 절대 위치 임베딩으로, 각 위치 ID \\( 0, \ldots, N \\)에 대해 고유한 임베딩을 인코딩합니다. [Huang et al.](https://arxiv.org/abs/2009.13658) 및 [Su et al.](https://arxiv.org/abs/2104.09864)의 연구에 따르면, 절대 위치 임베딩은 긴 텍스트 입력에 대해 대규모 언어 모델 성능이 저하됩니다. 긴 텍스트 입력의 경우, 모델이 절대 위치 대신 입력 토큰 간의 상대적 위치 거리를 학습하는 것이 유리합니다.
+ 2. 학습된 위치 임베딩을 사용할 때, 대규모 언어 모델은 고정된 입력 길이 \\( N \\)으로 학습되어야 하므로, 학습된 입력 길이보다 더 긴 입력 길이에 대해 추론하는 것이 어렵습니다.
+
+최근에는 위에서 언급한 문제를 해결할 수 있는 상대적 위치 임베딩이 더 인기를 끌고 있습니다. 특히 다음과 같은 방법들이 주목받고 있습니다:
+
+- [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864)
+- [ALiBi](https://arxiv.org/abs/2108.12409)
+
+*RoPE*와 *ALiBi*는 모두 셀프 어텐션 알고리즘 내에서 직접적으로 문장 순서를 모델에게 알려주는 것이 최선이라고 주장합니다. 이는 단어 토큰이 서로 관계를 맺는 곳이기 때문입니다. 구체적으로, 문장 순서를 \\( \mathbf{QK}^T \\) 계산을 수정하는 방식으로 알려주어야 한다는 것입니다.
+
+너무 많은 세부 사항을 다루지 않고, *RoPE*는 위치 정보를 쿼리-키 쌍에 인코딩할 수 있다고 지적합니다. 예를 들어, 각 벡터 \\( \mathbf{q}_i \\)와 \\( \mathbf{x}_j \\)를 각각 \\( \theta * i \\)와 \\( \theta * j \\)의 각도로 회전시킴으로써 다음과 같이 표현할 수 있습니다:
+
+$$ \mathbf{\hat{q}}_i^T \mathbf{\hat{x}}_j = \mathbf{{q}}_i^T \mathbf{R}_{\theta, i -j} \mathbf{{x}}_j. $$
+
+여기서 \\( \mathbf{R}_{\theta, i - j} \\)는 회전 행렬을 나타냅니다. \\( \theta \\)는 훈련 중에 *학습되지 않으며*, 대신 학습 중 최대 입력 시퀀스 길이에 따라 사전 정의된 값으로 설정됩니다.
+
+> 이렇게 함으로써 \\( \mathbf{q}_i \\)와 \\( \mathbf{q}_j \\) 간의 확률 점수는 \\( i \ne j \\)인 경우에만 영향을 받으며, 각 벡터의 특정 위치 \\( i \\)와 \\( j \\)와는 상관없이 오직 상대적 거리 \\( i - j \\)에만 의존하게 됩니다.
+
+*RoPE*는 현재 여러 중요한 대규모 언어 모델이 사용되고 있습니다. 예를 들면:
+
+- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
+- [**Llama**](https://arxiv.org/abs/2302.13971)
+- [**PaLM**](https://arxiv.org/abs/2204.02311)
+
+대안으로, *ALiBi*는 훨씬 더 간단한 상대적 위치 인코딩 방식을 제안합니다. 입력 토큰 간의 상대적 거리를 음수인 정수로서 사전 정의된 값 `m`으로 스케일링하여 \\( \mathbf{QK}^T \\) 행렬의 각 쿼리-키 항목에 소프트맥스 계산 직전에 추가합니다.
+
+
+
+[ALiBi](https://arxiv.org/abs/2108.12409) 논문에서 보여주듯이, 이 간단한 상대적 위치 인코딩은 매우 긴 텍스트 입력 시퀀스에서도 모델이 높은 성능을 유지할 수 있게 합니다.
+
+*ALiBi*는 현재 여러 중요한 대규모 언어 모델 모델이 사용하고 있습니다. 예를 들면:
+
+- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
+- [**BLOOM**](https://huggingface.co/bigscience/bloom)
+
+*RoPE*와 *ALiBi* 위치 인코딩은 모두 학습 중에 보지 못한 입력 길이에 대해 확장할 수 있으며, *ALiBi*가 *RoPE*보다 더 잘 확장되는 것으로 나타났습니다. *ALiBi*의 경우, 하삼각 위치 행렬의 값을 입력 시퀀스 길이에 맞추어 증가시키기만 하면 됩니다. *RoPE*의 경우, 학습 중에 사용된 동일한 \\( \theta \\)를 유지하면 학습 중에 보지 못한 매우 긴 텍스트 입력을 전달할 때 성능이 저하됩니다(참고: [Press et al.](https://arxiv.org/abs/2108.12409)). 그러나 커뮤니티는 \\( \theta \\)를 조정하는 몇 가지 효과적인 트릭을 찾아냈으며, 이를 통해 *RoPE* 위치 임베딩이 확장된 텍스트 입력 시퀀스에서도 잘 작동할 수 있게 되었습니다(참고: [here](https://github.com/huggingface/transformers/pull/24653)).
+
+> RoPE와 ALiBi는 모두 훈련 중에 *학습되지 않는* 상대적 위치 임베딩으로 다음과 같은 직관에 기반합니다:
+ - 텍스트 입력에 대한 위치 단서는 셀프 어텐션 레이어의 \\( QK^T \\) 행렬에 직접 제공되어야 합니다.
+ - 대규모 언어 모델은 일정한 *상대적* 거리 위치 인코딩을 서로 학습하도록 유도되어야 합니다.
+ - 텍스트 입력 토큰 간의 거리가 멀어질수록, 그들의 쿼리-값 확률은 낮아져야 합니다. RoPE와 ALiBi는 서로 멀리 떨어진 토큰의 쿼리-키 확률을 낮춥니다. RoPE는 쿼리-키 벡터 간의 각도를 증가시켜 벡터 곱을 감소시키는 방식으로, ALiBi는 벡터 곱에 큰 음수를 추가하는 방식으로 이 작업을 수행합니다.
+
+결론적으로, 큰 텍스트 입력을 처리해야 하는 작업에 배포될 예정인 대규모 언어 모델은 RoPE와 ALiBi와 같은 상대적 위치 임베딩으로 훈련하는 것이 더 좋습니다. 또한 RoPE와 ALiBi를 사용하여 훈련된 대규모 언어 모델이 고정 길이 \\( N_1 = 2048 \\)에서만 훈련되었더라도 위치 임베딩을 외삽하여 \\( N_1 \\)보다 훨씬 큰 텍스트 입력 \\( N_2 = 8192 > N_1 \\)로 실습에서 사용할 수 있음을 유의하세요.
+
+### 3.2 키-값 캐시 [[32-the-key-value-cache]]
+
+대규모 언어 모델을 이용한 자기회귀 텍스트 생성은 입력 시퀀스를 반복적으로 넣고, 다음 토큰을 샘플링하며, 그 다음 토큰을 입력 시퀀스에 추가하고, 대규모 언어 모델이 생성을 완료했다는 토큰을 생성할 때까지 이를 계속 수행하는 방식으로 작동합니다.
+
+자기회귀 생성이 어떻게 작동하는지에 대한 시각적 설명을 보려면 [Transformer's Generate Text Tutorial](https://huggingface.co/docs/transformers/llm_tutorial#generate-text)을 참조하세요.
+
+자기회귀 생성이 실제로 어떻게 작동하는지 보여주는 간단한 코드 스니펫을 실행해 보겠습니다. 여기서는 `torch.argmax`를 통해 가장 가능성이 높은 다음 토큰을 가져올 것입니다.
+
+```python
+input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
+
+for _ in range(5):
+ next_logits = model(input_ids)["logits"][:, -1:]
+ next_token_id = torch.argmax(next_logits,dim=-1)
+
+ input_ids = torch.cat([input_ids, next_token_id], dim=-1)
+ print("shape of input_ids", input_ids.shape)
+
+generated_text = tokenizer.batch_decode(input_ids[:, -5:])
+generated_text
+```
+
+**출력**:
+```
+shape of input_ids torch.Size([1, 21])
+shape of input_ids torch.Size([1, 22])
+shape of input_ids torch.Size([1, 23])
+shape of input_ids torch.Size([1, 24])
+shape of input_ids torch.Size([1, 25])
+[' Here is a Python function']
+```
+
+보시다시피 샘플링된 토큰에 의해 텍스트 입력 토큰을 매번 증가시킵니다.
+
+매우 예외적인 경우를 제외하고, 대규모 언어 모델은 [인과적인 언어 모델링 목표](https://huggingface.co/docs/transformers/tasks/language_modeling#causal-language-modeling)를 사용하여 학습되므로 어텐션 점수의 상삼각 행렬을 마스킹합니다. 이것이 위의 두 다이어그램에서 어텐션 점수가 비어 있는 이유입니다 (즉, 0 확률을 가짐). 인과 언어 모델링에 대한 빠른 요약은 [*Illustrated Self Attention 블로그*](https://jalammar.github.io/illustrated-gpt2/#part-2-illustrated-self-attention)를 참조할 수 있습니다.
+
+결과적으로, 토큰은 *절대* 이전 토큰에 의존하지 않습니다. 더 구체적으로는 \\( \mathbf{q}_i \\) 벡터가 \\( j > i \\)인 경우 어떤 키, 값 벡터 \\( \mathbf{k}_j, \mathbf{v}j \\)와도 연관되지 않습니다. 대신 \\( \mathbf{q}i \\)는 이전의 키-값 벡터 \\( \mathbf{k}{m < i}, \mathbf{v}{m < i} \text{ , for } m \in {0, \ldots i - 1} \\)에만 주의를 기울입니다. 불필요한 계산을 줄이기 위해 각 층의 키-값 벡터를 모든 이전 시간 단계에 대해 캐시할 수 있습니다.
+
+다음으로, 대규모 언어 모델이 각 포워드 패스마다 키-값 캐시를 검색하고 전달하여 이를 활용하도록 합니다.
+Transformers에서는 `forward` 호출에 `use_cache` 플래그를 전달하여 키-값 캐시를 검색한 다음 현재 토큰과 함께 전달할 수 있습니다.
+
+```python
+past_key_values = None # past_key_values 는 키-값 캐시를 의미
+generated_tokens = []
+next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
+
+for _ in range(5):
+ next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
+ next_logits = next_logits[:, -1:]
+ next_token_id = torch.argmax(next_logits, dim=-1)
+
+ print("shape of input_ids", next_token_id.shape)
+ print("length of key-value cache", len(past_key_values[0][0])) # past_key_values 형태: [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
+ generated_tokens.append(next_token_id.item())
+
+generated_text = tokenizer.batch_decode(generated_tokens)
+generated_text
+```
+
+**출력**:
+```
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 20
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 21
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 22
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 23
+shape of input_ids torch.Size([1, 1])
+length of key-value cache 24
+[' Here', ' is', ' a', ' Python', ' function']
+```
+
+키-값 캐시를 사용할 때, 텍스트 입력 토큰의 길이는 *증가하지 않고* 단일 입력 벡터로 유지되는 것을 볼 수 있습니다. 반면에 키-값 캐시의 길이는 각 디코딩 단계마다 하나씩 증가합니다.
+
+> 키-값 캐시를 사용하면 \\( \mathbf{QK}^T \\)가 본질적으로 \\( \mathbf{q}_c\mathbf{K}^T \\)로 줄어드는데, 여기서 \\( \mathbf{q}_c \\)는 현재 전달된 입력 토큰의 쿼리 프로젝션으로, *항상* 단일 벡터입니다.
+
+키-값 캐시를 사용하는 것에는 두 가지 장점이 있습니다:
+- 전체 \\( \mathbf{QK}^T \\) 행렬을 계산하는 것과 비교하여 계산 효율성이 크게 향상됩니다. 이는 추론 속도의 증가로 이어집니다.
+- 생성된 토큰 수에 따라 필요한 최대 메모리가 이차적으로 증가하지 않고, 선형적으로만 증가합니다.
+
+> 더 긴 입력 시퀀스에 대해 동일한 결과와 큰 속도 향상을 가져오기 때문에 키-값 캐시를 *항상* 사용해야 합니다. Transformers는 텍스트 파이프라인이나 [`generate` 메서드](https://huggingface.co/docs/transformers/main_classes/text_generation)를 사용할 때 기본적으로 키-값 캐시를 활성화합니다.
+
+
+
+참고로, 키-값 캐시를 사용할 것을 권장하지만, 이를 사용할 때 LLM 출력이 약간 다를 수 있습니다. 이것은 행렬 곱셈 커널 자체의 특성 때문입니다 -- 더 자세한 내용은 [여기](https://github.com/huggingface/transformers/issues/25420#issuecomment-1775317535)에서 읽어볼 수 있습니다.
+
+
+
+#### 3.2.1 멀티 라운드 대화 [[321-multi-round-conversation]]
+
+키-값 캐시는 여러 번의 자기회귀 디코딩이 필요한 채팅과 같은 애플리케이션에 특히 유용합니다. 예제를 살펴보겠습니다.
+
+```
+User: How many people live in France?
+Assistant: Roughly 75 million people live in France
+User: And how many are in Germany?
+Assistant: Germany has ca. 81 million inhabitants
+```
+
+이 채팅에서 대규모 언어 모델은 두 번의 자기회귀 디코딩을 실행합니다:
+ 1. 첫 번째로, 키-값 캐시는 비어 있고 입력 프롬프트는 `"User: How many people live in France?"`입니다. 모델은 자기회귀적으로 `"Roughly 75 million people live in France"`라는 텍스트를 생성하며 디코딩 단계마다 키-값 캐시를 증가시킵니다.
+ 2. 두 번째로, 입력 프롬프트는 `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"`입니다. 캐시 덕분에 첫 번째 두 문장에 대한 모든 키-값 벡터는 이미 계산되어 있습니다. 따라서 입력 프롬프트는 `"User: And how many in Germany?"`로만 구성됩니다. 줄어든 입력 프롬프트를 처리하는 동안 계산된 키-값 벡터가 첫 번째 디코딩의 키-값 캐시에 연결됩니다. 두 번째 어시스턴트의 답변인 `"Germany has ca. 81 million inhabitants"`는 `"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"`의 인코딩된 키-값 벡터로 구성된 키-값 캐시를 사용하여 자기회귀적으로 생성됩니다.
+
+여기서 두 가지를 주목해야 합니다:
+ 1. 대규모 언어 모델이 대화의 모든 이전 문맥을 이해할 수 있도록 모든 문맥을 유지하는 것이 채팅에 배포된 대규모 언어 모델에서는 매우 중요합니다. 예를 들어, 위의 예에서 대규모 언어 모델은 사용자가 `"And how many are in Germany"`라고 물을 때 인구를 언급하고 있음을 이해해야 합니다.
+ 2. 키-값 캐시는 채팅에서 매우 유용합니다. 이는 인코딩된 채팅 기록을 처음부터 다시 인코딩할 필요 없이 계속해서 확장할 수 있게 해주기 때문입니다(예: 인코더-디코더 아키텍처를 사용할 때와 같은 경우).
+
+`transformers`에서 `generate` 호출은 기본적으로 `use_cache=True`와 함께 `return_dict_in_generate=True`를 전달하면 `past_key_values`를 반환합니다. 이는 아직 `pipeline` 인터페이스를 통해서는 사용할 수 없습니다.
+
+```python
+# 일반적인 생성
+prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
+model_inputs = tokenizer(prompt, return_tensors='pt')
+generation_output = model.generate(**model_inputs, max_new_tokens=60, return_dict_in_generate=True)
+decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
+
+# 리턴된 `past_key_values`를 파이프라인화하여 다음 대화 라운드를 가속화
+prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
+model_inputs = tokenizer(prompt, return_tensors='pt')
+generation_output = model.generate(
+ **model_inputs,
+ past_key_values=generation_output.past_key_values,
+ max_new_tokens=60,
+ return_dict_in_generate=True
+)
+tokenizer.batch_decode(generation_output.sequences)[0][len(prompt):]
+```
+
+**출력**:
+```
+ is a modified version of the function that returns Mega bytes instead.
+
+def bytes_to_megabytes(bytes):
+ return bytes / 1024 / 1024
+
+Answer: The function takes a number of bytes as input and returns the number of
+```
+
+훌륭합니다. 어텐션 층의 동일한 키와 값을 다시 계산하는 데 추가 시간이 소요되지 않습니다! 그러나 한 가지 문제가 있습니다. \\( \mathbf{QK}^T \\) 행렬에 필요한 최대 메모리는 크게 줄어들지만, 긴 입력 시퀀스나 다회차 채팅의 경우 키-값 캐시를 메모리에 보관하는 것이 매우 메모리 집약적이 될 수 있습니다. 키-값 캐시는 모든 자기 어텐션 층과 모든 어텐션 헤드에 대해 이전 입력 벡터 \\( \mathbf{x}_i \text{, for } i \in {1, \ldots, c - 1} \\)의 키-값 벡터를 저장해야 한다는 점을 기억하세요.
+
+이전에 사용한 대규모 언어 모델 `bigcode/octocoder`에 대해 키-값 캐시에 저장해야 하는 부동 소수점 값의 수를 계산해 봅시다.
+부동 소수점 값의 수는 시퀀스 길이의 두 배의 어텐션 헤드 수, 어텐션 헤드 차원, 레이어 수를 곱한 값입니다.
+가상의 입력 시퀀스 길이 16000에서 대규모 언어 모델에 대해 이를 계산하면 다음과 같습니다.
+
+```python
+config = model.config
+2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head
+```
+
+**출력**:
+```
+7864320000
+```
+
+대략 80억 개의 부동 소수점 값입니다! `float16` 정밀도로 80억 개의 부동 소수점 값을 저장하는 데는 약 15GB의 RAM이 필요하며, 이는 모델 가중치 자체의 절반 정도입니다.
+연구자들은 키-값 캐시를 저장하는 데 필요한 메모리 비용을 크게 줄일 수 있는 두 가지 방법을 제안했으며, 이는 다음 절에서 살펴보겠습니다.
+
+#### 3.2.2 멀티 쿼리 어텐션 (MQA) [[322-multi-query-attention-mqa]]
+
+[멀티 쿼리 어텐션 (MQA)](https://arxiv.org/abs/1911.02150)은 Noam Shazeer의 *Fast Transformer Decoding: One Write-Head is All You Need* 논문에서 제안되었습니다. 제목에서 알 수 있듯이, Noam은 `n_head` 키-값 프로젝션 가중치 대신, 모든 어텐션 헤드에서 공유되는 단일 헤드-값 프로젝션 가중치를 사용할 수 있으며, 이를 통해 모델 성능이 크게 저하되지 않는다는 것을 발견했습니다.
+
+> 단일 헤드-값 프로젝션 가중치를 사용함으로써, 키-값 벡터 \\( \mathbf{k}_i, \mathbf{v}_i \\)는 모든 어텐션 헤드에서 동일해야 하며, 이는 캐시에 `n_head` 개 대신 하나의 키-값 프로젝션 쌍만 저장하면 된다는 것을 의미합니다.
+
+대부분의 대규모 언어 모델이 20에서 100 사이의 어텐션 헤드를 사용하기 때문에, MQA는 키-값 캐시의 메모리 소비를 크게 줄입니다. 이 노트북에서 사용된 대규모 언어 모델의 경우, 입력 시퀀스 길이 16000에서 필요한 메모리 소비를 15GB에서 400MB 미만으로 줄일 수 있습니다.
+
+메모리 절감 외에도, MQA는 계산 효율성도 향상시킵니다. 다음과 같이 설명합니다.
+자기회귀 디코딩에서는 큰 키-값 벡터를 다시 로드하고, 현재 키-값 벡터 쌍과 연결한 후 \\( \mathbf{q}_c\mathbf{K}^T \\) 계산에 매 단계마다 입력해야 합니다. 자기회귀 디코딩의 경우, 지속적인 재로드에 필요한 메모리 대역폭이 심각한 시간 병목 현상을 가져올 수 있습니다. 키-값 벡터의 크기를 줄이면 접근해야 하는 메모리 양이 줄어들어 메모리 대역폭 병목 현상이 감소합니다. 자세한 내용은 [Noam의 논문](https://arxiv.org/abs/1911.02150)을 참조하세요.
+
+여기서 이해해야 할 중요한 부분은 키-값 어텐션 헤드 수를 1로 줄이는 것이 키-값 캐시를 사용할 때만 의미가 있다는 것입니다. 키-값 캐시 없이 단일 포워드 패스에 대한 모델의 최대 메모리 소비는 변경되지 않으며, 각 어텐션 헤드는 여전히 고유한 쿼리 벡터를 가지므로 각 어텐션 헤드는 여전히 다른 \\( \mathbf{QK}^T \\) 행렬을 가집니다.
+
+MQA는 커뮤니티에서 널리 채택되어 현재 가장 인기 있는 많은 대규모 언어 모델에서 사용되고 있습니다.
+
+- [**Falcon**](https://huggingface.co/tiiuae/falcon-40b)
+- [**PaLM**](https://arxiv.org/abs/2204.02311)
+- [**MPT**](https://huggingface.co/mosaicml/mpt-30b)
+- [**BLOOM**](https://huggingface.co/bigscience/bloom)
+
+또한, 이 노트북에서 사용된 체크포인트 `bigcode/octocoder`는 MQA를 사용합니다.
+
+#### 3.2.3 그룹 쿼리 어텐션 (GQA) [[323-grouped-query-attention-gqa]]
+
+[그룹 쿼리 어텐션 (GQA)](https://arxiv.org/abs/2305.13245)은 Google의 Ainslie 등의 연구진들에 의해 제안되었습니다. 그들은 MQA를 사용하는 것이 종종 일반적인 멀티 키-값 헤드 프로젝션을 사용하는 것보다 품질 저하를 가져올 수 있다는 것을 발견했습니다. 이 논문은 쿼리 헤드 프로젝션 가중치의 수를 너무 극단적으로 줄이는 대신, 더 많은 모델 성능을 유지할 수 있다고 주장합니다. 단일 키-값 프로젝션 가중치 대신, `n < n_head` 키-값 프로젝션 가중치를 사용해야 합니다. `n_head`보다 훨씬 작은 `n`값, 예를 들어 2, 4 또는 8을 선택하면, MQA의 거의 모든 메모리 및 속도 이점을 유지하면서 모델 용량을 덜 희생하고 따라서 성능 저하를 줄일 수 있습니다.
+
+또한, GQA의 저자들은 기존 모델 체크포인트를 원래 사전 학습 계산의 5% 정도의 적은 양으로 GQA 아키텍처로 *업트레이닝*할 수 있음을 발견했습니다. 원래 사전 학습 계산의 5%가 여전히 엄청난 양일 수 있지만, GQA *업트레이닝*은 기존 체크포인트가 더 긴 입력 시퀀스에서도 유용하도록 합니다.
+
+GQA는 최근에 제안되었기 때문에 이 노트북을 작성할 당시에는 채택이 덜 되었습니다.
+GQA의 가장 주목할 만한 적용 사례는 [Llama-v2](https://huggingface.co/meta-llama/Llama-2-70b-hf)입니다.
+
+> 결론적으로, 대규모 언어 모델이 자기회귀 디코딩으로 배포되면서 채팅과 같이 큰 입력 시퀀스를 가진 작업을 처리해야 하는 경우 GQA 또는 MQA를 사용하는 것이 강력히 권장됩니다.
+
+
+## 결론 [[conclusion]]
+
+연구 커뮤니티는 점점 더 큰 대규모 언어 모델의 추론 시간을 가속화하기 위한 새로운 기발한 방법들을 끊임없이 찾아내고 있습니다. 예를 들어, [추측 디코딩](https://arxiv.org/abs/2211.17192)이라는 유망한 연구 방향이 있습니다. 여기서 "쉬운 토큰"은 더 작고 빠른 언어 모델에 의해 생성되고, "어려운 토큰"만 대규모 언어 모델 자체에 의해 생성됩니다. 자세한 내용은 이 노트북의 범위를 벗어나지만, [멋진 블로그 포스트](https://huggingface.co/blog/assisted-generation)에서 읽어볼 수 있습니다.
+
+GPT3/4, Llama-2-70b, Claude, PaLM과 같은 거대한 대규모 언어 모델이 [Hugging Face Chat](https://huggingface.co/chat/) 또는 ChatGPT와 같은 채팅 인터페이스에서 빠르게 실행될 수 있는 이유는 위에서 언급한 정밀도, 알고리즘, 아키텍처의 개선 덕분입니다. 앞으로 GPU, TPU 등과 같은 가속기는 점점 더 빨라지고 더 많은 메모리를 사용할 것입니다. 따라서 가장 좋은 알고리즘과 아키텍처를 사용하여 최고의 효율을 얻는 것이 중요합니다 🤗
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/main_classes/callback.md b/docs/transformers/docs/source/ko/main_classes/callback.md
new file mode 100644
index 0000000000000000000000000000000000000000..c8d122a8ef9247089b27d2d8b6a21d667bffa45b
--- /dev/null
+++ b/docs/transformers/docs/source/ko/main_classes/callback.md
@@ -0,0 +1,137 @@
+
+
+# 콜백 [[callbacks]]
+
+콜백은 PyTorch [`Trainer`]의 반복 학습 동작을 사용자 정의할 수 있는 객체입니다
+(이 기능은 TensorFlow에서는 아직 구현되지 않았습니다). 콜백은 반복 학습의 상태를
+검사하여 (진행 상황 보고, TensorBoard 또는 기타 머신 러닝 플랫폼에 로그 남기기 등)
+결정(예: 조기 종료)을 내릴 수 있습니다.
+
+콜백은 [`TrainerControl`] 객체를 반환하는 것 외에는 반복 학습에서 어떤 것도 변경할 수 없는
+"읽기 전용" 코드 조각입니다. 반복 학습에 변경이 필요한 사용자 정의 작업이 필요한 경우,
+[`Trainer`]를 서브클래스로 만들어 필요한 메소드들을 오버라이드해야 합니다 (예시는 [trainer](trainer)를 참조하세요).
+
+기본적으로 `TrainingArguments.report_to`는 `"all"`로 설정되어 있으므로, [`Trainer`]는 다음 콜백을 사용합니다.
+
+- [`DefaultFlowCallback`]는 로그, 저장, 평가에 대한 기본 동작을 처리합니다.
+- [`PrinterCallback`] 또는 [`ProgressCallback`]는 진행 상황을 표시하고 로그를 출력합니다
+ ([`TrainingArguments`]를 통해 tqdm을 비활성화하면 첫 번째 콜백이 사용되고, 그렇지 않으면 두 번째가 사용됩니다).
+- [`~integrations.TensorBoardCallback`]는 TensorBoard가 (PyTorch >= 1.4
+ 또는 tensorboardX를 통해) 접근 가능하면 사용됩니다.
+- [`~integrations.WandbCallback`]는 [wandb](https://www.wandb.com/)가 설치되어 있으면
+ 사용됩니다.
+- [`~integrations.CometCallback`]는 [comet_ml](https://www.comet.com/site/)이 설치되어 있으면 사용됩니다.
+- [`~integrations.MLflowCallback`]는 [mlflow](https://www.mlflow.org/)가 설치되어 있으면 사용됩니다.
+- [`~integrations.NeptuneCallback`]는 [neptune](https://neptune.ai/)이 설치되어 있으면 사용됩니다.
+- [`~integrations.AzureMLCallback`]는 [azureml-sdk](https://pypi.org/project/azureml-sdk/)가 설치되어
+ 있으면 사용됩니다.
+- [`~integrations.CodeCarbonCallback`]는 [codecarbon](https://pypi.org/project/codecarbon/)이 설치되어
+ 있으면 사용됩니다.
+- [`~integrations.ClearMLCallback`]는 [clearml](https://github.com/allegroai/clearml)이 설치되어 있으면 사용됩니다.
+- [`~integrations.DagsHubCallback`]는 [dagshub](https://dagshub.com/)이 설치되어 있으면 사용됩니다.
+- [`~integrations.FlyteCallback`]는 [flyte](https://flyte.org/)가 설치되어 있으면 사용됩니다.
+- [`~integrations.DVCLiveCallback`]는 [dvclive](https://dvc.org/doc/dvclive)가 설치되어 있으면 사용됩니다.
+- [`~integrations.SwanLabCallback`]는 [swanlab](https://swanlab.cn)가 설치되어 있으면 사용됩니다.
+
+패키지가 설치되어 있지만 해당 통합 기능을 사용하고 싶지 않다면, `TrainingArguments.report_to`를 사용하고자 하는 통합 기능 목록으로 변경할 수 있습니다 (예: `["azure_ml", "wandb"]`).
+
+콜백을 구현하는 주요 클래스는 [`TrainerCallback`]입니다. 이 클래스는 [`Trainer`]를
+인스턴스화하는 데 사용된 [`TrainingArguments`]를 가져오고, 해당 Trainer의 내부 상태를
+[`TrainerState`]를 통해 접근할 수 있으며, [`TrainerControl`]을 통해 반복 학습에서 일부
+작업을 수행할 수 있습니다.
+
+
+## 사용 가능한 콜백 [[available-callbacks]]
+
+라이브러리에서 사용 가능한 [`TrainerCallback`] 목록은 다음과 같습니다:
+
+[[autodoc]] integrations.CometCallback
+ - setup
+
+[[autodoc]] DefaultFlowCallback
+
+[[autodoc]] PrinterCallback
+
+[[autodoc]] ProgressCallback
+
+[[autodoc]] EarlyStoppingCallback
+
+[[autodoc]] integrations.TensorBoardCallback
+
+[[autodoc]] integrations.WandbCallback
+ - setup
+
+[[autodoc]] integrations.MLflowCallback
+ - setup
+
+[[autodoc]] integrations.AzureMLCallback
+
+[[autodoc]] integrations.CodeCarbonCallback
+
+[[autodoc]] integrations.NeptuneCallback
+
+[[autodoc]] integrations.ClearMLCallback
+
+[[autodoc]] integrations.DagsHubCallback
+
+[[autodoc]] integrations.FlyteCallback
+
+[[autodoc]] integrations.DVCLiveCallback
+ - setup
+
+[[autodoc]] integrations.SwanLabCallback
+ - setup
+
+## TrainerCallback [[trainercallback]]
+
+[[autodoc]] TrainerCallback
+
+여기 PyTorch [`Trainer`]와 함께 사용자 정의 콜백을 등록하는 예시가 있습니다:
+
+```python
+class MyCallback(TrainerCallback):
+ "A callback that prints a message at the beginning of training"
+
+ def on_train_begin(self, args, state, control, **kwargs):
+ print("Starting training")
+
+
+trainer = Trainer(
+ model,
+ args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ callbacks=[MyCallback], # 우리는 콜백 클래스를 이 방식으로 전달하거나 그것의 인스턴스(MyCallback())를 전달할 수 있습니다
+)
+```
+
+또 다른 콜백을 등록하는 방법은 `trainer.add_callback()`을 호출하는 것입니다:
+
+```python
+trainer = Trainer(...)
+trainer.add_callback(MyCallback)
+# 다른 방법으로는 콜백 클래스의 인스턴스를 전달할 수 있습니다
+trainer.add_callback(MyCallback())
+```
+
+## TrainerState [[trainerstate]]
+
+[[autodoc]] TrainerState
+
+## TrainerControl [[trainercontrol]]
+
+[[autodoc]] TrainerControl
diff --git a/docs/transformers/docs/source/ko/main_classes/configuration.md b/docs/transformers/docs/source/ko/main_classes/configuration.md
new file mode 100644
index 0000000000000000000000000000000000000000..6c6278a02585608a66a600cd610c81af995aaebf
--- /dev/null
+++ b/docs/transformers/docs/source/ko/main_classes/configuration.md
@@ -0,0 +1,28 @@
+
+
+# 구성[[configuration]]
+
+기본 클래스 [`PretrainedConfig`]는 로컬 파일이나 디렉토리, 또는 라이브러리에서 제공하는 사전 학습된 모델 구성(HuggingFace의 AWS S3 저장소에서 다운로드됨)으로부터 구성을 불러오거나 저장하는 공통 메서드를 구현합니다. 각 파생 구성 클래스는 모델별 특성을 구현합니다.
+
+모든 구성 클래스에 존재하는 공통 속성은 다음과 같습니다: `hidden_size`, `num_attention_heads`, `num_hidden_layers`. 텍스트 모델은 추가로 `vocab_size`를 구현합니다.
+
+
+## PretrainedConfig[[transformers.PretrainedConfig]]
+
+[[autodoc]] PretrainedConfig
+ - push_to_hub
+ - all
diff --git a/docs/transformers/docs/source/ko/main_classes/data_collator.md b/docs/transformers/docs/source/ko/main_classes/data_collator.md
new file mode 100644
index 0000000000000000000000000000000000000000..0e677c7d8979b87b418d800978174f1a65701f3a
--- /dev/null
+++ b/docs/transformers/docs/source/ko/main_classes/data_collator.md
@@ -0,0 +1,66 @@
+
+
+# 데이터 콜레이터(Data Collator)[[data-collator]]
+
+데이터 콜레이터는 데이터셋 요소들의 리스트를 입력으로 사용하여 배치를 형성하는 객체입니다. 이러한 요소들은 `train_dataset` 또는 `eval_dataset의` 요소들과 동일한 타입 입니다. 배치를 구성하기 위해, 데이터 콜레이터는 (패딩과 같은) 일부 처리를 적용할 수 있습니다. [`DataCollatorForLanguageModeling`]과 같은 일부 콜레이터는 형성된 배치에 (무작위 마스킹과 같은) 일부 무작위 데이터 증강도 적용합니다. 사용 예시는 [예제 스크립트](../examples)나 [예제 노트북](../notebooks)에서 찾을 수 있습니다.
+
+
+## 기본 데이터 콜레이터[[transformers.default_data_collator]]
+
+[[autodoc]] data.data_collator.default_data_collator
+
+## DefaultDataCollator[[transformers.DefaultDataCollator]]
+
+[[autodoc]] data.data_collator.DefaultDataCollator
+
+## DataCollatorWithPadding[[transformers.DataCollatorWithPadding]]
+
+[[autodoc]] data.data_collator.DataCollatorWithPadding
+
+## DataCollatorForTokenClassification[[transformers.DataCollatorForTokenClassification]]
+
+[[autodoc]] data.data_collator.DataCollatorForTokenClassification
+
+## DataCollatorForSeq2Seq[[transformers.DataCollatorForSeq2Seq]]
+
+[[autodoc]] data.data_collator.DataCollatorForSeq2Seq
+
+## DataCollatorForLanguageModeling[[transformers.DataCollatorForLanguageModeling]]
+
+[[autodoc]] data.data_collator.DataCollatorForLanguageModeling
+ - numpy_mask_tokens
+ - tf_mask_tokens
+ - torch_mask_tokens
+
+## DataCollatorForWholeWordMask[[transformers.DataCollatorForWholeWordMask]]
+
+[[autodoc]] data.data_collator.DataCollatorForWholeWordMask
+ - numpy_mask_tokens
+ - tf_mask_tokens
+ - torch_mask_tokens
+
+## DataCollatorForPermutationLanguageModeling[[transformers.DataCollatorForPermutationLanguageModeling]]
+
+[[autodoc]] data.data_collator.DataCollatorForPermutationLanguageModeling
+ - numpy_mask_tokens
+ - tf_mask_tokens
+ - torch_mask_tokens
+
+## DataCollatorWithFlatteningtransformers.DataCollatorWithFlattening
+
+[[autodoc]] data.data_collator.DataCollatorWithFlattening
+
diff --git a/docs/transformers/docs/source/ko/main_classes/executorch.md b/docs/transformers/docs/source/ko/main_classes/executorch.md
new file mode 100644
index 0000000000000000000000000000000000000000..a94418ece1a7abcc88b46afea148d02e89683c61
--- /dev/null
+++ b/docs/transformers/docs/source/ko/main_classes/executorch.md
@@ -0,0 +1,33 @@
+
+
+
+# ExecuTorch [[executorch]]
+
+[`ExecuTorch`](https://github.com/pytorch/executorch) 는 웨어러블, 임베디드 장치, 마이크로컨트롤러를 포함한 모바일 및 엣지 장치에서 온디바이스 추론 기능을 가능하게 하는 종합 솔루션입니다. PyTorch 생태계에 속해있으며, 이식성, 생산성, 성능에 중점을 둔 PyTorch 모델 배포를 지원합니다.
+
+ExecuTorch는 백엔드 위임, 사용자 정의 컴파일러 변환, 메모리 계획 등 모델, 장치 또는 특정 유즈케이스 맞춤 최적화를 수행할 수 있는 진입점을 명확하게 정의합니다. ExecuTorch를 사용해 엣지 장치에서 PyTorch 모델을 실행하는 첫 번째 단계는 모델을 익스포트하는 것입니다. 이 작업은 PyTorch API인 [`torch.export`](https://pytorch.org/docs/stable/export.html)를 사용하여 수행합니다.
+
+
+## ExecuTorch 통합 [[transformers.TorchExportableModuleWithStaticCache]]
+
+`torch.export`를 사용하여 🤗 Transformers를 익스포트 할 수 있도록 통합 지점이 개발되고 있습니다. 이 통합의 목표는 익스포트뿐만 아니라, 익스포트한 아티팩트가 `ExecuTorch`에서 효율적으로 실행될 수 있도록 더 축소하고 최적화하는 것입니다. 특히 모바일 및 엣지 유즈케이스에 중점을 두고 있습니다.
+
+[[autodoc]] integrations.executorch.TorchExportableModuleWithStaticCache
+ - forward
+
+[[autodoc]] integrations.executorch.convert_and_export_with_cache
diff --git a/docs/transformers/docs/source/ko/main_classes/feature_extractor.md b/docs/transformers/docs/source/ko/main_classes/feature_extractor.md
new file mode 100644
index 0000000000000000000000000000000000000000..7c667424c4ff956a1b1dce95db970b88d5aa7eb4
--- /dev/null
+++ b/docs/transformers/docs/source/ko/main_classes/feature_extractor.md
@@ -0,0 +1,39 @@
+
+
+# 특성 추출기 [[feature-extractor]]
+
+특성 추출기는 오디오 또는 비전 모델을 위한 입력 특성을 준비하는 역할을 합니다. 여기에는 시퀀스에서 특성을 추출하는 작업(예를 들어, 오디오 파일을 전처리하여 Log-Mel 스펙트로그램 특성을 생성하는 것), 이미지에서 특성을 추출하는 작업(예를 들어, 이미지 파일을 자르는 것)이 포함됩니다. 뿐만 아니라 패딩, 정규화 및 NumPy, PyTorch, TensorFlow 텐서로의 변환도 포함됩니다.
+
+
+## FeatureExtractionMixin [[transformers.FeatureExtractionMixin]]
+
+[[autodoc]] feature_extraction_utils.FeatureExtractionMixin
+ - from_pretrained
+ - save_pretrained
+
+## SequenceFeatureExtractor [[transformers.SequenceFeatureExtractor]]
+
+[[autodoc]] SequenceFeatureExtractor
+ - pad
+
+## BatchFeature [[transformers.BatchFeature]]
+
+[[autodoc]] BatchFeature
+
+## ImageFeatureExtractionMixin [[transformers.ImageFeatureExtractionMixin]]
+
+[[autodoc]] image_utils.ImageFeatureExtractionMixin
diff --git a/docs/transformers/docs/source/ko/main_classes/keras_callbacks.md b/docs/transformers/docs/source/ko/main_classes/keras_callbacks.md
new file mode 100644
index 0000000000000000000000000000000000000000..25d5ea3e40083acad8fa9257ce2c7cfef7c3d9c8
--- /dev/null
+++ b/docs/transformers/docs/source/ko/main_classes/keras_callbacks.md
@@ -0,0 +1,27 @@
+
+
+# 케라스 콜백[[keras-callbacks]]
+
+케라스로 트랜스포머 모델을 학습할 때, 일반적인 작업을 자동화하기 위한 라이브러리 전용 콜백들을 사용 할 수 있습니다.
+
+## KerasMetricCallback[[transformers.KerasMetricCallback]]
+
+[[autodoc]] KerasMetricCallback
+
+## PushToHubCallback[[transformers.PushToHubCallback]]
+
+[[autodoc]] PushToHubCallback
diff --git a/docs/transformers/docs/source/ko/main_classes/logging.md b/docs/transformers/docs/source/ko/main_classes/logging.md
new file mode 100644
index 0000000000000000000000000000000000000000..55e1a21c7bd57bb1b9f8e0f47052fa085340f65b
--- /dev/null
+++ b/docs/transformers/docs/source/ko/main_classes/logging.md
@@ -0,0 +1,108 @@
+
+
+# 로깅 [[logging]]
+
+🤗 트랜스포머는 중앙 집중식 로깅 시스템을 제공하여 라이브러리의 출력 레벨을 쉽게 설정할 수 있습니다.
+
+현재 라이브러리의 기본 출력 레벨은 `WARNING`으로 설정되어 있습니다.
+
+출력 레벨을 변경하려면 직접적인 설정 메서드를 사용할 수 있습니다. 예를 들어, 출력 레벨을 INFO 수준으로 변경하는 방법은 다음과 같습니다.
+
+```python
+import transformers
+
+transformers.logging.set_verbosity_info()
+```
+
+환경 변수 `TRANSFORMERS_VERBOSITY`를 사용하여 기본 출력 레벨을 재정의할 수도 있습니다. 이를 `debug`, `info`, `warning`, `error`, `critical`, `fatal` 중 하나로 설정할 수 있습니다. 예를 들어 다음과 같습니다.
+
+```bash
+TRANSFORMERS_VERBOSITY=error ./myprogram.py
+```
+
+또한, 일부 `warnings`는 환경 변수 `TRANSFORMERS_NO_ADVISORY_WARNINGS`를 1과 같은 true 값으로 설정하여 비활성화할 수 있습니다. 이렇게 하면 [`logger.warning_advice`]를 사용하여 기록된 경고가 비활성화됩니다. 예를 들어 다음과 같습니다.
+
+```bash
+TRANSFORMERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
+```
+
+다음은 라이브러리와 동일한 로거를 자신의 모듈이나 스크립트에서 사용하는 방법에 대한 예시입니다.
+
+```python
+from transformers.utils import logging
+
+logging.set_verbosity_info()
+logger = logging.get_logger("transformers")
+logger.info("INFO")
+logger.warning("WARN")
+```
+
+
+이 로깅 모듈의 모든 메서드는 아래에 문서화되어 있으며, 주요 메서드는 현재 로거의 출력 수준을 가져오는 [`logging.get_verbosity`]와 원하는 출력 수준으로 설정하는 [`logging.set_verbosity`] 입니다. 출력 수준은 (가장 적은 출력에서 가장 많은 출력 순으로) 다음과 같으며, 해당 수준에 대응하는 정수 값은 괄호 안에 표시됩니다.
+
+- `transformers.logging.CRITICAL` 또는 `transformers.logging.FATAL` (정숫값, 50): 가장 심각한 오류만 보고합니다.
+- `transformers.logging.ERROR` (정숫값, 40): 오류만 보고합니다.
+- `transformers.logging.WARNING` 또는 `transformers.logging.WARN` (정숫값, 30): 오류와 경고만 보고합니다. 이는 라이브러리에서 기본으로 사용되는 수준입니다.
+- `transformers.logging.INFO` (정숫값, 20): 오류, 경고, 그리고 기본적인 정보를 보고합니다.
+- `transformers.logging.DEBUG` (정숫값, 10): 모든 정보를 보고합니다.
+
+기본적으로 모델 다운로드 중에는 `tqdm` 진행 표시줄이 표시됩니다. [`logging.disable_progress_bar`]와 [`logging.enable_progress_bar`]를 사용하여 이 동작을 숨기거나 다시 표시할 수 있습니다.
+
+## `logging` vs `warnings`[[transformers.utils.logging.captureWarnings]]
+
+Python에는 종종 함께 사용되는 두 가지 로깅 시스템이 있습니다. 위에서 설명한 `logging`과 `warnings`입니다. `warnings`는 특정 범주로 경고를 세분화할 수 있습니다. 예를 들어, 이미 더 이상 사용되지 않는 기능이나 경로에 대해 `FutureWarning`이 사용되고, 곧 사용 중단될 기능을 알리기 위해 `DeprecationWarning`이 사용됩니다.
+
+트랜스포머 라이브러리에서는 두 시스템 모두를 사용합니다. `logging`의 `captureWarnings` 메서드를 활용하고 이를 조정하여 위에서 설명한 출력 수준 설정자들을 통해 이러한 경고 메시지들을 관리할 수 있도록 합니다.
+
+라이브러리 개발자는 다음과 같은 지침을 따르는 것이 좋습니다.
+
+- `warnings`는 라이브러리 개발자와 `transformers`에 의존하는 라이브러리 개발자들에게 유리합니다.
+- `logging`은 일반적인 프로젝트 라이브러리 개발자보다는, 라이브러리를 사용하는 최종 사용자들에게 유리할 것입니다.
+
+아래에서 `captureWarnings` 메소드에 대한 참고 사항을 확인할 수 있습니다.
+
+[[autodoc]] logging.captureWarnings
+
+## 기본 설정자 [[transformers.utils.logging.set_verbosity_error]]
+
+[[autodoc]] logging.set_verbosity_error
+
+[[autodoc]] logging.set_verbosity_warning
+
+[[autodoc]] logging.set_verbosity_info
+
+[[autodoc]] logging.set_verbosity_debug
+
+## 기타 함수 [[transformers.utils.logging.get_verbosity]]
+
+[[autodoc]] logging.get_verbosity
+
+[[autodoc]] logging.set_verbosity
+
+[[autodoc]] logging.get_logger
+
+[[autodoc]] logging.enable_default_handler
+
+[[autodoc]] logging.disable_default_handler
+
+[[autodoc]] logging.enable_explicit_format
+
+[[autodoc]] logging.reset_format
+
+[[autodoc]] logging.enable_progress_bar
+
+[[autodoc]] logging.disable_progress_bar
diff --git a/docs/transformers/docs/source/ko/main_classes/model.md b/docs/transformers/docs/source/ko/main_classes/model.md
new file mode 100644
index 0000000000000000000000000000000000000000..71a9768deee1ecf1badbbe60fe0152eb1756cde6
--- /dev/null
+++ b/docs/transformers/docs/source/ko/main_classes/model.md
@@ -0,0 +1,68 @@
+
+
+# 모델
+
+기본 클래스 [`PreTrainedModel`], [`TFPreTrainedModel`], [`FlaxPreTrainedModel`]는 로컬 파일과 디렉토리로부터 모델을 로드하고 저장하거나 또는 (허깅페이스 AWS S3 리포지토리로부터 다운로드된) 라이브러리에서 제공하는 사전 훈련된 모델 설정을 로드하고 저장하는 것을 지원하는 기본 메소드를 구현하였습니다.
+
+[`PreTrainedModel`]과 [`TFPreTrainedModel`]은 또한 모든 모델들을 공통적으로 지원하는 메소드 여러개를 구현하였습니다:
+
+- 새 토큰이 단어장에 추가될 때, 입력 토큰 임베딩의 크기를 조정합니다.
+- 모델의 어텐션 헤드를 가지치기합니다.
+
+각 모델에 공통인 다른 메소드들은 다음의 클래스에서 정의됩니다.
+- [`~modeling_utils.ModuleUtilsMixin`](파이토치 모델용)
+- 텍스트 생성을 위한 [`~modeling_tf_utils.TFModuleUtilsMixin`](텐서플로 모델용)
+- [`~generation.GenerationMixin`](파이토치 모델용)
+- [`~generation.FlaxGenerationMixin`](Flax/JAX 모델용)
+
+## PreTrainedModel
+
+[[autodoc]] PreTrainedModel
+ - push_to_hub
+ - all
+
+사용자 정의 모델은 초고속 초기화(superfast init)가 특정 모델에 적용될 수 있는지 여부를 결정하는 `_supports_assign_param_buffer`도 포함해야 합니다.
+`test_save_and_load_from_pretrained` 실패 시, 모델이 `_supports_assign_param_buffer`를 필요로 하는지 확인하세요.
+필요로 한다면 `False`로 설정하세요.
+
+## ModuleUtilsMixin
+
+[[autodoc]] modeling_utils.ModuleUtilsMixin
+
+## TFPreTrainedModel
+
+[[autodoc]] TFPreTrainedModel
+ - push_to_hub
+ - all
+
+## TFModelUtilsMixin
+
+[[autodoc]] modeling_tf_utils.TFModelUtilsMixin
+
+## FlaxPreTrainedModel
+
+[[autodoc]] FlaxPreTrainedModel
+ - push_to_hub
+ - all
+
+## 허브에 저장하기
+
+[[autodoc]] utils.PushToHubMixin
+
+## 공유된 체크포인트
+
+[[autodoc]] modeling_utils.load_sharded_checkpoint
diff --git a/docs/transformers/docs/source/ko/main_classes/onnx.md b/docs/transformers/docs/source/ko/main_classes/onnx.md
new file mode 100644
index 0000000000000000000000000000000000000000..510dab9df2f9332ca5a69252bd7c444e44bdf2e9
--- /dev/null
+++ b/docs/transformers/docs/source/ko/main_classes/onnx.md
@@ -0,0 +1,50 @@
+
+
+# 🤗 Transformers 모델을 ONNX로 내보내기[[exporting--transformers-models-to-onnx]]
+
+🤗 트랜스포머는 `transformers.onnx` 패키지를 제공하며, 이 패키지는 설정 객체를 활용하여 모델 체크포인트를 ONNX 그래프로 변환할 수 있게 합니다.
+
+🤗 Transformers에 대한 자세한 내용은 [이 가이드](../serialization)를 참조하세요.
+
+## ONNX 설정[[onnx-configurations]]
+
+내보내려는(export) 모델 아키텍처의 유형에 따라 상속받아야 할 세 가지 추상 클래스를 제공합니다:
+
+* 인코더 기반 모델은 [`~onnx.config.OnnxConfig`]을 상속받습니다.
+* 디코더 기반 모델은 [`~onnx.config.OnnxConfigWithPast`]을 상속받습니다.
+* 인코더-디코더 기반 모델은 [`~onnx.config.OnnxSeq2SeqConfigWithPast`]을 상속받습니다.
+
+### OnnxConfig[[transformers.onnx.OnnxConfig]]
+
+[[autodoc]] onnx.config.OnnxConfig
+
+### OnnxConfigWithPast[[transformers.onnx.OnnxConfigWithPast]]
+
+[[autodoc]] onnx.config.OnnxConfigWithPast
+
+### OnnxSeq2SeqConfigWithPast[[OnnxSeq2SeqConfigWithPast]]
+
+[[autodoc]] onnx.config.OnnxSeq2SeqConfigWithPast
+
+## ONNX 특징[[onnx-features]]
+
+각 ONNX 설정은 다양한 유형의 토폴로지나 작업에 대해 모델을 내보낼 수 있게(exporting) 해주는 _features_ 세트와 연관되어 있습니다.
+
+### FeaturesManager[[transformers.onnx.FeaturesManager]]
+
+[[autodoc]] onnx.features.FeaturesManager
+
diff --git a/docs/transformers/docs/source/ko/main_classes/output.md b/docs/transformers/docs/source/ko/main_classes/output.md
new file mode 100644
index 0000000000000000000000000000000000000000..e65a2c2c35906eef6cc4011994d4bdd50d9d3d76
--- /dev/null
+++ b/docs/transformers/docs/source/ko/main_classes/output.md
@@ -0,0 +1,314 @@
+
+
+# 모델 출력[[model-outputs]]
+
+모든 모델에는 [`~utils.ModelOutput`]의 서브클래스의 인스턴스인 모델 출력이 있습니다. 이들은
+모델에서 반환되는 모든 정보를 포함하는 데이터 구조이지만 튜플이나 딕셔너리로도 사용할 수 있습니다.
+
+예제를 통해 살펴보겠습니다:
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # 배치 크기 1
+outputs = model(**inputs, labels=labels)
+```
+
+`outputs` 객체는 [`~modeling_outputs.SequenceClassifierOutput`]입니다.
+아래 해당 클래스의 문서에서 볼 수 있듯이, `loss`(선택적), `logits`, `hidden_states`(선택적) 및 `attentions`(선택적) 항목이 있습니다. 여기에서는 `labels`를 전달했기 때문에 `loss`가 있지만 `hidden_states`와 `attentions`가 없는데, 이는 `output_hidden_states=True` 또는 `output_attentions=True`를 전달하지 않았기 때문입니다.
+
+
+
+`output_hidden_states=True`를 전달할 때 `outputs.hidden_states[-1]`가 `outputs.last_hidden_state`와 정확히 일치할 것으로 예상할 수 있습니다.
+하지만 항상 그런 것은 아닙니다. 일부 모델은 마지막 은닉 상태가 반환될 때 정규화를 적용하거나 다른 후속 프로세스를 적용합니다.
+
+
+
+
+일반적으로 사용할 때와 동일하게 각 속성들에 접근할 수 있으며, 모델이 해당 속성을 반환하지 않은 경우 `None`이 반환됩니다. 예시에서는 `outputs.loss`는 모델에서 계산한 손실이고 `outputs.attentions`는 `None`입니다.
+
+`outputs` 객체를 튜플로 간주할 때는 `None` 값이 없는 속성만 고려합니다.
+예시에서는 `loss`와 `logits`라는 두 개의 요소가 있습니다. 그러므로,
+
+```python
+outputs[:2]
+```
+
+는 `(outputs.loss, outputs.logits)` 튜플을 반환합니다.
+
+`outputs` 객체를 딕셔너리로 간주할 때는 `None` 값이 없는 속성만 고려합니다.
+예시에는 `loss`와 `logits`라는 두 개의 키가 있습니다.
+
+여기서부터는 두 가지 이상의 모델 유형에서 사용되는 일반 모델 출력을 다룹니다. 구체적인 출력 유형은 해당 모델 페이지에 문서화되어 있습니다.
+
+## ModelOutput[[transformers.utils.ModelOutput]]
+
+[[autodoc]] utils.ModelOutput
+ - to_tuple
+
+## BaseModelOutput[[transformers.BaseModelOutput]]
+
+[[autodoc]] modeling_outputs.BaseModelOutput
+
+## BaseModelOutputWithPooling[[transformers.modeling_outputs.BaseModelOutputWithPooling]]
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPooling
+
+## BaseModelOutputWithCrossAttentions[[transformers.modeling_outputs.BaseModelOutputWithCrossAttentions]]
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithCrossAttentions
+
+## BaseModelOutputWithPoolingAndCrossAttentions[[transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions]]
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
+
+## BaseModelOutputWithPast[[transformers.modeling_outputs.BaseModelOutputWithPast]]
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPast
+
+## BaseModelOutputWithPastAndCrossAttentions[[transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions]]
+
+[[autodoc]] modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
+
+## Seq2SeqModelOutput[[transformers.modeling_outputs.Seq2SeqModelOutput]]
+
+[[autodoc]] modeling_outputs.Seq2SeqModelOutput
+
+## CausalLMOutput[[transformers.modeling_outputs.CausalLMOutput]]
+
+[[autodoc]] modeling_outputs.CausalLMOutput
+
+## CausalLMOutputWithCrossAttentions[[transformers.modeling_outputs.CausalLMOutputWithCrossAttentions]]
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithCrossAttentions
+
+## CausalLMOutputWithPast[[transformers.modeling_outputs.CausalLMOutputWithPast]]
+
+[[autodoc]] modeling_outputs.CausalLMOutputWithPast
+
+## MaskedLMOutput[[transformers.modeling_outputs.MaskedLMOutput]]
+
+[[autodoc]] modeling_outputs.MaskedLMOutput
+
+## Seq2SeqLMOutput[[transformers.modeling_outputs.Seq2SeqLMOutput]]
+
+[[autodoc]] modeling_outputs.Seq2SeqLMOutput
+
+## NextSentencePredictorOutput[[transformers.modeling_outputs.NextSentencePredictorOutput]]
+
+[[autodoc]] modeling_outputs.NextSentencePredictorOutput
+
+## SequenceClassifierOutput[[transformers.modeling_outputs.SequenceClassifierOutput]]
+
+[[autodoc]] modeling_outputs.SequenceClassifierOutput
+
+## Seq2SeqSequenceClassifierOutput[[transformers.modeling_outputs.Seq2SeqSequenceClassifierOutput]]
+
+[[autodoc]] modeling_outputs.Seq2SeqSequenceClassifierOutput
+
+## MultipleChoiceModelOutput[[transformers.modeling_outputs.MultipleChoiceModelOutput]]
+
+[[autodoc]] modeling_outputs.MultipleChoiceModelOutput
+
+## TokenClassifierOutput[[transformers.modeling_outputs.TokenClassifierOutput]]
+
+[[autodoc]] modeling_outputs.TokenClassifierOutput
+
+## QuestionAnsweringModelOutput[[transformers.modeling_outputs.QuestionAnsweringModelOutput]]
+
+[[autodoc]] modeling_outputs.QuestionAnsweringModelOutput
+
+## Seq2SeqQuestionAnsweringModelOutput[[transformers.modeling_outputs.Seq2SeqQuestionAnsweringModelOutput]]
+
+[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
+
+## Seq2SeqSpectrogramOutput[[transformers.modeling_outputs.Seq2SeqSpectrogramOutput]]
+
+[[autodoc]] modeling_outputs.Seq2SeqSpectrogramOutput
+
+## SemanticSegmenterOutput[[transformers.modeling_outputs.SemanticSegmenterOutput]]
+
+[[autodoc]] modeling_outputs.SemanticSegmenterOutput
+
+## ImageClassifierOutput[[transformers.modeling_outputs.ImageClassifierOutput]]
+
+[[autodoc]] modeling_outputs.ImageClassifierOutput
+
+## ImageClassifierOutputWithNoAttention[[transformers.modeling_outputs.ImageClassifierOutputWithNoAttention]]
+
+[[autodoc]] modeling_outputs.ImageClassifierOutputWithNoAttention
+
+## DepthEstimatorOutput[[transformers.modeling_outputs.DepthEstimatorOutput]]
+
+[[autodoc]] modeling_outputs.DepthEstimatorOutput
+
+## Wav2Vec2BaseModelOutput[[transformers.modeling_outputs.Wav2Vec2BaseModelOutput]]
+
+[[autodoc]] modeling_outputs.Wav2Vec2BaseModelOutput
+
+## XVectorOutput[[transformers.modeling_outputs.XVectorOutput]]
+
+[[autodoc]] modeling_outputs.XVectorOutput
+
+## Seq2SeqTSModelOutput[[transformers.modeling_outputs.Seq2SeqTSModelOutput]]
+
+[[autodoc]] modeling_outputs.Seq2SeqTSModelOutput
+
+## Seq2SeqTSPredictionOutput[[transformers.modeling_outputs.Seq2SeqTSPredictionOutput]]
+
+[[autodoc]] modeling_outputs.Seq2SeqTSPredictionOutput
+
+## SampleTSPredictionOutput[[transformers.modeling_outputs.SampleTSPredictionOutput]]
+
+[[autodoc]] modeling_outputs.SampleTSPredictionOutput
+
+## TFBaseModelOutput[[transformers.modeling_outputs.TFBaseModelOutput]]
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutput
+
+## TFBaseModelOutputWithPooling[[transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling]]
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPooling
+
+## TFBaseModelOutputWithPoolingAndCrossAttentions[[transformers.modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions]]
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions
+
+## TFBaseModelOutputWithPast[[transformers.modeling_tf_outputs.TFBaseModelOutputWithPast]]
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPast
+
+## TFBaseModelOutputWithPastAndCrossAttentions[[transformers.modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions]]
+
+[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions
+
+## TFSeq2SeqModelOutput[[transformers.modeling_tf_outputs.TFSeq2SeqModelOutput]]
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqModelOutput
+
+## TFCausalLMOutput[[transformers.modeling_tf_outputs.TFCausalLMOutput]]
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutput
+
+## TFCausalLMOutputWithCrossAttentions[[transformers.modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions]]
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions
+
+## TFCausalLMOutputWithPast[[transformers.modeling_tf_outputs.TFCausalLMOutputWithPast]]
+
+[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithPast
+
+## TFMaskedLMOutput[[transformers.modeling_tf_outputs.TFMaskedLMOutput]]
+
+[[autodoc]] modeling_tf_outputs.TFMaskedLMOutput
+
+## TFSeq2SeqLMOutput[[transformers.modeling_tf_outputs.TFSeq2SeqLMOutput]]
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqLMOutput
+
+## TFNextSentencePredictorOutput[[transformers.modeling_tf_outputs.TFNextSentencePredictorOutput]]
+
+[[autodoc]] modeling_tf_outputs.TFNextSentencePredictorOutput
+
+## TFSequenceClassifierOutput[[transformers.modeling_tf_outputs.TFSequenceClassifierOutput]]
+
+[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutput
+
+## TFSeq2SeqSequenceClassifierOutput[[transformers.modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput]]
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput
+
+## TFMultipleChoiceModelOutput[[transformers.modeling_tf_outputs.TFMultipleChoiceModelOutput]]
+
+[[autodoc]] modeling_tf_outputs.TFMultipleChoiceModelOutput
+
+## TFTokenClassifierOutput[[transformers.modeling_tf_outputs.TFTokenClassifierOutput]]
+
+[[autodoc]] modeling_tf_outputs.TFTokenClassifierOutput
+
+## TFQuestionAnsweringModelOutput[[transformers.modeling_tf_outputs.TFQuestionAnsweringModelOutput]]
+
+[[autodoc]] modeling_tf_outputs.TFQuestionAnsweringModelOutput
+
+## TFSeq2SeqQuestionAnsweringModelOutput[[transformers.modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput]]
+
+[[autodoc]] modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput
+
+## FlaxBaseModelOutput[[transformers.modeling_flax_outputs.FlaxBaseModelOutput]]
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutput
+
+## FlaxBaseModelOutputWithPast[[transformers.modeling_flax_outputs.FlaxBaseModelOutputWithPast]]
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPast
+
+## FlaxBaseModelOutputWithPooling[[transformers.modeling_flax_outputs.FlaxBaseModelOutputWithPooling]]
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPooling
+
+## FlaxBaseModelOutputWithPastAndCrossAttentions[[transformers.modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions]]
+
+[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions
+
+## FlaxSeq2SeqModelOutput[[transformers.modeling_flax_outputs.FlaxSeq2SeqModelOutput]]
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqModelOutput
+
+## FlaxCausalLMOutputWithCrossAttentions[[transformers.modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions]]
+
+[[autodoc]] modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions
+
+## FlaxMaskedLMOutput[[transformers.modeling_flax_outputs.FlaxMaskedLMOutput]]
+
+[[autodoc]] modeling_flax_outputs.FlaxMaskedLMOutput
+
+## FlaxSeq2SeqLMOutput[[transformers.modeling_flax_outputs.FlaxSeq2SeqLMOutput]]
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqLMOutput
+
+## FlaxNextSentencePredictorOutput[[transformers.modeling_flax_outputs.FlaxNextSentencePredictorOutput]]
+
+[[autodoc]] modeling_flax_outputs.FlaxNextSentencePredictorOutput
+
+## FlaxSequenceClassifierOutput[[transformers.modeling_flax_outputs.FlaxSequenceClassifierOutput]]
+
+[[autodoc]] modeling_flax_outputs.FlaxSequenceClassifierOutput
+
+## FlaxSeq2SeqSequenceClassifierOutput[[transformers.modeling_flax_outputs.FlaxSeq2SeqSequenceClassifierOutput]]
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqSequenceClassifierOutput
+
+## FlaxMultipleChoiceModelOutput[[transformers.modeling_flax_outputs.FlaxMultipleChoiceModelOutput]]
+
+[[autodoc]] modeling_flax_outputs.FlaxMultipleChoiceModelOutput
+
+## FlaxTokenClassifierOutput[[transformers.modeling_flax_outputs.FlaxTokenClassifierOutput]]
+
+[[autodoc]] modeling_flax_outputs.FlaxTokenClassifierOutput
+
+## FlaxQuestionAnsweringModelOutput[[transformers.modeling_flax_outputs.FlaxQuestionAnsweringModelOutput]]
+
+[[autodoc]] modeling_flax_outputs.FlaxQuestionAnsweringModelOutput
+
+## FlaxSeq2SeqQuestionAnsweringModelOutput[[transformers.modeling_flax_outputs.FlaxSeq2SeqQuestionAnsweringModelOutput]]
+
+[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqQuestionAnsweringModelOutput
diff --git a/docs/transformers/docs/source/ko/main_classes/quantization.md b/docs/transformers/docs/source/ko/main_classes/quantization.md
new file mode 100644
index 0000000000000000000000000000000000000000..6f793f2210741788cf67a2e2a8232c654ea77484
--- /dev/null
+++ b/docs/transformers/docs/source/ko/main_classes/quantization.md
@@ -0,0 +1,75 @@
+
+
+# 양자화[[quantization]]
+
+
+
+양자화 기법은 가중치와 활성화를 8비트 정수(int8)와 같은 더 낮은 정밀도의 데이터 타입으로 표현함으로써 메모리와 계산 비용을 줄입니다. 이를 통해 일반적으로는 메모리에 올릴 수 없는 더 큰 모델을 로드할 수 있고, 추론 속도를 높일 수 있습니다. Transformers는 AWQ와 GPTQ 양자화 알고리즘을 지원하며, bitsandbytes를 통해 8비트와 4비트 양자화를 지원합니다.
+Transformers에서 지원되지 않는 양자화 기법들은 [`HfQuantizer`] 클래스를 통해 추가될 수 있습니다.
+
+
+
+모델을 양자화하는 방법은 이 [양자화](../quantization) 가이드를 통해 배울 수 있습니다.
+
+
+
+## QuantoConfig[[transformers.QuantoConfig]]
+
+[[autodoc]] QuantoConfig
+
+## AqlmConfig[[transformers.AqlmConfig]]
+
+[[autodoc]] AqlmConfig
+
+## VptqConfig[[transformers.VptqConfig]]
+
+[[autodoc]] VptqConfig
+
+## AwqConfig[[transformers.AwqConfig]]
+
+[[autodoc]] AwqConfig
+
+## EetqConfig[[transformers.EetqConfig]]
+[[autodoc]] EetqConfig
+
+## GPTQConfig[[transformers.GPTQConfig]]
+
+[[autodoc]] GPTQConfig
+
+## BitsAndBytesConfig[[#transformers.BitsAndBytesConfig]]
+
+[[autodoc]] BitsAndBytesConfig
+
+## HfQuantizer[[transformers.quantizers.HfQuantizer]]
+
+[[autodoc]] quantizers.base.HfQuantizer
+
+## HqqConfig[[transformers.HqqConfig]]
+
+[[autodoc]] HqqConfig
+
+## FbgemmFp8Config[[transformers.FbgemmFp8Config]]
+
+[[autodoc]] FbgemmFp8Config
+
+## CompressedTensorsConfig[[transformers.CompressedTensorsConfig]]
+
+[[autodoc]] CompressedTensorsConfig
+
+## TorchAoConfig[[transformers.TorchAoConfig]]
+
+[[autodoc]] TorchAoConfig
diff --git a/docs/transformers/docs/source/ko/main_classes/text_generation.md b/docs/transformers/docs/source/ko/main_classes/text_generation.md
new file mode 100644
index 0000000000000000000000000000000000000000..917d995e6ec15c4a642e2c3bf4c5fc7b865fdb85
--- /dev/null
+++ b/docs/transformers/docs/source/ko/main_classes/text_generation.md
@@ -0,0 +1,56 @@
+
+
+# 생성 [[generation]]
+
+각 프레임워크에는 해당하는 `GenerationMixin` 클래스에서 구현된 텍스트 생성을 위한 generate 메소드가 있습니다:
+
+- PyTorch에서는 [`~generation.GenerationMixin.generate`]가 [`~generation.GenerationMixin`]에 구현되어 있습니다.
+- TensorFlow에서는 [`~generation.TFGenerationMixin.generate`]가 [`~generation.TFGenerationMixin`]에 구현되어 있습니다.
+- Flax/JAX에서는 [`~generation.FlaxGenerationMixin.generate`]가 [`~generation.FlaxGenerationMixin`]에 구현되어 있습니다.
+
+사용하는 프레임워크에 상관없이, generate 메소드는 [`~generation.GenerationConfig`] 클래스 인스턴스로 매개변수화 할 수 있습니다. generate 메소드의 동작을 제어하는 모든 생성 매개변수 목록을 확인하려면 이 클래스를 참조하세요.
+
+모델의 생성 설정을 어떻게 확인하고, 기본값이 무엇인지, 매개변수를 어떻게 임시로 변경하는지, 그리고 사용자 지정 생성 설정을 만들고 저장하는 방법을 배우려면 [텍스트 생성 전략 가이드](../generation_strategies)를 참조하세요. 이 가이드는 토큰 스트리밍과 같은 관련 기능을 사용하는 방법도 설명합니다.
+
+## GenerationConfig [[transformers.GenerationConfig]]
+
+[[autodoc]] generation.GenerationConfig
+ - from_pretrained
+ - from_model_config
+ - save_pretrained
+ - update
+ - validate
+ - get_generation_mode
+
+[[autodoc]] generation.WatermarkingConfig
+
+## GenerationMixin [[transformers.GenerationMixin]]
+
+[[autodoc]] generation.GenerationMixin
+ - generate
+ - compute_transition_scores
+
+## TFGenerationMixin [[transformers.TFGenerationMixin]]
+
+[[autodoc]] generation.TFGenerationMixin
+ - generate
+ - compute_transition_scores
+
+## FlaxGenerationMixin [[transformers.FlaxGenerationMixin]]
+
+[[autodoc]] generation.FlaxGenerationMixin
+ - generate
diff --git a/docs/transformers/docs/source/ko/main_classes/trainer.md b/docs/transformers/docs/source/ko/main_classes/trainer.md
new file mode 100644
index 0000000000000000000000000000000000000000..23eda74a8bd669c16fcb3ebdbd21ea7cd8d6cd65
--- /dev/null
+++ b/docs/transformers/docs/source/ko/main_classes/trainer.md
@@ -0,0 +1,52 @@
+
+
+# Trainer [[trainer]]
+
+[`Trainer`] 클래스는 PyTorch에서 완전한 기능(feature-complete)의 훈련을 위한 API를 제공하며, 다중 GPU/TPU에서의 분산 훈련, [NVIDIA GPU](https://nvidia.github.io/apex/), [AMD GPU](https://rocm.docs.amd.com/en/latest/rocm.html)를 위한 혼합 정밀도, 그리고 PyTorch의 [`torch.amp`](https://pytorch.org/docs/stable/amp.html)를 지원합니다. [`Trainer`]는 모델의 훈련 방식을 커스터마이즈할 수 있는 다양한 옵션을 제공하는 [`TrainingArguments`] 클래스와 함께 사용됩니다. 이 두 클래스는 함께 완전한 훈련 API를 제공합니다.
+
+[`Seq2SeqTrainer`]와 [`Seq2SeqTrainingArguments`]는 [`Trainer`]와 [`TrainingArguments`] 클래스를 상속하며, 요약이나 번역과 같은 시퀀스-투-시퀀스 작업을 위한 모델 훈련에 적합하게 조정되어 있습니다.
+
+
+
+[`Trainer`] 클래스는 🤗 Transformers 모델에 최적화되어 있으며, 다른 모델과 함께 사용될 때 예상치 못한 동작을 하게 될 수 있습니다. 자신만의 모델을 사용할 때는 다음을 확인하세요:
+
+- 모델은 항상 튜플이나 [`~utils.ModelOutput`]의 서브클래스를 반환해야 합니다.
+- 모델은 `labels` 인자가 제공되면 손실을 계산할 수 있고, 모델이 튜플을 반환하는 경우 그 손실이 튜플의 첫 번째 요소로 반환되어야 합니다.
+- 모델은 여러 개의 레이블 인자를 수용할 수 있어야 하며, [`Trainer`]에게 이름을 알리기 위해 [`TrainingArguments`]에서 `label_names`를 사용하지만, 그 중 어느 것도 `"label"`로 명명되어서는 안 됩니다.
+
+
+
+## Trainer [[transformers.Trainer]]
+
+[[autodoc]] Trainer
+ - all
+
+## Seq2SeqTrainer [[transformers.Seq2SeqTrainer]]
+
+[[autodoc]] Seq2SeqTrainer
+ - evaluate
+ - predict
+
+## TrainingArguments [[transformers.TrainingArguments]]
+
+[[autodoc]] TrainingArguments
+ - all
+
+## Seq2SeqTrainingArguments [[transformers.Seq2SeqTrainingArguments]]
+
+[[autodoc]] Seq2SeqTrainingArguments
+ - all
diff --git a/docs/transformers/docs/source/ko/model_doc/altclip.md b/docs/transformers/docs/source/ko/model_doc/altclip.md
new file mode 100644
index 0000000000000000000000000000000000000000..1236bcc9aaa7da8da5fb4820bb87b3f9413cb805
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/altclip.md
@@ -0,0 +1,78 @@
+# AltCLIP
+
+## 개요[[overview]]
+
+AltCLIP 모델은 Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu의 [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679v2) 논문에서 제안되었습니다. AltCLIP(CLIP의 언어 인코더를 변경하여 언어 기능 확장)은 다양한 이미지-텍스트 및 텍스트-텍스트 쌍으로 훈련된 신경망입니다. CLIP의 텍스트 인코더를 사전 훈련된 다국어 텍스트 인코더 XLM-R로 교체하여, 거의 모든 작업에서 CLIP과 유사한 성능을 얻을 수 있었으며, 원래 CLIP의 다국어 이해와 같은 기능도 확장되었습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*본 연구에서는 강력한 이중 언어 멀티모달 표현 모델을 훈련하는 개념적으로 간단하고 효과적인 방법을 제시합니다. OpenAI에서 출시한 사전 훈련된 멀티모달 표현 모델 CLIP에서 시작하여, 그 텍스트 인코더를 사전 훈련된 다국어 텍스트 인코더 XLM-R로 교체하고, 교사 학습과 대조 학습으로 구성된 2단계 훈련 스키마를 통해 언어와 이미지 표현을 정렬했습니다. 우리는 광범위한 작업 평가를 통해 우리의 방법을 검증했습니다. ImageNet-CN, Flicker30k-CN, COCO-CN을 포함한 여러 작업에서 새로운 최고 성능을 달성했으며, 거의 모든 작업에서 CLIP과 유사한 성능을 얻었습니다. 이는 CLIP의 텍스트 인코더를 단순히 변경하여 다국어 이해와 같은 확장 기능을 얻을 수 있음을 시사합니다.*
+
+이 모델은 [jongjyh](https://huggingface.co/jongjyh)에 의해 기여되었습니다.
+
+## 사용 팁과 예제[[usage-tips-and-example]]
+
+AltCLIP의 사용법은 CLIP과 매우 유사하며, 차이점은 텍스트 인코더에 있습니다. 일반적인 어텐션 대신 양방향 어텐션을 사용하며, XLM-R의 [CLS] 토큰을 사용하여 텍스트 임베딩을 나타냅니다.
+
+AltCLIP은 멀티모달 비전 및 언어 모델입니다. 이미지와 텍스트 간의 유사성 계산 및 제로샷 이미지 분류에 사용할 수 있습니다. AltCLIP은 ViT와 같은 트랜스포머를 사용하여 시각적 특징을 얻고, 양방향 언어 모델을 사용하여 텍스트 특징을 얻습니다. 이후 텍스트와 시각적 특징 모두 동일한 차원의 잠재 공간으로 투사됩니다. 투사된 이미지와 텍스트 특징 간의 내적을 유사도 점수로 사용합니다.
+
+이미지를 트랜스포머 인코더에 입력하기 위해, 각 이미지를 일정한 크기의 겹치지 않는 패치 시퀀스로 분할한 뒤, 이를 선형 임베딩합니다. 전체 이미지를 나타내기 위해 [CLS] 토큰이 추가됩니다. 저자들은 절대 위치 임베딩도 추가하여 결과 벡터 시퀀스를 표준 트랜스포머 인코더에 입력합니다. [`CLIPImageProcessor`]는 모델을 위해 이미지를 크기 조정하고 정규화하는 데 사용할 수 있습니다.
+
+[`AltCLIPProcessor`]는 [`CLIPImageProcessor`]와 [`XLMRobertaTokenizer`]를 하나의 인스턴스로 묶어 텍스트를 인코딩하고 이미지를 준비합니다. 다음 예제는 [`AltCLIPProcessor`]와 [`AltCLIPModel`]을 사용하여 이미지와 텍스트 간의 유사성 점수를 얻는 방법을 보여줍니다.
+```python
+>>> from PIL import Image
+>>> import requests
+
+>>> from transformers import AltCLIPModel, AltCLIPProcessor
+
+>>> model = AltCLIPModel.from_pretrained("BAAI/AltCLIP")
+>>> processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
+
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # 이미지-텍스트 유사도 점수
+>>> probs = logits_per_image.softmax(dim=1) # 라벨 마다 확률을 얻기 위해 softmax 적용
+```
+
+
+이 모델은 `CLIPModel`을 기반으로 하므로, 원래 CLIP처럼 사용할 수 있습니다.
+
+
+
+## AltCLIPConfig
+
+[[autodoc]] AltCLIPConfig
+ - from_text_vision_configs
+
+## AltCLIPTextConfig
+
+[[autodoc]] AltCLIPTextConfig
+
+## AltCLIPVisionConfig
+
+[[autodoc]] AltCLIPVisionConfig
+
+## AltCLIPProcessor
+
+[[autodoc]] AltCLIPProcessor
+
+## AltCLIPModel
+
+[[autodoc]] AltCLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## AltCLIPTextModel
+
+[[autodoc]] AltCLIPTextModel
+ - forward
+
+## AltCLIPVisionModel
+
+[[autodoc]] AltCLIPVisionModel
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/auto.md b/docs/transformers/docs/source/ko/model_doc/auto.md
new file mode 100644
index 0000000000000000000000000000000000000000..cda00adc33a663c1b426a61f10ace8d708936da8
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/auto.md
@@ -0,0 +1,375 @@
+
+
+# Auto 클래스[[auto-classes]]
+
+많은 경우, 사용하려는 아키텍처는 `from_pretrained()` 메소드에서 제공하는 사전 훈련된 모델의 이름이나 경로로부터 유추할 수 있습니다. AutoClasses는 이 작업을 위해 존재하며, 사전 학습된 모델 가중치/구성/단어사전에 대한 이름/경로를 제공하면 자동으로 관련 모델을 가져오도록 도와줍니다.
+
+[`AutoConfig`], [`AutoModel`], [`AutoTokenizer`] 중 하나를 인스턴스화하면 해당 아키텍처의 클래스를 직접 생성합니다. 예를 들어,
+
+
+```python
+model = AutoModel.from_pretrained("google-bert/bert-base-cased")
+```
+
+위 코드는 [`BertModel`]의 인스턴스인 모델을 생성합니다.
+
+각 작업에 대해 하나의 `AutoModel` 클래스가 있으며, 각각의 백엔드(PyTorch, TensorFlow 또는 Flax)에 해당하는 클래스가 존재합니다.
+
+## 자동 클래스 확장[[extending-the-auto-classes]]
+
+각 자동 클래스는 사용자의 커스텀 클래스로 확장될 수 있는 메소드를 가지고 있습니다. 예를 들어, `NewModel`이라는 커스텀 모델 클래스를 정의했다면, `NewModelConfig`를 준비한 후 다음과 같이 자동 클래스에 추가할 수 있습니다:
+
+```python
+from transformers import AutoConfig, AutoModel
+
+AutoConfig.register("new-model", NewModelConfig)
+AutoModel.register(NewModelConfig, NewModel)
+```
+
+이후에는 일반적으로 자동 클래스를 사용하는 것처럼 사용할 수 있습니다!
+
+
+
+만약 `NewModelConfig`가 [`~transformers.PretrainedConfig`]의 서브클래스라면, 해당 `model_type` 속성이 등록할 때 사용하는 키(여기서는 `"new-model"`)와 동일하게 설정되어 있는지 확인하세요.
+
+마찬가지로, `NewModel`이 [`PreTrainedModel`]의 서브클래스라면, 해당 `config_class` 속성이 등록할 때 사용하는 클래스(여기서는 `NewModelConfig`)와 동일하게 설정되어 있는지 확인하세요.
+
+
+
+## AutoConfig[[transformers.AutoConfig]]
+
+[[autodoc]] AutoConfig
+
+## AutoTokenizer[[transformers.AutoTokenizer]]
+
+[[autodoc]] AutoTokenizer
+
+## AutoFeatureExtractor[[transformers.AutoFeatureExtractor]]
+
+[[autodoc]] AutoFeatureExtractor
+
+## AutoImageProcessor[[transformers.AutoImageProcessor]]
+
+[[autodoc]] AutoImageProcessor
+
+## AutoProcessor[[transformers.AutoProcessor]]
+
+[[autodoc]] AutoProcessor
+
+## 일반적인 모델 클래스[[generic-model-classes]]
+
+다음 자동 클래스들은 특정 헤드 없이 기본 모델 클래스를 인스턴스화하는 데 사용할 수 있습니다.
+
+### AutoModel[[transformers.AutoModel]]
+
+[[autodoc]] AutoModel
+
+### TFAutoModel[[transformers.TFAutoModel]]
+
+[[autodoc]] TFAutoModel
+
+### FlaxAutoModel[[transformers.FlaxAutoModel]]
+
+[[autodoc]] FlaxAutoModel
+
+## 일반적인 사전 학습 클래스[[generic-pretraining-classes]]
+
+다음 자동 클래스들은 사전 훈련 헤드가 포함된 모델을 인스턴스화하는 데 사용할 수 있습니다.
+
+### AutoModelForPreTraining[[transformers.AutoModelForPreTraining]]
+
+[[autodoc]] AutoModelForPreTraining
+
+### TFAutoModelForPreTraining[[transformers.TFAutoModelForPreTraining]]
+
+[[autodoc]] TFAutoModelForPreTraining
+
+### FlaxAutoModelForPreTraining[[transformers.FlaxAutoModelForPreTraining]]
+
+[[autodoc]] FlaxAutoModelForPreTraining
+
+## 자연어 처리[[natural-language-processing]]
+
+다음 자동 클래스들은 아래의 자연어 처리 작업에 사용할 수 있습니다.
+
+### AutoModelForCausalLM[[transformers.AutoModelForCausalLM]]
+
+[[autodoc]] AutoModelForCausalLM
+
+### TFAutoModelForCausalLM[[transformers.TFAutoModelForCausalLM]]
+
+[[autodoc]] TFAutoModelForCausalLM
+
+### FlaxAutoModelForCausalLM[[transformers.FlaxAutoModelForCausalLM]]
+
+[[autodoc]] FlaxAutoModelForCausalLM
+
+### AutoModelForMaskedLM[[transformers.AutoModelForMaskedLM]]
+
+[[autodoc]] AutoModelForMaskedLM
+
+### TFAutoModelForMaskedLM[[transformers.TFAutoModelForMaskedLM]]
+
+[[autodoc]] TFAutoModelForMaskedLM
+
+### FlaxAutoModelForMaskedLM[[transformers.FlaxAutoModelForMaskedLM]]
+
+[[autodoc]] FlaxAutoModelForMaskedLM
+
+### AutoModelForMaskGeneration[[transformers.AutoModelForMaskGeneration]]
+
+[[autodoc]] AutoModelForMaskGeneration
+
+### TFAutoModelForMaskGeneration[[transformers.TFAutoModelForMaskGeneration]]
+
+[[autodoc]] TFAutoModelForMaskGeneration
+
+### AutoModelForSeq2SeqLM[[transformers.AutoModelForSeq2SeqLM]]
+
+[[autodoc]] AutoModelForSeq2SeqLM
+
+### TFAutoModelForSeq2SeqLM[[transformers.TFAutoModelForSeq2SeqLM]]
+
+[[autodoc]] TFAutoModelForSeq2SeqLM
+
+### FlaxAutoModelForSeq2SeqLM[[transformers.FlaxAutoModelForSeq2SeqLM]]
+
+[[autodoc]] FlaxAutoModelForSeq2SeqLM
+
+### AutoModelForSequenceClassification[[transformers.AutoModelForSequenceClassification]]
+
+[[autodoc]] AutoModelForSequenceClassification
+
+### TFAutoModelForSequenceClassification[[transformers.TFAutoModelForSequenceClassification]]
+
+[[autodoc]] TFAutoModelForSequenceClassification
+
+### FlaxAutoModelForSequenceClassification[[transformers.FlaxAutoModelForSequenceClassification]]
+
+[[autodoc]] FlaxAutoModelForSequenceClassification
+
+### AutoModelForMultipleChoice[[transformers.AutoModelForMultipleChoice]]
+
+[[autodoc]] AutoModelForMultipleChoice
+
+### TFAutoModelForMultipleChoice[[transformers.TFAutoModelForMultipleChoice]]
+
+[[autodoc]] TFAutoModelForMultipleChoice
+
+### FlaxAutoModelForMultipleChoice[[transformers.FlaxAutoModelForMultipleChoice]]
+
+[[autodoc]] FlaxAutoModelForMultipleChoice
+
+### AutoModelForNextSentencePrediction[[transformers.AutoModelForNextSentencePrediction]]
+
+[[autodoc]] AutoModelForNextSentencePrediction
+
+### TFAutoModelForNextSentencePrediction[[transformers.TFAutoModelForNextSentencePrediction]]
+
+[[autodoc]] TFAutoModelForNextSentencePrediction
+
+### FlaxAutoModelForNextSentencePrediction[[transformers.FlaxAutoModelForNextSentencePrediction]]
+
+[[autodoc]] FlaxAutoModelForNextSentencePrediction
+
+### AutoModelForTokenClassification[[transformers.AutoModelForTokenClassification]]
+
+[[autodoc]] AutoModelForTokenClassification
+
+### TFAutoModelForTokenClassification[[transformers.TFAutoModelForTokenClassification]]
+
+[[autodoc]] TFAutoModelForTokenClassification
+
+### FlaxAutoModelForTokenClassification[[transformers.FlaxAutoModelForTokenClassification]]
+
+[[autodoc]] FlaxAutoModelForTokenClassification
+
+### AutoModelForQuestionAnswering[[transformers.AutoModelForQuestionAnswering]]
+
+[[autodoc]] AutoModelForQuestionAnswering
+
+### TFAutoModelForQuestionAnswering[[transformers.TFAutoModelForQuestionAnswering]]
+
+[[autodoc]] TFAutoModelForQuestionAnswering
+
+### FlaxAutoModelForQuestionAnswering[[transformers.FlaxAutoModelForQuestionAnswering]]
+
+[[autodoc]] FlaxAutoModelForQuestionAnswering
+
+### AutoModelForTextEncoding[[transformers.AutoModelForTextEncoding]]
+
+[[autodoc]] AutoModelForTextEncoding
+
+### TFAutoModelForTextEncoding[[transformers.TFAutoModelForTextEncoding]]
+
+[[autodoc]] TFAutoModelForTextEncoding
+
+## 컴퓨터 비전[[computer-vision]]
+
+다음 자동 클래스들은 아래의 컴퓨터 비전 작업에 사용할 수 있습니다.
+
+### AutoModelForDepthEstimation[[transformers.AutoModelForDepthEstimation]]
+
+[[autodoc]] AutoModelForDepthEstimation
+
+### AutoModelForImageClassification[[transformers.AutoModelForImageClassification]]
+
+[[autodoc]] AutoModelForImageClassification
+
+### TFAutoModelForImageClassification[[transformers.TFAutoModelForImageClassification]]
+
+[[autodoc]] TFAutoModelForImageClassification
+
+### FlaxAutoModelForImageClassification[[transformers.FlaxAutoModelForImageClassification]]
+
+[[autodoc]] FlaxAutoModelForImageClassification
+
+### AutoModelForVideoClassification[[transformers.AutoModelForVideoClassification]]
+
+[[autodoc]] AutoModelForVideoClassification
+
+### AutoModelForKeypointDetection[[transformers.AutoModelForKeypointDetection]]
+
+[[autodoc]] AutoModelForKeypointDetection
+
+### AutoModelForMaskedImageModeling[[transformers.AutoModelForMaskedImageModeling]]
+
+[[autodoc]] AutoModelForMaskedImageModeling
+
+### TFAutoModelForMaskedImageModeling[[transformers.TFAutoModelForMaskedImageModeling]]
+
+[[autodoc]] TFAutoModelForMaskedImageModeling
+
+### AutoModelForObjectDetection[[transformers.AutoModelForObjectDetection]]
+
+[[autodoc]] AutoModelForObjectDetection
+
+### AutoModelForImageSegmentation[[transformers.AutoModelForImageSegmentation]]
+
+[[autodoc]] AutoModelForImageSegmentation
+
+### AutoModelForImageToImage[[transformers.AutoModelForImageToImage]]
+
+[[autodoc]] AutoModelForImageToImage
+
+### AutoModelForSemanticSegmentation[[transformers.AutoModelForSemanticSegmentation]]
+
+[[autodoc]] AutoModelForSemanticSegmentation
+
+### TFAutoModelForSemanticSegmentation[[transformers.TFAutoModelForSemanticSegmentation]]
+
+[[autodoc]] TFAutoModelForSemanticSegmentation
+
+### AutoModelForInstanceSegmentation[[transformers.AutoModelForInstanceSegmentation]]
+
+[[autodoc]] AutoModelForInstanceSegmentation
+
+### AutoModelForUniversalSegmentation[[transformers.AutoModelForUniversalSegmentation]]
+
+[[autodoc]] AutoModelForUniversalSegmentation
+
+### AutoModelForZeroShotImageClassification[[transformers.AutoModelForZeroShotImageClassification]]
+
+[[autodoc]] AutoModelForZeroShotImageClassification
+
+### TFAutoModelForZeroShotImageClassification[[transformers.TFAutoModelForZeroShotImageClassification]]
+
+[[autodoc]] TFAutoModelForZeroShotImageClassification
+
+### AutoModelForZeroShotObjectDetection[[transformers.AutoModelForZeroShotObjectDetection]]
+
+[[autodoc]] AutoModelForZeroShotObjectDetection
+
+## 오디오[[audio]]
+
+다음 자동 클래스들은 아래의 오디오 작업에 사용할 수 있습니다.
+
+### AutoModelForAudioClassification[[transformers.AutoModelForAudioClassification]]
+
+[[autodoc]] AutoModelForAudioClassification
+
+### TFAutoModelForAudioClassification[[transformers.TFAutoModelForAudioClassification]]
+
+[[autodoc]] TFAutoModelForAudioClassification
+
+### AutoModelForAudioFrameClassification[[transformers.AutoModelForAudioFrameClassification]]
+
+[[autodoc]] AutoModelForAudioFrameClassification
+
+### AutoModelForCTC[[transformers.AutoModelForCTC]]
+
+[[autodoc]] AutoModelForCTC
+
+### AutoModelForSpeechSeq2Seq[[transformers.AutoModelForSpeechSeq2Seq]]
+
+[[autodoc]] AutoModelForSpeechSeq2Seq
+
+### TFAutoModelForSpeechSeq2Seq[[transformers.TFAutoModelForSpeechSeq2Seq]]
+
+[[autodoc]] TFAutoModelForSpeechSeq2Seq
+
+### FlaxAutoModelForSpeechSeq2Seq[[transformers.FlaxAutoModelForSpeechSeq2Seq]]
+
+[[autodoc]] FlaxAutoModelForSpeechSeq2Seq
+
+### AutoModelForAudioXVector[[transformers.AutoModelForAudioXVector]]
+
+[[autodoc]] AutoModelForAudioXVector
+
+### AutoModelForTextToSpectrogram[[transformers.AutoModelForTextToSpectrogram]]
+
+[[autodoc]] AutoModelForTextToSpectrogram
+
+### AutoModelForTextToWaveform[[transformers.AutoModelForTextToWaveform]]
+
+[[autodoc]] AutoModelForTextToWaveform
+
+## 멀티모달[[multimodal]]
+
+다음 자동 클래스들은 아래의 멀티모달 작업에 사용할 수 있습니다.
+
+### AutoModelForTableQuestionAnswering[[transformers.AutoModelForTableQuestionAnswering]]
+
+[[autodoc]] AutoModelForTableQuestionAnswering
+
+### TFAutoModelForTableQuestionAnswering[[transformers.TFAutoModelForTableQuestionAnswering]]
+
+[[autodoc]] TFAutoModelForTableQuestionAnswering
+
+### AutoModelForDocumentQuestionAnswering[[transformers.AutoModelForDocumentQuestionAnswering]]
+
+[[autodoc]] AutoModelForDocumentQuestionAnswering
+
+### TFAutoModelForDocumentQuestionAnswering[[transformers.TFAutoModelForDocumentQuestionAnswering]]
+
+[[autodoc]] TFAutoModelForDocumentQuestionAnswering
+
+### AutoModelForVisualQuestionAnswering[[transformers.AutoModelForVisualQuestionAnswering]]
+
+[[autodoc]] AutoModelForVisualQuestionAnswering
+
+### AutoModelForVision2Seq[[transformers.AutoModelForVision2Seq]]
+
+[[autodoc]] AutoModelForVision2Seq
+
+### TFAutoModelForVision2Seq[[transformers.TFAutoModelForVision2Seq]]
+
+[[autodoc]] TFAutoModelForVision2Seq
+
+### FlaxAutoModelForVision2Seq[[transformers.FlaxAutoModelForVision2Seq]]
+
+[[autodoc]] FlaxAutoModelForVision2Seq
diff --git a/docs/transformers/docs/source/ko/model_doc/autoformer.md b/docs/transformers/docs/source/ko/model_doc/autoformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..e8534ac95c327ab65a1ccc8a3c3fa67fab446344
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/autoformer.md
@@ -0,0 +1,50 @@
+
+
+# Autoformer[[autoformer]]
+
+## 개요[[overview]]
+
+The Autoformer 모델은 Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long가 제안한 [오토포머: 장기 시계열 예측을 위한 자기상관 분해 트랜스포머](https://arxiv.org/abs/2106.13008) 라는 논문에서 소개 되었습니다.
+
+이 모델은 트랜스포머를 심층 분해 아키텍처로 확장하여, 예측 과정에서 추세와 계절성 요소를 점진적으로 분해할 수 있습니다.
+
+해당 논문의 초록입니다:
+
+*예측 시간을 연장하는 것은 극한 기상 조기 경보 및 장기 에너지 소비 계획과 같은 실제 응용 프로그램에 중요한 요구 사항입니다. 본 논문은 시계열의 장기 예측 문제를 연구합니다. 기존의 트랜스포머 기반 모델들은 장거리 종속성을 발견하기 위해 다양한 셀프 어텐션 메커니즘을 채택합니다. 그러나 장기 미래의 복잡한 시간적 패턴으로 인해 모델이 신뢰할 수 있는 종속성을 찾기 어렵습니다. 또한, 트랜스포머는 긴 시계열의 효율성을 위해 점별 셀프 어텐션의 희소 버전을 채택해야 하므로 정보 활용의 병목 현상이 발생합니다. 우리는 트랜스포머를 넘어서 자기상관 메커니즘을 갖춘 새로운 분해 아키텍처인 Autoformer를 설계했습니다. 우리는 시계열 분해의 전처리 관행을 깨고 이를 심층 모델의 기본 내부 블록으로 혁신했습니다. 이 설계는 Autoformer에 복잡한 시계열에 대한 점진적 분해 능력을 부여합니다. 또한, 확률 과정 이론에서 영감을 받아 시계열의 주기성을 기반으로 자기상관 메커니즘을 설계했으며, 이는 하위 시계열 수준에서 종속성 발견과 표현 집계를 수행합니다. 자기상관은 효율성과 정확도 면에서 셀프 어텐션를 능가합니다. 장기 예측에서 Autoformer는 에너지, 교통, 경제, 날씨, 질병 등 5가지 실용적 응용 분야를 포괄하는 6개 벤치마크에서 38%의 상대적 개선으로 최첨단 정확도를 달성했습니다.*
+
+이 모델은 [elisim](https://huggingface.co/elisim)과 [kashif](https://huggingface.co/kashif)에 의해 기여 되었습니다.
+원본 코드는 [이곳](https://github.com/thuml/Autoformer)에서 확인할 수 있습니다.
+
+## 자료[[resources]]
+
+시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다. 여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰 해드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
+
+- HuggingFace 블로그에서 Autoformer 포스트를 확인하세요: [네, 그렇습니다, 트랜스포머는 시계열 예측에 효과적입니다(+ Autoformer)](https://huggingface.co/blog/autoformer)
+
+## AutoformerConfig[[transformers.AutoformerConfig]]
+
+[[autodoc]] AutoformerConfig
+
+## AutoformerModel[[transformers.AutoformerModel]]
+
+[[autodoc]] AutoformerModel
+ - forward
+
+## AutoformerForPrediction[[transformers.AutoformerForPrediction]]
+
+[[autodoc]] AutoformerForPrediction
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/bart.md b/docs/transformers/docs/source/ko/model_doc/bart.md
new file mode 100644
index 0000000000000000000000000000000000000000..0f7636b3cc95c284de5eb5a650b6393c6d0c69bf
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/bart.md
@@ -0,0 +1,217 @@
+
+
+# BART[[bart]]
+
+
+
+## 개요 [[overview]]
+
+Bart 모델은 2019년 10월 29일 Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer가 발표한 [BART: 자연어 생성, 번역, 이해를 위한 잡음 제거 seq2seq 사전 훈련](https://arxiv.org/abs/1910.13461)이라는 논문에서 소개되었습니다.
+
+논문의 초록에 따르면,
+
+- Bart는 양방향 인코더(BERT와 유사)와 왼쪽에서 오른쪽으로 디코딩하는 디코더(GPT와 유사)를 사용하는 표준 seq2seq/기계 번역 아키텍처를 사용합니다.
+- 사전 훈련 작업은 원래 문장의 순서를 무작위로 섞고, 텍스트의 일부 구간을 단일 마스크 토큰으로 대체하는 새로운 인필링(in-filling) 방식을 포함합니다.
+- BART는 특히 텍스트 생성을 위한 미세 조정에 효과적이지만 이해 작업에도 잘 작동합니다. GLUE와 SQuAD에서 비슷한 훈련 리소스로 RoBERTa의 성능과 일치하며, 추상적 대화, 질의응답, 요약 작업 등에서 최대 6 ROUGE 점수의 향상을 보이며 새로운 최고 성능을 달성했습니다.
+
+이 모델은 [sshleifer](https://huggingface.co/sshleifer)에 의해 기여 되었습니다. 저자의 코드는 [이곳](https://github.com/pytorch/fairseq/tree/master/examples/bart)에서 확인할 수 있습니다.
+
+## 사용 팁:[[usage-tips]]
+
+- BART는 절대 위치 임베딩을 사용하는 모델이므로 일반적으로 입력을 왼쪽보다는 오른쪽에 패딩하는 것이 좋습니다.
+- 인코더와 디코더가 있는 seq2seq 모델입니다. 인코더에는 손상된 토큰이(corrupted tokens) 입력되고, 디코더에는 원래 토큰이 입력됩니다(단, 일반적인 트랜스포머 디코더처럼 미래 단어를 숨기는 마스크가 있습니다). 사전 훈련 작업에서 인코더에 적용되는 변환들의 구성은 다음과 같습니다:
+
+사전 훈련 작업에서 인코더에 적용되는 변환들의 구성은 다음과 같습니다:
+
+ * 무작위 토큰 마스킹 (BERT 처럼)
+ * 무작위 토큰 삭제
+ * k개 토큰의 범위를 단일 마스크 토큰으로 마스킹 (0개 토큰의 범위는 마스크 토큰의 삽입을 의미)
+ * 문장 순서 뒤섞기
+ * 특정 토큰에서 시작하도록 문서 회전
+
+## 구현 노트[[implementation-notes]]
+
+- Bart는 시퀀스 분류에 `token_type_ids`를 사용하지 않습니다. 적절하게 나누기 위해서 [`BartTokenizer`]나
+ [`~BartTokenizer.encode`]를 사용합니다.
+- [`BartModel`]의 정방향 전달은 `decoder_input_ids`가 전달되지 않으면 `decoder_input_ids`를 자동으로 생성할 것입니다. 이는 다른 일부 모델링 API와 다른 점입니다. 이 기능의 일반적인 사용 사례는 마스크 채우기(mask filling)입니다.
+- 모델 예측은 `forced_bos_token_id=0`일 때 기존 구현과 동일하게 작동하도록 의도되었습니다. 하지만, [`fairseq.encode`]에 전달하는 문자열이 공백으로 시작할 때만 이 기능이 작동합니다.
+- [`~generation.GenerationMixin.generate`]는 요약과 같은 조건부 생성 작업에 사용되어야 합니다. 자세한 내용은 해당 문서의 예제를 참조하세요.
+- *facebook/bart-large-cnn* 가중치를 로드하는 모델은 `mask_token_id`가 없거나, 마스크 채우기 작업을 수행할 수 없습니다.
+
+## 마스크 채우기[[mask-filling]]
+
+`facebook/bart-base`와 `facebook/bart-large` 체크포인트는 멀티 토큰 마스크를 채우는데 사용될 수 있습니다.
+
+```python
+from transformers import BartForConditionalGeneration, BartTokenizer
+
+model = BartForConditionalGeneration.from_pretrained("facebook/bart-large", forced_bos_token_id=0)
+tok = BartTokenizer.from_pretrained("facebook/bart-large")
+example_english_phrase = "UN Chief Says There Is No in Syria"
+batch = tok(example_english_phrase, return_tensors="pt")
+generated_ids = model.generate(batch["input_ids"])
+assert tok.batch_decode(generated_ids, skip_special_tokens=True) == [
+ "UN Chief Says There Is No Plan to Stop Chemical Weapons in Syria"
+]
+```
+
+## 자료[[resources]]
+
+BART를 시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다. 여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰 해드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
+
+
+
+- [분산형 학습: 🤗 Transformers와 Amazon SageMaker를 이용하여 요약하기 위한 BART/T5 학습](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq)에 대한 블로그 포스트.
+- [blurr를 이용하여 fastai로 요약하기 위한 BART를 미세 조정](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb)하는 방법에 대한 노트북. 🌎
+- [Trainer 클래스를 사용하여 두 가지 언어로 요약하기 위한 BART 미세 조정](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb)하는 방법에 대한 노트북. 🌎
+- 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)에서는 [`BartForConditionalGeneration`]이 지원됩니다.
+- [`TFBartForConditionalGeneration`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)에서 지원됩니다.
+- 이 [예제 스크립트에서는](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization)[`FlaxBartForConditionalGeneration`]이 지원됩니다.
+- Hugging Face `datasets` 객체를 활용하여 [`BartForConditionalGeneration`]을 학습시키는 방법의 예는 이 [포럼 토론](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904)에서 찾을 수 있습니다.
+- 🤗 Hugging Face 코스의 [요약](https://huggingface.co/course/chapter7/5?fw=pt#summarization)장.
+- [요약 작업 가이드](../tasks/summarization)
+
+
+
+- [`BartForConditionalGeneration`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)을 참고하세요.
+- [`TFBartForConditionalGeneration`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)을 참고하세요.
+- [`FlaxBartForConditionalGeneration`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb)을 참고 하세요.
+- 🤗 Hugging Face 코스의 [마스크 언어 모델링](https://huggingface.co/course/chapter7/3?fw=pt) 챕터.
+- [마스크 언어 모델링 작업 가이드](../tasks/masked_language_modeling)
+
+
+
+- [Seq2SeqTrainer를 이용하여 인도어를 영어로 번역하는 mBART를 미세 조정](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb)하는 방법에 대한 가이드. 🌎
+- [`BartForConditionalGeneration`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)을 참고하세요.
+- [`TFBartForConditionalGeneration`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/translation)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)을 참고 하세요.
+- [번역 작업 가이드](../tasks/translation)
+
+추가적으로 볼 것들:
+- [텍스트 분류 작업 가이드](../tasks/sequence_classification)
+- [질문 답변 작업 가이드](../tasks/question_answering)
+- [인과적 언어 모델링 작업 가이드](../tasks/language_modeling)
+- 이 [논문](https://arxiv.org/abs/2010.13002)은 [증류된 체크포인트](https://huggingface.co/models?search=distilbart)에 대해 설명합니다.
+
+## BartConfig[[transformers.BartConfig]]
+
+[[autodoc]] BartConfig
+ - all
+
+## BartTokenizer[[transformers.BartTokenizer]]
+
+[[autodoc]] BartTokenizer
+ - all
+
+## BartTokenizerFast[[transformers.BartTokenizerFast]]
+
+[[autodoc]] BartTokenizerFast
+ - all
+
+
+
+
+
+## BartModel[[transformers.BartModel]]
+
+[[autodoc]] BartModel
+ - forward
+
+## BartForConditionalGeneration[[transformers.BartForConditionalGeneration]]
+
+[[autodoc]] BartForConditionalGeneration
+ - forward
+
+## BartForSequenceClassification[[transformers.BartForSequenceClassification]]
+
+[[autodoc]] BartForSequenceClassification
+ - forward
+
+## BartForQuestionAnswering[[transformers.BartForQuestionAnswering]]
+
+[[autodoc]] BartForQuestionAnswering
+ - forward
+
+## BartForCausalLM[[transformers.BartForCausalLM]]
+
+[[autodoc]] BartForCausalLM
+ - forward
+
+
+
+
+## TFBartModel[[transformers.TFBartModel]]
+
+[[autodoc]] TFBartModel
+ - call
+
+## TFBartForConditionalGeneration[[transformers.TFBartForConditionalGeneration]]
+
+[[autodoc]] TFBartForConditionalGeneration
+ - call
+
+## TFBartForSequenceClassification[[transformers.TFBartForSequenceClassification]]
+
+[[autodoc]] TFBartForSequenceClassification
+ - call
+
+
+
+
+## FlaxBartModel[[transformers.FlaxBartModel]]
+
+[[autodoc]] FlaxBartModel
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForConditionalGeneration[[transformers.FlaxBartForConditionalGeneration]]
+
+[[autodoc]] FlaxBartForConditionalGeneration
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForSequenceClassification[[transformers.FlaxBartForSequenceClassification]]
+
+[[autodoc]] FlaxBartForSequenceClassification
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForQuestionAnswering[[transformers.FlaxBartForQuestionAnswering]]
+
+[[autodoc]] FlaxBartForQuestionAnswering
+ - __call__
+ - encode
+ - decode
+
+## FlaxBartForCausalLM[[transformers.FlaxBartForCausalLM]]
+
+[[autodoc]] FlaxBartForCausalLM
+ - __call__
+
+
+
+
+
diff --git a/docs/transformers/docs/source/ko/model_doc/barthez.md b/docs/transformers/docs/source/ko/model_doc/barthez.md
new file mode 100644
index 0000000000000000000000000000000000000000..131db38856cc1b253a6cbdaa6e3d45de9197de1c
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/barthez.md
@@ -0,0 +1,60 @@
+
+
+# BARThez [[barthez]]
+
+## 개요 [[overview]]
+
+BARThez 모델은 2020년 10월 23일, Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis에 의해 [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321)에서 제안되었습니다.
+
+이 논문의 초록:
+
+
+*자기지도 학습에 의해 가능해진 귀납적 전이 학습은 자연어 처리(NLP) 분야 전반에 걸쳐 큰 반향을 일으켰으며,
+BERT와 BART와 같은 모델들은 수많은 자연어 이해 작업에서 새로운 최첨단 성과를 기록했습니다. 일부 주목할 만한 예외가 있지만,
+대부분의 사용 가능한 모델과 연구는 영어에 집중되어 있었습니다. 본 연구에서는 BARThez를 소개합니다.
+이는 (우리가 아는 한) 프랑스어를 위한 첫 번째 BART 모델입니다.
+BARThez는 과거 연구에서 얻은 매우 큰 프랑스어 단일 언어 말뭉치로 사전훈련되었으며,
+BART의 변형 방식에 맞게 조정되었습니다.
+CamemBERT 및 FlauBERT와 같은 기존의 BERT 기반 프랑스어 모델과 달리, BARThez는 생성 작업에 특히 적합합니다.
+이는 인코더뿐만 아니라 디코더도 사전훈련되었기 때문입니다.
+우리는 FLUE 벤치마크에서의 판별 작업 외에도 이 논문과 함께 공개하는 새로운 요약 데이터셋인 OrangeSum에서 BARThez를 평가했습니다.
+또한 이미 사전훈련된 다국어 BART의 사전훈련을 BARThez의 말뭉치로 계속 진행하였으며,
+결과적으로 얻어진 모델인 mBARTHez가 기본 BARThez보다 유의미한 성능 향상을 보였고,
+CamemBERT 및 FlauBERT와 동등하거나 이를 능가함을 보였습니다.*
+
+이 모델은 [moussakam](https://huggingface.co/moussakam)이 기여했습니다. 저자의 코드는 [여기](https://github.com/moussaKam/BARThez)에서 찾을 수 있습니다.
+
+
+
+BARThez 구현은 🤗 BART와 동일하나, 토큰화에서 차이가 있습니다. 구성 클래스와 그 매개변수에 대한 정보는 [BART 문서](bart)를 참조하십시오.
+BARThez 전용 토크나이저는 아래에 문서화되어 있습니다.
+
+
+
+## 리소스 [[resources]]
+
+- BARThez는 🤗 BART와 유사한 방식으로 시퀀스-투-시퀀스 작업에 맞춰 미세 조정될 수 있습니다. 다음을 확인하세요:
+ [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
+
+
+## BarthezTokenizer [[bartheztokenizer]]
+
+[[autodoc]] BarthezTokenizer
+
+## BarthezTokenizerFast [[bartheztokenizerfast]]
+
+[[autodoc]] BarthezTokenizerFast
diff --git a/docs/transformers/docs/source/ko/model_doc/bartpho.md b/docs/transformers/docs/source/ko/model_doc/bartpho.md
new file mode 100644
index 0000000000000000000000000000000000000000..a323c28152c5d9969cee4b08b9dd21a8cb9ab999
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/bartpho.md
@@ -0,0 +1,86 @@
+
+
+# BARTpho [[bartpho]]
+
+## 개요 [[overview]]
+
+BARTpho 모델은 Nguyen Luong Tran, Duong Minh Le, Dat Quoc Nguyen에 의해 [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701)에서 제안되었습니다.
+
+이 논문의 초록은 다음과 같습니다:
+
+*우리는 BARTpho_word와 BARTpho_syllable의 두 가지 버전으로 BARTpho를 제시합니다.
+이는 베트남어를 위해 사전훈련된 최초의 대규모 단일 언어 시퀀스-투-시퀀스 모델입니다.
+우리의 BARTpho는 시퀀스-투-시퀀스 디노이징 모델인 BART의 "large" 아키텍처와 사전훈련 방식을 사용하여, 생성형 NLP 작업에 특히 적합합니다.
+베트남어 텍스트 요약의 다운스트림 작업 실험에서,
+자동 및 인간 평가 모두에서 BARTpho가 강력한 기준인 mBART를 능가하고 최신 성능을 개선했음을 보여줍니다.
+우리는 향후 연구 및 베트남어 생성형 NLP 작업의 응용을 촉진하기 위해 BARTpho를 공개합니다.*
+
+이 모델은 [dqnguyen](https://huggingface.co/dqnguyen)이 기여했습니다. 원본 코드는 [여기](https://github.com/VinAIResearch/BARTpho)에서 찾을 수 있습니다.
+
+## 사용 예시 [[usage-example]]
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bartpho = AutoModel.from_pretrained("vinai/bartpho-syllable")
+
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bartpho-syllable")
+
+>>> line = "Chúng tôi là những nghiên cứu viên."
+
+>>> input_ids = tokenizer(line, return_tensors="pt")
+
+>>> with torch.no_grad():
+... features = bartpho(**input_ids) # 이제 모델 출력은 튜플입니다
+
+>>> # With TensorFlow 2.0+:
+>>> from transformers import TFAutoModel
+
+>>> bartpho = TFAutoModel.from_pretrained("vinai/bartpho-syllable")
+>>> input_ids = tokenizer(line, return_tensors="tf")
+>>> features = bartpho(**input_ids)
+```
+
+## 사용 팁 [[usage-tips]]
+
+- mBART를 따르며, BARTpho는 BART의 "large" 아키텍처에 인코더와 디코더의 상단에 추가적인 레이어 정규화 레이어를 사용합니다.
+따라서 [BART 문서](bart)에 있는 사용 예시를 BARTpho에 맞게 적용하려면
+BART 전용 클래스를 mBART 전용 클래스로 대체하여 조정해야 합니다.
+예를 들어:
+
+```python
+>>> from transformers import MBartForConditionalGeneration
+
+>>> bartpho = MBartForConditionalGeneration.from_pretrained("vinai/bartpho-syllable")
+>>> TXT = "Chúng tôi là nghiên cứu viên."
+>>> input_ids = tokenizer([TXT], return_tensors="pt")["input_ids"]
+>>> logits = bartpho(input_ids).logits
+>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
+>>> probs = logits[0, masked_index].softmax(dim=0)
+>>> values, predictions = probs.topk(5)
+>>> print(tokenizer.decode(predictions).split())
+```
+
+- 이 구현은 토큰화만을 위한 것입니다: "monolingual_vocab_file"은 다국어
+ XLM-RoBERTa에서 제공되는 사전훈련된 SentencePiece 모델
+ "vocab_file"에서 추출된 베트남어 전용 유형으로 구성됩니다.
+ 다른 언어들도 이 사전훈련된 다국어 SentencePiece 모델 "vocab_file"을 하위 단어 분할에 사용하면, 자신의 언어 전용 "monolingual_vocab_file"과 함께 BartphoTokenizer를 재사용할 수 있습니다.
+
+## BartphoTokenizer [[bartphotokenizer]]
+
+[[autodoc]] BartphoTokenizer
diff --git a/docs/transformers/docs/source/ko/model_doc/bert-japanese.md b/docs/transformers/docs/source/ko/model_doc/bert-japanese.md
new file mode 100644
index 0000000000000000000000000000000000000000..8c21ef3558908e76288f670cf57d97252775252f
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/bert-japanese.md
@@ -0,0 +1,79 @@
+
+
+# 일본어 BERT (BertJapanese) [[bertjapanese]]
+
+## 개요 [[overview]]
+
+일본어 문장에 학습된 BERT 모델 입니다.
+
+각각 서로 다른 토큰화 방법을 사용하는 두 모델:
+
+- MeCab와 WordPiece를 사용하여 토큰화합니다. 이를 위해 추가 의존성 [fugashi](https://github.com/polm/fugashi)이 필요합니다. (이는 [MeCab](https://taku910.github.io/mecab/)의 래퍼입니다.)
+- 문자 단위로 토큰화합니다.
+
+*MecabTokenizer*를 사용하려면, 의존성을 설치하기 위해 `pip install transformers["ja"]` (또는 소스에서 설치하는 경우 `pip install -e .["ja"]`) 명령을 실행해야 합니다.
+
+자세한 내용은 [cl-tohoku 리포지토리](https://github.com/cl-tohoku/bert-japanese)에서 확인하세요.
+
+MeCab과 WordPiece 토큰화를 사용하는 모델 예시:
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese")
+>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese")
+
+>>> ## Input Japanese Text
+>>> line = "吾輩は猫である。"
+
+>>> inputs = tokenizer(line, return_tensors="pt")
+
+>>> print(tokenizer.decode(inputs["input_ids"][0]))
+[CLS] 吾輩 は 猫 で ある 。 [SEP]
+
+>>> outputs = bertjapanese(**inputs)
+```
+
+문자 토큰화를 사용하는 모델 예시:
+
+```python
+>>> bertjapanese = AutoModel.from_pretrained("cl-tohoku/bert-base-japanese-char")
+>>> tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-char")
+
+>>> ## Input Japanese Text
+>>> line = "吾輩は猫である。"
+
+>>> inputs = tokenizer(line, return_tensors="pt")
+
+>>> print(tokenizer.decode(inputs["input_ids"][0]))
+[CLS] 吾 輩 は 猫 で あ る 。 [SEP]
+
+>>> outputs = bertjapanese(**inputs)
+```
+
+
+
+이는 토큰화 방법을 제외하고는 BERT와 동일합니다. API 참조 정보는 [BERT 문서](https://huggingface.co/docs/transformers/main/en/model_doc/bert)를 참조하세요.
+이 모델은 [cl-tohoku](https://huggingface.co/cl-tohoku)께서 기여하였습니다.
+
+
+
+
+## BertJapaneseTokenizer
+
+[[autodoc]] BertJapaneseTokenizer
diff --git a/docs/transformers/docs/source/ko/model_doc/bert.md b/docs/transformers/docs/source/ko/model_doc/bert.md
new file mode 100644
index 0000000000000000000000000000000000000000..531d3e3dd6394766531b64adacf280d6392576c4
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/bert.md
@@ -0,0 +1,340 @@
+
+
+# BERT[[BERT]]
+
+
+
+## 개요[[Overview]]
+
+BERT 모델은 Jacob Devlin. Ming-Wei Chang, Kenton Lee, Kristina Touranova가 제안한 논문 [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805)에서 소개되었습니다. BERT는 사전 학습된 양방향 트랜스포머로, Toronto Book Corpus와 Wikipedia로 구성된 대규모 코퍼스에서 마스킹된 언어 모델링과 다음 문장 예측(Next Sentence Prediction) 목표를 결합해 학습되었습니다.
+
+해당 논문의 초록입니다:
+
+*우리는 BERT(Bidirectional Encoder Representations from Transformers)라는 새로운 언어 표현 모델을 소개합니다. 최근의 다른 언어 표현 모델들과 달리, BERT는 모든 계층에서 양방향으로 양쪽 문맥을 조건으로 사용하여 비지도 학습된 텍스트에서 깊이 있는 양방향 표현을 사전 학습하도록 설계되었습니다. 그 결과, 사전 학습된 BERT 모델은 추가적인 출력 계층 하나만으로 질문 응답, 언어 추론과 같은 다양한 작업에서 미세 조정될 수 있으므로, 특정 작업을 위해 아키텍처를 수정할 필요가 없습니다.*
+
+*BERT는 개념적으로 단순하면서도 실증적으로 강력한 모델입니다. BERT는 11개의 자연어 처리 과제에서 새로운 최고 성능을 달성했으며, GLUE 점수를 80.5% (7.7% 포인트 절대 개선)로, MultiNLI 정확도를 86.7% (4.6% 포인트 절대 개선), SQuAD v1.1 질문 응답 테스트에서 F1 점수를 93.2 (1.5% 포인트 절대 개선)로, SQuAD v2.0에서 F1 점수를 83.1 (5.1% 포인트 절대 개선)로 향상시켰습니다.*
+
+이 모델은 [thomwolf](https://huggingface.co/thomwolf)가 기여하였습니다. 원본 코드는 [여기](https://github.com/google-research/bert)에서 확인할 수 있습니다.
+
+## 사용 팁[[Usage tips]]
+
+- BERT는 절대 위치 임베딩을 사용하는 모델이므로 입력을 왼쪽이 아니라 오른쪽에서 패딩하는 것이 일반적으로 권장됩니다.
+- BERT는 마스킹된 언어 모델(MLM)과 Next Sentence Prediction(NSP) 목표로 학습되었습니다. 이는 마스킹된 토큰 예측과 전반적인 자연어 이해(NLU)에 뛰어나지만, 텍스트 생성에는 최적화되어있지 않습니다.
+- BERT의 사전 학습 과정에서는 입력 데이터를 무작위로 마스킹하여 일부 토큰을 마스킹합니다. 전체 토큰 중 약 15%가 다음과 같은 방식으로 마스킹됩니다:
+
+ * 80% 확률로 마스크 토큰으로 대체
+ * 10% 확률로 임의의 다른 토큰으로 대체
+ * 10% 확률로 원래 토큰 그대로 유지
+
+- 모델의 주요 목표는 원본 문장을 예측하는 것이지만, 두 번째 목표가 있습니다: 입력으로 문장 A와 B (사이에는 구분 토큰이 있음)가 주어집니다. 이 문장 쌍이 연속될 확률은 50%이며, 나머지 50%는 서로 무관한 문장들입니다. 모델은 이 두 문장이 아닌지를 예측해야 합니다.
+
+### Scaled Dot Product Attention(SDPA) 사용하기 [[Using Scaled Dot Product Attention (SDPA)]]
+
+Pytorch는 `torch.nn.functional`의 일부로 Scaled Dot Product Attention(SDPA) 연산자를 기본적으로 제공합니다. 이 함수는 입력과 하드웨어에 따라 여러 구현 방식을 사용할 수 있습니다. 자세한 내용은 [공식 문서](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)나 [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)에서 확인할 수 있습니다.
+
+`torch>=2.1.1`에서는 구현이 가능한 경우 SDPA가 기본적으로 사용되지만, `from_pretrained()`함수에서 `attn_implementation="sdpa"`를 설정하여 SDPA를 명시적으로 사용하도록 지정할 수도 있습니다.
+
+```
+from transformers import BertModel
+
+model = BertModel.from_pretrained("bert-base-uncased", torch_dtype=torch.float16, attn_implementation="sdpa")
+...
+```
+
+최적 성능 향상을 위해 모델을 반정밀도(예: `torch.float16` 또는 `torch.bfloat16`)로 불러오는 것을 권장합니다.
+
+로컬 벤치마크 (A100-80GB, CPUx12, RAM 96.6GB, PyTorch 2.2.0, OS Ubuntu 22.04)에서 `float16`을 사용해 학습 및 추론을 수행한 결과, 다음과 같은 속도 향상이 관찰되었습니다.
+
+#### 학습 [[Training]]
+
+|batch_size|seq_len|Time per batch (eager - s)|Time per batch (sdpa - s)|Speedup (%)|Eager peak mem (MB)|sdpa peak mem (MB)|Mem saving (%)|
+|----------|-------|--------------------------|-------------------------|-----------|-------------------|------------------|--------------|
+|4 |256 |0.023 |0.017 |35.472 |939.213 |764.834 |22.800 |
+|4 |512 |0.023 |0.018 |23.687 |1970.447 |1227.162 |60.569 |
+|8 |256 |0.023 |0.018 |23.491 |1594.295 |1226.114 |30.028 |
+|8 |512 |0.035 |0.025 |43.058 |3629.401 |2134.262 |70.054 |
+|16 |256 |0.030 |0.024 |25.583 |2874.426 |2134.262 |34.680 |
+|16 |512 |0.064 |0.044 |46.223 |6964.659 |3961.013 |75.830 |
+
+#### 추론 [[Inference]]
+
+|batch_size|seq_len|Per token latency eager (ms)|Per token latency SDPA (ms)|Speedup (%)|Mem eager (MB)|Mem BT (MB)|Mem saved (%)|
+|----------|-------|----------------------------|---------------------------|-----------|--------------|-----------|-------------|
+|1 |128 |5.736 |4.987 |15.022 |282.661 |282.924 |-0.093 |
+|1 |256 |5.689 |4.945 |15.055 |298.686 |298.948 |-0.088 |
+|2 |128 |6.154 |4.982 |23.521 |314.523 |314.785 |-0.083 |
+|2 |256 |6.201 |4.949 |25.303 |347.546 |347.033 |0.148 |
+|4 |128 |6.049 |4.987 |21.305 |378.895 |379.301 |-0.107 |
+|4 |256 |6.285 |5.364 |17.166 |443.209 |444.382 |-0.264 |
+
+
+
+## 자료[[Resources]]
+
+BERT를 시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다. 여기에 포함될 자료를 제출하고 싶다면 PR(Pull Request)를 열어주세요. 리뷰 해드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
+
+
+
+- [BERT 텍스트 분류 (다른 언어로)](https://www.philschmid.de/bert-text-classification-in-a-different-language)에 대한 블로그 포스트.
+- [다중 레이블 텍스트 분류를 위한 BERT (및 관련 모델) 미세 조정](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/BERT/Fine_tuning_BERT_(and_friends)_for_multi_label_text_classification.ipynb)에 대한 노트북.
+- [PyTorch를 이용해 BERT를 다중 레이블 분류를 위해 미세 조정하는 방법](htt기ps://colab.research.google.com/github/abhimishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)에 대한 노트북. 🌎
+- [BERT로 EncoderDecoder 모델을 warm-start하여 요약하기](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)에 대한 노트북.
+- [`BertForSequenceClassification`]이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)에서 지원됩니다.
+- [`TFBertForSequenceClassification`]이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)에서 지원됩니다.
+- [`FlaxBertForSequenceClassification`]이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb)에서 지원됩니다.
+- [텍스트 분류 작업 가이드](../tasks/sequence_classification)
+
+
+
+- [Keras와 함께 Hugging Face Transformers를 사용하여 비영리 BERT를 개체명 인식(NER)용으로 미세 조정하는 방법](https://www.philschmid.de/huggingface-transformers-keras-tf)에 대한 블로그 포스트.
+- [BERT를 개체명 인식을 위해 미세 조정하기](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/BERT/Custom_Named_Entity_Recognition_with_BERT_only_first_wordpiece.ipynb)에 대한 노트북. 각 단어의 첫 번째 wordpiece에만 레이블을 지정하여 학습하는 방법을 설명합니다. 모든 wordpiece에 레이블을 전파하는 방법은 [이 버전](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/BERT/Custom_Named_Entity_Recognition_with_BERT.ipynb)에서 확인할 수 있습니다.
+- [`BertForTokenClassification`]이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)에서 지원됩니다.
+- [`TFBertForTokenClassification`]이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)에서 지원됩니다.
+- [`FlaxBertForTokenClassification`]이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification)에서 지원됩니다.
+- 🤗 Hugging Face 코스의 [토큰 분류 챕터](https://huggingface.co/course/chapter7/2?fw=pt).
+- [토큰 분류 작업 가이드](../tasks/token_classification)
+
+
+
+- [`BertForMaskedLM`]이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)에서 지원됩니다.
+- [`TFBertForMaskedLM`]이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) 와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)에서 지원됩니다.
+- [`FlaxBertForMaskedLM`]이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb)에서 지원됩니다.
+- 🤗 Hugging Face 코스의 [마스킹된 언어 모델링 챕터](https://huggingface.co/course/chapter7/3?fw=pt).
+- [마스킹된 언어 모델링 작업 가이드](../tasks/masked_language_modeling)
+
+
+
+- [`BertForQuestionAnswering`]이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)에서 지원됩니다.
+- [`TFBertForQuestionAnswering`]이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) 와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)에서 지원됩니다.
+- [`FlaxBertForQuestionAnswering`]이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering)에서 지원됩니다.
+- 🤗 Hugging Face 코스의 [질문 답변 챕터](https://huggingface.co/course/chapter7/7?fw=pt).
+- [질문 답변 작업 가이드](../tasks/question_answering)
+
+**다중 선택**
+- [`BertForMultipleChoice`]이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)에서 지원됩니다.
+- [`TFBertForMultipleChoice`]이 [에제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)에서 지원됩니다.
+- [다중 선택 작업 가이드](../tasks/multiple_choice)
+
+⚡️ **추론**
+- [Hugging Face Transformers와 AWS Inferentia를 사용하여 BERT 추론을 가속화하는 방법](https://huggingface.co/blog/bert-inferentia-sagemaker)에 대한 블로그 포스트.
+- [GPU에서 DeepSpeed-Inference로 BERT 추론을 가속화하는 방법](https://www.philschmid.de/bert-deepspeed-inference)에 대한 블로그 포스트.
+
+⚙️ **사전 학습**
+- [Hugging Face Optimum으로 Transformers를 ONMX로 변환하는 방법](https://www.philschmid.de/pre-training-bert-habana)에 대한 블로그 포스트.
+
+🚀 **배포**
+- [Hugging Face Optimum으로 Transformers를 ONMX로 변환하는 방법](https://www.philschmid.de/convert-transformers-to-onnx)에 대한 블로그 포스트.
+- [AWS에서 Hugging Face Transformers를 위한 Habana Gaudi 딥러닝 환경 설정 방법](https://www.philschmid.de/getting-started-habana-gaudi#conclusion)에 대한 블로그 포스트.
+- [Hugging Face Transformers, Amazon SageMaker 및 Terraform 모듈을 이용한 BERT 자동 확장](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker-advanced)에 대한 블로그 포스트.
+- [Hugging Face, AWS Lambda, Docker를 활용하여 서버리스 BERT 설정하는 방법](https://www.philschmid.de/serverless-bert-with-huggingface-aws-lambda-docker)에 대한 블로그 포스트.
+- [Amazon SageMaker와 Training Compiler를 사용하여 Hugging Face Transformers에서 BERT 미세 조정하는 방법](https://www.philschmid.de/huggingface-amazon-sagemaker-training-compiler)에 대한 블로그.
+- [Amazon SageMaker를 사용한 Transformers와 BERT의 작업별 지식 증류](https://www.philschmid.de/knowledge-distillation-bert-transformers)에 대한 블로그 포스트.
+
+## BertConfig
+
+[[autodoc]] BertConfig
+ - all
+
+## BertTokenizer
+
+[[autodoc]] BertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+
+
+
+## BertTokenizerFast
+
+[[autodoc]] BertTokenizerFast
+
+
+
+
+## TFBertTokenizer
+
+[[autodoc]] TFBertTokenizer
+
+
+
+
+## Bert specific outputs
+
+[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
+
+[[autodoc]] models.bert.modeling_tf_bert.TFBertForPreTrainingOutput
+
+[[autodoc]] models.bert.modeling_flax_bert.FlaxBertForPreTrainingOutput
+
+
+
+
+
+## BertModel
+
+[[autodoc]] BertModel
+ - forward
+
+## BertForPreTraining
+
+[[autodoc]] BertForPreTraining
+ - forward
+
+## BertLMHeadModel
+
+[[autodoc]] BertLMHeadModel
+ - forward
+
+## BertForMaskedLM
+
+[[autodoc]] BertForMaskedLM
+ - forward
+
+## BertForNextSentencePrediction
+
+[[autodoc]] BertForNextSentencePrediction
+ - forward
+
+## BertForSequenceClassification
+
+[[autodoc]] BertForSequenceClassification
+ - forward
+
+## BertForMultipleChoice
+
+[[autodoc]] BertForMultipleChoice
+ - forward
+
+## BertForTokenClassification
+
+[[autodoc]] BertForTokenClassification
+ - forward
+
+## BertForQuestionAnswering
+
+[[autodoc]] BertForQuestionAnswering
+ - forward
+
+
+
+
+## TFBertModel
+
+[[autodoc]] TFBertModel
+ - call
+
+## TFBertForPreTraining
+
+[[autodoc]] TFBertForPreTraining
+ - call
+
+## TFBertModelLMHeadModel
+
+[[autodoc]] TFBertLMHeadModel
+ - call
+
+## TFBertForMaskedLM
+
+[[autodoc]] TFBertForMaskedLM
+ - call
+
+## TFBertForNextSentencePrediction
+
+[[autodoc]] TFBertForNextSentencePrediction
+ - call
+
+## TFBertForSequenceClassification
+
+[[autodoc]] TFBertForSequenceClassification
+ - call
+
+## TFBertForMultipleChoice
+
+[[autodoc]] TFBertForMultipleChoice
+ - call
+
+## TFBertForTokenClassification
+
+[[autodoc]] TFBertForTokenClassification
+ - call
+
+## TFBertForQuestionAnswering
+
+[[autodoc]] TFBertForQuestionAnswering
+ - call
+
+
+
+
+## FlaxBertModel
+
+[[autodoc]] FlaxBertModel
+ - __call__
+
+## FlaxBertForPreTraining
+
+[[autodoc]] FlaxBertForPreTraining
+ - __call__
+
+## FlaxBertForCausalLM
+
+[[autodoc]] FlaxBertForCausalLM
+ - __call__
+
+## FlaxBertForMaskedLM
+
+[[autodoc]] FlaxBertForMaskedLM
+ - __call__
+
+## FlaxBertForNextSentencePrediction
+
+[[autodoc]] FlaxBertForNextSentencePrediction
+ - __call__
+
+## FlaxBertForSequenceClassification
+
+[[autodoc]] FlaxBertForSequenceClassification
+ - __call__
+
+## FlaxBertForMultipleChoice
+
+[[autodoc]] FlaxBertForMultipleChoice
+ - __call__
+
+## FlaxBertForTokenClassification
+
+[[autodoc]] FlaxBertForTokenClassification
+ - __call__
+
+## FlaxBertForQuestionAnswering
+
+[[autodoc]] FlaxBertForQuestionAnswering
+ - __call__
+
+
+
+
+
diff --git a/docs/transformers/docs/source/ko/model_doc/bertweet.md b/docs/transformers/docs/source/ko/model_doc/bertweet.md
new file mode 100644
index 0000000000000000000000000000000000000000..7a46087d0a8ebf85929aadbb74808ffe029537c9
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/bertweet.md
@@ -0,0 +1,67 @@
+
+
+# BERTweet [[bertweet]]
+
+## 개요 [[overview]]
+
+BERTweet 모델은 Dat Quoc Nguyen, Thanh Vu, Anh Tuan Nguyen에 의해 [BERTweet: A pre-trained language model for English Tweets](https://www.aclweb.org/anthology/2020.emnlp-demos.2.pdf) 에서 제안되었습니다.
+
+해당 논문의 초록 :
+
+*영어 트윗을 위한 최초의 공개 대규모 사전 학습된 언어 모델인 BERTweet을 소개합니다.
+BERTweet은 BERT-base(Devlin et al., 2019)와 동일한 아키텍처를 가지고 있으며, RoBERTa 사전 학습 절차(Liu et al., 2019)를 사용하여 학습되었습니다.
+실험 결과, BERTweet은 강력한 기준 모델인 RoBERTa-base 및 XLM-R-base(Conneau et al., 2020)의 성능을 능가하여 세 가지 트윗 NLP 작업(품사 태깅, 개체명 인식, 텍스트 분류)에서 이전 최신 모델보다 더 나은 성능을 보여주었습니다.*
+
+이 모델은 [dqnguyen](https://huggingface.co/dqnguyen) 께서 기여하셨습니다. 원본 코드는 [여기](https://github.com/VinAIResearch/BERTweet).에서 확인할 수 있습니다.
+
+
+## 사용 예시 [[usage-example]]
+
+```python
+>>> import torch
+>>> from transformers import AutoModel, AutoTokenizer
+
+>>> bertweet = AutoModel.from_pretrained("vinai/bertweet-base")
+
+>>> # 트랜스포머 버전 4.x 이상 :
+>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base", use_fast=False)
+
+>>> # 트랜스포머 버전 3.x 이상:
+>>> # tokenizer = AutoTokenizer.from_pretrained("vinai/bertweet-base")
+
+>>> # 입력된 트윗은 이미 정규화되었습니다!
+>>> line = "SC has first two presumptive cases of coronavirus , DHEC confirms HTTPURL via @USER :cry:"
+
+>>> input_ids = torch.tensor([tokenizer.encode(line)])
+
+>>> with torch.no_grad():
+... features = bertweet(input_ids) # Models outputs are now tuples
+
+>>> # With TensorFlow 2.0+:
+>>> # from transformers import TFAutoModel
+>>> # bertweet = TFAutoModel.from_pretrained("vinai/bertweet-base")
+```
+
+
+
+이 구현은 토큰화 방법을 제외하고는 BERT와 동일합니다. API 참조 정보는 [BERT 문서](bert) 를 참조하세요.
+
+
+
+## Bertweet 토큰화(BertweetTokenizer) [[transformers.BertweetTokenizer]]
+
+[[autodoc]] BertweetTokenizer
diff --git a/docs/transformers/docs/source/ko/model_doc/biogpt.md b/docs/transformers/docs/source/ko/model_doc/biogpt.md
new file mode 100644
index 0000000000000000000000000000000000000000..4b24af8493b9d5dc025416476cb75876c91e5249
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/biogpt.md
@@ -0,0 +1,109 @@
+
+
+# BioGPT [[biogpt]]
+
+## 개요 [[overview]]
+
+BioGPT는 Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, Tie-Yan Liu에 의해 [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) 에서 제안된 모델입니다. BioGPT는 생물의학 텍스트 생성과 마이닝을 위해 도메인에 특화된 생성형 사전 학습 트랜스포머 언어 모델입니다. BioGPT는 트랜스포머 언어 모델 구조를 따르며, 1,500만 개의 PubMed 초록을 이용해 처음부터 학습되었습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*생물의학 분야에서 사전 학습된 언어 모델은 일반 자연어 처리 분야에서의 성공에 영감을 받아 점점 더 많은 주목을 받고 있습니다. 일반 언어 분야에서 사전 학습된 언어 모델의 두 가지 주요 계통인 BERT(및 그 변형)와 GPT(및 그 변형) 중 첫 번째는 생물의학 분야에서 BioBERT와 PubMedBERT와 같이 광범위하게 연구되었습니다. 이들은 다양한 분류 기반의 생물의학 작업에서 큰 성공을 거두었지만, 생성 능력의 부족은 그들의 적용 범위를 제한했습니다. 본 논문에서는 대규모 생물의학 문헌을 사전 학습한 도메인 특화 생성형 트랜스포머 언어 모델인 BioGPT를 제안합니다. 우리는 6개의 생물의학 자연어 처리 작업에서 BioGPT를 평가한 결과, 대부분의 작업에서 이전 모델보다 우수한 성능을 보였습니다. 특히, BC5CDR, KD-DTI, DDI 엔드-투-엔드 관계 추출 작업에서 각각 44.98%, 38.42%, 40.76%의 F1 점수를 기록하였으며, PubMedQA에서 78.2%의 정확도를 달성해 새로운 기록을 세웠습니다. 또한 텍스트 생성에 대한 사례 연구는 생물의학 용어에 대한 유창한 설명을 생성하는 데 있어 BioGPT의 장점을 더욱 입증했습니다.*
+
+이 모델은 [kamalkraj](https://huggingface.co/kamalkraj)에 의해 기여되었습니다. 원본 코드는 [여기](https://github.com/microsoft/BioGPT)에서 찾을 수 있습니다.
+
+## 사용 팁 [[usage-tips]]
+
+- BioGPT는 절대적 위치 임베딩(absolute position embedding)을 사용하므로, 입력을 왼쪽이 아닌 오른쪽에서 패딩하는 것이 권장됩니다.
+- BioGPT는 인과적 언어 모델링(Casual Langague Modeling, CLM) 목표로 학습되었기 때문에, 다음 토큰을 예측하는 데 강력한 성능을 보입니다. 이 기능을 활용하여 BioGPT는 구문적으로 일관된 텍스트를 생성할 수 있으며, 예시 스크립트 `run_generation.py`에서 이를 확인할 수 있습니다.
+- 이 모델은 `past_key_values`(PyTorch 용)를 입력으로 받을 수 있는데, 이는 이전에 계산된 키/값 어텐션 쌍입니다. 이 값을 사용하면 텍스트 생성 중 이미 계산된 값을 다시 계산하지 않도록 할 수 있습니다. PyTorch에서 `past_key_values` 인수는 BioGptForCausalLM.forward() 메소드에서 자세히 설명되어 있습니다.
+
+### Scaled Dot Product Attention(SDPA) 사용 [[using-scaled-dot-product-attention-sdpa]]
+
+PyTorch는 `torch.nn.functional`의 일부로 스케일된 점곱 어텐션(SDPA) 연산자를 기본적으로 포함합니다. 이 함수는 입력과 사용 중인 하드웨어에 따라 여러 구현을 적용할 수 있습니다. 자세한 내용은 [공식 문서](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html) 또는 [GPU 추론](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention) 페이지를 참조하세요.
+
+`torch>=2.1.1`에서 구현이 가능한 경우 SDPA는 기본적으로 사용되며, `attn_implementation="sdpa"`를 `from_pretrained()`에서 설정하여 SDPA 사용을 명시적으로 요청할 수 있습니다.
+
+```
+from transformers import BioGptForCausalLM
+model = BioGptForCausalLM.from_pretrained("microsoft/biogpt", attn_implementation="sdpa", torch_dtype=torch.float16)
+```
+
+NVIDIA GeForce RTX 2060-8GB, PyTorch 2.3.1, Ubuntu 20.04 환경에서 `float16` 및 CausalLM 헤드가 있는 `microsoft/biogpt` 모델로 로컬 벤치마크를 수행한 결과, 훈련 중 다음과 같은 속도 향상을 확인했습니다.
+
+최적의 속도 향상을 위해 모델을 반정밀도(예: `torch.float16` 또는 `torch.bfloat16`)로 로드하는 것이 좋습니다.
+
+| num_training_steps | batch_size | seq_len | is cuda | Time per batch (eager - s) | Time per batch (sdpa - s) | Speedup (%) | Eager peak mem (MB) | sdpa peak mem (MB) | Mem saving (%) |
+|--------------------|------------|---------|---------|----------------------------|---------------------------|-------------|---------------------|--------------------|----------------|
+| 100 | 1 | 128 | False | 0.038 | 0.031 | 21.301 | 1601.862 | 1601.497 | 0.023 |
+| 100 | 1 | 256 | False | 0.039 | 0.034 | 15.084 | 1624.944 | 1625.296 | -0.022 |
+| 100 | 2 | 128 | False | 0.039 | 0.033 | 16.820 | 1624.567 | 1625.296 | -0.045 |
+| 100 | 2 | 256 | False | 0.065 | 0.059 | 10.255 | 1672.164 | 1672.164 | 0.000 |
+| 100 | 4 | 128 | False | 0.062 | 0.058 | 6.998 | 1671.435 | 1672.164 | -0.044 |
+| 100 | 4 | 256 | False | 0.113 | 0.100 | 13.316 | 2350.179 | 1848.435 | 27.144 |
+| 100 | 8 | 128 | False | 0.107 | 0.098 | 9.883 | 2098.521 | 1848.435 | 13.530 |
+| 100 | 8 | 256 | False | 0.222 | 0.196 | 13.413 | 3989.980 | 2986.492 | 33.601 |
+
+NVIDIA GeForce RTX 2060-8GB, PyTorch 2.3.1, Ubuntu 20.04 환경에서 `float16` 및 AutoModel 헤드가 있는 `microsoft/biogpt` 모델로 추론 중 다음과 같은 속도 향상을 확인했습니다.
+
+| num_batches | batch_size | seq_len | is cuda | is half | use mask | Per token latency eager (ms) | Per token latency SDPA (ms) | Speedup (%) | Mem eager (MB) | Mem BT (MB) | Mem saved (%) |
+|-------------|------------|---------|---------|---------|----------|------------------------------|-----------------------------|-------------|----------------|--------------|---------------|
+| 50 | 1 | 64 | True | True | True | 0.115 | 0.098 | 17.392 | 716.998 | 716.998 | 0.000 |
+| 50 | 1 | 128 | True | True | True | 0.115 | 0.093 | 24.640 | 730.916 | 730.916 | 0.000 |
+| 50 | 2 | 64 | True | True | True | 0.114 | 0.096 | 19.204 | 730.900 | 730.900 | 0.000 |
+| 50 | 2 | 128 | True | True | True | 0.117 | 0.095 | 23.529 | 759.262 | 759.262 | 0.000 |
+| 50 | 4 | 64 | True | True | True | 0.113 | 0.096 | 18.325 | 759.229 | 759.229 | 0.000 |
+| 50 | 4 | 128 | True | True | True | 0.186 | 0.178 | 4.289 | 816.478 | 816.478 | 0.000 |
+
+
+## 리소스 [[resources]]
+
+- [인과적 언어 모델링 작업 가이드](../tasks/language_modeling)
+
+## BioGptConfig [[transformers.BioGptConfig]]
+
+[[autodoc]] BioGptConfig
+
+
+## BioGptTokenizer [[transformers.BioGptTokenizer]]
+
+[[autodoc]] BioGptTokenizer
+ - save_vocabulary
+
+
+## BioGptModel [[transformers.BioGptModel]]
+
+[[autodoc]] BioGptModel
+ - forward
+
+
+## BioGptForCausalLM [[transformers.BioGptForCausalLM]]
+
+[[autodoc]] BioGptForCausalLM
+ - forward
+
+
+## BioGptForTokenClassification [[transformers.BioGptForTokenClassification]]
+
+[[autodoc]] BioGptForTokenClassification
+ - forward
+
+
+## BioGptForSequenceClassification [[transformers.BioGptForSequenceClassification]]
+
+[[autodoc]] BioGptForSequenceClassification
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/model_doc/blip-2.md b/docs/transformers/docs/source/ko/model_doc/blip-2.md
new file mode 100644
index 0000000000000000000000000000000000000000..ae3da11d3a18c310568f2b3360f5e8079c48a02c
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/blip-2.md
@@ -0,0 +1,98 @@
+
+
+# BLIP-2[[blip-2]]
+
+## 개요[[overview]]
+BLIP-2 모델은 Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi의 [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) 논문에서 제안되었습니다. BLIP-2는 동결된 사전 학습 이미지 인코더와 대규모 언어 모델(LLM)을 연결하는 12층의 경량 Transformer 인코더를 학습시켜, 여러 비전-언어 작업에서 SOTA(현재 최고의 성능)을 달성했습니다. 특히, BLIP-2는 800억 개의 파라미터를 가진 Flamingo 모델보다 제로샷 VQAv2에서 8.7% 더 높은 성능을 기록했으며, 학습 가능한 파라미터 수는 Flamingo보다 54배 적습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*비전-언어 사전 학습의 비용은 대규모 모델의 엔드-투-엔드 학습으로 인해 점점 더 부담스러워지고 있습니다. 본 논문은 사전 학습된 이미지 인코더와 대규모 언어 모델을 활용하여 비전-언어 사전 학습을 부트스트래핑하는 일반적이고 효율적인 사전 학습 전략인 BLIP-2를 제안합니다. BLIP-2는 경량화된 Querying Transformer를 통해 모달리티 간의 차이를 연결하며, 두 단계로 사전 학습됩니다. 첫 번째 단계는 동결된 이미지 인코더로부터 비전-언어 표현 학습을 부트스트래핑하고, 두 번째 단계는 동결된 언어 모델로부터 비전-언어 생성 학습을 부트스트래핑합니다. BLIP-2는 기존 방법들에 비해 훨씬 적은 학습 가능한 파라미터로 다양한 비전-언어 작업에서 최첨단 성능을 달성합니다. 예를 들어, 우리 모델은 제로샷 VQAv2에서 Flamingo80B보다 8.7% 높은 성능을 기록하며, 학습 가능한 파라미터 수는 54배 적습니다. 우리는 또한 자연어 명령을 따를 수 있는 제로샷 이미지-텍스트 생성의 새로운 기능을 입증했습니다.*
+
+
+
+ BLIP-2 구조. 원본 논문 에서 발췌.
+
+이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여했습니다. 원본 코드는 [여기](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207)에서 확인할 수 있습니다.
+
+## 사용 팁[[usage-tips]]
+
+- BLIP-2는 이미지와 조건에 따라 텍스트 프롬프트를 입력받아 조건부 텍스트를 생성합니다. 추론 시 [`generate`] 메소드를 사용하는 것이 권장됩니다.
+- [`Blip2Processor`]를 사용하여 모델에 이미지를 준비하고, 예측된 토큰 ID를 텍스트로 디코딩할 수 있습니다.
+
+## 자료[[resources]]
+
+BLIP-2를 시작하는 데 도움이 되는 공식 Hugging Face 및 커뮤니티(🌎 표시) 자료 목록입니다.
+
+- 이미지 캡셔닝, 시각 질문 응답(VQA), 채팅과 같은 대화형 작업을 위한 BLIP-2 데모 노트북은 [여기](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BLIP-2)에서 찾을 수 있습니다.
+
+리소스를 제출하여 여기에 포함하고 싶다면 언제든지 풀 리퀘스트를 열어주세요! 리소스는 기존 리소스를 복제하지 않고 새로운 내용이어야 합니다.
+
+## Blip2Config[[transformers.Blip2Config]]
+
+[[autodoc]] Blip2Config
+ - from_vision_qformer_text_configs
+
+## Blip2VisionConfig[[transformers.Blip2VisionConfig]]
+
+[[autodoc]] Blip2VisionConfig
+
+## Blip2QFormerConfig[[transformers.Blip2QFormerConfig]]
+
+[[autodoc]] Blip2QFormerConfig
+
+## Blip2Processor[[transformers.Blip2Processor]]
+
+[[autodoc]] Blip2Processor
+
+## Blip2VisionModel[[transformers.Blip2VisionModel]]
+
+[[autodoc]] Blip2VisionModel
+ - forward
+
+## Blip2QFormerModel[[transformers.Blip2QFormerModel]]
+
+[[autodoc]] Blip2QFormerModel
+ - forward
+
+## Blip2Model[[transformers.Blip2Model]]
+
+[[autodoc]] Blip2Model
+ - forward
+ - get_text_features
+ - get_image_features
+ - get_qformer_features
+
+## Blip2ForConditionalGeneration[[transformers.Blip2ForConditionalGeneration]]
+
+[[autodoc]] Blip2ForConditionalGeneration
+ - forward
+ - generate
+
+## Blip2ForImageTextRetrieval[[transformers.Blip2ForImageTextRetrieval]]
+
+[[autodoc]] Blip2ForImageTextRetrieval
+ - forward
+
+## Blip2TextModelWithProjection[[transformers.Blip2TextModelWithProjection]]
+
+[[autodoc]] Blip2TextModelWithProjection
+
+## Blip2VisionModelWithProjection[[transformers.Blip2VisionModelWithProjection]]
+
+[[autodoc]] Blip2VisionModelWithProjection
diff --git a/docs/transformers/docs/source/ko/model_doc/blip.md b/docs/transformers/docs/source/ko/model_doc/blip.md
new file mode 100644
index 0000000000000000000000000000000000000000..27e085315b891130598a49e4de909ccc28ecc8d5
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/blip.md
@@ -0,0 +1,136 @@
+
+
+# BLIP[[blip]]
+
+## 개요[[overview]]
+
+BLIP 모델은 Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi의 [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) 논문에서 제안되었습니다.
+
+BLIP은 여러 멀티모달 작업을 수행할 수 있는 모델입니다:
+
+- 시각 질문 응답 (Visual Question Answering, VQA)
+- 이미지-텍스트 검색 (이미지-텍스트 매칭)
+- 이미지 캡셔닝
+
+논문의 초록은 다음과 같습니다:
+
+*비전-언어 사전 학습(Vision-Language Pre-training, VLP)은 다양한 비전-언어 작업의 성능을 크게 향상시켰습니다. 하지만, 대부분의 기존 사전 학습 모델들은 이해 기반 작업이나 생성 기반 작업 중 하나에서만 뛰어난 성능을 발휘합니다. 또한 성능 향상은 주로 웹에서 수집한 노이즈가 많은 이미지-텍스트 쌍으로 데이터셋의 규모를 키우는 방식으로 이루어졌는데, 이는 최적의 지도 학습 방식이라고 보기 어렵습니다. 본 논문에서는 BLIP이라는 새로운 VLP 프레임워크를 제안합니다. 이 프레임워크는 비전-언어 이해 및 생성 작업 모두에 유연하게 적용될 수 있습니다. BLIP는 캡셔너가 합성 캡션을 생성하고 필터가 노이즈 캡션을 제거하는 부트스트래핑 방법을 통해 웹 데이터의 노이즈를 효과적으로 활용합니다. 우리는 이미지-텍스트 검색(Recall@1에서 +2.7%), 이미지 캡셔닝(CIDEr에서 +2.8%), 그리고 VQA(VQA 점수에서 +1.6%)와 같은 다양한 비전-언어 작업에서 최신 성과를 달성했습니다. 또한 BLIP은 제로샷 방식으로 비디오-언어 작업에 직접 전이될 때도 강력한 일반화 능력을 보여줍니다. 이 논문의 코드, 모델, 데이터셋은 공개되었습니다.*
+
+
+
+이 모델은 [ybelkada](https://huggingface.co/ybelkada)가 기여했습니다.
+원본 코드는 [여기](https://github.com/salesforce/BLIP)에서 찾을 수 있습니다.
+
+## 자료[[resources]]
+
+- [Jupyter notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb): 사용자 정의 데이터셋에서 BLIP를 이미지 캡셔닝으로 미세 조정하는 방법
+
+## BlipConfig[[transformers.BlipConfig]]
+
+[[autodoc]] BlipConfig
+ - from_text_vision_configs
+
+## BlipTextConfig[[transformers.BlipTextConfig]]
+
+[[autodoc]] BlipTextConfig
+
+## BlipVisionConfig[[transformers.BlipVisionConfig]]
+
+[[autodoc]] BlipVisionConfig
+
+## BlipProcessor[[transformers.BlipProcessor]]
+
+[[autodoc]] BlipProcessor
+
+## BlipImageProcessor[[transformers.BlipImageProcessor]]
+
+[[autodoc]] BlipImageProcessor
+ - preprocess
+
+
+
+
+## BlipModel[[transformers.BlipModel]]
+
+`BlipModel`은 향후 버전에서 더 이상 지원되지 않을 예정입니다. 목적에 따라 `BlipForConditionalGeneration`, `BlipForImageTextRetrieval` 또는 `BlipForQuestionAnswering`을 사용하십시오.
+
+[[autodoc]] BlipModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## BlipTextModel[[transformers.BlipTextModel]]
+
+[[autodoc]] BlipTextModel
+ - forward
+
+## BlipVisionModel[[transformers.BlipVisionModel]]
+
+[[autodoc]] BlipVisionModel
+ - forward
+
+## BlipForConditionalGeneration[[transformers.BlipForConditionalGeneration]]
+
+[[autodoc]] BlipForConditionalGeneration
+ - forward
+
+## BlipForImageTextRetrieval[[transformers.BlipForImageTextRetrieval]]
+
+[[autodoc]] BlipForImageTextRetrieval
+ - forward
+
+## BlipForQuestionAnswering[[transformers.BlipForQuestionAnswering]]
+
+[[autodoc]] BlipForQuestionAnswering
+ - forward
+
+
+
+
+## TFBlipModel[[transformers.TFBlipModel]]
+
+[[autodoc]] TFBlipModel
+ - call
+ - get_text_features
+ - get_image_features
+
+## TFBlipTextModel[[transformers.TFBlipTextModel]]
+
+[[autodoc]] TFBlipTextModel
+ - call
+
+## TFBlipVisionModel[[transformers.TFBlipVisionModel]]
+
+[[autodoc]] TFBlipVisionModel
+ - call
+
+## TFBlipForConditionalGeneration[[transformers.TFBlipForConditionalGeneration]]
+
+[[autodoc]] TFBlipForConditionalGeneration
+ - call
+
+## TFBlipForImageTextRetrieval[[transformers.TFBlipForImageTextRetrieval]]
+
+[[autodoc]] TFBlipForImageTextRetrieval
+ - call
+
+## TFBlipForQuestionAnswering[[transformers.TFBlipForQuestionAnswering]]
+
+[[autodoc]] TFBlipForQuestionAnswering
+ - call
+
+
diff --git a/docs/transformers/docs/source/ko/model_doc/chameleon.md b/docs/transformers/docs/source/ko/model_doc/chameleon.md
new file mode 100644
index 0000000000000000000000000000000000000000..14a18a09765bd4cd737dcf40f0a8ffa82f173e3f
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/chameleon.md
@@ -0,0 +1,186 @@
+
+
+# Chameleon [[chameleon]]
+
+## 개요 [[overview]]
+
+Chameleon 모델은 META AI Chameleon 팀의 논문 [Chameleon: Mixed-Modal Early-Fusion Foundation Models](https://arxiv.org/abs/2405.09818v1)에서 제안되었습니다. Chameleon은 벡터 양자화를 사용하여 이미지를 토큰화함으로써 멀티모달 출력을 생성할 수 있는 비전-언어 모델입니다. 이 모델은 교차된 형식을 포함한 이미지와 텍스트를 입력으로 받으며, 텍스트 응답을 생성합니다. 이미지 생성 모듈은 아직 공개되지 않았습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*우리는 이미지와 텍스트를 임의의 순서로 이해하고 생성할 수 있는 early-fusion 토큰 기반의 혼합 모달(mixed-modal) 모델의 일종인 Chameleon을 소개합니다. 우리는 초기부터 안정적인 훈련 접근법, 정렬 방법, 그리고 early-fusion, 토큰 기반, 혼합 모달 설정에 맞춘 아키텍처 매개변수를 제시합니다. 이 모델들은 시각적 질문 응답, 이미지 캡션 생성, 텍스트 생성, 이미지 생성, 장문 혼합 모달 생성 등 포괄적인 작업 범위에서 평가되었습니다. Chameleon은 단일 모델에서 이미지 캡션 생성 작업에서의 최첨단 성능을 포함한 광범위하고 일반적으로 적용 가능한 능력을 보여주며, 텍스트 전용 작업에서 Llama-2를 능가하면서 Mixtral 8x7B와 Gemini-Pro와 같은 모델들 사이에서도 경쟁력을 갖추고 있습니다. 그리고 상당한 성능의 이미지 생성도 수행합니다. 또한 프롬프트나 출력에 이미지와 텍스트의 혼합 시퀀스가 포함된 새로운 장문 혼합 모달 생성 평가에서, 인간의 판단에 따르면 Gemini Pro와 GPT-4V를 포함한 훨씬 더 큰 모델의 성능과 동등하거나 이를 능가합니다. Chameleon은 완전한 멀티모달 문서의 통합 모델링에서 중요한 발전을 보여줍니다.*
+
+
+
+Chameleon은 이미지를 이산적인 토큰으로 변환하기 위해 벡터 양자화 모듈을 통합합니다. 이는 자기회귀 transformer를 사용한 이미지 생성을 가능하게 합니다. 원본 논문에서 가져왔습니다.
+
+이 모델은 [joaogante](https://huggingface.co/joaogante)와 [RaushanTurganbay](https://huggingface.co/RaushanTurganbay)가 기여했습니다. 원본 코드는 [여기](https://github.com/facebookresearch/chameleon)에서 찾을 수 있습니다.
+
+## 사용 팁 [[usage-tips]]
+
+- 더 정확한 결과를 위해, 배치 생성 시 `padding_side="left"`를 사용하는 것을 권장합니다. 생성하기 전에 `processor.tokenizer.padding_side = "left"`로 설정하십시오.
+
+- Chameleon은 안전성 정렬을 위해 튜닝되었음을 유의하십시오. 모델이 응답을 거부하는 경우, 열린 질문보다는 더 구체적으로 질문을 해보세요.
+
+- Chameleon은 채팅 형식으로 생성하므로, 생성된 텍스트는 항상 "assistant's turn"으로 표시됩니다. 프로세서를 호출할 때 `return_for_text_completion=True`를 전달하여 텍스트 완성 생성을 활성화할 수 있습니다.
+
+> [!NOTE]
+> Transformers에서의 Chameleon 구현은 이미지 임베딩을 병합할 위치를 나타내기 위해 특별한 이미지 토큰을 사용합니다. 특별한 이미지 토큰을 위해 새로운 토큰을 추가하지 않고 예약된 토큰 중 하나인 ``를 사용했습니다. 올바른 생성을 위해 프롬프트에서 이미지가 임베딩될 위치에 ``를 추가해야 합니다.
+
+## 사용 예제 [[usage-example]]
+
+### 단일 이미지 추론 [[single-image-inference]]
+
+Chameleon은 게이티드(gated) 모델이므로 Hugging Face Hub에 대한 액세스 권한이 있고 토큰으로 로그인했는지 확인하세요. 다음은 모델을 로드하고 반정밀도(`torch.bfloat16`)로 추론하는 방법입니다:
+
+```python
+from transformers import ChameleonProcessor, ChameleonForConditionalGeneration
+import torch
+from PIL import Image
+import requests
+
+processor = ChameleonProcessor.from_pretrained("facebook/chameleon-7b")
+model = ChameleonForConditionalGeneration.from_pretrained("facebook/chameleon-7b", torch_dtype=torch.bfloat16, device_map="cuda")
+
+# 이미지와 텍스트 프롬프트 준비
+url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+image = Image.open(requests.get(url, stream=True).raw)
+prompt = "이 이미지에서 무엇을 보나요?"
+
+inputs = processor(images=image, text=prompt, return_tensors="pt").to(model.device, dtype=torch.bfloat16)
+
+# 프롬프트를 자기회귀적으로 완성
+output = model.generate(**inputs, max_new_tokens=50)
+print(processor.decode(output[0], skip_special_tokens=True))
+```
+
+### 다중 이미지 추론 [[multi-image-inference]]
+
+Chameleon은 여러 이미지를 입력으로 받아들이며, 이미지들은 동일한 프롬프트에 속하거나 다른 프롬프트에 속할 수 있습니다(배치 추론에서). 다음은 그 방법입니다:
+
+```python
+from transformers import ChameleonProcessor, ChameleonForConditionalGeneration
+import torch
+from PIL import Image
+import requests
+
+processor = ChameleonProcessor.from_pretrained("facebook/chameleon-7b")
+
+model = ChameleonForConditionalGeneration.from_pretrained("facebook/chameleon-7b", torch_dtype=torch.bfloat16, device_map="cuda")
+
+# 세 가지 다른 이미지 가져오기
+url = "https://www.ilankelman.org/stopsigns/australia.jpg"
+image_stop = Image.open(requests.get(url, stream=True).raw)
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image_cats = Image.open(requests.get(url, stream=True).raw)
+
+url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
+image_snowman = Image.open(requests.get(url, stream=True).raw)
+
+# 배치된 프롬프트 준비: 첫 번째는 다중 이미지 프롬프트이고 두 번째는 단일 이미지 프롬프트입니다
+prompts = [
+ "이 이미지들은 무엇이 공통점인가요?",
+ "이 이미지에 무엇이 나타나 있나요?"
+]
+
+# 이미지들을 텍스트 프롬프트에서 사용되어야 하는 순서대로 입력할 수 있습니다
+# 각 "" 토큰은 하나의 이미지를 사용하며, 다음 "" 토큰은 다음 이미지를 사용합니다
+inputs = processor(images=[image_stop, image_cats, image_snowman], text=prompts, padding=True, return_tensors="pt").to(device="cuda", dtype=torch.bfloat16)
+
+# 생성
+generate_ids = model.generate(**inputs, max_new_tokens=50)
+processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
+```
+
+## 모델 최적화 [[model-optimization]]
+
+### Bitsandbytes를 사용한 양자화 [[quantization-using-bitsandbytes]]
+
+모델은 8비트 또는 4비트로 로드할 수 있으며, 이는 원본 모델의 성능을 유지하면서 메모리 요구 사항을 크게 줄여줍니다. 먼저 bitsandbytes를 설치하고(`pip install bitsandbytes`), 라이브러리가 지원하는 GPU/가속기를 사용 중인지 확인하십시오.
+
+
+
+bitsandbytes는 CUDA 이외의 여러 백엔드를 지원하도록 리팩터링되고 있습니다. 현재 ROCm(AMD GPU) 및 Intel CPU 구현이 성숙 단계이며, Intel XPU는 진행 중이고 Apple Silicon 지원은 Q4/Q1에 예상됩니다. 설치 지침 및 최신 백엔드 업데이트는 [이 링크](https://huggingface.co/docs/bitsandbytes/main/en/installation#multi-backend)를 방문하세요.
+
+전체 공개 전에 버그를 식별하는 데 도움이 되는 피드백을 환영합니다! 자세한 내용과 피드백은 [이 문서](https://huggingface.co/docs/bitsandbytes/main/en/non_cuda_backends)를 확인하세요.
+
+
+
+위의 코드 스니펫을 다음과 같이 변경하면 됩니다:
+
+```python
+from transformers import ChameleonForConditionalGeneration, BitsAndBytesConfig
+
+# 모델 양자화 방식 지정
+quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.bfloat16,
+)
+
+model = ChameleonForConditionalGeneration.from_pretrained("facebook/chameleon-7b", quantization_config=quantization_config, device_map="cuda")
+```
+
+### Flash-Attention 2와 SDPA를 사용하여 생성 속도 향상 [[use-flash-attention-2-and-sdpa-to-further-speed-up-generation]]
+
+이 모델은 최적화를 위해 Flash-Attention 2와 PyTorch의 [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html)를 모두 지원합니다. SDPA는 모델을 로드할 때 기본 옵션입니다. Flash Attention 2로 전환하려면 먼저 flash-attn을 설치해야 합니다. 해당 패키지 설치에 대해서는 [원본 리포지토리](https://github.com/Dao-AILab/flash-attention)를 참고하십시오. 위의 코드 스니펫을 다음과 같이 변경하면 됩니다:
+
+```python
+from transformers import ChameleonForConditionalGeneration
+
+model_id = "facebook/chameleon-7b"
+model = ChameleonForConditionalGeneration.from_pretrained(
+ model_id,
+ torch_dtype=torch.bfloat16,
+ low_cpu_mem_usage=True,
+ attn_implementation="flash_attention_2"
+).to(0)
+```
+
+## ChameleonConfig [[transformers.ChameleonConfig]]
+
+[[autodoc]] ChameleonConfig
+
+## ChameleonVQVAEConfig [[transformers.ChameleonVQVAEConfig]]
+
+[[autodoc]] ChameleonVQVAEConfig
+
+## ChameleonProcessor [[transformers.ChameleonProcessor]]
+
+[[autodoc]] ChameleonProcessor
+
+## ChameleonImageProcessor [[transformers.ChameleonImageProcessor]]
+
+[[autodoc]] ChameleonImageProcessor
+ - preprocess
+
+## ChameleonVQVAE [[transformers.ChameleonVQVAE]]
+
+[[autodoc]] ChameleonVQVAE
+ - forward
+
+## ChameleonModel [[transformers.ChameleonModel]]
+
+[[autodoc]] ChameleonModel
+ - forward
+
+## ChameleonForConditionalGeneration [[transformers.ChameleonForConditionalGeneration]]
+
+[[autodoc]] ChameleonForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/clip.md b/docs/transformers/docs/source/ko/model_doc/clip.md
new file mode 100644
index 0000000000000000000000000000000000000000..5c19a31e10e658a694464cb079b513f5fccf62f6
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/clip.md
@@ -0,0 +1,318 @@
+
+
+# CLIP[[clip]]
+
+## 개요[[overview]]
+
+CLIP 모델은 Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh,
+Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever가 제안한 [자연어 지도(supervision)를 통한 전이 가능한 시각 모델 학습](https://arxiv.org/abs/2103.00020)라는 논문에서 소개되었습니다. CLIP(Contrastive Language-Image Pre-Training)은 다양한 이미지와 텍스트 쌍으로 훈련된 신경망 입니다. GPT-2와 3의 제로샷 능력과 유사하게, 해당 작업에 직접적으로 최적화하지 않고도 주어진 이미지에 대해 가장 관련성 있는 텍스트 스니펫을 예측하도록 자연어로 지시할 수 있습니다.
+
+해당 논문의 초록입니다.
+
+*최신 컴퓨터 비전 시스템은 미리 정해진 고정된 객체 카테고리 집합을 예측하도록 훈련됩니다. 이러한 제한된 형태의 지도는 다른 시각적 개념을 지정하기 위해 추가적인 라벨링된 데이터가 필요하므로 그 일반성과 사용성을 제한합니다. 이미지 원시 텍스트에서 직접 학습하는 것은 훨씬 더 광범위한 지도 소스를 활용하는 아주 좋은 대안입니다. 이미지와 캡션을 맞추는 간단한 사전 학습 작업이, 인터넷에서 수집한 4억 쌍의 이미지-텍스트 데이터셋에서 SOTA 수준의 이미지 표현을 처음부터 효율적이고 확장 가능하게 학습하는 방법임을 확인할 수 있습니다. 사전 훈련 후, 자연어는 학습된 시각적 개념을 참조하거나 새로운 개념을 설명하는 데 사용되어 모델의 하위 작업으로의 제로샷 전이를 가능하게 합니다. 해당 논문에서는 OCR, 비디오 내 행동 인식, 지리적 위치 파악, 그리고 많은 종류의 세밀한 객체 분류 등 30개 이상의 다양한 기존 컴퓨터 비전 데이터셋에 대한 벤치마킹을 통해 이 접근 방식의 성능을 연구합니다. 이 모델은 대부분의 작업에 대해 의미 있게 전이되며, 종종 데이터셋별 훈련 없이도 완전 지도 학습 기준선과 경쟁력 있는 성능을 보입니다. 예를 들어, ImageNet에서 원래 ResNet-50의 정확도를 제로샷으로 일치시키는데, 이는 ResNet-50이 훈련된 128만 개의 훈련 예제를 전혀 사용할 필요가 없었습니다. 코드 및 사전 훈련된 모델 가중치는 이 https URL에서 공개합니다.*
+
+이 모델은 [valhalla](https://huggingface.co/valhalla)에 의해 기여되었습니다.
+원본 코드는 [이곳](https://github.com/openai/CLIP)에서 확인할 수 있습니다.
+
+## 사용 팁과 예시[[usage-tips-and-example]]
+
+CLIP은 멀티모달 비전 밒 언어 모델입니다. 이미지-텍스트 유사도 계산과 제로샷 이미지 분류에 사용될 수 있습니다. CLIP은 ViT와 유사한 트랜스포머를 사용하여 시각적 특징을 추출하고, 인과적 언어 모델을 사용하여 텍스트 특징을 추출합니다. 그 후 텍스트와 시각적 특징 모두 동일한 차원의 잠재(latent) 공간으로 투영됩니다. 투영된 이미지와 텍스트 특징 사이의 내적이 유사도 점수로 사용됩니다.
+
+트랜스포머 인코더에 이미지를 입력하기 위해, 각 이미지는 고정 크기의 겹치지 않는 패치들의 시퀀스로 분할되고, 이후 선형 임베딩됩니다. [CLS]토큰이 전체 이미지의 표현으로 추가됩니다. 저자들은 또한 절대 위치 임베딩을 추가하고, 결과로 나온 벡터 시퀀스를 표준 트랜스포머 인토더에 입력합니다. [`CLIPImageProcessor`]는 모델을 위해 이미지를 리사이즈(또는 재스캐일링)하고 정규화하는데 사용될 수 있습니다.
+
+[`CLIPTokenizer`]는 텍스트를 인코딩하는데 사용됩니다. [`CLIPProcessor`]는 [`CLIPImageProcessor`]와 [`CLIPTokenizer`]를 하나의 인스턴스로 감싸서 텍스트를 인코딩하고 이미지를 준비하는데 모두 사용됩니다.
+
+다음 예시는 [`CLIPProcessor`]와 [`CLIPModel`]을 사용하여 이미지-텍스트 유사도 점수를 얻는 방법을 보여줍니다.
+
+
+```python
+>>> from PIL import Image
+>>> import requests
+
+>>> from transformers import CLIPProcessor, CLIPModel
+
+>>> model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
+>>> processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
+
+>>> outputs = model(**inputs)
+>>> logits_per_image = outputs.logits_per_image # 이미지-텍스트 유사성 점수
+>>> probs = logits_per_image.softmax(dim=1) # 확률을 레이블링 하기위해서 소프트맥스를 취합니다.
+```
+
+
+### CLIP과 플래시 어텐션2 결합[[combining-clip-and-flash-attention-2]]
+
+먼저 최신버전의 플래시 어텐션2를 설치합니다.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+플래시 어텐션2와 호환되는 하드웨어를 가지고 있는지 확인하세요. 이에 대한 자세한 내용은 flash-attn 리포지토리의 공식문서에서 확인할 수 있습니다. 또한 모델을 반정밀도(`torch.float16`)로 로드하는 것을 잊지 마세요.
+
+
+
+작은 배치 크기를 사용할 때, 플래시 어텐션을 사용하면 모델이 느려지는 것을 느낄 수 있습니다.아래의 [플래시 어텐션과 SDPA를 사용한 예상 속도 향상](#Expected-speedups-with-Flash-Attention-and-SDPA) 섹션을 참조하여 적절한 어텐션 구현을 선택하세요.
+
+
+
+플래시 어텐션2를 사용해서 모델을 로드하고 구동하기 위해서 다음 스니펫을 참고하세요:
+
+```python
+>>> import torch
+>>> import requests
+>>> from PIL import Image
+
+>>> from transformers import CLIPProcessor, CLIPModel
+
+>>> device = "cuda"
+>>> torch_dtype = torch.float16
+
+>>> model = CLIPModel.from_pretrained(
+... "openai/clip-vit-base-patch32",
+... attn_implementation="flash_attention_2",
+... device_map=device,
+... torch_dtype=torch_dtype,
+... )
+>>> processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
+>>> inputs.to(device)
+
+>>> with torch.no_grad():
+... with torch.autocast(device):
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image # 이미지-텍스트 유사성 점수
+>>> probs = logits_per_image.softmax(dim=1) # 확률을 레이블링 하기위해서 소프트맥스를 취합니다.
+>>> print(probs)
+tensor([[0.9946, 0.0052]], device='cuda:0', dtype=torch.float16)
+```
+
+
+### 스케일된 내적 어텐션 (Scaled dot-product Attention(SDPA)) 사용하기[[using-scaled-dot-product-attention-sdpa]]
+
+파이토치는 `torch.nn.functional`의 일부로 네이티브 스케일된 내적 어텐션(SPDA) 연산자를 포함하고 있습니다. 이 함수는 입력과 사용 중인 하드웨어에 따라 적용될 수 있는 여러 구현을 포함합니다. 자세한 정보는 [공식문서](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)나 [GPU 추론](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention) 페이지를 참조하세요.
+
+`torch>=2.1.1`에서는 구현이 가능할 때 SDPA가 기본적으로 사용되지만, `from_pretrained()` 함수에서 `attn_implementation="sdpa"`를 설정하여 SDPA를 명시적으로 사용하도록 요청할 수도 있습니다.
+
+```python
+from transformers import CLIPModel
+
+model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32", torch_dtype=torch.float16, attn_implementation="sdpa")
+```
+
+최고의 속도향상을 위해서, 반정밀도로 모델을 로드하는 것을 추천합니다. (예를들면 `torch.float16` 또는 `torch.bfloat16`).
+
+### 플래시 어텐션과 스케일된 내적 어텐션(SDPA)으로 인해 예상되는 속도향상[[expected-speedups-with-flash-attention-and-sdpa]]
+
+로컬 벤치마크(NVIDIA A10G, PyTorch 2.3.1+cu121)에서 `float16`을 사용하여 `"openai/clip-vit-large-patch14"` 체크포인트로 추론을 수행했을 때, 다음과 같은 속도 향상을 확인 했습니다.
+[코드](https://gist.github.com/qubvel/ac691a54e54f9fae8144275f866a7ff8):
+
+#### CLIPTextModel[[cliptextmodel]]
+
+| Num text labels | Eager (s/iter) | FA2 (s/iter) | FA2 speedup | SDPA (s/iter) | SDPA speedup |
+|------------------:|-----------------:|---------------:|--------------:|----------------:|---------------:|
+| 4 | 0.009 | 0.012 | 0.737 | 0.007 | 1.269 |
+| 16 | 0.009 | 0.014 | 0.659 | 0.008 | 1.187 |
+| 32 | 0.018 | 0.021 | 0.862 | 0.016 | 1.142 |
+| 64 | 0.034 | 0.034 | 1.001 | 0.03 | 1.163 |
+| 128 | 0.063 | 0.058 | 1.09 | 0.054 | 1.174 |
+
+
+
+#### CLIPVisionModel[[clipvisionmodel]]
+
+| Image batch size | Eager (s/iter) | FA2 (s/iter) | FA2 speedup | SDPA (s/iter) | SDPA speedup |
+|-------------------:|-----------------:|---------------:|--------------:|----------------:|---------------:|
+| 1 | 0.016 | 0.013 | 1.247 | 0.012 | 1.318 |
+| 4 | 0.025 | 0.021 | 1.198 | 0.021 | 1.202 |
+| 16 | 0.093 | 0.075 | 1.234 | 0.075 | 1.24 |
+| 32 | 0.181 | 0.147 | 1.237 | 0.146 | 1.241 |
+
+
+
+#### CLIPModel[[clipmodel]]
+
+| Image batch size | Num text labels | Eager (s/iter) | FA2 (s/iter) | FA2 speedup | SDPA (s/iter) | SDPA speedup |
+|-------------------:|------------------:|-----------------:|---------------:|--------------:|----------------:|---------------:|
+| 1 | 4 | 0.025 | 0.026 | 0.954 | 0.02 | 1.217 |
+| 1 | 16 | 0.026 | 0.028 | 0.918 | 0.02 | 1.287 |
+| 1 | 64 | 0.042 | 0.046 | 0.906 | 0.036 | 1.167 |
+| 4 | 4 | 0.028 | 0.033 | 0.849 | 0.024 | 1.189 |
+| 4 | 16 | 0.034 | 0.035 | 0.955 | 0.029 | 1.169 |
+| 4 | 64 | 0.059 | 0.055 | 1.072 | 0.05 | 1.179 |
+| 16 | 4 | 0.096 | 0.088 | 1.091 | 0.078 | 1.234 |
+| 16 | 16 | 0.102 | 0.09 | 1.129 | 0.083 | 1.224 |
+| 16 | 64 | 0.127 | 0.11 | 1.157 | 0.105 | 1.218 |
+| 32 | 4 | 0.185 | 0.159 | 1.157 | 0.149 | 1.238 |
+| 32 | 16 | 0.19 | 0.162 | 1.177 | 0.154 | 1.233 |
+| 32 | 64 | 0.216 | 0.181 | 1.19 | 0.176 | 1.228 |
+
+## 자료[[resources]]
+
+CLIP을 시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다.
+
+- [원격 센싱 (인공위성) 이미지와 캡션을 가지고 CLIP 미세조정하기](https://huggingface.co/blog/fine-tune-clip-rsicd):
+[RSICD dataset](https://github.com/201528014227051/RSICD_optimal)을 가지고 CLIP을 미세조정 하는 방법과 데이터 증강에 대한 성능 비교에 대한 블로그 포스트
+- 이 [예시 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/contrastive-image-text)는 [COCO dataset](https://cocodataset.org/#home)를 이용한 사전학습된 비전과 텍스트와 인코더를 사용해서 CLIP같은 비전-텍스트 듀얼 모델을 어떻게 학습시키는지 보여줍니다.
+
+
+
+- 사전학습된 CLIP모델을 이미지 캡셔닝을 위한 빔서치 추론에 어떻게 활용하는지에 관한 [노트북](https://colab.research.google.com/drive/1tuoAC5F4sC7qid56Z0ap-stR3rwdk0ZV?usp=sharing)
+
+**이미지 검색**
+
+- 사전학습된 CLIP모델과 MRR(Mean Reciprocal Rank) 점수 연산을 사용한 이미지 검색에 대한 [노트북](https://colab.research.google.com/drive/1bLVwVKpAndpEDHqjzxVPr_9nGrSbuOQd?usp=sharing). 🌎
+- 이미지 검색과 유사성 점수에 대해 보여주는 [노트북](https://colab.research.google.com/github/deep-diver/image_search_with_natural_language/blob/main/notebooks/Image_Search_CLIP.ipynb). 🌎
+- Multilingual CLIP를 사용해서 이미지와 텍스트를 어떻게 같은 벡터 공간에 매핑 시키는지에 대한 [노트북](https://colab.research.google.com/drive/1xO-wC_m_GNzgjIBQ4a4znvQkvDoZJvH4?usp=sharing). 🌎
+- [Unsplash](https://unsplash.com)와 [TMDB](https://www.themoviedb.org/) 데이터셋을 활용한 의미론적(semantic) 이미지 검색에서 CLIP을 구동하는 방법에 대한 [노트북](https://colab.research.google.com/github/vivien000/clip-demo/blob/master/clip.ipynb#scrollTo=uzdFhRGqiWkR). 🌎
+
+**설명 가능성**
+
+- 입력 토큰과 이미지 조각(segment) 사이의 유사성을 시각화 시키는 방법에 대한 [노트북](https://colab.research.google.com/github/hila-chefer/Transformer-MM-Explainability/blob/main/CLIP_explainability.ipynb). 🌎
+
+여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰 해드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
+
+## CLIPConfig[[transformers.CLIPConfig]]
+
+[[autodoc]] CLIPConfig
+ - from_text_vision_configs
+
+## CLIPTextConfig[[transformers.CLIPTextConfig]]
+
+[[autodoc]] CLIPTextConfig
+
+## CLIPVisionConfig[[transformers.CLIPVisionConfig]]
+
+[[autodoc]] CLIPVisionConfig
+
+## CLIPTokenizer[[transformers.CLIPTokenizer]]
+
+[[autodoc]] CLIPTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CLIPTokenizerFast[[transformers.CLIPTokenizerFast]]
+
+[[autodoc]] CLIPTokenizerFast
+
+## CLIPImageProcessor[[transformers.CLIPImageProcessor]]
+
+[[autodoc]] CLIPImageProcessor
+ - preprocess
+
+## CLIPFeatureExtractor[[transformers.CLIPFeatureExtractor]]
+
+[[autodoc]] CLIPFeatureExtractor
+
+## CLIPProcessor[[transformers.CLIPProcessor]]
+
+[[autodoc]] CLIPProcessor
+
+
+
+
+## CLIPModel[[transformers.CLIPModel]]
+
+[[autodoc]] CLIPModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## CLIPTextModel[[transformers.CLIPTextModel]]
+
+[[autodoc]] CLIPTextModel
+ - forward
+
+## CLIPTextModelWithProjection[[transformers.CLIPTextModelWithProjection]]
+
+[[autodoc]] CLIPTextModelWithProjection
+ - forward
+
+## CLIPVisionModelWithProjection[[transformers.CLIPVisionModelWithProjection]]
+
+[[autodoc]] CLIPVisionModelWithProjection
+ - forward
+
+## CLIPVisionModel[[transformers.CLIPVisionModel]]
+
+[[autodoc]] CLIPVisionModel
+ - forward
+
+## CLIPForImageClassification[[transformers.CLIPForImageClassification]]
+
+[[autodoc]] CLIPForImageClassification
+ - forward
+
+
+
+
+## TFCLIPModel[[transformers.TFCLIPModel]]
+
+[[autodoc]] TFCLIPModel
+ - call
+ - get_text_features
+ - get_image_features
+
+## TFCLIPTextModel[[transformers.TFCLIPTextModel]]
+
+[[autodoc]] TFCLIPTextModel
+ - call
+
+## TFCLIPVisionModel[[transformers.TFCLIPVisionModel]]
+
+[[autodoc]] TFCLIPVisionModel
+ - call
+
+
+
+
+## FlaxCLIPModel[[transformers.FlaxCLIPModel]]
+
+[[autodoc]] FlaxCLIPModel
+ - __call__
+ - get_text_features
+ - get_image_features
+
+## FlaxCLIPTextModel[[transformers.FlaxCLIPTextModel]]
+
+[[autodoc]] FlaxCLIPTextModel
+ - __call__
+
+## FlaxCLIPTextModelWithProjection[[transformers.FlaxCLIPTextModelWithProjection]]
+
+[[autodoc]] FlaxCLIPTextModelWithProjection
+ - __call__
+
+## FlaxCLIPVisionModel[[transformers.FlaxCLIPVisionModel]]
+
+[[autodoc]] FlaxCLIPVisionModel
+ - __call__
+
+
+
diff --git a/docs/transformers/docs/source/ko/model_doc/codegen.md b/docs/transformers/docs/source/ko/model_doc/codegen.md
new file mode 100644
index 0000000000000000000000000000000000000000..264f10e89b06aa0b65ca247eba2e87c819dc65df
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/codegen.md
@@ -0,0 +1,94 @@
+
+
+# CodeGen[[Codegen]]
+
+
+
+
+
+## 개요[[Overview]]
+
+CodeGen 모델은 Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong이 작성한 논문 [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474)에서 제안되었습니다.
+
+CodeGen 모델은 프로그램 합성(program synthesis)을 위한 자기회귀(autoregressive) 언어 모델로, [The Pile](https://pile.eleuther.ai/), BigQuery, BigPython 데이터로 순차적으로 학습되었습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*프로그램 합성(program synthesis)은 주어진 문제 명세에 대한 해답으로 프로그램을 생성하는 것을 목표로 합니다. 이 논문에서는 대규모 언어 모델(LLM)을 활용한 대화형 프로그램 합성(conversational program synthesis) 접근법을 제안하여, 기존 접근법에서의 방대한 프로그램 탐색 공간과 사용자의 의도를 명세화하는 과정에서의 어려움을 해결합니다. 제안된 방식에서는 프로그램 명세 작성과 실제 프로그램 작성을 사용자와 시스템 간 다회 대화(multi-turn conversation)로 바라봅니다. 즉, 프로그램 합성 과정 명세를 자연어로 표현하고, 기대하는 프로그램 합성을 조건부로 예측하여 생성하는 일종의 순차적 예측 문제(sequence prediction problem)로 접근했습니다. 이를 위해 자연어와 프로그래밍 언어 데이터를 기반으로 CodeGen이라는 대규모 언어 모델 그룹을 학습시켰으며, 데이터로부터 약한 지도(weak supervision)와 데이터 및 모델 규모의 확장만으로도 모델이 자연스럽게 대화 능력을 갖추게 된다는 점을 확인하였습니다. 더해서 모델의 대화형 프로그램 합성 능력을 평가하기 위해 다회 대화 기반 프로그래밍 벤치마크(MTPB)를 개발했습니다. 이 벤치마크는 각 문제를 해결하기 위해 사용자와 모델 간 여러 단계의 대화를 거쳐 프로그램이 점진적으로 합성되는 과정을 요구합니다. 연구 결과, CodeGen 모델은 대화형 능력을 성공적으로 발휘했으며 본 논문에서 제안한 대화형 합성 패러다임의 우수성과 효율성을 입증했습니다. 특히 16B 파라미터 규모로 TPU-v4에서 학습된 CodeGen 모델은 HumanEval 벤치마크에서 OpenAI의 Codex를 뛰어넘는 성능을 기록했습니다. 학습된 사용된 라이브러리인 JaxFormer와 모델 체크포인트는 오픈소스로 공개되었습니다: [이 https URL에서 확인하세요](https://github.com/salesforce/codegen).*
+
+이 모델은[Hiroaki Hayashi](https://huggingface.co/rooa)가 기여했습니다.
+모델의 원본 코드는 [여기](https://github.com/salesforce/codegen)에 있습니다.
+
+## 체크포인트 명명 규칙[[Checkpoint Naming]]
+
+* CodeGen 모델의 [체크포인트](https://huggingface.co/models?other=codegen)는 서로 다른 사전 학습 데이터와 다양한 크기로 제공됩니다.
+* 체크포인트의 형식은 다음과 같습니다: `Salesforce/codegen-{size}-{data}`
+ * `size`: `350M`, `2B`, `6B`, `16B`
+ * `data`:
+ * `nl`: The Pile 데이터로 사전학습된 모델
+ * `multi`: `nl` 모델에서 시작하여 다양한 프로그래밍 언어를 추가적으로 학습한 모델
+ * `mono`: `multi` 모델에서 시작하여 추가로 Python 데이터에 대해 학습된 모델
+* 예를 들어, `Salesforce/codegen-350M-mono`는 3억 5천만(350M) 개의 파라미터를 모델로, The Pile, 다양한 프로그래밍 언어, Python 데이터의 순서로 단계적으로 학습한 체크포인트를 의미합니다.
+
+## 사용 예시[[Usage example]]
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> checkpoint = "Salesforce/codegen-350M-mono"
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+
+>>> text = "def hello_world():"
+
+>>> completion = model.generate(**tokenizer(text, return_tensors="pt"))
+
+>>> print(tokenizer.decode(completion[0]))
+def hello_world():
+ print("Hello World")
+
+hello_world()
+```
+
+## 자료[[Resources]]
+
+- [Causal language modeling task guide](../tasks/language_modeling)
+
+## CodeGenConfig
+
+[[autodoc]] CodeGenConfig
+ - all
+
+## CodeGenTokenizer
+
+[[autodoc]] CodeGenTokenizer
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## CodeGenTokenizerFast
+
+[[autodoc]] CodeGenTokenizerFast
+
+## CodeGenModel
+
+[[autodoc]] CodeGenModel
+ - forward
+
+## CodeGenForCausalLM
+
+[[autodoc]] CodeGenForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/cohere.md b/docs/transformers/docs/source/ko/model_doc/cohere.md
new file mode 100644
index 0000000000000000000000000000000000000000..c577764623f49672a27b78f850828cc21fa7a37b
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/cohere.md
@@ -0,0 +1,139 @@
+# Cohere[[cohere]]
+
+## 개요[[overview]]
+
+The Cohere Command-R 모델은 Cohere팀이 [Command-R: 프로덕션 규모의 검색 증강 생성](https://txt.cohere.com/command-r/)라는 블로그 포스트에서 소개 되었습니다.
+
+논문 초록:
+
+*Command-R은 기업의 프로덕션 규모 AI를 가능하게 하기 위해 RAG(검색 증강 생성)와 도구 사용을 목표로 하는 확장 가능한 생성 모델입니다. 오늘 우리는 대규모 프로덕션 워크로드를 목표로 하는 새로운 LLM인 Command-R을 소개합니다. Command-R은 높은 효율성과 강력한 정확성의 균형을 맞추는 '확장 가능한' 모델 카테고리를 대상으로 하여, 기업들이 개념 증명을 넘어 프로덕션 단계로 나아갈 수 있게 합니다.*
+
+*Command-R은 검색 증강 생성(RAG)이나 외부 API 및 도구 사용과 같은 긴 문맥 작업에 최적화된 생성 모델입니다. 이 모델은 RAG 애플리케이션을 위한 최고 수준의 통합을 제공하고 기업 사용 사례에서 뛰어난 성능을 발휘하기 위해 우리의 업계 선도적인 Embed 및 Rerank 모델과 조화롭게 작동하도록 설계되었습니다. 기업이 대규모로 구현할 수 있도록 만들어진 모델로서, Command-R은 다음과 같은 특징을 자랑합니다:
+- RAG 및 도구 사용에 대한 강력한 정확성
+- 낮은 지연 시간과 높은 처리량
+- 더 긴 128k 컨텍스트와 낮은 가격
+- 10개의 주요 언어에 걸친 강력한 기능
+- 연구 및 평가를 위해 HuggingFace에서 사용 가능한 모델 가중치
+
+모델 체크포인트는 [이곳](https://huggingface.co/CohereForAI/c4ai-command-r-v01)에서 확인하세요.
+이 모델은 [Saurabh Dash](https://huggingface.co/saurabhdash)과 [Ahmet Üstün](https://huggingface.co/ahmetustun)에 의해 기여 되었습니다. Hugging Face에서 이 코드의 구현은 [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)에 기반하였습니다.
+
+## 사용 팁[[usage-tips]]
+
+
+
+Hub에 업로드된 체크포인트들은 `torch_dtype = 'float16'`을 사용합니다.
+이는 `AutoModel` API가 체크포인트를 `torch.float32`에서 `torch.float16`으로 변환하는 데 사용됩니다.
+
+온라인 가중치의 `dtype`은 `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`를 사용하여 모델을 초기화할 때 `torch_dtype="auto"`를 사용하지 않는 한 대부분 무관합니다. 그 이유는 모델이 먼저 다운로드되고(온라인 체크포인트의 `dtype` 사용), 그 다음 `torch`의 기본 `dtype`으로 변환되며(이때 `torch.float32`가 됨), 마지막으로 config에 `torch_dtype`이 제공된 경우 이를 사용하기 때문입니다.
+
+모델을 `float16`으로 훈련하는 것은 권장되지 않으며 `nan`을 생성하는 것으로 알려져 있습니다. 따라서 모델은 `bfloat16`으로 훈련해야 합니다.
+
+모델과 토크나이저는 다음과 같이 로드할 수 있습니다:
+
+```python
+# pip install transformers
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+model_id = "CohereForAI/c4ai-command-r-v01"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = AutoModelForCausalLM.from_pretrained(model_id)
+
+# Format message with the command-r chat template
+messages = [{"role": "user", "content": "Hello, how are you?"}]
+input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
+## <|START_OF_TURN_TOKEN|><|USER_TOKEN|>Hello, how are you?<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+
+gen_tokens = model.generate(
+ input_ids,
+ max_new_tokens=100,
+ do_sample=True,
+ temperature=0.3,
+ )
+
+gen_text = tokenizer.decode(gen_tokens[0])
+print(gen_text)
+```
+
+- Flash Attention 2를 `attn_implementation="flash_attention_2"`를 통해 사용할 때는, `from_pretrained` 클래스 메서드에 `torch_dtype`을 전달하지 말고 자동 혼합 정밀도 훈련(Automatic Mixed-Precision training)을 사용하세요. `Trainer`를 사용할 때는 단순히 `fp16` 또는 `bf16`을 `True`로 지정하면 됩니다. 그렇지 않은 경우에는 `torch.autocast`를 사용하고 있는지 확인하세요. 이는 Flash Attention이 `fp16`와 `bf16` 데이터 타입만 지원하기 때문에 필요합니다.
+
+## 리소스[[resources]]
+
+Command-R을 시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다. 여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰 해드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
+
+
+
+
+FP16 모델 로딩
+```python
+# pip install transformers
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+model_id = "CohereForAI/c4ai-command-r-v01"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = AutoModelForCausalLM.from_pretrained(model_id)
+
+# command-r 챗 템플릿으로 메세지 형식을 정하세요
+messages = [{"role": "user", "content": "Hello, how are you?"}]
+input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
+## <|START_OF_TURN_TOKEN|><|USER_TOKEN|>Hello, how are you?<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+
+gen_tokens = model.generate(
+ input_ids,
+ max_new_tokens=100,
+ do_sample=True,
+ temperature=0.3,
+ )
+
+gen_text = tokenizer.decode(gen_tokens[0])
+print(gen_text)
+```
+
+bitsandbytes 라이브러리를 이용해서 4bit 양자화된 모델 로딩
+```python
+# pip install transformers bitsandbytes accelerate
+from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
+
+bnb_config = BitsAndBytesConfig(load_in_4bit=True)
+
+model_id = "CohereForAI/c4ai-command-r-v01"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config)
+
+gen_tokens = model.generate(
+ input_ids,
+ max_new_tokens=100,
+ do_sample=True,
+ temperature=0.3,
+ )
+
+gen_text = tokenizer.decode(gen_tokens[0])
+print(gen_text)
+```
+
+
+## CohereConfig[[transformers.CohereConfig]]
+
+[[autodoc]] CohereConfig
+
+## CohereTokenizerFast[[transformers.CohereTokenizerFast]]
+
+[[autodoc]] CohereTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - update_post_processor
+ - save_vocabulary
+
+## CohereModel[[transformers.CohereModel]]
+
+[[autodoc]] CohereModel
+ - forward
+
+
+## CohereForCausalLM[[transformers.CohereForCausalLM]]
+
+[[autodoc]] CohereForCausalLM
+ - forward
+
+
diff --git a/docs/transformers/docs/source/ko/model_doc/convbert.md b/docs/transformers/docs/source/ko/model_doc/convbert.md
new file mode 100644
index 0000000000000000000000000000000000000000..ec64a369b56a3f0e33f9e41c44f6b95555dc36dd
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/convbert.md
@@ -0,0 +1,135 @@
+
+
+# ConvBERT [[convbert]]
+
+
+
+## 개요 [[overview]]
+
+ConvBERT 모델은 Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan에 의해 제안되었으며, 제안 논문 제목은 [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496)입니다.
+
+논문의 초록은 다음과 같습니다:
+
+*BERT와 그 변형 모델과 같은 사전 학습된 언어 모델들은 최근 다양한 자연어 이해 과제에서 놀라운 성과를 이루었습니다. 그러나 BERT는 글로벌 셀프 어텐션 블록에 크게 의존하기 때문에 메모리 사용량이 많고 계산 비용이 큽니다. 모든 어텐션 헤드가 글로벌 관점에서 어텐션 맵을 생성하기 위해 입력 시퀀스 전체를 탐색하지만, 일부 헤드는 로컬 종속성만 학습할 필요가 있다는 것을 발견했습니다. 이는 불필요한 계산이 포함되어 있음을 의미합니다. 따라서 우리는 이러한 self-attention 헤드들을 대체하여 로컬 종속성을 직접 모델링하기 위해 새로운 span 기반 동적 컨볼루션을 제안합니다. 새로운 컨볼루션 헤드와 나머지 self-attention 헤드들이 결합하여 글로벌 및 로컬 문맥 학습에 더 효율적인 혼합 어텐션 블록을 구성합니다. 우리는 BERT에 이 혼합 어텐션 설계를 적용하여 ConvBERT 모델을 구축했습니다. 실험 결과, ConvBERT는 다양한 다운스트림 과제에서 BERT 및 그 변형 모델보다 더 우수한 성능을 보였으며, 훈련 비용과 모델 파라미터 수가 더 적었습니다. 특히 ConvBERTbase 모델은 GLUE 스코어 86.4를 달성하여 ELECTRAbase보다 0.7 높은 성과를 보이며, 훈련 비용은 1/4 이하로 줄었습니다. 코드와 사전 학습된 모델은 공개될 예정입니다.*
+
+이 모델은 [abhishek](https://huggingface.co/abhishek)에 의해 기여되었으며, 원본 구현은 여기에서 찾을 수 있습니다 : https://github.com/yitu-opensource/ConvBert
+
+
+
+## 사용 팁 [[usage-tips]]
+ConvBERT 훈련 팁은 BERT와 유사합니다. 사용 팁은 [BERT 문서](bert).를 참고하십시오.
+
+
+## 리소스 [[resources]]
+
+- [텍스트 분류 작업 가이드 (Text classification task guide)](../tasks/sequence_classification)
+- [토큰 분류 작업 가이드 (Token classification task guide)](../tasks/token_classification)
+- [질의응답 작업 가이드 (Question answering task guide)](../tasks/question_answering)
+- [마스킹된 언어 모델링 작업 가이드 (Masked language modeling task guide)](../tasks/masked_language_modeling)
+- [다중 선택 작업 가이드 (Multiple choice task guide)](../tasks/multiple_choice)
+
+## ConvBertConfig [[transformers.ConvBertConfig]]
+
+[[autodoc]] ConvBertConfig
+
+## ConvBertTokenizer [[transformers.ConvBertTokenizer]]
+
+[[autodoc]] ConvBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## ConvBertTokenizerFast [[transformers.ConvBertTokenizerFast]]
+
+[[autodoc]] ConvBertTokenizerFast
+
+
+
+
+## ConvBertModel [[transformers.ConvBertModel]]
+
+[[autodoc]] ConvBertModel
+ - forward
+
+## ConvBertForMaskedLM [[transformers.ConvBertForMaskedLM]]
+
+[[autodoc]] ConvBertForMaskedLM
+ - forward
+
+## ConvBertForSequenceClassification [[transformers.ConvBertForSequenceClassification]]
+
+[[autodoc]] ConvBertForSequenceClassification
+ - forward
+
+## ConvBertForMultipleChoice [[transformers.ConvBertForMultipleChoice]]
+
+[[autodoc]] ConvBertForMultipleChoice
+ - forward
+
+## ConvBertForTokenClassification [[transformers.ConvBertForTokenClassification]]
+
+[[autodoc]] ConvBertForTokenClassification
+ - forward
+
+## ConvBertForQuestionAnswering [[transformers.ConvBertForQuestionAnswering]]
+
+[[autodoc]] ConvBertForQuestionAnswering
+ - forward
+
+
+
+
+## TFConvBertModel [[transformers.TFConvBertModel]]
+
+[[autodoc]] TFConvBertModel
+ - call
+
+## TFConvBertForMaskedLM [[transformers.TFConvBertForMaskedLM]]
+
+[[autodoc]] TFConvBertForMaskedLM
+ - call
+
+## TFConvBertForSequenceClassification [[transformers.TFConvBertForSequenceClassification]]
+
+[[autodoc]] TFConvBertForSequenceClassification
+ - call
+
+## TFConvBertForMultipleChoice [[transformers.TFConvBertForMultipleChoice]]
+
+[[autodoc]] TFConvBertForMultipleChoice
+ - call
+
+## TFConvBertForTokenClassification [[transformers.TFConvBertForTokenClassification]]
+
+[[autodoc]] TFConvBertForTokenClassification
+ - call
+
+## TFConvBertForQuestionAnswering [[transformers.TFConvBertForQuestionAnswering]]
+
+[[autodoc]] TFConvBertForQuestionAnswering
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/ko/model_doc/dbrx.md b/docs/transformers/docs/source/ko/model_doc/dbrx.md
new file mode 100644
index 0000000000000000000000000000000000000000..4b33e95700691edd07f82c989c9c07e36aa0b419
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/dbrx.md
@@ -0,0 +1,125 @@
+
+
+# DBRX[[dbrx]]
+
+## 개요[[overview]]
+
+DBRX는 [트랜스포머 기반의](https://www.isattentionallyouneed.com/) 다음 토큰을 예측하는 디코더 전용 LLM 모델입니다.
+총 132B 매개변수를 가진 *세밀한* 전문가 혼합(MoE) 아키텍처를 사용하며, 이 중 36B 매개변수가 입력마다 활성화됩니다.
+12T 토큰의 텍스트와 코드 데이터로 사전 학습되었습니다.
+
+Mixtral-8x7B와 Grok-1과 같은 다른 공개 MoE 모델들과 비교했을 때, DBRX는 더 많은 수의 작은 전문가들을 사용하는 세밀한 구조를 가지고 있습니다. DBRX는 16개의 전문가 중 4개를 선택하는 반면, Mixtral-8x7B와 Grok-1은 8개의 전문가 중 2개를 선택합니다.
+
+이는 65배 더 많은 전문가 조합을 가능하게 하며, 이를 통해 모델의 품질이 향상되는 것을 발견했습니다.
+DBRX는 회전 위치 인코딩(RoPE), 게이트 선형 유닛(GLU), 그룹 쿼리 어텐션(GQA)을 사용합니다.
+BPE 기반 모델이며 [tiktoken](https://github.com/openai/tiktoken) 저장소에 설명된 GPT-4 토크나이저를 사용합니다.
+이러한 선택들은 철저한 평가와 스케일링 실험을 기반으로 이루어졌습니다.
+
+DBRX는 신중하게 선별된 12T 토큰의 데이터로 사전 학습되었으며, 최대 문맥 길이는 32K 토큰입니다.
+이 데이터는 토큰 대비 MPT 계열 모델 학습에 사용된 데이터보다 최소 2배 이상 더 좋은 것으로 추정됩니다.
+이 새로운 데이터셋은 데이터 처리를 위한 Apache Spark™와 Databricks 노트북, 그리고 데이터 관리와 거버넌스를 위한 Unity Catalog를 포함한 Databricks 도구 전체를 활용하여 개발되었습니다.
+우리는 사전 학습을 위해 커리큘럼 학습을 사용했으며, 학습 중 데이터 믹스를 변경하는 방식이 모델 품질을 상당히 개선한다는 것을 발견했습니다.
+
+
+DBRX Instruct와 DBRX Base에 대한 더 자세한 정보는 이 [기술 블로그 포스트](https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm)에서 확인할 수 있습니다.
+
+이 모델은 [eitan-turok](https://huggingface.co/eitanturok)와 [abhi-db](https://huggingface.co/abhi-db)가 기여했습니다. 원본 코드는 [이곳](https://github.com/databricks/dbrx-instruct)에서 찾을 수 있지만, 최신 버전이 아닐 수 있습니다.
+
+## 사용 예[[usage-examples]]
+
+`generate()` 메소드는 DBRX를 사용하여 텍스트를 생성하는 데 사용될 수 있습니다. 표준 어텐션 구현, 플래시 어텐션, PyTorch의 스케일된 내적 어텐션(Scaled Dot-Product Attention)을 사용하여 생성할 수 있습니다. 후자의 두 어텐션 구현 방식은 처리 속도를 크게 높여줍니다.
+
+```python
+from transformers import DbrxForCausalLM, AutoTokenizer
+import torch
+
+tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", token="YOUR_HF_TOKEN")
+model = DbrxForCausalLM.from_pretrained(
+ "databricks/dbrx-instruct",
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+ token="YOUR_HF_TOKEN",
+ )
+
+input_text = "What does it take to build a great LLM?"
+messages = [{"role": "user", "content": input_text}]
+input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
+
+outputs = model.generate(**input_ids, max_new_tokens=200)
+print(tokenizer.decode(outputs[0]))
+```
+
+`pip install flash-attn`를 통해 플래시 어텐션을 설치하면, 더 빠른 생성이 가능합니다. (플래시 어텐션에 대한 HuggingFace 문서는 [이곳](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2)에서 확인할 수 있습니다.)
+
+
+```python
+from transformers import DbrxForCausalLM, AutoTokenizer
+import torch
+
+tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", token="YOUR_HF_TOKEN")
+model = DbrxForCausalLM.from_pretrained(
+ "databricks/dbrx-instruct",
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+ token="YOUR_HF_TOKEN",
+ attn_implementation="flash_attention_2",
+ )
+
+input_text = "What does it take to build a great LLM?"
+messages = [{"role": "user", "content": input_text}]
+input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
+
+outputs = model.generate(**input_ids, max_new_tokens=200)
+print(tokenizer.decode(outputs[0]))
+```
+
+PyTorch의 스케일된 내적 어텐션을 사용하여도 더 빠른 생성이 가능합니다. (스케일된 내적 어텐션에 대한 HuggingFace 문서는 [이곳](https://huggingface.co/docs/transformers/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)에서 확인할 수 있습니다.)
+
+
+```python
+from transformers import DbrxForCausalLM, AutoTokenizer
+import torch
+
+tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", token="YOUR_HF_TOKEN")
+model = DbrxForCausalLM.from_pretrained(
+ "databricks/dbrx-instruct",
+ device_map="auto",
+ torch_dtype=torch.bfloat16,
+ token="YOUR_HF_TOKEN",
+ attn_implementation="sdpa",
+ )
+
+input_text = "What does it take to build a great LLM?"
+messages = [{"role": "user", "content": input_text}]
+input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt").to("cuda")
+
+outputs = model.generate(**input_ids, max_new_tokens=200)
+print(tokenizer.decode(outputs[0]))
+```
+
+## DbrxConfig[[transformers.DbrxConfig]]
+
+[[autodoc]] DbrxConfig
+
+
+## DbrxModel[[transformers.DbrxModel]]
+
+[[autodoc]] DbrxModel
+ - forward
+
+
+## DbrxForCausalLM[[transformers.DbrxForCausalLM]]
+
+[[autodoc]] DbrxForCausalLM
+ - forward
+
diff --git a/docs/transformers/docs/source/ko/model_doc/deberta-v2.md b/docs/transformers/docs/source/ko/model_doc/deberta-v2.md
new file mode 100644
index 0000000000000000000000000000000000000000..2e590ad8a5abcf90da995dc90b6592c8a205b309
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/deberta-v2.md
@@ -0,0 +1,147 @@
+
+
+# DeBERTa-v2
+
+## 개요
+
+
+DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://arxiv.org/abs/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
+DeBERTa는 RoBERTa에서 사용된 데이터의 절반만을 사용하여 분리된(disentangled) 어텐션과 향상된 마스크 디코더 학습을 통해 RoBERTa를 개선했습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*사전 학습된 신경망 언어 모델의 최근 발전은 많은 자연어 처리(NLP) 작업의 성능을 크게 향상시켰습니다. 본 논문에서는 두 가지 새로운 기술을 사용하여 BERT와 RoBERTa 모델을 개선한 새로운 모델 구조인 DeBERTa를 제안합니다. 첫 번째는 분리된 어텐션 메커니즘으로, 각 단어가 내용과 위치를 각각 인코딩하는 두 개의 벡터로 표현되며, 단어들 간의 어텐션 가중치는 내용과 상대적 위치에 대한 분리된 행렬을 사용하여 계산됩니다. 두 번째로, 모델 사전 학습을 위해 마스킹된 토큰을 예측하는 출력 소프트맥스 층을 대체하는 향상된 마스크 디코더가 사용됩니다. 우리는 이 두 가지 기술이 모델 사전 학습의 효율성과 다운스트림 작업의 성능을 크게 향상시킨다는 것을 보여줍니다. RoBERTa-Large와 비교했을 때, 절반의 학습 데이터로 학습된 DeBERTa 모델은 광범위한 NLP 작업에서 일관되게 더 나은 성능을 보여주며, MNLI에서 +0.9%(90.2% vs 91.1%), SQuAD v2.0에서 +2.3%(88.4% vs 90.7%), RACE에서 +3.6%(83.2% vs 86.8%)의 성능 향상을 달성했습니다. DeBERTa 코드와 사전 학습된 모델은 https://github.com/microsoft/DeBERTa 에서 공개될 예정입니다.*
+
+
+다음 정보들은 [원본 구현 저장소](https://github.com/microsoft/DeBERTa)에서 보실 수 있습니다. DeBERTa v2는 DeBERTa의 두번째 모델입니다.
+DeBERTa v2는 SuperGLUE 단일 모델 제출에 사용된 1.5B 모델을 포함하며, 인간 기준점(베이스라인) 89.8점 대비 89.9점을 달성했습니다. 저자의
+[블로그](https://www.microsoft.com/en-us/research/blog/microsoft-deberta-surpasses-human-performance-on-the-superglue-benchmark/)에서 더 자세한 정보를 확인할 수 있습니다.
+
+v2의 새로운 점:
+
+- **어휘(Vocabulary)** v2에서는 학습 데이터로부터 구축된 128K 크기의 새로운 어휘를 사용하도록 토크나이저가 변경되었습니다. GPT2 기반 토크나이저 대신, 이제는 [센텐스피스 기반](https://github.com/google/sentencepiece) 토크나이저를 사용합니다.
+- **nGiE[n그램 유도(Induced) 입력 인코딩]** DeBERTa-v2 모델은 입력 토큰들의 지역적 의존성을 더 잘 학습하기 위해 첫 번째 트랜스포머 층과 함께 추가적인 합성곱 층을 사용합니다.
+- **어텐션 층에서 위치 투영 행렬과 내용 투영 행렬 공유** 이전 실험들을 기반으로, 이는 성능에 영향을 주지 않으면서 매개변수를 절약할 수 있습니다.
+- **상대적 위치를 인코딩하기 위한 버킷 적용** DeBERTa-v2 모델은 T5와 유사하게 상대적 위치를 인코딩하기 위해 로그 버킷을 사용합니다.
+- **900M 모델 & 1.5B 모델** 900M과 1.5B, 두 가지 추가 모델 크기가 제공되며, 이는 다운스트림 작업의 성능을 크게 향상시킵니다.
+
+[DeBERTa](https://huggingface.co/DeBERTa) 모델의 텐서플로 2.0 구현은 [kamalkraj](https://huggingface.co/kamalkraj)가 기여했습니다. 원본 코드는 [이곳](https://github.com/microsoft/DeBERTa)에서 확인하실 수 있습니다.
+
+## 자료
+
+- [텍스트 분류 작업 가이드](../tasks/sequence_classification)
+- [토큰 분류 작업 가이드](../tasks/token_classification)
+- [질의응답 작업 가이드](../tasks/question_answering)
+- [마스크 언어 모델링 작업 가이드](../tasks/masked_language_modeling)
+- [다중 선택 작업 가이드](../tasks/multiple_choice)
+
+## DebertaV2Config
+
+[[autodoc]] DebertaV2Config
+
+## DebertaV2Tokenizer
+
+[[autodoc]] DebertaV2Tokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## DebertaV2TokenizerFast
+
+[[autodoc]] DebertaV2TokenizerFast
+ - build_inputs_with_special_tokens
+ - create_token_type_ids_from_sequences
+
+
+
+
+## DebertaV2Model
+
+[[autodoc]] DebertaV2Model
+ - forward
+
+## DebertaV2PreTrainedModel
+
+[[autodoc]] DebertaV2PreTrainedModel
+ - forward
+
+## DebertaV2ForMaskedLM
+
+[[autodoc]] DebertaV2ForMaskedLM
+ - forward
+
+## DebertaV2ForSequenceClassification
+
+[[autodoc]] DebertaV2ForSequenceClassification
+ - forward
+
+## DebertaV2ForTokenClassification
+
+[[autodoc]] DebertaV2ForTokenClassification
+ - forward
+
+## DebertaV2ForQuestionAnswering
+
+[[autodoc]] DebertaV2ForQuestionAnswering
+ - forward
+
+## DebertaV2ForMultipleChoice
+
+[[autodoc]] DebertaV2ForMultipleChoice
+ - forward
+
+
+
+
+## TFDebertaV2Model
+
+[[autodoc]] TFDebertaV2Model
+ - call
+
+## TFDebertaV2PreTrainedModel
+
+[[autodoc]] TFDebertaV2PreTrainedModel
+ - call
+
+## TFDebertaV2ForMaskedLM
+
+[[autodoc]] TFDebertaV2ForMaskedLM
+ - call
+
+## TFDebertaV2ForSequenceClassification
+
+[[autodoc]] TFDebertaV2ForSequenceClassification
+ - call
+
+## TFDebertaV2ForTokenClassification
+
+[[autodoc]] TFDebertaV2ForTokenClassification
+ - call
+
+## TFDebertaV2ForQuestionAnswering
+
+[[autodoc]] TFDebertaV2ForQuestionAnswering
+ - call
+
+## TFDebertaV2ForMultipleChoice
+
+[[autodoc]] TFDebertaV2ForMultipleChoice
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/ko/model_doc/deberta.md b/docs/transformers/docs/source/ko/model_doc/deberta.md
new file mode 100644
index 0000000000000000000000000000000000000000..6f82bed033a0e063b80210a71325741868fdc994
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/deberta.md
@@ -0,0 +1,152 @@
+
+
+# DeBERTa[[deberta]]
+
+## 개요[[overview]]
+
+
+DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://arxiv.org/abs/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
+DeBERTa는 RoBERTa에서 사용된 데이터의 절반만을 사용하여 분리된(disentangled) 어텐션과 향상된 마스크 디코더 학습을 통해 RoBERTa를 개선했습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*사전 학습된 신경망 언어 모델의 최근 발전은 많은 자연어 처리(NLP) 작업의 성능을 크게 향상시켰습니다. 본 논문에서는 두 가지 새로운 기술을 사용하여 BERT와 RoBERTa 모델을 개선한 새로운 모델 구조인 DeBERTa를 제안합니다. 첫 번째는 분리된 어텐션 메커니즘으로, 각 단어가 내용과 위치를 각각 인코딩하는 두 개의 벡터로 표현되며, 단어들 간의 어텐션 가중치는 내용과 상대적 위치에 대한 분리된 행렬을 사용하여 계산됩니다. 두 번째로, 모델 사전 학습을 위해 마스킹된 토큰을 예측하는 출력 소프트맥스 층을 대체하는 향상된 마스크 디코더가 사용됩니다. 우리는 이 두 가지 기술이 모델 사전 학습의 효율성과 다운스트림 작업의 성능을 크게 향상시킨다는 것을 보여줍니다. RoBERTa-Large와 비교했을 때, 절반의 학습 데이터로 학습된 DeBERTa 모델은 광범위한 NLP 작업에서 일관되게 더 나은 성능을 보여주며, MNLI에서 +0.9%(90.2% vs 91.1%), SQuAD v2.0에서 +2.3%(88.4% vs 90.7%), RACE에서 +3.6%(83.2% vs 86.8%)의 성능 향상을 달성했습니다. DeBERTa 코드와 사전 학습된 모델은 https://github.com/microsoft/DeBERTa 에서 공개될 예정입니다.*
+
+[DeBERTa](https://huggingface.co/DeBERTa) 모델의 텐서플로 2.0 구현은 [kamalkraj](https://huggingface.co/kamalkraj)가 기여했습니다. 원본 코드는 [이곳](https://github.com/microsoft/DeBERTa)에서 확인하실 수 있습니다.
+
+## 리소스[[resources]]
+
+
+DeBERTa를 시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다. 여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰해 드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
+
+
+
+
+- DeBERTa와 [DeepSpeed를 이용해서 대형 모델 학습을 가속시키는](https://huggingface.co/blog/accelerate-deepspeed) 방법에 대한 포스트.
+- DeBERTa와 [머신러닝으로 한층 향상된 고객 서비스](https://huggingface.co/blog/supercharge-customer-service-with-machine-learning)에 대한 블로그 포스트.
+- [`DebertaForSequenceClassification`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)에서 지원됩니다.
+- [`TFDebertaForSequenceClassification`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)에서 지원됩니다.
+- [텍스트 분류 작업 가이드](../tasks/sequence_classification)
+
+
+
+- [`DebertaForTokenClassification`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)에서 지원합니다.
+- [`TFDebertaForTokenClassification`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)에서 지원합니다.
+- 🤗 Hugging Face 코스의 [토큰 분류](https://huggingface.co/course/chapter7/2?fw=pt) 장.
+- 🤗 Hugging Face 코스의 [BPE(Byte-Pair Encoding) 토큰화](https://huggingface.co/course/chapter6/5?fw=pt) 장.
+- [토큰 분류 작업 가이드](../tasks/token_classification)
+
+
+
+- [`DebertaForMaskedLM`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)에서 지원합니다.
+- [`TFDebertaForMaskedLM`]은 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)에서 지원합니다.
+- 🤗 Hugging Face 코스의 [마스크 언어 모델링](https://huggingface.co/course/chapter7/3?fw=pt) 장.
+- [마스크 언어 모델링 작업 가이드](../tasks/masked_language_modeling)
+
+
+
+- [`DebertaForQuestionAnswering`]은 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)에서 지원합니다.
+- [`TFDebertaForQuestionAnswering`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)에서 지원합니다.
+- 🤗 Hugging Face 코스의 [질의응답(Question answering)](https://huggingface.co/course/chapter7/7?fw=pt) 장.
+- [질의응답 작업 가이드](../tasks/question_answering)
+
+## DebertaConfig[[transformers.DebertaConfig]]
+
+[[autodoc]] DebertaConfig
+
+## DebertaTokenizer[[transformers.DebertaTokenizer]]
+
+[[autodoc]] DebertaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## DebertaTokenizerFast[[transformers.DebertaTokenizerFast]]
+
+[[autodoc]] DebertaTokenizerFast
+ - build_inputs_with_special_tokens
+ - create_token_type_ids_from_sequences
+
+
+
+
+## DebertaModel[[transformers.DebertaModel]]
+
+[[autodoc]] DebertaModel
+ - forward
+
+## DebertaPreTrainedModel[[transformers.DebertaPreTrainedModel]]
+
+[[autodoc]] DebertaPreTrainedModel
+
+## DebertaForMaskedLM[[transformers.DebertaForMaskedLM]]
+
+[[autodoc]] DebertaForMaskedLM
+ - forward
+
+## DebertaForSequenceClassification[[transformers.DebertaForSequenceClassification]]
+
+[[autodoc]] DebertaForSequenceClassification
+ - forward
+
+## DebertaForTokenClassification[[transformers.DebertaForTokenClassification]]
+
+[[autodoc]] DebertaForTokenClassification
+ - forward
+
+## DebertaForQuestionAnswering[[transformers.DebertaForQuestionAnswering]]
+
+[[autodoc]] DebertaForQuestionAnswering
+ - forward
+
+
+
+
+## TFDebertaModel[[transformers.TFDebertaModel]]
+
+[[autodoc]] TFDebertaModel
+ - call
+
+## TFDebertaPreTrainedModel[[transformers.TFDebertaPreTrainedModel]]
+
+[[autodoc]] TFDebertaPreTrainedModel
+ - call
+
+## TFDebertaForMaskedLM[[transformers.TFDebertaForMaskedLM]]
+
+[[autodoc]] TFDebertaForMaskedLM
+ - call
+
+## TFDebertaForSequenceClassification[[transformers.TFDebertaForSequenceClassification]]
+
+[[autodoc]] TFDebertaForSequenceClassification
+ - call
+
+## TFDebertaForTokenClassification[[transformers.TFDebertaForTokenClassification]]
+
+[[autodoc]] TFDebertaForTokenClassification
+ - call
+
+## TFDebertaForQuestionAnswering[[transformers.TFDebertaForQuestionAnswering]]
+
+[[autodoc]] TFDebertaForQuestionAnswering
+ - call
+
+
+
+
diff --git a/docs/transformers/docs/source/ko/model_doc/encoder-decoder.md b/docs/transformers/docs/source/ko/model_doc/encoder-decoder.md
new file mode 100644
index 0000000000000000000000000000000000000000..c5c553561395361bf2ea588f50a5bb3756d213a8
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/encoder-decoder.md
@@ -0,0 +1,167 @@
+
+
+# 인코더-디코더 모델[[Encoder Decoder Models]]
+
+## 개요[[Overview]]
+
+[`EncoderDecoderModel`]은 사전 학습된 자동 인코딩(autoencoding) 모델을 인코더로, 사전 학습된 자가 회귀(autoregressive) 모델을 디코더로 활용하여 시퀀스-투-시퀀스(sequence-to-sequence) 모델을 초기화하는 데 이용됩니다.
+
+사전 학습된 체크포인트를 활용해 시퀀스-투-시퀀스 모델을 초기화하는 것이 시퀀스 생성(sequence generation) 작업에 효과적이라는 점이 Sascha Rothe, Shashi Narayan, Aliaksei Severyn의 논문 [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461)에서 입증되었습니다.
+
+[`EncoderDecoderModel`]이 학습/미세 조정된 후에는 다른 모델과 마찬가지로 저장/불러오기가 가능합니다. 자세한 사용법은 예제를 참고하세요.
+
+이 아키텍처의 한 가지 응용 사례는 두 개의 사전 학습된 [`BertModel`]을 각각 인코더와 디코더로 활용하여 요약 모델(summarization model)을 구축하는 것입니다. 이는 Yang Liu와 Mirella Lapata의 논문 [Text Summarization with Pretrained Encoders](https://arxiv.org/abs/1908.08345)에서 제시된 바 있습니다.
+
+## 모델 설정에서 `EncoderDecoderModel`을 무작위 초기화하기[[Randomly initializing `EncoderDecoderModel` from model configurations.]]
+
+[`EncoderDecoderModel`]은 인코더와 디코더 설정(config)을 기반으로 무작위 초기화를 할 수 있습니다. 아래 예시는 [`BertModel`] 설정을 인코더로, 기본 [`BertForCausalLM`] 설정을 디코더로 사용하는 방법을 보여줍니다.
+
+```python
+>>> from transformers import BertConfig, EncoderDecoderConfig, EncoderDecoderModel
+
+>>> config_encoder = BertConfig()
+>>> config_decoder = BertConfig()
+
+>>> config = EncoderDecoderConfig.from_encoder_decoder_configs(config_encoder, config_decoder)
+>>> model = EncoderDecoderModel(config=config)
+```
+
+## 사전 학습된 인코더와 디코더로 `EncoderDecoderModel` 초기화하기[[Initialising `EncoderDecoderModel` from a pretrained encoder and a pretrained decoder.]]
+
+[`EncoderDecoderModel`]은 사전 학습된 인코더 체크포인트와 사전 학습된 디코더 체크포인트를 사용해 초기화할 수 있습니다. BERT와 같은 모든 사전 학습된 자동 인코딩(auto-encoding) 모델은 인코더로 활용할 수 있으며, GPT2와 같은 자가 회귀(autoregressive) 모델이나 BART의 디코더와 같이 사전 학습된 시퀀스-투-시퀀스 디코더 모델을 디코더로 사용할 수 있습니다. 디코더로 선택한 아키텍처에 따라 교차 어텐션(cross-attention) 레이어가 무작위로 초기화될 수 있습니다. 사전 학습된 인코더와 디코더 체크포인트를 이용해 [`EncoderDecoderModel`]을 초기화하려면, 모델을 다운스트림 작업에 대해 미세 조정(fine-tuning)해야 합니다. 이에 대한 자세한 내용은 [the *Warm-starting-encoder-decoder blog post*](https://huggingface.co/blog/warm-starting-encoder-decoder)에 설명되어 있습니다. 이 작업을 위해 `EncoderDecoderModel` 클래스는 [`EncoderDecoderModel.from_encoder_decoder_pretrained`] 메서드를 제공합니다.
+
+
+```python
+>>> from transformers import EncoderDecoderModel, BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = EncoderDecoderModel.from_encoder_decoder_pretrained("google-bert/bert-base-uncased", "google-bert/bert-base-uncased")
+```
+
+## 기존 `EncoderDecoderModel` 체크포인트 불러오기 및 추론하기[[Loading an existing `EncoderDecoderModel` checkpoint and perform inference.]]
+
+`EncoderDecoderModel` 클래스의 미세 조정(fine-tuned)된 체크포인트를 불러오려면, Transformers의 다른 모델 아키텍처와 마찬가지로 [`EncoderDecoderModel`]에서 제공하는 `from_pretrained(...)`를 사용할 수 있습니다.
+
+추론을 수행하려면 [`generate`] 메서드를 활용하여 텍스트를 자동 회귀(autoregressive) 방식으로 생성할 수 있습니다. 이 메서드는 탐욕 디코딩(greedy decoding), 빔 서치(beam search), 다항 샘플링(multinomial sampling) 등 다양한 디코딩 방식을 지원합니다.
+
+```python
+>>> from transformers import AutoTokenizer, EncoderDecoderModel
+
+>>> # 미세 조정된 seq2seq 모델과 대응하는 토크나이저 가져오기
+>>> model = EncoderDecoderModel.from_pretrained("patrickvonplaten/bert2bert_cnn_daily_mail")
+>>> tokenizer = AutoTokenizer.from_pretrained("patrickvonplaten/bert2bert_cnn_daily_mail")
+
+>>> # let's perform inference on a long piece of text
+>>> ARTICLE_TO_SUMMARIZE = (
+... "PG&E stated it scheduled the blackouts in response to forecasts for high winds "
+... "amid dry conditions. The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were "
+... "scheduled to be affected by the shutoffs which were expected to last through at least midday tomorrow."
+... )
+>>> input_ids = tokenizer(ARTICLE_TO_SUMMARIZE, return_tensors="pt").input_ids
+
+>>> # 자기회귀적으로 요약 생성 (기본적으로 그리디 디코딩 사용)
+>>> generated_ids = model.generate(input_ids)
+>>> generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
+>>> print(generated_text)
+nearly 800 thousand customers were affected by the shutoffs. the aim is to reduce the risk of wildfires. nearly 800, 000 customers were expected to be affected by high winds amid dry conditions. pg & e said it scheduled the blackouts to last through at least midday tomorrow.
+```
+
+## `TFEncoderDecoderModel`에 Pytorch 체크포인트 불러오기[[Loading a PyTorch checkpoint into `TFEncoderDecoderModel`.]]
+
+[`TFEncoderDecoderModel.from_pretrained`] 메서드는 현재 Pytorch 체크포인트를 사용한 모델 초기화를 지원하지 않습니다. 이 메서드에 `from_pt=True`를 전달하면 예외(exception)가 발생합니다. 특정 인코더-디코더 모델에 대한 Pytorch 체크포인트만 존재하는 경우, 다음과 같은 해결 방법을 사용할 수 있습니다:
+
+```python
+>>> # 파이토치 체크포인트에서 로드하는 해결 방법
+>>> from transformers import EncoderDecoderModel, TFEncoderDecoderModel
+
+>>> _model = EncoderDecoderModel.from_pretrained("patrickvonplaten/bert2bert-cnn_dailymail-fp16")
+
+>>> _model.encoder.save_pretrained("./encoder")
+>>> _model.decoder.save_pretrained("./decoder")
+
+>>> model = TFEncoderDecoderModel.from_encoder_decoder_pretrained(
+... "./encoder", "./decoder", encoder_from_pt=True, decoder_from_pt=True
+... )
+>>> # 이 부분은 특정 모델의 구체적인 세부사항을 복사할 때에만 사용합니다.
+>>> model.config = _model.config
+```
+
+## 학습[[Training]]
+
+모델이 생성된 후에는 BART, T5 또는 기타 인코더-디코더 모델과 유사한 방식으로 미세 조정(fine-tuning)할 수 있습니다.
+보시다시피, 손실(loss)을 계산하려면 단 2개의 입력만 필요합니다: `input_ids`(입력 시퀀스를 인코딩한 `input_ids`)와 `labels`(목표 시퀀스를 인코딩한 `input_ids`).
+
+```python
+>>> from transformers import BertTokenizer, EncoderDecoderModel
+
+>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = EncoderDecoderModel.from_encoder_decoder_pretrained("google-bert/bert-base-uncased", "google-bert/bert-base-uncased")
+
+>>> model.config.decoder_start_token_id = tokenizer.cls_token_id
+>>> model.config.pad_token_id = tokenizer.pad_token_id
+
+>>> input_ids = tokenizer(
+... "The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side.During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930. It was the first structure to reach a height of 300 metres. Due to the addition of a broadcasting aerial at the top of the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft).Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France after the Millau Viaduct.",
+... return_tensors="pt",
+... ).input_ids
+
+>>> labels = tokenizer(
+... "the eiffel tower surpassed the washington monument to become the tallest structure in the world. it was the first structure to reach a height of 300 metres in paris in 1930. it is now taller than the chrysler building by 5. 2 metres ( 17 ft ) and is the second tallest free - standing structure in paris.",
+... return_tensors="pt",
+... ).input_ids
+
+>>> # forward 함수가 자동으로 적합한 decoder_input_ids를 생성합니다.
+>>> loss = model(input_ids=input_ids, labels=labels).loss
+```
+훈련에 대한 자세한 내용은 [colab](https://colab.research.google.com/drive/1WIk2bxglElfZewOHboPFNj8H44_VAyKE?usp=sharing#scrollTo=ZwQIEhKOrJpl) 노트북을 참조하세요.
+
+이 모델은 [thomwolf](https://github.com/thomwolf)가 기여했으며, 이 모델에 대한 TensorFlow 및 Flax 버전은 [ydshieh](https://github.com/ydshieh)가 기여했습니다.
+
+
+## EncoderDecoderConfig
+
+[[autodoc]] EncoderDecoderConfig
+
+
+
+
+## EncoderDecoderModel
+
+[[autodoc]] EncoderDecoderModel
+ - forward
+ - from_encoder_decoder_pretrained
+
+
+
+
+## TFEncoderDecoderModel
+
+[[autodoc]] TFEncoderDecoderModel
+ - call
+ - from_encoder_decoder_pretrained
+
+
+
+
+## FlaxEncoderDecoderModel
+
+[[autodoc]] FlaxEncoderDecoderModel
+ - __call__
+ - from_encoder_decoder_pretrained
+
+
+
diff --git a/docs/transformers/docs/source/ko/model_doc/esm.md b/docs/transformers/docs/source/ko/model_doc/esm.md
new file mode 100644
index 0000000000000000000000000000000000000000..6ea1191dabe0bae8306f981b7bffe9dfd8edbd94
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/esm.md
@@ -0,0 +1,115 @@
+
+
+# ESM [[esm]]
+
+## 개요 [[overview]]
+
+이 페이지는 Meta AI의 Fundamental AI Research 팀에서 제공하는 Transformer 단백질 언어 모델에 대한 코드와 사전 훈련된 가중치를 제공합니다. 여기에는 최첨단인 ESMFold와 ESM-2, 그리고 이전에 공개된 ESM-1b와 ESM-1v가 포함됩니다. Transformer 단백질 언어 모델은 Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, Rob Fergus의 논문 [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118)에서 소개되었습니다. 이 논문의 첫 번째 버전은 2019년에 [출판 전 논문](https://www.biorxiv.org/content/10.1101/622803v1?versioned=true) 형태로 공개되었습니다.
+
+ESM-2는 다양한 구조 예측 작업에서 테스트된 모든 단일 시퀀스 단백질 언어 모델을 능가하며, 원자 수준의 구조 예측을 가능하게 합니다. 이 모델은 Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives의 논문 [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902)에서 공개되었습니다.
+
+이 논문에서 함께 소개된 ESMFold는 ESM-2 스템을 사용하며, 최첨단의 정확도로 단백질 접힘 구조를 예측할 수 있는 헤드를 갖추고 있습니다. [AlphaFold2](https://www.nature.com/articles/s41586-021-03819-2)와 달리, 이는 대형 사전 훈련된 단백질 언어 모델 스템의 토큰 임베딩에 의존하며, 추론 시 다중 시퀀스 정렬(MSA) 단계를 수행하지 않습니다. 이는 ESMFold 체크포인트가 완전히 "독립적"이며, 예측을 위해 알려진 단백질 시퀀스와 구조의 데이터베이스, 그리고 그와 관련 외부 쿼리 도구를 필요로 하지 않는다는 것을 의미합니다. 그리고 그 결과, 훨씬 빠릅니다.
+
+"Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences"의 초록은 다음과 같습니다:
+
+*인공지능 분야에서는 대규모의 데이터와 모델 용량을 갖춘 비지도 학습의 조합이 표현 학습과 통계적 생성에서 주요한 발전을 이끌어냈습니다. 생명 과학에서는 시퀀싱 기술의 성장이 예상되며, 자연 시퀀스 다양성에 대한 전례 없는 데이터가 나올 것으로 기대됩니다. 진화적 단계에서 볼 때, 단백질 언어 모델링은 생물학을 위한 예측 및 생성 인공지능을 향한 논리적인 단계에 있습니다. 이를 위해 우리는 진화적 다양성을 아우르는 2억 5천만 개의 단백질 시퀀스에서 추출한 860억 개의 아미노산에 대해 심층 컨텍스트 언어 모델을 비지도 학습으로 훈련합니다. 그 결과 모델은 그 표현에서 생물학적 속성에 대한 정보를 포함합니다. 이 표현은 시퀀스 데이터만으로 학습됩니다. 학습된 표현 공간은 아미노산의 생화학적 특성 수준에서부터 단백질의 원거리 상동성까지 구조를 반영하는 다중 규모의 조직을 가지고 있습니다. 이 표현에는 2차 및 3차 구조에 대한 정보가 인코딩되어 있으며, 선형 전사에 의해 식별 될 수 있습니다. 표현 학습은 돌연변이에 의한 효과와 2차 구조의 최첨단 지도 예측을 가능하게 하고, 넓은 범위의 접촉 부위 예측을 위한 최첨단 특징을 향상시킵니다.*
+
+"Language models of protein sequences at the scale of evolution enable accurate structure prediction"의 초록은 다음과 같습니다:
+
+*대형 언어 모델은 최근 규모가 커짐에 따라 긴급한 기능을 개발하여 단순한 패턴 매칭을 넘어 더 높은 수준의 추론을 수행하고 생생한 이미지와 텍스트를 생성하는 것으로 나타났습니다. 더 작은 규모에서 훈련된 단백질 시퀀스의 언어 모델이 연구되었지만, 그들이 규모가 커짐에 따라 생물학에 대해 무엇을 배우는지는 거의 알려져 있지 않습니다. 이 연구에서 우리는 현재까지 평가된 가장 큰 150억 개의 매개변수를 가진 모델을 훈련합니다. 우리는 모델이 규모가 커짐에 따라 단일 아미노산의 해상도로 단백질의 3차원 구조를 예측할 수 있는 정보를 학습한다는 것을 발견했습니다. 우리는 개별 단백질 시퀀스로부터 직접 고정밀 원자 수준의 엔드-투-엔드 구조 예측을 하기 위한 ESMFold를 제시합니다. ESMFold는 언어 모델에 잘 이해되는 낮은 퍼플렉서티를 가진 시퀀스에 대해 AlphaFold2와 RoseTTAFold와 유사한 정확도를 가지고 있습니다. ESMFold의 추론은 AlphaFold2보다 한 자릿수 빠르며, 메타게놈 단백질의 구조적 공간을 실용적인 시간 내에 탐색할 수 있게 합니다.*
+
+원본 코드는 [여기](https://github.com/facebookresearch/esm)에서 찾을 수 있으며, Meta AI의 Fundamental AI Research 팀에서 개발되었습니다. ESM-1b, ESM-1v, ESM-2는 [jasonliu](https://huggingface.co/jasonliu)와 [Matt](https://huggingface.co/Rocketknight1)에 의해 HuggingFace에 기여되었습니다.
+
+ESMFold는 [Matt](https://huggingface.co/Rocketknight1)와 [Sylvain](https://huggingface.co/sgugger)에 의해 HuggingFace에 기여되었으며, 이 과정에서 많은 도움을 준 Nikita Smetanin, Roshan Rao, Tom Sercu에게 큰 감사를 드립니다!
+
+## 사용 팁 [[usage-tips]]
+
+- ESM 모델은 마스크드 언어 모델링(MLM) 목표로 훈련되었습니다.
+- HuggingFace의 ESMFold 포트는 [openfold](https://github.com/aqlaboratory/openfold) 라이브러리의 일부를 사용합니다. `openfold` 라이브러리는 Apache License 2.0에 따라 라이선스가 부여됩니다.
+
+## 리소스 [[resources]]
+
+- [텍스트 분류 작업 가이드](../tasks/sequence_classification)
+- [토큰 분류 작업 가이드](../tasks/token_classification)
+- [마스킹드 언어 모델링 작업 가이드](../tasks/masked_language_modeling)
+
+## EsmConfig [[transformers.EsmConfig]]
+
+[[autodoc]] EsmConfig
+ - all
+
+## EsmTokenizer [[transformers.EsmTokenizer]]
+
+[[autodoc]] EsmTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+
+
+
+## EsmModel [[transformers.EsmModel]]
+
+[[autodoc]] EsmModel
+ - forward
+
+## EsmForMaskedLM [[transformers.EsmForMaskedLM]]
+
+[[autodoc]] EsmForMaskedLM
+ - forward
+
+## EsmForSequenceClassification [[transformers.EsmForSequenceClassification]]
+
+[[autodoc]] EsmForSequenceClassification
+ - forward
+
+## EsmForTokenClassification [[transformers.EsmForTokenClassification]]
+
+[[autodoc]] EsmForTokenClassification
+ - forward
+
+## EsmForProteinFolding [[transformers.EsmForProteinFolding]]
+
+[[autodoc]] EsmForProteinFolding
+ - forward
+
+
+
+
+## TFEsmModel [[transformers.TFEsmModel]]
+
+[[autodoc]] TFEsmModel
+ - call
+
+## TFEsmForMaskedLM [[transformers.TFEsmForMaskedLM]]
+
+[[autodoc]] TFEsmForMaskedLM
+ - call
+
+## TFEsmForSequenceClassification [[transformers.TFEsmForSequenceClassification]]
+
+[[autodoc]] TFEsmForSequenceClassification
+ - call
+
+## TFEsmForTokenClassification [[transformers.TFEsmForTokenClassification]]
+
+[[autodoc]] TFEsmForTokenClassification
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/ko/model_doc/gemma.md b/docs/transformers/docs/source/ko/model_doc/gemma.md
new file mode 100644
index 0000000000000000000000000000000000000000..25fe6f1c772950ec5bab3d0f3a9850666d90b94f
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/gemma.md
@@ -0,0 +1,76 @@
+
+
+# Gemma [[gemma]]
+
+## 개요 [[overview]]
+
+Gemma 모델은 Google의 Gemma 팀이 작성한 [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/)에서 제안되었습니다.
+
+Gemma 모델은 6조 토큰으로 학습되었으며, 2b와 7b의 두 가지 버전으로 출시되었습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*이 연구는 언어 이해, 추론 및 안전성에 대한 학술 벤치마크에서 뛰어난 성능을 보이는 새로운 오픈 언어 모델 계열인 Gemma를 소개합니다. 우리는 두 가지 크기(20억 및 70억 매개변수)의 모델을 출시하며, 사전 학습된 체크포인트와 미세 조정된 체크포인트를 모두 제공합니다. Gemma는 18개의 텍스트 기반 작업 중 11개에서 유사한 크기의 오픈 모델을 능가하며, 우리는 모델 개발에 대한 상세한 설명과 함께 안전성과 책임 측면에 대한 종합적인 평가를 제공합니다. 우리는 LLM의 책임감 있는 공개가 최첨단 모델의 안전성을 향상시키고 다음 세대의 LLM 혁신을 가능하게 하는 데 중요하다고 믿습니다.*
+
+팁:
+
+- 원본 체크포인트는 변환 스크립트 `src/transformers/models/gemma/convert_gemma_weights_to_hf.py`를 사용하여 변환할 수 있습니다.
+
+이 모델은 [Arthur Zucker](https://huggingface.co/ArthurZ), [Younes Belkada](https://huggingface.co/ybelkada), [Sanchit Gandhi](https://huggingface.co/sanchit-gandhi), [Pedro Cuenca](https://huggingface.co/pcuenq)가 기여했습니다.
+
+## GemmaConfig [[transformers.GemmaConfig]]
+
+[[autodoc]] GemmaConfig
+
+## GemmaTokenizer [[transformers.GemmaTokenizer]]
+
+[[autodoc]] GemmaTokenizer
+
+
+## GemmaTokenizerFast [[transformers.GemmaTokenizerFast]]
+
+[[autodoc]] GemmaTokenizerFast
+
+## GemmaModel [[transformers.GemmaModel]]
+
+[[autodoc]] GemmaModel
+ - forward
+
+## GemmaForCausalLM [[transformers.GemmaForCausalLM]]
+
+[[autodoc]] GemmaForCausalLM
+ - forward
+
+## GemmaForSequenceClassification [[transformers.GemmaForSequenceClassification]]
+
+[[autodoc]] GemmaForSequenceClassification
+ - forward
+
+## GemmaForTokenClassification [[transformers.GemmaForTokenClassification]]
+
+[[autodoc]] GemmaForTokenClassification
+ - forward
+
+## FlaxGemmaModel [[transformers.FlaxGemmaModel]]
+
+[[autodoc]] FlaxGemmaModel
+ - __call__
+
+## FlaxGemmaForCausalLM [[transformers.FlaxGemmaForCausalLM]]
+
+[[autodoc]] FlaxGemmaForCausalLM
+ - __call__
diff --git a/docs/transformers/docs/source/ko/model_doc/gemma2.md b/docs/transformers/docs/source/ko/model_doc/gemma2.md
new file mode 100644
index 0000000000000000000000000000000000000000..6bffec616c6e97d853a8e4d0b8f279bf1033d668
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/gemma2.md
@@ -0,0 +1,63 @@
+
+
+
+# Gemma2 [[gemma2]]
+
+## 개요 [[overview]]
+
+Gemma2 모델은 Google의 Gemma2 팀이 작성한 [Gemma2: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/google-gemma-2/)에서 제안되었습니다.
+파라미터 크기가 각각 90억(9B)과 270억(27B)인 두 가지 Gemma2 모델이 출시되었습니다.
+
+블로그 게시물의 초록은 다음과 같습니다:
+
+*이제 우리는 전 세계의 연구자와 개발자들에게 Gemma 2를 공식적으로 출시합니다. 90억(9B)과 270억(27B) 파라미터 크기로 제공되는 Gemma 2는 1세대보다 더 높은 성능과 추론 효율성을 제공하며, 상당한 안전성 향상을 포함하고 있습니다. 사실 270억 규모의 모델은 크기가 두 배 이상인 모델과 비교해도 경쟁력 있는 대안을 제공하며, 이는 작년 12월까지만 해도 독점 모델에서만 가능했던 성능을 제공합니다.*
+
+팁:
+
+- 원본 체크포인트는 변환 스크립트 `src/transformers/models/Gemma2/convert_Gemma2_weights_to_hf.py`를 사용하여 변환할 수 있습니다.
+
+
+
+- Gemma2는 매 두 번째 레이어마다 슬라이딩 윈도우 어텐션을 사용하므로 [`~DynamicCache`] 또는 텐서의 튜플과 같은 일반적인 kv 캐싱에는 적합하지 않습니다. Gemma2의 forward 호출에서 캐싱을 활성화하려면 [`~HybridCache`] 인스턴스를 초기화하고 이를 `past_key_values`로 forward 호출에 전달해야 합니다. 또한 `past_key_values`에 이미 이전의 키와 값이 포함되어 있다면 `cache_position`도 준비해야 합니다.
+
+
+
+이 모델은 [Arthur Zucker](https://huggingface.co/ArthurZ), [Pedro Cuenca](https://huggingface.co/pcuenq), [Tom Arsen]()이 기여했습니다.
+
+## Gemma2Config [[transformers.Gemma2Config]]
+
+[[autodoc]] Gemma2Config
+
+## Gemma2Model [[transformers.Gemma2Model]]
+
+[[autodoc]] Gemma2Model
+ - forward
+
+## Gemma2ForCausalLM [[transformers.Gemma2ForCausalLM]]
+
+[[autodoc]] Gemma2ForCausalLM
+ - forward
+
+## Gemma2ForSequenceClassification [[transformers.Gemma2ForSequenceClassification]]
+
+[[autodoc]] Gemma2ForSequenceClassification
+ - forward
+
+## Gemma2ForTokenClassification [[transformers.Gemma2ForTokenClassification]]
+
+[[autodoc]] Gemma2ForTokenClassification
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/model_doc/gpt_neox_japanese.md b/docs/transformers/docs/source/ko/model_doc/gpt_neox_japanese.md
new file mode 100644
index 0000000000000000000000000000000000000000..13fb656dd50e9463740e1ea273bfcb9073ecd1e1
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/gpt_neox_japanese.md
@@ -0,0 +1,76 @@
+
+
+# GPT-NeoX-Japanese [[gpt-neox-japanese]]
+
+## 개요 [[overview]]
+
+
+일본어를 위한 자동회귀 언어 모델인 GPT-NeoX-Japanese를 소개합니다. 이 모델은 [https://github.com/EleutherAI/gpt-neox](https://github.com/EleutherAI/gpt-neox)에서 학습되었습니다. 일본어는 많은 어휘와 히라가나, 가타카나, 한자의 조합으로 이루어진 독특한 언어입니다. 이러한 일본어의 독특한 구조를 해결하기 위해 [특수 서브워드 토크나이저](https://github.com/tanreinama/Japanese-BPEEncoder_V2)를 사용했습니다. 이 유용한 토크나이저를 오픈소스로 제공해 준 *tanreinama*에게 매우 감사드립니다.
+
+이 모델은 Google의 [PaLM](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html) 연구 권장 사항을 따르며, 트랜스포머 블록에서 편향 파라미터를 제거하여 모델 성능을 향상시켰습니다. 자세한 내용은 [이 기사](https://medium.com/ml-abeja/training-a-better-gpt-2-93b157662ae4)를 참조하세요.
+
+모델 개발은 [ABEJA, Inc.](https://www.abejainc.com/)의 [신야 오타니](https://github.com/SO0529), [타카요시 마카베](https://github.com/spider-man-tm), [안주 아로라](https://github.com/Anuj040), [쿄 하토리](https://github.com/go5paopao)에 의해 주도되었습니다. 이 모델 개발 활동에 대한 자세한 내용은 [여기](https://tech-blog.abeja.asia/entry/abeja-gpt-project-202207)를 참조하세요.
+
+
+
+### 사용 예시 [[usage-example]]
+
+`generate()` 메서드를 사용하면 GPT NeoX Japanese 모델을 통해 텍스트를 생성할 수 있습니다.
+
+```python
+>>> from transformers import GPTNeoXJapaneseForCausalLM, GPTNeoXJapaneseTokenizer
+
+>>> model = GPTNeoXJapaneseForCausalLM.from_pretrained("abeja/gpt-neox-japanese-2.7b")
+>>> tokenizer = GPTNeoXJapaneseTokenizer.from_pretrained("abeja/gpt-neox-japanese-2.7b")
+
+>>> prompt = "人とAIが協調するためには、"
+
+>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
+
+>>> gen_tokens = model.generate(
+... input_ids,
+... do_sample=True,
+... temperature=0.9,
+... max_length=100,
+... )
+>>> gen_text = tokenizer.batch_decode(gen_tokens, skip_special_tokens=True)[0]
+
+>>> print(gen_text)
+人とAIが協調するためには、AIと人が共存し、AIを正しく理解する必要があります。
+```
+
+## 자료 [[resources]]
+
+- [일상 언어 모델링 작업 가이드 ](../tasks/language_modeling)
+
+## GPTNeoXJapanese 설정 (GPTNeoXJapaneseConfig) [[transformers.GPTNeoXJapaneseConfig]]
+
+[[autodoc]] GPTNeoXJapaneseConfig
+
+## GPTNeoXJapanese토큰화 (GPTNeoXJapaneseTokenizer) [[transformers.GPTNeoXJapaneseTokenizer]]
+
+[[autodoc]] GPTNeoXJapaneseTokenizer
+
+## GPTNeoXJapaneseModel [[transformers.GPTNeoXJapaneseModel]]
+
+[[autodoc]] GPTNeoXJapaneseModel
+ - forward
+
+## 일상 LLM 을 위한 GPTNeoXJapanese(GPTNeoXJapaneseForCausalLM) [[transformers.GPTNeoXJapaneseForCausalLM]]
+
+[[autodoc]] GPTNeoXJapaneseForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/graphormer.md b/docs/transformers/docs/source/ko/model_doc/graphormer.md
new file mode 100644
index 0000000000000000000000000000000000000000..fc6aa2c9e2f7eef354a1ae4835f12d1a883f4938
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/graphormer.md
@@ -0,0 +1,52 @@
+
+
+# Graphormer[[graphormer]]
+
+
+
+이 모델은 유지 보수 모드로만 운영되며, 코드를 변경하는 새로운 PR(Pull Request)은 받지 않습니다.
+이 모델을 실행하는 데 문제가 발생한다면, 이 모델을 지원하는 마지막 버전인 v4.40.2를 다시 설치해 주세요. 다음 명령어를 실행하여 재설치할 수 있습니다: `pip install -U transformers==4.40.2`.
+
+
+
+## 개요[[overview]]
+
+Graphormer 모델은 Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu가 제안한 [트랜스포머가 그래프 표현에 있어서 정말 약할까?](https://arxiv.org/abs/2106.05234) 라는 논문에서 소개되었습니다. Graphormer는 그래프 트랜스포머 모델입니다. 텍스트 시퀀스 대신 그래프에서 계산을 수행할 수 있도록 수정되었으며, 전처리와 병합 과정에서 임베딩과 관심 특성을 생성한 후 수정된 어텐션을 사용합니다.
+
+해당 논문의 초록입니다:
+
+*트랜스포머 아키텍처는 자연어 처리와 컴퓨터 비전 등 많은 분야에서 지배적인 선택을 받고 있는 아키텍처 입니다. 그러나 그래프 수준 예측 리더보드 상에서는 주류 GNN 변형모델들에 비해 경쟁력 있는 성능을 달성하지 못했습니다. 따라서 트랜스포머가 그래프 표현 학습에서 어떻게 잘 수행될 수 있을지는 여전히 미스터리였습니다. 본 논문에서는 Graphormer를 제시함으로써 이 미스터리를 해결합니다. Graphormer는 표준 트랜스포머 아키텍처를 기반으로 구축되었으며, 특히 최근의 OpenGraphBenchmark Large-Scale Challenge(OGB-LSC)의 광범위한 그래프 표현 학습 작업에서 탁월한 결과를 얻을 수 있었습니다. 그래프에서 트랜스포머를 활용하는데 핵심은 그래프의 구조적 정보를 모델에 효과적으로 인코딩하는 것입니다. 이를 위해 우리는 Graphormer가 그래프 구조 데이터를 더 잘 모델링할 수 있도록 돕는 몇 가지 간단하면서도 효과적인 구조적 인코딩 방법을 제안합니다. 또한, 우리는 Graphormer의 표현을 수학적으로 특성화하고, 그래프의 구조적 정보를 인코딩하는 우리의 방식으로 많은 인기 있는 GNN 변형모델들이 Graphormer의 특수한 경우로 포함될 수 있음을 보여줍니다.*
+
+이 모델은 [clefourrier](https://huggingface.co/clefourrier)가 기여했습니다. 원본 코드는 [이곳](https://github.com/microsoft/Graphormer)에서 확인할 수 있습니다.
+
+## 사용 팁[[usage-tips]]
+
+이 모델은 큰 그래프(100개 이상의 노드개수/엣지개수)에서는 메모리 사용량이 폭발적으로 증가하므로 잘 작동하지 않습니다. 대안으로 배치 크기를 줄이거나, RAM을 늘리거나 또는 algos_graphormer.pyx 파일의 `UNREACHABLE_NODE_DISTANCE` 매개변수를 줄이는 방법도 있지만, 700개 이상의 노드개수/엣지개수를 처리하기에는 여전히 어려울 것입니다.
+
+이 모델은 토크나이저를 사용하지 않고, 대신 훈련 중에 특별한 콜레이터(collator)를 사용합니다.
+
+## GraphormerConfig[[transformers.GraphormerConfig]]
+
+[[autodoc]] GraphormerConfig
+
+## GraphormerModel[[transformers.GraphormerModel]]
+
+[[autodoc]] GraphormerModel
+ - forward
+
+## GraphormerForGraphClassification[[transformers.GraphormerForGraphClassification]]
+
+[[autodoc]] GraphormerForGraphClassification
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/informer.md b/docs/transformers/docs/source/ko/model_doc/informer.md
new file mode 100644
index 0000000000000000000000000000000000000000..03722545a5625e7340eedb4a64948d366d190fa4
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/informer.md
@@ -0,0 +1,55 @@
+
+
+# Informer[[informer]]
+
+## 개요[[overview]]
+
+The Informer 모델은 Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, Wancai Zhang가 제안한 [Informer: 장기 시퀀스 시계열 예측(LSTF)을 위한 더욱 효율적인 트랜스포머(Beyond Efficient Transformer)](https://arxiv.org/abs/2012.07436)라는 논문에서 소개되었습니다.
+
+이 방법은 확률적 어텐션 메커니즘을 도입하여 "게으른" 쿼리가 아닌 "활성" 쿼리를 선택하고, 희소 트랜스포머를 제공하여 기존 어텐션의 이차적 계산 및 메모리 요구사항을 완화합니다.
+
+해당 논문의 초록입니다:
+
+*실제로 많은 응용프로그램에서는 장기 시퀀스 시계열 예측(LSTF)을 필요로 합니다. LSTF는 출력 - 입력 간 정확한 장기 의존성 결합도를 포착해내는 높은 예측 능력을 모델에 요구합니다. 최근 연구들은 예측 능력을 향상시킬 수 있는 트랜스포머의 잠재력을 보여주고 있습니다. 그러나, 트랜스포머를 LSTF에 직접 적용하지 못하도록 막는 몇 심각한 문제점들이 있습니다. 예로, 이차 시간 복잡도, 높은 메모리 사용량, 인코더-디코더 아키텍처의 본질적 한계를 들 수 있습니다. 이러한 문제를 해결하기 위해 LSTF를 위한 효율적인 트랜스포머 기반 모델인 Informer를 설계했습니다.
+
+Informer의 세가지 독특한 특성:
+(i) ProbSparse 셀프 어텐션 메커니즘으로, 시간 복잡도와 메모리 사용량에서 O(L logL)를 달성하며 시퀀스 의존성 정렬에서 비교 가능한 성능을 보입니다.
+(ii) 셀프 어텐션 증류는 계단식 레이어 입력을 반으로 줄여 지배적인 어텐션을 강조하고 극단적으로 긴 입력 시퀀스를 효율적으로 처리합니다.
+(iii) 생성 스타일 디코더는 개념적으로 단순하지만 장기 시계열 시퀀스를 단계별 방식이 아닌 한 번의 전방 연산으로 예측하여 장기 시퀀스 예측의 추론 속도를 크게 향상시킵니다. 4개의 대규모 데이터셋에 걸친 광범위한 실험은 Informer가 기존 방법들을 크게 능가하며 LSTF 문제에 새로운 해결책을 제공함을 보여줍니다.*
+
+이 모델은 [elisim](https://huggingface.co/elisim)와 [kashif](https://huggingface.co/kashif)가 기여했습니다.
+원본 코드는 [이곳](https://github.com/zhouhaoyi/Informer2020)에서 확인할 수 있습니다.
+
+## 자료[[resources]]
+
+시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다. 여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰 해드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
+
+- HuggingFace 블로그에서 Informer 포스트를 확인하세요: [Informer를 활용한 다변량 확률적 시계열 예측](https://huggingface.co/blog/informer)
+
+## InformerConfig[[transformers.InformerConfig]]
+
+[[autodoc]] InformerConfig
+
+## InformerModel[[transformers.InformerModel]]
+
+[[autodoc]] InformerModel
+ - forward
+
+## InformerForPrediction[[transformers.InformerForPrediction]]
+
+[[autodoc]] InformerForPrediction
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/model_doc/llama.md b/docs/transformers/docs/source/ko/model_doc/llama.md
new file mode 100644
index 0000000000000000000000000000000000000000..282befac213ddd24d7869bc3438bd3b88959f050
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/llama.md
@@ -0,0 +1,117 @@
+
+
+# LLaMA [[llama]]
+
+## 개요 [[overview]]
+
+LLaMA 모델은 Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample에 의해 제안된 [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971)에서 소개되었습니다. 이 모델은 7B에서 65B개의 파라미터까지 다양한 크기의 기초 언어 모델을 모아놓은 것입니다.
+
+논문의 초록은 다음과 같습니다:
+
+*"LLaMA는 7B에서 65B개의 파라미터 수를 가진 기초 언어 모델의 모음입니다. 우리는 수조 개의 토큰으로 모델을 훈련시켰고, 공개적으로 이용 가능한 데이터셋만을 사용하여 최고 수준의 모델을 훈련시킬 수 있음을 보여줍니다. 특히, LLaMA-13B 모델은 대부분의 벤치마크에서 GPT-3 (175B)를 능가하며, LLaMA-65B는 최고 수준의 모델인 Chinchilla-70B와 PaLM-540B에 버금가는 성능을 보입니다. 우리는 모든 모델을 연구 커뮤니티에 공개합니다."*
+
+팁:
+
+- LLaMA 모델의 가중치는 [이 양식](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform?usp=send_form)을 작성하여 얻을 수 있습니다.
+- 가중치를 다운로드한 후에는 이를 [변환 스크립트](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py)를 사용하여 Hugging Face Transformers 형식으로 변환해야합니다. 변환 스크립트를 실행하려면 아래의 예시 명령어를 참고하세요:
+
+```bash
+python src/transformers/models/llama/convert_llama_weights_to_hf.py \
+ --input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
+```
+
+- 변환을 하였다면 모델과 토크나이저는 다음과 같이 로드할 수 있습니다:
+
+```python
+from transformers import LlamaForCausalLM, LlamaTokenizer
+
+tokenizer = LlamaTokenizer.from_pretrained("/output/path")
+model = LlamaForCausalLM.from_pretrained("/output/path")
+```
+
+스크립트를 실행하기 위해서는 모델을 float16 정밀도로 전부 로드할 수 있을 만큼의 충분한 CPU RAM이 필요합니다. (가장 큰 버전의 모델이 여러 체크포인트로 나뉘어 있더라도, 각 체크포인트는 모델의 각 가중치의 일부를 포함하고 있기 때문에 모든 체크포인트를 RAM에 로드해야 합니다) 65B 모델의 경우, 총 130GB의 RAM이 필요합니다.
+
+
+- LLaMA 토크나이저는 [sentencepiece](https://github.com/google/sentencepiece)를 기반으로 하는 BPE 모델입니다. sentencepiece의 특징 중 하나는 시퀀스를 디코딩할 때 첫 토큰이 단어의 시작이라면 (예를 들어 "Banana"), 토크나이저는 문자열 앞에 공백을 추가하지 않는다는 것입니다.
+
+이 모델은 [BlackSamorez](https://huggingface.co/BlackSamorez)의 기여와 함께, [zphang](https://huggingface.co/zphang)에 의해 제공되었습니다. Hugging Face에서의 구현 코드는 GPT-NeoX를 기반으로 하며 [여기](https://github.com/EleutherAI/gpt-neox)에서 찾을 수 있고, 저자의 코드 원본은 [여기](https://github.com/facebookresearch/llama)에서 확인할 수 있습니다.
+
+
+원래 LLaMA 모델을 기반으로 Meta AI에서 몇 가지 후속 작업을 발표했습니다:
+
+- **Llama2**: Llama2는 구조적인 몇 가지 수정(Grouped Query Attention)을 통해 개선된 버전이며, 2조 개의 토큰으로 사전 훈련이 되어 있습니다. Llama2에 대한 자세한 내용은 [이 문서](llama2)를 참고하세요.
+
+## 리소스 [[resources]]
+
+LLaMA를 시작하는 데 도움이 될 Hugging Face 및 커뮤니티(🌎로 표시)의 공식 자료 목록입니다. 여기에 자료를 제출하고 싶다면 Pull Request를 올려주세요! 추가할 자료는 기존의 자료와 중복되지 않고 새로운 내용을 보여주는 것이 좋습니다.
+
+
+
+- LLaMA 모델을 텍스트 분류 작업에 적용하기 위한 프롬프트 튜닝 방법에 대한 [노트북](https://colab.research.google.com/github/bigscience-workshop/petals/blob/main/examples/prompt-tuning-sst2.ipynb#scrollTo=f04ba4d2) 🌎
+
+
+
+- [Stack Exchange](https://stackexchange.com/)에서 질문에 답하는 LLaMA를 훈련하는 방법을 위한 [StackLLaMA: RLHF로 LLaMA를 훈련하는 실전 가이드](https://huggingface.co/blog/stackllama#stackllama-a-hands-on-guide-to-train-llama-with-rlhf) 🌎
+
+⚗️ 최적화
+- 제한된 메모리를 가진 GPU에서 xturing 라이브러리를 사용하여 LLaMA 모델을 미세 조정하는 방법에 대한 [노트북](https://colab.research.google.com/drive/1SQUXq1AMZPSLD4mk3A3swUIc6Y2dclme?usp=sharing) 🌎
+
+⚡️ 추론
+- 🤗 PEFT 라이브러리의 PeftModel을 사용하여 LLaMA 모델을 실행하는 방법에 대한 [노트북](https://colab.research.google.com/github/DominguesM/alpaca-lora-ptbr-7b/blob/main/notebooks/02%20-%20Evaluate.ipynb) 🌎
+- LangChain을 사용하여 PEFT 어댑터 LLaMA 모델을 로드하는 방법에 대한 [노트북](https://colab.research.google.com/drive/1l2GiSSPbajVyp2Nk3CFT4t3uH6-5TiBe?usp=sharing) 🌎
+
+🚀 배포
+- 🤗 PEFT 라이브러리와 사용자 친화적인 UI로 LLaMA 모델을 미세 조정하는 방법에 대한 [노트북](https://colab.research.google.com/github/lxe/simple-llama-finetuner/blob/master/Simple_LLaMA_FineTuner.ipynb#scrollTo=3PM_DilAZD8T) 🌎
+- Amazon SageMaker에서 텍스트 생성을 위해 Open-LLaMA 모델을 배포하는 방법에 대한 [노트북](https://github.com/aws/amazon-sagemaker-examples/blob/main/introduction_to_amazon_algorithms/jumpstart-foundation-models/text-generation-open-llama.ipynb) 🌎
+
+## LlamaConfig [[llamaconfig]]
+
+[[autodoc]] LlamaConfig
+
+
+## LlamaTokenizer [[llamatokenizer]]
+
+[[autodoc]] LlamaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## LlamaTokenizerFast [[llamatokenizerfast]]
+
+[[autodoc]] LlamaTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - update_post_processor
+ - save_vocabulary
+
+## LlamaModel [[llamamodel]]
+
+[[autodoc]] LlamaModel
+ - forward
+
+
+## LlamaForCausalLM [[llamaforcausallm]]
+
+[[autodoc]] LlamaForCausalLM
+ - forward
+
+## LlamaForSequenceClassification [[llamaforsequenceclassification]]
+
+[[autodoc]] LlamaForSequenceClassification
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/llama2.md b/docs/transformers/docs/source/ko/model_doc/llama2.md
new file mode 100644
index 0000000000000000000000000000000000000000..5290f2bb7b6f8d39ca6fb4fd1bba98e4f1b449aa
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/llama2.md
@@ -0,0 +1,129 @@
+
+
+# Llama2 [[llama2]]
+
+## 개요 [[overview]]
+
+Llama2 모델은 Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Ya1smine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing EllenTan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom의 논문 [LLaMA: Open Foundation and Fine-Tuned Chat Models](https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/)에서 제안되었습니다. 채팅 어플리케이션에 맞게 미세 조정된 체크포인트를 포함된 7B에서 70B 범위의 매개변수를 가진 기초 언어 모델 모음입니다!
+
+논문의 초록은 다음과 같습니다:
+
+*이 연구에서 우리는 70억에서 700억 파라미터의 범위에서 사전 훈련 및 미세 조정된 대규모 언어 모델(LLMs)의 모음인 Llama 2를 개발 및 공개합니다. Llama 2-Chat라고 불리는 미세 조정된 LLMs은 대화 사용 사례에 최적화되었습니다. 우리의 모델은 테스트한 대부분의 벤치마크에서 오픈 소스 채팅 모델보다 성능이 뛰어나며, 유용성과 안전성에 대한 인적 평가를 바탕으로 비공개 소스 모델을 대체할 수 있는 적절한 대안이 될 수 있습니다. 우리는 Llama 2-Chat의 미세 조정 및 안전성 향상의 접근 방식에 대한 자세한 설명을 제공하여 커뮤니티가 우리의 작업을 기반으로 LLMs의 책임있는 개발에 기여할 수 있도록 합니다.*
+
+[여기](https://huggingface.co/models?search=llama2)에서 모든 Llama2 모델을 확인할 수 있습니다.
+
+
+
+`Llama2` 모델은 `bfloat16`을 사용하여 훈련되었지만, 원래 추론은 `float16`을 사용합니다. 허브에 업로드된 체크포인트는 `torch_dtype = 'float16'`을 사용하며, 이는 `AutoModel` API에 의해 체크포인트를 `torch.float32`에서 `torch.float16`으로 캐스팅하는 데 사용됩니다.
+
+온라인 가중치의 `dtype`은 `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`를 사용하여 모델을 초기화할 때 `torch_dtype="auto"`를 사용하지 않는 한 대부분 관련이 없습니다. 그 이유는 모델이 먼저 다운로드될 것이고 (온라인 체크포인트의 `dtype`을 사용하여) 그다음에 기본 `dtype`인 `torch`로 캐스팅하고(`torch.float32`가 됨), 마지막으로 구성(configuration)에서 제공된 `torch_dtype`이 있는 경우 이를 사용하기 때문입니다.
+
+모델을 `float16`에서 훈련하는 것은 권장되지 않으며 `nan`을 생성하는 것으로 알려져 있습니다. 따라서 모델은 `bfloat16`에서 훈련되어야 합니다.
+
+
+
+🍯 팁:
+
+- Llama2 모델의 가중치는 [이 양식](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)을 작성하여 얻을 수 있습니다.
+- 아키텍처는 처음 버전의 Llama와 매우 유사하며, [이 논문](https://arxiv.org/pdf/2305.13245.pdf)의 내용에 따라 Grouped Query Attention (GQA)이 추가되었습니다.
+- `config.pretraining_tp`를 1과 다른 값으로 설정하면 더 정확하지만 느린 선형 레이어 계산이 활성화되어 원본 로짓과 더 잘 일치하게 됩니다.
+- 원래 모델은 `pad_id = -1`을 사용하는데, 이는 패딩 토큰이 없음을 의미합니다. 동일한 로직을 사용할 수 없으므로 `tokenizer.add_special_tokens({"pad_token":""})`를 사용하여 패딩 토큰을 추가하고 이에 따라 토큰 임베딩 크기를 조정해야 합니다. 또한 `model.config.pad_token_id`를 설정해야 합니다. 모델의 `embed_tokens` 레이어는 `self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.config.padding_idx)`로 초기화되어, 패딩 토큰 인코딩이 0을 출력하도록 합니다. 따라서 초기화 시에 전달하는 것을 권장합니다.
+- 양식을 작성하고 모델 체크포인트 접근 권한을 얻은 후에는 이미 변환된 체크포인트를 사용할 수 있습니다. 그렇지 않고 자신의 모델을 직접 변환하려는 경우, [변환 스크립트](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py)를 자유롭게 사용하세요. 스크립트는 다음과 같은 예시의 명령어로 호출할 수 있습니다:
+
+```bash
+python src/transformers/models/llama/convert_llama_weights_to_hf.py \
+ --input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
+```
+
+- 변환 후 모델과 토크나이저는 다음과 같이 로드할 수 있습니다:
+
+```python
+from transformers import LlamaForCausalLM, LlamaTokenizer
+
+tokenizer = LlamaTokenizer.from_pretrained("/output/path")
+model = LlamaForCausalLM.from_pretrained("/output/path")
+```
+
+스크립트를 실행하려면 모델을 float16 정밀도로 전부 호스트할 수 있을 만큼 충분한 CPU RAM이 필요합니다 (가장 큰 버전이 여러 체크포인트로 제공되더라도 각 체크포인트는 모델 가중치의 일부만을 포함하므로 모두 RAM에 로드해야 합니다). 75B 모델의 경우, 총 145GB의 RAM이 필요합니다.
+
+- LLaMA 토크나이저는 [sentencepiece](https://github.com/google/sentencepiece)를 기반으로 한 BPE 모델입니다. sentencepiece의 특징 중 하나는 시퀀스를 디코딩할 때 첫 번째 토큰이 단어의 시작이면 (예: "Banana") 토크나이저는 문자열 앞에 접두사 공간을 추가하지 않는 것입니다.
+
+이 모델은 [Arthur Zucker](https://huggingface.co/ArthurZ)가 [Lysandre Debut](https://huggingface.co/lysandre)의 도움을 받아 제공하였습니다. Hugging Face에서의 구현 코드는 [여기](https://github.com/EleutherAI/gpt-neox)의 GPT-NeoX 를 기반으로 합니다. 저자의 원래 코드는 [여기](https://github.com/facebookresearch/llama)에서 찾을 수 있습니다.
+
+## 리소스 [[resources]]
+
+LLaMA2를 시작하는 데 도움이 될 Hugging Face의 공식 및 커뮤니티(🌎로 표시) 리소스 목록입니다. 여기에 새로운 리소스를 추가하기 위해서 Pull Request를 열어 주시면 검토하겠습니다! 리소스는 기존 리소스와 중복되지 않는 새로운 것을 보여주는 것이 이상적입니다.
+
+- [Llama 2 is here - get it on Hugging Face](https://huggingface.co/blog/llama2), Llama 2에 관한 블로그 포스트와 🤗 Transformers 및 🤗 PEFT와 함께 사용하는 방법에 대한 내용입니다.
+- [LLaMA 2 - Every Resource you need](https://www.philschmid.de/llama-2), LLaMA 2에 대해 알아보고 빠르게 시작하는 데 필요한 관련 리소스의 모음입니다.
+
+
+
+- Google Colab에서 QLoRA와 4-bit 정밀도를 사용하여 Llama 2를 미세 조정하는 방법에 대한 [노트북](https://colab.research.google.com/drive/1PEQyJO1-f6j0S_XJ8DV50NkpzasXkrzd?usp=sharing)입니다. 🌎
+- "Llama-v2-7b-guanaco" 모델을 4-bit QLoRA로 미세 조정하고 PDF에서 Q&A 데이터셋을 생성하는 방법에 대한 [노트북](https://colab.research.google.com/drive/134o_cXcMe_lsvl15ZE_4Y75Kstepsntu?usp=sharing)입니다. 🌎
+
+⚗️ 최적화
+- [Llama 2를 DPO로 미세 조정하기](https://huggingface.co/blog/dpo-trl), TRL 라이브러리의 DPO 방법을 사용하여 특정 데이터셋에서 Llama 2를 미세 조정하는 방법을 안내하는 가이드입니다.
+- [확장 가이드: Llama 2 명령어 조정](https://www.philschmid.de/instruction-tune-llama-2), 입력에서 명령어를 생성하도록 Llama 2를 훈련시키는 방법을 안내하는 가이드로, 명령어를 따르는 모델에서 명령어를 주는 모델로 변환합니다.
+- 개인 컴퓨터에서 QLoRA와 TRL을 사용하여 Llama 2 모델을 미세 조정하는 방법에 대한 [노트북](https://colab.research.google.com/drive/1SYpgFpcmtIUzdE7pxqknrM4ArCASfkFQ?usp=sharing)입니다. 🌎
+
+⚡️ 추론
+- AutoGPTQ 라이브러리의 GPTQ를 사용하여 Llama 2 모델을 양자화하는 방법에 대한 [노트북](https://colab.research.google.com/drive/1TC56ArKerXUpbgRy5vM3woRsbTEVNq7h?usp=sharing)입니다. 🌎
+- 로컬 컴퓨터나 Google Colab에서 4-bit 양자화로 Llama 2 채팅 모델을 실행하는 방법에 대한 [노트북](https://colab.research.google.com/drive/1X1z9Q6domMKl2CnEM0QGHNwidLfR4dW2?usp=sharing)입니다. 🌎
+
+🚀 배포
+- [Amazon SageMaker에서 LLaMA 2 (7-70B) 미세 조정하기](https://www.philschmid.de/sagemaker-llama2-qlora), Amazon SageMaker에서 QLoRA 미세 조정 및 배포에 이르기까지의 완전한 가이드입니다.
+- [Amazon SageMaker에서 Llama 2 7B/13B/70B 배포하기](https://www.philschmid.de/sagemaker-llama-llm), 안전하고 확장 가능한 배포를 위해 Hugging Face의 LLM DLC 컨테이너를 사용하는 방법에 대한 가이드입니다.
+
+
+## LlamaConfig [[llamaconfig]]
+
+[[autodoc]] LlamaConfig
+
+
+## LlamaTokenizer [[llamatokenizer]]
+
+[[autodoc]] LlamaTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## LlamaTokenizerFast [[llamatokenizerfast]]
+
+[[autodoc]] LlamaTokenizerFast
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - update_post_processor
+ - save_vocabulary
+
+## LlamaModel [[llamamodel]]
+
+[[autodoc]] LlamaModel
+ - forward
+
+
+## LlamaForCausalLM [[llamaforcausallm]]
+
+[[autodoc]] LlamaForCausalLM
+ - forward
+
+## LlamaForSequenceClassification [[llamaforsequenceclassification]]
+
+[[autodoc]] LlamaForSequenceClassification
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/llama3.md b/docs/transformers/docs/source/ko/model_doc/llama3.md
new file mode 100644
index 0000000000000000000000000000000000000000..ca819bfcabaf882e54f5f175fdad3732e1e22cd1
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/llama3.md
@@ -0,0 +1,80 @@
+
+
+# Llama3[[llama3]]
+
+```py3
+import transformers
+import torch
+
+model_id = "meta-llama/Meta-Llama-3-8B"
+
+pipeline = transformers.pipeline("text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto")
+pipeline("Hey how are you doing today?")
+```
+
+## 개요[[overview]]
+
+라마3 모델은 Meta AI 팀이 제안한 [메타 라마3 소개: 현재까지 가장 유능한 공개 가능 LLM](https://ai.meta.com/blog/meta-llama-3/)에서 소개되었습니다.
+
+해당 블로그 포스트의 초록입니다:
+
+*오늘, 광범위한 사용을 위해 이용 가능한 라마의 차세대 모델인 메타 라마3의 첫 두 모델을 공유하게 되어 기쁩니다. 이번 출시는 8B와 70B 매개변수를 가진 사전 훈련 및 지시 미세 조정된 언어 모델을 특징으로 하며, 광범위한 사용 사례를 지원할 수 있습니다. 라마의 이 차세대 모델은 다양한 산업 벤치마크에서 최첨단의 성능을 보여주며, 개선된 추론 능력을 포함한 새로운 기능을 제공합니다. 우리는 이것들이 단연코 해당 클래스에서 최고의 오픈 소스 모델이라고 믿습니다. 오랜 개방적 접근 방식을 지지하며, 우리는 라마3를 커뮤니티 기여자들에게 맡기고 있습니다. 애플리케이션에서 개발자 도구, 평가, 추론 최적화 등에 이르기까지 AI 스택 전반에 걸친 다음 혁신의 물결을 촉발하길 희망합니다. 여러분이 무엇을 만들지 기대하며 여러분의 피드백을 고대합니다.*
+
+라마3 모델의 모든 체크포인트는 [이곳](https://huggingface.co/models?search=llama3)에서 확인하세요.
+원본 코드는 [이곳](https://github.com/meta-llama/llama3)에서 확인할 수 있습니다.
+
+## 사용 팁[[usage-tips]]
+
+
+
+`라마3` 모델들은 `bfloat16`를 사용하여 훈련되었지만, 원래의 추론은 `float16`을 사용합니다. Hub에 업로드된 체크포인트들은 `torch_dtype = 'float16'`을 사용하는데, 이는 `AutoModel` API가 체크포인트를 `torch.float32`에서 `torch.float16`으로 변환하는데 이용됩니다.
+
+ `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`를 사용하여 모델을 초기화할 때, 온라인 가중치의 `dtype`는 `torch_dtype="auto"`를 사용하지 않는 한 대부분 무관합니다. 그 이유는 모델이 먼저 다운로드되고(온라인 체크포인트의 `dtype`를 사용), 그 다음 `torch`의 `dtype`으로 변환되어(`torch.float32`가 됨), 마지막으로 config에 `torch_dtype`이 제공된 경우 가중치가 사용되기 때문입니다.
+
+`float16`으로 모델을 훈련하는 것은 권장되지 않으며 `nan`을 생성하는 것으로 알려져 있습니다. 따라서 모든 모델은 `bfloat16`으로 훈련되어야 합니다.
+
+
+
+팁:
+
+- 라마3 모델을 위한 가중치는 [이 폼](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)을 채우면서 얻어져야 합니다.
+- 아키텍처는 라마2와 정확히 같습니다.
+- 토크나이저는 [tiktoken](https://github.com/openai/tiktoken) (sentencepiece 구현에 기반한 라마2 와는 다르게)에 기반한 BPE 모델입니다. tiktoken 기반 토크나이저가 sebtencepiece 기반 방식과 다른점은 입력 토큰이 vocab에 이미 존재할 때 BPE 병합 룰을 무시하고 싱글 토큰으로 토크나이징한다는 점에서 가장 큰 차이를 보입니다. 자세히 말하면 `"hugging"`이 vocab에 존재하고 기존에 병합이 존재하지 않으면, `["hug","ging"]` 처럼 두 토큰으로 더 작은 단위의 단어를 가지는 것이 아니라, 하나의 토큰만을 자동으로 리턴하는 것을 의미합니다.
+- 기본 모델은 패딩 토큰이 없다는 것을 의미하는 `pad_id = -1`을 사용합니다. 같은 로직을 사용할 수 없으니 `tokenizer.add_special_tokens({"pad_token":""})`를 사용하여 토큰을 추가하고 임베딩 크기도 확실히 조정해야 합니다. `model.config.pad_token_id`도 설정이 필요합니다. 모델의 `embed_tokens` 레이어는 `self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.config.padding_idx)`로 초기화되며, 패딩 토큰을 인코딩하는 것이 0(zero)를 출력하게 할 것인지 그래서 초기화가 추천될때 이를 통화시킬 것인지를 정하게 합니다.
+- 원본 체크포인트는 이 [변환 스크립트](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py)를 이용해서 변환 가능합니다. 스크립트는 다음 명령어로 호출할 수 있습니다:
+
+ ```bash
+ python src/transformers/models/llama/convert_llama_weights_to_hf.py \
+ --input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path --llama_version 3
+ ```
+
+- 변환 후, 모델과 토크나이저는 다음을 통해 로드된다.
+
+ ```python
+ from transformers import AutoModelForCausalLM, AutoTokenizer
+
+ tokenizer = AutoTokenizer.from_pretrained("/output/path")
+ model = AutoModelForCausalLM.from_pretrained("/output/path")
+ ```
+
+ 이 스크립트를 실행시키려면 모델 전체를 float16 정밀도로 호스팅할 수 있는 충분한 메인메모리가 필요하다는 점을 유의하세요. 가장 큰 버전이 여러 체크포인트로 나뉘어 있더라도, 각 체크포인트가 모델의 가중치 일부를 포함하고 있기 때문에 이를 모두 RAM에 로드해야 합니다. 75B 모델을 예로 들면 대략 145GB의 RAM이 필요합니다.
+
+- `attn_implementation="flash_attention_2"`를 통해서 플래시 어텐션2를 사용할 때, `from_pretrained` 클래스 메서드에 `torch_dtype`를 전달하지 말고 자동 혼합 정밀도(Automatic Mixed-Precision) 학습을 사용하세요. `Trainer`를 사용할 때는 단순히 `fp16` 또는 `bf16`을 `True`로 설정하면 됩니다. 그렇지 않으면 반드시 `torch.autocast`를 사용해야 합니다. 플래시 어텐션은 `fp16`과 `bf16` 데이터 유형만 지원하기 때문입니다.
+
+## 자료[[resources]]
+
+[라마2](./llama2) 문서 페이지에서는 이미 수 많은 멋지고 유익한 자료들을 제공하고 있습니다. 이곳에 라마3에 대한 새로운 자료를 더해주실 컨트리뷰터들을 초대합니다! 🤗
diff --git a/docs/transformers/docs/source/ko/model_doc/mamba.md b/docs/transformers/docs/source/ko/model_doc/mamba.md
new file mode 100644
index 0000000000000000000000000000000000000000..404b9b06b41353949a8db18867d4fce4a8fa452e
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/mamba.md
@@ -0,0 +1,105 @@
+
+
+# 맘바[[mamba]]
+
+## 개요[[overview]]
+
+맘바(Mamba) 모델은 Albert Gu, Tri Dao가 제안한 [맘바: 선택적 상태 공간을 이용한 선형 시간 시퀀스 모델링](https://arxiv.org/abs/2312.00752)라는 논문에서 소개 되었습니다.
+
+이 모델은 `state-space-models`을 기반으로 한 새로운 패러다임 아키텍처입니다. 직관적인 이해를 얻고 싶다면 [이곳](https://srush.github.io/annotated-s4/)을 참고 하세요.
+
+해당 논문의 초록입니다:
+
+*현재 딥러닝에서 흥미로운 응용 프로그램을 구동하는 대부분의 기초 모델들은 거의 보편적으로 트랜스포머 아키텍처와 그 핵심 어텐션 모듈을 기반으로 합니다. 선형 어텐션, 게이트된 컨볼루션과 순환 모델, 구조화된 상태 공간 모델(SSM) 등 많은 준이차시간(subquadratic-time) 아키텍처가 긴 시퀀스에 대한 트랜스포머의 계산 비효율성을 해결하기 위해 개발되었지만, 언어와 같은 중요한 양식에서는 어텐션만큼 성능을 내지 못했습니다. 우리는 이러한 모델의 주요 약점이 내용 기반 추론을 수행하지 못한다는 점임을 알고 몇 가지를 개선했습니다. 첫째, SSM 매개변수를 입력의 함수로 만드는 것만으로도 이산 모달리티(discrete modalities)의 약점을 해결할 수 있어, 현재 토큰에 따라 시퀀스 길이 차원을 따라 정보를 선택적으로 전파하거나 잊을 수 있게 합니다. 둘째, 이러한 변경으로 효율적인 컨볼루션을 사용할 수 없게 되었지만, 우리는 순환 모드에서 하드웨어를 인식하는 병렬 알고리즘을 설계했습니다. 우리는 이러한 선택적 SSM을 어텐션이나 MLP 블록도 없는 단순화된 종단간 신경망 아키텍처인 맘바에 통합시켰습니다. 맘바는 빠른 추론(트랜스포머보다 5배 높은 처리량)과 시퀀스 길이에 대한 선형 확장성을 누리며, 백만 길이 시퀀스까지 실제 데이터에서 성능이 향상됩니다. 일반적인 시퀀스 모델 백본으로서 맘바는 언어, 오디오, 유전체학과 같은 여러 양식에서 최첨단 성능을 달성합니다. 언어 모델링에서 우리의 맘바-3B 모델은 같은 크기의 트랜스포머를 능가하고 두 배 크기의 트랜스포머와 맞먹는 성능을 보이며, 사전 훈련과 다운스트림 평가 모두에서 성능을 나타납니다.*
+
+팁:
+
+- 맘바는 고전적인 트랜스포머와 견줄 만한 새로운 `상태 공간 모델` 아키텍처입니다. 이는 구조화된 상태 공간 모델의 발전 선상에 있으며, [플래시어텐션](https://github.com/Dao-AILab/flash-attention)의 정신을 따르는 효율적인 하드웨어 인식 설계와 구현을 특징으로 합니다.
+- 맘바는 `어텐션` 레이어와 동등한 `믹서(mixer)` 레이어를 쌓습니다. `맘바`의 핵심 로직은 `MambaMixer` 클래스에 있습니다.
+- 두 가지 구현이 공존합니다: 하나는 최적화되어 빠른 cuda커널을 사용하고, 다른 하나는 단순하지만 모든 장치에서 실행할 수 있습니다!
+- 현재 구현은 원본 cuda커널을 활용합니다: 맘바를 위한 플래시 어텐션의 역할을 하는 것은 [`mamba-ssm`](https://github.com/state-spaces/mamba)와 [`causal_conv1d`](https://github.com/Dao-AILab/causal-conv1d) 저장소에 호스팅되어 있습니다. 하드웨어가 지원한다면 반드시 설치하세요!
+- cuda 커널을 최적화하는 방향 보다는, 단순하지만 모든 장치에서 실행가능하도록하는 방향인 '단순구현'의 성능을 빠르게 향상시키는 기여를 더 환영하고 있습니다. 🤗
+
+이 모델은 [ArthurZ](https://huggingface.co/ArthurZ)에 의해 기여되었습니다.
+원본 코드는 [이곳](https://github.com/state-spaces/mamba)에서 확인할 수 있습니다.
+
+# 사용
+
+### 간단한 생성 예제
+
+```python
+from transformers import MambaConfig, MambaForCausalLM, AutoTokenizer
+import torch
+
+tokenizer = AutoTokenizer.from_pretrained("state-spaces/mamba-130m-hf")
+model = MambaForCausalLM.from_pretrained("state-spaces/mamba-130m-hf")
+input_ids = tokenizer("Hey how are you doing?", return_tensors= "pt")["input_ids"]
+
+out = model.generate(input_ids, max_new_tokens=10)
+print(tokenizer.batch_decode(out))
+```
+
+### Peft 파인튜닝
+느린 버전은 학습에서 아주 안정적이진 않습니다. 빠른 버전은 `float32`가 필요합니다!
+
+```python
+from datasets import load_dataset
+from trl import SFTTrainer
+from peft import LoraConfig
+from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments
+model_id = "state-spaces/mamba-130m-hf"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = AutoModelForCausalLM.from_pretrained(model_id)
+dataset = load_dataset("Abirate/english_quotes", split="train")
+training_args = TrainingArguments(
+ output_dir="./results",
+ num_train_epochs=3,
+ per_device_train_batch_size=4,
+ logging_dir='./logs',
+ logging_steps=10,
+ learning_rate=2e-3
+)
+lora_config = LoraConfig(
+ r=8,
+ target_modules=["x_proj", "embeddings", "in_proj", "out_proj"],
+ task_type="CAUSAL_LM",
+ bias="none"
+)
+trainer = SFTTrainer(
+ model=model,
+ tokenizer=tokenizer,
+ args=training_args,
+ peft_config=lora_config,
+ train_dataset=dataset,
+ dataset_text_field="quote",
+)
+trainer.train()
+```
+
+## MambaConfig
+
+[[autodoc]] MambaConfig
+
+## MambaModel
+
+[[autodoc]] MambaModel
+ - forward
+
+## MambaLMHeadModel
+
+[[autodoc]] MambaForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/mamba2.md b/docs/transformers/docs/source/ko/model_doc/mamba2.md
new file mode 100644
index 0000000000000000000000000000000000000000..b023914bc1276ab99a3aafb693f97b068d055e82
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/mamba2.md
@@ -0,0 +1,111 @@
+
+
+# 맘바2[[mamba-2]]
+
+## 개요[[overview]]
+
+맘바2 모델은 Tri Dao, Albert Gu가 제안한 [트랜스포머는 SSM이다: 구조화된 상태 공간 이중성을 통한 일반화된 모델과 효율적인 알고리즘](https://arxiv.org/abs/2405.21060)라는 논문에서 소개되었습니다. 맘바2는 맘바1과 유사한 상태 공간 모델로, 단순화된 아키텍처에서 더 나은 성능을 보입니다.
+
+해당 논문의 초록입니다:
+
+*트랜스포머는 언어 모델링에서 딥러닝 성공의 주요 아키텍처였지만, 맘바와 같은 상태 공간 모델(SSM)이 최근 소규모 혹은 중간 규모에서 트랜스포머와 대등하거나 더 나은 성능을 보이는 것으로 나타났습니다. 우리는 이러한 모델 계열들이 실제로 매우 밀접하게 연관되어 있음을 파악했습니다. 그리고 구조화된 준분리(semiseparable) 행렬 중 연구가 잘 이루어진 클래스의 다양한 분해를 통해 연결된 SSM과 어텐션 변형 사이의 풍부한 이론적 연결 프레임워크를 개발했습니다. 상태 공간 이중성(SSD) 프레임워크를 통해 맘바1의 선택적 SSM을 개선한 새로운 아키텍처를 설계할 수 있었고, 트랜스포머와 경쟁력을 유지하면서도 속도는 2~8배 더 빠른 성능을 냅니다.*
+
+팁:
+
+이 버전은 맘바2 구현을 지원해야 하며, 특히 Mistral AI의 [Mamba-2 codestral](https://huggingface.co/mistralai/Mamba-Codestral-7B-v0.1)을 지원합니다. 특히, mamba 2 codestral은 8개의 `groups`로 출시되었는데, 이는 어텐션 기반 모델의 KV 헤드 수와 유사하다고 판단 가능합니다.
+
+이 모델은 `torch_forward`와 `cuda_kernels_forward`라는 두 가지 다른 전방 패스를 가집니다. `cuda_kernels_forward`는 환경에서 cuda 커널을 찾으면 이를 사용하며, prefill에서는 더 느립니다. 즉, 높은 CPU 오버헤드로 인해 "웜업 실행"이 필요하기 때문입니다. 관련 내용은 [이곳](https://github.com/state-spaces/mamba/issues/389#issuecomment-2171755306)과 [이곳](https://github.com/state-spaces/mamba/issues/355#issuecomment-2147597457)을 참고하세요.
+
+컴파일 없이는 `torch_forward` 구현이 3~4배 빠릅니다. 또한, 이 모델에는 위치 임베딩이 없지만 `attention_mask`와 배치 생성의 경우 두 곳에서 은닉 상태(hidden state)를 마스킹하는 특정 로직이 있습니다. 관련 내용은 [이곳](https://github.com/state-spaces/mamba/issues/66#issuecomment-1863563829)을 참고하세요.
+
+이로인해 맘바2 커널의 재구현과 함께 배치 생성 및 캐시된 생성에서 약간의 차이가 예상됩니다. 또한 cuda 커널 또는 torch forward가 제공하는 결과가 약간 다를 것으로 예상됩니다. SSM 알고리즘은 텐서 수축에 크게 의존하는데, 이는 matmul과 동등하지만 연산 순서가 약간 다르며, 이로 인해 더 작은 정밀도에서 차이가 더 커집니다.
+
+또 다른 참고사항으로, 패딩 토큰에 해당하는 은닉 상태(hidden state)의 종료는 두 곳에서 이루어지며 주로 왼쪽 패딩으로 테스트되었습니다. 오른쪽 패딩은 노이즈를 전파하므로 만족스러운 결과를 보장하지 않습니다. `tokenizer.padding_side = "left"`를 사용하면 올바른 패딩 방향을 사용할 수 있습니다.
+
+이 모델은 [Molbap](https://huggingface.co/Molbap)이 기여했으며, [Anton Vlasjuk](https://github.com/vasqu)의 큰 도움을 받았습니다.
+원본 코드는 [이곳](https://github.com/state-spaces/mamba)에서 확인할 수 있습니다.
+
+
+# 사용
+
+### 간단한 생성 예:
+```python
+from transformers import Mamba2Config, Mamba2ForCausalLM, AutoTokenizer
+import torch
+model_id = 'mistralai/Mamba-Codestral-7B-v0.1'
+tokenizer = AutoTokenizer.from_pretrained(model_id, revision='refs/pr/9', from_slow=True, legacy=False)
+model = Mamba2ForCausalLM.from_pretrained(model_id, revision='refs/pr/9')
+input_ids = tokenizer("Hey how are you doing?", return_tensors= "pt")["input_ids"]
+
+out = model.generate(input_ids, max_new_tokens=10)
+print(tokenizer.batch_decode(out))
+```
+
+이곳은 미세조정을 위한 초안 스크립트입니다:
+```python
+from trl import SFTTrainer
+from peft import LoraConfig
+from transformers import AutoTokenizer, Mamba2ForCausalLM, TrainingArguments
+model_id = 'mistralai/Mamba-Codestral-7B-v0.1'
+tokenizer = AutoTokenizer.from_pretrained(model_id, revision='refs/pr/9', from_slow=True, legacy=False)
+tokenizer.pad_token = tokenizer.eos_token
+tokenizer.padding_side = "left" #왼쪽 패딩으로 설정
+
+model = Mamba2ForCausalLM.from_pretrained(model_id, revision='refs/pr/9')
+dataset = load_dataset("Abirate/english_quotes", split="train")
+# CUDA 커널없이는, 배치크기 2가 80GB 장치를 하나 차지합니다.
+# 하지만 정확도는 감소합니다.
+# 실험과 시도를 환영합니다!
+training_args = TrainingArguments(
+ output_dir="./results",
+ num_train_epochs=3,
+ per_device_train_batch_size=2,
+ logging_dir='./logs',
+ logging_steps=10,
+ learning_rate=2e-3
+)
+lora_config = LoraConfig(
+ r=8,
+ target_modules=["embeddings", "in_proj", "out_proj"],
+ task_type="CAUSAL_LM",
+ bias="none"
+)
+trainer = SFTTrainer(
+ model=model,
+ tokenizer=tokenizer,
+ args=training_args,
+ peft_config=lora_config,
+ train_dataset=dataset,
+ dataset_text_field="quote",
+)
+trainer.train()
+```
+
+
+## Mamba2Config
+
+[[autodoc]] Mamba2Config
+
+## Mamba2Model
+
+[[autodoc]] Mamba2Model
+ - forward
+
+## Mamba2LMHeadModel
+
+[[autodoc]] Mamba2ForCausalLM
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/marian.md b/docs/transformers/docs/source/ko/model_doc/marian.md
new file mode 100644
index 0000000000000000000000000000000000000000..79a9641401d01e400c42de70d65f2157fefc97fa
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/marian.md
@@ -0,0 +1,217 @@
+
+
+# MarianMT[[MarianMT]]
+
+
+
+## 개요[[Overview]]
+
+BART와 동일한 모델을 사용하는 번역 모델 프레임워크입니다. 번역 결과는 각 모델 카드의 테스트 세트와 유사하지만, 정확히 일치하지는 않을 수 있습니다. 이 모델은 [sshleifer](https://huggingface.co/sshleifer)가 제공했습니다.
+
+
+## 구현 노트[[Implementation Notes]]
+
+- 각 모델은 약 298 MB를 차지하며, 1,000개 이상의 모델이 제공됩니다.
+- 지원되는 언어 쌍 목록은 [여기](https://huggingface.co/Helsinki-NLP)에서 확인할 수 있습니다.
+- 모델들은 [Jörg Tiedemann](https://researchportal.helsinki.fi/en/persons/j%C3%B6rg-tiedemann)에 의해 [Marian](https://marian-nmt.github.io/) C++ 라이브러리를 이용하여 학습되었습니다. 이 라이브러리는 빠른 학습과 번역을 지원합니다.
+- 모든 모델은 6개 레이어로 이루어진 Transformer 기반의 인코더-디코더 구조입니다. 각 모델의 성능은 모델 카드에 기입되어 있습니다.
+- BPE 전처리가 필요한 80개의 OPUS 모델은 지원되지 않습니다.
+- 모델링 코드는 [`BartForConditionalGeneration`]을 기반으로 하며, 일부 수정사항이 반영되어 있습니다:
+
+ - 정적 (사인 함수 기반) 위치 임베딩 사용 (`MarianConfig.static_position_embeddings=True`)
+ - 임베딩 레이어 정규화 생략 (`MarianConfig.normalize_embedding=False`)
+ - 모델은 생성 시 프리픽스로 `pad_token_id` (해당 토큰 임베딩 값은 0)를 사용하여 시작합니다 (Bart는
+ ``를 사용),
+- Marian 모델을 PyTorch로 대량 변환하는 코드는 `convert_marian_to_pytorch.py`에서 찾을 수 있습니다.
+
+
+## 모델 이름 규칙[[Naming]]
+
+- 모든 모델 이름은 `Helsinki-NLP/opus-mt-{src}-{tgt}` 형식을 따릅니다.
+- 모델의 언어 코드 표기는 일관되지 않습니다. 두 자리 코드는 일반적으로 [여기](https://developers.google.com/admin-sdk/directory/v1/languages)에서 찾을 수 있으며, 세 자리 코드는 "언어 코드 {code}"로 구글 검색을 통해 찾습니다.
+- `es_AR`과 같은 형태의 코드는 `code_{region}` 형식을 의미합니다. 여기서의 예시는 아르헨티나의 스페인어를 의미합니다.
+- 모델 변환은 두 단계로 이루어졌습니다. 처음 1,000개 모델은 ISO-639-2 코드를 사용하고, 두 번째 그룹은 ISO-639-5와 ISO-639-2 코드를 조합하여 언어를 식별합니다.
+
+
+## 예시[[Examples]]
+
+- Marian 모델은 라이브러리의 다른 번역 모델들보다 크기가 작아 파인튜닝 실험과 통합 테스트에 유용합니다.
+- [GPU에서 파인튜닝하기](https://github.com/huggingface/transformers/blob/master/examples/legacy/seq2seq/train_distil_marian_enro.sh)
+
+## 다국어 모델 사용법[[Multilingual Models]]
+
+- 모든 모델 이름은`Helsinki-NLP/opus-mt-{src}-{tgt}` 형식을 따릅니다.
+- 다중 언어 출력을 지원하는 모델의 경우, 출력을 원하는 언어의 언어 코드를 `src_text`의 시작 부분에 추가하여 지정해야 합니다.
+- 모델 카드에서 지원되는 언어 코드의 목록을 확인할 수 있습니다! 예를 들어 [opus-mt-en-roa](https://huggingface.co/Helsinki-NLP/opus-mt-en-roa)에서 확인할 수 있습니다.
+- `Helsinki-NLP/opus-mt-roa-en`처럼 소스 측에서만 다국어를 지원하는 모델의 경우, 별도의 언어 코드 지정이 필요하지 않습니다.
+
+[Tatoeba-Challenge 리포지토리](https://github.com/Helsinki-NLP/Tatoeba-Challenge)의 새로운 다국적 모델은 3자리 언어 코드를 사용합니다:
+
+
+```python
+>>> from transformers import MarianMTModel, MarianTokenizer
+
+>>> src_text = [
+... ">>fra<< this is a sentence in english that we want to translate to french",
+... ">>por<< This should go to portuguese",
+... ">>esp<< And this to Spanish",
+... ]
+
+>>> model_name = "Helsinki-NLP/opus-mt-en-roa"
+>>> tokenizer = MarianTokenizer.from_pretrained(model_name)
+>>> print(tokenizer.supported_language_codes)
+['>>zlm_Latn<<', '>>mfe<<', '>>hat<<', '>>pap<<', '>>ast<<', '>>cat<<', '>>ind<<', '>>glg<<', '>>wln<<', '>>spa<<', '>>fra<<', '>>ron<<', '>>por<<', '>>ita<<', '>>oci<<', '>>arg<<', '>>min<<']
+
+>>> model = MarianMTModel.from_pretrained(model_name)
+>>> translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
+>>> [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
+["c'est une phrase en anglais que nous voulons traduire en français",
+ 'Isto deve ir para o português.',
+ 'Y esto al español']
+```
+
+허브에 있는 모든 사전 학습된 모델을 확인하는 코드입니다:
+
+```python
+from huggingface_hub import list_models
+
+model_list = list_models()
+org = "Helsinki-NLP"
+model_ids = [x.id for x in model_list if x.id.startswith(org)]
+suffix = [x.split("/")[1] for x in model_ids]
+old_style_multi_models = [f"{org}/{s}" for s in suffix if s != s.lower()]
+```
+
+## 구형 다국어 모델[[Old Style Multi-Lingual Models]]
+
+이 모델들은 OPUS-MT-Train 리포지토리의 구형 다국어 모델들입니다. 각 언어 그룹에 포함된 언어들은 다음과 같습니다:
+
+```python no-style
+['Helsinki-NLP/opus-mt-NORTH_EU-NORTH_EU',
+ 'Helsinki-NLP/opus-mt-ROMANCE-en',
+ 'Helsinki-NLP/opus-mt-SCANDINAVIA-SCANDINAVIA',
+ 'Helsinki-NLP/opus-mt-de-ZH',
+ 'Helsinki-NLP/opus-mt-en-CELTIC',
+ 'Helsinki-NLP/opus-mt-en-ROMANCE',
+ 'Helsinki-NLP/opus-mt-es-NORWAY',
+ 'Helsinki-NLP/opus-mt-fi-NORWAY',
+ 'Helsinki-NLP/opus-mt-fi-ZH',
+ 'Helsinki-NLP/opus-mt-fi_nb_no_nn_ru_sv_en-SAMI',
+ 'Helsinki-NLP/opus-mt-sv-NORWAY',
+ 'Helsinki-NLP/opus-mt-sv-ZH']
+GROUP_MEMBERS = {
+ 'ZH': ['cmn', 'cn', 'yue', 'ze_zh', 'zh_cn', 'zh_CN', 'zh_HK', 'zh_tw', 'zh_TW', 'zh_yue', 'zhs', 'zht', 'zh'],
+ 'ROMANCE': ['fr', 'fr_BE', 'fr_CA', 'fr_FR', 'wa', 'frp', 'oc', 'ca', 'rm', 'lld', 'fur', 'lij', 'lmo', 'es', 'es_AR', 'es_CL', 'es_CO', 'es_CR', 'es_DO', 'es_EC', 'es_ES', 'es_GT', 'es_HN', 'es_MX', 'es_NI', 'es_PA', 'es_PE', 'es_PR', 'es_SV', 'es_UY', 'es_VE', 'pt', 'pt_br', 'pt_BR', 'pt_PT', 'gl', 'lad', 'an', 'mwl', 'it', 'it_IT', 'co', 'nap', 'scn', 'vec', 'sc', 'ro', 'la'],
+ 'NORTH_EU': ['de', 'nl', 'fy', 'af', 'da', 'fo', 'is', 'no', 'nb', 'nn', 'sv'],
+ 'SCANDINAVIA': ['da', 'fo', 'is', 'no', 'nb', 'nn', 'sv'],
+ 'SAMI': ['se', 'sma', 'smj', 'smn', 'sms'],
+ 'NORWAY': ['nb_NO', 'nb', 'nn_NO', 'nn', 'nog', 'no_nb', 'no'],
+ 'CELTIC': ['ga', 'cy', 'br', 'gd', 'kw', 'gv']
+}
+```
+
+영어를 여러 로망스 언어로 번역하는 예제입니다. 여기서는 구형 2자리 언어 코드를 사용합니다:
+
+
+```python
+>>> from transformers import MarianMTModel, MarianTokenizer
+
+>>> src_text = [
+... ">>fr<< this is a sentence in english that we want to translate to french",
+... ">>pt<< This should go to portuguese",
+... ">>es<< And this to Spanish",
+... ]
+
+>>> model_name = "Helsinki-NLP/opus-mt-en-ROMANCE"
+>>> tokenizer = MarianTokenizer.from_pretrained(model_name)
+
+>>> model = MarianMTModel.from_pretrained(model_name)
+>>> translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
+>>> tgt_text = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
+["c'est une phrase en anglais que nous voulons traduire en français",
+ 'Isto deve ir para o português.',
+ 'Y esto al español']
+```
+
+## 자료[[Resources]]
+
+- [번역 작업 가이드](../tasks/translation)
+- [요약 작업 가이드](../tasks/summarization)
+- [언어 모델링 작업 가이드](../tasks/language_modeling)
+
+## MarianConfig
+
+[[autodoc]] MarianConfig
+
+## MarianTokenizer
+
+[[autodoc]] MarianTokenizer
+ - build_inputs_with_special_tokens
+
+
+
+
+## MarianModel
+
+[[autodoc]] MarianModel
+ - forward
+
+## MarianMTModel
+
+[[autodoc]] MarianMTModel
+ - forward
+
+## MarianForCausalLM
+
+[[autodoc]] MarianForCausalLM
+ - forward
+
+
+
+
+## TFMarianModel
+
+[[autodoc]] TFMarianModel
+ - call
+
+## TFMarianMTModel
+
+[[autodoc]] TFMarianMTModel
+ - call
+
+
+
+
+## FlaxMarianModel
+
+[[autodoc]] FlaxMarianModel
+ - __call__
+
+## FlaxMarianMTModel
+
+[[autodoc]] FlaxMarianMTModel
+ - __call__
+
+
+
diff --git a/docs/transformers/docs/source/ko/model_doc/mistral.md b/docs/transformers/docs/source/ko/model_doc/mistral.md
new file mode 100644
index 0000000000000000000000000000000000000000..4c9f2d7a77d4a2fee499e4db14e88f4c122c10e5
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/mistral.md
@@ -0,0 +1,233 @@
+
+
+# Mistral[[mistral]]
+
+## 개요[[overview]]
+
+미스트랄은 Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed가 작성한 [이 블로그 포스트](https://mistral.ai/news/announcing-mistral-7b/)에서 소개되었습니다.
+
+블로그 포스트의 서두는 다음과 같습니다:
+
+*미스트랄 AI팀은 현존하는 언어 모델 중 크기 대비 가장 강력한 미스트랄7B를 출시하게 되어 자랑스럽습니다.*
+
+미스트랄-7B는 [mistral.ai](https://mistral.ai/)에서 출시한 첫 번째 대규모 언어 모델(LLM)입니다.
+
+### 아키텍처 세부사항[[architectural-details]]
+
+미스트랄-7B는 다음과 같은 구조적 특징을 가진 디코더 전용 트랜스포머입니다:
+
+- 슬라이딩 윈도우 어텐션: 8k 컨텍스트 길이와 고정 캐시 크기로 훈련되었으며, 이론상 128K 토큰의 어텐션 범위를 가집니다.
+- GQA(Grouped Query Attention): 더 빠른 추론이 가능하고 더 작은 크기의 캐시를 사용합니다.
+- 바이트 폴백(Byte-fallback) BPE 토크나이저: 문자들이 절대 어휘 목록 외의 토큰으로 매핑되지 않도록 보장합니다.
+
+더 자세한 내용은 [출시 블로그 포스트](https://mistral.ai/news/announcing-mistral-7b/)를 참조하세요.
+
+### 라이선스[[license]]
+
+`미스트랄-7B`는 아파치 2.0 라이선스로 출시되었습니다.
+
+## 사용 팁[[usage-tips]]
+
+미스트랄 AI팀은 다음 3가지 체크포인트를 공개했습니다:
+
+- 기본 모델인 [미스트랄-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)은 인터넷 규모의 데이터에서 다음 토큰을 예측하도록 사전 훈련되었습니다.
+- 지시 조정 모델인 [미스트랄-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)은 지도 미세 조정(SFT)과 직접 선호도 최적화(DPO)를 사용한 채팅에 최적화된 기본 모델입니다.
+- 개선된 지시 조정 모델인 [미스트랄-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)는 v1을 개선한 버전입니다.
+
+기본 모델은 다음과 같이 사용할 수 있습니다:
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
+
+>>> prompt = "My favourite condiment is"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"My favourite condiment is to ..."
+```
+
+지시 조정 모델은 다음과 같이 사용할 수 있습니다:
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
+
+>>> messages = [
+... {"role": "user", "content": "What is your favourite condiment?"},
+... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
+... {"role": "user", "content": "Do you have mayonnaise recipes?"}
+... ]
+
+>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
+
+>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"Mayonnaise can be made as follows: (...)"
+```
+
+지시 조정 모델은 입력이 올바른 형식으로 준비되도록 [채팅 템플릿](../chat_templating)을 적용해야 합니다.
+
+## 플래시 어텐션을 이용한 미스트랄 속도향상[[speeding-up-mistral-by-using-flash-attention]]
+
+위의 코드 스니펫들은 어떤 최적화 기법도 사용하지 않은 추론 과정을 보여줍니다. 하지만 모델 내부에서 사용되는 어텐션 메커니즘의 더 빠른 구현인 [플래시 어텐션2](../perf_train_gpu_one.md#flash-attention-2)을 활용하면 모델의 속도를 크게 높일 수 있습니다.
+
+먼저, 슬라이딩 윈도우 어텐션 기능을 포함하는 플래시 어텐션2의 최신 버전을 설치해야 합니다.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+하드웨어와 플래시 어텐션2의 호환여부를 확인하세요. 이에 대한 자세한 내용은 [플래시 어텐션 저장소](https://github.com/Dao-AILab/flash-attention)의 공식 문서에서 확인할 수 있습니다. 또한 모델을 반정밀도(예: `torch.float16`)로 불러와야합니다.
+
+플래시 어텐션2를 사용하여 모델을 불러오고 실행하려면 아래 코드 스니펫을 참조하세요:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
+
+>>> prompt = "My favourite condiment is"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"My favourite condiment is to (...)"
+```
+
+### 기대하는 속도 향상[[expected-speedups]]
+
+다음은 `mistralai/Mistral-7B-v0.1` 체크포인트를 사용한 트랜스포머의 기본 구현과 플래시 어텐션2 버전 모델 사이의 순수 추론 시간을 비교한 예상 속도 향상 다이어그램입니다.
+
+
+
+
+
+### 슬라이딩 윈도우 어텐션[[sliding-window-attention]]
+
+현재 구현은 슬라이딩 윈도우 어텐션 메커니즘과 메모리 효율적인 캐시 관리 기능을 지원합니다. 슬라이딩 윈도우 어텐션을 활성화하려면, 슬라이딩 윈도우 어텐션과 호환되는`flash-attn`(`>=2.3.0`)버전을 사용하면 됩니다.
+
+또한 플래시 어텐션2 모델은 더 메모리 효율적인 캐시 슬라이싱 메커니즘을 사용합니다. 미스트랄 모델의 공식 구현에서 권장하는 롤링 캐시 메커니즘을 따라, 캐시 크기를 고정(`self.config.sliding_window`)으로 유지하고, `padding_side="left"`인 경우에만 배치 생성(batch generation)을 지원하며, 현재 토큰의 절대 위치를 사용해 위치 임베딩을 계산합니다.
+
+## 양자화로 미스트랄 크기 줄이기[[shrinking-down-mistral-using-quantization]]
+
+미스트랄 모델은 70억 개의 파라미터를 가지고 있어, 절반의 정밀도(float16)로 약 14GB의 GPU RAM이 필요합니다. 각 파라미터가 2바이트로 저장되기 때문입니다. 하지만 [양자화](../quantization.md)를 사용하면 모델 크기를 줄일 수 있습니다. 모델을 4비트(즉, 파라미터당 반 바이트)로 양자화하면 약 3.5GB의 RAM만 필요합니다.
+
+모델을 양자화하는 것은 `quantization_config`를 모델에 전달하는 것만큼 간단합니다. 아래에서는 BitsAndBytes 양자화를 사용하지만, 다른 양자화 방법은 [이 페이지](../quantization.md)를 참고하세요:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
+
+>>> # specify how to quantize the model
+>>> quantization_config = BitsAndBytesConfig(
+... load_in_4bit=True,
+... bnb_4bit_quant_type="nf4",
+... bnb_4bit_compute_dtype="torch.float16",
+... )
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", quantization_config=True, device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
+
+>>> prompt = "My favourite condiment is"
+
+>>> messages = [
+... {"role": "user", "content": "What is your favourite condiment?"},
+... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
+... {"role": "user", "content": "Do you have mayonnaise recipes?"}
+... ]
+
+>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
+
+>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"The expected output"
+```
+
+이 모델은 [Younes Belkada](https://huggingface.co/ybelkada)와 [Arthur Zucker](https://huggingface.co/ArthurZ)가 기여했습니다.
+원본 코드는 [이곳](https://github.com/mistralai/mistral-src)에서 확인할 수 있습니다.
+
+## 리소스[[resources]]
+
+미스트랄을 시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다. 여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰해 드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
+
+
+
+- 미스트랄-7B의 지도형 미세조정(SFT)을 수행하는 데모 노트북은 [이곳](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Mistral/Supervised_fine_tuning_(SFT)_of_an_LLM_using_Hugging_Face_tooling.ipynb)에서 확인할 수 있습니다. 🌎
+- 2024년에 Hugging Face 도구를 사용해 LLM을 미세 조정하는 방법에 대한 [블로그 포스트](https://www.philschmid.de/fine-tune-llms-in-2024-with-trl). 🌎
+- Hugging Face의 [정렬(Alignment) 핸드북](https://github.com/huggingface/alignment-handbook)에는 미스트랄-7B를 사용한 지도형 미세 조정(SFT) 및 직접 선호 최적화(DPO)를 수행하기 위한 스크립트와 레시피가 포함되어 있습니다. 여기에는 단일 GPU에서 QLoRa 및 다중 GPU를 사용한 전체 미세 조정을 위한 스크립트가 포함되어 있습니다.
+- [인과적 언어 모델링 작업 가이드](../tasks/language_modeling)
+
+## MistralConfig[[transformers.MistralConfig]]
+
+[[autodoc]] MistralConfig
+
+## MistralModel[[transformers.MistralModel]]
+
+[[autodoc]] MistralModel
+ - forward
+
+## MistralForCausalLM[[transformers.MistralForCausalLM]]
+
+[[autodoc]] MistralForCausalLM
+ - forward
+
+## MistralForSequenceClassification[[transformers.MistralForSequenceClassification]]
+
+[[autodoc]] MistralForSequenceClassification
+ - forward
+
+## MistralForTokenClassification[[transformers.MistralForTokenClassification]]
+
+[[autodoc]] MistralForTokenClassification
+ - forward
+
+## FlaxMistralModel[[transformers.FlaxMistralModel]]
+
+[[autodoc]] FlaxMistralModel
+ - __call__
+
+## FlaxMistralForCausalLM[[transformers.FlaxMistralForCausalLM]]
+
+[[autodoc]] FlaxMistralForCausalLM
+ - __call__
+
+## TFMistralModel[[transformers.TFMistralModel]]
+
+[[autodoc]] TFMistralModel
+ - call
+
+## TFMistralForCausalLM[[transformers.TFMistralForCausalLM]]
+
+[[autodoc]] TFMistralForCausalLM
+ - call
+
+## TFMistralForSequenceClassification[[transformers.TFMistralForSequenceClassification]]
+
+[[autodoc]] TFMistralForSequenceClassification
+ - call
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/model_doc/openai-gpt.md b/docs/transformers/docs/source/ko/model_doc/openai-gpt.md
new file mode 100644
index 0000000000000000000000000000000000000000..7e8f57c743bf7173e4fd31657abfb0b27b469f83
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/openai-gpt.md
@@ -0,0 +1,149 @@
+
+
+# OpenAI GPT [[openai-gpt]]
+
+
+
+## 개요 [[overview]]
+
+OpenAI GPT 모델은 Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever가 작성한 [Improving Language Understanding by Generative Pre-Training](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf) 논문에서 제안되었습니다. 이는 Toronto Book Corpus와 같은 장기 의존성을 가진 대규모 말뭉치를 사용하여 언어 모델링으로 사전 학습된 인과적(단방향) 트랜스포머입니다.
+
+논문의 초록은 다음과 같습니다:
+
+*자연어 이해는 텍스트 함의, 질문 응답, 의미 유사성 평가, 문서 분류와 같은 다양한 작업을 포함합니다. 비록 대규모의 레이블이 없는 텍스트 말뭉치가 풍부하기는 하지만, 이러한 특정 작업에 대한 학습을 위한 레이블된 데이터는 부족하여 판별적으로 학습된 모델이 적절하게 성능을 발휘하기 어렵습니다. 우리는 다양한 레이블이 없는 텍스트 말뭉치에 대한 언어 모델의 생성적 사전 학습을 수행하고, 각 특정 과제에 대한 판별적 미세 조정을 수행함으로써 이러한 과제에서 큰 성과를 달성할 수 있음을 보여줍니다. 이전 접근 방식과 달리, 우리는 모델 아키텍처에 최소한의 변화를 요구하면서 효과적인 전이를 달성하기 위해 미세 조정 중에 과제 인식 입력 변환(task-aware input transformation)을 사용합니다. 우리는 자연어 이해를 위한 다양한 벤치마크에서 우리의 접근 방식의 효과를 입증합니다. 우리의 general task-agnostic 모델은 각 과제에 특별히 설계된 아키텍처를 사용하는 판별적으로 학습된 모델보다 뛰어나며, 연구된 12개 과제 중 9개 부문에서 최첨단 성능(state of the art)을 크게 향상시킵니다.*
+
+[Write With Transformer](https://transformer.huggingface.co/doc/gpt)는 Hugging Face가 만든 웹 애플리케이션으로, 여러 모델의 생성 능력을 보여주며 그 중에는 GPT도 포함되어 있습니다.
+
+이 모델은 [thomwolf](https://huggingface.co/thomwolf)에 의해 기여되었으며, 원본 코드는 [여기](https://github.com/openai/finetune-transformer-lm)에서 확인할 수 있습니다.
+
+## 사용 팁 [[usage-tips]]
+
+- GPT는 절대 위치 임베딩을 사용하는 모델이므로 입력을 일반적으로 왼쪽보다는 오른쪽에 패딩하는 것이 권장됩니다.
+- GPT는 인과 언어 모델링(Causal Language Modeling, CLM) 목표로 학습되었기 때문에 시퀀스에서 다음 토큰을 예측하는 데 강력한 성능을 보여줍니다. 이를 활용하면 *run_generation.py* 예제 스크립트에서 볼 수 있듯이 GPT-2는 구문적으로 일관된 텍스트를 생성할 수 있습니다.
+
+참고:
+
+*OpenAI GPT* 논문의 원래 토큰화 과정을 재현하려면 `ftfy`와 `SpaCy`를 설치해야 합니다:
+
+```bash
+pip install spacy ftfy==4.4.3
+python -m spacy download en
+```
+
+`ftfy`와 `SpaCy`를 설치하지 않으면 [`OpenAIGPTTokenizer`]는 기본적으로 BERT의 `BasicTokenizer`를 사용한 후 Byte-Pair Encoding을 통해 토큰화합니다(대부분의 사용에 문제가 없으니 걱정하지 마세요).
+
+## 리소스 [[resources]]
+
+OpenAI GPT를 시작하는 데 도움이 되는 공식 Hugging Face 및 커뮤니티(🌎 표시) 리소스 목록입니다. 여기에 리소스를 추가하고 싶다면, Pull Request를 열어주시면 검토하겠습니다! 리소스는 기존 리소스를 복제하지 않고 새로운 것을 보여주는 것이 좋습니다.
+
+
+
+- [SetFit을 사용하여 텍스트 분류에서 OpenAI GPT-3을 능가하는 방법](https://www.philschmid.de/getting-started-setfit) 블로그 게시물.
+- 추가 자료: [텍스트 분류 과제 가이드](../tasks/sequence_classification)
+
+
+
+- [Hugging Face와 함께 비영어 GPT-2 모델을 미세 조정하는 방법](https://www.philschmid.de/fine-tune-a-non-english-gpt-2-model-with-huggingface) 블로그.
+- GPT-2와 함께 [Transformers를 사용한 언어 생성의 다양한 디코딩 방법](https://huggingface.co/blog/how-to-generate)에 대한 블로그.
+- [Scratch에서 CodeParrot 🦜을 훈련하는 방법](https://huggingface.co/blog/codeparrot), 대규모 GPT-2 모델에 대한 블로그.
+- GPT-2와 함께 [TensorFlow 및 XLA를 사용한 더 빠른 텍스트 생성](https://huggingface.co/blog/tf-xla-generate)에 대한 블로그.
+- [Megatron-LM으로 언어 모델을 훈련하는 방법](https://huggingface.co/blog/megatron-training)에 대한 블로그.
+- [좋아하는 아티스트의 스타일로 가사를 생성하도록 GPT2를 미세 조정하는 방법](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb)에 대한 노트북. 🌎
+- [좋아하는 트위터 사용자의 스타일로 트윗을 생성하도록 GPT2를 미세 조정하는 방법](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)에 대한 노트북. 🌎
+- 🤗 Hugging Face 코스의 [인과 언어 모델링](https://huggingface.co/course/en/chapter7/6?fw=pt#training-a-causal-language-model-from-scratch) 장.
+- [`OpenAIGPTLMHeadModel`]은 [인과 언어 모델링 예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling), [텍스트 생성 예제 스크립트](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-generation/run_generation.py) 및 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)에 의해 지원됩니다.
+- [`TFOpenAIGPTLMHeadModel`]은 [인과 언어 모델링 예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_clmpy) 및 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)에 의해 지원됩니다.
+- 추가 자료: [인과 언어 모델링 과제 가이드](../tasks/language_modeling)
+
+
+
+- [Byte-Pair Encoding 토큰화](https://huggingface.co/course/en/chapter6/5)에 대한 강의 자료.
+
+## OpenAIGPTConfig [[transformers.OpenAIGPTConfig]]
+
+[[autodoc]] OpenAIGPTConfig
+
+## OpenAIGPTTokenizer [[transformers.OpenAIGPTTokenizer]]
+
+[[autodoc]] OpenAIGPTTokenizer
+ - save_vocabulary
+
+## OpenAIGPTTokenizerFast [[transformers.OpenAIGPTTokenizerFast]]
+
+[[autodoc]] OpenAIGPTTokenizerFast
+
+## OpenAI specific outputs [[transformers.models.openai.modeling_openai.OpenAIGPTDoubleHeadsModelOutput]]
+
+[[autodoc]] models.openai.modeling_openai.OpenAIGPTDoubleHeadsModelOutput
+
+[[autodoc]] models.openai.modeling_tf_openai.TFOpenAIGPTDoubleHeadsModelOutput
+
+
+
+
+## OpenAIGPTModel [[transformers.OpenAIGPTModel]]
+
+[[autodoc]] OpenAIGPTModel
+ - forward
+
+## OpenAIGPTLMHeadModel [[transformers.OpenAIGPTLMHeadModel]]
+
+[[autodoc]] OpenAIGPTLMHeadModel
+ - forward
+
+## OpenAIGPTDoubleHeadsModel [[transformers.OpenAIGPTDoubleHeadsModel]]
+
+[[autodoc]] OpenAIGPTDoubleHeadsModel
+ - forward
+
+## OpenAIGPTForSequenceClassification [[transformers.OpenAIGPTForSequenceClassification]]
+
+[[autodoc]] OpenAIGPTForSequenceClassification
+ - forward
+
+
+
+
+## TFOpenAIGPTModel [[transformers.TFOpenAIGPTModel]]
+
+[[autodoc]] TFOpenAIGPTModel
+ - call
+
+## TFOpenAIGPTLMHeadModel [[transformers.TFOpenAIGPTLMHeadModel]]
+
+[[autodoc]] TFOpenAIGPTLMHeadModel
+ - call
+
+## TFOpenAIGPTDoubleHeadsModel [[transformers.TFOpenAIGPTDoubleHeadsModel]]
+
+[[autodoc]] TFOpenAIGPTDoubleHeadsModel
+ - call
+
+## TFOpenAIGPTForSequenceClassification [[transformers.TFOpenAIGPTForSequenceClassification]]
+
+[[autodoc]] TFOpenAIGPTForSequenceClassification
+ - call
+
+
+
diff --git a/docs/transformers/docs/source/ko/model_doc/paligemma.md b/docs/transformers/docs/source/ko/model_doc/paligemma.md
new file mode 100644
index 0000000000000000000000000000000000000000..9f5b48086855094ed1d0ad9e746c486760c60ef5
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/paligemma.md
@@ -0,0 +1,80 @@
+
+
+# PaliGemma[[paligemma]]
+
+## 개요[[overview]]
+
+PaliGemma 모델은 구글이 제안한 [PaliGemma – Google의 최첨단 오픈 비전 언어 모델](https://huggingface.co/blog/paligemma)에서 소개 되었습니다. PaliGemma는 [SigLIP](siglip) 비전 인코더와 [Gemma](gemma) 언어 인코더로 구성된 3B 규모의 비전-언어 모델로, 두 인코더가 멀티모달 선형 프로젝션으로 연결되어 있습니다. 이 모델은 이미지를 고정된 수의 VIT토큰으로 분할하고 이를 선택적 프롬프트 앞에 추가 하며, 모든 이미지 토큰과 입력 텍스트 토큰에 대해 전체 블록 어텐션을 사용하는 특징을 가지고 있습니다.
+
+PaliGemma는 224x224, 448x448, 896x896의 3가지 해상도로 제공되며, 3개의 기본 모델과 55개의 다양한 작업에 대해 미세 조정된 버전, 그리고 2개의 혼합 모델이 있습니다.
+
+
+
+ PaliGemma 아키텍처 블로그 포스트.
+
+이 모델은 [Molbap](https://huggingface.co/Molbap)에 의해 기여 되었습니다.
+
+## 사용 팁[[usage-tips]]
+
+PaliGemma의 추론은 다음처럼 수행됩니다:
+
+```python
+from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
+
+model_id = "google/paligemma-3b-mix-224"
+model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
+processor = AutoProcessor.from_pretrained(model_id)
+
+prompt = "What is on the flower?"
+image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg?download=true"
+raw_image = Image.open(requests.get(image_file, stream=True).raw)
+inputs = processor(raw_image, prompt, return_tensors="pt")
+output = model.generate(**inputs, max_new_tokens=20)
+
+print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
+```
+
+- PaliGemma는 대화용으로 설계되지 않았으며, 특정 사용 사례에 대해 미세 조정할 때 가장 잘 작동합니다. PaliGemma를 미세 조정할 수 있는 몇 가지 하위 작업에는 이미지 캡셔닝, 시각적 질문 답변(VQA), 오브젝트 디텍션, 참조 표현 분할 및 문서 이해가 포함됩니다.
+- 모델에 필요한 이미지, 텍스트 및 선택적 레이블을 준비하는데 `PaliGemmaProcessor`를 사용할 수 있습니다. PaliGemma 모델을 미세 조정할 때는, 프로세서에 `suffix`인자를 전달하여 다음 처럼 모델의 `labels`를 생성할 수 있습니다:
+
+```python
+prompt = "What is on the flower?"
+answer = "a bee"
+inputs = processor(images=raw_image, text=prompt, suffix=answer, return_tensors="pt")
+```
+
+## 자료[[resources]]
+
+PaliGemma를 시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다.여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰 해드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
+
+- PaliGemma의 모든 기능을 소개하는 블로그 포스트는 [이곳](https://huggingface.co/blog/paligemma)에서 찾을 수 있습니다. 🌎
+- Trainer API를 사용하여 VQA(Visual Question Answering)를 위해 PaliGemma를 미세 조정하는 방법과 추론에 대한 데모 노트북은 [이곳](https://github.com/huggingface/notebooks/tree/main/examples/paligemma)에서 찾을 수 있습니다. 🌎
+- 사용자 정의 데이터셋(영수증 이미지 -> JSON)에 대해 PaliGemma를 미세 조정하는 방법과 추론에 대한 데모 노트북은 [이곳](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/PaliGemma)에서 찾을 수 있습니다. 🌎
+
+## PaliGemmaConfig[[transformers.PaliGemmaConfig]]
+
+[[autodoc]] PaliGemmaConfig
+
+## PaliGemmaProcessor[[transformers.PaliGemmaProcessor]]
+
+[[autodoc]] PaliGemmaProcessor
+
+## PaliGemmaForConditionalGeneration[[transformers.PaliGemmaForConditionalGeneration]]
+
+[[autodoc]] PaliGemmaForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/patchtsmixer.md b/docs/transformers/docs/source/ko/model_doc/patchtsmixer.md
new file mode 100644
index 0000000000000000000000000000000000000000..e1463eb85de3e5aca2623fe038da4b249f9c629c
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/patchtsmixer.md
@@ -0,0 +1,95 @@
+
+
+# PatchTSMixer[[patchtsmixer]]
+
+## 개요[[overview]]
+
+PatchTSMixer 모델은 Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam이 제안한 [TSMixer: 다변량 시계열 예측을 위한 경량 MLP-Mixer 모델](https://arxiv.org/pdf/2306.09364.pdf)이라는 논문에서 소개되었습니다.
+
+
+PatchTSMixer는 MLP-Mixer 아키텍처를 기반으로 한 경량 시계열 모델링 접근법입니다. 허깅페이스 구현에서는 PatchTSMixer의 기능을 제공하여 패치, 채널, 숨겨진 특성 간의 경량 혼합을 쉽게 수행하여 효과적인 다변량 시계열 모델링을 가능하게 합니다. 또한 간단한 게이트 어텐션부터 사용자 정의된 더 복잡한 셀프 어텐션 블록까지 다양한 어텐션 메커니즘을 지원합니다. 이 모델은 사전 훈련될 수 있으며 이후 예측, 분류, 회귀와 같은 다양한 다운스트림 작업에 사용될 수 있습니다.
+
+
+해당 논문의 초록입니다:
+
+*TSMixer는 패치 처리된 시계열의 다변량 예측 및 표현 학습을 위해 설계된 다층 퍼셉트론(MLP) 모듈로만 구성된 경량 신경망 아키텍처입니다. 우리의 모델은 컴퓨터 비전 분야에서 MLP-Mixer 모델의 성공에서 영감을 받았습니다. 우리는 Vision MLP-Mixer를 시계열에 적용하는 데 따르는 과제를 보여주고, 정확도를 향상시키기 위해 경험적으로 검증된 구성 요소들을 도입합니다. 여기에는 계층 구조 및 채널 상관관계와 같은 시계열 특성을 명시적으로 모델링하기 위해 MLP-Mixer 백본에 온라인 조정 헤드를 부착하는 새로운 설계 패러다임이 포함됩니다. 또한 기존 패치 채널 혼합 방법의 일반적인 문제인 노이즈가 있는 채널 상호작용을 효과적으로 처리하고 다양한 데이터셋에 걸쳐 일반화하기 위한 하이브리드 채널 모델링 접근법을 제안합니다. 추가로, 중요한 특성을 우선시하기 위해 백본에 간단한 게이트 주의 메커니즘을 도입합니다. 이러한 경량 구성 요소들을 통합함으로써, 우리는 단순한 MLP 구조의 학습 능력을 크게 향상시켜 최소한의 컴퓨팅 사용으로 복잡한 트랜스포머 모델들을 능가하는 성능을 달성합니다. 더욱이, TSMixer의 모듈식 설계는 감독 학습과 마스크 자기 감독 학습 방법 모두와 호환되어 시계열 기초 모델의 유망한 구성 요소가 됩니다. TSMixer는 예측 작업에서 최첨단 MLP 및 트랜스포머 모델들을 상당한 차이(8-60%)로 능가합니다. 또한 최신의 강력한 Patch-Transformer 모델 벤치마크들을 메모리와 실행 시간을 크게 줄이면서(2-3배) 성능 면에서도 앞섭니다(1-2%).*
+
+이 모델은 [ajati](https://huggingface.co/ajati), [vijaye12](https://huggingface.co/vijaye12),
+[gsinthong](https://huggingface.co/gsinthong), [namctin](https://huggingface.co/namctin),
+[wmgifford](https://huggingface.co/wmgifford), [kashif](https://huggingface.co/kashif)가 기여했습니다.
+
+## 사용 예[[usage-example]]
+
+아래의 코드 스니펫은 PatchTSMixer 모델을 무작위로 초기화하는 방법을 보여줍니다.
+PatchTSMixer 모델은 [Trainer API](../trainer.md)와 호환됩니다.
+
+```python
+
+from transformers import PatchTSMixerConfig, PatchTSMixerForPrediction
+from transformers import Trainer, TrainingArguments,
+
+
+config = PatchTSMixerConfig(context_length = 512, prediction_length = 96)
+model = PatchTSMixerForPrediction(config)
+trainer = Trainer(model=model, args=training_args,
+ train_dataset=train_dataset,
+ eval_dataset=valid_dataset)
+trainer.train()
+results = trainer.evaluate(test_dataset)
+```
+
+## 사용 팁[[usage-tips]]
+
+이 모델은 시계열 분류와 시계열 회귀에도 사용될 수 있습니다. 각각[`PatchTSMixerForTimeSeriesClassification`]와 [`PatchTSMixerForRegression`] 클래스를 참조하세요.
+
+## 자료[[resources]]
+
+- PatchTSMixer를 자세히 설명하는 블로그 포스트는 여기에서 찾을 수 있습니다 [이곳](https://huggingface.co/blog/patchtsmixer). 이 블로그는 Google Colab에서도 열어볼 수 있습니다.
+
+## PatchTSMixerConfig[[transformers.PatchTSMixerConfig]]
+
+[[autodoc]] PatchTSMixerConfig
+
+
+## PatchTSMixerModel[[transformers.PatchTSMixerModel]]
+
+[[autodoc]] PatchTSMixerModel
+ - forward
+
+
+## PatchTSMixerForPrediction[[transformers.PatchTSMixerForPrediction]]
+
+[[autodoc]] PatchTSMixerForPrediction
+ - forward
+
+
+## PatchTSMixerForTimeSeriesClassification[[transformers.PatchTSMixerForTimeSeriesClassification]]
+
+[[autodoc]] PatchTSMixerForTimeSeriesClassification
+ - forward
+
+
+## PatchTSMixerForPretraining[[transformers.PatchTSMixerForPretraining]]
+
+[[autodoc]] PatchTSMixerForPretraining
+ - forward
+
+
+## PatchTSMixerForRegression[[transformers.PatchTSMixerForRegression]]
+
+[[autodoc]] PatchTSMixerForRegression
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/model_doc/patchtst.md b/docs/transformers/docs/source/ko/model_doc/patchtst.md
new file mode 100644
index 0000000000000000000000000000000000000000..fc9b0eb51e4a427b26f832a30e8d5c007e9a9bb1
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/patchtst.md
@@ -0,0 +1,76 @@
+
+
+# PatchTST[[patchtst]]
+
+## 개요[[overview]]
+
+The PatchTST 모델은 Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam이 제안한 [시계열 하나가 64개의 단어만큼 가치있다: 트랜스포머를 이용한 장기예측](https://arxiv.org/abs/2211.14730)라는 논문에서 소개되었습니다.
+
+이 모델은 고수준에서 시계열을 주어진 크기의 패치로 벡터화하고, 결과로 나온 벡터 시퀀스를 트랜스포머를 통해 인코딩한 다음 적절한 헤드를 통해 예측 길이의 예측을 출력합니다. 모델은 다음 그림과 같이 도식화됩니다:
+
+
+
+해당 논문의 초록입니다:
+
+*우리는 다변량 시계열 예측과 자기 감독 표현 학습을 위한 효율적인 트랜스포머 기반 모델 설계를 제안합니다. 이는 두 가지 주요 구성 요소를 기반으로 합니다:
+
+(i) 시계열을 하위 시리즈 수준의 패치로 분할하여 트랜스포머의 입력 토큰으로 사용
+(ii) 각 채널이 모든 시리즈에 걸쳐 동일한 임베딩과 트랜스포머 가중치를 공유하는 단일 단변량 시계열을 포함하는 채널 독립성. 패칭 설계는 자연스럽게 세 가지 이점을 가집니다:
+ - 지역적 의미 정보가 임베딩에 유지됩니다;
+ - 동일한 룩백 윈도우에 대해 어텐션 맵의 계산과 메모리 사용량이 제곱으로 감소합니다
+ - 모델이 더 긴 과거를 참조할 수 있습니다.
+ 우리의 채널 독립적 패치 시계열 트랜스포머(PatchTST)는 최신 트랜스포머 기반 모델들과 비교했을 때 장기 예측 정확도를 크게 향상시킬 수 있습니다. 또한 모델을 자기지도 사전 훈련 작업에 적용하여, 대규모 데이터셋에 대한 지도 학습을 능가하는 아주 뛰어난 미세 조정 성능을 달성했습니다. 한 데이터셋에서 마스크된 사전 훈련 표현을 다른 데이터셋으로 전이하는 것도 최고 수준의 예측 정확도(SOTA)를 산출했습니다.*
+
+이 모델은 [namctin](https://huggingface.co/namctin), [gsinthong](https://huggingface.co/gsinthong), [diepi](https://huggingface.co/diepi), [vijaye12](https://huggingface.co/vijaye12), [wmgifford](https://huggingface.co/wmgifford), [kashif](https://huggingface.co/kashif)에 의해 기여 되었습니다. 원본코드는 [이곳](https://github.com/yuqinie98/PatchTST)에서 확인할 수 있습니다.
+
+## 사용 팁[[usage-tips]]
+
+이 모델은 시계열 분류와 시계열 회귀에도 사용될 수 있습니다. 각각 [`PatchTSTForClassification`]와 [`PatchTSTForRegression`] 클래스를 참조하세요.
+
+## 자료[[resources]]
+
+- PatchTST를 자세히 설명하는 블로그 포스트는 [이곳](https://huggingface.co/blog/patchtst)에서 찾을 수 있습니다.
+이 블로그는 Google Colab에서도 열어볼 수 있습니다.
+
+## PatchTSTConfig[[transformers.PatchTSTConfig]]
+
+[[autodoc]] PatchTSTConfig
+
+## PatchTSTModel[[transformers.PatchTSTModel]]
+
+[[autodoc]] PatchTSTModel
+ - forward
+
+## PatchTSTForPrediction[[transformers.PatchTSTForPrediction]]
+
+[[autodoc]] PatchTSTForPrediction
+ - forward
+
+## PatchTSTForClassification[[transformers.PatchTSTForClassification]]
+
+[[autodoc]] PatchTSTForClassification
+ - forward
+
+## PatchTSTForPretraining[[transformers.PatchTSTForPretraining]]
+
+[[autodoc]] PatchTSTForPretraining
+ - forward
+
+## PatchTSTForRegression[[transformers.PatchTSTForRegression]]
+
+[[autodoc]] PatchTSTForRegression
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/qwen2_vl.md b/docs/transformers/docs/source/ko/model_doc/qwen2_vl.md
new file mode 100644
index 0000000000000000000000000000000000000000..fb4ed27391e015918fa90b836b17ffa6a40369ea
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/qwen2_vl.md
@@ -0,0 +1,303 @@
+
+
+# Qwen2-VL[[Qwen2-VL]]
+
+
+
+
+
+
+## Overview[[Overview]]
+
+[Qwen2-VL](https://qwenlm.github.io/blog/qwen2-vl/) 모델은 알리바바 리서치의 Qwen팀에서 개발한 [Qwen-VL](https://arxiv.org/pdf/2308.12966) 모델의 주요 업데이트 버전입니다.
+
+블로그의 요약은 다음과 같습니다:
+
+*이 블로그는 지난 몇 년간 Qwen-VL에서 중대한 개선을 거쳐 발전된 Qwen2-VL 모델을 소개합니다. 중요 개선 사항은 향상된 이미지 이해, 고급 비디오 이해, 통합 시각 에이전트 기능, 확장된 다언어 지원을 포함하고 있습니다.모델 아키텍처는 Naive Dynamic Resolution 지원을 통해 임의의 이미지 해상도를 처리할 수 있도록 최적화되었으며, 멀티모달 회전 위치 임베딩(M-ROPE)을 활용하여 1D 텍스트와 다차원 시각 데이터를 효과적으로 처리합니다. 이 업데이트된 모델은 시각 관련 작업에서 GPT-4o와 Claude 3.5 Sonnet 같은 선도적인 AI 시스템과 경쟁력 있는 성능을 보여주며, 텍스트 능력에서는 오픈소스 모델 중 상위권에 랭크되어 있습니다. 이러한 발전은 Qwen2-VL을 강력한 멀티모달 처리 및 추론 능력이 필요한 다양한 응용 분야에서 활용할 수 있는 다재다능한 도구로 만들어줍니다.*
+
+
+
+ Qwen2-VL 구조. 출처: 블로그 게시글
+
+이 모델은 [simonJJJ](https://huggingface.co/simonJJJ)에 의해 기여되었습니다.
+
+## 사용 예시[[Usage example]]
+
+### 단일 미디어 추론[[Single Media inference]]
+
+이 모델은 이미지와 비디오를 모두 인풋으로 받을 수 있습니다. 다음은 추론을 위한 예제 코드입니다.
+
+```python
+
+import torch
+from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
+
+# 사용 가능한 장치에서 모델을 반 정밀도(half-precision)로 로드
+model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", device_map="auto")
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
+
+
+conversation = [
+ {
+ "role":"user",
+ "content":[
+ {
+ "type":"image",
+ "url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"
+ },
+ {
+ "type":"text",
+ "text":"Describe this image."
+ }
+ ]
+ }
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+# 추론: 아웃풋 생성
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+
+
+
+# 비디오
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "video", "path": "/path/to/video.mp4"},
+ {"type": "text", "text": "What happened in the video?"},
+ ],
+ }
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ video_fps=1,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+
+# 추론: 아웃풋 생성
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+```
+
+### 배치 혼합 미디어 추론[[Batch Mixed Media Inference]]
+
+이 모델은 이미지, 비디오, 텍스트 등 다양한 유형의 데이터를 혼합하여 배치 입력으로 처리할 수 있습니다. 다음은 예제입니다.
+
+```python
+
+# 첫번째 이미지에 대한 대화
+conversation1 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image1.jpg"},
+ {"type": "text", "text": "Describe this image."}
+ ]
+ }
+]
+
+# 두 개의 이미지에 대한 대화
+conversation2 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image2.jpg"},
+ {"type": "image", "path": "/path/to/image3.jpg"},
+ {"type": "text", "text": "What is written in the pictures?"}
+ ]
+ }
+]
+
+# 순수 텍스트로만 이루어진 대화
+conversation3 = [
+ {
+ "role": "user",
+ "content": "who are you?"
+ }
+]
+
+
+# 혼합된 미디어로 이루어진 대화
+conversation4 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image3.jpg"},
+ {"type": "image", "path": "/path/to/image4.jpg"},
+ {"type": "video", "path": "/path/to/video.jpg"},
+ {"type": "text", "text": "What are the common elements in these medias?"},
+ ],
+ }
+]
+
+conversations = [conversation1, conversation2, conversation3, conversation4]
+# 배치 추론을 위한 준비
+ipnuts = processor.apply_chat_template(
+ conversations,
+ video_fps=1,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+
+# 배치 추론
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+```
+
+### 사용 팁[[Usage Tips]]
+
+#### 이미지 해상도 트레이드오프[[Image Resolution trade-off]]
+
+이 모델은 다양한 해상도의 입력을 지원합니다. 디폴트로 입력에 대해 네이티브(native) 해상도를 사용하지만, 더 높은 해상도를 적용하면 성능이 향상될 수 있습니다. 다만, 이는 더 많은 연산 비용을 초래합니다. 사용자는 최적의 설정을 위해 최소 및 최대 픽셀 수를 조정할 수 있습니다.
+
+```python
+min_pixels = 224*224
+max_pixels = 2048*2048
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+```
+
+제한된 GPU RAM의 경우, 다음과 같이 해상도를 줄일 수 있습니다:
+
+```python
+min_pixels = 256*28*28
+max_pixels = 1024*28*28
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+```
+이렇게 하면 각 이미지가 256~1024개의 토큰으로 인코딩됩니다. 여기서 28은 모델이 14 크기의 패치(patch)와 2의 시간 패치(temporal patch size)를 사용하기 때문에 나온 값입니다 (14 × 2 = 28).
+
+
+#### 다중 이미지 인풋[[Multiple Image Inputs]]
+
+기본적으로 이미지와 비디오 콘텐츠는 대화에 직접 포함됩니다. 여러 개의 이미지를 처리할 때는 이미지 및 비디오에 라벨을 추가하면 참조하기가 더 쉬워집니다. 사용자는 다음 설정을 통해 이 동작을 제어할 수 있습니다:
+
+```python
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "Hello, how are you?"}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'm doing well, thank you for asking. How can I assist you today?"
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Can you describe these images and video?"},
+ {"type": "image"},
+ {"type": "image"},
+ {"type": "video"},
+ {"type": "text", "text": "These are from my vacation."}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'd be happy to describe the images and video for you. Could you please provide more context about your vacation?"
+ },
+ {
+ "role": "user",
+ "content": "It was a trip to the mountains. Can you see the details in the images and video?"
+ }
+]
+
+# 디폴트:
+prompt_without_id = processor.apply_chat_template(conversation, add_generation_prompt=True)
+# 예상 아웃풋: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?<|vision_start|><|image_pad|><|vision_end|><|vision_start|><|image_pad|><|vision_end|><|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+
+
+# id 추가
+prompt_with_id = processor.apply_chat_template(conversation, add_generation_prompt=True, add_vision_id=True)
+# 예상 아웃풋: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nPicture 1: <|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?Picture 2: <|vision_start|><|image_pad|><|vision_end|>Picture 3: <|vision_start|><|image_pad|><|vision_end|>Video 1: <|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+
+```
+
+#### 빠른 생성을 위한 Flash-Attention 2[[Flash-Attention 2 to speed up generation]]
+
+첫번째로, Flash Attention 2의 최신 버전을 설치합니다:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+또한, Flash-Attention 2를 지원하는 하드웨어가 필요합니다. 자세한 내용은 공식 문서인 [flash attention repository](https://github.com/Dao-AILab/flash-attention)에서 확인할 수 있습니다. FlashAttention-2는 모델이 `torch.float16` 또는 `torch.bfloat16` 형식으로 로드된 경우에만 사용할 수 있습니다.
+
+Flash Attention-2를 사용하여 모델을 로드하고 실행하려면, 다음과 같이 모델을 로드할 때 `attn_implementation="flash_attention_2"` 옵션을 추가하면 됩니다:
+
+```python
+from transformers import Qwen2VLForConditionalGeneration
+
+model = Qwen2VLForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2-VL-7B-Instruct",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+```
+
+## Qwen2VLConfig
+
+[[autodoc]] Qwen2VLConfig
+
+## Qwen2VLImageProcessor
+
+[[autodoc]] Qwen2VLImageProcessor
+ - preprocess
+
+## Qwen2VLImageProcessorFast
+
+[[autodoc]] Qwen2VLImageProcessorFast
+ - preprocess
+
+## Qwen2VLProcessor
+
+[[autodoc]] Qwen2VLProcessor
+
+## Qwen2VLModel
+
+[[autodoc]] Qwen2VLModel
+ - forward
+
+## Qwen2VLForConditionalGeneration
+
+[[autodoc]] Qwen2VLForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/rag.md b/docs/transformers/docs/source/ko/model_doc/rag.md
new file mode 100644
index 0000000000000000000000000000000000000000..0ae88cc7ac5e3e08fc85a3619fb59aaef54a86a1
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/rag.md
@@ -0,0 +1,100 @@
+
+
+# RAG(검색 증강 생성) [[rag]]
+
+
+
+## 개요 [[overview]]
+
+검색 증강 생성(Retrieval-augmented generation, "RAG") 모델은 사전 훈련된 밀집 검색(DPR)과 시퀀스-투-시퀀스 모델의 장점을 결합합니다. RAG 모델은 문서를 검색하고, 이를 시퀀스-투-시퀀스 모델에 전달한 다음, 주변화(marginalization)를 통해 출력을 생성합니다. 검색기와 시퀀스-투-시퀀스 모듈은 사전 훈련된 모델로 초기화되며, 함께 미세 조정되어 검색과 생성 모두 다운스트림 작업(모델을 특정 태스크에 적용하는 것)에 적응할 수 있게 합니다.
+
+이 모델은 Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela의 논문 [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401)를 기반으로 합니다.
+
+논문의 초록은 다음과 같습니다.
+
+*대규모 사전 훈련 언어 모델들은 그들의 매개변수에 사실적 지식을 저장하고 있으며, 다운스트림 NLP 작업에 대해 미세 조정될 때 최첨단 결과를 달성합니다. 그러나 지식에 접근하고 정확하게 조작하는 능력은 여전히 제한적이며, 따라서 지식 집약적 작업에서 그들의 성능은 작업별 아키텍처에 비해 뒤떨어집니다. 또한, 그들의 결정에 대한 근거를 제공하고 세계 지식을 업데이트하는 것은 여전히 열린 연구 문제로 남아 있습니다. 명시적 비매개변수 메모리에 대한 미분 가능한 접근 메커니즘을 가진 사전 훈련 모델은 이 문제를 극복할 수 있지만, 지금까지는 추출적 다운스트림 작업에 대해서만 연구되었습니다. 우리는 언어 생성을 위해 사전 훈련된 매개변수 및 비매개변수 메모리를 결합하는 모델인 검색 증강 생성(RAG)에 대한 일반적인 목적의 미세 조정 방법을 탐구합니다. 우리는 매개변수 메모리가 사전 훈련된 시퀀스-투-시퀀스 모델이고 비매개변수 메모리가 사전 훈련된 신경 검색기로 접근되는 위키피디아의 밀집 벡터 인덱스인 RAG 모델을 소개합니다. 우리는 생성된 전체 시퀀스에 걸쳐 동일한 검색된 구절을 조건으로 하는 RAG 공식과 토큰별로 다른 구절을 사용할 수 있는 RAG 공식을 비교합니다. 우리는 광범위한 지식 집약적 NLP 작업에 대해 모델을 미세 조정하고 평가하며, 매개변수 시퀀스-투-시퀀스 모델과 작업별 검색-추출 아키텍처를 능가하여 세 가지 개방형 도메인 QA 작업에서 최첨단 성능을 달성합니다. 언어 생성 작업의 경우, RAG 모델이 최첨단 매개변수 전용 시퀀스-투-시퀀스 기준선보다 더 구체적이고, 다양하며, 사실적인 언어를 생성한다는 것을 발견했습니다.*
+
+이 모델은 [ola13](https://huggingface.co/ola13)에 의해 기여되었습니다.
+
+## 사용 팁 [[usage-tips]]
+
+검색 증강 생성(Retrieval-augmented generation, "RAG") 모델은 사전 훈련된 밀집 검색(DPR)과 시퀀스-투-시퀀스 모델의 강점을 결합합니다. RAG 모델은 문서를 검색하고, 이를 시퀀스-투-시퀀스 모델에 전달한 다음, 주변화(marginalization)를 통해 출력을 생성합니다. 검색기와 시퀀스-투-시퀀스 모듈은 사전 훈련된 모델로 초기화되며, 함께 미세 조정됩니다. 이를 통해 검색과 생성 모두 다운스트림 작업에 적응할 수 있게 됩니다.
+
+## RagConfig [[transformers.RagConfig]]
+
+[[autodoc]] RagConfig
+
+## RagTokenizer [[transformers.RagTokenizer]]
+
+[[autodoc]] RagTokenizer
+
+## Rag specific outputs [[transformers.models.rag.modeling_rag.RetrievAugLMMarginOutput]]
+
+[[autodoc]] models.rag.modeling_rag.RetrievAugLMMarginOutput
+
+[[autodoc]] models.rag.modeling_rag.RetrievAugLMOutput
+
+## RagRetriever [[transformers.RagRetriever]]
+
+[[autodoc]] RagRetriever
+
+
+
+
+## RagModel [[transformers.RagModel]]
+
+[[autodoc]] RagModel
+ - forward
+
+## RagSequenceForGeneration [[transformers.RagSequenceForGeneration]]
+
+[[autodoc]] RagSequenceForGeneration
+ - forward
+ - generate
+
+## RagTokenForGeneration [[transformers.RagTokenForGeneration]]
+
+[[autodoc]] RagTokenForGeneration
+ - forward
+ - generate
+
+
+
+
+## TFRagModel [[transformers.TFRagModel]]
+
+[[autodoc]] TFRagModel
+ - call
+
+## TFRagSequenceForGeneration [[transformers.TFRagSequenceForGeneration]]
+
+[[autodoc]] TFRagSequenceForGeneration
+ - call
+ - generate
+
+## TFRagTokenForGeneration [[transformers.TFRagTokenForGeneration]]
+
+[[autodoc]] TFRagTokenForGeneration
+ - call
+ - generate
+
+
+
diff --git a/docs/transformers/docs/source/ko/model_doc/siglip.md b/docs/transformers/docs/source/ko/model_doc/siglip.md
new file mode 100644
index 0000000000000000000000000000000000000000..d0eaf93cf040648a4928230e1aaefbdb23d29efc
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/siglip.md
@@ -0,0 +1,253 @@
+
+
+# SigLIP[[siglip]]
+
+
+
+
+
+
+
+## 개요[[overview]]
+
+SigLIP 모델은 Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer의 [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) 논문에서 제안되었습니다. SigLIP은 [CLIP](clip)에서 사용된 손실 함수를 간단한 쌍별 시그모이드 손실(pairwise sigmoid loss)로 대체할 것을 제안합니다. 이는 ImageNet에서 제로샷 분류 정확도 측면에서 더 나은 성능을 보입니다.
+
+논문의 초록은 다음과 같습니다:
+
+*우리는 언어-이미지 사전 학습(Language-Image Pre-training, SigLIP)을 위한 간단한 쌍별 시그모이드 손실을 제안합니다. 소프트맥스 정규화를 사용하는 표준 대조 학습과 달리, 시그모이드 손실은 이미지-텍스트 쌍에만 작용하며 정규화를 위해 쌍별 유사성의 전역적 관점을 필요로 하지 않습니다. 시그모이드 손실은 배치 크기를 더욱 확장할 수 있게 하는 동시에 작은 배치 크기에서도 더 나은 성능을 보입니다. Locked-image Tuning과 결합하여, 단 4개의 TPUv4 칩만으로 이틀 만에 84.5%의 ImageNet 제로샷 정확도를 달성하는 SigLiT 모델을 학습했습니다. 손실 함수에서 배치 크기를 분리함으로써 예제 대 쌍의 영향과 Negative 대 Positive 비율을 연구할 수 있게 되었습니다. 마지막으로, 우리는 배치 크기를 100만 개까지 극단적으로 늘려보았고, 배치 크기 증가의 이점이 빠르게 감소하며 32k의 더 합리적인 배치 크기로도 충분하다는 것을 발견했습니다.*
+
+## 사용 팁[[usage-tips]]
+
+- SigLIP의 사용법은 [CLIP](clip)과 유사합니다. 주요 차이점은 학습 손실 함수로, 배치 내 모든 이미지와 텍스트 간의 쌍별 유사성에 대한 전역적 관점이 필요하지 않습니다. 소프트맥스 대신 로짓에 시그모이드 활성화 함수를 적용해야 합니다.
+- 학습은 지원되지만 `torch.distributed` 유틸리티를 사용하지 않아 배치 크기의 확장성이 제한될 수 있습니다. 그러나 단일 노드 다중 GPU 설정에서는 DDP와 FDSP가 작동합니다.
+- 독립형 [`SiglipTokenizer`] 또는 [`SiglipProcessor`]를 사용할 때는 모델이 그렇게 학습되었으므로 `padding="max_length"`를 전달해야 합니다.
+- 파이프라인과 동일한 결과를 얻으려면 "This is a photo of {label}."의 프롬프트 템플릿을 사용해야 합니다.
+
+
+
+ CLIP과 비교한 SigLIP 평가 결과. 원본 논문에서 발췌.
+
+이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여했습니다.
+원본 코드는 [여기](https://github.com/google-research/big_vision/tree/main)에서 찾을 수 있습니다.
+
+## 사용 예시[[usage-example]]
+
+SigLIP을 사용하는 방법에는 두 가지 주요 방법이 있습니다: 모든 복잡성을 추상화하는 파이프라인 API를 사용하거나, 직접 `SiglipModel` 클래스를 사용하는 방법입니다.
+
+### 파이프라인 API[[pipeline-API]]
+
+파이프라인을 사용하면 몇 줄의 코드로 모델을 사용할 수 있습니다:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # 파이프라인 로드
+>>> image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
+
+>>> # 이미지 로드
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # 추론
+>>> candidate_labels = ["2 cats", "a plane", "a remote"]
+>>> outputs = image_classifier(image, candidate_labels=candidate_labels)
+>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
+>>> print(outputs)
+[{'score': 0.1979, 'label': '2 cats'}, {'score': 0.0, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
+```
+
+### 직접 모델 사용하기[[using-the-model-yourself]]
+
+전처리와 후처리를 직접 수행하려면 다음과 같이 하면 됩니다:
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, AutoModel
+>>> import torch
+
+>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
+>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# 파이프라인 프롬프트 템플릿을 따라 동일한 결과를 얻습니다
+>>> texts = [f'This is a photo of {label}.' for label in candidate_labels]
+# 중요: 모델이 이렇게 학습되었으므로 `padding=max_length`를 전달합니다
+>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # 시그모이드 활성화 함수를 적용한 확률입니다
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+19.8% that image 0 is '2 cats'
+```
+
+## 리소스[[resources]]
+
+SigLIP을 시작하는 데 도움이 되는 공식 Hugging Face 및 커뮤니티(🌎로 표시) 리소스 목록입니다.
+
+- [제로샷 이미지 분류 작업 가이드](../tasks/zero_shot_image_classification)
+- SigLIP에 대한 데모 노트북은 [여기](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SigLIP)에서 찾을 수 있습니다. 🌎
+
+여기에 포함될 리소스를 제출하는 데 관심이 있으시면 Pull Request를 열어주시면 검토하겠습니다! 리소스는 이상적으로 기존 리소스를 복제하는 대신 새로운 것을 보여주어야 합니다.
+
+
+## SigLIP과 Flash Attention 2 결합하기[[combining-siglip-with-flash-attention-2]]
+
+먼저 Flash Attention 2의 최신 버전을 설치해야 합니다.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+또한 Flash-Attention 2와 호환되는 하드웨어가 있는지 확인하세요. flash-attn 저장소의 공식 문서에서 자세히 알아보세요. 또한 모델을 반정밀도(예: `torch.float16`)로 로드해야 합니다.
+
+Flash Attention 2를 사용하여 모델을 로드하고 실행하려면 아래 코드를 참조하세요:
+
+```python
+>>> import torch
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import SiglipProcessor, SiglipModel
+>>> device = "cuda" # 모델을 로드할 장치
+
+>>> model = SiglipModel.from_pretrained(
+... "google/siglip-so400m-patch14-384",
+... attn_implementation="flash_attention_2",
+... torch_dtype=torch.float16,
+... device_map=device,
+... )
+>>> processor = SiglipProcessor.from_pretrained("google/siglip-so400m-patch14-384")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# 파이프라인 프롬프트 템플릿을 따라 동일한 결과를 얻습니다
+>>> texts = [f'This is a photo of {label}.' for label in candidate_labels]
+# 중요: 모델이 이렇게 학습되었으므로 `padding=max_length`를 전달합니다
+>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt").to(device)
+
+>>> with torch.no_grad():
+... with torch.autocast(device):
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # 시그모이드 활성화 함수를 적용한 확률입니다
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+19.8% that image 0 is '2 cats'
+```
+
+
+## Scaled Dot Product Attention(SDPA) 사용하기[using-scaled-dot-product-attention(SDPA)]]
+
+PyTorch는 `torch.nn.functional`의 일부로 스케일된 점곱 어텐션(SDPA) 연산자를 포함합니다. 이 함수는
+입력과 사용 중인 하드웨어에 따라 적용할 수 있는 여러 구현을 포함합니다. 자세한 내용은
+[공식 문서](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+또는 [GPU 추론](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+페이지를 참조하세요.
+
+`from_pretrained()`에서 `attn_implementation="sdpa"`를 설정하여 SDPA를 명시적으로 요청할 수 있습니다. `torch>=2.1.1`이 설치되어 있는지 확인하세요.
+
+```python
+>>> from transformers import SiglipModel
+
+>>> model = SiglipModel.from_pretrained(
+... "google/siglip-so400m-patch14-384",
+... attn_implementation="sdpa",
+... torch_dtype=torch.float16,
+... device_map=device,
+... )
+```
+
+최상의 속도 향상을 위해 모델을 반정밀도(예: `torch.float16` 또는 `torch.bfloat16`)로 로드하는 것이 좋습니다.
+
+
+## 예상 속도 향상[[expected-speedups]]
+
+아래는 `google/siglip-so400m-patch14-384` 체크포인트를 `float16` 정밀도로 사용하는 transformers의 네이티브 구현과 Flash Attention 2 / SDPA 버전의 모델을 다양한 배치 크기로 비교한 추론 시간의 예상 속도 향상 다이어그램입니다.
+
+
+
+
+
+
+## SiglipConfig
+
+[[autodoc]] SiglipConfig
+ - from_text_vision_configs
+
+## SiglipTextConfig
+
+[[autodoc]] SiglipTextConfig
+
+## SiglipVisionConfig
+
+[[autodoc]] SiglipVisionConfig
+
+## SiglipTokenizer
+
+[[autodoc]] SiglipTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## SiglipImageProcessor
+
+[[autodoc]] SiglipImageProcessor
+ - preprocess
+
+## SiglipImageProcessorFast
+
+[[autodoc]] SiglipImageProcessorFast
+ - preprocess
+
+## SiglipProcessor
+
+[[autodoc]] SiglipProcessor
+
+## SiglipModel
+
+[[autodoc]] SiglipModel
+ - forward
+ - get_text_features
+ - get_image_features
+
+## SiglipTextModel
+
+[[autodoc]] SiglipTextModel
+ - forward
+
+## SiglipVisionModel
+
+[[autodoc]] SiglipVisionModel
+ - forward
+
+
+## SiglipForImageClassification
+
+[[autodoc]] SiglipForImageClassification
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/model_doc/swin.md b/docs/transformers/docs/source/ko/model_doc/swin.md
new file mode 100644
index 0000000000000000000000000000000000000000..6919d7e9978e07af4938c633cedb22f80667d9a1
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/swin.md
@@ -0,0 +1,95 @@
+
+
+# Swin Transformer [[swin-transformer]]
+
+## 개요 [[overview]]
+
+Swin Transformer는 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo가 제안한 논문 [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)에서 소개되었습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*이 논문은 Swin Transformer라는 새로운 비전 트랜스포머를 소개합니다. 이 모델은 컴퓨터 비전에서 범용 백본(backbone)으로 사용될 수 있습니다. 트랜스포머를 언어에서 비전으로 적용할 때의 어려움은 두 분야 간의 차이에서 비롯되는데, 예를 들어 시각적 객체의 크기가 크게 변동하며, 이미지의 픽셀 해상도가 텍스트의 단어에 비해 매우 높다는 점이 있습니다. 이러한 차이를 해결하기 위해, 우리는 'Shifted Windows'를 이용해 표현을 계산하는 계층적 트랜스포머를 제안합니다. Shifted Windows 방식은 겹치지 않는 로컬 윈도우에서 self-attention 계산을 제한하여 효율성을 높이는 동시에 윈도우 간 연결을 가능하게 합니다. 이 계층적 구조는 다양한 크기의 패턴을 모델링할 수 있는 유연성을 제공하며, 이미지 크기에 비례한 선형 계산 복잡성을 가지고 있습니다. Swin Transformer의 이러한 특징들은 이미지 분류(Imagenet-1K에서 87.3의 top-1 정확도) 및 객체 검출(COCO test-dev에서 58.7의 박스 AP, 51.1의 마스크 AP)과 같은 밀집 예측 작업, 의미적 분할(ADE20K val에서 53.5의 mIoU)과 같은 광범위한 비전 작업에 적합합니다. 이 모델은 COCO에서 이전 최고 성능을 박스 AP에서 +2.7, 마스크 AP에서 +2.6, ADE20K에서 mIoU에서 +3.2를 초과하는 성과를 보여주며, 트랜스포머 기반 모델이 비전 백본으로서의 잠재력을 입증했습니다. 계층적 설계와 Shifted Windows 방식은 순수 MLP 아키텍처에도 유리하게 작용합니다.*
+
+
+
+ Swin Transformer 아키텍처. 원본 논문에서 발췌.
+
+이 모델은 [novice03](https://huggingface.co/novice03)이 기여하였습니다. Tensorflow 버전은 [amyeroberts](https://huggingface.co/amyeroberts)가 기여했습니다. 원본 코드는 [여기](https://github.com/microsoft/Swin-Transformer)에서 확인할 수 있습니다.
+
+## 사용 팁 [[usage-tips]]
+
+- Swin은 입력의 높이와 너비가 `32`로 나누어질 수 있으면 어떤 크기든 지원할 수 있도록 패딩을 추가합니다.
+- Swin은 *백본*으로 사용할 수 있습니다. `output_hidden_states = True`로 설정하면, `hidden_states`와 `reshaped_hidden_states`를 모두 출력합니다. `reshaped_hidden_states`는 `(batch, num_channels, height, width)` 형식을 가지며, 이는 `(batch_size, sequence_length, num_channels)` 형식과 다릅니다.
+
+## 리소스 [[resources]]
+
+Swin Transformer의 사용을 도울 수 있는 Hugging Face 및 커뮤니티(🌎로 표시)의 공식 자료 목록입니다.
+
+
+
+- [`SwinForImageClassification`]은 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)을 통해 지원됩니다.
+- 관련 자료: [이미지 분류 작업 가이드](../tasks/image_classification)
+
+또한:
+
+- [`SwinForMaskedImageModeling`]은 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining)를 통해 지원됩니다.
+
+새로운 자료를 추가하고 싶으시다면, 언제든지 Pull Request를 열어주세요! 저희가 검토해 드릴게요. 이때, 추가하는 자료는 기존 자료와 중복되지 않고 새로운 내용을 보여주는 자료여야 합니다.
+
+## SwinConfig [[transformers.SwinConfig]]
+
+[[autodoc]] SwinConfig
+
+
+
+
+## SwinModel [[transformers.SwinModel]]
+
+[[autodoc]] SwinModel
+ - forward
+
+## SwinForMaskedImageModeling [[transformers.SwinForMaskedImageModeling]]
+
+[[autodoc]] SwinForMaskedImageModeling
+ - forward
+
+## SwinForImageClassification [[transformers.SwinForImageClassification]]
+
+[[autodoc]] transformers.SwinForImageClassification
+ - forward
+
+
+
+
+## TFSwinModel [[transformers.TFSwinModel]]
+
+[[autodoc]] TFSwinModel
+ - call
+
+## TFSwinForMaskedImageModeling [[transformers.TFSwinForMaskedImageModeling]]
+
+[[autodoc]] TFSwinForMaskedImageModeling
+ - call
+
+## TFSwinForImageClassification [[transformers.TFSwinForImageClassification]]
+
+[[autodoc]] transformers.TFSwinForImageClassification
+ - call
+
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/model_doc/swin2sr.md b/docs/transformers/docs/source/ko/model_doc/swin2sr.md
new file mode 100644
index 0000000000000000000000000000000000000000..931298b9593c632790f7c1e12183ed1795051f77
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/swin2sr.md
@@ -0,0 +1,59 @@
+
+
+# Swin2SR [[swin2sr]]
+
+## 개요 [[overview]]
+
+Swin2SR 모델은 Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte가 제안한 논문 [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345)에서 소개되었습니다.
+Swin2SR은 [SwinIR](https://github.com/JingyunLiang/SwinIR/) 모델을 개선하고자 [Swin Transformer v2](swinv2) 레이어를 도입함으로써, 훈련 불안정성, 사전 훈련과 미세 조정 간의 해상도 차이, 그리고 데이터 의존성 문제를 완화시킵니다.
+
+논문의 초록은 다음과 같습니다:
+
+*압축은 스트리밍 서비스, 가상 현실, 비디오 게임과 같은 대역폭이 제한된 시스템을 통해 이미지와 영상을 효율적으로 전송하고 저장하는 데 중요한 역할을 합니다. 하지만 압축은 필연적으로 원본 정보의 손실과 아티팩트를 초래하며, 이는 시각적 품질을 심각하게 저하시킬 수 있습니다. 이러한 이유로, 압축된 이미지의 품질 향상은 활발한 연구 주제가 되고 있습니다. 현재 대부분의 최첨단 이미지 복원 방법은 합성곱 신경망을 기반으로 하지만, SwinIR과 같은 트랜스포머 기반 방법들도 이 작업에서 인상적인 성능을 보여주고 있습니다. 이번 논문에서는 Swin Transformer V2를 사용해 SwinIR을 개선하여 이미지 초해상도 작업, 특히 압축된 입력 시나리오에서 성능을 향상시키고자 합니다. 이 방법을 통해 트랜스포머 비전 모델을 훈련할 때 발생하는 주요 문제들, 예를 들어 훈련 불안정성, 사전 훈련과 미세 조정 간 해상도 차이, 그리고 데이터 의존성을 해결할 수 있습니다. 우리는 JPEG 압축 아티팩트 제거, 이미지 초해상도(클래식 및 경량), 그리고 압축된 이미지 초해상도라는 세 가지 대표적인 작업에서 실험을 수행했습니다. 실험 결과, 우리의 방법인 Swin2SR은 SwinIR의 훈련 수렴성과 성능을 향상시킬 수 있으며, "AIM 2022 Challenge on Super-Resolution of Compressed Image and Video"에서 상위 5위 솔루션으로 선정되었습니다.*
+
+
+
+ Swin2SR 아키텍처. 원본 논문에서 발췌.
+
+이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여하였습니다.
+원본 코드는 [여기](https://github.com/mv-lab/swin2sr)에서 확인할 수 있습니다.
+
+## 리소스 [[resources]]
+
+Swin2SR demo notebook은 [여기](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Swin2SR)에서 확인할 수 있습니다.
+
+SwinSR을 활용한 image super-resolution demo space는 [여기](https://huggingface.co/spaces/jjourney1125/swin2sr)에서 확인할 수 있습니다.
+
+## Swin2SRImageProcessor [[transformers.Swin2SRImageProcessor]]
+
+[[autodoc]] Swin2SRImageProcessor
+ - preprocess
+
+## Swin2SRConfig [[transformers.Swin2SRConfig]]
+
+[[autodoc]] Swin2SRConfig
+
+## Swin2SRModel [[transformers.Swin2SRModel]]
+
+[[autodoc]] Swin2SRModel
+ - forward
+
+## Swin2SRForImageSuperResolution [[transformers.Swin2SRForImageSuperResolution]]
+
+[[autodoc]] Swin2SRForImageSuperResolution
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/swinv2.md b/docs/transformers/docs/source/ko/model_doc/swinv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..3bc420a292ad7bfd80791aafa6f4ecb40bdd4242
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/swinv2.md
@@ -0,0 +1,63 @@
+
+
+# Swin Transformer V2 [[swin-transformer-v2]]
+
+## 개요 [[overview]]
+
+Swin Transformer V2는 Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo가 제안한 논문 [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883)에서 소개되었습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*대규모 NLP 모델들은 언어 작업에서의 성능을 크게 향상하며, 성능이 포화하는 징후를 보이지 않습니다. 또한, 사람과 유사한 few-shot 학습 능력을 보여줍니다. 이 논문은 대규모 모델을 컴퓨터 비전 분야에서 탐구하고자 합니다. 대형 비전 모델을 훈련하고 적용하는 데 있어 세 가지 주요 문제를 다룹니다: 훈련 불안정성, 사전 학습과 파인튜닝 간의 해상도 차이, 그리고 레이블이 달린 데이터에 대한 높은 요구입니다. 세 가지 주요 기법을 제안합니다: 1) 훈련 안정성을 개선하기 위한 residual-post-norm 방법과 cosine attention의 결합; 2) 저해상도 이미지로 사전 학습된 모델을 고해상도 입력으로 전이할 수 있는 log-spaced continuous position bias 방법; 3) 레이블이 달린 방대한 이미지의 필요성을 줄이기 위한 self-supervised 사전 학습 방법인 SimMIM입니다. 이러한 기법들을 통해 30억 개의 파라미터를 가진 Swin Transformer V2 모델을 성공적으로 훈련하였으며, 이는 현재까지 가장 크고 고밀도의 비전 모델로, 최대 1,536×1,536 해상도의 이미지를 다룰 수 있습니다. 이 모델은 ImageNet-V2 이미지 분류, COCO 객체 탐지, ADE20K 의미론적 분할, Kinetics-400 비디오 행동 분류 등 네 가지 대표적인 비전 작업에서 새로운 성능 기록을 세웠습니다. 또한, 우리의 훈련은 Google의 billion-level 비전 모델과 비교해 40배 적은 레이블이 달린 데이터와 40배 적은 훈련 시간으로 이루어졌다는 점에서 훨씬 더 효율적입니다.*
+
+이 모델은 [nandwalritik](https://huggingface.co/nandwalritik)이 기여하였습니다.
+원본 코드는 [여기](https://github.com/microsoft/Swin-Transformer)에서 확인할 수 있습니다.
+
+## 리소스 [[resources]]
+
+Swin Transformer v2의 사용을 도울 수 있는 Hugging Face 및 커뮤니티(🌎로 표시)의 공식 자료 목록입니다.
+
+
+
+
+- [`Swinv2ForImageClassification`]은 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)을 통해 지원됩니다.
+- 관련 자료: [이미지 분류 작업 가이드](../tasks/image_classification)
+
+또한:
+
+- [`Swinv2ForMaskedImageModeling`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining)를 통해 지원됩니다.
+
+새로운 자료를 추가하고 싶으시다면, 언제든지 Pull Request를 열어주세요! 저희가 검토해 드릴게요. 이때, 추가하는 자료는 기존 자료와 중복되지 않고 새로운 내용을 보여주는 자료여야 합니다.
+
+## Swinv2Config [[transformers.Swinv2Config]]
+
+[[autodoc]] Swinv2Config
+
+## Swinv2Model [[transformers.Swinv2Model]]
+
+[[autodoc]] Swinv2Model
+ - forward
+
+## Swinv2ForMaskedImageModeling [[transformers.Swinv2ForMaskedImageModeling]]
+
+[[autodoc]] Swinv2ForMaskedImageModeling
+ - forward
+
+## Swinv2ForImageClassification [[transformers.Swinv2ForImageClassification]]
+
+[[autodoc]] transformers.Swinv2ForImageClassification
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/time_series_transformer.md b/docs/transformers/docs/source/ko/model_doc/time_series_transformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..2473b0e143b7500ab13d911a34ab406f6f3d0906
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/time_series_transformer.md
@@ -0,0 +1,62 @@
+
+
+# 시계열 트랜스포머[[time-series-transformer]]
+
+## 개요[[overview]]
+
+이 시계열 트랜스포머 모델은 시계열 예측을 위한 기본적인 인코더-디코더 구조의 트랜스포머 입니다.
+이 모델은 [kashif](https://huggingface.co/kashif)에 의해 기여되었습니다.
+
+## 사용 팁[[usage-tips]]
+
+- 다른 라이브러리의 모델들과 마찬가지로, [`TimeSeriesTransformerModel`]은 상단에 헤드가 없는 기본적인 트랜스포머 입니다. [`TimeSeriesTransformerForPrediction`]은 상단에 분포 헤드를 추가하여 시계열 예측에 사용할 수 있습니다. 이 모델은 이른바 확률적 예측 모델이며, 포인트 예측 모델이 아닙니다. 즉 샘플링할 수 있는 분포를 학습하며, 값을 직접 출력 하지는 않습니다.
+- [`TimeSeriesTransformerForPrediction`]은 두개의 블록으로 구성되어 있습니다. 인코더는 `context_length`의 시계열 값을 입력(`past_values`라고 부름)으로 받아들이며, 디코더는 미래의 `prediction_length`만큼 시계열 값을 예측합니다(`future_values`라고 부름). 학습중에는 모델에 `past_values` 와 `future_values`쌍을 모델에 제공해야 합니다.
+- 가공하지 않은 `past_values` 와 `future_values` 쌍 외에도, 일반적으로 모델에 추가적인 특징을 제공합니다. 다음은 그 특징들에 대해 소개합니다:
+ - `past_time_features`: 모델이 `past_values`에 추가할 시간적 특성. 이는 트랜스포머 인코더의 "위치 인코딩" 역할을 합니다.
+ 예를 들어 "월의 일", "연도의 월" 등을 스칼라 값으로 (그리고 벡터로 쌓아서) 나타냅니다.
+ 예시: 특정 시계열 값이 8월 11일에 기록되었다면, [11, 8]을 시간 특성 벡터로 사용할 수 있습니다 (11은 "월의 일", 8은 "연도의 월").
+ - `future_time_features`: 모델이 `future_values`에 추가할 시간적 특성. 이는 트랜스포머 디코더의 "위치 인코딩" 역할을 합니다.
+ 예를 들어 "월의 일", "연도의 월" 등을 스칼라 값으로 (그리고 벡터로 쌓아서) 나타냅니다.
+ 예: 특정 시계열 값이 8월 11일에 얻어졌다면, [11, 8]을 시간 특성 벡터로 사용할 수 있습니다 (11은 "월의 일", 8은 "연도의 월").
+ - `static_categorical_features`: 시간에 따라 변하지 않는 범주형 특성 (즉, 모든 `past_values`와 `future_values`에 대해 동일한 값을 가짐).
+ 예를 들어 특정 시계열을 식별하는 매장 ID나 지역 ID가 있습니다.
+ 이러한 특성은 모든 데이터 포인트(미래의 데이터 포인트 포함)에 대해 알려져 있어야 합니다.
+ - `static_real_features`: 시간에 따라 변하지 않는 실수값 특성 (즉, 모든 `past_values`와 `future_values`에 대해 동일한 값을 가짐).
+ 예를 들어 시계열 값을 가진 제품의 이미지 표현 (시계열이 신발 판매에 관한 것이라면 "신발" 사진의 [ResNet](resnet) 임베딩 처럼)이 있습니다.
+ 이러한 특성은 모든 데이터 포인트(미래의 데이터 포인트 포함)에 대해 알려져 있어야 합니다.
+- 이 모델은 기계 번역을 위한 트랜스포머 훈련과 유사하게 "교사 강제(teacher-forcing)" 방식으로 훈련됩니다. 즉, 훈련 중에 `future_values`를 디코더의 입력으로 오른쪽으로 한 위치 이동시키고, `past_values`의 마지막 값을 앞에 붙입니다. 각 시간 단계에서 모델은 다음 타겟을 예측해야 합니다. 따라서 훈련 설정은 언어를 위한 GPT 모델과 유사하지만, `decoder_start_token_id` 개념이 없습니다 (우리는 단순히 컨텍스트의 마지막 값을 디코더의 초기 입력으로 사용합니다).
+- 추론 시에는 `past_values`의 최종 값을 디코더의 입력으로 제공합니다. 그 다음, 모델에서 샘플링하여 다음 시간 단계에서의 예측을 만들고, 이를 디코더에 공급하여 다음 예측을 만듭니다 (자기회귀 생성이라고도 함).
+
+## 자료 [[resources]]
+
+시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다. 여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰 해드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
+
+- HuggingFace 블로그에서 시계열 트랜스포머 포스트를 확인하세요: [🤗 트랜스포머와 확률적 시계열 예측](https://huggingface.co/blog/time-series-transformers)
+
+## TimeSeriesTransformerConfig[[transformers.TimeSeriesTransformerConfig]]
+
+[[autodoc]] TimeSeriesTransformerConfig
+
+## TimeSeriesTransformerModel[[transformers.TimeSeriesTransformerModel]]
+
+[[autodoc]] TimeSeriesTransformerModel
+ - forward
+
+## TimeSeriesTransformerForPrediction[[transformers.TimeSeriesTransformerForPrediction]]
+
+[[autodoc]] TimeSeriesTransformerForPrediction
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/timesformer.md b/docs/transformers/docs/source/ko/model_doc/timesformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..aa75cee447a47fc3e45696c7eea4320425006e0d
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/timesformer.md
@@ -0,0 +1,51 @@
+
+
+# TimeSformer [[timesformer]]
+
+## 개요 [[overview]]
+
+TimeSformer 모델은 Facebook Research에서 제안한 [TimeSformer: Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095)에서 소개되었습니다. 이 연구는 첫 번째 비디오 Transformer로서, 행동 인식 분야에서 중요한 이정표가 되었습니다. 또한 Transformer 기반의 비디오 이해 및 분류 논문에 많은 영감을 주었습니다.
+
+논문의 초록은 다음과 같습니다.
+
+*우리는 공간과 시간에 걸쳐 셀프 어텐션만을 사용하는 합성곱이 없는(convolution-free) 비디오 분류 방법을 제안합니다. 이 방법은 “TimeSformer”라고 불리며, 표준 Transformer 아키텍처를 비디오에 적용하여 프레임 수준 패치 시퀀스로부터 직접 시공간적 특징을 학습할 수 있게 합니다. 우리의 실험적 연구는 다양한 셀프 어텐션 방식을 비교하며, 시간적 어텐션과 공간적 어텐션을 각각의 블록 내에서 별도로 적용하는 “분할 어텐션” 방식이 고려된 설계 선택 중 가장 우수한 비디오 분류 정확도를 제공한다는 것을 시사합니다. 이 혁신적인 설계에도 불구하고, TimeSformer는 Kinetics-400 및 Kinetics-600을 포함한 여러 행동 인식 벤치마크에서 최첨단 결과를 달성했으며, 현재까지 보고된 가장 높은 정확도를 기록했습니다. 마지막으로, 3D 합성곱 네트워크와 비교했을 때, TimeSformer는 더 빠르게 학습할 수 있으며, 약간의 정확도 저하를 감수하면 테스트 효율성이 크게 향상되고, 1분 이상의 긴 비디오 클립에도 적용할 수 있습니다. 코드와 모델은 다음 링크에서 확인할 수 있습니다: [https URL 링크](https://github.com/facebookresearch/TimeSformer).*
+
+이 모델은 [fcakyon](https://huggingface.co/fcakyon)이 기여하였습니다.
+원본 코드는 [여기](https://github.com/facebookresearch/TimeSformer)에서 확인할 수 있습니다.
+
+## 사용 팁 [[usage-tips]]
+
+다양한 사전 학습된 모델의 변형들이 있습니다. 사용하려는 데이터셋에 맞춰 사전 학습된 모델을 선택해야 합니다. 또한, 모델 크기에 따라 클립당 입력 프레임 수가 달라지므로, 사전 학습된 모델을 선택할 때 이 매개변수를 고려해야 합니다.
+
+
+## 리소스 [[resources]]
+
+- [Video classification task guide](../tasks/video_classification)
+
+## TimesformerConfig [[transformers.TimesformerConfig]]
+
+[[autodoc]] TimesformerConfig
+
+## TimesformerModel [[transformers.TimesformerModel]]
+
+[[autodoc]] TimesformerModel
+ - forward
+
+## TimesformerForVideoClassification [[transformers.TimesformerForVideoClassification]]
+
+[[autodoc]] TimesformerForVideoClassification
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/model_doc/trajectory_transformer.md b/docs/transformers/docs/source/ko/model_doc/trajectory_transformer.md
new file mode 100644
index 0000000000000000000000000000000000000000..ac279eff0441965b20ed6523ac0cf7a653ab20dc
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/trajectory_transformer.md
@@ -0,0 +1,49 @@
+
+
+# 궤적 트랜스포머[[trajectory-transformer]]
+
+
+
+
+이 모델은 유지 보수 모드로만 운영되며, 코드를 변경하는 새로운 PR(Pull Request)은 받지 않습니다.
+이 모델을 실행하는 데 문제가 발생한다면, 이 모델을 지원하는 마지막 버전인 v4.30.0를 다시 설치해 주세요. 다음 명령어를 실행하여 재설치할 수 있습니다: `pip install -U transformers==4.30.0`.
+
+
+
+## 개요[[overview]]
+
+Trajectory Transformer 모델은 Michael Janner, Qiyang Li, Sergey Levine이 제안한 [하나의 커다란 시퀀스 모델링 문제로서의 오프라인 강화학습](https://arxiv.org/abs/2106.02039)라는 논문에서 소개되었습니다.
+
+해당 논문의 초록입니다:
+
+*강화학습(RL)은 일반적으로 마르코프 속성을 활용하여 시간에 따라 문제를 인수분해하면서 정적 정책이나 단일 단계 모델을 추정하는 데 중점을 둡니다. 하지만 우리는 RL을 높은 보상 시퀀스로 이어지는 행동 시퀀스를 생성하는 것을 목표로 하는 일반적인 시퀀스 모델링 문제로 볼 수도 있습니다. 이러한 관점에서, 자연어 처리와 같은 다른 도메인에서 잘 작동하는 고용량 시퀀스 예측 모델이 RL 문제에도 효과적인 해결책을 제공할 수 있는지 고려해 볼 만합니다. 이를 위해 우리는 RL을 시퀀스 모델링의 도구로 어떻게 다룰 수 있는지 탐구하며, 트랜스포머 아키텍처를 사용하여 궤적에 대한 분포를 모델링하고 빔 서치를 계획 알고리즘으로 재활용합니다. RL을 시퀀스 모델링 문제로 프레임화하면 다양한 설계 결정이 단순화되어, 오프라인 RL 알고리즘에서 흔히 볼 수 있는 많은 구성 요소를 제거할 수 있습니다. 우리는 이 접근 방식의 유연성을 장기 동역학 예측, 모방 학습, 목표 조건부 RL, 오프라인 RL에 걸쳐 입증합니다. 더 나아가, 이 접근 방식을 기존의 모델 프리 알고리즘과 결합하여 희소 보상, 장기 과제에서 최신 계획기(planner)를 얻을 수 있음을 보여줍니다.*
+
+이 모델은 [CarlCochet](https://huggingface.co/CarlCochet)에 의해 기여되었습니다.
+원본 코드는 [이곳](https://github.com/jannerm/trajectory-transformer)에서 확인할 수 있습니다.
+
+## 사용 팁[[usage-tips]]
+
+이 트랜스포머는 심층 강화학습에 사용됩니다. 사용하려면 이전의 모든 타임스텝에서의 행동, 상태, 보상으로부터 시퀀스를 생성해야 합니다. 이 모델은 이 모든 요소를 함께 하나의 큰 시퀀스(궤적)로 취급합니다.
+
+## TrajectoryTransformerConfig[[transformers.TrajectoryTransformerConfig]]
+
+[[autodoc]] TrajectoryTransformerConfig
+
+## TrajectoryTransformerModel[[transformers.TrajectoryTransformerModel]]
+
+[[autodoc]] TrajectoryTransformerModel
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/vit.md b/docs/transformers/docs/source/ko/model_doc/vit.md
new file mode 100644
index 0000000000000000000000000000000000000000..5f3eb3342718b14d05a4d908f405eac1c67a33e1
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/vit.md
@@ -0,0 +1,172 @@
+
+
+# Vision Transformer (ViT) [[vision-transformer-vit]]
+
+## 개요 [[overview]]
+
+Vision Transformer (ViT) 모델은 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby가 제안한 논문 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)에서 소개되었습니다. 이는 Transformer 인코더를 ImageNet에서 성공적으로 훈련시킨 첫 번째 논문으로, 기존의 잘 알려진 합성곱 신경망(CNN) 구조와 비교해 매우 우수한 결과를 달성했습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*Transformer 아키텍처는 자연어 처리 작업에서 사실상 표준으로 자리 잡았으나, 컴퓨터 비전 분야에서의 적용은 여전히 제한적입니다. 비전에서 어텐션 메커니즘은 종종 합성곱 신경망(CNN)과 결합하여 사용되거나, 전체 구조를 유지하면서 합성곱 신경망의 특정 구성 요소를 대체하는 데 사용됩니다. 우리는 이러한 CNN 의존성이 필요하지 않으며, 이미지 패치를 순차적으로 입력받는 순수한 Transformer가 이미지 분류 작업에서 매우 우수한 성능을 발휘할 수 있음을 보여줍니다. 대규모 데이터로 사전 학습된 후, ImageNet, CIFAR-100, VTAB 등 다양한 중소형 이미지 인식 벤치마크에 적용하면 Vision Transformer(ViT)는 최신 합성곱 신경망과 비교해 매우 우수한 성능을 발휘하면서도 훈련에 필요한 계산 자원을 상당히 줄일 수 있습니다.*
+
+
+
+ ViT 아키텍처. 원본 논문에서 발췌.
+
+원래의 Vision Transformer에 이어, 여러 후속 연구들이 진행되었습니다:
+
+
+- [DeiT](deit) (Data-efficient Image Transformers) (Facebook AI 개발). DeiT 모델은 distilled vision transformers입니다.
+ DeiT의 저자들은 더 효율적으로 훈련된 ViT 모델도 공개했으며, 이는 [`ViTModel`] 또는 [`ViTForImageClassification`]에 바로 사용할 수 있습니다. 여기에는 3가지 크기로 4개의 변형이 제공됩니다: *facebook/deit-tiny-patch16-224*, *facebook/deit-small-patch16-224*, *facebook/deit-base-patch16-224* and *facebook/deit-base-patch16-384*. 그리고 모델에 이미지를 준비하려면 [`DeiTImageProcessor`]를 사용해야 한다는 점에 유의하십시오.
+
+- [BEiT](beit) (BERT pre-training of Image Transformers) (Microsoft Research 개발). BEiT 모델은 BERT (masked image modeling)에 영감을 받고 VQ-VAE에 기반한 self-supervised 방법을 이용하여 supervised pre-trained vision transformers보다 더 우수한 성능을 보입니다.
+
+- DINO (Vision Transformers의 self-supervised 훈련을 위한 방법) (Facebook AI 개발). DINO 방법으로 훈련된 Vision Transformer는 학습되지 않은 상태에서도 객체를 분할할 수 있는 합성곱 신경망에서는 볼 수 없는 매우 흥미로운 능력을 보여줍니다. DINO 체크포인트는 [hub](https://huggingface.co/models?other=dino)에서 찾을 수 있습니다.
+
+- [MAE](vit_mae) (Masked Autoencoders) (Facebook AI 개발). Vision Transformer를 비대칭 인코더-디코더 아키텍처를 사용하여 마스크된 패치의 높은 비율(75%)에서 픽셀 값을 재구성하도록 사전 학습함으로써, 저자들은 이 간단한 방법이 미세 조정 후 supervised 방식의 사전 학습을 능가한다는 것을 보여주었습니다.
+
+이 모델은 [nielsr](https://huggingface.co/nielsr)에 의해 기여되었습니다. 원본 코드(JAX로 작성됨)은 [여기](https://github.com/google-research/vision_transformer)에서 확인할 수 있습니다.
+
+
+참고로, 우리는 Ross Wightman의 [timm 라이브러리](https://github.com/rwightman/pytorch-image-models)에서 JAX에서 PyTorch로 변환된 가중치를 다시 변환했습니다. 모든 공로는 그에게 돌립니다!
+
+## 사용 팁 [[usage-tips]]
+
+- Transformer 인코더에 이미지를 입력하기 위해, 각 이미지는 고정 크기의 겹치지 않는 패치들로 분할된 후 선형 임베딩됩니다. 전체 이미지를 대표하는 [CLS] 토큰이 추가되어, 분류에 사용할 수 있습니다. 저자들은 또한 절대 위치 임베딩을 추가하여, 결과적으로 생성된 벡터 시퀀스를 표준 Transformer 인코더에 입력합니다.
+- Vision Transformer는 모든 이미지가 동일한 크기(해상도)여야 하므로, [ViTImageProcessor]를 사용하여 이미지를 모델에 맞게 리사이즈(또는 리스케일)하고 정규화할 수 있습니다.
+- 사전 학습이나 미세 조정 시 사용된 패치 해상도와 이미지 해상도는 각 체크포인트의 이름에 반영됩니다. 예를 들어, `google/vit-base-patch16-224`는 패치 해상도가 16x16이고 미세 조정 해상도가 224x224인 기본 크기 아키텍처를 나타냅니다. 모든 체크포인트는 [hub](https://huggingface.co/models?search=vit)에서 확인할 수 있습니다.
+- 사용할 수 있는 체크포인트는 (1) [ImageNet-21k](http://www.image-net.org/) (1,400만 개의 이미지와 21,000개의 클래스)에서만 사전 학습되었거나, 또는 (2) [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (ILSVRC 2012, 130만 개의 이미지와 1,000개의 클래스)에서 추가로 미세 조정된 경우입니다.
+- Vision Transformer는 224x224 해상도로 사전 학습되었습니다. 미세 조정 시, 사전 학습보다 더 높은 해상도를 사용하는 것이 유리한 경우가 많습니다 ([(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikovet al., 2020)](https://arxiv.org/abs/1912.11370). 더 높은 해상도로 미세 조정하기 위해, 저자들은 원본 이미지에서의 위치에 따라 사전 학습된 위치 임베딩의 2D 보간(interpolation)을 수행합니다.
+- 최고의 결과는 supervised 방식의 사전 학습에서 얻어졌으며, 이는 NLP에서는 해당되지 않는 경우가 많습니다. 저자들은 마스크된 패치 예측(마스크된 언어 모델링에서 영감을 받은 self-supervised 사전 학습 목표)을 사용한 실험도 수행했습니다. 이 접근 방식으로 더 작은 ViT-B/16 모델은 ImageNet에서 79.9%의 정확도를 달성하였으며, 이는 처음부터 학습한 것보다 2% 개선된 결과이지만, 여전히 supervised 사전 학습보다 4% 낮습니다.
+
+### Scaled Dot Product Attention (SDPA) 사용하기 [[using-scaled-dot-product-attention-sdpa]]
+
+PyTorch는 `torch.nn.functional`의 일부로서 native scaled dot-product attention (SDPA) 연산자를 포함하고 있습니다. 이 함수는 입력 및 사용 중인 하드웨어에 따라 여러 구현 방식을 적용할 수 있습니다.자세한 내용은 [공식 문서](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)나 [GPU 추론](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention) 페이지를 참조하십시오.
+
+SDPA는 `torch>=2.1.1`에서 구현이 가능한 경우 기본적으로 사용되지만, `from_pretrained()`에서 `attn_implementation="sdpa"`로 설정하여 SDPA를 명시적으로 요청할 수도 있습니다.
+
+```
+from transformers import ViTForImageClassification
+model = ViTForImageClassification.from_pretrained("google/vit-base-patch16-224", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+최적의 속도 향상을 위해 모델을 반정밀도(예: `torch.float16` 또는 `torch.bfloat16`)로 로드하는 것을 권장합니다.
+
+로컬 벤치마크(A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04)에서 `float32`와 `google/vit-base-patch16-224` 모델을 사용한 추론 시, 다음과 같은 속도 향상을 확인했습니다.
+
+| Batch size | Average inference time (ms), eager mode | Average inference time (ms), sdpa model | Speed up, Sdpa / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 7 | 6 | 1.17 |
+| 2 | 8 | 6 | 1.33 |
+| 4 | 8 | 6 | 1.33 |
+| 8 | 8 | 6 | 1.33 |
+
+## 리소스 [[resources]]
+
+ViT의 추론 및 커스텀 데이터에 대한 미세 조정과 관련된 데모 노트북은 [여기](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)에서 확인할 수 있습니다. Hugging Face에서 공식적으로 제공하는 자료와 커뮤니티(🌎로 표시된) 자료 목록은 ViT를 시작하는 데 도움이 될 것입니다. 이 목록에 포함될 자료를 제출하고 싶다면 Pull Request를 열어 주시면 검토하겠습니다. 새로운 내용을 설명하는 자료가 가장 이상적이며, 기존 자료를 중복하지 않도록 해주십시오.
+
+`ViTForImageClassification` 은 다음에서 지원됩니다:
+
+
+- [Hugging Face Transformers로 ViT를 이미지 분류에 맞게 미세 조정하는 방법](https://huggingface.co/blog/fine-tune-vit)에 대한 블로그 포스트
+- [Hugging Face Transformers와 `Keras`를 사용한 이미지 분류](https://www.philschmid.de/image-classification-huggingface-transformers-keras)에 대한 블로그 포스트
+- [Hugging Face Transformers를 사용한 이미지 분류 미세 조정](https://github.com/huggingface/notebooks/blob/main/examples/image_classification.ipynb)에 대한 노트북
+- [Hugging Face Trainer로 CIFAR-10에서 Vision Transformer 미세 조정](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_the_%F0%9F%A4%97_Trainer.ipynb)에 대한 노트북
+- [PyTorch Lightning으로 CIFAR-10에서 Vision Transformer 미세 조정](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Fine_tuning_the_Vision_Transformer_on_CIFAR_10_with_PyTorch_Lightning.ipynb)에 대한 노트북
+
+⚗️ 최적화
+
+- [Optimum을 사용한 양자화를 통해 Vision Transformer(ViT) 가속](https://www.philschmid.de/optimizing-vision-transformer)에 대한 블로그 포스트
+
+⚡️ 추론
+
+- [Google Brain의 Vision Transformer(ViT) 빠른 데모](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/VisionTransformer/Quick_demo_of_HuggingFace_version_of_Vision_Transformer_inference.ipynb)에 대한 노트북
+
+🚀 배포
+
+- [TF Serving으로 Hugging Face에서 Tensorflow Vision 모델 배포](https://huggingface.co/blog/tf-serving-vision)에 대한 블로그 포스트
+- [Vertex AI에서 Hugging Face ViT 배포](https://huggingface.co/blog/deploy-vertex-ai)에 대한 블로그 포스트
+- [TF Serving을 사용하여 Kubernetes에서 Hugging Face ViT 배포](https://huggingface.co/blog/deploy-tfserving-kubernetes)에 대한 블로그 포스트
+
+## ViTConfig [[transformers.ViTConfig]]
+
+[[autodoc]] ViTConfig
+
+## ViTFeatureExtractor [[transformers.ViTFeatureExtractor]]
+
+[[autodoc]] ViTFeatureExtractor
+ - __call__
+
+## ViTImageProcessor [[transformers.ViTImageProcessor]]
+
+[[autodoc]] ViTImageProcessor
+ - preprocess
+
+## ViTImageProcessorFast [[transformers.ViTImageProcessorFast]]
+
+[[autodoc]] ViTImageProcessorFast
+ - preprocess
+
+
+
+
+## ViTModel [[transformers.ViTModel]]
+
+[[autodoc]] ViTModel
+ - forward
+
+## ViTForMaskedImageModeling [[transformers.ViTForMaskedImageModeling]]
+
+[[autodoc]] ViTForMaskedImageModeling
+ - forward
+
+## ViTForImageClassification [[transformers.ViTForImageClassification]]
+
+[[autodoc]] ViTForImageClassification
+ - forward
+
+
+
+
+## TFViTModel [[transformers.TFViTModel]]
+
+[[autodoc]] TFViTModel
+ - call
+
+## TFViTForImageClassification [[transformers.TFViTForImageClassification]]
+
+[[autodoc]] TFViTForImageClassification
+ - call
+
+
+
+
+## FlaxVitModel [[transformers.FlaxViTModel]]
+
+[[autodoc]] FlaxViTModel
+ - __call__
+
+## FlaxViTForImageClassification [[transformers.FlaxViTForImageClassification]]
+
+[[autodoc]] FlaxViTForImageClassification
+ - __call__
+
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/model_doc/vivit.md b/docs/transformers/docs/source/ko/model_doc/vivit.md
new file mode 100644
index 0000000000000000000000000000000000000000..c9eee17cb20afc7e808423a4af02f99ec3fc2db9
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/vivit.md
@@ -0,0 +1,42 @@
+
+
+# Video Vision Transformer (ViViT) [[video-vision-transformer-vivit]]
+
+## 개요 [[overview]]
+
+Vivit 모델은 Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, Cordelia Schmid가 제안한 논문 [ViViT: A Video Vision Transformer](https://arxiv.org/abs/2103.15691)에서 소개되었습니다. 이 논문은 비디오 이해를 위한 pure-transformer 기반의 모델 집합 중에서 최초로 성공한 모델 중 하나를 소개합니다.
+
+논문의 초록은 다음과 같습니다:
+
+*우리는 이미지 분류에서 최근 성공을 거둔 순수 트랜스포머 기반 모델을 바탕으로 비디오 분류를 위한 모델을 제안합니다. 본 모델은 입력 비디오로부터 시공간 토큰을 추출한 후, 이를 일련의 트랜스포머 레이어로 인코딩합니다. 비디오에서 발생하는 긴 토큰 시퀀스를 처리하기 위해, 입력의 공간 및 시간 차원을 분리하는 여러 효율적인 모델 변형을 제안합니다. 트랜스포머 기반 모델은 대규모 학습 데이터셋에서만 효과적이라는 것이 일반적이지만, 우리는 학습 중 모델을 효과적으로 정규화하고, 사전 학습된 이미지 모델을 활용함으로써 상대적으로 작은 데이터셋에서도 학습할 수 있는 방법을 보여줍니다. 또한, 철저한 소거(ablation) 연구를 수행하고 Kinetics 400 및 600, Epic Kitchens, Something-Something v2, Moments in Time을 포함한 여러 비디오 분류 벤치마크에서 최첨단 성과를 달성하여, 기존의 3D 합성곱 신경망 기반 방법들을 능가합니다.*
+
+이 모델은 [jegormeister](https://huggingface.co/jegormeister)가 기여하였습니다. 원본 코드(JAX로 작성됨)는 [여기](https://github.com/google-research/scenic/tree/main/scenic/projects/vivit)에서 확인할 수 있습니다.
+
+## VivitConfig [[transformers.VivitConfig]]
+
+[[autodoc]] VivitConfig
+
+## VivitImageProcessor [[transformers.VivitImageProcessor]]
+
+[[autodoc]] VivitImageProcessor
+ - preprocess
+
+## VivitModel [[transformers.VivitModel]]
+
+[[autodoc]] VivitModel
+ - forward
+
+## VivitForVideoClassification [[transformers.VivitForVideoClassification]]
+
+[[autodoc]] transformers.VivitForVideoClassification
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/whisper.md b/docs/transformers/docs/source/ko/model_doc/whisper.md
new file mode 100644
index 0000000000000000000000000000000000000000..f48bae1e60f5d0d7ba7ffe7c69b26bca837f0fa9
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/whisper.md
@@ -0,0 +1,128 @@
+
+
+# Whisper [[whisper]]
+
+## 개요 [[overview]]
+
+Whisper 모델은 Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever에 의해 [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf)에서 제안되었습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*우리는 인터넷에서 대량의 오디오를 글로 옮긴 것을 예측하도록 간단히 훈련된 음성 처리 시스템의 성능을 연구합니다. 68만 시간의 다국어 및 다중 작업 지도(multitask supervision)에 확장했을 때, 결과 모델은 표준 벤치마크에 잘 일반화되며, 미세 조정이 필요 없는 제로샷 전송 설정에서 이전의 완전히 지도된(fully-supervised) 결과와 경쟁할 수 있는 경우가 많습니다. 사람과 비교하면, 이 모델은 사람의 정확도와 견고성에 근접합니다. 우리는 강력한 음성 처리를 위한 추가 작업의 기반이 될 모델과 추론 코드를 공개합니다.*
+
+
+
+팁:
+
+- 이 모델은 일반적으로 별도의 미세 조정 없이도 잘 작동합니다.
+- 아키텍처는 고전적인 인코더-디코더 아키텍처를 따르기 때문에, 추론을 위해 [`~generation.GenerationMixin.generate`] 함수를 사용합니다.
+- 현재 추론은 짧은 형식에만 구현되어 있으며, 오디오는 30초 미만의 세그먼트로 미리 분할되어야 합니다. 타임스탬프를 포함한 긴 형식에 대한 추론은 향후 릴리스에서 구현될 예정입니다.
+- [`WhisperProcessor`]를 사용하여 모델에 사용할 오디오를 준비하고, 예측된 ID를 텍스트로 디코딩할 수 있습니다.
+
+- 모델과 프로세서를 변환하려면 다음을 사용하는 것이 좋습니다:
+
+```bash
+python src/transformers/models/whisper/convert_openai_to_hf.py --checkpoint_path "" --pytorch_dump_folder_path "Arthur/whisper-3" --convert_preprocessor True
+```
+스크립트는 OpenAI 체크포인트에서 필요한 모든 매개변수를 자동으로 결정합니다. OpenAI 변환을 수행하려면 `tiktoken` 라이브러리를 설치해야 합니다.
+라이브러리를 설치해야 OpenAI 토큰화기를 `tokenizers` 버전으로 변환할 수 있습니다.
+
+이 모델은 [Arthur Zucker](https://huggingface.co/ArthurZ)에 의해 제공되었습니다. 이 모델의 Tensorflow 버전은 [amyeroberts](https://huggingface.co/amyeroberts)에 의해 제공되었습니다.
+원본 코드는 [여기](https://github.com/openai/whisper)에서 찾을 수 있습니다.
+
+
+
+## WhisperConfig [[whisperconfig]]
+
+[[autodoc]] WhisperConfig
+
+## WhisperTokenizer [[whispertokenizer]]
+
+[[autodoc]] WhisperTokenizer
+ - set_prefix_tokens
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## WhisperTokenizerFast [[whispertokenizerfast]]
+
+[[autodoc]] WhisperTokenizerFast
+ - set_prefix_tokens
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## WhisperFeatureExtractor [[whisperfeatureextractor]]
+
+[[autodoc]] WhisperFeatureExtractor
+ - __call__
+
+## WhisperProcessor [[whisperprocessor]]
+
+[[autodoc]] WhisperProcessor
+ - __call__
+ - from_pretrained
+ - save_pretrained
+ - batch_decode
+ - decode
+
+## WhisperModel [[whispermodel]]
+
+[[autodoc]] WhisperModel
+ - forward
+ - _mask_input_features
+
+## WhisperForConditionalGeneration [[whisperforconditionalgeneration]]
+
+[[autodoc]] WhisperForConditionalGeneration
+ - forward
+
+## WhisperForAudioClassification [[whisperforaudioclassification]]
+
+[[autodoc]] WhisperForAudioClassification
+ - forward
+
+
+
+## TFWhisperModel [[tfwhispermodel]]
+
+[[autodoc]] TFWhisperModel
+ - call
+
+## TFWhisperForConditionalGeneration [[tfwhisperforconditionalgeneration]]
+
+[[autodoc]] TFWhisperForConditionalGeneration
+ - call
+
+
+## FlaxWhisperModel [[flaxwhispermodel]]
+
+[[autodoc]] FlaxWhisperModel
+ - __call__
+
+## FlaxWhisperForConditionalGeneration [[flaxwhisperforconditionalgeneration]]
+
+[[autodoc]] FlaxWhisperForConditionalGeneration
+ - __call__
+
+## FlaxWhisperForAudioClassification [[flaxwhisperforaudioclassification]]
+
+[[autodoc]] FlaxWhisperForAudioClassification
+ - __call__
+
diff --git a/docs/transformers/docs/source/ko/model_memory_anatomy.md b/docs/transformers/docs/source/ko/model_memory_anatomy.md
new file mode 100644
index 0000000000000000000000000000000000000000..a5c3a0f35292af514fc7ab2efca9f765d6ee7941
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_memory_anatomy.md
@@ -0,0 +1,242 @@
+
+
+# 모델 학습 해부하기 [[model-training-anatomy]]
+
+모델 훈련 속도와 메모리 활용의 효율성을 향상시키기 위해 적용할 수 있는 성능 최적화 기술을 이해하려면 GPU가 훈련 중에 어떻게 활용되는지, 그리고 수행되는 연산에 따라 연산 강도가 어떻게 변하는지에 익숙해져야 합니다.
+
+먼저 GPU 활용과 모델 훈련 실행에 대한 예시를 살펴보겠습니다. 데모를 위해 몇몇 라이브러리를 설치해야 합니다:
+
+```bash
+pip install transformers datasets accelerate nvidia-ml-py3
+```
+
+`nvidia-ml-py3` 라이브러리는 Python 내부에서 모델의 메모리 사용량을 모니터링할 수 있게 해줍니다. 터미널의 `nvidia-smi` 명령어에 익숙할 수 있는데, 이 라이브러리는 Python에서 직접 동일한 정보에 접근할 수 있게 해줍니다.
+
+그 다음, 100과 30000 사이의 무작위 토큰 ID와 분류기를 위한 이진 레이블인 더미 데이터를 생성합니다.
+길이가 각각 512인 총 512개의 시퀀스를 가져와 PyTorch 형식의 [`~datasets.Dataset`]에 저장합니다.
+
+
+```py
+>>> import numpy as np
+>>> from datasets import Dataset
+
+
+>>> seq_len, dataset_size = 512, 512
+>>> dummy_data = {
+... "input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
+... "labels": np.random.randint(0, 1, (dataset_size)),
+... }
+>>> ds = Dataset.from_dict(dummy_data)
+>>> ds.set_format("pt")
+```
+
+GPU 활용 및 [`Trainer`]로 실행한 훈련 과정에 대한 요약 통계를 출력하기 위해 두 개의 도우미 함수를 정의하겠습니다:
+
+```py
+>>> from pynvml import *
+
+
+>>> def print_gpu_utilization():
+... nvmlInit()
+... handle = nvmlDeviceGetHandleByIndex(0)
+... info = nvmlDeviceGetMemoryInfo(handle)
+... print(f"GPU memory occupied: {info.used//1024**2} MB.")
+
+
+>>> def print_summary(result):
+... print(f"Time: {result.metrics['train_runtime']:.2f}")
+... print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
+... print_gpu_utilization()
+```
+
+시작할 때 GPU 메모리가 비어 있는지 확인해 봅시다:
+
+```py
+>>> print_gpu_utilization()
+GPU memory occupied: 0 MB.
+```
+
+좋습니다. 모델을 로드하기 전에는 예상대로 GPU 메모리가 점유되지 않았습니다. 그렇지 않다면 사용자의 기기에서 GPU 메모리를 사용하는 모든 프로세스를 중단해야 합니다. 그러나 사용자는 모든 여유 GPU 메모리를 사용할 수는 없습니다. 모델이 GPU에 로드될 때 커널도 로드되므로 1-2GB의 메모리를 차지할 수 있습니다. 얼마나 되는지 확인하기 위해 GPU에 작은 텐서를 로드하여 커널이 로드되도록 트리거합니다.
+
+```py
+>>> import torch
+
+
+>>> torch.ones((1, 1)).to("cuda")
+>>> print_gpu_utilization()
+GPU memory occupied: 1343 MB.
+```
+
+커널만으로도 GPU 메모리의 1.3GB를 차지합니다. 이제 모델이 얼마나 많은 공간을 사용하는지 확인해 보겠습니다.
+
+## 모델 로드 [[load-model]]
+
+우선, `google-bert/bert-large-uncased` 모델을 로드합니다. 모델의 가중치를 직접 GPU에 로드해서 가중치만이 얼마나 많은 공간을 차지하는지 확인할 수 있습니다.
+
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-large-uncased").to("cuda")
+>>> print_gpu_utilization()
+GPU memory occupied: 2631 MB.
+```
+
+모델의 가중치만으로도 GPU 메모리를 1.3 GB 차지하는 것을 볼 수 있습니다. 정확한 숫자는 사용하는 GPU에 따라 다릅니다. 최신 GPU에서는 모델 사용 속도를 높이는 최적화된 방식으로 가중치가 로드되므로, 모델이 더 많은 공간을 차지할 수 있습니다. 이제 `nvidia-smi` CLI와 동일한 결과를 얻는지 빠르게 확인할 수 있습니다:
+
+
+```bash
+nvidia-smi
+```
+
+```bash
+Tue Jan 11 08:58:05 2022
++-----------------------------------------------------------------------------+
+| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
+|-------------------------------+----------------------+----------------------+
+| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
+| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
+| | | MIG M. |
+|===============================+======================+======================|
+| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
+| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
+| | | N/A |
++-------------------------------+----------------------+----------------------+
+
++-----------------------------------------------------------------------------+
+| Processes: |
+| GPU GI CI PID Type Process name GPU Memory |
+| ID ID Usage |
+|=============================================================================|
+| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
++-----------------------------------------------------------------------------+
+```
+
+이전과 동일한 숫자가 출력되고 16GB 메모리를 가진 V100 GPU를 사용하고 있다는 것도 볼 수 있습니다. 그러므로 이제 모델 훈련을 시작하여 GPU 메모리 사용량이 어떻게 달라지는지 볼 수 있습니다. 우선 몇몇 표준 훈련 인수를 설정합니다:
+
+```py
+default_args = {
+ "output_dir": "tmp",
+ "eval_strategy": "steps",
+ "num_train_epochs": 1,
+ "log_level": "error",
+ "report_to": "none",
+}
+```
+
+
+
+여러 실험을 실행할 계획이라면, 실험 간에 메모리를 제대로 비우기 위해서 Python 커널을 실험 사이마다 재시작해야 합니다.
+
+
+
+## 기본 훈련에서의 메모리 활용 [[memory-utilization-at-vanilla-training]]
+
+[`Trainer`]를 사용하여, GPU 성능 최적화 기술을 사용하지 않고 배치 크기가 4인 모델을 훈련시키겠습니다:
+
+```py
+>>> from transformers import TrainingArguments, Trainer, logging
+
+>>> logging.set_verbosity_error()
+
+
+>>> training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
+>>> trainer = Trainer(model=model, args=training_args, train_dataset=ds)
+>>> result = trainer.train()
+>>> print_summary(result)
+```
+
+```
+Time: 57.82
+Samples/second: 8.86
+GPU memory occupied: 14949 MB.
+```
+
+우리는 비교적 작은 배치 크기로도 전체 GPU 메모리를 거의 다 차지하는 것을 볼 수 있습니다. 그러나 배치 크기가 클수록 모델 수렴 속도가 빨라지고 최종 성능이 향상되는 경우가 많습니다. 그래서 이상적으로는 GPU 제한이 아닌 우리 모델의 요구사항에 맞게 배치 크기를 조정하려고 합니다. 흥미롭게도 우리는 모델의 크기보다 훨씬 더 많은 메모리를 사용합니다. 왜 이런 현상이 발생하는지 조금 더 잘 이해하기 위해 모델의 연산과 메모리 요구 사항을 살펴보겠습니다.
+
+## 모델의 연산 해부하기 [[anatomy-of-models-operations]]
+
+트랜스포머 아키텍처에는 연산 강도(compute-intensity)에 따라 그룹화된 3가지 주요 연산 그룹이 있습니다.
+
+1. **텐서 축약(Tensor Contractions)**
+
+ 선형 레이어와 멀티헤드 어텐션의 구성 요소는 모두 **행렬-행렬 곱셈(matrix-matrix multiplications)**을 일괄적으로 처리합니다. 이 연산은 트랜스포머 훈련에서 가장 연산 강도가 높은 부분입니다.
+
+2. **통계 정규화(Statistical Normalizations)**
+
+ 소프트맥스와 레이어 정규화는 텐서 축약보다 연산 강도가 낮습니다. 하나 이상의 **감소 연산(reduction operations)**을 포함하며, 그 결과는 map을 통해 적용됩니다.
+
+3. **원소별 연산자(Element-wise Operators)**
+
+ 그 외 연산자들, **편향(biases), 드롭아웃(dropout), 활성화 함수(activations), 잔차 연결(residual connections)**이 여기에 해당합니다. 이 연산들은 연산 강도가 가장 낮습니다.
+
+이러한 지식은 성능 병목 현상을 분석할 때 도움이 될 수 있습니다.
+
+이 내용은 [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)을 참고하였습니다.
+
+
+## 모델의 메모리 구조 [[anatomy-of-models-memory]]
+
+모델을 훈련시키는 데는 단순히 GPU에 모델을 올리는 것보다 훨씬 더 많은 메모리를 사용한다는 것을 보았습니다. 이는 훈련 중 GPU 메모리를 사용하는 많은 구성 요소가 있기 때문입니다. GPU 메모리의 구성 요소는 다음과 같습니다:
+
+1. 모델 가중치
+2. 옵티마이저 상태
+3. 그라디언트
+4. 그라디언트 계산을 위해 저장된 순방향 활성화
+5. 임시 버퍼
+6. 기능별 메모리
+
+AdamW를 사용하여 혼합 정밀도로 훈련된 일반적인 모델은 모델 파라미터당 18 바이트와 활성화 메모리가 필요합니다. 추론 단계에서는 옵티마이저와 그라디언트가 필요하지 않으므로 이들은 제외합니다. 따라서 혼합 정밀도 추론의 경우 모델 매개변수당 6 바이트와 활성화 메모리가 필요합니다.
+
+자세히 살펴보겠습니다.
+
+**모델 가중치:**
+
+- fp32 훈련의 경우 매개 변수 수 * 4 바이트
+- 혼합 정밀도 훈련의 경우 매개 변수 수 * 6 바이트 (메모리에 fp32와 fp16 두 가지 모델을 유지)
+
+**옵티마이저 상태:**
+
+- 일반 AdamW의 경우 매개 변수 수 * 8 바이트 (2가지 상태 유지)
+- [bitsandbytes](https://github.com/TimDettmers/bitsandbytes)와 같은 8비트 AdamW 옵티마이저의 경우 매개 변수 수 * 2 바이트
+- Momentum을 가진 SGD와 같은 옵티마이저의 경우 매개 변수 수 * 4 바이트 (하나의 상태만 유지)
+
+**그라디언트**
+
+- fp32 또는 혼합 정밀도 훈련의 경우 매개 변수 수 * 4 바이트 (그라디언트는 항상 fp32으로 유지됩니다.)
+
+**순방향 활성화**
+
+- 크기는 여러 요인에 따라 달라지며, 주요 요인은 시퀀스 길이, 은닉 상태의 크기 및 배치 크기입니다.
+
+순방향 및 역방향 함수에서 전달 및 반환되는 입력과 출력이 있으며, 그라디언트 계산을 위해 저장된 순방향 활성화가 있습니다.
+
+**임시 메모리**
+
+더불어 모든 종류의 임시 변수는 연산이 완료되면 곧바로 해제되지만, 그 순간에는 추가 메모리가 필요할 수 있고 OOM을 유발할 수 있습니다. 따라서 코딩할 때 이러한 임시 변수에 대해 전략적으로 생각하고 때로는 더 이상 필요 없는 임시 변수를 즉시 명시적으로 메모리에서 제거하는 것이 중요합니다.
+
+**기능별 메모리**
+
+그런 다음, 소프트웨어에는 특별한 메모리 요구 사항이 있을 수 있습니다. 예를 들어, 빔 검색을 사용하여 텍스트를 생성할 때 소프트웨어는 입력과 출력 사본을 여러 개 유지해야 합니다.
+
+**`forward` vs `backward` 실행 속도**
+
+합성곱과 선형 레이어의 경우 순방향에 비해 역방향에서는 2배의 플롭스가 필요하므로 일반적으로 2배 정도 느리게 변환됩니다(역방향의 경우 사이즈가 부자연스럽기 때문에, 때로는 더욱 느릴 수도 있습니다). 활성화는 일반적으로 대역폭이 제한되어 있으며, 일반적으로 순방향보다 역방향에서 더 많은 데이터를 읽어야 합니다. (예를 들어, 순방향 활성화 시 한 번 씩 읽고 쓰지만, 역방향 활성화에서는 순방향 gradOutput과 출력에 대해 총 두 번 읽고 gradInput에 대해 한 번 씁니다.)
+
+보다시피, GPU 메모리를 절약하거나 작업 속도를 높일 수 있는 몇 가지 방법이 있습니다.
+이제 GPU 활용과 계산 속도에 영향을 주는 것이 무엇인지를 이해했으므로, [Methods and tools for efficient training on a single GPU](perf_train_gpu_one) 문서 페이지를 참조하여 성능 최적화 기법에 대해 알아보세요.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/model_sharing.md b/docs/transformers/docs/source/ko/model_sharing.md
new file mode 100644
index 0000000000000000000000000000000000000000..3811507796627522c8e91c229b2cbbe9786eb7f0
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_sharing.md
@@ -0,0 +1,232 @@
+
+
+# 모델 공유하기[[share-a-model]]
+
+지난 두 튜토리얼에서 분산 설정을 위해 PyTorch, Keras 및 🤗 Accelerate를 사용하여 모델을 미세 조정하는 방법을 보았습니다. 다음 단계는 모델을 커뮤니티와 공유하는 것입니다! Hugging Face는 인공지능의 민주화를 위해 모두에게 지식과 자원을 공개적으로 공유해야 한다고 믿습니다. 다른 사람들이 시간과 자원을 절약할 수 있도록 커뮤니티에 모델을 공유하는 것을 고려해 보세요.
+
+이 튜토리얼에서 [Model Hub](https://huggingface.co/models)에서 훈련되거나 미세 조정 모델을 공유하는 두 가지 방법에 대해 알아봅시다:
+
+- API를 통해 파일을 Hub에 푸시합니다.
+- 웹사이트를 통해 파일을 Hub로 끌어다 놓습니다.
+
+
+
+
+
+커뮤니티에 모델을 공유하려면, [huggingface.co](https://huggingface.co/join)에 계정이 필요합니다. 기존 조직에 가입하거나 새로 만들 수도 있습니다.
+
+
+
+## 저장소 특징[[repository-features]]
+
+모델 허브의 각 저장소는 일반적인 GitHub 저장소처럼 작동합니다. 저장소는 버전 관리, 커밋 기록, 차이점 시각화 기능을 제공합니다.
+
+모델 허브에 내장된 버전 관리는 git 및 [git-lfs](https://git-lfs.github.com/)를 기반으로 합니다. 즉, 하나의 모델을 하나의 저장소로 취급하여 접근 제어 및 확장성이 향상됩니다. 버전 제어는 커밋 해시, 태그 또는 브랜치로 모델의 특정 버전을 고정하는 방법인 *revision*을 허용합니다.
+
+따라서 `revision` 매개변수를 사용하여 특정 모델 버전을 가져올 수 있습니다:
+
+```py
+>>> model = AutoModel.from_pretrained(
+... "julien-c/EsperBERTo-small", revision="4c77982" # tag name, or branch name, or commit hash
+... )
+```
+
+또한 저장소에서 파일을 쉽게 편집할 수 있으며, 커밋 기록과 차이를 볼 수 있습니다:
+
+
+
+## 설정[[setup]]
+
+모델을 허브에 공유하기 전에 Hugging Face 자격 증명이 필요합니다. 터미널에 액세스할 수 있는 경우, 🤗 Transformers가 설치된 가상 환경에서 다음 명령을 실행합니다. 그러면 Hugging Face 캐시 폴더(기본적으로 `~/.cache/`)에 액세스 토큰을 저장합니다:
+
+```bash
+huggingface-cli login
+```
+
+Jupyter 또는 Colaboratory와 같은 노트북을 사용 중인 경우, [`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library) 라이브러리가 설치되었는지 확인하세요. 이 라이브러리를 사용하면 API로 허브와 상호 작용할 수 있습니다.
+
+```bash
+pip install huggingface_hub
+```
+
+그런 다음 `notebook_login`로 허브에 로그인하고, [여기](https://huggingface.co/settings/token) 링크에서 로그인할 토큰을 생성합니다:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## 프레임워크 간 모델 변환하기[[convert-a-model-for-all-frameworks]]
+
+다른 프레임워크로 작업하는 사용자가 모델을 사용할 수 있도록 하려면, PyTorch 및 TensorFlow 체크포인트를 모두 사용하여 모델을 변환하고 업로드하는 것이 좋습니다. 이 단계를 건너뛰어도 사용자는 다른 프레임워크에서 모델을 가져올 수 있지만, 🤗 Transformers가 체크포인트를 즉석에서 변환해야 하므로 속도가 느려질 수 있습니다.
+
+체크포인트를 다른 프레임워크로 변환하는 것은 쉽습니다. PyTorch 및 TensorFlow가 설치되어 있는지 확인한 다음(설치 지침은 [여기](installation) 참조) 다른 프레임워크에서 작업에 대한 특정 모델을 찾습니다.
+
+
+
+체크포인트를 TensorFlow에서 PyTorch로 변환하려면 `from_tf=True`를 지정하세요:
+
+```py
+>>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
+>>> pt_model.save_pretrained("path/to/awesome-name-you-picked")
+```
+
+
+체크포인트를 PyTorch에서 TensorFlow로 변환하려면 `from_pt=True`를 지정하세요:
+
+```py
+>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)
+```
+
+그런 다음 새로운 체크포인트와 함께 새로운 TensorFlow 모델을 저장할 수 있습니다:
+
+```py
+>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")
+```
+
+
+Flax에서 모델을 사용하는 경우, PyTorch에서 Flax로 체크포인트를 변환할 수도 있습니다:
+
+```py
+>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
+... "path/to/awesome-name-you-picked", from_pt=True
+... )
+```
+
+
+
+## 훈련 중 모델 푸시하기[[push-a-model-during-training]]
+
+
+
+
+
+모델을 허브에 공유하는 것은 추가 매개변수나 콜백을 추가하는 것만큼 간단합니다. [미세 조정 튜토리얼](training)에서 [`TrainingArguments`] 클래스는 하이퍼파라미터와 추가 훈련 옵션을 지정하는 곳이라는 것을 기억하세요. 이러한 훈련 옵션 중 하나는 모델을 허브로 직접 푸시하는 기능을 포함합니다. [`TrainingArguments`]에서 `push_to_hub=True`를 설정하세요:
+
+```py
+>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)
+```
+
+평소와 같이 훈련 인수를 [`Trainer`]에 전달합니다:
+
+```py
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=small_train_dataset,
+... eval_dataset=small_eval_dataset,
+... compute_metrics=compute_metrics,
+... )
+```
+
+모델을 미세 조정한 후, [`Trainer`]에서 [`~transformers.Trainer.push_to_hub`]를 호출하여 훈련된 모델을 허브로 푸시하세요. 🤗 Transformers는 훈련 하이퍼파라미터, 훈련 결과 및 프레임워크 버전을 모델 카드에 자동으로 추가합니다!
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+[`PushToHubCallback`]을 사용하여 모델을 허브에 공유하려면, [`PushToHubCallback`]에 다음 인수를 정의하세요:
+
+- 출력된 모델의 파일 경로
+- 토크나이저
+- `{Hub 사용자 이름}/{모델 이름}` 형식의 `hub_model_id`
+
+```py
+>>> from transformers import PushToHubCallback
+
+>>> push_to_hub_callback = PushToHubCallback(
+... output_dir="./your_model_save_path", tokenizer=tokenizer, hub_model_id="your-username/my-awesome-model"
+... )
+```
+
+[`fit`](https://keras.io/api/models/model_training_apis/)에 콜백을 추가하면, 🤗 Transformers가 훈련된 모델을 허브로 푸시합니다:
+
+```py
+>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
+```
+
+
+
+## `push_to_hub` 함수 사용하기[[use-the-pushtohub-function]]
+
+모델에서 직접 `push_to_hub`를 호출하여 허브에 업로드할 수도 있습니다.
+
+`push_to_hub`에 모델 이름을 지정하세요:
+
+```py
+>>> pt_model.push_to_hub("my-awesome-model")
+```
+
+이렇게 하면 사용자 이름 아래에 모델 이름 `my-awesome-model`로 저장소가 생성됩니다. 이제 사용자는 `from_pretrained` 함수를 사용하여 모델을 가져올 수 있습니다:
+
+```py
+>>> from transformers import AutoModel
+
+>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
+```
+
+조직에 속하고 모델을 조직 이름으로 대신 푸시하려면 `repo_id`에 추가하세요:
+
+```py
+>>> pt_model.push_to_hub("my-awesome-org/my-awesome-model")
+```
+
+`push_to_hub` 함수는 모델 저장소에 다른 파일을 추가하는 데에도 사용할 수 있습니다. 예를 들어 모델 저장소에 토크나이저를 추가할 수 있습니다:
+
+```py
+>>> tokenizer.push_to_hub("my-awesome-model")
+```
+
+또는 미세 조정된 PyTorch 모델의 TensorFlow 버전을 추가할 수도 있습니다:
+
+```py
+>>> tf_model.push_to_hub("my-awesome-model")
+```
+
+이제 Hugging Face 프로필로 이동하면, 새로 생성한 모델 저장소가 표시됩니다. **Files** 탭을 클릭하면 저장소에 업로드한 모든 파일이 표시됩니다.
+
+저장소에 파일을 만들고 업로드하는 방법에 대한 자세한 내용은 허브 설명서 [여기](https://huggingface.co/docs/hub/how-to-upstream)를 참조하세요.
+
+## 웹 인터페이스로 업로드하기[[upload-with-the-web-interface]]
+
+코드 없는 접근 방식을 선호하는 사용자는 허브의 웹 인터페이스를 통해 모델을 업로드할 수 있습니다. [huggingface.co/new](https://huggingface.co/new)를 방문하여 새로운 저장소를 생성하세요:
+
+
+
+여기서 모델에 대한 몇 가지 정보를 추가하세요:
+
+- 저장소의 **소유자**를 선택합니다. 이는 사용자 또는 사용자가 속한 조직일 수 있습니다.
+- 저장소 이름이 될 모델의 이름을 선택합니다.
+- 모델이 공개인지 비공개인지 선택합니다.
+- 모델의 라이센스 사용을 지정합니다.
+
+이제 **Files** 탭을 클릭하고 **Add file** 버튼을 클릭하여 새로운 파일을 저장소에 업로드합니다. 그런 다음 업로드할 파일을 끌어다 놓고 커밋 메시지를 추가하세요.
+
+
+
+## 모델 카드 추가하기[[add-a-model-card]]
+
+사용자가 모델의 기능, 제한, 잠재적 편향 및 윤리적 고려 사항을 이해할 수 있도록 저장소에 모델 카드를 추가하세요. 모델 카드는 `README.md` 파일에 정의되어 있습니다. 다음 방법으로 모델 카드를 추가할 수 있습니다:
+
+* `README.md` 파일을 수동으로 생성하여 업로드합니다.
+* 모델 저장소에서 **Edit model card** 버튼을 클릭합니다.
+
+모델 카드에 포함할 정보 유형에 대한 좋은 예는 DistilBert [모델 카드](https://huggingface.co/distilbert/distilbert-base-uncased)를 참조하세요. 모델의 탄소 발자국이나 위젯 예시 등 `README.md` 파일에서 제어할 수 있는 다른 옵션에 대한 자세한 내용은 [여기](https://huggingface.co/docs/hub/models-cards) 문서를 참조하세요.
diff --git a/docs/transformers/docs/source/ko/model_summary.md b/docs/transformers/docs/source/ko/model_summary.md
new file mode 100644
index 0000000000000000000000000000000000000000..568b9425335d7f95063daca468fe67f31913a2c1
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_summary.md
@@ -0,0 +1,107 @@
+
+
+# Transformer 모델군[[the-transformer-model-family]]
+
+2017년에 소개된 [기본 Transformer](https://arxiv.org/abs/1706.03762) 모델은 자연어 처리(NLP) 작업을 넘어 새롭고 흥미로운 모델들에 영감을 주었습니다. [단백질 접힘 구조 예측](https://huggingface.co/blog/deep-learning-with-proteins), [치타의 달리기 훈련](https://huggingface.co/blog/train-decision-transformers), [시계열 예측](https://huggingface.co/blog/time-series-transformers) 등을 위한 다양한 모델이 생겨났습니다. Transformer의 변형이 너무 많아서, 큰 그림을 놓치기 쉽습니다. 하지만 여기 있는 모든 모델의 공통점은 기본 Trasnformer 아키텍처를 기반으로 한다는 점입니다. 일부 모델은 인코더 또는 디코더만 사용하고, 다른 모델들은 인코더와 디코더를 모두 사용하기도 합니다. 이렇게 Transformer 모델군 내 상위 레벨에서의 차이점을 분류하고 검토하면 유용한 분류 체계를 얻을 수 있으며, 이전에 접해보지 못한 Transformer 모델들 또한 이해하는 데 도움이 될 것입니다.
+
+기본 Transformer 모델에 익숙하지 않거나 복습이 필요한 경우, Hugging Face 강의의 [트랜스포머는 어떻게 동작하나요?](https://huggingface.co/course/chapter1/4?fw=pt) 챕터를 확인하세요.
+
+
+
+
+
+## 컴퓨터 비전[[computer-vision]]
+
+
+
+### 합성곱 네트워크[[convolutional-network]]
+
+[Vision Transformer](https://arxiv.org/abs/2010.11929)가 확장성과 효율성을 입증하기 전까지 오랫동안 합성곱 네트워크(CNN)가 컴퓨터 비전 작업의 지배적인 패러다임이었습니다. 그럼에도 불구하고, 이동 불변성(translation invariance)과 같은 CNN의 우수한 부분이 도드라지기 때문에 몇몇 (특히 특정 과업에서의) Transformer 모델은 아키텍처에 합성곱을 통합하기도 했습니다. [ConvNeXt](model_doc/convnext)는 이런 관례를 뒤집어 CNN을 현대화하기 위해 Transformer의 디자인을 차용합니다. 예를 들면 ConvNeXt는 겹치지 않는 슬라이딩 창(sliding window)을 사용하여 이미지를 패치화하고, 더 큰 커널로 전역 수용 필드(global receptive field)를 확장시킵니다. ConvNeXt는 또한 메모리 효율을 높이고 성능을 향상시키기 위해 여러 레이어 설계를 선택하기 때문에 Transformer와 견줄만합니다!
+
+### 인코더[[cv-encoder]]
+
+[Vision Transformer(ViT)](model_doc/vit)는 합성곱 없는 컴퓨터 비전 작업의 막을 열었습니다. ViT는 표준 Transformer 인코더를 사용하지만, 가장 큰 혁신은 이미지를 처리하는 방식이었습니다. 문장을 토큰으로 분할하는 것처럼 이미지를 고정된 크기의 패치로 분할하고, 이를 사용하여 임베딩을 생성합니다. ViT는 Transformer의 효율적인 아키텍처를 활용하여 훈련에 더 적은 자원을 사용하면서도 당시 CNN에 비견하는 결과를 입증했습니다. 그리고 ViT를 뒤이어 분할(segmentation)과 같은 고밀도 비전 작업과 탐지 작업도 다룰 수 있는 다른 비전 모델이 등장했습니다.
+
+이러한 모델 중 하나가 [Swin](model_doc/swin) Transformer입니다. 이 모델은 작은 크기의 패치에서 계층적 특징 맵(CNN 👀과 같지만 ViT와는 다름)을 만들고 더 깊은 레이어의 인접 패치와 병합합니다. 어텐션(Attention)은 지역 윈도우 내에서만 계산되며, 모델이 더 잘 학습할 수 있도록 어텐션 레이어 간에 윈도우를 이동하며 연결을 생성합니다. Swin Transformer는 계층적 특징 맵을 생성할 수 있으므로, 분할(segmentation)과 탐지와 같은 고밀도 예측 작업에 적합합니다. [SegFormer](model_doc/segformer) 역시 Transformer 인코더를 사용하여 계층적 특징 맵을 구축하지만, 상단에 간단한 다층 퍼셉트론(MLP) 디코더를 추가하여 모든 특징 맵을 결합하고 예측을 수행합니다.
+
+BeIT와 ViTMAE와 같은 다른 비전 모델은 BERT의 사전훈련 목표(objective)에서 영감을 얻었습니다. [BeIT](model_doc/beit)는 *마스크드 이미지 모델링(MIM)*으로 사전훈련되며, 이미지 패치는 임의로 마스킹되고 이미지도 시각적 토큰으로 토큰화됩니다. BeIT는 마스킹된 패치에 해당하는 시각적 토큰을 예측하도록 학습됩니다. [ViTMAE](model_doc/vitmae)도 비슷한 사전훈련 목표가 있지만, 시각적 토큰 대신 픽셀을 예측해야 한다는 점이 다릅니다. 특이한 점은 이미지 패치의 75%가 마스킹되어 있다는 것입니다! 디코더는 마스킹된 토큰과 인코딩된 패치에서 픽셀을 재구성합니다. 사전훈련이 끝나면 디코더는 폐기되고 인코더는 다운스트림 작업에 사용할 준비가 됩니다.
+
+### 디코더[[cv-decoder]]
+
+대부분의 비전 모델은 인코더에 의존하여 이미지 표현을 학습하기 때문에 디코더 전용 비전 모델은 드뭅니다. 하지만 이미지 생성 등의 사례의 경우, GPT-2와 같은 텍스트 생성 모델에서 보았듯이 디코더가 가장 적합합니다. [ImageGPT](model_doc/imagegpt)는 GPT-2와 동일한 아키텍처를 사용하지만, 시퀀스의 다음 토큰을 예측하는 대신 이미지의 다음 픽셀을 예측합니다. ImageGPT는 이미지 생성 뿐만 아니라 이미지 분류를 위해 미세 조정할 수도 있습니다.
+
+### 인코더-디코더[[cv-encoder-decoder]]
+
+비전 모델은 일반적으로 인코더(백본으로도 알려짐)를 사용하여 중요한 이미지 특징을 추출한 후, 이를 Transformer 디코더로 전달합니다. [DETR](model_doc/detr)에 사전훈련된 백본이 있지만, 객체 탐지를 위해 완전한 Transformer 인코더-디코더 아키텍처도 사용합니다. 인코더는 이미지 표현을 학습하고 이를 디코더에서 객체 쿼리(각 객체 쿼리는 이미지의 영역 또는 객체에 중점을 두고 학습된 임베딩)와 결합합니다. DETR은 각 객체 쿼리에 대한 바운딩 박스 좌표와 클래스 레이블을 예측합니다.
+
+## 자연어처리[[natural-language-processing]]
+
+
+
+### 인코더[[nlp-encoder]]
+
+[BERT](model_doc/bert)는 인코더 전용 Transformer로, 다른 토큰을 보고 소위 "부정 행위"를 저지르는 걸 막기 위해 입력에서 특정 토큰을 임의로 마스킹합니다. 사전훈련의 목표는 컨텍스트를 기반으로 마스킹된 토큰을 예측하는 것입니다. 이를 통해 BERT는 왼쪽과 오른쪽 컨텍스트를 충분히 활용하여 입력에 대해 더 깊고 풍부한 표현을 학습할 수 있습니다. 그러나 BERT의 사전훈련 전략에는 여전히 개선의 여지가 남아 있었습니다. [RoBERTa](model_doc/roberta)는 더 긴 시간 동안 더 큰 배치에 대한 훈련을 포함하고, 전처리 중에 한 번만 마스킹하는 것이 아니라 각 에폭에서 토큰을 임의로 마스킹하고, 다음 문장 예측 목표를 제거하는 새로운 사전훈련 방식을 도입함으로써 이를 개선했습니다.
+
+성능 개선을 위한 전략으로 모델 크기를 키우는 것이 지배적입니다. 하지만 큰 모델을 훈련하려면 계산 비용이 많이 듭니다. 계산 비용을 줄이는 한 가지 방법은 [DistilBERT](model_doc/distilbert)와 같이 작은 모델을 사용하는 것입니다. DistilBERT는 압축 기법인 [지식 증류(knowledge distillation)](https://arxiv.org/abs/1503.02531)를 사용하여, 거의 모든 언어 이해 능력을 유지하면서 더 작은 버전의 BERT를 만듭니다.
+
+그러나 대부분의 Transformer 모델에 더 많은 매개변수를 사용하는 경향이 이어졌고, 이에 따라 훈련 효율성을 개선하는 것에 중점을 둔 새로운 모델이 등장했습니다. [ALBERT](model_doc/albert)는 두 가지 방법으로 매개변수 수를 줄여 메모리 사용량을 줄였습니다. 바로 큰 어휘를 두 개의 작은 행렬로 분리하는 것과 레이어가 매개변수를 공유하도록 하는 것입니다. [DeBERTa](model_doc/deberta)는 단어와 그 위치를 두 개의 벡터로 개별적으로 인코딩하는 분리된(disentangled) 어텐션 메커니즘을 추가했습니다. 어텐션은 단어와 위치 임베딩을 포함하는 단일 벡터 대신 이 별도의 벡터에서 계산됩니다. [Longformer](model_doc/longformer)는 특히 시퀀스 길이가 긴 문서를 처리할 때, 어텐션을 더 효율적으로 만드는 것에 중점을 두었습니다. 지역(local) 윈도우 어텐션(각 토큰 주변의 고정된 윈도우 크기에서만 계산되는 어텐션)과 전역(global) 어텐션(분류를 위해 `[CLS]`와 같은 특정 작업 토큰에만 해당)의 조합을 사용하여 전체(full) 어텐션 행렬 대신 희소(sparse) 어텐션 행렬을 생성합니다.
+
+### 디코더[[nlp-decoder]]
+
+[GPT-2](model_doc/gpt2)는 시퀀스에서 다음 단어를 예측하는 디코더 전용 Transformer입니다. 토큰을 오른쪽으로 마스킹하여 모델이 이전 토큰을 보고 "부정 행위"를 하지 못하도록 합니다. GPT-2는 방대한 텍스트에 대해 사전훈련하여 텍스트가 일부만 정확하거나 사실인 경우에도 상당히 능숙하게 텍스트를 생성할 수 있게 되었습니다. 하지만 GPT-2는 BERT가 사전훈련에서 갖는 양방향 컨텍스트가 부족하기 때문에 특정 작업에 적합하지 않았습니다. [XLNET](model_doc/xlnet)은 양방향 훈련이 가능한 permutation language modeling objective(PLM)를 사용하여 BERT와 GPT-2의 사전훈련 목표에 대한 장점을 함께 가지고 있습니다.
+
+GPT-2 이후, 언어 모델은 더욱 거대해졌고 현재는 *대규모 언어 모델(LLM)*로 알려져 있습니다. 충분히 큰 데이터 세트로 사전훈련된 LLM은 퓨샷(few-shot) 또는 제로샷(zero-shot) 학습을 수행합니다. [GPT-J](model_doc/gptj)는 6B 크기의 매개변수가 있고 400B 크기의 토큰으로 훈련된 LLM입니다. GPT-J에 이어 디코더 전용 모델군인 [OPT](model_doc/opt)가 등장했으며, 이 중 가장 큰 모델은 175B 크기이고 180B 크기의 토큰으로 훈련되었습니다. [BLOOM](model_doc/bloom)은 비슷한 시기에 출시되었으며, 이 중 가장 큰 모델은 176B 크기의 매개변수가 있고 46개의 언어와 13개의 프로그래밍 언어로 된 366B 크기의 토큰으로 훈련되었습니다.
+
+### 인코더-디코더[[nlp-encoder-decoder]]
+
+[BART](model_doc/bart)는 기본 Transformer 아키텍처를 유지하지만, 일부 텍스트 스팬(span)이 단일 `마스크` 토큰으로 대체되는 *text infilling* 변형으로 사전훈련 목표를 수정합니다. 디코더는 변형되지 않은 토큰(향후 토큰은 마스킹됨)을 예측하고 인코더의 은닉 상태를 사용하여 이 작업을 돕습니다. [Pegasus](model_doc/pegasus)는 BART와 유사하지만, Pegasus는 텍스트 스팬 대신 전체 문장을 마스킹합니다. Pegasus는 마스크드 언어 모델링 외에도 gap sentence generation(GSG)로 사전훈련됩니다. GSG는 문서에 중요한 문장 전체를 마스킹하여 `마스크` 토큰으로 대체하는 것을 목표로 합니다. 디코더는 남은 문장에서 출력을 생성해야 합니다. [T5](model_doc/t5)는 특정 접두사를 사용하여 모든 NLP 작업을 텍스트 투 텍스트 문제로 변환하는 더 특수한 모델입니다. 예를 들어, 접두사 `Summarize:`은 요약 작업을 나타냅니다. T5는 지도(GLUE 및 SuperGLUE) 훈련과 자기지도 훈련(토큰의 15%를 임의로 샘플링하여 제거)으로 사전훈련됩니다.
+
+## 오디오[[audio]]
+
+
+
+### 인코더[[audio-encoder]]
+
+[Wav2Vec2](model_doc/wav2vec2)는 Transformer 인코더를 사용하여 원본 오디오 파형(raw audio waveform)에서 직접 음성 표현을 학습합니다. 허위 음성 표현 세트에서 실제 음성 표현을 판별하는 대조 작업으로 사전훈련됩니다. [HuBERT](model_doc/hubert)는 Wav2Vec2와 유사하지만 훈련 과정이 다릅니다. 타겟 레이블이 유사한 오디오 세그먼트가 클러스터에 할당되어 은닉 단위(unit)가 되는 군집화(clustering) 단계에서 생성됩니다. 은닉 단위는 예측을 위한 임베딩에 매핑됩니다.
+
+### 인코더-디코더[[audio-encoder-decoder]]
+
+[Speech2Text](model_doc/speech_to_text)는 자동 음성 인식(ASR) 및 음성 번역을 위해 고안된 음성 모델입니다. 이 모델은 오디오 파형에서 추출한 log mel-filter bank 특징을 채택하고 자기회귀 방식으로 사전훈련하여, 전사본 또는 번역을 만듭니다. [Whisper](model_doc/whisper)은 ASR 모델이지만, 다른 많은 음성 모델과 달리 제로샷 성능을 위해 대량의 ✨ 레이블이 지정된 ✨ 오디오 전사 데이터에 대해 사전훈련됩니다. 데이터 세트의 큰 묶음에는 영어가 아닌 언어도 포함되어 있어서 자원이 적은 언어에도 Whisper를 사용할 수 있습니다. 구조적으로, Whisper는 Speech2Text와 유사합니다. 오디오 신호는 인코더에 의해 인코딩된 log-mel spectrogram으로 변환됩니다. 디코더는 인코더의 은닉 상태와 이전 토큰으로부터 자기회귀 방식으로 전사를 생성합니다.
+
+## 멀티모달[[multimodal]]
+
+
+
+### 인코더[[mm-encoder]]
+
+[VisualBERT](model_doc/visual_bert)는 BERT 이후에 출시된 비전 언어 작업을 위한 멀티모달 모델입니다. 이 모델은 BERT와 사전훈련된 객체 탐지 시스템을 결합하여 이미지 특징을 시각 임베딩으로 추출하고, 텍스트 임베딩과 함께 BERT로 전달합니다. VisualBERT는 마스킹되지 않은 텍스트와 시각 임베딩을 기반으로 마스킹된 텍스트를 예측하고, 텍스트가 이미지와 일치하는지 예측해야 합니다. ViT가 이미지 임베딩을 구하는 방식이 더 쉬웠기 때문에, ViT가 출시된 후 [ViLT](model_doc/vilt)는 아키텍처에 ViT를 채택했습니다. 이미지 임베딩은 텍스트 임베딩과 함께 처리됩니다. 여기에서, ViLT는 이미지 텍스트 매칭, 마스크드 언어 모델링, 전체 단어 마스킹을 통해 사전훈련됩니다.
+
+[CLIP](model_doc/clip)은 다른 접근 방식을 사용하여 (`이미지`, `텍스트`)의 쌍 예측을 수행합니다. (`이미지`, `텍스트`) 쌍에서의 이미지와 텍스트 임베딩 간의 유사도를 최대화하기 위해 4억 개의 (`이미지`, `텍스트`) 쌍 데이터 세트에 대해 이미지 인코더(ViT)와 텍스트 인코더(Transformer)를 함께 훈련합니다. 사전훈련 후, 자연어를 사용하여 이미지가 주어진 텍스트를 예측하거나 그 반대로 예측하도록 CLIP에 지시할 수 있습니다. [OWL-ViT](model_doc/owlvit)는 CLIP을 제로샷 객체 탐지를 위한 백본(backbone)으로 사용하여 CLIP 상에 구축됩니다. 사전훈련 후, 객체 탐지 헤드가 추가되어 (`클래스`, `바운딩 박스`) 쌍에 대한 집합(set) 예측을 수행합니다.
+
+### 인코더-디코더[[mm-encoder-decoder]]
+
+광학 문자 인식(OCR)은 이미지를 이해하고 텍스트를 생성하기 위해 다양한 구성 요소를 필요로 하는 전통적인 텍스트 인식 작업입니다. [TrOCR](model_doc/trocr)은 종단간(end-to-end) Transformer를 사용하여 이 프로세스를 간소화합니다. 인코더는 이미지 이해를 위한 ViT 방식의 모델이며 이미지를 고정된 크기의 패치로 처리합니다. 디코더는 인코더의 은닉 상태를 받아서 자기회귀 방식으로 텍스트를 생성합니다. [Donut](model_doc/donut)은 OCR 기반 접근 방식에 의존하지 않는 더 일반적인 시각 문서 이해 모델입니다. 이 모델은 Swin Transformer를 인코더로, 다국어 BART를 디코더로 사용합니다. Donut은 이미지와 텍스트 주석을 기반으로 다음 단어를 예측하여 텍스트를 읽도록 사전훈련됩니다. 디코더는 프롬프트가 주어지면 토큰 시퀀스를 생성합니다. 프롬프트는 각 다운스트림 작업에 대한 특수 토큰으로 표현됩니다. 예를 들어, 문서 파싱(parsing)에는 인코더의 은닉 상태와 결합되어 문서를 정형 출력 형식(JSON)으로 파싱하는 특수 `파싱` 토큰이 있습니다.
+
+## 강화 학습[[reinforcement-learning]]
+
+
+
+### 디코더[[rl-decoder]]
+
+Decision 및 Trajectory Transformer는 상태(state), 행동(action), 보상(reward)을 시퀀스 모델링 문제로 표현합니다. [Decision Transformer](model_doc/decision_transformer)는 기대 보상(returns-to-go), 과거 상태 및 행동을 기반으로 미래의 원하는 수익(return)으로 이어지는 일련의 행동을 생성합니다. 마지막 *K* 시간 스텝(timestep)에 대해, 세 가지 모달리티는 각각 토큰 임베딩으로 변환되고 GPT와 같은 모델에 의해 처리되어 미래의 액션 토큰을 예측합니다. [Trajectory Transformer](model_doc/trajectory_transformer)도 상태, 행동, 보상을 토큰화하여 GPT 아키텍처로 처리합니다. 보상 조건에 중점을 둔 Decision Transformer와 달리 Trajectory Transformer는 빔 서치(beam search)로 미래 행동을 생성합니다.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/modular_transformers.md b/docs/transformers/docs/source/ko/modular_transformers.md
new file mode 100644
index 0000000000000000000000000000000000000000..096dd4f13a9889dad2c3ab0a6ca3c1308ab952b2
--- /dev/null
+++ b/docs/transformers/docs/source/ko/modular_transformers.md
@@ -0,0 +1,96 @@
+# 모듈식 트랜스포머 [[modular-transformers]]
+
+`transformers`는 opinionated(자기 의견이 강한) 프레임워크이며, 우리의 철학은 다음의 [개념 가이드](./philosophy)에 정의되어 있습니다.
+
+이 철학의 핵심은 라이브러리의 [단일 모델, 단일 파일](https://huggingface.co/blog/transformers-design-philosophy) 측면에서 잘 나타납니다. 이 구성 요소의 단점은 파일 간에 구성 요소의 상속과 임포트 가능성을 제한한다는 것입니다.
+
+그 결과, 모델 구성 요소가 여러 파일에 걸쳐 반복되는 경향이 있습니다. `transformers`에는 모델 수만큼 많은 어텐션 레이어가 정의되어 있으며, 그 중 상당수는 서로 동일합니다. 안타깝게도, 수정과 변경 사항이 코드의 특정 부분에 적용되면서 독립적인 구현들이 서로 분기되는 경향이 있습니다.
+
+이 문제를 적절히 해결하기 위해, 우리는 라이브러리 전체에 "복사본"의 개념을 도입했습니다. 코드가 다른 코드의 복사본임을 나타내는 주석을 추가함으로써, CI 및 로컬 명령을 통해 복사본이 분기되지 않도록 강제할 수 있습니다. 그러나 복잡성이 낮더라도 이는 종종 매우 번거로운 작업입니다.
+
+마지막으로, 이 방식은 우리가 줄이고자 하는 상당한 오버헤드를 모델 기여 과정에 추가하게 됩니다. 이 접근 방식은 종종 모델 기여에 모델링 코드(~1,000줄), 프로세서(~500줄), 테스트, 문서 등을 추가해야 합니다. 모델 기여 PR은 대부분 3,000~5,000줄 이상의 코드를 추가하며, 이 중 많은 부분이 보일러플레이트(boilerplate) 코드입니다.
+
+이는 기여의 장벽을 높이며, 모듈식 트랜스포머를 통해 우리는 이러한 장벽을 훨씬 더 수용 가능한 수준으로 낮추고자 합니다.
+
+## 무엇인가요 [[what-is-it]]
+
+모듈식 트랜스포머는 모델 폴더에 "모듈식" 파일의 개념을 도입합니다. 이 모듈식 파일은 일반적으로 모델링/프로세싱 파일에서 허용되지 않는 코드를 허용하며, 이는 인접한 모델로부터의 임포트와 클래스 간의 상속을 허용합니다.
+
+이 모듈식 파일은 각각의 별도의 모듈에서 정의되었을 모델, 프로세서 및 구성 클래스를 정의합니다.
+
+마지막으로, 이 기능은 모듈식 파일을 "풀어내어" 단일 모델, 단일 파일 디렉토리 구조로 변환하는 새로운 `linter`를 도입합니다. 이 파일들은 스크립트가 실행될 때마다 자동으로 생성되며, 기여해야 할 내용을 모듈식 파일, 그리고 기여된 모델과 다른 모델 간의 차이점으로만 줄여줍니다.
+
+모델 사용자는 단일 파일 인터페이스를 임포트하고 사용하게 되므로, 여기에는 변화가 없을 것입니다. 이를 통해 간단한 기여를 가능하게 하면서도 우리의 철학을 유지하는 양쪽의 장점을 결합하고자 합니다.
+
+따라서 이는 `# Copied from` 마커의 대체품이며, 이전에 기여된 모델은 앞으로 몇 달 내에 새로운 모듈식 트랜스포머 형식으로 전환될 예정입니다.
+
+### 자세한 내용 [[details]]
+
+“linter”는 상속 구조를 풀어서 모듈화된 파일로부터 모든 단일 파일을 생성하며, Python 사용자들에게는 그 과정이 보이지 않도록 동작합니다. 현재 linter는 **단일** 수준의 상속만을 평탄화합니다.
+
+예를 들어:
+- 구성 클래스가 다른 클래스를 상속하고 인자를 추가/삭제하는 경우, 생성된 파일은 직접 참조(추가의 경우)하거나 완전히 제거합니다(삭제의 경우).
+- 클래스가 다른 클래스를 상속하는 경우, 예를 들어 class GemmaModel(LlamaModel): 의 경우, 종속성이 자동으로 추론됩니다. 모든 서브모듈은 슈퍼클래스로부터 자동으로 추론됩니다.
+
+토크나이저, 이미지 프로세서, 모델, 구성 등을 이 `modular` 파일에 모두 작성할 수 있으며, 해당 파일들이 자동으로 생성됩니다.
+
+### 시행 [[enforcement]]
+
+[TODO] 우리는 새로운 테스트를 도입하여 생성된 콘텐츠가 `modular_xxxx.py`에 있는 내용과 일치하는지 확인합니다.
+
+### 예시 [[examples]]
+
+여기 BERT와 RoBERTa의 간단한 예가 있습니다. 두 모델은 밀접하게 관련되어 있으며, 모델 구현의 차이는 임베딩 레이어의 변경에서만 있습니다.
+
+모델을 완전히 재정의하는 대신, `modular_roberta.py` 파일은 모델링 및 구성 클래스를 위해 다음과 같이 생겼습니다. (예시를 위해, 토크나이저는 매우 다르므로 일단 무시합니다.)
+
+```python
+from torch import nn
+from ..bert.configuration_bert import BertConfig
+from ..bert.modeling_bert import (
+ BertModel,
+ BertEmbeddings,
+ BertForMaskedLM
+)
+
+# RoBERTa 구성은 BERT의 구성과 동일합니다
+class RobertaConfig(BertConfig):
+ model_type = 'roberta'
+
+# 여기서 패딩 ID 차이를 강조하기 위해 임베딩을 재정의하고, 위치 임베딩을 재정의합니다
+class RobertaEmbeddings(BertEmbeddings):
+ def __init__(self, config):
+ super().__init__(config())
+
+ self.padding_idx = config.pad_token_id
+ self.position_embeddings = nn.Embedding(
+ config.max_position_embeddings, config.hidden_size, padding_idx=self.padding_idx
+ )
+
+# RoBERTa 모델은 임베딩 레이어를 제외하면 BERT 모델과 동일합니다.
+# 위에서 임베딩을 재정의했으므로, 여기서는 추가 작업이 필요 없습니다
+class RobertaModel(BertModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.embeddings = RobertaEmbeddings(config)
+
+# 헤드는 이제 내부에서 올바른 `RobertaModel`을 재정의하기만 하면 됩니다
+class RobertaForMaskedLM(BertForMaskedLM):
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = RobertaModel(config)
+```
+
+정의한 종속성을 사용하지 않으면 다음과 같은 오류가 발생합니다:
+
+```bash
+ValueError: You defined `RobertaEmbeddings` in the modular_roberta.py, it should be used
+ when you define `BertModel`, as it is one of it's direct dependencies. Make sure
+ you use it in the `__init__` function.
+```
+
+또한, 다음에서 예시 목록을 찾을 수 있습니다:
+
+## 무엇이 아닌가요 [[what-it-is-not]]
+
+(아직은?) 모델링 코드를 대체하는 것은 아닙니다. 그리고 여러분의 모델이 지금까지 존재했던 다른 어떤 것에도 기반하지 않는다면, 기존과 같이 `modeling` 파일을 추가할 수 있습니다.
diff --git a/docs/transformers/docs/source/ko/multilingual.md b/docs/transformers/docs/source/ko/multilingual.md
new file mode 100644
index 0000000000000000000000000000000000000000..c0eee024358f3e1a42ed08834183e810a271d8f8
--- /dev/null
+++ b/docs/transformers/docs/source/ko/multilingual.md
@@ -0,0 +1,192 @@
+
+
+# 다국어 모델 추론하기[[multilingual-models-for-inference]]
+
+[[open-in-colab]]
+
+🤗 Transformers에는 여러 종류의 다국어(multilingual) 모델이 있으며, 단일 언어(monolingual) 모델과 추론 시 사용법이 다릅니다.
+그렇다고 해서 *모든* 다국어 모델의 사용법이 다른 것은 아닙니다.
+
+[google-bert/bert-base-multilingual-uncased](https://huggingface.co/google-bert/bert-base-multilingual-uncased)와 같은 몇몇 모델은 단일 언어 모델처럼 사용할 수 있습니다.
+이번 가이드에서 다국어 모델의 추론 시 사용 방법을 알아볼 것입니다.
+
+## XLM[[xlm]]
+
+XLM에는 10가지 체크포인트(checkpoint)가 있는데, 이 중 하나만 단일 언어입니다.
+나머지 체크포인트 9개는 언어 임베딩을 사용하는 체크포인트와 그렇지 않은 체크포인트의 두 가지 범주로 나눌 수 있습니다.
+
+### 언어 임베딩을 사용하는 XLM[[xlm-with-language-embeddings]]
+
+다음 XLM 모델은 추론 시에 언어 임베딩을 사용합니다:
+
+- `FacebookAI/xlm-mlm-ende-1024` (마스킹된 언어 모델링, 영어-독일어)
+- `FacebookAI/xlm-mlm-enfr-1024` (마스킹된 언어 모델링, 영어-프랑스어)
+- `FacebookAI/xlm-mlm-enro-1024` (마스킹된 언어 모델링, 영어-루마니아어)
+- `FacebookAI/xlm-mlm-xnli15-1024` (마스킹된 언어 모델링, XNLI 데이터 세트에서 제공하는 15개 국어)
+- `FacebookAI/xlm-mlm-tlm-xnli15-1024` (마스킹된 언어 모델링 + 번역, XNLI 데이터 세트에서 제공하는 15개 국어)
+- `FacebookAI/xlm-clm-enfr-1024` (Causal language modeling, 영어-프랑스어)
+- `FacebookAI/xlm-clm-ende-1024` (Causal language modeling, 영어-독일어)
+
+언어 임베딩은 모델에 전달된 `input_ids`와 동일한 shape의 텐서로 표현됩니다.
+이러한 텐서의 값은 사용된 언어에 따라 다르며 토크나이저의 `lang2id` 및 `id2lang` 속성에 의해 식별됩니다.
+
+다음 예제에서는 `FacebookAI/xlm-clm-enfr-1024` 체크포인트(코잘 언어 모델링(causal language modeling), 영어-프랑스어)를 가져옵니다:
+
+```py
+>>> import torch
+>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
+
+>>> tokenizer = XLMTokenizer.from_pretrained("FacebookAI/xlm-clm-enfr-1024")
+>>> model = XLMWithLMHeadModel.from_pretrained("FacebookAI/xlm-clm-enfr-1024")
+```
+
+토크나이저의 `lang2id` 속성은 모델의 언어와 해당 ID를 표시합니다:
+
+```py
+>>> print(tokenizer.lang2id)
+{'en': 0, 'fr': 1}
+```
+
+다음으로, 예제 입력을 만듭니다:
+
+```py
+>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # 배치 크기는 1입니다
+```
+
+언어 ID를 `"en"`으로 설정해 언어 임베딩을 정의합니다.
+언어 임베딩은 영어의 언어 ID인 `0`으로 채워진 텐서입니다.
+이 텐서는 `input_ids`와 같은 크기여야 합니다.
+
+```py
+>>> language_id = tokenizer.lang2id["en"] # 0
+>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
+
+>>> # (batch_size, sequence_length) shape의 텐서가 되도록 만듭니다.
+>>> langs = langs.view(1, -1) # 이제 [1, sequence_length] shape이 되었습니다(배치 크기는 1입니다)
+```
+
+이제 `input_ids`와 언어 임베딩을 모델로 전달합니다:
+
+```py
+>>> outputs = model(input_ids, langs=langs)
+```
+
+[run_generation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation/run_generation.py) 스크립트로 `xlm-clm` 체크포인트를 사용해 텍스트와 언어 임베딩을 생성할 수 있습니다.
+
+### 언어 임베딩을 사용하지 않는 XLM[[xlm-without-language-embeddings]]
+
+다음 XLM 모델은 추론 시에 언어 임베딩이 필요하지 않습니다:
+
+- `FacebookAI/xlm-mlm-17-1280` (마스킹된 언어 모델링, 17개 국어)
+- `FacebookAI/xlm-mlm-100-1280` (마스킹된 언어 모델링, 100개 국어)
+
+이전의 XLM 체크포인트와 달리 이 모델은 일반 문장 표현에 사용됩니다.
+
+## BERT[[bert]]
+
+다음 BERT 모델은 다국어 태스크에 사용할 수 있습니다:
+
+- `google-bert/bert-base-multilingual-uncased` (마스킹된 언어 모델링 + 다음 문장 예측, 102개 국어)
+- `google-bert/bert-base-multilingual-cased` (마스킹된 언어 모델링 + 다음 문장 예측, 104개 국어)
+
+이러한 모델은 추론 시에 언어 임베딩이 필요하지 않습니다.
+문맥에서 언어를 식별하고, 식별된 언어로 추론합니다.
+
+## XLM-RoBERTa[[xlmroberta]]
+
+다음 XLM-RoBERTa 또한 다국어 다국어 태스크에 사용할 수 있습니다:
+
+- `FacebookAI/xlm-roberta-base` (마스킹된 언어 모델링, 100개 국어)
+- `FacebookAI/xlm-roberta-large` (마스킹된 언어 모델링, 100개 국어)
+
+XLM-RoBERTa는 100개 국어에 대해 새로 생성되고 정제된 2.5TB 규모의 CommonCrawl 데이터로 학습되었습니다.
+이전에 공개된 mBERT나 XLM과 같은 다국어 모델에 비해 분류, 시퀀스 라벨링, 질의 응답과 같은 다운스트림(downstream) 작업에서 이점이 있습니다.
+
+## M2M100[[m2m100]]
+
+다음 M2M100 모델 또한 다국어 다국어 태스크에 사용할 수 있습니다:
+
+- `facebook/m2m100_418M` (번역)
+- `facebook/m2m100_1.2B` (번역)
+
+이 예제에서는 `facebook/m2m100_418M` 체크포인트를 가져와서 중국어를 영어로 번역합니다.
+토크나이저에서 번역 대상 언어(source language)를 설정할 수 있습니다:
+
+```py
+>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
+
+>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
+>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
+
+>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
+>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
+```
+
+문장을 토큰화합니다:
+
+```py
+>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
+```
+
+M2M100은 번역을 진행하기 위해 첫 번째로 생성되는 토큰은 번역할 언어(target language) ID로 강제 지정합니다.
+영어로 번역하기 위해 `generate` 메소드에서 `forced_bos_token_id`를 `en`으로 설정합니다:
+
+```py
+>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
+```
+
+## MBart[[mbart]]
+
+다음 MBart 모델 또한 다국어 태스크에 사용할 수 있습니다:
+
+- `facebook/mbart-large-50-one-to-many-mmt` (일대다 다국어 번역, 50개 국어)
+- `facebook/mbart-large-50-many-to-many-mmt` (다대다 다국어 번역, 50개 국어)
+- `facebook/mbart-large-50-many-to-one-mmt` (다대일 다국어 번역, 50개 국어)
+- `facebook/mbart-large-50` (다국어 번역, 50개 국어)
+- `facebook/mbart-large-cc25`
+
+이 예제에서는 핀란드어를 영어로 번역하기 위해 `facebook/mbart-large-50-many-to-many-mmt` 체크포인트를 가져옵니다.
+토크나이저에서 번역 대상 언어(source language)를 설정할 수 있습니다:
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
+>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
+
+>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
+```
+
+문장을 토큰화합니다:
+
+```py
+>>> encoded_en = tokenizer(en_text, return_tensors="pt")
+```
+
+MBart는 번역을 진행하기 위해 첫 번째로 생성되는 토큰은 번역할 언어(target language) ID로 강제 지정합니다.
+영어로 번역하기 위해 `generate` 메소드에서 `forced_bos_token_id`를 `en`으로 설정합니다:
+
+```py
+>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
+```
+
+`facebook/mbart-large-50-many-to-one-mmt` 체크포인트를 사용하고 있다면, 첫 번째로 생성되는 토큰을 번역할 언어(target language) ID로 강제 지정할 필요는 없습니다.
diff --git a/docs/transformers/docs/source/ko/pad_truncation.md b/docs/transformers/docs/source/ko/pad_truncation.md
new file mode 100644
index 0000000000000000000000000000000000000000..9ee4dc839b8416f2114b0a12e7e86ada591926a6
--- /dev/null
+++ b/docs/transformers/docs/source/ko/pad_truncation.md
@@ -0,0 +1,68 @@
+
+
+# 패딩과 잘라내기[[padding-and-truncation]]
+
+배치 입력은 길이가 다른 경우가 많아서 고정 크기 텐서로 변환할 수 없습니다. 패딩과 잘라내기는 다양한 길이의 배치에서 직사각형 텐서를 생성할 수 있도록 이 문제를 해결하는 전략입니다. 패딩은 특수한 **패딩 토큰**을 추가하여 짧은 시퀀스가 배치에서 가장 긴 시퀀스 또는 모델에서 허용하는 최대 길이와 동일한 길이를 갖도록 합니다. 잘라내기는 긴 시퀀스를 잘라내어 패딩과 다른 방식으로 시퀀스의 길이를 동일하게 합니다.
+
+대부분의 경우 배치에 가장 긴 시퀀스의 길이로 패딩하고 모델이 허용할 수 있는 최대 길이로 잘라내는 것이 잘 작동합니다. 그러나 필요하다면 API가 지원하는 더 많은 전략을 사용할 수 있습니다. 필요한 인수는 `padding`, `truncation`, `max_length` 세 가지입니다.
+
+`padding` 인수는 패딩을 제어합니다. 불리언 또는 문자열일 수 있습니다:
+
+ - `True` 또는 `'longest'`: 배치에서 가장 긴 시퀀스로 패딩합니다(단일 시퀀스만 제공하는 경우 패딩이 적용되지 않습니다).
+ - `'max_length'`: `max_length` 인수가 지정한 길이로 패딩하거나, `max_length`가 제공되지 않은 경우(`max_length=None`) 모델에서 허용되는 최대 길이로 패딩합니다. 단일 시퀀스만 제공하는 경우에도 패딩이 적용됩니다.
+ - `False` 또는 `'do_not_pad'`: 패딩이 적용되지 않습니다. 이것이 기본 동작입니다.
+
+`truncation` 인수는 잘라낼 방법을 정합니다. 불리언 또는 문자열일 수 있습니다:
+
+ - `True` 또는 `longest_first`: `max_length` 인수가 지정한 최대 길이로 잘라내거나,
+ `max_length`가 제공되지 않은 경우(`max_length=None`) 모델에서 허용되는 최대 길이로 잘라냅니다.
+ 시퀀스 쌍에서 가장 긴 시퀀스의 토큰을 적절한 길이에 도달할 때까지 하나씩 제거합니다.
+ - `'only_second'`: `max_length` 인수가 지정한 최대 길이로 잘라내거나,
+ `max_length`가 제공되지 않은 경우(`max_length=None`) 모델에서 허용되는 최대 길이로 잘라냅니다.
+ 시퀀스 쌍(또는 시퀀스 쌍의 배치)가 제공된 경우 쌍의 두 번째 문장만 잘라냅니다.
+ - `'only_first'`: `max_length` 인수가 지정한 최대 길이로 잘라내거나,
+ `max_length`가 제공되지 않은 경우(`max_length=None`) 모델에서 허용되는 최대 길이로 잘라냅니다.
+ 시퀀스 쌍(또는 시퀀스 쌍의 배치)가 제공된 경우 쌍의 첫 번째 문장만 잘라냅니다.
+ - `False` 또는 `'do_not_truncate'`: 잘라내기를 적용하지 않습니다. 이것이 기본 동작입니다.
+
+`max_length` 인수는 패딩 및 잘라내기를 적용할 길이를 제어합니다. 이 인수는 정수 또는 `None`일 수 있으며, `None`일 경우 모델이 허용할 수 있는 최대 길이로 기본값이 설정됩니다. 모델에 특정한 최대 입력 길이가 없는 경우 `max_length`에 대한 잘라내기 또는 패딩이 비활성화됩니다.
+
+다음 표에는 패딩 및 잘라내기를 설정하는 권장 방법이 요약되어 있습니다.
+입력으로 시퀀스 쌍을 사용하는 경우, 다음 예제에서 `truncation=True`를 `['only_first', 'only_second', 'longest_first']`에서 선택한 `STRATEGY`, 즉 `truncation='only_second'` 또는 `truncation='longest_first'`로 바꾸면 앞서 설명한 대로 쌍의 두 시퀀스가 잘리는 방식을 제어할 수 있습니다.
+
+| 잘라내기 | 패딩 | 사용 방법 |
+|--------------------------------------|-----------------------------------|------------------------------------------------------------------------------------------|
+| 잘라내기 없음 | 패딩 없음 | `tokenizer(batch_sentences)` |
+| | 배치 내 최대 길이로 패딩 | `tokenizer(batch_sentences, padding=True)` 또는 |
+| | | `tokenizer(batch_sentences, padding='longest')` |
+| | 모델의 최대 입력 길이로 패딩 | `tokenizer(batch_sentences, padding='max_length')` |
+| | 특정 길이로 패딩 | `tokenizer(batch_sentences, padding='max_length', max_length=42)` |
+| | 다양한 길이로 패딩 | `tokenizer(batch_sentences, padding=True, pad_to_multiple_of=8)` |
+| 모델의 최대 입력 길이로 잘라내기 | 패딩 없음 | `tokenizer(batch_sentences, truncation=True)` 또는 |
+| | | `tokenizer(batch_sentences, truncation=STRATEGY)` |
+| | 배치 내 최대 길이로 패딩 | `tokenizer(batch_sentences, padding=True, truncation=True)` 또는 |
+| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY)` |
+| | 모델의 최대 입력 길이로 패딩 | `tokenizer(batch_sentences, padding='max_length', truncation=True)` 또는 |
+| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY)` |
+| | 특정 길이로 패딩 | 사용 불가 |
+| 특정 길이로 잘라내기 | 패딩 없음 | `tokenizer(batch_sentences, truncation=True, max_length=42)` 또는 |
+| | | `tokenizer(batch_sentences, truncation=STRATEGY, max_length=42)` |
+| | 배치 내 최대 길이로 패딩 | `tokenizer(batch_sentences, padding=True, truncation=True, max_length=42)` 또는 |
+| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY, max_length=42)` |
+| | 모델의 최대 입력 길이로 패딩 | 사용 불가 |
+| | 특정 길이로 패딩 | `tokenizer(batch_sentences, padding='max_length', truncation=True, max_length=42)` 또는 |
+| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY, max_length=42)` |
diff --git a/docs/transformers/docs/source/ko/peft.md b/docs/transformers/docs/source/ko/peft.md
new file mode 100644
index 0000000000000000000000000000000000000000..d4ef0ba539e2de598a6d7504908f632c34e7c560
--- /dev/null
+++ b/docs/transformers/docs/source/ko/peft.md
@@ -0,0 +1,209 @@
+
+
+# 🤗 PEFT로 어댑터 가져오기 [[load-adapters-with-peft]]
+
+[[open-in-colab]]
+
+[Parameter-Efficient Fine Tuning (PEFT)](https://huggingface.co/blog/peft) 방법은 사전훈련된 모델의 매개변수를 미세 조정 중 고정시키고, 그 위에 훈련할 수 있는 매우 적은 수의 매개변수(어댑터)를 추가합니다. 어댑터는 작업별 정보를 학습하도록 훈련됩니다. 이 접근 방식은 완전히 미세 조정된 모델에 필적하는 결과를 생성하면서, 메모리 효율적이고 비교적 적은 컴퓨팅 리소스를 사용합니다.
+
+또한 PEFT로 훈련된 어댑터는 일반적으로 전체 모델보다 훨씬 작기 때문에 공유, 저장 및 가져오기가 편리합니다.
+
+
+
+ Hub에 저장된 OPTForCausalLM 모델의 어댑터 가중치는 최대 700MB에 달하는 모델 가중치의 전체 크기에 비해 약 6MB에 불과합니다.
+
+
+🤗 PEFT 라이브러리에 대해 자세히 알아보려면 [문서](https://huggingface.co/docs/peft/index)를 확인하세요.
+
+## 설정 [[setup]]
+
+🤗 PEFT를 설치하여 시작하세요:
+
+```bash
+pip install peft
+```
+
+새로운 기능을 사용해보고 싶다면, 다음 소스에서 라이브러리를 설치하는 것이 좋습니다:
+
+```bash
+pip install git+https://github.com/huggingface/peft.git
+```
+
+## 지원되는 PEFT 모델 [[supported-peft-models]]
+
+🤗 Transformers는 기본적으로 일부 PEFT 방법을 지원하며, 로컬이나 Hub에 저장된 어댑터 가중치를 가져오고 몇 줄의 코드만으로 쉽게 실행하거나 훈련할 수 있습니다. 다음 방법을 지원합니다:
+
+- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
+- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
+- [AdaLoRA](https://arxiv.org/abs/2303.10512)
+
+🤗 PEFT와 관련된 다른 방법(예: 프롬프트 훈련 또는 프롬프트 튜닝) 또는 일반적인 🤗 PEFT 라이브러리에 대해 자세히 알아보려면 [문서](https://huggingface.co/docs/peft/index)를 참조하세요.
+
+
+## PEFT 어댑터 가져오기 [[load-a-peft-adapter]]
+
+🤗 Transformers에서 PEFT 어댑터 모델을 가져오고 사용하려면 Hub 저장소나 로컬 디렉터리에 `adapter_config.json` 파일과 어댑터 가중치가 포함되어 있는지 확인하십시오. 그런 다음 `AutoModelFor` 클래스를 사용하여 PEFT 어댑터 모델을 가져올 수 있습니다. 예를 들어 인과 관계 언어 모델용 PEFT 어댑터 모델을 가져오려면 다음 단계를 따르십시오:
+
+1. PEFT 모델 ID를 지정하십시오.
+2. [`AutoModelForCausalLM`] 클래스에 전달하십시오.
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+peft_model_id = "ybelkada/opt-350m-lora"
+model = AutoModelForCausalLM.from_pretrained(peft_model_id)
+```
+
+
+
+`AutoModelFor` 클래스나 기본 모델 클래스(예: `OPTForCausalLM` 또는 `LlamaForCausalLM`) 중 하나를 사용하여 PEFT 어댑터를 가져올 수 있습니다.
+
+
+
+`load_adapter` 메소드를 호출하여 PEFT 어댑터를 가져올 수도 있습니다.
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_id = "facebook/opt-350m"
+peft_model_id = "ybelkada/opt-350m-lora"
+
+model = AutoModelForCausalLM.from_pretrained(model_id)
+model.load_adapter(peft_model_id)
+```
+
+## 8비트 또는 4비트로 가져오기 [[load-in-8bit-or-4bit]]
+
+`bitsandbytes` 통합은 8비트와 4비트 정밀도 데이터 유형을 지원하므로 큰 모델을 가져올 때 유용하면서 메모리도 절약합니다. 모델을 하드웨어에 효과적으로 분배하려면 [`~PreTrainedModel.from_pretrained`]에 `load_in_8bit` 또는 `load_in_4bit` 매개변수를 추가하고 `device_map="auto"`를 설정하세요:
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
+
+peft_model_id = "ybelkada/opt-350m-lora"
+model = AutoModelForCausalLM.from_pretrained(peft_model_id, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
+```
+
+## 새 어댑터 추가 [[add-a-new-adapter]]
+
+새 어댑터가 현재 어댑터와 동일한 유형인 경우에 한해 기존 어댑터가 있는 모델에 새 어댑터를 추가하려면 [`~peft.PeftModel.add_adapter`]를 사용할 수 있습니다. 예를 들어 모델에 기존 LoRA 어댑터가 연결되어 있는 경우:
+
+```py
+from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
+from peft import PeftConfig
+
+model_id = "facebook/opt-350m"
+model = AutoModelForCausalLM.from_pretrained(model_id)
+
+lora_config = LoraConfig(
+ target_modules=["q_proj", "k_proj"],
+ init_lora_weights=False
+)
+
+model.add_adapter(lora_config, adapter_name="adapter_1")
+```
+
+새 어댑터를 추가하려면:
+
+```py
+# attach new adapter with same config
+model.add_adapter(lora_config, adapter_name="adapter_2")
+```
+
+이제 [`~peft.PeftModel.set_adapter`]를 사용하여 어댑터를 사용할 어댑터로 설정할 수 있습니다:
+
+```py
+# use adapter_1
+model.set_adapter("adapter_1")
+output = model.generate(**inputs)
+print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
+
+# use adapter_2
+model.set_adapter("adapter_2")
+output_enabled = model.generate(**inputs)
+print(tokenizer.decode(output_enabled[0], skip_special_tokens=True))
+```
+
+## 어댑터 활성화 및 비활성화 [[enable-and-disable-adapters]]
+
+모델에 어댑터를 추가한 후 어댑터 모듈을 활성화 또는 비활성화할 수 있습니다. 어댑터 모듈을 활성화하려면:
+
+```py
+from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
+from peft import PeftConfig
+
+model_id = "facebook/opt-350m"
+adapter_model_id = "ybelkada/opt-350m-lora"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+text = "Hello"
+inputs = tokenizer(text, return_tensors="pt")
+
+model = AutoModelForCausalLM.from_pretrained(model_id)
+peft_config = PeftConfig.from_pretrained(adapter_model_id)
+
+# to initiate with random weights
+peft_config.init_lora_weights = False
+
+model.add_adapter(peft_config)
+model.enable_adapters()
+output = model.generate(**inputs)
+```
+
+어댑터 모듈을 비활성화하려면:
+
+```py
+model.disable_adapters()
+output = model.generate(**inputs)
+```
+
+## PEFT 어댑터 훈련 [[train-a-peft-adapter]]
+
+PEFT 어댑터는 [`Trainer`] 클래스에서 지원되므로 특정 사용 사례에 맞게 어댑터를 훈련할 수 있습니다. 몇 줄의 코드를 추가하기만 하면 됩니다. 예를 들어 LoRA 어댑터를 훈련하려면:
+
+
+
+[`Trainer`]를 사용하여 모델을 미세 조정하는 것이 익숙하지 않다면 [사전훈련된 모델을 미세 조정하기](training) 튜토리얼을 확인하세요.
+
+
+
+1. 작업 유형 및 하이퍼파라미터를 지정하여 어댑터 구성을 정의합니다. 하이퍼파라미터에 대한 자세한 내용은 [`~peft.LoraConfig`]를 참조하세요.
+
+```py
+from peft import LoraConfig
+
+peft_config = LoraConfig(
+ lora_alpha=16,
+ lora_dropout=0.1,
+ r=64,
+ bias="none",
+ task_type="CAUSAL_LM",
+)
+```
+
+2. 모델에 어댑터를 추가합니다.
+
+```py
+model.add_adapter(peft_config)
+```
+
+3. 이제 모델을 [`Trainer`]에 전달할 수 있습니다!
+
+```py
+trainer = Trainer(model=model, ...)
+trainer.train()
+```
+
+훈련한 어댑터를 저장하고 다시 가져오려면:
+
+```py
+model.save_pretrained(save_dir)
+model = AutoModelForCausalLM.from_pretrained(save_dir)
+```
diff --git a/docs/transformers/docs/source/ko/perf_hardware.md b/docs/transformers/docs/source/ko/perf_hardware.md
new file mode 100644
index 0000000000000000000000000000000000000000..01282a0c711147318121f71e07e1a638549906cc
--- /dev/null
+++ b/docs/transformers/docs/source/ko/perf_hardware.md
@@ -0,0 +1,156 @@
+
+
+
+# 훈련용 사용자 맞춤형 하드웨어 [[custom-hardware-for-training]]
+
+모델 훈련과 추론에 사용하는 하드웨어는 성능에 큰 영향을 미칠 수 있습니다. GPU에 대해 자세히 알아보려면, Tim Dettmer의 훌륭한 블로그 포스트를 확인해보세요. [블로그 포스트 링크](https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/) (영어로 작성됨).
+
+GPU 설정에 대한 실용적인 조언을 살펴보겠습니다.
+
+## GPU [[gpu]]
+더 큰 모델을 훈련시킬 때는 기본적으로 세 가지 옵션이 있습니다:
+
+- 더 큰 GPU
+- 더 많은 GPU
+- 더 많은 CPU 및 NVMe ([DeepSpeed-Infinity](../en/main_classes/deepspeed#nvme-support)를 통한 오프로드(offload))
+
+우선, 하나의 GPU만 사용하는 경우부터 시작해봅시다.
+
+### 전원 공급과 냉각 [[power-and-cooling]]
+
+비싼 고성능 GPU를 구매한 경우, 올바른 전원 공급과 충분한 냉각을 제공해야 합니다.
+
+**전원 공급**:
+
+일부 고성능 소비자용 GPU는 2개 혹은 가끔가다 3개의 PCI-E 8핀 전원 소켓이 있습니다. 카드에 있는 소켓 수만큼 독립적인 12V PCI-E 8핀 케이블이 연결되어 있는지 확인하세요. 같은 케이블의 한쪽 끝에 있는 2개의 스플릿(또는 피그테일(pigtail) 케이블)을 사용하지 마세요. 즉, GPU에 2개의 소켓이 있다면, PSU(전원 공급 장치)에서 카드로 연결되는 2개의 PCI-E 8핀 케이블이 필요하며, 끝에 2개의 PCI-E 8핀 커넥터가 있는 케이블이 필요하지 않습니다! 그렇지 않으면 카드의 전체 성능을 제대로 발휘하지 못할 수 있습니다.
+
+각각의 PCI-E 8핀 전원 케이블은 PSU 쪽의 12V 레일에 연결되어야 하며 최대 150W의 전력을 공급할 수 있습니다.
+
+일부 다른 GPU는 PCI-E 12핀 커넥터를 사용하며, 이러한 커넥터는 최대 500W-600W의 전력을 공급할 수 있습니다.
+
+저가형 GPU는 6핀 커넥터를 사용하며, 최대 75W의 전력을 공급합니다.
+
+또한 GPU가 안정적인 전압을 받을 수 있도록 고급 PSU를 선택해야 합니다. 일부 저품질의 PSU는 GPU가 최고 성능으로 동작하기 위해 필요한 전압을 안정적으로 공급하지 못할 수 있습니다.
+
+물론, PSU는 GPU에 전원을 공급하기에 충분한 여분의 전력 용량을 가져야 합니다.
+
+**냉각**:
+
+GPU가 과열되면 성능이 저하되고 최대 성능을 발휘하지 못할 수 있으며, 너무 뜨거워지면 중지될 수 있습니다.
+
+GPU가 과열될 때 정확한 적정 온도를 알기 어려우나, 아마도 +80℃ 미만이면 좋지만 더 낮을수록 좋습니다. 70℃-75℃ 정도가 훌륭한 온도 범위입니다. 성능 저하가 발생하기 시작하는 온도는 대략 84℃-90℃ 정도일 것입니다. 하지만 성능 저하 이외에도 지속적으로 매우 높은 온도는 GPU 수명을 단축시킬 수 있습니다.
+
+이어서, 여러 개의 GPU를 사용할 때 가장 중요한 측면 중 하나인 GPU 간 연결 방식을 살펴보겠습니다.
+
+### 다중 GPU 연결 방식 [[multigpu-connectivity]]
+
+다중 GPU를 사용하는 경우 GPU 간의 연결 방식은 전체 훈련 시간에 큰 영향을 미칠 수 있습니다. 만약 GPU가 동일한 물리적 노드에 있을 경우, 다음과 같이 확인할 수 있습니다:
+
+```bash
+nvidia-smi topo -m
+```
+
+만약 NVLink로 연결된 듀얼 GPU 환경이라면, 다음과 같은 결과를 확인할 수 있습니다:
+
+```
+ GPU0 GPU1 CPU Affinity NUMA Affinity
+GPU0 X NV2 0-23 N/A
+GPU1 NV2 X 0-23 N/A
+```
+
+NVLink를 지원하지 않는 다른 환경의 경우에는 다음과 같은 결과를 확인할 수 있습니다:
+```
+ GPU0 GPU1 CPU Affinity NUMA Affinity
+GPU0 X PHB 0-11 N/A
+GPU1 PHB X 0-11 N/A
+```
+
+이 결과에는 다음과 같은 범례가 포함되어 있습니다:
+
+```
+ X = Self
+ SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
+ NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
+ PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
+ PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
+ PIX = Connection traversing at most a single PCIe bridge
+ NV# = Connection traversing a bonded set of # NVLinks
+```
+
+따라서 첫 번째 결과의 `NV2`는 GPU가 2개의 NVLink로 연결되어 있다는 것을 나타내고, 두 번째 결과의 `PHB`는 일반적인 소비자용 PCIe+브릿지 설정을 가지고 있다는 것을 나타냅니다.
+
+설정에서 어떤 유형의 연결 방식을 가지고 있는지 확인하세요. 일부 연결 방식은 GPU 간 통신을 더 빠르게 만들 수 있으며(NVLink와 같이), 어떤 연결 방식은 더 느리게 만들 수 있습니다(PHB와 같이).
+
+사용하는 확장성 솔루션의 종류에 따라 연결 속도가 주요한 영향을 미칠 수도 있고 미미한 영향을 미칠 수도 있습니다. DDP와 같이 GPU가 거의 동기화하지 않아도 되는 경우, 연결 속도가 느려도 큰 영향을 받지 않습니다. 반면 ZeRO-DP와 같이 GPU간 통신이 많이 필요한 경우, 더 빠른 훈련을 위해서는 더 빠른 연결 속도가 중요합니다.
+
+#### NVLink [[nvlink]]
+
+[NVLink](https://en.wikipedia.org/wiki/NVLink)는 Nvidia에서 개발한 유선 기반의 직렬 다중 레인 근거리 통신 링크입니다.
+
+새로운 세대의 NVLink는 더 빠른 대역폭을 제공합니다. [Nvidia Ampere GA102 GPU Architecture](https://www.nvidia.com/content/dam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102-GPU-Architecture-Whitepaper-V1.pdf)에서 아래와 같은 정보를 확인하실 수 있습니다:
+
+> 3세대 NVLink®
+> GA102 GPU는 4개의 x4 링크를 포함하는 NVIDIA의 3세대 NVLink 인터페이스를 활용하며,
+> 각 링크는 두 개의 GPU 간에 각 방향으로 초당 14.0625GB의 대역폭을 제공합니다.
+> 4개의 링크는 각 방향에 초당 56.25GB의 대역폭을 제공하며, 두 개의 GPU 간에는 초당 112.5GB의 총 대역폭을 제공합니다.
+> 두 개의 RTX 3090 GPU를 NVLink를 사용해 SLI로 연결할 수 있습니다.
+> (3-Way 및 4-Way SLI 구성은 지원되지 않음에 유의하세요.)
+
+
+따라서 `nvidia-smi topo -m`의 결과에서 `NVX`의 값이 높을수록 더 좋습니다. 세대는 GPU 아키텍처에 따라 다를 수 있습니다.
+
+그렇다면, openai-community/gpt2를 작은 wikitext 샘플로 학습시키는 예제를 통해, NVLink가 훈련에 어떤 영향을 미치는지 살펴보겠습니다.
+
+결과는 다음과 같습니다:
+
+
+| NVlink | Time |
+| ----- | ---: |
+| Y | 101s |
+| N | 131s |
+
+
+NVLink 사용 시 훈련이 약 23% 더 빠르게 완료됨을 확인할 수 있습니다. 두 번째 벤치마크에서는 `NCCL_P2P_DISABLE=1`을 사용하여 NVLink를 사용하지 않도록 설정했습니다.
+
+전체 벤치마크 코드와 결과는 다음과 같습니다:
+
+```bash
+# DDP w/ NVLink
+
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 torchrun \
+--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path openai-community/gpt2 \
+--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train \
+--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
+
+# DDP w/o NVLink
+
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 NCCL_P2P_DISABLE=1 torchrun \
+--nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py --model_name_or_path openai-community/gpt2 \
+--dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train
+--output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
+```
+
+하드웨어: 각각 2개의 TITAN RTX 24GB + 2개의 NVLink (`NV2` in `nvidia-smi topo -m`)
+소프트웨어: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
diff --git a/docs/transformers/docs/source/ko/perf_infer_cpu.md b/docs/transformers/docs/source/ko/perf_infer_cpu.md
new file mode 100644
index 0000000000000000000000000000000000000000..123e56b4f32c2fdf6d90f7e127c74a0a3803d5ea
--- /dev/null
+++ b/docs/transformers/docs/source/ko/perf_infer_cpu.md
@@ -0,0 +1,73 @@
+
+
+# CPU에서 효율적인 추론하기 [[efficient-inference-on-cpu]]
+
+이 가이드는 CPU에서 대규모 모델을 효율적으로 추론하는 방법에 중점을 두고 있습니다.
+
+## 더 빠른 추론을 위한 `BetterTransformer` [[bettertransformer-for-faster-inference]]
+
+우리는 최근 CPU에서 텍스트, 이미지 및 오디오 모델의 빠른 추론을 위해 `BetterTransformer`를 통합했습니다. 이 통합에 대한 더 자세한 내용은 [이 문서](https://huggingface.co/docs/optimum/bettertransformer/overview)를 참조하세요.
+
+## PyTorch JIT 모드 (TorchScript) [[pytorch-jitmode-torchscript]]
+TorchScript는 PyTorch 코드에서 직렬화와 최적화가 가능한 모델을 생성할때 쓰입니다. TorchScript로 만들어진 프로그램은 기존 Python 프로세스에서 저장한 뒤, 종속성이 없는 새로운 프로세스로 가져올 수 있습니다. PyTorch의 기본 설정인 `eager` 모드와 비교했을때, `jit` 모드는 연산자 결합과 같은 최적화 방법론을 통해 모델 추론에서 대부분 더 나은 성능을 제공합니다.
+
+TorchScript에 대한 친절한 소개는 [PyTorch TorchScript 튜토리얼](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html#tracing-modules)을 참조하세요.
+
+### JIT 모드와 함께하는 IPEX 그래프 최적화 [[ipex-graph-optimization-with-jitmode]]
+Intel® Extension for PyTorch(IPEX)는 Transformers 계열 모델의 jit 모드에서 추가적인 최적화를 제공합니다. jit 모드와 더불어 Intel® Extension for PyTorch(IPEX)를 활용하시길 강력히 권장드립니다. Transformers 모델에서 자주 사용되는 일부 연산자 패턴은 이미 jit 모드 연산자 결합(operator fusion)의 형태로 Intel® Extension for PyTorch(IPEX)에서 지원되고 있습니다. Multi-head-attention, Concat Linear, Linear+Add, Linear+Gelu, Add+LayerNorm 결합 패턴 등이 이용 가능하며 활용했을 때 성능이 우수합니다. 연산자 결합의 이점은 사용자에게 고스란히 전달됩니다. 분석에 따르면, 질의 응답, 텍스트 분류 및 토큰 분류와 같은 가장 인기 있는 NLP 태스크 중 약 70%가 이러한 결합 패턴을 사용하여 Float32 정밀도와 BFloat16 혼합 정밀도 모두에서 성능상의 이점을 얻을 수 있습니다.
+
+[IPEX 그래프 최적화](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/graph_optimization.html)에 대한 자세한 정보를 확인하세요.
+
+#### IPEX 설치: [[ipex-installation]]
+
+IPEX 배포 주기는 PyTorch를 따라서 이루어집니다. 자세한 정보는 [IPEX 설치 방법](https://intel.github.io/intel-extension-for-pytorch/)을 확인하세요.
+
+### JIT 모드 사용법 [[usage-of-jitmode]]
+평가 또는 예측을 위해 Trainer에서 JIT 모드를 사용하려면 Trainer의 명령 인수에 `jit_mode_eval`을 추가해야 합니다.
+
+
+
+PyTorch의 버전이 1.14.0 이상이라면, jit 모드는 jit.trace에서 dict 입력이 지원되므로, 모든 모델의 예측과 평가가 개선될 수 있습니다.
+
+PyTorch의 버전이 1.14.0 미만이라면, 질의 응답 모델과 같이 forward 매개변수의 순서가 jit.trace의 튜플 입력 순서와 일치하는 모델에 득이 될 수 있습니다. 텍스트 분류 모델과 같이 forward 매개변수 순서가 jit.trace의 튜플 입력 순서와 다른 경우, jit.trace가 실패하며 예외가 발생합니다. 이때 예외상황을 사용자에게 알리기 위해 Logging이 사용됩니다.
+
+
+
+[Transformers 질의 응답](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)의 사용 사례 예시를 참조하세요.
+
+
+- CPU에서 jit 모드를 사용한 추론:
+
diff --git a/docs/transformers/docs/source/ko/perf_infer_gpu_one.md b/docs/transformers/docs/source/ko/perf_infer_gpu_one.md
new file mode 100644
index 0000000000000000000000000000000000000000..d6ddca6cd039cb54e6b3d273a7336f6a4e73ac8c
--- /dev/null
+++ b/docs/transformers/docs/source/ko/perf_infer_gpu_one.md
@@ -0,0 +1,184 @@
+
+
+# 단일 GPU에서 효율적인 추론 [[efficient-inference-on-a-single-gpu]]
+
+이 가이드 외에도, [단일 GPU에서의 훈련 가이드](perf_train_gpu_one)와 [CPU에서의 추론 가이드](perf_infer_cpu)에서도 관련 정보를 찾을 수 있습니다.
+
+## Better Transformer: PyTorch 네이티브 Transformer 패스트패스 [[better-transformer-pytorchnative-transformer-fastpath]]
+
+PyTorch 네이티브 [`nn.MultiHeadAttention`](https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/) 어텐션 패스트패스인 BetterTransformer는 [🤗 Optimum 라이브러리](https://huggingface.co/docs/optimum/bettertransformer/overview)의 통합을 통해 Transformers와 함께 사용할 수 있습니다.
+
+PyTorch의 어텐션 패스트패스는 커널 퓨전과 [중첩된 텐서](https://pytorch.org/docs/stable/nested.html)의 사용을 통해 추론 속도를 높일 수 있습니다. 자세한 벤치마크는 [이 블로그 글](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2)에서 확인할 수 있습니다.
+
+[`optimum`](https://github.com/huggingface/optimum) 패키지를 설치한 후에는 추론 중 Better Transformer를 사용할 수 있도록 [`~PreTrainedModel.to_bettertransformer`]를 호출하여 관련 내부 모듈을 대체합니다:
+
+```python
+model = model.to_bettertransformer()
+```
+
+[`~PreTrainedModel.reverse_bettertransformer`] 메소드는 정규화된 transformers 모델링을 사용하기 위해 모델을 저장하기 전 원래의 모델링으로 돌아갈 수 있도록 해줍니다:
+
+```python
+model = model.reverse_bettertransformer()
+model.save_pretrained("saved_model")
+```
+
+PyTorch 2.0부터는 어텐션 패스트패스가 인코더와 디코더 모두에서 지원됩니다. 지원되는 아키텍처 목록은 [여기](https://huggingface.co/docs/optimum/bettertransformer/overview#supported-models)에서 확인할 수 있습니다.
+
+## FP4 혼합 정밀도 추론을 위한 `bitsandbytes` 통합 [[bitsandbytes-integration-for-fp4-mixedprecision-inference]]
+
+`bitsandbytes`를 설치하면 GPU에서 손쉽게 모델을 압축할 수 있습니다. FP4 양자화를 사용하면 원래의 전체 정밀도 버전과 비교하여 모델 크기를 최대 8배 줄일 수 있습니다. 아래에서 시작하는 방법을 확인하세요.
+
+
+
+이 기능은 다중 GPU 설정에서도 사용할 수 있습니다.
+
+
+
+### 요구 사항 [[requirements-for-fp4-mixedprecision-inference]]
+
+- 최신 `bitsandbytes` 라이브러리
+`pip install bitsandbytes>=0.39.0`
+
+- 최신 `accelerate`를 소스에서 설치
+`pip install git+https://github.com/huggingface/accelerate.git`
+
+- 최신 `transformers`를 소스에서 설치
+`pip install git+https://github.com/huggingface/transformers.git`
+
+### FP4 모델 실행 - 단일 GPU 설정 - 빠른 시작 [[running-fp4-models-single-gpu-setup-quickstart]]
+
+다음 코드를 실행하여 단일 GPU에서 빠르게 FP4 모델을 실행할 수 있습니다.
+
+```py
+from transformers import AutoModelForCausalLM
+
+model_name = "bigscience/bloom-2b5"
+model_4bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)
+```
+`device_map`은 선택 사항입니다. 그러나 `device_map = 'auto'`로 설정하는 것이 사용 가능한 리소스를 효율적으로 디스패치하기 때문에 추론에 있어 권장됩니다.
+
+### FP4 모델 실행 - 다중 GPU 설정 [[running-fp4-models-multi-gpu-setup]]
+
+다중 GPU에서 혼합 4비트 모델을 가져오는 방법은 단일 GPU 설정과 동일합니다(동일한 명령어 사용):
+```py
+model_name = "bigscience/bloom-2b5"
+model_4bit = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", load_in_4bit=True)
+```
+하지만 `accelerate`를 사용하여 각 GPU에 할당할 GPU RAM을 제어할 수 있습니다. 다음과 같이 `max_memory` 인수를 사용하세요:
+
+```py
+max_memory_mapping = {0: "600MB", 1: "1GB"}
+model_name = "bigscience/bloom-3b"
+model_4bit = AutoModelForCausalLM.from_pretrained(
+ model_name, device_map="auto", load_in_4bit=True, max_memory=max_memory_mapping
+)
+```
+이 예에서는 첫 번째 GPU가 600MB의 메모리를 사용하고 두 번째 GPU가 1GB를 사용합니다.
+
+### 고급 사용법 [[advanced-usage]]
+
+이 방법의 더 고급 사용법에 대해서는 [양자화](main_classes/quantization) 문서 페이지를 참조하세요.
+
+## Int8 혼합 정밀도 행렬 분해를 위한 `bitsandbytes` 통합 [[bitsandbytes-integration-for-int8-mixedprecision-matrix-decomposition]]
+
+
+
+이 기능은 다중 GPU 설정에서도 사용할 수 있습니다.
+
+
+
+[`LLM.int8() : 8-bit Matrix Multiplication for Transformers at Scale`](https://arxiv.org/abs/2208.07339) 논문에서 우리는 몇 줄의 코드로 Hub의 모든 모델에 대한 Hugging Face 통합을 지원합니다.
+이 방법은 `float16` 및 `bfloat16` 가중치에 대해 `nn.Linear` 크기를 2배로 줄이고, `float32` 가중치에 대해 4배로 줄입니다. 이는 절반 정밀도에서 이상치를 처리함으로써 품질에 거의 영향을 미치지 않습니다.
+
+
+
+Int8 혼합 정밀도 행렬 분해는 행렬 곱셈을 두 개의 스트림으로 분리합니다: (1) fp16로 곱해지는 체계적인 특이값 이상치 스트림 행렬(0.01%) 및 (2) int8 행렬 곱셈의 일반적인 스트림(99.9%). 이 방법을 사용하면 매우 큰 모델에 대해 예측 저하 없이 int8 추론이 가능합니다.
+이 방법에 대한 자세한 내용은 [논문](https://arxiv.org/abs/2208.07339)이나 [통합에 관한 블로그 글](https://huggingface.co/blog/hf-bitsandbytes-integration)에서 확인할 수 있습니다.
+
+
+
+커널은 GPU 전용으로 컴파일되어 있기 때문에 혼합 8비트 모델을 실행하려면 GPU가 필요합니다. 이 기능을 사용하기 전에 모델의 1/4(또는 모델 가중치가 절반 정밀도인 경우 절반)을 저장할 충분한 GPU 메모리가 있는지 확인하세요.
+이 모듈을 사용하는 데 도움이 되는 몇 가지 참고 사항이 아래에 나와 있습니다. 또는 [Google colab](#colab-demos)에서 데모를 따라할 수도 있습니다.
+
+### 요구 사항 [[requirements-for-int8-mixedprecision-matrix-decomposition]]
+
+- `bitsandbytes<0.37.0`을 사용하는 경우, 8비트 텐서 코어(Turing, Ampere 또는 이후 아키텍처 - 예: T4, RTX20s RTX30s, A40-A100)를 지원하는 NVIDIA GPU에서 실행하는지 확인하세요. `bitsandbytes>=0.37.0`을 사용하는 경우, 모든 GPU가 지원됩니다.
+- 올바른 버전의 `bitsandbytes`를 다음 명령으로 설치하세요:
+`pip install bitsandbytes>=0.31.5`
+- `accelerate`를 설치하세요
+`pip install accelerate>=0.12.0`
+
+### 혼합 Int8 모델 실행 - 단일 GPU 설정 [[running-mixedint8-models-single-gpu-setup]]
+
+필요한 라이브러리를 설치한 후 혼합 8비트 모델을 가져오는 방법은 다음과 같습니다:
+
+```py
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig
+
+model_name = "bigscience/bloom-2b5"
+model_8bit = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
+```
+
+텍스트 생성의 경우:
+
+* `pipeline()` 함수 대신 모델의 `generate()` 메소드를 사용하는 것을 권장합니다. `pipeline()` 함수로는 추론이 가능하지만, 혼합 8비트 모델에 최적화되지 않았기 때문에 `generate()` 메소드를 사용하는 것보다 느릴 수 있습니다. 또한, nucleus 샘플링과 같은 일부 샘플링 전략은 혼합 8비트 모델에 대해 `pipeline()` 함수에서 지원되지 않습니다.
+* 입력을 모델과 동일한 GPU에 배치하는 것이 좋습니다.
+
+다음은 간단한 예입니다:
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
+
+model_name = "bigscience/bloom-2b5"
+tokenizer = AutoTokenizer.from_pretrained(model_name)
+model_8bit = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
+
+prompt = "Hello, my llama is cute"
+inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
+generated_ids = model.generate(**inputs)
+outputs = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+```
+
+
+### 혼합 Int8 모델 실행 - 다중 GPU 설정 [[running-mixedint8-models-multi-gpu-setup]]
+
+다중 GPU에서 혼합 8비트 모델을 로드하는 방법은 단일 GPU 설정과 동일합니다(동일한 명령어 사용):
+```py
+model_name = "bigscience/bloom-2b5"
+model_8bit = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
+```
+하지만 `accelerate`를 사용하여 각 GPU에 할당할 GPU RAM을 제어할 수 있습니다. 다음과 같이 `max_memory` 인수를 사용하세요:
+
+```py
+max_memory_mapping = {0: "1GB", 1: "2GB"}
+model_name = "bigscience/bloom-3b"
+model_8bit = AutoModelForCausalLM.from_pretrained(
+ model_name, device_map="auto", load_in_8bit=True, max_memory=max_memory_mapping
+)
+```
+이 예시에서는 첫 번째 GPU가 1GB의 메모리를 사용하고 두 번째 GPU가 2GB를 사용합니다.
+
+### Colab 데모 [[colab-demos]]
+
+이 방법을 사용하면 이전에 Google Colab에서 추론할 수 없었던 모델에 대해 추론할 수 있습니다.
+Google Colab에서 8비트 양자화를 사용하여 T5-11b(42GB in fp32)를 실행하는 데모를 확인하세요:
+
+[](https://colab.research.google.com/drive/1YORPWx4okIHXnjW7MSAidXN29mPVNT7F?usp=sharing)
+
+또는 BLOOM-3B에 대한 데모를 확인하세요:
+
+[](https://colab.research.google.com/drive/1qOjXfQIAULfKvZqwCen8-MoWKGdSatZ4?usp=sharing)
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/perf_train_cpu.md b/docs/transformers/docs/source/ko/perf_train_cpu.md
new file mode 100644
index 0000000000000000000000000000000000000000..1a6c58b25afae10db053e7ae94b7f5c36c75fb7a
--- /dev/null
+++ b/docs/transformers/docs/source/ko/perf_train_cpu.md
@@ -0,0 +1,67 @@
+
+
+# CPU에서 효율적인 훈련 [[efficient-training-on-cpu]]
+
+이 가이드는 CPU에서 대규모 모델을 효율적으로 훈련하는 데 초점을 맞춥니다.
+
+## IPEX와 혼합 정밀도 [[mixed-precision-with-ipex]]
+
+IPEX는 AVX-512 이상을 지원하는 CPU에 최적화되어 있으며, AVX2만 지원하는 CPU에도 기능적으로 작동합니다. 따라서 AVX-512 이상의 Intel CPU 세대에서는 성능상 이점이 있을 것으로 예상되지만, AVX2만 지원하는 CPU (예: AMD CPU 또는 오래된 Intel CPU)의 경우에는 IPEX 아래에서 더 나은 성능을 보일 수 있지만 이는 보장되지 않습니다. IPEX는 Float32와 BFloat16를 모두 사용하여 CPU 훈련을 위한 성능 최적화를 제공합니다. BFloat16의 사용은 다음 섹션의 주요 초점입니다.
+
+저정밀도 데이터 타입인 BFloat16은 3세대 Xeon® Scalable 프로세서 (코드명: Cooper Lake)에서 AVX512 명령어 집합을 네이티브로 지원해 왔으며, 다음 세대의 Intel® Xeon® Scalable 프로세서에서 Intel® Advanced Matrix Extensions (Intel® AMX) 명령어 집합을 지원하여 성능을 크게 향상시킬 예정입니다. CPU 백엔드의 자동 혼합 정밀도 기능은 PyTorch-1.10부터 활성화되었습니다. 동시에, Intel® Extension for PyTorch에서 BFloat16에 대한 CPU의 자동 혼합 정밀도 및 연산자의 BFloat16 최적화를 대규모로 활성화하고, PyTorch 마스터 브랜치로 부분적으로 업스트림을 반영했습니다. 사용자들은 IPEX 자동 혼합 정밀도를 사용하여 더 나은 성능과 사용자 경험을 얻을 수 있습니다.
+
+[자동 혼합 정밀도](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/amp.html)에 대한 자세한 정보를 확인하십시오.
+
+### IPEX 설치: [[ipex-installation]]
+
+IPEX 릴리스는 PyTorch를 따라갑니다. pip를 통해 설치하려면:
+
+| PyTorch Version | IPEX version |
+| :---------------: | :----------: |
+| 1.13 | 1.13.0+cpu |
+| 1.12 | 1.12.300+cpu |
+| 1.11 | 1.11.200+cpu |
+| 1.10 | 1.10.100+cpu |
+
+```bash
+pip install intel_extension_for_pytorch== -f https://developer.intel.com/ipex-whl-stable-cpu
+```
+
+[IPEX 설치](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/installation.html)에 대한 더 많은 접근 방법을 확인하십시오.
+
+### Trainer에서의 사용법 [[usage-in-trainer]]
+Trainer에서 IPEX의 자동 혼합 정밀도를 활성화하려면 사용자는 훈련 명령 인수에 `use_ipex`, `bf16`, `no_cuda`를 추가해야 합니다.
+
+[Transformers 질문-응답](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)의 사용 사례를 살펴보겠습니다.
+
+- CPU에서 BF16 자동 혼합 정밀도를 사용하여 IPEX로 훈련하기:
+
+
+### 실습 예시 [[practice-example]]
+
+블로그: [Intel Sapphire Rapids로 PyTorch Transformers 가속화](https://huggingface.co/blog/intel-sapphire-rapids)
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/perf_train_cpu_many.md b/docs/transformers/docs/source/ko/perf_train_cpu_many.md
new file mode 100644
index 0000000000000000000000000000000000000000..e7a68971a7dc54e465dfbefb3290a5a46daf0524
--- /dev/null
+++ b/docs/transformers/docs/source/ko/perf_train_cpu_many.md
@@ -0,0 +1,134 @@
+
+
+# 다중 CPU에서 효율적으로 훈련하기 [[efficient-training-on-multiple-cpus]]
+
+하나의 CPU에서 훈련하는 것이 너무 느릴 때는 다중 CPU를 사용할 수 있습니다. 이 가이드는 PyTorch 기반의 DDP를 사용하여 분산 CPU 훈련을 효율적으로 수행하는 방법에 대해 설명합니다.
+
+## PyTorch용 Intel® oneCCL 바인딩 [[intel-oneccl-bindings-for-pytorch]]
+
+[Intel® oneCCL](https://github.com/oneapi-src/oneCCL) (collective communications library)은 allreduce, allgather, alltoall과 같은 집합 통신(collective communications)을 구현한 효율적인 분산 딥러닝 훈련을 위한 라이브러리입니다. oneCCL에 대한 자세한 정보는 [oneCCL 문서](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html)와 [oneCCL 사양](https://spec.oneapi.com/versions/latest/elements/oneCCL/source/index.html)을 참조하세요.
+
+`oneccl_bindings_for_pytorch` 모듈 (`torch_ccl`은 버전 1.12 이전에 사용)은 PyTorch C10D ProcessGroup API를 구현하며, 외부 ProcessGroup로 동적으로 가져올 수 있으며 현재 Linux 플랫폼에서만 작동합니다.
+
+[oneccl_bind_pt](https://github.com/intel/torch-ccl)에서 더 자세한 정보를 확인하세요.
+
+### PyTorch용 Intel® oneCCL 바인딩 설치: [[intel-oneccl-bindings-for-pytorch-installation]]
+
+다음 Python 버전에 대한 Wheel 파일을 사용할 수 있습니다.
+
+| Extension Version | Python 3.6 | Python 3.7 | Python 3.8 | Python 3.9 | Python 3.10 |
+| :---------------: | :--------: | :--------: | :--------: | :--------: | :---------: |
+| 1.13.0 | | √ | √ | √ | √ |
+| 1.12.100 | | √ | √ | √ | √ |
+| 1.12.0 | | √ | √ | √ | √ |
+| 1.11.0 | | √ | √ | √ | √ |
+| 1.10.0 | √ | √ | √ | √ | |
+
+```bash
+pip install oneccl_bind_pt=={pytorch_version} -f https://developer.intel.com/ipex-whl-stable-cpu
+```
+`{pytorch_version}`은 1.13.0과 같이 PyTorch 버전을 나타냅니다.
+[oneccl_bind_pt 설치](https://github.com/intel/torch-ccl)에 대한 더 많은 접근 방법을 확인해 보세요.
+oneCCL과 PyTorch의 버전은 일치해야 합니다.
+
+
+
+oneccl_bindings_for_pytorch 1.12.0 버전의 미리 빌드된 Wheel 파일은 PyTorch 1.12.1과 호환되지 않습니다(PyTorch 1.12.0용입니다).
+PyTorch 1.12.1은 oneccl_bindings_for_pytorch 1.12.10 버전과 함께 사용해야 합니다.
+
+
+
+## Intel® MPI 라이브러리 [[intel-mpi-library]]
+이 표준 기반 MPI 구현을 사용하여 Intel® 아키텍처에서 유연하고 효율적이며 확장 가능한 클러스터 메시징을 제공하세요. 이 구성 요소는 Intel® oneAPI HPC Toolkit의 일부입니다.
+
+oneccl_bindings_for_pytorch는 MPI 도구 세트와 함께 설치됩니다. 사용하기 전에 환경을 소스로 지정해야 합니다.
+
+Intel® oneCCL 버전 1.12.0 이상인 경우
+```bash
+oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
+source $oneccl_bindings_for_pytorch_path/env/setvars.sh
+```
+
+Intel® oneCCL 버전이 1.12.0 미만인 경우
+```bash
+torch_ccl_path=$(python -c "import torch; import torch_ccl; import os; print(os.path.abspath(os.path.dirname(torch_ccl.__file__)))")
+source $torch_ccl_path/env/setvars.sh
+```
+
+#### IPEX 설치: [[ipex-installation]]
+
+IPEX는 Float32와 BFloat16을 모두 사용하는 CPU 훈련을 위한 성능 최적화를 제공합니다. [single CPU section](./perf_train_cpu)을 참조하세요.
+
+
+이어서 나오는 "Trainer에서의 사용"은 Intel® MPI 라이브러리의 mpirun을 예로 들었습니다.
+
+
+## Trainer에서의 사용 [[usage-in-trainer]]
+Trainer에서 ccl 백엔드를 사용하여 멀티 CPU 분산 훈련을 활성화하려면 명령 인수에 **`--ddp_backend ccl`**을 추가해야 합니다.
+
+[질의 응답 예제](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)를 사용한 예를 살펴보겠습니다.
+
+
+다음 명령은 한 Xeon 노드에서 2개의 프로세스로 훈련을 활성화하며, 각 소켓당 하나의 프로세스가 실행됩니다. OMP_NUM_THREADS/CCL_WORKER_COUNT 변수는 최적의 성능을 위해 조정할 수 있습니다.
+```shell script
+ export CCL_WORKER_COUNT=1
+ export MASTER_ADDR=127.0.0.1
+ mpirun -n 2 -genv OMP_NUM_THREADS=23 \
+ python3 run_qa.py \
+ --model_name_or_path google-bert/bert-large-uncased \
+ --dataset_name squad \
+ --do_train \
+ --do_eval \
+ --per_device_train_batch_size 12 \
+ --learning_rate 3e-5 \
+ --num_train_epochs 2 \
+ --max_seq_length 384 \
+ --doc_stride 128 \
+ --output_dir /tmp/debug_squad/ \
+ --no_cuda \
+ --ddp_backend ccl \
+ --use_ipex
+```
+다음 명령은 두 개의 Xeon(노드0 및 노드1, 주 프로세스로 노드0을 사용)에서 총 4개의 프로세스로 훈련을 활성화하며, 각 소켓당 하나의 프로세스가 실행됩니다. OMP_NUM_THREADS/CCL_WORKER_COUNT 변수는 최적의 성능을 위해 조정할 수 있습니다.
+
+노드0에서는 각 노드의 IP 주소를 포함하는 구성 파일(예: hostfile)을 생성하고 해당 구성 파일 경로를 인수로 전달해야 합니다.
+```shell script
+ cat hostfile
+ xxx.xxx.xxx.xxx #node0 ip
+ xxx.xxx.xxx.xxx #node1 ip
+```
+이제 노드0에서 다음 명령을 실행하면 **4DDP**가 노드0 및 노드1에서 BF16 자동 혼합 정밀도로 활성화됩니다.
+```shell script
+ export CCL_WORKER_COUNT=1
+ export MASTER_ADDR=xxx.xxx.xxx.xxx #node0 ip
+ mpirun -f hostfile -n 4 -ppn 2 \
+ -genv OMP_NUM_THREADS=23 \
+ python3 run_qa.py \
+ --model_name_or_path google-bert/bert-large-uncased \
+ --dataset_name squad \
+ --do_train \
+ --do_eval \
+ --per_device_train_batch_size 12 \
+ --learning_rate 3e-5 \
+ --num_train_epochs 2 \
+ --max_seq_length 384 \
+ --doc_stride 128 \
+ --output_dir /tmp/debug_squad/ \
+ --no_cuda \
+ --ddp_backend ccl \
+ --use_ipex \
+ --bf16
+```
diff --git a/docs/transformers/docs/source/ko/perf_train_gpu_many.md b/docs/transformers/docs/source/ko/perf_train_gpu_many.md
new file mode 100644
index 0000000000000000000000000000000000000000..b8553ea499ef10af4746e50aac6a2362309cdb55
--- /dev/null
+++ b/docs/transformers/docs/source/ko/perf_train_gpu_many.md
@@ -0,0 +1,533 @@
+
+
+# 다중 GPU에서 효율적인 훈련 [[efficient-training-on-multiple-gpus]]
+
+단일 GPU에서의 훈련이 너무 느리거나 모델 가중치가 단일 GPU의 메모리에 맞지 않는 경우, 다중-GPU 설정을 사용합니다. 단일 GPU에서 다중 GPU로 전환하기 위해서는 작업을 분산해야 합니다. 데이터, 텐서 또는 파이프라인과 같은 병렬화 기법을 사용하여 작업을 병렬로 처리할 수 있습니다. 그러나 이러한 설정을 모두에게 적용할 수 있는 완벽한 해결책은 없으며, 어떤 설정이 가장 적합한지는 사용하는 하드웨어에 따라 달라집니다. 이 문서는 주로 PyTorch 기반의 구현을 중심으로 설명하며, 대부분의 개념은 다른 프레임워크에도 적용될 수 있을 것으로 예상됩니다.
+
+
+
+ 참고: [단일 GPU 섹션](perf_train_gpu_one)에서 소개된 전략(혼합 정밀도 훈련 또는 그래디언트 누적 등)은 일반적으로 모델 훈련에 적용되며, 다중-GPU 또는 CPU 훈련과 같은 다음 섹션으로 진입하기 전에 해당 섹션을 참고하는 것이 좋습니다.
+
+
+
+먼저 1D 병렬화 기술에 대해 자세히 논의한 후, 이러한 기술을 결합하여 2D 및 3D 병렬화를 구현하여 더 빠른 훈련과 더 큰 모델을 지원하는 방법을 살펴볼 것입니다. 또한 다른 효과적인 대안 방식도 소개될 예정입니다.
+
+## 개념 [[concepts]]
+
+다음은 이 문서에서 자세히 설명될 주요 개념에 대한 간단한 설명입니다.
+
+1. **DataParallel (DP)** - 동일한 설정이 여러 번 복제되고, 각 설정에 데이터 일부를 받습니다. 처리는 병렬로 수행되며 모든 설정은 각 훈련 단계의 끝날 때 동기화됩니다.
+2. **TensorParallel (TP)** - 각 텐서는 여러 개의 묶음으로 분할되기에, 전체 텐서가 단일 GPU에 상주하는 대신 텐서의 각 샤드가 지정된 GPU에 상주합니다. 처리하는 동안 각 샤드는 서로 다른 GPU에서 개별적으로 병렬 처리되며 결과는 단계가 끝날 때 동기화됩니다. 분할이 수평 수준에서 이루어지기 때문에 이를 수평 병렬 처리라고 부를 수 있습니다.
+3. **PipelineParallel (PP)** - 모델이 수직으로 (레이어 수준) 여러 GPU에 분할되어 모델의 단일 GPU에는 하나 또는 여러 레이어가 배치됩니다. 각 GPU는 파이프라인의 서로 다른 단계를 병렬로 처리하며 작은 배치 묶음에서 작동합니다.
+4. **Zero Redundancy Optimizer (ZeRO)** - TP와 유사하게 텐서를 샤딩하지만, 전체 텐서는 순방향 또는 역방향 계산을 위해 재구성되므로 모델을 수정할 필요가 없습니다. 또한 제한된 GPU 메모리를 보완하기 위해 다양한 오프로드 기술을 지원합니다.
+5. **Sharded DDP** - ZeRO의 기본 개념으로 다른 ZeRO 구현에서도 사용되는 용어입니다.
+
+각 개념의 구체적인 내용에 대해 자세히 들어가기 전에 대규모 인프라에서 대규모 모델을 훈련하는 경우의 대략적인 결정 과정을 살펴보겠습니다.
+
+## 확장성 전략 [[scalability-strategy]]
+
+**⇨ 단일 노드 / 다중-GPU**
+* 모델이 단일 GPU에 맞는 경우:
+
+ 1. DDP - 분산 DP
+ 2. ZeRO - 상황과 구성에 따라 더 빠를 수도 있고 그렇지 않을 수도 있음
+
+* 모델이 단일 GPU에 맞지 않는 경우:
+
+ 1. PP
+ 2. ZeRO
+ 3. TP
+
+ 노드 내 연결 속도가 매우 빠른 NVLINK 또는 NVSwitch의 경우 세 가지 방법은 대부분 비슷한 성능을 보여야 하며, PP가 없는 경우 TP 또는 ZeRO보다 빠를 것입니다. TP의 정도도 차이를 만들 수 있습니다. 특정 설정에서 승자를 찾기 위해 실험하는 것이 가장 좋습니다.
+
+ TP는 거의 항상 단일 노드 내에서 사용됩니다. 즉, TP 크기 <= 노드당 GPU 수입니다.
+
+* 가장 큰 레이어가 단일 GPU에 맞지 않는 경우:
+
+ 1. ZeRO를 사용하지 않는 경우 - PP만으로는 맞지 않으므로 TP를 반드시 사용해야 함
+ 2. ZeRO를 사용하는 경우에는 위의 "단일 GPU" 항목과 동일
+
+
+**⇨ 다중 노드 / 다중 GPU**
+
+* 노드 간 연결 속도가 빠른 경우:
+
+ 1. ZeRO - 모델에 대부분의 수정을 필요로 하지 않음
+ 2. PP+TP+DP - 통신이 적지만 모델에 대대적인 변경이 필요함
+
+* 노드 간 연결 속도가 느리며, GPU 메모리가 여전히 부족한 경우:
+
+ 1. DP+PP+TP+ZeRO-1
+
+
+
+## 데이터 병렬화 [[data-parallelism]]
+
+2개의 GPU만으로도 대부분의 사용자들은 `DataParallel` (DP)과 `DistributedDataParallel` (DDP)을 통해 향상된 훈련 속도를 누릴 수 있습니다. 이는 PyTorch의 내장 기능입니다. 일반적으로 DDP를 사용하는 것이 좋으며, DP는 일부 모델에서 작동하지 않을 수 있으므로 주의해야 합니다. [PyTorch 문서](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html)에서도 DDP의 사용을 권장합니다.
+
+### DP vs DDP [[dp-vs-ddp]]
+
+`DistributedDataParallel` (DDP)은 일반적으로 `DataParallel` (DP)보다 빠르지만, 항상 그렇지는 않습니다:
+* DP는 파이썬 스레드 기반인 반면, DDP는 다중 프로세스 기반이기 때문에 GIL과 같은 파이썬 스레드 제한이 없습니다.
+* 그러나 GPU 카드 간의 느린 상호 연결성은 DDP로 인해 실제로 느린 결과를 낼 수 있습니다.
+
+이 두 모드 간의 GPU 간 통신 오버헤드의 주요 차이점은 다음과 같습니다:
+
+[DDP](https://pytorch.org/docs/master/notes/ddp.html):
+
+- 시작할 때, 주 프로세스가 모델을 gpu 0에서 다른 모든 gpu로 복제합니다.
+- 그런 다음 각 배치에 대해:
+ 1. 각 gpu는 자체 미니 배치 데이터를 직접 사용합니다.
+ 2. `backward` 동안 로컬 그래디언트가 준비되면, 모든 프로세스에 평균화됩니다.
+
+[DP](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html):
+
+각 배치에 대해:
+ 1. gpu 0은 데이터 배치를 읽고 각 gpu에 미니 배치를 보냅니다.
+ 2. 업데이트된 모델을 gpu 0에서 각 gpu로 복제합니다.
+ 3. `forward`를 실행하고 각 gpu의 출력을 gpu 0으로 보내고 손실을 계산합니다.
+ 4. gpu 0에서 모든 gpu로 손실을 분산하고 `backward`를 실행합니다.
+ 5. 각 gpu에서 그래디언트를 gpu 0으로 보내고 이를 평균화합니다.
+
+DDP는 각 배치마다 그래디언트를 보내는 통신만을 수행하며, DP는 배치마다 5개의 다른 데이터 교환을 수행합니다.
+
+DP는 파이썬 스레드를 통해 프로세스 내에서 데이터를 복제하며, DDP는 [torch.distributed](https://pytorch.org/docs/master/distributed.html)를 통해 데이터를 복제합니다.
+
+DP에서는 gpu 0이 다른 gpu보다 훨씬 더 많은 작업을 수행하므로, gpu의 활용도가 낮아집니다.
+
+DDP는 여러 대의 컴퓨터에서 사용할 수 있지만, DP의 경우는 그렇지 않습니다.
+
+DP와 DDP 사이에는 다른 차이점이 있지만, 이 토론과는 관련이 없습니다.
+
+이 2가지 모드를 깊게 이해하고 싶다면, [이 문서](https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/)를 강력히 추천합니다. 이 문서는 멋진 다이어그램을 포함하고 있으며, 다양한 하드웨어에서 여러 벤치마크와 프로파일러 출력을 설명하여 필요한 세부 사항을 모두 설명합니다.
+
+실제 벤치마크를 살펴보겠습니다:
+
+| Type | NVlink | Time |
+| :----- | ----- | ---: |
+| 2:DP | Y | 110s |
+| 2:DDP | Y | 101s |
+| 2:DDP | N | 131s |
+
+
+분석:
+
+여기서 DP는 NVlink가 있는 DDP보다 약 10% 느립니다. 그러나 NVlink가 없는 DDP보다 약 15% 빠릅니다.
+
+실제 차이는 각 GPU가 다른 GPU와 동기화해야 하는 데이터 양에 따라 달라질 것입니다. 동기화할 데이터가 많을수록 느린 링크가 총 실행 시간을 늦출 수 있습니다.
+
+다음은 전체 벤치마크 코드와 출력입니다:
+
+해당 벤치마크에서 `NCCL_P2P_DISABLE=1`을 사용하여 NVLink 기능을 비활성화했습니다.
+
+```bash
+
+# DP
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
+python examples/pytorch/language-modeling/run_clm.py \
+--model_name_or_path openai-community/gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
+--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 110.5948, 'train_samples_per_second': 1.808, 'epoch': 0.69}
+
+# DDP w/ NVlink
+rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
+torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+--model_name_or_path openai-community/gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
+--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
+
+# DDP w/o NVlink
+rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
+torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
+--model_name_or_path openai-community/gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
+--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
+
+{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
+```
+
+하드웨어: 각각 24GB의 TITAN RTX 2개 + NVlink과 2개의 NVLink (`nvidia-smi topo -m`에서 `NV2`입니다.)
+소프트웨어: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
+
+## ZeRO 데이터 병렬화 [[zero-data-parallelism]]
+
+ZeRO를 기반으로 한 데이터 병렬화 (ZeRO-DP)는 다음 [블로그 글](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/)의 다음 다이어그램에서 설명되고 있습니다.
+
+
+이 개념은 이해하기 어려울 수 있지만, 실제로는 매우 간단한 개념입니다. 이는 일반적인 `DataParallel` (DP)과 동일하지만, 전체 모델 매개변수, 그래디언트 및 옵티마이저 상태를 복제하는 대신 각 GPU는 그 중 일부만 저장합니다. 그리고 실행 시간에는 주어진 레이어에 대해 전체 레이어 매개변수가 필요할 때 각 GPU가 서로에게 필요한 부분을 제공하기 위해 동기화됩니다 - 그게 전부입니다.
+
+각각 3개의 레이어와 3개의 매개변수가 있는 간단한 모델을 생각해 봅시다:
+```
+La | Lb | Lc
+---|----|---
+a0 | b0 | c0
+a1 | b1 | c1
+a2 | b2 | c2
+```
+레이어 La에는 가중치 a0, a1 및 a2가 있습니다.
+
+3개의 GPU가 있는 경우, Sharded DDP (= Zero-DP)는 다음과 같이 모델을 3개의 GPU에 분할합니다:
+
+```
+GPU0:
+La | Lb | Lc
+---|----|---
+a0 | b0 | c0
+
+GPU1:
+La | Lb | Lc
+---|----|---
+a1 | b1 | c1
+
+GPU2:
+La | Lb | Lc
+---|----|---
+a2 | b2 | c2
+```
+
+일반적인 DNN 다이어그램을 상상해보면 이는 텐서 병렬 처리와 같은 수평 슬라이싱입니다. 수직 슬라이싱은 전체 레이어 그룹을 다른 GPU에 배치하는 것입니다. 이는 시작에 불과합니다.
+
+이제 이러한 각각의 GPU는 DP에서 작동하는 것과 마찬가지로 일반적인 미니 배치를 받습니다:
+```
+x0 => GPU0
+x1 => GPU1
+x2 => GPU2
+```
+
+입력은 수정되지 않은 상태로 일반 모델에 의해 처리될 것으로 간주합니다.
+
+먼저, 입력은 레이어 La에 도달합니다.
+
+GPU0에만 집중해 보겠습니다. x0은 순방향 경로를 수행하기 위해 a0, a1, a2 파라미터가 필요하지만 GPU0에는 a0만 있습니다. GPU1에서 a1을, GPU2에서 a2를 전송받아 모델의 모든 조각을 하나로 모읍니다.
+
+병렬적으로, GPU1은 미니 배치 x1을 받고 a1만 가지고 있지만, a0 및 a2 매개변수가 필요합니다. 따라서 GPU0 및 GPU2에서 이를 가져옵니다.
+
+GPU2도 동일한 작업을 수행합니다. 입력 x2를 받고 GPU0 및 GPU1에서 각각 a0과 a1을, 그리고 자신의 a2와 함께 전체 텐서를 복원합니다.
+
+3개의 GPU는 복원된 전체 텐서를 받고 forward가 수행됩니다.
+
+계산이 완료되면 더 이상 필요하지 않은 데이터는 삭제되고, 해당 데이터는 계산 중에만 사용됩니다. 복원은 사전 패치를 통해 효율적으로 수행됩니다.
+
+그리고 전체 프로세스는 레이어 Lb에 대해 반복되고, 그 다음 Lc로 순방향으로, 그다음은 역방향으로 Lc -> Lb -> La로 반복됩니다.
+
+개인적으로 이것은 효율적인 그룹 배낭 여행자의 중량 분배 전략처럼 들립니다:
+
+1. 사람 A가 텐트를 운반합니다.
+2. 사람 B가 난로를 운반합니다.
+3. 사람 C가 도끼를 운반합니다.
+
+이제 매일 밤 각자 가진 것을 다른 사람들과 공유하고, 가지지 않은 것은 다른 사람들로부터 받고, 아침에는 할당된 유형의 장비를 싸고 계속해서 여행을 진행합니다. 이것이 Sharded DDP / Zero DP입니다.
+
+이 전략을 각각 자신의 텐트, 난로 및 도끼를 개별적으로 운반해야 하는 단순한 전략과 비교해보면 훨씬 비효율적일 것입니다. 이것이 Pytorch의 DataParallel (DP 및 DDP)입니다.
+
+이 주제에 대해 논문을 읽을 때 다음 동의어를 만날 수 있습니다: Sharded, Partitioned.
+
+ZeRO가 모델 가중치를 분할하는 방식을 자세히 살펴보면, 텐서 병렬화와 매우 유사한 것을 알 수 있습니다. 이는 이후에 설명될 수직 모델 병렬화와는 달리 각 레이어의 가중치를 분할/분할하기 때문입니다.
+
+구현:
+
+- [DeepSpeed](https://www.deepspeed.ai/tutorials/zero/)는 1단계 + 2단계 + 3단계의 ZeRO-DP를 제공합니다.
+- [Fairscale](https://github.com/facebookresearch/fairscale/#optimizer-state-sharding-zero)은 1단계 + 2단계 + 3단계의 ZeRO-DP를 제공합니다.
+- [`transformers` 통합](main_classes/trainer#trainer-integrations)
+
+## 네이티브 모델 병렬 처리(수직적) 및 파이프라인 병렬 처리[[naive-model-parallelism-vertical-and-pipeline-parallelism]]
+
+Naive Model Parallelism (MP)은 모델 레이어 그룹을 다중 GPU에 분산하는 방식입니다. 메커니즘은 상대적으로 간단합니다. 원하는 레이어를 `.to()`를 사용하여 원하는 장치로 전환하면 데이터가 해당 레이어로 들어오고 나갈 때 데이터도 레이어와 동일한 장치로 전환되고 나머지는 수정되지 않습니다.
+
+대부분의 모델이 그려지는 방식이 레이어를 세로로 슬라이스하기 때문에 이를 수직 모델 병렬화라고 부릅니다. 예를 들어 다음 다이어그램은 8레이어 모델을 보여줍니다:
+
+```
+=================== ===================
+| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
+=================== ===================
+ gpu0 gpu1
+```
+우리는 모델을 수직으로 2개로 분할하여 레이어 0-3을 GPU0에 배치하고 레이어 4-7을 GPU1에 배치했습니다.
+
+이제 데이터가 레이어 0에서 1로, 1에서 2로, 2에서 3으로 이동하는 동안에는 일반적인 모델입니다. 그러나 데이터가 레이어 3에서 레이어 4로 전달되어야 할 때는 GPU0에서 GPU1로 이동해야 하므로 통신 오버헤드가 발생합니다. 참여하는 GPU가 동일한 컴퓨팅 노드(예: 동일한 물리적인 기계)에 있는 경우 이 복사는 매우 빠릅니다. 그러나 GPU가 서로 다른 컴퓨팅 노드(예: 여러 기계)에 위치한 경우 통신 오버헤드는 상당히 크게 될 수 있습니다.
+
+그런 다음 레이어 4부터 5로, 6으로, 7로 진행되는 것은 일반적인 모델과 동일하게 진행되고, 7번째 레이어가 완료되면 데이터를 다시 레이어 0으로 보내거나 또는 레이블을 마지막 레이어로 보내야 할 필요가 있습니다. 이제 손실을 계산하고 옵티마이저가 작동할 수 있습니다.
+
+문제점:
+- 이 방식을 "naive" MP라고 부르는 이유는 주어진 상황에 하나의 GPU를 제외한 모든 GPU가 유휴 상태라는 점입니다. 따라서 4개의 GPU를 사용하는 경우 단일 GPU의 메모리 양을 4배로 늘리고 나머지 하드웨어는 무시하는 것과 거의 동일합니다. 또한 장치 간 데이터 복사의 오버헤드도 있습니다. 따라서 4개의 6GB 카드는 naive MP를 사용하여 1개의 24GB 카드와 동일한 크기를 수용할 수 있지만, 후자는 데이터 복사의 오버헤드가 없으므로 훈련을 더 빨리 완료합니다. 그러나 예를 들어 40GB 카드가 있고 45GB 모델을 맞추어야 할 경우 4개의 40GB 카드로 맞출 수 있습니다 (하지만 그래디언트와 옵티마이저 상태 때문에 가까스로 가능합니다).
+- 공유 임베딩은 GPU 간에 복사해야 할 수도 있습니다.
+
+파이프라인 병렬화 (PP)은 거의 naive MP와 동일하지만 GPU 유휴 상태 문제를 해결하기 위해 들어오는 배치를 마이크로 배치로 나누고 인공적으로 파이프라인을 생성하여 서로 다른 GPU가 동시에 계산에 참여할 수 있게 합니다.
+
+[GPipe 논문](https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html)에서 가져온 그림은 상단에 naive MP를, 하단에는 PP를 보여줍니다:
+
+
+
+하단 다이어그램에서 PP가 유휴 영역이 적은 것을 쉽게 볼 수 있습니다. 유휴 부분을 "bubble"이라고 합니다.
+
+다이어그램의 양쪽 부분은 참여하는 GPU가 4개인 병렬성을 보여줍니다. 즉, 4개의 GPU가 파이프라인에 참여합니다. 따라서 4개의 파이프 단계 F0, F1, F2 및 F3의 순방향 경로와 B3, B2, B1 및 B0의 역방향 경로가 있습니다.
+
+PP는 조정해야 할 새로운 하이퍼파라미터인 `chunks`를 도입합니다. 이는 동일한 파이프 단계를 통해 일련의 데이터를 묶어서 보내는 방식을 정의합니다. 예를 들어, 아래 다이어그램에서 `chunks=4`를 볼 수 있습니다. GPU0은 0, 1, 2 및 3 (F0,0, F0,1, F0,2, F0,3) 묶음에서 동일한 순방향 경로를 수행하고, 다른 GPU가 작업을 수행하기 시작하고 완료가 시작될 때만 GPU0이 묶음의 역순으로 3, 2, 1 및 0 (B0,3, B0,2, B0,1, B0,0) 경로를 수행합니다.
+
+개념적으로 이는 그래디언트 누적 단계 (GAS)와 동일한 개념입니다. 파이토치에서는 `chunks`를 사용하고 DeepSpeed에서는 동일한 하이퍼파라미터를 GAS로 참조합니다.
+
+묶음으로 인해 PP는 마이크로 배치 (MBS)의 개념을 도입합니다. DP는 전역 데이터 배치 크기를 미니 배치로 나눕니다. 따라서 DP 차수가 4이고 전역 배치 크기가 1024이면 256씩 4개의 미니 배치로 분할됩니다 (1024/4). 그리고 `chunks` (또는 GAS)의 수가 32이면 마이크로 배치 크기는 8이 됩니다 (256/32). 각 파이프라인 단계는 한 번에 하나의 마이크로 배치와 함께 작동합니다.
+
+DP + PP 설정의 전역 배치 크기를 계산하려면 `mbs*chunks*dp_degree` (`8*32*4=1024`)를 수행합니다.
+
+다이어그램으로 돌아가 보겠습니다.
+
+`chunks=1`로 설정하면 매우 비효율적인 naive MP가 생성되며, 매우 큰 `chunks` 값으로 설정하면 아주 작은 마이크로 배치 크기가 생성되어 효율적이지 않을 수 있습니다. 따라서 가장 효율적인 GPU 활용을 위해 어떤 값이 가장 적절한지 실험을 해야 합니다.
+
+다이어그램에서 보이는 것처럼 "dead" 시간의 버블이 존재하여 마지막 `forward` 단계가 `backward` 단계가 파이프라인을 완료하기를 기다려야 하는 상황이 발생하지만, `chunks`의 가장 적절한 값을 찾는 것의 목적은 모든 참여하는 GPU에서 동시에 고도로 활용되는 GPU 활용을 가능하게 하여 버블의 크기를 최소화하는 것입니다.
+
+해결책은 전통적인 파이프라인 API와 더 현대적인 솔루션으로 나뉩니다. 전통적인 파이프라인 API 솔루션과 현대적인 솔루션에 대해 알아보겠습니다.
+
+전통적인 파이프라인 API 솔루션:
+- 파이토치
+- FairScale
+- DeepSpeed
+- Megatron-LM
+
+현대적인 솔루션:
+- Varuna
+- Sagemaker
+
+전통적인 파이프라인 API 솔루션의 문제점:
+- 모델을 상당히 수정해야 한다는 점이 문제입니다. 파이프라인은 모듈의 정상적인 흐름을 `nn.Sequential` 시퀀스로 다시 작성해야 하므로 모델의 설계를 변경해야 할 수 있습니다.
+- 현재 파이프라인 API는 매우 제한적입니다. 파이프라인의 매우 첫 번째 단계에서 전달되는 많은 파이썬 변수가 있는 경우 이를 해결해야 합니다. 현재 파이프라인 인터페이스는 하나의 텐서 또는 텐서의 튜플을 유일한 입력 및 출력으로 요구합니다. 이러한 텐서는 마이크로 배치로 미니 배치로 묶을 것이므로 첫 번째 차원으로 배치 크기가 있어야 합니다. 가능한 개선 사항은 여기에서 논의되고 있습니다. https://github.com/pytorch/pytorch/pull/50693
+- 파이프 단계 수준에서 조건부 제어 흐름은 불가능합니다. 예를 들어, T5와 같은 인코더-디코더 모델은 조건부 인코더 단계를 처리하기 위해 특별한 해결책이 필요합니다.
+- 각 레이어를 정렬하여 하나의 모델의 출력이 다른 모델의 입력이 되도록해야 합니다.
+
+우리는 아직 Varuna와 SageMaker로 실험하지 않았지만, 해당 논문들은 위에서 언급한 문제들의 목록을 극복했고 사용자의 모델에 대한 변경 사항이 훨씬 적게 필요하다고 보고하고 있습니다.
+
+구현:
+- [파이토치](https://pytorch.org/docs/stable/pipeline.html) (파이토치-1.8에서 초기 지원, 1.9에서 점진적으로 개선되고 1.10에서 더 개선됨). [예제](https://github.com/pytorch/pytorch/blob/master/benchmarks/distributed/pipeline/pipe.py)도 참고하세요.
+- [FairScale](https://fairscale.readthedocs.io/en/latest/tutorials/pipe.html)
+- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
+- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)은 내부 구현을 가지고 있습니다 - API 없음.
+- [Varuna](https://github.com/microsoft/varuna)
+- [SageMaker](https://arxiv.org/abs/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
+- [OSLO](https://github.com/tunib-ai/oslo) - 이는 Hugging Face Transformers를 기반으로 구현된 파이프라인 병렬화입니다.
+
+🤗 Transformers 상태: 이 작성 시점에서 모델 중 어느 것도 완전한 PP를 지원하지 않습니다. GPT2와 T5 모델은 naive MP를 지원합니다. 주요 장애물은 모델을 `nn.Sequential`로 변환하고 모든 입력을 텐서로 가져와야 하는 것을 처리할 수 없기 때문입니다. 현재 모델에는 이러한 변환을 매우 복잡하게 만드는 많은 기능이 포함되어 있어 제거해야 합니다.
+
+기타 접근 방법:
+
+DeepSpeed, Varuna 및 SageMaker는 [교차 파이프라인(Interleaved Pipeline)](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features.html) 개념을 사용합니다.
+
+
+여기서는 버블(유휴 시간)을 역방향 패스에 우선순위를 부여하여 최소화합니다.
+
+Varuna는 가장 효율적인 스케줄링을 찾기 위해 시뮬레이션을 사용하여 스케줄을 개선하려고 합니다.
+
+OSLO는 `nn.Sequential`로 변환하지 않고 Transformers를 기반으로 한 파이프라인 병렬화를 구현했습니다.
+
+## 텐서 병렬 처리 [[tensor-parallelism]]
+
+텐서 병렬 처리에서는 각 GPU가 텐서의 일부분만 처리하고 전체 텐서가 필요한 연산에 대해서만 전체 텐서를 집계합니다.
+
+이 섹션에서는 [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) 논문인 [Efficient Large-Scale Language Model Training on GPU Clusters](https://arxiv.org/abs/2104.04473)에서의 개념과 다이어그램을 사용합니다.
+
+Transformer의 주요 구성 요소는 fully connected `nn.Linear`와 비선형 활성화 함수인 `GeLU`입니다.
+
+Megatron 논문의 표기법을 따라 행렬의 점곱 부분을 `Y = GeLU(XA)`로 표현할 수 있습니다. 여기서 `X`와 `Y`는 입력 및 출력 벡터이고 `A`는 가중치 행렬입니다.
+
+행렬 형태로 계산을 살펴보면, 행렬 곱셈을 다중 GPU로 분할할 수 있는 방법을 쉽게 알 수 있습니다:
+
+
+가중치 행렬 `A`를 `N`개의 GPU에 대해 열별로 분할하고 병렬로 행렬 곱셈 `XA_1`에서 `XA_n`까지 수행하면 `N`개의 출력 벡터 `Y_1, Y_2, ..., Y_n`가 생성되며 독립적으로 `GeLU`에 전달될 수 있습니다:
+
+
+이 원리를 사용하여 동기화가 필요하지 않은 GPU 간의 임의 깊이의 MLP를 업데이트할 수 있습니다. 그러나 결과 벡터를 샤드로부터 재구성해야 하는 마지막 단계까지는 GPU 간의 동기화가 필요합니다. Megatron-LM 논문의 저자들은 이에 대한 유용한 그림을 제공합니다:
+
+
+다중 헤드 어텐션 레이어의 병렬화는 더욱 간단합니다. 이미 독립적인 다중 헤드를 가지고 있기 때문에 이미 병렬화되어 있습니다!
+
+
+특별 고려사항: TP는 매우 빠른 네트워크가 필요하므로 한 개 이상의 노드에서 TP를 수행하는 것은 권장되지 않습니다. 실제로 노드에 4개의 GPU가 있는 경우 TP의 최대 차수는 4입니다. TP 차수가 8인 경우 최소한 8개의 GPU가 있는 노드를 사용해야 합니다.
+
+이 섹션은 원래의 [더 자세한 TP 개요](https://github.com/huggingface/transformers/issues/10321#issuecomment-783543530)를 기반으로 합니다.
+작성자는 [@anton-l](https://github.com/anton-l)입니다.
+
+SageMaker는 더 효율적인 처리를 위해 TP와 DP를 결합합니다.
+
+대체 이름:
+- DeepSpeed는 이를 [텐서 슬라이싱](https://www.deepspeed.ai/training/#model-parallelism)이라고 부릅니다.
+
+구현:
+- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)은 내부 구현을 가지고 있으므로 모델에 매우 특화되어 있습니다.
+- [parallelformers](https://github.com/tunib-ai/parallelformers) (현재는 추론에만 해당)
+- [SageMaker](https://arxiv.org/abs/2111.05972) - 이는 AWS에서만 사용할 수 있는 소유 솔루션입니다.
+- [OSLO](https://github.com/tunib-ai/oslo)은 Transformers를 기반으로 한 텐서 병렬 처리 구현을 가지고 있습니다.
+
+🤗 Transformers 현황:
+- core: 아직 핵심 부분에 구현되지 않음
+- 그러나 추론을 하려면 [parallelformers](https://github.com/tunib-ai/parallelformers)가 대부분의 모델을 지원합니다. 따라서 핵심 부분에 구현되기 전까지 그들의 것을 사용할 수 있습니다. 그리고 훈련 모드도 지원될 예정입니다.
+- Deepspeed-Inference는 CUDA 커널을 기반으로 하는 매우 빠른 추론 모드에서 BERT, GPT-2 및 GPT-Neo 모델을 지원합니다. 자세한 내용은 [여기](https://www.deepspeed.ai/tutorials/inference-tutorial/)를 참조하세요.
+
+## DP+PP [[dppp]]
+
+DeepSpeed [pipeline tutorial](https://www.deepspeed.ai/tutorials/pipeline/)에서 다음 다이어그램은 DP와 PP를 결합하는 방법을 보여줍니다.
+
+
+
+여기서 DP 랭크 0은 GPU2를 보지 못하고, DP 랭크 1은 GPU3을 보지 못하는 것이 중요합니다. DP에게는 딱 2개의 GPU인 것처럼 데이터를 공급합니다. GPU0은 PP를 사용하여 GPU2에게 일부 작업을 "비밀리에" 할당합니다. 그리고 GPU1도 GPU3을 도움으로 삼아 같은 방식으로 작업합니다.
+
+각 차원마다 적어도 2개의 GPU가 필요하므로 최소한 4개의 GPU가 필요합니다.
+
+구현:
+- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed)
+- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
+- [Varuna](https://github.com/microsoft/varuna)
+- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [OSLO](https://github.com/tunib-ai/oslo)
+
+🤗 Transformers 현황: 아직 구현되지 않음
+
+## DP+PP+TP [[dppptp]]
+
+더 효율적인 훈련을 위해 PP와 TP 및 DP를 결합하여 3D 병렬 처리를 사용합니다. 다음 다이어그램에서 이를 확인할 수 있습니다.
+
+
+
+이 다이어그램은 [3D parallelism: Scaling to trillion-parameter models](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/)이라는 블로그 글에서 확인할 수 있습니다.
+
+각 차원마다 적어도 2개의 GPU가 필요하므로 최소한 8개의 GPU가 필요합니다.
+
+구현:
+- [DeepSpeed](https://github.com/deepspeedai/DeepSpeed) - DeepSpeed는 더욱 효율적인 DP인 ZeRO-DP라고도 부릅니다.
+- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
+- [Varuna](https://github.com/microsoft/varuna)
+- [SageMaker](https://arxiv.org/abs/2111.05972)
+- [OSLO](https://github.com/tunib-ai/oslo)
+
+🤗 Transformers 현황: 아직 구현되지 않음. PP와 TP가 없기 때문입니다.
+
+## ZeRO DP+PP+TP [[zero-dppptp]]
+
+DeepSpeed의 주요 기능 중 하나는 DP의 확장인 ZeRO입니다. ZeRO-DP에 대해 이미 [ZeRO Data Parallelism](#zero-data-parallelism)에서 논의되었습니다. 일반적으로 이는 PP나 TP를 필요로하지 않는 독립적인 기능입니다. 그러나 PP와 TP와 결합할 수도 있습니다.
+
+ZeRO-DP가 PP와 (선택적으로 TP와) 결합되면 일반적으로 ZeRO 단계 1(옵티마이저 분할)만 활성화됩니다.
+
+이론적으로는 ZeRO 단계 2(그라디언트 분할)를 파이프라인 병렬 처리와 함께 사용할 수도 있지만, 이는 성능에 나쁜 영향을 미칠 것입니다. 각 마이크로 배치마다 그라디언트를 샤딩하기 전에 추가적인 리듀스-스캐터 컬렉티브가 필요하며, 이는 잠재적으로 상당한 통신 오버헤드를 추가합니다. 파이프라인 병렬 처리의 특성상 작은 마이크로 배치가 사용되며, 산술 연산 강도(마이크로 배치 크기)를 균형 있게 유지하면서 파이프라인 버블(마이크로 배치 수)을 최소화하는 것에 중점을 둡니다. 따라서 해당 통신 비용은 문제가 될 것입니다.
+
+또한, PP로 인해 정상보다 적은 수의 레이어가 있으므로 메모리 절약은 크지 않을 것입니다. PP는 이미 그래디언트 크기를 ``1/PP``로 줄이기 때문에 그래디언트 샤딩의 절약 효과는 순수 DP보다는 미미합니다.
+
+ZeRO 단계 3도 같은 이유로 좋은 선택이 아닙니다 - 더 많은 노드 간 통신이 필요합니다.
+
+그리고 ZeRO가 있기 때문에 다른 이점은 ZeRO-Offload입니다. 이는 단계 1이므로 옵티마이저 상태를 CPU로 오프로드할 수 있습니다.
+
+구현:
+- [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed) 및 [BigScience의 Megatron-Deepspeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed), 이전 저장소의 포크입니다.
+- [OSLO](https://github.com/tunib-ai/oslo)
+
+중요한 논문:
+
+- [Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](
+https://arxiv.org/abs/2201.11990)
+
+🤗 Transformers 현황: 아직 구현되지 않음, PP와 TP가 없기 때문입니다.
+
+## FlexFlow [[flexflow]]
+
+[FlexFlow](https://github.com/flexflow/FlexFlow)는 약간 다른 방식으로 병렬화 문제를 해결합니다.
+
+논문: ["Beyond Data and Model Parallelism for Deep Neural Networks" by Zhihao Jia, Matei Zaharia, Alex Aiken](https://arxiv.org/abs/1807.05358)
+
+이는 Sample-Operator-Attribute-Parameter를 기반으로 하는 일종의 4D 병렬화를 수행합니다.
+
+1. Sample = 데이터 병렬화 (샘플별 병렬)
+2. Operator = 단일 연산을 여러 하위 연산으로 병렬화
+3. Attribute = 데이터 병렬화 (길이별 병렬)
+4. Parameter = 모델 병렬화 (수평 또는 수직과 관계없이)
+
+예시:
+* Sample
+
+512 길이의 10개의 배치를 가정해 봅시다. 이를 sample 차원으로 2개의 장치에 병렬화하면, 10 x 512는 5 x 2 x 512가 됩니다.
+
+* Operator
+
+레이어 정규화를 수행한다면, 우선 std를 계산하고 두 번째로 mean을 계산한 다음 데이터를 정규화할 수 있습니다. Operator 병렬화는 std와 mean을 병렬로 계산할 수 있도록 합니다. 따라서 operator 차원으로 2개의 장치 (cuda:0, cuda:1)에 병렬화하면, 먼저 입력 데이터를 두 장치로 복사한 다음 cuda:0에서 std를 계산하고 cuda:1에서 동시에 mean을 계산합니다.
+
+* Attribute
+
+512 길이의 10개의 배치가 있습니다. 이를 attribute 차원으로 2개의 장치에 병렬화하면, 10 x 512는 10 x 2 x 256이 됩니다.
+
+* Parameter
+
+이는 tensor 모델 병렬화 또는 naive layer-wise 모델 병렬화와 유사합니다.
+
+
+
+이 프레임워크의 중요한 점은 (1) GPU/TPU/CPU 대 (2) RAM/DRAM 대 (3) 빠른 인트라-커넥트 대 느린 인터-커넥트와 같은 리소스를 고려하여 어디에서 어떤 병렬화를 사용할지를 알고리즘적으로 자동으로 최적화한다는 것입니다.
+
+하나 매우 중요한 측면은 FlexFlow가 정적이고 고정된 워크로드를 가진 모델에 대한 DNN 병렬화를 최적화하기 위해 설계되었다는 것입니다. 동적인 동작을 가진 모델은 반복마다 다른 병렬화 전략을 선호할 수 있습니다.
+
+따라서 이 프레임워크의 장점은 선택한 클러스터에서 30분 동안 시뮬레이션을 실행하고 이 특정 환경을 최적으로 활용하기 위한 최상의 전략을 제안한다는 것입니다. 부품을 추가/제거/교체하면 실행하고 그에 대한 계획을 다시 최적화한 후 훈련할 수 있습니다. 다른 설정은 자체적인 사용자 정의 최적화를 가질 수 있습니다.
+
+🤗 Transformers 현황: 아직 통합되지 않음. 이미 [transformers.utils.fx](https://github.com/huggingface/transformers/blob/master/src/transformers/utils/fx.py)를 통해 모델을 FX-추적할 수 있으며, 이는 FlexFlow의 선행 조건입니다. 따라서 어떤 작업을 수행해야 FlexFlow가 우리의 모델과 함께 작동할 수 있는지 파악해야 합니다.
+
+
+## 어떤 전략을 사용해야 할까요? [[which-strategy-to-use-when]]
+
+다음은 어떤 병렬화 전략을 언제 사용해야 하는지에 대한 매우 대략적인 개요입니다. 각 목록의 첫 번째 전략이 일반적으로 더 빠릅니다.
+
+**⇨ 단일 GPU**
+
+* 모델이 단일 GPU에 맞는 경우:
+
+ 1. 일반적인 사용
+
+* 모델이 단일 GPU에 맞지 않는 경우:
+
+ 1. ZeRO + CPU 및 옵션으로 NVMe 언로드
+ 2. 위와 동일하게 사용하되, 가장 큰 레이어가 단일 GPU에 맞지 않는 경우 Memory Centric Tiling(자세한 내용은 아래 참조)을 추가적으로 사용
+
+* 가장 큰 레이어가 단일 GPU에 맞지 않는 경우:
+
+1. ZeRO - [Memory Centric Tiling](https://deepspeed.readthedocs.io/en/latest/zero3.html#memory-centric-tiling) (MCT) 활성화. 이를 통해 크기가 매우 큰 레이어를 임의로 분할하여 순차적으로 실행할 수 있습니다. MCT는 GPU에 활성화된 매개변수의 수를 줄이지만 활성화 메모리에는 영향을 주지 않습니다. 현재 작성 기준으로 이 요구사항은 매우 드물기 때문에 사용자가 `torch.nn.Linear`를 수동으로 수정해야 합니다.
+
+**⇨ 단일 노드 / 다중 GPU**
+
+* 모델이 단일 GPU에 맞는 경우:
+
+ 1. DDP - 분산 DP
+ 2. ZeRO - 상황과 구성에 따라 빠를 수도 있고 그렇지 않을 수도 있습니다.
+
+* 모델이 단일 GPU에 맞지 않는 경우:
+
+ 1. PP
+ 2. ZeRO
+ 3. TP
+
+ NVLINK 또는 NVSwitch를 통한 매우 빠른 인트라-노드 연결이 있는 경우 이 세 가지 방법은 거의 동등할 것이며, 이러한 연결이 없는 경우 PP가 TP나 ZeRO보다 빠를 것입니다. 또한 TP의 차수도 영향을 줄 수 있습니다. 특정 설정에서 우승자를 찾기 위해 실험하는 것이 가장 좋습니다.
+
+ TP는 거의 항상 단일 노드 내에서 사용됩니다. 즉, TP 크기 <= 노드당 GPU 수입니다.
+
+* 가장 큰 레이어가 단일 GPU에 맞지 않는 경우:
+
+ 1. ZeRO를 사용하지 않을 경우 - PP만 사용할 수 없으므로 TP를 사용해야 합니다.
+ 2. ZeRO를 사용할 경우, "단일 GPU"의 항목과 동일한 항목 참조
+
+
+**⇨ 다중 노드 / 다중 GPU**
+
+* 빠른 노드 간 연결이 있는 경우:
+
+ 1. ZeRO - 모델에 대한 수정이 거의 필요하지 않습니다.
+ 2. PP+TP+DP - 통신이 적지만 모델에 대한 대규모 변경이 필요합니다.
+
+* 느린 노드 간 연결 및 GPU 메모리 부족한 경우:
+
+ 1. DP+PP+TP+ZeRO-1
diff --git a/docs/transformers/docs/source/ko/perf_train_special.md b/docs/transformers/docs/source/ko/perf_train_special.md
new file mode 100644
index 0000000000000000000000000000000000000000..188db542f7c01f00396e64184e376bfea13744ec
--- /dev/null
+++ b/docs/transformers/docs/source/ko/perf_train_special.md
@@ -0,0 +1,63 @@
+
+
+# Apple 실리콘에서 Pytorch 학습 [[PyTorch training on Apple silicon]]
+
+이전에는 Mac에서 모델을 학습할 때 CPU만 사용할 수 있었습니다. 그러나 이제 PyTorch v1.12의 출시로 Apple의 실리콘 GPU를 사용하여 훨씬 더 빠른 성능으로 모델을 학습할 수 있게 되었습니다. 이는 Pytorch에서 Apple의 Metal Performance Shaders (MPS)를 백엔드로 통합하면서 가능해졌습니다. [MPS 백엔드](https://pytorch.org/docs/stable/notes/mps.html)는 Pytorch 연산을 Metal 세이더로 구현하고 이 모듈들을 mps 장치에서 실행할 수 있도록 지원합니다.
+
+
+
+일부 Pytorch 연산들은 아직 MPS에서 지원되지 않아 오류가 발생할 수 있습니다. 이를 방지하려면 환경 변수 `PYTORCH_ENABLE_MPS_FALLBACK=1` 를 설정하여 CPU 커널을 대신 사용하도록 해야 합니다(이때 `UserWarning`이 여전히 표시될 수 있습니다).
+
+
+
+다른 오류가 발생할 경우 [PyTorch](https://github.com/pytorch/pytorch/issues) 리포지토리에 이슈를 등록해주세요. 현재 [`Trainer`]는 MPS 백엔드만 통합하고 있습니다.
+
+
+
+`mps` 장치를 이용하면 다음과 같은 이점들을 얻을 수 있습니다:
+
+* 로컬에서 더 큰 네트워크나 배치 크기로 학습 가능
+* GPU의 통합 메모리 아키텍처로 인해 메모리에 직접 접근할 수 있어 데이터 로딩 지연 감소
+* 클라우드 기반 GPU나 추가 GPU가 필요 없으므로 비용 절감 가능
+
+Pytorch가 설치되어 있는지 확인하고 시작하세요. MPS 가속은 macOS 12.3 이상에서 지원됩니다.
+
+```bash
+pip install torch torchvision torchaudio
+```
+
+[`TrainingArguments`]는 `mps` 장치가 사용 가능한 경우 이를 기본적으로 사용하므로 장치를 따로 설정할 필요가 없습니다. 예를 들어, MPS 백엔드를 자동으로 활성화하여 [run_glue.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-classification/run_glue.py) 스크립트를 아무 수정 없이 실행할 수 있습니다.
+
+```diff
+export TASK_NAME=mrpc
+
+python examples/pytorch/text-classification/run_glue.py \
+ --model_name_or_path google-bert/bert-base-cased \
+ --task_name $TASK_NAME \
+- --use_mps_device \
+ --do_train \
+ --do_eval \
+ --max_seq_length 128 \
+ --per_device_train_batch_size 32 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/$TASK_NAME/ \
+ --overwrite_output_dir
+```
+
+`gloco`와 `nccl`과 같은 [분산 학습 백엔드](https://pytorch.org/docs/stable/distributed.html#backends)는 `mps` 장치에서 지원되지 않으므로, MPS 백엔드에서는 단일 GPU로만 학습이 가능합니다.
+
+Mac에서 가속된 PyTorch 학습에 대한 더 자세한 내용은 [Introducing Accelerated PyTorch Training on Mac](https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/) 블로그 게시물에서 확인할 수 있습니다.
diff --git a/docs/transformers/docs/source/ko/perf_train_tpu_tf.md b/docs/transformers/docs/source/ko/perf_train_tpu_tf.md
new file mode 100644
index 0000000000000000000000000000000000000000..28d4fdafb96ca85278c3190c7c46be29397ac2f8
--- /dev/null
+++ b/docs/transformers/docs/source/ko/perf_train_tpu_tf.md
@@ -0,0 +1,162 @@
+
+
+# TensorFlow로 TPU에서 훈련하기[[training-on-tpu-with-tensorflow]]
+
+
+
+자세한 설명이 필요하지 않고 바로 TPU 샘플 코드를 시작하고 싶다면 [우리의 TPU 예제 노트북!](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb)을 확인하세요.
+
+
+
+### TPU가 무엇인가요?[[what-is-a-tpu]]
+
+TPU는 **텐서 처리 장치**입니다. Google에서 설계한 하드웨어로, GPU처럼 신경망 내에서 텐서 연산을 더욱 빠르게 처리하기 위해 사용됩니다. 네트워크 훈련과 추론 모두에 사용할 수 있습니다. 일반적으로 Google의 클라우드 서비스를 통해 이용할 수 있지만, Google Colab과 Kaggle Kernel을 통해 소규모 TPU를 무료로 직접 이용할 수도 있습니다.
+
+[🤗 Transformers의 모든 Tensorflow 모델은 Keras 모델](https://huggingface.co/blog/tensorflow-philosophy)이기 때문에, 이 문서에서 다루는 대부분의 메소드는 대체로 모든 Keras 모델을 위한 TPU 훈련에 적용할 수 있습니다! 하지만 Transformer와 데이터 세트의 HuggingFace 생태계(hug-o-system?)에 특화된 몇 가지 사항이 있으며, 해당 사항에 대해 설명할 때 반드시 언급하도록 하겠습니다.
+
+### 어떤 종류의 TPU가 있나요?[[what-kinds-of-tpu-are-available]]
+
+신규 사용자는 TPU의 범위와 다양한 이용 방법에 대해 매우 혼란스러워하는 경우가 많습니다. **TPU 노드**와 **TPU VM**의 차이점은 가장 먼저 이해해야 할 핵심적인 구분 사항입니다.
+
+**TPU 노드**를 사용한다면, 실제로는 원격 TPU를 간접적으로 이용하는 것입니다. 네트워크와 데이터 파이프라인을 초기화한 다음, 이를 원격 노드로 전달할 별도의 VM이 필요합니다. Google Colab에서 TPU를 사용하는 경우, **TPU 노드** 방식으로 이용하게 됩니다.
+
+TPU 노드를 사용하는 것은 이를 사용하지 않는 사용자에게 예기치 않은 현상이 발생하기도 합니다! 특히, TPU는 파이썬 코드를 실행하는 기기(machine)와 물리적으로 다른 시스템에 있기 때문에 로컬 기기에 데이터를 저장할 수 없습니다. 즉, 컴퓨터의 내부 저장소에서 가져오는 데이터 파이프라인은 절대 작동하지 않습니다! 로컬 기기에 데이터를 저장하는 대신에, 데이터 파이프라인이 원격 TPU 노드에서 실행 중일 때에도 데이터 파이프라인이 계속 이용할 수 있는 Google Cloud Storage에 데이터를 저장해야 합니다.
+
+
+
+메모리에 있는 모든 데이터를 `np.ndarray` 또는 `tf.Tensor`로 맞출 수 있다면, Google Cloud Storage에 업로드할 필요 없이, Colab 또는 TPU 노드를 사용해서 해당 데이터에 `fit()` 할 수 있습니다.
+
+
+
+
+
+**🤗특수한 Hugging Face 팁🤗:** TF 코드 예제에서 볼 수 있는 `Dataset.to_tf_dataset()` 메소드와 그 상위 래퍼(wrapper)인 `model.prepare_tf_dataset()`는 모두 TPU 노드에서 작동하지 않습니다. 그 이유는 `tf.data.Dataset`을 생성하더라도 “순수한” `tf.data` 파이프라인이 아니며 `tf.numpy_function` 또는 `Dataset.from_generator()`를 사용하여 기본 HuggingFace `Dataset`에서 데이터를 전송하기 때문입니다. 이 HuggingFace `Dataset`는 로컬 디스크에 있는 데이터로 지원되며 원격 TPU 노드가 읽을 수 없습니다.
+
+
+
+TPU를 이용하는 두 번째 방법은 **TPU VM**을 사용하는 것입니다. TPU VM을 사용할 때, GPU VM에서 훈련하는 것과 같이 TPU가 장착된 기기에 직접 연결합니다. 특히 데이터 파이프라인과 관련하여, TPU VM은 대체로 작업하기 더 쉽습니다. 위의 모든 경고는 TPU VM에는 해당되지 않습니다!
+
+이 문서는 의견이 포함된 문서이며, 저희의 의견이 여기에 있습니다: **가능하면 TPU 노드를 사용하지 마세요.** TPU 노드는 TPU VM보다 더 복잡하고 디버깅하기가 더 어렵습니다. 또한 향후에는 지원되지 않을 가능성이 높습니다. Google의 최신 TPU인 TPUv4는 TPU VM으로만 이용할 수 있으므로, TPU 노드는 점점 더 "구식" 이용 방법이 될 것으로 전망됩니다. 그러나 TPU 노드를 사용하는 Colab과 Kaggle Kernel에서만 무료 TPU 이용이 가능한 것으로 확인되어, 필요한 경우 이를 다루는 방법을 설명해 드리겠습니다! 이에 대한 자세한 설명이 담긴 코드 샘플은 [TPU 예제 노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb)에서 확인하시기 바랍니다.
+
+### 어떤 크기의 TPU를 사용할 수 있나요?[[what-sizes-of-tpu-are-available]]
+
+단일 TPU(v2-8/v3-8/v4-8)는 8개의 복제본(replicas)을 실행합니다. TPU는 수백 또는 수천 개의 복제본을 동시에 실행할 수 있는 **pod**로 존재합니다. 단일 TPU를 하나 이상 사용하지만 전체 Pod보다 적게 사용하는 경우(예를 들면, v3-32), TPU 구성을 **pod 슬라이스**라고 합니다.
+
+Colab을 통해 무료 TPU에 이용하는 경우, 기본적으로 단일 v2-8 TPU를 제공받습니다.
+
+### XLA에 대해 들어본 적이 있습니다. XLA란 무엇이고 TPU와 어떤 관련이 있나요?[[i-keep-hearing-about-this-xla-thing-whats-xla-and-how-does-it-relate-to-tpus]]
+
+XLA는 최적화 컴파일러로, TensorFlow와 JAX에서 모두 사용됩니다. JAX에서는 유일한 컴파일러이지만, TensorFlow에서는 선택 사항입니다(하지만 TPU에서는 필수입니다!). Keras 모델을 훈련할 때 이를 활성화하는 가장 쉬운 방법은 `jit_compile=True` 인수를 `model.compile()`에 전달하는 것입니다. 오류가 없고 성능이 양호하다면, TPU로 전환할 준비가 되었다는 좋은 신호입니다!
+
+TPU에서 디버깅하는 것은 대개 CPU/GPU보다 조금 더 어렵기 때문에, TPU에서 시도하기 전에 먼저 XLA로 CPU/GPU에서 코드를 실행하는 것을 권장합니다. 물론 오래 학습할 필요는 없습니다. 즉, 모델과 데이터 파이프라인이 예상대로 작동하는지 확인하기 위해 몇 단계만 거치면 됩니다.
+
+
+
+XLA로 컴파일된 코드는 대체로 더 빠릅니다. 따라서 TPU에서 실행할 계획이 없더라도, `jit_compile=True`를 추가하면 성능이 향상될 수 있습니다. 하지만 XLA 호환성에 대한 아래 주의 사항을 반드시 확인하세요!
+
+
+
+
+
+**뼈아픈 경험에서 얻은 팁:** `jit_compile=True`를 사용하면 속도를 높이고 CPU/GPU 코드가 XLA와 호환되는지 검증할 수 있는 좋은 방법이지만, 실제 TPU에서 훈련할 때 그대로 남겨두면 많은 문제를 초래할 수 있습니다. XLA 컴파일은 TPU에서 암시적으로 이뤄지므로, 실제 TPU에서 코드를 실행하기 전에 해당 줄을 제거하는 것을 잊지 마세요!
+
+
+
+### 제 XLA 모델과 호환하려면 어떻게 해야 하나요?[[how-do-i-make-my-model-xla-compatible]]
+
+대부분의 경우, 여러분의 코드는 이미 XLA와 호환될 것입니다! 그러나 표준 TensorFlow에서 작동하지만, XLA에서는 작동하지 않는 몇 가지 사항이 있습니다. 이를 아래 세 가지 핵심 규칙으로 간추렸습니다:
+
+
+
+**특수한 HuggingFace 팁🤗:** 저희는 TensorFlow 모델과 손실 함수를 XLA와 호환되도록 재작성하는 데 많은 노력을 기울였습니다. 저희의 모델과 손실 함수는 대개 기본적으로 규칙 #1과 #2를 따르므로 `transformers` 모델을 사용하는 경우, 이를 건너뛸 수 있습니다. 하지만 자체 모델과 손실 함수를 작성할 때는 이러한 규칙을 잊지 마세요!
+
+
+
+#### XLA 규칙 #1: 코드에서 “데이터 종속 조건문”을 사용할 수 없습니다[[xla-rule-1-your-code-cannot-have-datadependent-conditionals]]
+
+어떤 `if`문도 `tf.Tensor` 내부의 값에 종속될 수 없다는 것을 의미합니다. 예를 들어, 이 코드 블록은 XLA로 컴파일할 수 없습니다!
+
+```python
+if tf.reduce_sum(tensor) > 10:
+ tensor = tensor / 2.0
+```
+
+처음에는 매우 제한적으로 보일 수 있지만, 대부분의 신경망 코드에서는 이를 수행할 필요가 없습니다. `tf.cond`를 사용하거나([여기](https://www.tensorflow.org/api_docs/python/tf/cond) 문서를 참조), 다음과 같이 조건문을 제거하고 대신 지표 변수를 사용하는 영리한 수학 트릭을 찾아내어 이 제한을 우회할 수 있습니다:
+
+```python
+sum_over_10 = tf.cast(tf.reduce_sum(tensor) > 10, tf.float32)
+tensor = tensor / (1.0 + sum_over_10)
+```
+
+이 코드는 위의 코드와 정확히 동일한 효과를 구현하지만, 조건문을 제거하여 문제 없이 XLA로 컴파일되도록 합니다!
+
+#### XLA 규칙 #2: 코드에서 "데이터 종속 크기"를 가질 수 없습니다[[xla-rule-2-your-code-cannot-have-datadependent-shapes]]
+
+코드에서 모든 `tf.Tensor` 객체의 크기가 해당 값에 종속될 수 없다는 것을 의미합니다. 예를 들어, `tf.unique` 함수는 입력에서 각 고유 값의 인스턴스 하나를 포함하는 `tensor`를 반환하기 때문에 XLA로 컴파일할 수 없습니다. 이 출력의 크기는 입력 `Tensor`가 얼마나 반복적인지에 따라 분명히 달라질 것이므로, XLA는 이를 처리하지 못합니다!
+
+일반적으로, 대부분의 신경망 코드는 기본값으로 규칙 2를 따릅니다. 그러나 문제가 되는 몇 가지 대표적인 사례가 있습니다. 가장 흔한 사례 중 하나는 **레이블 마스킹**을 사용하여 손실(loss)을 계산할 때, 해당 위치를 무시하도록 나타내기 위해 레이블을 음수 값으로 설정하는 경우입니다. 레이블 마스킹을 지원하는 NumPy나 PyTorch 손실 함수를 보면 [불 인덱싱](https://numpy.org/doc/stable/user/basics.indexing.html#boolean-array-indexing)을 사용하는 다음과 같은 코드를 자주 접할 수 있습니다:
+
+```python
+label_mask = labels >= 0
+masked_outputs = outputs[label_mask]
+masked_labels = labels[label_mask]
+loss = compute_loss(masked_outputs, masked_labels)
+mean_loss = torch.mean(loss)
+```
+
+이 코드는 NumPy나 PyTorch에서는 문제 없이 작동하지만, XLA에서는 손상됩니다! 왜 그럴까요? 얼마나 많은 위치가 마스킹되는지에 따라 `masked_outputs`와 `masked_labels`의 크기가 달라져서, **데이터 종속 크기**가 되기 때문입니다. 그러나 규칙 #1과 마찬가지로, 이 코드를 다시 작성하면 데이터 종속적 모양 크기가 정확히 동일한 출력을 산출할 수 있습니다.
+
+```python
+label_mask = tf.cast(labels >= 0, tf.float32)
+loss = compute_loss(outputs, labels)
+loss = loss * label_mask # Set negative label positions to 0
+mean_loss = tf.reduce_sum(loss) / tf.reduce_sum(label_mask)
+```
+
+여기서, 모든 위치에 대한 손실을 계산하지만, 평균을 계산할 때 분자와 분모 모두에서 마스크된 위치를 0으로 처리합니다. 이는 데이터 종속 크기를 방지하고 XLA 호환성을 유지하면서 첫 번째 블록과 정확히 동일한 결과를 산출합니다. 규칙 #1에서와 동일한 트릭을 사용하여 `tf.bool`을 `tf.float32`로 변환하고 이를 지표 변수로 사용합니다. 해당 트릭은 매우 유용하며, 자체 코드를 XLA로 변환해야 할 경우 기억해 두세요!
+
+#### XLA 규칙 #3: XLA는 각기 다른 입력 크기가 나타날 때마다 모델을 다시 컴파일해야 합니다[[xla-rule-3-xla-will-need-to-recompile-your-model-for-every-different-input-shape-it-sees]]
+
+이것은 가장 큰 문제입니다. 입력 크기가 매우 가변적인 경우, XLA는 모델을 반복해서 다시 컴파일해야 하므로 성능에 큰 문제가 발생할 수 있습니다. 이 문제는 토큰화 후 입력 텍스트의 길이가 가변적인 NLP 모델에서 주로 발생합니다. 다른 모달리티에서는 정적 크기가 더 흔하며, 해당 규칙이 훨씬 덜 문제시 됩니다.
+
+규칙 #3을 어떻게 우회할 수 있을까요? 핵심은 **패딩**입니다. 모든 입력을 동일한 길이로 패딩한 다음, `attention_mask`를 사용하면 어떤 XLA 문제도 없이 가변 크기에서 가져온 것과 동일한 결과를 가져올 수 있습니다. 그러나 과도한 패딩은 심각한 속도 저하를 야기할 수도 있습니다. 모든 샘플을 전체 데이터 세트의 최대 길이로 패딩하면, 무한한 패딩 토큰으로 구성된 배치가 생성되어 많은 연산과 메모리가 낭비될 수 있습니다!
+
+이 문제에 대한 완벽한 해결책은 없습니다. 하지만, 몇 가지 트릭을 시도해볼 수 있습니다. 한 가지 유용한 트릭은 **샘플 배치를 32 또는 64 토큰과 같은 숫자의 배수까지 패딩하는 것입니다.** 이는 토큰 수가 소폭 증가하지만, 모든 입력 크기가 32 또는 64의 배수여야 하기 때문에 고유한 입력 크기의 수가 대폭 줄어듭니다. 고유한 입력 크기가 적다는 것은 XLA 컴파일 횟수가 적어진다는 것을 의미합니다!
+
+
+
+**🤗특수한 HuggingFace 팁🤗:** 토크나이저와 데이터 콜레이터에 도움이 될 수 있는 메소드가 있습니다. 토크나이저를 불러올 때 `padding="max_length"` 또는 `padding="longest"`를 사용하여 패딩된 데이터를 출력하도록 할 수 있습니다. 토크나이저와 데이터 콜레이터는 나타나는 고유한 입력 크기의 수를 줄이기 위해 사용할 수 있는 `pad_to_multiple_of` 인수도 있습니다!
+
+
+
+### 실제 TPU로 모델을 훈련하려면 어떻게 해야 하나요?[[how-do-i-actually-train-my-model-on-tpu]]
+
+훈련이 XLA와 호환되고 (TPU 노드/Colab을 사용하는 경우) 데이터 세트가 적절하게 준비되었다면, TPU에서 실행하는 것은 놀랍도록 쉽습니다! 코드에서 몇 줄만 추가하여, TPU를 초기화하고 모델과 데이터 세트가 `TPUStrategy` 범위 내에 생성되도록 변경하면 됩니다. [우리의 TPU 예제 노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb)을 참조하여 실제로 작동하는 모습을 확인해 보세요!
+
+### 요약[[summary]]
+
+여기에 많은 내용이 포함되어 있으므로, TPU 훈련을 위한 모델을 준비할 때 따를 수 있는 간략한 체크리스트로 요약해 보겠습니다:
+
+- 코드가 XLA의 세 가지 규칙을 따르는지 확인합니다.
+- CPU/GPU에서 `jit_compile=True`로 모델을 컴파일하고 XLA로 훈련할 수 있는지 확인합니다.
+- 데이터 세트를 메모리에 가져오거나 TPU 호환 데이터 세트를 가져오는 방식을 사용합니다([노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) 참조)
+- 코드를 Colab(accelerator가 “TPU”로 설정됨) 또는 Google Cloud의 TPU VM으로 마이그레이션합니다.
+- TPU 초기화 코드를 추가합니다([노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) 참조)
+- `TPUStrategy`를 생성하고 데이터 세트를 가져오는 것과 모델 생성이 `strategy.scope()` 내에 있는지 확인합니다([노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) 참조)
+- TPU로 이동할 때 `jit_compile=True`를 다시 설정하는 것을 잊지 마세요!
+- 🙏🙏🙏🥺🥺🥺
+- model.fit()을 불러옵니다.
+- 여러분이 해냈습니다!
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/performance.md b/docs/transformers/docs/source/ko/performance.md
new file mode 100644
index 0000000000000000000000000000000000000000..226bd5f249af5da28d4af4c33251f3eb2d588721
--- /dev/null
+++ b/docs/transformers/docs/source/ko/performance.md
@@ -0,0 +1,96 @@
+
+
+# 성능 및 확장성 [[performance-and-scalability]]
+
+점점 더 큰 규모의 트랜스포머 모델을 훈련하고 프로덕션에 배포하는 데에는 다양한 어려움이 따릅니다. 훈련 중에는 모델이 사용 가능한 GPU 메모리보다 더 많은 메모리를 필요로 하거나 훈련 속도가 매우 느릴 수 있으며, 추론을 위해 배포할 때는 제품 환경에서 요구되는 처리량으로 인해 과부하가 발생할 수 있습니다. 이 문서는 이러한 문제를 극복하고 사용 사례에 가장 적합한 설정을 찾도록 도움을 주기 위해 설계되었습니다. 훈련과 추론으로 가이드를 분할했는데, 이는 각각 다른 문제와 해결 방법이 있기 때문입니다. 그리고 각 가이드에는 다양한 종류의 하드웨어 설정에 대한 별도의 가이드가 있습니다(예: 훈련을 위한 단일 GPU vs 다중 GPU 또는 추론을 위한 CPU vs GPU).
+
+
+
+이 문서는 사용자의 상황에 유용할 수 있는 방법들에 대한 개요 및 시작점 역할을 합니다.
+
+## 훈련 [[training]]
+
+효율적인 트랜스포머 모델 훈련에는 GPU나 TPU와 같은 가속기가 필요합니다. 가장 일반적인 경우는 단일 GPU만 사용하는 경우지만, 다중 GPU 및 CPU 훈련에 대한 섹션도 있습니다(곧 더 많은 내용이 추가될 예정).
+
+
+
+ 참고: 단일 GPU 섹션에서 소개된 대부분의 전략(예: 혼합 정밀도 훈련 또는 그라디언트 누적)은 일반적인 모델 훈련에도 적용되므로, 다중 GPU나 CPU 훈련과 같은 섹션을 살펴보기 전에 꼭 참고하시길 바랍니다.
+
+
+
+### 단일 GPU [[single-gpu]]
+
+단일 GPU에서 대규모 모델을 훈련하는 것은 어려울 수 있지만, 이를 가능하게 하는 여러 가지 도구와 방법이 있습니다. 이 섹션에서는 혼합 정밀도 훈련, 그라디언트 누적 및 체크포인팅, 효율적인 옵티마이저, 최적의 배치 크기를 결정하기 위한 전략 등에 대해 논의합니다.
+
+[단일 GPU 훈련 섹션으로 이동](perf_train_gpu_one)
+
+### 다중 GPU [[multigpu]]
+
+단일 GPU에서 훈련하는 것이 너무 느리거나 대규모 모델에 적합하지 않은 경우도 있습니다. 다중 GPU 설정으로 전환하는 것은 논리적인 단계이지만, 여러 GPU에서 한 번에 훈련하려면 각 GPU마다 모델의 전체 사본을 둘지, 혹은 모델 자체도 여러 GPU에 분산하여 둘지 등 새로운 결정을 내려야 합니다. 이 섹션에서는 데이터, 텐서 및 파이프라인 병렬화에 대해 살펴봅니다.
+
+[다중 GPU 훈련 섹션으로 이동](perf_train_gpu_many)
+
+### CPU [[cpu]]
+
+
+[CPU 훈련 섹션으로 이동](perf_train_cpu)
+
+
+### TPU [[tpu]]
+
+[_곧 제공될 예정_](perf_train_tpu)
+
+### 특수한 하드웨어 [[specialized-hardware]]
+
+[_곧 제공될 예정_](perf_train_special)
+
+## 추론 [[inference]]
+
+제품 및 서비스 환경에서 대규모 모델을 효율적으로 추론하는 것은 모델을 훈련하는 것만큼 어려울 수 있습니다. 이어지는 섹션에서는 CPU 및 단일/다중 GPU 설정에서 추론을 진행하는 단계를 살펴봅니다.
+
+### CPU [[cpu]]
+
+[CPU 추론 섹션으로 이동](perf_infer_cpu)
+
+### 단일 GPU [[single-gpu]]
+
+[단일 GPU 추론 섹션으로 이동](perf_infer_gpu_one)
+
+### 다중 GPU [[multigpu]]
+
+[다중 GPU 추론 섹션으로 이동](perf_infer_gpu_many)
+
+### 특수한 하드웨어 [[specialized-hardware]]
+
+[_곧 제공될 예정_](perf_infer_special)
+
+## 하드웨어 [[hardware]]
+
+하드웨어 섹션에서는 자신만의 딥러닝 장비를 구축할 때 유용한 팁과 요령을 살펴볼 수 있습니다.
+
+[하드웨어 섹션으로 이동](perf_hardware)
+
+
+## 기여하기 [[contribute]]
+
+이 문서는 완성되지 않은 상태이며, 추가해야 할 내용이나 수정 사항이 많이 있습니다. 따라서 추가하거나 수정할 내용이 있으면 주저하지 말고 PR을 열어 주시거나, 자세한 내용을 논의하기 위해 Issue를 시작해 주시기 바랍니다.
+
+A가 B보다 좋다고 하는 기여를 할 때는, 재현 가능한 벤치마크와/또는 해당 정보의 출처 링크를 포함해주세요(당신으로부터의 직접적인 정보가 아닌 경우).
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/perplexity.md b/docs/transformers/docs/source/ko/perplexity.md
new file mode 100644
index 0000000000000000000000000000000000000000..9de84a5f289b942875aa88386f430cc67e306bb9
--- /dev/null
+++ b/docs/transformers/docs/source/ko/perplexity.md
@@ -0,0 +1,135 @@
+
+
+# 고정 길이 모델의 펄플렉서티(Perplexity)[[perplexity-of-fixedlength-models]]
+
+[[open-in-colab]]
+
+펄플렉서티(Perplexity, PPL)는 가장 일반적인 언어 모델 평가지표 중 하나입니다.
+자세히 알아보기 전에 이 평가지표는 고전적인 언어 모델(자기회귀 또는 인과적 언어 모델이라고도 함)에만 적용되며 BERT와 같은 마스킹된 언어 모델에는 잘 적용하지 않습니다 (BERT는 [summary of the models](../en/model_summary) 문서를 참고하세요).
+
+펄플렉서티는 시퀀스의 음의 로그 우도(negative log-likelihood, NLL) 값의 평균에 지수(exponentiate)를 취한 값으로 정의됩니다.
+토큰화된 시퀀스 \\(X = (x_0, x_1, \dots, x_t)\\) 가 있을 때, \\(X\\) 의 펄플렉서티는 아래 수식과 같이 구할 수 있습니다.
+
+$$\text{PPL}(X) = \exp \left\{ {-\frac{1}{t}\sum_i^t \log p_\theta (x_i|x_{
+
+그러나 모델의 근사치를 구할 때는 일반적으로 모델이 처리할 수 있는 토큰 수에 제한이 있습니다.
+예를 들어, 가장 큰 버전의 [GPT-2](model_doc/gpt2)는 토큰의 길이가 1024로 고정되어 있습니다.
+따라서 \\(t\\) 가 1024보다 큰 경우에 \\(p_\theta(x_t|x_{
+
+이 방법은 각 부분의 펄플렉서티를 한 번의 포워드 패스로 계산할 수 있어 빠르지만 일반적으로 더 높은(더 나쁜) PPL을 산출합니다.
+왜냐하면 대부분의 예측 단계에서 모델의 컨텍스트가 적기 때문입니다.
+
+대신, 고정 길이 모델의 PPL은 슬라이딩 윈도우 전략으로 평가해야 합니다.
+이 전략에는 컨텍스트 윈도우을 반복적으로 슬라이딩해 모델이 각 예측을 수행할 때 더 많은 컨텍스트를 갖도록 하는 작업이 포함됩니다.
+
+
+
+이는 시퀀스 확률의 실제 분해에 더 가까운 근사치이며 일반적으로 더 유리한 점수를 산출합니다.
+단점은 말뭉치의 각 토큰에 대해 별도의 포워드 패스가 필요하다는 것입니다.
+현실적으로 좋은 절충안은 한 번에 한 토큰씩 슬라이딩하는 것이 아니라 더 큰 간격으로 컨텍스트를 이동하는 스트라이드가 적용된 슬라이딩 윈도우을 사용하는 것입니다.
+이렇게 하면 계산을 훨씬 더 빠르게 진행하면서도 모델에 각 단계에서 예측을 수행할 수 있는 긴 컨텍스트를 제공할 수 있습니다.
+
+## 예제: 🤗 Transformers에서 GPT-2로 펄플렉서티(perplexity) 계산하기[[example-calculating-perplexity-with-gpt2-in-transformers]]
+
+이제 GPT-2로 위의 과정을 시연해 보겠습니다.
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "openai-community/gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+WikiText-2 데이터 세트를 가져오고 몇 가지 슬라이딩 윈도우 전략을 사용해 펄플렉서티를 계산해보겠습니다.
+이 데이터 세트는 크기가 작고 포워드 패스 한 번만 수행하기 때문에 전체 데이터 세트를 메모리에 가져오고 인코딩할 수 있습니다.
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+🤗 Transformers를 사용하면 모델의 `labels`로 `input_ids`를 전달해 각 토큰에 대한 평균 음의 우도 값을 손실로 반환할 수 있습니다.
+하지만 슬라이딩 윈도우 방식을 사용하면 각 반복마다 모델에 전달하는 토큰이 겹칩니다.
+컨텍스트로 처리하는 토큰에 대한 로그 우도 값이 손실에 포함되는 것을 원하지 않기 때문에 이러한 토큰의 `input_ids`를 `-100`으로 설정하여 무시할 수 있습니다.
+
+다음은 스트라이드(stride)를 `512`로 사용한 예시입니다.
+즉, 모델이 한 토큰의 조건부 우도 값을 계산할 때 컨텍스트에 최소한 512개의 토큰이 포함되어있다는 의미입니다 (해당 토큰 앞에 512개의 토큰이 있는 경우).
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+seq_len = encodings.input_ids.size(1)
+
+nlls = []
+prev_end_loc = 0
+for begin_loc in tqdm(range(0, seq_len, stride)):
+ end_loc = min(begin_loc + max_length, seq_len)
+ trg_len = end_loc - prev_end_loc # 마지막 루프의 스트라이드 값과 다를 수 있음
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+
+ # 손실은 모든 유효한 레이블에 대한 평균값을 구하는 교차 엔트로피(cross entropy)로 계산됩니다.
+ # 나이브 베이지안 모델은 내부적으로 레이블을 왼쪽으로 1개씩 밀기 때문에, (타켓 - 1)개 만큼의 레이블에 대해 손실을 계산합니다.
+ neg_log_likelihood = outputs.loss
+
+ nlls.append(neg_log_likelihood)
+
+ prev_end_loc = end_loc
+ if end_loc == seq_len:
+ break
+
+ppl = torch.exp(torch.stack(nlls).mean())
+```
+
+스트라이드를 최대 입력 길이와 동일하게 설정하면 위에서 설명한 차선책인 비슬라이딩 윈도우 전략과 동일합니다.
+일반적으로 스트라이드가 작을수록 모델이 각 예측을 할 때 더 많은 컨텍스트를 볼 수 있게 되어 펄플렉서티 값이 좋아집니다.
+
+위의 계산을 토큰이 겹치지 않도록 `stride = 1024`로 설정하면 PPL은 `19.44`로 GPT-2 논문에서 보고된 `19.93`과 거의 동일합니다.
+`stride = 512`로 슬라이딩 윈도우 전략을 사용하면 PPL은 `16.45`로 떨어집니다.
+이는 더 좋은 점수일 뿐만 아니라 시퀀스 확률의 실제 자동 회귀 분해에 더 가까운 방식으로 계산됩니다.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/philosophy.md b/docs/transformers/docs/source/ko/philosophy.md
new file mode 100644
index 0000000000000000000000000000000000000000..e303709a11b8336a3cae1f6a6c5321ef953c4bc9
--- /dev/null
+++ b/docs/transformers/docs/source/ko/philosophy.md
@@ -0,0 +1,66 @@
+
+
+# 이념과 목표 [[philosophy]]
+
+🤗 Transformers는 다음과 같은 목적으로 만들어진 독자적인 라이브러리입니다:
+
+- 대규모 Transformers 모델을 사용하거나 연구하거나 확장하려는 기계 학습 연구원 및 교육자를 위한 것입니다.
+- 모델을 미세 조정하거나 제작용으로 사용하고자 하는 실전 개발자를 위한 것입니다.
+- 특정 기계 학습 작업을 해결하기 위해 사전훈련된 모델을 다운로드하고 사용하기만 하려는 엔지니어를 위한 것입니다.
+
+이 라이브러리는 두 가지 주요 목표를 가지고 설계되었습니다:
+
+1. 사용하기 쉽고 빠르게 만드는 것:
+
+- 학습해야 할 사용자 대상 추상화의 수를 제한했습니다. 실제로 거의 추상화가 없으며, 각 모델을 사용하기 위해 필요한 세 가지 표준 클래스인 [configuration](main_classes/configuration), [models](main_classes/model) 및 전처리 클래스인 ([tokenizer](main_classes/tokenizer)는 NLP용, [image processor](main_classes/image_processor)는 비전용, [feature extractor](main_classes/feature_extractor)는 오디오용, [processor](main_classes/processors)는 멀티모달 입력용)만 사용합니다.
+- 이러한 클래스는 공통적인 `from_pretrained()` 메서드를 사용하여 미리 훈련된 인스턴스에서 간단하고 통일된 방식으로 초기화할 수 있습니다. 이 메소드는 미리 훈련된 체크포인트에서 관련 클래스 인스턴스와 관련 데이터(구성의 하이퍼파라미터, 토크나이저의 어휘, 모델의 가중치)를 (필요한 경우) 다운로드하고 캐시하며 가져옵니다. 체크포인트는 [Hugging Face Hub](https://huggingface.co/models)에서 제공되거나 사용자 자체의 저장된 체크포인트에서 제공됩니다.
+- 이 세 가지 기본 클래스 위에 라이브러리는 [`pipeline`] API를 제공하여 주어진 작업에 대해 모델을 빠르게 추론하는 데 사용하고, [`Trainer`]를 제공하여 PyTorch 모델을 빠르게 훈련하거나 미세 조정할 수 있도록 합니다(모든 TensorFlow 모델은 `Keras.fit`과 호환됩니다).
+- 결과적으로, 이 라이브러리는 신경망을 구축하기 위한 모듈식 도구 상자가 아닙니다. 라이브러리를 확장하거나 구축하려면 일반적인 Python, PyTorch, TensorFlow, Keras 모듈을 사용하고 라이브러리의 기본 클래스를 상속하여 모델 로딩 및 저장과 같은 기능을 재사용하면 됩니다. 모델에 대한 코딩 철학에 대해 더 자세히 알고 싶다면 [Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy) 블로그 글을 확인해보세요.
+
+2. 원래 모델과 가능한 한 근접한 성능을 제공하는 최신 모델을 제공하는 것:
+
+- 각 아키텍처에 대해 공식 저자가 제공한 결과를 재현하는 적어도 한 가지 예제를 제공합니다.
+- 코드는 원래 코드와 가능한 한 유사하게 유지되므로 PyTorch 코드는 TensorFlow 코드로 변환되어 *pytorchic*하지 않을 수 있고, 그 반대의 경우도 마찬가지입니다.
+
+기타 목표 몇 가지:
+
+- 모델의 내부를 가능한 일관되게 노출시키기:
+
+ - 전체 은닉 상태와 어텐션 가중치에 대한 액세스를 단일 API를 사용하여 제공합니다.
+ - 전처리 클래스 및 기본 모델 API는 모델 간에 쉽게 전환할 수 있도록 표준화되어 있습니다.
+
+- 미세 조정 및 모델 탐색을 위한 유망한 도구들을 주관적으로 선택하기:
+
+ - 미세 조정을 위해 어휘 및 임베딩에 새로운 토큰을 간단하고 일관된 방식으로 추가하는 방법을 제공합니다.
+ - Transformer 헤드를 마스킹하고 가지치기하는 간단한 방법을 제공합니다.
+
+- PyTorch, TensorFlow 2.0 및 Flax 간에 쉽게 전환할 수 있도록 하여 하나의 프레임워크로 훈련하고 다른 프레임워크로 추론할 수 있게 합니다.
+
+## 주요 개념 [[main-concepts]]
+
+이 라이브러리는 각 모델에 대해 세 가지 유형의 클래스를 기반으로 구축되었습니다:
+
+- **모델 클래스**는 라이브러리에서 제공하는 사전 훈련된 가중치와 함께 작동하는 PyTorch 모델([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)), Keras 모델([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model)), JAX/Flax 모델([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html))일 수 있습니다.
+- **구성 클래스**는 모델을 구축하는 데 필요한 하이퍼파라미터(예: 레이어 수 및 은닉 크기)를 저장합니다. 구성 클래스를 직접 인스턴스화할 필요는 없습니다. 특히, 수정 없이 고 사전 학습된 모델을 사용하는 경우 모델을 생성하면 모델의 일부인 구성을 자동으로 인스턴스화됩니다.
+- **전처리 클래스**는 원시 데이터를 모델이 수용하는 형식으로 변환합니다. [Tokenizer](main_classes/tokenizer)는 각 모델의 어휘를 저장하고, 문자열을 토큰 임베딩 인덱스 리스트로 인코딩하고 디코딩하기 위한 메소드를 제공합니다. [Image processors](main_classes/image_processor)는 비전 입력을 전처리하고, [feature extractors](main_classes/feature_extractor)는 오디오 입력을 전처리하며, [processor](main_classes/processors)는 멀티모달 입력을 처리합니다.
+
+모든 이러한 클래스는 사전 훈련된 인스턴스에서 인스턴스화하고 로컬로 저장하며, 세 가지 메소드를 사용하여 Hub에서 공유할 수 있습니다:
+
+- `from_pretrained()` 메소드를 사용하면 라이브러리 자체에서 제공하는 사전 훈련된 버전(지원되는 모델은 [Model Hub](https://huggingface.co/models)에서 찾을 수 있음)이나 사용자가 로컬로 저장한 경우(또는 서버에 저장한 경우)의 모델, 구성 및 전처리 클래스를 인스턴스화할 수 있습니다.
+- `save_pretrained()` 메소드를 사용하면 모델, 구성 및 전처리 클래스를 로컬로 저장하여 `from_pretrained()`를 사용하여 다시 가져올 수 있습니다.
+- `push_to_hub()` 메소드를 사용하면 모델, 구성 및 전처리 클래스를 Hub에 공유하여 모두에게 쉽게 접근할 수 있습니다.
+
diff --git a/docs/transformers/docs/source/ko/pipeline_tutorial.md b/docs/transformers/docs/source/ko/pipeline_tutorial.md
new file mode 100644
index 0000000000000000000000000000000000000000..2f166fc6939f3206f3b03490c140a5c3f360045f
--- /dev/null
+++ b/docs/transformers/docs/source/ko/pipeline_tutorial.md
@@ -0,0 +1,243 @@
+
+
+# 추론을 위한 Pipeline[[pipelines-for-inference]]
+
+[`pipeline`]을 사용하면 언어, 컴퓨터 비전, 오디오 및 멀티모달 태스크에 대한 추론을 위해 [Hub](https://huggingface.co/models)의 어떤 모델이든 쉽게 사용할 수 있습니다. 특정 분야에 대한 경험이 없거나, 모델을 이루는 코드가 익숙하지 않은 경우에도 [`pipeline`]을 사용해서 추론할 수 있어요! 이 튜토리얼에서는 다음을 배워보겠습니다.
+
+* 추론을 위해 [`pipeline`]을 사용하는 방법
+* 특정 토크나이저 또는 모델을 사용하는 방법
+* 언어, 컴퓨터 비전, 오디오 및 멀티모달 태스크에서 [`pipeline`]을 사용하는 방법
+
+
+
+지원하는 모든 태스크와 쓸 수 있는 매개변수를 담은 목록은 [`pipeline`] 설명서를 참고해주세요.
+
+
+
+## Pipeline 사용하기[[pipeline-usage]]
+
+각 태스크마다 고유의 [`pipeline`]이 있지만, 개별 파이프라인을 담고있는 추상화된 [`pipeline`]를 사용하는 것이 일반적으로 더 간단합니다. [`pipeline`]은 태스크에 알맞게 추론이 가능한 기본 모델과 전처리 클래스를 자동으로 로드합니다.
+
+1. 먼저 [`pipeline`]을 생성하고 태스크를 지정하세요.
+
+```py
+>>> from transformers import pipeline
+
+>>> generator = pipeline(task="automatic-speech-recognition")
+```
+
+2. 그리고 [`pipeline`]에 입력을 넣어주세요.
+
+```py
+>>> generator("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
+{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}
+```
+
+기대했던 결과가 아닌가요? Hub에서 [가장 많이 다운로드된 자동 음성 인식 모델](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&sort=downloads)로 더 나은 결과를 얻을 수 있는지 확인해보세요.
+다음은 [openai/whisper-large](https://huggingface.co/openai/whisper-large)로 시도해보겠습니다.
+
+```py
+>>> generator = pipeline(model="openai/whisper-large")
+>>> generator("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
+{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
+```
+
+훨씬 더 나아졌군요!
+Hub의 모델들은 여러 다양한 언어와 전문분야를 아우르기 때문에 꼭 자신의 언어나 분야에 특화된 모델을 찾아보시기 바랍니다.
+브라우저를 벗어날 필요없이 Hub에서 직접 모델의 출력을 확인하고 다른 모델과 비교해서 자신의 상황에 더 적합한지, 애매한 입력을 더 잘 처리하는지도 확인할 수 있습니다.
+만약 상황에 알맞는 모델을 없다면 언제나 직접 [훈련](training)시킬 수 있습니다!
+
+입력이 여러 개 있는 경우, 리스트 형태로 전달할 수 있습니다.
+
+```py
+generator(
+ [
+ "https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
+ "https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
+ ]
+)
+```
+
+전체 데이터세트을 순회하거나 웹서버에 올려두어 추론에 사용하고 싶다면, 각 상세 페이지를 참조하세요.
+
+[데이터세트에서 Pipeline 사용하기](#using-pipelines-on-a-dataset)
+
+[웹서버에서 Pipeline 사용하기](./pipeline_webserver)
+
+## 매개변수[[parameters]]
+
+[`pipeline`]은 많은 매개변수를 지원합니다. 특정 태스크용인 것도 있고, 범용인 것도 있습니다.
+일반적으로 원하는 위치에 어디든 매개변수를 넣을 수 있습니다.
+
+```py
+generator(model="openai/whisper-large", my_parameter=1)
+out = generate(...) # This will use `my_parameter=1`.
+out = generate(..., my_parameter=2) # This will override and use `my_parameter=2`.
+out = generate(...) # This will go back to using `my_parameter=1`.
+```
+
+중요한 3가지 매개변수를 살펴보겠습니다.
+
+### 기기(device)[[device]]
+
+`device=n`처럼 기기를 지정하면 파이프라인이 자동으로 해당 기기에 모델을 배치합니다.
+파이토치에서나 텐서플로우에서도 모두 작동합니다.
+
+```py
+generator(model="openai/whisper-large", device=0)
+```
+
+모델이 GPU 하나에 돌아가기 버겁다면, `device_map="auto"`를 지정해서 🤗 [Accelerate](https://huggingface.co/docs/accelerate)가 모델 가중치를 어떻게 로드하고 저장할지 자동으로 결정하도록 할 수 있습니다.
+
+```py
+#!pip install accelerate
+generator(model="openai/whisper-large", device_map="auto")
+```
+
+### 배치 사이즈[[batch-size]]
+
+기본적으로 파이프라인은 [여기](https://huggingface.co/docs/transformers/main_classes/pipelines#pipeline-batching)에 나온 이유로 추론을 일괄 처리하지 않습니다. 간단히 설명하자면 일괄 처리가 반드시 더 빠르지 않고 오히려 더 느려질 수도 있기 때문입니다.
+
+하지만 자신의 상황에 적합하다면, 이렇게 사용하세요.
+
+```py
+generator(model="openai/whisper-large", device=0, batch_size=2)
+audio_filenames = [f"audio_{i}.flac" for i in range(10)]
+texts = generator(audio_filenames)
+```
+
+파이프라인 위 제공된 10개의 오디오 파일을 추가로 처리하는 코드 없이 (일괄 처리에 보다 효과적인 GPU 위) 모델에 2개씩 전달합니다.
+출력은 일괄 처리하지 않았을 때와 똑같아야 합니다. 파이프라인에서 속도를 더 낼 수도 있는 방법 중 하나일 뿐입니다.
+
+파이프라인은 일괄 처리의 복잡한 부분을 줄여주기도 합니다. (예를 들어 긴 오디오 파일처럼) 여러 부분으로 나눠야 모델이 처리할 수 있는 것을 [*chunk batching*](./main_classes/pipelines#pipeline-chunk-batching)이라고 하는데, 파이프라인을 사용하면 자동으로 나눠줍니다.
+
+### 특정 태스크용 매개변수[[task-specific-parameters]]
+
+각 태스크마다 구현할 때 유연성과 옵션을 제공하기 위해 태스크용 매개변수가 있습니다.
+예를 들어 [`transformers.AutomaticSpeechRecognitionPipeline.__call__`] 메서드에는 동영상의 자막을 넣을 때 유용할 것 같은 `return_timestamps` 매개변수가 있습니다.
+
+```py
+>>> # Not using whisper, as it cannot provide timestamps.
+>>> generator = pipeline(model="facebook/wav2vec2-large-960h-lv60-self", return_timestamps="word")
+>>> generator("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
+{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP AND LIVE OUT THE TRUE MEANING OF ITS CREED', 'chunks': [{'text': 'I', 'timestamp': (1.22, 1.24)}, {'text': 'HAVE', 'timestamp': (1.42, 1.58)}, {'text': 'A', 'timestamp': (1.66, 1.68)}, {'text': 'DREAM', 'timestamp': (1.76, 2.14)}, {'text': 'BUT', 'timestamp': (3.68, 3.8)}, {'text': 'ONE', 'timestamp': (3.94, 4.06)}, {'text': 'DAY', 'timestamp': (4.16, 4.3)}, {'text': 'THIS', 'timestamp': (6.36, 6.54)}, {'text': 'NATION', 'timestamp': (6.68, 7.1)}, {'text': 'WILL', 'timestamp': (7.32, 7.56)}, {'text': 'RISE', 'timestamp': (7.8, 8.26)}, {'text': 'UP', 'timestamp': (8.38, 8.48)}, {'text': 'AND', 'timestamp': (10.08, 10.18)}, {'text': 'LIVE', 'timestamp': (10.26, 10.48)}, {'text': 'OUT', 'timestamp': (10.58, 10.7)}, {'text': 'THE', 'timestamp': (10.82, 10.9)}, {'text': 'TRUE', 'timestamp': (10.98, 11.18)}, {'text': 'MEANING', 'timestamp': (11.26, 11.58)}, {'text': 'OF', 'timestamp': (11.66, 11.7)}, {'text': 'ITS', 'timestamp': (11.76, 11.88)}, {'text': 'CREED', 'timestamp': (12.0, 12.38)}]}
+```
+
+보시다시피 모델이 텍스트를 추론할 뿐만 아니라 각 단어를 말한 시점까지도 출력했습니다.
+
+태스크마다 다양한 매개변수를 가지고 있는데요. 원하는 태스크의 API를 참조해서 바꿔볼 수 있는 여러 매개변수를 살펴보세요!
+지금까지 다뤄본 [`~transformers.AutomaticSpeechRecognitionPipeline`]에는 `chunk_length_s` 매개변수가 있습니다. 영화나 1시간 분량의 동영상의 자막 작업을 할 때처럼, 일반적으로 모델이 자체적으로 처리할 수 없는 매우 긴 오디오 파일을 처리할 때 유용하죠.
+
+
+도움이 될 만한 매개변수를 찾지 못했다면 언제든지 [요청](https://github.com/huggingface/transformers/issues/new?assignees=&labels=feature&template=feature-request.yml)해주세요!
+
+
+## 데이터세트에서 Pipeline 사용하기[[using-pipelines-on-a-dataset]]
+
+파이프라인은 대규모 데이터세트에서도 추론 작업을 할 수 있습니다. 이때 이터레이터를 사용하는 걸 추천드립니다.
+
+```py
+def data():
+ for i in range(1000):
+ yield f"My example {i}"
+
+
+pipe = pipe(model="openai-community/gpt2", device=0)
+generated_characters = 0
+for out in pipe(data()):
+ generated_characters += len(out["generated_text"])
+```
+
+이터레이터 `data()`는 각 결과를 호출마다 생성하고, 파이프라인은 입력이 순회할 수 있는 자료구조임을 자동으로 인식하여 GPU에서 기존 데이터가 처리되는 동안 새로운 데이터를 가져오기 시작합니다.(이때 내부적으로 [DataLoader](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader)를 사용해요.) 이 과정은 전체 데이터세트를 메모리에 적재하지 않고도 GPU에 최대한 빠르게 새로운 작업을 공급할 수 있기 때문에 중요합니다.
+
+그리고 일괄 처리가 더 빠를 수 있기 때문에, `batch_size` 매개변수를 조정해봐도 좋아요.
+
+데이터세트를 순회하는 가장 간단한 방법은 🤗 [Datasets](https://github.com/huggingface/datasets/)를 활용하는 것인데요.
+
+```py
+# KeyDataset is a util that will just output the item we're interested in.
+from transformers.pipelines.pt_utils import KeyDataset
+
+pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
+dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
+
+for out in pipe(KeyDataset(dataset["audio"])):
+ print(out)
+```
+
+
+## 웹서버에서 Pipeline 사용하기[[using-pipelines-for-a-webserver]]
+
+
+추론 엔진을 만드는 과정은 따로 페이지를 작성할만한 복잡한 주제입니다.
+
+
+[Link](./pipeline_webserver)
+
+## 비전 Pipeline[[vision-pipeline]]
+
+비전 태스크를 위해 [`pipeline`]을 사용하는 일은 거의 동일합니다.
+
+태스크를 지정하고 이미지를 분류기에 전달하면 됩니다. 이미지는 인터넷 링크 또는 로컬 경로의 형태로 전달해주세요. 예를 들어 아래에 표시된 고양이는 어떤 종인가요?
+
+
+
+```py
+>>> from transformers import pipeline
+
+>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
+>>> preds = vision_classifier(
+... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
+>>> preds
+[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
+```
+
+### 텍스트 Pipeline[[text-pipeline]]
+
+NLP 태스크를 위해 [`pipeline`]을 사용하는 일도 거의 동일합니다.
+
+```py
+>>> from transformers import pipeline
+
+>>> # This model is a `zero-shot-classification` model.
+>>> # It will classify text, except you are free to choose any label you might imagine
+>>> classifier = pipeline(model="facebook/bart-large-mnli")
+>>> classifier(
+... "I have a problem with my iphone that needs to be resolved asap!!",
+... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
+... )
+{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}
+```
+
+### 멀티모달 Pipeline[[multimodal-pipeline]]
+
+[`pipeline`]은 여러 모달리티(역주: 오디오, 비디오, 텍스트와 같은 데이터 형태)를 지원합니다. 예시로 시각적 질의응답(VQA; Visual Question Answering) 태스크는 텍스트와 이미지를 모두 사용합니다. 그 어떤 이미지 링크나 묻고 싶은 질문도 자유롭게 전달할 수 있습니다. 이미지는 URL 또는 로컬 경로의 형태로 전달해주세요.
+
+예를 들어 이 [거래명세서 사진](https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png)에서 거래명세서 번호를 묻고 싶다면,
+
+```py
+>>> from transformers import pipeline
+
+>>> vqa = pipeline(model="impira/layoutlm-document-qa")
+>>> vqa(
+... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
+... question="What is the invoice number?",
+... )
+[{'score': 0.42514941096305847, 'answer': 'us-001', 'start': 16, 'end': 16}]
+```
diff --git a/docs/transformers/docs/source/ko/pipeline_webserver.md b/docs/transformers/docs/source/ko/pipeline_webserver.md
new file mode 100644
index 0000000000000000000000000000000000000000..b7d5366c57c4ef2edc7fb7505304299cf76317c2
--- /dev/null
+++ b/docs/transformers/docs/source/ko/pipeline_webserver.md
@@ -0,0 +1,144 @@
+
+
+# 웹 서버를 위한 파이프라인 사용하기[[using_pipelines_for_a_webserver]]
+
+
+추론 엔진을 만드는 것은 복잡한 주제이며, "최선의" 솔루션은 문제 공간에 따라 달라질 가능성이 높습니다. CPU 또는 GPU를 사용하는지에 따라 다르고 낮은 지연 시간을 원하는지, 높은 처리량을 원하는지, 다양한 모델을 지원할 수 있길 원하는지, 하나의 특정 모델을 고도로 최적화하길 원하는지 등에 따라 달라집니다. 이 주제를 해결하는 방법에는 여러 가지가 있으므로, 이 장에서 제시하는 것은 처음 시도해 보기에 좋은 출발점일 수는 있지만, 이 장을 읽는 여러분이 필요로 하는 최적의 솔루션은 아닐 수 있습니다.
+
+
+핵심적으로 이해해야 할 점은 [dataset](pipeline_tutorial#using-pipelines-on-a-dataset)를 다룰 때와 마찬가지로 반복자를 사용 가능하다는 것입니다. 왜냐하면, 웹 서버는 기본적으로 요청을 기다리고 들어오는 대로 처리하는 시스템이기 때문입니다.
+
+보통 웹 서버는 다양한 요청을 동시에 다루기 위해 매우 다중화된 구조(멀티 스레딩, 비동기 등)를 지니고 있습니다. 반면에, 파이프라인(대부분 파이프라인 안에 있는 모델)은 병렬처리에 그다지 좋지 않습니다. 왜냐하면 파이프라인은 많은 RAM을 차지하기 때문입니다. 따라서, 파이프라인이 실행 중이거나 계산 집약적인 작업 중일 때 모든 사용 가능한 리소스를 제공하는 것이 가장 좋습니다.
+
+이 문제를 우리는 웹 서버가 요청을 받고 보내는 가벼운 부하를 처리하고, 실제 작업을 처리하는 단일 스레드를 갖는 방법으로 해결할 것입니다. 이 예제는 `starlette` 라이브러리를 사용합니다.
+실제 프레임워크는 중요하지 않지만, 다른 프레임워크를 사용하는 경우 동일한 효과를 보기 위해선 코드를 조정하거나 변경해야 할 수 있습니다.
+
+`server.py`를 생성하세요:
+
+```py
+from starlette.applications import Starlette
+from starlette.responses import JSONResponse
+from starlette.routing import Route
+from transformers import pipeline
+import asyncio
+
+
+async def homepage(request):
+ payload = await request.body()
+ string = payload.decode("utf-8")
+ response_q = asyncio.Queue()
+ await request.app.model_queue.put((string, response_q))
+ output = await response_q.get()
+ return JSONResponse(output)
+
+
+async def server_loop(q):
+ pipe = pipeline(model="google-bert/bert-base-uncased")
+ while True:
+ (string, response_q) = await q.get()
+ out = pipe(string)
+ await response_q.put(out)
+
+
+app = Starlette(
+ routes=[
+ Route("/", homepage, methods=["POST"]),
+ ],
+)
+
+
+@app.on_event("startup")
+async def startup_event():
+ q = asyncio.Queue()
+ app.model_queue = q
+ asyncio.create_task(server_loop(q))
+```
+
+이제 다음 명령어로 실행시킬 수 있습니다:
+
+```bash
+uvicorn server:app
+```
+
+이제 쿼리를 날려볼 수 있습니다:
+
+```bash
+curl -X POST -d "test [MASK]" http://localhost:8000/
+#[{"score":0.7742936015129089,"token":1012,"token_str":".","sequence":"test."},...]
+```
+
+자, 이제 웹 서버를 만드는 방법에 대한 좋은 개념을 알게 되었습니다!
+
+중요한 점은 모델을 **한 번만** 가져온다는 것입니다. 따라서 웹 서버에는 모델의 사본이 없습니다. 이런 방식은 불필요한 RAM이 사용되지 않습니다. 그런 다음 큐 메커니즘을 사용하면, 다음과 같은
+동적 배치를 사용하기 위해 추론 전 단계에 몇 개의 항목을 축적하는 것과 같은 멋진 작업을 할 수 있습니다:
+
+
+코드는 의도적으로 가독성을 위해 의사 코드처럼 작성되었습니다!
+아래 코드를 작동시키기 전에 시스템 자원이 충분한지 확인하세요!
+
+
+```py
+(string, rq) = await q.get()
+strings = []
+queues = []
+while True:
+ try:
+ (string, rq) = await asyncio.wait_for(q.get(), timeout=0.001) # 1ms
+ except asyncio.exceptions.TimeoutError:
+ break
+ strings.append(string)
+ queues.append(rq)
+strings
+outs = pipe(strings, batch_size=len(strings))
+for rq, out in zip(queues, outs):
+ await rq.put(out)
+```
+
+다시 말씀 드리자면, 제안된 코드는 가독성을 위해 최적화되었으며, 최상의 코드는 아닙니다.
+첫째, 배치 크기 제한이 없으며 이는 일반적으로 좋은 방식이 아닙니다.
+둘째, 모든 큐 가져오기에서 타임아웃이 재설정되므로 추론을 실행하기 전에 1ms보다 훨씬 오래 기다릴 수 있습니다(첫 번째 요청을 그만큼 지연시킴).
+
+단일 1ms 길이의 데드라인을 두는 편이 더 좋습니다.
+
+이 방식을 사용하면 큐가 비어 있어도 항상 1ms를 기다리게 될 것입니다.
+큐에 아무것도 없을 때 추론을 원하는 경우에는 최선의 방법이 아닐 수 있습니다.
+하지만 배치 작업이 사용례에 따라 정말로 중요하다면 의미가 있을 수도 있습니다.
+다시 말하지만, 최상의 솔루션은 없습니다.
+
+## 고려해야 할 몇 가지 사항[[few_things_you_might want_to_consider]]
+
+### 에러 확인[[error_checking]]
+
+프로덕션 환경에서는 문제가 발생할 여지가 많습니다.
+메모리가 모자라거나, 공간이 부족하거나, 모델을 가져오는 데에 실패하거나, 쿼리가 잘못되었거나, 쿼리는 정확해도 모델 설정이 잘못되어 실행에 실패하는 등등 많은 경우가 존재합니다.
+
+일반적으로 서버가 사용자에게 오류를 출력하는 것이 좋으므로
+오류를 표시하기 위해 `try...except` 문을 많이 추가하는 것이 좋습니다.
+하지만 보안 상황에 따라 모든 오류를 표시하는 것은 보안상 위험할 수도 있다는 점을 명심해야합니다.
+
+### 서킷 브레이킹[[circuit_breaking]]
+
+웹 서버는 일반적으로 서킷 브레이킹을 수행할 때 더 나은 상황에 직면합니다.
+즉, 이는 서버가 쿼리를 무기한 기다리는 대신 과부하 상태일 때 적절한 오류를 반환하는 것을 의미합니다.
+서버가 매우 오랜 시간 동안 대기하거나 적당한 시간이 지난 후에 504 에러를 반환하는 대신 503 에러를 빠르게 반환하게 하는 것입니다.
+
+제안된 코드에는 단일 큐가 있으므로 구현하기가 비교적 쉽습니다.
+큐 크기를 확인하는 것은 웹 서버가 과부하 상항 하에 있을 때 에러를 반환하기 위한 가장 기초적인 작업입니다.
+
+### 메인 쓰레드 차단[[blocking_the_main_thread]]
+
+현재 PyTorch는 비동기 처리를 지원하지 않으며, 실행 중에는 메인 스레드가 차단됩니다.
+따라서 PyTorch를 별도의 스레드/프로세스에서 실행하도록 강제하는 것이 좋습니다.
+여기서는 이 작업이 수행되지 않았습니다. 왜냐하면 코드가 훨씬 더 복잡하기 때문입니다(주로 스레드, 비동기 처리, 큐가 서로 잘 맞지 않기 때문입니다).
+하지만 궁극적으로는 같은 작업을 수행하는 것입니다.
+
+단일 항목의 추론이 오래 걸린다면 (> 1초), 메인 쓰레드를 차단하는 것은 중요할 수 있습니다. 왜냐하면 이 경우 추론 중 모든 쿼리는 오류를 받기 전에 1초를 기다려야 하기 때문입니다.
+
+### 동적 배치[[dynamic_batching]]
+
+일반적으로, 배치 처리가 1개 항목을 한 번에 전달하는 것에 비해 반드시 성능 향상이 있는 것은 아닙니다(자세한 내용은 [`batching details`](./main_classes/pipelines#pipeline-batching)을 참고하세요).
+하지만 올바른 설정에서 사용하면 매우 효과적일 수 있습니다.
+API에는 기본적으로 속도 저하의 가능성이 매우 높기 때문에 동적 배치 처리가 없습니다.
+하지만 매우 큰 모델인 BLOOM 추론의 경우 동적 배치 처리는 모든 사람에게 적절한 경험을 제공하는 데 **필수**입니다.
diff --git a/docs/transformers/docs/source/ko/pr_checks.md b/docs/transformers/docs/source/ko/pr_checks.md
new file mode 100644
index 0000000000000000000000000000000000000000..1d155cd1fb9ddbc0f4c70b16faeba261b75f573f
--- /dev/null
+++ b/docs/transformers/docs/source/ko/pr_checks.md
@@ -0,0 +1,200 @@
+
+
+# Pull Request에 대한 검사 [[checks-on-a-pull-request]]
+
+🤗 Transformers에서 Pull Request를 열 때, 기존에 있는 것을 망가뜨리지 않는지 확인하기 위해 상당한 수의 검사가 실행됩니다. 이러한 검사는 다음과 같은 네 가지 유형으로 구성됩니다:
+- 일반적인 테스트
+- 문서 빌드
+- 코드 및 문서 스타일
+- 일반 저장소 일관성
+
+이 문서에서는 이러한 다양한 검사와 그 이유를 설명하고, PR에서 하나 이상의 검사가 실패한 경우 로컬에서 어떻게 디버그하는지 알아보겠습니다.
+
+참고로, 이러한 검사를 사용하려면 개발 설치가 필요합니다:
+
+```bash
+pip install transformers[dev]
+```
+
+또는 Transformers 저장소 내에 편집 가능한 설치가 필요합니다:
+
+```bash
+pip install -e .[dev]
+```
+
+Transformers의 선택적 종속성 수가 많이 늘어났기 때문에 개발 설치를 실패할 수도 있습니다. 개발 설치가 실패하는 경우, 작업 중인 Deep Learning 프레임워크 (PyTorch, TensorFlow 및/또는 Flax)를 설치하고 다음 명령을 실행하세요.
+
+```bash
+pip install transformers[quality]
+```
+
+편집 가능한 설치의 경우는 다음 명령을 실행하세요.
+
+```bash
+pip install -e .[quality]
+```
+
+
+## 테스트 [[tests]]
+
+`ci/circleci: run_tests_`로 시작하는 모든 작업은 Transformers 테스트 모음의 일부를 실행합니다. 이러한 작업은 특정 환경에서 일부 라이브러리에 중점을 둡니다. 예를 들어 `ci/circleci: run_tests_pipelines_tf`는 TensorFlow만 설치된 환경에서 파이프라인 테스트를 실행합니다.
+
+테스트 모듈에서 실제로 변경 사항이 없을 때 테스트를 실행하지 않기 위해, 테스트 모음의 일부만 실행됩니다. 라이브러리의 변경 전후에 대한 차이를 확인하기 위해 유틸리티가 실행되고, 해당 차이에 영향을 받는 테스트가 선택됩니다. 이 유틸리티는 로컬에서 다음과 같이 실행할 수 있습니다:
+
+```bash
+python utils/tests_fetcher.py
+```
+
+Transformers 저장소의 최상단에서 실행합니다. 이 유틸리티는 다음과 같은 작업을 수행합니다:
+
+1. 변경 사항이 있는 파일마다 변경 사항이 코드인지 주석 또는 문서 문자열인지 확인합니다. 실제 코드 변경이 있는 파일만 유지됩니다.
+2. 소스 코드 파일의 각 파일에 대해 재귀적으로 영향을 주는 모든 파일을 제공하는 내부 맵을 작성합니다. 모듈 B가 모듈 A를 가져오면 모듈 A는 모듈 B에 영향을 줍니다. 재귀적인 영향에는 각 모듈이 이전 모듈을 가져오는 모듈 체인이 필요합니다.
+3. 단계 1에서 수집한 파일에 이 맵을 적용하여 PR에 영향을 받는 모델 파일 목록을 얻습니다.
+4. 각 파일을 해당하는 테스트 파일에 매핑하고 실행할 테스트 목록을 가져옵니다.
+
+로컬에서 스크립트를 실행하면 단계 1, 3 및 4의 결과를 출력하여 실행되는 테스트를 알 수 있습니다. 스크립트는 또한 `test_list.txt`라는 파일을 생성하여 실행할 테스트 목록을 포함하며, 다음 명령으로 해당 테스트를 로컬에서 실행할 수 있습니다:
+
+```bash
+python -m pytest -n 8 --dist=loadfile -rA -s $(cat test_list.txt)
+```
+
+잘못된 사항이 누락되었을 경우, 전체 테스트 모음도 매일 실행됩니다.
+
+## 문서 빌드 [[documentation-build]]
+
+`build_pr_documentation` 작업은 문서를 빌드하고 미리 보기를 생성하여 PR이 병합된 후 모든 것이 제대로 보이는지 확인합니다. 로봇은 PR에 문서 미리보기 링크를 추가합니다. PR에서 만든 변경 사항은 자동으로 미리보기에 업데이트됩니다. 문서 빌드에 실패한 경우 **세부 정보**를 클릭하여 어디에서 문제가 발생했는지 확인할 수 있습니다. 오류는 주로 `toctree`에 누락된 파일과 같이 간단한 오류입니다.
+
+로컬에서 문서를 빌드하거나 미리 볼 경우, docs 폴더의 [`README.md`](https://github.com/huggingface/transformers/tree/main/docs)를 참조하세요.
+
+## 코드 및 문서 스타일 [[code-and-documentation-style]]
+
+`black`과 `ruff`를 사용하여 모든 소스 파일, 예제 및 테스트에 코드 형식을 적용합니다. 또한, `utils/style_doc.py`에서 문서 문자열과 `rst` 파일의 형식, 그리고 Transformers의 `__init__.py` 파일에서 실행되는 지연된 임포트의 순서에 대한 사용자 정의 도구가 있습니다. 이 모든 것은 다음을 실행함으로써 실행할 수 있습니다:
+
+```bash
+make style
+```
+
+CI는 이러한 사항이 `ci/circleci: check_code_quality` 검사 내에서 적용되었는지 확인합니다. 또한 `ruff`도 실행되며, 정의되지 않은 변수나 사용되지 않은 변수를 발견하면 경고합니다. 이 검사를 로컬에서 실행하려면 다음을 사용하세요:
+
+```bash
+make quality
+```
+
+이 작업은 많은 시간이 소요될 수 있으므로 현재 브랜치에서 수정한 파일에 대해서만 동일한 작업을 실행하려면 다음을 실행하세요.
+
+```bash
+make fixup
+```
+
+이 명령은 현재 브랜치에서 수정한 파일에 대한 모든 추가적인 검사도 실행합니다. 이제 이들을 살펴보겠습니다.
+
+## 저장소 일관성 [[repository-consistency]]
+
+이는 PR이 저장소를 정상적인 상태로 유지하는지 확인하는 모든 테스트를 모은 것이며, `ci/circleci: check_repository_consistency` 검사에서 수행됩니다. 다음을 실행함으로써 로컬에서 이 검사를 실행할 수 있습니다.
+
+```bash
+make repo-consistency
+```
+
+이 검사는 다음을 확인합니다.
+
+- init에 추가된 모든 객체가 문서화되었는지 (`utils/check_repo.py`에서 수행)
+- `__init__.py` 파일의 두 섹션에 동일한 내용이 있는지 (`utils/check_inits.py`에서 수행)
+- 다른 모듈에서 복사된 코드가 원본과 일치하는지 (`utils/check_copies.py`에서 수행)
+- 모든 구성 클래스에 docstring에 언급된 유효한 체크포인트가 적어도 하나 있는지 (`utils/check_config_docstrings.py`에서 수행)
+- 모든 구성 클래스가 해당하는 모델링 파일에서 사용되는 속성만 포함하고 있는지 (`utils/check_config_attributes.py`에서 수행)
+- README와 문서 인덱스의 번역이 메인 README와 동일한 모델 목록을 가지고 있는지 (`utils/check_copies.py`에서 수행)
+- 문서의 자동 생성된 테이블이 최신 상태인지 (`utils/check_table.py`에서 수행)
+- 라이브러리에는 선택적 종속성이 설치되지 않았더라도 모든 객체가 사용 가능한지 (`utils/check_dummies.py`에서 수행)
+
+이러한 검사가 실패하는 경우, 처음 두 가지 항목은 수동으로 수정해야 하며, 나머지 네 가지 항목은 다음 명령을 실행하여 자동으로 수정할 수 있습니다.
+
+```bash
+make fix-copies
+```
+
+추가적인 검사는 새로운 모델을 추가하는 PR에 대한 것으로, 주로 다음과 같습니다:
+
+- 추가된 모든 모델이 Auto-mapping에 있는지 (`utils/check_repo.py`에서 수행)
+
+- 모든 모델이 올바르게 테스트되었는지 (`utils/check_repo.py`에서 수행)
+
+
+
+### 복사본 확인 [[check-copies]]
+
+Transformers 라이브러리는 모델 코드에 대해 매우 완고하며, 각 모델은 다른 모델에 의존하지 않고 완전히 단일 파일로 구현되어야 합니다. 이렇게 하기 위해 특정 모델의 코드 복사본이 원본과 일관된 상태로 유지되는지 확인하는 메커니즘을 추가했습니다. 따라서 버그 수정이 필요한 경우 다른 모델에 영향을 주는 모든 모델을 볼 수 있으며 수정을 적용할지 수정된 사본을 삭제할지 선택할 수 있습니다.
+
+
+
+파일이 다른 파일의 완전한 사본인 경우 해당 파일을 `utils/check_copies.py`의 `FULL_COPIES` 상수에 등록해야 합니다.
+
+
+
+이 메커니즘은 `# Copied from xxx` 형식의 주석을 기반으로 합니다. `xxx`에는 아래에 복사되는 클래스 또는 함수의 전체 경로가 포함되어야 합니다. 예를 들어 `RobertaSelfOutput`은 `BertSelfOutput` 클래스의 복사본입니다. 따라서 [여기](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L289)에서 주석이 있습니다:
+
+
+```py
+# Copied from transformers.models.bert.modeling_bert.BertSelfOutput
+```
+
+클래스 전체에 수정을 적용하는 대신에 복사본과 관련있는 메서드에 적용할 수도 있습니다. 예를 들어 [여기](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L598)에서 `RobertaPreTrainedModel._init_weights`가 `BertPreTrainedModel`의 동일한 메서드에서 복사된 것을 볼 수 있으며 해당 주석이 있습니다:
+
+```py
+# Copied from transformers.models.bert.modeling_bert.BertPreTrainedModel._init_weights
+```
+
+복사본이 이름만 다른 경우가 있습니다: 예를 들어 `RobertaAttention`에서 `BertSelfAttention` 대신 `RobertaSelfAttention`을 사용하지만 그 외에는 코드가 완전히 동일합니다: 이 때 `# Copied from`은 `Copied from xxx with foo->bar`와 같은 간단한 문자열 대체를 지원합니다. 이는 모든 `foo` 인스턴스를 `bar`로 바꿔서 코드를 복사합니다. [여기](https://github.com/huggingface/transformers/blob/2bd7a27a671fd1d98059124024f580f8f5c0f3b5/src/transformers/models/roberta/modeling_roberta.py#L304C1-L304C86)에서 어떻게 사용되는지 볼 수 있습니다:
+
+```py
+# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->Roberta
+```
+
+화살표 주변에는 공백이 없어야 합니다(공백이 대체 패턴의 일부인 경우는 예외입니다).
+
+대체 패턴을 쉼표로 구분하여 여러 패턴을 추가할 수 있습니다. 예를 들어 `CamemberForMaskedLM`은 두 가지 대체 사항을 가진 `RobertaForMaskedLM`의 복사본입니다: `Roberta`를 `Camembert`로 대체하고 `ROBERTA`를 `CAMEMBERT`로 대체합니다. [여기](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/camembert/modeling_camembert.py#L929)에서 이것이 주석으로 어떻게 구현되었는지 확인할 수 있습니다:
+
+```py
+# Copied from transformers.models.roberta.modeling_roberta.RobertaForMaskedLM with Roberta->Camembert, ROBERTA->CAMEMBERT
+```
+
+순서가 중요한 경우(이전 수정과 충돌할 수 있는 경우) 수정은 왼쪽에서 오른쪽으로 실행됩니다.
+
+
+
+새 변경이 서식을 변경하는 경우(짧은 이름을 매우 긴 이름으로 바꾸는 경우) 자동 서식 지정기를 적용한 후 복사본이 검사됩니다.
+
+
+
+패턴의 대소문자가 다른 경우(대문자와 소문자가 혼용된 대체 양식) `all-casing` 옵션을 추가하는 방법도 있습니다. [여기](https://github.com/huggingface/transformers/blob/15082a9dc6950ecae63a0d3e5060b2fc7f15050a/src/transformers/models/mobilebert/modeling_mobilebert.py#L1237)에서 `MobileBertForSequenceClassification`에서 사용된 예시를 볼 수 있습니다:
+
+```py
+# Copied from transformers.models.bert.modeling_bert.BertForSequenceClassification with Bert->MobileBert all-casing
+```
+
+이 경우, 코드는 다음과 같이 복사됩니다:
+- `MobileBert`에서 `Bert`로(예: `MobileBertModel`을 init에서 사용할 때)
+- `mobilebert`에서 `bert`로(예: `self.mobilebert`를 정의할 때)
+- `MOBILEBERT`에서 `BERT`로(`MOBILEBERT_INPUTS_DOCSTRING` 상수에서)
diff --git a/docs/transformers/docs/source/ko/preprocessing.md b/docs/transformers/docs/source/ko/preprocessing.md
new file mode 100644
index 0000000000000000000000000000000000000000..4466b63585723d49a5165135c40ec287d25ff907
--- /dev/null
+++ b/docs/transformers/docs/source/ko/preprocessing.md
@@ -0,0 +1,539 @@
+
+
+# 전처리[[preprocess]]
+
+[[open-in-colab]]
+
+모델을 훈련하려면 데이터 세트를 모델에 맞는 입력 형식으로 전처리해야 합니다. 텍스트, 이미지 또는 오디오인지 관계없이 데이터를 텐서 배치로 변환하고 조립할 필요가 있습니다. 🤗 Transformers는 모델에 대한 데이터를 준비하는 데 도움이 되는 일련의 전처리 클래스를 제공합니다. 이 튜토리얼에서는 다음 내용을 배울 수 있습니다:
+
+* 텍스트는 [Tokenizer](./main_classes/tokenizer)를 사용하여 토큰 시퀀스로 변환하고 토큰의 숫자 표현을 만든 후 텐서로 조립합니다.
+* 음성 및 오디오는 [Feature extractor](./main_classes/feature_extractor)를 사용하여 오디오 파형에서 시퀀스 특성을 파악하여 텐서로 변환합니다.
+* 이미지 입력은 [ImageProcessor](./main_classes/image)을 사용하여 이미지를 텐서로 변환합니다.
+* 멀티모달 입력은 [Processor](./main_classes/processors)을 사용하여 토크나이저와 특성 추출기 또는 이미지 프로세서를 결합합니다.
+
+
+
+`AutoProcessor`는 **언제나** 작동하여 토크나이저, 이미지 프로세서, 특성 추출기 또는 프로세서 등 사용 중인 모델에 맞는 클래스를 자동으로 선택합니다.
+
+
+
+시작하기 전에 🤗 Datasets를 설치하여 실험에 사용할 데이터를 불러올 수 있습니다:
+
+```bash
+pip install datasets
+```
+
+## 자연어처리[[natural-language-processing]]
+
+
+
+텍스트 데이터를 전처리하기 위한 기본 도구는 [tokenizer](main_classes/tokenizer)입니다. 토크나이저는 일련의 규칙에 따라 텍스트를 *토큰*으로 나눕니다. 토큰은 숫자로 변환되고 텐서는 모델 입력이 됩니다. 모델에 필요한 추가 입력은 토크나이저에 의해 추가됩니다.
+
+
+
+사전훈련된 모델을 사용할 계획이라면 모델과 함께 사전훈련된 토크나이저를 사용하는 것이 중요합니다. 이렇게 하면 텍스트가 사전훈련 말뭉치와 동일한 방식으로 분할되고 사전훈련 중에 동일한 해당 토큰-인덱스 쌍(일반적으로 *vocab*이라고 함)을 사용합니다.
+
+
+
+시작하려면 [`AutoTokenizer.from_pretrained`] 메소드를 사용하여 사전훈련된 토크나이저를 불러오세요. 모델과 함께 사전훈련된 *vocab*을 다운로드합니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
+```
+
+그 다음으로 텍스트를 토크나이저에 넣어주세요:
+
+```py
+>>> encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
+>>> print(encoded_input)
+{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+토크나이저는 세 가지 중요한 항목을 포함한 딕셔너리를 반환합니다:
+
+* [input_ids](glossary#input-ids)는 문장의 각 토큰에 해당하는 인덱스입니다.
+* [attention_mask](glossary#attention-mask)는 토큰을 처리해야 하는지 여부를 나타냅니다.
+* [token_type_ids](glossary#token-type-ids)는 두 개 이상의 시퀀스가 있을 때 토큰이 속한 시퀀스를 식별합니다.
+
+`input_ids`를 디코딩하여 입력을 반환합니다:
+
+```py
+>>> tokenizer.decode(encoded_input["input_ids"])
+'[CLS] Do not meddle in the affairs of wizards, for they are subtle and quick to anger. [SEP]'
+```
+
+토크나이저가 두 개의 특수한 토큰(분류 토큰 `CLS`와 분할 토큰 `SEP`)을 문장에 추가했습니다.
+모든 모델에 특수한 토큰이 필요한 것은 아니지만, 필요하다면 토크나이저가 자동으로 추가합니다.
+
+전처리할 문장이 여러 개 있는 경우에는 리스트로 토크나이저에 전달합니다:
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_inputs = tokenizer(batch_sentences)
+>>> print(encoded_inputs)
+{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
+ [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
+ [101, 1327, 1164, 5450, 23434, 136, 102]],
+ 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0]],
+ 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1]]}
+```
+
+### 패딩[[pad]]
+
+모델 입력인 텐서는 모양이 균일해야 하지만, 문장의 길이가 항상 같지는 않기 때문에 문제가 될 수 있습니다. 패딩은 짧은 문장에 특수한 *패딩 토큰*을 추가하여 텐서를 직사각형 모양이 되도록 하는 전략입니다.
+
+`padding` 매개변수를 `True`로 설정하여 배치 내의 짧은 시퀀스를 가장 긴 시퀀스에 맞춰 패딩합니다.
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_input = tokenizer(batch_sentences, padding=True)
+>>> print(encoded_input)
+{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
+ [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
+ [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
+ 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
+ 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
+```
+
+길이가 짧은 첫 문장과 세 번째 문장이 이제 `0`으로 채워졌습니다.
+
+### 잘라내기[[truncation]]
+
+한편, 때로는 시퀀스가 모델에서 처리하기에 너무 길 수도 있습니다. 이 경우, 시퀀스를 더 짧게 줄일 필요가 있습니다.
+
+모델에서 허용하는 최대 길이로 시퀀스를 자르려면 `truncation` 매개변수를 `True`로 설정하세요:
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
+>>> print(encoded_input)
+{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
+ [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
+ [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
+ 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
+ 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
+```
+
+
+
+다양한 패딩과 잘라내기 인수에 대해 더 알아보려면 [패딩과 잘라내기](./pad_truncation) 개념 가이드를 확인해보세요.
+
+
+
+### 텐서 만들기[[build-tensors]]
+
+마지막으로, 토크나이저가 모델에 공급되는 실제 텐서를 반환하도록 합니다.
+
+`return_tensors` 매개변수를 PyTorch의 경우 `pt`, TensorFlow의 경우 `tf`로 설정하세요:
+
+
+
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
+>>> print(encoded_input)
+{'input_ids': tensor([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
+ [101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
+ [101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]]),
+ 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
+ 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
+```
+
+
+```py
+>>> batch_sentences = [
+... "But what about second breakfast?",
+... "Don't think he knows about second breakfast, Pip.",
+... "What about elevensies?",
+... ]
+>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
+>>> print(encoded_input)
+{'input_ids': ,
+ 'token_type_ids': ,
+ 'attention_mask': }
+```
+
+
+
+## 오디오[[audio]]
+
+오디오 작업은 모델에 맞는 데이터 세트를 준비하기 위해 [특성 추출기](main_classes/feature_extractor)가 필요합니다. 특성 추출기는 원시 오디오 데이터에서 특성를 추출하고 이를 텐서로 변환하는 것이 목적입니다.
+
+오디오 데이터 세트에 특성 추출기를 사용하는 방법을 보기 위해 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트를 가져오세요. (데이터 세트를 가져오는 방법은 🤗 [데이터 세트 튜토리얼](https://huggingface.co/docs/datasets/load_hub)에서 자세히 설명하고 있습니다.)
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
+```
+
+`audio` 열의 첫 번째 요소에 접근하여 입력을 살펴보세요. `audio` 열을 호출하면 오디오 파일을 자동으로 가져오고 리샘플링합니다.
+
+```py
+>>> dataset[0]["audio"]
+{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
+ 0. , 0. ], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
+ 'sampling_rate': 8000}
+```
+
+이렇게 하면 세 가지 항목이 반환됩니다:
+
+* `array`는 1D 배열로 가져와서 (필요한 경우) 리샘플링된 음성 신호입니다.
+* `path`는 오디오 파일의 위치를 가리킵니다.
+* `sampling_rate`는 음성 신호에서 초당 측정되는 데이터 포인트 수를 나타냅니다.
+
+이 튜토리얼에서는 [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) 모델을 사용합니다. 모델 카드를 보면 Wav2Vec2가 16kHz 샘플링된 음성 오디오를 기반으로 사전훈련된 것을 알 수 있습니다.
+모델을 사전훈련하는 데 사용된 데이터 세트의 샘플링 레이트와 오디오 데이터의 샘플링 레이트가 일치해야 합니다. 데이터의 샘플링 레이트가 다르면 데이터를 리샘플링해야 합니다.
+
+1. 🤗 Datasets의 [`~datasets.Dataset.cast_column`] 메소드를 사용하여 샘플링 레이트를 16kHz로 업샘플링하세요:
+
+```py
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
+```
+
+2. 오디오 파일을 리샘플링하기 위해 `audio` 열을 다시 호출합니다:
+
+```py
+>>> dataset[0]["audio"]
+{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ...,
+ 3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
+ 'sampling_rate': 16000}
+```
+
+다음으로, 입력을 정규화하고 패딩할 특성 추출기를 가져오세요. 텍스트 데이터의 경우, 더 짧은 시퀀스에 대해 `0`이 추가됩니다. 오디오 데이터에도 같은 개념이 적용됩니다.
+특성 추출기는 배열에 `0`(묵음으로 해석)을 추가합니다.
+
+[`AutoFeatureExtractor.from_pretrained`]를 사용하여 특성 추출기를 가져오세요:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
+```
+
+오디오 `array`를 특성 추출기에 전달하세요. 또한, 발생할 수 있는 조용한 오류(silent errors)를 더 잘 디버깅할 수 있도록 특성 추출기에 `sampling_rate` 인수를 추가하는 것을 권장합니다.
+
+```py
+>>> audio_input = [dataset[0]["audio"]["array"]]
+>>> feature_extractor(audio_input, sampling_rate=16000)
+{'input_values': [array([ 3.8106556e-04, 2.7506407e-03, 2.8015103e-03, ...,
+ 5.6335266e-04, 4.6588284e-06, -1.7142107e-04], dtype=float32)]}
+```
+
+토크나이저와 마찬가지로 배치 내에서 가변적인 시퀀스를 처리하기 위해 패딩 또는 잘라내기를 적용할 수 있습니다. 이 두 개의 오디오 샘플의 시퀀스 길이를 확인해보세요:
+
+```py
+>>> dataset[0]["audio"]["array"].shape
+(173398,)
+
+>>> dataset[1]["audio"]["array"].shape
+(106496,)
+```
+
+오디오 샘플의 길이가 동일하도록 데이터 세트를 전처리하는 함수를 만드세요. 최대 샘플 길이를 지정하면 특성 추출기가 해당 길이에 맞춰 시퀀스를 패딩하거나 잘라냅니다:
+
+```py
+>>> def preprocess_function(examples):
+... audio_arrays = [x["array"] for x in examples["audio"]]
+... inputs = feature_extractor(
+... audio_arrays,
+... sampling_rate=16000,
+... padding=True,
+... max_length=100000,
+... truncation=True,
+... )
+... return inputs
+```
+
+`preprocess_function`을 데이터 세트의 처음 예시 몇 개에 적용해보세요:
+
+```py
+>>> processed_dataset = preprocess_function(dataset[:5])
+```
+
+이제 샘플 길이가 모두 같고 지정된 최대 길이에 맞게 되었습니다. 드디어 전처리된 데이터 세트를 모델에 전달할 수 있습니다!
+
+```py
+>>> processed_dataset["input_values"][0].shape
+(100000,)
+
+>>> processed_dataset["input_values"][1].shape
+(100000,)
+```
+
+## 컴퓨터 비전[[computer-vision]]
+
+컴퓨터 비전 작업의 경우, 모델에 대한 데이터 세트를 준비하기 위해 [이미지 프로세서](main_classes/image_processor)가 필요합니다.
+이미지 전처리는 이미지를 모델이 예상하는 입력으로 변환하는 여러 단계로 이루어집니다.
+이러한 단계에는 크기 조정, 정규화, 색상 채널 보정, 이미지의 텐서 변환 등이 포함됩니다.
+
+
+
+이미지 전처리는 이미지 증강 기법을 몇 가지 적용한 뒤에 할 수도 있습니다.
+이미지 전처리 및 이미지 증강은 모두 이미지 데이터를 변형하지만, 서로 다른 목적을 가지고 있습니다:
+
+* 이미지 증강은 과적합(over-fitting)을 방지하고 모델의 견고함(resiliency)을 높이는 데 도움이 되는 방식으로 이미지를 수정합니다.
+밝기와 색상 조정, 자르기, 회전, 크기 조정, 확대/축소 등 다양한 방법으로 데이터를 증강할 수 있습니다.
+그러나 증강으로 이미지의 의미가 바뀌지 않도록 주의해야 합니다.
+* 이미지 전처리는 이미지가 모델이 예상하는 입력 형식과 일치하도록 보장합니다.
+컴퓨터 비전 모델을 미세 조정할 때 이미지는 모델이 초기에 훈련될 때와 정확히 같은 방식으로 전처리되어야 합니다.
+
+이미지 증강에는 원하는 라이브러리를 무엇이든 사용할 수 있습니다. 이미지 전처리에는 모델과 연결된 `ImageProcessor`를 사용합니다.
+
+
+
+[food101](https://huggingface.co/datasets/food101) 데이터 세트를 가져와서 컴퓨터 비전 데이터 세트에서 이미지 프로세서를 어떻게 사용하는지 알아보세요.
+데이터 세트를 불러오는 방법은 🤗 [데이터 세트 튜토리얼](https://huggingface.co/docs/datasets/load_hub)을 참고하세요.
+
+
+
+데이터 세트가 상당히 크기 때문에 🤗 Datasets의 `split` 매개변수를 사용하여 훈련 세트에서 작은 샘플만 가져오세요!
+
+
+
+```py
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("food101", split="train[:100]")
+```
+
+다음으로, 🤗 Datasets의 [`image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image)로 이미지를 확인해보세요:
+
+```py
+>>> dataset[0]["image"]
+```
+
+
+
+
+
+[`AutoImageProcessor.from_pretrained`]로 이미지 프로세서를 가져오세요:
+
+```py
+>>> from transformers import AutoImageProcessor
+
+>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
+```
+
+먼저 이미지 증강 단계를 추가해 봅시다. 아무 라이브러리나 사용해도 괜찮지만, 이번 튜토리얼에서는 torchvision의 [`transforms`](https://pytorch.org/vision/stable/transforms.html) 모듈을 사용하겠습니다.
+다른 데이터 증강 라이브러리를 사용해보고 싶다면, [Albumentations](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) 또는 [Kornia notebooks](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb)에서 어떻게 사용하는지 배울 수 있습니다.
+
+1. [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html)로 [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html)와 [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html) 등 변환을 몇 가지 연결하세요.
+참고로 크기 조정에 필요한 이미지의 크기 요구사항은 `image_processor`에서 가져올 수 있습니다.
+일부 모델은 정확한 높이와 너비를 요구하지만, 제일 짧은 변의 길이(`shortest_edge`)만 정의된 모델도 있습니다.
+
+```py
+>>> from torchvision.transforms import RandomResizedCrop, ColorJitter, Compose
+
+>>> size = (
+... image_processor.size["shortest_edge"]
+... if "shortest_edge" in image_processor.size
+... else (image_processor.size["height"], image_processor.size["width"])
+... )
+
+>>> _transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5)])
+```
+
+2. 모델은 입력으로 [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values)를 받습니다.
+`ImageProcessor`는 이미지 정규화 및 적절한 텐서 생성을 처리할 수 있습니다.
+배치 이미지에 대한 이미지 증강 및 이미지 전처리를 결합하고 `pixel_values`를 생성하는 함수를 만듭니다:
+
+```py
+>>> def transforms(examples):
+... images = [_transforms(img.convert("RGB")) for img in examples["image"]]
+... examples["pixel_values"] = image_processor(images, do_resize=False, return_tensors="pt")["pixel_values"]
+... return examples
+```
+
+
+
+위의 예에서는 이미지 증강 중에 이미지 크기를 조정했기 때문에 `do_resize=False`로 설정하고, 해당 `image_processor`에서 `size` 속성을 활용했습니다.
+이미지 증강 중에 이미지 크기를 조정하지 않은 경우 이 매개변수를 생략하세요.
+기본적으로는 `ImageProcessor`가 크기 조정을 처리합니다.
+
+증강 변환 과정에서 이미지를 정규화하려면 `image_processor.image_mean` 및 `image_processor.image_std` 값을 사용하세요.
+
+
+
+3. 🤗 Datasets의 [`set_transform`](https://huggingface.co/docs/datasets/process#format-transform)를 사용하여 실시간으로 변환을 적용합니다:
+
+```py
+>>> dataset.set_transform(transforms)
+```
+
+4. 이제 이미지에 접근하면 이미지 프로세서가 `pixel_values`를 추가한 것을 알 수 있습니다.
+드디어 처리된 데이터 세트를 모델에 전달할 수 있습니다!
+
+```py
+>>> dataset[0].keys()
+```
+
+다음은 변형이 적용된 후의 이미지입니다. 이미지가 무작위로 잘려나갔고 색상 속성이 다릅니다.
+
+```py
+>>> import numpy as np
+>>> import matplotlib.pyplot as plt
+
+>>> img = dataset[0]["pixel_values"]
+>>> plt.imshow(img.permute(1, 2, 0))
+```
+
+
+
+
+
+
+
+`ImageProcessor`는 객체 감지, 시맨틱 세그멘테이션(semantic segmentation), 인스턴스 세그멘테이션(instance segmentation), 파놉틱 세그멘테이션(panoptic segmentation)과 같은 작업에 대한 후처리 방법을 제공합니다.
+이러한 방법은 모델의 원시 출력을 경계 상자나 세그멘테이션 맵과 같은 의미 있는 예측으로 변환해줍니다.
+
+
+
+### 패딩[[pad]]
+
+예를 들어, [DETR](./model_doc/detr)와 같은 경우에는 모델이 훈련할 때 크기 조정 증강을 적용합니다.
+이로 인해 배치 내 이미지 크기가 달라질 수 있습니다.
+[`DetrImageProcessor`]의 [`DetrImageProcessor.pad`]를 사용하고 사용자 정의 `collate_fn`을 정의해서 배치 이미지를 처리할 수 있습니다.
+
+```py
+>>> def collate_fn(batch):
+... pixel_values = [item["pixel_values"] for item in batch]
+... encoding = image_processor.pad(pixel_values, return_tensors="pt")
+... labels = [item["labels"] for item in batch]
+... batch = {}
+... batch["pixel_values"] = encoding["pixel_values"]
+... batch["pixel_mask"] = encoding["pixel_mask"]
+... batch["labels"] = labels
+... return batch
+```
+
+## 멀티모달[[multimodal]]
+
+멀티모달 입력이 필요한 작업의 경우, 모델에 데이터 세트를 준비하기 위한 [프로세서](main_classes/processors)가 필요합니다.
+프로세서는 토크나이저와 특성 추출기와 같은 두 가지 처리 객체를 결합합니다.
+
+[LJ Speech](https://huggingface.co/datasets/lj_speech) 데이터 세트를 가져와서 자동 음성 인식(ASR)을 위한 프로세서를 사용하는 방법을 확인하세요.
+(데이터 세트를 가져오는 방법에 대한 자세한 내용은 🤗 [데이터 세트 튜토리얼](https://huggingface.co/docs/datasets/load_hub)에서 볼 수 있습니다.)
+
+```py
+>>> from datasets import load_dataset
+
+>>> lj_speech = load_dataset("lj_speech", split="train")
+```
+
+자동 음성 인식(ASR)에서는 `audio`와 `text`에만 집중하면 되므로, 다른 열들은 제거할 수 있습니다:
+
+```py
+>>> lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
+```
+
+이제 `audio`와 `text`열을 살펴보세요:
+
+```py
+>>> lj_speech[0]["audio"]
+{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
+ 7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
+ 'sampling_rate': 22050}
+
+>>> lj_speech[0]["text"]
+'Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition'
+```
+
+기존에 사전훈련된 모델에서 사용된 데이터 세트와 새로운 오디오 데이터 세트의 샘플링 레이트를 일치시키기 위해 오디오 데이터 세트의 샘플링 레이트를 [리샘플링](preprocessing#audio)해야 합니다!
+
+```py
+>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
+```
+
+[`AutoProcessor.from_pretrained`]로 프로세서를 가져오세요:
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
+```
+
+1. `array`에 들어 있는 오디오 데이터를 `input_values`로 변환하고 `text`를 토큰화하여 `labels`로 변환하는 함수를 만듭니다.
+모델의 입력은 다음과 같습니다:
+
+```py
+>>> def prepare_dataset(example):
+... audio = example["audio"]
+
+... example.update(processor(audio=audio["array"], text=example["text"], sampling_rate=16000))
+
+... return example
+```
+
+2. 샘플을 `prepare_dataset` 함수에 적용하세요:
+
+```py
+>>> prepare_dataset(lj_speech[0])
+```
+
+이제 프로세서가 `input_values`와 `labels`를 추가하고, 샘플링 레이트도 올바르게 16kHz로 다운샘플링했습니다.
+드디어 처리된 데이터 세트를 모델에 전달할 수 있습니다!
diff --git a/docs/transformers/docs/source/ko/quantization/awq.md b/docs/transformers/docs/source/ko/quantization/awq.md
new file mode 100644
index 0000000000000000000000000000000000000000..3855b42a73525ab9bebbb15d37df9070f1ffa143
--- /dev/null
+++ b/docs/transformers/docs/source/ko/quantization/awq.md
@@ -0,0 +1,233 @@
+
+
+# AWQ [[awq]]
+
+
+
+이 [노트북](https://colab.research.google.com/drive/1HzZH89yAXJaZgwJDhQj9LqSBux932BvY) 으로 AWQ 양자화를 실습해보세요 !
+
+
+
+[Activation-aware Weight Quantization (AWQ)](https://hf.co/papers/2306.00978)은 모델의 모든 가중치를 양자화하지 않고, LLM 성능에 중요한 가중치를 유지합니다. 이로써 4비트 정밀도로 모델을 실행해도 성능 저하 없이 양자화 손실을 크게 줄일 수 있습니다.
+
+AWQ 알고리즘을 사용하여 모델을 양자화할 수 있는 여러 라이브러리가 있습니다. 예를 들어 [llm-awq](https://github.com/mit-han-lab/llm-awq), [autoawq](https://github.com/casper-hansen/AutoAWQ) , [optimum-intel](https://huggingface.co/docs/optimum/main/en/intel/optimization_inc) 등이 있습니다. Transformers는 llm-awq, autoawq 라이브러리를 이용해 양자화된 모델을 가져올 수 있도록 지원합니다. 이 가이드에서는 autoawq로 양자화된 모델을 가져오는 방법을 보여드리나, llm-awq로 양자화된 모델의 경우도 유사한 절차를 따릅니다.
+
+autoawq가 설치되어 있는지 확인하세요:
+
+```bash
+pip install autoawq
+```
+
+AWQ 양자화된 모델은 해당 모델의 [config.json](https://huggingface.co/TheBloke/zephyr-7B-alpha-AWQ/blob/main/config.json) 파일의 `quantization_config` 속성을 통해 식별할 수 있습니다.:
+
+```json
+{
+ "_name_or_path": "/workspace/process/huggingfaceh4_zephyr-7b-alpha/source",
+ "architectures": [
+ "MistralForCausalLM"
+ ],
+ ...
+ ...
+ ...
+ "quantization_config": {
+ "quant_method": "awq",
+ "zero_point": true,
+ "group_size": 128,
+ "bits": 4,
+ "version": "gemm"
+ }
+}
+```
+
+양자화된 모델은 [`~PreTrainedModel.from_pretrained`] 메서드를 사용하여 가져옵니다. 모델을 CPU에 가져왔다면, 먼저 모델을 GPU 장치로 옮겨야 합니다. `device_map` 파라미터를 사용하여 모델을 배치할 위치를 지정하세요:
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_id = "TheBloke/zephyr-7B-alpha-AWQ"
+model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0")
+```
+
+AWQ 양자화 모델을 가져오면 자동으로 성능상의 이유로 인해 가중치들의 기본값이 fp16으로 설정됩니다. 가중치를 다른 형식으로 가져오려면, `torch_dtype` 파라미터를 사용하세요:
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model_id = "TheBloke/zephyr-7B-alpha-AWQ"
+model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float32)
+```
+
+추론을 더욱 가속화하기 위해 AWQ 양자화와 [FlashAttention-2](../perf_infer_gpu_one#flashattention-2) 를 결합 할 수 있습니다:
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("TheBloke/zephyr-7B-alpha-AWQ", attn_implementation="flash_attention_2", device_map="cuda:0")
+```
+
+## 퓨즈된 모듈 [[fused-modules]]
+
+퓨즈된 모듈은 정확도와 성능을 개선합니다. 퓨즈된 모듈은 [Llama](https://huggingface.co/meta-llama) 아키텍처와 [Mistral](https://huggingface.co/mistralai/Mistral-7B-v0.1) 아키텍처의 AWQ모듈에 기본적으로 지원됩니다. 그러나 지원되지 않는 아키텍처에 대해서도 AWQ 모듈을 퓨즈할 수 있습니다.
+
+
+
+퓨즈된 모듈은 FlashAttention-2와 같은 다른 최적화 기술과 결합할 수 없습니다.
+
+
+
+
+
+
+
+지원되는 아키텍처에서 퓨즈된 모듈을 활성화하려면, [`AwqConfig`] 를 생성하고 매개변수 `fuse_max_seq_len` 과 `do_fuse=True`를 설정해야 합니다. `fuse_max_seq_len` 매개변수는 전체 시퀀스 길이로, 컨텍스트 길이와 예상 생성 길이를 포함해야 합니다. 안전하게 사용하기 위해 더 큰 값으로 설정할 수 있습니다.
+
+예를 들어, [TheBloke/Mistral-7B-OpenOrca-AWQ](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-AWQ) 모델의 AWQ 모듈을 퓨즈해보겠습니다.
+
+```python
+import torch
+from transformers import AwqConfig, AutoModelForCausalLM
+
+model_id = "TheBloke/Mistral-7B-OpenOrca-AWQ"
+
+quantization_config = AwqConfig(
+ bits=4,
+ fuse_max_seq_len=512,
+ do_fuse=True,
+)
+
+model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config).to(0)
+```
+
+[TheBloke/Mistral-7B-OpenOrca-AWQ](https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-AWQ) 모델은 퓨즈된 모듈이 있는 경우와 없는 경우 모두 `batch_size=1` 로 성능 평가되었습니다.
+
+퓨즈되지 않은 모듈
+
+| 배치 크기 | 프리필 길이 | 디코드 길이 | 프리필 토큰/초 | 디코드 토큰/초 | 메모리 (VRAM) |
+|-------------:|-----------------:|----------------:|-------------------:|------------------:|:----------------|
+| 1 | 32 | 32 | 60.0984 | 38.4537 | 4.50 GB (5.68%) |
+| 1 | 64 | 64 | 1333.67 | 31.6604 | 4.50 GB (5.68%) |
+| 1 | 128 | 128 | 2434.06 | 31.6272 | 4.50 GB (5.68%) |
+| 1 | 256 | 256 | 3072.26 | 38.1731 | 4.50 GB (5.68%) |
+| 1 | 512 | 512 | 3184.74 | 31.6819 | 4.59 GB (5.80%) |
+| 1 | 1024 | 1024 | 3148.18 | 36.8031 | 4.81 GB (6.07%) |
+| 1 | 2048 | 2048 | 2927.33 | 35.2676 | 5.73 GB (7.23%) |
+
+퓨즈된 모듈
+
+| 배치 크기 | 프리필 길이 | 디코드 길이 | 프리필 토큰/초 | 디코드 토큰/초 | 메모리 (VRAM) |
+|-------------:|-----------------:|----------------:|-------------------:|------------------:|:----------------|
+| 1 | 32 | 32 | 81.4899 | 80.2569 | 4.00 GB (5.05%) |
+| 1 | 64 | 64 | 1756.1 | 106.26 | 4.00 GB (5.05%) |
+| 1 | 128 | 128 | 2479.32 | 105.631 | 4.00 GB (5.06%) |
+| 1 | 256 | 256 | 1813.6 | 85.7485 | 4.01 GB (5.06%) |
+| 1 | 512 | 512 | 2848.9 | 97.701 | 4.11 GB (5.19%) |
+| 1 | 1024 | 1024 | 3044.35 | 87.7323 | 4.41 GB (5.57%) |
+| 1 | 2048 | 2048 | 2715.11 | 89.4709 | 5.57 GB (7.04%) |
+
+퓨즈된 모듈 및 퓨즈되지 않은 모듈의 속도와 처리량은 [optimum-benchmark](https://github.com/huggingface/optimum-benchmark)라이브러리를 사용하여 테스트 되었습니다.
+
+
+
+
+ 포워드 피크 메모리 (forward peak memory)/배치 크기
+
+
+
+ 생성 처리량/배치크기
+
+
+
+
+
+
+퓨즈된 모듈을 지원하지 않는 아키텍처의 경우, `modules_to_fuse` 매개변수를 사용해 직접 퓨즈 매핑을 만들어 어떤 모듈을 퓨즈할지 정의해야합니다. 예로, [TheBloke/Yi-34B-AWQ](https://huggingface.co/TheBloke/Yi-34B-AWQ) 모델의 AWQ 모듈을 퓨즈하는 방법입니다.
+
+```python
+import torch
+from transformers import AwqConfig, AutoModelForCausalLM
+
+model_id = "TheBloke/Yi-34B-AWQ"
+
+quantization_config = AwqConfig(
+ bits=4,
+ fuse_max_seq_len=512,
+ modules_to_fuse={
+ "attention": ["q_proj", "k_proj", "v_proj", "o_proj"],
+ "layernorm": ["ln1", "ln2", "norm"],
+ "mlp": ["gate_proj", "up_proj", "down_proj"],
+ "use_alibi": False,
+ "num_attention_heads": 56,
+ "num_key_value_heads": 8,
+ "hidden_size": 7168
+ }
+)
+
+model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config).to(0)
+```
+
+ `modules_to_fuse` 매개변수는 다음을 포함해야 합니다:
+
+- `"attention"`: 어텐션 레이어는 다음 순서로 퓨즈하세요 : 쿼리 (query), 키 (key), 값 (value) , 출력 프로젝션 계층 (output projection layer). 해당 레이어를 퓨즈하지 않으려면 빈 리스트를 전달하세요.
+- `"layernorm"`: 사용자 정의 퓨즈 레이어 정규화로 교할 레이어 정규화 레이어명. 해당 레이어를 퓨즈하지 않으려면 빈 리스트를 전달하세요.
+- `"mlp"`: 단일 MLP 레이어로 퓨즈할 MLP 레이어 순서 : (게이트 (gate) (덴스(dense), 레이어(layer), 포스트 어텐션(post-attention)) / 위 / 아래 레이어).
+- `"use_alibi"`: 모델이 ALiBi positional embedding을 사용할 경우 설정합니다.
+- `"num_attention_heads"`: 어텐션 헤드 (attention heads)의 수를 설정합니다.
+- `"num_key_value_heads"`: 그룹화 쿼리 어텐션 (GQA)을 구현하는데 사용되는 키 값 헤드의 수를 설정합니다. `num_key_value_heads=num_attention_heads`로 설정할 경우, 모델은 다중 헤드 어텐션 (MHA)가 사용되며, `num_key_value_heads=1` 는 다중 쿼리 어텐션 (MQA)가, 나머지는 GQA가 사용됩니다.
+- `"hidden_size"`: 숨겨진 표현(hidden representations)의 차원을 설정합니다.
+
+
+
+
+
+
+## ExLlama-v2 서포트 [[exllama-v2-support]]
+
+최신 버전 `autoawq`는 빠른 프리필과 디코딩을 위해 ExLlama-v2 커널을 지원합니다. 시작하기 위해 먼저 최신 버전 `autoawq` 를 설치하세요 :
+
+```bash
+pip install git+https://github.com/casper-hansen/AutoAWQ.git
+```
+
+매개변수를 `version="exllama"`로 설정해 `AwqConfig()`를 생성하고 모델에 넘겨주세요.
+
+```python
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer, AwqConfig
+
+quantization_config = AwqConfig(version="exllama")
+
+model = AutoModelForCausalLM.from_pretrained(
+ "TheBloke/Mistral-7B-Instruct-v0.1-AWQ",
+ quantization_config=quantization_config,
+ device_map="auto",
+)
+
+input_ids = torch.randint(0, 100, (1, 128), dtype=torch.long, device="cuda")
+output = model(input_ids)
+print(output.logits)
+
+tokenizer = AutoTokenizer.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-AWQ")
+input_ids = tokenizer.encode("How to make a cake", return_tensors="pt").to(model.device)
+output = model.generate(input_ids, do_sample=True, max_length=50, pad_token_id=50256)
+print(tokenizer.decode(output[0], skip_special_tokens=True))
+```
+
+
+
+이 기능은 AMD GPUs에서 지원됩니다.
+
+
diff --git a/docs/transformers/docs/source/ko/quantization/bitsandbytes.md b/docs/transformers/docs/source/ko/quantization/bitsandbytes.md
new file mode 100644
index 0000000000000000000000000000000000000000..f0420c2869ea13e104980c1847ac765909e0f1cd
--- /dev/null
+++ b/docs/transformers/docs/source/ko/quantization/bitsandbytes.md
@@ -0,0 +1,307 @@
+
+
+# bitsandbytes [[bitsandbytes]]
+
+[bitsandbytes](https://github.com/TimDettmers/bitsandbytes)는 모델을 8비트 및 4비트로 양자화하는 가장 쉬운 방법입니다. 8비트 양자화는 fp16의 이상치와 int8의 비이상치를 곱한 후, 비이상치 값을 fp16으로 다시 변환하고, 이들을 합산하여 fp16으로 가중치를 반환합니다. 이렇게 하면 이상치 값이 모델 성능에 미치는 저하 효과를 줄일 수 있습니다. 4비트 양자화는 모델을 더욱 압축하며, [QLoRA](https://hf.co/papers/2305.14314)와 함께 사용하여 양자화된 대규모 언어 모델을 미세 조정하는 데 흔히 사용됩니다.
+
+bitsandbytes를 사용하려면 다음 라이브러리가 설치되어 있어야 합니다:
+
+
+
+
+```bash
+pip install transformers accelerate bitsandbytes>0.37.0
+```
+
+
+
+
+```bash
+pip install bitsandbytes>=0.39.0
+pip install --upgrade accelerate transformers
+```
+
+
+
+
+이제 `BitsAndBytesConfig`를 [`~PreTrainedModel.from_pretrained`] 메소드에 전달하여 모델을 양자화할 수 있습니다. 이는 Accelerate 가져오기를 지원하고 `torch.nn.Linear` 레이어가 포함된 모든 모델에서 작동합니다.
+
+
+
+
+모델을 8비트로 양자화하면 메모리 사용량이 절반으로 줄어들며, 대규모 모델의 경우 사용 가능한 GPU를 효율적으로 활용하려면 `device_map="auto"`를 설정하세요.
+
+```py
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_8bit=True)
+
+model_8bit = AutoModelForCausalLM.from_pretrained(
+ "bigscience/bloom-1b7",
+ quantization_config=quantization_config
+)
+```
+
+기본적으로 `torch.nn.LayerNorm`과 같은 다른 모듈은 `torch.float16`으로 변환됩니다. 원한다면 `torch_dtype` 매개변수로 이들 모듈의 데이터 유형을 변경할 수 있습니다:
+
+```py
+import torch
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_8bit=True)
+
+model_8bit = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-350m",
+ quantization_config=quantization_config,
+ torch_dtype=torch.float32
+)
+model_8bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
+```
+
+모델이 8비트로 양자화되면 최신 버전의 Transformers와 bitsandbytes를 사용하지 않는 한 양자화된 가중치를 Hub에 푸시할 수 없습니다. 최신 버전을 사용하는 경우, [`~PreTrainedModel.push_to_hub`] 메소드를 사용하여 8비트 모델을 Hub에 푸시할 수 있습니다. 양자화 config.json 파일이 먼저 푸시되고, 그 다음 양자화된 모델 가중치가 푸시됩니다.
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_8bit=True)
+
+model = AutoModelForCausalLM.from_pretrained(
+ "bigscience/bloom-560m",
+ quantization_config=quantization_config
+)
+tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-560m")
+
+model.push_to_hub("bloom-560m-8bit")
+```
+
+
+
+
+모델을 4비트로 양자화하면 메모리 사용량이 4배 줄어들며, 대규모 모델의 경우 사용 가능한 GPU를 효율적으로 활용하려면 `device_map="auto"`를 설정하세요:
+
+```py
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_4bit=True)
+
+model_4bit = AutoModelForCausalLM.from_pretrained(
+ "bigscience/bloom-1b7",
+ quantization_config=quantization_config
+)
+```
+
+기본적으로 `torch.nn.LayerNorm`과 같은 다른 모듈은 `torch.float16`으로 변환됩니다. 원한다면 `torch_dtype` 매개변수로 이들 모듈의 데이터 유형을 변경할 수 있습니다:
+
+```py
+import torch
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_4bit=True)
+
+model_4bit = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-350m",
+ quantization_config=quantization_config,
+ torch_dtype=torch.float32
+)
+model_4bit.model.decoder.layers[-1].final_layer_norm.weight.dtype
+```
+
+`bitsandbytes>=0.41.3`을 사용하는 경우 4비트 모델을 직렬화하고 Hugging Face Hub에 푸시할 수 있습니다. 모델을 4비트 정밀도로 가져온 후 `model.push_to_hub()`를 호출하면 됩니다. 또한 `model.save_pretrained()` 명령어로 로컬에 직렬화된 4비트 모델을 저장할 수도 있습니다.
+
+
+
+
+
+
+8비트 및 4비트 가중치로 훈련하는 것은 *추가* 매개변수에 대해서만 지원됩니다.
+
+
+
+메모리 사용량을 확인하려면 `get_memory_footprint`를 사용하세요:
+
+```py
+print(model.get_memory_footprint())
+```
+
+양자화된 모델은 [`~PreTrainedModel.from_pretrained`] 메소드를 사용하여 `load_in_8bit` 또는 `load_in_4bit` 매개변수를 지정하지 않고도 가져올 수 있습니다:
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("{your_username}/bloom-560m-8bit", device_map="auto")
+```
+
+## 8비트 (LLM.int8() 알고리즘)[[8-bit-(llm.int8()-algorithm)]]
+
+
+
+8비트 양자화에 대한 자세한 내용을 알고 싶다면 이 [블로그 포스트](https://huggingface.co/blog/hf-bitsandbytes-integration)를 참조하세요!
+
+
+
+이 섹션에서는 오프로딩, 이상치 임곗값, 모듈 변환 건너뛰기 및 미세 조정과 같은 8비트 모델의 특정 기능을 살펴봅니다.
+
+### 오프로딩 [[offloading]]
+
+8비트 모델은 CPU와 GPU 간에 가중치를 오프로드하여 매우 큰 모델을 메모리에 장착할 수 있습니다. CPU로 전송된 가중치는 실제로 **float32**로 저장되며 8비트로 변환되지 않습니다. 예를 들어, [bigscience/bloom-1b7](https://huggingface.co/bigscience/bloom-1b7) 모델의 오프로드를 활성화하려면 [`BitsAndBytesConfig`]를 생성하는 것부터 시작하세요:
+
+```py
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True)
+```
+
+CPU에 전달할 `lm_head`를 제외한 모든 것을 GPU에 적재할 수 있도록 사용자 정의 디바이스 맵을 설계합니다:
+
+```py
+device_map = {
+ "transformer.word_embeddings": 0,
+ "transformer.word_embeddings_layernorm": 0,
+ "lm_head": "cpu",
+ "transformer.h": 0,
+ "transformer.ln_f": 0,
+}
+```
+
+이제 사용자 정의 `device_map`과 `quantization_config`을 사용하여 모델을 가져옵니다:
+
+```py
+model_8bit = AutoModelForCausalLM.from_pretrained(
+ "bigscience/bloom-1b7",
+ device_map=device_map,
+ quantization_config=quantization_config,
+)
+```
+
+### 이상치 임곗값[[outlier-threshold]]
+
+"이상치"는 특정 임곗값을 초과하는 은닉 상태 값을 의미하며, 이러한 값은 fp16으로 계산됩니다. 값은 일반적으로 정규 분포 ([-3.5, 3.5])를 따르지만, 대규모 모델의 경우 이 분포는 매우 다를 수 있습니다 ([-60, 6] 또는 [6, 60]). 8비트 양자화는 ~5 정도의 값에서 잘 작동하지만, 그 이상에서는 상당한 성능 저하가 발생합니다. 좋은 기본 임곗값 값은 6이지만, 더 불안정한 모델 (소형 모델 또는 미세 조정)에는 더 낮은 임곗값이 필요할 수 있습니다.
+
+모델에 가장 적합한 임곗값을 찾으려면 [`BitsAndBytesConfig`]에서 `llm_int8_threshold` 매개변수를 실험해보는 것이 좋습니다:
+
+```py
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig
+
+model_id = "bigscience/bloom-1b7"
+
+quantization_config = BitsAndBytesConfig(
+ llm_int8_threshold=10,
+)
+
+model_8bit = AutoModelForCausalLM.from_pretrained(
+ model_id,
+ device_map=device_map,
+ quantization_config=quantization_config,
+)
+```
+
+### 모듈 변환 건너뛰기[[skip-module-conversion]]
+
+[Jukebox](model_doc/jukebox)와 같은 일부 모델은 모든 모듈을 8비트로 양자화할 필요가 없으며, 이는 실제로 불안정성을 유발할 수 있습니다. Jukebox의 경우, [`BitsAndBytesConfig`]의 `llm_int8_skip_modules` 매개변수를 사용하여 여러 `lm_head` 모듈을 건너뛰어야 합니다:
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
+
+model_id = "bigscience/bloom-1b7"
+
+quantization_config = BitsAndBytesConfig(
+ llm_int8_skip_modules=["lm_head"],
+)
+
+model_8bit = AutoModelForCausalLM.from_pretrained(
+ model_id,
+ device_map="auto",
+ quantization_config=quantization_config,
+)
+```
+
+### 미세 조정[[finetuning]]
+
+[PEFT](https://github.com/huggingface/peft) 라이브러리를 사용하면 [flan-t5-large](https://huggingface.co/google/flan-t5-large) 및 [facebook/opt-6.7b](https://huggingface.co/facebook/opt-6.7b)와 같은 대규모 모델을 8비트 양자화로 미세 조정할 수 있습니다. 훈련 시 `device_map` 매개변수를 전달할 필요가 없으며, 모델을 자동으로 GPU에 가져옵니다. 그러나 원하는 경우 `device_map` 매개변수로 장치 맵을 사용자 정의할 수 있습니다 (`device_map="auto"`는 추론에만 사용해야 합니다).
+
+## 4비트 (QLoRA 알고리즘)[[4-bit-(qlora-algorithm)]]
+
+
+
+이 [노트북](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf)에서 4비트 양자화를 시도해보고 자세한 내용은 이 [블로그 게시물](https://huggingface.co/blog/4bit-transformers-bitsandbytes)에서 확인하세요.
+
+
+
+이 섹션에서는 계산 데이터 유형 변경, Normal Float 4 (NF4) 데이터 유형 사용, 중첩 양자화 사용과 같은 4비트 모델의 특정 기능 일부를 탐구합니다.
+
+
+### 데이터 유형 계산[[compute-data-type]]
+
+계산 속도를 높이기 위해 [`BitsAndBytesConfig`]에서 `bnb_4bit_compute_dtype` 매개변수를 사용하여 데이터 유형을 float32(기본값)에서 bf16으로 변경할 수 있습니다:
+
+```py
+import torch
+from transformers import BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16)
+```
+
+### Normal Float 4 (NF4)[[normal-float-4-(nf4)]]
+
+NF4는 [QLoRA](https://hf.co/papers/2305.14314) 논문에서 소개된 4비트 데이터 유형으로, 정규 분포에서 초기화된 가중치에 적합합니다. 4비트 기반 모델을 훈련할 때 NF4를 사용해야 합니다. 이는 [`BitsAndBytesConfig`]에서 `bnb_4bit_quant_type` 매개변수로 설정할 수 있습니다:
+
+```py
+from transformers import BitsAndBytesConfig
+
+nf4_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+)
+
+model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
+```
+
+추론의 경우, `bnb_4bit_quant_type`은 성능에 큰 영향을 미치지 않습니다. 그러나 모델 가중치와 일관성을 유지하기 위해 `bnb_4bit_compute_dtype` 및 `torch_dtype` 값을 사용해야 합니다.
+
+### 중첩 양자화[[nested-quantization]]
+
+중첩 양자화는 추가적인 성능 손실 없이 추가적인 메모리를 절약할 수 있는 기술입니다. 이 기능은 이미 양자화된 가중치의 2차 양자화를 수행하여 매개변수당 추가로 0.4비트를 절약합니다. 예를 들어, 중첩 양자화를 통해 16GB NVIDIA T4 GPU에서 시퀀스 길이 1024, 배치 크기 1, 그레이디언트 누적 4단계를 사용하여 [Llama-13b](https://huggingface.co/meta-llama/Llama-2-13b) 모델을 미세 조정할 수 있습니다.
+
+```py
+from transformers import BitsAndBytesConfig
+
+double_quant_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=True,
+)
+
+model_double_quant = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-13b", quantization_config=double_quant_config)
+```
+
+## `bitsandbytes` 모델의 비양자화[[dequantizing-`bitsandbytes`-models]]
+양자화된 후에는 모델을 원래의 정밀도로 비양자화할 수 있지만, 이는 모델의 품질이 약간 저하될 수 있습니다. 비양자화된 모델에 맞출 수 있는 충분한 GPU RAM이 있는지 확인하세요.
+
+```python
+from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer
+
+model_id = "facebook/opt-125m"
+
+model = AutoModelForCausalLM.from_pretrained(model_id, BitsAndBytesConfig(load_in_4bit=True))
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+
+model.dequantize()
+
+text = tokenizer("Hello my name is", return_tensors="pt").to(0)
+
+out = model.generate(**text)
+print(tokenizer.decode(out[0]))
+```
diff --git a/docs/transformers/docs/source/ko/quantization/eetq.md b/docs/transformers/docs/source/ko/quantization/eetq.md
new file mode 100644
index 0000000000000000000000000000000000000000..ef4f4a2684b9f00dd0bd82e1bb75cdf3639ed550
--- /dev/null
+++ b/docs/transformers/docs/source/ko/quantization/eetq.md
@@ -0,0 +1,47 @@
+
+
+# EETQ [[eetq]]
+
+[EETQ](https://github.com/NetEase-FuXi/EETQ) 라이브러리는 NVIDIA GPU에 대해 int8 채널별(per-channel) 가중치 전용 양자화(weight-only quantization)을 지원합니다. 고성능 GEMM 및 GEMV 커널은 FasterTransformer 및 TensorRT-LLM에서 가져왔습니다. 교정(calibration) 데이터셋이 필요 없으며, 모델을 사전에 양자화할 필요도 없습니다. 또한, 채널별 양자화(per-channel quantization) 덕분에 정확도 저하가 미미합니다.
+
+[릴리스 페이지](https://github.com/NetEase-FuXi/EETQ/releases)에서 eetq를 설치했는지 확인하세요.
+```
+pip install --no-cache-dir https://github.com/NetEase-FuXi/EETQ/releases/download/v1.0.0/EETQ-1.0.0+cu121+torch2.1.2-cp310-cp310-linux_x86_64.whl
+```
+또는 소스 코드 https://github.com/NetEase-FuXi/EETQ 에서 설치할 수 있습니다. EETQ는 CUDA 기능이 8.9 이하이고 7.0 이상이어야 합니다.
+```
+git clone https://github.com/NetEase-FuXi/EETQ.git
+cd EETQ/
+git submodule update --init --recursive
+pip install .
+```
+
+비양자화 모델은 "from_pretrained"를 통해 양자화할 수 있습니다.
+```py
+from transformers import AutoModelForCausalLM, EetqConfig
+path = "/path/to/model".
+quantization_config = EetqConfig("int8")
+model = AutoModelForCausalLM.from_pretrained(path, device_map="auto", quantization_config=quantization_config)
+```
+
+양자화된 모델은 "save_pretrained"를 통해 저장할 수 있으며, "from_pretrained"를 통해 다시 사용할 수 있습니다.
+
+```py
+quant_path = "/path/to/save/quantized/model"
+model.save_pretrained(quant_path)
+model = AutoModelForCausalLM.from_pretrained(quant_path, device_map="auto")
+```
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/quantization/gptq.md b/docs/transformers/docs/source/ko/quantization/gptq.md
new file mode 100644
index 0000000000000000000000000000000000000000..c54f09c94a33036400b8992bab8fb34fb2a657c5
--- /dev/null
+++ b/docs/transformers/docs/source/ko/quantization/gptq.md
@@ -0,0 +1,120 @@
+
+
+# GPTQ [[gptq]]
+
+
+
+PEFT를 활용한 GPTQ 양자화를 사용해보시려면 이 [노트북](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94iLKUFu6ZX4ceb)을 참고하시고, 자세한 내용은 이 [블로그 게시물](https://huggingface.co/blog/gptq-integration)에서 확인하세요!
+
+
+
+[AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ) 라이브러리는 GPTQ 알고리즘을 구현합니다. 이는 훈련 후 양자화 기법으로, 가중치 행렬의 각 행을 독립적으로 양자화하여 오차를 최소화하는 가중치 버전을 찾습니다. 이 가중치는 int4로 양자화되지만, 추론 중에는 실시간으로 fp16으로 복원됩니다. 이는 int4 가중치가 GPU의 전역 메모리 대신 결합된 커널에서 역양자화되기 때문에 메모리 사용량을 4배 절약할 수 있으며, 더 낮은 비트 너비를 사용함으로써 통신 시간이 줄어들어 추론 속도가 빨라질 것으로 기대할 수 있습니다.
+
+시작하기 전에 다음 라이브러리들이 설치되어 있는지 확인하세요:
+
+```bash
+pip install auto-gptq
+pip install --upgrade accelerate optimum transformers
+```
+
+모델을 양자화하려면(현재 텍스트 모델만 지원됨) [`GPTQConfig`] 클래스를 생성하고 양자화할 비트 수, 양자화를 위한 가중치 교정 데이터셋, 그리고 데이터셋을 준비하기 위한 토크나이저를 설정해야 합니다.
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
+
+model_id = "facebook/opt-125m"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+gptq_config = GPTQConfig(bits=4, dataset="c4", tokenizer=tokenizer)
+```
+
+자신의 데이터셋을 문자열 리스트 형태로 전달할 수도 있지만, GPTQ 논문에서 사용한 동일한 데이터셋을 사용하는 것을 강력히 권장합니다.
+
+```py
+dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]
+gptq_config = GPTQConfig(bits=4, dataset=dataset, tokenizer=tokenizer)
+```
+
+양자화할 모델을 로드하고 `gptq_config`을 [`~AutoModelForCausalLM.from_pretrained`] 메소드에 전달하세요. 모델을 메모리에 맞추기 위해 `device_map="auto"`를 설정하여 모델을 자동으로 CPU로 오프로드하고, 양자화를 위해 모델 모듈이 CPU와 GPU 간에 이동할 수 있도록 합니다.
+
+```py
+quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=gptq_config)
+```
+
+데이터셋이 너무 커서 메모리가 부족한 경우를 대비한 디스크 오프로드는 현재 지원하지 않고 있습니다. 이럴 때는 `max_memory` 매개변수를 사용하여 디바이스(GPU 및 CPU)에서 사용할 메모리 양을 할당해 보세요:
+
+```py
+quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", max_memory={0: "30GiB", 1: "46GiB", "cpu": "30GiB"}, quantization_config=gptq_config)
+```
+
+
+
+하드웨어와 모델 매개변수량에 따라 모델을 처음부터 양자화하는 데 드는 시간이 서로 다를 수 있습니다. 예를 들어, 무료 등급의 Google Colab GPU로 비교적 가벼운 [facebook/opt-350m](https://huggingface.co/facebook/opt-350m) 모델을 양자화하는 데 약 5분이 걸리지만, NVIDIA A100으로 175B에 달하는 매개변수를 가진 모델을 양자화하는 데는 약 4시간에 달하는 시간이 걸릴 수 있습니다. 모델을 양자화하기 전에, Hub에서 해당 모델의 GPTQ 양자화 버전이 이미 존재하는지 확인하는 것이 좋습니다.
+
+
+
+모델이 양자화되면, 모델과 토크나이저를 Hub에 푸시하여 쉽게 공유하고 접근할 수 있습니다. [`GPTQConfig`]를 저장하기 위해 [`~PreTrainedModel.push_to_hub`] 메소드를 사용하세요:
+
+```py
+quantized_model.push_to_hub("opt-125m-gptq")
+tokenizer.push_to_hub("opt-125m-gptq")
+```
+
+양자화된 모델을 로컬에 저장하려면 [`~PreTrainedModel.save_pretrained`] 메소드를 사용할 수 있습니다. 모델이 `device_map` 매개변수로 양자화되었을 경우, 저장하기 전에 전체 모델을 GPU나 CPU로 이동해야 합니다. 예를 들어, 모델을 CPU에 저장하려면 다음과 같이 합니다:
+
+```py
+quantized_model.save_pretrained("opt-125m-gptq")
+tokenizer.save_pretrained("opt-125m-gptq")
+
+# device_map이 설정된 상태에서 양자화된 경우
+quantized_model.to("cpu")
+quantized_model.save_pretrained("opt-125m-gptq")
+```
+
+양자화된 모델을 다시 로드하려면 [`~PreTrainedModel.from_pretrained`] 메소드를 사용하고, `device_map="auto"`를 설정하여 모든 사용 가능한 GPU에 모델을 자동으로 분산시켜 더 많은 메모리를 사용하지 않으면서 모델을 더 빠르게 로드할 수 있습니다.
+
+```py
+from transformers import AutoModelForCausalLM
+
+model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto")
+```
+
+## ExLlama [[exllama]]
+
+[ExLlama](https://github.com/turboderp/exllama)은 [Llama](model_doc/llama) 모델의 Python/C++/CUDA 구현체로, 4비트 GPTQ 가중치를 사용하여 더 빠른 추론을 위해 설계되었습니다(이 [벤치마크](https://github.com/huggingface/optimum/tree/main/tests/benchmark#gptq-benchmark)를 참고하세요). ['GPTQConfig'] 객체를 생성할 때 ExLlama 커널이 기본적으로 활성화됩니다. 추론 속도를 더욱 높이기 위해, `exllama_config` 매개변수를 구성하여 [ExLlamaV2](https://github.com/turboderp/exllamav2) 커널을 사용할 수 있습니다:
+
+```py
+import torch
+from transformers import AutoModelForCausalLM, GPTQConfig
+
+gptq_config = GPTQConfig(bits=4, exllama_config={"version":2})
+model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="auto", quantization_config=gptq_config)
+```
+
+
+
+4비트 모델만 지원되며, 양자화된 모델을 PEFT로 미세 조정하는 경우 ExLlama 커널을 비활성화할 것을 권장합니다.
+
+
+
+ExLlama 커널은 전체 모델이 GPU에 있을 때만 지원됩니다. AutoGPTQ(버전 0.4.2 이상)로 CPU에서 추론을 수행하는 경우 ExLlama 커널을 비활성화해야 합니다. 이를 위해 config.json 파일의 양자화 설정에서 ExLlama 커널과 관련된 속성을 덮어써야 합니다.
+
+```py
+import torch
+from transformers import AutoModelForCausalLM, GPTQConfig
+gptq_config = GPTQConfig(bits=4, use_exllama=False)
+model = AutoModelForCausalLM.from_pretrained("{your_username}/opt-125m-gptq", device_map="cpu", quantization_config=gptq_config)
+```
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/quantization/quanto.md b/docs/transformers/docs/source/ko/quantization/quanto.md
new file mode 100644
index 0000000000000000000000000000000000000000..7eff695051d6b8d14fed33672f337ace703d0c71
--- /dev/null
+++ b/docs/transformers/docs/source/ko/quantization/quanto.md
@@ -0,0 +1,67 @@
+
+
+# Quanto[[quanto]]
+
+
+
+이 [노트북](https://colab.research.google.com/drive/16CXfVmtdQvciSh9BopZUDYcmXCDpvgrT?usp=sharing)으로 Quanto와 transformers를 사용해 보세요!
+
+
+
+
+[🤗 Quanto](https://github.com/huggingface/optimum-quanto) 라이브러리는 다목적 파이토치 양자화 툴킷입니다. 이 라이브러리에서 사용되는 양자화 방법은 선형 양자화입니다. Quanto는 다음과 같은 여러 가지 기능을 제공합니다:
+
+- 가중치 양자화 (`float8`,`int8`,`int4`,`int2`)
+- 활성화 양자화 (`float8`,`int8`)
+- 모달리티에 구애받지 않음 (e.g CV,LLM)
+- 장치에 구애받지 않음 (e.g CUDA,MPS,CPU)
+- `torch.compile` 호환성
+- 특정 장치에 대한 사용자 정의 커널의 쉬운 추가
+- QAT(양자화를 고려한 학습) 지원
+
+
+시작하기 전에 다음 라이브러리가 설치되어 있는지 확인하세요:
+
+```bash
+pip install quanto accelerate transformers
+```
+
+이제 [`~PreTrainedModel.from_pretrained`] 메소드에 [`QuantoConfig`] 객체를 전달하여 모델을 양자화할 수 있습니다. 이 방식은 `torch.nn.Linear` 레이어를 포함하는 모든 모달리티의 모든 모델에서 잘 작동합니다.
+
+허깅페이스의 transformers 라이브러리는 개발자 편의를 위해 quanto의 인터페이스를 일부 통합하여 지원하고 있으며, 이 방식으로는 가중치 양자화만 지원합니다. 활성화 양자화, 캘리브레이션, QAT 같은 더 복잡한 기능을 수행하기 위해서는 [quanto](https://github.com/huggingface/optimum-quanto) 라이브러리의 해당 함수를 직접 호출해야 합니다.
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
+
+model_id = "facebook/opt-125m"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+quantization_config = QuantoConfig(weights="int8")
+quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0", quantization_config=quantization_config)
+```
+
+참고로, transformers에서는 아직 직렬화가 지원되지 않지만 곧 지원될 예정입니다!
+모델을 저장하고 싶으면 quanto 라이브러리를 대신 사용할 수 있습니다.
+
+Quanto 라이브러리는 양자화를 위해 선형 양자화 알고리즘을 사용합니다. 비록 기본적인 양자화 기술이지만, 좋은 결과를 얻는데 아주 큰 도움이 됩니다! 바로 아래에 있는 벤치마크(llama-2-7b의 펄플렉서티 지표)를 확인해 보세요. 더 많은 벤치마크는 [여기](https://github.com/huggingface/quanto/tree/main/bench/generation) 에서 찾을 수 있습니다.
+
+
+
+
+
+
+
+이 라이브러리는 대부분의 PTQ 최적화 알고리즘과 호환될 만큼 충분히 유연합니다. 앞으로의 계획은 가장 인기 있는 알고리즘(AWQ, Smoothquant)을 최대한 매끄럽게 통합하는 것입니다.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/quicktour.md b/docs/transformers/docs/source/ko/quicktour.md
new file mode 100644
index 0000000000000000000000000000000000000000..4c3b137aa00ff9d5221258a4e788ccdfd4841fd6
--- /dev/null
+++ b/docs/transformers/docs/source/ko/quicktour.md
@@ -0,0 +1,557 @@
+
+
+# 둘러보기 [[quick-tour]]
+
+[[open-in-colab]]
+
+🤗 Transformers를 시작해보세요! 개발해본 적이 없더라도 쉽게 읽을 수 있도록 쓰인 이 글은 [`pipeline`](./main_classes/pipelines)을 사용하여 추론하고, 사전학습된 모델과 전처리기를 [AutoClass](./model_doc/auto)로 로드하고, PyTorch 또는 TensorFlow로 모델을 빠르게 학습시키는 방법을 소개해 드릴 것입니다. 본 가이드에서 소개되는 개념을 (특히 초보자의 관점으로) 더 친절하게 접하고 싶다면, 튜토리얼이나 [코스](https://huggingface.co/course/chapter1/1)를 참조하기를 권장합니다.
+
+시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
+
+```bash
+!pip install transformers datasets evaluate accelerate
+```
+
+또한 선호하는 머신 러닝 프레임워크를 설치해야 합니다:
+
+
+
+
+```bash
+pip install torch
+```
+
+
+
+```bash
+pip install tensorflow
+```
+
+
+
+## 파이프라인 [[pipeline]]
+
+
+
+[`pipeline`](./main_classes/pipelines)은 사전 훈련된 모델로 추론하기에 가장 쉽고 빠른 방법입니다. [`pipeline`]은 여러 모달리티에서 다양한 과업을 쉽게 처리할 수 있으며, 아래 표에 표시된 몇 가지 과업을 기본적으로 지원합니다:
+
+
+
+사용 가능한 작업의 전체 목록은 [Pipelines API 참조](./main_classes/pipelines)를 확인하세요.
+
+
+
+| **태스크** | **설명** | **모달리티** | **파이프라인 ID** |
+|-----------------|----------------------------------------------------------------------|------------------|-----------------------------------------------|
+| 텍스트 분류 | 텍스트에 알맞은 레이블 붙이기 | 자연어 처리(NLP) | pipeline(task="sentiment-analysis") |
+| 텍스트 생성 | 주어진 문자열 입력과 이어지는 텍스트 생성하기 | 자연어 처리(NLP) | pipeline(task="text-generation") |
+| 개체명 인식 | 문자열의 각 토큰마다 알맞은 레이블 붙이기 (인물, 조직, 장소 등등) | 자연어 처리(NLP) | pipeline(task="ner") |
+| 질의응답 | 주어진 문맥과 질문에 따라 올바른 대답하기 | 자연어 처리(NLP) | pipeline(task="question-answering") |
+| 빈칸 채우기 | 문자열의 빈칸에 알맞은 토큰 맞추기 | 자연어 처리(NLP) | pipeline(task="fill-mask") |
+| 요약 | 텍스트나 문서를 요약하기 | 자연어 처리(NLP) | pipeline(task="summarization") |
+| 번역 | 텍스트를 한 언어에서 다른 언어로 번역하기 | 자연어 처리(NLP) | pipeline(task="translation") |
+| 이미지 분류 | 이미지에 알맞은 레이블 붙이기 | 컴퓨터 비전(CV) | pipeline(task="image-classification") |
+| 이미지 분할 | 이미지의 픽셀마다 레이블 붙이기(시맨틱, 파놉틱 및 인스턴스 분할 포함) | 컴퓨터 비전(CV) | pipeline(task="image-segmentation") |
+| 객체 탐지 | 이미지 속 객체의 경계 상자를 그리고 클래스를 예측하기 | 컴퓨터 비전(CV) | pipeline(task="object-detection") |
+| 오디오 분류 | 오디오 파일에 알맞은 레이블 붙이기 | 오디오 | pipeline(task="audio-classification") |
+| 자동 음성 인식 | 오디오 파일 속 음성을 텍스트로 바꾸기 | 오디오 | pipeline(task="automatic-speech-recognition") |
+| 시각 질의응답 | 주어진 이미지와 질문에 대해 올바르게 대답하기 | 멀티모달 | pipeline(task="vqa") |
+| 문서 질의응답 | 주어진 문서와 질문에 대해 올바르게 대답하기 | 멀티모달 | pipeline(task="document-question-answering") |
+| 이미지 캡션 달기 | 주어진 이미지의 캡션 생성하기 | 멀티모달 | pipeline(task="image-to-text") |
+
+먼저 [`pipeline`]의 인스턴스를 생성하고 사용할 작업을 지정합니다. 이 가이드에서는 감정 분석을 위해 [`pipeline`]을 사용하는 예제를 보여드리겠습니다:
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline("sentiment-analysis")
+```
+
+[`pipeline`]은 감정 분석을 위한 [사전 훈련된 모델](https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english)과 토크나이저를 자동으로 다운로드하고 캐시합니다. 이제 `classifier`를 대상 텍스트에 사용할 수 있습니다:
+
+```py
+>>> classifier("We are very happy to show you the 🤗 Transformers library.")
+[{'label': 'POSITIVE', 'score': 0.9998}]
+```
+
+만약 입력이 여러 개 있는 경우, 입력을 리스트로 [`pipeline`]에 전달하여, 사전 훈련된 모델의 출력을 딕셔너리로 이루어진 리스트 형태로 받을 수 있습니다:
+
+```py
+>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
+>>> for result in results:
+... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
+label: POSITIVE, with score: 0.9998
+label: NEGATIVE, with score: 0.5309
+```
+
+[`pipeline`]은 주어진 과업에 관계없이 데이터셋 전부를 순회할 수도 있습니다. 이 예제에서는 자동 음성 인식을 과업으로 선택해 보겠습니다:
+
+```py
+>>> import torch
+>>> from transformers import pipeline
+
+>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
+```
+
+데이터셋을 로드할 차례입니다. (자세한 내용은 🤗 Datasets [시작하기](https://huggingface.co/docs/datasets/quickstart#audio)을 참조하세요) 여기에서는 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터셋을 로드하겠습니다:
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
+```
+
+데이터셋의 샘플링 레이트가 기존 모델인 [`facebook/wav2vec2-base-960h`](https://huggingface.co/facebook/wav2vec2-base-960h)의 훈련 당시 샘플링 레이트와 일치하는지 확인해야 합니다:
+
+```py
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
+```
+
+`"audio"` 열을 호출하면 자동으로 오디오 파일을 가져와서 리샘플링합니다. 첫 4개 샘플에서 원시 웨이브폼 배열을 추출하고 파이프라인에 리스트로 전달하세요:
+
+```py
+>>> result = speech_recognizer(dataset[:4]["audio"])
+>>> print([d["text"] for d in result])
+['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HELL T WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AN I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I FURN A JOINA COUT']
+```
+
+음성이나 비전과 같이 입력이 큰 대규모 데이터셋의 경우, 모든 입력을 메모리에 로드하려면 리스트 대신 제너레이터 형태로 전달해야 합니다. 자세한 내용은 [Pipelines API 참조](./main_classes/pipelines)를 확인하세요.
+
+### 파이프라인에서 다른 모델과 토크나이저 사용하기 [[use-another-model-and-tokenizer-in-the-pipeline]]
+
+[`pipeline`]은 [Hub](https://huggingface.co/models)의 모든 모델을 사용할 수 있기 때문에, [`pipeline`]을 다른 용도에 맞게 쉽게 수정할 수 있습니다. 예를 들어, 프랑스어 텍스트를 처리할 수 있는 모델을 사용하기 위해선 Hub의 태그를 사용하여 적절한 모델을 필터링하면 됩니다. 필터링된 결과의 상위 항목으로는 프랑스어 텍스트에 사용할 수 있는 다국어 [BERT 모델](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment)이 반환됩니다:
+
+```py
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+```
+
+
+
+[`AutoModelForSequenceClassification`]과 [`AutoTokenizer`]를 사용하여 사전 훈련된 모델과 관련된 토크나이저를 로드하세요 (다음 섹션에서 [`AutoClass`]에 대해 더 자세히 알아보겠습니다):
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+
+[`TFAutoModelForSequenceClassification`]과 [`AutoTokenizer`]를 사용하여 사전 훈련된 모델과 관련된 토크나이저를 로드하세요 (다음 섹션에서 [`TFAutoClass`]에 대해 더 자세히 알아보겠습니다):
+
+```py
+>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+
+
+[`pipeline`]에서 모델과 토크나이저를 지정하면, 이제 `classifier`를 프랑스어 텍스트에 적용할 수 있습니다:
+
+```py
+>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
+>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
+[{'label': '5 stars', 'score': 0.7273}]
+```
+
+마땅한 모델을 찾을 수 없는 경우 데이터를 기반으로 사전 훈련된 모델을 미세조정해야 합니다. 미세조정 방법에 대한 자세한 내용은 [미세조정 튜토리얼](./training)을 참조하세요. 사전 훈련된 모델을 미세조정한 후에는 모델을 Hub의 커뮤니티와 공유하여 머신러닝 민주화에 기여해주세요! 🤗
+
+## AutoClass [[autoclass]]
+
+
+
+[`AutoModelForSequenceClassification`]과 [`AutoTokenizer`] 클래스는 위에서 다룬 [`pipeline`]의 기능을 구현하는 데 사용됩니다. [AutoClass](./model_doc/auto)는 사전 훈련된 모델의 아키텍처를 이름이나 경로에서 자동으로 가져오는 '바로가기'입니다. 과업에 적합한 `AutoClass`를 선택하고 해당 전처리 클래스를 선택하기만 하면 됩니다.
+
+이전 섹션의 예제로 돌아가서 [`pipeline`]의 결과를 `AutoClass`를 활용해 복제하는 방법을 살펴보겠습니다.
+
+### AutoTokenizer [[autotokenizer]]
+
+토크나이저는 텍스트를 모델의 입력으로 사용하기 위해 숫자 배열 형태로 전처리하는 역할을 담당합니다. 토큰화 과정에는 단어를 어디에서 끊을지, 어느 수준까지 나눌지와 같은 여러 규칙들이 있습니다 (토큰화에 대한 자세한 내용은 [토크나이저 요약](./tokenizer_summary)을 참조하세요). 가장 중요한 점은 모델이 사전 훈련된 모델과 동일한 토큰화 규칙을 사용하도록 동일한 모델 이름으로 토크나이저를 인스턴스화해야 한다는 것입니다.
+
+[`AutoTokenizer`]로 토크나이저를 로드하세요:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+텍스트를 토크나이저에 전달하세요:
+
+```py
+>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
+>>> print(encoding)
+{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+토크나이저는 다음을 포함한 딕셔너리를 반환합니다:
+
+* [input_ids](./glossary#input-ids): 토큰의 숫자 표현.
+* [attention_mask](.glossary#attention-mask): 어떤 토큰에 주의를 기울여야 하는지를 나타냅니다.
+
+토크나이저는 입력을 리스트 형태로도 받을 수 있으며, 텍스트를 패딩하고 잘라내어 일정한 길이의 묶음을 반환할 수도 있습니다:
+
+
+
+
+```py
+>>> pt_batch = tokenizer(
+... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
+... padding=True,
+... truncation=True,
+... max_length=512,
+... return_tensors="pt",
+... )
+```
+
+
+
+```py
+>>> tf_batch = tokenizer(
+... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
+... padding=True,
+... truncation=True,
+... max_length=512,
+... return_tensors="tf",
+... )
+```
+
+
+
+
+
+[전처리](./preprocessing) 튜토리얼을 참조하시면 토큰화에 대한 자세한 설명과 함께 이미지, 오디오와 멀티모달 입력을 전처리하기 위한 [`AutoImageProcessor`]와 [`AutoFeatureExtractor`], [`AutoProcessor`]의 사용방법도 알 수 있습니다.
+
+
+
+### AutoModel [[automodel]]
+
+
+
+🤗 Transformers는 사전 훈련된 인스턴스를 간단하고 통합된 방법으로 로드할 수 있습니다. 즉, [`AutoTokenizer`]처럼 [`AutoModel`]을 로드할 수 있습니다. 유일한 차이점은 과업에 알맞은 [`AutoModel`]을 선택해야 한다는 점입니다. 텍스트 (또는 시퀀스) 분류의 경우 [`AutoModelForSequenceClassification`]을 로드해야 합니다:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
+```
+
+
+
+[`AutoModel`] 클래스에서 지원하는 과업에 대해서는 [과업 요약](./task_summary)을 참조하세요.
+
+
+
+이제 전처리된 입력 묶음을 직접 모델에 전달해야 합니다. 아래처럼 `**`를 앞에 붙여 딕셔너리를 풀어주면 됩니다:
+
+```py
+>>> pt_outputs = pt_model(**pt_batch)
+```
+
+모델의 최종 활성화 함수 출력은 `logits` 속성에 담겨있습니다. `logits`에 softmax 함수를 적용하여 확률을 얻을 수 있습니다:
+
+```py
+>>> from torch import nn
+
+>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
+>>> print(pt_predictions)
+tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
+ [0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=)
+```
+
+
+🤗 Transformers는 사전 훈련된 인스턴스를 간단하고 통합된 방법으로 로드할 수 있습니다. 즉, [`AutoTokenizer`]처럼 [`TFAutoModel`]을 로드할 수 있습니다. 유일한 차이점은 과업에 알맞은 [`TFAutoModel`]을 선택해야 한다는 점입니다. 텍스트 (또는 시퀀스) 분류의 경우 [`TFAutoModelForSequenceClassification`]을 로드해야 합니다:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
+```
+
+
+
+[`AutoModel`] 클래스에서 지원하는 과업에 대해서는 [과업 요약](./task_summary)을 참조하세요.
+
+
+
+이제 전처리된 입력 묶음을 직접 모델에 전달해야 합니다. 아래처럼 그대로 텐서를 전달하면 됩니다:
+
+```py
+>>> tf_outputs = tf_model(tf_batch)
+```
+
+모델의 최종 활성화 함수 출력은 `logits` 속성에 담겨있습니다. `logits`에 softmax 함수를 적용하여 확률을 얻을 수 있습니다:
+
+```py
+>>> import tensorflow as tf
+
+>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
+>>> tf_predictions # doctest: +IGNORE_RESULT
+```
+
+
+
+
+
+모든 🤗 Transformers 모델(PyTorch 또는 TensorFlow)은 (softmax와 같은) 최종 활성화 함수 *이전에* 텐서를 출력합니다. 왜냐하면 최종 활성화 함수의 출력은 종종 손실 함수 출력과 결합되기 때문입니다. 모델 출력은 특수한 데이터 클래스이므로 IDE에서 자동 완성됩니다. 모델 출력은 튜플이나 딕셔너리처럼 동작하며 (정수, 슬라이스 또는 문자열로 인덱싱 가능), None인 속성은 무시됩니다.
+
+
+
+### 모델 저장하기 [[save-a-model]]
+
+
+
+미세조정된 모델을 토크나이저와 함께 저장하려면 [`PreTrainedModel.save_pretrained`]를 사용하세요:
+
+```py
+>>> pt_save_directory = "./pt_save_pretrained"
+>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
+>>> pt_model.save_pretrained(pt_save_directory)
+```
+
+모델을 다시 사용하려면 [`PreTrainedModel.from_pretrained`]로 모델을 다시 로드하세요:
+
+```py
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
+```
+
+
+미세조정된 모델을 토크나이저와 함께 저장하려면 [`TFPreTrainedModel.save_pretrained`]를 사용하세요:
+
+```py
+>>> tf_save_directory = "./tf_save_pretrained"
+>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
+>>> tf_model.save_pretrained(tf_save_directory)
+```
+
+모델을 다시 사용하려면 [`TFPreTrainedModel.from_pretrained`]로 모델을 다시 로드하세요:
+
+```py
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
+```
+
+
+
+🤗 Transformers의 멋진 기능 중 하나는 모델을 PyTorch 또는 TensorFlow 모델로 저장해뒀다가 다른 프레임워크로 다시 로드할 수 있는 점입니다. `from_pt` 또는 `from_tf` 매개변수를 사용하여 모델을 한 프레임워크에서 다른 프레임워크로 변환할 수 있습니다:
+
+
+
+
+```py
+>>> from transformers import AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
+```
+
+
+
+```py
+>>> from transformers import TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
+```
+
+
+
+## 커스텀 모델 구축하기 [[custom-model-builds]]
+
+모델의 구성 클래스를 수정하여 모델의 구조를 바꿀 수 있습니다. (은닉층이나 어텐션 헤드의 수와 같은) 모델의 속성은 구성에서 지정되기 때문입니다. 커스텀 구성 클래스로 모델을 만들면 처음부터 시작해야 합니다. 모델 속성은 무작위로 초기화되므로 의미 있는 결과를 얻으려면 먼저 모델을 훈련시켜야 합니다.
+
+먼저 [`AutoConfig`]를 가져오고 수정하고 싶은 사전학습된 모델을 로드하세요. [`AutoConfig.from_pretrained`] 내부에서 (어텐션 헤드 수와 같이) 변경하려는 속성를 지정할 수 있습니다:
+
+```py
+>>> from transformers import AutoConfig
+
+>>> my_config = AutoConfig.from_pretrained("distilbert/distilbert-base-uncased", n_heads=12)
+```
+
+
+
+[`AutoModel.from_config`]를 사용하여 바꾼 구성대로 모델을 생성하세요:
+
+```py
+>>> from transformers import AutoModel
+
+>>> my_model = AutoModel.from_config(my_config)
+```
+
+
+[`TFAutoModel.from_config`]를 사용하여 바꾼 구성대로 모델을 생성하세요:
+
+```py
+>>> from transformers import TFAutoModel
+
+>>> my_model = TFAutoModel.from_config(my_config)
+```
+
+
+
+커스텀 구성에 대한 자세한 내용은 [커스텀 아키텍처 만들기](./create_a_model) 가이드를 확인하세요.
+
+## Trainer - PyTorch에 최적화된 훈련 루프 [[trainer-a-pytorch-optimized-training-loop]]
+
+모든 모델은 [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)이므로 일반적인 훈련 루프에서 사용할 수 있습니다. 직접 훈련 루프를 작성할 수도 있지만, 🤗 Transformers는 PyTorch를 위한 [`Trainer`] 클래스를 제공합니다. 이 클래스에는 기본 훈련 루프가 포함되어 있으며 분산 훈련, 혼합 정밀도 등과 같은 기능을 추가로 제공합니다.
+
+과업에 따라 다르지만 일반적으로 [`Trainer`]에 다음 매개변수를 전달합니다:
+
+1. [`PreTrainedModel`] 또는 [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)로 시작합니다:
+
+ ```py
+ >>> from transformers import AutoModelForSequenceClassification
+
+ >>> model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
+ ```
+
+2. [`TrainingArguments`]는 학습률, 배치 크기, 훈련할 에포크 수와 같은 모델 하이퍼파라미터를 포함합니다. 훈련 인자를 지정하지 않으면 기본값이 사용됩니다:
+
+ ```py
+ >>> from transformers import TrainingArguments
+
+ >>> training_args = TrainingArguments(
+ ... output_dir="path/to/save/folder/",
+ ... learning_rate=2e-5,
+ ... per_device_train_batch_size=8,
+ ... per_device_eval_batch_size=8,
+ ... num_train_epochs=2,
+ ... )
+ ```
+
+3. 토크나이저, 이미지 프로세서, 특징 추출기(feature extractor) 또는 프로세서와 전처리 클래스를 로드하세요:
+
+ ```py
+ >>> from transformers import AutoTokenizer
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+ ```
+
+4. 데이터셋을 로드하세요:
+
+ ```py
+ >>> from datasets import load_dataset
+
+ >>> dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
+ ```
+
+5. 데이터셋을 토큰화하는 함수를 생성하세요:
+
+ ```py
+ >>> def tokenize_dataset(dataset):
+ ... return tokenizer(dataset["text"])
+ ```
+
+ 그리고 [`~datasets.Dataset.map`]로 데이터셋 전체에 적용하세요:
+
+ ```py
+ >>> dataset = dataset.map(tokenize_dataset, batched=True)
+ ```
+
+6. [`DataCollatorWithPadding`]을 사용하여 데이터셋의 표본 묶음을 만드세요:
+
+ ```py
+ >>> from transformers import DataCollatorWithPadding
+
+ >>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
+ ```
+
+이제 위의 모든 클래스를 [`Trainer`]로 모으세요:
+
+```py
+>>> from transformers import Trainer
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=dataset["train"],
+... eval_dataset=dataset["test"],
+... processing_class=tokenizer,
+... data_collator=data_collator,
+... ) # doctest: +SKIP
+```
+
+준비가 되었으면 [`~Trainer.train`]을 호출하여 훈련을 시작하세요:
+
+```py
+>>> trainer.train() # doctest: +SKIP
+```
+
+
+
+번역이나 요약과 같이 시퀀스-시퀀스 모델을 사용하는 과업에는 [`Seq2SeqTrainer`] 및 [`Seq2SeqTrainingArguments`] 클래스를 사용하세요.
+
+
+
+[`Trainer`] 내의 메서드를 서브클래스화하여 훈련 루프를 바꿀 수도 있습니다. 이러면 손실 함수, 옵티마이저, 스케줄러와 같은 기능 또한 바꿀 수 있게 됩니다. 변경 가능한 메소드에 대해서는 [`Trainer`] 문서를 참고하세요.
+
+훈련 루프를 수정하는 다른 방법은 [Callbacks](./main_classes/callback)를 사용하는 것입니다. Callbacks로 다른 라이브러리와 통합하고, 훈련 루프를 체크하여 진행 상황을 보고받거나, 훈련을 조기에 중단할 수 있습니다. Callbacks은 훈련 루프 자체를 바꾸지는 않습니다. 손실 함수와 같은 것을 바꾸려면 [`Trainer`]를 서브클래스화해야 합니다.
+
+## TensorFlow로 훈련시키기 [[train-with-tensorflow]]
+
+모든 모델은 [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)이므로 [Keras](https://keras.io/) API를 통해 TensorFlow에서 훈련시킬 수 있습니다. 🤗 Transformers는 데이터셋을 쉽게 `tf.data.Dataset` 형태로 쉽게 로드할 수 있는 [`~TFPreTrainedModel.prepare_tf_dataset`] 메소드를 제공하기 때문에, Keras의 [`compile`](https://keras.io/api/models/model_training_apis/#compile-method) 및 [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) 메소드로 바로 훈련을 시작할 수 있습니다.
+
+1. [`TFPreTrainedModel`] 또는 [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)로 시작합니다:
+
+ ```py
+ >>> from transformers import TFAutoModelForSequenceClassification
+
+ >>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
+ ```
+
+2. 토크나이저, 이미지 프로세서, 특징 추출기(feature extractor) 또는 프로세서와 같은 전처리 클래스를 로드하세요:
+
+ ```py
+ >>> from transformers import AutoTokenizer
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+ ```
+
+3. 데이터셋을 토큰화하는 함수를 생성하세요:
+
+ ```py
+ >>> def tokenize_dataset(dataset):
+ ... return tokenizer(dataset["text"]) # doctest: +SKIP
+ ```
+
+4. [`~datasets.Dataset.map`]을 사용하여 전체 데이터셋에 토큰화 함수를 적용하고, 데이터셋과 토크나이저를 [`~TFPreTrainedModel.prepare_tf_dataset`]에 전달하세요. 배치 크기를 변경하거나 데이터셋을 섞을 수도 있습니다:
+
+ ```py
+ >>> dataset = dataset.map(tokenize_dataset) # doctest: +SKIP
+ >>> tf_dataset = model.prepare_tf_dataset(
+ ... dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer
+ ... ) # doctest: +SKIP
+ ```
+
+5. 준비되었으면 `compile` 및 `fit`를 호출하여 훈련을 시작하세요. 🤗 Transformers의 모든 모델은 과업과 관련된 기본 손실 함수를 가지고 있으므로 명시적으로 지정하지 않아도 됩니다:
+
+ ```py
+ >>> from tensorflow.keras.optimizers import Adam
+
+ >>> model.compile(optimizer=Adam(3e-5)) # No loss argument!
+ >>> model.fit(tf_dataset) # doctest: +SKIP
+ ```
+
+## 다음 단계는 무엇인가요? [[whats-next]]
+
+🤗 Transformers 둘러보기를 모두 읽으셨다면, 가이드를 살펴보고 더 구체적인 것을 수행하는 방법을 알아보세요. 이를테면 커스텀 모델 구축하는 방법, 과업에 알맞게 모델을 미세조정하는 방법, 스크립트로 모델 훈련하는 방법 등이 있습니다. 🤗 Transformers 핵심 개념에 대해 더 알아보려면 커피 한 잔 들고 개념 가이드를 살펴보세요!
diff --git a/docs/transformers/docs/source/ko/run_scripts.md b/docs/transformers/docs/source/ko/run_scripts.md
new file mode 100644
index 0000000000000000000000000000000000000000..70520f1a97f87c1513ab81f6c0861fb74e29dbcd
--- /dev/null
+++ b/docs/transformers/docs/source/ko/run_scripts.md
@@ -0,0 +1,375 @@
+
+
+# 스크립트로 실행하기[[train-with-a-script]]
+
+🤗 Transformers 노트북과 함께 [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), 또는 [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax)를 사용해 특정 태스크에 대한 모델을 훈련하는 방법을 보여주는 예제 스크립트도 있습니다.
+
+또한 [연구 프로젝트](https://github.com/huggingface/transformers-research-projects/) 및 [레거시 예제](https://github.com/huggingface/transformers/tree/main/examples/legacy)에서 대부분 커뮤니티에서 제공한 스크립트를 찾을 수 있습니다.
+이러한 스크립트는 적극적으로 유지 관리되지 않으며 최신 버전의 라이브러리와 호환되지 않을 가능성이 높은 특정 버전의 🤗 Transformers를 필요로 합니다.
+
+예제 스크립트가 모든 문제에서 바로 작동하는 것은 아니며, 해결하려는 문제에 맞게 스크립트를 변경해야 할 수도 있습니다.
+이를 위해 대부분의 스크립트에는 데이터 전처리 방법이 나와있어 필요에 따라 수정할 수 있습니다.
+
+예제 스크립트에 구현하고 싶은 기능이 있으면 pull request를 제출하기 전에 [포럼](https://discuss.huggingface.co/) 또는 [이슈](https://github.com/huggingface/transformers/issues)에서 논의해 주세요.
+버그 수정은 환영하지만 가독성을 희생하면서까지 더 많은 기능을 추가하는 pull request는 병합(merge)하지 않을 가능성이 높습니다.
+
+이 가이드에서는 [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) 및 [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization)에서 요약 훈련하는
+ 스크립트 예제를 실행하는 방법을 설명합니다.
+특별한 설명이 없는 한 모든 예제는 두 프레임워크 모두에서 작동할 것으로 예상됩니다.
+
+## 설정하기[[setup]]
+
+최신 버전의 예제 스크립트를 성공적으로 실행하려면 새 가상 환경에서 **소스로부터 🤗 Transformers를 설치**해야 합니다:
+
+```bash
+git clone https://github.com/huggingface/transformers
+cd transformers
+pip install .
+```
+
+이전 버전의 예제 스크립트를 보려면 아래 토글을 클릭하세요:
+
+
+ 이전 버전의 🤗 Transformers 예제
+
+
+
+그리고 다음과 같이 복제(clone)해온 🤗 Transformers 버전을 특정 버전(예: v3.5.1)으로 전환하세요:
+
+```bash
+git checkout tags/v3.5.1
+```
+
+올바른 라이브러리 버전을 설정한 후 원하는 예제 폴더로 이동하여 예제별로 라이브러리에 대한 요구 사항(requirements)을 설치합니다:
+
+```bash
+pip install -r requirements.txt
+```
+
+## 스크립트 실행하기[[run-a-script]]
+
+
+
+예제 스크립트는 🤗 [Datasets](https://huggingface.co/docs/datasets/) 라이브러리에서 데이터 세트를 다운로드하고 전처리합니다.
+그런 다음 스크립트는 요약 기능을 지원하는 아키텍처에서 [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer)를 사용하여 데이터 세트를 미세 조정합니다.
+다음 예는 [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) 데이터 세트에서 [T5-small](https://huggingface.co/google-t5/t5-small)을 미세 조정합니다.
+T5 모델은 훈련 방식에 따라 추가 `source_prefix` 인수가 필요하며, 이 프롬프트는 요약 작업임을 T5에 알려줍니다.
+
+```bash
+python examples/pytorch/summarization/run_summarization.py \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+
+예제 스크립트는 🤗 [Datasets](https://huggingface.co/docs/datasets/) 라이브러리에서 데이터 세트를 다운로드하고 전처리합니다.
+그런 다음 스크립트는 요약 기능을 지원하는 아키텍처에서 Keras를 사용하여 데이터 세트를 미세 조정합니다.
+다음 예는 [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) 데이터 세트에서 [T5-small](https://huggingface.co/google-t5/t5-small)을 미세 조정합니다.
+T5 모델은 훈련 방식에 따라 추가 `source_prefix` 인수가 필요하며, 이 프롬프트는 요약 작업임을 T5에 알려줍니다.
+```bash
+python examples/tensorflow/summarization/run_summarization.py \
+ --model_name_or_path google-t5/t5-small \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 16 \
+ --num_train_epochs 3 \
+ --do_train \
+ --do_eval
+```
+
+
+
+## 혼합 정밀도(mixed precision)로 분산 훈련하기[[distributed-training-and-mixed-precision]]
+
+[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) 클래스는 분산 훈련과 혼합 정밀도(mixed precision)를 지원하므로 스크립트에서도 사용할 수 있습니다.
+이 두 가지 기능을 모두 활성화하려면 다음 두 가지를 설정해야 합니다:
+
+- `fp16` 인수를 추가해 혼합 정밀도(mixed precision)를 활성화합니다.
+- `nproc_per_node` 인수를 추가해 사용할 GPU 개수를 설정합니다.
+
+```bash
+torchrun \
+ --nproc_per_node 8 pytorch/summarization/run_summarization.py \
+ --fp16 \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+TensorFlow 스크립트는 분산 훈련을 위해 [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy)를 활용하며, 훈련 스크립트에 인수를 추가할 필요가 없습니다.
+다중 GPU 환경이라면, TensorFlow 스크립트는 기본적으로 여러 개의 GPU를 사용합니다.
+
+## TPU 위에서 스크립트 실행하기[[run-a-script-on-a-tpu]]
+
+
+
+Tensor Processing Units (TPUs)는 성능을 가속화하기 위해 특별히 설계되었습니다.
+PyTorch는 [XLA](https://www.tensorflow.org/xla) 딥러닝 컴파일러와 함께 TPU를 지원합니다(자세한 내용은 [여기](https://github.com/pytorch/xla/blob/master/README.md) 참조).
+TPU를 사용하려면 `xla_spawn.py` 스크립트를 실행하고 `num_cores` 인수를 사용하여 사용하려는 TPU 코어 수를 설정합니다.
+
+```bash
+python xla_spawn.py --num_cores 8 \
+ summarization/run_summarization.py \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+
+Tensor Processing Units (TPUs)는 성능을 가속화하기 위해 특별히 설계되었습니다.
+TensorFlow 스크립트는 TPU를 훈련에 사용하기 위해 [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy)를 활용합니다.
+TPU를 사용하려면 TPU 리소스의 이름을 `tpu` 인수에 전달합니다.
+
+```bash
+python run_summarization.py \
+ --tpu name_of_tpu_resource \
+ --model_name_or_path google-t5/t5-small \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 16 \
+ --num_train_epochs 3 \
+ --do_train \
+ --do_eval
+```
+
+
+
+## 🤗 Accelerate로 스크립트 실행하기[[run-a-script-with-accelerate]]
+
+🤗 [Accelerate](https://huggingface.co/docs/accelerate)는 PyTorch 훈련 과정에 대한 완전한 가시성을 유지하면서 여러 유형의 설정(CPU 전용, 다중 GPU, TPU)에서 모델을 훈련할 수 있는 통합 방법을 제공하는 PyTorch 전용 라이브러리입니다.
+🤗 Accelerate가 설치되어 있는지 확인하세요:
+
+> 참고: Accelerate는 빠르게 개발 중이므로 스크립트를 실행하려면 accelerate를 설치해야 합니다.
+```bash
+pip install git+https://github.com/huggingface/accelerate
+```
+
+`run_summarization.py` 스크립트 대신 `run_summarization_no_trainer.py` 스크립트를 사용해야 합니다.
+🤗 Accelerate 클래스가 지원되는 스크립트는 폴더에 `task_no_trainer.py` 파일이 있습니다.
+다음 명령을 실행하여 구성 파일을 생성하고 저장합니다:
+```bash
+accelerate config
+```
+
+설정을 테스트하여 올바르게 구성되었는지 확인합니다:
+
+```bash
+accelerate test
+```
+
+이제 훈련을 시작할 준비가 되었습니다:
+
+```bash
+accelerate launch run_summarization_no_trainer.py \
+ --model_name_or_path google-t5/t5-small \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir ~/tmp/tst-summarization
+```
+
+## 사용자 정의 데이터 세트 사용하기[[use-a-custom-dataset]]
+
+요약 스크립트는 사용자 지정 데이터 세트가 CSV 또는 JSON 파일인 경우 지원합니다.
+사용자 지정 데이터 세트를 사용하는 경우에는 몇 가지 추가 인수를 지정해야 합니다:
+
+- `train_file`과 `validation_file`은 훈련 및 검증 파일의 경로를 지정합니다.
+- `text_column`은 요약할 입력 텍스트입니다.
+- `summary_column`은 출력할 대상 텍스트입니다.
+
+사용자 지정 데이터 세트를 사용하는 요약 스크립트는 다음과 같습니다:
+
+```bash
+python examples/pytorch/summarization/run_summarization.py \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --train_file path_to_csv_or_jsonlines_file \
+ --validation_file path_to_csv_or_jsonlines_file \
+ --text_column text_column_name \
+ --summary_column summary_column_name \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --overwrite_output_dir \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --predict_with_generate
+```
+
+## 스크립트 테스트하기[[test-a-script]]
+
+전체 데이터 세트를 대상으로 훈련을 완료하는데 꽤 오랜 시간이 걸리기 때문에, 작은 데이터 세트에서 모든 것이 예상대로 실행되는지 확인하는 것이 좋습니다.
+
+다음 인수를 사용하여 데이터 세트를 최대 샘플 수로 잘라냅니다:
+- `max_train_samples`
+- `max_eval_samples`
+- `max_predict_samples`
+
+```bash
+python examples/pytorch/summarization/run_summarization.py \
+ --model_name_or_path google-t5/t5-small \
+ --max_train_samples 50 \
+ --max_eval_samples 50 \
+ --max_predict_samples 50 \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+모든 예제 스크립트가 `max_predict_samples` 인수를 지원하지는 않습니다.
+스크립트가 이 인수를 지원하는지 확실하지 않은 경우 `-h` 인수를 추가하여 확인하세요:
+
+```bash
+examples/pytorch/summarization/run_summarization.py -h
+```
+
+## 체크포인트(checkpoint)에서 훈련 이어서 하기[[resume-training-from-checkpoint]]
+
+또 다른 유용한 옵션은 이전 체크포인트에서 훈련을 재개하는 것입니다.
+이렇게 하면 훈련이 중단되더라도 처음부터 다시 시작하지 않고 중단한 부분부터 다시 시작할 수 있습니다.
+체크포인트에서 훈련을 재개하는 방법에는 두 가지가 있습니다.
+
+첫 번째는 `output_dir previous_output_dir` 인수를 사용하여 `output_dir`에 저장된 최신 체크포인트부터 훈련을 재개하는 방법입니다.
+이 경우 `overwrite_output_dir`을 제거해야 합니다:
+```bash
+python examples/pytorch/summarization/run_summarization.py
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --output_dir previous_output_dir \
+ --predict_with_generate
+```
+
+두 번째는 `resume_from_checkpoint path_to_specific_checkpoint` 인수를 사용하여 특정 체크포인트 폴더에서 훈련을 재개하는 방법입니다.
+
+```bash
+python examples/pytorch/summarization/run_summarization.py
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --resume_from_checkpoint path_to_specific_checkpoint \
+ --predict_with_generate
+```
+
+## 모델 공유하기[[share-your-model]]
+
+모든 스크립트는 최종 모델을 [Model Hub](https://huggingface.co/models)에 업로드할 수 있습니다.
+시작하기 전에 Hugging Face에 로그인했는지 확인하세요:
+```bash
+huggingface-cli login
+```
+
+그런 다음 스크립트에 `push_to_hub` 인수를 추가합니다.
+이 인수는 Hugging Face 사용자 이름과 `output_dir`에 지정된 폴더 이름으로 저장소를 생성합니다.
+
+저장소에 특정 이름을 지정하려면 `push_to_hub_model_id` 인수를 사용하여 추가합니다.
+저장소는 네임스페이스 아래에 자동으로 나열됩니다.
+다음 예는 특정 저장소 이름으로 모델을 업로드하는 방법입니다:
+
+```bash
+python examples/pytorch/summarization/run_summarization.py
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --push_to_hub \
+ --push_to_hub_model_id finetuned-t5-cnn_dailymail \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/sagemaker.md b/docs/transformers/docs/source/ko/sagemaker.md
new file mode 100644
index 0000000000000000000000000000000000000000..18aafc28a1612d3c59cc39d9aeefc628c1ef697d
--- /dev/null
+++ b/docs/transformers/docs/source/ko/sagemaker.md
@@ -0,0 +1,28 @@
+
+
+# Amazon SageMaker에서 학습 실행하기[[run-training-on-amazon-sagemaker]]
+
+문서가 [hf.co/docs/sagemaker](https://huggingface.co/docs/sagemaker)로 이동되었습니다. 이 페이지는 `transformers` 5.0 에서 삭제될 예정입니다.
+
+### 목차[[table-of-content]]
+
+- [Train Hugging Face models on Amazon SageMaker with the SageMaker Python SDK](https://huggingface.co/docs/sagemaker/train)
+- [Deploy Hugging Face models to Amazon SageMaker with the SageMaker Python SDK](https://huggingface.co/docs/sagemaker/inference)
diff --git a/docs/transformers/docs/source/ko/serialization.md b/docs/transformers/docs/source/ko/serialization.md
new file mode 100644
index 0000000000000000000000000000000000000000..2e521e2b7b4af83b4a95df0c3e28f17f957ba411
--- /dev/null
+++ b/docs/transformers/docs/source/ko/serialization.md
@@ -0,0 +1,181 @@
+
+
+# ONNX로 내보내기 [[export-to-onnx]]
+
+🤗 Transformers 모델을 제품 환경에서 배포하기 위해서는 모델을 직렬화된 형식으로 내보내고 특정 런타임과 하드웨어에서 로드하고 실행할 수 있으면 유용합니다.
+
+🤗 Optimum은 Transformers의 확장으로, PyTorch 또는 TensorFlow에서 모델을 ONNX와 TFLite와 같은 직렬화된 형식으로 내보낼 수 있도록 하는 `exporters` 모듈을 통해 제공됩니다. 🤗 Optimum은 또한 성능 최적화 도구 세트를 제공하여 특정 하드웨어에서 모델을 훈련하고 실행할 때 최대 효율성을 달성할 수 있습니다.
+
+이 안내서는 🤗 Optimum을 사용하여 🤗 Transformers 모델을 ONNX로 내보내는 방법을 보여줍니다. TFLite로 모델을 내보내는 안내서는 [TFLite로 내보내기 페이지](tflite)를 참조하세요.
+
+## ONNX로 내보내기 [[export-to-onnx]]
+
+[ONNX (Open Neural Network eXchange)](http://onnx.ai)는 PyTorch와 TensorFlow를 포함한 다양한 프레임워크에서 심층 학습 모델을 나타내는 데 사용되는 공통 연산자 세트와 공통 파일 형식을 정의하는 오픈 표준입니다. 모델이 ONNX 형식으로 내보내지면 이러한 연산자를 사용하여 신경망을 통해 데이터가 흐르는 흐름을 나타내는 계산 그래프(일반적으로 _중간 표현_이라고 함)가 구성됩니다.
+
+표준화된 연산자와 데이터 유형을 가진 그래프를 노출함으로써, ONNX는 프레임워크 간에 쉽게 전환할 수 있습니다. 예를 들어, PyTorch에서 훈련된 모델을 ONNX 형식으로 내보내고 TensorFlow에서 가져올 수 있습니다(그 반대도 가능합니다).
+
+ONNX 형식으로 내보낸 모델은 다음과 같이 사용할 수 있습니다:
+- [그래프 최적화](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/optimization) 및 [양자화](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/quantization)와 같은 기법을 사용하여 추론을 위해 최적화됩니다.
+- ONNX Runtime을 통해 실행할 수 있습니다. [`ORTModelForXXX` 클래스들](https://huggingface.co/docs/optimum/onnxruntime/package_reference/modeling_ort)을 통해 동일한 `AutoModel` API를 따릅니다. 이 API는 🤗 Transformers에서 사용하는 것과 동일합니다.
+- [최적화된 추론 파이프라인](https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/pipelines)을 사용할 수 있습니다. 이는 🤗 Transformers의 [`pipeline`] 함수와 동일한 API를 가지고 있습니다.
+
+🤗 Optimum은 구성 객체를 활용하여 ONNX 내보내기를 지원합니다. 이러한 구성 객체는 여러 모델 아키텍처에 대해 미리 준비되어 있으며 다른 아키텍처에 쉽게 확장할 수 있도록 설계되었습니다.
+
+미리 준비된 구성 목록은 [🤗 Optimum 문서](https://huggingface.co/docs/optimum/exporters/onnx/overview)를 참조하세요.
+
+🤗 Transformers 모델을 ONNX로 내보내는 두 가지 방법이 있습니다. 여기에서 두 가지 방법을 모두 보여줍니다:
+
+- 🤗 Optimum을 사용하여 CLI로 내보내기
+- `optimum.onnxruntime`을 사용하여 🤗 Optimum으로 ONNX로 내보내기
+
+### CLI를 사용하여 🤗 Transformers 모델을 ONNX로 내보내기 [[exporting-a-transformers-model-to-onnx-with-cli]]
+
+🤗 Transformers 모델을 ONNX로 내보내려면 먼저 추가 종속성을 설치하세요:
+
+```bash
+pip install optimum[exporters]
+```
+
+사용 가능한 모든 인수를 확인하려면 [🤗 Optimum 문서](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/export_a_model#exporting-a-model-to-onnx-using-the-cli)를 참조하거나 명령줄에서 도움말을 보세요.
+
+```bash
+optimum-cli export onnx --help
+```
+
+예를 들어, 🤗 Hub에서 `distilbert/distilbert-base-uncased-distilled-squad`와 같은 모델의 체크포인트를 내보내려면 다음 명령을 실행하세요:
+
+```bash
+optimum-cli export onnx --model distilbert/distilbert-base-uncased-distilled-squad distilbert_base_uncased_squad_onnx/
+```
+
+위와 같이 진행 상황을 나타내는 로그가 표시되고 결과인 `model.onnx`가 저장된 위치가 표시됩니다.
+
+```bash
+Validating ONNX model distilbert_base_uncased_squad_onnx/model.onnx...
+ -[✓] ONNX model output names match reference model (start_logits, end_logits)
+ - Validating ONNX Model output "start_logits":
+ -[✓] (2, 16) matches (2, 16)
+ -[✓] all values close (atol: 0.0001)
+ - Validating ONNX Model output "end_logits":
+ -[✓] (2, 16) matches (2, 16)
+ -[✓] all values close (atol: 0.0001)
+The ONNX export succeeded and the exported model was saved at: distilbert_base_uncased_squad_onnx
+```
+
+위의 예제는 🤗 Hub에서 체크포인트를 내보내는 것을 설명합니다. 로컬 모델을 내보낼 때에는 모델의 가중치와 토크나이저 파일을 동일한 디렉토리(`local_path`)에 저장했는지 확인하세요. CLI를 사용할 때에는 🤗 Hub의 체크포인트 이름 대신 `model` 인수에 `local_path`를 전달하고 `--task` 인수를 제공하세요. 지원되는 작업의 목록은 [🤗 Optimum 문서](https://huggingface.co/docs/optimum/exporters/task_manager)를 참조하세요. `task` 인수가 제공되지 않으면 작업에 특화된 헤드 없이 모델 아키텍처로 기본 설정됩니다.
+
+```bash
+optimum-cli export onnx --model local_path --task question-answering distilbert_base_uncased_squad_onnx/
+```
+
+그 결과로 생성된 `model.onnx` 파일은 ONNX 표준을 지원하는 많은 [가속기](https://onnx.ai/supported-tools.html#deployModel) 중 하나에서 실행할 수 있습니다. 예를 들어, [ONNX Runtime](https://onnxruntime.ai/)을 사용하여 모델을 로드하고 실행할 수 있습니다:
+
+```python
+>>> from transformers import AutoTokenizer
+>>> from optimum.onnxruntime import ORTModelForQuestionAnswering
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert_base_uncased_squad_onnx")
+>>> model = ORTModelForQuestionAnswering.from_pretrained("distilbert_base_uncased_squad_onnx")
+>>> inputs = tokenizer("What am I using?", "Using DistilBERT with ONNX Runtime!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+
+Hub의 TensorFlow 체크포인트에 대해서도 동일한 프로세스가 적용됩니다. 예를 들어, [Keras organization](https://huggingface.co/keras-io)에서 순수한 TensorFlow 체크포인트를 내보내는 방법은 다음과 같습니다:
+
+```bash
+optimum-cli export onnx --model keras-io/transformers-qa distilbert_base_cased_squad_onnx/
+```
+
+### `optimum.onnxruntime`을 사용하여 🤗 Transformers 모델을 ONNX로 내보내기 [[exporting-a-transformers-model-to-onnx-with-optimumonnxruntime]]
+
+CLI 대신에 `optimum.onnxruntime`을 사용하여 프로그래밍 방식으로 🤗 Transformers 모델을 ONNX로 내보낼 수도 있습니다. 다음과 같이 진행하세요:
+
+```python
+>>> from optimum.onnxruntime import ORTModelForSequenceClassification
+>>> from transformers import AutoTokenizer
+
+>>> model_checkpoint = "distilbert_base_uncased_squad"
+>>> save_directory = "onnx/"
+
+>>> # Load a model from transformers and export it to ONNX
+>>> ort_model = ORTModelForSequenceClassification.from_pretrained(model_checkpoint, export=True)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
+
+>>> # Save the onnx model and tokenizer
+>>> ort_model.save_pretrained(save_directory)
+>>> tokenizer.save_pretrained(save_directory)
+```
+
+### 지원되지 않는 아키텍처의 모델 내보내기 [[exporting-a-model-for-an-unsupported-architecture]]
+
+현재 내보낼 수 없는 모델을 지원하기 위해 기여하려면, 먼저 [`optimum.exporters.onnx`](https://huggingface.co/docs/optimum/exporters/onnx/overview)에서 지원되는지 확인한 후 지원되지 않는 경우에는 [🤗 Optimum에 기여](https://huggingface.co/docs/optimum/exporters/onnx/usage_guides/contribute)하세요.
+
+### `transformers.onnx`를 사용하여 모델 내보내기 [[exporting-a-model-with-transformersonnx]]
+
+
+
+`tranformers.onnx`는 더 이상 유지되지 않습니다. 위에서 설명한 대로 🤗 Optimum을 사용하여 모델을 내보내세요. 이 섹션은 향후 버전에서 제거될 예정입니다.
+
+
+
+🤗 Transformers 모델을 ONNX로 내보내려면 추가 종속성을 설치하세요:
+
+```bash
+pip install transformers[onnx]
+```
+
+`transformers.onnx` 패키지를 Python 모듈로 사용하여 준비된 구성을 사용하여 체크포인트를 내보냅니다:
+
+```bash
+python -m transformers.onnx --model=distilbert/distilbert-base-uncased onnx/
+```
+
+이렇게 하면 `--model` 인수에 정의된 체크포인트의 ONNX 그래프가 내보내집니다. 🤗 Hub에서 제공하는 체크포인트나 로컬에 저장된 체크포인트를 전달할 수 있습니다. 결과로 생성된 `model.onnx` 파일은 ONNX 표준을 지원하는 많은 가속기 중 하나에서 실행할 수 있습니다. 예를 들어, 다음과 같이 ONNX Runtime을 사용하여 모델을 로드하고 실행할 수 있습니다:
+
+```python
+>>> from transformers import AutoTokenizer
+>>> from onnxruntime import InferenceSession
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+>>> session = InferenceSession("onnx/model.onnx")
+>>> # ONNX Runtime expects NumPy arrays as input
+>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
+>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
+```
+
+필요한 출력 이름(예: `["last_hidden_state"]`)은 각 모델의 ONNX 구성을 확인하여 얻을 수 있습니다. 예를 들어, DistilBERT의 경우 다음과 같습니다:
+
+```python
+>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
+
+>>> config = DistilBertConfig()
+>>> onnx_config = DistilBertOnnxConfig(config)
+>>> print(list(onnx_config.outputs.keys()))
+["last_hidden_state"]
+```
+
+Hub의 TensorFlow 체크포인트에 대해서도 동일한 프로세스가 적용됩니다. 예를 들어, 다음과 같이 순수한 TensorFlow 체크포인트를 내보냅니다:
+
+```bash
+python -m transformers.onnx --model=keras-io/transformers-qa onnx/
+```
+
+로컬에 저장된 모델을 내보내려면 모델의 가중치 파일과 토크나이저 파일을 동일한 디렉토리에 저장한 다음, transformers.onnx 패키지의 --model 인수를 원하는 디렉토리로 지정하여 ONNX로 내보냅니다:
+
+```bash
+python -m transformers.onnx --model=local-pt-checkpoint onnx/
+```
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/task_summary.md b/docs/transformers/docs/source/ko/task_summary.md
new file mode 100644
index 0000000000000000000000000000000000000000..a0e60c60924b99989eb14bcc322297c8d3bcc5d6
--- /dev/null
+++ b/docs/transformers/docs/source/ko/task_summary.md
@@ -0,0 +1,341 @@
+
+
+# 🤗 Transformers로 할 수 있는 것[[what__transformers_can_do]]
+
+🤗 Transformers는 자연어처리(NLP), 컴퓨터 비전, 오디오 및 음성 처리 작업에 대한 사전훈련된 최첨단 모델 라이브러리입니다.
+이 라이브러리는 트랜스포머 모델뿐만 아니라 컴퓨터 비전 작업을 위한 현대적인 합성곱 신경망과 같은 트랜스포머가 아닌 모델도 포함하고 있습니다.
+
+스마트폰, 앱, 텔레비전과 같은 오늘날 가장 인기 있는 소비자 제품을 살펴보면, 딥러닝 기술이 그 뒤에 사용되고 있을 확률이 높습니다.
+스마트폰으로 촬영한 사진에서 배경 객체를 제거하고 싶다면 어떻게 할까요? 이는 파놉틱 세그멘테이션 작업의 예입니다(아직 이게 무엇인지 모른다면, 다음 섹션에서 설명하겠습니다!).
+
+이 페이지는 다양한 음성 및 오디오, 컴퓨터 비전, NLP 작업을 🤗 Transformers 라이브러리를 활용하여 다루는 간단한 예제를 3줄의 코드로 제공합니다.
+
+## 오디오[[audio]]
+
+
+음성 및 오디오 처리 작업은 다른 모달리티와 약간 다릅니다. 이는 주로 오디오가 연속적인 신호로 입력되기 때문입니다.
+텍스트와 달리 원본 오디오 파형(waveform)은 문장이 단어로 나눠지는 것처럼 깔끔하게 이산적인 묶음으로 나눌 수 없습니다.
+이를 극복하기 위해 원본 오디오 신호는 일정한 간격으로 샘플링됩니다. 해당 간격 내에서 더 많은 샘플을 취할 경우 샘플링률이 높아지며, 오디오는 원본 오디오 소스에 더 가까워집니다.
+
+과거의 접근 방식은 오디오에서 유용한 특징을 추출하기 위해 오디오를 전처리하는 것이었습니다.
+하지만 현재는 원본 오디오 파형을 특성 인코더에 직접 넣어서 오디오 표현(representation)을 추출하는 것이 더 일반적입니다.
+이렇게 하면 전처리 단계가 단순해지고 모델이 가장 중요한 특징을 학습할 수 있습니다.
+
+### 오디오 분류[[audio_classification]]
+
+
+오디오 분류는 오디오 데이터에 미리 정의된 클래스 집합의 레이블을 지정하는 작업입니다. 이는 많은 구체적인 응용 프로그램을 포함한 넓은 범주입니다.
+
+일부 예시는 다음과 같습니다:
+
+* 음향 장면 분류: 오디오에 장면 레이블("사무실", "해변", "경기장")을 지정합니다.
+* 음향 이벤트 감지: 오디오에 소리 이벤트 레이블("차 경적", "고래 울음소리", "유리 파손")을 지정합니다.
+* 태깅: 여러 가지 소리(새 지저귐, 회의에서의 화자 식별)가 포함된 오디오에 레이블을 지정합니다.
+* 음악 분류: 음악에 장르 레이블("메탈", "힙합", "컨트리")을 지정합니다.
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline(task="audio-classification", model="superb/hubert-base-superb-er")
+>>> preds = classifier("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
+>>> preds
+[{'score': 0.4532, 'label': 'hap'},
+ {'score': 0.3622, 'label': 'sad'},
+ {'score': 0.0943, 'label': 'neu'},
+ {'score': 0.0903, 'label': 'ang'}]
+```
+
+### 자동 음성 인식[[automatic_speech_recognition]]
+
+
+자동 음성 인식(ASR)은 음성을 텍스트로 변환하는 작업입니다.
+음성은 인간의 자연스러운 의사소통 형태이기 때문에 ASR은 가장 일반적인 오디오 작업 중 하나입니다.
+오늘날 ASR 시스템은 스피커, 전화 및 자동차와 같은 "스마트" 기술 제품에 내장되어 있습니다.
+우리는 가상 비서에게 음악 재생, 알림 설정 및 날씨 정보를 요청할 수 있습니다.
+
+하지만 트랜스포머 아키텍처가 해결하는 데 도움을 준 핵심 도전 과제 중 하나는 양이 데이터 양이 적은 언어(low-resource language)에 대한 것입니다. 대량의 음성 데이터로 사전 훈련한 후 데이터 양이 적은 언어에서 레이블이 지정된 음성 데이터 1시간만으로 모델을 미세 조정하면 이전의 100배 많은 레이블이 지정된 데이터로 훈련된 ASR 시스템보다 훨씬 더 높은 품질의 결과를 얻을 수 있습니다.
+```py
+>>> from transformers import pipeline
+
+>>> transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-small")
+>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
+{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
+```
+
+## 컴퓨터 비전[[computer_vision]]
+
+컴퓨터 비전 작업 중 가장 초기의 성공적인 작업 중 하나는 [합성곱 신경망(CNN)](glossary#convolution)을 사용하여 우편번호 숫자 이미지를 인식하는 것이었습니다. 이미지는 픽셀로 구성되어 있으며 각 픽셀은 숫자 값으로 표현됩니다. 이로써 이미지를 픽셀 값의 행렬로 나타내는 것이 쉬워집니다. 특정한 픽셀 값의 조합은 이미지의 색상을 의미합니다.
+
+컴퓨터 비전 작업은 일반적으로 다음 두 가지 방법으로 접근 가능합니다:
+
+1. 합성곱을 사용하여 이미지의 낮은 수준 특징에서 높은 수준의 추상적인 요소까지 계층적으로 학습합니다.
+
+2. 이미지를 패치로 나누고 트랜스포머를 사용하여 점진적으로 각 이미지 패치가 서로 어떠한 방식으로 연관되어 이미지를 형성하는지 학습합니다. `CNN`에서 선호하는 상향식 접근법과는 달리, 이 방식은 흐릿한 이미지로 초안을 그리고 점진적으로 선명한 이미지로 만들어가는 것과 유사합니다.
+
+### 이미지 분류[[image_classification]]
+
+
+이미지 분류는 한 개의 전체 이미지에 미리 정의된 클래스 집합의 레이블을 지정하는 작업입니다.
+
+대부분의 분류 작업과 마찬가지로, 이미지 분류에는 다양한 실용적인 용도가 있으며, 일부 예시는 다음과 같습니다:
+
+
+* 의료: 질병을 감지하거나 환자 건강을 모니터링하기 위해 의료 이미지에 레이블을 지정합니다.
+* 환경: 위성 이미지를 분류하여 산림 벌채를 감시하고 야생 지역 관리를 위한 정보를 제공하거나 산불을 감지합니다.
+* 농업: 작물 이미지를 분류하여 식물 건강을 확인하거나 위성 이미지를 분류하여 토지 이용 관찰에 사용합니다.
+* 생태학: 동물이나 식물 종 이미지를 분류하여 야생 동물 개체군을 조사하거나 멸종 위기에 처한 종을 추적합니다.
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline(task="image-classification")
+>>> preds = classifier(
+... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
+>>> print(*preds, sep="\n")
+{'score': 0.4335, 'label': 'lynx, catamount'}
+{'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}
+{'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}
+{'score': 0.0239, 'label': 'Egyptian cat'}
+{'score': 0.0229, 'label': 'tiger cat'}
+```
+
+### 객체 탐지[[object_detection]]
+
+
+이미지 분류와 달리 객체 탐지는 이미지 내에서 여러 객체를 식별하고 바운딩 박스로 정의된 객체의 위치를 파악합니다.
+
+객체 탐지의 몇 가지 응용 예시는 다음과 같습니다:
+
+* 자율 주행 차량: 다른 차량, 보행자 및 신호등과 같은 일상적인 교통 객체를 감지합니다.
+* 원격 감지: 재난 모니터링, 도시 계획 및 기상 예측 등을 수행합니다.
+* 결함 탐지: 건물의 균열이나 구조적 손상, 제조 결함 등을 탐지합니다.
+
+
+```py
+>>> from transformers import pipeline
+
+>>> detector = pipeline(task="object-detection")
+>>> preds = detector(
+... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"], "box": pred["box"]} for pred in preds]
+>>> preds
+[{'score': 0.9865,
+ 'label': 'cat',
+ 'box': {'xmin': 178, 'ymin': 154, 'xmax': 882, 'ymax': 598}}]
+```
+
+### 이미지 분할[[image_segmentation]]
+
+
+이미지 분할은 픽셀 차원의 작업으로, 이미지 내의 모든 픽셀을 클래스에 할당합니다. 이는 객체 탐지와 다릅니다. 객체 탐지는 바운딩 박스를 사용하여 이미지 내의 객체를 레이블링하고 예측하는 반면, 분할은 더 세분화된 작업입니다. 분할은 픽셀 수준에서 객체를 감지할 수 있습니다.
+
+이미지 분할에는 여러 유형이 있습니다:
+
+* 인스턴스 분할: 개체의 클래스를 레이블링하는 것 외에도, 개체의 각 구분된 인스턴스에도 레이블을 지정합니다 ("개-1", "개-2" 등).
+* 파놉틱 분할: 의미적 분할과 인스턴스 분할의 조합입니다. 각 픽셀을 의미적 클래스로 레이블링하는 **동시에** 개체의 각각 구분된 인스턴스로도 레이블을 지정합니다.
+
+분할 작업은 자율 주행 차량에서 유용하며, 주변 환경의 픽셀 수준 지도를 생성하여 보행자와 다른 차량 주변에서 안전하게 탐색할 수 있습니다. 또한 의료 영상에서도 유용합니다. 분할 작업이 픽셀 수준에서 객체를 감지할 수 있기 때문에 비정상적인 세포나 장기의 특징을 식별하는 데 도움이 될 수 있습니다. 이미지 분할은 의류 가상 시착이나 카메라를 통해 실제 세계에 가상 개체를 덧씌워 증강 현실 경험을 만드는 등 전자 상거래 분야에서도 사용될 수 있습니다.
+
+```py
+>>> from transformers import pipeline
+
+>>> segmenter = pipeline(task="image-segmentation")
+>>> preds = segmenter(
+... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
+>>> print(*preds, sep="\n")
+{'score': 0.9879, 'label': 'LABEL_184'}
+{'score': 0.9973, 'label': 'snow'}
+{'score': 0.9972, 'label': 'cat'}
+```
+
+### 깊이 추정[[depth_estimation]]
+
+깊이 추정은 카메라로부터 이미지 내부의 각 픽셀의 거리를 예측합니다. 이 컴퓨터 비전 작업은 특히 장면 이해와 재구성에 중요합니다. 예를 들어, 자율 주행 차량은 보행자, 교통 표지판 및 다른 차량과 같은 객체와의 거리를 이해하여 장애물과 충돌을 피해야 합니다. 깊이 정보는 또한 2D 이미지에서 3D 표현을 구성하는 데 도움이 되며 생물학적 구조나 건물의 고품질 3D 표현을 생성하는 데 사용될 수 있습니다.
+
+깊이 추정에는 두 가지 접근 방식이 있습니다:
+
+* 스테레오: 약간 다른 각도에서 촬영된 동일한 이미지 두 장을 비교하여 깊이를 추정합니다.
+* 단안: 단일 이미지에서 깊이를 추정합니다.
+
+
+```py
+>>> from transformers import pipeline
+
+>>> depth_estimator = pipeline(task="depth-estimation")
+>>> preds = depth_estimator(
+... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+```
+
+## 자연어처리[[natural_language_processing]]
+
+텍스트는 인간이 의사 소통하는 자연스러운 방식 중 하나이기 때문에 자연어처리 역시 가장 일반적인 작업 유형 중 하나입니다. 모델이 인식하는 형식으로 텍스트를 변환하려면 토큰화해야 합니다. 이는 텍스트 시퀀스를 개별 단어 또는 하위 단어(토큰)로 분할한 다음 이러한 토큰을 숫자로 변환하는 것을 의미합니다. 결과적으로 텍스트 시퀀스를 숫자 시퀀스로 표현할 수 있으며, 숫자 시퀀스를 다양한 자연어처리 작업을 해결하기 위한 모델에 입력할 수 있습니다!
+
+### 텍스트 분류[[text_classification]]
+
+다른 모달리티에서의 분류 작업과 마찬가지로 텍스트 분류는 미리 정의된 클래스 집합에서 텍스트 시퀀스(문장 수준, 단락 또는 문서 등)에 레이블을 지정합니다. 텍스트 분류에는 다양한 실용적인 응용 사례가 있으며, 일부 예시는 다음과 같습니다:
+
+* 감성 분석: 텍스트를 `긍정` 또는 `부정`과 같은 어떤 극성에 따라 레이블링하여 정치, 금융, 마케팅과 같은 분야에서 의사 결정에 정보를 제공하고 지원할 수 있습니다.
+* 콘텐츠 분류: 텍스트를 주제에 따라 레이블링(날씨, 스포츠, 금융 등)하여 뉴스 및 소셜 미디어 피드에서 정보를 구성하고 필터링하는 데 도움이 될 수 있습니다.
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline(task="sentiment-analysis")
+>>> preds = classifier("Hugging Face is the best thing since sliced bread!")
+>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
+>>> preds
+[{'score': 0.9991, 'label': 'POSITIVE'}]
+```
+
+### 토큰 분류[[token_classification]]
+
+모든 자연어처리 작업에서는 텍스트가 개별 단어나 하위 단어로 분리되어 전처리됩니다. 분리된 단어를 [토큰](/glossary#token)이라고 합니다. 토큰 분류는 각 토큰에 미리 정의된 클래스 집합의 레이블을 할당합니다.
+
+토큰 분류의 두 가지 일반적인 유형은 다음과 같습니다:
+
+* 개체명 인식 (NER): 토큰을 조직, 인물, 위치 또는 날짜와 같은 개체 범주에 따라 레이블링합니다. NER은 특히 유전체학적인 환경에서 유전자, 단백질 및 약물 이름에 레이블을 지정하는 데 널리 사용됩니다.
+* 품사 태깅 (POS): 명사, 동사, 형용사와 같은 품사에 따라 토큰에 레이블을 할당합니다. POS는 번역 시스템이 동일한 단어가 문법적으로 어떻게 다른지 이해하는 데 도움이 됩니다 (명사로 사용되는 "bank(은행)"과 동사로 사용되는 "bank(예금을 예치하다)"과 같은 경우).
+
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline(task="ner")
+>>> preds = classifier("Hugging Face is a French company based in New York City.")
+>>> preds = [
+... {
+... "entity": pred["entity"],
+... "score": round(pred["score"], 4),
+... "index": pred["index"],
+... "word": pred["word"],
+... "start": pred["start"],
+... "end": pred["end"],
+... }
+... for pred in preds
+... ]
+>>> print(*preds, sep="\n")
+{'entity': 'I-ORG', 'score': 0.9968, 'index': 1, 'word': 'Hu', 'start': 0, 'end': 2}
+{'entity': 'I-ORG', 'score': 0.9293, 'index': 2, 'word': '##gging', 'start': 2, 'end': 7}
+{'entity': 'I-ORG', 'score': 0.9763, 'index': 3, 'word': 'Face', 'start': 8, 'end': 12}
+{'entity': 'I-MISC', 'score': 0.9983, 'index': 6, 'word': 'French', 'start': 18, 'end': 24}
+{'entity': 'I-LOC', 'score': 0.999, 'index': 10, 'word': 'New', 'start': 42, 'end': 45}
+{'entity': 'I-LOC', 'score': 0.9987, 'index': 11, 'word': 'York', 'start': 46, 'end': 50}
+{'entity': 'I-LOC', 'score': 0.9992, 'index': 12, 'word': 'City', 'start': 51, 'end': 55}
+```
+
+### 질의응답[[question_answering]]
+
+질의응답은 또 하나의 토큰 차원의 작업으로, 문맥이 있을 때(개방형 도메인)와 문맥이 없을 때(폐쇄형 도메인) 질문에 대한 답변을 반환합니다. 이 작업은 가상 비서에게 식당이 영업 중인지와 같은 질문을 할 때마다 발생할 수 있습니다. 고객 지원 또는 기술 지원을 제공하거나 검색 엔진이 요청한 정보를 검색하는 데 도움을 줄 수 있습니다.
+
+질문 답변에는 일반적으로 두 가지 유형이 있습니다:
+
+* 추출형: 질문과 문맥이 주어졌을 때, 모델이 주어진 문맥의 일부에서 가져온 텍스트의 범위를 답변으로 합니다.
+* 생성형: 질문과 문맥이 주어졌을 때, 주어진 문맥을 통해 답변을 생성합니다. 이 접근 방식은 [`QuestionAnsweringPipeline`] 대신 [`Text2TextGenerationPipeline`]을 통해 처리됩니다.
+
+```py
+>>> from transformers import pipeline
+
+>>> question_answerer = pipeline(task="question-answering")
+>>> preds = question_answerer(
+... question="What is the name of the repository?",
+... context="The name of the repository is huggingface/transformers",
+... )
+>>> print(
+... f"score: {round(preds['score'], 4)}, start: {preds['start']}, end: {preds['end']}, answer: {preds['answer']}"
+... )
+score: 0.9327, start: 30, end: 54, answer: huggingface/transformers
+```
+
+### 요약[[summarization]]
+
+요약은 원본 문서의 의미를 최대한 보존하면서 긴 문서를 짧은 문서로 만드는 작업입니다. 요약은 `sequence-to-sequence` 작업입니다. 입력보다 짧은 텍스트 시퀀스를 출력합니다. 요약 작업은 독자가 장문 문서들의 주요 포인트를 빠르게 이해하는 데 도움을 줄 수 있습니다. 입법안, 법률 및 금융 문서, 특허 및 과학 논문은 요약 작업이 독자의 시간을 절약하고 독서 보조 도구로 사용될 수 있는 몇 가지 예시입니다.
+
+질문 답변과 마찬가지로 요약에는 두 가지 유형이 있습니다:
+
+* 추출형: 원본 텍스트에서 가장 중요한 문장을 식별하고 추출합니다.
+* 생성형: 원본 텍스트에서 목표 요약을 생성합니다. 입력 문서에 없는 새로운 단어를 포함할 수도 있습니다. [`SummarizationPipeline`]은 생성형 접근 방식을 사용합니다.
+
+```py
+>>> from transformers import pipeline
+
+>>> summarizer = pipeline(task="summarization")
+>>> summarizer(
+... "In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention. For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles."
+... )
+[{'summary_text': ' The Transformer is the first sequence transduction model based entirely on attention . It replaces the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention . For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers .'}]
+```
+
+### 번역[[translation]]
+
+번역은 한 언어로 된 텍스트 시퀀스를 다른 언어로 변환하는 작업입니다. 이는 서로 다른 배경을 가진 사람들이 서로 소통하는 데 도움을 주는 중요한 역할을 합니다. 더 넓은 대중에게 콘텐츠를 번역하여 전달하거나, 새로운 언어를 배우는 데 도움이 되는 학습 도구가 될 수도 있습니다. 요약과 마찬가지로, 번역은 `sequence-to-sequence` 작업입니다. 즉, 모델은 입력 시퀀스를 받아서 출력이 되는 목표 시퀀스를 반환합니다.
+
+초기의 번역 모델은 대부분 단일 언어로 이루어져 있었지만, 최근에는 많은 언어 쌍 간에 번역을 수행할 수 있는 다중 언어 모델에 대한 관심이 높아지고 있습니다.
+
+```py
+>>> from transformers import pipeline
+
+>>> text = "translate English to French: Hugging Face is a community-based open-source platform for machine learning."
+>>> translator = pipeline(task="translation", model="google-t5/t5-small")
+>>> translator(text)
+[{'translation_text': "Hugging Face est une tribune communautaire de l'apprentissage des machines."}]
+```
+
+### 언어 모델링[[language_modeling]]
+
+언어 모델링은 텍스트 시퀀스에서 단어를 예측하는 작업입니다. 사전 훈련된 언어 모델은 많은 다른 하위 작업에 따라 미세 조정될 수 있기 때문에 매우 인기 있는 자연어처리 작업이 되었습니다. 최근에는 제로 샷(zero-shot) 또는 퓨 샷(few-shot) 학습이 가능한 대규모 언어 모델(Large Language Models, LLM)에 대한 많은 관심이 발생하고 있습니다. 이는 모델이 명시적으로 훈련되지 않은 작업도 해결할 수 있다는 것을 의미합니다! 언어 모델은 유창하고 설득력 있는 텍스트를 생성하는 데 사용될 수 있지만, 텍스트가 항상 정확하지는 않을 수 있으므로 주의가 필요합니다.
+
+언어 모델링에는 두 가지 유형이 있습니다:
+
+* 인과적 언어 모델링: 이 모델의 목적은 시퀀스에서 다음 토큰을 예측하는 것이며, 미래 토큰이 마스킹 됩니다.
+ ```py
+ >>> from transformers import pipeline
+
+ >>> prompt = "Hugging Face is a community-based open-source platform for machine learning."
+ >>> generator = pipeline(task="text-generation")
+ >>> generator(prompt) # doctest: +SKIP
+ ```
+
+* 마스킹된 언어 모델링: 이 모델의 목적은 시퀀스 내의 마스킹된 토큰을 예측하는 것이며, 시퀀스 내의 모든 토큰에 대한 접근이 제공됩니다.
+
+ ```py
+ >>> text = "Hugging Face is a community-based open-source for machine learning."
+ >>> fill_mask = pipeline(task="fill-mask")
+ >>> preds = fill_mask(text, top_k=1)
+ >>> preds = [
+ ... {
+ ... "score": round(pred["score"], 4),
+ ... "token": pred["token"],
+ ... "token_str": pred["token_str"],
+ ... "sequence": pred["sequence"],
+ ... }
+ ... for pred in preds
+ ... ]
+ >>> preds
+ [{'score': 0.2236,
+ 'token': 1761,
+ 'token_str': ' platform',
+ 'sequence': 'Hugging Face is a community-based open-source platform for machine learning.'}]
+ ```
+
+이 페이지를 통해 각 모달리티의 다양한 작업 유형과 각 작업의 실용적 중요성에 대해 추가적인 배경 정보를 얻으셨기를 바랍니다. 다음 [섹션](tasks_explained)에서는 🤗 Transformer가 이러한 작업을 해결하는 **방법**에 대해 알아보실 수 있습니다.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/tasks/asr.md b/docs/transformers/docs/source/ko/tasks/asr.md
new file mode 100644
index 0000000000000000000000000000000000000000..d1e4a5e1d919831fc18ebbc36b82a2fb8269dcbc
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/asr.md
@@ -0,0 +1,375 @@
+
+
+# 자동 음성 인식[[automatic-speech-recognition]]
+
+[[open-in-colab]]
+
+
+
+자동 음성 인식(Automatic Speech Recognition, ASR)은 음성 신호를 텍스트로 변환하여 음성 입력 시퀀스를 텍스트 출력에 매핑합니다.
+Siri와 Alexa와 같은 가상 어시스턴트는 ASR 모델을 사용하여 일상적으로 사용자를 돕고 있으며, 회의 중 라이브 캡션 및 메모 작성과 같은 유용한 사용자 친화적 응용 프로그램도 많이 있습니다.
+
+이 가이드에서 소개할 내용은 아래와 같습니다:
+
+1. [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트에서 [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base)를 미세 조정하여 오디오를 텍스트로 변환합니다.
+2. 미세 조정한 모델을 추론에 사용합니다.
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/automatic-speech-recognition)를 확인하는 것이 좋습니다.
+
+
+
+시작하기 전에 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers datasets evaluate jiwer
+```
+
+Hugging Face 계정에 로그인하면 모델을 업로드하고 커뮤니티에 공유할 수 있습니다. 토큰을 입력하여 로그인하세요.
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## MInDS-14 데이터 세트 가져오기[[load-minds-14-dataset]]
+
+먼저, 🤗 Datasets 라이브러리에서 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트의 일부분을 가져오세요.
+이렇게 하면 전체 데이터 세트에 대한 훈련에 시간을 들이기 전에 모든 것이 작동하는지 실험하고 검증할 수 있습니다.
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train[:100]")
+```
+
+[`~Dataset.train_test_split`] 메소드를 사용하여 데이터 세트의 `train`을 훈련 세트와 테스트 세트로 나누세요:
+
+```py
+>>> minds = minds.train_test_split(test_size=0.2)
+```
+
+그리고 데이터 세트를 확인하세요:
+
+```py
+>>> minds
+DatasetDict({
+ train: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 16
+ })
+ test: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 4
+ })
+})
+```
+
+데이터 세트에는 `lang_id`와 `english_transcription`과 같은 유용한 정보가 많이 포함되어 있지만, 이 가이드에서는 `audio`와 `transcription`에 초점을 맞출 것입니다. 다른 열은 [`~datasets.Dataset.remove_columns`] 메소드를 사용하여 제거하세요:
+
+```py
+>>> minds = minds.remove_columns(["english_transcription", "intent_class", "lang_id"])
+```
+
+예시를 다시 한번 확인해보세요:
+
+```py
+>>> minds["train"][0]
+{'audio': {'array': array([-0.00024414, 0. , 0. , ..., 0.00024414,
+ 0.00024414, 0.00024414], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'sampling_rate': 8000},
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
+```
+
+두 개의 필드가 있습니다:
+
+- `audio`: 오디오 파일을 가져오고 리샘플링하기 위해 호출해야 하는 음성 신호의 1차원 `array(배열)`
+- `transcription`: 목표 텍스트
+
+## 전처리[[preprocess]]
+
+다음으로 오디오 신호를 처리하기 위한 Wav2Vec2 프로세서를 가져옵니다:
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base")
+```
+
+MInDS-14 데이터 세트의 샘플링 레이트는 8000kHz이므로([데이터 세트 카드](https://huggingface.co/datasets/PolyAI/minds14)에서 확인), 사전 훈련된 Wav2Vec2 모델을 사용하려면 데이터 세트를 16000kHz로 리샘플링해야 합니다:
+
+```py
+>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
+>>> minds["train"][0]
+{'audio': {'array': array([-2.38064706e-04, -1.58618059e-04, -5.43987835e-06, ...,
+ 2.78103951e-04, 2.38446111e-04, 1.18740834e-04], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'sampling_rate': 16000},
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
+ 'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
+```
+
+위의 'transcription'에서 볼 수 있듯이 텍스트는 대문자와 소문자가 섞여 있습니다. Wav2Vec2 토크나이저는 대문자 문자에 대해서만 훈련되어 있으므로 텍스트가 토크나이저의 어휘와 일치하는지 확인해야 합니다:
+
+```py
+>>> def uppercase(example):
+... return {"transcription": example["transcription"].upper()}
+
+
+>>> minds = minds.map(uppercase)
+```
+
+이제 다음 작업을 수행할 전처리 함수를 만들어보겠습니다:
+
+1. `audio` 열을 호출하여 오디오 파일을 가져오고 리샘플링합니다.
+2. 오디오 파일에서 `input_values`를 추출하고 프로세서로 `transcription` 열을 토큰화합니다.
+
+```py
+>>> def prepare_dataset(batch):
+... audio = batch["audio"]
+... batch = processor(audio["array"], sampling_rate=audio["sampling_rate"], text=batch["transcription"])
+... batch["input_length"] = len(batch["input_values"][0])
+... return batch
+```
+
+전체 데이터 세트에 전처리 함수를 적용하려면 🤗 Datasets [`~datasets.Dataset.map`] 함수를 사용하세요. `num_proc` 매개변수를 사용하여 프로세스 수를 늘리면 `map`의 속도를 높일 수 있습니다. [`~datasets.Dataset.remove_columns`] 메소드를 사용하여 필요하지 않은 열을 제거하세요:
+
+```py
+>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
+```
+
+🤗 Transformers에는 자동 음성 인식용 데이터 콜레이터가 없으므로 예제 배치를 생성하려면 [`DataCollatorWithPadding`]을 조정해야 합니다. 이렇게 하면 데이터 콜레이터는 텍스트와 레이블을 배치에서 가장 긴 요소의 길이에 동적으로 패딩하여 길이를 균일하게 합니다. `tokenizer` 함수에서 `padding=True`를 설정하여 텍스트를 패딩할 수 있지만, 동적 패딩이 더 효율적입니다.
+
+다른 데이터 콜레이터와 달리 이 특정 데이터 콜레이터는 `input_values`와 `labels`에 대해 다른 패딩 방법을 적용해야 합니다.
+
+```py
+>>> import torch
+
+>>> from dataclasses import dataclass, field
+>>> from typing import Any, Dict, List, Optional, Union
+
+
+>>> @dataclass
+... class DataCollatorCTCWithPadding:
+... processor: AutoProcessor
+... padding: Union[bool, str] = "longest"
+
+... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
+... # 입력과 레이블을 분할합니다
+... # 길이가 다르고, 각각 다른 패딩 방법을 사용해야 하기 때문입니다
+... input_features = [{"input_values": feature["input_values"][0]} for feature in features]
+... label_features = [{"input_ids": feature["labels"]} for feature in features]
+
+... batch = self.processor.pad(input_features, padding=self.padding, return_tensors="pt")
+
+... labels_batch = self.processor.pad(labels=label_features, padding=self.padding, return_tensors="pt")
+
+... # 패딩에 대해 손실을 적용하지 않도록 -100으로 대체합니다
+... labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
+
+... batch["labels"] = labels
+
+... return batch
+```
+
+이제 `DataCollatorForCTCWithPadding`을 인스턴스화합니다:
+
+```py
+>>> data_collator = DataCollatorCTCWithPadding(processor=processor, padding="longest")
+```
+
+## 평가하기[[evaluate]]
+
+훈련 중에 평가 지표를 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하면 평가 방법을 빠르게 불러올 수 있습니다.
+이 작업에서는 [단어 오류율(Word Error Rate, WER)](https://huggingface.co/spaces/evaluate-metric/wer) 평가 지표를 가져옵니다.
+(평가 지표를 불러오고 계산하는 방법은 🤗 Evaluate [둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하세요):
+
+```py
+>>> import evaluate
+
+>>> wer = evaluate.load("wer")
+```
+
+그런 다음 예측값과 레이블을 [`~evaluate.EvaluationModule.compute`]에 전달하여 WER을 계산하는 함수를 만듭니다:
+
+```py
+>>> import numpy as np
+
+
+>>> def compute_metrics(pred):
+... pred_logits = pred.predictions
+... pred_ids = np.argmax(pred_logits, axis=-1)
+
+... pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
+
+... pred_str = processor.batch_decode(pred_ids)
+... label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
+
+... wer = wer.compute(predictions=pred_str, references=label_str)
+
+... return {"wer": wer}
+```
+
+이제 `compute_metrics` 함수를 사용할 준비가 되었으며, 훈련을 설정할 때 이 함수로 되돌아올 것입니다.
+
+## 훈련하기[[train]]
+
+
+
+
+
+[`Trainer`]로 모델을 미세 조정하는 것이 익숙하지 않다면, [여기](../training#train-with-pytorch-trainer)에서 기본 튜토리얼을 확인해보세요!
+
+
+
+이제 모델 훈련을 시작할 준비가 되었습니다! [`AutoModelForCTC`]로 Wav2Vec2를 가져오세요. `ctc_loss_reduction` 매개변수로 CTC 손실에 적용할 축소(reduction) 방법을 지정하세요. 기본값인 합계 대신 평균을 사용하는 것이 더 좋은 경우가 많습니다:
+
+```py
+>>> from transformers import AutoModelForCTC, TrainingArguments, Trainer
+
+>>> model = AutoModelForCTC.from_pretrained(
+... "facebook/wav2vec2-base",
+... ctc_loss_reduction="mean",
+... pad_token_id=processor.tokenizer.pad_token_id,
+... )
+```
+
+이제 세 단계만 남았습니다:
+
+1. [`TrainingArguments`]에서 훈련 하이퍼파라미터를 정의하세요. `output_dir`은 모델을 저장할 경로를 지정하는 유일한 필수 매개변수입니다. `push_to_hub=True`를 설정하여 모델을 Hub에 업로드 할 수 있습니다(모델을 업로드하려면 Hugging Face에 로그인해야 합니다). [`Trainer`]는 각 에폭마다 WER을 평가하고 훈련 체크포인트를 저장합니다.
+2. 모델, 데이터 세트, 토크나이저, 데이터 콜레이터, `compute_metrics` 함수와 함께 [`Trainer`]에 훈련 인수를 전달하세요.
+3. [`~Trainer.train`]을 호출하여 모델을 미세 조정하세요.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_asr_mind_model",
+... per_device_train_batch_size=8,
+... gradient_accumulation_steps=2,
+... learning_rate=1e-5,
+... warmup_steps=500,
+... max_steps=2000,
+... gradient_checkpointing=True,
+... fp16=True,
+... group_by_length=True,
+... eval_strategy="steps",
+... per_device_eval_batch_size=8,
+... save_steps=1000,
+... eval_steps=1000,
+... logging_steps=25,
+... load_best_model_at_end=True,
+... metric_for_best_model="wer",
+... greater_is_better=False,
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=encoded_minds["train"],
+... eval_dataset=encoded_minds["test"],
+... processing_class=processor.feature_extractor,
+... data_collator=data_collator,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+
+훈련이 완료되면 모두가 모델을 사용할 수 있도록 [`~transformers.Trainer.push_to_hub`] 메소드를 사용하여 모델을 Hub에 공유하세요:
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+
+자동 음성 인식을 위해 모델을 미세 조정하는 더 자세한 예제는 영어 자동 음성 인식을 위한 [블로그 포스트](https://huggingface.co/blog/fine-tune-wav2vec2-english)와 다국어 자동 음성 인식을 위한 [포스트](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2)를 참조하세요.
+
+
+
+## 추론하기[[inference]]
+
+좋아요, 이제 모델을 미세 조정했으니 추론에 사용할 수 있습니다!
+
+추론에 사용할 오디오 파일을 가져오세요. 필요한 경우 오디오 파일의 샘플링 비율을 모델의 샘플링 레이트에 맞게 리샘플링하는 것을 잊지 마세요!
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
+>>> sampling_rate = dataset.features["audio"].sampling_rate
+>>> audio_file = dataset[0]["audio"]["path"]
+```
+
+추론을 위해 미세 조정된 모델을 시험해보는 가장 간단한 방법은 [`pipeline`]을 사용하는 것입니다. 모델을 사용하여 자동 음성 인식을 위한 `pipeline`을 인스턴스화하고 오디오 파일을 전달하세요:
+
+```py
+>>> from transformers import pipeline
+
+>>> transcriber = pipeline("automatic-speech-recognition", model="stevhliu/my_awesome_asr_minds_model")
+>>> transcriber(audio_file)
+{'text': 'I WOUD LIKE O SET UP JOINT ACOUNT WTH Y PARTNER'}
+```
+
+
+
+텍스트로 변환된 결과가 꽤 괜찮지만 더 좋을 수도 있습니다! 더 나은 결과를 얻으려면 더 많은 예제로 모델을 미세 조정하세요!
+
+
+
+`pipeline`의 결과를 수동으로 재현할 수도 있습니다:
+
+
+
+오디오 파일과 텍스트를 전처리하고 PyTorch 텐서로 `input`을 반환할 프로세서를 가져오세요:
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained("stevhliu/my_awesome_asr_mind_model")
+>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
+```
+
+입력을 모델에 전달하고 로짓을 반환하세요:
+
+```py
+>>> from transformers import AutoModelForCTC
+
+>>> model = AutoModelForCTC.from_pretrained("stevhliu/my_awesome_asr_mind_model")
+>>> with torch.no_grad():
+... logits = model(**inputs).logits
+```
+
+가장 높은 확률의 `input_ids`를 예측하고, 프로세서를 사용하여 예측된 `input_ids`를 다시 텍스트로 디코딩하세요:
+
+```py
+>>> import torch
+
+>>> predicted_ids = torch.argmax(logits, dim=-1)
+>>> transcription = processor.batch_decode(predicted_ids)
+>>> transcription
+['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
+```
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/audio_classification.md b/docs/transformers/docs/source/ko/tasks/audio_classification.md
new file mode 100644
index 0000000000000000000000000000000000000000..2defa691edef75ffaefb7a66a3d8ebfc3a95ae5e
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/audio_classification.md
@@ -0,0 +1,324 @@
+
+
+# 오디오 분류[[audio_classification]]
+
+[[open-in-colab]]
+
+
+
+오디오 분류는 텍스트와 마찬가지로 입력 데이터에 클래스 레이블 출력을 할당합니다. 유일한 차이점은 텍스트 입력 대신 원시 오디오 파형이 있다는 것입니다. 오디오 분류의 실제 적용 분야에는 화자의 의도 파악, 언어 분류, 소리로 동물 종을 식별하는 것 등이 있습니다.
+
+이 문서에서 방법을 알아보겠습니다:
+
+1. [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트를 [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base)로 미세 조정하여 화자의 의도를 분류합니다.
+2. 추론에 미세 조정된 모델을 사용하세요.
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/audio-classification)를 확인하는 것이 좋습니다.
+
+
+
+시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers datasets evaluate
+```
+
+모델을 업로드하고 커뮤니티와 공유할 수 있도록 허깅페이스 계정에 로그인하는 것이 좋습니다. 메시지가 표시되면 토큰을 입력하여 로그인합니다:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## MInDS-14 데이터셋 불러오기[[load_minds_14_dataset]]
+
+먼저 🤗 Datasets 라이브러리에서 MinDS-14 데이터 세트를 가져옵니다:
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train")
+```
+
+데이터 세트의 `train` 분할을 [`~datasets.Dataset.train_test_split`] 메소드를 사용하여 더 작은 훈련 및 테스트 집합으로 분할합니다. 이렇게 하면 전체 데이터 세트에 더 많은 시간을 소비하기 전에 모든 것이 작동하는지 실험하고 확인할 수 있습니다.
+
+```py
+>>> minds = minds.train_test_split(test_size=0.2)
+```
+
+이제 데이터 집합을 살펴볼게요:
+
+```py
+>>> minds
+DatasetDict({
+ train: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 450
+ })
+ test: Dataset({
+ features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
+ num_rows: 113
+ })
+})
+```
+
+데이터 세트에는 `lang_id` 및 `english_transcription`과 같은 유용한 정보가 많이 포함되어 있지만 이 가이드에서는 `audio` 및 `intent_class`에 중점을 둘 것입니다. 다른 열은 [`~datasets.Dataset.remove_columns`] 메소드를 사용하여 제거합니다:
+
+```py
+>>> minds = minds.remove_columns(["path", "transcription", "english_transcription", "lang_id"])
+```
+
+예시를 살펴보겠습니다:
+
+```py
+>>> minds["train"][0]
+{'audio': {'array': array([ 0. , 0. , 0. , ..., -0.00048828,
+ -0.00024414, -0.00024414], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
+ 'sampling_rate': 8000},
+ 'intent_class': 2}
+```
+
+두 개의 필드가 있습니다:
+
+- `audio`: 오디오 파일을 가져오고 리샘플링하기 위해 호출해야 하는 음성 신호의 1차원 `배열`입니다.
+- `intent_class`: 화자의 의도에 대한 클래스 ID를 나타냅니다.
+
+모델이 레이블 ID에서 레이블 이름을 쉽게 가져올 수 있도록 레이블 이름을 정수로 매핑하는 사전을 만들거나 그 반대로 매핑하는 사전을 만듭니다:
+
+```py
+>>> labels = minds["train"].features["intent_class"].names
+>>> label2id, id2label = dict(), dict()
+>>> for i, label in enumerate(labels):
+... label2id[label] = str(i)
+... id2label[str(i)] = label
+```
+
+이제 레이블 ID를 레이블 이름으로 변환할 수 있습니다:
+
+```py
+>>> id2label[str(2)]
+'app_error'
+```
+
+## 전처리[[preprocess]]
+
+다음 단계는 오디오 신호를 처리하기 위해 Wav2Vec2 특징 추출기를 가져오는 것입니다:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
+```
+
+MinDS-14 데이터 세트의 샘플링 속도는 8khz이므로(이 정보는 [데이터세트 카드](https://huggingface.co/datasets/PolyAI/minds14)에서 확인할 수 있습니다), 사전 훈련된 Wav2Vec2 모델을 사용하려면 데이터 세트를 16kHz로 리샘플링해야 합니다:
+
+```py
+>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
+>>> minds["train"][0]
+{'audio': {'array': array([ 2.2098757e-05, 4.6582241e-05, -2.2803260e-05, ...,
+ -2.8419291e-04, -2.3305941e-04, -1.1425107e-04], dtype=float32),
+ 'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
+ 'sampling_rate': 16000},
+ 'intent_class': 2}
+```
+
+이제 전처리 함수를 만듭니다:
+
+1. 가져올 `오디오` 열을 호출하고 필요한 경우 오디오 파일을 리샘플링합니다.
+2. 오디오 파일의 샘플링 속도가 모델에 사전 훈련된 오디오 데이터의 샘플링 속도와 일치하는지 확인합니다. 이 정보는 Wav2Vec2 [모델 카드](https://huggingface.co/facebook/wav2vec2-base)에서 확인할 수 있습니다.
+3. 긴 입력이 잘리지 않고 일괄 처리되도록 최대 입력 길이를 설정합니다.
+
+```py
+>>> def preprocess_function(examples):
+... audio_arrays = [x["array"] for x in examples["audio"]]
+... inputs = feature_extractor(
+... audio_arrays, sampling_rate=feature_extractor.sampling_rate, max_length=16000, truncation=True
+... )
+... return inputs
+```
+
+전체 데이터 세트에 전처리 기능을 적용하려면 🤗 Datasets [`~datasets.Dataset.map`] 함수를 사용합니다. `batched=True`를 설정하여 데이터 집합의 여러 요소를 한 번에 처리하면 `map`의 속도를 높일 수 있습니다. 필요하지 않은 열을 제거하고 `intent_class`의 이름을 모델이 예상하는 이름인 `label`로 변경합니다:
+
+```py
+>>> encoded_minds = minds.map(preprocess_function, remove_columns="audio", batched=True)
+>>> encoded_minds = encoded_minds.rename_column("intent_class", "label")
+```
+
+## 평가하기[[evaluate]]
+
+훈련 중에 메트릭을 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하여 평가 방법을 빠르게 가져올 수 있습니다. 이 작업에서는 [accuracy(정확도)](https://huggingface.co/spaces/evaluate-metric/accuracy) 메트릭을 가져옵니다(메트릭을 가져오고 계산하는 방법에 대한 자세한 내용은 🤗 Evalutate [빠른 둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour) 참조하세요):
+
+```py
+>>> import evaluate
+
+>>> accuracy = evaluate.load("accuracy")
+```
+
+그런 다음 예측과 레이블을 [`~evaluate.EvaluationModule.compute`]에 전달하여 정확도를 계산하는 함수를 만듭니다:
+
+```py
+>>> import numpy as np
+
+
+>>> def compute_metrics(eval_pred):
+... predictions = np.argmax(eval_pred.predictions, axis=1)
+... return accuracy.compute(predictions=predictions, references=eval_pred.label_ids)
+```
+
+이제 `compute_metrics` 함수를 사용할 준비가 되었으며, 트레이닝을 설정할 때 이 함수를 사용합니다.
+
+## 훈련[[train]]
+
+
+
+
+
+[`Trainer`]로 모델을 미세 조정하는 데 익숙하지 않다면 기본 튜토리얼 [여기](../training#train-with-pytorch-trainer)을 살펴보세요!
+
+
+
+이제 모델 훈련을 시작할 준비가 되었습니다! [`AutoModelForAudioClassification`]을 이용해서 Wav2Vec2를 불러옵니다. 예상되는 레이블 수와 레이블 매핑을 지정합니다:
+
+```py
+>>> from transformers import AutoModelForAudioClassification, TrainingArguments, Trainer
+
+>>> num_labels = len(id2label)
+>>> model = AutoModelForAudioClassification.from_pretrained(
+... "facebook/wav2vec2-base", num_labels=num_labels, label2id=label2id, id2label=id2label
+... )
+```
+
+이제 세 단계만 남았습니다:
+
+1. 훈련 하이퍼파라미터를 [`TrainingArguments`]에 정의합니다. 유일한 필수 매개변수는 모델을 저장할 위치를 지정하는 `output_dir`입니다. `push_to_hub = True`를 설정하여 이 모델을 허브로 푸시합니다(모델을 업로드하려면 허깅 페이스에 로그인해야 합니다). 각 에폭이 끝날 때마다 [`Trainer`]가 정확도를 평가하고 훈련 체크포인트를 저장합니다.
+2. 모델, 데이터 세트, 토크나이저, 데이터 콜레이터, `compute_metrics` 함수와 함께 훈련 인자를 [`Trainer`]에 전달합니다.
+3. [`~Trainer.train`]을 호출하여 모델을 미세 조정합니다.
+
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_mind_model",
+... eval_strategy="epoch",
+... save_strategy="epoch",
+... learning_rate=3e-5,
+... per_device_train_batch_size=32,
+... gradient_accumulation_steps=4,
+... per_device_eval_batch_size=32,
+... num_train_epochs=10,
+... warmup_ratio=0.1,
+... logging_steps=10,
+... load_best_model_at_end=True,
+... metric_for_best_model="accuracy",
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=encoded_minds["train"],
+... eval_dataset=encoded_minds["test"],
+... processing_class=feature_extractor,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+
+훈련이 완료되면 모든 사람이 모델을 사용할 수 있도록 [`~transformers.Trainer.push_to_hub`] 메소드를 사용하여 모델을 허브에 공유하세요:
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+
+For a more in-depth example of how to finetune a model for audio classification, take a look at the corresponding [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb).
+
+
+
+## 추론[[inference]]
+
+이제 모델을 미세 조정했으니 추론에 사용할 수 있습니다!
+
+추론을 실행할 오디오 파일을 가져옵니다. 필요한 경우 오디오 파일의 샘플링 속도를 모델의 샘플링 속도와 일치하도록 리샘플링하는 것을 잊지 마세요!
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
+>>> sampling_rate = dataset.features["audio"].sampling_rate
+>>> audio_file = dataset[0]["audio"]["path"]
+```
+
+추론을 위해 미세 조정한 모델을 시험해 보는 가장 간단한 방법은 [`pipeline`]에서 사용하는 것입니다. 모델을 사용하여 오디오 분류를 위한 `pipeline`을 인스턴스화하고 오디오 파일을 전달합니다:
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline("audio-classification", model="stevhliu/my_awesome_minds_model")
+>>> classifier(audio_file)
+[
+ {'score': 0.09766869246959686, 'label': 'cash_deposit'},
+ {'score': 0.07998877018690109, 'label': 'app_error'},
+ {'score': 0.0781070664525032, 'label': 'joint_account'},
+ {'score': 0.07667109370231628, 'label': 'pay_bill'},
+ {'score': 0.0755252093076706, 'label': 'balance'}
+]
+```
+
+원하는 경우 `pipeline`의 결과를 수동으로 복제할 수도 있습니다:
+
+
+
+특징 추출기를 가져와서 오디오 파일을 전처리하고 `입력`을 PyTorch 텐서로 반환합니다:
+
+```py
+>>> from transformers import AutoFeatureExtractor
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained("stevhliu/my_awesome_minds_model")
+>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
+```
+
+모델에 입력을 전달하고 로짓을 반환합니다:
+
+```py
+>>> from transformers import AutoModelForAudioClassification
+
+>>> model = AutoModelForAudioClassification.from_pretrained("stevhliu/my_awesome_minds_model")
+>>> with torch.no_grad():
+... logits = model(**inputs).logits
+```
+
+확률이 가장 높은 클래스를 가져온 다음 모델의 `id2label` 매핑을 사용하여 이를 레이블로 변환합니다:
+
+```py
+>>> import torch
+
+>>> predicted_class_ids = torch.argmax(logits).item()
+>>> predicted_label = model.config.id2label[predicted_class_ids]
+>>> predicted_label
+'cash_deposit'
+```
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/document_question_answering.md b/docs/transformers/docs/source/ko/tasks/document_question_answering.md
new file mode 100644
index 0000000000000000000000000000000000000000..6c2d04f4ee859836401cf1e5d9c37c12c77f5827
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/document_question_answering.md
@@ -0,0 +1,476 @@
+
+
+# 문서 질의 응답(Document Question Answering) [[document_question_answering]]
+
+[[open-in-colab]]
+
+문서 시각적 질의 응답(Document Visual Question Answering)이라고도 하는
+문서 질의 응답(Document Question Answering)은 문서 이미지에 대한 질문에 답변을 주는 태스크입니다.
+이 태스크를 지원하는 모델의 입력은 일반적으로 이미지와 질문의 조합이고, 출력은 자연어로 된 답변입니다. 이러한 모델은 텍스트, 단어의 위치(바운딩 박스), 이미지 등 다양한 모달리티를 활용합니다.
+
+이 가이드는 다음 내용을 설명합니다:
+
+- [DocVQA dataset](https://huggingface.co/datasets/nielsr/docvqa_1200_examples_donut)을 사용해 [LayoutLMv2](../model_doc/layoutlmv2) 미세 조정하기
+- 추론을 위해 미세 조정된 모델을 사용하기
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/image-to-text)를 확인하는 것이 좋습니다.
+
+
+
+LayoutLMv2는 토큰의 마지막 은닉층 위에 질의 응답 헤드를 추가해 답변의 시작 토큰과 끝 토큰의 위치를 예측함으로써 문서 질의 응답 태스크를 해결합니다. 즉, 문맥이 주어졌을 때 질문에 답하는 정보를 추출하는 추출형 질의 응답(Extractive question answering)으로 문제를 처리합니다.
+문맥은 OCR 엔진의 출력에서 가져오며, 여기서는 Google의 Tesseract를 사용합니다.
+
+시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요. LayoutLMv2는 detectron2, torchvision 및 테서랙트를 필요로 합니다.
+
+```bash
+pip install -q transformers datasets
+```
+
+```bash
+pip install 'git+https://github.com/facebookresearch/detectron2.git'
+pip install torchvision
+```
+
+```bash
+sudo apt install tesseract-ocr
+pip install -q pytesseract
+```
+
+필요한 라이브러리들을 모두 설치한 후 런타임을 다시 시작합니다.
+
+커뮤니티에 당신의 모델을 공유하는 것을 권장합니다. Hugging Face 계정에 로그인해서 모델을 🤗 Hub에 업로드하세요.
+프롬프트가 실행되면, 로그인을 위해 토큰을 입력하세요:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+몇 가지 전역 변수를 정의해 보겠습니다.
+
+```py
+>>> model_checkpoint = "microsoft/layoutlmv2-base-uncased"
+>>> batch_size = 4
+```
+
+## 데이터 불러오기 [[load-the-data]]
+
+이 가이드에서는 🤗 Hub에서 찾을 수 있는 전처리된 DocVQA의 작은 샘플을 사용합니다.
+DocVQA의 전체 데이터 세트를 사용하고 싶다면, [DocVQA homepage](https://rrc.cvc.uab.es/?ch=17)에 가입 후 다운로드 할 수 있습니다. 전체 데이터 세트를 다운로드 했다면, 이 가이드를 계속 진행하기 위해 [🤗 dataset에 파일을 가져오는 방법](https://huggingface.co/docs/datasets/loading#local-and-remote-files)을 확인하세요.
+
+```py
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("nielsr/docvqa_1200_examples")
+>>> dataset
+DatasetDict({
+ train: Dataset({
+ features: ['id', 'image', 'query', 'answers', 'words', 'bounding_boxes', 'answer'],
+ num_rows: 1000
+ })
+ test: Dataset({
+ features: ['id', 'image', 'query', 'answers', 'words', 'bounding_boxes', 'answer'],
+ num_rows: 200
+ })
+})
+```
+
+보시다시피, 데이터 세트는 이미 훈련 세트와 테스트 세트로 나누어져 있습니다. 무작위로 예제를 살펴보면서 특성을 확인해보세요.
+
+```py
+>>> dataset["train"].features
+```
+
+각 필드가 나타내는 내용은 다음과 같습니다:
+* `id`: 예제의 id
+* `image`: 문서 이미지를 포함하는 PIL.Image.Image 객체
+* `query`: 질문 문자열 - 여러 언어의 자연어로 된 질문
+* `answers`: 사람이 주석을 단 정답 리스트
+* `words` and `bounding_boxes`: OCR의 결과값들이며 이 가이드에서는 사용하지 않을 예정
+* `answer`: 다른 모델과 일치하는 답변이며 이 가이드에서는 사용하지 않을 예정
+
+영어로 된 질문만 남기고 다른 모델에 대한 예측을 포함하는 `answer` 특성을 삭제하겠습니다.
+그리고 주석 작성자가 제공한 데이터 세트에서 첫 번째 답변을 가져옵니다. 또는 무작위로 샘플을 추출할 수도 있습니다.
+
+```py
+>>> updated_dataset = dataset.map(lambda example: {"question": example["query"]["en"]}, remove_columns=["query"])
+>>> updated_dataset = updated_dataset.map(
+... lambda example: {"answer": example["answers"][0]}, remove_columns=["answer", "answers"]
+... )
+```
+
+이 가이드에서 사용하는 LayoutLMv2 체크포인트는 `max_position_embeddings = 512`로 훈련되었습니다(이 정보는 [체크포인트의 `config.json` 파일](https://huggingface.co/microsoft/layoutlmv2-base-uncased/blob/main/config.json#L18)에서 확인할 수 있습니다).
+바로 예제를 잘라낼 수도 있지만, 긴 문서의 끝에 답변이 있어 잘리는 상황을 피하기 위해 여기서는 임베딩이 512보다 길어질 가능성이 있는 몇 가지 예제를 제거하겠습니다.
+데이터 세트에 있는 대부분의 문서가 긴 경우 슬라이딩 윈도우 방법을 사용할 수 있습니다 - 자세한 내용을 확인하고 싶으면 이 [노트북](https://github.com/huggingface/notebooks/blob/main/examples/question_answering.ipynb)을 확인하세요.
+
+```py
+>>> updated_dataset = updated_dataset.filter(lambda x: len(x["words"]) + len(x["question"].split()) < 512)
+```
+
+이 시점에서 이 데이터 세트의 OCR 특성도 제거해 보겠습니다. OCR 특성은 다른 모델을 미세 조정하기 위한 것으로, 이 가이드에서 사용하는 모델의 입력 요구 사항과 일치하지 않기 때문에 이 특성을 사용하기 위해서는 일부 처리가 필요합니다.
+대신, 원본 데이터에 [`LayoutLMv2Processor`]를 사용하여 OCR 및 토큰화를 모두 수행할 수 있습니다.
+이렇게 하면 모델이 요구하는 입력을 얻을 수 있습니다.
+이미지를 수동으로 처리하려면, [`LayoutLMv2` model documentation](../model_doc/layoutlmv2)에서 모델이 요구하는 입력 포맷을 확인해보세요.
+
+```py
+>>> updated_dataset = updated_dataset.remove_columns("words")
+>>> updated_dataset = updated_dataset.remove_columns("bounding_boxes")
+```
+
+마지막으로, 데이터 탐색을 완료하기 위해 이미지 예시를 살펴봅시다.
+
+```py
+>>> updated_dataset["train"][11]["image"]
+```
+
+
+
+
+
+## 데이터 전처리 [[preprocess-the-data]]
+
+
+문서 질의 응답 태스크는 멀티모달 태스크이며, 각 모달리티의 입력이 모델의 요구에 맞게 전처리 되었는지 확인해야 합니다.
+이미지 데이터를 처리할 수 있는 이미지 프로세서와 텍스트 데이터를 인코딩할 수 있는 토크나이저를 결합한 [`LayoutLMv2Processor`]를 가져오는 것부터 시작해 보겠습니다.
+
+```py
+>>> from transformers import AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained(model_checkpoint)
+```
+
+### 문서 이미지 전처리 [[preprocessing-document-images]]
+
+먼저, 프로세서의 `image_processor`를 사용해 모델에 대한 문서 이미지를 준비해 보겠습니다.
+기본값으로, 이미지 프로세서는 이미지 크기를 224x224로 조정하고 색상 채널의 순서가 올바른지 확인한 후 단어와 정규화된 바운딩 박스를 얻기 위해 테서랙트를 사용해 OCR를 적용합니다.
+이 튜토리얼에서 우리가 필요한 것과 기본값은 완전히 동일합니다. 이미지 배치에 기본 이미지 처리를 적용하고 OCR의 결과를 변환하는 함수를 작성합니다.
+
+```py
+>>> image_processor = processor.image_processor
+
+
+>>> def get_ocr_words_and_boxes(examples):
+... images = [image.convert("RGB") for image in examples["image"]]
+... encoded_inputs = image_processor(images)
+
+... examples["image"] = encoded_inputs.pixel_values
+... examples["words"] = encoded_inputs.words
+... examples["boxes"] = encoded_inputs.boxes
+
+... return examples
+```
+
+이 전처리를 데이터 세트 전체에 빠르게 적용하려면 [`~datasets.Dataset.map`]를 사용하세요.
+
+```py
+>>> dataset_with_ocr = updated_dataset.map(get_ocr_words_and_boxes, batched=True, batch_size=2)
+```
+
+### 텍스트 데이터 전처리 [[preprocessing-text-data]]
+
+이미지에 OCR을 적용했으면 데이터 세트의 텍스트 부분을 모델에 맞게 인코딩해야 합니다.
+이 인코딩에는 이전 단계에서 가져온 단어와 박스를 토큰 수준의 `input_ids`, `attention_mask`, `token_type_ids` 및 `bbox`로 변환하는 작업이 포함됩니다.
+텍스트를 전처리하려면 프로세서의 `tokenizer`가 필요합니다.
+
+```py
+>>> tokenizer = processor.tokenizer
+```
+
+위에서 언급한 전처리 외에도 모델을 위해 레이블을 추가해야 합니다. 🤗 Transformers의 `xxxForQuestionAnswering` 모델의 경우, 레이블은 `start_positions`와 `end_positions`로 구성되며 어떤 토큰이 답변의 시작과 끝에 있는지를 나타냅니다.
+
+레이블 추가를 위해서, 먼저 더 큰 리스트(단어 리스트)에서 하위 리스트(단어로 분할된 답변)을 찾을 수 있는 헬퍼 함수를 정의합니다.
+
+이 함수는 `words_list`와 `answer_list`, 이렇게 두 리스트를 입력으로 받습니다.
+그런 다음 `words_list`를 반복하여 `words_list`의 현재 단어(words_list[i])가 `answer_list`의 첫 번째 단어(answer_list[0])와 같은지,
+현재 단어에서 시작해 `answer_list`와 같은 길이만큼의 `words_list`의 하위 리스트가 `answer_list`와 일치하는지 확인합니다.
+이 조건이 참이라면 일치하는 항목을 발견했음을 의미하며, 함수는 일치 항목, 시작 인덱스(idx) 및 종료 인덱스(idx + len(answer_list) - 1)를 기록합니다. 일치하는 항목이 두 개 이상 발견되면 함수는 첫 번째 항목만 반환합니다. 일치하는 항목이 없다면 함수는 (`None`, 0, 0)을 반환합니다.
+
+```py
+>>> def subfinder(words_list, answer_list):
+... matches = []
+... start_indices = []
+... end_indices = []
+... for idx, i in enumerate(range(len(words_list))):
+... if words_list[i] == answer_list[0] and words_list[i : i + len(answer_list)] == answer_list:
+... matches.append(answer_list)
+... start_indices.append(idx)
+... end_indices.append(idx + len(answer_list) - 1)
+... if matches:
+... return matches[0], start_indices[0], end_indices[0]
+... else:
+... return None, 0, 0
+```
+
+이 함수가 어떻게 정답의 위치를 찾는지 설명하기 위해 다음 예제에서 함수를 사용해 보겠습니다:
+
+```py
+>>> example = dataset_with_ocr["train"][1]
+>>> words = [word.lower() for word in example["words"]]
+>>> match, word_idx_start, word_idx_end = subfinder(words, example["answer"].lower().split())
+>>> print("Question: ", example["question"])
+>>> print("Words:", words)
+>>> print("Answer: ", example["answer"])
+>>> print("start_index", word_idx_start)
+>>> print("end_index", word_idx_end)
+Question: Who is in cc in this letter?
+Words: ['wie', 'baw', 'brown', '&', 'williamson', 'tobacco', 'corporation', 'research', '&', 'development', 'internal', 'correspondence', 'to:', 'r.', 'h.', 'honeycutt', 'ce:', 't.f.', 'riehl', 'from:', '.', 'c.j.', 'cook', 'date:', 'may', '8,', '1995', 'subject:', 'review', 'of', 'existing', 'brainstorming', 'ideas/483', 'the', 'major', 'function', 'of', 'the', 'product', 'innovation', 'graup', 'is', 'to', 'develop', 'marketable', 'nove!', 'products', 'that', 'would', 'be', 'profitable', 'to', 'manufacture', 'and', 'sell.', 'novel', 'is', 'defined', 'as:', 'of', 'a', 'new', 'kind,', 'or', 'different', 'from', 'anything', 'seen', 'or', 'known', 'before.', 'innovation', 'is', 'defined', 'as:', 'something', 'new', 'or', 'different', 'introduced;', 'act', 'of', 'innovating;', 'introduction', 'of', 'new', 'things', 'or', 'methods.', 'the', 'products', 'may', 'incorporate', 'the', 'latest', 'technologies,', 'materials', 'and', 'know-how', 'available', 'to', 'give', 'then', 'a', 'unique', 'taste', 'or', 'look.', 'the', 'first', 'task', 'of', 'the', 'product', 'innovation', 'group', 'was', 'to', 'assemble,', 'review', 'and', 'categorize', 'a', 'list', 'of', 'existing', 'brainstorming', 'ideas.', 'ideas', 'were', 'grouped', 'into', 'two', 'major', 'categories', 'labeled', 'appearance', 'and', 'taste/aroma.', 'these', 'categories', 'are', 'used', 'for', 'novel', 'products', 'that', 'may', 'differ', 'from', 'a', 'visual', 'and/or', 'taste/aroma', 'point', 'of', 'view', 'compared', 'to', 'canventional', 'cigarettes.', 'other', 'categories', 'include', 'a', 'combination', 'of', 'the', 'above,', 'filters,', 'packaging', 'and', 'brand', 'extensions.', 'appearance', 'this', 'category', 'is', 'used', 'for', 'novel', 'cigarette', 'constructions', 'that', 'yield', 'visually', 'different', 'products', 'with', 'minimal', 'changes', 'in', 'smoke', 'chemistry', 'two', 'cigarettes', 'in', 'cne.', 'emulti-plug', 'te', 'build', 'yaur', 'awn', 'cigarette.', 'eswitchable', 'menthol', 'or', 'non', 'menthol', 'cigarette.', '*cigarettes', 'with', 'interspaced', 'perforations', 'to', 'enable', 'smoker', 'to', 'separate', 'unburned', 'section', 'for', 'future', 'smoking.', '«short', 'cigarette,', 'tobacco', 'section', '30', 'mm.', '«extremely', 'fast', 'buming', 'cigarette.', '«novel', 'cigarette', 'constructions', 'that', 'permit', 'a', 'significant', 'reduction', 'iretobacco', 'weight', 'while', 'maintaining', 'smoking', 'mechanics', 'and', 'visual', 'characteristics.', 'higher', 'basis', 'weight', 'paper:', 'potential', 'reduction', 'in', 'tobacco', 'weight.', '«more', 'rigid', 'tobacco', 'column;', 'stiffing', 'agent', 'for', 'tobacco;', 'e.g.', 'starch', '*colored', 'tow', 'and', 'cigarette', 'papers;', 'seasonal', 'promotions,', 'e.g.', 'pastel', 'colored', 'cigarettes', 'for', 'easter', 'or', 'in', 'an', 'ebony', 'and', 'ivory', 'brand', 'containing', 'a', 'mixture', 'of', 'all', 'black', '(black', 'paper', 'and', 'tow)', 'and', 'ail', 'white', 'cigarettes.', '499150498']
+Answer: T.F. Riehl
+start_index 17
+end_index 18
+```
+
+한편, 위 예제가 인코딩되면 다음과 같이 표시됩니다:
+
+```py
+>>> encoding = tokenizer(example["question"], example["words"], example["boxes"])
+>>> tokenizer.decode(encoding["input_ids"])
+[CLS] who is in cc in this letter? [SEP] wie baw brown & williamson tobacco corporation research & development ...
+```
+
+이제 인코딩된 입력에서 정답의 위치를 찾아야 합니다.
+* `token_type_ids`는 어떤 토큰이 질문에 속하는지, 그리고 어떤 토큰이 문서의 단어에 포함되는지를 알려줍니다.
+* `tokenizer.cls_token_id` 입력의 시작 부분에 있는 특수 토큰을 찾는 데 도움을 줍니다.
+* `word_ids`는 원본 `words`에서 찾은 답변을 전체 인코딩된 입력의 동일한 답과 일치시키고 인코딩된 입력에서 답변의 시작/끝 위치를 결정합니다.
+
+위 내용들을 염두에 두고 데이터 세트 예제의 배치를 인코딩하는 함수를 만들어 보겠습니다:
+
+```py
+>>> def encode_dataset(examples, max_length=512):
+... questions = examples["question"]
+... words = examples["words"]
+... boxes = examples["boxes"]
+... answers = examples["answer"]
+
+... # 예제 배치를 인코딩하고 start_positions와 end_positions를 초기화합니다
+... encoding = tokenizer(questions, words, boxes, max_length=max_length, padding="max_length", truncation=True)
+... start_positions = []
+... end_positions = []
+
+... # 배치의 예제를 반복합니다
+... for i in range(len(questions)):
+... cls_index = encoding["input_ids"][i].index(tokenizer.cls_token_id)
+
+... # 예제의 words에서 답변의 위치를 찾습니다
+... words_example = [word.lower() for word in words[i]]
+... answer = answers[i]
+... match, word_idx_start, word_idx_end = subfinder(words_example, answer.lower().split())
+
+... if match:
+... # 일치하는 항목을 발견하면, `token_type_ids`를 사용해 인코딩에서 단어가 시작하는 위치를 찾습니다
+... token_type_ids = encoding["token_type_ids"][i]
+... token_start_index = 0
+... while token_type_ids[token_start_index] != 1:
+... token_start_index += 1
+
+... token_end_index = len(encoding["input_ids"][i]) - 1
+... while token_type_ids[token_end_index] != 1:
+... token_end_index -= 1
+
+... word_ids = encoding.word_ids(i)[token_start_index : token_end_index + 1]
+... start_position = cls_index
+... end_position = cls_index
+
+... # words의 답변 위치와 일치할 때까지 word_ids를 반복하고 `token_start_index`를 늘립니다
+... # 일치하면 `token_start_index`를 인코딩에서 답변의 `start_position`으로 저장합니다
+... for id in word_ids:
+... if id == word_idx_start:
+... start_position = token_start_index
+... else:
+... token_start_index += 1
+
+... # 비슷하게, 끝에서 시작해 `word_ids`를 반복하며 답변의 `end_position`을 찾습니다
+... for id in word_ids[::-1]:
+... if id == word_idx_end:
+... end_position = token_end_index
+... else:
+... token_end_index -= 1
+
+... start_positions.append(start_position)
+... end_positions.append(end_position)
+
+... else:
+... start_positions.append(cls_index)
+... end_positions.append(cls_index)
+
+... encoding["image"] = examples["image"]
+... encoding["start_positions"] = start_positions
+... encoding["end_positions"] = end_positions
+
+... return encoding
+```
+
+이제 이 전처리 함수가 있으니 전체 데이터 세트를 인코딩할 수 있습니다:
+
+```py
+>>> encoded_train_dataset = dataset_with_ocr["train"].map(
+... encode_dataset, batched=True, batch_size=2, remove_columns=dataset_with_ocr["train"].column_names
+... )
+>>> encoded_test_dataset = dataset_with_ocr["test"].map(
+... encode_dataset, batched=True, batch_size=2, remove_columns=dataset_with_ocr["test"].column_names
+... )
+```
+
+인코딩된 데이터 세트의 특성이 어떻게 생겼는지 확인해 보겠습니다:
+
+```py
+>>> encoded_train_dataset.features
+{'image': Sequence(feature=Sequence(feature=Sequence(feature=Value(dtype='uint8', id=None), length=-1, id=None), length=-1, id=None), length=-1, id=None),
+ 'input_ids': Sequence(feature=Value(dtype='int32', id=None), length=-1, id=None),
+ 'token_type_ids': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None),
+ 'attention_mask': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None),
+ 'bbox': Sequence(feature=Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), length=-1, id=None),
+ 'start_positions': Value(dtype='int64', id=None),
+ 'end_positions': Value(dtype='int64', id=None)}
+```
+
+## 평가 [[evaluation]]
+
+문서 질의 응답을 평가하려면 상당한 양의 후처리가 필요합니다. 시간이 너무 많이 걸리지 않도록 이 가이드에서는 평가 단계를 생략합니다.
+[`Trainer`]가 훈련 과정에서 평가 손실(evaluation loss)을 계속 계산하기 때문에 모델의 성능을 대략적으로 알 수 있습니다.
+추출적(Extractive) 질의 응답은 보통 F1/exact match 방법을 사용해 평가됩니다.
+직접 구현해보고 싶으시다면, Hugging Face course의 [Question Answering chapter](https://huggingface.co/course/chapter7/7?fw=pt#postprocessing)을 참고하세요.
+
+## 훈련 [[train]]
+
+축하합니다! 이 가이드의 가장 어려운 부분을 성공적으로 처리했으니 이제 나만의 모델을 훈련할 준비가 되었습니다.
+훈련은 다음과 같은 단계로 이루어져 있습니다:
+* 전처리에서의 동일한 체크포인트를 사용하기 위해 [`AutoModelForDocumentQuestionAnswering`]으로 모델을 가져옵니다.
+* [`TrainingArguments`]로 훈련 하이퍼파라미터를 정합니다.
+* 예제를 배치 처리하는 함수를 정의합니다. 여기서는 [`DefaultDataCollator`]가 적당합니다.
+* 모델, 데이터 세트, 데이터 콜레이터(Data collator)와 함께 [`Trainer`]에 훈련 인수들을 전달합니다.
+* [`~Trainer.train`]을 호출해서 모델을 미세 조정합니다.
+
+```py
+>>> from transformers import AutoModelForDocumentQuestionAnswering
+
+>>> model = AutoModelForDocumentQuestionAnswering.from_pretrained(model_checkpoint)
+```
+
+[`TrainingArguments`]에서 `output_dir`을 사용하여 모델을 저장할 위치를 지정하고, 적절한 하이퍼파라미터를 설정합니다.
+모델을 커뮤니티와 공유하려면 `push_to_hub`를 `True`로 설정하세요 (모델을 업로드하려면 Hugging Face에 로그인해야 합니다).
+이 경우 `output_dir`은 모델의 체크포인트를 푸시할 레포지토리의 이름이 됩니다.
+
+```py
+>>> from transformers import TrainingArguments
+
+>>> # 본인의 레포지토리 ID로 바꾸세요
+>>> repo_id = "MariaK/layoutlmv2-base-uncased_finetuned_docvqa"
+
+>>> training_args = TrainingArguments(
+... output_dir=repo_id,
+... per_device_train_batch_size=4,
+... num_train_epochs=20,
+... save_steps=200,
+... logging_steps=50,
+... eval_strategy="steps",
+... learning_rate=5e-5,
+... save_total_limit=2,
+... remove_unused_columns=False,
+... push_to_hub=True,
+... )
+```
+
+간단한 데이터 콜레이터를 정의하여 예제를 함께 배치합니다.
+
+```py
+>>> from transformers import DefaultDataCollator
+
+>>> data_collator = DefaultDataCollator()
+```
+
+마지막으로, 모든 것을 한 곳에 모아 [`~Trainer.train`]을 호출합니다:
+
+```py
+>>> from transformers import Trainer
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... data_collator=data_collator,
+... train_dataset=encoded_train_dataset,
+... eval_dataset=encoded_test_dataset,
+... processing_class=processor,
+... )
+
+>>> trainer.train()
+```
+
+최종 모델을 🤗 Hub에 추가하려면, 모델 카드를 생성하고 `push_to_hub`를 호출합니다:
+
+```py
+>>> trainer.create_model_card()
+>>> trainer.push_to_hub()
+```
+
+## 추론 [[inference]]
+
+이제 LayoutLMv2 모델을 미세 조정하고 🤗 Hub에 업로드했으니 추론에도 사용할 수 있습니다.
+추론을 위해 미세 조정된 모델을 사용해 보는 가장 간단한 방법은 [`Pipeline`]을 사용하는 것 입니다.
+
+예를 들어 보겠습니다:
+```py
+>>> example = dataset["test"][2]
+>>> question = example["query"]["en"]
+>>> image = example["image"]
+>>> print(question)
+>>> print(example["answers"])
+'Who is ‘presiding’ TRRF GENERAL SESSION (PART 1)?'
+['TRRF Vice President', 'lee a. waller']
+```
+
+그 다음, 모델로 문서 질의 응답을 하기 위해 파이프라인을 인스턴스화하고 이미지 + 질문 조합을 전달합니다.
+
+```py
+>>> from transformers import pipeline
+
+>>> qa_pipeline = pipeline("document-question-answering", model="MariaK/layoutlmv2-base-uncased_finetuned_docvqa")
+>>> qa_pipeline(image, question)
+[{'score': 0.9949808120727539,
+ 'answer': 'Lee A. Waller',
+ 'start': 55,
+ 'end': 57}]
+```
+
+원한다면 파이프라인의 결과를 수동으로 복제할 수도 있습니다:
+1. 이미지와 질문을 가져와 모델의 프로세서를 사용해 모델에 맞게 준비합니다.
+2. 모델을 통해 결과 또는 전처리를 전달합니다.
+3. 모델은 어떤 토큰이 답변의 시작에 있는지, 어떤 토큰이 답변이 끝에 있는지를 나타내는 `start_logits`와 `end_logits`를 반환합니다. 둘 다 (batch_size, sequence_length) 형태를 갖습니다.
+4. `start_logits`와 `end_logits`의 마지막 차원을 최대로 만드는 값을 찾아 예상 `start_idx`와 `end_idx`를 얻습니다.
+5. 토크나이저로 답변을 디코딩합니다.
+
+```py
+>>> import torch
+>>> from transformers import AutoProcessor
+>>> from transformers import AutoModelForDocumentQuestionAnswering
+
+>>> processor = AutoProcessor.from_pretrained("MariaK/layoutlmv2-base-uncased_finetuned_docvqa")
+>>> model = AutoModelForDocumentQuestionAnswering.from_pretrained("MariaK/layoutlmv2-base-uncased_finetuned_docvqa")
+
+>>> with torch.no_grad():
+... encoding = processor(image.convert("RGB"), question, return_tensors="pt")
+... outputs = model(**encoding)
+... start_logits = outputs.start_logits
+... end_logits = outputs.end_logits
+... predicted_start_idx = start_logits.argmax(-1).item()
+... predicted_end_idx = end_logits.argmax(-1).item()
+
+>>> processor.tokenizer.decode(encoding.input_ids.squeeze()[predicted_start_idx : predicted_end_idx + 1])
+'lee a. waller'
+```
diff --git a/docs/transformers/docs/source/ko/tasks/idefics.md b/docs/transformers/docs/source/ko/tasks/idefics.md
new file mode 100644
index 0000000000000000000000000000000000000000..40dc794ecc141e14e52d02da3f61c05b7ddac43b
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/idefics.md
@@ -0,0 +1,391 @@
+
+
+# IDEFICS를 이용한 이미지 작업[[image-tasks-with-idefics]]
+
+[[open-in-colab]]
+
+개별 작업은 특화된 모델을 미세 조정하여 처리할 수 있지만, 최근 등장하여 인기를 얻고 있는 방식은 대규모 모델을 미세 조정 없이 다양한 작업에 사용하는 것입니다. 예를 들어, 대규모 언어 모델은 요약, 번역, 분류 등과 같은 자연어처리 (NLP) 작업을 처리할 수 있습니다. 이 접근 방식은 텍스트와 같은 단일 모달리티에 국한되지 않으며, 이 가이드에서는 IDEFICS라는 대규모 멀티모달 모델을 사용하여 이미지-텍스트 작업을 다루는 방법을 설명합니다.
+
+[IDEFICS](../model_doc/idefics)는 [Flamingo](https://huggingface.co/papers/2204.14198)를 기반으로 하는 오픈 액세스 비전 및 언어 모델로, DeepMind에서 처음 개발한 최신 시각 언어 모델입니다. 이 모델은 임의의 이미지 및 텍스트 입력 시퀀스를 받아 일관성 있는 텍스트를 출력으로 생성합니다. 이미지에 대한 질문에 답변하고, 시각적인 내용을 설명하며, 여러 이미지에 기반한 이야기를 생성하는 등 다양한 작업을 수행할 수 있습니다. IDEFICS는 [800억 파라미터](https://huggingface.co/HuggingFaceM4/idefics-80b)와 [90억 파라미터](https://huggingface.co/HuggingFaceM4/idefics-9b) 두 가지 버전을 제공하며, 두 버전 모두 🤗 Hub에서 이용할 수 있습니다. 각 버전에는 대화형 사용 사례에 맞게 미세 조정된 버전도 있습니다.
+
+이 모델은 매우 다재다능하며 광범위한 이미지 및 멀티모달 작업에 사용될 수 있습니다. 그러나 대규모 모델이기 때문에 상당한 컴퓨팅 자원과 인프라가 필요합니다. 각 개별 작업에 특화된 모델을 미세 조정하는 것보다 모델을 그대로 사용하는 것이 더 적합한지는 사용자가 판단해야 합니다.
+
+이 가이드에서는 다음을 배우게 됩니다:
+- [IDEFICS 로드하기](#loading-the-model) 및 [양자화된 버전의 모델 로드하기](#quantized-model)
+- IDEFICS를 사용하여:
+ - [이미지 캡셔닝](#image-captioning)
+ - [프롬프트 이미지 캡셔닝](#prompted-image-captioning)
+ - [퓨샷 프롬프트](#few-shot-prompting)
+ - [시각적 질의 응답](#visual-question-answering)
+ - [이미지 분류](#image-classification)
+ - [이미지 기반 텍스트 생성](#image-guided-text-generation)
+- [배치 모드에서 추론 실행](#running-inference-in-batch-mode)
+- [대화형 사용을 위한 IDEFICS 인스트럭트 실행](#idefics-instruct-for-conversational-use)
+
+시작하기 전에 필요한 모든 라이브러리가 설치되어 있는지 확인하세요.
+
+```bash
+pip install -q bitsandbytes sentencepiece accelerate transformers
+```
+
+
+다음 예제를 비양자화된 버전의 모델 체크포인트로 실행하려면 최소 20GB의 GPU 메모리가 필요합니다.
+
+
+## 모델 로드[[loading-the-model]]
+
+모델을 90억 파라미터 버전의 체크포인트로 로드해 봅시다:
+
+```py
+>>> checkpoint = "HuggingFaceM4/idefics-9b"
+```
+
+다른 Transformers 모델과 마찬가지로, 체크포인트에서 프로세서와 모델 자체를 로드해야 합니다.
+IDEFICS 프로세서는 [`LlamaTokenizer`]와 IDEFICS 이미지 프로세서를 하나의 프로세서로 감싸서 텍스트와 이미지 입력을 모델에 맞게 준비합니다.
+
+```py
+>>> import torch
+
+>>> from transformers import IdeficsForVisionText2Text, AutoProcessor
+
+>>> processor = AutoProcessor.from_pretrained(checkpoint)
+
+>>> model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16, device_map="auto")
+```
+
+`device_map`을 `"auto"`로 설정하면 사용 중인 장치를 고려하여 모델 가중치를 가장 최적화된 방식으로 로드하고 저장하는 방법을 자동으로 결정합니다.
+
+### 양자화된 모델[[quantized-model]]
+
+고용량 GPU 사용이 어려운 경우, 모델의 양자화된 버전을 로드할 수 있습니다. 모델과 프로세서를 4비트 정밀도로 로드하기 위해서, `from_pretrained` 메소드에 `BitsAndBytesConfig`를 전달하면 모델이 로드되는 동안 실시간으로 압축됩니다.
+
+```py
+>>> import torch
+>>> from transformers import IdeficsForVisionText2Text, AutoProcessor, BitsAndBytesConfig
+
+>>> quantization_config = BitsAndBytesConfig(
+... load_in_4bit=True,
+... bnb_4bit_compute_dtype=torch.float16,
+... )
+
+>>> processor = AutoProcessor.from_pretrained(checkpoint)
+
+>>> model = IdeficsForVisionText2Text.from_pretrained(
+... checkpoint,
+... quantization_config=quantization_config,
+... device_map="auto"
+... )
+```
+
+이제 모델을 제안된 방법 중 하나로 로드했으니, IDEFICS를 사용할 수 있는 작업들을 탐구해봅시다.
+
+## 이미지 캡셔닝[[image-captioning]]
+이미지 캡셔닝은 주어진 이미지에 대한 캡션을 예측하는 작업입니다. 일반적인 응용 분야는 시각 장애인이 다양한 상황을 탐색할 수 있도록 돕는 것입니다. 예를 들어, 온라인에서 이미지 콘텐츠를 탐색하는 데 도움을 줄 수 있습니다.
+
+작업을 설명하기 위해 캡션을 달 이미지 예시를 가져옵니다. 예시:
+
+
+
+
+
+사진 제공: [Hendo Wang](https://unsplash.com/@hendoo).
+
+IDEFICS는 텍스트 및 이미지 프롬프트를 모두 수용합니다. 그러나 이미지를 캡션하기 위해 모델에 텍스트 프롬프트를 제공할 필요는 없습니다. 전처리된 입력 이미지만 제공하면 됩니다. 텍스트 프롬프트 없이 모델은 BOS(시퀀스 시작) 토큰부터 텍스트 생성을 시작하여 캡션을 만듭니다.
+
+모델에 이미지 입력으로는 이미지 객체(`PIL.Image`) 또는 이미지를 가져올 수 있는 URL을 사용할 수 있습니다.
+
+```py
+>>> prompt = [
+... "https://images.unsplash.com/photo-1583160247711-2191776b4b91?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3542&q=80",
+... ]
+
+>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> print(generated_text[0])
+A puppy in a flower bed
+```
+
+
+
+`max_new_tokens`의 크기를 증가시킬 때 발생할 수 있는 오류를 피하기 위해 `generate` 호출 시 `bad_words_ids`를 포함하는 것이 좋습니다. 모델로부터 생성된 이미지가 없을 때 새로운 `` 또는 `` 토큰을 생성하려고 하기 때문입니다.
+이 가이드에서처럼 `bad_words_ids`를 함수 호출 시에 매개변수로 설정하거나, [텍스트 생성 전략](../generation_strategies) 가이드에 설명된 대로 `GenerationConfig`에 저장할 수도 있습니다.
+
+
+## 프롬프트 이미지 캡셔닝[[prompted-image-captioning]]
+
+텍스트 프롬프트를 이용하여 이미지 캡셔닝을 확장할 수 있으며, 모델은 주어진 이미지를 바탕으로 텍스트를 계속 생성합니다. 다음 이미지를 예시로 들어보겠습니다:
+
+
+
+
+
+사진 제공: [Denys Nevozhai](https://unsplash.com/@dnevozhai).
+
+텍스트 및 이미지 프롬프트는 적절한 입력을 생성하기 위해 모델의 프로세서에 하나의 목록으로 전달될 수 있습니다.
+
+```py
+>>> prompt = [
+... "https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
+... "This is an image of ",
+... ]
+
+>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> print(generated_text[0])
+This is an image of the Eiffel Tower in Paris, France.
+```
+
+## 퓨샷 프롬프트[[few-shot-prompting]]
+
+IDEFICS는 훌륭한 제로샷 결과를 보여주지만, 작업에 특정 형식의 캡션이 필요하거나 작업의 복잡성을 높이는 다른 제한 사항이나 요구 사항이 있을 수 있습니다. 이럴 때 퓨샷 프롬프트를 사용하여 맥락 내 학습(In-Context Learning)을 가능하게 할 수 있습니다.
+프롬프트에 예시를 제공함으로써 모델이 주어진 예시의 형식을 모방한 결과를 생성하도록 유도할 수 있습니다.
+
+이전의 에펠탑 이미지를 모델에 예시로 사용하고, 모델에게 이미지의 객체를 학습하는 것 외에도 흥미로운 정보를 얻고 싶다는 것을 보여주는 프롬프트를 작성해 봅시다.
+그런 다음 자유의 여신상 이미지에 대해 동일한 응답 형식을 얻을 수 있는지 확인해 봅시다:
+
+
+
+
+
+사진 제공: [Juan Mayobre](https://unsplash.com/@jmayobres).
+
+```py
+>>> prompt = ["User:",
+... "https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
+... "Describe this image.\nAssistant: An image of the Eiffel Tower at night. Fun fact: the Eiffel Tower is the same height as an 81-storey building.\n",
+... "User:",
+... "https://images.unsplash.com/photo-1524099163253-32b7f0256868?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3387&q=80",
+... "Describe this image.\nAssistant:"
+... ]
+
+>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, max_new_tokens=30, bad_words_ids=bad_words_ids)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> print(generated_text[0])
+User: Describe this image.
+Assistant: An image of the Eiffel Tower at night. Fun fact: the Eiffel Tower is the same height as an 81-storey building.
+User: Describe this image.
+Assistant: An image of the Statue of Liberty. Fun fact: the Statue of Liberty is 151 feet tall.
+```
+
+단 하나의 예시만으로도(즉, 1-shot) 모델이 작업 수행 방법을 학습했다는 점이 주목할 만합니다. 더 복잡한 작업의 경우, 더 많은 예시(예: 3-shot, 5-shot 등)를 사용하여 실험해 보는 것도 좋은 방법입니다.
+
+## 시각적 질의 응답[[visual-question-answering]]
+
+시각적 질의 응답(VQA)은 이미지를 기반으로 개방형 질문에 답하는 작업입니다. 이미지 캡셔닝과 마찬가지로 접근성 애플리케이션에서 사용할 수 있지만, 교육(시각 자료에 대한 추론), 고객 서비스(이미지를 기반으로 한 제품 질문), 이미지 검색 등에서도 사용할 수 있습니다.
+
+이 작업을 위해 새로운 이미지를 가져옵니다:
+
+
+
+
+
+사진 제공: [Jarritos Mexican Soda](https://unsplash.com/@jarritos).
+
+적절한 지시문을 사용하면 이미지 캡셔닝에서 시각적 질의 응답으로 모델을 유도할 수 있습니다:
+
+```py
+>>> prompt = [
+... "Instruction: Provide an answer to the question. Use the image to answer.\n",
+... "https://images.unsplash.com/photo-1623944889288-cd147dbb517c?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
+... "Question: Where are these people and what's the weather like? Answer:"
+... ]
+
+>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, max_new_tokens=20, bad_words_ids=bad_words_ids)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> print(generated_text[0])
+Instruction: Provide an answer to the question. Use the image to answer.
+ Question: Where are these people and what's the weather like? Answer: They're in a park in New York City, and it's a beautiful day.
+```
+
+## 이미지 분류[[image-classification]]
+
+IDEFICS는 특정 카테고리의 라벨이 포함된 데이터로 명시적으로 학습되지 않아도 이미지를 다양한 카테고리로 분류할 수 있습니다. 카테고리 목록이 주어지면, 모델은 이미지와 텍스트 이해 능력을 사용하여 이미지가 속할 가능성이 높은 카테고리를 추론할 수 있습니다.
+
+여기에 야채 가판대 이미지가 있습니다.
+
+
+
+
+
+사진 제공: [Peter Wendt](https://unsplash.com/@peterwendt).
+
+우리는 모델에게 우리가 가진 카테고리 중 하나로 이미지를 분류하도록 지시할 수 있습니다:
+
+```py
+>>> categories = ['animals','vegetables', 'city landscape', 'cars', 'office']
+>>> prompt = [f"Instruction: Classify the following image into a single category from the following list: {categories}.\n",
+... "https://images.unsplash.com/photo-1471193945509-9ad0617afabf?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
+... "Category: "
+... ]
+
+>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, max_new_tokens=6, bad_words_ids=bad_words_ids)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> print(generated_text[0])
+Instruction: Classify the following image into a single category from the following list: ['animals', 'vegetables', 'city landscape', 'cars', 'office'].
+Category: Vegetables
+```
+
+위 예제에서는 모델에게 이미지를 단일 카테고리로 분류하도록 지시했지만, 순위 분류를 하도록 모델에 프롬프트를 제공할 수도 있습니다.
+
+## 이미지 기반 텍스트 생성[[image-guided-text-generation]]
+
+이미지를 활용한 텍스트 생성 기술을 사용하면 더욱 창의적인 작업이 가능합니다. 이 기술은 이미지를 바탕으로 텍스트를 만들어내며, 제품 설명, 광고 문구, 장면 묘사 등 다양한 용도로 활용할 수 있습니다.
+
+간단한 예로, 빨간 문 이미지를 IDEFICS에 입력하여 이야기를 만들어보겠습니다:
+
+
+
+
+
+사진 제공: [Craig Tidball](https://unsplash.com/@devonshiremedia).
+
+```py
+>>> prompt = ["Instruction: Use the image to write a story. \n",
+... "https://images.unsplash.com/photo-1517086822157-2b0358e7684a?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=2203&q=80",
+... "Story: \n"]
+
+>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, num_beams=2, max_new_tokens=200, bad_words_ids=bad_words_ids)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> print(generated_text[0])
+Instruction: Use the image to write a story.
+ Story:
+Once upon a time, there was a little girl who lived in a house with a red door. She loved her red door. It was the prettiest door in the whole world.
+
+One day, the little girl was playing in her yard when she noticed a man standing on her doorstep. He was wearing a long black coat and a top hat.
+
+The little girl ran inside and told her mother about the man.
+
+Her mother said, “Don’t worry, honey. He’s just a friendly ghost.”
+
+The little girl wasn’t sure if she believed her mother, but she went outside anyway.
+
+When she got to the door, the man was gone.
+
+The next day, the little girl was playing in her yard again when she noticed the man standing on her doorstep.
+
+He was wearing a long black coat and a top hat.
+
+The little girl ran
+```
+
+IDEFICS가 문 앞에 있는 호박을 보고 유령에 대한 으스스한 할로윈 이야기를 만든 것 같습니다.
+
+
+
+이처럼 긴 텍스트를 생성할 때는 텍스트 생성 전략을 조정하는 것이 좋습니다. 이렇게 하면 생성된 결과물의 품질을 크게 향상시킬 수 있습니다. 자세한 내용은 [텍스트 생성 전략](../generation_strategies)을 참조하세요.
+
+
+## 배치 모드에서 추론 실행[[running-inference-in-batch-mode]]
+
+앞선 모든 섹션에서는 단일 예시에 대해 IDEFICS를 설명했습니다. 이와 매우 유사한 방식으로, 프롬프트 목록을 전달하여 여러 예시에 대한 추론을 실행할 수 있습니다:
+
+```py
+>>> prompts = [
+... [ "https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
+... "This is an image of ",
+... ],
+... [ "https://images.unsplash.com/photo-1623944889288-cd147dbb517c?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
+... "This is an image of ",
+... ],
+... [ "https://images.unsplash.com/photo-1471193945509-9ad0617afabf?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
+... "This is an image of ",
+... ],
+... ]
+
+>>> inputs = processor(prompts, return_tensors="pt").to("cuda")
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> for i,t in enumerate(generated_text):
+... print(f"{i}:\n{t}\n")
+0:
+This is an image of the Eiffel Tower in Paris, France.
+
+1:
+This is an image of a couple on a picnic blanket.
+
+2:
+This is an image of a vegetable stand.
+```
+
+## 대화형 사용을 위한 IDEFICS 인스트럭트 실행[[idefics-instruct-for-conversational-use]]
+
+대화형 사용 사례를 위해, 🤗 Hub에서 명령어 수행에 최적화된 버전의 모델을 찾을 수 있습니다. 이곳에는 `HuggingFaceM4/idefics-80b-instruct`와 `HuggingFaceM4/idefics-9b-instruct`가 있습니다.
+
+이 체크포인트는 지도 학습 및 명령어 미세 조정 데이터셋의 혼합으로 각각의 기본 모델을 미세 조정한 결과입니다. 이를 통해 모델의 하위 작업 성능을 향상시키는 동시에 대화형 환경에서 모델을 더 사용하기 쉽게 합니다.
+
+대화형 사용을 위한 사용법 및 프롬프트는 기본 모델을 사용하는 것과 매우 유사합니다.
+
+```py
+>>> import torch
+>>> from transformers import IdeficsForVisionText2Text, AutoProcessor
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+
+>>> checkpoint = "HuggingFaceM4/idefics-9b-instruct"
+>>> model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
+>>> processor = AutoProcessor.from_pretrained(checkpoint)
+
+>>> prompts = [
+... [
+... "User: What is in this image?",
+... "https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
+... "",
+
+... "\nAssistant: This picture depicts Idefix, the dog of Obelix in Asterix and Obelix. Idefix is running on the ground.",
+
+... "\nUser:",
+... "https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
+... "And who is that?",
+
+... "\nAssistant:",
+... ],
+... ]
+
+>>> # --batched mode
+>>> inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
+>>> # --single sample mode
+>>> # inputs = processor(prompts[0], return_tensors="pt").to(device)
+
+>>> # args 생성
+>>> exit_condition = processor.tokenizer("", add_special_tokens=False).input_ids
+>>> bad_words_ids = processor.tokenizer(["", ""], add_special_tokens=False).input_ids
+
+>>> generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> for i, t in enumerate(generated_text):
+... print(f"{i}:\n{t}\n")
+```
diff --git a/docs/transformers/docs/source/ko/tasks/image_captioning.md b/docs/transformers/docs/source/ko/tasks/image_captioning.md
new file mode 100644
index 0000000000000000000000000000000000000000..c4d0f99b6170ee067c49a2a6bf7734617bb5851f
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/image_captioning.md
@@ -0,0 +1,281 @@
+
+
+
+# 이미지 캡셔닝[[image-captioning]]
+
+[[open-in-colab]]
+
+이미지 캡셔닝(Image captioning)은 주어진 이미지에 대한 캡션을 예측하는 작업입니다.
+이미지 캡셔닝은 시각 장애인이 다양한 상황을 탐색하는 데 도움을 줄 수 있도록 시각 장애인을 보조하는 등 실생활에서 흔히 활용됩니다.
+따라서 이미지 캡셔닝은 이미지를 설명함으로써 사람들의 콘텐츠 접근성을 개선하는 데 도움이 됩니다.
+
+이 가이드에서는 소개할 내용은 아래와 같습니다:
+
+* 이미지 캡셔닝 모델을 파인튜닝합니다.
+* 파인튜닝된 모델을 추론에 사용합니다.
+
+시작하기 전에 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers datasets evaluate -q
+pip install jiwer -q
+```
+
+Hugging Face 계정에 로그인하면 모델을 업로드하고 커뮤니티에 공유할 수 있습니다.
+토큰을 입력하여 로그인하세요.
+
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+## 포켓몬 BLIP 캡션 데이터세트 가져오기[[load-the-pokmon-blip-captions-dataset]]
+
+{이미지-캡션} 쌍으로 구성된 데이터세트를 가져오려면 🤗 Dataset 라이브러리를 사용합니다.
+PyTorch에서 자신만의 이미지 캡션 데이터세트를 만들려면 [이 노트북](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/GIT/Fine_tune_GIT_on_an_image_captioning_dataset.ipynb)을 참조하세요.
+
+
+```python
+from datasets import load_dataset
+
+ds = load_dataset("lambdalabs/pokemon-blip-captions")
+ds
+```
+```bash
+DatasetDict({
+ train: Dataset({
+ features: ['image', 'text'],
+ num_rows: 833
+ })
+})
+```
+
+이 데이터세트는 `image`와 `text`라는 두 특성을 가지고 있습니다.
+
+
+
+많은 이미지 캡션 데이터세트에는 이미지당 여러 개의 캡션이 포함되어 있습니다.
+이러한 경우, 일반적으로 학습 중에 사용 가능한 캡션 중에서 무작위로 샘플을 추출합니다.
+
+
+
+[`~datasets.Dataset.train_test_split`] 메소드를 사용하여 데이터세트의 학습 분할을 학습 및 테스트 세트로 나눕니다:
+
+
+```python
+ds = ds["train"].train_test_split(test_size=0.1)
+train_ds = ds["train"]
+test_ds = ds["test"]
+```
+
+학습 세트의 샘플 몇 개를 시각화해 봅시다.
+Let's visualize a couple of samples from the training set.
+
+
+```python
+from textwrap import wrap
+import matplotlib.pyplot as plt
+import numpy as np
+
+
+def plot_images(images, captions):
+ plt.figure(figsize=(20, 20))
+ for i in range(len(images)):
+ ax = plt.subplot(1, len(images), i + 1)
+ caption = captions[i]
+ caption = "\n".join(wrap(caption, 12))
+ plt.title(caption)
+ plt.imshow(images[i])
+ plt.axis("off")
+
+
+sample_images_to_visualize = [np.array(train_ds[i]["image"]) for i in range(5)]
+sample_captions = [train_ds[i]["text"] for i in range(5)]
+plot_images(sample_images_to_visualize, sample_captions)
+```
+
+
+
+
+
+## 데이터세트 전처리[[preprocess-the-dataset]]
+
+데이터세트에는 이미지와 텍스트라는 두 가지 양식이 있기 때문에, 전처리 파이프라인에서 이미지와 캡션을 모두 전처리합니다.
+
+전처리 작업을 위해, 파인튜닝하려는 모델에 연결된 프로세서 클래스를 가져옵니다.
+
+```python
+from transformers import AutoProcessor
+
+checkpoint = "microsoft/git-base"
+processor = AutoProcessor.from_pretrained(checkpoint)
+```
+
+프로세서는 내부적으로 크기 조정 및 픽셀 크기 조정을 포함한 이미지 전처리를 수행하고 캡션을 토큰화합니다.
+
+```python
+def transforms(example_batch):
+ images = [x for x in example_batch["image"]]
+ captions = [x for x in example_batch["text"]]
+ inputs = processor(images=images, text=captions, padding="max_length")
+ inputs.update({"labels": inputs["input_ids"]})
+ return inputs
+
+
+train_ds.set_transform(transforms)
+test_ds.set_transform(transforms)
+```
+
+데이터세트가 준비되었으니 이제 파인튜닝을 위해 모델을 설정할 수 있습니다.
+
+## 기본 모델 가져오기[[load-a-base-model]]
+
+["microsoft/git-base"](https://huggingface.co/microsoft/git-base)를 [`AutoModelForCausalLM`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForCausalLM) 객체로 가져옵니다.
+
+
+```python
+from transformers import AutoModelForCausalLM
+
+model = AutoModelForCausalLM.from_pretrained(checkpoint)
+```
+
+## 평가[[evaluate]]
+
+이미지 캡션 모델은 일반적으로 [Rouge 점수](https://huggingface.co/spaces/evaluate-metric/rouge) 또는 [단어 오류율(Word Error Rate)](https://huggingface.co/spaces/evaluate-metric/wer)로 평가합니다.
+이 가이드에서는 단어 오류율(WER)을 사용합니다.
+
+이를 위해 🤗 Evaluate 라이브러리를 사용합니다.
+WER의 잠재적 제한 사항 및 기타 문제점은 [이 가이드](https://huggingface.co/spaces/evaluate-metric/wer)를 참조하세요.
+
+
+```python
+from evaluate import load
+import torch
+
+wer = load("wer")
+
+
+def compute_metrics(eval_pred):
+ logits, labels = eval_pred
+ predicted = logits.argmax(-1)
+ decoded_labels = processor.batch_decode(labels, skip_special_tokens=True)
+ decoded_predictions = processor.batch_decode(predicted, skip_special_tokens=True)
+ wer_score = wer.compute(predictions=decoded_predictions, references=decoded_labels)
+ return {"wer_score": wer_score}
+```
+
+## 학습![[train!]]
+
+이제 모델 파인튜닝을 시작할 준비가 되었습니다. 이를 위해 🤗 [`Trainer`]를 사용합니다.
+
+먼저, [`TrainingArguments`]를 사용하여 학습 인수를 정의합니다.
+
+
+```python
+from transformers import TrainingArguments, Trainer
+
+model_name = checkpoint.split("/")[1]
+
+training_args = TrainingArguments(
+ output_dir=f"{model_name}-pokemon",
+ learning_rate=5e-5,
+ num_train_epochs=50,
+ fp16=True,
+ per_device_train_batch_size=32,
+ per_device_eval_batch_size=32,
+ gradient_accumulation_steps=2,
+ save_total_limit=3,
+ eval_strategy="steps",
+ eval_steps=50,
+ save_strategy="steps",
+ save_steps=50,
+ logging_steps=50,
+ remove_unused_columns=False,
+ push_to_hub=True,
+ label_names=["labels"],
+ load_best_model_at_end=True,
+)
+```
+
+학습 인수를 데이터세트, 모델과 함께 🤗 Trainer에 전달합니다.
+
+```python
+trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_ds,
+ eval_dataset=test_ds,
+ compute_metrics=compute_metrics,
+)
+```
+
+학습을 시작하려면 [`Trainer`] 객체에서 [`~Trainer.train`]을 호출하기만 하면 됩니다.
+
+```python
+trainer.train()
+```
+
+학습이 진행되면서 학습 손실이 원활하게 감소하는 것을 볼 수 있습니다.
+
+학습이 완료되면 모든 사람이 모델을 사용할 수 있도록 [`~Trainer.push_to_hub`] 메소드를 사용하여 모델을 허브에 공유하세요:
+
+
+```python
+trainer.push_to_hub()
+```
+
+## 추론[[inference]]
+
+`test_ds`에서 샘플 이미지를 가져와 모델을 테스트합니다.
+
+
+```python
+from PIL import Image
+import requests
+
+url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/pokemon.png"
+image = Image.open(requests.get(url, stream=True).raw)
+image
+```
+
+
+
+
+
+모델에 사용할 이미지를 준비합니다.
+
+```python
+device = "cuda" if torch.cuda.is_available() else "cpu"
+
+inputs = processor(images=image, return_tensors="pt").to(device)
+pixel_values = inputs.pixel_values
+```
+
+[`generate`]를 호출하고 예측을 디코딩합니다.
+
+```python
+generated_ids = model.generate(pixel_values=pixel_values, max_length=50)
+generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
+print(generated_caption)
+```
+```bash
+a drawing of a pink and blue pokemon
+```
+
+파인튜닝된 모델이 꽤 괜찮은 캡션을 생성한 것 같습니다!
diff --git a/docs/transformers/docs/source/ko/tasks/image_classification.md b/docs/transformers/docs/source/ko/tasks/image_classification.md
new file mode 100644
index 0000000000000000000000000000000000000000..4955bd6cdf8108624fb706a0d5c0605814858eb5
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/image_classification.md
@@ -0,0 +1,542 @@
+
+
+# 이미지 분류[[image-classification]]
+
+[[open-in-colab]]
+
+
+
+이미지 분류는 이미지에 레이블 또는 클래스를 할당합니다. 텍스트 또는 오디오 분류와 달리 입력은
+이미지를 구성하는 픽셀 값입니다. 이미지 분류에는 자연재해 후 피해 감지, 농작물 건강 모니터링, 의료 이미지에서 질병의 징후 검사 지원 등
+다양한 응용 사례가 있습니다.
+
+이 가이드에서는 다음을 설명합니다:
+
+1. [Food-101](https://huggingface.co/datasets/food101) 데이터 세트에서 [ViT](model_doc/vit)를 미세 조정하여 이미지에서 식품 항목을 분류합니다.
+2. 추론을 위해 미세 조정 모델을 사용합니다.
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/image-classification)를 확인하는 것이 좋습니다.
+
+
+
+시작하기 전에, 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers datasets evaluate
+```
+
+Hugging Face 계정에 로그인하여 모델을 업로드하고 커뮤니티에 공유하는 것을 권장합니다. 메시지가 표시되면, 토큰을 입력하여 로그인하세요:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## Food-101 데이터 세트 가져오기[[load-food101-dataset]]
+
+🤗 Datasets 라이브러리에서 Food-101 데이터 세트의 더 작은 부분 집합을 가져오는 것으로 시작합니다. 이렇게 하면 전체 데이터 세트에 대한
+훈련에 많은 시간을 할애하기 전에 실험을 통해 모든 것이 제대로 작동하는지 확인할 수 있습니다.
+
+```py
+>>> from datasets import load_dataset
+
+>>> food = load_dataset("food101", split="train[:5000]")
+```
+
+데이터 세트의 `train`을 [`~datasets.Dataset.train_test_split`] 메소드를 사용하여 훈련 및 테스트 세트로 분할하세요:
+
+```py
+>>> food = food.train_test_split(test_size=0.2)
+```
+
+그리고 예시를 살펴보세요:
+
+```py
+>>> food["train"][0]
+{'image': ,
+ 'label': 79}
+```
+
+데이터 세트의 각 예제에는 두 개의 필드가 있습니다:
+
+- `image`: 식품 항목의 PIL 이미지
+- `label`: 식품 항목의 레이블 클래스
+
+모델이 레이블 ID에서 레이블 이름을 쉽게 가져올 수 있도록
+레이블 이름을 정수로 매핑하고, 정수를 레이블 이름으로 매핑하는 사전을 만드세요:
+
+```py
+>>> labels = food["train"].features["label"].names
+>>> label2id, id2label = dict(), dict()
+>>> for i, label in enumerate(labels):
+... label2id[label] = str(i)
+... id2label[str(i)] = label
+```
+
+이제 레이블 ID를 레이블 이름으로 변환할 수 있습니다:
+
+```py
+>>> id2label[str(79)]
+'prime_rib'
+```
+
+## 전처리[[preprocess]]
+
+다음 단계는 이미지를 텐서로 처리하기 위해 ViT 이미지 프로세서를 가져오는 것입니다:
+
+```py
+>>> from transformers import AutoImageProcessor
+
+>>> checkpoint = "google/vit-base-patch16-224-in21k"
+>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint)
+```
+
+
+
+이미지에 몇 가지 이미지 변환을 적용하여 과적합에 대해 모델을 더 견고하게 만듭니다. 여기서 Torchvision의 [`transforms`](https://pytorch.org/vision/stable/transforms.html) 모듈을 사용하지만, 원하는 이미지 라이브러리를 사용할 수도 있습니다.
+
+이미지의 임의 부분을 크롭하고 크기를 조정한 다음, 이미지 평균과 표준 편차로 정규화하세요:
+
+```py
+>>> from torchvision.transforms import RandomResizedCrop, Compose, Normalize, ToTensor
+
+>>> normalize = Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
+>>> size = (
+... image_processor.size["shortest_edge"]
+... if "shortest_edge" in image_processor.size
+... else (image_processor.size["height"], image_processor.size["width"])
+... )
+>>> _transforms = Compose([RandomResizedCrop(size), ToTensor(), normalize])
+```
+
+그런 다음 전처리 함수를 만들어 변환을 적용하고 이미지의 `pixel_values`(모델에 대한 입력)를 반환하세요:
+
+```py
+>>> def transforms(examples):
+... examples["pixel_values"] = [_transforms(img.convert("RGB")) for img in examples["image"]]
+... del examples["image"]
+... return examples
+```
+
+전체 데이터 세트에 전처리 기능을 적용하려면 🤗 Datasets [`~datasets.Dataset.with_transform`]을 사용합니다. 데이터 세트의 요소를 가져올 때 변환이 즉시 적용됩니다:
+
+```py
+>>> food = food.with_transform(transforms)
+```
+
+이제 [`DefaultDataCollator`]를 사용하여 예제 배치를 만듭니다. 🤗 Transformers의 다른 데이터 콜레이터와 달리, `DefaultDataCollator`는 패딩과 같은 추가적인 전처리를 적용하지 않습니다.
+
+```py
+>>> from transformers import DefaultDataCollator
+
+>>> data_collator = DefaultDataCollator()
+```
+
+
+
+
+
+
+
+과적합을 방지하고 모델을 보다 견고하게 만들기 위해 데이터 세트의 훈련 부분에 데이터 증강을 추가합니다.
+여기서 Keras 전처리 레이어로 훈련 데이터에 대한 변환(데이터 증강 포함)과
+검증 데이터에 대한 변환(중앙 크로핑, 크기 조정, 정규화만)을 정의합니다.
+`tf.image` 또는 다른 원하는 라이브러리를 사용할 수 있습니다.
+
+```py
+>>> from tensorflow import keras
+>>> from tensorflow.keras import layers
+
+>>> size = (image_processor.size["height"], image_processor.size["width"])
+
+>>> train_data_augmentation = keras.Sequential(
+... [
+... layers.RandomCrop(size[0], size[1]),
+... layers.Rescaling(scale=1.0 / 127.5, offset=-1),
+... layers.RandomFlip("horizontal"),
+... layers.RandomRotation(factor=0.02),
+... layers.RandomZoom(height_factor=0.2, width_factor=0.2),
+... ],
+... name="train_data_augmentation",
+... )
+
+>>> val_data_augmentation = keras.Sequential(
+... [
+... layers.CenterCrop(size[0], size[1]),
+... layers.Rescaling(scale=1.0 / 127.5, offset=-1),
+... ],
+... name="val_data_augmentation",
+... )
+```
+
+다음으로 한 번에 하나의 이미지가 아니라 이미지 배치에 적절한 변환을 적용하는 함수를 만듭니다.
+
+```py
+>>> import numpy as np
+>>> import tensorflow as tf
+>>> from PIL import Image
+
+
+>>> def convert_to_tf_tensor(image: Image):
+... np_image = np.array(image)
+... tf_image = tf.convert_to_tensor(np_image)
+... # `expand_dims()` is used to add a batch dimension since
+... # the TF augmentation layers operates on batched inputs.
+... return tf.expand_dims(tf_image, 0)
+
+
+>>> def preprocess_train(example_batch):
+... """Apply train_transforms across a batch."""
+... images = [
+... train_data_augmentation(convert_to_tf_tensor(image.convert("RGB"))) for image in example_batch["image"]
+... ]
+... example_batch["pixel_values"] = [tf.transpose(tf.squeeze(image)) for image in images]
+... return example_batch
+
+
+... def preprocess_val(example_batch):
+... """Apply val_transforms across a batch."""
+... images = [
+... val_data_augmentation(convert_to_tf_tensor(image.convert("RGB"))) for image in example_batch["image"]
+... ]
+... example_batch["pixel_values"] = [tf.transpose(tf.squeeze(image)) for image in images]
+... return example_batch
+```
+
+🤗 Datasets [`~datasets.Dataset.set_transform`]를 사용하여 즉시 변환을 적용하세요:
+
+```py
+food["train"].set_transform(preprocess_train)
+food["test"].set_transform(preprocess_val)
+```
+
+최종 전처리 단계로 `DefaultDataCollator`를 사용하여 예제 배치를 만듭니다. 🤗 Transformers의 다른 데이터 콜레이터와 달리
+`DefaultDataCollator`는 패딩과 같은 추가 전처리를 적용하지 않습니다.
+
+```py
+>>> from transformers import DefaultDataCollator
+
+>>> data_collator = DefaultDataCollator(return_tensors="tf")
+```
+
+
+
+## 평가[[evaluate]]
+
+훈련 중에 평가 지표를 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다.
+🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리로 평가 방법을 빠르게 가져올 수 있습니다. 이 작업에서는
+[accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) 평가 지표를 가져옵니다. (🤗 Evaluate [빠른 둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하여 평가 지표를 가져오고 계산하는 방법에 대해 자세히 알아보세요):
+
+```py
+>>> import evaluate
+
+>>> accuracy = evaluate.load("accuracy")
+```
+
+그런 다음 예측과 레이블을 [`~evaluate.EvaluationModule.compute`]에 전달하여 정확도를 계산하는 함수를 만듭니다:
+
+```py
+>>> import numpy as np
+
+
+>>> def compute_metrics(eval_pred):
+... predictions, labels = eval_pred
+... predictions = np.argmax(predictions, axis=1)
+... return accuracy.compute(predictions=predictions, references=labels)
+```
+
+이제 `compute_metrics` 함수를 사용할 준비가 되었으며, 훈련을 설정하면 이 함수로 되돌아올 것입니다.
+
+## 훈련[[train]]
+
+
+
+
+
+[`Trainer`]를 사용하여 모델을 미세 조정하는 방법에 익숙하지 않은 경우, [여기](../training#train-with-pytorch-trainer)에서 기본 튜토리얼을 확인하세요!
+
+
+
+이제 모델을 훈련시킬 준비가 되었습니다! [`AutoModelForImageClassification`]로 ViT를 가져옵니다. 예상되는 레이블 수, 레이블 매핑 및 레이블 수를 지정하세요:
+
+```py
+>>> from transformers import AutoModelForImageClassification, TrainingArguments, Trainer
+
+>>> model = AutoModelForImageClassification.from_pretrained(
+... checkpoint,
+... num_labels=len(labels),
+... id2label=id2label,
+... label2id=label2id,
+... )
+```
+
+이제 세 단계만 거치면 끝입니다:
+
+1. [`TrainingArguments`]에서 훈련 하이퍼파라미터를 정의하세요. `image` 열이 삭제되기 때문에 미사용 열을 제거하지 않는 것이 중요합니다. `image` 열이 없으면 `pixel_values`을 생성할 수 없습니다. 이 동작을 방지하려면 `remove_unused_columns=False`로 설정하세요! 다른 유일한 필수 매개변수는 모델 저장 위치를 지정하는 `output_dir`입니다. `push_to_hub=True`로 설정하면 이 모델을 허브에 푸시합니다(모델을 업로드하려면 Hugging Face에 로그인해야 합니다). 각 에폭이 끝날 때마다, [`Trainer`]가 정확도를 평가하고 훈련 체크포인트를 저장합니다.
+2. [`Trainer`]에 모델, 데이터 세트, 토크나이저, 데이터 콜레이터 및 `compute_metrics` 함수와 함께 훈련 인수를 전달하세요.
+3. [`~Trainer.train`]을 호출하여 모델을 미세 조정하세요.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_food_model",
+... remove_unused_columns=False,
+... eval_strategy="epoch",
+... save_strategy="epoch",
+... learning_rate=5e-5,
+... per_device_train_batch_size=16,
+... gradient_accumulation_steps=4,
+... per_device_eval_batch_size=16,
+... num_train_epochs=3,
+... warmup_ratio=0.1,
+... logging_steps=10,
+... load_best_model_at_end=True,
+... metric_for_best_model="accuracy",
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... data_collator=data_collator,
+... train_dataset=food["train"],
+... eval_dataset=food["test"],
+... processing_class=image_processor,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+
+훈련이 완료되면, 모든 사람이 모델을 사용할 수 있도록 [`~transformers.Trainer.push_to_hub`] 메소드로 모델을 허브에 공유하세요:
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+
+
+
+
+Keras를 사용하여 모델을 미세 조정하는 방법에 익숙하지 않은 경우, 먼저 [기본 튜토리얼](./training#train-a-tensorflow-model-with-keras)을 확인하세요!
+
+
+
+TensorFlow에서 모델을 미세 조정하려면 다음 단계를 따르세요:
+1. 훈련 하이퍼파라미터를 정의하고 옵티마이저와 학습률 스케쥴을 설정합니다.
+2. 사전 훈련된 모델을 인스턴스화합니다.
+3. 🤗 Dataset을 `tf.data.Dataset`으로 변환합니다.
+4. 모델을 컴파일합니다.
+5. 콜백을 추가하고 훈련을 수행하기 위해 `fit()` 메소드를 사용합니다.
+6. 커뮤니티와 공유하기 위해 모델을 🤗 Hub에 업로드합니다.
+
+하이퍼파라미터, 옵티마이저 및 학습률 스케쥴을 정의하는 것으로 시작합니다:
+
+```py
+>>> from transformers import create_optimizer
+
+>>> batch_size = 16
+>>> num_epochs = 5
+>>> num_train_steps = len(food["train"]) * num_epochs
+>>> learning_rate = 3e-5
+>>> weight_decay_rate = 0.01
+
+>>> optimizer, lr_schedule = create_optimizer(
+... init_lr=learning_rate,
+... num_train_steps=num_train_steps,
+... weight_decay_rate=weight_decay_rate,
+... num_warmup_steps=0,
+... )
+```
+
+그런 다음 레이블 매핑과 함께 [`TFAuto ModelForImageClassification`]으로 ViT를 가져옵니다:
+
+```py
+>>> from transformers import TFAutoModelForImageClassification
+
+>>> model = TFAutoModelForImageClassification.from_pretrained(
+... checkpoint,
+... id2label=id2label,
+... label2id=label2id,
+... )
+```
+
+데이터 세트를 [`~datasets.Dataset.to_tf_dataset`]와 `data_collator`를 사용하여 `tf.data.Dataset` 형식으로 변환하세요:
+
+```py
+>>> # converting our train dataset to tf.data.Dataset
+>>> tf_train_dataset = food["train"].to_tf_dataset(
+... columns="pixel_values", label_cols="label", shuffle=True, batch_size=batch_size, collate_fn=data_collator
+... )
+
+>>> # converting our test dataset to tf.data.Dataset
+>>> tf_eval_dataset = food["test"].to_tf_dataset(
+... columns="pixel_values", label_cols="label", shuffle=True, batch_size=batch_size, collate_fn=data_collator
+... )
+```
+
+`compile()`를 사용하여 훈련 모델을 구성하세요:
+
+```py
+>>> from tensorflow.keras.losses import SparseCategoricalCrossentropy
+
+>>> loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
+>>> model.compile(optimizer=optimizer, loss=loss)
+```
+
+예측에서 정확도를 계산하고 모델을 🤗 Hub로 푸시하려면 [Keras callbacks](../main_classes/keras_callbacks)를 사용하세요.
+`compute_metrics` 함수를 [KerasMetricCallback](../main_classes/keras_callbacks#transformers.KerasMetricCallback)에 전달하고,
+[PushToHubCallback](../main_classes/keras_callbacks#transformers.PushToHubCallback)을 사용하여 모델을 업로드합니다:
+
+```py
+>>> from transformers.keras_callbacks import KerasMetricCallback, PushToHubCallback
+
+>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_eval_dataset)
+>>> push_to_hub_callback = PushToHubCallback(
+... output_dir="food_classifier",
+... tokenizer=image_processor,
+... save_strategy="no",
+... )
+>>> callbacks = [metric_callback, push_to_hub_callback]
+```
+
+이제 모델을 훈련할 준비가 되었습니다! 훈련 및 검증 데이터 세트, 에폭 수와 함께 `fit()`을 호출하고,
+콜백을 사용하여 모델을 미세 조정합니다:
+
+```py
+>>> model.fit(tf_train_dataset, validation_data=tf_eval_dataset, epochs=num_epochs, callbacks=callbacks)
+Epoch 1/5
+250/250 [==============================] - 313s 1s/step - loss: 2.5623 - val_loss: 1.4161 - accuracy: 0.9290
+Epoch 2/5
+250/250 [==============================] - 265s 1s/step - loss: 0.9181 - val_loss: 0.6808 - accuracy: 0.9690
+Epoch 3/5
+250/250 [==============================] - 252s 1s/step - loss: 0.3910 - val_loss: 0.4303 - accuracy: 0.9820
+Epoch 4/5
+250/250 [==============================] - 251s 1s/step - loss: 0.2028 - val_loss: 0.3191 - accuracy: 0.9900
+Epoch 5/5
+250/250 [==============================] - 238s 949ms/step - loss: 0.1232 - val_loss: 0.3259 - accuracy: 0.9890
+```
+
+축하합니다! 모델을 미세 조정하고 🤗 Hub에 공유했습니다. 이제 추론에 사용할 수 있습니다!
+
+
+
+
+
+
+이미지 분류를 위한 모델을 미세 조정하는 자세한 예제는 다음 [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)을 참조하세요.
+
+
+
+## 추론[[inference]]
+
+좋아요, 이제 모델을 미세 조정했으니 추론에 사용할 수 있습니다!
+
+추론을 수행하고자 하는 이미지를 가져와봅시다:
+
+```py
+>>> ds = load_dataset("food101", split="validation[:10]")
+>>> image = ds["image"][0]
+```
+
+
+
+
+
+미세 조정 모델로 추론을 시도하는 가장 간단한 방법은 [`pipeline`]을 사용하는 것입니다. 모델로 이미지 분류를 위한 `pipeline`을 인스턴스화하고 이미지를 전달합니다:
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline("image-classification", model="my_awesome_food_model")
+>>> classifier(image)
+[{'score': 0.31856709718704224, 'label': 'beignets'},
+ {'score': 0.015232225880026817, 'label': 'bruschetta'},
+ {'score': 0.01519392803311348, 'label': 'chicken_wings'},
+ {'score': 0.013022331520915031, 'label': 'pork_chop'},
+ {'score': 0.012728818692266941, 'label': 'prime_rib'}]
+```
+
+원한다면, `pipeline`의 결과를 수동으로 복제할 수도 있습니다:
+
+
+
+이미지를 전처리하기 위해 이미지 프로세서를 가져오고 `input`을 PyTorch 텐서로 반환합니다:
+
+```py
+>>> from transformers import AutoImageProcessor
+>>> import torch
+
+>>> image_processor = AutoImageProcessor.from_pretrained("my_awesome_food_model")
+>>> inputs = image_processor(image, return_tensors="pt")
+```
+
+입력을 모델에 전달하고 logits을 반환합니다:
+
+```py
+>>> from transformers import AutoModelForImageClassification
+
+>>> model = AutoModelForImageClassification.from_pretrained("my_awesome_food_model")
+>>> with torch.no_grad():
+... logits = model(**inputs).logits
+```
+
+확률이 가장 높은 예측 레이블을 가져오고, 모델의 `id2label` 매핑을 사용하여 레이블로 변환합니다:
+
+```py
+>>> predicted_label = logits.argmax(-1).item()
+>>> model.config.id2label[predicted_label]
+'beignets'
+```
+
+
+
+
+
+이미지를 전처리하기 위해 이미지 프로세서를 가져오고 `input`을 TensorFlow 텐서로 반환합니다:
+
+```py
+>>> from transformers import AutoImageProcessor
+
+>>> image_processor = AutoImageProcessor.from_pretrained("MariaK/food_classifier")
+>>> inputs = image_processor(image, return_tensors="tf")
+```
+
+입력을 모델에 전달하고 logits을 반환합니다:
+
+```py
+>>> from transformers import TFAutoModelForImageClassification
+
+>>> model = TFAutoModelForImageClassification.from_pretrained("MariaK/food_classifier")
+>>> logits = model(**inputs).logits
+```
+
+확률이 가장 높은 예측 레이블을 가져오고, 모델의 `id2label` 매핑을 사용하여 레이블로 변환합니다:
+
+```py
+>>> predicted_class_id = int(tf.math.argmax(logits, axis=-1)[0])
+>>> model.config.id2label[predicted_class_id]
+'beignets'
+```
+
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/image_feature_extraction.md b/docs/transformers/docs/source/ko/tasks/image_feature_extraction.md
new file mode 100644
index 0000000000000000000000000000000000000000..965ea771100b5e73f55d9c03bfe9b1644d36f6bd
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/image_feature_extraction.md
@@ -0,0 +1,136 @@
+
+
+# 이미지 특징 추출[[image-feature-extraction]]
+
+[[open-in-colab]]
+
+이미지 특징 추출은 주어진 이미지에서 의미론적으로 의미 있는 특징을 추출하는 작업입니다. 이는 이미지 유사성 및 이미지 검색 등 다양한 사용 사례가 있습니다.
+게다가 대부분의 컴퓨터 비전 모델은 이미지 특징 추출에 사용할 수 있으며, 여기서 작업 특화 헤드(이미지 분류, 물체 감지 등)를 제거하고 특징을 얻을 수 있습니다. 이러한 특징은 가장자리 감지, 모서리 감지 등 고차원 수준에서 매우 유용합니다.
+또한 모델의 깊이에 따라 실제 세계에 대한 정보(예: 고양이가 어떻게 생겼는지)를 포함할 수도 있습니다. 따라서 이러한 출력은 특정 데이터 세트에 대한 새로운 분류기를 훈련하는 데 사용할 수 있습니다.
+
+이 가이드에서는:
+
+- `image-feature-extraction` 파이프라인을 활용하여 간단한 이미지 유사성 시스템을 구축하는 방법을 배웁니다.
+- 기본 모델 추론으로 동일한 작업을 수행합니다.
+
+## `image-feature-extraction` 파이프라인을 이용한 이미지 유사성[[image-similarity-using-image-feature-extraction-pipeline]]
+
+물고기 그물 위에 앉아 있는 두 장의 고양이 사진이 있습니다. 이 중 하나는 생성된 이미지입니다.
+
+```python
+from PIL import Image
+import requests
+
+img_urls = ["https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/cats.png", "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/cats.jpeg"]
+image_real = Image.open(requests.get(img_urls[0], stream=True).raw).convert("RGB")
+image_gen = Image.open(requests.get(img_urls[1], stream=True).raw).convert("RGB")
+```
+
+파이프라인을 실행해 봅시다. 먼저 파이프라인을 초기화하세요. 모델을 지정하지 않으면, 파이프라인은 자동으로 [google/vit-base-patch16-224](google/vit-base-patch16-224) 모델로 초기화됩니다. 유사도를 계산하려면 `pool`을 True로 설정하세요.
+
+
+```python
+import torch
+from transformers import pipeline
+
+DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+pipe = pipeline(task="image-feature-extraction", model_name="google/vit-base-patch16-384", device=DEVICE, pool=True)
+```
+
+`pipe`를 사용하여 추론하려면 두 이미지를 모두 전달하세요.
+
+```python
+outputs = pipe([image_real, image_gen])
+```
+
+출력에는 두 이미지의 풀링된(pooled) 임베딩이 포함되어 있습니다.
+
+```python
+# 단일 출력의 길이 구하기
+print(len(outputs[0][0]))
+# 출력 결과 표시하기
+print(outputs)
+
+# 768
+# [[[-0.03909236937761307, 0.43381670117378235, -0.06913255900144577,
+```
+
+유사도 점수를 얻으려면, 이들을 유사도 함수에 전달해야 합니다.
+
+```python
+from torch.nn.functional import cosine_similarity
+
+similarity_score = cosine_similarity(torch.Tensor(outputs[0]),
+ torch.Tensor(outputs[1]), dim=1)
+
+print(similarity_score)
+
+# tensor([0.6043])
+```
+
+풀링 이전의 마지막 은닉 상태를 얻고 싶다면, `pool` 매개변수에 아무 값도 전달하지 마세요. 또한, 기본값은 `False`로 설정되어 있습니다. 이 은닉 상태는 모델의 특징을 기반으로 새로운 분류기나 모델을 훈련시키는 데 유용합니다.
+
+```python
+pipe = pipeline(task="image-feature-extraction", model_name="google/vit-base-patch16-224", device=DEVICE)
+output = pipe(image_real)
+```
+
+아직 출력이 풀링되지 않았기 때문에, 첫 번째 차원은 배치 크기이고 마지막 두 차원은 임베딩 형태인 마지막 은닉 상태를 얻을 수 있습니다.
+
+```python
+import numpy as np
+print(np.array(outputs).shape)
+# (1, 197, 768)
+```
+
+## `AutoModel`을 사용하여 특징과 유사성 얻기[[getting-features-and-similarities-using-automodel]]
+
+transformers의 `AutoModel` 클래스를 사용하여 특징을 얻을 수도 있습니다. `AutoModel`은 작업 특화 헤드 없이 모든 transformers 모델을 로드할 수 있으며, 이를 통해 특징을 추출할 수 있습니다.
+
+```python
+from transformers import AutoImageProcessor, AutoModel
+
+processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
+model = AutoModel.from_pretrained("google/vit-base-patch16-224").to(DEVICE)
+```
+
+추론을 위한 간단한 함수를 작성해 보겠습니다. 먼저 입력값을 `processor`에 전달한 다음, 그 출력값을 `model`에 전달할 것입니다.
+
+```python
+def infer(image):
+ inputs = processor(image, return_tensors="pt").to(DEVICE)
+ outputs = model(**inputs)
+ return outputs.pooler_output
+```
+
+이 함수에 이미지를 직접 전달하여 임베딩을 얻을 수 있습니다.
+
+```python
+embed_real = infer(image_real)
+embed_gen = infer(image_gen)
+```
+
+그리고 이 임베딩을 사용하여 다시 유사도를 계산할 수 있습니다.
+
+```python
+from torch.nn.functional import cosine_similarity
+
+similarity_score = cosine_similarity(embed_real, embed_gen, dim=1)
+print(similarity_score)
+
+# tensor([0.6061], device='cuda:0', grad_fn=)
+```
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/tasks/image_to_image.md b/docs/transformers/docs/source/ko/tasks/image_to_image.md
new file mode 100644
index 0000000000000000000000000000000000000000..f76122f78445055872188d382bec93cf3af75799
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/image_to_image.md
@@ -0,0 +1,132 @@
+
+
+# Image-to-Image 작업 가이드 [[image-to-image-task-guide]]
+
+[[open-in-colab]]
+
+Image-to-Image 작업은 애플리케이션이 이미지를 입력받아 또 다른 이미지를 출력하는 작업입니다. 여기에는 이미지 향상(초고해상도, 저조도 향상, 빗줄기 제거 등), 이미지 복원 등 다양한 하위 작업이 포함됩니다.
+
+이 가이드에서는 다음을 수행하는 방법을 보여줍니다.
+- 초고해상도 작업을 위한 image-to-image 파이프라인 사용,
+- 파이프라인 없이 동일한 작업을 위한 image-to-image 모델 실행
+
+이 가이드가 발표된 시점에서는, `image-to-image` 파이프라인은 초고해상도 작업만 지원한다는 점을 유의하세요.
+
+필요한 라이브러리를 설치하는 것부터 시작하겠습니다.
+
+```bash
+pip install transformers
+```
+
+이제 [Swin2SR 모델](https://huggingface.co/caidas/swin2SR-lightweight-x2-64)을 사용하여 파이프라인을 초기화할 수 있습니다. 그런 다음 이미지와 함께 호출하여 파이프라인으로 추론할 수 있습니다. 현재 이 파이프라인에서는 [Swin2SR 모델](https://huggingface.co/caidas/swin2SR-lightweight-x2-64)만 지원됩니다.
+
+```python
+from transformers import pipeline
+
+device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+pipe = pipeline(task="image-to-image", model="caidas/swin2SR-lightweight-x2-64", device=device)
+```
+
+이제 이미지를 불러와 봅시다.
+
+```python
+from PIL import Image
+import requests
+
+url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/cat.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+print(image.size)
+```
+```bash
+# (532, 432)
+```
+
+
+
+
+이제 파이프라인으로 추론을 수행할 수 있습니다. 고양이 이미지의 업스케일된 버전을 얻을 수 있습니다.
+
+```python
+upscaled = pipe(image)
+print(upscaled.size)
+```
+```bash
+# (1072, 880)
+```
+
+파이프라인 없이 직접 추론을 수행하려면 Transformers의 `Swin2SRForImageSuperResolution` 및 `Swin2SRImageProcessor` 클래스를 사용할 수 있습니다. 이를 위해 동일한 모델 체크포인트를 사용합니다. 모델과 프로세서를 초기화해 보겠습니다.
+
+```python
+from transformers import Swin2SRForImageSuperResolution, Swin2SRImageProcessor
+
+model = Swin2SRForImageSuperResolution.from_pretrained("caidas/swin2SR-lightweight-x2-64").to(device)
+processor = Swin2SRImageProcessor("caidas/swin2SR-lightweight-x2-64")
+```
+
+`pipeline` 우리가 직접 수행해야 하는 전처리와 후처리 단계를 추상화하므로, 이미지를 전처리해 보겠습니다. 이미지를 프로세서에 전달한 다음 픽셀값을 GPU로 이동시키겠습니다.
+
+```python
+pixel_values = processor(image, return_tensors="pt").pixel_values
+print(pixel_values.shape)
+
+pixel_values = pixel_values.to(device)
+```
+
+이제 픽셀값을 모델에 전달하여 이미지를 추론할 수 있습니다.
+
+```python
+import torch
+
+with torch.no_grad():
+ outputs = model(pixel_values)
+```
+출력은 아래와 같은 `ImageSuperResolutionOutput` 유형의 객체입니다 👇
+
+```
+(loss=None, reconstruction=tensor([[[[0.8270, 0.8269, 0.8275, ..., 0.7463, 0.7446, 0.7453],
+ [0.8287, 0.8278, 0.8283, ..., 0.7451, 0.7448, 0.7457],
+ [0.8280, 0.8273, 0.8269, ..., 0.7447, 0.7446, 0.7452],
+ ...,
+ [0.5923, 0.5933, 0.5924, ..., 0.0697, 0.0695, 0.0706],
+ [0.5926, 0.5932, 0.5926, ..., 0.0673, 0.0687, 0.0705],
+ [0.5927, 0.5914, 0.5922, ..., 0.0664, 0.0694, 0.0718]]]],
+ device='cuda:0'), hidden_states=None, attentions=None)
+```
+`reconstruction`를 가져와 시각화를 위해 후처리해야 합니다. 어떻게 생겼는지 살펴봅시다.
+
+```python
+outputs.reconstruction.data.shape
+# torch.Size([1, 3, 880, 1072])
+```
+
+출력 텐서의 차원을 축소하고 0번째 축을 제거한 다음, 값을 클리핑하고 NumPy 부동소수점 배열로 변환해야 합니다. 그런 다음 [1072, 880] 모양을 갖도록 축을 재정렬하고 마지막으로 출력을 0과 255 사이의 값을 갖도록 되돌립니다.
+
+```python
+import numpy as np
+
+# 크기를 줄이고, CPU로 이동하고, 값을 클리핑
+output = outputs.reconstruction.data.squeeze().cpu().clamp_(0, 1).numpy()
+# 축을 재정렬
+output = np.moveaxis(output, source=0, destination=-1)
+# 값을 픽셀값 범위로 되돌리기
+output = (output * 255.0).round().astype(np.uint8)
+Image.fromarray(output)
+```
+
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md b/docs/transformers/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md
new file mode 100644
index 0000000000000000000000000000000000000000..37c0cc25083e0c0f8e2d298d13df18adf8c6efb6
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/knowledge_distillation_for_image_classification.md
@@ -0,0 +1,193 @@
+
+# 컴퓨터 비전을 위한 지식 증류[[Knowledge-Distillation-for-Computer-Vision]]
+
+[[open-in-colab]]
+
+지식 증류(Knowledge distillation)는 더 크고 복잡한 모델(교사)에서 더 작고 간단한 모델(학생)로 지식을 전달하는 기술입니다. 한 모델에서 다른 모델로 지식을 증류하기 위해, 특정 작업(이 경우 이미지 분류)에 대해 학습된 사전 훈련된 교사 모델을 사용하고, 랜덤으로 초기화된 학생 모델을 이미지 분류 작업에 대해 학습합니다. 그다음, 학생 모델이 교사 모델의 출력을 모방하여 두 모델의 출력 차이를 최소화하도록 훈련합니다. 이 기법은 Hinton 등 연구진의 [Distilling the Knowledge in a Neural Network](https://arxiv.org/abs/1503.02531)에서 처음 소개되었습니다. 이 가이드에서는 특정 작업에 맞춘 지식 증류를 수행할 것입니다. 이번에는 [beans dataset](https://huggingface.co/datasets/beans)을 사용할 것입니다.
+
+이 가이드는 [미세 조정된 ViT 모델](https://huggingface.co/merve/vit-mobilenet-beans-224) (교사 모델)을 [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (학생 모델)으로 증류하는 방법을 🤗 Transformers의 [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) 를 사용하여 보여줍니다.
+
+증류와 과정 평가를 위해 필요한 라이브러리를 설치해 봅시다.
+
+
+```bash
+pip install transformers datasets accelerate tensorboard evaluate --upgrade
+```
+
+이 예제에서는 `merve/beans-vit-224` 모델을 교사 모델로 사용하고 있습니다. 이 모델은 beans 데이터셋에서 파인 튜닝된 `google/vit-base-patch16-224-in21k` 기반의 이미지 분류 모델입니다. 이 모델을 무작위로 초기화된 MobileNetV2로 증류해볼 것입니다.
+
+이제 데이터셋을 로드하겠습니다.
+
+```python
+from datasets import load_dataset
+
+dataset = load_dataset("beans")
+```
+
+이 경우 두 모델의 이미지 프로세서가 동일한 해상도로 동일한 출력을 반환하기 때문에, 두가지를 모두 사용할 수 있습니다. 데이터셋의 모든 분할마다 전처리를 적용하기 위해 `dataset`의 `map()` 메소드를 사용할 것 입니다.
+
+
+```python
+from transformers import AutoImageProcessor
+teacher_processor = AutoImageProcessor.from_pretrained("merve/beans-vit-224")
+
+def process(examples):
+ processed_inputs = teacher_processor(examples["image"])
+ return processed_inputs
+
+processed_datasets = dataset.map(process, batched=True)
+```
+
+학생 모델(무작위로 초기화된 MobileNet)이 교사 모델(파인 튜닝된 비전 트랜스포머)을 모방하도록 할 것 입니다. 이를 위해 먼저 교사와 학생 모델의 로짓 출력값을 구합니다. 그런 다음 각 출력값을 매개변수 `temperature` 값으로 나누는데, 이 매개변수는 각 소프트 타겟의 중요도를 조절하는 역할을 합니다. 매개변수 `lambda` 는 증류 손실의 중요도에 가중치를 줍니다. 이 예제에서는 `temperature=5`와 `lambda=0.5`를 사용할 것입니다. 학생과 교사 간의 발산을 계산하기 위해 Kullback-Leibler Divergence 손실을 사용합니다. 두 데이터 P와 Q가 주어졌을 때, KL Divergence는 Q를 사용하여 P를 표현하는 데 얼만큼의 추가 정보가 필요한지를 말해줍니다. 두 데이터가 동일하다면, KL Divergence는 0이며, Q로 P를 설명하는 데 추가 정보가 필요하지 않음을 의미합니다. 따라서 지식 증류의 맥락에서 KL Divergence는 유용합니다.
+
+
+```python
+from transformers import TrainingArguments, Trainer
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+class ImageDistilTrainer(Trainer):
+ def __init__(self, teacher_model=None, student_model=None, temperature=None, lambda_param=None, *args, **kwargs):
+ super().__init__(model=student_model, *args, **kwargs)
+ self.teacher = teacher_model
+ self.student = student_model
+ self.loss_function = nn.KLDivLoss(reduction="batchmean")
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+ self.teacher.to(device)
+ self.teacher.eval()
+ self.temperature = temperature
+ self.lambda_param = lambda_param
+
+ def compute_loss(self, student, inputs, return_outputs=False):
+ student_output = self.student(**inputs)
+
+ with torch.no_grad():
+ teacher_output = self.teacher(**inputs)
+
+ # 교사와 학생의 소프트 타겟(soft targets) 계산
+
+ soft_teacher = F.softmax(teacher_output.logits / self.temperature, dim=-1)
+ soft_student = F.log_softmax(student_output.logits / self.temperature, dim=-1)
+
+ # 손실(loss) 계산
+ distillation_loss = self.loss_function(soft_student, soft_teacher) * (self.temperature ** 2)
+
+ # 실제 레이블 손실 계산
+ student_target_loss = student_output.loss
+
+ # 최종 손실 계산
+ loss = (1. - self.lambda_param) * student_target_loss + self.lambda_param * distillation_loss
+ return (loss, student_output) if return_outputs else loss
+```
+
+이제 Hugging Face Hub에 로그인하여 `Trainer`를 통해 Hugging Face Hub에 모델을 푸시할 수 있도록 하겠습니다.
+
+
+```python
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+이제 `TrainingArguments`, 교사 모델과 학생 모델을 설정하겠습니다.
+
+
+```python
+from transformers import AutoModelForImageClassification, MobileNetV2Config, MobileNetV2ForImageClassification
+
+training_args = TrainingArguments(
+ output_dir="my-awesome-model",
+ num_train_epochs=30,
+ fp16=True,
+ logging_dir=f"{repo_name}/logs",
+ logging_strategy="epoch",
+ eval_strategy="epoch",
+ save_strategy="epoch",
+ load_best_model_at_end=True,
+ metric_for_best_model="accuracy",
+ report_to="tensorboard",
+ push_to_hub=True,
+ hub_strategy="every_save",
+ hub_model_id=repo_name,
+ )
+
+num_labels = len(processed_datasets["train"].features["labels"].names)
+
+# 모델 초기화
+teacher_model = AutoModelForImageClassification.from_pretrained(
+ "merve/beans-vit-224",
+ num_labels=num_labels,
+ ignore_mismatched_sizes=True
+)
+
+# MobileNetV2 밑바닥부터 학습
+student_config = MobileNetV2Config()
+student_config.num_labels = num_labels
+student_model = MobileNetV2ForImageClassification(student_config)
+```
+
+`compute_metrics` 함수를 사용하여 테스트 세트에서 모델을 평가할 수 있습니다. 이 함수는 훈련 과정에서 모델의 `accuracy`와 `f1`을 계산하는 데 사용됩니다.
+
+
+```python
+import evaluate
+import numpy as np
+
+accuracy = evaluate.load("accuracy")
+
+def compute_metrics(eval_pred):
+ predictions, labels = eval_pred
+ acc = accuracy.compute(references=labels, predictions=np.argmax(predictions, axis=1))
+ return {"accuracy": acc["accuracy"]}
+```
+
+정의한 훈련 인수로 `Trainer`를 초기화해봅시다. 또한 데이터 콜레이터(data collator)를 초기화하겠습니다.
+
+```python
+from transformers import DefaultDataCollator
+
+data_collator = DefaultDataCollator()
+trainer = ImageDistilTrainer(
+ student_model=student_model,
+ teacher_model=teacher_model,
+ training_args=training_args,
+ train_dataset=processed_datasets["train"],
+ eval_dataset=processed_datasets["validation"],
+ data_collator=data_collator,
+ tokenizer=teacher_processor,
+ compute_metrics=compute_metrics,
+ temperature=5,
+ lambda_param=0.5
+)
+```
+
+이제 모델을 훈련할 수 있습니다.
+
+```python
+trainer.train()
+```
+
+모델을 테스트 세트에서 평가할 수 있습니다.
+
+```python
+trainer.evaluate(processed_datasets["test"])
+```
+
+
+테스트 세트에서 모델의 정확도는 72%에 도달했습니다. 증류의 효율성을 검증하기 위해 동일한 하이퍼파라미터로 beans 데이터셋에서 MobileNet을 처음부터 훈련하였고, 테스트 세트에서의 정확도는 63% 였습니다. 다양한 사전 훈련된 교사 모델, 학생 구조, 증류 매개변수를 시도해보시고 결과를 보고하기를 권장합니다. 증류된 모델의 훈련 로그와 체크포인트는 [이 저장소](https://huggingface.co/merve/vit-mobilenet-beans-224)에서 찾을 수 있으며, 처음부터 훈련된 MobileNetV2는 이 [저장소](https://huggingface.co/merve/resnet-mobilenet-beans-5)에서 찾을 수 있습니다.
diff --git a/docs/transformers/docs/source/ko/tasks/language_modeling.md b/docs/transformers/docs/source/ko/tasks/language_modeling.md
new file mode 100644
index 0000000000000000000000000000000000000000..1b531e49d6176df4c27e2bab1e96378535bccfc7
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/language_modeling.md
@@ -0,0 +1,411 @@
+
+
+# 인과 언어 모델링[[causal-language-modeling]]
+
+[[open-in-colab]]
+
+언어 모델링은 인과적 언어 모델링과 마스크드 언어 모델링, 두 가지 유형으로 나뉩니다. 이 가이드에서는 인과적 언어 모델링을 설명합니다.
+인과 언어 모델은 텍스트 생성에 자주 사용됩니다. 또 창의적인 방향으로 응용할 수 있습니다.
+직접 사용하며 재미있는 탐구를 해보거나, Copilot 또는 CodeParrot와 같은 지능형 코딩 어시스턴트의 기반이 되기도 합니다.
+
+
+
+인과 언어 모델링은 토큰 시퀀스에서 다음 토큰을 예측하며, 모델은 왼쪽의 토큰에만 접근할 수 있습니다.
+이는 모델이 미래의 토큰을 볼 수 없다는 것을 의미합니다. 인과 언어 모델의 예로 GPT-2가 있죠.
+
+이 가이드에서는 다음 작업을 수행하는 방법을 안내합니다:
+
+1. [DistilGPT2](https://huggingface.co/distilbert/distilgpt2) 모델을 [ELI5](https://huggingface.co/datasets/eli5) 데이터 세트의 [r/askscience](https://www.reddit.com/r/askscience/) 하위 집합으로 미세 조정
+2. 미세 조정된 모델을 추론에 사용
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/text-generation)를 확인하는 것이 좋습니다.
+
+
+
+시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers datasets evaluate
+```
+
+커뮤니티에 모델을 업로드하고 공유하기 위해 Hugging Face 계정에 로그인하는 것을 권장합니다. 알림이 표시되면 토큰을 입력하여 로그인하세요:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## ELI5 데이터 세트 불러오기[[load-eli5-dataset]]
+
+먼저, 🤗 Datasets 라이브러리에서 r/askscience의 작은 하위 집합인 ELI5 데이터 세트를 불러옵니다.
+이를 통해 전체 데이터 세트에서 학습하는 데 더 많은 시간을 투자하기 전에, 실험해봄으로써 모든 것이 작동하는지 확인할 수 있습니다.
+
+```py
+>>> from datasets import load_dataset
+
+>>> eli5 = load_dataset("eli5", split="train_asks[:5000]")
+```
+
+데이터 세트의 `train_asks` 분할을 [`~datasets.Dataset.train_test_split`] 메소드를 사용하여 학습 및 테스트 세트로 분할합니다:
+
+```py
+>>> eli5 = eli5.train_test_split(test_size=0.2)
+```
+
+그런 다음 예제를 살펴보세요:
+
+```py
+>>> eli5["train"][0]
+{'answers': {'a_id': ['c3d1aib', 'c3d4lya'],
+ 'score': [6, 3],
+ 'text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
+ "Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"]},
+ 'answers_urls': {'url': []},
+ 'document': '',
+ 'q_id': 'nyxfp',
+ 'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
+ 'selftext_urls': {'url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg']},
+ 'subreddit': 'askscience',
+ 'title': 'Few questions about this space walk photograph.',
+ 'title_urls': {'url': []}}
+```
+
+많아 보일 수 있지만, 실제로는 `text` 필드만 중요합니다. 언어 모델링 작업의 장점은 레이블이 필요하지 않다는 것입니다. 다음 단어 *자체가* 레이블입니다. (이렇게 레이블을 제공하지 않아도 되는 학습을 비지도 학습이라고 일컫습니다)
+
+## 전처리[[preprocess]]
+
+
+
+다음 단계는 `text` 필드를 전처리하기 위해 DistilGPT2 토크나이저를 불러오는 것입니다.
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
+```
+
+위의 예제에서 알 수 있듯이, `text` 필드는 `answers` 아래에 중첩되어 있습니다. 따라서 [`flatten`](https://huggingface.co/docs/datasets/process#flatten) 메소드를 사용하여 중첩 구조에서 `text` 하위 필드를 추출해야 합니다.
+
+```py
+>>> eli5 = eli5.flatten()
+>>> eli5["train"][0]
+{'answers.a_id': ['c3d1aib', 'c3d4lya'],
+ 'answers.score': [6, 3],
+ 'answers.text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
+ "Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"],
+ 'answers_urls.url': [],
+ 'document': '',
+ 'q_id': 'nyxfp',
+ 'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
+ 'selftext_urls.url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg'],
+ 'subreddit': 'askscience',
+ 'title': 'Few questions about this space walk photograph.',
+ 'title_urls.url': []}
+```
+
+각 하위 필드는 이제 `answers` 접두사를 가진 별도의 열로 나뉘었으며, `text` 필드는 이제 리스트입니다. 각 문장을 개별적으로 토큰화하는 대신, 먼저 리스트를 문자열로 변환하여 한꺼번에 토큰화할 수 있습니다.
+
+다음은 문자열 리스트를 결합하고 결과를 토큰화하는 첫 번째 전처리 함수입니다:
+
+```py
+>>> def preprocess_function(examples):
+... return tokenizer([" ".join(x) for x in examples["answers.text"]])
+```
+
+이 전처리 함수를 전체 데이터 세트에 적용하려면 🤗 Datasets [`~datasets.Dataset.map`] 메소드를 사용하세요. `batched=True`로 설정하여 데이터셋의 여러 요소를 한 번에 처리하고, `num_proc`를 증가시켜 프로세스 수를 늘릴 수 있습니다. 필요 없는 열은 제거하세요:
+
+```py
+>>> tokenized_eli5 = eli5.map(
+... preprocess_function,
+... batched=True,
+... num_proc=4,
+... remove_columns=eli5["train"].column_names,
+... )
+```
+
+이제 데이터 세트는 시퀀스가 토큰화됐지만, 일부 시퀀스는 모델의 최대 입력 길이보다 길 수 있습니다.
+
+이제 두 번째 전처리 함수를 사용하여
+- 모든 시퀀스를 연결하고,
+- `block_size`로 정의된 길이로 연결된 시퀀스를 여러 개의 짧은 묶음으로 나눕니다. 이 값은 최대 입력 길이와 GPU RAM을 고려해 충분히 짧아야 합니다.
+
+```py
+>>> block_size = 128
+
+
+>>> def group_texts(examples):
+... # Concatenate all texts.
+... concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
+... total_length = len(concatenated_examples[list(examples.keys())[0]])
+... # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
+... # customize this part to your needs.
+... if total_length >= block_size:
+... total_length = (total_length // block_size) * block_size
+... # Split by chunks of block_size.
+... result = {
+... k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
+... for k, t in concatenated_examples.items()
+... }
+... result["labels"] = result["input_ids"].copy()
+... return result
+```
+
+전체 데이터 세트에 `group_texts` 함수를 적용하세요:
+
+```py
+>>> lm_dataset = tokenized_eli5.map(group_texts, batched=True, num_proc=4)
+```
+
+그런 다음 [`DataCollatorForLanguageModeling`]을 사용하여 예제의 배치를 만듭니다. 데이터 세트 전체를 최대 길이로 패딩하는 것보다, 취합 단계에서 각 배치의 최대 길이로 문장을 *동적으로 패딩*하는 것이 더 효율적입니다.
+
+
+
+패딩 토큰으로 종결 토큰을 사용하고 `mlm=False`로 설정하세요. 이렇게 하면 입력을 오른쪽으로 한 칸씩 시프트한 값을 레이블로 사용합니다:
+
+```py
+>>> from transformers import DataCollatorForLanguageModeling
+
+>>> tokenizer.pad_token = tokenizer.eos_token
+>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
+```
+
+
+
+패딩 토큰으로 종결 토큰을 사용하고 `mlm=False`로 설정하세요. 이렇게 하면 입력을 오른쪽으로 한 칸씩 시프트한 값을 레이블로 사용합니다:
+
+```py
+>>> from transformers import DataCollatorForLanguageModeling
+
+>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False, return_tensors="tf")
+```
+
+
+
+
+
+## 훈련[[train]]
+
+
+
+
+
+[`Trainer`]를 사용하여 모델을 미세 조정하는 방법을 잘 모르신다면 [기본 튜토리얼](../training#train-with-pytorch-trainer)을 확인해보세요!
+
+
+
+이제 모델을 훈련하기 준비가 되었습니다! [`AutoModelForCausalLM`]를 사용하여 DistilGPT2를 불러옵니다:
+
+```py
+>>> from transformers import AutoModelForCausalLM, TrainingArguments, Trainer
+
+>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
+```
+
+여기까지 진행하면 세 단계만 남았습니다:
+
+1. [`TrainingArguments`]에서 훈련 하이퍼파라미터를 정의하세요. `output_dir`은 유일한 필수 매개변수로, 모델을 저장할 위치를 지정합니다. (먼저 Hugging Face에 로그인 필수) `push_to_hub=True`로 설정하여 이 모델을 허브에 업로드할 수 있습니다.
+2. 훈련 인수를 [`Trainer`]에 모델, 데이터 세트 및 데이터 콜레이터와 함께 전달하세요.
+3. [`~Trainer.train`]을 호출하여 모델을 미세 조정하세요.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_eli5_clm-model",
+... eval_strategy="epoch",
+... learning_rate=2e-5,
+... weight_decay=0.01,
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=lm_dataset["train"],
+... eval_dataset=lm_dataset["test"],
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+훈련이 완료되면 [`~transformers.Trainer.evaluate`] 메소드를 사용하여 모델을 평가하고 퍼플렉서티를 얻을 수 있습니다:
+
+```py
+>>> import math
+
+>>> eval_results = trainer.evaluate()
+>>> print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
+Perplexity: 49.61
+```
+
+그런 다음 [`~transformers.Trainer.push_to_hub`] 메소드를 사용하여 모델을 허브에 공유하세요. 이렇게 하면 누구나 모델을 사용할 수 있습니다:
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+Keras를 사용하여 모델을 미세 조정하는 방법에 익숙하지 않다면 [기본 튜토리얼](../training#train-a-tensorflow-model-with-keras)을 확인해보세요!
+
+
+TensorFlow에서 모델을 미세 조정하려면, 먼저 옵티마이저 함수, 학습률 스케줄 및 일부 훈련 하이퍼파라미터를 설정하세요:
+
+```py
+>>> from transformers import create_optimizer, AdamWeightDecay
+
+>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
+```
+
+그런 다음 [`TFAutoModelForCausalLM`]를 사용하여 DistilGPT2를 불러옵니다:
+
+```py
+>>> from transformers import TFAutoModelForCausalLM
+
+>>> model = TFAutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
+```
+
+[`~transformers.TFPreTrainedModel.prepare_tf_dataset`]을 사용하여 데이터 세트를 `tf.data.Dataset` 형식으로 변환하세요:
+
+```py
+>>> tf_train_set = model.prepare_tf_dataset(
+... lm_dataset["train"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_test_set = model.prepare_tf_dataset(
+... lm_dataset["test"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+[`compile`](https://keras.io/api/models/model_training_apis/#compile-method)을 사용하여 모델을 훈련하기 위해 구성하세요. Transformers 모델은 모두 기본적인 작업 관련 손실 함수를 가지고 있으므로, 원한다면 별도로 지정하지 않아도 됩니다:
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer) # 별도로 loss 인자를 넣지 않았어요!
+```
+
+[`~transformers.PushToHubCallback`]에서 모델과 토크나이저를 업로드할 위치를 지정할 수 있습니다:
+
+```py
+>>> from transformers.keras_callbacks import PushToHubCallback
+
+>>> callback = PushToHubCallback(
+... output_dir="my_awesome_eli5_clm-model",
+... tokenizer=tokenizer,
+... )
+```
+
+마지막으로, 모델을 훈련하기 위해 [`fit`](https://keras.io/api/models/model_training_apis/#fit-method)을 호출하세요. 훈련 데이터 세트, 검증 데이터 세트, 에폭 수 및 콜백을 전달하세요:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=[callback])
+```
+
+훈련이 완료되면 모델이 자동으로 허브에 업로드되어 모두가 사용할 수 있습니다!
+
+
+
+
+
+인과 언어 모델링을 위해 모델을 미세 조정하는 더 자세한 예제는 해당하는 [PyTorch 노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb) 또는 [TensorFlow 노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)을 참조하세요.
+
+
+
+## 추론[[inference]]
+
+좋아요, 이제 모델을 미세 조정했으므로 추론에 사용할 수 있습니다!
+
+생성할 텍스트를 위한 프롬프트를 만들어보세요:
+
+```py
+>>> prompt = "Somatic hypermutation allows the immune system to"
+```
+
+추론을 위해 미세 조정된 모델을 간단히 사용하는 가장 간단한 방법은 [`pipeline`]에서 사용하는 것입니다. 모델과 함께 텍스트 생성을 위한 `pipeline`을 인스턴스화하고 텍스트를 전달하세요:
+
+```py
+>>> from transformers import pipeline
+
+>>> generator = pipeline("text-generation", model="my_awesome_eli5_clm-model")
+>>> generator(prompt)
+[{'generated_text': "Somatic hypermutation allows the immune system to be able to effectively reverse the damage caused by an infection.\n\n\nThe damage caused by an infection is caused by the immune system's ability to perform its own self-correcting tasks."}]
+```
+
+
+
+텍스트를 토큰화하고 `input_ids`를 PyTorch 텐서로 반환하세요:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_eli5_clm-model")
+>>> inputs = tokenizer(prompt, return_tensors="pt").input_ids
+```
+
+[`~generation.GenerationMixin.generate`] 메소드를 사용하여 텍스트를 생성하세요. 생성을 제어하는 다양한 텍스트 생성 전략과 매개변수에 대한 자세한 내용은 [텍스트 생성 전략](../generation_strategies) 페이지를 확인하세요.
+
+```py
+>>> from transformers import AutoModelForCausalLM
+
+>>> model = AutoModelForCausalLM.from_pretrained("my_awesome_eli5_clm-model")
+>>> outputs = model.generate(inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
+```
+
+생성된 토큰 ID를 다시 텍스트로 디코딩하세요:
+
+```py
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+["Somatic hypermutation allows the immune system to react to drugs with the ability to adapt to a different environmental situation. In other words, a system of 'hypermutation' can help the immune system to adapt to a different environmental situation or in some cases even a single life. In contrast, researchers at the University of Massachusetts-Boston have found that 'hypermutation' is much stronger in mice than in humans but can be found in humans, and that it's not completely unknown to the immune system. A study on how the immune system"]
+```
+
+
+텍스트를 토큰화하고 `input_ids`를 TensorFlow 텐서로 반환하세요:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_eli5_clm-model")
+>>> inputs = tokenizer(prompt, return_tensors="tf").input_ids
+```
+
+[`~transformers.generation_tf_utils.TFGenerationMixin.generate`] 메소드를 사용하여 요약을 생성하세요. 생성을 제어하는 다양한 텍스트 생성 전략과 매개변수에 대한 자세한 내용은 [텍스트 생성 전략](../generation_strategies) 페이지를 확인하세요.
+
+```py
+>>> from transformers import TFAutoModelForCausalLM
+
+>>> model = TFAutoModelForCausalLM.from_pretrained("my_awesome_eli5_clm-model")
+>>> outputs = model.generate(input_ids=inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
+```
+
+생성된 토큰 ID를 다시 텍스트로 디코딩하세요:
+
+```py
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['Somatic hypermutation allows the immune system to detect the presence of other viruses as they become more prevalent. Therefore, researchers have identified a high proportion of human viruses. The proportion of virus-associated viruses in our study increases with age. Therefore, we propose a simple algorithm to detect the presence of these new viruses in our samples as a sign of improved immunity. A first study based on this algorithm, which will be published in Science on Friday, aims to show that this finding could translate into the development of a better vaccine that is more effective for']
+```
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/mask_generation.md b/docs/transformers/docs/source/ko/tasks/mask_generation.md
new file mode 100644
index 0000000000000000000000000000000000000000..7a937399391b7149b36a8f1d1374b3b30fc5e798
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/mask_generation.md
@@ -0,0 +1,228 @@
+
+
+# 마스크 생성[[mask-generation]]
+
+마스크 생성(Mask generation)은 이미지에 대한 의미 있는 마스크를 생성하는 작업입니다.
+이 작업은 [이미지 분할](semantic_segmentation)과 매우 유사하지만, 많은 차이점이 있습니다. 이미지 분할 모델은 라벨이 달린 데이터셋으로 학습되며, 학습 중에 본 클래스들로만 제한됩니다. 이미지가 주어지면, 이미지 분할 모델은 여러 마스크와 그에 해당하는 클래스를 반환합니다.
+
+반면, 마스크 생성 모델은 대량의 데이터로 학습되며 두 가지 모드로 작동합니다.
+- 프롬프트 모드(Prompting mode): 이 모드에서는 모델이 이미지와 프롬프트를 입력받습니다. 프롬프트는 이미지 내 객체의 2D 좌표(XY 좌표)나 객체를 둘러싼 바운딩 박스가 될 수 있습니다. 프롬프트 모드에서는 모델이 프롬프트가 가리키는 객체의 마스크만 반환합니다.
+- 전체 분할 모드(Segment Everything mode): 이 모드에서는 주어진 이미지 내에서 모든 마스크를 생성합니다. 이를 위해 그리드 형태의 점들을 생성하고 이를 이미지에 오버레이하여 추론합니다.
+
+마스크 생성 작업은 [전체 분할 모드(Segment Anything Model, SAM)](model_doc/sam)에 의해 지원됩니다. SAM은 Vision Transformer 기반 이미지 인코더, 프롬프트 인코더, 그리고 양방향 트랜스포머 마스크 디코더로 구성된 강력한 모델입니다. 이미지와 프롬프트는 인코딩되고, 디코더는 이러한 임베딩을 받아 유효한 마스크를 생성합니다.
+
+
+
+
+
+SAM은 대규모 데이터를 다룰 수 있는 강력한 분할 기반 모델입니다. 이 모델은 100만 개의 이미지와 11억 개의 마스크를 포함하는 [SA-1B](https://ai.meta.com/datasets/segment-anything/) 데이터 세트로 학습되었습니다.
+
+이 가이드에서는 다음과 같은 내용을 배우게 됩니다:
+- 배치 처리와 함께 전체 분할 모드에서 추론하는 방법
+- 포인트 프롬프팅 모드에서 추론하는 방법
+- 박스 프롬프팅 모드에서 추론하는 방법
+
+먼저, `transformers`를 설치해 봅시다:
+
+```bash
+pip install -q transformers
+```
+
+## 마스크 생성 파이프라인[[mask-generation-pipeline]]
+
+마스크 생성 모델로 추론하는 가장 쉬운 방법은 `mask-generation` 파이프라인을 사용하는 것입니다.
+
+```python
+>>> from transformers import pipeline
+
+>>> checkpoint = "facebook/sam-vit-base"
+>>> mask_generator = pipeline(model=checkpoint, task="mask-generation")
+```
+
+이미지를 예시로 봅시다.
+
+```python
+from PIL import Image
+import requests
+
+img_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"
+image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
+```
+
+
+
+
+
+전체적으로 분할해봅시다. `points-per-batch`는 전체 분할 모드에서 점들의 병렬 추론을 가능하게 합니다. 이를 통해 추론 속도가 빨라지지만, 더 많은 메모리를 소모하게 됩니다. 또한, SAM은 이미지가 아닌 점들에 대해서만 배치 처리를 지원합니다. `pred_iou_thresh`는 IoU 신뢰 임계값으로, 이 임계값을 초과하는 마스크만 반환됩니다.
+
+```python
+masks = mask_generator(image, points_per_batch=128, pred_iou_thresh=0.88)
+```
+
+`masks` 는 다음과 같이 생겼습니다:
+
+```bash
+{'masks': [array([[False, False, False, ..., True, True, True],
+ [False, False, False, ..., True, True, True],
+ [False, False, False, ..., True, True, True],
+ ...,
+ [False, False, False, ..., False, False, False],
+ [False, False, False, ..., False, False, False],
+ [False, False, False, ..., False, False, False]]),
+ array([[False, False, False, ..., False, False, False],
+ [False, False, False, ..., False, False, False],
+ [False, False, False, ..., False, False, False],
+ ...,
+'scores': tensor([0.9972, 0.9917,
+ ...,
+}
+```
+
+위 내용을 아래와 같이 시각화할 수 있습니다:
+
+```python
+import matplotlib.pyplot as plt
+
+plt.imshow(image, cmap='gray')
+
+for i, mask in enumerate(masks["masks"]):
+ plt.imshow(mask, cmap='viridis', alpha=0.1, vmin=0, vmax=1)
+
+plt.axis('off')
+plt.show()
+```
+
+아래는 회색조 원본 이미지에 다채로운 색상의 맵을 겹쳐놓은 모습입니다. 매우 인상적인 결과입니다.
+
+
+
+
+
+## 모델 추론[[model-inference]]
+
+### 포인트 프롬프팅[[point-prompting]]
+
+파이프라인 없이도 모델을 사용할 수 있습니다. 이를 위해 모델과 프로세서를 초기화해야 합니다.
+
+```python
+from transformers import SamModel, SamProcessor
+import torch
+
+device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+
+model = SamModel.from_pretrained("facebook/sam-vit-base").to(device)
+processor = SamProcessor.from_pretrained("facebook/sam-vit-base")
+```
+
+포인트 프롬프팅을 하기 위해, 입력 포인트를 프로세서에 전달한 다음, 프로세서 출력을 받아 모델에 전달하여 추론합니다. 모델 출력을 후처리하려면, 출력과 함께 프로세서의 초기 출력에서 가져온 `original_sizes`와 `reshaped_input_sizes`를 전달해야 합니다. 왜냐하면, 프로세서가 이미지 크기를 조정하고 출력을 추정해야 하기 때문입니다.
+
+```python
+input_points = [[[2592, 1728]]] # 벌의 포인트 위치
+
+inputs = processor(image, input_points=input_points, return_tensors="pt").to(device)
+with torch.no_grad():
+ outputs = model(**inputs)
+masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu())
+```
+
+`masks` 출력으로 세 가지 마스크를 시각화할 수 있습니다.
+
+```python
+import matplotlib.pyplot as plt
+import numpy as np
+
+fig, axes = plt.subplots(1, 4, figsize=(15, 5))
+
+axes[0].imshow(image)
+axes[0].set_title('Original Image')
+mask_list = [masks[0][0][0].numpy(), masks[0][0][1].numpy(), masks[0][0][2].numpy()]
+
+for i, mask in enumerate(mask_list, start=1):
+ overlayed_image = np.array(image).copy()
+
+ overlayed_image[:,:,0] = np.where(mask == 1, 255, overlayed_image[:,:,0])
+ overlayed_image[:,:,1] = np.where(mask == 1, 0, overlayed_image[:,:,1])
+ overlayed_image[:,:,2] = np.where(mask == 1, 0, overlayed_image[:,:,2])
+
+ axes[i].imshow(overlayed_image)
+ axes[i].set_title(f'Mask {i}')
+for ax in axes:
+ ax.axis('off')
+
+plt.show()
+```
+
+
+
+
+
+### 박스 프롬프팅[[box-prompting]]
+
+박스 프롬프팅도 포인트 프롬프팅과 유사한 방식으로 할 수 있습니다. 입력 박스를 `[x_min, y_min, x_max, y_max]` 형식의 리스트로 작성하여 이미지와 함께 `processor`에 전달할 수 있습니다. 프로세서 출력을 받아 모델에 직접 전달한 후, 다시 출력을 후처리해야 합니다.
+
+```python
+# 벌 주위의 바운딩 박스
+box = [2350, 1600, 2850, 2100]
+
+inputs = processor(
+ image,
+ input_boxes=[[[box]]],
+ return_tensors="pt"
+ ).to("cuda")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+mask = processor.image_processor.post_process_masks(
+ outputs.pred_masks.cpu(),
+ inputs["original_sizes"].cpu(),
+ inputs["reshaped_input_sizes"].cpu()
+)[0][0][0].numpy()
+```
+
+이제 아래와 같이, 벌 주위의 바운딩 박스를 시각화할 수 있습니다.
+
+```python
+import matplotlib.patches as patches
+
+fig, ax = plt.subplots()
+ax.imshow(image)
+
+rectangle = patches.Rectangle((2350, 1600), 500, 500, linewidth=2, edgecolor='r', facecolor='none')
+ax.add_patch(rectangle)
+ax.axis("off")
+plt.show()
+```
+
+
+
+
+
+아래에서 추론 결과를 확인할 수 있습니다.
+
+```python
+fig, ax = plt.subplots()
+ax.imshow(image)
+ax.imshow(mask, cmap='viridis', alpha=0.4)
+
+ax.axis("off")
+plt.show()
+```
+
+
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/masked_language_modeling.md b/docs/transformers/docs/source/ko/tasks/masked_language_modeling.md
new file mode 100644
index 0000000000000000000000000000000000000000..74df085c5b558fcaecc6828076a7cd4e9b6601c8
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/masked_language_modeling.md
@@ -0,0 +1,441 @@
+
+
+# 마스킹된 언어 모델링(Masked language modeling)[[masked-language-modeling]]
+
+[[open-in-colab]]
+
+
+
+마스킹된 언어 모델링은 시퀀스에서 마스킹된 토큰을 예측하며, 모델은 양방향으로 토큰에 액세스할 수 있습니다.
+즉, 모델은 토큰의 왼쪽과 오른쪽 양쪽에서 접근할 수 있습니다.
+마스킹된 언어 모델링은 전체 시퀀스에 대한 문맥적 이해가 필요한 작업에 적합하며, BERT가 그 예에 해당합니다.
+
+이번 가이드에서 다룰 내용은 다음과 같습니다:
+
+1. [ELI5](https://huggingface.co/datasets/eli5) 데이터 세트에서 [r/askscience](https://www.reddit.com/r/askscience/) 부분을 사용해 [DistilRoBERTa](https://huggingface.co/distilbert/distilroberta-base) 모델을 미세 조정합니다.
+2. 추론 시에 직접 미세 조정한 모델을 사용합니다.
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/fill-mask)를 확인하는 것이 좋습니다.
+
+
+
+시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers datasets evaluate
+```
+
+Hugging Face 계정에 로그인하여 모델을 업로드하고 커뮤니티와의 공유를 권장합니다. 메시지가 표시되면(When prompted) 토큰을 입력하여 로그인합니다:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## ELI5 데이터 세트 가져오기[[load-eli5-dataset]]
+
+먼저 🤗 Datasets 라이브러리에서 ELI5 데이터 세트의 r/askscience 중 일부만 가져옵니다.
+이렇게 하면 전체 데이터 세트 학습에 더 많은 시간을 할애하기 전에 모든 것이 작동하는지 실험하고 확인할 수 있습니다.
+
+```py
+>>> from datasets import load_dataset
+
+>>> eli5 = load_dataset("eli5", split="train_asks[:5000]")
+```
+
+데이터 세트의 `train_asks`를 [`~datasets.Dataset.train_test_split`] 메소드를 사용해 훈련 데이터와 테스트 데이터로 분할합니다:
+
+```py
+>>> eli5 = eli5.train_test_split(test_size=0.2)
+```
+
+그리고 아래 예시를 살펴보세요:
+
+```py
+>>> eli5["train"][0]
+{'answers': {'a_id': ['c3d1aib', 'c3d4lya'],
+ 'score': [6, 3],
+ 'text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
+ "Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"]},
+ 'answers_urls': {'url': []},
+ 'document': '',
+ 'q_id': 'nyxfp',
+ 'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
+ 'selftext_urls': {'url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg']},
+ 'subreddit': 'askscience',
+ 'title': 'Few questions about this space walk photograph.',
+ 'title_urls': {'url': []}}
+```
+
+많아 보일 수 있지만 실제로는 `text` 필드에만 집중하면 됩나다.
+언어 모델링 작업의 멋진 점은 (비지도 학습으로) *다음 단어가 레이블*이기 때문에 레이블이 따로 필요하지 않습니다.
+
+## 전처리[[preprocess]]
+
+
+
+마스킹된 언어 모델링을 위해, 다음 단계로 DistilRoBERTa 토크나이저를 가져와서 `text` 하위 필드를 처리합니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilroberta-base")
+```
+
+위의 예제에서와 마찬가지로, `text` 필드는 `answers` 안에 중첩되어 있습니다.
+따라서 중첩된 구조에서 [`flatten`](https://huggingface.co/docs/datasets/process#flatten) 메소드를 사용하여 `text` 하위 필드를 추출합니다:
+
+```py
+>>> eli5 = eli5.flatten()
+>>> eli5["train"][0]
+{'answers.a_id': ['c3d1aib', 'c3d4lya'],
+ 'answers.score': [6, 3],
+ 'answers.text': ["The velocity needed to remain in orbit is equal to the square root of Newton's constant times the mass of earth divided by the distance from the center of the earth. I don't know the altitude of that specific mission, but they're usually around 300 km. That means he's going 7-8 km/s.\n\nIn space there are no other forces acting on either the shuttle or the guy, so they stay in the same position relative to each other. If he were to become unable to return to the ship, he would presumably run out of oxygen, or slowly fall into the atmosphere and burn up.",
+ "Hope you don't mind me asking another question, but why aren't there any stars visible in this photo?"],
+ 'answers_urls.url': [],
+ 'document': '',
+ 'q_id': 'nyxfp',
+ 'selftext': '_URL_0_\n\nThis was on the front page earlier and I have a few questions about it. Is it possible to calculate how fast the astronaut would be orbiting the earth? Also how does he stay close to the shuttle so that he can return safely, i.e is he orbiting at the same speed and can therefore stay next to it? And finally if his propulsion system failed, would he eventually re-enter the atmosphere and presumably die?',
+ 'selftext_urls.url': ['http://apod.nasa.gov/apod/image/1201/freeflyer_nasa_3000.jpg'],
+ 'subreddit': 'askscience',
+ 'title': 'Few questions about this space walk photograph.',
+ 'title_urls.url': []}
+```
+
+이제 각 하위 필드는 `answers` 접두사(prefix)로 표시된 대로 별도의 열이 되고, `text` 필드는 이제 리스트가 되었습니다.
+각 문장을 개별적으로 토큰화하는 대신 리스트를 문자열로 변환하여 한번에 토큰화할 수 있습니다.
+
+다음은 각 예제에 대해 문자열로 이루어진 리스트를 `join`하고 결과를 토큰화하는 첫 번째 전처리 함수입니다:
+
+```py
+>>> def preprocess_function(examples):
+... return tokenizer([" ".join(x) for x in examples["answers.text"]])
+```
+
+이 전처리 함수를 전체 데이터 세트에 적용하기 위해 🤗 Datasets [`~datasets.Dataset.map`] 메소드를 사용합니다.
+데이터 세트의 여러 요소를 한 번에 처리하도록 `batched=True`를 설정하고 `num_proc`로 처리 횟수를 늘리면 `map` 함수의 속도를 높일 수 있습니다.
+필요하지 않은 열은 제거합니다:
+
+```py
+>>> tokenized_eli5 = eli5.map(
+... preprocess_function,
+... batched=True,
+... num_proc=4,
+... remove_columns=eli5["train"].column_names,
+... )
+```
+
+이 데이터 세트에는 토큰 시퀀스가 포함되어 있지만 이 중 일부는 모델의 최대 입력 길이보다 깁니다.
+
+이제 두 번째 전처리 함수를 사용해
+- 모든 시퀀스를 연결하고
+- 연결된 시퀀스를 정의한 `block_size` 보다 더 짧은 덩어리로 분할하는데, 이 덩어리는 모델의 최대 입력 길이보다 짧고 GPU RAM이 수용할 수 있는 길이여야 합니다.
+
+
+```py
+>>> block_size = 128
+
+
+>>> def group_texts(examples):
+... # Concatenate all texts.
+... concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
+... total_length = len(concatenated_examples[list(examples.keys())[0]])
+... # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
+... # customize this part to your needs.
+... if total_length >= block_size:
+... total_length = (total_length // block_size) * block_size
+... # Split by chunks of block_size.
+... result = {
+... k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
+... for k, t in concatenated_examples.items()
+... }
+... result["labels"] = result["input_ids"].copy()
+... return result
+```
+
+전체 데이터 세트에 `group_texts` 함수를 적용합니다:
+
+```py
+>>> lm_dataset = tokenized_eli5.map(group_texts, batched=True, num_proc=4)
+```
+
+이제 [`DataCollatorForLanguageModeling`]을 사용하여 데이터 예제의 배치를 생성합니다.
+데이터 세트 전체를 최대 길이로 패딩하는 것보다 collation 단계에서 매 배치안에서의 최대 길이로 문장을 *동적으로 패딩*하는 것이 더 효율적입니다.
+
+
+
+
+시퀀스 끝 토큰을 패딩 토큰으로 사용하고 데이터를 반복할 때마다 토큰을 무작위로 마스킹하도록 `mlm_-probability`를 지정합니다:
+
+```py
+>>> from transformers import DataCollatorForLanguageModeling
+
+>>> tokenizer.pad_token = tokenizer.eos_token
+>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
+```
+
+
+
+시퀀스 끝 토큰을 패딩 토큰으로 사용하고 데이터를 반복할 때마다 토큰을 무작위로 마스킹하도록 `mlm_-probability`를 지정합니다:
+
+```py
+>>> from transformers import DataCollatorForLanguageModeling
+
+>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15, return_tensors="tf")
+```
+
+
+
+## 훈련[[train]]
+
+
+
+
+
+[`Trainer`]로 모델을 미세 조정하는 데 익숙하지 않다면 기본 튜토리얼 [여기](../training#train-with-pytorch-trainer)를 살펴보세요!
+
+
+이제 모델 훈련을 시작할 준비가 되었습니다! [`AutoModelForMaskedLM`]를 사용해 DistilRoBERTa 모델을 가져옵니다:
+
+```py
+>>> from transformers import AutoModelForMaskedLM
+
+>>> model = AutoModelForMaskedLM.from_pretrained("distilbert/distilroberta-base")
+```
+
+이제 세 단계가 남았습니다:
+
+1. [`TrainingArguments`]의 훈련 하이퍼파라미터를 정의합니다. 모델 저장 위치를 지정하는 `output_dir`은 유일한 필수 파라미터입니다. `push_to_hub=True`를 설정하여 이 모델을 Hub에 업로드합니다 (모델을 업로드하려면 Hugging Face에 로그인해야 합니다).
+2. 모델, 데이터 세트 및 데이터 콜레이터(collator)와 함께 훈련 인수를 [`Trainer`]에 전달합니다.
+3. [`~Trainer.train`]을 호출하여 모델을 미세 조정합니다.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_eli5_mlm_model",
+... eval_strategy="epoch",
+... learning_rate=2e-5,
+... num_train_epochs=3,
+... weight_decay=0.01,
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=lm_dataset["train"],
+... eval_dataset=lm_dataset["test"],
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+훈련이 완료되면 [`~transformers.Trainer.evaluate`] 메소드를 사용하여 펄플렉서티(perplexity)를 계산하고 모델을 평가합니다:
+
+```py
+>>> import math
+
+>>> eval_results = trainer.evaluate()
+>>> print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
+Perplexity: 8.76
+```
+
+그리고 [`~transformers.Trainer.push_to_hub`] 메소드를 사용해 다른 사람들이 사용할 수 있도록, Hub로 모델을 업로드합니다.
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+Keras로 모델을 미세 조정하는 데 익숙하지 않다면 기본 튜토리얼 [여기](../training#train-a-tensorflow-model-with-keras)를 살펴보세요!
+
+
+TensorFlow로 모델을 미세 조정하기 위해서는 옵티마이저(optimizer) 함수 설정, 학습률(learning rate) 스케쥴링, 훈련 하이퍼파라미터 설정부터 시작하세요:
+
+```py
+>>> from transformers import create_optimizer, AdamWeightDecay
+
+>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
+```
+
+다음으로 [`TFAutoModelForMaskedLM`]를 사용해 DistilRoBERTa 모델을 가져옵니다:
+
+```py
+>>> from transformers import TFAutoModelForMaskedLM
+
+>>> model = TFAutoModelForMaskedLM.from_pretrained("distilbert/distilroberta-base")
+```
+
+[`~transformers.TFPreTrainedModel.prepare_tf_dataset`] 메소드를 사용해 데이터 세트를 `tf.data.Dataset` 형식으로 변환하세요:
+
+```py
+>>> tf_train_set = model.prepare_tf_dataset(
+... lm_dataset["train"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_test_set = model.prepare_tf_dataset(
+... lm_dataset["test"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+[`compile`](https://keras.io/api/models/model_training_apis/#compile-method) 메소드를 통해 모델 훈련을 구성합니다:
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer)
+```
+
+이는 업로드할 모델과 토크나이저의 위치를 [`~transformers.PushToHubCallback`]에 지정하여 수행할 수 있습니다:
+
+```py
+>>> from transformers.keras_callbacks import PushToHubCallback
+
+>>> callback = PushToHubCallback(
+... output_dir="my_awesome_eli5_mlm_model",
+... tokenizer=tokenizer,
+... )
+```
+
+드디어 모델을 훈련할 준비가 되었습니다!
+모델을 미세 조정할 때 훈련 및 검증 데이터 세트, 에포크 수, 콜백이 포함된 [`fit`](https://keras.io/api/models/model_training_apis/#fit-method)을 호출합니다:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=[callback])
+```
+
+훈련이 완료되면, 자동으로 Hub로 업로드되어 누구나 사용할 수 있습니다!
+
+
+
+
+
+마스킹된 언어 모델링을 위해 모델을 미세 조정하는 방법에 대한 보다 심층적인 예제는
+[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
+또는 [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)을 참조하세요.
+
+
+## 추론[[inference]]
+
+지금까지 모델 미세 조정을 잘 했으니, 추론에 사용할 수 있습니다!
+
+모델이 빈칸을 채울 텍스트를 스페셜 토큰(special token)인 `` 토큰으로 표시합니다:
+
+
+```py
+>>> text = "The Milky Way is a galaxy."
+```
+추론을 위해 미세 조정한 모델을 테스트하는 가장 간단한 방법은 [`pipeline`]에서 사용하는 것입니다.
+`fill-mask`태스크로 `pipeline`을 인스턴스화하고 텍스트를 전달합니다.
+`top_k` 매개변수를 사용하여 반환하는 예측의 수를 지정할 수 있습니다:
+
+```py
+>>> from transformers import pipeline
+
+>>> mask_filler = pipeline("fill-mask", "stevhliu/my_awesome_eli5_mlm_model")
+>>> mask_filler(text, top_k=3)
+[{'score': 0.5150994658470154,
+ 'token': 21300,
+ 'token_str': ' spiral',
+ 'sequence': 'The Milky Way is a spiral galaxy.'},
+ {'score': 0.07087188959121704,
+ 'token': 2232,
+ 'token_str': ' massive',
+ 'sequence': 'The Milky Way is a massive galaxy.'},
+ {'score': 0.06434620916843414,
+ 'token': 650,
+ 'token_str': ' small',
+ 'sequence': 'The Milky Way is a small galaxy.'}]
+```
+
+
+
+텍스트를 토큰화하고 `input_ids`를 PyTorch 텐서 형태로 반환합니다.
+또한, `` 토큰의 위치를 지정해야 합니다:
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_eli5_mlm_model")
+>>> inputs = tokenizer(text, return_tensors="pt")
+>>> mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
+```
+
+모델에 `inputs`를 입력하고, 마스킹된 토큰의 `logits`를 반환합니다:
+
+```py
+>>> from transformers import AutoModelForMaskedLM
+
+>>> model = AutoModelForMaskedLM.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
+>>> logits = model(**inputs).logits
+>>> mask_token_logits = logits[0, mask_token_index, :]
+```
+
+그런 다음 가장 높은 확률은 가진 마스크 토큰 3개를 반환하고, 출력합니다:
+```py
+>>> top_3_tokens = torch.topk(mask_token_logits, 3, dim=1).indices[0].tolist()
+
+>>> for token in top_3_tokens:
+... print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
+The Milky Way is a spiral galaxy.
+The Milky Way is a massive galaxy.
+The Milky Way is a small galaxy.
+```
+
+
+텍스트를 토큰화하고 `input_ids`를 TensorFlow 텐서 형태로 반환합니다.
+또한, `` 토큰의 위치를 지정해야 합니다:
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_eli5_mlm_model")
+>>> inputs = tokenizer(text, return_tensors="tf")
+>>> mask_token_index = tf.where(inputs["input_ids"] == tokenizer.mask_token_id)[0, 1]
+```
+
+모델에 `inputs`를 입력하고, 마스킹된 토큰의 `logits`를 반환합니다:
+
+```py
+>>> from transformers import TFAutoModelForMaskedLM
+
+>>> model = TFAutoModelForMaskedLM.from_pretrained("stevhliu/my_awesome_eli5_mlm_model")
+>>> logits = model(**inputs).logits
+>>> mask_token_logits = logits[0, mask_token_index, :]
+```
+
+그런 다음 가장 높은 확률은 가진 마스크 토큰 3개를 반환하고, 출력합니다:
+```py
+>>> top_3_tokens = tf.math.top_k(mask_token_logits, 3).indices.numpy()
+
+>>> for token in top_3_tokens:
+... print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
+The Milky Way is a spiral galaxy.
+The Milky Way is a massive galaxy.
+The Milky Way is a small galaxy.
+```
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/monocular_depth_estimation.md b/docs/transformers/docs/source/ko/tasks/monocular_depth_estimation.md
new file mode 100644
index 0000000000000000000000000000000000000000..2c640d2a86db3d59e63111be73a314313e7aee08
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/monocular_depth_estimation.md
@@ -0,0 +1,144 @@
+
+
+# 단일 영상 기반 깊이 추정[[depth-estimation-pipeline]]
+
+단일 영상 기반 깊이 추정은 한 장면의 단일 이미지에서 장면의 깊이 정보를 예측하는 컴퓨터 비전 작업입니다.
+즉, 단일 카메라 시점의 장면에 있는 물체의 거리를 예측하는 과정입니다.
+
+단일 영상 기반 깊이 추정은 3D 재구성, 증강 현실, 자율 주행, 로봇 공학 등 다양한 분야에서 응용됩니다.
+조명 조건, 가려짐, 텍스처와 같은 요소의 영향을 받을 수 있는 장면 내 물체와 해당 깊이 정보 간의 복잡한 관계를 모델이 이해해야 하므로 까다로운 작업입니다.
+
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/depth-estimation)를 확인하는 것이 좋습니다.
+
+
+
+이번 가이드에서 배울 내용은 다음과 같습니다:
+
+* 깊이 추정 파이프라인 만들기
+* 직접 깊이 추정 추론하기
+
+시작하기 전에, 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
+
+```bash
+pip install -q transformers
+```
+
+## 깊이 추정 파이프라인[[depth-estimation-inference-by-hand]]
+
+깊이 추정을 추론하는 가장 간단한 방법은 해당 기능을 제공하는 [`pipeline`]을 사용하는 것입니다.
+[Hugging Face Hub 체크포인트](https://huggingface.co/models?pipeline_tag=depth-estimation&sort=downloads)에서 파이프라인을 초기화합니다:
+
+```py
+>>> from transformers import pipeline
+
+>>> checkpoint = "vinvino02/glpn-nyu"
+>>> depth_estimator = pipeline("depth-estimation", model=checkpoint)
+```
+
+
+다음으로, 분석할 이미지를 한 장 선택하세요:
+
+```py
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "https://unsplash.com/photos/HwBAsSbPBDU/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8MzR8fGNhciUyMGluJTIwdGhlJTIwc3RyZWV0fGVufDB8MHx8fDE2Nzg5MDEwODg&force=true&w=640"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> image
+```
+
+
+
+
+
+이미지를 파이프라인으로 전달합니다.
+
+```py
+>>> predictions = depth_estimator(image)
+```
+
+파이프라인은 두 개의 항목을 가지는 딕셔너리를 반환합니다.
+첫 번째는 `predicted_depth`로 각 픽셀의 깊이를 미터로 표현한 값을 가지는 텐서입니다.
+두 번째는 `depth`로 깊이 추정 결과를 시각화하는 PIL 이미지입니다.
+
+이제 시각화한 결과를 살펴보겠습니다:
+
+```py
+>>> predictions["depth"]
+```
+
+
+
+
+
+## 직접 깊이 추정 추론하기[[depth-estimation-inference-by-hand]]
+
+이제 깊이 추정 파이프라인 사용법을 살펴보았으니 동일한 결과를 복제하는 방법을 살펴보겠습니다.
+[Hugging Face Hub 체크포인트](https://huggingface.co/models?pipeline_tag=depth-estimation&sort=downloads)에서 모델과 관련 프로세서를 가져오는 것부터 시작합니다.
+여기서 이전에 사용한 체크포인트와 동일한 것을 사용합니다:
+
+```py
+>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
+
+>>> checkpoint = "vinvino02/glpn-nyu"
+
+>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint)
+>>> model = AutoModelForDepthEstimation.from_pretrained(checkpoint)
+```
+
+필요한 이미지 변환을 처리하는 `image_processor`를 사용하여 모델에 대한 이미지 입력을 준비합니다.
+`image_processor`는 크기 조정 및 정규화 등 필요한 이미지 변환을 처리합니다:
+
+```py
+>>> pixel_values = image_processor(image, return_tensors="pt").pixel_values
+```
+
+준비한 입력을 모델로 전달합니다:
+
+```py
+>>> import torch
+
+>>> with torch.no_grad():
+... outputs = model(pixel_values)
+... predicted_depth = outputs.predicted_depth
+```
+
+결과를 시각화합니다:
+
+```py
+>>> import numpy as np
+
+>>> # 원본 사이즈로 복원
+>>> prediction = torch.nn.functional.interpolate(
+... predicted_depth.unsqueeze(1),
+... size=image.size[::-1],
+... mode="bicubic",
+... align_corners=False,
+... ).squeeze()
+>>> output = prediction.numpy()
+
+>>> formatted = (output * 255 / np.max(output)).astype("uint8")
+>>> depth = Image.fromarray(formatted)
+>>> depth
+```
+
+
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/multiple_choice.md b/docs/transformers/docs/source/ko/tasks/multiple_choice.md
new file mode 100644
index 0000000000000000000000000000000000000000..e0888f4a0b6de15fdd7afafea07194a91ce67424
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/multiple_choice.md
@@ -0,0 +1,369 @@
+
+
+# 객관식 문제[[multiple-choice]]
+
+[[open-in-colab]]
+
+객관식 과제는 문맥과 함께 여러 개의 후보 답변이 제공되고 모델이 정답을 선택하도록 학습된다는 점을 제외하면 질의응답과 유사합니다.
+
+진행하는 방법은 아래와 같습니다:
+
+1. [SWAG](https://huggingface.co/datasets/swag) 데이터 세트의 'regular' 구성으로 [BERT](https://huggingface.co/google-bert/bert-base-uncased)를 미세 조정하여 여러 옵션과 일부 컨텍스트가 주어졌을 때 가장 적합한 답을 선택합니다.
+2. 추론에 미세 조정된 모델을 사용합니다.
+
+시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers datasets evaluate
+```
+
+모델을 업로드하고 커뮤니티와 공유할 수 있도록 허깅페이스 계정에 로그인하는 것이 좋습니다. 메시지가 표시되면 토큰을 입력하여 로그인합니다:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## SWAG 데이터 세트 가져오기[[load-swag-dataset]]
+
+먼저 🤗 Datasets 라이브러리에서 SWAG 데이터셋의 '일반' 구성을 가져옵니다:
+
+```py
+>>> from datasets import load_dataset
+
+>>> swag = load_dataset("swag", "regular")
+```
+
+이제 데이터를 살펴봅니다:
+
+```py
+>>> swag["train"][0]
+{'ending0': 'passes by walking down the street playing their instruments.',
+ 'ending1': 'has heard approaching them.',
+ 'ending2': "arrives and they're outside dancing and asleep.",
+ 'ending3': 'turns the lead singer watches the performance.',
+ 'fold-ind': '3416',
+ 'gold-source': 'gold',
+ 'label': 0,
+ 'sent1': 'Members of the procession walk down the street holding small horn brass instruments.',
+ 'sent2': 'A drum line',
+ 'startphrase': 'Members of the procession walk down the street holding small horn brass instruments. A drum line',
+ 'video-id': 'anetv_jkn6uvmqwh4'}
+```
+
+여기에는 많은 필드가 있는 것처럼 보이지만 실제로는 매우 간단합니다:
+
+- `sent1` 및 `sent2`: 이 필드는 문장이 어떻게 시작되는지 보여주며, 이 두 필드를 합치면 `시작 구절(startphrase)` 필드가 됩니다.
+- `종료 구절(ending)`: 문장이 어떻게 끝날 수 있는지에 대한 가능한 종료 구절를 제시하지만 그 중 하나만 정답입니다.
+- `레이블(label)`: 올바른 문장 종료 구절을 식별합니다.
+
+## 전처리[[preprocess]]
+
+다음 단계는 문장의 시작과 네 가지 가능한 구절을 처리하기 위해 BERT 토크나이저를 불러옵니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+```
+
+생성하려는 전처리 함수는 다음과 같아야 합니다:
+
+1. `sent1` 필드를 네 개 복사한 다음 각각을 `sent2`와 결합하여 문장이 시작되는 방식을 재현합니다.
+2. `sent2`를 네 가지 가능한 문장 구절 각각과 결합합니다.
+3. 이 두 목록을 토큰화할 수 있도록 평탄화(flatten)하고, 각 예제에 해당하는 `input_ids`, `attention_mask` 및 `labels` 필드를 갖도록 다차원화(unflatten) 합니다.
+
+```py
+>>> ending_names = ["ending0", "ending1", "ending2", "ending3"]
+
+
+>>> def preprocess_function(examples):
+... first_sentences = [[context] * 4 for context in examples["sent1"]]
+... question_headers = examples["sent2"]
+... second_sentences = [
+... [f"{header} {examples[end][i]}" for end in ending_names] for i, header in enumerate(question_headers)
+... ]
+
+... first_sentences = sum(first_sentences, [])
+... second_sentences = sum(second_sentences, [])
+
+... tokenized_examples = tokenizer(first_sentences, second_sentences, truncation=True)
+... return {k: [v[i : i + 4] for i in range(0, len(v), 4)] for k, v in tokenized_examples.items()}
+```
+
+전체 데이터 집합에 전처리 기능을 적용하려면 🤗 Datasets [`~datasets.Dataset.map`] 메소드를 사용합니다. `batched=True`를 설정하여 데이터 집합의 여러 요소를 한 번에 처리하면 `map` 함수의 속도를 높일 수 있습니다:
+
+```py
+tokenized_swag = swag.map(preprocess_function, batched=True)
+```
+
+[`DataCollatorForMultipleChoice`]는 모든 모델 입력을 평탄화하고 패딩을 적용하며 그 결과를 결과를 다차원화합니다:
+```py
+>>> from transformers import DataCollatorForMultipleChoice
+>>> collator = DataCollatorForMultipleChoice(tokenizer=tokenizer)
+```
+
+## 평가 하기[[evaluate]]
+
+훈련 중에 메트릭을 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다. 🤗[Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하여 평가 방법을 빠르게 가져올 수 있습니다. 이 작업에서는 [accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) 지표를 가져옵니다(🤗 Evaluate [둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하여 지표를 가져오고 계산하는 방법에 대해 자세히 알아보세요):
+
+```py
+>>> import evaluate
+
+>>> accuracy = evaluate.load("accuracy")
+```
+
+그리고 예측과 레이블을 [`~evaluate.EvaluationModule.compute`]에 전달하여 정확도를 계산하는 함수를 만듭니다:
+
+```py
+>>> import numpy as np
+
+
+>>> def compute_metrics(eval_pred):
+... predictions, labels = eval_pred
+... predictions = np.argmax(predictions, axis=1)
+... return accuracy.compute(predictions=predictions, references=labels)
+```
+
+이제 `compute_metrics` 함수를 사용할 준비가 되었으며, 훈련을 설정할 때 이 함수로 돌아가게 됩니다.
+
+## 훈련 하기[[train]]
+
+
+
+
+
+[`Trainer`]로 모델을 미세 조정하는 데 익숙하지 않다면 기본 튜토리얼 [여기](../training#train-with-pytorch-trainer)를 살펴보세요!
+
+
+
+이제 모델 훈련을 시작할 준비가 되었습니다! [`AutoModelForMultipleChoice`]로 BERT를 로드합니다:
+
+```py
+>>> from transformers import AutoModelForMultipleChoice, TrainingArguments, Trainer
+
+>>> model = AutoModelForMultipleChoice.from_pretrained("google-bert/bert-base-uncased")
+```
+
+이제 세 단계만 남았습니다:
+
+1. 훈련 하이퍼파라미터를 [`TrainingArguments`]에 정의합니다. 유일한 필수 매개변수는 모델을 저장할 위치를 지정하는 `output_dir`입니다. `push_to_hub=True`를 설정하여 이 모델을 허브에 푸시합니다(모델을 업로드하려면 허깅 페이스에 로그인해야 합니다). 각 에폭이 끝날 때마다 [`Trainer`]가 정확도를 평가하고 훈련 체크포인트를 저장합니다.
+2. 모델, 데이터 세트, 토크나이저, 데이터 콜레이터, `compute_metrics` 함수와 함께 훈련 인자를 [`Trainer`]에 전달합니다.
+3. [`~Trainer.train`]을 사용하여 모델을 미세 조정합니다.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_swag_model",
+... eval_strategy="epoch",
+... save_strategy="epoch",
+... load_best_model_at_end=True,
+... learning_rate=5e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... num_train_epochs=3,
+... weight_decay=0.01,
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_swag["train"],
+... eval_dataset=tokenized_swag["validation"],
+... processing_class=tokenizer,
+... data_collator=collator,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+
+훈련이 완료되면 모든 사람이 모델을 사용할 수 있도록 [`~transformers.Trainer.push_to_hub`] 메소드를 사용하여 모델을 허브에 공유하세요:
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+Keras로 모델을 미세 조정하는 데 익숙하지 않다면 기본 튜토리얼 [여기](../training#train-a-tensorflow-model-with-keras)를 살펴보시기 바랍니다!
+
+
+TensorFlow에서 모델을 미세 조정하려면 최적화 함수, 학습률 스케쥴 및 몇 가지 학습 하이퍼파라미터를 설정하는 것부터 시작하세요:
+
+```py
+>>> from transformers import create_optimizer
+
+>>> batch_size = 16
+>>> num_train_epochs = 2
+>>> total_train_steps = (len(tokenized_swag["train"]) // batch_size) * num_train_epochs
+>>> optimizer, schedule = create_optimizer(init_lr=5e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
+```
+
+그리고 [`TFAutoModelForMultipleChoice`]로 BERT를 가져올 수 있습니다:
+
+```py
+>>> from transformers import TFAutoModelForMultipleChoice
+
+>>> model = TFAutoModelForMultipleChoice.from_pretrained("google-bert/bert-base-uncased")
+```
+
+[`~transformers.TFPreTrainedModel.prepare_tf_dataset`]을 사용하여 데이터 세트를 `tf.data.Dataset` 형식으로 변환합니다:
+
+```py
+>>> data_collator = DataCollatorForMultipleChoice(tokenizer=tokenizer)
+>>> tf_train_set = model.prepare_tf_dataset(
+... tokenized_swag["train"],
+... shuffle=True,
+... batch_size=batch_size,
+... collate_fn=data_collator,
+... )
+
+>>> tf_validation_set = model.prepare_tf_dataset(
+... tokenized_swag["validation"],
+... shuffle=False,
+... batch_size=batch_size,
+... collate_fn=data_collator,
+... )
+```
+
+[`compile`](https://keras.io/api/models/model_training_apis/#compile-method)을 사용하여 훈련 모델을 구성합니다:
+
+```py
+>>> model.compile(optimizer=optimizer)
+```
+
+훈련을 시작하기 전에 설정해야 할 마지막 두 가지는 예측의 정확도를 계산하고 모델을 허브로 푸시하는 방법을 제공하는 것입니다. 이 두 가지 작업은 모두 [Keras 콜백](../main_classes/keras_callbacks)을 사용하여 수행할 수 있습니다.
+
+`compute_metrics`함수를 [`~transformers.KerasMetricCallback`]에 전달하세요:
+
+```py
+>>> from transformers.keras_callbacks import KerasMetricCallback
+
+>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
+```
+
+모델과 토크나이저를 업로드할 위치를 [`~transformers.PushToHubCallback`]에서 지정하세요:
+
+```py
+>>> from transformers.keras_callbacks import PushToHubCallback
+
+>>> push_to_hub_callback = PushToHubCallback(
+... output_dir="my_awesome_model",
+... tokenizer=tokenizer,
+... )
+```
+
+그리고 콜백을 함께 묶습니다:
+
+```py
+>>> callbacks = [metric_callback, push_to_hub_callback]
+```
+
+이제 모델 훈련을 시작합니다! 훈련 및 검증 데이터 세트, 에폭 수, 콜백을 사용하여 [`fit`](https://keras.io/api/models/model_training_apis/#fit-method)을 호출하고 모델을 미세 조정합니다:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=2, callbacks=callbacks)
+```
+
+훈련이 완료되면 모델이 자동으로 허브에 업로드되어 누구나 사용할 수 있습니다!
+
+
+
+
+
+
+객관식 모델을 미세 조정하는 방법에 대한 보다 심층적인 예는 아래 문서를 참조하세요.
+[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)
+또는 [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb).
+
+
+
+## 추론 하기[[inference]]
+
+이제 모델을 미세 조정했으니 추론에 사용할 수 있습니다!
+
+텍스트와 두 개의 후보 답안을 작성합니다:
+
+```py
+>>> prompt = "France has a bread law, Le Décret Pain, with strict rules on what is allowed in a traditional baguette."
+>>> candidate1 = "The law does not apply to croissants and brioche."
+>>> candidate2 = "The law applies to baguettes."
+```
+
+
+
+각 프롬프트와 후보 답변 쌍을 토큰화하여 PyTorch 텐서를 반환합니다. 또한 `labels`을 생성해야 합니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_swag_model")
+>>> inputs = tokenizer([[prompt, candidate1], [prompt, candidate2]], return_tensors="pt", padding=True)
+>>> labels = torch.tensor(0).unsqueeze(0)
+```
+
+입력과 레이블을 모델에 전달하고 `logits`을 반환합니다:
+
+```py
+>>> from transformers import AutoModelForMultipleChoice
+
+>>> model = AutoModelForMultipleChoice.from_pretrained("my_awesome_swag_model")
+>>> outputs = model(**{k: v.unsqueeze(0) for k, v in inputs.items()}, labels=labels)
+>>> logits = outputs.logits
+```
+
+가장 높은 확률을 가진 클래스를 가져옵니다:
+
+```py
+>>> predicted_class = logits.argmax().item()
+>>> predicted_class
+'0'
+```
+
+
+각 프롬프트와 후보 답안 쌍을 토큰화하여 텐서플로 텐서를 반환합니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_swag_model")
+>>> inputs = tokenizer([[prompt, candidate1], [prompt, candidate2]], return_tensors="tf", padding=True)
+```
+
+모델에 입력을 전달하고 `logits`를 반환합니다:
+
+```py
+>>> from transformers import TFAutoModelForMultipleChoice
+
+>>> model = TFAutoModelForMultipleChoice.from_pretrained("my_awesome_swag_model")
+>>> inputs = {k: tf.expand_dims(v, 0) for k, v in inputs.items()}
+>>> outputs = model(inputs)
+>>> logits = outputs.logits
+```
+
+가장 높은 확률을 가진 클래스를 가져옵니다:
+
+```py
+>>> predicted_class = int(tf.math.argmax(logits, axis=-1)[0])
+>>> predicted_class
+'0'
+```
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/object_detection.md b/docs/transformers/docs/source/ko/tasks/object_detection.md
new file mode 100644
index 0000000000000000000000000000000000000000..e027ad65a9ada8c07b0af7403cf62d1e31f37099
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/object_detection.md
@@ -0,0 +1,583 @@
+
+
+# 객체 탐지 [[object-detection]]
+
+[[open-in-colab]]
+
+객체 탐지는 이미지에서 인스턴스(예: 사람, 건물 또는 자동차)를 감지하는 컴퓨터 비전 작업입니다. 객체 탐지 모델은 이미지를 입력으로 받고 탐지된 바운딩 박스의 좌표와 관련된 레이블을 출력합니다.
+하나의 이미지에는 여러 객체가 있을 수 있으며 각각은 자체적인 바운딩 박스와 레이블을 가질 수 있습니다(예: 차와 건물이 있는 이미지).
+또한 각 객체는 이미지의 다른 부분에 존재할 수 있습니다(예: 이미지에 여러 대의 차가 있을 수 있음).
+이 작업은 보행자, 도로 표지판, 신호등과 같은 것들을 감지하는 자율 주행에 일반적으로 사용됩니다.
+다른 응용 분야로는 이미지 내 객체 수 계산 및 이미지 검색 등이 있습니다.
+
+이 가이드에서 다음을 배울 것입니다:
+
+ 1. 합성곱 백본(인풋 데이터의 특성을 추출하는 합성곱 네트워크)과 인코더-디코더 트랜스포머 모델을 결합한 [DETR](https://huggingface.co/docs/transformers/model_doc/detr) 모델을 [CPPE-5](https://huggingface.co/datasets/cppe-5) 데이터 세트에 대해 미세조정 하기
+ 2. 미세조정 한 모델을 추론에 사용하기.
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/object-detection)를 확인하는 것이 좋습니다.
+
+
+
+시작하기 전에 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
+```bash
+pip install -q datasets transformers evaluate timm albumentations
+```
+
+허깅페이스 허브에서 데이터 세트를 가져오기 위한 🤗 Datasets과 모델을 학습하기 위한 🤗 Transformers, 데이터를 증강하기 위한 `albumentations`를 사용합니다.
+DETR 모델의 합성곱 백본을 가져오기 위해서는 현재 `timm`이 필요합니다.
+
+커뮤니티에 모델을 업로드하고 공유할 수 있도록 Hugging Face 계정에 로그인하는 것을 권장합니다. 프롬프트가 나타나면 토큰을 입력하여 로그인하세요:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## CPPE-5 데이터 세트 가져오기 [[load-the-CPPE-5-dataset]]
+
+[CPPE-5](https://huggingface.co/datasets/cppe-5) 데이터 세트는 COVID-19 대유행 상황에서 의료 전문인력 보호 장비(PPE)를 식별하는 어노테이션이 포함된 이미지를 담고 있습니다.
+
+데이터 세트를 가져오세요:
+
+```py
+>>> from datasets import load_dataset
+
+>>> cppe5 = load_dataset("cppe-5")
+>>> cppe5
+DatasetDict({
+ train: Dataset({
+ features: ['image_id', 'image', 'width', 'height', 'objects'],
+ num_rows: 1000
+ })
+ test: Dataset({
+ features: ['image_id', 'image', 'width', 'height', 'objects'],
+ num_rows: 29
+ })
+})
+```
+
+이 데이터 세트는 학습 세트 이미지 1,000개와 테스트 세트 이미지 29개를 갖고 있습니다.
+
+데이터에 익숙해지기 위해, 예시가 어떻게 구성되어 있는지 살펴보세요.
+
+```py
+>>> cppe5["train"][0]
+{'image_id': 15,
+ 'image': ,
+ 'width': 943,
+ 'height': 663,
+ 'objects': {'id': [114, 115, 116, 117],
+ 'area': [3796, 1596, 152768, 81002],
+ 'bbox': [[302.0, 109.0, 73.0, 52.0],
+ [810.0, 100.0, 57.0, 28.0],
+ [160.0, 31.0, 248.0, 616.0],
+ [741.0, 68.0, 202.0, 401.0]],
+ 'category': [4, 4, 0, 0]}}
+```
+
+데이터 세트에 있는 예시는 다음의 영역을 가지고 있습니다:
+
+- `image_id`: 예시 이미지 id
+- `image`: 이미지를 포함하는 `PIL.Image.Image` 객체
+- `width`: 이미지의 너비
+- `height`: 이미지의 높이
+- `objects`: 이미지 안의 객체들의 바운딩 박스 메타데이터를 포함하는 딕셔너리:
+ - `id`: 어노테이션 id
+ - `area`: 바운딩 박스의 면적
+ - `bbox`: 객체의 바운딩 박스 ([COCO 포맷](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco)으로)
+ - `category`: 객체의 카테고리, 가능한 값으로는 `Coverall (0)`, `Face_Shield (1)`, `Gloves (2)`, `Goggles (3)` 및 `Mask (4)` 가 포함됩니다.
+
+`bbox` 필드가 DETR 모델이 요구하는 COCO 형식을 따른다는 것을 알 수 있습니다.
+그러나 `objects` 내부의 필드 그룹은 DETR이 요구하는 어노테이션 형식과 다릅니다. 따라서 이 데이터를 학습에 사용하기 전에 전처리를 적용해야 합니다.
+
+데이터를 더 잘 이해하기 위해서 데이터 세트에서 한 가지 예시를 시각화하세요.
+
+```py
+>>> import numpy as np
+>>> import os
+>>> from PIL import Image, ImageDraw
+
+>>> image = cppe5["train"][0]["image"]
+>>> annotations = cppe5["train"][0]["objects"]
+>>> draw = ImageDraw.Draw(image)
+
+>>> categories = cppe5["train"].features["objects"].feature["category"].names
+
+>>> id2label = {index: x for index, x in enumerate(categories, start=0)}
+>>> label2id = {v: k for k, v in id2label.items()}
+
+>>> for i in range(len(annotations["id"])):
+... box = annotations["bbox"][i - 1]
+... class_idx = annotations["category"][i - 1]
+... x, y, w, h = tuple(box)
+... draw.rectangle((x, y, x + w, y + h), outline="red", width=1)
+... draw.text((x, y), id2label[class_idx], fill="white")
+
+>>> image
+```
+
+
+
+
+
+바운딩 박스와 연결된 레이블을 시각화하려면 데이터 세트의 메타 데이터, 특히 `category` 필드에서 레이블을 가져와야 합니다.
+또한 레이블 ID를 레이블 클래스에 매핑하는 `id2label`과 반대로 매핑하는 `label2id` 딕셔너리를 만들어야 합니다.
+모델을 설정할 때 이러한 매핑을 사용할 수 있습니다. 이러한 매핑은 허깅페이스 허브에서 모델을 공유했을 때 다른 사람들이 재사용할 수 있습니다.
+
+데이터를 더 잘 이해하기 위한 최종 단계로, 잠재적인 문제를 찾아보세요.
+객체 감지를 위한 데이터 세트에서 자주 발생하는 문제 중 하나는 바운딩 박스가 이미지의 가장자리를 넘어가는 것입니다.
+이러한 바운딩 박스를 "넘어가는 것(run away)"은 훈련 중에 오류를 발생시킬 수 있기에 이 단계에서 처리해야 합니다.
+이 데이터 세트에도 같은 문제가 있는 몇 가지 예가 있습니다. 이 가이드에서는 간단하게하기 위해 데이터에서 이러한 이미지를 제거합니다.
+
+```py
+>>> remove_idx = [590, 821, 822, 875, 876, 878, 879]
+>>> keep = [i for i in range(len(cppe5["train"])) if i not in remove_idx]
+>>> cppe5["train"] = cppe5["train"].select(keep)
+```
+
+## 데이터 전처리하기 [[preprocess-the-data]]
+
+모델을 미세 조정 하려면, 미리 학습된 모델에서 사용한 전처리 방식과 정확하게 일치하도록 사용할 데이터를 전처리해야 합니다.
+[`AutoImageProcessor`]는 이미지 데이터를 처리하여 DETR 모델이 학습에 사용할 수 있는 `pixel_values`, `pixel_mask`, 그리고 `labels`를 생성하는 작업을 담당합니다.
+이 이미지 프로세서에는 걱정하지 않아도 되는 몇 가지 속성이 있습니다:
+
+- `image_mean = [0.485, 0.456, 0.406 ]`
+- `image_std = [0.229, 0.224, 0.225]`
+
+
+이 값들은 모델 사전 훈련 중 이미지를 정규화하는 데 사용되는 평균과 표준 편차입니다.
+이 값들은 추론 또는 사전 훈련된 이미지 모델을 세밀하게 조정할 때 복제해야 하는 중요한 값입니다.
+
+사전 훈련된 모델과 동일한 체크포인트에서 이미지 프로세서를 인스턴스화합니다.
+
+```py
+>>> from transformers import AutoImageProcessor
+
+>>> checkpoint = "facebook/detr-resnet-50"
+>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint)
+```
+
+`image_processor`에 이미지를 전달하기 전에, 데이터 세트에 두 가지 전처리를 적용해야 합니다:
+
+- 이미지 증강
+- DETR 모델의 요구에 맞게 어노테이션을 다시 포맷팅
+
+첫째로, 모델이 학습 데이터에 과적합 되지 않도록 데이터 증강 라이브러리 중 아무거나 사용하여 변환을 적용할 수 있습니다. 여기에서는 [Albumentations](https://albumentations.ai/docs/) 라이브러리를 사용합니다...
+이 라이브러리는 변환을 이미지에 적용하고 바운딩 박스를 적절하게 업데이트하도록 보장합니다.
+🤗 Datasets 라이브러리 문서에는 [객체 탐지를 위해 이미지를 보강하는 방법에 대한 자세한 가이드](https://huggingface.co/docs/datasets/object_detection)가 있으며,
+이 예제와 정확히 동일한 데이터 세트를 사용합니다. 여기서는 각 이미지를 (480, 480) 크기로 조정하고, 좌우로 뒤집고, 밝기를 높이는 동일한 접근법을 적용합니다:
+
+
+```py
+>>> import albumentations
+>>> import numpy as np
+>>> import torch
+
+>>> transform = albumentations.Compose(
+... [
+... albumentations.Resize(480, 480),
+... albumentations.HorizontalFlip(p=1.0),
+... albumentations.RandomBrightnessContrast(p=1.0),
+... ],
+... bbox_params=albumentations.BboxParams(format="coco", label_fields=["category"]),
+... )
+```
+
+이미지 프로세서는 어노테이션이 다음과 같은 형식일 것으로 예상합니다: `{'image_id': int, 'annotations': List[Dict]}`, 여기서 각 딕셔너리는 COCO 객체 어노테이션입니다. 단일 예제에 대해 어노테이션의 형식을 다시 지정하는 함수를 추가해 보겠습니다:
+
+```py
+>>> def formatted_anns(image_id, category, area, bbox):
+... annotations = []
+... for i in range(0, len(category)):
+... new_ann = {
+... "image_id": image_id,
+... "category_id": category[i],
+... "isCrowd": 0,
+... "area": area[i],
+... "bbox": list(bbox[i]),
+... }
+... annotations.append(new_ann)
+
+... return annotations
+```
+
+이제 이미지와 어노테이션 전처리 변환을 결합하여 예제 배치에 사용할 수 있습니다:
+
+```py
+>>> # transforming a batch
+>>> def transform_aug_ann(examples):
+... image_ids = examples["image_id"]
+... images, bboxes, area, categories = [], [], [], []
+... for image, objects in zip(examples["image"], examples["objects"]):
+... image = np.array(image.convert("RGB"))[:, :, ::-1]
+... out = transform(image=image, bboxes=objects["bbox"], category=objects["category"])
+
+... area.append(objects["area"])
+... images.append(out["image"])
+... bboxes.append(out["bboxes"])
+... categories.append(out["category"])
+
+... targets = [
+... {"image_id": id_, "annotations": formatted_anns(id_, cat_, ar_, box_)}
+... for id_, cat_, ar_, box_ in zip(image_ids, categories, area, bboxes)
+... ]
+
+... return image_processor(images=images, annotations=targets, return_tensors="pt")
+```
+
+이전 단계에서 만든 전처리 함수를 🤗 Datasets의 [`~datasets.Dataset.with_transform`] 메소드를 사용하여 데이터 세트 전체에 적용합니다.
+이 메소드는 데이터 세트의 요소를 가져올 때마다 전처리 함수를 적용합니다.
+
+이 시점에서는 전처리 후 데이터 세트에서 예시 하나를 가져와서 변환 후 모양이 어떻게 되는지 확인해 볼 수 있습니다.
+이때, `pixel_values` 텐서, `pixel_mask` 텐서, 그리고 `labels`로 구성된 텐서가 있어야 합니다.
+
+```py
+>>> cppe5["train"] = cppe5["train"].with_transform(transform_aug_ann)
+>>> cppe5["train"][15]
+{'pixel_values': tensor([[[ 0.9132, 0.9132, 0.9132, ..., -1.9809, -1.9809, -1.9809],
+ [ 0.9132, 0.9132, 0.9132, ..., -1.9809, -1.9809, -1.9809],
+ [ 0.9132, 0.9132, 0.9132, ..., -1.9638, -1.9638, -1.9638],
+ ...,
+ [-1.5699, -1.5699, -1.5699, ..., -1.9980, -1.9980, -1.9980],
+ [-1.5528, -1.5528, -1.5528, ..., -1.9980, -1.9809, -1.9809],
+ [-1.5528, -1.5528, -1.5528, ..., -1.9980, -1.9809, -1.9809]],
+
+ [[ 1.3081, 1.3081, 1.3081, ..., -1.8431, -1.8431, -1.8431],
+ [ 1.3081, 1.3081, 1.3081, ..., -1.8431, -1.8431, -1.8431],
+ [ 1.3081, 1.3081, 1.3081, ..., -1.8256, -1.8256, -1.8256],
+ ...,
+ [-1.3179, -1.3179, -1.3179, ..., -1.8606, -1.8606, -1.8606],
+ [-1.3004, -1.3004, -1.3004, ..., -1.8606, -1.8431, -1.8431],
+ [-1.3004, -1.3004, -1.3004, ..., -1.8606, -1.8431, -1.8431]],
+
+ [[ 1.4200, 1.4200, 1.4200, ..., -1.6476, -1.6476, -1.6476],
+ [ 1.4200, 1.4200, 1.4200, ..., -1.6476, -1.6476, -1.6476],
+ [ 1.4200, 1.4200, 1.4200, ..., -1.6302, -1.6302, -1.6302],
+ ...,
+ [-1.0201, -1.0201, -1.0201, ..., -1.5604, -1.5604, -1.5604],
+ [-1.0027, -1.0027, -1.0027, ..., -1.5604, -1.5430, -1.5430],
+ [-1.0027, -1.0027, -1.0027, ..., -1.5604, -1.5430, -1.5430]]]),
+ 'pixel_mask': tensor([[1, 1, 1, ..., 1, 1, 1],
+ [1, 1, 1, ..., 1, 1, 1],
+ [1, 1, 1, ..., 1, 1, 1],
+ ...,
+ [1, 1, 1, ..., 1, 1, 1],
+ [1, 1, 1, ..., 1, 1, 1],
+ [1, 1, 1, ..., 1, 1, 1]]),
+ 'labels': {'size': tensor([800, 800]), 'image_id': tensor([756]), 'class_labels': tensor([4]), 'boxes': tensor([[0.7340, 0.6986, 0.3414, 0.5944]]), 'area': tensor([519544.4375]), 'iscrowd': tensor([0]), 'orig_size': tensor([480, 480])}}
+```
+
+각각의 이미지를 성공적으로 증강하고 이미지의 어노테이션을 준비했습니다.
+그러나 전처리는 아직 끝나지 않았습니다. 마지막 단계로, 이미지를 배치로 만들 사용자 정의 `collate_fn`을 생성합니다.
+해당 배치에서 가장 큰 이미지에 이미지(현재 `pixel_values` 인)를 패드하고, 실제 픽셀(1)과 패딩(0)을 나타내기 위해 그에 해당하는 새로운 `pixel_mask`를 생성해야 합니다.
+
+```py
+>>> def collate_fn(batch):
+... pixel_values = [item["pixel_values"] for item in batch]
+... encoding = image_processor.pad(pixel_values, return_tensors="pt")
+... labels = [item["labels"] for item in batch]
+... batch = {}
+... batch["pixel_values"] = encoding["pixel_values"]
+... batch["pixel_mask"] = encoding["pixel_mask"]
+... batch["labels"] = labels
+... return batch
+```
+
+## DETR 모델 학습시키기 [[training-the-DETR-model]]
+
+이전 섹션에서 대부분의 작업을 수행하여 이제 모델을 학습할 준비가 되었습니다!
+이 데이터 세트의 이미지는 리사이즈 후에도 여전히 용량이 크기 때문에, 이 모델을 미세 조정 하려면 적어도 하나의 GPU가 필요합니다.
+
+학습은 다음의 단계를 수행합니다:
+
+1. [`AutoModelForObjectDetection`]을 사용하여 전처리와 동일한 체크포인트를 사용하여 모델을 가져옵니다.
+2. [`TrainingArguments`]에서 학습 하이퍼파라미터를 정의합니다.
+3. 모델, 데이터 세트, 이미지 프로세서 및 데이터 콜레이터와 함께 [`Trainer`]에 훈련 인수를 전달합니다.
+4. [`~Trainer.train`]를 호출하여 모델을 미세 조정 합니다.
+
+전처리에 사용한 체크포인트와 동일한 체크포인트에서 모델을 가져올 때, 데이터 세트의 메타데이터에서 만든 `label2id`와 `id2label` 매핑을 전달해야 합니다.
+또한, `ignore_mismatched_sizes=True`를 지정하여 기존 분류 헤드(모델에서 분류에 사용되는 마지막 레이어)를 새 분류 헤드로 대체합니다.
+
+```py
+>>> from transformers import AutoModelForObjectDetection
+
+>>> model = AutoModelForObjectDetection.from_pretrained(
+... checkpoint,
+... id2label=id2label,
+... label2id=label2id,
+... ignore_mismatched_sizes=True,
+... )
+```
+
+[`TrainingArguments`]에서 `output_dir`을 사용하여 모델을 저장할 위치를 지정한 다음, 필요에 따라 하이퍼파라미터를 구성하세요.
+사용하지 않는 열을 제거하지 않도록 주의해야 합니다. 만약 `remove_unused_columns`가 `True`일 경우 이미지 열이 삭제됩니다.
+이미지 열이 없는 경우 `pixel_values`를 생성할 수 없기 때문에 `remove_unused_columns`를 `False`로 설정해야 합니다.
+모델을 Hub에 업로드하여 공유하려면 `push_to_hub`를 `True`로 설정하십시오(허깅페이스에 로그인하여 모델을 업로드해야 합니다).
+
+
+```py
+>>> from transformers import TrainingArguments
+
+>>> training_args = TrainingArguments(
+... output_dir="detr-resnet-50_finetuned_cppe5",
+... per_device_train_batch_size=8,
+... num_train_epochs=10,
+... fp16=True,
+... save_steps=200,
+... logging_steps=50,
+... learning_rate=1e-5,
+... weight_decay=1e-4,
+... save_total_limit=2,
+... remove_unused_columns=False,
+... push_to_hub=True,
+... )
+```
+
+마지막으로 `model`, `training_args`, `collate_fn`, `image_processor`와 데이터 세트(`cppe5`)를 모두 가져온 후, [`~transformers.Trainer.train`]를 호출합니다.
+
+```py
+>>> from transformers import Trainer
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... data_collator=collate_fn,
+... train_dataset=cppe5["train"],
+... processing_class=image_processor,
+... )
+
+>>> trainer.train()
+```
+
+`training_args`에서 `push_to_hub`를 `True`로 설정한 경우, 학습 체크포인트는 허깅페이스 허브에 업로드됩니다.
+학습 완료 후, [`~transformers.Trainer.push_to_hub`] 메소드를 호출하여 최종 모델을 허깅페이스 허브에 업로드합니다.
+
+```py
+>>> trainer.push_to_hub()
+```
+
+## 평가하기 [[evaluate]]
+
+객체 탐지 모델은 일반적으로 일련의 COCO-스타일 지표로 평가됩니다.
+기존에 구현된 평가 지표 중 하나를 사용할 수도 있지만, 여기에서는 허깅페이스 허브에 푸시한 최종 모델을 평가하는 데 `torchvision`에서 제공하는 평가 지표를 사용합니다.
+
+`torchvision` 평가자(evaluator)를 사용하려면 실측값인 COCO 데이터 세트를 준비해야 합니다.
+COCO 데이터 세트를 빌드하는 API는 데이터를 특정 형식으로 저장해야 하므로, 먼저 이미지와 어노테이션을 디스크에 저장해야 합니다.
+학습을 위해 데이터를 준비할 때와 마찬가지로, cppe5["test"]에서의 어노테이션은 포맷을 맞춰야 합니다. 그러나 이미지는 그대로 유지해야 합니다.
+
+평가 단계는 약간의 작업이 필요하지만, 크게 세 가지 주요 단계로 나눌 수 있습니다.
+먼저, `cppe5["test"]` 세트를 준비합니다: 어노테이션을 포맷에 맞게 만들고 데이터를 디스크에 저장합니다.
+
+```py
+>>> import json
+
+
+>>> # format annotations the same as for training, no need for data augmentation
+>>> def val_formatted_anns(image_id, objects):
+... annotations = []
+... for i in range(0, len(objects["id"])):
+... new_ann = {
+... "id": objects["id"][i],
+... "category_id": objects["category"][i],
+... "iscrowd": 0,
+... "image_id": image_id,
+... "area": objects["area"][i],
+... "bbox": objects["bbox"][i],
+... }
+... annotations.append(new_ann)
+
+... return annotations
+
+
+>>> # Save images and annotations into the files torchvision.datasets.CocoDetection expects
+>>> def save_cppe5_annotation_file_images(cppe5):
+... output_json = {}
+... path_output_cppe5 = f"{os.getcwd()}/cppe5/"
+
+... if not os.path.exists(path_output_cppe5):
+... os.makedirs(path_output_cppe5)
+
+... path_anno = os.path.join(path_output_cppe5, "cppe5_ann.json")
+... categories_json = [{"supercategory": "none", "id": id, "name": id2label[id]} for id in id2label]
+... output_json["images"] = []
+... output_json["annotations"] = []
+... for example in cppe5:
+... ann = val_formatted_anns(example["image_id"], example["objects"])
+... output_json["images"].append(
+... {
+... "id": example["image_id"],
+... "width": example["image"].width,
+... "height": example["image"].height,
+... "file_name": f"{example['image_id']}.png",
+... }
+... )
+... output_json["annotations"].extend(ann)
+... output_json["categories"] = categories_json
+
+... with open(path_anno, "w") as file:
+... json.dump(output_json, file, ensure_ascii=False, indent=4)
+
+... for im, img_id in zip(cppe5["image"], cppe5["image_id"]):
+... path_img = os.path.join(path_output_cppe5, f"{img_id}.png")
+... im.save(path_img)
+
+... return path_output_cppe5, path_anno
+```
+
+다음으로, `cocoevaluator`와 함께 사용할 수 있는 `CocoDetection` 클래스의 인스턴스를 준비합니다.
+
+```py
+>>> import torchvision
+
+
+>>> class CocoDetection(torchvision.datasets.CocoDetection):
+... def __init__(self, img_folder, image_processor, ann_file):
+... super().__init__(img_folder, ann_file)
+... self.image_processor = image_processor
+
+... def __getitem__(self, idx):
+... # read in PIL image and target in COCO format
+... img, target = super(CocoDetection, self).__getitem__(idx)
+
+... # preprocess image and target: converting target to DETR format,
+... # resizing + normalization of both image and target)
+... image_id = self.ids[idx]
+... target = {"image_id": image_id, "annotations": target}
+... encoding = self.image_processor(images=img, annotations=target, return_tensors="pt")
+... pixel_values = encoding["pixel_values"].squeeze() # remove batch dimension
+... target = encoding["labels"][0] # remove batch dimension
+
+... return {"pixel_values": pixel_values, "labels": target}
+
+
+>>> im_processor = AutoImageProcessor.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
+
+>>> path_output_cppe5, path_anno = save_cppe5_annotation_file_images(cppe5["test"])
+>>> test_ds_coco_format = CocoDetection(path_output_cppe5, im_processor, path_anno)
+```
+
+마지막으로, 평가 지표를 가져와서 평가를 실행합니다.
+
+```py
+>>> import evaluate
+>>> from tqdm import tqdm
+
+>>> model = AutoModelForObjectDetection.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
+>>> module = evaluate.load("ybelkada/cocoevaluate", coco=test_ds_coco_format.coco)
+>>> val_dataloader = torch.utils.data.DataLoader(
+... test_ds_coco_format, batch_size=8, shuffle=False, num_workers=4, collate_fn=collate_fn
+... )
+
+>>> with torch.no_grad():
+... for idx, batch in enumerate(tqdm(val_dataloader)):
+... pixel_values = batch["pixel_values"]
+... pixel_mask = batch["pixel_mask"]
+
+... labels = [
+... {k: v for k, v in t.items()} for t in batch["labels"]
+... ] # these are in DETR format, resized + normalized
+
+... # forward pass
+... outputs = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
+
+... orig_target_sizes = torch.stack([target["orig_size"] for target in labels], dim=0)
+... results = im_processor.post_process(outputs, orig_target_sizes) # convert outputs of model to Pascal VOC format (xmin, ymin, xmax, ymax)
+
+... module.add(prediction=results, reference=labels)
+... del batch
+
+>>> results = module.compute()
+>>> print(results)
+Accumulating evaluation results...
+DONE (t=0.08s).
+IoU metric: bbox
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.352
+ Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.681
+ Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.292
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.168
+ Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.208
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.429
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.274
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.484
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.501
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.191
+ Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.323
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.590
+```
+
+이러한 결과는 [`~transformers.TrainingArguments`]의 하이퍼파라미터를 조정하여 더욱 개선될 수 있습니다. 한번 시도해 보세요!
+
+## 추론하기 [[inference]]
+
+DETR 모델을 미세 조정 및 평가하고, 허깅페이스 허브에 업로드 했으므로 추론에 사용할 수 있습니다.
+
+미세 조정된 모델을 추론에 사용하는 가장 간단한 방법은 [`pipeline`]에서 모델을 사용하는 것입니다.
+모델과 함께 객체 탐지를 위한 파이프라인을 인스턴스화하고, 이미지를 전달하세요:
+
+```py
+>>> from transformers import pipeline
+>>> import requests
+
+>>> url = "https://i.imgur.com/2lnWoly.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> obj_detector = pipeline("object-detection", model="devonho/detr-resnet-50_finetuned_cppe5")
+>>> obj_detector(image)
+```
+
+만약 원한다면 수동으로 `pipeline`의 결과를 재현할 수 있습니다:
+
+```py
+>>> image_processor = AutoImageProcessor.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
+>>> model = AutoModelForObjectDetection.from_pretrained("devonho/detr-resnet-50_finetuned_cppe5")
+
+>>> with torch.no_grad():
+... inputs = image_processor(images=image, return_tensors="pt")
+... outputs = model(**inputs)
+... target_sizes = torch.tensor([image.size[::-1]])
+... results = image_processor.post_process_object_detection(outputs, threshold=0.5, target_sizes=target_sizes)[0]
+
+>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
+... box = [round(i, 2) for i in box.tolist()]
+... print(
+... f"Detected {model.config.id2label[label.item()]} with confidence "
+... f"{round(score.item(), 3)} at location {box}"
+... )
+Detected Coverall with confidence 0.566 at location [1215.32, 147.38, 4401.81, 3227.08]
+Detected Mask with confidence 0.584 at location [2449.06, 823.19, 3256.43, 1413.9]
+```
+
+결과를 시각화하겠습니다:
+```py
+>>> draw = ImageDraw.Draw(image)
+
+>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
+... box = [round(i, 2) for i in box.tolist()]
+... x, y, x2, y2 = tuple(box)
+... draw.rectangle((x, y, x2, y2), outline="red", width=1)
+... draw.text((x, y), model.config.id2label[label.item()], fill="white")
+
+>>> image
+```
+
+
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/prompting.md b/docs/transformers/docs/source/ko/tasks/prompting.md
new file mode 100644
index 0000000000000000000000000000000000000000..8f154dbe74c913ce34ae9a614a6705eb7b4ba13a
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/prompting.md
@@ -0,0 +1,384 @@
+
+
+
+# 대규모 언어 모델(LLM) 프롬프팅 가이드 [[llm-prompting-guide]]
+
+[[open-in-colab]]
+
+Falcon, LLaMA 등의 대규모 언어 모델은 사전 훈련된 트랜스포머 모델로, 초기에는 주어진 입력 텍스트에 대해 다음 토큰을 예측하도록 훈련됩니다. 이들은 보통 수십억 개의 매개변수를 가지고 있으며, 장기간에 걸쳐 수조 개의 토큰으로 훈련됩니다. 그 결과, 이 모델들은 매우 강력하고 다재다능해져서, 자연어 프롬프트로 모델에 지시하여 다양한 자연어 처리 작업을 즉시 수행할 수 있습니다.
+
+최적의 출력을 보장하기 위해 이러한 프롬프트를 설계하는 것을 흔히 "프롬프트 엔지니어링"이라고 합니다. 프롬프트 엔지니어링은 상당한 실험이 필요한 반복적인 과정입니다. 자연어는 프로그래밍 언어보다 훨씬 유연하고 표현력이 풍부하지만, 동시에 모호성을 초래할 수 있습니다. 또한, 자연어 프롬프트는 변화에 매우 민감합니다. 프롬프트의 사소한 수정만으로도 완전히 다른 출력이 나올 수 있습니다.
+
+모든 경우에 적용할 수 있는 정확한 프롬프트 생성 공식은 없지만, 연구자들은 더 일관되게 최적의 결과를 얻는 데 도움이 되는 여러 가지 모범 사례를 개발했습니다.
+
+이 가이드에서는 더 나은 대규모 언어 모델 프롬프트를 작성하고 다양한 자연어 처리 작업을 해결하는 데 도움이 되는 프롬프트 엔지니어링 모범 사례를 다룹니다:
+
+- [프롬프팅의 기초](#basics-of-prompting)
+- [대규모 언어 모델 프롬프팅의 모범 사례](#best-practices-of-llm-prompting)
+- [고급 프롬프팅 기법: 퓨샷(Few-shot) 프롬프팅과 생각의 사슬(Chain-of-thought, CoT) 기법](#advanced-prompting-techniques)
+- [프롬프팅 대신 미세 조정을 해야 하는 경우](#prompting-vs-fine-tuning)
+
+
+
+프롬프트 엔지니어링은 대규모 언어 모델 출력 최적화 과정의 일부일 뿐입니다. 또 다른 중요한 구성 요소는 최적의 텍스트 생성 전략을 선택하는 것입니다. 학습 가능한 매개변수를 수정하지 않고도 대규모 언어 모델이 텍스트를 생성하리 때 각각의 후속 토큰을 선택하는 방식을 사용자가 직접 정의할 수 있습니다. 텍스트 생성 매개변수를 조정함으로써 생성된 텍스트의 반복을 줄이고 더 일관되고 사람이 말하는 것 같은 텍스트를 만들 수 있습니다. 텍스트 생성 전략과 매개변수는 이 가이드의 범위를 벗어나지만, 다음 가이드에서 이러한 주제에 대해 자세히 알아볼 수 있습니다:
+
+* [대규모 언어 모델을 이용한 생성](../llm_tutorial)
+* [텍스트 생성 전략](../generation_strategies)
+
+
+
+## 프롬프팅의 기초 [[basics-of-prompting]]
+
+### 모델의 유형 [[types-of-models]]
+
+현대의 대부분의 대규모 언어 모델은 디코더만을 이용한 트랜스포머입니다. 예를 들어 [LLaMA](../model_doc/llama),
+[Llama2](../model_doc/llama2), [Falcon](../model_doc/falcon), [GPT2](../model_doc/gpt2) 등이 있습니다. 그러나 [Flan-T5](../model_doc/flan-t5)와 [BART](../model_doc/bart)와 같은 인코더-디코더 기반의 트랜스포머 대규모 언어 모델을 접할 수도 있습니다.
+
+인코더-디코더 기반의 모델은 일반적으로 출력이 입력에 **크게** 의존하는 생성 작업에 사용됩니다. 예를 들어, 번역과 요약 작업에 사용됩니다. 디코더 전용 모델은 다른 모든 유형의 생성 작업에 사용됩니다.
+
+파이프라인을 사용하여 대규모 언어 모델으로 텍스트를 생성할 때, 어떤 유형의 대규모 언어 모델을 사용하고 있는지 아는 것이 중요합니다. 왜냐하면 이들은 서로 다른 파이프라인을 사용하기 때문입니다.
+
+디코더 전용 모델로 추론을 실행하려면 `text-generation` 파이프라인을 사용하세요:
+
+```python
+>>> from transformers import pipeline
+>>> import torch
+
+>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
+
+>>> generator = pipeline('text-generation', model = 'openai-community/gpt2')
+>>> prompt = "Hello, I'm a language model"
+
+>>> generator(prompt, max_length = 30)
+[{'generated_text': "Hello, I'm a language model programmer so you can use some of my stuff. But you also need some sort of a C program to run."}]
+```
+
+인코더-디코더로 추론을 실행하려면 `text2text-generation` 파이프라인을 사용하세요:
+
+```python
+>>> text2text_generator = pipeline("text2text-generation", model = 'google/flan-t5-base')
+>>> prompt = "Translate from English to French: I'm very happy to see you"
+
+>>> text2text_generator(prompt)
+[{'generated_text': 'Je suis très heureuse de vous rencontrer.'}]
+```
+
+### 기본 모델 vs 지시/채팅 모델 [[base-vs-instructchat-models]]
+
+🤗 Hub에서 최근 사용 가능한 대부분의 대규모 언어 모델 체크포인트는 기본 버전과 지시(또는 채팅) 두 가지 버전이 제공됩니다. 예를 들어, [`tiiuae/falcon-7b`](https://huggingface.co/tiiuae/falcon-7b)와 [`tiiuae/falcon-7b-instruct`](https://huggingface.co/tiiuae/falcon-7b-instruct)가 있습니다.
+
+기본 모델은 초기 프롬프트가 주어졌을 때 텍스트를 완성하는 데 탁월하지만, 지시를 따라야 하거나 대화형 사용이 필요한 자연어 처리작업에는 이상적이지 않습니다. 이때 지시(채팅) 버전이 필요합니다. 이러한 체크포인트는 사전 훈련된 기본 버전을 지시사항과 대화 데이터로 추가 미세 조정한 결과입니다. 이 추가적인 미세 조정으로 인해 많은 자연어 처리 작업에 더 적합한 선택이 됩니다.
+
+[`tiiuae/falcon-7b-instruct`](https://huggingface.co/tiiuae/falcon-7b-instruct)를 사용하여 일반적인 자연어 처리 작업을 해결하는 데 사용할 수 있는 몇 가지 간단한 프롬프트를 살펴보겠습니다.
+
+### 자연어 처리 작업 [[nlp-tasks]]
+
+먼저, 환경을 설정해 보겠습니다:
+
+```bash
+pip install -q transformers accelerate
+```
+
+다음으로, 적절한 파이프라인("text-generation")을 사용하여 모델을 로드하겠습니다:
+
+```python
+>>> from transformers import pipeline, AutoTokenizer
+>>> import torch
+
+>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
+>>> model = "tiiuae/falcon-7b-instruct"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(model)
+>>> pipe = pipeline(
+... "text-generation",
+... model=model,
+... tokenizer=tokenizer,
+... torch_dtype=torch.bfloat16,
+... device_map="auto",
+... )
+```
+
+
+
+Falcon 모델은 bfloat16 데이터 타입을 사용하여 훈련되었으므로, 같은 타입을 사용하는 것을 권장합니다. 이를 위해서는 최신 버전의 CUDA가 필요하며, 최신 그래픽 카드에서 가장 잘 작동합니다.
+
+
+
+이제 파이프라인을 통해 모델을 로드했으니, 프롬프트를 사용하여 자연어 처리 작업을 해결하는 방법을 살펴보겠습니다.
+
+#### 텍스트 분류 [[text-classification]]
+
+텍스트 분류의 가장 일반적인 형태 중 하나는 감정 분석입니다. 이는 텍스트 시퀀스에 "긍정적", "부정적" 또는 "중립적"과 같은 레이블을 할당합니다. 주어진 텍스트(영화 리뷰)를 분류하도록 모델에 지시하는 프롬프트를 작성해 보겠습니다. 먼저 지시사항을 제공한 다음, 분류할 텍스트를 지정하겠습니다. 여기서 주목할 점은 단순히 거기서 끝내지 않고, 응답의 시작 부분인 `"Sentiment: "`을 추가한다는 것입니다:
+
+```python
+>>> torch.manual_seed(0)
+>>> prompt = """Classify the text into neutral, negative or positive.
+... Text: This movie is definitely one of my favorite movies of its kind. The interaction between respectable and morally strong characters is an ode to chivalry and the honor code amongst thieves and policemen.
+... Sentiment:
+... """
+
+>>> sequences = pipe(
+... prompt,
+... max_new_tokens=10,
+... )
+
+>>> for seq in sequences:
+... print(f"Result: {seq['generated_text']}")
+Result: Classify the text into neutral, negative or positive.
+Text: This movie is definitely one of my favorite movies of its kind. The interaction between respectable and morally strong characters is an ode to chivalry and the honor code amongst thieves and policemen.
+Sentiment:
+Positive
+```
+
+결과적으로, 우리가 지시사항에서 제공한 목록에서 선택된 분류 레이블이 정확하게 포함되어 생성된 것을 확인할 수 있습니다!
+
+
+프롬프트 외에도 `max_new_tokens` 매개변수를 전달하는 것을 볼 수 있습니다. 이 매개변수는 모델이 생성할 토큰의 수를 제어하며, [텍스트 생성 전략](../generation_strategies) 가이드에서 배울 수 있는 여러 텍스트 생성 매개변수 중 하나입니다.
+
+
+
+#### 개체명 인식 [[named-entity-recognition]]
+
+개체명 인식(Named Entity Recognition, NER)은 텍스트에서 인물, 장소, 조직과 같은 명명된 개체를 찾는 작업입니다. 프롬프트의 지시사항을 수정하여 대규모 언어 모델이 이 작업을 수행하도록 해보겠습니다. 여기서는 `return_full_text = False`로 설정하여 출력에 프롬프트가 포함되지 않도록 하겠습니다:
+
+```python
+>>> torch.manual_seed(1) # doctest: +IGNORE_RESULT
+>>> prompt = """Return a list of named entities in the text.
+... Text: The Golden State Warriors are an American professional basketball team based in San Francisco.
+... Named entities:
+... """
+
+>>> sequences = pipe(
+... prompt,
+... max_new_tokens=15,
+... return_full_text = False,
+... )
+
+>>> for seq in sequences:
+... print(f"{seq['generated_text']}")
+- Golden State Warriors
+- San Francisco
+```
+
+보시다시피, 모델이 주어진 텍스트에서 두 개의 명명된 개체를 정확하게 식별했습니다.
+
+#### 번역 [[translation]]
+
+대규모 언어 모델이 수행할 수 있는 또 다른 작업은 번역입니다. 이 작업을 위해 인코더-디코더 모델을 사용할 수 있지만, 여기서는 예시의 단순성을 위해 꽤 좋은 성능을 보이는 Falcon-7b-instruct를 계속 사용하겠습니다. 다시 한 번, 모델에게 영어에서 이탈리아어로 텍스트를 번역하도록 지시하는 기본적인 프롬프트를 작성하는 방법은 다음과 같습니다:
+
+```python
+>>> torch.manual_seed(2) # doctest: +IGNORE_RESULT
+>>> prompt = """Translate the English text to Italian.
+... Text: Sometimes, I've believed as many as six impossible things before breakfast.
+... Translation:
+... """
+
+>>> sequences = pipe(
+... prompt,
+... max_new_tokens=20,
+... do_sample=True,
+... top_k=10,
+... return_full_text = False,
+... )
+
+>>> for seq in sequences:
+... print(f"{seq['generated_text']}")
+A volte, ho creduto a sei impossibili cose prima di colazione.
+```
+
+여기서는 모델이 출력을 생성할 때 조금 더 유연해질 수 있도록 `do_sample=True`와 `top_k=10`을 추가했습니다.
+
+#### 텍스트 요약 [[text-summarization]]
+
+번역과 마찬가지로, 텍스트 요약은 출력이 입력에 크게 의존하는 또 다른 생성 작업이며, 인코더-디코더 기반 모델이 더 나은 선택일 수 있습니다. 그러나 디코더 기반의 모델도 이 작업에 사용될 수 있습니다. 이전에는 프롬프트의 맨 처음에 지시사항을 배치했습니다. 하지만 프롬프트의 맨 끝도 지시사항을 넣을 적절한 위치가 될 수 있습니다. 일반적으로 지시사항을 양 극단 중 하나에 배치하는 것이 더 좋습니다.
+
+```python
+>>> torch.manual_seed(3) # doctest: +IGNORE_RESULT
+>>> prompt = """Permaculture is a design process mimicking the diversity, functionality and resilience of natural ecosystems. The principles and practices are drawn from traditional ecological knowledge of indigenous cultures combined with modern scientific understanding and technological innovations. Permaculture design provides a framework helping individuals and communities develop innovative, creative and effective strategies for meeting basic needs while preparing for and mitigating the projected impacts of climate change.
+... Write a summary of the above text.
+... Summary:
+... """
+
+>>> sequences = pipe(
+... prompt,
+... max_new_tokens=30,
+... do_sample=True,
+... top_k=10,
+... return_full_text = False,
+... )
+
+>>> for seq in sequences:
+... print(f"{seq['generated_text']}")
+Permaculture is an ecological design mimicking natural ecosystems to meet basic needs and prepare for climate change. It is based on traditional knowledge and scientific understanding.
+```
+
+#### 질의 응답 [[question-answering]]
+
+질의 응답 작업을 위해 프롬프트를 다음과 같은 논리적 구성요소로 구조화할 수 있습니다. 지시사항, 맥락, 질문, 그리고 모델이 답변 생성을 시작하도록 유도하는 선도 단어나 구문(`"Answer:"`) 을 사용할 수 있습니다:
+
+```python
+>>> torch.manual_seed(4) # doctest: +IGNORE_RESULT
+>>> prompt = """Answer the question using the context below.
+... Context: Gazpacho is a cold soup and drink made of raw, blended vegetables. Most gazpacho includes stale bread, tomato, cucumbers, onion, bell peppers, garlic, olive oil, wine vinegar, water, and salt. Northern recipes often include cumin and/or pimentón (smoked sweet paprika). Traditionally, gazpacho was made by pounding the vegetables in a mortar with a pestle; this more laborious method is still sometimes used as it helps keep the gazpacho cool and avoids the foam and silky consistency of smoothie versions made in blenders or food processors.
+... Question: What modern tool is used to make gazpacho?
+... Answer:
+... """
+
+>>> sequences = pipe(
+... prompt,
+... max_new_tokens=10,
+... do_sample=True,
+... top_k=10,
+... return_full_text = False,
+... )
+
+>>> for seq in sequences:
+... print(f"Result: {seq['generated_text']}")
+Result: Modern tools often used to make gazpacho include
+```
+
+#### 추론 [[reasoning]]
+
+추론은 대규모 언어 모델(LLM)에게 가장 어려운 작업 중 하나이며, 좋은 결과를 얻기 위해서는 종종 [생각의 사슬(Chain-of-thought, CoT)](#chain-of-thought)과 같은 고급 프롬프팅 기법을 적용해야 합니다. 간단한 산술 작업에 대해 기본적인 프롬프트로 모델이 추론할 수 있는지 시도해 보겠습니다:
+
+```python
+>>> torch.manual_seed(5) # doctest: +IGNORE_RESULT
+>>> prompt = """There are 5 groups of students in the class. Each group has 4 students. How many students are there in the class?"""
+
+>>> sequences = pipe(
+... prompt,
+... max_new_tokens=30,
+... do_sample=True,
+... top_k=10,
+... return_full_text = False,
+... )
+
+>>> for seq in sequences:
+... print(f"Result: {seq['generated_text']}")
+Result:
+There are a total of 5 groups, so there are 5 x 4=20 students in the class.
+```
+
+정확한 답변이 생성되었습니다! 복잡성을 조금 높여보고 기본적인 프롬프트로도 여전히 해결할 수 있는지 확인해 보겠습니다:
+
+```python
+>>> torch.manual_seed(6)
+>>> prompt = """I baked 15 muffins. I ate 2 muffins and gave 5 muffins to a neighbor. My partner then bought 6 more muffins and ate 2. How many muffins do we now have?"""
+
+>>> sequences = pipe(
+... prompt,
+... max_new_tokens=10,
+... do_sample=True,
+... top_k=10,
+... return_full_text = False,
+... )
+
+>>> for seq in sequences:
+... print(f"Result: {seq['generated_text']}")
+Result:
+The total number of muffins now is 21
+```
+
+정답은 12여야 하는데 21이라는 잘못된 답변이 나왔습니다. 이 경우, 프롬프트가 너무 기본적이거나 모델의 크기가 작아서 생긴 문제일 수 있습니다. 우리는 Falcon의 가장 작은 버전을 선택했습니다. 추론은 큰 모델에게도 어려운 작업이지만, 더 큰 모델들이 더 나은 성능을 보일 가능성이 높습니다.
+
+## 대규모 언어 모델 프롬프트 작성의 모범 사례 [[best-practices-of-llm-prompting]]
+
+이 섹션에서는 프롬프트 결과를 향상시킬 수 있는 모범 사례 목록을 작성했습니다:
+
+* 작업할 모델을 선택할 때 최신 및 가장 강력한 모델이 더 나은 성능을 발휘할 가능성이 높습니다.
+* 간단하고 짧은 프롬프트로 시작하여 점진적으로 개선해 나가세요.
+* 프롬프트의 시작 부분이나 맨 끝에 지시사항을 배치하세요. 대규모 컨텍스트를 다룰 때, 모델들은 어텐션 복잡도가 2차적으로 증가하는 것을 방지하기 위해 다양한 최적화를 적용합니다. 이렇게 함으로써 모델이 프롬프트의 중간보다 시작이나 끝 부분에 더 주의를 기울일 수 있습니다.
+* 지시사항을 적용할 텍스트와 명확하게 분리해보세요. (이에 대해서는 다음 섹션에서 더 자세히 다룹니다.)
+* 작업과 원하는 결과에 대해 구체적이고 풍부한 설명을 제공하세요. 형식, 길이, 스타일, 언어 등을 명확하게 작성해야 합니다.
+* 모호한 설명과 지시사항을 피하세요.
+* "하지 말라"는 지시보다는 "무엇을 해야 하는지"를 말하는 지시를 사용하는 것이 좋습니다.
+* 첫 번째 단어를 쓰거나 첫 번째 문장을 시작하여 출력을 올바른 방향으로 "유도"하세요.
+* [퓨샷(Few-shot) 프롬프팅](#few-shot-prompting) 및 [생각의 사슬(Chain-of-thought, CoT)](#chain-of-thought) 같은 고급 기술을 사용해보세요.
+* 프롬프트의 견고성을 평가하기 위해 다른 모델로도 테스트하세요.
+* 프롬프트의 버전을 관리하고 성능을 추적하세요.
+
+## 고급 프롬프트 기법 [[advanced-prompting-techniques]]
+
+### 퓨샷(Few-shot) 프롬프팅 [[few-shot-prompting]]
+
+위 섹션의 기본 프롬프트들은 "제로샷(Zero-shot)" 프롬프트의 예시입니다. 이는 모델에 지시사항과 맥락은 주어졌지만, 해결책이 포함된 예시는 제공되지 않았다는 의미입니다. 지시 데이터셋으로 미세 조정된 대규모 언어 모델은 일반적으로 이러한 "제로샷" 작업에서 좋은 성능을 보입니다. 하지만 여러분의 작업이 더 복잡하거나 미묘한 차이가 있을 수 있고, 아마도 지시사항만으로는 모델이 포착하지 못하는 출력에 대한 요구사항이 있을 수 있습니다. 이런 경우에는 퓨샷(Few-shot) 프롬프팅이라는 기법을 시도해 볼 수 있습니다.
+
+퓨샷 프롬프팅에서는 프롬프트에 예시를 제공하여 모델에 더 많은 맥락을 주고 성능을 향상시킵니다. 이 예시들은 모델이 예시의 패턴을 따라 출력을 생성하도록 조건화합니다.
+
+다음은 예시입니다:
+
+```python
+>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
+>>> prompt = """Text: The first human went into space and orbited the Earth on April 12, 1961.
+... Date: 04/12/1961
+... Text: The first-ever televised presidential debate in the United States took place on September 28, 1960, between presidential candidates John F. Kennedy and Richard Nixon.
+... Date:"""
+
+>>> sequences = pipe(
+... prompt,
+... max_new_tokens=8,
+... do_sample=True,
+... top_k=10,
+... )
+
+>>> for seq in sequences:
+... print(f"Result: {seq['generated_text']}")
+Result: Text: The first human went into space and orbited the Earth on April 12, 1961.
+Date: 04/12/1961
+Text: The first-ever televised presidential debate in the United States took place on September 28, 1960, between presidential candidates John F. Kennedy and Richard Nixon.
+Date: 09/28/1960
+```
+
+위의 코드 스니펫에서는 모델에 원하는 출력을 보여주기 위해 단일 예시를 사용했으므로, 이를 "원샷(One-shot)" 프롬프팅이라고 부를 수 있습니다. 그러나 작업의 복잡성에 따라 하나 이상의 예시를 사용해야 할 수도 있습니다.
+
+퓨샷 프롬프팅 기법의 한계:
+- 대규모 언어 모델이 예시의 패턴을 파악할 수 있지만, 이 기법은 복잡한 추론 작업에는 잘 작동하지 않습니다.
+- 퓨샷 프롬프팅을 적용하면 프롬프트의 길이가 길어집니다. 토큰 수가 많은 프롬프트는 계산량과 지연 시간을 증가시킬 수 있으며 프롬프트 길이에도 제한이 있습니다.
+- 때로는 여러 예시가 주어질 때, 모델은 의도하지 않은 패턴을 학습할 수 있습니다. 예를 들어, 세 번째 영화 리뷰가 항상 부정적이라고 학습할 수 있습니다.
+
+### 생각의 사슬(Chain-of-thought, CoT) [[chain-of-thought]]
+
+생각의 사슬(Chain-of-thought, CoT) 프롬프팅은 모델이 중간 추론 단계를 생성하도록 유도하는 기법으로, 복잡한 추론 작업의 결과를 개선합니다.
+
+모델이 추론 단계를 생성하도록 유도하는 두 가지 방법이 있습니다:
+- 질문에 대한 상세한 답변을 예시로 제시하는 퓨샷 프롬프팅을 통해 모델에게 문제를 어떻게 해결해 나가는지 보여줍니다.
+- "단계별로 생각해 봅시다" 또는 "깊게 숨을 쉬고 문제를 단계별로 해결해 봅시다"와 같은 문구를 추가하여 모델에게 추론하도록 지시합니다.
+
+[reasoning section](#reasoning)의 머핀 예시에 생각의 사슬(Chain-of-thought, CoT) 기법을 적용하고 [HuggingChat](https://huggingface.co/chat/)에서 사용할 수 있는 (`tiiuae/falcon-180B-chat`)과 같은 더 큰 모델을 사용하면, 추론 결과가 크게 개선됩니다:
+
+```text
+단계별로 살펴봅시다:
+1. 처음에 15개의 머핀이 있습니다.
+2. 2개의 머핀을 먹으면 13개의 머핀이 남습니다.
+3. 이웃에게 5개의 머핀을 주면 8개의 머핀이 남습니다.
+4. 파트너가 6개의 머핀을 더 사오면 총 머핀 수는 14개가 됩니다.
+5. 파트너가 2개의 머핀을 먹으면 12개의 머핀이 남습니다.
+따라서, 현재 12개의 머핀이 있습니다.
+```
+
+## 프롬프팅 vs 미세 조정 [[prompting-vs-fine-tuning]]
+
+프롬프트를 최적화하여 훌륭한 결과를 얻을 수 있지만, 여전히 모델을 미세 조정하는 것이 더 좋을지 고민할 수 있습니다. 다음은 더 작은 모델을 미세 조정하는 것이 선호되는 시나리오입니다:
+
+- 도메인이 대규모 언어 모델이 사전 훈련된 것과 크게 다르고 광범위한 프롬프트 최적화로도 충분한 결과를 얻지 못한 경우.
+- 저자원 언어에서 모델이 잘 작동해야 하는 경우.
+- 엄격한 규제 하에 있는 민감한 데이터로 모델을 훈련해야 하는 경우.
+- 비용, 개인정보 보호, 인프라 또는 기타 제한으로 인해 작은 모델을 사용해야 하는 경우.
+
+위의 모든 예시에서, 모델을 미세 조정하기 위해 충분히 큰 도메인별 데이터셋을 이미 가지고 있거나 합리적인 비용으로 쉽게 얻을 수 있는지 확인해야 합니다. 또한 모델을 미세 조정할 충분한 시간과 자원이 필요합니다.
+
+만약 위의 예시들이 여러분의 경우에 해당하지 않는다면, 프롬프트를 최적화하는 것이 더 유익할 수 있습니다.
diff --git a/docs/transformers/docs/source/ko/tasks/question_answering.md b/docs/transformers/docs/source/ko/tasks/question_answering.md
new file mode 100644
index 0000000000000000000000000000000000000000..8309dd7d753244f355747d0bff29e564df2cde33
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/question_answering.md
@@ -0,0 +1,422 @@
+
+
+# 질의 응답(Question Answering)[[question-answering]]
+
+[[open-in-colab]]
+
+
+
+질의 응답 태스크는 주어진 질문에 대한 답변을 제공합니다. Alexa, Siri 또는 Google과 같은 가상 비서에게 날씨가 어떤지 물어본 적이 있다면 질의 응답 모델을 사용해본 적이 있을 것입니다. 질의 응답 태스크에는 일반적으로 두 가지 유형이 있습니다.
+
+- 추출적(Extractive) 질의 응답: 주어진 문맥에서 답변을 추출합니다.
+- 생성적(Abstractive) 질의 응답: 문맥에서 질문에 올바르게 답하는 답변을 생성합니다.
+
+이 가이드는 다음과 같은 방법들을 보여줍니다.
+
+1. 추출적 질의 응답을 하기 위해 [SQuAD](https://huggingface.co/datasets/squad) 데이터 세트에서 [DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased) 미세 조정하기
+2. 추론에 미세 조정된 모델 사용하기
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/question-answering)를 확인하는 것이 좋습니다.
+
+
+
+시작하기 전에, 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers datasets evaluate
+```
+
+여러분의 모델을 업로드하고 커뮤니티에 공유할 수 있도록 Hugging Face 계정에 로그인하는 것이 좋습니다. 메시지가 표시되면 토큰을 입력해서 로그인합니다:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## SQuAD 데이터 세트 가져오기[[load-squad-dataset]]
+
+먼저 🤗 Datasets 라이브러리에서 SQuAD 데이터 세트의 일부를 가져옵니다. 이렇게 하면 전체 데이터 세트로 훈련하며 더 많은 시간을 할애하기 전에 모든 것이 잘 작동하는지 실험하고 확인할 수 있습니다.
+
+```py
+>>> from datasets import load_dataset
+
+>>> squad = load_dataset("squad", split="train[:5000]")
+```
+
+데이터 세트의 분할된 `train`을 [`~datasets.Dataset.train_test_split`] 메소드를 사용해 훈련 데이터 세트와 테스트 데이터 세트로 나누어줍니다:
+
+```py
+>>> squad = squad.train_test_split(test_size=0.2)
+```
+
+그리고나서 예시로 데이터를 하나 살펴봅니다:
+
+```py
+>>> squad["train"][0]
+{'answers': {'answer_start': [515], 'text': ['Saint Bernadette Soubirous']},
+ 'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.',
+ 'id': '5733be284776f41900661182',
+ 'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?',
+ 'title': 'University_of_Notre_Dame'
+}
+```
+
+이 중에서 몇 가지 중요한 항목이 있습니다:
+
+- `answers`: 답안 토큰의 시작 위치와 답안 텍스트
+- `context`: 모델이 답을 추출하는데 필요한 배경 지식
+- `question`: 모델이 답해야 하는 질문
+
+## 전처리[[preprocess]]
+
+
+
+다음 단계에서는 `question` 및 `context` 항목을 처리하기 위해 DistilBERT 토크나이저를 가져옵니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+질의 응답 태스크와 관련해서 특히 유의해야할 몇 가지 전처리 단계가 있습니다:
+
+1. 데이터 세트의 일부 예제에는 모델의 최대 입력 길이를 초과하는 매우 긴 `context`가 있을 수 있습니다. 긴 시퀀스를 다루기 위해서는, `truncation="only_second"`로 설정해 `context`만 잘라내면 됩니다.
+2. 그 다음, `return_offset_mapping=True`로 설정해 답변의 시작과 종료 위치를 원래의 `context`에 매핑합니다.
+3. 매핑을 완료하면, 이제 답변에서 시작 토큰과 종료 토큰을 찾을 수 있습니다. 오프셋의 어느 부분이 `question`과 `context`에 해당하는지 찾을 수 있도록 [`~tokenizers.Encoding.sequence_ids`] 메소드를 사용하세요.
+
+다음은 `answer`의 시작 토큰과 종료 토큰을 잘라내서 `context`에 매핑하는 함수를 만드는 방법입니다:
+
+```py
+>>> def preprocess_function(examples):
+... questions = [q.strip() for q in examples["question"]]
+... inputs = tokenizer(
+... questions,
+... examples["context"],
+... max_length=384,
+... truncation="only_second",
+... return_offsets_mapping=True,
+... padding="max_length",
+... )
+
+... offset_mapping = inputs.pop("offset_mapping")
+... answers = examples["answers"]
+... start_positions = []
+... end_positions = []
+
+... for i, offset in enumerate(offset_mapping):
+... answer = answers[i]
+... start_char = answer["answer_start"][0]
+... end_char = answer["answer_start"][0] + len(answer["text"][0])
+... sequence_ids = inputs.sequence_ids(i)
+
+... # Find the start and end of the context
+... idx = 0
+... while sequence_ids[idx] != 1:
+... idx += 1
+... context_start = idx
+... while sequence_ids[idx] == 1:
+... idx += 1
+... context_end = idx - 1
+
+... # If the answer is not fully inside the context, label it (0, 0)
+... if offset[context_start][0] > end_char or offset[context_end][1] < start_char:
+... start_positions.append(0)
+... end_positions.append(0)
+... else:
+... # Otherwise it's the start and end token positions
+... idx = context_start
+... while idx <= context_end and offset[idx][0] <= start_char:
+... idx += 1
+... start_positions.append(idx - 1)
+
+... idx = context_end
+... while idx >= context_start and offset[idx][1] >= end_char:
+... idx -= 1
+... end_positions.append(idx + 1)
+
+... inputs["start_positions"] = start_positions
+... inputs["end_positions"] = end_positions
+... return inputs
+```
+
+모든 데이터 세트에 전처리를 적용하려면, 🤗 Datasets [`~datasets.Dataset.map`] 함수를 사용하세요. `batched=True`로 설정해 데이터 세트의 여러 요소들을 한 번에 처리하면 `map` 함수의 속도를 빠르게 할 수 있습니다. 필요하지 않은 열은 모두 제거합니다:
+
+```py
+>>> tokenized_squad = squad.map(preprocess_function, batched=True, remove_columns=squad["train"].column_names)
+```
+
+이제 [`DefaultDataCollator`]를 이용해 예시 배치를 생성합니다. 🤗 Transformers의 다른 데이터 콜레이터(data collator)와 달리, [`DefaultDataCollator`]는 패딩과 같은 추가 전처리를 적용하지 않습니다:
+
+
+
+```py
+>>> from transformers import DefaultDataCollator
+
+>>> data_collator = DefaultDataCollator()
+```
+
+
+```py
+>>> from transformers import DefaultDataCollator
+
+>>> data_collator = DefaultDataCollator(return_tensors="tf")
+```
+
+
+
+## 훈련[[train]]
+
+
+
+
+
+[`Trainer`]를 이용해 모델을 미세 조정하는 것에 익숙하지 않다면, [여기](../training#train-with-pytorch-trainer)에서 기초 튜토리얼을 살펴보세요!
+
+
+
+이제 모델 훈련을 시작할 준비가 되었습니다! [`AutoModelForQuestionAnswering`]으로 DistilBERT를 가져옵니다:
+
+```py
+>>> from transformers import AutoModelForQuestionAnswering, TrainingArguments, Trainer
+
+>>> model = AutoModelForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+이제 세 단계만 남았습니다:
+
+1. [`TrainingArguments`]에서 훈련 하이퍼파라미터를 정합니다. 꼭 필요한 매개변수는 모델을 저장할 위치를 지정하는 `output_dir` 입니다. `push_to_hub=True`로 설정해서 이 모델을 Hub로 푸시합니다 (모델을 업로드하려면 Hugging Face에 로그인해야 합니다).
+2. 모델, 데이터 세트, 토크나이저, 데이터 콜레이터와 함께 [`Trainer`]에 훈련 인수들을 전달합니다.
+3. [`~Trainer.train`]을 호출해서 모델을 미세 조정합니다.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_qa_model",
+... eval_strategy="epoch",
+... learning_rate=2e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... num_train_epochs=3,
+... weight_decay=0.01,
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_squad["train"],
+... eval_dataset=tokenized_squad["test"],
+... processing_class=tokenizer,
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+훈련이 완료되면, [`~transformers.Trainer.push_to_hub`] 매소드를 사용해 모델을 Hub에 공유해서 모든 사람들이 사용할 수 있게 공유해주세요:
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+Keras로 모델을 미세 조정하는 것에 익숙하지 않다면, [여기](../training#train-a-tensorflow-model-with-keras)에서 기초 튜토리얼을 살펴보세요!
+
+
+TensorFlow를 이용한 모델을 미세 조정하려면 옵티마이저 함수, 학습률 스케쥴 및 몇 가지 훈련 하이퍼파라미터를 설정하는 것부터 시작해야합니다:
+
+```py
+>>> from transformers import create_optimizer
+
+>>> batch_size = 16
+>>> num_epochs = 2
+>>> total_train_steps = (len(tokenized_squad["train"]) // batch_size) * num_epochs
+>>> optimizer, schedule = create_optimizer(
+... init_lr=2e-5,
+... num_warmup_steps=0,
+... num_train_steps=total_train_steps,
+... )
+```
+
+그 다음 [`TFAutoModelForQuestionAnswering`]으로 DistilBERT를 가져옵니다:
+
+```py
+>>> from transformers import TFAutoModelForQuestionAnswering
+
+>>> model = TFAutoModelForQuestionAnswering("distilbert/distilbert-base-uncased")
+```
+
+[`~transformers.TFPreTrainedModel.prepare_tf_dataset`]을 사용해서 데이터 세트를 `tf.data.Dataset` 형식으로 변환합니다:
+
+```py
+>>> tf_train_set = model.prepare_tf_dataset(
+... tokenized_squad["train"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_validation_set = model.prepare_tf_dataset(
+... tokenized_squad["test"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+[`compile`](https://keras.io/api/models/model_training_apis/#compile-method)로 훈련할 모델을 설정합니다:
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer)
+```
+
+마지막으로 모델을 Hub로 푸시할 방법을 설정합니다. [`~transformers.PushToHubCallback`]에서 모델과 토크나이저를 푸시할 경로를 설정합니다:
+
+```py
+>>> from transformers.keras_callbacks import PushToHubCallback
+
+>>> callback = PushToHubCallback(
+... output_dir="my_awesome_qa_model",
+... tokenizer=tokenizer,
+... )
+```
+
+드디어 모델 훈련을 시작할 준비가 되었습니다! 훈련 데이터 세트와 평가 데이터 세트, 에폭 수, 콜백을 설정한 후 [`fit`](https://keras.io/api/models/model_training_apis/#fit-method)을 이용해 모델을 미세 조정합니다:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3, callbacks=[callback])
+```
+훈련이 완료되면 모델이 자동으로 Hub에 업로드되어 누구나 사용할 수 있습니다!
+
+
+
+
+
+질의 응답을 위해 모델을 미세 조정하는 방법에 대한 더 자세한 예시는 [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb) 또는 [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)을 참조하세요.
+
+
+
+## 평가[[evaluate]]
+
+질의 응답을 평가하려면 상당한 양의 후처리가 필요합니다. 시간이 너무 많이 걸리지 않도록 이 가이드에서는 평가 단계를 생략합니다. [`Trainer`]는 훈련 과정에서 평가 손실(evaluation loss)을 계속 계산하기 때문에 모델의 성능을 대략적으로 알 수 있습니다.
+
+시간에 여유가 있고 질의 응답 모델을 평가하는 방법에 관심이 있다면 🤗 Hugging Face Course의 [Question answering](https://huggingface.co/course/chapter7/7?fw=pt#postprocessing) 챕터를 살펴보세요!
+
+## 추론[[inference]]
+
+이제 모델을 미세 조정했으니 추론에 사용할 수 있습니다!
+
+질문과 모델이 예측하기 원하는 문맥(context)를 생각해보세요:
+
+```py
+>>> question = "How many programming languages does BLOOM support?"
+>>> context = "BLOOM has 176 billion parameters and can generate text in 46 languages natural languages and 13 programming languages."
+```
+
+추론을 위해 미세 조정한 모델을 테스트하는 가장 쉬운 방법은 [`pipeline`]을 사용하는 것 입니다. 모델을 사용해 질의 응답을 하기 위해서 `pipeline`을 인스턴스화하고 텍스트를 입력합니다:
+
+```py
+>>> from transformers import pipeline
+
+>>> question_answerer = pipeline("question-answering", model="my_awesome_qa_model")
+>>> question_answerer(question=question, context=context)
+{'score': 0.2058267742395401,
+ 'start': 10,
+ 'end': 95,
+ 'answer': '176 billion parameters and can generate text in 46 languages natural languages and 13'}
+```
+
+원한다면 `pipeline`의 결과를 직접 복제할 수도 있습니다:
+
+
+
+텍스트를 토큰화해서 PyTorch 텐서를 반환합니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_qa_model")
+>>> inputs = tokenizer(question, context, return_tensors="pt")
+```
+
+모델에 입력을 전달하고 `logits`을 반환합니다:
+
+```py
+>>> from transformers import AutoModelForQuestionAnswering
+
+>>> model = AutoModelForQuestionAnswering.from_pretrained("my_awesome_qa_model")
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+```
+
+모델의 출력에서 시작 및 종료 위치가 어딘지 가장 높은 확률을 얻습니다:
+
+```py
+>>> answer_start_index = outputs.start_logits.argmax()
+>>> answer_end_index = outputs.end_logits.argmax()
+```
+
+예측된 토큰을 해독해서 답을 얻습니다:
+
+```py
+>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
+>>> tokenizer.decode(predict_answer_tokens)
+'176 billion parameters and can generate text in 46 languages natural languages and 13'
+```
+
+
+텍스트를 토큰화해서 TensorFlow 텐서를 반환합니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_qa_model")
+>>> inputs = tokenizer(question, text, return_tensors="tf")
+```
+
+모델에 입력을 전달하고 `logits`을 반환합니다:
+
+```py
+>>> from transformers import TFAutoModelForQuestionAnswering
+
+>>> model = TFAutoModelForQuestionAnswering.from_pretrained("my_awesome_qa_model")
+>>> outputs = model(**inputs)
+```
+
+모델의 출력에서 시작 및 종료 위치가 어딘지 가장 높은 확률을 얻습니다:
+
+```py
+>>> answer_start_index = int(tf.math.argmax(outputs.start_logits, axis=-1)[0])
+>>> answer_end_index = int(tf.math.argmax(outputs.end_logits, axis=-1)[0])
+```
+
+예측된 토큰을 해독해서 답을 얻습니다:
+
+```py
+>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
+>>> tokenizer.decode(predict_answer_tokens)
+'176 billion parameters and can generate text in 46 languages natural languages and 13'
+```
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/semantic_segmentation.md b/docs/transformers/docs/source/ko/tasks/semantic_segmentation.md
new file mode 100644
index 0000000000000000000000000000000000000000..04a727448dacd392fc9d1ac449e53f52fe6a69a1
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/semantic_segmentation.md
@@ -0,0 +1,587 @@
+
+
+# 의미적 분할(Semantic segmentation)[[semantic-segmentation]]
+
+[[open-in-colab]]
+
+
+
+의미적 분할(semantic segmentation)은 이미지의 각 픽셀에 레이블 또는 클래스를 할당합니다. 분할(segmentation)에는 여러 종류가 있으며, 의미적 분할의 경우 동일한 물체의 고유 인스턴스를 구분하지 않습니다. 두 물체 모두 동일한 레이블이 지정됩니다(예시로, "car-1" 과 "car-2" 대신 "car"로 지정합니다).
+실생활에서 흔히 볼 수 있는 의미적 분할의 적용 사례로는 보행자와 중요한 교통 정보를 식별하는 자율 주행 자동차 학습, 의료 이미지의 세포와 이상 징후 식별, 그리고 위성 이미지의 환경 변화 모니터링등이 있습니다.
+
+이번 가이드에서 배울 내용은 다음과 같습니다:
+
+1. [SceneParse150](https://huggingface.co/datasets/scene_parse_150) 데이터 세트를 이용해 [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer#segformer) 미세 조정하기.
+2. 미세 조정된 모델을 추론에 사용하기.
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/image-segmentation)를 확인하는 것이 좋습니다.
+
+
+
+시작하기 전에 필요한 모든 라이브러리가 설치되었는지 확인하세요:
+
+```bash
+pip install -q datasets transformers evaluate
+```
+커뮤니티에 모델을 업로드하고 공유할 수 있도록 Hugging Face 계정에 로그인하는 것을 권장합니다. 프롬프트가 나타나면 토큰을 입력하여 로그인하세요:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## SceneParse150 데이터 세트 불러오기[[load-sceneparse150-dataset]]
+
+🤗 Datasets 라이브러리에서 SceneParse150 데이터 세트의 더 작은 부분 집합을 가져오는 것으로 시작합니다. 이렇게 하면 데이터 세트 전체에 대한 훈련에 많은 시간을 할애하기 전에 실험을 통해 모든 것이 제대로 작동하는지 확인할 수 있습니다.
+
+```py
+>>> from datasets import load_dataset
+
+>>> ds = load_dataset("scene_parse_150", split="train[:50]")
+```
+
+데이터 세트의 `train`을 [`~datasets.Dataset.train_test_split`] 메소드를 사용하여 훈련 및 테스트 세트로 분할하세요:
+
+```py
+>>> ds = ds.train_test_split(test_size=0.2)
+>>> train_ds = ds["train"]
+>>> test_ds = ds["test"]
+```
+
+그리고 예시를 살펴보세요:
+
+```py
+>>> train_ds[0]
+{'image': ,
+ 'annotation': ,
+ 'scene_category': 368}
+```
+
+- `image`: 장면의 PIL 이미지입니다.
+- `annotation`: 분할 지도(segmentation map)의 PIL 이미지입니다. 모델의 타겟이기도 합니다.
+- `scene_category`: "주방" 또는 "사무실"과 같이 이미지 장면을 설명하는 카테고리 ID입니다. 이 가이드에서는 둘 다 PIL 이미지인 `image`와 `annotation`만을 사용합니다.
+
+나중에 모델을 설정할 때 유용하게 사용할 수 있도록 레이블 ID를 레이블 클래스에 매핑하는 사전도 만들고 싶을 것입니다. Hub에서 매핑을 다운로드하고 `id2label` 및 `label2id` 사전을 만드세요:
+
+```py
+>>> import json
+>>> from pathlib import Path
+>>> from huggingface_hub import hf_hub_download
+
+>>> repo_id = "huggingface/label-files"
+>>> filename = "ade20k-id2label.json"
+>>> id2label = json.loads(Path(hf_hub_download(repo_id, filename, repo_type="dataset")).read_text())
+>>> id2label = {int(k): v for k, v in id2label.items()}
+>>> label2id = {v: k for k, v in id2label.items()}
+>>> num_labels = len(id2label)
+```
+
+## 전처리하기[[preprocess]
+
+다음 단계는 모델에 사용할 이미지와 주석을 준비하기 위해 SegFormer 이미지 프로세서를 불러오는 것입니다. 우리가 사용하는 데이터 세트와 같은 일부 데이터 세트는 배경 클래스로 제로 인덱스를 사용합니다. 하지만 배경 클래스는 150개의 클래스에 실제로는 포함되지 않기 때문에 `do_reduce_labels=True` 를 설정해 모든 레이블에서 배경 클래스를 제거해야 합니다. 제로 인덱스는 `255`로 대체되므로 SegFormer의 손실 함수에서 무시됩니다:
+
+```py
+>>> from transformers import AutoImageProcessor
+
+>>> checkpoint = "nvidia/mit-b0"
+>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint, do_reduce_labels=True)
+```
+
+
+
+
+이미지 데이터 세트에 데이터 증강을 적용하여 과적합에 대해 모델을 보다 강건하게 만드는 것이 일반적입니다. 이 가이드에서는 [torchvision](https://pytorch.org/vision/stable/index.html)의 [`ColorJitter`](https://pytorch.org/vision/stable/generated/torchvision.transforms.ColorJitter.html)를 사용하여 이미지의 색상 속성을 임의로 변경합니다. 하지만, 자신이 원하는 이미지 라이브러리를 사용할 수도 있습니다.
+
+```py
+>>> from torchvision.transforms import ColorJitter
+
+>>> jitter = ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)
+```
+
+이제 모델에 사용할 이미지와 주석을 준비하기 위해 두 개의 전처리 함수를 만듭니다. 이 함수들은 이미지를 `pixel_values`로, 주석을 `labels`로 변환합니다. 훈련 세트의 경우 이미지 프로세서에 이미지를 제공하기 전에 `jitter`를 적용합니다. 테스트 세트의 경우 이미지 프로세서는 `images`를 자르고 정규화하며, 테스트 중에는 데이터 증강이 적용되지 않으므로 `labels`만 자릅니다.
+
+```py
+>>> def train_transforms(example_batch):
+... images = [jitter(x) for x in example_batch["image"]]
+... labels = [x for x in example_batch["annotation"]]
+... inputs = image_processor(images, labels)
+... return inputs
+
+
+>>> def val_transforms(example_batch):
+... images = [x for x in example_batch["image"]]
+... labels = [x for x in example_batch["annotation"]]
+... inputs = image_processor(images, labels)
+... return inputs
+```
+
+모든 데이터 세트에 `jitter`를 적용하려면, 🤗 Datasets [`~datasets.Dataset.set_transform`] 함수를 사용하세요. 즉시 변환이 적용되기 때문에 더 빠르고 디스크 공간을 덜 차지합니다:
+
+```py
+>>> train_ds.set_transform(train_transforms)
+>>> test_ds.set_transform(val_transforms)
+```
+
+
+
+
+
+
+
+이미지 데이터 세트에 데이터 증강을 적용하여 과적합에 대해 모델을 보다 강건하게 만드는 것이 일반적입니다. 이 가이드에서는 [`tf.image`](https://www.tensorflow.org/api_docs/python/tf/image)를 사용하여 이미지의 색상 속성을 임의로 변경합니다. 하지만, 자신이 원하는 이미지 라이브러리를 사용할 수도 있습니다.
+
+별개의 두 변환 함수를 정의합니다:
+- 이미지 증강을 포함하는 학습 데이터 변환
+- 🤗 Transformers의 컴퓨터 비전 모델은 채널 우선 레이아웃을 기대하기 때문에, 이미지만 바꾸는 검증 데이터 변환
+
+```py
+>>> import tensorflow as tf
+
+
+>>> def aug_transforms(image):
+... image = tf.keras.utils.img_to_array(image)
+... image = tf.image.random_brightness(image, 0.25)
+... image = tf.image.random_contrast(image, 0.5, 2.0)
+... image = tf.image.random_saturation(image, 0.75, 1.25)
+... image = tf.image.random_hue(image, 0.1)
+... image = tf.transpose(image, (2, 0, 1))
+... return image
+
+
+>>> def transforms(image):
+... image = tf.keras.utils.img_to_array(image)
+... image = tf.transpose(image, (2, 0, 1))
+... return image
+```
+
+그런 다음 모델을 위해 두 개의 전처리 함수를 만들어 이미지 및 주석 배치를 준비합니다. 이 함수들은 이미지 변환을 적용하고 이전에 로드한 `image_processor`를 사용하여 이미지를 `pixel_values`로, 주석을 `label`로 변환합니다. `ImageProcessor` 는 이미지의 크기 조정과 정규화도 처리합니다.
+
+```py
+>>> def train_transforms(example_batch):
+... images = [aug_transforms(x.convert("RGB")) for x in example_batch["image"]]
+... labels = [x for x in example_batch["annotation"]]
+... inputs = image_processor(images, labels)
+... return inputs
+
+
+>>> def val_transforms(example_batch):
+... images = [transforms(x.convert("RGB")) for x in example_batch["image"]]
+... labels = [x for x in example_batch["annotation"]]
+... inputs = image_processor(images, labels)
+... return inputs
+```
+
+전체 데이터 집합에 전처리 변환을 적용하려면 🤗 Datasets [`~datasets.Dataset.set_transform`] 함수를 사용하세요.
+즉시 변환이 적용되기 때문에 더 빠르고 디스크 공간을 덜 차지합니다:
+
+```py
+>>> train_ds.set_transform(train_transforms)
+>>> test_ds.set_transform(val_transforms)
+```
+
+
+
+## 평가하기[[evaluate]]
+
+훈련 중에 메트릭을 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하여 평가 방법을 빠르게 로드할 수 있습니다. 이 태스크에서는 [mean Intersection over Union](https://huggingface.co/spaces/evaluate-metric/accuracy) (IoU) 메트릭을 로드하세요 (메트릭을 로드하고 계산하는 방법에 대해 자세히 알아보려면 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour)를 살펴보세요).
+
+```py
+>>> import evaluate
+
+>>> metric = evaluate.load("mean_iou")
+```
+
+그런 다음 메트릭을 [`~evaluate.EvaluationModule.compute`]하는 함수를 만듭니다. 예측을 먼저 로짓으로 변환한 다음, 레이블의 크기에 맞게 모양을 다시 지정해야 [`~evaluate.EvaluationModule.compute`]를 호출할 수 있습니다:
+
+
+
+
+```py
+>>> import numpy as np
+>>> import torch
+>>> from torch import nn
+
+>>> def compute_metrics(eval_pred):
+... with torch.no_grad():
+... logits, labels = eval_pred
+... logits_tensor = torch.from_numpy(logits)
+... logits_tensor = nn.functional.interpolate(
+... logits_tensor,
+... size=labels.shape[-2:],
+... mode="bilinear",
+... align_corners=False,
+... ).argmax(dim=1)
+
+... pred_labels = logits_tensor.detach().cpu().numpy()
+... metrics = metric.compute(
+... predictions=pred_labels,
+... references=labels,
+... num_labels=num_labels,
+... ignore_index=255,
+... reduce_labels=False,
+... )
+... for key, value in metrics.items():
+... if isinstance(value, np.ndarray):
+... metrics[key] = value.tolist()
+... return metrics
+```
+
+
+
+
+
+
+
+
+```py
+>>> def compute_metrics(eval_pred):
+... logits, labels = eval_pred
+... logits = tf.transpose(logits, perm=[0, 2, 3, 1])
+... logits_resized = tf.image.resize(
+... logits,
+... size=tf.shape(labels)[1:],
+... method="bilinear",
+... )
+
+... pred_labels = tf.argmax(logits_resized, axis=-1)
+... metrics = metric.compute(
+... predictions=pred_labels,
+... references=labels,
+... num_labels=num_labels,
+... ignore_index=-1,
+... reduce_labels=image_processor.do_reduce_labels,
+... )
+
+... per_category_accuracy = metrics.pop("per_category_accuracy").tolist()
+... per_category_iou = metrics.pop("per_category_iou").tolist()
+
+... metrics.update({f"accuracy_{id2label[i]}": v for i, v in enumerate(per_category_accuracy)})
+... metrics.update({f"iou_{id2label[i]}": v for i, v in enumerate(per_category_iou)})
+... return {"val_" + k: v for k, v in metrics.items()}
+```
+
+
+
+
+이제 `compute_metrics` 함수를 사용할 준비가 되었습니다. 트레이닝을 설정할 때 이 함수로 돌아가게 됩니다.
+
+## 학습하기[[train]]
+
+
+
+
+만약 [`Trainer`]를 사용해 모델을 미세 조정하는 것에 익숙하지 않다면, [여기](../training#finetune-with-trainer)에서 기본 튜토리얼을 살펴보세요!
+
+
+
+이제 모델 학습을 시작할 준비가 되었습니다! [`AutoModelForSemanticSegmentation`]로 SegFormer를 불러오고, 모델에 레이블 ID와 레이블 클래스 간의 매핑을 전달합니다:
+
+```py
+>>> from transformers import AutoModelForSemanticSegmentation, TrainingArguments, Trainer
+
+>>> model = AutoModelForSemanticSegmentation.from_pretrained(checkpoint, id2label=id2label, label2id=label2id)
+```
+
+이제 세 단계만 남았습니다:
+
+1. 학습 하이퍼파라미터를 [`TrainingArguments`]에 정의합니다. `image` 열이 삭제되기 때문에 사용하지 않는 열을 제거하지 않는 것이 중요합니다. `image` 열이 없으면 `pixel_values`을 생성할 수 없습니다. 이런 경우를 방지하려면 `remove_unused_columns=False`로 설정하세요! 유일하게 필요한 다른 매개변수는 모델을 저장할 위치를 지정하는 `output_dir`입니다. `push_to_hub=True`를 설정하여 이 모델을 Hub에 푸시합니다(모델을 업로드하려면 Hugging Face에 로그인해야 합니다). 각 에포크가 끝날 때마다 [`Trainer`]가 IoU 메트릭을 평가하고 학습 체크포인트를 저장합니다.
+2. 모델, 데이터 세트, 토크나이저, 데이터 콜레이터, `compute_metrics` 함수와 함께 학습 인자를 [`Trainer`]에 전달하세요.
+3. 모델을 미세 조정하기 위해 [`~Trainer.train`]를 호출하세요.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="segformer-b0-scene-parse-150",
+... learning_rate=6e-5,
+... num_train_epochs=50,
+... per_device_train_batch_size=2,
+... per_device_eval_batch_size=2,
+... save_total_limit=3,
+... eval_strategy="steps",
+... save_strategy="steps",
+... save_steps=20,
+... eval_steps=20,
+... logging_steps=1,
+... eval_accumulation_steps=5,
+... remove_unused_columns=False,
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=train_ds,
+... eval_dataset=test_ds,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+학습이 완료되면, 누구나 모델을 사용할 수 있도록 [`~transformers.Trainer.push_to_hub`] 메서드를 사용해 Hub에 모델을 공유하세요:
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+
+
+
+Keras로 모델을 미세 조정하는 데 익숙하지 않은 경우, 먼저 [기본 튜토리얼](../training#train-a-tensorflow-model-with-keras)을 확인해보세요!
+
+
+
+TensorFlow에서 모델을 미세 조정하려면 다음 단계를 따르세요:
+1. 학습 하이퍼파라미터를 정의하고 옵티마이저와 학습률 스케쥴러를 설정하세요.
+2. 사전 학습된 모델을 인스턴스화하세요.
+3. 🤗 Dataset을 `tf.data.Dataset`로 변환하세요.
+4. 모델을 컴파일하세요.
+5. 콜백을 추가하여 메트릭을 계산하고 🤗 Hub에 모델을 업로드하세요.
+6. `fit()` 메서드를 사용하여 훈련을 실행하세요.
+
+하이퍼파라미터, 옵티마이저, 학습률 스케쥴러를 정의하는 것으로 시작하세요:
+
+```py
+>>> from transformers import create_optimizer
+
+>>> batch_size = 2
+>>> num_epochs = 50
+>>> num_train_steps = len(train_ds) * num_epochs
+>>> learning_rate = 6e-5
+>>> weight_decay_rate = 0.01
+
+>>> optimizer, lr_schedule = create_optimizer(
+... init_lr=learning_rate,
+... num_train_steps=num_train_steps,
+... weight_decay_rate=weight_decay_rate,
+... num_warmup_steps=0,
+... )
+```
+
+그런 다음 레이블 매핑과 함께 [`TFAutoModelForSemanticSegmentation`]을 사용하여 SegFormer를 불러오고 옵티마이저로 컴파일합니다. 트랜스포머 모델은 모두 디폴트로 태스크 관련 손실 함수가 있으므로 원치 않으면 지정할 필요가 없습니다:
+
+```py
+>>> from transformers import TFAutoModelForSemanticSegmentation
+
+>>> model = TFAutoModelForSemanticSegmentation.from_pretrained(
+... checkpoint,
+... id2label=id2label,
+... label2id=label2id,
+... )
+>>> model.compile(optimizer=optimizer) # 손실 함수 인자가 없습니다!
+```
+
+[`~datasets.Dataset.to_tf_dataset`] 와 [`DefaultDataCollator`]를 사용해 데이터 세트를 `tf.data.Dataset` 포맷으로 변환하세요:
+
+```py
+>>> from transformers import DefaultDataCollator
+
+>>> data_collator = DefaultDataCollator(return_tensors="tf")
+
+>>> tf_train_dataset = train_ds.to_tf_dataset(
+... columns=["pixel_values", "label"],
+... shuffle=True,
+... batch_size=batch_size,
+... collate_fn=data_collator,
+... )
+
+>>> tf_eval_dataset = test_ds.to_tf_dataset(
+... columns=["pixel_values", "label"],
+... shuffle=True,
+... batch_size=batch_size,
+... collate_fn=data_collator,
+... )
+```
+
+예측으로 정확도를 계산하고 모델을 🤗 Hub로 푸시하려면 [Keras callbacks](../main_classes/keras_callbacks)를 사용하세요. `compute_metrics` 함수를 [`KerasMetricCallback`]에 전달하고, 모델 업로드를 위해 [`PushToHubCallback`]를 사용하세요:
+
+```py
+>>> from transformers.keras_callbacks import KerasMetricCallback, PushToHubCallback
+
+>>> metric_callback = KerasMetricCallback(
+... metric_fn=compute_metrics, eval_dataset=tf_eval_dataset, batch_size=batch_size, label_cols=["labels"]
+... )
+
+>>> push_to_hub_callback = PushToHubCallback(output_dir="scene_segmentation", tokenizer=image_processor)
+
+>>> callbacks = [metric_callback, push_to_hub_callback]
+```
+
+이제 모델을 훈련할 준비가 되었습니다! 훈련 및 검증 데이터 세트, 에포크 수와 함께 `fit()`을 호출하고, 콜백을 사용하여 모델을 미세 조정합니다:
+
+```py
+>>> model.fit(
+... tf_train_dataset,
+... validation_data=tf_eval_dataset,
+... callbacks=callbacks,
+... epochs=num_epochs,
+... )
+```
+
+축하합니다! 모델을 미세 조정하고 🤗 Hub에 공유했습니다. 이제 추론에 사용할 수 있습니다!
+
+
+
+
+
+## 추론하기[[inference]]
+
+이제 모델을 미세 조정했으니 추론에 사용할 수 있습니다!
+
+추론할 이미지를 로드하세요:
+
+```py
+>>> image = ds[0]["image"]
+>>> image
+```
+
+
+
+
+
+
+
+
+추론을 위해 미세 조정한 모델을 시험해 보는 가장 간단한 방법은 [`pipeline`]에서 사용하는 것입니다. 모델을 사용하여 이미지 분할을 위한 `pipeline`을 인스턴스화하고 이미지를 전달합니다:
+
+```py
+>>> from transformers import pipeline
+
+>>> segmenter = pipeline("image-segmentation", model="my_awesome_seg_model")
+>>> segmenter(image)
+[{'score': None,
+ 'label': 'wall',
+ 'mask': },
+ {'score': None,
+ 'label': 'sky',
+ 'mask': },
+ {'score': None,
+ 'label': 'floor',
+ 'mask': },
+ {'score': None,
+ 'label': 'ceiling',
+ 'mask': },
+ {'score': None,
+ 'label': 'bed ',
+ 'mask': },
+ {'score': None,
+ 'label': 'windowpane',
+ 'mask': },
+ {'score': None,
+ 'label': 'cabinet',
+ 'mask': },
+ {'score': None,
+ 'label': 'chair',
+ 'mask': },
+ {'score': None,
+ 'label': 'armchair',
+ 'mask': }]
+```
+원하는 경우 `pipeline`의 결과를 수동으로 복제할 수도 있습니다. 이미지 프로세서로 이미지를 처리하고 `pixel_values`을 GPU에 배치합니다:
+
+```py
+>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 가능하다면 GPU를 사용하고, 그렇지 않다면 CPU를 사용하세요
+>>> encoding = image_processor(image, return_tensors="pt")
+>>> pixel_values = encoding.pixel_values.to(device)
+```
+
+모델에 입력을 전달하고 `logits`를 반환합니다:
+
+```py
+>>> outputs = model(pixel_values=pixel_values)
+>>> logits = outputs.logits.cpu()
+```
+그런 다음 로짓의 크기를 원본 이미지 크기로 다시 조정합니다:
+
+```py
+>>> upsampled_logits = nn.functional.interpolate(
+... logits,
+... size=image.size[::-1],
+... mode="bilinear",
+... align_corners=False,
+... )
+
+>>> pred_seg = upsampled_logits.argmax(dim=1)[0]
+```
+
+
+
+
+
+
+이미지 프로세서를 로드하여 이미지를 전처리하고 입력을 TensorFlow 텐서로 반환합니다:
+
+```py
+>>> from transformers import AutoImageProcessor
+
+>>> image_processor = AutoImageProcessor.from_pretrained("MariaK/scene_segmentation")
+>>> inputs = image_processor(image, return_tensors="tf")
+```
+
+모델에 입력을 전달하고 `logits`를 반환합니다:
+
+```py
+>>> from transformers import TFAutoModelForSemanticSegmentation
+
+>>> model = TFAutoModelForSemanticSegmentation.from_pretrained("MariaK/scene_segmentation")
+>>> logits = model(**inputs).logits
+```
+
+그런 다음 로그를 원본 이미지 크기로 재조정하고 클래스 차원에 argmax를 적용합니다:
+
+```py
+>>> logits = tf.transpose(logits, [0, 2, 3, 1])
+
+>>> upsampled_logits = tf.image.resize(
+... logits,
+... # `image.size`가 너비와 높이를 반환하기 때문에 `image`의 모양을 반전시킵니다
+... image.size[::-1],
+... )
+
+>>> pred_seg = tf.math.argmax(upsampled_logits, axis=-1)[0]
+```
+
+
+
+
+결과를 시각화하려면 [dataset color palette](https://github.com/tensorflow/models/blob/3f1ca33afe3c1631b733ea7e40c294273b9e406d/research/deeplab/utils/get_dataset_colormap.py#L51)를 각 클래스를 RGB 값에 매핑하는 `ade_palette()`로 로드합니다. 그런 다음 이미지와 예측된 분할 지도(segmentation map)을 결합하여 구성할 수 있습니다:
+
+```py
+>>> import matplotlib.pyplot as plt
+>>> import numpy as np
+
+>>> color_seg = np.zeros((pred_seg.shape[0], pred_seg.shape[1], 3), dtype=np.uint8)
+>>> palette = np.array(ade_palette())
+>>> for label, color in enumerate(palette):
+... color_seg[pred_seg == label, :] = color
+>>> color_seg = color_seg[..., ::-1] # BGR로 변환
+
+>>> img = np.array(image) * 0.5 + color_seg * 0.5 # 분할 지도으로 이미지 구성
+>>> img = img.astype(np.uint8)
+
+>>> plt.figure(figsize=(15, 10))
+>>> plt.imshow(img)
+>>> plt.show()
+```
+
+
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/sequence_classification.md b/docs/transformers/docs/source/ko/tasks/sequence_classification.md
new file mode 100644
index 0000000000000000000000000000000000000000..11dae1a965a4f2634cf304bb8c805715e2791f9b
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/sequence_classification.md
@@ -0,0 +1,389 @@
+
+
+# 텍스트 분류[[text-classification]]
+
+[[open-in-colab]]
+
+
+
+텍스트 분류는 자연어 처리의 일종으로, 텍스트에 레이블 또는 클래스를 지정하는 작업입니다. 많은 대기업이 다양한 실용적인 응용 분야에서 텍스트 분류를 운영하고 있습니다. 가장 인기 있는 텍스트 분류 형태 중 하나는 감성 분석으로, 텍스트 시퀀스에 🙂 긍정, 🙁 부정 또는 😐 중립과 같은 레이블을 지정합니다.
+
+이 가이드에서 학습할 내용은:
+
+1. [IMDb](https://huggingface.co/datasets/imdb) 데이터셋에서 [DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased)를 파인 튜닝하여 영화 리뷰가 긍정적인지 부정적인지 판단합니다.
+2. 추론을 위해 파인 튜닝 모델을 사용합니다.
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/text-classification)를 확인하는 것이 좋습니다.
+
+
+
+시작하기 전에, 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers datasets evaluate
+```
+
+Hugging Face 계정에 로그인하여 모델을 업로드하고 커뮤니티에 공유하는 것을 권장합니다. 메시지가 표시되면, 토큰을 입력하여 로그인하세요:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## IMDb 데이터셋 가져오기[[load-imdb-dataset]]
+
+먼저 🤗 Datasets 라이브러리에서 IMDb 데이터셋을 가져옵니다:
+
+```py
+>>> from datasets import load_dataset
+
+>>> imdb = load_dataset("imdb")
+```
+
+그런 다음 예시를 살펴봅시다:
+
+```py
+>>> imdb["test"][0]
+{
+ "label": 0,
+ "text": "I love sci-fi and am willing to put up with a lot. Sci-fi movies/TV are usually underfunded, under-appreciated and misunderstood. I tried to like this, I really did, but it is to good TV sci-fi as Babylon 5 is to Star Trek (the original). Silly prosthetics, cheap cardboard sets, stilted dialogues, CG that doesn't match the background, and painfully one-dimensional characters cannot be overcome with a 'sci-fi' setting. (I'm sure there are those of you out there who think Babylon 5 is good sci-fi TV. It's not. It's clichéd and uninspiring.) While US viewers might like emotion and character development, sci-fi is a genre that does not take itself seriously (cf. Star Trek). It may treat important issues, yet not as a serious philosophy. It's really difficult to care about the characters here as they are not simply foolish, just missing a spark of life. Their actions and reactions are wooden and predictable, often painful to watch. The makers of Earth KNOW it's rubbish as they have to always say \"Gene Roddenberry's Earth...\" otherwise people would not continue watching. Roddenberry's ashes must be turning in their orbit as this dull, cheap, poorly edited (watching it without advert breaks really brings this home) trudging Trabant of a show lumbers into space. Spoiler. So, kill off a main character. And then bring him back as another actor. Jeeez! Dallas all over again.",
+}
+```
+
+이 데이터셋에는 두 가지 필드가 있습니다:
+
+- `text`: 영화 리뷰 텍스트
+- `label`: `0`은 부정적인 리뷰, `1`은 긍정적인 리뷰를 나타냅니다.
+
+## 전처리[[preprocess]]
+
+다음 단계는 DistilBERT 토크나이저를 가져와서 `text` 필드를 전처리하는 것입니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+`text`를 토큰화하고 시퀀스가 DistilBERT의 최대 입력 길이보다 길지 않도록 자르기 위한 전처리 함수를 생성하세요:
+
+```py
+>>> def preprocess_function(examples):
+... return tokenizer(examples["text"], truncation=True)
+```
+
+전체 데이터셋에 전처리 함수를 적용하려면, 🤗 Datasets [`~datasets.Dataset.map`] 함수를 사용하세요. 데이터셋의 여러 요소를 한 번에 처리하기 위해 `batched=True`로 설정함으로써 데이터셋 `map`를 더 빠르게 처리할 수 있습니다:
+
+```py
+tokenized_imdb = imdb.map(preprocess_function, batched=True)
+```
+
+이제 [`DataCollatorWithPadding`]를 사용하여 예제 배치를 만들어봅시다. 데이터셋 전체를 최대 길이로 패딩하는 대신, *동적 패딩*을 사용하여 배치에서 가장 긴 길이에 맞게 문장을 패딩하는 것이 효율적입니다.
+
+
+
+```py
+>>> from transformers import DataCollatorWithPadding
+
+>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
+```
+
+
+```py
+>>> from transformers import DataCollatorWithPadding
+
+>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
+```
+
+
+
+## 평가하기[[evaluate]]
+
+훈련 중 모델의 성능을 평가하기 위해 메트릭을 포함하는 것이 유용합니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하여 빠르게 평가 방법을 로드할 수 있습니다. 이 작업에서는 [accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) 메트릭을 가져옵니다. (메트릭을 가져오고 계산하는 방법에 대해서는 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하세요):
+
+```py
+>>> import evaluate
+
+>>> accuracy = evaluate.load("accuracy")
+```
+
+그런 다음 `compute_metrics` 함수를 만들어서 예측과 레이블을 계산하여 정확도를 계산하도록 [`~evaluate.EvaluationModule.compute`]를 호출합니다:
+
+```py
+>>> import numpy as np
+
+
+>>> def compute_metrics(eval_pred):
+... predictions, labels = eval_pred
+... predictions = np.argmax(predictions, axis=1)
+... return accuracy.compute(predictions=predictions, references=labels)
+```
+
+이제 `compute_metrics` 함수는 준비되었고, 훈련 과정을 설정할 때 다시 살펴볼 예정입니다.
+
+## 훈련[[train]]
+
+모델을 훈련하기 전에, `id2label`와 `label2id`를 사용하여 예상되는 id와 레이블의 맵을 생성하세요:
+
+```py
+>>> id2label = {0: "NEGATIVE", 1: "POSITIVE"}
+>>> label2id = {"NEGATIVE": 0, "POSITIVE": 1}
+```
+
+
+
+
+
+[`Trainer`]를 사용하여 모델을 파인 튜닝하는 방법에 익숙하지 않은 경우, [여기](../training#train-with-pytorch-trainer)의 기본 튜토리얼을 확인하세요!
+
+
+
+이제 모델을 훈련시킬 준비가 되었습니다! [`AutoModelForSequenceClassification`]로 DistilBERT를 가쳐오고 예상되는 레이블 수와 레이블 매핑을 지정하세요:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
+
+>>> model = AutoModelForSequenceClassification.from_pretrained(
+... "distilbert/distilbert-base-uncased", num_labels=2, id2label=id2label, label2id=label2id
+... )
+```
+
+이제 세 단계만 거치면 끝입니다:
+
+1. [`TrainingArguments`]에서 하이퍼파라미터를 정의하세요. `output_dir`는 모델을 저장할 위치를 지정하는 유일한 파라미터입니다. 이 모델을 Hub에 업로드하기 위해 `push_to_hub=True`를 설정합니다. (모델을 업로드하기 위해 Hugging Face에 로그인해야합니다.) 각 에폭이 끝날 때마다, [`Trainer`]는 정확도를 평가하고 훈련 체크포인트를 저장합니다.
+2. [`Trainer`]에 훈련 인수와 모델, 데이터셋, 토크나이저, 데이터 수집기 및 `compute_metrics` 함수를 전달하세요.
+3. [`~Trainer.train`]를 호출하여 모델은 파인 튜닝하세요.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_model",
+... learning_rate=2e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... num_train_epochs=2,
+... weight_decay=0.01,
+... eval_strategy="epoch",
+... save_strategy="epoch",
+... load_best_model_at_end=True,
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_imdb["train"],
+... eval_dataset=tokenized_imdb["test"],
+... processing_class=tokenizer,
+... data_collator=data_collator,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+
+
+
+[`Trainer`]는 `tokenizer`를 전달하면 기본적으로 동적 매핑을 적용합니다. 이 경우, 명시적으로 데이터 수집기를 지정할 필요가 없습니다.
+
+
+
+훈련이 완료되면, [`~transformers.Trainer.push_to_hub`] 메소드를 사용하여 모델을 Hub에 공유할 수 있습니다.
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+Keras를 사용하여 모델을 파인 튜닝하는 방법에 익숙하지 않은 경우, [여기](../training#train-a-tensorflow-model-with-keras)의 기본 튜토리얼을 확인하세요!
+
+
+TensorFlow에서 모델을 파인 튜닝하려면, 먼저 옵티마이저 함수와 학습률 스케쥴, 그리고 일부 훈련 하이퍼파라미터를 설정해야 합니다:
+
+```py
+>>> from transformers import create_optimizer
+>>> import tensorflow as tf
+
+>>> batch_size = 16
+>>> num_epochs = 5
+>>> batches_per_epoch = len(tokenized_imdb["train"]) // batch_size
+>>> total_train_steps = int(batches_per_epoch * num_epochs)
+>>> optimizer, schedule = create_optimizer(init_lr=2e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
+```
+
+그런 다음 [`TFAutoModelForSequenceClassification`]을 사용하여 DistilBERT를 로드하고, 예상되는 레이블 수와 레이블 매핑을 로드할 수 있습니다:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained(
+... "distilbert/distilbert-base-uncased", num_labels=2, id2label=id2label, label2id=label2id
+... )
+```
+
+[`~transformers.TFPreTrainedModel.prepare_tf_dataset`]을 사용하여 데이터셋을 `tf.data.Dataset` 형식으로 변환합니다:
+
+```py
+>>> tf_train_set = model.prepare_tf_dataset(
+... tokenized_imdb["train"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_validation_set = model.prepare_tf_dataset(
+... tokenized_imdb["test"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+[`compile`](https://keras.io/api/models/model_training_apis/#compile-method)를 사용하여 훈련할 모델을 구성합니다:
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer)
+```
+
+훈련을 시작하기 전에 설정해야할 마지막 두 가지는 예측에서 정확도를 계산하고, 모델을 Hub에 업로드할 방법을 제공하는 것입니다. 모두 [Keras callbacks](../main_classes/keras_callbacks)를 사용하여 수행됩니다.
+
+[`~transformers.KerasMetricCallback`]에 `compute_metrics`를 전달하여 정확도를 높입니다.
+
+```py
+>>> from transformers.keras_callbacks import KerasMetricCallback
+
+>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
+```
+
+[`~transformers.PushToHubCallback`]에서 모델과 토크나이저를 업로드할 위치를 지정합니다:
+
+```py
+>>> from transformers.keras_callbacks import PushToHubCallback
+
+>>> push_to_hub_callback = PushToHubCallback(
+... output_dir="my_awesome_model",
+... tokenizer=tokenizer,
+... )
+```
+
+그런 다음 콜백을 함께 묶습니다:
+
+```py
+>>> callbacks = [metric_callback, push_to_hub_callback]
+```
+
+드디어, 모델 훈련을 시작할 준비가 되었습니다! [`fit`](https://keras.io/api/models/model_training_apis/#fit-method)에 훈련 데이터셋, 검증 데이터셋, 에폭의 수 및 콜백을 전달하여 파인 튜닝합니다:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3, callbacks=callbacks)
+```
+
+훈련이 완료되면, 모델이 자동으로 Hub에 업로드되어 모든 사람이 사용할 수 있습니다!
+
+
+
+
+
+텍스트 분류를 위한 모델을 파인 튜닝하는 자세한 예제는 다음 [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb) 또는 [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)를 참조하세요.
+
+
+
+## 추론[[inference]]
+
+좋아요, 이제 모델을 파인 튜닝했으니 추론에 사용할 수 있습니다!
+
+추론을 수행하고자 하는 텍스트를 가져와봅시다:
+
+```py
+>>> text = "This was a masterpiece. Not completely faithful to the books, but enthralling from beginning to end. Might be my favorite of the three."
+```
+
+파인 튜닝된 모델로 추론을 시도하는 가장 간단한 방법은 [`pipeline`]를 사용하는 것입니다. 모델로 감정 분석을 위한 `pipeline`을 인스턴스화하고, 텍스트를 전달해보세요:
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline("sentiment-analysis", model="stevhliu/my_awesome_model")
+>>> classifier(text)
+[{'label': 'POSITIVE', 'score': 0.9994940757751465}]
+```
+
+원한다면, `pipeline`의 결과를 수동으로 복제할 수도 있습니다.
+
+
+
+텍스트를 토큰화하고 PyTorch 텐서를 반환합니다.
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")
+>>> inputs = tokenizer(text, return_tensors="pt")
+```
+
+입력을 모델에 전달하고 `logits`을 반환합니다:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model")
+>>> with torch.no_grad():
+... logits = model(**inputs).logits
+```
+
+가장 높은 확률을 가진 클래스를 모델의 `id2label` 매핑을 사용하여 텍스트 레이블로 변환합니다:
+
+```py
+>>> predicted_class_id = logits.argmax().item()
+>>> model.config.id2label[predicted_class_id]
+'POSITIVE'
+```
+
+
+텍스트를 토큰화하고 TensorFlow 텐서를 반환합니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")
+>>> inputs = tokenizer(text, return_tensors="tf")
+```
+
+입력값을 모델에 전달하고 `logits`을 반환합니다:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model")
+>>> logits = model(**inputs).logits
+```
+
+가장 높은 확률을 가진 클래스를 모델의 `id2label` 매핑을 사용하여 텍스트 레이블로 변환합니다:
+
+```py
+>>> predicted_class_id = int(tf.math.argmax(logits, axis=-1)[0])
+>>> model.config.id2label[predicted_class_id]
+'POSITIVE'
+```
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/summarization.md b/docs/transformers/docs/source/ko/tasks/summarization.md
new file mode 100644
index 0000000000000000000000000000000000000000..a2b2b1fbc95498baaeb02b00b39894d60e801370
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/summarization.md
@@ -0,0 +1,413 @@
+
+
+# 요약[[summarization]]
+
+[[open-in-colab]]
+
+
+
+요약은 문서나 기사에서 중요한 정보를 모두 포함하되 짧게 만드는 일입니다.
+번역과 마찬가지로, 시퀀스-투-시퀀스 문제로 구성할 수 있는 대표적인 작업 중 하나입니다.
+요약에는 아래와 같이 유형이 있습니다:
+
+- 추출(Extractive) 요약: 문서에서 가장 관련성 높은 정보를 추출합니다.
+- 생성(Abstractive) 요약: 가장 관련성 높은 정보를 포착해내는 새로운 텍스트를 생성합니다.
+
+이 가이드에서 소개할 내용은 아래와 같습니다:
+
+1. 생성 요약을 위한 [BillSum](https://huggingface.co/datasets/billsum) 데이터셋 중 캘리포니아 주 법안 하위 집합으로 [T5](https://huggingface.co/google-t5/t5-small)를 파인튜닝합니다.
+2. 파인튜닝된 모델을 사용하여 추론합니다.
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/summarization)를 확인하는 것이 좋습니다.
+
+
+
+시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers datasets evaluate rouge_score
+```
+
+Hugging Face 계정에 로그인하면 모델을 업로드하고 커뮤니티에 공유할 수 있습니다.
+토큰을 입력하여 로그인하세요.
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## BillSum 데이터셋 가져오기[[load-billsum-dataset]]
+
+🤗 Datasets 라이브러리에서 BillSum 데이터셋의 작은 버전인 캘리포니아 주 법안 하위 집합을 가져오세요:
+
+```py
+>>> from datasets import load_dataset
+
+>>> billsum = load_dataset("billsum", split="ca_test")
+```
+
+[`~datasets.Dataset.train_test_split`] 메소드로 데이터셋을 학습용와 테스트용으로 나누세요:
+
+```py
+>>> billsum = billsum.train_test_split(test_size=0.2)
+```
+
+그런 다음 예시를 하나 살펴보세요:
+
+```py
+>>> billsum["train"][0]
+{'summary': 'Existing law authorizes state agencies to enter into contracts for the acquisition of goods or services upon approval by the Department of General Services. Existing law sets forth various requirements and prohibitions for those contracts, including, but not limited to, a prohibition on entering into contracts for the acquisition of goods or services of $100,000 or more with a contractor that discriminates between spouses and domestic partners or same-sex and different-sex couples in the provision of benefits. Existing law provides that a contract entered into in violation of those requirements and prohibitions is void and authorizes the state or any person acting on behalf of the state to bring a civil action seeking a determination that a contract is in violation and therefore void. Under existing law, a willful violation of those requirements and prohibitions is a misdemeanor.\nThis bill would also prohibit a state agency from entering into contracts for the acquisition of goods or services of $100,000 or more with a contractor that discriminates between employees on the basis of gender identity in the provision of benefits, as specified. By expanding the scope of a crime, this bill would impose a state-mandated local program.\nThe California Constitution requires the state to reimburse local agencies and school districts for certain costs mandated by the state. Statutory provisions establish procedures for making that reimbursement.\nThis bill would provide that no reimbursement is required by this act for a specified reason.',
+ 'text': 'The people of the State of California do enact as follows:\n\n\nSECTION 1.\nSection 10295.35 is added to the Public Contract Code, to read:\n10295.35.\n(a) (1) Notwithstanding any other law, a state agency shall not enter into any contract for the acquisition of goods or services in the amount of one hundred thousand dollars ($100,000) or more with a contractor that, in the provision of benefits, discriminates between employees on the basis of an employee’s or dependent’s actual or perceived gender identity, including, but not limited to, the employee’s or dependent’s identification as transgender.\n(2) For purposes of this section, “contract” includes contracts with a cumulative amount of one hundred thousand dollars ($100,000) or more per contractor in each fiscal year.\n(3) For purposes of this section, an employee health plan is discriminatory if the plan is not consistent with Section 1365.5 of the Health and Safety Code and Section 10140 of the Insurance Code.\n(4) The requirements of this section shall apply only to those portions of a contractor’s operations that occur under any of the following conditions:\n(A) Within the state.\n(B) On real property outside the state if the property is owned by the state or if the state has a right to occupy the property, and if the contractor’s presence at that location is connected to a contract with the state.\n(C) Elsewhere in the United States where work related to a state contract is being performed.\n(b) Contractors shall treat as confidential, to the maximum extent allowed by law or by the requirement of the contractor’s insurance provider, any request by an employee or applicant for employment benefits or any documentation of eligibility for benefits submitted by an employee or applicant for employment.\n(c) After taking all reasonable measures to find a contractor that complies with this section, as determined by the state agency, the requirements of this section may be waived under any of the following circumstances:\n(1) There is only one prospective contractor willing to enter into a specific contract with the state agency.\n(2) The contract is necessary to respond to an emergency, as determined by the state agency, that endangers the public health, welfare, or safety, or the contract is necessary for the provision of essential services, and no entity that complies with the requirements of this section capable of responding to the emergency is immediately available.\n(3) The requirements of this section violate, or are inconsistent with, the terms or conditions of a grant, subvention, or agreement, if the agency has made a good faith attempt to change the terms or conditions of any grant, subvention, or agreement to authorize application of this section.\n(4) The contractor is providing wholesale or bulk water, power, or natural gas, the conveyance or transmission of the same, or ancillary services, as required for ensuring reliable services in accordance with good utility practice, if the purchase of the same cannot practically be accomplished through the standard competitive bidding procedures and the contractor is not providing direct retail services to end users.\n(d) (1) A contractor shall not be deemed to discriminate in the provision of benefits if the contractor, in providing the benefits, pays the actual costs incurred in obtaining the benefit.\n(2) If a contractor is unable to provide a certain benefit, despite taking reasonable measures to do so, the contractor shall not be deemed to discriminate in the provision of benefits.\n(e) (1) Every contract subject to this chapter shall contain a statement by which the contractor certifies that the contractor is in compliance with this section.\n(2) The department or other contracting agency shall enforce this section pursuant to its existing enforcement powers.\n(3) (A) If a contractor falsely certifies that it is in compliance with this section, the contract with that contractor shall be subject to Article 9 (commencing with Section 10420), unless, within a time period specified by the department or other contracting agency, the contractor provides to the department or agency proof that it has complied, or is in the process of complying, with this section.\n(B) The application of the remedies or penalties contained in Article 9 (commencing with Section 10420) to a contract subject to this chapter shall not preclude the application of any existing remedies otherwise available to the department or other contracting agency under its existing enforcement powers.\n(f) Nothing in this section is intended to regulate the contracting practices of any local jurisdiction.\n(g) This section shall be construed so as not to conflict with applicable federal laws, rules, or regulations. In the event that a court or agency of competent jurisdiction holds that federal law, rule, or regulation invalidates any clause, sentence, paragraph, or section of this code or the application thereof to any person or circumstances, it is the intent of the state that the court or agency sever that clause, sentence, paragraph, or section so that the remainder of this section shall remain in effect.\nSEC. 2.\nSection 10295.35 of the Public Contract Code shall not be construed to create any new enforcement authority or responsibility in the Department of General Services or any other contracting agency.\nSEC. 3.\nNo reimbursement is required by this act pursuant to Section 6 of Article XIII\u2009B of the California Constitution because the only costs that may be incurred by a local agency or school district will be incurred because this act creates a new crime or infraction, eliminates a crime or infraction, or changes the penalty for a crime or infraction, within the meaning of Section 17556 of the Government Code, or changes the definition of a crime within the meaning of Section 6 of Article XIII\u2009B of the California Constitution.',
+ 'title': 'An act to add Section 10295.35 to the Public Contract Code, relating to public contracts.'}
+```
+
+여기서 다음 두 개의 필드를 사용하게 됩니다:
+
+- `text`: 모델의 입력이 될 법안 텍스트입니다.
+- `summary`: `text`의 간략한 버전으로 모델의 타겟이 됩니다.
+
+## 전처리[[preprocess]]
+
+다음으로 `text`와 `summary`를 처리하기 위한 T5 토크나이저를 가져옵니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> checkpoint = "google-t5/t5-small"
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+```
+
+생성하려는 전처리 함수는 아래 조건을 만족해야 합니다:
+
+1. 입력 앞에 프롬프트를 붙여 T5가 요약 작업임을 인식할 수 있도록 합니다. 여러 NLP 작업을 수행할 수 있는 일부 모델은 특정 작업에 대한 프롬프트가 필요합니다.
+2. 레이블을 토큰화할 때 `text_target` 인수를 사용합니다.
+3. `max_length` 매개변수로 설정된 최대 길이를 넘지 않도록 긴 시퀀스를 잘라냅니다.
+
+```py
+>>> prefix = "summarize: "
+
+
+>>> def preprocess_function(examples):
+... inputs = [prefix + doc for doc in examples["text"]]
+... model_inputs = tokenizer(inputs, max_length=1024, truncation=True)
+
+... labels = tokenizer(text_target=examples["summary"], max_length=128, truncation=True)
+
+... model_inputs["labels"] = labels["input_ids"]
+... return model_inputs
+```
+
+전체 데이터셋에 전처리 함수를 적용하려면 🤗 Datasets의 [`~datasets.Dataset.map`] 메소드를 사용하세요.
+`batched=True`로 설정하여 데이터셋의 여러 요소를 한 번에 처리하면 `map` 함수의 속도를 높일 수 있습니다.
+
+```py
+>>> tokenized_billsum = billsum.map(preprocess_function, batched=True)
+```
+
+이제 [`DataCollatorForSeq2Seq`]를 사용하여 예제 배치를 만드세요.
+전체 데이터셋을 최대 길이로 패딩하는 것보다 배치마다 가장 긴 문장 길이에 맞춰 *동적 패딩*하는 것이 더 효율적입니다.
+
+
+
+```py
+>>> from transformers import DataCollatorForSeq2Seq
+
+>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint)
+```
+
+
+```py
+>>> from transformers import DataCollatorForSeq2Seq
+
+>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint, return_tensors="tf")
+```
+
+
+
+## 평가[[evaluate]]
+
+학습 중에 평가 지표를 포함하면 모델의 성능을 평가하는 데 도움이 되는 경우가 많습니다.
+🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하면 평가 방법을 빠르게 불러올 수 있습니다.
+이 작업에서는 [ROUGE](https://huggingface.co/spaces/evaluate-metric/rouge) 평가 지표를 가져옵니다.
+(평가 지표를 불러오고 계산하는 방법은 🤗 Evaluate [둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하세요.)
+
+```py
+>>> import evaluate
+
+>>> rouge = evaluate.load("rouge")
+```
+
+그런 다음 예측값과 레이블을 [`~evaluate.EvaluationModule.compute`]에 전달하여 ROUGE 지표를 계산하는 함수를 만듭니다:
+
+```py
+>>> import numpy as np
+
+
+>>> def compute_metrics(eval_pred):
+... predictions, labels = eval_pred
+... decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+... labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+... decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+... result = rouge.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
+
+... prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]
+... result["gen_len"] = np.mean(prediction_lens)
+
+... return {k: round(v, 4) for k, v in result.items()}
+```
+
+이제 `compute_metrics` 함수를 사용할 준비가 되었으며, 학습을 설정할 때 이 함수로 되돌아올 것입니다.
+
+## 학습[[train]]
+
+
+
+
+
+모델을 [`Trainer`]로 파인튜닝 하는 것이 익숙하지 않다면, [여기](../training#train-with-pytorch-trainer)에서 기본 튜토리얼을 확인해보세요!
+
+
+
+이제 모델 학습을 시작할 준비가 되었습니다! [`AutoModelForSeq2SeqLM`]로 T5를 가져오세요:
+
+```py
+>>> from transformers import AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+```
+
+이제 세 단계만 남았습니다:
+
+1. [`Seq2SeqTrainingArguments`]에서 학습 하이퍼파라미터를 정의하세요.
+유일한 필수 매개변수는 모델을 저장할 위치를 지정하는 `output_dir`입니다.
+`push_to_hub=True`를 설정하여 이 모델을 Hub에 푸시할 수 있습니다(모델을 업로드하려면 Hugging Face에 로그인해야 합니다.)
+[`Trainer`]는 각 에폭이 끝날 때마다 ROUGE 지표를 평가하고 학습 체크포인트를 저장합니다.
+2. 모델, 데이터셋, 토크나이저, 데이터 콜레이터 및 `compute_metrics` 함수와 함께 학습 인수를 [`Seq2SeqTrainer`]에 전달하세요.
+3. [`~Trainer.train`]을 호출하여 모델을 파인튜닝하세요.
+
+```py
+>>> training_args = Seq2SeqTrainingArguments(
+... output_dir="my_awesome_billsum_model",
+... eval_strategy="epoch",
+... learning_rate=2e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... weight_decay=0.01,
+... save_total_limit=3,
+... num_train_epochs=4,
+... predict_with_generate=True,
+... fp16=True,
+... push_to_hub=True,
+... )
+
+>>> trainer = Seq2SeqTrainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_billsum["train"],
+... eval_dataset=tokenized_billsum["test"],
+... processing_class=tokenizer,
+... data_collator=data_collator,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+
+학습이 완료되면, 누구나 모델을 사용할 수 있도록 [`~transformers.Trainer.push_to_hub`] 메소드로 Hub에 공유합니다:
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+Keras로 모델 파인튜닝을 하는 것이 익숙하지 않다면, [여기](../training#train-a-tensorflow-model-with-keras)에서 기본적인 튜토리얼을 확인하세요!
+
+
+TensorFlow에서 모델을 파인튜닝하려면, 먼저 옵티마이저, 학습률 스케줄 그리고 몇 가지 학습 하이퍼파라미터를 설정하세요:
+
+```py
+>>> from transformers import create_optimizer, AdamWeightDecay
+
+>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
+```
+
+그런 다음 [`TFAutoModelForSeq2SeqLM`]을 사용하여 T5를 가져오세요:
+
+```py
+>>> from transformers import TFAutoModelForSeq2SeqLM
+
+>>> model = TFAutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+```
+
+[`~transformers.TFPreTrainedModel.prepare_tf_dataset`]을 사용하여 데이터셋을 `tf.data.Dataset` 형식으로 변환하세요:
+
+```py
+>>> tf_train_set = model.prepare_tf_dataset(
+... tokenized_billsum["train"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_test_set = model.prepare_tf_dataset(
+... tokenized_billsum["test"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+[`compile`](https://keras.io/api/models/model_training_apis/#compile-method)을 사용하여 모델을 학습할 수 있도록 구성하세요:
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer)
+```
+
+학습을 시작하기 전에 설정해야 할 마지막 두 가지는 예측에서 ROUGE 점수를 계산하고 모델을 Hub에 푸시하는 방법을 제공하는 것입니다.
+두 작업 모두 [Keras callbacks](../main_classes/keras_callbacks)으로 수행할 수 있습니다.
+
+[`~transformers.KerasMetricCallback`]에 `compute_metrics` 함수를 전달하세요:
+
+```py
+>>> from transformers.keras_callbacks import KerasMetricCallback
+
+>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
+```
+
+[`~transformers.PushToHubCallback`]에서 모델과 토크나이저를 푸시할 위치를 지정하세요:
+
+```py
+>>> from transformers.keras_callbacks import PushToHubCallback
+
+>>> push_to_hub_callback = PushToHubCallback(
+... output_dir="my_awesome_billsum_model",
+... tokenizer=tokenizer,
+... )
+```
+
+그런 다음 콜백을 번들로 묶어줍니다:
+
+```py
+>>> callbacks = [metric_callback, push_to_hub_callback]
+```
+
+드디어 모델 학습을 시작할 준비가 되었습니다!
+학습 및 검증 데이터셋, 에폭 수 및 콜백과 함께 [`fit`](https://keras.io/api/models/model_training_apis/#fit-method)을 호출하여 모델을 파인튜닝하세요.
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=callbacks)
+```
+
+학습이 완료되면 모델이 자동으로 Hub에 업로드되어 누구나 사용할 수 있게 됩니다!
+
+
+
+
+
+요약을 위해 모델을 파인튜닝하는 방법에 대한 더 자세한 예제를 보려면 [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)
+또는 [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)을 참고하세요.
+
+
+
+## 추론[[inference]]
+
+좋아요, 이제 모델을 파인튜닝했으니 추론에 사용할 수 있습니다!
+
+요약할 텍스트를 작성해보세요. T5의 경우 작업에 따라 입력 앞에 접두사를 붙여야 합니다. 요약의 경우, 아래와 같은 접두사를 입력 앞에 붙여야 합니다:
+
+```py
+>>> text = "summarize: The Inflation Reduction Act lowers prescription drug costs, health care costs, and energy costs. It's the most aggressive action on tackling the climate crisis in American history, which will lift up American workers and create good-paying, union jobs across the country. It'll lower the deficit and ask the ultra-wealthy and corporations to pay their fair share. And no one making under $400,000 per year will pay a penny more in taxes."
+```
+
+추론을 위해 파인튜닝한 모델을 시험해 보는 가장 간단한 방법은 [`pipeline`]에서 사용하는 것입니다.
+모델을 사용하여 요약을 수행할 [`pipeline`]을 인스턴스화하고 텍스트를 전달하세요:
+
+```py
+>>> from transformers import pipeline
+
+>>> summarizer = pipeline("summarization", model="stevhliu/my_awesome_billsum_model")
+>>> summarizer(text)
+[{"summary_text": "The Inflation Reduction Act lowers prescription drug costs, health care costs, and energy costs. It's the most aggressive action on tackling the climate crisis in American history, which will lift up American workers and create good-paying, union jobs across the country."}]
+```
+
+원한다면 수동으로 다음과 같은 작업을 수행하여 [`pipeline`]의 결과와 동일한 결과를 얻을 수 있습니다:
+
+
+
+
+텍스트를 토크나이즈하고 `input_ids`를 PyTorch 텐서로 반환합니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_billsum_model")
+>>> inputs = tokenizer(text, return_tensors="pt").input_ids
+```
+
+요약문을 생성하려면 [`~generation.GenerationMixin.generate`] 메소드를 사용하세요.
+텍스트 생성에 대한 다양한 전략과 생성을 제어하기 위한 매개변수에 대한 자세한 내용은 [텍스트 생성](../main_classes/text_generation) API를 참조하세요.
+
+```py
+>>> from transformers import AutoModelForSeq2SeqLM
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("stevhliu/my_awesome_billsum_model")
+>>> outputs = model.generate(inputs, max_new_tokens=100, do_sample=False)
+```
+
+생성된 토큰 ID를 텍스트로 디코딩합니다:
+
+```py
+>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
+'the inflation reduction act lowers prescription drug costs, health care costs, and energy costs. it's the most aggressive action on tackling the climate crisis in american history. it will ask the ultra-wealthy and corporations to pay their fair share.'
+```
+
+
+텍스트를 토크나이즈하고 `input_ids`를 TensorFlow 텐서로 반환합니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_billsum_model")
+>>> inputs = tokenizer(text, return_tensors="tf").input_ids
+```
+
+요약문을 생성하려면 [`~transformers.generation_tf_utils.TFGenerationMixin.generate`] 메소드를 사용하세요.
+텍스트 생성에 대한 다양한 전략과 생성을 제어하기 위한 매개변수에 대한 자세한 내용은 [텍스트 생성](../main_classes/text_generation) API를 참조하세요.
+
+```py
+>>> from transformers import TFAutoModelForSeq2SeqLM
+
+>>> model = TFAutoModelForSeq2SeqLM.from_pretrained("stevhliu/my_awesome_billsum_model")
+>>> outputs = model.generate(inputs, max_new_tokens=100, do_sample=False)
+```
+
+생성된 토큰 ID를 텍스트로 디코딩합니다:
+
+```py
+>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
+'the inflation reduction act lowers prescription drug costs, health care costs, and energy costs. it's the most aggressive action on tackling the climate crisis in american history. it will ask the ultra-wealthy and corporations to pay their fair share.'
+```
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/token_classification.md b/docs/transformers/docs/source/ko/tasks/token_classification.md
new file mode 100644
index 0000000000000000000000000000000000000000..a65503092cee1decc8e2983ba4df1bf5e1db6921
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/token_classification.md
@@ -0,0 +1,555 @@
+
+
+# 토큰 분류[[token-classification]]
+
+[[open-in-colab]]
+
+
+
+토큰 분류는 문장의 개별 토큰에 레이블을 할당합니다. 가장 일반적인 토큰 분류 작업 중 하나는 개체명 인식(Named Entity Recognition, NER)입니다. 개체명 인식은 문장에서 사람, 위치 또는 조직과 같은 각 개체의 레이블을 찾으려고 시도합니다.
+
+이 가이드에서 학습할 내용은:
+
+1. [WNUT 17](https://huggingface.co/datasets/wnut_17) 데이터 세트에서 [DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased)를 파인 튜닝하여 새로운 개체를 탐지합니다.
+2. 추론을 위해 파인 튜닝 모델을 사용합니다.
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/token-classification)를 확인하는 것이 좋습니다.
+
+
+
+시작하기 전에, 필요한 모든 라이브러리가 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers datasets evaluate seqeval
+```
+
+Hugging Face 계정에 로그인하여 모델을 업로드하고 커뮤니티에 공유하는 것을 권장합니다. 메시지가 표시되면, 토큰을 입력하여 로그인하세요:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## WNUT 17 데이터 세트 가져오기[[load-wnut-17-dataset]]
+
+먼저 🤗 Datasets 라이브러리에서 WNUT 17 데이터 세트를 가져옵니다:
+
+```py
+>>> from datasets import load_dataset
+
+>>> wnut = load_dataset("wnut_17")
+```
+
+다음 예제를 살펴보세요:
+
+```py
+>>> wnut["train"][0]
+{'id': '0',
+ 'ner_tags': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 7, 8, 8, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'tokens': ['@paulwalk', 'It', "'s", 'the', 'view', 'from', 'where', 'I', "'m", 'living', 'for', 'two', 'weeks', '.', 'Empire', 'State', 'Building', '=', 'ESB', '.', 'Pretty', 'bad', 'storm', 'here', 'last', 'evening', '.']
+}
+```
+
+`ner_tags`의 각 숫자는 개체를 나타냅니다. 숫자를 레이블 이름으로 변환하여 개체가 무엇인지 확인합니다:
+
+```py
+>>> label_list = wnut["train"].features[f"ner_tags"].feature.names
+>>> label_list
+[
+ "O",
+ "B-corporation",
+ "I-corporation",
+ "B-creative-work",
+ "I-creative-work",
+ "B-group",
+ "I-group",
+ "B-location",
+ "I-location",
+ "B-person",
+ "I-person",
+ "B-product",
+ "I-product",
+]
+```
+
+각 `ner_tag`의 앞에 붙은 문자는 개체의 토큰 위치를 나타냅니다:
+
+- `B-`는 개체의 시작을 나타냅니다.
+- `I-`는 토큰이 동일한 개체 내부에 포함되어 있음을 나타냅니다(예를 들어 `State` 토큰은 `Empire State Building`와 같은 개체의 일부입니다).
+- `0`는 토큰이 어떤 개체에도 해당하지 않음을 나타냅니다.
+
+## 전처리[[preprocess]]
+
+
+
+다음으로 `tokens` 필드를 전처리하기 위해 DistilBERT 토크나이저를 가져옵니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+위의 예제 `tokens` 필드를 보면 입력이 이미 토큰화된 것처럼 보입니다. 그러나 실제로 입력은 아직 토큰화되지 않았으므로 단어를 하위 단어로 토큰화하기 위해 `is_split_into_words=True`를 설정해야 합니다. 예제로 확인합니다:
+
+```py
+>>> example = wnut["train"][0]
+>>> tokenized_input = tokenizer(example["tokens"], is_split_into_words=True)
+>>> tokens = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
+>>> tokens
+['[CLS]', '@', 'paul', '##walk', 'it', "'", 's', 'the', 'view', 'from', 'where', 'i', "'", 'm', 'living', 'for', 'two', 'weeks', '.', 'empire', 'state', 'building', '=', 'es', '##b', '.', 'pretty', 'bad', 'storm', 'here', 'last', 'evening', '.', '[SEP]']
+```
+
+그러나 이로 인해 `[CLS]`과 `[SEP]`라는 특수 토큰이 추가되고, 하위 단어 토큰화로 인해 입력과 레이블 간에 불일치가 발생합니다. 하나의 레이블에 해당하는 단일 단어는 이제 두 개의 하위 단어로 분할될 수 있습니다. 토큰과 레이블을 다음과 같이 재정렬해야 합니다:
+
+1. [`word_ids`](https://huggingface.co/docs/transformers/main_classes/tokenizer#transformers.BatchEncoding.word_ids) 메소드로 모든 토큰을 해당 단어에 매핑합니다.
+2. 특수 토큰 `[CLS]`와 `[SEP]`에 `-100` 레이블을 할당하여, PyTorch 손실 함수가 해당 토큰을 무시하도록 합니다.
+3. 주어진 단어의 첫 번째 토큰에만 레이블을 지정합니다. 같은 단어의 다른 하위 토큰에 `-100`을 할당합니다.
+
+다음은 토큰과 레이블을 재정렬하고 DistilBERT의 최대 입력 길이보다 길지 않도록 시퀀스를 잘라내는 함수를 만드는 방법입니다:
+
+```py
+>>> def tokenize_and_align_labels(examples):
+... tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
+
+... labels = []
+... for i, label in enumerate(examples[f"ner_tags"]):
+... word_ids = tokenized_inputs.word_ids(batch_index=i) # Map tokens to their respective word.
+... previous_word_idx = None
+... label_ids = []
+... for word_idx in word_ids: # Set the special tokens to -100.
+... if word_idx is None:
+... label_ids.append(-100)
+... elif word_idx != previous_word_idx: # Only label the first token of a given word.
+... label_ids.append(label[word_idx])
+... else:
+... label_ids.append(-100)
+... previous_word_idx = word_idx
+... labels.append(label_ids)
+
+... tokenized_inputs["labels"] = labels
+... return tokenized_inputs
+```
+
+전체 데이터 세트에 전처리 함수를 적용하려면, 🤗 Datasets [`~datasets.Dataset.map`] 함수를 사용하세요. `batched=True`로 설정하여 데이터 세트의 여러 요소를 한 번에 처리하면 `map` 함수의 속도를 높일 수 있습니다:
+```py
+>>> tokenized_wnut = wnut.map(tokenize_and_align_labels, batched=True)
+```
+
+이제 [`DataCollatorWithPadding`]를 사용하여 예제 배치를 만들어봅시다. 데이터 세트 전체를 최대 길이로 패딩하는 대신, *동적 패딩*을 사용하여 배치에서 가장 긴 길이에 맞게 문장을 패딩하는 것이 효율적입니다.
+
+
+
+```py
+>>> from transformers import DataCollatorForTokenClassification
+
+>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
+```
+
+
+```py
+>>> from transformers import DataCollatorForTokenClassification
+
+>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer, return_tensors="tf")
+```
+
+
+
+## 평가[[evaluation]]
+
+훈련 중 모델의 성능을 평가하기 위해 평가 지표를 포함하는 것이 유용합니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리를 사용하여 빠르게 평가 방법을 가져올 수 있습니다. 이 작업에서는 [seqeval](https://huggingface.co/spaces/evaluate-metric/seqeval) 평가 지표를 가져옵니다. (평가 지표를 가져오고 계산하는 방법에 대해서는 🤗 Evaluate [빠른 둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하세요). Seqeval은 실제로 정밀도, 재현률, F1 및 정확도와 같은 여러 점수를 산출합니다.
+
+```py
+>>> import evaluate
+
+>>> seqeval = evaluate.load("seqeval")
+```
+
+먼저 NER 레이블을 가져온 다음, [`~evaluate.EvaluationModule.compute`]에 실제 예측과 실제 레이블을 전달하여 점수를 계산하는 함수를 만듭니다:
+
+```py
+>>> import numpy as np
+
+>>> labels = [label_list[i] for i in example[f"ner_tags"]]
+
+
+>>> def compute_metrics(p):
+... predictions, labels = p
+... predictions = np.argmax(predictions, axis=2)
+
+... true_predictions = [
+... [label_list[p] for (p, l) in zip(prediction, label) if l != -100]
+... for prediction, label in zip(predictions, labels)
+... ]
+... true_labels = [
+... [label_list[l] for (p, l) in zip(prediction, label) if l != -100]
+... for prediction, label in zip(predictions, labels)
+... ]
+
+... results = seqeval.compute(predictions=true_predictions, references=true_labels)
+... return {
+... "precision": results["overall_precision"],
+... "recall": results["overall_recall"],
+... "f1": results["overall_f1"],
+... "accuracy": results["overall_accuracy"],
+... }
+```
+
+이제 `compute_metrics` 함수를 사용할 준비가 되었으며, 훈련을 설정하면 이 함수로 되돌아올 것입니다.
+
+## 훈련[[train]]
+
+모델을 훈련하기 전에, `id2label`와 `label2id`를 사용하여 예상되는 id와 레이블의 맵을 생성하세요:
+
+```py
+>>> id2label = {
+... 0: "O",
+... 1: "B-corporation",
+... 2: "I-corporation",
+... 3: "B-creative-work",
+... 4: "I-creative-work",
+... 5: "B-group",
+... 6: "I-group",
+... 7: "B-location",
+... 8: "I-location",
+... 9: "B-person",
+... 10: "I-person",
+... 11: "B-product",
+... 12: "I-product",
+... }
+>>> label2id = {
+... "O": 0,
+... "B-corporation": 1,
+... "I-corporation": 2,
+... "B-creative-work": 3,
+... "I-creative-work": 4,
+... "B-group": 5,
+... "I-group": 6,
+... "B-location": 7,
+... "I-location": 8,
+... "B-person": 9,
+... "I-person": 10,
+... "B-product": 11,
+... "I-product": 12,
+... }
+```
+
+
+
+
+
+[`Trainer`]를 사용하여 모델을 파인 튜닝하는 방법에 익숙하지 않은 경우, [여기](../training#train-with-pytorch-trainer)에서 기본 튜토리얼을 확인하세요!
+
+
+
+이제 모델을 훈련시킬 준비가 되었습니다! [`AutoModelForSequenceClassification`]로 DistilBERT를 가져오고 예상되는 레이블 수와 레이블 매핑을 지정하세요:
+
+```py
+>>> from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer
+
+>>> model = AutoModelForTokenClassification.from_pretrained(
+... "distilbert/distilbert-base-uncased", num_labels=13, id2label=id2label, label2id=label2id
+... )
+```
+
+이제 세 단계만 거치면 끝입니다:
+
+1. [`TrainingArguments`]에서 하이퍼파라미터를 정의하세요. `output_dir`는 모델을 저장할 위치를 지정하는 유일한 매개변수입니다. 이 모델을 허브에 업로드하기 위해 `push_to_hub=True`를 설정합니다(모델을 업로드하기 위해 Hugging Face에 로그인해야합니다.) 각 에폭이 끝날 때마다, [`Trainer`]는 seqeval 점수를 평가하고 훈련 체크포인트를 저장합니다.
+2. [`Trainer`]에 훈련 인수와 모델, 데이터 세트, 토크나이저, 데이터 콜레이터 및 `compute_metrics` 함수를 전달하세요.
+3. [`~Trainer.train`]를 호출하여 모델을 파인 튜닝하세요.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="my_awesome_wnut_model",
+... learning_rate=2e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... num_train_epochs=2,
+... weight_decay=0.01,
+... eval_strategy="epoch",
+... save_strategy="epoch",
+... load_best_model_at_end=True,
+... push_to_hub=True,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_wnut["train"],
+... eval_dataset=tokenized_wnut["test"],
+... processing_class=tokenizer,
+... data_collator=data_collator,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+
+훈련이 완료되면, [`~transformers.Trainer.push_to_hub`] 메소드를 사용하여 모델을 허브에 공유할 수 있습니다.
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+Keras를 사용하여 모델을 파인 튜닝하는 방법에 익숙하지 않은 경우, [여기](../training#train-a-tensorflow-model-with-keras)의 기본 튜토리얼을 확인하세요!
+
+
+TensorFlow에서 모델을 파인 튜닝하려면, 먼저 옵티마이저 함수와 학습률 스케쥴, 그리고 일부 훈련 하이퍼파라미터를 설정해야 합니다:
+
+```py
+>>> from transformers import create_optimizer
+
+>>> batch_size = 16
+>>> num_train_epochs = 3
+>>> num_train_steps = (len(tokenized_wnut["train"]) // batch_size) * num_train_epochs
+>>> optimizer, lr_schedule = create_optimizer(
+... init_lr=2e-5,
+... num_train_steps=num_train_steps,
+... weight_decay_rate=0.01,
+... num_warmup_steps=0,
+... )
+```
+
+그런 다음 [`TFAutoModelForSequenceClassification`]을 사용하여 DistilBERT를 가져오고, 예상되는 레이블 수와 레이블 매핑을 지정합니다:
+
+```py
+>>> from transformers import TFAutoModelForTokenClassification
+
+>>> model = TFAutoModelForTokenClassification.from_pretrained(
+... "distilbert/distilbert-base-uncased", num_labels=13, id2label=id2label, label2id=label2id
+... )
+```
+
+[`~transformers.TFPreTrainedModel.prepare_tf_dataset`]을 사용하여 데이터 세트를 `tf.data.Dataset` 형식으로 변환합니다:
+
+```py
+>>> tf_train_set = model.prepare_tf_dataset(
+... tokenized_wnut["train"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_validation_set = model.prepare_tf_dataset(
+... tokenized_wnut["validation"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+[`compile`](https://keras.io/api/models/model_training_apis/#compile-method)를 사용하여 훈련할 모델을 구성합니다:
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer)
+```
+
+훈련을 시작하기 전에 설정해야할 마지막 두 가지는 예측에서 seqeval 점수를 계산하고, 모델을 허브에 업로드할 방법을 제공하는 것입니다. 모두 [Keras callbacks](../main_classes/keras_callbacks)를 사용하여 수행됩니다.
+
+[`~transformers.KerasMetricCallback`]에 `compute_metrics` 함수를 전달하세요:
+
+```py
+>>> from transformers.keras_callbacks import KerasMetricCallback
+
+>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
+```
+
+[`~transformers.PushToHubCallback`]에서 모델과 토크나이저를 업로드할 위치를 지정합니다:
+
+```py
+>>> from transformers.keras_callbacks import PushToHubCallback
+
+>>> push_to_hub_callback = PushToHubCallback(
+... output_dir="my_awesome_wnut_model",
+... tokenizer=tokenizer,
+... )
+```
+
+그런 다음 콜백을 함께 묶습니다:
+
+```py
+>>> callbacks = [metric_callback, push_to_hub_callback]
+```
+
+드디어, 모델 훈련을 시작할 준비가 되었습니다! [`fit`](https://keras.io/api/models/model_training_apis/#fit-method)에 훈련 데이터 세트, 검증 데이터 세트, 에폭의 수 및 콜백을 전달하여 파인 튜닝합니다:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3, callbacks=callbacks)
+```
+
+훈련이 완료되면, 모델이 자동으로 허브에 업로드되어 누구나 사용할 수 있습니다!
+
+
+
+
+
+토큰 분류를 위한 모델을 파인 튜닝하는 자세한 예제는 다음
+[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)
+또는 [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)를 참조하세요.
+
+
+
+## 추론[[inference]]
+
+좋아요, 이제 모델을 파인 튜닝했으니 추론에 사용할 수 있습니다!
+
+추론을 수행하고자 하는 텍스트를 가져와봅시다:
+
+```py
+>>> text = "The Golden State Warriors are an American professional basketball team based in San Francisco."
+```
+
+파인 튜닝된 모델로 추론을 시도하는 가장 간단한 방법은 [`pipeline`]를 사용하는 것입니다. 모델로 NER의 `pipeline`을 인스턴스화하고, 텍스트를 전달해보세요:
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline("ner", model="stevhliu/my_awesome_wnut_model")
+>>> classifier(text)
+[{'entity': 'B-location',
+ 'score': 0.42658573,
+ 'index': 2,
+ 'word': 'golden',
+ 'start': 4,
+ 'end': 10},
+ {'entity': 'I-location',
+ 'score': 0.35856336,
+ 'index': 3,
+ 'word': 'state',
+ 'start': 11,
+ 'end': 16},
+ {'entity': 'B-group',
+ 'score': 0.3064001,
+ 'index': 4,
+ 'word': 'warriors',
+ 'start': 17,
+ 'end': 25},
+ {'entity': 'B-location',
+ 'score': 0.65523505,
+ 'index': 13,
+ 'word': 'san',
+ 'start': 80,
+ 'end': 83},
+ {'entity': 'B-location',
+ 'score': 0.4668663,
+ 'index': 14,
+ 'word': 'francisco',
+ 'start': 84,
+ 'end': 93}]
+```
+
+원한다면, `pipeline`의 결과를 수동으로 복제할 수도 있습니다:
+
+
+
+텍스트를 토큰화하고 PyTorch 텐서를 반환합니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
+>>> inputs = tokenizer(text, return_tensors="pt")
+```
+
+입력을 모델에 전달하고 `logits`을 반환합니다:
+
+```py
+>>> from transformers import AutoModelForTokenClassification
+
+>>> model = AutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
+>>> with torch.no_grad():
+... logits = model(**inputs).logits
+```
+
+가장 높은 확률을 가진 클래스를 모델의 `id2label` 매핑을 사용하여 텍스트 레이블로 변환합니다:
+
+```py
+>>> predictions = torch.argmax(logits, dim=2)
+>>> predicted_token_class = [model.config.id2label[t.item()] for t in predictions[0]]
+>>> predicted_token_class
+['O',
+ 'O',
+ 'B-location',
+ 'I-location',
+ 'B-group',
+ 'O',
+ 'O',
+ 'O',
+ 'O',
+ 'O',
+ 'O',
+ 'O',
+ 'O',
+ 'B-location',
+ 'B-location',
+ 'O',
+ 'O']
+```
+
+
+텍스트를 토큰화하고 TensorFlow 텐서를 반환합니다:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
+>>> inputs = tokenizer(text, return_tensors="tf")
+```
+
+입력값을 모델에 전달하고 `logits`을 반환합니다:
+
+```py
+>>> from transformers import TFAutoModelForTokenClassification
+
+>>> model = TFAutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
+>>> logits = model(**inputs).logits
+```
+
+가장 높은 확률을 가진 클래스를 모델의 `id2label` 매핑을 사용하여 텍스트 레이블로 변환합니다:
+
+```py
+>>> predicted_token_class_ids = tf.math.argmax(logits, axis=-1)
+>>> predicted_token_class = [model.config.id2label[t] for t in predicted_token_class_ids[0].numpy().tolist()]
+>>> predicted_token_class
+['O',
+ 'O',
+ 'B-location',
+ 'I-location',
+ 'B-group',
+ 'O',
+ 'O',
+ 'O',
+ 'O',
+ 'O',
+ 'O',
+ 'O',
+ 'O',
+ 'B-location',
+ 'B-location',
+ 'O',
+ 'O']
+```
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/translation.md b/docs/transformers/docs/source/ko/tasks/translation.md
new file mode 100644
index 0000000000000000000000000000000000000000..5b4eaaa6125a11b0167be3c45d8cc1d021846ec0
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/translation.md
@@ -0,0 +1,407 @@
+
+
+# 번역[[translation]]
+
+[[open-in-colab]]
+
+
+
+번역은 한 언어로 된 시퀀스를 다른 언어로 변환합니다. 번역이나 요약은 입력을 받아 일련의 출력을 반환하는 강력한 프레임워크인 시퀀스-투-시퀀스 문제로 구성할 수 있는 대표적인 태스크입니다. 번역 시스템은 일반적으로 다른 언어로 된 텍스트 간의 번역에 사용되지만, 음성 간의 통역이나 텍스트-음성 또는 음성-텍스트와 같은 조합에도 사용될 수 있습니다.
+
+이 가이드에서 학습할 내용은:
+
+1. 영어 텍스트를 프랑스어로 번역하기 위해 [T5](https://huggingface.co/google-t5/t5-small) 모델을 OPUS Books 데이터세트의 영어-프랑스어 하위 집합으로 파인튜닝하는 방법과
+2. 파인튜닝된 모델을 추론에 사용하는 방법입니다.
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/translation)를 확인하는 것이 좋습니다.
+
+
+
+시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers datasets evaluate sacrebleu
+```
+
+모델을 업로드하고 커뮤니티와 공유할 수 있도록 Hugging Face 계정에 로그인하는 것이 좋습니다. 새로운 창이 표시되면 토큰을 입력하여 로그인하세요.
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## OPUS Books 데이터세트 가져오기[[load-opus-books-dataset]]
+
+먼저 🤗 Datasets 라이브러리에서 [OPUS Books](https://huggingface.co/datasets/opus_books) 데이터세트의 영어-프랑스어 하위 집합을 가져오세요.
+
+```py
+>>> from datasets import load_dataset
+
+>>> books = load_dataset("opus_books", "en-fr")
+```
+
+데이터세트를 [`~datasets.Dataset.train_test_split`] 메서드를 사용하여 훈련 및 테스트 데이터로 분할하세요.
+
+```py
+>>> books = books["train"].train_test_split(test_size=0.2)
+```
+
+훈련 데이터에서 예시를 살펴볼까요?
+
+```py
+>>> books["train"][0]
+{'id': '90560',
+ 'translation': {'en': 'But this lofty plateau measured only a few fathoms, and soon we reentered Our Element.',
+ 'fr': 'Mais ce plateau élevé ne mesurait que quelques toises, et bientôt nous fûmes rentrés dans notre élément.'}}
+```
+
+반환된 딕셔너리의 `translation` 키가 텍스트의 영어, 프랑스어 버전을 포함하고 있는 것을 볼 수 있습니다.
+
+## 전처리[[preprocess]]
+
+
+
+다음 단계로 영어-프랑스어 쌍을 처리하기 위해 T5 토크나이저를 가져오세요.
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> checkpoint = "google-t5/t5-small"
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+```
+
+만들 전처리 함수는 아래 요구사항을 충족해야 합니다:
+
+1. T5가 번역 태스크임을 인지할 수 있도록 입력 앞에 프롬프트를 추가하세요. 여러 NLP 태스크를 할 수 있는 모델 중 일부는 이렇게 태스크 프롬프트를 미리 줘야합니다.
+2. 원어(영어)과 번역어(프랑스어)를 별도로 토큰화하세요. 영어 어휘로 사전 학습된 토크나이저로 프랑스어 텍스트를 토큰화할 수는 없기 때문입니다.
+3. `max_length` 매개변수로 설정한 최대 길이보다 길지 않도록 시퀀스를 truncate하세요.
+
+```py
+>>> source_lang = "en"
+>>> target_lang = "fr"
+>>> prefix = "translate English to French: "
+
+
+>>> def preprocess_function(examples):
+... inputs = [prefix + example[source_lang] for example in examples["translation"]]
+... targets = [example[target_lang] for example in examples["translation"]]
+... model_inputs = tokenizer(inputs, text_target=targets, max_length=128, truncation=True)
+... return model_inputs
+```
+
+전체 데이터세트에 전처리 함수를 적용하려면 🤗 Datasets의 [`~datasets.Dataset.map`] 메서드를 사용하세요. `map` 함수의 속도를 높이려면 `batched=True`를 설정하여 데이터세트의 여러 요소를 한 번에 처리하는 방법이 있습니다.
+
+```py
+>>> tokenized_books = books.map(preprocess_function, batched=True)
+```
+
+이제 [`DataCollatorForSeq2Seq`]를 사용하여 예제 배치를 생성합니다. 데이터세트의 최대 길이로 전부를 padding하는 대신, 데이터 정렬 중 각 배치의 최대 길이로 문장을 *동적으로 padding*하는 것이 더 효율적입니다.
+
+
+
+```py
+>>> from transformers import DataCollatorForSeq2Seq
+
+>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint)
+```
+
+
+
+```py
+>>> from transformers import DataCollatorForSeq2Seq
+
+>>> data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint, return_tensors="tf")
+```
+
+
+
+## 평가[[evalulate]]
+
+훈련 중에 메트릭을 포함하면 모델의 성능을 평가하는 데 도움이 됩니다. 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리로 평가 방법(evaluation method)을 빠르게 가져올 수 있습니다. 현재 태스크에 적합한 SacreBLEU 메트릭을 가져오세요. (메트릭을 가져오고 계산하는 방법에 대해 자세히 알아보려면 🤗 Evaluate [둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하세요):
+
+```py
+>>> import evaluate
+
+>>> metric = evaluate.load("sacrebleu")
+```
+
+그런 다음 [`~evaluate.EvaluationModule.compute`]에 예측값과 레이블을 전달하여 SacreBLEU 점수를 계산하는 함수를 생성하세요:
+
+```py
+>>> import numpy as np
+
+
+>>> def postprocess_text(preds, labels):
+... preds = [pred.strip() for pred in preds]
+... labels = [[label.strip()] for label in labels]
+
+... return preds, labels
+
+
+>>> def compute_metrics(eval_preds):
+... preds, labels = eval_preds
+... if isinstance(preds, tuple):
+... preds = preds[0]
+... decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
+
+... labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+... decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+... decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
+
+... result = metric.compute(predictions=decoded_preds, references=decoded_labels)
+... result = {"bleu": result["score"]}
+
+... prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
+... result["gen_len"] = np.mean(prediction_lens)
+... result = {k: round(v, 4) for k, v in result.items()}
+... return result
+```
+
+이제 `compute_metrics` 함수는 준비되었고, 훈련 과정을 설정할 때 다시 살펴볼 예정입니다.
+
+## 훈련[[train]]
+
+
+
+
+
+[`Trainer`]로 모델을 파인튜닝하는 방법에 익숙하지 않다면 [여기](../training#train-with-pytorch-trainer)에서 기본 튜토리얼을 살펴보시기 바랍니다!
+
+
+
+모델을 훈련시킬 준비가 되었군요! [`AutoModelForSeq2SeqLM`]으로 T5를 로드하세요:
+
+```py
+>>> from transformers import AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+```
+
+이제 세 단계만 거치면 끝입니다:
+
+1. [`Seq2SeqTrainingArguments`]에서 훈련 하이퍼파라미터를 정의하세요. 유일한 필수 매개변수는 모델을 저장할 위치인 `output_dir`입니다. 모델을 Hub에 푸시하기 위해 `push_to_hub=True`로 설정하세요. (모델을 업로드하려면 Hugging Face에 로그인해야 합니다.) [`Trainer`]는 에폭이 끝날때마다 SacreBLEU 메트릭을 평가하고 훈련 체크포인트를 저장합니다.
+2. [`Seq2SeqTrainer`]에 훈련 인수를 전달하세요. 모델, 데이터 세트, 토크나이저, data collator 및 `compute_metrics` 함수도 덩달아 전달해야 합니다.
+3. [`~Trainer.train`]을 호출하여 모델을 파인튜닝하세요.
+
+```py
+>>> training_args = Seq2SeqTrainingArguments(
+... output_dir="my_awesome_opus_books_model",
+... eval_strategy="epoch",
+... learning_rate=2e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... weight_decay=0.01,
+... save_total_limit=3,
+... num_train_epochs=2,
+... predict_with_generate=True,
+... fp16=True,
+... push_to_hub=True,
+... )
+
+>>> trainer = Seq2SeqTrainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_books["train"],
+... eval_dataset=tokenized_books["test"],
+... processing_class=tokenizer,
+... data_collator=data_collator,
+... compute_metrics=compute_metrics,
+... )
+
+>>> trainer.train()
+```
+
+학습이 완료되면 [`~transformers.Trainer.push_to_hub`] 메서드로 모델을 Hub에 공유하세요. 이러면 누구나 모델을 사용할 수 있게 됩니다:
+
+```py
+>>> trainer.push_to_hub()
+```
+
+
+
+
+Keras로 모델을 파인튜닝하는 방법이 익숙하지 않다면, [여기](../training#train-a-tensorflow-model-with-keras)에서 기본 튜토리얼을 살펴보시기 바랍니다!
+
+
+TensorFlow에서 모델을 파인튜닝하려면 우선 optimizer 함수, 학습률 스케줄 등의 훈련 하이퍼파라미터를 설정하세요:
+
+```py
+>>> from transformers import AdamWeightDecay
+
+>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
+```
+
+이제 [`TFAutoModelForSeq2SeqLM`]로 T5를 가져오세요:
+
+```py
+>>> from transformers import TFAutoModelForSeq2SeqLM
+
+>>> model = TFAutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+```
+
+[`~transformers.TFPreTrainedModel.prepare_tf_dataset`]로 데이터 세트를 `tf.data.Dataset` 형식으로 변환하세요:
+
+```py
+>>> tf_train_set = model.prepare_tf_dataset(
+... tokenized_books["train"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_test_set = model.prepare_tf_dataset(
+... tokenized_books["test"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+훈련하기 위해 [`compile`](https://keras.io/api/models/model_training_apis/#compile-method) 메서드로 모델을 구성하세요:
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer)
+```
+
+훈련을 시작하기 전에 예측값으로부터 SacreBLEU 메트릭을 계산하는 방법과 모델을 Hub에 업로드하는 방법 두 가지를 미리 설정해둬야 합니다. 둘 다 [Keras callbacks](../main_classes/keras_callbacks)로 구현하세요.
+
+[`~transformers.KerasMetricCallback`]에 `compute_metrics` 함수를 전달하세요.
+
+```py
+>>> from transformers.keras_callbacks import KerasMetricCallback
+
+>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
+```
+
+모델과 토크나이저를 업로드할 위치를 [`~transformers.PushToHubCallback`]에서 지정하세요:
+
+```py
+>>> from transformers.keras_callbacks import PushToHubCallback
+
+>>> push_to_hub_callback = PushToHubCallback(
+... output_dir="my_awesome_opus_books_model",
+... tokenizer=tokenizer,
+... )
+```
+
+이제 콜백들을 한데로 묶어주세요:
+
+```py
+>>> callbacks = [metric_callback, push_to_hub_callback]
+```
+
+드디어 모델을 훈련시킬 모든 준비를 마쳤군요! 이제 훈련 및 검증 데이터 세트에 [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) 메서드를 에폭 수와 만들어둔 콜백과 함께 호출하여 모델을 파인튜닝하세요:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=callbacks)
+```
+
+학습이 완료되면 모델이 자동으로 Hub에 업로드되고, 누구나 사용할 수 있게 됩니다!
+
+
+
+
+
+번역을 위해 모델을 파인튜닝하는 방법에 대한 보다 자세한 예제는 해당 [PyTorch 노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb) 또는 [TensorFlow 노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)을 참조하세요.
+
+
+
+## 추론[[inference]]
+
+좋아요, 이제 모델을 파인튜닝했으니 추론에 사용할 수 있습니다!
+
+다른 언어로 번역하고 싶은 텍스트를 써보세요. T5의 경우 원하는 태스크를 입력의 접두사로 추가해야 합니다. 예를 들어 영어에서 프랑스어로 번역하는 경우, 아래와 같은 접두사가 추가됩니다:
+
+```py
+>>> text = "translate English to French: Legumes share resources with nitrogen-fixing bacteria."
+```
+
+파인튜닝된 모델로 추론하기에 제일 간단한 방법은 [`pipeline`]을 사용하는 것입니다. 해당 모델로 번역 `pipeline`을 만든 뒤, 텍스트를 전달하세요:
+
+```py
+>>> from transformers import pipeline
+
+# Change `xx` to the language of the input and `yy` to the language of the desired output.
+# Examples: "en" for English, "fr" for French, "de" for German, "es" for Spanish, "zh" for Chinese, etc; translation_en_to_fr translates English to French
+# You can view all the lists of languages here - https://huggingface.co/languages
+>>> translator = pipeline("translation_xx_to_yy", model="my_awesome_opus_books_model")
+>>> translator(text)
+[{'translation_text': 'Legumes partagent des ressources avec des bactéries azotantes.'}]
+```
+
+원한다면 `pipeline`의 결과를 직접 복제할 수도 있습니다:
+
+
+
+텍스트를 토큰화하고 `input_ids`를 PyTorch 텐서로 반환하세요:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_opus_books_model")
+>>> inputs = tokenizer(text, return_tensors="pt").input_ids
+```
+
+[`~generation.GenerationMixin.generate`] 메서드로 번역을 생성하세요. 다양한 텍스트 생성 전략 및 생성을 제어하기 위한 매개변수에 대한 자세한 내용은 [Text Generation](../main_classes/text_generation) API를 살펴보시기 바랍니다.
+
+```py
+>>> from transformers import AutoModelForSeq2SeqLM
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("my_awesome_opus_books_model")
+>>> outputs = model.generate(inputs, max_new_tokens=40, do_sample=True, top_k=30, top_p=0.95)
+```
+
+생성된 토큰 ID들을 다시 텍스트로 디코딩하세요:
+
+```py
+>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
+'Les lignées partagent des ressources avec des bactéries enfixant l'azote.'
+```
+
+
+텍스트를 토큰화하고 `input_ids`를 TensorFlow 텐서로 반환하세요:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("my_awesome_opus_books_model")
+>>> inputs = tokenizer(text, return_tensors="tf").input_ids
+```
+
+[`~transformers.generation_tf_utils.TFGenerationMixin.generate`] 메서드로 번역을 생성하세요. 다양한 텍스트 생성 전략 및 생성을 제어하기 위한 매개변수에 대한 자세한 내용은 [Text Generation](../main_classes/text_generation) API를 살펴보시기 바랍니다.
+
+```py
+>>> from transformers import TFAutoModelForSeq2SeqLM
+
+>>> model = TFAutoModelForSeq2SeqLM.from_pretrained("my_awesome_opus_books_model")
+>>> outputs = model.generate(inputs, max_new_tokens=40, do_sample=True, top_k=30, top_p=0.95)
+```
+
+생성된 토큰 ID들을 다시 텍스트로 디코딩하세요:
+
+```py
+>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
+'Les lugumes partagent les ressources avec des bactéries fixatrices d'azote.'
+```
+
+
diff --git a/docs/transformers/docs/source/ko/tasks/video_classification.md b/docs/transformers/docs/source/ko/tasks/video_classification.md
new file mode 100644
index 0000000000000000000000000000000000000000..10569083c09f85f6db4e81f88bf78d73742a4702
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/video_classification.md
@@ -0,0 +1,492 @@
+
+
+# 영상 분류 [[video-classification]]
+
+[[open-in-colab]]
+
+
+영상 분류는 영상 전체에 레이블 또는 클래스를 지정하는 작업입니다. 각 영상에는 하나의 클래스가 있을 것으로 예상됩니다. 영상 분류 모델은 영상을 입력으로 받아 어느 클래스에 속하는지에 대한 예측을 반환합니다. 이러한 모델은 영상이 어떤 내용인지 분류하는 데 사용될 수 있습니다. 영상 분류의 실제 응용 예는 피트니스 앱에서 유용한 동작 / 운동 인식 서비스가 있습니다. 이는 또한 시각 장애인이 이동할 때 보조하는데 사용될 수 있습니다
+
+이 가이드에서는 다음을 수행하는 방법을 보여줍니다:
+
+1. [UCF101](https://www.crcv.ucf.edu/data/UCF101.php) 데이터 세트의 하위 집합을 통해 [VideoMAE](https://huggingface.co/docs/transformers/main/en/model_doc/videomae) 모델을 미세 조정하기.
+2. 미세 조정한 모델을 추론에 사용하기.
+
+
+
+이 작업과 호환되는 모든 아키텍처와 체크포인트를 보려면 [작업 페이지](https://huggingface.co/tasks/video-classification)를 확인하는 것이 좋습니다.
+
+
+
+
+시작하기 전에 필요한 모든 라이브러리가 설치되었는지 확인하세요:
+```bash
+pip install -q pytorchvideo transformers evaluate
+```
+
+영상을 처리하고 준비하기 위해 [PyTorchVideo](https://pytorchvideo.org/)(이하 `pytorchvideo`)를 사용합니다.
+
+커뮤니티에 모델을 업로드하고 공유할 수 있도록 Hugging Face 계정에 로그인하는 것을 권장합니다. 프롬프트가 나타나면 토큰을 입력하여 로그인하세요:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+## UCF101 데이터셋 불러오기 [[load-ufc101-dataset]]
+
+[UCF-101](https://www.crcv.ucf.edu/data/UCF101.php) 데이터 세트의 하위 집합(subset)을 불러오는 것으로 시작할 수 있습니다. 전체 데이터 세트를 학습하는데 더 많은 시간을 할애하기 전에 데이터의 하위 집합을 불러와 모든 것이 잘 작동하는지 실험하고 확인할 수 있습니다.
+
+```py
+>>> from huggingface_hub import hf_hub_download
+
+>>> hf_dataset_identifier = "sayakpaul/ucf101-subset"
+>>> filename = "UCF101_subset.tar.gz"
+>>> file_path = hf_hub_download(repo_id=hf_dataset_identifier, filename=filename, repo_type="dataset")
+```
+
+데이터 세트의 하위 집합이 다운로드 되면, 압축된 파일의 압축을 해제해야 합니다:
+```py
+>>> import tarfile
+
+>>> with tarfile.open(file_path) as t:
+... t.extractall(".")
+```
+
+전체 데이터 세트는 다음과 같이 구성되어 있습니다.
+
+```bash
+UCF101_subset/
+ train/
+ BandMarching/
+ video_1.mp4
+ video_2.mp4
+ ...
+ Archery
+ video_1.mp4
+ video_2.mp4
+ ...
+ ...
+ val/
+ BandMarching/
+ video_1.mp4
+ video_2.mp4
+ ...
+ Archery
+ video_1.mp4
+ video_2.mp4
+ ...
+ ...
+ test/
+ BandMarching/
+ video_1.mp4
+ video_2.mp4
+ ...
+ Archery
+ video_1.mp4
+ video_2.mp4
+ ...
+ ...
+```
+
+
+정렬된 영상의 경로는 다음과 같습니다:
+
+```bash
+...
+'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c04.avi',
+'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g07_c06.avi',
+'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g08_c01.avi',
+'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c02.avi',
+'UCF101_subset/train/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c06.avi'
+...
+```
+
+동일한 그룹/장면에 속하는 영상 클립은 파일 경로에서 `g`로 표시되어 있습니다. 예를 들면, `v_ApplyEyeMakeup_g07_c04.avi`와 `v_ApplyEyeMakeup_g07_c06.avi` 이 있습니다. 이 둘은 같은 그룹입니다.
+
+검증 및 평가 데이터 분할을 할 때, [데이터 누출(data leakage)](https://www.kaggle.com/code/alexisbcook/data-leakage)을 방지하기 위해 동일한 그룹 / 장면의 영상 클립을 사용하지 않아야 합니다. 이 튜토리얼에서 사용하는 하위 집합은 이러한 정보를 고려하고 있습니다.
+
+그 다음으로, 데이터 세트에 존재하는 라벨을 추출합니다. 또한, 모델을 초기화할 때 도움이 될 딕셔너리(dictionary data type)를 생성합니다.
+
+* `label2id`: 클래스 이름을 정수에 매핑합니다.
+* `id2label`: 정수를 클래스 이름에 매핑합니다.
+
+```py
+>>> class_labels = sorted({str(path).split("/")[2] for path in all_video_file_paths})
+>>> label2id = {label: i for i, label in enumerate(class_labels)}
+>>> id2label = {i: label for label, i in label2id.items()}
+
+>>> print(f"Unique classes: {list(label2id.keys())}.")
+
+# Unique classes: ['ApplyEyeMakeup', 'ApplyLipstick', 'Archery', 'BabyCrawling', 'BalanceBeam', 'BandMarching', 'BaseballPitch', 'Basketball', 'BasketballDunk', 'BenchPress'].
+```
+
+이 데이터 세트에는 총 10개의 고유한 클래스가 있습니다. 각 클래스마다 30개의 영상이 훈련 세트에 있습니다
+
+## 미세 조정하기 위해 모델 가져오기 [[load-a-model-to-fine-tune]]
+
+사전 훈련된 체크포인트와 체크포인트에 연관된 이미지 프로세서를 사용하여 영상 분류 모델을 인스턴스화합니다. 모델의 인코더에는 미리 학습된 매개변수가 제공되며, 분류 헤드(데이터를 분류하는 마지막 레이어)는 무작위로 초기화됩니다. 데이터 세트의 전처리 파이프라인을 작성할 때는 이미지 프로세서가 유용합니다.
+
+```py
+>>> from transformers import VideoMAEImageProcessor, VideoMAEForVideoClassification
+
+>>> model_ckpt = "MCG-NJU/videomae-base"
+>>> image_processor = VideoMAEImageProcessor.from_pretrained(model_ckpt)
+>>> model = VideoMAEForVideoClassification.from_pretrained(
+... model_ckpt,
+... label2id=label2id,
+... id2label=id2label,
+... ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint
+... )
+```
+
+모델을 가져오는 동안, 다음과 같은 경고를 마주칠 수 있습니다:
+
+```bash
+Some weights of the model checkpoint at MCG-NJU/videomae-base were not used when initializing VideoMAEForVideoClassification: [..., 'decoder.decoder_layers.1.attention.output.dense.bias', 'decoder.decoder_layers.2.attention.attention.key.weight']
+- This IS expected if you are initializing VideoMAEForVideoClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
+- This IS NOT expected if you are initializing VideoMAEForVideoClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
+Some weights of VideoMAEForVideoClassification were not initialized from the model checkpoint at MCG-NJU/videomae-base and are newly initialized: ['classifier.bias', 'classifier.weight']
+You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
+```
+
+
+위 경고는 우리가 일부 가중치(예: `classifier` 층의 가중치와 편향)를 버리고 새로운 `classifier` 층의 가중치와 편향을 무작위로 초기화하고 있다는 것을 알려줍니다. 이 경우에는 미리 학습된 가중치가 없는 새로운 헤드를 추가하고 있으므로, 라이브러리가 모델을 추론에 사용하기 전에 미세 조정하라고 경고를 보내는 것은 당연합니다. 그리고 이제 우리는 이 모델을 미세 조정할 예정입니다.
+
+**참고** 이 [체크포인트](https://huggingface.co/MCG-NJU/videomae-base-finetuned-kinetics)는 도메인이 많이 중첩된 유사한 다운스트림 작업에 대해 미세 조정하여 얻은 체크포인트이므로 이 작업에서 더 나은 성능을 보일 수 있습니다. `MCG-NJU/videomae-base-finetuned-kinetics` 데이터 세트를 미세 조정하여 얻은 [체크포인트](https://huggingface.co/sayakpaul/videomae-base-finetuned-kinetics-finetuned-ucf101-subset)도 있습니다.
+
+## 훈련을 위한 데이터 세트 준비하기[[prepare-the-datasets-for-training]]
+
+영상 전처리를 위해 [PyTorchVideo 라이브러리](https://pytorchvideo.org/)를 활용할 것입니다. 필요한 종속성을 가져오는 것으로 시작하세요.
+
+```py
+>>> import pytorchvideo.data
+
+>>> from pytorchvideo.transforms import (
+... ApplyTransformToKey,
+... Normalize,
+... RandomShortSideScale,
+... RemoveKey,
+... ShortSideScale,
+... UniformTemporalSubsample,
+... )
+
+>>> from torchvision.transforms import (
+... Compose,
+... Lambda,
+... RandomCrop,
+... RandomHorizontalFlip,
+... Resize,
+... )
+```
+
+학습 데이터 세트 변환에는 '균일한 시간 샘플링(uniform temporal subsampling)', '픽셀 정규화(pixel normalization)', '랜덤 잘라내기(random cropping)' 및 '랜덤 수평 뒤집기(random horizontal flipping)'의 조합을 사용합니다. 검증 및 평가 데이터 세트 변환에는 '랜덤 잘라내기'와 '랜덤 뒤집기'를 제외한 동일한 변환 체인을 유지합니다. 이러한 변환에 대해 자세히 알아보려면 [PyTorchVideo 공식 문서](https://pytorchvideo.org)를 확인하세요.
+
+사전 훈련된 모델과 관련된 이미지 프로세서를 사용하여 다음 정보를 얻을 수 있습니다:
+
+* 영상 프레임 픽셀을 정규화하는 데 사용되는 이미지 평균과 표준 편차
+* 영상 프레임이 조정될 공간 해상도
+
+
+먼저, 몇 가지 상수를 정의합니다.
+
+```py
+>>> mean = image_processor.image_mean
+>>> std = image_processor.image_std
+>>> if "shortest_edge" in image_processor.size:
+... height = width = image_processor.size["shortest_edge"]
+>>> else:
+... height = image_processor.size["height"]
+... width = image_processor.size["width"]
+>>> resize_to = (height, width)
+
+>>> num_frames_to_sample = model.config.num_frames
+>>> sample_rate = 4
+>>> fps = 30
+>>> clip_duration = num_frames_to_sample * sample_rate / fps
+```
+
+이제 데이터 세트에 특화된 전처리(transform)과 데이터 세트 자체를 정의합니다. 먼저 훈련 데이터 세트로 시작합니다:
+
+```py
+>>> train_transform = Compose(
+... [
+... ApplyTransformToKey(
+... key="video",
+... transform=Compose(
+... [
+... UniformTemporalSubsample(num_frames_to_sample),
+... Lambda(lambda x: x / 255.0),
+... Normalize(mean, std),
+... RandomShortSideScale(min_size=256, max_size=320),
+... RandomCrop(resize_to),
+... RandomHorizontalFlip(p=0.5),
+... ]
+... ),
+... ),
+... ]
+... )
+
+>>> train_dataset = pytorchvideo.data.Ucf101(
+... data_path=os.path.join(dataset_root_path, "train"),
+... clip_sampler=pytorchvideo.data.make_clip_sampler("random", clip_duration),
+... decode_audio=False,
+... transform=train_transform,
+... )
+```
+
+같은 방식의 작업 흐름을 검증과 평가 세트에도 적용할 수 있습니다.
+
+```py
+>>> val_transform = Compose(
+... [
+... ApplyTransformToKey(
+... key="video",
+... transform=Compose(
+... [
+... UniformTemporalSubsample(num_frames_to_sample),
+... Lambda(lambda x: x / 255.0),
+... Normalize(mean, std),
+... Resize(resize_to),
+... ]
+... ),
+... ),
+... ]
+... )
+
+>>> val_dataset = pytorchvideo.data.Ucf101(
+... data_path=os.path.join(dataset_root_path, "val"),
+... clip_sampler=pytorchvideo.data.make_clip_sampler("uniform", clip_duration),
+... decode_audio=False,
+... transform=val_transform,
+... )
+
+>>> test_dataset = pytorchvideo.data.Ucf101(
+... data_path=os.path.join(dataset_root_path, "test"),
+... clip_sampler=pytorchvideo.data.make_clip_sampler("uniform", clip_duration),
+... decode_audio=False,
+... transform=val_transform,
+... )
+```
+
+
+**참고**: 위의 데이터 세트의 파이프라인은 [공식 파이토치 예제](https://pytorchvideo.org/docs/tutorial_classification#dataset)에서 가져온 것입니다. 우리는 UCF-101 데이터셋에 맞게 [`pytorchvideo.data.Ucf101()`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.Ucf101) 함수를 사용하고 있습니다. 내부적으로 이 함수는 [`pytorchvideo.data.labeled_video_dataset.LabeledVideoDataset`](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html#pytorchvideo.data.LabeledVideoDataset) 객체를 반환합니다. `LabeledVideoDataset` 클래스는 PyTorchVideo 데이터셋에서 모든 영상 관련 작업의 기본 클래스입니다. 따라서 PyTorchVideo에서 미리 제공하지 않는 사용자 지정 데이터 세트를 사용하려면, 이 클래스를 적절하게 확장하면 됩니다. 더 자세한 사항이 알고 싶다면 `data` API [문서](https://pytorchvideo.readthedocs.io/en/latest/api/data/data.html) 를 참고하세요. 또한 위의 예시와 유사한 구조를 갖는 데이터 세트를 사용하고 있다면, `pytorchvideo.data.Ucf101()` 함수를 사용하는 데 문제가 없을 것입니다.
+
+데이터 세트에 영상의 개수를 알기 위해 `num_videos` 인수에 접근할 수 있습니다.
+
+```py
+>>> print(train_dataset.num_videos, val_dataset.num_videos, test_dataset.num_videos)
+# (300, 30, 75)
+```
+
+## 더 나은 디버깅을 위해 전처리 영상 시각화하기[[visualize-the-preprocessed-video-for-better-debugging]]
+
+```py
+>>> import imageio
+>>> import numpy as np
+>>> from IPython.display import Image
+
+>>> def unnormalize_img(img):
+... """Un-normalizes the image pixels."""
+... img = (img * std) + mean
+... img = (img * 255).astype("uint8")
+... return img.clip(0, 255)
+
+>>> def create_gif(video_tensor, filename="sample.gif"):
+... """Prepares a GIF from a video tensor.
+...
+... The video tensor is expected to have the following shape:
+... (num_frames, num_channels, height, width).
+... """
+... frames = []
+... for video_frame in video_tensor:
+... frame_unnormalized = unnormalize_img(video_frame.permute(1, 2, 0).numpy())
+... frames.append(frame_unnormalized)
+... kargs = {"duration": 0.25}
+... imageio.mimsave(filename, frames, "GIF", **kargs)
+... return filename
+
+>>> def display_gif(video_tensor, gif_name="sample.gif"):
+... """Prepares and displays a GIF from a video tensor."""
+... video_tensor = video_tensor.permute(1, 0, 2, 3)
+... gif_filename = create_gif(video_tensor, gif_name)
+... return Image(filename=gif_filename)
+
+>>> sample_video = next(iter(train_dataset))
+>>> video_tensor = sample_video["video"]
+>>> display_gif(video_tensor)
+```
+
+
+
+
+
+## 모델 훈련하기[[train-the-model]]
+
+🤗 Transformers의 [`Trainer`](https://huggingface.co/docs/transformers/main_classes/trainer)를 사용하여 모델을 훈련시켜보세요. `Trainer`를 인스턴스화하려면 훈련 설정과 평가 지표를 정의해야 합니다. 가장 중요한 것은 [`TrainingArguments`](https://huggingface.co/transformers/main_classes/trainer.html#transformers.TrainingArguments)입니다. 이 클래스는 훈련을 구성하는 모든 속성을 포함하며, 훈련 중 체크포인트를 저장할 출력 폴더 이름을 필요로 합니다. 또한 🤗 Hub의 모델 저장소의 모든 정보를 동기화하는 데 도움이 됩니다.
+
+대부분의 훈련 인수는 따로 설명할 필요는 없습니다. 하지만 여기에서 중요한 인수는 `remove_unused_columns=False` 입니다. 이 인자는 모델의 호출 함수에서 사용되지 않는 모든 속성 열(columns)을 삭제합니다. 기본값은 일반적으로 True입니다. 이는 사용되지 않는 기능 열을 삭제하는 것이 이상적이며, 입력을 모델의 호출 함수로 풀기(unpack)가 쉬워지기 때문입니다. 하지만 이 경우에는 `pixel_values`(모델의 입력으로 필수적인 키)를 생성하기 위해 사용되지 않는 기능('video'가 특히 그렇습니다)이 필요합니다. 따라서 remove_unused_columns을 False로 설정해야 합니다.
+
+```py
+>>> from transformers import TrainingArguments, Trainer
+
+>>> model_name = model_ckpt.split("/")[-1]
+>>> new_model_name = f"{model_name}-finetuned-ucf101-subset"
+>>> num_epochs = 4
+
+>>> args = TrainingArguments(
+... new_model_name,
+... remove_unused_columns=False,
+... eval_strategy="epoch",
+... save_strategy="epoch",
+... learning_rate=5e-5,
+... per_device_train_batch_size=batch_size,
+... per_device_eval_batch_size=batch_size,
+... warmup_ratio=0.1,
+... logging_steps=10,
+... load_best_model_at_end=True,
+... metric_for_best_model="accuracy",
+... push_to_hub=True,
+... max_steps=(train_dataset.num_videos // batch_size) * num_epochs,
+... )
+```
+
+`pytorchvideo.data.Ucf101()` 함수로 반환되는 데이터 세트는 `__len__` 메소드가 이식되어 있지 않습니다. 따라서, `TrainingArguments`를 인스턴스화할 때 `max_steps`를 정의해야 합니다.
+
+다음으로, 평가지표를 불러오고, 예측값에서 평가지표를 계산할 함수를 정의합니다. 필요한 전처리 작업은 예측된 로짓(logits)에 argmax 값을 취하는 것뿐입니다:
+
+```py
+import evaluate
+
+metric = evaluate.load("accuracy")
+
+
+def compute_metrics(eval_pred):
+ predictions = np.argmax(eval_pred.predictions, axis=1)
+ return metric.compute(predictions=predictions, references=eval_pred.label_ids)
+```
+
+**평가에 대한 참고사항**:
+
+[VideoMAE 논문](https://arxiv.org/abs/2203.12602)에서 저자는 다음과 같은 평가 전략을 사용합니다. 테스트 영상에서 여러 클립을 선택하고 그 클립에 다양한 크롭을 적용하여 집계 점수를 보고합니다. 그러나 이번 튜토리얼에서는 간단함과 간결함을 위해 해당 전략을 고려하지 않습니다.
+
+또한, 예제를 묶어서 배치를 형성하는 `collate_fn`을 정의해야합니다. 각 배치는 `pixel_values`와 `labels`라는 2개의 키로 구성됩니다.
+
+```py
+>>> def collate_fn(examples):
+... # permute to (num_frames, num_channels, height, width)
+... pixel_values = torch.stack(
+... [example["video"].permute(1, 0, 2, 3) for example in examples]
+... )
+... labels = torch.tensor([example["label"] for example in examples])
+... return {"pixel_values": pixel_values, "labels": labels}
+```
+
+그런 다음 이 모든 것을 데이터 세트와 함께 `Trainer`에 전달하기만 하면 됩니다:
+
+```py
+>>> trainer = Trainer(
+... model,
+... args,
+... train_dataset=train_dataset,
+... eval_dataset=val_dataset,
+... processing_class=image_processor,
+... compute_metrics=compute_metrics,
+... data_collator=collate_fn,
+... )
+```
+
+데이터를 이미 처리했는데도 불구하고 `image_processor`를 토크나이저 인수로 넣은 이유는 JSON으로 저장되는 이미지 프로세서 구성 파일이 Hub의 저장소에 업로드되도록 하기 위함입니다.
+
+`train` 메소드를 호출하여 모델을 미세 조정하세요:
+
+```py
+>>> train_results = trainer.train()
+```
+
+학습이 완료되면, 모델을 [`~transformers.Trainer.push_to_hub`] 메소드를 사용하여 허브에 공유하여 누구나 모델을 사용할 수 있도록 합니다:
+```py
+>>> trainer.push_to_hub()
+```
+
+## 추론하기[[inference]]
+
+좋습니다. 이제 미세 조정된 모델을 추론하는 데 사용할 수 있습니다.
+
+추론에 사용할 영상을 불러오세요:
+```py
+>>> sample_test_video = next(iter(test_dataset))
+```
+
+
+
+
+
+미세 조정된 모델을 추론에 사용하는 가장 간단한 방법은 [`pipeline`](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#transformers.VideoClassificationPipeline)에서 모델을 사용하는 것입니다. 모델로 영상 분류를 하기 위해 `pipeline`을 인스턴스화하고 영상을 전달하세요:
+
+```py
+>>> from transformers import pipeline
+
+>>> video_cls = pipeline(model="my_awesome_video_cls_model")
+>>> video_cls("https://huggingface.co/datasets/sayakpaul/ucf101-subset/resolve/main/v_BasketballDunk_g14_c06.avi")
+[{'score': 0.9272987842559814, 'label': 'BasketballDunk'},
+ {'score': 0.017777055501937866, 'label': 'BabyCrawling'},
+ {'score': 0.01663011871278286, 'label': 'BalanceBeam'},
+ {'score': 0.009560945443809032, 'label': 'BandMarching'},
+ {'score': 0.0068979403004050255, 'label': 'BaseballPitch'}]
+```
+
+만약 원한다면 수동으로 `pipeline`의 결과를 재현할 수 있습니다:
+
+
+```py
+>>> def run_inference(model, video):
+... # (num_frames, num_channels, height, width)
+... perumuted_sample_test_video = video.permute(1, 0, 2, 3)
+... inputs = {
+... "pixel_values": perumuted_sample_test_video.unsqueeze(0),
+... "labels": torch.tensor(
+... [sample_test_video["label"]]
+... ), # this can be skipped if you don't have labels available.
+... }
+
+... device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+... inputs = {k: v.to(device) for k, v in inputs.items()}
+... model = model.to(device)
+
+... # forward pass
+... with torch.no_grad():
+... outputs = model(**inputs)
+... logits = outputs.logits
+
+... return logits
+```
+
+모델에 입력값을 넣고 `logits`을 반환받으세요:
+
+```py
+>>> logits = run_inference(trained_model, sample_test_video["video"])
+```
+
+`logits`을 디코딩하면, 우리는 다음 결과를 얻을 수 있습니다:
+
+```py
+>>> predicted_class_idx = logits.argmax(-1).item()
+>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
+# Predicted class: BasketballDunk
+```
diff --git a/docs/transformers/docs/source/ko/tasks/visual_question_answering.md b/docs/transformers/docs/source/ko/tasks/visual_question_answering.md
new file mode 100644
index 0000000000000000000000000000000000000000..9bc87c071e62b124ed6c941d83242c845fb9aeab
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/visual_question_answering.md
@@ -0,0 +1,375 @@
+
+
+# 시각적 질의응답 (Visual Question Answering)
+
+[[open-in-colab]]
+
+시각적 질의응답(VQA)은 이미지를 기반으로 개방형 질문에 대응하는 작업입니다. 이 작업을 지원하는 모델의 입력은 대부분 이미지와 질문의 조합이며, 출력은 자연어로 된 답변입니다.
+
+VQA의 주요 사용 사례는 다음과 같습니다:
+* 시각 장애인을 위한 접근성 애플리케이션을 구축할 수 있습니다.
+* 교육: 강의나 교과서에 나온 시각 자료에 대한 질문에 답할 수 있습니다. 또한 체험형 전시와 유적 등에서도 VQA를 활용할 수 있습니다.
+* 고객 서비스 및 전자상거래: VQA는 사용자가 제품에 대해 질문할 수 있게 함으로써 사용자 경험을 향상시킬 수 있습니다.
+* 이미지 검색: VQA 모델을 사용하여 원하는 특성을 가진 이미지를 검색할 수 있습니다. 예를 들어 사용자는 "강아지가 있어?"라고 물어봐서 주어진 이미지 묶음에서 강아지가 있는 모든 이미지를 받아볼 수 있습니다.
+
+이 가이드에서 학습할 내용은 다음과 같습니다:
+
+- VQA 모델 중 하나인 [ViLT](../../en/model_doc/vilt)를 [`Graphcore/vqa` 데이터셋](https://huggingface.co/datasets/Graphcore/vqa) 에서 미세조정하는 방법
+- 미세조정된 ViLT 모델로 추론하는 방법
+- BLIP-2 같은 생성 모델로 제로샷 VQA 추론을 실행하는 방법
+
+## ViLT 미세 조정 [[finetuning-vilt]]
+
+ViLT는 Vision Transformer (ViT) 내에 텍스트 임베딩을 포함하여 비전/자연어 사전훈련(VLP; Vision-and-Language Pretraining)을 위한 기본 디자인을 제공합니다.
+ViLT 모델은 비전 트랜스포머(ViT)에 텍스트 임베딩을 넣어 비전/언어 사전훈련(VLP; Vision-and-Language Pre-training)을 위한 기본적인 디자인을 갖췄습니다. 이 모델은 여러 다운스트림 작업에 사용할 수 있습니다. VQA 태스크에서는 (`[CLS]` 토큰의 최종 은닉 상태 위에 선형 레이어인) 분류 헤더가 있으며 무작위로 초기화됩니다.
+따라서 여기에서 시각적 질의응답은 **분류 문제**로 취급됩니다.
+
+최근의 BLIP, BLIP-2, InstructBLIP와 같은 모델들은 VQA를 생성형 작업으로 간주합니다. 가이드의 후반부에서는 이런 모델들을 사용하여 제로샷 VQA 추론을 하는 방법에 대해 설명하겠습니다.
+
+시작하기 전 필요한 모든 라이브러리를 설치했는지 확인하세요.
+
+```bash
+pip install -q transformers datasets
+```
+
+커뮤니티에 모델을 공유하는 것을 권장 드립니다. Hugging Face 계정에 로그인하여 🤗 Hub에 업로드할 수 있습니다.
+메시지가 나타나면 로그인할 토큰을 입력하세요:
+
+```py
+>>> from huggingface_hub import notebook_login
+
+>>> notebook_login()
+```
+
+모델 체크포인트를 전역 변수로 선언하세요.
+
+```py
+>>> model_checkpoint = "dandelin/vilt-b32-mlm"
+```
+
+## 데이터 가져오기 [[load-the-data]]
+
+이 가이드에서는 `Graphcore/vqa` 데이터세트의 작은 샘플을 사용합니다. 전체 데이터세트는 [🤗 Hub](https://huggingface.co/datasets/Graphcore/vqa) 에서 확인할 수 있습니다.
+
+[`Graphcore/vqa` 데이터세트](https://huggingface.co/datasets/Graphcore/vqa) 의 대안으로 공식 [VQA 데이터세트 페이지](https://visualqa.org/download.html) 에서 동일한 데이터를 수동으로 다운로드할 수 있습니다. 직접 공수한 데이터로 튜토리얼을 따르고 싶다면 [이미지 데이터세트 만들기](https://huggingface.co/docs/datasets/image_dataset#loading-script) 라는
+🤗 Datasets 문서를 참조하세요.
+
+검증 데이터의 첫 200개 항목을 불러와 데이터세트의 특성을 확인해 보겠습니다:
+
+```python
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("Graphcore/vqa", split="validation[:200]")
+>>> dataset
+Dataset({
+ features: ['question', 'question_type', 'question_id', 'image_id', 'answer_type', 'label'],
+ num_rows: 200
+})
+```
+
+예제를 하나 뽑아 데이터세트의 특성을 이해해 보겠습니다.
+
+```py
+>>> dataset[0]
+{'question': 'Where is he looking?',
+ 'question_type': 'none of the above',
+ 'question_id': 262148000,
+ 'image_id': '/root/.cache/huggingface/datasets/downloads/extracted/ca733e0e000fb2d7a09fbcc94dbfe7b5a30750681d0e965f8e0a23b1c2f98c75/val2014/COCO_val2014_000000262148.jpg',
+ 'answer_type': 'other',
+ 'label': {'ids': ['at table', 'down', 'skateboard', 'table'],
+ 'weights': [0.30000001192092896,
+ 1.0,
+ 0.30000001192092896,
+ 0.30000001192092896]}}
+```
+
+데이터세트에는 다음과 같은 특성이 포함되어 있습니다:
+* `question`: 이미지에 대한 질문
+* `image_id`: 질문과 관련된 이미지의 경로
+* `label`: 데이터의 레이블 (annotations)
+
+나머지 특성들은 필요하지 않기 때문에 삭제해도 됩니다:
+
+```py
+>>> dataset = dataset.remove_columns(['question_type', 'question_id', 'answer_type'])
+```
+
+보시다시피 `label` 특성은 같은 질문마다 답변이 여러 개 있을 수 있습니다. 모두 다른 데이터 라벨러들로부터 수집되었기 때문인데요. 질문의 답변은 주관적일 수 있습니다. 이 경우 질문은 "그는 어디를 보고 있나요?" 였지만, 어떤 사람들은 "아래"로 레이블을 달았고, 다른 사람들은 "테이블" 또는 "스케이트보드" 등으로 주석을 달았습니다.
+
+아래의 이미지를 보고 어떤 답변을 선택할 것인지 생각해 보세요:
+
+```python
+>>> from PIL import Image
+
+>>> image = Image.open(dataset[0]['image_id'])
+>>> image
+```
+
+
+
+
+
+질문과 답변의 모호성으로 인해 이러한 데이터세트는 여러 개의 답변이 가능하므로 다중 레이블 분류 문제로 처리됩니다. 게다가, 원핫(one-hot) 인코딩 벡터를 생성하기보다는 레이블에서 특정 답변이 나타나는 횟수를 기반으로 소프트 인코딩을 생성합니다.
+
+위의 예시에서 "아래"라는 답변이 다른 답변보다 훨씬 더 자주 선택되었기 때문에 데이터세트에서 `weight`라고 불리는 점수로 1.0을 가지며, 나머지 답변들은 1.0 미만의 점수를 가집니다.
+
+적절한 분류 헤더로 모델을 나중에 인스턴스화하기 위해 레이블을 정수로 매핑한 딕셔너리 하나, 반대로 정수를 레이블로 매핑한 딕셔너리 하나 총 2개의 딕셔너리를 생성하세요:
+
+```py
+>>> import itertools
+
+>>> labels = [item['ids'] for item in dataset['label']]
+>>> flattened_labels = list(itertools.chain(*labels))
+>>> unique_labels = list(set(flattened_labels))
+
+>>> label2id = {label: idx for idx, label in enumerate(unique_labels)}
+>>> id2label = {idx: label for label, idx in label2id.items()}
+```
+
+이제 매핑이 완료되었으므로 문자열 답변을 해당 id로 교체하고, 데이터세트의 더 편리한 후처리를 위해 편평화 할 수 있습니다.
+
+```python
+>>> def replace_ids(inputs):
+... inputs["label"]["ids"] = [label2id[x] for x in inputs["label"]["ids"]]
+... return inputs
+
+
+>>> dataset = dataset.map(replace_ids)
+>>> flat_dataset = dataset.flatten()
+>>> flat_dataset.features
+{'question': Value(dtype='string', id=None),
+ 'image_id': Value(dtype='string', id=None),
+ 'label.ids': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None),
+ 'label.weights': Sequence(feature=Value(dtype='float64', id=None), length=-1, id=None)}
+```
+
+## 데이터 전처리 [[preprocessing-data]]
+
+다음 단계는 모델을 위해 이미지와 텍스트 데이터를 준비하기 위해 ViLT 프로세서를 가져오는 것입니다.
+[`ViltProcessor`]는 BERT 토크나이저와 ViLT 이미지 프로세서를 편리하게 하나의 프로세서로 묶습니다:
+
+```py
+>>> from transformers import ViltProcessor
+
+>>> processor = ViltProcessor.from_pretrained(model_checkpoint)
+```
+
+데이터를 전처리하려면 이미지와 질문을 [`ViltProcessor`]로 인코딩해야 합니다. 프로세서는 [`BertTokenizerFast`]로 텍스트를 토크나이즈하고 텍스트 데이터를 위해 `input_ids`, `attention_mask` 및 `token_type_ids`를 생성합니다.
+이미지는 [`ViltImageProcessor`]로 이미지를 크기 조정하고 정규화하며, `pixel_values`와 `pixel_mask`를 생성합니다.
+
+이런 전처리 단계는 모두 내부에서 이루어지므로, `processor`를 호출하기만 하면 됩니다. 하지만 아직 타겟 레이블이 완성되지 않았습니다. 타겟의 표현에서 각 요소는 가능한 답변(레이블)에 해당합니다. 정확한 답변의 요소는 해당 점수(weight)를 유지시키고 나머지 요소는 0으로 설정해야 합니다.
+
+아래 함수가 위에서 설명한대로 이미지와 질문에 `processor`를 적용하고 레이블을 형식에 맞춥니다:
+
+```py
+>>> import torch
+
+>>> def preprocess_data(examples):
+... image_paths = examples['image_id']
+... images = [Image.open(image_path) for image_path in image_paths]
+... texts = examples['question']
+
+... encoding = processor(images, texts, padding="max_length", truncation=True, return_tensors="pt")
+
+... for k, v in encoding.items():
+... encoding[k] = v.squeeze()
+
+... targets = []
+
+... for labels, scores in zip(examples['label.ids'], examples['label.weights']):
+... target = torch.zeros(len(id2label))
+
+... for label, score in zip(labels, scores):
+... target[label] = score
+
+... targets.append(target)
+
+... encoding["labels"] = targets
+
+... return encoding
+```
+
+전체 데이터세트에 전처리 함수를 적용하려면 🤗 Datasets의 [`~datasets.map`] 함수를 사용하십시오. `batched=True`를 설정하여 데이터세트의 여러 요소를 한 번에 처리함으로써 `map`을 더 빠르게 할 수 있습니다. 이 시점에서 필요하지 않은 열은 제거하세요.
+
+```py
+>>> processed_dataset = flat_dataset.map(preprocess_data, batched=True, remove_columns=['question','question_type', 'question_id', 'image_id', 'answer_type', 'label.ids', 'label.weights'])
+>>> processed_dataset
+Dataset({
+ features: ['input_ids', 'token_type_ids', 'attention_mask', 'pixel_values', 'pixel_mask', 'labels'],
+ num_rows: 200
+})
+```
+
+마지막 단계로, [`DefaultDataCollator`]를 사용하여 예제로 쓸 배치를 생성하세요:
+
+```py
+>>> from transformers import DefaultDataCollator
+
+>>> data_collator = DefaultDataCollator()
+```
+
+## 모델 훈련 [[train-the-model]]
+
+이제 모델을 훈련하기 위해 준비되었습니다! [`ViltForQuestionAnswering`]으로 ViLT를 가져올 차례입니다. 레이블의 수와 레이블 매핑을 지정하세요:
+
+```py
+>>> from transformers import ViltForQuestionAnswering
+
+>>> model = ViltForQuestionAnswering.from_pretrained(model_checkpoint, num_labels=len(id2label), id2label=id2label, label2id=label2id)
+```
+
+이 시점에서는 다음 세 단계만 남았습니다:
+
+1. [`TrainingArguments`]에서 훈련 하이퍼파라미터를 정의하세요:
+
+```py
+>>> from transformers import TrainingArguments
+
+>>> repo_id = "MariaK/vilt_finetuned_200"
+
+>>> training_args = TrainingArguments(
+... output_dir=repo_id,
+... per_device_train_batch_size=4,
+... num_train_epochs=20,
+... save_steps=200,
+... logging_steps=50,
+... learning_rate=5e-5,
+... save_total_limit=2,
+... remove_unused_columns=False,
+... push_to_hub=True,
+... )
+```
+
+2. 모델, 데이터세트, 프로세서, 데이터 콜레이터와 함께 훈련 인수를 [`Trainer`]에 전달하세요:
+
+```py
+>>> from transformers import Trainer
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... data_collator=data_collator,
+... train_dataset=processed_dataset,
+... processing_class=processor,
+... )
+```
+
+3. [`~Trainer.train`]을 호출하여 모델을 미세 조정하세요:
+
+```py
+>>> trainer.train()
+```
+
+훈련이 완료되면, [`~Trainer.push_to_hub`] 메소드를 사용하여 🤗 Hub에 모델을 공유하세요:
+
+```py
+>>> trainer.push_to_hub()
+```
+
+## 추론 [[inference]]
+
+ViLT 모델을 미세 조정하고 🤗 Hub에 업로드했다면 추론에 사용할 수 있습니다. 미세 조정된 모델을 추론에 사용해보는 가장 간단한 방법은 [`Pipeline`]에서 사용하는 것입니다.
+
+```py
+>>> from transformers import pipeline
+
+>>> pipe = pipeline("visual-question-answering", model="MariaK/vilt_finetuned_200")
+```
+
+이 가이드의 모델은 200개의 예제에서만 훈련되었으므로 그다지 많은 것을 기대할 수는 없습니다. 데이터세트의 첫 번째 예제를 사용하여 추론 결과를 설명해보겠습니다:
+
+```py
+>>> example = dataset[0]
+>>> image = Image.open(example['image_id'])
+>>> question = example['question']
+>>> print(question)
+>>> pipe(image, question, top_k=1)
+"Where is he looking?"
+[{'score': 0.5498199462890625, 'answer': 'down'}]
+```
+
+비록 확신은 별로 없지만, 모델은 실제로 무언가를 배웠습니다. 더 많은 예제와 더 긴 훈련 기간이 주어진다면 분명 더 나은 결과를 얻을 수 있을 것입니다!
+
+원한다면 파이프라인의 결과를 수동으로 복제할 수도 있습니다:
+1. 이미지와 질문을 가져와서 프로세서를 사용하여 모델에 준비합니다.
+2. 전처리된 결과를 모델에 전달합니다.
+3. 로짓에서 가장 가능성 있는 답변의 id를 가져와서 `id2label`에서 실제 답변을 찾습니다.
+
+```py
+>>> processor = ViltProcessor.from_pretrained("MariaK/vilt_finetuned_200")
+
+>>> image = Image.open(example['image_id'])
+>>> question = example['question']
+
+>>> # prepare inputs
+>>> inputs = processor(image, question, return_tensors="pt")
+
+>>> model = ViltForQuestionAnswering.from_pretrained("MariaK/vilt_finetuned_200")
+
+>>> # forward pass
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits = outputs.logits
+>>> idx = logits.argmax(-1).item()
+>>> print("Predicted answer:", model.config.id2label[idx])
+Predicted answer: down
+```
+
+## 제로샷 VQA [[zeroshot-vqa]]
+
+이전 모델은 VQA를 분류 문제로 처리했습니다. BLIP, BLIP-2 및 InstructBLIP와 같은 최근의 모델은 VQA를 생성 작업으로 접근합니다. [BLIP-2](../../en/model_doc/blip-2)를 예로 들어 보겠습니다. 이 모델은 사전훈련된 비전 인코더와 LLM의 모든 조합을 사용할 수 있는 새로운 비전-자연어 사전 학습 패러다임을 도입했습니다. ([BLIP-2 블로그 포스트](https://huggingface.co/blog/blip-2)를 통해 더 자세히 알아볼 수 있어요)
+이를 통해 시각적 질의응답을 포함한 여러 비전-자연어 작업에서 SOTA를 달성할 수 있었습니다.
+
+이 모델을 어떻게 VQA에 사용할 수 있는지 설명해 보겠습니다. 먼저 모델을 가져와 보겠습니다. 여기서 GPU가 사용 가능한 경우 모델을 명시적으로 GPU로 전송할 것입니다. 이전에는 훈련할 때 쓰지 않은 이유는 [`Trainer`]가 이 부분을 자동으로 처리하기 때문입니다:
+
+```py
+>>> from transformers import AutoProcessor, Blip2ForConditionalGeneration
+>>> import torch
+
+>>> processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
+>>> model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model.to(device)
+```
+
+모델은 이미지와 텍스트를 입력으로 받으므로, VQA 데이터세트의 첫 번째 예제에서와 동일한 이미지/질문 쌍을 사용해 보겠습니다:
+
+```py
+>>> example = dataset[0]
+>>> image = Image.open(example['image_id'])
+>>> question = example['question']
+```
+
+BLIP-2를 시각적 질의응답 작업에 사용하려면 텍스트 프롬프트가 `Question: {} Answer:` 형식을 따라야 합니다.
+
+```py
+>>> prompt = f"Question: {question} Answer:"
+```
+
+이제 모델의 프로세서로 이미지/프롬프트를 전처리하고, 처리된 입력을 모델을 통해 전달하고, 출력을 디코드해야 합니다:
+
+```py
+>>> inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
+
+>>> generated_ids = model.generate(**inputs, max_new_tokens=10)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
+>>> print(generated_text)
+"He is looking at the crowd"
+```
+
+보시다시피 모델은 군중을 인식하고, 얼굴의 방향(아래쪽을 보고 있음)을 인식했지만, 군중이 스케이터 뒤에 있다는 사실을 놓쳤습니다. 그러나 사람이 직접 라벨링한 데이터셋을 얻을 수 없는 경우에, 이 접근법은 빠르게 유용한 결과를 생성할 수 있습니다.
diff --git a/docs/transformers/docs/source/ko/tasks/zero_shot_image_classification.md b/docs/transformers/docs/source/ko/tasks/zero_shot_image_classification.md
new file mode 100644
index 0000000000000000000000000000000000000000..f824de93b8652201f72e9b78aa8b2ff634047cb8
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/zero_shot_image_classification.md
@@ -0,0 +1,144 @@
+
+
+# 제로샷(zero-shot) 이미지 분류[[zeroshot-image-classification]]
+
+[[open-in-colab]]
+
+제로샷(zero-shot) 이미지 분류는 특정 카테고리의 예시가 포함된 데이터를 학습되지 않은 모델을 사용해 이미지 분류를 수행하는 작업입니다.
+
+일반적으로 이미지 분류를 위해서는 레이블이 달린 특정 이미지 데이터로 모델 학습이 필요하며, 이 모델은 특정 이미지의 특징을 레이블에 "매핑"하는 방법을 학습합니다.
+새로운 레이블이 있는 분류 작업에 이러한 모델을 사용해야 하는 경우에는, 모델을 "재보정"하기 위해 미세 조정이 필요합니다.
+
+이와 대조적으로, 제로샷 또는 개방형 어휘(open vocabulary) 이미지 분류 모델은 일반적으로 대규모 이미지 데이터와 해당 설명에 대해 학습된 멀티모달(multimodal) 모델입니다.
+이러한 모델은 제로샷 이미지 분류를 포함한 많은 다운스트림 작업에 사용할 수 있는 정렬된(aligned) 비전 언어 표현을 학습합니다.
+
+이는 이미지 분류에 대한 보다 유연한 접근 방식으로, 추가 학습 데이터 없이 새로운 레이블이나 학습하지 못한 카테고리에 대해 모델을 일반화할 수 있습니다.
+또한, 사용자가 대상 개체에 대한 자유 형식의 텍스트 설명으로 이미지를 검색할 수 있습니다.
+
+이번 가이드에서 배울 내용은 다음과 같습니다:
+
+* 제로샷 이미지 분류 파이프라인 만들기
+* 직접 제로샷 이미지 분류 모델 추론 실행하기
+
+시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
+
+```bash
+pip install -q transformers
+```
+
+## 제로샷(zero-shot) 이미지 분류 파이프라인[[zeroshot-image-classification-pipeline]]
+
+[`pipeline`]을 활용하면 가장 간단하게 제로샷 이미지 분류를 지원하는 모델로 추론해볼 수 있습니다.
+[Hugging Face Hub에 업로드된 체크포인트](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads)에서 파이프라인을 인스턴스화합니다.
+
+```python
+>>> from transformers import pipeline
+
+>>> checkpoint = "openai/clip-vit-large-patch14"
+>>> detector = pipeline(model=checkpoint, task="zero-shot-image-classification")
+```
+
+다음으로, 분류하고 싶은 이미지를 선택하세요.
+
+```py
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "https://unsplash.com/photos/g8oS8-82DxI/download?ixid=MnwxMjA3fDB8MXx0b3BpY3x8SnBnNktpZGwtSGt8fHx8fDJ8fDE2NzgxMDYwODc&force=true&w=640"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image
+```
+
+
+
+
+
+이미지와 해당 이미지의 후보 레이블인 `candidate_labels`를 파이프라인으로 전달합니다.
+여기서는 이미지를 직접 전달하지만, 컴퓨터에 저장된 이미지의 경로나 url로 전달할 수도 있습니다.
+`candidate_labels`는 이 예시처럼 간단한 단어일 수도 있고 좀 더 설명적인 단어일 수도 있습니다.
+
+```py
+>>> predictions = classifier(image, candidate_labels=["fox", "bear", "seagull", "owl"])
+>>> predictions
+[{'score': 0.9996670484542847, 'label': 'owl'},
+ {'score': 0.000199399160919711, 'label': 'seagull'},
+ {'score': 7.392891711788252e-05, 'label': 'fox'},
+ {'score': 5.96074532950297e-05, 'label': 'bear'}]
+```
+
+## 직접 제로샷(zero-shot) 이미지 분류하기[[zeroshot-image-classification-by-hand]]
+
+이제 제로샷 이미지 분류 파이프라인 사용 방법을 살펴보았으니, 실행하는 방법을 살펴보겠습니다.
+
+[Hugging Face Hub에 업로드된 체크포인트](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads)에서 모델과 프로세서를 가져오는 것으로 시작합니다.
+여기서는 이전과 동일한 체크포인트를 사용하겠습니다:
+
+```py
+>>> from transformers import AutoProcessor, AutoModelForZeroShotImageClassification
+
+>>> model = AutoModelForZeroShotImageClassification.from_pretrained(checkpoint)
+>>> processor = AutoProcessor.from_pretrained(checkpoint)
+```
+
+다른 이미지를 사용해 보겠습니다.
+
+```py
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "https://unsplash.com/photos/xBRQfR2bqNI/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjc4Mzg4ODEx&force=true&w=640"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image
+```
+
+
+
+
+
+프로세서를 사용해 모델의 입력을 준비합니다.
+프로세서는 모델의 입력으로 사용하기 위해 이미지 크기를 변환하고 정규화하는 이미지 프로세서와 텍스트 입력을 처리하는 토크나이저로 구성됩니다.
+
+```py
+>>> candidate_labels = ["tree", "car", "bike", "cat"]
+>>> inputs = processor(images=image, text=candidate_labels, return_tensors="pt", padding=True)
+```
+
+모델에 입력을 전달하고, 결과를 후처리합니다:
+
+```py
+>>> import torch
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits = outputs.logits_per_image[0]
+>>> probs = logits.softmax(dim=-1).numpy()
+>>> scores = probs.tolist()
+
+>>> result = [
+... {"score": score, "label": candidate_label}
+... for score, candidate_label in sorted(zip(probs, candidate_labels), key=lambda x: -x[0])
+... ]
+
+>>> result
+[{'score': 0.998572, 'label': 'car'},
+ {'score': 0.0010570387, 'label': 'bike'},
+ {'score': 0.0003393686, 'label': 'tree'},
+ {'score': 3.1572064e-05, 'label': 'cat'}]
+```
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/tasks/zero_shot_object_detection.md b/docs/transformers/docs/source/ko/tasks/zero_shot_object_detection.md
new file mode 100644
index 0000000000000000000000000000000000000000..8e9b52e8c7a20fd5e14b5c3288dcbf2e758f6294
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks/zero_shot_object_detection.md
@@ -0,0 +1,307 @@
+
+
+# 제로샷(zero-shot) 객체 탐지[[zeroshot-object-detection]]
+
+[[open-in-colab]]
+
+일반적으로 [객체 탐지](object_detection)에 사용되는 모델을 학습하기 위해서는 레이블이 지정된 이미지 데이터 세트가 필요합니다.
+그리고 학습 데이터에 존재하는 클래스(레이블)만 탐지할 수 있다는 한계점이 있습니다.
+
+다른 방식을 사용하는 [OWL-ViT](../model_doc/owlvit) 모델로 제로샷 객체 탐지가 가능합니다.
+OWL-ViT는 개방형 어휘(open-vocabulary) 객체 탐지기입니다.
+즉, 레이블이 지정된 데이터 세트에 미세 조정하지 않고 자유 텍스트 쿼리를 기반으로 이미지에서 객체를 탐지할 수 있습니다.
+
+OWL-ViT 모델은 멀티 모달 표현을 활용해 개방형 어휘 탐지(open-vocabulary detection)를 수행합니다.
+[CLIP](../model_doc/clip) 모델에 경량화(lightweight)된 객체 분류와 지역화(localization) 헤드를 결합합니다.
+개방형 어휘 탐지는 CLIP의 텍스트 인코더로 free-text 쿼리를 임베딩하고, 객체 분류와 지역화 헤드의 입력으로 사용합니다.
+이미지와 해당 텍스트 설명을 연결하면 ViT가 이미지 패치(image patches)를 입력으로 처리합니다.
+OWL-ViT 모델의 저자들은 CLIP 모델을 처음부터 학습(scratch learning)한 후에, bipartite matching loss를 사용하여 표준 객체 인식 데이터셋으로 OWL-ViT 모델을 미세 조정했습니다.
+
+이 접근 방식을 사용하면 모델은 레이블이 지정된 데이터 세트에 대한 사전 학습 없이도 텍스트 설명을 기반으로 객체를 탐지할 수 있습니다.
+
+이번 가이드에서는 OWL-ViT 모델의 사용법을 다룰 것입니다:
+- 텍스트 프롬프트 기반 객체 탐지
+- 일괄 객체 탐지
+- 이미지 가이드 객체 탐지
+
+시작하기 전에 필요한 라이브러리가 모두 설치되어 있는지 확인하세요:
+```bash
+pip install -q transformers
+```
+
+## 제로샷(zero-shot) 객체 탐지 파이프라인[[zeroshot-object-detection-pipeline]]
+
+[`pipeline`]을 활용하면 가장 간단하게 OWL-ViT 모델을 추론해볼 수 있습니다.
+[Hugging Face Hub에 업로드된 체크포인트](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads)에서 제로샷(zero-shot) 객체 탐지용 파이프라인을 인스턴스화합니다:
+
+```python
+>>> from transformers import pipeline
+
+>>> checkpoint = "google/owlvit-base-patch32"
+>>> detector = pipeline(model=checkpoint, task="zero-shot-object-detection")
+```
+
+다음으로, 객체를 탐지하고 싶은 이미지를 선택하세요.
+여기서는 [NASA](https://www.nasa.gov/multimedia/imagegallery/index.html) Great Images 데이터 세트의 일부인 우주비행사 에일린 콜린스(Eileen Collins) 사진을 사용하겠습니다.
+
+```py
+>>> import skimage
+>>> import numpy as np
+>>> from PIL import Image
+
+>>> image = skimage.data.astronaut()
+>>> image = Image.fromarray(np.uint8(image)).convert("RGB")
+
+>>> image
+```
+
+
+
+## 텍스트 프롬프트 기반 객체 탐지[[textprompted-zeroshot-object-detection-by-hand]]
+
+제로샷 객체 탐지 파이프라인 사용법에 대해 살펴보았으니, 이제 동일한 결과를 복제해보겠습니다.
+
+[Hugging Face Hub에 업로드된 체크포인트](https://huggingface.co/models?other=owlvit)에서 관련 모델과 프로세서를 가져오는 것으로 시작합니다.
+여기서는 이전과 동일한 체크포인트를 사용하겠습니다:
+
+```py
+>>> from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
+
+>>> model = AutoModelForZeroShotObjectDetection.from_pretrained(checkpoint)
+>>> processor = AutoProcessor.from_pretrained(checkpoint)
+```
+
+다른 이미지를 사용해 보겠습니다:
+
+```py
+>>> import requests
+
+>>> url = "https://unsplash.com/photos/oj0zeY2Ltk4/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8MTR8fHBpY25pY3xlbnwwfHx8fDE2Nzc0OTE1NDk&force=true&w=640"
+>>> im = Image.open(requests.get(url, stream=True).raw)
+>>> im
+```
+
+
+
+
+
+프로세서를 사용해 모델의 입력을 준비합니다.
+프로세서는 모델의 입력으로 사용하기 위해 이미지 크기를 변환하고 정규화하는 이미지 프로세서와 텍스트 입력을 처리하는 [`CLIPTokenizer`]로 구성됩니다.
+
+```py
+>>> text_queries = ["hat", "book", "sunglasses", "camera"]
+>>> inputs = processor(text=text_queries, images=im, return_tensors="pt")
+```
+
+모델에 입력을 전달하고 결과를 후처리 및 시각화합니다.
+이미지 프로세서가 모델에 이미지를 입력하기 전에 이미지 크기를 조정했기 때문에, [`~OwlViTImageProcessor.post_process_object_detection`] 메소드를 사용해
+예측값의 바운딩 박스(bounding box)가 원본 이미지의 좌표와 상대적으로 동일한지 확인해야 합니다.
+
+```py
+>>> import torch
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+... target_sizes = torch.tensor([im.size[::-1]])
+... results = processor.post_process_object_detection(outputs, threshold=0.1, target_sizes=target_sizes)[0]
+
+>>> draw = ImageDraw.Draw(im)
+
+>>> scores = results["scores"].tolist()
+>>> labels = results["labels"].tolist()
+>>> boxes = results["boxes"].tolist()
+
+>>> for box, score, label in zip(boxes, scores, labels):
+... xmin, ymin, xmax, ymax = box
+... draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
+... draw.text((xmin, ymin), f"{text_queries[label]}: {round(score,2)}", fill="white")
+
+>>> im
+```
+
+
+
+
+
+## 일괄 처리[[batch-processing]]
+
+여러 이미지와 텍스트 쿼리를 전달하여 여러 이미지에서 서로 다른(또는 동일한) 객체를 검색할 수 있습니다.
+일괄 처리를 위해서 텍스트 쿼리는 이중 리스트로, 이미지는 PIL 이미지, PyTorch 텐서, 또는 NumPy 배열로 이루어진 리스트로 프로세서에 전달해야 합니다.
+
+```py
+>>> images = [image, im]
+>>> text_queries = [
+... ["human face", "rocket", "nasa badge", "star-spangled banner"],
+... ["hat", "book", "sunglasses", "camera"],
+... ]
+>>> inputs = processor(text=text_queries, images=images, return_tensors="pt")
+```
+
+이전에는 후처리를 위해 단일 이미지의 크기를 텐서로 전달했지만, 튜플을 전달할 수 있고, 여러 이미지를 처리하는 경우에는 튜플로 이루어진 리스트를 전달할 수도 있습니다.
+아래 두 예제에 대한 예측을 생성하고, 두 번째 이미지(`image_idx = 1`)를 시각화해 보겠습니다.
+
+```py
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+... target_sizes = [x.size[::-1] for x in images]
+... results = processor.post_process_object_detection(outputs, threshold=0.1, target_sizes=target_sizes)
+
+>>> image_idx = 1
+>>> draw = ImageDraw.Draw(images[image_idx])
+
+>>> scores = results[image_idx]["scores"].tolist()
+>>> labels = results[image_idx]["labels"].tolist()
+>>> boxes = results[image_idx]["boxes"].tolist()
+
+>>> for box, score, label in zip(boxes, scores, labels):
+... xmin, ymin, xmax, ymax = box
+... draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
+... draw.text((xmin, ymin), f"{text_queries[image_idx][label]}: {round(score,2)}", fill="white")
+
+>>> images[image_idx]
+```
+
+
+
+
+
+## 이미지 가이드 객체 탐지[[imageguided-object-detection]]
+
+텍스트 쿼리를 이용한 제로샷 객체 탐지 외에도 OWL-ViT 모델은 이미지 가이드 객체 탐지 기능을 제공합니다.
+이미지를 쿼리로 사용해 대상 이미지에서 유사한 객체를 찾을 수 있다는 의미입니다.
+텍스트 쿼리와 달리 하나의 예제 이미지에서만 가능합니다.
+
+소파에 고양이 두 마리가 있는 이미지를 대상 이미지(target image)로, 고양이 한 마리가 있는 이미지를 쿼리로 사용해보겠습니다:
+
+```py
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image_target = Image.open(requests.get(url, stream=True).raw)
+
+>>> query_url = "http://images.cocodataset.org/val2017/000000524280.jpg"
+>>> query_image = Image.open(requests.get(query_url, stream=True).raw)
+```
+
+다음 이미지를 살펴보겠습니다:
+
+```py
+>>> import matplotlib.pyplot as plt
+
+>>> fig, ax = plt.subplots(1, 2)
+>>> ax[0].imshow(image_target)
+>>> ax[1].imshow(query_image)
+```
+
+
+
+
+
+전처리 단계에서 텍스트 쿼리 대신에 `query_images`를 사용합니다:
+
+```py
+>>> inputs = processor(images=image_target, query_images=query_image, return_tensors="pt")
+```
+
+예측의 경우, 모델에 입력을 전달하는 대신 [`~OwlViTForObjectDetection.image_guided_detection`]에 전달합니다.
+레이블이 없다는 점을 제외하면 이전과 동일합니다.
+이전과 동일하게 이미지를 시각화합니다.
+
+```py
+>>> with torch.no_grad():
+... outputs = model.image_guided_detection(**inputs)
+... target_sizes = torch.tensor([image_target.size[::-1]])
+... results = processor.post_process_image_guided_detection(outputs=outputs, target_sizes=target_sizes)[0]
+
+>>> draw = ImageDraw.Draw(image_target)
+
+>>> scores = results["scores"].tolist()
+>>> boxes = results["boxes"].tolist()
+
+>>> for box, score, label in zip(boxes, scores, labels):
+... xmin, ymin, xmax, ymax = box
+... draw.rectangle((xmin, ymin, xmax, ymax), outline="white", width=4)
+
+>>> image_target
+```
+
+
+
+
+
+OWL-ViT 모델을 추론하고 싶다면 아래 데모를 확인하세요:
+
+
diff --git a/docs/transformers/docs/source/ko/tasks_explained.md b/docs/transformers/docs/source/ko/tasks_explained.md
new file mode 100644
index 0000000000000000000000000000000000000000..78c90849bb89bfd71a4a9d554e443c8246a1dec6
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tasks_explained.md
@@ -0,0 +1,295 @@
+
+
+# 🤗 Transformers로 작업을 해결하는 방법[[how-transformers-solve-tasks]]
+
+[🤗 Transformers로 할 수 있는 작업](task_summary)에서 자연어 처리(NLP), 음성 및 오디오, 컴퓨터 비전 작업 등의 중요한 응용을 배웠습니다. 이 페이지에서는 모델이 이러한 작업을 어떻게 해결하는지 자세히 살펴보고 내부에서 어떤 일이 일어나는지 설명합니다. 주어진 작업을 해결하는 많은 방법이 있으며, 일부 모델은 특정 기술을 구현하거나 심지어 새로운 방식으로 작업에 접근할 수도 있지만, Transformer 모델의 경우 일반적인 아이디어는 동일합니다. 유연한 아키텍처 덕분에 대부분의 모델은 인코더, 디코더 또는 인코더-디코더 구조의 변형입니다. Transformer 모델뿐만 아니라 우리의 라이브러리에는 오늘날 컴퓨터 비전 작업에 사용되는 몇 가지 합성곱 신경망(CNNs)도 있습니다. 또한, 우리는 현대 CNN의 작동 방식에 대해 설명할 것입니다.
+
+작업이 어떻게 해결되는지 설명하기 위해, 유용한 예측을 출력하고자 모델 내부에서 어떤 일이 일어나는지 살펴봅니다.
+
+- 오디오 분류 및 자동 음성 인식(ASR)을 위한 [Wav2Vec2](model_doc/wav2vec2)
+- 이미지 분류를 위한 [Vision Transformer (ViT)](model_doc/vit) 및 [ConvNeXT](model_doc/convnext)
+- 객체 탐지를 위한 [DETR](model_doc/detr)
+- 이미지 분할을 위한 [Mask2Former](model_doc/mask2former)
+- 깊이 추정을 위한 [GLPN](model_doc/glpn)
+- 인코더를 사용하는 텍스트 분류, 토큰 분류 및 질의응답과 같은 NLP 작업을 위한 [BERT](model_doc/bert)
+- 디코더를 사용하는 텍스트 생성과 같은 NLP 작업을 위한 [GPT2](model_doc/gpt2)
+- 인코더-디코더를 사용하는 요약 및 번역과 같은 NLP 작업을 위한 [BART](model_doc/bart)
+
+
+
+더 나아가기 전에, 기존 Transformer 아키텍처에 대한 기본적인 지식을 숙지하는 것이 좋습니다. 인코더, 디코더 및 어텐션의 작동 방식을 알면 다양한 Transformer 모델이 어떻게 작동하는지 이해하는 데 도움이 됩니다. 시작 단계거나 복습이 필요한 경우, 더 많은 정보를 위해 [코스](https://huggingface.co/course/chapter1/4?fw=pt)를 확인하세요!
+
+
+
+## 음성 및 오디오[[speech-and-audio]]
+
+[Wav2Vec2](model_doc/wav2vec2)는 레이블이 지정되지 않은 음성 데이터에 대해 사전훈련된 모델로, 오디오 분류 및 자동 음성 인식을 위해 레이블이 지정된 데이터로 미세 조정합니다.
+
+
+
+
+
+이 모델에는 4가지 주요 구성 요소가 있습니다:
+
+1. *특징 인코더(feature encoder)*는 원시 오디오 파형(raw audio waveform)을 가져와서 제로 평균 및 단위 분산으로 표준화하고, 각각 20ms 길이의 특징 벡터의 시퀀스로 변환합니다.
+
+2. 오디오 파형은 본질적으로 연속적이기 때문에, 텍스트 시퀀스를 단어로 나누는 것과 같이 분할할 수 없습니다. 그래서 *양자화 모듈(quantization module)*로 전달되는 특징 벡터는 이산형 음성 단위를 학습하기 위한 것입니다. 음성 단위는 *코드북(codebook)*(어휘집이라고 생각할 수 있습니다)이라는 코드단어(codewords) 콜렉션에서 선택됩니다. 코드북에서 연속적인 오디오 입력을 가장 잘 나타내는 벡터 또는 음성 단위가 선택되어 모델을 통과합니다.
+
+3. 특징 벡터의 절반은 무작위로 마스크가 적용되며, 마스크된 특징 벡터는 *상대적 위치 임베딩*을 추가하는 Transformer 인코더인 *문맥 네트워크(context network)*로 전달됩니다.
+
+4. 문맥 네트워크의 사전훈련 목표는 *대조적 작업(contrastive task)*입니다. 모델은 잘못된 예측 시퀀스에서 마스크된 예측의 실제 양자화된 음성 표현을 예측하며, 모델이 가장 유사한 컨텍스트 벡터와 양자화된 음성 단위(타겟 레이블)를 찾도록 권장합니다.
+
+이제 wav2vec2가 사전훈련되었으므로, 오디오 분류 또는 자동 음성 인식을 위해 데이터에 맞춰 미세 조정할 수 있습니다!
+
+### 오디오 분류[[audio-classification]]
+
+사전훈련된 모델을 오디오 분류에 사용하려면, 기본 Wav2Vec2 모델 상단에 시퀀스 분류 헤드를 추가하면 됩니다. 분류 헤드는 인코더의 은닉 상태(hidden states)를 받는 선형 레이어입니다. 은닉 상태는 각각 길이가 다른 오디오 프레임에서 학습된 특징을 나타냅니다. 고정 길이의 벡터 하나를 만들기 위해, 은닉 상태는 먼저 풀링되고, 클래스 레이블에 대한 로짓으로 변환됩니다. 가장 가능성이 높은 클래스를 찾기 위해 로짓과 타겟 사이의 교차 엔트로피 손실이 계산됩니다.
+
+오디오 분류에 직접 도전할 준비가 되셨나요? 완전한 [오디오 분류 가이드](tasks/audio_classification)를 확인하여 Wav2Vec2를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
+
+### 자동 음성 인식[[automatic-speech-recognition]]
+
+사전훈련된 모델을 자동 음성 인식에 사용하려면, [연결주의적 시간 분류(CTC, Connectionist Temporal Classification)](glossary#connectionist-temporal-classification-ctc)를 위해 기본 Wav2Vec2 모델 상단에 언어 모델링 헤드를 추가합니다. 언어 모델링 헤드는 인코더의 은닉 상태를 받아서 로짓으로 변환합니다. 각 로짓은 토큰 클래스(토큰 수는 작업의 어휘에서 나타납니다)를 나타냅니다. CTC 손실은 텍스트로 디코딩된 토큰에서 가장 가능성이 높은 토큰 시퀀스를 찾기 위해 로짓과 타겟 사이에서 계산됩니다.
+
+자동 음성 인식에 직접 도전할 준비가 되셨나요? 완전한 [자동 음성 인식 가이드](tasks/asr)를 확인하여 Wav2Vec2를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
+
+## 컴퓨터 비전[[computer-vision]]
+
+컴퓨터 비전 작업에 접근하는 2가지 방법이 있습니다:
+
+1. 이미지를 패치 시퀀스로 분리하고 Transformer로 병렬 처리합니다.
+2. [ConvNeXT](model_doc/convnext)와 같은 현대 CNN을 사용합니다. 이는 합성곱 레이어를 기반으로 하지만 현대 네트워크 설계를 적용합니다.
+
+
+
+세 번째 방법은 Transformer와 합성곱(예를 들어, [Convolutional Vision Transformer](model_doc/cvt) 또는 [LeViT](model_doc/levit))을 결합하는 것입니다. 우리는 살펴볼 두 가지 방법만 결합하기 때문에 여기서 이 방법을 다루지 않습니다.
+
+
+
+ViT와 ConvNeXT는 일반적으로 이미지 분류에서 사용되지만, 물체 감지, 분할, 깊이 추정과 같은 다른 비전 작업에는 각각 DETR, Mask2Former, GLPN이 더 적합하므로 이러한 모델을 살펴보겠습니다.
+
+### 이미지 분류[[image-classification]]
+
+ViT와 ConvNeXT 모두 이미지 분류에 사용될 수 있지만, ViT는 어텐션 메커니즘을, ConvNeXT는 합성곱을 사용하는 것이 주된 차이입니다.
+
+#### Transformer[[transformer]]
+
+[ViT](model_doc/vit)은 합성곱을 전적으로 순수 Transformer 아키텍처로 대체합니다. 기존 Transformer에 익숙하다면, ViT를 이해하는 방법의 대부분을 이미 파악했다고 볼 수 있습니다.
+
+
+
+
+
+ViT가 도입한 주요 변경 사항은 이미지가 Transformer로 어떻게 전달되는지에 있습니다:
+
+1. 이미지는 서로 중첩되지 않는 정사각형 패치로 분할되고, 각 패치는 벡터 또는 *패치 임베딩(patch embedding)*으로 변환됩니다. 패치 임베딩은 적절한 입력 차원을 만드는 2D 합성곱 계층에서 생성됩니다(기본 Transformer의 경우 각 패치의 임베딩마다 768개의 값이 필요합니다). 224x224 픽셀 이미지가 있다면, 16x16 이미지 패치 196개로 분할할 수 있습니다. 텍스트가 단어로 토큰화되는 것처럼, 이미지도 패치 시퀀스로 "토큰화"됩니다.
+
+2. *학습 가능한 임베딩(learnable embedding)*(특수한 `[CLS]` 토큰)이 BERT와 같이 패치 임베딩의 시작 부분에 추가됩니다. `[CLS]` 토큰의 마지막 은닉 상태는 부착된 분류 헤드의 입력으로 사용되고, 다른 출력은 무시됩니다. 이 토큰은 모델이 이미지의 표현을 인코딩하는 방법을 학습하는 데 도움이 됩니다.
+
+3. 패치와 학습 가능한 임베딩에 마지막으로 추가할 것은 *위치 임베딩*입니다. 왜냐하면 모델은 이미지 패치의 순서를 모르기 때문입니다. 위치 임베딩도 학습 가능하며, 패치 임베딩과 동일한 크기를 가집니다. 최종적으로, 모든 임베딩이 Transformer 인코더에 전달됩니다.
+
+4. `[CLS]` 토큰을 포함한 출력은 다층 퍼셉트론 헤드(MLP)에 전달됩니다. ViT의 사전훈련 목표는 단순히 분류입니다. 다른 분류 헤드와 같이, MLP 헤드는 출력을 클래스 레이블에 대해 로짓으로 변환하고 교차 엔트로피 손실을 계산하여 가장 가능성이 높은 클래스를 찾습니다.
+
+이미지 분류에 직접 도전할 준비가 되셨나요? 완전한 [이미지 분류 가이드](tasks/image_classification)를 확인하여 ViT를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
+
+#### CNN[[cnn]]
+
+
+
+이 섹션에서는 합성곱에 대해 간략하게 설명합니다. 그러나 이미지의 모양과 크기가 어떻게 변화하는지에 대한 사전 이해가 있다면 도움이 될 것입니다. 합성곱에 익숙하지 않은 경우, fastai book의 [합성곱 신경망 챕터](https://github.com/fastai/fastbook/blob/master/13_convolutions.ipynb)를 확인하세요!
+
+
+
+[ConvNeXT](model_doc/convnext)는 성능을 높이기 위해 새로운 현대 네트워크 설계를 적용한 CNN 구조입니다. 그러나 합성곱은 여전히 모델의 핵심입니다. 높은 수준의 관점에서 볼 때, [합성곱](glossary#convolution)은 작은 행렬(*커널*)에 이미지 픽셀의 작은 윈도우를 곱하는 연산입니다. 이는 특정 텍스쳐(texture)이나 선의 곡률과 같은 일부 특징을 계산합니다. 그러고 다음 픽셀 윈도우로 넘어가는데, 여기서 합성곱이 이동하는 거리를 *보폭(stride)*이라고 합니다.
+
+
+
+
+
+패딩이나 보폭이 없는 기본 합성곱, 딥러닝을 위한 합성곱 연산 가이드
+
+이 출력을 다른 합성곱 레이어에 전달할 수 있으며, 각 연속적인 레이어를 통해 네트워크는 핫도그나 로켓과 같이 더 복잡하고 추상적인 것을 학습합니다. 합성곱 레이어 사이에 풀링 레이어를 추가하여 차원을 줄이고 특징의 위치 변화에 대해 모델을 더 견고하게 만드는 것이 일반적입니다.
+
+
+
+
+
+ConvNeXT는 CNN을 5가지 방식으로 현대화합니다:
+
+1. 각 단계의 블록 수를 변경하고 더 큰 보폭과 그에 대응하는 커널 크기로 이미지를 "패치화(patchify)"합니다. 겹치지 않는 슬라이딩 윈도우는 ViT가 이미지를 패치로 분할하는 방법과 유사하게 이 패치화 전략을 만듭니다.
+
+2. *병목(bottleneck)* 레이어는 채널 수를 줄였다가 다시 복원합니다. 왜냐하면 1x1 합성곱을 수행하는 것이 더 빠르고, 깊이를 늘릴 수 있기 때문입니다. 역 병목(inverted bottlenect)은 채널 수를 확장하고 축소함으로써 그 반대로 수행하므로, 메모리 효율이 더 높습니다.
+
+3. 병목 레이어의 일반적인 3x3 합성곱 레이어를 각 입력 채널에 개별적으로 합성곱을 적용한 다음 마지막에 쌓는 *깊이별 합성곱(depthwise convolution)*으로 대체합니다. 이는 네트워크 폭이 넓혀 성능이 향상됩니다.
+
+4. ViT는 어텐션 메커니즘 덕분에 한 번에 더 많은 이미지를 볼 수 있는 전역 수신 필드를 가지고 있습니다. ConvNeXT는 커널 크기를 7x7로 늘려 이 효과를 재현하려고 시도합니다.
+
+5. 또한 ConvNeXT는 Transformer 모델을 모방하는 몇 가지 레이어 설계를 변경합니다. 활성화 및 정규화 레이어가 더 적고, 활성화 함수가 ReLU 대신 GELU로 전환되고, BatchNorm 대신 LayerNorm을 사용합니다.
+
+합성곱 블록의 출력은 분류 헤드로 전달되며, 분류 헤드는 출력을 로짓으로 변환하고 교차 엔트로피 손실을 계산하여 가장 가능성이 높은 레이블을 찾습니다.
+
+### 객체 탐지[[object-detection]]
+
+[DETR](model_doc/detr), *DEtection TRansformer*는 CNN과 Transformer 인코더-디코더를 결합한 종단간(end-to-end) 객체 탐지 모델입니다.
+
+
+
+
+
+1. 사전훈련된 CNN *백본(backbone)*은 픽셀 값으로 나타낸 이미지를 가져와 저해상도 특징 맵을 만듭니다. 특징 맵에 대해 1x1 합성곱을 적용하여 차원을 줄이고, 고수준 이미지 표현을 가진 새로운 특징 맵을 생성합니다. Transformer는 시퀀스 모델이기 때문에 특징 맵을 위치 임베딩과 결합된 특징 벡터의 시퀀스로 평탄화합니다.
+
+2. 특징 벡터는 어텐션 레이어를 사용하여 이미지 표현을 학습하는 인코더에 전달됩니다. 다음으로, 인코더의 은닉 상태는 디코더에서 *객체 쿼리*와 결합됩니다. 객체 쿼리는 이미지의 다른 영역에 초점을 맞춘 학습된 임베딩으로 학습되고, 각 어텐션 레이어를 진행하면서 갱신됩니다. 디코더의 은닉 상태는 각 객체 쿼리에 대한 바운딩 박스 좌표와 클래스 레이블을 예측하는 순방향 네트워크에 전달되며, 객체가 없는 경우 `no object`가 출력됩니다.
+
+ DETR은 각 객체 쿼리를 병렬로 디코딩하여 *N* 개의 최종 예측을 출력합니다. 여기서 *N*은 쿼리 수입니다. 한 번에 하나의 요소를 예측하는 일반적인 자기회귀 모델과 달리, 객체 탐지는 한 번에 *N* 개의 예측을 수행하는 집합 예측 작업(`바운딩 박스`, `클래스 레이블`)입니다.
+
+3. DETR은 훈련 중 *이분 매칭 손실(bipartite matching loss)*을 사용하여 고정된 수의 예측과 고정된 실제 정답 레이블(ground truth labels) 세트를 비교합니다. *N*개의 레이블 세트에 실제 정답 레이블보다 적은 경우, `no object` 클래스로 패딩됩니다. 이 손실 함수는 DETR이 예측과 실제 정답 레이블 간 1:1 대응을 찾도록 권장합니다. 바운딩 박스 또는 클래스 레이블 중 하나라도 잘못된 경우, 손실이 발생합니다. 마찬가지로, 존재하지 않는 객체를 예측하는 경우, 패널티를 받습니다. 이로 인해 DETR은 이미지에서 눈에 잘 띄는 물체 하나에 집중하는 대신, 다른 객체를 찾도록 권장됩니다.
+
+객체 탐지 헤드가 DETR 상단에 추가되어 클래스 레이블과 바운딩 박스의 좌표를 찾습니다. 객체 탐지 헤드에는 두 가지 구성 요소가 있습니다: 디코더 은닉 상태를 클래스 레이블의 로짓으로 변환하는 선형 레이어 및 바운딩 박스를 예측하는 MLP
+
+객체 탐지에 직접 도전할 준비가 되셨나요? 완전한 [객체 탐지 가이드](tasks/object_detection)를 확인하여 DETR을 미세 조정하고 추론에 사용하는 방법을 학습하세요!
+
+### 이미지 분할[[image-segmentation]]
+
+[Mask2Former](model_doc/mask2former)는 모든 유형의 이미지 분할 작업을 해결하는 범용 아키텍처입니다. 전통적인 분할 모델은 일반적으로 시멘틱(semantic) 또는 파놉틱(panoptic) 분할과 같은 이미지 분할의 특정 하위 작업에 맞춰 조정됩니다. Mask2Former는 모든 작업을 *마스크 분류* 문제로 구성합니다. 마스크 분류는 픽셀을 *N*개 세그먼트로 그룹화하고, 주어진 이미지에 대해 *N*개의 마스크와 그에 대응하는 클래스 레이블을 예측합니다. 이 섹션에서 Mask2Former의 작동 방법을 설명한 다음, 마지막에 SegFormer를 미세 조정해볼 수 있습니다.
+
+
+
+
+
+Mask2Former에는 3가지 주요 구성 요소가 있습니다:
+
+1. [Swin](model_doc/swin) 백본이 이미지를 받아 3개의 연속된 3x3 합성곱에서 저해상도 이미지 특징 맵을 생성합니다.
+
+2. 특징 맵은 *픽셀 디코더*에 전달됩니다. 이 디코더는 저해상도 특징을 고해상도 픽셀 임베딩으로 점진적으로 업샘플링합니다. 픽셀 디코더는 실제로 원본 이미지의 1/32, 1/16, 1/8 해상도의 다중 스케일 특징(저해상도 및 고해상도 특징 모두 포함)을 생성합니다.
+
+3. 이러한 서로 다른 크기의 특징 맵은 고해상도 특징에서 작은 객체를 포착하기 위해 한 번에 하나의 Transformer 디코더 레이어에 연속적으로 공급됩니다. Mask2Former의 핵심은 디코더의 *마스크 어텐션* 메커니즘입니다. 전체 이미지를 참조할 수 있는 크로스 어텐션(cross-attention)과 달리, 마스크 어텐션은 이미지의 특정 영역에만 집중합니다. 이는 이미지의 지역적 특징만으로 모델이 충분히 학습할 수 있기 때문에 더 빠르고 성능이 우수합니다.
+
+4. [DETR](tasks_explained#object-detection)과 같이, Mask2Former는 학습된 객체 쿼리를 사용하고 이를 픽셀 디코더에서의 이미지 특징과 결합하여 예측 집합(`클래스 레이블`, `마스크 예측`)을 생성합니다. 디코더의 은닉 상태는 선형 레이어로 전달되어 클래스 레이블에 대한 로짓으로 변환됩니다. 로짓과 클래스 레이블 사이의 교차 엔트로피 손실을 계산하여 가장 가능성이 높은 것을 찾습니다.
+
+ 마스크 예측은 픽셀 임베딩과 최종 디코더 은닉 상태를 결합하여 생성됩니다. 시그모이드 교차 엔트로피 및 Dice 손실은 로짓과 실제 정답 마스크(ground truth mask) 사이에서 계산되어 가장 가능성이 높은 마스크를 찾습니다.
+
+이미지 분할에 직접 도전할 준비가 되셨나요? 완전한 [이미지 분할 가이드](tasks/semantic_segmentation)를 확인하여 SegFormer를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
+
+### 깊이 추정[[depth-estimation]]
+
+[GLPN](model_doc/glpn), *Global-Local Path Network*는 [SegFormer](model_doc/segformer) 인코더와 경량 디코더를 결합한 깊이 추정을 위한 Transformer입니다.
+
+
+
+
+
+1. ViT와 같이, 이미지는 패치 시퀀스로 분할되지만, 이미지 패치가 더 작다는 점이 다릅니다. 이는 세그멘테이션이나 깊이 추정과 같은 밀도 예측 작업에 더 적합합니다. 이미지 패치는 패치 임베딩으로 변환되어(패치 임베딩이 생성되는 방법은 [이미지 분류](#image-classification) 섹션을 참조하세요), 인코더로 전달됩니다.
+
+2. 인코더는 패치 임베딩을 받아, 여러 인코더 블록에 전달합니다. 각 블록은 어텐션 및 Mix-FFN 레이어로 구성됩니다. 후자의 목적은 위치 정보를 제공하는 것입니다. 각 인코더 블록의 끝에는 계층적 표현을 생성하기 위한 *패치 병합(patch merging)* 레이어가 있습니다. 각 인접한 패치 그룹의 특징은 연결되고, 연결된 특징에 선형 레이어가 적용되어 패치 수를 1/4의 해상도로 줄입니다. 이는 다음 인코더 블록의 입력이 되며, 이러한 전체 프로세스는 1/8, 1/16, 1/32 해상도의 이미지 특징을 가질 때까지 반복됩니다.
+
+3. 경량 디코더는 인코더에서 마지막 특징 맵(1/32 크기)을 가져와 1/16 크기로 업샘플링합니다. 여기서, 특징은 *선택적 특징 융합(SFF, Selective Feature Fusion)* 모듈로 전달됩니다. 이 모듈은 각 특징에 대해 어텐션 맵에서 로컬 및 전역 특징을 선택하고 결합한 다음, 1/8로 업샘플링합니다. 이 프로세스는 디코딩된 특성이 원본 이미지와 동일한 크기가 될 때까지 반복됩니다. 출력은 두 개의 합성곱 레이어를 거친 다음, 시그모이드 활성화가 적용되어 각 픽셀의 깊이를 예측합니다.
+
+## 자연어처리[[natural-language-processing]]
+
+Transformer는 초기에 기계 번역을 위해 설계되었고, 그 이후로는 사실상 모든 NLP 작업을 해결하기 위한 기본 아키텍처가 되었습니다. 어떤 작업은 Transformer의 인코더 구조에 적합하며, 다른 작업은 디코더에 더 적합합니다. 또 다른 작업은 Transformer의 인코더-디코더 구조를 모두 활용합니다.
+
+### 텍스트 분류[[text-classification]]
+
+[BERT](model_doc/bert)는 인코더 전용 모델이며, 텍스트의 풍부한 표현을 학습하기 위해 양방향의 단어에 주목함으로써 심층 양방향성(deep bidirectionality)을 효과적으로 구현한 최초의 모델입니다.
+
+1. BERT는 [WordPiece](tokenizer_summary#wordpiece) 토큰화를 사용하여 문장의 토큰 임베딩을 생성합니다. 단일 문장과 한 쌍의 문장을 구분하기 위해 특수한 `[SEP]` 토큰이 추가됩니다. 모든 텍스트 시퀀스의 시작 부분에는 특수한 `[CLS]` 토큰이 추가됩니다. `[CLS]` 토큰이 있는 최종 출력은 분류 작업을 위한 분류 헤드로 입력에 사용됩니다. BERT는 또한 한 쌍의 문장에서 각 토큰이 첫 번째 문장인지 두 번째 문장에 속하는지 나타내는 세그먼트 임베딩(segment embedding)을 추가합니다.
+
+2. BERT는 마스크드 언어 모델링과 다음 문장 예측, 두 가지 목적으로 사전훈련됩니다. 마스크드 언어 모델링에서는 입력 토큰의 일부가 무작위로 마스킹되고, 모델은 이를 예측해야 합니다. 이는 모델이 모든 단어를 보고 다음 단어를 "예측"할 수 있는 양방향성 문제를 해결합니다. 예측된 마스크 토큰의 최종 은닉 상태는 어휘에 대한 소프트맥스가 있는 순방향 네트워크로 전달되어 마스크된 단어를 예측합니다.
+
+ 두 번째 사전훈련 대상은 다음 문장 예측입니다. 모델은 문장 B가 문장 A 다음에 오는지 예측해야 합니다. 문장 B가 다음 문장인 경우와 무작위 문장인 경우 각각 50%의 확률로 발생합니다. 다음 문장인지 아닌지에 대한 예측은 두 개의 클래스(`IsNext` 및 `NotNext`)에 대한 소프트맥스가 있는 순방향 네트워크로 전달됩니다.
+
+3. 입력 임베딩은 여러 인코더 레이어를 거쳐서 최종 은닉 상태를 출력합니다.
+
+사전훈련된 모델을 텍스트 분류에 사용하려면, 기본 BERT 모델 상단에 시퀀스 분류 헤드를 추가합니다. 시퀀스 분류 헤드는 최종 은닉 상태를 받는 선형 레이어이며, 로짓으로 변환하기 위해 선형 변환을 수행합니다. 교차 엔트로피 손실은 로짓과 타겟 간에 계산되어 가장 가능성이 높은 레이블을 찾습니다.
+
+텍스트 분류에 직접 도전할 준비가 되셨나요? 완전한 [텍스트 분류 가이드](tasks/sequence_classification)를 확인하여 DistilBERT를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
+
+### 토큰 분류[[token-classification]]
+
+개체명 인식(Named Entity Recognition, NER)과 같은 토큰 분류 작업에 BERT를 사용하려면, 기본 BERT 모델 상단에 토큰 분류 헤드를 추가합니다. 토큰 분류 헤드는 최종 은닉 상태를 받는 선형 레이어이며, 로짓으로 변환하기 위해 선형 변환을 수행합니다. 교차 엔트로피 손실은 로짓과 각 토큰 간에 계산되어 가장 가능성이 높은 레이블을 찾습니다.
+
+토큰 분류에 직접 도전할 준비가 되셨나요? 완전한 [토큰 분류 가이드](tasks/token_classification)를 확인하여 DistilBERT를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
+
+### 질의응답[[question-answering]]
+
+질의응답에 BERT를 사용하려면, 기본 BERT 모델 위에 스팬(span) 분류 헤드를 추가합니다. 이 선형 레이어는 최종 은닉 상태를 받고, 답변에 대응하는 `스팬`의 시작과 끝 로그를 계산하기 위해 선형 변환을 수행합니다. 교차 엔트로피 손실은 로짓과 각 레이블 위치 간에 계산되어 답변에 대응하는 가장 가능성이 높은 텍스트의 스팬을 찾습니다.
+
+질의응답에 직접 도전할 준비가 되셨나요? 완전한 [질의응답 가이드](tasks/question_answering)를 확인하여 DistilBERT를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
+
+
+
+💡 사전훈련된 BERT를 다양한 작업에 사용하는 것이 얼마나 쉬운지 주목하세요. 사전훈련된 모델에 특정 헤드를 추가하기만 하면 은닉 상태를 원하는 출력으로 조작할 수 있습니다!
+
+
+
+### 텍스트 생성[[text-generation]]
+
+[GPT-2](model_doc/gpt2)는 대량의 텍스트에 대해 사전훈련된 디코딩 전용 모델입니다. 프롬프트를 주어지면 설득력 있는 (항상 사실은 아니지만!) 텍스트를 생성하고 명시적으로 훈련되지 않았음에도 불구하고 질의응답과 같은 다른 NLP 작업을 완수할 수 있습니다.
+
+
+
+
+
+1. GPT-2는 단어를 토큰화하고 토큰 임베딩을 생성하기 위해 [바이트 페어 인코딩(BPE, byte pair encoding)](tokenizer_summary#bytepair-encoding-bpe)을 사용합니다. 위치 인코딩은 시퀀스에서 각 토큰의 위치를 나타내기 위해 토큰 임베딩에 추가됩니다. 입력 임베딩은 여러 디코더 블록을 거쳐 일부 최종 은닉 상태를 출력합니다. 각 디코더 블록 내에서 GPT-2는 *마스크드 셀프 어텐션(masked self-attention)* 레이어를 사용합니다. 이는 GPT-2가 이후 토큰(future tokens)에 주의를 기울일 수 없도록 합니다. 왼쪽에 있는 토큰에만 주의를 기울일 수 있습니다. 마스크드 셀프 어텐션에서는 어텐션 마스크를 사용하여 이후 토큰에 대한 점수(score)를 `0`으로 설정하기 때문에 BERT의 [`mask`] 토큰과 다릅니다.
+
+2. 디코더의 출력은 언어 모델링 헤드에 전달되며, 언어 모델링 헤드는 은닉 상태를 로짓으로 선형 변환을 수행합니다. 레이블은 시퀀스의 다음 토큰으로, 로짓을 오른쪽으로 하나씩 이동하여 생성됩니다. 교차 엔트로피 손실은 이동된 로짓과 레이블 간에 계산되어 가장 가능성이 높은 다음 토큰을 출력합니다.
+
+GPT-2의 사전훈련 목적은 전적으로 [인과적 언어 모델링](glossary#causal-language-modeling)에 기반하여, 시퀀스에서 다음 단어를 예측하는 것입니다. 이는 GPT-2가 텍스트 생성에 관련된 작업에 특히 우수하도록 합니다.
+
+텍스트 생성에 직접 도전할 준비가 되셨나요? 완전한 [인과적 언어 모델링 가이드](tasks/language_modeling#causal-language-modeling)를 확인하여 DistilGPT-2를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
+
+
+
+텍스트 생성에 대한 자세한 내용은 [텍스트 생성 전략](generation_strategies) 가이드를 확인하세요!
+
+
+
+### 요약[[summarization]]
+
+[BART](model_doc/bart) 및 [T5](model_doc/t5)와 같은 인코더-디코더 모델은 요약 작업의 시퀀스-투-시퀀스 패턴을 위해 설계되었습니다. 이 섹션에서 BART의 작동 방법을 설명한 다음, 마지막에 T5를 미세 조정해볼 수 있습니다.
+
+
+
+
+
+1. BART의 인코더 아키텍처는 BERT와 매우 유사하며 텍스트의 토큰 및 위치 임베딩을 받습니다. BART는 입력을 변형시키고 디코더로 재구성하여 사전훈련됩니다. 특정 변형 기법이 있는 다른 인코더와는 달리, BART는 모든 유형의 변형을 적용할 수 있습니다. 그러나 *text infilling* 변형 기법이 가장 잘 작동합니다. Text Infiling에서는 여러 텍스트 스팬을 **단일** [`mask`] 토큰으로 대체합니다. 이는 모델이 마스크된 토큰을 예측해야 하고, 모델에 누락된 토큰의 수를 예측하도록 가르치기 때문에 중요합니다. 입력 임베딩과 마스크된 스팬이 인코더를 거쳐 최종 은닉 상태를 출력하지만, BERT와 달리 BART는 마지막에 단어를 예측하는 순방향 네트워크를 추가하지 않습니다.
+
+2. 인코더의 출력은 디코더로 전달되며, 디코더는 인코더의 출력에서 마스크 토큰과 변형되지 않은 토큰을 예측해야 합니다. 이는 디코더가 원본 텍스트를 복원하는 데 도움이 되는 추가적인 문맥을 얻도록 합니다. 디코더의 출력은 언어 모델링 헤드에 전달되며, 언어 모델링 헤드는 은닉 상태를 로짓으로 선형 변환을 수행합니다. 교차 엔트로피 손실은 로짓과 토큰이 오른쪽으로 이동된 레이블 간에 계산됩니다.
+
+요약에 직접 도전할 준비가 되셨나요? 완전한 [요약 가이드](tasks/summarization)를 확인하여 T5를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
+
+
+
+텍스트 생성에 대한 자세한 내용은 [텍스트 생성 전략](generation_strategies) 가이드를 확인하세요!
+
+
+
+### 번역[[translation]]
+
+번역은 시퀀스-투-시퀀스 작업의 또 다른 예로, [BART](model_doc/bart) 또는 [T5](model_doc/t5)와 같은 인코더-디코더 모델을 사용할 수 있습니다. 이 섹션에서 BART의 작동 방법을 설명한 다음, 마지막에 T5를 미세 조정해볼 수 있습니다.
+
+BART는 원천 언어를 타겟 언어로 디코딩할 수 있는 입력에 매핑하기 위해 무작위로 초기화된 별도의 인코더를 추가하여 번역에 적용합니다. 이 새로운 인코더의 임베딩은 원본 단어 임베딩 대신 사전훈련된 인코더로 전달됩니다. 원천 인코더는 모델 출력의 교차 엔트로피 손실로부터 원천 인코더, 위치 임베딩, 입력 임베딩을 갱신하여 훈련됩니다. 첫 번째 단계에서는 모델 파라미터가 고정되고, 두 번째 단계에서는 모든 모델 파라미터가 함께 훈련됩니다.
+
+BART는 이후 번역을 위해 다양한 언어로 사전훈련된 다국어 버전의 mBART로 확장되었습니다.
+
+번역에 직접 도전할 준비가 되셨나요? 완전한 [번역 가이드](tasks/summarization)를 확인하여 T5를 미세 조정하고 추론에 사용하는 방법을 학습하세요!
+
+
+
+텍스트 생성에 대한 자세한 내용은 [텍스트 생성 전략](generation_strategies) 가이드를 확인하세요!
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/testing.md b/docs/transformers/docs/source/ko/testing.md
new file mode 100644
index 0000000000000000000000000000000000000000..fd3f548eeb812910fda5c0040ceb8cb6710538e0
--- /dev/null
+++ b/docs/transformers/docs/source/ko/testing.md
@@ -0,0 +1,1278 @@
+
+
+# 테스트[[testing]]
+
+
+먼저 🤗 Transformers 모델이 어떻게 테스트되는지 살펴보고, 새로운 테스트를 작성 및 기존 테스트를 개선하는 방법을 알아봅시다.
+
+이 저장소에는 2개의 테스트 스위트가 있습니다:
+
+1. `tests` - 일반 API에 대한 테스트
+2. `examples` - API의 일부가 아닌 다양한 응용 프로그램에 대한 테스트
+
+## Transformers 테스트 방법[[how-transformers-are-tested]]
+
+1. PR이 제출되면 9개의 CircleCi 작업으로 테스트가 진행됩니다. 해당 PR에 대해 새로운 커밋이 생성될 때마다 테스트는 다시 진행됩니다. 이 작업들은
+ 이 [config 파일](https://github.com/huggingface/transformers/tree/main/.circleci/config.yml)에 정의되어 있으므로 필요하다면
+ 사용자의 로컬 환경에서 동일하게 재현해 볼 수 있습니다.
+
+ 이 CI 작업은 `@slow` 테스트를 실행하지 않습니다.
+
+2. [github actions](https://github.com/huggingface/transformers/actions)에 의해 실행되는 작업은 3개입니다:
+
+ - [torch hub integration](https://github.com/huggingface/transformers/tree/main/.github/workflows/github-torch-hub.yml):
+ torch hub integration이 작동하는지 확인합니다.
+
+ - [self-hosted (push)](https://github.com/huggingface/transformers/tree/main/.github/workflows/self-push.yml): `main` 브랜치에서 커밋이 업데이트된 경우에만 GPU를 이용한 빠른 테스트를 실행합니다.
+ 이는 `src`, `tests`, `.github` 폴더 중 하나에 코드가 업데이트된 경우에만 실행됩니다.
+ (model card, notebook, 기타 등등을 추가한 경우 실행되지 않도록 하기 위해서입니다)
+
+ - [self-hosted runner](https://github.com/huggingface/transformers/tree/main/.github/workflows/self-scheduled.yml): `tests` 및 `examples`에서
+ GPU를 이용한 일반 테스트, 느린 테스트를 실행합니다.
+
+
+```bash
+RUN_SLOW=1 pytest tests/
+RUN_SLOW=1 pytest examples/
+```
+
+ 결과는 [여기](https://github.com/huggingface/transformers/actions)에서 확인할 수 있습니다.
+
+
+## 테스트 실행[[running-tests]]
+
+
+
+
+
+### 실행할 테스트 선택[[choosing-which-tests-to-run]]
+
+이 문서는 테스트를 실행하는 다양한 방법에 대해 자세히 설명합니다.
+모든 내용을 읽은 후에도, 더 자세한 내용이 필요하다면 [여기](https://docs.pytest.org/en/latest/usage.html)에서 확인할 수 있습니다.
+
+다음은 가장 유용한 테스트 실행 방법 몇 가지입니다.
+
+모두 실행:
+
+```console
+pytest
+```
+
+또는:
+
+```bash
+make test
+```
+
+후자는 다음과 같이 정의됩니다:
+
+```bash
+python -m pytest -n auto --dist=loadfile -s -v ./tests/
+```
+
+위의 명령어는 pytest에게 아래의 내용을 전달합니다:
+
+- 사용 가능한 CPU 코어 수만큼 테스트 프로세스를 실행합니다. (RAM이 충분하지 않다면, 테스트 프로세스 수가 너무 많을 수 있습니다!)
+- 동일한 파일의 모든 테스트는 동일한 테스트 프로세스에서 실행되어야 합니다.
+- 출력을 캡처하지 않습니다.
+- 자세한 모드로 실행합니다.
+
+
+
+### 모든 테스트 목록 가져오기[[getting-the-list-of-all-tests]]
+
+테스트 스위트의 모든 테스트:
+
+```bash
+pytest --collect-only -q
+```
+
+지정된 테스트 파일의 모든 테스트:
+
+```bash
+pytest tests/test_optimization.py --collect-only -q
+```
+
+### 특정 테스트 모듈 실행[[run-a-specific-test-module]]
+
+개별 테스트 모듈 실행하기:
+
+```bash
+pytest tests/utils/test_logging.py
+```
+
+### 특정 테스트 실행[[run-specific-tests]]
+
+대부분의 테스트 내부에서는 unittest가 사용됩니다. 따라서 특정 하위 테스트를 실행하려면 해당 테스트를 포함하는 unittest 클래스의 이름을 알아야 합니다.
+예를 들어 다음과 같을 수 있습니다:
+
+```bash
+pytest tests/test_optimization.py::OptimizationTest::test_adam_w
+```
+
+위의 명령어의 의미는 다음과 같습니다:
+
+- `tests/test_optimization.py` - 테스트가 있는 파일
+- `OptimizationTest` - 클래스의 이름
+- `test_adam_w` - 특정 테스트 함수의 이름
+
+파일에 여러 클래스가 포함된 경우, 특정 클래스의 테스트만 실행할 수도 있습니다. 예를 들어 다음과 같습니다:
+
+```bash
+pytest tests/test_optimization.py::OptimizationTest
+```
+
+이 명령어는 해당 클래스 내부의 모든 테스트를 실행합니다.
+
+앞에서 언급한 것처럼 `OptimizationTest` 클래스에 포함된 테스트를 확인할 수 있습니다.
+
+```bash
+pytest tests/test_optimization.py::OptimizationTest --collect-only -q
+```
+
+키워드 표현식을 사용하여 테스트를 실행할 수도 있습니다.
+
+`adam`이라는 이름을 포함하는 테스트만 실행하려면 다음과 같습니다:
+
+```bash
+pytest -k adam tests/test_optimization.py
+```
+
+논리 연산자 `and`와 `or`를 사용하여 모든 키워드가 일치해야 하는지 또는 어느 하나가 일치해야 하는지를 나타낼 수 있습니다.
+`not`은 부정할 때 사용할 수 있습니다.
+
+`adam`이라는 이름을 포함하지 않는 모든 테스트를 실행하려면 다음과 같습니다:
+
+```bash
+pytest -k "not adam" tests/test_optimization.py
+```
+
+두 가지 패턴을 하나로 결합할 수도 있습니다:
+
+```bash
+pytest -k "ada and not adam" tests/test_optimization.py
+```
+
+예를 들어 `test_adafactor`와 `test_adam_w`를 모두 실행하려면 다음을 사용할 수 있습니다:
+
+```bash
+pytest -k "test_adam_w or test_adam_w" tests/test_optimization.py
+```
+
+여기서 `or`를 사용하는 것에 유의하세요. 두 키워드 중 하나가 일치하도록 하기 위한 목적으로 사용하기 때문입니다.
+
+두 패턴이 모두 포함되어야 하는 테스트만 실행하려면, `and`를 사용해야 합니다:
+
+```bash
+pytest -k "test and ada" tests/test_optimization.py
+```
+
+### `accelerate` 테스트 실행[[run-`accelerate`-tests]]
+
+모델에서 `accelerate` 테스트를 실행해야 할 때가 있습니다. 이를 위해서는 명령어에 `-m accelerate_tests`를 추가하면 됩니다.
+예를 들어, `OPT`에서 이러한 테스트를 실행하려면 다음과 같습니다:
+```bash
+RUN_SLOW=1 pytest -m accelerate_tests tests/models/opt/test_modeling_opt.py
+```
+
+### 문서 테스트 실행[[run-documentation-tests]]
+
+예시 문서가 올바른지 테스트하려면 `doctests`가 통과하는지 확인해야 합니다.
+예를 들어, [`WhisperModel.forward`'s docstring](https://github.com/huggingface/transformers/blob/main/src/transformers/models/whisper/modeling_whisper.py#L1017-L1035)를 사용해 봅시다:
+
+```python
+r"""
+Returns:
+
+Example:
+ ```python
+ >>> import torch
+ >>> from transformers import WhisperModel, WhisperFeatureExtractor
+ >>> from datasets import load_dataset
+
+ >>> model = WhisperModel.from_pretrained("openai/whisper-base")
+ >>> feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-base")
+ >>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ >>> inputs = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt")
+ >>> input_features = inputs.input_features
+ >>> decoder_input_ids = torch.tensor([[1, 1]]) * model.config.decoder_start_token_id
+ >>> last_hidden_state = model(input_features, decoder_input_ids=decoder_input_ids).last_hidden_state
+ >>> list(last_hidden_state.shape)
+ [1, 2, 512]
+ ```"""
+
+```
+
+원하는 파일의 모든 docstring 예제를 자동으로 테스트하려면 다음 명령을 실행하면 됩니다:
+```bash
+pytest --doctest-modules
+```
+파일의 확장자가 markdown인 경우 `--doctest-glob="*.md"` 인수를 추가해야 합니다.
+
+### 수정된 테스트만 실행[[run-only-modified-tests]]
+
+수정된 파일 또는 현재 브랜치 (Git 기준)와 관련된 테스트를 실행하려면 [pytest-picked](https://github.com/anapaulagomes/pytest-picked)을 사용할 수 있습니다.
+이는 변경한 내용이 테스트에 영향을 주지 않았는지 빠르게 확인할 수 있는 좋은 방법입니다.
+
+```bash
+pip install pytest-picked
+```
+
+```bash
+pytest --picked
+```
+
+수정되었지만, 아직 커밋되지 않은 모든 파일 및 폴더에서 테스트가 실행됩니다.
+
+### 소스 수정 시 실패한 테스트 자동 재실행[[automatically-rerun-failed-tests-on-source-modification]]
+
+[pytest-xdist](https://github.com/pytest-dev/pytest-xdist)는 모든 실패한 테스트를 감지하고,
+파일을 수정한 후에 파일을 계속 재실행하여 테스트가 성공할 때까지 기다리는 매우 유용한 기능을 제공합니다.
+따라서 수정한 내용을 확인한 후 pytest를 다시 시작할 필요가 없습니다.
+모든 테스트가 통과될 때까지 이 과정을 반복한 후 다시 전체 실행이 이루어집니다.
+
+```bash
+pip install pytest-xdist
+```
+
+재귀적 모드의 사용: `pytest -f` 또는 `pytest --looponfail`
+
+파일의 변경 사항은 `looponfailroots` 루트 디렉터리와 해당 내용을 (재귀적으로) 확인하여 감지됩니다.
+이 값의 기본값이 작동하지 않는 경우,
+`setup.cfg`의 설정 옵션을 변경하여 프로젝트에서 변경할 수 있습니다:
+
+```ini
+[tool:pytest]
+looponfailroots = transformers tests
+```
+
+또는 `pytest.ini`/`tox.ini`` 파일:
+
+```ini
+[pytest]
+looponfailroots = transformers tests
+```
+
+이렇게 하면 ini-file의 디렉터리를 기준으로 상대적으로 지정된 각 디렉터리에서 파일 변경 사항만 찾게 됩니다.
+
+
+이 기능을 대체할 수 있는 구현 방법인 [pytest-watch](https://github.com/joeyespo/pytest-watch)도 있습니다.
+
+
+### 특정 테스트 모듈 건너뛰기[[skip-a-test-module]]
+
+모든 테스트 모듈을 실행하되 특정 모듈을 제외하려면, 실행할 테스트 목록을 명시적으로 지정할 수 있습니다.
+예를 들어, `test_modeling_*.py` 테스트를 제외한 모든 테스트를 실행하려면 다음을 사용할 수 있습니다:
+
+```bash
+pytest *ls -1 tests/*py | grep -v test_modeling*
+```
+
+### 상태 초기화[[clearing state]]
+
+CI 빌드 및 (속도에 대한) 격리가 중요한 경우, 캐시를 지워야 합니다:
+
+```bash
+pytest --cache-clear tests
+```
+
+### 테스트를 병렬로 실행[[running-tests-in-parallel]]
+
+이전에 언급한 것처럼 `make test`는 테스트를 병렬로 실행하기 위해
+`pytest-xdist` 플러그인(`-n X` 인수, 예를 들어 `-n 2`를 사용하여 2개의 병렬 작업 실행)을 통해 실행됩니다.
+
+`pytest-xdist`의 `--dist=` 옵션을 사용하여 테스트를 어떻게 그룹화할지 제어할 수 있습니다.
+`--dist=loadfile`은 하나의 파일에 있는 테스트를 동일한 프로세스로 그룹화합니다.
+
+실행된 테스트의 순서가 다르고 예측할 수 없기 때문에, `pytest-xdist`로 테스트 스위트를 실행하면 실패가 발생할 수 있습니다 (검출되지 않은 결합된 테스트가 있는 경우).
+이 경우 [pytest-replay](https://github.com/ESSS/pytest-replay)를 사용하면 동일한 순서로 테스트를 다시 실행해서
+실패하는 시퀀스를 최소화하는 데에 도움이 됩니다.
+
+### 테스트 순서와 반복[[test-order-and-repetition]]
+
+잠재적인 종속성 및 상태 관련 버그(tear down)를 감지하기 위해
+테스트를 여러 번, 연속으로, 무작위로 또는 세트로 반복하는 것이 좋습니다.
+그리고 직접적인 여러 번의 반복은 DL의 무작위성에 의해 발견되는 일부 문제를 감지하는 데에도 유용합니다.
+
+
+#### 테스트를 반복[[repeat-tests]]
+
+- [pytest-flakefinder](https://github.com/dropbox/pytest-flakefinder):
+
+```bash
+pip install pytest-flakefinder
+```
+
+모든 테스트를 여러 번 실행합니다(기본값은 50번):
+
+```bash
+pytest --flake-finder --flake-runs=5 tests/test_failing_test.py
+```
+
+
+
+이 플러그인은 `pytest-xdist`의 `-n` 플래그와 함께 작동하지 않습니다.
+
+
+
+
+
+`pytest-repeat`라는 또 다른 플러그인도 있지만 `unittest`와 함께 작동하지 않습니다.
+
+
+
+#### 테스트를 임의의 순서로 실행[[run-tests-in-a-random-order]]
+
+```bash
+pip install pytest-random-order
+```
+
+중요: `pytest-random-order`가 설치되면 테스트가 자동으로 임의의 순서로 섞입니다.
+구성 변경이나 커맨드 라인 옵션이 필요하지 않습니다.
+
+앞서 설명한 것처럼 이를 통해 한 테스트의 상태가 다른 테스트의 상태에 영향을 미치는 결합된 테스트를 감지할 수 있습니다.
+`pytest-random-order`가 설치되면 해당 세션에서 사용된 랜덤 시드가 출력되며 예를 들어 다음과 같습니다:
+
+```bash
+pytest tests
+[...]
+Using --random-order-bucket=module
+Using --random-order-seed=573663
+```
+
+따라서 특정 시퀀스가 실패하는 경우에는 정확한 시드를 추가하여 재현할 수 있습니다. 예를 들어 다음과 같습니다:
+
+```bash
+pytest --random-order-seed=573663
+[...]
+Using --random-order-bucket=module
+Using --random-order-seed=573663
+```
+
+정확히 동일한 테스트 목록(또는 목록이 없음)을 사용하는 경우에만 정확한 순서를 재현합니다.
+목록을 수동으로 좁히기 시작하면 더 이상 시드에 의존할 수 없고 실패했던 정확한 순서로 수동으로 목록을 나열해야합니다. 그리고 `--random-order-bucket=none`을 사용하여 pytest에게 순서를 임의로 설정하지 않도록 알려야 합니다.
+예를 들어 다음과 같습니다:
+
+```bash
+pytest --random-order-bucket=none tests/test_a.py tests/test_c.py tests/test_b.py
+```
+
+모든 테스트에 대해 섞기를 비활성화하려면 다음과 같습니다:
+
+```bash
+pytest --random-order-bucket=none
+```
+
+기본적으로 `--random-order-bucket=module`이 내재되어 있으므로, 모듈 수준에서 파일을 섞습니다.
+또한 `class`, `package`, `global` 및 `none` 수준에서도 섞을 수 있습니다.
+자세한 내용은 해당 [문서](https://github.com/jbasko/pytest-random-order)를 참조하세요.
+
+또 다른 무작위화의 대안은 [`pytest-randomly`](https://github.com/pytest-dev/pytest-randomly)입니다.
+이 모듈은 매우 유사한 기능/인터페이스를 가지고 있지만, `pytest-random-order`에 있는 버킷 모드를 사용할 수는 없습니다.
+설치 후에는 자동으로 적용되는 문제도 동일하게 가집니다.
+
+### 외관과 느낌을 변경[[look-and-feel-variations]
+
+#### pytest-sugar 사용[[pytest-sugar]]
+
+[pytest-sugar](https://github.com/Frozenball/pytest-sugar)는 테스트가 보여지는 형태를 개선하고,
+진행 상황 바를 추가하며, 실패한 테스트와 검증을 즉시 표시하는 플러그인입니다. 설치하면 자동으로 활성화됩니다.
+
+```bash
+pip install pytest-sugar
+```
+
+pytest-sugar 없이 테스트를 실행하려면 다음과 같습니다:
+
+```bash
+pytest -p no:sugar
+```
+
+또는 제거하세요.
+
+
+
+#### 각 하위 테스트 이름과 진행 상황 보고[[report-each-sub-test-name-and-its-progress]]
+
+`pytest`를 통해 단일 또는 그룹의 테스트를 실행하는 경우(`pip install pytest-pspec` 이후):
+
+```bash
+pytest --pspec tests/test_optimization.py
+```
+
+#### 실패한 테스트 즉시 표시[[instantly-shows-failed-tests]]
+
+[pytest-instafail](https://github.com/pytest-dev/pytest-instafail)은 테스트 세션의 끝까지 기다리지 않고
+실패 및 오류를 즉시 표시합니다.
+
+```bash
+pip install pytest-instafail
+```
+
+```bash
+pytest --instafail
+```
+
+### GPU 사용 여부[[to-GPU-or-not-to-GPU]]
+
+GPU가 활성화된 환경에서, CPU 전용 모드로 테스트하려면 `CUDA_VISIBLE_DEVICES=""`를 추가합니다:
+
+```bash
+CUDA_VISIBLE_DEVICES="" pytest tests/utils/test_logging.py
+```
+
+또는 다중 GPU가 있는 경우 `pytest`에서 사용할 GPU를 지정할 수도 있습니다.
+예를 들어, GPU `0` 및 `1`이 있는 경우 다음을 실행할 수 있습니다:
+
+```bash
+CUDA_VISIBLE_DEVICES="1" pytest tests/utils/test_logging.py
+```
+
+이렇게 하면 다른 GPU에서 다른 작업을 실행하려는 경우 유용합니다.
+
+일부 테스트는 반드시 CPU 전용으로 실행해야 하며, 일부는 CPU 또는 GPU 또는 TPU에서 실행해야 하고, 일부는 여러 GPU에서 실행해야 합니다.
+다음 스킵 데코레이터는 테스트의 요구 사항을 CPU/GPU/TPU별로 설정하는 데 사용됩니다:
+
+- `require_torch` - 이 테스트는 torch에서만 실행됩니다.
+- `require_torch_gpu` - `require_torch`에 추가로 적어도 1개의 GPU가 필요합니다.
+- `require_torch_multi_gpu` - `require_torch`에 추가로 적어도 2개의 GPU가 필요합니다.
+- `require_torch_non_multi_gpu` - `require_torch`에 추가로 0개 또는 1개의 GPU가 필요합니다.
+- `require_torch_up_to_2_gpus` - `require_torch`에 추가로 0개, 1개 또는 2개의 GPU가 필요합니다.
+- `require_torch_xla` - `require_torch`에 추가로 적어도 1개의 TPU가 필요합니다.
+
+GPU 요구 사항을 표로 정리하면 아래와 같습니디ㅏ:
+
+
+| n gpus | decorator |
+|--------+--------------------------------|
+| `>= 0` | `@require_torch` |
+| `>= 1` | `@require_torch_gpu` |
+| `>= 2` | `@require_torch_multi_gpu` |
+| `< 2` | `@require_torch_non_multi_gpu` |
+| `< 3` | `@require_torch_up_to_2_gpus` |
+
+
+예를 들어, 2개 이상의 GPU가 있고 pytorch가 설치되어 있을 때에만 실행되어야 하는 테스트는 다음과 같습니다:
+
+```python no-style
+@require_torch_multi_gpu
+def test_example_with_multi_gpu():
+```
+
+`tensorflow`가 필요한 경우 `require_tf` 데코레이터를 사용합니다. 예를 들어 다음과 같습니다:
+
+```python no-style
+@require_tf
+def test_tf_thing_with_tensorflow():
+```
+
+이러한 데코레이터는 중첩될 수 있습니다.
+예를 들어, 느린 테스트로 진행되고 pytorch에서 적어도 하나의 GPU가 필요한 경우 다음과 같이 설정할 수 있습니다:
+
+```python no-style
+@require_torch_gpu
+@slow
+def test_example_slow_on_gpu():
+```
+
+`@parametrized`와 같은 일부 데코레이터는 테스트 이름을 다시 작성하기 때문에 `@require_*` 스킵 데코레이터는 올바르게 작동하려면 항상 맨 마지막에 나열되어야 합니다.
+다음은 올바른 사용 예입니다:
+
+```python no-style
+@parameterized.expand(...)
+@require_torch_multi_gpu
+def test_integration_foo():
+```
+
+`@pytest.mark.parametrize`에는 이러한 순서 문제는 없으므로 처음 혹은 마지막에 위치시킬 수 있고 이러한 경우에도 잘 작동할 것입니다.
+하지만 unittest가 아닌 경우에만 작동합니다.
+
+테스트 내부에서 다음을 사용할 수 있습니다:
+
+- 사용 가능한 GPU 수:
+
+```python
+from transformers.testing_utils import get_gpu_count
+
+n_gpu = get_gpu_count() #torch와 tf와 함께 작동
+```
+
+### 분산 훈련[[distributed-training]]
+
+`pytest`는 분산 훈련을 직접적으로 다루지 못합니다.
+이를 시도하면 하위 프로세스가 올바른 작업을 수행하지 않고 `pytest`라고 생각하기에 테스트 스위트를 반복해서 실행하게 됩니다.
+그러나 일반 프로세스를 생성한 다음 여러 워커를 생성하고 IO 파이프를 관리하도록 하면 동작합니다.
+
+다음은 사용 가능한 테스트입니다:
+
+- [test_trainer_distributed.py](https://github.com/huggingface/transformers/tree/main/tests/trainer/test_trainer_distributed.py)
+- [test_deepspeed.py](https://github.com/huggingface/transformers/tree/main/tests/deepspeed/test_deepspeed.py)
+
+실행 지점으로 바로 이동하려면, 해당 테스트에서 `execute_subprocess_async` 호출을 검색하세요.
+
+이러한 테스트를 실행하려면 적어도 2개의 GPU가 필요합니다.
+
+```bash
+CUDA_VISIBLE_DEVICES=0,1 RUN_SLOW=1 pytest -sv tests/test_trainer_distributed.py
+```
+
+### 출력 캡처[[output-capture]]
+
+테스트 실행 중 `stdout` 및 `stderr`로 전송된 모든 출력이 캡처됩니다.
+테스트나 설정 메소드가 실패하면 캡처된 출력은 일반적으로 실패 추적 정보와 함께 표시됩니다.
+
+출력 캡처를 비활성화하고 `stdout` 및 `stderr`를 정상적으로 받으려면 `-s` 또는 `--capture=no`를 사용하세요:
+
+```bash
+pytest -s tests/utils/test_logging.py
+```
+
+테스트 결과를 JUnit 형식의 출력으로 보내려면 다음을 사용하세요:
+
+```bash
+py.test tests --junitxml=result.xml
+```
+
+### 색상 조절[[color-control]]
+
+색상이 없게 하려면 다음과 같이 설정하세요(예를 들어 흰색 배경에 노란색 글씨는 가독성이 좋지 않습니다):
+
+```bash
+pytest --color=no tests/utils/test_logging.py
+```
+
+### online pastebin service에 테스트 보고서 전송[[sending test report to online pastebin service]]
+
+각 테스트 실패에 대한 URL을 만듭니다:
+
+```bash
+pytest --pastebin=failed tests/utils/test_logging.py
+```
+
+이렇게 하면 각 실패에 대한 URL을 제공하는 remote Paste service에 테스트 실행 정보를 제출합니다.
+일반적인 테스트를 선택할 수도 있고 혹은 특정 실패만 보내려면 `-x`와 같이 추가할 수도 있습니다.
+
+전체 테스트 세션 로그에 대한 URL을 생성합니다:
+
+```bash
+pytest --pastebin=all tests/utils/test_logging.py
+```
+
+## 테스트 작성[[writing-tests]]
+
+🤗 transformers 테스트는 대부분 `unittest`를 기반으로 하지만,
+`pytest`에서 실행되므로 대부분의 경우 두 시스템의 기능을 사용할 수 있습니다.
+
+지원되는 기능에 대해 [여기](https://docs.pytest.org/en/stable/unittest.html)에서 확인할 수 있지만,
+기억해야 할 중요한 점은 대부분의 `pytest` fixture가 작동하지 않는다는 것입니다.
+파라미터화도 작동하지 않지만, 우리는 비슷한 방식으로 작동하는 `parameterized` 모듈을 사용합니다.
+
+
+### 매개변수화[[parametrization]]
+
+동일한 테스트를 다른 인수로 여러 번 실행해야 하는 경우가 종종 있습니다.
+테스트 내에서 이 작업을 수행할 수 있지만, 그렇게 하면 하나의 인수 세트에 대해 테스트를 실행할 수 없습니다.
+
+```python
+# test_this1.py
+import unittest
+from parameterized import parameterized
+
+
+class TestMathUnitTest(unittest.TestCase):
+ @parameterized.expand(
+ [
+ ("negative", -1.5, -2.0),
+ ("integer", 1, 1.0),
+ ("large fraction", 1.6, 1),
+ ]
+ )
+ def test_floor(self, name, input, expected):
+ assert_equal(math.floor(input), expected)
+```
+
+이제 기본적으로 이 테스트는 `test_floor`의 마지막 3개 인수가
+매개변수 목록의 해당 인수에 할당되는 것으로 3번 실행될 것입니다.
+
+그리고 `negative` 및 `integer` 매개변수 집합만 실행하려면 다음과 같이 실행할 수 있습니다:
+
+```bash
+pytest -k "negative and integer" tests/test_mytest.py
+```
+
+또는 `negative` 하위 테스트를 제외한 모든 서브 테스트를 다음과 같이 실행할 수 있습니다:
+
+```bash
+pytest -k "not negative" tests/test_mytest.py
+```
+
+앞에서 언급한 `-k` 필터를 사용하는 것 외에도,
+각 서브 테스트의 정확한 이름을 확인한 후에 일부 혹은 전체 서브 테스트를 실행할 수 있습니다.
+
+```bash
+pytest test_this1.py --collect-only -q
+```
+
+그리고 다음의 내용을 확인할 수 있을 것입니다:
+
+```bash
+test_this1.py::TestMathUnitTest::test_floor_0_negative
+test_this1.py::TestMathUnitTest::test_floor_1_integer
+test_this1.py::TestMathUnitTest::test_floor_2_large_fraction
+```
+
+2개의 특정한 서브 테스트만 실행할 수도 있습니다:
+
+```bash
+pytest test_this1.py::TestMathUnitTest::test_floor_0_negative test_this1.py::TestMathUnitTest::test_floor_1_integer
+```
+
+`transformers`의 개발자 종속성에 이미 있는 [parameterized](https://pypi.org/project/parameterized/) 모듈은
+`unittests`와 `pytest` 테스트 모두에서 작동합니다.
+
+그러나 테스트가 `unittest`가 아닌 경우 `pytest.mark.parametrize`를 사용할 수 있습니다(이미 있는 일부 테스트에서 사용되는 경우도 있습니다.
+주로 `examples` 하위에 있습니다).
+
+다음은 `pytest`의 `parametrize` 마커를 사용한 동일한 예입니다:
+
+```python
+# test_this2.py
+import pytest
+
+
+@pytest.mark.parametrize(
+ "name, input, expected",
+ [
+ ("negative", -1.5, -2.0),
+ ("integer", 1, 1.0),
+ ("large fraction", 1.6, 1),
+ ],
+)
+def test_floor(name, input, expected):
+ assert_equal(math.floor(input), expected)
+```
+
+`parameterized`와 마찬가지로 `pytest.mark.parametrize`를 사용하면
+`-k` 필터가 작동하지 않는 경우에도 실행할 서브 테스트를 정확하게 지정할 수 있습니다.
+단, 이 매개변수화 함수는 서브 테스트의 이름 집합을 약간 다르게 생성합니다. 다음과 같은 모습입니다:
+
+```bash
+pytest test_this2.py --collect-only -q
+```
+
+그리고 다음의 내용을 확인할 수 있을 것입니다:
+
+```bash
+test_this2.py::test_floor[integer-1-1.0]
+test_this2.py::test_floor[negative--1.5--2.0]
+test_this2.py::test_floor[large fraction-1.6-1]
+```
+
+특정한 테스트에 대해서만 실행할 수도 있습니다:
+
+```bash
+pytest test_this2.py::test_floor[negative--1.5--2.0] test_this2.py::test_floor[integer-1-1.0]
+```
+
+이전의 예시와 같이 실행할 수 있습니다.
+
+
+
+### 파일 및 디렉터리[[files-and-directories]]
+
+테스트에서 종종 현재 테스트 파일과 관련된 상대적인 위치를 알아야 하는 경우가 있습니다.
+테스트가 여러 디렉터리에서 호출되거나 깊이가 다른 하위 디렉터리에 있을 수 있기 때문에 그 위치를 아는 것은 간단하지 않습니다.
+`transformers.test_utils.TestCasePlus`라는 헬퍼 클래스는 모든 기본 경로를 처리하고 간단한 액세서를 제공하여 이 문제를 해결합니다:
+
+
+- `pathlib` 객체(완전히 정해진 경로)
+
+ - `test_file_path` - 현재 테스트 파일 경로 (예: `__file__`)
+ - test_file_dir` - 현재 테스트 파일이 포함된 디렉터리
+ - tests_dir` - `tests` 테스트 스위트의 디렉터리
+ - examples_dir` - `examples` 테스트 스위트의 디렉터리
+ - repo_root_dir` - 저장소 디렉터리
+ - src_dir` - `src`의 디렉터리(예: `transformers` 하위 디렉터리가 있는 곳)
+
+- 문자열로 변환된 경로---위와 동일하지만, `pathlib` 객체가 아닌 문자열로 경로를 반환합니다:
+
+ - `test_file_path_str`
+ - `test_file_dir_str`
+ - `tests_dir_str`
+ - `examples_dir_str`
+ - `repo_root_dir_str`
+ - `src_dir_str`
+
+위의 내용을 사용하려면 테스트가 'transformers.test_utils.TestCasePlus'의 서브클래스에 있는지 확인해야 합니다.
+예를 들어 다음과 같습니다:
+
+```python
+from transformers.testing_utils import TestCasePlus
+
+
+class PathExampleTest(TestCasePlus):
+ def test_something_involving_local_locations(self):
+ data_dir = self.tests_dir / "fixtures/tests_samples/wmt_en_ro"
+```
+
+만약 `pathlib`를 통해 경로를 조작할 필요가 없거나 경로를 문자열로만 필요로 하는 경우에는 `pathlib` 객체에 `str()`을 호출하거나 `_str`로 끝나는 접근자를 사용할 수 있습니다.
+예를 들어 다음과 같습니다:
+
+```python
+from transformers.testing_utils import TestCasePlus
+
+
+class PathExampleTest(TestCasePlus):
+ def test_something_involving_stringified_locations(self):
+ examples_dir = self.examples_dir_str
+```
+
+### 임시 파일 및 디렉터리[[temporary-files-and-directories]]
+
+고유한 임시 파일 및 디렉터리를 사용하는 것은 병렬 테스트 실행에 있어 필수적입니다.
+이렇게 함으로써 테스트들이 서로의 데이터를 덮어쓰지 않게 할 수 있습니다. 또한 우리는 생성된 테스트의 종료 단계에서 이러한 임시 파일 및 디렉터리를 제거하고 싶습니다.
+따라서 이러한 요구 사항을 충족시켜주는 `tempfile`과 같은 패키지를 사용하는 것이 중요합니다.
+
+그러나 테스트를 디버깅할 때는 임시 파일이나 디렉터리에 들어가는 내용을 확인할 수 있어야 하며,
+재실행되는 각 테스트마다 임시 파일이나 디렉터리의 경로에 대해 무작위 값이 아닌 정확한 값을 알고 싶을 것입니다.
+
+`transformers.test_utils.TestCasePlus`라는 도우미 클래스는 이러한 목적에 가장 적합합니다.
+이 클래스는 `unittest.TestCase`의 하위 클래스이므로, 우리는 이것을 테스트 모듈에서 쉽게 상속할 수 있습니다.
+
+다음은 해당 클래스를 사용하는 예시입니다:
+
+```python
+from transformers.testing_utils import TestCasePlus
+
+
+class ExamplesTests(TestCasePlus):
+ def test_whatever(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+```
+
+이 코드는 고유한 임시 디렉터리를 생성하고 `tmp_dir`을 해당 위치로 설정합니다.
+
+- 고유한 임시 디렉터리를 생성합니다:
+
+```python
+def test_whatever(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+```
+
+`tmp_dir`에는 생성된 임시 디렉터리의 경로가 포함됩니다.
+이는 테스트의 종료 단계에서 자동으로 제거됩니다.
+
+- 선택한 경로로 임시 디렉터리 생성 후에 테스트 시작 전에 비어 있는 상태인지 확인하고, 테스트 후에는 비우지 마세요.
+
+```python
+def test_whatever(self):
+ tmp_dir = self.get_auto_remove_tmp_dir("./xxx")
+```
+
+이것은 디버깅할 때 특정 디렉터리를 모니터링하고,
+그 디렉터리에 이전에 실행된 테스트가 데이터를 남기지 않도록 하는 데에 유용합니다.
+
+- `before` 및 `after` 인수를 직접 오버라이딩하여 기본 동작을 변경할 수 있으며
+다음 중 하나의 동작으로 이어집니다:
+
+ - `before=True`: 테스트 시작 시 임시 디렉터리가 항상 지워집니다.
+ - `before=False`: 임시 디렉터리가 이미 존재하는 경우 기존 파일은 그대로 남습니다.
+ - `after=True`: 테스트 종료 시 임시 디렉터리가 항상 삭제됩니다.
+ - `after=False`: 테스트 종료 시 임시 디렉터리가 항상 그대로 유지됩니다.
+
+
+
+`rm -r`에 해당하는 명령을 안전하게 실행하기 위해,
+명시적인 `tmp_dir`을 사용하는 경우 프로젝트 저장소 체크 아웃의 하위 디렉터리만 허용됩니다.
+따라서 실수로 `/tmp`가 아닌 중요한 파일 시스템의 일부가 삭제되지 않도록 항상 `./`로 시작하는 경로를 전달해야 합니다.
+
+
+
+
+
+각 테스트는 여러 개의 임시 디렉터리를 등록할 수 있으며,
+별도로 요청하지 않는 한 모두 자동으로 제거됩니다.
+
+
+
+### 임시 sys.path 오버라이드[[temporary-sys.path-override]]
+
+`sys.path`를 다른 테스트로 임시로 오버라이드하기 위해 예를 들어 `ExtendSysPath` 컨텍스트 관리자를 사용할 수 있습니다.
+예를 들어 다음과 같습니다:
+
+
+```python
+import os
+from transformers.testing_utils import ExtendSysPath
+
+bindir = os.path.abspath(os.path.dirname(__file__))
+with ExtendSysPath(f"{bindir}/.."):
+ from test_trainer import TrainerIntegrationCommon # noqa
+```
+
+### 테스트 건너뛰기[[skipping-tests]]
+
+이것은 버그가 발견되어 새로운 테스트가 작성되었지만 아직 그 버그가 수정되지 않은 경우에 유용합니다.
+이 테스트를 주 저장소에 커밋하려면 `make test` 중에 건너뛰도록 해야 합니다.
+
+방법:
+
+- **skip**은 테스트가 일부 조건이 충족될 경우에만 통과될 것으로 예상되고, 그렇지 않으면 pytest가 전체 테스트를 건너뛰어야 함을 의미합니다.
+일반적인 예로는 Windows가 아닌 플랫폼에서 Windows 전용 테스트를 건너뛰거나
+외부 리소스(예를 들어 데이터베이스)에 의존하는 테스트를 건너뛰는 것이 있습니다.
+
+- **xfail**은 테스트가 특정한 이유로 인해 실패할 것으로 예상하는 것을 의미합니다.
+일반적인 예로는 아직 구현되지 않은 기능이나 아직 수정되지 않은 버그의 테스트가 있습니다.
+`xfail`로 표시된 테스트가 예상대로 실패하지 않고 통과된 경우, 이것은 xpass이며 테스트 결과 요약에 기록됩니다.
+
+두 가지 중요한 차이점 중 하나는 `skip`은 테스트를 실행하지 않지만 `xfail`은 실행한다는 것입니다.
+따라서 오류가 있는 코드가 일부 테스트에 영향을 미칠 수 있는 경우 `xfail`을 사용하지 마세요.
+
+#### 구현[[implementation]]
+
+- 전체 테스트를 무조건 건너뛰려면 다음과 같이 할 수 있습니다:
+
+```python no-style
+@unittest.skip(reason="this bug needs to be fixed")
+def test_feature_x():
+```
+
+또는 pytest를 통해:
+
+```python no-style
+@pytest.mark.skip(reason="this bug needs to be fixed")
+```
+
+또는 `xfail` 방식으로:
+
+```python no-style
+@pytest.mark.xfail
+def test_feature_x():
+```
+
+- 테스트 내부에서 내부 확인에 따라 테스트를 건너뛰는 방법은 다음과 같습니다:
+
+```python
+def test_feature_x():
+ if not has_something():
+ pytest.skip("unsupported configuration")
+```
+
+또는 모듈 전체:
+
+```python
+import pytest
+
+if not pytest.config.getoption("--custom-flag"):
+ pytest.skip("--custom-flag is missing, skipping tests", allow_module_level=True)
+```
+
+또는 `xfail` 방식으로:
+
+```python
+def test_feature_x():
+ pytest.xfail("expected to fail until bug XYZ is fixed")
+```
+
+- import가 missing된 모듈이 있을 때 그 모듈의 모든 테스트를 건너뛰는 방법:
+
+```python
+docutils = pytest.importorskip("docutils", minversion="0.3")
+```
+
+- 조건에 따라 테스트를 건너뛰는 방법:
+
+```python no-style
+@pytest.mark.skipif(sys.version_info < (3,6), reason="requires python3.6 or higher")
+def test_feature_x():
+```
+
+또는:
+
+```python no-style
+@unittest.skipIf(torch_device == "cpu", "Can't do half precision")
+def test_feature_x():
+```
+
+또는 모듈 전체를 건너뛰는 방법:
+
+```python no-style
+@pytest.mark.skipif(sys.platform == 'win32', reason="does not run on windows")
+class TestClass():
+ def test_feature_x(self):
+```
+
+보다 자세한 예제 및 방법은 [여기](https://docs.pytest.org/en/latest/skipping.html)에서 확인할 수 있습니다.
+
+### 느린 테스트[[slow-tests]]
+
+테스트 라이브러리는 지속적으로 확장되고 있으며, 일부 테스트는 실행하는 데 몇 분이 걸립니다.
+그리고 우리에게는 테스트 스위트가 CI를 통해 완료되기까지 한 시간을 기다릴 여유가 없습니다.
+따라서 필수 테스트를 위한 일부 예외를 제외하고 느린 테스트는 다음과 같이 표시해야 합니다.
+
+```python no-style
+from transformers.testing_utils import slow
+@slow
+def test_integration_foo():
+```
+
+`@slow`로 표시된 테스트를 실행하려면 `RUN_SLOW=1` 환경 변수를 설정하세요. 예를 들어 다음과 같습니다:
+
+```bash
+RUN_SLOW=1 pytest tests
+```
+
+`@parameterized`와 같은 몇 가지 데코레이터는 테스트 이름을 다시 작성합니다.
+그러므로 `@slow`와 나머지 건너뛰기 데코레이터 `@require_*`가 올바르게 작동되려면 마지막에 나열되어야 합니다. 다음은 올바른 사용 예입니다.
+
+```python no-style
+@parameterized.expand(...)
+@slow
+def test_integration_foo():
+```
+
+이 문서의 초반부에 설명된 것처럼 느린 테스트는 PR의 CI 확인이 아닌 예약된 일정 기반으로 실행됩니다.
+따라서 PR 제출 중에 일부 문제를 놓친 채로 병합될 수 있습니다.
+이러한 문제들은 다음번의 예정된 CI 작업 중에 감지됩니다.
+하지만 PR을 제출하기 전에 자신의 컴퓨터에서 느린 테스트를 실행하는 것 또한 중요합니다.
+
+느린 테스트로 표시해야 하는지 여부를 결정하는 대략적인 결정 기준은 다음과 같습니다.
+
+만약 테스트가 라이브러리의 내부 구성 요소 중 하나에 집중되어 있다면(예: 모델링 파일, 토큰화 파일, 파이프라인),
+해당 테스트를 느린 테스트 스위트에서 실행해야 합니다.
+만약 라이브러리의 다른 측면(예: 문서 또는 예제)에 집중되어 있다면,
+해당 테스트를 느린 테스트 스위트에서 실행해야 합니다. 그리고 이 접근 방식을 보완하기 위해 예외를 만들어야 합니다.
+
+- 무거운 가중치 세트나 50MB보다 큰 데이터셋을 다운로드해야 하는 모든 테스트(예: 모델 통합 테스트, 토크나이저 통합 테스트, 파이프라인 통합 테스트)를
+ 느린 테스트로 설정해야 합니다.
+ 새로운 모델을 추가하는 경우 통합 테스트용으로 무작위 가중치로 작은 버전을 만들어 허브에 업로드해야 합니다.
+ 이 내용은 아래 단락에서 설명됩니다.
+- 특별히 빠르게 실행되도록 최적화되지 않은 학습을 수행해야 하는 테스트는 느린 테스트로 설정해야 합니다.
+- 느리지 않아야 할 테스트 중 일부가 극도로 느린 경우
+ 예외를 도입하고 이를 `@slow`로 설정할 수 있습니다.
+ 대용량 파일을 디스크에 저장하고 불러오는 자동 모델링 테스트는 `@slow`으로 표시된 테스트의 좋은 예입니다.
+- CI에서 1초 이내에 테스트가 완료되는 경우(다운로드 포함)에는 느린 테스트가 아니어야 합니다.
+
+느린 테스트가 아닌 경우에는 다양한 내부를 완전히 커버하면서 빠르게 유지되어야 합니다.
+예를 들어, 무작위 가중치를 사용하여 특별히 생성된 작은 모델로 테스트하면 상당한 커버리지를 얻을 수 있습니다.
+이러한 모델은 최소한의 레이어 수(예: 2), 어휘 크기(예: 1000) 등의 요소만 가집니다. 그런 다음 `@slow` 테스트는 대형 느린 모델을 사용하여 정성적인 테스트를 수행할 수 있습니다.
+이러한 작은 모델을 사용하는 방법을 확인하려면 다음과 같이 *tiny* 모델을 찾아보세요.
+
+```bash
+grep tiny tests examples
+```
+
+다음은 작은 모델[stas/tiny-wmt19-en-de](https://huggingface.co/stas/tiny-wmt19-en-de)을 만든
+[script](https://github.com/huggingface/transformers/tree/main/scripts/fsmt/fsmt-make-tiny-model.py) 예시입니다.
+특정 모델의 아키텍처에 맞게 쉽게 조정할 수 있습니다.
+
+예를 들어 대용량 모델을 다운로드하는 경우 런타임을 잘못 측정하기 쉽지만,
+로컬에서 테스트하면 다운로드한 파일이 캐시되어 다운로드 시간이 측정되지 않습니다.
+대신 CI 로그의 실행 속도 보고서를 확인하세요(`pytest --durations=0 tests`의 출력).
+
+이 보고서는 느린 이상값으로 표시되지 않거나 빠르게 다시 작성해야 하는 느린 이상값을 찾는 데도 유용합니다.
+CI에서 테스트 스위트가 느려지기 시작하면 이 보고서의 맨 위 목록에 가장 느린 테스트가 표시됩니다.
+
+
+
+### stdout/stderr 출력 테스트[[testing-the-stdout/stderr-output]]
+
+`stdout` 및/또는 `stderr`로 쓰는 함수를 테스트하려면 `pytest`의 [capsys 시스템](https://docs.pytest.org/en/latest/capture.html)을 사용하여 해당 스트림에 액세스할 수 있습니다.
+다음과 같이 수행할 수 있습니다.
+
+```python
+import sys
+
+
+def print_to_stdout(s):
+ print(s)
+
+
+def print_to_stderr(s):
+ sys.stderr.write(s)
+
+
+def test_result_and_stdout(capsys):
+ msg = "Hello"
+ print_to_stdout(msg)
+ print_to_stderr(msg)
+ out, err = capsys.readouterr() # 캡처된 출력 스트림 사용
+ # 선택 사항: 캡처된 스트림 재생성
+ sys.stdout.write(out)
+ sys.stderr.write(err)
+ # 테스트:
+ assert msg in out
+ assert msg in err
+```
+
+그리고, 물론 대부분의 경우에는 `stderr`는 예외의 일부로 제공됩니다.
+그러므로 해당 경우에는 try/except를 사용해야 합니다.
+
+```python
+def raise_exception(msg):
+ raise ValueError(msg)
+
+
+def test_something_exception():
+ msg = "Not a good value"
+ error = ""
+ try:
+ raise_exception(msg)
+ except Exception as e:
+ error = str(e)
+ assert msg in error, f"{msg} is in the exception:\n{error}"
+```
+
+`stdout`를 캡처하는 또 다른 방법은 `contextlib.redirect_stdout`를 사용하는 것입니다.
+
+```python
+from io import StringIO
+from contextlib import redirect_stdout
+
+
+def print_to_stdout(s):
+ print(s)
+
+
+def test_result_and_stdout():
+ msg = "Hello"
+ buffer = StringIO()
+ with redirect_stdout(buffer):
+ print_to_stdout(msg)
+ out = buffer.getvalue()
+ # 선택 사항: 캡처된 스트림 재생성
+ sys.stdout.write(out)
+ # 테스트:
+ assert msg in out
+```
+
+`stdout` 캡처에 관련된 중요한 문제 중 하나는 보통 `print`에서 이전에 인쇄된 내용을 재설정하는 `\r` 문자가 포함될 수 있다는 것입니다.
+`pytest`에서는 문제가 없지만 `pytest -s`에서는 이러한 문자가 버퍼에 포함되므로
+`-s`가 있거나 없는 상태에서 태스트를 수행할 수 있으려면 캡처된 출력에 대해 추가적인 정리가 필요합니다.
+이 경우에는 `re.sub(r'~.*\r', '', buf, 0, re.M)`을 사용할 수 있습니다.
+
+하지만 도우미 컨텍스트 관리자 래퍼를 사용하면
+출력에 `\r`이 포함되어 있는지의 여부에 관계없이 모든 것을 자동으로 처리하므로 편리합니다.
+
+```python
+from transformers.testing_utils import CaptureStdout
+
+with CaptureStdout() as cs:
+ function_that_writes_to_stdout()
+print(cs.out)
+```
+
+다음은 전체 테스트 예제입니다.
+
+```python
+from transformers.testing_utils import CaptureStdout
+
+msg = "Secret message\r"
+final = "Hello World"
+with CaptureStdout() as cs:
+ print(msg + final)
+assert cs.out == final + "\n", f"captured: {cs.out}, expecting {final}"
+```
+
+`stderr`를 캡처하고 싶다면, 대신 `CaptureStderr` 클래스를 사용하세요.
+
+```python
+from transformers.testing_utils import CaptureStderr
+
+with CaptureStderr() as cs:
+ function_that_writes_to_stderr()
+print(cs.err)
+```
+
+두 스트림을 동시에 캡처해야 한다면, 부모 `CaptureStd` 클래스를 사용하세요.
+
+```python
+from transformers.testing_utils import CaptureStd
+
+with CaptureStd() as cs:
+ function_that_writes_to_stdout_and_stderr()
+print(cs.err, cs.out)
+```
+
+또한, 테스트의 디버깅을 지원하기 위해
+이러한 컨텍스트 관리자는 기본적으로 컨텍스트에서 종료할 때 캡처된 스트림을 자동으로 다시 실행합니다.
+
+
+### 로거 스트림 캡처[[capturing-logger-stream]]
+
+로거 출력을 검증해야 하는 경우 `CaptureLogger`를 사용할 수 있습니다.
+
+```python
+from transformers import logging
+from transformers.testing_utils import CaptureLogger
+
+msg = "Testing 1, 2, 3"
+logging.set_verbosity_info()
+logger = logging.get_logger("transformers.models.bart.tokenization_bart")
+with CaptureLogger(logger) as cl:
+ logger.info(msg)
+assert cl.out, msg + "\n"
+```
+
+### 환경 변수를 이용하여 테스트[[testing-with-environment-variables]]
+
+특정 테스트의 환경 변수 영향을 검증하려면
+`transformers.testing_utils.mockenv`라는 도우미 데코레이터를 사용할 수 있습니다.
+
+```python
+from transformers.testing_utils import mockenv
+
+
+class HfArgumentParserTest(unittest.TestCase):
+ @mockenv(TRANSFORMERS_VERBOSITY="error")
+ def test_env_override(self):
+ env_level_str = os.getenv("TRANSFORMERS_VERBOSITY", None)
+```
+
+일부 경우에는 외부 프로그램을 호출해야할 수도 있는데, 이 때에는 여러 개의 로컬 경로를 포함하는 `os.environ`에서 `PYTHONPATH`의 설정이 필요합니다.
+헬퍼 클래스 `transformers.test_utils.TestCasePlus`가 도움이 됩니다:
+
+```python
+from transformers.testing_utils import TestCasePlus
+
+
+class EnvExampleTest(TestCasePlus):
+ def test_external_prog(self):
+ env = self.get_env()
+ # 이제 `env`를 사용하여 외부 프로그램 호출
+```
+
+테스트 파일이 `tests` 테스트 스위트 또는 `examples`에 있는지에 따라
+`env[PYTHONPATH]`가 두 디렉터리 중 하나를 포함하도록 설정되며,
+현재 저장소에 대해 테스트가 수행되도록 `src` 디렉터리도 포함됩니다.
+테스트 호출 이전에 설정된 경우에는 `env[PYTHONPATH]`를 그대로 사용합니다.
+
+이 헬퍼 메소드는 `os.environ` 객체의 사본을 생성하므로 원본은 그대로 유지됩니다.
+
+
+### 재현 가능한 결과 얻기[[getting-reproducible-results]]
+
+일부 상황에서 테스트에서 임의성을 제거하여 동일하게 재현 가능한 결과를 얻고 싶을 수 있습니다.
+이를 위해서는 다음과 같이 시드를 고정해야 합니다.
+
+```python
+seed = 42
+
+# 파이썬 RNG
+import random
+
+random.seed(seed)
+
+# 파이토치 RNG
+import torch
+
+torch.manual_seed(seed)
+torch.backends.cudnn.deterministic = True
+if torch.cuda.is_available():
+ torch.cuda.manual_seed_all(seed)
+
+# 넘파이 RNG
+import numpy as np
+
+np.random.seed(seed)
+
+# 텐서플로 RNG
+tf.random.set_seed(seed)
+```
+
+### 테스트 디버깅[[debugging tests]]
+
+경고가 있는 곳에서 디버거를 시작하려면 다음을 수행하세요.
+
+```bash
+pytest tests/utils/test_logging.py -W error::UserWarning --pdb
+```
+
+## Github Actions 워크플로우 작업 처리[[working-with-github-actions-workflows]]
+
+셀프 푸시 워크플로우 CI 작업을 트리거하려면, 다음을 수행해야 합니다.
+
+1. `transformers` 원본에서 새 브랜치를 만듭니다(포크가 아닙니다!).
+2. 브랜치 이름은 `ci_` 또는 `ci-`로 시작해야 합니다(`main`도 트리거하지만 `main`에서는 PR을 할 수 없습니다).
+ 또한 특정 경로에 대해서만 트리거되므로 이 문서가 작성된 후에 변경된 내용은
+ [여기](https://github.com/huggingface/transformers/blob/main/.github/workflows/self-push.yml)의 *push:*에서 확인할 수 있습니다.
+3. 이 브랜치에서 PR을 생성합니다
+4. 그런 다음 [여기](https://github.com/huggingface/transformers/actions/workflows/self-push.yml)에서 작업이 나타나는지 확인할 수 있습니다.
+ 백로그가 있는 경우, 바로 실행되지 않을 수도 있습니다.
+
+
+
+
+## 실험적인 CI 기능 테스트[[testing-Experimental-CI-Features]]
+
+CI 기능을 테스트하는 것은 일반 CI 작동에 방해가 될 수 있기 때문에 잠재적으로 문제가 발생할 수 있습니다.
+따라서 새로운 CI 기능을 추가하는 경우 다음과 같이 수행해야 합니다.
+
+1. 테스트해야 할 내용을 테스트하는 새로운 전용 작업을 생성합니다.
+2. 새로운 작업은 항상 성공해야만 녹색 ✓를 받을 수 있습니다(아래에 자세한 내용이 있습니다).
+3. 다양한 PR 유형에 대한 확인을 위해
+ (사용자 포크 브랜치, 포크되지 않은 브랜치, github.com UI 직접 파일 편집에서 생성된 브랜치, 강제 푸시 등 PR의 유형은 아주 다양합니다.)
+ 며칠 동안 실험 작업의 로그를 모니터링하면서 실행해봅니다.
+ (의도적으로 항상 녹색을 표시하므로 작업 전체가 녹색은 아니라는 점에 유의합니다.)
+4. 모든 것이 안정적인지 확인한 후, 새로운 변경 사항을 기존 작업에 병합합니다.
+
+이렇게 하면 CI 기능 자체에 대한 실험이 일반 작업 흐름에 방해가 되지 않습니다.
+
+그러나 새로운 CI 기능이 개발 중인 동안, 항상 성공하도록 할 수 있는 방법은 무엇일까요?
+
+TravisCI와 같은 일부 CI는 `ignore-step-failure`를 지원하며 전체 작업을 성공한 것으로 보고하지만,
+현재 우리가 사용하는 CircleCI와 Github Actions는 이를 지원하지 않습니다.
+
+따라서 다음과 같은 해결책을 사용할 수 있습니다.
+
+1. bash 스크립트에서 가능한 많은 오류를 억제하기 위해 실행 명령의 시작 부분에 `set +euo pipefail`을 추가합니다.
+2. 마지막 명령은 반드시 성공해야 합니다. `echo "done"` 또는 `true`를 사용하면 됩니다.
+
+예시는 다음과 같습니다.
+
+```yaml
+- run:
+ name: run CI experiment
+ command: |
+ set +euo pipefail
+ echo "setting run-all-despite-any-errors-mode"
+ this_command_will_fail
+ echo "but bash continues to run"
+ # emulate another failure
+ false
+ # but the last command must be a success
+ echo "during experiment do not remove: reporting success to CI, even if there were failures"
+```
+
+간단한 명령의 경우 다음과 같이 수행할 수도 있습니다.
+
+```bash
+cmd_that_may_fail || true
+```
+
+결과에 만족한 후에는 물론, 실험적인 단계 또는 작업을 일반 작업의 나머지 부분과 통합하면서
+`set +euo pipefail` 또는 기타 추가한 요소를 제거하여
+실험 작업이 일반 CI 작동에 방해되지 않도록 해야 합니다.
+
+이 전반적인 과정은 실험 단계가 PR의 전반적인 상태에 영향을 주지 않고 실패하도록
+`allow-failure`와 같은 기능을 설정할 수 있다면 훨씬 더 쉬웠을 것입니다.
+그러나 앞에서 언급한 바와 같이 CircleCI와 Github Actions는 현재 이러한 기능들 지원하지 않습니다.
+
+이 기능의 지원을 위한 투표에 참여하고 CI 관련 스레드들에서 이러한 상황을 확인할 수도 있습니다.
+
+- [Github Actions:](https://github.com/actions/toolkit/issues/399)
+- [CircleCI:](https://ideas.circleci.com/ideas/CCI-I-344)
diff --git a/docs/transformers/docs/source/ko/tf_xla.md b/docs/transformers/docs/source/ko/tf_xla.md
new file mode 100644
index 0000000000000000000000000000000000000000..0b47d6fbad89d61dd4708285ab7960165e2124ca
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tf_xla.md
@@ -0,0 +1,174 @@
+
+
+# TensorFlow 모델을 위한 XLA 통합 [[xla-integration-for-tensorflow-models]]
+
+[[open-in-colab]]
+
+XLA(Accelerated Linear Algebra)는 TensorFlow 모델의 실행 시간을 가속화하기 위한 컴파일러입니다. [공식 문서](https://www.tensorflow.org/xla)에 따르면 다음과 같습니다:
+
+XLA(Accelerated Linear Algebra)는 선형 대수를 위한 도메인 특화 컴파일러로, TensorFlow 모델을 소스 코드 변경 없이 가속화할 수 있습니다.
+
+TensorFlow에서 XLA를 사용하는 것은 간단합니다. XLA는 `tensorflow` 라이브러리 내에 패키지로 제공되며, [`tf.function`](https://www.tensorflow.org/guide/intro_to_graphs)과 같은 그래프 생성 함수에서 `jit_compile` 인수를 사용하여 활성화할 수 있습니다. `fit()` 및 `predict()`와 같은 Keras 메소드를 사용하는 경우, `jit_compile` 인수를 `model.compile()`에 전달하여 XLA를 간단하게 활성화할 수 있습니다. 그러나 XLA는 이러한 메소드에 국한되지 않고 임의의 `tf.function`을 가속화하는 데에도 사용할 수 있습니다.
+
+🤗 Transformers에서는 [GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2), [T5](https://huggingface.co/docs/transformers/model_doc/t5), [OPT](https://huggingface.co/docs/transformers/model_doc/opt)와 같은 모델의 텍스트 생성, 그리고 [Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)와 같은 모델의 음성 처리를 포함하여 여러 TensorFlow 메소드가 XLA와 호환되도록 다시 작성되었습니다.
+
+정확한 속도 향상은 모델에 따라 다르지만, 🤗 Transformers 내의 TensorFlow 텍스트 생성 모델의 경우 최대 100배의 속도 향상을 확인했습니다. 이 문서에서는 이러한 모델에 대해 XLA를 사용하여 최대 성능을 얻는 방법을 설명합니다. 또한 XLA 통합의 벤치마크 및 디자인 철학에 대한 추가 자료 링크도 제공할 것입니다.
+
+## XLA를 사용하여 TF 함수 실행하기 [[running-tf-functions-with-xla]]
+
+TensorFlow에서 다음과 같은 모델을 고려해 봅시다:
+
+```py
+import tensorflow as tf
+
+model = tf.keras.Sequential(
+ [tf.keras.layers.Dense(10, input_shape=(10,), activation="relu"), tf.keras.layers.Dense(5, activation="softmax")]
+)
+```
+
+위 모델은 차원이 `(10, )`인 입력을 받습니다. 다음과 같이 모델을 사용하여 순전파를 실행할 수 있습니다:
+
+```py
+# 모델에 대한 임의의 입력을 생성합니다.
+batch_size = 16
+input_vector_dim = 10
+random_inputs = tf.random.normal((batch_size, input_vector_dim))
+
+# 순전파를 실행합니다.
+_ = model(random_inputs)
+```
+
+XLA로 컴파일된 함수로 순전파를 실행하려면 다음과 같이 해야 합니다:
+
+```py
+xla_fn = tf.function(model, jit_compile=True)
+_ = xla_fn(random_inputs)
+```
+
+`model`의 기본 `call()` 함수는 XLA 그래프를 컴파일하는 데 사용됩니다. 그러나 다른 모델 함수를 XLA로 컴파일하려면 다음과 같이 할 수도 있습니다:
+
+```py
+my_xla_fn = tf.function(model.my_xla_fn, jit_compile=True)
+```
+
+## 🤗 Transformers에서 XLA를 사용하여 TF 텍스트 생성 모델 실행하기 [[running-a-tf-text-generation-model-with-xla-from-transformers]]
+
+🤗 Transformers에서 XLA로 가속화된 생성을 활성화하려면 최신 버전의 `transformers`가 설치되어 있어야 합니다. 다음과 같이 설치할 수 있습니다:
+
+```bash
+pip install transformers --upgrade
+```
+
+그리고 다음 코드를 실행할 수 있습니다:
+
+```py
+import tensorflow as tf
+from transformers import AutoTokenizer, TFAutoModelForCausalLM
+
+# 최소 버전의 Transformers가 설치되어 있지 않다면 오류가 발생합니다.
+from transformers.utils import check_min_version
+
+check_min_version("4.21.0")
+
+
+tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2", padding_side="left", pad_token="")
+model = TFAutoModelForCausalLM.from_pretrained("openai-community/gpt2")
+input_string = ["TensorFlow is"]
+
+# XLA 생성 함수를 만들기 위한 한 줄
+xla_generate = tf.function(model.generate, jit_compile=True)
+
+tokenized_input = tokenizer(input_string, return_tensors="tf")
+generated_tokens = xla_generate(**tokenized_input, num_beams=2)
+
+decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
+print(f"Generated -- {decoded_text}")
+# Generated -- TensorFlow is an open-source, open-source, distributed-source application # framework for the
+```
+
+알 수 있듯이, `generate()`에서 XLA를 활성화하는 것은 단 한 줄의 코드입니다. 코드의 나머지 부분은 변경되지 않습니다. 그러나 위 코드 스니펫에서는 XLA에 특정한 몇 가지 주의할 점이 있습니다. XLA가 가져다줄 속도 향상을 실현하기 위해서는 이를 알고 있어야 합니다. 다음 섹션에서 이에 대해 논의합니다.
+
+## 주의할 점 [[gotchas-to-be-aware-of]]
+
+XLA 활성화 함수(`xla_generate()`와 같은)를 처음 실행할 때 내부적으로 계산 그래프를 추론하려고 하며, 이는 시간이 소요됩니다. 이 과정은 [“추적(tracing)”](https://www.tensorflow.org/guide/intro_to_graphs#when_is_a_function_tracing)이라고 알려져 있습니다.
+
+생성 시간이 빠르지 않다는 것을 알 수 있을 것입니다. `xla_generate()`(또는 다른 XLA 활성화 함수)의 연속 호출은 함수에 전달된 입력이 초기에 구축된 계산 그래프와 동일한 형태를 따른다면, 계산 그래프를 추론할 필요가 없습니다. 이는 입력 형태가 고정된 모달리티(예: 이미지)에는 문제가 되지 않지만, 가변 입력 형태 모달리티(예: 텍스트)를 사용할 때 주의해야 합니다.
+
+`xla_generate()`가 항상 동일한 입력 형태로 동작하도록 하려면, 토크나이저를 호출할 때 `padding` 인수를 지정할 수 있습니다.
+
+```py
+import tensorflow as tf
+from transformers import AutoTokenizer, TFAutoModelForCausalLM
+
+tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2", padding_side="left", pad_token="")
+model = TFAutoModelForCausalLM.from_pretrained("openai-community/gpt2")
+input_string = ["TensorFlow is"]
+
+xla_generate = tf.function(model.generate, jit_compile=True)
+
+# 여기서, padding 옵션이 있는 토크나이저를 호출합니다.
+tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
+
+generated_tokens = xla_generate(**tokenized_input, num_beams=2)
+decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
+print(f"Generated -- {decoded_text}")
+```
+
+이렇게 하면 `xla_generate()`에 대한 입력이 항상 추적된 형태로 전달되어 생성 시간이 가속화됩니다. 다음 코드로 이를 확인할 수 있습니다:
+
+```py
+import time
+import tensorflow as tf
+from transformers import AutoTokenizer, TFAutoModelForCausalLM
+
+tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2", padding_side="left", pad_token="")
+model = TFAutoModelForCausalLM.from_pretrained("openai-community/gpt2")
+
+xla_generate = tf.function(model.generate, jit_compile=True)
+
+for input_string in ["TensorFlow is", "TensorFlow is a", "TFLite is a"]:
+ tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
+ start = time.time_ns()
+ generated_tokens = xla_generate(**tokenized_input, num_beams=2)
+ end = time.time_ns()
+ print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
+```
+
+Tesla T4 GPU에서는 다음과 같은 출력을 예상할 수 있습니다:
+
+```bash
+Execution time -- 30819.6 ms
+
+Execution time -- 79.0 ms
+
+Execution time -- 78.9 ms
+```
+`xla_generate()`의 첫 번째 호출은 추적 때문에 시간이 오래 걸리지만, 연속 호출은 몇 배나 빠릅니다. 생성 옵션에 대한 어떤 변경이든 다시 추적을 유발하므로 생성 시간이 느려질 수 있음을 명심하세요.
+
+이 문서에서는 🤗 Transformers에서 제공하는 모든 텍스트 생성 옵션을 다루지 않았습니다. 고급 사용 사례에 대해 문서를 참조하시기 바랍니다.
+
+## 추가 자료 [[additional-resources]]
+
+여기에 🤗 Transformers와 XLA에 대해 더 자세히 알고 싶은 경우 도움이 될 수 있는 몇 가지 추가 자료를 제공합니다.
+
+* [이 Colab 노트북](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/91_tf_xla_generate.ipynb)은 XLA와 호환되는 인코더-디코더([T5](https://huggingface.co/docs/transformers/model_doc/t5)와 같은) 및 디코더 전용([GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)와 같은) 텍스트 생성 모델을 실험해 볼 수 있는 대화형 데모를 제공합니다.
+* [이 블로그 글](https://huggingface.co/blog/tf-xla-generate)은 TensorFlow에서 XLA에 대한 친절한 소개와 함께 XLA와 호환되는 모델의 비교 벤치마크에 대한 개요를 제공합니다.
+* [이 블로그 글](https://blog.tensorflow.org/2022/11/how-hugging-face-improved-text-generation-performance-with-xla.html)은 🤗 Transformers의 TensorFlow 모델에 XLA 지원을 추가하는 것에 대한 디자인 철학을 논의합니다.
+* XLA와 TensorFlow 그래프에 대해 더 자세히 알고 싶은 경우 추천하는 글:
+ * [XLA: 기계 학습을 위한 최적화 컴파일러](https://www.tensorflow.org/xla)
+ * [그래프 및 tf.function 소개](https://www.tensorflow.org/guide/intro_to_graphs)
+ * [tf.function으로 성능 향상하기](https://www.tensorflow.org/guide/function)
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/tflite.md b/docs/transformers/docs/source/ko/tflite.md
new file mode 100644
index 0000000000000000000000000000000000000000..464106a6b7c2612b93a25848b750d90f7258e4cd
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tflite.md
@@ -0,0 +1,62 @@
+
+
+# TFLite로 내보내기[[export-to-tflite]]
+
+[TensorFlow Lite](https://www.tensorflow.org/lite/guide)는 자원이 제한된 휴대폰, 임베디드 시스템, 사물인터넷(IoT) 기기에서
+기계학습 모델을 배포하기 위한 경량 프레임워크입니다.
+TFLite는 연산 능력, 메모리, 전력 소비가 제한된 기기에서 모델을 효율적으로 최적화하고 실행하기 위해
+설계되었습니다.
+TensorFlow Lite 모델은 `.tflite` 파일 확장자로 식별되는 특수하고 효율적인 휴대용 포맷으로 표현됩니다.
+
+🤗 Optimum은 `exporters.tflite` 모듈로 🤗 Transformers 모델을 TFLite로 내보내는 기능을 제공합니다.
+지원되는 모델 아키텍처 목록은 [🤗 Optimum 문서](https://huggingface.co/docs/optimum/exporters/tflite/overview)를 참고하세요.
+
+모델을 TFLite로 내보내려면, 필요한 종속성을 설치하세요:
+
+```bash
+pip install optimum[exporters-tf]
+```
+
+모든 사용 가능한 인수를 확인하려면, [🤗 Optimum 문서](https://huggingface.co/docs/optimum/main/en/exporters/tflite/usage_guides/export_a_model)를 참고하거나
+터미널에서 도움말을 살펴보세요:
+
+```bash
+optimum-cli export tflite --help
+```
+
+예를 들어 🤗 Hub에서의 `google-bert/bert-base-uncased` 모델 체크포인트를 내보내려면, 다음 명령을 실행하세요:
+
+```bash
+optimum-cli export tflite --model google-bert/bert-base-uncased --sequence_length 128 bert_tflite/
+```
+
+다음과 같이 진행 상황을 나타내는 로그와 결과물인 `model.tflite`가 저장된 위치를 보여주는 로그가 표시됩니다:
+
+```bash
+Validating TFLite model...
+ -[✓] TFLite model output names match reference model (logits)
+ - Validating TFLite Model output "logits":
+ -[✓] (1, 128, 30522) matches (1, 128, 30522)
+ -[x] values not close enough, max diff: 5.817413330078125e-05 (atol: 1e-05)
+The TensorFlow Lite export succeeded with the warning: The maximum absolute difference between the output of the reference model and the TFLite exported model is not within the set tolerance 1e-05:
+- logits: max diff = 5.817413330078125e-05.
+ The exported model was saved at: bert_tflite
+ ```
+
+위 예제는 🤗 Hub에서의 체크포인트를 내보내는 방법을 보여줍니다.
+로컬 모델을 내보낸다면, 먼저 모델 가중치와 토크나이저 파일이 모두 같은 디렉터리( `local_path` )에 저장됐는지 확인하세요.
+CLI를 사용할 때, 🤗 Hub에서의 체크포인트 이름 대신 `model` 인수에 `local_path`를 전달하면 됩니다.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/tokenizer_summary.md b/docs/transformers/docs/source/ko/tokenizer_summary.md
new file mode 100644
index 0000000000000000000000000000000000000000..0a4ece29a476d942b6cfc5067f723a301cb2e278
--- /dev/null
+++ b/docs/transformers/docs/source/ko/tokenizer_summary.md
@@ -0,0 +1,253 @@
+
+
+# 토크나이저 요약[[summary-of-the-tokenizers]]
+
+[[open-in-colab]]
+
+이 페이지에서는 토큰화에 대해 자세히 살펴보겠습니다.
+
+
+
+[데이터 전처리하기 튜토리얼](preprocessing)에서 살펴본 것처럼, 텍스트를 토큰화하는 것은 텍스트를 단어 또는 서브워드로 분할하고 룩업 테이블을 통해 id로 변환하는 과정입니다.
+단어 또는 서브워드를 id로 변환하는 것은 간단하기 때문에 이번 문서에서는 텍스트를 단어 또는 서브워드로 쪼개는 것(즉, 텍스트를 토큰화하는 것)에 중점을 두겠습니다.
+구체적으로, 🤗 Transformers에서 사용되는 세 가지 주요 토큰화 유형인 [Byte-Pair Encoding (BPE)](#byte-pair-encoding), [WordPiece](#wordpiece), [SentencePiece](#sentencepiece)를 살펴보고 어떤 모델에서 어떤 토큰화 유형을 사용하는지 예시를 보여드리겠습니다.
+
+각 모델 페이지에 연결된 토크나이저의 문서를 보면 사전 훈련 모델에서 어떤 토크나이저를 사용했는지 알 수 있습니다.
+예를 들어, [`BertTokenizer`]를 보면 이 모델이 [WordPiece](#wordpiece)를 사용하는 것을 알 수 있습니다.
+
+## 개요[[introduction]]
+
+텍스트를 작은 묶음(chunk)으로 쪼개는 것은 보기보다 어려운 작업이며, 여러 가지 방법이 있습니다.
+예를 들어, `"Don't you love 🤗 Transformers? We sure do."` 라는 문장을 살펴보도록 하겠습니다.
+
+
+
+위 문장을 토큰화하는 간단한 방법은 공백을 기준으로 쪼개는 것입니다.
+토큰화된 결과는 다음과 같습니다:
+
+```
+["Don't", "you", "love", "🤗", "Transformers?", "We", "sure", "do."]
+```
+이는 첫 번째 결과로는 합리적이지만, `"Transformers?"`와 `"do."`토큰을 보면 각각 `"Transformer"`와 `"do"`에 구두점이 붙어있는 것을 확인할 수 있습니다.
+구두점을 고려해야 모델이 단어의 다른 표현과 그 뒤에 올 수 있는 모든 가능한 구두점을 학습할 필요가 없습니다. 그렇지 않으면 모델이 학습해야 하는 표현의 수가 폭발적으로 증가하게 됩니다.
+
+구두점을 고려한 토큰화 결과는 다음과 같습니다:
+
+```
+["Don", "'", "t", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
+```
+
+이전보다 나아졌습니다. 하지만, `"Don't"`의 토큰화 결과도 수정이 필요합니다.
+`"Don't"`는 `"do not"`의 줄임말이기 때문에 `["Do", "n't"]`로 토큰화되는 것이 좋습니다.
+여기서부터 복잡해지기 시작합니다. 그리고 이 점이 각 모델마다 고유한 토큰화 유형이 존재하는 이유 중 하나입니다.
+텍스트를 토큰화하는 데 적용하는 규칙에 따라 동일한 텍스트에 대해 토큰화된 결과가 달라집니다.
+사전 훈련된 모델은 훈련 데이터를 토큰화하는 데 사용된 것과 동일한 규칙으로 토큰화된 입력을 제공해야만 제대로 작동합니다.
+
+[spaCy](https://spacy.io/)와 [Moses](http://www.statmt.org/moses/?n=Development.GetStarted)는 유명한 규칙 기반 토크나이저입니다. 예제에 *spaCy*와 *Moses* 를 적용한 결과는 다음과 같습니다:
+
+```
+["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
+```
+
+보시다시피 공백 및 구두점 토큰화와 규칙 기반 토큰화가 사용됩니다.
+공백 및 구두점, 규칙 기반 토큰화은 모두 단어 문장을 단어로 쪼개는 단어 토큰화에 해당합니다.
+이 토큰화 방법은 텍스트를 더 작은 묶음(chunk)로 분할하는 가장 직관적인 방법이지만, 대규모 텍스트 말뭉치에 대해서는 문제가 발생할 수 있습니다.
+이 경우 공백 및 구두점 토큰화는 일반적으로 매우 큰 어휘(사용된 모든 고유 단어와 토큰 집합)을 생성합니다.
+*예를 들어*, [Transformer XL](model_doc/transformerxl)은 공백 및 구두점 토큰화를 사용해 어휘(vocabulary) 크기가 267,735입니다!
+
+어휘 크기가 크면 모델에 입력 및 출력 레이어로 엄청난 임베딩 행렬이 필요하므로 메모리와 시간 복잡성이 모두 증가합니다.
+일반적으로 트랜스포머 모델은 어휘 크기가 50,000개를 넘는 경우가 드물며, 특히 단일 언어에 대해서만 사전 훈련된 경우에는 더욱 그렇습니다.
+단순한 공백과 구두점 토큰화가 만족스럽지 않다면 단순히 문자를 토큰화하면 어떨까요?
+
+
+
+문자 토큰화는 아주 간단하고 메모리와 시간 복잡도를 크게 줄일 수 있지만, 모델이 의미 있는 입력 표현을 학습하기에는 훨씬 더 어렵습니다.
+
+*예를 들어*, 문자 `"t"`에 대한 의미 있는 문맥 독립적 표현을 배우는 것 보다 단어 `"today"`에 대한 의미 있는 문맥 독립적 표현을 배우는 것이 훨씬 더 어렵습니다.
+문자 토큰화는 종종 성능 저하를 동반하기 때문에 두 가지 장점을 모두 얻기 위해 트랜스포머 모델은 **서브워드** 토큰화라고 하는 단어 수준과 문자 수준 토큰화의 하이브리드를 사용합니다.
+
+## 서브워드 토큰화[[subword-tokenization]]
+
+
+
+서브워드 토큰화 알고리즘은 자주 사용되는 단어는 더 작은 하위 단어로 쪼개고, 드문 단어는 의미 있는 하위 단어로 분해되어야 한다는 원칙에 따라 작동합니다.
+예를 들어 `"annoyingly"`는 드문 단어로 간주되어 `"annoying"`과 `"ly"`로 분해될 수 있습니다.
+`"annoyingly"`가 `"annoying"`과 `"ly"`의 합성어인 반면, `"annoying"`과 `"ly"` 둘 다 독립적인 서브워드로 자주 등장합니다.
+이는 터키어와 같은 응집성 언어에서 특히 유용하며, 서브워드를 묶어 임의로 긴 복합 단어를 만들 수 있습니다.
+
+서브워드 토큰화를 사용하면 모델이 의미 있는 문맥 독립적 표현을 학습하면서 합리적인 어휘 크기를 가질 수 있습니다.
+또한, 서브워드 토큰화를 통해 모델은 이전에 본 적이 없는 단어를 알려진 서브워드로 분해하여 처리할 수 있습니다.
+
+예를 들어, [`~transformers.BertTokenizer`]는 `"I have a new GPU!"` 라는 문장을 아래와 같이 토큰화합니다:
+
+```py
+>>> from transformers import BertTokenizer
+
+>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> tokenizer.tokenize("I have a new GPU!")
+["i", "have", "a", "new", "gp", "##u", "!"]
+```
+
+대소문자가 없는 모델을 사용해 문장의 시작이 소문자로 표기되었습니다.
+단어 `["i", "have", "a", "new"]`는 토크나이저의 어휘에 속하지만, `"gpu"`는 속하지 않는 것을 확인할 수 있습니다.
+결과적으로 토크나이저는 `"gpu"`를 알려진 두 개의 서브워드로 쪼갭니다: `["gp" and "##u"]`.
+`"##"`은 토큰의 나머지 부분이 공백 없이 이전 토큰에 연결되어야(attach) 함을 의미합니다(토큰화 디코딩 또는 역전을 위해).
+
+또 다른 예로, [`~transformers.XLNetTokenizer`]는 이전에 예시 문장을 다음과 같이 토큰화합니다:
+```py
+>>> from transformers import XLNetTokenizer
+
+>>> tokenizer = XLNetTokenizer.from_pretrained("xlnet/xlnet-base-cased")
+>>> tokenizer.tokenize("Don't you love 🤗 Transformers? We sure do.")
+["▁Don", "'", "t", "▁you", "▁love", "▁", "🤗", "▁", "Transform", "ers", "?", "▁We", "▁sure", "▁do", "."]
+```
+
+`"▁"`가 가지는 의미는 [SentencePiece](#sentencepiece)에서 다시 살펴보도록 하겠습니다.
+보다시피 `"Transformers"` 라는 드문 단어는 서브워드 `"Transform"`와 `"ers"`로 쪼개집니다.
+
+이제 다양한 하위 단어 토큰화 알고리즘이 어떻게 작동하는지 살펴보겠습니다.
+이러한 토큰화 알고리즘은 일반적으로 해당 모델이 학습되는 말뭉치에 대해 수행되는 어떤 형태의 학습에 의존한다는 점에 유의하세요.
+
+
+
+### 바이트 페어 인코딩 (Byte-Pair Encoding, BPE)[[bytepair-encoding-bpe]]
+
+바이트 페어 인코딩(BPE)은 [Neural Machine Translation of Rare Words with Subword Units (Sennrich et
+al., 2015)](https://arxiv.org/abs/1508.07909) 에서 소개되었습니다.
+BPE는 훈련 데이터를 단어로 분할하는 사전 토크나이저(pre-tokenizer)에 의존합니다.
+사전 토큰화(Pretokenization)에는 [GPT-2](model_doc/gpt2), [Roberta](model_doc/roberta)와 같은 간단한 공백 토큰화가 있습니다.
+복잡한 사전 토큰화에는 규칙 기반 토큰화가 해당하는데, 훈련 말뭉치에서 각 단어의 빈도를 계산하기 위해 사용합니다.
+[XLM](model_doc/xlm), 대부분의 언어에서 Moses를 사용하는 [FlauBERT](model_doc/flaubert), Spacy와 ftfy를 사용하는 [GPT](model_doc/gpt)가 해당합니다.
+
+
+사전 토큰화 이후에, 고유 단어 집합가 생성되고 훈련 데이터에서 각 단어가 등장하는 빈도가 결정됩니다.
+다음으로, BPE는 고유 단어 집합에 나타나는 모든 기호로 구성된 기본 어휘를 생성하고 기본 어휘의 두 기호에서 새로운 기호를 형성하는 병합 규칙을 학습합니다.
+어휘가 원하는 어휘 크기에 도달할 때까지 위의 과정을 반복합니다.
+어휘 크기는 토크나이저를 훈련시키기 전에 정의해야 하는 하이퍼파라미터라는 점을 유의하세요.
+
+예를 들어, 사전 토큰화 후 빈도를 포함한 다음과 같은 어휘 집합이 결정되었다고 가정해 보겠습니다:
+
+```
+("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
+```
+
+결과적으로 기본 어휘는 `["b", "g", "h", "n", "p", "s", "u"]` 이고, 각 단어를 기본 어휘에 속하는 기호로 쪼개면 아래와 같습니다:
+
+```
+("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
+```
+
+그런 다음 BPE는 가능한 각 기호 쌍의 빈도를 계산하여 가장 자주 발생하는 기호 쌍을 선택합니다.
+위의 예시에서 `"h"` 뒤에 오는 `"u"`는 _10 + 5 = 15_ 번 등장합니다. (`"hug"`에서 10번, `"hugs"`에서 5번 등장)
+
+하지만, 가장 등장 빈도가 높은 기호 쌍은 `"u"` 뒤에 오는 `"g"`입니다. _10 + 5 + 5 = 20_ 으로 총 20번 등장합니다.
+따라서 토크나이저가 병합하는 가장 첫 번째 쌍은 `"u"` 뒤에 오는 `"g"`입니다. `"ug"`가 어휘에 추가되어 어휘는 다음과 같습니다:
+
+```
+("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
+```
+
+BPE는 다음으로 가장 많이 등장하는 기호 쌍을 식별합니다.
+`"u"` 뒤에 오는 `"n"`은 16번 등장해 `"un"` 으로 병합되어 어휘에 추가됩니다.
+그 다음으로 빈도수가 놓은 기호 쌍은 `"h"` 뒤에 오는 `"ug"`로 15번 등장합니다.
+다시 한 번 `"hug"`로 병합되어 어휘에 추가됩니다.
+
+현재 단계에서 어휘는 `["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]` 이고, 고유 단어 집합은 다음과 같습니다:
+
+```
+("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
+```
+
+이 시점에서 바이트 페어 인코딩 훈련이 중단된다고 가정하면, 훈련된 병합 규칙은 새로운 단어에 적용됩니다(기본 어휘에 포함된 기호가 새로운 단어에 포함되지 않는 한).
+예를 들어, 단어 `"bug"`는 `["b", "ug"]`로 토큰화되지만, `"m"`이 기본 어휘에 없기 때문에 `"mug"`는 `["", "ug"]`로 토큰화될 것입니다.
+훈련 데이터에는 단일 문자가 최소한 한 번 등장하기 때문에 일반적으로 `"m"`과 같은 단일 문자는 `""` 기호로 대체되지 않지만, 이모티콘과 같은 특별한 문자인 경우에는 대체될 수 있습니다.
+
+이전에 언급했듯이 어휘 크기(즉 기본 어휘 크기 + 병합 횟수)는 선택해야하는 하이퍼파라미터입니다.
+예를 들어 [GPT](model_doc/gpt)의 기본 어휘 크기는 478, 40,000번의 병합 이후에 훈련을 종료하기 때문에 어휘 크기가 40,478입니다.
+
+#### 바이트 수준 BPE (Byte-level BPE)[[bytelevel-bpe]]
+
+가능한 모든 기본 문자를 포함하는 기본 어휘의 크기는 굉장히 커질 수 있습니다. (예: 모든 유니코드 문자를 기본 문자로 간주하는 경우)
+더 나은 기본 어휘를 갖도록 [GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)는 기본 어휘로 바이트(bytes)를 사용합니다.
+이 방식은 모든 기본 문자가 어휘에 포함되도록 하면서 기본 어휘의 크기를 256으로 제한합니다.
+구두점을 다루는 추가적인 규칙을 사용해 GPT2 토크나이저는 모든 텍스트를 기호 없이 토큰화할 수 있습니다.
+[GPT-2](model_doc/gpt)의 어휘 크기는 50,257로 256 바이트 크기의 기본 토큰, 특별한 end-of-text 토큰과 50,000번의 병합으로 학습한 기호로 구성됩니다.
+
+
+
+### 워드피스 (WordPiece)[[wordpiece]]
+
+워드피스는 [BERT](model_doc/bert), [DistilBERT](model_doc/distilbert), [Electra](model_doc/electra)에 사용된 서브워드 토큰화 알고리즘입니다.
+이 알고리즘은 [Japanese and Korean Voice Search (Schuster et al., 2012)](https://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/37842.pdf)에서 소개되었고, BPE와 굉장히 유사합니다.
+워드피스는 훈련 데이터에 등장하는 모든 문자로 기본 어휘를 초기화한 후, 주어진 병합 규칙에 따라 점진적으로 학습합니다.
+BPE와는 대조적으로 워드피스는 가장 빈도수가 높은 기호 쌍을 선택하지 않고, 어휘에 추가되었을 때 훈련 데이터의 우도가 최대화되는 쌍을 선택합니다.
+
+정확히 무슨 의미일까요?
+이전 예시를 참조하면, 훈련 데이터의 우도 값을 최대화하는 것은 모든 기호 쌍 중에서 첫 번째 기호와 두 번째 기호의 확률로 나눈 확률이 가장 큰 기호 쌍을 찾는 것과 동일합니다.
+예를 들어 `"ug"`의 확률이 `"u"`와 `"g"` 각각으로 쪼개졌을 때 보다 높아야 `"u"` 뒤에 오는 `"g"`는 병합될 것입니다.
+직관적으로 워드피스는 두 기호를 병합하여 _잃는_ 것을 평가하여 그만한 _가치_가 있는지 확인한다는 점에서 BPE와 약간 다릅니다.
+
+
+
+### 유니그램 (Unigram)[[unigram]]
+
+유니그램은 [Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates (Kudo, 2018)](https://arxiv.org/pdf/1804.10959.pdf)에서 제안된 서브워드 토큰화 알고리즘입니다.
+BPE나 워드피스와 달리 유니그램은 기본 어휘를 많은 수의 기호로 초기화한 후 각 기호를 점진적으로 줄여 더 작은 어휘를 얻습니다.
+예를 들어 기본 어휘는 모든 사전 토큰화된 단어와 가장 일반적인 하위 문자열에 해당할 수 있습니다.
+유니그램은 transformers 모델에서 직접적으로 사용되지는 않지만, [SentencePiece](#sentencepiece)와 함께 사용됩니다.
+
+각 훈련 단계에서 유니그램 알고리즘은 현재 어휘와 유니그램 언어 모델이 주어졌을 때 훈련 데이터에 대한 손실(흔히 로그 우도로 정의됨)을 정의합니다.
+그런 다음 어휘의 각 기호에 대해 알고리즘은 해당 기호를 어휘에서 제거할 경우 전체 손실이 얼마나 증가할지 계산합니다.
+이후에 유니그램은 손실 증가율이 가장 낮은 기호의 p(보통 10% 또는 20%) 퍼센트를 제거합니다. (제거되는 기호는 훈련 데이터에 대한 전체 손실에 가장 작은 영향을 미칩니다.)
+어휘가 원하는 크기에 도달할 때까지 이 과정을 반복합니다.
+유니그램 알고리즘은 항상 기본 문자를 포함해 어떤 단어라도 토큰화할 수 있습니다.
+유니그램이 병합 규칙에 기반하지 않기 떄문에 (BPE나 워드피스와는 대조적으로), 해당 알고리즘은 훈련 이후에 새로운 텍스트를 토큰화하는데 여러 가지 방법이 있습니다.
+
+예를 들어, 훈련된 유니그램 토큰화가 다음과 같은 어휘를 가진다면:
+
+```
+["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"],
+```
+
+`"hugs"`는 두 가지로 토큰화할 수 있습니다. `["hug", "s"]`와 `["h", "ug", "s"]` 또는 `["h", "u", "g", "s"]`.
+
+그렇다면 어떤 토큰화 방법을 선택해야 할까요?
+유니그램은 어휘를 저장하는 것 외에도 훈련 말뭉치에 각 토큰의 확률을 저장하여 훈련 후 가능한 각 토큰화의 확률을 계산할 수 있도록 합니다.
+이 알고리즘은 단순히 실제로 가장 가능성이 높은 토큰화를 선택하지만, 확률에 따라 가능한 토큰화를 샘플링할 수 있는 가능성도 제공합니다.
+이러한 확률은 토크나이저가 학습한 손실에 의해 정의됩니다.
+
+단어로 구성된 훈련 데이터를 \\(x_{1}, \dots, x_{N}\\)라 하고, 단어 \\(x_{i}\\)에 대한 가능한 모든 토큰화 결과를 \\(S(x_{i})\\)라 한다면, 전체 손실은 다음과 같이 정의됩니다:
+
+$$\mathcal{L} = -\sum_{i=1}^{N} \log \left ( \sum_{x \in S(x_{i})} p(x) \right )$$
+
+
+
+
+
+### 센텐스피스 (SentencePiece)[[sentencepiece]]
+
+지금까지 다룬 토큰화 알고리즘은 동일한 문제를 가집니다: 입력 텍스트는 공백을 사용하여 단어를 구분한다고 가정합니다.
+하지만, 모든 언어에서 단어를 구분하기 위해 공백을 사용하지 않습니다.
+한가지 가능한 해결방안은 특정 언어에 특화된 사전 토크나이저를 사용하는 것입니다. 예를 들어 [XLM](model_doc/xlm)은 특정 중국어, 일본어, 태국어 사전 토크나이저를 사용합니다.
+이 문제를 일반적인 방법으로 해결하기 위해, [SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing (Kudo et al., 2018)](https://arxiv.org/pdf/1808.06226.pdf)는 입력을 스트림으로 처리해 공백를 하나의 문자로 사용합니다.
+이후에 BPE 또는 유니그램 알고리즘을 사용해 적절한 어휘를 구성합니다.
+
+[`XLNetTokenizer`]는 센텐스피스를 사용하기 때문에, 위에서 다룬 예시에서 어휘에 `"▁"`가 포함되어있습니다.
+모든 토큰을 합친 후 `"▁"`을 공백으로 대체하면 되기 때문에 센텐스피스로 토큰화된 결과는 디코딩하기 수월합니다.
+
+transformers에서 제공하는 센텐스피스 토크나이저를 사용하는 모든 모델은 유니그램과 함께 사용됩니다.
+[ALBERT](model_doc/albert), [XLNet](model_doc/xlnet), [Marian](model_doc/marian), [T5](model_doc/t5) 모델이 센텐스피스 토크나이저를 사용합니다.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/torchscript.md b/docs/transformers/docs/source/ko/torchscript.md
new file mode 100644
index 0000000000000000000000000000000000000000..28e198c5ec9306cf7f91fe2cf3a1b60485b47a26
--- /dev/null
+++ b/docs/transformers/docs/source/ko/torchscript.md
@@ -0,0 +1,189 @@
+
+
+# TorchScript로 내보내기[[export-to-torchscript]]
+
+
+
+TorchScript를 활용한 실험은 아직 초기 단계로, 가변적인 입력 크기 모델들을 통해 그 기능성을 계속 탐구하고 있습니다.
+이 기능은 저희가 관심을 두고 있는 분야 중 하나이며,
+앞으로 출시될 버전에서 더 많은 코드 예제, 더 유연한 구현, 그리고 Python 기반 코드와 컴파일된 TorchScript를 비교하는 벤치마크를 등을 통해 분석을 심화할 예정입니다.
+
+
+
+[TorchScript 문서](https://pytorch.org/docs/stable/jit.html)에서는 이렇게 말합니다.
+
+> TorchScript는 PyTorch 코드에서 직렬화 및 최적화 가능한 모델을 생성하는 방법입니다.
+
+[JIT과 TRACE](https://pytorch.org/docs/stable/jit.html)는 개발자가 모델을 내보내서 효율 지향적인 C++ 프로그램과 같은 다른 프로그램에서 재사용할 수 있도록 하는 PyTorch 모듈입니다.
+
+PyTorch 기반 Python 프로그램과 다른 환경에서 모델을 재사용할 수 있도록, 🤗 Transformers 모델을 TorchScript로 내보낼 수 있는 인터페이스를 제공합니다.
+이 문서에서는 TorchScript를 사용하여 모델을 내보내고 사용하는 방법을 설명합니다.
+
+모델을 내보내려면 두 가지가 필요합니다:
+
+- `torchscript` 플래그로 모델 인스턴스화
+- 더미 입력을 사용한 순전파(forward pass)
+
+이 필수 조건들은 아래에 자세히 설명된 것처럼 개발자들이 주의해야 할 여러 사항들을 의미합니다.
+
+## TorchScript 플래그와 묶인 가중치(tied weights)[[torchscript-flag-and-tied-weights]]
+
+`torchscript` 플래그가 필요한 이유는 대부분의 🤗 Transformers 언어 모델에서 `Embedding` 레이어와 `Decoding` 레이어 간의 묶인 가중치(tied weights)가 존재하기 때문입니다.
+TorchScript는 묶인 가중치를 가진 모델을 내보낼 수 없으므로, 미리 가중치를 풀고 복제해야 합니다.
+
+`torchscript` 플래그로 인스턴스화된 모델은 `Embedding` 레이어와 `Decoding` 레이어가 분리되어 있으므로 이후에 훈련해서는 안 됩니다.
+훈련을 하게 되면 두 레이어 간 동기화가 해제되어 예상치 못한 결과가 발생할 수 있습니다.
+
+언어 모델 헤드를 갖지 않은 모델은 가중치가 묶여 있지 않아서 이 문제가 발생하지 않습니다.
+이러한 모델들은 `torchscript` 플래그 없이 안전하게 내보낼 수 있습니다.
+
+## 더미 입력과 표준 길이[[dummy-inputs-and-standard-lengths]]
+
+더미 입력(dummy inputs)은 모델의 순전파(forward pass)에 사용됩니다.
+입력 값이 레이어를 통해 전파되는 동안, PyTorch는 각 텐서에서 실행된 다른 연산을 추적합니다.
+이러한 기록된 연산은 모델의 *추적(trace)*을 생성하는 데 사용됩니다.
+
+추적은 입력의 차원을 기준으로 생성됩니다.
+따라서 더미 입력의 차원에 제한되어, 다른 시퀀스 길이나 배치 크기에서는 작동하지 않습니다.
+다른 크기로 시도할 경우 다음과 같은 오류가 발생합니다:
+
+```
+`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
+```
+추론 중 모델에 공급될 가장 큰 입력만큼 큰 더미 입력 크기로 모델을 추적하는 것이 좋습니다.
+패딩은 누락된 값을 채우는 데 도움이 될 수 있습니다.
+그러나 모델이 더 큰 입력 크기로 추적되기 때문에, 행렬의 차원이 커지고 계산량이 많아집니다.
+
+다양한 시퀀스 길이 모델을 내보낼 때는 각 입력에 대해 수행되는 총 연산 횟수에 주의하고 성능을 주의 깊게 확인하세요.
+
+## Python에서 TorchScript 사용하기[[using-torchscript-in-python]]
+
+이 섹션에서는 모델을 저장하고 가져오는 방법, 추적을 사용하여 추론하는 방법을 보여줍니다.
+
+### 모델 저장하기[[saving-a-model]]
+
+`BertModel`을 TorchScript로 내보내려면 `BertConfig` 클래스에서 `BertModel`을 인스턴스화한 다음, `traced_bert.pt`라는 파일명으로 디스크에 저장하면 됩니다.
+
+```python
+from transformers import BertModel, BertTokenizer, BertConfig
+import torch
+
+enc = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+
+# 입력 텍스트 토큰화하기
+text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
+tokenized_text = enc.tokenize(text)
+
+# 입력 토큰 중 하나를 마스킹하기
+masked_index = 8
+tokenized_text[masked_index] = "[MASK]"
+indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
+segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
+
+# 더미 입력 만들기
+tokens_tensor = torch.tensor([indexed_tokens])
+segments_tensors = torch.tensor([segments_ids])
+dummy_input = [tokens_tensor, segments_tensors]
+
+# torchscript 플래그로 모델 초기화하기
+# 이 모델은 LM 헤드가 없으므로 필요하지 않지만, 플래그를 True로 설정합니다.
+config = BertConfig(
+ vocab_size_or_config_json_file=32000,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ torchscript=True,
+)
+
+# 모델을 인스턴트화하기
+model = BertModel(config)
+
+# 모델을 평가 모드로 두어야 합니다.
+model.eval()
+
+# 만약 *from_pretrained*를 사용하여 모델을 인스턴스화하는 경우, TorchScript 플래그를 쉽게 설정할 수 있습니다
+model = BertModel.from_pretrained("google-bert/bert-base-uncased", torchscript=True)
+
+# 추적 생성하기
+traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
+torch.jit.save(traced_model, "traced_bert.pt")
+```
+
+### 모델 가져오기[[loading-a-model]]
+
+이제 이전에 저장한 `BertModel`, 즉 `traced_bert.pt`를 디스크에서 가져오고, 이전에 초기화한 `dummy_input`에서 사용할 수 있습니다.
+
+```python
+loaded_model = torch.jit.load("traced_bert.pt")
+loaded_model.eval()
+
+all_encoder_layers, pooled_output = loaded_model(*dummy_input)
+```
+
+### 추적된 모델을 사용하여 추론하기[[using-a-traced-model-for-inference]]
+
+`__call__` 이중 언더스코어(dunder) 메소드를 사용하여 추론에 추적된 모델을 사용하세요:
+
+```python
+traced_model(tokens_tensor, segments_tensors)
+```
+
+## Neuron SDK로 Hugging Face TorchScript 모델을 AWS에 배포하기[[deploy-hugging-face-torchscript-models-to-aws-with-the-neuron-sdk]]
+
+AWS가 클라우드에서 저비용, 고성능 머신 러닝 추론을 위한 [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/) 인스턴스 제품군을 출시했습니다.
+Inf1 인스턴스는 딥러닝 추론 워크로드에 특화된 맞춤 하드웨어 가속기인 AWS Inferentia 칩으로 구동됩니다.
+[AWS Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#)은 Inferentia를 위한 SDK로, Inf1에 배포하기 위한 transformers 모델 추적 및 최적화를 지원합니다.
+Neuron SDK는 다음과 같은 기능을 제공합니다:
+
+1. 코드 한 줄만 변경하면 클라우드 추론를 위해 TorchScript 모델을 추적하고 최적화할 수 있는 쉬운 API
+2. 즉시 사용 가능한 성능 최적화로 [비용 효율 향상](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/>)
+3. [PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html) 또는 [TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html)로 구축된 Hugging Face transformers 모델 지원
+
+### 시사점[[implications]]
+
+[BERT (Bidirectional Encoder Representations from Transformers)](https://huggingface.co/docs/transformers/main/model_doc/bert) 아키텍처 또는 그 변형인 [distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert) 및 [roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta)를 기반으로 한 Transformers 모델은 추출 기반 질의응답, 시퀀스 분류 및 토큰 분류와 같은 비생성 작업 시 Inf1에서 최상의 성능을 보입니다.
+그러나 텍스트 생성 작업도 [AWS Neuron MarianMT 튜토리얼](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html)을 따라 Inf1에서 실행되도록 조정할 수 있습니다.
+
+Inferentia에서 바로 변환할 수 있는 모델에 대한 자세한 정보는 Neuron 문서의 [Model Architecture Fit](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia) 섹션에서 확인할 수 있습니다.
+
+### 종속성[[dependencies]]
+
+AWS Neuron을 사용하여 모델을 변환하려면 [Neuron SDK 환경](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide)이 필요합니다.
+ 이는 [AWS Deep Learning AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html)에 미리 구성되어 있습니다.
+
+### AWS Neuron으로 모델 변환하기[[converting-a-model-for-aws-neuron]]
+
+`BertModel`을 추적하려면, [Python에서 TorchScript 사용하기](torchscript#using-torchscript-in-python)에서와 동일한 코드를 사용해서 AWS NEURON용 모델을 변환합니다.
+`torch.neuron` 프레임워크 익스텐션을 가져와 Python API를 통해 Neuron SDK의 구성 요소에 접근합니다:
+
+```python
+from transformers import BertModel, BertTokenizer, BertConfig
+import torch
+import torch.neuron
+```
+
+다음 줄만 수정하면 됩니다:
+
+```diff
+- torch.jit.trace(model, [tokens_tensor, segments_tensors])
++ torch.neuron.trace(model, [token_tensor, segments_tensors])
+```
+
+이로써 Neuron SDK가 모델을 추적하고 Inf1 인스턴스에 최적화할 수 있게 됩니다.
+
+AWS Neuron SDK의 기능, 도구, 예제 튜토리얼 및 최신 업데이트에 대해 자세히 알아보려면 [AWS NeuronSDK 문서](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html)를 참조하세요.
diff --git a/docs/transformers/docs/source/ko/trainer.md b/docs/transformers/docs/source/ko/trainer.md
new file mode 100644
index 0000000000000000000000000000000000000000..0e6f1d7ed59c04ecf03d6280f4cb2d6f28a19528
--- /dev/null
+++ b/docs/transformers/docs/source/ko/trainer.md
@@ -0,0 +1,597 @@
+
+
+# Trainer [[trainer]]
+
+[`Trainer`]는 Transformers 라이브러리에 구현된 PyTorch 모델을 반복하여 훈련 및 평가 과정입니다. 훈련에 필요한 요소(모델, 토크나이저, 데이터셋, 평가 함수, 훈련 하이퍼파라미터 등)만 제공하면 [`Trainer`]가 필요한 나머지 작업을 처리합니다. 이를 통해 직접 훈련 루프를 작성하지 않고도 빠르게 훈련을 시작할 수 있습니다. 또한 [`Trainer`]는 강력한 맞춤 설정과 다양한 훈련 옵션을 제공하여 사용자 맞춤 훈련이 가능합니다.
+
+
+
+Transformers는 [`Trainer`] 클래스 외에도 번역이나 요약과 같은 시퀀스-투-시퀀스 작업을 위한 [`Seq2SeqTrainer`] 클래스도 제공합니다. 또한 [TRL](https://hf.co/docs/trl) 라이브러리에는 [`Trainer`] 클래스를 감싸고 Llama-2 및 Mistral과 같은 언어 모델을 자동 회귀 기법으로 훈련하는 데 최적화된 [`~trl.SFTTrainer`] 클래스 입니다. [`~trl.SFTTrainer`]는 시퀀스 패킹, LoRA, 양자화 및 DeepSpeed와 같은 기능을 지원하여 크기 상관없이 모델 효율적으로 확장할 수 있습니다.
+
+
+
+이들 다른 [`Trainer`] 유형 클래스에 대해 더 알고 싶다면 [API 참조](./main_classes/trainer)를 확인하여 언제 어떤 클래스가 적합할지 얼마든지 확인하세요. 일반적으로 [`Trainer`]는 가장 다재다능한 옵션으로, 다양한 작업에 적합합니다. [`Seq2SeqTrainer`]는 시퀀스-투-시퀀스 작업을 위해 설계되었고, [`~trl.SFTTrainer`]는 언어 모델 훈련을 위해 설계되었습니다.
+
+
+
+시작하기 전에, 분산 환경에서 PyTorch 훈련과 실행을 할 수 있게 [Accelerate](https://hf.co/docs/accelerate) 라이브러리가 설치되었는지 확인하세요.
+
+```bash
+pip install accelerate
+
+# 업그레이드
+pip install accelerate --upgrade
+```
+
+이 가이드는 [`Trainer`] 클래스에 대한 개요를 제공합니다.
+
+## 기본 사용법 [[basic-usage]]
+
+[`Trainer`]는 기본적인 훈련 루프에 필요한 모든 코드를 포함하고 있습니다.
+
+1. 손실을 계산하는 훈련 단계를 수행합니다.
+2. [`~accelerate.Accelerator.backward`] 메소드로 그레이디언트를 계산합니다.
+3. 그레이디언트를 기반으로 가중치를 업데이트합니다.
+4. 정해진 에폭 수에 도달할 때까지 이 과정을 반복합니다.
+
+[`Trainer`] 클래스는 PyTorch와 훈련 과정에 익숙하지 않거나 막 시작한 경우에도 훈련이 가능하도록 필요한 모든 코드를 추상화하였습니다. 또한 매번 훈련 루프를 손수 작성하지 않아도 되며, 훈련에 필요한 모델과 데이터셋 같은 필수 구성 요소만 제공하면, [Trainer] 클래스가 나머지를 처리합니다.
+
+훈련 옵션이나 하이퍼파라미터를 지정하려면, [`TrainingArguments`] 클래스에서 확인 할 수 있습니다. 예를 들어, 모델을 저장할 디렉토리를 `output_dir`에 정의하고, 훈련 후에 Hub로 모델을 푸시하려면 `push_to_hub=True`로 설정합니다.
+
+```py
+from transformers import TrainingArguments
+
+training_args = TrainingArguments(
+ output_dir="your-model",
+ learning_rate=2e-5,
+ per_device_train_batch_size=16,
+ per_device_eval_batch_size=16,
+ num_train_epochs=2,
+ weight_decay=0.01,
+ eval_strategy="epoch",
+ save_strategy="epoch",
+ load_best_model_at_end=True,
+ push_to_hub=True,
+)
+```
+
+`training_args`를 [`Trainer`]에 모델, 데이터셋, 데이터셋 전처리 도구(데이터 유형에 따라 토크나이저, 특징 추출기 또는 이미지 프로세서일 수 있음), 데이터 수집기 및 훈련 중 확인할 지표를 계산할 함수를 함께 전달하세요.
+
+마지막으로, [`~Trainer.train`]를 호출하여 훈련을 시작하세요!
+
+```py
+from transformers import Trainer
+
+trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=dataset["train"],
+ eval_dataset=dataset["test"],
+ tokenizer=tokenizer,
+ data_collator=data_collator,
+ compute_metrics=compute_metrics,
+)
+
+trainer.train()
+```
+
+### 체크포인트 [[checkpoints]]
+
+[`Trainer`] 클래스는 [`TrainingArguments`]의 `output_dir` 매개변수에 지정된 디렉토리에 모델 체크포인트를 저장합니다. 체크포인트는 `checkpoint-000` 하위 폴더에 저장되며, 여기서 끝의 숫자는 훈련 단계에 해당합니다. 체크포인트를 저장하면 나중에 훈련을 재개할 때 유용합니다.
+
+```py
+# 최신 체크포인트에서 재개
+trainer.train(resume_from_checkpoint=True)
+
+# 출력 디렉토리에 저장된 특정 체크포인트에서 재개
+trainer.train(resume_from_checkpoint="your-model/checkpoint-1000")
+```
+
+체크포인트를 Hub에 푸시하려면 [`TrainingArguments`]에서 `push_to_hub=True`로 설정하여 커밋하고 푸시할 수 있습니다. 체크포인트 저장 방법을 결정하는 다른 옵션은 [`hub_strategy`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.hub_strategy) 매개변수에서 설정합니다:
+
+* `hub_strategy="checkpoint"`는 최신 체크포인트를 "last-checkpoint"라는 하위 폴더에 푸시하여 훈련을 재개할 수 있습니다.
+* `hub_strategy="all_checkpoints"`는 모든 체크포인트를 `output_dir`에 정의된 디렉토리에 푸시합니다(모델 리포지토리에서 폴더당 하나의 체크포인트를 볼 수 있습니다).
+
+체크포인트에서 훈련을 재개할 때, [`Trainer`]는 체크포인트가 저장될 때와 동일한 Python, NumPy 및 PyTorch RNG 상태를 유지하려고 합니다. 하지만 PyTorch는 기본 설정으로 '일관된 결과를 보장하지 않음'으로 많이 되어있기 때문에, RNG 상태가 동일할 것이라고 보장할 수 없습니다. 따라서, 일관된 결과가 보장되도록 활성화 하려면, [랜덤성 제어](https://pytorch.org/docs/stable/notes/randomness#controlling-sources-of-randomness) 가이드를 참고하여 훈련을 완전히 일관된 결과를 보장 받도록 만들기 위해 활성화할 수 있는 항목을 확인하세요. 다만, 특정 설정을 결정적으로 만들면 훈련이 느려질 수 있습니다.
+
+## Trainer 맞춤 설정 [[customize-the-trainer]]
+
+[`Trainer`] 클래스는 접근성과 용이성을 염두에 두고 설계되었지만, 더 다양한 기능을 원하는 사용자들을 위해 다양한 맞춤 설정 옵션을 제공합니다. [`Trainer`]의 많은 메소드는 서브클래스화 및 오버라이드하여 원하는 기능을 제공할 수 있으며, 이를 통해 전체 훈련 루프를 다시 작성할 필요 없이 원하는 기능을 추가할 수 있습니다. 이러한 메소드에는 다음이 포함됩니다:
+
+* [`~Trainer.get_train_dataloader`]는 훈련 데이터로더를 생성합니다.
+* [`~Trainer.get_eval_dataloader`]는 평가 데이터로더를 생성합니다.
+* [`~Trainer.get_test_dataloader`]는 테스트 데이터로더를 생성합니다.
+* [`~Trainer.log`]는 훈련을 모니터링하는 다양한 객체에 대한 정보를 로그로 남깁니다.
+* [`~Trainer.create_optimizer_and_scheduler`]는 `__init__`에서 전달되지 않은 경우 옵티마이저와 학습률 스케줄러를 생성합니다. 이들은 각각 [`~Trainer.create_optimizer`] 및 [`~Trainer.create_scheduler`]로 별도로 맞춤 설정 할 수 있습니다.
+* [`~Trainer.compute_loss`]는 훈련 입력 배치에 대한 손실을 계산합니다.
+* [`~Trainer.training_step`]는 훈련 단계를 수행합니다.
+* [`~Trainer.prediction_step`]는 예측 및 테스트 단계를 수행합니다.
+* [`~Trainer.evaluate`]는 모델을 평가하고 평가 지표을 반환합니다.
+* [`~Trainer.predict`]는 테스트 세트에 대한 예측(레이블이 있는 경우 지표 포함)을 수행합니다.
+
+예를 들어, [`~Trainer.compute_loss`] 메소드를 맞춤 설정하여 가중 손실을 사용하려는 경우:
+
+```py
+from torch import nn
+from transformers import Trainer
+
+class CustomTrainer(Trainer):
+ def compute_loss(self,
+
+ model, inputs, return_outputs=False):
+ labels = inputs.pop("labels")
+ # 순방향 전파
+ outputs = model(**inputs)
+ logits = outputs.get("logits")
+ # 서로 다른 가중치로 3개의 레이블에 대한 사용자 정의 손실을 계산
+ loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0], device=model.device))
+ loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
+ return (loss, outputs) if return_outputs else loss
+```
+
+### 콜백 [[callbacks]]
+
+[`Trainer`]를 맞춤 설정하는 또 다른 방법은 [콜백](callbacks)을 사용하는 것입니다. 콜백은 훈련 루프에서 *변화를 주지 않습니다*. 훈련 루프의 상태를 검사한 후 상태에 따라 일부 작업(조기 종료, 결과 로그 등)을 실행합니다. 즉, 콜백은 사용자 정의 손실 함수와 같은 것을 구현하는 데 사용할 수 없으며, 이를 위해서는 [`~Trainer.compute_loss`] 메소드를 서브클래스화하고 오버라이드해야 합니다.
+
+예를 들어, 훈련 루프에 10단계 후 조기 종료 콜백을 추가하려면 다음과 같이 합니다.
+
+```py
+from transformers import TrainerCallback
+
+class EarlyStoppingCallback(TrainerCallback):
+ def __init__(self, num_steps=10):
+ self.num_steps = num_steps
+
+ def on_step_end(self, args, state, control, **kwargs):
+ if state.global_step >= self.num_steps:
+ return {"should_training_stop": True}
+ else:
+ return {}
+```
+
+그런 다음, 이를 [`Trainer`]의 `callback` 매개변수에 전달합니다.
+
+```py
+from transformers import Trainer
+
+trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=dataset["train"],
+ eval_dataset=dataset["test"],
+ tokenizer=tokenizer,
+ data_collator=data_collator,
+ compute_metrics=compute_metrics,
+ callbacks=[EarlyStoppingCallback()],
+)
+```
+
+## 로깅 [[logging]]
+
+
+
+로깅 API에 대한 자세한 내용은 [로깅](./main_classes/logging) API 레퍼런스를 확인하세요.
+
+
+
+[`Trainer`]는 기본적으로 `logging.INFO`로 설정되어 있어 오류, 경고 및 기타 기본 정보를 보고합니다. 분산 환경에서는 [`Trainer`] 복제본이 `logging.WARNING`으로 설정되어 오류와 경고만 보고합니다. [`TrainingArguments`]의 [`log_level`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.log_level) 및 [`log_level_replica`](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments.log_level_replica) 매개변수로 로그 레벨을 변경할 수 있습니다.
+
+각 노드의 로그 레벨 설정을 구성하려면 [`log_on_each_node`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.TrainingArguments.log_on_each_node) 매개변수를 사용하여 각 노드에서 로그 레벨을 사용할지 아니면 주 노드에서만 사용할지 결정하세요.
+
+
+
+[`Trainer`]는 [`Trainer.__init__`] 메소드에서 각 노드에 대해 로그 레벨을 별도로 설정하므로, 다른 Transformers 기능을 사용할 경우 [`Trainer`] 객체를 생성하기 전에 이를 미리 설정하는 것이 좋습니다.
+
+
+
+예를 들어, 메인 코드와 모듈을 각 노드에 따라 동일한 로그 레벨을 사용하도록 설정하려면 다음과 같이 합니다.
+
+```py
+logger = logging.getLogger(__name__)
+
+logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+)
+
+log_level = training_args.get_process_log_level()
+logger.setLevel(log_level)
+datasets.utils.logging.set_verbosity(log_level)
+transformers.utils.logging.set_verbosity(log_level)
+
+trainer = Trainer(...)
+```
+
+각 노드에서 기록될 내용을 구성하기 위해 `log_level`과 `log_level_replica`를 다양한 조합으로 사용해보세요.
+
+
+
+
+```bash
+my_app.py ... --log_level warning --log_level_replica error
+```
+
+
+
+
+멀티 노드 환경에서는 `log_on_each_node 0` 매개변수를 추가합니다.
+
+```bash
+my_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0
+
+# 오류만 보고하도록 설정
+my_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
+```
+
+
+
+
+## NEFTune [[neftune]]
+
+[NEFTune](https://hf.co/papers/2310.05914)은 훈련 중 임베딩 벡터에 노이즈를 추가하여 성능을 향상시킬 수 있는 기술입니다. [`Trainer`]에서 이를 활성화하려면 [`TrainingArguments`]의 `neftune_noise_alpha` 매개변수를 설정하여 노이즈의 양을 조절합니다.
+
+```py
+from transformers import TrainingArguments, Trainer
+
+training_args = TrainingArguments(..., neftune_noise_alpha=0.1)
+trainer = Trainer(..., args=training_args)
+```
+
+NEFTune은 예상치 못한 동작을 피할 목적으로 처음 임베딩 레이어로 복원하기 위해 훈련 후 비활성화 됩니다.
+
+## GaLore [[galore]]
+
+Gradient Low-Rank Projection (GaLore)은 전체 매개변수를 학습하면서도 LoRA와 같은 일반적인 저계수 적응 방법보다 더 메모리 효율적인 저계수 학습 전략입니다.
+
+먼저 GaLore 공식 리포지토리를 설치합니다:
+
+```bash
+pip install galore-torch
+```
+
+그런 다음 `optim`에 `["galore_adamw", "galore_adafactor", "galore_adamw_8bit"]` 중 하나와 함께 `optim_target_modules`를 추가합니다. 이는 적용하려는 대상 모듈 이름에 해당하는 문자열, 정규 표현식 또는 전체 경로의 목록일 수 있습니다. 아래는 end-to-end 예제 스크립트입니다(필요한 경우 `pip install trl datasets`를 실행):
+
+```python
+import torch
+import datasets
+import trl
+
+from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
+
+train_dataset = datasets.load_dataset('imdb', split='train')
+
+args = TrainingArguments(
+ output_dir="./test-galore",
+ max_steps=100,
+ per_device_train_batch_size=2,
+ optim="galore_adamw",
+ optim_target_modules=["attn", "mlp"]
+)
+
+model_id = "google/gemma-2b"
+
+config = AutoConfig.from_pretrained(model_id)
+
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = AutoModelForCausalLM.from_config(config).to(0)
+
+trainer = trl.SFTTrainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ dataset_text_field='text',
+ max_seq_length=512,
+)
+
+trainer.train()
+```
+
+GaLore가 지원하는 추가 매개변수를 전달하려면 `optim_args`를 설정합니다. 예를 들어:
+
+```python
+import torch
+import datasets
+import trl
+
+from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
+
+train_dataset = datasets.load_dataset('imdb', split='train')
+
+args = TrainingArguments(
+ output_dir="./test-galore",
+ max_steps=100,
+ per_device_train_batch_size=2,
+ optim="galore_adamw",
+ optim_target_modules=["attn", "mlp"],
+ optim_args="rank=64, update_proj_gap=100, scale=0.10",
+)
+
+model_id = "google/gemma-2b"
+
+config = AutoConfig.from_pretrained(model_id)
+
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = AutoModelForCausalLM.from_config(config).to(0)
+
+trainer = trl.SFTTrainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ dataset_text_field='text',
+ max_seq_length=512,
+)
+
+trainer.train()
+```
+
+해당 방법에 대한 자세한 내용은 [원본 리포지토리](https://github.com/jiaweizzhao/GaLore) 또는 [논문](https://arxiv.org/abs/2403.03507)을 참고하세요.
+
+현재 GaLore 레이어로 간주되는 Linear 레이어만 훈련 할수 있으며, 저계수 분해를 사용하여 훈련되고 나머지 레이어는 기존 방식으로 최적화됩니다.
+
+훈련 시작 전에 시간이 약간 걸릴 수 있습니다(NVIDIA A100에서 2B 모델의 경우 약 3분), 하지만 이후 훈련은 원활하게 진행됩니다.
+
+다음과 같이 옵티마이저 이름에 `layerwise`를 추가하여 레이어별 최적화를 수행할 수도 있습니다:
+
+```python
+import torch
+import datasets
+import trl
+
+from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
+
+train_dataset = datasets.load_dataset('imdb', split='train')
+
+args = TrainingArguments(
+ output_dir="./test-galore",
+ max_steps=100,
+ per_device_train_batch_size=2,
+ optim="galore_adamw_layerwise",
+ optim_target_modules=["attn", "mlp"]
+)
+
+model_id = "google/gemma-2b"
+
+config = AutoConfig.from_pretrained(model_id)
+
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = AutoModelForCausalLM.from_config(config).to(0)
+
+trainer = trl.SFTTrainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ dataset_text_field='text',
+ max_seq_length=512,
+)
+
+trainer.train()
+```
+
+레이어별 최적화는 다소 실험적이며 DDP(분산 데이터 병렬)를 지원하지 않으므로, 단일 GPU에서만 훈련 스크립트를 실행할 수 있습니다. 자세한 내용은 [이 문서를](https://github.com/jiaweizzhao/GaLore?tab=readme-ov-file#train-7b-model-with-a-single-gpu-with-24gb-memory)을 참조하세요. gradient clipping, DeepSpeed 등 다른 기능은 기본적으로 지원되지 않을 수 있습니다. 이러한 문제가 발생하면 [GitHub에 이슈를 올려주세요](https://github.com/huggingface/transformers/issues).
+
+## LOMO 옵티마이저 [[lomo-optimizer]]
+
+LOMO 옵티마이저는 [제한된 자원으로 대형 언어 모델의 전체 매개변수 미세 조정](https://hf.co/papers/2306.09782)과 [적응형 학습률을 통한 저메모리 최적화(AdaLomo)](https://hf.co/papers/2310.10195)에서 도입되었습니다.
+이들은 모두 효율적인 전체 매개변수 미세 조정 방법으로 구성되어 있습니다. 이러한 옵티마이저들은 메모리 사용량을 줄이기 위해 그레이디언트 계산과 매개변수 업데이트를 하나의 단계로 융합합니다. LOMO에서 지원되는 옵티마이저는 `"lomo"`와 `"adalomo"`입니다. 먼저 pypi에서 `pip install lomo-optim`를 통해 `lomo`를 설치하거나, GitHub 소스에서 `pip install git+https://github.com/OpenLMLab/LOMO.git`로 설치하세요.
+
+
+
+저자에 따르면, `grad_norm` 없이 `AdaLomo`를 사용하는 것이 더 나은 성능과 높은 처리량을 제공한다고 합니다.
+
+
+
+다음은 IMDB 데이터셋에서 [google/gemma-2b](https://huggingface.co/google/gemma-2b)를 최대 정밀도로 미세 조정하는 간단한 스크립트입니다:
+
+```python
+import torch
+import datasets
+from transformers import TrainingArguments, AutoTokenizer, AutoModelForCausalLM
+import trl
+
+train_dataset = datasets.load_dataset('imdb', split='train')
+
+args = TrainingArguments(
+ output_dir="./test-lomo",
+ max_steps=1000,
+ per_device_train_batch_size=4,
+ optim="adalomo",
+ gradient_checkpointing=True,
+ logging_strategy="steps",
+ logging_steps=1,
+ learning_rate=2e-6,
+ save_strategy="no",
+ run_name="lomo-imdb",
+)
+
+model_id = "google/gemma-2b"
+
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+model = AutoModelForCausalLM.from_pretrained(model_id, low_cpu_mem_usage=True).to(0)
+
+trainer = trl.SFTTrainer(
+ model=model,
+ args=args,
+ train_dataset=train_dataset,
+ dataset_text_field='text',
+ max_seq_length=1024,
+)
+
+trainer.train()
+```
+
+## Accelerate와 Trainer [[accelerate-and-trainer]]
+
+[`Trainer`] 클래스는 [Accelerate](https://hf.co/docs/accelerate)로 구동되며, 이는 [FullyShardedDataParallel (FSDP)](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/) 및 [DeepSpeed](https://www.deepspeed.ai/)와 같은 통합을 지원하는 분산 환경에서 PyTorch 모델을 쉽게 훈련할 수 있는 라이브러리입니다.
+
+
+
+FSDP 샤딩 전략, CPU 오프로드 및 [`Trainer`]와 함께 사용할 수 있는 더 많은 기능을 알아보려면 [Fully Sharded Data Parallel](fsdp) 가이드를 확인하세요.
+
+
+
+[`Trainer`]와 Accelerate를 사용하려면 [`accelerate.config`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-config) 명령을 실행하여 훈련 환경을 설정하세요. 이 명령은 훈련 스크립트를 실행할 때 사용할 `config_file.yaml`을 생성합니다. 예를 들어, 다음 예시는 설정할 수 있는 일부 구성 예입니다.
+
+
+
+
+```yml
+compute_environment: LOCAL_MACHINE
+distributed_type: MULTI_GPU
+downcast_bf16: 'no'
+gpu_ids: all
+machine_rank: 0 # 노드에 따라 순위를 변경하세요
+main_process_ip: 192.168.20.1
+main_process_port: 9898
+main_training_function: main
+mixed_precision: fp16
+num_machines: 2
+num_processes: 8
+rdzv_backend: static
+same_network: true
+tpu_env: []
+tpu_use_cluster: false
+tpu_use_sudo: false
+use_cpu: false
+```
+
+
+
+
+```yml
+compute_environment: LOCAL_MACHINE
+distributed_type: FSDP
+downcast_bf16: 'no'
+fsdp_config:
+ fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
+ fsdp_backward_prefetch_policy: BACKWARD_PRE
+ fsdp_forward_prefetch: true
+ fsdp_offload_params: false
+ fsdp_sharding_strategy: 1
+ fsdp_state_dict_type: FULL_STATE_DICT
+ fsdp_sync_module_states: true
+ fsdp_transformer_layer_cls_to_wrap: BertLayer
+ fsdp_use_orig_params: true
+machine_rank: 0
+main_training_function: main
+mixed_precision: bf16
+num_machines: 1
+num_processes: 2
+rdzv_backend: static
+same_network: true
+tpu_env: []
+tpu_use_cluster: false
+tpu_use_sudo: false
+use_cpu: false
+```
+
+
+
+
+```yml
+compute_environment: LOCAL_MACHINE
+deepspeed_config:
+ deepspeed_config_file: /home/user/configs/ds_zero3_config.json
+ zero3_init_flag: true
+distributed_type: DEEPSPEED
+downcast_bf16: 'no'
+machine_rank: 0
+main_training_function: main
+num_machines: 1
+num_processes: 4
+rdzv_backend: static
+same_network: true
+tpu_env: []
+tpu_use_cluster: false
+tpu_use_sudo: false
+use_cpu: false
+```
+
+
+
+
+```yml
+compute_environment: LOCAL_MACHINE
+deepspeed_config:
+ gradient_accumulation_steps: 1
+ gradient_clipping: 0.7
+ offload_optimizer_device: cpu
+ offload_param_device: cpu
+ zero3_init_flag: true
+ zero_stage: 2
+distributed_type: DEEPSPEED
+downcast_bf16: 'no'
+machine_rank: 0
+main_training_function: main
+mixed_precision: bf16
+num_machines: 1
+num_processes: 4
+rdzv_backend: static
+same_network: true
+tpu_env: []
+tpu_use_cluster: false
+tpu_use_sudo: false
+use_cpu: false
+```
+
+
+
+
+
+[`accelerate_launch`](https://huggingface.co/docs/accelerate/package_reference/cli#accelerate-launch) 명령은 Accelerate와 [`Trainer`]를 사용하여 분산 시스템에서 훈련 스크립트를 실행하는 권장 방법이며, `config_file.yaml`에 지정된 매개변수를 사용합니다. 이 파일은 Accelerate 캐시 폴더에 저장되며 `accelerate_launch`를 실행할 때 자동으로 로드됩니다.
+
+예를 들어, FSDP 구성을 사용하여 [run_glue.py](https://github.com/huggingface/transformers/blob/f4db565b695582891e43a5e042e5d318e28f20b8/examples/pytorch/text-classification/run_glue.py#L4) 훈련 스크립트를 실행하려면 다음과 같이 합니다:
+
+```bash
+accelerate launch \
+ ./examples/pytorch/text-classification/run_glue.py \
+ --model_name_or_path google-bert/bert-base-cased \
+ --task_name $TASK_NAME \
+ --do_train \
+ --do_eval \
+ --max_seq_length 128 \
+ --per_device_train_batch_size 16 \
+ --learning_rate 5e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/$TASK_NAME/ \
+ --overwrite_output_dir
+```
+
+`config_file.yaml` 파일의 매개변수를 직접 지정할 수도 있습니다:
+
+```bash
+accelerate launch --num_processes=2 \
+ --use_fsdp \
+ --mixed_precision=bf16 \
+ --fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
+ --fsdp_transformer_layer_cls_to_wrap="BertLayer" \
+ --fsdp_sharding_strategy=1 \
+ --fsdp_state_dict_type=FULL_STATE_DICT \
+ ./examples/pytorch/text-classification/run_glue.py \
+ --model_name_or_path google-bert/bert-base-cased \
+ --task_name $TASK_NAME \
+ --do_train \
+ --do_eval \
+ --max_seq_length 128 \
+ --per_device_train_batch_size 16 \
+ --learning_rate 5e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/$TASK_NAME/ \
+ --overwrite_output_dir
+```
+
+`accelerate_launch`와 사용자 정의 구성에 대해 더 알아보려면 [Accelerate 스크립트 실행](https://huggingface.co/docs/accelerate/basic_tutorials/launch) 튜토리얼을 확인하세요.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/training.md b/docs/transformers/docs/source/ko/training.md
new file mode 100644
index 0000000000000000000000000000000000000000..432ba186c3df0c36e298fee6fb0c939c6f206a6e
--- /dev/null
+++ b/docs/transformers/docs/source/ko/training.md
@@ -0,0 +1,428 @@
+
+
+# 사전 학습된 모델 미세 튜닝하기[[finetune-a-pretrained-model]]
+
+[[open-in-colab]]
+
+사전 학습된 모델을 사용하면 상당한 이점이 있습니다. 계산 비용과 탄소발자국을 줄이고, 처음부터 모델을 학습시킬 필요 없이 최신 모델을 사용할 수 있습니다. 🤗 Transformers는 다양한 작업을 위해 사전 학습된 수천 개의 모델에 액세스할 수 있습니다. 사전 학습된 모델을 사용하는 경우, 자신의 작업과 관련된 데이터셋을 사용해 학습합니다. 이것은 미세 튜닝이라고 하는 매우 강력한 훈련 기법입니다. 이 튜토리얼에서는 당신이 선택한 딥러닝 프레임워크로 사전 학습된 모델을 미세 튜닝합니다:
+
+* 🤗 Transformers로 사전 학습된 모델 미세 튜닝하기 [`Trainer`].
+* Keras를 사용하여 TensorFlow에서 사전 학습된 모델을 미세 튜닝하기.
+* 기본 PyTorch에서 사전 학습된 모델을 미세 튜닝하기.
+
+
+
+## 데이터셋 준비[[prepare-a-dataset]]
+
+
+
+사전 학습된 모델을 미세 튜닝하기 위해서 데이터셋을 다운로드하고 훈련할 수 있도록 준비하세요. 이전 튜토리얼에서 훈련을 위해 데이터를 처리하는 방법을 보여드렸는데, 지금이 배울 걸 되짚을 기회입니다!
+
+먼저 [Yelp 리뷰](https://huggingface.co/datasets/yelp_review_full) 데이터 세트를 로드합니다:
+
+```py
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("yelp_review_full")
+>>> dataset["train"][100]
+{'label': 0,
+ 'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
+```
+
+텍스트를 처리하고 서로 다른 길이의 시퀀스 패딩 및 잘라내기 전략을 포함하려면 토크나이저가 필요합니다. 데이터셋을 한 번에 처리하려면 🤗 Dataset [`map`](https://huggingface.co/docs/datasets/process#map) 메서드를 사용하여 전체 데이터셋에 전처리 함수를 적용하세요:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
+
+
+>>> def tokenize_function(examples):
+... return tokenizer(examples["text"], padding="max_length", truncation=True)
+
+
+>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
+```
+
+필요한 경우 미세 튜닝을 위해 데이터셋의 작은 부분 집합을 만들어 미세 튜닝 작업 시간을 줄일 수 있습니다:
+
+```py
+>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
+>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
+```
+
+
+
+## Train
+
+여기서부터는 사용하려는 프레임워크에 해당하는 섹션을 따라야 합니다. 오른쪽 사이드바의 링크를 사용하여 원하는 프레임워크로 이동할 수 있으며, 특정 프레임워크의 모든 콘텐츠를 숨기려면 해당 프레임워크 블록의 오른쪽 상단에 있는 버튼을 사용하면 됩니다!
+
+
+
+
+
+## 파이토치 Trainer로 훈련하기[[train-with-pytorch-trainer]]
+
+🤗 Transformers는 🤗 Transformers 모델 훈련에 최적화된 [`Trainer`] 클래스를 제공하여 훈련 루프를 직접 작성하지 않고도 쉽게 훈련을 시작할 수 있습니다. [`Trainer`] API는 로깅(logging), 경사 누적(gradient accumulation), 혼합 정밀도(mixed precision) 등 다양한 훈련 옵션과 기능을 지원합니다.
+
+먼저 모델을 가져오고 예상되는 레이블 수를 지정합니다. Yelp 리뷰 [데이터셋 카드](https://huggingface.co/datasets/yelp_review_full#data-fields)에서 5개의 레이블이 있음을 알 수 있습니다:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=5)
+```
+
+
+
+사전 훈련된 가중치 중 일부가 사용되지 않고 일부 가중치가 무작위로 표시된다는 경고가 표시됩니다.
+걱정마세요. 이것은 올바른 동작입니다! 사전 학습된 BERT 모델의 헤드는 폐기되고 무작위로 초기화된 분류 헤드로 대체됩니다. 이제 사전 학습된 모델의 지식으로 시퀀스 분류 작업을 위한 새로운 모델 헤드를 미세 튜닝 합니다.
+
+
+
+### 하이퍼파라미터 훈련[[training-hyperparameters]]
+
+다음으로 정할 수 있는 모든 하이퍼파라미터와 다양한 훈련 옵션을 활성화하기 위한 플래그를 포함하는 [`TrainingArguments`] 클래스를 생성합니다.
+
+이 튜토리얼에서는 기본 훈련 [하이퍼파라미터](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments)로 시작하지만, 자유롭게 실험하여 여러분들에게 맞는 최적의 설정을 찾을 수 있습니다.
+
+훈련에서 체크포인트(checkpoints)를 저장할 위치를 지정합니다:
+
+```py
+>>> from transformers import TrainingArguments
+
+>>> training_args = TrainingArguments(output_dir="test_trainer")
+```
+
+### 평가 하기[[evaluate]]
+
+[`Trainer`]는 훈련 중에 모델 성능을 자동으로 평가하지 않습니다. 평가 지표를 계산하고 보고할 함수를 [`Trainer`]에 전달해야 합니다.
+[🤗 Evaluate](https://huggingface.co/docs/evaluate/index) 라이브러리는 [`evaluate.load`](https://huggingface.co/spaces/evaluate-metric/accuracy) 함수로 로드할 수 있는 간단한 [`accuracy`]함수를 제공합니다 (자세한 내용은 [둘러보기](https://huggingface.co/docs/evaluate/a_quick_tour)를 참조하세요):
+
+```py
+>>> import numpy as np
+>>> import evaluate
+
+>>> metric = evaluate.load("accuracy")
+```
+
+`metric`에서 [`~evaluate.compute`]를 호출하여 예측의 정확도를 계산합니다. 예측을 `compute`에 전달하기 전에 예측을 로짓으로 변환해야 합니다(모든 🤗 Transformers 모델은 로짓으로 반환한다는 점을 기억하세요):
+
+```py
+>>> def compute_metrics(eval_pred):
+... logits, labels = eval_pred
+... predictions = np.argmax(logits, axis=-1)
+... return metric.compute(predictions=predictions, references=labels)
+```
+
+미세 튜닝 중에 평가 지표를 모니터링하려면 훈련 인수에 `eval_strategy` 파라미터를 지정하여 각 에폭이 끝날 때 평가 지표를 확인할 수 있습니다:
+
+```py
+>>> from transformers import TrainingArguments, Trainer
+
+>>> training_args = TrainingArguments(output_dir="test_trainer", eval_strategy="epoch")
+```
+
+### 훈련 하기[[trainer]]
+
+모델, 훈련 인수, 훈련 및 테스트 데이터셋, 평가 함수가 포함된 [`Trainer`] 객체를 만듭니다:
+
+```py
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=small_train_dataset,
+... eval_dataset=small_eval_dataset,
+... compute_metrics=compute_metrics,
+... )
+```
+
+그리고 [`~transformers.Trainer.train`]을 호출하여 모델을 미세 튜닝합니다:
+
+```py
+>>> trainer.train()
+```
+
+
+
+
+
+
+## Keras로 텐서플로우 모델 훈련하기[[train-a-tensorflow-model-with-keras]]
+
+Keras API를 사용하여 텐서플로우에서 🤗 Transformers 모델을 훈련할 수도 있습니다!
+
+### Keras용 데이터 로드[[loading-data-for-keras]]
+
+Keras API로 🤗 Transformers 모델을 학습시키려면 데이터셋을 Keras가 이해할 수 있는 형식으로 변환해야 합니다.
+데이터 세트가 작은 경우, 전체를 NumPy 배열로 변환하여 Keras로 전달하면 됩니다.
+더 복잡한 작업을 수행하기 전에 먼저 이 작업을 시도해 보겠습니다.
+
+먼저 데이터 세트를 로드합니다. [GLUE 벤치마크](https://huggingface.co/datasets/glue)의 CoLA 데이터 세트를 사용하겠습니다.
+간단한 바이너리 텍스트 분류 작업이므로 지금은 훈련 데이터 분할만 사용합니다.
+
+```py
+from datasets import load_dataset
+
+dataset = load_dataset("glue", "cola")
+dataset = dataset["train"] # Just take the training split for now
+```
+
+다음으로 토크나이저를 로드하고 데이터를 NumPy 배열로 토큰화합니다. 레이블은 이미 0과 1로 된 리스트이기 때문에 토큰화하지 않고 바로 NumPy 배열로 변환할 수 있습니다!
+
+```py
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
+tokenized_data = tokenizer(dataset["sentence"], return_tensors="np", padding=True)
+# Tokenizer returns a BatchEncoding, but we convert that to a dict for Keras
+tokenized_data = dict(tokenized_data)
+
+labels = np.array(dataset["label"]) # Label is already an array of 0 and 1
+```
+
+마지막으로 모델을 로드, [`compile`](https://keras.io/api/models/model_training_apis/#compile-method), [`fit`](https://keras.io/api/models/model_training_apis/#fit-method)합니다:
+
+```py
+from transformers import TFAutoModelForSequenceClassification
+from tensorflow.keras.optimizers import Adam
+
+# Load and compile our model
+model = TFAutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased")
+# Lower learning rates are often better for fine-tuning transformers
+model.compile(optimizer=Adam(3e-5))
+
+model.fit(tokenized_data, labels)
+```
+
+
+
+모델을 `compile()`할 때 손실 인수를 모델에 전달할 필요가 없습니다!
+이 인수를 비워두면 허깅 페이스 모델은 작업과 모델 아키텍처에 적합한 손실을 자동으로 선택합니다.
+원한다면 언제든지 직접 손실을 지정하여 이를 재정의할 수 있습니다!
+
+
+
+이 접근 방식은 소규모 데이터 집합에서는 잘 작동하지만, 대규모 데이터 집합에서는 문제가 될 수 있습니다. 왜 그럴까요?
+토큰화된 배열과 레이블을 메모리에 완전히 로드하고 NumPy는 "들쭉날쭉한" 배열을 처리하지 않기 때문에,
+모든 토큰화된 샘플을 전체 데이터셋에서 가장 긴 샘플의 길이만큼 패딩해야 합니다. 이렇게 하면 배열이 훨씬 더 커지고 이 패딩 토큰으로 인해 학습 속도도 느려집니다!
+
+### 데이터를 tf.data.Dataset으로 로드하기[[loading-data-as-a-tfdatadataset]]
+
+학습 속도가 느려지는 것을 피하려면 데이터를 `tf.data.Dataset`으로 로드할 수 있습니다. 원한다면 직접
+`tf.data` 파이프라인을 직접 작성할 수도 있지만, 이 작업을 간편하게 수행하는 수 있는 두 가지 방법이 있습니다:
+
+- [`~TFPreTrainedModel.prepare_tf_dataset`]: 대부분의 경우 이 방법을 권장합니다. 모델의 메서드이기 때문에 모델을 검사하여 모델 입력으로 사용할 수 있는 열을 자동으로 파악하고
+나머지는 버려서 더 단순하고 성능이 좋은 데이터 집합을 만들 수 있습니다.
+- [`~datasets.Dataset.to_tf_dataset`]: 이 방법은 좀 더 낮은 수준이며, 포함할 '열'과 '레이블'을 정확히 지정하여
+데이터셋을 생성하는 방법을 정확히 제어하고 싶을 때 유용하며, 포함할 'columns'과 'label_cols'을 정확히 지정할 수 있습니다.
+
+[`~TFPreTrainedModel.prepare_tf_dataset`]을 사용하려면 먼저 다음 코드 샘플과 같이 토크나이저 출력을 데이터 세트에 열로 추가해야 합니다:
+
+```py
+def tokenize_dataset(data):
+ # Keys of the returned dictionary will be added to the dataset as columns
+ return tokenizer(data["text"])
+
+
+dataset = dataset.map(tokenize_dataset)
+```
+
+허깅 페이스 데이터셋은 기본적으로 디스크에 저장되므로 메모리 사용량을 늘리지 않는다는 점을 기억하세요!
+열이 추가되면 데이터셋에서 배치를 스트리밍하고 각 배치에 패딩을 추가할 수 있으므로 전체 데이터셋에 패딩을 추가하는 것보다 패딩 토큰의 수를 크게 줄일 수 있습니다.
+
+
+```py
+>>> tf_dataset = model.prepare_tf_dataset(dataset, batch_size=16, shuffle=True, tokenizer=tokenizer)
+```
+
+위의 코드 샘플에서는 배치가 로드될 때 올바르게 패딩할 수 있도록 `prepare_tf_dataset`에 토크나이저를 전달해야 합니다.
+데이터셋의 모든 샘플 길이가 같고 패딩이 필요하지 않은 경우 이 인수를 건너뛸 수 있습니다.
+샘플을 채우는 것보다 더 복잡한 작업(예: 마스킹된 언어의 토큰 손상 모델링)을 수행하기 위해 토큰을 손상시켜야 하는 경우,
+`collate_fn` 인수를 사용하여 샘플 목록을 배치로 변환하고 원하는 전처리를 적용할 함수를 전달할 수 있습니다.
+[예시](https://github.com/huggingface/transformers/tree/main/examples) 또는
+[노트북](https://huggingface.co/docs/transformers/notebooks)을 참조하여 이 접근 방식이 실제로 작동하는 모습을 확인하세요.
+
+`tf.data.Dataset`을 생성한 후에는 이전과 마찬가지로 모델을 컴파일하고 훈련(fit)할 수 있습니다:
+
+```py
+model.compile(optimizer=Adam(3e-5))
+
+model.fit(tf_dataset)
+```
+
+
+
+
+
+
+## 기본 파이토치로 훈련하기[[train-in-native-pytorch]]
+
+
+
+
+
+[`Trainer`]는 훈련 루프를 처리하며 한 줄의 코드로 모델을 미세 조정할 수 있습니다. 직접 훈련 루프를 작성하는 것을 선호하는 사용자의 경우, 기본 PyTorch에서 🤗 Transformers 모델을 미세 조정할 수도 있습니다.
+
+이 시점에서 노트북을 다시 시작하거나 다음 코드를 실행해 메모리를 확보해야 할 수 있습니다:
+
+```py
+del model
+del trainer
+torch.cuda.empty_cache()
+```
+
+다음으로, '토큰화된 데이터셋'을 수동으로 후처리하여 훈련련에 사용할 수 있도록 준비합니다.
+
+1. 모델이 원시 텍스트를 입력으로 허용하지 않으므로 `text` 열을 제거합니다:
+
+ ```py
+ >>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
+ ```
+
+2. 모델에서 인수의 이름이 `labels`로 지정될 것으로 예상하므로 `label` 열의 이름을 `labels`로 변경합니다:
+
+ ```py
+ >>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
+ ```
+
+3. 데이터셋의 형식을 List 대신 PyTorch 텐서를 반환하도록 설정합니다:
+
+ ```py
+ >>> tokenized_datasets.set_format("torch")
+ ```
+
+그리고 앞서 표시된 대로 데이터셋의 더 작은 하위 집합을 생성하여 미세 조정 속도를 높입니다:
+
+```py
+>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
+>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
+```
+
+### DataLoader[[dataloader]]
+
+훈련 및 테스트 데이터셋에 대한 'DataLoader'를 생성하여 데이터 배치를 반복할 수 있습니다:
+
+```py
+>>> from torch.utils.data import DataLoader
+
+>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
+>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
+```
+
+예측을 위한 레이블 개수를 사용하여 모델을 로드합니다:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=5)
+```
+
+### 옵티마이저 및 학습 속도 스케줄러[[optimizer-and-learning-rate-scheduler]]
+
+옵티마이저와 학습 속도 스케줄러를 생성하여 모델을 미세 조정합니다. 파이토치에서 제공하는 [`AdamW`](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html) 옵티마이저를 사용해 보겠습니다:
+
+```py
+>>> from torch.optim import AdamW
+
+>>> optimizer = AdamW(model.parameters(), lr=5e-5)
+```
+
+[`Trainer`]에서 기본 학습 속도 스케줄러를 생성합니다:
+
+```py
+>>> from transformers import get_scheduler
+
+>>> num_epochs = 3
+>>> num_training_steps = num_epochs * len(train_dataloader)
+>>> lr_scheduler = get_scheduler(
+... name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
+... )
+```
+
+마지막으로, GPU에 액세스할 수 있는 경우 'device'를 지정하여 GPU를 사용하도록 합니다. 그렇지 않으면 CPU에서 훈련하며 몇 분이 아닌 몇 시간이 걸릴 수 있습니다.
+
+```py
+>>> import torch
+
+>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+>>> model.to(device)
+```
+
+
+
+[Colaboratory](https://colab.research.google.com/) 또는 [SageMaker StudioLab](https://studiolab.sagemaker.aws/)과 같은 호스팅 노트북이 없는 경우 클라우드 GPU에 무료로 액세스할 수 있습니다.
+
+
+
+이제 훈련할 준비가 되었습니다! 🥳
+
+### 훈련 루프[[training-loop]]
+
+훈련 진행 상황을 추적하려면 [tqdm](https://tqdm.github.io/) 라이브러리를 사용하여 트레이닝 단계 수에 진행률 표시줄을 추가하세요:
+
+```py
+>>> from tqdm.auto import tqdm
+
+>>> progress_bar = tqdm(range(num_training_steps))
+
+>>> model.train()
+>>> for epoch in range(num_epochs):
+... for batch in train_dataloader:
+... batch = {k: v.to(device) for k, v in batch.items()}
+... outputs = model(**batch)
+... loss = outputs.loss
+... loss.backward()
+
+... optimizer.step()
+... lr_scheduler.step()
+... optimizer.zero_grad()
+... progress_bar.update(1)
+```
+
+### 평가 하기[[evaluate]]
+
+[`Trainer`]에 평가 함수를 추가한 방법과 마찬가지로, 훈련 루프를 직접 작성할 때도 동일한 작업을 수행해야 합니다. 하지만 이번에는 각 에포크가 끝날 때마다 평가지표를 계산하여 보고하는 대신, [`~evaluate.add_batch`]를 사용하여 모든 배치를 누적하고 맨 마지막에 평가지표를 계산합니다.
+
+```py
+>>> import evaluate
+
+>>> metric = evaluate.load("accuracy")
+>>> model.eval()
+>>> for batch in eval_dataloader:
+... batch = {k: v.to(device) for k, v in batch.items()}
+... with torch.no_grad():
+... outputs = model(**batch)
+
+... logits = outputs.logits
+... predictions = torch.argmax(logits, dim=-1)
+... metric.add_batch(predictions=predictions, references=batch["labels"])
+
+>>> metric.compute()
+```
+
+
+
+
+
+## 추가 자료[[additional-resources]]
+
+더 많은 미세 튜닝 예제는 다음을 참조하세요:
+
+- [🤗 Trnasformers 예제](https://github.com/huggingface/transformers/tree/main/examples)에는 PyTorch 및 텐서플로우에서 일반적인 NLP 작업을 훈련할 수 있는 스크립트가 포함되어 있습니다.
+
+- [🤗 Transformers 노트북](notebooks)에는 PyTorch 및 텐서플로우에서 특정 작업을 위해 모델을 미세 튜닝하는 방법에 대한 다양한 노트북이 포함되어 있습니다.
diff --git a/docs/transformers/docs/source/ko/troubleshooting.md b/docs/transformers/docs/source/ko/troubleshooting.md
new file mode 100644
index 0000000000000000000000000000000000000000..263d693c23da65f7a964ee64fdde70dff595ad2c
--- /dev/null
+++ b/docs/transformers/docs/source/ko/troubleshooting.md
@@ -0,0 +1,198 @@
+
+
+# 문제 해결[[troubleshoot]]
+
+때때로 오류가 발생할 수 있지만, 저희가 도와드리겠습니다! 이 가이드는 현재까지 확인된 가장 일반적인 문제 몇 가지와 그것들을 해결하는 방법에 대해 다룹니다. 그러나 이 가이드는 모든 🤗 Transformers 문제를 포괄적으로 다루고 있지 않습니다. 문제 해결에 더 많은 도움을 받으려면 다음을 시도해보세요:
+
+
+
+1. [포럼](https://discuss.huggingface.co/)에서 도움을 요청하세요. [Beginners](https://discuss.huggingface.co/c/beginners/5) 또는 [🤗 Transformers](https://discuss.huggingface.co/c/transformers/9)와 같은 특정 카테고리에 질문을 게시할 수 있습니다. 재현 가능한 코드와 함께 잘 서술된 포럼 게시물을 작성하여 여러분의 문제가 해결될 가능성을 극대화하세요!
+
+
+
+2. 라이브러리와 관련된 버그이면 🤗 Transformers 저장소에서 [이슈](https://github.com/huggingface/transformers/issues/new/choose)를 생성하세요. 버그에 대해 설명하는 정보를 가능한 많이 포함하려고 노력하여, 무엇이 잘못 되었는지와 어떻게 수정할 수 있는지 더 잘 파악할 수 있도록 도와주세요.
+
+3. 이전 버전의 🤗 Transformers을 사용하는 경우 중요한 변경 사항이 버전 사이에 도입되었기 때문에 [마이그레이션](migration) 가이드를 확인하세요.
+
+문제 해결 및 도움 매뉴얼에 대한 자세한 내용은 Hugging Face 강좌의 [8장](https://huggingface.co/course/chapter8/1?fw=pt)을 참조하세요.
+
+
+## 방화벽 환경[[firewalled-environments]]
+
+클라우드 및 내부망(intranet) 설정의 일부 GPU 인스턴스는 외부 연결에 대한 방화벽으로 차단되어 연결 오류가 발생할 수 있습니다. 스크립트가 모델 가중치나 데이터를 다운로드하려고 할 때, 다운로드가 중단되고 다음 메시지와 함께 시간 초과됩니다:
+
+```
+ValueError: Connection error, and we cannot find the requested files in the cached path.
+Please try again or make sure your Internet connection is on.
+```
+
+이 경우에는 연결 오류를 피하기 위해 🤗 Transformers를 [오프라인 모드](installation#offline-mode)로 실행해야 합니다.
+
+## CUDA 메모리 부족(CUDA out of memory)[[cuda-out-of-memory]]
+
+수백만 개의 매개변수로 대규모 모델을 훈련하는 것은 적절한 하드웨어 없이 어려울 수 있습니다. GPU 메모리가 부족한 경우 발생할 수 있는 일반적인 오류는 다음과 같습니다:
+
+```
+CUDA out of memory. Tried to allocate 256.00 MiB (GPU 0; 11.17 GiB total capacity; 9.70 GiB already allocated; 179.81 MiB free; 9.85 GiB reserved in total by PyTorch)
+```
+
+다음은 메모리 사용을 줄이기 위해 시도해 볼 수 있는 몇 가지 잠재적인 해결책입니다:
+
+- [`TrainingArguments`]의 [`per_device_train_batch_size`](main_classes/trainer#transformers.TrainingArguments.per_device_train_batch_size) 값을 줄이세요.
+- [`TrainingArguments`]의 [`gradient_accumulation_steps`](main_classes/trainer#transformers.TrainingArguments.gradient_accumulation_steps)은 전체 배치 크기를 효과적으로 늘리세요.
+
+
+
+메모리 절약 기술에 대한 자세한 내용은 성능 [가이드](performance)를 참조하세요.
+
+
+
+## 저장된 TensorFlow 모델을 가져올 수 없습니다(Unable to load a saved TensorFlow model)[[unable-to-load-a-saved-uensorFlow-model]]
+
+TensorFlow의 [model.save](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model) 메소드는 아키텍처, 가중치, 훈련 구성 등 전체 모델을 단일 파일에 저장합니다. 그러나 모델 파일을 다시 가져올 때 🤗 Transformers는 모델 파일에 있는 모든 TensorFlow 관련 객체를 가져오지 않을 수 있기 때문에 오류가 발생할 수 있습니다. TensorFlow 모델 저장 및 가져오기 문제를 피하려면 다음을 권장합니다:
+
+- 모델 가중치를 `h5` 파일 확장자로 [`model.save_weights`](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model)로 저장한 다음 [`~TFPreTrainedModel.from_pretrained`]로 모델을 다시 가져옵니다:
+
+```py
+>>> from transformers import TFPreTrainedModel
+>>> from tensorflow import keras
+
+>>> model.save_weights("some_folder/tf_model.h5")
+>>> model = TFPreTrainedModel.from_pretrained("some_folder")
+```
+
+- 모델을 [`~TFPretrainedModel.save_pretrained`]로 저장하고 [`~TFPreTrainedModel.from_pretrained`]로 다시 가져옵니다:
+
+```py
+>>> from transformers import TFPreTrainedModel
+
+>>> model.save_pretrained("path_to/model")
+>>> model = TFPreTrainedModel.from_pretrained("path_to/model")
+```
+
+## ImportError[[importerror]]
+
+특히 최신 모델인 경우 만날 수 있는 다른 일반적인 오류는 `ImportError`입니다:
+
+```
+ImportError: cannot import name 'ImageGPTImageProcessor' from 'transformers' (unknown location)
+```
+
+이러한 오류 유형의 경우 최신 모델에 액세스할 수 있도록 최신 버전의 🤗 Transformers가 설치되어 있는지 확인하세요:
+
+```bash
+pip install transformers --upgrade
+```
+
+## CUDA error: device-side assert triggered[[cuda-error-deviceside-assert-triggered]]
+
+때때로 장치 코드 오류에 대한 일반적인 CUDA 오류가 발생할 수 있습니다.
+
+```
+RuntimeError: CUDA error: device-side assert triggered
+```
+
+더 자세한 오류 메시지를 얻으려면 우선 코드를 CPU에서 실행합니다. 다음 환경 변수를 코드의 시작 부분에 추가하여 CPU로 전환하세요:
+
+```py
+>>> import os
+
+>>> os.environ["CUDA_VISIBLE_DEVICES"] = ""
+```
+
+또 다른 옵션은 GPU에서 더 나은 역추적(traceback)을 얻는 것입니다. 다음 환경 변수를 코드의 시작 부분에 추가하여 역추적이 오류가 발생한 소스를 가리키도록 하세요:
+
+```py
+>>> import os
+
+>>> os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
+```
+
+## 패딩 토큰이 마스킹되지 않은 경우 잘못된 출력(Incorrect output when padding tokens aren't masked)[[incorrect-output-when-padding-tokens-arent-masked]]
+
+경우에 따라 `input_ids`에 패딩 토큰이 포함된 경우 `hidden_state` 출력이 올바르지 않을 수 있습니다. 데모를 위해 모델과 토크나이저를 가져오세요. 모델의 `pad_token_id`에 액세스하여 해당 값을 확인할 수 있습니다. 일부 모델의 경우 `pad_token_id`가 `None`일 수 있지만 언제든지 수동으로 설정할 수 있습니다.
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+>>> import torch
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
+>>> model.config.pad_token_id
+0
+```
+
+다음 예제는 패딩 토큰을 마스킹하지 않은 출력을 보여줍니다:
+
+```py
+>>> input_ids = torch.tensor([[7592, 2057, 2097, 2393, 9611, 2115], [7592, 0, 0, 0, 0, 0]])
+>>> output = model(input_ids)
+>>> print(output.logits)
+tensor([[ 0.0082, -0.2307],
+ [ 0.1317, -0.1683]], grad_fn=)
+```
+
+다음은 두 번째 시퀀스의 실제 출력입니다:
+
+```py
+>>> input_ids = torch.tensor([[7592]])
+>>> output = model(input_ids)
+>>> print(output.logits)
+tensor([[-0.1008, -0.4061]], grad_fn=)
+```
+
+대부분의 경우 모델에 `attention_mask`를 제공하여 패딩 토큰을 무시해야 이러한 조용한 오류를 방지할 수 있습니다. 이제 두 번째 시퀀스의 출력이 실제 출력과 일치합니다:
+
+
+
+일반적으로 토크나이저는 특정 토크나이저의 기본 값을 기준으로 사용자에 대한 'attention_mask'를 만듭니다.
+
+
+
+```py
+>>> attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0]])
+>>> output = model(input_ids, attention_mask=attention_mask)
+>>> print(output.logits)
+tensor([[ 0.0082, -0.2307],
+ [-0.1008, -0.4061]], grad_fn=)
+```
+
+🤗 Transformers는 패딩 토큰이 제공된 경우 패딩 토큰을 마스킹하기 위한 `attention_mask`를 자동으로 생성하지 않습니다. 그 이유는 다음과 같습니다:
+
+- 일부 모델에는 패딩 토큰이 없습니다.
+- 일부 사용 사례의 경우 사용자가 모델이 패딩 토큰을 관리하기를 원합니다.
+
+## ValueError: 이 유형의 AutoModel에 대해 인식할 수 없는 XYZ 구성 클래스(ValueError: Unrecognized configuration class XYZ for this kind of AutoModel)[[valueerror-unrecognized-configuration-class-xyz-for-this-kind-of-automodel]]
+
+일반적으로, 사전 학습된 모델의 인스턴스를 가져오기 위해 [`AutoModel`] 클래스를 사용하는 것이 좋습니다.
+이 클래스는 구성에 따라 주어진 체크포인트에서 올바른 아키텍처를 자동으로 추론하고 가져올 수 있습니다.
+모델을 체크포인트에서 가져올 때 이 `ValueError`가 발생하면, 이는 Auto 클래스가 주어진 체크포인트의 구성에서
+가져오려는 모델 유형과 매핑을 찾을 수 없다는 것을 의미합니다. 가장 흔하게 발생하는 경우는
+체크포인트가 주어진 태스크를 지원하지 않을 때입니다.
+예를 들어, 다음 예제에서 질의응답에 대한 GPT2가 없기 때문에 오류가 발생합니다:
+
+```py
+>>> from transformers import AutoProcessor, AutoModelForQuestionAnswering
+
+>>> processor = AutoProcessor.from_pretrained("openai-community/gpt2-medium")
+>>> model = AutoModelForQuestionAnswering.from_pretrained("openai-community/gpt2-medium")
+ValueError: Unrecognized configuration class for this kind of AutoModel: AutoModelForQuestionAnswering.
+Model type should be one of AlbertConfig, BartConfig, BertConfig, BigBirdConfig, BigBirdPegasusConfig, BloomConfig, ...
+```
diff --git a/docs/transformers/docs/source/ms/_toctree.yml b/docs/transformers/docs/source/ms/_toctree.yml
new file mode 100644
index 0000000000000000000000000000000000000000..56a4744b8b86857e2c293879153c453eea2be906
--- /dev/null
+++ b/docs/transformers/docs/source/ms/_toctree.yml
@@ -0,0 +1,680 @@
+- sections:
+ - local: index
+ title: 🤗 Transformers
+ - local: quicktour
+ title: Lawatan cepat
+ - local: installation
+ title: Pemasangan
+ title: Mulakan
+- sections:
+ - local: pipeline_tutorial
+ title: Jalankan inferens dengan saluran paip
+ - local: autoclass_tutorial
+ title: Tulis kod mudah alih dengan AutoClass
+ - local: preprocessing
+ title: Praproses data
+ - local: training
+ title: Perhalusi model yang telah dilatih
+ - local: run_scripts
+ title: Latih dengan skrip
+ - local: accelerate
+ title: Sediakan latihan yang diedarkan dengan 🤗 Accelerate
+ - local: model_sharing
+ title: Kongsi model anda
+ title: Tutorials
+- sections:
+ - sections:
+ - local: tasks/sequence_classification
+ title: Klasifikasi teks
+ - local: tasks/token_classification
+ title: Klasifikasi token
+ - local: tasks/question_answering
+ title: Soalan menjawab
+ - local: tasks/language_modeling
+ title: Pemodelan bahasa sebab-akibat
+ - local: tasks/masked_language_modeling
+ title: Pemodelan bahasa Masked
+ - local: tasks/translation
+ title: Terjemahan
+ - local: tasks/summarization
+ title: Rumusan
+ - local: tasks/multiple_choice
+ title: Pilihan
+ title: Natural Language Processing
+ isExpanded: false
+ - sections:
+ - local: tasks/audio_classification
+ title: Klasifikasi audio
+ - local: tasks/asr
+ title: Pengecaman pertuturan automatik
+ title: Audio
+ isExpanded: false
+ - sections:
+ - local: tasks/image_classification
+ title: Klasifikasi imej
+ - local: tasks/semantic_segmentation
+ title: Segmentasi semantik
+ - local: tasks/video_classification
+ title: Klasifikasi video
+ - local: tasks/object_detection
+ title: Pengesanan objek
+ - local: tasks/zero_shot_object_detection
+ title: Pengesanan objek Zero-Shot
+ - local: tasks/zero_shot_image_classification
+ title: Klasifikasi imej tangkapan Zero-Shot
+ - local: tasks/monocular_depth_estimation
+ title: Anggaran kedalaman
+ title: Visi komputer
+ isExpanded: false
+ - sections:
+ - local: tasks/image_captioning
+ title: Kapsyen imej
+ - local: tasks/document_question_answering
+ title: Menjawab Soalan Dokumen
+ - local: tasks/text-to-speech
+ title: Teks kepada ucapan
+ title: Multimodal
+ isExpanded: false
+ title: Panduan Tugasan
+- sections:
+ - local: fast_tokenizers
+ title: Gunakan tokenizer cepat dari 🤗 Tokenizers
+ - local: multilingual
+ title: Jalankan inferens dengan model berbilang bahasa
+ - local: generation_strategies
+ title: Sesuaikan strategi penjanaan teks
+ - local: create_a_model
+ title: Gunakan API khusus model
+ - local: custom_models
+ title: Kongsi model tersuai
+ - local: sagemaker
+ title: Jalankan latihan di Amazon SageMaker
+ - local: serialization
+ title: Eksport ke ONNX
+ - local: torchscript
+ title: Eksport ke TorchScript
+ - local: Buku nota dengan contoh
+ title: Notebooks with examples
+ - local: Sumber komuniti
+ title: Community resources
+ - local: Sumber komuniti
+ title: Custom Tools and Prompts
+ - local: Alat dan Gesaan Tersuai
+ title: Selesaikan masalah
+ title: Panduan Developer
+- sections:
+ - local: performance
+ title: Gambaran keseluruhan
+ - local: perf_train_gpu_one
+ title: Latihan pada satu GPU
+ - local: perf_train_gpu_many
+ title: Latihan pada banyak GPU
+ - local: perf_train_cpu
+ title: Latihan mengenai CPU
+ - local: perf_train_cpu_many
+ title: Latihan pada banyak CPU
+ - local: perf_train_tpu
+ title: Latihan mengenai TPU
+ - local: perf_train_tpu_tf
+ title: Latihan tentang TPU dengan TensorFlow
+ - local: perf_train_special
+ title: Latihan mengenai Perkakasan Khusus
+ - local: perf_infer_cpu
+ title: Inferens pada CPU
+ - local: perf_infer_gpu_one
+ title: Inferens pada satu GPU
+ - local: perf_infer_gpu_many
+ title: Inferens pada banyak GPUs
+ - local: perf_infer_special
+ title: Inferens pada Perkakasan Khusus
+ - local: perf_hardware
+ title: Perkakasan tersuai untuk latihan
+ - local: big_models
+ title: Menghidupkan model besar
+ - local: debugging
+ title: Penyahpepijatan
+ - local: hpo_train
+ title: Carian Hiperparameter menggunakan API Pelatih
+ - local: tf_xla
+ title: Penyepaduan XLA untuk Model TensorFlow
+ title: Prestasi dan kebolehskalaan
+- sections:
+ - local: contributing
+ title: Bagaimana untuk menyumbang kepada transformer?
+ - local: add_new_model
+ title: Bagaimana untuk menambah model pada 🤗 Transformers?
+ - local: add_new_pipeline
+ title: Bagaimana untuk menambah saluran paip ke 🤗 Transformers?
+ - local: testing
+ title: Ujian
+ - local: pr_checks
+ title: Menyemak Permintaan Tarik
+ title: Sumbangkan
+
+- sections:
+ - local: philosophy
+ title: Falsafah
+ - local: glossary
+ title: Glosari
+ - local: task_summary
+ title: Apa 🤗 Transformers boleh buat
+ - local: tasks_explained
+ title: Bagaimana 🤗 Transformers menyelesaikan tugasan
+ - local: model_summary
+ title: Keluarga model Transformer
+ - local: tokenizer_summary
+ title: Ringkasan tokenizer
+ - local: attention
+ title: Mekanisme perhatian
+ - local: pad_truncation
+ title: Padding dan pemotongan
+ - local: bertology
+ title: BERTology
+ - local: perplexity
+ title: Kekeliruan model panjang tetap
+ - local: pipeline_webserver
+ title: Saluran paip untuk inferens pelayan web
+ title: Panduan konsep
+- sections:
+ - sections:
+ - local: model_doc/auto
+ title: Kelas Auto
+ - local: main_classes/callback
+ title: Panggilan balik
+ - local: main_classes/configuration
+ title: Configuration
+ - local: main_classes/data_collator
+ title: Data Collator
+ - local: main_classes/keras_callbacks
+ title: Keras callbacks
+ - local: main_classes/logging
+ title: Logging
+ - local: main_classes/model
+ title: Models
+ - local: main_classes/text_generation
+ title: Text Generation
+ - local: main_classes/onnx
+ title: ONNX
+ - local: main_classes/optimizer_schedules
+ title: Optimization
+ - local: main_classes/output
+ title: Model outputs
+ - local: main_classes/pipelines
+ title: Pipelines
+ - local: main_classes/processors
+ title: Processors
+ - local: main_classes/quantization
+ title: Quantization
+ - local: main_classes/tokenizer
+ title: Tokenizer
+ - local: main_classes/trainer
+ title: Trainer
+ - local: main_classes/deepspeed
+ title: DeepSpeed Integration
+ - local: main_classes/feature_extractor
+ title: Feature Extractor
+ - local: main_classes/image_processor
+ title: Image Processor
+ title: Main Classes
+ - sections:
+ - isExpanded: false
+ sections:
+ - local: model_doc/albert
+ title: ALBERT
+ - local: model_doc/bart
+ title: BART
+ - local: model_doc/barthez
+ title: BARThez
+ - local: model_doc/bartpho
+ title: BARTpho
+ - local: model_doc/bert
+ title: BERT
+ - local: model_doc/bert-generation
+ title: BertGeneration
+ - local: model_doc/bert-japanese
+ title: BertJapanese
+ - local: model_doc/bertweet
+ title: Bertweet
+ - local: model_doc/big_bird
+ title: BigBird
+ - local: model_doc/bigbird_pegasus
+ title: BigBirdPegasus
+ - local: model_doc/biogpt
+ title: BioGpt
+ - local: model_doc/blenderbot
+ title: Blenderbot
+ - local: model_doc/blenderbot-small
+ title: Blenderbot Small
+ - local: model_doc/bloom
+ title: BLOOM
+ - local: model_doc/bort
+ title: BORT
+ - local: model_doc/byt5
+ title: ByT5
+ - local: model_doc/camembert
+ title: CamemBERT
+ - local: model_doc/canine
+ title: CANINE
+ - local: model_doc/codegen
+ title: CodeGen
+ - local: model_doc/convbert
+ title: ConvBERT
+ - local: model_doc/cpm
+ title: CPM
+ - local: model_doc/cpmant
+ title: CPMANT
+ - local: model_doc/ctrl
+ title: CTRL
+ - local: model_doc/deberta
+ title: DeBERTa
+ - local: model_doc/deberta-v2
+ title: DeBERTa-v2
+ - local: model_doc/dialogpt
+ title: DialoGPT
+ - local: model_doc/distilbert
+ title: DistilBERT
+ - local: model_doc/dpr
+ title: DPR
+ - local: model_doc/electra
+ title: ELECTRA
+ - local: model_doc/encoder-decoder
+ title: Encoder Decoder Models
+ - local: model_doc/ernie
+ title: ERNIE
+ - local: model_doc/ernie_m
+ title: ErnieM
+ - local: model_doc/esm
+ title: ESM
+ - local: model_doc/flan-t5
+ title: FLAN-T5
+ - local: model_doc/flan-ul2
+ title: FLAN-UL2
+ - local: model_doc/flaubert
+ title: FlauBERT
+ - local: model_doc/fnet
+ title: FNet
+ - local: model_doc/fsmt
+ title: FSMT
+ - local: model_doc/funnel
+ title: Funnel Transformer
+ - local: model_doc/openai-gpt
+ title: GPT
+ - local: model_doc/gpt_neo
+ title: GPT Neo
+ - local: model_doc/gpt_neox
+ title: GPT NeoX
+ - local: model_doc/gpt_neox_japanese
+ title: GPT NeoX Japanese
+ - local: model_doc/gptj
+ title: GPT-J
+ - local: model_doc/gpt2
+ title: GPT2
+ - local: model_doc/gpt_bigcode
+ title: GPTBigCode
+ - local: model_doc/gptsan-japanese
+ title: GPTSAN Japanese
+ - local: model_doc/gpt-sw3
+ title: GPTSw3
+ - local: model_doc/herbert
+ title: HerBERT
+ - local: model_doc/ibert
+ title: I-BERT
+ - local: model_doc/jukebox
+ title: Jukebox
+ - local: model_doc/led
+ title: LED
+ - local: model_doc/llama
+ title: LLaMA
+ - local: model_doc/longformer
+ title: Longformer
+ - local: model_doc/longt5
+ title: LongT5
+ - local: model_doc/luke
+ title: LUKE
+ - local: model_doc/m2m_100
+ title: M2M100
+ - local: model_doc/marian
+ title: MarianMT
+ - local: model_doc/markuplm
+ title: MarkupLM
+ - local: model_doc/mbart
+ title: MBart and MBart-50
+ - local: model_doc/mega
+ title: MEGA
+ - local: model_doc/megatron-bert
+ title: MegatronBERT
+ - local: model_doc/megatron_gpt2
+ title: MegatronGPT2
+ - local: model_doc/mluke
+ title: mLUKE
+ - local: model_doc/mobilebert
+ title: MobileBERT
+ - local: model_doc/mpnet
+ title: MPNet
+ - local: model_doc/mt5
+ title: MT5
+ - local: model_doc/mvp
+ title: MVP
+ - local: model_doc/nezha
+ title: NEZHA
+ - local: model_doc/nllb
+ title: NLLB
+ - local: model_doc/nllb-moe
+ title: NLLB-MoE
+ - local: model_doc/nystromformer
+ title: Nyströmformer
+ - local: model_doc/open-llama
+ title: Open-Llama
+ - local: model_doc/opt
+ title: OPT
+ - local: model_doc/pegasus
+ title: Pegasus
+ - local: model_doc/pegasus_x
+ title: PEGASUS-X
+ - local: model_doc/phobert
+ title: PhoBERT
+ - local: model_doc/plbart
+ title: PLBart
+ - local: model_doc/prophetnet
+ title: ProphetNet
+ - local: model_doc/qdqbert
+ title: QDQBert
+ - local: model_doc/rag
+ title: RAG
+ - local: model_doc/realm
+ title: REALM
+ - local: model_doc/reformer
+ title: Reformer
+ - local: model_doc/rembert
+ title: RemBERT
+ - local: model_doc/retribert
+ title: RetriBERT
+ - local: model_doc/roberta
+ title: RoBERTa
+ - local: model_doc/roberta-prelayernorm
+ title: RoBERTa-PreLayerNorm
+ - local: model_doc/roc_bert
+ title: RoCBert
+ - local: model_doc/roformer
+ title: RoFormer
+ - local: model_doc/rwkv
+ title: RWKV
+ - local: model_doc/splinter
+ title: Splinter
+ - local: model_doc/squeezebert
+ title: SqueezeBERT
+ - local: model_doc/switch_transformers
+ title: SwitchTransformers
+ - local: model_doc/t5
+ title: T5
+ - local: model_doc/t5v1.1
+ title: T5v1.1
+ - local: model_doc/tapex
+ title: TAPEX
+ - local: model_doc/transfo-xl
+ title: Transformer XL
+ - local: model_doc/ul2
+ title: UL2
+ - local: model_doc/xmod
+ title: X-MOD
+ - local: model_doc/xglm
+ title: XGLM
+ - local: model_doc/xlm
+ title: XLM
+ - local: model_doc/xlm-prophetnet
+ title: XLM-ProphetNet
+ - local: model_doc/xlm-roberta
+ title: XLM-RoBERTa
+ - local: model_doc/xlm-roberta-xl
+ title: XLM-RoBERTa-XL
+ - local: model_doc/xlm-v
+ title: XLM-V
+ - local: model_doc/xlnet
+ title: XLNet
+ - local: model_doc/yoso
+ title: YOSO
+ title: Text models
+ - isExpanded: false
+ sections:
+ - local: model_doc/beit
+ title: BEiT
+ - local: model_doc/bit
+ title: BiT
+ - local: model_doc/conditional_detr
+ title: Conditional DETR
+ - local: model_doc/convnext
+ title: ConvNeXT
+ - local: model_doc/convnextv2
+ title: ConvNeXTV2
+ - local: model_doc/cvt
+ title: CvT
+ - local: model_doc/deformable_detr
+ title: Deformable DETR
+ - local: model_doc/deit
+ title: DeiT
+ - local: model_doc/deta
+ title: DETA
+ - local: model_doc/detr
+ title: DETR
+ - local: model_doc/dinat
+ title: DiNAT
+ - local: model_doc/dit
+ title: DiT
+ - local: model_doc/dpt
+ title: DPT
+ - local: model_doc/efficientformer
+ title: EfficientFormer
+ - local: model_doc/efficientnet
+ title: EfficientNet
+ - local: model_doc/focalnet
+ title: FocalNet
+ - local: model_doc/glpn
+ title: GLPN
+ - local: model_doc/imagegpt
+ title: ImageGPT
+ - local: model_doc/levit
+ title: LeViT
+ - local: model_doc/mask2former
+ title: Mask2Former
+ - local: model_doc/maskformer
+ title: MaskFormer
+ - local: model_doc/mobilenet_v1
+ title: MobileNetV1
+ - local: model_doc/mobilenet_v2
+ title: MobileNetV2
+ - local: model_doc/mobilevit
+ title: MobileViT
+ - local: model_doc/nat
+ title: NAT
+ - local: model_doc/poolformer
+ title: PoolFormer
+ - local: model_doc/regnet
+ title: RegNet
+ - local: model_doc/resnet
+ title: ResNet
+ - local: model_doc/segformer
+ title: SegFormer
+ - local: model_doc/swiftformer
+ title: SwiftFormer
+ - local: model_doc/swin
+ title: Swin Transformer
+ - local: model_doc/swinv2
+ title: Swin Transformer V2
+ - local: model_doc/swin2sr
+ title: Swin2SR
+ - local: model_doc/table-transformer
+ title: Table Transformer
+ - local: model_doc/timesformer
+ title: TimeSformer
+ - local: model_doc/upernet
+ title: UperNet
+ - local: model_doc/van
+ title: VAN
+ - local: model_doc/videomae
+ title: VideoMAE
+ - local: model_doc/vit
+ title: Vision Transformer (ViT)
+ - local: model_doc/vit_hybrid
+ title: ViT Hybrid
+ - local: model_doc/vit_mae
+ title: ViTMAE
+ - local: model_doc/vit_msn
+ title: ViTMSN
+ - local: model_doc/yolos
+ title: YOLOS
+ title: Vision models
+ - isExpanded: false
+ sections:
+ - local: model_doc/audio-spectrogram-transformer
+ title: Audio Spectrogram Transformer
+ - local: model_doc/clap
+ title: CLAP
+ - local: model_doc/hubert
+ title: Hubert
+ - local: model_doc/mctct
+ title: MCTCT
+ - local: model_doc/sew
+ title: SEW
+ - local: model_doc/sew-d
+ title: SEW-D
+ - local: model_doc/speech_to_text
+ title: Speech2Text
+ - local: model_doc/speech_to_text_2
+ title: Speech2Text2
+ - local: model_doc/speecht5
+ title: SpeechT5
+ - local: model_doc/unispeech
+ title: UniSpeech
+ - local: model_doc/unispeech-sat
+ title: UniSpeech-SAT
+ - local: model_doc/wav2vec2
+ title: Wav2Vec2
+ - local: model_doc/wav2vec2-conformer
+ title: Wav2Vec2-Conformer
+ - local: model_doc/wav2vec2_phoneme
+ title: Wav2Vec2Phoneme
+ - local: model_doc/wavlm
+ title: WavLM
+ - local: model_doc/whisper
+ title: Whisper
+ - local: model_doc/xls_r
+ title: XLS-R
+ - local: model_doc/xlsr_wav2vec2
+ title: XLSR-Wav2Vec2
+ title: Audio models
+ - isExpanded: false
+ sections:
+ - local: model_doc/align
+ title: ALIGN
+ - local: model_doc/altclip
+ title: AltCLIP
+ - local: model_doc/blip
+ title: BLIP
+ - local: model_doc/blip-2
+ title: BLIP-2
+ - local: model_doc/bridgetower
+ title: BridgeTower
+ - local: model_doc/chinese_clip
+ title: Chinese-CLIP
+ - local: model_doc/clip
+ title: CLIP
+ - local: model_doc/clipseg
+ title: CLIPSeg
+ - local: model_doc/data2vec
+ title: Data2Vec
+ - local: model_doc/deplot
+ title: DePlot
+ - local: model_doc/donut
+ title: Donut
+ - local: model_doc/flava
+ title: FLAVA
+ - local: model_doc/git
+ title: GIT
+ - local: model_doc/groupvit
+ title: GroupViT
+ - local: model_doc/layoutlm
+ title: LayoutLM
+ - local: model_doc/layoutlmv2
+ title: LayoutLMV2
+ - local: model_doc/layoutlmv3
+ title: LayoutLMV3
+ - local: model_doc/layoutxlm
+ title: LayoutXLM
+ - local: model_doc/lilt
+ title: LiLT
+ - local: model_doc/lxmert
+ title: LXMERT
+ - local: model_doc/matcha
+ title: MatCha
+ - local: model_doc/mgp-str
+ title: MGP-STR
+ - local: model_doc/oneformer
+ title: OneFormer
+ - local: model_doc/owlvit
+ title: OWL-ViT
+ - local: model_doc/perceiver
+ title: Perceiver
+ - local: model_doc/pix2struct
+ title: Pix2Struct
+ - local: model_doc/sam
+ title: Segment Anything
+ - local: model_doc/speech-encoder-decoder
+ title: Speech Encoder Decoder Models
+ - local: model_doc/tapas
+ title: TAPAS
+ - local: model_doc/trocr
+ title: TrOCR
+ - local: model_doc/tvlt
+ title: TVLT
+ - local: model_doc/vilt
+ title: ViLT
+ - local: model_doc/vision-encoder-decoder
+ title: Vision Encoder Decoder Models
+ - local: model_doc/vision-text-dual-encoder
+ title: Vision Text Dual Encoder
+ - local: model_doc/visual_bert
+ title: VisualBERT
+ - local: model_doc/xclip
+ title: X-CLIP
+ title: Multimodal models
+ - isExpanded: false
+ sections:
+ - local: model_doc/decision_transformer
+ title: Decision Transformer
+ - local: model_doc/trajectory_transformer
+ title: Trajectory Transformer
+ title: Reinforcement learning models
+ - isExpanded: false
+ sections:
+ - local: model_doc/informer
+ title: Informer
+ - local: model_doc/time_series_transformer
+ title: Time Series Transformer
+ title: Time series models
+ - isExpanded: false
+ sections:
+ - local: model_doc/graphormer
+ title: Graphormer
+ title: Graph models
+ title: Models
+ - sections:
+ - local: internal/modeling_utils
+ title: Custom Layers and Utilities
+ - local: internal/pipelines_utils
+ title: Utilities for pipelines
+ - local: internal/tokenization_utils
+ title: Utilities for Tokenizers
+ - local: internal/trainer_utils
+ title: Utilities for Trainer
+ - local: internal/generation_utils
+ title: Utilities for Generation
+ - local: internal/image_processing_utils
+ title: Utilities for Image Processors
+ - local: internal/audio_utils
+ title: Utilities for Audio processing
+ - local: internal/file_utils
+ title: General Utilities
+ - local: internal/time_series_utils
+ title: Utilities for Time Series
+ title: Internal Helpers
+ title: API
diff --git a/docs/transformers/docs/source/ms/index.md b/docs/transformers/docs/source/ms/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..e0adb8a8a8e53b588eb032085e35f2c87781dcc9
--- /dev/null
+++ b/docs/transformers/docs/source/ms/index.md
@@ -0,0 +1,464 @@
+
+
+# 🤗 Transformers
+
+Pembelajaran Mesin terkini untuk [PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/), dan [JAX](https://jax.readthedocs.io/en/latest/).
+
+🤗 Transformers menyediakan API dan alatan untuk memuat turun dan melatih model pra-latihan terkini dengan mudah. Menggunakan model terlatih boleh mengurangkan kos pengiraan anda, jejak karbon dan menjimatkan masa serta sumber yang diperlukan untuk melatih model dari awal. Model ini menyokong tugas biasa dalam modaliti yang berbeza, seperti:
+
+📝 **Natural Language Processing**: klasifikasi teks, pengecaman entiti bernama, menjawab soalan, pemodelan bahasa, ringkasan, terjemahan, pilihan berganda dan penjanaan teks.
+🖼️ **Computer Vision**: pengelasan imej, pengesanan objek dan pembahagian.
+🗣️ **Audio**: pengecaman pertuturan automatik dan klasifikasi audio.
+🐙 **Multimodal**: jawapan soalan jadual, pengecaman aksara optik, pengekstrakan maklumat daripada dokumen yang diimbas, klasifikasi video dan jawapan soalan visual.
+
+🤗 Transformer menyokong kebolehoperasian rangka kerja antara PyTorch, TensorFlow, and JAX. Ini memberikan fleksibiliti untuk menggunakan rangka kerja yang berbeza pada setiap peringkat kehidupan model; latih model dalam tiga baris kod dalam satu rangka kerja, dan muatkannya untuk inferens dalam rangka kerja yang lain. Model juga boleh dieksport ke format seperti ONNX.
+
+Sertai komuniti yang semakin berkembang di [Hub](https://huggingface.co/models), [forum](https://discuss.huggingface.co/), atau [Discord](https://discord.com/invite/JfAtkvEtRb) hari ini!
+
+## Jika anda sedang mencari sokongan tersuai daripada pasukan Hugging Face
+
+
+
+
+
+## Kandungan
+
+Dokumentasi disusun kepada lima bahagian:
+
+- **MULAKAN** menyediakan lawatan pantas ke perpustakaan dan arahan pemasangan untuk bangun dan berjalan.
+- **TUTORIAL** ialah tempat yang bagus untuk bermula jika anda seorang pemula. Bahagian ini akan membantu anda memperoleh kemahiran asas yang anda perlukan untuk mula menggunakan perpustakaan.
+- **PANDUAN CARA-CARA** menunjukkan kepada anda cara untuk mencapai matlamat tertentu, seperti memperhalusi model terlatih untuk pemodelan bahasa atau cara menulis dan berkongsi model tersuai.
+- **PANDUAN KONSEP** menawarkan lebih banyak perbincangan dan penjelasan tentang konsep dan idea asas di sebalik model, tugasan dan falsafah reka bentuk 🤗 Transformers.
+- **API** menerangkan semua kelas dan fungsi:
+
+ - **KELAS UTAMA** memperincikan kelas yang paling penting seperti konfigurasi, model, tokenizer dan saluran paip.
+ - **MODEL** memperincikan kelas dan fungsi yang berkaitan dengan setiap model yang dilaksanakan dalam perpustakaan.
+ - **PEMBANTU DALAMAN** memperincikan kelas utiliti dan fungsi yang digunakan secara dalaman.
+
+### Model yang disokong
+
+
+
+1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[ALIGN](model_doc/align)** (from Google Research) released with the paper [Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision](https://arxiv.org/abs/2102.05918) by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig.
+1. **[AltCLIP](model_doc/altclip)** (from BAAI) released with the paper [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679) by Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell.
+1. **[Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer)** (from MIT) released with the paper [AST: Audio Spectrogram Transformer](https://arxiv.org/abs/2104.01778) by Yuan Gong, Yu-An Chung, James Glass.
+1. **[Autoformer](model_doc/autoformer)** (from Tsinghua University) released with the paper [Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting](https://arxiv.org/abs/2106.13008) by Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long.
+1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BioGpt](model_doc/biogpt)** (from Microsoft Research AI4Science) released with the paper [BioGPT: generative pre-trained transformer for biomedical text generation and mining](https://academic.oup.com/bib/advance-article/doi/10.1093/bib/bbac409/6713511?guestAccessKey=a66d9b5d-4f83-4017-bb52-405815c907b9) by Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon and Tie-Yan Liu.
+1. **[BiT](model_doc/bit)** (from Google AI) released with the paper [Big Transfer (BiT): General Visual Representation Learning](https://arxiv.org/abs/1912.11370) by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby.
+1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BLIP](model_doc/blip)** (from Salesforce) released with the paper [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) by Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
+1. **[BLIP-2](model_doc/blip-2)** (from Salesforce) released with the paper [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by Junnan Li, Dongxu Li, Silvio Savarese, Steven Hoi.
+1. **[BLOOM](model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
+1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[BridgeTower](model_doc/bridgetower)** (from Harbin Institute of Technology/Microsoft Research Asia/Intel Labs) released with the paper [BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning](https://arxiv.org/abs/2206.08657) by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
+1. **[Bros](model_doc/bros)** (from NAVER) released with the paper [BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents](https://arxiv.org/abs/2108.04539) by Teakgyu Hong, Donghyun Kim, Mingi Ji, Wonseok Hwang, Daehyun Nam, Sungrae Park.
+1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[Chinese-CLIP](model_doc/chinese_clip)** (from OFA-Sys) released with the paper [Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese](https://arxiv.org/abs/2211.01335) by An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, Chang Zhou.
+1. **[CLAP](model_doc/clap)** (from LAION-AI) released with the paper [Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation](https://arxiv.org/abs/2211.06687) by Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, Shlomo Dubnov.
+1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
+1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
+1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
+1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CPM-Ant](model_doc/cpmant)** (from OpenBMB) released by the [OpenBMB](https://www.openbmb.org/).
+1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
+1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
+1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DePlot](model_doc/deplot)** (from Google AI) released with the paper [DePlot: One-shot visual language reasoning by plot-to-table translation](https://arxiv.org/abs/2212.10505) by Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen, Nigel Collier, Yasemin Altun.
+1. **[DETA](model_doc/deta)** (from The University of Texas at Austin) released with the paper [NMS Strikes Back](https://arxiv.org/abs/2212.06137) by Jeffrey Ouyang-Zhang, Jang Hyun Cho, Xingyi Zhou, Philipp Krähenbühl.
+1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DiNAT](model_doc/dinat)** (from SHI Labs) released with the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Ali Hassani and Humphrey Shi.
+1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
+1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
+1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientFormer](model_doc/efficientformer)** (from Snap Research) released with the paper [EfficientFormer: Vision Transformers at MobileNetSpeed](https://arxiv.org/abs/2206.01191) by Yanyu Li, Geng Yuan, Yang Wen, Ju Hu, Georgios Evangelidis, Sergey Tulyakov, Yanzhi Wang, Jian Ren.
+1. **[EfficientNet](model_doc/efficientnet)** (from Google Brain) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan, Quoc V. Le.
+1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
+1. **[ErnieM](model_doc/ernie_m)** (from Baidu) released with the paper [ERNIE-M: Enhanced Multilingual Representation by Aligning Cross-lingual Semantics with Monolingual Corpora](https://arxiv.org/abs/2012.15674) by Xuan Ouyang, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang.
+1. **[ESM](model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
+1. **[FLAN-T5](model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
+1. **[FLAN-UL2](model_doc/flan-ul2)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
+1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
+1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[FocalNet](model_doc/focalnet)** (from Microsoft Research) released with the paper [Focal Modulation Networks](https://arxiv.org/abs/2203.11926) by Jianwei Yang, Chunyuan Li, Xiyang Dai, Lu Yuan, Jianfeng Gao.
+1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GIT](model_doc/git)** (from Microsoft Research) released with the paper [GIT: A Generative Image-to-text Transformer for Vision and Language](https://arxiv.org/abs/2205.14100) by Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, Lijuan Wang.
+1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
+1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
+1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
+1. **[GPT NeoX Japanese](model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
+1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
+1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
+1. **[GPT-Sw3](model_doc/gpt-sw3)** (from AI-Sweden) released with the paper [Lessons Learned from GPT-SW3: Building the First Large-Scale Generative Language Model for Swedish](http://www.lrec-conf.org/proceedings/lrec2022/pdf/2022.lrec-1.376.pdf) by Ariel Ekgren, Amaru Cuba Gyllensten, Evangelia Gogoulou, Alice Heiman, Severine Verlinden, Joey Öhman, Fredrik Carlsson, Magnus Sahlgren.
+1. **[GPTBigCode](model_doc/gpt_bigcode)** (from BigCode) released with the paper [SantaCoder: don't reach for the stars!](https://arxiv.org/abs/2301.03988) by Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, Leandro von Werra.
+1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
+1. **[Graphormer](model_doc/graphormer)** (from Microsoft) released with the paper [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) by Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng, Guolin Ke, Di He, Yanming Shen, Tie-Yan Liu.
+1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
+1. **[Informer](model_doc/informer)** (from Beihang University, UC Berkeley, Rutgers University, SEDD Company) released with the paper [Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting](https://arxiv.org/abs/2012.07436) by Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang.
+1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
+1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
+1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
+1. **[LLaMA](model_doc/llama)** (from The FAIR team of Meta AI) released with the paper [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) by Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample.
+1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
+1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
+1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
+1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[MatCha](model_doc/matcha)** (from Google AI) released with the paper [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662) by Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
+1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[MEGA](model_doc/mega)** (from Meta/USC/CMU/SJTU) released with the paper [Mega: Moving Average Equipped Gated Attention](https://arxiv.org/abs/2209.10655) by Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, and Luke Zettlemoyer.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[MGP-STR](model_doc/mgp-str)** (from Alibaba Research) released with the paper [Multi-Granularity Prediction for Scene Text Recognition](https://arxiv.org/abs/2209.03592) by Peng Wang, Cheng Da, and Cong Yao.
+1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
+1. **[MobileNetV1](model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
+1. **[MobileNetV2](model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
+1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
+1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
+1. **[NAT](model_doc/nat)** (from SHI Labs) released with the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
+1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
+1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
+1. **[NLLB-MOE](model_doc/nllb-moe)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
+1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[OpenLlama](model_doc/open-llama)** (from [s-JoL](https://huggingface.co/s-JoL)) released on GitHub (now removed).
+1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
+1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
+1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[Pix2Struct](model_doc/pix2struct)** (from Google) released with the paper [Pix2Struct: Screenshot Parsing as Pretraining for Visual Language Understanding](https://arxiv.org/abs/2210.03347) by Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, Kristina Toutanova.
+1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
+1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm)** (from Facebook) released with the paper [fairseq: A Fast, Extensible Toolkit for Sequence Modeling](https://arxiv.org/abs/1904.01038) by Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, Michael Auli.
+1. **[RoCBert](model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
+1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[RWKV](model_doc/rwkv)** (from Bo Peng), released on [this repo](https://github.com/BlinkDL/RWKV-LM) by Bo Peng.
+1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[Segment Anything](model_doc/sam)** (from Meta AI) released with the paper [Segment Anything](https://arxiv.org/pdf/2304.02643v1.pdf) by Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick.
+1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechT5](model_doc/speecht5)** (from Microsoft Research) released with the paper [SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing](https://arxiv.org/abs/2110.07205) by Junyi Ao, Rui Wang, Long Zhou, Chengyi Wang, Shuo Ren, Yu Wu, Shujie Liu, Tom Ko, Qing Li, Yu Zhang, Zhihua Wei, Yao Qian, Jinyu Li, Furu Wei.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[SwiftFormer](model_doc/swiftformer)** (from MBZUAI) released with the paper [SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications](https://arxiv.org/abs/2303.15446) by Abdelrahman Shaker, Muhammad Maaz, Hanoona Rasheed, Salman Khan, Ming-Hsuan Yang, Fahad Shahbaz Khan.
+1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
+1. **[Swin2SR](model_doc/swin2sr)** (from University of Würzburg) released with the paper [Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration](https://arxiv.org/abs/2209.11345) by Marcos V. Conde, Ui-Jin Choi, Maxime Burchi, Radu Timofte.
+1. **[SwitchTransformers](model_doc/switch_transformers)** (from Google) released with the paper [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961) by William Fedus, Barret Zoph, Noam Shazeer.
+1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
+1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Time Series Transformer](model_doc/time_series_transformer)** (from HuggingFace).
+1. **[TimeSformer](model_doc/timesformer)** (from Facebook) released with the paper [Is Space-Time Attention All You Need for Video Understanding?](https://arxiv.org/abs/2102.05095) by Gedas Bertasius, Heng Wang, Lorenzo Torresani.
+1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
+1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[TVLT](model_doc/tvlt)** (from UNC Chapel Hill) released with the paper [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156) by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal.
+1. **[TVP](model_doc/tvp)** (from Intel) released with the paper [Text-Visual Prompting for Efficient 2D Temporal Video Grounding](https://arxiv.org/abs/2303.04995) by Yimeng Zhang, Xin Chen, Jinghan Jia, Sijia Liu, Ke Ding.
+1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
+1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[UPerNet](model_doc/upernet)** (from Peking University) released with the paper [Unified Perceptual Parsing for Scene Understanding](https://arxiv.org/abs/1807.10221) by Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, Jian Sun.
+1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
+1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[ViT Hybrid](model_doc/vit_hybrid)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[Whisper](model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
+1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
+1. **[X-MOD](model_doc/xmod)** (from Meta AI) released with the paper [Lifting the Curse of Multilinguality by Pre-training Modular Transformers](http://dx.doi.org/10.18653/v1/2022.naacl-main.255) by Jonas Pfeiffer, Naman Goyal, Xi Lin, Xian Li, James Cross, Sebastian Riedel, Mikel Artetxe.
+1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLM-V](model_doc/xlm-v)** (from Meta AI) released with the paper [XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models](https://arxiv.org/abs/2301.10472) by Davis Liang, Hila Gonen, Yuning Mao, Rui Hou, Naman Goyal, Marjan Ghazvininejad, Luke Zettlemoyer, Madian Khabsa.
+1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+
+
+### Rangka kerja yang disokong
+
+Jadual di bawah mewakili sokongan semasa dalam perpustakaan untuk setiap model tersebut, sama ada model tersebut mempunyai Python
+tokenizer (dipanggil ""lambat""). Tokenizer ""pantas"" yang disokong oleh perpustakaan Tokenizers 🤗, sama ada mereka mempunyai sokongan dalam Jax (melalui
+Flax), PyTorch, dan/atau TensorFlow.
+
+
+
+| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
+|:-----------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
+| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| ALIGN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| AltCLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Audio Spectrogram Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Autoformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
+| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
+| BigBird-Pegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
+| BioGpt | ✅ | ❌ | ✅ | ❌ | ❌ |
+| BiT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BLIP | ❌ | ❌ | ✅ | ✅ | ❌ |
+| BLIP-2 | ❌ | ❌ | ✅ | ❌ | ❌ |
+| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
+| BridgeTower | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Bros | ✅ | ✅ | ✅ | ❌ | ❌ |
+| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| Chinese-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
+| CLAP | ❌ | ❌ | ✅ | ❌ | ❌ |
+| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
+| CLIPSeg | ❌ | ❌ | ✅ | ❌ | ❌ |
+| CodeGen | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Conditional DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ConvNeXT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| ConvNeXTV2 | ❌ | ❌ | ✅ | ❌ | ❌ |
+| CPM-Ant | ✅ | ❌ | ✅ | ❌ | ❌ |
+| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| CvT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
+| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Deformable DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DeiT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| DETA | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DiNAT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| DonutSwin | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| EfficientFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
+| EfficientNet | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ERNIE | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ErnieM | ✅ | ❌ | ✅ | ❌ | ❌ |
+| ESM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FLAVA | ❌ | ❌ | ✅ | ❌ | ❌ |
+| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
+| FocalNet | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| GIT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
+| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
+| GPT NeoX Japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
+| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
+| GPT-Sw3 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| GPTBigCode | ❌ | ❌ | ✅ | ❌ | ❌ |
+| GPTSAN-japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
+| Graphormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| GroupViT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
+| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Informer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Jukebox | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
+| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| LiLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| LLaMA | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LongT5 | ❌ | ❌ | ✅ | ❌ | ✅ |
+| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| M-CTC-T | ❌ | ❌ | ✅ | ❌ | ❌ |
+| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
+| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
+| MarkupLM | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Mask2Former | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MaskFormerSwin | ❌ | ❌ | ❌ | ❌ | ❌ |
+| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| MEGA | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Megatron-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MGP-STR | ✅ | ❌ | ✅ | ❌ | ❌ |
+| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MobileNetV1 | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MobileNetV2 | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MobileViT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| MVP | ✅ | ✅ | ✅ | ❌ | ❌ |
+| NAT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Nezha | ❌ | ❌ | ✅ | ❌ | ❌ |
+| NLLB-MOE | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Nyströmformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| OneFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| OpenLlama | ❌ | ❌ | ✅ | ❌ | ❌ |
+| OPT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| OWL-ViT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
+| PEGASUS-X | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
+| Pix2Struct | ❌ | ❌ | ✅ | ❌ | ❌ |
+| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
+| REALM | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
+| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ResNet | ❌ | ❌ | ✅ | ✅ | ✅ |
+| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| RoBERTa-PreLayerNorm | ❌ | ❌ | ✅ | ✅ | ✅ |
+| RoCBert | ✅ | ❌ | ✅ | ❌ | ❌ |
+| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
+| RWKV | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SAM | ❌ | ❌ | ✅ | ✅ | ❌ |
+| SegFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
+| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
+| SpeechT5 | ✅ | ❌ | ✅ | ❌ | ❌ |
+| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
+| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| SwiftFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Swin Transformer | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Swin Transformer V2 | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Swin2SR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SwitchTransformers | ❌ | ❌ | ✅ | ❌ | ❌ |
+| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Table Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Time Series Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| TimeSformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| TVLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| TVP | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UPerNet | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VideoMAE | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| VisionTextDualEncoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| VisualBERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ViT Hybrid | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
+| ViTMSN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
+| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Whisper | ✅ | ✅ | ✅ | ✅ | ✅ |
+| X-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
+| X-MOD | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| XLM-ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
+| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/transformers/docs/source/pt/_config.py b/docs/transformers/docs/source/pt/_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..f49e4e4731965a504b8da443c2cd979638cd22bb
--- /dev/null
+++ b/docs/transformers/docs/source/pt/_config.py
@@ -0,0 +1,14 @@
+# docstyle-ignore
+INSTALL_CONTENT = """
+# Transformers installation
+! pip install transformers datasets evaluate accelerate
+# To install from source instead of the last release, comment the command above and uncomment the following one.
+# ! pip install git+https://github.com/huggingface/transformers.git
+"""
+
+notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
+black_avoid_patterns = {
+ "{processor_class}": "FakeProcessorClass",
+ "{model_class}": "FakeModelClass",
+ "{object_class}": "FakeObjectClass",
+}
diff --git a/docs/transformers/docs/source/pt/_toctree.yml b/docs/transformers/docs/source/pt/_toctree.yml
new file mode 100644
index 0000000000000000000000000000000000000000..d042168f7b9b693d92c0f85e2142ca1ec43e1236
--- /dev/null
+++ b/docs/transformers/docs/source/pt/_toctree.yml
@@ -0,0 +1,38 @@
+- sections:
+ - local: index
+ title: 🤗 Transformers
+ - local: quicktour
+ title: Tour rápido
+ - local: installation
+ title: Instalação
+ title: Início
+- sections:
+ - local: pipeline_tutorial
+ title: Pipelines para inferência
+ - local: training
+ title: Fine-tuning de um modelo pré-treinado
+ - local: accelerate
+ title: Treinamento distribuído com 🤗 Accelerate
+ title: Tutoriais
+- sections:
+ - local: fast_tokenizers
+ title: Usando os Tokenizers do 🤗 Tokenizers
+ - local: create_a_model
+ title: Criando uma arquitetura customizada
+ - local: custom_models
+ title: Compartilhando modelos customizados
+ - local: run_scripts
+ title: Treinamento a partir de um script
+ - local: converting_tensorflow_models
+ title: Convertendo checkpoints do TensorFlow para Pytorch
+ - local: serialization
+ title: Exportando modelos para ONNX
+ - sections:
+ - local: tasks/sequence_classification
+ title: Classificação de texto
+ - local: tasks/token_classification
+ title: Classificação de tokens
+ title: Fine-tuning para tarefas específicas
+ - local: multilingual
+ title: Modelos multilinguísticos para inferência
+ title: Guias práticos
diff --git a/docs/transformers/docs/source/pt/accelerate.md b/docs/transformers/docs/source/pt/accelerate.md
new file mode 100644
index 0000000000000000000000000000000000000000..a4e346a2b4873ff475ff9c3e34ff75e276fb58a7
--- /dev/null
+++ b/docs/transformers/docs/source/pt/accelerate.md
@@ -0,0 +1,145 @@
+
+
+# Treinamento distribuído com o 🤗 Accelerate
+
+O paralelismo surgiu como uma estratégia para treinar modelos grandes em hardware limitado e aumentar a velocidade
+de treinamento em várias órdens de magnitude. Na Hugging Face criamos a biblioteca [🤗 Accelerate](https://huggingface.co/docs/accelerate)
+para ajudar os usuários a treinar modelos 🤗 Transformers com qualquer configuração distribuída, seja em uma máquina
+com múltiplos GPUs ou em múltiplos GPUs distribuidos entre muitas máquinas. Neste tutorial, você irá aprender como
+personalizar seu laço de treinamento de PyTorch para poder treinar em ambientes distribuídos.
+
+## Configuração
+
+De início, instale o 🤗 Accelerate:
+
+```bash
+pip install accelerate
+```
+
+Logo, devemos importar e criar um objeto [`Accelerator`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator).
+O `Accelerator` detectará automáticamente a configuração distribuída disponível e inicializará todos os
+componentes necessários para o treinamento. Não há necessidade portanto de especificar o dispositivo onde deve colocar seu modelo.
+
+```py
+>>> from accelerate import Accelerator
+
+>>> accelerator = Accelerator()
+```
+
+## Preparando a aceleração
+
+Passe todos os objetos relevantes ao treinamento para o método [`prepare`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.prepare).
+Isto inclui os DataLoaders de treino e evaluação, um modelo e um otimizador:
+
+```py
+>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+... train_dataloader, eval_dataloader, model, optimizer
+... )
+```
+
+## Backward
+
+Por último, substitua o `loss.backward()` padrão em seu laço de treinamento com o método [`backward`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.backward) do 🤗 Accelerate:
+
+```py
+>>> for epoch in range(num_epochs):
+... for batch in train_dataloader:
+... outputs = model(**batch)
+... loss = outputs.loss
+... accelerator.backward(loss)
+
+... optimizer.step()
+... lr_scheduler.step()
+... optimizer.zero_grad()
+... progress_bar.update(1)
+```
+
+Como se poder ver no seguinte código, só precisará adicionar quatro linhas de código ao seu laço de treinamento
+para habilitar o treinamento distribuído!
+
+```diff
++ from accelerate import Accelerator
+ from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+
++ accelerator = Accelerator()
+
+ model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+ optimizer = AdamW(model.parameters(), lr=3e-5)
+
+- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+- model.to(device)
+
++ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
++ train_dataloader, eval_dataloader, model, optimizer
++ )
+
+ num_epochs = 3
+ num_training_steps = num_epochs * len(train_dataloader)
+ lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps
+ )
+
+ progress_bar = tqdm(range(num_training_steps))
+
+ model.train()
+ for epoch in range(num_epochs):
+ for batch in train_dataloader:
+- batch = {k: v.to(device) for k, v in batch.items()}
+ outputs = model(**batch)
+ loss = outputs.loss
+- loss.backward()
++ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+```
+
+## Treinamento
+
+Quando tiver adicionado as linhas de código relevantes, inicie o treinamento por um script ou notebook como o Colab.
+
+### Treinamento em um Script
+
+Se estiver rodando seu treinamento em um Script, execute o seguinte comando para criar e guardar um arquivo de configuração:
+
+```bash
+accelerate config
+```
+
+Comece o treinamento com:
+
+```bash
+accelerate launch train.py
+```
+
+### Treinamento em um Notebook
+
+O 🤗 Accelerate pode rodar em um notebook, por exemplo, se estiver planejando usar as TPUs do Google Colab.
+Encapsule o código responsável pelo treinamento de uma função e passe-o ao `notebook_launcher`:
+
+```py
+>>> from accelerate import notebook_launcher
+
+>>> notebook_launcher(training_function)
+```
+
+Para obter mais informações sobre o 🤗 Accelerate e suas numerosas funções, consulte a [documentación](https://huggingface.co/docs/accelerate/index).
diff --git a/docs/transformers/docs/source/pt/converting_tensorflow_models.md b/docs/transformers/docs/source/pt/converting_tensorflow_models.md
new file mode 100644
index 0000000000000000000000000000000000000000..63e926d4dcfe6c2a8c65c112a37b0a42f77786d5
--- /dev/null
+++ b/docs/transformers/docs/source/pt/converting_tensorflow_models.md
@@ -0,0 +1,152 @@
+
+
+# Convertendo checkpoints do TensorFlow para Pytorch
+
+Uma interface de linha de comando é fornecida para converter os checkpoints originais Bert/GPT/GPT-2/Transformer-XL/XLNet/XLM em modelos
+que podem ser carregados usando os métodos `from_pretrained` da biblioteca.
+
+
+
+A partir da versão 2.3.0 o script de conversão agora faz parte do transformers CLI (**transformers-cli**) disponível em qualquer instalação
+transformers >= 2.3.0.
+
+A documentação abaixo reflete o formato do comando **transformers-cli convert**.
+
+
+
+## BERT
+
+Você pode converter qualquer checkpoint do BERT em TensorFlow (em particular [os modelos pré-treinados lançados pelo Google](https://github.com/google-research/bert#pre-trained-models)) em um arquivo PyTorch usando um
+[convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert/convert_bert_original_tf_checkpoint_to_pytorch.py) script.
+
+Esta Interface de Linha de Comando (CLI) recebe como entrada um checkpoint do TensorFlow (três arquivos começando com `bert_model.ckpt`) e o
+arquivo de configuração (`bert_config.json`), e então cria um modelo PyTorch para esta configuração, carrega os pesos
+do checkpoint do TensorFlow no modelo PyTorch e salva o modelo resultante em um arquivo PyTorch que pode
+ser importado usando `from_pretrained()` (veja o exemplo em [quicktour](quicktour) , [run_glue.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_glue.py) ).
+
+Você só precisa executar este script de conversão **uma vez** para obter um modelo PyTorch. Você pode então desconsiderar o checkpoint em
+ TensorFlow (os três arquivos começando com `bert_model.ckpt`), mas certifique-se de manter o arquivo de configuração (\
+`bert_config.json`) e o arquivo de vocabulário (`vocab.txt`), pois eles também são necessários para o modelo PyTorch.
+
+Para executar este script de conversão específico, você precisará ter o TensorFlow e o PyTorch instalados (`pip install tensorflow`). O resto do repositório requer apenas o PyTorch.
+
+Aqui está um exemplo do processo de conversão para um modelo `BERT-Base Uncased` pré-treinado:
+
+```bash
+export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
+
+transformers-cli convert --model_type bert \
+ --tf_checkpoint $BERT_BASE_DIR/bert_model.ckpt \
+ --config $BERT_BASE_DIR/bert_config.json \
+ --pytorch_dump_output $BERT_BASE_DIR/pytorch_model.bin
+```
+
+Você pode baixar os modelos pré-treinados do Google para a conversão [aqui](https://github.com/google-research/bert#pre-trained-models).
+
+## ALBERT
+
+Converta os checkpoints do modelo ALBERT em TensorFlow para PyTorch usando o
+[convert_albert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py) script.
+
+A Interface de Linha de Comando (CLI) recebe como entrada um checkpoint do TensorFlow (três arquivos começando com `model.ckpt-best`) e o
+arquivo de configuração (`albert_config.json`), então cria e salva um modelo PyTorch. Para executar esta conversão, você
+precisa ter o TensorFlow e o PyTorch instalados.
+
+Aqui está um exemplo do processo de conversão para o modelo `ALBERT Base` pré-treinado:
+
+```bash
+export ALBERT_BASE_DIR=/path/to/albert/albert_base
+
+transformers-cli convert --model_type albert \
+ --tf_checkpoint $ALBERT_BASE_DIR/model.ckpt-best \
+ --config $ALBERT_BASE_DIR/albert_config.json \
+ --pytorch_dump_output $ALBERT_BASE_DIR/pytorch_model.bin
+```
+
+Você pode baixar os modelos pré-treinados do Google para a conversão [aqui](https://github.com/google-research/albert#pre-trained-models).
+
+## OpenAI GPT
+
+Aqui está um exemplo do processo de conversão para um modelo OpenAI GPT pré-treinado, supondo que seu checkpoint NumPy
+foi salvo com o mesmo formato do modelo pré-treinado OpenAI (veja [aqui](https://github.com/openai/finetune-transformer-lm)\
+)
+
+```bash
+export OPENAI_GPT_CHECKPOINT_FOLDER_PATH=/path/to/openai/pretrained/numpy/weights
+
+transformers-cli convert --model_type gpt \
+ --tf_checkpoint $OPENAI_GPT_CHECKPOINT_FOLDER_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
+ [--config OPENAI_GPT_CONFIG] \
+ [--finetuning_task_name OPENAI_GPT_FINETUNED_TASK] \
+```
+
+## OpenAI GPT-2
+
+Aqui está um exemplo do processo de conversão para um modelo OpenAI GPT-2 pré-treinado (consulte [aqui](https://github.com/openai/gpt-2))
+
+```bash
+export OPENAI_GPT2_CHECKPOINT_PATH=/path/to/openai-community/gpt2/pretrained/weights
+
+transformers-cli convert --model_type gpt2 \
+ --tf_checkpoint $OPENAI_GPT2_CHECKPOINT_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
+ [--config OPENAI_GPT2_CONFIG] \
+ [--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
+```
+
+## XLNet
+
+Aqui está um exemplo do processo de conversão para um modelo XLNet pré-treinado:
+
+```bash
+export TRANSFO_XL_CHECKPOINT_PATH=/path/to/xlnet/checkpoint
+export TRANSFO_XL_CONFIG_PATH=/path/to/xlnet/config
+
+transformers-cli convert --model_type xlnet \
+ --tf_checkpoint $TRANSFO_XL_CHECKPOINT_PATH \
+ --config $TRANSFO_XL_CONFIG_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
+ [--finetuning_task_name XLNET_FINETUNED_TASK] \
+```
+
+## XLM
+
+Aqui está um exemplo do processo de conversão para um modelo XLM pré-treinado:
+
+```bash
+export XLM_CHECKPOINT_PATH=/path/to/xlm/checkpoint
+
+transformers-cli convert --model_type xlm \
+ --tf_checkpoint $XLM_CHECKPOINT_PATH \
+ --pytorch_dump_output $PYTORCH_DUMP_OUTPUT
+ [--config XML_CONFIG] \
+ [--finetuning_task_name XML_FINETUNED_TASK]
+```
+
+## T5
+
+Aqui está um exemplo do processo de conversão para um modelo T5 pré-treinado:
+
+```bash
+export T5=/path/to/t5/uncased_L-12_H-768_A-12
+
+transformers-cli convert --model_type t5 \
+ --tf_checkpoint $T5/t5_model.ckpt \
+ --config $T5/t5_config.json \
+ --pytorch_dump_output $T5/pytorch_model.bin
+```
diff --git a/docs/transformers/docs/source/pt/create_a_model.md b/docs/transformers/docs/source/pt/create_a_model.md
new file mode 100644
index 0000000000000000000000000000000000000000..dd71963236f4fa9eb37add6c04ebd4b967069175
--- /dev/null
+++ b/docs/transformers/docs/source/pt/create_a_model.md
@@ -0,0 +1,359 @@
+
+
+# Criar uma arquitetura customizada
+
+Uma [`AutoClass`](model_doc/auto) automaticamente infere a arquitetura do modelo e baixa configurações e pesos pré-treinados. Geralmente, nós recomendamos usar uma `AutoClass` para produzir um código independente de checkpoints. Mas usuários que querem mais contole sobre parâmetros específicos do modelo pode criar um modelo customizado 🤗 Transformers a partir de algumas classes bases. Isso pode ser particulamente útil para alguém que está interessado em estudar, treinar ou fazer experimentos com um modelo 🤗 Transformers. Nesse tutorial, será explicado como criar um modelo customizado sem uma `AutoClass`. Aprenda como:
+
+- Carregar e customizar a configuração de um modelo.
+- Criar a arquitetura de um modelo.
+- Criar um tokenizer rápido e devagar para textos.
+- Criar extrator de features para tarefas envolvendo audio e imagem.
+- Criar um processador para tarefas multimodais.
+
+## configuration
+
+A [configuration](main_classes/configuration) refere-se a atributos específicos de um modelo. Cada configuração de modelo tem atributos diferentes; por exemplo, todos modelo de PLN possuem os atributos `hidden_size`, `num_attention_heads`, `num_hidden_layers` e `vocab_size` em comum. Esse atributos especificam o numero de 'attention heads' ou 'hidden layers' para construir um modelo.
+
+Dê uma olhada a mais em [DistilBERT](model_doc/distilbert) acessando [`DistilBertConfig`] para observar esses atributos:
+
+```py
+>>> from transformers import DistilBertConfig
+
+>>> config = DistilBertConfig()
+>>> print(config)
+DistilBertConfig {
+ "activation": "gelu",
+ "attention_dropout": 0.1,
+ "dim": 768,
+ "dropout": 0.1,
+ "hidden_dim": 3072,
+ "initializer_range": 0.02,
+ "max_position_embeddings": 512,
+ "model_type": "distilbert",
+ "n_heads": 12,
+ "n_layers": 6,
+ "pad_token_id": 0,
+ "qa_dropout": 0.1,
+ "seq_classif_dropout": 0.2,
+ "sinusoidal_pos_embds": false,
+ "transformers_version": "4.16.2",
+ "vocab_size": 30522
+}
+```
+
+[`DistilBertConfig`] mostra todos os atributos padrões usados para construir um [`DistilBertModel`] base. Todos atributos são customizáveis, o que cria espaço para experimentos. Por exemplo, você pode customizar um modelo padrão para:
+
+- Tentar uma função de ativação diferente com o parâmetro `activation`.
+- Usar uma taxa de desistência maior para as probabilidades de 'attention' com o parâmetro `attention_dropout`.
+
+```py
+>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
+>>> print(my_config)
+DistilBertConfig {
+ "activation": "relu",
+ "attention_dropout": 0.4,
+ "dim": 768,
+ "dropout": 0.1,
+ "hidden_dim": 3072,
+ "initializer_range": 0.02,
+ "max_position_embeddings": 512,
+ "model_type": "distilbert",
+ "n_heads": 12,
+ "n_layers": 6,
+ "pad_token_id": 0,
+ "qa_dropout": 0.1,
+ "seq_classif_dropout": 0.2,
+ "sinusoidal_pos_embds": false,
+ "transformers_version": "4.16.2",
+ "vocab_size": 30522
+}
+```
+
+Atributos de um modelo pré-treinado podem ser modificados na função [`~PretrainedConfig.from_pretrained`]:
+
+```py
+>>> my_config = DistilBertConfig.from_pretrained("distilbert/distilbert-base-uncased", activation="relu", attention_dropout=0.4)
+```
+
+Uma vez que você está satisfeito com as configurações do seu modelo, você consegue salvar elas com [`~PretrainedConfig.save_pretrained`]. Seu arquivo de configurações está salvo como um arquivo JSON no diretório especificado:
+
+```py
+>>> my_config.save_pretrained(save_directory="./your_model_save_path")
+```
+
+Para reusar o arquivo de configurações, carregue com [`~PretrainedConfig.from_pretrained`]:
+
+```py
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
+```
+
+
+
+Você pode também salvar seu arquivo de configurações como um dicionário ou até mesmo com a diferença entre as seus atributos de configuração customizados e os atributos de configuração padrões! Olhe a documentação [configuration](main_classes/configuration) para mais detalhes.
+
+
+
+## Modelo
+
+O próximo passo é criar um [model](main_classes/models). O modelo - também vagamente referido como arquitetura - define o que cada camada está fazendo e quais operações estão acontecendo. Atributos como `num_hidden_layers` das configurações são utilizados para definir a arquitetura. Todo modelo compartilha a classe base [`PreTrainedModel`] e alguns métodos em comum como redimensionar o tamanho dos embeddings de entrada e podar as 'self-attention heads'. Além disso, todos os modelos também são subclasses de [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) ou [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html). Isso significa que os modelos são compatíveis com cada respectivo uso de framework.
+
+
+
+Carregar seus atributos de configuração customizados em um modelo:
+
+```py
+>>> from transformers import DistilBertModel
+
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
+>>> model = DistilBertModel(my_config)
+```
+
+Isso cria um modelo com valores aleatórios ao invés de pré-treinar os pesos. Você não irá conseguir usar usar esse modelo para nada útil ainda, até você treinar ele. Treino é um processo caro e demorado. Geralmente é melhor utilizar um modelo pré-treinado para obter melhores resultados mais rápido, enquanto usa apenas uma fração dos recursos necessários para treinar.
+
+Criar um modelo pré-treinado com [`~PreTrainedModel.from_pretrained`]:
+
+```py
+>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+Quando você carregar os pesos pré-treinados, a configuração padrão do modelo é automaticamente carregada se o modelo é provido pelo 🤗 Transformers. No entanto, você ainda consegue mudar - alguns ou todos - os atributos padrões de configuração do modelo com os seus próprio atributos, se você preferir:
+
+```py
+>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
+```
+
+
+Carregar os seus próprios atributos padrões de contiguração no modelo:
+
+```py
+>>> from transformers import TFDistilBertModel
+
+>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
+>>> tf_model = TFDistilBertModel(my_config)
+```
+
+Isso cria um modelo com valores aleatórios ao invés de pré-treinar os pesos. Você não irá conseguir usar usar esse modelo para nada útil ainda, até você treinar ele. Treino é um processo caro e demorado. Geralmente é melhor utilizar um modelo pré-treinado para obter melhores resultados mais rápido, enquanto usa apenas uma fração dos recursos necessários para treinar.
+
+Criar um modelo pré-treinado com [`~TFPreTrainedModel.from_pretrained`]:
+
+```py
+>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+Quando você carregar os pesos pré-treinados, a configuração padrão do modelo é automaticamente carregada se o modelo é provido pelo 🤗 Transformers. No entanto, você ainda consegue mudar - alguns ou todos - os atributos padrões de configuração do modelo com os seus próprio atributos, se você preferir:
+
+```py
+>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
+```
+
+
+
+### Heads do modelo
+
+Neste ponto, você tem um modelo básico do DistilBERT que gera os *estados ocultos*. Os estados ocultos são passados como entrada para a head do moelo para produzir a saída final. 🤗 Transformers fornece uma head de modelo diferente para cada tarefa desde que o modelo suporte essa tarefa (por exemplo, você não consegue utilizar o modelo DistilBERT para uma tarefa de 'sequence-to-sequence' como tradução).
+
+
+
+Por exemplo, [`DistilBertForSequenceClassification`] é um modelo DistilBERT base com uma head de classificação de sequência. A head de calssificação de sequência é uma camada linear no topo das saídas agrupadas.
+
+```py
+>>> from transformers import DistilBertForSequenceClassification
+
+>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+Reutilize facilmente esse ponto de parada para outra tarefe mudando para uma head de modelo diferente. Para uma tarefe de responder questões, você usaria a head do modelo [`DistilBertForQuestionAnswering`]. A head de responder questões é similar com a de classificação de sequências exceto o fato de que ela é uma camada no topo dos estados das saídas ocultas.
+
+```py
+>>> from transformers import DistilBertForQuestionAnswering
+
+>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+
+Por exemplo, [`TFDistilBertForSequenceClassification`] é um modelo DistilBERT base com uma head de classificação de sequência. A head de calssificação de sequência é uma camada linear no topo das saídas agrupadas.
+
+```py
+>>> from transformers import TFDistilBertForSequenceClassification
+
+>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+Reutilize facilmente esse ponto de parada para outra tarefe mudando para uma head de modelo diferente. Para uma tarefe de responder questões, você usaria a head do modelo [`TFDistilBertForQuestionAnswering`]. A head de responder questões é similar com a de classificação de sequências exceto o fato de que ela é uma camada no topo dos estados das saídas ocultas.
+
+```py
+>>> from transformers import TFDistilBertForQuestionAnswering
+
+>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+
+
+## Tokenizer
+
+A útlima classe base que você precisa antes de usar um modelo para dados textuais é a [tokenizer](main_classes/tokenizer) para converter textos originais para tensores. Existem dois tipos de tokenizers que você pode usar com 🤗 Transformers:
+
+- [`PreTrainedTokenizer`]: uma implementação em Python de um tokenizer.
+- [`PreTrainedTokenizerFast`]: um tokenizer da nossa biblioteca [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) baseada em Rust. Esse tipo de tokenizer é significantemente mais rapido - especialmente durante tokenization de codificação - devido a implementação em Rust. O tokenizer rápido tambem oferece métodos adicionais como *offset mapping* que mapeia tokens para suar palavras ou caracteres originais.
+
+Os dois tokenizers suporta métodos comuns como os de codificar e decodificar, adicionar novos tokens, e gerenciar tokens especiais.
+
+
+
+Nem todo modelo suporta um 'fast tokenizer'. De uma olhada aqui [table](index#supported-frameworks) pra checar se um modelo suporta 'fast tokenizer'.
+
+
+
+Se você treinou seu prórpio tokenizer, você pode criar um a partir do seu arquivo *vocabulary*:
+
+```py
+>>> from transformers import DistilBertTokenizer
+
+>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
+```
+
+É importante lembrar que o vocabulário de um tokenizer customizado será diferente de um vocabulário gerado pelo tokenizer de um modelo pré treinado. Você precisa usar o vocabulário de um modelo pré treinado se você estiver usando um modelo pré treinado, caso contrário as entradas não farão sentido. Criando um tokenizer com um vocabulário de um modelo pré treinado com a classe [`DistilBertTokenizer`]:
+
+```py
+>>> from transformers import DistilBertTokenizer
+
+>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+Criando um 'fast tokenizer' com a classe [`DistilBertTokenizerFast`]:
+
+```py
+>>> from transformers import DistilBertTokenizerFast
+
+>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+
+
+Pos padrão, [`AutoTokenizer`] tentará carregar um 'fast tokenizer'. Você pode disabilitar esse comportamento colocando `use_fast=False` no `from_pretrained`.
+
+
+
+## Extrator de features
+
+Um extrator de features processa entradas de imagem ou áudio. Ele herda da classe base [`~feature_extraction_utils.FeatureExtractionMixin`], e pode também herdar da classe [`ImageFeatureExtractionMixin`] para processamento de features de imagem ou da classe [`SequenceFeatureExtractor`] para processamento de entradas de áudio.
+
+Dependendo do que você está trabalhando em um audio ou uma tarefa de visão, crie um estrator de features associado com o modelo que você está usando. Por exemplo, crie um [`ViTFeatureExtractor`] padrão se você estiver usando [ViT](model_doc/vit) para classificação de imagens:
+
+```py
+>>> from transformers import ViTFeatureExtractor
+
+>>> vit_extractor = ViTFeatureExtractor()
+>>> print(vit_extractor)
+ViTFeatureExtractor {
+ "do_normalize": true,
+ "do_resize": true,
+ "feature_extractor_type": "ViTFeatureExtractor",
+ "image_mean": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "image_std": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "resample": 2,
+ "size": 224
+}
+```
+
+
+
+Se você não estiver procurando por nenhuma customização, apenas use o método `from_pretrained` para carregar parâmetros do modelo de extrator de features padrão.
+
+
+
+Modifique qualquer parâmetro dentre os [`ViTFeatureExtractor`] para criar seu extrator de features customizado.
+
+```py
+>>> from transformers import ViTFeatureExtractor
+
+>>> my_vit_extractor = ViTFeatureExtractor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
+>>> print(my_vit_extractor)
+ViTFeatureExtractor {
+ "do_normalize": false,
+ "do_resize": true,
+ "feature_extractor_type": "ViTFeatureExtractor",
+ "image_mean": [
+ 0.3,
+ 0.3,
+ 0.3
+ ],
+ "image_std": [
+ 0.5,
+ 0.5,
+ 0.5
+ ],
+ "resample": "PIL.Image.BOX",
+ "size": 224
+}
+```
+
+Para entradas de áutio, você pode criar um [`Wav2Vec2FeatureExtractor`] e customizar os parâmetros de uma forma similar:
+
+```py
+>>> from transformers import Wav2Vec2FeatureExtractor
+
+>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
+>>> print(w2v2_extractor)
+Wav2Vec2FeatureExtractor {
+ "do_normalize": true,
+ "feature_extractor_type": "Wav2Vec2FeatureExtractor",
+ "feature_size": 1,
+ "padding_side": "right",
+ "padding_value": 0.0,
+ "return_attention_mask": false,
+ "sampling_rate": 16000
+}
+```
+
+## Processor
+
+Para modelos que suportam tarefas multimodais, 🤗 Transformers oferece uma classe processadora que convenientemente cobre um extrator de features e tokenizer dentro de um único objeto. Por exemplo, vamos usar o [`Wav2Vec2Processor`] para uma tarefa de reconhecimento de fala automática (ASR). ASR transcreve áudio para texto, então você irá precisar de um extrator de um features e um tokenizer.
+
+Crie um extrator de features para lidar com as entradas de áudio.
+
+```py
+>>> from transformers import Wav2Vec2FeatureExtractor
+
+>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
+```
+
+Crie um tokenizer para lidar com a entrada de textos:
+
+```py
+>>> from transformers import Wav2Vec2CTCTokenizer
+
+>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
+```
+
+Combine o extrator de features e o tokenizer no [`Wav2Vec2Processor`]:
+
+```py
+>>> from transformers import Wav2Vec2Processor
+
+>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
+```
+
+Com duas classes básicas - configuração e modelo - e um preprocessamento de classe adicional (tokenizer, extrator de features, ou processador), você pode criar qualquer modelo que suportado por 🤗 Transformers. Qualquer uma dessas classes base são configuráveis, te permitindo usar os atributos específicos que você queira. Você pode facilmente preparar um modelo para treinamento ou modificar um modelo pré-treinado com poucas mudanças.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/pt/custom_models.md b/docs/transformers/docs/source/pt/custom_models.md
new file mode 100644
index 0000000000000000000000000000000000000000..27633f9d1bb238751ab0e49a254c0bec28ae4013
--- /dev/null
+++ b/docs/transformers/docs/source/pt/custom_models.md
@@ -0,0 +1,358 @@
+
+
+# Compartilhando modelos customizados
+
+A biblioteca 🤗 Transformers foi projetada para ser facilmente extensível. Cada modelo é totalmente codificado em uma determinada subpasta
+do repositório sem abstração, para que você possa copiar facilmente um arquivo de modelagem e ajustá-lo às suas necessidades.
+
+Se você estiver escrevendo um modelo totalmente novo, pode ser mais fácil começar do zero. Neste tutorial, mostraremos
+como escrever um modelo customizado e sua configuração para que possa ser usado com Transformers, e como você pode compartilhá-lo
+com a comunidade (com o código em que se baseia) para que qualquer pessoa possa usá-lo, mesmo se não estiver presente na biblioteca 🤗 Transformers.
+
+Ilustraremos tudo isso em um modelo ResNet, envolvendo a classe ResNet do
+[biblioteca timm](https://github.com/rwightman/pytorch-image-models) em um [`PreTrainedModel`].
+
+## Escrevendo uma configuração customizada
+
+Antes de mergulharmos no modelo, vamos primeiro escrever sua configuração. A configuração de um modelo é um objeto que
+terá todas as informações necessárias para construir o modelo. Como veremos na próxima seção, o modelo só pode
+ter um `config` para ser inicializado, então realmente precisamos que esse objeto seja o mais completo possível.
+
+Em nosso exemplo, pegaremos alguns argumentos da classe ResNet que podemos querer ajustar. Diferentes
+configurações nos dará os diferentes tipos de ResNets que são possíveis. Em seguida, apenas armazenamos esses argumentos,
+após verificar a validade de alguns deles.
+
+```python
+from transformers import PretrainedConfig
+from typing import List
+
+
+class ResnetConfig(PretrainedConfig):
+ model_type = "resnet"
+
+ def __init__(
+ self,
+ block_type="bottleneck",
+ layers: List[int] = [3, 4, 6, 3],
+ num_classes: int = 1000,
+ input_channels: int = 3,
+ cardinality: int = 1,
+ base_width: int = 64,
+ stem_width: int = 64,
+ stem_type: str = "",
+ avg_down: bool = False,
+ **kwargs,
+ ):
+ if block_type not in ["basic", "bottleneck"]:
+ raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
+ if stem_type not in ["", "deep", "deep-tiered"]:
+ raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
+
+ self.block_type = block_type
+ self.layers = layers
+ self.num_classes = num_classes
+ self.input_channels = input_channels
+ self.cardinality = cardinality
+ self.base_width = base_width
+ self.stem_width = stem_width
+ self.stem_type = stem_type
+ self.avg_down = avg_down
+ super().__init__(**kwargs)
+```
+
+As três coisas importantes a serem lembradas ao escrever sua própria configuração são:
+- você tem que herdar de `PretrainedConfig`,
+- o `__init__` do seu `PretrainedConfig` deve aceitar quaisquer kwargs,
+- esses `kwargs` precisam ser passados para a superclasse `__init__`.
+
+A herança é para garantir que você obtenha todas as funcionalidades da biblioteca 🤗 Transformers, enquanto as outras duas
+restrições vêm do fato de um `PretrainedConfig` ter mais campos do que os que você está configurando. Ao recarregar um
+config com o método `from_pretrained`, esses campos precisam ser aceitos pelo seu config e então enviados para a
+superclasse.
+
+Definir um `model_type` para sua configuração (aqui `model_type="resnet"`) não é obrigatório, a menos que você queira
+registrar seu modelo com as classes automáticas (veja a última seção).
+
+Com isso feito, você pode facilmente criar e salvar sua configuração como faria com qualquer outra configuração de modelo da
+biblioteca. Aqui está como podemos criar uma configuração resnet50d e salvá-la:
+
+```py
+resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
+resnet50d_config.save_pretrained("custom-resnet")
+```
+
+Isso salvará um arquivo chamado `config.json` dentro da pasta `custom-resnet`. Você pode então recarregar sua configuração com o
+método `from_pretrained`:
+
+```py
+resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
+```
+
+Você também pode usar qualquer outro método da classe [`PretrainedConfig`], como [`~PretrainedConfig.push_to_hub`] para
+carregar diretamente sua configuração para o Hub.
+
+## Escrevendo um modelo customizado
+
+Agora que temos nossa configuração ResNet, podemos continuar escrevendo o modelo. Na verdade, escreveremos dois: um que
+extrai os recursos ocultos de um lote de imagens (como [`BertModel`]) e um que é adequado para classificação de imagem
+(como [`BertForSequenceClassification`]).
+
+Como mencionamos antes, escreveremos apenas um wrapper solto do modelo para mantê-lo simples para este exemplo. A única
+coisa que precisamos fazer antes de escrever esta classe é um mapa entre os tipos de bloco e as classes de bloco reais. Então o
+modelo é definido a partir da configuração passando tudo para a classe `ResNet`:
+
+```py
+from transformers import PreTrainedModel
+from timm.models.resnet import BasicBlock, Bottleneck, ResNet
+from .configuration_resnet import ResnetConfig
+
+
+BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
+
+
+class ResnetModel(PreTrainedModel):
+ config_class = ResnetConfig
+
+ def __init__(self, config):
+ super().__init__(config)
+ block_layer = BLOCK_MAPPING[config.block_type]
+ self.model = ResNet(
+ block_layer,
+ config.layers,
+ num_classes=config.num_classes,
+ in_chans=config.input_channels,
+ cardinality=config.cardinality,
+ base_width=config.base_width,
+ stem_width=config.stem_width,
+ stem_type=config.stem_type,
+ avg_down=config.avg_down,
+ )
+
+ def forward(self, tensor):
+ return self.model.forward_features(tensor)
+```
+
+Para o modelo que irá classificar as imagens, vamos apenas alterar o método forward:
+
+```py
+import torch
+
+
+class ResnetModelForImageClassification(PreTrainedModel):
+ config_class = ResnetConfig
+
+ def __init__(self, config):
+ super().__init__(config)
+ block_layer = BLOCK_MAPPING[config.block_type]
+ self.model = ResNet(
+ block_layer,
+ config.layers,
+ num_classes=config.num_classes,
+ in_chans=config.input_channels,
+ cardinality=config.cardinality,
+ base_width=config.base_width,
+ stem_width=config.stem_width,
+ stem_type=config.stem_type,
+ avg_down=config.avg_down,
+ )
+
+ def forward(self, tensor, labels=None):
+ logits = self.model(tensor)
+ if labels is not None:
+ loss = torch.nn.functional.cross_entropy(logits, labels)
+ return {"loss": loss, "logits": logits}
+ return {"logits": logits}
+```
+
+Em ambos os casos, observe como herdamos de `PreTrainedModel` e chamamos a inicialização da superclasse com o `config`
+(um pouco parecido quando você escreve um `torch.nn.Module`). A linha que define o `config_class` não é obrigatória, a menos que
+você deseje registrar seu modelo com as classes automáticas (consulte a última seção).
+
+
+
+Se o seu modelo for muito semelhante a um modelo dentro da biblioteca, você poderá reutilizar a mesma configuração desse modelo.
+
+
+
+Você pode fazer com que seu modelo retorne o que você quiser,porém retornando um dicionário como fizemos para
+`ResnetModelForImageClassification`, com a função de perda incluída quando os rótulos são passados, vai tornar seu modelo diretamente
+utilizável dentro da classe [`Trainer`]. Você pode usar outro formato de saída, desde que esteja planejando usar seu próprio
+laço de treinamento ou outra biblioteca para treinamento.
+
+Agora que temos nossa classe do modelo, vamos criar uma:
+
+```py
+resnet50d = ResnetModelForImageClassification(resnet50d_config)
+```
+
+Novamente, você pode usar qualquer um dos métodos do [`PreTrainedModel`], como [`~PreTrainedModel.save_pretrained`] ou
+[`~PreTrainedModel.push_to_hub`]. Usaremos o segundo na próxima seção e veremos como enviar os pesos e
+o código do nosso modelo. Mas primeiro, vamos carregar alguns pesos pré-treinados dentro do nosso modelo.
+
+Em seu próprio caso de uso, você provavelmente estará treinando seu modelo customizado em seus próprios dados. Para este tutorial ser rápido,
+usaremos a versão pré-treinada do resnet50d. Como nosso modelo é apenas um wrapper em torno dele, será
+fácil de transferir esses pesos:
+
+```py
+import timm
+
+pretrained_model = timm.create_model("resnet50d", pretrained=True)
+resnet50d.model.load_state_dict(pretrained_model.state_dict())
+```
+
+Agora vamos ver como ter certeza de que quando fazemos [`~PreTrainedModel.save_pretrained`] ou [`~PreTrainedModel.push_to_hub`], o
+código do modelo é salvo.
+
+## Enviando o código para o Hub
+
+
+
+Esta API é experimental e pode ter algumas pequenas alterações nas próximas versões.
+
+
+
+Primeiro, certifique-se de que seu modelo esteja totalmente definido em um arquivo `.py`. Ele pode contar com importações relativas para alguns outros arquivos
+desde que todos os arquivos estejam no mesmo diretório (ainda não suportamos submódulos para este recurso). Para o nosso exemplo,
+vamos definir um arquivo `modeling_resnet.py` e um arquivo `configuration_resnet.py` em uma pasta no
+diretório de trabalho atual chamado `resnet_model`. O arquivo de configuração contém o código para `ResnetConfig` e o arquivo de modelagem
+contém o código do `ResnetModel` e `ResnetModelForImageClassification`.
+
+```
+.
+└── resnet_model
+ ├── __init__.py
+ ├── configuration_resnet.py
+ └── modeling_resnet.py
+```
+
+O `__init__.py` pode estar vazio, apenas está lá para que o Python detecte que o `resnet_model` possa ser usado como um módulo.
+
+
+
+Se estiver copiando arquivos de modelagem da biblioteca, você precisará substituir todas as importações relativas na parte superior do arquivo
+para importar do pacote `transformers`.
+
+
+
+Observe que você pode reutilizar (ou subclasse) uma configuração/modelo existente.
+
+Para compartilhar seu modelo com a comunidade, siga estas etapas: primeiro importe o modelo ResNet e a configuração do
+arquivos criados:
+
+```py
+from resnet_model.configuration_resnet import ResnetConfig
+from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
+```
+
+Então você tem que dizer à biblioteca que deseja copiar os arquivos de código desses objetos ao usar o `save_pretrained`
+e registrá-los corretamente com uma determinada classe automáticas (especialmente para modelos), basta executar:
+
+```py
+ResnetConfig.register_for_auto_class()
+ResnetModel.register_for_auto_class("AutoModel")
+ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
+```
+
+Observe que não há necessidade de especificar uma classe automática para a configuração (há apenas uma classe automática,
+[`AutoConfig`]), mas é diferente para os modelos. Seu modelo customizado pode ser adequado para muitas tarefas diferentes, então você
+tem que especificar qual das classes automáticas é a correta para o seu modelo.
+
+Em seguida, vamos criar a configuração e os modelos como fizemos antes:
+
+```py
+resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
+resnet50d = ResnetModelForImageClassification(resnet50d_config)
+
+pretrained_model = timm.create_model("resnet50d", pretrained=True)
+resnet50d.model.load_state_dict(pretrained_model.state_dict())
+```
+
+Agora para enviar o modelo para o Hub, certifique-se de estar logado. Ou execute no seu terminal:
+
+```bash
+huggingface-cli login
+```
+
+ou a partir do notebook:
+
+```py
+from huggingface_hub import notebook_login
+
+notebook_login()
+```
+
+Você pode então enviar para seu próprio namespace (ou uma organização da qual você é membro) assim:
+
+
+```py
+resnet50d.push_to_hub("custom-resnet50d")
+```
+
+Além dos pesos do modelo e da configuração no formato json, isso também copiou o modelo e
+configuração `.py` na pasta `custom-resnet50d` e carregou o resultado para o Hub. Você pode conferir o resultado
+neste [repositório de modelos](https://huggingface.co/sgugger/custom-resnet50d).
+
+Consulte o [tutorial de compartilhamento](model_sharing) para obter mais informações sobre o método push_to_hub.
+
+## Usando um modelo com código customizado
+
+Você pode usar qualquer configuração, modelo ou tokenizador com arquivos de código customizados em seu repositório com as classes automáticas e
+o método `from_pretrained`. Todos os arquivos e códigos carregados no Hub são verificados quanto a malware (consulte a documentação de [Segurança do Hub](https://huggingface.co/docs/hub/security#malware-scanning) para obter mais informações), mas você ainda deve
+revisar o código do modelo e o autor para evitar a execução de código malicioso em sua máquina. Defina `trust_remote_code=True` para usar
+um modelo com código customizado:
+
+```py
+from transformers import AutoModelForImageClassification
+
+model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
+```
+
+Também é fortemente recomendado passar um hash de confirmação como uma `revisão` para garantir que o autor dos modelos não
+atualize o código com novas linhas maliciosas (a menos que você confie totalmente nos autores dos modelos).
+
+
+```py
+commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
+model = AutoModelForImageClassification.from_pretrained(
+ "sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
+)
+```
+
+Observe que ao navegar no histórico de commits do repositório do modelo no Hub, há um botão para copiar facilmente o commit
+hash de qualquer commit.
+
+## Registrando um modelo com código customizado para as classes automáticas
+
+Se você estiver escrevendo uma biblioteca que estende 🤗 Transformers, talvez queira estender as classes automáticas para incluir seus próprios
+modelos. Isso é diferente de enviar o código para o Hub no sentido de que os usuários precisarão importar sua biblioteca para
+obter os modelos customizados (ao contrário de baixar automaticamente o código do modelo do Hub).
+
+Desde que sua configuração tenha um atributo `model_type` diferente dos tipos de modelo existentes e que as classes do seu modelo
+tenha os atributos `config_class` corretos, você pode simplesmente adicioná-los às classes automáticas assim:
+
+```py
+from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
+
+AutoConfig.register("resnet", ResnetConfig)
+AutoModel.register(ResnetConfig, ResnetModel)
+AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
+```
+
+Observe que o primeiro argumento usado ao registrar sua configuração customizada para [`AutoConfig`] precisa corresponder ao `model_type`
+de sua configuração customizada. E o primeiro argumento usado ao registrar seus modelos customizados, para qualquer necessidade de classe de modelo automático
+deve corresponder ao `config_class` desses modelos.
+
diff --git a/docs/transformers/docs/source/pt/fast_tokenizers.md b/docs/transformers/docs/source/pt/fast_tokenizers.md
new file mode 100644
index 0000000000000000000000000000000000000000..ea1da8a61571f1a4969e1b7751de08a8b0ca40ea
--- /dev/null
+++ b/docs/transformers/docs/source/pt/fast_tokenizers.md
@@ -0,0 +1,66 @@
+
+
+# Usando os Tokenizers do 🤗 Tokenizers
+
+O [`PreTrainedTokenizerFast`] depende da biblioteca [🤗 Tokenizers](https://huggingface.co/docs/tokenizers). O Tokenizer obtido da biblioteca 🤗 Tokenizers pode ser carregado facilmente pelo 🤗 Transformers.
+
+Antes de entrar nos detalhes, vamos começar criando um tokenizer fictício em algumas linhas:
+
+```python
+>>> from tokenizers import Tokenizer
+>>> from tokenizers.models import BPE
+>>> from tokenizers.trainers import BpeTrainer
+>>> from tokenizers.pre_tokenizers import Whitespace
+
+>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
+>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
+
+>>> tokenizer.pre_tokenizer = Whitespace()
+>>> files = [...]
+>>> tokenizer.train(files, trainer)
+```
+
+Agora temos um tokenizer treinado nos arquivos que foram definidos. Nós podemos continuar usando nessa execução ou salvar em um arquivo JSON para re-utilizar no futuro.
+
+## Carregando diretamente de um objeto tokenizer
+
+Vamos ver como aproveitar esse objeto tokenizer na biblioteca 🤗 Transformers. A classe [`PreTrainedTokenizerFast`] permite uma instanciação fácil, aceitando o objeto *tokenizer* instanciado como um argumento:
+
+```python
+>>> from transformers import PreTrainedTokenizerFast
+
+>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
+```
+Esse objeto pode ser utilizado com todos os métodos compartilhados pelos tokenizers dos 🤗 Transformers! Vá para [a página do tokenizer](main_classes/tokenizer) para mais informações.
+
+## Carregando de um arquivo JSON
+
+Para carregar um tokenizer de um arquivo JSON vamos primeiro começar salvando nosso tokenizer:
+
+```python
+>>> tokenizer.save("tokenizer.json")
+```
+
+A pasta para qual salvamos esse arquivo pode ser passada para o método de inicialização do [`PreTrainedTokenizerFast`] usando o `tokenizer_file` parâmetro:
+
+```python
+>>> from transformers import PreTrainedTokenizerFast
+
+>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
+```
+
+Esse objeto pode ser utilizado com todos os métodos compartilhados pelos tokenizers dos 🤗 Transformers! Vá para [a página do tokenizer](main_classes/tokenizer) para mais informações.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/pt/index.md b/docs/transformers/docs/source/pt/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..365933bd658de5347d3fe1c641e4bc094d5964a2
--- /dev/null
+++ b/docs/transformers/docs/source/pt/index.md
@@ -0,0 +1,296 @@
+
+
+# 🤗 Transformers
+
+
+Estado da Arte para Aprendizado de Máquina em PyTorch, TensorFlow e JAX.
+O 🤗 Transformers disponibiliza APIs para facilmente baixar e treinar modelos pré-treinados de última geração.
+O uso de modelos pré-treinados pode diminuir os seus custos de computação, a sua pegada de carbono, além de economizar o
+tempo necessário para se treinar um modelo do zero. Os modelos podem ser usados para diversas tarefas:
+
+* 📝 Textos: classificação, extração de informações, perguntas e respostas, resumir, traduzir e gerar textos em mais de 100 idiomas.
+* 🖼 Imagens: classificação, deteção de objetos, e segmentação.
+* 🗣 Audio: reconhecimento de fala e classificação de áudio.
+* 🐙 Multimodal: perguntas tabeladas e respsostas, reconhecimento ótico de charactéres, extração de informação de
+documentos escaneados, classificação de vídeo, perguntas e respostas visuais.
+
+Nossa biblioteca aceita integração contínua entre três das bibliotecas mais populares de aprendizado profundo:
+Our library supports seamless integration between three of the most popular deep learning libraries:
+[PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/) e [JAX](https://jax.readthedocs.io/en/latest/).
+Treine seu modelo em três linhas de código em um framework, e carregue-o para execução em outro.
+
+Cada arquitetura 🤗 Transformers é definida em um módulo individual do Python, para que seja facilmente customizável para pesquisa e experimentos.
+
+## Se você estiver procurando suporte do time da Hugging Face, acesse
+
+
+
+
+
+## Conteúdo
+
+A documentação é dividida em cinco partes:
+ - **INÍCIO** contém um tour rápido de instalação e instruções para te dar um empurrão inicial com os 🤗 Transformers.
+ - **TUTORIAIS** são perfeitos para começar a aprender sobre a nossa biblioteca. Essa seção irá te ajudar a desenvolver
+ habilidades básicas necessárias para usar o 🤗 Transformers.
+ - **GUIAS PRÁTICOS** irão te mostrar como alcançar um certo objetivo, como o fine-tuning de um modelo pré-treinado
+ para modelamento de idioma, ou como criar um cabeçalho personalizado para um modelo.
+ - **GUIAS CONCEITUAIS** te darão mais discussões e explicações dos conceitos fundamentais e idéias por trás dos modelos,
+ tarefas e da filosofia de design por trás do 🤗 Transformers.
+ - **API** descreve o funcionamento de cada classe e função, agrupada em:
+
+ - **CLASSES PRINCIPAIS** para as classes que expõe as APIs importantes da biblioteca.
+ - **MODELOS** para as classes e funções relacionadas à cada modelo implementado na biblioteca.
+ - **AUXILIARES INTERNOS** para as classes e funções usadas internamente.
+
+Atualmente a biblioteca contém implementações do PyTorch, TensorFlow e JAX, pesos para modelos pré-treinados e scripts de uso e conversão de utilidades para os seguintes modelos:
+
+### Modelos atuais
+
+
+
+1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
+1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
+1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
+1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
+1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
+1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
+1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
+1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[MBart](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[MBart-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBert](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+
+
+### Frameworks aceitos
+
+A tabela abaixo representa a lista de suporte na biblioteca para cada um dos seguintes modelos, caso tenham um tokenizer
+do Python (chamado de "slow"), ou um tokenizer construído em cima da biblioteca 🤗 Tokenizers (chamado de "fast"). Além
+disso, são diferenciados pelo suporte em diferentes frameworks: JAX (por meio do Flax); PyTorch; e/ou Tensorflow.
+
+
+
+| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
+|:---------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
+| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
+| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
+| BigBirdPegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
+| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Canine | ✅ | ❌ | ✅ | ❌ | ❌ |
+| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
+| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ConvNext | ❌ | ❌ | ✅ | ✅ | ❌ |
+| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecVision | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DeiT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
+| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
+| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
+| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
+| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
+| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
+| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| MegatronBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| mT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Nystromformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Realm | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
+| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ResNet | ❌ | ❌ | ✅ | ❌ | ✅ |
+| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
+| SegFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
+| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
+| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Swin | ❌ | ❌ | ✅ | ❌ | ❌ |
+| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
+| TAPEX | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| VisualBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
+| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XGLM | ✅ | ✅ | ✅ | ❌ | ✅ |
+| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XLMProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/transformers/docs/source/pt/installation.md b/docs/transformers/docs/source/pt/installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..f548736589ac0d81bc7ebe2d73d60652ce03040b
--- /dev/null
+++ b/docs/transformers/docs/source/pt/installation.md
@@ -0,0 +1,262 @@
+
+
+# Guia de Instalação
+
+Neste guia poderá encontrar informações para a instalação do 🤗 Transformers para qualquer biblioteca de
+Machine Learning com a qual esteja a trabalhar. Além disso, poderá encontrar informações sobre como gerar cachês e
+configurar o 🤗 Transformers para execução em modo offline (opcional).
+
+🤗 Transformers foi testado com Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, e Flax. Para instalar a biblioteca de
+deep learning com que deseja trabalhar, siga as instruções correspondentes listadas a seguir:
+
+* [PyTorch](https://pytorch.org/get-started/locally/)
+* [TensorFlow 2.0](https://www.tensorflow.org/install/pip)
+* [Flax](https://flax.readthedocs.io/en/latest/)
+
+## Instalação pelo Pip
+
+É sugerido instalar o 🤗 Transformers num [ambiente virtual](https://docs.python.org/3/library/venv.html). Se precisar
+de mais informações sobre ambientes virtuais em Python, consulte este [guia](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+Um ambiente virtual facilitará a manipulação e organização de projetos e evita problemas de compatibilidade entre dependências.
+
+Comece criando um ambiente virtual no diretório do seu projeto:
+
+```bash
+python -m venv .env
+```
+
+E para ativar o ambiente virtual:
+
+```bash
+source .env/bin/activate
+```
+
+Agora É possível instalar o 🤗 Transformers com o comando a seguir:
+
+```bash
+pip install transformers
+```
+
+Somente para a CPU, é possível instalar o 🤗 Transformers e a biblioteca de deep learning respectiva apenas numa linha.
+
+Por exemplo, para instalar o 🤗 Transformers e o PyTorch, digite:
+
+```bash
+pip install transformers[torch]
+```
+
+🤗 Transformers e TensorFlow 2.0:
+
+```bash
+pip install transformers[tf-cpu]
+```
+
+🤗 Transformers e Flax:
+
+```bash
+pip install transformers[flax]
+```
+
+Por último, verifique se o 🤗 Transformers foi instalado com sucesso usando o seguinte comando para baixar um modelo pré-treinado:
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
+```
+
+Em seguida, imprima um rótulo e sua pontuação:
+
+```bash
+[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
+```
+
+## Instalação usando a fonte
+
+Para instalar o 🤗 Transformers a partir da fonte use o seguinte comando:
+
+```bash
+pip install git+https://github.com/huggingface/transformers
+```
+
+O comando acima instalará a versão `master` mais atual em vez da última versão estável. A versão `master` é útil para
+utilizar os últimos updates contidos em 🤗 Transformers. Por exemplo, um erro recente pode ter sido corrigido somente
+após a última versão estável, antes que houvesse um novo lançamento. No entanto, há a possibilidade que a versão `master` não esteja estável.
+A equipa trata de mantér a versão `master` operacional e a maioria dos erros são resolvidos em poucas horas ou dias.
+Se encontrar quaisquer problemas, por favor abra um [Issue](https://github.com/huggingface/transformers/issues) para que o
+mesmo possa ser corrigido o mais rápido possível.
+
+Verifique que o 🤗 Transformers está instalado corretamente usando o seguinte comando:
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
+```
+
+## Instalação editável
+
+Uma instalação editável será necessária caso desejas um dos seguintes:
+* Usar a versão `master` do código fonte.
+* Contribuir ao 🤗 Transformers e precisa testar mudanças ao código.
+
+Para tal, clone o repositório e instale o 🤗 Transformers com os seguintes comandos:
+
+```bash
+git clone https://github.com/huggingface/transformers.git
+cd transformers
+pip install -e .
+```
+
+Estes comandos vão ligar o diretório para o qual foi clonado o repositório ao caminho de bibliotecas do Python.
+O Python agora buscará dentro dos arquivos que foram clonados além dos caminhos normais da biblioteca.
+Por exemplo, se os pacotes do Python se encontram instalados no caminho `~/anaconda3/envs/main/lib/python3.7/site-packages/`,
+o Python também buscará módulos no diretório onde clonamos o repositório `~/transformers/`.
+
+
+
+É necessário manter o diretório `transformers` se desejas continuar usando a biblioteca.
+
+
+
+Assim, É possível atualizar sua cópia local para com a última versão do 🤗 Transformers com o seguinte comando:
+
+```bash
+cd ~/transformers/
+git pull
+```
+
+O ambiente de Python que foi criado para a instalação do 🤗 Transformers encontrará a versão `master` em execuções seguintes.
+
+## Instalação usando o Conda
+
+É possível instalar o 🤗 Transformers a partir do canal conda `conda-forge` com o seguinte comando:
+
+```bash
+conda install conda-forge::transformers
+```
+
+## Configuração do Cachê
+
+Os modelos pré-treinados são baixados e armazenados no cachê local, encontrado em `~/.cache/huggingface/transformers/`.
+Este é o diretório padrão determinado pela variável `TRANSFORMERS_CACHE` dentro do shell.
+No Windows, este diretório pré-definido é dado por `C:\Users\username\.cache\huggingface\transformers`.
+É possível mudar as variáveis dentro do shell em ordem de prioridade para especificar um diretório de cachê diferente:
+
+1. Variável de ambiente do shell (por padrão): `TRANSFORMERS_CACHE`.
+2. Variável de ambiente do shell:`HF_HOME` + `transformers/`.
+3. Variável de ambiente do shell: `XDG_CACHE_HOME` + `/huggingface/transformers`.
+
+
+
+ O 🤗 Transformers usará as variáveis de ambiente do shell `PYTORCH_TRANSFORMERS_CACHE` ou `PYTORCH_PRETRAINED_BERT_CACHE`
+ se estiver vindo de uma versão anterior da biblioteca que tenha configurado essas variáveis de ambiente, a menos que
+ você especifique a variável de ambiente do shell `TRANSFORMERS_CACHE`.
+
+
+
+
+## Modo Offline
+
+O 🤗 Transformers também pode ser executado num ambiente de firewall ou fora da rede (offline) usando arquivos locais.
+Para tal, configure a variável de ambiente de modo que `HF_HUB_OFFLINE=1`.
+
+
+
+Você pode adicionar o [🤗 Datasets](https://huggingface.co/docs/datasets/) ao pipeline de treinamento offline declarando
+ a variável de ambiente `HF_DATASETS_OFFLINE=1`.
+
+
+
+Segue um exemplo de execução do programa numa rede padrão com firewall para instâncias externas, usando o seguinte comando:
+
+```bash
+python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en ...
+```
+
+Execute esse mesmo programa numa instância offline com o seguinte comando:
+
+```bash
+HF_DATASETS_OFFLINE=1 HF_HUB_OFFLINE=1 \
+python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en ...
+```
+
+O script agora deve ser executado sem travar ou expirar, pois procurará apenas por arquivos locais.
+
+### Obtendo modelos e tokenizers para uso offline
+
+Outra opção para usar o 🤗 Transformers offline é baixar os arquivos antes e depois apontar para o caminho local onde estão localizados. Existem três maneiras de fazer isso:
+
+* Baixe um arquivo por meio da interface de usuário do [Model Hub](https://huggingface.co/models) clicando no ícone ↓.
+
+ 
+
+
+* Use o pipeline do [`PreTrainedModel.from_pretrained`] e [`PreTrainedModel.save_pretrained`]:
+ 1. Baixa os arquivos previamente com [`PreTrainedModel.from_pretrained`]:
+
+ ```py
+ >>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
+ >>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
+ ```
+
+
+ 2. Salve os arquivos em um diretório específico com [`PreTrainedModel.save_pretrained`]:
+
+ ```py
+ >>> tokenizer.save_pretrained("./your/path/bigscience_t0")
+ >>> model.save_pretrained("./your/path/bigscience_t0")
+ ```
+
+ 3. Quando estiver offline, acesse os arquivos com [`PreTrainedModel.from_pretrained`] do diretório especificado:
+
+ ```py
+ >>> tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0")
+ >>> model = AutoModel.from_pretrained("./your/path/bigscience_t0")
+ ```
+
+* Baixando arquivos programaticamente com a biblioteca [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub):
+
+ 1. Instale a biblioteca [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub) em seu ambiente virtual:
+
+ ```bash
+ python -m pip install huggingface_hub
+ ```
+
+ 2. Utiliza a função [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) para baixar um arquivo para um caminho específico. Por exemplo, o comando a seguir baixará o arquivo `config.json` para o modelo [T0](https://huggingface.co/bigscience/T0_3B) no caminho desejado:
+
+ ```py
+ >>> from huggingface_hub import hf_hub_download
+
+ >>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
+ ```
+
+Depois que o arquivo for baixado e armazenado no cachê local, especifique seu caminho local para carregá-lo e usá-lo:
+
+```py
+>>> from transformers import AutoConfig
+
+>>> config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")
+```
+
+
+
+Para obter mais detalhes sobre como baixar arquivos armazenados no Hub, consulte a seção [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream).
+
+
diff --git a/docs/transformers/docs/source/pt/multilingual.md b/docs/transformers/docs/source/pt/multilingual.md
new file mode 100644
index 0000000000000000000000000000000000000000..5515c6a922a7019b60f7b8e9baf0eb1ab0f84c43
--- /dev/null
+++ b/docs/transformers/docs/source/pt/multilingual.md
@@ -0,0 +1,195 @@
+
+
+# Modelos multilinguísticos para inferência
+
+[[open-in-colab]]
+
+Existem vários modelos multilinguísticos no 🤗 Transformers e seus usos para inferência diferem dos modelos monolíngues.
+No entanto, nem *todos* os usos dos modelos multilíngues são tão diferentes.
+Alguns modelos, como o [google-bert/bert-base-multilingual-uncased](https://huggingface.co/google-bert/bert-base-multilingual-uncased),
+podem ser usados como se fossem monolíngues. Este guia irá te ajudar a usar modelos multilíngues cujo uso difere
+para o propósito de inferência.
+
+## XLM
+
+O XLM tem dez checkpoints diferentes dos quais apenas um é monolíngue.
+Os nove checkpoints restantes do modelo são subdivididos em duas categorias:
+checkpoints que usam de language embeddings e os que não.
+
+### XLM com language embeddings
+
+Os seguintes modelos de XLM usam language embeddings para especificar a linguagem utilizada para a inferência.
+
+- `FacebookAI/xlm-mlm-ende-1024` (Masked language modeling, English-German)
+- `FacebookAI/xlm-mlm-enfr-1024` (Masked language modeling, English-French)
+- `FacebookAI/xlm-mlm-enro-1024` (Masked language modeling, English-Romanian)
+- `FacebookAI/xlm-mlm-xnli15-1024` (Masked language modeling, XNLI languages)
+- `FacebookAI/xlm-mlm-tlm-xnli15-1024` (Masked language modeling + translation, XNLI languages)
+- `FacebookAI/xlm-clm-enfr-1024` (Causal language modeling, English-French)
+- `FacebookAI/xlm-clm-ende-1024` (Causal language modeling, English-German)
+
+Os language embeddings são representados por um tensor de mesma dimensão que os `input_ids` passados ao modelo.
+Os valores destes tensores dependem do idioma utilizado e se identificam pelos atributos `lang2id` e `id2lang` do tokenizador.
+
+Neste exemplo, carregamos o checkpoint `FacebookAI/xlm-clm-enfr-1024`(Causal language modeling, English-French):
+
+```py
+>>> import torch
+>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
+
+>>> tokenizer = XLMTokenizer.from_pretrained("FacebookAI/xlm-clm-enfr-1024")
+>>> model = XLMWithLMHeadModel.from_pretrained("FacebookAI/xlm-clm-enfr-1024")
+```
+
+O atributo `lang2id` do tokenizador mostra os idiomas deste modelo e seus ids:
+
+```py
+>>> print(tokenizer.lang2id)
+{'en': 0, 'fr': 1}
+```
+
+Em seguida, cria-se um input de exemplo:
+
+```py
+>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
+```
+
+Estabelece-se o id do idioma, por exemplo `"en"`, e utiliza-se o mesmo para definir a language embedding.
+A language embedding é um tensor preenchido com `0`, que é o id de idioma para o inglês.
+Este tensor deve ser do mesmo tamanho que os `input_ids`.
+
+```py
+>>> language_id = tokenizer.lang2id["en"] # 0
+>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
+
+>>> # We reshape it to be of size (batch_size, sequence_length)
+>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
+```
+
+Agora você pode passar os `input_ids` e a language embedding ao modelo:
+
+```py
+>>> outputs = model(input_ids, langs=langs)
+```
+
+O script [run_generation.py](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-generation/run_generation.py) pode gerar um texto com language embeddings utilizando os checkpoints `xlm-clm`.
+
+### XLM sem language embeddings
+
+Os seguintes modelos XLM não requerem o uso de language embeddings durante a inferência:
+
+- `FacebookAI/xlm-mlm-17-1280` (Modelagem de linguagem com máscara, 17 idiomas)
+- `FacebookAI/xlm-mlm-100-1280` (Modelagem de linguagem com máscara, 100 idiomas)
+
+Estes modelos são utilizados para representações genéricas de frase diferentemente dos checkpoints XLM anteriores.
+
+## BERT
+
+Os seguintes modelos do BERT podem ser utilizados para tarefas multilinguísticas:
+
+- `google-bert/bert-base-multilingual-uncased` (Modelagem de linguagem com máscara + Previsão de frases, 102 idiomas)
+- `google-bert/bert-base-multilingual-cased` (Modelagem de linguagem com máscara + Previsão de frases, 104 idiomas)
+
+Estes modelos não requerem language embeddings durante a inferência. Devem identificar a linguagem a partir
+do contexto e realizar a inferência em sequência.
+
+## XLM-RoBERTa
+
+Os seguintes modelos do XLM-RoBERTa podem ser utilizados para tarefas multilinguísticas:
+
+- `FacebookAI/xlm-roberta-base` (Modelagem de linguagem com máscara, 100 idiomas)
+- `FacebookAI/xlm-roberta-large` Modelagem de linguagem com máscara, 100 idiomas)
+
+O XLM-RoBERTa foi treinado com 2,5 TB de dados do CommonCrawl recém-criados e testados em 100 idiomas.
+Proporciona fortes vantagens sobre os modelos multilinguísticos publicados anteriormente como o mBERT e o XLM em tarefas
+subsequentes como a classificação, a rotulagem de sequências e à respostas a perguntas.
+
+## M2M100
+
+Os seguintes modelos de M2M100 podem ser utilizados para traduções multilinguísticas:
+
+- `facebook/m2m100_418M` (Tradução)
+- `facebook/m2m100_1.2B` (Tradução)
+
+Neste exemplo, o checkpoint `facebook/m2m100_418M` é carregado para traduzir do mandarim ao inglês. É possível
+estabelecer o idioma de origem no tokenizador:
+
+```py
+>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
+
+>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
+>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
+
+>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
+>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
+```
+
+Tokenização do texto:
+
+```py
+>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
+```
+
+O M2M100 força o id do idioma de destino como o primeiro token gerado para traduzir ao idioma de destino.
+É definido o `forced_bos_token_id` como `en` no método `generate` para traduzir ao inglês.
+
+```py
+>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
+```
+
+## MBart
+
+Os seguintes modelos do MBart podem ser utilizados para tradução multilinguística:
+
+- `facebook/mbart-large-50-one-to-many-mmt` (Tradução automática multilinguística de um a vários, 50 idiomas)
+- `facebook/mbart-large-50-many-to-many-mmt` (Tradução automática multilinguística de vários a vários, 50 idiomas)
+- `facebook/mbart-large-50-many-to-one-mmt` (Tradução automática multilinguística vários a um, 50 idiomas)
+- `facebook/mbart-large-50` (Tradução multilinguística, 50 idiomas)
+- `facebook/mbart-large-cc25`
+
+Neste exemplo, carrega-se o checkpoint `facebook/mbart-large-50-many-to-many-mmt` para traduzir do finlandês ao inglês.
+Pode-se definir o idioma de origem no tokenizador:
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
+>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
+
+>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
+>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
+```
+
+Tokenizando o texto:
+
+```py
+>>> encoded_en = tokenizer(en_text, return_tensors="pt")
+```
+
+O MBart força o id do idioma de destino como o primeiro token gerado para traduzir ao idioma de destino.
+É definido o `forced_bos_token_id` como `en` no método `generate` para traduzir ao inglês.
+
+```py
+>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
+>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
+```
+
+Se estiver usando o checkpoint `facebook/mbart-large-50-many-to-one-mmt` não será necessário forçar o id do idioma de destino
+como sendo o primeiro token generado, caso contrário a usagem é a mesma.
diff --git a/docs/transformers/docs/source/pt/pipeline_tutorial.md b/docs/transformers/docs/source/pt/pipeline_tutorial.md
new file mode 100644
index 0000000000000000000000000000000000000000..9c0cb3567e72e38c373d60e7fd9813000333eef1
--- /dev/null
+++ b/docs/transformers/docs/source/pt/pipeline_tutorial.md
@@ -0,0 +1,157 @@
+
+
+# Pipelines para inferência
+
+Um [pipeline] simplifica o uso dos modelos no [Model Hub](https://huggingface.co/models) para a inferência de uma diversidade de tarefas,
+como a geração de texto, a segmentação de imagens e a classificação de áudio.
+Inclusive, se não tem experiência com alguma modalidade específica ou não compreende o código que forma os modelos,
+pode usar eles mesmo assim com o [pipeline]! Este tutorial te ensinará a:
+
+* Utilizar um [`pipeline`] para inferência.
+* Utilizar um tokenizador ou model específico.
+* Utilizar um [`pipeline`] para tarefas de áudio e visão computacional.
+
+
+
+ Acesse a documentação do [`pipeline`] para obter uma lista completa de tarefas possíveis.
+
+
+
+## Uso do pipeline
+
+Mesmo que cada tarefa tenha um [`pipeline`] associado, é mais simples usar a abstração geral do [`pipeline`] que
+contém todos os pipelines das tarefas mais específicas.
+O [`pipeline`] carrega automaticamenta um modelo predeterminado e um tokenizador com capacidade de inferência para sua
+tarefa.
+
+1. Comece carregando um [`pipeline`] e especifique uma tarefa de inferência:
+
+```py
+>>> from transformers import pipeline
+
+>>> generator = pipeline(task="text-generation")
+```
+
+2. Passe seu dado de entrada, no caso um texto, ao [`pipeline`]:
+
+```py
+>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
+[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Iron-priests at the door to the east, and thirteen for the Lord Kings at the end of the mountain'}]
+```
+
+Se tiver mais de uma entrada, passe-a como uma lista:
+
+```py
+>>> generator(
+... [
+... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
+... "Nine for Mortal Men, doomed to die, One for the Dark Lord on his dark throne",
+... ]
+... )
+```
+
+Qualquer parâmetro adicional para a sua tarefa também pode ser incluído no [`pipeline`]. A tarefa `text-generation` tem um método
+[`~generation.GenerationMixin.generate`] com vários parâmetros para controlar a saída.
+Por exemplo, se quiser gerar mais de uma saída, defina-a no parâmetro `num_return_sequences`:
+
+```py
+>>> generator(
+... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
+... num_return_sequences=2,
+... )
+```
+
+### Selecionando um modelo e um tokenizador
+
+O [`pipeline`] aceita qualquer modelo do [Model Hub](https://huggingface.co/models). Há rótulos adicionais no Model Hub
+que te permitem filtrar pelo modelo que gostaria de usar para sua tarefa. Uma vez que tiver escolhido o modelo apropriado,
+carregue-o com as classes `AutoModelFor` e [`AutoTokenizer`] correspondentes. Por exemplo, carregue a classe [`AutoModelForCausalLM`]
+para uma tarefa de modelagem de linguagem causal:
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForCausalLM
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
+>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
+```
+
+Crie uma [`pipeline`] para a sua tarefa e especifíque o modelo e o tokenizador que foram carregados:
+
+```py
+>>> from transformers import pipeline
+
+>>> generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
+```
+
+Passe seu texto de entrada ao [`pipeline`] para gerar algum texto:
+
+```py
+>>> generator("Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone")
+[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Dragon-lords (for them to rule in a world ruled by their rulers, and all who live within the realm'}]
+```
+
+## Pipeline de audio
+
+A flexibilidade do [`pipeline`] significa que também pode-se extender às tarefas de áudio.
+La flexibilidad de [`pipeline`] significa que también se puede extender a tareas de audio.
+
+Por exemplo, classifiquemos a emoção de um breve fragmento do famoso discurso de John F. Kennedy /home/rzimmerdev/dev/transformers/docs/source/pt/pipeline_tutorial.md
+Encontre um modelo de [audio classification](https://huggingface.co/models?pipeline_tag=audio-classification) para
+reconhecimento de emoções no Model Hub e carregue-o usando o [`pipeline`]:
+
+```py
+>>> from transformers import pipeline
+
+>>> audio_classifier = pipeline(
+... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
+... )
+```
+
+Passe o arquivo de áudio ao [`pipeline`]:
+
+```py
+>>> audio_classifier("jfk_moon_speech.wav")
+[{'label': 'calm', 'score': 0.13856211304664612},
+ {'label': 'disgust', 'score': 0.13148026168346405},
+ {'label': 'happy', 'score': 0.12635163962841034},
+ {'label': 'angry', 'score': 0.12439591437578201},
+ {'label': 'fearful', 'score': 0.12404385954141617}]
+```
+
+## Pipeline de visão computacional
+
+Finalmente, utilizar um [`pipeline`] para tarefas de visão é praticamente a mesma coisa.
+Especifique a sua tarefa de visão e passe a sua imagem ao classificador.
+A imagem pode ser um link ou uma rota local à imagem. Por exemplo, que espécie de gato está presente na imagem?
+
+
+
+```py
+>>> from transformers import pipeline
+
+>>> vision_classifier = pipeline(task="image-classification")
+>>> vision_classifier(
+... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
+... )
+[{'label': 'lynx, catamount', 'score': 0.4403027892112732},
+ {'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor',
+ 'score': 0.03433405980467796},
+ {'label': 'snow leopard, ounce, Panthera uncia',
+ 'score': 0.032148055732250214},
+ {'label': 'Egyptian cat', 'score': 0.02353910356760025},
+ {'label': 'tiger cat', 'score': 0.023034192621707916}]
+```
diff --git a/docs/transformers/docs/source/pt/quicktour.md b/docs/transformers/docs/source/pt/quicktour.md
new file mode 100644
index 0000000000000000000000000000000000000000..5ccdd63376e3984885c234cd4bab24283e9d5d6e
--- /dev/null
+++ b/docs/transformers/docs/source/pt/quicktour.md
@@ -0,0 +1,399 @@
+
+
+# Tour rápido
+
+[[open-in-colab]]
+
+Comece a trabalhar com 🤗 Transformers! Comece usando [`pipeline`] para rápida inferência e facilmente carregue um modelo pré-treinado e um tokenizer com [AutoClass](./model_doc/auto) para resolver tarefas de texto, visão ou áudio.
+
+
+
+Todos os exemplos de código apresentados na documentação têm um botão no canto superior direito para escolher se você deseja ocultar ou mostrar o código no Pytorch ou no TensorFlow. Caso contrário, é esperado que funcione para ambos back-ends sem nenhuma alteração.
+
+
+
+## Pipeline
+
+[`pipeline`] é a maneira mais fácil de usar um modelo pré-treinado para uma dada tarefa.
+
+
+
+A [`pipeline`] apoia diversas tarefas fora da caixa:
+
+**Texto**:
+* Análise sentimental: classifica a polaridade de um texto.
+* Geração de texto (em Inglês): gera texto a partir de uma entrada.
+* Reconhecimento de entidade mencionada: legenda cada palavra com uma classe que a representa (pessoa, data, local, etc...)
+* Respostas: extrai uma resposta dado algum contexto e uma questão
+* Máscara de preenchimento: preenche o espaço, dado um texto com máscaras de palavras.
+* Sumarização: gera o resumo de um texto longo ou documento.
+* Tradução: traduz texto para outra língua.
+* Extração de características: cria um tensor que representa o texto.
+
+**Imagem**:
+* Classificação de imagens: classifica uma imagem.
+* Segmentação de imagem: classifica cada pixel da imagem.
+* Detecção de objetos: detecta objetos em uma imagem.
+
+**Audio**:
+* Classficação de áudio: legenda um trecho de áudio fornecido.
+* Reconhecimento de fala automático: transcreve audio em texto.
+
+
+
+Para mais detalhes sobre a [`pipeline`] e tarefas associadas, siga a documentação [aqui](./main_classes/pipelines).
+
+
+
+### Uso da pipeline
+
+No exemplo a seguir, você usará [`pipeline`] para análise sentimental.
+
+Instale as seguintes dependências se você ainda não o fez:
+
+
+
+
+```bash
+pip install torch
+```
+
+
+```bash
+pip install tensorflow
+```
+
+
+
+Importe [`pipeline`] e especifique a tarefa que deseja completar:
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline("sentiment-analysis")
+```
+
+A pipeline baixa and armazena um [modelo pré-treinado](https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english) padrão e tokenizer para análise sentimental. Agora você pode usar `classifier` no texto alvo:
+
+```py
+>>> classifier("We are very happy to show you the 🤗 Transformers library.")
+[{'label': 'POSITIVE', 'score': 0.9998}]
+```
+
+Para mais de uma sentença, passe uma lista para a [`pipeline`], a qual retornará uma lista de dicionários:
+
+```py
+>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
+>>> for result in results:
+... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
+label: POSITIVE, with score: 0.9998
+label: NEGATIVE, with score: 0.5309
+```
+
+A [`pipeline`] também pode iterar sobre um Dataset inteiro. Comece instalando a biblioteca de [🤗 Datasets](https://huggingface.co/docs/datasets/):
+
+```bash
+pip install datasets
+```
+
+Crie uma [`pipeline`] com a tarefa que deseja resolver e o modelo que deseja usar.
+
+```py
+>>> import torch
+>>> from transformers import pipeline
+
+>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
+```
+
+A seguir, carregue uma base de dados (confira a 🤗 [Iniciação em Datasets](https://huggingface.co/docs/datasets/quickstart) para mais detalhes) que você gostaria de iterar sobre. Por exemplo, vamos carregar o dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
+```
+
+Precisamos garantir que a taxa de amostragem do conjunto de dados corresponda à taxa de amostragem em que o facebook/wav2vec2-base-960h foi treinado.
+
+```py
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
+```
+
+Os arquivos de áudio são carregados e re-amostrados automaticamente ao chamar a coluna `"audio"`.
+Vamos extrair as arrays de formas de onda originais das primeiras 4 amostras e passá-las como uma lista para o pipeline:
+
+```py
+>>> result = speech_recognizer(dataset[:4]["audio"])
+>>> print([d["text"] for d in result])
+['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HET WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AND I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I TURN A JOIN A COUNT']
+```
+
+Para um conjunto de dados maior onde as entradas são maiores (como em fala ou visão), será necessário passar um gerador em vez de uma lista que carregue todas as entradas na memória. Consulte a [documentação do pipeline](./main_classes/pipelines) para mais informações.
+
+### Use outro modelo e tokenizer na pipeline
+
+A [`pipeline`] pode acomodar qualquer modelo do [Model Hub](https://huggingface.co/models), facilitando sua adaptação para outros casos de uso. Por exemplo, se você quiser um modelo capaz de lidar com texto em francês, use as tags no Model Hub para filtrar um modelo apropriado. O principal resultado filtrado retorna um [modelo BERT](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) bilíngue ajustado para análise de sentimentos. Ótimo, vamos usar este modelo!
+
+```py
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+```
+
+
+
+Use o [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] para carregar o modelo pré-treinado e seu tokenizer associado (mais em `AutoClass` abaixo):
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+
+
+Use o [`TFAutoModelForSequenceClassification`] and [`AutoTokenizer`] para carregar o modelo pré-treinado e o tokenizer associado (mais em `TFAutoClass` abaixo):
+
+```py
+>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+
+
+Então você pode especificar o modelo e o tokenizador na [`pipeline`] e aplicar o `classifier` no seu texto alvo:
+
+```py
+>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
+>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
+[{'label': '5 stars', 'score': 0.7273}]
+```
+
+Se você não conseguir achar um modelo para o seu caso de uso, precisará usar fine-tune em um modelo pré-treinado nos seus dados. Veja nosso [tutorial de fine-tuning](./training) para descobrir como. Finalmente, depois que você tiver usado esse processo em seu modelo, considere compartilhá-lo conosco (veja o tutorial [aqui](./model_sharing)) na plataforma Model Hub afim de democratizar NLP! 🤗
+
+## AutoClass
+
+
+
+Por baixo dos panos, as classes [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] trabalham juntas para fortificar o [`pipeline`]. Um [AutoClass](./model_doc/auto) é um atalho que automaticamente recupera a arquitetura de um modelo pré-treinado a partir de seu nome ou caminho. Basta selecionar a `AutoClass` apropriada para sua tarefa e seu tokenizer associado com [`AutoTokenizer`].
+
+Vamos voltar ao nosso exemplo e ver como você pode usar a `AutoClass` para replicar os resultados do [`pipeline`].
+
+### AutoTokenizer
+
+Um tokenizer é responsável por pré-processar o texto em um formato que seja compreensível para o modelo. Primeiro, o tokenizer dividirá o texto em palavras chamadas *tokens*. Existem várias regras que regem o processo de tokenização, incluindo como dividir uma palavra e em que nível (saiba mais sobre tokenização [aqui](./tokenizer_summary)). A coisa mais importante a lembrar, porém, é que você precisa instanciar o tokenizer com o mesmo nome do modelo para garantir que está usando as mesmas regras de tokenização com as quais um modelo foi pré-treinado.
+
+Carregue um tokenizer com [`AutoTokenizer`]:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+Em seguida, o tokenizer converte os tokens em números para construir um tensor como entrada para o modelo. Isso é conhecido como o *vocabulário* do modelo.
+
+Passe o texto para o tokenizer:
+
+```py
+>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
+>>> print(encoding)
+{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+O tokenizer retornará um dicionário contendo:
+
+* [input_ids](./glossary#input-ids): representações numéricas de seus tokens.
+* [attention_mask](.glossary#attention-mask): indica quais tokens devem ser atendidos.
+
+Assim como o [`pipeline`], o tokenizer aceitará uma lista de entradas. Além disso, o tokenizer também pode preencher e truncar o texto para retornar um lote com comprimento uniforme:
+
+
+
+
+```py
+>>> pt_batch = tokenizer(
+... ["We are very happy to show you the 🤗 transformers library.", "We hope you don't hate it."],
+... padding=True,
+... truncation=True,
+... max_length=512,
+... return_tensors="pt",
+... )
+```
+
+
+
+```py
+>>> tf_batch = tokenizer(
+... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
+... padding=True,
+... truncation=True,
+... max_length=512,
+... return_tensors="tf",
+... )
+```
+
+
+
+Leia o tutorial de [pré-processamento](./pré-processamento) para obter mais detalhes sobre tokenização.
+
+### AutoModel
+
+
+
+🤗 Transformers fornecem uma maneira simples e unificada de carregar instâncias pré-treinadas. Isso significa que você pode carregar um [`AutoModel`] como carregaria um [`AutoTokenizer`]. A única diferença é selecionar o [`AutoModel`] correto para a tarefa. Como você está fazendo classificação de texto ou sequência, carregue [`AutoModelForSequenceClassification`]:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
+```
+
+
+
+Veja o [sumário de tarefas](./task_summary) para qual classe de [`AutoModel`] usar para cada tarefa.
+
+
+
+Agora você pode passar seu grupo de entradas pré-processadas diretamente para o modelo. Você apenas tem que descompactar o dicionário usando `**`:
+
+```py
+>>> pt_outputs = pt_model(**pt_batch)
+```
+
+O modelo gera as ativações finais no atributo `logits`. Aplique a função softmax aos `logits` para recuperar as probabilidades:
+
+```py
+>>> from torch import nn
+
+>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
+>>> print(pt_predictions)
+tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
+ [0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=)
+```
+
+
+🤗 Transformers fornecem uma maneira simples e unificada de carregar instâncias pré-treinadas. Isso significa que você pode carregar um [`TFAutoModel`] como carregaria um [`AutoTokenizer`]. A única diferença é selecionar o [`TFAutoModel`] correto para a tarefa. Como você está fazendo classificação de texto ou sequência, carregue [`TFAutoModelForSequenceClassification`]:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
+```
+
+
+
+Veja o [sumário de tarefas](./task_summary) para qual classe de [`AutoModel`] usar para cada tarefa.
+
+
+
+Agora você pode passar seu grupo de entradas pré-processadas diretamente para o modelo através da passagem de chaves de dicionários ao tensor.
+
+```py
+>>> tf_outputs = tf_model(tf_batch)
+```
+
+O modelo gera as ativações finais no atributo `logits`. Aplique a função softmax aos `logits` para recuperar as probabilidades:
+
+```py
+>>> import tensorflow as tf
+
+>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
+>>> tf_predictions # doctest: +IGNORE_RESULT
+```
+
+
+
+
+
+Todos os modelos de 🤗 Transformers (PyTorch ou TensorFlow) geram tensores *antes* da função de ativação final (como softmax) pois essa função algumas vezes é fundida com a perda.
+
+
+
+
+Os modelos são um standard [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) ou um [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) para que você possa usá-los em seu loop de treinamento habitual. No entanto, para facilitar as coisas, 🤗 Transformers fornece uma classe [`Trainer`] para PyTorch que adiciona funcionalidade para treinamento distribuído, precisão mista e muito mais. Para o TensorFlow, você pode usar o método `fit` de [Keras](https://keras.io/). Consulte o [tutorial de treinamento](./training) para obter mais detalhes.
+
+
+
+As saídas do modelo 🤗 Transformers são classes de dados especiais para que seus atributos sejam preenchidos automaticamente em um IDE.
+As saídas do modelo também se comportam como uma tupla ou um dicionário (por exemplo, você pode indexar com um inteiro, uma parte ou uma string), caso em que os atributos `None` são ignorados.
+
+
+
+### Salvar um modelo
+
+
+
+Uma vez que seu modelo estiver afinado, você pode salvá-lo com seu Tokenizer usando [`PreTrainedModel.save_pretrained`]:
+
+```py
+>>> pt_save_directory = "./pt_save_pretrained"
+>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
+>>> pt_model.save_pretrained(pt_save_directory)
+```
+
+Quando você estiver pronto para usá-lo novamente, recarregue com [`PreTrainedModel.from_pretrained`]:
+
+```py
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
+```
+
+
+Uma vez que seu modelo estiver afinado, você pode salvá-lo com seu Tokenizer usando [`TFPreTrainedModel.save_pretrained`]:
+
+```py
+>>> tf_save_directory = "./tf_save_pretrained"
+>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
+>>> tf_model.save_pretrained(tf_save_directory)
+```
+
+Quando você estiver pronto para usá-lo novamente, recarregue com [`TFPreTrainedModel.from_pretrained`]
+
+```py
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
+```
+
+
+
+Um recurso particularmente interessante dos 🤗 Transformers é a capacidade de salvar um modelo e recarregá-lo como um modelo PyTorch ou TensorFlow. Use `from_pt` ou `from_tf` para converter o modelo de um framework para outro:
+
+
+
+
+```py
+>>> from transformers import AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
+```
+
+
+
+```py
+>>> from transformers import TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
+```
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/pt/run_scripts.md b/docs/transformers/docs/source/pt/run_scripts.md
new file mode 100644
index 0000000000000000000000000000000000000000..ad19a8fdea09b060bc6096ae7b28dfd96f7cc77b
--- /dev/null
+++ b/docs/transformers/docs/source/pt/run_scripts.md
@@ -0,0 +1,354 @@
+
+
+# Treinamento a partir de um script
+
+Junto com os 🤗 Transformers [notebooks](./notebooks), também há scripts de exemplo demonstrando como treinar um modelo para uma tarefa com [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow) ou [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
+
+Você também encontrará scripts que usamos em nossos [projetos de pesquisa](https://github.com/huggingface/transformers-research-projects/) e [exemplos legados](https://github.com/huggingface/transformers/tree/main/examples/legacy) que são principalmente contribuições da comunidade. Esses scripts não são mantidos ativamente e exigem uma versão específica de 🤗 Transformers que provavelmente será incompatível com a versão mais recente da biblioteca.
+
+Não se espera que os scripts de exemplo funcionem imediatamente em todos os problemas, você pode precisar adaptar o script ao problema que está tentando resolver. Para ajudá-lo com isso, a maioria dos scripts expõe totalmente como os dados são pré-processados, permitindo que você os edite conforme necessário para seu caso de uso.
+
+Para qualquer recurso que você gostaria de implementar em um script de exemplo, discuta-o no [fórum](https://discuss.huggingface.co/) ou em uma [issue](https://github.com/huggingface/transformers/issues) antes de enviar um Pull Request. Embora recebamos correções de bugs, é improvável que mesclaremos um Pull Request que adicione mais funcionalidades ao custo de legibilidade.
+
+Este guia mostrará como executar um exemplo de script de treinamento de sumarização em [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) e [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). Espera-se que todos os exemplos funcionem com ambas as estruturas, a menos que especificado de outra forma.
+
+## Configuração
+
+Para executar com êxito a versão mais recente dos scripts de exemplo, você precisa **instalar o 🤗 Transformers da fonte** em um novo ambiente virtual:
+
+```bash
+git clone https://github.com/huggingface/transformers
+cd transformers
+pip install .
+```
+
+Para versões mais antigas dos scripts de exemplo, clique no botão abaixo:
+
+
+ Exemplos para versões antigas dos 🤗 Transformers
+
+
+
+Em seguida, mude seu clone atual dos 🤗 Transformers para uma versão específica, como v3.5.1, por exemplo:
+
+```bash
+git checkout tags/v3.5.1
+```
+
+Depois de configurar a versão correta da biblioteca, navegue até a pasta de exemplo de sua escolha e instale os requisitos específicos do exemplo:
+
+```bash
+pip install -r requirements.txt
+```
+
+## Executando um script
+
+
+
+
+O script de exemplo baixa e pré-processa um conjunto de dados da biblioteca 🤗 [Datasets](https://huggingface.co/docs/datasets/). Em seguida, o script ajusta um conjunto de dados com o [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) em uma arquitetura que oferece suporte à sumarização. O exemplo a seguir mostra como ajustar [T5-small](https://huggingface.co/google-t5/t5-small) no conjunto de dados [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). O modelo T5 requer um argumento `source_prefix` adicional devido à forma como foi treinado. Este prompt informa ao T5 que esta é uma tarefa de sumarização.
+
+```bash
+python examples/pytorch/summarization/run_summarization.py \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+
+Este outro script de exemplo baixa e pré-processa um conjunto de dados da biblioteca 🤗 [Datasets](https://huggingface.co/docs/datasets/). Em seguida, o script ajusta um conjunto de dados usando Keras em uma arquitetura que oferece suporte à sumarização. O exemplo a seguir mostra como ajustar [T5-small](https://huggingface.co/google-t5/t5-small) no conjunto de dados [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). O modelo T5 requer um argumento `source_prefix` adicional devido à forma como foi treinado. Este prompt informa ao T5 que esta é uma tarefa de sumarização.
+
+```bash
+python examples/tensorflow/summarization/run_summarization.py \
+ --model_name_or_path google-t5/t5-small \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 16 \
+ --num_train_epochs 3 \
+ --do_train \
+ --do_eval
+```
+
+
+
+## Treinamento distribuído e precisão mista
+
+O [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) oferece suporte a treinamento distribuído e precisão mista, o que significa que você também pode usá-lo em um script. Para habilitar esses dois recursos:
+
+- Adicione o argumento `fp16` para habilitar a precisão mista.
+- Defina o número de GPUs a serem usadas com o argumento `nproc_per_node`.
+
+```bash
+torchrun \
+ --nproc_per_node 8 pytorch/summarization/run_summarization.py \
+ --fp16 \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+Os scripts do TensorFlow utilizam um [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) para treinamento distribuído, e você não precisa adicionar argumentos adicionais ao script de treinamento. O script do TensorFlow usará várias GPUs por padrão, se estiverem disponíveis.
+
+## Executando um script em uma TPU
+
+
+
+As Unidades de Processamento de Tensor (TPUs) são projetadas especificamente para acelerar o desempenho. O PyTorch oferece suporte a TPUs com o compilador de aprendizado profundo [XLA](https://www.tensorflow.org/xla) (consulte [aqui](https://github.com/pytorch/xla/blob/master/README.md) para mais detalhes). Para usar uma TPU, inicie o script `xla_spawn.py` e use o argumento `num_cores` para definir o número de núcleos de TPU que você deseja usar.
+
+```bash
+python xla_spawn.py --num_cores 8 \
+ summarization/run_summarization.py \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+
+
+As Unidades de Processamento de Tensor (TPUs) são projetadas especificamente para acelerar o desempenho. Os scripts do TensorFlow utilizam uma [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) para treinamento em TPUs. Para usar uma TPU, passe o nome do recurso TPU para o argumento `tpu`.
+
+```bash
+python run_summarization.py \
+ --tpu name_of_tpu_resource \
+ --model_name_or_path google-t5/t5-small \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 16 \
+ --num_train_epochs 3 \
+ --do_train \
+ --do_eval
+```
+
+
+
+## Execute um script com 🤗 Accelerate
+
+🤗 [Accelerate](https://huggingface.co/docs/accelerate) é uma biblioteca somente do PyTorch que oferece um método unificado para treinar um modelo em vários tipos de configurações (CPU, multiplas GPUs, TPUs), mantendo visibilidade no loop de treinamento do PyTorch. Certifique-se de ter o 🤗 Accelerate instalado se ainda não o tiver:
+
+> Nota: Como o Accelerate está se desenvolvendo rapidamente, a versão git do Accelerate deve ser instalada para executar os scripts
+
+```bash
+pip install git+https://github.com/huggingface/accelerate
+```
+
+Em vez do script `run_summarization.py`, você precisa usar o script `run_summarization_no_trainer.py`. Os scripts suportados pelo 🤗 Accelerate terão um arquivo `task_no_trainer.py` na pasta. Comece executando o seguinte comando para criar e salvar um arquivo de configuração:
+
+```bash
+accelerate config
+```
+
+Teste sua configuração para garantir que ela esteja corretamente configurada :
+
+```bash
+accelerate test
+```
+
+Agora você está pronto para iniciar o treinamento:
+
+```bash
+accelerate launch run_summarization_no_trainer.py \
+ --model_name_or_path google-t5/t5-small \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir ~/tmp/tst-summarization
+```
+
+## Usando um conjunto de dados personalizado
+
+O script de resumo oferece suporte a conjuntos de dados personalizados, desde que sejam um arquivo CSV ou JSON. Ao usar seu próprio conjunto de dados, você precisa especificar vários argumentos adicionais:
+
+- `train_file` e `validation_file` especificam o caminho para seus arquivos de treinamento e validação respectivamente.
+- `text_column` é o texto de entrada para sumarização.
+- `summary_column` é o texto de destino para saída.
+
+Um script para sumarização usando um conjunto de dados customizado ficaria assim:
+
+```bash
+python examples/pytorch/summarization/run_summarization.py \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --train_file path_to_csv_or_jsonlines_file \
+ --validation_file path_to_csv_or_jsonlines_file \
+ --text_column text_column_name \
+ --summary_column summary_column_name \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --overwrite_output_dir \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --predict_with_generate
+```
+
+## Testando um script
+
+Geralmente, é uma boa ideia executar seu script em um número menor de exemplos de conjuntos de dados para garantir que tudo funcione conforme o esperado antes de se comprometer com um conjunto de dados inteiro, que pode levar horas para ser concluído. Use os seguintes argumentos para truncar o conjunto de dados para um número máximo de amostras:
+
+- `max_train_samples`
+- `max_eval_samples`
+- `max_predict_samples`
+
+```bash
+python examples/pytorch/summarization/run_summarization.py \
+ --model_name_or_path google-t5/t5-small \
+ --max_train_samples 50 \
+ --max_eval_samples 50 \
+ --max_predict_samples 50 \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+Nem todos os scripts de exemplo suportam o argumento `max_predict_samples`. Se você não tiver certeza se seu script suporta este argumento, adicione o argumento `-h` para verificar:
+
+```bash
+examples/pytorch/summarization/run_summarization.py -h
+```
+
+## Retomar o treinamento a partir de um checkpoint
+
+Outra opção útil para habilitar é retomar o treinamento de um checkpoint anterior. Isso garantirá que você possa continuar de onde parou sem recomeçar se o seu treinamento for interrompido. Existem dois métodos para retomar o treinamento a partir de um checkpoint.
+
+O primeiro método usa o argumento `output_dir previous_output_dir` para retomar o treinamento do último checkpoint armazenado em `output_dir`. Neste caso, você deve remover `overwrite_output_dir`:
+
+```bash
+python examples/pytorch/summarization/run_summarization.py
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --output_dir previous_output_dir \
+ --predict_with_generate
+```
+
+O segundo método usa o argumento `resume_from_checkpoint path_to_specific_checkpoint` para retomar o treinamento de uma pasta de checkpoint específica.
+
+```bash
+python examples/pytorch/summarization/run_summarization.py
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --resume_from_checkpoint path_to_specific_checkpoint \
+ --predict_with_generate
+```
+
+## Compartilhando seu modelo
+
+Todos os scripts podem enviar seu modelo final para o [Model Hub](https://huggingface.co/models). Certifique-se de estar conectado ao Hugging Face antes de começar:
+
+```bash
+huggingface-cli login
+```
+
+Em seguida, adicione o argumento `push_to_hub` ao script. Este argumento criará um repositório com seu nome de usuário do Hugging Face e o nome da pasta especificado em `output_dir`.
+
+Para dar um nome específico ao seu repositório, use o argumento `push_to_hub_model_id` para adicioná-lo. O repositório será listado automaticamente em seu namespace.
+
+O exemplo a seguir mostra como fazer upload de um modelo com um nome de repositório específico:
+
+```bash
+python examples/pytorch/summarization/run_summarization.py
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --push_to_hub \
+ --push_to_hub_model_id finetuned-t5-cnn_dailymail \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
diff --git a/docs/transformers/docs/source/pt/serialization.md b/docs/transformers/docs/source/pt/serialization.md
new file mode 100644
index 0000000000000000000000000000000000000000..9e390f07bde41ded4d80a6d8faf75d563c3a2457
--- /dev/null
+++ b/docs/transformers/docs/source/pt/serialization.md
@@ -0,0 +1,502 @@
+
+
+# Exportando modelos para ONNX
+
+Se você precisar implantar modelos 🤗 Transformers em ambientes de produção, recomendamos
+exporta-los para um formato serializado que pode ser carregado e executado em
+tempos de execução e hardware. Neste guia, mostraremos como exportar modelos 🤗 Transformers
+para [ONNX (Open Neural Network eXchange)](http://onnx.ai).
+
+
+
+Uma vez exportado, um modelo pode ser otimizado para inferência por meio de técnicas como
+quantização e poda. Se você estiver interessado em otimizar seus modelos para serem executados com
+máxima eficiência, confira a biblioteca [🤗 Optimum
+](https://github.com/huggingface/optimum).
+
+
+
+ONNX é um padrão aberto que define um conjunto comum de operadores e um formato de arquivo comum
+para representar modelos de aprendizado profundo em uma ampla variedade de estruturas, incluindo PyTorch e
+TensorFlow. Quando um modelo é exportado para o formato ONNX, esses operadores são usados para
+construir um grafo computacional (muitas vezes chamado de _representação intermediária_) que
+representa o fluxo de dados através da rede neural.
+
+Ao expor um grafo com operadores e tipos de dados padronizados, o ONNX facilita a
+alternar entre os frameworks. Por exemplo, um modelo treinado em PyTorch pode ser exportado para
+formato ONNX e depois importado no TensorFlow (e vice-versa).
+
+🤗 Transformers fornece um pacote [`transformers.onnx`](main_classes/onnx) que permite
+que você converta os checkpoints do modelo em um grafo ONNX aproveitando os objetos de configuração.
+Esses objetos de configuração vêm prontos para várias arquiteturas de modelo e são
+projetado para ser facilmente extensível a outras arquiteturas.
+
+As configurações prontas incluem as seguintes arquiteturas:
+
+
+
+- ALBERT
+- BART
+- BEiT
+- BERT
+- BigBird
+- BigBird-Pegasus
+- Blenderbot
+- BlenderbotSmall
+- BLOOM
+- CamemBERT
+- CLIP
+- CodeGen
+- Conditional DETR
+- ConvBERT
+- ConvNeXT
+- ConvNeXTV2
+- Data2VecText
+- Data2VecVision
+- DeBERTa
+- DeBERTa-v2
+- DeiT
+- DETR
+- DistilBERT
+- ELECTRA
+- ERNIE
+- FlauBERT
+- GPT Neo
+- GPT-J
+- GroupViT
+- I-BERT
+- LayoutLM
+- LayoutLMv3
+- LeViT
+- Longformer
+- LongT5
+- M2M100
+- Marian
+- mBART
+- MobileBERT
+- MobileViT
+- MT5
+- OpenAI GPT-2
+- OWL-ViT
+- Perceiver
+- PLBart
+- ResNet
+- RoBERTa
+- RoFormer
+- SegFormer
+- SqueezeBERT
+- Swin Transformer
+- T5
+- Table Transformer
+- Vision Encoder decoder
+- ViT
+- XLM
+- XLM-RoBERTa
+- XLM-RoBERTa-XL
+- YOLOS
+
+Nas próximas duas seções, mostraremos como:
+
+* Exportar um modelo suportado usando o pacote `transformers.onnx`.
+* Exportar um modelo personalizado para uma arquitetura sem suporte.
+
+## Exportando um modelo para ONNX
+
+Para exportar um modelo 🤗 Transformers para o ONNX, primeiro você precisa instalar algumas
+dependências extras:
+
+```bash
+pip install transformers[onnx]
+```
+
+O pacote `transformers.onnx` pode então ser usado como um módulo Python:
+
+```bash
+python -m transformers.onnx --help
+
+usage: Hugging Face Transformers ONNX exporter [-h] -m MODEL [--feature {causal-lm, ...}] [--opset OPSET] [--atol ATOL] output
+
+positional arguments:
+ output Path indicating where to store generated ONNX model.
+
+optional arguments:
+ -h, --help show this help message and exit
+ -m MODEL, --model MODEL
+ Model ID on huggingface.co or path on disk to load model from.
+ --feature {causal-lm, ...}
+ The type of features to export the model with.
+ --opset OPSET ONNX opset version to export the model with.
+ --atol ATOL Absolute difference tolerance when validating the model.
+```
+
+A exportação de um checkpoint usando uma configuração pronta pode ser feita da seguinte forma:
+
+```bash
+python -m transformers.onnx --model=distilbert/distilbert-base-uncased onnx/
+```
+
+Você deve ver os seguintes logs:
+
+```bash
+Validating ONNX model...
+ -[✓] ONNX model output names match reference model ({'last_hidden_state'})
+ - Validating ONNX Model output "last_hidden_state":
+ -[✓] (2, 8, 768) matches (2, 8, 768)
+ -[✓] all values close (atol: 1e-05)
+All good, model saved at: onnx/model.onnx
+```
+
+Isso exporta um grafo ONNX do ponto de verificação definido pelo argumento `--model`. Nisso
+Por exemplo, é `distilbert/distilbert-base-uncased`, mas pode ser qualquer checkpoint no Hugging
+Face Hub ou um armazenado localmente.
+
+O arquivo `model.onnx` resultante pode ser executado em um dos [muitos
+aceleradores](https://onnx.ai/supported-tools.html#deployModel) que suportam o ONNX
+padrão. Por exemplo, podemos carregar e executar o modelo com [ONNX
+Tempo de execução](https://onnxruntime.ai/) da seguinte forma:
+
+```python
+>>> from transformers import AutoTokenizer
+>>> from onnxruntime import InferenceSession
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+>>> session = InferenceSession("onnx/model.onnx")
+>>> # ONNX Runtime expects NumPy arrays as input
+>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
+>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
+```
+
+Os nomes de saída necessários (como `["last_hidden_state"]`) podem ser obtidos pegando uma
+ configuração ONNX de cada modelo. Por exemplo, para DistilBERT temos:
+
+```python
+>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
+
+>>> config = DistilBertConfig()
+>>> onnx_config = DistilBertOnnxConfig(config)
+>>> print(list(onnx_config.outputs.keys()))
+["last_hidden_state"]
+```
+
+O processo é idêntico para os checkpoints do TensorFlow no Hub. Por exemplo, podemos
+exportar um checkpoint TensorFlow puro do [Keras
+](https://huggingface.co/keras-io) da seguinte forma:
+
+```bash
+python -m transformers.onnx --model=keras-io/transformers-qa onnx/
+```
+
+Para exportar um modelo armazenado localmente, você precisará ter os pesos e
+arquivos tokenizer armazenados em um diretório. Por exemplo, podemos carregar e salvar um checkpoint como:
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+
+>>> # Load tokenizer and PyTorch weights form the Hub
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
+>>> # Save to disk
+>>> tokenizer.save_pretrained("local-pt-checkpoint")
+>>> pt_model.save_pretrained("local-pt-checkpoint")
+```
+
+Uma vez que o checkpoint é salvo, podemos exportá-lo para o ONNX apontando o `--model`
+argumento do pacote `transformers.onnx` para o diretório desejado:
+
+```bash
+python -m transformers.onnx --model=local-pt-checkpoint onnx/
+```
+
+```python
+>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
+
+>>> # Load tokenizer and TensorFlow weights from the Hub
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
+>>> # Save to disk
+>>> tokenizer.save_pretrained("local-tf-checkpoint")
+>>> tf_model.save_pretrained("local-tf-checkpoint")
+```
+
+Uma vez que o checkpoint é salvo, podemos exportá-lo para o ONNX apontando o `--model`
+argumento do pacote `transformers.onnx` para o diretório desejado:
+
+```bash
+python -m transformers.onnx --model=local-tf-checkpoint onnx/
+```
+
+## Selecionando features para diferentes tarefas do modelo
+
+Cada configuração pronta vem com um conjunto de _features_ que permitem exportar
+modelos para diferentes tipos de tarefas. Conforme mostrado na tabela abaixo, cada recurso é
+associado a uma `AutoClass` diferente:
+
+| Feature | Auto Class |
+| ------------------------------------ | ------------------------------------ |
+| `causal-lm`, `causal-lm-with-past` | `AutoModelForCausalLM` |
+| `default`, `default-with-past` | `AutoModel` |
+| `masked-lm` | `AutoModelForMaskedLM` |
+| `question-answering` | `AutoModelForQuestionAnswering` |
+| `seq2seq-lm`, `seq2seq-lm-with-past` | `AutoModelForSeq2SeqLM` |
+| `sequence-classification` | `AutoModelForSequenceClassification` |
+| `token-classification` | `AutoModelForTokenClassification` |
+
+Para cada configuração, você pode encontrar a lista de recursos suportados por meio do
+[`~transformers.onnx.FeaturesManager`]. Por exemplo, para DistilBERT temos:
+
+```python
+>>> from transformers.onnx.features import FeaturesManager
+
+>>> distilbert_features = list(FeaturesManager.get_supported_features_for_model_type("distilbert").keys())
+>>> print(distilbert_features)
+["default", "masked-lm", "causal-lm", "sequence-classification", "token-classification", "question-answering"]
+```
+
+Você pode então passar um desses recursos para o argumento `--feature` no
+pacote `transformers.onnx`. Por exemplo, para exportar um modelo de classificação de texto, podemos
+escolher um modelo ajustado no Hub e executar:
+
+```bash
+python -m transformers.onnx --model=distilbert/distilbert-base-uncased-finetuned-sst-2-english \
+ --feature=sequence-classification onnx/
+```
+
+Isso exibe os seguintes logs:
+
+```bash
+Validating ONNX model...
+ -[✓] ONNX model output names match reference model ({'logits'})
+ - Validating ONNX Model output "logits":
+ -[✓] (2, 2) matches (2, 2)
+ -[✓] all values close (atol: 1e-05)
+All good, model saved at: onnx/model.onnx
+```
+
+Observe que, neste caso, os nomes de saída do modelo ajustado são `logits`
+em vez do `last_hidden_state` que vimos com o checkpoint `distilbert/distilbert-base-uncased`
+mais cedo. Isso é esperado, pois o modelo ajustado (fine-tuned) possui uma cabeça de classificação de sequência.
+
+
+
+Os recursos que têm um sufixo `with-pass` (como `causal-lm-with-pass`) correspondem a
+classes de modelo com estados ocultos pré-computados (chave e valores nos blocos de atenção)
+que pode ser usado para decodificação autorregressiva rápida.
+
+
+
+
+
+Para modelos do tipo `VisionEncoderDecoder`, as partes do codificador e do decodificador são
+exportados separadamente como dois arquivos ONNX chamados `encoder_model.onnx` e `decoder_model.onnx` respectivamente.
+
+
+
+## Exportando um modelo para uma arquitetura sem suporte
+
+Se você deseja exportar um modelo cuja arquitetura não é suportada nativamente pela
+biblioteca, há três etapas principais a seguir:
+
+1. Implemente uma configuração ONNX personalizada.
+2. Exporte o modelo para o ONNX.
+3. Valide as saídas do PyTorch e dos modelos exportados.
+
+Nesta seção, veremos como o DistilBERT foi implementado para mostrar o que está envolvido
+em cada passo.
+
+### Implementando uma configuração ONNX personalizada
+
+Vamos começar com o objeto de configuração ONNX. Fornecemos três classes abstratas que
+você deve herdar, dependendo do tipo de arquitetura de modelo que deseja exportar:
+
+* Modelos baseados em codificador herdam de [`~onnx.config.OnnxConfig`]
+* Modelos baseados em decodificador herdam de [`~onnx.config.OnnxConfigWithPast`]
+* Os modelos codificador-decodificador herdam de [`~onnx.config.OnnxSeq2SeqConfigWithPast`]
+
+
+
+Uma boa maneira de implementar uma configuração ONNX personalizada é observar as
+implementação no arquivo `configuration_.py` de uma arquitetura semelhante.
+
+
+
+Como o DistilBERT é um modelo baseado em codificador, sua configuração é herdada de
+`OnnxConfig`:
+
+```python
+>>> from typing import Mapping, OrderedDict
+>>> from transformers.onnx import OnnxConfig
+
+
+>>> class DistilBertOnnxConfig(OnnxConfig):
+... @property
+... def inputs(self) -> Mapping[str, Mapping[int, str]]:
+... return OrderedDict(
+... [
+... ("input_ids", {0: "batch", 1: "sequence"}),
+... ("attention_mask", {0: "batch", 1: "sequence"}),
+... ]
+... )
+```
+
+Todo objeto de configuração deve implementar a propriedade `inputs` e retornar um mapeamento,
+onde cada chave corresponde a uma entrada esperada e cada valor indica o eixo
+dessa entrada. Para o DistilBERT, podemos ver que duas entradas são necessárias: `input_ids` e
+`attention_mask`. Essas entradas têm a mesma forma de `(batch_size, sequence_length)`
+é por isso que vemos os mesmos eixos usados na configuração.
+
+
+
+Notice that `inputs` property for `DistilBertOnnxConfig` returns an `OrderedDict`. This
+ensures that the inputs are matched with their relative position within the
+`PreTrainedModel.forward()` method when tracing the graph. We recommend using an
+`OrderedDict` for the `inputs` and `outputs` properties when implementing custom ONNX
+configurations.
+
+Observe que a propriedade `inputs` para `DistilBertOnnxConfig` retorna um `OrderedDict`. Este
+garante que as entradas sejam combinadas com sua posição relativa dentro do
+método `PreTrainedModel.forward()` ao traçar o grafo. Recomendamos o uso de um
+`OrderedDict` para as propriedades `inputs` e `outputs` ao implementar configurações personalizadas ONNX.
+
+
+
+Depois de implementar uma configuração ONNX, você pode instanciá-la fornecendo a
+configuração do modelo base da seguinte forma:
+
+```python
+>>> from transformers import AutoConfig
+
+>>> config = AutoConfig.from_pretrained("distilbert/distilbert-base-uncased")
+>>> onnx_config = DistilBertOnnxConfig(config)
+```
+
+O objeto resultante tem várias propriedades úteis. Por exemplo, você pode visualizar o conjunto de operadores ONNX
+ que será usado durante a exportação:
+
+```python
+>>> print(onnx_config.default_onnx_opset)
+11
+```
+
+Você também pode visualizar as saídas associadas ao modelo da seguinte forma:
+
+```python
+>>> print(onnx_config.outputs)
+OrderedDict([("last_hidden_state", {0: "batch", 1: "sequence"})])
+```
+
+Observe que a propriedade outputs segue a mesma estrutura das entradas; ele retorna um
+`OrderedDict` de saídas nomeadas e suas formas. A estrutura de saída está ligada a
+escolha do recurso com o qual a configuração é inicializada. Por padrão, a configuração do ONNX
+é inicializada com o recurso `default` que corresponde à exportação de um
+modelo carregado com a classe `AutoModel`. Se você deseja exportar um modelo para outra tarefa,
+apenas forneça um recurso diferente para o argumento `task` quando você inicializar a configuração ONNX
+. Por exemplo, se quisermos exportar o DistilBERT com uma sequência
+de classificação, poderíamos usar:
+
+```python
+>>> from transformers import AutoConfig
+
+>>> config = AutoConfig.from_pretrained("distilbert/distilbert-base-uncased")
+>>> onnx_config_for_seq_clf = DistilBertOnnxConfig(config, task="sequence-classification")
+>>> print(onnx_config_for_seq_clf.outputs)
+OrderedDict([('logits', {0: 'batch'})])
+```
+
+
+
+Todas as propriedades e métodos básicos associados a [`~onnx.config.OnnxConfig`] e
+as outras classes de configuração podem ser substituídas se necessário. Confira [`BartOnnxConfig`]
+para um exemplo avançado.
+
+
+
+### Exportando um modelo
+
+Depois de ter implementado a configuração do ONNX, o próximo passo é exportar o modelo.
+Aqui podemos usar a função `export()` fornecida pelo pacote `transformers.onnx`.
+Esta função espera a configuração do ONNX, juntamente com o modelo base e o tokenizer,
+e o caminho para salvar o arquivo exportado:
+
+```python
+>>> from pathlib import Path
+>>> from transformers.onnx import export
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> onnx_path = Path("model.onnx")
+>>> model_ckpt = "distilbert/distilbert-base-uncased"
+>>> base_model = AutoModel.from_pretrained(model_ckpt)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
+
+>>> onnx_inputs, onnx_outputs = export(tokenizer, base_model, onnx_config, onnx_config.default_onnx_opset, onnx_path)
+```
+
+Os `onnx_inputs` e `onnx_outputs` retornados pela função `export()` são listas de
+ chaves definidas nas propriedades `inputs` e `outputs` da configuração. Uma vez que o
+modelo é exportado, você pode testar se o modelo está bem formado da seguinte forma:
+
+```python
+>>> import onnx
+
+>>> onnx_model = onnx.load("model.onnx")
+>>> onnx.checker.check_model(onnx_model)
+```
+
+
+
+Se o seu modelo for maior que 2GB, você verá que muitos arquivos adicionais são criados
+durante a exportação. Isso é _esperado_ porque o ONNX usa [Protocol
+Buffers](https://developers.google.com/protocol-buffers/) para armazenar o modelo e estes
+têm um limite de tamanho de 2GB. Veja a [ONNX
+documentação](https://github.com/onnx/onnx/blob/master/docs/ExternalData.md) para
+instruções sobre como carregar modelos com dados externos.
+
+
+
+### Validando a saída dos modelos
+
+A etapa final é validar se as saídas do modelo base e exportado concordam
+dentro de alguma tolerância absoluta. Aqui podemos usar a função `validate_model_outputs()`
+fornecida pelo pacote `transformers.onnx` da seguinte forma:
+
+```python
+>>> from transformers.onnx import validate_model_outputs
+
+>>> validate_model_outputs(
+... onnx_config, tokenizer, base_model, onnx_path, onnx_outputs, onnx_config.atol_for_validation
+... )
+```
+
+Esta função usa o método [`~transformers.onnx.OnnxConfig.generate_dummy_inputs`] para
+gerar entradas para o modelo base e o exportado, e a tolerância absoluta pode ser
+definida na configuração. Geralmente encontramos concordância numérica em 1e-6 a 1e-4
+de alcance, embora qualquer coisa menor que 1e-3 provavelmente esteja OK.
+
+## Contribuindo com uma nova configuração para 🤗 Transformers
+
+Estamos procurando expandir o conjunto de configurações prontas e receber contribuições
+da comunidade! Se você gostaria de contribuir para a biblioteca, você
+precisará:
+
+* Implemente a configuração do ONNX no arquivo `configuration_.py` correspondente
+Arquivo
+* Incluir a arquitetura do modelo e recursos correspondentes em
+ [`~onnx.features.FeatureManager`]
+* Adicione sua arquitetura de modelo aos testes em `test_onnx_v2.py`
+
+Confira como ficou a configuração do [IBERT
+](https://github.com/huggingface/transformers/pull/14868/files) para obter uma
+idéia do que está envolvido.
diff --git a/docs/transformers/docs/source/pt/tasks/sequence_classification.md b/docs/transformers/docs/source/pt/tasks/sequence_classification.md
new file mode 100644
index 0000000000000000000000000000000000000000..a2e6865c92e5b619d2427c972bf54122dfcc9096
--- /dev/null
+++ b/docs/transformers/docs/source/pt/tasks/sequence_classification.md
@@ -0,0 +1,216 @@
+
+
+# Classificação de texto
+
+
+
+A classificação de texto é uma tarefa comum de NLP que atribui um rótulo ou classe a um texto. Existem muitas aplicações práticas de classificação de texto amplamente utilizadas em produção por algumas das maiores empresas da atualidade. Uma das formas mais populares de classificação de texto é a análise de sentimento, que atribui um rótulo como positivo, negativo ou neutro a um texto.
+
+Este guia mostrará como realizar o fine-tuning do [DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased) no conjunto de dados [IMDb](https://huggingface.co/datasets/imdb) para determinar se a crítica de filme é positiva ou negativa.
+
+
+
+Consulte a [página de tarefas de classificação de texto](https://huggingface.co/tasks/text-classification) para obter mais informações sobre outras formas de classificação de texto e seus modelos, conjuntos de dados e métricas associados.
+
+
+
+## Carregue o conjunto de dados IMDb
+
+Carregue o conjunto de dados IMDb utilizando a biblioteca 🤗 Datasets:
+
+```py
+>>> from datasets import load_dataset
+
+>>> imdb = load_dataset("imdb")
+```
+
+Em seguida, dê uma olhada em um exemplo:
+
+```py
+>>> imdb["test"][0]
+{
+ "label": 0,
+ "text": "I love sci-fi and am willing to put up with a lot. Sci-fi movies/TV are usually underfunded, under-appreciated and misunderstood. I tried to like this, I really did, but it is to good TV sci-fi as Babylon 5 is to Star Trek (the original). Silly prosthetics, cheap cardboard sets, stilted dialogues, CG that doesn't match the background, and painfully one-dimensional characters cannot be overcome with a 'sci-fi' setting. (I'm sure there are those of you out there who think Babylon 5 is good sci-fi TV. It's not. It's clichéd and uninspiring.) While US viewers might like emotion and character development, sci-fi is a genre that does not take itself seriously (cf. Star Trek). It may treat important issues, yet not as a serious philosophy. It's really difficult to care about the characters here as they are not simply foolish, just missing a spark of life. Their actions and reactions are wooden and predictable, often painful to watch. The makers of Earth KNOW it's rubbish as they have to always say \"Gene Roddenberry's Earth...\" otherwise people would not continue watching. Roddenberry's ashes must be turning in their orbit as this dull, cheap, poorly edited (watching it without advert breaks really brings this home) trudging Trabant of a show lumbers into space. Spoiler. So, kill off a main character. And then bring him back as another actor. Jeeez! Dallas all over again.",
+}
+```
+
+Existem dois campos neste dataset:
+
+- `text`: uma string contendo o texto da crítica do filme.
+- `label`: um valor que pode ser `0` para uma crítica negativa ou `1` para uma crítica positiva.
+
+## Pré-processamento dos dados
+
+Carregue o tokenizador do DistilBERT para processar o campo `text`:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+Crie uma função de pré-processamento para tokenizar o campo `text` e truncar as sequências para que não sejam maiores que o comprimento máximo de entrada do DistilBERT:
+
+```py
+>>> def preprocess_function(examples):
+... return tokenizer(examples["text"], truncation=True)
+```
+
+Use a função [`map`](https://huggingface.co/docs/datasets/process#map) do 🤗 Datasets para aplicar a função de pré-processamento em todo o conjunto de dados. Você pode acelerar a função `map` definindo `batched=True` para processar vários elementos do conjunto de dados de uma só vez:
+
+```py
+tokenized_imdb = imdb.map(preprocess_function, batched=True)
+```
+
+Use o [`DataCollatorWithPadding`] para criar um batch de exemplos. Ele também *preencherá dinamicamente* seu texto até o comprimento do elemento mais longo em seu batch, para que os exemplos do batch tenham um comprimento uniforme. Embora seja possível preencher seu texto com a função `tokenizer` definindo `padding=True`, o preenchimento dinâmico utilizando um data collator é mais eficiente.
+
+
+
+```py
+>>> from transformers import DataCollatorWithPadding
+
+>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
+```
+
+
+```py
+>>> from transformers import DataCollatorWithPadding
+
+>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
+```
+
+
+
+## Train
+
+
+
+Carregue o DistilBERT com [`AutoModelForSequenceClassification`] junto com o número de rótulos esperados:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased", num_labels=2)
+```
+
+
+
+Se você não estiver familiarizado com o fine-tuning de um modelo com o [`Trainer`], dê uma olhada no tutorial básico [aqui](../training#finetune-with-trainer)!
+
+
+
+Nesse ponto, restam apenas três passos:
+
+1. Definir seus hiperparâmetros de treinamento em [`TrainingArguments`].
+2. Passar os argumentos de treinamento para o [`Trainer`] junto com o modelo, conjunto de dados, tokenizador e o data collator.
+3. Chamar a função [`~Trainer.train`] para executar o fine-tuning do seu modelo.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="./results",
+... learning_rate=2e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... num_train_epochs=5,
+... weight_decay=0.01,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_imdb["train"],
+... eval_dataset=tokenized_imdb["test"],
+... processing_class=tokenizer,
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+
+
+O [`Trainer`] aplicará o preenchimento dinâmico por padrão quando você definir o argumento `tokenizer` dele. Nesse caso, você não precisa especificar um data collator explicitamente.
+
+
+
+
+Para executar o fine-tuning de um modelo no TensorFlow, comece convertendo seu conjunto de dados para o formato `tf.data.Dataset` com [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Nessa execução você deverá especificar as entradas e rótulos (no parâmetro `columns`), se deseja embaralhar o conjunto de dados, o tamanho do batch e o data collator:
+
+```py
+>>> tf_train_set = tokenized_imdb["train"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "label"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_validation_set = tokenized_imdb["test"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "label"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+
+
+Se você não estiver familiarizado com o fine-tuning de um modelo com o Keras, dê uma olhada no tutorial básico [aqui](training#finetune-with-keras)!
+
+
+
+Configure o otimizador e alguns hiperparâmetros de treinamento:
+
+```py
+>>> from transformers import create_optimizer
+>>> import tensorflow as tf
+
+>>> batch_size = 16
+>>> num_epochs = 5
+>>> batches_per_epoch = len(tokenized_imdb["train"]) // batch_size
+>>> total_train_steps = int(batches_per_epoch * num_epochs)
+>>> optimizer, schedule = create_optimizer(init_lr=2e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
+```
+
+Carregue o DistilBERT com [`TFAutoModelForSequenceClassification`] junto com o número de rótulos esperados:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased", num_labels=2)
+```
+
+Configure o modelo para treinamento com o método [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer)
+```
+
+Chame o método [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) para executar o fine-tuning do modelo:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3)
+```
+
+
+
+
+
+Para obter um exemplo mais aprofundado de como executar o fine-tuning de um modelo para classificação de texto, dê uma olhada nesse [notebook utilizando PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb) ou nesse [notebook utilizando TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb).
+
+
diff --git a/docs/transformers/docs/source/pt/tasks/token_classification.md b/docs/transformers/docs/source/pt/tasks/token_classification.md
new file mode 100644
index 0000000000000000000000000000000000000000..45ce0d87429c58cf2f27b7b50666cb42df100ec4
--- /dev/null
+++ b/docs/transformers/docs/source/pt/tasks/token_classification.md
@@ -0,0 +1,272 @@
+
+
+# Classificação de tokens
+
+
+
+A classificação de tokens atribui um rótulo a tokens individuais em uma frase. Uma das tarefas de classificação de tokens mais comuns é o Reconhecimento de Entidade Nomeada, também chamada de NER (sigla em inglês para Named Entity Recognition). O NER tenta encontrar um rótulo para cada entidade em uma frase, como uma pessoa, local ou organização.
+
+Este guia mostrará como realizar o fine-tuning do [DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased) no conjunto de dados [WNUT 17](https://huggingface.co/datasets/wnut_17) para detectar novas entidades.
+
+
+
+Consulte a [página de tarefas de classificação de tokens](https://huggingface.co/tasks/token-classification) para obter mais informações sobre outras formas de classificação de tokens e seus modelos, conjuntos de dados e métricas associadas.
+
+
+
+## Carregando o conjunto de dados WNUT 17
+
+Carregue o conjunto de dados WNUT 17 da biblioteca 🤗 Datasets:
+
+```py
+>>> from datasets import load_dataset
+
+>>> wnut = load_dataset("wnut_17")
+```
+
+E dê uma olhada em um exemplo:
+
+```py
+>>> wnut["train"][0]
+{'id': '0',
+ 'ner_tags': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 7, 8, 8, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'tokens': ['@paulwalk', 'It', "'s", 'the', 'view', 'from', 'where', 'I', "'m", 'living', 'for', 'two', 'weeks', '.', 'Empire', 'State', 'Building', '=', 'ESB', '.', 'Pretty', 'bad', 'storm', 'here', 'last', 'evening', '.']
+}
+```
+
+Cada número em `ner_tags` representa uma entidade. Converta o número em um rótulo para obter mais informações:
+
+```py
+>>> label_list = wnut["train"].features[f"ner_tags"].feature.names
+>>> label_list
+[
+ "O",
+ "B-corporation",
+ "I-corporation",
+ "B-creative-work",
+ "I-creative-work",
+ "B-group",
+ "I-group",
+ "B-location",
+ "I-location",
+ "B-person",
+ "I-person",
+ "B-product",
+ "I-product",
+]
+```
+
+O `ner_tag` descreve uma entidade, como uma organização, local ou pessoa. A letra que prefixa cada `ner_tag` indica a posição do token da entidade:
+
+- `B-` indica o início de uma entidade.
+- `I-` indica que um token está contido dentro da mesma entidade (por exemplo, o token `State` pode fazer parte de uma entidade como `Empire State Building`).
+- `0` indica que o token não corresponde a nenhuma entidade.
+
+## Pré-processamento
+
+
+
+Carregue o tokenizer do DistilBERT para processar os `tokens`:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+```
+
+Como a entrada já foi dividida em palavras, defina `is_split_into_words=True` para tokenizar as palavras em subpalavras:
+
+```py
+>>> tokenized_input = tokenizer(example["tokens"], is_split_into_words=True)
+>>> tokens = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
+>>> tokens
+['[CLS]', '@', 'paul', '##walk', 'it', "'", 's', 'the', 'view', 'from', 'where', 'i', "'", 'm', 'living', 'for', 'two', 'weeks', '.', 'empire', 'state', 'building', '=', 'es', '##b', '.', 'pretty', 'bad', 'storm', 'here', 'last', 'evening', '.', '[SEP]']
+```
+
+Ao adicionar os tokens especiais `[CLS]` e `[SEP]` e a tokenização de subpalavras uma incompatibilidade é gerada entre a entrada e os rótulos. Uma única palavra correspondente a um único rótulo pode ser dividida em duas subpalavras. Você precisará realinhar os tokens e os rótulos da seguinte forma:
+
+1. Mapeie todos os tokens para a palavra correspondente com o método [`word_ids`](https://huggingface.co/docs/tokenizers/python/latest/api/reference.html#tokenizers.Encoding.word_ids).
+2. Atribuindo o rótulo `-100` aos tokens especiais `[CLS]` e `[SEP]` para que a função de loss do PyTorch ignore eles.
+3. Rotular apenas o primeiro token de uma determinada palavra. Atribuindo `-100` a outros subtokens da mesma palavra.
+
+Aqui está como você pode criar uma função para realinhar os tokens e rótulos e truncar sequências para não serem maiores que o comprimento máximo de entrada do DistilBERT:
+
+```py
+>>> def tokenize_and_align_labels(examples):
+... tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
+
+... labels = []
+... for i, label in enumerate(examples[f"ner_tags"]):
+... word_ids = tokenized_inputs.word_ids(batch_index=i) # Map tokens to their respective word.
+... previous_word_idx = None
+... label_ids = []
+... for word_idx in word_ids: # Set the special tokens to -100.
+... if word_idx is None:
+... label_ids.append(-100)
+... elif word_idx != previous_word_idx: # Only label the first token of a given word.
+... label_ids.append(label[word_idx])
+... else:
+... label_ids.append(-100)
+... previous_word_idx = word_idx
+... labels.append(label_ids)
+
+... tokenized_inputs["labels"] = labels
+... return tokenized_inputs
+```
+
+Use a função [`map`](https://huggingface.co/docs/datasets/process#map) do 🤗 Datasets para tokenizar e alinhar os rótulos em todo o conjunto de dados. Você pode acelerar a função `map` configurando `batched=True` para processar vários elementos do conjunto de dados de uma só vez:
+
+```py
+>>> tokenized_wnut = wnut.map(tokenize_and_align_labels, batched=True)
+```
+
+Use o [`DataCollatorForTokenClassification`] para criar um batch de exemplos. Ele também *preencherá dinamicamente* seu texto e rótulos para o comprimento do elemento mais longo em seu batch, para que tenham um comprimento uniforme. Embora seja possível preencher seu texto na função `tokenizer` configurando `padding=True`, o preenchimento dinâmico é mais eficiente.
+
+
+
+```py
+>>> from transformers import DataCollatorForTokenClassification
+
+>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
+```
+
+
+```py
+>>> from transformers import DataCollatorForTokenClassification
+
+>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer, return_tensors="tf")
+```
+
+
+
+## Treinamento
+
+
+
+Carregue o DistilBERT com o [`AutoModelForTokenClassification`] junto com o número de rótulos esperados:
+
+```py
+>>> from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer
+
+>>> model = AutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased", num_labels=14)
+```
+
+
+
+Se você não estiver familiarizado com o fine-tuning de um modelo com o [`Trainer`], dê uma olhada no tutorial básico [aqui](../training#finetune-with-trainer)!
+
+
+
+Nesse ponto, restam apenas três passos:
+
+1. Definir seus hiperparâmetros de treinamento em [`TrainingArguments`].
+2. Passar os argumentos de treinamento para o [`Trainer`] junto com o modelo, conjunto de dados, tokenizador e o data collator.
+3. Chamar a função [`~Trainer.train`] para executar o fine-tuning do seu modelo.
+
+```py
+>>> training_args = TrainingArguments(
+... output_dir="./results",
+... eval_strategy="epoch",
+... learning_rate=2e-5,
+... per_device_train_batch_size=16,
+... per_device_eval_batch_size=16,
+... num_train_epochs=3,
+... weight_decay=0.01,
+... )
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=tokenized_wnut["train"],
+... eval_dataset=tokenized_wnut["test"],
+... processing_class=tokenizer,
+... data_collator=data_collator,
+... )
+
+>>> trainer.train()
+```
+
+
+Para executar o fine-tuning de um modelo no TensorFlow, comece convertendo seu conjunto de dados para o formato `tf.data.Dataset` com [`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset). Nessa execução você deverá especificar as entradas e rótulos (no parâmetro `columns`), se deseja embaralhar o conjunto de dados, o tamanho do batch e o data collator:
+
+```py
+>>> tf_train_set = tokenized_wnut["train"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "labels"],
+... shuffle=True,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+
+>>> tf_validation_set = tokenized_wnut["validation"].to_tf_dataset(
+... columns=["attention_mask", "input_ids", "labels"],
+... shuffle=False,
+... batch_size=16,
+... collate_fn=data_collator,
+... )
+```
+
+
+
+Se você não estiver familiarizado com o fine-tuning de um modelo com o Keras, dê uma olhada no tutorial básico [aqui](training#finetune-with-keras)!
+
+
+
+Configure o otimizador e alguns hiperparâmetros de treinamento:
+
+```py
+>>> from transformers import create_optimizer
+
+>>> batch_size = 16
+>>> num_train_epochs = 3
+>>> num_train_steps = (len(tokenized_wnut["train"]) // batch_size) * num_train_epochs
+>>> optimizer, lr_schedule = create_optimizer(
+... init_lr=2e-5,
+... num_train_steps=num_train_steps,
+... weight_decay_rate=0.01,
+... num_warmup_steps=0,
+... )
+```
+
+Carregue o DistilBERT com o [`TFAutoModelForTokenClassification`] junto com o número de rótulos esperados:
+
+```py
+>>> from transformers import TFAutoModelForTokenClassification
+
+>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased", num_labels=2)
+```
+
+Configure o modelo para treinamento com o método [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
+
+```py
+>>> import tensorflow as tf
+
+>>> model.compile(optimizer=optimizer)
+```
+
+Chame o método [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) para executar o fine-tuning do modelo:
+
+```py
+>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3)
+```
+
+
+
+
+
+Para obter um exemplo mais aprofundado de como executar o fine-tuning de um modelo para classificação de tokens, dê uma olhada nesse [notebook utilizando PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb) ou nesse [notebook utilizando TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb).
+
+
diff --git a/docs/transformers/docs/source/pt/training.md b/docs/transformers/docs/source/pt/training.md
new file mode 100644
index 0000000000000000000000000000000000000000..67294baee35c1f8108ddfb65fdba2165c65e6ee2
--- /dev/null
+++ b/docs/transformers/docs/source/pt/training.md
@@ -0,0 +1,416 @@
+
+
+# Fine-tuning de um modelo pré-treinado
+
+[[open-in-colab]]
+
+O uso de um modelo pré-treinado tem importantes vantagens. Redução do custo computacional, a pegada de carbono, e te
+permite utilizar modelos de última geração sem ter que treinar um novo desde o início.
+O 🤗 Transformers proporciona acesso a milhares de modelos pré-treinados numa ampla gama de tarefas.
+Quando utilizar um modelo pré-treinado, treine-o com um dataset específico para a sua tarefa.
+Isto é chamado de fine-tuning, uma técnica de treinamento incrivelmente poderosa. Neste tutorial faremos o fine-tuning
+de um modelo pré-treinado com um framework de Deep Learning da sua escolha:
+
+* Fine-tuning de um modelo pré-treinado com o 🤗 Transformers [`Trainer`].
+* Fine-tuning de um modelo pré-treinado no TensorFlow com o Keras.
+* Fine-tuning de um modelo pré-treinado em PyTorch nativo.
+
+
+
+## Preparando um dataset
+
+
+
+Antes de aplicar o fine-tuning a um modelo pré-treinado, baixe um dataset e prepare-o para o treinamento.
+O tutorial anterior ensinará a processar os dados para o treinamento, e então poderá ter a oportunidade de testar
+esse novo conhecimento em algo prático.
+
+Comece carregando o dataset [Yelp Reviews](https://huggingface.co/datasets/yelp_review_full):
+
+```py
+>>> from datasets import load_dataset
+
+>>> dataset = load_dataset("yelp_review_full")
+>>> dataset[100]
+{'label': 0,
+ 'text': 'My expectations for McDonalds are t rarely high. But for one to still fail so spectacularly...that takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. I waited over five minutes for a gigantic order that included precisely one kid\'s meal. After watching two people who ordered after me be handed their food, I asked where mine was. The manager started yelling at the cashiers for \\"serving off their orders\\" when they didn\'t have their food. But neither cashier was anywhere near those controls, and the manager was the one serving food to customers and clearing the boards.\\nThe manager was rude when giving me my order. She didn\'t make sure that I had everything ON MY RECEIPT, and never even had the decency to apologize that I felt I was getting poor service.\\nI\'ve eaten at various McDonalds restaurants for over 30 years. I\'ve worked at more than one location. I expect bad days, bad moods, and the occasional mistake. But I have yet to have a decent experience at this store. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. Perhaps I should go back to the racially biased service of Steak n Shake instead!'}
+```
+
+Como já sabe, é necessário ter um tokenizador para processar o texto e incluir uma estratégia de padding e truncamento,
+para manejar qualquer tamanho varíavel de sequência. Para processar o seu dataset em apenas um passo, utilize o método de
+🤗 Datasets [`map`](https://huggingface.co/docs/datasets/process#map) para aplicar uma função de preprocessamento sobre
+todo o dataset.
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
+
+
+>>> def tokenize_function(examples):
+... return tokenizer(examples["text"], padding="max_length", truncation=True)
+
+
+>>> tokenized_datasets = dataset.map(tokenize_function, batched=True)
+```
+
+Se desejar, é possível criar um subconjunto menor do dataset completo para aplicar o fine-tuning e assim reduzir o tempo necessário.
+
+```py
+>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
+>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
+```
+
+
+
+## Fine-tuning com o `Trainer`
+
+
+
+O 🤗 Transformers proporciona uma classe [`Trainer`] otimizada para o treinamento de modelos de 🤗 Transformers,
+facilitando os primeiros passos do treinamento sem a necessidade de escrever manualmente o seu próprio ciclo.
+A API do [`Trainer`] suporta um grande conjunto de opções de treinamento e funcionalidades, como o logging,
+o gradient accumulation e o mixed precision.
+
+Comece carregando seu modelo e especifique o número de labels de previsão.
+A partir do [Card Dataset](https://huggingface.co/datasets/yelp_review_full#data-fields) do Yelp Reveiw, que ja
+sabemos ter 5 labels usamos o seguinte código:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=5)
+```
+
+
+
+ Você verá um alerta sobre alguns pesos pré-treinados que não estão sendo utilizados e que alguns pesos estão
+ sendo inicializados aleatoriamente. Não se preocupe, essa mensagem é completamente normal.
+ O header/cabeçário pré-treinado do modelo BERT é descartado e substitui-se por um header de classificação
+ inicializado aleatoriamente. Assim, pode aplicar o fine-tuning a este novo header do modelo em sua tarefa
+ de classificação de sequências fazendo um transfer learning do modelo pré-treinado.
+
+
+
+### Hiperparâmetros de treinamento
+
+Em seguida, crie uma classe [`TrainingArguments`] que contenha todos os hiperparâmetros que possam ser ajustados, assim
+como os indicadores para ativar as diferentes opções de treinamento. Para este tutorial, você pode começar o treinamento
+usando os [hiperparámetros](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) padrão,
+porém, sinta-se livre para experimentar com eles e encontrar uma configuração ótima.
+
+Especifique onde salvar os checkpoints do treinamento:
+
+```py
+>>> from transformers import TrainingArguments
+
+>>> training_args = TrainingArguments(output_dir="test_trainer")
+```
+
+### Métricas
+
+O [`Trainer`] não avalia automaticamente o rendimento do modelo durante o treinamento. Será necessário passar ao
+[`Trainer`] uma função para calcular e fazer um diagnóstico sobre as métricas. A biblioteca 🤗 Datasets proporciona
+uma função de [`accuracy`](https://huggingface.co/metrics/accuracy) simples que pode ser carregada com a função
+`load_metric` (ver este [tutorial](https://huggingface.co/docs/datasets/metrics) para mais informações):
+
+```py
+>>> import numpy as np
+>>> from datasets import load_metric
+
+>>> metric = load_metric("accuracy")
+```
+
+Defina a função `compute` dentro de `metric` para calcular a precisão das suas predições.
+Antes de passar as suas predições ao `compute`, é necessário converter as predições à logits (lembre-se que
+todos os modelos de 🤗 Transformers retornam logits).
+
+```py
+>>> def compute_metrics(eval_pred):
+... logits, labels = eval_pred
+... predictions = np.argmax(logits, axis=-1)
+... return metric.compute(predictions=predictions, references=labels)
+```
+
+Se quiser controlar as suas métricas de avaliação durante o fine-tuning, especifique o parâmetro `eval_strategy`
+nos seus argumentos de treinamento para que o modelo considere a métrica de avaliação ao final de cada época:
+
+```py
+>>> from transformers import TrainingArguments
+
+>>> training_args = TrainingArguments(output_dir="test_trainer", eval_strategy="epoch")
+```
+
+### Trainer
+
+Crie um objeto [`Trainer`] com o seu modelo, argumentos de treinamento, conjuntos de dados de treinamento e de teste, e a sua função de avaliação:
+
+```py
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=small_train_dataset,
+... eval_dataset=small_eval_dataset,
+... compute_metrics=compute_metrics,
+... )
+```
+
+Em seguida, aplique o fine-tuning a seu modelo chamado [`~transformers.Trainer.train`]:
+
+```py
+>>> trainer.train()
+```
+
+
+
+## Fine-tuning com Keras
+
+
+
+Os modelos de 🤗 Transformers também permitem realizar o treinamento com o TensorFlow com a API do Keras.
+Contudo, será necessário fazer algumas mudanças antes de realizar o fine-tuning.
+
+### Conversão do dataset ao formato do TensorFlow
+
+O [`DefaultDataCollator`] junta os tensores em um batch para que o modelo possa ser treinado em cima deles.
+Assegure-se de especificar os `return_tensors` para retornar os tensores do TensorFlow:
+
+```py
+>>> from transformers import DefaultDataCollator
+
+>>> data_collator = DefaultDataCollator(return_tensors="tf")
+```
+
+
+
+ O [`Trainer`] utiliza [`DataCollatorWithPadding`] por padrão, então você não precisa especificar explicitamente um
+ colador de dados (data collator).
+
+
+
+Em seguida, converta os datasets tokenizados em datasets do TensorFlow com o método
+[`to_tf_dataset`](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.to_tf_dataset).
+Especifique suas entradas em `columns` e seu rótulo em `label_cols`:
+
+```py
+>>> tf_train_dataset = small_train_dataset.to_tf_dataset(
+... columns=["attention_mask", "input_ids", "token_type_ids"],
+... label_cols="labels",
+... shuffle=True,
+... collate_fn=data_collator,
+... batch_size=8,
+... )
+
+>>> tf_validation_dataset = small_eval_dataset.to_tf_dataset(
+... columns=["attention_mask", "input_ids", "token_type_ids"],
+... label_cols="labels",
+... shuffle=False,
+... collate_fn=data_collator,
+... batch_size=8,
+... )
+```
+
+### Compilação e ajustes
+
+Carregue um modelo do TensorFlow com o número esperado de rótulos:
+
+```py
+>>> import tensorflow as tf
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=5)
+```
+
+A seguir, compile e ajuste o fine-tuning a seu modelo com [`fit`](https://keras.io/api/models/model_training_apis/) como
+faria com qualquer outro modelo do Keras:
+
+```py
+>>> model.compile(
+... optimizer=tf.keras.optimizers.Adam(learning_rate=5e-5),
+... loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+... metrics=tf.metrics.SparseCategoricalAccuracy(),
+... )
+
+>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3)
+```
+
+
+
+## Fine-tune em PyTorch nativo
+
+
+
+O [`Trainer`] se encarrega do ciclo de treinamento e permite aplicar o fine-tuning a um modelo em uma linha de código apenas.
+Para os usuários que preferirem escrever o seu próprio ciclo de treinamento, também é possível aplicar o fine-tuning a um
+modelo de 🤗 Transformers em PyTorch nativo.
+
+Neste momento, talvez ocorra a necessidade de reinicar seu notebook ou executar a seguinte linha de código para liberar
+memória:
+
+```py
+del model
+del pytorch_model
+del trainer
+torch.cuda.empty_cache()
+```
+
+Em sequência, faremos um post-processing manual do `tokenized_dataset` e assim prepará-lo para o treinamento.
+
+1. Apague a coluna de `text` porque o modelo não aceita texto cru como entrada:
+
+ ```py
+ >>> tokenized_datasets = tokenized_datasets.remove_columns(["text"])
+ ```
+
+2. Troque o nome da coluna `label` para `labels`, pois o modelo espera um argumento de mesmo nome:
+
+ ```py
+ >>> tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
+ ```
+
+3. Defina o formato do dataset para retornar tensores do PyTorch no lugar de listas:
+
+ ```py
+ >>> tokenized_datasets.set_format("torch")
+ ```
+
+Em sequência, crie um subconjunto menor do dataset, como foi mostrado anteriormente, para acelerá-lo o fine-tuning.
+
+```py
+>>> small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
+>>> small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
+```
+
+### DataLoader
+
+Crie um `DataLoader` para os seus datasets de treinamento e de teste para poder iterar sobre batches de dados:
+
+```py
+>>> from torch.utils.data import DataLoader
+
+>>> train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=8)
+>>> eval_dataloader = DataLoader(small_eval_dataset, batch_size=8)
+```
+
+Carregue seu modelo com o número de labels esperados:
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=5)
+```
+
+### Otimização e configuração do Learning Rate
+
+Crie um otimizador e um learning rate para aplicar o fine-tuning ao modelo.
+Iremos utilizar o otimizador [`AdamW`](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html) do PyTorch:
+
+```py
+>>> from torch.optim import AdamW
+
+>>> optimizer = AdamW(model.parameters(), lr=5e-5)
+```
+
+Defina o learning rate do [`Trainer`]:
+
+```py
+>>> from transformers import get_scheduler
+
+>>> num_epochs = 3
+>>> num_training_steps = num_epochs * len(train_dataloader)
+>>> lr_scheduler = get_scheduler(
+... name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
+... )
+```
+
+Por último, especifique o `device` do ambiente para utilizar uma GPU se tiver acesso à alguma. Caso contrário, o treinamento
+em uma CPU pode acabar levando várias horas em vez de minutos.
+
+```py
+>>> import torch
+
+>>> device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+>>> model.to(device)
+```
+
+
+
+ Se necessário, você pode obter o acesso gratuito a uma GPU na núvem por meio de um notebook no
+ [Colaboratory](https://colab.research.google.com/) ou [SageMaker StudioLab](https://studiolab.sagemaker.aws/)
+ se não tiver esse recurso de forma local.
+
+
+
+Perfeito, agora estamos prontos para começar o treinamento! 🥳
+
+### Ciclo de treinamento
+
+Para visualizar melhor o processo de treinamento, utilize a biblioteca [tqdm](https://tqdm.github.io/) para adicionar
+uma barra de progresso sobre o número de passos percorridos no treinamento atual:
+
+```py
+>>> from tqdm.auto import tqdm
+
+>>> progress_bar = tqdm(range(num_training_steps))
+
+>>> model.train()
+>>> for epoch in range(num_epochs):
+... for batch in train_dataloader:
+... batch = {k: v.to(device) for k, v in batch.items()}
+... outputs = model(**batch)
+... loss = outputs.loss
+... loss.backward()
+
+... optimizer.step()
+... lr_scheduler.step()
+... optimizer.zero_grad()
+... progress_bar.update(1)
+```
+
+### Métricas
+
+Da mesma forma que é necessário adicionar uma função de avaliação ao [`Trainer`], é necessário fazer o mesmo quando
+escrevendo o próprio ciclo de treinamento. Contudo, em vez de calcular e retornar a métrica final de cada época,
+você deverá adicionar todos os batches com [`add_batch`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=add_batch#datasets.Metric.add_batch)
+e calcular a métrica apenas no final.
+
+```py
+>>> metric = load_metric("accuracy")
+>>> model.eval()
+>>> for batch in eval_dataloader:
+... batch = {k: v.to(device) for k, v in batch.items()}
+... with torch.no_grad():
+... outputs = model(**batch)
+
+... logits = outputs.logits
+... predictions = torch.argmax(logits, dim=-1)
+... metric.add_batch(predictions=predictions, references=batch["labels"])
+
+>>> metric.compute()
+```
+
+
+
+## Recursos adicionais
+
+Para mais exemplos de fine-tuning acesse:
+
+- [🤗 Transformers Examples](https://github.com/huggingface/transformers/tree/main/examples) inclui scripts
+para treinas tarefas comuns de NLP em PyTorch e TensorFlow.
+
+- [🤗 Transformers Notebooks](notebooks) contém vários notebooks sobre como aplicar o fine-tuning a um modelo
+para tarefas específicas no PyTorch e TensorFlow.
diff --git a/docs/transformers/docs/source/te/_toctree.yml b/docs/transformers/docs/source/te/_toctree.yml
new file mode 100644
index 0000000000000000000000000000000000000000..5e6b45eb472f8dd998ddbaa3940d7fed96f12444
--- /dev/null
+++ b/docs/transformers/docs/source/te/_toctree.yml
@@ -0,0 +1,6 @@
+- sections:
+ - local: index
+ title: 🤗 Transformers
+ - local: quicktour
+ title: త్వరిత పర్యటన
+ title: ప్రారంభించడానికి
diff --git a/docs/transformers/docs/source/te/index.md b/docs/transformers/docs/source/te/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..3e23f8f5eb1392ff0f7fec76a606c625806b6ff7
--- /dev/null
+++ b/docs/transformers/docs/source/te/index.md
@@ -0,0 +1,298 @@
+
+
+[పైటోర్చ్](https://pytorch.org/), [టెన్సర్ఫ్లో](https://www.tensorflow.org/), మరియు [జాక్స్](https://jax.readthedocs.io/en/latest/) కోసం స్థితి-కలాన యంత్ర అభ్యాసం.
+
+🤗 ట్రాన్స్ఫార్మర్స్ అభివృద్ధిస్తున్నది API మరియు ఉపకరణాలు, పూర్వ-చేతన మోడల్లను సులభంగా డౌన్లోడ్ మరియు శిక్షణ చేయడానికి అవసరమైన సమయం, వనరులు, మరియు వస్తువులను నుంచి మోడల్ను శీర్షికం నుంచి ప్రశిక్షించడం వరకు దేవాయనం చేస్తుంది. ఈ మోడల్లు విభిన్న మోడాలిటీలలో సాధారణ పనులకు మద్దతు చేస్తాయి, వంటివి:
+
+📝 **ప్రాకృతిక భాష ప్రక్రియ**: వచన వర్గీకరణ, పేరుల యొక్క యెంటిటీ గుర్తువు, ప్రశ్న సంవాద, భాషా రచన, సంక్షేపణ, అనువాదం, అనేక ప్రకారాలు, మరియు వచన సృష్టి.
+🖼️ **కంప్యూటర్ విషయం**: చిత్రం వర్గీకరణ, వస్త్రం గుర్తువు, మరియు విభజన.
+🗣️ **ఆడియో**: స్వయంచలన ప్రసంగాన్ని గుర్తుచేసేందుకు, ఆడియో వర్గీకరణ.
+🐙 **బహుమూలిక**: పట్టి ప్రశ్న సంవాద, ఆప్టికల్ సిఫర్ గుర్తువు, డాక్యుమెంట్లు స్క్యాన్ చేసినంతగా సమాచార పొందడం, వీడియో వర్గీకరణ, మరియు దృశ్య ప్రశ్న సంవాద.
+
+🤗 ట్రాన్స్ఫార్మర్స్ పైన మద్దతు చేస్తుంది పైన తొలగించడానికి పైన పైన పైన ప్రోగ్రామ్లో మోడల్ను శిక్షించండి, మరియు అన్ని ప్రాథమిక యొక్కడా ఇన్ఫరెన్స్ కోసం లోడ్ చేయండి. మో
+
+డల్లు కూడా ప్రొడక్షన్ వాతావరణాలలో వాడుకోవడానికి ONNX మరియు TorchScript వంటి ఆకృతులకు ఎగుమతి చేయవచ్చు.
+
+ఈరువులకు [హబ్](https://huggingface.co/models), [ఫోరం](https://discuss.huggingface.co/), లేదా [డిస్కార్డ్](https://discord.com/invite/JfAtkvEtRb) లో ఈ పెద్ద సముదాయంలో చేరండి!
+
+## మీరు హగ్గింగ్ ఫేస్ టీమ్ నుండి అనుకూల మద్దతు కోసం చూస్తున్నట్లయితే
+
+
+
+
+
+## విషయాలు
+
+డాక్యుమెంటేషన్ ఐదు విభాగాలుగా నిర్వహించబడింది:
+
+- **ప్రారంభించండి** లైబ్రరీ యొక్క శీఘ్ర పర్యటన మరియు రన్నింగ్ కోసం ఇన్స్టాలేషన్ సూచనలను అందిస్తుంది.
+- **ట్యుటోరియల్స్** మీరు అనుభవశూన్యుడు అయితే ప్రారంభించడానికి గొప్ప ప్రదేశం. మీరు లైబ్రరీని ఉపయోగించడం ప్రారంభించడానికి అవసరమైన ప్రాథమిక నైపుణ్యాలను పొందడానికి ఈ విభాగం మీకు సహాయం చేస్తుంది.
+- **హౌ-టు-గైడ్లు** లాంగ్వేజ్ మోడలింగ్ కోసం ప్రిట్రైన్డ్ మోడల్ని ఫైన్ట్యూన్ చేయడం లేదా కస్టమ్ మోడల్ను ఎలా వ్రాయాలి మరియు షేర్ చేయాలి వంటి నిర్దిష్ట లక్ష్యాన్ని ఎలా సాధించాలో మీకు చూపుతాయి.
+- **కాన్సెప్చువల్ గైడ్స్** మోడల్లు, టాస్క్లు మరియు 🤗 ట్రాన్స్ఫార్మర్ల డిజైన్ ఫిలాసఫీ వెనుక ఉన్న అంతర్లీన భావనలు మరియు ఆలోచనల గురించి మరింత చర్చ మరియు వివరణను అందిస్తుంది.
+- **API** అన్ని తరగతులు మరియు విధులను వివరిస్తుంది:
+
+ - **ప్రధాన తరగతులు** కాన్ఫిగరేషన్, మోడల్, టోకెనైజర్ మరియు పైప్లైన్ వంటి అత్యంత ముఖ్యమైన తరగతులను వివరిస్తుంది.
+ - **మోడల్స్** లైబ్రరీలో అమలు చేయబడిన ప్రతి మోడల్కు సంబంధించిన తరగతులు మరియు విధులను వివరిస్తుంది.
+ - **అంతర్గత సహాయకులు** అంతర్గతంగా ఉపయోగించే యుటిలిటీ క్లాస్లు మరియు ఫంక్షన్ల వివరాలు.
+
+## మద్దతు ఉన్న నమూనాలు మరియు ఫ్రేమ్వర్క్లు
+
+దిగువన ఉన్న పట్టిక ఆ ప్రతి మోడల్కు పైథాన్ కలిగి ఉన్నా లైబ్రరీలో ప్రస్తుత మద్దతును సూచిస్తుంది
+టోకెనైజర్ ("నెమ్మదిగా" అని పిలుస్తారు). Jax (ద్వారా
+ఫ్లాక్స్), పైటార్చ్ మరియు/లేదా టెన్సర్ఫ్లో.
+
+
+
+| Model | PyTorch support | TensorFlow support | Flax Support |
+|:------------------------------------------------------------------------:|:---------------:|:------------------:|:------------:|
+| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
+| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
+| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
+| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
+| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
+| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
+| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
+| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
+| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
+| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
+| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
+| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
+| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
+| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
+| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
+| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
+| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
+| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
+| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
+| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
+| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
+| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
+| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
+| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
+| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
+| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
+| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
+| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
+| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
+| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
+| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
+| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
+| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
+| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
+| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ❌ |
+| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
+| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
+| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
+| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ❌ | ❌ |
+| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
+| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
+| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
+| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
+| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
+| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
+| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
+| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
+| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
+| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
+| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
+| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
+| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
+| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
+| [DiNAT](model_doc/dinat) | ✅ | ❌ | ❌ |
+| [DINOv2](model_doc/dinov2) | ✅ | ❌ | ❌ |
+| [DistilBERT](model_doc/distilbert) | ✅ | ✅ | ✅ |
+| [DiT](model_doc/dit) | ✅ | ❌ | ✅ |
+| [DonutSwin](model_doc/donut) | ✅ | ❌ | ❌ |
+| [DPR](model_doc/dpr) | ✅ | ✅ | ❌ |
+| [DPT](model_doc/dpt) | ✅ | ❌ | ❌ |
+| [EfficientFormer](model_doc/efficientformer) | ✅ | ✅ | ❌ |
+| [EfficientNet](model_doc/efficientnet) | ✅ | ❌ | ❌ |
+| [ELECTRA](model_doc/electra) | ✅ | ✅ | ✅ |
+| [EnCodec](model_doc/encodec) | ✅ | ❌ | ❌ |
+| [Encoder decoder](model_doc/encoder-decoder) | ✅ | ✅ | ✅ |
+| [ERNIE](model_doc/ernie) | ✅ | ❌ | ❌ |
+| [ErnieM](model_doc/ernie_m) | ✅ | ❌ | ❌ |
+| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
+| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
+| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
+| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
+| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
+| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
+| [FLAVA](model_doc/flava) | ✅ | ❌ | ❌ |
+| [FNet](model_doc/fnet) | ✅ | ❌ | ❌ |
+| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
+| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
+| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
+| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
+| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
+| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
+| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
+| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
+| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
+| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
+| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
+| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
+| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
+| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
+| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
+| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
+| [IDEFICS](model_doc/idefics) | ✅ | ❌ | ❌ |
+| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
+| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
+| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
+| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
+| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
+| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
+| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
+| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
+| [LED](model_doc/led) | ✅ | ✅ | ❌ |
+| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
+| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
+| [LLaMA](model_doc/llama) | ✅ | ❌ | ❌ |
+| [Llama2](model_doc/llama2) | ✅ | ❌ | ❌ |
+| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
+| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
+| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
+| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
+| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
+| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
+| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
+| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
+| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
+| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
+| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
+| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
+| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
+| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
+| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
+| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
+| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
+| [Mistral](model_doc/mistral) | ✅ | ❌ | ❌ |
+| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
+| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
+| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
+| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
+| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
+| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
+| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
+| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
+| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
+| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
+| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
+| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
+| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
+| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
+| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
+| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
+| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
+| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
+| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
+| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
+| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
+| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
+| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
+| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
+| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
+| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
+| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
+| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
+| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
+| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
+| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
+| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
+| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
+| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
+| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
+| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
+| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
+| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
+| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
+| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
+| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
+| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
+| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
+| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
+| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
+| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
+| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
+| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
+| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
+| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
+| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
+| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
+| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
+| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
+| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
+| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
+| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
+| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
+| [SwiftFormer](model_doc/swiftformer) | ✅ | ❌ | ❌ |
+| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
+| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
+| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
+| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
+| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
+| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
+| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
+| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
+| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
+| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
+| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
+| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
+| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
+| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
+| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
+| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
+| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
+| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
+| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
+| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
+| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
+| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
+| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
+| [Vision Encoder decoder](model_doc/vision-encoder-decoder) | ✅ | ✅ | ✅ |
+| [VisionTextDualEncoder](model_doc/vision-text-dual-encoder) | ✅ | ✅ | ✅ |
+| [VisualBERT](model_doc/visual_bert) | ✅ | ❌ | ❌ |
+| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
+| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
+| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
+| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
+| [ViTMatte](model_doc/vitmatte) | ✅ | ❌ | ❌ |
+| [ViTMSN](model_doc/vit_msn) | ✅ | ❌ | ❌ |
+| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
+| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
+| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
+| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
+| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
+| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
+| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
+| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
+| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
+| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
+| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
+| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
+| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
+| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
+| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
+| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
+| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
+| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
+| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
+| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/transformers/docs/source/te/quicktour.md b/docs/transformers/docs/source/te/quicktour.md
new file mode 100644
index 0000000000000000000000000000000000000000..6045b673d2d3d0e71f097ff6666f3dd9bb9a5f06
--- /dev/null
+++ b/docs/transformers/docs/source/te/quicktour.md
@@ -0,0 +1,557 @@
+
+
+# శీఘ్ర పర్యటన
+
+[[ఓపెన్-ఇన్-కోలాబ్]]
+
+🤗 ట్రాన్స్ఫార్మర్లతో లేచి పరుగెత్తండి! మీరు డెవలపర్ అయినా లేదా రోజువారీ వినియోగదారు అయినా, ఈ శీఘ్ర పర్యటన మీకు ప్రారంభించడానికి సహాయం చేస్తుంది మరియు [`pipeline`] అనుమితి కోసం ఎలా ఉపయోగించాలో మీకు చూపుతుంది, [AutoClass](./model_doc/auto) తో ప్రీట్రైన్డ్ మోడల్ మరియు ప్రిప్రాసెసర్/ ఆటో, మరియు PyTorch లేదా TensorFlowతో మోడల్కు త్వరగా శిక్షణ ఇవ్వండి. మీరు ఒక అనుభవశూన్యుడు అయితే, ఇక్కడ పరిచయం చేయబడిన భావనల గురించి మరింత లోతైన వివరణల కోసం మా ట్యుటోరియల్స్ లేదా [course](https://huggingface.co/course/chapter1/1)ని తనిఖీ చేయమని మేము సిఫార్సు చేస్తున్నాము.
+
+మీరు ప్రారంభించడానికి ముందు, మీరు అవసరమైన అన్ని లైబ్రరీలను ఇన్స్టాల్ చేశారని నిర్ధారించుకోండి:
+
+```bash
+!pip install transformers datasets evaluate accelerate
+```
+
+మీరు మీ ప్రాధాన్య యంత్ర అభ్యాస ఫ్రేమ్వర్క్ను కూడా ఇన్స్టాల్ చేయాలి:
+
+
+
+
+```bash
+pip install torch
+```
+
+
+
+```bash
+pip install tensorflow
+```
+
+
+
+## పైప్లైన్
+
+
+
+[`pipeline`] అనుమితి కోసం ముందుగా శిక్షణ పొందిన నమూనాను ఉపయోగించడానికి సులభమైన మరియు వేగవంతమైన మార్గం. మీరు వివిధ పద్ధతులలో అనేక పనుల కోసం [`pipeline`] వెలుపల ఉపయోగించవచ్చు, వాటిలో కొన్ని క్రింది పట్టికలో చూపబడ్డాయి:
+
+
+
+
+అందుబాటులో ఉన్న పనుల పూర్తి జాబితా కోసం, [పైప్లైన్ API సూచన](./main_classes/pipelines)ని తనిఖీ చేయండి.
+
+
+
+Here is the translation in Telugu:
+
+| **పని** | **వివరణ** | **మోడాలిటీ** | **పైప్లైన్ ఐడెంటిఫైయర్** |
+|------------------------------|--------------------------------------------------------------------------------------------------------|-----------------|------------------------------------------|
+| వచన వర్గీకరణు | కొన్ని వచనాల అంతా ఒక లేబుల్ను కొడి | NLP | pipeline(task=“sentiment-analysis”) |
+| వచన సృష్టి | ప్రమ్పుటం కలిగినంత వచనం సృష్టించండి | NLP | pipeline(task=“text-generation”) |
+| సంక్షేపణ | వచనం లేదా పత్రం కొరకు సంక్షేపణ తయారుచేసండి | NLP | pipeline(task=“summarization”) |
+| చిత్రం వర్గీకరణు | చిత్రంలో ఒక లేబుల్ను కొడి | కంప్యూటర్ విషయం | pipeline(task=“image-classification”) |
+| చిత్రం విభజన | ఒక చిత్రంలో ప్రతి వ్యక్తిగత పిక్సల్ను ఒక లేబుల్గా నమోదు చేయండి (సెమాంటిక్, పానొప్టిక్, మరియు ఇన్స్టన్స్ విభజనలను మద్దతు చేస్తుంది) | కంప్యూటర్ విషయం | pipeline(task=“image-segmentation”) |
+| వస్త్రం గుర్తువు | ఒక చిత్రంలో పదాల యొక్క బౌండింగ్ బాక్స్లను మరియు వస్త్రాల వర్గాలను అంచనా చేయండి | కంప్యూటర్ విషయం | pipeline(task=“object-detection”) |
+| ఆడియో గుర్తువు | కొన్ని ఆడియో డేటానికి ఒక లేబుల్ను కొడి | ఆడియో | pipeline(task=“audio-classification”) |
+| స్వయంచలన ప్రసంగ గుర్తువు | ప్రసంగాన్ని వచనంగా వర్ణించండి | ఆడియో | pipeline(task=“automatic-speech-recognition”) |
+| దృశ్య ప్రశ్న సంవాదం | వచనం మరియు ప్రశ్నను నమోదు చేసిన చిత్రంతో ప్రశ్నకు సమాధానం ఇవ్వండి | బహుమూలిక | pipeline(task=“vqa”) |
+| పత్రం ప్రశ్న సంవాదం | ప్రశ్నను పత్రం లేదా డాక్యుమెంట్తో సమాధానం ఇవ్వండి | బహుమూలిక | pipeline(task="document-question-answering") |
+| చిత్రం వ్రాసాయింగ్ | కొన్ని చిత్రానికి పిటియార్లను సృష్టించండి | బహుమూలిక | pipeline(task="image-to-text") |
+
+
+[`pipeline`] యొక్క ఉదాహరణను సృష్టించడం ద్వారా మరియు మీరు దానిని ఉపయోగించాలనుకుంటున్న పనిని పేర్కొనడం ద్వారా ప్రారంభించండి. ఈ గైడ్లో, మీరు సెంటిమెంట్ విశ్లేషణ కోసం [`pipeline`]ని ఉదాహరణగా ఉపయోగిస్తారు:
+
+```py
+>>> from transformers import pipeline
+
+>>> classifier = pipeline("sentiment-analysis")
+```
+
+సెంటిమెంట్ విశ్లేషణ కోసం [`pipeline`] డిఫాల్ట్ [ప్రీట్రైన్డ్ మోడల్](https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english) మరియు టోకెనైజర్ని డౌన్లోడ్ చేస్తుంది మరియు కాష్ చేస్తుంది. ఇప్పుడు మీరు మీ లక్ష్య వచనంలో `classifier`ని ఉపయోగించవచ్చు:
+
+```py
+>>> classifier("We are very happy to show you the 🤗 Transformers library.")
+[{'label': 'POSITIVE', 'score': 0.9998}]
+```
+
+మీరు ఒకటి కంటే ఎక్కువ ఇన్పుట్లను కలిగి ఉంటే, నిఘంటువుల జాబితాను అందించడానికి మీ ఇన్పుట్లను జాబితాగా [`pipeline`]కి పంపండి:
+
+```py
+>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
+>>> for result in results:
+... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
+label: POSITIVE, with score: 0.9998
+label: NEGATIVE, with score: 0.5309
+```
+
+[`pipeline`] మీకు నచ్చిన ఏదైనా పని కోసం మొత్తం డేటాసెట్ను కూడా పునరావృతం చేయగలదు. ఈ ఉదాహరణ కోసం, స్వయంచాలక ప్రసంగ గుర్తింపును మన పనిగా ఎంచుకుందాం:
+
+```py
+>>> import torch
+>>> from transformers import pipeline
+
+>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
+```
+
+మీరు మళ్లీ మళ్లీ చెప్పాలనుకుంటున్న ఆడియో డేటాసెట్ను లోడ్ చేయండి (మరిన్ని వివరాల కోసం 🤗 డేటాసెట్లు [త్వరిత ప్రారంభం](https://huggingface.co/docs/datasets/quickstart#audio) చూడండి. ఉదాహరణకు, [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) డేటాసెట్ను లోడ్ చేయండి:
+
+```py
+>>> from datasets import load_dataset, Audio
+
+>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
+```
+
+డేటాసెట్ యొక్క నమూనా రేటు నమూనాతో సరిపోలుతుందని మీరు నిర్ధారించుకోవాలి
+రేటు [`facebook/wav2vec2-base-960h`](https://huggingface.co/facebook/wav2vec2-base-960h) దీనిపై శిక్షణ పొందింది:
+
+```py
+>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
+```
+
+`"ఆడియో"` కాలమ్కి కాల్ చేస్తున్నప్పుడు ఆడియో ఫైల్లు స్వయంచాలకంగా లోడ్ చేయబడతాయి మరియు మళ్లీ నమూనా చేయబడతాయి.
+మొదటి 4 నమూనాల నుండి ముడి వేవ్ఫార్మ్ శ్రేణులను సంగ్రహించి, పైప్లైన్కు జాబితాగా పాస్ చేయండి:
+
+```py
+>>> result = speech_recognizer(dataset[:4]["audio"])
+>>> print([d["text"] for d in result])
+['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HELL T WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AN I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I FURN A JOINA COUT']
+```
+
+ఇన్పుట్లు పెద్దగా ఉన్న పెద్ద డేటాసెట్ల కోసం (స్పీచ్ లేదా విజన్ వంటివి), మెమరీలోని అన్ని ఇన్పుట్లను లోడ్ చేయడానికి మీరు జాబితాకు బదులుగా జెనరేటర్ను పాస్ చేయాలనుకుంటున్నారు. మరింత సమాచారం కోసం [పైప్లైన్ API సూచన](./main_classes/pipelines)ని చూడండి.
+
+### పైప్లైన్లో మరొక మోడల్ మరియు టోకెనైజర్ని ఉపయోగించండి
+
+[`pipeline`] [Hub](https://huggingface.co/models) నుండి ఏదైనా మోడల్ను కలిగి ఉంటుంది, దీని వలన ఇతర వినియోగ-కేసుల కోసం [`pipeline`]ని సులభంగా స్వీకరించవచ్చు. ఉదాహరణకు, మీరు ఫ్రెంచ్ టెక్స్ట్ను హ్యాండిల్ చేయగల మోడల్ కావాలనుకుంటే, తగిన మోడల్ కోసం ఫిల్టర్ చేయడానికి హబ్లోని ట్యాగ్లను ఉపయోగించండి. అగ్ర ఫిల్టర్ చేసిన ఫలితం మీరు ఫ్రెంచ్ టెక్స్ట్ కోసం ఉపయోగించగల సెంటిమెంట్ విశ్లేషణ కోసం ఫైన్ట్యూన్ చేయబడిన బహుభాషా [BERT మోడల్](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment)ని అందిస్తుంది:
+
+```py
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+```
+
+
+
+ముందుగా శిక్షణ పొందిన మోడల్ను లోడ్ చేయడానికి [`AutoModelForSequenceClassification`] మరియు [`AutoTokenizer`]ని ఉపయోగించండి మరియు దాని అనుబంధిత టోకెనైజర్ (తదుపరి విభాగంలో `AutoClass`పై మరిన్ని):
+
+```py
+>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
+
+>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+
+ముందుగా శిక్షణ పొందిన మోడల్ను లోడ్ చేయడానికి [`TFAutoModelForSequenceClassification`] మరియు [`AutoTokenizer`]ని ఉపయోగించండి మరియు దాని అనుబంధిత టోకెనైజర్ (తదుపరి విభాగంలో `TFAutoClass`పై మరిన్ని):
+
+```py
+>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
+
+>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+
+
+[`pipeline`]లో మోడల్ మరియు టోకెనైజర్ను పేర్కొనండి మరియు ఇప్పుడు మీరు ఫ్రెంచ్ టెక్స్ట్పై `క్లాసిఫైయర్`ని వర్తింపజేయవచ్చు:
+
+```py
+>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
+>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
+[{'label': '5 stars', 'score': 0.7273}]
+```
+
+మీరు మీ వినియోగ-కేస్ కోసం మోడల్ను కనుగొనలేకపోతే, మీరు మీ డేటాపై ముందుగా శిక్షణ పొందిన మోడల్ను చక్కగా మార్చాలి. ఎలాగో తెలుసుకోవడానికి మా [ఫైన్ట్యూనింగ్ ట్యుటోరియల్](./training)ని చూడండి. చివరగా, మీరు మీ ప్రీట్రైన్డ్ మోడల్ని ఫైన్ట్యూన్ చేసిన తర్వాత, దయచేసి అందరి కోసం మెషిన్ లెర్నింగ్ని డెమోక్రటైజ్ చేయడానికి హబ్లోని సంఘంతో మోడల్ను [షేరింగ్](./model_sharing) పరిగణించండి! 🤗
+
+## AutoClass
+
+
+
+హుడ్ కింద, మీరు పైన ఉపయోగించిన [`pipeline`]కి శక్తిని అందించడానికి [`AutoModelForSequenceClassification`] మరియు [`AutoTokenizer`] తరగతులు కలిసి పని చేస్తాయి. ఒక [AutoClass](./model_doc/auto) అనేది ముందుగా శిక్షణ పొందిన మోడల్ యొక్క ఆర్కిటెక్చర్ను దాని పేరు లేదా మార్గం నుండి స్వయంచాలకంగా తిరిగి పొందే సత్వరమార్గం. మీరు మీ టాస్క్ కోసం తగిన `ఆటోక్లాస్`ని మాత్రమే ఎంచుకోవాలి మరియు ఇది అనుబంధిత ప్రీప్రాసెసింగ్ క్లాస్.
+
+మునుపటి విభాగం నుండి ఉదాహరణకి తిరిగి వెళ్లి, [`pipeline`] ఫలితాలను ప్రతిబింబించడానికి మీరు `ఆటోక్లాస్`ని ఎలా ఉపయోగించవచ్చో చూద్దాం.
+
+### AutoTokenizer
+
+ఒక మోడల్కు ఇన్పుట్లుగా సంఖ్యల శ్రేణిలో వచనాన్ని ప్రీప్రాసెసింగ్ చేయడానికి టోకెనైజర్ బాధ్యత వహిస్తుంది. పదాన్ని ఎలా విభజించాలి మరియు ఏ స్థాయిలో పదాలను విభజించాలి ([tokenizer సారాంశం](./tokenizer_summary)లో టోకనైజేషన్ గురించి మరింత తెలుసుకోండి) సహా టోకనైజేషన్ ప్రక్రియను నియంత్రించే అనేక నియమాలు ఉన్నాయి. గుర్తుంచుకోవలసిన ముఖ్యమైన విషయం ఏమిటంటే, మీరు మోడల్కు ముందే శిక్షణ పొందిన అదే టోకనైజేషన్ నియమాలను ఉపయోగిస్తున్నారని నిర్ధారించుకోవడానికి మీరు అదే మోడల్ పేరుతో టోకెనైజర్ను తక్షణం చేయాలి.
+
+[`AutoTokenizer`]తో టోకెనైజర్ను లోడ్ చేయండి:
+
+```py
+>>> from transformers import AutoTokenizer
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
+```
+
+మీ వచనాన్ని టోకెనైజర్కు పంపండి:
+
+```py
+>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
+>>> print(encoding)
+{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
+ 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
+```
+
+టోకెనైజర్ వీటిని కలిగి ఉన్న నిఘంటువుని అందిస్తుంది:
+
+* [input_ids](./glossary#input-ids): మీ టోకెన్ల సంఖ్యాపరమైన ప్రాతినిధ్యం.
+* [అటెన్షన్_మాస్క్](./glossary#attention-mask): ఏ టోకెన్లకు హాజరు కావాలో సూచిస్తుంది.
+
+ఒక టోకెనైజర్ ఇన్పుట్ల జాబితాను కూడా ఆమోదించగలదు మరియు ఏకరీతి పొడవుతో బ్యాచ్ను తిరిగి ఇవ్వడానికి టెక్స్ట్ను ప్యాడ్ చేసి కత్తిరించవచ్చు:
+
+
+
+
+```py
+>>> pt_batch = tokenizer(
+... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
+... padding=True,
+... truncation=True,
+... max_length=512,
+... return_tensors="pt",
+... )
+```
+
+
+
+```py
+>>> tf_batch = tokenizer(
+... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
+... padding=True,
+... truncation=True,
+... max_length=512,
+... return_tensors="tf",
+... )
+```
+
+
+
+
+
+టోకనైజేషన్ గురించి మరిన్ని వివరాల కోసం [ప్రీప్రాసెస్](./preprocessing) ట్యుటోరియల్ని చూడండి మరియు ఇమేజ్, ఆడియో మరియు మల్టీమోడల్ ఇన్పుట్లను ప్రీప్రాసెస్ చేయడానికి [`AutoImageProcessor`], [`AutoFeatureExtractor`] మరియు [`AutoProcessor`] ఎలా ఉపయోగించాలి.
+
+
+
+### AutoModel
+
+
+
+🤗 ట్రాన్స్ఫార్మర్లు ప్రీట్రైన్డ్ ఇన్స్టాన్స్లను లోడ్ చేయడానికి సులభమైన మరియు ఏకీకృత మార్గాన్ని అందిస్తాయి. దీని అర్థం మీరు [`AutoTokenizer`]ని లోడ్ చేసినట్లుగా [`AutoModel`]ని లోడ్ చేయవచ్చు. టాస్క్ కోసం సరైన [`AutoModel`]ని ఎంచుకోవడం మాత్రమే తేడా. టెక్స్ట్ (లేదా సీక్వెన్స్) వర్గీకరణ కోసం, మీరు [`AutoModelForSequenceClassification`]ని లోడ్ చేయాలి:
+
+
+```py
+>>> from transformers import AutoModelForSequenceClassification
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
+```
+
+
+
+[`AutoModel`] క్లాస్ ద్వారా సపోర్ట్ చేసే టాస్క్ల కోసం [టాస్క్ సారాంశం](./task_summary)ని చూడండి.
+
+
+
+ఇప్పుడు మీ ప్రీప్రాసెస్ చేయబడిన బ్యాచ్ ఇన్పుట్లను నేరుగా మోడల్కి పంపండి. మీరు `**`ని జోడించడం ద్వారా నిఘంటువుని అన్ప్యాక్ చేయాలి:
+
+```py
+>>> pt_outputs = pt_model(**pt_batch)
+```
+
+మోడల్ తుది యాక్టివేషన్లను `logits` లక్షణంలో అవుట్పుట్ చేస్తుంది. సంభావ్యతలను తిరిగి పొందడానికి సాఫ్ట్మాక్స్ ఫంక్షన్ను `logits` కు వర్తింపజేయండి:
+
+
+```py
+>>> from torch import nn
+
+>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
+>>> print(pt_predictions)
+tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
+ [0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=)
+```
+
+
+
+🤗 ట్రాన్స్ఫార్మర్లు ప్రీట్రైన్డ్ ఇన్స్టాన్స్లను లోడ్ చేయడానికి సులభమైన మరియు ఏకీకృత మార్గాన్ని అందిస్తాయి. మీరు [`AutoTokenizer`]ని లోడ్ చేసినట్లుగా మీరు [`TFAutoModel`]ని లోడ్ చేయవచ్చని దీని అర్థం. టాస్క్ కోసం సరైన [`TFAutoModel`]ని ఎంచుకోవడం మాత్రమే తేడా. టెక్స్ట్ (లేదా సీక్వెన్స్) వర్గీకరణ కోసం, మీరు [`TFAutoModelForSequenceClassification`]ని లోడ్ చేయాలి:
+
+```py
+>>> from transformers import TFAutoModelForSequenceClassification
+
+>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
+```
+
+
+
+[`AutoModel`] క్లాస్ ద్వారా సపోర్ట్ చేసే టాస్క్ల కోసం [టాస్క్ సారాంశం](./task_summary)ని చూడండి.
+
+
+
+ఇప్పుడు మీ ప్రీప్రాసెస్ చేయబడిన బ్యాచ్ ఇన్పుట్లను నేరుగా మోడల్కి పంపండి. మీరు టెన్సర్లను ఇలా పాస్ చేయవచ్చు:
+
+```py
+>>> tf_outputs = tf_model(tf_batch)
+```
+
+మోడల్ తుది యాక్టివేషన్లను `logits` లక్షణంలో అవుట్పుట్ చేస్తుంది. సంభావ్యతలను తిరిగి పొందడానికి సాఫ్ట్మాక్స్ ఫంక్షన్ను `logits`కు వర్తింపజేయండి:
+
+```py
+>>> import tensorflow as tf
+
+>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
+>>> tf_predictions # doctest: +IGNORE_RESULT
+```
+
+
+
+
+
+అన్ని 🤗 ట్రాన్స్ఫార్మర్స్ మోడల్లు (PyTorch లేదా TensorFlow) తుది యాక్టివేషన్కు *ముందు* టెన్సర్లను అవుట్పుట్ చేస్తాయి
+ఫంక్షన్ (softmax వంటిది) ఎందుకంటే చివరి యాక్టివేషన్ ఫంక్షన్ తరచుగా నష్టంతో కలిసిపోతుంది. మోడల్ అవుట్పుట్లు ప్రత్యేక డేటాక్లాస్లు కాబట్టి వాటి లక్షణాలు IDEలో స్వయంచాలకంగా పూర్తి చేయబడతాయి. మోడల్ అవుట్పుట్లు టుపుల్ లేదా డిక్షనరీ లాగా ప్రవర్తిస్తాయి (మీరు పూర్ణాంకం, స్లైస్ లేదా స్ట్రింగ్తో ఇండెక్స్ చేయవచ్చు) ఈ సందర్భంలో, ఏదీ లేని గుణాలు విస్మరించబడతాయి.
+
+
+
+### మోడల్ను సేవ్ చేయండి
+
+
+
+మీ మోడల్ చక్కగా ట్యూన్ చేయబడిన తర్వాత, మీరు దానిని [`PreTrainedModel.save_pretrained`]ని ఉపయోగించి దాని టోకెనైజర్తో సేవ్ చేయవచ్చు:
+
+```py
+>>> pt_save_directory = "./pt_save_pretrained"
+>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
+>>> pt_model.save_pretrained(pt_save_directory)
+```
+
+మీరు మోడల్ని మళ్లీ ఉపయోగించడానికి సిద్ధంగా ఉన్నప్పుడు, దాన్ని [`PreTrainedModel.from_pretrained`]తో రీలోడ్ చేయండి:
+
+```py
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
+```
+
+
+మీ మోడల్ చక్కగా ట్యూన్ చేయబడిన తర్వాత, మీరు దానిని [`TFPreTrainedModel.save_pretrained`]ని ఉపయోగించి దాని టోకెనైజర్తో సేవ్ చేయవచ్చు:
+
+```py
+>>> tf_save_directory = "./tf_save_pretrained"
+>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
+>>> tf_model.save_pretrained(tf_save_directory)
+```
+మీరు మోడల్ని మళ్లీ ఉపయోగించడానికి సిద్ధంగా ఉన్నప్పుడు, దాన్ని [`TFPreTrainedModel.from_pretrained`]తో రీలోడ్ చేయండి:
+
+```py
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
+```
+
+
+
+ఒక ప్రత్యేకించి అద్భుతమైన 🤗 ట్రాన్స్ఫార్మర్స్ ఫీచర్ మోడల్ను సేవ్ చేయగల సామర్థ్యం మరియు దానిని PyTorch లేదా TensorFlow మోడల్గా రీలోడ్ చేయగలదు. `from_pt` లేదా `from_tf` పరామితి మోడల్ను ఒక ఫ్రేమ్వర్క్ నుండి మరొక ఫ్రేమ్వర్క్కి మార్చగలదు:
+
+
+
+
+```py
+>>> from transformers import AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
+>>> pt_model = AutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
+```
+
+
+
+```py
+>>> from transformers import TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
+>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
+```
+
+
+
+## కస్టమ్ మోడల్ బిల్డ్స్
+మోడల్ ఎలా నిర్మించబడుతుందో మార్చడానికి మీరు మోడల్ కాన్ఫిగరేషన్ క్లాస్ని సవరించవచ్చు. దాచిన లేయర్లు లేదా అటెన్షన్ హెడ్ల సంఖ్య వంటి మోడల్ లక్షణాలను కాన్ఫిగరేషన్ నిర్దేశిస్తుంది. మీరు కస్టమ్ కాన్ఫిగరేషన్ క్లాస్ నుండి మోడల్ను ప్రారంభించినప్పుడు మీరు మొదటి నుండి ప్రారంభిస్తారు. మోడల్ అట్రిబ్యూట్లు యాదృచ్ఛికంగా ప్రారంభించబడ్డాయి మరియు అర్థవంతమైన ఫలితాలను పొందడానికి మీరు మోడల్ను ఉపయోగించే ముందు దానికి శిక్షణ ఇవ్వాలి.
+
+[`AutoConfig`]ని దిగుమతి చేయడం ద్వారా ప్రారంభించండి, ఆపై మీరు సవరించాలనుకుంటున్న ప్రీట్రైన్డ్ మోడల్ను లోడ్ చేయండి. [`AutoConfig.from_pretrained`]లో, మీరు అటెన్షన్ హెడ్ల సంఖ్య వంటి మీరు మార్చాలనుకుంటున్న లక్షణాన్ని పేర్కొనవచ్చు:
+
+```py
+>>> from transformers import AutoConfig
+
+>>> my_config = AutoConfig.from_pretrained("distilbert/distilbert-base-uncased", n_heads=12)
+```
+
+
+
+[`AutoModel.from_config`]తో మీ అనుకూల కాన్ఫిగరేషన్ నుండి మోడల్ను సృష్టించండి:
+
+```py
+>>> from transformers import AutoModel
+
+>>> my_model = AutoModel.from_config(my_config)
+```
+
+
+[`TFAutoModel.from_config`]తో మీ అనుకూల కాన్ఫిగరేషన్ నుండి మోడల్ను సృష్టించండి:
+
+```py
+>>> from transformers import TFAutoModel
+
+>>> my_model = TFAutoModel.from_config(my_config)
+```
+
+
+
+అనుకూల కాన్ఫిగరేషన్లను రూపొందించడం గురించి మరింత సమాచారం కోసం [కస్టమ్ ఆర్కిటెక్చర్ని సృష్టించండి](./create_a_model) గైడ్ను చూడండి.
+
+## శిక్షకుడు - పైటార్చ్ ఆప్టిమైజ్ చేసిన శిక్షణ లూప్
+
+అన్ని మోడల్లు ప్రామాణికమైన [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) కాబట్టి మీరు వాటిని ఏదైనా సాధారణ శిక్షణ లూప్లో ఉపయోగించవచ్చు. మీరు మీ స్వంత శిక్షణ లూప్ను వ్రాయగలిగినప్పటికీ, 🤗 ట్రాన్స్ఫార్మర్లు PyTorch కోసం [`ట్రైనర్`] తరగతిని అందజేస్తాయి, ఇందులో ప్రాథమిక శిక్షణ లూప్ ఉంటుంది మరియు పంపిణీ చేయబడిన శిక్షణ, మిశ్రమ ఖచ్చితత్వం మరియు మరిన్ని వంటి ఫీచర్ల కోసం అదనపు కార్యాచరణను జోడిస్తుంది.
+
+మీ విధిని బట్టి, మీరు సాధారణంగా కింది పారామితులను [`ట్రైనర్`]కి పంపుతారు:
+
+1. మీరు [`PreTrainedModel`] లేదా [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)తో ప్రారంభిస్తారు:
+ ```py
+ >>> from transformers import AutoModelForSequenceClassification
+
+ >>> model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
+ ```
+
+2. [`TrainingArguments`] మీరు నేర్చుకునే రేటు, బ్యాచ్ పరిమాణం మరియు శిక్షణ పొందవలసిన యుగాల సంఖ్య వంటి మార్చగల మోడల్ హైపర్పారామీటర్లను కలిగి ఉంది. మీరు ఎలాంటి శిక్షణా వాదనలను పేర్కొనకుంటే డిఫాల్ట్ విలువలు ఉపయోగించబడతాయి:
+
+ ```py
+ >>> from transformers import TrainingArguments
+
+ >>> training_args = TrainingArguments(
+ ... output_dir="path/to/save/folder/",
+ ... learning_rate=2e-5,
+ ... per_device_train_batch_size=8,
+ ... per_device_eval_batch_size=8,
+ ... num_train_epochs=2,
+ ... )
+ ```
+
+3. టోకెనైజర్, ఇమేజ్ ప్రాసెసర్, ఫీచర్ ఎక్స్ట్రాక్టర్ లేదా ప్రాసెసర్ వంటి ప్రీప్రాసెసింగ్ క్లాస్ని లోడ్ చేయండి:
+ ```py
+ >>> from transformers import AutoTokenizer
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+ ```
+
+4. డేటాసెట్ను లోడ్ చేయండి:
+
+ ```py
+ >>> from datasets import load_dataset
+
+ >>> dataset = load_dataset("rotten_tomatoes") # doctest: +IGNORE_RESULT
+ ```
+
+5. డేటాసెట్ను టోకనైజ్ చేయడానికి ఒక ఫంక్షన్ను సృష్టించండి:
+
+ ```py
+ >>> def tokenize_dataset(dataset):
+ ... return tokenizer(dataset["text"])
+ ```
+
+ ఆపై దానిని [`~datasets.Dataset.map`]తో మొత్తం డేటాసెట్లో వర్తింపజేయండి:
+
+ ```py
+ >>> dataset = dataset.map(tokenize_dataset, batched=True)
+ ```
+
+6. మీ డేటాసెట్ నుండి ఉదాహరణల సమూహాన్ని సృష్టించడానికి [`DataCollatorWithPadding`]:
+
+ ```py
+ >>> from transformers import DataCollatorWithPadding
+
+ >>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
+ ```
+
+ఇప్పుడు ఈ తరగతులన్నింటినీ [`Trainer`]లో సేకరించండి:
+
+```py
+>>> from transformers import Trainer
+
+>>> trainer = Trainer(
+... model=model,
+... args=training_args,
+... train_dataset=dataset["train"],
+... eval_dataset=dataset["test"],
+... processing_class=tokenizer,
+... data_collator=data_collator,
+... ) # doctest: +SKIP
+```
+
+మీరు సిద్ధంగా ఉన్నప్పుడు, శిక్షణను ప్రారంభించడానికి [`~Trainer.train`]కి కాల్ చేయండి:
+
+```py
+>>> trainer.train() # doctest: +SKIP
+```
+
+
+
+సీక్వెన్స్-టు-సీక్వెన్స్ మోడల్ని ఉపయోగించే - అనువాదం లేదా సారాంశం వంటి పనుల కోసం, బదులుగా [`Seq2SeqTrainer`] మరియు [`Seq2SeqTrainingArguments`] తరగతులను ఉపయోగించండి.
+
+
+
+మీరు [`Trainer`] లోపల ఉన్న పద్ధతులను ఉపవర్గీకరించడం ద్వారా శిక్షణ లూప్ ప్రవర్తనను అనుకూలీకరించవచ్చు. ఇది లాస్ ఫంక్షన్, ఆప్టిమైజర్ మరియు షెడ్యూలర్ వంటి లక్షణాలను అనుకూలీకరించడానికి మిమ్మల్ని అనుమతిస్తుంది. ఉపవర్గీకరించబడే పద్ధతుల కోసం [`Trainer`] సూచనను పరిశీలించండి.
+
+శిక్షణ లూప్ను అనుకూలీకరించడానికి మరొక మార్గం [కాల్బ్యాక్లు](./main_classes/callback). మీరు ఇతర లైబ్రరీలతో అనుసంధానం చేయడానికి కాల్బ్యాక్లను ఉపయోగించవచ్చు మరియు పురోగతిపై నివేదించడానికి శిక్షణ లూప్ను తనిఖీ చేయవచ్చు లేదా శిక్షణను ముందుగానే ఆపవచ్చు. శిక్షణ లూప్లోనే కాల్బ్యాక్లు దేనినీ సవరించవు. లాస్ ఫంక్షన్ వంటివాటిని అనుకూలీకరించడానికి, మీరు బదులుగా [`Trainer`]ని ఉపవర్గం చేయాలి.
+
+## TensorFlowతో శిక్షణ పొందండి
+
+అన్ని మోడల్లు ప్రామాణికమైన [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) కాబట్టి వాటిని [Keras]తో TensorFlowలో శిక్షణ పొందవచ్చు(https: //keras.io/) API. 🤗 ట్రాన్స్ఫార్మర్లు మీ డేటాసెట్ని సులభంగా `tf.data.Dataset`గా లోడ్ చేయడానికి [`~TFPreTrainedModel.prepare_tf_dataset`] పద్ధతిని అందజేస్తుంది కాబట్టి మీరు వెంటనే Keras' [`compile`](https://keras.io/api/models/model_training_apis/#compile-method) మరియు [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) పద్ధతులు.
+
+1. మీరు [`TFPreTrainedModel`] లేదా [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)తో ప్రారంభిస్తారు:
+ ```py
+ >>> from transformers import TFAutoModelForSequenceClassification
+
+ >>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
+ ```
+
+2. టోకెనైజర్, ఇమేజ్ ప్రాసెసర్, ఫీచర్ ఎక్స్ట్రాక్టర్ లేదా ప్రాసెసర్ వంటి ప్రీప్రాసెసింగ్ క్లాస్ని లోడ్ చేయండి:
+
+ ```py
+ >>> from transformers import AutoTokenizer
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
+ ```
+
+3. డేటాసెట్ను టోకనైజ్ చేయడానికి ఒక ఫంక్షన్ను సృష్టించండి:
+
+ ```py
+ >>> def tokenize_dataset(dataset):
+ ... return tokenizer(dataset["text"]) # doctest: +SKIP
+ ```
+
+4. [`~datasets.Dataset.map`]తో మొత్తం డేటాసెట్పై టోకెనైజర్ని వర్తింపజేయి, ఆపై డేటాసెట్ మరియు టోకెనైజర్ను [`~TFPreTrainedModel.prepare_tf_dataset`]కి పంపండి. మీరు కావాలనుకుంటే బ్యాచ్ పరిమాణాన్ని కూడా మార్చవచ్చు మరియు డేటాసెట్ను ఇక్కడ షఫుల్ చేయవచ్చు:
+ ```py
+ >>> dataset = dataset.map(tokenize_dataset) # doctest: +SKIP
+ >>> tf_dataset = model.prepare_tf_dataset(
+ ... dataset["train"], batch_size=16, shuffle=True, tokenizer=tokenizer
+ ... ) # doctest: +SKIP
+ ```
+
+5. మీరు సిద్ధంగా ఉన్నప్పుడు, శిక్షణను ప్రారంభించడానికి మీరు `కంపైల్` మరియు `ఫిట్`కి కాల్ చేయవచ్చు. ట్రాన్స్ఫార్మర్స్ మోడల్స్ అన్నీ డిఫాల్ట్ టాస్క్-సంబంధిత లాస్ ఫంక్షన్ని కలిగి ఉన్నాయని గుర్తుంచుకోండి, కాబట్టి మీరు కోరుకునే వరకు మీరు ఒకదానిని పేర్కొనవలసిన అవసరం లేదు:
+
+ ```py
+ >>> from tensorflow.keras.optimizers import Adam
+
+ >>> model.compile(optimizer=Adam(3e-5)) # No loss argument!
+ >>> model.fit(tf_dataset) # doctest: +SKIP
+ ```
+
+## తరవాత ఏంటి?
+
+ఇప్పుడు మీరు 🤗 ట్రాన్స్ఫార్మర్స్ త్వరిత పర్యటనను పూర్తి చేసారు, మా గైడ్లను తనిఖీ చేయండి మరియు అనుకూల మోడల్ను వ్రాయడం, టాస్క్ కోసం మోడల్ను చక్కగా తీర్చిదిద్దడం మరియు స్క్రిప్ట్తో మోడల్కు శిక్షణ ఇవ్వడం వంటి మరింత నిర్దిష్టమైన పనులను ఎలా చేయాలో తెలుసుకోండి. 🤗 ట్రాన్స్ఫార్మర్స్ కోర్ కాన్సెప్ట్ల గురించి మరింత తెలుసుకోవడానికి మీకు ఆసక్తి ఉంటే, ఒక కప్పు కాఫీ తాగి, మా కాన్సెప్టువల్ గైడ్లను చూడండి!
diff --git a/docs/transformers/docs/source/tr/_toctree.yml b/docs/transformers/docs/source/tr/_toctree.yml
new file mode 100644
index 0000000000000000000000000000000000000000..8401da6e4eb0aedae36913b7e053f8cf842d9d3e
--- /dev/null
+++ b/docs/transformers/docs/source/tr/_toctree.yml
@@ -0,0 +1,4 @@
+- sections:
+ - local: index
+ title: 🤗 Transformers
+ title: Get started
\ No newline at end of file
diff --git a/docs/transformers/docs/source/tr/index.md b/docs/transformers/docs/source/tr/index.md
new file mode 100644
index 0000000000000000000000000000000000000000..1b2c665e169d808e778852d5fb4292739ed43b6f
--- /dev/null
+++ b/docs/transformers/docs/source/tr/index.md
@@ -0,0 +1,295 @@
+
+
+# 🤗 Transformers
+
+[PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/) ve [JAX](https://jax.readthedocs.io/en/latest/) için son teknoloji makine öğrenimi.
+
+🤗 Transformers, güncel önceden eğitilmiş (pretrained) modelleri indirmenizi ve eğitmenizi kolaylaştıran API'ler ve araçlar sunar. Önceden eğitilmiş modeller kullanarak, hesaplama maliyetlerinizi ve karbon ayak izinizi azaltabilir, ve sıfırdan bir modeli eğitmek için gereken zaman ve kaynaklardan tasarruf edebilirsiniz. Bu modeller farklı modalitelerde ortak görevleri destekler. Örneğin:
+
+📝 **Doğal Dil İşleme**: metin sınıflandırma, adlandırılmış varlık tanıma, soru cevaplama, dil modelleme, özetleme, çeviri, çoktan seçmeli ve metin oluşturma.
+🖼️ **Bilgisayarlı Görü**: görüntü sınıflandırma, nesne tespiti ve bölümleme (segmentation).
+🗣️ **Ses**: otomatik konuşma tanıma ve ses sınıflandırma.
+🐙 **Çoklu Model**: tablo soru cevaplama, optik karakter tanıma, taranmış belgelerden bilgi çıkarma, video sınıflandırma ve görsel soru cevaplama.
+
+🤗 Transformers, PyTorch, TensorFlow ve JAX arasında çerçeve (framework) uyumluluğu sağlar. Bu, bir modelin yaşam döngüsünün her aşamasında farklı bir çerçeve kullanma esnekliği sunar; bir çerçevede üç satır kodla bir modeli eğitebilir ve başka bir çerçevede tahminleme için kullanabilirsiniz. Modeller ayrıca üretim ortamlarında kullanılmak üzere ONNX ve TorchScript gibi bir formata aktarılabilir.
+
+Büyüyen topluluğa [Hub](https://huggingface.co/models), [Forum](https://discuss.huggingface.co/) veya [Discord](https://discord.com/invite/JfAtkvEtRb) üzerinden katılabilirsiniz!
+
+## Hugging Face ekibinden özel destek arıyorsanız
+
+
+
+
+
+## İçindekiler
+
+Dokümantasyon, beş bölüme ayrılmıştır:
+
+- **BAŞLARKEN**, kütüphanenin hızlı bir turunu ve çalışmaya başlamak için kurulum talimatlarını sağlar.
+- **ÖĞRETİCİLER**, başlangıç yapmak için harika bir yerdir. Bu bölüm, kütüphane kullanmaya başlamak için ihtiyacınız olan temel becerileri kazanmanıza yardımcı olacaktır.
+- **NASIL YAPILIR KILAVUZLARI**, önceden eğitilmiş bir modele dil modellemesi için ince ayar (fine-tuning) yapmak veya özel bir model yazmak, ve paylaşmak gibi belirli bir hedefe nasıl ulaşılacağını gösterir.
+- **KAVRAMSAL REHBERLER**, modellerin, görevlerin ve 🤗 Transformers tasarım felsefesinin temel kavramları ve fikirleri hakkında daha fazla tartışma ve açıklama sunar.
+- **API** tüm sınıfları (class) ve fonksiyonları (functions) açıklar:
+
+ - **ANA SINIFLAR**, yapılandırma, model, tokenizer ve pipeline gibi en önemli sınıfları (classes) ayrıntılandırır.
+ - **MODELLER**, kütüphanede kullanılan her modelle ilgili sınıfları ve fonksiyonları detaylı olarak inceler.
+ - **DAHİLİ YARDIMCILAR**, kullanılan yardımcı sınıfları ve fonksiyonları detaylı olarak inceler.
+
+## Desteklenen Modeller ve Çerçeveler
+
+Aşağıdaki tablo, her bir model için kütüphanede yer alan mevcut desteği temsil etmektedir. Her bir model için bir Python tokenizer'ına ("slow" olarak adlandırılır) sahip olup olmadıkları, 🤗 Tokenizers kütüphanesi tarafından desteklenen hızlı bir tokenizer'a sahip olup olmadıkları, Jax (Flax aracılığıyla), PyTorch ve/veya TensorFlow'da destek olup olmadıklarını göstermektedir.
+
+
+
+| Model | PyTorch support | TensorFlow support | Flax Support |
+|:------------------------------------------------------------------------:|:---------------:|:------------------:|:------------:|
+| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
+| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
+| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
+| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
+| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
+| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
+| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
+| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
+| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
+| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
+| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
+| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
+| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
+| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
+| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
+| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
+| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
+| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
+| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
+| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
+| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
+| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
+| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
+| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
+| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
+| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
+| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
+| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
+| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
+| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
+| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
+| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
+| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
+| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
+| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ❌ |
+| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
+| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
+| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
+| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ❌ | ❌ |
+| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
+| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
+| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
+| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
+| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
+| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
+| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
+| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
+| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
+| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
+| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
+| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
+| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
+| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
+| [DiNAT](model_doc/dinat) | ✅ | ❌ | ❌ |
+| [DINOv2](model_doc/dinov2) | ✅ | ❌ | ❌ |
+| [DistilBERT](model_doc/distilbert) | ✅ | ✅ | ✅ |
+| [DiT](model_doc/dit) | ✅ | ❌ | ✅ |
+| [DonutSwin](model_doc/donut) | ✅ | ❌ | ❌ |
+| [DPR](model_doc/dpr) | ✅ | ✅ | ❌ |
+| [DPT](model_doc/dpt) | ✅ | ❌ | ❌ |
+| [EfficientFormer](model_doc/efficientformer) | ✅ | ✅ | ❌ |
+| [EfficientNet](model_doc/efficientnet) | ✅ | ❌ | ❌ |
+| [ELECTRA](model_doc/electra) | ✅ | ✅ | ✅ |
+| [EnCodec](model_doc/encodec) | ✅ | ❌ | ❌ |
+| [Encoder decoder](model_doc/encoder-decoder) | ✅ | ✅ | ✅ |
+| [ERNIE](model_doc/ernie) | ✅ | ❌ | ❌ |
+| [ErnieM](model_doc/ernie_m) | ✅ | ❌ | ❌ |
+| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
+| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
+| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
+| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
+| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
+| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
+| [FLAVA](model_doc/flava) | ✅ | ❌ | ❌ |
+| [FNet](model_doc/fnet) | ✅ | ❌ | ❌ |
+| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
+| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
+| [Fuyu](model_doc/fuyu) | ✅ | ❌ | ❌ |
+| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
+| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
+| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
+| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
+| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
+| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
+| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
+| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
+| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
+| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
+| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
+| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
+| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
+| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
+| [IDEFICS](model_doc/idefics) | ✅ | ❌ | ❌ |
+| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
+| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
+| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
+| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
+| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
+| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
+| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
+| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
+| [LED](model_doc/led) | ✅ | ✅ | ❌ |
+| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
+| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
+| [LLaMA](model_doc/llama) | ✅ | ❌ | ❌ |
+| [Llama2](model_doc/llama2) | ✅ | ❌ | ❌ |
+| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
+| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
+| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
+| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
+| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
+| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
+| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
+| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
+| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
+| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
+| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
+| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
+| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
+| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
+| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
+| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
+| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
+| [Mistral](model_doc/mistral) | ✅ | ❌ | ❌ |
+| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
+| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
+| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
+| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
+| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
+| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
+| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
+| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
+| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
+| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
+| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
+| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
+| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
+| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
+| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
+| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
+| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
+| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
+| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
+| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
+| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
+| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
+| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
+| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
+| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
+| [OWLv2](model_doc/owlv2) | ✅ | ❌ | ❌ |
+| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
+| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
+| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
+| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
+| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
+| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
+| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
+| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
+| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
+| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
+| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
+| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
+| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
+| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
+| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
+| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
+| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
+| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
+| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
+| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
+| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
+| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
+| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
+| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
+| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
+| [SeamlessM4T](model_doc/seamless_m4t) | ✅ | ❌ | ❌ |
+| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
+| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
+| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
+| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
+| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
+| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
+| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
+| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
+| [SwiftFormer](model_doc/swiftformer) | ✅ | ❌ | ❌ |
+| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
+| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
+| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
+| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
+| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
+| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
+| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
+| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
+| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
+| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
+| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
+| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
+| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
+| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
+| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
+| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
+| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
+| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
+| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
+| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
+| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
+| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
+| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
+| [Vision Encoder decoder](model_doc/vision-encoder-decoder) | ✅ | ✅ | ✅ |
+| [VisionTextDualEncoder](model_doc/vision-text-dual-encoder) | ✅ | ✅ | ✅ |
+| [VisualBERT](model_doc/visual_bert) | ✅ | ❌ | ❌ |
+| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
+| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
+| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
+| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
+| [ViTMatte](model_doc/vitmatte) | ✅ | ❌ | ❌ |
+| [ViTMSN](model_doc/vit_msn) | ✅ | ❌ | ❌ |
+| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
+| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
+| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
+| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
+| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
+| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
+| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
+| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
+| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
+| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
+| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
+| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
+| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
+| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
+| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
+| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
+| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
+| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
+| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
+| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/transformers/docs/source/zh/_toctree.yml b/docs/transformers/docs/source/zh/_toctree.yml
new file mode 100644
index 0000000000000000000000000000000000000000..66816a5309863bd25b0f3cc85d8ca659021a9c4b
--- /dev/null
+++ b/docs/transformers/docs/source/zh/_toctree.yml
@@ -0,0 +1,161 @@
+- sections:
+ - local: index
+ title: 🤗 Transformers 简介
+ - local: quicktour
+ title: 快速上手
+ - local: installation
+ title: 安装
+ title: 开始使用
+- sections:
+ - local: pipeline_tutorial
+ title: 使用pipelines进行推理
+ - local: autoclass_tutorial
+ title: 使用AutoClass编写可移植的代码
+ - local: preprocessing
+ title: 预处理数据
+ - local: training
+ title: 微调预训练模型
+ - local: run_scripts
+ title: 通过脚本训练模型
+ - local: accelerate
+ title: 使用🤗Accelerate进行分布式训练
+ - local: peft
+ title: 使用🤗 PEFT加载和训练adapters
+ - local: model_sharing
+ title: 分享您的模型
+ - local: llm_tutorial
+ title: 使用LLMs进行生成
+ title: 教程
+- sections:
+ - isExpanded: false
+ sections:
+ - local: tasks/asr
+ title: 自动语音识别
+- sections:
+ - local: fast_tokenizers
+ title: 使用 🤗 Tokenizers 中的分词器
+ - local: multilingual
+ title: 使用多语言模型进行推理
+ - local: create_a_model
+ title: 使用特定于模型的 API
+ - local: custom_models
+ title: 共享自定义模型
+ - local: chat_templating
+ title: 聊天模型的模板
+ - local: serialization
+ title: 导出为 ONNX
+ - local: tflite
+ title: 导出为 TFLite
+ - local: torchscript
+ title: 导出为 TorchScript
+ - local: gguf
+ title: 与 GGUF 格式的互操作性
+ - local: tiktoken
+ title: 与 Tiktoken 文件的互操作性
+ - local: community
+ title: 社区资源
+ title: 开发者指南
+- sections:
+ - local: performance
+ title: 综述
+ - sections:
+ - local: fsdp
+ title: 完全分片数据并行
+ - local: perf_train_special
+ title: 在 Apple silicon 芯片上进行 PyTorch 训练
+ - local: perf_infer_gpu_multi
+ title: 多GPU推理
+ - local: perf_train_cpu
+ title: 在CPU上进行高效训练
+ - local: perf_hardware
+ title: 用于训练的定制硬件
+ - local: hpo_train
+ title: 使用Trainer API 进行超参数搜索
+ title: 高效训练技术
+ - local: big_models
+ title: 实例化大模型
+ - local: debugging
+ title: 问题定位及解决
+ - local: tf_xla
+ title: TensorFlow模型的XLA集成
+ - local: perf_torch_compile
+ title: 使用 `torch.compile()` 优化推理
+ title: 性能和可扩展性
+- sections:
+ - local: contributing
+ title: 如何为 🤗 Transformers 做贡献?
+ - local: add_new_pipeline
+ title: 如何将流水线添加到 🤗 Transformers?
+ title: 贡献
+- sections:
+ - local: philosophy
+ title: Transformers的设计理念
+ - local: task_summary
+ title: 🤗Transformers能做什么
+ - local: tokenizer_summary
+ title: 分词器的摘要
+ - local: attention
+ title: 注意力机制
+ - local: bertology
+ title: 基于BERT进行的相关研究
+ title: 概念指南
+- sections:
+ - sections:
+ - local: main_classes/callback
+ title: Callbacks
+ - local: main_classes/configuration
+ title: Configuration
+ - local: main_classes/data_collator
+ title: Data Collator
+ - local: main_classes/keras_callbacks
+ title: Keras callbacks
+ - local: main_classes/logging
+ title: Logging
+ - local: main_classes/model
+ title: 模型
+ - local: main_classes/text_generation
+ title: 文本生成
+ - local: main_classes/onnx
+ title: ONNX
+ - local: main_classes/optimizer_schedules
+ title: Optimization
+ - local: main_classes/output
+ title: 模型输出
+ - local: main_classes/pipelines
+ title: Pipelines
+ - local: main_classes/processors
+ title: Processors
+ - local: main_classes/quantization
+ title: Quantization
+ - local: main_classes/tokenizer
+ title: Tokenizer
+ - local: main_classes/trainer
+ title: Trainer
+ - local: main_classes/deepspeed
+ title: DeepSpeed集成
+ - local: main_classes/feature_extractor
+ title: Feature Extractor
+ - local: main_classes/image_processor
+ title: Image Processor
+ title: 主要类
+ - sections:
+ - local: internal/modeling_utils
+ title: 自定义层和工具
+ - local: internal/pipelines_utils
+ title: pipelines工具
+ - local: internal/tokenization_utils
+ title: Tokenizers工具
+ - local: internal/trainer_utils
+ title: 训练器工具
+ - local: internal/generation_utils
+ title: 生成工具
+ - local: internal/image_processing_utils
+ title: 图像处理工具
+ - local: internal/audio_utils
+ title: 音频处理工具
+ - local: internal/file_utils
+ title: 通用工具
+ - local: internal/time_series_utils
+ title: 时序数据工具
+ title: 内部辅助工具
+ title: 应用程序接口 (API)
diff --git a/docs/transformers/docs/source/zh/accelerate.md b/docs/transformers/docs/source/zh/accelerate.md
new file mode 100644
index 0000000000000000000000000000000000000000..12c626199477dd14cfc322f642909132832cf258
--- /dev/null
+++ b/docs/transformers/docs/source/zh/accelerate.md
@@ -0,0 +1,132 @@
+
+
+# 🤗 加速分布式训练
+
+随着模型变得越来越大,并行性已经成为在有限硬件上训练更大模型和加速训练速度的策略,增加了数个数量级。在Hugging Face,我们创建了[🤗 加速](https://huggingface.co/docs/accelerate)库,以帮助用户在任何类型的分布式设置上轻松训练🤗 Transformers模型,无论是在一台机器上的多个GPU还是在多个机器上的多个GPU。在本教程中,了解如何自定义您的原生PyTorch训练循环,以启用分布式环境中的训练。
+
+## 设置
+
+通过安装🤗 加速开始:
+
+```bash
+pip install accelerate
+```
+
+然后导入并创建[`~accelerate.Accelerator`]对象。[`~accelerate.Accelerator`]将自动检测您的分布式设置类型,并初始化所有必要的训练组件。您不需要显式地将模型放在设备上。
+
+```py
+>>> from accelerate import Accelerator
+
+>>> accelerator = Accelerator()
+```
+
+## 准备加速
+
+下一步是将所有相关的训练对象传递给[`~accelerate.Accelerator.prepare`]方法。这包括您的训练和评估DataLoader、一个模型和一个优化器:
+
+```py
+>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+... train_dataloader, eval_dataloader, model, optimizer
+... )
+```
+
+## 反向传播
+
+最后一步是用🤗 加速的[`~accelerate.Accelerator.backward`]方法替换训练循环中的典型`loss.backward()`:
+
+```py
+>>> for epoch in range(num_epochs):
+... for batch in train_dataloader:
+... outputs = model(**batch)
+... loss = outputs.loss
+... accelerator.backward(loss)
+
+... optimizer.step()
+... lr_scheduler.step()
+... optimizer.zero_grad()
+... progress_bar.update(1)
+```
+
+如您在下面的代码中所见,您只需要添加四行额外的代码到您的训练循环中即可启用分布式训练!
+
+```diff
++ from accelerate import Accelerator
+ from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+
++ accelerator = Accelerator()
+
+ model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+ optimizer = AdamW(model.parameters(), lr=3e-5)
+
+- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+- model.to(device)
+
++ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
++ train_dataloader, eval_dataloader, model, optimizer
++ )
+
+ num_epochs = 3
+ num_training_steps = num_epochs * len(train_dataloader)
+ lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps
+ )
+
+ progress_bar = tqdm(range(num_training_steps))
+
+ model.train()
+ for epoch in range(num_epochs):
+ for batch in train_dataloader:
+- batch = {k: v.to(device) for k, v in batch.items()}
+ outputs = model(**batch)
+ loss = outputs.loss
+- loss.backward()
++ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+```
+
+## 训练
+
+在添加了相关代码行后,可以在脚本或笔记本(如Colaboratory)中启动训练。
+
+### 用脚本训练
+
+如果您从脚本中运行训练,请运行以下命令以创建和保存配置文件:
+
+```bash
+accelerate config
+```
+
+然后使用以下命令启动训练:
+
+```bash
+accelerate launch train.py
+```
+
+### 用笔记本训练
+
+🤗 加速还可以在笔记本中运行,如果您计划使用Colaboratory的TPU,则可在其中运行。将负责训练的所有代码包装在一个函数中,并将其传递给[`~accelerate.notebook_launcher`]:
+
+```py
+>>> from accelerate import notebook_launcher
+
+>>> notebook_launcher(training_function)
+```
+
+有关🤗 加速及其丰富功能的更多信息,请参阅[文档](https://huggingface.co/docs/accelerate)。
\ No newline at end of file
diff --git a/docs/transformers/docs/source/zh/add_new_pipeline.md b/docs/transformers/docs/source/zh/add_new_pipeline.md
new file mode 100644
index 0000000000000000000000000000000000000000..57fd53636b0a1360f44ecf9af9f94c37d1e84f45
--- /dev/null
+++ b/docs/transformers/docs/source/zh/add_new_pipeline.md
@@ -0,0 +1,238 @@
+
+
+# 如何创建自定义流水线?
+
+在本指南中,我们将演示如何创建一个自定义流水线并分享到 [Hub](https://hf.co/models),或将其添加到 🤗 Transformers 库中。
+
+首先,你需要决定流水线将能够接受的原始条目。它可以是字符串、原始字节、字典或任何看起来最可能是期望的输入。
+尽量保持输入为纯 Python 语言,因为这样可以更容易地实现兼容性(甚至通过 JSON 在其他语言之间)。
+这些将是流水线 (`preprocess`) 的 `inputs`。
+
+然后定义 `outputs`。与 `inputs` 相同的策略。越简单越好。这些将是 `postprocess` 方法的输出。
+
+首先继承基类 `Pipeline`,其中包含实现 `preprocess`、`_forward`、`postprocess` 和 `_sanitize_parameters` 所需的 4 个方法。
+
+```python
+from transformers import Pipeline
+
+
+class MyPipeline(Pipeline):
+ def _sanitize_parameters(self, **kwargs):
+ preprocess_kwargs = {}
+ if "maybe_arg" in kwargs:
+ preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
+ return preprocess_kwargs, {}, {}
+
+ def preprocess(self, inputs, maybe_arg=2):
+ model_input = Tensor(inputs["input_ids"])
+ return {"model_input": model_input}
+
+ def _forward(self, model_inputs):
+ # model_inputs == {"model_input": model_input}
+ outputs = self.model(**model_inputs)
+ # Maybe {"logits": Tensor(...)}
+ return outputs
+
+ def postprocess(self, model_outputs):
+ best_class = model_outputs["logits"].softmax(-1)
+ return best_class
+```
+
+这种分解的结构旨在为 CPU/GPU 提供相对无缝的支持,同时支持在不同线程上对 CPU 进行预处理/后处理。
+
+`preprocess` 将接受最初定义的输入,并将其转换为可供模型输入的内容。它可能包含更多信息,通常是一个 `Dict`。
+
+`_forward` 是实现细节,不应直接调用。`forward` 是首选的调用方法,因为它包含保障措施,以确保一切都在预期的设备上运作。
+如果任何内容与实际模型相关,它应该属于 `_forward` 方法,其他内容应该在 preprocess/postprocess 中。
+
+`postprocess` 方法将接受 `_forward` 的输出,并将其转换为之前确定的最终输出。
+
+`_sanitize_parameters` 存在是为了允许用户在任何时候传递任何参数,无论是在初始化时 `pipeline(...., maybe_arg=4)`
+还是在调用时 `pipe = pipeline(...); output = pipe(...., maybe_arg=4)`。
+
+`_sanitize_parameters` 的返回值是将直接传递给 `preprocess`、`_forward` 和 `postprocess` 的 3 个关键字参数字典。
+如果调用方没有使用任何额外参数调用,则不要填写任何内容。这样可以保留函数定义中的默认参数,这总是更"自然"的。
+
+在分类任务中,一个经典的例子是在后处理中使用 `top_k` 参数。
+
+```python
+>>> pipe = pipeline("my-new-task")
+>>> pipe("This is a test")
+[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}, {"label": "3-star", "score": 0.05}
+{"label": "4-star", "score": 0.025}, {"label": "5-star", "score": 0.025}]
+
+>>> pipe("This is a test", top_k=2)
+[{"label": "1-star", "score": 0.8}, {"label": "2-star", "score": 0.1}]
+```
+
+为了实现这一点,我们将更新我们的 `postprocess` 方法,将默认参数设置为 `5`,
+并编辑 `_sanitize_parameters` 方法,以允许这个新参数。
+
+```python
+def postprocess(self, model_outputs, top_k=5):
+ best_class = model_outputs["logits"].softmax(-1)
+ # Add logic to handle top_k
+ return best_class
+
+
+def _sanitize_parameters(self, **kwargs):
+ preprocess_kwargs = {}
+ if "maybe_arg" in kwargs:
+ preprocess_kwargs["maybe_arg"] = kwargs["maybe_arg"]
+
+ postprocess_kwargs = {}
+ if "top_k" in kwargs:
+ postprocess_kwargs["top_k"] = kwargs["top_k"]
+ return preprocess_kwargs, {}, postprocess_kwargs
+```
+
+尽量保持简单输入/输出,最好是可 JSON 序列化的,因为这样可以使流水线的使用非常简单,而不需要用户了解新的对象类型。
+通常也相对常见地支持许多不同类型的参数以便使用(例如音频文件,可以是文件名、URL 或纯字节)。
+
+## 将其添加到支持的任务列表中
+
+要将你的 `new-task` 注册到支持的任务列表中,你需要将其添加到 `PIPELINE_REGISTRY` 中:
+
+```python
+from transformers.pipelines import PIPELINE_REGISTRY
+
+PIPELINE_REGISTRY.register_pipeline(
+ "new-task",
+ pipeline_class=MyPipeline,
+ pt_model=AutoModelForSequenceClassification,
+)
+```
+
+如果需要,你可以指定一个默认模型,此时它应该带有一个特定的修订版本(可以是分支名称或提交哈希,这里我们使用了 `"abcdef"`),以及类型:
+
+```python
+PIPELINE_REGISTRY.register_pipeline(
+ "new-task",
+ pipeline_class=MyPipeline,
+ pt_model=AutoModelForSequenceClassification,
+ default={"pt": ("user/awesome_model", "abcdef")},
+ type="text", # current support type: text, audio, image, multimodal
+)
+```
+
+## 在 Hub 上分享你的流水线
+
+要在 Hub 上分享你的自定义流水线,你只需要将 `Pipeline` 子类的自定义代码保存在一个 Python 文件中。
+例如,假设我们想使用一个自定义流水线进行句对分类,如下所示:
+
+```py
+import numpy as np
+
+from transformers import Pipeline
+
+
+def softmax(outputs):
+ maxes = np.max(outputs, axis=-1, keepdims=True)
+ shifted_exp = np.exp(outputs - maxes)
+ return shifted_exp / shifted_exp.sum(axis=-1, keepdims=True)
+
+
+class PairClassificationPipeline(Pipeline):
+ def _sanitize_parameters(self, **kwargs):
+ preprocess_kwargs = {}
+ if "second_text" in kwargs:
+ preprocess_kwargs["second_text"] = kwargs["second_text"]
+ return preprocess_kwargs, {}, {}
+
+ def preprocess(self, text, second_text=None):
+ return self.tokenizer(text, text_pair=second_text, return_tensors=self.framework)
+
+ def _forward(self, model_inputs):
+ return self.model(**model_inputs)
+
+ def postprocess(self, model_outputs):
+ logits = model_outputs.logits[0].numpy()
+ probabilities = softmax(logits)
+
+ best_class = np.argmax(probabilities)
+ label = self.model.config.id2label[best_class]
+ score = probabilities[best_class].item()
+ logits = logits.tolist()
+ return {"label": label, "score": score, "logits": logits}
+```
+
+这个实现与框架无关,适用于 PyTorch 和 TensorFlow 模型。如果我们将其保存在一个名为
+`pair_classification.py` 的文件中,然后我们可以像这样导入并注册它:
+
+```py
+from pair_classification import PairClassificationPipeline
+from transformers.pipelines import PIPELINE_REGISTRY
+from transformers import AutoModelForSequenceClassification, TFAutoModelForSequenceClassification
+
+PIPELINE_REGISTRY.register_pipeline(
+ "pair-classification",
+ pipeline_class=PairClassificationPipeline,
+ pt_model=AutoModelForSequenceClassification,
+ tf_model=TFAutoModelForSequenceClassification,
+)
+```
+
+完成这些步骤后,我们可以将其与预训练模型一起使用。例如,`sgugger/finetuned-bert-mrpc`
+已经在 MRPC 数据集上进行了微调,用于将句子对分类为是释义或不是释义。
+
+```py
+from transformers import pipeline
+
+classifier = pipeline("pair-classification", model="sgugger/finetuned-bert-mrpc")
+```
+
+然后,我们可以通过在 `Repository` 中使用 `save_pretrained` 方法将其分享到 Hub 上:
+
+```py
+from huggingface_hub import Repository
+
+repo = Repository("test-dynamic-pipeline", clone_from="{your_username}/test-dynamic-pipeline")
+classifier.save_pretrained("test-dynamic-pipeline")
+repo.push_to_hub()
+```
+
+这将会复制包含你定义的 `PairClassificationPipeline` 的文件到文件夹 `"test-dynamic-pipeline"` 中,
+同时保存流水线的模型和分词器,然后将所有内容推送到仓库 `{your_username}/test-dynamic-pipeline` 中。
+之后,只要提供选项 `trust_remote_code=True`,任何人都可以使用它:
+
+```py
+from transformers import pipeline
+
+classifier = pipeline(model="{your_username}/test-dynamic-pipeline", trust_remote_code=True)
+```
+
+## 将流水线添加到 🤗 Transformers
+
+如果你想将你的流水线贡献给 🤗 Transformers,你需要在 `pipelines` 子模块中添加一个新模块,
+其中包含你的流水线的代码,然后将其添加到 `pipelines/__init__.py` 中定义的任务列表中。
+
+然后,你需要添加测试。创建一个新文件 `tests/test_pipelines_MY_PIPELINE.py`,其中包含其他测试的示例。
+
+`run_pipeline_test` 函数将非常通用,并在每种可能的架构上运行小型随机模型,如 `model_mapping` 和 `tf_model_mapping` 所定义。
+
+这对于测试未来的兼容性非常重要,这意味着如果有人为 `XXXForQuestionAnswering` 添加了一个新模型,
+流水线测试将尝试在其上运行。由于模型是随机的,所以不可能检查实际值,这就是为什么有一个帮助函数 `ANY`,它只是尝试匹配流水线的输出类型。
+
+你还 **需要** 实现 2(最好是 4)个测试。
+
+- `test_small_model_pt`:为这个流水线定义一个小型模型(结果是否合理并不重要),并测试流水线的输出。
+ 结果应该与 `test_small_model_tf` 的结果相同。
+- `test_small_model_tf`:为这个流水线定义一个小型模型(结果是否合理并不重要),并测试流水线的输出。
+ 结果应该与 `test_small_model_pt` 的结果相同。
+- `test_large_model_pt`(可选):在一个真实的流水线上测试流水线,结果应该是有意义的。
+ 这些测试速度较慢,应该被如此标记。这里的目标是展示流水线,并确保在未来的发布中没有漂移。
+- `test_large_model_tf`(可选):在一个真实的流水线上测试流水线,结果应该是有意义的。
+ 这些测试速度较慢,应该被如此标记。这里的目标是展示流水线,并确保在未来的发布中没有漂移。
diff --git a/docs/transformers/docs/source/zh/attention.md b/docs/transformers/docs/source/zh/attention.md
new file mode 100644
index 0000000000000000000000000000000000000000..357a574a2d2e697f2c5b5254e21cb5037521587f
--- /dev/null
+++ b/docs/transformers/docs/source/zh/attention.md
@@ -0,0 +1,37 @@
+
+
+# 注意力机制
+
+大多数 transformer 模型使用完全注意力机制,该机制采用正方形的注意力矩阵。当输入很长的文本时,这将导致巨大的计算瓶颈。Longformer 和 Reformer 是提高注意力机制效率的改进模型,它们使用稀疏化的注意力矩阵来加速训练。
+
+## 局部敏感哈希注意力机制(LSH attention)
+
+[Reformer](model_doc/reformer)使用LSH(局部敏感哈希)的注意力机制。在计算softmax(QK^t)时,只有矩阵QK^t中的最大元素(在softmax维度上)会做出有用的贡献。所以对于Q中的每个查询q,我们只需要考虑K中与q接近的键k,这里使用了一个哈希函数来确定q和k是否接近。注意力掩码被修改以掩盖当前的词符(token)(除了第一个位置之外),因为这样会使得查询和键相等(因此非常相似)。由于哈希可能会有些随机性,所以在实践中使用多个哈希函数(由n_rounds参数确定),然后一起求平均。
+
+## 局部注意力机制(Local attention)
+[Longformer](model_doc/longformer)使用局部注意力机制:通常情况下,局部上下文(例如,左边和右边的两个词符是什么?)对于给定词符的操作已经足够了。此外,通过堆叠具有小窗口的注意力层,最后一层将拥有不仅仅是窗口内词符的感受野,这使得它们能构建整个句子的表示。
+
+一些预先选定的输入词符也被赋予全局注意力:对于这些少数词符,注意力矩阵可以访问所有词符(tokens),并且这个过程是对称的:所有其他词符除了它们局部窗口内的词符之外,也可以访问这些特定的词符。这在论文的图2d中有展示,下面是一个样本注意力掩码:
+
+
+
+
+Alternatively, you can switch your cloned 🤗 Transformers to a specific version (for instance with v3.5.1) with
+```bash
+git checkout tags/v3.5.1
+```
+and run the example command as usual afterward.
+
+## Running the Examples on Remote Hardware with Auto-Setup
+
+[run_on_remote.py](./run_on_remote.py) is a script that launches any example on remote self-hosted hardware,
+with automatic hardware and environment setup. It uses [Runhouse](https://github.com/run-house/runhouse) to launch
+on self-hosted hardware (e.g. in your own cloud account or on-premise cluster) but there are other options
+for running remotely as well. You can easily customize the example used, command line arguments, dependencies,
+and type of compute hardware, and then run the script to automatically launch the example.
+
+You can refer to
+[hardware setup](https://www.run.house/docs/tutorials/quick-start-cloud)
+for more information about hardware and dependency setup with Runhouse, or this
+[Colab tutorial](https://colab.research.google.com/drive/1sh_aNQzJX5BKAdNeXthTNGxKz7sM9VPc) for a more in-depth
+walkthrough.
+
+You can run the script with the following commands:
+
+```bash
+# First install runhouse:
+pip install runhouse
+
+# For an on-demand V100 with whichever cloud provider you have configured:
+python run_on_remote.py \
+ --example pytorch/text-generation/run_generation.py \
+ --model_type=gpt2 \
+ --model_name_or_path=openai-community/gpt2 \
+ --prompt "I am a language model and"
+
+# For byo (bring your own) cluster:
+python run_on_remote.py --host --user --key_path \
+ --example
+
+# For on-demand instances
+python run_on_remote.py --instance --provider \
+ --example
+```
+
+You can also adapt the script to your own needs.
diff --git a/docs/transformers/examples/flax/README.md b/docs/transformers/examples/flax/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..074aaa292ceb1d586d855a7c674a97be37c5513d
--- /dev/null
+++ b/docs/transformers/examples/flax/README.md
@@ -0,0 +1,83 @@
+
+
+# JAX/Flax Examples
+
+This folder contains actively maintained examples of 🤗 Transformers using the JAX/Flax backend. Porting models and examples to JAX/Flax is an ongoing effort, and more will be added in the coming months. In particular, these examples are all designed to run fast on Cloud TPUs, and we include step-by-step guides to getting started with Cloud TPU.
+
+*NOTE*: Currently, there is no "Trainer" abstraction for JAX/Flax -- all examples contain an explicit training loop.
+
+The following table lists all of our examples on how to use 🤗 Transformers with the JAX/Flax backend:
+- with information about the model and dataset used,
+- whether or not they leverage the [🤗 Datasets](https://github.com/huggingface/datasets) library,
+- links to **Colab notebooks** to walk through the scripts and run them easily.
+
+| Task | Example model | Example dataset | 🤗 Datasets | Colab
+|---|---|---|:---:|:---:|
+| [**`causal-language-modeling`**](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling) | GPT2 | OSCAR | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/causal_language_modeling_flax.ipynb)
+| [**`masked-language-modeling`**](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling) | RoBERTa | OSCAR | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb)
+| [**`text-classification`**](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) | BERT | GLUE | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb)
+
+## Intro: JAX and Flax
+
+[JAX](https://github.com/google/jax) is a numerical computation library that exposes a NumPy-like API with tracing capabilities. With JAX's `jit`, you can
+trace pure functions and compile them into efficient, fused accelerator code on both GPU and TPU. JAX
+supports additional transformations such as `grad` (for arbitrary gradients), `pmap` (for parallelizing computation on multiple devices), `remat` (for gradient checkpointing), `vmap` (automatic
+efficient vectorization), and `pjit` (for automatically sharded model parallelism). All JAX transformations compose arbitrarily with each other -- e.g., efficiently
+computing per-example gradients is simply `vmap(grad(f))`.
+
+[Flax](https://github.com/google/flax) builds on top of JAX with an ergonomic
+module abstraction using Python dataclasses that leads to concise and explicit code. Flax's "lifted" JAX transformations (e.g. `vmap`, `remat`) allow you to nest JAX transformation and modules in any way you wish. Flax is the most widely used JAX library, with [129 dependent projects](https://github.com/google/flax/network/dependents?package_id=UGFja2FnZS01MjEyMjA2MA%3D%3D) as of May 2021. It is also the library underlying all of the official Cloud TPU JAX examples.
+
+## Running on Cloud TPU
+
+All of our JAX/Flax models are designed to run efficiently on Google
+Cloud TPUs. Here is [a guide for running JAX on Google Cloud TPU](https://cloud.google.com/tpu/docs/jax-quickstart-tpu-vm).
+
+Consider applying for the [Google TPU Research Cloud project](https://sites.research.google/trc/) for free TPU compute.
+
+Each example README contains more details on the specific model and training
+procedure.
+
+
+## Running on single or multiple GPUs
+
+All of our JAX/Flax examples also run efficiently on single and multiple GPUs. You can use the same instructions in the README to launch training on GPU.
+Distributed training is supported out-of-the box and scripts will use all the GPUs that are detected.
+
+You should follow this [guide for installing JAX on GPUs](https://github.com/google/jax/#pip-installation-gpu-cuda) since the installation depends on
+your CUDA and CuDNN version.
+
+## Supported models
+
+Porting models from PyTorch to JAX/Flax is an ongoing effort.
+Feel free to reach out if you are interested in contributing a model in JAX/Flax -- we'll
+be adding a guide for porting models from PyTorch in the upcoming few weeks.
+
+For a complete overview of models that are supported in JAX/Flax, please have a look at [this](https://huggingface.co/transformers/main/index.html#supported-frameworks) table.
+
+Over 3000 pretrained checkpoints are supported in JAX/Flax as of May 2021.
+Click [here](https://huggingface.co/models?filter=jax) to see the full list on the 🤗 hub.
+
+## Upload the trained/fine-tuned model to the Hub
+
+All the example scripts support automatic upload of your final model to the [Model Hub](https://huggingface.co/models) by adding a `--push_to_hub` argument. It will then create a repository with your username slash the name of the folder you are using as `output_dir`. For instance, `"sgugger/test-mrpc"` if your username is `sgugger` and you are working in the folder `~/tmp/test-mrpc`.
+
+To specify a given repository name, use the `--hub_model_id` argument. You will need to specify the whole repository name (including your username), for instance `--hub_model_id sgugger/finetuned-bert-mrpc`. To upload to an organization you are a member of, just use the name of that organization instead of your username: `--hub_model_id huggingface/finetuned-bert-mrpc`.
+
+A few notes on this integration:
+
+- you will need to be logged in to the Hugging Face website locally for it to work, the easiest way to achieve this is to run `huggingface-cli login` and then type your username and password when prompted. You can also pass along your authentication token with the `--hub_token` argument.
+- the `output_dir` you pick will either need to be a new folder or a local clone of the distant repository you are using.
diff --git a/docs/transformers/examples/flax/_tests_requirements.txt b/docs/transformers/examples/flax/_tests_requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..2e93a1f2c549fffb24f6fa404b67b70323dea051
--- /dev/null
+++ b/docs/transformers/examples/flax/_tests_requirements.txt
@@ -0,0 +1,10 @@
+datasets >= 1.13.3
+pytest<8.0.1
+conllu
+nltk
+rouge-score
+seqeval
+tensorboard
+evaluate >= 0.2.0
+torch
+accelerate
diff --git a/docs/transformers/examples/flax/conftest.py b/docs/transformers/examples/flax/conftest.py
new file mode 100644
index 0000000000000000000000000000000000000000..4cf2e46ef07393af6c9ad4f637ee76e442ba8707
--- /dev/null
+++ b/docs/transformers/examples/flax/conftest.py
@@ -0,0 +1,45 @@
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# tests directory-specific settings - this file is run automatically
+# by pytest before any tests are run
+
+import sys
+import warnings
+from os.path import abspath, dirname, join
+
+
+# allow having multiple repository checkouts and not needing to remember to rerun
+# `pip install -e '.[dev]'` when switching between checkouts and running tests.
+git_repo_path = abspath(join(dirname(dirname(dirname(__file__))), "src"))
+sys.path.insert(1, git_repo_path)
+
+
+# silence FutureWarning warnings in tests since often we can't act on them until
+# they become normal warnings - i.e. the tests still need to test the current functionality
+warnings.simplefilter(action="ignore", category=FutureWarning)
+
+
+def pytest_addoption(parser):
+ from transformers.testing_utils import pytest_addoption_shared
+
+ pytest_addoption_shared(parser)
+
+
+def pytest_terminal_summary(terminalreporter):
+ from transformers.testing_utils import pytest_terminal_summary_main
+
+ make_reports = terminalreporter.config.getoption("--make-reports")
+ if make_reports:
+ pytest_terminal_summary_main(terminalreporter, id=make_reports)
diff --git a/docs/transformers/examples/flax/image-captioning/README.md b/docs/transformers/examples/flax/image-captioning/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..dd2b420639258fbfc31a610d3d1d7609d07a691b
--- /dev/null
+++ b/docs/transformers/examples/flax/image-captioning/README.md
@@ -0,0 +1,68 @@
+# Image Captioning (vision-encoder-text-decoder model) training example
+
+The following example showcases how to finetune a vision-encoder-text-decoder model for image captioning
+using the JAX/Flax backend, leveraging 🤗 Transformers library's [FlaxVisionEncoderDecoderModel](https://huggingface.co/docs/transformers/model_doc/vision-encoder-decoder#transformers.FlaxVisionEncoderDecoderModel).
+
+JAX/Flax allows you to trace pure functions and compile them into efficient, fused accelerator code on both GPU and TPU.
+Models written in JAX/Flax are **immutable** and updated in a purely functional
+way which enables simple and efficient model parallelism.
+
+`run_image_captioning_flax.py` is a lightweight example of how to download and preprocess a dataset from the 🤗 Datasets
+library or use your own files (jsonlines or csv), then fine-tune one of the architectures above on it.
+
+For custom datasets in `jsonlines` format please see: https://huggingface.co/docs/datasets/loading_datasets#json-files and you also will find examples of these below.
+
+### Download COCO dataset (2017)
+This example uses COCO dataset (2017) through a custom dataset script, which requires users to manually download the
+COCO dataset before training.
+
+```bash
+mkdir data
+cd data
+wget http://images.cocodataset.org/zips/train2017.zip
+wget http://images.cocodataset.org/zips/val2017.zip
+wget http://images.cocodataset.org/zips/test2017.zip
+wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
+wget http://images.cocodataset.org/annotations/image_info_test2017.zip
+cd ..
+```
+
+### Create a model from a vision encoder model and a text decoder model
+Next, we create a [FlaxVisionEncoderDecoderModel](https://huggingface.co/docs/transformers/model_doc/visionencoderdecoder#transformers.FlaxVisionEncoderDecoderModel) instance from a pre-trained vision encoder ([ViT](https://huggingface.co/docs/transformers/model_doc/vit#transformers.FlaxViTModel)) and a pre-trained text decoder ([GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2#transformers.FlaxGPT2Model)):
+
+```bash
+python3 create_model_from_encoder_decoder_models.py \
+ --output_dir model \
+ --encoder_model_name_or_path google/vit-base-patch16-224-in21k \
+ --decoder_model_name_or_path openai-community/gpt2
+```
+
+### Train the model
+Finally, we can run the example script to train the model:
+
+```bash
+python3 run_image_captioning_flax.py \
+ --output_dir ./image-captioning-training-results \
+ --model_name_or_path model \
+ --dataset_name ydshieh/coco_dataset_script \
+ --dataset_config_name=2017 \
+ --data_dir $PWD/data \
+ --image_column image_path \
+ --caption_column caption \
+ --do_train --do_eval --predict_with_generate \
+ --num_train_epochs 1 \
+ --eval_steps 500 \
+ --learning_rate 3e-5 --warmup_steps 0 \
+ --per_device_train_batch_size 32 \
+ --per_device_eval_batch_size 32 \
+ --overwrite_output_dir \
+ --max_target_length 32 \
+ --num_beams 8 \
+ --preprocessing_num_workers 16 \
+ --logging_steps 10 \
+ --block_size 16384 \
+ --push_to_hub
+```
+
+This should finish in about 1h30 on Cloud TPU, with validation loss and ROUGE2 score of 2.0153 and 14.64 respectively
+after 1 epoch. Training statistics can be accessed on [Models](https://huggingface.co/ydshieh/image-captioning-training-results/tensorboard).
diff --git a/docs/transformers/examples/flax/image-captioning/create_model_from_encoder_decoder_models.py b/docs/transformers/examples/flax/image-captioning/create_model_from_encoder_decoder_models.py
new file mode 100644
index 0000000000000000000000000000000000000000..557bfcd27a3308b93480028848017dcb987ad0a5
--- /dev/null
+++ b/docs/transformers/examples/flax/image-captioning/create_model_from_encoder_decoder_models.py
@@ -0,0 +1,115 @@
+#!/usr/bin/env python
+# Copyright 2022 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Create a VisionEncoderDecoderModel instance from pretrained encoder/decoder models.
+
+The cross-attention will be randomly initialized.
+"""
+
+from dataclasses import dataclass, field
+from typing import Optional
+
+from transformers import AutoConfig, AutoImageProcessor, AutoTokenizer, FlaxVisionEncoderDecoderModel, HfArgumentParser
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ output_dir: str = field(
+ metadata={"help": "The output directory where the model will be written."},
+ )
+ encoder_model_name_or_path: str = field(
+ metadata={
+ "help": (
+ "The encoder model checkpoint for weights initialization. "
+ "Don't set if you want to train an encoder model from scratch."
+ )
+ },
+ )
+ decoder_model_name_or_path: str = field(
+ metadata={
+ "help": (
+ "The decoder model checkpoint for weights initialization. "
+ "Don't set if you want to train a decoder model from scratch."
+ )
+ },
+ )
+ encoder_config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained encoder config name or path if not the same as encoder_model_name"}
+ )
+ decoder_config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained decoder config name or path if not the same as decoder_model_name"}
+ )
+
+
+def main():
+ parser = HfArgumentParser((ModelArguments,))
+ (model_args,) = parser.parse_args_into_dataclasses()
+
+ # Load pretrained model and tokenizer
+
+ # Use explicit specified encoder config
+ if model_args.encoder_config_name:
+ encoder_config = AutoConfig.from_pretrained(model_args.encoder_config_name)
+ # Use pretrained encoder model's config
+ else:
+ encoder_config = AutoConfig.from_pretrained(model_args.encoder_model_name_or_path)
+
+ # Use explicit specified decoder config
+ if model_args.decoder_config_name:
+ decoder_config = AutoConfig.from_pretrained(model_args.decoder_config_name)
+ # Use pretrained decoder model's config
+ else:
+ decoder_config = AutoConfig.from_pretrained(model_args.decoder_model_name_or_path)
+
+ # necessary for `from_encoder_decoder_pretrained` when `decoder_config` is passed
+ decoder_config.is_decoder = True
+ decoder_config.add_cross_attention = True
+
+ model = FlaxVisionEncoderDecoderModel.from_encoder_decoder_pretrained(
+ encoder_pretrained_model_name_or_path=model_args.encoder_model_name_or_path,
+ decoder_pretrained_model_name_or_path=model_args.decoder_model_name_or_path,
+ encoder_config=encoder_config,
+ decoder_config=decoder_config,
+ )
+
+ # GPT2 only has bos/eos tokens but not decoder_start/pad tokens
+ decoder_start_token_id = decoder_config.decoder_start_token_id
+ pad_token_id = decoder_config.pad_token_id
+ if decoder_start_token_id is None:
+ decoder_start_token_id = decoder_config.bos_token_id
+ if pad_token_id is None:
+ pad_token_id = decoder_config.eos_token_id
+
+ # This is necessary to make Flax's generate() work
+ model.config.eos_token_id = decoder_config.eos_token_id
+ model.config.decoder_start_token_id = decoder_start_token_id
+ model.config.pad_token_id = pad_token_id
+
+ image_processor = AutoImageProcessor.from_pretrained(model_args.encoder_model_name_or_path)
+
+ tokenizer = AutoTokenizer.from_pretrained(model_args.decoder_model_name_or_path)
+ tokenizer.pad_token = tokenizer.convert_ids_to_tokens(model.config.pad_token_id)
+
+ model.save_pretrained(model_args.output_dir)
+ image_processor.save_pretrained(model_args.output_dir)
+ tokenizer.save_pretrained(model_args.output_dir)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/flax/image-captioning/run_image_captioning_flax.py b/docs/transformers/examples/flax/image-captioning/run_image_captioning_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..f156057212e4e9de3ce23dc2f5924c035a7ec30e
--- /dev/null
+++ b/docs/transformers/examples/flax/image-captioning/run_image_captioning_flax.py
@@ -0,0 +1,1283 @@
+#!/usr/bin/env python
+# Copyright 2022 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library vision-encoder-decoder models for image captioning.
+"""
+
+import json
+import logging
+import os
+import sys
+import time
+from dataclasses import asdict, dataclass, field
+from enum import Enum
+from functools import partial
+from pathlib import Path
+from typing import Callable, Optional
+
+import datasets
+import evaluate
+import jax
+import jax.numpy as jnp
+import nltk # Here to have a nice missing dependency error message early on
+import numpy as np
+import optax
+from datasets import Dataset, load_dataset
+from filelock import FileLock
+from flax import jax_utils, traverse_util
+from flax.jax_utils import unreplicate
+from flax.training import train_state
+from flax.training.common_utils import get_metrics, onehot, shard, shard_prng_key
+from huggingface_hub import HfApi
+from PIL import Image
+from tqdm import tqdm
+
+import transformers
+from transformers import (
+ AutoImageProcessor,
+ AutoTokenizer,
+ FlaxVisionEncoderDecoderModel,
+ HfArgumentParser,
+ is_tensorboard_available,
+)
+from transformers.utils import is_offline_mode, send_example_telemetry
+
+
+logger = logging.getLogger(__name__)
+
+try:
+ nltk.data.find("tokenizers/punkt")
+except (LookupError, OSError):
+ if is_offline_mode():
+ raise LookupError(
+ "Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
+ )
+ with FileLock(".lock") as lock:
+ nltk.download("punkt", quiet=True)
+
+
+# Copied from transformers.models.bart.modeling_flax_bart.shift_tokens_right
+def shift_tokens_right(input_ids: np.ndarray, pad_token_id: int, decoder_start_token_id: int) -> np.ndarray:
+ """
+ Shift input ids one token to the right.
+ """
+ shifted_input_ids = np.zeros_like(input_ids)
+ shifted_input_ids[:, 1:] = input_ids[:, :-1]
+ shifted_input_ids[:, 0] = decoder_start_token_id
+
+ shifted_input_ids = np.where(shifted_input_ids == -100, pad_token_id, shifted_input_ids)
+ return shifted_input_ids
+
+
+@dataclass
+class TrainingArguments:
+ output_dir: str = field(
+ metadata={"help": "The output directory where the model predictions and checkpoints will be written."},
+ )
+ overwrite_output_dir: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Overwrite the content of the output directory. "
+ "Use this to continue training if output_dir points to a checkpoint directory."
+ )
+ },
+ )
+ do_train: bool = field(default=False, metadata={"help": "Whether to run training."})
+ do_eval: bool = field(default=False, metadata={"help": "Whether to run eval on the dev set."})
+ do_predict: bool = field(default=False, metadata={"help": "Whether to run predictions on the test set."})
+ per_device_train_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for training."}
+ )
+ per_device_eval_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for evaluation."}
+ )
+ _block_size_doc = """
+ The default value `0` will preprocess (tokenization + image processing) the whole dataset before training and
+ cache the results. This uses more disk space, but avoids (repeated) processing time during training. This is a
+ good option if your disk space is large enough to store the whole processed dataset.
+ If a positive value is given, the captions in the dataset will be tokenized before training and the results are
+ cached. During training, it iterates the dataset in chunks of size `block_size`. On each block, images are
+ transformed by the image processor with the results being kept in memory (no cache), and batches of size
+ `batch_size` are yielded before processing the next block. This could avoid the heavy disk usage when the
+ dataset is large.
+ """
+ block_size: int = field(default=0, metadata={"help": _block_size_doc})
+ learning_rate: float = field(default=5e-5, metadata={"help": "The initial learning rate for AdamW."})
+ weight_decay: float = field(default=0.0, metadata={"help": "Weight decay for AdamW if we apply some."})
+ adam_beta1: float = field(default=0.9, metadata={"help": "Beta1 for AdamW optimizer"})
+ adam_beta2: float = field(default=0.999, metadata={"help": "Beta2 for AdamW optimizer"})
+ adam_epsilon: float = field(default=1e-8, metadata={"help": "Epsilon for AdamW optimizer."})
+ label_smoothing_factor: float = field(
+ default=0.0, metadata={"help": "The label smoothing epsilon to apply (zero means no label smoothing)."}
+ )
+ num_train_epochs: float = field(default=3.0, metadata={"help": "Total number of training epochs to perform."})
+ warmup_steps: int = field(default=0, metadata={"help": "Linear warmup over warmup_steps."})
+ logging_steps: int = field(default=500, metadata={"help": "Log every X updates steps."})
+ eval_steps: int = field(default=None, metadata={"help": "Run an evaluation every X steps."})
+ seed: int = field(default=42, metadata={"help": "Random seed that will be set at the beginning of training."})
+ push_to_hub: bool = field(
+ default=False, metadata={"help": "Whether or not to upload the trained model to the model hub after training."}
+ )
+ hub_model_id: str = field(
+ default=None, metadata={"help": "The name of the repository to keep in sync with the local `output_dir`."}
+ )
+ hub_token: str = field(default=None, metadata={"help": "The token to use to push to the Model Hub."})
+
+ def __post_init__(self):
+ if self.output_dir is not None:
+ self.output_dir = os.path.expanduser(self.output_dir)
+
+ def to_dict(self):
+ """
+ Serializes this instance while replace `Enum` by their values (for JSON serialization support). It obfuscates
+ the token values by removing their value.
+ """
+ d = asdict(self)
+ for k, v in d.items():
+ if isinstance(v, Enum):
+ d[k] = v.value
+ if isinstance(v, list) and len(v) > 0 and isinstance(v[0], Enum):
+ d[k] = [x.value for x in v]
+ if k.endswith("_token"):
+ d[k] = f"<{k.upper()}>"
+ return d
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "The model checkpoint for weights initialization."},
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ dtype: Optional[str] = field(
+ default="float32",
+ metadata={
+ "help": (
+ "Floating-point format in which the model weights should be initialized and trained. Choose one of"
+ " `[float32, float16, bfloat16]`."
+ )
+ },
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ data_dir: Optional[str] = field(
+ default=None, metadata={"help": "The data directory of the dataset to use (via the datasets library)."}
+ )
+ image_column: Optional[str] = field(
+ default=None,
+ metadata={"help": "The name of the column in the datasets containing the full image file paths."},
+ )
+ caption_column: Optional[str] = field(
+ default=None,
+ metadata={"help": "The name of the column in the datasets containing the image captions."},
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input predict data file to do prediction on (a text file)."},
+ )
+ max_target_length: Optional[int] = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total sequence length for target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ val_max_target_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total sequence length for validation target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
+ "This argument is also used to override the `max_length` param of `model.generate`, which is used "
+ "during evaluation."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ predict_with_generate: bool = field(
+ default=False, metadata={"help": "Whether to use generate to calculate generative metrics (ROUGE, BLEU)."}
+ )
+ num_beams: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Number of beams to use for evaluation. This argument will be passed to `model.generate`, "
+ "which is used during evaluation."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ if extension not in ["csv", "json"]:
+ raise ValueError(f"`train_file` should be a csv or a json file, got {extension}.")
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ if extension not in ["csv", "json"]:
+ raise ValueError(f"`validation_file` should be a csv or a json file, got {extension}.")
+ if self.val_max_target_length is None:
+ self.val_max_target_length = self.max_target_length
+
+
+image_captioning_name_mapping = {
+ "image_caption_dataset.py": ("image_path", "caption"),
+}
+
+
+class TrainState(train_state.TrainState):
+ dropout_rng: jnp.ndarray
+
+ def replicate(self):
+ return jax_utils.replicate(self).replace(dropout_rng=shard_prng_key(self.dropout_rng))
+
+
+def data_loader(rng: jax.random.PRNGKey, dataset: Dataset, batch_size: int, shuffle: bool = False):
+ """
+ Returns batches of size `batch_size` from truncated `dataset`, sharded over all local devices.
+ Shuffle batches if `shuffle` is `True`.
+ """
+ steps = len(dataset) // batch_size # Skip incomplete batch.
+
+ # We use `numpy.ndarray` to interact with `datasets.Dataset`, since using `jax.numpy.array` to index into a
+ # dataset is significantly slow. Using JAX array at the 1st place is only to keep JAX's PRNGs generation
+ # mechanism, which works differently from NumPy/SciPy.
+ if shuffle:
+ batch_idx = jax.random.permutation(rng, len(dataset))
+ batch_idx = np.asarray(batch_idx)
+ else:
+ batch_idx = np.arange(len(dataset))
+
+ for idx in range(steps):
+ start_idx = batch_size * idx
+ end_idx = batch_size * (idx + 1)
+
+ selected_indices = batch_idx[start_idx:end_idx]
+ batch = dataset[selected_indices]
+ batch = shard(batch)
+
+ yield batch
+
+
+def write_metric(summary_writer, metrics, train_time, step, metric_key_prefix="train"):
+ if train_time:
+ summary_writer.scalar("train_time", train_time, step)
+
+ metrics = get_metrics(metrics)
+ for key, vals in metrics.items():
+ tag = f"{metric_key_prefix}_{key}"
+ for i, val in enumerate(vals):
+ summary_writer.scalar(tag, val, step - len(vals) + i + 1)
+
+ else:
+ for metric_name, value in metrics.items():
+ summary_writer.scalar(f"{metric_key_prefix}_{metric_name}", value, step)
+
+
+def create_learning_rate_fn(
+ train_ds_size: int, train_batch_size: int, num_train_epochs: int, num_warmup_steps: int, learning_rate: float
+) -> Callable[[int], jnp.ndarray]:
+ """Returns a linear warmup, linear_decay learning rate function."""
+ steps_per_epoch = train_ds_size // train_batch_size
+ num_train_steps = steps_per_epoch * num_train_epochs
+ warmup_fn = optax.linear_schedule(init_value=0.0, end_value=learning_rate, transition_steps=num_warmup_steps)
+ decay_fn = optax.linear_schedule(
+ init_value=learning_rate, end_value=0, transition_steps=num_train_steps - num_warmup_steps
+ )
+ schedule_fn = optax.join_schedules(schedules=[warmup_fn, decay_fn], boundaries=[num_warmup_steps])
+ return schedule_fn
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_image_captioning", model_args, data_args, framework="flax")
+
+ if (
+ os.path.exists(training_args.output_dir)
+ and os.listdir(training_args.output_dir)
+ and training_args.do_train
+ and not training_args.overwrite_output_dir
+ ):
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ # Setup logging, we only want one process per machine to log things on the screen.
+ logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
+ if jax.process_index() == 0:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Handle the repository creation
+ if training_args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = training_args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(training_args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
+
+ # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files this script will use the first column for the full image path and the second column for the
+ # captions (unless you specify column names for this with the `image_column` and `caption_column` arguments).
+ #
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ dataset = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ keep_in_memory=False,
+ data_dir=data_args.data_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if data_args.test_file is not None:
+ data_files["test"] = data_args.test_file
+ extension = data_args.test_file.split(".")[-1]
+ dataset = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ model = FlaxVisionEncoderDecoderModel.from_pretrained(
+ model_args.model_name_or_path,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ image_processor = AutoImageProcessor.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer.pad_token = tokenizer.convert_ids_to_tokens(model.config.pad_token_id)
+
+ # Preprocessing the datasets.
+ # We need to tokenize inputs and targets.
+ if training_args.do_train:
+ column_names = dataset["train"].column_names
+ elif training_args.do_eval:
+ column_names = dataset["validation"].column_names
+ elif training_args.do_predict:
+ column_names = dataset["test"].column_names
+ else:
+ logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
+ return
+
+ # Get the column names for input/target.
+ dataset_columns = image_captioning_name_mapping.get(data_args.dataset_name, None)
+ if data_args.image_column is None:
+ if dataset_columns is None:
+ raise ValueError(
+ f"`--dataset_name` {data_args.dataset_name} not found in dataset '{data_args.dataset_name}'. Make sure"
+ " to set `--dataset_name` to the correct dataset name, one of"
+ f" {', '.join(image_captioning_name_mapping.keys())}."
+ )
+ image_column = dataset_columns[0]
+ else:
+ image_column = data_args.image_column
+ if image_column not in column_names:
+ raise ValueError(
+ f"--image_column' value '{data_args.image_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if data_args.caption_column is None:
+ if dataset_columns is None:
+ raise ValueError(
+ f"`--dataset_name` {data_args.dataset_name} not found in dataset '{data_args.dataset_name}'. Make sure"
+ " to set `--dataset_name` to the correct dataset name, one of"
+ f" {', '.join(image_captioning_name_mapping.keys())}."
+ )
+ caption_column = dataset_columns[1]
+ else:
+ caption_column = data_args.caption_column
+ if caption_column not in column_names:
+ raise ValueError(
+ f"--caption_column' value '{data_args.caption_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # In Flax, for seq2seq models we need to pass `decoder_input_ids`
+ # as the Flax models don't accept `labels`, we need to prepare the decoder_input_ids here
+ # for that dynamically import the `shift_tokens_right` function from the model file
+ model_module = __import__(model.__module__, fromlist=["shift_tokens_right"])
+ shift_tokens_right_fn = getattr(model_module, "shift_tokens_right", shift_tokens_right)
+
+ def filter_fn(examples):
+ """remove problematic images"""
+
+ bools = []
+ for image_file in examples[image_column]:
+ try:
+ image = Image.open(image_file)
+ image_processor(images=image, return_tensors="np")
+ bools.append(True)
+ except Exception:
+ bools.append(False)
+
+ return bools
+
+ # Setting padding="max_length" as we need fixed length inputs for jitted functions
+ def tokenization_fn(examples, max_target_length):
+ """Run tokenization on captions."""
+
+ captions = []
+ for caption in examples[caption_column]:
+ captions.append(caption.lower() + " " + tokenizer.eos_token)
+ targets = captions
+
+ model_inputs = {}
+
+ labels = tokenizer(
+ text_target=targets,
+ max_length=max_target_length,
+ padding="max_length",
+ truncation=True,
+ return_tensors="np",
+ )
+ model_inputs["labels"] = labels["input_ids"]
+ decoder_input_ids = shift_tokens_right_fn(
+ labels["input_ids"], model.config.pad_token_id, model.config.decoder_start_token_id
+ )
+ model_inputs["decoder_input_ids"] = np.asarray(decoder_input_ids)
+ # We need decoder_attention_mask so we can ignore pad tokens from loss
+ model_inputs["decoder_attention_mask"] = labels["attention_mask"]
+ model_inputs[image_column] = examples[image_column]
+
+ return model_inputs
+
+ def image_processing_fn(examples, check_image=True):
+ """
+ Run preprocessing on images
+
+ If `check_image` is `True`, the examples that fails during `Image.open()` will be caught and discarded.
+ Otherwise, an exception will be thrown.
+ """
+
+ model_inputs = {}
+
+ if check_image:
+ images = []
+ to_keep = []
+ for image_file in examples[image_column]:
+ try:
+ img = Image.open(image_file)
+ images.append(img)
+ to_keep.append(True)
+ except Exception:
+ to_keep.append(False)
+
+ for k, v in examples.items():
+ if k != image_column:
+ model_inputs[k] = v[to_keep]
+ else:
+ images = [Image.open(image_file) for image_file in examples[image_column]]
+
+ encoder_inputs = image_processor(images=images, return_tensors="np")
+ model_inputs["pixel_values"] = encoder_inputs.pixel_values
+
+ return model_inputs
+
+ def preprocess_fn(examples, max_target_length, check_image=True):
+ """Run tokenization + image processing"""
+
+ model_inputs = {}
+ # This contains image path column
+ model_inputs.update(tokenization_fn(examples, max_target_length))
+ model_inputs.update(image_processing_fn(model_inputs, check_image=check_image))
+ # Remove image path column
+ model_inputs.pop(image_column)
+
+ return model_inputs
+
+ features = datasets.Features(
+ {
+ "pixel_values": datasets.Array3D(
+ shape=(
+ getattr(model.config.encoder, "num_channels", 3),
+ model.config.encoder.image_size,
+ model.config.encoder.image_size,
+ ),
+ dtype="float32",
+ ),
+ "labels": datasets.Sequence(feature=datasets.Value(dtype="int32", id=None), length=-1, id=None),
+ "decoder_input_ids": datasets.Sequence(feature=datasets.Value(dtype="int32", id=None), length=-1, id=None),
+ "decoder_attention_mask": datasets.Sequence(
+ feature=datasets.Value(dtype="int32", id=None), length=-1, id=None
+ ),
+ }
+ )
+
+ # If `block_size` is `0`, tokenization & image processing is done at the beginning
+ run_img_proc_at_beginning = training_args.block_size == 0
+ # Used in .map() below
+ function_kwarg = preprocess_fn if run_img_proc_at_beginning else tokenization_fn
+ # `features` is used only for the final preprocessed dataset (for the performance purpose).
+ features_kwarg = features if run_img_proc_at_beginning else None
+ # Keep `image_column` if the image processing is done during training
+ remove_columns_kwarg = [x for x in column_names if x != image_column or run_img_proc_at_beginning]
+ processor_names = "tokenizer and image processor" if run_img_proc_at_beginning else "tokenizer"
+
+ # Store some constant
+ train_batch_size = int(training_args.per_device_train_batch_size) * jax.device_count()
+ eval_batch_size = int(training_args.per_device_eval_batch_size) * jax.device_count()
+ if training_args.block_size % train_batch_size > 0 or training_args.block_size % eval_batch_size > 0:
+ raise ValueError(
+ "`training_args.block_size` needs to be a multiple of the global train/eval batch size. "
+ f"Got {training_args.block_size}, {train_batch_size} and {eval_batch_size} respectively instead."
+ )
+
+ if training_args.do_train:
+ if "train" not in dataset:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = dataset["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ # remove problematic examples
+ # (if image processing is performed at the beginning, the filtering is done during preprocessing below
+ # instead here.)
+ if not run_img_proc_at_beginning:
+ train_dataset = train_dataset.filter(filter_fn, batched=True, num_proc=data_args.preprocessing_num_workers)
+ train_dataset = train_dataset.map(
+ function=function_kwarg,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ # kept image paths
+ remove_columns=remove_columns_kwarg,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc=f"Running {processor_names} on train dataset",
+ fn_kwargs={"max_target_length": data_args.max_target_length},
+ features=features_kwarg,
+ )
+ if run_img_proc_at_beginning:
+ # set format (for performance) since the dataset is ready to be used
+ train_dataset = train_dataset.with_format("numpy")
+
+ steps_per_epoch = len(train_dataset) // train_batch_size
+ num_train_examples_per_epoch = steps_per_epoch * train_batch_size
+ num_epochs = int(training_args.num_train_epochs)
+ total_train_steps = steps_per_epoch * num_epochs
+ else:
+ num_train_examples_per_epoch = 0
+
+ if training_args.do_eval:
+ if "validation" not in dataset:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = dataset["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+ # remove problematic examples
+ # (if image processing is performed at the beginning, the filtering is done during preprocessing below
+ # instead here.)
+ if not run_img_proc_at_beginning:
+ eval_dataset = eval_dataset.filter(filter_fn, batched=True, num_proc=data_args.preprocessing_num_workers)
+ eval_dataset = eval_dataset.map(
+ function=function_kwarg,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ # kept image paths
+ remove_columns=remove_columns_kwarg,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc=f"Running {processor_names} on validation dataset",
+ fn_kwargs={"max_target_length": data_args.val_max_target_length},
+ features=features_kwarg,
+ )
+ if run_img_proc_at_beginning:
+ # set format (for performance) since the dataset is ready to be used
+ eval_dataset = eval_dataset.with_format("numpy")
+
+ num_eval_examples = len(eval_dataset)
+ eval_steps = num_eval_examples // eval_batch_size
+
+ if training_args.do_predict:
+ if "test" not in dataset:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_dataset = dataset["test"]
+ if data_args.max_predict_samples is not None:
+ max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
+ predict_dataset = predict_dataset.select(range(max_predict_samples))
+ # remove problematic examples
+ # (if image processing is performed at the beginning, the filtering is done during preprocessing below
+ # instead here.)
+ if not run_img_proc_at_beginning:
+ predict_dataset = predict_dataset.filter(
+ filter_fn, batched=True, num_proc=data_args.preprocessing_num_workers
+ )
+ predict_dataset = predict_dataset.map(
+ function=function_kwarg,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ # kept image paths
+ remove_columns=remove_columns_kwarg,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc=f"Running {processor_names} on prediction dataset",
+ fn_kwargs={"max_target_length": data_args.val_max_target_length},
+ features=features_kwarg,
+ )
+ if run_img_proc_at_beginning:
+ # set format (for performance) since the dataset is ready to be used
+ predict_dataset = predict_dataset.with_format("numpy")
+
+ num_test_examples = len(predict_dataset)
+ test_steps = num_test_examples // eval_batch_size
+
+ def blockwise_data_loader(
+ rng: jax.random.PRNGKey,
+ ds: Dataset,
+ block_size: int,
+ batch_size: int,
+ shuffle: bool = False,
+ keep_in_memory: bool = False,
+ split: str = "",
+ ):
+ """
+ Wrap the simple `data_loader` in a block-wise way if `block_size` > 0, else it's the same as `data_loader`.
+
+ If `block_size` > 0, it requires `ds` to have a column that gives image paths in order to perform image
+ processing (with the column name being specified by `image_column`). The tokenization should be done before
+ training in this case.
+ """
+
+ # We use `numpy.ndarray` to interact with `datasets.Dataset`, since using `jax.numpy.array` to index into a
+ # dataset is significantly slow. Using JAX array at the 1st place is only to keep JAX's PRNGs generation
+ # mechanism, which works differently from NumPy/SciPy.
+ if shuffle:
+ indices = jax.random.permutation(rng, len(ds))
+ indices = np.asarray(indices)
+ else:
+ indices = np.arange(len(ds))
+
+ _block_size = len(ds) if not block_size else block_size
+
+ steps_per_block = _block_size // batch_size
+ num_examples = len(ds)
+ steps = num_examples // batch_size
+ num_splits = steps // steps_per_block + int(steps % steps_per_block > 0)
+
+ for idx in range(num_splits):
+ if not block_size:
+ _ds = ds
+ else:
+ start_idx = block_size * idx
+ end_idx = block_size * (idx + 1)
+
+ selected_indices = indices[start_idx:end_idx]
+
+ _ds = ds.select(selected_indices)
+
+ _ds = _ds.map(
+ image_processing_fn,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=[image_column],
+ load_from_cache_file=not data_args.overwrite_cache,
+ features=features,
+ keep_in_memory=keep_in_memory,
+ # The images are already checked either in `.filter()` or in `preprocess_fn()`
+ fn_kwargs={"check_image": False},
+ desc=f"Running image processing on {split} dataset".replace(" ", " "),
+ )
+ _ds = _ds.with_format("numpy")
+
+ # No need to shuffle here
+ loader = data_loader(rng, _ds, batch_size=batch_size, shuffle=False)
+
+ yield from loader
+
+ # Metric
+ metric = evaluate.load("rouge", cache_dir=model_args.cache_dir)
+
+ def postprocess_text(preds, labels):
+ preds = [pred.strip() for pred in preds]
+ labels = [label.strip() for label in labels]
+
+ # rougeLSum expects newline after each sentence
+ preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
+ labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
+
+ return preds, labels
+
+ def compute_metrics(preds, labels):
+ decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Some simple post-processing
+ decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
+
+ result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
+ # Extract a few results from ROUGE
+ result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
+
+ prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
+ result["gen_len"] = np.mean(prediction_lens)
+ result = {k: round(v, 6) for k, v in result.items()}
+
+ return result, decoded_preds, decoded_labels
+
+ # Enable tensorboard only on the master node
+ has_tensorboard = is_tensorboard_available()
+ if has_tensorboard and jax.process_index() == 0:
+ try:
+ from flax.metrics.tensorboard import SummaryWriter
+
+ summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir))
+ except ImportError as ie:
+ has_tensorboard = False
+ logger.warning(
+ f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
+ )
+ else:
+ logger.warning(
+ "Unable to display metrics through TensorBoard because the package is not installed: "
+ "Please run pip install tensorboard to enable."
+ )
+
+ # Initialize our training
+ rng = jax.random.PRNGKey(training_args.seed)
+ rng, dropout_rng = jax.random.split(rng)
+
+ # Create learning rate schedule
+ linear_decay_lr_schedule_fn = create_learning_rate_fn(
+ num_train_examples_per_epoch,
+ train_batch_size,
+ training_args.num_train_epochs,
+ training_args.warmup_steps,
+ training_args.learning_rate,
+ )
+
+ # We use Optax's "masking" functionality to not apply weight decay
+ # to bias and LayerNorm scale parameters. decay_mask_fn returns a
+ # mask boolean with the same structure as the parameters.
+ # The mask is True for parameters that should be decayed.
+ def decay_mask_fn(params):
+ flat_params = traverse_util.flatten_dict(params)
+ # find out all LayerNorm parameters
+ layer_norm_candidates = ["layernorm", "layer_norm", "ln"]
+ layer_norm_named_params = {
+ layer[-2:]
+ for layer_norm_name in layer_norm_candidates
+ for layer in flat_params.keys()
+ if layer_norm_name in "".join(layer).lower()
+ }
+ flat_mask = {path: (path[-1] != "bias" and path[-2:] not in layer_norm_named_params) for path in flat_params}
+ return traverse_util.unflatten_dict(flat_mask)
+
+ # create adam optimizer
+ adamw = optax.adamw(
+ learning_rate=linear_decay_lr_schedule_fn,
+ b1=training_args.adam_beta1,
+ b2=training_args.adam_beta2,
+ eps=training_args.adam_epsilon,
+ weight_decay=training_args.weight_decay,
+ mask=decay_mask_fn,
+ )
+
+ # Setup train state
+ state = TrainState.create(apply_fn=model.__call__, params=model.params, tx=adamw, dropout_rng=dropout_rng)
+
+ # label smoothed cross entropy
+ def loss_fn(logits, labels, padding_mask, label_smoothing_factor=0.0):
+ """
+ The label smoothing implementation is adapted from Flax's official example:
+ https://github.com/google/flax/blob/87a211135c6a377c8f29048a1cac3840e38b9da4/examples/wmt/train.py#L104
+ """
+ vocab_size = logits.shape[-1]
+ confidence = 1.0 - label_smoothing_factor
+ low_confidence = (1.0 - confidence) / (vocab_size - 1)
+ normalizing_constant = -(
+ confidence * jnp.log(confidence) + (vocab_size - 1) * low_confidence * jnp.log(low_confidence + 1e-20)
+ )
+ soft_labels = onehot(labels, vocab_size, on_value=confidence, off_value=low_confidence)
+
+ loss = optax.softmax_cross_entropy(logits, soft_labels)
+ loss = loss - normalizing_constant
+
+ # ignore padded tokens from loss
+ loss = loss * padding_mask
+ loss = loss.sum()
+ num_labels = padding_mask.sum()
+ return loss, num_labels
+
+ # Define gradient update step fn
+ def train_step(state, batch, label_smoothing_factor=0.0):
+ dropout_rng, new_dropout_rng = jax.random.split(state.dropout_rng)
+
+ def compute_loss(params):
+ labels = batch.pop("labels")
+ logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
+ loss, num_labels = loss_fn(logits, labels, batch["decoder_attention_mask"], label_smoothing_factor)
+ return loss, num_labels
+
+ grad_fn = jax.value_and_grad(compute_loss, has_aux=True)
+ (loss, num_labels), grad = grad_fn(state.params)
+ num_labels = jax.lax.psum(num_labels, "batch")
+
+ # true loss = total loss / total samples
+ loss = jax.lax.psum(loss, "batch")
+ loss = jax.tree_util.tree_map(lambda x: x / num_labels, loss)
+
+ # true grad = total grad / total samples
+ grad = jax.lax.psum(grad, "batch")
+ grad = jax.tree_util.tree_map(lambda x: x / num_labels, grad)
+ new_state = state.apply_gradients(grads=grad, dropout_rng=new_dropout_rng)
+
+ metrics = {"loss": loss, "learning_rate": linear_decay_lr_schedule_fn(state.step)}
+ return new_state, metrics
+
+ # Define eval fn
+ def eval_step(params, batch, label_smoothing_factor=0.0):
+ labels = batch.pop("labels")
+ logits = model(**batch, params=params, train=False)[0]
+
+ loss, num_labels = loss_fn(logits, labels, batch["decoder_attention_mask"], label_smoothing_factor)
+ num_labels = jax.lax.psum(num_labels, "batch")
+
+ # true loss = total loss / total samples
+ loss = jax.lax.psum(loss, "batch")
+ loss = jax.tree_util.tree_map(lambda x: x / num_labels, loss)
+
+ metrics = {"loss": loss}
+ return metrics
+
+ # Define generation function
+ max_length = (
+ data_args.val_max_target_length if data_args.val_max_target_length is not None else model.config.max_length
+ )
+ num_beams = data_args.num_beams if data_args.num_beams is not None else model.config.num_beams
+ gen_kwargs = {"max_length": max_length, "num_beams": num_beams}
+
+ def generate_step(params, batch):
+ model.params = params
+ output_ids = model.generate(batch["pixel_values"], **gen_kwargs)
+ return output_ids.sequences
+
+ # Create parallel version of the train and eval step
+ p_train_step = jax.pmap(
+ partial(train_step, label_smoothing_factor=training_args.label_smoothing_factor), "batch", donate_argnums=(0,)
+ )
+ p_eval_step = jax.pmap(partial(eval_step, label_smoothing_factor=training_args.label_smoothing_factor), "batch")
+ p_generate_step = jax.pmap(generate_step, "batch")
+
+ # Replicate the train state on each device
+ state = state.replicate()
+
+ if training_args.do_train:
+ logger.info("***** Running training *****")
+ logger.info(f" Num train examples = {num_train_examples_per_epoch}")
+ logger.info(f" Num Epochs = {num_epochs}")
+ logger.info(f" Instantaneous train batch size per device = {training_args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel & distributed) = {train_batch_size}")
+ logger.info(f" Optimization steps per epoch = {steps_per_epoch}")
+ logger.info(f" Total optimization steps = {total_train_steps}")
+ if training_args.do_eval:
+ logger.info(f" Num evaluation examples = {num_eval_examples}")
+ logger.info(f" Instantaneous evaluation batch size per device = {training_args.per_device_eval_batch_size}")
+ logger.info(f" Total evaluation batch size (w. parallel & distributed) = {eval_batch_size}")
+ logger.info(f" Evaluation steps = {eval_steps}")
+ if training_args.do_predict:
+ logger.info(f" Num test examples = {num_test_examples}")
+ logger.info(f" Instantaneous test batch size per device = {training_args.per_device_eval_batch_size}")
+ logger.info(f" Total test batch size (w. parallel & distributed) = {eval_batch_size}")
+ logger.info(f" Test steps = {test_steps}")
+
+ # create output directory
+ if not os.path.isdir(os.path.join(training_args.output_dir)):
+ os.makedirs(os.path.join(training_args.output_dir), exist_ok=True)
+
+ def save_ckpt(ckpt_dir: str, commit_msg: str = ""):
+ """save checkpoints and push to Hugging Face Hub if specified"""
+
+ # save checkpoint after each epoch and push checkpoint to the hub
+ if jax.process_index() == 0:
+ params = jax.device_get(jax.tree_util.tree_map(lambda x: x[0], state.params))
+ model.save_pretrained(os.path.join(training_args.output_dir, ckpt_dir), params=params)
+ tokenizer.save_pretrained(os.path.join(training_args.output_dir, ckpt_dir))
+ if training_args.push_to_hub:
+ api.upload_folder(
+ commit_message=commit_msg,
+ folder_path=training_args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=training_args.hub_token,
+ )
+
+ def evaluation_loop(
+ rng: jax.random.PRNGKey,
+ dataset: Dataset,
+ metric_key_prefix: str = "eval",
+ ckpt_dir: str = "",
+ is_prediction=False,
+ ):
+ logger.info(f"*** {'Predict' if is_prediction else 'Evaluate'} ***")
+
+ metrics = []
+ preds = []
+ labels = []
+
+ batches = blockwise_data_loader(
+ rng,
+ dataset,
+ block_size=training_args.block_size,
+ batch_size=eval_batch_size,
+ keep_in_memory=False,
+ shuffle=False,
+ split="prediction" if is_prediction else "validation",
+ )
+ steps = len(dataset) // eval_batch_size
+ for _ in tqdm(
+ range(steps), desc=f"{'Predicting' if is_prediction else 'Evaluating'}...", position=2, leave=False
+ ):
+ # Model forward
+ batch = next(batches)
+ _labels = batch.get("labels", None)
+ if not is_prediction and _labels is None:
+ raise ValueError("Evaluation requires the validation dataset to have `labels`")
+
+ if _labels is not None:
+ _metrics = p_eval_step(state.params, batch)
+ metrics.append(_metrics)
+
+ # generation
+ if data_args.predict_with_generate:
+ generated_ids = p_generate_step(state.params, batch)
+ preds.extend(jax.device_get(generated_ids.reshape(-1, gen_kwargs["max_length"])))
+ if _labels is not None:
+ labels.extend(jax.device_get(_labels.reshape(-1, _labels.shape[-1])))
+
+ if metrics:
+ # normalize metrics
+ metrics = get_metrics(metrics)
+ metrics = jax.tree_util.tree_map(jnp.mean, metrics)
+
+ # compute ROUGE metrics
+ generations = []
+ rouge_desc = ""
+ if data_args.predict_with_generate:
+ if labels:
+ rouge_metrics, decoded_preds, decoded_labels = compute_metrics(preds, labels)
+ metrics.update(rouge_metrics)
+ rouge_desc = " ".join(
+ [
+ f"{'Predict' if is_prediction else 'Eval'} {key}: {value} |"
+ for key, value in rouge_metrics.items()
+ ]
+ )
+ for pred, label in zip(decoded_preds, decoded_labels):
+ pred = pred.replace("\n", " ")
+ label = label.replace("\n", " ")
+ generations.append({"label": label, "pred": pred})
+ else:
+ decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
+ # Some simple post-processing
+ decoded_preds = [pred.strip() for pred in decoded_preds]
+ # rougeLSum expects newline after each sentence
+ decoded_preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in decoded_preds]
+ for pred in decoded_preds:
+ pred = pred.replace("\n", " ")
+ generations.append({"pred": pred})
+
+ if metrics:
+ # Print metrics and update progress bar
+ desc = f"{'Predict' if is_prediction else 'Eval'} Loss: {metrics['loss']} | {rouge_desc})"
+ if training_args.do_train and not is_prediction:
+ desc = f"Epoch... ({epoch + 1}/{num_epochs} | Step: {cur_step} | " + desc
+ epochs.write(desc)
+ epochs.desc = desc
+ logger.info(desc)
+
+ if jax.process_index() == 0:
+ if not os.path.isdir(os.path.join(training_args.output_dir, ckpt_dir)):
+ os.makedirs(os.path.join(training_args.output_dir, ckpt_dir), exist_ok=True)
+
+ if metrics:
+ # Save metrics (only for the evaluation/prediction being done along with training)
+ if has_tensorboard and training_args.do_train:
+ write_metric(
+ summary_writer, metrics, train_time=None, step=cur_step, metric_key_prefix=metric_key_prefix
+ )
+
+ # save final metrics in json
+ metrics = {
+ f"{metric_key_prefix}_{metric_name}": round(value.item(), 6)
+ for metric_name, value in metrics.items()
+ }
+ _path = os.path.join(training_args.output_dir, ckpt_dir, f"{metric_key_prefix}_results.json")
+ with open(_path, "w") as f:
+ json.dump(metrics, f, indent=4, sort_keys=True)
+
+ # Update report
+ with open(os.path.join(training_args.output_dir, "log"), "a", encoding="UTF-8") as fp:
+ fp.write(desc + "\n")
+
+ # Save generations
+ if generations:
+ output_file = os.path.join(training_args.output_dir, ckpt_dir, f"{metric_key_prefix}_generation.json")
+ with open(output_file, "w", encoding="UTF-8") as fp:
+ json.dump(generations, fp, ensure_ascii=False, indent=4)
+
+ def evaluate(rng: jax.random.PRNGKey, dataset: Dataset, ckpt_dir: str = ""):
+ evaluation_loop(rng, dataset, metric_key_prefix="eval", ckpt_dir=ckpt_dir)
+
+ def predict(rng: jax.random.PRNGKey, dataset: Dataset):
+ evaluation_loop(rng, dataset, metric_key_prefix="test", is_prediction=True)
+
+ input_rng = None
+
+ if training_args.do_train:
+ cur_step = 0
+ train_time = 0
+ epochs = tqdm(range(num_epochs), desc=f"Epoch ... (1/{num_epochs})", position=0)
+
+ for epoch in epochs:
+ # ======================== Training ================================
+ # Create sampling rng
+ rng, input_rng = jax.random.split(rng)
+
+ train_metrics = []
+ train_batches = blockwise_data_loader(
+ input_rng,
+ train_dataset,
+ block_size=training_args.block_size,
+ batch_size=train_batch_size,
+ keep_in_memory=True,
+ shuffle=True,
+ split="train",
+ )
+
+ # train
+ for batch_idx, _ in enumerate(tqdm(range(steps_per_epoch), desc="Training...", position=1, leave=False)):
+ cur_step += 1
+ batch = next(train_batches)
+ batch_start = time.time()
+ state, train_metric = p_train_step(state, batch)
+ train_metrics.append(train_metric)
+ train_time += time.time() - batch_start
+ time_per_step = train_time / cur_step
+
+ # log and save info
+ if training_args.logging_steps > 0 and cur_step % training_args.logging_steps == 0:
+ _train_metric = unreplicate(train_metric)
+ desc = (
+ f"Epoch... ({epoch + 1}/{num_epochs} | Step: {cur_step} | Loss: {_train_metric['loss']} |"
+ f" Learning Rate: {_train_metric['learning_rate']} | Time per step: {time_per_step})"
+ )
+ epochs.desc = desc
+ epochs.write(desc)
+
+ logger.info(desc)
+
+ with open(os.path.join(training_args.output_dir, "log"), "a", encoding="UTF-8") as fp:
+ fp.write(desc + "\n")
+
+ # Save metrics
+ if has_tensorboard and jax.process_index() == 0:
+ write_metric(
+ summary_writer,
+ train_metrics,
+ train_time=train_time,
+ step=cur_step,
+ metric_key_prefix="train",
+ )
+
+ # ======================== Evaluating (inside an epoch) ==============================
+
+ if (
+ training_args.do_eval
+ and (training_args.eval_steps is not None and training_args.eval_steps > 0)
+ and cur_step % training_args.eval_steps == 0
+ ):
+ ckpt_dir = f"ckpt_epoch_{epoch + 1}_step_{cur_step}"
+ commit_msg = f"Saving weights and logs of epoch {epoch + 1} - step {cur_step}"
+ evaluate(input_rng, eval_dataset, ckpt_dir)
+ save_ckpt(ckpt_dir=ckpt_dir, commit_msg=commit_msg)
+
+ # ======================== Epoch End ==============================
+
+ # log and save info
+ if training_args.logging_steps <= 0:
+ logger.info(desc)
+
+ with open(os.path.join(training_args.output_dir, "log"), "a", encoding="UTF-8") as fp:
+ fp.write(desc + "\n")
+
+ # Save metrics
+ if has_tensorboard and jax.process_index() == 0:
+ write_metric(
+ summary_writer, train_metrics, train_time=train_time, step=cur_step, metric_key_prefix="train"
+ )
+
+ # ======================== Evaluating (after each epoch) ==============================
+
+ if training_args.do_eval and (training_args.eval_steps is None or training_args.eval_steps <= 0):
+ ckpt_dir = f"ckpt_epoch_{epoch + 1}_step_{cur_step}"
+ commit_msg = f"Saving weights and logs of epoch {epoch + 1} - step {cur_step}"
+ evaluate(input_rng, eval_dataset, ckpt_dir)
+ save_ckpt(ckpt_dir=ckpt_dir, commit_msg=commit_msg)
+
+ # ======================== Evaluating | Predicting ==============================
+
+ # Create sampling rng
+ if input_rng is None:
+ rng, input_rng = jax.random.split(rng)
+
+ # run evaluation without training
+ if training_args.do_eval and not training_args.do_train:
+ evaluate(input_rng, eval_dataset)
+
+ # run prediction after (or without) training
+ if training_args.do_predict:
+ predict(input_rng, predict_dataset)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/flax/language-modeling/README.md b/docs/transformers/examples/flax/language-modeling/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..9e2dee36213d7e1ad8f5c8ba5575501ed7a2b346
--- /dev/null
+++ b/docs/transformers/examples/flax/language-modeling/README.md
@@ -0,0 +1,568 @@
+
+
+# Language model training and inference examples
+
+The following example showcases how to train a language model from scratch
+using the JAX/Flax backend.
+
+JAX/Flax allows you to trace pure functions and compile them into efficient, fused accelerator code on both GPU and TPU.
+Models written in JAX/Flax are **immutable** and updated in a purely functional
+way which enables simple and efficient model parallelism.
+
+## Masked language modeling
+
+In the following, we demonstrate how to train a bi-directional transformer model
+using masked language modeling objective as introduced in [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805).
+More specifically, we demonstrate how JAX/Flax can be leveraged
+to pre-train [**`FacebookAI/roberta-base`**](https://huggingface.co/FacebookAI/roberta-base)
+in Norwegian on a single TPUv3-8 pod.
+
+The example script uses the 🤗 Datasets library. You can easily customize them to your needs if you need extra processing on your datasets.
+
+To setup all relevant files for training, let's create a directory.
+
+```bash
+mkdir ./norwegian-roberta-base
+```
+
+### Train tokenizer
+
+In the first step, we train a tokenizer to efficiently process the text input for the model. Similar to how it is shown in [How to train a new language model from scratch using Transformers and Tokenizers](https://huggingface.co/blog/how-to-train), we use a **`ByteLevelBPETokenizer`**.
+The tokenizer is trained on the complete Norwegian dataset of OSCAR
+and consequently saved in the cloned model directory.
+This can take up to 10 minutes depending on your hardware ☕.
+
+```python
+from datasets import load_dataset
+from tokenizers import trainers, Tokenizer, normalizers, ByteLevelBPETokenizer
+
+# load dataset
+dataset = load_dataset("oscar", "unshuffled_deduplicated_no", split="train")
+
+# Instantiate tokenizer
+tokenizer = ByteLevelBPETokenizer()
+
+def batch_iterator(batch_size=1000):
+ for i in range(0, len(dataset), batch_size):
+ yield dataset[i: i + batch_size]["text"]
+
+# Customized training
+tokenizer.train_from_iterator(batch_iterator(), vocab_size=50265, min_frequency=2, special_tokens=[
+ "",
+ "",
+ "",
+ "",
+ "",
+])
+
+# Save files to disk
+tokenizer.save("./norwegian-roberta-base/tokenizer.json")
+```
+
+### Create configuration
+
+Next, we create the model's configuration file. This is as simple
+as loading and storing [`**FacebookAI/roberta-base**`](https://huggingface.co/FacebookAI/roberta-base)
+in the local model folder:
+
+```python
+from transformers import RobertaConfig
+
+config = RobertaConfig.from_pretrained("FacebookAI/roberta-base", vocab_size=50265)
+config.save_pretrained("./norwegian-roberta-base")
+```
+
+Great, we have set up our model repository. During training, we will automatically
+push the training logs and model weights to the repo.
+
+### Train model
+
+Next we can run the example script to pretrain the model:
+
+```bash
+python run_mlm_flax.py \
+ --output_dir="./norwegian-roberta-base" \
+ --model_type="roberta" \
+ --config_name="./norwegian-roberta-base" \
+ --tokenizer_name="./norwegian-roberta-base" \
+ --dataset_name="oscar" \
+ --dataset_config_name="unshuffled_deduplicated_no" \
+ --max_seq_length="128" \
+ --weight_decay="0.01" \
+ --per_device_train_batch_size="128" \
+ --per_device_eval_batch_size="128" \
+ --learning_rate="3e-4" \
+ --warmup_steps="1000" \
+ --overwrite_output_dir \
+ --num_train_epochs="18" \
+ --adam_beta1="0.9" \
+ --adam_beta2="0.98" \
+ --logging_steps="500" \
+ --save_steps="2500" \
+ --eval_steps="2500" \
+ --push_to_hub
+```
+
+Training should converge at a loss and accuracy
+of 1.78 and 0.64 respectively after 18 epochs on a single TPUv3-8.
+This should take less than 18 hours.
+Training statistics can be accessed on [tfhub.dev](https://tensorboard.dev/experiment/GdYmdak2TWeVz0DDRYOrrg).
+
+For a step-by-step walkthrough of how to do masked language modeling in Flax, please have a
+look at [this](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb) google colab.
+
+## Causal language modeling
+
+In the following, we demonstrate how to train an auto-regressive causal transformer model
+in JAX/Flax.
+More specifically, we pretrain a randomly initialized [**`openai-community/gpt2`**](https://huggingface.co/openai-community/gpt2) model in Norwegian on a single TPUv3-8.
+to pre-train 124M [**`openai-community/gpt2`**](https://huggingface.co/openai-community/gpt2)
+in Norwegian on a single TPUv3-8 pod.
+
+The example script uses the 🤗 Datasets library. You can easily customize them to your needs if you need extra processing on your datasets.
+
+
+To setup all relevant files for training, let's create a directory.
+
+```bash
+mkdir ./norwegian-gpt2
+```
+
+### Train tokenizer
+
+In the first step, we train a tokenizer to efficiently process the text input for the model. Similar to how it is shown in [How to train a new language model from scratch using Transformers and Tokenizers](https://huggingface.co/blog/how-to-train), we use a **`ByteLevelBPETokenizer`**.
+The tokenizer is trained on the complete Norwegian dataset of OSCAR
+and consequently saved in the cloned model directory.
+This can take up to 10 minutes depending on your hardware ☕.
+
+```python
+from datasets import load_dataset
+from tokenizers import trainers, Tokenizer, normalizers, ByteLevelBPETokenizer
+
+# load dataset
+dataset = load_dataset("oscar", "unshuffled_deduplicated_no", split="train")
+
+# Instantiate tokenizer
+tokenizer = ByteLevelBPETokenizer()
+
+def batch_iterator(batch_size=1000):
+ for i in range(0, len(dataset), batch_size):
+ yield dataset[i: i + batch_size]["text"]
+
+# Customized training
+tokenizer.train_from_iterator(batch_iterator(), vocab_size=50257, min_frequency=2, special_tokens=[
+ "",
+ "",
+ "",
+ "",
+ "",
+])
+
+# Save files to disk
+tokenizer.save("./norwegian-gpt2/tokenizer.json")
+```
+
+### Create configuration
+
+Next, we create the model's configuration file. This is as simple
+as loading and storing [`**openai-community/gpt2**`](https://huggingface.co/openai-community/gpt2)
+in the local model folder:
+
+```python
+from transformers import GPT2Config
+
+config = GPT2Config.from_pretrained("openai-community/gpt2", resid_pdrop=0.0, embd_pdrop=0.0, attn_pdrop=0.0, vocab_size=50257)
+config.save_pretrained("./norwegian-gpt2")
+```
+
+Great, we have set up our model repository. During training, we will now automatically
+push the training logs and model weights to the repo.
+
+### Train model
+
+Finally, we can run the example script to pretrain the model:
+
+```bash
+python run_clm_flax.py \
+ --output_dir="./norwegian-gpt2" \
+ --model_type="gpt2" \
+ --config_name="./norwegian-gpt2" \
+ --tokenizer_name="./norwegian-gpt2" \
+ --dataset_name="oscar" \
+ --dataset_config_name="unshuffled_deduplicated_no" \
+ --do_train --do_eval \
+ --block_size="512" \
+ --per_device_train_batch_size="64" \
+ --per_device_eval_batch_size="64" \
+ --learning_rate="5e-3" --warmup_steps="1000" \
+ --adam_beta1="0.9" --adam_beta2="0.98" --weight_decay="0.01" \
+ --overwrite_output_dir \
+ --num_train_epochs="20" \
+ --logging_steps="500" \
+ --save_steps="2500" \
+ --eval_steps="2500" \
+ --push_to_hub
+```
+
+Training should converge at a loss and perplexity
+of 3.24 and 25.72 respectively after 20 epochs on a single TPUv3-8.
+This should take less than ~21 hours.
+Training statistics can be accessed on [tfhub.dev](https://tensorboard.dev/experiment/2zEhLwJ0Qp2FAkI3WVH9qA).
+
+For a step-by-step walkthrough of how to do causal language modeling in Flax, please have a
+look at [this](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/causal_language_modeling_flax.ipynb) google colab.
+
+## T5-like span-masked language modeling
+
+In the following, we demonstrate how to train a T5 model using the span-masked language model
+objective as proposed in the [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683).
+More specifically, we demonstrate how JAX/Flax can be leveraged
+to pre-train [**`google/t5-v1_1-base`**](https://huggingface.co/google/t5-v1_1-base)
+in Norwegian on a single TPUv3-8 pod.
+
+The example script uses the 🤗 Datasets library. You can easily customize them to your needs if you need extra processing on your datasets.
+
+Let's start by creating a model repository to save the trained model and logs.
+Here we call the model `"norwegian-t5-base"`, but you can change the model name as you like.
+
+To setup all relevant files for training, let's create a directory.
+
+```bash
+cd ./norwegian-t5-base
+```
+
+### Train tokenizer
+
+In the first step, we train a tokenizer to efficiently process the text input for the model.
+We make use of the [tokenizers](https://github.com/huggingface/tokenizers) library to train
+a sentencepiece unigram tokenizer as shown in [t5_tokenizer_model.py](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling/t5_tokenizer_model.py)
+which is heavily inspired from [yandex-research/DeDLOC's tokenizer model](https://github.com/yandex-research/DeDLOC/blob/5c994bc64e573702a9a79add3ecd68b38f14b548/sahajbert/tokenizer/tokenizer_model.py) .
+
+The tokenizer is trained on the complete Norwegian dataset of OSCAR
+and consequently saved in the cloned model directory.
+This can take up to 120 minutes depending on your hardware ☕☕☕ .
+
+```python
+import datasets
+
+from t5_tokenizer_model import SentencePieceUnigramTokenizer
+
+
+vocab_size = 32_000
+input_sentence_size = None
+
+# Initialize a dataset
+dataset = datasets.load_dataset("oscar", name="unshuffled_deduplicated_no", split="train")
+
+tokenizer = SentencePieceUnigramTokenizer(unk_token="", eos_token="", pad_token="")
+
+
+# Build an iterator over this dataset
+def batch_iterator(input_sentence_size=None):
+ if input_sentence_size is None:
+ input_sentence_size = len(dataset)
+ batch_length = 100
+ for i in range(0, input_sentence_size, batch_length):
+ yield dataset[i: i + batch_length]["text"]
+
+
+# Train tokenizer
+tokenizer.train_from_iterator(
+ iterator=batch_iterator(input_sentence_size=input_sentence_size),
+ vocab_size=vocab_size,
+ show_progress=True,
+)
+
+# Save files to disk
+tokenizer.save("./norwegian-t5-base/tokenizer.json")
+```
+
+### Create configuration
+
+Next, we create the model's configuration file. This is as simple
+as loading and storing [`**google/t5-v1_1-base**`](https://huggingface.co/google/t5-v1_1-base)
+in the local model folder:
+
+```python
+from transformers import T5Config
+
+config = T5Config.from_pretrained("google/t5-v1_1-base", vocab_size=tokenizer.get_vocab_size())
+config.save_pretrained("./norwegian-t5-base")
+```
+
+Great, we have set up our model repository. During training, we will automatically
+push the training logs and model weights to the repo.
+
+### Train model
+
+Next we can run the example script to pretrain the model:
+
+```bash
+python run_t5_mlm_flax.py \
+ --output_dir="./norwegian-t5-base" \
+ --model_type="t5" \
+ --config_name="./norwegian-t5-base" \
+ --tokenizer_name="./norwegian-t5-base" \
+ --dataset_name="oscar" \
+ --dataset_config_name="unshuffled_deduplicated_no" \
+ --max_seq_length="512" \
+ --per_device_train_batch_size="32" \
+ --per_device_eval_batch_size="32" \
+ --adafactor \
+ --learning_rate="0.005" \
+ --weight_decay="0.001" \
+ --warmup_steps="2000" \
+ --overwrite_output_dir \
+ --logging_steps="500" \
+ --save_steps="10000" \
+ --eval_steps="2500" \
+ --push_to_hub
+```
+
+Training should converge at a loss and accuracy
+of 2.36 and 57.0 respectively after 3 epochs on a single TPUv3-8.
+This should take around 4.5 hours.
+Training statistics can be accessed on directly on the 🤗 [hub](https://huggingface.co/patrickvonplaten/t5-base-norwegian/tensorboard)
+
+## BART: Denoising language modeling
+
+In the following, we demonstrate how to train a BART model
+using denoising language modeling objective as introduced in [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461).
+More specifically, we demonstrate how JAX/Flax can be leveraged
+to pre-train [**`bart-base`**](https://huggingface.co/facebook/bart-base)
+in Norwegian on a single TPUv3-8 pod.
+
+The example script uses the 🤗 Datasets library. You can easily customize them to your needs if you need extra processing on your datasets.
+
+To setup all relevant files for training, let's create a directory.
+
+```bash
+mkdir ./norwegian-bart-base
+```
+
+### Train tokenizer
+In the first step, we train a tokenizer to efficiently process the text input for the model. Similar to how it is shown in [How to train a new language model from scratch using Transformers and Tokenizers](https://huggingface.co/blog/how-to-train), we use a **`ByteLevelBPETokenizer`**.
+The tokenizer is trained on the complete Norwegian dataset of OSCAR
+and consequently saved in the cloned model directory.
+This can take up to 10 minutes depending on your hardware ☕.
+
+```python
+from datasets import load_dataset
+from tokenizers import trainers, Tokenizer, normalizers, ByteLevelBPETokenizer
+
+# load dataset
+dataset = load_dataset("oscar", "unshuffled_deduplicated_no", split="train")
+
+# Instantiate tokenizer
+tokenizer = ByteLevelBPETokenizer()
+
+def batch_iterator(batch_size=1000):
+ for i in range(0, len(dataset), batch_size):
+ yield dataset[i: i + batch_size]["text"]
+
+# Customized training
+tokenizer.train_from_iterator(batch_iterator(), vocab_size=50265, min_frequency=2, special_tokens=[
+ "",
+ "",
+ "",
+ "",
+ "",
+])
+
+# Save files to disk
+tokenizer.save("./norwegian-bart-base/tokenizer.json")
+```
+
+### Create configuration
+
+Next, we create the model's configuration file. This is as simple
+as loading and storing [`**facebook/bart-base**`](https://huggingface.co/facebook/bart-base)
+in the local model folder:
+
+```python
+from transformers import BartConfig
+config = BartConfig.from_pretrained("facebook/bart-base", vocab_size=50265)
+config.save_pretrained("./norwegian-bart-base")
+```
+
+Great, we have set up our model repository. During training, we will automatically
+push the training logs and model weights to the repo.
+
+### Train model
+
+Next we can run the example script to pretrain the model:
+
+```bash
+python run_bart_dlm_flax.py \
+ --output_dir="./norwegian-bart-base" \
+ --config_name="./norwegian-bart-base" \
+ --tokenizer_name="./norwegian-bart-base" \
+ --dataset_name="oscar" \
+ --dataset_config_name="unshuffled_deduplicated_no" \
+ --max_seq_length="1024" \
+ --per_device_train_batch_size="32" \
+ --per_device_eval_batch_size="32" \
+ --learning_rate="1e-4" \
+ --warmup_steps="2000" \
+ --overwrite_output_dir \
+ --logging_steps="500" \
+ --save_steps="2000" \
+ --eval_steps="2000" \
+ --push_to_hub
+```
+
+Training should converge at a loss and accuracy
+of 1.36 and 0.77 respectively after 3 epochs on a single TPUv3-8.
+This should take less than 6 hours.
+Training statistics can be accessed on [tfhub.dev](https://tensorboard.dev/experiment/Maw62QlaSXWS0MOf2V2lbg/).
+
+## Runtime evaluation
+
+We also ran masked language modeling using PyTorch/XLA on a TPUv3-8, and PyTorch on 8 V100 GPUs. We report the
+overall training time below.
+For reproducibility, we state the training commands used for PyTorch/XLA and PyTorch further below.
+
+| Task | [TPU v3-8 (Flax)](https://tensorboard.dev/experiment/GdYmdak2TWeVz0DDRYOrrg/) | [TPU v3-8 (Pytorch/XLA)](https://tensorboard.dev/experiment/7Jq1kcQQRAmy12KOdXek7A/)| [8 GPU (PyTorch)](https://tensorboard.dev/experiment/PJneV8FQRxa2unPw1QnVHA) |
+|-------|-----------|------------|------------|
+| MLM | 15h32m | 23h46m | 44h14m |
+
+*All experiments are ran on Google Cloud Platform.
+GPU experiments are ran without further optimizations besides JAX
+transformations. GPU experiments are ran with full precision (fp32). "TPU v3-8"
+are 8 TPU cores on 4 chips (each chips has 2 cores), while "8 GPU" are 8 GPU chips.
+
+### Script to run MLM with PyTorch/XLA on TPUv3-8
+
+For comparison one can run the same pre-training with PyTorch/XLA on TPU. To set up PyTorch/XLA on Cloud TPU VMs, please
+refer to [this](https://cloud.google.com/tpu/docs/pytorch-xla-ug-tpu-vm) guide.
+Having created the tokenizer and configuration in `norwegian-roberta-base`, we create the following symbolic links:
+
+```bash
+ln -s ~/transformers/examples/pytorch/language-modeling/run_mlm.py ./
+ln -s ~/transformers/examples/pytorch/xla_spawn.py ./
+```
+
+, set the following environment variables:
+
+```bash
+export XRT_TPU_CONFIG="localservice;0;localhost:51011"
+unset LD_PRELOAD
+
+export NUM_TPUS=8
+export TOKENIZERS_PARALLELISM=0
+export MODEL_DIR="./norwegian-roberta-base"
+mkdir -p ${MODEL_DIR}
+```
+
+, and start training as follows:
+
+```bash
+python3 xla_spawn.py --num_cores ${NUM_TPUS} run_mlm.py --output_dir="./runs" \
+ --model_type="roberta" \
+ --config_name="${MODEL_DIR}" \
+ --tokenizer_name="${MODEL_DIR}" \
+ --dataset_name="oscar" \
+ --dataset_config_name="unshuffled_deduplicated_no" \
+ --max_seq_length="128" \
+ --weight_decay="0.01" \
+ --per_device_train_batch_size="128" \
+ --per_device_eval_batch_size="128" \
+ --learning_rate="3e-4" \
+ --warmup_steps="1000" \
+ --overwrite_output_dir \
+ --num_train_epochs="18" \
+ --adam_beta1="0.9" \
+ --adam_beta2="0.98" \
+ --do_train \
+ --do_eval \
+ --logging_steps="500" \
+ --eval_strategy="epoch" \
+ --report_to="tensorboard" \
+ --save_strategy="no"
+```
+
+### Script to compare pre-training with PyTorch on 8 GPU V100's
+
+For comparison you can run the same pre-training with PyTorch on GPU. Note that we have to make use of `gradient_accumulation`
+because the maximum batch size that fits on a single V100 GPU is 32 instead of 128.
+Having created the tokenizer and configuration in `norwegian-roberta-base`, we create the following symbolic links:
+
+```bash
+ln -s ~/transformers/examples/pytorch/language-modeling/run_mlm.py ./
+```
+
+, set some environment variables:
+
+```bash
+export NUM_GPUS=8
+export TOKENIZERS_PARALLELISM=0
+export MODEL_DIR="./norwegian-roberta-base"
+mkdir -p ${MODEL_DIR}
+```
+
+, and can start training as follows:
+
+```bash
+python3 -m torch.distributed.launch --nproc_per_node ${NUM_GPUS} run_mlm.py \
+ --output_dir="${MODEL_DIR}" \
+ --model_type="roberta" \
+ --config_name="${MODEL_DIR}" \
+ --tokenizer_name="${MODEL_DIR}" \
+ --dataset_name="oscar" \
+ --dataset_config_name="unshuffled_deduplicated_no" \
+ --max_seq_length="128" \
+ --weight_decay="0.01" \
+ --per_device_train_batch_size="32" \
+ --per_device_eval_batch_size="32" \
+ --gradient_accumulation="4" \
+ --learning_rate="3e-4" \
+ --warmup_steps="1000" \
+ --overwrite_output_dir \
+ --num_train_epochs="18" \
+ --adam_beta1="0.9" \
+ --adam_beta2="0.98" \
+ --do_train \
+ --do_eval \
+ --logging_steps="500" \
+ --eval_strategy="steps" \
+ --report_to="tensorboard" \
+ --save_strategy="no"
+```
+
+## Language model inference with bfloat16
+
+The following example demonstrates performing inference with a language model using the JAX/Flax backend.
+
+The example script run_bert_flax.py uses bert-base-uncased, and the model is loaded into `FlaxBertModel`.
+The input data are randomly generated tokens, and the model is also jitted with JAX.
+By default, it uses float32 precision for inference. To enable bfloat16, add the flag shown in the command below.
+
+```bash
+python3 run_bert_flax.py --precision bfloat16
+> NOTE: For JAX Versions after v0.4.33 or later, users will need to set the below environment variables as a \
+> temporary workaround to use Bfloat16 datatype. \
+> This restriction is expected to be removed in future version
+```bash
+export XLA_FLAGS=--xla_cpu_use_thunk_runtime=false
+```
+bfloat16 gives better performance on GPUs and also Intel CPUs (Sapphire Rapids or later) with Advanced Matrix Extension (Intel AMX).
+By changing the dtype for `FlaxBertModel `to `jax.numpy.bfloat16`, you get the performance benefits of the underlying hardware.
+```python
+import jax
+model = FlaxBertModel.from_pretrained("bert-base-uncased", config=config, dtype=jax.numpy.bfloat16)
+```
+Switching from float32 to bfloat16 can increase the speed of an AWS c7i.4xlarge with Intel Sapphire Rapids by more than 2x.
diff --git a/docs/transformers/examples/flax/language-modeling/requirements.txt b/docs/transformers/examples/flax/language-modeling/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f7263bf6385b907928687640ad70d2687720aab0
--- /dev/null
+++ b/docs/transformers/examples/flax/language-modeling/requirements.txt
@@ -0,0 +1,5 @@
+datasets >= 1.1.3
+jax>=0.2.8
+jaxlib>=0.1.59
+flax>=0.3.5
+optax>=0.0.9
diff --git a/docs/transformers/examples/flax/language-modeling/run_bart_dlm_flax.py b/docs/transformers/examples/flax/language-modeling/run_bart_dlm_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..2bbb66a24ac4d11ac75b4f7d7491e36d8abf680b
--- /dev/null
+++ b/docs/transformers/examples/flax/language-modeling/run_bart_dlm_flax.py
@@ -0,0 +1,993 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Pretraining the library models for denoising language modeling on a text file or a dataset.
+Here is the full list of checkpoints on the hub that can be pretrained by this script:
+https://huggingface.co/models?filter=bart
+"""
+# You can also adapt this script on your own denoising language modeling task. Pointers for this are left as comments.
+
+import json
+import logging
+import math
+import os
+import sys
+import time
+from dataclasses import asdict, dataclass, field
+from enum import Enum
+from itertools import chain
+from pathlib import Path
+from typing import Optional
+
+import flax
+import jax
+import jax.numpy as jnp
+import nltk
+import numpy as np
+import optax
+from datasets import load_dataset
+from flax import jax_utils, traverse_util
+from flax.jax_utils import pad_shard_unpad
+from flax.training import train_state
+from flax.training.common_utils import get_metrics, onehot, shard
+from huggingface_hub import HfApi
+from tqdm import tqdm
+
+from transformers import (
+ CONFIG_MAPPING,
+ FLAX_MODEL_FOR_MASKED_LM_MAPPING,
+ AutoTokenizer,
+ BartConfig,
+ BatchEncoding,
+ FlaxBartForConditionalGeneration,
+ HfArgumentParser,
+ PreTrainedTokenizerBase,
+ is_tensorboard_available,
+ set_seed,
+)
+from transformers.models.bart.modeling_flax_bart import shift_tokens_right
+from transformers.utils import send_example_telemetry
+
+
+MODEL_CONFIG_CLASSES = list(FLAX_MODEL_FOR_MASKED_LM_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class TrainingArguments:
+ output_dir: str = field(
+ metadata={"help": "The output directory where the model predictions and checkpoints will be written."},
+ )
+ overwrite_output_dir: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Overwrite the content of the output directory. "
+ "Use this to continue training if output_dir points to a checkpoint directory."
+ )
+ },
+ )
+ do_train: bool = field(default=False, metadata={"help": "Whether to run training."})
+ do_eval: bool = field(default=False, metadata={"help": "Whether to run eval on the dev set."})
+ per_device_train_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for training."}
+ )
+ per_device_eval_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for evaluation."}
+ )
+ learning_rate: float = field(default=5e-5, metadata={"help": "The initial learning rate for AdamW."})
+ weight_decay: float = field(default=0.0, metadata={"help": "Weight decay for AdamW if we apply some."})
+ adam_beta1: float = field(default=0.9, metadata={"help": "Beta1 for AdamW optimizer"})
+ adam_beta2: float = field(default=0.999, metadata={"help": "Beta2 for AdamW optimizer"})
+ adam_epsilon: float = field(default=1e-8, metadata={"help": "Epsilon for AdamW optimizer."})
+ adafactor: bool = field(default=False, metadata={"help": "Whether or not to replace AdamW by Adafactor."})
+ num_train_epochs: float = field(default=3.0, metadata={"help": "Total number of training epochs to perform."})
+ warmup_steps: int = field(default=0, metadata={"help": "Linear warmup over warmup_steps."})
+ logging_steps: int = field(default=500, metadata={"help": "Log every X updates steps."})
+ save_steps: int = field(default=500, metadata={"help": "Save checkpoint every X updates steps."})
+ eval_steps: int = field(default=None, metadata={"help": "Run an evaluation every X steps."})
+ seed: int = field(default=42, metadata={"help": "Random seed that will be set at the beginning of training."})
+ push_to_hub: bool = field(
+ default=False, metadata={"help": "Whether or not to upload the trained model to the model hub after training."}
+ )
+ hub_model_id: str = field(
+ default=None, metadata={"help": "The name of the repository to keep in sync with the local `output_dir`."}
+ )
+ hub_token: str = field(default=None, metadata={"help": "The token to use to push to the Model Hub."})
+
+ def __post_init__(self):
+ if self.output_dir is not None:
+ self.output_dir = os.path.expanduser(self.output_dir)
+
+ def to_dict(self):
+ """
+ Serializes this instance while replace `Enum` by their values (for JSON serialization support). It obfuscates
+ the token values by removing their value.
+ """
+ d = asdict(self)
+ for k, v in d.items():
+ if isinstance(v, Enum):
+ d[k] = v.value
+ if isinstance(v, list) and len(v) > 0 and isinstance(v[0], Enum):
+ d[k] = [x.value for x in v]
+ if k.endswith("_token"):
+ d[k] = f"<{k.upper()}>"
+ return d
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ dtype: Optional[str] = field(
+ default="float32",
+ metadata={
+ "help": (
+ "Floating-point format in which the model weights should be initialized and trained. Choose one of"
+ " `[float32, float16, bfloat16]`."
+ )
+ },
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ train_ref_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input train ref data file for whole word masking in Chinese."},
+ )
+ validation_ref_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input validation ref data file for whole word masking in Chinese."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ validation_split_percentage: Optional[int] = field(
+ default=5,
+ metadata={
+ "help": "The percentage of the train set used as validation set in case there's no validation split"
+ },
+ )
+ max_seq_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization and masking. Sequences longer than this"
+ " will be truncated. Default to the max input length of the model."
+ )
+ },
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ mlm_probability: float = field(
+ default=0.3, metadata={"help": "Ratio of tokens to mask for span masked language modeling loss"}
+ )
+ permute_sentence_ratio: float = field(
+ default=1.0, metadata={"help": "Ratio of sentences to be permuted in each document"}
+ )
+ poisson_lambda: float = field(
+ default=3.0, metadata={"help": "Mean of Poisson distribution used to generate span-lengths to be masked"}
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ if extension not in ["csv", "json", "txt"]:
+ raise ValueError("train_file` should be a csv, json or text file.")
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ if extension not in ["csv", "json", "txt"]:
+ raise ValueError("`validation_file` should be a csv, json or text file.")
+
+
+@flax.struct.dataclass
+class FlaxDataCollatorForBartDenoisingLM:
+ """
+ Data collator used for BART denoising language modeling. The code is largely copied from
+ ``__.
+ For more information on how BART denoising language modeling works, one can take a look
+ at the `official paper `__
+ or the `official code for preprocessing `__ .
+ Args:
+ tokenizer (:class:`~transformers.PreTrainedTokenizer` or :class:`~transformers.PreTrainedTokenizerFast`):
+ The tokenizer used for encoding the data
+ mask_ratio (:obj:`float`):
+ The probability with which to (randomly) mask tokens in the input
+ poisson_lambda (:obj:`float`):
+ Mean parameter of Poisson distribution used to generate span-lengths to be masked
+ permute_sentence_ratio (:obj:`float`):
+ Ratio of sentences to be permuted in each document
+ decoder_start_token_id: (:obj:`int):
+ The decoder start token id of the model
+ """
+
+ tokenizer: PreTrainedTokenizerBase
+ decoder_start_token_id: int
+ mask_ratio: float = 0.3
+ poisson_lambda: float = 3.0
+ permute_sentence_ratio: float = 1.0
+
+ def __post_init__(self):
+ if self.tokenizer.mask_token is None or self.tokenizer.eos_token is None:
+ raise ValueError(
+ "This tokenizer does not have a mask token or eos token which is necessary for denoising"
+ " language modeling. "
+ )
+
+ def __call__(self, examples: list[dict[str, list[int]]]) -> BatchEncoding:
+ # convert list to dict and tensorize input
+ batch = BatchEncoding(
+ {k: np.array([examples[i][k] for i in range(len(examples))]) for k, v in examples[0].items()}
+ )
+ batch["labels"] = batch["input_ids"].copy()
+ batch["decoder_input_ids"] = shift_tokens_right(
+ batch["labels"], self.tokenizer.pad_token_id, self.decoder_start_token_id
+ )
+ # permuting sentences
+ do_permute = False
+ if self.permute_sentence_ratio > 0.0:
+ batch["input_ids"] = self.permute_sentences(batch["input_ids"])
+ do_permute = True
+
+ # masking span of tokens (text infilling in the paper)
+ if self.mask_ratio:
+ batch["input_ids"], batch["labels"] = self.span_mask_tokens(
+ batch["input_ids"], batch["labels"], do_permute
+ )
+
+ # ignore pad tokens
+ batch["attention_mask"] = (batch["input_ids"] != self.tokenizer.pad_token_id).astype(int)
+ batch["decoder_attention_mask"] = (batch["decoder_input_ids"] != self.tokenizer.pad_token_id).astype(int)
+ return batch
+
+ def permute_sentences(self, input_ids):
+ """
+ Shuffle sentences in each document.
+ """
+ results = input_ids.copy()
+
+ # find end locations of sentences
+ end_sentence_mask = input_ids == self.tokenizer.pad_token_id
+ sentence_ends = np.argwhere(end_sentence_mask)
+ sentence_ends[:, 1] += 1
+ example_has_multiple_sentences, num_sentences = np.unique(sentence_ends[:, 0], return_counts=True)
+ num_sentences_map = dict(zip(example_has_multiple_sentences, num_sentences))
+
+ num_to_permute = np.ceil(num_sentences * self.permute_sentence_ratio).astype(int)
+ num_to_permute_map = dict(zip(example_has_multiple_sentences, num_to_permute))
+
+ sentence_ends = np.split(sentence_ends[:, 1], np.unique(sentence_ends[:, 0], return_index=True)[1][1:])
+ sentence_ends_map = dict(zip(example_has_multiple_sentences, sentence_ends))
+
+ for i in range(input_ids.shape[0]):
+ if i not in example_has_multiple_sentences:
+ continue
+ substitutions = np.random.permutation(num_sentences_map[i])[: num_to_permute_map[i]]
+ ordering = np.arange(0, num_sentences_map[i])
+ ordering[substitutions] = substitutions[np.random.permutation(num_to_permute_map[i])]
+
+ # write shuffled sentences into results
+ index = 0
+ for j in ordering:
+ sentence = input_ids[i, (sentence_ends_map[i][j - 1] if j > 0 else 0) : sentence_ends_map[i][j]]
+ results[i, index : index + sentence.shape[0]] = sentence
+ index += sentence.shape[0]
+ return results
+
+ def span_mask_tokens(self, input_ids, labels, do_permute):
+ """
+ Sampling text spans with span lengths drawn from a Poisson distribution and masking them.
+ """
+ special_tokens_mask_labels = [
+ self.tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True) for val in labels.tolist()
+ ]
+ special_tokens_mask_inputs = [
+ self.tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True) for val in input_ids.tolist()
+ ]
+ special_tokens_mask_labels = np.array(special_tokens_mask_labels, dtype=bool)
+ special_tokens_mask_inputs = np.array(special_tokens_mask_inputs, dtype=bool)
+
+ # determine how many tokens we need to mask in total
+ is_token_mask = ~(input_ids == self.tokenizer.pad_token_id) & ~special_tokens_mask_inputs
+ num_tokens_to_mask = int(math.ceil(is_token_mask.astype(float).sum() * self.mask_ratio))
+ if num_tokens_to_mask == 0:
+ return input_ids, labels
+
+ # generate a sufficient number of span lengths
+ span_lengths = np.random.poisson(lam=self.poisson_lambda, size=(num_tokens_to_mask,))
+ while np.cumsum(span_lengths, 0)[-1] < num_tokens_to_mask:
+ span_lengths = np.concatenate(
+ [span_lengths, np.random.poisson(lam=self.poisson_lambda, size=(num_tokens_to_mask,))]
+ )
+
+ # remove all spans of length 0
+ # note that BART inserts additional mask tokens where length == 0,
+ # which we do not implement for now as it adds additional complexity
+ span_lengths = span_lengths[span_lengths > 0]
+
+ # trim to about num_tokens_to_mask tokens
+ cutoff_idx = np.argmin(np.abs(np.cumsum(span_lengths, 0) - num_tokens_to_mask)) + 1
+ span_lengths = span_lengths[:cutoff_idx]
+
+ # randomly choose starting positions for masking
+ token_indices = np.argwhere(is_token_mask == 1)
+ span_starts = np.random.permutation(token_indices.shape[0])[: span_lengths.shape[0]]
+ # prepare mask
+ masked_indices = np.array(token_indices[span_starts])
+ mask = np.full_like(input_ids, fill_value=False)
+
+ # mask starting positions
+ for mi in masked_indices:
+ mask[tuple(mi)] = True
+ span_lengths -= 1
+
+ # fill up spans
+ max_index = input_ids.shape[1] - 1
+ remaining = (span_lengths > 0) & (masked_indices[:, 1] < max_index)
+ while np.any(remaining):
+ masked_indices[remaining, 1] += 1
+ for mi in masked_indices:
+ mask[tuple(mi)] = True
+ span_lengths -= 1
+ remaining = (span_lengths > 0) & (masked_indices[:, 1] < max_index)
+
+ # place the mask tokens
+ mask[np.where(special_tokens_mask_inputs)] = False
+ input_ids[np.where(mask)] = self.tokenizer.mask_token_id
+ if not do_permute:
+ labels[np.where(mask == 0)] = -100
+ else:
+ labels[np.where(special_tokens_mask_labels)] = -100
+
+ # remove mask tokens that are not starts of spans
+ to_remove = (mask == 1) & np.roll((mask == 1), 1, 1)
+ new_input_ids = np.full_like(input_ids, fill_value=self.tokenizer.pad_token_id)
+ for i, example in enumerate(input_ids):
+ new_example = example[~to_remove[i]]
+ new_input_ids[i, : new_example.shape[0]] = new_example
+
+ return new_input_ids, labels
+
+
+def generate_batch_splits(samples_idx: np.ndarray, batch_size: int, drop_last=True) -> np.ndarray:
+ """Generate batches of data for a specified batch size from sample indices. If the dataset size is not divisible by
+ the batch size and `drop_last` is `True`, the last incomplete batch is dropped. Else, it is returned."""
+ num_samples = len(samples_idx)
+ if drop_last:
+ samples_to_remove = num_samples % batch_size
+ if samples_to_remove != 0:
+ samples_idx = samples_idx[:-samples_to_remove]
+ sections_split = num_samples // batch_size
+ samples_idx = samples_idx.reshape((sections_split, batch_size))
+ else:
+ sections_split = math.ceil(num_samples / batch_size)
+ samples_idx = np.array_split(samples_idx, sections_split)
+ return samples_idx
+
+
+def write_train_metric(summary_writer, train_metrics, train_time, step):
+ summary_writer.scalar("train_time", train_time, step)
+
+ train_metrics = get_metrics(train_metrics)
+ for key, vals in train_metrics.items():
+ tag = f"train_{key}"
+ for i, val in enumerate(vals):
+ summary_writer.scalar(tag, val, step - len(vals) + i + 1)
+
+
+def write_eval_metric(summary_writer, eval_metrics, step):
+ for metric_name, value in eval_metrics.items():
+ summary_writer.scalar(f"eval_{metric_name}", value, step)
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_bart_dlm", model_args, data_args, framework="flax")
+
+ if (
+ os.path.exists(training_args.output_dir)
+ and os.listdir(training_args.output_dir)
+ and training_args.do_train
+ and not training_args.overwrite_output_dir
+ ):
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ level=logging.INFO,
+ datefmt="[%X]",
+ )
+
+ # Log on each process the small summary:
+ logger = logging.getLogger(__name__)
+
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Handle the repository creation
+ if training_args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = training_args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(training_args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ if "validation" not in datasets.keys():
+ datasets["validation"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+ datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if extension == "txt":
+ extension = "text"
+ datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ )
+
+ if "validation" not in datasets.keys():
+ datasets["validation"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ )
+ datasets["train"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ )
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if model_args.config_name:
+ config = BartConfig.from_pretrained(
+ model_args.config_name,
+ cache_dir=model_args.cache_dir,
+ vocab_size=len(tokenizer),
+ token=model_args.token,
+ )
+ elif model_args.model_name_or_path:
+ config = BartConfig.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ if training_args.do_train:
+ column_names = datasets["train"].column_names
+ else:
+ column_names = datasets["validation"].column_names
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ # Use Punkt Sentence Tokenizer to divide a document into a list of sentences
+ nltk.download("punkt")
+ sentence_tokenizer = nltk.data.load("tokenizers/punkt/english.pickle")
+
+ def sentence_split_function(example):
+ sents = sentence_tokenizer.tokenize(example["text"])
+ # use pad token as end of sentence indicator
+ new_text = tokenizer.bos_token + f"{tokenizer.pad_token}".join(sents) + tokenizer.eos_token
+ return {"text": new_text}
+
+ split_datasets = datasets.map(
+ sentence_split_function,
+ batched=False,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ # Tokenize every text, then concatenate them together before splitting them in smaller parts.
+ # Since we make sure that all sequences are of the same length, no attention_mask is needed.
+ def tokenize_function(examples):
+ return tokenizer(examples[text_column_name], add_special_tokens=False, return_attention_mask=False)
+
+ tokenized_datasets = split_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=text_column_name,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ # Main data processing function that will concatenate all texts from our dataset and generate chunks of
+ # max_seq_length.
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
+ # customize this part to your needs.
+ if total_length >= max_seq_length:
+ total_length = (total_length // max_seq_length) * max_seq_length
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + max_seq_length] for i in range(0, total_length, max_seq_length)]
+ for k, t in concatenated_examples.items()
+ }
+ return result
+
+ # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a
+ # remainder for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value
+ # might be slower to preprocess.
+ #
+ # To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
+ # https://huggingface.co/docs/datasets/process#map
+ tokenized_datasets = tokenized_datasets.map(
+ group_texts,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ # Enable tensorboard only on the master node
+ has_tensorboard = is_tensorboard_available()
+ if has_tensorboard and jax.process_index() == 0:
+ try:
+ from flax.metrics.tensorboard import SummaryWriter
+
+ summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir))
+ except ImportError as ie:
+ has_tensorboard = False
+ logger.warning(
+ f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
+ )
+ else:
+ logger.warning(
+ "Unable to display metrics through TensorBoard because the package is not installed: "
+ "Please run pip install tensorboard to enable."
+ )
+
+ # Initialize our training
+ rng = jax.random.PRNGKey(training_args.seed)
+ dropout_rngs = jax.random.split(rng, jax.local_device_count())
+
+ if model_args.model_name_or_path:
+ model = FlaxBartForConditionalGeneration.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ token=model_args.token,
+ )
+ else:
+ config.vocab_size = len(tokenizer)
+ model = FlaxBartForConditionalGeneration(
+ config,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ )
+
+ # Data collator
+ # This one will take care of randomly masking the tokens and permuting the sentences.
+ data_collator = FlaxDataCollatorForBartDenoisingLM(
+ tokenizer=tokenizer,
+ decoder_start_token_id=model.config.decoder_start_token_id,
+ mask_ratio=data_args.mlm_probability,
+ poisson_lambda=data_args.poisson_lambda,
+ permute_sentence_ratio=data_args.permute_sentence_ratio,
+ )
+
+ # Store some constant
+ num_epochs = int(training_args.num_train_epochs)
+ train_batch_size = int(training_args.per_device_train_batch_size) * jax.device_count()
+ per_device_eval_batch_size = int(training_args.per_device_eval_batch_size)
+ eval_batch_size = per_device_eval_batch_size * jax.device_count()
+
+ num_train_steps = len(tokenized_datasets["train"]) // train_batch_size * num_epochs
+
+ # Create learning rate schedule
+ warmup_fn = optax.linear_schedule(
+ init_value=0.0, end_value=training_args.learning_rate, transition_steps=training_args.warmup_steps
+ )
+ decay_fn = optax.linear_schedule(
+ init_value=training_args.learning_rate,
+ end_value=0,
+ transition_steps=num_train_steps - training_args.warmup_steps,
+ )
+ linear_decay_lr_schedule_fn = optax.join_schedules(
+ schedules=[warmup_fn, decay_fn], boundaries=[training_args.warmup_steps]
+ )
+
+ # We use Optax's "masking" functionality to not apply weight decay
+ # to bias and LayerNorm scale parameters. decay_mask_fn returns a
+ # mask boolean with the same structure as the parameters.
+ # The mask is True for parameters that should be decayed.
+ def decay_mask_fn(params):
+ flat_params = traverse_util.flatten_dict(params)
+ # find out all LayerNorm parameters
+ layer_norm_candidates = ["layernorm", "layer_norm", "ln"]
+ layer_norm_named_params = {
+ layer[-2:]
+ for layer_norm_name in layer_norm_candidates
+ for layer in flat_params.keys()
+ if layer_norm_name in "".join(layer).lower()
+ }
+ flat_mask = {path: (path[-1] != "bias" and path[-2:] not in layer_norm_named_params) for path in flat_params}
+ return traverse_util.unflatten_dict(flat_mask)
+
+ # create adam optimizer
+ if training_args.adafactor:
+ # We use the default parameters here to initialize adafactor,
+ # For more details about the parameters please check https://github.com/deepmind/optax/blob/ed02befef9bf81cbbf236be3d2b0e032e9ed4a40/optax/_src/alias.py#L74
+ optimizer = optax.adafactor(
+ learning_rate=linear_decay_lr_schedule_fn,
+ )
+ else:
+ optimizer = optax.adamw(
+ learning_rate=linear_decay_lr_schedule_fn,
+ b1=training_args.adam_beta1,
+ b2=training_args.adam_beta2,
+ weight_decay=training_args.weight_decay,
+ mask=decay_mask_fn,
+ )
+
+ # Setup train state
+ state = train_state.TrainState.create(apply_fn=model.__call__, params=model.params, tx=optimizer)
+
+ # Define gradient update step fn
+ def train_step(state, batch, dropout_rng):
+ dropout_rng, new_dropout_rng = jax.random.split(dropout_rng)
+
+ def loss_fn(params):
+ labels = batch.pop("labels")
+
+ logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
+
+ # compute loss, ignore padded input tokens and special tokens
+ label_mask = jnp.where(labels > 0, 1.0, 0.0)
+ loss = optax.softmax_cross_entropy(logits, onehot(labels, logits.shape[-1])) * label_mask
+
+ # take average
+ loss = loss.sum()
+ num_labels = label_mask.sum()
+
+ return loss, num_labels
+
+ grad_fn = jax.value_and_grad(loss_fn, has_aux=True)
+ (loss, num_labels), grad = grad_fn(state.params)
+ num_labels = jax.lax.psum(num_labels, "batch")
+
+ # true loss = total loss / total samples
+ loss = jax.lax.psum(loss, "batch")
+ loss = jax.tree_util.tree_map(lambda x: x / num_labels, loss)
+
+ # true grad = total grad / total samples
+ grad = jax.lax.psum(grad, "batch")
+ grad = jax.tree_util.tree_map(lambda x: x / num_labels, grad)
+ new_state = state.apply_gradients(grads=grad)
+
+ metrics = {"loss": loss, "learning_rate": linear_decay_lr_schedule_fn(state.step)}
+ return new_state, metrics, new_dropout_rng
+
+ # Create parallel version of the train step
+ p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
+
+ # Define eval fn
+ def eval_step(params, batch):
+ labels = batch.pop("labels")
+
+ logits = model(**batch, params=params, train=False)[0]
+
+ # compute loss, ignore padded input tokens and special tokens
+ label_mask = jnp.where(labels > 0, 1.0, 0.0)
+ loss = optax.softmax_cross_entropy(logits, onehot(labels, logits.shape[-1])) * label_mask
+
+ # compute accuracy
+ accuracy = jnp.equal(jnp.argmax(logits, axis=-1), labels) * label_mask
+
+ # summarize metrics
+ metrics = {"loss": loss.sum(), "accuracy": accuracy.sum(), "normalizer": label_mask.sum()}
+ metrics = jax.lax.psum(metrics, axis_name="batch")
+
+ return metrics
+
+ p_eval_step = jax.pmap(eval_step, "batch", donate_argnums=(0,))
+
+ # Replicate the train state on each device
+ state = jax_utils.replicate(state)
+
+ train_time = 0
+ epochs = tqdm(range(num_epochs), desc="Epoch ... ", position=0)
+ for epoch in epochs:
+ # ======================== Training ================================
+ train_start = time.time()
+ train_metrics = []
+
+ # Create sampling rng
+ rng, input_rng = jax.random.split(rng)
+
+ # Generate an epoch by shuffling sampling indices from the train dataset
+ num_train_samples = len(tokenized_datasets["train"])
+ # Avoid using jax.numpy here in case of TPU training
+ train_samples_idx = np.random.permutation(np.arange(num_train_samples))
+ train_batch_idx = generate_batch_splits(train_samples_idx, train_batch_size)
+
+ # Gather the indexes for creating the batch and do a training step
+ for step, batch_idx in enumerate(tqdm(train_batch_idx, desc="Training...", position=1)):
+ samples = [tokenized_datasets["train"][int(idx)] for idx in batch_idx]
+ model_inputs = data_collator(samples)
+
+ # Model forward
+ model_inputs = shard(model_inputs.data)
+ state, train_metric, dropout_rngs = p_train_step(state, model_inputs, dropout_rngs)
+ train_metrics.append(train_metric)
+
+ cur_step = epoch * (num_train_samples // train_batch_size) + step
+
+ if cur_step % training_args.logging_steps == 0 and cur_step > 0:
+ # Save metrics
+ train_metric = jax_utils.unreplicate(train_metric)
+ train_time += time.time() - train_start
+ if has_tensorboard and jax.process_index() == 0:
+ write_train_metric(summary_writer, train_metrics, train_time, cur_step)
+
+ epochs.write(
+ f"Step... ({cur_step} | Loss: {train_metric['loss']}, Learning Rate:"
+ f" {train_metric['learning_rate']})"
+ )
+
+ train_metrics = []
+
+ if cur_step % training_args.eval_steps == 0 and cur_step > 0:
+ # ======================== Evaluating ==============================
+ num_eval_samples = len(tokenized_datasets["validation"])
+ # Avoid using jax.numpy here in case of TPU training
+ eval_samples_idx = np.arange(num_eval_samples)
+ eval_batch_idx = generate_batch_splits(eval_samples_idx, eval_batch_size)
+
+ eval_metrics = []
+ for i, batch_idx in enumerate(tqdm(eval_batch_idx, desc="Evaluating ...", position=2)):
+ samples = [tokenized_datasets["validation"][int(idx)] for idx in batch_idx]
+ model_inputs = data_collator(samples)
+
+ # Model forward
+ metrics = pad_shard_unpad(p_eval_step, static_return=True)(
+ state.params, model_inputs.data, min_device_batch=per_device_eval_batch_size
+ )
+ eval_metrics.append(metrics)
+
+ # normalize eval metrics
+ eval_metrics = get_metrics(eval_metrics)
+ eval_metrics = jax.tree_util.tree_map(jnp.sum, eval_metrics)
+ eval_normalizer = eval_metrics.pop("normalizer")
+ eval_metrics = jax.tree_util.tree_map(lambda x: x / eval_normalizer, eval_metrics)
+
+ # Update progress bar
+ epochs.desc = f"Step... ({cur_step} | Loss: {eval_metrics['loss']}, Acc: {eval_metrics['accuracy']})"
+
+ # Save metrics
+ if has_tensorboard and jax.process_index() == 0:
+ write_eval_metric(summary_writer, eval_metrics, cur_step)
+
+ if cur_step % training_args.save_steps == 0 and cur_step > 0:
+ # save checkpoint after each epoch and push checkpoint to the hub
+ if jax.process_index() == 0:
+ params = jax.device_get(jax.tree_util.tree_map(lambda x: x[0], state.params))
+ model.save_pretrained(training_args.output_dir, params=params)
+ tokenizer.save_pretrained(training_args.output_dir)
+ if training_args.push_to_hub:
+ api.upload_folder(
+ commit_message=f"Saving weights and logs of step {cur_step}",
+ folder_path=training_args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=training_args.hub_token,
+ )
+
+ # Eval after training
+ if training_args.do_eval:
+ num_eval_samples = len(tokenized_datasets["validation"])
+ # Avoid using jax.numpy here in case of TPU training
+ eval_samples_idx = np.arange(num_eval_samples)
+ eval_batch_idx = generate_batch_splits(eval_samples_idx, eval_batch_size)
+
+ eval_metrics = []
+ for _, batch_idx in enumerate(tqdm(eval_batch_idx, desc="Evaluating ...", position=2)):
+ samples = [tokenized_datasets["validation"][int(idx)] for idx in batch_idx]
+ model_inputs = data_collator(samples)
+
+ # Model forward
+ metrics = pad_shard_unpad(p_eval_step, static_return=True)(
+ state.params, model_inputs.data, min_device_batch=per_device_eval_batch_size
+ )
+ eval_metrics.append(metrics)
+
+ # normalize eval metrics
+ eval_metrics = get_metrics(eval_metrics)
+ eval_metrics = jax.tree_util.tree_map(lambda metric: jnp.sum(metric).item(), eval_metrics)
+ eval_normalizer = eval_metrics.pop("normalizer")
+ eval_metrics = jax.tree_util.tree_map(lambda x: x / eval_normalizer, eval_metrics)
+
+ try:
+ perplexity = math.exp(eval_metrics["loss"])
+ except OverflowError:
+ perplexity = float("inf")
+ eval_metrics["perplexity"] = perplexity
+
+ if jax.process_index() == 0:
+ eval_metrics = {f"eval_{metric_name}": value for metric_name, value in eval_metrics.items()}
+ path = os.path.join(training_args.output_dir, "eval_results.json")
+ with open(path, "w") as f:
+ json.dump(eval_metrics, f, indent=4, sort_keys=True)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/flax/language-modeling/run_bert_flax.py b/docs/transformers/examples/flax/language-modeling/run_bert_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..2faea6b5c56e6a102dd2bf2bbefb279f93de880c
--- /dev/null
+++ b/docs/transformers/examples/flax/language-modeling/run_bert_flax.py
@@ -0,0 +1,56 @@
+#!/usr/bin/env python3
+import time
+from argparse import ArgumentParser
+
+import jax
+import numpy as np
+
+from transformers import BertConfig, FlaxBertModel
+
+
+parser = ArgumentParser()
+parser.add_argument("--precision", type=str, choices=["float32", "bfloat16"], default="float32")
+args = parser.parse_args()
+
+dtype = jax.numpy.float32
+if args.precision == "bfloat16":
+ dtype = jax.numpy.bfloat16
+
+VOCAB_SIZE = 30522
+BS = 32
+SEQ_LEN = 128
+
+
+def get_input_data(batch_size=1, seq_length=384):
+ shape = (batch_size, seq_length)
+ input_ids = np.random.randint(1, VOCAB_SIZE, size=shape).astype(np.int32)
+ token_type_ids = np.ones(shape).astype(np.int32)
+ attention_mask = np.ones(shape).astype(np.int32)
+ return {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": attention_mask}
+
+
+inputs = get_input_data(BS, SEQ_LEN)
+config = BertConfig.from_pretrained("bert-base-uncased", hidden_act="gelu_new")
+model = FlaxBertModel.from_pretrained("bert-base-uncased", config=config, dtype=dtype)
+
+
+@jax.jit
+def func():
+ outputs = model(**inputs)
+ return outputs
+
+
+(nwarmup, nbenchmark) = (5, 100)
+
+# warmpup
+for _ in range(nwarmup):
+ func()
+
+# benchmark
+
+start = time.time()
+for _ in range(nbenchmark):
+ func()
+end = time.time()
+print(end - start)
+print(f"Throughput: {((nbenchmark * BS) / (end - start)):.3f} examples/sec")
diff --git a/docs/transformers/examples/flax/language-modeling/run_clm_flax.py b/docs/transformers/examples/flax/language-modeling/run_clm_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb3ab65dc8b24e8a44830c940fac859768983bfb
--- /dev/null
+++ b/docs/transformers/examples/flax/language-modeling/run_clm_flax.py
@@ -0,0 +1,869 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Pre-training/Fine-tuning the library models for causal language modeling (GPT, GPT-2, CTRL, ...) on a text file or a dataset.
+
+Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
+https://huggingface.co/models?filter=text-generation
+"""
+# You can also adapt this script on your own causal language modeling task. Pointers for this are left as comments.
+
+import json
+import logging
+import math
+import os
+import sys
+import time
+from dataclasses import asdict, dataclass, field
+from enum import Enum
+from itertools import chain
+from pathlib import Path
+from typing import Callable, Optional
+
+import datasets
+import jax
+import jax.numpy as jnp
+import numpy as np
+import optax
+from datasets import Dataset, load_dataset
+from flax import jax_utils, traverse_util
+from flax.jax_utils import pad_shard_unpad, unreplicate
+from flax.training import train_state
+from flax.training.common_utils import get_metrics, onehot, shard, shard_prng_key
+from huggingface_hub import HfApi
+from tqdm import tqdm
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ FLAX_MODEL_FOR_CAUSAL_LM_MAPPING,
+ AutoConfig,
+ AutoTokenizer,
+ FlaxAutoModelForCausalLM,
+ HfArgumentParser,
+ is_tensorboard_available,
+ set_seed,
+)
+from transformers.testing_utils import CaptureLogger
+from transformers.utils import send_example_telemetry
+
+
+logger = logging.getLogger(__name__)
+
+MODEL_CONFIG_CLASSES = list(FLAX_MODEL_FOR_CAUSAL_LM_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class TrainingArguments:
+ output_dir: str = field(
+ metadata={"help": "The output directory where the model predictions and checkpoints will be written."},
+ )
+ overwrite_output_dir: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Overwrite the content of the output directory. "
+ "Use this to continue training if output_dir points to a checkpoint directory."
+ )
+ },
+ )
+ do_train: bool = field(default=False, metadata={"help": "Whether to run training."})
+ do_eval: bool = field(default=False, metadata={"help": "Whether to run eval on the dev set."})
+ per_device_train_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for training."}
+ )
+ per_device_eval_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for evaluation."}
+ )
+ learning_rate: float = field(default=5e-5, metadata={"help": "The initial learning rate for AdamW."})
+ weight_decay: float = field(default=0.0, metadata={"help": "Weight decay for AdamW if we apply some."})
+ adam_beta1: float = field(default=0.9, metadata={"help": "Beta1 for AdamW optimizer"})
+ adam_beta2: float = field(default=0.999, metadata={"help": "Beta2 for AdamW optimizer"})
+ adam_epsilon: float = field(default=1e-8, metadata={"help": "Epsilon for AdamW optimizer."})
+ adafactor: bool = field(default=False, metadata={"help": "Whether or not to replace AdamW by Adafactor."})
+ num_train_epochs: float = field(default=3.0, metadata={"help": "Total number of training epochs to perform."})
+ warmup_steps: int = field(default=0, metadata={"help": "Linear warmup over warmup_steps."})
+ logging_steps: int = field(default=500, metadata={"help": "Log every X updates steps."})
+ save_steps: int = field(default=500, metadata={"help": "Save checkpoint every X updates steps."})
+ eval_steps: int = field(default=None, metadata={"help": "Run an evaluation every X steps."})
+ seed: int = field(default=42, metadata={"help": "Random seed that will be set at the beginning of training."})
+ push_to_hub: bool = field(
+ default=False, metadata={"help": "Whether or not to upload the trained model to the model hub after training."}
+ )
+ hub_model_id: str = field(
+ default=None, metadata={"help": "The name of the repository to keep in sync with the local `output_dir`."}
+ )
+ hub_token: str = field(default=None, metadata={"help": "The token to use to push to the Model Hub."})
+
+ def __post_init__(self):
+ if self.output_dir is not None:
+ self.output_dir = os.path.expanduser(self.output_dir)
+
+ def to_dict(self):
+ """
+ Serializes this instance while replace `Enum` by their values (for JSON serialization support). It obfuscates
+ the token values by removing their value.
+ """
+ d = asdict(self)
+ for k, v in d.items():
+ if isinstance(v, Enum):
+ d[k] = v.value
+ if isinstance(v, list) and len(v) > 0 and isinstance(v[0], Enum):
+ d[k] = [x.value for x in v]
+ if k.endswith("_token"):
+ d[k] = f"<{k.upper()}>"
+ return d
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ dtype: Optional[str] = field(
+ default="float32",
+ metadata={
+ "help": (
+ "Floating-point format in which the model weights should be initialized and trained. Choose one of"
+ " `[float32, float16, bfloat16]`."
+ )
+ },
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ validation_split_percentage: Optional[int] = field(
+ default=5,
+ metadata={
+ "help": "The percentage of the train set used as validation set in case there's no validation split"
+ },
+ )
+ block_size: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Optional input sequence length after tokenization. "
+ "The training dataset will be truncated in block of this size for training. "
+ "Default to the model max input length for single sentence inputs (take into account special tokens)."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ keep_linebreaks: bool = field(
+ default=True, metadata={"help": "Whether to keep line breaks when using TXT files or not."}
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ if extension not in ["csv", "json", "txt"]:
+ raise ValueError("train_file` should be a csv, json or text file.")
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ if extension not in ["csv", "json", "txt"]:
+ raise ValueError("`validation_file` should be a csv, json or text file.")
+
+
+class TrainState(train_state.TrainState):
+ dropout_rng: jnp.ndarray
+
+ def replicate(self):
+ return jax_utils.replicate(self).replace(dropout_rng=shard_prng_key(self.dropout_rng))
+
+
+def data_loader(rng: jax.random.PRNGKey, dataset: Dataset, batch_size: int, shuffle: bool = False, drop_last=True):
+ """
+ Returns batches of size `batch_size` from `dataset`. If `drop_last` is set to `False`, the final batch may be incomplete,
+ and range in size from 1 to `batch_size`. Shuffle batches if `shuffle` is `True`.
+ """
+ if shuffle:
+ batch_idx = jax.random.permutation(rng, len(dataset))
+ batch_idx = np.asarray(batch_idx)
+ else:
+ batch_idx = np.arange(len(dataset))
+
+ if drop_last:
+ steps_per_epoch = len(dataset) // batch_size
+ batch_idx = batch_idx[: steps_per_epoch * batch_size] # Skip incomplete batch.
+ batch_idx = batch_idx.reshape((steps_per_epoch, batch_size))
+ else:
+ steps_per_epoch = math.ceil(len(dataset) / batch_size)
+ batch_idx = np.array_split(batch_idx, steps_per_epoch)
+
+ for idx in batch_idx:
+ batch = dataset[idx]
+ batch = {k: np.array(v) for k, v in batch.items()}
+
+ yield batch
+
+
+def write_train_metric(summary_writer, train_metrics, train_time, step):
+ summary_writer.scalar("train_time", train_time, step)
+
+ train_metrics = get_metrics(train_metrics)
+ for key, vals in train_metrics.items():
+ tag = f"train_{key}"
+ for i, val in enumerate(vals):
+ summary_writer.scalar(tag, val, step - len(vals) + i + 1)
+
+
+def write_eval_metric(summary_writer, eval_metrics, step):
+ for metric_name, value in eval_metrics.items():
+ summary_writer.scalar(f"eval_{metric_name}", value, step)
+
+
+def create_learning_rate_fn(
+ train_ds_size: int, train_batch_size: int, num_train_epochs: int, num_warmup_steps: int, learning_rate: float
+) -> Callable[[int], jnp.ndarray]:
+ """Returns a linear warmup, linear_decay learning rate function."""
+ steps_per_epoch = train_ds_size // train_batch_size
+ num_train_steps = steps_per_epoch * num_train_epochs
+ warmup_fn = optax.linear_schedule(init_value=0.0, end_value=learning_rate, transition_steps=num_warmup_steps)
+ decay_fn = optax.linear_schedule(
+ init_value=learning_rate, end_value=0, transition_steps=num_train_steps - num_warmup_steps
+ )
+ schedule_fn = optax.join_schedules(schedules=[warmup_fn, decay_fn], boundaries=[num_warmup_steps])
+ return schedule_fn
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_clm", model_args, data_args, framework="flax")
+
+ if (
+ os.path.exists(training_args.output_dir)
+ and os.listdir(training_args.output_dir)
+ and training_args.do_train
+ and not training_args.overwrite_output_dir
+ ):
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ # Setup logging, we only want one process per machine to log things on the screen.
+ logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
+ if jax.process_index() == 0:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Handle the repository creation
+ if training_args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = training_args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(training_args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ dataset = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ keep_in_memory=False,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ if "validation" not in dataset.keys():
+ dataset["validation"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ dataset["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ dataset_args = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if extension == "txt":
+ extension = "text"
+ dataset_args["keep_linebreaks"] = data_args.keep_linebreaks
+ dataset = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ **dataset_args,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ )
+
+ if "validation" not in dataset.keys():
+ dataset["validation"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ **dataset_args,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ )
+ dataset["train"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ **dataset_args,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ if model_args.config_name:
+ config = AutoConfig.from_pretrained(
+ model_args.config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if model_args.model_name_or_path:
+ model = FlaxAutoModelForCausalLM.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ model = FlaxAutoModelForCausalLM.from_config(
+ config,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ if training_args.do_train:
+ column_names = dataset["train"].column_names
+ else:
+ column_names = dataset["validation"].column_names
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ # since this will be pickled to avoid _LazyModule error in Hasher force logger loading before tokenize_function
+ tok_logger = transformers.utils.logging.get_logger("transformers.tokenization_utils_base")
+
+ def tokenize_function(examples):
+ with CaptureLogger(tok_logger) as cl:
+ output = tokenizer(examples[text_column_name])
+ # clm input could be much much longer than block_size
+ if "Token indices sequence length is longer than the" in cl.out:
+ tok_logger.warning(
+ "^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits"
+ " before being passed to the model."
+ )
+ return output
+
+ tokenized_datasets = dataset.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ if data_args.block_size is None:
+ block_size = tokenizer.model_max_length
+ if block_size > config.max_position_embeddings:
+ logger.warning(
+ f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). "
+ f"Using block_size={min(1024, config.max_position_embeddings)} instead. You can change that default value by passing --block_size xxx."
+ )
+ block_size = min(1024, config.max_position_embeddings)
+ else:
+ if data_args.block_size > tokenizer.model_max_length:
+ logger.warning(
+ f"The block_size passed ({data_args.block_size}) is larger than the maximum length for the model "
+ f"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}."
+ )
+ block_size = min(data_args.block_size, tokenizer.model_max_length)
+
+ # Main data processing function that will concatenate all texts from our dataset and generate chunks of block_size.
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
+ # customize this part to your needs.
+ if total_length >= block_size:
+ total_length = (total_length // block_size) * block_size
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
+ for k, t in concatenated_examples.items()
+ }
+ result["labels"] = result["input_ids"].copy()
+ return result
+
+ # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a remainder
+ # for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value might be slower
+ # to preprocess.
+ #
+ # To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
+ # https://huggingface.co/docs/datasets/process#map
+
+ lm_datasets = tokenized_datasets.map(
+ group_texts,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ if training_args.do_train:
+ if "train" not in tokenized_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = lm_datasets["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+
+ if training_args.do_eval:
+ if "validation" not in tokenized_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = lm_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ # Enable tensorboard only on the master node
+ has_tensorboard = is_tensorboard_available()
+ if has_tensorboard and jax.process_index() == 0:
+ try:
+ from flax.metrics.tensorboard import SummaryWriter
+
+ summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir))
+ except ImportError as ie:
+ has_tensorboard = False
+ logger.warning(
+ f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
+ )
+ else:
+ logger.warning(
+ "Unable to display metrics through TensorBoard because the package is not installed: "
+ "Please run pip install tensorboard to enable."
+ )
+
+ # Initialize our training
+ rng = jax.random.PRNGKey(training_args.seed)
+ rng, dropout_rng = jax.random.split(rng)
+
+ # Store some constant
+ num_epochs = int(training_args.num_train_epochs)
+ train_batch_size = int(training_args.per_device_train_batch_size) * jax.device_count()
+ per_device_eval_batch_size = int(training_args.per_device_eval_batch_size)
+ eval_batch_size = per_device_eval_batch_size * jax.device_count()
+ steps_per_epoch = len(train_dataset) // train_batch_size
+ total_train_steps = steps_per_epoch * num_epochs
+
+ # Create learning rate schedule
+ linear_decay_lr_schedule_fn = create_learning_rate_fn(
+ len(train_dataset),
+ train_batch_size,
+ training_args.num_train_epochs,
+ training_args.warmup_steps,
+ training_args.learning_rate,
+ )
+
+ # We use Optax's "masking" functionality to not apply weight decay
+ # to bias and LayerNorm scale parameters. decay_mask_fn returns a
+ # mask boolean with the same structure as the parameters.
+ # The mask is True for parameters that should be decayed.
+ def decay_mask_fn(params):
+ flat_params = traverse_util.flatten_dict(params)
+ # find out all LayerNorm parameters
+ layer_norm_candidates = ["layernorm", "layer_norm", "ln"]
+ layer_norm_named_params = {
+ layer[-2:]
+ for layer_norm_name in layer_norm_candidates
+ for layer in flat_params.keys()
+ if layer_norm_name in "".join(layer).lower()
+ }
+ flat_mask = {path: (path[-1] != "bias" and path[-2:] not in layer_norm_named_params) for path in flat_params}
+ return traverse_util.unflatten_dict(flat_mask)
+
+ # create adam optimizer
+ if training_args.adafactor:
+ # We use the default parameters here to initialize adafactor,
+ # For more details about the parameters please check https://github.com/deepmind/optax/blob/ed02befef9bf81cbbf236be3d2b0e032e9ed4a40/optax/_src/alias.py#L74
+ optimizer = optax.adafactor(
+ learning_rate=linear_decay_lr_schedule_fn,
+ )
+ else:
+ optimizer = optax.adamw(
+ learning_rate=linear_decay_lr_schedule_fn,
+ b1=training_args.adam_beta1,
+ b2=training_args.adam_beta2,
+ eps=training_args.adam_epsilon,
+ weight_decay=training_args.weight_decay,
+ mask=decay_mask_fn,
+ )
+
+ # Setup train state
+ state = TrainState.create(apply_fn=model.__call__, params=model.params, tx=optimizer, dropout_rng=dropout_rng)
+
+ def loss_fn(logits, labels):
+ shift_logits = logits[..., :-1, :]
+ shift_labels = labels[..., 1:]
+ loss = optax.softmax_cross_entropy(shift_logits, onehot(shift_labels, shift_logits.shape[-1]))
+ return loss.mean()
+
+ # Define gradient update step fn
+ def train_step(state, batch):
+ dropout_rng, new_dropout_rng = jax.random.split(state.dropout_rng)
+
+ def compute_loss(params):
+ labels = batch.pop("labels")
+ logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
+ loss = loss_fn(logits, labels)
+ return loss
+
+ grad_fn = jax.value_and_grad(compute_loss)
+ loss, grad = grad_fn(state.params)
+ grad = jax.lax.pmean(grad, "batch")
+
+ new_state = state.apply_gradients(grads=grad, dropout_rng=new_dropout_rng)
+
+ metrics = {"loss": loss, "learning_rate": linear_decay_lr_schedule_fn(state.step)}
+ metrics = jax.lax.pmean(metrics, axis_name="batch")
+
+ return new_state, metrics
+
+ # Define eval fn
+ def eval_step(params, batch):
+ labels = batch.pop("labels")
+ logits = model(**batch, params=params, train=False)[0]
+ loss = loss_fn(logits, labels)
+
+ # summarize metrics
+ metrics = {"loss": loss}
+ metrics = jax.lax.pmean(metrics, axis_name="batch")
+ return metrics
+
+ # Create parallel version of the train and eval step
+ p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
+ p_eval_step = jax.pmap(eval_step, "batch")
+
+ # Replicate the train state on each device
+ state = state.replicate()
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {num_epochs}")
+ logger.info(f" Instantaneous batch size per device = {training_args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel & distributed) = {train_batch_size}")
+ logger.info(f" Total optimization steps = {total_train_steps}")
+
+ train_time = 0
+ train_metrics = []
+ epochs = tqdm(range(num_epochs), desc="Epoch ... ", position=0)
+ for epoch in epochs:
+ # ======================== Training ================================
+ train_start = time.time()
+
+ # Create sampling rng
+ rng, input_rng = jax.random.split(rng)
+
+ # Generate an epoch by shuffling sampling indices from the train dataset
+ train_loader = data_loader(input_rng, train_dataset, train_batch_size, shuffle=True)
+ steps_per_epoch = len(train_dataset) // train_batch_size
+ # train
+ for step in tqdm(range(steps_per_epoch), desc="Training...", position=1, leave=False):
+ batch = next(train_loader)
+ batch = shard(batch)
+ state, train_metric = p_train_step(state, batch)
+ train_metrics.append(train_metric)
+
+ cur_step = epoch * (len(train_dataset) // train_batch_size) + step
+
+ if cur_step % training_args.logging_steps == 0 and cur_step > 0:
+ # Save metrics
+ train_metric = unreplicate(train_metric)
+ train_time += time.time() - train_start
+ if has_tensorboard and jax.process_index() == 0:
+ write_train_metric(summary_writer, train_metrics, train_time, cur_step)
+
+ epochs.write(
+ f"Step... ({cur_step} | Loss: {train_metric['loss'].mean()}, Learning Rate:"
+ f" {train_metric['learning_rate'].mean()})"
+ )
+
+ train_metrics = []
+
+ if cur_step % training_args.eval_steps == 0 and cur_step > 0:
+ # ======================== Evaluating ==============================
+ eval_metrics = []
+ eval_loader = data_loader(input_rng, eval_dataset, eval_batch_size, drop_last=False)
+ eval_steps = math.ceil(len(eval_dataset) / eval_batch_size)
+ for _ in tqdm(range(eval_steps), desc="Evaluating...", position=2, leave=False):
+ # Model forward
+ batch = next(eval_loader)
+ metrics = pad_shard_unpad(p_eval_step, static_return=True)(
+ state.params, batch, min_device_batch=per_device_eval_batch_size
+ )
+ eval_metrics.append(metrics)
+
+ # normalize eval metrics
+ eval_metrics = get_metrics(eval_metrics)
+ eval_metrics = jax.tree_util.tree_map(jnp.mean, eval_metrics)
+
+ try:
+ eval_metrics["perplexity"] = math.exp(eval_metrics["loss"])
+ except OverflowError:
+ eval_metrics["perplexity"] = float("inf")
+
+ # Print metrics and update progress bar
+ desc = (
+ f"Step... ({cur_step} | Eval Loss: {eval_metrics['loss']} | Eval Perplexity:"
+ f" {eval_metrics['perplexity']})"
+ )
+ epochs.write(desc)
+ epochs.desc = desc
+
+ # Save metrics
+ if has_tensorboard and jax.process_index() == 0:
+ write_eval_metric(summary_writer, eval_metrics, cur_step)
+
+ if cur_step % training_args.save_steps == 0 and cur_step > 0:
+ # save checkpoint after each epoch and push checkpoint to the hub
+ if jax.process_index() == 0:
+ params = jax.device_get(unreplicate(state.params))
+ model.save_pretrained(training_args.output_dir, params=params)
+ tokenizer.save_pretrained(training_args.output_dir)
+ if training_args.push_to_hub:
+ api.upload_folder(
+ commit_message=f"Saving weights and logs of step {cur_step}",
+ folder_path=training_args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=training_args.hub_token,
+ )
+ # Eval after training
+ if training_args.do_eval:
+ eval_metrics = []
+ eval_loader = data_loader(input_rng, eval_dataset, eval_batch_size, drop_last=False)
+ eval_steps = math.ceil(len(eval_dataset) / eval_batch_size)
+ for _ in tqdm(range(eval_steps), desc="Evaluating...", position=2, leave=False):
+ # Model forward
+ batch = next(eval_loader)
+ metrics = pad_shard_unpad(p_eval_step, static_return=True)(
+ state.params, batch, min_device_batch=per_device_eval_batch_size
+ )
+ eval_metrics.append(metrics)
+
+ # normalize eval metrics
+ eval_metrics = get_metrics(eval_metrics)
+ eval_metrics = jax.tree_util.tree_map(lambda x: jnp.mean(x).item(), eval_metrics)
+
+ try:
+ eval_metrics["perplexity"] = math.exp(eval_metrics["loss"])
+ except OverflowError:
+ eval_metrics["perplexity"] = float("inf")
+
+ if jax.process_index() == 0:
+ eval_metrics = {f"eval_{metric_name}": value for metric_name, value in eval_metrics.items()}
+ path = os.path.join(training_args.output_dir, "eval_results.json")
+ with open(path, "w") as f:
+ json.dump(eval_metrics, f, indent=4, sort_keys=True)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/flax/language-modeling/run_mlm_flax.py b/docs/transformers/examples/flax/language-modeling/run_mlm_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b83c8db394cea0d404121fe7c6085cf16810140
--- /dev/null
+++ b/docs/transformers/examples/flax/language-modeling/run_mlm_flax.py
@@ -0,0 +1,924 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for masked language modeling (BERT, ALBERT, RoBERTa...) with whole word masking on a
+text file or a dataset.
+
+Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
+https://huggingface.co/models?filter=fill-mask
+"""
+
+import json
+import logging
+import math
+import os
+import sys
+import time
+from dataclasses import asdict, dataclass, field
+from enum import Enum
+from itertools import chain
+
+# You can also adapt this script on your own masked language modeling task. Pointers for this are left as comments.
+from pathlib import Path
+from typing import Optional
+
+import flax
+import jax
+import jax.numpy as jnp
+import numpy as np
+import optax
+from datasets import load_dataset
+from flax import jax_utils, traverse_util
+from flax.jax_utils import pad_shard_unpad
+from flax.training import train_state
+from flax.training.common_utils import get_metrics, onehot, shard
+from huggingface_hub import HfApi
+from tqdm import tqdm
+
+from transformers import (
+ CONFIG_MAPPING,
+ FLAX_MODEL_FOR_MASKED_LM_MAPPING,
+ AutoConfig,
+ AutoTokenizer,
+ FlaxAutoModelForMaskedLM,
+ HfArgumentParser,
+ PreTrainedTokenizerBase,
+ TensorType,
+ is_tensorboard_available,
+ set_seed,
+)
+from transformers.utils import send_example_telemetry
+
+
+MODEL_CONFIG_CLASSES = list(FLAX_MODEL_FOR_MASKED_LM_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class TrainingArguments:
+ output_dir: str = field(
+ metadata={"help": "The output directory where the model predictions and checkpoints will be written."},
+ )
+ overwrite_output_dir: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Overwrite the content of the output directory. "
+ "Use this to continue training if output_dir points to a checkpoint directory."
+ )
+ },
+ )
+ do_train: bool = field(default=False, metadata={"help": "Whether to run training."})
+ do_eval: bool = field(default=False, metadata={"help": "Whether to run eval on the dev set."})
+ per_device_train_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for training."}
+ )
+ per_device_eval_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for evaluation."}
+ )
+ learning_rate: float = field(default=5e-5, metadata={"help": "The initial learning rate for AdamW."})
+ weight_decay: float = field(default=0.0, metadata={"help": "Weight decay for AdamW if we apply some."})
+ adam_beta1: float = field(default=0.9, metadata={"help": "Beta1 for AdamW optimizer"})
+ adam_beta2: float = field(default=0.999, metadata={"help": "Beta2 for AdamW optimizer"})
+ adam_epsilon: float = field(default=1e-8, metadata={"help": "Epsilon for AdamW optimizer."})
+ adafactor: bool = field(default=False, metadata={"help": "Whether or not to replace AdamW by Adafactor."})
+ num_train_epochs: float = field(default=3.0, metadata={"help": "Total number of training epochs to perform."})
+ warmup_steps: int = field(default=0, metadata={"help": "Linear warmup over warmup_steps."})
+ logging_steps: int = field(default=500, metadata={"help": "Log every X updates steps."})
+ save_steps: int = field(default=500, metadata={"help": "Save checkpoint every X updates steps."})
+ eval_steps: int = field(default=None, metadata={"help": "Run an evaluation every X steps."})
+ seed: int = field(default=42, metadata={"help": "Random seed that will be set at the beginning of training."})
+ push_to_hub: bool = field(
+ default=False, metadata={"help": "Whether or not to upload the trained model to the model hub after training."}
+ )
+ hub_model_id: str = field(
+ default=None, metadata={"help": "The name of the repository to keep in sync with the local `output_dir`."}
+ )
+ hub_token: str = field(default=None, metadata={"help": "The token to use to push to the Model Hub."})
+ gradient_checkpointing: bool = field(
+ default=False,
+ metadata={
+ "help": "If True, use gradient checkpointing to save memory at the expense of slower backward pass."
+ },
+ )
+
+ def __post_init__(self):
+ if self.output_dir is not None:
+ self.output_dir = os.path.expanduser(self.output_dir)
+
+ def to_dict(self):
+ """
+ Serializes this instance while replace `Enum` by their values (for JSON serialization support). It obfuscates
+ the token values by removing their value.
+ """
+ d = asdict(self)
+ for k, v in d.items():
+ if isinstance(v, Enum):
+ d[k] = v.value
+ if isinstance(v, list) and len(v) > 0 and isinstance(v[0], Enum):
+ d[k] = [x.value for x in v]
+ if k.endswith("_token"):
+ d[k] = f"<{k.upper()}>"
+ return d
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ dtype: Optional[str] = field(
+ default="float32",
+ metadata={
+ "help": (
+ "Floating-point format in which the model weights should be initialized and trained. Choose one of"
+ " `[float32, float16, bfloat16]`."
+ )
+ },
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ train_ref_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input train ref data file for whole word masking in Chinese."},
+ )
+ validation_ref_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input validation ref data file for whole word masking in Chinese."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ validation_split_percentage: Optional[int] = field(
+ default=5,
+ metadata={
+ "help": "The percentage of the train set used as validation set in case there's no validation split"
+ },
+ )
+ max_seq_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated. Default to the max input length of the model."
+ )
+ },
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ mlm_probability: float = field(
+ default=0.15, metadata={"help": "Ratio of tokens to mask for masked language modeling loss"}
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch."
+ )
+ },
+ )
+ line_by_line: bool = field(
+ default=False,
+ metadata={"help": "Whether distinct lines of text in the dataset are to be handled as distinct sequences."},
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
+
+
+@flax.struct.dataclass
+class FlaxDataCollatorForLanguageModeling:
+ """
+ Data collator used for language modeling. Inputs are dynamically padded to the maximum length of a batch if they
+ are not all of the same length.
+
+ Args:
+ tokenizer (:class:`~transformers.PreTrainedTokenizer` or :class:`~transformers.PreTrainedTokenizerFast`):
+ The tokenizer used for encoding the data.
+ mlm_probability (:obj:`float`, `optional`, defaults to 0.15):
+ The probability with which to (randomly) mask tokens in the input.
+
+ .. note::
+
+ For best performance, this data collator should be used with a dataset having items that are dictionaries or
+ BatchEncoding, with the :obj:`"special_tokens_mask"` key, as returned by a
+ :class:`~transformers.PreTrainedTokenizer` or a :class:`~transformers.PreTrainedTokenizerFast` with the
+ argument :obj:`return_special_tokens_mask=True`.
+ """
+
+ tokenizer: PreTrainedTokenizerBase
+ mlm_probability: float = 0.15
+
+ def __post_init__(self):
+ if self.tokenizer.mask_token is None:
+ raise ValueError(
+ "This tokenizer does not have a mask token which is necessary for masked language modeling. "
+ "You should pass `mlm=False` to train on causal language modeling instead."
+ )
+
+ def __call__(self, examples: list[dict[str, np.ndarray]], pad_to_multiple_of: int) -> dict[str, np.ndarray]:
+ # Handle dict or lists with proper padding and conversion to tensor.
+ batch = self.tokenizer.pad(examples, pad_to_multiple_of=pad_to_multiple_of, return_tensors=TensorType.NUMPY)
+
+ # If special token mask has been preprocessed, pop it from the dict.
+ special_tokens_mask = batch.pop("special_tokens_mask", None)
+
+ batch["input_ids"], batch["labels"] = self.mask_tokens(
+ batch["input_ids"], special_tokens_mask=special_tokens_mask
+ )
+ return batch
+
+ def mask_tokens(
+ self, inputs: np.ndarray, special_tokens_mask: Optional[np.ndarray]
+ ) -> tuple[np.ndarray, np.ndarray]:
+ """
+ Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original.
+ """
+ labels = inputs.copy()
+ # We sample a few tokens in each sequence for MLM training (with probability `self.mlm_probability`)
+ probability_matrix = np.full(labels.shape, self.mlm_probability)
+ special_tokens_mask = special_tokens_mask.astype("bool")
+
+ probability_matrix[special_tokens_mask] = 0.0
+ masked_indices = np.random.binomial(1, probability_matrix).astype("bool")
+ labels[~masked_indices] = -100 # We only compute loss on masked tokens
+
+ # 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
+ indices_replaced = np.random.binomial(1, np.full(labels.shape, 0.8)).astype("bool") & masked_indices
+ inputs[indices_replaced] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)
+
+ # 10% of the time, we replace masked input tokens with random word
+ indices_random = np.random.binomial(1, np.full(labels.shape, 0.5)).astype("bool")
+ indices_random &= masked_indices & ~indices_replaced
+
+ random_words = np.random.randint(self.tokenizer.vocab_size, size=labels.shape, dtype="i4")
+ inputs[indices_random] = random_words[indices_random]
+
+ # The rest of the time (10% of the time) we keep the masked input tokens unchanged
+ return inputs, labels
+
+
+def generate_batch_splits(samples_idx: np.ndarray, batch_size: int, drop_last=True) -> np.ndarray:
+ """Generate batches of data for a specified batch size from sample indices. If the dataset size is not divisible by
+ the batch size and `drop_last` is `True`, the last incomplete batch is dropped. Else, it is returned."""
+ num_samples = len(samples_idx)
+ if drop_last:
+ samples_to_remove = num_samples % batch_size
+ if samples_to_remove != 0:
+ samples_idx = samples_idx[:-samples_to_remove]
+ sections_split = num_samples // batch_size
+ samples_idx = samples_idx.reshape((sections_split, batch_size))
+ else:
+ sections_split = math.ceil(num_samples / batch_size)
+ samples_idx = np.array_split(samples_idx, sections_split)
+ return samples_idx
+
+
+def write_train_metric(summary_writer, train_metrics, train_time, step):
+ summary_writer.scalar("train_time", train_time, step)
+
+ train_metrics = get_metrics(train_metrics)
+ for key, vals in train_metrics.items():
+ tag = f"train_{key}"
+ for i, val in enumerate(vals):
+ summary_writer.scalar(tag, val, step - len(vals) + i + 1)
+
+
+def write_eval_metric(summary_writer, eval_metrics, step):
+ for metric_name, value in eval_metrics.items():
+ summary_writer.scalar(f"eval_{metric_name}", value, step)
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_mlm", model_args, data_args, framework="flax")
+
+ if (
+ os.path.exists(training_args.output_dir)
+ and os.listdir(training_args.output_dir)
+ and training_args.do_train
+ and not training_args.overwrite_output_dir
+ ):
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ level=logging.INFO,
+ datefmt="[%X]",
+ )
+
+ # Log on each process the small summary:
+ logger = logging.getLogger(__name__)
+
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Handle the repository creation
+ if training_args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = training_args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(training_args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ if "validation" not in datasets.keys():
+ datasets["validation"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if extension == "txt":
+ extension = "text"
+ datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ )
+
+ if "validation" not in datasets.keys():
+ datasets["validation"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ )
+ datasets["train"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ if model_args.config_name:
+ config = AutoConfig.from_pretrained(
+ model_args.config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ if training_args.do_train:
+ column_names = datasets["train"].column_names
+ else:
+ column_names = datasets["validation"].column_names
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ if data_args.line_by_line:
+ # When using line_by_line, we just tokenize each nonempty line.
+ padding = "max_length" if data_args.pad_to_max_length else False
+
+ def tokenize_function(examples):
+ # Remove empty lines
+ examples = [line for line in examples if len(line) > 0 and not line.isspace()]
+ return tokenizer(
+ examples,
+ return_special_tokens_mask=True,
+ padding=padding,
+ truncation=True,
+ max_length=max_seq_length,
+ )
+
+ tokenized_datasets = datasets.map(
+ tokenize_function,
+ input_columns=[text_column_name],
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ else:
+ # Otherwise, we tokenize every text, then concatenate them together before splitting them in smaller parts.
+ # We use `return_special_tokens_mask=True` because DataCollatorForLanguageModeling (see below) is more
+ # efficient when it receives the `special_tokens_mask`.
+ def tokenize_function(examples):
+ return tokenizer(examples[text_column_name], return_special_tokens_mask=True)
+
+ tokenized_datasets = datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ # Main data processing function that will concatenate all texts from our dataset and generate chunks of
+ # max_seq_length.
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
+ # customize this part to your needs.
+ if total_length >= max_seq_length:
+ total_length = (total_length // max_seq_length) * max_seq_length
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + max_seq_length] for i in range(0, total_length, max_seq_length)]
+ for k, t in concatenated_examples.items()
+ }
+ return result
+
+ # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a
+ # remainder for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value
+ # might be slower to preprocess.
+ #
+ # To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
+ # https://huggingface.co/docs/datasets/process#map
+ tokenized_datasets = tokenized_datasets.map(
+ group_texts,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ # Enable tensorboard only on the master node
+ has_tensorboard = is_tensorboard_available()
+ if has_tensorboard and jax.process_index() == 0:
+ try:
+ from flax.metrics.tensorboard import SummaryWriter
+
+ summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir))
+ except ImportError as ie:
+ has_tensorboard = False
+ logger.warning(
+ f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
+ )
+ else:
+ logger.warning(
+ "Unable to display metrics through TensorBoard because the package is not installed: "
+ "Please run pip install tensorboard to enable."
+ )
+
+ # Data collator
+ # This one will take care of randomly masking the tokens.
+ data_collator = FlaxDataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=data_args.mlm_probability)
+
+ # Initialize our training
+ rng = jax.random.PRNGKey(training_args.seed)
+ dropout_rngs = jax.random.split(rng, jax.local_device_count())
+
+ if model_args.model_name_or_path:
+ model = FlaxAutoModelForMaskedLM.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ model = FlaxAutoModelForMaskedLM.from_config(
+ config,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ if training_args.gradient_checkpointing:
+ model.enable_gradient_checkpointing()
+
+ # Store some constant
+ num_epochs = int(training_args.num_train_epochs)
+ train_batch_size = int(training_args.per_device_train_batch_size) * jax.device_count()
+ per_device_eval_batch_size = int(training_args.per_device_eval_batch_size)
+ eval_batch_size = per_device_eval_batch_size * jax.device_count()
+
+ num_train_steps = len(tokenized_datasets["train"]) // train_batch_size * num_epochs
+
+ # Create learning rate schedule
+ warmup_fn = optax.linear_schedule(
+ init_value=0.0, end_value=training_args.learning_rate, transition_steps=training_args.warmup_steps
+ )
+ decay_fn = optax.linear_schedule(
+ init_value=training_args.learning_rate,
+ end_value=0,
+ transition_steps=num_train_steps - training_args.warmup_steps,
+ )
+ linear_decay_lr_schedule_fn = optax.join_schedules(
+ schedules=[warmup_fn, decay_fn], boundaries=[training_args.warmup_steps]
+ )
+
+ # We use Optax's "masking" functionality to not apply weight decay
+ # to bias and LayerNorm scale parameters. decay_mask_fn returns a
+ # mask boolean with the same structure as the parameters.
+ # The mask is True for parameters that should be decayed.
+ def decay_mask_fn(params):
+ flat_params = traverse_util.flatten_dict(params)
+ # find out all LayerNorm parameters
+ layer_norm_candidates = ["layernorm", "layer_norm", "ln"]
+ layer_norm_named_params = {
+ layer[-2:]
+ for layer_norm_name in layer_norm_candidates
+ for layer in flat_params.keys()
+ if layer_norm_name in "".join(layer).lower()
+ }
+ flat_mask = {path: (path[-1] != "bias" and path[-2:] not in layer_norm_named_params) for path in flat_params}
+ return traverse_util.unflatten_dict(flat_mask)
+
+ # create adam optimizer
+ if training_args.adafactor:
+ # We use the default parameters here to initialize adafactor,
+ # For more details about the parameters please check https://github.com/deepmind/optax/blob/ed02befef9bf81cbbf236be3d2b0e032e9ed4a40/optax/_src/alias.py#L74
+ optimizer = optax.adafactor(
+ learning_rate=linear_decay_lr_schedule_fn,
+ )
+ else:
+ optimizer = optax.adamw(
+ learning_rate=linear_decay_lr_schedule_fn,
+ b1=training_args.adam_beta1,
+ b2=training_args.adam_beta2,
+ eps=training_args.adam_epsilon,
+ weight_decay=training_args.weight_decay,
+ mask=decay_mask_fn,
+ )
+
+ # Setup train state
+ state = train_state.TrainState.create(apply_fn=model.__call__, params=model.params, tx=optimizer)
+
+ # Define gradient update step fn
+ def train_step(state, batch, dropout_rng):
+ dropout_rng, new_dropout_rng = jax.random.split(dropout_rng)
+
+ def loss_fn(params):
+ labels = batch.pop("labels")
+
+ logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
+
+ # compute loss, ignore padded input tokens
+ label_mask = jnp.where(labels > 0, 1.0, 0.0)
+ loss = optax.softmax_cross_entropy(logits, onehot(labels, logits.shape[-1])) * label_mask
+
+ # take average
+ loss = loss.sum()
+ num_labels = label_mask.sum()
+
+ return loss, num_labels
+
+ grad_fn = jax.value_and_grad(loss_fn, has_aux=True)
+ (loss, num_labels), grad = grad_fn(state.params)
+ num_labels = jax.lax.psum(num_labels, "batch")
+
+ # true loss = total loss / total samples
+ loss = jax.lax.psum(loss, "batch")
+ loss = jax.tree_util.tree_map(lambda x: x / num_labels, loss)
+
+ # true grad = total grad / total samples
+ grad = jax.lax.psum(grad, "batch")
+ grad = jax.tree_util.tree_map(lambda x: x / num_labels, grad)
+ new_state = state.apply_gradients(grads=grad)
+
+ metrics = {"loss": loss, "learning_rate": linear_decay_lr_schedule_fn(state.step)}
+
+ return new_state, metrics, new_dropout_rng
+
+ # Create parallel version of the train step
+ p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
+
+ # Define eval fn
+ def eval_step(params, batch):
+ labels = batch.pop("labels")
+
+ logits = model(**batch, params=params, train=False)[0]
+
+ # compute loss, ignore padded input tokens
+ label_mask = jnp.where(labels > 0, 1.0, 0.0)
+ loss = optax.softmax_cross_entropy(logits, onehot(labels, logits.shape[-1])) * label_mask
+
+ # compute accuracy
+ accuracy = jnp.equal(jnp.argmax(logits, axis=-1), labels) * label_mask
+
+ # summarize metrics
+ metrics = {"loss": loss.sum(), "accuracy": accuracy.sum(), "normalizer": label_mask.sum()}
+ metrics = jax.lax.psum(metrics, axis_name="batch")
+
+ return metrics
+
+ p_eval_step = jax.pmap(eval_step, "batch", donate_argnums=(0,))
+
+ # Replicate the train state on each device
+ state = jax_utils.replicate(state)
+
+ train_time = 0
+ epochs = tqdm(range(num_epochs), desc=f"Epoch ... (1/{num_epochs})", position=0)
+ for epoch in epochs:
+ # ======================== Training ================================
+ train_start = time.time()
+ train_metrics = []
+
+ # Create sampling rng
+ rng, input_rng = jax.random.split(rng)
+
+ # Generate an epoch by shuffling sampling indices from the train dataset
+ num_train_samples = len(tokenized_datasets["train"])
+ # Avoid using jax.numpy here in case of TPU training
+ train_samples_idx = np.random.permutation(np.arange(num_train_samples))
+ train_batch_idx = generate_batch_splits(train_samples_idx, train_batch_size)
+
+ # Gather the indexes for creating the batch and do a training step
+ for step, batch_idx in enumerate(tqdm(train_batch_idx, desc="Training...", position=1)):
+ samples = [tokenized_datasets["train"][int(idx)] for idx in batch_idx]
+ model_inputs = data_collator(samples, pad_to_multiple_of=16)
+
+ # Model forward
+ model_inputs = shard(model_inputs.data)
+ state, train_metric, dropout_rngs = p_train_step(state, model_inputs, dropout_rngs)
+ train_metrics.append(train_metric)
+
+ cur_step = epoch * (num_train_samples // train_batch_size) + step
+
+ if cur_step % training_args.logging_steps == 0 and cur_step > 0:
+ # Save metrics
+ train_metric = jax_utils.unreplicate(train_metric)
+ train_time += time.time() - train_start
+ if has_tensorboard and jax.process_index() == 0:
+ write_train_metric(summary_writer, train_metrics, train_time, cur_step)
+
+ epochs.write(
+ f"Step... ({cur_step} | Loss: {train_metric['loss']}, Learning Rate:"
+ f" {train_metric['learning_rate']})"
+ )
+
+ train_metrics = []
+
+ if cur_step % training_args.eval_steps == 0 and cur_step > 0:
+ # ======================== Evaluating ==============================
+ num_eval_samples = len(tokenized_datasets["validation"])
+ # Avoid using jax.numpy here in case of TPU training
+ eval_samples_idx = np.arange(num_eval_samples)
+ eval_batch_idx = generate_batch_splits(eval_samples_idx, eval_batch_size, drop_last=False)
+
+ eval_metrics = []
+ for i, batch_idx in enumerate(tqdm(eval_batch_idx, desc="Evaluating ...", position=2)):
+ samples = [tokenized_datasets["validation"][int(idx)] for idx in batch_idx]
+ model_inputs = data_collator(samples, pad_to_multiple_of=16)
+
+ # Model forward
+ metrics = pad_shard_unpad(p_eval_step, static_return=True)(
+ state.params, model_inputs.data, min_device_batch=per_device_eval_batch_size
+ )
+ eval_metrics.append(metrics)
+
+ # normalize eval metrics
+ eval_metrics = get_metrics(eval_metrics)
+ eval_metrics = jax.tree_util.tree_map(jnp.sum, eval_metrics)
+ eval_normalizer = eval_metrics.pop("normalizer")
+ eval_metrics = jax.tree_util.tree_map(lambda x: x / eval_normalizer, eval_metrics)
+
+ # Update progress bar
+ epochs.desc = f"Step... ({cur_step} | Loss: {eval_metrics['loss']}, Acc: {eval_metrics['accuracy']})"
+
+ # Save metrics
+ if has_tensorboard and jax.process_index() == 0:
+ write_eval_metric(summary_writer, eval_metrics, cur_step)
+
+ if cur_step % training_args.save_steps == 0 and cur_step > 0:
+ # save checkpoint after each epoch and push checkpoint to the hub
+ if jax.process_index() == 0:
+ params = jax.device_get(jax.tree_util.tree_map(lambda x: x[0], state.params))
+ model.save_pretrained(training_args.output_dir, params=params)
+ tokenizer.save_pretrained(training_args.output_dir)
+ if training_args.push_to_hub:
+ api.upload_folder(
+ commit_message=f"Saving weights and logs of step {cur_step}",
+ folder_path=training_args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=training_args.hub_token,
+ )
+ # Eval after training
+ if training_args.do_eval:
+ num_eval_samples = len(tokenized_datasets["validation"])
+ # Avoid using jax.numpy here in case of TPU training
+ eval_samples_idx = np.arange(num_eval_samples)
+ eval_batch_idx = generate_batch_splits(eval_samples_idx, eval_batch_size, drop_last=False)
+
+ eval_metrics = []
+ for _, batch_idx in enumerate(tqdm(eval_batch_idx, desc="Evaluating ...", position=2)):
+ samples = [tokenized_datasets["validation"][int(idx)] for idx in batch_idx]
+ model_inputs = data_collator(samples, pad_to_multiple_of=16)
+
+ # Model forward
+ metrics = pad_shard_unpad(p_eval_step, static_return=True)(
+ state.params, model_inputs.data, min_device_batch=per_device_eval_batch_size
+ )
+ eval_metrics.append(metrics)
+
+ # normalize eval metrics
+ eval_metrics = get_metrics(eval_metrics)
+ eval_metrics = jax.tree_util.tree_map(lambda metric: jnp.sum(metric).item(), eval_metrics)
+ eval_normalizer = eval_metrics.pop("normalizer")
+ eval_metrics = jax.tree_util.tree_map(lambda x: x / eval_normalizer, eval_metrics)
+
+ try:
+ perplexity = math.exp(eval_metrics["loss"])
+ except OverflowError:
+ perplexity = float("inf")
+ eval_metrics["perplexity"] = perplexity
+
+ if jax.process_index() == 0:
+ eval_metrics = {f"eval_{metric_name}": value for metric_name, value in eval_metrics.items()}
+ path = os.path.join(training_args.output_dir, "eval_results.json")
+ with open(path, "w") as f:
+ json.dump(eval_metrics, f, indent=4, sort_keys=True)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/flax/language-modeling/run_t5_mlm_flax.py b/docs/transformers/examples/flax/language-modeling/run_t5_mlm_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..b376c26d32cccbcf3c346f0848acfed475f5dc11
--- /dev/null
+++ b/docs/transformers/examples/flax/language-modeling/run_t5_mlm_flax.py
@@ -0,0 +1,1013 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Pretraining the library models for T5-like span-masked language modeling on a text file or a dataset.
+
+Here is the full list of checkpoints on the hub that can be pretrained by this script:
+https://huggingface.co/models?filter=t5
+"""
+
+import json
+import logging
+import math
+import os
+import sys
+import time
+from dataclasses import asdict, dataclass, field
+
+# You can also adapt this script on your own masked language modeling task. Pointers for this are left as comments.
+from enum import Enum
+from itertools import chain
+from pathlib import Path
+from typing import Optional
+
+import flax
+import jax
+import jax.numpy as jnp
+import numpy as np
+import optax
+from datasets import load_dataset
+from flax import jax_utils, traverse_util
+from flax.jax_utils import pad_shard_unpad
+from flax.training import train_state
+from flax.training.common_utils import get_metrics, onehot, shard
+from huggingface_hub import HfApi
+from tqdm import tqdm
+
+from transformers import (
+ CONFIG_MAPPING,
+ FLAX_MODEL_FOR_MASKED_LM_MAPPING,
+ AutoTokenizer,
+ BatchEncoding,
+ FlaxT5ForConditionalGeneration,
+ HfArgumentParser,
+ PreTrainedTokenizerBase,
+ T5Config,
+ is_tensorboard_available,
+ set_seed,
+)
+from transformers.models.t5.modeling_flax_t5 import shift_tokens_right
+from transformers.utils import send_example_telemetry
+
+
+MODEL_CONFIG_CLASSES = list(FLAX_MODEL_FOR_MASKED_LM_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class TrainingArguments:
+ output_dir: str = field(
+ metadata={"help": "The output directory where the model predictions and checkpoints will be written."},
+ )
+ overwrite_output_dir: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Overwrite the content of the output directory. "
+ "Use this to continue training if output_dir points to a checkpoint directory."
+ )
+ },
+ )
+ do_train: bool = field(default=False, metadata={"help": "Whether to run training."})
+ do_eval: bool = field(default=False, metadata={"help": "Whether to run eval on the dev set."})
+ per_device_train_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for training."}
+ )
+ per_device_eval_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for evaluation."}
+ )
+ learning_rate: float = field(default=5e-5, metadata={"help": "The initial learning rate for AdamW."})
+ weight_decay: float = field(default=0.0, metadata={"help": "Weight decay for AdamW if we apply some."})
+ adam_beta1: float = field(default=0.9, metadata={"help": "Beta1 for AdamW optimizer"})
+ adam_beta2: float = field(default=0.999, metadata={"help": "Beta2 for AdamW optimizer"})
+ adam_epsilon: float = field(default=1e-8, metadata={"help": "Epsilon for AdamW optimizer."})
+ adafactor: bool = field(default=False, metadata={"help": "Whether or not to replace AdamW by Adafactor."})
+ num_train_epochs: float = field(default=3.0, metadata={"help": "Total number of training epochs to perform."})
+ warmup_steps: int = field(default=0, metadata={"help": "Linear warmup over warmup_steps."})
+ logging_steps: int = field(default=500, metadata={"help": "Log every X updates steps."})
+ save_steps: int = field(default=500, metadata={"help": "Save checkpoint every X updates steps."})
+ eval_steps: int = field(default=None, metadata={"help": "Run an evaluation every X steps."})
+ seed: int = field(default=42, metadata={"help": "Random seed that will be set at the beginning of training."})
+ push_to_hub: bool = field(
+ default=False, metadata={"help": "Whether or not to upload the trained model to the model hub after training."}
+ )
+ hub_model_id: str = field(
+ default=None, metadata={"help": "The name of the repository to keep in sync with the local `output_dir`."}
+ )
+ hub_token: str = field(default=None, metadata={"help": "The token to use to push to the Model Hub."})
+
+ def __post_init__(self):
+ if self.output_dir is not None:
+ self.output_dir = os.path.expanduser(self.output_dir)
+
+ def to_dict(self):
+ """
+ Serializes this instance while replace `Enum` by their values (for JSON serialization support). It obfuscates
+ the token values by removing their value.
+ """
+ d = asdict(self)
+ for k, v in d.items():
+ if isinstance(v, Enum):
+ d[k] = v.value
+ if isinstance(v, list) and len(v) > 0 and isinstance(v[0], Enum):
+ d[k] = [x.value for x in v]
+ if k.endswith("_token"):
+ d[k] = f"<{k.upper()}>"
+ return d
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ dtype: Optional[str] = field(
+ default="float32",
+ metadata={
+ "help": (
+ "Floating-point format in which the model weights should be initialized and trained. Choose one of"
+ " `[float32, float16, bfloat16]`."
+ )
+ },
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ train_ref_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input train ref data file for whole word masking in Chinese."},
+ )
+ validation_ref_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input validation ref data file for whole word masking in Chinese."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ validation_split_percentage: Optional[int] = field(
+ default=5,
+ metadata={
+ "help": "The percentage of the train set used as validation set in case there's no validation split"
+ },
+ )
+ max_seq_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization and masking. Sequences longer than this"
+ " will be truncated. Default to the max input length of the model."
+ )
+ },
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ mlm_probability: float = field(
+ default=0.15, metadata={"help": "Ratio of tokens to mask for span masked language modeling loss"}
+ )
+ mean_noise_span_length: float = field(
+ default=3.0,
+ metadata={"help": "Mean span length of masked tokens"},
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
+
+
+def compute_input_and_target_lengths(inputs_length, noise_density, mean_noise_span_length):
+ """This function is copy of `random_spans_helper `__ .
+
+ Training parameters to avoid padding with random_spans_noise_mask.
+ When training a model with random_spans_noise_mask, we would like to set the other
+ training hyperparmeters in a way that avoids padding.
+ This function helps us compute these hyperparameters.
+ We assume that each noise span in the input is replaced by extra_tokens_per_span_inputs sentinel tokens,
+ and each non-noise span in the targets is replaced by extra_tokens_per_span_targets sentinel tokens.
+ This function tells us the required number of tokens in the raw example (for split_tokens())
+ as well as the length of the encoded targets. Note that this function assumes
+ the inputs and targets will have EOS appended and includes that in the reported length.
+
+ Args:
+ inputs_length: an integer - desired length of the tokenized inputs sequence
+ noise_density: a float
+ mean_noise_span_length: a float
+ Returns:
+ tokens_length: length of original text in tokens
+ targets_length: an integer - length in tokens of encoded targets sequence
+ """
+
+ def _tokens_length_to_inputs_length_targets_length(tokens_length):
+ num_noise_tokens = int(round(tokens_length * noise_density))
+ num_nonnoise_tokens = tokens_length - num_noise_tokens
+ num_noise_spans = int(round(num_noise_tokens / mean_noise_span_length))
+ # inputs contain all nonnoise tokens, sentinels for all noise spans
+ # and one EOS token.
+ _input_length = num_nonnoise_tokens + num_noise_spans + 1
+ _output_length = num_noise_tokens + num_noise_spans + 1
+ return _input_length, _output_length
+
+ tokens_length = inputs_length
+
+ while _tokens_length_to_inputs_length_targets_length(tokens_length + 1)[0] <= inputs_length:
+ tokens_length += 1
+
+ inputs_length, targets_length = _tokens_length_to_inputs_length_targets_length(tokens_length)
+
+ # minor hack to get the targets length to be equal to inputs length
+ # which is more likely to have been set to a nice round number.
+ if noise_density == 0.5 and targets_length > inputs_length:
+ tokens_length -= 1
+ targets_length -= 1
+ return tokens_length, targets_length
+
+
+@flax.struct.dataclass
+class FlaxDataCollatorForT5MLM:
+ """
+ Data collator used for T5 span-masked language modeling.
+ It is made sure that after masking the inputs are of length `data_args.max_seq_length` and targets are also of fixed length.
+ For more information on how T5 span-masked language modeling works, one can take a look
+ at the `official paper `__
+ or the `official code for preprocessing `__ .
+
+ Args:
+ tokenizer (:class:`~transformers.PreTrainedTokenizer` or :class:`~transformers.PreTrainedTokenizerFast`):
+ The tokenizer used for encoding the data.
+ noise_density (:obj:`float`):
+ The probability with which to (randomly) mask tokens in the input.
+ mean_noise_span_length (:obj:`float`):
+ The average span length of the masked tokens.
+ input_length (:obj:`int`):
+ The expected input length after masking.
+ target_length (:obj:`int`):
+ The expected target length after masking.
+ pad_token_id: (:obj:`int`):
+ The pad token id of the model
+ decoder_start_token_id: (:obj:`int):
+ The decoder start token id of the model
+ """
+
+ tokenizer: PreTrainedTokenizerBase
+ noise_density: float
+ mean_noise_span_length: float
+ input_length: int
+ target_length: int
+ pad_token_id: int
+ decoder_start_token_id: int
+
+ def __call__(self, examples: list[dict[str, np.ndarray]]) -> BatchEncoding:
+ # convert list to dict and tensorize input
+ batch = BatchEncoding(
+ {k: np.array([examples[i][k] for i in range(len(examples))]) for k, v in examples[0].items()}
+ )
+
+ input_ids = batch["input_ids"]
+ batch_size, expandend_input_length = input_ids.shape
+
+ mask_indices = np.asarray([self.random_spans_noise_mask(expandend_input_length) for i in range(batch_size)])
+ labels_mask = ~mask_indices
+
+ input_ids_sentinel = self.create_sentinel_ids(mask_indices.astype(np.int8))
+ labels_sentinel = self.create_sentinel_ids(labels_mask.astype(np.int8))
+
+ batch["input_ids"] = self.filter_input_ids(input_ids, input_ids_sentinel)
+ batch["labels"] = self.filter_input_ids(input_ids, labels_sentinel)
+
+ if batch["input_ids"].shape[-1] != self.input_length:
+ raise ValueError(
+ f"`input_ids` are incorrectly preprocessed. `input_ids` length is {batch['input_ids'].shape[-1]}, but"
+ f" should be {self.input_length}."
+ )
+
+ if batch["labels"].shape[-1] != self.target_length:
+ raise ValueError(
+ f"`labels` are incorrectly preprocessed. `labels` length is {batch['labels'].shape[-1]}, but should be"
+ f" {self.target_length}."
+ )
+
+ # to check that tokens are correctly preprocessed, one can run `self.tokenizer.batch_decode(input_ids)` and `self.tokenizer.batch_decode(labels)` here...
+ batch["decoder_input_ids"] = shift_tokens_right(
+ batch["labels"], self.pad_token_id, self.decoder_start_token_id
+ )
+
+ return batch
+
+ def create_sentinel_ids(self, mask_indices):
+ """
+ Sentinel ids creation given the indices that should be masked.
+ The start indices of each mask are replaced by the sentinel ids in increasing
+ order. Consecutive mask indices to be deleted are replaced with `-1`.
+ """
+ start_indices = mask_indices - np.roll(mask_indices, 1, axis=-1) * mask_indices
+ start_indices[:, 0] = mask_indices[:, 0]
+
+ sentinel_ids = np.where(start_indices != 0, np.cumsum(start_indices, axis=-1), start_indices)
+ sentinel_ids = np.where(sentinel_ids != 0, (len(self.tokenizer) - sentinel_ids), 0)
+ sentinel_ids -= mask_indices - start_indices
+
+ return sentinel_ids
+
+ def filter_input_ids(self, input_ids, sentinel_ids):
+ """
+ Puts sentinel mask on `input_ids` and fuse consecutive mask tokens into a single mask token by deleting.
+ This will reduce the sequence length from `expanded_inputs_length` to `input_length`.
+ """
+ batch_size = input_ids.shape[0]
+
+ input_ids_full = np.where(sentinel_ids != 0, sentinel_ids, input_ids)
+ # input_ids tokens and sentinel tokens are >= 0, tokens < 0 are
+ # masked tokens coming after sentinel tokens and should be removed
+ input_ids = input_ids_full[input_ids_full >= 0].reshape((batch_size, -1))
+ input_ids = np.concatenate(
+ [input_ids, np.full((batch_size, 1), self.tokenizer.eos_token_id, dtype=np.int32)], axis=-1
+ )
+ return input_ids
+
+ def random_spans_noise_mask(self, length):
+ """This function is copy of `random_spans_helper `__ .
+
+ Noise mask consisting of random spans of noise tokens.
+ The number of noise tokens and the number of noise spans and non-noise spans
+ are determined deterministically as follows:
+ num_noise_tokens = round(length * noise_density)
+ num_nonnoise_spans = num_noise_spans = round(num_noise_tokens / mean_noise_span_length)
+ Spans alternate between non-noise and noise, beginning with non-noise.
+ Subject to the above restrictions, all masks are equally likely.
+
+ Args:
+ length: an int32 scalar (length of the incoming token sequence)
+ noise_density: a float - approximate density of output mask
+ mean_noise_span_length: a number
+
+ Returns:
+ a boolean tensor with shape [length]
+ """
+
+ orig_length = length
+
+ num_noise_tokens = int(np.round(length * self.noise_density))
+ num_nonnoise_tokens = length - num_noise_tokens
+ # avoid degeneracy by ensuring positive numbers of noise and nonnoise tokens.
+ num_noise_tokens = min(max(num_noise_tokens, 1), length - 1)
+ # num_noise_tokens should be less than num_noise_tokens and num_nonnoise_tokens
+ num_noise_spans = int(np.round(min(num_noise_tokens, num_nonnoise_tokens) / self.mean_noise_span_length))
+
+ # avoid degeneracy by ensuring positive number of noise spans
+ num_noise_spans = max(num_noise_spans, 1)
+
+ # pick the lengths of the noise spans and the non-noise spans
+ def _random_segmentation(num_items, num_segments):
+ """Partition a sequence of items randomly into non-empty segments.
+ Args:
+ num_items: an integer scalar > 0
+ num_segments: an integer scalar in [1, num_items]
+ Returns:
+ a Tensor with shape [num_segments] containing positive integers that add
+ up to num_items
+ """
+ mask_indices = np.arange(num_items - 1) < (num_segments - 1)
+ np.random.shuffle(mask_indices)
+ first_in_segment = np.pad(mask_indices, [[1, 0]])
+ segment_id = np.cumsum(first_in_segment)
+ # count length of sub segments assuming that list is sorted
+ _, segment_length = np.unique(segment_id, return_counts=True)
+ return segment_length
+
+ noise_span_lengths = _random_segmentation(num_noise_tokens, num_noise_spans)
+ nonnoise_span_lengths = _random_segmentation(num_nonnoise_tokens, num_noise_spans)
+
+ interleaved_span_lengths = np.reshape(
+ np.stack([nonnoise_span_lengths, noise_span_lengths], axis=1), [num_noise_spans * 2]
+ )
+ span_starts = np.cumsum(interleaved_span_lengths)[:-1]
+ span_start_indicator = np.zeros((length,), dtype=np.int8)
+ span_start_indicator[span_starts] = True
+ span_num = np.cumsum(span_start_indicator)
+ is_noise = np.equal(span_num % 2, 1)
+
+ return is_noise[:orig_length]
+
+
+def generate_batch_splits(samples_idx: np.ndarray, batch_size: int, drop_last=True) -> np.ndarray:
+ """Generate batches of data for a specified batch size from sample indices. If the dataset size is not divisible by
+ the batch size and `drop_last` is `True`, the last incomplete batch is dropped. Else, it is returned."""
+ num_samples = len(samples_idx)
+ if drop_last:
+ samples_to_remove = num_samples % batch_size
+ if samples_to_remove != 0:
+ samples_idx = samples_idx[:-samples_to_remove]
+ sections_split = num_samples // batch_size
+ samples_idx = samples_idx.reshape((sections_split, batch_size))
+ else:
+ sections_split = math.ceil(num_samples / batch_size)
+ samples_idx = np.array_split(samples_idx, sections_split)
+ return samples_idx
+
+
+def write_train_metric(summary_writer, train_metrics, train_time, step):
+ summary_writer.scalar("train_time", train_time, step)
+
+ train_metrics = get_metrics(train_metrics)
+ for key, vals in train_metrics.items():
+ tag = f"train_{key}"
+ for i, val in enumerate(vals):
+ summary_writer.scalar(tag, val, step - len(vals) + i + 1)
+
+
+def write_eval_metric(summary_writer, eval_metrics, step):
+ for metric_name, value in eval_metrics.items():
+ summary_writer.scalar(f"eval_{metric_name}", value, step)
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_t5_mlm", model_args, data_args, framework="flax")
+
+ if (
+ os.path.exists(training_args.output_dir)
+ and os.listdir(training_args.output_dir)
+ and training_args.do_train
+ and not training_args.overwrite_output_dir
+ ):
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ level=logging.INFO,
+ datefmt="[%X]",
+ )
+
+ # Log on each process the small summary:
+ logger = logging.getLogger(__name__)
+
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Handle the repository creation
+ if training_args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = training_args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(training_args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ if "validation" not in datasets.keys():
+ datasets["validation"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+ datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if extension == "txt":
+ extension = "text"
+ datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ )
+
+ if "validation" not in datasets.keys():
+ datasets["validation"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ )
+ datasets["train"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ num_proc=data_args.preprocessing_num_workers,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ )
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if model_args.config_name:
+ config = T5Config.from_pretrained(
+ model_args.config_name,
+ cache_dir=model_args.cache_dir,
+ vocab_size=len(tokenizer),
+ token=model_args.token,
+ )
+ elif model_args.model_name_or_path:
+ config = T5Config.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ if training_args.do_train:
+ column_names = datasets["train"].column_names
+ else:
+ column_names = datasets["validation"].column_names
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ # Otherwise, we tokenize every text, then concatenate them together before splitting them in smaller parts.
+ # Since we make sure that all sequences are of the same length, no attention_mask is needed.
+ def tokenize_function(examples):
+ return tokenizer(examples[text_column_name], return_attention_mask=False)
+
+ tokenized_datasets = datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ # T5-like span masked language modeling will fuse consecutively masked tokens to a single sentinel token.
+ # To ensure that the input length is `max_seq_length`, we need to increase the maximum length
+ # according to `mlm_probability` and `mean_noise_span_length`. We can also define the label length accordingly.
+ expanded_inputs_length, targets_length = compute_input_and_target_lengths(
+ inputs_length=max_seq_length,
+ noise_density=data_args.mlm_probability,
+ mean_noise_span_length=data_args.mean_noise_span_length,
+ )
+
+ # Main data processing function that will concatenate all texts from our dataset and generate chunks of expanded_inputs_length.
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
+ # customize this part to your needs.
+ if total_length >= expanded_inputs_length:
+ total_length = (total_length // expanded_inputs_length) * expanded_inputs_length
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + expanded_inputs_length] for i in range(0, total_length, expanded_inputs_length)]
+ for k, t in concatenated_examples.items()
+ }
+ return result
+
+ # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a
+ # remainder for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value
+ # might be slower to preprocess.
+ #
+ # To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
+ # https://huggingface.co/docs/datasets/process#map
+ tokenized_datasets = tokenized_datasets.map(
+ group_texts,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ # Enable tensorboard only on the master node
+ has_tensorboard = is_tensorboard_available()
+ if has_tensorboard and jax.process_index() == 0:
+ try:
+ from flax.metrics.tensorboard import SummaryWriter
+
+ summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir))
+ except ImportError as ie:
+ has_tensorboard = False
+ logger.warning(
+ f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
+ )
+ else:
+ logger.warning(
+ "Unable to display metrics through TensorBoard because the package is not installed: "
+ "Please run pip install tensorboard to enable."
+ )
+
+ # Initialize our training
+ rng = jax.random.PRNGKey(training_args.seed)
+ dropout_rngs = jax.random.split(rng, jax.local_device_count())
+
+ if model_args.model_name_or_path:
+ model = FlaxT5ForConditionalGeneration.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ token=model_args.token,
+ )
+ else:
+ config.vocab_size = len(tokenizer)
+ model = FlaxT5ForConditionalGeneration(
+ config,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ )
+
+ # Data collator
+ # This one will take care of randomly masking the tokens.
+ data_collator = FlaxDataCollatorForT5MLM(
+ tokenizer=tokenizer,
+ noise_density=data_args.mlm_probability,
+ mean_noise_span_length=data_args.mean_noise_span_length,
+ input_length=max_seq_length,
+ target_length=targets_length,
+ pad_token_id=model.config.pad_token_id,
+ decoder_start_token_id=model.config.decoder_start_token_id,
+ )
+
+ # Store some constant
+ num_epochs = int(training_args.num_train_epochs)
+ train_batch_size = int(training_args.per_device_train_batch_size) * jax.device_count()
+ per_device_eval_batch_size = int(training_args.per_device_eval_batch_size)
+ eval_batch_size = per_device_eval_batch_size * jax.device_count()
+
+ num_train_steps = len(tokenized_datasets["train"]) // train_batch_size * num_epochs
+
+ num_of_hosts = jax.process_count()
+ current_host_idx = jax.process_index()
+
+ # Create learning rate schedule
+ warmup_fn = optax.linear_schedule(
+ init_value=0.0, end_value=training_args.learning_rate, transition_steps=training_args.warmup_steps
+ )
+ decay_fn = optax.linear_schedule(
+ init_value=training_args.learning_rate,
+ end_value=0,
+ transition_steps=num_train_steps - training_args.warmup_steps,
+ )
+ linear_decay_lr_schedule_fn = optax.join_schedules(
+ schedules=[warmup_fn, decay_fn], boundaries=[training_args.warmup_steps]
+ )
+
+ # We use Optax's "masking" functionality to not apply weight decay
+ # to bias and LayerNorm scale parameters. decay_mask_fn returns a
+ # mask boolean with the same structure as the parameters.
+ # The mask is True for parameters that should be decayed.
+ def decay_mask_fn(params):
+ flat_params = traverse_util.flatten_dict(params)
+ # find out all LayerNorm parameters
+ layer_norm_candidates = ["layernorm", "layer_norm", "ln"]
+ layer_norm_named_params = {
+ layer[-2:]
+ for layer_norm_name in layer_norm_candidates
+ for layer in flat_params.keys()
+ if layer_norm_name in "".join(layer).lower()
+ }
+ flat_mask = {path: (path[-1] != "bias" and path[-2:] not in layer_norm_named_params) for path in flat_params}
+ return traverse_util.unflatten_dict(flat_mask)
+
+ # create adam optimizer
+ if training_args.adafactor:
+ # We use the default parameters here to initialize adafactor,
+ # For more details about the parameters please check https://github.com/deepmind/optax/blob/ed02befef9bf81cbbf236be3d2b0e032e9ed4a40/optax/_src/alias.py#L74
+ optimizer = optax.adafactor(
+ learning_rate=linear_decay_lr_schedule_fn,
+ )
+ else:
+ optimizer = optax.adamw(
+ learning_rate=linear_decay_lr_schedule_fn,
+ b1=training_args.adam_beta1,
+ b2=training_args.adam_beta2,
+ weight_decay=training_args.weight_decay,
+ mask=decay_mask_fn,
+ )
+
+ # Setup train state
+ state = train_state.TrainState.create(apply_fn=model.__call__, params=model.params, tx=optimizer)
+
+ # Define gradient update step fn
+ def train_step(state, batch, dropout_rng):
+ dropout_rng, new_dropout_rng = jax.random.split(dropout_rng)
+
+ def loss_fn(params):
+ labels = batch.pop("labels")
+
+ logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
+
+ # compute loss
+ loss = optax.softmax_cross_entropy(logits, onehot(labels, logits.shape[-1])).mean()
+
+ return loss
+
+ grad_fn = jax.value_and_grad(loss_fn)
+ loss, grad = grad_fn(state.params)
+ grad = jax.lax.pmean(grad, "batch")
+ new_state = state.apply_gradients(grads=grad)
+
+ metrics = jax.lax.pmean(
+ {"loss": loss, "learning_rate": linear_decay_lr_schedule_fn(state.step)}, axis_name="batch"
+ )
+
+ return new_state, metrics, new_dropout_rng
+
+ # Create parallel version of the train step
+ p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
+
+ # Define eval fn
+ def eval_step(params, batch):
+ labels = batch.pop("labels")
+
+ logits = model(**batch, params=params, train=False)[0]
+
+ # compute loss
+ loss = optax.softmax_cross_entropy(logits, onehot(labels, logits.shape[-1]))
+
+ # compute accuracy
+ accuracy = jnp.equal(jnp.argmax(logits, axis=-1), labels)
+
+ # summarize metrics
+ metrics = {"loss": loss.mean(), "accuracy": accuracy.mean()}
+ metrics = jax.lax.pmean(metrics, axis_name="batch")
+
+ return metrics
+
+ p_eval_step = jax.pmap(eval_step, "batch", donate_argnums=(0,))
+
+ # Replicate the train state on each device
+ state = jax_utils.replicate(state)
+
+ train_time = 0
+ epochs = tqdm(range(num_epochs), desc="Epoch ... ", position=0)
+ for epoch in epochs:
+ # ======================== Training ================================
+ train_start = time.time()
+ train_metrics = []
+
+ # Create sampling rng
+ rng, input_rng = jax.random.split(rng)
+
+ # Generate an epoch by shuffling sampling indices from the train dataset
+ num_train_samples = len(tokenized_datasets["train"])
+ # Avoid using jax.numpy here in case of TPU training
+ train_samples_idx = np.random.permutation(np.arange(num_train_samples))
+ train_batch_idx = generate_batch_splits(train_samples_idx, train_batch_size)
+
+ # Gather the indexes for creating the batch and do a training step
+ for step, batch_idx in enumerate(tqdm(train_batch_idx, desc="Training...", position=1)):
+ samples = [tokenized_datasets["train"][int(idx)] for idx in batch_idx]
+ model_inputs = data_collator(samples)
+
+ local_host_model_inputs = {
+ key: np.split(model_inputs.data[key], num_of_hosts, axis=0)[current_host_idx]
+ for key, value in model_inputs.data.items()
+ }
+
+ # Model forward
+ model_inputs = shard(local_host_model_inputs)
+ state, train_metric, dropout_rngs = p_train_step(state, model_inputs, dropout_rngs)
+ train_metrics.append(train_metric)
+
+ cur_step = epoch * (num_train_samples // train_batch_size) + step
+
+ if cur_step % training_args.logging_steps == 0 and cur_step > 0:
+ # Save metrics
+ train_metric = jax_utils.unreplicate(train_metric)
+ train_time += time.time() - train_start
+ if has_tensorboard and jax.process_index() == 0:
+ write_train_metric(summary_writer, train_metrics, train_time, cur_step)
+
+ epochs.write(
+ f"Step... ({cur_step} | Loss: {train_metric['loss'].mean()}, Learning Rate:"
+ f" {train_metric['learning_rate'].mean()})"
+ )
+
+ train_metrics = []
+
+ if cur_step % training_args.eval_steps == 0 and cur_step > 0:
+ # ======================== Evaluating ==============================
+ num_eval_samples = len(tokenized_datasets["validation"])
+ # Avoid using jax.numpy here in case of TPU training
+ eval_samples_idx = np.arange(num_eval_samples)
+ eval_batch_idx = generate_batch_splits(eval_samples_idx, eval_batch_size, drop_last=False)
+
+ eval_metrics = []
+ for i, batch_idx in enumerate(tqdm(eval_batch_idx, desc="Evaluating ...", position=2)):
+ samples = [tokenized_datasets["validation"][int(idx)] for idx in batch_idx]
+ model_inputs = data_collator(samples)
+
+ # Model forward
+ metrics = pad_shard_unpad(p_eval_step, static_return=True)(
+ state.params, model_inputs.data, min_device_batch=per_device_eval_batch_size
+ )
+ eval_metrics.append(metrics)
+
+ # get eval metrics
+ eval_metrics = get_metrics(eval_metrics)
+ eval_metrics = jax.tree_util.tree_map(jnp.mean, eval_metrics)
+
+ # Update progress bar
+ epochs.write(f"Step... ({cur_step} | Loss: {eval_metrics['loss']}, Acc: {eval_metrics['accuracy']})")
+
+ # Save metrics
+ if has_tensorboard and jax.process_index() == 0:
+ write_eval_metric(summary_writer, eval_metrics, cur_step)
+
+ if cur_step % training_args.save_steps == 0 and cur_step > 0:
+ # save checkpoint after each epoch and push checkpoint to the hub
+ if jax.process_index() == 0:
+ params = jax.device_get(jax.tree_util.tree_map(lambda x: x[0], state.params))
+ model.save_pretrained(training_args.output_dir, params=params)
+ tokenizer.save_pretrained(training_args.output_dir)
+ if training_args.push_to_hub:
+ api.upload_folder(
+ commit_message=f"Saving weights and logs of step {cur_step}",
+ folder_path=training_args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=training_args.hub_token,
+ )
+ # Eval after training
+ if training_args.do_eval:
+ num_eval_samples = len(tokenized_datasets["validation"])
+ # Avoid using jax.numpy here in case of TPU training
+ eval_samples_idx = np.arange(num_eval_samples)
+ eval_batch_idx = generate_batch_splits(eval_samples_idx, eval_batch_size, drop_last=False)
+
+ eval_metrics = []
+ for i, batch_idx in enumerate(tqdm(eval_batch_idx, desc="Evaluating ...", position=2)):
+ samples = [tokenized_datasets["validation"][int(idx)] for idx in batch_idx]
+ model_inputs = data_collator(samples)
+
+ # Model forward
+ metrics = pad_shard_unpad(p_eval_step, static_return=True)(
+ state.params, model_inputs.data, min_device_batch=per_device_eval_batch_size
+ )
+ eval_metrics.append(metrics)
+
+ # get eval metrics
+ eval_metrics = get_metrics(eval_metrics)
+ eval_metrics = jax.tree_util.tree_map(lambda metric: jnp.mean(metric).item(), eval_metrics)
+
+ if jax.process_index() == 0:
+ eval_metrics = {f"eval_{metric_name}": value for metric_name, value in eval_metrics.items()}
+ path = os.path.join(training_args.output_dir, "eval_results.json")
+ with open(path, "w") as f:
+ json.dump(eval_metrics, f, indent=4, sort_keys=True)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/flax/language-modeling/t5_tokenizer_model.py b/docs/transformers/examples/flax/language-modeling/t5_tokenizer_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b9885279668093a7089614767db6cd237e64e93
--- /dev/null
+++ b/docs/transformers/examples/flax/language-modeling/t5_tokenizer_model.py
@@ -0,0 +1,117 @@
+#!/usr/bin/env python3
+import json
+from collections.abc import Iterator
+from typing import Union
+
+from tokenizers import AddedToken, Regex, Tokenizer, decoders, normalizers, pre_tokenizers, trainers
+from tokenizers.implementations.base_tokenizer import BaseTokenizer
+from tokenizers.models import Unigram
+from tokenizers.processors import TemplateProcessing
+
+
+class SentencePieceUnigramTokenizer(BaseTokenizer):
+ """
+ This class is a copy of `DeDLOC's tokenizer implementation `__ .
+
+ Custom SentencePiece Unigram Tokenizer with NMT, NKFC, spaces and lower-casing characters normalization
+ Represents the Unigram algorithm, with the pretokenization used by SentencePiece
+ """
+
+ def __init__(
+ self,
+ replacement: str = "▁",
+ add_prefix_space: bool = True,
+ unk_token: Union[str, AddedToken] = "",
+ eos_token: Union[str, AddedToken] = "",
+ pad_token: Union[str, AddedToken] = "",
+ ):
+ self.special_tokens = {
+ "pad": {"id": 0, "token": pad_token},
+ "eos": {"id": 1, "token": eos_token},
+ "unk": {"id": 2, "token": unk_token},
+ }
+
+ self.special_tokens_list = [None] * len(self.special_tokens)
+ for token_dict in self.special_tokens.values():
+ self.special_tokens_list[token_dict["id"]] = token_dict["token"]
+
+ tokenizer = Tokenizer(Unigram())
+
+ tokenizer.normalizer = normalizers.Sequence(
+ [
+ normalizers.Nmt(),
+ normalizers.NFKC(),
+ normalizers.Replace(Regex(" {2,}"), " "),
+ normalizers.Lowercase(),
+ ]
+ )
+ tokenizer.pre_tokenizer = pre_tokenizers.Sequence(
+ [
+ pre_tokenizers.Metaspace(
+ replacement=replacement, prepend_scheme="always" if add_prefix_space else "never"
+ ),
+ pre_tokenizers.Digits(individual_digits=True),
+ pre_tokenizers.Punctuation(),
+ ]
+ )
+ tokenizer.decoder = decoders.Metaspace(
+ replacement=replacement, prepend_scheme="always" if add_prefix_space else "never"
+ )
+
+ tokenizer.post_processor = TemplateProcessing(
+ single=f"$A {self.special_tokens['eos']['token']}",
+ special_tokens=[(self.special_tokens["eos"]["token"], self.special_tokens["eos"]["id"])],
+ )
+
+ parameters = {
+ "model": "SentencePieceUnigram",
+ "replacement": replacement,
+ "add_prefix_space": add_prefix_space,
+ }
+
+ super().__init__(tokenizer, parameters)
+
+ def train(
+ self,
+ files: Union[str, list[str]],
+ vocab_size: int = 8000,
+ show_progress: bool = True,
+ ):
+ """Train the model using the given files"""
+
+ trainer = trainers.UnigramTrainer(
+ vocab_size=vocab_size,
+ special_tokens=self.special_tokens_list,
+ show_progress=show_progress,
+ )
+
+ if isinstance(files, str):
+ files = [files]
+ self._tokenizer.train(files, trainer=trainer)
+
+ self.add_unk_id()
+
+ def train_from_iterator(
+ self,
+ iterator: Union[Iterator[str], Iterator[Iterator[str]]],
+ vocab_size: int = 8000,
+ show_progress: bool = True,
+ ):
+ """Train the model using the given iterator"""
+
+ trainer = trainers.UnigramTrainer(
+ vocab_size=vocab_size,
+ special_tokens=self.special_tokens_list,
+ show_progress=show_progress,
+ )
+
+ self._tokenizer.train_from_iterator(iterator, trainer=trainer)
+
+ self.add_unk_id()
+
+ def add_unk_id(self):
+ tokenizer_json = json.loads(self._tokenizer.to_str())
+
+ tokenizer_json["model"]["unk_id"] = self.special_tokens["unk"]["id"]
+
+ self._tokenizer = Tokenizer.from_str(json.dumps(tokenizer_json))
diff --git a/docs/transformers/examples/flax/question-answering/README.md b/docs/transformers/examples/flax/question-answering/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2f6caa984d4bc19cabc32e6a23daa6a3cfacaf6f
--- /dev/null
+++ b/docs/transformers/examples/flax/question-answering/README.md
@@ -0,0 +1,104 @@
+
+
+# Question Answering examples
+
+Based on the script [`run_qa.py`](https://github.com/huggingface/transformers/blob/main/examples/flax/question-answering/run_qa.py).
+
+**Note:** This script only works with models that have a fast tokenizer (backed by the 🤗 Tokenizers library) as it
+uses special features of those tokenizers. You can check if your favorite model has a fast tokenizer in
+[this table](https://huggingface.co/transformers/index.html#supported-frameworks), if it doesn't you can still use the old version
+of the script.
+
+
+The following example fine-tunes BERT on SQuAD:
+
+
+```bash
+python run_qa.py \
+ --model_name_or_path google-bert/bert-base-uncased \
+ --dataset_name squad \
+ --do_train \
+ --do_eval \
+ --max_seq_length 384 \
+ --doc_stride 128 \
+ --learning_rate 3e-5 \
+ --num_train_epochs 2 \
+ --per_device_train_batch_size 12 \
+ --output_dir ./bert-qa-squad \
+ --eval_steps 1000 \
+ --push_to_hub
+```
+
+Using the command above, the script will train for 2 epochs and run eval after each epoch.
+Metrics and hyperparameters are stored in Tensorflow event files in `--output_dir`.
+You can see the results by running `tensorboard` in that directory:
+
+```bash
+$ tensorboard --logdir .
+```
+
+or directly on the hub under *Training metrics*.
+
+Training with the previously defined hyper-parameters yields the following results:
+
+```bash
+f1 = 88.62
+exact_match = 81.34
+```
+
+sample Metrics - [tfhub.dev](https://tensorboard.dev/experiment/6gU75Hx8TGCnc6tr4ZgI9Q)
+
+Here is an example training on 4 TITAN RTX GPUs and Bert Whole Word Masking uncased model to reach a F1 > 93 on SQuAD1.1:
+
+```bash
+export CUDA_VISIBLE_DEVICES=0,1,2,3
+python run_qa.py \
+--model_name_or_path google-bert/bert-large-uncased-whole-word-masking \
+--dataset_name squad \
+--do_train \
+--do_eval \
+--per_device_train_batch_size 6 \
+--learning_rate 3e-5 \
+--num_train_epochs 2 \
+--max_seq_length 384 \
+--doc_stride 128 \
+--output_dir ./wwm_uncased_finetuned_squad/ \
+--eval_steps 1000 \
+--push_to_hub
+```
+
+Training with the previously defined hyper-parameters yields the following results:
+
+```bash
+f1 = 93.31
+exact_match = 87.04
+```
+
+
+### Usage notes
+
+Note that when contexts are long they may be split into multiple training cases, not all of which may contain
+the answer span.
+
+As-is, the example script will train on SQuAD or any other question-answering dataset formatted the same way, and can handle user
+inputs as well.
+
+### Memory usage and data loading
+
+One thing to note is that all data is loaded into memory in this script. Most question answering datasets are small
+enough that this is not an issue, but if you have a very large dataset you will need to modify the script to handle
+data streaming.
diff --git a/docs/transformers/examples/flax/question-answering/requirements.txt b/docs/transformers/examples/flax/question-answering/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e7bf43910c3c8aa6ee05dec90748834304430e0f
--- /dev/null
+++ b/docs/transformers/examples/flax/question-answering/requirements.txt
@@ -0,0 +1,5 @@
+datasets >= 1.8.0
+jax>=0.2.17
+jaxlib>=0.1.68
+flax>=0.3.5
+optax>=0.0.8
\ No newline at end of file
diff --git a/docs/transformers/examples/flax/question-answering/run_qa.py b/docs/transformers/examples/flax/question-answering/run_qa.py
new file mode 100644
index 0000000000000000000000000000000000000000..eb506fff04855c431e3efb82db932e44206637f9
--- /dev/null
+++ b/docs/transformers/examples/flax/question-answering/run_qa.py
@@ -0,0 +1,1085 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for question answering.
+"""
+# You can also adapt this script on your own question answering task. Pointers for this are left as comments.
+
+import json
+import logging
+import math
+import os
+import random
+import sys
+import time
+from dataclasses import asdict, dataclass, field
+from enum import Enum
+from pathlib import Path
+from typing import Any, Callable, Optional
+
+import datasets
+import evaluate
+import jax
+import jax.numpy as jnp
+import numpy as np
+import optax
+from datasets import load_dataset
+from flax import struct, traverse_util
+from flax.jax_utils import pad_shard_unpad, replicate, unreplicate
+from flax.training import train_state
+from flax.training.common_utils import get_metrics, onehot, shard
+from huggingface_hub import HfApi
+from tqdm import tqdm
+from utils_qa import postprocess_qa_predictions
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoTokenizer,
+ EvalPrediction,
+ FlaxAutoModelForQuestionAnswering,
+ HfArgumentParser,
+ PreTrainedTokenizerFast,
+ is_tensorboard_available,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+Array = Any
+Dataset = datasets.arrow_dataset.Dataset
+PRNGKey = Any
+
+
+# region Arguments
+@dataclass
+class TrainingArguments:
+ output_dir: str = field(
+ metadata={"help": "The output directory where the model predictions and checkpoints will be written."},
+ )
+ overwrite_output_dir: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Overwrite the content of the output directory. "
+ "Use this to continue training if output_dir points to a checkpoint directory."
+ )
+ },
+ )
+ do_train: bool = field(default=False, metadata={"help": "Whether to run training."})
+ do_eval: bool = field(default=False, metadata={"help": "Whether to run eval on the dev set."})
+ do_predict: bool = field(default=False, metadata={"help": "Whether to run predictions on the test set."})
+ per_device_train_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for training."}
+ )
+ per_device_eval_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for evaluation."}
+ )
+ learning_rate: float = field(default=5e-5, metadata={"help": "The initial learning rate for AdamW."})
+ weight_decay: float = field(default=0.0, metadata={"help": "Weight decay for AdamW if we apply some."})
+ adam_beta1: float = field(default=0.9, metadata={"help": "Beta1 for AdamW optimizer"})
+ adam_beta2: float = field(default=0.999, metadata={"help": "Beta2 for AdamW optimizer"})
+ adam_epsilon: float = field(default=1e-8, metadata={"help": "Epsilon for AdamW optimizer."})
+ adafactor: bool = field(default=False, metadata={"help": "Whether or not to replace AdamW by Adafactor."})
+ num_train_epochs: float = field(default=3.0, metadata={"help": "Total number of training epochs to perform."})
+ warmup_steps: int = field(default=0, metadata={"help": "Linear warmup over warmup_steps."})
+ logging_steps: int = field(default=500, metadata={"help": "Log every X updates steps."})
+ save_steps: int = field(default=500, metadata={"help": "Save checkpoint every X updates steps."})
+ eval_steps: int = field(default=None, metadata={"help": "Run an evaluation every X steps."})
+ seed: int = field(default=42, metadata={"help": "Random seed that will be set at the beginning of training."})
+ push_to_hub: bool = field(
+ default=False, metadata={"help": "Whether or not to upload the trained model to the model hub after training."}
+ )
+ hub_model_id: str = field(
+ default=None, metadata={"help": "The name of the repository to keep in sync with the local `output_dir`."}
+ )
+ hub_token: str = field(default=None, metadata={"help": "The token to use to push to the Model Hub."})
+
+ def __post_init__(self):
+ if self.output_dir is not None:
+ self.output_dir = os.path.expanduser(self.output_dir)
+
+ def to_dict(self):
+ """
+ Serializes this instance while replace `Enum` by their values (for JSON serialization support). It obfuscates
+ the token values by removing their value.
+ """
+ d = asdict(self)
+ for k, v in d.items():
+ if isinstance(v, Enum):
+ d[k] = v.value
+ if isinstance(v, list) and len(v) > 0 and isinstance(v[0], Enum):
+ d[k] = [x.value for x in v]
+ if k.endswith("_token"):
+ d[k] = f"<{k.upper()}>"
+ return d
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Path to directory to store the pretrained models downloaded from huggingface.co"},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ dtype: Optional[str] = field(
+ default="float32",
+ metadata={
+ "help": (
+ "Floating-point format in which the model weights should be initialized and trained. Choose one of"
+ " `[float32, float16, bfloat16]`."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input test data file to evaluate the perplexity on (a text file)."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_seq_length: int = field(
+ default=384,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. If False, will pad the samples dynamically when"
+ " batching to the maximum length in the batch (which can be faster on GPU but will be slower on TPU)."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ version_2_with_negative: bool = field(
+ default=False, metadata={"help": "If true, some of the examples do not have an answer."}
+ )
+ null_score_diff_threshold: float = field(
+ default=0.0,
+ metadata={
+ "help": (
+ "The threshold used to select the null answer: if the best answer has a score that is less than "
+ "the score of the null answer minus this threshold, the null answer is selected for this example. "
+ "Only useful when `version_2_with_negative=True`."
+ )
+ },
+ )
+ doc_stride: int = field(
+ default=128,
+ metadata={"help": "When splitting up a long document into chunks, how much stride to take between chunks."},
+ )
+ n_best_size: int = field(
+ default=20,
+ metadata={"help": "The total number of n-best predictions to generate when looking for an answer."},
+ )
+ max_answer_length: int = field(
+ default=30,
+ metadata={
+ "help": (
+ "The maximum length of an answer that can be generated. This is needed because the start "
+ "and end predictions are not conditioned on one another."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if (
+ self.dataset_name is None
+ and self.train_file is None
+ and self.validation_file is None
+ and self.test_file is None
+ ):
+ raise ValueError("Need either a dataset name or a training/validation file/test_file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ if self.test_file is not None:
+ extension = self.test_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
+
+
+# endregion
+
+
+# region Create a train state
+def create_train_state(
+ model: FlaxAutoModelForQuestionAnswering,
+ learning_rate_fn: Callable[[int], float],
+ num_labels: int,
+ training_args: TrainingArguments,
+) -> train_state.TrainState:
+ """Create initial training state."""
+
+ class TrainState(train_state.TrainState):
+ """Train state with an Optax optimizer.
+
+ The two functions below differ depending on whether the task is classification
+ or regression.
+
+ Args:
+ logits_fn: Applied to last layer to obtain the logits.
+ loss_fn: Function to compute the loss.
+ """
+
+ logits_fn: Callable = struct.field(pytree_node=False)
+ loss_fn: Callable = struct.field(pytree_node=False)
+
+ # We use Optax's "masking" functionality to not apply weight decay
+ # to bias and LayerNorm scale parameters. decay_mask_fn returns a
+ # mask boolean with the same structure as the parameters.
+ # The mask is True for parameters that should be decayed.
+ def decay_mask_fn(params):
+ flat_params = traverse_util.flatten_dict(params)
+ # find out all LayerNorm parameters
+ layer_norm_candidates = ["layernorm", "layer_norm", "ln"]
+ layer_norm_named_params = {
+ layer[-2:]
+ for layer_norm_name in layer_norm_candidates
+ for layer in flat_params.keys()
+ if layer_norm_name in "".join(layer).lower()
+ }
+ flat_mask = {path: (path[-1] != "bias" and path[-2:] not in layer_norm_named_params) for path in flat_params}
+ return traverse_util.unflatten_dict(flat_mask)
+
+ tx = optax.adamw(
+ learning_rate=learning_rate_fn,
+ b1=training_args.adam_beta1,
+ b2=training_args.adam_beta2,
+ eps=training_args.adam_epsilon,
+ weight_decay=training_args.weight_decay,
+ mask=decay_mask_fn,
+ )
+
+ def cross_entropy_loss(logits, labels):
+ start_loss = optax.softmax_cross_entropy(logits[0], onehot(labels[0], num_classes=num_labels))
+ end_loss = optax.softmax_cross_entropy(logits[1], onehot(labels[1], num_classes=num_labels))
+ xentropy = (start_loss + end_loss) / 2.0
+ return jnp.mean(xentropy)
+
+ return TrainState.create(
+ apply_fn=model.__call__,
+ params=model.params,
+ tx=tx,
+ logits_fn=lambda logits: logits,
+ loss_fn=cross_entropy_loss,
+ )
+
+
+# endregion
+
+
+# region Create learning rate function
+def create_learning_rate_fn(
+ train_ds_size: int, train_batch_size: int, num_train_epochs: int, num_warmup_steps: int, learning_rate: float
+) -> Callable[[int], jnp.ndarray]:
+ """Returns a linear warmup, linear_decay learning rate function."""
+ steps_per_epoch = train_ds_size // train_batch_size
+ num_train_steps = steps_per_epoch * num_train_epochs
+ warmup_fn = optax.linear_schedule(init_value=0.0, end_value=learning_rate, transition_steps=num_warmup_steps)
+ decay_fn = optax.linear_schedule(
+ init_value=learning_rate, end_value=0, transition_steps=num_train_steps - num_warmup_steps
+ )
+ schedule_fn = optax.join_schedules(schedules=[warmup_fn, decay_fn], boundaries=[num_warmup_steps])
+ return schedule_fn
+
+
+# endregion
+
+
+# region train data iterator
+def train_data_collator(rng: PRNGKey, dataset: Dataset, batch_size: int):
+ """Returns shuffled batches of size `batch_size` from truncated `train dataset`, sharded over all local devices."""
+ steps_per_epoch = len(dataset) // batch_size
+ perms = jax.random.permutation(rng, len(dataset))
+ perms = perms[: steps_per_epoch * batch_size] # Skip incomplete batch.
+ perms = perms.reshape((steps_per_epoch, batch_size))
+
+ for perm in perms:
+ batch = dataset[perm]
+ batch = {k: np.array(v) for k, v in batch.items()}
+ batch = shard(batch)
+
+ yield batch
+
+
+# endregion
+
+
+# region eval data iterator
+def eval_data_collator(dataset: Dataset, batch_size: int):
+ """Returns batches of size `batch_size` from `eval dataset`. Sharding handled by `pad_shard_unpad` in the eval loop."""
+ batch_idx = np.arange(len(dataset))
+
+ steps_per_epoch = math.ceil(len(dataset) / batch_size)
+ batch_idx = np.array_split(batch_idx, steps_per_epoch)
+
+ for idx in batch_idx:
+ batch = dataset[idx]
+ # Ignore `offset_mapping` to avoid numpy/JAX array conversion issue.
+ batch = {k: np.array(v) for k, v in batch.items() if k != "offset_mapping"}
+
+ yield batch
+
+
+# endregion
+
+
+def main():
+ # region Argument parsing
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_qa", model_args, data_args, framework="flax")
+ # endregion
+
+ # region Logging
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ # Setup logging, we only want one process per machine to log things on the screen.
+ logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
+ if jax.process_index() == 0:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+ # endregion
+
+ # Handle the repository creation
+ if training_args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = training_args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(training_args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
+
+ # region Load Data
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ # Loading the dataset from local csv or json file.
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if data_args.test_file is not None:
+ data_files["test"] = data_args.test_file
+ extension = data_args.test_file.split(".")[-1]
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ field="data",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+ # endregion
+
+ # region Load pretrained model and tokenizer
+ #
+ # Load pretrained model and tokenizer
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=True,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ # endregion
+
+ # region Tokenizer check: this script requires a fast tokenizer.
+ if not isinstance(tokenizer, PreTrainedTokenizerFast):
+ raise ValueError(
+ "This example script only works for models that have a fast tokenizer. Checkout the big table of models at"
+ " https://huggingface.co/transformers/index.html#supported-frameworks to find the model types that meet"
+ " this requirement"
+ )
+ # endregion
+
+ # region Preprocessing the datasets
+ # Preprocessing is slightly different for training and evaluation.
+ if training_args.do_train:
+ column_names = raw_datasets["train"].column_names
+ elif training_args.do_eval:
+ column_names = raw_datasets["validation"].column_names
+ else:
+ column_names = raw_datasets["test"].column_names
+ question_column_name = "question" if "question" in column_names else column_names[0]
+ context_column_name = "context" if "context" in column_names else column_names[1]
+ answer_column_name = "answers" if "answers" in column_names else column_names[2]
+
+ # Padding side determines if we do (question|context) or (context|question).
+ pad_on_right = tokenizer.padding_side == "right"
+
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ # Training preprocessing
+ def prepare_train_features(examples):
+ # Some of the questions have lots of whitespace on the left, which is not useful and will make the
+ # truncation of the context fail (the tokenized question will take a lots of space). So we remove that
+ # left whitespace
+ examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
+
+ # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
+ # in one example possible giving several features when a context is long, each of those features having a
+ # context that overlaps a bit the context of the previous feature.
+ tokenized_examples = tokenizer(
+ examples[question_column_name if pad_on_right else context_column_name],
+ examples[context_column_name if pad_on_right else question_column_name],
+ truncation="only_second" if pad_on_right else "only_first",
+ max_length=max_seq_length,
+ stride=data_args.doc_stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ padding="max_length",
+ )
+
+ # Since one example might give us several features if it has a long context, we need a map from a feature to
+ # its corresponding example. This key gives us just that.
+ sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
+ # The offset mappings will give us a map from token to character position in the original context. This will
+ # help us compute the start_positions and end_positions.
+ offset_mapping = tokenized_examples.pop("offset_mapping")
+
+ # Let's label those examples!
+ tokenized_examples["start_positions"] = []
+ tokenized_examples["end_positions"] = []
+
+ for i, offsets in enumerate(offset_mapping):
+ # We will label impossible answers with the index of the CLS token.
+ input_ids = tokenized_examples["input_ids"][i]
+ cls_index = input_ids.index(tokenizer.cls_token_id)
+
+ # Grab the sequence corresponding to that example (to know what is the context and what is the question).
+ sequence_ids = tokenized_examples.sequence_ids(i)
+
+ # One example can give several spans, this is the index of the example containing this span of text.
+ sample_index = sample_mapping[i]
+ answers = examples[answer_column_name][sample_index]
+ # If no answers are given, set the cls_index as answer.
+ if len(answers["answer_start"]) == 0:
+ tokenized_examples["start_positions"].append(cls_index)
+ tokenized_examples["end_positions"].append(cls_index)
+ else:
+ # Start/end character index of the answer in the text.
+ start_char = answers["answer_start"][0]
+ end_char = start_char + len(answers["text"][0])
+
+ # Start token index of the current span in the text.
+ token_start_index = 0
+ while sequence_ids[token_start_index] != (1 if pad_on_right else 0):
+ token_start_index += 1
+
+ # End token index of the current span in the text.
+ token_end_index = len(input_ids) - 1
+ while sequence_ids[token_end_index] != (1 if pad_on_right else 0):
+ token_end_index -= 1
+
+ # Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
+ if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
+ tokenized_examples["start_positions"].append(cls_index)
+ tokenized_examples["end_positions"].append(cls_index)
+ else:
+ # Otherwise move the token_start_index and token_end_index to the two ends of the answer.
+ # Note: we could go after the last offset if the answer is the last word (edge case).
+ while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
+ token_start_index += 1
+ tokenized_examples["start_positions"].append(token_start_index - 1)
+ while offsets[token_end_index][1] >= end_char:
+ token_end_index -= 1
+ tokenized_examples["end_positions"].append(token_end_index + 1)
+
+ return tokenized_examples
+
+ processed_raw_datasets = {}
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if data_args.max_train_samples is not None:
+ # We will select sample from whole data if argument is specified
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ # Create train feature from dataset
+ train_dataset = train_dataset.map(
+ prepare_train_features,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+ if data_args.max_train_samples is not None:
+ # Number of samples might increase during Feature Creation, We select only specified max samples
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ processed_raw_datasets["train"] = train_dataset
+
+ # Validation preprocessing
+ def prepare_validation_features(examples):
+ # Some of the questions have lots of whitespace on the left, which is not useful and will make the
+ # truncation of the context fail (the tokenized question will take a lots of space). So we remove that
+ # left whitespace
+ examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
+
+ # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
+ # in one example possible giving several features when a context is long, each of those features having a
+ # context that overlaps a bit the context of the previous feature.
+ tokenized_examples = tokenizer(
+ examples[question_column_name if pad_on_right else context_column_name],
+ examples[context_column_name if pad_on_right else question_column_name],
+ truncation="only_second" if pad_on_right else "only_first",
+ max_length=max_seq_length,
+ stride=data_args.doc_stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ padding="max_length",
+ )
+
+ # Since one example might give us several features if it has a long context, we need a map from a feature to
+ # its corresponding example. This key gives us just that.
+ sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
+
+ # For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
+ # corresponding example_id and we will store the offset mappings.
+ tokenized_examples["example_id"] = []
+
+ for i in range(len(tokenized_examples["input_ids"])):
+ # Grab the sequence corresponding to that example (to know what is the context and what is the question).
+ sequence_ids = tokenized_examples.sequence_ids(i)
+ context_index = 1 if pad_on_right else 0
+
+ # One example can give several spans, this is the index of the example containing this span of text.
+ sample_index = sample_mapping[i]
+ tokenized_examples["example_id"].append(examples["id"][sample_index])
+
+ # Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
+ # position is part of the context or not.
+ tokenized_examples["offset_mapping"][i] = [
+ (o if sequence_ids[k] == context_index else None)
+ for k, o in enumerate(tokenized_examples["offset_mapping"][i])
+ ]
+
+ return tokenized_examples
+
+ if training_args.do_eval:
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_examples = raw_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ # We will select sample from whole data
+ max_eval_samples = min(len(eval_examples), data_args.max_eval_samples)
+ eval_examples = eval_examples.select(range(max_eval_samples))
+ # Validation Feature Creation
+ eval_dataset = eval_examples.map(
+ prepare_validation_features,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+ if data_args.max_eval_samples is not None:
+ # During Feature creation dataset samples might increase, we will select required samples again
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+ processed_raw_datasets["validation"] = eval_dataset
+
+ if training_args.do_predict:
+ if "test" not in raw_datasets:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_examples = raw_datasets["test"]
+ if data_args.max_predict_samples is not None:
+ # We will select sample from whole data
+ predict_examples = predict_examples.select(range(data_args.max_predict_samples))
+ # Predict Feature Creation
+ predict_dataset = predict_examples.map(
+ prepare_validation_features,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+ if data_args.max_predict_samples is not None:
+ # During Feature creation dataset samples might increase, we will select required samples again
+ max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
+ predict_dataset = predict_dataset.select(range(max_predict_samples))
+ processed_raw_datasets["test"] = predict_dataset
+ # endregion
+
+ # region Metrics and Post-processing:
+ def post_processing_function(examples, features, predictions, stage="eval"):
+ # Post-processing: we match the start logits and end logits to answers in the original context.
+ predictions = postprocess_qa_predictions(
+ examples=examples,
+ features=features,
+ predictions=predictions,
+ version_2_with_negative=data_args.version_2_with_negative,
+ n_best_size=data_args.n_best_size,
+ max_answer_length=data_args.max_answer_length,
+ null_score_diff_threshold=data_args.null_score_diff_threshold,
+ output_dir=training_args.output_dir,
+ prefix=stage,
+ )
+ # Format the result to the format the metric expects.
+ if data_args.version_2_with_negative:
+ formatted_predictions = [
+ {"id": k, "prediction_text": v, "no_answer_probability": 0.0} for k, v in predictions.items()
+ ]
+ else:
+ formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
+
+ references = [{"id": ex["id"], "answers": ex[answer_column_name]} for ex in examples]
+ return EvalPrediction(predictions=formatted_predictions, label_ids=references)
+
+ metric = evaluate.load(
+ "squad_v2" if data_args.version_2_with_negative else "squad", cache_dir=model_args.cache_dir
+ )
+
+ def compute_metrics(p: EvalPrediction):
+ return metric.compute(predictions=p.predictions, references=p.label_ids)
+
+ # Create and fill numpy array of size len_of_validation_data * max_length_of_output_tensor
+ def create_and_fill_np_array(start_or_end_logits, dataset, max_len):
+ """
+ Create and fill numpy array of size len_of_validation_data * max_length_of_output_tensor
+
+ Args:
+ start_or_end_logits(:obj:`tensor`):
+ This is the output predictions of the model. We can only enter either start or end logits.
+ eval_dataset: Evaluation dataset
+ max_len(:obj:`int`):
+ The maximum length of the output tensor. ( See the model.eval() part for more details )
+ """
+
+ step = 0
+ # create a numpy array and fill it with -100.
+ logits_concat = np.full((len(dataset), max_len), -100, dtype=np.float64)
+ # Now since we have create an array now we will populate it with the outputs of the model.
+ for i, output_logit in enumerate(start_or_end_logits): # populate columns
+ # We have to fill it such that we have to take the whole tensor and replace it on the newly created array
+ # And after every iteration we have to change the step
+
+ batch_size = output_logit.shape[0]
+ cols = output_logit.shape[1]
+
+ if step + batch_size < len(dataset):
+ logits_concat[step : step + batch_size, :cols] = output_logit
+ else:
+ logits_concat[step:, :cols] = output_logit[: len(dataset) - step]
+
+ step += batch_size
+
+ return logits_concat
+
+ # endregion
+
+ # region Training steps and logging init
+ train_dataset = processed_raw_datasets["train"]
+ eval_dataset = processed_raw_datasets["validation"]
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # Define a summary writer
+ has_tensorboard = is_tensorboard_available()
+ if has_tensorboard and jax.process_index() == 0:
+ try:
+ from flax.metrics.tensorboard import SummaryWriter
+
+ summary_writer = SummaryWriter(training_args.output_dir)
+ summary_writer.hparams({**training_args.to_dict(), **vars(model_args), **vars(data_args)})
+ except ImportError as ie:
+ has_tensorboard = False
+ logger.warning(
+ f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
+ )
+ else:
+ logger.warning(
+ "Unable to display metrics through TensorBoard because the package is not installed: "
+ "Please run pip install tensorboard to enable."
+ )
+
+ def write_train_metric(summary_writer, train_metrics, train_time, step):
+ summary_writer.scalar("train_time", train_time, step)
+
+ train_metrics = get_metrics(train_metrics)
+ for key, vals in train_metrics.items():
+ tag = f"train_{key}"
+ for i, val in enumerate(vals):
+ summary_writer.scalar(tag, val, step - len(vals) + i + 1)
+
+ def write_eval_metric(summary_writer, eval_metrics, step):
+ for metric_name, value in eval_metrics.items():
+ summary_writer.scalar(f"eval_{metric_name}", value, step)
+
+ num_epochs = int(training_args.num_train_epochs)
+ rng = jax.random.PRNGKey(training_args.seed)
+ dropout_rngs = jax.random.split(rng, jax.local_device_count())
+
+ train_batch_size = int(training_args.per_device_train_batch_size) * jax.local_device_count()
+ per_device_eval_batch_size = int(training_args.per_device_eval_batch_size)
+ eval_batch_size = per_device_eval_batch_size * jax.local_device_count()
+ # endregion
+
+ # region Load model
+ model = FlaxAutoModelForQuestionAnswering.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ )
+
+ learning_rate_fn = create_learning_rate_fn(
+ len(train_dataset),
+ train_batch_size,
+ training_args.num_train_epochs,
+ training_args.warmup_steps,
+ training_args.learning_rate,
+ )
+
+ state = create_train_state(model, learning_rate_fn, num_labels=max_seq_length, training_args=training_args)
+ # endregion
+
+ # region Define train step functions
+ def train_step(
+ state: train_state.TrainState, batch: dict[str, Array], dropout_rng: PRNGKey
+ ) -> tuple[train_state.TrainState, float]:
+ """Trains model with an optimizer (both in `state`) on `batch`, returning a pair `(new_state, loss)`."""
+ dropout_rng, new_dropout_rng = jax.random.split(dropout_rng)
+ start_positions = batch.pop("start_positions")
+ end_positions = batch.pop("end_positions")
+ targets = (start_positions, end_positions)
+
+ def loss_fn(params):
+ logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)
+ loss = state.loss_fn(logits, targets)
+ return loss
+
+ grad_fn = jax.value_and_grad(loss_fn)
+ loss, grad = grad_fn(state.params)
+ grad = jax.lax.pmean(grad, "batch")
+ new_state = state.apply_gradients(grads=grad)
+ metrics = jax.lax.pmean({"loss": loss, "learning_rate": learning_rate_fn(state.step)}, axis_name="batch")
+ return new_state, metrics, new_dropout_rng
+
+ p_train_step = jax.pmap(train_step, axis_name="batch", donate_argnums=(0,))
+ # endregion
+
+ # region Define eval step functions
+ def eval_step(state, batch):
+ logits = state.apply_fn(**batch, params=state.params, train=False)
+ return state.logits_fn(logits)
+
+ p_eval_step = jax.pmap(eval_step, axis_name="batch")
+ # endregion
+
+ # region Define train and eval loop
+ logger.info(f"===== Starting training ({num_epochs} epochs) =====")
+ train_time = 0
+
+ # make sure weights are replicated on each device
+ state = replicate(state)
+
+ train_time = 0
+ step_per_epoch = len(train_dataset) // train_batch_size
+ total_steps = step_per_epoch * num_epochs
+ epochs = tqdm(range(num_epochs), desc=f"Epoch ... (1/{num_epochs})", position=0)
+ for epoch in epochs:
+ train_start = time.time()
+ train_metrics = []
+
+ # Create sampling rng
+ rng, input_rng = jax.random.split(rng)
+
+ # train
+ for step, batch in enumerate(
+ tqdm(
+ train_data_collator(input_rng, train_dataset, train_batch_size),
+ total=step_per_epoch,
+ desc="Training...",
+ position=1,
+ ),
+ 1,
+ ):
+ state, train_metric, dropout_rngs = p_train_step(state, batch, dropout_rngs)
+ train_metrics.append(train_metric)
+
+ cur_step = epoch * step_per_epoch + step
+
+ if cur_step % training_args.logging_steps == 0 and cur_step > 0:
+ # Save metrics
+ train_metric = unreplicate(train_metric)
+ train_time += time.time() - train_start
+ if has_tensorboard and jax.process_index() == 0:
+ write_train_metric(summary_writer, train_metrics, train_time, cur_step)
+
+ epochs.write(
+ f"Step... ({cur_step}/{total_steps} | Training Loss: {train_metric['loss']}, Learning Rate:"
+ f" {train_metric['learning_rate']})"
+ )
+
+ train_metrics = []
+
+ if (
+ training_args.do_eval
+ and (cur_step % training_args.eval_steps == 0 or cur_step % step_per_epoch == 0)
+ and cur_step > 0
+ ):
+ eval_metrics = {}
+ all_start_logits = []
+ all_end_logits = []
+ # evaluate
+ for batch in tqdm(
+ eval_data_collator(eval_dataset, eval_batch_size),
+ total=math.ceil(len(eval_dataset) / eval_batch_size),
+ desc="Evaluating ...",
+ position=2,
+ ):
+ _ = batch.pop("example_id")
+ predictions = pad_shard_unpad(p_eval_step)(
+ state, batch, min_device_batch=per_device_eval_batch_size
+ )
+ start_logits = np.array(predictions[0])
+ end_logits = np.array(predictions[1])
+ all_start_logits.append(start_logits)
+ all_end_logits.append(end_logits)
+
+ max_len = max([x.shape[1] for x in all_start_logits]) # Get the max_length of the tensor
+
+ # concatenate the numpy array
+ start_logits_concat = create_and_fill_np_array(all_start_logits, eval_dataset, max_len)
+ end_logits_concat = create_and_fill_np_array(all_end_logits, eval_dataset, max_len)
+
+ # delete the list of numpy arrays
+ del all_start_logits
+ del all_end_logits
+ outputs_numpy = (start_logits_concat, end_logits_concat)
+ prediction = post_processing_function(eval_examples, eval_dataset, outputs_numpy)
+ eval_metrics = compute_metrics(prediction)
+
+ logger.info(f"Step... ({cur_step}/{total_steps} | Evaluation metrics: {eval_metrics})")
+
+ if has_tensorboard and jax.process_index() == 0:
+ write_eval_metric(summary_writer, eval_metrics, cur_step)
+
+ if (cur_step % training_args.save_steps == 0 and cur_step > 0) or (cur_step == total_steps):
+ # save checkpoint after each epoch and push checkpoint to the hub
+ if jax.process_index() == 0:
+ params = jax.device_get(unreplicate(state.params))
+ model.save_pretrained(training_args.output_dir, params=params)
+ tokenizer.save_pretrained(training_args.output_dir)
+ if training_args.push_to_hub:
+ api.upload_folder(
+ commit_message=f"Saving weights and logs of step {cur_step}",
+ folder_path=training_args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=training_args.hub_token,
+ )
+ epochs.desc = f"Epoch ... {epoch + 1}/{num_epochs}"
+ # endregion
+
+ # Eval after training
+ if training_args.do_eval:
+ eval_metrics = {}
+ all_start_logits = []
+ all_end_logits = []
+
+ eval_loader = eval_data_collator(eval_dataset, eval_batch_size)
+ for batch in tqdm(
+ eval_loader, total=math.ceil(len(eval_dataset) / eval_batch_size), desc="Evaluating ...", position=2
+ ):
+ _ = batch.pop("example_id")
+ predictions = pad_shard_unpad(p_eval_step)(state, batch, min_device_batch=per_device_eval_batch_size)
+ start_logits = np.array(predictions[0])
+ end_logits = np.array(predictions[1])
+ all_start_logits.append(start_logits)
+ all_end_logits.append(end_logits)
+
+ max_len = max([x.shape[1] for x in all_start_logits]) # Get the max_length of the tensor
+
+ # concatenate the numpy array
+ start_logits_concat = create_and_fill_np_array(all_start_logits, eval_dataset, max_len)
+ end_logits_concat = create_and_fill_np_array(all_end_logits, eval_dataset, max_len)
+
+ # delete the list of numpy arrays
+ del all_start_logits
+ del all_end_logits
+ outputs_numpy = (start_logits_concat, end_logits_concat)
+ prediction = post_processing_function(eval_examples, eval_dataset, outputs_numpy)
+ eval_metrics = compute_metrics(prediction)
+
+ if jax.process_index() == 0:
+ eval_metrics = {f"eval_{metric_name}": value for metric_name, value in eval_metrics.items()}
+ path = os.path.join(training_args.output_dir, "eval_results.json")
+ with open(path, "w") as f:
+ json.dump(eval_metrics, f, indent=4, sort_keys=True)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/flax/question-answering/utils_qa.py b/docs/transformers/examples/flax/question-answering/utils_qa.py
new file mode 100644
index 0000000000000000000000000000000000000000..f0cc5c26a6927179d83dab56d21f4acb357884ee
--- /dev/null
+++ b/docs/transformers/examples/flax/question-answering/utils_qa.py
@@ -0,0 +1,443 @@
+# Copyright 2020 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Post-processing utilities for question answering.
+"""
+
+import collections
+import json
+import logging
+import os
+from typing import Optional
+
+import numpy as np
+from tqdm.auto import tqdm
+
+
+logger = logging.getLogger(__name__)
+
+
+def postprocess_qa_predictions(
+ examples,
+ features,
+ predictions: tuple[np.ndarray, np.ndarray],
+ version_2_with_negative: bool = False,
+ n_best_size: int = 20,
+ max_answer_length: int = 30,
+ null_score_diff_threshold: float = 0.0,
+ output_dir: Optional[str] = None,
+ prefix: Optional[str] = None,
+ log_level: Optional[int] = logging.WARNING,
+):
+ """
+ Post-processes the predictions of a question-answering model to convert them to answers that are substrings of the
+ original contexts. This is the base postprocessing functions for models that only return start and end logits.
+
+ Args:
+ examples: The non-preprocessed dataset (see the main script for more information).
+ features: The processed dataset (see the main script for more information).
+ predictions (:obj:`Tuple[np.ndarray, np.ndarray]`):
+ The predictions of the model: two arrays containing the start logits and the end logits respectively. Its
+ first dimension must match the number of elements of :obj:`features`.
+ version_2_with_negative (:obj:`bool`, `optional`, defaults to :obj:`False`):
+ Whether or not the underlying dataset contains examples with no answers.
+ n_best_size (:obj:`int`, `optional`, defaults to 20):
+ The total number of n-best predictions to generate when looking for an answer.
+ max_answer_length (:obj:`int`, `optional`, defaults to 30):
+ The maximum length of an answer that can be generated. This is needed because the start and end predictions
+ are not conditioned on one another.
+ null_score_diff_threshold (:obj:`float`, `optional`, defaults to 0):
+ The threshold used to select the null answer: if the best answer has a score that is less than the score of
+ the null answer minus this threshold, the null answer is selected for this example (note that the score of
+ the null answer for an example giving several features is the minimum of the scores for the null answer on
+ each feature: all features must be aligned on the fact they `want` to predict a null answer).
+
+ Only useful when :obj:`version_2_with_negative` is :obj:`True`.
+ output_dir (:obj:`str`, `optional`):
+ If provided, the dictionaries of predictions, n_best predictions (with their scores and logits) and, if
+ :obj:`version_2_with_negative=True`, the dictionary of the scores differences between best and null
+ answers, are saved in `output_dir`.
+ prefix (:obj:`str`, `optional`):
+ If provided, the dictionaries mentioned above are saved with `prefix` added to their names.
+ log_level (:obj:`int`, `optional`, defaults to ``logging.WARNING``):
+ ``logging`` log level (e.g., ``logging.WARNING``)
+ """
+ if len(predictions) != 2:
+ raise ValueError("`predictions` should be a tuple with two elements (start_logits, end_logits).")
+ all_start_logits, all_end_logits = predictions
+
+ if len(predictions[0]) != len(features):
+ raise ValueError(f"Got {len(predictions[0])} predictions and {len(features)} features.")
+
+ # Build a map example to its corresponding features.
+ example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
+ features_per_example = collections.defaultdict(list)
+ for i, feature in enumerate(features):
+ features_per_example[example_id_to_index[feature["example_id"]]].append(i)
+
+ # The dictionaries we have to fill.
+ all_predictions = collections.OrderedDict()
+ all_nbest_json = collections.OrderedDict()
+ if version_2_with_negative:
+ scores_diff_json = collections.OrderedDict()
+
+ # Logging.
+ logger.setLevel(log_level)
+ logger.info(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
+
+ # Let's loop over all the examples!
+ for example_index, example in enumerate(tqdm(examples)):
+ # Those are the indices of the features associated to the current example.
+ feature_indices = features_per_example[example_index]
+
+ min_null_prediction = None
+ prelim_predictions = []
+
+ # Looping through all the features associated to the current example.
+ for feature_index in feature_indices:
+ # We grab the predictions of the model for this feature.
+ start_logits = all_start_logits[feature_index]
+ end_logits = all_end_logits[feature_index]
+ # This is what will allow us to map some the positions in our logits to span of texts in the original
+ # context.
+ offset_mapping = features[feature_index]["offset_mapping"]
+ # Optional `token_is_max_context`, if provided we will remove answers that do not have the maximum context
+ # available in the current feature.
+ token_is_max_context = features[feature_index].get("token_is_max_context", None)
+
+ # Update minimum null prediction.
+ feature_null_score = start_logits[0] + end_logits[0]
+ if min_null_prediction is None or min_null_prediction["score"] > feature_null_score:
+ min_null_prediction = {
+ "offsets": (0, 0),
+ "score": feature_null_score,
+ "start_logit": start_logits[0],
+ "end_logit": end_logits[0],
+ }
+
+ # Go through all possibilities for the `n_best_size` greater start and end logits.
+ start_indexes = np.argsort(start_logits)[-1 : -n_best_size - 1 : -1].tolist()
+ end_indexes = np.argsort(end_logits)[-1 : -n_best_size - 1 : -1].tolist()
+ for start_index in start_indexes:
+ for end_index in end_indexes:
+ # Don't consider out-of-scope answers, either because the indices are out of bounds or correspond
+ # to part of the input_ids that are not in the context.
+ if (
+ start_index >= len(offset_mapping)
+ or end_index >= len(offset_mapping)
+ or offset_mapping[start_index] is None
+ or len(offset_mapping[start_index]) < 2
+ or offset_mapping[end_index] is None
+ or len(offset_mapping[end_index]) < 2
+ ):
+ continue
+ # Don't consider answers with a length that is either < 0 or > max_answer_length.
+ if end_index < start_index or end_index - start_index + 1 > max_answer_length:
+ continue
+ # Don't consider answer that don't have the maximum context available (if such information is
+ # provided).
+ if token_is_max_context is not None and not token_is_max_context.get(str(start_index), False):
+ continue
+
+ prelim_predictions.append(
+ {
+ "offsets": (offset_mapping[start_index][0], offset_mapping[end_index][1]),
+ "score": start_logits[start_index] + end_logits[end_index],
+ "start_logit": start_logits[start_index],
+ "end_logit": end_logits[end_index],
+ }
+ )
+ if version_2_with_negative and min_null_prediction is not None:
+ # Add the minimum null prediction
+ prelim_predictions.append(min_null_prediction)
+ null_score = min_null_prediction["score"]
+
+ # Only keep the best `n_best_size` predictions.
+ predictions = sorted(prelim_predictions, key=lambda x: x["score"], reverse=True)[:n_best_size]
+
+ # Add back the minimum null prediction if it was removed because of its low score.
+ if (
+ version_2_with_negative
+ and min_null_prediction is not None
+ and not any(p["offsets"] == (0, 0) for p in predictions)
+ ):
+ predictions.append(min_null_prediction)
+
+ # Use the offsets to gather the answer text in the original context.
+ context = example["context"]
+ for pred in predictions:
+ offsets = pred.pop("offsets")
+ pred["text"] = context[offsets[0] : offsets[1]]
+
+ # In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
+ # failure.
+ if len(predictions) == 0 or (len(predictions) == 1 and predictions[0]["text"] == ""):
+ predictions.insert(0, {"text": "empty", "start_logit": 0.0, "end_logit": 0.0, "score": 0.0})
+
+ # Compute the softmax of all scores (we do it with numpy to stay independent from torch/tf in this file, using
+ # the LogSumExp trick).
+ scores = np.array([pred.pop("score") for pred in predictions])
+ exp_scores = np.exp(scores - np.max(scores))
+ probs = exp_scores / exp_scores.sum()
+
+ # Include the probabilities in our predictions.
+ for prob, pred in zip(probs, predictions):
+ pred["probability"] = prob
+
+ # Pick the best prediction. If the null answer is not possible, this is easy.
+ if not version_2_with_negative:
+ all_predictions[example["id"]] = predictions[0]["text"]
+ else:
+ # Otherwise we first need to find the best non-empty prediction.
+ i = 0
+ while predictions[i]["text"] == "":
+ i += 1
+ best_non_null_pred = predictions[i]
+
+ # Then we compare to the null prediction using the threshold.
+ score_diff = null_score - best_non_null_pred["start_logit"] - best_non_null_pred["end_logit"]
+ scores_diff_json[example["id"]] = float(score_diff) # To be JSON-serializable.
+ if score_diff > null_score_diff_threshold:
+ all_predictions[example["id"]] = ""
+ else:
+ all_predictions[example["id"]] = best_non_null_pred["text"]
+
+ # Make `predictions` JSON-serializable by casting np.float back to float.
+ all_nbest_json[example["id"]] = [
+ {k: (float(v) if isinstance(v, (np.float16, np.float32, np.float64)) else v) for k, v in pred.items()}
+ for pred in predictions
+ ]
+
+ # If we have an output_dir, let's save all those dicts.
+ if output_dir is not None:
+ if not os.path.isdir(output_dir):
+ raise OSError(f"{output_dir} is not a directory.")
+
+ prediction_file = os.path.join(
+ output_dir, "predictions.json" if prefix is None else f"{prefix}_predictions.json"
+ )
+ nbest_file = os.path.join(
+ output_dir, "nbest_predictions.json" if prefix is None else f"{prefix}_nbest_predictions.json"
+ )
+ if version_2_with_negative:
+ null_odds_file = os.path.join(
+ output_dir, "null_odds.json" if prefix is None else f"{prefix}_null_odds.json"
+ )
+
+ logger.info(f"Saving predictions to {prediction_file}.")
+ with open(prediction_file, "w") as writer:
+ writer.write(json.dumps(all_predictions, indent=4) + "\n")
+ logger.info(f"Saving nbest_preds to {nbest_file}.")
+ with open(nbest_file, "w") as writer:
+ writer.write(json.dumps(all_nbest_json, indent=4) + "\n")
+ if version_2_with_negative:
+ logger.info(f"Saving null_odds to {null_odds_file}.")
+ with open(null_odds_file, "w") as writer:
+ writer.write(json.dumps(scores_diff_json, indent=4) + "\n")
+
+ return all_predictions
+
+
+def postprocess_qa_predictions_with_beam_search(
+ examples,
+ features,
+ predictions: tuple[np.ndarray, np.ndarray],
+ version_2_with_negative: bool = False,
+ n_best_size: int = 20,
+ max_answer_length: int = 30,
+ start_n_top: int = 5,
+ end_n_top: int = 5,
+ output_dir: Optional[str] = None,
+ prefix: Optional[str] = None,
+ log_level: Optional[int] = logging.WARNING,
+):
+ """
+ Post-processes the predictions of a question-answering model with beam search to convert them to answers that are substrings of the
+ original contexts. This is the postprocessing functions for models that return start and end logits, indices, as well as
+ cls token predictions.
+
+ Args:
+ examples: The non-preprocessed dataset (see the main script for more information).
+ features: The processed dataset (see the main script for more information).
+ predictions (:obj:`Tuple[np.ndarray, np.ndarray]`):
+ The predictions of the model: two arrays containing the start logits and the end logits respectively. Its
+ first dimension must match the number of elements of :obj:`features`.
+ version_2_with_negative (:obj:`bool`, `optional`, defaults to :obj:`False`):
+ Whether or not the underlying dataset contains examples with no answers.
+ n_best_size (:obj:`int`, `optional`, defaults to 20):
+ The total number of n-best predictions to generate when looking for an answer.
+ max_answer_length (:obj:`int`, `optional`, defaults to 30):
+ The maximum length of an answer that can be generated. This is needed because the start and end predictions
+ are not conditioned on one another.
+ start_n_top (:obj:`int`, `optional`, defaults to 5):
+ The number of top start logits too keep when searching for the :obj:`n_best_size` predictions.
+ end_n_top (:obj:`int`, `optional`, defaults to 5):
+ The number of top end logits too keep when searching for the :obj:`n_best_size` predictions.
+ output_dir (:obj:`str`, `optional`):
+ If provided, the dictionaries of predictions, n_best predictions (with their scores and logits) and, if
+ :obj:`version_2_with_negative=True`, the dictionary of the scores differences between best and null
+ answers, are saved in `output_dir`.
+ prefix (:obj:`str`, `optional`):
+ If provided, the dictionaries mentioned above are saved with `prefix` added to their names.
+ log_level (:obj:`int`, `optional`, defaults to ``logging.WARNING``):
+ ``logging`` log level (e.g., ``logging.WARNING``)
+ """
+ if len(predictions) != 5:
+ raise ValueError("`predictions` should be a tuple with five elements.")
+ start_top_log_probs, start_top_index, end_top_log_probs, end_top_index, cls_logits = predictions
+
+ if len(predictions[0]) != len(features):
+ raise ValueError(f"Got {len(predictions[0])} predictions and {len(features)} features.")
+
+ # Build a map example to its corresponding features.
+ example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
+ features_per_example = collections.defaultdict(list)
+ for i, feature in enumerate(features):
+ features_per_example[example_id_to_index[feature["example_id"]]].append(i)
+
+ # The dictionaries we have to fill.
+ all_predictions = collections.OrderedDict()
+ all_nbest_json = collections.OrderedDict()
+ scores_diff_json = collections.OrderedDict() if version_2_with_negative else None
+
+ # Logging.
+ logger.setLevel(log_level)
+ logger.info(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
+
+ # Let's loop over all the examples!
+ for example_index, example in enumerate(tqdm(examples)):
+ # Those are the indices of the features associated to the current example.
+ feature_indices = features_per_example[example_index]
+
+ min_null_score = None
+ prelim_predictions = []
+
+ # Looping through all the features associated to the current example.
+ for feature_index in feature_indices:
+ # We grab the predictions of the model for this feature.
+ start_log_prob = start_top_log_probs[feature_index]
+ start_indexes = start_top_index[feature_index]
+ end_log_prob = end_top_log_probs[feature_index]
+ end_indexes = end_top_index[feature_index]
+ feature_null_score = cls_logits[feature_index]
+ # This is what will allow us to map some the positions in our logits to span of texts in the original
+ # context.
+ offset_mapping = features[feature_index]["offset_mapping"]
+ # Optional `token_is_max_context`, if provided we will remove answers that do not have the maximum context
+ # available in the current feature.
+ token_is_max_context = features[feature_index].get("token_is_max_context", None)
+
+ # Update minimum null prediction
+ if min_null_score is None or feature_null_score < min_null_score:
+ min_null_score = feature_null_score
+
+ # Go through all possibilities for the `n_start_top`/`n_end_top` greater start and end logits.
+ for i in range(start_n_top):
+ for j in range(end_n_top):
+ start_index = int(start_indexes[i])
+ j_index = i * end_n_top + j
+ end_index = int(end_indexes[j_index])
+ # Don't consider out-of-scope answers (last part of the test should be unnecessary because of the
+ # p_mask but let's not take any risk)
+ if (
+ start_index >= len(offset_mapping)
+ or end_index >= len(offset_mapping)
+ or offset_mapping[start_index] is None
+ or len(offset_mapping[start_index]) < 2
+ or offset_mapping[end_index] is None
+ or len(offset_mapping[end_index]) < 2
+ ):
+ continue
+
+ # Don't consider answers with a length negative or > max_answer_length.
+ if end_index < start_index or end_index - start_index + 1 > max_answer_length:
+ continue
+ # Don't consider answer that don't have the maximum context available (if such information is
+ # provided).
+ if token_is_max_context is not None and not token_is_max_context.get(str(start_index), False):
+ continue
+ prelim_predictions.append(
+ {
+ "offsets": (offset_mapping[start_index][0], offset_mapping[end_index][1]),
+ "score": start_log_prob[i] + end_log_prob[j_index],
+ "start_log_prob": start_log_prob[i],
+ "end_log_prob": end_log_prob[j_index],
+ }
+ )
+
+ # Only keep the best `n_best_size` predictions.
+ predictions = sorted(prelim_predictions, key=lambda x: x["score"], reverse=True)[:n_best_size]
+
+ # Use the offsets to gather the answer text in the original context.
+ context = example["context"]
+ for pred in predictions:
+ offsets = pred.pop("offsets")
+ pred["text"] = context[offsets[0] : offsets[1]]
+
+ # In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
+ # failure.
+ if len(predictions) == 0:
+ # Without predictions min_null_score is going to be None and None will cause an exception later
+ min_null_score = -2e-6
+ predictions.insert(0, {"text": "", "start_logit": -1e-6, "end_logit": -1e-6, "score": min_null_score})
+
+ # Compute the softmax of all scores (we do it with numpy to stay independent from torch/tf in this file, using
+ # the LogSumExp trick).
+ scores = np.array([pred.pop("score") for pred in predictions])
+ exp_scores = np.exp(scores - np.max(scores))
+ probs = exp_scores / exp_scores.sum()
+
+ # Include the probabilities in our predictions.
+ for prob, pred in zip(probs, predictions):
+ pred["probability"] = prob
+
+ # Pick the best prediction and set the probability for the null answer.
+ all_predictions[example["id"]] = predictions[0]["text"]
+ if version_2_with_negative:
+ scores_diff_json[example["id"]] = float(min_null_score)
+
+ # Make `predictions` JSON-serializable by casting np.float back to float.
+ all_nbest_json[example["id"]] = [
+ {k: (float(v) if isinstance(v, (np.float16, np.float32, np.float64)) else v) for k, v in pred.items()}
+ for pred in predictions
+ ]
+
+ # If we have an output_dir, let's save all those dicts.
+ if output_dir is not None:
+ if not os.path.isdir(output_dir):
+ raise OSError(f"{output_dir} is not a directory.")
+
+ prediction_file = os.path.join(
+ output_dir, "predictions.json" if prefix is None else f"{prefix}_predictions.json"
+ )
+ nbest_file = os.path.join(
+ output_dir, "nbest_predictions.json" if prefix is None else f"{prefix}_nbest_predictions.json"
+ )
+ if version_2_with_negative:
+ null_odds_file = os.path.join(
+ output_dir, "null_odds.json" if prefix is None else f"{prefix}_null_odds.json"
+ )
+
+ logger.info(f"Saving predictions to {prediction_file}.")
+ with open(prediction_file, "w") as writer:
+ writer.write(json.dumps(all_predictions, indent=4) + "\n")
+ logger.info(f"Saving nbest_preds to {nbest_file}.")
+ with open(nbest_file, "w") as writer:
+ writer.write(json.dumps(all_nbest_json, indent=4) + "\n")
+ if version_2_with_negative:
+ logger.info(f"Saving null_odds to {null_odds_file}.")
+ with open(null_odds_file, "w") as writer:
+ writer.write(json.dumps(scores_diff_json, indent=4) + "\n")
+
+ return all_predictions, scores_diff_json
diff --git a/docs/transformers/examples/flax/speech-recognition/README.md b/docs/transformers/examples/flax/speech-recognition/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..943c98761aa660c8d03e8f3d8fdd462ff612a8db
--- /dev/null
+++ b/docs/transformers/examples/flax/speech-recognition/README.md
@@ -0,0 +1,68 @@
+
+
+# Automatic Speech Recognition - Flax Examples
+
+## Sequence to Sequence
+
+The script [`run_flax_speech_recognition_seq2seq.py`](https://github.com/huggingface/transformers/blob/main/examples/flax/speech-recognition/run_flax_speech_recognition_seq2seq.py)
+can be used to fine-tune any [Flax Speech Sequence-to-Sequence Model](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.FlaxAutoModelForSpeechSeq2Seq)
+for automatic speech recognition on one of the [official speech recognition datasets](https://huggingface.co/datasets?task_ids=task_ids:automatic-speech-recognition)
+or a custom dataset. This includes the Whisper model from OpenAI, or a warm-started Speech-Encoder-Decoder Model,
+an example for which is included below.
+
+### Whisper Model
+
+We can load all components of the Whisper model directly from the pretrained checkpoint, including the pretrained model
+weights, feature extractor and tokenizer. We simply have to specify the id of fine-tuning dataset and the necessary
+training hyperparameters.
+
+The following example shows how to fine-tune the [Whisper small](https://huggingface.co/openai/whisper-small) checkpoint
+on the Hindi subset of the [Common Voice 13](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0) dataset.
+Note that before running this script you must accept the dataset's [terms of use](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0)
+and register your Hugging Face Hub token on your device by running `huggingface-hub login`.
+
+```bash
+python run_flax_speech_recognition_seq2seq.py \
+ --model_name_or_path="openai/whisper-small" \
+ --dataset_name="mozilla-foundation/common_voice_13_0" \
+ --dataset_config_name="hi" \
+ --language="hindi" \
+ --train_split_name="train+validation" \
+ --eval_split_name="test" \
+ --output_dir="./whisper-small-hi-flax" \
+ --per_device_train_batch_size="16" \
+ --per_device_eval_batch_size="16" \
+ --num_train_epochs="10" \
+ --learning_rate="1e-4" \
+ --warmup_steps="500" \
+ --logging_steps="25" \
+ --generation_max_length="40" \
+ --preprocessing_num_workers="32" \
+ --dataloader_num_workers="32" \
+ --max_duration_in_seconds="30" \
+ --text_column_name="sentence" \
+ --overwrite_output_dir \
+ --do_train \
+ --do_eval \
+ --predict_with_generate \
+ --push_to_hub \
+ --use_auth_token
+```
+
+On a TPU v4-8, training should take approximately 25 minutes, with a final cross-entropy loss of 0.02 and word error
+rate of **34%**. See the checkpoint [sanchit-gandhi/whisper-small-hi-flax](https://huggingface.co/sanchit-gandhi/whisper-small-hi-flax)
+for an example training run.
diff --git a/docs/transformers/examples/flax/speech-recognition/requirements.txt b/docs/transformers/examples/flax/speech-recognition/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..b68b236ad76c2b06e7e7e7711d90c5f2914a7bcb
--- /dev/null
+++ b/docs/transformers/examples/flax/speech-recognition/requirements.txt
@@ -0,0 +1,8 @@
+datasets[audio]>=2.14.0
+jax>=0.3.6
+jaxlib>=0.3.6
+flax>=0.4.1
+optax>=0.0.8
+torch>=1.9.0
+jiwer
+evaluate
diff --git a/docs/transformers/examples/flax/speech-recognition/run_flax_speech_recognition_seq2seq.py b/docs/transformers/examples/flax/speech-recognition/run_flax_speech_recognition_seq2seq.py
new file mode 100644
index 0000000000000000000000000000000000000000..e70618eef0ce43b03839f8509416eaf5f187fcba
--- /dev/null
+++ b/docs/transformers/examples/flax/speech-recognition/run_flax_speech_recognition_seq2seq.py
@@ -0,0 +1,877 @@
+#!/usr/bin/env python
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the Flax library models for sequence to sequence speech recognition.
+"""
+# You can also adapt this script on your own sequence to sequence task. Pointers for this are left as comments.
+
+import logging
+import os
+import sys
+import time
+from dataclasses import field
+from functools import partial
+from pathlib import Path
+from typing import Any, Callable, Optional, Union
+
+import datasets
+import evaluate
+import flax
+import jax
+import jax.numpy as jnp
+import numpy as np
+import optax
+from datasets import DatasetDict, load_dataset
+from flax import jax_utils, traverse_util
+from flax.jax_utils import pad_shard_unpad, unreplicate
+from flax.training import train_state
+from flax.training.common_utils import get_metrics, onehot, shard, shard_prng_key
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from tqdm import tqdm
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoFeatureExtractor,
+ AutoProcessor,
+ AutoTokenizer,
+ FlaxAutoModelForSpeechSeq2Seq,
+ HfArgumentParser,
+ Seq2SeqTrainingArguments,
+ is_tensorboard_available,
+)
+from transformers.file_utils import get_full_repo_name
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risk.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=2.14.0", "To fix: pip install -r examples/flax/speech-recognition/requirements.txt")
+
+logger = logging.getLogger(__name__)
+
+
+@flax.struct.dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ feature_extractor_name: Optional[str] = field(
+ default=None, metadata={"help": "feature extractor name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ use_auth_token: bool = field(
+ default=False,
+ metadata={
+ "help": "Will use the token generated when running `transformers-cli login` (necessary to use this script "
+ "with private models)."
+ },
+ )
+ dtype: Optional[str] = field(
+ default="float32",
+ metadata={
+ "help": (
+ "Floating-point format in which the model weights should be initialized and trained. Choose one of"
+ " `[float32, float16, bfloat16]`."
+ )
+ },
+ )
+ num_beams: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Number of beams to use for evaluation. This argument will be passed to `model.generate`, "
+ "which is used during evaluation."
+ )
+ },
+ )
+
+
+@flax.struct.dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: str = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ text_column: Optional[str] = field(
+ default=None,
+ metadata={"help": "The name of the column in the datasets containing the full texts (for summarization)."},
+ )
+ dataset_cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Path to cache directory for saving and loading datasets"}
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ },
+ )
+ audio_column_name: str = field(
+ default="audio",
+ metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
+ )
+ text_column_name: str = field(
+ default="text",
+ metadata={"help": "The name of the dataset column containing the text data. Defaults to 'text'"},
+ )
+ max_duration_in_seconds: float = field(
+ default=20.0,
+ metadata={"help": "Filter audio files that are longer than `max_duration_in_seconds` seconds"},
+ )
+ min_duration_in_seconds: float = field(
+ default=0.0,
+ metadata={"help": "Filter audio files that are shorter than `min_duration_in_seconds` seconds"},
+ )
+ max_label_length: float = field(
+ default=128,
+ metadata={"help": "Truncate transcriptions that are longer `max_eval_length` tokens."},
+ )
+ pad_input_to_multiple_of: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "If set will pad the input sequence to a multiple of the provided value. "
+ "This is important to avoid triggering recompilations on TPU. If unspecified, will default to padding the inputs to max length."
+ },
+ )
+ pad_target_to_multiple_of: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "If set will pad the target sequence to a multiple of the provided value. "
+ "This is important to avoid triggering recompilations on TPU. If unspecified, will default to padding the targets to max length."
+ },
+ )
+ preprocessing_only: bool = field(
+ default=False,
+ metadata={
+ "help": "Whether to only do data preprocessing and skip training. "
+ "This is especially useful when data preprocessing errors out in distributed training due to timeout. "
+ "In this case, one should run the preprocessing in a non-distributed setup with `preprocessing_only=True` "
+ "so that the cached datasets can consequently be loaded in distributed training"
+ },
+ )
+ train_split_name: str = field(
+ default="train",
+ metadata={
+ "help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
+ },
+ )
+ eval_split_name: str = field(
+ default="validation",
+ metadata={
+ "help": "The name of the evaluation data set split to use (via the datasets library). Defaults to 'validation'"
+ },
+ )
+ do_lower_case: bool = field(
+ default=True,
+ metadata={"help": "Whether the target text should be lower cased."},
+ )
+ language: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "Language for multilingual fine-tuning. This argument should be set for multilingual fine-tuning "
+ "only. For English speech recognition, it should be set to `None`."
+ )
+ },
+ )
+ task: str = field(
+ default="transcribe",
+ metadata={"help": "Task, either `transcribe` for speech recognition or `translate` for speech translation."},
+ )
+
+
+def shift_tokens_right(label_ids: np.array, decoder_start_token_id: int) -> np.ndarray:
+ """
+ Shift label ids one token to the right.
+ """
+ shifted_label_ids = np.zeros_like(label_ids)
+ shifted_label_ids[:, 1:] = label_ids[:, :-1]
+ shifted_label_ids[:, 0] = decoder_start_token_id
+
+ return shifted_label_ids
+
+
+@flax.struct.dataclass
+class FlaxDataCollatorSpeechSeq2SeqWithPadding:
+ """
+ Data collator that will dynamically pad the inputs received.
+ Args:
+ processor ([`Wav2Vec2Processor`])
+ The processor used for processing the data.
+ decoder_start_token_id (:obj: `int`)
+ The begin-of-sentence of the decoder.
+ input_padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
+ Select a strategy to pad the returned input sequences (according to the model's padding side and padding index)
+ among:
+ * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
+ sequence if provided).
+ * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided.
+ * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
+ different lengths).
+ target_padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
+ Select a strategy to pad the returned target sequences (according to the model's padding side and padding index).
+ See above for details.
+ max_input_length (:obj:`float`, `optional`):
+ Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
+ max_target_length (:obj:`int`, `optional`):
+ Maximum length of the ``labels`` of the returned list and optionally padding length (see above).
+ pad_input_to_multiple_of (:obj:`int`, `optional`):
+ If set will pad the input sequence to a multiple of the provided value.
+ This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
+ 7.5 (Volta).
+ pad_target_to_multiple_of (:obj:`int`, `optional`):
+ If set will pad the target sequence to a multiple of the provided value.
+ This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
+ 7.5 (Volta).
+ """
+
+ processor: Any
+ decoder_start_token_id: int
+ input_padding: Union[bool, str] = "longest"
+ target_padding: Union[bool, str] = "max_length"
+ max_input_length: Optional[float] = None
+ max_target_length: Optional[int] = None
+ pad_input_to_multiple_of: Optional[int] = None
+ pad_target_to_multiple_of: Optional[int] = None
+
+ def __call__(self, features: list[dict[str, Union[list[int], np.ndarray]]]) -> dict[str, np.ndarray]:
+ # split inputs and labels since they have to be of different lengths and need
+ # different padding methods
+ model_input_name = self.processor.model_input_names[0]
+
+ # dataloader returns a list of features which we convert to a dict
+ input_features = {model_input_name: [feature[model_input_name] for feature in features]}
+ label_features = {"input_ids": [feature["labels"] for feature in features]}
+
+ # reformat list to dict and set to pytorch format
+ batch = self.processor.feature_extractor.pad(
+ input_features,
+ max_length=self.max_input_length,
+ padding=self.input_padding,
+ pad_to_multiple_of=self.pad_input_to_multiple_of,
+ return_tensors="np",
+ )
+
+ labels_batch = self.processor.tokenizer.pad(
+ label_features,
+ max_length=self.max_target_length,
+ padding=self.target_padding,
+ pad_to_multiple_of=self.pad_target_to_multiple_of,
+ return_tensors="np",
+ )
+
+ # if bos token is appended in previous tokenization step,
+ # cut bos token here as it's append later anyways
+ labels = labels_batch["input_ids"]
+ if (labels[:, 0] == self.decoder_start_token_id).all().item():
+ labels = labels[:, 1:]
+ labels_batch.attention_mask = labels_batch.attention_mask[:, 1:]
+
+ decoder_input_ids = shift_tokens_right(labels, self.decoder_start_token_id)
+
+ # replace padding with -100 to ignore correctly when computing the loss
+ labels = np.ma.array(labels, mask=np.not_equal(labels_batch.attention_mask, 1))
+ labels = labels.filled(fill_value=-100)
+
+ batch["labels"] = labels
+ batch["decoder_input_ids"] = decoder_input_ids
+
+ return batch
+
+
+class TrainState(train_state.TrainState):
+ dropout_rng: jnp.ndarray
+
+ def replicate(self):
+ return jax_utils.replicate(self).replace(dropout_rng=shard_prng_key(self.dropout_rng))
+
+
+def write_metric(summary_writer, train_metrics, eval_metrics, train_time, step):
+ summary_writer.scalar("train_time", train_time, step)
+
+ train_metrics = get_metrics(train_metrics)
+ for key, vals in train_metrics.items():
+ tag = f"train_{key}"
+ for i, val in enumerate(vals):
+ summary_writer.scalar(tag, val, step - len(vals) + i + 1)
+
+ for metric_name, value in eval_metrics.items():
+ summary_writer.scalar(f"eval_{metric_name}", value, step)
+
+
+def create_learning_rate_fn(
+ num_train_steps: int, num_warmup_steps: int, learning_rate: float
+) -> Callable[[int], jnp.ndarray]:
+ """Returns a linear warmup, linear_decay learning rate function."""
+ warmup_fn = optax.linear_schedule(init_value=0.0, end_value=learning_rate, transition_steps=num_warmup_steps)
+ decay_fn = optax.linear_schedule(
+ init_value=learning_rate, end_value=0, transition_steps=num_train_steps - num_warmup_steps
+ )
+ schedule_fn = optax.join_schedules(schedules=[warmup_fn, decay_fn], boundaries=[num_warmup_steps])
+ return schedule_fn
+
+
+def main():
+ # 1. Parse input arguments
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
+
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your JAX/Flax versions.
+ send_example_telemetry("run_speech_recognition_seq2seq", model_args, data_args, framework="flax")
+
+ # 2. Setup logging
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+ # Set the verbosity to info of the Transformers logger.
+ # We only want one process per machine to log things on the screen.
+ logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
+ if jax.process_index() == 0:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ logger.info("Training/evaluation parameters %s", training_args)
+
+ # Check the output dir is valid
+ if (
+ os.path.exists(training_args.output_dir)
+ and os.listdir(training_args.output_dir)
+ and training_args.do_train
+ and not training_args.overwrite_output_dir
+ ):
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use `--overwrite_output_dir` to overcome."
+ )
+
+ # Handle the repository creation
+ if training_args.push_to_hub:
+ if training_args.hub_model_id is None:
+ repo_name = get_full_repo_name(
+ Path(training_args.output_dir).absolute().name, token=training_args.hub_token
+ )
+ else:
+ repo_name = training_args.hub_model_id
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
+
+ # 3. Load dataset
+ raw_datasets = DatasetDict()
+
+ if training_args.do_train:
+ raw_datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=data_args.train_split_name,
+ cache_dir=data_args.dataset_cache_dir,
+ num_proc=data_args.preprocessing_num_workers,
+ token=True if model_args.use_auth_token else None,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ if training_args.do_eval:
+ raw_datasets["eval"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=data_args.eval_split_name,
+ cache_dir=data_args.dataset_cache_dir,
+ num_proc=data_args.preprocessing_num_workers,
+ token=True if model_args.use_auth_token else None,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ if not training_args.do_train and not training_args.do_eval:
+ raise ValueError(
+ "Cannot not train and not do evaluation. At least one of training or evaluation has to be performed."
+ )
+
+ if data_args.audio_column_name not in next(iter(raw_datasets.values())).column_names:
+ raise ValueError(
+ f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--audio_column_name` to the correct audio column - one of "
+ f"{', '.join(next(iter(raw_datasets.values())).column_names)}."
+ )
+
+ if data_args.text_column_name not in next(iter(raw_datasets.values())).column_names:
+ raise ValueError(
+ f"--text_column_name {data_args.text_column_name} not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--text_column_name` to the correct text column - one of "
+ f"{', '.join(next(iter(raw_datasets.values())).column_names)}."
+ )
+
+ # 5. Load pretrained model, tokenizer, and feature extractor
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=True if model_args.use_auth_token else None,
+ )
+ feature_extractor = AutoFeatureExtractor.from_pretrained(
+ model_args.feature_extractor_name if model_args.feature_extractor_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=True if model_args.use_auth_token else None,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=True if model_args.use_auth_token else None,
+ )
+
+ model = FlaxAutoModelForSpeechSeq2Seq.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ dtype=getattr(jnp, model_args.dtype),
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=True if model_args.use_auth_token else None,
+ )
+
+ if model.config.decoder_start_token_id is None:
+ raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
+
+ # 6. Resample speech dataset: `datasets` takes care of automatically loading and resampling the audio,
+ # so we just need to set the correct target sampling rate.
+ raw_datasets = raw_datasets.cast_column(
+ data_args.audio_column_name, datasets.features.Audio(sampling_rate=feature_extractor.sampling_rate)
+ )
+
+ # 7. Preprocessing the datasets.
+ # We need to read the audio files as arrays and tokenize the targets.
+ max_input_length = int(data_args.max_duration_in_seconds * feature_extractor.sampling_rate)
+ min_input_length = int(data_args.min_duration_in_seconds * feature_extractor.sampling_rate)
+ max_label_length = (
+ data_args.max_label_length if data_args.max_label_length is not None else model.config.max_length
+ )
+ pad_input_to_multiple_of = data_args.pad_input_to_multiple_of
+ pad_target_to_multiple_of = data_args.pad_target_to_multiple_of
+ audio_column_name = data_args.audio_column_name
+ num_workers = data_args.preprocessing_num_workers
+ text_column_name = data_args.text_column_name
+ model_input_name = feature_extractor.model_input_names[0]
+ do_lower_case = data_args.do_lower_case
+
+ if training_args.do_train and data_args.max_train_samples is not None:
+ raw_datasets["train"] = raw_datasets["train"].select(range(data_args.max_train_samples))
+
+ if training_args.do_eval and data_args.max_eval_samples is not None:
+ raw_datasets["eval"] = raw_datasets["eval"].select(range(data_args.max_eval_samples))
+
+ if data_args.language is not None:
+ # We only need to set the task id when the language is specified (i.e. in a multilingual setting)
+ tokenizer.set_prefix_tokens(language=data_args.language, task=data_args.task)
+
+ def prepare_dataset(batch):
+ # process audio
+ sample = batch[audio_column_name]
+ inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
+ # process audio length
+ batch[model_input_name] = inputs.get(model_input_name)[0]
+ batch["input_length"] = len(sample["array"])
+
+ # process targets
+ input_str = batch[text_column_name].lower() if do_lower_case else batch[text_column_name]
+ batch["labels"] = tokenizer(input_str).input_ids
+ return batch
+
+ vectorized_datasets = raw_datasets.map(
+ prepare_dataset,
+ remove_columns=next(iter(raw_datasets.values())).column_names,
+ num_proc=num_workers,
+ desc="preprocess train and eval dataset",
+ )
+
+ # filter training data with inputs longer than max_input_length
+ def is_audio_in_length_range(length):
+ return min_input_length < length < max_input_length
+
+ vectorized_datasets = vectorized_datasets.filter(
+ is_audio_in_length_range,
+ num_proc=num_workers,
+ input_columns=["input_length"],
+ )
+
+ # for large datasets it is advised to run the preprocessing on a
+ # single machine first with `args.preprocessing_only` since there will mostly likely
+ # be a timeout when running the script in distributed mode.
+ # In a second step `args.preprocessing_only` can then be set to `False` to load the
+ # cached dataset
+ if data_args.preprocessing_only:
+ cache = {k: v.cache_files for k, v in vectorized_datasets.items()}
+ logger.info(f"Data preprocessing finished. Files cached at {cache}.")
+ return
+
+ # 8. Load Metric
+ metric = evaluate.load("wer", cache_dir=model_args.cache_dir)
+
+ def compute_metrics(preds, labels):
+ # replace padded labels by the padding token
+ for idx in range(len(labels)):
+ labels[idx][labels[idx] == -100] = tokenizer.pad_token_id
+
+ pred_str = tokenizer.batch_decode(preds, skip_special_tokens=True)
+ # we do not want to group tokens when computing the metrics
+ label_str = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ wer = metric.compute(predictions=pred_str, references=label_str)
+ return {"wer": wer}
+
+ # 9. Save feature extractor, tokenizer and config
+ feature_extractor.save_pretrained(training_args.output_dir)
+ tokenizer.save_pretrained(training_args.output_dir)
+ config.save_pretrained(training_args.output_dir)
+
+ processor = AutoProcessor.from_pretrained(training_args.output_dir)
+
+ data_collator = FlaxDataCollatorSpeechSeq2SeqWithPadding(
+ processor=processor,
+ decoder_start_token_id=model.config.decoder_start_token_id,
+ input_padding="longest",
+ target_padding="longest",
+ max_target_length=max_label_length,
+ pad_input_to_multiple_of=pad_input_to_multiple_of,
+ pad_target_to_multiple_of=pad_target_to_multiple_of if pad_target_to_multiple_of else max_label_length,
+ )
+
+ # Enable tensorboard only on the master node
+ has_tensorboard = is_tensorboard_available()
+ if has_tensorboard and jax.process_index() == 0:
+ try:
+ from flax.metrics.tensorboard import SummaryWriter
+
+ summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir))
+ except ImportError as ie:
+ has_tensorboard = False
+ logger.warning(
+ f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
+ )
+ else:
+ logger.warning(
+ "Unable to display metrics through TensorBoard because the package is not installed: "
+ "Please run pip install tensorboard to enable."
+ )
+
+ # Initialize our training
+ rng = jax.random.PRNGKey(training_args.seed)
+ rng, dropout_rng = jax.random.split(rng)
+
+ # Store some constant
+ num_epochs = int(training_args.num_train_epochs)
+ train_batch_size = int(training_args.per_device_train_batch_size) * jax.device_count()
+ per_device_eval_batch_size = int(training_args.per_device_eval_batch_size)
+ eval_batch_size = per_device_eval_batch_size * jax.device_count()
+ steps_per_epoch = len(vectorized_datasets["train"]) // train_batch_size
+ total_train_steps = steps_per_epoch * num_epochs
+
+ # Create learning rate schedule
+ linear_decay_lr_schedule_fn = create_learning_rate_fn(
+ total_train_steps,
+ training_args.warmup_steps,
+ training_args.learning_rate,
+ )
+
+ # We use Optax's "masking" functionality to not apply weight decay
+ # to bias and LayerNorm scale parameters. decay_mask_fn returns a
+ # mask boolean with the same structure as the parameters.
+ # The mask is True for parameters that should be decayed.
+ def decay_mask_fn(params):
+ flat_params = traverse_util.flatten_dict(params)
+ # find out all LayerNorm parameters
+ layer_norm_candidates = ["layer_norm", "self_attn_layer_norm", "final_layer_norm", "encoder_attn_layer_norm"]
+ layer_norm_named_params = {
+ layer[-2:]
+ for layer_norm_name in layer_norm_candidates
+ for layer in flat_params.keys()
+ if layer_norm_name in "".join(layer).lower()
+ }
+ flat_mask = {path: (path[-1] != "bias" and path[-2:] not in layer_norm_named_params) for path in flat_params}
+ return traverse_util.unflatten_dict(flat_mask)
+
+ # create adam optimizer
+ adamw = optax.adamw(
+ learning_rate=linear_decay_lr_schedule_fn,
+ b1=training_args.adam_beta1,
+ b2=training_args.adam_beta2,
+ eps=training_args.adam_epsilon,
+ weight_decay=training_args.weight_decay,
+ mask=decay_mask_fn,
+ )
+
+ # Setup train state
+ state = TrainState.create(apply_fn=model.__call__, params=model.params, tx=adamw, dropout_rng=dropout_rng)
+
+ # label smoothed cross entropy
+ def loss_fn(logits, labels, label_smoothing_factor=0.0):
+ """
+ The label smoothing implementation is adapted from Flax's official example:
+ https://github.com/google/flax/blob/87a211135c6a377c8f29048a1cac3840e38b9da4/examples/wmt/train.py#L104
+ """
+ vocab_size = logits.shape[-1]
+ confidence = 1.0 - label_smoothing_factor
+ low_confidence = (1.0 - confidence) / (vocab_size - 1)
+ normalizing_constant = -(
+ confidence * jnp.log(confidence) + (vocab_size - 1) * low_confidence * jnp.log(low_confidence + 1e-20)
+ )
+ soft_labels = onehot(labels, vocab_size, on_value=confidence, off_value=low_confidence)
+
+ loss = optax.softmax_cross_entropy(logits, soft_labels)
+ loss = loss - normalizing_constant
+
+ # ignore padded tokens from loss, i.e. where labels are not set to -100
+ padding_mask = labels >= 0
+ loss = loss * padding_mask
+ loss = loss.sum()
+ num_labels = padding_mask.sum()
+ return loss, num_labels
+
+ # Define gradient update step fn
+ def train_step(state, batch, label_smoothing_factor=0.0):
+ dropout_rng, new_dropout_rng = jax.random.split(state.dropout_rng)
+
+ def compute_loss(params):
+ labels = batch.pop("labels")
+ logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
+ loss, num_labels = loss_fn(logits, labels, label_smoothing_factor)
+ return loss, num_labels
+
+ grad_fn = jax.value_and_grad(compute_loss, has_aux=True)
+ (loss, num_labels), grad = grad_fn(state.params)
+ num_labels = jax.lax.psum(num_labels, "batch")
+
+ # true loss = total loss / total samples
+ loss = jax.lax.psum(loss, "batch")
+ loss = jax.tree_util.tree_map(lambda x: x / num_labels, loss)
+
+ # true grad = total grad / total samples
+ grad = jax.lax.psum(grad, "batch")
+ grad = jax.tree_util.tree_map(lambda x: x / num_labels, grad)
+ new_state = state.apply_gradients(grads=grad, dropout_rng=new_dropout_rng)
+
+ metrics = {"loss": loss, "learning_rate": linear_decay_lr_schedule_fn(state.step)}
+ return new_state, metrics
+
+ # Define eval fn
+ def eval_step(params, batch, label_smoothing_factor=0.0):
+ labels = batch.pop("labels")
+ logits = model(**batch, params=params, train=False)[0]
+
+ loss, num_labels = loss_fn(logits, labels, label_smoothing_factor)
+ num_labels = jax.lax.psum(num_labels, "batch")
+
+ # true loss = total loss / total samples
+ loss = jax.lax.psum(loss, "batch")
+ loss = jax.tree_util.tree_map(lambda x: x / num_labels, loss)
+
+ metrics = {"loss": loss}
+ return metrics
+
+ # Define generation function
+ num_beams = model_args.num_beams if model_args.num_beams is not None else model.config.num_beams
+ gen_kwargs = {"max_length": max_label_length, "num_beams": num_beams}
+
+ def generate_step(params, batch):
+ model.params = params
+ output_ids = model.generate(batch[model_input_name], attention_mask=batch.get("attention_mask"), **gen_kwargs)
+ return output_ids.sequences
+
+ # Create parallel version of the train and eval step
+ p_train_step = jax.pmap(
+ partial(train_step, label_smoothing_factor=training_args.label_smoothing_factor), "batch", donate_argnums=(0,)
+ )
+ p_eval_step = jax.pmap(partial(eval_step, label_smoothing_factor=training_args.label_smoothing_factor), "batch")
+ p_generate_step = jax.pmap(generate_step, "batch")
+
+ # Replicate the train state on each device
+ state = state.replicate()
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(vectorized_datasets['train'])}")
+ logger.info(f" Num Epochs = {num_epochs}")
+ logger.info(f" Instantaneous batch size per device = {training_args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel & distributed) = {train_batch_size}")
+ logger.info(f" Total optimization steps = {total_train_steps}")
+
+ train_time = 0
+ epochs = tqdm(range(num_epochs), desc=f"Epoch ... (1/{num_epochs})", position=0)
+ for epoch in epochs:
+ # ======================== Training ================================
+ train_start = time.time()
+
+ train_metrics = []
+
+ # Generate an epoch by shuffling sampling indices from the train dataset and create a data loader
+ vectorized_datasets["train"] = vectorized_datasets["train"].shuffle(training_args.seed)
+ train_loader = DataLoader(
+ vectorized_datasets["train"],
+ batch_size=train_batch_size,
+ drop_last=True,
+ collate_fn=data_collator,
+ num_workers=training_args.dataloader_num_workers,
+ )
+ # train
+ for batch in tqdm(train_loader, desc="Training...", position=1, leave=False):
+ batch = shard(batch.data)
+ state, train_metric = p_train_step(state, batch)
+ train_metrics.append(train_metric)
+
+ train_time += time.time() - train_start
+
+ train_metric = unreplicate(train_metric)
+
+ epochs.write(
+ f"Epoch... ({epoch + 1}/{num_epochs} | Loss: {train_metric['loss']}, Learning Rate:"
+ f" {train_metric['learning_rate']})"
+ )
+
+ # ======================== Evaluating ==============================
+ eval_metrics = []
+ eval_preds = []
+ eval_labels = []
+
+ eval_loader = DataLoader(
+ vectorized_datasets["eval"],
+ batch_size=eval_batch_size,
+ drop_last=False,
+ collate_fn=data_collator,
+ num_workers=training_args.dataloader_num_workers,
+ )
+ for batch in tqdm(eval_loader, desc="Evaluating...", position=2, leave=False):
+ # Model forward
+ labels = batch["labels"]
+
+ metrics = pad_shard_unpad(p_eval_step, static_return=True)(
+ state.params, batch.data, min_device_batch=per_device_eval_batch_size
+ )
+ eval_metrics.append(metrics)
+
+ # generation
+ if training_args.predict_with_generate:
+ generated_ids = pad_shard_unpad(p_generate_step)(state.params, batch.data)
+ eval_preds.extend(jax.device_get(generated_ids.reshape(-1, gen_kwargs["max_length"])))
+ eval_labels.extend(labels)
+
+ # normalize eval metrics
+ eval_metrics = get_metrics(eval_metrics)
+ eval_metrics = jax.tree_util.tree_map(jnp.mean, eval_metrics)
+
+ # compute WER metric
+ wer_desc = ""
+ if training_args.predict_with_generate:
+ wer_metric = compute_metrics(eval_preds, eval_labels)
+ eval_metrics.update(wer_metric)
+ wer_desc = " ".join([f"Eval {key}: {value} |" for key, value in wer_metric.items()])
+
+ # Print metrics and update progress bar
+ desc = f"Epoch... ({epoch + 1}/{num_epochs} | Eval Loss: {eval_metrics['loss']} | {wer_desc})"
+ epochs.write(desc)
+ epochs.desc = desc
+
+ # Save metrics
+ if has_tensorboard and jax.process_index() == 0:
+ cur_step = epoch * (len(vectorized_datasets["train"]) // train_batch_size)
+ write_metric(summary_writer, train_metrics, eval_metrics, train_time, cur_step)
+
+ # save checkpoint after each epoch and push checkpoint to the hub
+ if jax.process_index() == 0:
+ params = jax.device_get(jax.tree_util.tree_map(lambda x: x[0], state.params))
+ model.save_pretrained(training_args.output_dir, params=params)
+ tokenizer.save_pretrained(training_args.output_dir)
+ if training_args.push_to_hub:
+ api.upload_folder(
+ commit_message=f"Saving weights and logs of epoch {epoch}",
+ folder_path=training_args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=training_args.hub_token,
+ )
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/flax/summarization/README.md b/docs/transformers/examples/flax/summarization/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2eb21f49b65fe282f0e7768554555a94d2962ed2
--- /dev/null
+++ b/docs/transformers/examples/flax/summarization/README.md
@@ -0,0 +1,35 @@
+# Summarization (Seq2Seq model) training examples
+
+The following example showcases how to finetune a sequence-to-sequence model for summarization
+using the JAX/Flax backend.
+
+JAX/Flax allows you to trace pure functions and compile them into efficient, fused accelerator code on both GPU and TPU.
+Models written in JAX/Flax are **immutable** and updated in a purely functional
+way which enables simple and efficient model parallelism.
+
+`run_summarization_flax.py` is a lightweight example of how to download and preprocess a dataset from the 🤗 Datasets library or use your own files (jsonlines or csv), then fine-tune one of the architectures above on it.
+
+For custom datasets in `jsonlines` format please see: https://huggingface.co/docs/datasets/loading_datasets#json-files and you also will find examples of these below.
+
+### Train the model
+Next we can run the example script to train the model:
+
+```bash
+python run_summarization_flax.py \
+ --output_dir ./bart-base-xsum \
+ --model_name_or_path facebook/bart-base \
+ --tokenizer_name facebook/bart-base \
+ --dataset_name="xsum" \
+ --do_train --do_eval --do_predict --predict_with_generate \
+ --num_train_epochs 6 \
+ --learning_rate 5e-5 --warmup_steps 0 \
+ --per_device_train_batch_size 64 \
+ --per_device_eval_batch_size 64 \
+ --overwrite_output_dir \
+ --max_source_length 512 --max_target_length 64 \
+ --push_to_hub
+```
+
+This should finish in 37min, with validation loss and ROUGE2 score of 1.7785 and 17.01 respectively after 6 epochs. training statistics can be accessed on [tfhub.dev](https://tensorboard.dev/experiment/OcPfOIgXRMSJqYB4RdK2tA/#scalars).
+
+> Note that here we used default `generate` arguments, using arguments specific for `xsum` dataset should give better ROUGE scores.
diff --git a/docs/transformers/examples/flax/summarization/requirements.txt b/docs/transformers/examples/flax/summarization/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..58c7c26af78a065713b0413428a4adeefa365aa4
--- /dev/null
+++ b/docs/transformers/examples/flax/summarization/requirements.txt
@@ -0,0 +1,6 @@
+datasets >= 1.1.3
+jax>=0.2.8
+jaxlib>=0.1.59
+flax>=0.3.5
+optax>=0.0.8
+evaluate>=0.2.0
diff --git a/docs/transformers/examples/flax/summarization/run_summarization_flax.py b/docs/transformers/examples/flax/summarization/run_summarization_flax.py
new file mode 100644
index 0000000000000000000000000000000000000000..aab44c88a02cbf02671a086197fff4632ffa9811
--- /dev/null
+++ b/docs/transformers/examples/flax/summarization/run_summarization_flax.py
@@ -0,0 +1,1020 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for summarization.
+"""
+# You can also adapt this script on your own sequence to sequence task. Pointers for this are left as comments.
+
+import json
+import logging
+import math
+import os
+import sys
+import time
+from dataclasses import asdict, dataclass, field
+from enum import Enum
+from functools import partial
+from pathlib import Path
+from typing import Callable, Optional
+
+import datasets
+import evaluate
+import jax
+import jax.numpy as jnp
+import nltk # Here to have a nice missing dependency error message early on
+import numpy as np
+import optax
+from datasets import Dataset, load_dataset
+from filelock import FileLock
+from flax import jax_utils, traverse_util
+from flax.jax_utils import pad_shard_unpad, unreplicate
+from flax.training import train_state
+from flax.training.common_utils import get_metrics, onehot, shard, shard_prng_key
+from huggingface_hub import HfApi
+from tqdm import tqdm
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
+ AutoConfig,
+ AutoTokenizer,
+ FlaxAutoModelForSeq2SeqLM,
+ HfArgumentParser,
+ is_tensorboard_available,
+)
+from transformers.utils import is_offline_mode, send_example_telemetry
+
+
+logger = logging.getLogger(__name__)
+
+try:
+ nltk.data.find("tokenizers/punkt")
+except (LookupError, OSError):
+ if is_offline_mode():
+ raise LookupError(
+ "Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
+ )
+ with FileLock(".lock") as lock:
+ nltk.download("punkt", quiet=True)
+
+
+MODEL_CONFIG_CLASSES = list(FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class TrainingArguments:
+ output_dir: str = field(
+ metadata={"help": "The output directory where the model predictions and checkpoints will be written."},
+ )
+ overwrite_output_dir: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Overwrite the content of the output directory. "
+ "Use this to continue training if output_dir points to a checkpoint directory."
+ )
+ },
+ )
+ do_train: bool = field(default=False, metadata={"help": "Whether to run training."})
+ do_eval: bool = field(default=False, metadata={"help": "Whether to run eval on the dev set."})
+ do_predict: bool = field(default=False, metadata={"help": "Whether to run predictions on the test set."})
+ per_device_train_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for training."}
+ )
+ per_device_eval_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for evaluation."}
+ )
+ learning_rate: float = field(default=5e-5, metadata={"help": "The initial learning rate for AdamW."})
+ weight_decay: float = field(default=0.0, metadata={"help": "Weight decay for AdamW if we apply some."})
+ adam_beta1: float = field(default=0.9, metadata={"help": "Beta1 for AdamW optimizer"})
+ adam_beta2: float = field(default=0.999, metadata={"help": "Beta2 for AdamW optimizer"})
+ adam_epsilon: float = field(default=1e-8, metadata={"help": "Epsilon for AdamW optimizer."})
+ label_smoothing_factor: float = field(
+ default=0.0, metadata={"help": "The label smoothing epsilon to apply (zero means no label smoothing)."}
+ )
+ adafactor: bool = field(default=False, metadata={"help": "Whether or not to replace AdamW by Adafactor."})
+ num_train_epochs: float = field(default=3.0, metadata={"help": "Total number of training epochs to perform."})
+ warmup_steps: int = field(default=0, metadata={"help": "Linear warmup over warmup_steps."})
+ logging_steps: int = field(default=500, metadata={"help": "Log every X updates steps."})
+ save_steps: int = field(default=500, metadata={"help": "Save checkpoint every X updates steps."})
+ eval_steps: int = field(default=None, metadata={"help": "Run an evaluation every X steps."})
+ seed: int = field(default=42, metadata={"help": "Random seed that will be set at the beginning of training."})
+ push_to_hub: bool = field(
+ default=False, metadata={"help": "Whether or not to upload the trained model to the model hub after training."}
+ )
+ hub_model_id: str = field(
+ default=None, metadata={"help": "The name of the repository to keep in sync with the local `output_dir`."}
+ )
+ hub_token: str = field(default=None, metadata={"help": "The token to use to push to the Model Hub."})
+ gradient_checkpointing: bool = field(
+ default=False,
+ metadata={
+ "help": "If True, use gradient checkpointing to save memory at the expense of slower backward pass."
+ },
+ )
+
+ def __post_init__(self):
+ if self.output_dir is not None:
+ self.output_dir = os.path.expanduser(self.output_dir)
+
+ def to_dict(self):
+ """
+ Serializes this instance while replace `Enum` by their values (for JSON serialization support). It obfuscates
+ the token values by removing their value.
+ """
+ d = asdict(self)
+ for k, v in d.items():
+ if isinstance(v, Enum):
+ d[k] = v.value
+ if isinstance(v, list) and len(v) > 0 and isinstance(v[0], Enum):
+ d[k] = [x.value for x in v]
+ if k.endswith("_token"):
+ d[k] = f"<{k.upper()}>"
+ return d
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ dtype: Optional[str] = field(
+ default="float32",
+ metadata={
+ "help": (
+ "Floating-point format in which the model weights should be initialized and trained. Choose one of"
+ " `[float32, float16, bfloat16]`."
+ )
+ },
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ text_column: Optional[str] = field(
+ default=None,
+ metadata={"help": "The name of the column in the datasets containing the full texts (for summarization)."},
+ )
+ summary_column: Optional[str] = field(
+ default=None,
+ metadata={"help": "The name of the column in the datasets containing the summaries (for summarization)."},
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input predict data file to do prediction on (a text file)."},
+ )
+ max_source_length: Optional[int] = field(
+ default=1024,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ max_target_length: Optional[int] = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total sequence length for target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ val_max_target_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total sequence length for validation target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
+ "This argument is also used to override the `max_length` param of `model.generate`, which is used "
+ "during evaluation."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ source_prefix: Optional[str] = field(
+ default=None, metadata={"help": "A prefix to add before every source text (useful for T5 models)."}
+ )
+ predict_with_generate: bool = field(
+ default=False, metadata={"help": "Whether to use generate to calculate generative metrics (ROUGE, BLEU)."}
+ )
+ num_beams: Optional[int] = field(
+ default=1,
+ metadata={
+ "help": (
+ "Number of beams to use for evaluation. This argument will be passed to `model.generate`, "
+ "which is used during evaluation."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+
+ def __post_init__(self):
+ if (
+ self.dataset_name is None
+ and self.train_file is None
+ and self.validation_file is None
+ and self.test_file is None
+ ):
+ raise ValueError("Need either a dataset name or a training, validation, or test file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ if self.test_file is not None:
+ extension = self.test_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
+ if self.val_max_target_length is None:
+ self.val_max_target_length = self.max_target_length
+
+
+summarization_name_mapping = {
+ "amazon_reviews_multi": ("review_body", "review_title"),
+ "big_patent": ("description", "abstract"),
+ "cnn_dailymail": ("article", "highlights"),
+ "orange_sum": ("text", "summary"),
+ "pn_summary": ("article", "summary"),
+ "psc": ("extract_text", "summary_text"),
+ "samsum": ("dialogue", "summary"),
+ "thaisum": ("body", "summary"),
+ "xglue": ("news_body", "news_title"),
+ "xsum": ("document", "summary"),
+ "wiki_summary": ("article", "highlights"),
+}
+
+
+class TrainState(train_state.TrainState):
+ dropout_rng: jnp.ndarray
+
+ def replicate(self):
+ return jax_utils.replicate(self).replace(dropout_rng=shard_prng_key(self.dropout_rng))
+
+
+def data_loader(rng: jax.random.PRNGKey, dataset: Dataset, batch_size: int, shuffle: bool = False, drop_last=True):
+ """
+ Returns batches of size `batch_size` from `dataset`. If `drop_last` is set to `False`, the final batch may be incomplete,
+ and range in size from 1 to `batch_size`. Shuffle batches if `shuffle` is `True`.
+ """
+ if shuffle:
+ batch_idx = jax.random.permutation(rng, len(dataset))
+ batch_idx = np.asarray(batch_idx)
+ else:
+ batch_idx = np.arange(len(dataset))
+
+ if drop_last:
+ steps_per_epoch = len(dataset) // batch_size
+ batch_idx = batch_idx[: steps_per_epoch * batch_size] # Skip incomplete batch.
+ batch_idx = batch_idx.reshape((steps_per_epoch, batch_size))
+ else:
+ steps_per_epoch = math.ceil(len(dataset) / batch_size)
+ batch_idx = np.array_split(batch_idx, steps_per_epoch)
+
+ for idx in batch_idx:
+ batch = dataset[idx]
+ batch = {k: np.array(v) for k, v in batch.items()}
+
+ yield batch
+
+
+def write_metric(summary_writer, train_metrics, eval_metrics, train_time, step):
+ summary_writer.scalar("train_time", train_time, step)
+
+ train_metrics = get_metrics(train_metrics)
+ for key, vals in train_metrics.items():
+ tag = f"train_{key}"
+ for i, val in enumerate(vals):
+ summary_writer.scalar(tag, val, step - len(vals) + i + 1)
+
+ for metric_name, value in eval_metrics.items():
+ summary_writer.scalar(f"eval_{metric_name}", value, step)
+
+
+def create_learning_rate_fn(
+ train_ds_size: int, train_batch_size: int, num_train_epochs: int, num_warmup_steps: int, learning_rate: float
+) -> Callable[[int], jnp.ndarray]:
+ """Returns a linear warmup, linear_decay learning rate function."""
+ steps_per_epoch = train_ds_size // train_batch_size
+ num_train_steps = steps_per_epoch * num_train_epochs
+ warmup_fn = optax.linear_schedule(init_value=0.0, end_value=learning_rate, transition_steps=num_warmup_steps)
+ decay_fn = optax.linear_schedule(
+ init_value=learning_rate, end_value=0, transition_steps=num_train_steps - num_warmup_steps
+ )
+ schedule_fn = optax.join_schedules(schedules=[warmup_fn, decay_fn], boundaries=[num_warmup_steps])
+ return schedule_fn
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_summarization", model_args, data_args, framework="flax")
+
+ if (
+ os.path.exists(training_args.output_dir)
+ and os.listdir(training_args.output_dir)
+ and training_args.do_train
+ and not training_args.overwrite_output_dir
+ ):
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ # Setup logging, we only want one process per machine to log things on the screen.
+ logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
+ if jax.process_index() == 0:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Handle the repository creation
+ if training_args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = training_args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(training_args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
+
+ # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files this script will use the first column for the full texts and the second column for the
+ # summaries (unless you specify column names for this with the `text_column` and `summary_column` arguments).
+ #
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ dataset = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ keep_in_memory=False,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if data_args.test_file is not None:
+ data_files["test"] = data_args.test_file
+ extension = data_args.test_file.split(".")[-1]
+ dataset = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+
+ if model_args.config_name:
+ config = AutoConfig.from_pretrained(
+ model_args.config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if model_args.model_name_or_path:
+ model = FlaxAutoModelForSeq2SeqLM.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ model = FlaxAutoModelForSeq2SeqLM.from_config(
+ config,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ if training_args.gradient_checkpointing:
+ model.enable_gradient_checkpointing()
+
+ if model.config.decoder_start_token_id is None:
+ raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
+
+ prefix = data_args.source_prefix if data_args.source_prefix is not None else ""
+
+ # Preprocessing the datasets.
+ # We need to tokenize inputs and targets.
+ if training_args.do_train:
+ if "train" not in dataset:
+ raise ValueError("--do_train requires a train dataset")
+ column_names = dataset["train"].column_names
+ elif training_args.do_eval:
+ if "validation" not in dataset:
+ raise ValueError("--do_eval requires a validation dataset")
+ column_names = dataset["validation"].column_names
+ elif training_args.do_predict:
+ if "test" not in dataset:
+ raise ValueError("--do_predict requires a test dataset")
+ column_names = dataset["test"].column_names
+ else:
+ logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
+ return
+
+ # Get the column names for input/target.
+ dataset_columns = summarization_name_mapping.get(data_args.dataset_name, None)
+ if data_args.text_column is None:
+ text_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ text_column = data_args.text_column
+ if text_column not in column_names:
+ raise ValueError(
+ f"--text_column' value '{data_args.text_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if data_args.summary_column is None:
+ summary_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ summary_column = data_args.summary_column
+ if summary_column not in column_names:
+ raise ValueError(
+ f"--summary_column' value '{data_args.summary_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # Temporarily set max_target_length for training.
+ max_target_length = data_args.max_target_length
+
+ # In Flax, for seq2seq models we need to pass `decoder_input_ids`
+ # as the Flax models don't accept `labels`, we need to prepare the decoder_input_ids here
+ # for that dynamically import the `shift_tokens_right` function from the model file
+ model_module = __import__(model.__module__, fromlist=["shift_tokens_tight"])
+ shift_tokens_right_fn = getattr(model_module, "shift_tokens_right")
+
+ # Setting padding="max_length" as we need fixed length inputs for jitted functions
+ def preprocess_function(examples):
+ inputs = examples[text_column]
+ targets = examples[summary_column]
+ inputs = [prefix + inp for inp in inputs]
+ model_inputs = tokenizer(
+ inputs, max_length=data_args.max_source_length, padding="max_length", truncation=True, return_tensors="np"
+ )
+
+ # Setup the tokenizer for targets
+ labels = tokenizer(
+ text_target=targets,
+ max_length=max_target_length,
+ padding="max_length",
+ truncation=True,
+ return_tensors="np",
+ )
+
+ model_inputs["labels"] = labels["input_ids"]
+ decoder_input_ids = shift_tokens_right_fn(
+ labels["input_ids"], config.pad_token_id, config.decoder_start_token_id
+ )
+ model_inputs["decoder_input_ids"] = np.asarray(decoder_input_ids)
+
+ # We need decoder_attention_mask so we can ignore pad tokens from loss
+ model_inputs["decoder_attention_mask"] = labels["attention_mask"]
+
+ return model_inputs
+
+ if training_args.do_train:
+ train_dataset = dataset["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ train_dataset = train_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+
+ if training_args.do_eval:
+ max_target_length = data_args.val_max_target_length
+ eval_dataset = dataset["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+ eval_dataset = eval_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+
+ if training_args.do_predict:
+ max_target_length = data_args.val_max_target_length
+ predict_dataset = dataset["test"]
+ if data_args.max_predict_samples is not None:
+ max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
+ predict_dataset = predict_dataset.select(range(max_predict_samples))
+ predict_dataset = predict_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on prediction dataset",
+ )
+
+ # Metric
+ metric = evaluate.load("rouge", cache_dir=model_args.cache_dir)
+
+ def postprocess_text(preds, labels):
+ preds = [pred.strip() for pred in preds]
+ labels = [label.strip() for label in labels]
+
+ # rougeLSum expects newline after each sentence
+ preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
+ labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
+
+ return preds, labels
+
+ def compute_metrics(preds, labels):
+ decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Some simple post-processing
+ decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
+
+ result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
+ result = {k: round(v * 100, 4) for k, v in result.items()}
+ prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
+ result["gen_len"] = np.mean(prediction_lens)
+ return result
+
+ # Enable tensorboard only on the master node
+ has_tensorboard = is_tensorboard_available()
+ if has_tensorboard and jax.process_index() == 0:
+ try:
+ from flax.metrics.tensorboard import SummaryWriter
+
+ summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir))
+ except ImportError as ie:
+ has_tensorboard = False
+ logger.warning(
+ f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
+ )
+ else:
+ logger.warning(
+ "Unable to display metrics through TensorBoard because the package is not installed: "
+ "Please run pip install tensorboard to enable."
+ )
+
+ # Initialize our training
+ rng = jax.random.PRNGKey(training_args.seed)
+ rng, dropout_rng = jax.random.split(rng)
+
+ # Store some constant
+ num_epochs = int(training_args.num_train_epochs)
+ train_batch_size = int(training_args.per_device_train_batch_size) * jax.device_count()
+ per_device_eval_batch_size = int(training_args.per_device_eval_batch_size)
+ eval_batch_size = per_device_eval_batch_size * jax.device_count()
+ steps_per_epoch = len(train_dataset) // train_batch_size
+ total_train_steps = steps_per_epoch * num_epochs
+
+ # Create learning rate schedule
+ linear_decay_lr_schedule_fn = create_learning_rate_fn(
+ len(train_dataset),
+ train_batch_size,
+ training_args.num_train_epochs,
+ training_args.warmup_steps,
+ training_args.learning_rate,
+ )
+
+ # We use Optax's "masking" functionality to not apply weight decay
+ # to bias and LayerNorm scale parameters. decay_mask_fn returns a
+ # mask boolean with the same structure as the parameters.
+ # The mask is True for parameters that should be decayed.
+ def decay_mask_fn(params):
+ flat_params = traverse_util.flatten_dict(params)
+ # find out all LayerNorm parameters
+ layer_norm_candidates = ["layernorm", "layer_norm", "ln"]
+ layer_norm_named_params = {
+ layer[-2:]
+ for layer_norm_name in layer_norm_candidates
+ for layer in flat_params.keys()
+ if layer_norm_name in "".join(layer).lower()
+ }
+ flat_mask = {path: (path[-1] != "bias" and path[-2:] not in layer_norm_named_params) for path in flat_params}
+ return traverse_util.unflatten_dict(flat_mask)
+
+ # create adam optimizer
+ adamw = optax.adamw(
+ learning_rate=linear_decay_lr_schedule_fn,
+ b1=training_args.adam_beta1,
+ b2=training_args.adam_beta2,
+ eps=training_args.adam_epsilon,
+ weight_decay=training_args.weight_decay,
+ mask=decay_mask_fn,
+ )
+
+ # Setup train state
+ state = TrainState.create(apply_fn=model.__call__, params=model.params, tx=adamw, dropout_rng=dropout_rng)
+
+ # label smoothed cross entropy
+ def loss_fn(logits, labels, padding_mask, label_smoothing_factor=0.0):
+ """
+ The label smoothing implementation is adapted from Flax's official example:
+ https://github.com/google/flax/blob/87a211135c6a377c8f29048a1cac3840e38b9da4/examples/wmt/train.py#L104
+ """
+ vocab_size = logits.shape[-1]
+ confidence = 1.0 - label_smoothing_factor
+ low_confidence = (1.0 - confidence) / (vocab_size - 1)
+ normalizing_constant = -(
+ confidence * jnp.log(confidence) + (vocab_size - 1) * low_confidence * jnp.log(low_confidence + 1e-20)
+ )
+ soft_labels = onehot(labels, vocab_size, on_value=confidence, off_value=low_confidence)
+
+ loss = optax.softmax_cross_entropy(logits, soft_labels)
+ loss = loss - normalizing_constant
+
+ # ignore padded tokens from loss
+ loss = loss * padding_mask
+ loss = loss.sum()
+ num_labels = padding_mask.sum()
+ return loss, num_labels
+
+ # Define gradient update step fn
+ def train_step(state, batch, label_smoothing_factor=0.0):
+ dropout_rng, new_dropout_rng = jax.random.split(state.dropout_rng)
+
+ def compute_loss(params):
+ labels = batch.pop("labels")
+ logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
+ loss, num_labels = loss_fn(logits, labels, batch["decoder_attention_mask"], label_smoothing_factor)
+ return loss, num_labels
+
+ grad_fn = jax.value_and_grad(compute_loss, has_aux=True)
+ (loss, num_labels), grad = grad_fn(state.params)
+ num_labels = jax.lax.psum(num_labels, "batch")
+
+ # true loss = total loss / total samples
+ loss = jax.lax.psum(loss, "batch")
+ loss = jax.tree_util.tree_map(lambda x: x / num_labels, loss)
+
+ # true grad = total grad / total samples
+ grad = jax.lax.psum(grad, "batch")
+ grad = jax.tree_util.tree_map(lambda x: x / num_labels, grad)
+ new_state = state.apply_gradients(grads=grad, dropout_rng=new_dropout_rng)
+
+ metrics = {"loss": loss, "learning_rate": linear_decay_lr_schedule_fn(state.step)}
+ return new_state, metrics
+
+ # Define eval fn
+ def eval_step(params, batch, label_smoothing_factor=0.0):
+ labels = batch.pop("labels")
+ logits = model(**batch, params=params, train=False)[0]
+
+ loss, num_labels = loss_fn(logits, labels, batch["decoder_attention_mask"], label_smoothing_factor)
+ num_labels = jax.lax.psum(num_labels, "batch")
+
+ # true loss = total loss / total samples
+ loss = jax.lax.psum(loss, "batch")
+ loss = jax.tree_util.tree_map(lambda x: x / num_labels, loss)
+
+ metrics = {"loss": loss}
+ return metrics
+
+ # Define generation function
+ max_length = (
+ data_args.val_max_target_length if data_args.val_max_target_length is not None else model.config.max_length
+ )
+ num_beams = data_args.num_beams if data_args.num_beams is not None else model.config.num_beams
+ gen_kwargs = {"max_length": max_length, "num_beams": num_beams}
+
+ def generate_step(params, batch):
+ model.params = params
+ output_ids = model.generate(batch["input_ids"], attention_mask=batch["attention_mask"], **gen_kwargs)
+ return output_ids.sequences
+
+ # Create parallel version of the train and eval step
+ p_train_step = jax.pmap(
+ partial(train_step, label_smoothing_factor=training_args.label_smoothing_factor), "batch", donate_argnums=(0,)
+ )
+ p_eval_step = jax.pmap(partial(eval_step, label_smoothing_factor=training_args.label_smoothing_factor), "batch")
+ p_generate_step = jax.pmap(generate_step, "batch")
+
+ # Replicate the train state on each device
+ state = state.replicate()
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {num_epochs}")
+ logger.info(f" Instantaneous batch size per device = {training_args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel & distributed) = {train_batch_size}")
+ logger.info(f" Total optimization steps = {total_train_steps}")
+
+ train_time = 0
+ epochs = tqdm(range(num_epochs), desc=f"Epoch ... (1/{num_epochs})", position=0)
+ for epoch in epochs:
+ # ======================== Training ================================
+ train_start = time.time()
+
+ # Create sampling rng
+ rng, input_rng = jax.random.split(rng)
+ train_metrics = []
+
+ # Generate an epoch by shuffling sampling indices from the train dataset
+ train_loader = data_loader(input_rng, train_dataset, train_batch_size, shuffle=True)
+ steps_per_epoch = len(train_dataset) // train_batch_size
+ # train
+ for _ in tqdm(range(steps_per_epoch), desc="Training...", position=1, leave=False):
+ batch = next(train_loader)
+ batch = shard(batch)
+ state, train_metric = p_train_step(state, batch)
+ train_metrics.append(train_metric)
+
+ train_time += time.time() - train_start
+
+ train_metric = unreplicate(train_metric)
+
+ epochs.write(
+ f"Epoch... ({epoch + 1}/{num_epochs} | Loss: {train_metric['loss']}, Learning Rate:"
+ f" {train_metric['learning_rate']})"
+ )
+
+ # ======================== Evaluating ==============================
+ eval_metrics = []
+ eval_preds = []
+ eval_labels = []
+
+ eval_loader = data_loader(input_rng, eval_dataset, eval_batch_size, drop_last=False)
+ eval_steps = math.ceil(len(eval_dataset) / eval_batch_size)
+ for _ in tqdm(range(eval_steps), desc="Evaluating...", position=2, leave=False):
+ # Model forward
+ batch = next(eval_loader)
+ labels = batch["labels"]
+
+ metrics = pad_shard_unpad(p_eval_step, static_return=True)(
+ state.params, batch, min_device_batch=per_device_eval_batch_size
+ )
+ eval_metrics.append(metrics)
+
+ # generation
+ if data_args.predict_with_generate:
+ generated_ids = pad_shard_unpad(p_generate_step)(state.params, batch)
+ eval_preds.extend(jax.device_get(generated_ids.reshape(-1, gen_kwargs["max_length"])))
+ eval_labels.extend(labels)
+
+ # normalize eval metrics
+ eval_metrics = get_metrics(eval_metrics)
+ eval_metrics = jax.tree_util.tree_map(jnp.mean, eval_metrics)
+
+ # compute ROUGE metrics
+ rouge_desc = ""
+ if data_args.predict_with_generate:
+ rouge_metrics = compute_metrics(eval_preds, eval_labels)
+ eval_metrics.update(rouge_metrics)
+ rouge_desc = " ".join([f"Eval {key}: {value} |" for key, value in rouge_metrics.items()])
+
+ # Print metrics and update progress bar
+ desc = f"Epoch... ({epoch + 1}/{num_epochs} | Eval Loss: {eval_metrics['loss']} | {rouge_desc})"
+ epochs.write(desc)
+ epochs.desc = desc
+
+ # Save metrics
+ if has_tensorboard and jax.process_index() == 0:
+ cur_step = epoch * (len(train_dataset) // train_batch_size)
+ write_metric(summary_writer, train_metrics, eval_metrics, train_time, cur_step)
+
+ # save checkpoint after each epoch and push checkpoint to the hub
+ if jax.process_index() == 0:
+ params = jax.device_get(jax.tree_util.tree_map(lambda x: x[0], state.params))
+ model.save_pretrained(training_args.output_dir, params=params)
+ tokenizer.save_pretrained(training_args.output_dir)
+ if training_args.push_to_hub:
+ api.upload_folder(
+ commit_message=f"Saving weights and logs of epoch {epoch}",
+ folder_path=training_args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=training_args.hub_token,
+ )
+
+ # ======================== Prediction loop ==============================
+ if training_args.do_predict:
+ logger.info("*** Predict ***")
+
+ pred_metrics = []
+ pred_generations = []
+ pred_labels = []
+
+ pred_loader = data_loader(input_rng, predict_dataset, eval_batch_size, drop_last=False)
+ pred_steps = math.ceil(len(predict_dataset) / eval_batch_size)
+ for _ in tqdm(range(pred_steps), desc="Predicting...", position=2, leave=False):
+ # Model forward
+ batch = next(pred_loader)
+ labels = batch["labels"]
+
+ metrics = pad_shard_unpad(p_eval_step, static_return=True)(
+ state.params, batch, min_device_batch=per_device_eval_batch_size
+ )
+ pred_metrics.append(metrics)
+
+ # generation
+ if data_args.predict_with_generate:
+ generated_ids = pad_shard_unpad(p_generate_step)(state.params, batch)
+ pred_generations.extend(jax.device_get(generated_ids.reshape(-1, gen_kwargs["max_length"])))
+ pred_labels.extend(labels)
+
+ # normalize prediction metrics
+ pred_metrics = get_metrics(pred_metrics)
+ pred_metrics = jax.tree_util.tree_map(jnp.mean, pred_metrics)
+
+ # compute ROUGE metrics
+ rouge_desc = ""
+ if data_args.predict_with_generate:
+ rouge_metrics = compute_metrics(pred_generations, pred_labels)
+ pred_metrics.update(rouge_metrics)
+ rouge_desc = " ".join([f"Predict {key}: {value} |" for key, value in rouge_metrics.items()])
+
+ # Print metrics
+ desc = f"Predict Loss: {pred_metrics['loss']} | {rouge_desc})"
+ logger.info(desc)
+
+ # save final metrics in json
+ if jax.process_index() == 0:
+ rouge_metrics = {f"test_{metric_name}": value for metric_name, value in rouge_metrics.items()}
+ path = os.path.join(training_args.output_dir, "test_results.json")
+ with open(path, "w") as f:
+ json.dump(rouge_metrics, f, indent=4, sort_keys=True)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/flax/test_flax_examples.py b/docs/transformers/examples/flax/test_flax_examples.py
new file mode 100644
index 0000000000000000000000000000000000000000..132be94e3184cc99f63920409d0a15e115184c0e
--- /dev/null
+++ b/docs/transformers/examples/flax/test_flax_examples.py
@@ -0,0 +1,285 @@
+# Copyright 2021 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import argparse
+import json
+import logging
+import os
+import sys
+from unittest.mock import patch
+
+from transformers.testing_utils import TestCasePlus, get_gpu_count, slow
+
+
+SRC_DIRS = [
+ os.path.join(os.path.dirname(__file__), dirname)
+ for dirname in [
+ "text-classification",
+ "language-modeling",
+ "summarization",
+ "token-classification",
+ "question-answering",
+ "speech-recognition",
+ ]
+]
+sys.path.extend(SRC_DIRS)
+
+
+if SRC_DIRS is not None:
+ import run_clm_flax
+ import run_flax_glue
+ import run_flax_ner
+ import run_flax_speech_recognition_seq2seq
+ import run_mlm_flax
+ import run_qa
+ import run_summarization_flax
+ import run_t5_mlm_flax
+
+
+logging.basicConfig(level=logging.DEBUG)
+
+logger = logging.getLogger()
+
+
+def get_setup_file():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-f")
+ args = parser.parse_args()
+ return args.f
+
+
+def get_results(output_dir, split="eval"):
+ path = os.path.join(output_dir, f"{split}_results.json")
+ if os.path.exists(path):
+ with open(path) as f:
+ return json.load(f)
+ raise ValueError(f"can't find {path}")
+
+
+stream_handler = logging.StreamHandler(sys.stdout)
+logger.addHandler(stream_handler)
+
+
+class ExamplesTests(TestCasePlus):
+ def test_run_glue(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_glue.py
+ --model_name_or_path distilbert/distilbert-base-uncased
+ --output_dir {tmp_dir}
+ --train_file ./tests/fixtures/tests_samples/MRPC/train.csv
+ --validation_file ./tests/fixtures/tests_samples/MRPC/dev.csv
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --learning_rate=1e-4
+ --eval_steps=2
+ --warmup_steps=2
+ --seed=42
+ --max_seq_length=128
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_flax_glue.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_accuracy"], 0.75)
+
+ @slow
+ def test_run_clm(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_clm_flax.py
+ --model_name_or_path distilbert/distilgpt2
+ --train_file ./tests/fixtures/sample_text.txt
+ --validation_file ./tests/fixtures/sample_text.txt
+ --do_train
+ --do_eval
+ --block_size 128
+ --per_device_train_batch_size 4
+ --per_device_eval_batch_size 4
+ --num_train_epochs 2
+ --logging_steps 2 --eval_steps 2
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_clm_flax.main()
+ result = get_results(tmp_dir)
+ self.assertLess(result["eval_perplexity"], 100)
+
+ @slow
+ def test_run_summarization(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_summarization.py
+ --model_name_or_path google-t5/t5-small
+ --train_file tests/fixtures/tests_samples/xsum/sample.json
+ --validation_file tests/fixtures/tests_samples/xsum/sample.json
+ --test_file tests/fixtures/tests_samples/xsum/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --num_train_epochs=3
+ --warmup_steps=8
+ --do_train
+ --do_eval
+ --do_predict
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --predict_with_generate
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_summarization_flax.main()
+ result = get_results(tmp_dir, split="test")
+ self.assertGreaterEqual(result["test_rouge1"], 10)
+ self.assertGreaterEqual(result["test_rouge2"], 2)
+ self.assertGreaterEqual(result["test_rougeL"], 7)
+ self.assertGreaterEqual(result["test_rougeLsum"], 7)
+
+ @slow
+ def test_run_mlm(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_mlm.py
+ --model_name_or_path distilbert/distilroberta-base
+ --train_file ./tests/fixtures/sample_text.txt
+ --validation_file ./tests/fixtures/sample_text.txt
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --max_seq_length 128
+ --per_device_train_batch_size 4
+ --per_device_eval_batch_size 4
+ --logging_steps 2 --eval_steps 2
+ --do_train
+ --do_eval
+ --num_train_epochs=1
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_mlm_flax.main()
+ result = get_results(tmp_dir)
+ self.assertLess(result["eval_perplexity"], 42)
+
+ @slow
+ def test_run_t5_mlm(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_t5_mlm_flax.py
+ --model_name_or_path google-t5/t5-small
+ --train_file ./tests/fixtures/sample_text.txt
+ --validation_file ./tests/fixtures/sample_text.txt
+ --do_train
+ --do_eval
+ --max_seq_length 128
+ --per_device_train_batch_size 4
+ --per_device_eval_batch_size 4
+ --num_train_epochs 2
+ --logging_steps 2 --eval_steps 2
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_t5_mlm_flax.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_accuracy"], 0.42)
+
+ @slow
+ def test_run_ner(self):
+ # with so little data distributed training needs more epochs to get the score on par with 0/1 gpu
+ epochs = 7 if get_gpu_count() > 1 else 2
+
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_flax_ner.py
+ --model_name_or_path google-bert/bert-base-uncased
+ --train_file tests/fixtures/tests_samples/conll/sample.json
+ --validation_file tests/fixtures/tests_samples/conll/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --do_train
+ --do_eval
+ --warmup_steps=2
+ --learning_rate=2e-4
+ --logging_steps 2 --eval_steps 2
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=2
+ --num_train_epochs={epochs}
+ --seed 7
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_flax_ner.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_accuracy"], 0.75)
+ self.assertGreaterEqual(result["eval_f1"], 0.3)
+
+ @slow
+ def test_run_qa(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_qa.py
+ --model_name_or_path google-bert/bert-base-uncased
+ --version_2_with_negative
+ --train_file tests/fixtures/tests_samples/SQUAD/sample.json
+ --validation_file tests/fixtures/tests_samples/SQUAD/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --num_train_epochs=3
+ --warmup_steps=2
+ --do_train
+ --do_eval
+ --logging_steps 2 --eval_steps 2
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_qa.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_f1"], 30)
+ self.assertGreaterEqual(result["eval_exact"], 30)
+
+ @slow
+ def test_run_flax_speech_recognition_seq2seq(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_flax_speech_recognition_seq2seq.py
+ --model_name_or_path openai/whisper-tiny.en
+ --dataset_name hf-internal-testing/librispeech_asr_dummy
+ --dataset_config clean
+ --train_split_name validation
+ --eval_split_name validation
+ --trust_remote_code
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --num_train_epochs=2
+ --max_train_samples 10
+ --max_eval_samples 10
+ --warmup_steps=8
+ --do_train
+ --do_eval
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --predict_with_generate
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_flax_speech_recognition_seq2seq.main()
+ result = get_results(tmp_dir, split="eval")
+ self.assertLessEqual(result["eval_wer"], 0.05)
diff --git a/docs/transformers/examples/flax/text-classification/README.md b/docs/transformers/examples/flax/text-classification/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..65e50a075b78d59541093fe1fc830eb447e8d6ca
--- /dev/null
+++ b/docs/transformers/examples/flax/text-classification/README.md
@@ -0,0 +1,108 @@
+
+
+# Text classification examples
+
+## GLUE tasks
+
+Based on the script [`run_flax_glue.py`](https://github.com/huggingface/transformers/blob/main/examples/flax/text-classification/run_flax_glue.py).
+
+Fine-tuning the library models for sequence classification on the GLUE benchmark: [General Language Understanding
+Evaluation](https://gluebenchmark.com/). This script can fine-tune any of the models on the [hub](https://huggingface.co/models) and can also be used for a
+dataset hosted on our [hub](https://huggingface.co/datasets) or your own data in a csv or a JSON file (the script might need some tweaks in that case,
+refer to the comments inside for help).
+
+GLUE is made up of a total of 9 different tasks. Here is how to run the script on one of them:
+
+```bash
+export TASK_NAME=mrpc
+
+python run_flax_glue.py \
+ --model_name_or_path google-bert/bert-base-cased \
+ --task_name ${TASK_NAME} \
+ --max_seq_length 128 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3 \
+ --per_device_train_batch_size 4 \
+ --eval_steps 100 \
+ --output_dir ./$TASK_NAME/ \
+ --push_to_hub
+```
+
+where task name can be one of cola, mnli, mnli_mismatched, mnli_matched, mrpc, qnli, qqp, rte, sst2, stsb, wnli.
+
+Using the command above, the script will train for 3 epochs and run eval after each epoch.
+Metrics and hyperparameters are stored in Tensorflow event files in `--output_dir`.
+You can see the results by running `tensorboard` in that directory:
+
+```bash
+$ tensorboard --logdir .
+```
+
+or directly on the hub under *Training metrics*.
+
+### Accuracy Evaluation
+
+We train five replicas and report mean accuracy and stdev on the dev set below.
+We use the settings as in the command above (with an exception for MRPC and
+WNLI which are tiny and where we used 5 epochs instead of 3), and we use a total
+train batch size of 32 (we train on 8 Cloud v3 TPUs, so a per-device batch size of 4),
+
+On the task other than MRPC and WNLI we train for 3 these epochs because this is the standard,
+but looking at the training curves of some of them (e.g., SST-2, STS-b), it appears the models
+are undertrained and we could get better results when training longer.
+
+In the Tensorboard results linked below, the random seed of each model is equal to the ID of the run. So in order to reproduce run 1, run the command above with `--seed=1`. The best run used random seed 3, which is the default in the script. The results of all runs are in [this Google Sheet](https://docs.google.com/spreadsheets/d/1p3XzReMO75m_XdEJvPue-PIq_PN-96J2IJpJW1yS-10/edit?usp=sharing).
+
+| Task | Metric | Acc (best run) | Acc (avg/5runs) | Stdev | Metrics |
+|-------|------------------------------|----------------|-----------------|-----------|--------------------------------------------------------------------------|
+| CoLA | Matthews corr | 60.57 | 59.04 | 1.06 | [tfhub.dev](https://tensorboard.dev/experiment/lfr2adVpRtmLDALKrElkzg/) |
+| SST-2 | Accuracy | 92.66 | 92.23 | 0.57 | [tfhub.dev](https://tensorboard.dev/experiment/jYvfv2trRHKMjoWnXVwrZA/) |
+| MRPC | F1/Accuracy | 89.90/85.78 | 88.97/84.36 | 0.72/1.09 | [tfhub.dev](https://tensorboard.dev/experiment/bo3W3DEoRw2Q7YXjWrJkfg/) |
+| STS-B | Pearson/Spearman corr. | 89.04/88.70 | 88.94/88.63 | 0.07/0.07 | [tfhub.dev](https://tensorboard.dev/experiment/fxVwbLD7QpKhbot0r9rn2w/) |
+| QQP | Accuracy/F1 | 90.81/87.58 | 90.76/87.51 | 0.05/0.06 | [tfhub.dev](https://tensorboard.dev/experiment/di089Rc9TZmsnKRMrYNLsA/) |
+| MNLI | Matched acc. | 84.10 | 83.80 | 0.16 | [tfhub.dev](https://tensorboard.dev/experiment/JgNCGHDJSRaW6HBx6YQFYQ/) |
+| QNLI | Accuracy | 91.01 | 90.82 | 0.17 | [tfhub.dev](https://tensorboard.dev/experiment/Bq7cMGJnQMSggYgL8qNGeQ/) |
+| RTE | Accuracy | 66.06 | 64.76 | 1.04 | [tfhub.dev](https://tensorboard.dev/experiment/66Eq24bhRjqN6CEhgDSGqQ/) |
+| WNLI | Accuracy | 46.48 | 37.01 | 6.83 | [tfhub.dev](https://tensorboard.dev/experiment/TAqcnddqTkWvVEeGaWwIdQ/) |
+
+Some of these results are significantly different from the ones reported on the test set of GLUE benchmark on the
+website. For QQP and WNLI, please refer to [FAQ #12](https://gluebenchmark.com/faq) on the website.
+
+### Runtime evaluation
+
+We also ran each task once on a single V100 GPU, 8 V100 GPUs, and 8 Cloud v3 TPUs and report the
+overall training time below. For comparison we ran Pytorch's [run_glue.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-classification/run_glue.py) on a single GPU (last column).
+
+
+| Task | TPU v3-8 | 8 GPU | [1 GPU](https://tensorboard.dev/experiment/mkPS4Zh8TnGe1HB6Yzwj4Q) | 1 GPU (Pytorch) |
+|-------|-----------|------------|------------|-----------------|
+| CoLA | 1m 42s | 1m 26s | 3m 9s | 4m 6s |
+| SST-2 | 5m 12s | 6m 28s | 22m 33s | 34m 37s |
+| MRPC | 1m 29s | 1m 14s | 2m 20s | 2m 56s |
+| STS-B | 1m 30s | 1m 12s | 2m 16s | 2m 48s |
+| QQP | 22m 50s | 31m 48s | 1h 59m 41s | 2h 54m |
+| MNLI | 25m 03s | 33m 55s | 2h 9m 37s | 3h 7m 6s |
+| QNLI | 7m30s | 9m 40s | 34m 40s | 49m 8s |
+| RTE | 1m 20s | 55s | 1m 10s | 1m 16s |
+| WNLI | 1m 11s | 48s | 39s | 36s |
+|-------|
+| **TOTAL** | 1h 03m | 1h 28m | 5h 16m | 6h 37m |
+
+*All experiments are ran on Google Cloud Platform.
+GPU experiments are ran without further optimizations besides JAX
+transformations. GPU experiments are ran with full precision (fp32). "TPU v3-8"
+are 8 TPU cores on 4 chips (each chips has 2 cores), while "8 GPU" are 8 GPU chips.
diff --git a/docs/transformers/examples/flax/text-classification/requirements.txt b/docs/transformers/examples/flax/text-classification/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..7507ae1b69c9aa60e4ad35f0b2ec2771b0ac8e39
--- /dev/null
+++ b/docs/transformers/examples/flax/text-classification/requirements.txt
@@ -0,0 +1,5 @@
+datasets >= 1.1.3
+jax>=0.2.8
+jaxlib>=0.1.59
+flax>=0.3.5
+optax>=0.0.8
diff --git a/docs/transformers/examples/flax/text-classification/run_flax_glue.py b/docs/transformers/examples/flax/text-classification/run_flax_glue.py
new file mode 100644
index 0000000000000000000000000000000000000000..b5378b8c1171c173f394aec83b3b439f5d8fd863
--- /dev/null
+++ b/docs/transformers/examples/flax/text-classification/run_flax_glue.py
@@ -0,0 +1,697 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Finetuning a 🤗 Flax Transformers model for sequence classification on GLUE."""
+
+import json
+import logging
+import math
+import os
+import random
+import sys
+import time
+import warnings
+from dataclasses import dataclass, field
+from pathlib import Path
+from typing import Any, Callable, Optional
+
+import datasets
+import evaluate
+import jax
+import jax.numpy as jnp
+import numpy as np
+import optax
+from datasets import load_dataset
+from flax import struct, traverse_util
+from flax.jax_utils import pad_shard_unpad, replicate, unreplicate
+from flax.training import train_state
+from flax.training.common_utils import get_metrics, onehot, shard
+from huggingface_hub import HfApi
+from tqdm import tqdm
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoTokenizer,
+ FlaxAutoModelForSequenceClassification,
+ HfArgumentParser,
+ PretrainedConfig,
+ TrainingArguments,
+ is_tensorboard_available,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+
+
+logger = logging.getLogger(__name__)
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+Array = Any
+Dataset = datasets.arrow_dataset.Dataset
+PRNGKey = Any
+
+
+task_to_keys = {
+ "cola": ("sentence", None),
+ "mnli": ("premise", "hypothesis"),
+ "mrpc": ("sentence1", "sentence2"),
+ "qnli": ("question", "sentence"),
+ "qqp": ("question1", "question2"),
+ "rte": ("sentence1", "sentence2"),
+ "sst2": ("sentence", None),
+ "stsb": ("sentence1", "sentence2"),
+ "wnli": ("sentence1", "sentence2"),
+}
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ use_slow_tokenizer: Optional[bool] = field(
+ default=False,
+ metadata={"help": "If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library)."},
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ use_auth_token: bool = field(
+ default=None,
+ metadata={
+ "help": "The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead."
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
+ "should only be set to `True` for repositories you trust and in which you have read the code, as it will "
+ "execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ task_name: Optional[str] = field(
+ default=None, metadata={"help": f"The name of the glue task to train on. choices {list(task_to_keys.keys())}"}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(
+ default=None, metadata={"help": "The input training data file (a csv or JSON file)."}
+ )
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate on (a csv or JSON file)."},
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input test data file to predict on (a csv or JSON file)."},
+ )
+ text_column_name: Optional[str] = field(
+ default=None, metadata={"help": "The column name of text to input in the file (a csv or JSON file)."}
+ )
+ label_column_name: Optional[str] = field(
+ default=None, metadata={"help": "The column name of label to input in the file (a csv or JSON file)."}
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_seq_length: int = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. If set, sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if self.task_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ self.task_name = self.task_name.lower() if isinstance(self.task_name, str) else self.task_name
+
+
+def create_train_state(
+ model: FlaxAutoModelForSequenceClassification,
+ learning_rate_fn: Callable[[int], float],
+ is_regression: bool,
+ num_labels: int,
+ weight_decay: float,
+) -> train_state.TrainState:
+ """Create initial training state."""
+
+ class TrainState(train_state.TrainState):
+ """Train state with an Optax optimizer.
+
+ The two functions below differ depending on whether the task is classification
+ or regression.
+
+ Args:
+ logits_fn: Applied to last layer to obtain the logits.
+ loss_fn: Function to compute the loss.
+ """
+
+ logits_fn: Callable = struct.field(pytree_node=False)
+ loss_fn: Callable = struct.field(pytree_node=False)
+
+ # We use Optax's "masking" functionality to not apply weight decay
+ # to bias and LayerNorm scale parameters. decay_mask_fn returns a
+ # mask boolean with the same structure as the parameters.
+ # The mask is True for parameters that should be decayed.
+ def decay_mask_fn(params):
+ flat_params = traverse_util.flatten_dict(params)
+ # find out all LayerNorm parameters
+ layer_norm_candidates = ["layernorm", "layer_norm", "ln"]
+ layer_norm_named_params = {
+ layer[-2:]
+ for layer_norm_name in layer_norm_candidates
+ for layer in flat_params.keys()
+ if layer_norm_name in "".join(layer).lower()
+ }
+ flat_mask = {path: (path[-1] != "bias" and path[-2:] not in layer_norm_named_params) for path in flat_params}
+ return traverse_util.unflatten_dict(flat_mask)
+
+ tx = optax.adamw(
+ learning_rate=learning_rate_fn, b1=0.9, b2=0.999, eps=1e-6, weight_decay=weight_decay, mask=decay_mask_fn
+ )
+
+ if is_regression:
+
+ def mse_loss(logits, labels):
+ return jnp.mean((logits[..., 0] - labels) ** 2)
+
+ return TrainState.create(
+ apply_fn=model.__call__,
+ params=model.params,
+ tx=tx,
+ logits_fn=lambda logits: logits[..., 0],
+ loss_fn=mse_loss,
+ )
+ else: # Classification.
+
+ def cross_entropy_loss(logits, labels):
+ xentropy = optax.softmax_cross_entropy(logits, onehot(labels, num_classes=num_labels))
+ return jnp.mean(xentropy)
+
+ return TrainState.create(
+ apply_fn=model.__call__,
+ params=model.params,
+ tx=tx,
+ logits_fn=lambda logits: logits.argmax(-1),
+ loss_fn=cross_entropy_loss,
+ )
+
+
+def create_learning_rate_fn(
+ train_ds_size: int, train_batch_size: int, num_train_epochs: int, num_warmup_steps: int, learning_rate: float
+) -> Callable[[int], jnp.ndarray]:
+ """Returns a linear warmup, linear_decay learning rate function."""
+ steps_per_epoch = train_ds_size // train_batch_size
+ num_train_steps = steps_per_epoch * num_train_epochs
+ warmup_fn = optax.linear_schedule(init_value=0.0, end_value=learning_rate, transition_steps=num_warmup_steps)
+ decay_fn = optax.linear_schedule(
+ init_value=learning_rate, end_value=0, transition_steps=num_train_steps - num_warmup_steps
+ )
+ schedule_fn = optax.join_schedules(schedules=[warmup_fn, decay_fn], boundaries=[num_warmup_steps])
+ return schedule_fn
+
+
+def glue_train_data_collator(rng: PRNGKey, dataset: Dataset, batch_size: int):
+ """Returns shuffled batches of size `batch_size` from truncated `train dataset`, sharded over all local devices."""
+ steps_per_epoch = len(dataset) // batch_size
+ perms = jax.random.permutation(rng, len(dataset))
+ perms = perms[: steps_per_epoch * batch_size] # Skip incomplete batch.
+ perms = perms.reshape((steps_per_epoch, batch_size))
+
+ for perm in perms:
+ batch = dataset[perm]
+ batch = {k: np.array(v) for k, v in batch.items()}
+ batch = shard(batch)
+
+ yield batch
+
+
+def glue_eval_data_collator(dataset: Dataset, batch_size: int):
+ """Returns batches of size `batch_size` from `eval dataset`. Sharding handled by `pad_shard_unpad` in the eval loop."""
+ batch_idx = np.arange(len(dataset))
+
+ steps_per_epoch = math.ceil(len(dataset) / batch_size)
+ batch_idx = np.array_split(batch_idx, steps_per_epoch)
+
+ for idx in batch_idx:
+ batch = dataset[idx]
+ batch = {k: np.array(v) for k, v in batch.items()}
+
+ yield batch
+
+
+def main():
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ if model_args.use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead.",
+ FutureWarning,
+ )
+ if model_args.token is not None:
+ raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
+ model_args.token = model_args.use_auth_token
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_glue", model_args, data_args, framework="flax")
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ # Setup logging, we only want one process per machine to log things on the screen.
+ logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
+ if jax.process_index() == 0:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # Handle the repository creation
+ if training_args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = training_args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(training_args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
+
+ # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
+ # or specify a GLUE benchmark task (the dataset will be downloaded automatically from the datasets Hub).
+
+ # For CSV/JSON files, this script will use as labels the column called 'label' and as pair of sentences the
+ # sentences in columns called 'sentence1' and 'sentence2' if such column exists or the first two columns not named
+ # label if at least two columns are provided.
+
+ # If the CSVs/JSONs contain only one non-label column, the script does single sentence classification on this
+ # single column. You can easily tweak this behavior (see below)
+
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.task_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ "glue",
+ data_args.task_name,
+ token=model_args.token,
+ )
+ else:
+ # Loading the dataset from local csv or json file.
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = (data_args.train_file if data_args.train_file is not None else data_args.valid_file).split(".")[-1]
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Labels
+ if data_args.task_name is not None:
+ is_regression = data_args.task_name == "stsb"
+ if not is_regression:
+ label_list = raw_datasets["train"].features["label"].names
+ num_labels = len(label_list)
+ else:
+ num_labels = 1
+ else:
+ # Trying to have good defaults here, don't hesitate to tweak to your needs.
+ is_regression = raw_datasets["train"].features["label"].dtype in ["float32", "float64"]
+ if is_regression:
+ num_labels = 1
+ else:
+ # A useful fast method:
+ # https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.unique
+ label_list = raw_datasets["train"].unique("label")
+ label_list.sort() # Let's sort it for determinism
+ num_labels = len(label_list)
+
+ # Load pretrained model and tokenizer
+ config = AutoConfig.from_pretrained(
+ model_args.model_name_or_path,
+ num_labels=num_labels,
+ finetuning_task=data_args.task_name,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.model_name_or_path,
+ use_fast=not model_args.use_slow_tokenizer,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = FlaxAutoModelForSequenceClassification.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # Preprocessing the datasets
+ if data_args.task_name is not None:
+ sentence1_key, sentence2_key = task_to_keys[data_args.task_name]
+ else:
+ # Again, we try to have some nice defaults but don't hesitate to tweak to your use case.
+ non_label_column_names = [name for name in raw_datasets["train"].column_names if name != "label"]
+ if "sentence1" in non_label_column_names and "sentence2" in non_label_column_names:
+ sentence1_key, sentence2_key = "sentence1", "sentence2"
+ else:
+ if len(non_label_column_names) >= 2:
+ sentence1_key, sentence2_key = non_label_column_names[:2]
+ else:
+ sentence1_key, sentence2_key = non_label_column_names[0], None
+
+ # Some models have set the order of the labels to use, so let's make sure we do use it.
+ label_to_id = None
+ if (
+ model.config.label2id != PretrainedConfig(num_labels=num_labels).label2id
+ and data_args.task_name is not None
+ and not is_regression
+ ):
+ # Some have all caps in their config, some don't.
+ label_name_to_id = {k.lower(): v for k, v in model.config.label2id.items()}
+ if sorted(label_name_to_id.keys()) == sorted(label_list):
+ logger.info(
+ f"The configuration of the model provided the following label correspondence: {label_name_to_id}. "
+ "Using it!"
+ )
+ label_to_id = {i: label_name_to_id[label_list[i]] for i in range(num_labels)}
+ else:
+ logger.warning(
+ "Your model seems to have been trained with labels, but they don't match the dataset: "
+ f"model labels: {sorted(label_name_to_id.keys())}, dataset labels: {sorted(label_list)}."
+ "\nIgnoring the model labels as a result.",
+ )
+ elif data_args.task_name is None:
+ label_to_id = {v: i for i, v in enumerate(label_list)}
+
+ def preprocess_function(examples):
+ # Tokenize the texts
+ texts = (
+ (examples[sentence1_key],) if sentence2_key is None else (examples[sentence1_key], examples[sentence2_key])
+ )
+ result = tokenizer(*texts, padding="max_length", max_length=data_args.max_seq_length, truncation=True)
+
+ if "label" in examples:
+ if label_to_id is not None:
+ # Map labels to IDs (not necessary for GLUE tasks)
+ result["labels"] = [label_to_id[l] for l in examples["label"]]
+ else:
+ # In all cases, rename the column to labels because the model will expect that.
+ result["labels"] = examples["label"]
+ return result
+
+ processed_datasets = raw_datasets.map(
+ preprocess_function, batched=True, remove_columns=raw_datasets["train"].column_names
+ )
+
+ train_dataset = processed_datasets["train"]
+ eval_dataset = processed_datasets["validation_matched" if data_args.task_name == "mnli" else "validation"]
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # Define a summary writer
+ has_tensorboard = is_tensorboard_available()
+ if has_tensorboard and jax.process_index() == 0:
+ try:
+ from flax.metrics.tensorboard import SummaryWriter
+
+ summary_writer = SummaryWriter(training_args.output_dir)
+ summary_writer.hparams({**training_args.to_dict(), **vars(model_args), **vars(data_args)})
+ except ImportError as ie:
+ has_tensorboard = False
+ logger.warning(
+ f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
+ )
+ else:
+ logger.warning(
+ "Unable to display metrics through TensorBoard because the package is not installed: "
+ "Please run pip install tensorboard to enable."
+ )
+
+ def write_train_metric(summary_writer, train_metrics, train_time, step):
+ summary_writer.scalar("train_time", train_time, step)
+
+ train_metrics = get_metrics(train_metrics)
+ for key, vals in train_metrics.items():
+ tag = f"train_{key}"
+ for i, val in enumerate(vals):
+ summary_writer.scalar(tag, val, step - len(vals) + i + 1)
+
+ def write_eval_metric(summary_writer, eval_metrics, step):
+ for metric_name, value in eval_metrics.items():
+ summary_writer.scalar(f"eval_{metric_name}", value, step)
+
+ num_epochs = int(training_args.num_train_epochs)
+ rng = jax.random.PRNGKey(training_args.seed)
+ dropout_rngs = jax.random.split(rng, jax.local_device_count())
+
+ train_batch_size = int(training_args.per_device_train_batch_size) * jax.local_device_count()
+ per_device_eval_batch_size = int(training_args.per_device_eval_batch_size)
+ eval_batch_size = per_device_eval_batch_size * jax.device_count()
+
+ learning_rate_fn = create_learning_rate_fn(
+ len(train_dataset),
+ train_batch_size,
+ training_args.num_train_epochs,
+ training_args.warmup_steps,
+ training_args.learning_rate,
+ )
+
+ state = create_train_state(
+ model, learning_rate_fn, is_regression, num_labels=num_labels, weight_decay=training_args.weight_decay
+ )
+
+ # define step functions
+ def train_step(
+ state: train_state.TrainState, batch: dict[str, Array], dropout_rng: PRNGKey
+ ) -> tuple[train_state.TrainState, float]:
+ """Trains model with an optimizer (both in `state`) on `batch`, returning a pair `(new_state, loss)`."""
+ dropout_rng, new_dropout_rng = jax.random.split(dropout_rng)
+ targets = batch.pop("labels")
+
+ def loss_fn(params):
+ logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
+ loss = state.loss_fn(logits, targets)
+ return loss
+
+ grad_fn = jax.value_and_grad(loss_fn)
+ loss, grad = grad_fn(state.params)
+ grad = jax.lax.pmean(grad, "batch")
+ new_state = state.apply_gradients(grads=grad)
+ metrics = jax.lax.pmean({"loss": loss, "learning_rate": learning_rate_fn(state.step)}, axis_name="batch")
+ return new_state, metrics, new_dropout_rng
+
+ p_train_step = jax.pmap(train_step, axis_name="batch", donate_argnums=(0,))
+
+ def eval_step(state, batch):
+ logits = state.apply_fn(**batch, params=state.params, train=False)[0]
+ return state.logits_fn(logits)
+
+ p_eval_step = jax.pmap(eval_step, axis_name="batch")
+
+ if data_args.task_name is not None:
+ metric = evaluate.load("glue", data_args.task_name, cache_dir=model_args.cache_dir)
+ else:
+ metric = evaluate.load("accuracy", cache_dir=model_args.cache_dir)
+
+ logger.info(f"===== Starting training ({num_epochs} epochs) =====")
+ train_time = 0
+
+ # make sure weights are replicated on each device
+ state = replicate(state)
+
+ steps_per_epoch = len(train_dataset) // train_batch_size
+ total_steps = steps_per_epoch * num_epochs
+ epochs = tqdm(range(num_epochs), desc=f"Epoch ... (0/{num_epochs})", position=0)
+ for epoch in epochs:
+ train_start = time.time()
+ train_metrics = []
+
+ # Create sampling rng
+ rng, input_rng = jax.random.split(rng)
+
+ # train
+ train_loader = glue_train_data_collator(input_rng, train_dataset, train_batch_size)
+ for step, batch in enumerate(
+ tqdm(
+ train_loader,
+ total=steps_per_epoch,
+ desc="Training...",
+ position=1,
+ ),
+ ):
+ state, train_metric, dropout_rngs = p_train_step(state, batch, dropout_rngs)
+ train_metrics.append(train_metric)
+
+ cur_step = (epoch * steps_per_epoch) + (step + 1)
+
+ if cur_step % training_args.logging_steps == 0 and cur_step > 0:
+ # Save metrics
+ train_metric = unreplicate(train_metric)
+ train_time += time.time() - train_start
+ if has_tensorboard and jax.process_index() == 0:
+ write_train_metric(summary_writer, train_metrics, train_time, cur_step)
+
+ epochs.write(
+ f"Step... ({cur_step}/{total_steps} | Training Loss: {train_metric['loss']}, Learning Rate:"
+ f" {train_metric['learning_rate']})"
+ )
+
+ train_metrics = []
+
+ if (cur_step % training_args.eval_steps == 0 or cur_step % steps_per_epoch == 0) and cur_step > 0:
+ # evaluate
+ eval_loader = glue_eval_data_collator(eval_dataset, eval_batch_size)
+ for batch in tqdm(
+ eval_loader,
+ total=math.ceil(len(eval_dataset) / eval_batch_size),
+ desc="Evaluating ...",
+ position=2,
+ ):
+ labels = batch.pop("labels")
+ predictions = pad_shard_unpad(p_eval_step)(
+ state, batch, min_device_batch=per_device_eval_batch_size
+ )
+ metric.add_batch(predictions=np.array(predictions), references=labels)
+
+ eval_metric = metric.compute()
+
+ logger.info(f"Step... ({cur_step}/{total_steps} | Eval metrics: {eval_metric})")
+
+ if has_tensorboard and jax.process_index() == 0:
+ write_eval_metric(summary_writer, eval_metric, cur_step)
+
+ if (cur_step % training_args.save_steps == 0 and cur_step > 0) or (cur_step == total_steps):
+ # save checkpoint after each epoch and push checkpoint to the hub
+ if jax.process_index() == 0:
+ params = jax.device_get(unreplicate(state.params))
+ model.save_pretrained(training_args.output_dir, params=params)
+ tokenizer.save_pretrained(training_args.output_dir)
+ if training_args.push_to_hub:
+ api.upload_folder(
+ commit_message=f"Saving weights and logs of epoch {epoch}",
+ folder_path=training_args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=training_args.hub_token,
+ )
+ epochs.desc = f"Epoch ... {epoch + 1}/{num_epochs}"
+
+ # save the eval metrics in json
+ if jax.process_index() == 0:
+ eval_metric = {f"eval_{metric_name}": value for metric_name, value in eval_metric.items()}
+ path = os.path.join(training_args.output_dir, "eval_results.json")
+ with open(path, "w") as f:
+ json.dump(eval_metric, f, indent=4, sort_keys=True)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/flax/token-classification/README.md b/docs/transformers/examples/flax/token-classification/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..1f8175072148bbbe9fc9aa884616589104e05ed5
--- /dev/null
+++ b/docs/transformers/examples/flax/token-classification/README.md
@@ -0,0 +1,49 @@
+
+
+# Token classification examples
+
+Fine-tuning the library models for token classification task such as Named Entity Recognition (NER), Parts-of-speech tagging (POS) or phrase extraction (CHUNKS). The main script run_flax_ner.py leverages the 🤗 Datasets library. You can easily customize it to your needs if you need extra processing on your datasets.
+
+It will either run on a datasets hosted on our hub or with your own text files for training and validation, you might just need to add some tweaks in the data preprocessing.
+
+The following example fine-tunes BERT on CoNLL-2003:
+
+
+```bash
+python run_flax_ner.py \
+ --model_name_or_path google-bert/bert-base-cased \
+ --dataset_name conll2003 \
+ --max_seq_length 128 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3 \
+ --per_device_train_batch_size 4 \
+ --output_dir ./bert-ner-conll2003 \
+ --eval_steps 300 \
+ --push_to_hub
+```
+
+Using the command above, the script will train for 3 epochs and run eval after each epoch.
+Metrics and hyperparameters are stored in Tensorflow event files in `--output_dir`.
+You can see the results by running `tensorboard` in that directory:
+
+```bash
+$ tensorboard --logdir .
+```
+
+or directly on the hub under *Training metrics*.
+
+sample Metrics - [tfhub.dev](https://tensorboard.dev/experiment/u52qsBIpQSKEEXEJd2LVYA)
\ No newline at end of file
diff --git a/docs/transformers/examples/flax/token-classification/requirements.txt b/docs/transformers/examples/flax/token-classification/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f5ae92023d0c41158dd73931a1dc9ba0d5b80e25
--- /dev/null
+++ b/docs/transformers/examples/flax/token-classification/requirements.txt
@@ -0,0 +1,6 @@
+datasets >= 1.8.0
+jax>=0.2.8
+jaxlib>=0.1.59
+flax>=0.3.5
+optax>=0.0.8
+seqeval
\ No newline at end of file
diff --git a/docs/transformers/examples/flax/token-classification/run_flax_ner.py b/docs/transformers/examples/flax/token-classification/run_flax_ner.py
new file mode 100644
index 0000000000000000000000000000000000000000..854d7c71366035379f8185dd584ab4a33c41e48d
--- /dev/null
+++ b/docs/transformers/examples/flax/token-classification/run_flax_ner.py
@@ -0,0 +1,832 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Fine-tuning a 🤗 Flax Transformers model on token classification tasks (NER, POS, CHUNKS)"""
+
+import json
+import logging
+import math
+import os
+import random
+import sys
+import time
+import warnings
+from dataclasses import asdict, dataclass, field
+from enum import Enum
+from itertools import chain
+from pathlib import Path
+from typing import Any, Callable, Optional
+
+import datasets
+import evaluate
+import jax
+import jax.numpy as jnp
+import numpy as np
+import optax
+from datasets import ClassLabel, load_dataset
+from flax import struct, traverse_util
+from flax.jax_utils import pad_shard_unpad, replicate, unreplicate
+from flax.training import train_state
+from flax.training.common_utils import get_metrics, onehot, shard
+from huggingface_hub import HfApi
+from tqdm import tqdm
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoTokenizer,
+ FlaxAutoModelForTokenClassification,
+ HfArgumentParser,
+ is_tensorboard_available,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+logger = logging.getLogger(__name__)
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
+
+Array = Any
+Dataset = datasets.arrow_dataset.Dataset
+PRNGKey = Any
+
+
+@dataclass
+class TrainingArguments:
+ output_dir: str = field(
+ metadata={"help": "The output directory where the model predictions and checkpoints will be written."},
+ )
+ overwrite_output_dir: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Overwrite the content of the output directory. "
+ "Use this to continue training if output_dir points to a checkpoint directory."
+ )
+ },
+ )
+ do_train: bool = field(default=False, metadata={"help": "Whether to run training."})
+ do_eval: bool = field(default=False, metadata={"help": "Whether to run eval on the dev set."})
+ per_device_train_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for training."}
+ )
+ per_device_eval_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for evaluation."}
+ )
+ learning_rate: float = field(default=5e-5, metadata={"help": "The initial learning rate for AdamW."})
+ weight_decay: float = field(default=0.0, metadata={"help": "Weight decay for AdamW if we apply some."})
+ adam_beta1: float = field(default=0.9, metadata={"help": "Beta1 for AdamW optimizer"})
+ adam_beta2: float = field(default=0.999, metadata={"help": "Beta2 for AdamW optimizer"})
+ adam_epsilon: float = field(default=1e-8, metadata={"help": "Epsilon for AdamW optimizer."})
+ adafactor: bool = field(default=False, metadata={"help": "Whether or not to replace AdamW by Adafactor."})
+ num_train_epochs: float = field(default=3.0, metadata={"help": "Total number of training epochs to perform."})
+ warmup_steps: int = field(default=0, metadata={"help": "Linear warmup over warmup_steps."})
+ logging_steps: int = field(default=500, metadata={"help": "Log every X updates steps."})
+ save_steps: int = field(default=500, metadata={"help": "Save checkpoint every X updates steps."})
+ eval_steps: int = field(default=None, metadata={"help": "Run an evaluation every X steps."})
+ seed: int = field(default=42, metadata={"help": "Random seed that will be set at the beginning of training."})
+ push_to_hub: bool = field(
+ default=False, metadata={"help": "Whether or not to upload the trained model to the model hub after training."}
+ )
+ hub_model_id: str = field(
+ default=None, metadata={"help": "The name of the repository to keep in sync with the local `output_dir`."}
+ )
+ hub_token: str = field(default=None, metadata={"help": "The token to use to push to the Model Hub."})
+
+ def __post_init__(self):
+ if self.output_dir is not None:
+ self.output_dir = os.path.expanduser(self.output_dir)
+
+ def to_dict(self):
+ """
+ Serializes this instance while replace `Enum` by their values (for JSON serialization support). It obfuscates
+ the token values by removing their value.
+ """
+ d = asdict(self)
+ for k, v in d.items():
+ if isinstance(v, Enum):
+ d[k] = v.value
+ if isinstance(v, list) and len(v) > 0 and isinstance(v[0], Enum):
+ d[k] = [x.value for x in v]
+ if k.endswith("_token"):
+ d[k] = f"<{k.upper()}>"
+ return d
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ use_auth_token: bool = field(
+ default=None,
+ metadata={
+ "help": "The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead."
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ task_name: Optional[str] = field(default="ner", metadata={"help": "The name of the task (ner, pos...)."})
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(
+ default=None, metadata={"help": "The input training data file (a csv or JSON file)."}
+ )
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate on (a csv or JSON file)."},
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input test data file to predict on (a csv or JSON file)."},
+ )
+ text_column_name: Optional[str] = field(
+ default=None, metadata={"help": "The column name of text to input in the file (a csv or JSON file)."}
+ )
+ label_column_name: Optional[str] = field(
+ default=None, metadata={"help": "The column name of label to input in the file (a csv or JSON file)."}
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_seq_length: int = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. If set, sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ label_all_tokens: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to put the label for one word on all tokens of generated by that word or just on the "
+ "one (in which case the other tokens will have a padding index)."
+ )
+ },
+ )
+ return_entity_level_metrics: bool = field(
+ default=False,
+ metadata={"help": "Whether to return all the entity levels during evaluation or just the overall ones."},
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ self.task_name = self.task_name.lower()
+
+
+def create_train_state(
+ model: FlaxAutoModelForTokenClassification,
+ learning_rate_fn: Callable[[int], float],
+ num_labels: int,
+ training_args: TrainingArguments,
+) -> train_state.TrainState:
+ """Create initial training state."""
+
+ class TrainState(train_state.TrainState):
+ """Train state with an Optax optimizer.
+
+ The two functions below differ depending on whether the task is classification
+ or regression.
+
+ Args:
+ logits_fn: Applied to last layer to obtain the logits.
+ loss_fn: Function to compute the loss.
+ """
+
+ logits_fn: Callable = struct.field(pytree_node=False)
+ loss_fn: Callable = struct.field(pytree_node=False)
+
+ # We use Optax's "masking" functionality to not apply weight decay
+ # to bias and LayerNorm scale parameters. decay_mask_fn returns a
+ # mask boolean with the same structure as the parameters.
+ # The mask is True for parameters that should be decayed.
+ def decay_mask_fn(params):
+ flat_params = traverse_util.flatten_dict(params)
+ # find out all LayerNorm parameters
+ layer_norm_candidates = ["layernorm", "layer_norm", "ln"]
+ layer_norm_named_params = {
+ layer[-2:]
+ for layer_norm_name in layer_norm_candidates
+ for layer in flat_params.keys()
+ if layer_norm_name in "".join(layer).lower()
+ }
+ flat_mask = {path: (path[-1] != "bias" and path[-2:] not in layer_norm_named_params) for path in flat_params}
+ return traverse_util.unflatten_dict(flat_mask)
+
+ tx = optax.adamw(
+ learning_rate=learning_rate_fn,
+ b1=training_args.adam_beta1,
+ b2=training_args.adam_beta2,
+ eps=training_args.adam_epsilon,
+ weight_decay=training_args.weight_decay,
+ mask=decay_mask_fn,
+ )
+
+ def cross_entropy_loss(logits, labels):
+ xentropy = optax.softmax_cross_entropy(logits, onehot(labels, num_classes=num_labels))
+ return jnp.mean(xentropy)
+
+ return TrainState.create(
+ apply_fn=model.__call__,
+ params=model.params,
+ tx=tx,
+ logits_fn=lambda logits: logits.argmax(-1),
+ loss_fn=cross_entropy_loss,
+ )
+
+
+def create_learning_rate_fn(
+ train_ds_size: int, train_batch_size: int, num_train_epochs: int, num_warmup_steps: int, learning_rate: float
+) -> Callable[[int], jnp.ndarray]:
+ """Returns a linear warmup, linear_decay learning rate function."""
+ steps_per_epoch = train_ds_size // train_batch_size
+ num_train_steps = steps_per_epoch * num_train_epochs
+ warmup_fn = optax.linear_schedule(init_value=0.0, end_value=learning_rate, transition_steps=num_warmup_steps)
+ decay_fn = optax.linear_schedule(
+ init_value=learning_rate, end_value=0, transition_steps=num_train_steps - num_warmup_steps
+ )
+ schedule_fn = optax.join_schedules(schedules=[warmup_fn, decay_fn], boundaries=[num_warmup_steps])
+ return schedule_fn
+
+
+def train_data_collator(rng: PRNGKey, dataset: Dataset, batch_size: int):
+ """Returns shuffled batches of size `batch_size` from truncated `train dataset`, sharded over all local devices."""
+ steps_per_epoch = len(dataset) // batch_size
+ perms = jax.random.permutation(rng, len(dataset))
+ perms = perms[: steps_per_epoch * batch_size] # Skip incomplete batch.
+ perms = perms.reshape((steps_per_epoch, batch_size))
+
+ for perm in perms:
+ batch = dataset[perm]
+ batch = {k: np.array(v) for k, v in batch.items()}
+ batch = shard(batch)
+
+ yield batch
+
+
+def eval_data_collator(dataset: Dataset, batch_size: int):
+ """Returns batches of size `batch_size` from `eval dataset`. Sharding handled by `pad_shard_unpad` in the eval loop."""
+ batch_idx = np.arange(len(dataset))
+
+ steps_per_epoch = math.ceil(len(dataset) / batch_size)
+ batch_idx = np.array_split(batch_idx, steps_per_epoch)
+
+ for idx in batch_idx:
+ batch = dataset[idx]
+ batch = {k: np.array(v) for k, v in batch.items()}
+
+ yield batch
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ if model_args.use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead.",
+ FutureWarning,
+ )
+ if model_args.token is not None:
+ raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
+ model_args.token = model_args.use_auth_token
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_ner", model_args, data_args, framework="flax")
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ # Setup logging, we only want one process per machine to log things on the screen.
+ logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
+ if jax.process_index() == 0:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # Handle the repository creation
+ if training_args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = training_args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(training_args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets for token classification task available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'tokens' or the first column if no column called
+ # 'tokens' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ # Loading the dataset from local csv or json file.
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = (data_args.train_file if data_args.train_file is not None else data_args.valid_file).split(".")[-1]
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ if raw_datasets["train"] is not None:
+ column_names = raw_datasets["train"].column_names
+ features = raw_datasets["train"].features
+ else:
+ column_names = raw_datasets["validation"].column_names
+ features = raw_datasets["validation"].features
+
+ if data_args.text_column_name is not None:
+ text_column_name = data_args.text_column_name
+ elif "tokens" in column_names:
+ text_column_name = "tokens"
+ else:
+ text_column_name = column_names[0]
+
+ if data_args.label_column_name is not None:
+ label_column_name = data_args.label_column_name
+ elif f"{data_args.task_name}_tags" in column_names:
+ label_column_name = f"{data_args.task_name}_tags"
+ else:
+ label_column_name = column_names[1]
+
+ # In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
+ # unique labels.
+ def get_label_list(labels):
+ unique_labels = set()
+ for label in labels:
+ unique_labels = unique_labels | set(label)
+ label_list = list(unique_labels)
+ label_list.sort()
+ return label_list
+
+ if isinstance(features[label_column_name].feature, ClassLabel):
+ label_list = features[label_column_name].feature.names
+ # No need to convert the labels since they are already ints.
+ label_to_id = {i: i for i in range(len(label_list))}
+ else:
+ label_list = get_label_list(raw_datasets["train"][label_column_name])
+ label_to_id = {l: i for i, l in enumerate(label_list)}
+ num_labels = len(label_list)
+
+ # Load pretrained model and tokenizer
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ num_labels=num_labels,
+ label2id=label_to_id,
+ id2label={i: l for l, i in label_to_id.items()},
+ finetuning_task=data_args.task_name,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer_name_or_path = model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path
+ if config.model_type in {"gpt2", "roberta"}:
+ tokenizer = AutoTokenizer.from_pretrained(
+ tokenizer_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ add_prefix_space=True,
+ )
+ else:
+ tokenizer = AutoTokenizer.from_pretrained(
+ tokenizer_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = FlaxAutoModelForTokenClassification.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # Preprocessing the datasets
+ # Tokenize all texts and align the labels with them.
+ def tokenize_and_align_labels(examples):
+ tokenized_inputs = tokenizer(
+ examples[text_column_name],
+ max_length=data_args.max_seq_length,
+ padding="max_length",
+ truncation=True,
+ # We use this argument because the texts in our dataset are lists of words (with a label for each word).
+ is_split_into_words=True,
+ )
+
+ labels = []
+
+ for i, label in enumerate(examples[label_column_name]):
+ word_ids = tokenized_inputs.word_ids(batch_index=i)
+ previous_word_idx = None
+ label_ids = []
+ for word_idx in word_ids:
+ # Special tokens have a word id that is None. We set the label to -100 so they are automatically
+ # ignored in the loss function.
+ if word_idx is None:
+ label_ids.append(-100)
+ # We set the label for the first token of each word.
+ elif word_idx != previous_word_idx:
+ label_ids.append(label_to_id[label[word_idx]])
+ # For the other tokens in a word, we set the label to either the current label or -100, depending on
+ # the label_all_tokens flag.
+ else:
+ label_ids.append(label_to_id[label[word_idx]] if data_args.label_all_tokens else -100)
+ previous_word_idx = word_idx
+
+ labels.append(label_ids)
+ tokenized_inputs["labels"] = labels
+ return tokenized_inputs
+
+ processed_raw_datasets = raw_datasets.map(
+ tokenize_and_align_labels,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ remove_columns=raw_datasets["train"].column_names,
+ desc="Running tokenizer on dataset",
+ )
+
+ train_dataset = processed_raw_datasets["train"]
+ eval_dataset = processed_raw_datasets["validation"]
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # Define a summary writer
+ has_tensorboard = is_tensorboard_available()
+ if has_tensorboard and jax.process_index() == 0:
+ try:
+ from flax.metrics.tensorboard import SummaryWriter
+
+ summary_writer = SummaryWriter(training_args.output_dir)
+ summary_writer.hparams({**training_args.to_dict(), **vars(model_args), **vars(data_args)})
+ except ImportError as ie:
+ has_tensorboard = False
+ logger.warning(
+ f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
+ )
+ else:
+ logger.warning(
+ "Unable to display metrics through TensorBoard because the package is not installed: "
+ "Please run pip install tensorboard to enable."
+ )
+
+ def write_train_metric(summary_writer, train_metrics, train_time, step):
+ summary_writer.scalar("train_time", train_time, step)
+
+ train_metrics = get_metrics(train_metrics)
+ for key, vals in train_metrics.items():
+ tag = f"train_{key}"
+ for i, val in enumerate(vals):
+ summary_writer.scalar(tag, val, step - len(vals) + i + 1)
+
+ def write_eval_metric(summary_writer, eval_metrics, step):
+ for metric_name, value in eval_metrics.items():
+ summary_writer.scalar(f"eval_{metric_name}", value, step)
+
+ num_epochs = int(training_args.num_train_epochs)
+ rng = jax.random.PRNGKey(training_args.seed)
+ dropout_rngs = jax.random.split(rng, jax.local_device_count())
+
+ train_batch_size = training_args.per_device_train_batch_size * jax.local_device_count()
+ per_device_eval_batch_size = int(training_args.per_device_eval_batch_size)
+ eval_batch_size = training_args.per_device_eval_batch_size * jax.local_device_count()
+
+ learning_rate_fn = create_learning_rate_fn(
+ len(train_dataset),
+ train_batch_size,
+ training_args.num_train_epochs,
+ training_args.warmup_steps,
+ training_args.learning_rate,
+ )
+
+ state = create_train_state(model, learning_rate_fn, num_labels=num_labels, training_args=training_args)
+
+ # define step functions
+ def train_step(
+ state: train_state.TrainState, batch: dict[str, Array], dropout_rng: PRNGKey
+ ) -> tuple[train_state.TrainState, float]:
+ """Trains model with an optimizer (both in `state`) on `batch`, returning a pair `(new_state, loss)`."""
+ dropout_rng, new_dropout_rng = jax.random.split(dropout_rng)
+ targets = batch.pop("labels")
+
+ def loss_fn(params):
+ logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
+ loss = state.loss_fn(logits, targets)
+ return loss
+
+ grad_fn = jax.value_and_grad(loss_fn)
+ loss, grad = grad_fn(state.params)
+ grad = jax.lax.pmean(grad, "batch")
+ new_state = state.apply_gradients(grads=grad)
+ metrics = jax.lax.pmean({"loss": loss, "learning_rate": learning_rate_fn(state.step)}, axis_name="batch")
+ return new_state, metrics, new_dropout_rng
+
+ p_train_step = jax.pmap(train_step, axis_name="batch", donate_argnums=(0,))
+
+ def eval_step(state, batch):
+ logits = state.apply_fn(**batch, params=state.params, train=False)[0]
+ return state.logits_fn(logits)
+
+ p_eval_step = jax.pmap(eval_step, axis_name="batch")
+
+ metric = evaluate.load("seqeval", cache_dir=model_args.cache_dir)
+
+ def get_labels(y_pred, y_true):
+ # Transform predictions and references tensos to numpy arrays
+
+ # Remove ignored index (special tokens)
+ true_predictions = [
+ [label_list[p] for (p, l) in zip(pred, gold_label) if l != -100]
+ for pred, gold_label in zip(y_pred, y_true)
+ ]
+ true_labels = [
+ [label_list[l] for (p, l) in zip(pred, gold_label) if l != -100]
+ for pred, gold_label in zip(y_pred, y_true)
+ ]
+ return true_predictions, true_labels
+
+ def compute_metrics():
+ results = metric.compute()
+ if data_args.return_entity_level_metrics:
+ # Unpack nested dictionaries
+ final_results = {}
+ for key, value in results.items():
+ if isinstance(value, dict):
+ for n, v in value.items():
+ final_results[f"{key}_{n}"] = v
+ else:
+ final_results[key] = value
+ return final_results
+ else:
+ return {
+ "precision": results["overall_precision"],
+ "recall": results["overall_recall"],
+ "f1": results["overall_f1"],
+ "accuracy": results["overall_accuracy"],
+ }
+
+ logger.info(f"===== Starting training ({num_epochs} epochs) =====")
+ train_time = 0
+
+ # make sure weights are replicated on each device
+ state = replicate(state)
+
+ train_time = 0
+ step_per_epoch = len(train_dataset) // train_batch_size
+ total_steps = step_per_epoch * num_epochs
+ epochs = tqdm(range(num_epochs), desc=f"Epoch ... (1/{num_epochs})", position=0)
+ for epoch in epochs:
+ train_start = time.time()
+ train_metrics = []
+
+ # Create sampling rng
+ rng, input_rng = jax.random.split(rng)
+
+ # train
+ for step, batch in enumerate(
+ tqdm(
+ train_data_collator(input_rng, train_dataset, train_batch_size),
+ total=step_per_epoch,
+ desc="Training...",
+ position=1,
+ )
+ ):
+ state, train_metric, dropout_rngs = p_train_step(state, batch, dropout_rngs)
+ train_metrics.append(train_metric)
+
+ cur_step = (epoch * step_per_epoch) + (step + 1)
+
+ if cur_step % training_args.logging_steps == 0 and cur_step > 0:
+ # Save metrics
+ train_metric = unreplicate(train_metric)
+ train_time += time.time() - train_start
+ if has_tensorboard and jax.process_index() == 0:
+ write_train_metric(summary_writer, train_metrics, train_time, cur_step)
+
+ epochs.write(
+ f"Step... ({cur_step}/{total_steps} | Training Loss: {train_metric['loss']}, Learning Rate:"
+ f" {train_metric['learning_rate']})"
+ )
+
+ train_metrics = []
+
+ if cur_step % training_args.eval_steps == 0 and cur_step > 0:
+ eval_metrics = {}
+ # evaluate
+ for batch in tqdm(
+ eval_data_collator(eval_dataset, eval_batch_size),
+ total=math.ceil(len(eval_dataset) / eval_batch_size),
+ desc="Evaluating ...",
+ position=2,
+ ):
+ labels = batch.pop("labels")
+ predictions = pad_shard_unpad(p_eval_step)(
+ state, batch, min_device_batch=per_device_eval_batch_size
+ )
+ predictions = np.array(predictions)
+ labels[np.array(chain(*batch["attention_mask"])) == 0] = -100
+ preds, refs = get_labels(predictions, labels)
+ metric.add_batch(
+ predictions=preds,
+ references=refs,
+ )
+
+ eval_metrics = compute_metrics()
+
+ if data_args.return_entity_level_metrics:
+ logger.info(f"Step... ({cur_step}/{total_steps} | Validation metrics: {eval_metrics}")
+ else:
+ logger.info(
+ f"Step... ({cur_step}/{total_steps} | Validation f1: {eval_metrics['f1']}, Validation Acc:"
+ f" {eval_metrics['accuracy']})"
+ )
+
+ if has_tensorboard and jax.process_index() == 0:
+ write_eval_metric(summary_writer, eval_metrics, cur_step)
+
+ if (cur_step % training_args.save_steps == 0 and cur_step > 0) or (cur_step == total_steps):
+ # save checkpoint after each epoch and push checkpoint to the hub
+ if jax.process_index() == 0:
+ params = jax.device_get(unreplicate(state.params))
+ model.save_pretrained(training_args.output_dir, params=params)
+ tokenizer.save_pretrained(training_args.output_dir)
+ if training_args.push_to_hub:
+ api.upload_folder(
+ commit_message=f"Saving weights and logs of step {cur_step}",
+ folder_path=training_args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=training_args.hub_token,
+ )
+ epochs.desc = f"Epoch ... {epoch + 1}/{num_epochs}"
+
+ # Eval after training
+ if training_args.do_eval:
+ eval_metrics = {}
+ eval_loader = eval_data_collator(eval_dataset, eval_batch_size)
+ for batch in tqdm(eval_loader, total=len(eval_dataset) // eval_batch_size, desc="Evaluating ...", position=2):
+ labels = batch.pop("labels")
+ predictions = pad_shard_unpad(p_eval_step)(state, batch, min_device_batch=per_device_eval_batch_size)
+ predictions = np.array(predictions)
+ labels[np.array(chain(*batch["attention_mask"])) == 0] = -100
+ preds, refs = get_labels(predictions, labels)
+ metric.add_batch(predictions=preds, references=refs)
+
+ eval_metrics = compute_metrics()
+
+ if jax.process_index() == 0:
+ eval_metrics = {f"eval_{metric_name}": value for metric_name, value in eval_metrics.items()}
+ path = os.path.join(training_args.output_dir, "eval_results.json")
+ with open(path, "w") as f:
+ json.dump(eval_metrics, f, indent=4, sort_keys=True)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/flax/vision/README.md b/docs/transformers/examples/flax/vision/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..d865b8a30ce5e0ce4236262cef00e61822f7794f
--- /dev/null
+++ b/docs/transformers/examples/flax/vision/README.md
@@ -0,0 +1,70 @@
+
+
+# Image Classification training examples
+
+The following example showcases how to train/fine-tune `ViT` for image-classification using the JAX/Flax backend.
+
+JAX/Flax allows you to trace pure functions and compile them into efficient, fused accelerator code on both GPU and TPU.
+Models written in JAX/Flax are **immutable** and updated in a purely functional
+way which enables simple and efficient model parallelism.
+
+
+In this example we will train/fine-tune the model on the [imagenette](https://github.com/fastai/imagenette) dataset.
+
+## Prepare the dataset
+
+We will use the [imagenette](https://github.com/fastai/imagenette) dataset to train/fine-tune our model. Imagenette is a subset of 10 easily classified classes from Imagenet (tench, English springer, cassette player, chain saw, church, French horn, garbage truck, gas pump, golf ball, parachute).
+
+
+### Download and extract the data.
+
+```bash
+wget https://s3.amazonaws.com/fast-ai-imageclas/imagenette2.tgz
+tar -xvzf imagenette2.tgz
+```
+
+This will create a `imagenette2` dir with two subdirectories `train` and `val` each with multiple subdirectories per class. The training script expects the following directory structure
+
+```bash
+root/dog/xxx.png
+root/dog/xxy.png
+root/dog/[...]/xxz.png
+
+root/cat/123.png
+root/cat/nsdf3.png
+root/cat/[...]/asd932_.png
+```
+
+## Train the model
+
+Next we can run the example script to fine-tune the model:
+
+```bash
+python run_image_classification.py \
+ --output_dir ./vit-base-patch16-imagenette \
+ --model_name_or_path google/vit-base-patch16-224-in21k \
+ --train_dir="imagenette2/train" \
+ --validation_dir="imagenette2/val" \
+ --num_train_epochs 5 \
+ --learning_rate 1e-3 \
+ --per_device_train_batch_size 128 --per_device_eval_batch_size 128 \
+ --overwrite_output_dir \
+ --preprocessing_num_workers 32 \
+ --push_to_hub
+```
+
+This should finish in ~7mins with 99% validation accuracy.
\ No newline at end of file
diff --git a/docs/transformers/examples/flax/vision/requirements.txt b/docs/transformers/examples/flax/vision/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8c0e472c86a7f541f2bdb1987baf1902dd063ffb
--- /dev/null
+++ b/docs/transformers/examples/flax/vision/requirements.txt
@@ -0,0 +1,8 @@
+jax>=0.2.8
+jaxlib>=0.1.59
+flax>=0.3.5
+optax>=0.0.8
+-f https://download.pytorch.org/whl/torch_stable.html
+torch==2.2.0
+-f https://download.pytorch.org/whl/torch_stable.html
+torchvision==0.12.0+cpu
diff --git a/docs/transformers/examples/flax/vision/run_image_classification.py b/docs/transformers/examples/flax/vision/run_image_classification.py
new file mode 100644
index 0000000000000000000000000000000000000000..4eddd36f962fa580e12a1b1a874c69c04970f660
--- /dev/null
+++ b/docs/transformers/examples/flax/vision/run_image_classification.py
@@ -0,0 +1,590 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Pre-training/Fine-tuning ViT for image classification .
+
+Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
+https://huggingface.co/models?filter=vit
+"""
+
+import logging
+import os
+import sys
+import time
+from dataclasses import asdict, dataclass, field
+from enum import Enum
+from pathlib import Path
+from typing import Callable, Optional
+
+import jax
+import jax.numpy as jnp
+import optax
+
+# for dataset and preprocessing
+import torch
+import torchvision
+from flax import jax_utils
+from flax.jax_utils import pad_shard_unpad, unreplicate
+from flax.training import train_state
+from flax.training.common_utils import get_metrics, onehot, shard, shard_prng_key
+from huggingface_hub import HfApi
+from torchvision import transforms
+from tqdm import tqdm
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ FLAX_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
+ AutoConfig,
+ FlaxAutoModelForImageClassification,
+ HfArgumentParser,
+ is_tensorboard_available,
+ set_seed,
+)
+from transformers.utils import send_example_telemetry
+
+
+logger = logging.getLogger(__name__)
+
+
+MODEL_CONFIG_CLASSES = list(FLAX_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class TrainingArguments:
+ output_dir: str = field(
+ metadata={"help": "The output directory where the model predictions and checkpoints will be written."},
+ )
+ overwrite_output_dir: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Overwrite the content of the output directory. "
+ "Use this to continue training if output_dir points to a checkpoint directory."
+ )
+ },
+ )
+ do_train: bool = field(default=False, metadata={"help": "Whether to run training."})
+ do_eval: bool = field(default=False, metadata={"help": "Whether to run eval on the dev set."})
+ per_device_train_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for training."}
+ )
+ per_device_eval_batch_size: int = field(
+ default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for evaluation."}
+ )
+ learning_rate: float = field(default=5e-5, metadata={"help": "The initial learning rate for AdamW."})
+ weight_decay: float = field(default=0.0, metadata={"help": "Weight decay for AdamW if we apply some."})
+ adam_beta1: float = field(default=0.9, metadata={"help": "Beta1 for AdamW optimizer"})
+ adam_beta2: float = field(default=0.999, metadata={"help": "Beta2 for AdamW optimizer"})
+ adam_epsilon: float = field(default=1e-8, metadata={"help": "Epsilon for AdamW optimizer."})
+ adafactor: bool = field(default=False, metadata={"help": "Whether or not to replace AdamW by Adafactor."})
+ num_train_epochs: float = field(default=3.0, metadata={"help": "Total number of training epochs to perform."})
+ warmup_steps: int = field(default=0, metadata={"help": "Linear warmup over warmup_steps."})
+ logging_steps: int = field(default=500, metadata={"help": "Log every X updates steps."})
+ save_steps: int = field(default=500, metadata={"help": "Save checkpoint every X updates steps."})
+ eval_steps: int = field(default=None, metadata={"help": "Run an evaluation every X steps."})
+ seed: int = field(default=42, metadata={"help": "Random seed that will be set at the beginning of training."})
+ push_to_hub: bool = field(
+ default=False, metadata={"help": "Whether or not to upload the trained model to the model hub after training."}
+ )
+ hub_model_id: str = field(
+ default=None, metadata={"help": "The name of the repository to keep in sync with the local `output_dir`."}
+ )
+ hub_token: str = field(default=None, metadata={"help": "The token to use to push to the Model Hub."})
+
+ def __post_init__(self):
+ if self.output_dir is not None:
+ self.output_dir = os.path.expanduser(self.output_dir)
+
+ def to_dict(self):
+ """
+ Serializes this instance while replace `Enum` by their values (for JSON serialization support). It obfuscates
+ the token values by removing their value.
+ """
+ d = asdict(self)
+ for k, v in d.items():
+ if isinstance(v, Enum):
+ d[k] = v.value
+ if isinstance(v, list) and len(v) > 0 and isinstance(v[0], Enum):
+ d[k] = [x.value for x in v]
+ if k.endswith("_token"):
+ d[k] = f"<{k.upper()}>"
+ return d
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ dtype: Optional[str] = field(
+ default="float32",
+ metadata={
+ "help": (
+ "Floating-point format in which the model weights should be initialized and trained. Choose one of"
+ " `[float32, float16, bfloat16]`."
+ )
+ },
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
+ "should only be set to `True` for repositories you trust and in which you have read the code, as it will "
+ "execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ train_dir: str = field(
+ metadata={"help": "Path to the root training directory which contains one subdirectory per class."}
+ )
+ validation_dir: str = field(
+ metadata={"help": "Path to the root validation directory which contains one subdirectory per class."},
+ )
+ image_size: Optional[int] = field(default=224, metadata={"help": " The size (resolution) of each image."})
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+
+
+class TrainState(train_state.TrainState):
+ dropout_rng: jnp.ndarray
+
+ def replicate(self):
+ return jax_utils.replicate(self).replace(dropout_rng=shard_prng_key(self.dropout_rng))
+
+
+def write_metric(summary_writer, train_metrics, eval_metrics, train_time, step):
+ summary_writer.scalar("train_time", train_time, step)
+
+ train_metrics = get_metrics(train_metrics)
+ for key, vals in train_metrics.items():
+ tag = f"train_{key}"
+ for i, val in enumerate(vals):
+ summary_writer.scalar(tag, val, step - len(vals) + i + 1)
+
+ for metric_name, value in eval_metrics.items():
+ summary_writer.scalar(f"eval_{metric_name}", value, step)
+
+
+def create_learning_rate_fn(
+ train_ds_size: int, train_batch_size: int, num_train_epochs: int, num_warmup_steps: int, learning_rate: float
+) -> Callable[[int], jnp.ndarray]:
+ """Returns a linear warmup, linear_decay learning rate function."""
+ steps_per_epoch = train_ds_size // train_batch_size
+ num_train_steps = steps_per_epoch * num_train_epochs
+ warmup_fn = optax.linear_schedule(init_value=0.0, end_value=learning_rate, transition_steps=num_warmup_steps)
+ decay_fn = optax.linear_schedule(
+ init_value=learning_rate, end_value=0, transition_steps=num_train_steps - num_warmup_steps
+ )
+ schedule_fn = optax.join_schedules(schedules=[warmup_fn, decay_fn], boundaries=[num_warmup_steps])
+ return schedule_fn
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_image_classification", model_args, data_args, framework="flax")
+
+ if (
+ os.path.exists(training_args.output_dir)
+ and os.listdir(training_args.output_dir)
+ and training_args.do_train
+ and not training_args.overwrite_output_dir
+ ):
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ # Setup logging, we only want one process per machine to log things on the screen.
+ logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
+ if jax.process_index() == 0:
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ transformers.utils.logging.set_verbosity_error()
+
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # set seed for random transforms and torch dataloaders
+ set_seed(training_args.seed)
+
+ # Handle the repository creation
+ if training_args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = training_args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(training_args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
+
+ # Initialize datasets and pre-processing transforms
+ # We use torchvision here for faster pre-processing
+ # Note that here we are using some default pre-processing, for maximum accuracy
+ # one should tune this part and carefully select what transformations to use.
+ normalize = transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
+ train_dataset = torchvision.datasets.ImageFolder(
+ data_args.train_dir,
+ transforms.Compose(
+ [
+ transforms.RandomResizedCrop(data_args.image_size),
+ transforms.RandomHorizontalFlip(),
+ transforms.ToTensor(),
+ normalize,
+ ]
+ ),
+ )
+
+ eval_dataset = torchvision.datasets.ImageFolder(
+ data_args.validation_dir,
+ transforms.Compose(
+ [
+ transforms.Resize(data_args.image_size),
+ transforms.CenterCrop(data_args.image_size),
+ transforms.ToTensor(),
+ normalize,
+ ]
+ ),
+ )
+
+ # Load pretrained model and tokenizer
+ if model_args.config_name:
+ config = AutoConfig.from_pretrained(
+ model_args.config_name,
+ num_labels=len(train_dataset.classes),
+ image_size=data_args.image_size,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(
+ model_args.model_name_or_path,
+ num_labels=len(train_dataset.classes),
+ image_size=data_args.image_size,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if model_args.model_name_or_path:
+ model = FlaxAutoModelForImageClassification.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ model = FlaxAutoModelForImageClassification.from_config(
+ config,
+ seed=training_args.seed,
+ dtype=getattr(jnp, model_args.dtype),
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # Store some constant
+ num_epochs = int(training_args.num_train_epochs)
+ train_batch_size = int(training_args.per_device_train_batch_size) * jax.device_count()
+ per_device_eval_batch_size = int(training_args.per_device_eval_batch_size)
+ eval_batch_size = per_device_eval_batch_size * jax.device_count()
+ steps_per_epoch = len(train_dataset) // train_batch_size
+ total_train_steps = steps_per_epoch * num_epochs
+
+ def collate_fn(examples):
+ pixel_values = torch.stack([example[0] for example in examples])
+ labels = torch.tensor([example[1] for example in examples])
+
+ batch = {"pixel_values": pixel_values, "labels": labels}
+ batch = {k: v.numpy() for k, v in batch.items()}
+
+ return batch
+
+ # Create data loaders
+ train_loader = torch.utils.data.DataLoader(
+ train_dataset,
+ batch_size=train_batch_size,
+ shuffle=True,
+ num_workers=data_args.preprocessing_num_workers,
+ persistent_workers=True,
+ drop_last=True,
+ collate_fn=collate_fn,
+ )
+
+ eval_loader = torch.utils.data.DataLoader(
+ eval_dataset,
+ batch_size=eval_batch_size,
+ shuffle=False,
+ num_workers=data_args.preprocessing_num_workers,
+ persistent_workers=True,
+ drop_last=False,
+ collate_fn=collate_fn,
+ )
+
+ # Enable tensorboard only on the master node
+ has_tensorboard = is_tensorboard_available()
+ if has_tensorboard and jax.process_index() == 0:
+ try:
+ from flax.metrics.tensorboard import SummaryWriter
+
+ summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir))
+ except ImportError as ie:
+ has_tensorboard = False
+ logger.warning(
+ f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
+ )
+ else:
+ logger.warning(
+ "Unable to display metrics through TensorBoard because the package is not installed: "
+ "Please run pip install tensorboard to enable."
+ )
+
+ # Initialize our training
+ rng = jax.random.PRNGKey(training_args.seed)
+ rng, dropout_rng = jax.random.split(rng)
+
+ # Create learning rate schedule
+ linear_decay_lr_schedule_fn = create_learning_rate_fn(
+ len(train_dataset),
+ train_batch_size,
+ training_args.num_train_epochs,
+ training_args.warmup_steps,
+ training_args.learning_rate,
+ )
+
+ # create adam optimizer
+ adamw = optax.adamw(
+ learning_rate=linear_decay_lr_schedule_fn,
+ b1=training_args.adam_beta1,
+ b2=training_args.adam_beta2,
+ eps=training_args.adam_epsilon,
+ weight_decay=training_args.weight_decay,
+ )
+
+ # Setup train state
+ state = TrainState.create(apply_fn=model.__call__, params=model.params, tx=adamw, dropout_rng=dropout_rng)
+
+ def loss_fn(logits, labels):
+ loss = optax.softmax_cross_entropy(logits, onehot(labels, logits.shape[-1]))
+ return loss.mean()
+
+ # Define gradient update step fn
+ def train_step(state, batch):
+ dropout_rng, new_dropout_rng = jax.random.split(state.dropout_rng)
+
+ def compute_loss(params):
+ labels = batch.pop("labels")
+ logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
+ loss = loss_fn(logits, labels)
+ return loss
+
+ grad_fn = jax.value_and_grad(compute_loss)
+ loss, grad = grad_fn(state.params)
+ grad = jax.lax.pmean(grad, "batch")
+
+ new_state = state.apply_gradients(grads=grad, dropout_rng=new_dropout_rng)
+
+ metrics = {"loss": loss, "learning_rate": linear_decay_lr_schedule_fn(state.step)}
+ metrics = jax.lax.pmean(metrics, axis_name="batch")
+
+ return new_state, metrics
+
+ # Define eval fn
+ def eval_step(params, batch):
+ labels = batch.pop("labels")
+ logits = model(**batch, params=params, train=False)[0]
+ loss = loss_fn(logits, labels)
+
+ # summarize metrics
+ accuracy = (jnp.argmax(logits, axis=-1) == labels).mean()
+ metrics = {"loss": loss, "accuracy": accuracy}
+ metrics = jax.lax.pmean(metrics, axis_name="batch")
+ return metrics
+
+ # Create parallel version of the train and eval step
+ p_train_step = jax.pmap(train_step, "batch", donate_argnums=(0,))
+ p_eval_step = jax.pmap(eval_step, "batch")
+
+ # Replicate the train state on each device
+ state = state.replicate()
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {num_epochs}")
+ logger.info(f" Instantaneous batch size per device = {training_args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel & distributed) = {train_batch_size}")
+ logger.info(f" Total optimization steps = {total_train_steps}")
+
+ train_time = 0
+ epochs = tqdm(range(num_epochs), desc=f"Epoch ... (1/{num_epochs})", position=0)
+ for epoch in epochs:
+ # ======================== Training ================================
+ train_start = time.time()
+
+ # Create sampling rng
+ rng, input_rng = jax.random.split(rng)
+ train_metrics = []
+
+ steps_per_epoch = len(train_dataset) // train_batch_size
+ train_step_progress_bar = tqdm(total=steps_per_epoch, desc="Training...", position=1, leave=False)
+ # train
+ for batch in train_loader:
+ batch = shard(batch)
+ state, train_metric = p_train_step(state, batch)
+ train_metrics.append(train_metric)
+
+ train_step_progress_bar.update(1)
+
+ train_time += time.time() - train_start
+
+ train_metric = unreplicate(train_metric)
+
+ train_step_progress_bar.close()
+ epochs.write(
+ f"Epoch... ({epoch + 1}/{num_epochs} | Loss: {train_metric['loss']}, Learning Rate:"
+ f" {train_metric['learning_rate']})"
+ )
+
+ # ======================== Evaluating ==============================
+ eval_metrics = []
+ eval_steps = len(eval_dataset) // eval_batch_size
+ eval_step_progress_bar = tqdm(total=eval_steps, desc="Evaluating...", position=2, leave=False)
+ for batch in eval_loader:
+ # Model forward
+ metrics = pad_shard_unpad(p_eval_step, static_return=True)(
+ state.params, batch, min_device_batch=per_device_eval_batch_size
+ )
+ eval_metrics.append(metrics)
+
+ eval_step_progress_bar.update(1)
+
+ # normalize eval metrics
+ eval_metrics = get_metrics(eval_metrics)
+ eval_metrics = jax.tree_util.tree_map(jnp.mean, eval_metrics)
+
+ # Print metrics and update progress bar
+ eval_step_progress_bar.close()
+ desc = (
+ f"Epoch... ({epoch + 1}/{num_epochs} | Eval Loss: {round(eval_metrics['loss'].item(), 4)} | "
+ f"Eval Accuracy: {round(eval_metrics['accuracy'].item(), 4)})"
+ )
+ epochs.write(desc)
+ epochs.desc = desc
+
+ # Save metrics
+ if has_tensorboard and jax.process_index() == 0:
+ cur_step = epoch * (len(train_dataset) // train_batch_size)
+ write_metric(summary_writer, train_metrics, eval_metrics, train_time, cur_step)
+
+ # save checkpoint after each epoch and push checkpoint to the hub
+ if jax.process_index() == 0:
+ params = jax.device_get(jax.tree_util.tree_map(lambda x: x[0], state.params))
+ model.save_pretrained(training_args.output_dir, params=params)
+ if training_args.push_to_hub:
+ api.upload_folder(
+ commit_message=f"Saving weights and logs of epoch {epoch}",
+ folder_path=training_args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=training_args.hub_token,
+ )
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/README.md b/docs/transformers/examples/legacy/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..eaf64f624637778d9b07fe3e034c30ca0acb70e9
--- /dev/null
+++ b/docs/transformers/examples/legacy/README.md
@@ -0,0 +1,21 @@
+
+
+# Legacy examples
+
+This folder contains examples which are not actively maintained (mostly contributed by the community).
+
+Using these examples together with a recent version of the library usually requires to make small (sometimes big) adaptations to get the scripts working.
diff --git a/docs/transformers/examples/legacy/benchmarking/README.md b/docs/transformers/examples/legacy/benchmarking/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..63cf4e367c3d31f355b2c5282f93a3d7de34e09b
--- /dev/null
+++ b/docs/transformers/examples/legacy/benchmarking/README.md
@@ -0,0 +1,26 @@
+
+
+# 🤗 Benchmark results
+
+Here, you can find a list of the different benchmark results created by the community.
+
+If you would like to list benchmark results on your favorite models of the [model hub](https://huggingface.co/models) here, please open a Pull Request and add it below.
+
+| Benchmark description | Results | Environment info | Author |
+|:----------|:-------------|:-------------|------:|
+| PyTorch Benchmark on inference for `google-bert/bert-base-cased` |[memory](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/inference_memory.csv) | [env](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/env.csv) | [Patrick von Platen](https://github.com/patrickvonplaten) |
+| PyTorch Benchmark on inference for `google-bert/bert-base-cased` |[time](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/inference_time.csv) | [env](https://github.com/patrickvonplaten/files_to_link_to/blob/master/bert_benchmark/env.csv) | [Patrick von Platen](https://github.com/patrickvonplaten) |
diff --git a/docs/transformers/examples/legacy/benchmarking/plot_csv_file.py b/docs/transformers/examples/legacy/benchmarking/plot_csv_file.py
new file mode 100644
index 0000000000000000000000000000000000000000..d802dbe67e83aaaddbacb4a90320bfe999a24c67
--- /dev/null
+++ b/docs/transformers/examples/legacy/benchmarking/plot_csv_file.py
@@ -0,0 +1,178 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import csv
+from collections import defaultdict
+from dataclasses import dataclass, field
+from typing import Optional
+
+import matplotlib.pyplot as plt
+import numpy as np
+from matplotlib.ticker import ScalarFormatter
+
+from transformers import HfArgumentParser
+
+
+def list_field(default=None, metadata=None):
+ return field(default_factory=lambda: default, metadata=metadata)
+
+
+@dataclass
+class PlotArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ csv_file: str = field(
+ metadata={"help": "The csv file to plot."},
+ )
+ plot_along_batch: bool = field(
+ default=False,
+ metadata={"help": "Whether to plot along batch size or sequence length. Defaults to sequence length."},
+ )
+ is_time: bool = field(
+ default=False,
+ metadata={"help": "Whether the csv file has time results or memory results. Defaults to memory results."},
+ )
+ no_log_scale: bool = field(
+ default=False,
+ metadata={"help": "Disable logarithmic scale when plotting"},
+ )
+ is_train: bool = field(
+ default=False,
+ metadata={
+ "help": "Whether the csv file has training results or inference results. Defaults to inference results."
+ },
+ )
+ figure_png_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "Filename under which the plot will be saved. If unused no plot is saved."},
+ )
+ short_model_names: Optional[list[str]] = list_field(
+ default=None, metadata={"help": "List of model names that are used instead of the ones in the csv file."}
+ )
+
+
+def can_convert_to_int(string):
+ try:
+ int(string)
+ return True
+ except ValueError:
+ return False
+
+
+def can_convert_to_float(string):
+ try:
+ float(string)
+ return True
+ except ValueError:
+ return False
+
+
+class Plot:
+ def __init__(self, args):
+ self.args = args
+ self.result_dict = defaultdict(lambda: {"bsz": [], "seq_len": [], "result": {}})
+
+ with open(self.args.csv_file, newline="") as csv_file:
+ reader = csv.DictReader(csv_file)
+ for row in reader:
+ model_name = row["model"]
+ self.result_dict[model_name]["bsz"].append(int(row["batch_size"]))
+ self.result_dict[model_name]["seq_len"].append(int(row["sequence_length"]))
+ if can_convert_to_int(row["result"]):
+ # value is not None
+ self.result_dict[model_name]["result"][(int(row["batch_size"]), int(row["sequence_length"]))] = (
+ int(row["result"])
+ )
+ elif can_convert_to_float(row["result"]):
+ # value is not None
+ self.result_dict[model_name]["result"][(int(row["batch_size"]), int(row["sequence_length"]))] = (
+ float(row["result"])
+ )
+
+ def plot(self):
+ fig, ax = plt.subplots()
+ title_str = "Time usage" if self.args.is_time else "Memory usage"
+ title_str = title_str + " for training" if self.args.is_train else title_str + " for inference"
+
+ if not self.args.no_log_scale:
+ # set logarithm scales
+ ax.set_xscale("log")
+ ax.set_yscale("log")
+
+ for axis in [ax.xaxis, ax.yaxis]:
+ axis.set_major_formatter(ScalarFormatter())
+
+ for model_name_idx, model_name in enumerate(self.result_dict.keys()):
+ batch_sizes = sorted(set(self.result_dict[model_name]["bsz"]))
+ sequence_lengths = sorted(set(self.result_dict[model_name]["seq_len"]))
+ results = self.result_dict[model_name]["result"]
+
+ (x_axis_array, inner_loop_array) = (
+ (batch_sizes, sequence_lengths) if self.args.plot_along_batch else (sequence_lengths, batch_sizes)
+ )
+
+ label_model_name = (
+ model_name if self.args.short_model_names is None else self.args.short_model_names[model_name_idx]
+ )
+
+ for inner_loop_value in inner_loop_array:
+ if self.args.plot_along_batch:
+ y_axis_array = np.asarray(
+ [results[(x, inner_loop_value)] for x in x_axis_array if (x, inner_loop_value) in results],
+ dtype=int,
+ )
+ else:
+ y_axis_array = np.asarray(
+ [results[(inner_loop_value, x)] for x in x_axis_array if (inner_loop_value, x) in results],
+ dtype=np.float32,
+ )
+
+ (x_axis_label, inner_loop_label) = (
+ ("batch_size", "len") if self.args.plot_along_batch else ("in #tokens", "bsz")
+ )
+
+ x_axis_array = np.asarray(x_axis_array, int)[: len(y_axis_array)]
+ plt.scatter(
+ x_axis_array, y_axis_array, label=f"{label_model_name} - {inner_loop_label}: {inner_loop_value}"
+ )
+ plt.plot(x_axis_array, y_axis_array, "--")
+
+ title_str += f" {label_model_name} vs."
+
+ title_str = title_str[:-4]
+ y_axis_label = "Time in s" if self.args.is_time else "Memory in MB"
+
+ # plot
+ plt.title(title_str)
+ plt.xlabel(x_axis_label)
+ plt.ylabel(y_axis_label)
+ plt.legend()
+
+ if self.args.figure_png_file is not None:
+ plt.savefig(self.args.figure_png_file)
+ else:
+ plt.show()
+
+
+def main():
+ parser = HfArgumentParser(PlotArguments)
+ plot_args = parser.parse_args_into_dataclasses()[0]
+ plot = Plot(args=plot_args)
+ plot.plot()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/benchmarking/requirements.txt b/docs/transformers/examples/legacy/benchmarking/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..68c56b321909d91ccabb62ebc9a6bca869e9c288
--- /dev/null
+++ b/docs/transformers/examples/legacy/benchmarking/requirements.txt
@@ -0,0 +1 @@
+torch >= 1.3
\ No newline at end of file
diff --git a/docs/transformers/examples/legacy/benchmarking/run_benchmark.py b/docs/transformers/examples/legacy/benchmarking/run_benchmark.py
new file mode 100644
index 0000000000000000000000000000000000000000..1bdd69bbe29d6e8626f5046359619d0b168f0507
--- /dev/null
+++ b/docs/transformers/examples/legacy/benchmarking/run_benchmark.py
@@ -0,0 +1,47 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Benchmarking the library on inference and training"""
+
+from transformers import HfArgumentParser, PyTorchBenchmark, PyTorchBenchmarkArguments
+
+
+def main():
+ parser = HfArgumentParser(PyTorchBenchmarkArguments)
+ try:
+ benchmark_args = parser.parse_args_into_dataclasses()[0]
+ except ValueError as e:
+ arg_error_msg = "Arg --no_{0} is no longer used, please use --no-{0} instead."
+ begin_error_msg = " ".join(str(e).split(" ")[:-1])
+ full_error_msg = ""
+ depreciated_args = eval(str(e).split(" ")[-1])
+ wrong_args = []
+ for arg in depreciated_args:
+ # arg[2:] removes '--'
+ if arg[2:] in PyTorchBenchmarkArguments.deprecated_args:
+ # arg[5:] removes '--no_'
+ full_error_msg += arg_error_msg.format(arg[5:])
+ else:
+ wrong_args.append(arg)
+ if len(wrong_args) > 0:
+ full_error_msg = full_error_msg + begin_error_msg + str(wrong_args)
+ raise ValueError(full_error_msg)
+
+ benchmark = PyTorchBenchmark(args=benchmark_args)
+ benchmark.run()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/multiple_choice/run_multiple_choice.py b/docs/transformers/examples/legacy/multiple_choice/run_multiple_choice.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa1297656a909d9767e2b10701df5306fa8f8393
--- /dev/null
+++ b/docs/transformers/examples/legacy/multiple_choice/run_multiple_choice.py
@@ -0,0 +1,243 @@
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Finetuning the library models for multiple choice (Bert, Roberta, XLNet)."""
+
+import logging
+import os
+from dataclasses import dataclass, field
+from typing import Optional
+
+import numpy as np
+from utils_multiple_choice import MultipleChoiceDataset, Split, processors
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForMultipleChoice,
+ AutoTokenizer,
+ DataCollatorWithPadding,
+ EvalPrediction,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ set_seed,
+)
+from transformers.trainer_utils import is_main_process
+
+
+logger = logging.getLogger(__name__)
+
+
+def simple_accuracy(preds, labels):
+ return (preds == labels).mean()
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ task_name: str = field(metadata={"help": "The name of the task to train on: " + ", ".join(processors.keys())})
+ data_dir: str = field(metadata={"help": "Should contain the data files for the task."})
+ max_seq_length: int = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ if (
+ os.path.exists(training_args.output_dir)
+ and os.listdir(training_args.output_dir)
+ and training_args.do_train
+ and not training_args.overwrite_output_dir
+ ):
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
+ " --overwrite_output_dir to overcome."
+ )
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
+ )
+ logger.warning(
+ "Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
+ training_args.local_rank,
+ training_args.device,
+ training_args.n_gpu,
+ bool(training_args.local_rank != -1),
+ training_args.fp16,
+ )
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(training_args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+ logger.info("Training/evaluation parameters %s", training_args)
+
+ # Set seed
+ set_seed(training_args.seed)
+
+ try:
+ processor = processors[data_args.task_name]()
+ label_list = processor.get_labels()
+ num_labels = len(label_list)
+ except KeyError:
+ raise ValueError("Task not found: %s" % (data_args.task_name))
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ num_labels=num_labels,
+ finetuning_task=data_args.task_name,
+ cache_dir=model_args.cache_dir,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ )
+ model = AutoModelForMultipleChoice.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ )
+
+ # Get datasets
+ train_dataset = (
+ MultipleChoiceDataset(
+ data_dir=data_args.data_dir,
+ tokenizer=tokenizer,
+ task=data_args.task_name,
+ max_seq_length=data_args.max_seq_length,
+ overwrite_cache=data_args.overwrite_cache,
+ mode=Split.train,
+ )
+ if training_args.do_train
+ else None
+ )
+ eval_dataset = (
+ MultipleChoiceDataset(
+ data_dir=data_args.data_dir,
+ tokenizer=tokenizer,
+ task=data_args.task_name,
+ max_seq_length=data_args.max_seq_length,
+ overwrite_cache=data_args.overwrite_cache,
+ mode=Split.dev,
+ )
+ if training_args.do_eval
+ else None
+ )
+
+ def compute_metrics(p: EvalPrediction) -> dict:
+ preds = np.argmax(p.predictions, axis=1)
+ return {"acc": simple_accuracy(preds, p.label_ids)}
+
+ # Data collator
+ data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8) if training_args.fp16 else None
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ compute_metrics=compute_metrics,
+ data_collator=data_collator,
+ )
+
+ # Training
+ if training_args.do_train:
+ trainer.train(
+ model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
+ )
+ trainer.save_model()
+ # For convenience, we also re-save the tokenizer to the same directory,
+ # so that you can share your model easily on huggingface.co/models =)
+ if trainer.is_world_master():
+ tokenizer.save_pretrained(training_args.output_dir)
+
+ # Evaluation
+ results = {}
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+
+ result = trainer.evaluate()
+
+ output_eval_file = os.path.join(training_args.output_dir, "eval_results.txt")
+ if trainer.is_world_master():
+ with open(output_eval_file, "w") as writer:
+ logger.info("***** Eval results *****")
+ for key, value in result.items():
+ logger.info(" %s = %s", key, value)
+ writer.write("{} = {}\n".format(key, value))
+
+ results.update(result)
+
+ return results
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/multiple_choice/utils_multiple_choice.py b/docs/transformers/examples/legacy/multiple_choice/utils_multiple_choice.py
new file mode 100644
index 0000000000000000000000000000000000000000..ddae47e5880ce50ff3a93aec871f512ff532653c
--- /dev/null
+++ b/docs/transformers/examples/legacy/multiple_choice/utils_multiple_choice.py
@@ -0,0 +1,576 @@
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Multiple choice fine-tuning: utilities to work with multiple choice tasks of reading comprehension"""
+
+import csv
+import glob
+import json
+import logging
+import os
+from dataclasses import dataclass
+from enum import Enum
+from typing import Optional
+
+import tqdm
+from filelock import FileLock
+
+from transformers import PreTrainedTokenizer, is_tf_available, is_torch_available
+
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass(frozen=True)
+class InputExample:
+ """
+ A single training/test example for multiple choice
+
+ Args:
+ example_id: Unique id for the example.
+ question: string. The untokenized text of the second sequence (question).
+ contexts: list of str. The untokenized text of the first sequence (context of corresponding question).
+ endings: list of str. multiple choice's options. Its length must be equal to contexts' length.
+ label: (Optional) string. The label of the example. This should be
+ specified for train and dev examples, but not for test examples.
+ """
+
+ example_id: str
+ question: str
+ contexts: list[str]
+ endings: list[str]
+ label: Optional[str]
+
+
+@dataclass(frozen=True)
+class InputFeatures:
+ """
+ A single set of features of data.
+ Property names are the same names as the corresponding inputs to a model.
+ """
+
+ example_id: str
+ input_ids: list[list[int]]
+ attention_mask: Optional[list[list[int]]]
+ token_type_ids: Optional[list[list[int]]]
+ label: Optional[int]
+
+
+class Split(Enum):
+ train = "train"
+ dev = "dev"
+ test = "test"
+
+
+if is_torch_available():
+ import torch
+ from torch.utils.data import Dataset
+
+ class MultipleChoiceDataset(Dataset):
+ """
+ This will be superseded by a framework-agnostic approach
+ soon.
+ """
+
+ features: list[InputFeatures]
+
+ def __init__(
+ self,
+ data_dir: str,
+ tokenizer: PreTrainedTokenizer,
+ task: str,
+ max_seq_length: Optional[int] = None,
+ overwrite_cache=False,
+ mode: Split = Split.train,
+ ):
+ processor = processors[task]()
+
+ cached_features_file = os.path.join(
+ data_dir,
+ "cached_{}_{}_{}_{}".format(
+ mode.value,
+ tokenizer.__class__.__name__,
+ str(max_seq_length),
+ task,
+ ),
+ )
+
+ # Make sure only the first process in distributed training processes the dataset,
+ # and the others will use the cache.
+ lock_path = cached_features_file + ".lock"
+ with FileLock(lock_path):
+ if os.path.exists(cached_features_file) and not overwrite_cache:
+ logger.info(f"Loading features from cached file {cached_features_file}")
+ self.features = torch.load(cached_features_file, weights_only=True)
+ else:
+ logger.info(f"Creating features from dataset file at {data_dir}")
+ label_list = processor.get_labels()
+ if mode == Split.dev:
+ examples = processor.get_dev_examples(data_dir)
+ elif mode == Split.test:
+ examples = processor.get_test_examples(data_dir)
+ else:
+ examples = processor.get_train_examples(data_dir)
+ logger.info("Training examples: %s", len(examples))
+ self.features = convert_examples_to_features(
+ examples,
+ label_list,
+ max_seq_length,
+ tokenizer,
+ )
+ logger.info("Saving features into cached file %s", cached_features_file)
+ torch.save(self.features, cached_features_file)
+
+ def __len__(self):
+ return len(self.features)
+
+ def __getitem__(self, i) -> InputFeatures:
+ return self.features[i]
+
+
+if is_tf_available():
+ import tensorflow as tf
+
+ class TFMultipleChoiceDataset:
+ """
+ This will be superseded by a framework-agnostic approach
+ soon.
+ """
+
+ features: list[InputFeatures]
+
+ def __init__(
+ self,
+ data_dir: str,
+ tokenizer: PreTrainedTokenizer,
+ task: str,
+ max_seq_length: Optional[int] = 128,
+ overwrite_cache=False,
+ mode: Split = Split.train,
+ ):
+ processor = processors[task]()
+
+ logger.info(f"Creating features from dataset file at {data_dir}")
+ label_list = processor.get_labels()
+ if mode == Split.dev:
+ examples = processor.get_dev_examples(data_dir)
+ elif mode == Split.test:
+ examples = processor.get_test_examples(data_dir)
+ else:
+ examples = processor.get_train_examples(data_dir)
+ logger.info("Training examples: %s", len(examples))
+
+ self.features = convert_examples_to_features(
+ examples,
+ label_list,
+ max_seq_length,
+ tokenizer,
+ )
+
+ def gen():
+ for ex_index, ex in tqdm.tqdm(enumerate(self.features), desc="convert examples to features"):
+ if ex_index % 10000 == 0:
+ logger.info("Writing example %d of %d" % (ex_index, len(examples)))
+
+ yield (
+ {
+ "example_id": 0,
+ "input_ids": ex.input_ids,
+ "attention_mask": ex.attention_mask,
+ "token_type_ids": ex.token_type_ids,
+ },
+ ex.label,
+ )
+
+ self.dataset = tf.data.Dataset.from_generator(
+ gen,
+ (
+ {
+ "example_id": tf.int32,
+ "input_ids": tf.int32,
+ "attention_mask": tf.int32,
+ "token_type_ids": tf.int32,
+ },
+ tf.int64,
+ ),
+ (
+ {
+ "example_id": tf.TensorShape([]),
+ "input_ids": tf.TensorShape([None, None]),
+ "attention_mask": tf.TensorShape([None, None]),
+ "token_type_ids": tf.TensorShape([None, None]),
+ },
+ tf.TensorShape([]),
+ ),
+ )
+
+ def get_dataset(self):
+ self.dataset = self.dataset.apply(tf.data.experimental.assert_cardinality(len(self.features)))
+
+ return self.dataset
+
+ def __len__(self):
+ return len(self.features)
+
+ def __getitem__(self, i) -> InputFeatures:
+ return self.features[i]
+
+
+class DataProcessor:
+ """Base class for data converters for multiple choice data sets."""
+
+ def get_train_examples(self, data_dir):
+ """Gets a collection of `InputExample`s for the train set."""
+ raise NotImplementedError()
+
+ def get_dev_examples(self, data_dir):
+ """Gets a collection of `InputExample`s for the dev set."""
+ raise NotImplementedError()
+
+ def get_test_examples(self, data_dir):
+ """Gets a collection of `InputExample`s for the test set."""
+ raise NotImplementedError()
+
+ def get_labels(self):
+ """Gets the list of labels for this data set."""
+ raise NotImplementedError()
+
+
+class RaceProcessor(DataProcessor):
+ """Processor for the RACE data set."""
+
+ def get_train_examples(self, data_dir):
+ """See base class."""
+ logger.info(f"LOOKING AT {data_dir} train")
+ high = os.path.join(data_dir, "train/high")
+ middle = os.path.join(data_dir, "train/middle")
+ high = self._read_txt(high)
+ middle = self._read_txt(middle)
+ return self._create_examples(high + middle, "train")
+
+ def get_dev_examples(self, data_dir):
+ """See base class."""
+ logger.info(f"LOOKING AT {data_dir} dev")
+ high = os.path.join(data_dir, "dev/high")
+ middle = os.path.join(data_dir, "dev/middle")
+ high = self._read_txt(high)
+ middle = self._read_txt(middle)
+ return self._create_examples(high + middle, "dev")
+
+ def get_test_examples(self, data_dir):
+ """See base class."""
+ logger.info(f"LOOKING AT {data_dir} test")
+ high = os.path.join(data_dir, "test/high")
+ middle = os.path.join(data_dir, "test/middle")
+ high = self._read_txt(high)
+ middle = self._read_txt(middle)
+ return self._create_examples(high + middle, "test")
+
+ def get_labels(self):
+ """See base class."""
+ return ["0", "1", "2", "3"]
+
+ def _read_txt(self, input_dir):
+ lines = []
+ files = glob.glob(input_dir + "/*txt")
+ for file in tqdm.tqdm(files, desc="read files"):
+ with open(file, encoding="utf-8") as fin:
+ data_raw = json.load(fin)
+ data_raw["race_id"] = file
+ lines.append(data_raw)
+ return lines
+
+ def _create_examples(self, lines, set_type):
+ """Creates examples for the training and dev sets."""
+ examples = []
+ for _, data_raw in enumerate(lines):
+ race_id = "{}-{}".format(set_type, data_raw["race_id"])
+ article = data_raw["article"]
+ for i in range(len(data_raw["answers"])):
+ truth = str(ord(data_raw["answers"][i]) - ord("A"))
+ question = data_raw["questions"][i]
+ options = data_raw["options"][i]
+
+ examples.append(
+ InputExample(
+ example_id=race_id,
+ question=question,
+ contexts=[article, article, article, article], # this is not efficient but convenient
+ endings=[options[0], options[1], options[2], options[3]],
+ label=truth,
+ )
+ )
+ return examples
+
+
+class SynonymProcessor(DataProcessor):
+ """Processor for the Synonym data set."""
+
+ def get_train_examples(self, data_dir):
+ """See base class."""
+ logger.info(f"LOOKING AT {data_dir} train")
+ return self._create_examples(self._read_csv(os.path.join(data_dir, "mctrain.csv")), "train")
+
+ def get_dev_examples(self, data_dir):
+ """See base class."""
+ logger.info(f"LOOKING AT {data_dir} dev")
+ return self._create_examples(self._read_csv(os.path.join(data_dir, "mchp.csv")), "dev")
+
+ def get_test_examples(self, data_dir):
+ """See base class."""
+ logger.info(f"LOOKING AT {data_dir} dev")
+
+ return self._create_examples(self._read_csv(os.path.join(data_dir, "mctest.csv")), "test")
+
+ def get_labels(self):
+ """See base class."""
+ return ["0", "1", "2", "3", "4"]
+
+ def _read_csv(self, input_file):
+ with open(input_file, encoding="utf-8") as f:
+ return list(csv.reader(f))
+
+ def _create_examples(self, lines: list[list[str]], type: str):
+ """Creates examples for the training and dev sets."""
+
+ examples = [
+ InputExample(
+ example_id=line[0],
+ question="", # in the swag dataset, the
+ # common beginning of each
+ # choice is stored in "sent2".
+ contexts=[line[1], line[1], line[1], line[1], line[1]],
+ endings=[line[2], line[3], line[4], line[5], line[6]],
+ label=line[7],
+ )
+ for line in lines # we skip the line with the column names
+ ]
+
+ return examples
+
+
+class SwagProcessor(DataProcessor):
+ """Processor for the SWAG data set."""
+
+ def get_train_examples(self, data_dir):
+ """See base class."""
+ logger.info(f"LOOKING AT {data_dir} train")
+ return self._create_examples(self._read_csv(os.path.join(data_dir, "train.csv")), "train")
+
+ def get_dev_examples(self, data_dir):
+ """See base class."""
+ logger.info(f"LOOKING AT {data_dir} dev")
+ return self._create_examples(self._read_csv(os.path.join(data_dir, "val.csv")), "dev")
+
+ def get_test_examples(self, data_dir):
+ """See base class."""
+ logger.info(f"LOOKING AT {data_dir} dev")
+ raise ValueError(
+ "For swag testing, the input file does not contain a label column. It can not be tested in current code "
+ "setting!"
+ )
+ return self._create_examples(self._read_csv(os.path.join(data_dir, "test.csv")), "test")
+
+ def get_labels(self):
+ """See base class."""
+ return ["0", "1", "2", "3"]
+
+ def _read_csv(self, input_file):
+ with open(input_file, encoding="utf-8") as f:
+ return list(csv.reader(f))
+
+ def _create_examples(self, lines: list[list[str]], type: str):
+ """Creates examples for the training and dev sets."""
+ if type == "train" and lines[0][-1] != "label":
+ raise ValueError("For training, the input file must contain a label column.")
+
+ examples = [
+ InputExample(
+ example_id=line[2],
+ question=line[5], # in the swag dataset, the
+ # common beginning of each
+ # choice is stored in "sent2".
+ contexts=[line[4], line[4], line[4], line[4]],
+ endings=[line[7], line[8], line[9], line[10]],
+ label=line[11],
+ )
+ for line in lines[1:] # we skip the line with the column names
+ ]
+
+ return examples
+
+
+class ArcProcessor(DataProcessor):
+ """Processor for the ARC data set (request from allennlp)."""
+
+ def get_train_examples(self, data_dir):
+ """See base class."""
+ logger.info(f"LOOKING AT {data_dir} train")
+ return self._create_examples(self._read_json(os.path.join(data_dir, "train.jsonl")), "train")
+
+ def get_dev_examples(self, data_dir):
+ """See base class."""
+ logger.info(f"LOOKING AT {data_dir} dev")
+ return self._create_examples(self._read_json(os.path.join(data_dir, "dev.jsonl")), "dev")
+
+ def get_test_examples(self, data_dir):
+ logger.info(f"LOOKING AT {data_dir} test")
+ return self._create_examples(self._read_json(os.path.join(data_dir, "test.jsonl")), "test")
+
+ def get_labels(self):
+ """See base class."""
+ return ["0", "1", "2", "3"]
+
+ def _read_json(self, input_file):
+ with open(input_file, encoding="utf-8") as fin:
+ lines = fin.readlines()
+ return lines
+
+ def _create_examples(self, lines, type):
+ """Creates examples for the training and dev sets."""
+
+ # There are two types of labels. They should be normalized
+ def normalize(truth):
+ if truth in "ABCD":
+ return ord(truth) - ord("A")
+ elif truth in "1234":
+ return int(truth) - 1
+ else:
+ logger.info("truth ERROR! %s", str(truth))
+ return None
+
+ examples = []
+ three_choice = 0
+ four_choice = 0
+ five_choice = 0
+ other_choices = 0
+ # we deleted example which has more than or less than four choices
+ for line in tqdm.tqdm(lines, desc="read arc data"):
+ data_raw = json.loads(line.strip("\n"))
+ if len(data_raw["question"]["choices"]) == 3:
+ three_choice += 1
+ continue
+ elif len(data_raw["question"]["choices"]) == 5:
+ five_choice += 1
+ continue
+ elif len(data_raw["question"]["choices"]) != 4:
+ other_choices += 1
+ continue
+ four_choice += 1
+ truth = str(normalize(data_raw["answerKey"]))
+ assert truth != "None"
+ question_choices = data_raw["question"]
+ question = question_choices["stem"]
+ id = data_raw["id"]
+ options = question_choices["choices"]
+ if len(options) == 4:
+ examples.append(
+ InputExample(
+ example_id=id,
+ question=question,
+ contexts=[
+ options[0]["para"].replace("_", ""),
+ options[1]["para"].replace("_", ""),
+ options[2]["para"].replace("_", ""),
+ options[3]["para"].replace("_", ""),
+ ],
+ endings=[options[0]["text"], options[1]["text"], options[2]["text"], options[3]["text"]],
+ label=truth,
+ )
+ )
+
+ if type == "train":
+ assert len(examples) > 1
+ assert examples[0].label is not None
+ logger.info("len examples: %s}", str(len(examples)))
+ logger.info("Three choices: %s", str(three_choice))
+ logger.info("Five choices: %s", str(five_choice))
+ logger.info("Other choices: %s", str(other_choices))
+ logger.info("four choices: %s", str(four_choice))
+
+ return examples
+
+
+def convert_examples_to_features(
+ examples: list[InputExample],
+ label_list: list[str],
+ max_length: int,
+ tokenizer: PreTrainedTokenizer,
+) -> list[InputFeatures]:
+ """
+ Loads a data file into a list of `InputFeatures`
+ """
+
+ label_map = {label: i for i, label in enumerate(label_list)}
+
+ features = []
+ for ex_index, example in tqdm.tqdm(enumerate(examples), desc="convert examples to features"):
+ if ex_index % 10000 == 0:
+ logger.info("Writing example %d of %d" % (ex_index, len(examples)))
+ choices_inputs = []
+ for ending_idx, (context, ending) in enumerate(zip(example.contexts, example.endings)):
+ text_a = context
+ if example.question.find("_") != -1:
+ # this is for cloze question
+ text_b = example.question.replace("_", ending)
+ else:
+ text_b = example.question + " " + ending
+
+ inputs = tokenizer(
+ text_a,
+ text_b,
+ add_special_tokens=True,
+ max_length=max_length,
+ padding="max_length",
+ truncation=True,
+ return_overflowing_tokens=True,
+ )
+ if "num_truncated_tokens" in inputs and inputs["num_truncated_tokens"] > 0:
+ logger.info(
+ "Attention! you are cropping tokens (swag task is ok). "
+ "If you are training ARC and RACE and you are poping question + options, "
+ "you need to try to use a bigger max seq length!"
+ )
+
+ choices_inputs.append(inputs)
+
+ label = label_map[example.label]
+
+ input_ids = [x["input_ids"] for x in choices_inputs]
+ attention_mask = (
+ [x["attention_mask"] for x in choices_inputs] if "attention_mask" in choices_inputs[0] else None
+ )
+ token_type_ids = (
+ [x["token_type_ids"] for x in choices_inputs] if "token_type_ids" in choices_inputs[0] else None
+ )
+
+ features.append(
+ InputFeatures(
+ example_id=example.example_id,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ label=label,
+ )
+ )
+
+ for f in features[:2]:
+ logger.info("*** Example ***")
+ logger.info("feature: %s" % f)
+
+ return features
+
+
+processors = {"race": RaceProcessor, "swag": SwagProcessor, "arc": ArcProcessor, "syn": SynonymProcessor}
+MULTIPLE_CHOICE_TASKS_NUM_LABELS = {"race", 4, "swag", 4, "arc", 4, "syn", 5}
diff --git a/docs/transformers/examples/legacy/pytorch-lightning/lightning_base.py b/docs/transformers/examples/legacy/pytorch-lightning/lightning_base.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c34fbe7e07d4f89a6c354e91f08baa8ee6b5969
--- /dev/null
+++ b/docs/transformers/examples/legacy/pytorch-lightning/lightning_base.py
@@ -0,0 +1,397 @@
+import argparse
+import logging
+import os
+from pathlib import Path
+from typing import Any
+
+import pytorch_lightning as pl
+from pytorch_lightning.utilities import rank_zero_info
+
+from transformers import (
+ AutoConfig,
+ AutoModel,
+ AutoModelForPreTraining,
+ AutoModelForQuestionAnswering,
+ AutoModelForSeq2SeqLM,
+ AutoModelForSequenceClassification,
+ AutoModelForTokenClassification,
+ AutoModelWithLMHead,
+ AutoTokenizer,
+ PretrainedConfig,
+ PreTrainedTokenizer,
+ is_torch_available,
+)
+from transformers.optimization import (
+ Adafactor,
+ get_cosine_schedule_with_warmup,
+ get_cosine_with_hard_restarts_schedule_with_warmup,
+ get_linear_schedule_with_warmup,
+ get_polynomial_decay_schedule_with_warmup,
+)
+from transformers.utils.versions import require_version
+
+
+if is_torch_available():
+ import torch
+
+
+logger = logging.getLogger(__name__)
+
+require_version("pytorch_lightning>=1.0.4")
+
+MODEL_MODES = {
+ "base": AutoModel,
+ "sequence-classification": AutoModelForSequenceClassification,
+ "question-answering": AutoModelForQuestionAnswering,
+ "pretraining": AutoModelForPreTraining,
+ "token-classification": AutoModelForTokenClassification,
+ "language-modeling": AutoModelWithLMHead,
+ "summarization": AutoModelForSeq2SeqLM,
+ "translation": AutoModelForSeq2SeqLM,
+}
+
+
+# update this and the import above to support new schedulers from transformers.optimization
+arg_to_scheduler = {
+ "linear": get_linear_schedule_with_warmup,
+ "cosine": get_cosine_schedule_with_warmup,
+ "cosine_w_restarts": get_cosine_with_hard_restarts_schedule_with_warmup,
+ "polynomial": get_polynomial_decay_schedule_with_warmup,
+ # '': get_constant_schedule, # not supported for now
+ # '': get_constant_schedule_with_warmup, # not supported for now
+}
+arg_to_scheduler_choices = sorted(arg_to_scheduler.keys())
+arg_to_scheduler_metavar = "{" + ", ".join(arg_to_scheduler_choices) + "}"
+
+
+class BaseTransformer(pl.LightningModule):
+ def __init__(
+ self,
+ hparams: argparse.Namespace,
+ num_labels=None,
+ mode="base",
+ config=None,
+ tokenizer=None,
+ model=None,
+ **config_kwargs,
+ ):
+ """Initialize a model, tokenizer and config."""
+ super().__init__()
+ # TODO: move to self.save_hyperparameters()
+ # self.save_hyperparameters()
+ # can also expand arguments into trainer signature for easier reading
+
+ self.save_hyperparameters(hparams)
+ self.step_count = 0
+ self.output_dir = Path(self.hparams.output_dir)
+ cache_dir = self.hparams.cache_dir if self.hparams.cache_dir else None
+ if config is None:
+ self.config = AutoConfig.from_pretrained(
+ self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
+ **({"num_labels": num_labels} if num_labels is not None else {}),
+ cache_dir=cache_dir,
+ **config_kwargs,
+ )
+ else:
+ self.config: PretrainedConfig = config
+
+ extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
+ for p in extra_model_params:
+ if getattr(self.hparams, p, None):
+ assert hasattr(self.config, p), f"model config doesn't have a `{p}` attribute"
+ setattr(self.config, p, getattr(self.hparams, p))
+
+ if tokenizer is None:
+ self.tokenizer = AutoTokenizer.from_pretrained(
+ self.hparams.tokenizer_name if self.hparams.tokenizer_name else self.hparams.model_name_or_path,
+ cache_dir=cache_dir,
+ )
+ else:
+ self.tokenizer: PreTrainedTokenizer = tokenizer
+ self.model_type = MODEL_MODES[mode]
+ if model is None:
+ self.model = self.model_type.from_pretrained(
+ self.hparams.model_name_or_path,
+ from_tf=bool(".ckpt" in self.hparams.model_name_or_path),
+ config=self.config,
+ cache_dir=cache_dir,
+ )
+ else:
+ self.model = model
+
+ def load_hf_checkpoint(self, *args, **kwargs):
+ self.model = self.model_type.from_pretrained(*args, **kwargs)
+
+ def get_lr_scheduler(self):
+ get_schedule_func = arg_to_scheduler[self.hparams.lr_scheduler]
+ scheduler = get_schedule_func(
+ self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=self.total_steps()
+ )
+ scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
+ return scheduler
+
+ def configure_optimizers(self):
+ """Prepare optimizer and schedule (linear warmup and decay)"""
+ model = self.model
+ no_decay = ["bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": self.hparams.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ if self.hparams.adafactor:
+ optimizer = Adafactor(
+ optimizer_grouped_parameters, lr=self.hparams.learning_rate, scale_parameter=False, relative_step=False
+ )
+
+ else:
+ optimizer = torch.optim.AdamW(
+ optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon
+ )
+ self.opt = optimizer
+
+ scheduler = self.get_lr_scheduler()
+
+ return [optimizer], [scheduler]
+
+ def test_step(self, batch, batch_nb):
+ return self.validation_step(batch, batch_nb)
+
+ def test_epoch_end(self, outputs):
+ return self.validation_end(outputs)
+
+ def total_steps(self) -> int:
+ """The number of total training steps that will be run. Used for lr scheduler purposes."""
+ num_devices = max(1, self.hparams.gpus) # TODO: consider num_tpu_cores
+ effective_batch_size = self.hparams.train_batch_size * self.hparams.accumulate_grad_batches * num_devices
+ return (self.dataset_size / effective_batch_size) * self.hparams.max_epochs
+
+ def setup(self, mode):
+ if mode == "test":
+ self.dataset_size = len(self.test_dataloader().dataset)
+ else:
+ self.train_loader = self.get_dataloader("train", self.hparams.train_batch_size, shuffle=True)
+ self.dataset_size = len(self.train_dataloader().dataset)
+
+ def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False):
+ raise NotImplementedError("You must implement this for your task")
+
+ def train_dataloader(self):
+ return self.train_loader
+
+ def val_dataloader(self):
+ return self.get_dataloader("dev", self.hparams.eval_batch_size, shuffle=False)
+
+ def test_dataloader(self):
+ return self.get_dataloader("test", self.hparams.eval_batch_size, shuffle=False)
+
+ def _feature_file(self, mode):
+ return os.path.join(
+ self.hparams.data_dir,
+ "cached_{}_{}_{}".format(
+ mode,
+ list(filter(None, self.hparams.model_name_or_path.split("/"))).pop(),
+ str(self.hparams.max_seq_length),
+ ),
+ )
+
+ @pl.utilities.rank_zero_only
+ def on_save_checkpoint(self, checkpoint: dict[str, Any]) -> None:
+ save_path = self.output_dir.joinpath("best_tfmr")
+ self.model.config.save_step = self.step_count
+ self.model.save_pretrained(save_path)
+ self.tokenizer.save_pretrained(save_path)
+
+ @staticmethod
+ def add_model_specific_args(parser, root_dir):
+ parser.add_argument(
+ "--model_name_or_path",
+ default=None,
+ type=str,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models",
+ )
+ parser.add_argument(
+ "--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ default=None,
+ type=str,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--cache_dir",
+ default="",
+ type=str,
+ help="Where do you want to store the pre-trained models downloaded from huggingface.co",
+ )
+ parser.add_argument(
+ "--encoder_layerdrop",
+ type=float,
+ help="Encoder layer dropout probability (Optional). Goes into model.config",
+ )
+ parser.add_argument(
+ "--decoder_layerdrop",
+ type=float,
+ help="Decoder layer dropout probability (Optional). Goes into model.config",
+ )
+ parser.add_argument(
+ "--dropout",
+ type=float,
+ help="Dropout probability (Optional). Goes into model.config",
+ )
+ parser.add_argument(
+ "--attention_dropout",
+ type=float,
+ help="Attention dropout probability (Optional). Goes into model.config",
+ )
+ parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
+ parser.add_argument(
+ "--lr_scheduler",
+ default="linear",
+ choices=arg_to_scheduler_choices,
+ metavar=arg_to_scheduler_metavar,
+ type=str,
+ help="Learning rate scheduler",
+ )
+ parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
+ parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
+ parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
+ parser.add_argument("--num_workers", default=4, type=int, help="kwarg passed to DataLoader")
+ parser.add_argument("--num_train_epochs", dest="max_epochs", default=3, type=int)
+ parser.add_argument("--train_batch_size", default=32, type=int)
+ parser.add_argument("--eval_batch_size", default=32, type=int)
+ parser.add_argument("--adafactor", action="store_true")
+
+
+class LoggingCallback(pl.Callback):
+ def on_batch_end(self, trainer, pl_module):
+ lr_scheduler = trainer.lr_schedulers[0]["scheduler"]
+ lrs = {f"lr_group_{i}": lr for i, lr in enumerate(lr_scheduler.get_lr())}
+ pl_module.logger.log_metrics(lrs)
+
+ def on_validation_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
+ rank_zero_info("***** Validation results *****")
+ metrics = trainer.callback_metrics
+ # Log results
+ for key in sorted(metrics):
+ if key not in ["log", "progress_bar"]:
+ rank_zero_info(f"{key} = {str(metrics[key])}\n")
+
+ def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
+ rank_zero_info("***** Test results *****")
+ metrics = trainer.callback_metrics
+ # Log and save results to file
+ output_test_results_file = os.path.join(pl_module.hparams.output_dir, "test_results.txt")
+ with open(output_test_results_file, "w") as writer:
+ for key in sorted(metrics):
+ if key not in ["log", "progress_bar"]:
+ rank_zero_info(f"{key} = {str(metrics[key])}\n")
+ writer.write(f"{key} = {str(metrics[key])}\n")
+
+
+def add_generic_args(parser, root_dir) -> None:
+ # To allow all pl args uncomment the following line
+ # parser = pl.Trainer.add_argparse_args(parser)
+ parser.add_argument(
+ "--output_dir",
+ default=None,
+ type=str,
+ required=True,
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument(
+ "--fp16",
+ action="store_true",
+ help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
+ )
+
+ parser.add_argument(
+ "--fp16_opt_level",
+ type=str,
+ default="O2",
+ help=(
+ "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
+ "See details at https://nvidia.github.io/apex/amp.html"
+ ),
+ )
+ parser.add_argument("--n_tpu_cores", dest="tpu_cores", type=int)
+ parser.add_argument("--max_grad_norm", dest="gradient_clip_val", default=1.0, type=float, help="Max gradient norm")
+ parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
+ parser.add_argument("--do_predict", action="store_true", help="Whether to run predictions on the test set.")
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ dest="accumulate_grad_batches",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
+ parser.add_argument(
+ "--data_dir",
+ default=None,
+ type=str,
+ required=True,
+ help="The input data dir. Should contain the training files for the CoNLL-2003 NER task.",
+ )
+
+
+def generic_train(
+ model: BaseTransformer,
+ args: argparse.Namespace,
+ early_stopping_callback=None,
+ logger=True, # can pass WandbLogger() here
+ extra_callbacks=[],
+ checkpoint_callback=None,
+ logging_callback=None,
+ **extra_train_kwargs,
+):
+ pl.seed_everything(args.seed)
+
+ # init model
+ odir = Path(model.hparams.output_dir)
+ odir.mkdir(exist_ok=True)
+
+ # add custom checkpoints
+ if checkpoint_callback is None:
+ checkpoint_callback = pl.callbacks.ModelCheckpoint(
+ filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=1
+ )
+ if early_stopping_callback:
+ extra_callbacks.append(early_stopping_callback)
+ if logging_callback is None:
+ logging_callback = LoggingCallback()
+
+ train_params = {}
+
+ # TODO: remove with PyTorch 1.6 since pl uses native amp
+ if args.fp16:
+ train_params["precision"] = 16
+ train_params["amp_level"] = args.fp16_opt_level
+
+ if args.gpus > 1:
+ train_params["distributed_backend"] = "ddp"
+
+ train_params["accumulate_grad_batches"] = args.accumulate_grad_batches
+ train_params["accelerator"] = extra_train_kwargs.get("accelerator", None)
+ train_params["profiler"] = extra_train_kwargs.get("profiler", None)
+
+ trainer = pl.Trainer.from_argparse_args(
+ args,
+ weights_summary=None,
+ callbacks=[logging_callback] + extra_callbacks,
+ logger=logger,
+ checkpoint_callback=checkpoint_callback,
+ **train_params,
+ )
+
+ if args.do_train:
+ trainer.fit(model)
+
+ return trainer
diff --git a/docs/transformers/examples/legacy/pytorch-lightning/requirements.txt b/docs/transformers/examples/legacy/pytorch-lightning/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a6f2d6dce5a9d53013a3c124da6198901486867d
--- /dev/null
+++ b/docs/transformers/examples/legacy/pytorch-lightning/requirements.txt
@@ -0,0 +1,21 @@
+tensorboard
+scikit-learn
+seqeval
+psutil
+sacrebleu
+rouge-score
+tensorflow_datasets
+matplotlib
+git-python==1.0.3
+faiss-cpu
+streamlit
+elasticsearch
+nltk
+pandas
+datasets >= 1.1.3
+fire
+pytest<8.0.1
+conllu
+sentencepiece != 0.1.92
+protobuf
+ray
diff --git a/docs/transformers/examples/legacy/pytorch-lightning/run_glue.py b/docs/transformers/examples/legacy/pytorch-lightning/run_glue.py
new file mode 100644
index 0000000000000000000000000000000000000000..00302c5061c4e71f1002e7b7e73bd9fa319bbdd6
--- /dev/null
+++ b/docs/transformers/examples/legacy/pytorch-lightning/run_glue.py
@@ -0,0 +1,201 @@
+import argparse
+import glob
+import logging
+import os
+import time
+from argparse import Namespace
+
+import numpy as np
+import torch
+from lightning_base import BaseTransformer, add_generic_args, generic_train
+from torch.utils.data import DataLoader, TensorDataset
+
+from transformers import glue_compute_metrics as compute_metrics
+from transformers import glue_convert_examples_to_features as convert_examples_to_features
+from transformers import glue_output_modes, glue_tasks_num_labels
+from transformers import glue_processors as processors
+
+
+logger = logging.getLogger(__name__)
+
+
+class GLUETransformer(BaseTransformer):
+ mode = "sequence-classification"
+
+ def __init__(self, hparams):
+ if isinstance(hparams, dict):
+ hparams = Namespace(**hparams)
+ hparams.glue_output_mode = glue_output_modes[hparams.task]
+ num_labels = glue_tasks_num_labels[hparams.task]
+
+ super().__init__(hparams, num_labels, self.mode)
+
+ def forward(self, **inputs):
+ return self.model(**inputs)
+
+ def training_step(self, batch, batch_idx):
+ inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
+
+ if self.config.model_type not in ["distilbert", "bart"]:
+ inputs["token_type_ids"] = batch[2] if self.config.model_type in ["bert", "xlnet", "albert"] else None
+
+ outputs = self(**inputs)
+ loss = outputs[0]
+
+ lr_scheduler = self.trainer.lr_schedulers[0]["scheduler"]
+ tensorboard_logs = {"loss": loss, "rate": lr_scheduler.get_last_lr()[-1]}
+ return {"loss": loss, "log": tensorboard_logs}
+
+ def prepare_data(self):
+ "Called to initialize data. Use the call to construct features"
+ args = self.hparams
+ processor = processors[args.task]()
+ self.labels = processor.get_labels()
+
+ for mode in ["train", "dev"]:
+ cached_features_file = self._feature_file(mode)
+ if os.path.exists(cached_features_file) and not args.overwrite_cache:
+ logger.info("Loading features from cached file %s", cached_features_file)
+ else:
+ logger.info("Creating features from dataset file at %s", args.data_dir)
+ examples = (
+ processor.get_dev_examples(args.data_dir)
+ if mode == "dev"
+ else processor.get_train_examples(args.data_dir)
+ )
+ features = convert_examples_to_features(
+ examples,
+ self.tokenizer,
+ max_length=args.max_seq_length,
+ label_list=self.labels,
+ output_mode=args.glue_output_mode,
+ )
+ logger.info("Saving features into cached file %s", cached_features_file)
+ torch.save(features, cached_features_file)
+
+ def get_dataloader(self, mode: str, batch_size: int, shuffle: bool = False) -> DataLoader:
+ "Load datasets. Called after prepare data."
+
+ # We test on dev set to compare to benchmarks without having to submit to GLUE server
+ mode = "dev" if mode == "test" else mode
+
+ cached_features_file = self._feature_file(mode)
+ logger.info("Loading features from cached file %s", cached_features_file)
+ features = torch.load(cached_features_file, weights_only=True)
+ all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
+ all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
+ all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
+ if self.hparams.glue_output_mode == "classification":
+ all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
+ elif self.hparams.glue_output_mode == "regression":
+ all_labels = torch.tensor([f.label for f in features], dtype=torch.float)
+
+ return DataLoader(
+ TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_labels),
+ batch_size=batch_size,
+ shuffle=shuffle,
+ )
+
+ def validation_step(self, batch, batch_idx):
+ inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
+
+ if self.config.model_type not in ["distilbert", "bart"]:
+ inputs["token_type_ids"] = batch[2] if self.config.model_type in ["bert", "xlnet", "albert"] else None
+
+ outputs = self(**inputs)
+ tmp_eval_loss, logits = outputs[:2]
+ preds = logits.detach().cpu().numpy()
+ out_label_ids = inputs["labels"].detach().cpu().numpy()
+
+ return {"val_loss": tmp_eval_loss.detach().cpu(), "pred": preds, "target": out_label_ids}
+
+ def _eval_end(self, outputs) -> tuple:
+ val_loss_mean = torch.stack([x["val_loss"] for x in outputs]).mean().detach().cpu().item()
+ preds = np.concatenate([x["pred"] for x in outputs], axis=0)
+
+ if self.hparams.glue_output_mode == "classification":
+ preds = np.argmax(preds, axis=1)
+ elif self.hparams.glue_output_mode == "regression":
+ preds = np.squeeze(preds)
+
+ out_label_ids = np.concatenate([x["target"] for x in outputs], axis=0)
+ out_label_list = [[] for _ in range(out_label_ids.shape[0])]
+ preds_list = [[] for _ in range(out_label_ids.shape[0])]
+
+ results = {**{"val_loss": val_loss_mean}, **compute_metrics(self.hparams.task, preds, out_label_ids)}
+
+ ret = dict(results.items())
+ ret["log"] = results
+ return ret, preds_list, out_label_list
+
+ def validation_epoch_end(self, outputs: list) -> dict:
+ ret, preds, targets = self._eval_end(outputs)
+ logs = ret["log"]
+ return {"val_loss": logs["val_loss"], "log": logs, "progress_bar": logs}
+
+ def test_epoch_end(self, outputs) -> dict:
+ ret, predictions, targets = self._eval_end(outputs)
+ logs = ret["log"]
+ # `val_loss` is the key returned by `self._eval_end()` but actually refers to `test_loss`
+ return {"avg_test_loss": logs["val_loss"], "log": logs, "progress_bar": logs}
+
+ @staticmethod
+ def add_model_specific_args(parser, root_dir):
+ BaseTransformer.add_model_specific_args(parser, root_dir)
+ parser.add_argument(
+ "--max_seq_length",
+ default=128,
+ type=int,
+ help=(
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ ),
+ )
+
+ parser.add_argument(
+ "--task",
+ default="",
+ type=str,
+ required=True,
+ help="The GLUE task to run",
+ )
+ parser.add_argument(
+ "--gpus",
+ default=0,
+ type=int,
+ help="The number of GPUs allocated for this, it is by default 0 meaning none",
+ )
+
+ parser.add_argument(
+ "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
+ )
+
+ return parser
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ add_generic_args(parser, os.getcwd())
+ parser = GLUETransformer.add_model_specific_args(parser, os.getcwd())
+ args = parser.parse_args()
+
+ # If output_dir not provided, a folder will be generated in pwd
+ if args.output_dir is None:
+ args.output_dir = os.path.join(
+ "./results",
+ f"{args.task}_{time.strftime('%Y%m%d_%H%M%S')}",
+ )
+ os.makedirs(args.output_dir)
+
+ model = GLUETransformer(args)
+ trainer = generic_train(model, args)
+
+ # Optionally, predict on dev set and write to output_dir
+ if args.do_predict:
+ checkpoints = sorted(glob.glob(os.path.join(args.output_dir, "checkpoint-epoch=*.ckpt"), recursive=True))
+ model = model.load_from_checkpoint(checkpoints[-1])
+ return trainer.test(model)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/pytorch-lightning/run_glue.sh b/docs/transformers/examples/legacy/pytorch-lightning/run_glue.sh
new file mode 100644
index 0000000000000000000000000000000000000000..7cd57306d4e18596b5d7ea70847b5ed5fdcdd7dd
--- /dev/null
+++ b/docs/transformers/examples/legacy/pytorch-lightning/run_glue.sh
@@ -0,0 +1,34 @@
+# Install example requirements
+pip install -r ../requirements.txt
+
+# Download glue data
+python3 ../../utils/download_glue_data.py
+
+export TASK=mrpc
+export DATA_DIR=./glue_data/MRPC/
+export MAX_LENGTH=128
+export LEARNING_RATE=2e-5
+export BERT_MODEL=bert-base-cased
+export BATCH_SIZE=32
+export NUM_EPOCHS=3
+export SEED=2
+export OUTPUT_DIR_NAME=mrpc-pl-bert
+export CURRENT_DIR=${PWD}
+export OUTPUT_DIR=${CURRENT_DIR}/${OUTPUT_DIR_NAME}
+
+# Make output directory if it doesn't exist
+mkdir -p $OUTPUT_DIR
+# Add parent directory to python path to access lightning_base.py
+export PYTHONPATH="../":"${PYTHONPATH}"
+
+python3 run_glue.py --gpus 1 --data_dir $DATA_DIR \
+--task $TASK \
+--model_name_or_path $BERT_MODEL \
+--output_dir $OUTPUT_DIR \
+--max_seq_length $MAX_LENGTH \
+--learning_rate $LEARNING_RATE \
+--num_train_epochs $NUM_EPOCHS \
+--train_batch_size $BATCH_SIZE \
+--seed $SEED \
+--do_train \
+--do_predict
diff --git a/docs/transformers/examples/legacy/pytorch-lightning/run_ner.py b/docs/transformers/examples/legacy/pytorch-lightning/run_ner.py
new file mode 100644
index 0000000000000000000000000000000000000000..144759d36aac50bd65a5777017b8299c8b55b33b
--- /dev/null
+++ b/docs/transformers/examples/legacy/pytorch-lightning/run_ner.py
@@ -0,0 +1,216 @@
+import argparse
+import glob
+import logging
+import os
+from argparse import Namespace
+from importlib import import_module
+
+import numpy as np
+import torch
+from lightning_base import BaseTransformer, add_generic_args, generic_train
+from seqeval.metrics import accuracy_score, f1_score, precision_score, recall_score
+from torch.nn import CrossEntropyLoss
+from torch.utils.data import DataLoader, TensorDataset
+from utils_ner import TokenClassificationTask
+
+
+logger = logging.getLogger(__name__)
+
+
+class NERTransformer(BaseTransformer):
+ """
+ A training module for NER. See BaseTransformer for the core options.
+ """
+
+ mode = "token-classification"
+
+ def __init__(self, hparams):
+ if isinstance(hparams, dict):
+ hparams = Namespace(**hparams)
+ module = import_module("tasks")
+ try:
+ token_classification_task_clazz = getattr(module, hparams.task_type)
+ self.token_classification_task: TokenClassificationTask = token_classification_task_clazz()
+ except AttributeError:
+ raise ValueError(
+ f"Task {hparams.task_type} needs to be defined as a TokenClassificationTask subclass in {module}. "
+ f"Available tasks classes are: {TokenClassificationTask.__subclasses__()}"
+ )
+ self.labels = self.token_classification_task.get_labels(hparams.labels)
+ self.pad_token_label_id = CrossEntropyLoss().ignore_index
+ super().__init__(hparams, len(self.labels), self.mode)
+
+ def forward(self, **inputs):
+ return self.model(**inputs)
+
+ def training_step(self, batch, batch_num):
+ "Compute loss and log."
+ inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
+ if self.config.model_type != "distilbert":
+ inputs["token_type_ids"] = (
+ batch[2] if self.config.model_type in ["bert", "xlnet"] else None
+ ) # XLM and RoBERTa don"t use token_type_ids
+
+ outputs = self(**inputs)
+ loss = outputs[0]
+ # tensorboard_logs = {"loss": loss, "rate": self.lr_scheduler.get_last_lr()[-1]}
+ return {"loss": loss}
+
+ def prepare_data(self):
+ "Called to initialize data. Use the call to construct features"
+ args = self.hparams
+ for mode in ["train", "dev", "test"]:
+ cached_features_file = self._feature_file(mode)
+ if os.path.exists(cached_features_file) and not args.overwrite_cache:
+ logger.info("Loading features from cached file %s", cached_features_file)
+ features = torch.load(cached_features_file, weights_only=True)
+ else:
+ logger.info("Creating features from dataset file at %s", args.data_dir)
+ examples = self.token_classification_task.read_examples_from_file(args.data_dir, mode)
+ features = self.token_classification_task.convert_examples_to_features(
+ examples,
+ self.labels,
+ args.max_seq_length,
+ self.tokenizer,
+ cls_token_at_end=bool(self.config.model_type in ["xlnet"]),
+ cls_token=self.tokenizer.cls_token,
+ cls_token_segment_id=2 if self.config.model_type in ["xlnet"] else 0,
+ sep_token=self.tokenizer.sep_token,
+ sep_token_extra=False,
+ pad_on_left=bool(self.config.model_type in ["xlnet"]),
+ pad_token=self.tokenizer.pad_token_id,
+ pad_token_segment_id=self.tokenizer.pad_token_type_id,
+ pad_token_label_id=self.pad_token_label_id,
+ )
+ logger.info("Saving features into cached file %s", cached_features_file)
+ torch.save(features, cached_features_file)
+
+ def get_dataloader(self, mode: int, batch_size: int, shuffle: bool = False) -> DataLoader:
+ "Load datasets. Called after prepare data."
+ cached_features_file = self._feature_file(mode)
+ logger.info("Loading features from cached file %s", cached_features_file)
+ features = torch.load(cached_features_file, weights_only=True)
+ all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
+ all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
+ if features[0].token_type_ids is not None:
+ all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
+ else:
+ all_token_type_ids = torch.tensor([0 for f in features], dtype=torch.long)
+ # HACK(we will not use this anymore soon)
+ all_label_ids = torch.tensor([f.label_ids for f in features], dtype=torch.long)
+ return DataLoader(
+ TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_label_ids), batch_size=batch_size
+ )
+
+ def validation_step(self, batch, batch_nb):
+ """Compute validation""" ""
+ inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
+ if self.config.model_type != "distilbert":
+ inputs["token_type_ids"] = (
+ batch[2] if self.config.model_type in ["bert", "xlnet"] else None
+ ) # XLM and RoBERTa don"t use token_type_ids
+ outputs = self(**inputs)
+ tmp_eval_loss, logits = outputs[:2]
+ preds = logits.detach().cpu().numpy()
+ out_label_ids = inputs["labels"].detach().cpu().numpy()
+ return {"val_loss": tmp_eval_loss.detach().cpu(), "pred": preds, "target": out_label_ids}
+
+ def _eval_end(self, outputs):
+ "Evaluation called for both Val and Test"
+ val_loss_mean = torch.stack([x["val_loss"] for x in outputs]).mean()
+ preds = np.concatenate([x["pred"] for x in outputs], axis=0)
+ preds = np.argmax(preds, axis=2)
+ out_label_ids = np.concatenate([x["target"] for x in outputs], axis=0)
+
+ label_map = dict(enumerate(self.labels))
+ out_label_list = [[] for _ in range(out_label_ids.shape[0])]
+ preds_list = [[] for _ in range(out_label_ids.shape[0])]
+
+ for i in range(out_label_ids.shape[0]):
+ for j in range(out_label_ids.shape[1]):
+ if out_label_ids[i, j] != self.pad_token_label_id:
+ out_label_list[i].append(label_map[out_label_ids[i][j]])
+ preds_list[i].append(label_map[preds[i][j]])
+
+ results = {
+ "val_loss": val_loss_mean,
+ "accuracy_score": accuracy_score(out_label_list, preds_list),
+ "precision": precision_score(out_label_list, preds_list),
+ "recall": recall_score(out_label_list, preds_list),
+ "f1": f1_score(out_label_list, preds_list),
+ }
+
+ ret = dict(results.items())
+ ret["log"] = results
+ return ret, preds_list, out_label_list
+
+ def validation_epoch_end(self, outputs):
+ # when stable
+ ret, preds, targets = self._eval_end(outputs)
+ logs = ret["log"]
+ return {"val_loss": logs["val_loss"], "log": logs, "progress_bar": logs}
+
+ def test_epoch_end(self, outputs):
+ # updating to test_epoch_end instead of deprecated test_end
+ ret, predictions, targets = self._eval_end(outputs)
+
+ # Converting to the dict required by pl
+ # https://github.com/PyTorchLightning/pytorch-lightning/blob/master/\
+ # pytorch_lightning/trainer/logging.py#L139
+ logs = ret["log"]
+ # `val_loss` is the key returned by `self._eval_end()` but actually refers to `test_loss`
+ return {"avg_test_loss": logs["val_loss"], "log": logs, "progress_bar": logs}
+
+ @staticmethod
+ def add_model_specific_args(parser, root_dir):
+ # Add NER specific options
+ BaseTransformer.add_model_specific_args(parser, root_dir)
+ parser.add_argument(
+ "--task_type", default="NER", type=str, help="Task type to fine tune in training (e.g. NER, POS, etc)"
+ )
+ parser.add_argument(
+ "--max_seq_length",
+ default=128,
+ type=int,
+ help=(
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ ),
+ )
+
+ parser.add_argument(
+ "--labels",
+ default="",
+ type=str,
+ help="Path to a file containing all labels. If not specified, CoNLL-2003 labels are used.",
+ )
+ parser.add_argument(
+ "--gpus",
+ default=0,
+ type=int,
+ help="The number of GPUs allocated for this, it is by default 0 meaning none",
+ )
+
+ parser.add_argument(
+ "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
+ )
+
+ return parser
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ add_generic_args(parser, os.getcwd())
+ parser = NERTransformer.add_model_specific_args(parser, os.getcwd())
+ args = parser.parse_args()
+ model = NERTransformer(args)
+ trainer = generic_train(model, args)
+
+ if args.do_predict:
+ # See https://github.com/huggingface/transformers/issues/3159
+ # pl use this default format to create a checkpoint:
+ # https://github.com/PyTorchLightning/pytorch-lightning/blob/master\
+ # /pytorch_lightning/callbacks/model_checkpoint.py#L322
+ checkpoints = sorted(glob.glob(os.path.join(args.output_dir, "checkpoint-epoch=*.ckpt"), recursive=True))
+ model = model.load_from_checkpoint(checkpoints[-1])
+ trainer.test(model)
diff --git a/docs/transformers/examples/legacy/pytorch-lightning/run_ner.sh b/docs/transformers/examples/legacy/pytorch-lightning/run_ner.sh
new file mode 100644
index 0000000000000000000000000000000000000000..a5b185aa960d09394d7caa12fa5d5dda959cdd61
--- /dev/null
+++ b/docs/transformers/examples/legacy/pytorch-lightning/run_ner.sh
@@ -0,0 +1,44 @@
+#!/usr/bin/env bash
+
+# for seqeval metrics import
+pip install -r ../requirements.txt
+
+## The relevant files are currently on a shared Google
+## drive at https://drive.google.com/drive/folders/1kC0I2UGl2ltrluI9NqDjaQJGw5iliw_J
+## Monitor for changes and eventually migrate to use the `datasets` library
+curl -L 'https://drive.google.com/uc?export=download&id=1Jjhbal535VVz2ap4v4r_rN1UEHTdLK5P' \
+| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp
+curl -L 'https://drive.google.com/uc?export=download&id=1ZfRcQThdtAR5PPRjIDtrVP7BtXSCUBbm' \
+| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp
+curl -L 'https://drive.google.com/uc?export=download&id=1u9mb7kNJHWQCWyweMDRMuTFoOHOfeBTH' \
+| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp
+
+export MAX_LENGTH=128
+export BERT_MODEL=bert-base-multilingual-cased
+python3 scripts/preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt
+python3 scripts/preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt
+python3 scripts/preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt
+cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
+export BATCH_SIZE=32
+export NUM_EPOCHS=3
+export SEED=1
+
+export OUTPUT_DIR_NAME=germeval-model
+export CURRENT_DIR=${PWD}
+export OUTPUT_DIR=${CURRENT_DIR}/${OUTPUT_DIR_NAME}
+mkdir -p $OUTPUT_DIR
+
+# Add parent directory to python path to access lightning_base.py
+export PYTHONPATH="../":"${PYTHONPATH}"
+
+python3 run_ner.py --data_dir ./ \
+--labels ./labels.txt \
+--model_name_or_path $BERT_MODEL \
+--output_dir $OUTPUT_DIR \
+--max_seq_length $MAX_LENGTH \
+--num_train_epochs $NUM_EPOCHS \
+--train_batch_size $BATCH_SIZE \
+--seed $SEED \
+--gpus 1 \
+--do_train \
+--do_predict
diff --git a/docs/transformers/examples/legacy/pytorch-lightning/run_pos.sh b/docs/transformers/examples/legacy/pytorch-lightning/run_pos.sh
new file mode 100644
index 0000000000000000000000000000000000000000..93765366cf3123af5e361c236b46cf36680d90e2
--- /dev/null
+++ b/docs/transformers/examples/legacy/pytorch-lightning/run_pos.sh
@@ -0,0 +1,39 @@
+#!/usr/bin/env bash
+if ! [ -f ./dev.txt ]; then
+ echo "Download dev dataset...."
+ curl -L -o ./dev.txt 'https://github.com/UniversalDependencies/UD_English-EWT/raw/master/en_ewt-ud-dev.conllu'
+fi
+
+if ! [ -f ./test.txt ]; then
+ echo "Download test dataset...."
+ curl -L -o ./test.txt 'https://github.com/UniversalDependencies/UD_English-EWT/raw/master/en_ewt-ud-test.conllu'
+fi
+
+if ! [ -f ./train.txt ]; then
+ echo "Download train dataset...."
+ curl -L -o ./train.txt 'https://github.com/UniversalDependencies/UD_English-EWT/raw/master/en_ewt-ud-train.conllu'
+fi
+
+export MAX_LENGTH=200
+export BERT_MODEL=bert-base-uncased
+export OUTPUT_DIR=postagger-model
+export BATCH_SIZE=32
+export NUM_EPOCHS=3
+export SAVE_STEPS=750
+export SEED=1
+
+
+# Add parent directory to python path to access lightning_base.py
+export PYTHONPATH="../":"${PYTHONPATH}"
+
+python3 run_ner.py --data_dir ./ \
+--task_type POS \
+--model_name_or_path $BERT_MODEL \
+--output_dir $OUTPUT_DIR \
+--max_seq_length $MAX_LENGTH \
+--num_train_epochs $NUM_EPOCHS \
+--train_batch_size $BATCH_SIZE \
+--seed $SEED \
+--gpus 1 \
+--do_train \
+--do_predict
diff --git a/docs/transformers/examples/legacy/question-answering/README.md b/docs/transformers/examples/legacy/question-answering/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..339837c94f5d86c79e56f449d2a14b063a3dbf6e
--- /dev/null
+++ b/docs/transformers/examples/legacy/question-answering/README.md
@@ -0,0 +1,126 @@
+#### Fine-tuning BERT on SQuAD1.0 with relative position embeddings
+
+The following examples show how to fine-tune BERT models with different relative position embeddings. The BERT model
+`google-bert/bert-base-uncased` was pretrained with default absolute position embeddings. We provide the following pretrained
+models which were pre-trained on the same training data (BooksCorpus and English Wikipedia) as in the BERT model
+training, but with different relative position embeddings.
+
+* `zhiheng-huang/bert-base-uncased-embedding-relative-key`, trained from scratch with relative embedding proposed by
+Shaw et al., [Self-Attention with Relative Position Representations](https://arxiv.org/abs/1803.02155)
+* `zhiheng-huang/bert-base-uncased-embedding-relative-key-query`, trained from scratch with relative embedding method 4
+in Huang et al. [Improve Transformer Models with Better Relative Position Embeddings](https://arxiv.org/abs/2009.13658)
+* `zhiheng-huang/bert-large-uncased-whole-word-masking-embedding-relative-key-query`, fine-tuned from model
+`google-bert/bert-large-uncased-whole-word-masking` with 3 additional epochs with relative embedding method 4 in Huang et al.
+[Improve Transformer Models with Better Relative Position Embeddings](https://arxiv.org/abs/2009.13658)
+
+
+##### Base models fine-tuning
+
+```bash
+export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
+torchrun --nproc_per_node=8 ./examples/question-answering/run_squad.py \
+ --model_name_or_path zhiheng-huang/bert-base-uncased-embedding-relative-key-query \
+ --dataset_name squad \
+ --do_train \
+ --do_eval \
+ --learning_rate 3e-5 \
+ --num_train_epochs 2 \
+ --max_seq_length 512 \
+ --doc_stride 128 \
+ --output_dir relative_squad \
+ --per_device_eval_batch_size=60 \
+ --per_device_train_batch_size=6
+```
+Training with the above command leads to the following results. It boosts the BERT default from f1 score of 88.52 to 90.54.
+
+```bash
+'exact': 83.6802270577105, 'f1': 90.54772098174814
+```
+
+The change of `max_seq_length` from 512 to 384 in the above command leads to the f1 score of 90.34. Replacing the above
+model `zhiheng-huang/bert-base-uncased-embedding-relative-key-query` with
+`zhiheng-huang/bert-base-uncased-embedding-relative-key` leads to the f1 score of 89.51. The changing of 8 gpus to one
+gpu training leads to the f1 score of 90.71.
+
+##### Large models fine-tuning
+
+```bash
+export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
+torchrun --nproc_per_node=8 ./examples/question-answering/run_squad.py \
+ --model_name_or_path zhiheng-huang/bert-large-uncased-whole-word-masking-embedding-relative-key-query \
+ --dataset_name squad \
+ --do_train \
+ --do_eval \
+ --learning_rate 3e-5 \
+ --num_train_epochs 2 \
+ --max_seq_length 512 \
+ --doc_stride 128 \
+ --output_dir relative_squad \
+ --per_gpu_eval_batch_size=6 \
+ --per_gpu_train_batch_size=2 \
+ --gradient_accumulation_steps 3
+```
+Training with the above command leads to the f1 score of 93.52, which is slightly better than the f1 score of 93.15 for
+`google-bert/bert-large-uncased-whole-word-masking`.
+
+#### Distributed training
+
+Here is an example using distributed training on 8 V100 GPUs and Bert Whole Word Masking uncased model to reach a F1 > 93 on SQuAD1.1:
+
+```bash
+torchrun --nproc_per_node=8 ./examples/question-answering/run_squad.py \
+ --model_name_or_path google-bert/bert-large-uncased-whole-word-masking \
+ --dataset_name squad \
+ --do_train \
+ --do_eval \
+ --learning_rate 3e-5 \
+ --num_train_epochs 2 \
+ --max_seq_length 384 \
+ --doc_stride 128 \
+ --output_dir ./examples/models/wwm_uncased_finetuned_squad/ \
+ --per_device_eval_batch_size=3 \
+ --per_device_train_batch_size=3 \
+```
+
+Training with the previously defined hyper-parameters yields the following results:
+
+```bash
+f1 = 93.15
+exact_match = 86.91
+```
+
+This fine-tuned model is available as a checkpoint under the reference
+[`google-bert/bert-large-uncased-whole-word-masking-finetuned-squad`](https://huggingface.co/google-bert/bert-large-uncased-whole-word-masking-finetuned-squad).
+
+## Results
+
+Larger batch size may improve the performance while costing more memory.
+
+##### Results for SQuAD1.0 with the previously defined hyper-parameters:
+
+```python
+{
+"exact": 85.45884578997162,
+"f1": 92.5974600601065,
+"total": 10570,
+"HasAns_exact": 85.45884578997162,
+"HasAns_f1": 92.59746006010651,
+"HasAns_total": 10570
+}
+```
+
+##### Results for SQuAD2.0 with the previously defined hyper-parameters:
+
+```python
+{
+"exact": 80.4177545691906,
+"f1": 84.07154997729623,
+"total": 11873,
+"HasAns_exact": 76.73751686909581,
+"HasAns_f1": 84.05558584352873,
+"HasAns_total": 5928,
+"NoAns_exact": 84.0874684608915,
+"NoAns_f1": 84.0874684608915,
+"NoAns_total": 5945
+}
+```
\ No newline at end of file
diff --git a/docs/transformers/examples/legacy/question-answering/run_squad.py b/docs/transformers/examples/legacy/question-answering/run_squad.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ba8309fee54b7079e0dd36213984f8873b41bf0
--- /dev/null
+++ b/docs/transformers/examples/legacy/question-answering/run_squad.py
@@ -0,0 +1,839 @@
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Finetuning the library models for question-answering on SQuAD (DistilBERT, Bert, XLM, XLNet)."""
+
+import argparse
+import glob
+import logging
+import os
+import random
+import timeit
+
+import numpy as np
+import torch
+from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
+from torch.utils.data.distributed import DistributedSampler
+from tqdm import tqdm, trange
+
+import transformers
+from transformers import (
+ MODEL_FOR_QUESTION_ANSWERING_MAPPING,
+ WEIGHTS_NAME,
+ AutoConfig,
+ AutoModelForQuestionAnswering,
+ AutoTokenizer,
+ get_linear_schedule_with_warmup,
+ squad_convert_examples_to_features,
+)
+from transformers.data.metrics.squad_metrics import (
+ compute_predictions_log_probs,
+ compute_predictions_logits,
+ squad_evaluate,
+)
+from transformers.data.processors.squad import SquadResult, SquadV1Processor, SquadV2Processor
+from transformers.trainer_utils import is_main_process
+
+
+try:
+ from torch.utils.tensorboard import SummaryWriter
+except ImportError:
+ from tensorboardX import SummaryWriter
+
+
+logger = logging.getLogger(__name__)
+
+MODEL_CONFIG_CLASSES = list(MODEL_FOR_QUESTION_ANSWERING_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+def set_seed(args):
+ random.seed(args.seed)
+ np.random.seed(args.seed)
+ torch.manual_seed(args.seed)
+ if args.n_gpu > 0:
+ torch.cuda.manual_seed_all(args.seed)
+
+
+def to_list(tensor):
+ return tensor.tolist()
+
+
+def train(args, train_dataset, model, tokenizer):
+ """Train the model"""
+ if args.local_rank in [-1, 0]:
+ tb_writer = SummaryWriter()
+
+ args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
+ train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
+ train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
+
+ if args.max_steps > 0:
+ t_total = args.max_steps
+ args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
+ else:
+ t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
+
+ # Prepare optimizer and schedule (linear warmup and decay)
+ no_decay = ["bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
+ scheduler = get_linear_schedule_with_warmup(
+ optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
+ )
+
+ # Check if saved optimizer or scheduler states exist
+ if os.path.isfile(os.path.join(args.model_name_or_path, "optimizer.pt")) and os.path.isfile(
+ os.path.join(args.model_name_or_path, "scheduler.pt")
+ ):
+ # Load in optimizer and scheduler states
+ optimizer.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "optimizer.pt"), weights_only=True))
+ scheduler.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "scheduler.pt"), weights_only=True))
+
+ if args.fp16:
+ try:
+ from apex import amp
+ except ImportError:
+ raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
+
+ model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
+
+ # multi-gpu training (should be after apex fp16 initialization)
+ if args.n_gpu > 1:
+ model = torch.nn.DataParallel(model)
+
+ # Distributed training (should be after apex fp16 initialization)
+ if args.local_rank != -1:
+ model = torch.nn.parallel.DistributedDataParallel(
+ model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True
+ )
+
+ # Train!
+ logger.info("***** Running training *****")
+ logger.info(" Num examples = %d", len(train_dataset))
+ logger.info(" Num Epochs = %d", args.num_train_epochs)
+ logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
+ logger.info(
+ " Total train batch size (w. parallel, distributed & accumulation) = %d",
+ args.train_batch_size
+ * args.gradient_accumulation_steps
+ * (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
+ )
+ logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
+ logger.info(" Total optimization steps = %d", t_total)
+
+ global_step = 1
+ epochs_trained = 0
+ steps_trained_in_current_epoch = 0
+ # Check if continuing training from a checkpoint
+ if os.path.exists(args.model_name_or_path):
+ try:
+ # set global_step to global_step of last saved checkpoint from model path
+ checkpoint_suffix = args.model_name_or_path.split("-")[-1].split("/")[0]
+ global_step = int(checkpoint_suffix)
+ epochs_trained = global_step // (len(train_dataloader) // args.gradient_accumulation_steps)
+ steps_trained_in_current_epoch = global_step % (len(train_dataloader) // args.gradient_accumulation_steps)
+
+ logger.info(" Continuing training from checkpoint, will skip to saved global_step")
+ logger.info(" Continuing training from epoch %d", epochs_trained)
+ logger.info(" Continuing training from global step %d", global_step)
+ logger.info(" Will skip the first %d steps in the first epoch", steps_trained_in_current_epoch)
+ except ValueError:
+ logger.info(" Starting fine-tuning.")
+
+ tr_loss, logging_loss = 0.0, 0.0
+ model.zero_grad()
+ train_iterator = trange(
+ epochs_trained, int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0]
+ )
+ # Added here for reproducibility
+ set_seed(args)
+
+ for _ in train_iterator:
+ epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
+ for step, batch in enumerate(epoch_iterator):
+ # Skip past any already trained steps if resuming training
+ if steps_trained_in_current_epoch > 0:
+ steps_trained_in_current_epoch -= 1
+ continue
+
+ model.train()
+ batch = tuple(t.to(args.device) for t in batch)
+
+ inputs = {
+ "input_ids": batch[0],
+ "attention_mask": batch[1],
+ "token_type_ids": batch[2],
+ "start_positions": batch[3],
+ "end_positions": batch[4],
+ }
+
+ if args.model_type in ["xlm", "roberta", "distilbert", "camembert", "bart", "longformer"]:
+ del inputs["token_type_ids"]
+
+ if args.model_type in ["xlnet", "xlm"]:
+ inputs.update({"cls_index": batch[5], "p_mask": batch[6]})
+ if args.version_2_with_negative:
+ inputs.update({"is_impossible": batch[7]})
+ if hasattr(model, "config") and hasattr(model.config, "lang2id"):
+ inputs.update(
+ {"langs": (torch.ones(batch[0].shape, dtype=torch.int64) * args.lang_id).to(args.device)}
+ )
+
+ outputs = model(**inputs)
+ # model outputs are always tuple in transformers (see doc)
+ loss = outputs[0]
+
+ if args.n_gpu > 1:
+ loss = loss.mean() # mean() to average on multi-gpu parallel (not distributed) training
+ if args.gradient_accumulation_steps > 1:
+ loss = loss / args.gradient_accumulation_steps
+
+ if args.fp16:
+ with amp.scale_loss(loss, optimizer) as scaled_loss:
+ scaled_loss.backward()
+ else:
+ loss.backward()
+
+ tr_loss += loss.item()
+ if (step + 1) % args.gradient_accumulation_steps == 0:
+ if args.fp16:
+ torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
+ else:
+ torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
+
+ optimizer.step()
+ scheduler.step() # Update learning rate schedule
+ model.zero_grad()
+ global_step += 1
+
+ # Log metrics
+ if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
+ # Only evaluate when single GPU otherwise metrics may not average well
+ if args.local_rank == -1 and args.evaluate_during_training:
+ results = evaluate(args, model, tokenizer)
+ for key, value in results.items():
+ tb_writer.add_scalar(f"eval_{key}", value, global_step)
+ tb_writer.add_scalar("lr", scheduler.get_lr()[0], global_step)
+ tb_writer.add_scalar("loss", (tr_loss - logging_loss) / args.logging_steps, global_step)
+ logging_loss = tr_loss
+
+ # Save model checkpoint
+ if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
+ output_dir = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ # Take care of distributed/parallel training
+ model_to_save = model.module if hasattr(model, "module") else model
+ model_to_save.save_pretrained(output_dir)
+ tokenizer.save_pretrained(output_dir)
+
+ torch.save(args, os.path.join(output_dir, "training_args.bin"))
+ logger.info("Saving model checkpoint to %s", output_dir)
+
+ torch.save(optimizer.state_dict(), os.path.join(output_dir, "optimizer.pt"))
+ torch.save(scheduler.state_dict(), os.path.join(output_dir, "scheduler.pt"))
+ logger.info("Saving optimizer and scheduler states to %s", output_dir)
+
+ if args.max_steps > 0 and global_step > args.max_steps:
+ epoch_iterator.close()
+ break
+ if args.max_steps > 0 and global_step > args.max_steps:
+ train_iterator.close()
+ break
+
+ if args.local_rank in [-1, 0]:
+ tb_writer.close()
+
+ return global_step, tr_loss / global_step
+
+
+def evaluate(args, model, tokenizer, prefix=""):
+ dataset, examples, features = load_and_cache_examples(args, tokenizer, evaluate=True, output_examples=True)
+
+ if not os.path.exists(args.output_dir) and args.local_rank in [-1, 0]:
+ os.makedirs(args.output_dir)
+
+ args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
+
+ # Note that DistributedSampler samples randomly
+ eval_sampler = SequentialSampler(dataset)
+ eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
+
+ # multi-gpu evaluate
+ if args.n_gpu > 1 and not isinstance(model, torch.nn.DataParallel):
+ model = torch.nn.DataParallel(model)
+
+ # Eval!
+ logger.info(f"***** Running evaluation {prefix} *****")
+ logger.info(" Num examples = %d", len(dataset))
+ logger.info(" Batch size = %d", args.eval_batch_size)
+
+ all_results = []
+ start_time = timeit.default_timer()
+
+ for batch in tqdm(eval_dataloader, desc="Evaluating"):
+ model.eval()
+ batch = tuple(t.to(args.device) for t in batch)
+
+ with torch.no_grad():
+ inputs = {
+ "input_ids": batch[0],
+ "attention_mask": batch[1],
+ "token_type_ids": batch[2],
+ }
+
+ if args.model_type in ["xlm", "roberta", "distilbert", "camembert", "bart", "longformer"]:
+ del inputs["token_type_ids"]
+
+ feature_indices = batch[3]
+
+ # XLNet and XLM use more arguments for their predictions
+ if args.model_type in ["xlnet", "xlm"]:
+ inputs.update({"cls_index": batch[4], "p_mask": batch[5]})
+ # for lang_id-sensitive xlm models
+ if hasattr(model, "config") and hasattr(model.config, "lang2id"):
+ inputs.update(
+ {"langs": (torch.ones(batch[0].shape, dtype=torch.int64) * args.lang_id).to(args.device)}
+ )
+ outputs = model(**inputs)
+
+ for i, feature_index in enumerate(feature_indices):
+ eval_feature = features[feature_index.item()]
+ unique_id = int(eval_feature.unique_id)
+
+ output = [to_list(output[i]) for output in outputs.to_tuple()]
+
+ # Some models (XLNet, XLM) use 5 arguments for their predictions, while the other "simpler"
+ # models only use two.
+ if len(output) >= 5:
+ start_logits = output[0]
+ start_top_index = output[1]
+ end_logits = output[2]
+ end_top_index = output[3]
+ cls_logits = output[4]
+
+ result = SquadResult(
+ unique_id,
+ start_logits,
+ end_logits,
+ start_top_index=start_top_index,
+ end_top_index=end_top_index,
+ cls_logits=cls_logits,
+ )
+
+ else:
+ start_logits, end_logits = output
+ result = SquadResult(unique_id, start_logits, end_logits)
+
+ all_results.append(result)
+
+ evalTime = timeit.default_timer() - start_time
+ logger.info(" Evaluation done in total %f secs (%f sec per example)", evalTime, evalTime / len(dataset))
+
+ # Compute predictions
+ output_prediction_file = os.path.join(args.output_dir, f"predictions_{prefix}.json")
+ output_nbest_file = os.path.join(args.output_dir, f"nbest_predictions_{prefix}.json")
+
+ if args.version_2_with_negative:
+ output_null_log_odds_file = os.path.join(args.output_dir, f"null_odds_{prefix}.json")
+ else:
+ output_null_log_odds_file = None
+
+ # XLNet and XLM use a more complex post-processing procedure
+ if args.model_type in ["xlnet", "xlm"]:
+ start_n_top = model.config.start_n_top if hasattr(model, "config") else model.module.config.start_n_top
+ end_n_top = model.config.end_n_top if hasattr(model, "config") else model.module.config.end_n_top
+
+ predictions = compute_predictions_log_probs(
+ examples,
+ features,
+ all_results,
+ args.n_best_size,
+ args.max_answer_length,
+ output_prediction_file,
+ output_nbest_file,
+ output_null_log_odds_file,
+ start_n_top,
+ end_n_top,
+ args.version_2_with_negative,
+ tokenizer,
+ args.verbose_logging,
+ )
+ else:
+ predictions = compute_predictions_logits(
+ examples,
+ features,
+ all_results,
+ args.n_best_size,
+ args.max_answer_length,
+ args.do_lower_case,
+ output_prediction_file,
+ output_nbest_file,
+ output_null_log_odds_file,
+ args.verbose_logging,
+ args.version_2_with_negative,
+ args.null_score_diff_threshold,
+ tokenizer,
+ )
+
+ # Compute the F1 and exact scores.
+ results = squad_evaluate(examples, predictions)
+ return results
+
+
+def load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False):
+ if args.local_rank not in [-1, 0] and not evaluate:
+ # Make sure only the first process in distributed training process the dataset, and the others will use the cache
+ torch.distributed.barrier()
+
+ # Load data features from cache or dataset file
+ input_dir = args.data_dir if args.data_dir else "."
+ cached_features_file = os.path.join(
+ input_dir,
+ "cached_{}_{}_{}".format(
+ "dev" if evaluate else "train",
+ list(filter(None, args.model_name_or_path.split("/"))).pop(),
+ str(args.max_seq_length),
+ ),
+ )
+
+ # Init features and dataset from cache if it exists
+ if os.path.exists(cached_features_file) and not args.overwrite_cache:
+ logger.info("Loading features from cached file %s", cached_features_file)
+ features_and_dataset = torch.load(cached_features_file, weights_only=True)
+ features, dataset, examples = (
+ features_and_dataset["features"],
+ features_and_dataset["dataset"],
+ features_and_dataset["examples"],
+ )
+ else:
+ logger.info("Creating features from dataset file at %s", input_dir)
+
+ if not args.data_dir and ((evaluate and not args.predict_file) or (not evaluate and not args.train_file)):
+ try:
+ import tensorflow_datasets as tfds
+ except ImportError:
+ raise ImportError("If not data_dir is specified, tensorflow_datasets needs to be installed.")
+
+ if args.version_2_with_negative:
+ logger.warning("tensorflow_datasets does not handle version 2 of SQuAD.")
+
+ tfds_examples = tfds.load("squad")
+ examples = SquadV1Processor().get_examples_from_dataset(tfds_examples, evaluate=evaluate)
+ else:
+ processor = SquadV2Processor() if args.version_2_with_negative else SquadV1Processor()
+ if evaluate:
+ examples = processor.get_dev_examples(args.data_dir, filename=args.predict_file)
+ else:
+ examples = processor.get_train_examples(args.data_dir, filename=args.train_file)
+
+ features, dataset = squad_convert_examples_to_features(
+ examples=examples,
+ tokenizer=tokenizer,
+ max_seq_length=args.max_seq_length,
+ doc_stride=args.doc_stride,
+ max_query_length=args.max_query_length,
+ is_training=not evaluate,
+ return_dataset="pt",
+ threads=args.threads,
+ )
+
+ if args.local_rank in [-1, 0]:
+ logger.info("Saving features into cached file %s", cached_features_file)
+ torch.save({"features": features, "dataset": dataset, "examples": examples}, cached_features_file)
+
+ if args.local_rank == 0 and not evaluate:
+ # Make sure only the first process in distributed training process the dataset, and the others will use the cache
+ torch.distributed.barrier()
+
+ if output_examples:
+ return dataset, examples, features
+ return dataset
+
+
+def main():
+ parser = argparse.ArgumentParser()
+
+ # Required parameters
+ parser.add_argument(
+ "--model_type",
+ default=None,
+ type=str,
+ required=True,
+ help="Model type selected in the list: " + ", ".join(MODEL_TYPES),
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ default=None,
+ type=str,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models",
+ )
+ parser.add_argument(
+ "--output_dir",
+ default=None,
+ type=str,
+ required=True,
+ help="The output directory where the model checkpoints and predictions will be written.",
+ )
+
+ # Other parameters
+ parser.add_argument(
+ "--data_dir",
+ default=None,
+ type=str,
+ help="The input data dir. Should contain the .json files for the task."
+ + "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
+ )
+ parser.add_argument(
+ "--train_file",
+ default=None,
+ type=str,
+ help="The input training file. If a data dir is specified, will look for the file there"
+ + "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
+ )
+ parser.add_argument(
+ "--predict_file",
+ default=None,
+ type=str,
+ help="The input evaluation file. If a data dir is specified, will look for the file there"
+ + "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
+ )
+ parser.add_argument(
+ "--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ default="",
+ type=str,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--cache_dir",
+ default="",
+ type=str,
+ help="Where do you want to store the pre-trained models downloaded from huggingface.co",
+ )
+
+ parser.add_argument(
+ "--version_2_with_negative",
+ action="store_true",
+ help="If true, the SQuAD examples contain some that do not have an answer.",
+ )
+ parser.add_argument(
+ "--null_score_diff_threshold",
+ type=float,
+ default=0.0,
+ help="If null_score - best_non_null is greater than the threshold predict null.",
+ )
+
+ parser.add_argument(
+ "--max_seq_length",
+ default=384,
+ type=int,
+ help=(
+ "The maximum total input sequence length after WordPiece tokenization. Sequences "
+ "longer than this will be truncated, and sequences shorter than this will be padded."
+ ),
+ )
+ parser.add_argument(
+ "--doc_stride",
+ default=128,
+ type=int,
+ help="When splitting up a long document into chunks, how much stride to take between chunks.",
+ )
+ parser.add_argument(
+ "--max_query_length",
+ default=64,
+ type=int,
+ help=(
+ "The maximum number of tokens for the question. Questions longer than this will "
+ "be truncated to this length."
+ ),
+ )
+ parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
+ parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
+ parser.add_argument(
+ "--evaluate_during_training", action="store_true", help="Run evaluation during training at each logging step."
+ )
+ parser.add_argument(
+ "--do_lower_case", action="store_true", help="Set this flag if you are using an uncased model."
+ )
+
+ parser.add_argument("--per_gpu_train_batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.")
+ parser.add_argument(
+ "--per_gpu_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation."
+ )
+ parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
+ parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument(
+ "--num_train_epochs", default=3.0, type=float, help="Total number of training epochs to perform."
+ )
+ parser.add_argument(
+ "--max_steps",
+ default=-1,
+ type=int,
+ help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
+ )
+ parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
+ parser.add_argument(
+ "--n_best_size",
+ default=20,
+ type=int,
+ help="The total number of n-best predictions to generate in the nbest_predictions.json output file.",
+ )
+ parser.add_argument(
+ "--max_answer_length",
+ default=30,
+ type=int,
+ help=(
+ "The maximum length of an answer that can be generated. This is needed because the start "
+ "and end predictions are not conditioned on one another."
+ ),
+ )
+ parser.add_argument(
+ "--verbose_logging",
+ action="store_true",
+ help=(
+ "If true, all of the warnings related to data processing will be printed. "
+ "A number of warnings are expected for a normal SQuAD evaluation."
+ ),
+ )
+ parser.add_argument(
+ "--lang_id",
+ default=0,
+ type=int,
+ help=(
+ "language id of input for language-specific xlm models (see"
+ " tokenization_xlm.PRETRAINED_INIT_CONFIGURATION)"
+ ),
+ )
+
+ parser.add_argument("--logging_steps", type=int, default=500, help="Log every X updates steps.")
+ parser.add_argument("--save_steps", type=int, default=500, help="Save checkpoint every X updates steps.")
+ parser.add_argument(
+ "--eval_all_checkpoints",
+ action="store_true",
+ help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
+ )
+ parser.add_argument("--no_cuda", action="store_true", help="Whether not to use CUDA when available")
+ parser.add_argument(
+ "--overwrite_output_dir", action="store_true", help="Overwrite the content of the output directory"
+ )
+ parser.add_argument(
+ "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
+ )
+ parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
+
+ parser.add_argument("--local_rank", type=int, default=-1, help="local_rank for distributed training on gpus")
+ parser.add_argument(
+ "--fp16",
+ action="store_true",
+ help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
+ )
+ parser.add_argument(
+ "--fp16_opt_level",
+ type=str,
+ default="O1",
+ help=(
+ "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
+ "See details at https://nvidia.github.io/apex/amp.html"
+ ),
+ )
+ parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
+ parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
+
+ parser.add_argument("--threads", type=int, default=1, help="multiple threads for converting example to features")
+ args = parser.parse_args()
+
+ if args.doc_stride >= args.max_seq_length - args.max_query_length:
+ logger.warning(
+ "WARNING - You've set a doc stride which may be superior to the document length in some "
+ "examples. This could result in errors when building features from the examples. Please reduce the doc "
+ "stride or increase the maximum length to ensure the features are correctly built."
+ )
+
+ if (
+ os.path.exists(args.output_dir)
+ and os.listdir(args.output_dir)
+ and args.do_train
+ and not args.overwrite_output_dir
+ ):
+ raise ValueError(
+ "Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
+ args.output_dir
+ )
+ )
+
+ # Setup distant debugging if needed
+ if args.server_ip and args.server_port:
+ # Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
+ import ptvsd
+
+ print("Waiting for debugger attach")
+ ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
+ ptvsd.wait_for_attach()
+
+ # Setup CUDA, GPU & distributed training
+ if args.local_rank == -1 or args.no_cuda:
+ device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
+ args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
+ else: # Initializes the distributed backend which will take care of synchronizing nodes/GPUs
+ torch.cuda.set_device(args.local_rank)
+ device = torch.device("cuda", args.local_rank)
+ torch.distributed.init_process_group(backend="nccl")
+ args.n_gpu = 1
+ args.device = device
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
+ )
+ logger.warning(
+ "Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
+ args.local_rank,
+ device,
+ args.n_gpu,
+ bool(args.local_rank != -1),
+ args.fp16,
+ )
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+ # Set seed
+ set_seed(args)
+
+ # Load pretrained model and tokenizer
+ if args.local_rank not in [-1, 0]:
+ # Make sure only the first process in distributed training will download model & vocab
+ torch.distributed.barrier()
+
+ args.model_type = args.model_type.lower()
+ config = AutoConfig.from_pretrained(
+ args.config_name if args.config_name else args.model_name_or_path,
+ cache_dir=args.cache_dir if args.cache_dir else None,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
+ do_lower_case=args.do_lower_case,
+ cache_dir=args.cache_dir if args.cache_dir else None,
+ use_fast=False, # SquadDataset is not compatible with Fast tokenizers which have a smarter overflow handeling
+ )
+ model = AutoModelForQuestionAnswering.from_pretrained(
+ args.model_name_or_path,
+ from_tf=bool(".ckpt" in args.model_name_or_path),
+ config=config,
+ cache_dir=args.cache_dir if args.cache_dir else None,
+ )
+
+ if args.local_rank == 0:
+ # Make sure only the first process in distributed training will download model & vocab
+ torch.distributed.barrier()
+
+ model.to(args.device)
+
+ logger.info("Training/evaluation parameters %s", args)
+
+ # Before we do anything with models, we want to ensure that we get fp16 execution of torch.einsum if args.fp16 is set.
+ # Otherwise it'll default to "promote" mode, and we'll get fp32 operations. Note that running `--fp16_opt_level="O2"` will
+ # remove the need for this code, but it is still valid.
+ if args.fp16:
+ try:
+ import apex
+
+ apex.amp.register_half_function(torch, "einsum")
+ except ImportError:
+ raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
+
+ # Training
+ if args.do_train:
+ train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False)
+ global_step, tr_loss = train(args, train_dataset, model, tokenizer)
+ logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
+
+ # Save the trained model and the tokenizer
+ if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):
+ logger.info("Saving model checkpoint to %s", args.output_dir)
+ # Save a trained model, configuration and tokenizer using `save_pretrained()`.
+ # They can then be reloaded using `from_pretrained()`
+ # Take care of distributed/parallel training
+ model_to_save = model.module if hasattr(model, "module") else model
+ model_to_save.save_pretrained(args.output_dir)
+ tokenizer.save_pretrained(args.output_dir)
+
+ # Good practice: save your training arguments together with the trained model
+ torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
+
+ # Load a trained model and vocabulary that you have fine-tuned
+ model = AutoModelForQuestionAnswering.from_pretrained(args.output_dir) # , force_download=True)
+
+ # SquadDataset is not compatible with Fast tokenizers which have a smarter overflow handeling
+ # So we use use_fast=False here for now until Fast-tokenizer-compatible-examples are out
+ tokenizer = AutoTokenizer.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case, use_fast=False)
+ model.to(args.device)
+
+ # Evaluation - we can ask to evaluate all the checkpoints (sub-directories) in a directory
+ results = {}
+ if args.do_eval and args.local_rank in [-1, 0]:
+ if args.do_train:
+ logger.info("Loading checkpoints saved during training for evaluation")
+ checkpoints = [args.output_dir]
+ if args.eval_all_checkpoints:
+ checkpoints = [
+ os.path.dirname(c)
+ for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
+ ]
+
+ else:
+ logger.info("Loading checkpoint %s for evaluation", args.model_name_or_path)
+ checkpoints = [args.model_name_or_path]
+
+ logger.info("Evaluate the following checkpoints: %s", checkpoints)
+
+ for checkpoint in checkpoints:
+ # Reload the model
+ global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
+ model = AutoModelForQuestionAnswering.from_pretrained(checkpoint) # , force_download=True)
+ model.to(args.device)
+
+ # Evaluate
+ result = evaluate(args, model, tokenizer, prefix=global_step)
+
+ result = {k + (f"_{global_step}" if global_step else ""): v for k, v in result.items()}
+ results.update(result)
+
+ logger.info(f"Results: {results}")
+
+ return results
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/question-answering/run_squad_trainer.py b/docs/transformers/examples/legacy/question-answering/run_squad_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..159569c3277f9a02f94c7b94896712436cffe192
--- /dev/null
+++ b/docs/transformers/examples/legacy/question-answering/run_squad_trainer.py
@@ -0,0 +1,185 @@
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Fine-tuning the library models for question-answering."""
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForQuestionAnswering,
+ AutoTokenizer,
+ DataCollatorWithPadding,
+ HfArgumentParser,
+ SquadDataset,
+ Trainer,
+ TrainingArguments,
+)
+from transformers import SquadDataTrainingArguments as DataTrainingArguments
+from transformers.trainer_utils import is_main_process
+
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ use_fast: bool = field(default=False, metadata={"help": "Set this flag to use fast tokenization."})
+ # If you want to tweak more attributes on your tokenizer, you should do it in a distinct script,
+ # or just modify its tokenizer_config.json.
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ if (
+ os.path.exists(training_args.output_dir)
+ and os.listdir(training_args.output_dir)
+ and training_args.do_train
+ and not training_args.overwrite_output_dir
+ ):
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
+ " --overwrite_output_dir to overcome."
+ )
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
+ )
+ logger.warning(
+ "Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
+ training_args.local_rank,
+ training_args.device,
+ training_args.n_gpu,
+ bool(training_args.local_rank != -1),
+ training_args.fp16,
+ )
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(training_args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+ logger.info("Training/evaluation parameters %s", training_args)
+
+ # Prepare Question-Answering task
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=False, # SquadDataset is not compatible with Fast tokenizers which have a smarter overflow handeling
+ )
+ model = AutoModelForQuestionAnswering.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ )
+
+ # Get datasets
+ is_language_sensitive = hasattr(model.config, "lang2id")
+ train_dataset = (
+ SquadDataset(
+ data_args, tokenizer=tokenizer, is_language_sensitive=is_language_sensitive, cache_dir=model_args.cache_dir
+ )
+ if training_args.do_train
+ else None
+ )
+ eval_dataset = (
+ SquadDataset(
+ data_args,
+ tokenizer=tokenizer,
+ mode="dev",
+ is_language_sensitive=is_language_sensitive,
+ cache_dir=model_args.cache_dir,
+ )
+ if training_args.do_eval
+ else None
+ )
+
+ # Data collator
+ data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8) if training_args.fp16 else None
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ data_collator=data_collator,
+ )
+
+ # Training
+ if training_args.do_train:
+ trainer.train(
+ model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
+ )
+ trainer.save_model()
+ # For convenience, we also re-save the tokenizer to the same directory,
+ # so that you can share your model easily on huggingface.co/models =)
+ if trainer.is_world_master():
+ tokenizer.save_pretrained(training_args.output_dir)
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/run_camembert.py b/docs/transformers/examples/legacy/run_camembert.py
new file mode 100644
index 0000000000000000000000000000000000000000..9767ffbf8b30c0e797103a14cfa10f1c9f666fd5
--- /dev/null
+++ b/docs/transformers/examples/legacy/run_camembert.py
@@ -0,0 +1,47 @@
+#!/usr/bin/env python
+import torch
+
+from transformers import CamembertForMaskedLM, CamembertTokenizer
+
+
+def fill_mask(masked_input, model, tokenizer, topk=5):
+ # Adapted from https://github.com/pytorch/fairseq/blob/master/fairseq/models/roberta/hub_interface.py
+ assert masked_input.count("") == 1
+ input_ids = torch.tensor(tokenizer.encode(masked_input, add_special_tokens=True)).unsqueeze(0) # Batch size 1
+ logits = model(input_ids)[0] # The last hidden-state is the first element of the output tuple
+ masked_index = (input_ids.squeeze() == tokenizer.mask_token_id).nonzero().item()
+ logits = logits[0, masked_index, :]
+ prob = logits.softmax(dim=0)
+ values, indices = prob.topk(k=topk, dim=0)
+ topk_predicted_token_bpe = " ".join(
+ [tokenizer.convert_ids_to_tokens(indices[i].item()) for i in range(len(indices))]
+ )
+ masked_token = tokenizer.mask_token
+ topk_filled_outputs = []
+ for index, predicted_token_bpe in enumerate(topk_predicted_token_bpe.split(" ")):
+ predicted_token = predicted_token_bpe.replace("\u2581", " ")
+ if f" {masked_token}" in masked_input:
+ topk_filled_outputs.append(
+ (
+ masked_input.replace(f" {masked_token}", predicted_token),
+ values[index].item(),
+ predicted_token,
+ )
+ )
+ else:
+ topk_filled_outputs.append(
+ (
+ masked_input.replace(masked_token, predicted_token),
+ values[index].item(),
+ predicted_token,
+ )
+ )
+ return topk_filled_outputs
+
+
+tokenizer = CamembertTokenizer.from_pretrained("almanach/camembert-base")
+model = CamembertForMaskedLM.from_pretrained("almanach/camembert-base")
+model.eval()
+
+masked_input = "Le camembert est :)"
+print(fill_mask(masked_input, model, tokenizer, topk=3))
diff --git a/docs/transformers/examples/legacy/run_chinese_ref.py b/docs/transformers/examples/legacy/run_chinese_ref.py
new file mode 100644
index 0000000000000000000000000000000000000000..03d195e961c8faafb6a113c792acd7aef0113571
--- /dev/null
+++ b/docs/transformers/examples/legacy/run_chinese_ref.py
@@ -0,0 +1,147 @@
+#!/usr/bin/env python
+import argparse
+import json
+
+from ltp import LTP
+
+from transformers import BertTokenizer
+
+
+def _is_chinese_char(cp):
+ """Checks whether CP is the codepoint of a CJK character."""
+ # This defines a "chinese character" as anything in the CJK Unicode block:
+ # https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block)
+ #
+ # Note that the CJK Unicode block is NOT all Japanese and Korean characters,
+ # despite its name. The modern Korean Hangul alphabet is a different block,
+ # as is Japanese Hiragana and Katakana. Those alphabets are used to write
+ # space-separated words, so they are not treated specially and handled
+ # like the all of the other languages.
+ if (
+ (cp >= 0x4E00 and cp <= 0x9FFF)
+ or (cp >= 0x3400 and cp <= 0x4DBF) #
+ or (cp >= 0x20000 and cp <= 0x2A6DF) #
+ or (cp >= 0x2A700 and cp <= 0x2B73F) #
+ or (cp >= 0x2B740 and cp <= 0x2B81F) #
+ or (cp >= 0x2B820 and cp <= 0x2CEAF) #
+ or (cp >= 0xF900 and cp <= 0xFAFF)
+ or (cp >= 0x2F800 and cp <= 0x2FA1F) #
+ ): #
+ return True
+
+ return False
+
+
+def is_chinese(word: str):
+ # word like '180' or '身高' or '神'
+ for char in word:
+ char = ord(char)
+ if not _is_chinese_char(char):
+ return 0
+ return 1
+
+
+def get_chinese_word(tokens: list[str]):
+ word_set = set()
+
+ for token in tokens:
+ chinese_word = len(token) > 1 and is_chinese(token)
+ if chinese_word:
+ word_set.add(token)
+ word_list = list(word_set)
+ return word_list
+
+
+def add_sub_symbol(bert_tokens: list[str], chinese_word_set: set()):
+ if not chinese_word_set:
+ return bert_tokens
+ max_word_len = max([len(w) for w in chinese_word_set])
+
+ bert_word = bert_tokens
+ start, end = 0, len(bert_word)
+ while start < end:
+ single_word = True
+ if is_chinese(bert_word[start]):
+ l = min(end - start, max_word_len)
+ for i in range(l, 1, -1):
+ whole_word = "".join(bert_word[start : start + i])
+ if whole_word in chinese_word_set:
+ for j in range(start + 1, start + i):
+ bert_word[j] = "##" + bert_word[j]
+ start = start + i
+ single_word = False
+ break
+ if single_word:
+ start += 1
+ return bert_word
+
+
+def prepare_ref(lines: list[str], ltp_tokenizer: LTP, bert_tokenizer: BertTokenizer):
+ ltp_res = []
+
+ for i in range(0, len(lines), 100):
+ res = ltp_tokenizer.seg(lines[i : i + 100])[0]
+ res = [get_chinese_word(r) for r in res]
+ ltp_res.extend(res)
+ assert len(ltp_res) == len(lines)
+
+ bert_res = []
+ for i in range(0, len(lines), 100):
+ res = bert_tokenizer(lines[i : i + 100], add_special_tokens=True, truncation=True, max_length=512)
+ bert_res.extend(res["input_ids"])
+ assert len(bert_res) == len(lines)
+
+ ref_ids = []
+ for input_ids, chinese_word in zip(bert_res, ltp_res):
+ input_tokens = []
+ for id in input_ids:
+ token = bert_tokenizer._convert_id_to_token(id)
+ input_tokens.append(token)
+ input_tokens = add_sub_symbol(input_tokens, chinese_word)
+ ref_id = []
+ # We only save pos of chinese subwords start with ##, which mean is part of a whole word.
+ for i, token in enumerate(input_tokens):
+ if token[:2] == "##":
+ clean_token = token[2:]
+ # save chinese tokens' pos
+ if len(clean_token) == 1 and _is_chinese_char(ord(clean_token)):
+ ref_id.append(i)
+ ref_ids.append(ref_id)
+
+ assert len(ref_ids) == len(bert_res)
+
+ return ref_ids
+
+
+def main(args):
+ # For Chinese (Ro)Bert, the best result is from : RoBERTa-wwm-ext (https://github.com/ymcui/Chinese-BERT-wwm)
+ # If we want to fine-tune these model, we have to use same tokenizer : LTP (https://github.com/HIT-SCIR/ltp)
+ with open(args.file_name, encoding="utf-8") as f:
+ data = f.readlines()
+ data = [line.strip() for line in data if len(line) > 0 and not line.isspace()] # avoid delimiter like '\u2029'
+ ltp_tokenizer = LTP(args.ltp) # faster in GPU device
+ bert_tokenizer = BertTokenizer.from_pretrained(args.bert)
+
+ ref_ids = prepare_ref(data, ltp_tokenizer, bert_tokenizer)
+
+ with open(args.save_path, "w", encoding="utf-8") as f:
+ data = [json.dumps(ref) + "\n" for ref in ref_ids]
+ f.writelines(data)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser(description="prepare_chinese_ref")
+ parser.add_argument(
+ "--file_name",
+ type=str,
+ default="./resources/chinese-demo.txt",
+ help="file need process, same as training data in lm",
+ )
+ parser.add_argument(
+ "--ltp", type=str, default="./resources/ltp", help="resources for LTP tokenizer, usually a path"
+ )
+ parser.add_argument("--bert", type=str, default="./resources/robert", help="resources for Bert tokenizer")
+ parser.add_argument("--save_path", type=str, default="./resources/ref.txt", help="path to save res")
+
+ args = parser.parse_args()
+ main(args)
diff --git a/docs/transformers/examples/legacy/run_language_modeling.py b/docs/transformers/examples/legacy/run_language_modeling.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a6b8eded34a0c5899af36bc972c14e64aabdb9a
--- /dev/null
+++ b/docs/transformers/examples/legacy/run_language_modeling.py
@@ -0,0 +1,373 @@
+#!/usr/bin/env python
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for language modeling on a text file (GPT, GPT-2, CTRL, BERT, RoBERTa, XLNet).
+GPT, GPT-2 and CTRL are fine-tuned using a causal language modeling (CLM) loss. BERT and RoBERTa are fine-tuned
+using a masked language modeling (MLM) loss. XLNet is fine-tuned using a permutation language modeling (PLM) loss.
+"""
+
+import logging
+import math
+import os
+from dataclasses import dataclass, field
+from glob import glob
+from typing import Optional
+
+from torch.utils.data import ConcatDataset
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_WITH_LM_HEAD_MAPPING,
+ AutoConfig,
+ AutoModelWithLMHead,
+ AutoTokenizer,
+ DataCollatorForLanguageModeling,
+ DataCollatorForPermutationLanguageModeling,
+ DataCollatorForWholeWordMask,
+ HfArgumentParser,
+ LineByLineTextDataset,
+ LineByLineWithRefDataset,
+ PreTrainedTokenizer,
+ TextDataset,
+ Trainer,
+ TrainingArguments,
+ set_seed,
+)
+from transformers.trainer_utils import is_main_process
+
+
+logger = logging.getLogger(__name__)
+
+
+MODEL_CONFIG_CLASSES = list(MODEL_WITH_LM_HEAD_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Leave None if you want to train a model from"
+ " scratch."
+ )
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ train_data_file: Optional[str] = field(
+ default=None, metadata={"help": "The input training data file (a text file)."}
+ )
+ train_data_files: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The input training data files (multiple files in glob format). "
+ "Very often splitting large files to smaller files can prevent tokenizer going out of memory"
+ )
+ },
+ )
+ eval_data_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ train_ref_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input train ref data file for whole word mask in Chinese."},
+ )
+ eval_ref_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input eval ref data file for whole word mask in Chinese."},
+ )
+ line_by_line: bool = field(
+ default=False,
+ metadata={"help": "Whether distinct lines of text in the dataset are to be handled as distinct sequences."},
+ )
+
+ mlm: bool = field(
+ default=False, metadata={"help": "Train with masked-language modeling loss instead of language modeling."}
+ )
+ whole_word_mask: bool = field(default=False, metadata={"help": "Whether ot not to use whole word mask."})
+ mlm_probability: float = field(
+ default=0.15, metadata={"help": "Ratio of tokens to mask for masked language modeling loss"}
+ )
+ plm_probability: float = field(
+ default=1 / 6,
+ metadata={
+ "help": (
+ "Ratio of length of a span of masked tokens to surrounding context length for permutation language"
+ " modeling."
+ )
+ },
+ )
+ max_span_length: int = field(
+ default=5, metadata={"help": "Maximum length of a span of masked tokens for permutation language modeling."}
+ )
+
+ block_size: int = field(
+ default=-1,
+ metadata={
+ "help": (
+ "Optional input sequence length after tokenization. "
+ "The training dataset will be truncated in block of this size for training."
+ "Default to the model max input length for single sentence inputs (take into account special tokens)."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+
+
+def get_dataset(
+ args: DataTrainingArguments,
+ tokenizer: PreTrainedTokenizer,
+ evaluate: bool = False,
+ cache_dir: Optional[str] = None,
+):
+ def _dataset(file_path, ref_path=None):
+ if args.line_by_line:
+ if ref_path is not None:
+ if not args.whole_word_mask or not args.mlm:
+ raise ValueError("You need to set world whole masking and mlm to True for Chinese Whole Word Mask")
+ return LineByLineWithRefDataset(
+ tokenizer=tokenizer,
+ file_path=file_path,
+ block_size=args.block_size,
+ ref_path=ref_path,
+ )
+
+ return LineByLineTextDataset(tokenizer=tokenizer, file_path=file_path, block_size=args.block_size)
+ else:
+ return TextDataset(
+ tokenizer=tokenizer,
+ file_path=file_path,
+ block_size=args.block_size,
+ overwrite_cache=args.overwrite_cache,
+ cache_dir=cache_dir,
+ )
+
+ if evaluate:
+ return _dataset(args.eval_data_file, args.eval_ref_file)
+ elif args.train_data_files:
+ return ConcatDataset([_dataset(f) for f in glob(args.train_data_files)])
+ else:
+ return _dataset(args.train_data_file, args.train_ref_file)
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ if data_args.eval_data_file is None and training_args.do_eval:
+ raise ValueError(
+ "Cannot do evaluation without an evaluation data file. Either supply a file to --eval_data_file "
+ "or remove the --do_eval argument."
+ )
+ if (
+ os.path.exists(training_args.output_dir)
+ and os.listdir(training_args.output_dir)
+ and training_args.do_train
+ and not training_args.overwrite_output_dir
+ ):
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
+ " --overwrite_output_dir to overcome."
+ )
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
+ )
+ logger.warning(
+ "Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
+ training_args.local_rank,
+ training_args.device,
+ training_args.n_gpu,
+ bool(training_args.local_rank != -1),
+ training_args.fp16,
+ )
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(training_args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+ logger.info("Training/evaluation parameters %s", training_args)
+
+ # Set seed
+ set_seed(training_args.seed)
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+
+ if model_args.config_name:
+ config = AutoConfig.from_pretrained(model_args.config_name, cache_dir=model_args.cache_dir)
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(model_args.model_name_or_path, cache_dir=model_args.cache_dir)
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, cache_dir=model_args.cache_dir)
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, cache_dir=model_args.cache_dir)
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported, but you can do it from another"
+ " script, save it,and load it from here, using --tokenizer_name"
+ )
+
+ if model_args.model_name_or_path:
+ model = AutoModelWithLMHead.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelWithLMHead.from_config(config)
+
+ model.resize_token_embeddings(len(tokenizer))
+
+ if config.model_type in ["bert", "roberta", "distilbert", "camembert"] and not data_args.mlm:
+ raise ValueError(
+ "BERT and RoBERTa-like models do not have LM heads but masked LM heads. They must be run using the "
+ "--mlm flag (masked language modeling)."
+ )
+
+ if data_args.block_size <= 0:
+ data_args.block_size = tokenizer.max_len
+ # Our input block size will be the max possible for the model
+ else:
+ data_args.block_size = min(data_args.block_size, tokenizer.max_len)
+
+ # Get datasets
+
+ train_dataset = (
+ get_dataset(data_args, tokenizer=tokenizer, cache_dir=model_args.cache_dir) if training_args.do_train else None
+ )
+ eval_dataset = (
+ get_dataset(data_args, tokenizer=tokenizer, evaluate=True, cache_dir=model_args.cache_dir)
+ if training_args.do_eval
+ else None
+ )
+ if config.model_type == "xlnet":
+ data_collator = DataCollatorForPermutationLanguageModeling(
+ tokenizer=tokenizer,
+ plm_probability=data_args.plm_probability,
+ max_span_length=data_args.max_span_length,
+ )
+ else:
+ if data_args.mlm and data_args.whole_word_mask:
+ data_collator = DataCollatorForWholeWordMask(
+ tokenizer=tokenizer, mlm_probability=data_args.mlm_probability
+ )
+ else:
+ data_collator = DataCollatorForLanguageModeling(
+ tokenizer=tokenizer, mlm=data_args.mlm, mlm_probability=data_args.mlm_probability
+ )
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ data_collator=data_collator,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ prediction_loss_only=True,
+ )
+
+ # Training
+ if training_args.do_train:
+ model_path = (
+ model_args.model_name_or_path
+ if model_args.model_name_or_path is not None and os.path.isdir(model_args.model_name_or_path)
+ else None
+ )
+ trainer.train(model_path=model_path)
+ trainer.save_model()
+ # For convenience, we also re-save the tokenizer to the same directory,
+ # so that you can share your model easily on huggingface.co/models =)
+ if trainer.is_world_master():
+ tokenizer.save_pretrained(training_args.output_dir)
+
+ # Evaluation
+ results = {}
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+
+ eval_output = trainer.evaluate()
+
+ perplexity = math.exp(eval_output["eval_loss"])
+ result = {"perplexity": perplexity}
+
+ output_eval_file = os.path.join(training_args.output_dir, "eval_results_lm.txt")
+ if trainer.is_world_master():
+ with open(output_eval_file, "w") as writer:
+ logger.info("***** Eval results *****")
+ for key in sorted(result.keys()):
+ logger.info(" %s = %s", key, str(result[key]))
+ writer.write("{} = {}\n".format(key, str(result[key])))
+
+ results.update(result)
+
+ return results
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/run_openai_gpt.py b/docs/transformers/examples/legacy/run_openai_gpt.py
new file mode 100644
index 0000000000000000000000000000000000000000..62f9d3a3c083b606cce34cd35cf02442860be541
--- /dev/null
+++ b/docs/transformers/examples/legacy/run_openai_gpt.py
@@ -0,0 +1,319 @@
+#!/usr/bin/env python
+# Copyright 2018 Google AI, Google Brain and Carnegie Mellon University Authors and the HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" OpenAI GPT model fine-tuning script.
+ Adapted from https://github.com/huggingface/pytorch-openai-transformer-lm/blob/master/train.py
+ It self adapted from https://github.com/openai/finetune-transformer-lm/blob/master/train.py
+
+ This script with default values fine-tunes and evaluate a pretrained OpenAI GPT on the RocStories dataset:
+ python run_openai_gpt.py \
+ --model_name openai-community/openai-gpt \
+ --do_train \
+ --do_eval \
+ --train_dataset "$ROC_STORIES_DIR/cloze_test_val__spring2016 - cloze_test_ALL_val.csv" \
+ --eval_dataset "$ROC_STORIES_DIR/cloze_test_test__spring2016 - cloze_test_ALL_test.csv" \
+ --output_dir ../log \
+ --train_batch_size 16 \
+"""
+
+import argparse
+import csv
+import logging
+import os
+import random
+
+import numpy as np
+import torch
+from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
+from tqdm import tqdm, trange
+
+from transformers import (
+ CONFIG_NAME,
+ WEIGHTS_NAME,
+ OpenAIGPTDoubleHeadsModel,
+ OpenAIGPTTokenizer,
+ get_linear_schedule_with_warmup,
+)
+
+
+logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s", datefmt="%m/%d/%Y %H:%M:%S", level=logging.INFO
+)
+logger = logging.getLogger(__name__)
+
+
+def accuracy(out, labels):
+ outputs = np.argmax(out, axis=1)
+ return np.sum(outputs == labels)
+
+
+def load_rocstories_dataset(dataset_path):
+ """Output a list of tuples(story, 1st continuation, 2nd continuation, label)"""
+ with open(dataset_path, encoding="utf_8") as f:
+ f = csv.reader(f)
+ output = []
+ next(f) # skip the first line
+ for line in tqdm(f):
+ output.append((" ".join(line[1:5]), line[5], line[6], int(line[-1]) - 1))
+ return output
+
+
+def pre_process_datasets(encoded_datasets, input_len, cap_length, start_token, delimiter_token, clf_token):
+ """Pre-process datasets containing lists of tuples(story, 1st continuation, 2nd continuation, label)
+
+ To Transformer inputs of shape (n_batch, n_alternative, length) comprising for each batch, continuation:
+ input_ids[batch, alternative, :] = [start_token] + story[:cap_length] + [delimiter_token] + cont1[:cap_length] + [clf_token]
+ """
+ tensor_datasets = []
+ for dataset in encoded_datasets:
+ n_batch = len(dataset)
+ input_ids = np.zeros((n_batch, 2, input_len), dtype=np.int64)
+ mc_token_ids = np.zeros((n_batch, 2), dtype=np.int64)
+ lm_labels = np.full((n_batch, 2, input_len), fill_value=-100, dtype=np.int64)
+ mc_labels = np.zeros((n_batch,), dtype=np.int64)
+ for (
+ i,
+ (story, cont1, cont2, mc_label),
+ ) in enumerate(dataset):
+ with_cont1 = [start_token] + story[:cap_length] + [delimiter_token] + cont1[:cap_length] + [clf_token]
+ with_cont2 = [start_token] + story[:cap_length] + [delimiter_token] + cont2[:cap_length] + [clf_token]
+ input_ids[i, 0, : len(with_cont1)] = with_cont1
+ input_ids[i, 1, : len(with_cont2)] = with_cont2
+ mc_token_ids[i, 0] = len(with_cont1) - 1
+ mc_token_ids[i, 1] = len(with_cont2) - 1
+ lm_labels[i, 0, : len(with_cont1)] = with_cont1
+ lm_labels[i, 1, : len(with_cont2)] = with_cont2
+ mc_labels[i] = mc_label
+ all_inputs = (input_ids, mc_token_ids, lm_labels, mc_labels)
+ tensor_datasets.append(tuple(torch.tensor(t) for t in all_inputs))
+ return tensor_datasets
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--model_name", type=str, default="openai-community/openai-gpt", help="pretrained model name")
+ parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
+ parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
+ parser.add_argument(
+ "--output_dir",
+ default=None,
+ type=str,
+ required=True,
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--train_dataset", type=str, default="")
+ parser.add_argument("--eval_dataset", type=str, default="")
+ parser.add_argument("--seed", type=int, default=42)
+ parser.add_argument("--num_train_epochs", type=int, default=3)
+ parser.add_argument("--train_batch_size", type=int, default=8)
+ parser.add_argument("--eval_batch_size", type=int, default=16)
+ parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
+ parser.add_argument("--max_grad_norm", type=int, default=1)
+ parser.add_argument(
+ "--max_steps",
+ default=-1,
+ type=int,
+ help=(
+ "If > 0: set total number of training steps to perform. Override num_train_epochs."
+ ),
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument("--learning_rate", type=float, default=6.25e-5)
+ parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
+ parser.add_argument("--lr_schedule", type=str, default="warmup_linear")
+ parser.add_argument("--weight_decay", type=float, default=0.01)
+ parser.add_argument("--lm_coef", type=float, default=0.9)
+ parser.add_argument("--n_valid", type=int, default=374)
+
+ parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
+ parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
+ args = parser.parse_args()
+ print(args)
+
+ if args.server_ip and args.server_port:
+ # Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
+ import ptvsd
+
+ print("Waiting for debugger attach")
+ ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
+ ptvsd.wait_for_attach()
+
+ random.seed(args.seed)
+ np.random.seed(args.seed)
+ torch.manual_seed(args.seed)
+ torch.cuda.manual_seed_all(args.seed)
+
+ device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+ n_gpu = torch.cuda.device_count()
+ logger.info(f"device: {device}, n_gpu {n_gpu}")
+
+ if not args.do_train and not args.do_eval:
+ raise ValueError("At least one of `do_train` or `do_eval` must be True.")
+
+ if not os.path.exists(args.output_dir):
+ os.makedirs(args.output_dir)
+
+ # Load tokenizer and model
+ # This loading functions also add new tokens and embeddings called `special tokens`
+ # These new embeddings will be fine-tuned on the RocStories dataset
+ special_tokens = ["_start_", "_delimiter_", "_classify_"]
+ tokenizer = OpenAIGPTTokenizer.from_pretrained(args.model_name)
+ tokenizer.add_tokens(special_tokens)
+ special_tokens_ids = tokenizer.convert_tokens_to_ids(special_tokens)
+ model = OpenAIGPTDoubleHeadsModel.from_pretrained(args.model_name)
+ model.resize_token_embeddings(len(tokenizer))
+ model.to(device)
+
+ # Load and encode the datasets
+ def tokenize_and_encode(obj):
+ """Tokenize and encode a nested object"""
+ if isinstance(obj, str):
+ return tokenizer.convert_tokens_to_ids(tokenizer.tokenize(obj))
+ elif isinstance(obj, int):
+ return obj
+ return [tokenize_and_encode(o) for o in obj]
+
+ logger.info("Encoding dataset...")
+ train_dataset = load_rocstories_dataset(args.train_dataset)
+ eval_dataset = load_rocstories_dataset(args.eval_dataset)
+ datasets = (train_dataset, eval_dataset)
+ encoded_datasets = tokenize_and_encode(datasets)
+
+ # Compute the max input length for the Transformer
+ max_length = model.config.n_positions // 2 - 2
+ input_length = max(
+ len(story[:max_length]) + max(len(cont1[:max_length]), len(cont2[:max_length])) + 3
+ for dataset in encoded_datasets
+ for story, cont1, cont2, _ in dataset
+ )
+ input_length = min(input_length, model.config.n_positions) # Max size of input for the pre-trained model
+
+ # Prepare inputs tensors and dataloaders
+ tensor_datasets = pre_process_datasets(encoded_datasets, input_length, max_length, *special_tokens_ids)
+ train_tensor_dataset, eval_tensor_dataset = tensor_datasets[0], tensor_datasets[1]
+
+ train_data = TensorDataset(*train_tensor_dataset)
+ train_sampler = RandomSampler(train_data)
+ train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=args.train_batch_size)
+
+ eval_data = TensorDataset(*eval_tensor_dataset)
+ eval_sampler = SequentialSampler(eval_data)
+ eval_dataloader = DataLoader(eval_data, sampler=eval_sampler, batch_size=args.eval_batch_size)
+
+ # Prepare optimizer
+ if args.do_train:
+ if args.max_steps > 0:
+ t_total = args.max_steps
+ args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
+ else:
+ t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
+
+ param_optimizer = list(model.named_parameters())
+ no_decay = ["bias", "LayerNorm.bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {"params": [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
+ scheduler = get_linear_schedule_with_warmup(
+ optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
+ )
+
+ if args.do_train:
+ nb_tr_steps, tr_loss, exp_average_loss = 0, 0, None
+ model.train()
+ for _ in trange(int(args.num_train_epochs), desc="Epoch"):
+ tr_loss = 0
+ nb_tr_steps = 0
+ tqdm_bar = tqdm(train_dataloader, desc="Training")
+ for step, batch in enumerate(tqdm_bar):
+ batch = tuple(t.to(device) for t in batch)
+ input_ids, mc_token_ids, lm_labels, mc_labels = batch
+ losses = model(input_ids, mc_token_ids=mc_token_ids, lm_labels=lm_labels, mc_labels=mc_labels)
+ loss = args.lm_coef * losses[0] + losses[1]
+ loss.backward()
+ optimizer.step()
+ scheduler.step()
+ optimizer.zero_grad()
+ tr_loss += loss.item()
+ exp_average_loss = (
+ loss.item() if exp_average_loss is None else 0.7 * exp_average_loss + 0.3 * loss.item()
+ )
+ nb_tr_steps += 1
+ tqdm_bar.desc = f"Training loss: {exp_average_loss:.2e} lr: {scheduler.get_lr()[0]:.2e}"
+
+ # Save a trained model
+ if args.do_train:
+ # Save a trained model, configuration and tokenizer
+ model_to_save = model.module if hasattr(model, "module") else model # Only save the model itself
+
+ # If we save using the predefined names, we can load using `from_pretrained`
+ output_model_file = os.path.join(args.output_dir, WEIGHTS_NAME)
+ output_config_file = os.path.join(args.output_dir, CONFIG_NAME)
+
+ torch.save(model_to_save.state_dict(), output_model_file)
+ model_to_save.config.to_json_file(output_config_file)
+ tokenizer.save_vocabulary(args.output_dir)
+
+ # Load a trained model and vocabulary that you have fine-tuned
+ model = OpenAIGPTDoubleHeadsModel.from_pretrained(args.output_dir)
+ tokenizer = OpenAIGPTTokenizer.from_pretrained(args.output_dir)
+ model.to(device)
+
+ if args.do_eval:
+ model.eval()
+ eval_loss, eval_accuracy = 0, 0
+ nb_eval_steps, nb_eval_examples = 0, 0
+ for batch in tqdm(eval_dataloader, desc="Evaluating"):
+ batch = tuple(t.to(device) for t in batch)
+ input_ids, mc_token_ids, lm_labels, mc_labels = batch
+ with torch.no_grad():
+ _, mc_loss, _, mc_logits = model(
+ input_ids, mc_token_ids=mc_token_ids, lm_labels=lm_labels, mc_labels=mc_labels
+ )
+
+ mc_logits = mc_logits.detach().cpu().numpy()
+ mc_labels = mc_labels.to("cpu").numpy()
+ tmp_eval_accuracy = accuracy(mc_logits, mc_labels)
+
+ eval_loss += mc_loss.mean().item()
+ eval_accuracy += tmp_eval_accuracy
+
+ nb_eval_examples += input_ids.size(0)
+ nb_eval_steps += 1
+
+ eval_loss = eval_loss / nb_eval_steps
+ eval_accuracy = eval_accuracy / nb_eval_examples
+ train_loss = tr_loss / nb_tr_steps if args.do_train else None
+ result = {"eval_loss": eval_loss, "eval_accuracy": eval_accuracy, "train_loss": train_loss}
+
+ output_eval_file = os.path.join(args.output_dir, "eval_results.txt")
+ with open(output_eval_file, "w") as writer:
+ logger.info("***** Eval results *****")
+ for key in sorted(result.keys()):
+ logger.info(" %s = %s", key, str(result[key]))
+ writer.write("{} = {}\n".format(key, str(result[key])))
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/run_swag.py b/docs/transformers/examples/legacy/run_swag.py
new file mode 100644
index 0000000000000000000000000000000000000000..221f9cc9c98dae7b6fcb7594d73af5966cd177b5
--- /dev/null
+++ b/docs/transformers/examples/legacy/run_swag.py
@@ -0,0 +1,721 @@
+#!/usr/bin/env python
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""BERT finetuning runner.
+Finetuning the library models for multiple choice on SWAG (Bert).
+"""
+
+import argparse
+import csv
+import glob
+import logging
+import os
+import random
+
+import numpy as np
+import torch
+from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
+from torch.utils.data.distributed import DistributedSampler
+from tqdm import tqdm, trange
+
+import transformers
+from transformers import (
+ WEIGHTS_NAME,
+ AutoConfig,
+ AutoModelForMultipleChoice,
+ AutoTokenizer,
+ get_linear_schedule_with_warmup,
+)
+from transformers.trainer_utils import is_main_process
+
+
+try:
+ from torch.utils.tensorboard import SummaryWriter
+except ImportError:
+ from tensorboardX import SummaryWriter
+
+
+logger = logging.getLogger(__name__)
+
+
+class SwagExample:
+ """A single training/test example for the SWAG dataset."""
+
+ def __init__(self, swag_id, context_sentence, start_ending, ending_0, ending_1, ending_2, ending_3, label=None):
+ self.swag_id = swag_id
+ self.context_sentence = context_sentence
+ self.start_ending = start_ending
+ self.endings = [
+ ending_0,
+ ending_1,
+ ending_2,
+ ending_3,
+ ]
+ self.label = label
+
+ def __str__(self):
+ return self.__repr__()
+
+ def __repr__(self):
+ attributes = [
+ f"swag_id: {self.swag_id}",
+ f"context_sentence: {self.context_sentence}",
+ f"start_ending: {self.start_ending}",
+ f"ending_0: {self.endings[0]}",
+ f"ending_1: {self.endings[1]}",
+ f"ending_2: {self.endings[2]}",
+ f"ending_3: {self.endings[3]}",
+ ]
+
+ if self.label is not None:
+ attributes.append(f"label: {self.label}")
+
+ return ", ".join(attributes)
+
+
+class InputFeatures:
+ def __init__(self, example_id, choices_features, label):
+ self.example_id = example_id
+ self.choices_features = [
+ {"input_ids": input_ids, "input_mask": input_mask, "segment_ids": segment_ids}
+ for _, input_ids, input_mask, segment_ids in choices_features
+ ]
+ self.label = label
+
+
+def read_swag_examples(input_file, is_training=True):
+ with open(input_file, encoding="utf-8") as f:
+ lines = list(csv.reader(f))
+
+ if is_training and lines[0][-1] != "label":
+ raise ValueError("For training, the input file must contain a label column.")
+
+ examples = [
+ SwagExample(
+ swag_id=line[2],
+ context_sentence=line[4],
+ start_ending=line[5], # in the swag dataset, the
+ # common beginning of each
+ # choice is stored in "sent2".
+ ending_0=line[7],
+ ending_1=line[8],
+ ending_2=line[9],
+ ending_3=line[10],
+ label=int(line[11]) if is_training else None,
+ )
+ for line in lines[1:] # we skip the line with the column names
+ ]
+
+ return examples
+
+
+def convert_examples_to_features(examples, tokenizer, max_seq_length, is_training):
+ """Loads a data file into a list of `InputBatch`s."""
+
+ # Swag is a multiple choice task. To perform this task using Bert,
+ # we will use the formatting proposed in "Improving Language
+ # Understanding by Generative Pre-Training" and suggested by
+ # @jacobdevlin-google in this issue
+ # https://github.com/google-research/bert/issues/38.
+ #
+ # Each choice will correspond to a sample on which we run the
+ # inference. For a given Swag example, we will create the 4
+ # following inputs:
+ # - [CLS] context [SEP] choice_1 [SEP]
+ # - [CLS] context [SEP] choice_2 [SEP]
+ # - [CLS] context [SEP] choice_3 [SEP]
+ # - [CLS] context [SEP] choice_4 [SEP]
+ # The model will output a single value for each input. To get the
+ # final decision of the model, we will run a softmax over these 4
+ # outputs.
+ features = []
+ for example_index, example in tqdm(enumerate(examples)):
+ context_tokens = tokenizer.tokenize(example.context_sentence)
+ start_ending_tokens = tokenizer.tokenize(example.start_ending)
+
+ choices_features = []
+ for ending_index, ending in enumerate(example.endings):
+ # We create a copy of the context tokens in order to be
+ # able to shrink it according to ending_tokens
+ context_tokens_choice = context_tokens[:]
+ ending_tokens = start_ending_tokens + tokenizer.tokenize(ending)
+ # Modifies `context_tokens_choice` and `ending_tokens` in
+ # place so that the total length is less than the
+ # specified length. Account for [CLS], [SEP], [SEP] with
+ # "- 3"
+ _truncate_seq_pair(context_tokens_choice, ending_tokens, max_seq_length - 3)
+
+ tokens = ["[CLS]"] + context_tokens_choice + ["[SEP]"] + ending_tokens + ["[SEP]"]
+ segment_ids = [0] * (len(context_tokens_choice) + 2) + [1] * (len(ending_tokens) + 1)
+
+ input_ids = tokenizer.convert_tokens_to_ids(tokens)
+ input_mask = [1] * len(input_ids)
+
+ # Zero-pad up to the sequence length.
+ padding = [0] * (max_seq_length - len(input_ids))
+ input_ids += padding
+ input_mask += padding
+ segment_ids += padding
+
+ assert len(input_ids) == max_seq_length
+ assert len(input_mask) == max_seq_length
+ assert len(segment_ids) == max_seq_length
+
+ choices_features.append((tokens, input_ids, input_mask, segment_ids))
+
+ label = example.label
+ if example_index < 5:
+ logger.info("*** Example ***")
+ logger.info(f"swag_id: {example.swag_id}")
+ for choice_idx, (tokens, input_ids, input_mask, segment_ids) in enumerate(choices_features):
+ logger.info(f"choice: {choice_idx}")
+ logger.info("tokens: {}".format(" ".join(tokens)))
+ logger.info("input_ids: {}".format(" ".join(map(str, input_ids))))
+ logger.info("input_mask: {}".format(" ".join(map(str, input_mask))))
+ logger.info("segment_ids: {}".format(" ".join(map(str, segment_ids))))
+ if is_training:
+ logger.info(f"label: {label}")
+
+ features.append(InputFeatures(example_id=example.swag_id, choices_features=choices_features, label=label))
+
+ return features
+
+
+def _truncate_seq_pair(tokens_a, tokens_b, max_length):
+ """Truncates a sequence pair in place to the maximum length."""
+
+ # This is a simple heuristic which will always truncate the longer sequence
+ # one token at a time. This makes more sense than truncating an equal percent
+ # of tokens from each, since if one sequence is very short then each token
+ # that's truncated likely contains more information than a longer sequence.
+ while True:
+ total_length = len(tokens_a) + len(tokens_b)
+ if total_length <= max_length:
+ break
+ if len(tokens_a) > len(tokens_b):
+ tokens_a.pop()
+ else:
+ tokens_b.pop()
+
+
+def accuracy(out, labels):
+ outputs = np.argmax(out, axis=1)
+ return np.sum(outputs == labels)
+
+
+def select_field(features, field):
+ return [[choice[field] for choice in feature.choices_features] for feature in features]
+
+
+def set_seed(args):
+ random.seed(args.seed)
+ np.random.seed(args.seed)
+ torch.manual_seed(args.seed)
+ if args.n_gpu > 0:
+ torch.cuda.manual_seed_all(args.seed)
+
+
+def load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False):
+ if args.local_rank not in [-1, 0]:
+ torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
+
+ # Load data features from cache or dataset file
+ input_file = args.predict_file if evaluate else args.train_file
+ cached_features_file = os.path.join(
+ os.path.dirname(input_file),
+ "cached_{}_{}_{}".format(
+ "dev" if evaluate else "train",
+ list(filter(None, args.model_name_or_path.split("/"))).pop(),
+ str(args.max_seq_length),
+ ),
+ )
+ if os.path.exists(cached_features_file) and not args.overwrite_cache and not output_examples:
+ logger.info("Loading features from cached file %s", cached_features_file)
+ features = torch.load(cached_features_file, weights_only=True)
+ else:
+ logger.info("Creating features from dataset file at %s", input_file)
+ examples = read_swag_examples(input_file)
+ features = convert_examples_to_features(examples, tokenizer, args.max_seq_length, not evaluate)
+
+ if args.local_rank in [-1, 0]:
+ logger.info("Saving features into cached file %s", cached_features_file)
+ torch.save(features, cached_features_file)
+
+ if args.local_rank == 0:
+ torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
+
+ # Convert to Tensors and build dataset
+ all_input_ids = torch.tensor(select_field(features, "input_ids"), dtype=torch.long)
+ all_input_mask = torch.tensor(select_field(features, "input_mask"), dtype=torch.long)
+ all_segment_ids = torch.tensor(select_field(features, "segment_ids"), dtype=torch.long)
+ all_label = torch.tensor([f.label for f in features], dtype=torch.long)
+
+ if evaluate:
+ dataset = TensorDataset(all_input_ids, all_input_mask, all_segment_ids, all_label)
+ else:
+ dataset = TensorDataset(all_input_ids, all_input_mask, all_segment_ids, all_label)
+
+ if output_examples:
+ return dataset, examples, features
+ return dataset
+
+
+def train(args, train_dataset, model, tokenizer):
+ """Train the model"""
+ if args.local_rank in [-1, 0]:
+ tb_writer = SummaryWriter()
+
+ args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
+ train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
+ train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
+
+ if args.max_steps > 0:
+ t_total = args.max_steps
+ args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
+ else:
+ t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
+
+ # Prepare optimizer and schedule (linear warmup and decay)
+ no_decay = ["bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
+ scheduler = get_linear_schedule_with_warmup(
+ optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
+ )
+ if args.fp16:
+ try:
+ from apex import amp
+ except ImportError:
+ raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
+ model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
+
+ # multi-gpu training (should be after apex fp16 initialization)
+ if args.n_gpu > 1:
+ model = torch.nn.DataParallel(model)
+
+ # Distributed training (should be after apex fp16 initialization)
+ if args.local_rank != -1:
+ model = torch.nn.parallel.DistributedDataParallel(
+ model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True
+ )
+
+ # Train!
+ logger.info("***** Running training *****")
+ logger.info(" Num examples = %d", len(train_dataset))
+ logger.info(" Num Epochs = %d", args.num_train_epochs)
+ logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
+ logger.info(
+ " Total train batch size (w. parallel, distributed & accumulation) = %d",
+ args.train_batch_size
+ * args.gradient_accumulation_steps
+ * (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
+ )
+ logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
+ logger.info(" Total optimization steps = %d", t_total)
+
+ global_step = 0
+ tr_loss, logging_loss = 0.0, 0.0
+ model.zero_grad()
+ train_iterator = trange(int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0])
+ set_seed(args) # Added here for reproducibility
+ for _ in train_iterator:
+ epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
+ for step, batch in enumerate(epoch_iterator):
+ model.train()
+ batch = tuple(t.to(args.device) for t in batch)
+ inputs = {
+ "input_ids": batch[0],
+ "attention_mask": batch[1],
+ # 'token_type_ids': None if args.model_type == 'xlm' else batch[2],
+ "token_type_ids": batch[2],
+ "labels": batch[3],
+ }
+ # if args.model_type in ['xlnet', 'xlm']:
+ # inputs.update({'cls_index': batch[5],
+ # 'p_mask': batch[6]})
+ outputs = model(**inputs)
+ loss = outputs[0] # model outputs are always tuple in transformers (see doc)
+
+ if args.n_gpu > 1:
+ loss = loss.mean() # mean() to average on multi-gpu parallel (not distributed) training
+ if args.gradient_accumulation_steps > 1:
+ loss = loss / args.gradient_accumulation_steps
+
+ if args.fp16:
+ with amp.scale_loss(loss, optimizer) as scaled_loss:
+ scaled_loss.backward()
+ torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
+ else:
+ loss.backward()
+ torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
+
+ tr_loss += loss.item()
+ if (step + 1) % args.gradient_accumulation_steps == 0:
+ optimizer.step()
+ scheduler.step() # Update learning rate schedule
+ model.zero_grad()
+ global_step += 1
+
+ if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
+ # Log metrics
+ if (
+ args.local_rank == -1 and args.evaluate_during_training
+ ): # Only evaluate when single GPU otherwise metrics may not average well
+ results = evaluate(args, model, tokenizer)
+ for key, value in results.items():
+ tb_writer.add_scalar(f"eval_{key}", value, global_step)
+ tb_writer.add_scalar("lr", scheduler.get_lr()[0], global_step)
+ tb_writer.add_scalar("loss", (tr_loss - logging_loss) / args.logging_steps, global_step)
+ logging_loss = tr_loss
+
+ if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
+ # Save model checkpoint
+ output_dir = os.path.join(args.output_dir, f"checkpoint-{global_step}")
+ model_to_save = (
+ model.module if hasattr(model, "module") else model
+ ) # Take care of distributed/parallel training
+ model_to_save.save_pretrained(output_dir)
+ tokenizer.save_vocabulary(output_dir)
+ torch.save(args, os.path.join(output_dir, "training_args.bin"))
+ logger.info("Saving model checkpoint to %s", output_dir)
+
+ if args.max_steps > 0 and global_step > args.max_steps:
+ epoch_iterator.close()
+ break
+ if args.max_steps > 0 and global_step > args.max_steps:
+ train_iterator.close()
+ break
+
+ if args.local_rank in [-1, 0]:
+ tb_writer.close()
+
+ return global_step, tr_loss / global_step
+
+
+def evaluate(args, model, tokenizer, prefix=""):
+ dataset, examples, features = load_and_cache_examples(args, tokenizer, evaluate=True, output_examples=True)
+
+ if not os.path.exists(args.output_dir) and args.local_rank in [-1, 0]:
+ os.makedirs(args.output_dir)
+
+ args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
+ # Note that DistributedSampler samples randomly
+ eval_sampler = SequentialSampler(dataset) if args.local_rank == -1 else DistributedSampler(dataset)
+ eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
+
+ # Eval!
+ logger.info(f"***** Running evaluation {prefix} *****")
+ logger.info(" Num examples = %d", len(dataset))
+ logger.info(" Batch size = %d", args.eval_batch_size)
+
+ eval_loss, eval_accuracy = 0, 0
+ nb_eval_steps, nb_eval_examples = 0, 0
+
+ for batch in tqdm(eval_dataloader, desc="Evaluating"):
+ model.eval()
+ batch = tuple(t.to(args.device) for t in batch)
+ with torch.no_grad():
+ inputs = {
+ "input_ids": batch[0],
+ "attention_mask": batch[1],
+ # 'token_type_ids': None if args.model_type == 'xlm' else batch[2] # XLM don't use segment_ids
+ "token_type_ids": batch[2],
+ "labels": batch[3],
+ }
+
+ # if args.model_type in ['xlnet', 'xlm']:
+ # inputs.update({'cls_index': batch[4],
+ # 'p_mask': batch[5]})
+ outputs = model(**inputs)
+ tmp_eval_loss, logits = outputs[:2]
+ eval_loss += tmp_eval_loss.mean().item()
+
+ logits = logits.detach().cpu().numpy()
+ label_ids = inputs["labels"].to("cpu").numpy()
+ tmp_eval_accuracy = accuracy(logits, label_ids)
+ eval_accuracy += tmp_eval_accuracy
+
+ nb_eval_steps += 1
+ nb_eval_examples += inputs["input_ids"].size(0)
+
+ eval_loss = eval_loss / nb_eval_steps
+ eval_accuracy = eval_accuracy / nb_eval_examples
+ result = {"eval_loss": eval_loss, "eval_accuracy": eval_accuracy}
+
+ output_eval_file = os.path.join(args.output_dir, "eval_results.txt")
+ with open(output_eval_file, "w") as writer:
+ logger.info("***** Eval results *****")
+ for key in sorted(result.keys()):
+ logger.info("%s = %s", key, str(result[key]))
+ writer.write("{} = {}\n".format(key, str(result[key])))
+
+ return result
+
+
+def main():
+ parser = argparse.ArgumentParser()
+
+ # Required parameters
+ parser.add_argument(
+ "--train_file", default=None, type=str, required=True, help="SWAG csv for training. E.g., train.csv"
+ )
+ parser.add_argument(
+ "--predict_file",
+ default=None,
+ type=str,
+ required=True,
+ help="SWAG csv for predictions. E.g., val.csv or test.csv",
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ default=None,
+ type=str,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models",
+ )
+ parser.add_argument(
+ "--output_dir",
+ default=None,
+ type=str,
+ required=True,
+ help="The output directory where the model checkpoints and predictions will be written.",
+ )
+
+ # Other parameters
+ parser.add_argument(
+ "--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ default="",
+ type=str,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--max_seq_length",
+ default=384,
+ type=int,
+ help=(
+ "The maximum total input sequence length after tokenization. Sequences "
+ "longer than this will be truncated, and sequences shorter than this will be padded."
+ ),
+ )
+ parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
+ parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
+ parser.add_argument(
+ "--evaluate_during_training", action="store_true", help="Rul evaluation during training at each logging step."
+ )
+
+ parser.add_argument("--per_gpu_train_batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.")
+ parser.add_argument(
+ "--per_gpu_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation."
+ )
+ parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
+ parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument(
+ "--num_train_epochs", default=3.0, type=float, help="Total number of training epochs to perform."
+ )
+ parser.add_argument(
+ "--max_steps",
+ default=-1,
+ type=int,
+ help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
+ )
+ parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
+
+ parser.add_argument("--logging_steps", type=int, default=50, help="Log every X updates steps.")
+ parser.add_argument("--save_steps", type=int, default=50, help="Save checkpoint every X updates steps.")
+ parser.add_argument(
+ "--eval_all_checkpoints",
+ action="store_true",
+ help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
+ )
+ parser.add_argument("--no_cuda", action="store_true", help="Whether not to use CUDA when available")
+ parser.add_argument(
+ "--overwrite_output_dir", action="store_true", help="Overwrite the content of the output directory"
+ )
+ parser.add_argument(
+ "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
+ )
+ parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
+
+ parser.add_argument("--local_rank", type=int, default=-1, help="local_rank for distributed training on gpus")
+ parser.add_argument(
+ "--fp16",
+ action="store_true",
+ help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
+ )
+ parser.add_argument(
+ "--fp16_opt_level",
+ type=str,
+ default="O1",
+ help=(
+ "For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
+ "See details at https://nvidia.github.io/apex/amp.html"
+ ),
+ )
+ parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
+ parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
+ args = parser.parse_args()
+
+ if (
+ os.path.exists(args.output_dir)
+ and os.listdir(args.output_dir)
+ and args.do_train
+ and not args.overwrite_output_dir
+ ):
+ raise ValueError(
+ "Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
+ args.output_dir
+ )
+ )
+
+ # Setup distant debugging if needed
+ if args.server_ip and args.server_port:
+ # Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
+ import ptvsd
+
+ print("Waiting for debugger attach")
+ ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
+ ptvsd.wait_for_attach()
+
+ # Setup CUDA, GPU & distributed training
+ if args.local_rank == -1 or args.no_cuda:
+ device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
+ args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
+ else: # Initializes the distributed backend which will take care of synchronizing nodes/GPUs
+ torch.cuda.set_device(args.local_rank)
+ device = torch.device("cuda", args.local_rank)
+ torch.distributed.init_process_group(backend="nccl")
+ args.n_gpu = 1
+ args.device = device
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
+ )
+ logger.warning(
+ "Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
+ args.local_rank,
+ device,
+ args.n_gpu,
+ bool(args.local_rank != -1),
+ args.fp16,
+ )
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Set seed
+ set_seed(args)
+
+ # Load pretrained model and tokenizer
+ if args.local_rank not in [-1, 0]:
+ torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
+
+ config = AutoConfig.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
+ )
+ model = AutoModelForMultipleChoice.from_pretrained(
+ args.model_name_or_path, from_tf=bool(".ckpt" in args.model_name_or_path), config=config
+ )
+
+ if args.local_rank == 0:
+ torch.distributed.barrier() # Make sure only the first process in distributed training will download model & vocab
+
+ model.to(args.device)
+
+ logger.info("Training/evaluation parameters %s", args)
+
+ # Training
+ if args.do_train:
+ train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False)
+ global_step, tr_loss = train(args, train_dataset, model, tokenizer)
+ logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
+
+ # Save the trained model and the tokenizer
+ if args.local_rank == -1 or torch.distributed.get_rank() == 0:
+ logger.info("Saving model checkpoint to %s", args.output_dir)
+ # Save a trained model, configuration and tokenizer using `save_pretrained()`.
+ # They can then be reloaded using `from_pretrained()`
+ model_to_save = (
+ model.module if hasattr(model, "module") else model
+ ) # Take care of distributed/parallel training
+ model_to_save.save_pretrained(args.output_dir)
+ tokenizer.save_pretrained(args.output_dir)
+
+ # Good practice: save your training arguments together with the trained model
+ torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
+
+ # Load a trained model and vocabulary that you have fine-tuned
+ model = AutoModelForMultipleChoice.from_pretrained(args.output_dir)
+ tokenizer = AutoTokenizer.from_pretrained(args.output_dir)
+ model.to(args.device)
+
+ # Evaluation - we can ask to evaluate all the checkpoints (sub-directories) in a directory
+ results = {}
+ if args.do_eval and args.local_rank in [-1, 0]:
+ if args.do_train:
+ checkpoints = [args.output_dir]
+ else:
+ # if do_train is False and do_eval is true, load model directly from pretrained.
+ checkpoints = [args.model_name_or_path]
+
+ if args.eval_all_checkpoints:
+ checkpoints = [
+ os.path.dirname(c) for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
+ ]
+
+ logger.info("Evaluate the following checkpoints: %s", checkpoints)
+
+ for checkpoint in checkpoints:
+ # Reload the model
+ global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
+ model = AutoModelForMultipleChoice.from_pretrained(checkpoint)
+ tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+ model.to(args.device)
+
+ # Evaluate
+ result = evaluate(args, model, tokenizer, prefix=global_step)
+
+ result = {k + (f"_{global_step}" if global_step else ""): v for k, v in result.items()}
+ results.update(result)
+
+ logger.info(f"Results: {results}")
+
+ return results
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/run_transfo_xl.py b/docs/transformers/examples/legacy/run_transfo_xl.py
new file mode 100644
index 0000000000000000000000000000000000000000..7da9ee7fe9ca15f8930a128e59182a9ec1377ed0
--- /dev/null
+++ b/docs/transformers/examples/legacy/run_transfo_xl.py
@@ -0,0 +1,143 @@
+#!/usr/bin/env python
+# Copyright 2018 Google AI, Google Brain and Carnegie Mellon University Authors and the HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch Transformer XL model evaluation script.
+Adapted from https://github.com/kimiyoung/transformer-xl.
+In particular https://github.com/kimiyoung/transformer-xl/blob/master/pytorch/eval.py
+
+This script with default values evaluates a pretrained Transformer-XL on WikiText 103
+"""
+
+import argparse
+import logging
+import math
+import time
+
+import torch
+
+from transformers import TransfoXLCorpus, TransfoXLLMHeadModel
+
+
+logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s", datefmt="%m/%d/%Y %H:%M:%S", level=logging.INFO
+)
+logger = logging.getLogger(__name__)
+
+
+def main():
+ parser = argparse.ArgumentParser(description="PyTorch Transformer Language Model")
+ parser.add_argument("--model_name", type=str, default="transfo-xl/transfo-xl-wt103", help="pretrained model name")
+ parser.add_argument(
+ "--split", type=str, default="test", choices=["all", "valid", "test"], help="which split to evaluate"
+ )
+ parser.add_argument("--batch_size", type=int, default=10, help="batch size")
+ parser.add_argument("--tgt_len", type=int, default=128, help="number of tokens to predict")
+ parser.add_argument("--ext_len", type=int, default=0, help="length of the extended context")
+ parser.add_argument("--mem_len", type=int, default=1600, help="length of the retained previous heads")
+ parser.add_argument("--clamp_len", type=int, default=1000, help="max positional embedding index")
+ parser.add_argument("--no_cuda", action="store_true", help="Do not use CUDA even though CUA is available")
+ parser.add_argument("--work_dir", type=str, required=True, help="path to the work_dir")
+ parser.add_argument("--no_log", action="store_true", help="do not log the eval result")
+ parser.add_argument("--same_length", action="store_true", help="set same length attention with masking")
+ parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
+ parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
+ args = parser.parse_args()
+ assert args.ext_len >= 0, "extended context length must be non-negative"
+
+ if args.server_ip and args.server_port:
+ # Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
+ import ptvsd
+
+ print("Waiting for debugger attach")
+ ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
+ ptvsd.wait_for_attach()
+
+ device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
+ logger.info(f"device: {device}")
+
+ # Load a pre-processed dataset
+ # You can also build the corpus yourself using TransfoXLCorpus methods
+ # The pre-processing involve computing word frequencies to prepare the Adaptive input and SoftMax
+ # and tokenizing the dataset
+ # The pre-processed corpus is a convertion (using the conversion script )
+ corpus = TransfoXLCorpus.from_pretrained(args.model_name)
+
+ va_iter = corpus.get_iterator("valid", args.batch_size, args.tgt_len, device=device, ext_len=args.ext_len)
+ te_iter = corpus.get_iterator("test", args.batch_size, args.tgt_len, device=device, ext_len=args.ext_len)
+
+ # Load a pre-trained model
+ model = TransfoXLLMHeadModel.from_pretrained(args.model_name)
+ model.to(device)
+
+ logger.info(
+ "Evaluating with bsz {} tgt_len {} ext_len {} mem_len {} clamp_len {}".format(
+ args.batch_size, args.tgt_len, args.ext_len, args.mem_len, args.clamp_len
+ )
+ )
+
+ model.reset_memory_length(args.mem_len)
+ if args.clamp_len > 0:
+ model.clamp_len = args.clamp_len
+ if args.same_length:
+ model.same_length = True
+
+ ###############################################################################
+ # Evaluation code
+ ###############################################################################
+ def evaluate(eval_iter):
+ # Turn on evaluation mode which disables dropout.
+ model.eval()
+ total_len, total_loss = 0, 0.0
+ start_time = time.time()
+ with torch.no_grad():
+ mems = None
+ for idx, (data, target, seq_len) in enumerate(eval_iter):
+ ret = model(data, lm_labels=target, mems=mems)
+ loss, _, mems = ret
+ loss = loss.mean()
+ total_loss += seq_len * loss.item()
+ total_len += seq_len
+ total_time = time.time() - start_time
+ logger.info(f"Time : {total_time:.2f}s, {1000 * total_time / (idx + 1):.2f}ms/segment")
+ return total_loss / total_len
+
+ # Run on test data.
+ if args.split == "all":
+ test_loss = evaluate(te_iter)
+ valid_loss = evaluate(va_iter)
+ elif args.split == "valid":
+ valid_loss = evaluate(va_iter)
+ test_loss = None
+ elif args.split == "test":
+ test_loss = evaluate(te_iter)
+ valid_loss = None
+
+ def format_log(loss, split):
+ log_str = "| {0} loss {1:5.2f} | {0} ppl {2:9.3f} ".format(split, loss, math.exp(loss))
+ return log_str
+
+ log_str = ""
+ if valid_loss is not None:
+ log_str += format_log(valid_loss, "valid")
+ if test_loss is not None:
+ log_str += format_log(test_loss, "test")
+
+ logger.info("=" * 100)
+ logger.info(log_str)
+ logger.info("=" * 100)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/seq2seq/README.md b/docs/transformers/examples/legacy/seq2seq/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..741d8b5dd54b38c3ff0db0f51de5fa9249f5ec73
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/README.md
@@ -0,0 +1,334 @@
+
+
+# Sequence-to-Sequence Training and Evaluation
+
+This directory contains examples for finetuning and evaluating transformers on summarization and translation tasks.
+For deprecated `bertabs` instructions, see https://github.com/huggingface/transformers-research-projects/blob/main/bertabs/README.md.
+
+### Supported Architectures
+
+- `BartForConditionalGeneration`
+- `MarianMTModel`
+- `PegasusForConditionalGeneration`
+- `MBartForConditionalGeneration`
+- `FSMTForConditionalGeneration`
+- `T5ForConditionalGeneration`
+
+### Download the Datasets
+
+#### XSUM
+
+```bash
+cd examples/legacy/seq2seq
+wget https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz
+tar -xzvf xsum.tar.gz
+export XSUM_DIR=${PWD}/xsum
+```
+this should make a directory called `xsum/` with files like `test.source`.
+To use your own data, copy that files format. Each article to be summarized is on its own line.
+
+#### CNN/DailyMail
+
+```bash
+cd examples/legacy/seq2seq
+wget https://cdn-datasets.huggingface.co/summarization/cnn_dm_v2.tgz
+tar -xzvf cnn_dm_v2.tgz # empty lines removed
+mv cnn_cln cnn_dm
+export CNN_DIR=${PWD}/cnn_dm
+```
+this should make a directory called `cnn_dm/` with 6 files.
+
+#### WMT16 English-Romanian Translation Data
+
+download with this command:
+```bash
+wget https://cdn-datasets.huggingface.co/translation/wmt_en_ro.tar.gz
+tar -xzvf wmt_en_ro.tar.gz
+export ENRO_DIR=${PWD}/wmt_en_ro
+```
+this should make a directory called `wmt_en_ro/` with 6 files.
+
+#### WMT English-German
+
+```bash
+wget https://cdn-datasets.huggingface.co/translation/wmt_en_de.tgz
+tar -xzvf wmt_en_de.tgz
+export DATA_DIR=${PWD}/wmt_en_de
+```
+
+#### FSMT datasets (wmt)
+
+Refer to the scripts starting with `eval_` under:
+https://github.com/huggingface/transformers/tree/main/scripts/fsmt
+
+#### Pegasus (multiple datasets)
+
+Multiple eval datasets are available for download from:
+https://github.com/stas00/porting/tree/master/datasets/pegasus
+
+
+#### Your Data
+
+If you are using your own data, it must be formatted as one directory with 6 files:
+```
+train.source
+train.target
+val.source
+val.target
+test.source
+test.target
+```
+The `.source` files are the input, the `.target` files are the desired output.
+
+### Potential issues
+
+- native AMP (`--fp16` and no apex) may lead to a huge memory leak and require 10x gpu memory. This has been fixed in pytorch-nightly and the minimal official version to have this fix will be pytorch-1.7.1. Until then if you have to use mixed precision please use AMP only with pytorch-nightly or NVIDIA's apex. Reference: https://github.com/huggingface/transformers/issues/8403
+
+
+### Tips and Tricks
+
+General Tips:
+- since you need to run from `examples/legacy/seq2seq`, and likely need to modify code, the easiest workflow is fork transformers, clone your fork, and run `pip install -e .` before you get started.
+- try `--freeze_encoder` or `--freeze_embeds` for faster training/larger batch size. (3hr per epoch with bs=8, see the "xsum_shared_task" command below)
+- `fp16_opt_level=O1` (the default works best).
+- In addition to the pytorch-lightning .ckpt checkpoint, a transformers checkpoint will be saved.
+Load it with `BartForConditionalGeneration.from_pretrained(f'{output_dir}/best_tfmr)`.
+- At the moment, `--do_predict` does not work in a multi-gpu setting. You need to use `evaluate_checkpoint` or the `run_eval.py` code.
+- This warning can be safely ignored:
+ > "Some weights of BartForConditionalGeneration were not initialized from the model checkpoint at facebook/bart-large-xsum and are newly initialized: ['final_logits_bias']"
+- Both finetuning and eval are 30% faster with `--fp16`. For that you need to [install apex](https://github.com/NVIDIA/apex#quick-start).
+- Read scripts before you run them!
+
+Summarization Tips:
+- (summ) 1 epoch at batch size 1 for bart-large takes 24 hours and requires 13GB GPU RAM with fp16 on an NVIDIA-V100.
+- If you want to run experiments on improving the summarization finetuning process, try the XSUM Shared Task (below). It's faster to train than CNNDM because the summaries are shorter.
+- For CNN/DailyMail, the default `val_max_target_length` and `test_max_target_length` will truncate the ground truth labels, resulting in slightly higher rouge scores. To get accurate rouge scores, you should rerun calculate_rouge on the `{output_dir}/test_generations.txt` file saved by `trainer.test()`
+- `--max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 ` is a reasonable setting for XSUM.
+- `wandb` can be used by specifying `--logger_name wandb`. It is useful for reproducibility. Specify the environment variable `WANDB_PROJECT='hf_xsum'` to do the XSUM shared task.
+- If you are finetuning on your own dataset, start from `distilbart-cnn-12-6` if you want long summaries and `distilbart-xsum-12-6` if you want short summaries.
+(It rarely makes sense to start from `bart-large` unless you are a researching finetuning methods).
+
+**Update 2018-07-18**
+Datasets: `LegacySeq2SeqDataset` will be used for all tokenizers without a `prepare_seq2seq_batch` method. Otherwise, `Seq2SeqDataset` will be used.
+Future work/help wanted: A new dataset to support multilingual tasks.
+
+
+### Fine-tuning using Seq2SeqTrainer
+To use `Seq2SeqTrainer` for fine-tuning you should use the `finetune_trainer.py` script. It subclasses `Trainer` to extend it for seq2seq training. Except the `Trainer`-related `TrainingArguments`, it shares the same argument names as that of `finetune.py` file. One notable difference is that calculating generative metrics (BLEU, ROUGE) is optional and is controlled using the `--predict_with_generate` argument.
+
+With PyTorch 1.6+ it'll automatically use `native AMP` when `--fp16` is set.
+
+To see all the possible command line options, run:
+
+```bash
+python finetune_trainer.py --help
+```
+
+For multi-gpu training use `torch.distributed.launch`, e.g. with 2 gpus:
+```bash
+torchrun --nproc_per_node=2 finetune_trainer.py ...
+```
+
+**At the moment, `Seq2SeqTrainer` does not support *with teacher* distillation.**
+
+All `Seq2SeqTrainer`-based fine-tuning scripts are included in the `builtin_trainer` directory.
+
+#### TPU Training
+`Seq2SeqTrainer` supports TPU training with few caveats
+1. As `generate` method does not work on TPU at the moment, `predict_with_generate` cannot be used. You should use `--prediction_loss_only` to only calculate loss, and do not set `--do_predict` and `--predict_with_generate`.
+2. All sequences should be padded to be of equal length to avoid extremely slow training. (`finetune_trainer.py` does this automatically when running on TPU.)
+
+We provide a very simple launcher script named `xla_spawn.py` that lets you run our example scripts on multiple TPU cores without any boilerplate. Just pass a `--num_cores` flag to this script, then your regular training script with its arguments (this is similar to the `torch.distributed.launch` helper for `torch.distributed`).
+
+`builtin_trainer/finetune_tpu.sh` script provides minimal arguments needed for TPU training.
+
+The following command fine-tunes `sshleifer/student_marian_en_ro_6_3` on TPU V3-8 and should complete one epoch in ~5-6 mins.
+
+```bash
+./builtin_trainer/train_distil_marian_enro_tpu.sh
+```
+
+## Evaluation Commands
+
+To create summaries for each article in dataset, we use `run_eval.py`, here are a few commands that run eval for different tasks and models.
+If 'translation' is in your task name, the computed metric will be BLEU. Otherwise, ROUGE will be used.
+
+For t5, you need to specify --task translation_{src}_to_{tgt} as follows:
+```bash
+export DATA_DIR=wmt_en_ro
+./run_eval.py google-t5/t5-base \
+ $DATA_DIR/val.source t5_val_generations.txt \
+ --reference_path $DATA_DIR/val.target \
+ --score_path enro_bleu.json \
+ --task translation_en_to_ro \
+ --n_obs 100 \
+ --device cuda \
+ --fp16 \
+ --bs 32
+```
+
+This command works for MBART, although the BLEU score is suspiciously low.
+```bash
+export DATA_DIR=wmt_en_ro
+./run_eval.py facebook/mbart-large-en-ro $DATA_DIR/val.source mbart_val_generations.txt \
+ --reference_path $DATA_DIR/val.target \
+ --score_path enro_bleu.json \
+ --task translation \
+ --n_obs 100 \
+ --device cuda \
+ --fp16 \
+ --bs 32
+```
+
+Summarization (xsum will be very similar):
+```bash
+export DATA_DIR=cnn_dm
+./run_eval.py sshleifer/distilbart-cnn-12-6 $DATA_DIR/val.source dbart_val_generations.txt \
+ --reference_path $DATA_DIR/val.target \
+ --score_path cnn_rouge.json \
+ --task summarization \
+ --n_obs 100 \
+
+th 56 \
+ --fp16 \
+ --bs 32
+```
+
+### Multi-GPU Evaluation
+here is a command to run xsum evaluation on 8 GPUs. It is more than linearly faster than run_eval.py in some cases
+because it uses SortishSampler to minimize padding. You can also use it on 1 GPU. `data_dir` must have
+`{type_path}.source` and `{type_path}.target`. Run `./run_distributed_eval.py --help` for all clargs.
+
+```bash
+torchrun --nproc_per_node=8 run_distributed_eval.py \
+ --model_name sshleifer/distilbart-large-xsum-12-3 \
+ --save_dir xsum_generations \
+ --data_dir xsum \
+ --fp16 # you can pass generate kwargs like num_beams here, just like run_eval.py
+```
+
+Contributions that implement this command for other distributed hardware setups are welcome!
+
+#### Single-GPU Eval: Tips and Tricks
+
+When using `run_eval.py`, the following features can be useful:
+
+* if you running the script multiple times and want to make it easier to track what arguments produced that output, use `--dump-args`. Along with the results it will also dump any custom params that were passed to the script. For example if you used: `--num_beams 8 --early_stopping true`, the output will be:
+ ```json
+ {'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True}
+ ```
+
+ `--info` is an additional argument available for the same purpose of tracking the conditions of the experiment. It's useful to pass things that weren't in the argument list, e.g. a language pair `--info "lang:en-ru"`. But also if you pass `--info` without a value it will fallback to the current date/time string, e.g. `2020-09-13 18:44:43`.
+
+ If using `--dump-args --info`, the output will be:
+
+ ```json
+ {'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True, 'info': '2020-09-13 18:44:43'}
+ ```
+
+ If using `--dump-args --info "pair:en-ru chkpt=best`, the output will be:
+
+ ```json
+ {'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True, 'info': 'pair=en-ru chkpt=best'}
+ ```
+
+
+* if you need to perform a parametric search in order to find the best ones that lead to the highest BLEU score, let `run_eval_search.py` to do the searching for you.
+
+ The script accepts the exact same arguments as `run_eval.py`, plus an additional argument `--search`. The value of `--search` is parsed, reformatted and fed to ``run_eval.py`` as additional args.
+
+ The format for the `--search` value is a simple string with hparams and colon separated values to try, e.g.:
+ ```
+ --search "num_beams=5:10 length_penalty=0.8:1.0:1.2 early_stopping=true:false"
+ ```
+ which will generate `12` `(2*3*2)` searches for a product of each hparam. For example the example that was just used will invoke `run_eval.py` repeatedly with:
+
+ ```
+ --num_beams 5 --length_penalty 0.8 --early_stopping true
+ --num_beams 5 --length_penalty 0.8 --early_stopping false
+ [...]
+ --num_beams 10 --length_penalty 1.2 --early_stopping false
+ ```
+
+ On completion, this function prints a markdown table of the results sorted by the best BLEU score and the winning arguments.
+
+```
+bleu | num_beams | length_penalty | early_stopping
+----- | --------- | -------------- | --------------
+26.71 | 5 | 1.1 | 1
+26.66 | 5 | 0.9 | 1
+26.66 | 5 | 0.9 | 0
+26.41 | 5 | 1.1 | 0
+21.94 | 1 | 0.9 | 1
+21.94 | 1 | 0.9 | 0
+21.94 | 1 | 1.1 | 1
+21.94 | 1 | 1.1 | 0
+
+Best score args:
+stas/wmt19-en-ru data/en-ru/val.source data/en-ru/test_translations.txt --reference_path data/en-ru/val.target --score_path data/en-ru/test_bleu.json --bs 8 --task translation --num_beams 5 --length_penalty 1.1 --early_stopping True
+```
+
+If you pass `--info "some experiment-specific info"` it will get printed before the results table - this is useful for scripting and multiple runs, so one can tell the different sets of results from each other.
+
+
+### Contributing
+- follow the standard contributing guidelines and code of conduct.
+- add tests to `test_seq2seq_examples.py`
+- To run only the seq2seq tests, you must be in the root of the repository and run:
+```bash
+pytest examples/seq2seq/
+```
+
+### Converting pytorch-lightning checkpoints
+pytorch lightning ``-do_predict`` often fails, after you are done training, the best way to evaluate your model is to convert it.
+
+This should be done for you, with a file called `{save_dir}/best_tfmr`.
+
+If that file doesn't exist but you have a lightning `.ckpt` file, you can run
+```bash
+python convert_pl_checkpoint_to_hf.py PATH_TO_CKPT randomly_initialized_hf_model_path save_dir/best_tfmr
+```
+Then either `run_eval` or `run_distributed_eval` with `save_dir/best_tfmr` (see previous sections)
+
+
+# Experimental Features
+These features are harder to use and not always useful.
+
+### Dynamic Batch Size for MT
+`finetune.py` has a command line arg `--max_tokens_per_batch` that allows batches to be dynamically sized.
+This feature can only be used:
+- with fairseq installed
+- on 1 GPU
+- without sortish sampler
+- after calling `./save_len_file.py $tok $data_dir`
+
+For example,
+```bash
+./save_len_file.py Helsinki-NLP/opus-mt-en-ro wmt_en_ro
+./dynamic_bs_example.sh --max_tokens_per_batch=2000 --output_dir benchmark_dynamic_bs
+```
+splits `wmt_en_ro/train` into 11,197 uneven length batches and can finish 1 epoch in 8 minutes on a v100.
+
+For comparison,
+```bash
+./dynamic_bs_example.sh --sortish_sampler --train_batch_size 48
+```
+uses 12,723 batches of length 48 and takes slightly more time 9.5 minutes.
+
+The feature is still experimental, because:
++ we can make it much more robust if we have memory mapped/preprocessed datasets.
++ The speedup over sortish sampler is not that large at the moment.
diff --git a/docs/transformers/examples/legacy/seq2seq/__init__.py b/docs/transformers/examples/legacy/seq2seq/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3cee09bb7f51087e92d778c4c9e27d76085d1b30
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/__init__.py
@@ -0,0 +1,5 @@
+import os
+import sys
+
+
+sys.path.insert(1, os.path.dirname(os.path.realpath(__file__)))
diff --git a/docs/transformers/examples/legacy/seq2seq/convert_model_to_fp16.py b/docs/transformers/examples/legacy/seq2seq/convert_model_to_fp16.py
new file mode 100644
index 0000000000000000000000000000000000000000..8d568a7e4af0a8b15fea3580a1f580225cb9f639
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/convert_model_to_fp16.py
@@ -0,0 +1,36 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Union
+
+import fire
+import torch
+from tqdm import tqdm
+
+
+def convert(src_path: str, map_location: str = "cpu", save_path: Union[str, None] = None) -> None:
+ """Convert a pytorch_model.bin or model.pt file to torch.float16 for faster downloads, less disk space."""
+ state_dict = torch.load(src_path, map_location=map_location, weights_only=True)
+ for k, v in tqdm(state_dict.items()):
+ if not isinstance(v, torch.Tensor):
+ raise TypeError("FP16 conversion only works on paths that are saved state dicts, like pytorch_model.bin")
+ state_dict[k] = v.half()
+ if save_path is None: # overwrite src_path
+ save_path = src_path
+ torch.save(state_dict, save_path)
+
+
+if __name__ == "__main__":
+ fire.Fire(convert)
diff --git a/docs/transformers/examples/legacy/seq2seq/download_wmt.py b/docs/transformers/examples/legacy/seq2seq/download_wmt.py
new file mode 100644
index 0000000000000000000000000000000000000000..c52c0c7b4faca44e92b16313677ce6e788c27299
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/download_wmt.py
@@ -0,0 +1,67 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from pathlib import Path
+
+import fire
+from tqdm import tqdm
+
+
+def download_wmt_dataset(src_lang="ro", tgt_lang="en", dataset="wmt16", save_dir=None) -> None:
+ """Download a dataset using the datasets package and save it to the format expected by finetune.py
+ Format of save_dir: train.source, train.target, val.source, val.target, test.source, test.target.
+
+ Args:
+ src_lang: source language
+ tgt_lang: target language
+ dataset: wmt16, wmt17, etc. wmt16 is a good start as it's small. To get the full list run `import datasets; print([d.id for d in datasets.list_datasets() if "wmt" in d.id])`
+ save_dir: , where to save the datasets, defaults to f'{dataset}-{src_lang}-{tgt_lang}'
+
+ Usage:
+ >>> download_wmt_dataset('ro', 'en', dataset='wmt16') # saves to wmt16-ro-en
+ """
+ try:
+ import datasets
+ except (ModuleNotFoundError, ImportError):
+ raise ImportError("run pip install datasets")
+ pair = f"{src_lang}-{tgt_lang}"
+ print(f"Converting {dataset}-{pair}")
+ ds = datasets.load_dataset(dataset, pair)
+ if save_dir is None:
+ save_dir = f"{dataset}-{pair}"
+ save_dir = Path(save_dir)
+ save_dir.mkdir(exist_ok=True)
+
+ for split in ds.keys():
+ print(f"Splitting {split} with {ds[split].num_rows} records")
+
+ # to save to val.source, val.target like summary datasets
+ fn = "val" if split == "validation" else split
+ src_path = save_dir.joinpath(f"{fn}.source")
+ tgt_path = save_dir.joinpath(f"{fn}.target")
+ src_fp = src_path.open("w+")
+ tgt_fp = tgt_path.open("w+")
+
+ # reader is the bottleneck so writing one record at a time doesn't slow things down
+ for x in tqdm(ds[split]):
+ ex = x["translation"]
+ src_fp.write(ex[src_lang] + "\n")
+ tgt_fp.write(ex[tgt_lang] + "\n")
+
+ print(f"Saved {dataset} dataset to {save_dir}")
+
+
+if __name__ == "__main__":
+ fire.Fire(download_wmt_dataset)
diff --git a/docs/transformers/examples/legacy/seq2seq/finetune.sh b/docs/transformers/examples/legacy/seq2seq/finetune.sh
new file mode 100644
index 0000000000000000000000000000000000000000..60023df7bad6aedba86987650c3d730aeb1ac229
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/finetune.sh
@@ -0,0 +1,24 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# the proper usage is documented in the README, you need to specify data_dir, output_dir and model_name_or_path
+# run ./finetune.sh --help to see all the possible options
+python finetune_trainer.py \
+ --learning_rate=3e-5 \
+ --fp16 \
+ --do_train --do_eval --do_predict \
+ --eval_strategy steps \
+ --predict_with_generate \
+ --n_val 1000 \
+ "$@"
diff --git a/docs/transformers/examples/legacy/seq2seq/finetune_tpu.sh b/docs/transformers/examples/legacy/seq2seq/finetune_tpu.sh
new file mode 100644
index 0000000000000000000000000000000000000000..ef72b0953b440b88e86aee93d5aeb9ca0a864f16
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/finetune_tpu.sh
@@ -0,0 +1,26 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+export TPU_NUM_CORES=8
+
+# the proper usage is documented in the README, you need to specify data_dir, output_dir and model_name_or_path
+# run ./finetune_tpu.sh --help to see all the possible options
+python xla_spawn.py --num_cores $TPU_NUM_CORES \
+ finetune_trainer.py \
+ --learning_rate=3e-5 \
+ --do_train --do_eval \
+ --eval_strategy steps \
+ --prediction_loss_only \
+ --n_val 1000 \
+ "$@"
diff --git a/docs/transformers/examples/legacy/seq2seq/finetune_trainer.py b/docs/transformers/examples/legacy/seq2seq/finetune_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..e9daf9fc506df77c2e4a1709f124b4e5ccef519c
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/finetune_trainer.py
@@ -0,0 +1,375 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+from seq2seq_trainer import Seq2SeqTrainer
+from seq2seq_training_args import Seq2SeqTrainingArguments
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForSeq2SeqLM,
+ AutoTokenizer,
+ HfArgumentParser,
+ MBartTokenizer,
+ MBartTokenizerFast,
+ set_seed,
+)
+from transformers.trainer_utils import EvaluationStrategy, is_main_process
+from transformers.training_args import ParallelMode
+from utils import (
+ Seq2SeqDataCollator,
+ Seq2SeqDataset,
+ assert_all_frozen,
+ build_compute_metrics_fn,
+ check_output_dir,
+ freeze_embeds,
+ freeze_params,
+ lmap,
+ save_json,
+ use_task_specific_params,
+ write_txt_file,
+)
+
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ freeze_encoder: bool = field(default=False, metadata={"help": "Whether tp freeze the encoder."})
+ freeze_embeds: bool = field(default=False, metadata={"help": "Whether to freeze the embeddings."})
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ data_dir: str = field(
+ metadata={"help": "The input data dir. Should contain the .tsv files (or other data files) for the task."}
+ )
+ task: Optional[str] = field(
+ default="summarization",
+ metadata={"help": "Task name, summarization (or summarization_{dataset} for pegasus) or translation"},
+ )
+ max_source_length: Optional[int] = field(
+ default=1024,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ max_target_length: Optional[int] = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total sequence length for target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ val_max_target_length: Optional[int] = field(
+ default=142,
+ metadata={
+ "help": (
+ "The maximum total sequence length for validation target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded. "
+ "This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
+ "during ``evaluate`` and ``predict``."
+ )
+ },
+ )
+ test_max_target_length: Optional[int] = field(
+ default=142,
+ metadata={
+ "help": (
+ "The maximum total sequence length for test target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ n_train: Optional[int] = field(default=-1, metadata={"help": "# training examples. -1 means use all."})
+ n_val: Optional[int] = field(default=-1, metadata={"help": "# validation examples. -1 means use all."})
+ n_test: Optional[int] = field(default=-1, metadata={"help": "# test examples. -1 means use all."})
+ src_lang: Optional[str] = field(default=None, metadata={"help": "Source language id for translation."})
+ tgt_lang: Optional[str] = field(default=None, metadata={"help": "Target language id for translation."})
+ eval_beams: Optional[int] = field(default=None, metadata={"help": "# num_beams to use for evaluation."})
+ ignore_pad_token_for_loss: bool = field(
+ default=True,
+ metadata={"help": "If only pad tokens should be ignored. This assumes that `config.pad_token_id` is defined."},
+ )
+
+
+def handle_metrics(split, metrics, output_dir):
+ """
+ Log and save metrics
+
+ Args:
+ - split: one of train, val, test
+ - metrics: metrics dict
+ - output_dir: where to save the metrics
+ """
+
+ logger.info(f"***** {split} metrics *****")
+ for key in sorted(metrics.keys()):
+ logger.info(f" {key} = {metrics[key]}")
+ save_json(metrics, os.path.join(output_dir, f"{split}_results.json"))
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
+
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ check_output_dir(training_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
+ )
+ logger.warning(
+ "Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
+ training_args.local_rank,
+ training_args.device,
+ training_args.n_gpu,
+ bool(training_args.parallel_mode == ParallelMode.DISTRIBUTED),
+ training_args.fp16,
+ )
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(training_args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ logger.info("Training/evaluation parameters %s", training_args)
+
+ # Set seed
+ set_seed(training_args.seed)
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ )
+
+ extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
+ for p in extra_model_params:
+ if getattr(training_args, p, None):
+ assert hasattr(config, p), f"({config.__class__.__name__}) doesn't have a `{p}` attribute"
+ setattr(config, p, getattr(training_args, p))
+
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ )
+ model = AutoModelForSeq2SeqLM.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=".ckpt" in model_args.model_name_or_path,
+ config=config,
+ cache_dir=model_args.cache_dir,
+ )
+
+ # use task specific params
+ use_task_specific_params(model, data_args.task)
+
+ # set num_beams for evaluation
+ if data_args.eval_beams is None:
+ data_args.eval_beams = model.config.num_beams
+
+ # set decoder_start_token_id for MBart
+ if model.config.decoder_start_token_id is None and isinstance(tokenizer, (MBartTokenizer, MBartTokenizerFast)):
+ assert data_args.tgt_lang is not None and data_args.src_lang is not None, (
+ "mBart requires --tgt_lang and --src_lang"
+ )
+ if isinstance(tokenizer, MBartTokenizer):
+ model.config.decoder_start_token_id = tokenizer.lang_code_to_id[data_args.tgt_lang]
+ else:
+ model.config.decoder_start_token_id = tokenizer.convert_tokens_to_ids(data_args.tgt_lang)
+
+ if model_args.freeze_embeds:
+ freeze_embeds(model)
+ if model_args.freeze_encoder:
+ freeze_params(model.get_encoder())
+ assert_all_frozen(model.get_encoder())
+
+ dataset_class = Seq2SeqDataset
+
+ # Get datasets
+ train_dataset = (
+ dataset_class(
+ tokenizer,
+ type_path="train",
+ data_dir=data_args.data_dir,
+ n_obs=data_args.n_train,
+ max_target_length=data_args.max_target_length,
+ max_source_length=data_args.max_source_length,
+ prefix=model.config.prefix or "",
+ )
+ if training_args.do_train
+ else None
+ )
+ eval_dataset = (
+ dataset_class(
+ tokenizer,
+ type_path="val",
+ data_dir=data_args.data_dir,
+ n_obs=data_args.n_val,
+ max_target_length=data_args.val_max_target_length,
+ max_source_length=data_args.max_source_length,
+ prefix=model.config.prefix or "",
+ )
+ if training_args.do_eval or training_args.eval_strategy != EvaluationStrategy.NO
+ else None
+ )
+ test_dataset = (
+ dataset_class(
+ tokenizer,
+ type_path="test",
+ data_dir=data_args.data_dir,
+ n_obs=data_args.n_test,
+ max_target_length=data_args.test_max_target_length,
+ max_source_length=data_args.max_source_length,
+ prefix=model.config.prefix or "",
+ )
+ if training_args.do_predict
+ else None
+ )
+
+ # Initialize our Trainer
+ compute_metrics_fn = (
+ build_compute_metrics_fn(data_args.task, tokenizer) if training_args.predict_with_generate else None
+ )
+ trainer = Seq2SeqTrainer(
+ model=model,
+ args=training_args,
+ data_args=data_args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ data_collator=Seq2SeqDataCollator(
+ tokenizer, data_args, model.config.decoder_start_token_id, training_args.tpu_num_cores
+ ),
+ compute_metrics=compute_metrics_fn,
+ processing_class=tokenizer,
+ )
+
+ all_metrics = {}
+ # Training
+ if training_args.do_train:
+ logger.info("*** Train ***")
+
+ train_result = trainer.train(
+ model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
+ )
+ metrics = train_result.metrics
+ metrics["train_n_objs"] = data_args.n_train
+
+ trainer.save_model() # this also saves the tokenizer
+
+ if trainer.is_world_process_zero():
+ handle_metrics("train", metrics, training_args.output_dir)
+ all_metrics.update(metrics)
+
+ # Need to save the state, since Trainer.save_model saves only the tokenizer with the model
+ trainer.state.save_to_json(os.path.join(training_args.output_dir, "trainer_state.json"))
+
+ # For convenience, we also re-save the tokenizer to the same directory,
+ # so that you can share your model easily on huggingface.co/models =)
+ tokenizer.save_pretrained(training_args.output_dir)
+
+ # Evaluation
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+
+ metrics = trainer.evaluate(metric_key_prefix="val")
+ metrics["val_n_objs"] = data_args.n_val
+ metrics["val_loss"] = round(metrics["val_loss"], 4)
+
+ if trainer.is_world_process_zero():
+ handle_metrics("val", metrics, training_args.output_dir)
+ all_metrics.update(metrics)
+
+ if training_args.do_predict:
+ logger.info("*** Predict ***")
+
+ test_output = trainer.predict(test_dataset=test_dataset, metric_key_prefix="test")
+ metrics = test_output.metrics
+ metrics["test_n_objs"] = data_args.n_test
+
+ if trainer.is_world_process_zero():
+ metrics["test_loss"] = round(metrics["test_loss"], 4)
+ handle_metrics("test", metrics, training_args.output_dir)
+ all_metrics.update(metrics)
+
+ if training_args.predict_with_generate:
+ test_preds = tokenizer.batch_decode(
+ test_output.predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True
+ )
+ test_preds = lmap(str.strip, test_preds)
+ write_txt_file(test_preds, os.path.join(training_args.output_dir, "test_generations.txt"))
+
+ if trainer.is_world_process_zero():
+ save_json(all_metrics, os.path.join(training_args.output_dir, "all_results.json"))
+
+ return all_metrics
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/seq2seq/minify_dataset.py b/docs/transformers/examples/legacy/seq2seq/minify_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..e6095cecc8e99f231b80a3779b594cc29fd0ddda
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/minify_dataset.py
@@ -0,0 +1,34 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from pathlib import Path
+
+import fire
+
+
+def minify(src_dir: str, dest_dir: str, n: int):
+ """Write first n lines of each file f in src_dir to dest_dir/f"""
+ src_dir = Path(src_dir)
+ dest_dir = Path(dest_dir)
+ dest_dir.mkdir(exist_ok=True)
+ for path in src_dir.iterdir():
+ new = [x.rstrip() for x in list(path.open().readlines())][:n]
+ dest_path = dest_dir.joinpath(path.name)
+ print(dest_path)
+ dest_path.open("w").write("\n".join(new))
+
+
+if __name__ == "__main__":
+ fire.Fire(minify)
diff --git a/docs/transformers/examples/legacy/seq2seq/old_test_calculate_rouge.py b/docs/transformers/examples/legacy/seq2seq/old_test_calculate_rouge.py
new file mode 100644
index 0000000000000000000000000000000000000000..6cc15e02552be105a28ac93d177b09a7f9bc92a2
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/old_test_calculate_rouge.py
@@ -0,0 +1,109 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from collections import defaultdict
+from pathlib import Path
+
+import pandas as pd
+from rouge_cli import calculate_rouge_path
+
+from utils import calculate_rouge
+
+
+PRED = [
+ 'Prosecutor: "No videos were used in the crash investigation" German papers say they saw a cell phone video of the'
+ ' final seconds on board Flight 9525. The Germanwings co-pilot says he had a "previous episode of severe'
+ " depression\" German airline confirms it knew of Andreas Lubitz's depression years before he took control.",
+ "The Palestinian Authority officially becomes the 123rd member of the International Criminal Court. The formal"
+ " accession was marked with a ceremony at The Hague, in the Netherlands. The Palestinians signed the ICC's"
+ " founding Rome Statute in January. Israel and the United States opposed the Palestinians' efforts to join the"
+ " body.",
+ "Amnesty International releases its annual report on the death penalty. The report catalogs the use of"
+ " state-sanctioned killing as a punitive measure across the globe. At least 607 people were executed around the"
+ " world in 2014, compared to 778 in 2013. The U.S. remains one of the worst offenders for imposing capital"
+ " punishment.",
+]
+
+TGT = [
+ 'Marseille prosecutor says "so far no videos were used in the crash investigation" despite media reports .'
+ ' Journalists at Bild and Paris Match are "very confident" the video clip is real, an editor says . Andreas Lubitz'
+ " had informed his Lufthansa training school of an episode of severe depression, airline says .",
+ "Membership gives the ICC jurisdiction over alleged crimes committed in Palestinian territories since last June ."
+ " Israel and the United States opposed the move, which could open the door to war crimes investigations against"
+ " Israelis .",
+ "Amnesty's annual death penalty report catalogs encouraging signs, but setbacks in numbers of those sentenced to"
+ " death . Organization claims that governments around the world are using the threat of terrorism to advance"
+ " executions . The number of executions worldwide has gone down by almost 22% compared with 2013, but death"
+ " sentences up by 28% .",
+]
+
+
+def test_disaggregated_scores_are_determinstic():
+ no_aggregation = calculate_rouge(PRED, TGT, bootstrap_aggregation=False, rouge_keys=["rouge2", "rougeL"])
+ assert isinstance(no_aggregation, defaultdict)
+ no_aggregation_just_r2 = calculate_rouge(PRED, TGT, bootstrap_aggregation=False, rouge_keys=["rouge2"])
+ assert (
+ pd.DataFrame(no_aggregation["rouge2"]).fmeasure.mean()
+ == pd.DataFrame(no_aggregation_just_r2["rouge2"]).fmeasure.mean()
+ )
+
+
+def test_newline_cnn_improvement():
+ k = "rougeLsum"
+ score = calculate_rouge(PRED, TGT, newline_sep=True, rouge_keys=[k])[k]
+ score_no_sep = calculate_rouge(PRED, TGT, newline_sep=False, rouge_keys=[k])[k]
+ assert score > score_no_sep
+
+
+def test_newline_irrelevant_for_other_metrics():
+ k = ["rouge1", "rouge2", "rougeL"]
+ score_sep = calculate_rouge(PRED, TGT, newline_sep=True, rouge_keys=k)
+ score_no_sep = calculate_rouge(PRED, TGT, newline_sep=False, rouge_keys=k)
+ assert score_sep == score_no_sep
+
+
+def test_single_sent_scores_dont_depend_on_newline_sep():
+ pred = [
+ "Her older sister, Margot Frank, died in 1945, a month earlier than previously thought.",
+ 'Marseille prosecutor says "so far no videos were used in the crash investigation" despite media reports .',
+ ]
+ tgt = [
+ "Margot Frank, died in 1945, a month earlier than previously thought.",
+ 'Prosecutor: "No videos were used in the crash investigation" German papers say they saw a cell phone video of'
+ " the final seconds on board Flight 9525.",
+ ]
+ assert calculate_rouge(pred, tgt, newline_sep=True) == calculate_rouge(pred, tgt, newline_sep=False)
+
+
+def test_pegasus_newline():
+ pred = [
+ """" "a person who has such a video needs to immediately give it to the investigators," prosecutor says . "it is a very disturbing scene," editor-in-chief of bild online tells "erin burnett: outfront" """
+ ]
+ tgt = [
+ """ Marseille prosecutor says "so far no videos were used in the crash investigation" despite media reports . Journalists at Bild and Paris Match are "very confident" the video clip is real, an editor says . Andreas Lubitz had informed his Lufthansa training school of an episode of severe depression, airline says ."""
+ ]
+
+ prev_score = calculate_rouge(pred, tgt, rouge_keys=["rougeLsum"], newline_sep=False)["rougeLsum"]
+ new_score = calculate_rouge(pred, tgt, rouge_keys=["rougeLsum"])["rougeLsum"]
+ assert new_score > prev_score
+
+
+def test_rouge_cli():
+ data_dir = Path("examples/seq2seq/test_data/wmt_en_ro")
+ metrics = calculate_rouge_path(data_dir.joinpath("test.source"), data_dir.joinpath("test.target"))
+ assert isinstance(metrics, dict)
+ metrics_default_dict = calculate_rouge_path(
+ data_dir.joinpath("test.source"), data_dir.joinpath("test.target"), bootstrap_aggregation=False
+ )
+ assert isinstance(metrics_default_dict, defaultdict)
diff --git a/docs/transformers/examples/legacy/seq2seq/old_test_datasets.py b/docs/transformers/examples/legacy/seq2seq/old_test_datasets.py
new file mode 100644
index 0000000000000000000000000000000000000000..be108f7645f8a96e18a84430cee1e846a263a530
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/old_test_datasets.py
@@ -0,0 +1,247 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from pathlib import Path
+
+import numpy as np
+import pytest
+from pack_dataset import pack_data_dir
+from parameterized import parameterized
+from save_len_file import save_len_file
+from torch.utils.data import DataLoader
+
+from transformers import AutoTokenizer
+from transformers.models.mbart.modeling_mbart import shift_tokens_right
+from transformers.testing_utils import TestCasePlus, slow
+from utils import FAIRSEQ_AVAILABLE, DistributedSortishSampler, LegacySeq2SeqDataset, Seq2SeqDataset
+
+
+BERT_BASE_CASED = "google-bert/bert-base-cased"
+PEGASUS_XSUM = "google/pegasus-xsum"
+ARTICLES = [" Sam ate lunch today.", "Sams lunch ingredients."]
+SUMMARIES = ["A very interesting story about what I ate for lunch.", "Avocado, celery, turkey, coffee"]
+T5_TINY = "patrickvonplaten/t5-tiny-random"
+BART_TINY = "sshleifer/bart-tiny-random"
+MBART_TINY = "sshleifer/tiny-mbart"
+MARIAN_TINY = "sshleifer/tiny-marian-en-de"
+
+
+def _dump_articles(path: Path, articles: list):
+ content = "\n".join(articles)
+ Path(path).open("w").writelines(content)
+
+
+def make_test_data_dir(tmp_dir):
+ for split in ["train", "val", "test"]:
+ _dump_articles(os.path.join(tmp_dir, f"{split}.source"), ARTICLES)
+ _dump_articles(os.path.join(tmp_dir, f"{split}.target"), SUMMARIES)
+ return tmp_dir
+
+
+class TestAll(TestCasePlus):
+ @parameterized.expand(
+ [
+ MBART_TINY,
+ MARIAN_TINY,
+ T5_TINY,
+ BART_TINY,
+ PEGASUS_XSUM,
+ ],
+ )
+ @slow
+ def test_seq2seq_dataset_truncation(self, tok_name):
+ tokenizer = AutoTokenizer.from_pretrained(tok_name)
+ tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
+ max_len_source = max(len(tokenizer.encode(a)) for a in ARTICLES)
+ max_len_target = max(len(tokenizer.encode(a)) for a in SUMMARIES)
+ max_src_len = 4
+ max_tgt_len = 8
+ assert max_len_target > max_src_len # Will be truncated
+ assert max_len_source > max_src_len # Will be truncated
+ src_lang, tgt_lang = "ro_RO", "de_DE" # ignored for all but mbart, but never causes error.
+ train_dataset = Seq2SeqDataset(
+ tokenizer,
+ data_dir=tmp_dir,
+ type_path="train",
+ max_source_length=max_src_len,
+ max_target_length=max_tgt_len, # ignored
+ src_lang=src_lang,
+ tgt_lang=tgt_lang,
+ )
+ dataloader = DataLoader(train_dataset, batch_size=2, collate_fn=train_dataset.collate_fn)
+ for batch in dataloader:
+ assert isinstance(batch, dict)
+ assert batch["attention_mask"].shape == batch["input_ids"].shape
+ # show that articles were trimmed.
+ assert batch["input_ids"].shape[1] == max_src_len
+ # show that targets are the same len
+ assert batch["labels"].shape[1] == max_tgt_len
+ if tok_name != MBART_TINY:
+ continue
+ # check language codes in correct place
+ batch["decoder_input_ids"] = shift_tokens_right(batch["labels"], tokenizer.pad_token_id)
+ assert batch["decoder_input_ids"][0, 0].item() == tokenizer.lang_code_to_id[tgt_lang]
+ assert batch["decoder_input_ids"][0, -1].item() == tokenizer.eos_token_id
+ assert batch["input_ids"][0, -2].item() == tokenizer.eos_token_id
+ assert batch["input_ids"][0, -1].item() == tokenizer.lang_code_to_id[src_lang]
+
+ break # No need to test every batch
+
+ @parameterized.expand([BART_TINY, BERT_BASE_CASED])
+ def test_legacy_dataset_truncation(self, tok):
+ tokenizer = AutoTokenizer.from_pretrained(tok)
+ tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
+ max_len_source = max(len(tokenizer.encode(a)) for a in ARTICLES)
+ max_len_target = max(len(tokenizer.encode(a)) for a in SUMMARIES)
+ trunc_target = 4
+ train_dataset = LegacySeq2SeqDataset(
+ tokenizer,
+ data_dir=tmp_dir,
+ type_path="train",
+ max_source_length=20,
+ max_target_length=trunc_target,
+ )
+ dataloader = DataLoader(train_dataset, batch_size=2, collate_fn=train_dataset.collate_fn)
+ for batch in dataloader:
+ assert batch["attention_mask"].shape == batch["input_ids"].shape
+ # show that articles were trimmed.
+ assert batch["input_ids"].shape[1] == max_len_source
+ assert 20 >= batch["input_ids"].shape[1] # trimmed significantly
+ # show that targets were truncated
+ assert batch["labels"].shape[1] == trunc_target # Truncated
+ assert max_len_target > trunc_target # Truncated
+ break # No need to test every batch
+
+ def test_pack_dataset(self):
+ tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-cc25")
+
+ tmp_dir = Path(make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir()))
+ orig_examples = tmp_dir.joinpath("train.source").open().readlines()
+ save_dir = Path(make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir()))
+ pack_data_dir(tokenizer, tmp_dir, 128, save_dir)
+ orig_paths = {x.name for x in tmp_dir.iterdir()}
+ new_paths = {x.name for x in save_dir.iterdir()}
+ packed_examples = save_dir.joinpath("train.source").open().readlines()
+ # orig: [' Sam ate lunch today.\n', 'Sams lunch ingredients.']
+ # desired_packed: [' Sam ate lunch today.\n Sams lunch ingredients.']
+ assert len(packed_examples) < len(orig_examples)
+ assert len(packed_examples) == 1
+ assert len(packed_examples[0]) == sum(len(x) for x in orig_examples)
+ assert orig_paths == new_paths
+
+ @pytest.mark.skipif(not FAIRSEQ_AVAILABLE, reason="This test requires fairseq")
+ def test_dynamic_batch_size(self):
+ if not FAIRSEQ_AVAILABLE:
+ return
+ ds, max_tokens, tokenizer = self._get_dataset(max_len=64)
+ required_batch_size_multiple = 64
+ batch_sampler = ds.make_dynamic_sampler(max_tokens, required_batch_size_multiple=required_batch_size_multiple)
+ batch_sizes = [len(x) for x in batch_sampler]
+ assert len(set(batch_sizes)) > 1 # it's not dynamic batch size if every batch is the same length
+ assert sum(batch_sizes) == len(ds) # no dropped or added examples
+ data_loader = DataLoader(ds, batch_sampler=batch_sampler, collate_fn=ds.collate_fn, num_workers=2)
+ failures = []
+ num_src_per_batch = []
+ for batch in data_loader:
+ src_shape = batch["input_ids"].shape
+ bs = src_shape[0]
+ assert bs % required_batch_size_multiple == 0 or bs < required_batch_size_multiple
+ num_src_tokens = np.product(batch["input_ids"].shape)
+ num_src_per_batch.append(num_src_tokens)
+ if num_src_tokens > (max_tokens * 1.1):
+ failures.append(num_src_tokens)
+ assert num_src_per_batch[0] == max(num_src_per_batch)
+ if failures:
+ raise AssertionError(f"too many tokens in {len(failures)} batches")
+
+ def test_sortish_sampler_reduces_padding(self):
+ ds, _, tokenizer = self._get_dataset(max_len=512)
+ bs = 2
+ sortish_sampler = ds.make_sortish_sampler(bs, shuffle=False)
+
+ naive_dl = DataLoader(ds, batch_size=bs, collate_fn=ds.collate_fn, num_workers=2)
+ sortish_dl = DataLoader(ds, batch_size=bs, collate_fn=ds.collate_fn, num_workers=2, sampler=sortish_sampler)
+
+ pad = tokenizer.pad_token_id
+
+ def count_pad_tokens(data_loader, k="input_ids"):
+ return [batch[k].eq(pad).sum().item() for batch in data_loader]
+
+ assert sum(count_pad_tokens(sortish_dl, k="labels")) < sum(count_pad_tokens(naive_dl, k="labels"))
+ assert sum(count_pad_tokens(sortish_dl)) < sum(count_pad_tokens(naive_dl))
+ assert len(sortish_dl) == len(naive_dl)
+
+ def _get_dataset(self, n_obs=1000, max_len=128):
+ if os.getenv("USE_REAL_DATA", False):
+ data_dir = "examples/seq2seq/wmt_en_ro"
+ max_tokens = max_len * 2 * 64
+ if not Path(data_dir).joinpath("train.len").exists():
+ save_len_file(MARIAN_TINY, data_dir)
+ else:
+ data_dir = "examples/seq2seq/test_data/wmt_en_ro"
+ max_tokens = max_len * 4
+ save_len_file(MARIAN_TINY, data_dir)
+
+ tokenizer = AutoTokenizer.from_pretrained(MARIAN_TINY)
+ ds = Seq2SeqDataset(
+ tokenizer,
+ data_dir=data_dir,
+ type_path="train",
+ max_source_length=max_len,
+ max_target_length=max_len,
+ n_obs=n_obs,
+ )
+ return ds, max_tokens, tokenizer
+
+ def test_distributed_sortish_sampler_splits_indices_between_procs(self):
+ ds, max_tokens, tokenizer = self._get_dataset()
+ ids1 = set(DistributedSortishSampler(ds, 256, num_replicas=2, rank=0, add_extra_examples=False))
+ ids2 = set(DistributedSortishSampler(ds, 256, num_replicas=2, rank=1, add_extra_examples=False))
+ assert ids1.intersection(ids2) == set()
+
+ @parameterized.expand(
+ [
+ MBART_TINY,
+ MARIAN_TINY,
+ T5_TINY,
+ BART_TINY,
+ PEGASUS_XSUM,
+ ],
+ )
+ def test_dataset_kwargs(self, tok_name):
+ tokenizer = AutoTokenizer.from_pretrained(tok_name, use_fast=False)
+ if tok_name == MBART_TINY:
+ train_dataset = Seq2SeqDataset(
+ tokenizer,
+ data_dir=make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir()),
+ type_path="train",
+ max_source_length=4,
+ max_target_length=8,
+ src_lang="EN",
+ tgt_lang="FR",
+ )
+ kwargs = train_dataset.dataset_kwargs
+ assert "src_lang" in kwargs and "tgt_lang" in kwargs
+ else:
+ train_dataset = Seq2SeqDataset(
+ tokenizer,
+ data_dir=make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir()),
+ type_path="train",
+ max_source_length=4,
+ max_target_length=8,
+ )
+ kwargs = train_dataset.dataset_kwargs
+ assert "add_prefix_space" not in kwargs if tok_name != BART_TINY else "add_prefix_space" in kwargs
+ assert len(kwargs) == 1 if tok_name == BART_TINY else len(kwargs) == 0
diff --git a/docs/transformers/examples/legacy/seq2seq/old_test_fsmt_bleu_score.py b/docs/transformers/examples/legacy/seq2seq/old_test_fsmt_bleu_score.py
new file mode 100644
index 0000000000000000000000000000000000000000..93bd9839920d3b225b3a4806e416d4199387433d
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/old_test_fsmt_bleu_score.py
@@ -0,0 +1,70 @@
+# Copyright 2020 Huggingface
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import unittest
+
+from parameterized import parameterized
+
+from transformers import FSMTForConditionalGeneration, FSMTTokenizer
+from transformers.testing_utils import get_tests_dir, require_torch, slow, torch_device
+from utils import calculate_bleu
+
+
+filename = get_tests_dir() + "/test_data/fsmt/fsmt_val_data.json"
+with open(filename, encoding="utf-8") as f:
+ bleu_data = json.load(f)
+
+
+@require_torch
+class ModelEvalTester(unittest.TestCase):
+ def get_tokenizer(self, mname):
+ return FSMTTokenizer.from_pretrained(mname)
+
+ def get_model(self, mname):
+ model = FSMTForConditionalGeneration.from_pretrained(mname).to(torch_device)
+ if torch_device == "cuda":
+ model.half()
+ return model
+
+ @parameterized.expand(
+ [
+ ["en-ru", 26.0],
+ ["ru-en", 22.0],
+ ["en-de", 22.0],
+ ["de-en", 29.0],
+ ]
+ )
+ @slow
+ def test_bleu_scores(self, pair, min_bleu_score):
+ # note: this test is not testing the best performance since it only evals a small batch
+ # but it should be enough to detect a regression in the output quality
+ mname = f"facebook/wmt19-{pair}"
+ tokenizer = self.get_tokenizer(mname)
+ model = self.get_model(mname)
+
+ src_sentences = bleu_data[pair]["src"]
+ tgt_sentences = bleu_data[pair]["tgt"]
+
+ batch = tokenizer(src_sentences, return_tensors="pt", truncation=True, padding="longest").to(torch_device)
+ outputs = model.generate(
+ input_ids=batch.input_ids,
+ num_beams=8,
+ )
+ decoded_sentences = tokenizer.batch_decode(
+ outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False
+ )
+ scores = calculate_bleu(decoded_sentences, tgt_sentences)
+ print(scores)
+ self.assertGreaterEqual(scores["bleu"], min_bleu_score)
diff --git a/docs/transformers/examples/legacy/seq2seq/old_test_seq2seq_examples.py b/docs/transformers/examples/legacy/seq2seq/old_test_seq2seq_examples.py
new file mode 100644
index 0000000000000000000000000000000000000000..864b97c7466a36a27eec3bea2e9aa28e9695f21f
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/old_test_seq2seq_examples.py
@@ -0,0 +1,132 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import logging
+import os
+import sys
+from pathlib import Path
+from unittest.mock import patch
+
+from parameterized import parameterized
+from run_eval import run_generate
+from run_eval_search import run_search
+
+from transformers.testing_utils import CaptureStdout, TestCasePlus, slow
+from utils import ROUGE_KEYS
+
+
+logging.basicConfig(level=logging.DEBUG)
+logger = logging.getLogger()
+
+
+def _dump_articles(path: Path, articles: list):
+ content = "\n".join(articles)
+ Path(path).open("w").writelines(content)
+
+
+T5_TINY = "patrickvonplaten/t5-tiny-random"
+BART_TINY = "sshleifer/bart-tiny-random"
+MBART_TINY = "sshleifer/tiny-mbart"
+
+stream_handler = logging.StreamHandler(sys.stdout)
+logger.addHandler(stream_handler)
+logging.disable(logging.CRITICAL) # remove noisy download output from tracebacks
+
+
+class TestTheRest(TestCasePlus):
+ def run_eval_tester(self, model):
+ input_file_name = Path(self.get_auto_remove_tmp_dir()) / "utest_input.source"
+ output_file_name = input_file_name.parent / "utest_output.txt"
+ assert not output_file_name.exists()
+ articles = [" New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County."]
+ _dump_articles(input_file_name, articles)
+
+ score_path = str(Path(self.get_auto_remove_tmp_dir()) / "scores.json")
+ task = "translation_en_to_de" if model == T5_TINY else "summarization"
+ testargs = f"""
+ run_eval_search.py
+ {model}
+ {input_file_name}
+ {output_file_name}
+ --score_path {score_path}
+ --task {task}
+ --num_beams 2
+ --length_penalty 2.0
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_generate()
+ assert Path(output_file_name).exists()
+ # os.remove(Path(output_file_name))
+
+ # test one model to quickly (no-@slow) catch simple problems and do an
+ # extensive testing of functionality with multiple models as @slow separately
+ def test_run_eval(self):
+ self.run_eval_tester(T5_TINY)
+
+ # any extra models should go into the list here - can be slow
+ @parameterized.expand([BART_TINY, MBART_TINY])
+ @slow
+ def test_run_eval_slow(self, model):
+ self.run_eval_tester(model)
+
+ # testing with 2 models to validate: 1. translation (t5) 2. summarization (mbart)
+ @parameterized.expand([T5_TINY, MBART_TINY])
+ @slow
+ def test_run_eval_search(self, model):
+ input_file_name = Path(self.get_auto_remove_tmp_dir()) / "utest_input.source"
+ output_file_name = input_file_name.parent / "utest_output.txt"
+ assert not output_file_name.exists()
+
+ text = {
+ "en": ["Machine learning is great, isn't it?", "I like to eat bananas", "Tomorrow is another great day!"],
+ "de": [
+ "Maschinelles Lernen ist großartig, oder?",
+ "Ich esse gerne Bananen",
+ "Morgen ist wieder ein toller Tag!",
+ ],
+ }
+
+ tmp_dir = Path(self.get_auto_remove_tmp_dir())
+ score_path = str(tmp_dir / "scores.json")
+ reference_path = str(tmp_dir / "val.target")
+ _dump_articles(input_file_name, text["en"])
+ _dump_articles(reference_path, text["de"])
+ task = "translation_en_to_de" if model == T5_TINY else "summarization"
+ testargs = f"""
+ run_eval_search.py
+ {model}
+ {str(input_file_name)}
+ {str(output_file_name)}
+ --score_path {score_path}
+ --reference_path {reference_path}
+ --task {task}
+ """.split()
+ testargs.extend(["--search", "num_beams=1:2 length_penalty=0.9:1.0"])
+
+ with patch.object(sys, "argv", testargs):
+ with CaptureStdout() as cs:
+ run_search()
+ expected_strings = [" num_beams | length_penalty", model, "Best score args"]
+ un_expected_strings = ["Info"]
+ if "translation" in task:
+ expected_strings.append("bleu")
+ else:
+ expected_strings.extend(ROUGE_KEYS)
+ for w in expected_strings:
+ assert w in cs.out
+ for w in un_expected_strings:
+ assert w not in cs.out
+ assert Path(output_file_name).exists()
+ os.remove(Path(output_file_name))
diff --git a/docs/transformers/examples/legacy/seq2seq/old_test_seq2seq_examples_multi_gpu.py b/docs/transformers/examples/legacy/seq2seq/old_test_seq2seq_examples_multi_gpu.py
new file mode 100644
index 0000000000000000000000000000000000000000..6625f061b5660793a5a054acd4eab518622bf5f8
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/old_test_seq2seq_examples_multi_gpu.py
@@ -0,0 +1,55 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# as due to their complexity multi-gpu tests could impact other tests, and to aid debug we have those in a separate module.
+
+import os
+import sys
+
+from transformers.testing_utils import TestCasePlus, execute_subprocess_async, get_gpu_count, require_torch_gpu, slow
+
+from .utils import load_json
+
+
+class TestSummarizationDistillerMultiGPU(TestCasePlus):
+ @classmethod
+ def setUpClass(cls):
+ return cls
+
+ @slow
+ @require_torch_gpu
+ def test_distributed_eval(self):
+ output_dir = self.get_auto_remove_tmp_dir()
+ args = f"""
+ --model_name Helsinki-NLP/opus-mt-en-ro
+ --save_dir {output_dir}
+ --data_dir {self.test_file_dir_str}/test_data/wmt_en_ro
+ --num_beams 2
+ --task translation
+ """.split()
+
+ # we want this test to run even if there is only one GPU, but if there are more we use them all
+ n_gpu = get_gpu_count()
+ distributed_args = f"""
+ -m torch.distributed.launch
+ --nproc_per_node={n_gpu}
+ {self.test_file_dir}/run_distributed_eval.py
+ """.split()
+ cmd = [sys.executable] + distributed_args + args
+ execute_subprocess_async(cmd, env=self.get_env())
+
+ metrics_save_path = os.path.join(output_dir, "test_bleu.json")
+ metrics = load_json(metrics_save_path)
+ # print(metrics)
+ self.assertGreaterEqual(metrics["bleu"], 25)
diff --git a/docs/transformers/examples/legacy/seq2seq/old_test_tatoeba_conversion.py b/docs/transformers/examples/legacy/seq2seq/old_test_tatoeba_conversion.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9733daf85e186b72eeb24d2b07347f10cea2586
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/old_test_tatoeba_conversion.py
@@ -0,0 +1,38 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import tempfile
+import unittest
+
+from transformers.models.marian.convert_marian_tatoeba_to_pytorch import DEFAULT_REPO, TatoebaConverter
+from transformers.testing_utils import slow
+from transformers.utils import cached_property
+
+
+@unittest.skipUnless(os.path.exists(DEFAULT_REPO), "Tatoeba directory does not exist.")
+class TatoebaConversionTester(unittest.TestCase):
+ @cached_property
+ def resolver(self):
+ tmp_dir = tempfile.mkdtemp()
+ return TatoebaConverter(save_dir=tmp_dir)
+
+ @slow
+ def test_resolver(self):
+ self.resolver.convert_models(["heb-eng"])
+
+ @slow
+ def test_model_card(self):
+ content, mmeta = self.resolver.write_model_card("opus-mt-he-en", dry_run=True)
+ assert mmeta["long_pair"] == "heb-eng"
diff --git a/docs/transformers/examples/legacy/seq2seq/pack_dataset.py b/docs/transformers/examples/legacy/seq2seq/pack_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c13c74f412df6b46f0b7020c83f9a6476e3f2df
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/pack_dataset.py
@@ -0,0 +1,87 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Fill examples with bitext up to max_tokens without breaking up examples.
+[['I went', 'yo fui'],
+['to the store', 'a la tienda']
+]
+=> ['I went to the store', 'yo fui a la tienda']
+"""
+
+import argparse
+import shutil
+from pathlib import Path
+
+from tqdm import tqdm
+
+from transformers import AutoTokenizer
+
+
+def pack_examples(tok, src_examples, tgt_examples, max_tokens=1024):
+ finished_src, finished_tgt = [], []
+
+ sorted_examples = list(zip(src_examples, tgt_examples))
+ new_src, new_tgt = sorted_examples[0]
+
+ def is_too_big(strang):
+ return tok(strang, return_tensors="pt").input_ids.shape[1] > max_tokens
+
+ for src, tgt in tqdm(sorted_examples[1:]):
+ cand_src = new_src + " " + src
+ cand_tgt = new_tgt + " " + tgt
+ if is_too_big(cand_src) or is_too_big(cand_tgt): # cant fit, finalize example
+ finished_src.append(new_src)
+ finished_tgt.append(new_tgt)
+ new_src, new_tgt = src, tgt
+ else: # can fit, keep adding
+ new_src, new_tgt = cand_src, cand_tgt
+
+ # cleanup
+ if new_src:
+ assert new_tgt
+ finished_src.append(new_src)
+ finished_tgt.append(new_tgt)
+ return finished_src, finished_tgt
+
+
+def pack_data_dir(tok, data_dir: Path, max_tokens, save_path):
+ save_path = Path(save_path)
+ save_path.mkdir(exist_ok=True)
+ for split in ["train"]:
+ src_path, tgt_path = data_dir / f"{split}.source", data_dir / f"{split}.target"
+ src_docs = [x.rstrip() for x in Path(src_path).open().readlines()]
+ tgt_docs = [x.rstrip() for x in Path(tgt_path).open().readlines()]
+ packed_src, packed_tgt = pack_examples(tok, src_docs, tgt_docs, max_tokens)
+ print(f"packed {split} split from {len(src_docs)} examples -> {len(packed_src)}.")
+ Path(save_path / f"{split}.source").open("w").write("\n".join(packed_src))
+ Path(save_path / f"{split}.target").open("w").write("\n".join(packed_tgt))
+ for split in ["val", "test"]:
+ src_path, tgt_path = data_dir / f"{split}.source", data_dir / f"{split}.target"
+ shutil.copyfile(src_path, save_path / f"{split}.source")
+ shutil.copyfile(tgt_path, save_path / f"{split}.target")
+
+
+def packer_cli():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--tok_name", type=str, help="like facebook/bart-large-cnn,google-t5/t5-base, etc.")
+ parser.add_argument("--max_seq_len", type=int, default=128)
+ parser.add_argument("--data_dir", type=str)
+ parser.add_argument("--save_path", type=str)
+ args = parser.parse_args()
+ tokenizer = AutoTokenizer.from_pretrained(args.tok_name)
+ return pack_data_dir(tokenizer, Path(args.data_dir), args.max_seq_len, args.save_path)
+
+
+if __name__ == "__main__":
+ packer_cli()
diff --git a/docs/transformers/examples/legacy/seq2seq/requirements.txt b/docs/transformers/examples/legacy/seq2seq/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..434f647adea299b8dea378171fa687d38d78ead6
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/requirements.txt
@@ -0,0 +1,20 @@
+tensorboard
+scikit-learn
+seqeval
+psutil
+sacrebleu
+rouge-score
+tensorflow_datasets
+matplotlib
+git-python==1.0.3
+faiss-cpu
+streamlit
+elasticsearch
+nltk
+pandas
+datasets >= 1.1.3
+fire
+pytest<8.0.1
+conllu
+sentencepiece != 0.1.92
+protobuf
diff --git a/docs/transformers/examples/legacy/seq2seq/romanian_postprocessing.md b/docs/transformers/examples/legacy/seq2seq/romanian_postprocessing.md
new file mode 100644
index 0000000000000000000000000000000000000000..938f0d1d7227f5687ec45f35f8dcff659172dfe2
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/romanian_postprocessing.md
@@ -0,0 +1,65 @@
+### Motivation
+Without processing, english-> romanian mbart-large-en-ro gets BLEU score 26.8 on the WMT data.
+With post processing, it can score 37..
+Here is the postprocessing code, stolen from @mjpost in this [issue](https://github.com/pytorch/fairseq/issues/1758)
+
+
+
+### Instructions
+Note: You need to have your test_generations.txt before you start this process.
+(1) Setup `mosesdecoder` and `wmt16-scripts`
+```bash
+cd $HOME
+git clone git@github.com:moses-smt/mosesdecoder.git
+cd mosesdecoder
+git clone git@github.com:rsennrich/wmt16-scripts.git
+```
+
+(2) define a function for post processing.
+ It removes diacritics and does other things I don't understand
+```bash
+ro_post_process () {
+ sys=$1
+ ref=$2
+ export MOSES_PATH=$HOME/mosesdecoder
+ REPLACE_UNICODE_PUNCT=$MOSES_PATH/scripts/tokenizer/replace-unicode-punctuation.perl
+ NORM_PUNC=$MOSES_PATH/scripts/tokenizer/normalize-punctuation.perl
+ REM_NON_PRINT_CHAR=$MOSES_PATH/scripts/tokenizer/remove-non-printing-char.perl
+ REMOVE_DIACRITICS=$MOSES_PATH/wmt16-scripts/preprocess/remove-diacritics.py
+ NORMALIZE_ROMANIAN=$MOSES_PATH/wmt16-scripts/preprocess/normalise-romanian.py
+ TOKENIZER=$MOSES_PATH/scripts/tokenizer/tokenizer.perl
+
+
+
+ lang=ro
+ for file in $sys $ref; do
+ cat $file \
+ | $REPLACE_UNICODE_PUNCT \
+ | $NORM_PUNC -l $lang \
+ | $REM_NON_PRINT_CHAR \
+ | $NORMALIZE_ROMANIAN \
+ | $REMOVE_DIACRITICS \
+ | $TOKENIZER -no-escape -l $lang \
+ > $(basename $file).tok
+ done
+ # compute BLEU
+ cat $(basename $sys).tok | sacrebleu -tok none -s none -b $(basename $ref).tok
+}
+```
+
+(3) Call the function on test_generations.txt and test.target
+For example,
+```bash
+ro_post_process enro_finetune/test_generations.txt wmt_en_ro/test.target
+```
+This will split out a new blue score and write a new fine called `test_generations.tok` with post-processed outputs.
+
+
+
+
+
+
+
+
+
+```
diff --git a/docs/transformers/examples/legacy/seq2seq/rouge_cli.py b/docs/transformers/examples/legacy/seq2seq/rouge_cli.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd636bbcd1c10ca34ae36f8d348ef97a09c0e293
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/rouge_cli.py
@@ -0,0 +1,31 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import fire
+
+from utils import calculate_rouge, save_json
+
+
+def calculate_rouge_path(pred_path, tgt_path, save_path=None, **kwargs):
+ """Kwargs will be passed to calculate_rouge"""
+ pred_lns = [x.strip() for x in open(pred_path).readlines()]
+ tgt_lns = [x.strip() for x in open(tgt_path).readlines()][: len(pred_lns)]
+ metrics = calculate_rouge(pred_lns, tgt_lns, **kwargs)
+ if save_path is not None:
+ save_json(metrics, save_path, indent=None)
+ return metrics # these print nicely
+
+
+if __name__ == "__main__":
+ fire.Fire(calculate_rouge_path)
diff --git a/docs/transformers/examples/legacy/seq2seq/run_distributed_eval.py b/docs/transformers/examples/legacy/seq2seq/run_distributed_eval.py
new file mode 100644
index 0000000000000000000000000000000000000000..41855eaed6b2f0d6fc650bcc301db171b17fbf04
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/run_distributed_eval.py
@@ -0,0 +1,261 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import shutil
+import time
+from json import JSONDecodeError
+from logging import getLogger
+from pathlib import Path
+
+import torch
+from torch.utils.data import DataLoader
+from tqdm import tqdm
+
+from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+from utils import (
+ Seq2SeqDataset,
+ calculate_bleu,
+ calculate_rouge,
+ chunks,
+ lmap,
+ load_json,
+ parse_numeric_n_bool_cl_kwargs,
+ save_json,
+ use_task_specific_params,
+ write_txt_file,
+)
+
+
+logger = getLogger(__name__)
+
+
+def eval_data_dir(
+ data_dir,
+ save_dir: str,
+ model_name: str,
+ bs: int = 8,
+ max_source_length: int = 1024,
+ type_path="val",
+ n_obs=None,
+ fp16=False,
+ task="summarization",
+ local_rank=None,
+ num_return_sequences=1,
+ dataset_kwargs: dict = None,
+ prefix="",
+ **generate_kwargs,
+) -> dict:
+ """Run evaluation on part of the data for one gpu and save to {save_dir}/rank_{rank}_output.json"""
+ model_name = str(model_name)
+ assert local_rank is not None
+ torch.distributed.init_process_group(backend="nccl", rank=local_rank)
+
+ save_dir = Path(save_dir)
+ save_path = save_dir.joinpath(f"rank_{local_rank}_output.json")
+ torch.cuda.set_device(local_rank)
+ model = AutoModelForSeq2SeqLM.from_pretrained(model_name).cuda()
+ if fp16:
+ model = model.half()
+ # determine if we need to increase num_beams
+ use_task_specific_params(model, task) # update config with task specific params
+ num_beams = generate_kwargs.pop("num_beams", model.config.num_beams) # AttributeError risk?
+ if num_return_sequences > num_beams:
+ num_beams = num_return_sequences
+
+ tokenizer = AutoTokenizer.from_pretrained(model_name)
+ logger.info(f"Inferred tokenizer type: {tokenizer.__class__}") # if this is wrong, check config.model_type.
+
+ if max_source_length is None:
+ max_source_length = tokenizer.model_max_length
+ if prefix is None:
+ prefix = prefix or getattr(model.config, "prefix", "") or ""
+ ds = Seq2SeqDataset(
+ tokenizer,
+ data_dir,
+ max_source_length,
+ max_target_length=1024,
+ type_path=type_path,
+ n_obs=n_obs,
+ prefix=prefix,
+ **dataset_kwargs,
+ )
+ # I set shuffle=True for a more accurate progress bar.
+ # If all the longest samples are first, the prog bar estimate is too high at the beginning.
+ sampler = ds.make_sortish_sampler(bs, distributed=True, add_extra_examples=False, shuffle=True)
+ data_loader = DataLoader(ds, sampler=sampler, batch_size=bs, collate_fn=ds.collate_fn)
+ results = []
+ for batch in tqdm(data_loader):
+ summaries = model.generate(
+ input_ids=batch["input_ids"].to(model.device),
+ attention_mask=batch["attention_mask"].to(model.device),
+ num_return_sequences=num_return_sequences,
+ num_beams=num_beams,
+ **generate_kwargs,
+ )
+ preds = tokenizer.batch_decode(summaries, skip_special_tokens=True, clean_up_tokenization_spaces=False)
+ ids = batch["ids"]
+ if num_return_sequences > 1:
+ preds = chunks(preds, num_return_sequences) # batch size chunks, each of size num_return_seq
+ for i, pred in enumerate(preds):
+ results.append({"pred": pred, "id": ids[i].item()})
+ save_json(results, save_path)
+ return results, sampler.num_replicas
+
+
+def run_generate():
+ parser = argparse.ArgumentParser(
+ epilog="Unspecified args like --num_beams=2 --decoder_start_token_id=4 are passed to model.generate"
+ )
+ parser.add_argument("--data_dir", type=str, help="like cnn_dm/test.source")
+ parser.add_argument(
+ "--model_name",
+ type=str,
+ help="like facebook/bart-large-cnn,google-t5/t5-base, etc.",
+ default="sshleifer/distilbart-xsum-12-3",
+ )
+ parser.add_argument("--save_dir", type=str, help="where to save", default="tmp_gen")
+ parser.add_argument("--max_source_length", type=int, default=None)
+ parser.add_argument(
+ "--type_path", type=str, default="test", help="which subset to evaluate typically train/val/test"
+ )
+ parser.add_argument("--task", type=str, default="summarization", help="used for task_specific_params + metrics")
+ parser.add_argument("--bs", type=int, default=8, required=False, help="batch size")
+ parser.add_argument(
+ "--local_rank", type=int, default=-1, required=False, help="should be passed by distributed.launch"
+ )
+
+ parser.add_argument(
+ "--n_obs", type=int, default=None, required=False, help="How many observations. Defaults to all."
+ )
+ parser.add_argument(
+ "--num_return_sequences", type=int, default=1, required=False, help="How many sequences to return"
+ )
+ parser.add_argument(
+ "--sync_timeout",
+ type=int,
+ default=600,
+ required=False,
+ help="How long should master process wait for other processes to finish.",
+ )
+ parser.add_argument("--src_lang", type=str, default=None, required=False)
+ parser.add_argument("--tgt_lang", type=str, default=None, required=False)
+ parser.add_argument(
+ "--prefix", type=str, required=False, default=None, help="will be added to the beginning of src examples"
+ )
+ parser.add_argument("--fp16", action="store_true")
+ parser.add_argument("--debug", action="store_true")
+ start_time = time.time()
+ args, rest = parser.parse_known_args()
+ generate_kwargs = parse_numeric_n_bool_cl_kwargs(rest)
+ if generate_kwargs and args.local_rank <= 0:
+ print(f"parsed the following generate kwargs: {generate_kwargs}")
+ json_save_dir = Path(args.save_dir + "_tmp")
+ Path(json_save_dir).mkdir(exist_ok=True) # this handles locking.
+ intermediate_files = list(json_save_dir.glob("rank_*.json"))
+ if intermediate_files:
+ raise ValueError(f"Found files at {json_save_dir} please move or remove them.")
+ # In theory, a node could finish and save before another node hits this. If this happens, we can address later.
+ dataset_kwargs = {}
+ if args.src_lang is not None:
+ dataset_kwargs["src_lang"] = args.src_lang
+ if args.tgt_lang is not None:
+ dataset_kwargs["tgt_lang"] = args.tgt_lang
+
+ Path(args.save_dir).mkdir(exist_ok=True)
+ results, num_replicas = eval_data_dir(
+ args.data_dir,
+ json_save_dir,
+ args.model_name,
+ type_path=args.type_path,
+ bs=args.bs,
+ fp16=args.fp16,
+ task=args.task,
+ local_rank=args.local_rank,
+ n_obs=args.n_obs,
+ max_source_length=args.max_source_length,
+ num_return_sequences=args.num_return_sequences,
+ prefix=args.prefix,
+ dataset_kwargs=dataset_kwargs,
+ **generate_kwargs,
+ )
+
+ if args.local_rank <= 0:
+ save_dir = Path(args.save_dir)
+ save_dir.mkdir(exist_ok=True)
+ partial_results = gather_results_from_each_node(num_replicas, json_save_dir, args.sync_timeout)
+ preds = combine_partial_results(partial_results)
+ if args.num_return_sequences > 1:
+ save_path = save_dir.joinpath("pseudolabel_results.json")
+ print(f"Saving aggregated results at {save_path}, intermediate in {json_save_dir}/")
+ save_json(preds, save_path)
+ return
+ tgt_file = Path(args.data_dir).joinpath(args.type_path + ".target")
+ with open(tgt_file) as f:
+ labels = [x.rstrip() for x in f.readlines()][: len(preds)]
+
+ # Calculate metrics, save metrics, and save _generations.txt
+ calc_bleu = "translation" in args.task
+ score_fn = calculate_bleu if calc_bleu else calculate_rouge
+ metric_name = "bleu" if calc_bleu else "rouge"
+ metrics: dict = score_fn(preds, labels)
+ metrics["n_obs"] = len(preds)
+ runtime = time.time() - start_time
+ metrics["seconds_per_sample"] = round(runtime / metrics["n_obs"], 4)
+ metrics["n_gpus"] = num_replicas
+ # TODO(@stas00): add whatever metadata to metrics
+ metrics_save_path = save_dir.joinpath(f"{args.type_path}_{metric_name}.json")
+ save_json(metrics, metrics_save_path, indent=None)
+ print(metrics)
+ write_txt_file(preds, save_dir.joinpath(f"{args.type_path}_generations.txt"))
+ if args.debug:
+ write_txt_file(labels, save_dir.joinpath(f"{args.type_path}.target"))
+ else:
+ shutil.rmtree(json_save_dir)
+
+
+def combine_partial_results(partial_results) -> list:
+ """Concatenate partial results into one file, then sort it by id."""
+ records = []
+ for partial_result in partial_results:
+ records.extend(partial_result)
+ records = sorted(records, key=lambda x: x["id"])
+ preds = [x["pred"] for x in records]
+ return preds
+
+
+def gather_results_from_each_node(num_replicas, save_dir, timeout) -> list[dict[str, list]]:
+ # WAIT FOR lots of .json files
+ start_wait = time.time()
+ logger.info("waiting for all nodes to finish")
+ json_data = None
+ while (time.time() - start_wait) < timeout:
+ json_files = list(save_dir.glob("rank_*.json"))
+ if len(json_files) < num_replicas:
+ continue
+ try:
+ # make sure all json files are fully saved
+ json_data = lmap(load_json, json_files)
+ return json_data
+ except JSONDecodeError:
+ continue
+ else:
+ raise TimeoutError("Rank 0 gave up on waiting for other processes")
+ # Unreachable
+
+
+if __name__ == "__main__":
+ # Usage for MT:
+ run_generate()
diff --git a/docs/transformers/examples/legacy/seq2seq/run_eval.py b/docs/transformers/examples/legacy/seq2seq/run_eval.py
new file mode 100644
index 0000000000000000000000000000000000000000..f5ef4f5d165431e64f641ec61eadc464a980bb92
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/run_eval.py
@@ -0,0 +1,184 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import datetime
+import json
+import time
+import warnings
+from logging import getLogger
+from pathlib import Path
+
+import torch
+from tqdm import tqdm
+
+from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+from utils import calculate_bleu, calculate_rouge, chunks, parse_numeric_n_bool_cl_kwargs, use_task_specific_params
+
+
+logger = getLogger(__name__)
+
+
+DEFAULT_DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
+
+
+def generate_summaries_or_translations(
+ examples: list[str],
+ out_file: str,
+ model_name: str,
+ batch_size: int = 8,
+ device: str = DEFAULT_DEVICE,
+ fp16=False,
+ task="summarization",
+ prefix=None,
+ **generate_kwargs,
+) -> dict:
+ """Save model.generate results to , and return how long it took."""
+ fout = Path(out_file).open("w", encoding="utf-8")
+ model_name = str(model_name)
+ model = AutoModelForSeq2SeqLM.from_pretrained(model_name).to(device)
+ if fp16:
+ model = model.half()
+
+ tokenizer = AutoTokenizer.from_pretrained(model_name)
+ logger.info(f"Inferred tokenizer type: {tokenizer.__class__}") # if this is wrong, check config.model_type.
+
+ start_time = time.time()
+ # update config with task specific params
+ use_task_specific_params(model, task)
+ if prefix is None:
+ prefix = prefix or getattr(model.config, "prefix", "") or ""
+ for examples_chunk in tqdm(list(chunks(examples, batch_size))):
+ examples_chunk = [prefix + text for text in examples_chunk]
+ batch = tokenizer(examples_chunk, return_tensors="pt", truncation=True, padding="longest").to(device)
+ summaries = model.generate(
+ input_ids=batch.input_ids,
+ attention_mask=batch.attention_mask,
+ **generate_kwargs,
+ )
+ dec = tokenizer.batch_decode(summaries, skip_special_tokens=True, clean_up_tokenization_spaces=False)
+ for hypothesis in dec:
+ fout.write(hypothesis + "\n")
+ fout.flush()
+ fout.close()
+ runtime = int(time.time() - start_time) # seconds
+ n_obs = len(examples)
+ return {"n_obs": n_obs, "runtime": runtime, "seconds_per_sample": round(runtime / n_obs, 4)}
+
+
+def datetime_now():
+ return datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
+
+
+def run_generate(verbose=True):
+ """
+
+ Takes input text, generates output, and then using reference calculates the BLEU scores.
+
+ The results are saved to a file and returned to the caller, and printed out unless ``verbose=False`` is passed.
+
+ Args:
+ verbose (:obj:`bool`, `optional`, defaults to :obj:`True`): print results to stdout
+
+ Returns:
+ a tuple: ``(scores, params}``
+ - ``scores``: a dict of scores data ``{'bleu': 39.6501, 'n_obs': 2000, 'runtime': 186, 'seconds_per_sample': 0.093}``
+ - ``params``: a dict of custom params, e.g. ``{'num_beams': 5, 'length_penalty': 0.8}``
+ """
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument("model_name", type=str, help="like facebook/bart-large-cnn,google-t5/t5-base, etc.")
+ parser.add_argument("input_path", type=str, help="like cnn_dm/test.source")
+ parser.add_argument("save_path", type=str, help="where to save summaries")
+ parser.add_argument("--reference_path", type=str, required=False, help="like cnn_dm/test.target")
+ parser.add_argument("--score_path", type=str, required=False, default="metrics.json", help="where to save metrics")
+ parser.add_argument("--device", type=str, required=False, default=DEFAULT_DEVICE, help="cuda, cuda:1, cpu etc.")
+ parser.add_argument(
+ "--prefix", type=str, required=False, default=None, help="will be added to the beginning of src examples"
+ )
+ parser.add_argument("--task", type=str, default="summarization", help="used for task_specific_params + metrics")
+ parser.add_argument("--bs", type=int, default=8, required=False, help="batch size")
+ parser.add_argument(
+ "--n_obs", type=int, default=-1, required=False, help="How many observations. Defaults to all."
+ )
+ parser.add_argument("--fp16", action="store_true")
+ parser.add_argument("--dump-args", action="store_true", help="print the custom hparams with the results")
+ parser.add_argument(
+ "--info",
+ nargs="?",
+ type=str,
+ const=datetime_now(),
+ help=(
+ "use in conjunction w/ --dump-args to print with the results whatever other info you'd like, e.g."
+ " lang=en-ru. If no value is passed, the current datetime string will be used."
+ ),
+ )
+ # Unspecified args like --num_beams=2 --decoder_start_token_id=4 are passed to model.generate
+ args, rest = parser.parse_known_args()
+ parsed_args = parse_numeric_n_bool_cl_kwargs(rest)
+ if parsed_args and verbose:
+ print(f"parsed the following generate kwargs: {parsed_args}")
+ examples = [" " + x.rstrip() if "t5" in args.model_name else x.rstrip() for x in open(args.input_path).readlines()]
+ if args.n_obs > 0:
+ examples = examples[: args.n_obs]
+ Path(args.save_path).parent.mkdir(exist_ok=True)
+
+ if args.reference_path is None and Path(args.score_path).exists():
+ warnings.warn(f"score_path {args.score_path} will be overwritten unless you type ctrl-c.")
+
+ if args.device == "cpu" and args.fp16:
+ # this mix leads to RuntimeError: "threshold_cpu" not implemented for 'Half'
+ raise ValueError("Can't mix --fp16 and --device cpu")
+
+ runtime_metrics = generate_summaries_or_translations(
+ examples,
+ args.save_path,
+ args.model_name,
+ batch_size=args.bs,
+ device=args.device,
+ fp16=args.fp16,
+ task=args.task,
+ prefix=args.prefix,
+ **parsed_args,
+ )
+
+ if args.reference_path is None:
+ return {}
+
+ # Compute scores
+ score_fn = calculate_bleu if "translation" in args.task else calculate_rouge
+ output_lns = [x.rstrip() for x in open(args.save_path).readlines()]
+ reference_lns = [x.rstrip() for x in open(args.reference_path).readlines()][: len(output_lns)]
+ scores: dict = score_fn(output_lns, reference_lns)
+ scores.update(runtime_metrics)
+
+ if args.dump_args:
+ scores.update(parsed_args)
+ if args.info:
+ scores["info"] = args.info
+
+ if verbose:
+ print(scores)
+
+ if args.score_path is not None:
+ json.dump(scores, open(args.score_path, "w"))
+
+ return scores
+
+
+if __name__ == "__main__":
+ # Usage for MT:
+ # python run_eval.py MODEL_NAME $DATA_DIR/test.source $save_dir/test_translations.txt --reference_path $DATA_DIR/test.target --score_path $save_dir/test_bleu.json --task translation $@
+ run_generate(verbose=True)
diff --git a/docs/transformers/examples/legacy/seq2seq/run_eval_search.py b/docs/transformers/examples/legacy/seq2seq/run_eval_search.py
new file mode 100644
index 0000000000000000000000000000000000000000..e911eca57048ca5764177a7910e008950d6bc695
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/run_eval_search.py
@@ -0,0 +1,158 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import itertools
+import operator
+import sys
+from collections import OrderedDict
+
+from run_eval import datetime_now, run_generate
+
+from utils import ROUGE_KEYS
+
+
+# A table of supported tasks and the list of scores in the order of importance to be sorted by.
+# To add a new task, simply list the score names that `run_eval.run_generate()` returns
+task_score_names = {
+ "translation": ["bleu"],
+ "summarization": ROUGE_KEYS,
+}
+
+
+def parse_search_arg(search):
+ groups = search.split()
+ entries = dict(g.split("=") for g in groups)
+ entry_names = list(entries.keys())
+ sets = [[f"--{k} {v}" for v in vs.split(":")] for k, vs in entries.items()]
+ matrix = [list(x) for x in itertools.product(*sets)]
+ return matrix, entry_names
+
+
+def run_search():
+ """
+ Run parametric search over the desired hparam space with help of ``run_eval.py``.
+
+ All the arguments except ``--search`` are passed to ``run_eval.py`` as is. The values inside of "--search" are parsed, reformatted and fed to ``run_eval.py`` as additional args.
+
+ The format for the ``--search`` value is a simple string with hparams and colon separated values to try, e.g.:
+ ```
+ --search "num_beams=5:10 length_penalty=0.8:1.0:1.2 early_stopping=true:false"
+ ```
+ which will generate ``12`` ``(2*3*2)`` searches for a product of each hparam. For example the example that was just used will invoke ``run_eval.py`` repeatedly with:
+
+ ```
+ --num_beams 5 --length_penalty 0.8 --early_stopping true
+ --num_beams 5 --length_penalty 0.8 --early_stopping false
+ [...]
+ --num_beams 10 --length_penalty 1.2 --early_stopping false
+ ```
+
+ On completion, this function prints a markdown table of the results sorted by the best BLEU score and the winning arguments.
+
+
+ """
+ prog = sys.argv[0]
+
+ parser = argparse.ArgumentParser(
+ usage=(
+ "\n\nImportant: this script accepts all arguments `run_eval.py` accepts and then a few extra, therefore"
+ " refer to `run_eval.py -h` for the complete list."
+ )
+ )
+ parser.add_argument(
+ "--search",
+ type=str,
+ required=False,
+ help='param space to search, e.g. "num_beams=5:10 length_penalty=0.8:1.0:1.2"',
+ )
+ parser.add_argument(
+ "--bs", type=int, default=8, required=False, help="initial batch size (may get reduced if it's too big)"
+ )
+ parser.add_argument("--task", type=str, help="used for task_specific_params + metrics")
+ parser.add_argument(
+ "--info",
+ nargs="?",
+ type=str,
+ const=datetime_now(),
+ help=(
+ "add custom notes to be printed before the results table. If no value is passed, the current datetime"
+ " string will be used."
+ ),
+ )
+ args, args_main = parser.parse_known_args()
+ # we share some of the args
+ args_main.extend(["--task", args.task])
+ args_normal = [prog] + args_main
+
+ # to support variations like translation_en_to_de"
+ task = "translation" if "translation" in args.task else "summarization"
+
+ matrix, col_names = parse_search_arg(args.search)
+ col_names[0:0] = task_score_names[task] # score cols first
+ col_widths = {col: len(str(col)) for col in col_names}
+ results = []
+ for r in matrix:
+ hparams = dict(x.replace("--", "").split() for x in r)
+ args_exp = " ".join(r).split()
+ args_exp.extend(["--bs", str(args.bs)]) # in case we need to reduce its size due to CUDA OOM
+ sys.argv = args_normal + args_exp
+
+ # XXX: need to trap CUDA OOM and lower args.bs if that happens and retry
+
+ scores = run_generate(verbose=False)
+ # make sure scores are first in the table
+ result = OrderedDict()
+ for score in task_score_names[task]:
+ result[score] = scores[score]
+ result.update(hparams)
+ results.append(result)
+
+ # find widest entries
+ for k, v in result.items():
+ l = len(str(v))
+ if l > col_widths[k]:
+ col_widths[k] = l
+
+ results_sorted = sorted(results, key=operator.itemgetter(*task_score_names[task]), reverse=True)
+ print(" | ".join([f"{col:{col_widths[col]}}" for col in col_names]))
+ print(" | ".join([f"{'-' * col_widths[col]}" for col in col_names]))
+ for row in results_sorted:
+ print(" | ".join([f"{row[col]:{col_widths[col]}}" for col in col_names]))
+
+ best = results_sorted[0]
+ for score in task_score_names[task]:
+ del best[score]
+ best_args = [f"--{k} {v}" for k, v in best.items()]
+ dyn_args = ["--bs", str(args.bs)]
+ if args.info:
+ print(f"\nInfo: {args.info}")
+ print("\nBest score args:")
+ print(" ".join(args_main + best_args + dyn_args))
+
+ return results_sorted
+
+
+if __name__ == "__main__":
+ # Usage:
+ # [normal-run_eval_search.py cmd plus] \
+ # --search="num_beams=1:5:10 length_penalty=0.8:1:1.2 early_stopping=true:false"
+ #
+ # Example:
+ # PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py $MODEL_NAME \
+ # $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target \
+ # --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation \
+ # --search="num_beams=1:5:10 length_penalty=0.8:1:1.2 early_stopping=true:false"
+ run_search()
diff --git a/docs/transformers/examples/legacy/seq2seq/save_len_file.py b/docs/transformers/examples/legacy/seq2seq/save_len_file.py
new file mode 100644
index 0000000000000000000000000000000000000000..9e73b59e7e5a2b0a480779db987464f8b8320cee
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/save_len_file.py
@@ -0,0 +1,56 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import fire
+from torch.utils.data import DataLoader
+from tqdm import tqdm
+
+from transformers import AutoTokenizer
+from utils import Seq2SeqDataset, pickle_save
+
+
+def save_len_file(
+ tokenizer_name, data_dir, max_source_length=1024, max_target_length=1024, consider_target=False, **kwargs
+):
+ """Save max(src_len, tgt_len) for each example to allow dynamic batching."""
+ tok = AutoTokenizer.from_pretrained(tokenizer_name)
+ train_ds = Seq2SeqDataset(tok, data_dir, max_source_length, max_target_length, type_path="train", **kwargs)
+ pad = tok.pad_token_id
+
+ def get_lens(ds):
+ dl = tqdm(
+ DataLoader(ds, batch_size=512, num_workers=8, shuffle=False, collate_fn=ds.collate_fn),
+ desc=str(ds.len_file),
+ )
+ max_lens = []
+ for batch in dl:
+ src_lens = batch["input_ids"].ne(pad).sum(1).tolist()
+ tgt_lens = batch["labels"].ne(pad).sum(1).tolist()
+ if consider_target:
+ for src, tgt in zip(src_lens, tgt_lens):
+ max_lens.append(max(src, tgt))
+ else:
+ max_lens.extend(src_lens)
+ return max_lens
+
+ train_lens = get_lens(train_ds)
+ val_ds = Seq2SeqDataset(tok, data_dir, max_source_length, max_target_length, type_path="val", **kwargs)
+ val_lens = get_lens(val_ds)
+ pickle_save(train_lens, train_ds.len_file)
+ pickle_save(val_lens, val_ds.len_file)
+
+
+if __name__ == "__main__":
+ fire.Fire(save_len_file)
diff --git a/docs/transformers/examples/legacy/seq2seq/save_randomly_initialized_model.py b/docs/transformers/examples/legacy/seq2seq/save_randomly_initialized_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b7b17fde8d6b0e7f2eed7420c0570012558b1ed
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/save_randomly_initialized_model.py
@@ -0,0 +1,39 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import fire
+
+from transformers import AutoConfig, AutoModelForSeq2SeqLM, AutoTokenizer
+
+
+def save_randomly_initialized_version(config_name: str, save_dir: str, **config_kwargs):
+ """Save a randomly initialized version of a model using a pretrained config.
+ Args:
+ config_name: which config to use
+ save_dir: where to save the resulting model and tokenizer
+ config_kwargs: Passed to AutoConfig
+
+ Usage::
+ save_randomly_initialized_version("facebook/bart-large-cnn", "distilbart_random_cnn_6_3", encoder_layers=6, decoder_layers=3, num_beams=3)
+ """
+ cfg = AutoConfig.from_pretrained(config_name, **config_kwargs)
+ model = AutoModelForSeq2SeqLM.from_config(cfg)
+ model.save_pretrained(save_dir)
+ AutoTokenizer.from_pretrained(config_name).save_pretrained(save_dir)
+ return model
+
+
+if __name__ == "__main__":
+ fire.Fire(save_randomly_initialized_version)
diff --git a/docs/transformers/examples/legacy/seq2seq/sentence_splitter.py b/docs/transformers/examples/legacy/seq2seq/sentence_splitter.py
new file mode 100644
index 0000000000000000000000000000000000000000..54a07967efa31c31ee1219d1a25808df0108388a
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/sentence_splitter.py
@@ -0,0 +1,35 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import re
+
+from filelock import FileLock
+
+
+try:
+ import nltk
+
+ NLTK_AVAILABLE = True
+except (ImportError, ModuleNotFoundError):
+ NLTK_AVAILABLE = False
+
+if NLTK_AVAILABLE:
+ with FileLock(".lock") as lock:
+ nltk.download("punkt", quiet=True)
+
+
+def add_newline_to_end_of_each_sentence(x: str) -> str:
+ """This was added to get rougeLsum scores matching published rougeL scores for BART and PEGASUS."""
+ re.sub("", "", x) # remove pegasus newline char
+ assert NLTK_AVAILABLE, "nltk must be installed to separate newlines between sentences. (pip install nltk)"
+ return "\n".join(nltk.sent_tokenize(x))
diff --git a/docs/transformers/examples/legacy/seq2seq/seq2seq_trainer.py b/docs/transformers/examples/legacy/seq2seq/seq2seq_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..afdde6614e2e5f33f822016f3f3a525705a11549
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/seq2seq_trainer.py
@@ -0,0 +1,248 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Any, Optional, Union
+
+import torch
+from torch import nn
+from torch.utils.data import DistributedSampler, RandomSampler
+
+from transformers import PreTrainedModel, Trainer, logging
+from transformers.models.fsmt.configuration_fsmt import FSMTConfig
+from transformers.optimization import (
+ Adafactor,
+ get_constant_schedule,
+ get_constant_schedule_with_warmup,
+ get_cosine_schedule_with_warmup,
+ get_cosine_with_hard_restarts_schedule_with_warmup,
+ get_linear_schedule_with_warmup,
+ get_polynomial_decay_schedule_with_warmup,
+)
+from transformers.trainer_pt_utils import get_tpu_sampler
+from transformers.training_args import ParallelMode
+from transformers.utils import is_torch_xla_available
+
+
+logger = logging.get_logger(__name__)
+
+arg_to_scheduler = {
+ "linear": get_linear_schedule_with_warmup,
+ "cosine": get_cosine_schedule_with_warmup,
+ "cosine_w_restarts": get_cosine_with_hard_restarts_schedule_with_warmup,
+ "polynomial": get_polynomial_decay_schedule_with_warmup,
+ "constant": get_constant_schedule,
+ "constant_w_warmup": get_constant_schedule_with_warmup,
+}
+
+
+class Seq2SeqTrainer(Trainer):
+ def __init__(self, config=None, data_args=None, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ if config is None:
+ assert isinstance(self.model, PreTrainedModel), (
+ "If no `config` is passed the model to be trained has to be of type `PreTrainedModel`, but is"
+ f" {self.model.__class__}"
+ )
+ self.config = self.model.config
+ else:
+ self.config = config
+
+ self.data_args = data_args
+ self.vocab_size = self.config.tgt_vocab_size if isinstance(self.config, FSMTConfig) else self.config.vocab_size
+
+ if self.args.label_smoothing != 0 or (self.data_args is not None and self.data_args.ignore_pad_token_for_loss):
+ assert self.config.pad_token_id is not None, (
+ "Make sure that `config.pad_token_id` is correctly defined when ignoring `pad_token` for loss"
+ " calculation or doing label smoothing."
+ )
+
+ if self.config.pad_token_id is None and self.config.eos_token_id is not None:
+ logger.warning(
+ f"The `config.pad_token_id` is `None`. Using `config.eos_token_id` = {self.config.eos_token_id} for"
+ " padding.."
+ )
+
+ if self.args.label_smoothing == 0:
+ self.loss_fn = torch.nn.CrossEntropyLoss(ignore_index=self.config.pad_token_id)
+ else:
+ # dynamically import label_smoothed_nll_loss
+ from utils import label_smoothed_nll_loss
+
+ self.loss_fn = label_smoothed_nll_loss
+
+ def create_optimizer_and_scheduler(self, num_training_steps: int):
+ """
+ Setup the optimizer and the learning rate scheduler.
+
+ We provide a reasonable default that works well. If you want to use something else, you can pass a tuple in the
+ Trainer's init through :obj:`optimizers`, or subclass and override this method in a subclass.
+ """
+ if self.optimizer is None:
+ no_decay = ["bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in self.model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": self.args.weight_decay,
+ },
+ {
+ "params": [p for n, p in self.model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ if self.args.adafactor:
+ optimizer_cls = Adafactor
+ optimizer_kwargs = {"scale_parameter": False, "relative_step": False}
+ else:
+ optimizer_cls = torch.optim.AdamW
+ optimizer_kwargs = {
+ "betas": (self.args.adam_beta1, self.args.adam_beta2),
+ "eps": self.args.adam_epsilon,
+ }
+ optimizer_kwargs["lr"] = self.args.learning_rate
+ self.optimizer = optimizer_cls(optimizer_grouped_parameters, **optimizer_kwargs)
+
+ if self.lr_scheduler is None:
+ self.lr_scheduler = self._get_lr_scheduler(num_training_steps)
+ else: # ignoring --lr_scheduler
+ logger.warning("scheduler is passed to `Seq2SeqTrainer`, `--lr_scheduler` arg is ignored.")
+
+ def _get_lr_scheduler(self, num_training_steps):
+ schedule_func = arg_to_scheduler[self.args.lr_scheduler]
+ if self.args.lr_scheduler == "constant":
+ scheduler = schedule_func(self.optimizer)
+ elif self.args.lr_scheduler == "constant_w_warmup":
+ scheduler = schedule_func(self.optimizer, num_warmup_steps=self.args.warmup_steps)
+ else:
+ scheduler = schedule_func(
+ self.optimizer, num_warmup_steps=self.args.warmup_steps, num_training_steps=num_training_steps
+ )
+ return scheduler
+
+ def _get_train_sampler(self) -> Optional[torch.utils.data.Sampler]:
+ if isinstance(self.train_dataset, torch.utils.data.IterableDataset):
+ return None
+ elif is_torch_xla_available():
+ return get_tpu_sampler(self.train_dataset)
+ else:
+ if self.args.sortish_sampler:
+ self.train_dataset.make_sortish_sampler(
+ self.args.per_device_train_batch_size,
+ distributed=(self.args.parallel_mode == ParallelMode.DISTRIBUTED),
+ )
+
+ return (
+ RandomSampler(self.train_dataset)
+ if self.args.local_rank == -1
+ else DistributedSampler(self.train_dataset)
+ )
+
+ def _compute_loss(self, model, inputs, labels):
+ if self.args.label_smoothing == 0:
+ if self.data_args is not None and self.data_args.ignore_pad_token_for_loss:
+ # force training to ignore pad token
+ logits = model(**inputs, use_cache=False)[0]
+ loss = self.loss_fn(logits.view(-1, logits.shape[-1]), labels.view(-1))
+ else:
+ # compute usual loss via models
+ loss, logits = model(**inputs, labels=labels, use_cache=False)[:2]
+ else:
+ # compute label smoothed loss
+ logits = model(**inputs, use_cache=False)[0]
+ lprobs = torch.nn.functional.log_softmax(logits, dim=-1)
+ loss, _ = self.loss_fn(lprobs, labels, self.args.label_smoothing, ignore_index=self.config.pad_token_id)
+ return loss, logits
+
+ def compute_loss(self, model, inputs):
+ labels = inputs.pop("labels")
+ loss, _ = self._compute_loss(model, inputs, labels)
+ return loss
+
+ def prediction_step(
+ self,
+ model: nn.Module,
+ inputs: dict[str, Union[torch.Tensor, Any]],
+ prediction_loss_only: bool,
+ ignore_keys: Optional[list[str]] = None,
+ ) -> tuple[Optional[float], Optional[torch.Tensor], Optional[torch.Tensor]]:
+ """
+ Perform an evaluation step on :obj:`model` using obj:`inputs`.
+
+ Subclass and override to inject custom behavior.
+
+ Args:
+ model (:obj:`nn.Module`):
+ The model to evaluate.
+ inputs (:obj:`Dict[str, Union[torch.Tensor, Any]]`):
+ The inputs and targets of the model.
+
+ The dictionary will be unpacked before being fed to the model. Most models expect the targets under the
+ argument :obj:`labels`. Check your model's documentation for all accepted arguments.
+ prediction_loss_only (:obj:`bool`):
+ Whether or not to return the loss only.
+
+ Return:
+ Tuple[Optional[float], Optional[torch.Tensor], Optional[torch.Tensor]]:
+ A tuple with the loss, logits and labels (each being optional).
+ """
+ inputs = self._prepare_inputs(inputs)
+
+ gen_kwargs = {
+ "max_length": self.data_args.val_max_target_length
+ if self.data_args is not None
+ else self.config.max_length,
+ "num_beams": self.data_args.eval_beams if self.data_args is not None else self.config.num_beams,
+ }
+
+ if self.args.predict_with_generate and not self.args.prediction_loss_only:
+ generated_tokens = self.model.generate(
+ inputs["input_ids"],
+ attention_mask=inputs["attention_mask"],
+ **gen_kwargs,
+ )
+ # in case the batch is shorter than max length, the output should be padded
+ if generated_tokens.shape[-1] < gen_kwargs["max_length"]:
+ generated_tokens = self._pad_tensors_to_max_len(generated_tokens, gen_kwargs["max_length"])
+
+ labels = inputs.pop("labels")
+ with torch.no_grad():
+ # compute loss on predict data
+ loss, logits = self._compute_loss(model, inputs, labels)
+
+ loss = loss.mean().detach()
+ if self.args.prediction_loss_only:
+ return (loss, None, None)
+
+ logits = generated_tokens if self.args.predict_with_generate else logits
+
+ if labels.shape[-1] < gen_kwargs["max_length"]:
+ labels = self._pad_tensors_to_max_len(labels, gen_kwargs["max_length"])
+
+ return (loss, logits, labels)
+
+ def _pad_tensors_to_max_len(self, tensor, max_length):
+ # If PAD token is not defined at least EOS token has to be defined
+ pad_token_id = self.config.pad_token_id if self.config.pad_token_id is not None else self.config.eos_token_id
+
+ if pad_token_id is None:
+ raise ValueError(
+ "Make sure that either `config.pad_token_id` or `config.eos_token_id` is defined if tensor has to be"
+ f" padded to `max_length`={max_length}"
+ )
+
+ padded_tensor = pad_token_id * torch.ones(
+ (tensor.shape[0], max_length), dtype=tensor.dtype, device=tensor.device
+ )
+ padded_tensor[:, : tensor.shape[-1]] = tensor
+ return padded_tensor
diff --git a/docs/transformers/examples/legacy/seq2seq/seq2seq_training_args.py b/docs/transformers/examples/legacy/seq2seq/seq2seq_training_args.py
new file mode 100644
index 0000000000000000000000000000000000000000..9da1c69262a8c0c3907597ecffd435dc78929919
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/seq2seq_training_args.py
@@ -0,0 +1,60 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import logging
+from dataclasses import dataclass, field
+from typing import Optional
+
+from seq2seq_trainer import arg_to_scheduler
+
+from transformers import TrainingArguments
+
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class Seq2SeqTrainingArguments(TrainingArguments):
+ """
+ Parameters:
+ label_smoothing (:obj:`float`, `optional`, defaults to 0):
+ The label smoothing epsilon to apply (if not zero).
+ sortish_sampler (:obj:`bool`, `optional`, defaults to :obj:`False`):
+ Whether to SortishSampler or not. It sorts the inputs according to lengths in-order to minimizing the padding size.
+ predict_with_generate (:obj:`bool`, `optional`, defaults to :obj:`False`):
+ Whether to use generate to calculate generative metrics (ROUGE, BLEU).
+ """
+
+ label_smoothing: Optional[float] = field(
+ default=0.0, metadata={"help": "The label smoothing epsilon to apply (if not zero)."}
+ )
+ sortish_sampler: bool = field(default=False, metadata={"help": "Whether to SortishSampler or not."})
+ predict_with_generate: bool = field(
+ default=False, metadata={"help": "Whether to use generate to calculate generative metrics (ROUGE, BLEU)."}
+ )
+ adafactor: bool = field(default=False, metadata={"help": "whether to use adafactor"})
+ encoder_layerdrop: Optional[float] = field(
+ default=None, metadata={"help": "Encoder layer dropout probability. Goes into model.config."}
+ )
+ decoder_layerdrop: Optional[float] = field(
+ default=None, metadata={"help": "Decoder layer dropout probability. Goes into model.config."}
+ )
+ dropout: Optional[float] = field(default=None, metadata={"help": "Dropout probability. Goes into model.config."})
+ attention_dropout: Optional[float] = field(
+ default=None, metadata={"help": "Attention dropout probability. Goes into model.config."}
+ )
+ lr_scheduler: Optional[str] = field(
+ default="linear",
+ metadata={"help": f"Which lr scheduler to use. Selected in {sorted(arg_to_scheduler.keys())}"},
+ )
diff --git a/docs/transformers/examples/legacy/seq2seq/test_data/fsmt/build-eval-data.py b/docs/transformers/examples/legacy/seq2seq/test_data/fsmt/build-eval-data.py
new file mode 100644
index 0000000000000000000000000000000000000000..8f518822b4510ce36609a379fea5456075d2d245
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/test_data/fsmt/build-eval-data.py
@@ -0,0 +1,32 @@
+#!/usr/bin/env python
+
+import json
+import subprocess
+
+
+pairs = [
+ ["en", "ru"],
+ ["ru", "en"],
+ ["en", "de"],
+ ["de", "en"],
+]
+
+n_objs = 8
+
+
+def get_all_data(pairs, n_objs):
+ text = {}
+ for src, tgt in pairs:
+ pair = f"{src}-{tgt}"
+ cmd = f"sacrebleu -t wmt19 -l {pair} --echo src".split()
+ src_lines = subprocess.run(cmd, stdout=subprocess.PIPE).stdout.decode("utf-8").splitlines()
+ cmd = f"sacrebleu -t wmt19 -l {pair} --echo ref".split()
+ tgt_lines = subprocess.run(cmd, stdout=subprocess.PIPE).stdout.decode("utf-8").splitlines()
+ text[pair] = {"src": src_lines[:n_objs], "tgt": tgt_lines[:n_objs]}
+ return text
+
+
+text = get_all_data(pairs, n_objs)
+filename = "./fsmt_val_data.json"
+with open(filename, "w", encoding="utf-8") as f:
+ bleu_data = json.dump(text, f, indent=2, ensure_ascii=False)
diff --git a/docs/transformers/examples/legacy/seq2seq/test_data/fsmt/fsmt_val_data.json b/docs/transformers/examples/legacy/seq2seq/test_data/fsmt/fsmt_val_data.json
new file mode 100644
index 0000000000000000000000000000000000000000..f38b305733314aaa134ecdb016b7f3bbea81a6d0
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/test_data/fsmt/fsmt_val_data.json
@@ -0,0 +1,90 @@
+{
+ "en-ru": {
+ "src": [
+ "Welsh AMs worried about 'looking like muppets'",
+ "There is consternation among some AMs at a suggestion their title should change to MWPs (Member of the Welsh Parliament).",
+ "It has arisen because of plans to change the name of the assembly to the Welsh Parliament.",
+ "AMs across the political spectrum are worried it could invite ridicule.",
+ "One Labour AM said his group was concerned \"it rhymes with Twp and Pwp.\"",
+ "For readers outside of Wales: In Welsh twp means daft and pwp means poo.",
+ "A Plaid AM said the group as a whole was \"not happy\" and has suggested alternatives.",
+ "A Welsh Conservative said his group was \"open minded\" about the name change, but noted it was a short verbal hop from MWP to Muppet."
+ ],
+ "tgt": [
+ "Члены Национальной ассамблеи Уэльса обеспокоены, что \"выглядят как куклы\"",
+ "Некоторые члены Национальной ассамблеи Уэльса в ужасе от предложения о том, что их наименование должно измениться на MPW (члены Парламента Уэльса).",
+ "Этот вопрос был поднят в связи с планами по переименованию ассамблеи в Парламент Уэльса.",
+ "Члены Национальной ассамблеи Уэльса всего политического спектра обеспокоены, что это может породить насмешки.",
+ "Один из лейбористских членов Национальной ассамблеи Уэльса сказал, что его партия обеспокоена тем, что \"это рифмуется с Twp и Pwp\".",
+ "Для читателей за предлами Уэльса: по-валлийски twp означает \"глупый\", а pwp означает \"какашка\".",
+ "Член Национальной ассамблеи от Плайд сказал, что эта партия в целом \"не счастлива\" и предложил альтернативы.",
+ "Представитель Консервативной партии Уэльса сказал, что его партия \"открыта\" к переименованию, но отметил, что между WMP и Muppet небольшая разница в произношении."
+ ]
+ },
+ "ru-en": {
+ "src": [
+ "Названо число готовящихся к отправке в Донбасс новобранцев из Украины",
+ "Официальный представитель Народной милиции самопровозглашенной Луганской Народной Республики (ЛНР) Андрей Марочко заявил, что зимой 2018-2019 года Украина направит в Донбасс не менее 3 тыс. новобранцев.",
+ "По его словам, таким образом Киев планирует \"хоть как-то доукомплектовать подразделения\".",
+ "\"Нежелание граждан Украины проходить службу в рядах ВС Украины, массовые увольнения привели к низкой укомплектованности подразделений\", - рассказал Марочко, которого цитирует \"РИА Новости\".",
+ "Он также не исключил, что реальные цифры призванных в армию украинцев могут быть увеличены в случае необходимости.",
+ "В 2014-2017 годах Киев начал так называемую антитеррористическую операцию (АТО), которую позже сменили на операцию объединенных сил (ООС).",
+ "Предполагалось, что эта мера приведет к усилению роли украинских силовиков в урегулировании ситуации.",
+ "В конце августа 2018 года ситуация в Донбассе обострилась из-за убийства главы ДНР Александра Захарченко."
+ ],
+ "tgt": [
+ "The number of new Ukrainian recruits ready to go to Donbass has become public",
+ "Official representative of the peoples’ militia of the self-proclaimed Lugansk People’s Republic Andrey Marochko claimed that Ukrainian will send at least 3 thousand new recruits to Donbass in winter 2018-2019.",
+ "This is how Kyiv tries “at least somehow to staff the units,” he said.",
+ "“The unwillingness of Ukrainian citizens to serve in the Ukraine’s military forces, mass resignments lead to low understaffing,” said Marochko cited by RIA Novosti.",
+ "Also, he doesn’t exclude that the real numbers of conscripts in the Ukrainian army can be raised is necessary.",
+ "In 2014-2017, Kyiv started so-called antiterrorist operation, that ws later changed to the united forces operation.",
+ "This measure was supposed to strengthen the role of the Ukrainian military in settling the situation.",
+ "In the late August 2018, the situation in Donbass escalated as the DNR head Aleksandr Zakharchenko was killed."
+ ]
+ },
+ "en-de": {
+ "src": [
+ "Welsh AMs worried about 'looking like muppets'",
+ "There is consternation among some AMs at a suggestion their title should change to MWPs (Member of the Welsh Parliament).",
+ "It has arisen because of plans to change the name of the assembly to the Welsh Parliament.",
+ "AMs across the political spectrum are worried it could invite ridicule.",
+ "One Labour AM said his group was concerned \"it rhymes with Twp and Pwp.\"",
+ "For readers outside of Wales: In Welsh twp means daft and pwp means poo.",
+ "A Plaid AM said the group as a whole was \"not happy\" and has suggested alternatives.",
+ "A Welsh Conservative said his group was \"open minded\" about the name change, but noted it was a short verbal hop from MWP to Muppet."
+ ],
+ "tgt": [
+ "Walisische Ageordnete sorgen sich \"wie Dödel auszusehen\"",
+ "Es herrscht Bestürzung unter einigen Mitgliedern der Versammlung über einen Vorschlag, der ihren Titel zu MWPs (Mitglied der walisischen Parlament) ändern soll.",
+ "Der Grund dafür waren Pläne, den Namen der Nationalversammlung in Walisisches Parlament zu ändern.",
+ "Mitglieder aller Parteien der Nationalversammlung haben Bedenken, dass sie sich dadurch Spott aussetzen könnten.",
+ "Ein Labour-Abgeordneter sagte, dass seine Gruppe \"sich mit Twp und Pwp reimt\".",
+ "Hinweis für den Leser: „twp“ im Walisischen bedeutet „bescheuert“ und „pwp“ bedeutet „Kacke“.",
+ "Ein Versammlungsmitglied von Plaid Cymru sagte, die Gruppe als Ganzes sei \"nicht glücklich\" und hat Alternativen vorgeschlagen.",
+ "Ein walisischer Konservativer sagte, seine Gruppe wäre „offen“ für eine Namensänderung, wies aber darauf hin, dass es von „MWP“ (Mitglied des Walisischen Parlaments) nur ein kurzer verbaler Sprung zu „Muppet“ ist."
+ ]
+ },
+ "de-en": {
+ "src": [
+ "Schöne Münchnerin 2018: Schöne Münchnerin 2018 in Hvar: Neun Dates",
+ "Von az, aktualisiert am 04.05.2018 um 11:11",
+ "Ja, sie will...",
+ "\"Schöne Münchnerin\" 2018 werden!",
+ "Am Nachmittag wartet erneut eine Überraschung auf unsere Kandidatinnen: sie werden das romantische Candlelight-Shooting vor der MY SOLARIS nicht alleine bestreiten, sondern an der Seite von Male-Model Fabian!",
+ "Hvar - Flirten, kokettieren, verführen - keine einfachen Aufgaben für unsere Mädchen.",
+ "Insbesondere dann, wenn in Deutschland ein Freund wartet.",
+ "Dennoch liefern die neun \"Schöne Münchnerin\"-Kandidatinnen beim Shooting mit People-Fotograf Tuan ab und trotzen Wind, Gischt und Regen wie echte Profis."
+ ],
+ "tgt": [
+ "The Beauty of Munich 2018: the Beauty of Munich 2018 in Hvar: Nine dates",
+ "From A-Z, updated on 04/05/2018 at 11:11",
+ "Yes, she wants to...",
+ "to become \"The Beauty of Munich\" in 2018!",
+ "In the afternoon there is another surprise waiting for our contestants: they will be competing for the romantic candlelight photo shoot at MY SOLARIS not alone, but together with a male-model Fabian!",
+ "Hvar with its flirting, coquetting, and seduction is not an easy task for our girls.",
+ "Especially when there is a boyfriend waiting in Germany.",
+ "Despite dealing with wind, sprays and rain, the nine contestants of \"The Beauty of Munich\" behaved like real professionals at the photo shoot with People-photographer Tuan."
+ ]
+ }
+}
\ No newline at end of file
diff --git a/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/test.source b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/test.source
new file mode 100644
index 0000000000000000000000000000000000000000..3eea3d95b8e1548803217cb4c69cc44358b1e9fb
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/test.source
@@ -0,0 +1,20 @@
+UN Chief Says There Is No Military Solution in Syria Secretary-General Ban Ki-moon says his response to Russia's stepped up military support for Syria is that "there is no military solution" to the nearly five-year conflict and more weapons will only worsen the violence and misery for millions of people. The U.N. chief again urged all parties, including the divided U.N. Security Council, to unite and support inclusive negotiations to find a political solution. Ban told a news conference Wednesday that he plans to meet with foreign ministers of the five permanent council nations - the U.S., Russia, China, Britain and France - on the sidelines of the General Assembly's ministerial session later this month to discuss Syria.
+He expressed regret that divisions in the council and among the Syrian people and regional powers "made this situation unsolvable." Ban urged the five permanent members to show the solidarity and unity they did in achieving an Iran nuclear deal in addressing the Syria crisis. 8 Poll Numbers That Show Donald Trump Is For Real Some have tried to label him a flip-flopper. Others have dismissed him as a joke. And some are holding out for an implosion. But no matter how some Republicans are trying to drag Donald Trump down from atop the polls, it hasn't worked (yet).
+Ten of the last 11 national polls have shown Donald Trump's lead at double digits, and some are starting to ask seriously what it means for the real estate mogul's nomination chances. Of course, it's still early in the election cycle. None of this is to say that Trump is likely to win the Republican nomination. Pundits point out that at this time in 2011, Rick Perry's lead was giving way to a rising Herman Cain, neither of whom won even one state in the nomination process. And there are many reasons he would struggle in a general election. But outside groups like Jeb Bush's Super PAC and the economic conservative group Club for Growth are recognizing Trump's staying power and beginning to unload their dollars to topple him.
+Here are some recent poll numbers that suggest that the real estate mogul isn't just a passing phase: Trump's favorability ratings have turned 180 degrees. Right before Donald Trump announced his candidacy in mid-June, a Monmouth University poll showed only two in 10 Republicans had a positive view of the real estate mogul. By mid-July, it was 40 percent. In early August, it was 52 percent. Now, six in 10 Republicans have a favorable view of Donald Trump. Roughly three in 10 say they have a negative view. And these numbers hold up in early states. A Quinnipiac poll in Iowa last week found that 60 percent of Republicans there had a favorable view of Trump.
+Two-thirds of GOP voters would be happy with Trump as the nominee. In a CNN/ORC poll last week, 67 percent of Republicans said they would be either "enthusiastic" or "satisfied" if Trump were the nominee. Only two in 10 say they would be "upset" if he were the nominee. Only Ben Carson generates roughly the same level of enthusiasm as Trump (43 percent say they would be "enthusiastic" vs. 40 percent who say the same of Trump). The next closest in enthusiasm? Marco Rubio with only 21 percent.
+On the flip side, 47 percent of Republican voters say they would be "dissatisfied" or "upset" if establishment favorite Jeb Bush becomes the nominee. A majority of Republicans don't see Trump's temperament as a problem. While Donald Trump has been widely criticized for his bombast and insults, 52 percent of leaned Republican voters nationwide think that the real estate mogul has the right temperament to be president, according to Monday's ABC News/Washington Post poll. The same number holds in the first-in-the-nation caucus state of Iowa, where the same 52 percent of Republicans think he has the personality to be commander in chief, according to Quinnipiac last week.
+Still, 44 percent think he doesn't have the personality to serve effectively, and almost six in 10 independents say his temperament does not belong in the White House, according to ABC/Post. Republican voters are getting used to the idea. When they put on their pundit hats, Republican voters think Trump is for real. When asked who is most likely to win the GOP nomination, four in 10 said Trump was the best bet, according to a CNN/ORC poll out last week. That's a change from when four in 10 placed their money on Jeb Bush in late July. Full disclosure: GOP voters haven't had the clearest crystal ball in the past.
+At this time last cycle, four in 10 Republicans picked Rick Perry to win the nomination, vs. only 28 percent for eventual nominee Mitt Romney. Still, it shows that a plurality of GOP voters see Trump's campaign as plausible. Even if Republicans rallied around another candidate, Trump still beats almost everyone. Some pundits point out that the splintered field is likely contributing to Trump's lead, while anti-Trump support is be spread diffusely among more than a dozen other candidates. But a Monmouth University poll in early September shows that, in a hypothetical head-to-head matchup between Trump and most other Republican candidates, Trump almost always garners majority support.
+He leads Carly Fiorina by 13 points, Marco Rubio by 14 points, Walker by 15 points, Jeb Bush by 19 points, and, finally, Rand Paul, John Kasich and Chris Christie by 33 points each. He's in a dead heat with Ted Cruz. The only candidate who beats him? Ben Carson would lead the businessman by a wide 19 points in a hypothetical head-to-head. A bare majority of Donald Trump's supporters say they've made up their minds. A new CBS/NYT poll out on Tuesday shows that just more than half of voters who support Trump say they have locked in their votes. Obviously, a lot can happen to change that, and no one can really say they would never change their mind.
+46 percent said they are leaving the door open to switching candidates. Still, Trump's strongest competition at the moment is from fellow outsider neurosurgeon Ben Carson, but voters who say they have made up their minds are twice as likely to go for Trump. Six in 10 Republicans say they agree with Trump on immigration. Even since Donald Trump called immigrants from Mexico "rapists" in his campaign announcement speech two months ago, immigration has been front and center in the 2016 conversation. Some are worried that Trump's bombast will drive crucial Hispanic voters away from the Republican Party and damage rebranding efforts.
+But according to Monday's new ABC/Post poll, six in 10 Republicans say they agree with Trump on immigration issues. So as long as immigration remains in the spotlight, it seems Donald Trump will remain too. Frustration with government is climbing to new highs. Donald Trump and Ben Carson now account for roughly half of the support from Republican voters, largely due to their outsider status. Six in 10 Republicans in Monday's new ABC/Post poll say they want a political outsider over someone with government experience. And they are angry at Washington, too.
+A Des Moines Register/Bloomberg poll in Iowa from two weeks ago shows that three in four Iowa Republicans are frustrated with Republicans in Congress, with 54 percent "unsatisfied" and 21 percent "mad as hell." Jeremy Corbyn to make debut at Prime Minister's Questions Since his election, Mr Corbyn's debut at PMQs has been keenly awaited New Labour leader Jeremy Corbyn is to make his debut at Prime Minister's Questions later, taking on David Cameron for the first time.
+Mr Corbyn will rise to ask the first of his six allotted questions shortly after midday, with his performance likely to be closely scrutinised by the media and Labour MPs. He has called for "less theatre and more facts" at the weekly showpiece. He has also said he could skip some sessions, leaving them to colleagues. The encounter will be the first parliamentary test of Mr Corbyn's leadership, coming after his appointment of a shadow cabinet and his speech to the TUC annual congress on Tuesday.
+Meanwhile, the Labour leader's decision to stand in silence during the singing of the national anthem at a service on Tuesday to mark the 75th anniversary of the Battle of Britain has attracted criticism from a number of Tory MPs and is the focus of several front page stories in the newspapers. Mr Corbyn's decision not to sing the national anthem has attracted attention A spokesman for Mr Corbyn said he had "stood in respectful silence" and did recognise the "heroism of the Royal Air Force in the Battle of Britain."
+But a member of Mr Corbyn's shadow cabinet, Owen Smith, told BBC Two's Newsnight programme he would have advised the Labour leader to sing the national anthem "irrespective" of his belief that the monarchy should be abolished. Nearly a dozen shadow ministers have refused to serve in Mr Corbyn's top team, citing differences over the economy, defence and foreign affairs, while less than a sixth of the parliamentary party originally backed him as leader. BBC political correspondent Robin Brant says policy differences are also "stacking up" within Labour following Mr Corbyn's appointment over its position on the European Union and the government's cap on benefits.
+Mr Corbyn told the TUC conference Labour was putting forward amendments to remove the whole idea of a cap altogether. Hours later Mr Smith, the shadow work and pensions secretary, said the party was "very clear" that it was only opposing government plans to reduce the level of cap from £26,000 to £23,000. Mr Corbyn will be the fifth Labour leader that David Cameron has faced across the despatch box over the past decade since he became Tory leader. The Labour leader, who has promised a different approach to politics, says he has "crowd sourced" ideas for questions to ask Mr Cameron and has been given more than 30,000 suggestions.
+The Islington North MP has said PMQs is too confrontational and that he will refrain from both "repartee" and trading barbs, instead vowing to focus on serious issues such as poverty, inequality and the challenges facing young people. Mr Corbyn has said that Angela Eagle, the shadow business secretary, will deputise for him at PMQs when he does not attend - for instance when Mr Cameron is travelling abroad. He has also floated the idea of allowing other colleagues to take the floor on occasion, saying he had approached the Commons Speaker John Bercow to discuss the issue.
+When he became leader in 2005, Mr Cameron said he wanted to move away from the "Punch and Judy" style of politics often associated with PMQs but admitted some years later that he had failed. Since it was first televised in 1990, PMQs has been seen as a key barometer of a leader's judgement, their command of the Commons and their standing among their fellow MPs although critics have argued it has become a caricature and is in need of far-reaching reforms. 'Shot in Joburg': Homeless youth trained as photographers Downtown Johannesburg is a tough place to be homeless.
+But one group of former street children have found a way to learn a skill and make a living. "I was shot in Joburg" is a non-profit studio that teaches homeless youngsters how to take photographs of their neighbourhood and make a profit from it. BBC News went to meet one of the project's first graduates. JD Sports boss says higher wages could hurt expansion JD Sports Executive Chairman Peter Cowgill says a higher minimum wage for UK workers could mean "more spending power in the pockets of potential consumers." But that spending power is unlikely to outweigh the higher labour costs at his firm, he says.
+The costs could hit JD Sports' expansion plans, he added, which could mean fewer extra jobs. Thanasi Kokkinakis backed by Tennis Australia president Steve Healy Thanasi Kokkinakis deserves kudos rather than criticism for his behaviour. Thanasi Kokkinakis has been the collateral damage in the recent storm around his friend Nick Kyrgios and deserves kudos rather than criticism for his own behaviour, according to Tennis Australia president Steve Healy.
\ No newline at end of file
diff --git a/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/test.target b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/test.target
new file mode 100644
index 0000000000000000000000000000000000000000..8c88fd05326fcfe503ef7eba77921c182758a290
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/test.target
@@ -0,0 +1,20 @@
+Șeful ONU declară că nu există soluții militare în Siria Secretarul General Ban Ki-moon afirmă că răspunsul său la suportul militar al Rusiei pentru Siria este că „nu există o soluție militară” la conflictul care durează de aproape cinci ani iar mai multe arme nu ar face decât să agraveze violența și suferința a milioane de oameni. Șeful ONU a solicitat din nou tuturor părților, inclusiv Consiliului de securitate ONU divizat să se unifice și să susțină negocierile pentru a găsi o soluție politică. Ban a declarat miercuri în cadrul unei conferințe că intenționează să se întâlnească luna aceasta cu miniștrii de externe din cinci țări permanent prezente în consiliu - SUA, Rusia, China, Anglia și Franța - pe marginea sesiunii ministeriale a Adunării Generale pentru a discuta despre Siria.
+Ban și-a exprimat regretul că divizările în consiliu și între poporul sirian și puterile regionale „au făcut această situație de nerezolvat”. Ban le-a cerut celor cinci membri permanenți să dea dovadă de solidaritatea și unitatea arătate atunci când au reușit să încheie un acord referitor la armele nucleare ale Iranului, abordând astfel criza din Siria. 8 cifre din sondaje care arată că Donald Trump are șanse reale Unii au încercat să îl eticheteze ca politician „flip-flop”. Alții l-au numit o glumă. Iar alții așteaptă implozia. Însă indiferent de modul în care unii republicani încearcă să îl dărâme pe Donald Trump din vârful sondajelor, nu a funcționat (încă).
+Zece din ultimele 11 sondaje naționale au arătat că Donald Trump conduce cu un procent din două cifre iar unele voci încep să se întrebe serios ce înseamnă acest lucru pentru șansele de numire ale mogulului imobiliar. Desigur, este încă prematur. Nimic din toate acestea nu spune că Trump va câștiga cursa pentru nominalizarea republicanilor. Pundits arată că, în aceeași perioadă a anului 2011, avansul lui Rick Perry îi făcea loc lui Herman Cain în sondaje, dar niciunul dintre ei nu a câștigat în vreun stat în cursa de nominalizare. Iar motivele pentru care s-ar lupta din greu la alegerile generale sunt numeroase. Însă grupurile din exterior precum Super PAC al lui Jeb Bush și grupul conservator economic Club for Growth admit puterea lui Trump și încep să îl susțină cu bani.
+În continuare vă prezentăm câteva cifre din sondaje recente care sugerează că mogulul imobiliar nu este doar ceva trecător: Cifrele care indică susținerea față de Trump s-au întors la 180 grade. Chiar înainte ca Donald Trump să își anunțe candidatura, la mijlocul lui iunie, un sondaj realizat de Universitatea din Monmouth arăta că doar doi din 10 republicani aveau o părere pozitivă despre mogulul imobiliar. Până la mijlocul lui iulie, procentul a urcat la 40%. La începutul lui august, era 52%. În prezent, șase din 10 republicani au o părere favorabilă despre Donald Trump. Aproximativ trei din 10 declară că au o părere negativă. Aceste cifre se mențin. Un sondaj realizat săptămâna trecută de Quinnipiac în Iowa a concluzionat că 60% dintre republicanii din regiune au o părere favorabilă despre Trump.
+Două treimi dintre alegătorii GOP ar fi fericiți dacă Trump ar câștiga cursa pentru nominalizare. Într-un sondaj realizat săptămâna trecută de CNN/ORC, 67% dintre republicani au declarat că ar fi „entuziasmați” sau „mulțumiți” dacă Trump ar câștiga cursa pentru nominalizare. Doar doi din 10 declară că ar fi „supărați” dacă Trump ar câștiga cursa pentru nominalizare. Doar Ben Carson generează aproximativ același nivel de entuziasm ca Trump (43% declară că ar fi „entuziasmați” față de 40% care declară același lucru despre Trump). Cel mai aproape în ceea ce privește entuziasmul? Marco Rubio, cu doar 21%.
+De partea cealaltă, 47% dintre alegătorii republicani afirmă că ar fi „nemulțumiți” sau „supărați” dacă favoritul Jeb Bush câștigă cursa pentru nominalizare. Majoritatea republicanilor nu consideră temperamentul lui Trump o problemă. Deși Donald Trump a fost puternic criticat pentru insultele aduse și stilul său bombastic, 52% dintre alegătorii republicani la nivel național consideră că mogulul imobiliar are temperamentul potrivit pentru a fi președinte, conform sondajului realizat luni de ABC News/Washington Post. Regăsim aceleași cifre în statul Iowa, unde tot 52% dintre republicani cred că Trump are personalitatea potrivită pentru a fi conducător, conform sondajului realizat săptămâna trecută de Quinnipiac.
+Totuși, 44% sunt de părere că nu are personalitatea necesară pentru a acționa eficient și aproape șase din 10 independenți afirmă că temperamentul său nu are ce căuta la Casa Albă, conform ABC/Post. Alegătorii republicani se obișnuiesc cu ideea. Atunci când iau atitudinea de intelectuali, alegătorii republicani consideră că Trump este autentic. Conform unui sondaj realizat săptămâna trecută de CNN/ORC, la întrebarea cine are cele mai multe șanse să câștige cursa pentru nominalizare GOP, patru din 10 au declarat că Trump. Situația s-a schimbat față de finalul lui iulie, când patru din 10 ar fi pariat pe Jeb Bush. Informare completă: în trecut, alegătorii GOP nu au citit foarte bine viitorul.
+În aceeași perioadă a ultimelor alegeri, patru din 10 republicani l-au ales pe Rick Perry în cursa pentru nominalizare, față de doar 28% pentru Mitt Romney. Însă, aceste cifre arată că majoritatea alegătorilor GOP consideră plauzibilă campania lui Trump. Chiar dacă republicanii sau repliat spre un alt candidat. Trump încă se află în fruntea tuturor. Unele voci spun că situația divizată va contribui probabil la victoria lui Trump, în timp ce susținerea contra lui Trump se va împărți la mai mult de doisprezece candidați. Însă un sondaj derulat la începutul lui septembrie de Universitatea din Monmouth arată că, în situația ipotetică a unei colaborări între Trump și majoritatea celorlalți candidați republicani, aproape întotdeauna Trump va beneficia de susținerea majoritară.
+Trump se află la distanță de 13 puncte de Carly Fiorina, la 14 puncte de Marco Rubio, la 15 puncte de Walker, la 19 puncte de Jeb Bush și, în cele din urmă, la câte 33 de puncte față de Rand Paul, John Kasich și Chris Christie. Este aproape la egalitate cu Ted Cruz. Singurul candidat care îl învinge? Ben Carson l-ar învinge pe omul de afaceri cu 19 puncte într-o confruntare ipotetică de unu la unu. Majoritatea susținătorilor lui Donald Trump declară că s-au decis. Un nou sondaj realizat marți de CBS/NYT arată că peste jumătate dintre alegătorii care îl susțin pe Trump declară că nu își schimbă opțiunea de vot. Evident, se pot întâmpla multe în acest sens și nimeni nu poate spune că aceștia nu se vor răzgândi niciodată.
+46% afirmă că lasă portița deschisă posibilității de a-și schimba opțiunea. Cu toate acestea, cel mai important adversar al lui Trump este în prezent neurochirurgul Ben Carson, însă este de două ori mai probabil ca alegătorii care declară că s-au decis să voteze cu Trump. Șase din 10 republicani afirmă că sunt de acord cu Trump în problema imigrării. De când Donald Trump i-a numit pe imigranții din Mexic „violatori” în discursul de deschidere a campaniei sale, în urmă cu două luni, imigrarea a fost subiectul central în campania pentru 2016. Unii sunt îngrijorați că stilul bombastic al lui Trump va duce la o scindare între alegătorii hispanici importanți și Partidul Republican și va prejudicia eforturile de rebranding.
+Însă, conform sondajului realizat luni de ABC/Post, șase din 10 republicani afirmă că sunt de acord cu Trump în problema imigrării. Așa că, se pare că atâta timp cât problema imigrării rămâne în lumina reflectoarelor, la fel va rămâne și Doland Trump. Frustrarea față de autorități atinge noi culmi. Donald Trump și Ben Carson sunt acum susținuți de aproape jumătate dintre alegătorii republicani, în mare parte datorită statutului lor de outsideri. Conform sondajului realizat luni de ABC/Post, șase din 10 republicani afirmă că preferă un outsider politic în detrimentul cuiva cu experiență în guvernare. Oamenii sunt de asemenea supărați pe autoritățile de la Washington.
+Un sondaj derulat în urmă cu două săptămâni în Iowa de către Des Moines Register/Bloomberg arată că trei din patru republicani din Iowa sunt frustrați de prestația republicanilor din COngres, 54% declarându-se „nemulțumiți” iar 21% „nervoși la culme”. Jeremy Corbyn își face debutul la Prime Minister's Questions Încă de la alegerea sa, debutul domnului Corbyn la PMQs a fost îndelung așteptat Noul lider al Partidului Laburist, Jeremy Corbyn, își va face mai târziu debutul la Prime Minister's Questions, confruntându-se pentru prima dată cu David Cameron.
+Dl Corbyn va adresa primele dintre cele șase întrebări la care are dreptul la scurt timp după prânz; prestația sa va fi probabil analizată îndeaproape de mass-media și parlamentarii laburiști. În cadrul aparițiilor săptămânale, el a cerut „mai puțin teatru și mai multe fapte”. A declarat de asemenea că poate renunța la câteva participări și că le cedează colegilor săi. Confruntarea va fi primul test parlamentar al Dl Corbyn în poziție de lider, venind după ce a numit un „cabinet fantomă” și după discursul pe care l-a ținut marți la congresul anual TUC.
+Între timp, decizia liderului Partidului laburist de a păstra tăcerea la rostirea imnului național în cadrul unei slujbe ținute marți cu ocazia aniversării a 75 de ani de la Bătălia Angliei a atras critici din partea unor parlamentari conservatori și a ținut prima pagină a ziarelor. Decizia domnului Corbyn de a nu cânta imnul național a atras atenția Un purtător de cuvânt al Dl Corbyn a declarat că acesta „a păstrat tăcerea în mod respectuos” și a recunoscut „eroismul Forțelor aeriene britanice în Bătălia Angliei.”
+Însă un membru al cabinetului fantomă al Dl Corbyn, Owen Smith, a declarat pentru emisiunea Two's Newsnight transmisă de BBC că i-ar fi recomandat liderului laburist să cânte imnul național „indiferent” de credința sa că monarhia ar trebui abolită. În jur de doisprezece miniștri din cabinetul fantomă au refuzat să facă parte din echipa de frunte a Dl Corbyn, argumentând prin diferențe de opinie legate de economie, apărare și externe, în timp ce mai puțin de o șesime din partidul parlamentar l-a susținut ca lider. Corespondentul politic al BBC, Robin Brant, declară că diferențele de politică „se cumulează” în Partidul Laburist după numirea domnului Corbyn referitor la poziția sa față de Uniunea Europeană și limita de beneficii.
+Dl Corbyn a declarat la conferința TUC că Partidul Laburist va aduce modificări prin care se va elimina integral ideea limitării. Câteva ore mai târziu, Dl Smith, Ministrul Muncii și Pensiilor, a declarat că partidul „este foarte clar” în opoziția exclusivă față de planurile guvernului de a reduce nivelul „cap” de la 26.000 lire la 23.000 lire. Dl Corbyn va fi al cincilea lider laburist cu care se confruntă David Cameron la tribună în ultimul deceniu, de când a preluat conducerea Partidului Conservator. Liderul laburist, care a promis o abordare diferită a politicii, spune că are idei „din surse externe” pentru întrebări pe care să i le adreseze Domnului Cameron și că a primit peste 30.000 de sugestii.
+Parlamentarul Islington North a afirmat că PMQs implică un nivel de confruntare prea înalt și că se va abține de la replici și atacuri, angajându-se să se concentreze în schimb pe probleme serioase precum sărăcia, inegalitatea și provocările cu care se confruntă tinerii. Dl Corbyn a declarat că Angela Eagle, Ministrul de finanțe, îi va ține locul la PMQs atunci când el nu poate participa - de exemplu atunci când Dl Cameron se deplasează în străinătate. A exprimat de asemenea ideea că va permite altor colegi să ia cuvântul ocazional, spunând că l-a abordat pe Președintele Camerei Deputaților, John Bercow, pentru a discuta acest aspect.
+În 2005, când a preluat conducerea, Dl Cameron a declarat că dorește să renunțe la stilul politic „Punch and Judy” asociat adesea cu PMQs însă a recunoscut câțiva ani mai târziu că nu a reușit în demersul său. De la prima transmisie, în 1990, PMQs a fost considerată un barometru cheie al raționamentului unui lider, al modului în care acesta conduce Camera Deputaților și a poziției sale în rândul colegilor parlamentari, deși criticii afirmă a ca devenit o caricatură și că are nevoie de o reformare profundă. „Cadru în Joburg”: Tineri fără adăpost beneficiază de cursuri de fotografie Este dificil să fii un om fără adăpost în Johannesburg.
+Însă un grup de oameni care au trăit pe străzi în copilărie au găsit un mod de a învăța o meserie și de a-și câștiga traiul. „I was shot în Joburg” este un studio non-profit care îi învață pe tinerii fără adăpost să facă fotografii ale zonelor în care trăiesc și să câștige bani din asta. BBC News s-a întâlnit cu unul dintre primii absolvenți ai proiectului. Șeful JD Sports spune că salariile mai mari ar putea dăuna extinderii Președintele JD Sports, Peter Cowgill, declară că o creștere a salariului minim în Marea Britanie ar putea însemna „o putere de cumpărare mai mare în buzunarele potențialilor consumatori.” Este însă puțin probabil ca respectiva putere de cumpărare să depășească costurile mai mari pentru forța de muncă în cadrul firmei, afirmă el.
+Costurile ar putea avea impact asupra planurilor de extindere ale JD Sports, a adăugat el, ceea ce ar putea însemna mai puține locuri de muncă noi. Thanasi Kokkinakis susținut de președintele Tennis Australia, Steve Healy Thanasi Kokkinakis ar merita să fie lăudat și nu criticat pentru comportamentul său. Thanasi Kokkinakis a fost victimă colaterală în „furtuna” creată în jurul prietenului său, Nick Kyrgios, iar comportamentul său merită mai degrabă cuvinte de laudă și nu critică, în opinia președintelui Tennis Australia, Steve Healy.
\ No newline at end of file
diff --git a/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/train.len b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/train.len
new file mode 100644
index 0000000000000000000000000000000000000000..33ce003c8ae3139914a389a714812a2ab13aece4
Binary files /dev/null and b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/train.len differ
diff --git a/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/train.source b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/train.source
new file mode 100644
index 0000000000000000000000000000000000000000..d77722d4a57002e81b832fc94a326fc4acebb0d8
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/train.source
@@ -0,0 +1,11 @@
+Corrections to votes and voting intentions: see Minutes Assignment conferred on a Member: see Minutes Membership of committees and delegations: see Minutes Decisions concerning certain documents: see Minutes Forwarding of texts adopted during the sitting: see Minutes Dates for next sittings: see Minutes
+Membership of Parliament: see Minutes Approval of Minutes of previous sitting: see Minutes Membership of Parliament: see Minutes Verification of credentials: see Minutes Documents received: see Minutes Written statements and oral questions (tabling): see Minutes Petitions: see Minutes Texts of agreements forwarded by the Council: see Minutes Action taken on Parliament's resolutions: see Minutes Agenda for next sitting: see Minutes Closure of sitting (The sitting was closed at 7.45 p.m.)
+Election of Vice-Presidents of the European Parliament (deadline for submitting nominations): see Minutes (The sitting was suspended at 12.40 p.m. and resumed at 3.00 p.m.) Election of Quaestors of the European Parliament (deadline for submitting nominations): see Minutes (The sitting was suspended at 3.25 p.m. and resumed at 6.00 p.m.) Agenda for next sitting: see Minutes Closure of sitting (The sitting was closed at 6.15 p.m.) Opening of the sitting (The sitting was opened at 9.35 a.m.) Documents received: see Minutes Approval of Minutes of previous sitting: see Minutes Membership of Parliament: see Minutes
+Membership of committees (deadline for tabling amendments): see Minutes (The sitting was suspended at 7 p.m. and resumed at 9 p.m.) Agenda for next sitting: see Minutes Closure of sitting (The sitting was suspended at 23.25 p.m.) Documents received: see Minutes Communication of Council common positions: see Minutes (The sitting was suspended at 11.35 a.m. and resumed for voting time at noon) Approval of Minutes of previous sitting: see Minutes Committee of Inquiry into the crisis of the Equitable Life Assurance Society (extension of mandate): see Minutes
+Announcement by the President: see Minutes 1. Membership of committees (vote) 2. Amendment of the ACP-EC Partnership Agreement (vote) 4. Certification of train drivers operating locomotives and trains on the railway system in the Community (vote) 6. Law applicable to non-contractual obligations ("ROME II") (vote) 8. Seventh and eighth annual reports on arms exports (vote) Corrections to votes and voting intentions: see Minutes Membership of committees and delegations: see Minutes Request for waiver of parliamentary immunity: see Minutes Decisions concerning certain documents: see Minutes
+Written statements for entry
+Written statements for entry in the register (Rule 116): see Minutes Forwarding of texts adopted during the sitting: see Minutes Dates for next sittings: see Minutes Adjournment of the session I declare the session of the European Parliament adjourned. (The sitting was closed at 1 p.m.) Approval of Minutes of previous sitting: see Minutes Membership of Parliament: see Minutes Request for the defence of parliamentary immunity: see Minutes Appointments to committees (proposal by the Conference of Presidents): see Minutes Documents received: see Minutes Texts of agreements forwarded by the Council: see Minutes
+Action taken on Parliament's resolutions: see Minutes Oral questions and written statements (tabling): see Minutes Written statements (Rule 116): see Minutes Agenda: see Minutes 1. Appointments to parliamentary committees (vote): see Minutes Voting time Agenda for next sitting: see Minutes Closure of sitting (The sitting was closed at 12 midnight) Opening of the sitting (The sitting was opened at 09.05) Documents received: see Minutes Approval of Minutes of previous sitting: see Minutes 1. Protection of passengers against displaced luggage (vote) 2.
+Approval of motor vehicles with regard to the forward field of vision of the driver (vote) 3. EC-Korea Agreement on scientific and technological cooperation (vote) 4. Mainstreaming sustainability in development cooperation policies (vote) 5. Draft Amending Budget No 1/2007 (vote) 7. EC-Gabon Fisheries Partnership (vote) 10. Limitation periods in cross-border disputes involving personal injuries and fatal accidents (vote) 12. Strategy for a strengthened partnership with the Pacific Islands (vote) 13. The European private company statute (vote) That concludes the vote.
+Corrections to votes and voting intentions: see Minutes Assignment conferred on a Member: see Minutes Membership of committees and delegations: see Minutes Decisions concerning certain documents: see Minutes Forwarding of texts adopted during the sitting: see Minutes Dates for next sittings: see Minutes
+Written statements for entry
diff --git a/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/train.target b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/train.target
new file mode 100644
index 0000000000000000000000000000000000000000..f18d80d3d47d6cae112d7f705effdb26beeb1efe
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/train.target
@@ -0,0 +1,11 @@
+Corectările voturilor şi intenţiile de vot: a se vedea procesul-verbal Misiune încredinţată unui deputat: consultaţi procesul-verbal Componenţa comisiilor şi a delegaţiilor: a se vedea procesul-verbal Decizii privind anumite documente: a se vedea procesul-verbal Transmiterea textelor adoptate în cursul prezentei şedinţe: a se vedea procesul-verbal Calendarul următoarelor şedinţe: a se vedea procesul-verbal
+Componenţa Parlamentului: a se vedea procesul-verbal Aprobarea procesului-verbal al şedinţei precedente: a se vedea procesul-verbal Componenţa Parlamentului: a se vedea procesul-verbal Verificarea prerogativelor: a se vedea procesul-verbal Depunere de documente: a se vedea procesul-verbal Declaraţii scrise şi întrebări orale (depunere): consultaţi procesul-verbal Petiţii: a se vedea procesul-verbal Transmiterea de către Consiliu a textelor acordurilor: a se vedea procesul-verbal Cursul dat rezoluţiilor Parlamentului: a se vedea procesul-verbal Ordinea de zi a următoarei şedinţe: a se vedea procesul-verbal Ridicarea şedinţei (Se levanta la sesión a las 19.45 horas)
+Alegerea vicepreşedinţilor Parlamentului European (termenul de depunere a candidaturilor): consultaţi procesul-verbal (Die Sitzung wird um 12.40 Uhr unterbrochen und um 15.00 Uhr wiederaufgenommen). Alegerea chestorilor Parlamentului European (termenul de depunere a candidaturilor): consultaţi procesul-verbal (Die Sitzung wird um 15.25 Uhr unterbrochen und um 18.00 Uhr wiederaufgenommen). Ordinea de zi a următoarei şedinţe: a se vedea procesul-verbal Ridicarea şedinţei (Die Sitzung wird um 18.15 Uhr geschlossen.) Deschiderea şedinţei (Die Sitzung wird um 9.35 Uhr eröffnet.) Depunerea documentelor: a se vedea procesul-verbal Aprobarea procesului-verbal al şedinţei precedente: a se vedea procesul-verbal Componenţa Parlamentului: a se vedea procesul-verbal
+Componenţa comisiilor (termenul de depunere a amendamentelor): consultaţi procesul-verbal (La seduta, sospesa alle 19.00, è ripresa alle 21.00) Ordinea de zi a următoarei şedinţe: a se vedea procesul-verbal Ridicarea şedinţei (Die Sitzung wird um 23.25 Uhr geschlossen.) Depunerea documentelor: a se vedea procesul-verbal Comunicarea poziţiilor comune ale Parlamentului: a se vedea procesul-verbal (La séance, suspendue à 11h35 dans l'attente de l'Heure des votes, est reprise à midi) Aprobarea procesului-verbal al şedinţei precedente: a se vedea procesul-verbal Comisia de anchetă privind criza societăţii de asigurări "Equitable Life” (prelungirea mandatului): consultaţi procesul-verbal
+Comunicarea Preşedintelui: consultaţi procesul-verbal 1. Componenţa comisiilor (vot) 2. Modificarea Acordului de parteneriat ACP-CE ("Acordul de la Cotonou”) (vot) 4. Certificarea mecanicilor de locomotivă care conduc locomotive şi trenuri în sistemul feroviar comunitar (vot) 6. Legea aplicabilă obligaţiilor necontractuale ("Roma II”) (vot) 8. Al şaptelea şi al optulea raport anual privind exportul de armament (vot) Corectările voturilor şi intenţiile de vot: a se vedea procesul-verbal Componenţa comisiilor şi a delegaţiilor: a se vedea procesul-verbal Cerere de ridicare a imunităţii parlamentare: consultaţi procesul-verbal Decizii privind anumite documente: a se vedea procesul-verbal
+Declaraţii scrise înscrise
+Declaraţii scrise înscrise în registru (articolul 116 din Regulamentul de procedură): a se vedea procesul-verbal Transmiterea textelor adoptate în cursul prezentei şedinţe: a se vedea procesul-verbal Calendarul următoarelor şedinţe: a se vedea procesul-verbal Întreruperea sesiunii Dichiaro interrotta la sessione del Parlamento europeo. (La seduta è tolta alle 13.00) Aprobarea procesului-verbal al şedinţei precedente: a se vedea procesul-verbal Componenţa Parlamentului: a se vedea procesul-verbal Cerere de apărare a imunităţii parlamentare: consultaţi procesul-verbal Numiri în comisii (propunerea Conferinţei preşedinţilor): consultaţi procesul-verbal Depunerea documentelor: a se vedea procesul-verbal Transmiterea de către Consiliu a textelor acordurilor: a se vedea procesul-verbal
+Continuări ale rezoluţiilor Parlamentului: consultaţi procesul-verbal Declaraţii scrise şi întrebări orale (depunere): consultaţi procesul-verbal Declaraţii scrise (articolul 116 din Regulamentul de procedură) Ordinea de zi: a se vedea procesul-verbal 1. Numiri în comisiile parlamentare (vot): consultaţi procesul-verbal Timpul afectat votului Ordinea de zi a următoarei şedinţe: a se vedea procesul-verbal Ridicarea şedinţei (La seduta è tolta alle 24.00) Deschiderea şedinţei (The sitting was opened at 09.05) Depunerea documentelor: a se vedea procesul-verbal Aprobarea procesului-verbal al şedinţei precedente: a se vedea procesul-verbal 1. Protecţia pasagerilor împotriva deplasării bagajelor (vot) 2.
+Omologarea vehiculelor cu motor cu privire la câmpul de vizibilitate înainte al conducătorului auto (vot) 3. Acordul CE-Coreea de cooperare ştiinţifică şi tehnologică (vot) 4. Integrarea durabilităţii în politicile de cooperare pentru dezvoltare (vot) 5. Proiect de buget rectificativ nr.1/2007 (vot) 7. Acordul de parteneriat în domeniul pescuitului între Comunitatea Europeană şi Republica Gaboneză (vot) 10. Termenele de prescripţie aplicabile în cadrul litigiilor transfrontaliere cu privire la vătămările corporale şi accidentele mortale (vot) 12. Relaţiile UE cu insulele din Pacific: Strategie pentru un parteneriat consolidat (vot) 13. Statutul societăţii private europene (vot) Damit ist die Abstimmungsstunde beendet.
+Corectările voturilor şi intenţiile de vot: a se vedea procesul-verbal Misiune încredinţată unui deputat: consultaţi procesul-verbal Componenţa comisiilor şi a delegaţiilor: a se vedea procesul-verbal Decizii privind anumite documente: a se vedea procesul-verbal Transmiterea textelor adoptate în cursul prezentei şedinţe: a se vedea procesul-verbal Calendarul următoarelor şedinţe: a se vedea procesul-verbal
+Declaraţii scrise înscrise
diff --git a/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/val.len b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/val.len
new file mode 100644
index 0000000000000000000000000000000000000000..897314a960b28d927b597805693e63f9de71d903
Binary files /dev/null and b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/val.len differ
diff --git a/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/val.source b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/val.source
new file mode 100644
index 0000000000000000000000000000000000000000..c895d0ae247e2bc529ae4f94be6079cd36f50fa2
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/val.source
@@ -0,0 +1,16 @@
+Brazil's Former Presidential Chief-of-Staff to Stand Trial A federal judge on Tuesday accepted the charges filed against Brazil's former presidential chief of staff for his alleged involvement in a massive corruption scheme at state-owned oil company Petrobras. The federal prosecutor's office said Jose Dirceu will face trial on the corruption, racketeering and money laundering charges filed earlier this month. Fourteen other people will also be tried, including Joao Vaccari Neto, the former treasurer of Brazil's governing Workers' Party and Renato de Souza Duque, Petrobras' former head of corporate services.
+Dirceu is the most senior member of the ruling Workers' Party to be taken into custody in connection with the scheme. Dirceu served as former President Luiz Inacio Lula da Silva's chief of staff between 2003 and 2005. He was arrested early August in his home, where he already was under house arrest serving an 11-year sentence for his involvement in a cash-for-votes scheme in Congress more than 10 years ago. Prosecutors have said that Dirceu masterminded the kickback scheme at Petrobras, accepted bribes while in office and continued to receive payments from contractors after he was jailed in late 2013 for the vote-buying scandal.
+According to prosecutors, the scheme at Petrobras involved roughly $2 billion in bribes and other illegal funds. Some of that money was allegedly funneled back to campaign coffers of the ruling party and its allies. It also allegedly included the payment of bribes to Petrobras executives in return for inflated contracts. 'Miraculous' recovery for Peshawar massacre schoolboy A teenager paralysed after being shot four times in Pakistan's deadliest terror attack has made a "miraculous" recovery following treatment in the UK. Muhammad Ibrahim Khan, 13, had been told by doctors in Pakistan that he would never walk again.
+At least 140 people, mostly children, were killed when gunmen stormed Peshawar's Army Public School last December. Muhammad, who arrived in London last month for surgery, is being discharged from hospital later. Exactly nine months ago, on an ordinary Tuesday morning, Muhammad sat in his first aid class listening to his teachers intently. At the same time seven gunmen disguised in security uniforms were entering the Army Public School. They were strapped with explosives and had one simple mission in mind: Kill every man, woman and child they came across. "I can't forget what happened that day," Muhammad says with a severe stare.
+We were sitting in the auditorium, we were asking questions... and then we heard heavy gunfire outside. The terrorists moved inside and they started killing - our teacher was burned alive. Muhammad described pulling four other pupils out of the auditorium as the carnage unfolded. He said he then heard his friend, Hamza calling to him. He said, 'oh brother save me'. I held his hand. That's when I was shot in the back, and he was shot in the head. Most of the people killed in the attack were pupils Hamza died in Muhammad's arms. Muhammad recalled blacking out after that, and the next thing he knew he was in a hospital bed, paralysed from the waist down.
+Doctors in Peshawar in northern Pakistan, and then Rawalpindi, close to the capital, told his family there was no treatment, and he would never walk again. "Seeing him I felt like my soul had left my body," says Muhammad's father, Sher Khan Those nine months were the hardest in my life. But Mr Khan and his wife, Sherbano, refused to believe that their cricket-mad son would never be able to use his legs again. They campaigned, and appealed for help on Pakistani TV, gaining the support of high profile people such as cricketer turned politician Imran Khan.
+Finally, they were able to raise the funds to bring Muhammad to the UK and provide him with treatment at London's private Harley Street Clinic. Consultant neurosurgeon Irfan Malik described Muhammad as "terrified" when he first arrived at the hospital. "He'd spent the last [few] months lying on a bed, unable to move side to side," says Mr Malik. He was weak, he had a pressure sore on his back. He wasn't in great shape. A vertebra at the base of Muhammad's spine was destroyed Muhammad was shot in his shoulder, his hip, and his back during the attack, damaging his lower spine - leading to paralysis.
+But during six hours of surgery, Mr Malik and his team were able to reattach nerve endings and reconstruct the damaged part of the spine. Even Mr Malik was surprised at what happened next. Exactly one week after the surgery Muhammad stood up and started taking steps and walking. We were not expecting to get that sort of excellent result. That was miraculous," he says. Less than two weeks after his operation, Muhammad is ready to leave hospital and start the long road to recovery. Muhammad has defied the odds and started to walk again He says he wants to build his strength and continue his education in the UK. But he says he is determined to return to Pakistan, join the army and help fight terrorism.
+"I feel like I have a second chance at life," he says as he shows off pictures he's drawn of guns scribbled out next to school books and pens Muhammad grows physically stronger every day but the psychological trauma he continues to endure is unimaginable. "My anger is not diminishing" he says. In my school little kids were killed. What was their crime? His mother, wiping a tear from her eye, caressed his head and said: "I can see my son walking again." He'll be able to get on with his normal life. 'Super Voice' 4G service from Three offers better signal Three is making use of a lower frequency 4G spectrum that can travel more widely
+Mobile phone provider Three has launched a UK service it says will improve reception inside buildings and in rural black spots. Its 4G Super Voice enables customers to make calls and send texts using a lower frequency spectrum. Other networks are looking into introducing the technology, known as Voice Over Long-Term Evolution (VoLTE). It currently works on only the Samsung Galaxy S5, but recent iPhone handsets will be added in the coming months. Three said up to 5.5 million customers would have access to the service by 2017.
+Chief technology officer Bryn Jones said: "By the end of the year, one million of our customers will have access to better indoor coverage and be able to use their phones in more places than ever before." Stars prepare for panto season Pantomime season is big business for theatres up and down the UK, with many getting ready for this year's season now. Some of the biggest names in showbusiness now take part in the yuletide theatre. Matthew Kelly and Hayley Mills will be appearing in Cinderella - one as an ugly sister, the other as fairy godmother. They reveal their panto secrets to BBC Breakfast. Steven Wilson: 'If I don't do anything, I feel this creeping guilt'
+Steven Wilson was recently the big winner at the Progressive Music Awards Steven Wilson is often dubbed the hardest working musician in the world of progressive rock. The multi-talented musician won three prizes at this month's Progressive Music Awards in London, including album of the year for Hand. The Guardian's five-star review called it "a smart, soulful and immersive work of art." Since the 1980s, Wilson has been the driving force in a number of musical projects, the best known of which is the rock band Porcupine Tree. Now, ahead of two sell-out shows at the Royal Albert Hall, Wilson is releasing a vinyl-only double LP, Transience, to showcase the "more accessible" side of his solo output.
+He tells the BBC about his love of vinyl, his busy schedule and explains how comic actor Matt Berry came to be his support act. What does vinyl mean to you? I grew up at the very tail end of the vinyl era, and at the time, I remember, we couldn't wait for CD to come along because vinyl was so frustrating. You would buy the record, take it home, and it would have a scratch, and you would have to take it back again. I love CDs, and for some kinds of music - classical for example - it is better than vinyl. But the problem with the CD and digital downloads is that there's nothing you can really cherish or treasure. Owning vinyl is like having a beautiful painting hanging in your living room.
+It's something you can hold, pore over the lyrics and immerse yourself in the art work. I thought it was just a nostalgic thing, but it can't be if kids too young to remember vinyl are enjoying that kind of experience. Do you have a piece of vinyl that you treasure? The truth is I got rid of 100% of my vinyl in the 90s. All the vinyl I have is re-bought. I started off from the perspective that I wanted to recreate the collection I had when I was 15, but it's gone beyond that. The first record which I persuaded my parents to buy for me was Electric Light Orchestra's Out of the Blue.
+If I still had my original copy, it would have sentimental value, but, alas, it's in a charity shop somewhere. Steven Wilson hopes the album will be a doorway for potential new fans Why release your new compilation Transience on vinyl? It was originally conceived as an idea for Record Store Day, but we missed the boat on that. My record company had suggested I put together some of my shorter, more accessible songs. I got a bit obsessed by the idea to make something like "an introduction to Steven Wilson," and I was committed to it being a vinyl-only release. Anyone who buys the vinyl does also get a high-resolution download.
+Do you have a concern that the album won't show your work in a true light?
\ No newline at end of file
diff --git a/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/val.target b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/val.target
new file mode 100644
index 0000000000000000000000000000000000000000..178d85d71902c8104f7446c3b9b8880553b49ed0
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/test_data/wmt_en_ro/val.target
@@ -0,0 +1,16 @@
+Fostul șef al cabinetului prezidențial brazilian este adus în fața instanței Marți, un judecător federal a acceptat acuzațiile aduse împotriva fostului șef al cabinetului prezidențial brazilian pentru presupusa implicare a acestuia într-o schemă masivă de corupție privind compania petrolieră de stat Petrobras. Biroul procurorului federal a declarat că Jose Dirceu va fi trimis în judecată pentru acuzațiile de corupție, înșelătorie și spălare de bani aduse în această lună. Alte paisprezece persoane vor fi judecate, printre acestea numărându-se Joao Vaccari Neto, fostul trezorier al Partidului Muncitorilor, aflat la putere în Brazilia, și Renato de Souza Duque, fostul președinte al serviciilor pentru întreprinderi ale Petrobras.
+Dirceu este cel mai vechi membru al Partidului Muncitorilor aflat la guvernare luat în custodie pentru legăturile cu această schemă. Dirceu a servit ca șef de cabinet al fostului președinte Luiz Inacio Lula da Silva între 2003 și 2005. A fost arestat la începutul lui august de acasă, unde deja se afla sub arest la domiciliu, cu o pedeapsă de 11 ani pentru implicarea într-o schemă de cumpărare a voturilor în Congres cu peste 10 ani în urmă. Procurorii au declarat că Dirceu a dezvoltat schema de luare de mită de la Petrobras, a acceptat mită în timp ce se afla în funcție și a continuat să primească plăți de la antreprenori după ce a fost închis la sfârșitul lui 2013 pentru scandalul voturilor cumpărate.
+Conform procurorilor, schema de la Petrobras a implicat aproximativ 2 miliarde de dolari sub formă de mită și alte fonduri ilegale. O parte din acei bani s-ar fi întors în fondul de campanie al partidului aflat la guvernare și al aliaților acestora. De asemenea, ar fi inclus mită către directorii Petrobras în schimbul unor contracte umflate. Recuperarea „miraculoasă” a unui elev supraviețuitor al masacrului de la Peshawar Un adolescent paralizat după ce fusese împușcat de patru ori în cel mai cumplit atac terorist din Pakistan a reușit o recuperare „miraculoasă” după ce a urmat un tratament în Regatul Unit. Lui Mohamed Ibrahim Khan, în vârstă de 13 ani, doctorii din Pakistan îi spuseseră că nu va mai putea să meargă niciodată.
+Cel puțin 140 de persoane, majoritatea copii, au fost ucise când bărbați înarmați au atacat școala publică a armatei din Peshawar în luna decembrie a anului trecut. Mohamed, care a sosit la Londra luna trecută pentru operație, va fi externat mai târziu din spital. Exact cu nouă luni în urmă, într-o dimineață obișnuită de marți, Mohamed stătea la ora de primul ajutor și își asculta atent profesorii. Chiar atunci, șapte bărbați înarmați deghizați în uniformele agenților de pază intrau în școala publică a armatei. Purtau centuri cu explozivi și aveau de îndeplinit o misiune simplă: să îi ucidă pe toți bărbații, femeile și copiii care le ieșeau în cale. „Nu pot uita ce s-a întâmplat în acea zi”, spune Mohamed cu o privire aspră.
+Stăteam în amfiteatru, puneam întrebări... apoi am auzit focuri de armă afară. Teroriștii au intrat înăuntru și au început să ucidă. Profesorul nostru a fost ars de viu. Mohamed descrie cum a scos patru elevi din amfiteatru în timp ce se desfășura carnagiul. Apoi spune că și-a auzit prietenul, pe Hamza, strigându-l. Spunea „oh, frate, salvează-mă”. L-am ținut de mână. Atunci eu am fost împușcat în spate, iar el în cap. Cei mai mulți dintre cei uciși în atac erau elevi Hamza a murit în brațele lui Mohamed. Mohamed își amintește că imediat după asta a leșinat și că următorul lucru pe care l-a știut a fost că se afla pe un pat de spital, paralizat de la brâu în jos.
+Doctorii din Peshawar din nordul Pakistanului, apoi cei din Rawalpindi, aproape de capitală, i-au spus familiei sale că nu exista tratament și că nu va mai putea merge niciodată. „Când l-am văzut, am simțit cum îmi iese sufletul”, spune Sher Khan, tatăl lui Mohamed. Acele nouă luni au fost cele mai grele din viața mea. Însă Khan și soția lui, Sherbano, au refuzat să creadă că fiul lor atât de pasionat de crichet nu-și va mai putea folosi vreodată picioarele. Au făcut o campanie și au cerut ajutor de la televiziunea pakistaneză, atrăgând sprijinul unor oameni faimoși precum Imran Khan, jucător de crichet devenit politician.
+Într-un final, au reușit să strângă fonduri pentru a-l duce pe Mohamed în Regatul Unit și a-i oferi tratament la clinica privată Harley Street din Londra. Neurochirurgul consultant Irfan Malik l-a descris pe Mohamed drept „înspăimântat” când acesta a ajuns la spital. „Își petrecuse ultimele [câteva] luni zăcând în pat, fără să se poată mișca de pe o parte pe alta, spune Malik. Era slăbit, se pusese multă presiune pe spatele lui. Nu era într-o formă prea bună. O vertebră de la baza coloanei vertebrale a lui Mohamed fusese distrusă Mohamed fusese împușcat în umăr, în șold și în spate în timpul atacului, iar coloana vertebrală inferioară îi fusese distrusă, ducând la paralizie.
+Însă, în timpul unei operații care a durat șase ore, Malik și echipa lui au reușit să lege din nou terminațiile nervoase și să reconstruiască partea distrusă a coloanei. Chiar și Malik a fost surprins de ceea ce s-a întâmplat în continuare. Exact la o săptămână după operație, Mohamed s-a ridicat și a început să facă pași și să meargă. Nu ne așteptam la un rezultat atât de bun. A fost un miracol”, spune acesta. În mai puțin de două săptămâni de la operație, Mohamed este gata să părăsească spitalul și să înceapă procesul lung de recuperare. Mohamed a sfidat soarta și a început să meargă din nou Vrea să devină puternic și să își continue studiile în Regatul Unit. Însă este hotărât să revină în Pakistan, să se înroleze în armată și să lupte împotriva terorismului.
+„Simt că am încă o șansă la viață” spune el, arătând imaginile cu arme desenate de el lângă manuale școlare și stilouri Fizic, Mohamed devine tot mai puternic în fiecare zi, însă trauma psihologică prin care trece și acum este de neimaginat. „Furia mea nu a scăzut”, mărturisește el. În școala mea au fost uciși copii mici. Ce crimă au comis ei? Mama lui își șterge o lacrimă, îl mângâie pe creștet și spune: „Îmi văd fiul mergând din nou”. Va putea să-și continue firesc viața. Serviciul 4G „Super Voice” de la Three oferă semnal mai bun Three folosește un spectru 4G cu o frecvență mai joasă, care poate acoperi o zonă mai extinsă
+Furnizorul de telefonie mobilă Three a lansat în Regatul Unit un serviciu despre care spune că va îmbunătăți recepția în interiorul clădirilor și în zonele rurale fără semnal. Serviciul 4G Super Voice le permite clienților să efectueze apeluri și să trimită mesaje text folosind un spectru cu o frecvență mai joasă. Și alte rețele intenționează să introducă aceeași tehnologie, cunoscută ca „Voice Over Long-Term Evolution (VoLTE)”. Aceasta funcționează momentan doar cu Samsung Galaxy S5, însă telefoanele iPhone recente vor beneficia de ea în lunile următoare. Three menționează că până la 5,5 milioane de clienți vor avea acces la serviciu până în 2017.
+Responsabilul șef pentru tehnologie, Bryn Jones a declarat: „Până la sfârșitul anului, un milion dintre clienții noștri vor avea acces la o acoperire mai bună în interior și își vor putea folosi telefoanele în mai multe locuri ca până acum”. Vedetele se pregătesc pentru stagiunea de pantomimă Stagiunea de pantomimă este foarte importantă pentru teatrele din tot Regatul Unit, multe dintre ele pregătindu-se acum pentru stagiunea din acest an. Acum, la teatrul de Crăciun participă unele dintre numele cele mai mari din showbusiness. Matthew Kelly și Hayley Mills vor apărea în Cenușăreasa - primul în rolul uneia dintre surorile rele, iar a doua în rolul zânei. Aceștia dezvăluie secretele pantomimei lor la BBC Breakfast. Steven Wilson: „Dacă nu fac nimic, mă simt vinovat”
+Steven Wilson a fost desemnat recent drept marele câștigător al Progressive Music Awards Steven Wilson a fost numit de multe ori drept cel mai muncitor muzician din lumea rockului progresiv. Talentatul muzician a câștigat trei premii la Progressive Music Awards, care a avut loc luna aceasta la Londra, printre care și premiul pentru cel mai bun album al anului pentru Hand. În recenzia sa de cinci stele, The Guardian a numit albumul „o operă de artă inteligentă, expresivă și captivantă”. Încă din anii 1980, Wilson este motorul mai multor proiecte muzicale, cel mai cunoscut dintre acestea fiind trupa de rock Porcupine Tree. Acum, înainte de două spectacole cu casa închisă la Royal Albert Hall, Wilson lansează un dublu LP doar în format vinil, Transience, pentru a arăta latura „mai accesibilă” a activității sale solo.
+A povestit pentru BBC despre dragostea lui pentru viniluri și despre programul său încărcat și a explicat cum a ajuns actorul de comedie Matt Berry să îi deschidă spectacolele. Ce înseamnă vinil pentru tine? Am crescut chiar în perioada de sfârșit a erei vinilurilor și îmi amintesc că atunci abia așteptam apariția CD-ului, căci vinilul era atât de enervant. Cumpărai un disc, mergeai cu el acasă, avea o zgârietură și trebuia să îl aduci înapoi. Iubesc CD-urile, iar pentru anumite tipuri de muzică, de exemplu cea clasică, sunt mai bune decât vinilurile. Însă problema cu CD-urile și cu descărcările digitale este aceea că nu mai există nimic pe care să îl prețuiești cu adevărat. Să ai un vinil e ca și cum ai avea un tablou frumos agățat în sufragerie.
+E ceva ce poți ține în mână, în timp ce te lași absorbit de versuri și copleșit de actul artistic. Am crezut că e doar o chestie nostalgică, însă nu are cum să fie așa dacă unor puști prea tineri să-și amintească de viniluri le place acest gen de experiență. Ai vreun vinil la care ții în mod special? Recunosc că am scăpat de toate vinilurile în anii '90. Toate vinilurile pe care le am sunt cumpărate din nou. Am pornit de la ideea de a reface colecția pe care o aveam la 15 ani, însă am trecut de limita aceea. Primul disc pe care mi-am convins părinții să mi-l cumpere a fost Out of the Blue de la Electric Light Orchestra.
+Dacă aș mai fi avut încă exemplarul inițial, acesta ar fi avut valoare sentimentală, însă, din păcate, se află pe undeva printr-un magazin de caritate. Steven Wilson speră că albumul va fi o poartă către posibili fani noi De ce ți-ai lansat noua compilație Transience pe vinil? Aceasta a fost concepută inițial ca idee pentru Ziua magazinelor de discuri, însă am ratat ocazia. Casa mea de discuri sugerase să adun câteva dintre melodiile mele mai scurte și mai accesibile. Am ajuns să fiu ușor obsedat de ideea de a face ceva gen „introducere în muzica lui Steven Wilson” și am ținut neapărat ca proiectul să fie lansat doar pe vinil. Cine cumpără vinilul primește, de asemenea, și o variantă descărcată la rezoluție înaltă.
+Ești îngrijorat că albumul nu va arăta muzica ta în adevărata ei lumină?
\ No newline at end of file
diff --git a/docs/transformers/examples/legacy/seq2seq/train_distil_marian_enro.sh b/docs/transformers/examples/legacy/seq2seq/train_distil_marian_enro.sh
new file mode 100644
index 0000000000000000000000000000000000000000..5e86a6991c579edcc91cf8bfe75def0b52746293
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/train_distil_marian_enro.sh
@@ -0,0 +1,38 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+export WANDB_PROJECT=distil-marian
+export BS=64
+export GAS=1
+export m=sshleifer/student_marian_en_ro_6_3
+export MAX_LEN=128
+python finetune_trainer.py \
+ --tokenizer_name $m --model_name_or_path $m \
+ --data_dir $ENRO_DIR \
+ --output_dir marian_en_ro_6_3 --overwrite_output_dir \
+ --learning_rate=3e-4 \
+ --warmup_steps 500 --sortish_sampler \
+ --fp16 \
+ --gradient_accumulation_steps=$GAS \
+ --per_device_train_batch_size=$BS --per_device_eval_batch_size=$BS \
+ --freeze_encoder --freeze_embeds \
+ --num_train_epochs=6 \
+ --save_steps 3000 --eval_steps 3000 \
+ --max_source_length $MAX_LEN --max_target_length $MAX_LEN \
+ --val_max_target_length $MAX_TGT_LEN --test_max_target_length $MAX_TGT_LEN \
+ --do_train --do_eval --do_predict \
+ --eval_strategy steps \
+ --predict_with_generate --logging_first_step \
+ --task translation --label_smoothing_factor 0.1 \
+ "$@"
diff --git a/docs/transformers/examples/legacy/seq2seq/train_distil_marian_enro_tpu.sh b/docs/transformers/examples/legacy/seq2seq/train_distil_marian_enro_tpu.sh
new file mode 100644
index 0000000000000000000000000000000000000000..00ef672261963bec60a8b1e4b9bdf5e1c55ce713
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/train_distil_marian_enro_tpu.sh
@@ -0,0 +1,39 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+export WANDB_PROJECT=distil-marian
+export BS=64
+export m=sshleifer/student_marian_en_ro_6_3
+export MAX_LEN=128
+export TPU_NUM_CORES=8
+
+python xla_spawn.py --num_cores $TPU_NUM_CORES \
+ finetune_trainer.py \
+ --tokenizer_name $m --model_name_or_path $m \
+ --data_dir $ENRO_DIR \
+ --output_dir marian_en_ro_6_3 --overwrite_output_dir \
+ --learning_rate=3e-4 \
+ --warmup_steps 500 \
+ --per_device_train_batch_size=$BS --per_device_eval_batch_size=$BS \
+ --freeze_encoder --freeze_embeds \
+ --num_train_epochs=6 \
+ --save_steps 500 --eval_steps 500 \
+ --logging_first_step --logging_steps 200 \
+ --max_source_length $MAX_LEN --max_target_length $MAX_LEN \
+ --val_max_target_length $MAX_TGT_LEN --test_max_target_length $MAX_TGT_LEN \
+ --do_train --do_eval \
+ --eval_strategy steps \
+ --prediction_loss_only \
+ --task translation --label_smoothing_factor 0.1 \
+ "$@"
diff --git a/docs/transformers/examples/legacy/seq2seq/train_distilbart_cnn.sh b/docs/transformers/examples/legacy/seq2seq/train_distilbart_cnn.sh
new file mode 100644
index 0000000000000000000000000000000000000000..42f34e0cb6e75a7fa313a951f1e725772716821b
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/train_distilbart_cnn.sh
@@ -0,0 +1,39 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+export WANDB_PROJECT=distilbart-trainer
+export BS=32
+export m=sshleifer/student_cnn_12_6
+export tok=facebook/bart-large
+export MAX_TGT_LEN=142
+
+python finetune_trainer.py \
+ --model_name_or_path $m --tokenizer_name $tok \
+ --data_dir cnn_dm \
+ --output_dir distilbart-cnn-12-6 --overwrite_output_dir \
+ --learning_rate=3e-5 \
+ --warmup_steps 500 --sortish_sampler \
+ --fp16 \
+ --n_val 500 \
+ --gradient_accumulation_steps=1 \
+ --per_device_train_batch_size=$BS --per_device_eval_batch_size=$BS \
+ --freeze_encoder --freeze_embeds \
+ --num_train_epochs=2 \
+ --save_steps 3000 --eval_steps 3000 \
+ --logging_first_step \
+ --max_target_length 56 --val_max_target_length $MAX_TGT_LEN --test_max_target_length $MAX_TGT_LEN\
+ --do_train --do_eval --do_predict \
+ --eval_strategy steps \
+ --predict_with_generate --sortish_sampler \
+ "$@"
diff --git a/docs/transformers/examples/legacy/seq2seq/train_mbart_cc25_enro.sh b/docs/transformers/examples/legacy/seq2seq/train_mbart_cc25_enro.sh
new file mode 100644
index 0000000000000000000000000000000000000000..63c8051b47def1c80743e7cb38b948b33d20615d
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/train_mbart_cc25_enro.sh
@@ -0,0 +1,35 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+python finetune_trainer.py \
+ --model_name_or_path=facebook/mbart-large-cc25 \
+ --data_dir $ENRO_DIR \
+ --output_dir mbart_cc25_enro --overwrite_output_dir \
+ --learning_rate=3e-5 \
+ --warmup_steps 500 \
+ --fp16 \
+ --label_smoothing 0.1 \
+ --adam_eps 1e-06 \
+ --src_lang en_XX --tgt_lang ro_RO \
+ --freeze_embeds \
+ --per_device_train_batch_size=4 --per_device_eval_batch_size=4 \
+ --max_source_length 128 --max_target_length 128 --val_max_target_length 128 --test_max_target_length 128\
+ --sortish_sampler \
+ --num_train_epochs 6 \
+ --save_steps 25000 --eval_steps 25000 --logging_steps 1000 \
+ --do_train --do_eval --do_predict \
+ --eval_strategy steps \
+ --predict_with_generate --logging_first_step \
+ --task translation \
+ "$@"
diff --git a/docs/transformers/examples/legacy/seq2seq/utils.py b/docs/transformers/examples/legacy/seq2seq/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..001300f1869a3c0412a44ada4fe7393c156603da
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/utils.py
@@ -0,0 +1,665 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import itertools
+import json
+import linecache
+import math
+import os
+import pickle
+import socket
+from collections.abc import Iterable
+from logging import getLogger
+from pathlib import Path
+from typing import Callable, Union
+
+import git
+import numpy as np
+import torch
+import torch.distributed as dist
+from rouge_score import rouge_scorer, scoring
+from sacrebleu import corpus_bleu
+from sentence_splitter import add_newline_to_end_of_each_sentence
+from torch import nn
+from torch.utils.data import Dataset, Sampler
+
+from transformers import BartTokenizer, EvalPrediction, PreTrainedTokenizer, T5Tokenizer
+from transformers.models.bart.modeling_bart import shift_tokens_right
+from transformers.utils import cached_property
+
+
+try:
+ from fairseq.data.data_utils import batch_by_size
+
+ FAIRSEQ_AVAILABLE = True
+except (ImportError, ModuleNotFoundError):
+ FAIRSEQ_AVAILABLE = False
+
+
+def label_smoothed_nll_loss(lprobs, target, epsilon, ignore_index=-100):
+ """From fairseq"""
+ if target.dim() == lprobs.dim() - 1:
+ target = target.unsqueeze(-1)
+ nll_loss = -lprobs.gather(dim=-1, index=target)
+ smooth_loss = -lprobs.sum(dim=-1, keepdim=True)
+ if ignore_index is not None:
+ pad_mask = target.eq(ignore_index)
+ nll_loss.masked_fill_(pad_mask, 0.0)
+ smooth_loss.masked_fill_(pad_mask, 0.0)
+ else:
+ nll_loss = nll_loss.squeeze(-1)
+ smooth_loss = smooth_loss.squeeze(-1)
+
+ nll_loss = nll_loss.sum() # mean()? Scared to break other math.
+ smooth_loss = smooth_loss.sum()
+ eps_i = epsilon / lprobs.size(-1)
+ loss = (1.0 - epsilon) * nll_loss + eps_i * smooth_loss
+ return loss, nll_loss
+
+
+def lmap(f: Callable, x: Iterable) -> list:
+ """list(map(f, x))"""
+ return list(map(f, x))
+
+
+def calculate_bleu(output_lns, refs_lns, **kwargs) -> dict:
+ """Uses sacrebleu's corpus_bleu implementation."""
+ return {"bleu": round(corpus_bleu(output_lns, [refs_lns], **kwargs).score, 4)}
+
+
+def build_compute_metrics_fn(task_name: str, tokenizer: PreTrainedTokenizer) -> Callable[[EvalPrediction], dict]:
+ def non_pad_len(tokens: np.ndarray) -> int:
+ return np.count_nonzero(tokens != tokenizer.pad_token_id)
+
+ def decode_pred(pred: EvalPrediction) -> tuple[list[str], list[str]]:
+ pred_ids = pred.predictions
+ label_ids = pred.label_ids
+ pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
+ label_ids[label_ids == -100] = tokenizer.pad_token_id
+ label_str = tokenizer.batch_decode(label_ids, skip_special_tokens=True)
+ pred_str = lmap(str.strip, pred_str)
+ label_str = lmap(str.strip, label_str)
+ return pred_str, label_str
+
+ def summarization_metrics(pred: EvalPrediction) -> dict:
+ pred_str, label_str = decode_pred(pred)
+ rouge: dict = calculate_rouge(pred_str, label_str)
+ summ_len = np.round(np.mean(lmap(non_pad_len, pred.predictions)), 1)
+ rouge.update({"gen_len": summ_len})
+ return rouge
+
+ def translation_metrics(pred: EvalPrediction) -> dict:
+ pred_str, label_str = decode_pred(pred)
+ bleu: dict = calculate_bleu(pred_str, label_str)
+ gen_len = np.round(np.mean(lmap(non_pad_len, pred.predictions)), 1)
+ bleu.update({"gen_len": gen_len})
+ return bleu
+
+ compute_metrics_fn = summarization_metrics if "summarization" in task_name else translation_metrics
+ return compute_metrics_fn
+
+
+def trim_batch(
+ input_ids,
+ pad_token_id,
+ attention_mask=None,
+):
+ """Remove columns that are populated exclusively by pad_token_id"""
+ keep_column_mask = input_ids.ne(pad_token_id).any(dim=0)
+ if attention_mask is None:
+ return input_ids[:, keep_column_mask]
+ else:
+ return (input_ids[:, keep_column_mask], attention_mask[:, keep_column_mask])
+
+
+class AbstractSeq2SeqDataset(Dataset):
+ def __init__(
+ self,
+ tokenizer,
+ data_dir,
+ max_source_length,
+ max_target_length,
+ type_path="train",
+ n_obs=None,
+ prefix="",
+ **dataset_kwargs,
+ ):
+ super().__init__()
+ self.src_file = Path(data_dir).joinpath(type_path + ".source")
+ self.tgt_file = Path(data_dir).joinpath(type_path + ".target")
+ self.len_file = Path(data_dir).joinpath(type_path + ".len")
+ if os.path.exists(self.len_file):
+ self.src_lens = pickle_load(self.len_file)
+ self.used_char_len = False
+ else:
+ self.src_lens = self.get_char_lens(self.src_file)
+ self.used_char_len = True
+ self.max_source_length = max_source_length
+ self.max_target_length = max_target_length
+ assert min(self.src_lens) > 0, f"found empty line in {self.src_file}"
+ self.tokenizer = tokenizer
+ self.prefix = prefix if prefix is not None else ""
+
+ if n_obs is not None:
+ self.src_lens = self.src_lens[:n_obs]
+ self.pad_token_id = self.tokenizer.pad_token_id
+ self.dataset_kwargs = dataset_kwargs
+ dataset_kwargs.update({"add_prefix_space": True} if isinstance(self.tokenizer, BartTokenizer) else {})
+
+ def __len__(self):
+ return len(self.src_lens)
+
+ @staticmethod
+ def get_char_lens(data_file):
+ return [len(x) for x in Path(data_file).open().readlines()]
+
+ @cached_property
+ def tgt_lens(self):
+ """Length in characters of target documents"""
+ return self.get_char_lens(self.tgt_file)
+
+ def make_sortish_sampler(self, batch_size, distributed=False, shuffle=True, **kwargs):
+ if distributed:
+ return DistributedSortishSampler(self, batch_size, shuffle=shuffle, **kwargs)
+ else:
+ return SortishSampler(self.src_lens, batch_size, shuffle=shuffle)
+
+ def make_dynamic_sampler(self, max_tokens_per_batch=1024, **kwargs):
+ assert FAIRSEQ_AVAILABLE, "Dynamic batch size requires `pip install fairseq`"
+ assert not self.used_char_len, "You must call python make_len_file.py before calling make_dynamic_sampler"
+ sorted_indices = list(self.make_sortish_sampler(1024, shuffle=False))
+
+ def num_tokens_in_example(i):
+ return min(self.src_lens[i], self.max_target_length)
+
+ # call fairseq cython function
+ batch_sampler: list[list[int]] = batch_by_size(
+ sorted_indices,
+ num_tokens_fn=num_tokens_in_example,
+ max_tokens=max_tokens_per_batch,
+ required_batch_size_multiple=64,
+ )
+ shuffled_batches = [batch_sampler[i] for i in np.random.permutation(range(len(batch_sampler)))]
+ # move the largest batch to the front to OOM quickly (uses an approximation for padding)
+ approximate_toks_per_batch = [max(self.src_lens[i] for i in batch) * len(batch) for batch in shuffled_batches]
+ largest_batch_idx = np.argmax(approximate_toks_per_batch)
+ shuffled_batches[0], shuffled_batches[largest_batch_idx] = (
+ shuffled_batches[largest_batch_idx],
+ shuffled_batches[0],
+ )
+ return shuffled_batches
+
+ def __getitem__(self, item):
+ raise NotImplementedError("You must implement this")
+
+ def collate_fn(self, batch):
+ raise NotImplementedError("You must implement this")
+
+
+class LegacySeq2SeqDataset(AbstractSeq2SeqDataset):
+ def __getitem__(self, index) -> dict[str, torch.Tensor]:
+ """Call tokenizer on src and tgt_lines"""
+ index = index + 1 # linecache starts at 1
+ source_line = self.prefix + linecache.getline(str(self.src_file), index).rstrip("\n")
+ tgt_line = linecache.getline(str(self.tgt_file), index).rstrip("\n")
+ assert source_line, f"empty source line for index {index}"
+ assert tgt_line, f"empty tgt line for index {index}"
+ source_inputs = self.encode_line(self.tokenizer, source_line, self.max_source_length)
+ target_inputs = self.encode_line(self.tokenizer, tgt_line, self.max_target_length)
+
+ source_ids = source_inputs["input_ids"].squeeze()
+ target_ids = target_inputs["input_ids"].squeeze()
+ src_mask = source_inputs["attention_mask"].squeeze()
+ return {
+ "input_ids": source_ids,
+ "attention_mask": src_mask,
+ "labels": target_ids,
+ }
+
+ def encode_line(self, tokenizer, line, max_length, pad_to_max_length=True, return_tensors="pt"):
+ """Only used by LegacyDataset"""
+ return tokenizer(
+ [line],
+ max_length=max_length,
+ padding="max_length" if pad_to_max_length else None,
+ truncation=True,
+ return_tensors=return_tensors,
+ **self.dataset_kwargs,
+ )
+
+ def collate_fn(self, batch) -> dict[str, torch.Tensor]:
+ input_ids = torch.stack([x["input_ids"] for x in batch])
+ masks = torch.stack([x["attention_mask"] for x in batch])
+ target_ids = torch.stack([x["labels"] for x in batch])
+ pad_token_id = self.pad_token_id
+ y = trim_batch(target_ids, pad_token_id)
+ source_ids, source_mask = trim_batch(input_ids, pad_token_id, attention_mask=masks)
+ batch = {
+ "input_ids": source_ids,
+ "attention_mask": source_mask,
+ "labels": y,
+ }
+ return batch
+
+
+class Seq2SeqDataset(AbstractSeq2SeqDataset):
+ """A dataset that calls prepare_seq2seq_batch."""
+
+ def __getitem__(self, index) -> dict[str, str]:
+ index = index + 1 # linecache starts at 1
+ source_line = self.prefix + linecache.getline(str(self.src_file), index).rstrip("\n")
+ tgt_line = linecache.getline(str(self.tgt_file), index).rstrip("\n")
+ assert source_line, f"empty source line for index {index}"
+ assert tgt_line, f"empty tgt line for index {index}"
+ return {"tgt_texts": tgt_line, "src_texts": source_line, "id": index - 1}
+
+ def collate_fn(self, batch) -> dict[str, torch.Tensor]:
+ """Call prepare_seq2seq_batch."""
+ batch_encoding: dict[str, torch.Tensor] = self.tokenizer.prepare_seq2seq_batch(
+ [x["src_texts"] for x in batch],
+ tgt_texts=[x["tgt_texts"] for x in batch],
+ max_length=self.max_source_length,
+ max_target_length=self.max_target_length,
+ return_tensors="pt",
+ **self.dataset_kwargs,
+ ).data
+ batch_encoding["ids"] = torch.tensor([x["id"] for x in batch])
+ return batch_encoding
+
+
+class Seq2SeqDataCollator:
+ def __init__(self, tokenizer, data_args, decoder_start_token_id, tpu_num_cores=None):
+ self.tokenizer = tokenizer
+ self.pad_token_id = tokenizer.pad_token_id
+ self.decoder_start_token_id = decoder_start_token_id
+ assert self.pad_token_id is not None, (
+ f"pad_token_id is not defined for ({self.tokenizer.__class__.__name__}), it must be defined."
+ )
+ self.data_args = data_args
+ self.tpu_num_cores = tpu_num_cores
+ self.dataset_kwargs = {"add_prefix_space": True} if isinstance(tokenizer, BartTokenizer) else {}
+ if data_args.src_lang is not None:
+ self.dataset_kwargs["src_lang"] = data_args.src_lang
+ if data_args.tgt_lang is not None:
+ self.dataset_kwargs["tgt_lang"] = data_args.tgt_lang
+
+ def __call__(self, batch) -> dict[str, torch.Tensor]:
+ if hasattr(self.tokenizer, "prepare_seq2seq_batch"):
+ batch = self._encode(batch)
+ input_ids, attention_mask, labels = (
+ batch["input_ids"],
+ batch["attention_mask"],
+ batch["labels"],
+ )
+ else:
+ input_ids = torch.stack([x["input_ids"] for x in batch])
+ attention_mask = torch.stack([x["attention_mask"] for x in batch])
+ labels = torch.stack([x["labels"] for x in batch])
+
+ labels = trim_batch(labels, self.pad_token_id)
+ input_ids, attention_mask = trim_batch(input_ids, self.pad_token_id, attention_mask=attention_mask)
+
+ if isinstance(self.tokenizer, T5Tokenizer):
+ decoder_input_ids = self._shift_right_t5(labels)
+ else:
+ decoder_input_ids = shift_tokens_right(labels, self.pad_token_id, self.decoder_start_token_id)
+
+ batch = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "decoder_input_ids": decoder_input_ids,
+ "labels": labels,
+ }
+ return batch
+
+ def _shift_right_t5(self, input_ids):
+ # shift inputs to the right
+ shifted_input_ids = input_ids.new_zeros(input_ids.shape)
+ shifted_input_ids[..., 1:] = input_ids[..., :-1].clone()
+ shifted_input_ids[..., 0] = self.pad_token_id
+ return shifted_input_ids
+
+ def _encode(self, batch) -> dict[str, torch.Tensor]:
+ batch_encoding = self.tokenizer.prepare_seq2seq_batch(
+ [x["src_texts"] for x in batch],
+ tgt_texts=[x["tgt_texts"] for x in batch],
+ max_length=self.data_args.max_source_length,
+ max_target_length=self.data_args.max_target_length,
+ padding="max_length" if self.tpu_num_cores is not None else "longest", # TPU hack
+ return_tensors="pt",
+ **self.dataset_kwargs,
+ )
+ return batch_encoding.data
+
+
+class SortishSampler(Sampler):
+ "Go through the text data by order of src length with a bit of randomness. From fastai repo."
+
+ def __init__(self, data, batch_size, shuffle=True):
+ self.data, self.bs, self.shuffle = data, batch_size, shuffle
+
+ def __len__(self) -> int:
+ return len(self.data)
+
+ def __iter__(self):
+ return iter(sortish_sampler_indices(self.data, self.bs, shuffle=self.shuffle))
+
+
+def sortish_sampler_indices(data: list, bs: int, shuffle=True) -> np.array:
+ "Go through the text data by order of src length with a bit of randomness. From fastai repo."
+ if not shuffle:
+ return np.argsort(np.array(data) * -1)
+
+ def key_fn(i):
+ return data[i]
+
+ idxs = np.random.permutation(len(data))
+ sz = bs * 50
+ ck_idx = [idxs[i : i + sz] for i in range(0, len(idxs), sz)]
+ sort_idx = np.concatenate([sorted(s, key=key_fn, reverse=True) for s in ck_idx])
+ sz = bs
+ ck_idx = [sort_idx[i : i + sz] for i in range(0, len(sort_idx), sz)]
+ max_ck = np.argmax([key_fn(ck[0]) for ck in ck_idx]) # find the chunk with the largest key,
+ ck_idx[0], ck_idx[max_ck] = ck_idx[max_ck], ck_idx[0] # then make sure it goes first.
+ sort_idx = np.concatenate(np.random.permutation(ck_idx[1:])) if len(ck_idx) > 1 else np.array([], dtype=int)
+ sort_idx = np.concatenate((ck_idx[0], sort_idx))
+ return sort_idx
+
+
+class DistributedSortishSampler(Sampler):
+ """Copied from torch DistributedSampler"""
+
+ def __init__(self, dataset, batch_size, num_replicas=None, rank=None, add_extra_examples=True, shuffle=True):
+ if num_replicas is None:
+ if not dist.is_available():
+ raise RuntimeError("Requires distributed package to be available")
+ num_replicas = dist.get_world_size()
+ if rank is None:
+ if not dist.is_available():
+ raise RuntimeError("Requires distributed package to be available")
+ rank = dist.get_rank()
+ self.dataset = dataset
+ self.num_replicas = num_replicas
+ self.rank = rank
+ self.epoch = 0
+ if add_extra_examples:
+ self.num_samples = int(math.ceil(len(self.dataset) * 1.0 / self.num_replicas))
+ self.total_size = self.num_samples * self.num_replicas
+ else:
+ self.total_size = len(dataset)
+ self.num_samples = len(self.available_indices)
+ self.batch_size = batch_size
+ self.add_extra_examples = add_extra_examples
+ self.shuffle = shuffle
+
+ def __iter__(self) -> Iterable:
+ g = torch.Generator()
+ g.manual_seed(self.epoch)
+
+ sortish_data = [self.dataset.src_lens[i] for i in self.available_indices]
+ sortish_indices = sortish_sampler_indices(sortish_data, self.batch_size, shuffle=self.shuffle)
+ indices = [self.available_indices[i] for i in sortish_indices]
+ assert len(indices) == self.num_samples
+ return iter(indices)
+
+ @cached_property
+ def available_indices(self) -> np.array:
+ indices = list(range(len(self.dataset)))
+ # add extra samples to make it evenly divisible
+ indices += indices[: (self.total_size - len(indices))]
+ assert len(indices) == self.total_size
+ # subsample
+ available_indices = indices[self.rank : self.total_size : self.num_replicas]
+ return available_indices
+
+ def __len__(self):
+ return self.num_samples
+
+ def set_epoch(self, epoch):
+ self.epoch = epoch
+
+
+logger = getLogger(__name__)
+
+
+def use_task_specific_params(model, task):
+ """Update config with summarization specific params."""
+ task_specific_params = model.config.task_specific_params
+
+ if task_specific_params is not None:
+ pars = task_specific_params.get(task, {})
+ logger.info(f"setting model.config to task specific params for {task}:\n {pars}")
+ logger.info("note: command line args may override some of these")
+ model.config.update(pars)
+
+
+def pickle_load(path):
+ """pickle.load(path)"""
+ with open(path, "rb") as f:
+ return pickle.load(f)
+
+
+def pickle_save(obj, path):
+ """pickle.dump(obj, path)"""
+ with open(path, "wb") as f:
+ return pickle.dump(obj, f)
+
+
+def flatten_list(summary_ids: list[list]):
+ return list(itertools.chain.from_iterable(summary_ids))
+
+
+def save_git_info(folder_path: str) -> None:
+ """Save git information to output_dir/git_log.json"""
+ repo_infos = get_git_info()
+ save_json(repo_infos, os.path.join(folder_path, "git_log.json"))
+
+
+def save_json(content, path, indent=4, **json_dump_kwargs):
+ with open(path, "w") as f:
+ json.dump(content, f, indent=indent, sort_keys=True, **json_dump_kwargs)
+
+
+def load_json(path):
+ with open(path) as f:
+ return json.load(f)
+
+
+def get_git_info():
+ try:
+ repo = git.Repo(search_parent_directories=True)
+ repo_infos = {
+ "repo_id": str(repo),
+ "repo_sha": str(repo.head.object.hexsha),
+ "repo_branch": str(repo.active_branch),
+ "hostname": str(socket.gethostname()),
+ }
+ return repo_infos
+ except TypeError:
+ return {
+ "repo_id": None,
+ "repo_sha": None,
+ "repo_branch": None,
+ "hostname": None,
+ }
+
+
+ROUGE_KEYS = ["rouge1", "rouge2", "rougeL", "rougeLsum"]
+
+
+def extract_rouge_mid_statistics(dct):
+ new_dict = {}
+ for k1, v1 in dct.items():
+ mid = v1.mid
+ new_dict[k1] = {stat: round(getattr(mid, stat), 4) for stat in ["precision", "recall", "fmeasure"]}
+ return new_dict
+
+
+def calculate_rouge(
+ pred_lns: list[str],
+ tgt_lns: list[str],
+ use_stemmer=True,
+ rouge_keys=ROUGE_KEYS,
+ return_precision_and_recall=False,
+ bootstrap_aggregation=True,
+ newline_sep=True,
+) -> dict:
+ """Calculate rouge using rouge_scorer package.
+
+ Args:
+ pred_lns: list of summaries generated by model
+ tgt_lns: list of groundtruth summaries (e.g. contents of val.target)
+ use_stemmer: Bool indicating whether Porter stemmer should be used to
+ strip word suffixes to improve matching.
+ rouge_keys: which metrics to compute, defaults to rouge1, rouge2, rougeL, rougeLsum
+ return_precision_and_recall: (False) whether to also return precision and recall.
+ bootstrap_aggregation: whether to do the typical bootstrap resampling of scores. Defaults to True, if False
+ this function returns a collections.defaultdict[metric: list of values for each observation for each subscore]``
+ newline_sep:(default=True) whether to add newline between sentences. This is essential for calculation rougeL
+ on multi sentence summaries (CNN/DM dataset).
+
+ Returns:
+ Dict[score: value] if aggregate else defaultdict(list) keyed by rouge_keys
+
+ """
+ scorer = rouge_scorer.RougeScorer(rouge_keys, use_stemmer=use_stemmer)
+ aggregator = scoring.BootstrapAggregator()
+ for pred, tgt in zip(tgt_lns, pred_lns):
+ # rougeLsum expects "\n" separated sentences within a summary
+ if newline_sep:
+ pred = add_newline_to_end_of_each_sentence(pred)
+ tgt = add_newline_to_end_of_each_sentence(tgt)
+ scores = scorer.score(pred, tgt)
+ aggregator.add_scores(scores)
+
+ if bootstrap_aggregation:
+ result = aggregator.aggregate()
+ if return_precision_and_recall:
+ return extract_rouge_mid_statistics(result) # here we return dict
+ else:
+ return {k: round(v.mid.fmeasure * 100, 4) for k, v in result.items()}
+
+ else:
+ return aggregator._scores # here we return defaultdict(list)
+
+
+# Utilities for freezing parameters and checking whether they are frozen
+
+
+def freeze_params(model: nn.Module):
+ """Set requires_grad=False for each of model.parameters()"""
+ for par in model.parameters():
+ par.requires_grad = False
+
+
+def freeze_embeds(model):
+ """Freeze token embeddings and positional embeddings for bart, just token embeddings for t5."""
+ model_type = model.config.model_type
+
+ if model_type in ["t5", "mt5"]:
+ freeze_params(model.shared)
+ for d in [model.encoder, model.decoder]:
+ freeze_params(d.embed_tokens)
+ elif model_type == "fsmt":
+ for d in [model.model.encoder, model.model.decoder]:
+ freeze_params(d.embed_positions)
+ freeze_params(d.embed_tokens)
+ else:
+ freeze_params(model.model.shared)
+ for d in [model.model.encoder, model.model.decoder]:
+ freeze_params(d.embed_positions)
+ freeze_params(d.embed_tokens)
+
+
+def grad_status(model: nn.Module) -> Iterable:
+ return (par.requires_grad for par in model.parameters())
+
+
+def any_requires_grad(model: nn.Module) -> bool:
+ return any(grad_status(model))
+
+
+def assert_all_frozen(model):
+ model_grads: list[bool] = list(grad_status(model))
+ n_require_grad = sum(lmap(int, model_grads))
+ npars = len(model_grads)
+ assert not any(model_grads), f"{n_require_grad / npars:.1%} of {npars} weights require grad"
+
+
+def assert_not_all_frozen(model):
+ model_grads: list[bool] = list(grad_status(model))
+ npars = len(model_grads)
+ assert any(model_grads), f"none of {npars} weights require grad"
+
+
+def parse_numeric_n_bool_cl_kwargs(unparsed_args: list[str]) -> dict[str, Union[int, float, bool]]:
+ """
+ Parse an argv list of unspecified command line args to a dict.
+ Assumes all values are either numeric or boolean in the form of true/false.
+ """
+ result = {}
+ assert len(unparsed_args) % 2 == 0, f"got odd number of unparsed args: {unparsed_args}"
+ num_pairs = len(unparsed_args) // 2
+ for pair_num in range(num_pairs):
+ i = 2 * pair_num
+ assert unparsed_args[i].startswith("--")
+ if unparsed_args[i + 1].lower() == "true":
+ value = True
+ elif unparsed_args[i + 1].lower() == "false":
+ value = False
+ else:
+ try:
+ value = int(unparsed_args[i + 1])
+ except ValueError:
+ value = float(unparsed_args[i + 1]) # this can raise another informative ValueError
+
+ result[unparsed_args[i][2:]] = value
+ return result
+
+
+def write_txt_file(ordered_tgt, path):
+ f = Path(path).open("w")
+ for ln in ordered_tgt:
+ f.write(ln + "\n")
+ f.flush()
+
+
+def chunks(lst, n):
+ """Yield successive n-sized chunks from lst."""
+ for i in range(0, len(lst), n):
+ yield lst[i : i + n]
+
+
+def check_output_dir(args, expected_items=0):
+ """
+ Checks whether to bail out if output_dir already exists and has more than expected_items in it
+
+ `args`: needs to have the following attributes of `args`:
+ - output_dir
+ - do_train
+ - overwrite_output_dir
+
+ `expected_items`: normally 0 (default) - i.e. empty dir, but in some cases a few files are expected (e.g. recovery from OOM)
+ """
+ if (
+ os.path.exists(args.output_dir)
+ and len(os.listdir(args.output_dir)) > expected_items
+ and args.do_train
+ and not args.overwrite_output_dir
+ ):
+ raise ValueError(
+ f"Output directory ({args.output_dir}) already exists and "
+ f"has {len(os.listdir(args.output_dir))} items in it (expected {expected_items} items). "
+ "Use --overwrite_output_dir to overcome."
+ )
diff --git a/docs/transformers/examples/legacy/seq2seq/xla_spawn.py b/docs/transformers/examples/legacy/seq2seq/xla_spawn.py
new file mode 100644
index 0000000000000000000000000000000000000000..f9955acfa201a77b12ab4391c14190434e748bbb
--- /dev/null
+++ b/docs/transformers/examples/legacy/seq2seq/xla_spawn.py
@@ -0,0 +1,82 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+A simple launcher script for TPU training
+
+Inspired by https://github.com/pytorch/pytorch/blob/master/torch/distributed/launch.py
+
+::
+ >>> python xla_spawn.py --num_cores=NUM_CORES_YOU_HAVE
+ YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other
+ arguments of your training script)
+
+"""
+
+import importlib
+import sys
+from argparse import REMAINDER, ArgumentParser
+from pathlib import Path
+
+import torch_xla.distributed.xla_multiprocessing as xmp
+
+
+def parse_args():
+ """
+ Helper function parsing the command line options
+ @retval ArgumentParser
+ """
+ parser = ArgumentParser(
+ description=(
+ "PyTorch TPU distributed training launch helper utility that will spawn up multiple distributed processes"
+ )
+ )
+
+ # Optional arguments for the launch helper
+ parser.add_argument("--num_cores", type=int, default=1, help="Number of TPU cores to use (1 or 8).")
+
+ # positional
+ parser.add_argument(
+ "training_script",
+ type=str,
+ help=(
+ "The full path to the single TPU training "
+ "program/script to be launched in parallel, "
+ "followed by all the arguments for the "
+ "training script"
+ ),
+ )
+
+ # rest from the training program
+ parser.add_argument("training_script_args", nargs=REMAINDER)
+
+ return parser.parse_args()
+
+
+def main():
+ args = parse_args()
+
+ # Import training_script as a module.
+ script_fpath = Path(args.training_script)
+ sys.path.append(str(script_fpath.parent.resolve()))
+ mod_name = script_fpath.stem
+ mod = importlib.import_module(mod_name)
+
+ # Patch sys.argv
+ sys.argv = [args.training_script] + args.training_script_args + ["--tpu_num_cores", str(args.num_cores)]
+
+ xmp.spawn(mod._mp_fn, args=(), nprocs=args.num_cores)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/token-classification/README.md b/docs/transformers/examples/legacy/token-classification/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..fbf17f84d2d7eed9ad889e77c8b965f9d5115abd
--- /dev/null
+++ b/docs/transformers/examples/legacy/token-classification/README.md
@@ -0,0 +1,294 @@
+## Token classification
+
+Based on the scripts [`run_ner.py`](https://github.com/huggingface/transformers/blob/main/examples/legacy/token-classification/run_ner.py).
+
+The following examples are covered in this section:
+
+* NER on the GermEval 2014 (German NER) dataset
+* Emerging and Rare Entities task: WNUT’17 (English NER) dataset
+
+Details and results for the fine-tuning provided by @stefan-it.
+
+### GermEval 2014 (German NER) dataset
+
+#### Data (Download and pre-processing steps)
+
+Data can be obtained from the [GermEval 2014](https://sites.google.com/site/germeval2014ner/data) shared task page.
+
+Here are the commands for downloading and pre-processing train, dev and test datasets. The original data format has four (tab-separated) columns, in a pre-processing step only the two relevant columns (token and outer span NER annotation) are extracted:
+
+```bash
+curl -L 'https://drive.google.com/uc?export=download&id=1Jjhbal535VVz2ap4v4r_rN1UEHTdLK5P' \
+| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp
+curl -L 'https://drive.google.com/uc?export=download&id=1ZfRcQThdtAR5PPRjIDtrVP7BtXSCUBbm' \
+| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp
+curl -L 'https://drive.google.com/uc?export=download&id=1u9mb7kNJHWQCWyweMDRMuTFoOHOfeBTH' \
+| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp
+```
+
+The GermEval 2014 dataset contains some strange "control character" tokens like `'\x96', '\u200e', '\x95', '\xad' or '\x80'`.
+One problem with these tokens is, that `BertTokenizer` returns an empty token for them, resulting in misaligned `InputExample`s.
+The `preprocess.py` script located in the `scripts` folder a) filters these tokens and b) splits longer sentences into smaller ones (once the max. subtoken length is reached).
+
+Let's define some variables that we need for further pre-processing steps and training the model:
+
+```bash
+export MAX_LENGTH=128
+export BERT_MODEL=google-bert/bert-base-multilingual-cased
+```
+
+Run the pre-processing script on training, dev and test datasets:
+
+```bash
+python3 scripts/preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt
+python3 scripts/preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt
+python3 scripts/preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt
+```
+
+The GermEval 2014 dataset has much more labels than CoNLL-2002/2003 datasets, so an own set of labels must be used:
+
+```bash
+cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
+```
+
+#### Prepare the run
+
+Additional environment variables must be set:
+
+```bash
+export OUTPUT_DIR=germeval-model
+export BATCH_SIZE=32
+export NUM_EPOCHS=3
+export SAVE_STEPS=750
+export SEED=1
+```
+
+#### Run the Pytorch version
+
+To start training, just run:
+
+```bash
+python3 run_ner.py --data_dir ./ \
+--labels ./labels.txt \
+--model_name_or_path $BERT_MODEL \
+--output_dir $OUTPUT_DIR \
+--max_seq_length $MAX_LENGTH \
+--num_train_epochs $NUM_EPOCHS \
+--per_device_train_batch_size $BATCH_SIZE \
+--save_steps $SAVE_STEPS \
+--seed $SEED \
+--do_train \
+--do_eval \
+--do_predict
+```
+
+If your GPU supports half-precision training, just add the `--fp16` flag. After training, the model will be both evaluated on development and test datasets.
+
+#### JSON-based configuration file
+
+Instead of passing all parameters via commandline arguments, the `run_ner.py` script also supports reading parameters from a json-based configuration file:
+
+```json
+{
+ "data_dir": ".",
+ "labels": "./labels.txt",
+ "model_name_or_path": "google-bert/bert-base-multilingual-cased",
+ "output_dir": "germeval-model",
+ "max_seq_length": 128,
+ "num_train_epochs": 3,
+ "per_device_train_batch_size": 32,
+ "save_steps": 750,
+ "seed": 1,
+ "do_train": true,
+ "do_eval": true,
+ "do_predict": true
+}
+```
+
+It must be saved with a `.json` extension and can be used by running `python3 run_ner.py config.json`.
+
+#### Evaluation
+
+Evaluation on development dataset outputs the following for our example:
+
+```bash
+10/04/2019 00:42:06 - INFO - __main__ - ***** Eval results *****
+10/04/2019 00:42:06 - INFO - __main__ - f1 = 0.8623348017621146
+10/04/2019 00:42:06 - INFO - __main__ - loss = 0.07183869666975543
+10/04/2019 00:42:06 - INFO - __main__ - precision = 0.8467916366258111
+10/04/2019 00:42:06 - INFO - __main__ - recall = 0.8784592370979806
+```
+
+On the test dataset the following results could be achieved:
+
+```bash
+10/04/2019 00:42:42 - INFO - __main__ - ***** Eval results *****
+10/04/2019 00:42:42 - INFO - __main__ - f1 = 0.8614389652384803
+10/04/2019 00:42:42 - INFO - __main__ - loss = 0.07064602487454782
+10/04/2019 00:42:42 - INFO - __main__ - precision = 0.8604651162790697
+10/04/2019 00:42:42 - INFO - __main__ - recall = 0.8624150210424085
+```
+
+#### Run the Tensorflow 2 version
+
+To start training, just run:
+
+```bash
+python3 run_tf_ner.py --data_dir ./ \
+--labels ./labels.txt \
+--model_name_or_path $BERT_MODEL \
+--output_dir $OUTPUT_DIR \
+--max_seq_length $MAX_LENGTH \
+--num_train_epochs $NUM_EPOCHS \
+--per_device_train_batch_size $BATCH_SIZE \
+--save_steps $SAVE_STEPS \
+--seed $SEED \
+--do_train \
+--do_eval \
+--do_predict
+```
+
+Such as the Pytorch version, if your GPU supports half-precision training, just add the `--fp16` flag. After training, the model will be both evaluated on development and test datasets.
+
+#### Evaluation
+
+Evaluation on development dataset outputs the following for our example:
+```bash
+ precision recall f1-score support
+
+ LOCderiv 0.7619 0.6154 0.6809 52
+ PERpart 0.8724 0.8997 0.8858 4057
+ OTHpart 0.9360 0.9466 0.9413 711
+ ORGpart 0.7015 0.6989 0.7002 269
+ LOCpart 0.7668 0.8488 0.8057 496
+ LOC 0.8745 0.9191 0.8963 235
+ ORGderiv 0.7723 0.8571 0.8125 91
+ OTHderiv 0.4800 0.6667 0.5581 18
+ OTH 0.5789 0.6875 0.6286 16
+ PERderiv 0.5385 0.3889 0.4516 18
+ PER 0.5000 0.5000 0.5000 2
+ ORG 0.0000 0.0000 0.0000 3
+
+micro avg 0.8574 0.8862 0.8715 5968
+macro avg 0.8575 0.8862 0.8713 5968
+```
+
+On the test dataset the following results could be achieved:
+```bash
+ precision recall f1-score support
+
+ PERpart 0.8847 0.8944 0.8896 9397
+ OTHpart 0.9376 0.9353 0.9365 1639
+ ORGpart 0.7307 0.7044 0.7173 697
+ LOC 0.9133 0.9394 0.9262 561
+ LOCpart 0.8058 0.8157 0.8107 1150
+ ORG 0.0000 0.0000 0.0000 8
+ OTHderiv 0.5882 0.4762 0.5263 42
+ PERderiv 0.6571 0.5227 0.5823 44
+ OTH 0.4906 0.6667 0.5652 39
+ ORGderiv 0.7016 0.7791 0.7383 172
+ LOCderiv 0.8256 0.6514 0.7282 109
+ PER 0.0000 0.0000 0.0000 11
+
+micro avg 0.8722 0.8774 0.8748 13869
+macro avg 0.8712 0.8774 0.8740 13869
+```
+
+### Emerging and Rare Entities task: WNUT’17 (English NER) dataset
+
+Description of the WNUT’17 task from the [shared task website](http://noisy-text.github.io/2017/index.html):
+
+> The WNUT’17 shared task focuses on identifying unusual, previously-unseen entities in the context of emerging discussions.
+> Named entities form the basis of many modern approaches to other tasks (like event clustering and summarization), but recall on
+> them is a real problem in noisy text - even among annotators. This drop tends to be due to novel entities and surface forms.
+
+Six labels are available in the dataset. An overview can be found on this [page](http://noisy-text.github.io/2017/files/).
+
+#### Data (Download and pre-processing steps)
+
+The dataset can be downloaded from the [official GitHub](https://github.com/leondz/emerging_entities_17) repository.
+
+The following commands show how to prepare the dataset for fine-tuning:
+
+```bash
+mkdir -p data_wnut_17
+
+curl -L 'https://github.com/leondz/emerging_entities_17/raw/master/wnut17train.conll' | tr '\t' ' ' > data_wnut_17/train.txt.tmp
+curl -L 'https://github.com/leondz/emerging_entities_17/raw/master/emerging.dev.conll' | tr '\t' ' ' > data_wnut_17/dev.txt.tmp
+curl -L 'https://raw.githubusercontent.com/leondz/emerging_entities_17/master/emerging.test.annotated' | tr '\t' ' ' > data_wnut_17/test.txt.tmp
+```
+
+Let's define some variables that we need for further pre-processing steps:
+
+```bash
+export MAX_LENGTH=128
+export BERT_MODEL=google-bert/bert-large-cased
+```
+
+Here we use the English BERT large model for fine-tuning.
+The `preprocess.py` scripts splits longer sentences into smaller ones (once the max. subtoken length is reached):
+
+```bash
+python3 scripts/preprocess.py data_wnut_17/train.txt.tmp $BERT_MODEL $MAX_LENGTH > data_wnut_17/train.txt
+python3 scripts/preprocess.py data_wnut_17/dev.txt.tmp $BERT_MODEL $MAX_LENGTH > data_wnut_17/dev.txt
+python3 scripts/preprocess.py data_wnut_17/test.txt.tmp $BERT_MODEL $MAX_LENGTH > data_wnut_17/test.txt
+```
+
+In the last pre-processing step, the `labels.txt` file needs to be generated. This file contains all available labels:
+
+```bash
+cat data_wnut_17/train.txt data_wnut_17/dev.txt data_wnut_17/test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > data_wnut_17/labels.txt
+```
+
+#### Run the Pytorch version
+
+Fine-tuning with the PyTorch version can be started using the `run_ner.py` script. In this example we use a JSON-based configuration file.
+
+This configuration file looks like:
+
+```json
+{
+ "data_dir": "./data_wnut_17",
+ "labels": "./data_wnut_17/labels.txt",
+ "model_name_or_path": "google-bert/bert-large-cased",
+ "output_dir": "wnut-17-model-1",
+ "max_seq_length": 128,
+ "num_train_epochs": 3,
+ "per_device_train_batch_size": 32,
+ "save_steps": 425,
+ "seed": 1,
+ "do_train": true,
+ "do_eval": true,
+ "do_predict": true,
+ "fp16": false
+}
+```
+
+If your GPU supports half-precision training, please set `fp16` to `true`.
+
+Save this JSON-based configuration under `wnut_17.json`. The fine-tuning can be started with `python3 run_ner_old.py wnut_17.json`.
+
+#### Evaluation
+
+Evaluation on development dataset outputs the following:
+
+```bash
+05/29/2020 23:33:44 - INFO - __main__ - ***** Eval results *****
+05/29/2020 23:33:44 - INFO - __main__ - eval_loss = 0.26505235286212275
+05/29/2020 23:33:44 - INFO - __main__ - eval_precision = 0.7008264462809918
+05/29/2020 23:33:44 - INFO - __main__ - eval_recall = 0.507177033492823
+05/29/2020 23:33:44 - INFO - __main__ - eval_f1 = 0.5884802220680084
+05/29/2020 23:33:44 - INFO - __main__ - epoch = 3.0
+```
+
+On the test dataset the following results could be achieved:
+
+```bash
+05/29/2020 23:33:44 - INFO - transformers.trainer - ***** Running Prediction *****
+05/29/2020 23:34:02 - INFO - __main__ - eval_loss = 0.30948806500973547
+05/29/2020 23:34:02 - INFO - __main__ - eval_precision = 0.5840108401084011
+05/29/2020 23:34:02 - INFO - __main__ - eval_recall = 0.3994439295644115
+05/29/2020 23:34:02 - INFO - __main__ - eval_f1 = 0.47440836543753434
+```
+
+WNUT’17 is a very difficult task. Current state-of-the-art results on this dataset can be found [here](https://nlpprogress.com/english/named_entity_recognition.html).
diff --git a/docs/transformers/examples/legacy/token-classification/run.sh b/docs/transformers/examples/legacy/token-classification/run.sh
new file mode 100644
index 0000000000000000000000000000000000000000..b5f1e5f83bc7ffa20756edbfff35b8282caef828
--- /dev/null
+++ b/docs/transformers/examples/legacy/token-classification/run.sh
@@ -0,0 +1,36 @@
+## The relevant files are currently on a shared Google
+## drive at https://drive.google.com/drive/folders/1kC0I2UGl2ltrluI9NqDjaQJGw5iliw_J
+## Monitor for changes and eventually migrate to use the `datasets` library
+curl -L 'https://drive.google.com/uc?export=download&id=1Jjhbal535VVz2ap4v4r_rN1UEHTdLK5P' \
+| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > train.txt.tmp
+curl -L 'https://drive.google.com/uc?export=download&id=1ZfRcQThdtAR5PPRjIDtrVP7BtXSCUBbm' \
+| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > dev.txt.tmp
+curl -L 'https://drive.google.com/uc?export=download&id=1u9mb7kNJHWQCWyweMDRMuTFoOHOfeBTH' \
+| grep -v "^#" | cut -f 2,3 | tr '\t' ' ' > test.txt.tmp
+
+export MAX_LENGTH=128
+export BERT_MODEL=bert-base-multilingual-cased
+python3 scripts/preprocess.py train.txt.tmp $BERT_MODEL $MAX_LENGTH > train.txt
+python3 scripts/preprocess.py dev.txt.tmp $BERT_MODEL $MAX_LENGTH > dev.txt
+python3 scripts/preprocess.py test.txt.tmp $BERT_MODEL $MAX_LENGTH > test.txt
+cat train.txt dev.txt test.txt | cut -d " " -f 2 | grep -v "^$"| sort | uniq > labels.txt
+export OUTPUT_DIR=germeval-model
+export BATCH_SIZE=32
+export NUM_EPOCHS=3
+export SAVE_STEPS=750
+export SEED=1
+
+python3 run_ner.py \
+--task_type NER \
+--data_dir . \
+--labels ./labels.txt \
+--model_name_or_path $BERT_MODEL \
+--output_dir $OUTPUT_DIR \
+--max_seq_length $MAX_LENGTH \
+--num_train_epochs $NUM_EPOCHS \
+--per_gpu_train_batch_size $BATCH_SIZE \
+--save_steps $SAVE_STEPS \
+--seed $SEED \
+--do_train \
+--do_eval \
+--do_predict
diff --git a/docs/transformers/examples/legacy/token-classification/run_chunk.sh b/docs/transformers/examples/legacy/token-classification/run_chunk.sh
new file mode 100644
index 0000000000000000000000000000000000000000..13341555b699a45f3c2aed59672d950291f54dd4
--- /dev/null
+++ b/docs/transformers/examples/legacy/token-classification/run_chunk.sh
@@ -0,0 +1,37 @@
+if ! [ -f ./dev.txt ]; then
+ echo "Downloading CONLL2003 dev dataset...."
+ curl -L -o ./dev.txt 'https://github.com/davidsbatista/NER-datasets/raw/master/CONLL2003/valid.txt'
+fi
+
+if ! [ -f ./test.txt ]; then
+ echo "Downloading CONLL2003 test dataset...."
+ curl -L -o ./test.txt 'https://github.com/davidsbatista/NER-datasets/raw/master/CONLL2003/test.txt'
+fi
+
+if ! [ -f ./train.txt ]; then
+ echo "Downloading CONLL2003 train dataset...."
+ curl -L -o ./train.txt 'https://github.com/davidsbatista/NER-datasets/raw/master/CONLL2003/train.txt'
+fi
+
+export MAX_LENGTH=200
+export BERT_MODEL=bert-base-uncased
+export OUTPUT_DIR=chunker-model
+export BATCH_SIZE=32
+export NUM_EPOCHS=3
+export SAVE_STEPS=750
+export SEED=1
+
+python3 run_ner.py \
+--task_type Chunk \
+--data_dir . \
+--model_name_or_path $BERT_MODEL \
+--output_dir $OUTPUT_DIR \
+--max_seq_length $MAX_LENGTH \
+--num_train_epochs $NUM_EPOCHS \
+--per_gpu_train_batch_size $BATCH_SIZE \
+--save_steps $SAVE_STEPS \
+--seed $SEED \
+--do_train \
+--do_eval \
+--do_predict
+
diff --git a/docs/transformers/examples/legacy/token-classification/run_ner.py b/docs/transformers/examples/legacy/token-classification/run_ner.py
new file mode 100644
index 0000000000000000000000000000000000000000..69b8a27ac799d757970d02f6042aa9e9c6c8e711
--- /dev/null
+++ b/docs/transformers/examples/legacy/token-classification/run_ner.py
@@ -0,0 +1,324 @@
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Fine-tuning the library models for named entity recognition on CoNLL-2003."""
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from importlib import import_module
+from typing import Optional
+
+import numpy as np
+from seqeval.metrics import accuracy_score, f1_score, precision_score, recall_score
+from torch import nn
+from utils_ner import Split, TokenClassificationDataset, TokenClassificationTask
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForTokenClassification,
+ AutoTokenizer,
+ DataCollatorWithPadding,
+ EvalPrediction,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ set_seed,
+)
+from transformers.trainer_utils import is_main_process
+
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ task_type: Optional[str] = field(
+ default="NER", metadata={"help": "Task type to fine tune in training (e.g. NER, POS, etc)"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ use_fast: bool = field(default=False, metadata={"help": "Set this flag to use fast tokenization."})
+ # If you want to tweak more attributes on your tokenizer, you should do it in a distinct script,
+ # or just modify its tokenizer_config.json.
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ data_dir: str = field(
+ metadata={"help": "The input data dir. Should contain the .txt files for a CoNLL-2003-formatted task."}
+ )
+ labels: Optional[str] = field(
+ default=None,
+ metadata={"help": "Path to a file containing all labels. If not specified, CoNLL-2003 labels are used."},
+ )
+ max_seq_length: int = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ if (
+ os.path.exists(training_args.output_dir)
+ and os.listdir(training_args.output_dir)
+ and training_args.do_train
+ and not training_args.overwrite_output_dir
+ ):
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
+ " --overwrite_output_dir to overcome."
+ )
+
+ module = import_module("tasks")
+ try:
+ token_classification_task_clazz = getattr(module, model_args.task_type)
+ token_classification_task: TokenClassificationTask = token_classification_task_clazz()
+ except AttributeError:
+ raise ValueError(
+ f"Task {model_args.task_type} needs to be defined as a TokenClassificationTask subclass in {module}. "
+ f"Available tasks classes are: {TokenClassificationTask.__subclasses__()}"
+ )
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
+ )
+ logger.warning(
+ "Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
+ training_args.local_rank,
+ training_args.device,
+ training_args.n_gpu,
+ bool(training_args.local_rank != -1),
+ training_args.fp16,
+ )
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(training_args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+ logger.info("Training/evaluation parameters %s", training_args)
+
+ # Set seed
+ set_seed(training_args.seed)
+
+ # Prepare CONLL-2003 task
+ labels = token_classification_task.get_labels(data_args.labels)
+ label_map: dict[int, str] = dict(enumerate(labels))
+ num_labels = len(labels)
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ num_labels=num_labels,
+ id2label=label_map,
+ label2id={label: i for i, label in enumerate(labels)},
+ cache_dir=model_args.cache_dir,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast,
+ )
+ model = AutoModelForTokenClassification.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ )
+
+ # Get datasets
+ train_dataset = (
+ TokenClassificationDataset(
+ token_classification_task=token_classification_task,
+ data_dir=data_args.data_dir,
+ tokenizer=tokenizer,
+ labels=labels,
+ model_type=config.model_type,
+ max_seq_length=data_args.max_seq_length,
+ overwrite_cache=data_args.overwrite_cache,
+ mode=Split.train,
+ )
+ if training_args.do_train
+ else None
+ )
+ eval_dataset = (
+ TokenClassificationDataset(
+ token_classification_task=token_classification_task,
+ data_dir=data_args.data_dir,
+ tokenizer=tokenizer,
+ labels=labels,
+ model_type=config.model_type,
+ max_seq_length=data_args.max_seq_length,
+ overwrite_cache=data_args.overwrite_cache,
+ mode=Split.dev,
+ )
+ if training_args.do_eval
+ else None
+ )
+
+ def align_predictions(predictions: np.ndarray, label_ids: np.ndarray) -> tuple[list[int], list[int]]:
+ preds = np.argmax(predictions, axis=2)
+
+ batch_size, seq_len = preds.shape
+
+ out_label_list = [[] for _ in range(batch_size)]
+ preds_list = [[] for _ in range(batch_size)]
+
+ for i in range(batch_size):
+ for j in range(seq_len):
+ if label_ids[i, j] != nn.CrossEntropyLoss().ignore_index:
+ out_label_list[i].append(label_map[label_ids[i][j]])
+ preds_list[i].append(label_map[preds[i][j]])
+
+ return preds_list, out_label_list
+
+ def compute_metrics(p: EvalPrediction) -> dict:
+ preds_list, out_label_list = align_predictions(p.predictions, p.label_ids)
+ return {
+ "accuracy_score": accuracy_score(out_label_list, preds_list),
+ "precision": precision_score(out_label_list, preds_list),
+ "recall": recall_score(out_label_list, preds_list),
+ "f1": f1_score(out_label_list, preds_list),
+ }
+
+ # Data collator
+ data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8) if training_args.fp16 else None
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset,
+ eval_dataset=eval_dataset,
+ compute_metrics=compute_metrics,
+ data_collator=data_collator,
+ )
+
+ # Training
+ if training_args.do_train:
+ trainer.train(
+ model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
+ )
+ trainer.save_model()
+ # For convenience, we also re-save the tokenizer to the same directory,
+ # so that you can share your model easily on huggingface.co/models =)
+ if trainer.is_world_process_zero():
+ tokenizer.save_pretrained(training_args.output_dir)
+
+ # Evaluation
+ results = {}
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+
+ result = trainer.evaluate()
+
+ output_eval_file = os.path.join(training_args.output_dir, "eval_results.txt")
+ if trainer.is_world_process_zero():
+ with open(output_eval_file, "w") as writer:
+ logger.info("***** Eval results *****")
+ for key, value in result.items():
+ logger.info(" %s = %s", key, value)
+ writer.write("{} = {}\n".format(key, value))
+
+ results.update(result)
+
+ # Predict
+ if training_args.do_predict:
+ test_dataset = TokenClassificationDataset(
+ token_classification_task=token_classification_task,
+ data_dir=data_args.data_dir,
+ tokenizer=tokenizer,
+ labels=labels,
+ model_type=config.model_type,
+ max_seq_length=data_args.max_seq_length,
+ overwrite_cache=data_args.overwrite_cache,
+ mode=Split.test,
+ )
+
+ predictions, label_ids, metrics = trainer.predict(test_dataset)
+ preds_list, _ = align_predictions(predictions, label_ids)
+
+ output_test_results_file = os.path.join(training_args.output_dir, "test_results.txt")
+ if trainer.is_world_process_zero():
+ with open(output_test_results_file, "w") as writer:
+ for key, value in metrics.items():
+ logger.info(" %s = %s", key, value)
+ writer.write("{} = {}\n".format(key, value))
+
+ # Save predictions
+ output_test_predictions_file = os.path.join(training_args.output_dir, "test_predictions.txt")
+ if trainer.is_world_process_zero():
+ with open(output_test_predictions_file, "w") as writer:
+ with open(os.path.join(data_args.data_dir, "test.txt")) as f:
+ token_classification_task.write_predictions_to_file(writer, f, preds_list)
+
+ return results
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/legacy/token-classification/run_pos.sh b/docs/transformers/examples/legacy/token-classification/run_pos.sh
new file mode 100644
index 0000000000000000000000000000000000000000..7d76ed8a2a8a94bc2cd258c42b78bcdb9ba3243b
--- /dev/null
+++ b/docs/transformers/examples/legacy/token-classification/run_pos.sh
@@ -0,0 +1,37 @@
+if ! [ -f ./dev.txt ]; then
+ echo "Download dev dataset...."
+ curl -L -o ./dev.txt 'https://github.com/UniversalDependencies/UD_English-EWT/raw/master/en_ewt-ud-dev.conllu'
+fi
+
+if ! [ -f ./test.txt ]; then
+ echo "Download test dataset...."
+ curl -L -o ./test.txt 'https://github.com/UniversalDependencies/UD_English-EWT/raw/master/en_ewt-ud-test.conllu'
+fi
+
+if ! [ -f ./train.txt ]; then
+ echo "Download train dataset...."
+ curl -L -o ./train.txt 'https://github.com/UniversalDependencies/UD_English-EWT/raw/master/en_ewt-ud-train.conllu'
+fi
+
+export MAX_LENGTH=200
+export BERT_MODEL=bert-base-uncased
+export OUTPUT_DIR=postagger-model
+export BATCH_SIZE=32
+export NUM_EPOCHS=3
+export SAVE_STEPS=750
+export SEED=1
+
+python3 run_ner.py \
+--task_type POS \
+--data_dir . \
+--model_name_or_path $BERT_MODEL \
+--output_dir $OUTPUT_DIR \
+--max_seq_length $MAX_LENGTH \
+--num_train_epochs $NUM_EPOCHS \
+--per_gpu_train_batch_size $BATCH_SIZE \
+--save_steps $SAVE_STEPS \
+--seed $SEED \
+--do_train \
+--do_eval \
+--do_predict
+
diff --git a/docs/transformers/examples/legacy/token-classification/scripts/preprocess.py b/docs/transformers/examples/legacy/token-classification/scripts/preprocess.py
new file mode 100644
index 0000000000000000000000000000000000000000..40ecf2b32acc3545a7f6d6eb3302e270fec1bd04
--- /dev/null
+++ b/docs/transformers/examples/legacy/token-classification/scripts/preprocess.py
@@ -0,0 +1,41 @@
+import sys
+
+from transformers import AutoTokenizer
+
+
+dataset = sys.argv[1]
+model_name_or_path = sys.argv[2]
+max_len = int(sys.argv[3])
+
+subword_len_counter = 0
+
+tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
+max_len -= tokenizer.num_special_tokens_to_add()
+
+with open(dataset) as f_p:
+ for line in f_p:
+ line = line.rstrip()
+
+ if not line:
+ print(line)
+ subword_len_counter = 0
+ continue
+
+ token = line.split()[0]
+
+ current_subwords_len = len(tokenizer.tokenize(token))
+
+ # Token contains strange control characters like \x96 or \x95
+ # Just filter out the complete line
+ if current_subwords_len == 0:
+ continue
+
+ if (subword_len_counter + current_subwords_len) > max_len:
+ print("")
+ print(line)
+ subword_len_counter = current_subwords_len
+ continue
+
+ subword_len_counter += current_subwords_len
+
+ print(line)
diff --git a/docs/transformers/examples/legacy/token-classification/tasks.py b/docs/transformers/examples/legacy/token-classification/tasks.py
new file mode 100644
index 0000000000000000000000000000000000000000..7e406fa7757ad6f43a6ab026a0182ce24c13e325
--- /dev/null
+++ b/docs/transformers/examples/legacy/token-classification/tasks.py
@@ -0,0 +1,162 @@
+import logging
+import os
+from typing import TextIO, Union
+
+from conllu import parse_incr
+from utils_ner import InputExample, Split, TokenClassificationTask
+
+
+logger = logging.getLogger(__name__)
+
+
+class NER(TokenClassificationTask):
+ def __init__(self, label_idx=-1):
+ # in NER datasets, the last column is usually reserved for NER label
+ self.label_idx = label_idx
+
+ def read_examples_from_file(self, data_dir, mode: Union[Split, str]) -> list[InputExample]:
+ if isinstance(mode, Split):
+ mode = mode.value
+ file_path = os.path.join(data_dir, f"{mode}.txt")
+ guid_index = 1
+ examples = []
+ with open(file_path, encoding="utf-8") as f:
+ words = []
+ labels = []
+ for line in f:
+ if line.startswith("-DOCSTART-") or line == "" or line == "\n":
+ if words:
+ examples.append(InputExample(guid=f"{mode}-{guid_index}", words=words, labels=labels))
+ guid_index += 1
+ words = []
+ labels = []
+ else:
+ splits = line.split(" ")
+ words.append(splits[0])
+ if len(splits) > 1:
+ labels.append(splits[self.label_idx].replace("\n", ""))
+ else:
+ # Examples could have no label for mode = "test"
+ labels.append("O")
+ if words:
+ examples.append(InputExample(guid=f"{mode}-{guid_index}", words=words, labels=labels))
+ return examples
+
+ def write_predictions_to_file(self, writer: TextIO, test_input_reader: TextIO, preds_list: list):
+ example_id = 0
+ for line in test_input_reader:
+ if line.startswith("-DOCSTART-") or line == "" or line == "\n":
+ writer.write(line)
+ if not preds_list[example_id]:
+ example_id += 1
+ elif preds_list[example_id]:
+ output_line = line.split()[0] + " " + preds_list[example_id].pop(0) + "\n"
+ writer.write(output_line)
+ else:
+ logger.warning("Maximum sequence length exceeded: No prediction for '%s'.", line.split()[0])
+
+ def get_labels(self, path: str) -> list[str]:
+ if path:
+ with open(path) as f:
+ labels = f.read().splitlines()
+ if "O" not in labels:
+ labels = ["O"] + labels
+ return labels
+ else:
+ return ["O", "B-MISC", "I-MISC", "B-PER", "I-PER", "B-ORG", "I-ORG", "B-LOC", "I-LOC"]
+
+
+class Chunk(NER):
+ def __init__(self):
+ # in CONLL2003 dataset chunk column is second-to-last
+ super().__init__(label_idx=-2)
+
+ def get_labels(self, path: str) -> list[str]:
+ if path:
+ with open(path) as f:
+ labels = f.read().splitlines()
+ if "O" not in labels:
+ labels = ["O"] + labels
+ return labels
+ else:
+ return [
+ "O",
+ "B-ADVP",
+ "B-INTJ",
+ "B-LST",
+ "B-PRT",
+ "B-NP",
+ "B-SBAR",
+ "B-VP",
+ "B-ADJP",
+ "B-CONJP",
+ "B-PP",
+ "I-ADVP",
+ "I-INTJ",
+ "I-LST",
+ "I-PRT",
+ "I-NP",
+ "I-SBAR",
+ "I-VP",
+ "I-ADJP",
+ "I-CONJP",
+ "I-PP",
+ ]
+
+
+class POS(TokenClassificationTask):
+ def read_examples_from_file(self, data_dir, mode: Union[Split, str]) -> list[InputExample]:
+ if isinstance(mode, Split):
+ mode = mode.value
+ file_path = os.path.join(data_dir, f"{mode}.txt")
+ guid_index = 1
+ examples = []
+
+ with open(file_path, encoding="utf-8") as f:
+ for sentence in parse_incr(f):
+ words = []
+ labels = []
+ for token in sentence:
+ words.append(token["form"])
+ labels.append(token["upos"])
+ assert len(words) == len(labels)
+ if words:
+ examples.append(InputExample(guid=f"{mode}-{guid_index}", words=words, labels=labels))
+ guid_index += 1
+ return examples
+
+ def write_predictions_to_file(self, writer: TextIO, test_input_reader: TextIO, preds_list: list):
+ example_id = 0
+ for sentence in parse_incr(test_input_reader):
+ s_p = preds_list[example_id]
+ out = ""
+ for token in sentence:
+ out += f"{token['form']} ({token['upos']}|{s_p.pop(0)}) "
+ out += "\n"
+ writer.write(out)
+ example_id += 1
+
+ def get_labels(self, path: str) -> list[str]:
+ if path:
+ with open(path) as f:
+ return f.read().splitlines()
+ else:
+ return [
+ "ADJ",
+ "ADP",
+ "ADV",
+ "AUX",
+ "CCONJ",
+ "DET",
+ "INTJ",
+ "NOUN",
+ "NUM",
+ "PART",
+ "PRON",
+ "PROPN",
+ "PUNCT",
+ "SCONJ",
+ "SYM",
+ "VERB",
+ "X",
+ ]
diff --git a/docs/transformers/examples/legacy/token-classification/utils_ner.py b/docs/transformers/examples/legacy/token-classification/utils_ner.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c1725b59b4ef0d4e6a45480d6049473b04b84b9
--- /dev/null
+++ b/docs/transformers/examples/legacy/token-classification/utils_ner.py
@@ -0,0 +1,370 @@
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Named entity recognition fine-tuning: utilities to work with CoNLL-2003 task."""
+
+import logging
+import os
+from dataclasses import dataclass
+from enum import Enum
+from typing import Optional, Union
+
+from filelock import FileLock
+
+from transformers import PreTrainedTokenizer, is_tf_available, is_torch_available
+
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class InputExample:
+ """
+ A single training/test example for token classification.
+
+ Args:
+ guid: Unique id for the example.
+ words: list. The words of the sequence.
+ labels: (Optional) list. The labels for each word of the sequence. This should be
+ specified for train and dev examples, but not for test examples.
+ """
+
+ guid: str
+ words: list[str]
+ labels: Optional[list[str]]
+
+
+@dataclass
+class InputFeatures:
+ """
+ A single set of features of data.
+ Property names are the same names as the corresponding inputs to a model.
+ """
+
+ input_ids: list[int]
+ attention_mask: list[int]
+ token_type_ids: Optional[list[int]] = None
+ label_ids: Optional[list[int]] = None
+
+
+class Split(Enum):
+ train = "train"
+ dev = "dev"
+ test = "test"
+
+
+class TokenClassificationTask:
+ @staticmethod
+ def read_examples_from_file(data_dir, mode: Union[Split, str]) -> list[InputExample]:
+ raise NotImplementedError
+
+ @staticmethod
+ def get_labels(path: str) -> list[str]:
+ raise NotImplementedError
+
+ @staticmethod
+ def convert_examples_to_features(
+ examples: list[InputExample],
+ label_list: list[str],
+ max_seq_length: int,
+ tokenizer: PreTrainedTokenizer,
+ cls_token_at_end=False,
+ cls_token="[CLS]",
+ cls_token_segment_id=1,
+ sep_token="[SEP]",
+ sep_token_extra=False,
+ pad_on_left=False,
+ pad_token=0,
+ pad_token_segment_id=0,
+ pad_token_label_id=-100,
+ sequence_a_segment_id=0,
+ mask_padding_with_zero=True,
+ ) -> list[InputFeatures]:
+ """Loads a data file into a list of `InputFeatures`
+ `cls_token_at_end` define the location of the CLS token:
+ - False (Default, BERT/XLM pattern): [CLS] + A + [SEP] + B + [SEP]
+ - True (XLNet/GPT pattern): A + [SEP] + B + [SEP] + [CLS]
+ `cls_token_segment_id` define the segment id associated to the CLS token (0 for BERT, 2 for XLNet)
+ """
+ # TODO clean up all this to leverage built-in features of tokenizers
+
+ label_map = {label: i for i, label in enumerate(label_list)}
+
+ features = []
+ for ex_index, example in enumerate(examples):
+ if ex_index % 10_000 == 0:
+ logger.info("Writing example %d of %d", ex_index, len(examples))
+
+ tokens = []
+ label_ids = []
+ for word, label in zip(example.words, example.labels):
+ word_tokens = tokenizer.tokenize(word)
+
+ # google-bert/bert-base-multilingual-cased sometimes output "nothing ([]) when calling tokenize with just a space.
+ if len(word_tokens) > 0:
+ tokens.extend(word_tokens)
+ # Use the real label id for the first token of the word, and padding ids for the remaining tokens
+ label_ids.extend([label_map[label]] + [pad_token_label_id] * (len(word_tokens) - 1))
+
+ # Account for [CLS] and [SEP] with "- 2" and with "- 3" for RoBERTa.
+ special_tokens_count = tokenizer.num_special_tokens_to_add()
+ if len(tokens) > max_seq_length - special_tokens_count:
+ tokens = tokens[: (max_seq_length - special_tokens_count)]
+ label_ids = label_ids[: (max_seq_length - special_tokens_count)]
+
+ # The convention in BERT is:
+ # (a) For sequence pairs:
+ # tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
+ # type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1
+ # (b) For single sequences:
+ # tokens: [CLS] the dog is hairy . [SEP]
+ # type_ids: 0 0 0 0 0 0 0
+ #
+ # Where "type_ids" are used to indicate whether this is the first
+ # sequence or the second sequence. The embedding vectors for `type=0` and
+ # `type=1` were learned during pre-training and are added to the wordpiece
+ # embedding vector (and position vector). This is not *strictly* necessary
+ # since the [SEP] token unambiguously separates the sequences, but it makes
+ # it easier for the model to learn the concept of sequences.
+ #
+ # For classification tasks, the first vector (corresponding to [CLS]) is
+ # used as the "sentence vector". Note that this only makes sense because
+ # the entire model is fine-tuned.
+ tokens += [sep_token]
+ label_ids += [pad_token_label_id]
+ if sep_token_extra:
+ # roberta uses an extra separator b/w pairs of sentences
+ tokens += [sep_token]
+ label_ids += [pad_token_label_id]
+ segment_ids = [sequence_a_segment_id] * len(tokens)
+
+ if cls_token_at_end:
+ tokens += [cls_token]
+ label_ids += [pad_token_label_id]
+ segment_ids += [cls_token_segment_id]
+ else:
+ tokens = [cls_token] + tokens
+ label_ids = [pad_token_label_id] + label_ids
+ segment_ids = [cls_token_segment_id] + segment_ids
+
+ input_ids = tokenizer.convert_tokens_to_ids(tokens)
+
+ # The mask has 1 for real tokens and 0 for padding tokens. Only real
+ # tokens are attended to.
+ input_mask = [1 if mask_padding_with_zero else 0] * len(input_ids)
+
+ # Zero-pad up to the sequence length.
+ padding_length = max_seq_length - len(input_ids)
+ if pad_on_left:
+ input_ids = ([pad_token] * padding_length) + input_ids
+ input_mask = ([0 if mask_padding_with_zero else 1] * padding_length) + input_mask
+ segment_ids = ([pad_token_segment_id] * padding_length) + segment_ids
+ label_ids = ([pad_token_label_id] * padding_length) + label_ids
+ else:
+ input_ids += [pad_token] * padding_length
+ input_mask += [0 if mask_padding_with_zero else 1] * padding_length
+ segment_ids += [pad_token_segment_id] * padding_length
+ label_ids += [pad_token_label_id] * padding_length
+
+ assert len(input_ids) == max_seq_length
+ assert len(input_mask) == max_seq_length
+ assert len(segment_ids) == max_seq_length
+ assert len(label_ids) == max_seq_length
+
+ if ex_index < 5:
+ logger.info("*** Example ***")
+ logger.info("guid: %s", example.guid)
+ logger.info("tokens: %s", " ".join([str(x) for x in tokens]))
+ logger.info("input_ids: %s", " ".join([str(x) for x in input_ids]))
+ logger.info("input_mask: %s", " ".join([str(x) for x in input_mask]))
+ logger.info("segment_ids: %s", " ".join([str(x) for x in segment_ids]))
+ logger.info("label_ids: %s", " ".join([str(x) for x in label_ids]))
+
+ if "token_type_ids" not in tokenizer.model_input_names:
+ segment_ids = None
+
+ features.append(
+ InputFeatures(
+ input_ids=input_ids, attention_mask=input_mask, token_type_ids=segment_ids, label_ids=label_ids
+ )
+ )
+ return features
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+ from torch.utils.data import Dataset
+
+ class TokenClassificationDataset(Dataset):
+ """
+ This will be superseded by a framework-agnostic approach
+ soon.
+ """
+
+ features: list[InputFeatures]
+ pad_token_label_id: int = nn.CrossEntropyLoss().ignore_index
+ # Use cross entropy ignore_index as padding label id so that only
+ # real label ids contribute to the loss later.
+
+ def __init__(
+ self,
+ token_classification_task: TokenClassificationTask,
+ data_dir: str,
+ tokenizer: PreTrainedTokenizer,
+ labels: list[str],
+ model_type: str,
+ max_seq_length: Optional[int] = None,
+ overwrite_cache=False,
+ mode: Split = Split.train,
+ ):
+ # Load data features from cache or dataset file
+ cached_features_file = os.path.join(
+ data_dir,
+ f"cached_{mode.value}_{tokenizer.__class__.__name__}_{str(max_seq_length)}",
+ )
+
+ # Make sure only the first process in distributed training processes the dataset,
+ # and the others will use the cache.
+ lock_path = cached_features_file + ".lock"
+ with FileLock(lock_path):
+ if os.path.exists(cached_features_file) and not overwrite_cache:
+ logger.info(f"Loading features from cached file {cached_features_file}")
+ self.features = torch.load(cached_features_file, weights_only=True)
+ else:
+ logger.info(f"Creating features from dataset file at {data_dir}")
+ examples = token_classification_task.read_examples_from_file(data_dir, mode)
+ # TODO clean up all this to leverage built-in features of tokenizers
+ self.features = token_classification_task.convert_examples_to_features(
+ examples,
+ labels,
+ max_seq_length,
+ tokenizer,
+ cls_token_at_end=bool(model_type in ["xlnet"]),
+ # xlnet has a cls token at the end
+ cls_token=tokenizer.cls_token,
+ cls_token_segment_id=2 if model_type in ["xlnet"] else 0,
+ sep_token=tokenizer.sep_token,
+ sep_token_extra=False,
+ # roberta uses an extra separator b/w pairs of sentences, cf. github.com/pytorch/fairseq/commit/1684e166e3da03f5b600dbb7855cb98ddfcd0805
+ pad_on_left=bool(tokenizer.padding_side == "left"),
+ pad_token=tokenizer.pad_token_id,
+ pad_token_segment_id=tokenizer.pad_token_type_id,
+ pad_token_label_id=self.pad_token_label_id,
+ )
+ logger.info(f"Saving features into cached file {cached_features_file}")
+ torch.save(self.features, cached_features_file)
+
+ def __len__(self):
+ return len(self.features)
+
+ def __getitem__(self, i) -> InputFeatures:
+ return self.features[i]
+
+
+if is_tf_available():
+ import tensorflow as tf
+
+ class TFTokenClassificationDataset:
+ """
+ This will be superseded by a framework-agnostic approach
+ soon.
+ """
+
+ features: list[InputFeatures]
+ pad_token_label_id: int = -100
+ # Use cross entropy ignore_index as padding label id so that only
+ # real label ids contribute to the loss later.
+
+ def __init__(
+ self,
+ token_classification_task: TokenClassificationTask,
+ data_dir: str,
+ tokenizer: PreTrainedTokenizer,
+ labels: list[str],
+ model_type: str,
+ max_seq_length: Optional[int] = None,
+ overwrite_cache=False,
+ mode: Split = Split.train,
+ ):
+ examples = token_classification_task.read_examples_from_file(data_dir, mode)
+ # TODO clean up all this to leverage built-in features of tokenizers
+ self.features = token_classification_task.convert_examples_to_features(
+ examples,
+ labels,
+ max_seq_length,
+ tokenizer,
+ cls_token_at_end=bool(model_type in ["xlnet"]),
+ # xlnet has a cls token at the end
+ cls_token=tokenizer.cls_token,
+ cls_token_segment_id=2 if model_type in ["xlnet"] else 0,
+ sep_token=tokenizer.sep_token,
+ sep_token_extra=False,
+ # roberta uses an extra separator b/w pairs of sentences, cf. github.com/pytorch/fairseq/commit/1684e166e3da03f5b600dbb7855cb98ddfcd0805
+ pad_on_left=bool(tokenizer.padding_side == "left"),
+ pad_token=tokenizer.pad_token_id,
+ pad_token_segment_id=tokenizer.pad_token_type_id,
+ pad_token_label_id=self.pad_token_label_id,
+ )
+
+ def gen():
+ for ex in self.features:
+ if ex.token_type_ids is None:
+ yield (
+ {"input_ids": ex.input_ids, "attention_mask": ex.attention_mask},
+ ex.label_ids,
+ )
+ else:
+ yield (
+ {
+ "input_ids": ex.input_ids,
+ "attention_mask": ex.attention_mask,
+ "token_type_ids": ex.token_type_ids,
+ },
+ ex.label_ids,
+ )
+
+ if "token_type_ids" not in tokenizer.model_input_names:
+ self.dataset = tf.data.Dataset.from_generator(
+ gen,
+ ({"input_ids": tf.int32, "attention_mask": tf.int32}, tf.int64),
+ (
+ {"input_ids": tf.TensorShape([None]), "attention_mask": tf.TensorShape([None])},
+ tf.TensorShape([None]),
+ ),
+ )
+ else:
+ self.dataset = tf.data.Dataset.from_generator(
+ gen,
+ ({"input_ids": tf.int32, "attention_mask": tf.int32, "token_type_ids": tf.int32}, tf.int64),
+ (
+ {
+ "input_ids": tf.TensorShape([None]),
+ "attention_mask": tf.TensorShape([None]),
+ "token_type_ids": tf.TensorShape([None]),
+ },
+ tf.TensorShape([None]),
+ ),
+ )
+
+ def get_dataset(self):
+ self.dataset = self.dataset.apply(tf.data.experimental.assert_cardinality(len(self.features)))
+
+ return self.dataset
+
+ def __len__(self):
+ return len(self.features)
+
+ def __getitem__(self, i) -> InputFeatures:
+ return self.features[i]
diff --git a/docs/transformers/examples/modular-transformers/README.md b/docs/transformers/examples/modular-transformers/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..4eba1d03aebc8b40a015d04c56e67b0c138f6084
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/README.md
@@ -0,0 +1,20 @@
+# Using the `modular_converter` linter
+
+`pip install libcst` is a must!
+
+# `sh examples/modular-transformers/convert_examples.sh` to get the converted outputs
+
+The modular converter is a new `linter` specific to `transformers`. It allows us to unpack inheritance in python to convert a modular file like `modular_gemma.py` into a `single model single file`.
+
+Examples of possible usage are available in the `examples/modular-transformers`, or `modular_gemma` for a full model usage.
+
+`python utils/modular_model_converter.py --files_to_parse "/Users/arthurzucker/Work/transformers/examples/modular-transformers/modular_my_new_model2.py"`
+
+## How it works
+We use the `libcst` parser to produce an AST representation of the `modular_xxx.py` file. For any imports that are made from `transformers.models.modeling_xxxx` we parse the source code of that module, and build a class dependency mapping, which allows us to unpack the modularerence dependencies.
+
+The code from the `modular` file and the class dependency mapping are "merged" to produce the single model single file.
+We use ruff to automatically remove the potential duplicate imports.
+
+## Why we use libcst instead of the native AST?
+AST is super powerful, but it does not keep the `docstring`, `comment` or code formatting. Thus we decided to go with `libcst`
\ No newline at end of file
diff --git a/docs/transformers/examples/modular-transformers/configuration_dummy.py b/docs/transformers/examples/modular-transformers/configuration_dummy.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/docs/transformers/examples/modular-transformers/configuration_my_new_model.py b/docs/transformers/examples/modular-transformers/configuration_my_new_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..febd1b886752c03819025276f6bac360fb7b714e
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/configuration_my_new_model.py
@@ -0,0 +1,211 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_my_new_model.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_my_new_model.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+
+from ...configuration_utils import PretrainedConfig
+from ...modeling_rope_utils import rope_config_validation
+
+
+class MyNewModelConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`MyNewModelModel`]. It is used to instantiate an MyNewModel
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the MyNewModel-7B.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 32000):
+ Vocabulary size of the MyNewModel model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`MyNewModelModel`]
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 11008):
+ Dimension of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 32):
+ Number of hidden layers in the Transformer decoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer decoder.
+ num_key_value_heads (`int`, *optional*):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ `num_attention_heads`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to 2048):
+ The maximum sequence length that this model might ever be used with. MyNewModel 1 supports up to 2048 tokens,
+ MyNewModel 2 up to 4096, CodeLlama up to 16384.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ pad_token_id (`int`, *optional*):
+ Padding token id.
+ bos_token_id (`int`, *optional*, defaults to 1):
+ Beginning of stream token id.
+ eos_token_id (`int`, *optional*, defaults to 2):
+ End of stream token id.
+ pretraining_tp (`int`, *optional*, defaults to 1):
+ Experimental feature. Tensor parallelism rank used during pretraining. Please refer to [this
+ document](https://huggingface.co/docs/transformers/main/perf_train_gpu_many#tensor-parallelism) to
+ understand more about it. This value is necessary to ensure exact reproducibility of the pretraining
+ results. Please refer to [this issue](https://github.com/pytorch/pytorch/issues/76232).
+ tie_word_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether to tie weight embeddings
+ rope_theta (`float`, *optional*, defaults to 10000.0):
+ The base period of the RoPE embeddings.
+ rope_scaling (`Dict`, *optional*):
+ Dictionary containing the scaling configuration for the RoPE embeddings. NOTE: if you apply new rope type
+ and you expect the model to work on longer `max_position_embeddings`, we recommend you to update this value
+ accordingly.
+ Expected contents:
+ `rope_type` (`str`):
+ The sub-variant of RoPE to use. Can be one of ['default', 'linear', 'dynamic', 'yarn', 'longrope',
+ 'my_new_model3'], with 'default' being the original RoPE implementation.
+ `factor` (`float`, *optional*):
+ Used with all rope types except 'default'. The scaling factor to apply to the RoPE embeddings. In
+ most scaling types, a `factor` of x will enable the model to handle sequences of length x *
+ original maximum pre-trained length.
+ `original_max_position_embeddings` (`int`, *optional*):
+ Used with 'dynamic', 'longrope' and 'my_new_model3'. The original max position embeddings used during
+ pretraining.
+ `attention_factor` (`float`, *optional*):
+ Used with 'yarn' and 'longrope'. The scaling factor to be applied on the attention
+ computation. If unspecified, it defaults to value recommended by the implementation, using the
+ `factor` field to infer the suggested value.
+ `beta_fast` (`float`, *optional*):
+ Only used with 'yarn'. Parameter to set the boundary for extrapolation (only) in the linear
+ ramp function. If unspecified, it defaults to 32.
+ `beta_slow` (`float`, *optional*):
+ Only used with 'yarn'. Parameter to set the boundary for interpolation (only) in the linear
+ ramp function. If unspecified, it defaults to 1.
+ `short_factor` (`List[float]`, *optional*):
+ Only used with 'longrope'. The scaling factor to be applied to short contexts (<
+ `original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
+ size divided by the number of attention heads divided by 2
+ `long_factor` (`List[float]`, *optional*):
+ Only used with 'longrope'. The scaling factor to be applied to long contexts (<
+ `original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
+ size divided by the number of attention heads divided by 2
+ `low_freq_factor` (`float`, *optional*):
+ Only used with 'my_new_model3'. Scaling factor applied to low frequency components of the RoPE
+ `high_freq_factor` (`float`, *optional*):
+ Only used with 'my_new_model3'. Scaling factor applied to high frequency components of the RoPE
+ attention_bias (`bool`, *optional*, defaults to `False`):
+ Whether to use a bias in the query, key, value and output projection layers during self-attention.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ mlp_bias (`bool`, *optional*, defaults to `False`):
+ Whether to use a bias in up_proj, down_proj and gate_proj layers in the MLP layers.
+ head_dim (`int`, *optional*):
+ The attention head dimension. If None, it will default to hidden_size // num_attention_heads
+
+ ```python
+ >>> from transformers import MyNewModelModel, MyNewModelConfig
+
+ >>> # Initializing a MyNewModel my_new_model-7b style configuration
+ >>> configuration = MyNewModelConfig()
+
+ >>> # Initializing a model from the my_new_model-7b style configuration
+ >>> model = MyNewModelModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```
+ new_param (`int`, *optional*, defaults to `False`):
+ A fun new parameter
+ """
+
+ model_type = "my_new_model"
+ keys_to_ignore_at_inference = ["past_key_values"]
+ # Default tensor parallel plan for base model `MyNewModelModel`
+ base_model_tp_plan = {
+ "layers.*.self_attn.q_proj": "colwise",
+ "layers.*.self_attn.k_proj": "colwise",
+ "layers.*.self_attn.v_proj": "colwise",
+ "layers.*.self_attn.o_proj": "rowwise",
+ "layers.*.mlp.gate_proj": "colwise",
+ "layers.*.mlp.up_proj": "colwise",
+ "layers.*.mlp.down_proj": "rowwise",
+ }
+ base_model_pp_plan = {
+ "embed_tokens": (["input_ids"], ["inputs_embeds"]),
+ "layers": (["hidden_states", "attention_mask"], ["hidden_states"]),
+ "norm": (["hidden_states"], ["hidden_states"]),
+ }
+
+ def __init__(
+ self,
+ vocab_size=32000,
+ hidden_size=4096,
+ intermediate_size=11008,
+ num_hidden_layers=32,
+ num_attention_heads=32,
+ num_key_value_heads=None,
+ hidden_act="silu",
+ max_position_embeddings=2048,
+ initializer_range=0.02,
+ rms_norm_eps=1e-6,
+ use_cache=True,
+ pad_token_id=None,
+ bos_token_id=1,
+ eos_token_id=2,
+ pretraining_tp=1,
+ tie_word_embeddings=False,
+ rope_theta=10000.0,
+ rope_scaling=None,
+ attention_bias=False,
+ attention_dropout=0.0,
+ mlp_bias=True,
+ head_dim=None,
+ new_param=0,
+ **kwargs,
+ ):
+ super().__init__(
+ pad_token_id=pad_token_id,
+ bos_token_id=bos_token_id,
+ eos_token_id=eos_token_id,
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+
+ # for backward compatibility
+ if num_key_value_heads is None:
+ num_key_value_heads = num_attention_heads
+
+ self.num_key_value_heads = num_key_value_heads
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.pretraining_tp = pretraining_tp
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.rope_scaling = rope_scaling
+ self.attention_bias = attention_bias
+ self.attention_dropout = attention_dropout
+ self.mlp_bias = mlp_bias
+ self.head_dim = head_dim if head_dim is not None else self.hidden_size // self.num_attention_heads
+ # Validate the correctness of rotary position embeddings parameters
+ # BC: if there is a 'type' field, copy it it to 'rope_type'.
+ if self.rope_scaling is not None and "type" in self.rope_scaling:
+ self.rope_scaling["rope_type"] = self.rope_scaling["type"]
+ rope_config_validation(self)
+ self.new_param = new_param
diff --git a/docs/transformers/examples/modular-transformers/configuration_my_new_model2.py b/docs/transformers/examples/modular-transformers/configuration_my_new_model2.py
new file mode 100644
index 0000000000000000000000000000000000000000..a5364a85d53720605bf35b228a20568606be4beb
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/configuration_my_new_model2.py
@@ -0,0 +1,113 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_my_new_model2.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_my_new_model2.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+
+from ...configuration_utils import PretrainedConfig
+from ...modeling_rope_utils import rope_config_validation
+
+
+class MyNewModel2Config(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`GemmaModel`]. It is used to instantiate an Gemma
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the Gemma-7B.
+ e.g. [google/gemma-7b](https://huggingface.co/google/gemma-7b)
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+ Args:
+ vocab_size (`int`, *optional*, defaults to 256000):
+ Vocabulary size of the Gemma model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`GemmaModel`]
+ ```python
+ >>> from transformers import GemmaModel, GemmaConfig
+ >>> # Initializing a Gemma gemma-7b style configuration
+ >>> configuration = GemmaConfig()
+ >>> # Initializing a model from the gemma-7b style configuration
+ >>> model = GemmaModel(configuration)
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "my_new_model2"
+ keys_to_ignore_at_inference = ["past_key_values"]
+ # Default tensor parallel plan for base model `MyNewModel2Model`
+ base_model_tp_plan = {
+ "layers.*.self_attn.q_proj": "colwise",
+ "layers.*.self_attn.k_proj": "colwise",
+ "layers.*.self_attn.v_proj": "colwise",
+ "layers.*.self_attn.o_proj": "rowwise",
+ "layers.*.mlp.gate_proj": "colwise",
+ "layers.*.mlp.up_proj": "colwise",
+ "layers.*.mlp.down_proj": "rowwise",
+ }
+ base_model_pp_plan = {
+ "embed_tokens": (["input_ids"], ["inputs_embeds"]),
+ "layers": (["hidden_states", "attention_mask"], ["hidden_states"]),
+ "norm": (["hidden_states"], ["hidden_states"]),
+ }
+
+ def __init__(
+ self,
+ vocab_size=32000,
+ hidden_size=4096,
+ intermediate_size=11008,
+ num_hidden_layers=32,
+ num_attention_heads=32,
+ num_key_value_heads=None,
+ hidden_act="silu",
+ max_position_embeddings=2048,
+ initializer_range=0.02,
+ rms_norm_eps=1e-6,
+ use_cache=True,
+ pad_token_id=None,
+ bos_token_id=1,
+ eos_token_id=2,
+ pretraining_tp=1,
+ tie_word_embeddings=False,
+ rope_theta=10000.0,
+ rope_scaling=None,
+ attention_bias=False,
+ attention_dropout=0.0,
+ mlp_bias=False,
+ head_dim=None,
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+
+ # for backward compatibility
+ if num_key_value_heads is None:
+ num_key_value_heads = num_attention_heads
+
+ self.num_key_value_heads = num_key_value_heads
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.pretraining_tp = pretraining_tp
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.rope_scaling = rope_scaling
+ self.attention_bias = attention_bias
+ self.attention_dropout = attention_dropout
+ self.mlp_bias = mlp_bias
+ self.head_dim = head_dim if head_dim is not None else self.hidden_size // self.num_attention_heads
+ # Validate the correctness of rotary position embeddings parameters
+ # BC: if there is a 'type' field, copy it it to 'rope_type'.
+ if self.rope_scaling is not None and "type" in self.rope_scaling:
+ self.rope_scaling["rope_type"] = self.rope_scaling["type"]
+ rope_config_validation(self)
+
+ super().__init__(
+ pad_token_id=pad_token_id,
+ bos_token_id=bos_token_id,
+ eos_token_id=eos_token_id,
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
diff --git a/docs/transformers/examples/modular-transformers/configuration_new_model.py b/docs/transformers/examples/modular-transformers/configuration_new_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..ba05b4ea51b2c5d455ce51ef10d1fb1ee47228a7
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/configuration_new_model.py
@@ -0,0 +1,147 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_new_model.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_new_model.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# Example where we only want to overwrite the defaults of an init
+
+from ...configuration_utils import PretrainedConfig
+
+
+class NewModelConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`NewModelModel`]. It is used to instantiate an NewModel
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the NewModel-7B.
+ e.g. [google/new_model-7b](https://huggingface.co/google/new_model-7b)
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+ Args:
+ vocab_size (`int`, *optional*, defaults to 256000):
+ Vocabulary size of the NewModel model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`NewModelModel`]
+ hidden_size (`int`, *optional*, defaults to 3072):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 24576):
+ Dimension of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 28):
+ Number of hidden layers in the Transformer decoder.
+ num_attention_heads (`int`, *optional*, defaults to 16):
+ Number of attention heads for each attention layer in the Transformer decoder.
+ num_key_value_heads (`int`, *optional*, defaults to 16):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ `num_attention_heads`.
+ head_dim (`int`, *optional*, defaults to 256):
+ The attention head dimension.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu_pytorch_tanh"`):
+ The legacy activation function. It is overwritten by the `hidden_activation`.
+ hidden_activation (`str` or `function`, *optional*):
+ The non-linear activation function (function or string) in the decoder. Will default to `"gelu_pytorch_tanh"`
+ if not specified. `"gelu_pytorch_tanh"` uses an approximation of the `"gelu"` activation function.
+ max_position_embeddings (`int`, *optional*, defaults to 8192):
+ The maximum sequence length that this model might ever be used with.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ pad_token_id (`int`, *optional*, defaults to 0):
+ Padding token id.
+ eos_token_id (`int`, *optional*, defaults to 1):
+ End of stream token id.
+ bos_token_id (`int`, *optional*, defaults to 2):
+ Beginning of stream token id.
+ tie_word_embeddings (`bool`, *optional*, defaults to `True`):
+ Whether to tie weight embeddings
+ rope_theta (`float`, *optional*, defaults to 10000.0):
+ The base period of the RoPE embeddings.
+ attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):
+ Whether to use a bias in the query, key, value and output projection layers during self-attention.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ ```python
+ >>> from transformers import NewModelModel, NewModelConfig
+ >>> # Initializing a NewModel new_model-7b style configuration
+ >>> configuration = NewModelConfig()
+ >>> # Initializing a model from the new_model-7b style configuration
+ >>> model = NewModelModel(configuration)
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "new_model"
+ keys_to_ignore_at_inference = ["past_key_values"]
+ base_model_tp_plan = {
+ "layers.*.self_attn.q_proj": "colwise",
+ "layers.*.self_attn.k_proj": "colwise",
+ "layers.*.self_attn.v_proj": "colwise",
+ "layers.*.self_attn.o_proj": "rowwise",
+ "layers.*.mlp.gate_proj": "colwise",
+ "layers.*.mlp.up_proj": "colwise",
+ "layers.*.mlp.down_proj": "rowwise",
+ }
+ base_model_pp_plan = {
+ "embed_tokens": (["input_ids"], ["inputs_embeds"]),
+ "layers": (["hidden_states", "attention_mask"], ["hidden_states"]),
+ "norm": (["hidden_states"], ["hidden_states"]),
+ }
+
+ def __init__(
+ self,
+ vocab_size=256030,
+ hidden_size=64,
+ intermediate_size=90,
+ num_hidden_layers=28,
+ num_attention_heads=16,
+ num_key_value_heads=16,
+ head_dim=256,
+ hidden_act="gelu_pytorch_tanh",
+ hidden_activation=None,
+ max_position_embeddings=1500,
+ initializer_range=0.02,
+ rms_norm_eps=1e-6,
+ use_cache=True,
+ pad_token_id=0,
+ eos_token_id=1,
+ bos_token_id=2,
+ tie_word_embeddings=True,
+ rope_theta=10000.0,
+ attention_bias=False,
+ attention_dropout=0.0,
+ **kwargs,
+ ):
+ super().__init__(
+ pad_token_id=pad_token_id,
+ bos_token_id=bos_token_id,
+ eos_token_id=eos_token_id,
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.head_dim = head_dim
+ self.num_key_value_heads = num_key_value_heads
+ self.hidden_act = hidden_act
+ self.hidden_activation = hidden_activation
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.attention_bias = attention_bias
+ self.attention_dropout = attention_dropout
+
+ @property
+ def num_heads(self):
+ return self.num_attention_heads
diff --git a/docs/transformers/examples/modular-transformers/configuration_super.py b/docs/transformers/examples/modular-transformers/configuration_super.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/docs/transformers/examples/modular-transformers/convert_examples.sh b/docs/transformers/examples/modular-transformers/convert_examples.sh
new file mode 100644
index 0000000000000000000000000000000000000000..49666ab1154d33c0d06930c01aa6d43b4a963d74
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/convert_examples.sh
@@ -0,0 +1,10 @@
+#!/bin/bash
+
+# Iterate over each file in the current directory
+for file in examples/modular-transformers/modular_*; do
+ # Check if it's a regular file
+ if [ -f "$file" ]; then
+ # Call the Python script with the file name as an argument
+ python utils/modular_model_converter.py --files_to_parse "$file"
+ fi
+done
\ No newline at end of file
diff --git a/docs/transformers/examples/modular-transformers/image_processing_new_imgproc_model.py b/docs/transformers/examples/modular-transformers/image_processing_new_imgproc_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..8320a25228c2139bcdb8d5af16c8feeb6951e075
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/image_processing_new_imgproc_model.py
@@ -0,0 +1,286 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_new_imgproc_model.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_new_imgproc_model.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+from typing import Optional, Union
+
+import numpy as np
+import torch
+
+from ...image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
+from ...image_transforms import convert_to_rgb, resize, to_channel_dimension_format
+from ...image_utils import (
+ OPENAI_CLIP_MEAN,
+ OPENAI_CLIP_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ infer_channel_dimension_format,
+ is_scaled_image,
+ make_flat_list_of_images,
+ to_numpy_array,
+ valid_images,
+ validate_preprocess_arguments,
+)
+from ...utils import TensorType, filter_out_non_signature_kwargs, is_vision_available, logging
+
+
+if is_vision_available():
+ import PIL
+
+
+logger = logging.get_logger(__name__)
+
+
+class ImgprocModelImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a IMGPROC_MODEL image processor.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the image's (height, width) dimensions to the specified `size`. Can be overridden by the
+ `do_resize` parameter in the `preprocess` method.
+ size (`dict`, *optional*, defaults to `{"height": 384, "width": 384}`):
+ Size of the output image after resizing. Can be overridden by the `size` parameter in the `preprocess`
+ method.
+ resample (`PILImageResampling`, *optional*, defaults to `Resampling.BICUBIC`):
+ Resampling filter to use if resizing the image. Only has an effect if `do_resize` is set to `True`. Can be
+ overridden by the `resample` parameter in the `preprocess` method.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by the
+ `do_rescale` parameter in the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Only has an effect if `do_rescale` is set to `True`. Can be
+ overridden by the `rescale_factor` parameter in the `preprocess` method.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image. Can be overridden by the `do_normalize` parameter in the `preprocess`
+ method. Can be overridden by the `do_normalize` parameter in the `preprocess` method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_MEAN`):
+ Mean to use if normalizing the image. This is a float or list of floats the length of the number of
+ channels in the image. Can be overridden by the `image_mean` parameter in the `preprocess` method. Can be
+ overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_STD`):
+ Standard deviation to use if normalizing the image. This is a float or list of floats the length of the
+ number of channels in the image. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ Can be overridden by the `image_std` parameter in the `preprocess` method.
+ do_convert_rgb (`bool`, *optional*, defaults to `True`):
+ Whether to convert the image to RGB.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize: bool = True,
+ size: dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BICUBIC,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Optional[Union[float, list[float]]] = None,
+ image_std: Optional[Union[float, list[float]]] = None,
+ do_convert_rgb: bool = True,
+ **kwargs,
+ ) -> None:
+ super().__init__(**kwargs)
+ size = size if size is not None else {"height": 384, "width": 384}
+ size = get_size_dict(size, default_to_square=True)
+
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else OPENAI_CLIP_MEAN
+ self.image_std = image_std if image_std is not None else OPENAI_CLIP_STD
+ self.do_convert_rgb = do_convert_rgb
+
+ def resize(
+ self,
+ image: np.ndarray,
+ size: dict[str, int],
+ resample: PILImageResampling = PILImageResampling.BICUBIC,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ **kwargs,
+ ) -> np.ndarray:
+ """
+ Resize an image to `(size["height"], size["width"])`.
+
+ Args:
+ image (`np.ndarray`):
+ Image to resize.
+ size (`Dict[str, int]`):
+ Dictionary in the format `{"height": int, "width": int}` specifying the size of the output image.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BICUBIC`):
+ `PILImageResampling` filter to use when resizing the image e.g. `PILImageResampling.BICUBIC`.
+ data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the output image. If unset, the channel dimension format of the input
+ image is used. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+
+ Returns:
+ `np.ndarray`: The resized image.
+ """
+ size = get_size_dict(size)
+ if "height" not in size or "width" not in size:
+ raise ValueError(f"The `size` dictionary must contain the keys `height` and `width`. Got {size.keys()}")
+ output_size = (size["height"], size["width"])
+ return resize(
+ image,
+ size=output_size,
+ resample=resample,
+ data_format=data_format,
+ input_data_format=input_data_format,
+ **kwargs,
+ )
+
+ @filter_out_non_signature_kwargs()
+ def preprocess(
+ self,
+ images: ImageInput,
+ do_resize: Optional[bool] = None,
+ size: Optional[dict[str, int]] = None,
+ resample: PILImageResampling = None,
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[float] = None,
+ do_normalize: Optional[bool] = None,
+ image_mean: Optional[Union[float, list[float]]] = None,
+ image_std: Optional[Union[float, list[float]]] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ do_convert_rgb: bool = None,
+ data_format: ChannelDimension = ChannelDimension.FIRST,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ) -> PIL.Image.Image:
+ """
+ Preprocess an image or batch of images.
+
+ Args:
+ images (`ImageInput`):
+ Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
+ passing in images with pixel values between 0 and 1, set `do_rescale=False`.
+ do_resize (`bool`, *optional*, defaults to `self.do_resize`):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to `self.size`):
+ Controls the size of the image after `resize`. The shortest edge of the image is resized to
+ `size["shortest_edge"]` whilst preserving the aspect ratio. If the longest edge of this resized image
+ is > `int(size["shortest_edge"] * (1333 / 800))`, then the image is resized again to make the longest
+ edge equal to `int(size["shortest_edge"] * (1333 / 800))`.
+ resample (`PILImageResampling`, *optional*, defaults to `self.resample`):
+ Resampling filter to use if resizing the image. Only has an effect if `do_resize` is set to `True`.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether to rescale the image values between [0 - 1].
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ Rescale factor to rescale the image by if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
+ Image mean to normalize the image by if `do_normalize` is set to `True`.
+ image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
+ Image standard deviation to normalize the image by if `do_normalize` is set to `True`.
+ do_convert_rgb (`bool`, *optional*, defaults to `self.do_convert_rgb`):
+ Whether to convert the image to RGB.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - Unset: Use the channel dimension format of the input image.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ """
+ do_resize = do_resize if do_resize is not None else self.do_resize
+ resample = resample if resample is not None else self.resample
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+ do_convert_rgb = do_convert_rgb if do_convert_rgb is not None else self.do_convert_rgb
+
+ size = size if size is not None else self.size
+ size = get_size_dict(size, default_to_square=False)
+ images = make_flat_list_of_images(images)
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ validate_preprocess_arguments(
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ do_resize=do_resize,
+ size=size,
+ resample=resample,
+ )
+ # PIL RGBA images are converted to RGB
+ if do_convert_rgb:
+ images = [convert_to_rgb(image) for image in images]
+
+ # All transformations expect numpy arrays.
+ images = [to_numpy_array(image) for image in images]
+
+ if do_rescale and is_scaled_image(images[0]):
+ logger.warning_once(
+ "It looks like you are trying to rescale already rescaled images. If the input"
+ " images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
+ )
+
+ if input_data_format is None:
+ # We assume that all images have the same channel dimension format.
+ input_data_format = infer_channel_dimension_format(images[0])
+
+ if do_resize:
+ images = [
+ self.resize(image=image, size=size, resample=resample, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ if do_rescale:
+ images = [
+ self.rescale(image=image, scale=rescale_factor, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ if do_normalize:
+ images = [
+ self.normalize(image=image, mean=image_mean, std=image_std, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ images = [
+ to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format) for image in images
+ ]
+
+ encoded_outputs = BatchFeature(data={"pixel_values": images}, tensor_type=return_tensors)
+
+ return encoded_outputs
+
+ def new_image_processing_method(self, pixel_values: torch.FloatTensor):
+ return pixel_values / 2
diff --git a/docs/transformers/examples/modular-transformers/modeling_add_function.py b/docs/transformers/examples/modular-transformers/modeling_add_function.py
new file mode 100644
index 0000000000000000000000000000000000000000..76b6dafb69a59267363a0f3b42f12e8f14ef0640
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modeling_add_function.py
@@ -0,0 +1,66 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_add_function.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_add_function.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# Note that zamba does not have the `apply_rotary_pos_emb` function!
+from typing import Optional
+
+import torch
+from torch import nn
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+class TestAttention(nn.Module):
+ """
+ Multi-headed attention from 'Attention Is All You Need' paper. Modified to use sliding window attention: Longformer
+ and "Generating Long Sequences with Sparse Transformers".
+
+ Adapted from transformers.models.mistral.modeling_mistral.MistralAttention:
+ The input dimension here is attention_hidden_size = 2 * hidden_size, and head_dim = attention_hidden_size // num_heads.
+ The extra factor of 2 comes from the input being the concatenation of original_hidden_states with the output of the previous (mamba) layer
+ (see fig. 2 in https://arxiv.org/pdf/2405.16712).
+ Additionally, replaced
+ attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim) with
+ attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim/2)
+ """
+
+ def __init__(self):
+ pass
+
+ def forward(self) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor]]]:
+ _ = apply_rotary_pos_emb(1, 1, 1, 1)
diff --git a/docs/transformers/examples/modular-transformers/modeling_dummy.py b/docs/transformers/examples/modular-transformers/modeling_dummy.py
new file mode 100644
index 0000000000000000000000000000000000000000..f793923cb2fc3a8a03f6345abe92e57f3d03a4e4
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modeling_dummy.py
@@ -0,0 +1,711 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_dummy.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_dummy.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+from functools import partial
+from typing import Callable, Optional, Union
+
+import torch
+from torch import nn
+
+from ...activations import ACT2FN
+from ...cache_utils import Cache, DynamicCache, StaticCache
+from ...modeling_attn_mask_utils import AttentionMaskConverter
+from ...modeling_flash_attention_utils import FlashAttentionKwargs
+from ...modeling_outputs import BaseModelOutputWithPast
+from ...modeling_rope_utils import ROPE_INIT_FUNCTIONS
+from ...modeling_utils import ALL_ATTENTION_FUNCTIONS, PreTrainedModel
+from ...processing_utils import Unpack
+from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging
+from .configuration_dummy import DummyConfig
+
+
+logger = logging.get_logger(__name__)
+
+
+class DummyRMSNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ DummyRMSNorm is equivalent to T5LayerNorm
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+ def extra_repr(self):
+ return f"{tuple(self.weight.shape)}, eps={self.variance_epsilon}"
+
+
+class DummyRotaryEmbedding(nn.Module):
+ def __init__(self, config: DummyConfig, device=None):
+ super().__init__()
+ # BC: "rope_type" was originally "type"
+ if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
+ self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
+ else:
+ self.rope_type = "default"
+ self.max_seq_len_cached = config.max_position_embeddings
+ self.original_max_seq_len = config.max_position_embeddings
+
+ self.config = config
+ self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
+
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+ self.original_inv_freq = self.inv_freq
+
+ def _dynamic_frequency_update(self, position_ids, device):
+ """
+ dynamic RoPE layers should recompute `inv_freq` in the following situations:
+ 1 - growing beyond the cached sequence length (allow scaling)
+ 2 - the current sequence length is in the original scale (avoid losing precision with small sequences)
+ """
+ seq_len = torch.max(position_ids) + 1
+ if seq_len > self.max_seq_len_cached: # growth
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device, seq_len=seq_len)
+ self.register_buffer("inv_freq", inv_freq, persistent=False) # TODO joao: may break with compilation
+ self.max_seq_len_cached = seq_len
+
+ if seq_len < self.original_max_seq_len and self.max_seq_len_cached > self.original_max_seq_len: # reset
+ # This .to() is needed if the model has been moved to a device after being initialized (because
+ # the buffer is automatically moved, but not the original copy)
+ self.original_inv_freq = self.original_inv_freq.to(device)
+ self.register_buffer("inv_freq", self.original_inv_freq, persistent=False)
+ self.max_seq_len_cached = self.original_max_seq_len
+
+ @torch.no_grad()
+ def forward(self, x, position_ids):
+ if "dynamic" in self.rope_type:
+ self._dynamic_frequency_update(position_ids, device=x.device)
+
+ # Core RoPE block
+ inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1)
+ position_ids_expanded = position_ids[:, None, :].float()
+ # Force float32 (see https://github.com/huggingface/transformers/pull/29285)
+ device_type = x.device.type
+ device_type = device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
+ with torch.autocast(device_type=device_type, enabled=False):
+ freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
+ emb = torch.cat((freqs, freqs), dim=-1)
+ cos = emb.cos()
+ sin = emb.sin()
+
+ # Advanced RoPE types (e.g. yarn) apply a post-processing scaling factor, equivalent to scaling attention
+ cos = cos * self.attention_scaling
+ sin = sin * self.attention_scaling
+
+ return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
+
+
+class DummyMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.intermediate_size = config.intermediate_size
+ self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
+ self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
+ self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=config.mlp_bias)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+ return down_proj
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 4]
+ x2 = x[..., x.shape[-1] // 4 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+def eager_attention_forward(
+ module: nn.Module,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ attention_mask: Optional[torch.Tensor],
+ scaling: float,
+ dropout: float = 0.0,
+ **kwargs,
+):
+ key_states = repeat_kv(key, module.num_key_value_groups)
+ value_states = repeat_kv(value, module.num_key_value_groups)
+
+ attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
+ if attention_mask is not None:
+ causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
+ attn_weights = attn_weights + causal_mask
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ return attn_output, attn_weights
+
+
+class DummyAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: DummyConfig, layer_idx: int):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
+ self.scaling = self.head_dim**-0.5
+ self.attention_dropout = config.attention_dropout
+ self.is_causal = True
+
+ self.q_proj = nn.Linear(
+ config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.k_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.v_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.o_proj = nn.Linear(
+ config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ position_embeddings: tuple[torch.Tensor, torch.Tensor],
+ attention_mask: Optional[torch.Tensor],
+ past_key_value: Optional[Cache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor]]]:
+ input_shape = hidden_states.shape[:-1]
+ hidden_shape = (*input_shape, -1, self.head_dim)
+
+ query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+
+ cos, sin = position_embeddings
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models; cache_position needed for the static cache
+ cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ attention_interface: Callable = eager_attention_forward
+ if self.config._attn_implementation != "eager":
+ if self.config._attn_implementation == "sdpa" and kwargs.get("output_attentions", False):
+ logger.warning_once(
+ "`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
+ 'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ else:
+ attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
+
+ attn_output, attn_weights = attention_interface(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ dropout=0.0 if not self.training else self.attention_dropout,
+ scaling=self.scaling,
+ **kwargs,
+ )
+
+ attn_output = attn_output.reshape(*input_shape, -1).contiguous()
+ attn_output = self.o_proj(attn_output)
+ return attn_output, attn_weights
+
+
+class DummyDecoderLayer(nn.Module):
+ def __init__(self, config: DummyConfig, layer_idx: int):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ self.self_attn = DummyAttention(config=config, layer_idx=layer_idx)
+
+ self.mlp = DummyMLP(config)
+ self.input_layernorm = DummyRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = DummyRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ position_embeddings: Optional[tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.FloatTensor, Optional[tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **kwargs,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ return outputs
+
+
+DUMMY_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`DummyConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare Dummy Model outputting raw hidden-states without any specific head on top.",
+ DUMMY_START_DOCSTRING,
+)
+class DummyPreTrainedModel(PreTrainedModel):
+ config_class = DummyConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["DummyDecoderLayer"]
+ _skip_keys_device_placement = ["past_key_values"]
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_flex_attn = True
+ _supports_cache_class = True
+ _supports_quantized_cache = True
+ _supports_static_cache = True
+ _supports_attention_backend = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+
+DUMMY_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`Cache` or `tuple(tuple(torch.FloatTensor))`, *optional*):
+ Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used to speed up sequential decoding. This typically consists in the `past_key_values`
+ returned by the model at a previous stage of decoding, when `use_cache=True` or `config.use_cache=True`.
+
+ Two formats are allowed:
+ - a [`~cache_utils.Cache`] instance, see our
+ [kv cache guide](https://huggingface.co/docs/transformers/en/kv_cache);
+ - Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`). This is also known as the legacy
+ cache format.
+
+ The model will output the same cache format that is fed as input. If no `past_key_values` are passed, the
+ legacy cache format will be returned.
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
+ have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
+ of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence. Contrarily to `position_ids`,
+ this tensor is not affected by padding. It is used to update the cache in the correct position and to infer
+ the complete sequence length.
+"""
+
+
+@add_start_docstrings(
+ "The bare Dummy Model outputting raw hidden-states without any specific head on top.",
+ DUMMY_START_DOCSTRING,
+)
+class DummyModel(DummyPreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`DummyDecoderLayer`]
+
+ Args:
+ config: DummyConfig
+ """
+
+ def __init__(self, config: DummyConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+ self.layers = nn.ModuleList(
+ [DummyDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
+ )
+ self.norm = DummyRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.rotary_emb = DummyRotaryEmbedding(config=config)
+ self.gradient_checkpointing = False
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(DUMMY_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Cache] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **flash_attn_kwargs: Unpack[FlashAttentionKwargs],
+ ) -> Union[tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if (input_ids is None) ^ (inputs_embeds is not None):
+ raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
+
+ if self.gradient_checkpointing and self.training and use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`."
+ )
+ use_cache = False
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if use_cache and past_key_values is None:
+ past_key_values = DynamicCache()
+
+ if cache_position is None:
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+ cache_position = torch.arange(
+ past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
+ )
+
+ if position_ids is None:
+ position_ids = cache_position.unsqueeze(0)
+
+ causal_mask = self._update_causal_mask(
+ attention_mask, inputs_embeds, cache_position, past_key_values, output_attentions
+ )
+
+ hidden_states = inputs_embeds
+
+ # create position embeddings to be shared across the decoder layers
+ position_embeddings = self.rotary_emb(hidden_states, position_ids)
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+
+ for decoder_layer in self.layers[: self.config.num_hidden_layers]:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ partial(decoder_layer.__call__, **flash_attn_kwargs),
+ hidden_states,
+ causal_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ use_cache,
+ cache_position,
+ position_embeddings,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=causal_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **flash_attn_kwargs,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ output = BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=past_key_values if use_cache else None,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+ return output if return_dict else output.to_tuple()
+
+ def _update_causal_mask(
+ self,
+ attention_mask: torch.Tensor,
+ input_tensor: torch.Tensor,
+ cache_position: torch.Tensor,
+ past_key_values: Cache,
+ output_attentions: bool,
+ ):
+ if self.config._attn_implementation == "flash_attention_2":
+ if attention_mask is not None and (attention_mask == 0.0).any():
+ return attention_mask
+ return None
+
+ # For SDPA, when possible, we will rely on its `is_causal` argument instead of its `attn_mask` argument, in
+ # order to dispatch on Flash Attention 2. This feature is not compatible with static cache, as SDPA will fail
+ # to infer the attention mask.
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+ using_static_cache = isinstance(past_key_values, StaticCache)
+
+ # When output attentions is True, sdpa implementation's forward method calls the eager implementation's forward
+ if self.config._attn_implementation == "sdpa" and not using_static_cache and not output_attentions:
+ if AttentionMaskConverter._ignore_causal_mask_sdpa(
+ attention_mask,
+ inputs_embeds=input_tensor,
+ past_key_values_length=past_seen_tokens,
+ is_training=self.training,
+ ):
+ return None
+
+ dtype, device = input_tensor.dtype, input_tensor.device
+ sequence_length = input_tensor.shape[1]
+ if using_static_cache:
+ target_length = past_key_values.get_max_cache_shape()
+ else:
+ target_length = (
+ attention_mask.shape[-1]
+ if isinstance(attention_mask, torch.Tensor)
+ else past_seen_tokens + sequence_length + 1
+ )
+
+ # In case the provided `attention` mask is 2D, we generate a causal mask here (4D).
+ causal_mask = self._prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask,
+ sequence_length=sequence_length,
+ target_length=target_length,
+ dtype=dtype,
+ device=device,
+ cache_position=cache_position,
+ batch_size=input_tensor.shape[0],
+ )
+
+ if (
+ self.config._attn_implementation == "sdpa"
+ and attention_mask is not None
+ and attention_mask.device.type in ["cuda", "xpu"]
+ and not output_attentions
+ ):
+ # Attend to all tokens in fully masked rows in the causal_mask, for example the relevant first rows when
+ # using left padding. This is required by F.scaled_dot_product_attention memory-efficient attention path.
+ # Details: https://github.com/pytorch/pytorch/issues/110213
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = AttentionMaskConverter._unmask_unattended(causal_mask, min_dtype)
+
+ return causal_mask
+
+ @staticmethod
+ def _prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask: torch.Tensor,
+ sequence_length: int,
+ target_length: int,
+ dtype: torch.dtype,
+ device: torch.device,
+ cache_position: torch.Tensor,
+ batch_size: int,
+ **kwargs,
+ ):
+ """
+ Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
+ `(batch_size, key_value_length)`, or if the input `attention_mask` is already 4D, do nothing.
+
+ Args:
+ attention_mask (`torch.Tensor`):
+ A 2D attention mask of shape `(batch_size, key_value_length)` or a 4D attention mask of shape
+ `(batch_size, 1, query_length, key_value_length)`.
+ sequence_length (`int`):
+ The sequence length being processed.
+ target_length (`int`):
+ The target length: when generating with static cache, the mask should be as long as the static cache,
+ to account for the 0 padding, the part of the cache that is not filled yet.
+ dtype (`torch.dtype`):
+ The dtype to use for the 4D attention mask.
+ device (`torch.device`):
+ The device to plcae the 4D attention mask on.
+ cache_position (`torch.Tensor`):
+ Indices depicting the position of the input sequence tokens in the sequence.
+ batch_size (`torch.Tensor`):
+ Batch size.
+ """
+ if attention_mask is not None and attention_mask.dim() == 4:
+ # In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
+ causal_mask = attention_mask
+ else:
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = torch.full(
+ (sequence_length, target_length), fill_value=min_dtype, dtype=dtype, device=device
+ )
+ if sequence_length != 1:
+ causal_mask = torch.triu(causal_mask, diagonal=1)
+ causal_mask *= torch.arange(target_length, device=device) > cache_position.reshape(-1, 1)
+ causal_mask = causal_mask[None, None, :, :].expand(batch_size, 1, -1, -1)
+ if attention_mask is not None:
+ causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
+ mask_length = attention_mask.shape[-1]
+ padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :].to(
+ causal_mask.device
+ )
+ padding_mask = padding_mask == 0
+ causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
+ padding_mask, min_dtype
+ )
+
+ return causal_mask
diff --git a/docs/transformers/examples/modular-transformers/modeling_dummy_bert.py b/docs/transformers/examples/modular-transformers/modeling_dummy_bert.py
new file mode 100644
index 0000000000000000000000000000000000000000..5de9ab576e5cc93137bdd39403e0e7e444c3ecb8
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modeling_dummy_bert.py
@@ -0,0 +1,1011 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_dummy_bert.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_dummy_bert.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+import math
+import os
+from typing import Optional, Union
+
+import torch
+from packaging import version
+from torch import nn
+
+from ...activations import ACT2FN
+from ...modeling_attn_mask_utils import _prepare_4d_attention_mask_for_sdpa, _prepare_4d_causal_attention_mask_for_sdpa
+from ...modeling_outputs import BaseModelOutputWithPastAndCrossAttentions, BaseModelOutputWithPoolingAndCrossAttentions
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import apply_chunking_to_forward, find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import (
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ get_torch_version,
+ logging,
+)
+from .configuration_dummy_bert import DummyBertConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = "google-dummy_bert/dummy_bert-base-uncased"
+_CONFIG_FOR_DOC = "DummyBertConfig"
+
+
+class DummyBertEmbeddings(nn.Module):
+ """Construct the embeddings from word, position and token_type embeddings."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
+ self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
+ self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
+
+ # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
+ self.register_buffer(
+ "position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
+ )
+ self.register_buffer(
+ "token_type_ids", torch.zeros(self.position_ids.size(), dtype=torch.long), persistent=False
+ )
+
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ past_key_values_length: int = 0,
+ ) -> torch.Tensor:
+ if input_ids is not None:
+ input_shape = input_ids.size()
+ else:
+ input_shape = inputs_embeds.size()[:-1]
+
+ seq_length = input_shape[1]
+
+ if position_ids is None:
+ position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
+
+ # Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
+ # when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
+ # issue #5664
+ if token_type_ids is None:
+ if hasattr(self, "token_type_ids"):
+ buffered_token_type_ids = self.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+ token_type_embeddings = self.token_type_embeddings(token_type_ids)
+
+ embeddings = inputs_embeds + token_type_embeddings
+ if self.position_embedding_type == "absolute":
+ position_embeddings = self.position_embeddings(position_ids)
+ embeddings += position_embeddings
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings
+
+
+class DummyBertSelfAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
+ f"heads ({config.num_attention_heads})"
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+ self.position_embedding_type = position_embedding_type or getattr(
+ config, "position_embedding_type", "absolute"
+ )
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ self.max_position_embeddings = config.max_position_embeddings
+ self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
+
+ self.is_decoder = config.is_decoder
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[tuple[tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor]:
+ mixed_query_layer = self.query(hidden_states)
+
+ # If this is instantiated as a cross-attention module, the keys
+ # and values come from an encoder; the attention mask needs to be
+ # such that the encoder's padding tokens are not attended to.
+ is_cross_attention = encoder_hidden_states is not None
+
+ if is_cross_attention and past_key_value is not None:
+ # reuse k,v, cross_attentions
+ key_layer = past_key_value[0]
+ value_layer = past_key_value[1]
+ attention_mask = encoder_attention_mask
+ elif is_cross_attention:
+ key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
+ value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
+ attention_mask = encoder_attention_mask
+ elif past_key_value is not None:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
+ value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
+ else:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ use_cache = past_key_value is not None
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_layer, value_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ query_length, key_length = query_layer.shape[2], key_layer.shape[2]
+ if use_cache:
+ position_ids_l = torch.tensor(key_length - 1, dtype=torch.long, device=hidden_states.device).view(
+ -1, 1
+ )
+ else:
+ position_ids_l = torch.arange(query_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(key_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+
+ positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == "relative_key":
+ relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores
+ elif self.position_embedding_type == "relative_key_query":
+ relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in DummyBertModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ if self.is_decoder:
+ outputs = outputs + (past_key_value,)
+ return outputs
+
+
+class DummyBertSdpaSelfAttention(DummyBertSelfAttention):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__(config, position_embedding_type=position_embedding_type)
+ self.dropout_prob = config.attention_probs_dropout_prob
+ self.require_contiguous_qkv = version.parse(get_torch_version()) < version.parse("2.2.0")
+
+ # Adapted from DummyBertSelfAttention
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[tuple[tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor]:
+ if self.position_embedding_type != "absolute" or output_attentions or head_mask is not None:
+ # TODO: Improve this warning with e.g. `model.config._attn_implementation = "manual"` once implemented.
+ logger.warning_once(
+ "DummyBertSdpaSelfAttention is used but `torch.nn.functional.scaled_dot_product_attention` does not support "
+ "non-absolute `position_embedding_type` or `output_attentions=True` or `head_mask`. Falling back to "
+ "the manual attention implementation, but specifying the manual implementation will be required from "
+ "Transformers version v5.0.0 onwards. This warning can be removed using the argument "
+ '`attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+
+ bsz, tgt_len, _ = hidden_states.size()
+
+ query_layer = self.transpose_for_scores(self.query(hidden_states))
+
+ # If this is instantiated as a cross-attention module, the keys and values come from an encoder; the attention
+ # mask needs to be such that the encoder's padding tokens are not attended to.
+ is_cross_attention = encoder_hidden_states is not None
+
+ current_states = encoder_hidden_states if is_cross_attention else hidden_states
+ attention_mask = encoder_attention_mask if is_cross_attention else attention_mask
+
+ # Check `seq_length` of `past_key_value` == `len(current_states)` to support prefix tuning
+ if is_cross_attention and past_key_value and past_key_value[0].shape[2] == current_states.shape[1]:
+ key_layer, value_layer = past_key_value
+ else:
+ key_layer = self.transpose_for_scores(self.key(current_states))
+ value_layer = self.transpose_for_scores(self.value(current_states))
+ if past_key_value is not None and not is_cross_attention:
+ key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
+ value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_layer, value_layer)
+
+ # SDPA with memory-efficient backend is broken in torch==2.1.2 when using non-contiguous inputs and a custom
+ # attn_mask, so we need to call `.contiguous()` here. This was fixed in torch==2.2.0.
+ # Reference: https://github.com/pytorch/pytorch/issues/112577
+ if self.require_contiguous_qkv and query_layer.device.type == "cuda" and attention_mask is not None:
+ query_layer = query_layer.contiguous()
+ key_layer = key_layer.contiguous()
+ value_layer = value_layer.contiguous()
+
+ # We dispatch to SDPA's Flash Attention or Efficient kernels via this `is_causal` if statement instead of an inline conditional assignment
+ # in SDPA to support both torch.compile's dynamic shapes and full graph options. An inline conditional prevents dynamic shapes from compiling.
+ # The tgt_len > 1 is necessary to match with AttentionMaskConverter.to_causal_4d that does not create
+ # a causal mask in case tgt_len == 1.
+ is_causal = (
+ True if self.is_decoder and not is_cross_attention and attention_mask is None and tgt_len > 1 else False
+ )
+
+ attn_output = torch.nn.functional.scaled_dot_product_attention(
+ query_layer,
+ key_layer,
+ value_layer,
+ attn_mask=attention_mask,
+ dropout_p=self.dropout_prob if self.training else 0.0,
+ is_causal=is_causal,
+ )
+
+ attn_output = attn_output.transpose(1, 2)
+ attn_output = attn_output.reshape(bsz, tgt_len, self.all_head_size)
+
+ outputs = (attn_output,)
+ if self.is_decoder:
+ outputs = outputs + (past_key_value,)
+ return outputs
+
+
+class DummyBertSelfOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+DUMMY_BERT_SELF_ATTENTION_CLASSES = {
+ "eager": DummyBertSelfAttention,
+ "sdpa": DummyBertSdpaSelfAttention,
+}
+
+
+class DummyBertAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ self.self = DUMMY_BERT_SELF_ATTENTION_CLASSES[config._attn_implementation](
+ config, position_embedding_type=position_embedding_type
+ )
+ self.output = DummyBertSelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.self.query = prune_linear_layer(self.self.query, index)
+ self.self.key = prune_linear_layer(self.self.key, index)
+ self.self.value = prune_linear_layer(self.self.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
+ self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[tuple[tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor]:
+ self_outputs = self.self(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ attention_output = self.output(self_outputs[0], hidden_states)
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+class DummyBertIntermediate(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+class DummyBertOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class DummyBertLayer(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = DummyBertAttention(config)
+ self.is_decoder = config.is_decoder
+ self.add_cross_attention = config.add_cross_attention
+ if self.add_cross_attention:
+ if not self.is_decoder:
+ raise ValueError(f"{self} should be used as a decoder model if cross attention is added")
+ self.crossattention = DummyBertAttention(config, position_embedding_type="absolute")
+ self.intermediate = DummyBertIntermediate(config)
+ self.output = DummyBertOutput(config)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[tuple[tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor]:
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
+ self_attention_outputs = self.attention(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ output_attentions=output_attentions,
+ past_key_value=self_attn_past_key_value,
+ )
+ attention_output = self_attention_outputs[0]
+
+ # if decoder, the last output is tuple of self-attn cache
+ if self.is_decoder:
+ outputs = self_attention_outputs[1:-1]
+ present_key_value = self_attention_outputs[-1]
+ else:
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ cross_attn_present_key_value = None
+ if self.is_decoder and encoder_hidden_states is not None:
+ if not hasattr(self, "crossattention"):
+ raise ValueError(
+ f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers"
+ " by setting `config.add_cross_attention=True`"
+ )
+
+ # cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
+ cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
+ cross_attention_outputs = self.crossattention(
+ attention_output,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ cross_attn_past_key_value,
+ output_attentions,
+ )
+ attention_output = cross_attention_outputs[0]
+ outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
+
+ # add cross-attn cache to positions 3,4 of present_key_value tuple
+ cross_attn_present_key_value = cross_attention_outputs[-1]
+ present_key_value = present_key_value + cross_attn_present_key_value
+
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
+ )
+ outputs = (layer_output,) + outputs
+
+ # if decoder, return the attn key/values as the last output
+ if self.is_decoder:
+ outputs = outputs + (present_key_value,)
+
+ return outputs
+
+ def feed_forward_chunk(self, attention_output):
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ return layer_output
+
+
+class DummyBertEncoder(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([DummyBertLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_values: Optional[tuple[tuple[torch.FloatTensor]]] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = True,
+ ) -> Union[tuple[torch.Tensor], BaseModelOutputWithPastAndCrossAttentions]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ next_decoder_cache = () if use_cache else None
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+ past_key_value = past_key_values[i] if past_key_values is not None else None
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ layer_module.__call__,
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ else:
+ layer_outputs = layer_module(
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+ if use_cache:
+ next_decoder_cache += (layer_outputs[-1],)
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+ if self.config.add_cross_attention:
+ all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ next_decoder_cache,
+ all_hidden_states,
+ all_self_attentions,
+ all_cross_attentions,
+ ]
+ if v is not None
+ )
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+
+class DummyBertPooler(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+def load_tf_weights_in_dummy_bert(model, config, tf_checkpoint_path):
+ """Load tf checkpoints in a pytorch model."""
+ try:
+ import re
+
+ import numpy as np
+ import tensorflow as tf
+ except ImportError:
+ logger.error(
+ "Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
+ "https://www.tensorflow.org/install/ for installation instructions."
+ )
+ raise
+ tf_path = os.path.abspath(tf_checkpoint_path)
+ logger.info(f"Converting TensorFlow checkpoint from {tf_path}")
+ # Load weights from TF model
+ init_vars = tf.train.list_variables(tf_path)
+ names = []
+ arrays = []
+ for name, shape in init_vars:
+ logger.info(f"Loading TF weight {name} with shape {shape}")
+ array = tf.train.load_variable(tf_path, name)
+ names.append(name)
+ arrays.append(array)
+
+ for name, array in zip(names, arrays):
+ name = name.split("/")
+ # adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v
+ # which are not required for using pretrained model
+ if any(
+ n in ["adam_v", "adam_m", "AdamWeightDecayOptimizer", "AdamWeightDecayOptimizer_1", "global_step"]
+ for n in name
+ ):
+ logger.info(f"Skipping {'/'.join(name)}")
+ continue
+ pointer = model
+ for m_name in name:
+ if re.fullmatch(r"[A-Za-z]+_\d+", m_name):
+ scope_names = re.split(r"_(\d+)", m_name)
+ else:
+ scope_names = [m_name]
+ if scope_names[0] == "kernel" or scope_names[0] == "gamma":
+ pointer = getattr(pointer, "weight")
+ elif scope_names[0] == "output_bias" or scope_names[0] == "beta":
+ pointer = getattr(pointer, "bias")
+ elif scope_names[0] == "output_weights":
+ pointer = getattr(pointer, "weight")
+ elif scope_names[0] == "squad":
+ pointer = getattr(pointer, "classifier")
+ else:
+ try:
+ pointer = getattr(pointer, scope_names[0])
+ except AttributeError:
+ logger.info(f"Skipping {'/'.join(name)}")
+ continue
+ if len(scope_names) >= 2:
+ num = int(scope_names[1])
+ pointer = pointer[num]
+ if m_name[-11:] == "_embeddings":
+ pointer = getattr(pointer, "weight")
+ elif m_name == "kernel":
+ array = np.transpose(array)
+ try:
+ if pointer.shape != array.shape:
+ raise ValueError(f"Pointer shape {pointer.shape} and array shape {array.shape} mismatched")
+ except ValueError as e:
+ e.args += (pointer.shape, array.shape)
+ raise
+ logger.info(f"Initialize PyTorch weight {name}")
+ pointer.data = torch.from_numpy(array)
+ return model
+
+
+class DummyBertPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = DummyBertConfig
+ load_tf_weights = load_tf_weights_in_dummy_bert
+ base_model_prefix = "dummy_bert"
+ supports_gradient_checkpointing = True
+ _supports_sdpa = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, nn.Linear):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+
+DUMMY_BERT_START_DOCSTRING = r"""
+
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`DummyBertConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+DUMMY_BERT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `({0})`):
+ Indices of input sequence tokens in the vocabulary.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.FloatTensor` of shape `({0})`or `(batch_size, sequence_length, target_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
+ 1]`:
+
+ - 0 corresponds to a *sentence A* token,
+ - 1 corresponds to a *sentence B* token.
+
+ [What are token type IDs?](../glossary#token-type-ids)
+ position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare DummyBert Model transformer outputting raw hidden-states without any specific head on top.",
+ DUMMY_BERT_START_DOCSTRING,
+)
+class DummyBertModel(DummyBertPreTrainedModel):
+ """
+
+ The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
+ cross-attention is added between the self-attention layers, following the architecture described in [Attention is
+ all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
+
+ To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
+ to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
+ `add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
+ """
+
+ _no_split_modules = ["DummyBertEmbeddings", "DummyBertLayer"]
+
+ def __init__(self, config, add_pooling_layer=True):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = DummyBertEmbeddings(config)
+ self.encoder = DummyBertEncoder(config)
+
+ self.pooler = DummyBertPooler(config) if add_pooling_layer else None
+
+ self.attn_implementation = config._attn_implementation
+ self.position_embedding_type = config.position_embedding_type
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value):
+ self.embeddings.word_embeddings = value
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(DUMMY_BERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @add_code_sample_docstrings(
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutputWithPoolingAndCrossAttentions,
+ config_class=_CONFIG_FOR_DOC,
+ )
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[list[torch.FloatTensor]] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[tuple[torch.Tensor], BaseModelOutputWithPoolingAndCrossAttentions]:
+ r"""
+ encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)` or `(batch_size, sequence_length, target_length)`, *optional*):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if self.config.is_decoder:
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ else:
+ use_cache = False
+
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
+ input_shape = input_ids.size()
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ batch_size, seq_length = input_shape
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+
+ # past_key_values_length
+ past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
+
+ if token_type_ids is None:
+ if hasattr(self.embeddings, "token_type_ids"):
+ buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
+
+ embedding_output = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids,
+ inputs_embeds=inputs_embeds,
+ past_key_values_length=past_key_values_length,
+ )
+
+ if attention_mask is None:
+ attention_mask = torch.ones((batch_size, seq_length + past_key_values_length), device=device)
+
+ use_sdpa_attention_masks = (
+ self.attn_implementation == "sdpa"
+ and self.position_embedding_type == "absolute"
+ and head_mask is None
+ and not output_attentions
+ )
+
+ # Expand the attention mask
+ if use_sdpa_attention_masks and attention_mask.dim() == 2:
+ # Expand the attention mask for SDPA.
+ # [bsz, seq_len] -> [bsz, 1, seq_len, seq_len]
+ if self.config.is_decoder:
+ extended_attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ input_shape,
+ embedding_output,
+ past_key_values_length,
+ )
+ else:
+ extended_attention_mask = _prepare_4d_attention_mask_for_sdpa(
+ attention_mask, embedding_output.dtype, tgt_len=seq_length
+ )
+ else:
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask = self.get_extended_attention_mask(attention_mask, input_shape)
+
+ # If a 2D or 3D attention mask is provided for the cross-attention
+ # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if self.config.is_decoder and encoder_hidden_states is not None:
+ encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
+ encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
+ if encoder_attention_mask is None:
+ encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
+
+ if use_sdpa_attention_masks and encoder_attention_mask.dim() == 2:
+ # Expand the attention mask for SDPA.
+ # [bsz, seq_len] -> [bsz, 1, seq_len, seq_len]
+ encoder_extended_attention_mask = _prepare_4d_attention_mask_for_sdpa(
+ encoder_attention_mask, embedding_output.dtype, tgt_len=seq_length
+ )
+ else:
+ encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = None
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ attention_mask=extended_attention_mask,
+ head_mask=head_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_extended_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+ pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPoolingAndCrossAttentions(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ past_key_values=encoder_outputs.past_key_values,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ cross_attentions=encoder_outputs.cross_attentions,
+ )
diff --git a/docs/transformers/examples/modular-transformers/modeling_from_uppercase_model.py b/docs/transformers/examples/modular-transformers/modeling_from_uppercase_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..4385ac7bcf389d82bb34d2e90587cb005244c52f
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modeling_from_uppercase_model.py
@@ -0,0 +1,357 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_from_uppercase_model.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_from_uppercase_model.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+from typing import Optional
+
+import torch
+from torch import nn
+
+from ...activations import ACT2FN
+from ...pytorch_utils import is_torch_greater_or_equal_than_2_2
+from ...utils import is_flash_attn_2_available, is_flash_attn_greater_or_equal_2_10, logging
+from .configuration_from_uppercase_model import FromUppercaseModelConfig
+
+
+if is_flash_attn_2_available():
+ from ...modeling_flash_attention_utils import _flash_attention_forward
+
+
+logger = logging.get_logger(__name__)
+
+
+class FromUppercaseModelAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.embed_dim = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.embed_dim // self.num_heads
+ if self.head_dim * self.num_heads != self.embed_dim:
+ raise ValueError(
+ f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
+ f" {self.num_heads})."
+ )
+ self.scale = self.head_dim**-0.5
+ self.dropout = config.attention_dropout
+
+ self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ causal_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor]]:
+ """Input shape: Batch x Time x Channel"""
+
+ bsz, tgt_len, embed_dim = hidden_states.size()
+
+ # get query proj
+ query_states = self.q_proj(hidden_states) * self.scale
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+
+ proj_shape = (bsz * self.num_heads, -1, self.head_dim)
+ query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
+ key_states = key_states.view(*proj_shape)
+ value_states = value_states.view(*proj_shape)
+
+ src_len = key_states.size(1)
+ attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
+
+ if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
+ raise ValueError(
+ f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ # apply the causal_attention_mask first
+ if causal_attention_mask is not None:
+ if causal_attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is"
+ f" {causal_attention_mask.size()}"
+ )
+ attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + causal_attention_mask
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
+ )
+ attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1)
+
+ if output_attentions:
+ # this operation is a bit akward, but it's required to
+ # make sure that attn_weights keeps its gradient.
+ # In order to do so, attn_weights have to reshaped
+ # twice and have to be reused in the following
+ attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
+ attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
+ else:
+ attn_weights_reshaped = None
+
+ attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
+
+ attn_output = torch.bmm(attn_probs, value_states)
+
+ if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
+ attn_output = attn_output.transpose(1, 2)
+ attn_output = attn_output.reshape(bsz, tgt_len, embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, attn_weights_reshaped
+
+
+class FromUppercaseModelFlashAttention2(FromUppercaseModelAttention):
+ """
+ FromUppercaseModelAttention flash attention module. This module inherits from `FromUppercaseModelAttention` as the weights of the module stays
+ untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
+ flash attention and deal with padding tokens in case the input contains any of them.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
+
+ # Adapted from transformers.models.llama.modeling_llama.LlamaFlashAttention2.forward
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ causal_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor]]:
+ output_attentions = False
+
+ batch_size, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ query_states = query_states.view(batch_size, q_len, self.num_heads, self.head_dim)
+ key_states = key_states.view(batch_size, q_len, self.num_heads, self.head_dim)
+ value_states = value_states.view(batch_size, q_len, self.num_heads, self.head_dim)
+
+ dropout_rate = self.dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in the correct dtype just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not cast the LayerNorms
+ # in fp32.
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, "_pre_quantization_dtype"):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ attn_output = _flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ q_len,
+ dropout=dropout_rate,
+ is_causal=causal_attention_mask is not None,
+ use_top_left_mask=self._flash_attn_uses_top_left_mask,
+ )
+
+ attn_output = attn_output.reshape(batch_size, q_len, self.embed_dim).contiguous()
+ attn_output = self.out_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights
+
+
+class FromUppercaseModelSdpaAttention(FromUppercaseModelAttention):
+ """
+ SDPA attention module using torch.nn.functional.scaled_dot_product_attention. This module inherits from
+ `FromUppercaseModelAttention` as the weights of the module stays untouched. The only changes are on the forward pass to adapt to
+ SDPA API.
+ """
+
+ # Adapted from FromUppercaseModelAttention.forward
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ causal_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor]]:
+ if output_attentions:
+ # TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.
+ logger.warning_once(
+ "FromUppercaseModelModel is using FromUppercaseModelSdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not "
+ "support `output_attentions=True`. Falling back to the manual attention implementation, but specifying "
+ "the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can "
+ 'be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ causal_attention_mask=causal_attention_mask,
+ output_attentions=output_attentions,
+ )
+
+ # FROM_UPPERCASE_MODEL text model uses both `causal_attention_mask` and `attention_mask`
+ if attention_mask is not None and causal_attention_mask is not None:
+ attn_mask = attention_mask + causal_attention_mask
+ elif causal_attention_mask is not None:
+ attn_mask = causal_attention_mask
+ else:
+ attn_mask = attention_mask
+
+ bsz, tgt_len, embed_dim = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, -1, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, -1, self.num_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, -1, self.num_heads, self.head_dim).transpose(1, 2)
+
+ # SDPA with memory-efficient backend is currently (torch==2.1.2) bugged with non-contiguous inputs with custom attn_mask,
+ # Reference: https://github.com/pytorch/pytorch/issues/112577.
+ if not is_torch_greater_or_equal_than_2_2 and query_states.device.type == "cuda" and attn_mask is not None:
+ query_states = query_states.contiguous()
+ key_states = key_states.contiguous()
+ value_states = value_states.contiguous()
+
+ # FROM_UPPERCASE_MODEL text model uses both `causal_attention_mask` and `attention_mask` sequentially.
+ attn_output = torch.nn.functional.scaled_dot_product_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_mask=attn_mask,
+ dropout_p=self.dropout if self.training else 0.0,
+ scale=self.scale,
+ )
+
+ attn_output = attn_output.transpose(1, 2)
+ attn_output = attn_output.reshape(bsz, tgt_len, embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, None
+
+
+class FromUppercaseModelMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.activation_fn = ACT2FN[config.hidden_act]
+ self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
+ self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.fc1(hidden_states)
+ hidden_states = self.activation_fn(hidden_states)
+ hidden_states = self.fc2(hidden_states)
+ return hidden_states
+
+
+FROM_UPPERCASE_MODEL_ATTENTION_CLASSES = {
+ "eager": FromUppercaseModelAttention,
+ "sdpa": FromUppercaseModelSdpaAttention,
+ "flash_attention_2": FromUppercaseModelFlashAttention2,
+}
+
+
+class FromUppercaseModelEncoderLayer(nn.Module):
+ def __init__(self, config: FromUppercaseModelConfig):
+ super().__init__()
+ self.embed_dim = config.hidden_size
+ self.self_attn = FROM_UPPERCASE_MODEL_ATTENTION_CLASSES[config._attn_implementation](config)
+ self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
+ self.mlp = FromUppercaseModelMLP(config)
+ self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ causal_attention_mask: torch.Tensor,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.FloatTensor]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ `(config.encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+
+ hidden_states = self.layer_norm1(hidden_states)
+ hidden_states, attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ causal_attention_mask=causal_attention_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = residual + hidden_states
+
+ residual = hidden_states
+ hidden_states = self.layer_norm2(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
diff --git a/docs/transformers/examples/modular-transformers/modeling_multimodal1.py b/docs/transformers/examples/modular-transformers/modeling_multimodal1.py
new file mode 100644
index 0000000000000000000000000000000000000000..e3ecbdd6974d2af3700e3390ca3ddb9c5240ec6c
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modeling_multimodal1.py
@@ -0,0 +1,711 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_multimodal1.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_multimodal1.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+from functools import partial
+from typing import Callable, Optional, Union
+
+import torch
+from torch import nn
+
+from ...activations import ACT2FN
+from ...cache_utils import Cache, DynamicCache, StaticCache
+from ...modeling_attn_mask_utils import AttentionMaskConverter
+from ...modeling_flash_attention_utils import FlashAttentionKwargs
+from ...modeling_outputs import BaseModelOutputWithPast
+from ...modeling_rope_utils import ROPE_INIT_FUNCTIONS
+from ...modeling_utils import ALL_ATTENTION_FUNCTIONS, PreTrainedModel
+from ...processing_utils import Unpack
+from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging
+from .configuration_multimodal1 import Multimodal1TextConfig
+
+
+logger = logging.get_logger(__name__)
+
+
+class Multimodal1TextRMSNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ Multimodal1TextRMSNorm is equivalent to T5LayerNorm
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+ def extra_repr(self):
+ return f"{tuple(self.weight.shape)}, eps={self.variance_epsilon}"
+
+
+class Multimodal1TextRotaryEmbedding(nn.Module):
+ def __init__(self, config: Multimodal1TextConfig, device=None):
+ super().__init__()
+ # BC: "rope_type" was originally "type"
+ if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
+ self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
+ else:
+ self.rope_type = "default"
+ self.max_seq_len_cached = config.max_position_embeddings
+ self.original_max_seq_len = config.max_position_embeddings
+
+ self.config = config
+ self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
+
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+ self.original_inv_freq = self.inv_freq
+
+ def _dynamic_frequency_update(self, position_ids, device):
+ """
+ dynamic RoPE layers should recompute `inv_freq` in the following situations:
+ 1 - growing beyond the cached sequence length (allow scaling)
+ 2 - the current sequence length is in the original scale (avoid losing precision with small sequences)
+ """
+ seq_len = torch.max(position_ids) + 1
+ if seq_len > self.max_seq_len_cached: # growth
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device, seq_len=seq_len)
+ self.register_buffer("inv_freq", inv_freq, persistent=False) # TODO joao: may break with compilation
+ self.max_seq_len_cached = seq_len
+
+ if seq_len < self.original_max_seq_len and self.max_seq_len_cached > self.original_max_seq_len: # reset
+ # This .to() is needed if the model has been moved to a device after being initialized (because
+ # the buffer is automatically moved, but not the original copy)
+ self.original_inv_freq = self.original_inv_freq.to(device)
+ self.register_buffer("inv_freq", self.original_inv_freq, persistent=False)
+ self.max_seq_len_cached = self.original_max_seq_len
+
+ @torch.no_grad()
+ def forward(self, x, position_ids):
+ if "dynamic" in self.rope_type:
+ self._dynamic_frequency_update(position_ids, device=x.device)
+
+ # Core RoPE block
+ inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1)
+ position_ids_expanded = position_ids[:, None, :].float()
+ # Force float32 (see https://github.com/huggingface/transformers/pull/29285)
+ device_type = x.device.type
+ device_type = device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
+ with torch.autocast(device_type=device_type, enabled=False):
+ freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
+ emb = torch.cat((freqs, freqs), dim=-1)
+ cos = emb.cos()
+ sin = emb.sin()
+
+ # Advanced RoPE types (e.g. yarn) apply a post-processing scaling factor, equivalent to scaling attention
+ cos = cos * self.attention_scaling
+ sin = sin * self.attention_scaling
+
+ return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
+
+
+class Multimodal1TextMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.intermediate_size = config.intermediate_size
+ self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
+ self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
+ self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=config.mlp_bias)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+ return down_proj
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+def eager_attention_forward(
+ module: nn.Module,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ attention_mask: Optional[torch.Tensor],
+ scaling: float,
+ dropout: float = 0.0,
+ **kwargs,
+):
+ key_states = repeat_kv(key, module.num_key_value_groups)
+ value_states = repeat_kv(value, module.num_key_value_groups)
+
+ attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
+ if attention_mask is not None:
+ causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
+ attn_weights = attn_weights + causal_mask
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ return attn_output, attn_weights
+
+
+class Multimodal1TextAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: Multimodal1TextConfig, layer_idx: int):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
+ self.scaling = self.head_dim**-0.5
+ self.attention_dropout = config.attention_dropout
+ self.is_causal = True
+
+ self.q_proj = nn.Linear(
+ config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.k_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.v_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.o_proj = nn.Linear(
+ config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ position_embeddings: tuple[torch.Tensor, torch.Tensor],
+ attention_mask: Optional[torch.Tensor],
+ past_key_value: Optional[Cache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor]]]:
+ input_shape = hidden_states.shape[:-1]
+ hidden_shape = (*input_shape, -1, self.head_dim)
+
+ query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+
+ cos, sin = position_embeddings
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models; cache_position needed for the static cache
+ cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ attention_interface: Callable = eager_attention_forward
+ if self.config._attn_implementation != "eager":
+ if self.config._attn_implementation == "sdpa" and kwargs.get("output_attentions", False):
+ logger.warning_once(
+ "`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
+ 'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ else:
+ attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
+
+ attn_output, attn_weights = attention_interface(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ dropout=0.0 if not self.training else self.attention_dropout,
+ scaling=self.scaling,
+ **kwargs,
+ )
+
+ attn_output = attn_output.reshape(*input_shape, -1).contiguous()
+ attn_output = self.o_proj(attn_output)
+ return attn_output, attn_weights
+
+
+class Multimodal1TextDecoderLayer(nn.Module):
+ def __init__(self, config: Multimodal1TextConfig, layer_idx: int):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ self.self_attn = Multimodal1TextAttention(config=config, layer_idx=layer_idx)
+
+ self.mlp = Multimodal1TextMLP(config)
+ self.input_layernorm = Multimodal1TextRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = Multimodal1TextRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ position_embeddings: Optional[tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.FloatTensor, Optional[tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **kwargs,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ return outputs
+
+
+MULTIMODAL1_TEXT_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`Multimodal1TextConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare Multimodal1Text Model outputting raw hidden-states without any specific head on top.",
+ MULTIMODAL1_TEXT_START_DOCSTRING,
+)
+class Multimodal1TextPreTrainedModel(PreTrainedModel):
+ config_class = Multimodal1TextConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["Multimodal1TextDecoderLayer"]
+ _skip_keys_device_placement = ["past_key_values"]
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_flex_attn = True
+ _supports_cache_class = True
+ _supports_quantized_cache = True
+ _supports_static_cache = True
+ _supports_attention_backend = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+
+MULTIMODAL1_TEXT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`Cache` or `tuple(tuple(torch.FloatTensor))`, *optional*):
+ Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used to speed up sequential decoding. This typically consists in the `past_key_values`
+ returned by the model at a previous stage of decoding, when `use_cache=True` or `config.use_cache=True`.
+
+ Two formats are allowed:
+ - a [`~cache_utils.Cache`] instance, see our
+ [kv cache guide](https://huggingface.co/docs/transformers/en/kv_cache);
+ - Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`). This is also known as the legacy
+ cache format.
+
+ The model will output the same cache format that is fed as input. If no `past_key_values` are passed, the
+ legacy cache format will be returned.
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
+ have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
+ of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence. Contrarily to `position_ids`,
+ this tensor is not affected by padding. It is used to update the cache in the correct position and to infer
+ the complete sequence length.
+"""
+
+
+@add_start_docstrings(
+ "The bare Multimodal1Text Model outputting raw hidden-states without any specific head on top.",
+ MULTIMODAL1_TEXT_START_DOCSTRING,
+)
+class Multimodal1TextModel(Multimodal1TextPreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`Multimodal1TextDecoderLayer`]
+
+ Args:
+ config: Multimodal1TextConfig
+ """
+
+ def __init__(self, config: Multimodal1TextConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+ self.layers = nn.ModuleList(
+ [Multimodal1TextDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
+ )
+ self.norm = Multimodal1TextRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.rotary_emb = Multimodal1TextRotaryEmbedding(config=config)
+ self.gradient_checkpointing = False
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(MULTIMODAL1_TEXT_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Cache] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **flash_attn_kwargs: Unpack[FlashAttentionKwargs],
+ ) -> Union[tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if (input_ids is None) ^ (inputs_embeds is not None):
+ raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
+
+ if self.gradient_checkpointing and self.training and use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`."
+ )
+ use_cache = False
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if use_cache and past_key_values is None:
+ past_key_values = DynamicCache()
+
+ if cache_position is None:
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+ cache_position = torch.arange(
+ past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
+ )
+
+ if position_ids is None:
+ position_ids = cache_position.unsqueeze(0)
+
+ causal_mask = self._update_causal_mask(
+ attention_mask, inputs_embeds, cache_position, past_key_values, output_attentions
+ )
+
+ hidden_states = inputs_embeds
+
+ # create position embeddings to be shared across the decoder layers
+ position_embeddings = self.rotary_emb(hidden_states, position_ids)
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+
+ for decoder_layer in self.layers[: self.config.num_hidden_layers]:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ partial(decoder_layer.__call__, **flash_attn_kwargs),
+ hidden_states,
+ causal_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ use_cache,
+ cache_position,
+ position_embeddings,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=causal_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **flash_attn_kwargs,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ output = BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=past_key_values if use_cache else None,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+ return output if return_dict else output.to_tuple()
+
+ def _update_causal_mask(
+ self,
+ attention_mask: torch.Tensor,
+ input_tensor: torch.Tensor,
+ cache_position: torch.Tensor,
+ past_key_values: Cache,
+ output_attentions: bool,
+ ):
+ if self.config._attn_implementation == "flash_attention_2":
+ if attention_mask is not None and (attention_mask == 0.0).any():
+ return attention_mask
+ return None
+
+ # For SDPA, when possible, we will rely on its `is_causal` argument instead of its `attn_mask` argument, in
+ # order to dispatch on Flash Attention 2. This feature is not compatible with static cache, as SDPA will fail
+ # to infer the attention mask.
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+ using_static_cache = isinstance(past_key_values, StaticCache)
+
+ # When output attentions is True, sdpa implementation's forward method calls the eager implementation's forward
+ if self.config._attn_implementation == "sdpa" and not using_static_cache and not output_attentions:
+ if AttentionMaskConverter._ignore_causal_mask_sdpa(
+ attention_mask,
+ inputs_embeds=input_tensor,
+ past_key_values_length=past_seen_tokens,
+ is_training=self.training,
+ ):
+ return None
+
+ dtype, device = input_tensor.dtype, input_tensor.device
+ sequence_length = input_tensor.shape[1]
+ if using_static_cache:
+ target_length = past_key_values.get_max_cache_shape()
+ else:
+ target_length = (
+ attention_mask.shape[-1]
+ if isinstance(attention_mask, torch.Tensor)
+ else past_seen_tokens + sequence_length + 1
+ )
+
+ # In case the provided `attention` mask is 2D, we generate a causal mask here (4D).
+ causal_mask = self._prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask,
+ sequence_length=sequence_length,
+ target_length=target_length,
+ dtype=dtype,
+ device=device,
+ cache_position=cache_position,
+ batch_size=input_tensor.shape[0],
+ )
+
+ if (
+ self.config._attn_implementation == "sdpa"
+ and attention_mask is not None
+ and attention_mask.device.type in ["cuda", "xpu"]
+ and not output_attentions
+ ):
+ # Attend to all tokens in fully masked rows in the causal_mask, for example the relevant first rows when
+ # using left padding. This is required by F.scaled_dot_product_attention memory-efficient attention path.
+ # Details: https://github.com/pytorch/pytorch/issues/110213
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = AttentionMaskConverter._unmask_unattended(causal_mask, min_dtype)
+
+ return causal_mask
+
+ @staticmethod
+ def _prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask: torch.Tensor,
+ sequence_length: int,
+ target_length: int,
+ dtype: torch.dtype,
+ device: torch.device,
+ cache_position: torch.Tensor,
+ batch_size: int,
+ **kwargs,
+ ):
+ """
+ Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
+ `(batch_size, key_value_length)`, or if the input `attention_mask` is already 4D, do nothing.
+
+ Args:
+ attention_mask (`torch.Tensor`):
+ A 2D attention mask of shape `(batch_size, key_value_length)` or a 4D attention mask of shape
+ `(batch_size, 1, query_length, key_value_length)`.
+ sequence_length (`int`):
+ The sequence length being processed.
+ target_length (`int`):
+ The target length: when generating with static cache, the mask should be as long as the static cache,
+ to account for the 0 padding, the part of the cache that is not filled yet.
+ dtype (`torch.dtype`):
+ The dtype to use for the 4D attention mask.
+ device (`torch.device`):
+ The device to plcae the 4D attention mask on.
+ cache_position (`torch.Tensor`):
+ Indices depicting the position of the input sequence tokens in the sequence.
+ batch_size (`torch.Tensor`):
+ Batch size.
+ """
+ if attention_mask is not None and attention_mask.dim() == 4:
+ # In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
+ causal_mask = attention_mask
+ else:
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = torch.full(
+ (sequence_length, target_length), fill_value=min_dtype, dtype=dtype, device=device
+ )
+ if sequence_length != 1:
+ causal_mask = torch.triu(causal_mask, diagonal=1)
+ causal_mask *= torch.arange(target_length, device=device) > cache_position.reshape(-1, 1)
+ causal_mask = causal_mask[None, None, :, :].expand(batch_size, 1, -1, -1)
+ if attention_mask is not None:
+ causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
+ mask_length = attention_mask.shape[-1]
+ padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :].to(
+ causal_mask.device
+ )
+ padding_mask = padding_mask == 0
+ causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
+ padding_mask, min_dtype
+ )
+
+ return causal_mask
diff --git a/docs/transformers/examples/modular-transformers/modeling_multimodal2.py b/docs/transformers/examples/modular-transformers/modeling_multimodal2.py
new file mode 100644
index 0000000000000000000000000000000000000000..a2a9d460bda573ddbd5dca2e927f60e869b01b52
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modeling_multimodal2.py
@@ -0,0 +1,705 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_multimodal2.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_multimodal2.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+
+from typing import Optional, Union
+
+import torch
+from torch import nn
+
+from transformers.utils import add_start_docstrings
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import is_torch_greater_or_equal_than_2_2
+from ...utils import (
+ add_start_docstrings_to_model_forward,
+ is_flash_attn_2_available,
+ is_flash_attn_greater_or_equal_2_10,
+ logging,
+ replace_return_docstrings,
+ torch_int,
+)
+from .configuration_multimodal2 import Multimodal2Config, Multimodal2VisionConfig
+
+
+if is_flash_attn_2_available():
+ from ...modeling_flash_attention_utils import _flash_attention_forward
+
+
+logger = logging.get_logger(__name__)
+
+
+class Multimodal2VisionAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.embed_dim = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.embed_dim // self.num_heads
+ if self.head_dim * self.num_heads != self.embed_dim:
+ raise ValueError(
+ f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
+ f" {self.num_heads})."
+ )
+ self.scale = self.head_dim**-0.5
+ self.dropout = config.attention_dropout
+
+ self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ causal_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor]]:
+ """Input shape: Batch x Time x Channel"""
+
+ bsz, tgt_len, embed_dim = hidden_states.size()
+
+ # get query proj
+ query_states = self.q_proj(hidden_states) * self.scale
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+
+ proj_shape = (bsz * self.num_heads, -1, self.head_dim)
+ query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
+ key_states = key_states.view(*proj_shape)
+ value_states = value_states.view(*proj_shape)
+
+ src_len = key_states.size(1)
+ attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
+
+ if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
+ raise ValueError(
+ f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ # apply the causal_attention_mask first
+ if causal_attention_mask is not None:
+ if causal_attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is"
+ f" {causal_attention_mask.size()}"
+ )
+ attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + causal_attention_mask
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
+ )
+ attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1)
+
+ if output_attentions:
+ # this operation is a bit akward, but it's required to
+ # make sure that attn_weights keeps its gradient.
+ # In order to do so, attn_weights have to reshaped
+ # twice and have to be reused in the following
+ attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
+ attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
+ else:
+ attn_weights_reshaped = None
+
+ attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
+
+ attn_output = torch.bmm(attn_probs, value_states)
+
+ if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
+ attn_output = attn_output.transpose(1, 2)
+ attn_output = attn_output.reshape(bsz, tgt_len, embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, attn_weights_reshaped
+
+
+class Multimodal2VisionSdpaAttention(Multimodal2VisionAttention):
+ """
+ SDPA attention module using torch.nn.functional.scaled_dot_product_attention. This module inherits from
+ `Multimodal2VisionAttention` as the weights of the module stays untouched. The only changes are on the forward pass to adapt to
+ SDPA API.
+ """
+
+ # Adapted from Multimodal2VisionAttention.forward
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ causal_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor]]:
+ if output_attentions:
+ # TODO: Improve this warning with e.g. `model.config.attn_implementation = "manual"` once this is implemented.
+ logger.warning_once(
+ "Multimodal2VisionModel is using Multimodal2VisionSdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not "
+ "support `output_attentions=True`. Falling back to the manual attention implementation, but specifying "
+ "the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can "
+ 'be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ causal_attention_mask=causal_attention_mask,
+ output_attentions=output_attentions,
+ )
+
+ # MULTIMODAL2_VISION text model uses both `causal_attention_mask` and `attention_mask`
+ if attention_mask is not None and causal_attention_mask is not None:
+ attn_mask = attention_mask + causal_attention_mask
+ elif causal_attention_mask is not None:
+ attn_mask = causal_attention_mask
+ else:
+ attn_mask = attention_mask
+
+ bsz, tgt_len, embed_dim = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, -1, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = key_states.view(bsz, -1, self.num_heads, self.head_dim).transpose(1, 2)
+ value_states = value_states.view(bsz, -1, self.num_heads, self.head_dim).transpose(1, 2)
+
+ # SDPA with memory-efficient backend is currently (torch==2.1.2) bugged with non-contiguous inputs with custom attn_mask,
+ # Reference: https://github.com/pytorch/pytorch/issues/112577.
+ if not is_torch_greater_or_equal_than_2_2 and query_states.device.type == "cuda" and attn_mask is not None:
+ query_states = query_states.contiguous()
+ key_states = key_states.contiguous()
+ value_states = value_states.contiguous()
+
+ # MULTIMODAL2_VISION text model uses both `causal_attention_mask` and `attention_mask` sequentially.
+ attn_output = torch.nn.functional.scaled_dot_product_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_mask=attn_mask,
+ dropout_p=self.dropout if self.training else 0.0,
+ scale=self.scale,
+ )
+
+ attn_output = attn_output.transpose(1, 2)
+ attn_output = attn_output.reshape(bsz, tgt_len, embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, None
+
+
+class Multimodal2VisionFlashAttention2(Multimodal2VisionAttention):
+ """
+ Multimodal2VisionAttention flash attention module. This module inherits from `Multimodal2VisionAttention` as the weights of the module stays
+ untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
+ flash attention and deal with padding tokens in case the input contains any of them.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
+
+ # Adapted from transformers.models.llama.modeling_llama.LlamaFlashAttention2.forward
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ causal_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor]]:
+ output_attentions = False
+
+ batch_size, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim
+ # therefore we just need to keep the original shape
+ query_states = query_states.view(batch_size, q_len, self.num_heads, self.head_dim)
+ key_states = key_states.view(batch_size, q_len, self.num_heads, self.head_dim)
+ value_states = value_states.view(batch_size, q_len, self.num_heads, self.head_dim)
+
+ dropout_rate = self.dropout if self.training else 0.0
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in the correct dtype just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not cast the LayerNorms
+ # in fp32.
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, "_pre_quantization_dtype"):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ attn_output = _flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ q_len,
+ dropout=dropout_rate,
+ is_causal=causal_attention_mask is not None,
+ use_top_left_mask=self._flash_attn_uses_top_left_mask,
+ )
+
+ attn_output = attn_output.reshape(batch_size, q_len, self.embed_dim).contiguous()
+ attn_output = self.out_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights
+
+
+class Multimodal2VisionMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.activation_fn = ACT2FN[config.hidden_act]
+ self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
+ self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.fc1(hidden_states)
+ hidden_states = self.activation_fn(hidden_states)
+ hidden_states = self.fc2(hidden_states)
+ return hidden_states
+
+
+MULTIMODAL2_VISION_ATTENTION_CLASSES = {
+ "eager": Multimodal2VisionAttention,
+ "sdpa": Multimodal2VisionSdpaAttention,
+ "flash_attention_2": Multimodal2VisionFlashAttention2,
+}
+
+
+class Multimodal2VisionEncoderLayer(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.embed_dim = config.hidden_size
+ self.self_attn = MULTIMODAL2_VISION_ATTENTION_CLASSES[config._attn_implementation](config)
+ self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
+ self.mlp = Multimodal2VisionMLP(config)
+ self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ causal_attention_mask: torch.Tensor,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.FloatTensor]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ `(config.encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+
+ hidden_states = self.layer_norm1(hidden_states)
+ hidden_states, attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ causal_attention_mask=causal_attention_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = residual + hidden_states
+
+ residual = hidden_states
+ hidden_states = self.layer_norm2(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+
+class Multimodal2VisionEncoder(nn.Module):
+ """
+ Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
+ [`Multimodal2VisionEncoderLayer`].
+
+ Args:
+ config: Multimodal2VisionConfig
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.layers = nn.ModuleList([Multimodal2VisionEncoderLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ inputs_embeds,
+ attention_mask: Optional[torch.Tensor] = None,
+ causal_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[tuple, BaseModelOutput]:
+ r"""
+ Args:
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ This is useful if you want more control over how to convert `input_ids` indices into associated vectors
+ than the model's internal embedding lookup matrix.
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ causal_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Causal mask for the text model. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ encoder_states = () if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+
+ hidden_states = inputs_embeds
+ for idx, encoder_layer in enumerate(self.layers):
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ encoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ causal_attention_mask,
+ output_attentions,
+ )
+ else:
+ layer_outputs = encoder_layer(
+ hidden_states,
+ attention_mask,
+ causal_attention_mask,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_attentions = all_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
+ )
+
+
+class Multimodal2VisionEmbeddings(nn.Module):
+ def __init__(self, config: Multimodal2VisionConfig):
+ super().__init__()
+ self.config = config
+ self.embed_dim = config.hidden_size
+ self.image_size = config.image_size
+ self.patch_size = config.patch_size
+
+ self.class_embedding = nn.Parameter(torch.randn(self.embed_dim))
+
+ self.patch_embedding = nn.Conv2d(
+ in_channels=config.num_channels,
+ out_channels=self.embed_dim,
+ kernel_size=self.patch_size,
+ stride=self.patch_size,
+ bias=False,
+ )
+
+ self.num_patches = (self.image_size // self.patch_size) ** 2
+ self.num_positions = self.num_patches + 1
+ self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
+ self.register_buffer("position_ids", torch.arange(self.num_positions).expand((1, -1)), persistent=False)
+
+ def interpolate_pos_encoding(self, embeddings: torch.Tensor, height: int, width: int) -> torch.Tensor:
+ """
+ This method allows to interpolate the pre-trained position encodings, to be able to use the model on higher resolution
+ images. This method is also adapted to support torch.jit tracing.
+
+ Adapted from:
+ - https://github.com/facebookresearch/dino/blob/de9ee3df6cf39fac952ab558447af1fa1365362a/vision_transformer.py#L174-L194, and
+ - https://github.com/facebookresearch/dinov2/blob/e1277af2ba9496fbadf7aec6eba56e8d882d1e35/dinov2/models/vision_transformer.py#L179-L211
+ """
+
+ num_patches = embeddings.shape[1] - 1
+ position_embedding = self.position_embedding.weight.unsqueeze(0)
+ num_positions = position_embedding.shape[1] - 1
+
+ # always interpolate when tracing to ensure the exported model works for dynamic input shapes
+ if not torch.jit.is_tracing() and num_patches == num_positions and height == width:
+ return self.position_embedding(self.position_ids)
+
+ class_pos_embed = position_embedding[:, :1]
+ patch_pos_embed = position_embedding[:, 1:]
+
+ dim = embeddings.shape[-1]
+
+ new_height = height // self.patch_size
+ new_width = width // self.patch_size
+
+ sqrt_num_positions = torch_int(num_positions**0.5)
+ patch_pos_embed = patch_pos_embed.reshape(1, sqrt_num_positions, sqrt_num_positions, dim)
+ patch_pos_embed = patch_pos_embed.permute(0, 3, 1, 2)
+
+ patch_pos_embed = nn.functional.interpolate(
+ patch_pos_embed,
+ size=(new_height, new_width),
+ mode="bicubic",
+ align_corners=False,
+ )
+
+ patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
+
+ return torch.cat((class_pos_embed, patch_pos_embed), dim=1)
+
+ def forward(self, pixel_values: torch.FloatTensor, interpolate_pos_encoding=False) -> torch.Tensor:
+ batch_size, _, height, width = pixel_values.shape
+ if not interpolate_pos_encoding and (height != self.image_size or width != self.image_size):
+ raise ValueError(
+ f"Input image size ({height}*{width}) doesn't match model ({self.image_size}*{self.image_size})."
+ )
+ target_dtype = self.patch_embedding.weight.dtype
+ patch_embeds = self.patch_embedding(pixel_values.to(dtype=target_dtype)) # shape = [*, width, grid, grid]
+ patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
+
+ class_embeds = self.class_embedding.expand(batch_size, 1, -1)
+ embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
+ if interpolate_pos_encoding:
+ embeddings = embeddings + self.interpolate_pos_encoding(embeddings, height, width)
+ else:
+ embeddings = embeddings + self.position_embedding(self.position_ids)
+ return embeddings
+
+
+MULTIMODAL2_VISION_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
+ [`AutoImageProcessor`]. See [`Multimodal2ImageProcessor.__call__`] for details.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ interpolate_pos_encoding (`bool`, *optional*, defaults `False`):
+ Whether to interpolate the pre-trained position encodings.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+class Multimodal2VisionTransformer(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ embed_dim = config.hidden_size
+
+ self.embeddings = Multimodal2VisionEmbeddings(config)
+ self.pre_layrnorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.encoder = Multimodal2VisionEncoder(config)
+ self.post_layernorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+
+ @add_start_docstrings_to_model_forward(MULTIMODAL2_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=Multimodal2VisionConfig)
+ def forward(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ interpolate_pos_encoding: Optional[bool] = False,
+ ) -> Union[tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ hidden_states = self.embeddings(pixel_values, interpolate_pos_encoding=interpolate_pos_encoding)
+ hidden_states = self.pre_layrnorm(hidden_states)
+
+ encoder_outputs = self.encoder(
+ inputs_embeds=hidden_states,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+ pooled_output = last_hidden_state[:, 0, :]
+ pooled_output = self.post_layernorm(pooled_output)
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class Multimodal2VisionPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = Multimodal2Config
+ base_model_prefix = "multimodal2_vision"
+ supports_gradient_checkpointing = True
+ _supports_sdpa = True
+ _supports_flash_attn_2 = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, Multimodal2VisionMLP):
+ pass
+
+
+MULTIMODAL2_VISION_START_DOCSTRING = "doc"
+
+
+@add_start_docstrings("New doc", MULTIMODAL2_VISION_START_DOCSTRING)
+class Multimodal2VisionModel(Multimodal2VisionPreTrainedModel):
+ config_class = Multimodal2VisionConfig
+ main_input_name = "pixel_values"
+ _no_split_modules = ["Multimodal2VisionEncoderLayer"]
+
+ def __init__(self, config: Multimodal2VisionConfig):
+ super().__init__(config)
+ self.vision_model = Multimodal2VisionTransformer(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> nn.Module:
+ return self.vision_model.embeddings.patch_embedding
+
+ @add_start_docstrings_to_model_forward(MULTIMODAL2_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=Multimodal2VisionConfig)
+ def forward(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ interpolate_pos_encoding: bool = False,
+ return_dict: Optional[bool] = None,
+ ) -> Union[tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, Multimodal2VisionModel
+
+ >>> model = Multimodal2VisionModel.from_pretrained("openai/multimodal2-vit-base-patch32")
+ >>> processor = AutoProcessor.from_pretrained("openai/multimodal2-vit-base-patch32")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_state = outputs.last_hidden_state
+ >>> pooled_output = outputs.pooler_output # pooled CLS states
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ return self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ interpolate_pos_encoding=interpolate_pos_encoding,
+ )
diff --git a/docs/transformers/examples/modular-transformers/modeling_my_new_model2.py b/docs/transformers/examples/modular-transformers/modeling_my_new_model2.py
new file mode 100644
index 0000000000000000000000000000000000000000..712d68c100fea6509d28b924eaef5f3ec94ff589
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modeling_my_new_model2.py
@@ -0,0 +1,823 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_my_new_model2.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_my_new_model2.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+from typing import Callable, Optional, Union
+
+import torch
+from torch import nn
+
+from ...activations import ACT2FN
+from ...cache_utils import Cache, DynamicCache, StaticCache
+from ...modeling_attn_mask_utils import AttentionMaskConverter
+from ...modeling_flash_attention_utils import FlashAttentionKwargs
+from ...modeling_outputs import BaseModelOutputWithPast, SequenceClassifierOutputWithPast
+from ...modeling_rope_utils import ROPE_INIT_FUNCTIONS
+from ...modeling_utils import ALL_ATTENTION_FUNCTIONS, PreTrainedModel
+from ...processing_utils import Unpack
+from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging
+from .configuration_my_new_model2 import MyNewModel2Config
+
+
+logger = logging.get_logger(__name__)
+
+
+class MyNewModel2RMSNorm(nn.Module):
+ def __init__(self, dim: int, eps: float = 1e-6):
+ super().__init__()
+ self.eps = eps
+ self.weight = nn.Parameter(torch.zeros(dim))
+
+ def _norm(self, x):
+ return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
+
+ def forward(self, x):
+ output = self._norm(x.float())
+ # Llama does x.to(float16) * w whilst MyNewModel2 is (x * w).to(float16)
+ # See https://github.com/huggingface/transformers/pull/29402
+ output = output * (1.0 + self.weight.float())
+ return output.type_as(x)
+
+ def extra_repr(self):
+ return f"{tuple(self.weight.shape)}, eps={self.eps}"
+
+
+class MyNewModel2MLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.intermediate_size = config.intermediate_size
+ self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
+ self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+ return down_proj
+
+
+class MyNewModel2RotaryEmbedding(nn.Module):
+ def __init__(self, config: MyNewModel2Config, device=None):
+ super().__init__()
+ # BC: "rope_type" was originally "type"
+ if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
+ self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
+ else:
+ self.rope_type = "default"
+ self.max_seq_len_cached = config.max_position_embeddings
+ self.original_max_seq_len = config.max_position_embeddings
+
+ self.config = config
+ self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
+
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+ self.original_inv_freq = self.inv_freq
+
+ def _dynamic_frequency_update(self, position_ids, device):
+ """
+ dynamic RoPE layers should recompute `inv_freq` in the following situations:
+ 1 - growing beyond the cached sequence length (allow scaling)
+ 2 - the current sequence length is in the original scale (avoid losing precision with small sequences)
+ """
+ seq_len = torch.max(position_ids) + 1
+ if seq_len > self.max_seq_len_cached: # growth
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device, seq_len=seq_len)
+ self.register_buffer("inv_freq", inv_freq, persistent=False) # TODO joao: may break with compilation
+ self.max_seq_len_cached = seq_len
+
+ if seq_len < self.original_max_seq_len and self.max_seq_len_cached > self.original_max_seq_len: # reset
+ # This .to() is needed if the model has been moved to a device after being initialized (because
+ # the buffer is automatically moved, but not the original copy)
+ self.original_inv_freq = self.original_inv_freq.to(device)
+ self.register_buffer("inv_freq", self.original_inv_freq, persistent=False)
+ self.max_seq_len_cached = self.original_max_seq_len
+
+ @torch.no_grad()
+ def forward(self, x, position_ids):
+ if "dynamic" in self.rope_type:
+ self._dynamic_frequency_update(position_ids, device=x.device)
+
+ # Core RoPE block
+ inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1)
+ position_ids_expanded = position_ids[:, None, :].float()
+ # Force float32 (see https://github.com/huggingface/transformers/pull/29285)
+ device_type = x.device.type
+ device_type = device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
+ with torch.autocast(device_type=device_type, enabled=False):
+ freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
+ emb = torch.cat((freqs, freqs), dim=-1)
+ cos = emb.cos()
+ sin = emb.sin()
+
+ # Advanced RoPE types (e.g. yarn) apply a post-processing scaling factor, equivalent to scaling attention
+ cos = cos * self.attention_scaling
+ sin = sin * self.attention_scaling
+
+ return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+def eager_attention_forward(
+ module: nn.Module,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ attention_mask: Optional[torch.Tensor],
+ scaling: float,
+ dropout: float = 0.0,
+ **kwargs,
+):
+ key_states = repeat_kv(key, module.num_key_value_groups)
+ value_states = repeat_kv(value, module.num_key_value_groups)
+
+ attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
+ if attention_mask is not None:
+ causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
+ attn_weights = attn_weights + causal_mask
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ return attn_output, attn_weights
+
+
+class MyNewModel2Attention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: MyNewModel2Config, layer_idx: int):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
+ self.scaling = self.head_dim**-0.5
+ self.attention_dropout = config.attention_dropout
+ self.is_causal = True
+
+ self.q_proj = nn.Linear(
+ config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.k_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.v_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.o_proj = nn.Linear(
+ config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ position_embeddings: tuple[torch.Tensor, torch.Tensor],
+ attention_mask: Optional[torch.Tensor],
+ past_key_value: Optional[Cache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor]]]:
+ input_shape = hidden_states.shape[:-1]
+ hidden_shape = (*input_shape, -1, self.head_dim)
+
+ query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+
+ cos, sin = position_embeddings
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models; cache_position needed for the static cache
+ cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ attention_interface: Callable = eager_attention_forward
+ if self.config._attn_implementation != "eager":
+ if self.config._attn_implementation == "sdpa" and kwargs.get("output_attentions", False):
+ logger.warning_once(
+ "`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
+ 'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ else:
+ attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
+
+ attn_output, attn_weights = attention_interface(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ dropout=0.0 if not self.training else self.attention_dropout,
+ scaling=self.scaling,
+ **kwargs,
+ )
+
+ attn_output = attn_output.reshape(*input_shape, -1).contiguous()
+ attn_output = self.o_proj(attn_output)
+ return attn_output, attn_weights
+
+
+class MyNewModel2DecoderLayer(nn.Module):
+ def __init__(self, config: MyNewModel2Config, layer_idx: int):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ self.self_attn = MyNewModel2Attention(config=config, layer_idx=layer_idx)
+
+ self.mlp = MyNewModel2MLP(config)
+ self.input_layernorm = MyNewModel2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = MyNewModel2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ position_embeddings: Optional[tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.FloatTensor, Optional[tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **kwargs,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ return outputs
+
+
+MY_NEW_MODEL2_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`MyNewModel2Config`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare MyNewModel2 Model outputting raw hidden-states without any specific head on top.",
+ MY_NEW_MODEL2_START_DOCSTRING,
+)
+class MyNewModel2PreTrainedModel(PreTrainedModel):
+ config_class = MyNewModel2Config
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["MyNewModel2DecoderLayer"]
+ _skip_keys_device_placement = ["past_key_values"]
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_flex_attn = True
+ _supports_cache_class = True
+ _supports_quantized_cache = True
+ _supports_static_cache = True
+ _supports_attention_backend = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+
+MY_NEW_MODEL2_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`Cache` or `tuple(tuple(torch.FloatTensor))`, *optional*):
+ Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used to speed up sequential decoding. This typically consists in the `past_key_values`
+ returned by the model at a previous stage of decoding, when `use_cache=True` or `config.use_cache=True`.
+
+ Two formats are allowed:
+ - a [`~cache_utils.Cache`] instance, see our
+ [kv cache guide](https://huggingface.co/docs/transformers/en/kv_cache);
+ - Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`). This is also known as the legacy
+ cache format.
+
+ The model will output the same cache format that is fed as input. If no `past_key_values` are passed, the
+ legacy cache format will be returned.
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
+ have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
+ of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence. Contrarily to `position_ids`,
+ this tensor is not affected by padding. It is used to update the cache in the correct position and to infer
+ the complete sequence length.
+"""
+
+
+@add_start_docstrings(
+ "The bare MyNewModel2 Model outputting raw hidden-states without any specific head on top.",
+ MY_NEW_MODEL2_START_DOCSTRING,
+)
+class MyNewModel2Model(MyNewModel2PreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`MyNewModel2DecoderLayer`]
+
+ Args:
+ config: MyNewModel2Config
+ """
+
+ def __init__(self, config: MyNewModel2Config):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+ self.layers = nn.ModuleList(
+ [MyNewModel2DecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
+ )
+ self.norm = MyNewModel2RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.rotary_emb = MyNewModel2RotaryEmbedding(config=config)
+ self.gradient_checkpointing = False
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(MY_NEW_MODEL2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Union[Cache, list[torch.FloatTensor]]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs, # NOOP kwarg for now
+ ) -> Union[tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if (input_ids is None) ^ (inputs_embeds is not None):
+ raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
+
+ if self.gradient_checkpointing and self.training and use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`."
+ )
+ use_cache = False
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if use_cache and past_key_values is None:
+ past_key_values = DynamicCache()
+
+ if cache_position is None:
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+ cache_position = torch.arange(
+ past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
+ )
+
+ if position_ids is None:
+ position_ids = cache_position.unsqueeze(0)
+
+ causal_mask = self._update_causal_mask(
+ attention_mask, inputs_embeds, cache_position, past_key_values, output_attentions
+ )
+
+ # embed positions
+ hidden_states = inputs_embeds
+
+ # create position embeddings to be shared across the decoder layers
+ position_embeddings = self.rotary_emb(hidden_states, position_ids)
+
+ # normalized
+ # MyNewModel2 downcasts the below to float16, causing sqrt(3072)=55.4256 to become 55.5
+ # See https://github.com/huggingface/transformers/pull/29402
+ normalizer = torch.tensor(self.config.hidden_size**0.5, dtype=hidden_states.dtype)
+ hidden_states = hidden_states * normalizer
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+
+ for decoder_layer in self.layers[: self.config.num_hidden_layers]:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ causal_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ use_cache,
+ cache_position,
+ position_embeddings,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=causal_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ output = BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=past_key_values if use_cache else None,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+ return output if return_dict else output.to_tuple()
+
+ def _update_causal_mask(
+ self,
+ attention_mask: torch.Tensor,
+ input_tensor: torch.Tensor,
+ cache_position: torch.Tensor,
+ past_key_values: Cache,
+ output_attentions: bool,
+ ):
+ if self.config._attn_implementation == "flash_attention_2":
+ if attention_mask is not None and (attention_mask == 0.0).any():
+ return attention_mask
+ return None
+
+ # For SDPA, when possible, we will rely on its `is_causal` argument instead of its `attn_mask` argument, in
+ # order to dispatch on Flash Attention 2. This feature is not compatible with static cache, as SDPA will fail
+ # to infer the attention mask.
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+ using_static_cache = isinstance(past_key_values, StaticCache)
+
+ # When output attentions is True, sdpa implementation's forward method calls the eager implementation's forward
+ if self.config._attn_implementation == "sdpa" and not using_static_cache and not output_attentions:
+ if AttentionMaskConverter._ignore_causal_mask_sdpa(
+ attention_mask,
+ inputs_embeds=input_tensor,
+ past_key_values_length=past_seen_tokens,
+ is_training=self.training,
+ ):
+ return None
+
+ dtype, device = input_tensor.dtype, input_tensor.device
+ sequence_length = input_tensor.shape[1]
+ if using_static_cache:
+ target_length = past_key_values.get_max_cache_shape()
+ else:
+ target_length = (
+ attention_mask.shape[-1]
+ if isinstance(attention_mask, torch.Tensor)
+ else past_seen_tokens + sequence_length + 1
+ )
+
+ # In case the provided `attention` mask is 2D, we generate a causal mask here (4D).
+ causal_mask = self._prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask,
+ sequence_length=sequence_length,
+ target_length=target_length,
+ dtype=dtype,
+ device=device,
+ cache_position=cache_position,
+ batch_size=input_tensor.shape[0],
+ )
+
+ if (
+ self.config._attn_implementation == "sdpa"
+ and attention_mask is not None
+ and attention_mask.device.type in ["cuda", "xpu"]
+ and not output_attentions
+ ):
+ # Attend to all tokens in fully masked rows in the causal_mask, for example the relevant first rows when
+ # using left padding. This is required by F.scaled_dot_product_attention memory-efficient attention path.
+ # Details: https://github.com/pytorch/pytorch/issues/110213
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = AttentionMaskConverter._unmask_unattended(causal_mask, min_dtype)
+
+ return causal_mask
+
+ @staticmethod
+ def _prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask: torch.Tensor,
+ sequence_length: int,
+ target_length: int,
+ dtype: torch.dtype,
+ device: torch.device,
+ cache_position: torch.Tensor,
+ batch_size: int,
+ **kwargs,
+ ):
+ """
+ Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
+ `(batch_size, key_value_length)`, or if the input `attention_mask` is already 4D, do nothing.
+
+ Args:
+ attention_mask (`torch.Tensor`):
+ A 2D attention mask of shape `(batch_size, key_value_length)` or a 4D attention mask of shape
+ `(batch_size, 1, query_length, key_value_length)`.
+ sequence_length (`int`):
+ The sequence length being processed.
+ target_length (`int`):
+ The target length: when generating with static cache, the mask should be as long as the static cache,
+ to account for the 0 padding, the part of the cache that is not filled yet.
+ dtype (`torch.dtype`):
+ The dtype to use for the 4D attention mask.
+ device (`torch.device`):
+ The device to plcae the 4D attention mask on.
+ cache_position (`torch.Tensor`):
+ Indices depicting the position of the input sequence tokens in the sequence.
+ batch_size (`torch.Tensor`):
+ Batch size.
+ """
+ if attention_mask is not None and attention_mask.dim() == 4:
+ # In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
+ causal_mask = attention_mask
+ else:
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = torch.full(
+ (sequence_length, target_length), fill_value=min_dtype, dtype=dtype, device=device
+ )
+ if sequence_length != 1:
+ causal_mask = torch.triu(causal_mask, diagonal=1)
+ causal_mask *= torch.arange(target_length, device=device) > cache_position.reshape(-1, 1)
+ causal_mask = causal_mask[None, None, :, :].expand(batch_size, 1, -1, -1)
+ if attention_mask is not None:
+ causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
+ mask_length = attention_mask.shape[-1]
+ padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :].to(
+ causal_mask.device
+ )
+ padding_mask = padding_mask == 0
+ causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
+ padding_mask, min_dtype
+ )
+
+ return causal_mask
+
+
+@add_start_docstrings(
+ """
+ The MyNewModel2 Model transformer with a sequence classification head on top (linear layer).
+
+ [`MyNewModel2ForSequenceClassification`] uses the last token in order to do the classification, as other causal models
+ (e.g. GPT-2) do.
+
+ Since it does classification on the last token, it requires to know the position of the last token. If a
+ `pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
+ no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
+ padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
+ each row of the batch).
+ """,
+ MY_NEW_MODEL2_START_DOCSTRING,
+)
+class MyNewModel2ForSequenceClassification(MyNewModel2PreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.model = MyNewModel2Model(config)
+ self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(MY_NEW_MODEL2_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Union[Cache, list[torch.FloatTensor]]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[tuple, SequenceClassifierOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ transformer_outputs = self.model(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ hidden_states = transformer_outputs[0]
+ logits = self.score(hidden_states)
+
+ if input_ids is not None:
+ batch_size = input_ids.shape[0]
+ else:
+ batch_size = inputs_embeds.shape[0]
+
+ if self.config.pad_token_id is None and batch_size != 1:
+ raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
+ if self.config.pad_token_id is None:
+ last_non_pad_token = -1
+ elif input_ids is not None:
+ # To handle both left- and right- padding, we take the rightmost token that is not equal to pad_token_id
+ non_pad_mask = (input_ids != self.config.pad_token_id).to(logits.device, torch.int32)
+ token_indices = torch.arange(input_ids.shape[-1], device=logits.device)
+ last_non_pad_token = (token_indices * non_pad_mask).argmax(-1)
+ else:
+ last_non_pad_token = -1
+ logger.warning_once(
+ f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be "
+ "unexpected if using padding tokens in conjunction with `inputs_embeds.`"
+ )
+
+ pooled_logits = logits[torch.arange(batch_size, device=logits.device), last_non_pad_token]
+
+ loss = None
+ if labels is not None:
+ loss = self.loss_function(logits=logits, labels=labels, pooled_logits=pooled_logits, config=self.config)
+
+ if not return_dict:
+ output = (pooled_logits,) + transformer_outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutputWithPast(
+ loss=loss,
+ logits=pooled_logits,
+ past_key_values=transformer_outputs.past_key_values,
+ hidden_states=transformer_outputs.hidden_states,
+ attentions=transformer_outputs.attentions,
+ )
diff --git a/docs/transformers/examples/modular-transformers/modeling_new_task_model.py b/docs/transformers/examples/modular-transformers/modeling_new_task_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..672adcf149dcf98a74b5be0f41da2a6549192ed1
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modeling_new_task_model.py
@@ -0,0 +1,469 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_new_task_model.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_new_task_model.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+from dataclasses import dataclass
+from typing import ClassVar, Optional, Union
+
+import torch
+from torch import nn
+
+from ...cache_utils import Cache, HybridCache, StaticCache
+from ...generation import GenerationMixin
+from ...modeling_utils import PreTrainedModel
+from ...utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ replace_return_docstrings,
+)
+from ..auto import AutoModel, AutoModelForCausalLM
+from .configuration_new_task_model import NewTaskModelConfig
+
+
+_CONFIG_FOR_DOC = "NewTaskModelConfig"
+
+
+@dataclass
+class NewTaskModelCausalLMOutputWithPast(ModelOutput):
+ """
+ Base class for NewTaskModelcausal language model (or autoregressive) outputs.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Language modeling loss (for next-token prediction).
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.text_config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`)
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ image_hidden_states (`torch.FloatTensor`, *optional*):
+ A `torch.FloatTensor` of size `(batch_size, num_images, sequence_length, hidden_size)`.
+ image_hidden_states of the model produced by the vision encoder after projecting last hidden state.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: torch.FloatTensor = None
+ past_key_values: Optional[Union[list[torch.FloatTensor], Cache]] = None
+ hidden_states: Optional[tuple[torch.FloatTensor]] = None
+ attentions: Optional[tuple[torch.FloatTensor]] = None
+ image_hidden_states: Optional[torch.FloatTensor] = None
+
+
+class NewTaskModelMultiModalProjector(nn.Module):
+ def __init__(self, config: NewTaskModelConfig):
+ super().__init__()
+ self.linear = nn.Linear(config.vision_config.hidden_size, config.vision_config.projection_dim, bias=True)
+
+ def forward(self, image_features):
+ hidden_states = self.linear(image_features)
+
+ return hidden_states
+
+
+NEW_TASK_MODEL_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`NewTaskModelConfig`] or [`NewTaskModelVisionConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare LLaMA Model outputting raw hidden-states without any specific head on top.",
+ NEW_TASK_MODEL_START_DOCSTRING,
+)
+class NewTaskModelPreTrainedModel(PreTrainedModel):
+ config_class = NewTaskModelConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["NewTaskModelMultiModalProjector"]
+ _skip_keys_device_placement = "past_key_values"
+ _supports_cache_class = True
+ _supports_quantized_cache = True
+ _supports_static_cache = True
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+
+ def _init_weights(self, module):
+ # important: this ported version of NewTaskModelisn't meant for training from scratch - only
+ # inference and fine-tuning
+ std = (
+ self.config.initializer_range
+ if hasattr(self.config, "initializer_range")
+ else self.config.text_config.initializer_range
+ )
+
+ if hasattr(module, "class_embedding"):
+ module.class_embedding.data.normal_(mean=0.0, std=std)
+
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+
+NEW_TASK_MODEL_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)):
+ The tensors corresponding to the input images. Pixel values can be obtained using
+ [`AutoImageProcessor`]. See [`SiglipImageProcessor.__call__`] for details ([]`NewTaskModelProcessor`] uses
+ [`SiglipImageProcessor`] for processing images).
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`. [What are position IDs?](../glossary#position-ids)
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence. Contrarily to `position_ids`,
+ this tensor is not affected by padding. It is used to update the cache in the correct position and to infer
+ the complete sequence length.
+"""
+
+
+@add_start_docstrings(
+ """The NEW_TASK_MODEL model which consists of a vision backbone and a language model.""",
+ NEW_TASK_MODEL_START_DOCSTRING,
+)
+class NewTaskModelForNewTask(NewTaskModelPreTrainedModel, GenerationMixin):
+ main_input_name: ClassVar[str] = "doc_input_ids" # transformers-related
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.vision_tower = AutoModel.from_config(config=config.vision_config)
+ self.multi_modal_projector = NewTaskModelMultiModalProjector(config)
+ self.vocab_size = config.text_config.vocab_size
+
+ language_model = AutoModelForCausalLM.from_config(config=config.text_config)
+
+ if language_model._tied_weights_keys is not None:
+ self._tied_weights_keys = [f"language_model.{k}" for k in language_model._tied_weights_keys]
+ self.language_model = language_model
+
+ self.pad_token_id = self.config.pad_token_id if self.config.pad_token_id is not None else -1
+
+ self.embedding_dim = self.config.embedding_dim
+ self.custom_text_proj = nn.Linear(self.config.text_config.hidden_size, self.embedding_dim)
+
+ if self.language_model._tied_weights_keys is not None:
+ self._tied_weights_keys = [f"model.language_model.{k}" for k in self.language_model._tied_weights_keys]
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.language_model.get_input_embeddings()
+
+ def set_input_embeddings(self, value):
+ self.language_model.set_input_embeddings(value)
+
+ def get_output_embeddings(self):
+ return self.language_model.get_output_embeddings()
+
+ def set_output_embeddings(self, new_embeddings):
+ self.language_model.set_output_embeddings(new_embeddings)
+
+ def set_decoder(self, decoder):
+ self.language_model.set_decoder(decoder)
+
+ def get_decoder(self):
+ return self.language_model.get_decoder()
+
+ def _update_causal_mask(
+ self,
+ attention_mask,
+ token_type_ids,
+ past_key_values,
+ cache_position,
+ input_tensor,
+ is_training: bool = False,
+ ):
+ if self.config.text_config._attn_implementation == "flash_attention_2":
+ if attention_mask is not None and 0.0 in attention_mask:
+ return attention_mask
+ return None
+
+ using_static_cache = isinstance(past_key_values, StaticCache)
+ min_dtype = torch.finfo(self.dtype).min
+ inputs_lead_dim, sequence_length = input_tensor.shape[:2]
+ if using_static_cache:
+ target_length = past_key_values.get_max_cache_shape()
+ elif isinstance(past_key_values, HybridCache):
+ target_length = past_key_values.get_max_cache_shape()
+ else:
+ target_length = (
+ attention_mask.shape[-1]
+ if isinstance(attention_mask, torch.Tensor)
+ else cache_position[0] + sequence_length + 1
+ )
+
+ if attention_mask is not None and attention_mask.dim() == 4:
+ # In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
+ return attention_mask
+
+ causal_mask = torch.full(
+ (sequence_length, target_length), fill_value=min_dtype, dtype=self.dtype, device=cache_position.device
+ )
+ # Causal diagonal mask only if training, otherwise attend to the whole prefix. Training-specific attn for prefix is handled below
+ if sequence_length != 1:
+ if is_training:
+ causal_mask = torch.triu(causal_mask, diagonal=1)
+ else:
+ causal_mask[:, :sequence_length] = 0.0
+
+ causal_mask *= torch.arange(target_length, device=cache_position.device) > cache_position.reshape(-1, 1)
+ causal_mask = causal_mask[None, None, :, :].expand(inputs_lead_dim, 1, -1, -1)
+ if attention_mask is not None:
+ causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
+ mask_length = attention_mask.shape[-1]
+
+ # First unmask prefix tokens during training
+ if is_training:
+ causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
+ token_type_ids[:, None, None, :].to(causal_mask.device) == 0, 0
+ )
+
+ # Then apply padding mask (will mask pad tokens)
+ padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :].to(causal_mask.device)
+ padding_mask = padding_mask == 0
+ causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
+ padding_mask, min_dtype
+ )
+
+ return causal_mask
+
+ def get_image_features(self, pixel_values: torch.FloatTensor):
+ """
+ Obtains image last hidden states from the vision tower and apply multimodal projection.
+
+ Args:
+ pixel_values (`torch.FloatTensor]` of shape `(batch_size, channels, height, width)`)
+ The tensors corresponding to the input images.
+ Returns:
+ image_features (`torch.Tensor`): Image feature tensor of shape `(num_images, image_length, embed_dim)`).
+ """
+ image_outputs = self.vision_tower(pixel_values)
+ selected_image_feature = image_outputs.last_hidden_state
+ image_features = self.multi_modal_projector(selected_image_feature)
+ image_features = image_features / (self.config.text_config.hidden_size**0.5)
+ return image_features
+
+ @add_start_docstrings_to_model_forward(NEW_TASK_MODEL_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=NewTaskModelCausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ pixel_values: torch.FloatTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Union[list[torch.FloatTensor], Cache]] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ num_logits_to_keep: int = 0,
+ ) -> Union[tuple, NewTaskModelCausalLMOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.text_config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.text_config.vocab_size]`.
+
+ logits_to_keep (`int` or `torch.Tensor`, *optional*):
+ If an `int`, compute logits for the last `logits_to_keep` tokens. If `0`, calculate logits for all
+ `input_ids` (special case). Only last token logits are needed for generation, and calculating them only for that
+ token can save memory, which becomes pretty significant for long sequences or large vocabulary size.
+ If a `torch.Tensor`, must be 1D corresponding to the indices to keep in the sequence length dimension.
+ This is useful when using packed tensor format (single dimension for batch and sequence length).
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, NewTaskModelForNewTask
+
+ >>> model = NewTaskModelForNewTask.from_pretrained("google/NewTaskModel-test-224px-hf")
+ >>> processor = AutoProcessor.from_pretrained("google/NewTaskModel-test-224px-hf")
+
+ >>> prompt = "answer en Where is the cow standing?"
+ >>> url = "https://huggingface.co/gv-hf/NewTaskModel-test-224px-hf/resolve/main/cow_beach_1.png"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(images=image, text=prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(**inputs, max_length=30)
+ >>> processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "answer en Where is the cow standing?\nbeach"
+ ```
+ Returns:
+ """
+ vlm_outputs = super().forward(
+ input_ids=input_ids,
+ pixel_values=pixel_values,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ token_type_ids=token_type_ids,
+ cache_position=cache_position,
+ inputs_embeds=inputs_embeds,
+ labels=labels,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=True,
+ return_dict=True,
+ num_logits_to_keep=num_logits_to_keep,
+ )
+ last_hidden_states = vlm_outputs.hidden_states[-1] # (batch_size, sequence_length, hidden_size)
+ proj = self.custom_text_proj(last_hidden_states) # (batch_size, sequence_length, dim)
+
+ # L2 normalization
+ embeddings = proj / proj.norm(dim=-1, keepdim=True) # (batch_size, sequence_length, dim)
+
+ embeddings = embeddings * attention_mask.unsqueeze(-1) # (batch_size, sequence_length, dim)
+
+ return (embeddings,) + vlm_outputs
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ inputs_embeds=None,
+ cache_position=None,
+ position_ids=None,
+ pixel_values=None,
+ attention_mask=None,
+ token_type_ids=None,
+ use_cache=True,
+ logits_to_keep=None,
+ labels=None,
+ **kwargs,
+ ):
+ # Overwritten -- custom `position_ids` and `pixel_values` handling
+ model_inputs = self.language_model.prepare_inputs_for_generation(
+ input_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ cache_position=cache_position,
+ use_cache=use_cache,
+ logits_to_keep=logits_to_keep,
+ token_type_ids=token_type_ids,
+ **kwargs,
+ )
+
+ # position_ids in NewTaskModel are 1-indexed
+ if model_inputs.get("position_ids") is not None:
+ model_inputs["position_ids"] += 1
+ # If we're in cached decoding stage, pixel values should be None because input ids do not contain special image token anymore
+ # Otherwise we need pixel values to be passed to model. NOTE: use_cache=False needs pixel_values always
+ if cache_position[0] == 0:
+ model_inputs["pixel_values"] = pixel_values
+ is_training = token_type_ids is not None and labels is not None
+ if cache_position[0] == 0 and isinstance(past_key_values, HybridCache):
+ input_tensor = inputs_embeds if inputs_embeds is not None else input_ids
+ causal_mask = self._update_causal_mask(
+ attention_mask, token_type_ids, past_key_values, cache_position, input_tensor, is_training
+ )
+ model_inputs["attention_mask"] = causal_mask
+
+ return model_inputs
+
+ def resize_token_embeddings(
+ self, new_num_tokens: Optional[int] = None, pad_to_multiple_of=None, mean_resizing=True
+ ) -> nn.Embedding:
+ model_embeds = self.language_model.resize_token_embeddings(new_num_tokens, pad_to_multiple_of, mean_resizing)
+
+ # Update vocab size
+ self.config.text_config.vocab_size = model_embeds.num_embeddings
+ self.config.vocab_size = model_embeds.num_embeddings
+ self.vocab_size = model_embeds.num_embeddings
+
+ return model_embeds
diff --git a/docs/transformers/examples/modular-transformers/modeling_roberta.py b/docs/transformers/examples/modular-transformers/modeling_roberta.py
new file mode 100644
index 0000000000000000000000000000000000000000..b03774e22851e3b84be110b36eb6b058fbbe45b4
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modeling_roberta.py
@@ -0,0 +1,1014 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_roberta.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_roberta.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+import math
+import os
+from typing import Optional, Union
+
+import torch
+import torch.nn as nn
+from packaging import version
+
+from ...activations import ACT2FN
+from ...modeling_attn_mask_utils import _prepare_4d_attention_mask_for_sdpa, _prepare_4d_causal_attention_mask_for_sdpa
+from ...modeling_outputs import BaseModelOutputWithPastAndCrossAttentions, BaseModelOutputWithPoolingAndCrossAttentions
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import apply_chunking_to_forward, find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import (
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ get_torch_version,
+ logging,
+)
+from .configuration_roberta import RobertaConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = "google-roberta/roberta-base-uncased"
+_CONFIG_FOR_DOC = "RobertaConfig"
+
+
+class RobertaEmbeddings(nn.Module):
+ """Construct the embeddings from word, position and token_type embeddings."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
+ self.position_embeddings = nn.Embedding(
+ config.max_position_embeddings, config.hidden_size, config.pad_token_id
+ )
+ self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
+
+ # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
+ self.register_buffer(
+ "position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
+ )
+ self.register_buffer(
+ "token_type_ids", torch.zeros(self.position_ids.size(), dtype=torch.long), persistent=False
+ )
+ self.pad_token_id = config.pad_token_id
+
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ past_key_values_length: int = 0,
+ ) -> torch.Tensor:
+ if input_ids is not None:
+ input_shape = input_ids.size()
+ else:
+ input_shape = inputs_embeds.size()[:-1]
+
+ seq_length = input_shape[1]
+
+ if position_ids is None:
+ position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
+
+ # Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
+ # when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
+ # issue #5664
+ if token_type_ids is None:
+ if hasattr(self, "token_type_ids"):
+ buffered_token_type_ids = self.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+ token_type_embeddings = self.token_type_embeddings(token_type_ids)
+
+ embeddings = inputs_embeds + token_type_embeddings
+ if self.position_embedding_type == "absolute":
+ position_embeddings = self.position_embeddings(position_ids)
+ embeddings += position_embeddings
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings
+
+
+class RobertaSelfAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
+ f"heads ({config.num_attention_heads})"
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+ self.position_embedding_type = position_embedding_type or getattr(
+ config, "position_embedding_type", "absolute"
+ )
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ self.max_position_embeddings = config.max_position_embeddings
+ self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
+
+ self.is_decoder = config.is_decoder
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[tuple[tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor]:
+ mixed_query_layer = self.query(hidden_states)
+
+ # If this is instantiated as a cross-attention module, the keys
+ # and values come from an encoder; the attention mask needs to be
+ # such that the encoder's padding tokens are not attended to.
+ is_cross_attention = encoder_hidden_states is not None
+
+ if is_cross_attention and past_key_value is not None:
+ # reuse k,v, cross_attentions
+ key_layer = past_key_value[0]
+ value_layer = past_key_value[1]
+ attention_mask = encoder_attention_mask
+ elif is_cross_attention:
+ key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
+ value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
+ attention_mask = encoder_attention_mask
+ elif past_key_value is not None:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
+ value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
+ else:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ use_cache = past_key_value is not None
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_layer, value_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ query_length, key_length = query_layer.shape[2], key_layer.shape[2]
+ if use_cache:
+ position_ids_l = torch.tensor(key_length - 1, dtype=torch.long, device=hidden_states.device).view(
+ -1, 1
+ )
+ else:
+ position_ids_l = torch.arange(query_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(key_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+
+ positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == "relative_key":
+ relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores
+ elif self.position_embedding_type == "relative_key_query":
+ relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in RobertaModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ if self.is_decoder:
+ outputs = outputs + (past_key_value,)
+ return outputs
+
+
+class RobertaSdpaSelfAttention(RobertaSelfAttention):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__(config, position_embedding_type=position_embedding_type)
+ self.dropout_prob = config.attention_probs_dropout_prob
+ self.require_contiguous_qkv = version.parse(get_torch_version()) < version.parse("2.2.0")
+
+ # Adapted from RobertaSelfAttention
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[tuple[tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor]:
+ if self.position_embedding_type != "absolute" or output_attentions or head_mask is not None:
+ # TODO: Improve this warning with e.g. `model.config._attn_implementation = "manual"` once implemented.
+ logger.warning_once(
+ "RobertaSdpaSelfAttention is used but `torch.nn.functional.scaled_dot_product_attention` does not support "
+ "non-absolute `position_embedding_type` or `output_attentions=True` or `head_mask`. Falling back to "
+ "the manual attention implementation, but specifying the manual implementation will be required from "
+ "Transformers version v5.0.0 onwards. This warning can be removed using the argument "
+ '`attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+
+ bsz, tgt_len, _ = hidden_states.size()
+
+ query_layer = self.transpose_for_scores(self.query(hidden_states))
+
+ # If this is instantiated as a cross-attention module, the keys and values come from an encoder; the attention
+ # mask needs to be such that the encoder's padding tokens are not attended to.
+ is_cross_attention = encoder_hidden_states is not None
+
+ current_states = encoder_hidden_states if is_cross_attention else hidden_states
+ attention_mask = encoder_attention_mask if is_cross_attention else attention_mask
+
+ # Check `seq_length` of `past_key_value` == `len(current_states)` to support prefix tuning
+ if is_cross_attention and past_key_value and past_key_value[0].shape[2] == current_states.shape[1]:
+ key_layer, value_layer = past_key_value
+ else:
+ key_layer = self.transpose_for_scores(self.key(current_states))
+ value_layer = self.transpose_for_scores(self.value(current_states))
+ if past_key_value is not None and not is_cross_attention:
+ key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
+ value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_layer, value_layer)
+
+ # SDPA with memory-efficient backend is broken in torch==2.1.2 when using non-contiguous inputs and a custom
+ # attn_mask, so we need to call `.contiguous()` here. This was fixed in torch==2.2.0.
+ # Reference: https://github.com/pytorch/pytorch/issues/112577
+ if self.require_contiguous_qkv and query_layer.device.type == "cuda" and attention_mask is not None:
+ query_layer = query_layer.contiguous()
+ key_layer = key_layer.contiguous()
+ value_layer = value_layer.contiguous()
+
+ # We dispatch to SDPA's Flash Attention or Efficient kernels via this `is_causal` if statement instead of an inline conditional assignment
+ # in SDPA to support both torch.compile's dynamic shapes and full graph options. An inline conditional prevents dynamic shapes from compiling.
+ # The tgt_len > 1 is necessary to match with AttentionMaskConverter.to_causal_4d that does not create
+ # a causal mask in case tgt_len == 1.
+ is_causal = (
+ True if self.is_decoder and not is_cross_attention and attention_mask is None and tgt_len > 1 else False
+ )
+
+ attn_output = torch.nn.functional.scaled_dot_product_attention(
+ query_layer,
+ key_layer,
+ value_layer,
+ attn_mask=attention_mask,
+ dropout_p=self.dropout_prob if self.training else 0.0,
+ is_causal=is_causal,
+ )
+
+ attn_output = attn_output.transpose(1, 2)
+ attn_output = attn_output.reshape(bsz, tgt_len, self.all_head_size)
+
+ outputs = (attn_output,)
+ if self.is_decoder:
+ outputs = outputs + (past_key_value,)
+ return outputs
+
+
+class RobertaSelfOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+ROBERTA_SELF_ATTENTION_CLASSES = {
+ "eager": RobertaSelfAttention,
+ "sdpa": RobertaSdpaSelfAttention,
+}
+
+
+class RobertaAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ self.self = ROBERTA_SELF_ATTENTION_CLASSES[config._attn_implementation](
+ config, position_embedding_type=position_embedding_type
+ )
+ self.output = RobertaSelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.self.query = prune_linear_layer(self.self.query, index)
+ self.self.key = prune_linear_layer(self.self.key, index)
+ self.self.value = prune_linear_layer(self.self.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
+ self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[tuple[tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor]:
+ self_outputs = self.self(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ attention_output = self.output(self_outputs[0], hidden_states)
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+class RobertaIntermediate(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+class RobertaOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class RobertaLayer(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = RobertaAttention(config)
+ self.is_decoder = config.is_decoder
+ self.add_cross_attention = config.add_cross_attention
+ if self.add_cross_attention:
+ if not self.is_decoder:
+ raise ValueError(f"{self} should be used as a decoder model if cross attention is added")
+ self.crossattention = RobertaAttention(config, position_embedding_type="absolute")
+ self.intermediate = RobertaIntermediate(config)
+ self.output = RobertaOutput(config)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[tuple[tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> tuple[torch.Tensor]:
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
+ self_attention_outputs = self.attention(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ output_attentions=output_attentions,
+ past_key_value=self_attn_past_key_value,
+ )
+ attention_output = self_attention_outputs[0]
+
+ # if decoder, the last output is tuple of self-attn cache
+ if self.is_decoder:
+ outputs = self_attention_outputs[1:-1]
+ present_key_value = self_attention_outputs[-1]
+ else:
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ cross_attn_present_key_value = None
+ if self.is_decoder and encoder_hidden_states is not None:
+ if not hasattr(self, "crossattention"):
+ raise ValueError(
+ f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers"
+ " by setting `config.add_cross_attention=True`"
+ )
+
+ # cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
+ cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
+ cross_attention_outputs = self.crossattention(
+ attention_output,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ cross_attn_past_key_value,
+ output_attentions,
+ )
+ attention_output = cross_attention_outputs[0]
+ outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
+
+ # add cross-attn cache to positions 3,4 of present_key_value tuple
+ cross_attn_present_key_value = cross_attention_outputs[-1]
+ present_key_value = present_key_value + cross_attn_present_key_value
+
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
+ )
+ outputs = (layer_output,) + outputs
+
+ # if decoder, return the attn key/values as the last output
+ if self.is_decoder:
+ outputs = outputs + (present_key_value,)
+
+ return outputs
+
+ def feed_forward_chunk(self, attention_output):
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ return layer_output
+
+
+class RobertaEncoder(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([RobertaLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_values: Optional[tuple[tuple[torch.FloatTensor]]] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = True,
+ ) -> Union[tuple[torch.Tensor], BaseModelOutputWithPastAndCrossAttentions]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ next_decoder_cache = () if use_cache else None
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+ past_key_value = past_key_values[i] if past_key_values is not None else None
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ layer_module.__call__,
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ else:
+ layer_outputs = layer_module(
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+ if use_cache:
+ next_decoder_cache += (layer_outputs[-1],)
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+ if self.config.add_cross_attention:
+ all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ next_decoder_cache,
+ all_hidden_states,
+ all_self_attentions,
+ all_cross_attentions,
+ ]
+ if v is not None
+ )
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+
+class RobertaPooler(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+def load_tf_weights_in_roberta(model, config, tf_checkpoint_path):
+ """Load tf checkpoints in a pytorch model."""
+ try:
+ import re
+
+ import numpy as np
+ import tensorflow as tf
+ except ImportError:
+ logger.error(
+ "Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
+ "https://www.tensorflow.org/install/ for installation instructions."
+ )
+ raise
+ tf_path = os.path.abspath(tf_checkpoint_path)
+ logger.info(f"Converting TensorFlow checkpoint from {tf_path}")
+ # Load weights from TF model
+ init_vars = tf.train.list_variables(tf_path)
+ names = []
+ arrays = []
+ for name, shape in init_vars:
+ logger.info(f"Loading TF weight {name} with shape {shape}")
+ array = tf.train.load_variable(tf_path, name)
+ names.append(name)
+ arrays.append(array)
+
+ for name, array in zip(names, arrays):
+ name = name.split("/")
+ # adam_v and adam_m are variables used in AdamWeightDecayOptimizer to calculated m and v
+ # which are not required for using pretrained model
+ if any(
+ n in ["adam_v", "adam_m", "AdamWeightDecayOptimizer", "AdamWeightDecayOptimizer_1", "global_step"]
+ for n in name
+ ):
+ logger.info(f"Skipping {'/'.join(name)}")
+ continue
+ pointer = model
+ for m_name in name:
+ if re.fullmatch(r"[A-Za-z]+_\d+", m_name):
+ scope_names = re.split(r"_(\d+)", m_name)
+ else:
+ scope_names = [m_name]
+ if scope_names[0] == "kernel" or scope_names[0] == "gamma":
+ pointer = getattr(pointer, "weight")
+ elif scope_names[0] == "output_bias" or scope_names[0] == "beta":
+ pointer = getattr(pointer, "bias")
+ elif scope_names[0] == "output_weights":
+ pointer = getattr(pointer, "weight")
+ elif scope_names[0] == "squad":
+ pointer = getattr(pointer, "classifier")
+ else:
+ try:
+ pointer = getattr(pointer, scope_names[0])
+ except AttributeError:
+ logger.info(f"Skipping {'/'.join(name)}")
+ continue
+ if len(scope_names) >= 2:
+ num = int(scope_names[1])
+ pointer = pointer[num]
+ if m_name[-11:] == "_embeddings":
+ pointer = getattr(pointer, "weight")
+ elif m_name == "kernel":
+ array = np.transpose(array)
+ try:
+ if pointer.shape != array.shape:
+ raise ValueError(f"Pointer shape {pointer.shape} and array shape {array.shape} mismatched")
+ except ValueError as e:
+ e.args += (pointer.shape, array.shape)
+ raise
+ logger.info(f"Initialize PyTorch weight {name}")
+ pointer.data = torch.from_numpy(array)
+ return model
+
+
+class RobertaPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = RobertaConfig
+ load_tf_weights = load_tf_weights_in_roberta
+ base_model_prefix = "roberta"
+ supports_gradient_checkpointing = True
+ _supports_sdpa = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, nn.Linear):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+
+ROBERTA_START_DOCSTRING = r"""
+
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`RobertaConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+ROBERTA_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `({0})`):
+ Indices of input sequence tokens in the vocabulary.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.FloatTensor` of shape `({0})`or `(batch_size, sequence_length, target_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
+ 1]`:
+
+ - 0 corresponds to a *sentence A* token,
+ - 1 corresponds to a *sentence B* token.
+
+ [What are token type IDs?](../glossary#token-type-ids)
+ position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare Roberta Model transformer outputting raw hidden-states without any specific head on top.",
+ ROBERTA_START_DOCSTRING,
+)
+class RobertaModel(RobertaPreTrainedModel):
+ """
+
+ The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
+ cross-attention is added between the self-attention layers, following the architecture described in [Attention is
+ all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
+
+ To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
+ to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
+ `add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
+ """
+
+ _no_split_modules = ["RobertaEmbeddings", "RobertaLayer"]
+
+ def __init__(self, config, add_pooling_layer=True):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = RobertaEmbeddings(config)
+ self.encoder = RobertaEncoder(config)
+
+ self.pooler = RobertaPooler(config) if add_pooling_layer else None
+
+ self.attn_implementation = config._attn_implementation
+ self.position_embedding_type = config.position_embedding_type
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value):
+ self.embeddings.word_embeddings = value
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(ROBERTA_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @add_code_sample_docstrings(
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutputWithPoolingAndCrossAttentions,
+ config_class=_CONFIG_FOR_DOC,
+ )
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[list[torch.FloatTensor]] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[tuple[torch.Tensor], BaseModelOutputWithPoolingAndCrossAttentions]:
+ r"""
+ encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)` or `(batch_size, sequence_length, target_length)`, *optional*):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if self.config.is_decoder:
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ else:
+ use_cache = False
+
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
+ input_shape = input_ids.size()
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ batch_size, seq_length = input_shape
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+
+ # past_key_values_length
+ past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
+
+ if token_type_ids is None:
+ if hasattr(self.embeddings, "token_type_ids"):
+ buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
+
+ embedding_output = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids,
+ inputs_embeds=inputs_embeds,
+ past_key_values_length=past_key_values_length,
+ )
+
+ if attention_mask is None:
+ attention_mask = torch.ones((batch_size, seq_length + past_key_values_length), device=device)
+
+ use_sdpa_attention_masks = (
+ self.attn_implementation == "sdpa"
+ and self.position_embedding_type == "absolute"
+ and head_mask is None
+ and not output_attentions
+ )
+
+ # Expand the attention mask
+ if use_sdpa_attention_masks and attention_mask.dim() == 2:
+ # Expand the attention mask for SDPA.
+ # [bsz, seq_len] -> [bsz, 1, seq_len, seq_len]
+ if self.config.is_decoder:
+ extended_attention_mask = _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask,
+ input_shape,
+ embedding_output,
+ past_key_values_length,
+ )
+ else:
+ extended_attention_mask = _prepare_4d_attention_mask_for_sdpa(
+ attention_mask, embedding_output.dtype, tgt_len=seq_length
+ )
+ else:
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask = self.get_extended_attention_mask(attention_mask, input_shape)
+
+ # If a 2D or 3D attention mask is provided for the cross-attention
+ # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if self.config.is_decoder and encoder_hidden_states is not None:
+ encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
+ encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
+ if encoder_attention_mask is None:
+ encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
+
+ if use_sdpa_attention_masks and encoder_attention_mask.dim() == 2:
+ # Expand the attention mask for SDPA.
+ # [bsz, seq_len] -> [bsz, 1, seq_len, seq_len]
+ encoder_extended_attention_mask = _prepare_4d_attention_mask_for_sdpa(
+ encoder_attention_mask, embedding_output.dtype, tgt_len=seq_length
+ )
+ else:
+ encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = None
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ attention_mask=extended_attention_mask,
+ head_mask=head_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_extended_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+ pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPoolingAndCrossAttentions(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ past_key_values=encoder_outputs.past_key_values,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ cross_attentions=encoder_outputs.cross_attentions,
+ )
diff --git a/docs/transformers/examples/modular-transformers/modeling_super.py b/docs/transformers/examples/modular-transformers/modeling_super.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ab9865f4385daead6e057ed0911902fa9f4d438
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modeling_super.py
@@ -0,0 +1,632 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_super.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_super.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+from typing import Callable, Optional, Union
+
+import torch
+from torch import nn
+
+from ...activations import ACT2FN
+from ...cache_utils import Cache, StaticCache
+from ...modeling_attn_mask_utils import AttentionMaskConverter
+from ...modeling_flash_attention_utils import FlashAttentionKwargs
+from ...modeling_outputs import BaseModelOutputWithPast
+from ...modeling_rope_utils import ROPE_INIT_FUNCTIONS
+from ...modeling_utils import ALL_ATTENTION_FUNCTIONS, PreTrainedModel
+from ...processing_utils import Unpack
+from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging
+from .configuration_super import SuperConfig
+
+
+logger = logging.get_logger(__name__)
+
+
+class SuperRMSNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ SuperRMSNorm is equivalent to T5LayerNorm
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+ def extra_repr(self):
+ return f"{tuple(self.weight.shape)}, eps={self.variance_epsilon}"
+
+
+class SuperRotaryEmbedding(nn.Module):
+ def __init__(self, config: SuperConfig, device=None):
+ super().__init__()
+ # BC: "rope_type" was originally "type"
+ if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
+ self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
+ else:
+ self.rope_type = "default"
+ self.max_seq_len_cached = config.max_position_embeddings
+ self.original_max_seq_len = config.max_position_embeddings
+
+ self.config = config
+ self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
+
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+ self.original_inv_freq = self.inv_freq
+
+ def _dynamic_frequency_update(self, position_ids, device):
+ """
+ dynamic RoPE layers should recompute `inv_freq` in the following situations:
+ 1 - growing beyond the cached sequence length (allow scaling)
+ 2 - the current sequence length is in the original scale (avoid losing precision with small sequences)
+ """
+ seq_len = torch.max(position_ids) + 1
+ if seq_len > self.max_seq_len_cached: # growth
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device, seq_len=seq_len)
+ self.register_buffer("inv_freq", inv_freq, persistent=False) # TODO joao: may break with compilation
+ self.max_seq_len_cached = seq_len
+
+ if seq_len < self.original_max_seq_len and self.max_seq_len_cached > self.original_max_seq_len: # reset
+ # This .to() is needed if the model has been moved to a device after being initialized (because
+ # the buffer is automatically moved, but not the original copy)
+ self.original_inv_freq = self.original_inv_freq.to(device)
+ self.register_buffer("inv_freq", self.original_inv_freq, persistent=False)
+ self.max_seq_len_cached = self.original_max_seq_len
+
+ @torch.no_grad()
+ def forward(self, x, position_ids):
+ if "dynamic" in self.rope_type:
+ self._dynamic_frequency_update(position_ids, device=x.device)
+
+ # Core RoPE block
+ inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1)
+ position_ids_expanded = position_ids[:, None, :].float()
+ # Force float32 (see https://github.com/huggingface/transformers/pull/29285)
+ device_type = x.device.type
+ device_type = device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
+ with torch.autocast(device_type=device_type, enabled=False):
+ freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
+ emb = torch.cat((freqs, freqs), dim=-1)
+ cos = emb.cos()
+ sin = emb.sin()
+
+ # Advanced RoPE types (e.g. yarn) apply a post-processing scaling factor, equivalent to scaling attention
+ cos = cos * self.attention_scaling
+ sin = sin * self.attention_scaling
+
+ return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
+
+
+class SuperMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.intermediate_size = config.intermediate_size
+ self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
+ self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
+ self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=config.mlp_bias)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+ return down_proj
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+def eager_attention_forward(
+ module: nn.Module,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ attention_mask: Optional[torch.Tensor],
+ scaling: float,
+ dropout: float = 0.0,
+ **kwargs,
+):
+ key_states = repeat_kv(key, module.num_key_value_groups)
+ value_states = repeat_kv(value, module.num_key_value_groups)
+
+ attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
+ if attention_mask is not None:
+ causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
+ attn_weights = attn_weights + causal_mask
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ return attn_output, attn_weights
+
+
+class SuperAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: SuperConfig, layer_idx: int):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
+ self.scaling = self.head_dim**-0.5
+ self.attention_dropout = config.attention_dropout
+ self.is_causal = True
+
+ self.q_proj = nn.Linear(
+ config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.k_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.v_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.o_proj = nn.Linear(
+ config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ position_embeddings: tuple[torch.Tensor, torch.Tensor],
+ attention_mask: Optional[torch.Tensor],
+ past_key_value: Optional[Cache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor]]]:
+ input_shape = hidden_states.shape[:-1]
+ hidden_shape = (*input_shape, -1, self.head_dim)
+
+ query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+
+ cos, sin = position_embeddings
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models; cache_position needed for the static cache
+ cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ attention_interface: Callable = eager_attention_forward
+ if self.config._attn_implementation != "eager":
+ if self.config._attn_implementation == "sdpa" and kwargs.get("output_attentions", False):
+ logger.warning_once(
+ "`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
+ 'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ else:
+ attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
+
+ attn_output, attn_weights = attention_interface(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ dropout=0.0 if not self.training else self.attention_dropout,
+ scaling=self.scaling,
+ **kwargs,
+ )
+
+ attn_output = attn_output.reshape(*input_shape, -1).contiguous()
+ attn_output = self.o_proj(attn_output)
+ return attn_output, attn_weights
+
+
+class SuperDecoderLayer(nn.Module):
+ def __init__(self, config: SuperConfig, layer_idx: int):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ self.self_attn = SuperAttention(config=config, layer_idx=layer_idx)
+
+ self.mlp = SuperMLP(config)
+ self.input_layernorm = SuperRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = SuperRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ position_embeddings: Optional[tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.FloatTensor, Optional[tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **kwargs,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ return outputs
+
+
+SUPER_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`SuperConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare Super Model outputting raw hidden-states without any specific head on top.",
+ SUPER_START_DOCSTRING,
+)
+class SuperPreTrainedModel(PreTrainedModel):
+ config_class = SuperConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["SuperDecoderLayer"]
+ _skip_keys_device_placement = ["past_key_values"]
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_flex_attn = True
+ _supports_cache_class = True
+ _supports_quantized_cache = True
+ _supports_static_cache = True
+ _supports_attention_backend = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+
+SUPER_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`Cache` or `tuple(tuple(torch.FloatTensor))`, *optional*):
+ Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used to speed up sequential decoding. This typically consists in the `past_key_values`
+ returned by the model at a previous stage of decoding, when `use_cache=True` or `config.use_cache=True`.
+
+ Two formats are allowed:
+ - a [`~cache_utils.Cache`] instance, see our
+ [kv cache guide](https://huggingface.co/docs/transformers/en/kv_cache);
+ - Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`). This is also known as the legacy
+ cache format.
+
+ The model will output the same cache format that is fed as input. If no `past_key_values` are passed, the
+ legacy cache format will be returned.
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
+ have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
+ of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence. Contrarily to `position_ids`,
+ this tensor is not affected by padding. It is used to update the cache in the correct position and to infer
+ the complete sequence length.
+"""
+
+
+@add_start_docstrings(
+ "The bare Super Model outputting raw hidden-states without any specific head on top.",
+ SUPER_START_DOCSTRING,
+)
+class SuperModel(SuperPreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`SuperDecoderLayer`]
+
+ Args:
+ config: SuperConfig
+ """
+
+ def __init__(self, config: SuperConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+ self.layers = nn.ModuleList(
+ [SuperDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
+ )
+ self.norm = SuperRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.rotary_emb = SuperRotaryEmbedding(config=config)
+ self.gradient_checkpointing = False
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @add_start_docstrings_to_model_forward(SUPER_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Union[Cache, list[torch.FloatTensor]]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ ) -> Union[tuple, BaseModelOutputWithPast]:
+ out = super().forward(
+ input_ids,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ inputs_embeds,
+ use_cache,
+ output_attentions,
+ output_hidden_states,
+ return_dict,
+ cache_position,
+ )
+ out.logits *= 2**4
+ return out
+
+ def _update_causal_mask(
+ self,
+ attention_mask: torch.Tensor,
+ input_tensor: torch.Tensor,
+ cache_position: torch.Tensor,
+ past_key_values: Cache,
+ output_attentions: bool,
+ ):
+ if self.config._attn_implementation == "flash_attention_2":
+ if attention_mask is not None and (attention_mask == 0.0).any():
+ return attention_mask
+ return None
+
+ # For SDPA, when possible, we will rely on its `is_causal` argument instead of its `attn_mask` argument, in
+ # order to dispatch on Flash Attention 2. This feature is not compatible with static cache, as SDPA will fail
+ # to infer the attention mask.
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+ using_static_cache = isinstance(past_key_values, StaticCache)
+
+ # When output attentions is True, sdpa implementation's forward method calls the eager implementation's forward
+ if self.config._attn_implementation == "sdpa" and not using_static_cache and not output_attentions:
+ if AttentionMaskConverter._ignore_causal_mask_sdpa(
+ attention_mask,
+ inputs_embeds=input_tensor,
+ past_key_values_length=past_seen_tokens,
+ is_training=self.training,
+ ):
+ return None
+
+ dtype, device = input_tensor.dtype, input_tensor.device
+ sequence_length = input_tensor.shape[1]
+ if using_static_cache:
+ target_length = past_key_values.get_max_cache_shape()
+ else:
+ target_length = (
+ attention_mask.shape[-1]
+ if isinstance(attention_mask, torch.Tensor)
+ else past_seen_tokens + sequence_length + 1
+ )
+
+ # In case the provided `attention` mask is 2D, we generate a causal mask here (4D).
+ causal_mask = self._prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask,
+ sequence_length=sequence_length,
+ target_length=target_length,
+ dtype=dtype,
+ device=device,
+ cache_position=cache_position,
+ batch_size=input_tensor.shape[0],
+ )
+
+ if (
+ self.config._attn_implementation == "sdpa"
+ and attention_mask is not None
+ and attention_mask.device.type in ["cuda", "xpu"]
+ and not output_attentions
+ ):
+ # Attend to all tokens in fully masked rows in the causal_mask, for example the relevant first rows when
+ # using left padding. This is required by F.scaled_dot_product_attention memory-efficient attention path.
+ # Details: https://github.com/pytorch/pytorch/issues/110213
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = AttentionMaskConverter._unmask_unattended(causal_mask, min_dtype)
+
+ return causal_mask
+
+ @staticmethod
+ def _prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask: torch.Tensor,
+ sequence_length: int,
+ target_length: int,
+ dtype: torch.dtype,
+ device: torch.device,
+ cache_position: torch.Tensor,
+ batch_size: int,
+ **kwargs,
+ ):
+ """
+ Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
+ `(batch_size, key_value_length)`, or if the input `attention_mask` is already 4D, do nothing.
+
+ Args:
+ attention_mask (`torch.Tensor`):
+ A 2D attention mask of shape `(batch_size, key_value_length)` or a 4D attention mask of shape
+ `(batch_size, 1, query_length, key_value_length)`.
+ sequence_length (`int`):
+ The sequence length being processed.
+ target_length (`int`):
+ The target length: when generating with static cache, the mask should be as long as the static cache,
+ to account for the 0 padding, the part of the cache that is not filled yet.
+ dtype (`torch.dtype`):
+ The dtype to use for the 4D attention mask.
+ device (`torch.device`):
+ The device to plcae the 4D attention mask on.
+ cache_position (`torch.Tensor`):
+ Indices depicting the position of the input sequence tokens in the sequence.
+ batch_size (`torch.Tensor`):
+ Batch size.
+ """
+ if attention_mask is not None and attention_mask.dim() == 4:
+ # In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
+ causal_mask = attention_mask
+ else:
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = torch.full(
+ (sequence_length, target_length), fill_value=min_dtype, dtype=dtype, device=device
+ )
+ if sequence_length != 1:
+ causal_mask = torch.triu(causal_mask, diagonal=1)
+ causal_mask *= torch.arange(target_length, device=device) > cache_position.reshape(-1, 1)
+ causal_mask = causal_mask[None, None, :, :].expand(batch_size, 1, -1, -1)
+ if attention_mask is not None:
+ causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
+ mask_length = attention_mask.shape[-1]
+ padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :].to(
+ causal_mask.device
+ )
+ padding_mask = padding_mask == 0
+ causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
+ padding_mask, min_dtype
+ )
+
+ return causal_mask
diff --git a/docs/transformers/examples/modular-transformers/modeling_switch_function.py b/docs/transformers/examples/modular-transformers/modeling_switch_function.py
new file mode 100644
index 0000000000000000000000000000000000000000..75811d8681c0574aaf011bf0d8854035e4253b5f
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modeling_switch_function.py
@@ -0,0 +1,170 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from examples/modular-transformers/modular_switch_function.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_switch_function.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# Note that llama and cohere have different definitions for rotate_half
+from typing import Callable, Optional
+
+import torch
+from torch import nn
+
+from ...cache_utils import Cache
+from ...modeling_flash_attention_utils import FlashAttentionKwargs
+from ...modeling_utils import ALL_ATTENTION_FUNCTIONS
+from ...processing_utils import Unpack
+from ...utils import logging
+from .configuration_switch_function import SwitchFunctionConfig
+
+
+logger = logging.get_logger(__name__)
+
+
+def rotate_half(x):
+ # Split and rotate. Note that this function is different from e.g. Llama.
+ x1 = x[..., ::2]
+ x2 = x[..., 1::2]
+ rot_x = torch.stack([-x2, x1], dim=-1).flatten(-2)
+ return rot_x
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+def eager_attention_forward(
+ module: nn.Module,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ attention_mask: Optional[torch.Tensor],
+ scaling: float,
+ dropout: float = 0.0,
+ **kwargs,
+):
+ key_states = repeat_kv(key, module.num_key_value_groups)
+ value_states = repeat_kv(value, module.num_key_value_groups)
+
+ attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
+ if attention_mask is not None:
+ causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
+ attn_weights = attn_weights + causal_mask
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ return attn_output, attn_weights
+
+
+class SwitchFunctionAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: SwitchFunctionConfig, layer_idx: int):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
+ self.scaling = self.head_dim**-0.5
+ self.attention_dropout = config.attention_dropout
+ self.is_causal = True
+
+ self.q_proj = nn.Linear(
+ config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.k_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.v_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.o_proj = nn.Linear(
+ config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ position_embeddings: tuple[torch.Tensor, torch.Tensor],
+ attention_mask: Optional[torch.Tensor],
+ past_key_value: Optional[Cache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor]]]:
+ input_shape = hidden_states.shape[:-1]
+ hidden_shape = (*input_shape, -1, self.head_dim)
+
+ query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+
+ cos, sin = position_embeddings
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models; cache_position needed for the static cache
+ cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ attention_interface: Callable = eager_attention_forward
+ if self.config._attn_implementation != "eager":
+ if self.config._attn_implementation == "sdpa" and kwargs.get("output_attentions", False):
+ logger.warning_once(
+ "`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
+ 'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ else:
+ attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
+
+ attn_output, attn_weights = attention_interface(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ dropout=0.0 if not self.training else self.attention_dropout,
+ scaling=self.scaling,
+ **kwargs,
+ )
+
+ attn_output = attn_output.reshape(*input_shape, -1).contiguous()
+ attn_output = self.o_proj(attn_output)
+ return attn_output, attn_weights
diff --git a/docs/transformers/examples/modular-transformers/modular_add_function.py b/docs/transformers/examples/modular-transformers/modular_add_function.py
new file mode 100644
index 0000000000000000000000000000000000000000..6a2426a67236bf4c4bb8db553382ace5f5df9407
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_add_function.py
@@ -0,0 +1,15 @@
+# Note that zamba does not have the `apply_rotary_pos_emb` function!
+from transformers.models.llama.modeling_llama import apply_rotary_pos_emb
+from transformers.models.zamba.modeling_zamba import ZambaAttention
+
+
+# When following ZambaAttention dependencies, the function `apply_rotary_pos_emb` is not present
+# by default as it is absent from the class definition (and the file altogether).
+# Note that this syntax should be able to add both `apply_rotary_pos_emb` as imported directly, but
+# `rotate_half` as well as a dependency from the imported function!!
+class TestAttention(ZambaAttention):
+ def __init__(self):
+ pass
+
+ def forward(self):
+ _ = apply_rotary_pos_emb(1, 1, 1, 1)
diff --git a/docs/transformers/examples/modular-transformers/modular_dummy.py b/docs/transformers/examples/modular-transformers/modular_dummy.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb64ba4d8566655604001f44bea2ed34363b7d3b
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_dummy.py
@@ -0,0 +1,15 @@
+import torch
+
+from transformers.models.llama.modeling_llama import LlamaModel
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 4]
+ x2 = x[..., x.shape[-1] // 4 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+# example where we need some deps and some functions
+class DummyModel(LlamaModel):
+ pass
diff --git a/docs/transformers/examples/modular-transformers/modular_dummy_bert.py b/docs/transformers/examples/modular-transformers/modular_dummy_bert.py
new file mode 100644
index 0000000000000000000000000000000000000000..34d2cd1b335e075e84c15f3c38c9c613df6eb542
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_dummy_bert.py
@@ -0,0 +1,27 @@
+from typing import Optional, Union
+
+import torch
+
+from transformers.models.bert.modeling_bert import BertModel
+
+from ...modeling_outputs import BaseModelOutputWithPoolingAndCrossAttentions
+
+
+class DummyBertModel(BertModel):
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[list[torch.FloatTensor]] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[tuple[torch.Tensor], BaseModelOutputWithPoolingAndCrossAttentions]:
+ return super().forward(input_ids)
diff --git a/docs/transformers/examples/modular-transformers/modular_from_uppercase_model.py b/docs/transformers/examples/modular-transformers/modular_from_uppercase_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef3044e7ee2cf023f0d23fed2ea4da678f06b98d
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_from_uppercase_model.py
@@ -0,0 +1,6 @@
+from transformers.models.clip.modeling_clip import CLIPEncoderLayer
+
+
+# Check if we can correctly grab dependencies with correct naming from all UPPERCASE old model
+class FromUppercaseModelEncoderLayer(CLIPEncoderLayer):
+ pass
diff --git a/docs/transformers/examples/modular-transformers/modular_multimodal1.py b/docs/transformers/examples/modular-transformers/modular_multimodal1.py
new file mode 100644
index 0000000000000000000000000000000000000000..8f8eaf91a371065beff347e9b5f1c7f58f1b614b
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_multimodal1.py
@@ -0,0 +1,6 @@
+from transformers.models.llama.modeling_llama import LlamaModel
+
+
+# Check that we can correctly change the prefix (here add Text part at the end of the name)
+class Multimodal1TextModel(LlamaModel):
+ pass
diff --git a/docs/transformers/examples/modular-transformers/modular_multimodal2.py b/docs/transformers/examples/modular-transformers/modular_multimodal2.py
new file mode 100644
index 0000000000000000000000000000000000000000..bc11e0b2869fb9ab758347f49ee145560120dafb
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_multimodal2.py
@@ -0,0 +1,88 @@
+"""
+Here, because clip is not consistent with the use of the "Text" and "Vision" prefixes, we cannot simply use
+```
+class Multimodal2VisionModel(CLIPVisionModel):
+ pass
+```
+with the hope that all dependencies will be renamed as `Multimodal2VisionClass`. For this reason, if we want consistency and
+use the "Vision" part everywhere, we need to overwrite the intermediate classes and add the prefix everytime.
+This adds noise to the modular, but is unfortunately unavoidable.
+"""
+
+from torch import nn
+
+from transformers.models.clip.modeling_clip import (
+ CLIPMLP,
+ CLIPAttention,
+ CLIPEncoder,
+ CLIPEncoderLayer,
+ CLIPFlashAttention2,
+ CLIPPreTrainedModel,
+ CLIPSdpaAttention,
+ CLIPVisionModel,
+ CLIPVisionTransformer,
+)
+from transformers.utils import add_start_docstrings
+
+
+class Multimodal2VisionAttention(CLIPAttention):
+ pass
+
+
+# Check that adding the second base class correctly set the parent, even though in clip it does not have the "Vision" part
+class Multimodal2VisionSdpaAttention(CLIPSdpaAttention, Multimodal2VisionAttention):
+ pass
+
+
+# Check that adding the second base class correctly set the parent, even though in clip it does not have the "Vision" part
+class Multimodal2VisionFlashAttention2(CLIPFlashAttention2, Multimodal2VisionAttention):
+ pass
+
+
+MULTIMODAL2_VISION_ATTENTION_CLASSES = {
+ "eager": Multimodal2VisionAttention,
+ "sdpa": Multimodal2VisionSdpaAttention,
+ "flash_attention_2": Multimodal2VisionFlashAttention2,
+}
+
+
+class Multimodal2VisionMLP(CLIPMLP):
+ pass
+
+
+class Multimodal2VisionEncoderLayer(CLIPEncoderLayer):
+ def __init__(self, config):
+ super().__init__()
+ self.self_attn = MULTIMODAL2_VISION_ATTENTION_CLASSES[config._attn_implementation](config)
+ self.mlp = Multimodal2VisionMLP(config)
+
+
+class Multimodal2VisionEncoder(CLIPEncoder):
+ def __init__(self, config):
+ super().__init__(config)
+ self.layers = nn.ModuleList([Multimodal2VisionEncoderLayer(config) for _ in range(config.num_hidden_layers)])
+
+
+# Finally here the `Vision` part was correct in CLIP, but we still need to tell it that the encoder arg should use it as well
+class Multimodal2VisionTransformer(CLIPVisionTransformer):
+ def __init__(self, config):
+ super().__init__(config)
+ self.encoder = Multimodal2VisionEncoder(config)
+
+
+class Multimodal2VisionPreTrainedModel(CLIPPreTrainedModel):
+ def _init_weights(self, module):
+ if isinstance(module, Multimodal2VisionMLP):
+ pass
+
+
+MULTIMODAL2_VISION_START_DOCSTRING = "doc"
+
+
+# Here the only arg `self.vision_model = CLIPVisionTransformer(config)` in CLIPVisionModel already has the "Vision" part, so
+# no need to overwrite it, it will look for `Multimodal2VisionTransformer` which has already being redefined above
+# Note: we may want to redefine decorator as well for full consistency, as CLIP does not use "CLIP_VISION_START_DOCSTRING" but only
+# "CLIP_START_DOCSTRING"
+@add_start_docstrings("New doc", MULTIMODAL2_VISION_START_DOCSTRING)
+class Multimodal2VisionModel(CLIPVisionModel, Multimodal2VisionPreTrainedModel):
+ _no_split_modules = ["Multimodal2VisionEncoderLayer"]
diff --git a/docs/transformers/examples/modular-transformers/modular_my_new_model.py b/docs/transformers/examples/modular-transformers/modular_my_new_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1ea8b0a72490b19412ed909c045660ddc5dc015
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_my_new_model.py
@@ -0,0 +1,15 @@
+from transformers.models.llama.configuration_llama import LlamaConfig
+
+
+# Example where we only want to only add a new config argument and new arg doc
+# here there is no `ARG` so we are gonna take parent doc
+class MyNewModelConfig(LlamaConfig):
+ r"""
+ new_param (`int`, *optional*, defaults to `False`):
+ A fun new parameter
+ """
+
+ def __init__(self, mlp_bias=True, new_param=0, **super_kwargs):
+ super().__init__(self, **super_kwargs)
+ self.mlp_bias = mlp_bias
+ self.new_param = new_param
diff --git a/docs/transformers/examples/modular-transformers/modular_my_new_model2.py b/docs/transformers/examples/modular-transformers/modular_my_new_model2.py
new file mode 100644
index 0000000000000000000000000000000000000000..2e449e06b16225a9dd45ab7c1ce81cb918404780
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_my_new_model2.py
@@ -0,0 +1,31 @@
+from transformers.models.gemma.modeling_gemma import GemmaForSequenceClassification
+from transformers.models.llama.configuration_llama import LlamaConfig
+
+
+# Example where we only want to only modify the docstring
+class MyNewModel2Config(LlamaConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`GemmaModel`]. It is used to instantiate an Gemma
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the Gemma-7B.
+ e.g. [google/gemma-7b](https://huggingface.co/google/gemma-7b)
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+ Args:
+ vocab_size (`int`, *optional*, defaults to 256000):
+ Vocabulary size of the Gemma model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`GemmaModel`]
+ ```python
+ >>> from transformers import GemmaModel, GemmaConfig
+ >>> # Initializing a Gemma gemma-7b style configuration
+ >>> configuration = GemmaConfig()
+ >>> # Initializing a model from the gemma-7b style configuration
+ >>> model = GemmaModel(configuration)
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+
+# Example where alllllll the dependencies are fetched to just copy the entire class
+class MyNewModel2ForSequenceClassification(GemmaForSequenceClassification):
+ pass
diff --git a/docs/transformers/examples/modular-transformers/modular_new_imgproc_model.py b/docs/transformers/examples/modular-transformers/modular_new_imgproc_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..1d054166c28d3e546dad4ca70b09372121dd318a
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_new_imgproc_model.py
@@ -0,0 +1,9 @@
+import torch
+import torch.utils.checkpoint
+
+from transformers.models.blip.image_processing_blip import BlipImageProcessor
+
+
+class ImgprocModelImageProcessor(BlipImageProcessor):
+ def new_image_processing_method(self, pixel_values: torch.FloatTensor):
+ return pixel_values / 2
diff --git a/docs/transformers/examples/modular-transformers/modular_new_model.py b/docs/transformers/examples/modular-transformers/modular_new_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..166c7955c1b5a91839a5b72ecdfb5c4b48660813
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_new_model.py
@@ -0,0 +1,35 @@
+# Example where we only want to overwrite the defaults of an init
+
+from transformers.models.gemma.configuration_gemma import GemmaConfig
+
+
+class NewModelConfig(GemmaConfig):
+ def __init__(
+ self,
+ vocab_size=256030,
+ hidden_size=64,
+ intermediate_size=90,
+ num_hidden_layers=28,
+ num_attention_heads=16,
+ num_key_value_heads=16,
+ head_dim=256,
+ hidden_act="gelu_pytorch_tanh",
+ hidden_activation=None,
+ max_position_embeddings=1500,
+ initializer_range=0.02,
+ rms_norm_eps=1e-6,
+ use_cache=True,
+ pad_token_id=0,
+ eos_token_id=1,
+ bos_token_id=2,
+ tie_word_embeddings=True,
+ rope_theta=10000.0,
+ attention_bias=False,
+ attention_dropout=0.0,
+ **kwargs,
+ ):
+ super().__init__(self, **kwargs)
+
+ @property
+ def num_heads(self):
+ return self.num_attention_heads
diff --git a/docs/transformers/examples/modular-transformers/modular_new_task_model.py b/docs/transformers/examples/modular-transformers/modular_new_task_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..f1943e37e1f92bcd0f18703e5879a3a157c2102b
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_new_task_model.py
@@ -0,0 +1,82 @@
+from typing import ClassVar, Optional, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+
+from transformers.models.paligemma.modeling_paligemma import PaliGemmaForConditionalGeneration
+
+from ...cache_utils import Cache
+
+
+class NewTaskModelForNewTask(PaliGemmaForConditionalGeneration):
+ main_input_name: ClassVar[str] = "doc_input_ids" # transformers-related
+
+ def __init__(self, config):
+ super().__init__(config=config)
+
+ self.embedding_dim = self.config.embedding_dim
+ self.custom_text_proj = nn.Linear(self.config.text_config.hidden_size, self.embedding_dim)
+
+ if self.language_model._tied_weights_keys is not None:
+ self._tied_weights_keys = [f"model.language_model.{k}" for k in self.language_model._tied_weights_keys]
+
+ self.post_init()
+
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ pixel_values: torch.FloatTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Union[list[torch.FloatTensor], Cache]] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ num_logits_to_keep: int = 0,
+ ):
+ r"""
+ Returns:
+ """
+ vlm_outputs = super().forward(
+ input_ids=input_ids,
+ pixel_values=pixel_values,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ token_type_ids=token_type_ids,
+ cache_position=cache_position,
+ inputs_embeds=inputs_embeds,
+ labels=labels,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=True,
+ return_dict=True,
+ num_logits_to_keep=num_logits_to_keep,
+ )
+ last_hidden_states = vlm_outputs.hidden_states[-1] # (batch_size, sequence_length, hidden_size)
+ proj = self.custom_text_proj(last_hidden_states) # (batch_size, sequence_length, dim)
+
+ # L2 normalization
+ embeddings = proj / proj.norm(dim=-1, keepdim=True) # (batch_size, sequence_length, dim)
+
+ embeddings = embeddings * attention_mask.unsqueeze(-1) # (batch_size, sequence_length, dim)
+
+ return (embeddings,) + vlm_outputs
+
+ def resize_token_embeddings(
+ self, new_num_tokens: Optional[int] = None, pad_to_multiple_of=None, mean_resizing=True
+ ) -> nn.Embedding:
+ model_embeds = self.language_model.resize_token_embeddings(new_num_tokens, pad_to_multiple_of, mean_resizing)
+
+ # Update vocab size
+ self.config.text_config.vocab_size = model_embeds.num_embeddings
+ self.config.vocab_size = model_embeds.num_embeddings
+ self.vocab_size = model_embeds.num_embeddings
+
+ return model_embeds
diff --git a/docs/transformers/examples/modular-transformers/modular_roberta.py b/docs/transformers/examples/modular-transformers/modular_roberta.py
new file mode 100644
index 0000000000000000000000000000000000000000..13dca4845c132b1e735bcc34d2df2b81111cc97d
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_roberta.py
@@ -0,0 +1,17 @@
+import torch.nn as nn
+
+from transformers.models.bert.modeling_bert import BertEmbeddings, BertModel
+
+
+class RobertaEmbeddings(BertEmbeddings):
+ def __init__(self, config):
+ super().__init__(config)
+ self.pad_token_id = config.pad_token_id
+ self.position_embeddings = nn.Embedding(
+ config.max_position_embeddings, config.hidden_size, config.pad_token_id
+ )
+
+
+class RobertaModel(BertModel):
+ def __init__(self, config, add_pooling_layer=True):
+ super().__init__(self, config)
diff --git a/docs/transformers/examples/modular-transformers/modular_super.py b/docs/transformers/examples/modular-transformers/modular_super.py
new file mode 100644
index 0000000000000000000000000000000000000000..f7a3f46d44ab084e00323ca989448a73edbc4b5a
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_super.py
@@ -0,0 +1,39 @@
+from typing import Optional, Union
+
+import torch
+
+from transformers.modeling_outputs import CausalLMOutputWithPast
+from transformers.models.llama.modeling_llama import LlamaModel
+
+from ...cache_utils import Cache
+
+
+# example where we need some deps and some functions
+class SuperModel(LlamaModel):
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Union[Cache, list[torch.FloatTensor]]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ ) -> Union[tuple, CausalLMOutputWithPast]:
+ out = super().forward(
+ input_ids,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ inputs_embeds,
+ use_cache,
+ output_attentions,
+ output_hidden_states,
+ return_dict,
+ cache_position,
+ )
+ out.logits *= 2**4
+ return out
diff --git a/docs/transformers/examples/modular-transformers/modular_switch_function.py b/docs/transformers/examples/modular-transformers/modular_switch_function.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c0c716a43979b3a18d7d48ec0b09a960e40ca0a
--- /dev/null
+++ b/docs/transformers/examples/modular-transformers/modular_switch_function.py
@@ -0,0 +1,10 @@
+# Note that llama and cohere have different definitions for rotate_half
+from transformers.models.cohere.modeling_cohere import rotate_half # noqa
+from transformers.models.llama.modeling_llama import LlamaAttention
+
+
+# When following LlamaAttention dependencies, we will grab the function `rotate_half` defined
+# in `modeling_llama.py`. But here we imported it explicitly from Cohere, so it should use Cohere's
+# definition instead
+class SwitchFunctionAttention(LlamaAttention):
+ pass
diff --git a/docs/transformers/examples/pytorch/README.md b/docs/transformers/examples/pytorch/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..4e318b3edb920c6c1d01fa332be596e4de87bd96
--- /dev/null
+++ b/docs/transformers/examples/pytorch/README.md
@@ -0,0 +1,381 @@
+
+
+# Examples
+
+This folder contains actively maintained examples of use of 🤗 Transformers using the PyTorch backend, organized by ML task.
+
+## The Big Table of Tasks
+
+Here is the list of all our examples:
+- with information on whether they are **built on top of `Trainer`** (if not, they still work, they might
+ just lack some features),
+- whether or not they have a version using the [🤗 Accelerate](https://github.com/huggingface/accelerate) library.
+- whether or not they leverage the [🤗 Datasets](https://github.com/huggingface/datasets) library.
+- links to **Colab notebooks** to walk through the scripts and run them easily,
+
+
+| Task | Example datasets | Trainer support | 🤗 Accelerate | 🤗 Datasets | Colab
+|---|---|:---:|:---:|:---:|:---:|
+| [**`language-modeling`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling) | [WikiText-2](https://huggingface.co/datasets/wikitext) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
+| [**`multiple-choice`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) | [SWAG](https://huggingface.co/datasets/swag) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)
+| [**`question-answering`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) | [SQuAD](https://huggingface.co/datasets/squad) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)
+| [**`summarization`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) | [XSum](https://huggingface.co/datasets/xsum) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)
+| [**`text-classification`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) | [GLUE](https://huggingface.co/datasets/glue) | ✅ | ✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)
+| [**`text-generation`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation) | - | n/a | - | - | [](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb)
+| [**`token-classification`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) | [CoNLL NER](https://huggingface.co/datasets/conll2003) | ✅ |✅ | ✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)
+| [**`translation`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation) | [WMT](https://huggingface.co/datasets/wmt17) | ✅ | ✅ |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)
+| [**`speech-recognition`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition) | [TIMIT](https://huggingface.co/datasets/timit_asr) | ✅ | - |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb)
+| [**`multi-lingual speech-recognition`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/speech-recognition) | [Common Voice](https://huggingface.co/datasets/common_voice) | ✅ | - |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb)
+| [**`audio-classification`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification) | [SUPERB KS](https://huggingface.co/datasets/superb) | ✅ | - |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)
+| [**`image-pretraining`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining) | [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) | ✅ | - |✅ | /
+| [**`image-classification`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) | [CIFAR-10](https://huggingface.co/datasets/cifar10) | ✅ | ✅ |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)
+| [**`semantic-segmentation`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) | [SCENE_PARSE_150](https://huggingface.co/datasets/scene_parse_150) | ✅ | ✅ |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb)
+| [**`object-detection`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection) | [CPPE-5](https://huggingface.co/datasets/cppe-5) | ✅ | ✅ |✅ | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/pytorch/object_detection.ipynb)
+| [**`instance-segmentation`**](https://github.com/huggingface/transformers/tree/main/examples/pytorch/instance-segmentation) | [ADE20K sample](https://huggingface.co/datasets/qubvel-hf/ade20k-mini) | ✅ | ✅ |✅ |
+
+
+## Running quick tests
+
+Most examples are equipped with a mechanism to truncate the number of dataset samples to the desired length. This is useful for debugging purposes, for example to quickly check that all stages of the programs can complete, before running the same setup on the full dataset which may take hours to complete.
+
+For example here is how to truncate all three splits to just 50 samples each:
+```bash
+examples/pytorch/token-classification/run_ner.py \
+--max_train_samples 50 \
+--max_eval_samples 50 \
+--max_predict_samples 50 \
+[...]
+```
+
+Most example scripts should have the first two command line arguments and some have the third one. You can quickly check if a given example supports any of these by passing a `-h` option, e.g.:
+```bash
+examples/pytorch/token-classification/run_ner.py -h
+```
+
+## Resuming training
+
+You can resume training from a previous checkpoint like this:
+
+1. Pass `--output_dir previous_output_dir` without `--overwrite_output_dir` to resume training from the latest checkpoint in `output_dir` (what you would use if the training was interrupted, for instance).
+2. Pass `--resume_from_checkpoint path_to_a_specific_checkpoint` to resume training from that checkpoint folder.
+
+Should you want to turn an example into a notebook where you'd no longer have access to the command
+line, 🤗 Trainer supports resuming from a checkpoint via `trainer.train(resume_from_checkpoint)`.
+
+1. If `resume_from_checkpoint` is `True` it will look for the last checkpoint in the value of `output_dir` passed via `TrainingArguments`.
+2. If `resume_from_checkpoint` is a path to a specific checkpoint it will use that saved checkpoint folder to resume the training from.
+
+
+### Upload the trained/fine-tuned model to the Hub
+
+All the example scripts support automatic upload of your final model to the [Model Hub](https://huggingface.co/models) by adding a `--push_to_hub` argument. It will then create a repository with your username slash the name of the folder you are using as `output_dir`. For instance, `"sgugger/test-mrpc"` if your username is `sgugger` and you are working in the folder `~/tmp/test-mrpc`.
+
+To specify a given repository name, use the `--hub_model_id` argument. You will need to specify the whole repository name (including your username), for instance `--hub_model_id sgugger/finetuned-bert-mrpc`. To upload to an organization you are a member of, just use the name of that organization instead of your username: `--hub_model_id huggingface/finetuned-bert-mrpc`.
+
+A few notes on this integration:
+
+- you will need to be logged in to the Hugging Face website locally for it to work, the easiest way to achieve this is to run `huggingface-cli login` and then type your username and password when prompted. You can also pass along your authentication token with the `--hub_token` argument.
+- the `output_dir` you pick will either need to be a new folder or a local clone of the distant repository you are using.
+
+## Distributed training and mixed precision
+
+All the PyTorch scripts mentioned above work out of the box with distributed training and mixed precision, thanks to
+the [Trainer API](https://huggingface.co/transformers/main_classes/trainer.html). To launch one of them on _n_ GPUs,
+use the following command:
+
+```bash
+torchrun \
+ --nproc_per_node number_of_gpu_you_have path_to_script.py \
+ --all_arguments_of_the_script
+```
+
+As an example, here is how you would fine-tune the BERT large model (with whole word masking) on the text
+classification MNLI task using the `run_glue` script, with 8 GPUs:
+
+```bash
+torchrun \
+ --nproc_per_node 8 pytorch/text-classification/run_glue.py \
+ --model_name_or_path google-bert/bert-large-uncased-whole-word-masking \
+ --task_name mnli \
+ --do_train \
+ --do_eval \
+ --max_seq_length 128 \
+ --per_device_train_batch_size 8 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3.0 \
+ --output_dir /tmp/mnli_output/
+```
+
+If you have a GPU with mixed precision capabilities (architecture Pascal or more recent), you can use mixed precision
+training with PyTorch 1.6.0 or latest, or by installing the [Apex](https://github.com/NVIDIA/apex) library for previous
+versions. Just add the flag `--fp16` to your command launching one of the scripts mentioned above!
+
+Using mixed precision training usually results in 2x-speedup for training with the same final results (as shown in
+[this table](https://github.com/huggingface/transformers/tree/main/examples/text-classification#mixed-precision-training)
+for text classification).
+
+## Running on TPUs
+
+When using Tensorflow, TPUs are supported out of the box as a `tf.distribute.Strategy`.
+
+When using PyTorch, we support TPUs thanks to `pytorch/xla`. For more context and information on how to setup your TPU environment refer to Google's documentation and to the
+very detailed [pytorch/xla README](https://github.com/pytorch/xla/blob/master/README.md).
+
+In this repo, we provide a very simple launcher script named
+[xla_spawn.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/xla_spawn.py) that lets you run our
+example scripts on multiple TPU cores without any boilerplate. Just pass a `--num_cores` flag to this script, then your
+regular training script with its arguments (this is similar to the `torch.distributed.launch` helper for
+`torch.distributed`):
+
+```bash
+python xla_spawn.py --num_cores num_tpu_you_have \
+ path_to_script.py \
+ --all_arguments_of_the_script
+```
+
+As an example, here is how you would fine-tune the BERT large model (with whole word masking) on the text
+classification MNLI task using the `run_glue` script, with 8 TPUs (from this folder):
+
+```bash
+python xla_spawn.py --num_cores 8 \
+ text-classification/run_glue.py \
+ --model_name_or_path google-bert/bert-large-uncased-whole-word-masking \
+ --task_name mnli \
+ --do_train \
+ --do_eval \
+ --max_seq_length 128 \
+ --per_device_train_batch_size 8 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3.0 \
+ --output_dir /tmp/mnli_output/
+```
+
+## Using Accelerate
+
+Most PyTorch example scripts have a version using the [🤗 Accelerate](https://github.com/huggingface/accelerate) library
+that exposes the training loop so it's easy for you to customize or tweak them to your needs. They all require you to
+install `accelerate` with the latest development version
+
+```bash
+pip install git+https://github.com/huggingface/accelerate
+```
+
+Then you can easily launch any of the scripts by running
+
+```bash
+accelerate config
+```
+
+and reply to the questions asked. Then
+
+```bash
+accelerate test
+```
+
+that will check everything is ready for training. Finally, you can launch training with
+
+```bash
+accelerate launch path_to_script.py --args_to_script
+```
+
+## Logging & Experiment tracking
+
+You can easily log and monitor your runs code. The following are currently supported:
+
+* [TensorBoard](https://www.tensorflow.org/tensorboard)
+* [Weights & Biases](https://docs.wandb.ai/integrations/huggingface)
+* [Comet ML](https://www.comet.com/docs/v2/integrations/ml-frameworks/transformers/)
+* [Neptune](https://docs.neptune.ai/integrations-and-supported-tools/model-training/hugging-face)
+* [ClearML](https://clear.ml/docs/latest/docs/getting_started/ds/ds_first_steps)
+* [DVCLive](https://dvc.org/doc/dvclive/ml-frameworks/huggingface)
+
+### Weights & Biases
+
+To use Weights & Biases, install the wandb package with:
+
+```bash
+pip install wandb
+```
+
+Then log in the command line:
+
+```bash
+wandb login
+```
+
+If you are in Jupyter or Colab, you should login with:
+
+```python
+import wandb
+wandb.login()
+```
+
+To enable logging to W&B, include `"wandb"` in the `report_to` of your `TrainingArguments` or script. Or just pass along `--report_to_all` if you have `wandb` installed.
+
+Whenever you use the `Trainer` class, your losses, evaluation metrics, model topology and gradients will automatically be logged.
+
+Advanced configuration is possible by setting environment variables:
+
+| Environment Variable | Value |
+|---|---|
+| WANDB_LOG_MODEL | Log the model as artifact (log the model as artifact at the end of training) (`false` by default) |
+| WANDB_WATCH | one of `gradients` (default) to log histograms of gradients, `all` to log histograms of both gradients and parameters, or `false` for no histogram logging |
+| WANDB_PROJECT | Organize runs by project |
+
+Set run names with `run_name` argument present in scripts or as part of `TrainingArguments`.
+
+Additional configuration options are available through generic [wandb environment variables](https://docs.wandb.com/library/environment-variables).
+
+Refer to related [documentation & examples](https://docs.wandb.ai/integrations/huggingface).
+
+### Comet
+
+To use `comet_ml`, install the Python package with:
+
+```bash
+pip install comet_ml
+```
+
+or if in a Conda environment:
+
+```bash
+conda install -c comet_ml -c anaconda -c conda-forge comet_ml
+```
+
+### Neptune
+
+First, install the Neptune client library. You can do it with either `pip` or `conda`:
+
+`pip`:
+
+```bash
+pip install neptune
+```
+
+`conda`:
+
+```bash
+conda install -c conda-forge neptune
+```
+
+Next, in your model training script, import `NeptuneCallback`:
+
+```python
+from transformers.integrations import NeptuneCallback
+```
+
+To enable Neptune logging, in your `TrainingArguments`, set the `report_to` argument to `"neptune"`:
+
+```python
+training_args = TrainingArguments(
+ "quick-training-distilbert-mrpc",
+ eval_strategy="steps",
+ eval_steps=20,
+ report_to="neptune",
+)
+
+trainer = Trainer(
+ model,
+ training_args,
+ ...
+)
+```
+
+**Note:** This method requires saving your Neptune credentials as environment variables (see the bottom of the section).
+
+Alternatively, for more logging options, create a Neptune callback:
+
+```python
+neptune_callback = NeptuneCallback()
+```
+
+To add more detail to the tracked run, you can supply optional arguments to `NeptuneCallback`.
+
+Some examples:
+
+```python
+neptune_callback = NeptuneCallback(
+ name = "DistilBERT",
+ description = "DistilBERT fine-tuned on GLUE/MRPC",
+ tags = ["args-callback", "fine-tune", "MRPC"], # tags help you manage runs in Neptune
+ base_namespace="callback", # the default is "finetuning"
+ log_checkpoints = "best", # other options are "last", "same", and None
+ capture_hardware_metrics = False, # additional keyword arguments for a Neptune run
+)
+```
+
+Pass the callback to the Trainer:
+
+```python
+training_args = TrainingArguments(..., report_to=None)
+trainer = Trainer(
+ model,
+ training_args,
+ ...
+ callbacks=[neptune_callback],
+)
+```
+
+Now, when you start the training with `trainer.train()`, your metadata will be logged in Neptune.
+
+**Note:** Although you can pass your **Neptune API token** and **project name** as arguments when creating the callback, the recommended way is to save them as environment variables:
+
+| Environment variable | Value |
+| :------------------- | :--------------------------------------------------- |
+| `NEPTUNE_API_TOKEN` | Your Neptune API token. To find and copy it, click your Neptune avatar and select **Get your API token**. |
+| `NEPTUNE_PROJECT` | The full name of your Neptune project (`workspace-name/project-name`). To find and copy it, head to **project settings** → **Properties**. |
+
+For detailed instructions and examples, see the [Neptune docs](https://docs.neptune.ai/integrations/transformers/).
+
+### ClearML
+
+To use ClearML, install the clearml package with:
+
+```bash
+pip install clearml
+```
+
+Then [create new credentials]() from the ClearML Server. You can get a free hosted server [here]() or [self-host your own]()!
+After creating your new credentials, you can either copy the local snippet which you can paste after running:
+
+```bash
+clearml-init
+```
+
+Or you can copy the jupyter snippet if you are in Jupyter or Colab:
+
+```python
+%env CLEARML_WEB_HOST=https://app.clear.ml
+%env CLEARML_API_HOST=https://api.clear.ml
+%env CLEARML_FILES_HOST=https://files.clear.ml
+%env CLEARML_API_ACCESS_KEY=***
+%env CLEARML_API_SECRET_KEY=***
+```
+
+
+To enable logging to ClearML, include `"clearml"` in the `report_to` of your `TrainingArguments` or script. Or just pass along `--report_to all` if you have `clearml` already installed.
+
+Advanced configuration is possible by setting environment variables:
+
+| Environment Variable | Value |
+|---|---|
+| CLEARML_PROJECT | Name of the project in ClearML. (default: `"HuggingFace Transformers"`) |
+| CLEARML_TASK | Name of the task in ClearML. (default: `"Trainer"`) |
+
+Additional configuration options are available through generic [clearml environment variables](https://clear.ml/docs/latest/docs/configs/env_vars).
diff --git a/docs/transformers/examples/pytorch/_tests_requirements.txt b/docs/transformers/examples/pytorch/_tests_requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..fb86259116d4e915d3b9a5c14ce95ffa165779dd
--- /dev/null
+++ b/docs/transformers/examples/pytorch/_tests_requirements.txt
@@ -0,0 +1,32 @@
+tensorboard
+scikit-learn
+seqeval
+psutil
+sacrebleu >= 1.4.12
+git+https://github.com/huggingface/accelerate@main#egg=accelerate
+rouge-score
+tensorflow_datasets
+matplotlib
+git-python==1.0.3
+faiss-cpu
+streamlit
+elasticsearch
+nltk
+pandas
+datasets >= 1.13.3
+fire
+pytest<8.0.1
+conllu
+sentencepiece != 0.1.92
+protobuf
+torch
+torchvision
+torchaudio
+jiwer
+librosa
+evaluate >= 0.2.0
+timm
+albumentations >= 1.4.16
+torchmetrics
+pycocotools
+Pillow>=10.0.1,<=15.0
diff --git a/docs/transformers/examples/pytorch/audio-classification/README.md b/docs/transformers/examples/pytorch/audio-classification/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..bc4581089c3fd2eaa9eb7d8489966d3acfe00686
--- /dev/null
+++ b/docs/transformers/examples/pytorch/audio-classification/README.md
@@ -0,0 +1,148 @@
+
+
+# Audio classification examples
+
+The following examples showcase how to fine-tune `Wav2Vec2` for audio classification using PyTorch.
+
+Speech recognition models that have been pretrained in unsupervised fashion on audio data alone,
+*e.g.* [Wav2Vec2](https://huggingface.co/transformers/main/model_doc/wav2vec2.html),
+[HuBERT](https://huggingface.co/transformers/main/model_doc/hubert.html),
+[XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html), have shown to require only
+very little annotated data to yield good performance on speech classification datasets.
+
+## Single-GPU
+
+The following command shows how to fine-tune [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the 🗣️ [Keyword Spotting subset](https://huggingface.co/datasets/superb#ks) of the SUPERB dataset.
+
+```bash
+python run_audio_classification.py \
+ --model_name_or_path facebook/wav2vec2-base \
+ --dataset_name superb \
+ --dataset_config_name ks \
+ --output_dir wav2vec2-base-ft-keyword-spotting \
+ --overwrite_output_dir \
+ --remove_unused_columns False \
+ --do_train \
+ --do_eval \
+ --fp16 \
+ --learning_rate 3e-5 \
+ --max_length_seconds 1 \
+ --attention_mask False \
+ --warmup_ratio 0.1 \
+ --num_train_epochs 5 \
+ --per_device_train_batch_size 32 \
+ --gradient_accumulation_steps 4 \
+ --per_device_eval_batch_size 32 \
+ --dataloader_num_workers 4 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --metric_for_best_model accuracy \
+ --save_total_limit 3 \
+ --seed 0 \
+ --push_to_hub
+```
+
+On a single V100 GPU (16GB), this script should run in ~14 minutes and yield accuracy of **98.26%**.
+
+👀 See the results here: [anton-l/wav2vec2-base-ft-keyword-spotting](https://huggingface.co/anton-l/wav2vec2-base-ft-keyword-spotting)
+
+> If your model classification head dimensions do not fit the number of labels in the dataset, you can specify `--ignore_mismatched_sizes` to adapt it.
+
+## Multi-GPU
+
+The following command shows how to fine-tune [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) for 🌎 **Language Identification** on the [CommonLanguage dataset](https://huggingface.co/datasets/anton-l/common_language).
+
+```bash
+python run_audio_classification.py \
+ --model_name_or_path facebook/wav2vec2-base \
+ --dataset_name common_language \
+ --audio_column_name audio \
+ --label_column_name language \
+ --output_dir wav2vec2-base-lang-id \
+ --overwrite_output_dir \
+ --remove_unused_columns False \
+ --do_train \
+ --do_eval \
+ --fp16 \
+ --learning_rate 3e-4 \
+ --max_length_seconds 16 \
+ --attention_mask False \
+ --warmup_ratio 0.1 \
+ --num_train_epochs 10 \
+ --per_device_train_batch_size 8 \
+ --gradient_accumulation_steps 4 \
+ --per_device_eval_batch_size 1 \
+ --dataloader_num_workers 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --metric_for_best_model accuracy \
+ --save_total_limit 3 \
+ --seed 0 \
+ --push_to_hub
+```
+
+On 4 V100 GPUs (16GB), this script should run in ~1 hour and yield accuracy of **79.45%**.
+
+👀 See the results here: [anton-l/wav2vec2-base-lang-id](https://huggingface.co/anton-l/wav2vec2-base-lang-id)
+
+## Sharing your model on 🤗 Hub
+
+0. If you haven't already, [sign up](https://huggingface.co/join) for a 🤗 account
+
+1. Make sure you have `git-lfs` installed and git set up.
+
+```bash
+$ apt install git-lfs
+```
+
+2. Log in with your HuggingFace account credentials using `huggingface-cli`
+
+```bash
+$ huggingface-cli login
+# ...follow the prompts
+```
+
+3. When running the script, pass the following arguments:
+
+```bash
+python run_audio_classification.py \
+ --push_to_hub \
+ --hub_model_id \
+ ...
+```
+
+### Examples
+
+The following table shows a couple of demonstration fine-tuning runs.
+It has been verified that the script works for the following datasets:
+
+- [SUPERB Keyword Spotting](https://huggingface.co/datasets/superb#ks)
+- [Common Language](https://huggingface.co/datasets/common_language)
+
+| Dataset | Pretrained Model | # transformer layers | Accuracy on eval | GPU setup | Training time | Fine-tuned Model & Logs |
+|---------|------------------|----------------------|------------------|-----------|---------------|--------------------------|
+| Keyword Spotting | [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) | 2 | 0.9706 | 1 V100 GPU | 11min | [here](https://huggingface.co/anton-l/distilhubert-ft-keyword-spotting) |
+| Keyword Spotting | [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) | 12 | 0.9826 | 1 V100 GPU | 14min | [here](https://huggingface.co/anton-l/wav2vec2-base-ft-keyword-spotting) |
+| Keyword Spotting | [facebook/hubert-base-ls960](https://huggingface.co/facebook/hubert-base-ls960) | 12 | 0.9819 | 1 V100 GPU | 14min | [here](https://huggingface.co/anton-l/hubert-base-ft-keyword-spotting) |
+| Keyword Spotting | [asapp/sew-mid-100k](https://huggingface.co/asapp/sew-mid-100k) | 24 | 0.9757 | 1 V100 GPU | 15min | [here](https://huggingface.co/anton-l/sew-mid-100k-ft-keyword-spotting) |
+| Common Language | [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) | 12 | 0.7945 | 4 V100 GPUs | 1h10m | [here](https://huggingface.co/anton-l/wav2vec2-base-lang-id) |
diff --git a/docs/transformers/examples/pytorch/audio-classification/requirements.txt b/docs/transformers/examples/pytorch/audio-classification/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..acf058d4cf46eaa3e7fe55012a9ecd9982a12bf3
--- /dev/null
+++ b/docs/transformers/examples/pytorch/audio-classification/requirements.txt
@@ -0,0 +1,5 @@
+datasets>=1.14.0
+evaluate
+librosa
+torchaudio
+torch>=1.6
\ No newline at end of file
diff --git a/docs/transformers/examples/pytorch/audio-classification/run_audio_classification.py b/docs/transformers/examples/pytorch/audio-classification/run_audio_classification.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ea627dbdd798f0859d13f3ea0c489edbce92deb
--- /dev/null
+++ b/docs/transformers/examples/pytorch/audio-classification/run_audio_classification.py
@@ -0,0 +1,432 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import logging
+import os
+import sys
+import warnings
+from dataclasses import dataclass, field
+from random import randint
+from typing import Optional
+
+import datasets
+import evaluate
+import numpy as np
+from datasets import DatasetDict, load_dataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoFeatureExtractor,
+ AutoModelForAudioClassification,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.14.0", "To fix: pip install -r examples/pytorch/audio-classification/requirements.txt")
+
+
+def random_subsample(wav: np.ndarray, max_length: float, sample_rate: int = 16000):
+ """Randomly sample chunks of `max_length` seconds from the input audio"""
+ sample_length = int(round(sample_rate * max_length))
+ if len(wav) <= sample_length:
+ return wav
+ random_offset = randint(0, len(wav) - sample_length - 1)
+ return wav[random_offset : random_offset + sample_length]
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ Using `HfArgumentParser` we can turn this class
+ into argparse arguments to be able to specify them on
+ the command line.
+ """
+
+ dataset_name: Optional[str] = field(default=None, metadata={"help": "Name of a dataset from the datasets package"})
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(
+ default=None, metadata={"help": "A file containing the training audio paths and labels."}
+ )
+ eval_file: Optional[str] = field(
+ default=None, metadata={"help": "A file containing the validation audio paths and labels."}
+ )
+ train_split_name: str = field(
+ default="train",
+ metadata={
+ "help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
+ },
+ )
+ eval_split_name: str = field(
+ default="validation",
+ metadata={
+ "help": (
+ "The name of the training data set split to use (via the datasets library). Defaults to 'validation'"
+ )
+ },
+ )
+ audio_column_name: str = field(
+ default="audio",
+ metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
+ )
+ label_column_name: str = field(
+ default="label", metadata={"help": "The name of the dataset column containing the labels. Defaults to 'label'"}
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_length_seconds: float = field(
+ default=20,
+ metadata={"help": "Audio clips will be randomly cut to this length during training if the value is set."},
+ )
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ default="facebook/wav2vec2-base",
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from the Hub"}
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ feature_extractor_name: Optional[str] = field(
+ default=None, metadata={"help": "Name or path of preprocessor config."}
+ )
+ freeze_feature_encoder: bool = field(
+ default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
+ )
+ attention_mask: bool = field(
+ default=True, metadata={"help": "Whether to generate an attention mask in the feature extractor."}
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ freeze_feature_extractor: Optional[bool] = field(
+ default=None, metadata={"help": "Whether to freeze the feature extractor layers of the model."}
+ )
+ ignore_mismatched_sizes: bool = field(
+ default=False,
+ metadata={"help": "Will enable to load a pretrained model whose head dimensions are different."},
+ )
+
+ def __post_init__(self):
+ if not self.freeze_feature_extractor and self.freeze_feature_encoder:
+ warnings.warn(
+ "The argument `--freeze_feature_extractor` is deprecated and "
+ "will be removed in a future version. Use `--freeze_feature_encoder` "
+ "instead. Setting `freeze_feature_encoder==True`.",
+ FutureWarning,
+ )
+ if self.freeze_feature_extractor and not self.freeze_feature_encoder:
+ raise ValueError(
+ "The argument `--freeze_feature_extractor` is deprecated and "
+ "should not be used in combination with `--freeze_feature_encoder`. "
+ "Only make use of `--freeze_feature_encoder`."
+ )
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_audio_classification", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to train from scratch."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Initialize our dataset and prepare it for the audio classification task.
+ raw_datasets = DatasetDict()
+ raw_datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=data_args.train_split_name,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ raw_datasets["eval"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=data_args.eval_split_name,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ if data_args.audio_column_name not in raw_datasets["train"].column_names:
+ raise ValueError(
+ f"--audio_column_name {data_args.audio_column_name} not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--audio_column_name` to the correct audio column - one of "
+ f"{', '.join(raw_datasets['train'].column_names)}."
+ )
+
+ if data_args.label_column_name not in raw_datasets["train"].column_names:
+ raise ValueError(
+ f"--label_column_name {data_args.label_column_name} not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--label_column_name` to the correct text column - one of "
+ f"{', '.join(raw_datasets['train'].column_names)}."
+ )
+
+ # Setting `return_attention_mask=True` is the way to get a correctly masked mean-pooling over
+ # transformer outputs in the classifier, but it doesn't always lead to better accuracy
+ feature_extractor = AutoFeatureExtractor.from_pretrained(
+ model_args.feature_extractor_name or model_args.model_name_or_path,
+ return_attention_mask=model_args.attention_mask,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # `datasets` takes care of automatically loading and resampling the audio,
+ # so we just need to set the correct target sampling rate.
+ raw_datasets = raw_datasets.cast_column(
+ data_args.audio_column_name, datasets.features.Audio(sampling_rate=feature_extractor.sampling_rate)
+ )
+
+ model_input_name = feature_extractor.model_input_names[0]
+
+ def train_transforms(batch):
+ """Apply train_transforms across a batch."""
+ subsampled_wavs = []
+ for audio in batch[data_args.audio_column_name]:
+ wav = random_subsample(
+ audio["array"], max_length=data_args.max_length_seconds, sample_rate=feature_extractor.sampling_rate
+ )
+ subsampled_wavs.append(wav)
+ inputs = feature_extractor(subsampled_wavs, sampling_rate=feature_extractor.sampling_rate)
+ output_batch = {model_input_name: inputs.get(model_input_name)}
+ output_batch["labels"] = list(batch[data_args.label_column_name])
+
+ return output_batch
+
+ def val_transforms(batch):
+ """Apply val_transforms across a batch."""
+ wavs = [audio["array"] for audio in batch[data_args.audio_column_name]]
+ inputs = feature_extractor(wavs, sampling_rate=feature_extractor.sampling_rate)
+ output_batch = {model_input_name: inputs.get(model_input_name)}
+ output_batch["labels"] = list(batch[data_args.label_column_name])
+
+ return output_batch
+
+ # Prepare label mappings.
+ # We'll include these in the model's config to get human readable labels in the Inference API.
+ labels = raw_datasets["train"].features[data_args.label_column_name].names
+ label2id, id2label = {}, {}
+ for i, label in enumerate(labels):
+ label2id[label] = str(i)
+ id2label[str(i)] = label
+
+ # Load the accuracy metric from the datasets package
+ metric = evaluate.load("accuracy", cache_dir=model_args.cache_dir)
+
+ # Define our compute_metrics function. It takes an `EvalPrediction` object (a namedtuple with
+ # `predictions` and `label_ids` fields) and has to return a dictionary string to float.
+ def compute_metrics(eval_pred):
+ """Computes accuracy on a batch of predictions"""
+ predictions = np.argmax(eval_pred.predictions, axis=1)
+ return metric.compute(predictions=predictions, references=eval_pred.label_ids)
+
+ config = AutoConfig.from_pretrained(
+ model_args.config_name or model_args.model_name_or_path,
+ num_labels=len(labels),
+ label2id=label2id,
+ id2label=id2label,
+ finetuning_task="audio-classification",
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = AutoModelForAudioClassification.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ ignore_mismatched_sizes=model_args.ignore_mismatched_sizes,
+ )
+
+ # freeze the convolutional waveform encoder
+ if model_args.freeze_feature_encoder:
+ model.freeze_feature_encoder()
+
+ if training_args.do_train:
+ if data_args.max_train_samples is not None:
+ raw_datasets["train"] = (
+ raw_datasets["train"].shuffle(seed=training_args.seed).select(range(data_args.max_train_samples))
+ )
+ # Set the training transforms
+ raw_datasets["train"].set_transform(train_transforms, output_all_columns=False)
+
+ if training_args.do_eval:
+ if data_args.max_eval_samples is not None:
+ raw_datasets["eval"] = (
+ raw_datasets["eval"].shuffle(seed=training_args.seed).select(range(data_args.max_eval_samples))
+ )
+ # Set the validation transforms
+ raw_datasets["eval"].set_transform(val_transforms, output_all_columns=False)
+
+ # Initialize our trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=raw_datasets["train"] if training_args.do_train else None,
+ eval_dataset=raw_datasets["eval"] if training_args.do_eval else None,
+ compute_metrics=compute_metrics,
+ processing_class=feature_extractor,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+ trainer.log_metrics("train", train_result.metrics)
+ trainer.save_metrics("train", train_result.metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ metrics = trainer.evaluate()
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Write model card and (optionally) push to hub
+ kwargs = {
+ "finetuned_from": model_args.model_name_or_path,
+ "tasks": "audio-classification",
+ "dataset": data_args.dataset_name,
+ "tags": ["audio-classification"],
+ }
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/conftest.py b/docs/transformers/examples/pytorch/conftest.py
new file mode 100644
index 0000000000000000000000000000000000000000..70b4d4c12bc48865c2dd98316b784844db237895
--- /dev/null
+++ b/docs/transformers/examples/pytorch/conftest.py
@@ -0,0 +1,45 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# tests directory-specific settings - this file is run automatically
+# by pytest before any tests are run
+
+import sys
+import warnings
+from os.path import abspath, dirname, join
+
+
+# allow having multiple repository checkouts and not needing to remember to rerun
+# `pip install -e '.[dev]'` when switching between checkouts and running tests.
+git_repo_path = abspath(join(dirname(dirname(dirname(__file__))), "src"))
+sys.path.insert(1, git_repo_path)
+
+
+# silence FutureWarning warnings in tests since often we can't act on them until
+# they become normal warnings - i.e. the tests still need to test the current functionality
+warnings.simplefilter(action="ignore", category=FutureWarning)
+
+
+def pytest_addoption(parser):
+ from transformers.testing_utils import pytest_addoption_shared
+
+ pytest_addoption_shared(parser)
+
+
+def pytest_terminal_summary(terminalreporter):
+ from transformers.testing_utils import pytest_terminal_summary_main
+
+ make_reports = terminalreporter.config.getoption("--make-reports")
+ if make_reports:
+ pytest_terminal_summary_main(terminalreporter, id=make_reports)
diff --git a/docs/transformers/examples/pytorch/contrastive-image-text/README.md b/docs/transformers/examples/pytorch/contrastive-image-text/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c39f17a138a632dfa6d1c79a149a45c9584bec51
--- /dev/null
+++ b/docs/transformers/examples/pytorch/contrastive-image-text/README.md
@@ -0,0 +1,102 @@
+
+
+# VisionTextDualEncoder and CLIP model training examples
+
+The following example showcases how to train a CLIP-like vision-text dual encoder model
+using a pre-trained vision and text encoder.
+
+Such a model can be used for natural language image search and potentially zero-shot image classification.
+The model is inspired by [CLIP](https://openai.com/blog/clip/), introduced by Alec Radford et al.
+The idea is to train a vision encoder and a text encoder jointly to project the representation of images and their
+captions into the same embedding space, such that the caption embeddings are located near the embeddings
+of the images they describe.
+
+### Download COCO dataset (2017)
+This example uses COCO dataset (2017) through a custom dataset script, which requires users to manually download the
+COCO dataset before training.
+
+```bash
+mkdir data
+cd data
+wget http://images.cocodataset.org/zips/train2017.zip
+wget http://images.cocodataset.org/zips/val2017.zip
+wget http://images.cocodataset.org/zips/test2017.zip
+wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
+wget http://images.cocodataset.org/annotations/image_info_test2017.zip
+cd ..
+```
+
+Having downloaded COCO dataset manually you should be able to load with the `ydshieh/coc_dataset_script` dataset loading script:
+
+```py
+import os
+import datasets
+
+COCO_DIR = os.path.join(os.getcwd(), "data")
+ds = datasets.load_dataset("ydshieh/coco_dataset_script", "2017", data_dir=COCO_DIR)
+```
+
+### Create a model from a vision encoder model and a text encoder model
+Next, we create a [VisionTextDualEncoderModel](https://huggingface.co/docs/transformers/model_doc/vision-text-dual-encoder#visiontextdualencoder).
+The `VisionTextDualEncoderModel` class lets you load any vision and text encoder model to create a dual encoder.
+Here is an example of how to load the model using pre-trained vision and text models.
+
+```python3
+from transformers import (
+ VisionTextDualEncoderModel,
+ VisionTextDualEncoderProcessor,
+ AutoTokenizer,
+ AutoImageProcessor
+)
+
+model = VisionTextDualEncoderModel.from_vision_text_pretrained(
+ "openai/clip-vit-base-patch32", "FacebookAI/roberta-base"
+)
+
+tokenizer = AutoTokenizer.from_pretrained("FacebookAI/roberta-base")
+image_processor = AutoImageProcessor.from_pretrained("openai/clip-vit-base-patch32")
+processor = VisionTextDualEncoderProcessor(image_processor, tokenizer)
+
+# save the model and processor
+model.save_pretrained("clip-roberta")
+processor.save_pretrained("clip-roberta")
+```
+
+This loads both the text and vision encoders using pre-trained weights, the projection layers are randomly
+initialized except for CLIP's vision model. If you use CLIP to initialize the vision model then the vision projection weights are also
+loaded using the pre-trained weights.
+
+### Train the model
+Finally, we can run the example script to train the model:
+
+```bash
+python examples/pytorch/contrastive-image-text/run_clip.py \
+ --output_dir ./clip-roberta-finetuned \
+ --model_name_or_path ./clip-roberta \
+ --data_dir $PWD/data \
+ --dataset_name ydshieh/coco_dataset_script \
+ --dataset_config_name=2017 \
+ --image_column image_path \
+ --caption_column caption \
+ --remove_unused_columns=False \
+ --do_train --do_eval \
+ --per_device_train_batch_size="64" \
+ --per_device_eval_batch_size="64" \
+ --learning_rate="5e-5" --warmup_steps="0" --weight_decay 0.1 \
+ --overwrite_output_dir \
+ --push_to_hub
+```
diff --git a/docs/transformers/examples/pytorch/contrastive-image-text/requirements.txt b/docs/transformers/examples/pytorch/contrastive-image-text/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a789fee85eef5d028375e406c5ea7df85a56c738
--- /dev/null
+++ b/docs/transformers/examples/pytorch/contrastive-image-text/requirements.txt
@@ -0,0 +1,3 @@
+torch>=1.5.0
+torchvision>=0.6.0
+datasets>=1.8.0
\ No newline at end of file
diff --git a/docs/transformers/examples/pytorch/contrastive-image-text/run_clip.py b/docs/transformers/examples/pytorch/contrastive-image-text/run_clip.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f5d8eef7c952edf82300f32b9bd366651d6ef3f
--- /dev/null
+++ b/docs/transformers/examples/pytorch/contrastive-image-text/run_clip.py
@@ -0,0 +1,531 @@
+#!/usr/bin/env python
+# Copyright 2022 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Training a CLIP like dual encoder models using text and vision encoders in the library.
+
+The script can be used to train CLIP like models for languages other than English by using
+a text encoder pre-trained in the desired language. Currently this script supports the following vision
+and text models:
+Vision models: ViT(https://huggingface.co/models?filter=vit), CLIP (https://huggingface.co/models?filter=clip)
+Text models: BERT, ROBERTa (https://huggingface.co/models?filter=fill-mask)
+"""
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import torch
+from datasets import load_dataset
+from PIL import Image
+from torchvision.io import ImageReadMode, read_image
+from torchvision.transforms import CenterCrop, ConvertImageDtype, Normalize, Resize
+from torchvision.transforms.functional import InterpolationMode
+
+import transformers
+from transformers import (
+ AutoImageProcessor,
+ AutoModel,
+ AutoTokenizer,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/contrastive-image-text/requirements.txt")
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ image_processor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ freeze_vision_model: bool = field(
+ default=False, metadata={"help": "Whether to freeze the vision model parameters or not."}
+ )
+ freeze_text_model: bool = field(
+ default=False, metadata={"help": "Whether to freeze the text model parameters or not."}
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ data_dir: Optional[str] = field(default=None, metadata={"help": "The data directory containing input files."})
+ image_column: Optional[str] = field(
+ default="image_path",
+ metadata={"help": "The name of the column in the datasets containing the full image file paths."},
+ )
+ caption_column: Optional[str] = field(
+ default="caption",
+ metadata={"help": "The name of the column in the datasets containing the image captions."},
+ )
+ train_file: Optional[str] = field(
+ default=None, metadata={"help": "The input training data file (a jsonlines file)."}
+ )
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file (a jsonlines file)."},
+ )
+ max_seq_length: Optional[int] = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+
+
+dataset_name_mapping = {
+ "image_caption_dataset.py": ("image_path", "caption"),
+}
+
+
+# We use torchvision for faster image pre-processing. The transforms are implemented as nn.Module,
+# so we jit it to be faster.
+class Transform(torch.nn.Module):
+ def __init__(self, image_size, mean, std):
+ super().__init__()
+ self.transforms = torch.nn.Sequential(
+ Resize([image_size], interpolation=InterpolationMode.BICUBIC),
+ CenterCrop(image_size),
+ ConvertImageDtype(torch.float),
+ Normalize(mean, std),
+ )
+
+ def forward(self, x) -> torch.Tensor:
+ """`x` should be an instance of `PIL.Image.Image`"""
+ with torch.no_grad():
+ x = self.transforms(x)
+ return x
+
+
+def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ input_ids = torch.tensor([example["input_ids"] for example in examples], dtype=torch.long)
+ attention_mask = torch.tensor([example["attention_mask"] for example in examples], dtype=torch.long)
+ return {
+ "pixel_values": pixel_values,
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "return_loss": True,
+ }
+
+
+def main():
+ # 1. Parse input arguments
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_clip", model_args, data_args)
+
+ # 2. Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # 3. Detecting last checkpoint and eventually continue from last checkpoint
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # 4. Load dataset
+ # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files this script will use the first column for the full image path and the second column for the
+ # captions (unless you specify column names for this with the `image_column` and `caption_column` arguments).
+ #
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ dataset = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ keep_in_memory=False,
+ data_dir=data_args.data_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ dataset = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # 5. Load pretrained model, tokenizer, and image processor
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ # Load image_processor, in this script we only use this to get the mean and std for normalization.
+ image_processor = AutoImageProcessor.from_pretrained(
+ model_args.image_processor_name or model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ model = AutoModel.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ config = model.config
+
+ def _freeze_params(module):
+ for param in module.parameters():
+ param.requires_grad = False
+
+ if model_args.freeze_vision_model:
+ _freeze_params(model.vision_model)
+
+ if model_args.freeze_text_model:
+ _freeze_params(model.text_model)
+
+ # set seed for torch dataloaders
+ set_seed(training_args.seed)
+
+ # Preprocessing the datasets.
+ # We need to tokenize inputs and targets.
+ if training_args.do_train:
+ column_names = dataset["train"].column_names
+ elif training_args.do_eval:
+ column_names = dataset["validation"].column_names
+ else:
+ logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
+ return
+
+ # 6. Get the column names for input/target.
+ dataset_columns = dataset_name_mapping.get(data_args.dataset_name, None)
+ if data_args.image_column is None:
+ image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ image_column = data_args.image_column
+ if image_column not in column_names:
+ raise ValueError(
+ f"--image_column' value '{data_args.image_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if data_args.caption_column is None:
+ caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ caption_column = data_args.caption_column
+ if caption_column not in column_names:
+ raise ValueError(
+ f"--caption_column' value '{data_args.caption_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # 7. Preprocessing the datasets.
+ # Initialize torchvision transforms and jit it for faster processing.
+ image_transformations = Transform(
+ config.vision_config.image_size, image_processor.image_mean, image_processor.image_std
+ )
+ image_transformations = torch.jit.script(image_transformations)
+
+ # Preprocessing the datasets.
+ # We need to tokenize input captions and transform the images.
+ def tokenize_captions(examples):
+ captions = list(examples[caption_column])
+ text_inputs = tokenizer(captions, max_length=data_args.max_seq_length, padding="max_length", truncation=True)
+ examples["input_ids"] = text_inputs.input_ids
+ examples["attention_mask"] = text_inputs.attention_mask
+ return examples
+
+ def transform_images(examples):
+ images = [read_image(image_file, mode=ImageReadMode.RGB) for image_file in examples[image_column]]
+ examples["pixel_values"] = [image_transformations(image) for image in images]
+ return examples
+
+ def filter_corrupt_images(examples):
+ """remove problematic images"""
+ valid_images = []
+ for image_file in examples[image_column]:
+ try:
+ Image.open(image_file)
+ valid_images.append(True)
+ except Exception:
+ valid_images.append(False)
+ return valid_images
+
+ if training_args.do_train:
+ if "train" not in dataset:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = dataset["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+
+ train_dataset = train_dataset.filter(
+ filter_corrupt_images, batched=True, num_proc=data_args.preprocessing_num_workers
+ )
+ train_dataset = train_dataset.map(
+ function=tokenize_captions,
+ batched=True,
+ remove_columns=[col for col in column_names if col != image_column],
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+
+ # Transform images on the fly as doing it on the whole dataset takes too much time.
+ train_dataset.set_transform(transform_images)
+
+ if training_args.do_eval:
+ if "validation" not in dataset:
+ raise ValueError("--do_eval requires a train validation")
+ eval_dataset = dataset["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ eval_dataset = eval_dataset.filter(
+ filter_corrupt_images, batched=True, num_proc=data_args.preprocessing_num_workers
+ )
+ eval_dataset = eval_dataset.map(
+ function=tokenize_captions,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=[col for col in column_names if col != image_column],
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+
+ # Transform images on the fly as doing it on the whole dataset takes too much time.
+ eval_dataset.set_transform(transform_images)
+
+ # 8. Initialize our trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ data_collator=collate_fn,
+ )
+
+ # 9. Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+ tokenizer.save_pretrained(training_args.output_dir)
+ image_processor.save_pretrained(training_args.output_dir)
+ trainer.log_metrics("train", train_result.metrics)
+ trainer.save_metrics("train", train_result.metrics)
+ trainer.save_state()
+
+ # 10. Evaluation
+ if training_args.do_eval:
+ metrics = trainer.evaluate()
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # 11. Write Training Stats and push to hub.
+ finetuned_from = model_args.model_name_or_path
+ # If from a local directory, don't set `finetuned_from` as this is required to be a valid repo. id on the Hub.
+ if os.path.isdir(finetuned_from):
+ finetuned_from = None
+ kwargs = {"finetuned_from": finetuned_from, "tasks": "contrastive-image-text-modeling"}
+ if data_args.dataset_name is not None:
+ kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ kwargs["dataset_args"] = data_args.dataset_config_name
+ kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/image-classification/README.md b/docs/transformers/examples/pytorch/image-classification/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..62996ee19e375ae8d802acaa1b8a02fbe5001ac5
--- /dev/null
+++ b/docs/transformers/examples/pytorch/image-classification/README.md
@@ -0,0 +1,212 @@
+
+
+# Image classification examples
+
+This directory contains 2 scripts that showcase how to fine-tune any model supported by the [`AutoModelForImageClassification` API](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForImageClassification) (such as [ViT](https://huggingface.co/docs/transformers/main/en/model_doc/vit), [ConvNeXT](https://huggingface.co/docs/transformers/main/en/model_doc/convnext), [ResNet](https://huggingface.co/docs/transformers/main/en/model_doc/resnet), [Swin Transformer](https://huggingface.co/docs/transformers/main/en/model_doc/swin)...) using PyTorch. They can be used to fine-tune models on both [datasets from the hub](#using-datasets-from-hub) as well as on [your own custom data](#using-your-own-data).
+
+
+
+Try out the inference widget here: https://huggingface.co/google/vit-base-patch16-224
+
+Content:
+- [PyTorch version, Trainer](#pytorch-version-trainer)
+- [PyTorch version, no Trainer](#pytorch-version-no-trainer)
+
+## PyTorch version, Trainer
+
+Based on the script [`run_image_classification.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/image-classification/run_image_classification.py).
+
+The script leverages the 🤗 [Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer) to automatically take care of the training for you, running on distributed environments right away.
+
+### Using datasets from Hub
+
+Here we show how to fine-tune a Vision Transformer (`ViT`) on the [beans](https://huggingface.co/datasets/beans) dataset, to classify the disease type of bean leaves.
+
+```bash
+python run_image_classification.py \
+ --dataset_name beans \
+ --output_dir ./beans_outputs/ \
+ --remove_unused_columns False \
+ --label_column_name labels \
+ --do_train \
+ --do_eval \
+ --push_to_hub \
+ --push_to_hub_model_id vit-base-beans \
+ --learning_rate 2e-5 \
+ --num_train_epochs 5 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+👀 See the results here: [nateraw/vit-base-beans](https://huggingface.co/nateraw/vit-base-beans).
+
+Note that you can replace the model and dataset by simply setting the `model_name_or_path` and `dataset_name` arguments respectively, with any model or dataset from the [hub](https://huggingface.co/). For an overview of all possible arguments, we refer to the [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) of the `TrainingArguments`, which can be passed as flags.
+
+> If your model classification head dimensions do not fit the number of labels in the dataset, you can specify `--ignore_mismatched_sizes` to adapt it.
+
+### Using your own data
+
+To use your own dataset, there are 2 ways:
+- you can either provide your own folders as `--train_dir` and/or `--validation_dir` arguments
+- you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
+
+Below, we explain both in more detail.
+
+#### Provide them as folders
+
+If you provide your own folders with images, the script expects the following directory structure:
+
+```bash
+root/dog/xxx.png
+root/dog/xxy.png
+root/dog/[...]/xxz.png
+
+root/cat/123.png
+root/cat/nsdf3.png
+root/cat/[...]/asd932_.png
+```
+
+In other words, you need to organize your images in subfolders, based on their class. You can then run the script like this:
+
+```bash
+python run_image_classification.py \
+ --train_dir \
+ --output_dir ./outputs/ \
+ --remove_unused_columns False \
+ --do_train \
+ --do_eval
+```
+
+Internally, the script will use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature which will automatically turn the folders into 🤗 Dataset objects.
+
+##### 💡 The above will split the train dir into training and evaluation sets
+ - To control the split amount, use the `--train_val_split` flag.
+ - To provide your own validation split in its own directory, you can pass the `--validation_dir ` flag.
+
+#### Upload your data to the hub, as a (possibly private) repo
+
+It's very easy (and convenient) to upload your image dataset to the hub using the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature available in 🤗 Datasets. Simply do the following:
+
+```python
+from datasets import load_dataset
+
+# example 1: local folder
+dataset = load_dataset("imagefolder", data_dir="path_to_your_folder")
+
+# example 2: local files (supported formats are tar, gzip, zip, xz, rar, zstd)
+dataset = load_dataset("imagefolder", data_files="path_to_zip_file")
+
+# example 3: remote files (supported formats are tar, gzip, zip, xz, rar, zstd)
+dataset = load_dataset("imagefolder", data_files="https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip")
+
+# example 4: providing several splits
+dataset = load_dataset("imagefolder", data_files={"train": ["path/to/file1", "path/to/file2"], "test": ["path/to/file3", "path/to/file4"]})
+```
+
+`ImageFolder` will create a `label` column, and the label name is based on the directory name.
+
+Next, push it to the hub!
+
+```python
+# assuming you have ran the huggingface-cli login command in a terminal
+dataset.push_to_hub("name_of_your_dataset")
+
+# if you want to push to a private repo, simply pass private=True:
+dataset.push_to_hub("name_of_your_dataset", private=True)
+```
+
+and that's it! You can now train your model by simply setting the `--dataset_name` argument to the name of your dataset on the hub (as explained in [Using datasets from the 🤗 hub](#using-datasets-from-hub)).
+
+More on this can also be found in [this blog post](https://huggingface.co/blog/image-search-datasets).
+
+### Sharing your model on 🤗 Hub
+
+0. If you haven't already, [sign up](https://huggingface.co/join) for a 🤗 account
+
+1. Make sure you have `git-lfs` installed and git set up.
+
+```bash
+$ apt install git-lfs
+$ git config --global user.email "you@example.com"
+$ git config --global user.name "Your Name"
+```
+
+2. Log in with your HuggingFace account credentials using `huggingface-cli`:
+
+```bash
+$ huggingface-cli login
+# ...follow the prompts
+```
+
+3. When running the script, pass the following arguments:
+
+```bash
+python run_image_classification.py \
+ --push_to_hub \
+ --push_to_hub_model_id \
+ ...
+```
+
+## PyTorch version, no Trainer
+
+Based on the script [`run_image_classification_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/image-classification/run_image_classification_no_trainer.py).
+
+Like `run_image_classification.py`, this script allows you to fine-tune any of the models on the [hub](https://huggingface.co/models) on an image classification task. The main difference is that this script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like.
+
+It offers less options than the script with `Trainer` (for instance you can easily change the options for the optimizer
+or the dataloaders directly in the script) but still run in a distributed setup, and supports mixed precision by
+the means of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
+after installing it:
+
+```bash
+pip install git+https://github.com/huggingface/accelerate
+```
+
+You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
+
+```bash
+accelerate config
+```
+
+and reply to the questions asked. Then
+
+```bash
+accelerate test
+```
+
+that will check everything is ready for training. Finally, you can launch training with
+
+```bash
+accelerate launch run_image_classification_no_trainer.py --image_column_name img
+```
+
+This command is the same and will work for:
+
+- single/multiple CPUs
+- single/multiple GPUs
+- TPUs
+
+Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
+
+Regarding using custom data with this script, we refer to [using your own data](#using-your-own-data).
diff --git a/docs/transformers/examples/pytorch/image-classification/requirements.txt b/docs/transformers/examples/pytorch/image-classification/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..4926040789832ba95a79eacccba57239e5b98757
--- /dev/null
+++ b/docs/transformers/examples/pytorch/image-classification/requirements.txt
@@ -0,0 +1,5 @@
+accelerate>=0.12.0
+torch>=1.5.0
+torchvision>=0.6.0
+datasets>=2.14.0
+evaluate
\ No newline at end of file
diff --git a/docs/transformers/examples/pytorch/image-classification/run_image_classification.py b/docs/transformers/examples/pytorch/image-classification/run_image_classification.py
new file mode 100644
index 0000000000000000000000000000000000000000..9d70c80ea6e216d89c2b1ddf139cdefd8ad302f0
--- /dev/null
+++ b/docs/transformers/examples/pytorch/image-classification/run_image_classification.py
@@ -0,0 +1,441 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import evaluate
+import numpy as np
+import torch
+from datasets import load_dataset
+from PIL import Image
+from torchvision.transforms import (
+ CenterCrop,
+ Compose,
+ Lambda,
+ Normalize,
+ RandomHorizontalFlip,
+ RandomResizedCrop,
+ Resize,
+ ToTensor,
+)
+
+import transformers
+from transformers import (
+ MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
+ AutoConfig,
+ AutoImageProcessor,
+ AutoModelForImageClassification,
+ HfArgumentParser,
+ TimmWrapperImageProcessor,
+ Trainer,
+ TrainingArguments,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+""" Fine-tuning a 🤗 Transformers model for image classification"""
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=2.14.0", "To fix: pip install -r examples/pytorch/image-classification/requirements.txt")
+
+MODEL_CONFIG_CLASSES = list(MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+def pil_loader(path: str):
+ with open(path, "rb") as f:
+ im = Image.open(f)
+ return im.convert("RGB")
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ Using `HfArgumentParser` we can turn this class into argparse arguments to be able to specify
+ them on the command line.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": "Name of a dataset from the hub (could be your own, possibly private dataset hosted on the hub)."
+ },
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the training data."})
+ validation_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the validation data."})
+ train_val_split: Optional[float] = field(
+ default=0.15, metadata={"help": "Percent to split off of train for validation."}
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ image_column_name: str = field(
+ default="image",
+ metadata={"help": "The name of the dataset column containing the image data. Defaults to 'image'."},
+ )
+ label_column_name: str = field(
+ default="label",
+ metadata={"help": "The name of the dataset column containing the labels. Defaults to 'label'."},
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and (self.train_dir is None and self.validation_dir is None):
+ raise ValueError(
+ "You must specify either a dataset name from the hub or a train and/or validation directory."
+ )
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ default="google/vit-base-patch16-224-in21k",
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ image_processor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ ignore_mismatched_sizes: bool = field(
+ default=False,
+ metadata={"help": "Will enable to load a pretrained model whose head dimensions are different."},
+ )
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_image_classification", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Initialize our dataset and prepare it for the 'image-classification' task.
+ if data_args.dataset_name is not None:
+ dataset = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_dir is not None:
+ data_files["train"] = os.path.join(data_args.train_dir, "**")
+ if data_args.validation_dir is not None:
+ data_files["validation"] = os.path.join(data_args.validation_dir, "**")
+ dataset = load_dataset(
+ "imagefolder",
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ )
+
+ dataset_column_names = dataset["train"].column_names if "train" in dataset else dataset["validation"].column_names
+ if data_args.image_column_name not in dataset_column_names:
+ raise ValueError(
+ f"--image_column_name {data_args.image_column_name} not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--image_column_name` to the correct audio column - one of "
+ f"{', '.join(dataset_column_names)}."
+ )
+ if data_args.label_column_name not in dataset_column_names:
+ raise ValueError(
+ f"--label_column_name {data_args.label_column_name} not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--label_column_name` to the correct text column - one of "
+ f"{', '.join(dataset_column_names)}."
+ )
+
+ def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ labels = torch.tensor([example[data_args.label_column_name] for example in examples])
+ return {"pixel_values": pixel_values, "labels": labels}
+
+ # If we don't have a validation split, split off a percentage of train as validation.
+ data_args.train_val_split = None if "validation" in dataset.keys() else data_args.train_val_split
+ if isinstance(data_args.train_val_split, float) and data_args.train_val_split > 0.0:
+ split = dataset["train"].train_test_split(data_args.train_val_split)
+ dataset["train"] = split["train"]
+ dataset["validation"] = split["test"]
+
+ # Prepare label mappings.
+ # We'll include these in the model's config to get human readable labels in the Inference API.
+ labels = dataset["train"].features[data_args.label_column_name].names
+ label2id, id2label = {}, {}
+ for i, label in enumerate(labels):
+ label2id[label] = str(i)
+ id2label[str(i)] = label
+
+ # Load the accuracy metric from the datasets package
+ metric = evaluate.load("accuracy", cache_dir=model_args.cache_dir)
+
+ # Define our compute_metrics function. It takes an `EvalPrediction` object (a namedtuple with a
+ # predictions and label_ids field) and has to return a dictionary string to float.
+ def compute_metrics(p):
+ """Computes accuracy on a batch of predictions"""
+ return metric.compute(predictions=np.argmax(p.predictions, axis=1), references=p.label_ids)
+
+ config = AutoConfig.from_pretrained(
+ model_args.config_name or model_args.model_name_or_path,
+ num_labels=len(labels),
+ label2id=label2id,
+ id2label=id2label,
+ finetuning_task="image-classification",
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = AutoModelForImageClassification.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ ignore_mismatched_sizes=model_args.ignore_mismatched_sizes,
+ )
+ image_processor = AutoImageProcessor.from_pretrained(
+ model_args.image_processor_name or model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # Define torchvision transforms to be applied to each image.
+ if isinstance(image_processor, TimmWrapperImageProcessor):
+ _train_transforms = image_processor.train_transforms
+ _val_transforms = image_processor.val_transforms
+ else:
+ if "shortest_edge" in image_processor.size:
+ size = image_processor.size["shortest_edge"]
+ else:
+ size = (image_processor.size["height"], image_processor.size["width"])
+
+ # Create normalization transform
+ if hasattr(image_processor, "image_mean") and hasattr(image_processor, "image_std"):
+ normalize = Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
+ else:
+ normalize = Lambda(lambda x: x)
+ _train_transforms = Compose(
+ [
+ RandomResizedCrop(size),
+ RandomHorizontalFlip(),
+ ToTensor(),
+ normalize,
+ ]
+ )
+ _val_transforms = Compose(
+ [
+ Resize(size),
+ CenterCrop(size),
+ ToTensor(),
+ normalize,
+ ]
+ )
+
+ def train_transforms(example_batch):
+ """Apply _train_transforms across a batch."""
+ example_batch["pixel_values"] = [
+ _train_transforms(pil_img.convert("RGB")) for pil_img in example_batch[data_args.image_column_name]
+ ]
+ return example_batch
+
+ def val_transforms(example_batch):
+ """Apply _val_transforms across a batch."""
+ example_batch["pixel_values"] = [
+ _val_transforms(pil_img.convert("RGB")) for pil_img in example_batch[data_args.image_column_name]
+ ]
+ return example_batch
+
+ if training_args.do_train:
+ if "train" not in dataset:
+ raise ValueError("--do_train requires a train dataset")
+ if data_args.max_train_samples is not None:
+ dataset["train"] = (
+ dataset["train"].shuffle(seed=training_args.seed).select(range(data_args.max_train_samples))
+ )
+ # Set the training transforms
+ dataset["train"].set_transform(train_transforms)
+
+ if training_args.do_eval:
+ if "validation" not in dataset:
+ raise ValueError("--do_eval requires a validation dataset")
+ if data_args.max_eval_samples is not None:
+ dataset["validation"] = (
+ dataset["validation"].shuffle(seed=training_args.seed).select(range(data_args.max_eval_samples))
+ )
+ # Set the validation transforms
+ dataset["validation"].set_transform(val_transforms)
+
+ # Initialize our trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=dataset["train"] if training_args.do_train else None,
+ eval_dataset=dataset["validation"] if training_args.do_eval else None,
+ compute_metrics=compute_metrics,
+ processing_class=image_processor,
+ data_collator=collate_fn,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+ trainer.log_metrics("train", train_result.metrics)
+ trainer.save_metrics("train", train_result.metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ metrics = trainer.evaluate()
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Write model card and (optionally) push to hub
+ kwargs = {
+ "finetuned_from": model_args.model_name_or_path,
+ "tasks": "image-classification",
+ "dataset": data_args.dataset_name,
+ "tags": ["image-classification", "vision"],
+ }
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/image-classification/run_image_classification_no_trainer.py b/docs/transformers/examples/pytorch/image-classification/run_image_classification_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..45259b1b0a6e59df6e0cd19b2945b6b3111988e4
--- /dev/null
+++ b/docs/transformers/examples/pytorch/image-classification/run_image_classification_no_trainer.py
@@ -0,0 +1,645 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Finetuning any 🤗 Transformers model for image classification leveraging 🤗 Accelerate."""
+
+import argparse
+import json
+import logging
+import math
+import os
+from pathlib import Path
+
+import datasets
+import evaluate
+import torch
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from datasets import load_dataset
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from torchvision.transforms import (
+ CenterCrop,
+ Compose,
+ Lambda,
+ Normalize,
+ RandomHorizontalFlip,
+ RandomResizedCrop,
+ Resize,
+ ToTensor,
+)
+from tqdm.auto import tqdm
+
+import transformers
+from transformers import AutoConfig, AutoImageProcessor, AutoModelForImageClassification, SchedulerType, get_scheduler
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logger = get_logger(__name__)
+
+require_version("datasets>=2.0.0", "To fix: pip install -r examples/pytorch/image-classification/requirements.txt")
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Fine-tune a Transformers model on an image classification dataset")
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default="cifar10",
+ help=(
+ "The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
+ " dataset)."
+ ),
+ )
+ parser.add_argument("--train_dir", type=str, default=None, help="A folder containing the training data.")
+ parser.add_argument("--validation_dir", type=str, default=None, help="A folder containing the validation data.")
+ parser.add_argument(
+ "--max_train_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--max_eval_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--train_val_split",
+ type=float,
+ default=0.15,
+ help="Percent to split off of train for validation",
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ default="google/vit-base-patch16-224-in21k",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--ignore_mismatched_sizes",
+ action="store_true",
+ help="Whether or not to enable to load a pretrained model whose head dimensions are different.",
+ )
+ parser.add_argument(
+ "--image_column_name",
+ type=str,
+ default="image",
+ help="The name of the dataset column containing the image data. Defaults to 'image'.",
+ )
+ parser.add_argument(
+ "--label_column_name",
+ type=str,
+ default="label",
+ help="The name of the dataset column containing the labels. Defaults to 'label'.",
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+ if args.dataset_name is None and args.train_dir is None and args.validation_dir is None:
+ raise ValueError("Need either a dataset name or a training/validation folder.")
+
+ if args.push_to_hub or args.with_tracking:
+ if args.output_dir is None:
+ raise ValueError(
+ "Need an `output_dir` to create a repo when `--push_to_hub` or `with_tracking` is specified."
+ )
+
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_image_classification_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator_log_kwargs = {}
+
+ if args.with_tracking:
+ accelerator_log_kwargs["log_with"] = args.report_to
+ accelerator_log_kwargs["project_dir"] = args.output_dir
+
+ accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
+
+ logger.info(accelerator.state)
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Get the datasets: you can either provide your own training and evaluation files (see below)
+ # or specify a Dataset from the hub (the dataset will be downloaded automatically from the datasets Hub).
+
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ dataset = load_dataset(args.dataset_name, trust_remote_code=args.trust_remote_code)
+ else:
+ data_files = {}
+ if args.train_dir is not None:
+ data_files["train"] = os.path.join(args.train_dir, "**")
+ if args.validation_dir is not None:
+ data_files["validation"] = os.path.join(args.validation_dir, "**")
+ dataset = load_dataset(
+ "imagefolder",
+ data_files=data_files,
+ )
+ # See more about loading custom images at
+ # https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder.
+
+ dataset_column_names = dataset["train"].column_names if "train" in dataset else dataset["validation"].column_names
+ if args.image_column_name not in dataset_column_names:
+ raise ValueError(
+ f"--image_column_name {args.image_column_name} not found in dataset '{args.dataset_name}'. "
+ "Make sure to set `--image_column_name` to the correct audio column - one of "
+ f"{', '.join(dataset_column_names)}."
+ )
+ if args.label_column_name not in dataset_column_names:
+ raise ValueError(
+ f"--label_column_name {args.label_column_name} not found in dataset '{args.dataset_name}'. "
+ "Make sure to set `--label_column_name` to the correct text column - one of "
+ f"{', '.join(dataset_column_names)}."
+ )
+
+ # If we don't have a validation split, split off a percentage of train as validation.
+ args.train_val_split = None if "validation" in dataset.keys() else args.train_val_split
+ if isinstance(args.train_val_split, float) and args.train_val_split > 0.0:
+ split = dataset["train"].train_test_split(args.train_val_split)
+ dataset["train"] = split["train"]
+ dataset["validation"] = split["test"]
+
+ # Prepare label mappings.
+ # We'll include these in the model's config to get human readable labels in the Inference API.
+ labels = dataset["train"].features[args.label_column_name].names
+ label2id = {label: str(i) for i, label in enumerate(labels)}
+ id2label = {str(i): label for i, label in enumerate(labels)}
+
+ # Load pretrained model and image processor
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ args.model_name_or_path,
+ num_labels=len(labels),
+ id2label=id2label,
+ label2id=label2id,
+ finetuning_task="image-classification",
+ trust_remote_code=args.trust_remote_code,
+ )
+ image_processor = AutoImageProcessor.from_pretrained(
+ args.model_name_or_path,
+ trust_remote_code=args.trust_remote_code,
+ )
+ model = AutoModelForImageClassification.from_pretrained(
+ args.model_name_or_path,
+ from_tf=bool(".ckpt" in args.model_name_or_path),
+ config=config,
+ ignore_mismatched_sizes=args.ignore_mismatched_sizes,
+ trust_remote_code=args.trust_remote_code,
+ )
+
+ # Preprocessing the datasets
+
+ # Define torchvision transforms to be applied to each image.
+ if "shortest_edge" in image_processor.size:
+ size = image_processor.size["shortest_edge"]
+ else:
+ size = (image_processor.size["height"], image_processor.size["width"])
+ normalize = (
+ Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
+ if hasattr(image_processor, "image_mean") and hasattr(image_processor, "image_std")
+ else Lambda(lambda x: x)
+ )
+ train_transforms = Compose(
+ [
+ RandomResizedCrop(size),
+ RandomHorizontalFlip(),
+ ToTensor(),
+ normalize,
+ ]
+ )
+ val_transforms = Compose(
+ [
+ Resize(size),
+ CenterCrop(size),
+ ToTensor(),
+ normalize,
+ ]
+ )
+
+ def preprocess_train(example_batch):
+ """Apply _train_transforms across a batch."""
+ example_batch["pixel_values"] = [
+ train_transforms(image.convert("RGB")) for image in example_batch[args.image_column_name]
+ ]
+ return example_batch
+
+ def preprocess_val(example_batch):
+ """Apply _val_transforms across a batch."""
+ example_batch["pixel_values"] = [
+ val_transforms(image.convert("RGB")) for image in example_batch[args.image_column_name]
+ ]
+ return example_batch
+
+ with accelerator.main_process_first():
+ if args.max_train_samples is not None:
+ dataset["train"] = dataset["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
+ # Set the training transforms
+ train_dataset = dataset["train"].with_transform(preprocess_train)
+ if args.max_eval_samples is not None:
+ dataset["validation"] = dataset["validation"].shuffle(seed=args.seed).select(range(args.max_eval_samples))
+ # Set the validation transforms
+ eval_dataset = dataset["validation"].with_transform(preprocess_val)
+
+ # DataLoaders creation:
+ def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ labels = torch.tensor([example[args.label_column_name] for example in examples])
+ return {"pixel_values": pixel_values, "labels": labels}
+
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, collate_fn=collate_fn, batch_size=args.per_device_train_batch_size
+ )
+ eval_dataloader = DataLoader(eval_dataset, collate_fn=collate_fn, batch_size=args.per_device_eval_batch_size)
+
+ # Optimizer
+ # Split weights in two groups, one with weight decay and the other not.
+ no_decay = ["bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps
+ if overrode_max_train_steps
+ else args.max_train_steps * accelerator.num_processes,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("image_classification_no_trainer", experiment_config)
+
+ # Get the metric function
+ metric = evaluate.load("accuracy")
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+ for step, batch in enumerate(active_dataloader):
+ with accelerator.accumulate(model):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+ accelerator.backward(loss)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir,
+ is_main_process=accelerator.is_main_process,
+ save_function=accelerator.save,
+ )
+ if accelerator.is_main_process:
+ image_processor.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ model.eval()
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+ predictions = outputs.logits.argmax(dim=-1)
+ predictions, references = accelerator.gather_for_metrics((predictions, batch["labels"]))
+ metric.add_batch(
+ predictions=predictions,
+ references=references,
+ )
+
+ eval_metric = metric.compute()
+ logger.info(f"epoch {epoch}: {eval_metric}")
+
+ if args.with_tracking:
+ accelerator.log(
+ {
+ "accuracy": eval_metric,
+ "train_loss": total_loss.item() / len(train_dataloader),
+ "epoch": epoch,
+ "step": completed_steps,
+ },
+ step=completed_steps,
+ )
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ image_processor.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ image_processor.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+ all_results = {f"eval_{k}": v for k, v in eval_metric.items()}
+ with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
+ json.dump(all_results, f)
+
+ accelerator.wait_for_everyone()
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/image-pretraining/README.md b/docs/transformers/examples/pytorch/image-pretraining/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..88c71e643e4c24ee06e59a816ce98b879fa69f1d
--- /dev/null
+++ b/docs/transformers/examples/pytorch/image-pretraining/README.md
@@ -0,0 +1,256 @@
+
+
+# Image pretraining examples
+
+This directory contains Python scripts that allow you to pre-train Transformer-based vision models (like [ViT](https://huggingface.co/docs/transformers/model_doc/vit), [Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)) on your own data, after which you can easily load the weights into a [`AutoModelForImageClassification`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForImageClassification). It currently includes scripts for:
+- [SimMIM](#simmim) (by Microsoft Research)
+- [MAE](#mae) (by Facebook AI).
+
+NOTE: If you encounter problems/have suggestions for improvement, open an issue on Github and tag @NielsRogge.
+
+
+## SimMIM
+
+The `run_mim.py` script can be used to pre-train any Transformer-based vision model in the library (concretely, any model supported by the `AutoModelForMaskedImageModeling` API) for masked image modeling as proposed in [SimMIM: A Simple Framework for Masked Image Modeling](https://arxiv.org/abs/2111.09886) using PyTorch.
+
+
+
+ SimMIM framework. Taken from the original paper.
+
+The goal for the model is to predict raw pixel values for the masked patches, using just a linear layer as prediction head. The model is trained using a simple L1 loss.
+
+### Using datasets from 🤗 datasets
+
+Here we show how to pre-train a `ViT` from scratch for masked image modeling on the [cifar10](https://huggingface.co/datasets/cifar10) dataset.
+
+Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "google/vit-base-patch16-224-in21k" for example (and not specifying the `model_type` argument).
+
+```bash
+!python run_mim.py \
+ --model_type vit \
+ --output_dir ./outputs/ \
+ --overwrite_output_dir \
+ --remove_unused_columns False \
+ --label_names bool_masked_pos \
+ --do_train \
+ --do_eval \
+ --learning_rate 2e-5 \
+ --weight_decay 0.05 \
+ --num_train_epochs 100 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+Here, we train for 100 epochs with a learning rate of 2e-5. Note that the SimMIM authors used a more sophisticated learning rate schedule, see the [config files](https://github.com/microsoft/SimMIM/blob/main/configs/vit_base__800ep/simmim_pretrain__vit_base__img224__800ep.yaml) for more info. One can easily tweak the script to include this learning rate schedule (several learning rate schedulers are supported via the [training arguments](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments)).
+
+We can also for instance replicate the pre-training of a Swin Transformer using the same architecture as used by the SimMIM authors. For this, we first create a custom configuration and save it locally:
+
+```python
+from transformers import SwinConfig
+
+IMAGE_SIZE = 192
+PATCH_SIZE = 4
+EMBED_DIM = 128
+DEPTHS = [2, 2, 18, 2]
+NUM_HEADS = [4, 8, 16, 32]
+WINDOW_SIZE = 6
+
+config = SwinConfig(
+ image_size=IMAGE_SIZE,
+ patch_size=PATCH_SIZE,
+ embed_dim=EMBED_DIM,
+ depths=DEPTHS,
+ num_heads=NUM_HEADS,
+ window_size=WINDOW_SIZE,
+)
+config.save_pretrained("path_to_config")
+```
+
+Next, we can run the script by providing the path to this custom configuration (replace `path_to_config` below with your path):
+
+```bash
+!python run_mim.py \
+ --config_name_or_path path_to_config \
+ --model_type swin \
+ --output_dir ./outputs/ \
+ --overwrite_output_dir \
+ --remove_unused_columns False \
+ --label_names bool_masked_pos \
+ --do_train \
+ --do_eval \
+ --learning_rate 2e-5 \
+ --num_train_epochs 5 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+This will train a Swin Transformer from scratch.
+
+### Using your own data
+
+To use your own dataset, the training script expects the following directory structure:
+
+```bash
+root/dog/xxx.png
+root/dog/xxy.png
+root/dog/[...]/xxz.png
+
+root/cat/123.png
+root/cat/nsdf3.png
+root/cat/[...]/asd932_.png
+```
+
+Note that you can put images in dummy subfolders, whose names will be ignored by default (as labels aren't required). You can also just place all images into a single dummy subfolder. Once you've prepared your dataset, you can run the script like this:
+
+```bash
+python run_mim.py \
+ --model_type vit \
+ --dataset_name nateraw/image-folder \
+ --train_dir \
+ --output_dir ./outputs/ \
+ --remove_unused_columns False \
+ --label_names bool_masked_pos \
+ --do_train \
+ --do_eval
+```
+
+## MAE
+
+The `run_mae.py` script can be used to pre-train a Vision Transformer as a masked autoencoder (MAE), as proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377). The script can be used to train a `ViTMAEForPreTraining` model in the Transformers library, using PyTorch. After self-supervised pre-training, one can load the weights of the encoder directly into a `ViTForImageClassification`. The MAE method allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data.
+
+The goal for the model is to predict raw pixel values for the masked patches. As the model internally masks patches and learns to reconstruct them, there's no need for any labels. The model uses the mean squared error (MSE) between the reconstructed and original images in the pixel space.
+
+### Using datasets from 🤗 `datasets`
+
+One can use the following command to pre-train a `ViTMAEForPreTraining` model from scratch on the [cifar10](https://huggingface.co/datasets/cifar10) dataset:
+
+```bash
+python run_mae.py \
+ --dataset_name cifar10 \
+ --output_dir ./vit-mae-demo \
+ --remove_unused_columns False \
+ --label_names pixel_values \
+ --mask_ratio 0.75 \
+ --norm_pix_loss \
+ --do_train \
+ --do_eval \
+ --base_learning_rate 1.5e-4 \
+ --lr_scheduler_type cosine \
+ --weight_decay 0.05 \
+ --num_train_epochs 800 \
+ --warmup_ratio 0.05 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+Here we set:
+- `mask_ratio` to 0.75 (to mask 75% of the patches for each image)
+- `norm_pix_loss` to use normalized pixel values as target (the authors reported better representations with this enabled)
+- `base_learning_rate` to 1.5e-4. Note that the effective learning rate is computed by the [linear schedule](https://arxiv.org/abs/1706.02677): `lr` = `blr` * total training batch size / 256. The total training batch size is computed as `training_args.train_batch_size` * `training_args.gradient_accumulation_steps` * `training_args.world_size`.
+
+This replicates the same hyperparameters as used in the original implementation, as shown in the table below.
+
+
+
+ Original hyperparameters. Taken from the original paper.
+
+Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "facebook/vit-mae-base" for example.
+
+
+### Using your own data
+
+To use your own dataset, the training script expects the following directory structure:
+
+```bash
+root/dog/xxx.png
+root/dog/xxy.png
+root/dog/[...]/xxz.png
+
+root/cat/123.png
+root/cat/nsdf3.png
+root/cat/[...]/asd932_.png
+```
+
+Note that you can put images in dummy subfolders, whose names will be ignored by default (as labels aren't required). You can also just place all images into a single dummy subfolder. Once you've prepared your dataset, you can run the script like this:
+
+```bash
+python run_mae.py \
+ --model_type vit_mae \
+ --dataset_name nateraw/image-folder \
+ --train_dir \
+ --output_dir ./outputs/ \
+ --remove_unused_columns False \
+ --label_names pixel_values \
+ --do_train \
+ --do_eval
+```
+
+#### 💡 The above will split the train dir into training and evaluation sets
+ - To control the split amount, use the `--train_val_split` flag.
+ - To provide your own validation split in its own directory, you can pass the `--validation_dir ` flag.
+
+
+## Sharing your model on 🤗 Hub
+
+0. If you haven't already, [sign up](https://huggingface.co/join) for a 🤗 account
+
+1. Make sure you have `git-lfs` installed and git set up.
+
+```bash
+$ apt install git-lfs
+$ git config --global user.email "you@example.com"
+$ git config --global user.name "Your Name"
+```
+
+2. Log in with your HuggingFace account credentials using `huggingface-cli`
+
+```bash
+$ huggingface-cli login
+# ...follow the prompts
+```
+
+3. When running the script, pass the following arguments:
+
+```bash
+python run_xxx.py \
+ --push_to_hub \
+ --push_to_hub_model_id \
+ ...
+```
\ No newline at end of file
diff --git a/docs/transformers/examples/pytorch/image-pretraining/requirements.txt b/docs/transformers/examples/pytorch/image-pretraining/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a789fee85eef5d028375e406c5ea7df85a56c738
--- /dev/null
+++ b/docs/transformers/examples/pytorch/image-pretraining/requirements.txt
@@ -0,0 +1,3 @@
+torch>=1.5.0
+torchvision>=0.6.0
+datasets>=1.8.0
\ No newline at end of file
diff --git a/docs/transformers/examples/pytorch/image-pretraining/run_mae.py b/docs/transformers/examples/pytorch/image-pretraining/run_mae.py
new file mode 100644
index 0000000000000000000000000000000000000000..f39fcd17c0d2a362993200954d44232678ac9a53
--- /dev/null
+++ b/docs/transformers/examples/pytorch/image-pretraining/run_mae.py
@@ -0,0 +1,407 @@
+#!/usr/bin/env python
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import torch
+from datasets import load_dataset
+from torchvision.transforms import Compose, Lambda, Normalize, RandomHorizontalFlip, RandomResizedCrop, ToTensor
+from torchvision.transforms.functional import InterpolationMode
+
+import transformers
+from transformers import (
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ ViTImageProcessor,
+ ViTMAEConfig,
+ ViTMAEForPreTraining,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+""" Pre-training a 🤗 ViT model as an MAE (masked autoencoder), as proposed in https://arxiv.org/abs/2111.06377."""
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ Using `HfArgumentParser` we can turn this class
+ into argparse arguments to be able to specify them on
+ the command line.
+ """
+
+ dataset_name: Optional[str] = field(
+ default="cifar10", metadata={"help": "Name of a dataset from the datasets package"}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ image_column_name: Optional[str] = field(
+ default=None, metadata={"help": "The column name of the images in the files."}
+ )
+ train_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the training data."})
+ validation_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the validation data."})
+ train_val_split: Optional[float] = field(
+ default=0.15, metadata={"help": "Percent to split off of train for validation."}
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ data_files = {}
+ if self.train_dir is not None:
+ data_files["train"] = self.train_dir
+ if self.validation_dir is not None:
+ data_files["val"] = self.validation_dir
+ self.data_files = data_files if data_files else None
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/image processor we are going to pre-train.
+ """
+
+ model_name_or_path: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name_or_path"}
+ )
+ config_overrides: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Override some existing default config settings when a model is trained from scratch. Example: "
+ "n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
+ )
+ },
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ image_processor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ mask_ratio: float = field(
+ default=0.75, metadata={"help": "The ratio of the number of masked tokens in the input sequence."}
+ )
+ norm_pix_loss: bool = field(
+ default=True, metadata={"help": "Whether or not to train with normalized pixel values as target."}
+ )
+
+
+@dataclass
+class CustomTrainingArguments(TrainingArguments):
+ base_learning_rate: float = field(
+ default=1e-3, metadata={"help": "Base learning rate: absolute_lr = base_lr * total_batch_size / 256."}
+ )
+
+
+def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ return {"pixel_values": pixel_values}
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, CustomTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_mae", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Initialize our dataset.
+ ds = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ data_files=data_args.data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ # If we don't have a validation split, split off a percentage of train as validation.
+ data_args.train_val_split = None if "validation" in ds.keys() else data_args.train_val_split
+ if isinstance(data_args.train_val_split, float) and data_args.train_val_split > 0.0:
+ split = ds["train"].train_test_split(data_args.train_val_split)
+ ds["train"] = split["train"]
+ ds["validation"] = split["test"]
+
+ # Load pretrained model and image processor
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "revision": model_args.model_revision,
+ "token": model_args.token,
+ }
+ if model_args.config_name:
+ config = ViTMAEConfig.from_pretrained(model_args.config_name, **config_kwargs)
+ elif model_args.model_name_or_path:
+ config = ViTMAEConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
+ else:
+ config = ViTMAEConfig()
+ logger.warning("You are instantiating a new config instance from scratch.")
+ if model_args.config_overrides is not None:
+ logger.info(f"Overriding config: {model_args.config_overrides}")
+ config.update_from_string(model_args.config_overrides)
+ logger.info(f"New config: {config}")
+
+ # adapt config
+ config.update(
+ {
+ "mask_ratio": model_args.mask_ratio,
+ "norm_pix_loss": model_args.norm_pix_loss,
+ }
+ )
+
+ # create image processor
+ if model_args.image_processor_name:
+ image_processor = ViTImageProcessor.from_pretrained(model_args.image_processor_name, **config_kwargs)
+ elif model_args.model_name_or_path:
+ image_processor = ViTImageProcessor.from_pretrained(model_args.model_name_or_path, **config_kwargs)
+ else:
+ image_processor = ViTImageProcessor()
+
+ # create model
+ if model_args.model_name_or_path:
+ model = ViTMAEForPreTraining.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = ViTMAEForPreTraining(config)
+
+ if training_args.do_train:
+ column_names = ds["train"].column_names
+ else:
+ column_names = ds["validation"].column_names
+
+ if data_args.image_column_name is not None:
+ image_column_name = data_args.image_column_name
+ elif "image" in column_names:
+ image_column_name = "image"
+ elif "img" in column_names:
+ image_column_name = "img"
+ else:
+ image_column_name = column_names[0]
+
+ # transformations as done in original MAE paper
+ # source: https://github.com/facebookresearch/mae/blob/main/main_pretrain.py
+ if "shortest_edge" in image_processor.size:
+ size = image_processor.size["shortest_edge"]
+ else:
+ size = (image_processor.size["height"], image_processor.size["width"])
+ transforms = Compose(
+ [
+ Lambda(lambda img: img.convert("RGB") if img.mode != "RGB" else img),
+ RandomResizedCrop(size, scale=(0.2, 1.0), interpolation=InterpolationMode.BICUBIC),
+ RandomHorizontalFlip(),
+ ToTensor(),
+ Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
+ ]
+ )
+
+ def preprocess_images(examples):
+ """Preprocess a batch of images by applying transforms."""
+
+ examples["pixel_values"] = [transforms(image) for image in examples[image_column_name]]
+ return examples
+
+ if training_args.do_train:
+ if "train" not in ds:
+ raise ValueError("--do_train requires a train dataset")
+ if data_args.max_train_samples is not None:
+ ds["train"] = ds["train"].shuffle(seed=training_args.seed).select(range(data_args.max_train_samples))
+ # Set the training transforms
+ ds["train"].set_transform(preprocess_images)
+
+ if training_args.do_eval:
+ if "validation" not in ds:
+ raise ValueError("--do_eval requires a validation dataset")
+ if data_args.max_eval_samples is not None:
+ ds["validation"] = (
+ ds["validation"].shuffle(seed=training_args.seed).select(range(data_args.max_eval_samples))
+ )
+ # Set the validation transforms
+ ds["validation"].set_transform(preprocess_images)
+
+ # Compute absolute learning rate
+ total_train_batch_size = (
+ training_args.train_batch_size * training_args.gradient_accumulation_steps * training_args.world_size
+ )
+ if training_args.base_learning_rate is not None:
+ training_args.learning_rate = training_args.base_learning_rate * total_train_batch_size / 256
+
+ # Initialize our trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=ds["train"] if training_args.do_train else None,
+ eval_dataset=ds["validation"] if training_args.do_eval else None,
+ processing_class=image_processor,
+ data_collator=collate_fn,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+ trainer.log_metrics("train", train_result.metrics)
+ trainer.save_metrics("train", train_result.metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ metrics = trainer.evaluate()
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Write model card and (optionally) push to hub
+ kwargs = {
+ "tasks": "masked-auto-encoding",
+ "dataset": data_args.dataset_name,
+ "tags": ["masked-auto-encoding"],
+ }
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/image-pretraining/run_mim.py b/docs/transformers/examples/pytorch/image-pretraining/run_mim.py
new file mode 100644
index 0000000000000000000000000000000000000000..842e7c8d606156c0c5b67e857b72dbe136bbc964
--- /dev/null
+++ b/docs/transformers/examples/pytorch/image-pretraining/run_mim.py
@@ -0,0 +1,482 @@
+#!/usr/bin/env python
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import numpy as np
+import torch
+from datasets import load_dataset
+from torchvision.transforms import Compose, Lambda, Normalize, RandomHorizontalFlip, RandomResizedCrop, ToTensor
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ IMAGE_PROCESSOR_MAPPING,
+ MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING,
+ AutoConfig,
+ AutoImageProcessor,
+ AutoModelForMaskedImageModeling,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+""" Pre-training a 🤗 Transformers model for simple masked image modeling (SimMIM).
+Any model supported by the AutoModelForMaskedImageModeling API can be used.
+"""
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
+
+MODEL_CONFIG_CLASSES = list(MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ Using `HfArgumentParser` we can turn this class into argparse arguments to be able to
+ specify them on the command line.
+ """
+
+ dataset_name: Optional[str] = field(
+ default="cifar10", metadata={"help": "Name of a dataset from the datasets package"}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ image_column_name: Optional[str] = field(
+ default=None,
+ metadata={"help": "The column name of the images in the files. If not set, will try to use 'image' or 'img'."},
+ )
+ train_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the training data."})
+ validation_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the validation data."})
+ train_val_split: Optional[float] = field(
+ default=0.15, metadata={"help": "Percent to split off of train for validation."}
+ )
+ mask_patch_size: int = field(default=32, metadata={"help": "The size of the square patches to use for masking."})
+ mask_ratio: float = field(
+ default=0.6,
+ metadata={"help": "Percentage of patches to mask."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ data_files = {}
+ if self.train_dir is not None:
+ data_files["train"] = self.train_dir
+ if self.validation_dir is not None:
+ data_files["val"] = self.validation_dir
+ self.data_files = data_files if data_files else None
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/image processor we are going to pre-train.
+ """
+
+ model_name_or_path: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Can be a local path to a pytorch_model.bin or a "
+ "checkpoint identifier on the hub. "
+ "Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_name_or_path: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ config_overrides: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Override some existing default config settings when a model is trained from scratch. Example: "
+ "n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
+ )
+ },
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store (cache) the pretrained models/datasets downloaded from the hub"},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ image_processor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ image_size: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The size (resolution) of each image. If not specified, will use `image_size` of the configuration."
+ )
+ },
+ )
+ patch_size: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The size (resolution) of each patch. If not specified, will use `patch_size` of the configuration."
+ )
+ },
+ )
+ encoder_stride: Optional[int] = field(
+ default=None,
+ metadata={"help": "Stride to use for the encoder."},
+ )
+
+
+class MaskGenerator:
+ """
+ A class to generate boolean masks for the pretraining task.
+
+ A mask is a 1D tensor of shape (model_patch_size**2,) where the value is either 0 or 1,
+ where 1 indicates "masked".
+ """
+
+ def __init__(self, input_size=192, mask_patch_size=32, model_patch_size=4, mask_ratio=0.6):
+ self.input_size = input_size
+ self.mask_patch_size = mask_patch_size
+ self.model_patch_size = model_patch_size
+ self.mask_ratio = mask_ratio
+
+ if self.input_size % self.mask_patch_size != 0:
+ raise ValueError("Input size must be divisible by mask patch size")
+ if self.mask_patch_size % self.model_patch_size != 0:
+ raise ValueError("Mask patch size must be divisible by model patch size")
+
+ self.rand_size = self.input_size // self.mask_patch_size
+ self.scale = self.mask_patch_size // self.model_patch_size
+
+ self.token_count = self.rand_size**2
+ self.mask_count = int(np.ceil(self.token_count * self.mask_ratio))
+
+ def __call__(self):
+ mask_idx = np.random.permutation(self.token_count)[: self.mask_count]
+ mask = np.zeros(self.token_count, dtype=int)
+ mask[mask_idx] = 1
+
+ mask = mask.reshape((self.rand_size, self.rand_size))
+ mask = mask.repeat(self.scale, axis=0).repeat(self.scale, axis=1)
+
+ return torch.tensor(mask.flatten())
+
+
+def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ mask = torch.stack([example["mask"] for example in examples])
+ return {"pixel_values": pixel_values, "bool_masked_pos": mask}
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_mim", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Initialize our dataset.
+ ds = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ data_files=data_args.data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # If we don't have a validation split, split off a percentage of train as validation.
+ data_args.train_val_split = None if "validation" in ds.keys() else data_args.train_val_split
+ if isinstance(data_args.train_val_split, float) and data_args.train_val_split > 0.0:
+ split = ds["train"].train_test_split(data_args.train_val_split)
+ ds["train"] = split["train"]
+ ds["validation"] = split["test"]
+
+ # Create config
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "revision": model_args.model_revision,
+ "token": model_args.token,
+ "trust_remote_code": model_args.trust_remote_code,
+ }
+ if model_args.config_name_or_path:
+ config = AutoConfig.from_pretrained(model_args.config_name_or_path, **config_kwargs)
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+ if model_args.config_overrides is not None:
+ logger.info(f"Overriding config: {model_args.config_overrides}")
+ config.update_from_string(model_args.config_overrides)
+ logger.info(f"New config: {config}")
+
+ # make sure the decoder_type is "simmim" (only relevant for BEiT)
+ if hasattr(config, "decoder_type"):
+ config.decoder_type = "simmim"
+
+ # adapt config
+ model_args.image_size = model_args.image_size if model_args.image_size is not None else config.image_size
+ model_args.patch_size = model_args.patch_size if model_args.patch_size is not None else config.patch_size
+ model_args.encoder_stride = (
+ model_args.encoder_stride if model_args.encoder_stride is not None else config.encoder_stride
+ )
+
+ config.update(
+ {
+ "image_size": model_args.image_size,
+ "patch_size": model_args.patch_size,
+ "encoder_stride": model_args.encoder_stride,
+ }
+ )
+
+ # create image processor
+ if model_args.image_processor_name:
+ image_processor = AutoImageProcessor.from_pretrained(model_args.image_processor_name, **config_kwargs)
+ elif model_args.model_name_or_path:
+ image_processor = AutoImageProcessor.from_pretrained(model_args.model_name_or_path, **config_kwargs)
+ else:
+ IMAGE_PROCESSOR_TYPES = {
+ conf.model_type: image_processor_class for conf, image_processor_class in IMAGE_PROCESSOR_MAPPING.items()
+ }
+ image_processor = IMAGE_PROCESSOR_TYPES[model_args.model_type][-1]()
+
+ # create model
+ if model_args.model_name_or_path:
+ model = AutoModelForMaskedImageModeling.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelForMaskedImageModeling.from_config(config, trust_remote_code=model_args.trust_remote_code)
+
+ if training_args.do_train:
+ column_names = ds["train"].column_names
+ else:
+ column_names = ds["validation"].column_names
+
+ if data_args.image_column_name is not None:
+ image_column_name = data_args.image_column_name
+ elif "image" in column_names:
+ image_column_name = "image"
+ elif "img" in column_names:
+ image_column_name = "img"
+ else:
+ image_column_name = column_names[0]
+
+ # transformations as done in original SimMIM paper
+ # source: https://github.com/microsoft/SimMIM/blob/main/data/data_simmim.py
+ transforms = Compose(
+ [
+ Lambda(lambda img: img.convert("RGB") if img.mode != "RGB" else img),
+ RandomResizedCrop(model_args.image_size, scale=(0.67, 1.0), ratio=(3.0 / 4.0, 4.0 / 3.0)),
+ RandomHorizontalFlip(),
+ ToTensor(),
+ Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
+ ]
+ )
+
+ # create mask generator
+ mask_generator = MaskGenerator(
+ input_size=model_args.image_size,
+ mask_patch_size=data_args.mask_patch_size,
+ model_patch_size=model_args.patch_size,
+ mask_ratio=data_args.mask_ratio,
+ )
+
+ def preprocess_images(examples):
+ """Preprocess a batch of images by applying transforms + creating a corresponding mask, indicating
+ which patches to mask."""
+
+ examples["pixel_values"] = [transforms(image) for image in examples[image_column_name]]
+ examples["mask"] = [mask_generator() for i in range(len(examples[image_column_name]))]
+
+ return examples
+
+ if training_args.do_train:
+ if "train" not in ds:
+ raise ValueError("--do_train requires a train dataset")
+ if data_args.max_train_samples is not None:
+ ds["train"] = ds["train"].shuffle(seed=training_args.seed).select(range(data_args.max_train_samples))
+ # Set the training transforms
+ ds["train"].set_transform(preprocess_images)
+
+ if training_args.do_eval:
+ if "validation" not in ds:
+ raise ValueError("--do_eval requires a validation dataset")
+ if data_args.max_eval_samples is not None:
+ ds["validation"] = (
+ ds["validation"].shuffle(seed=training_args.seed).select(range(data_args.max_eval_samples))
+ )
+ # Set the validation transforms
+ ds["validation"].set_transform(preprocess_images)
+
+ # Initialize our trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=ds["train"] if training_args.do_train else None,
+ eval_dataset=ds["validation"] if training_args.do_eval else None,
+ processing_class=image_processor,
+ data_collator=collate_fn,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+ trainer.log_metrics("train", train_result.metrics)
+ trainer.save_metrics("train", train_result.metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ metrics = trainer.evaluate()
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Write model card and (optionally) push to hub
+ kwargs = {
+ "finetuned_from": model_args.model_name_or_path,
+ "tasks": "masked-image-modeling",
+ "dataset": data_args.dataset_name,
+ "tags": ["masked-image-modeling"],
+ }
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/image-pretraining/run_mim_no_trainer.py b/docs/transformers/examples/pytorch/image-pretraining/run_mim_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..13a545d4cbd15606585ce7d0c0348288885fcc89
--- /dev/null
+++ b/docs/transformers/examples/pytorch/image-pretraining/run_mim_no_trainer.py
@@ -0,0 +1,803 @@
+#!/usr/bin/env python
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import argparse
+import logging
+import math
+import os
+from pathlib import Path
+
+import datasets
+import numpy as np
+import torch
+from accelerate import Accelerator, DistributedType
+from accelerate.utils import set_seed
+from datasets import load_dataset
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from torchvision.transforms import Compose, Lambda, Normalize, RandomHorizontalFlip, RandomResizedCrop, ToTensor
+from tqdm.auto import tqdm
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ IMAGE_PROCESSOR_MAPPING,
+ MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING,
+ AutoConfig,
+ AutoImageProcessor,
+ AutoModelForMaskedImageModeling,
+ SchedulerType,
+ get_scheduler,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+""" Pre-training a 🤗 Transformers model for simple masked image modeling (SimMIM)
+without using HuggingFace Trainer.
+Any model supported by the AutoModelForMaskedImageModeling API can be used.
+"""
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
+
+MODEL_CONFIG_CLASSES = list(MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description="Finetune a transformers model on a simple Masked Image Modeling task"
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default="cifar10",
+ help="Name of a dataset from the datasets package",
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The configuration name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--image_column_name",
+ type=str,
+ default=None,
+ help="The column name of the images in the files. If not set, will try to use 'image' or 'img'.",
+ )
+ parser.add_argument(
+ "--train_dir",
+ type=str,
+ default=None,
+ help="A folder containing the training data.",
+ )
+ parser.add_argument(
+ "--validation_dir",
+ type=None,
+ default=None,
+ help="A folder containing the validation data.",
+ )
+ parser.add_argument(
+ "--train_val_split",
+ type=float,
+ default=0.15,
+ help="Percent to split off of train for validation.",
+ )
+ parser.add_argument(
+ "--mask_patch_size",
+ type=int,
+ default=32,
+ help="The size of the square patches to use for masking.",
+ )
+ parser.add_argument(
+ "--mask_ratio",
+ type=float,
+ default=0.6,
+ help="Percentage of patches to mask.",
+ )
+ parser.add_argument(
+ "--max_train_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--max_eval_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ default=None,
+ help=(
+ "The model checkpoint for weights initialization. Can be a local path to a pytorch_model.bin or a "
+ "checkpoint identifier on the hub. "
+ "Don't set if you want to train a model from scratch."
+ ),
+ )
+ parser.add_argument(
+ "--model_type",
+ type=str,
+ default=None,
+ help="If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES),
+ )
+ parser.add_argument(
+ "--config_name_or_path",
+ type=str,
+ default=None,
+ help="Pretrained config name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--config_overrides",
+ type=str,
+ default=None,
+ help=(
+ "Override some existing default config settings when a model is trained from scratch. Example: "
+ "n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
+ ),
+ )
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ default=None,
+ help="Where do you want to store (cache) the pretrained models/datasets downloaded from the hub",
+ )
+ parser.add_argument(
+ "--model_revision",
+ type=str,
+ default="main",
+ help="The specific model version to use (can be a branch name, tag name or commit id).",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--image_processor_name",
+ type=str,
+ default=None,
+ help="Name or path of preprocessor config.",
+ )
+ parser.add_argument(
+ "--token",
+ type=str,
+ default=None,
+ help=(
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ ),
+ )
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--image_size",
+ type=int,
+ default=None,
+ help="The size (resolution) of each image. If not specified, will use `image_size` of the configuration.",
+ )
+ parser.add_argument(
+ "--patch_size",
+ type=int,
+ default=None,
+ help="The size (resolution) of each patch. If not specified, will use `patch_size` of the configuration.",
+ )
+ parser.add_argument(
+ "--encoder_stride",
+ type=int,
+ default=None,
+ help={"help": "Stride to use for the encoder."},
+ )
+ parser.add_argument(
+ "--push_to_hub",
+ action="store_true",
+ help="Whether or not to push the model to the Hub.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--seed",
+ type=int,
+ default=None,
+ help="A seed for reproducible training.",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="The initial learning rate for [`AdamW`] optimizer.",
+ )
+ parser.add_argument(
+ "--weight_decay",
+ type=float,
+ default=0.0,
+ help="Weight decay to use.",
+ )
+ parser.add_argument(
+ "--num_train_epochs",
+ type=float,
+ default=3.0,
+ help="Total number of training epochs to perform (if not an integer, will perform the decimal part percents of the last epoch before stopping training).",
+ )
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps",
+ type=int,
+ default=0,
+ help="Number of steps for the warmup in the lr scheduler.",
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default=None,
+ help="Where to store the final model.",
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+ data_files = {}
+ if args.train_dir is not None:
+ data_files["train"] = args.train_dir
+ if args.validation_dir is not None:
+ data_files["val"] = args.validation_dir
+ args.data_files = data_files if data_files else None
+
+ if args.push_to_hub:
+ assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
+
+ return args
+
+
+class MaskGenerator:
+ """
+ A class to generate boolean masks for the pretraining task.
+
+ A mask is a 1D tensor of shape (model_patch_size**2,) where the value is either 0 or 1,
+ where 1 indicates "masked".
+ """
+
+ def __init__(self, input_size=192, mask_patch_size=32, model_patch_size=4, mask_ratio=0.6):
+ self.input_size = input_size
+ self.mask_patch_size = mask_patch_size
+ self.model_patch_size = model_patch_size
+ self.mask_ratio = mask_ratio
+
+ if self.input_size % self.mask_patch_size != 0:
+ raise ValueError("Input size must be divisible by mask patch size")
+ if self.mask_patch_size % self.model_patch_size != 0:
+ raise ValueError("Mask patch size must be divisible by model patch size")
+
+ self.rand_size = self.input_size // self.mask_patch_size
+ self.scale = self.mask_patch_size // self.model_patch_size
+
+ self.token_count = self.rand_size**2
+ self.mask_count = int(np.ceil(self.token_count * self.mask_ratio))
+
+ def __call__(self):
+ mask_idx = np.random.permutation(self.token_count)[: self.mask_count]
+ mask = np.zeros(self.token_count, dtype=int)
+ mask[mask_idx] = 1
+
+ mask = mask.reshape((self.rand_size, self.rand_size))
+ mask = mask.repeat(self.scale, axis=0).repeat(self.scale, axis=1)
+
+ return torch.tensor(mask.flatten())
+
+
+def collate_fn(examples):
+ pixel_values = torch.stack([example["pixel_values"] for example in examples])
+ mask = torch.stack([example["mask"] for example in examples])
+ return {"pixel_values": pixel_values, "bool_masked_pos": mask}
+
+
+def main():
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_mim_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator_log_kwargs = {}
+
+ if args.with_tracking:
+ accelerator_log_kwargs["log_with"] = args.report_to
+ accelerator_log_kwargs["project_dir"] = args.output_dir
+
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ **accelerator_log_kwargs,
+ )
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Initialize our dataset.
+ ds = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ data_files=args.data_files,
+ cache_dir=args.cache_dir,
+ token=args.token,
+ trust_remote_code=args.trust_remote_code,
+ )
+
+ # If we don't have a validation split, split off a percentage of train as validation.
+ args.train_val_split = None if "validation" in ds.keys() else args.train_val_split
+ if isinstance(args.train_val_split, float) and args.train_val_split > 0.0:
+ split = ds["train"].train_test_split(args.train_val_split)
+ ds["train"] = split["train"]
+ ds["validation"] = split["test"]
+
+ # Create config
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config_kwargs = {
+ "cache_dir": args.cache_dir,
+ "revision": args.model_revision,
+ "token": args.token,
+ "trust_remote_code": args.trust_remote_code,
+ }
+ if args.config_name_or_path:
+ config = AutoConfig.from_pretrained(args.config_name_or_path, **config_kwargs)
+ elif args.model_name_or_path:
+ config = AutoConfig.from_pretrained(args.model_name_or_path, **config_kwargs)
+ else:
+ config = CONFIG_MAPPING[args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+ if args.config_overrides is not None:
+ logger.info(f"Overriding config: {args.config_overrides}")
+ config.update_from_string(args.config_overrides)
+ logger.info(f"New config: {config}")
+
+ # make sure the decoder_type is "simmim" (only relevant for BEiT)
+ if hasattr(config, "decoder_type"):
+ config.decoder_type = "simmim"
+
+ # adapt config
+ args.image_size = args.image_size if args.image_size is not None else config.image_size
+ args.patch_size = args.patch_size if args.patch_size is not None else config.patch_size
+ args.encoder_stride = args.encoder_stride if args.encoder_stride is not None else config.encoder_stride
+
+ config.update(
+ {
+ "image_size": args.image_size,
+ "patch_size": args.patch_size,
+ "encoder_stride": args.encoder_stride,
+ }
+ )
+
+ # create image processor
+ if args.image_processor_name:
+ image_processor = AutoImageProcessor.from_pretrained(args.image_processor_name, **config_kwargs)
+ elif args.model_name_or_path:
+ image_processor = AutoImageProcessor.from_pretrained(args.model_name_or_path, **config_kwargs)
+ else:
+ IMAGE_PROCESSOR_TYPES = {
+ conf.model_type: image_processor_class for conf, image_processor_class in IMAGE_PROCESSOR_MAPPING.items()
+ }
+ image_processor = IMAGE_PROCESSOR_TYPES[args.model_type]()
+
+ # create model
+ if args.model_name_or_path:
+ model = AutoModelForMaskedImageModeling.from_pretrained(
+ args.model_name_or_path,
+ from_tf=bool(".ckpt" in args.model_name_or_path),
+ config=config,
+ cache_dir=args.cache_dir,
+ revision=args.model_revision,
+ token=args.token,
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelForMaskedImageModeling.from_config(
+ config,
+ token=args.token,
+ trust_remote_code=args.trust_remote_code,
+ )
+
+ column_names = ds["train"].column_names
+
+ if args.image_column_name is not None:
+ image_column_name = args.image_column_name
+ elif "image" in column_names:
+ image_column_name = "image"
+ elif "img" in column_names:
+ image_column_name = "img"
+ else:
+ image_column_name = column_names[0]
+
+ # transformations as done in original SimMIM paper
+ # source: https://github.com/microsoft/SimMIM/blob/main/data/data_simmim.py
+ transforms = Compose(
+ [
+ Lambda(lambda img: img.convert("RGB")),
+ RandomResizedCrop(args.image_size, scale=(0.67, 1.0), ratio=(3.0 / 4.0, 4.0 / 3.0)),
+ RandomHorizontalFlip(),
+ ToTensor(),
+ Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
+ ]
+ )
+
+ # create mask generator
+ mask_generator = MaskGenerator(
+ input_size=args.image_size,
+ mask_patch_size=args.mask_patch_size,
+ model_patch_size=args.patch_size,
+ mask_ratio=args.mask_ratio,
+ )
+
+ def preprocess_images(examples):
+ """Preprocess a batch of images by applying transforms + creating a corresponding mask, indicating
+ which patches to mask."""
+
+ examples["pixel_values"] = [transforms(image) for image in examples[image_column_name]]
+ examples["mask"] = [mask_generator() for i in range(len(examples[image_column_name]))]
+
+ return examples
+
+ if args.max_train_samples is not None:
+ ds["train"] = ds["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
+ # Set the training transforms
+ ds["train"].set_transform(preprocess_images)
+
+ if args.max_eval_samples is not None:
+ ds["validation"] = ds["validation"].shuffle(seed=args.seed).select(range(args.max_eval_samples))
+ # Set the validation transforms
+ ds["validation"].set_transform(preprocess_images)
+
+ # DataLoaders creation:
+ train_dataloader = DataLoader(
+ ds["train"],
+ shuffle=True,
+ collate_fn=collate_fn,
+ batch_size=args.per_device_train_batch_size,
+ )
+ eval_dataloader = DataLoader(
+ ds["validation"],
+ collate_fn=collate_fn,
+ batch_size=args.per_device_eval_batch_size,
+ )
+
+ # Optimizer
+ # Split weights in two groups, one with weight decay and the other not.
+ no_decay = ["bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
+
+ # Note -> the training dataloader needs to be prepared before we grab his length below (cause its length will be
+ # shorter in multiprocess)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps
+ if overrode_max_train_steps
+ else args.max_train_steps * accelerator.num_processes,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ model,
+ optimizer,
+ train_dataloader,
+ eval_dataloader,
+ lr_scheduler,
+ )
+
+ # On TPU, the tie weights in our model have been disconnected, so we need to restore the ties.
+ if accelerator.distributed_type == DistributedType.TPU:
+ model.tie_weights()
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("mim_no_trainer", experiment_config)
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(ds['train'])}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(int(args.max_train_steps)), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+ for step, batch in enumerate(active_dataloader):
+ with accelerator.accumulate(model):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+ accelerator.backward(loss)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ model.eval()
+ losses = []
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ loss = outputs.loss
+ losses.append(accelerator.gather_for_metrics(loss.repeat(args.per_device_eval_batch_size)))
+
+ losses = torch.cat(losses)
+ eval_loss = torch.mean(losses)
+
+ logger.info(f"epoch {epoch}: eval_loss: {eval_loss}")
+
+ if args.with_tracking:
+ accelerator.log(
+ {
+ "eval_loss": eval_loss,
+ "train_loss": total_loss.item() / len(train_dataloader),
+ "epoch": epoch,
+ "step": completed_steps,
+ },
+ step=completed_steps,
+ )
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ image_processor.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ image_processor.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ accelerator.wait_for_everyone()
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/instance-segmentation/README.md b/docs/transformers/examples/pytorch/instance-segmentation/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..565e2ec71dd900ded276fe9ca3b56a89bb9c21bb
--- /dev/null
+++ b/docs/transformers/examples/pytorch/instance-segmentation/README.md
@@ -0,0 +1,235 @@
+
+
+# Instance Segmentation Examples
+
+This directory contains two scripts that demonstrate how to fine-tune [MaskFormer](https://huggingface.co/docs/transformers/model_doc/maskformer) and [Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former) for instance segmentation using PyTorch.
+For other instance segmentation models, such as [DETR](https://huggingface.co/docs/transformers/model_doc/detr) and [Conditional DETR](https://huggingface.co/docs/transformers/model_doc/conditional_detr), the scripts need to be adjusted to properly handle input and output data.
+
+Content:
+- [PyTorch Version with Trainer](#pytorch-version-with-trainer)
+- [PyTorch Version with Accelerate](#pytorch-version-with-accelerate)
+- [Reload and Perform Inference](#reload-and-perform-inference)
+- [Note on Custom Data](#note-on-custom-data)
+
+## PyTorch Version with Trainer
+
+This example is based on the script [`run_instance_segmentation.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/instance-segmentation/run_instance_segmentation.py).
+
+The script uses the [🤗 Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer) to manage training automatically, including distributed environments.
+
+Here, we show how to fine-tune a [Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former) model on a subsample of the [ADE20K](https://huggingface.co/datasets/zhoubolei/scene_parse_150) dataset. We created a [small dataset](https://huggingface.co/datasets/qubvel-hf/ade20k-mini) with approximately 2,000 images containing only "person" and "car" annotations; all other pixels are marked as "background."
+
+Here is the `label2id` mapping for this dataset:
+
+```python
+label2id = {
+ "background": 0,
+ "person": 1,
+ "car": 2,
+}
+```
+
+Since the `background` label is not an instance and we don't want to predict it, we will use `do_reduce_labels` to remove it from the data.
+
+Run the training with the following command:
+
+```bash
+python run_instance_segmentation.py \
+ --model_name_or_path facebook/mask2former-swin-tiny-coco-instance \
+ --output_dir finetune-instance-segmentation-ade20k-mini-mask2former \
+ --dataset_name qubvel-hf/ade20k-mini \
+ --do_reduce_labels \
+ --image_height 256 \
+ --image_width 256 \
+ --do_train \
+ --fp16 \
+ --num_train_epochs 40 \
+ --learning_rate 1e-5 \
+ --lr_scheduler_type constant \
+ --per_device_train_batch_size 8 \
+ --gradient_accumulation_steps 2 \
+ --dataloader_num_workers 8 \
+ --dataloader_persistent_workers \
+ --dataloader_prefetch_factor 4 \
+ --do_eval \
+ --eval_strategy epoch \
+ --logging_strategy epoch \
+ --save_strategy epoch \
+ --save_total_limit 2 \
+ --push_to_hub
+```
+
+The resulting model can be viewed [here](https://huggingface.co/qubvel-hf/finetune-instance-segmentation-ade20k-mini-mask2former). Always refer to the original paper for details on training hyperparameters. To improve model quality, consider:
+- Changing image size parameters (`--image_height`/`--image_width`)
+- Adjusting training parameters such as learning rate, batch size, warmup, optimizer, and more (see [TrainingArguments](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments))
+- Adding more image augmentations (we created a helpful [HF Space](https://huggingface.co/spaces/qubvel-hf/albumentations-demo) to choose some)
+
+You can also replace the model [checkpoint](https://huggingface.co/models?search=maskformer).
+
+## PyTorch Version with Accelerate
+
+This example is based on the script [`run_instance_segmentation_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/instance-segmentation/run_instance_segmentation_no_trainer.py).
+
+The script uses [🤗 Accelerate](https://github.com/huggingface/accelerate) to write your own training loop in PyTorch and run it on various environments, including CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for mixed precision.
+
+First, configure the environment:
+
+```bash
+accelerate config
+```
+
+Answer the questions regarding your training environment. Then, run:
+
+```bash
+accelerate test
+```
+
+This command ensures everything is ready for training. Finally, launch training with:
+
+```bash
+accelerate launch run_instance_segmentation_no_trainer.py \
+ --model_name_or_path facebook/mask2former-swin-tiny-coco-instance \
+ --output_dir finetune-instance-segmentation-ade20k-mini-mask2former-no-trainer \
+ --dataset_name qubvel-hf/ade20k-mini \
+ --do_reduce_labels \
+ --image_height 256 \
+ --image_width 256 \
+ --num_train_epochs 40 \
+ --learning_rate 1e-5 \
+ --lr_scheduler_type constant \
+ --per_device_train_batch_size 8 \
+ --gradient_accumulation_steps 2 \
+ --dataloader_num_workers 8 \
+ --push_to_hub
+```
+
+With this setup, you can train on multiple GPUs, log everything to trackers (like Weights and Biases, Tensorboard), and regularly push your model to the hub (with the repo name set to `args.output_dir` under your HF username).
+With the default settings, the script fine-tunes a [Mask2Former](https://huggingface.co/docs/transformers/model_doc/mask2former) model on the sample of [ADE20K](https://huggingface.co/datasets/qubvel-hf/ade20k-mini) dataset. The resulting model can be viewed [here](https://huggingface.co/qubvel-hf/finetune-instance-segmentation-ade20k-mini-mask2former-no-trainer).
+
+## Reload and Perform Inference
+
+After training, you can easily load your trained model and perform inference as follows:
+
+```python
+import torch
+import requests
+import matplotlib.pyplot as plt
+
+from PIL import Image
+from transformers import Mask2FormerForUniversalSegmentation, Mask2FormerImageProcessor
+
+# Load image
+image = Image.open(requests.get("http://farm4.staticflickr.com/3017/3071497290_31f0393363_z.jpg", stream=True).raw)
+
+# Load model and image processor
+device = "cuda"
+checkpoint = "qubvel-hf/finetune-instance-segmentation-ade20k-mini-mask2former"
+
+model = Mask2FormerForUniversalSegmentation.from_pretrained(checkpoint, device_map=device)
+image_processor = Mask2FormerImageProcessor.from_pretrained(checkpoint)
+
+# Run inference on image
+inputs = image_processor(images=[image], return_tensors="pt").to(device)
+with torch.no_grad():
+ outputs = model(**inputs)
+
+# Post-process outputs
+outputs = image_processor.post_process_instance_segmentation(outputs, target_sizes=[(image.height, image.width)])
+
+print("Mask shape: ", outputs[0]["segmentation"].shape)
+print("Mask values: ", outputs[0]["segmentation"].unique())
+for segment in outputs[0]["segments_info"]:
+ print("Segment: ", segment)
+```
+
+```
+Mask shape: torch.Size([427, 640])
+Mask values: tensor([-1., 0., 1., 2., 3., 4., 5., 6.])
+Segment: {'id': 0, 'label_id': 0, 'was_fused': False, 'score': 0.946127}
+Segment: {'id': 1, 'label_id': 1, 'was_fused': False, 'score': 0.961582}
+Segment: {'id': 2, 'label_id': 1, 'was_fused': False, 'score': 0.968367}
+Segment: {'id': 3, 'label_id': 1, 'was_fused': False, 'score': 0.819527}
+Segment: {'id': 4, 'label_id': 1, 'was_fused': False, 'score': 0.655761}
+Segment: {'id': 5, 'label_id': 1, 'was_fused': False, 'score': 0.531299}
+Segment: {'id': 6, 'label_id': 1, 'was_fused': False, 'score': 0.929477}
+```
+
+Use the following code to visualize the results:
+
+```python
+import numpy as np
+import matplotlib.pyplot as plt
+
+segmentation = outputs[0]["segmentation"].numpy()
+
+plt.figure(figsize=(10, 10))
+plt.subplot(1, 2, 1)
+plt.imshow(np.array(image))
+plt.axis("off")
+plt.subplot(1, 2, 2)
+plt.imshow(segmentation)
+plt.axis("off")
+plt.show()
+```
+
+
+
+## Note on Custom Data
+
+Here is a short script demonstrating how to create your own dataset for instance segmentation and push it to the hub:
+
+> Note: Annotations should be represented as 3-channel images (similar to the [scene_parsing_150](https://huggingface.co/datasets/zhoubolei/scene_parse_150#instance_segmentation-1) dataset). The first channel is a semantic-segmentation map with values corresponding to `label2id`, the second is an instance-segmentation map where each instance has a unique value, and the third channel should be empty (filled with zeros).
+
+```python
+from datasets import Dataset, DatasetDict
+from datasets import Image as DatasetImage
+
+label2id = {
+ "background": 0,
+ "person": 1,
+ "car": 2,
+}
+
+train_split = {
+ "image": [, , , ...],
+ "annotation": [, , , ...],
+}
+
+validation_split = {
+ "image": [, , , ...],
+ "annotation": [, , , ...],
+}
+
+def create_instance_segmentation_dataset(label2id, **splits):
+ dataset_dict = {}
+ for split_name, split in splits.items():
+ split["semantic_class_to_id"] = [label2id] * len(split["image"])
+ dataset_split = (
+ Dataset.from_dict(split)
+ .cast_column("image", DatasetImage())
+ .cast_column("annotation", DatasetImage())
+ )
+ dataset_dict[split_name] = dataset_split
+ return DatasetDict(dataset_dict)
+
+dataset = create_instance_segmentation_dataset(label2id, train=train_split, validation=validation_split)
+dataset.push_to_hub("qubvel-hf/ade20k-nano")
+```
+
+Use this dataset for fine-tuning by specifying its name with `--dataset_name `.
+
+See also: [Dataset Creation Guide](https://huggingface.co/docs/datasets/image_dataset#create-an-image-dataset)
\ No newline at end of file
diff --git a/docs/transformers/examples/pytorch/instance-segmentation/requirements.txt b/docs/transformers/examples/pytorch/instance-segmentation/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..7772958dee7af88f31167f8fe2fb5af4fb1e1866
--- /dev/null
+++ b/docs/transformers/examples/pytorch/instance-segmentation/requirements.txt
@@ -0,0 +1,5 @@
+albumentations >= 1.4.16
+timm
+datasets
+torchmetrics
+pycocotools
diff --git a/docs/transformers/examples/pytorch/instance-segmentation/run_instance_segmentation.py b/docs/transformers/examples/pytorch/instance-segmentation/run_instance_segmentation.py
new file mode 100644
index 0000000000000000000000000000000000000000..6c4087120de2a7b6553981a28b0a8381afb087b8
--- /dev/null
+++ b/docs/transformers/examples/pytorch/instance-segmentation/run_instance_segmentation.py
@@ -0,0 +1,480 @@
+#!/usr/bin/env python
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+"""Finetuning 🤗 Transformers model for instance segmentation leveraging the Trainer API."""
+
+import logging
+import os
+import sys
+from collections.abc import Mapping
+from dataclasses import dataclass, field
+from functools import partial
+from typing import Any, Optional
+
+import albumentations as A
+import numpy as np
+import torch
+from datasets import load_dataset
+from torchmetrics.detection.mean_ap import MeanAveragePrecision
+
+import transformers
+from transformers import (
+ AutoImageProcessor,
+ AutoModelForUniversalSegmentation,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+)
+from transformers.image_processing_utils import BatchFeature
+from transformers.trainer import EvalPrediction
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=2.0.0", "To fix: pip install -r examples/pytorch/instance-segmentation/requirements.txt")
+
+
+@dataclass
+class Arguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ Using `HfArgumentParser` we can turn this class into argparse arguments to be able to specify
+ them on the command line.
+ """
+
+ model_name_or_path: str = field(
+ default="facebook/mask2former-swin-tiny-coco-instance",
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
+ )
+ dataset_name: str = field(
+ default="qubvel-hf/ade20k-mini",
+ metadata={
+ "help": "Name of a dataset from the hub (could be your own, possibly private dataset hosted on the hub)."
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ image_height: Optional[int] = field(default=512, metadata={"help": "Image height after resizing."})
+ image_width: Optional[int] = field(default=512, metadata={"help": "Image width after resizing."})
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ do_reduce_labels: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "If background class is labeled as 0 and you want to remove it from the labels, set this flag to True."
+ )
+ },
+ )
+
+
+def augment_and_transform_batch(
+ examples: Mapping[str, Any], transform: A.Compose, image_processor: AutoImageProcessor
+) -> BatchFeature:
+ batch = {
+ "pixel_values": [],
+ "mask_labels": [],
+ "class_labels": [],
+ }
+
+ for pil_image, pil_annotation in zip(examples["image"], examples["annotation"]):
+ image = np.array(pil_image)
+ semantic_and_instance_masks = np.array(pil_annotation)[..., :2]
+
+ # Apply augmentations
+ output = transform(image=image, mask=semantic_and_instance_masks)
+
+ aug_image = output["image"]
+ aug_semantic_and_instance_masks = output["mask"]
+ aug_instance_mask = aug_semantic_and_instance_masks[..., 1]
+
+ # Create mapping from instance id to semantic id
+ unique_semantic_id_instance_id_pairs = np.unique(aug_semantic_and_instance_masks.reshape(-1, 2), axis=0)
+ instance_id_to_semantic_id = {
+ instance_id: semantic_id for semantic_id, instance_id in unique_semantic_id_instance_id_pairs
+ }
+
+ # Apply the image processor transformations: resizing, rescaling, normalization
+ model_inputs = image_processor(
+ images=[aug_image],
+ segmentation_maps=[aug_instance_mask],
+ instance_id_to_semantic_id=instance_id_to_semantic_id,
+ return_tensors="pt",
+ )
+
+ batch["pixel_values"].append(model_inputs.pixel_values[0])
+ batch["mask_labels"].append(model_inputs.mask_labels[0])
+ batch["class_labels"].append(model_inputs.class_labels[0])
+
+ return batch
+
+
+def collate_fn(examples):
+ batch = {}
+ batch["pixel_values"] = torch.stack([example["pixel_values"] for example in examples])
+ batch["class_labels"] = [example["class_labels"] for example in examples]
+ batch["mask_labels"] = [example["mask_labels"] for example in examples]
+ if "pixel_mask" in examples[0]:
+ batch["pixel_mask"] = torch.stack([example["pixel_mask"] for example in examples])
+ return batch
+
+
+@dataclass
+class ModelOutput:
+ class_queries_logits: torch.Tensor
+ masks_queries_logits: torch.Tensor
+
+
+def nested_cpu(tensors):
+ if isinstance(tensors, (list, tuple)):
+ return type(tensors)(nested_cpu(t) for t in tensors)
+ elif isinstance(tensors, Mapping):
+ return type(tensors)({k: nested_cpu(t) for k, t in tensors.items()})
+ elif isinstance(tensors, torch.Tensor):
+ return tensors.cpu().detach()
+ else:
+ return tensors
+
+
+class Evaluator:
+ """
+ Compute metrics for the instance segmentation task.
+ """
+
+ def __init__(
+ self,
+ image_processor: AutoImageProcessor,
+ id2label: Mapping[int, str],
+ threshold: float = 0.0,
+ ):
+ """
+ Initialize evaluator with image processor, id2label mapping and threshold for filtering predictions.
+
+ Args:
+ image_processor (AutoImageProcessor): Image processor for
+ `post_process_instance_segmentation` method.
+ id2label (Mapping[int, str]): Mapping from class id to class name.
+ threshold (float): Threshold to filter predicted boxes by confidence. Defaults to 0.0.
+ """
+ self.image_processor = image_processor
+ self.id2label = id2label
+ self.threshold = threshold
+ self.metric = self.get_metric()
+
+ def get_metric(self):
+ metric = MeanAveragePrecision(iou_type="segm", class_metrics=True)
+ return metric
+
+ def reset_metric(self):
+ self.metric.reset()
+
+ def postprocess_target_batch(self, target_batch) -> list[dict[str, torch.Tensor]]:
+ """Collect targets in a form of list of dictionaries with keys "masks", "labels"."""
+ batch_masks = target_batch[0]
+ batch_labels = target_batch[1]
+ post_processed_targets = []
+ for masks, labels in zip(batch_masks, batch_labels):
+ post_processed_targets.append(
+ {
+ "masks": masks.to(dtype=torch.bool),
+ "labels": labels,
+ }
+ )
+ return post_processed_targets
+
+ def get_target_sizes(self, post_processed_targets) -> list[list[int]]:
+ target_sizes = []
+ for target in post_processed_targets:
+ target_sizes.append(target["masks"].shape[-2:])
+ return target_sizes
+
+ def postprocess_prediction_batch(self, prediction_batch, target_sizes) -> list[dict[str, torch.Tensor]]:
+ """Collect predictions in a form of list of dictionaries with keys "masks", "labels", "scores"."""
+
+ model_output = ModelOutput(class_queries_logits=prediction_batch[0], masks_queries_logits=prediction_batch[1])
+ post_processed_output = self.image_processor.post_process_instance_segmentation(
+ model_output,
+ threshold=self.threshold,
+ target_sizes=target_sizes,
+ return_binary_maps=True,
+ )
+
+ post_processed_predictions = []
+ for image_predictions, target_size in zip(post_processed_output, target_sizes):
+ if image_predictions["segments_info"]:
+ post_processed_image_prediction = {
+ "masks": image_predictions["segmentation"].to(dtype=torch.bool),
+ "labels": torch.tensor([x["label_id"] for x in image_predictions["segments_info"]]),
+ "scores": torch.tensor([x["score"] for x in image_predictions["segments_info"]]),
+ }
+ else:
+ # for void predictions, we need to provide empty tensors
+ post_processed_image_prediction = {
+ "masks": torch.zeros([0, *target_size], dtype=torch.bool),
+ "labels": torch.tensor([]),
+ "scores": torch.tensor([]),
+ }
+ post_processed_predictions.append(post_processed_image_prediction)
+
+ return post_processed_predictions
+
+ @torch.no_grad()
+ def __call__(self, evaluation_results: EvalPrediction, compute_result: bool = False) -> Mapping[str, float]:
+ """
+ Update metrics with current evaluation results and return metrics if `compute_result` is True.
+
+ Args:
+ evaluation_results (EvalPrediction): Predictions and targets from evaluation.
+ compute_result (bool): Whether to compute and return metrics.
+
+ Returns:
+ Mapping[str, float]: Metrics in a form of dictionary {: }
+ """
+ prediction_batch = nested_cpu(evaluation_results.predictions)
+ target_batch = nested_cpu(evaluation_results.label_ids)
+
+ # For metric computation we need to provide:
+ # - targets in a form of list of dictionaries with keys "masks", "labels"
+ # - predictions in a form of list of dictionaries with keys "masks", "labels", "scores"
+ post_processed_targets = self.postprocess_target_batch(target_batch)
+ target_sizes = self.get_target_sizes(post_processed_targets)
+ post_processed_predictions = self.postprocess_prediction_batch(prediction_batch, target_sizes)
+
+ # Compute metrics
+ self.metric.update(post_processed_predictions, post_processed_targets)
+
+ if not compute_result:
+ return
+
+ metrics = self.metric.compute()
+
+ # Replace list of per class metrics with separate metric for each class
+ classes = metrics.pop("classes")
+ map_per_class = metrics.pop("map_per_class")
+ mar_100_per_class = metrics.pop("mar_100_per_class")
+ for class_id, class_map, class_mar in zip(classes, map_per_class, mar_100_per_class):
+ class_name = self.id2label[class_id.item()] if self.id2label is not None else class_id.item()
+ metrics[f"map_{class_name}"] = class_map
+ metrics[f"mar_100_{class_name}"] = class_mar
+
+ metrics = {k: round(v.item(), 4) for k, v in metrics.items()}
+
+ # Reset metric for next evaluation
+ self.reset_metric()
+
+ return metrics
+
+
+def setup_logging(training_args: TrainingArguments) -> None:
+ """Setup logging according to `training_args`."""
+
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+
+def find_last_checkpoint(training_args: TrainingArguments) -> Optional[str]:
+ """Find the last checkpoint in the output directory according to parameters specified in `training_args`."""
+
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif os.path.isdir(training_args.output_dir) and not training_args.overwrite_output_dir:
+ checkpoint = get_last_checkpoint(training_args.output_dir)
+ if checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ return checkpoint
+
+
+def main():
+ # See all possible arguments in https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments
+ # or by passing the --help flag to this script.
+
+ parser = HfArgumentParser([Arguments, TrainingArguments])
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ args, training_args = parser.parse_args_into_dataclasses()
+
+ # Set default training arguments for instance segmentation
+ training_args.eval_do_concat_batches = False
+ training_args.batch_eval_metrics = True
+ training_args.remove_unused_columns = False
+
+ # # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_instance_segmentation", args)
+
+ # Setup logging and log on each process the small summary:
+ setup_logging(training_args)
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Load last checkpoint from output_dir if it exists (and we are not overwriting it)
+ checkpoint = find_last_checkpoint(training_args)
+
+ # ------------------------------------------------------------------------------------------------
+ # Load dataset, prepare splits
+ # ------------------------------------------------------------------------------------------------
+
+ dataset = load_dataset(args.dataset_name, trust_remote_code=args.trust_remote_code)
+
+ # We need to specify the label2id mapping for the model
+ # it is a mapping from semantic class name to class index.
+ # In case your dataset does not provide it, you can create it manually:
+ # label2id = {"background": 0, "cat": 1, "dog": 2}
+ label2id = dataset["train"][0]["semantic_class_to_id"]
+
+ if args.do_reduce_labels:
+ label2id = {name: idx for name, idx in label2id.items() if idx != 0} # remove background class
+ label2id = {name: idx - 1 for name, idx in label2id.items()} # shift class indices by -1
+
+ id2label = {v: k for k, v in label2id.items()}
+
+ # ------------------------------------------------------------------------------------------------
+ # Load pretrained config, model and image processor
+ # ------------------------------------------------------------------------------------------------
+ model = AutoModelForUniversalSegmentation.from_pretrained(
+ args.model_name_or_path,
+ label2id=label2id,
+ id2label=id2label,
+ ignore_mismatched_sizes=True,
+ token=args.token,
+ )
+
+ image_processor = AutoImageProcessor.from_pretrained(
+ args.model_name_or_path,
+ do_resize=True,
+ size={"height": args.image_height, "width": args.image_width},
+ do_reduce_labels=args.do_reduce_labels,
+ reduce_labels=args.do_reduce_labels, # TODO: remove when mask2former support `do_reduce_labels`
+ token=args.token,
+ )
+
+ # ------------------------------------------------------------------------------------------------
+ # Define image augmentations and dataset transforms
+ # ------------------------------------------------------------------------------------------------
+ train_augment_and_transform = A.Compose(
+ [
+ A.HorizontalFlip(p=0.5),
+ A.RandomBrightnessContrast(p=0.5),
+ A.HueSaturationValue(p=0.1),
+ ],
+ )
+ validation_transform = A.Compose(
+ [A.NoOp()],
+ )
+
+ # Make transform functions for batch and apply for dataset splits
+ train_transform_batch = partial(
+ augment_and_transform_batch, transform=train_augment_and_transform, image_processor=image_processor
+ )
+ validation_transform_batch = partial(
+ augment_and_transform_batch, transform=validation_transform, image_processor=image_processor
+ )
+
+ dataset["train"] = dataset["train"].with_transform(train_transform_batch)
+ dataset["validation"] = dataset["validation"].with_transform(validation_transform_batch)
+
+ # ------------------------------------------------------------------------------------------------
+ # Model training and evaluation with Trainer API
+ # ------------------------------------------------------------------------------------------------
+
+ compute_metrics = Evaluator(image_processor=image_processor, id2label=id2label, threshold=0.0)
+
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=dataset["train"] if training_args.do_train else None,
+ eval_dataset=dataset["validation"] if training_args.do_eval else None,
+ processing_class=image_processor,
+ data_collator=collate_fn,
+ compute_metrics=compute_metrics,
+ )
+
+ # Training
+ if training_args.do_train:
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+ trainer.log_metrics("train", train_result.metrics)
+ trainer.save_metrics("train", train_result.metrics)
+ trainer.save_state()
+
+ # Final evaluation
+ if training_args.do_eval:
+ metrics = trainer.evaluate(eval_dataset=dataset["validation"], metric_key_prefix="test")
+ trainer.log_metrics("test", metrics)
+ trainer.save_metrics("test", metrics)
+
+ # Write model card and (optionally) push to hub
+ kwargs = {
+ "finetuned_from": args.model_name_or_path,
+ "dataset": args.dataset_name,
+ "tags": ["image-segmentation", "instance-segmentation", "vision"],
+ }
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/instance-segmentation/run_instance_segmentation_no_trainer.py b/docs/transformers/examples/pytorch/instance-segmentation/run_instance_segmentation_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb33681168cd69bae9e83b8a63490440528b3c1b
--- /dev/null
+++ b/docs/transformers/examples/pytorch/instance-segmentation/run_instance_segmentation_no_trainer.py
@@ -0,0 +1,744 @@
+#!/usr/bin/env python
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+"""Finetuning 🤗 Transformers model for instance segmentation with Accelerate 🚀."""
+
+import argparse
+import json
+import logging
+import math
+import os
+import sys
+from collections.abc import Mapping
+from functools import partial
+from pathlib import Path
+from typing import Any
+
+import albumentations as A
+import datasets
+import numpy as np
+import torch
+from accelerate import Accelerator
+from accelerate.utils import set_seed
+from datasets import load_dataset
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from torchmetrics.detection.mean_ap import MeanAveragePrecision
+from tqdm import tqdm
+
+import transformers
+from transformers import (
+ AutoImageProcessor,
+ AutoModelForUniversalSegmentation,
+ SchedulerType,
+ get_scheduler,
+)
+from transformers.image_processing_utils import BatchFeature
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=2.0.0", "To fix: pip install -r examples/pytorch/instance-segmentation/requirements.txt")
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Finetune a transformers model for instance segmentation task")
+
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to a pretrained model or model identifier from huggingface.co/models.",
+ default="facebook/mask2former-swin-tiny-coco-instance",
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ help="Name of the dataset on the hub.",
+ default="qubvel-hf/ade20k-mini",
+ )
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--image_height",
+ type=int,
+ default=384,
+ help="The height of the images to feed the model.",
+ )
+ parser.add_argument(
+ "--image_width",
+ type=int,
+ default=384,
+ help="The width of the images to feed the model.",
+ )
+ parser.add_argument(
+ "--do_reduce_labels",
+ action="store_true",
+ help="Whether to reduce the number of labels by removing the background class.",
+ )
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ help="Path to a folder in which the model and dataset will be cached.",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=4,
+ help="Number of workers to use for the dataloaders.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--adam_beta1",
+ type=float,
+ default=0.9,
+ help="Beta1 for AdamW optimizer",
+ )
+ parser.add_argument(
+ "--adam_beta2",
+ type=float,
+ default=0.999,
+ help="Beta2 for AdamW optimizer",
+ )
+ parser.add_argument(
+ "--adam_epsilon",
+ type=float,
+ default=1e-8,
+ help="Epsilon for AdamW optimizer",
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ required=False,
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+ if args.push_to_hub or args.with_tracking:
+ if args.output_dir is None:
+ raise ValueError(
+ "Need an `output_dir` to create a repo when `--push_to_hub` or `with_tracking` is specified."
+ )
+
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ return args
+
+
+def augment_and_transform_batch(
+ examples: Mapping[str, Any], transform: A.Compose, image_processor: AutoImageProcessor
+) -> BatchFeature:
+ batch = {
+ "pixel_values": [],
+ "mask_labels": [],
+ "class_labels": [],
+ }
+
+ for pil_image, pil_annotation in zip(examples["image"], examples["annotation"]):
+ image = np.array(pil_image)
+ semantic_and_instance_masks = np.array(pil_annotation)[..., :2]
+
+ # Apply augmentations
+ output = transform(image=image, mask=semantic_and_instance_masks)
+
+ aug_image = output["image"]
+ aug_semantic_and_instance_masks = output["mask"]
+ aug_instance_mask = aug_semantic_and_instance_masks[..., 1]
+
+ # Create mapping from instance id to semantic id
+ unique_semantic_id_instance_id_pairs = np.unique(aug_semantic_and_instance_masks.reshape(-1, 2), axis=0)
+ instance_id_to_semantic_id = {
+ instance_id: semantic_id for semantic_id, instance_id in unique_semantic_id_instance_id_pairs
+ }
+
+ # Apply the image processor transformations: resizing, rescaling, normalization
+ model_inputs = image_processor(
+ images=[aug_image],
+ segmentation_maps=[aug_instance_mask],
+ instance_id_to_semantic_id=instance_id_to_semantic_id,
+ return_tensors="pt",
+ )
+
+ batch["pixel_values"].append(model_inputs.pixel_values[0])
+ batch["mask_labels"].append(model_inputs.mask_labels[0])
+ batch["class_labels"].append(model_inputs.class_labels[0])
+
+ return batch
+
+
+def collate_fn(examples):
+ batch = {}
+ batch["pixel_values"] = torch.stack([example["pixel_values"] for example in examples])
+ batch["class_labels"] = [example["class_labels"] for example in examples]
+ batch["mask_labels"] = [example["mask_labels"] for example in examples]
+ if "pixel_mask" in examples[0]:
+ batch["pixel_mask"] = torch.stack([example["pixel_mask"] for example in examples])
+ return batch
+
+
+def nested_cpu(tensors):
+ if isinstance(tensors, (list, tuple)):
+ return type(tensors)(nested_cpu(t) for t in tensors)
+ elif isinstance(tensors, Mapping):
+ return type(tensors)({k: nested_cpu(t) for k, t in tensors.items()})
+ elif isinstance(tensors, torch.Tensor):
+ return tensors.cpu().detach()
+ else:
+ return tensors
+
+
+def evaluation_loop(model, image_processor, accelerator: Accelerator, dataloader, id2label):
+ metric = MeanAveragePrecision(iou_type="segm", class_metrics=True)
+
+ for inputs in tqdm(dataloader, total=len(dataloader), disable=not accelerator.is_local_main_process):
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ inputs = accelerator.gather_for_metrics(inputs)
+ inputs = nested_cpu(inputs)
+
+ outputs = accelerator.gather_for_metrics(outputs)
+ outputs = nested_cpu(outputs)
+
+ # For metric computation we need to provide:
+ # - targets in a form of list of dictionaries with keys "masks", "labels"
+ # - predictions in a form of list of dictionaries with keys "masks", "labels", "scores"
+
+ post_processed_targets = []
+ post_processed_predictions = []
+ target_sizes = []
+
+ # Collect targets
+ for masks, labels in zip(inputs["mask_labels"], inputs["class_labels"]):
+ post_processed_targets.append(
+ {
+ "masks": masks.to(dtype=torch.bool),
+ "labels": labels,
+ }
+ )
+ target_sizes.append(masks.shape[-2:])
+
+ # Collect predictions
+ post_processed_output = image_processor.post_process_instance_segmentation(
+ outputs,
+ threshold=0.0,
+ target_sizes=target_sizes,
+ return_binary_maps=True,
+ )
+
+ for image_predictions, target_size in zip(post_processed_output, target_sizes):
+ if image_predictions["segments_info"]:
+ post_processed_image_prediction = {
+ "masks": image_predictions["segmentation"].to(dtype=torch.bool),
+ "labels": torch.tensor([x["label_id"] for x in image_predictions["segments_info"]]),
+ "scores": torch.tensor([x["score"] for x in image_predictions["segments_info"]]),
+ }
+ else:
+ # for void predictions, we need to provide empty tensors
+ post_processed_image_prediction = {
+ "masks": torch.zeros([0, *target_size], dtype=torch.bool),
+ "labels": torch.tensor([]),
+ "scores": torch.tensor([]),
+ }
+ post_processed_predictions.append(post_processed_image_prediction)
+
+ # Update metric for batch targets and predictions
+ metric.update(post_processed_predictions, post_processed_targets)
+
+ # Compute metrics
+ metrics = metric.compute()
+
+ # Replace list of per class metrics with separate metric for each class
+ classes = metrics.pop("classes")
+ map_per_class = metrics.pop("map_per_class")
+ mar_100_per_class = metrics.pop("mar_100_per_class")
+ for class_id, class_map, class_mar in zip(classes, map_per_class, mar_100_per_class):
+ class_name = id2label[class_id.item()] if id2label is not None else class_id.item()
+ metrics[f"map_{class_name}"] = class_map
+ metrics[f"mar_100_{class_name}"] = class_mar
+
+ metrics = {k: round(v.item(), 4) for k, v in metrics.items()}
+
+ return metrics
+
+
+def setup_logging(accelerator: Accelerator) -> None:
+ """Setup logging according to `training_args`."""
+
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ logger.setLevel(logging.INFO)
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+
+def handle_repository_creation(accelerator: Accelerator, args: argparse.Namespace):
+ """Create a repository for the model and dataset if `args.push_to_hub` is set."""
+
+ repo_id = None
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ return repo_id
+
+
+def main():
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_instance_segmentation_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator_log_kwargs = {}
+
+ if args.with_tracking:
+ accelerator_log_kwargs["log_with"] = args.report_to
+ accelerator_log_kwargs["project_dir"] = args.output_dir
+
+ accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
+ setup_logging(accelerator)
+
+ # If passed along, set the training seed now.
+ # We set device_specific to True as we want different data augmentation per device.
+ if args.seed is not None:
+ set_seed(args.seed, device_specific=True)
+
+ # Create repository if push ot hub is specified
+ repo_id = handle_repository_creation(accelerator, args)
+
+ if args.push_to_hub:
+ api = HfApi()
+
+ # ------------------------------------------------------------------------------------------------
+ # Load dataset, prepare splits
+ # ------------------------------------------------------------------------------------------------
+
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ dataset = load_dataset(args.dataset_name, cache_dir=args.cache_dir, trust_remote_code=args.trust_remote_code)
+
+ # We need to specify the label2id mapping for the model
+ # it is a mapping from semantic class name to class index.
+ # In case your dataset does not provide it, you can create it manually:
+ # label2id = {"background": 0, "cat": 1, "dog": 2}
+ label2id = dataset["train"][0]["semantic_class_to_id"]
+
+ if args.do_reduce_labels:
+ label2id = {name: idx for name, idx in label2id.items() if idx != 0} # remove background class
+ label2id = {name: idx - 1 for name, idx in label2id.items()} # shift class indices by -1
+
+ id2label = {v: k for k, v in label2id.items()}
+
+ # ------------------------------------------------------------------------------------------------
+ # Load pretrained model and image processor
+ # ------------------------------------------------------------------------------------------------
+ model = AutoModelForUniversalSegmentation.from_pretrained(
+ args.model_name_or_path,
+ label2id=label2id,
+ id2label=id2label,
+ ignore_mismatched_sizes=True,
+ token=args.hub_token,
+ )
+
+ image_processor = AutoImageProcessor.from_pretrained(
+ args.model_name_or_path,
+ do_resize=True,
+ size={"height": args.image_height, "width": args.image_width},
+ do_reduce_labels=args.do_reduce_labels,
+ reduce_labels=args.do_reduce_labels, # TODO: remove when mask2former support `do_reduce_labels`
+ token=args.hub_token,
+ )
+
+ # ------------------------------------------------------------------------------------------------
+ # Define image augmentations and dataset transforms
+ # ------------------------------------------------------------------------------------------------
+ train_augment_and_transform = A.Compose(
+ [
+ A.HorizontalFlip(p=0.5),
+ A.RandomBrightnessContrast(p=0.5),
+ A.HueSaturationValue(p=0.1),
+ ],
+ )
+ validation_transform = A.Compose(
+ [A.NoOp()],
+ )
+
+ # Make transform functions for batch and apply for dataset splits
+ train_transform_batch = partial(
+ augment_and_transform_batch, transform=train_augment_and_transform, image_processor=image_processor
+ )
+ validation_transform_batch = partial(
+ augment_and_transform_batch, transform=validation_transform, image_processor=image_processor
+ )
+
+ with accelerator.main_process_first():
+ dataset["train"] = dataset["train"].with_transform(train_transform_batch)
+ dataset["validation"] = dataset["validation"].with_transform(validation_transform_batch)
+
+ dataloader_common_args = {
+ "num_workers": args.dataloader_num_workers,
+ "persistent_workers": True,
+ "collate_fn": collate_fn,
+ }
+ train_dataloader = DataLoader(
+ dataset["train"], shuffle=True, batch_size=args.per_device_train_batch_size, **dataloader_common_args
+ )
+ valid_dataloader = DataLoader(
+ dataset["validation"], shuffle=False, batch_size=args.per_device_eval_batch_size, **dataloader_common_args
+ )
+
+ # ------------------------------------------------------------------------------------------------
+ # Define optimizer, scheduler and prepare everything with the accelerator
+ # ------------------------------------------------------------------------------------------------
+
+ # Optimizer
+ optimizer = torch.optim.AdamW(
+ list(model.parameters()),
+ lr=args.learning_rate,
+ betas=[args.adam_beta1, args.adam_beta2],
+ eps=args.adam_epsilon,
+ )
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps
+ if overrode_max_train_steps
+ else args.max_train_steps * accelerator.num_processes,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, valid_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, valid_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("instance_segmentation_no_trainer", experiment_config)
+
+ # ------------------------------------------------------------------------------------------------
+ # Run training with evaluation on each epoch
+ # ------------------------------------------------------------------------------------------------
+
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(dataset['train'])}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+
+ for step, batch in enumerate(active_dataloader):
+ with accelerator.accumulate(model):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+ accelerator.backward(loss)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir,
+ is_main_process=accelerator.is_main_process,
+ save_function=accelerator.save,
+ )
+ if accelerator.is_main_process:
+ image_processor.save_pretrained(args.output_dir)
+ api.upload_folder(
+ repo_id=repo_id,
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ logger.info("***** Running evaluation *****")
+ metrics = evaluation_loop(model, image_processor, accelerator, valid_dataloader, id2label)
+
+ logger.info(f"epoch {epoch}: {metrics}")
+
+ if args.with_tracking:
+ accelerator.log(
+ {
+ "train_loss": total_loss.item() / len(train_dataloader),
+ **metrics,
+ "epoch": epoch,
+ "step": completed_steps,
+ },
+ step=completed_steps,
+ )
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ image_processor.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ # ------------------------------------------------------------------------------------------------
+ # Run evaluation on test dataset and save the model
+ # ------------------------------------------------------------------------------------------------
+
+ logger.info("***** Running evaluation on test dataset *****")
+ metrics = evaluation_loop(model, image_processor, accelerator, valid_dataloader, id2label)
+ metrics = {f"test_{k}": v for k, v in metrics.items()}
+
+ logger.info(f"Test metrics: {metrics}")
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
+ json.dump(metrics, f, indent=2)
+
+ image_processor.save_pretrained(args.output_dir)
+
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ ignore_patterns=["epoch_*"],
+ )
+
+ accelerator.wait_for_everyone()
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/language-modeling/README.md b/docs/transformers/examples/pytorch/language-modeling/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..700d1a2b561313c32c781a7fcac42e3928d83a1b
--- /dev/null
+++ b/docs/transformers/examples/pytorch/language-modeling/README.md
@@ -0,0 +1,246 @@
+
+
+## Language model training
+
+Fine-tuning (or training from scratch) the library models for language modeling on a text dataset for GPT, GPT-2,
+ALBERT, BERT, DistilBERT, RoBERTa, XLNet... GPT and GPT-2 are trained or fine-tuned using a causal language modeling
+(CLM) loss while ALBERT, BERT, DistilBERT and RoBERTa are trained or fine-tuned using a masked language modeling (MLM)
+loss. XLNet uses permutation language modeling (PLM), you can find more information about the differences between those
+objectives in our [model summary](https://huggingface.co/transformers/model_summary.html).
+
+There are two sets of scripts provided. The first set leverages the Trainer API. The second set with `no_trainer` in the suffix uses a custom training loop and leverages the 🤗 Accelerate library . Both sets use the 🤗 Datasets library. You can easily customize them to your needs if you need extra processing on your datasets.
+
+**Note:** The old script `run_language_modeling.py` is still available [here](https://github.com/huggingface/transformers/blob/main/examples/legacy/run_language_modeling.py).
+
+The following examples, will run on datasets hosted on our [hub](https://huggingface.co/datasets) or with your own
+text files for training and validation. We give examples of both below.
+
+### GPT-2/GPT and causal language modeling
+
+The following example fine-tunes GPT-2 on WikiText-2. We're using the raw WikiText-2 (no tokens were replaced before
+the tokenization). The loss here is that of causal language modeling.
+
+```bash
+python run_clm.py \
+ --model_name_or_path openai-community/gpt2 \
+ --dataset_name wikitext \
+ --dataset_config_name wikitext-2-raw-v1 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --do_train \
+ --do_eval \
+ --output_dir /tmp/test-clm
+```
+
+This takes about half an hour to train on a single K80 GPU and about one minute for the evaluation to run. It reaches
+a score of ~20 perplexity once fine-tuned on the dataset.
+
+To run on your own training and validation files, use the following command:
+
+```bash
+python run_clm.py \
+ --model_name_or_path openai-community/gpt2 \
+ --train_file path_to_train_file \
+ --validation_file path_to_validation_file \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --do_train \
+ --do_eval \
+ --output_dir /tmp/test-clm
+```
+
+This uses the built in HuggingFace `Trainer` for training. If you want to use a custom training loop, you can utilize or adapt the `run_clm_no_trainer.py` script. Take a look at the script for a list of supported arguments. An example is shown below:
+
+```bash
+python run_clm_no_trainer.py \
+ --dataset_name wikitext \
+ --dataset_config_name wikitext-2-raw-v1 \
+ --model_name_or_path openai-community/gpt2 \
+ --output_dir /tmp/test-clm
+```
+
+### GPT-2/GPT and causal language modeling with fill-in-the middle objective
+
+The following example fine-tunes GPT-2 on WikiText-2 but using the Fill-in-middle training objective. FIM objective was proposed in [Efficient Training of Language Models to Fill in the Middle](https://arxiv.org/abs/2207.14255). They showed that autoregressive language models can learn to infill text after applying a straightforward transformation to the dataset, which simply moves a span of text from the middle of a document to its end.
+
+We're using the raw WikiText-2 (no tokens were replaced before the tokenization). The loss here is that of causal language modeling.
+
+```bash
+python run_fim.py \
+ --model_name_or_path gpt2 \
+ --dataset_name wikitext \
+ --dataset_config_name wikitext-2-raw-v1 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --fim_rate 0.5 \
+ --fim_spm_rate 0.2 \
+ --do_train \
+ --do_eval \
+ --output_dir /tmp/test-clm
+```
+
+To run on your own training and validation files, use the following command:
+
+```bash
+python run_fim.py \
+ --model_name_or_path gpt2 \
+ --train_file path_to_train_file \
+ --validation_file path_to_validation_file \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --fim_rate 0.5 \
+ --fim_spm_rate 0.2 \
+ --do_train \
+ --do_eval \
+ --output_dir /tmp/test-clm
+```
+
+This uses the built in HuggingFace `Trainer` for training. If you want to use a custom training loop, you can utilize or adapt the `run_fim_no_trainer.py` script. Take a look at the script for a list of supported arguments. An example is shown below:
+
+```bash
+python run_fim_no_trainer.py \
+ --model_name_or_path gpt2 \
+ --dataset_name wikitext \
+ --dataset_config_name wikitext-2-raw-v1 \
+ --model_name_or_path gpt2 \
+ --fim_rate 0.5 \
+ --fim_spm_rate 0.2 \
+ --output_dir /tmp/test-clm
+```
+
+**Note**: Passing in FIM rate as `0.5` means that FIM transformations will be applied to the dataset with a probability of 50%. Whereas passing in FIM SPM rate as `0.2` means that 20% of FIM transformations will use SPM (or Suffix-Prefix-Middle) and the remaining 80% will use PSM (or Prefix-Suffix-Middle) mode of transformation.
+
+### RoBERTa/BERT/DistilBERT and masked language modeling
+
+The following example fine-tunes RoBERTa on WikiText-2. Here too, we're using the raw WikiText-2. The loss is different
+as BERT/RoBERTa have a bidirectional mechanism; we're therefore using the same loss that was used during their
+pre-training: masked language modeling.
+
+In accordance to the RoBERTa paper, we use dynamic masking rather than static masking. The model may, therefore,
+converge slightly slower (over-fitting takes more epochs).
+
+```bash
+python run_mlm.py \
+ --model_name_or_path FacebookAI/roberta-base \
+ --dataset_name wikitext \
+ --dataset_config_name wikitext-2-raw-v1 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --do_train \
+ --do_eval \
+ --output_dir /tmp/test-mlm
+```
+
+To run on your own training and validation files, use the following command:
+
+```bash
+python run_mlm.py \
+ --model_name_or_path FacebookAI/roberta-base \
+ --train_file path_to_train_file \
+ --validation_file path_to_validation_file \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --do_train \
+ --do_eval \
+ --output_dir /tmp/test-mlm
+```
+
+If your dataset is organized with one sample per line, you can use the `--line_by_line` flag (otherwise the script
+concatenates all texts and then splits them in blocks of the same length).
+
+This uses the built in HuggingFace `Trainer` for training. If you want to use a custom training loop, you can utilize or adapt the `run_mlm_no_trainer.py` script. Take a look at the script for a list of supported arguments. An example is shown below:
+
+```bash
+python run_mlm_no_trainer.py \
+ --dataset_name wikitext \
+ --dataset_config_name wikitext-2-raw-v1 \
+ --model_name_or_path FacebookAI/roberta-base \
+ --output_dir /tmp/test-mlm
+```
+
+**Note:** On TPU, you should use the flag `--pad_to_max_length` in conjunction with the `--line_by_line` flag to make
+sure all your batches have the same length.
+
+### Whole word masking
+
+This part was moved to https://github.com/huggingface/transformers-research-projects/tree/main/mlm_wwm.
+
+### XLNet and permutation language modeling
+
+XLNet uses a different training objective, which is permutation language modeling. It is an autoregressive method
+to learn bidirectional contexts by maximizing the expected likelihood over all permutations of the input
+sequence factorization order.
+
+We use the `--plm_probability` flag to define the ratio of length of a span of masked tokens to surrounding
+context length for permutation language modeling.
+
+The `--max_span_length` flag may also be used to limit the length of a span of masked tokens used
+for permutation language modeling.
+
+Here is how to fine-tune XLNet on wikitext-2:
+
+```bash
+python run_plm.py \
+ --model_name_or_path=xlnet/xlnet-base-cased \
+ --dataset_name wikitext \
+ --dataset_config_name wikitext-2-raw-v1 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --do_train \
+ --do_eval \
+ --output_dir /tmp/test-plm
+```
+
+To fine-tune it on your own training and validation file, run:
+
+```bash
+python run_plm.py \
+ --model_name_or_path=xlnet/xlnet-base-cased \
+ --train_file path_to_train_file \
+ --validation_file path_to_validation_file \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --do_train \
+ --do_eval \
+ --output_dir /tmp/test-plm
+```
+
+If your dataset is organized with one sample per line, you can use the `--line_by_line` flag (otherwise the script
+concatenates all texts and then splits them in blocks of the same length).
+
+**Note:** On TPU, you should use the flag `--pad_to_max_length` in conjunction with the `--line_by_line` flag to make
+sure all your batches have the same length.
+
+## Streaming
+
+To use the streaming dataset mode which can be very useful for large datasets, add `--streaming` to the command line. This is supported by `run_mlm.py`, `run_clm.py` and `run_fim.py`. Make sure to adapt the other scripts to your use case by taking inspiration from them.
+
+## Low Cpu Memory Usage
+
+To use low cpu memory mode which can be very useful for LLM, add `--low_cpu_mem_usage` to the command line. This is currently supported by `run_clm.py`,`run_mlm.py`, `run_plm.py`, `run_fim.py`, `run_mlm_no_trainer.py`, `run_clm_no_trainer.py` and `run_fim_no_trainer.py`.
+
+## Creating a model on the fly
+
+When training a model from scratch, configuration values may be overridden with the help of `--config_overrides`:
+
+
+```bash
+python run_clm.py --model_type gpt2 --tokenizer_name openai-community/gpt2 \ --config_overrides="n_embd=1024,n_head=16,n_layer=48,n_positions=102" \
+[...]
+```
+
+This feature is only available in `run_clm.py`, `run_plm.py`, `run_mlm.py` and `run_fim.py`.
diff --git a/docs/transformers/examples/pytorch/language-modeling/requirements.txt b/docs/transformers/examples/pytorch/language-modeling/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..851e8de09ccdc1f58eb698d63419a98bf53623cc
--- /dev/null
+++ b/docs/transformers/examples/pytorch/language-modeling/requirements.txt
@@ -0,0 +1,7 @@
+accelerate >= 0.12.0
+torch >= 1.3
+datasets >= 2.14.0
+sentencepiece != 0.1.92
+protobuf
+evaluate
+scikit-learn
diff --git a/docs/transformers/examples/pytorch/language-modeling/run_clm.py b/docs/transformers/examples/pytorch/language-modeling/run_clm.py
new file mode 100644
index 0000000000000000000000000000000000000000..44869b004b9d055669720639d70b72214bc9ad74
--- /dev/null
+++ b/docs/transformers/examples/pytorch/language-modeling/run_clm.py
@@ -0,0 +1,656 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for causal language modeling (GPT, GPT-2, CTRL, ...) on a text file or a dataset.
+
+Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
+https://huggingface.co/models?filter=text-generation
+"""
+# You can also adapt this script on your own causal language modeling task. Pointers for this are left as comments.
+
+import logging
+import math
+import os
+import sys
+from dataclasses import dataclass, field
+from itertools import chain
+from typing import Optional
+
+import datasets
+import evaluate
+import torch
+from datasets import load_dataset
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_FOR_CAUSAL_LM_MAPPING,
+ AutoConfig,
+ AutoModelForCausalLM,
+ AutoTokenizer,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ default_data_collator,
+ is_torch_xla_available,
+ set_seed,
+)
+from transformers.testing_utils import CaptureLogger
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=2.14.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
+
+logger = logging.getLogger(__name__)
+
+
+MODEL_CONFIG_CLASSES = list(MODEL_FOR_CAUSAL_LM_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_overrides: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Override some existing default config settings when a model is trained from scratch. Example: "
+ "n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
+ )
+ },
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ torch_dtype: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Override the default `torch.dtype` and load the model under this dtype. If `auto` is passed, the "
+ "dtype will be automatically derived from the model's weights."
+ ),
+ "choices": ["auto", "bfloat16", "float16", "float32"],
+ },
+ )
+ low_cpu_mem_usage: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "It is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded. "
+ "set True will benefit LLM loading time and RAM consumption."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if self.config_overrides is not None and (self.config_name is not None or self.model_name_or_path is not None):
+ raise ValueError(
+ "--config_overrides can't be used in combination with --config_name or --model_name_or_path"
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ streaming: bool = field(default=False, metadata={"help": "Enable streaming mode"})
+ block_size: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Optional input sequence length after tokenization. "
+ "The training dataset will be truncated in block of this size for training. "
+ "Default to the model max input length for single sentence inputs (take into account special tokens)."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ validation_split_percentage: Optional[int] = field(
+ default=5,
+ metadata={
+ "help": "The percentage of the train set used as validation set in case there's no validation split"
+ },
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ keep_linebreaks: bool = field(
+ default=True, metadata={"help": "Whether to keep line breaks when using TXT files or not."}
+ )
+
+ def __post_init__(self):
+ if self.streaming:
+ require_version("datasets>=2.0.0", "The streaming feature requires `datasets>=2.0.0`")
+
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_clm", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ streaming=data_args.streaming,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ streaming=data_args.streaming,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ raw_datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ streaming=data_args.streaming,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ dataset_args = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = (
+ data_args.train_file.split(".")[-1]
+ if data_args.train_file is not None
+ else data_args.validation_file.split(".")[-1]
+ )
+ if extension == "txt":
+ extension = "text"
+ dataset_args["keep_linebreaks"] = data_args.keep_linebreaks
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ **dataset_args,
+ )
+ # If no validation data is there, validation_split_percentage will be used to divide the dataset.
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ **dataset_args,
+ )
+ raw_datasets["train"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ **dataset_args,
+ )
+
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+
+ config_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "revision": model_args.model_revision,
+ "token": model_args.token,
+ "trust_remote_code": model_args.trust_remote_code,
+ }
+ if model_args.config_name:
+ config = AutoConfig.from_pretrained(model_args.config_name, **config_kwargs)
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+ if model_args.config_overrides is not None:
+ logger.info(f"Overriding config: {model_args.config_overrides}")
+ config.update_from_string(model_args.config_overrides)
+ logger.info(f"New config: {config}")
+
+ tokenizer_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "use_fast": model_args.use_fast_tokenizer,
+ "revision": model_args.model_revision,
+ "token": model_args.token,
+ "trust_remote_code": model_args.trust_remote_code,
+ }
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if model_args.model_name_or_path:
+ torch_dtype = (
+ model_args.torch_dtype
+ if model_args.torch_dtype in ["auto", None]
+ else getattr(torch, model_args.torch_dtype)
+ )
+ model = AutoModelForCausalLM.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ torch_dtype=torch_dtype,
+ low_cpu_mem_usage=model_args.low_cpu_mem_usage,
+ )
+ else:
+ model = AutoModelForCausalLM.from_config(config, trust_remote_code=model_args.trust_remote_code)
+ n_params = sum({p.data_ptr(): p.numel() for p in model.parameters()}.values())
+ logger.info(f"Training new model from scratch - Total size={n_params / 2**20:.2f}M params")
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embedding_size = model.get_input_embeddings().weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ if training_args.do_train:
+ column_names = list(raw_datasets["train"].features)
+ else:
+ column_names = list(raw_datasets["validation"].features)
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ # since this will be pickled to avoid _LazyModule error in Hasher force logger loading before tokenize_function
+ tok_logger = transformers.utils.logging.get_logger("transformers.tokenization_utils_base")
+
+ def tokenize_function(examples):
+ with CaptureLogger(tok_logger) as cl:
+ output = tokenizer(examples[text_column_name])
+ # clm input could be much much longer than block_size
+ if "Token indices sequence length is longer than the" in cl.out:
+ tok_logger.warning(
+ "^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits"
+ " before being passed to the model."
+ )
+ return output
+
+ with training_args.main_process_first(desc="dataset map tokenization"):
+ if not data_args.streaming:
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on dataset",
+ )
+ else:
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ remove_columns=column_names,
+ )
+ if hasattr(config, "max_position_embeddings"):
+ max_pos_embeddings = config.max_position_embeddings
+ else:
+ # Define a default value if the attribute is missing in the config.
+ max_pos_embeddings = 1024
+
+ if data_args.block_size is None:
+ block_size = tokenizer.model_max_length
+ if block_size > max_pos_embeddings:
+ logger.warning(
+ f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). "
+ f"Using block_size={min(1024, max_pos_embeddings)} instead. You can change that default value by passing --block_size xxx."
+ )
+ if max_pos_embeddings > 0:
+ block_size = min(1024, max_pos_embeddings)
+ else:
+ block_size = 1024
+ else:
+ if data_args.block_size > tokenizer.model_max_length:
+ logger.warning(
+ f"The block_size passed ({data_args.block_size}) is larger than the maximum length for the model "
+ f"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}."
+ )
+ block_size = min(data_args.block_size, tokenizer.model_max_length)
+
+ # Main data processing function that will concatenate all texts from our dataset and generate chunks of block_size.
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, and if the total_length < block_size we exclude this batch and return an empty dict.
+ # We could add padding if the model supported it instead of this drop, you can customize this part to your needs.
+ total_length = (total_length // block_size) * block_size
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
+ for k, t in concatenated_examples.items()
+ }
+ result["labels"] = result["input_ids"].copy()
+ return result
+
+ # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a remainder
+ # for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value might be slower
+ # to preprocess.
+ #
+ # To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
+ # https://huggingface.co/docs/datasets/process#map
+
+ with training_args.main_process_first(desc="grouping texts together"):
+ if not data_args.streaming:
+ lm_datasets = tokenized_datasets.map(
+ group_texts,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc=f"Grouping texts in chunks of {block_size}",
+ )
+ else:
+ lm_datasets = tokenized_datasets.map(
+ group_texts,
+ batched=True,
+ )
+
+ if training_args.do_train:
+ if "train" not in tokenized_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = lm_datasets["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+
+ if training_args.do_eval:
+ if "validation" not in tokenized_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = lm_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ def preprocess_logits_for_metrics(logits, labels):
+ if isinstance(logits, tuple):
+ # Depending on the model and config, logits may contain extra tensors,
+ # like past_key_values, but logits always come first
+ logits = logits[0]
+ return logits.argmax(dim=-1)
+
+ metric = evaluate.load("accuracy", cache_dir=model_args.cache_dir)
+
+ def compute_metrics(eval_preds):
+ preds, labels = eval_preds
+ # preds have the same shape as the labels, after the argmax(-1) has been calculated
+ # by preprocess_logits_for_metrics but we need to shift the labels
+ labels = labels[:, 1:].reshape(-1)
+ preds = preds[:, :-1].reshape(-1)
+ return metric.compute(predictions=preds, references=labels)
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ processing_class=tokenizer,
+ # Data collator will default to DataCollatorWithPadding, so we change it.
+ data_collator=default_data_collator,
+ compute_metrics=compute_metrics if training_args.do_eval and not is_torch_xla_available() else None,
+ preprocess_logits_for_metrics=preprocess_logits_for_metrics
+ if training_args.do_eval and not is_torch_xla_available()
+ else None,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model() # Saves the tokenizer too for easy upload
+
+ metrics = train_result.metrics
+
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+
+ metrics = trainer.evaluate()
+
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+ try:
+ perplexity = math.exp(metrics["eval_loss"])
+ except OverflowError:
+ perplexity = float("inf")
+ metrics["perplexity"] = perplexity
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "text-generation"}
+ if data_args.dataset_name is not None:
+ kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ kwargs["dataset_args"] = data_args.dataset_config_name
+ kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/language-modeling/run_clm_no_trainer.py b/docs/transformers/examples/pytorch/language-modeling/run_clm_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..2a5a0d5d72d92f36d274e91fa50454055f8ed2dd
--- /dev/null
+++ b/docs/transformers/examples/pytorch/language-modeling/run_clm_no_trainer.py
@@ -0,0 +1,724 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for causal language modeling (GPT, GPT-2, CTRL, ...)
+on a text file or a dataset without using HuggingFace Trainer.
+
+Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
+https://huggingface.co/models?filter=text-generation
+"""
+# You can also adapt this script on your own causal language modeling task. Pointers for this are left as comments.
+
+import argparse
+import json
+import logging
+import math
+import os
+import random
+from itertools import chain
+from pathlib import Path
+
+import datasets
+import torch
+from accelerate import Accelerator, DistributedType
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from datasets import load_dataset
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from tqdm.auto import tqdm
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_MAPPING,
+ AutoConfig,
+ AutoModelForCausalLM,
+ AutoTokenizer,
+ SchedulerType,
+ default_data_collator,
+ get_scheduler,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logger = get_logger(__name__)
+
+require_version("datasets>=2.14.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
+
+MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Finetune a transformers model on a causal language modeling task")
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help="The name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The configuration name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--train_file", type=str, default=None, help="A csv, txt or a json file containing the training data."
+ )
+ parser.add_argument(
+ "--validation_file", type=str, default=None, help="A csv, txt or a json file containing the validation data."
+ )
+ parser.add_argument(
+ "--validation_split_percentage",
+ default=5,
+ help="The percentage of the train set used as validation set in case there's no validation split",
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ required=False,
+ )
+ parser.add_argument(
+ "--config_name",
+ type=str,
+ default=None,
+ help="Pretrained config name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--use_slow_tokenizer",
+ action="store_true",
+ help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--model_type",
+ type=str,
+ default=None,
+ help="Model type to use if training from scratch.",
+ choices=MODEL_TYPES,
+ )
+ parser.add_argument(
+ "--block_size",
+ type=int,
+ default=None,
+ help=(
+ "Optional input sequence length after tokenization. The training dataset will be truncated in block of"
+ " this size for training. Default to the model max input length for single sentence inputs (take into"
+ " account special tokens)."
+ ),
+ )
+ parser.add_argument(
+ "--preprocessing_num_workers",
+ type=int,
+ default=None,
+ help="The number of processes to use for the preprocessing.",
+ )
+ parser.add_argument(
+ "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
+ )
+ parser.add_argument(
+ "--no_keep_linebreaks", action="store_true", help="Do not keep line breaks when using TXT files."
+ )
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--low_cpu_mem_usage",
+ action="store_true",
+ help=(
+ "It is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded. "
+ "If passed, LLM loading time and RAM consumption will be benefited."
+ ),
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+ if args.dataset_name is None and args.train_file is None and args.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if args.train_file is not None:
+ extension = args.train_file.split(".")[-1]
+ if extension not in ["csv", "json", "txt"]:
+ raise ValueError("`train_file` should be a csv, json or txt file.")
+ if args.validation_file is not None:
+ extension = args.validation_file.split(".")[-1]
+ if extension not in ["csv", "json", "txt"]:
+ raise ValueError("`validation_file` should be a csv, json or txt file.")
+
+ if args.push_to_hub:
+ if args.output_dir is None:
+ raise ValueError("Need an `output_dir` to create a repo when `--push_to_hub` is passed.")
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_clm_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator_log_kwargs = {}
+
+ if args.with_tracking:
+ accelerator_log_kwargs["log_with"] = args.report_to
+ accelerator_log_kwargs["project_dir"] = args.output_dir
+
+ accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ args.dataset_name, args.dataset_config_name, trust_remote_code=args.trust_remote_code
+ )
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ split=f"train[:{args.validation_split_percentage}%]",
+ trust_remote_code=args.trust_remote_code,
+ )
+ raw_datasets["train"] = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ split=f"train[{args.validation_split_percentage}%:]",
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ dataset_args = {}
+ if args.train_file is not None:
+ data_files["train"] = args.train_file
+ extension = args.train_file.split(".")[-1]
+ if args.validation_file is not None:
+ data_files["validation"] = args.validation_file
+ extension = args.validation_file.split(".")[-1]
+ if extension == "txt":
+ extension = "text"
+ dataset_args["keep_linebreaks"] = not args.no_keep_linebreaks
+ raw_datasets = load_dataset(extension, data_files=data_files, **dataset_args)
+ # If no validation data is there, validation_split_percentage will be used to divide the dataset.
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[:{args.validation_split_percentage}%]",
+ **dataset_args,
+ )
+ raw_datasets["train"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[{args.validation_split_percentage}%:]",
+ **dataset_args,
+ )
+
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ if args.config_name:
+ config = AutoConfig.from_pretrained(
+ args.config_name,
+ trust_remote_code=args.trust_remote_code,
+ )
+ elif args.model_name_or_path:
+ config = AutoConfig.from_pretrained(
+ args.model_name_or_path,
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ config = CONFIG_MAPPING[args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_name, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
+ )
+ elif args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if args.model_name_or_path:
+ model = AutoModelForCausalLM.from_pretrained(
+ args.model_name_or_path,
+ from_tf=bool(".ckpt" in args.model_name_or_path),
+ config=config,
+ low_cpu_mem_usage=args.low_cpu_mem_usage,
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelForCausalLM.from_config(config, trust_remote_code=args.trust_remote_code)
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embedding_size = model.get_input_embeddings().weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ column_names = raw_datasets["train"].column_names
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ def tokenize_function(examples):
+ return tokenizer(examples[text_column_name])
+
+ with accelerator.main_process_first():
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Running tokenizer on dataset",
+ )
+
+ if args.block_size is None:
+ block_size = tokenizer.model_max_length
+ if block_size > config.max_position_embeddings:
+ logger.warning(
+ f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). "
+ f"Using block_size={min(1024, config.max_position_embeddings)} instead. You can change that default value by passing --block_size xxx."
+ )
+ block_size = min(1024, config.max_position_embeddings)
+ else:
+ if args.block_size > tokenizer.model_max_length:
+ logger.warning(
+ f"The block_size passed ({args.block_size}) is larger than the maximum length for the model "
+ f"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}."
+ )
+ block_size = min(args.block_size, tokenizer.model_max_length)
+
+ # Main data processing function that will concatenate all texts from our dataset and generate chunks of block_size.
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, and if the total_length < block_size we exclude this batch and return an empty dict.
+ # We could add padding if the model supported it instead of this drop, you can customize this part to your needs.
+ total_length = (total_length // block_size) * block_size
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
+ for k, t in concatenated_examples.items()
+ }
+ result["labels"] = result["input_ids"].copy()
+ return result
+
+ # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a remainder
+ # for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value might be slower
+ # to preprocess.
+ #
+ # To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
+ # https://huggingface.co/docs/datasets/process#map
+
+ with accelerator.main_process_first():
+ lm_datasets = tokenized_datasets.map(
+ group_texts,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ load_from_cache_file=not args.overwrite_cache,
+ desc=f"Grouping texts in chunks of {block_size}",
+ )
+
+ train_dataset = lm_datasets["train"]
+ eval_dataset = lm_datasets["validation"]
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # DataLoaders creation:
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=args.per_device_train_batch_size
+ )
+ eval_dataloader = DataLoader(
+ eval_dataset, collate_fn=default_data_collator, batch_size=args.per_device_eval_batch_size
+ )
+
+ # Optimizer
+ # Split weights in two groups, one with weight decay and the other not.
+ no_decay = ["bias", "layer_norm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps
+ if overrode_max_train_steps
+ else args.max_train_steps * accelerator.num_processes,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
+
+ # On TPU, the tie weights in our model have been disconnected, so we need to restore the ties.
+ if accelerator.distributed_type == DistributedType.TPU:
+ model.tie_weights()
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("clm_no_trainer", experiment_config)
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+ for step, batch in enumerate(active_dataloader):
+ with accelerator.accumulate(model):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+ accelerator.backward(loss)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+ if completed_steps >= args.max_train_steps:
+ break
+
+ model.eval()
+ losses = []
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ loss = outputs.loss
+ losses.append(accelerator.gather_for_metrics(loss.repeat(args.per_device_eval_batch_size)))
+
+ losses = torch.cat(losses)
+ try:
+ eval_loss = torch.mean(losses)
+ perplexity = math.exp(eval_loss)
+ except OverflowError:
+ perplexity = float("inf")
+
+ logger.info(f"epoch {epoch}: perplexity: {perplexity} eval_loss: {eval_loss}")
+
+ if args.with_tracking:
+ accelerator.log(
+ {
+ "perplexity": perplexity,
+ "eval_loss": eval_loss,
+ "train_loss": total_loss.item() / len(train_dataloader),
+ "epoch": epoch,
+ "step": completed_steps,
+ },
+ step=completed_steps,
+ )
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+ with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
+ json.dump({"perplexity": perplexity}, f)
+
+ accelerator.wait_for_everyone()
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/language-modeling/run_fim.py b/docs/transformers/examples/pytorch/language-modeling/run_fim.py
new file mode 100644
index 0000000000000000000000000000000000000000..ac97a3c10d47742c259edba6ceaefb65cbfacd9e
--- /dev/null
+++ b/docs/transformers/examples/pytorch/language-modeling/run_fim.py
@@ -0,0 +1,866 @@
+#!/usr/bin/env python
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for causal language modeling using
+Fill-in-the middle (FIM) objective on a text file or a dataset.
+
+Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
+https://huggingface.co/models?filter=text-generation
+"""
+# You should adapt this script on your own causal language modeling task. Pointers for this are left as comments.
+
+import logging
+import math
+import os
+import sys
+from dataclasses import dataclass, field
+from itertools import chain
+from typing import Optional
+
+import datasets
+import evaluate
+import numpy as np
+import torch
+from datasets import load_dataset
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_FOR_CAUSAL_LM_MAPPING,
+ AutoConfig,
+ AutoModelForCausalLM,
+ AutoTokenizer,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ default_data_collator,
+ is_torch_xla_available,
+ set_seed,
+)
+from transformers.integrations import is_deepspeed_zero3_enabled
+from transformers.testing_utils import CaptureLogger
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=2.14.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
+
+logger = logging.getLogger(__name__)
+
+
+MODEL_CONFIG_CLASSES = list(MODEL_FOR_CAUSAL_LM_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_overrides: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Override some existing default config settings when a model is trained from scratch. Example: "
+ "n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
+ )
+ },
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ torch_dtype: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Override the default `torch.dtype` and load the model under this dtype. If `auto` is passed, the "
+ "dtype will be automatically derived from the model's weights."
+ ),
+ "choices": ["auto", "bfloat16", "float16", "float32"],
+ },
+ )
+ low_cpu_mem_usage: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "It is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded. "
+ "set True will benefit LLM loading time and RAM consumption."
+ )
+ },
+ )
+ pad_to_multiple_of: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad the embedding layer to a multiple depending on the device. ",
+ "For NVIDIA GPUs, this will be a multiple of 8, for TPUs a multiple of 128.",
+ )
+ },
+ )
+ attn_implementation: Optional[str] = field(
+ default="sdpa", metadata={"help": ("The attention implementation to use. ")}
+ )
+
+ def __post_init__(self):
+ if self.config_overrides is not None and (self.config_name is not None or self.model_name_or_path is not None):
+ raise ValueError(
+ "--config_overrides can't be used in combination with --config_name or --model_name_or_path"
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ streaming: bool = field(default=False, metadata={"help": "Enable streaming mode"})
+ block_size: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Optional input sequence length after tokenization. "
+ "The training dataset will be truncated in block of this size for training. "
+ "Default to the model max input length for single sentence inputs (take into account special tokens)."
+ )
+ },
+ )
+ fim_rate: Optional[float] = field(
+ default=0.5,
+ metadata={
+ "help": (
+ "Optional probability with which the FIM transformation is applied to the example. "
+ "Default is 0.5. A rate of 1.0 means every example will undergo FIM transformation, "
+ "while a rate of 0.0 means no example will."
+ )
+ },
+ )
+ fim_spm_rate: Optional[float] = field(
+ default=0.5,
+ metadata={
+ "help": (
+ "Within the examples undergoing FIM transformation, this rate determines the probability "
+ "of applying the Sentence Permutation Mode (SPM). "
+ "Default is 0.5. A rate of 1.0 means all FIM transformations will use SPM, "
+ "while a rate of 0.0 means none will."
+ )
+ },
+ )
+ truncate_or_pad: Optional[bool] = field(
+ default=True,
+ metadata={
+ "help": (
+ "Indicates whether the transformed example should be truncated or padded to maintain "
+ "the same length as the original example. "
+ "Default is True. If False, the function will not truncate or pad the examples."
+ )
+ },
+ )
+ fim_prefix_token: Optional[str] = field(
+ default="",
+ metadata={"help": ("Fill-in-Middle Prefix token. Defaults to ''.")},
+ )
+ fim_middle_token: Optional[str] = field(
+ default="",
+ metadata={"help": ("Fill-in-Middle Middle token. Defaults to ''.")},
+ )
+ fim_suffix_token: Optional[str] = field(
+ default="",
+ metadata={"help": ("Fill-in-Middle Suffix token. Defaults to ''.")},
+ )
+ pad_token: Optional[str] = field(
+ default="",
+ metadata={
+ "help": (
+ "Fill-in-Middle Pad token. Used only when 'truncate_or_pad' is set to True. Defaults to ''."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ validation_split_percentage: Optional[int] = field(
+ default=5,
+ metadata={
+ "help": "The percentage of the train set used as validation set in case there's no validation split"
+ },
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ keep_linebreaks: bool = field(
+ default=True, metadata={"help": "Whether to keep line breaks when using TXT files or not."}
+ )
+
+ def __post_init__(self):
+ if self.streaming:
+ require_version("datasets>=2.0.0", "The streaming feature requires `datasets>=2.0.0`")
+
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_fim", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Set a numpy random state for FIM transformations
+ np_rng = np.random.RandomState(seed=training_args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ streaming=data_args.streaming,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ streaming=data_args.streaming,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ raw_datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ streaming=data_args.streaming,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ dataset_args = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = (
+ data_args.train_file.split(".")[-1]
+ if data_args.train_file is not None
+ else data_args.validation_file.split(".")[-1]
+ )
+ if extension == "txt":
+ extension = "text"
+ dataset_args["keep_linebreaks"] = data_args.keep_linebreaks
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ **dataset_args,
+ )
+ # If no validation data is there, validation_split_percentage will be used to divide the dataset.
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ **dataset_args,
+ )
+ raw_datasets["train"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ **dataset_args,
+ )
+
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.html.
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+
+ config_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "revision": model_args.model_revision,
+ "token": model_args.token,
+ "trust_remote_code": model_args.trust_remote_code,
+ }
+ if model_args.config_name:
+ config = AutoConfig.from_pretrained(model_args.config_name, **config_kwargs)
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+ if model_args.config_overrides is not None:
+ logger.info(f"Overriding config: {model_args.config_overrides}")
+ config.update_from_string(model_args.config_overrides)
+ logger.info(f"New config: {config}")
+
+ tokenizer_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "use_fast": model_args.use_fast_tokenizer,
+ "revision": model_args.model_revision,
+ "token": model_args.token,
+ "trust_remote_code": model_args.trust_remote_code,
+ }
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if model_args.model_name_or_path:
+ torch_dtype = (
+ model_args.torch_dtype
+ if model_args.torch_dtype in ["auto", None]
+ else getattr(torch, model_args.torch_dtype)
+ )
+ model = AutoModelForCausalLM.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ torch_dtype=torch_dtype,
+ low_cpu_mem_usage=model_args.low_cpu_mem_usage,
+ attn_implementation=model_args.attn_implementation,
+ )
+
+ else:
+ model = AutoModelForCausalLM.from_config(
+ config,
+ trust_remote_code=model_args.trust_remote_code,
+ attn_implementation=model_args.attn_implementation,
+ )
+ n_params = sum({p.data_ptr(): p.numel() for p in model.parameters()}.values())
+ logger.info(f"Training new model from scratch - Total size={n_params / 2**20:.2f}M params")
+
+ # Add the new FIM tokens to the tokenizer and resize model's vocab embeddings
+ special_tokens = [data_args.fim_prefix_token, data_args.fim_middle_token, data_args.fim_suffix_token]
+ if data_args.truncate_or_pad:
+ special_tokens.append(data_args.pad_token)
+
+ # Get the factor by which the embedding layer should be padded based on the device
+ pad_factor = 1
+ if torch.cuda.is_availble():
+ pad_factor = 8
+
+ elif is_torch_xla_available(check_is_tpu=True):
+ pad_factor = 128
+
+ # Add the new tokens to the tokenizer
+ tokenizer.add_tokens(special_tokens)
+ original_embeddings = model.get_input_embeddings()
+
+ if is_deepspeed_zero3_enabled():
+ import deepspeed
+
+ with deepspeed.zero.GatheredParameters(original_embeddings.weight, modifier_rank=0):
+ # Get the pre-expansion embeddings of the model and resize the embedding layer
+ model.resize_token_embeddings(len(tokenizer), pad_to_multiple_of=pad_factor)
+ embeddings = model.get_input_embeddings()
+
+ # Sample the embeddings for the new tokens from a multivariate normal distribution
+ # We do this so that the new embeddings are close to the original embeddings and not necessarily zero
+ # More on this: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
+ mean = original_embeddings.mean(dim=0)
+ n = original_embeddings.size()[0]
+ sigma = ((original_embeddings - mean).T @ (original_embeddings - mean)) / n
+ dist = torch.distributions.multivariate_normal.MultivariateNormal(
+ mean,
+ covariance_matrix=1e-5 * sigma,
+ )
+ new_token_embeddings = torch.stack(
+ tuple(dist.sample() for _ in range(len(special_tokens))),
+ dim=0,
+ )
+ else:
+ original_embeddings = model.get_input_embeddings()
+ # Get the pre-expansion embeddings of the model and resize the embedding layer
+ model.resize_token_embeddings(len(tokenizer), pad_to_multiple_of=pad_factor)
+ embeddings = model.get_input_embeddings()
+
+ # Sample the embeddings for the new tokens from a multivariate normal distribution
+ # We do this so that the new embeddings are close to the original embeddings and not necessarily zero
+ # More on this: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
+ mean = original_embeddings.mean(dim=0)
+ n = original_embeddings.size()[0]
+ sigma = ((original_embeddings - mean).T @ (original_embeddings - mean)) / n
+ dist = torch.distributions.multivariate_normal.MultivariateNormal(
+ mean,
+ covariance_matrix=1e-5 * sigma,
+ )
+ new_token_embeddings = torch.stack(
+ tuple(dist.sample() for _ in range(len(special_tokens))),
+ dim=0,
+ )
+
+ if is_deepspeed_zero3_enabled():
+ import deepspeed
+
+ with deepspeed.zero.GatheredParameters(embeddings.weight, modifier_rank=0):
+ # Set the new tokens' embeddings to the newly sampled embeddings
+ embeddings.weight.data[-len(special_tokens) :] = new_token_embeddings
+ else:
+ # Set the new tokens' embeddings to the newly sampled embeddings
+ embeddings.weight.data[-len(special_tokens) :] = new_token_embeddings
+
+ # Update the model's embeddings with the new embeddings
+ model.set_input_embeddings(embeddings)
+
+ logger.info("Added special tokens to the tokenizer and resized model's embedding layer")
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ if training_args.do_train:
+ column_names = list(raw_datasets["train"].features)
+ else:
+ column_names = list(raw_datasets["validation"].features)
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ # since this will be pickled to avoid _LazyModule error in Hasher force logger loading before tokenize_function
+ tok_logger = transformers.utils.logging.get_logger("transformers.tokenization_utils_base")
+
+ def tokenize_function(examples):
+ with CaptureLogger(tok_logger) as cl:
+ output = tokenizer(examples[text_column_name])
+ # clm-fim input could be much much longer than block_size
+ if "Token indices sequence length is longer than the" in cl.out:
+ tok_logger.warning(
+ "^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits"
+ " before being passed to the model."
+ )
+ return output
+
+ with training_args.main_process_first(desc="dataset map tokenization"):
+ if not data_args.streaming:
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on dataset",
+ )
+ else:
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ remove_columns=column_names,
+ )
+
+ if data_args.block_size is None:
+ block_size = tokenizer.model_max_length
+ if block_size > config.max_position_embeddings:
+ logger.warning(
+ f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). "
+ f"Using block_size={min(1024, config.max_position_embeddings)} instead. You can change that default value by passing --block_size xxx."
+ )
+ block_size = min(1024, config.max_position_embeddings)
+ else:
+ if data_args.block_size > tokenizer.model_max_length:
+ logger.warning(
+ f"The block_size passed ({data_args.block_size}) is larger than the maximum length for the model "
+ f"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}."
+ )
+ block_size = min(data_args.block_size, tokenizer.model_max_length)
+
+ # Data processing function that will concatenate all texts from our dataset and generate chunks of block_size.
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, and if the total_length < block_size we exclude this batch and return an empty dict.
+ # We could add padding if the model supported it instead of this drop, you can customize this part to your needs.
+ total_length = (total_length // block_size) * block_size
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
+ for k, t in concatenated_examples.items()
+ }
+ result["labels"] = result["input_ids"].copy()
+ return result
+
+ # Get the FIM-specific token ids
+ prefix_tok_id = tokenizer.convert_tokens_to_ids(data_args.fim_prefix_token)
+ middle_tok_id = tokenizer.convert_tokens_to_ids(data_args.fim_middle_token)
+ suffix_tok_id = tokenizer.convert_tokens_to_ids(data_args.fim_suffix_token)
+ pad_tok_id = None
+
+ # If truncate_or_pad is on, also get pad token id
+ if data_args.truncate_or_pad:
+ pad_tok_id = tokenizer.convert_tokens_to_ids(data_args.pad_token)
+
+ # The two functions below perform the FIM transformation on the data (either PSM or SPM or PSM+SPM)
+ # Don't call fim_transform directly in .map()
+ # Adapted from https://github.com/loubnabnl/santacoder-finetuning/blob/main/fim.py#L22C13-L83
+ def fim_transform(example):
+ """
+ This function performs FIM transformation on a single example (list of tokens)
+ """
+ if np_rng.binomial(1, data_args.fim_rate):
+ boundaries = sorted(np_rng.randint(low=0, high=len(example) + 1, size=2))
+
+ prefix = example[: boundaries[0]]
+ middle = example[boundaries[0] : boundaries[1]]
+ suffix = example[boundaries[1] :]
+
+ if data_args.truncate_or_pad:
+ total_length = len(prefix) + len(middle) + len(suffix) + 3
+ diff = total_length - len(example)
+ if diff > 0:
+ suffix = suffix[: max(0, len(suffix) - diff)]
+ elif diff < 0:
+ suffix.extend([pad_tok_id] * (-diff))
+
+ if np_rng.binomial(1, data_args.fim_spm_rate):
+ # Apply Suffix-Prefix-Middle (SPM) transformation
+ transformed_example = [prefix_tok_id, suffix_tok_id] + suffix + [middle_tok_id] + prefix + middle
+ else:
+ # Apply Prefix-Suffix-Middle (PSM) transformation
+ transformed_example = [prefix_tok_id] + prefix + [suffix_tok_id] + suffix + [middle_tok_id] + middle
+ else:
+ transformed_example = example
+
+ return transformed_example
+
+ # Below function is the one you are supposed to call in the .map() function
+ def apply_fim(examples):
+ """
+ Apply FIM transformation to a batch of examples
+ """
+ fim_transform_ids = [fim_transform(ids) for ids in examples["input_ids"]]
+ examples["input_ids"] = fim_transform_ids
+ examples["labels"] = fim_transform_ids
+ # If your application requires custom attention mask, please adjust this function's below line.
+ # Since FIM transformation increases the number of tokens in input_ids and labels
+ # but leaves the number of tokens unchanged in attention_masks which would cause problems
+ examples["attention_mask"] = [[1] * len(mask) for mask in examples["input_ids"]]
+ return examples
+
+ # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a remainder
+ # for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value might be slower
+ # to preprocess.
+ #
+ # To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
+ # https://huggingface.co/docs/datasets/process#map
+
+ # FIM transformations are only supposed to be applied before group_texts processing otherwise some sentences will
+ # have 3-4 more tokens than others due to probabilistic addition of FIM-specific tokens which will raise errors
+ with training_args.main_process_first(desc="processing texts together"):
+ if not data_args.streaming:
+ fim_datasets = tokenized_datasets.map(
+ apply_fim,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Performing FIM transformation",
+ )
+ lm_datasets = fim_datasets.map(
+ group_texts,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc=f"Grouping texts in chunks of {block_size}",
+ )
+ else:
+ fim_datasets = tokenized_datasets.map(
+ apply_fim,
+ batched=True,
+ )
+ lm_datasets = fim_datasets.map(
+ group_texts,
+ batched=True,
+ )
+
+ if training_args.do_train:
+ if "train" not in tokenized_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = lm_datasets["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+
+ if training_args.do_eval:
+ if "validation" not in tokenized_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = lm_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ def preprocess_logits_for_metrics(logits, labels):
+ if isinstance(logits, tuple):
+ # Depending on the model and config, logits may contain extra tensors,
+ # like past_key_values, but logits always come first
+ logits = logits[0]
+ return logits.argmax(dim=-1)
+
+ metric = evaluate.load("accuracy")
+
+ def compute_metrics(eval_preds):
+ preds, labels = eval_preds
+ # preds have the same shape as the labels, after the argmax(-1) has been calculated
+ # by preprocess_logits_for_metrics but we need to shift the labels
+ labels = labels[:, 1:].reshape(-1)
+ preds = preds[:, :-1].reshape(-1)
+ return metric.compute(predictions=preds, references=labels)
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ processing_class=tokenizer,
+ # Data collator will default to DataCollatorWithPadding, so we change it.
+ data_collator=default_data_collator,
+ compute_metrics=compute_metrics
+ if training_args.do_eval and not is_torch_xla_available(check_is_tpu=True)
+ else None,
+ preprocess_logits_for_metrics=(
+ preprocess_logits_for_metrics
+ if training_args.do_eval and not is_torch_xla_available(check_is_tpu=True)
+ else None
+ ),
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model() # Saves the tokenizer too for easy upload
+
+ metrics = train_result.metrics
+
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+
+ metrics = trainer.evaluate()
+
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+ try:
+ perplexity = math.exp(metrics["eval_loss"])
+ except OverflowError:
+ perplexity = float("inf")
+ metrics["perplexity"] = perplexity
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "text-generation"}
+ if data_args.dataset_name is not None:
+ kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ kwargs["dataset_args"] = data_args.dataset_config_name
+ kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/language-modeling/run_fim_no_trainer.py b/docs/transformers/examples/pytorch/language-modeling/run_fim_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..a53cd5740a979bbb5e0fc90f769a7ccf56af7d39
--- /dev/null
+++ b/docs/transformers/examples/pytorch/language-modeling/run_fim_no_trainer.py
@@ -0,0 +1,913 @@
+#!/usr/bin/env python
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for causal language modeling using
+Fill-in-the middle (FIM) objective on a text file or a dataset without using HuggingFace Trainer.
+
+Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
+https://huggingface.co/models?filter=text-generation
+"""
+# You can also adapt this script on your own fim causal language modeling task. Pointers for this are left as comments.
+
+import argparse
+import json
+import logging
+import math
+import os
+import random
+from itertools import chain
+from pathlib import Path
+
+import datasets
+import numpy as np
+import torch
+from accelerate import Accelerator, DistributedType
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from datasets import load_dataset
+from huggingface_hub import Repository, create_repo
+from torch.utils.data import DataLoader
+from tqdm.auto import tqdm
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_MAPPING,
+ AutoConfig,
+ AutoModelForCausalLM,
+ AutoTokenizer,
+ SchedulerType,
+ default_data_collator,
+ get_scheduler,
+ is_torch_xla_available,
+)
+from transformers.integrations import is_deepspeed_zero3_enabled
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logger = get_logger(__name__)
+
+require_version("datasets>=2.14.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
+
+MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description="Finetune a transformers model on a causal language modeling task using fill-in-the middle objective"
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help="The name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The configuration name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--train_file", type=str, default=None, help="A csv, txt or a json file containing the training data."
+ )
+ parser.add_argument(
+ "--validation_file", type=str, default=None, help="A csv, txt or a json file containing the validation data."
+ )
+ parser.add_argument(
+ "--validation_split_percentage",
+ default=5,
+ help="The percentage of the train set used as validation set in case there's no validation split",
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ required=False,
+ )
+ parser.add_argument(
+ "--config_name",
+ type=str,
+ default=None,
+ help="Pretrained config name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--use_slow_tokenizer",
+ action="store_true",
+ help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=42, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--model_type",
+ type=str,
+ default=None,
+ help="Model type to use if training from scratch.",
+ choices=MODEL_TYPES,
+ )
+ parser.add_argument(
+ "--block_size",
+ type=int,
+ default=None,
+ help=(
+ "Optional input sequence length after tokenization. The training dataset will be truncated in block of"
+ " this size for training. Default to the model max input length for single sentence inputs (take into"
+ " account special tokens)."
+ ),
+ )
+ parser.add_argument(
+ "--fim_rate",
+ type=float,
+ default=0.5,
+ help=(
+ " Optional probability with which the FIM transformation is applied to the example."
+ " Default is 0.5. A rate of 1.0 means every example will undergo FIM transformation,"
+ " while a rate of 0.0 means no example will."
+ ),
+ )
+ parser.add_argument(
+ "--fim_spm_rate",
+ type=float,
+ default=0.5,
+ help=(
+ "Within the examples undergoing FIM transformation, this rate determines the probability"
+ " of applying the Sentence Permutation Mode (SPM)."
+ " Default is 0.5. A rate of 1.0 means all FIM transformations will use SPM,"
+ " while a rate of 0.0 means none will."
+ ),
+ )
+ parser.add_argument(
+ "--truncate_or_pad",
+ type=bool,
+ default=True,
+ help=(
+ "Indicates whether the transformed example should be truncated or padded to maintain"
+ " the same length as the original example."
+ " Default is True. If False, the function will not truncate or pad the examples."
+ ),
+ )
+ parser.add_argument(
+ "--fim_prefix_token",
+ type=str,
+ default="",
+ help="Fill-in-Middle Prefix token. Defaults to ''.",
+ )
+ parser.add_argument(
+ "--fim_middle_token",
+ type=str,
+ default="",
+ help="Fill-in-Middle Middle token. Defaults to ''.",
+ )
+ parser.add_argument(
+ "--fim_suffix_token",
+ type=str,
+ default="",
+ help="Fill-in-Middle Middle token. Defaults to ''.",
+ )
+ parser.add_argument(
+ "--fim_pad_token",
+ type=str,
+ default="",
+ help=("Fill-in-Middle Pad token. Used only when 'truncate_or_pad' is set to True. Defaults to ''."),
+ )
+ parser.add_argument(
+ "--preprocessing_num_workers",
+ type=int,
+ default=None,
+ help="The number of processes to use for the preprocessing.",
+ )
+ parser.add_argument(
+ "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
+ )
+ parser.add_argument(
+ "--no_keep_linebreaks", action="store_true", help="Do not keep line breaks when using TXT files."
+ )
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--low_cpu_mem_usage",
+ action="store_true",
+ help=(
+ "It is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded. "
+ "If passed, LLM loading time and RAM consumption will be benefited."
+ ),
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+ if args.dataset_name is None and args.train_file is None and args.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if args.train_file is not None:
+ extension = args.train_file.split(".")[-1]
+ if extension not in ["csv", "json", "txt"]:
+ raise ValueError("`train_file` should be a csv, json or txt file.")
+ if args.validation_file is not None:
+ extension = args.validation_file.split(".")[-1]
+ if extension not in ["csv", "json", "txt"]:
+ raise ValueError("`validation_file` should be a csv, json or txt file.")
+
+ if args.push_to_hub:
+ if args.output_dir is None:
+ raise ValueError("Need an `output_dir` to create a repo when `--push_to_hub` is passed.")
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_fim_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator_log_kwargs = {}
+
+ if args.with_tracking:
+ accelerator_log_kwargs["log_with"] = args.report_to
+ accelerator_log_kwargs["project_dir"] = args.output_dir
+
+ accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+ # Set a numpy random state for FIM transformations
+ np_rng = np.random.RandomState(seed=args.seed)
+ else:
+ # Still set a random state for FIM transformations
+ np_rng = np.random.RandomState(seed=42)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ repo_id = create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+ # Clone repo locally
+ repo = Repository(args.output_dir, clone_from=repo_id, token=args.hub_token)
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ args.dataset_name, args.dataset_config_name, trust_remote_code=args.trust_remote_code
+ )
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ split=f"train[:{args.validation_split_percentage}%]",
+ trust_remote_code=args.trust_remote_code,
+ )
+ raw_datasets["train"] = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ split=f"train[{args.validation_split_percentage}%:]",
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ dataset_args = {}
+ if args.train_file is not None:
+ data_files["train"] = args.train_file
+ if args.validation_file is not None:
+ data_files["validation"] = args.validation_file
+ extension = args.train_file.split(".")[-1]
+ if extension == "txt":
+ extension = "text"
+ dataset_args["keep_linebreaks"] = not args.no_keep_linebreaks
+ raw_datasets = load_dataset(extension, data_files=data_files, **dataset_args)
+ # If no validation data is there, validation_split_percentage will be used to divide the dataset.
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[:{args.validation_split_percentage}%]",
+ **dataset_args,
+ )
+ raw_datasets["train"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[{args.validation_split_percentage}%:]",
+ **dataset_args,
+ )
+
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.html.
+
+ # Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ if args.config_name:
+ config = AutoConfig.from_pretrained(
+ args.config_name,
+ trust_remote_code=args.trust_remote_code,
+ )
+ elif args.model_name_or_path:
+ config = AutoConfig.from_pretrained(
+ args.model_name_or_path,
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ config = CONFIG_MAPPING[args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_name, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
+ )
+ elif args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if args.model_name_or_path:
+ model = AutoModelForCausalLM.from_pretrained(
+ args.model_name_or_path,
+ from_tf=bool(".ckpt" in args.model_name_or_path),
+ config=config,
+ low_cpu_mem_usage=args.low_cpu_mem_usage,
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelForCausalLM.from_config(config, trust_remote_code=args.trust_remote_code)
+
+ # Add the new FIM tokens to the tokenizer and resize model's vocab embeddings
+ special_tokens = [args.fim_prefix_token, args.fim_middle_token, args.fim_suffix_token]
+ if args.truncate_or_pad:
+ special_tokens.append(args.fim_pad_token)
+
+ # Get the factor by which the embedding layer should be padded based on the device
+ pad_factor = 1
+ if torch.cuda.is_availble():
+ pad_factor = 8
+
+ elif is_torch_xla_available(check_is_tpu=True):
+ pad_factor = 128
+
+ # Add the new tokens to the tokenizer
+ tokenizer.add_tokens(special_tokens)
+ original_embeddings = model.get_input_embeddings()
+
+ if is_deepspeed_zero3_enabled():
+ import deepspeed
+
+ with deepspeed.zero.GatheredParameters(original_embeddings.weight, modifier_rank=0):
+ # Get the pre-expansion embeddings of the model and resize the embedding layer
+ model.resize_token_embeddings(len(tokenizer), pad_to_multiple_of=pad_factor)
+ embeddings = model.get_input_embeddings()
+
+ # Sample the embeddings for the new tokens from a multivariate normal distribution
+ # We do this so that the new embeddings are close to the original embeddings and not necessarily zero
+ # More on this: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
+ mean = original_embeddings.mean(dim=0)
+ n = original_embeddings.size()[0]
+ sigma = ((original_embeddings - mean).T @ (original_embeddings - mean)) / n
+ dist = torch.distributions.multivariate_normal.MultivariateNormal(
+ mean,
+ covariance_matrix=1e-5 * sigma,
+ )
+ new_token_embeddings = torch.stack(
+ tuple(dist.sample() for _ in range(len(special_tokens))),
+ dim=0,
+ )
+ else:
+ original_embeddings = model.get_input_embeddings()
+ # Get the pre-expansion embeddings of the model and resize the embedding layer
+ model.resize_token_embeddings(len(tokenizer), pad_to_multiple_of=pad_factor)
+ embeddings = model.get_input_embeddings()
+
+ # Sample the embeddings for the new tokens from a multivariate normal distribution
+ # We do this so that the new embeddings are close to the original embeddings and not necessarily zero
+ # More on this: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
+ mean = original_embeddings.mean(dim=0)
+ n = original_embeddings.size()[0]
+ sigma = ((original_embeddings - mean).T @ (original_embeddings - mean)) / n
+ dist = torch.distributions.multivariate_normal.MultivariateNormal(
+ mean,
+ covariance_matrix=1e-5 * sigma,
+ )
+ new_token_embeddings = torch.stack(
+ tuple(dist.sample() for _ in range(len(special_tokens))),
+ dim=0,
+ )
+
+ if is_deepspeed_zero3_enabled():
+ import deepspeed
+
+ with deepspeed.zero.GatheredParameters(embeddings.weight, modifier_rank=0):
+ # Set the new tokens' embeddings to the newly sampled embeddings
+ embeddings.weight.data[-len(special_tokens) :] = new_token_embeddings
+ else:
+ # Set the new tokens' embeddings to the newly sampled embeddings
+ embeddings.weight.data[-len(special_tokens) :] = new_token_embeddings
+
+ # Update the model's embeddings with the new embeddings
+ model.set_input_embeddings(embeddings)
+
+ logger.info("Added special tokens to the tokenizer and resized model's embedding layer")
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ column_names = raw_datasets["train"].column_names
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ def tokenize_function(examples):
+ return tokenizer(examples[text_column_name])
+
+ with accelerator.main_process_first():
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Running tokenizer on dataset",
+ )
+
+ if args.block_size is None:
+ block_size = tokenizer.model_max_length
+ if block_size > config.max_position_embeddings:
+ logger.warning(
+ f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). "
+ f"Using block_size={min(1024, config.max_position_embeddings)} instead. You can change that default value by passing --block_size xxx."
+ )
+ block_size = min(1024, config.max_position_embeddings)
+ else:
+ if args.block_size > tokenizer.model_max_length:
+ logger.warning(
+ f"The block_size passed ({args.block_size}) is larger than the maximum length for the model "
+ f"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}."
+ )
+ block_size = min(args.block_size, tokenizer.model_max_length)
+
+ # Main data processing function that will concatenate all texts from our dataset and generate chunks of block_size.
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, and if the total_length < block_size we exclude this batch and return an empty dict.
+ # We could add padding if the model supported it instead of this drop, you can customize this part to your needs.
+ total_length = (total_length // block_size) * block_size
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
+ for k, t in concatenated_examples.items()
+ }
+ result["labels"] = result["input_ids"].copy()
+ return result
+
+ # Get the FIM-specific token ids
+ prefix_tok_id = tokenizer.convert_tokens_to_ids(args.fim_prefix_token)
+ middle_tok_id = tokenizer.convert_tokens_to_ids(args.fim_middle_token)
+ suffix_tok_id = tokenizer.convert_tokens_to_ids(args.fim_suffix_token)
+ pad_tok_id = None
+
+ # If truncate_or_pad is on, also get pad token id
+ if args.truncate_or_pad:
+ pad_tok_id = tokenizer.convert_tokens_to_ids(args.fim_pad_token)
+
+ # The two functions below perform the FIM transformation on the data (either PSM or SPM or PSM+SPM)
+ # Don't call fim_transform directly in .map()
+ # Adapted from https://github.com/loubnabnl/santacoder-finetuning/blob/main/fim.py#L22C13-L83
+ def fim_transform(example):
+ """
+ This function performs FIM transformation on a single example (list of tokens)
+ """
+ if np_rng.binomial(1, args.fim_rate):
+ boundaries = sorted(np_rng.randint(low=0, high=len(example) + 1, size=2))
+
+ prefix = example[: boundaries[0]]
+ middle = example[boundaries[0] : boundaries[1]]
+ suffix = example[boundaries[1] :]
+
+ if args.truncate_or_pad:
+ total_length = len(prefix) + len(middle) + len(suffix) + 3
+ diff = total_length - len(example)
+ if diff > 0:
+ suffix = suffix[: max(0, len(suffix) - diff)]
+ elif diff < 0:
+ suffix.extend([pad_tok_id] * (-diff))
+
+ if np_rng.binomial(1, args.fim_spm_rate):
+ # Apply Suffix-Prefix-Middle (SPM) transformation
+ transformed_example = [prefix_tok_id, suffix_tok_id] + suffix + [middle_tok_id] + prefix + middle
+ else:
+ # Apply Prefix-Suffix-Middle (PSM) transformation
+ transformed_example = [prefix_tok_id] + prefix + [suffix_tok_id] + suffix + [middle_tok_id] + middle
+ else:
+ transformed_example = example
+
+ return transformed_example
+
+ # Below function is the one you are supposed to call in the .map() function
+ def apply_fim(examples):
+ """
+ Apply FIM transformation to a batch of examples
+ """
+ fim_transform_ids = [fim_transform(ids) for ids in examples["input_ids"]]
+ examples["input_ids"] = fim_transform_ids
+ examples["labels"] = fim_transform_ids
+ # If your application requires custom attention mask, please adjust this function's below line.
+ # Since FIM transformation increases the number of tokens in input_ids and labels
+ # but leaves the number of tokens unchanged in attention_masks which would cause problems
+ examples["attention_mask"] = [[1] * len(mask) for mask in examples["input_ids"]]
+ return examples
+
+ # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a remainder
+ # for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value might be slower
+ # to preprocess.
+ #
+ # To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
+ # https://huggingface.co/docs/datasets/process#map
+
+ # FIM transformations are only supposed to be applied before group_texts processing otherwise some sentences will
+ # have 3-4 more tokens than others due to probabilistic addition of FIM-specific tokens which will raise errors
+ with accelerator.main_process_first():
+ fim_datasets = tokenized_datasets.map(
+ apply_fim,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Performing FIM transformation",
+ )
+ lm_datasets = fim_datasets.map(
+ group_texts,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ load_from_cache_file=not args.overwrite_cache,
+ desc=f"Grouping texts in chunks of {block_size}",
+ )
+
+ train_dataset = lm_datasets["train"]
+ eval_dataset = lm_datasets["validation"]
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # DataLoaders creation:
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=args.per_device_train_batch_size
+ )
+ eval_dataloader = DataLoader(
+ eval_dataset, collate_fn=default_data_collator, batch_size=args.per_device_eval_batch_size
+ )
+
+ # Optimizer
+ # Split weights in two groups, one with weight decay and the other not.
+ no_decay = ["bias", "layer_norm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
+
+ # On TPU, the tie weights in our model have been disconnected, so we need to restore the ties.
+ if accelerator.distributed_type == DistributedType.TPU:
+ model.tie_weights()
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("fim_no_trainer", experiment_config)
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+ for step, batch in enumerate(active_dataloader):
+ with accelerator.accumulate(model):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+ accelerator.backward(loss)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+ if completed_steps >= args.max_train_steps:
+ break
+
+ model.eval()
+ losses = []
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ loss = outputs.loss
+ losses.append(accelerator.gather_for_metrics(loss.repeat(args.per_device_eval_batch_size)))
+
+ losses = torch.cat(losses)
+ try:
+ eval_loss = torch.mean(losses)
+ perplexity = math.exp(eval_loss)
+ except OverflowError:
+ perplexity = float("inf")
+
+ logger.info(f"epoch {epoch}: perplexity: {perplexity} eval_loss: {eval_loss}")
+
+ if args.with_tracking:
+ accelerator.log(
+ {
+ "perplexity": perplexity,
+ "eval_loss": eval_loss,
+ "train_loss": total_loss.item() / len(train_dataloader),
+ "epoch": epoch,
+ "step": completed_steps,
+ },
+ step=completed_steps,
+ )
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ repo.push_to_hub(
+ commit_message=f"Training in progress epoch {epoch}", blocking=False, auto_lfs_prune=True
+ )
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ repo.push_to_hub(commit_message="End of training", auto_lfs_prune=True)
+
+ with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
+ json.dump({"perplexity": perplexity}, f)
+
+ accelerator.wait_for_everyone()
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/language-modeling/run_mlm.py b/docs/transformers/examples/pytorch/language-modeling/run_mlm.py
new file mode 100644
index 0000000000000000000000000000000000000000..7a9abff0e30ecad631ad4ccfd4ad6487d955fb95
--- /dev/null
+++ b/docs/transformers/examples/pytorch/language-modeling/run_mlm.py
@@ -0,0 +1,690 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for masked language modeling (BERT, ALBERT, RoBERTa...) on a text file or a dataset.
+
+Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
+https://huggingface.co/models?filter=fill-mask
+"""
+# You can also adapt this script on your own masked language modeling task. Pointers for this are left as comments.
+
+import logging
+import math
+import os
+import sys
+from dataclasses import dataclass, field
+from itertools import chain
+from typing import Optional
+
+import datasets
+import evaluate
+import torch
+from datasets import load_dataset
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_FOR_MASKED_LM_MAPPING,
+ AutoConfig,
+ AutoModelForMaskedLM,
+ AutoTokenizer,
+ DataCollatorForLanguageModeling,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ is_torch_xla_available,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=2.14.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
+
+logger = logging.getLogger(__name__)
+MODEL_CONFIG_CLASSES = list(MODEL_FOR_MASKED_LM_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_overrides: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Override some existing default config settings when a model is trained from scratch. Example: "
+ "n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
+ )
+ },
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ torch_dtype: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Override the default `torch.dtype` and load the model under this dtype. If `auto` is passed, the "
+ "dtype will be automatically derived from the model's weights."
+ ),
+ "choices": ["auto", "bfloat16", "float16", "float32"],
+ },
+ )
+ low_cpu_mem_usage: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "It is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded. "
+ "set True will benefit LLM loading time and RAM consumption."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if self.config_overrides is not None and (self.config_name is not None or self.model_name_or_path is not None):
+ raise ValueError(
+ "--config_overrides can't be used in combination with --config_name or --model_name_or_path"
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ validation_split_percentage: Optional[int] = field(
+ default=5,
+ metadata={
+ "help": "The percentage of the train set used as validation set in case there's no validation split"
+ },
+ )
+ max_seq_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated."
+ )
+ },
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ mlm_probability: float = field(
+ default=0.15, metadata={"help": "Ratio of tokens to mask for masked language modeling loss"}
+ )
+ line_by_line: bool = field(
+ default=False,
+ metadata={"help": "Whether distinct lines of text in the dataset are to be handled as distinct sequences."},
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ streaming: bool = field(default=False, metadata={"help": "Enable streaming mode"})
+
+ def __post_init__(self):
+ if self.streaming:
+ require_version("datasets>=2.0.0", "The streaming feature requires `datasets>=2.0.0`")
+
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ if extension not in ["csv", "json", "txt"]:
+ raise ValueError("`train_file` should be a csv, a json or a txt file.")
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ if extension not in ["csv", "json", "txt"]:
+ raise ValueError("`validation_file` should be a csv, a json or a txt file.")
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_mlm", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column. You can easily tweak this
+ # behavior (see below)
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ streaming=data_args.streaming,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ streaming=data_args.streaming,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ raw_datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ streaming=data_args.streaming,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if extension == "txt":
+ extension = "text"
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+
+ # If no validation data is there, validation_split_percentage will be used to divide the dataset.
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ raw_datasets["train"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "revision": model_args.model_revision,
+ "token": model_args.token,
+ "trust_remote_code": model_args.trust_remote_code,
+ }
+ if model_args.config_name:
+ config = AutoConfig.from_pretrained(model_args.config_name, **config_kwargs)
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+ if model_args.config_overrides is not None:
+ logger.info(f"Overriding config: {model_args.config_overrides}")
+ config.update_from_string(model_args.config_overrides)
+ logger.info(f"New config: {config}")
+
+ tokenizer_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "use_fast": model_args.use_fast_tokenizer,
+ "revision": model_args.model_revision,
+ "token": model_args.token,
+ "trust_remote_code": model_args.trust_remote_code,
+ }
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if model_args.model_name_or_path:
+ torch_dtype = (
+ model_args.torch_dtype
+ if model_args.torch_dtype in ["auto", None]
+ else getattr(torch, model_args.torch_dtype)
+ )
+ model = AutoModelForMaskedLM.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ torch_dtype=torch_dtype,
+ low_cpu_mem_usage=model_args.low_cpu_mem_usage,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelForMaskedLM.from_config(config, trust_remote_code=model_args.trust_remote_code)
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embedding_size = model.get_input_embeddings().weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ if training_args.do_train:
+ column_names = list(raw_datasets["train"].features)
+ else:
+ column_names = list(raw_datasets["validation"].features)
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ if data_args.max_seq_length is None:
+ max_seq_length = tokenizer.model_max_length
+ if max_seq_length > 1024:
+ logger.warning(
+ "The chosen tokenizer supports a `model_max_length` that is longer than the default `block_size` value"
+ " of 1024. If you would like to use a longer `block_size` up to `tokenizer.model_max_length` you can"
+ " override this default with `--block_size xxx`."
+ )
+ max_seq_length = 1024
+ else:
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ if data_args.line_by_line:
+ # When using line_by_line, we just tokenize each nonempty line.
+ padding = "max_length" if data_args.pad_to_max_length else False
+
+ def tokenize_function(examples):
+ # Remove empty lines
+ examples[text_column_name] = [
+ line for line in examples[text_column_name] if len(line) > 0 and not line.isspace()
+ ]
+ return tokenizer(
+ examples[text_column_name],
+ padding=padding,
+ truncation=True,
+ max_length=max_seq_length,
+ # We use this option because DataCollatorForLanguageModeling (see below) is more efficient when it
+ # receives the `special_tokens_mask`.
+ return_special_tokens_mask=True,
+ )
+
+ with training_args.main_process_first(desc="dataset map tokenization"):
+ if not data_args.streaming:
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=[text_column_name],
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on dataset line_by_line",
+ )
+ else:
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ remove_columns=[text_column_name],
+ )
+ else:
+ # Otherwise, we tokenize every text, then concatenate them together before splitting them in smaller parts.
+ # We use `return_special_tokens_mask=True` because DataCollatorForLanguageModeling (see below) is more
+ # efficient when it receives the `special_tokens_mask`.
+ def tokenize_function(examples):
+ return tokenizer(examples[text_column_name], return_special_tokens_mask=True)
+
+ with training_args.main_process_first(desc="dataset map tokenization"):
+ if not data_args.streaming:
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on every text in dataset",
+ )
+ else:
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ remove_columns=column_names,
+ )
+
+ # Main data processing function that will concatenate all texts from our dataset and generate chunks of
+ # max_seq_length.
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, and if the total_length < max_seq_length we exclude this batch and return an empty dict.
+ # We could add padding if the model supported it instead of this drop, you can customize this part to your needs.
+ total_length = (total_length // max_seq_length) * max_seq_length
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + max_seq_length] for i in range(0, total_length, max_seq_length)]
+ for k, t in concatenated_examples.items()
+ }
+ return result
+
+ # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a
+ # remainder for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value
+ # might be slower to preprocess.
+ #
+ # To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
+ # https://huggingface.co/docs/datasets/process#map
+
+ with training_args.main_process_first(desc="grouping texts together"):
+ if not data_args.streaming:
+ tokenized_datasets = tokenized_datasets.map(
+ group_texts,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc=f"Grouping texts in chunks of {max_seq_length}",
+ )
+ else:
+ tokenized_datasets = tokenized_datasets.map(
+ group_texts,
+ batched=True,
+ )
+
+ if training_args.do_train:
+ if "train" not in tokenized_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = tokenized_datasets["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+
+ if training_args.do_eval:
+ if "validation" not in tokenized_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = tokenized_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ def preprocess_logits_for_metrics(logits, labels):
+ if isinstance(logits, tuple):
+ # Depending on the model and config, logits may contain extra tensors,
+ # like past_key_values, but logits always come first
+ logits = logits[0]
+ return logits.argmax(dim=-1)
+
+ metric = evaluate.load("accuracy", cache_dir=model_args.cache_dir)
+
+ def compute_metrics(eval_preds):
+ preds, labels = eval_preds
+ # preds have the same shape as the labels, after the argmax(-1) has been calculated
+ # by preprocess_logits_for_metrics
+ labels = labels.reshape(-1)
+ preds = preds.reshape(-1)
+ mask = labels != -100
+ labels = labels[mask]
+ preds = preds[mask]
+ return metric.compute(predictions=preds, references=labels)
+
+ # Data collator
+ # This one will take care of randomly masking the tokens.
+ pad_to_multiple_of_8 = data_args.line_by_line and training_args.fp16 and not data_args.pad_to_max_length
+ data_collator = DataCollatorForLanguageModeling(
+ tokenizer=tokenizer,
+ mlm_probability=data_args.mlm_probability,
+ pad_to_multiple_of=8 if pad_to_multiple_of_8 else None,
+ )
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ processing_class=tokenizer,
+ data_collator=data_collator,
+ compute_metrics=compute_metrics if training_args.do_eval and not is_torch_xla_available() else None,
+ preprocess_logits_for_metrics=preprocess_logits_for_metrics
+ if training_args.do_eval and not is_torch_xla_available()
+ else None,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model() # Saves the tokenizer too for easy upload
+ metrics = train_result.metrics
+
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+
+ metrics = trainer.evaluate()
+
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+ try:
+ perplexity = math.exp(metrics["eval_loss"])
+ except OverflowError:
+ perplexity = float("inf")
+ metrics["perplexity"] = perplexity
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "fill-mask"}
+ if data_args.dataset_name is not None:
+ kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ kwargs["dataset_args"] = data_args.dataset_config_name
+ kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/language-modeling/run_mlm_no_trainer.py b/docs/transformers/examples/pytorch/language-modeling/run_mlm_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..d8285bdc0d20524d4ce6761bafb42db64bc18b53
--- /dev/null
+++ b/docs/transformers/examples/pytorch/language-modeling/run_mlm_no_trainer.py
@@ -0,0 +1,762 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for masked language modeling (BERT, ALBERT, RoBERTa...)
+on a text file or a dataset without using HuggingFace Trainer.
+
+Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
+https://huggingface.co/models?filter=fill-mask
+"""
+# You can also adapt this script on your own mlm task. Pointers for this are left as comments.
+
+import argparse
+import json
+import logging
+import math
+import os
+import random
+from itertools import chain
+from pathlib import Path
+
+import datasets
+import torch
+from accelerate import Accelerator, DistributedType
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from datasets import load_dataset
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from tqdm.auto import tqdm
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_MAPPING,
+ AutoConfig,
+ AutoModelForMaskedLM,
+ AutoTokenizer,
+ DataCollatorForLanguageModeling,
+ SchedulerType,
+ get_scheduler,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logger = get_logger(__name__)
+require_version("datasets>=2.14.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
+MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Finetune a transformers model on a Masked Language Modeling task")
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help="The name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The configuration name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--train_file", type=str, default=None, help="A csv or a json file containing the training data."
+ )
+ parser.add_argument(
+ "--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
+ )
+ parser.add_argument(
+ "--validation_split_percentage",
+ default=5,
+ help="The percentage of the train set used as validation set in case there's no validation split",
+ )
+ parser.add_argument(
+ "--pad_to_max_length",
+ action="store_true",
+ help="If passed, pad all samples to `max_length`. Otherwise, dynamic padding is used.",
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ required=False,
+ )
+ parser.add_argument(
+ "--config_name",
+ type=str,
+ default=None,
+ help="Pretrained config name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--use_slow_tokenizer",
+ action="store_true",
+ help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--model_type",
+ type=str,
+ default=None,
+ help="Model type to use if training from scratch.",
+ choices=MODEL_TYPES,
+ )
+ parser.add_argument(
+ "--max_seq_length",
+ type=int,
+ default=None,
+ help=(
+ "The maximum total input sequence length after tokenization. Sequences longer than this will be truncated."
+ ),
+ )
+ parser.add_argument(
+ "--line_by_line",
+ type=bool,
+ default=False,
+ help="Whether distinct lines of text in the dataset are to be handled as distinct sequences.",
+ )
+ parser.add_argument(
+ "--preprocessing_num_workers",
+ type=int,
+ default=None,
+ help="The number of processes to use for the preprocessing.",
+ )
+ parser.add_argument(
+ "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
+ )
+ parser.add_argument(
+ "--mlm_probability", type=float, default=0.15, help="Ratio of tokens to mask for masked language modeling loss"
+ )
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--low_cpu_mem_usage",
+ action="store_true",
+ help=(
+ "It is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded. "
+ "If passed, LLM loading time and RAM consumption will be benefited."
+ ),
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+ if args.dataset_name is None and args.train_file is None and args.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if args.train_file is not None:
+ extension = args.train_file.split(".")[-1]
+ if extension not in ["csv", "json", "txt"]:
+ raise ValueError("`train_file` should be a csv, json or txt file.")
+ if args.validation_file is not None:
+ extension = args.validation_file.split(".")[-1]
+ if extension not in ["csv", "json", "txt"]:
+ raise ValueError("`validation_file` should be a csv, json or txt file.")
+
+ if args.push_to_hub:
+ if args.output_dir is None:
+ raise ValueError("Need an `output_dir` to create a repo when `--push_to_hub` is passed.")
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_mlm_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator_log_kwargs = {}
+
+ if args.with_tracking:
+ accelerator_log_kwargs["log_with"] = args.report_to
+ accelerator_log_kwargs["project_dir"] = args.output_dir
+
+ accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ args.dataset_name, args.dataset_config_name, trust_remote_code=args.trust_remote_code
+ )
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ split=f"train[:{args.validation_split_percentage}%]",
+ trust_remote_code=args.trust_remote_code,
+ )
+ raw_datasets["train"] = load_dataset(
+ args.dataset_name,
+ args.dataset_config_name,
+ split=f"train[{args.validation_split_percentage}%:]",
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if args.train_file is not None:
+ data_files["train"] = args.train_file
+ extension = args.train_file.split(".")[-1]
+ if args.validation_file is not None:
+ data_files["validation"] = args.validation_file
+ extension = args.validation_file.split(".")[-1]
+ if extension == "txt":
+ extension = "text"
+ raw_datasets = load_dataset(extension, data_files=data_files)
+ # If no validation data is there, validation_split_percentage will be used to divide the dataset.
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[:{args.validation_split_percentage}%]",
+ )
+ raw_datasets["train"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[{args.validation_split_percentage}%:]",
+ )
+
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ if args.config_name:
+ config = AutoConfig.from_pretrained(args.config_name, trust_remote_code=args.trust_remote_code)
+ elif args.model_name_or_path:
+ config = AutoConfig.from_pretrained(args.model_name_or_path, trust_remote_code=args.trust_remote_code)
+ else:
+ config = CONFIG_MAPPING[args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_name, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
+ )
+ elif args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if args.model_name_or_path:
+ model = AutoModelForMaskedLM.from_pretrained(
+ args.model_name_or_path,
+ from_tf=bool(".ckpt" in args.model_name_or_path),
+ config=config,
+ low_cpu_mem_usage=args.low_cpu_mem_usage,
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelForMaskedLM.from_config(config, trust_remote_code=args.trust_remote_code)
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embedding_size = model.get_input_embeddings().weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ column_names = raw_datasets["train"].column_names
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ if args.max_seq_length is None:
+ max_seq_length = tokenizer.model_max_length
+ if max_seq_length > 1024:
+ logger.warning(
+ "The chosen tokenizer supports a `model_max_length` that is longer than the default `block_size` value"
+ " of 1024. If you would like to use a longer `block_size` up to `tokenizer.model_max_length` you can"
+ " override this default with `--block_size xxx`."
+ )
+ max_seq_length = 1024
+ else:
+ if args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(args.max_seq_length, tokenizer.model_max_length)
+
+ if args.line_by_line:
+ # When using line_by_line, we just tokenize each nonempty line.
+ padding = "max_length" if args.pad_to_max_length else False
+
+ def tokenize_function(examples):
+ # Remove empty lines
+ examples[text_column_name] = [
+ line for line in examples[text_column_name] if len(line) > 0 and not line.isspace()
+ ]
+ return tokenizer(
+ examples[text_column_name],
+ padding=padding,
+ truncation=True,
+ max_length=max_seq_length,
+ # We use this option because DataCollatorForLanguageModeling (see below) is more efficient when it
+ # receives the `special_tokens_mask`.
+ return_special_tokens_mask=True,
+ )
+
+ with accelerator.main_process_first():
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=[text_column_name],
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Running tokenizer on dataset line_by_line",
+ )
+ else:
+ # Otherwise, we tokenize every text, then concatenate them together before splitting them in smaller parts.
+ # We use `return_special_tokens_mask=True` because DataCollatorForLanguageModeling (see below) is more
+ # efficient when it receives the `special_tokens_mask`.
+ def tokenize_function(examples):
+ return tokenizer(examples[text_column_name], return_special_tokens_mask=True)
+
+ with accelerator.main_process_first():
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Running tokenizer on every text in dataset",
+ )
+
+ # Main data processing function that will concatenate all texts from our dataset and generate chunks of
+ # max_seq_length.
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, and if the total_length < max_seq_length we exclude this batch and return an empty dict.
+ # We could add padding if the model supported it instead of this drop, you can customize this part to your needs.
+ total_length = (total_length // max_seq_length) * max_seq_length
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + max_seq_length] for i in range(0, total_length, max_seq_length)]
+ for k, t in concatenated_examples.items()
+ }
+ return result
+
+ # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a
+ # remainder for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value
+ # might be slower to preprocess.
+ #
+ # To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
+ # https://huggingface.co/docs/datasets/process#map
+
+ with accelerator.main_process_first():
+ tokenized_datasets = tokenized_datasets.map(
+ group_texts,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ load_from_cache_file=not args.overwrite_cache,
+ desc=f"Grouping texts in chunks of {max_seq_length}",
+ )
+
+ train_dataset = tokenized_datasets["train"]
+ eval_dataset = tokenized_datasets["validation"]
+
+ # Conditional for small test subsets
+ if len(train_dataset) > 3:
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # Data collator
+ # This one will take care of randomly masking the tokens.
+ data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=args.mlm_probability)
+
+ # DataLoaders creation:
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
+ )
+ eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
+
+ # Optimizer
+ # Split weights in two groups, one with weight decay and the other not.
+ no_decay = ["bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
+
+ # Note -> the training dataloader needs to be prepared before we grab his length below (cause its length will be
+ # shorter in multiprocess)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps
+ if overrode_max_train_steps
+ else args.max_train_steps * accelerator.num_processes,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
+
+ # On TPU, the tie weights in our model have been disconnected, so we need to restore the ties.
+ if accelerator.distributed_type == DistributedType.TPU:
+ model.tie_weights()
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("mlm_no_trainer", experiment_config)
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+ for step, batch in enumerate(active_dataloader):
+ with accelerator.accumulate(model):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+ accelerator.backward(loss)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ model.eval()
+ losses = []
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ loss = outputs.loss
+ losses.append(accelerator.gather_for_metrics(loss.repeat(args.per_device_eval_batch_size)))
+
+ losses = torch.cat(losses)
+ try:
+ eval_loss = torch.mean(losses)
+ perplexity = math.exp(eval_loss)
+ except OverflowError:
+ perplexity = float("inf")
+
+ logger.info(f"epoch {epoch}: perplexity: {perplexity} eval_loss: {eval_loss}")
+
+ if args.with_tracking:
+ accelerator.log(
+ {
+ "perplexity": perplexity,
+ "eval_loss": eval_loss,
+ "train_loss": total_loss.item() / len(train_dataloader),
+ "epoch": epoch,
+ "step": completed_steps,
+ },
+ step=completed_steps,
+ )
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+ with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
+ json.dump({"perplexity": perplexity}, f)
+
+ accelerator.wait_for_everyone()
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/language-modeling/run_plm.py b/docs/transformers/examples/pytorch/language-modeling/run_plm.py
new file mode 100644
index 0000000000000000000000000000000000000000..0eda261d17715b7b41b7bb2fa2b5791572c07317
--- /dev/null
+++ b/docs/transformers/examples/pytorch/language-modeling/run_plm.py
@@ -0,0 +1,583 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for permutation language modeling.
+"""
+# You can also adapt this script on your own permutation language modeling task. Pointers for this are left as comments.
+
+import logging
+import math
+import os
+import sys
+from dataclasses import dataclass, field
+from itertools import chain
+from typing import Optional
+
+import datasets
+from datasets import load_dataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoTokenizer,
+ DataCollatorForPermutationLanguageModeling,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ XLNetConfig,
+ XLNetLMHeadModel,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=2.14.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ config_overrides: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Override some existing default config settings when a model is trained from scratch. Example: "
+ "n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
+ )
+ },
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ low_cpu_mem_usage: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "It is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded. "
+ "set True will benefit LLM loading time and RAM consumption."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if self.config_overrides is not None and (self.config_name is not None or self.model_name_or_path is not None):
+ raise ValueError(
+ "--config_overrides can't be used in combination with --config_name or --model_name_or_path"
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ validation_split_percentage: Optional[int] = field(
+ default=5,
+ metadata={
+ "help": "The percentage of the train set used as validation set in case there's no validation split"
+ },
+ )
+ max_seq_length: int = field(
+ default=512,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated."
+ )
+ },
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ plm_probability: float = field(
+ default=1 / 6,
+ metadata={
+ "help": (
+ "Ratio of length of a span of masked tokens to surrounding context length for "
+ "permutation language modeling."
+ )
+ },
+ )
+ max_span_length: int = field(
+ default=5, metadata={"help": "Maximum length of a span of masked tokens for permutation language modeling."}
+ )
+ line_by_line: bool = field(
+ default=False,
+ metadata={"help": "Whether distinct lines of text in the dataset are to be handled as distinct sequences."},
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_plm", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+ raw_datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if extension == "txt":
+ extension = "text"
+ raw_datasets = load_dataset(extension, data_files=data_files, cache_dir=model_args.cache_dir)
+ # If no validation data is there, validation_split_percentage will be used to divide the dataset.
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ raw_datasets["train"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "revision": model_args.model_revision,
+ "token": model_args.token,
+ }
+ if model_args.config_name:
+ config = AutoConfig.from_pretrained(model_args.config_name, **config_kwargs)
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
+ else:
+ config = XLNetConfig()
+ logger.warning("You are instantiating a new config instance from scratch.")
+ if model_args.config_overrides is not None:
+ logger.info(f"Overriding config: {model_args.config_overrides}")
+ config.update_from_string(model_args.config_overrides)
+ logger.info(f"New config: {config}")
+
+ tokenizer_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "use_fast": model_args.use_fast_tokenizer,
+ "revision": model_args.model_revision,
+ "token": model_args.token,
+ }
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if model_args.model_name_or_path:
+ model = XLNetLMHeadModel.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ low_cpu_mem_usage=model_args.low_cpu_mem_usage,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = XLNetLMHeadModel(config)
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embedding_size = model.get_input_embeddings().weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ if training_args.do_train:
+ column_names = raw_datasets["train"].column_names
+ else:
+ column_names = raw_datasets["validation"].column_names
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ if data_args.line_by_line:
+ # When using line_by_line, we just tokenize each nonempty line.
+ padding = "max_length" if data_args.pad_to_max_length else False
+
+ def tokenize_function(examples):
+ # Remove empty lines
+ examples["text"] = [line for line in examples["text"] if len(line) > 0 and not line.isspace()]
+ return tokenizer(examples["text"], padding=padding, truncation=True, max_length=max_seq_length)
+
+ with training_args.main_process_first(desc="dataset map tokenization"):
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=[text_column_name],
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on dataset line_by_line",
+ )
+ else:
+ # Otherwise, we tokenize every text, then concatenate them together before splitting them in smaller parts.
+ def tokenize_function(examples):
+ return tokenizer(examples[text_column_name])
+
+ with training_args.main_process_first(desc="dataset map tokenization"):
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on every text in dataset",
+ )
+
+ # Main data processing function that will concatenate all texts from our dataset and generate chunks of
+ # max_seq_length.
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, and if the total_length < max_seq_length we exclude this batch and return an empty dict.
+ # We could add padding if the model supported it instead of this drop, you can customize this part to your needs.
+ total_length = (total_length // max_seq_length) * max_seq_length
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + max_seq_length] for i in range(0, total_length, max_seq_length)]
+ for k, t in concatenated_examples.items()
+ }
+ return result
+
+ # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a
+ # remainder for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value
+ # might be slower to preprocess.
+ #
+ # To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
+ # https://huggingface.co/docs/datasets/process#map
+
+ with training_args.main_process_first(desc="grouping texts together"):
+ tokenized_datasets = tokenized_datasets.map(
+ group_texts,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc=f"Grouping texts in chunks of {max_seq_length}",
+ )
+
+ if training_args.do_train:
+ if "train" not in tokenized_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = tokenized_datasets["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+
+ if training_args.do_eval:
+ if "validation" not in tokenized_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = tokenized_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ # Data collator
+ data_collator = DataCollatorForPermutationLanguageModeling(
+ tokenizer=tokenizer,
+ plm_probability=data_args.plm_probability,
+ max_span_length=data_args.max_span_length,
+ )
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ processing_classtokenizer=tokenizer,
+ data_collator=data_collator,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model() # Saves the tokenizer too for easy upload
+ metrics = train_result.metrics
+
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+
+ metrics = trainer.evaluate()
+
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+ try:
+ perplexity = math.exp(metrics["eval_loss"])
+ except OverflowError:
+ perplexity = float("inf")
+ metrics["perplexity"] = perplexity
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "language-modeling"}
+ if data_args.dataset_name is not None:
+ kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ kwargs["dataset_args"] = data_args.dataset_config_name
+ kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/multiple-choice/README.md b/docs/transformers/examples/pytorch/multiple-choice/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..91e28a51c85fd26d1f870505d2458f6ddc69213a
--- /dev/null
+++ b/docs/transformers/examples/pytorch/multiple-choice/README.md
@@ -0,0 +1,108 @@
+
+
+# Multiple Choice
+
+## Fine-tuning on SWAG with the Trainer
+
+`run_swag` allows you to fine-tune any model from our [hub](https://huggingface.co/models) (as long as its architecture as a `ForMultipleChoice` version in the library) on the SWAG dataset or your own csv/jsonlines files as long as they are structured the same way. To make it works on another dataset, you will need to tweak the `preprocess_function` inside the script.
+
+```bash
+python examples/pytorch/multiple-choice/run_swag.py \
+--model_name_or_path FacebookAI/roberta-base \
+--do_train \
+--do_eval \
+--learning_rate 5e-5 \
+--num_train_epochs 3 \
+--output_dir /tmp/swag_base \
+--per_device_eval_batch_size=16 \
+--per_device_train_batch_size=16 \
+--overwrite_output
+```
+Training with the defined hyper-parameters yields the following results:
+```
+***** Eval results *****
+eval_acc = 0.8338998300509847
+eval_loss = 0.44457291918821606
+```
+
+## With Accelerate
+
+Based on the script [run_swag_no_trainer.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/multiple-choice/run_swag_no_trainer.py).
+
+Like `run_swag.py`, this script allows you to fine-tune any of the models on the [hub](https://huggingface.co/models) (as long as its architecture as a `ForMultipleChoice` version in the library) on
+the SWAG dataset or your own data in a csv or a JSON file. The main difference is that this
+script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like.
+
+It offers less options than the script with `Trainer` (but you can easily change the options for the optimizer
+or the dataloaders directly in the script) but still run in a distributed setup, on TPU and supports mixed precision by
+the mean of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
+after installing it:
+
+```bash
+pip install git+https://github.com/huggingface/accelerate
+```
+
+then
+
+```bash
+export DATASET_NAME=swag
+
+python run_swag_no_trainer.py \
+ --model_name_or_path google-bert/bert-base-cased \
+ --dataset_name $DATASET_NAME \
+ --max_seq_length 128 \
+ --per_device_train_batch_size 32 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/$DATASET_NAME/
+```
+
+You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
+
+```bash
+accelerate config
+```
+
+and reply to the questions asked. Then
+
+```bash
+accelerate test
+```
+
+that will check everything is ready for training. Finally, you can launch training with
+
+```bash
+export DATASET_NAME=swag
+
+accelerate launch run_swag_no_trainer.py \
+ --model_name_or_path google-bert/bert-base-cased \
+ --dataset_name $DATASET_NAME \
+ --max_seq_length 128 \
+ --per_device_train_batch_size 32 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/$DATASET_NAME/
+```
+
+This command is the same and will work for:
+
+- a CPU-only setup
+- a setup with one GPU
+- a distributed training with several GPUs (single or multi node)
+- a training on TPUs
+
+Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
diff --git a/docs/transformers/examples/pytorch/multiple-choice/requirements.txt b/docs/transformers/examples/pytorch/multiple-choice/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3bbfaef38eab5fa5261008bd32769e615059d00e
--- /dev/null
+++ b/docs/transformers/examples/pytorch/multiple-choice/requirements.txt
@@ -0,0 +1,5 @@
+accelerate >= 0.12.0
+sentencepiece != 0.1.92
+protobuf
+torch >= 1.3
+evaluate
diff --git a/docs/transformers/examples/pytorch/multiple-choice/run_no_trainer.sh b/docs/transformers/examples/pytorch/multiple-choice/run_no_trainer.sh
new file mode 100644
index 0000000000000000000000000000000000000000..4fd84f37ed63fa9b3ae2da1a140ef65d514e25cf
--- /dev/null
+++ b/docs/transformers/examples/pytorch/multiple-choice/run_no_trainer.sh
@@ -0,0 +1,19 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+accelerate launch run_swag_no_trainer.py \
+ --model_name_or_path bert-base-uncased \
+ --dataset_name swag \
+ --output_dir /tmp/test-swag-no-trainer \
+ --pad_to_max_length
diff --git a/docs/transformers/examples/pytorch/multiple-choice/run_swag.py b/docs/transformers/examples/pytorch/multiple-choice/run_swag.py
new file mode 100644
index 0000000000000000000000000000000000000000..3817a2d55b7a3bdf07420449722065fbfd1147e3
--- /dev/null
+++ b/docs/transformers/examples/pytorch/multiple-choice/run_swag.py
@@ -0,0 +1,443 @@
+#!/usr/bin/env python
+# Copyright The HuggingFace Team and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for multiple choice.
+"""
+# You can also adapt this script on your own multiple choice task. Pointers for this are left as comments.
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from itertools import chain
+from typing import Optional
+
+import datasets
+import numpy as np
+from datasets import load_dataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForMultipleChoice,
+ AutoTokenizer,
+ DataCollatorForMultipleChoice,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ default_data_collator,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
+ "should only be set to `True` for repositories you trust and in which you have read the code, as it will "
+ "execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_seq_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. If passed, sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to the maximum sentence length. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
+ "efficient on GPU but very bad for TPU."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_swag", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.train_file is not None or data_args.validation_file is not None:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ else:
+ # Downloading and loading the swag dataset from the hub.
+ raw_datasets = load_dataset(
+ "swag",
+ "regular",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = AutoModelForMultipleChoice.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # When using your own dataset or a different dataset from swag, you will probably need to change this.
+ ending_names = [f"ending{i}" for i in range(4)]
+ context_name = "sent1"
+ question_header_name = "sent2"
+
+ if data_args.max_seq_length is None:
+ max_seq_length = tokenizer.model_max_length
+ if max_seq_length > 1024:
+ logger.warning(
+ "The chosen tokenizer supports a `model_max_length` that is longer than the default `block_size` value"
+ " of 1024. If you would like to use a longer `block_size` up to `tokenizer.model_max_length` you can"
+ " override this default with `--block_size xxx`."
+ )
+ max_seq_length = 1024
+ else:
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ # Preprocessing the datasets.
+ def preprocess_function(examples):
+ first_sentences = [[context] * 4 for context in examples[context_name]]
+ question_headers = examples[question_header_name]
+ second_sentences = [
+ [f"{header} {examples[end][i]}" for end in ending_names] for i, header in enumerate(question_headers)
+ ]
+
+ # Flatten out
+ first_sentences = list(chain(*first_sentences))
+ second_sentences = list(chain(*second_sentences))
+
+ # Tokenize
+ tokenized_examples = tokenizer(
+ first_sentences,
+ second_sentences,
+ truncation=True,
+ max_length=max_seq_length,
+ padding="max_length" if data_args.pad_to_max_length else False,
+ )
+ # Un-flatten
+ return {k: [v[i : i + 4] for i in range(0, len(v), 4)] for k, v in tokenized_examples.items()}
+
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ with training_args.main_process_first(desc="train dataset map pre-processing"):
+ train_dataset = train_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ if training_args.do_eval:
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = raw_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+ with training_args.main_process_first(desc="validation dataset map pre-processing"):
+ eval_dataset = eval_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ # Data collator
+ data_collator = (
+ default_data_collator
+ if data_args.pad_to_max_length
+ else DataCollatorForMultipleChoice(
+ tokenizer=tokenizer, pad_to_multiple_of=8 if training_args.fp16 else None, return_tensors="pt"
+ )
+ )
+
+ # Metric
+ def compute_metrics(eval_predictions):
+ predictions, label_ids = eval_predictions
+ preds = np.argmax(predictions, axis=1)
+ return {"accuracy": (preds == label_ids).astype(np.float32).mean().item()}
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ processing_class=tokenizer,
+ data_collator=data_collator,
+ compute_metrics=compute_metrics,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model() # Saves the tokenizer too for easy upload
+ metrics = train_result.metrics
+
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+
+ metrics = trainer.evaluate()
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ kwargs = {
+ "finetuned_from": model_args.model_name_or_path,
+ "tasks": "multiple-choice",
+ "dataset_tags": "swag",
+ "dataset_args": "regular",
+ "dataset": "SWAG",
+ "language": "en",
+ }
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/multiple-choice/run_swag_no_trainer.py b/docs/transformers/examples/pytorch/multiple-choice/run_swag_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..851346c6d2156915a9134be45dc8cce1fa1ebdcf
--- /dev/null
+++ b/docs/transformers/examples/pytorch/multiple-choice/run_swag_no_trainer.py
@@ -0,0 +1,650 @@
+#!/usr/bin/env python
+# Copyright The HuggingFace Team and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning a 🤗 Transformers model on multiple choice relying on the accelerate library without using a Trainer.
+"""
+# You can also adapt this script on your own multiple choice task. Pointers for this are left as comments.
+
+import argparse
+import json
+import logging
+import math
+import os
+import random
+from itertools import chain
+from pathlib import Path
+
+import datasets
+import evaluate
+import torch
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from datasets import load_dataset
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from tqdm.auto import tqdm
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_MAPPING,
+ AutoConfig,
+ AutoModelForMultipleChoice,
+ AutoTokenizer,
+ DataCollatorForMultipleChoice,
+ SchedulerType,
+ default_data_collator,
+ get_scheduler,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logger = get_logger(__name__)
+# You should update this to your particular problem to have better documentation of `model_type`
+MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Finetune a transformers model on a multiple choice task")
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help="The name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The configuration name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--train_file", type=str, default=None, help="A csv or a json file containing the training data."
+ )
+ parser.add_argument(
+ "--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
+ )
+ parser.add_argument(
+ "--max_seq_length",
+ type=int,
+ default=128,
+ help=(
+ "The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
+ " sequences shorter will be padded if `--pad_to_max_length` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--pad_to_max_length",
+ action="store_true",
+ help="If passed, pad all samples to `max_length`. Otherwise, dynamic padding is used.",
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ required=False,
+ )
+ parser.add_argument(
+ "--config_name",
+ type=str,
+ default=None,
+ help="Pretrained config name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--use_slow_tokenizer",
+ action="store_true",
+ help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--model_type",
+ type=str,
+ default=None,
+ help="Model type to use if training from scratch.",
+ choices=MODEL_TYPES,
+ )
+ parser.add_argument(
+ "--debug",
+ action="store_true",
+ help="Activate debug mode and run training only with a subset of data.",
+ )
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ args = parser.parse_args()
+
+ if args.push_to_hub:
+ assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_swag_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator_log_kwargs = {}
+
+ if args.with_tracking:
+ accelerator_log_kwargs["log_with"] = args.report_to
+ accelerator_log_kwargs["project_dir"] = args.output_dir
+
+ accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ args.dataset_name, args.dataset_config_name, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ data_files = {}
+ if args.train_file is not None:
+ data_files["train"] = args.train_file
+ extension = args.train_file.split(".")[-1]
+ if args.validation_file is not None:
+ data_files["validation"] = args.validation_file
+ extension = args.validation_file.split(".")[-1]
+ raw_datasets = load_dataset(extension, data_files=data_files)
+ # Trim a number of training examples
+ if args.debug:
+ for split in raw_datasets.keys():
+ raw_datasets[split] = raw_datasets[split].select(range(100))
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ if raw_datasets["train"] is not None:
+ column_names = raw_datasets["train"].column_names
+ else:
+ column_names = raw_datasets["validation"].column_names
+
+ # When using your own dataset or a different dataset from swag, you will probably need to change this.
+ ending_names = [f"ending{i}" for i in range(4)]
+ context_name = "sent1"
+ question_header_name = "sent2"
+ label_column_name = "label" if "label" in column_names else "labels"
+
+ # Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ if args.config_name:
+ config = AutoConfig.from_pretrained(args.model_name_or_path, trust_remote_code=args.trust_remote_code)
+ elif args.model_name_or_path:
+ config = AutoConfig.from_pretrained(args.model_name_or_path, trust_remote_code=args.trust_remote_code)
+ else:
+ config = CONFIG_MAPPING[args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_name, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
+ )
+ elif args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if args.model_name_or_path:
+ model = AutoModelForMultipleChoice.from_pretrained(
+ args.model_name_or_path,
+ from_tf=bool(".ckpt" in args.model_name_or_path),
+ config=config,
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelForMultipleChoice.from_config(config, trust_remote_code=args.trust_remote_code)
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embedding_size = model.get_input_embeddings().weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ padding = "max_length" if args.pad_to_max_length else False
+
+ def preprocess_function(examples):
+ first_sentences = [[context] * 4 for context in examples[context_name]]
+ question_headers = examples[question_header_name]
+ second_sentences = [
+ [f"{header} {examples[end][i]}" for end in ending_names] for i, header in enumerate(question_headers)
+ ]
+ labels = examples[label_column_name]
+
+ # Flatten out
+ first_sentences = list(chain(*first_sentences))
+ second_sentences = list(chain(*second_sentences))
+
+ # Tokenize
+ tokenized_examples = tokenizer(
+ first_sentences,
+ second_sentences,
+ max_length=args.max_seq_length,
+ padding=padding,
+ truncation=True,
+ )
+ # Un-flatten
+ tokenized_inputs = {k: [v[i : i + 4] for i in range(0, len(v), 4)] for k, v in tokenized_examples.items()}
+ tokenized_inputs["labels"] = labels
+ return tokenized_inputs
+
+ with accelerator.main_process_first():
+ processed_datasets = raw_datasets.map(
+ preprocess_function, batched=True, remove_columns=raw_datasets["train"].column_names
+ )
+
+ train_dataset = processed_datasets["train"]
+ eval_dataset = processed_datasets["validation"]
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # DataLoaders creation:
+ if args.pad_to_max_length:
+ # If padding was already done ot max length, we use the default data collator that will just convert everything
+ # to tensors.
+ data_collator = default_data_collator
+ else:
+ # Otherwise, `DataCollatorWithPadding` will apply dynamic padding for us (by padding to the maximum length of
+ # the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
+ # of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
+ # For fp8, we pad to multiple of 16.
+ if accelerator.mixed_precision == "fp8":
+ pad_to_multiple_of = 16
+ elif accelerator.mixed_precision != "no":
+ pad_to_multiple_of = 8
+ else:
+ pad_to_multiple_of = None
+ data_collator = DataCollatorForMultipleChoice(
+ tokenizer, pad_to_multiple_of=pad_to_multiple_of, return_tensors="pt"
+ )
+
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
+ )
+ eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
+
+ # Optimizer
+ # Split weights in two groups, one with weight decay and the other not.
+ no_decay = ["bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
+
+ # Use the device given by the `accelerator` object.
+ device = accelerator.device
+ model.to(device)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps
+ if overrode_max_train_steps
+ else args.max_train_steps * accelerator.num_processes,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("swag_no_trainer", experiment_config)
+
+ # Metrics
+ metric = evaluate.load("accuracy")
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+ for step, batch in enumerate(active_dataloader):
+ with accelerator.accumulate(model):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+ accelerator.backward(loss)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ model.eval()
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+ predictions = outputs.logits.argmax(dim=-1)
+ predictions, references = accelerator.gather_for_metrics((predictions, batch["labels"]))
+ metric.add_batch(
+ predictions=predictions,
+ references=references,
+ )
+
+ eval_metric = metric.compute()
+ accelerator.print(f"epoch {epoch}: {eval_metric}")
+
+ if args.with_tracking:
+ accelerator.log(
+ {
+ "accuracy": eval_metric,
+ "train_loss": total_loss.item() / len(train_dataloader),
+ "epoch": epoch,
+ "step": completed_steps,
+ },
+ step=completed_steps,
+ )
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+ all_results = {f"eval_{k}": v for k, v in eval_metric.items()}
+ with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
+ json.dump(all_results, f)
+
+ accelerator.wait_for_everyone()
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/object-detection/README.md b/docs/transformers/examples/pytorch/object-detection/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..3c0ce460f0d5e462fed6762eb4697a7415250f57
--- /dev/null
+++ b/docs/transformers/examples/pytorch/object-detection/README.md
@@ -0,0 +1,233 @@
+
+
+# Object detection examples
+
+This directory contains 2 scripts that showcase how to fine-tune any model supported by the [`AutoModelForObjectDetection` API](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForObjectDetection) (such as [DETR](https://huggingface.co/docs/transformers/main/en/model_doc/detr), [DETA](https://huggingface.co/docs/transformers/main/en/model_doc/deta), [Deformable DETR](https://huggingface.co/docs/transformers/main/en/model_doc/deformable_detr)) using PyTorch.
+
+Content:
+* [PyTorch version, Trainer](#pytorch-version-trainer)
+* [PyTorch version, no Trainer](#pytorch-version-no-trainer)
+* [Reload and perform inference](#reload-and-perform-inference)
+* [Note on custom data](#note-on-custom-data)
+
+
+## PyTorch version, Trainer
+
+Based on the script [`run_object_detection.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/object-detection/run_object_detection.py).
+
+The script leverages the [🤗 Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer) to automatically take care of the training for you, running on distributed environments right away.
+
+Here we show how to fine-tune a [DETR](https://huggingface.co/facebook/detr-resnet-50) model on the [CPPE-5](https://huggingface.co/datasets/cppe-5) dataset:
+
+```bash
+python run_object_detection.py \
+ --model_name_or_path facebook/detr-resnet-50 \
+ --dataset_name cppe-5 \
+ --do_train true \
+ --do_eval true \
+ --output_dir detr-finetuned-cppe-5-10k-steps \
+ --num_train_epochs 100 \
+ --image_square_size 600 \
+ --fp16 true \
+ --learning_rate 5e-5 \
+ --weight_decay 1e-4 \
+ --dataloader_num_workers 4 \
+ --dataloader_prefetch_factor 2 \
+ --per_device_train_batch_size 8 \
+ --gradient_accumulation_steps 1 \
+ --remove_unused_columns false \
+ --eval_do_concat_batches false \
+ --ignore_mismatched_sizes true \
+ --metric_for_best_model eval_map \
+ --greater_is_better true \
+ --load_best_model_at_end true \
+ --logging_strategy epoch \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --save_total_limit 2 \
+ --push_to_hub true \
+ --push_to_hub_model_id detr-finetuned-cppe-5-10k-steps \
+ --hub_strategy end \
+ --seed 1337
+```
+
+> Note:
+`--eval_do_concat_batches false` is required for correct evaluation of detection models;
+`--ignore_mismatched_sizes true` is required to load detection model for finetuning with different number of classes.
+
+The resulting model can be seen here: https://huggingface.co/qubvel-hf/qubvel-hf/detr-resnet-50-finetuned-10k-cppe5. The corresponding Weights and Biases report [here](https://api.wandb.ai/links/qubvel-hf-co/bnm0r5ex). Note that it's always advised to check the original paper to know the details regarding training hyperparameters. Hyperparameters for current example were not tuned. To improve model quality you could try:
+ - changing image size parameters (`--shortest_edge`/`--longest_edge`)
+ - changing training parameters, such as learning rate, batch size, warmup, optimizer and many more (see [TrainingArguments](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments))
+ - adding more image augmentations (we created a helpful [HF Space](https://huggingface.co/spaces/qubvel-hf/albumentations-demo) to choose some)
+
+Note that you can replace the model and dataset by simply setting the `model_name_or_path` and `dataset_name` arguments respectively, with model or dataset from the [hub](https://huggingface.co/).
+For dataset, make sure it provides labels in the same format as [CPPE-5](https://huggingface.co/datasets/cppe-5) dataset and boxes are provided in [COCO format](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco).
+
+
+
+
+## PyTorch version, no Trainer
+
+Based on the script [`run_object_detection_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/object-detection/run_object_detection.py).
+
+The script leverages [🤗 `Accelerate`](https://github.com/huggingface/accelerate), which allows to write your own training loop in PyTorch, but have it run instantly on any (distributed) environment, including CPU, multi-CPU, GPU, multi-GPU and TPU. It also supports mixed precision.
+
+First, run:
+
+```bash
+accelerate config
+```
+
+and reply to the questions asked regarding the environment on which you'd like to train. Then
+
+```bash
+accelerate test
+```
+
+that will check everything is ready for training. Finally, you can launch training with
+
+```bash
+accelerate launch run_object_detection_no_trainer.py \
+ --model_name_or_path "facebook/detr-resnet-50" \
+ --dataset_name cppe-5 \
+ --output_dir "detr-resnet-50-finetuned" \
+ --num_train_epochs 100 \
+ --image_square_size 600 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --checkpointing_steps epoch \
+ --learning_rate 5e-5 \
+ --ignore_mismatched_sizes \
+ --with_tracking \
+ --push_to_hub
+```
+
+and boom, you're training, possibly on multiple GPUs, logging everything to all trackers found in your environment (like Weights and Biases, Tensorboard) and regularly pushing your model to the hub (with the repo name being equal to `args.output_dir` at your HF username) 🤗
+
+With the default settings, the script fine-tunes a [DETR](https://huggingface.co/facebook/detr-resnet-50) model on the [CPPE-5](https://huggingface.co/datasets/cppe-5) dataset. The resulting model can be seen here: https://huggingface.co/qubvel-hf/detr-resnet-50-finetuned-10k-cppe5-no-trainer.
+
+
+## Reload and perform inference
+
+This means that after training, you can easily load your trained model and perform inference as follows::
+
+```python
+import requests
+import torch
+
+from PIL import Image
+from transformers import AutoImageProcessor, AutoModelForObjectDetection
+
+# Name of repo on the hub or path to a local folder
+model_name = "qubvel-hf/detr-resnet-50-finetuned-10k-cppe5"
+
+image_processor = AutoImageProcessor.from_pretrained(model_name)
+model = AutoModelForObjectDetection.from_pretrained(model_name)
+
+# Load image for inference
+url = "https://images.pexels.com/photos/8413299/pexels-photo-8413299.jpeg?auto=compress&cs=tinysrgb&w=630&h=375&dpr=2"
+image = Image.open(requests.get(url, stream=True).raw)
+
+# Prepare image for the model
+inputs = image_processor(images=image, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+
+# Post process model predictions
+# this include conversion to Pascal VOC format and filtering non confident boxes
+width, height = image.size
+target_sizes = torch.tensor([height, width]).unsqueeze(0) # add batch dim
+results = image_processor.post_process_object_detection(outputs, threshold=0.5, target_sizes=target_sizes)[0]
+
+for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
+ box = [round(i, 2) for i in box.tolist()]
+ print(
+ f"Detected {model.config.id2label[label.item()]} with confidence "
+ f"{round(score.item(), 3)} at location {box}"
+ )
+```
+
+And visualize with the following code:
+```python
+from PIL import ImageDraw
+draw = ImageDraw.Draw(image)
+
+for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
+ box = [round(i, 2) for i in box.tolist()]
+ x, y, x2, y2 = tuple(box)
+ draw.rectangle((x, y, x2, y2), outline="red", width=1)
+ draw.text((x, y), model.config.id2label[label.item()], fill="white")
+
+image
+```
+
+
+## Note on custom data
+
+In case you'd like to use the script with custom data, you could prepare your data with the following way:
+
+```bash
+custom_dataset/
+└── train
+ ├── 0001.jpg
+ ├── 0002.jpg
+ ├── ...
+ └── metadata.jsonl
+└── validation
+ └── ...
+└── test
+ └── ...
+```
+
+Where `metadata.jsonl` is a file with the following structure:
+```json
+{"file_name": "0001.jpg", "objects": {"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0], "id": [1], "area": [50.0]}}
+{"file_name": "0002.jpg", "objects": {"bbox": [[810.0, 100.0, 57.0, 28.0]], "categories": [1], "id": [2], "area": [40.0]}}
+...
+```
+Trining script support bounding boxes in COCO format (x_min, y_min, width, height).
+
+Then, you cat load the dataset with just a few lines of code:
+
+```python
+from datasets import load_dataset
+
+# Load dataset
+dataset = load_dataset("imagefolder", data_dir="custom_dataset/")
+
+# >>> DatasetDict({
+# ... train: Dataset({
+# ... features: ['image', 'objects'],
+# ... num_rows: 2
+# ... })
+# ... })
+
+# Push to hub (assumes you have ran the huggingface-cli login command in a terminal/notebook)
+dataset.push_to_hub("name of repo on the hub")
+
+# optionally, you can push to a private repo on the hub
+# dataset.push_to_hub("name of repo on the hub", private=True)
+```
+
+And the final step, for training you should provide id2label mapping in the following way:
+```python
+id2label = {0: "Car", 1: "Bird", ...}
+```
+Just find it in code and replace for simplicity, or save `json` locally and with the dataset on the hub!
+
+See also: [Dataset Creation Guide](https://huggingface.co/docs/datasets/image_dataset#create-an-image-dataset)
diff --git a/docs/transformers/examples/pytorch/object-detection/requirements.txt b/docs/transformers/examples/pytorch/object-detection/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..7772958dee7af88f31167f8fe2fb5af4fb1e1866
--- /dev/null
+++ b/docs/transformers/examples/pytorch/object-detection/requirements.txt
@@ -0,0 +1,5 @@
+albumentations >= 1.4.16
+timm
+datasets
+torchmetrics
+pycocotools
diff --git a/docs/transformers/examples/pytorch/object-detection/run_object_detection.py b/docs/transformers/examples/pytorch/object-detection/run_object_detection.py
new file mode 100644
index 0000000000000000000000000000000000000000..cc319d331e2f0dec5547589ac4362607ba1f62e4
--- /dev/null
+++ b/docs/transformers/examples/pytorch/object-detection/run_object_detection.py
@@ -0,0 +1,528 @@
+#!/usr/bin/env python
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+"""Finetuning any 🤗 Transformers model supported by AutoModelForObjectDetection for object detection leveraging the Trainer API."""
+
+import logging
+import os
+import sys
+from collections.abc import Mapping
+from dataclasses import dataclass, field
+from functools import partial
+from typing import Any, Optional, Union
+
+import albumentations as A
+import numpy as np
+import torch
+from datasets import load_dataset
+from torchmetrics.detection.mean_ap import MeanAveragePrecision
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoImageProcessor,
+ AutoModelForObjectDetection,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+)
+from transformers.image_processing_utils import BatchFeature
+from transformers.image_transforms import center_to_corners_format
+from transformers.trainer import EvalPrediction
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=2.0.0", "To fix: pip install -r examples/pytorch/object-detection/requirements.txt")
+
+
+@dataclass
+class ModelOutput:
+ logits: torch.Tensor
+ pred_boxes: torch.Tensor
+
+
+def format_image_annotations_as_coco(
+ image_id: str, categories: list[int], areas: list[float], bboxes: list[tuple[float]]
+) -> dict:
+ """Format one set of image annotations to the COCO format
+
+ Args:
+ image_id (str): image id. e.g. "0001"
+ categories (List[int]): list of categories/class labels corresponding to provided bounding boxes
+ areas (List[float]): list of corresponding areas to provided bounding boxes
+ bboxes (List[Tuple[float]]): list of bounding boxes provided in COCO format
+ ([center_x, center_y, width, height] in absolute coordinates)
+
+ Returns:
+ dict: {
+ "image_id": image id,
+ "annotations": list of formatted annotations
+ }
+ """
+ annotations = []
+ for category, area, bbox in zip(categories, areas, bboxes):
+ formatted_annotation = {
+ "image_id": image_id,
+ "category_id": category,
+ "iscrowd": 0,
+ "area": area,
+ "bbox": list(bbox),
+ }
+ annotations.append(formatted_annotation)
+
+ return {
+ "image_id": image_id,
+ "annotations": annotations,
+ }
+
+
+def convert_bbox_yolo_to_pascal(boxes: torch.Tensor, image_size: tuple[int, int]) -> torch.Tensor:
+ """
+ Convert bounding boxes from YOLO format (x_center, y_center, width, height) in range [0, 1]
+ to Pascal VOC format (x_min, y_min, x_max, y_max) in absolute coordinates.
+
+ Args:
+ boxes (torch.Tensor): Bounding boxes in YOLO format
+ image_size (Tuple[int, int]): Image size in format (height, width)
+
+ Returns:
+ torch.Tensor: Bounding boxes in Pascal VOC format (x_min, y_min, x_max, y_max)
+ """
+ # convert center to corners format
+ boxes = center_to_corners_format(boxes)
+
+ # convert to absolute coordinates
+ height, width = image_size
+ boxes = boxes * torch.tensor([[width, height, width, height]])
+
+ return boxes
+
+
+def augment_and_transform_batch(
+ examples: Mapping[str, Any],
+ transform: A.Compose,
+ image_processor: AutoImageProcessor,
+ return_pixel_mask: bool = False,
+) -> BatchFeature:
+ """Apply augmentations and format annotations in COCO format for object detection task"""
+
+ images = []
+ annotations = []
+ for image_id, image, objects in zip(examples["image_id"], examples["image"], examples["objects"]):
+ image = np.array(image.convert("RGB"))
+
+ # apply augmentations
+ output = transform(image=image, bboxes=objects["bbox"], category=objects["category"])
+ images.append(output["image"])
+
+ # format annotations in COCO format
+ formatted_annotations = format_image_annotations_as_coco(
+ image_id, output["category"], objects["area"], output["bboxes"]
+ )
+ annotations.append(formatted_annotations)
+
+ # Apply the image processor transformations: resizing, rescaling, normalization
+ result = image_processor(images=images, annotations=annotations, return_tensors="pt")
+
+ if not return_pixel_mask:
+ result.pop("pixel_mask", None)
+
+ return result
+
+
+def collate_fn(batch: list[BatchFeature]) -> Mapping[str, Union[torch.Tensor, list[Any]]]:
+ data = {}
+ data["pixel_values"] = torch.stack([x["pixel_values"] for x in batch])
+ data["labels"] = [x["labels"] for x in batch]
+ if "pixel_mask" in batch[0]:
+ data["pixel_mask"] = torch.stack([x["pixel_mask"] for x in batch])
+ return data
+
+
+@torch.no_grad()
+def compute_metrics(
+ evaluation_results: EvalPrediction,
+ image_processor: AutoImageProcessor,
+ threshold: float = 0.0,
+ id2label: Optional[Mapping[int, str]] = None,
+) -> Mapping[str, float]:
+ """
+ Compute mean average mAP, mAR and their variants for the object detection task.
+
+ Args:
+ evaluation_results (EvalPrediction): Predictions and targets from evaluation.
+ threshold (float, optional): Threshold to filter predicted boxes by confidence. Defaults to 0.0.
+ id2label (Optional[dict], optional): Mapping from class id to class name. Defaults to None.
+
+ Returns:
+ Mapping[str, float]: Metrics in a form of dictionary {: }
+ """
+
+ predictions, targets = evaluation_results.predictions, evaluation_results.label_ids
+
+ # For metric computation we need to provide:
+ # - targets in a form of list of dictionaries with keys "boxes", "labels"
+ # - predictions in a form of list of dictionaries with keys "boxes", "scores", "labels"
+
+ image_sizes = []
+ post_processed_targets = []
+ post_processed_predictions = []
+
+ # Collect targets in the required format for metric computation
+ for batch in targets:
+ # collect image sizes, we will need them for predictions post processing
+ batch_image_sizes = torch.tensor([x["orig_size"] for x in batch])
+ image_sizes.append(batch_image_sizes)
+ # collect targets in the required format for metric computation
+ # boxes were converted to YOLO format needed for model training
+ # here we will convert them to Pascal VOC format (x_min, y_min, x_max, y_max)
+ for image_target in batch:
+ boxes = torch.tensor(image_target["boxes"])
+ boxes = convert_bbox_yolo_to_pascal(boxes, image_target["orig_size"])
+ labels = torch.tensor(image_target["class_labels"])
+ post_processed_targets.append({"boxes": boxes, "labels": labels})
+
+ # Collect predictions in the required format for metric computation,
+ # model produce boxes in YOLO format, then image_processor convert them to Pascal VOC format
+ for batch, target_sizes in zip(predictions, image_sizes):
+ batch_logits, batch_boxes = batch[1], batch[2]
+ output = ModelOutput(logits=torch.tensor(batch_logits), pred_boxes=torch.tensor(batch_boxes))
+ post_processed_output = image_processor.post_process_object_detection(
+ output, threshold=threshold, target_sizes=target_sizes
+ )
+ post_processed_predictions.extend(post_processed_output)
+
+ # Compute metrics
+ metric = MeanAveragePrecision(box_format="xyxy", class_metrics=True)
+ metric.update(post_processed_predictions, post_processed_targets)
+ metrics = metric.compute()
+
+ # Replace list of per class metrics with separate metric for each class
+ classes = metrics.pop("classes")
+ map_per_class = metrics.pop("map_per_class")
+ mar_100_per_class = metrics.pop("mar_100_per_class")
+ for class_id, class_map, class_mar in zip(classes, map_per_class, mar_100_per_class):
+ class_name = id2label[class_id.item()] if id2label is not None else class_id.item()
+ metrics[f"map_{class_name}"] = class_map
+ metrics[f"mar_100_{class_name}"] = class_mar
+
+ metrics = {k: round(v.item(), 4) for k, v in metrics.items()}
+
+ return metrics
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ Using `HfArgumentParser` we can turn this class into argparse arguments to be able to specify
+ them on the command line.
+ """
+
+ dataset_name: str = field(
+ default="cppe-5",
+ metadata={
+ "help": "Name of a dataset from the hub (could be your own, possibly private dataset hosted on the hub)."
+ },
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_val_split: Optional[float] = field(
+ default=0.15, metadata={"help": "Percent to split off of train for validation."}
+ )
+ image_square_size: Optional[int] = field(
+ default=600,
+ metadata={"help": "Image longest size will be resized to this value, then image will be padded to square."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ use_fast: Optional[bool] = field(
+ default=True,
+ metadata={"help": "Use a fast torchvision-base image processor if it is supported for a given model."},
+ )
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ default="facebook/detr-resnet-50",
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ image_processor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
+ ignore_mismatched_sizes: bool = field(
+ default=False,
+ metadata={
+ "help": "Whether or not to raise an error if some of the weights from the checkpoint do not have the same size as the weights of the model (if for instance, you are instantiating a model with 10 labels from a checkpoint with 3 labels)."
+ },
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_object_detection", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif os.path.isdir(training_args.output_dir) and not training_args.overwrite_output_dir:
+ checkpoint = get_last_checkpoint(training_args.output_dir)
+ if checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # ------------------------------------------------------------------------------------------------
+ # Load dataset, prepare splits
+ # ------------------------------------------------------------------------------------------------
+
+ dataset = load_dataset(
+ data_args.dataset_name, cache_dir=model_args.cache_dir, trust_remote_code=model_args.trust_remote_code
+ )
+
+ # If we don't have a validation split, split off a percentage of train as validation
+ data_args.train_val_split = None if "validation" in dataset.keys() else data_args.train_val_split
+ if isinstance(data_args.train_val_split, float) and data_args.train_val_split > 0.0:
+ split = dataset["train"].train_test_split(data_args.train_val_split, seed=training_args.seed)
+ dataset["train"] = split["train"]
+ dataset["validation"] = split["test"]
+
+ # Get dataset categories and prepare mappings for label_name <-> label_id
+ categories = dataset["train"].features["objects"].feature["category"].names
+ id2label = dict(enumerate(categories))
+ label2id = {v: k for k, v in id2label.items()}
+
+ # ------------------------------------------------------------------------------------------------
+ # Load pretrained config, model and image processor
+ # ------------------------------------------------------------------------------------------------
+
+ common_pretrained_args = {
+ "cache_dir": model_args.cache_dir,
+ "revision": model_args.model_revision,
+ "token": model_args.token,
+ "trust_remote_code": model_args.trust_remote_code,
+ }
+ config = AutoConfig.from_pretrained(
+ model_args.config_name or model_args.model_name_or_path,
+ label2id=label2id,
+ id2label=id2label,
+ **common_pretrained_args,
+ )
+ model = AutoModelForObjectDetection.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ ignore_mismatched_sizes=model_args.ignore_mismatched_sizes,
+ **common_pretrained_args,
+ )
+ image_processor = AutoImageProcessor.from_pretrained(
+ model_args.image_processor_name or model_args.model_name_or_path,
+ do_resize=True,
+ size={"max_height": data_args.image_square_size, "max_width": data_args.image_square_size},
+ do_pad=True,
+ pad_size={"height": data_args.image_square_size, "width": data_args.image_square_size},
+ use_fast=data_args.use_fast,
+ **common_pretrained_args,
+ )
+
+ # ------------------------------------------------------------------------------------------------
+ # Define image augmentations and dataset transforms
+ # ------------------------------------------------------------------------------------------------
+ max_size = data_args.image_square_size
+ train_augment_and_transform = A.Compose(
+ [
+ A.Compose(
+ [
+ A.SmallestMaxSize(max_size=max_size, p=1.0),
+ A.RandomSizedBBoxSafeCrop(height=max_size, width=max_size, p=1.0),
+ ],
+ p=0.2,
+ ),
+ A.OneOf(
+ [
+ A.Blur(blur_limit=7, p=0.5),
+ A.MotionBlur(blur_limit=7, p=0.5),
+ A.Defocus(radius=(1, 5), alias_blur=(0.1, 0.25), p=0.1),
+ ],
+ p=0.1,
+ ),
+ A.Perspective(p=0.1),
+ A.HorizontalFlip(p=0.5),
+ A.RandomBrightnessContrast(p=0.5),
+ A.HueSaturationValue(p=0.1),
+ ],
+ bbox_params=A.BboxParams(format="coco", label_fields=["category"], clip=True, min_area=25),
+ )
+ validation_transform = A.Compose(
+ [A.NoOp()],
+ bbox_params=A.BboxParams(format="coco", label_fields=["category"], clip=True),
+ )
+
+ # Make transform functions for batch and apply for dataset splits
+ train_transform_batch = partial(
+ augment_and_transform_batch, transform=train_augment_and_transform, image_processor=image_processor
+ )
+ validation_transform_batch = partial(
+ augment_and_transform_batch, transform=validation_transform, image_processor=image_processor
+ )
+
+ dataset["train"] = dataset["train"].with_transform(train_transform_batch)
+ dataset["validation"] = dataset["validation"].with_transform(validation_transform_batch)
+ dataset["test"] = dataset["test"].with_transform(validation_transform_batch)
+
+ # ------------------------------------------------------------------------------------------------
+ # Model training and evaluation with Trainer API
+ # ------------------------------------------------------------------------------------------------
+
+ eval_compute_metrics_fn = partial(
+ compute_metrics, image_processor=image_processor, id2label=id2label, threshold=0.0
+ )
+
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=dataset["train"] if training_args.do_train else None,
+ eval_dataset=dataset["validation"] if training_args.do_eval else None,
+ processing_class=image_processor,
+ data_collator=collate_fn,
+ compute_metrics=eval_compute_metrics_fn,
+ )
+
+ # Training
+ if training_args.do_train:
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+ trainer.log_metrics("train", train_result.metrics)
+ trainer.save_metrics("train", train_result.metrics)
+ trainer.save_state()
+
+ # Final evaluation
+ if training_args.do_eval:
+ metrics = trainer.evaluate(eval_dataset=dataset["test"], metric_key_prefix="test")
+ trainer.log_metrics("test", metrics)
+ trainer.save_metrics("test", metrics)
+
+ # Write model card and (optionally) push to hub
+ kwargs = {
+ "finetuned_from": model_args.model_name_or_path,
+ "dataset": data_args.dataset_name,
+ "tags": ["object-detection", "vision"],
+ }
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/object-detection/run_object_detection_no_trainer.py b/docs/transformers/examples/pytorch/object-detection/run_object_detection_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..5265ca0c40a236ce8964e6fe4ddc0a41d9c8c958
--- /dev/null
+++ b/docs/transformers/examples/pytorch/object-detection/run_object_detection_no_trainer.py
@@ -0,0 +1,789 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Finetuning 🤗 Transformers model for object detection with Accelerate."""
+
+import argparse
+import json
+import logging
+import math
+import os
+from collections.abc import Mapping
+from functools import partial
+from pathlib import Path
+from typing import Any, Union
+
+import albumentations as A
+import datasets
+import numpy as np
+import torch
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from datasets import load_dataset
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from torchmetrics.detection.mean_ap import MeanAveragePrecision
+from tqdm.auto import tqdm
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoImageProcessor,
+ AutoModelForObjectDetection,
+ SchedulerType,
+ get_scheduler,
+)
+from transformers.image_processing_utils import BatchFeature
+from transformers.image_transforms import center_to_corners_format
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logging.basicConfig(level=logging.INFO)
+logger = get_logger(__name__)
+
+require_version("datasets>=2.0.0", "To fix: pip install -r examples/pytorch/semantic-segmentation/requirements.txt")
+
+
+# Copied from examples/pytorch/object-detection/run_object_detection.format_image_annotations_as_coco
+def format_image_annotations_as_coco(
+ image_id: str, categories: list[int], areas: list[float], bboxes: list[tuple[float]]
+) -> dict:
+ """Format one set of image annotations to the COCO format
+
+ Args:
+ image_id (str): image id. e.g. "0001"
+ categories (List[int]): list of categories/class labels corresponding to provided bounding boxes
+ areas (List[float]): list of corresponding areas to provided bounding boxes
+ bboxes (List[Tuple[float]]): list of bounding boxes provided in COCO format
+ ([center_x, center_y, width, height] in absolute coordinates)
+
+ Returns:
+ dict: {
+ "image_id": image id,
+ "annotations": list of formatted annotations
+ }
+ """
+ annotations = []
+ for category, area, bbox in zip(categories, areas, bboxes):
+ formatted_annotation = {
+ "image_id": image_id,
+ "category_id": category,
+ "iscrowd": 0,
+ "area": area,
+ "bbox": list(bbox),
+ }
+ annotations.append(formatted_annotation)
+
+ return {
+ "image_id": image_id,
+ "annotations": annotations,
+ }
+
+
+# Copied from examples/pytorch/object-detection/run_object_detection.convert_bbox_yolo_to_pascal
+def convert_bbox_yolo_to_pascal(boxes: torch.Tensor, image_size: tuple[int, int]) -> torch.Tensor:
+ """
+ Convert bounding boxes from YOLO format (x_center, y_center, width, height) in range [0, 1]
+ to Pascal VOC format (x_min, y_min, x_max, y_max) in absolute coordinates.
+
+ Args:
+ boxes (torch.Tensor): Bounding boxes in YOLO format
+ image_size (Tuple[int, int]): Image size in format (height, width)
+
+ Returns:
+ torch.Tensor: Bounding boxes in Pascal VOC format (x_min, y_min, x_max, y_max)
+ """
+ # convert center to corners format
+ boxes = center_to_corners_format(boxes)
+
+ # convert to absolute coordinates
+ height, width = image_size
+ boxes = boxes * torch.tensor([[width, height, width, height]])
+
+ return boxes
+
+
+# Copied from examples/pytorch/object-detection/run_object_detection.augment_and_transform_batch
+def augment_and_transform_batch(
+ examples: Mapping[str, Any],
+ transform: A.Compose,
+ image_processor: AutoImageProcessor,
+ return_pixel_mask: bool = False,
+) -> BatchFeature:
+ """Apply augmentations and format annotations in COCO format for object detection task"""
+
+ images = []
+ annotations = []
+ for image_id, image, objects in zip(examples["image_id"], examples["image"], examples["objects"]):
+ image = np.array(image.convert("RGB"))
+
+ # apply augmentations
+ output = transform(image=image, bboxes=objects["bbox"], category=objects["category"])
+ images.append(output["image"])
+
+ # format annotations in COCO format
+ formatted_annotations = format_image_annotations_as_coco(
+ image_id, output["category"], objects["area"], output["bboxes"]
+ )
+ annotations.append(formatted_annotations)
+
+ # Apply the image processor transformations: resizing, rescaling, normalization
+ result = image_processor(images=images, annotations=annotations, return_tensors="pt")
+
+ if not return_pixel_mask:
+ result.pop("pixel_mask", None)
+
+ return result
+
+
+# Copied from examples/pytorch/object-detection/run_object_detection.collate_fn
+def collate_fn(batch: list[BatchFeature]) -> Mapping[str, Union[torch.Tensor, list[Any]]]:
+ data = {}
+ data["pixel_values"] = torch.stack([x["pixel_values"] for x in batch])
+ data["labels"] = [x["labels"] for x in batch]
+ if "pixel_mask" in batch[0]:
+ data["pixel_mask"] = torch.stack([x["pixel_mask"] for x in batch])
+ return data
+
+
+def nested_to_cpu(objects):
+ """Move nested tesnors in objects to CPU if they are on GPU"""
+ if isinstance(objects, torch.Tensor):
+ return objects.cpu()
+ elif isinstance(objects, Mapping):
+ return type(objects)({k: nested_to_cpu(v) for k, v in objects.items()})
+ elif isinstance(objects, (list, tuple)):
+ return type(objects)([nested_to_cpu(v) for v in objects])
+ elif isinstance(objects, (np.ndarray, str, int, float, bool)):
+ return objects
+ raise ValueError(f"Unsupported type {type(objects)}")
+
+
+def evaluation_loop(
+ model: torch.nn.Module,
+ image_processor: AutoImageProcessor,
+ accelerator: Accelerator,
+ dataloader: DataLoader,
+ id2label: Mapping[int, str],
+) -> dict:
+ model.eval()
+ metric = MeanAveragePrecision(box_format="xyxy", class_metrics=True)
+
+ for step, batch in enumerate(tqdm(dataloader, disable=not accelerator.is_local_main_process)):
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ # For metric computation we need to collect ground truth and predicted boxes in the same format
+
+ # 1. Collect predicted boxes, classes, scores
+ # image_processor convert boxes from YOLO format to Pascal VOC format
+ # ([x_min, y_min, x_max, y_max] in absolute coordinates)
+ image_size = torch.stack([example["orig_size"] for example in batch["labels"]], dim=0)
+ predictions = image_processor.post_process_object_detection(outputs, threshold=0.0, target_sizes=image_size)
+ predictions = nested_to_cpu(predictions)
+
+ # 2. Collect ground truth boxes in the same format for metric computation
+ # Do the same, convert YOLO boxes to Pascal VOC format
+ target = []
+ for label in batch["labels"]:
+ label = nested_to_cpu(label)
+ boxes = convert_bbox_yolo_to_pascal(label["boxes"], label["orig_size"])
+ labels = label["class_labels"]
+ target.append({"boxes": boxes, "labels": labels})
+
+ metric.update(predictions, target)
+
+ metrics = metric.compute()
+
+ # Replace list of per class metrics with separate metric for each class
+ classes = metrics.pop("classes")
+ map_per_class = metrics.pop("map_per_class")
+ mar_100_per_class = metrics.pop("mar_100_per_class")
+ for class_id, class_map, class_mar in zip(classes, map_per_class, mar_100_per_class):
+ class_name = id2label[class_id.item()]
+ metrics[f"map_{class_name}"] = class_map
+ metrics[f"mar_100_{class_name}"] = class_mar
+
+ # Convert metrics to float
+ metrics = {k: round(v.item(), 4) for k, v in metrics.items()}
+
+ return metrics
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Finetune a transformers model for object detection task")
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to a pretrained model or model identifier from huggingface.co/models.",
+ default="facebook/detr-resnet-50",
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ help="Name of the dataset on the hub.",
+ default="cppe-5",
+ )
+ parser.add_argument(
+ "--train_val_split",
+ type=float,
+ default=0.15,
+ help="Fraction of the dataset to be used for validation.",
+ )
+ parser.add_argument(
+ "--ignore_mismatched_sizes",
+ action="store_true",
+ help="Ignore mismatched sizes between the model and the dataset.",
+ )
+ parser.add_argument(
+ "--image_square_size",
+ type=int,
+ default=1333,
+ help="Image longest size will be resized to this value, then image will be padded to square.",
+ )
+ parser.add_argument(
+ "--use_fast",
+ type=bool,
+ default=True,
+ help="Use a fast torchvision-base image processor if it is supported for a given model.",
+ )
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ help="Path to a folder in which the model and dataset will be cached.",
+ )
+ parser.add_argument(
+ "--use_auth_token",
+ action="store_true",
+ help="Whether to use an authentication token to access the model repository.",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--dataloader_num_workers",
+ type=int,
+ default=4,
+ help="Number of workers to use for the dataloaders.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--adam_beta1",
+ type=float,
+ default=0.9,
+ help="Beta1 for AdamW optimizer",
+ )
+ parser.add_argument(
+ "--adam_beta2",
+ type=float,
+ default=0.999,
+ help="Beta2 for AdamW optimizer",
+ )
+ parser.add_argument(
+ "--adam_epsilon",
+ type=float,
+ default=1e-8,
+ help="Epsilon for AdamW optimizer",
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ required=False,
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+ if args.push_to_hub or args.with_tracking:
+ if args.output_dir is None:
+ raise ValueError(
+ "Need an `output_dir` to create a repo when `--push_to_hub` or `with_tracking` is specified."
+ )
+
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_object_detection_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator_log_kwargs = {}
+
+ if args.with_tracking:
+ accelerator_log_kwargs["log_with"] = args.report_to
+ accelerator_log_kwargs["project_dir"] = args.output_dir
+
+ accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
+
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ # We set device_specific to True as we want different data augmentation per device.
+ if args.seed is not None:
+ set_seed(args.seed, device_specific=True)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Load dataset
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ dataset = load_dataset(args.dataset_name, cache_dir=args.cache_dir, trust_remote_code=args.trust_remote_code)
+
+ # If we don't have a validation split, split off a percentage of train as validation.
+ args.train_val_split = None if "validation" in dataset.keys() else args.train_val_split
+ if isinstance(args.train_val_split, float) and args.train_val_split > 0.0:
+ split = dataset["train"].train_test_split(args.train_val_split, seed=args.seed)
+ dataset["train"] = split["train"]
+ dataset["validation"] = split["test"]
+
+ # Get dataset categories and prepare mappings for label_name <-> label_id
+ categories = dataset["train"].features["objects"].feature["category"].names
+ id2label = dict(enumerate(categories))
+ label2id = {v: k for k, v in id2label.items()}
+
+ # ------------------------------------------------------------------------------------------------
+ # Load pretrained config, model and image processor
+ # ------------------------------------------------------------------------------------------------
+
+ common_pretrained_args = {
+ "cache_dir": args.cache_dir,
+ "token": args.hub_token,
+ "trust_remote_code": args.trust_remote_code,
+ }
+ config = AutoConfig.from_pretrained(
+ args.model_name_or_path, label2id=label2id, id2label=id2label, **common_pretrained_args
+ )
+ model = AutoModelForObjectDetection.from_pretrained(
+ args.model_name_or_path,
+ config=config,
+ ignore_mismatched_sizes=args.ignore_mismatched_sizes,
+ **common_pretrained_args,
+ )
+ image_processor = AutoImageProcessor.from_pretrained(
+ args.model_name_or_path,
+ do_resize=True,
+ size={"max_height": args.image_square_size, "max_width": args.image_square_size},
+ do_pad=True,
+ pad_size={"height": args.image_square_size, "width": args.image_square_size},
+ use_fast=args.use_fast,
+ **common_pretrained_args,
+ )
+
+ # ------------------------------------------------------------------------------------------------
+ # Define image augmentations and dataset transforms
+ # ------------------------------------------------------------------------------------------------
+ max_size = args.image_square_size
+ train_augment_and_transform = A.Compose(
+ [
+ A.Compose(
+ [
+ A.SmallestMaxSize(max_size=max_size, p=1.0),
+ A.RandomSizedBBoxSafeCrop(height=max_size, width=max_size, p=1.0),
+ ],
+ p=0.2,
+ ),
+ A.OneOf(
+ [
+ A.Blur(blur_limit=7, p=0.5),
+ A.MotionBlur(blur_limit=7, p=0.5),
+ A.Defocus(radius=(1, 5), alias_blur=(0.1, 0.25), p=0.1),
+ ],
+ p=0.1,
+ ),
+ A.Perspective(p=0.1),
+ A.HorizontalFlip(p=0.5),
+ A.RandomBrightnessContrast(p=0.5),
+ A.HueSaturationValue(p=0.1),
+ ],
+ bbox_params=A.BboxParams(format="coco", label_fields=["category"], clip=True, min_area=25),
+ )
+ validation_transform = A.Compose(
+ [A.NoOp()],
+ bbox_params=A.BboxParams(format="coco", label_fields=["category"], clip=True),
+ )
+
+ # Make transform functions for batch and apply for dataset splits
+ train_transform_batch = partial(
+ augment_and_transform_batch, transform=train_augment_and_transform, image_processor=image_processor
+ )
+ validation_transform_batch = partial(
+ augment_and_transform_batch, transform=validation_transform, image_processor=image_processor
+ )
+
+ with accelerator.main_process_first():
+ train_dataset = dataset["train"].with_transform(train_transform_batch)
+ valid_dataset = dataset["validation"].with_transform(validation_transform_batch)
+ test_dataset = dataset["test"].with_transform(validation_transform_batch)
+
+ dataloader_common_args = {
+ "num_workers": args.dataloader_num_workers,
+ "collate_fn": collate_fn,
+ }
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, batch_size=args.per_device_train_batch_size, **dataloader_common_args
+ )
+ valid_dataloader = DataLoader(
+ valid_dataset, shuffle=False, batch_size=args.per_device_eval_batch_size, **dataloader_common_args
+ )
+ test_dataloader = DataLoader(
+ test_dataset, shuffle=False, batch_size=args.per_device_eval_batch_size, **dataloader_common_args
+ )
+
+ # ------------------------------------------------------------------------------------------------
+ # Define optimizer, scheduler and prepare everything with the accelerator
+ # ------------------------------------------------------------------------------------------------
+
+ # Optimizer
+ optimizer = torch.optim.AdamW(
+ list(model.parameters()),
+ lr=args.learning_rate,
+ betas=[args.adam_beta1, args.adam_beta2],
+ eps=args.adam_epsilon,
+ )
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps
+ if overrode_max_train_steps
+ else args.max_train_steps * accelerator.num_processes,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, valid_dataloader, test_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, valid_dataloader, test_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("object_detection_no_trainer", experiment_config)
+
+ # ------------------------------------------------------------------------------------------------
+ # Run training with evaluation on each epoch
+ # ------------------------------------------------------------------------------------------------
+
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+
+ for step, batch in enumerate(active_dataloader):
+ with accelerator.accumulate(model):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+ accelerator.backward(loss)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir,
+ is_main_process=accelerator.is_main_process,
+ save_function=accelerator.save,
+ )
+ if accelerator.is_main_process:
+ image_processor.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ logger.info("***** Running evaluation *****")
+ metrics = evaluation_loop(model, image_processor, accelerator, valid_dataloader, id2label)
+
+ logger.info(f"epoch {epoch}: {metrics}")
+
+ if args.with_tracking:
+ accelerator.log(
+ {
+ "train_loss": total_loss.item() / len(train_dataloader),
+ **metrics,
+ "epoch": epoch,
+ "step": completed_steps,
+ },
+ step=completed_steps,
+ )
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ image_processor.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ # ------------------------------------------------------------------------------------------------
+ # Run evaluation on test dataset and save the model
+ # ------------------------------------------------------------------------------------------------
+
+ logger.info("***** Running evaluation on test dataset *****")
+ metrics = evaluation_loop(model, image_processor, accelerator, test_dataloader, id2label)
+ metrics = {f"test_{k}": v for k, v in metrics.items()}
+
+ logger.info(f"Test metrics: {metrics}")
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
+ json.dump(metrics, f, indent=2)
+
+ image_processor.save_pretrained(args.output_dir)
+
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ ignore_patterns=["epoch_*"],
+ )
+
+ accelerator.wait_for_everyone()
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/old_test_xla_examples.py b/docs/transformers/examples/pytorch/old_test_xla_examples.py
new file mode 100644
index 0000000000000000000000000000000000000000..b3101aa06b98a30c6246d28cce46d04c87e6de39
--- /dev/null
+++ b/docs/transformers/examples/pytorch/old_test_xla_examples.py
@@ -0,0 +1,93 @@
+# Copyright 2018 HuggingFace Inc..
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import logging
+import os
+import sys
+from time import time
+from unittest.mock import patch
+
+from transformers.testing_utils import TestCasePlus, require_torch_xla
+
+
+logging.basicConfig(level=logging.DEBUG)
+
+logger = logging.getLogger()
+
+
+def get_results(output_dir):
+ results = {}
+ path = os.path.join(output_dir, "all_results.json")
+ if os.path.exists(path):
+ with open(path) as f:
+ results = json.load(f)
+ else:
+ raise ValueError(f"can't find {path}")
+ return results
+
+
+stream_handler = logging.StreamHandler(sys.stdout)
+logger.addHandler(stream_handler)
+
+
+@require_torch_xla
+class TorchXLAExamplesTests(TestCasePlus):
+ def test_run_glue(self):
+ import xla_spawn
+
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ ./examples/pytorch/text-classification/run_glue.py
+ --num_cores=8
+ ./examples/pytorch/text-classification/run_glue.py
+ --model_name_or_path distilbert/distilbert-base-uncased
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --train_file ./tests/fixtures/tests_samples/MRPC/train.csv
+ --validation_file ./tests/fixtures/tests_samples/MRPC/dev.csv
+ --do_train
+ --do_eval
+ --debug tpu_metrics_debug
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --learning_rate=1e-4
+ --max_steps=10
+ --warmup_steps=2
+ --seed=42
+ --max_seq_length=128
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ start = time()
+ xla_spawn.main()
+ end = time()
+
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_accuracy"], 0.75)
+
+ # Assert that the script takes less than 500 seconds to make sure it doesn't hang.
+ self.assertLess(end - start, 500)
+
+ def test_trainer_tpu(self):
+ import xla_spawn
+
+ testargs = """
+ ./tests/test_trainer_tpu.py
+ --num_cores=8
+ ./tests/test_trainer_tpu.py
+ """.split()
+ with patch.object(sys, "argv", testargs):
+ xla_spawn.main()
diff --git a/docs/transformers/examples/pytorch/question-answering/README.md b/docs/transformers/examples/pytorch/question-answering/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..9fac0b303850930ab3fcd2fbf5556dca847eb808
--- /dev/null
+++ b/docs/transformers/examples/pytorch/question-answering/README.md
@@ -0,0 +1,183 @@
+
+
+# Question answering
+
+This folder contains several scripts that showcase how to fine-tune a 🤗 Transformers model on a question answering dataset,
+like SQuAD.
+
+## Trainer-based scripts
+
+The [`run_qa.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_qa.py),
+[`run_qa_beam_search.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_qa_beam_search.py) and [`run_seq2seq_qa.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_seq2seq_qa.py) leverage the 🤗 [Trainer](https://huggingface.co/transformers/main_classes/trainer.html) for fine-tuning.
+
+### Fine-tuning BERT on SQuAD1.0
+
+The [`run_qa.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_qa.py) script
+allows to fine-tune any model from our [hub](https://huggingface.co/models) (as long as its architecture has a `ForQuestionAnswering` version in the library) on a question-answering dataset (such as SQuAD, or any other QA dataset available in the `datasets` library, or your own csv/jsonlines files) as long as they are structured the same way as SQuAD. You might need to tweak the data processing inside the script if your data is structured differently.
+
+**Note:** This script only works with models that have a fast tokenizer (backed by the 🤗 Tokenizers library) as it
+uses special features of those tokenizers. You can check if your favorite model has a fast tokenizer in
+[this table](https://huggingface.co/transformers/index.html#supported-frameworks), if it doesn't you can still use the old version of the script which can be found [here](https://github.com/huggingface/transformers/tree/main/examples/legacy/question-answering).
+
+Note that if your dataset contains samples with no possible answers (like SQuAD version 2), you need to pass along the flag `--version_2_with_negative`.
+
+This example code fine-tunes BERT on the SQuAD1.0 dataset. It runs in 24 min (with BERT-base) or 68 min (with BERT-large)
+on a single tesla V100 16GB.
+
+```bash
+python run_qa.py \
+ --model_name_or_path google-bert/bert-base-uncased \
+ --dataset_name squad \
+ --do_train \
+ --do_eval \
+ --per_device_train_batch_size 12 \
+ --learning_rate 3e-5 \
+ --num_train_epochs 2 \
+ --max_seq_length 384 \
+ --doc_stride 128 \
+ --output_dir /tmp/debug_squad/
+```
+
+Training with the previously defined hyper-parameters yields the following results:
+
+```bash
+f1 = 88.52
+exact_match = 81.22
+```
+
+### Fine-tuning XLNet with beam search on SQuAD
+
+The [`run_qa_beam_search.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_qa_beam_search.py) script is only meant to fine-tune XLNet, which is a special encoder-only Transformer model. The example code below fine-tunes XLNet on the SQuAD1.0 and SQuAD2.0 datasets.
+
+#### Command for SQuAD1.0:
+
+```bash
+python run_qa_beam_search.py \
+ --model_name_or_path xlnet/xlnet-large-cased \
+ --dataset_name squad \
+ --do_train \
+ --do_eval \
+ --learning_rate 3e-5 \
+ --num_train_epochs 2 \
+ --max_seq_length 384 \
+ --doc_stride 128 \
+ --output_dir ./wwm_cased_finetuned_squad/ \
+ --per_device_eval_batch_size=4 \
+ --per_device_train_batch_size=4 \
+ --save_steps 5000
+```
+
+#### Command for SQuAD2.0:
+
+```bash
+export SQUAD_DIR=/path/to/SQUAD
+
+python run_qa_beam_search.py \
+ --model_name_or_path xlnet/xlnet-large-cased \
+ --dataset_name squad_v2 \
+ --do_train \
+ --do_eval \
+ --version_2_with_negative \
+ --learning_rate 3e-5 \
+ --num_train_epochs 4 \
+ --max_seq_length 384 \
+ --doc_stride 128 \
+ --output_dir ./wwm_cased_finetuned_squad/ \
+ --per_device_eval_batch_size=2 \
+ --per_device_train_batch_size=2 \
+ --save_steps 5000
+```
+
+### Fine-tuning T5 on SQuAD2.0
+
+The [`run_seq2seq_qa.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/question-answering/run_seq2seq_qa.py) script is meant for encoder-decoder (also called seq2seq) Transformer models, such as T5 or BART. These
+models are generative, rather than discriminative. This means that they learn to generate the correct answer, rather than predicting the start and end position of the tokens of the answer.
+
+This example code fine-tunes T5 on the SQuAD2.0 dataset.
+
+```bash
+python run_seq2seq_qa.py \
+ --model_name_or_path google-t5/t5-small \
+ --dataset_name squad_v2 \
+ --context_column context \
+ --question_column question \
+ --answer_column answers \
+ --do_train \
+ --do_eval \
+ --per_device_train_batch_size 12 \
+ --learning_rate 3e-5 \
+ --num_train_epochs 2 \
+ --max_seq_length 384 \
+ --doc_stride 128 \
+ --output_dir /tmp/debug_seq2seq_squad/
+```
+
+## Accelerate-based scripts
+
+Based on the scripts `run_qa_no_trainer.py` and `run_qa_beam_search_no_trainer.py`.
+
+Like `run_qa.py` and `run_qa_beam_search.py`, these scripts allow you to fine-tune any of the models supported on a
+SQuAD or a similar dataset, the main difference is that this script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like. It offers less options than the script with `Trainer` (for instance you can easily change the options for the optimizer or the dataloaders directly in the script), but still run in a distributed setup, on TPU and supports mixed precision by leveraging the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library.
+
+You can use the script normally after installing it:
+
+```bash
+pip install git+https://github.com/huggingface/accelerate
+```
+
+then
+
+```bash
+python run_qa_no_trainer.py \
+ --model_name_or_path google-bert/bert-base-uncased \
+ --dataset_name squad \
+ --max_seq_length 384 \
+ --doc_stride 128 \
+ --output_dir ~/tmp/debug_squad
+```
+
+You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
+
+```bash
+accelerate config
+```
+
+and reply to the questions asked. Then
+
+```bash
+accelerate test
+```
+
+that will check everything is ready for training. Finally, you can launch training with
+
+```bash
+accelerate launch run_qa_no_trainer.py \
+ --model_name_or_path google-bert/bert-base-uncased \
+ --dataset_name squad \
+ --max_seq_length 384 \
+ --doc_stride 128 \
+ --output_dir ~/tmp/debug_squad
+```
+
+This command is the same and will work for:
+
+- a CPU-only setup
+- a setup with one GPU
+- a distributed training with several GPUs (single or multi node)
+- a training on TPUs
+
+Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
diff --git a/docs/transformers/examples/pytorch/question-answering/requirements.txt b/docs/transformers/examples/pytorch/question-answering/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..c8200d867ec4f79ebb3c2649a5aa3773d0b7eb54
--- /dev/null
+++ b/docs/transformers/examples/pytorch/question-answering/requirements.txt
@@ -0,0 +1,4 @@
+accelerate >= 0.12.0
+datasets >= 1.8.0
+torch >= 1.3.0
+evaluate
\ No newline at end of file
diff --git a/docs/transformers/examples/pytorch/question-answering/run_qa.py b/docs/transformers/examples/pytorch/question-answering/run_qa.py
new file mode 100644
index 0000000000000000000000000000000000000000..dbdc52cedea2e19aa0513344627bf63368c325f7
--- /dev/null
+++ b/docs/transformers/examples/pytorch/question-answering/run_qa.py
@@ -0,0 +1,714 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for question answering using a slightly adapted version of the 🤗 Trainer.
+"""
+# You can also adapt this script on your own question answering task. Pointers for this are left as comments.
+
+import logging
+import os
+import sys
+import warnings
+from dataclasses import dataclass, field
+from typing import Optional
+
+import datasets
+import evaluate
+from datasets import load_dataset
+from trainer_qa import QuestionAnsweringTrainer
+from utils_qa import postprocess_qa_predictions
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForQuestionAnswering,
+ AutoTokenizer,
+ DataCollatorWithPadding,
+ EvalPrediction,
+ HfArgumentParser,
+ PreTrainedTokenizerFast,
+ TrainingArguments,
+ default_data_collator,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Path to directory to store the pretrained models downloaded from huggingface.co"},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input test data file to evaluate the perplexity on (a text file)."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_seq_length: int = field(
+ default=384,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ pad_to_max_length: bool = field(
+ default=True,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. If False, will pad the samples dynamically when"
+ " batching to the maximum length in the batch (which can be faster on GPU but will be slower on TPU)."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ version_2_with_negative: bool = field(
+ default=False, metadata={"help": "If true, some of the examples do not have an answer."}
+ )
+ null_score_diff_threshold: float = field(
+ default=0.0,
+ metadata={
+ "help": (
+ "The threshold used to select the null answer: if the best answer has a score that is less than "
+ "the score of the null answer minus this threshold, the null answer is selected for this example. "
+ "Only useful when `version_2_with_negative=True`."
+ )
+ },
+ )
+ doc_stride: int = field(
+ default=128,
+ metadata={"help": "When splitting up a long document into chunks, how much stride to take between chunks."},
+ )
+ n_best_size: int = field(
+ default=20,
+ metadata={"help": "The total number of n-best predictions to generate when looking for an answer."},
+ )
+ max_answer_length: int = field(
+ default=30,
+ metadata={
+ "help": (
+ "The maximum length of an answer that can be generated. This is needed because the start "
+ "and end predictions are not conditioned on one another."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if (
+ self.dataset_name is None
+ and self.train_file is None
+ and self.validation_file is None
+ and self.test_file is None
+ ):
+ raise ValueError("Need either a dataset name or a training/validation file/test_file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ if self.test_file is not None:
+ extension = self.test_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_qa", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if data_args.test_file is not None:
+ data_files["test"] = data_args.test_file
+ extension = data_args.test_file.split(".")[-1]
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ field="data",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=True,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = AutoModelForQuestionAnswering.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # Tokenizer check: this script requires a fast tokenizer.
+ if not isinstance(tokenizer, PreTrainedTokenizerFast):
+ raise ValueError(
+ "This example script only works for models that have a fast tokenizer. Checkout the big table of models at"
+ " https://huggingface.co/transformers/index.html#supported-frameworks to find the model types that meet"
+ " this requirement"
+ )
+
+ # Preprocessing the datasets.
+ # Preprocessing is slightly different for training and evaluation.
+ if training_args.do_train:
+ column_names = raw_datasets["train"].column_names
+ elif training_args.do_eval:
+ column_names = raw_datasets["validation"].column_names
+ else:
+ column_names = raw_datasets["test"].column_names
+ question_column_name = "question" if "question" in column_names else column_names[0]
+ context_column_name = "context" if "context" in column_names else column_names[1]
+ answer_column_name = "answers" if "answers" in column_names else column_names[2]
+
+ # Padding side determines if we do (question|context) or (context|question).
+ pad_on_right = tokenizer.padding_side == "right"
+
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ # Training preprocessing
+ def prepare_train_features(examples):
+ # Some of the questions have lots of whitespace on the left, which is not useful and will make the
+ # truncation of the context fail (the tokenized question will take a lots of space). So we remove that
+ # left whitespace
+ examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
+
+ # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
+ # in one example possible giving several features when a context is long, each of those features having a
+ # context that overlaps a bit the context of the previous feature.
+ tokenized_examples = tokenizer(
+ examples[question_column_name if pad_on_right else context_column_name],
+ examples[context_column_name if pad_on_right else question_column_name],
+ truncation="only_second" if pad_on_right else "only_first",
+ max_length=max_seq_length,
+ stride=data_args.doc_stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ padding="max_length" if data_args.pad_to_max_length else False,
+ )
+
+ # Since one example might give us several features if it has a long context, we need a map from a feature to
+ # its corresponding example. This key gives us just that.
+ sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
+ # The offset mappings will give us a map from token to character position in the original context. This will
+ # help us compute the start_positions and end_positions.
+ offset_mapping = tokenized_examples.pop("offset_mapping")
+
+ # Let's label those examples!
+ tokenized_examples["start_positions"] = []
+ tokenized_examples["end_positions"] = []
+
+ for i, offsets in enumerate(offset_mapping):
+ # We will label impossible answers with the index of the CLS token.
+ input_ids = tokenized_examples["input_ids"][i]
+ if tokenizer.cls_token_id in input_ids:
+ cls_index = input_ids.index(tokenizer.cls_token_id)
+ elif tokenizer.bos_token_id in input_ids:
+ cls_index = input_ids.index(tokenizer.bos_token_id)
+ else:
+ cls_index = 0
+
+ # Grab the sequence corresponding to that example (to know what is the context and what is the question).
+ sequence_ids = tokenized_examples.sequence_ids(i)
+
+ # One example can give several spans, this is the index of the example containing this span of text.
+ sample_index = sample_mapping[i]
+ answers = examples[answer_column_name][sample_index]
+ # If no answers are given, set the cls_index as answer.
+ if len(answers["answer_start"]) == 0:
+ tokenized_examples["start_positions"].append(cls_index)
+ tokenized_examples["end_positions"].append(cls_index)
+ else:
+ # Start/end character index of the answer in the text.
+ start_char = answers["answer_start"][0]
+ end_char = start_char + len(answers["text"][0])
+
+ # Start token index of the current span in the text.
+ token_start_index = 0
+ while sequence_ids[token_start_index] != (1 if pad_on_right else 0):
+ token_start_index += 1
+
+ # End token index of the current span in the text.
+ token_end_index = len(input_ids) - 1
+ while sequence_ids[token_end_index] != (1 if pad_on_right else 0):
+ token_end_index -= 1
+
+ # Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
+ if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
+ tokenized_examples["start_positions"].append(cls_index)
+ tokenized_examples["end_positions"].append(cls_index)
+ else:
+ # Otherwise move the token_start_index and token_end_index to the two ends of the answer.
+ # Note: we could go after the last offset if the answer is the last word (edge case).
+ while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
+ token_start_index += 1
+ tokenized_examples["start_positions"].append(token_start_index - 1)
+ while offsets[token_end_index][1] >= end_char:
+ token_end_index -= 1
+ tokenized_examples["end_positions"].append(token_end_index + 1)
+
+ return tokenized_examples
+
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if data_args.max_train_samples is not None:
+ # We will select sample from whole data if argument is specified
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ # Create train feature from dataset
+ with training_args.main_process_first(desc="train dataset map pre-processing"):
+ train_dataset = train_dataset.map(
+ prepare_train_features,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+ if data_args.max_train_samples is not None:
+ # Number of samples might increase during Feature Creation, We select only specified max samples
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+
+ # Validation preprocessing
+ def prepare_validation_features(examples):
+ # Some of the questions have lots of whitespace on the left, which is not useful and will make the
+ # truncation of the context fail (the tokenized question will take a lots of space). So we remove that
+ # left whitespace
+ examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
+
+ # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
+ # in one example possible giving several features when a context is long, each of those features having a
+ # context that overlaps a bit the context of the previous feature.
+ tokenized_examples = tokenizer(
+ examples[question_column_name if pad_on_right else context_column_name],
+ examples[context_column_name if pad_on_right else question_column_name],
+ truncation="only_second" if pad_on_right else "only_first",
+ max_length=max_seq_length,
+ stride=data_args.doc_stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ padding="max_length" if data_args.pad_to_max_length else False,
+ )
+
+ # Since one example might give us several features if it has a long context, we need a map from a feature to
+ # its corresponding example. This key gives us just that.
+ sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
+
+ # For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
+ # corresponding example_id and we will store the offset mappings.
+ tokenized_examples["example_id"] = []
+
+ for i in range(len(tokenized_examples["input_ids"])):
+ # Grab the sequence corresponding to that example (to know what is the context and what is the question).
+ sequence_ids = tokenized_examples.sequence_ids(i)
+ context_index = 1 if pad_on_right else 0
+
+ # One example can give several spans, this is the index of the example containing this span of text.
+ sample_index = sample_mapping[i]
+ tokenized_examples["example_id"].append(examples["id"][sample_index])
+
+ # Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
+ # position is part of the context or not.
+ tokenized_examples["offset_mapping"][i] = [
+ (o if sequence_ids[k] == context_index else None)
+ for k, o in enumerate(tokenized_examples["offset_mapping"][i])
+ ]
+
+ return tokenized_examples
+
+ if training_args.do_eval:
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_examples = raw_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ # We will select sample from whole data
+ max_eval_samples = min(len(eval_examples), data_args.max_eval_samples)
+ eval_examples = eval_examples.select(range(max_eval_samples))
+ # Validation Feature Creation
+ with training_args.main_process_first(desc="validation dataset map pre-processing"):
+ eval_dataset = eval_examples.map(
+ prepare_validation_features,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+ if data_args.max_eval_samples is not None:
+ # During Feature creation dataset samples might increase, we will select required samples again
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ if training_args.do_predict:
+ if "test" not in raw_datasets:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_examples = raw_datasets["test"]
+ if data_args.max_predict_samples is not None:
+ # We will select sample from whole data
+ predict_examples = predict_examples.select(range(data_args.max_predict_samples))
+ # Predict Feature Creation
+ with training_args.main_process_first(desc="prediction dataset map pre-processing"):
+ predict_dataset = predict_examples.map(
+ prepare_validation_features,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on prediction dataset",
+ )
+ if data_args.max_predict_samples is not None:
+ # During Feature creation dataset samples might increase, we will select required samples again
+ max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
+ predict_dataset = predict_dataset.select(range(max_predict_samples))
+
+ # Data collator
+ # We have already padded to max length if the corresponding flag is True, otherwise we need to pad in the data
+ # collator.
+ data_collator = (
+ default_data_collator
+ if data_args.pad_to_max_length
+ else DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8 if training_args.fp16 else None)
+ )
+
+ # Post-processing:
+ def post_processing_function(examples, features, predictions, stage="eval"):
+ # Post-processing: we match the start logits and end logits to answers in the original context.
+ predictions = postprocess_qa_predictions(
+ examples=examples,
+ features=features,
+ predictions=predictions,
+ version_2_with_negative=data_args.version_2_with_negative,
+ n_best_size=data_args.n_best_size,
+ max_answer_length=data_args.max_answer_length,
+ null_score_diff_threshold=data_args.null_score_diff_threshold,
+ output_dir=training_args.output_dir,
+ log_level=log_level,
+ prefix=stage,
+ )
+ # Format the result to the format the metric expects.
+ if data_args.version_2_with_negative:
+ formatted_predictions = [
+ {"id": str(k), "prediction_text": v, "no_answer_probability": 0.0} for k, v in predictions.items()
+ ]
+ else:
+ formatted_predictions = [{"id": str(k), "prediction_text": v} for k, v in predictions.items()]
+
+ references = [{"id": str(ex["id"]), "answers": ex[answer_column_name]} for ex in examples]
+ return EvalPrediction(predictions=formatted_predictions, label_ids=references)
+
+ if data_args.version_2_with_negative:
+ accepted_best_metrics = ("exact", "f1", "HasAns_exact", "HasAns_f1")
+ else:
+ accepted_best_metrics = ("exact_match", "f1")
+
+ if training_args.load_best_model_at_end and training_args.metric_for_best_model not in accepted_best_metrics:
+ warnings.warn(f"--metric_for_best_model should be set to one of {accepted_best_metrics}")
+
+ metric = evaluate.load(
+ "squad_v2" if data_args.version_2_with_negative else "squad", cache_dir=model_args.cache_dir
+ )
+
+ def compute_metrics(p: EvalPrediction):
+ return metric.compute(predictions=p.predictions, references=p.label_ids)
+
+ # Initialize our Trainer
+ trainer = QuestionAnsweringTrainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ eval_examples=eval_examples if training_args.do_eval else None,
+ processing_class=tokenizer,
+ data_collator=data_collator,
+ post_process_function=post_processing_function,
+ compute_metrics=compute_metrics,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model() # Saves the tokenizer too for easy upload
+
+ metrics = train_result.metrics
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+ metrics = trainer.evaluate()
+
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Prediction
+ if training_args.do_predict:
+ logger.info("*** Predict ***")
+ results = trainer.predict(predict_dataset, predict_examples)
+ metrics = results.metrics
+
+ max_predict_samples = (
+ data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
+ )
+ metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
+
+ trainer.log_metrics("predict", metrics)
+ trainer.save_metrics("predict", metrics)
+
+ kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "question-answering"}
+ if data_args.dataset_name is not None:
+ kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ kwargs["dataset_args"] = data_args.dataset_config_name
+ kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/question-answering/run_qa_beam_search.py b/docs/transformers/examples/pytorch/question-answering/run_qa_beam_search.py
new file mode 100644
index 0000000000000000000000000000000000000000..6ea909a7da067b6b52f4964d5b8555d01dd0cd2d
--- /dev/null
+++ b/docs/transformers/examples/pytorch/question-answering/run_qa_beam_search.py
@@ -0,0 +1,741 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning XLNet for question answering with beam search using a slightly adapted version of the 🤗 Trainer.
+"""
+# You can also adapt this script on your own question answering task. Pointers for this are left as comments.
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import datasets
+import evaluate
+from datasets import load_dataset
+from trainer_qa import QuestionAnsweringTrainer
+from utils_qa import postprocess_qa_predictions_with_beam_search
+
+import transformers
+from transformers import (
+ DataCollatorWithPadding,
+ EvalPrediction,
+ HfArgumentParser,
+ TrainingArguments,
+ XLNetConfig,
+ XLNetForQuestionAnswering,
+ XLNetTokenizerFast,
+ default_data_collator,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input test data file to test the perplexity on (a text file)."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_seq_length: int = field(
+ default=384,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ pad_to_max_length: bool = field(
+ default=True,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. If False, will pad the samples dynamically when"
+ " batching to the maximum length in the batch (which can be faster on GPU but will be slower on TPU)."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ version_2_with_negative: bool = field(
+ default=False, metadata={"help": "If true, some of the examples do not have an answer."}
+ )
+ null_score_diff_threshold: float = field(
+ default=0.0,
+ metadata={
+ "help": (
+ "The threshold used to select the null answer: if the best answer has a score that is less than "
+ "the score of the null answer minus this threshold, the null answer is selected for this example. "
+ "Only useful when `version_2_with_negative=True`."
+ )
+ },
+ )
+ doc_stride: int = field(
+ default=128,
+ metadata={"help": "When splitting up a long document into chunks, how much stride to take between chunks."},
+ )
+ n_best_size: int = field(
+ default=20,
+ metadata={"help": "The total number of n-best predictions to generate when looking for an answer."},
+ )
+ max_answer_length: int = field(
+ default=30,
+ metadata={
+ "help": (
+ "The maximum length of an answer that can be generated. This is needed because the start "
+ "and end predictions are not conditioned on one another."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if (
+ self.dataset_name is None
+ and self.train_file is None
+ and self.validation_file is None
+ and self.test_file is None
+ ):
+ raise ValueError("Need either a dataset name or a training/validation/test file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ if self.test_file is not None:
+ extension = self.test_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_qa_beam_search", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if data_args.test_file is not None:
+ data_files["test"] = data_args.test_file
+ extension = data_args.test_file.split(".")[-1]
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ field="data",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = XLNetConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ )
+ tokenizer = XLNetTokenizerFast.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ )
+ model = XLNetForQuestionAnswering.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ )
+
+ # Preprocessing the datasets.
+ # Preprocessing is slightly different for training and evaluation.
+ if training_args.do_train:
+ column_names = raw_datasets["train"].column_names
+ elif training_args.do_eval:
+ column_names = raw_datasets["validation"].column_names
+ else:
+ column_names = raw_datasets["test"].column_names
+ question_column_name = "question" if "question" in column_names else column_names[0]
+ context_column_name = "context" if "context" in column_names else column_names[1]
+ answer_column_name = "answers" if "answers" in column_names else column_names[2]
+
+ # Padding side determines if we do (question|context) or (context|question).
+ pad_on_right = tokenizer.padding_side == "right"
+
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ # Training preprocessing
+ def prepare_train_features(examples):
+ # Some of the questions have lots of whitespace on the left, which is not useful and will make the
+ # truncation of the context fail (the tokenized question will take a lots of space). So we remove that
+ # left whitespace
+ examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
+
+ # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
+ # in one example possible giving several features when a context is long, each of those features having a
+ # context that overlaps a bit the context of the previous feature.
+ tokenized_examples = tokenizer(
+ examples[question_column_name if pad_on_right else context_column_name],
+ examples[context_column_name if pad_on_right else question_column_name],
+ truncation="only_second" if pad_on_right else "only_first",
+ max_length=max_seq_length,
+ stride=data_args.doc_stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ return_special_tokens_mask=True,
+ return_token_type_ids=True,
+ padding="max_length",
+ )
+
+ # Since one example might give us several features if it has a long context, we need a map from a feature to
+ # its corresponding example. This key gives us just that.
+ sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
+ # The offset mappings will give us a map from token to character position in the original context. This will
+ # help us compute the start_positions and end_positions.
+ offset_mapping = tokenized_examples.pop("offset_mapping")
+ # The special tokens will help us build the p_mask (which indicates the tokens that can't be in answers).
+ special_tokens = tokenized_examples.pop("special_tokens_mask")
+
+ # Let's label those examples!
+ tokenized_examples["start_positions"] = []
+ tokenized_examples["end_positions"] = []
+ tokenized_examples["is_impossible"] = []
+ tokenized_examples["cls_index"] = []
+ tokenized_examples["p_mask"] = []
+
+ for i, offsets in enumerate(offset_mapping):
+ # We will label impossible answers with the index of the CLS token.
+ input_ids = tokenized_examples["input_ids"][i]
+ if tokenizer.cls_token_id in input_ids:
+ cls_index = input_ids.index(tokenizer.cls_token_id)
+ elif tokenizer.bos_token_id in input_ids:
+ cls_index = input_ids.index(tokenizer.bos_token_id)
+ else:
+ cls_index = 0
+ tokenized_examples["cls_index"].append(cls_index)
+
+ # Grab the sequence corresponding to that example (to know what is the context and what is the question).
+ sequence_ids = tokenized_examples["token_type_ids"][i]
+ for k, s in enumerate(special_tokens[i]):
+ if s:
+ sequence_ids[k] = 3
+ context_idx = 1 if pad_on_right else 0
+
+ # Build the p_mask: non special tokens and context gets 0.0, the others get 1.0.
+ # The cls token gets 1.0 too (for predictions of empty answers).
+ tokenized_examples["p_mask"].append(
+ [
+ 0.0 if (not special_tokens[i][k] and s == context_idx) or k == cls_index else 1.0
+ for k, s in enumerate(sequence_ids)
+ ]
+ )
+
+ # One example can give several spans, this is the index of the example containing this span of text.
+ sample_index = sample_mapping[i]
+ answers = examples[answer_column_name][sample_index]
+ # If no answers are given, set the cls_index as answer.
+ if len(answers["answer_start"]) == 0:
+ tokenized_examples["start_positions"].append(cls_index)
+ tokenized_examples["end_positions"].append(cls_index)
+ tokenized_examples["is_impossible"].append(1.0)
+ else:
+ # Start/end character index of the answer in the text.
+ start_char = answers["answer_start"][0]
+ end_char = start_char + len(answers["text"][0])
+
+ # Start token index of the current span in the text.
+ token_start_index = 0
+ while sequence_ids[token_start_index] != context_idx:
+ token_start_index += 1
+
+ # End token index of the current span in the text.
+ token_end_index = len(input_ids) - 1
+ while sequence_ids[token_end_index] != context_idx:
+ token_end_index -= 1
+ # Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
+ if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
+ tokenized_examples["start_positions"].append(cls_index)
+ tokenized_examples["end_positions"].append(cls_index)
+ tokenized_examples["is_impossible"].append(1.0)
+ else:
+ # Otherwise move the token_start_index and token_end_index to the two ends of the answer.
+ # Note: we could go after the last offset if the answer is the last word (edge case).
+ while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
+ token_start_index += 1
+ tokenized_examples["start_positions"].append(token_start_index - 1)
+ while offsets[token_end_index][1] >= end_char:
+ token_end_index -= 1
+ tokenized_examples["end_positions"].append(token_end_index + 1)
+ tokenized_examples["is_impossible"].append(0.0)
+
+ return tokenized_examples
+
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if data_args.max_train_samples is not None:
+ # Select samples from Dataset, This will help to decrease processing time
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ # Create Training Features
+ with training_args.main_process_first(desc="train dataset map pre-processing"):
+ train_dataset = train_dataset.map(
+ prepare_train_features,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+ if data_args.max_train_samples is not None:
+ # Select samples from dataset again since Feature Creation might increase number of features
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+
+ # Validation preprocessing
+ def prepare_validation_features(examples):
+ # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
+ # in one example possible giving several features when a context is long, each of those features having a
+ # context that overlaps a bit the context of the previous feature.
+ tokenized_examples = tokenizer(
+ examples[question_column_name if pad_on_right else context_column_name],
+ examples[context_column_name if pad_on_right else question_column_name],
+ truncation="only_second" if pad_on_right else "only_first",
+ max_length=max_seq_length,
+ stride=data_args.doc_stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ return_special_tokens_mask=True,
+ return_token_type_ids=True,
+ padding="max_length",
+ )
+
+ # Since one example might give us several features if it has a long context, we need a map from a feature to
+ # its corresponding example. This key gives us just that.
+ sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
+
+ # The special tokens will help us build the p_mask (which indicates the tokens that can't be in answers).
+ special_tokens = tokenized_examples.pop("special_tokens_mask")
+
+ # For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
+ # corresponding example_id and we will store the offset mappings.
+ tokenized_examples["example_id"] = []
+
+ # We still provide the index of the CLS token and the p_mask to the model, but not the is_impossible label.
+ tokenized_examples["cls_index"] = []
+ tokenized_examples["p_mask"] = []
+
+ for i, input_ids in enumerate(tokenized_examples["input_ids"]):
+ # Find the CLS token in the input ids.
+ if tokenizer.cls_token_id in input_ids:
+ cls_index = input_ids.index(tokenizer.cls_token_id)
+ elif tokenizer.bos_token_id in input_ids:
+ cls_index = input_ids.index(tokenizer.bos_token_id)
+ else:
+ cls_index = 0
+ tokenized_examples["cls_index"].append(cls_index)
+
+ # Grab the sequence corresponding to that example (to know what is the context and what is the question).
+ sequence_ids = tokenized_examples["token_type_ids"][i]
+ for k, s in enumerate(special_tokens[i]):
+ if s:
+ sequence_ids[k] = 3
+ context_idx = 1 if pad_on_right else 0
+
+ # Build the p_mask: non special tokens and context gets 0.0, the others 1.0.
+ tokenized_examples["p_mask"].append(
+ [
+ 0.0 if (not special_tokens[i][k] and s == context_idx) or k == cls_index else 1.0
+ for k, s in enumerate(sequence_ids)
+ ]
+ )
+
+ # One example can give several spans, this is the index of the example containing this span of text.
+ sample_index = sample_mapping[i]
+ tokenized_examples["example_id"].append(examples["id"][sample_index])
+
+ # Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
+ # position is part of the context or not.
+ tokenized_examples["offset_mapping"][i] = [
+ (o if sequence_ids[k] == context_idx else None)
+ for k, o in enumerate(tokenized_examples["offset_mapping"][i])
+ ]
+
+ return tokenized_examples
+
+ if training_args.do_eval:
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_examples = raw_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ # Selecting Eval Samples from Dataset
+ max_eval_samples = min(len(eval_examples), data_args.max_eval_samples)
+ eval_examples = eval_examples.select(range(max_eval_samples))
+ # Create Features from Eval Dataset
+ with training_args.main_process_first(desc="validation dataset map pre-processing"):
+ eval_dataset = eval_examples.map(
+ prepare_validation_features,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+ if data_args.max_eval_samples is not None:
+ # Selecting Samples from Dataset again since Feature Creation might increase samples size
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ if training_args.do_predict:
+ if "test" not in raw_datasets:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_examples = raw_datasets["test"]
+ if data_args.max_predict_samples is not None:
+ # We will select sample from whole data
+ predict_examples = predict_examples.select(range(data_args.max_predict_samples))
+ # Test Feature Creation
+ with training_args.main_process_first(desc="prediction dataset map pre-processing"):
+ predict_dataset = predict_examples.map(
+ prepare_validation_features,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on prediction dataset",
+ )
+ if data_args.max_predict_samples is not None:
+ # During Feature creation dataset samples might increase, we will select required samples again
+ max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
+ predict_dataset = predict_dataset.select(range(max_predict_samples))
+
+ # Data collator
+ # We have already padded to max length if the corresponding flag is True, otherwise we need to pad in the data
+ # collator.
+ data_collator = (
+ default_data_collator
+ if data_args.pad_to_max_length
+ else DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8 if training_args.fp16 else None)
+ )
+
+ # Post-processing:
+ def post_processing_function(examples, features, predictions, stage="eval"):
+ # Post-processing: we match the start logits and end logits to answers in the original context.
+ predictions, scores_diff_json = postprocess_qa_predictions_with_beam_search(
+ examples=examples,
+ features=features,
+ predictions=predictions,
+ version_2_with_negative=data_args.version_2_with_negative,
+ n_best_size=data_args.n_best_size,
+ max_answer_length=data_args.max_answer_length,
+ start_n_top=model.config.start_n_top,
+ end_n_top=model.config.end_n_top,
+ output_dir=training_args.output_dir,
+ log_level=log_level,
+ prefix=stage,
+ )
+ # Format the result to the format the metric expects.
+ if data_args.version_2_with_negative:
+ formatted_predictions = [
+ {"id": k, "prediction_text": v, "no_answer_probability": scores_diff_json[k]}
+ for k, v in predictions.items()
+ ]
+ else:
+ formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
+
+ references = [{"id": ex["id"], "answers": ex[answer_column_name]} for ex in examples]
+ return EvalPrediction(predictions=formatted_predictions, label_ids=references)
+
+ metric = evaluate.load(
+ "squad_v2" if data_args.version_2_with_negative else "squad", cache_dir=model_args.cache_dir
+ )
+
+ def compute_metrics(p: EvalPrediction):
+ return metric.compute(predictions=p.predictions, references=p.label_ids)
+
+ # Initialize our Trainer
+ trainer = QuestionAnsweringTrainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ eval_examples=eval_examples if training_args.do_eval else None,
+ processing_class=tokenizer,
+ data_collator=data_collator,
+ post_process_function=post_processing_function,
+ compute_metrics=compute_metrics,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model() # Saves the tokenizer too for easy upload
+
+ metrics = train_result.metrics
+
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+ metrics = trainer.evaluate()
+
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Prediction
+ if training_args.do_predict:
+ logger.info("*** Predict ***")
+ results = trainer.predict(predict_dataset, predict_examples)
+ metrics = results.metrics
+
+ max_predict_samples = (
+ data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
+ )
+ metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
+
+ trainer.log_metrics("predict", metrics)
+ trainer.save_metrics("predict", metrics)
+
+ kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "question-answering"}
+ if data_args.dataset_name is not None:
+ kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ kwargs["dataset_args"] = data_args.dataset_config_name
+ kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py b/docs/transformers/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..84bead830a7d7817a3ded68ece2e88b8c4709f87
--- /dev/null
+++ b/docs/transformers/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py
@@ -0,0 +1,1065 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning XLNet for question answering with beam search using 🤗 Accelerate.
+"""
+# You can also adapt this script on your own question answering task. Pointers for this are left as comments.
+
+import argparse
+import json
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import datasets
+import evaluate
+import numpy as np
+import torch
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from datasets import load_dataset
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from tqdm.auto import tqdm
+from utils_qa import postprocess_qa_predictions_with_beam_search
+
+import transformers
+from transformers import (
+ DataCollatorWithPadding,
+ EvalPrediction,
+ SchedulerType,
+ XLNetConfig,
+ XLNetForQuestionAnswering,
+ XLNetTokenizerFast,
+ default_data_collator,
+ get_scheduler,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
+
+logger = get_logger(__name__)
+
+
+def save_prefixed_metrics(results, output_dir, file_name: str = "all_results.json", metric_key_prefix: str = "eval"):
+ """
+ Save results while prefixing metric names.
+
+ Args:
+ results: (:obj:`dict`):
+ A dictionary of results.
+ output_dir: (:obj:`str`):
+ An output directory.
+ file_name: (:obj:`str`, `optional`, defaults to :obj:`all_results.json`):
+ An output file name.
+ metric_key_prefix: (:obj:`str`, `optional`, defaults to :obj:`eval`):
+ A metric name prefix.
+ """
+ # Prefix all keys with metric_key_prefix + '_'
+ for key in list(results.keys()):
+ if not key.startswith(f"{metric_key_prefix}_"):
+ results[f"{metric_key_prefix}_{key}"] = results.pop(key)
+
+ with open(os.path.join(output_dir, file_name), "w") as f:
+ json.dump(results, f, indent=4)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Finetune a transformers model on a Question Answering task")
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help="The name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The configuration name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--train_file", type=str, default=None, help="A csv or a json file containing the training data."
+ )
+ parser.add_argument(
+ "--preprocessing_num_workers", type=int, default=1, help="A csv or a json file containing the training data."
+ )
+ parser.add_argument("--do_predict", action="store_true", help="Eval the question answering model")
+ parser.add_argument(
+ "--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
+ )
+ parser.add_argument(
+ "--test_file", type=str, default=None, help="A csv or a json file containing the Prediction data."
+ )
+ parser.add_argument(
+ "--max_seq_length",
+ type=int,
+ default=384,
+ help=(
+ "The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
+ " sequences shorter will be padded if `--pad_to_max_length` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--pad_to_max_length",
+ action="store_true",
+ help="If passed, pad all samples to `max_seq_length`. Otherwise, dynamic padding is used.",
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ required=True,
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--doc_stride",
+ type=int,
+ default=128,
+ help="When splitting up a long document into chunks how much stride to take between chunks.",
+ )
+ parser.add_argument(
+ "--n_best_size",
+ type=int,
+ default=20,
+ help="The total number of n-best predictions to generate when looking for an answer.",
+ )
+ parser.add_argument(
+ "--null_score_diff_threshold",
+ type=float,
+ default=0.0,
+ help=(
+ "The threshold used to select the null answer: if the best answer has a score that is less than "
+ "the score of the null answer minus this threshold, the null answer is selected for this example. "
+ "Only useful when `version_2_with_negative=True`."
+ ),
+ )
+ parser.add_argument(
+ "--version_2_with_negative",
+ action="store_true",
+ help="If true, some of the examples do not have an answer.",
+ )
+ parser.add_argument(
+ "--max_answer_length",
+ type=int,
+ default=30,
+ help=(
+ "The maximum length of an answer that can be generated. This is needed because the start "
+ "and end predictions are not conditioned on one another."
+ ),
+ )
+ parser.add_argument(
+ "--max_train_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--max_eval_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
+ )
+ parser.add_argument(
+ "--max_predict_samples",
+ type=int,
+ default=None,
+ help="For debugging purposes or quicker training, truncate the number of prediction examples to this",
+ )
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ action="store_true",
+ help="Whether to load in all available experiment trackers from the environment and use them for logging.",
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+ if (
+ args.dataset_name is None
+ and args.train_file is None
+ and args.validation_file is None
+ and args.test_file is None
+ ):
+ raise ValueError("Need either a dataset name or a training/validation/test file.")
+ else:
+ if args.train_file is not None:
+ extension = args.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if args.validation_file is not None:
+ extension = args.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ if args.test_file is not None:
+ extension = args.test_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
+
+ if args.push_to_hub:
+ assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_qa_beam_search_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will pick up all supported trackers
+ # in the environment
+ accelerator_log_kwargs = {}
+
+ if args.with_tracking:
+ accelerator_log_kwargs["log_with"] = args.report_to
+ accelerator_log_kwargs["project_dir"] = args.output_dir
+
+ accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ args.dataset_name, args.dataset_config_name, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ data_files = {}
+ if args.train_file is not None:
+ data_files["train"] = args.train_file
+ extension = args.train_file.split(".")[-1]
+ if args.validation_file is not None:
+ data_files["validation"] = args.validation_file
+ extension = args.validation_file.split(".")[-1]
+ if args.test_file is not None:
+ data_files["test"] = args.test_file
+ extension = args.test_file.split(".")[-1]
+ raw_datasets = load_dataset(extension, data_files=data_files, field="data")
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+
+ config = XLNetConfig.from_pretrained(args.model_name_or_path)
+ tokenizer = XLNetTokenizerFast.from_pretrained(args.model_name_or_path)
+ model = XLNetForQuestionAnswering.from_pretrained(
+ args.model_name_or_path, from_tf=bool(".ckpt" in args.model_name_or_path), config=config
+ )
+
+ # Preprocessing the datasets.
+ # Preprocessing is slightly different for training and evaluation.
+ column_names = raw_datasets["train"].column_names
+
+ question_column_name = "question" if "question" in column_names else column_names[0]
+ context_column_name = "context" if "context" in column_names else column_names[1]
+ answer_column_name = "answers" if "answers" in column_names else column_names[2]
+
+ # Padding side determines if we do (question|context) or (context|question).
+ pad_on_right = tokenizer.padding_side == "right"
+
+ if args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+
+ max_seq_length = min(args.max_seq_length, tokenizer.model_max_length)
+
+ # Training preprocessing
+ def prepare_train_features(examples):
+ # Some of the questions have lots of whitespace on the left, which is not useful and will make the
+ # truncation of the context fail (the tokenized question will take a lots of space). So we remove that
+ # left whitespace
+ examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
+
+ # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
+ # in one example possible giving several features when a context is long, each of those features having a
+ # context that overlaps a bit the context of the previous feature.
+ tokenized_examples = tokenizer(
+ examples[question_column_name if pad_on_right else context_column_name],
+ examples[context_column_name if pad_on_right else question_column_name],
+ truncation="only_second" if pad_on_right else "only_first",
+ max_length=max_seq_length,
+ stride=args.doc_stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ return_special_tokens_mask=True,
+ return_token_type_ids=True,
+ padding="max_length",
+ )
+
+ # Since one example might give us several features if it has a long context, we need a map from a feature to
+ # its corresponding example. This key gives us just that.
+ sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
+ # The offset mappings will give us a map from token to character position in the original context. This will
+ # help us compute the start_positions and end_positions.
+ offset_mapping = tokenized_examples.pop("offset_mapping")
+ # The special tokens will help us build the p_mask (which indicates the tokens that can't be in answers).
+ special_tokens = tokenized_examples.pop("special_tokens_mask")
+
+ # Let's label those examples!
+ tokenized_examples["start_positions"] = []
+ tokenized_examples["end_positions"] = []
+ tokenized_examples["is_impossible"] = []
+ tokenized_examples["cls_index"] = []
+ tokenized_examples["p_mask"] = []
+
+ for i, offsets in enumerate(offset_mapping):
+ # We will label impossible answers with the index of the CLS token.
+ input_ids = tokenized_examples["input_ids"][i]
+ if tokenizer.cls_token_id in input_ids:
+ cls_index = input_ids.index(tokenizer.cls_token_id)
+ elif tokenizer.bos_token_id in input_ids:
+ cls_index = input_ids.index(tokenizer.bos_token_id)
+ else:
+ cls_index = 0
+ tokenized_examples["cls_index"].append(cls_index)
+
+ # Grab the sequence corresponding to that example (to know what is the context and what is the question).
+ sequence_ids = tokenized_examples["token_type_ids"][i]
+ for k, s in enumerate(special_tokens[i]):
+ if s:
+ sequence_ids[k] = 3
+ context_idx = 1 if pad_on_right else 0
+
+ # Build the p_mask: non special tokens and context gets 0.0, the others get 1.0.
+ # The cls token gets 1.0 too (for predictions of empty answers).
+ tokenized_examples["p_mask"].append(
+ [
+ 0.0 if (not special_tokens[i][k] and s == context_idx) or k == cls_index else 1.0
+ for k, s in enumerate(sequence_ids)
+ ]
+ )
+
+ # One example can give several spans, this is the index of the example containing this span of text.
+ sample_index = sample_mapping[i]
+ answers = examples[answer_column_name][sample_index]
+ # If no answers are given, set the cls_index as answer.
+ if len(answers["answer_start"]) == 0:
+ tokenized_examples["start_positions"].append(cls_index)
+ tokenized_examples["end_positions"].append(cls_index)
+ tokenized_examples["is_impossible"].append(1.0)
+ else:
+ # Start/end character index of the answer in the text.
+ start_char = answers["answer_start"][0]
+ end_char = start_char + len(answers["text"][0])
+
+ # Start token index of the current span in the text.
+ token_start_index = 0
+ while sequence_ids[token_start_index] != context_idx:
+ token_start_index += 1
+
+ # End token index of the current span in the text.
+ token_end_index = len(input_ids) - 1
+ while sequence_ids[token_end_index] != context_idx:
+ token_end_index -= 1
+ # Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
+ if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
+ tokenized_examples["start_positions"].append(cls_index)
+ tokenized_examples["end_positions"].append(cls_index)
+ tokenized_examples["is_impossible"].append(1.0)
+ else:
+ # Otherwise move the token_start_index and token_end_index to the two ends of the answer.
+ # Note: we could go after the last offset if the answer is the last word (edge case).
+ while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
+ token_start_index += 1
+ tokenized_examples["start_positions"].append(token_start_index - 1)
+ while offsets[token_end_index][1] >= end_char:
+ token_end_index -= 1
+ tokenized_examples["end_positions"].append(token_end_index + 1)
+ tokenized_examples["is_impossible"].append(0.0)
+
+ return tokenized_examples
+
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if args.max_train_samples is not None:
+ # We will select sample from whole data if argument is specified
+ train_dataset = train_dataset.select(range(args.max_train_samples))
+ # Create train feature from dataset
+ with accelerator.main_process_first():
+ train_dataset = train_dataset.map(
+ prepare_train_features,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+ if args.max_train_samples is not None:
+ # Number of samples might increase during Feature Creation, We select only specified max samples
+ train_dataset = train_dataset.select(range(args.max_train_samples))
+
+ # Validation preprocessing
+ def prepare_validation_features(examples):
+ # Some of the questions have lots of whitespace on the left, which is not useful and will make the
+ # truncation of the context fail (the tokenized question will take a lots of space). So we remove that
+ # left whitespace
+ examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
+
+ # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
+ # in one example possible giving several features when a context is long, each of those features having a
+ # context that overlaps a bit the context of the previous feature.
+ tokenized_examples = tokenizer(
+ examples[question_column_name if pad_on_right else context_column_name],
+ examples[context_column_name if pad_on_right else question_column_name],
+ truncation="only_second" if pad_on_right else "only_first",
+ max_length=max_seq_length,
+ stride=args.doc_stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ return_special_tokens_mask=True,
+ return_token_type_ids=True,
+ padding="max_length",
+ )
+
+ # Since one example might give us several features if it has a long context, we need a map from a feature to
+ # its corresponding example. This key gives us just that.
+ sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
+
+ # The special tokens will help us build the p_mask (which indicates the tokens that can't be in answers).
+ special_tokens = tokenized_examples.pop("special_tokens_mask")
+
+ # For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
+ # corresponding example_id and we will store the offset mappings.
+ tokenized_examples["example_id"] = []
+
+ # We still provide the index of the CLS token and the p_mask to the model, but not the is_impossible label.
+ tokenized_examples["cls_index"] = []
+ tokenized_examples["p_mask"] = []
+
+ for i, input_ids in enumerate(tokenized_examples["input_ids"]):
+ # Find the CLS token in the input ids.
+ if tokenizer.cls_token_id in input_ids:
+ cls_index = input_ids.index(tokenizer.cls_token_id)
+ elif tokenizer.bos_token_id in input_ids:
+ cls_index = input_ids.index(tokenizer.bos_token_id)
+ else:
+ cls_index = 0
+ tokenized_examples["cls_index"].append(cls_index)
+
+ # Grab the sequence corresponding to that example (to know what is the context and what is the question).
+ sequence_ids = tokenized_examples["token_type_ids"][i]
+ for k, s in enumerate(special_tokens[i]):
+ if s:
+ sequence_ids[k] = 3
+ context_idx = 1 if pad_on_right else 0
+
+ # Build the p_mask: non special tokens and context gets 0.0, the others 1.0.
+ tokenized_examples["p_mask"].append(
+ [
+ 0.0 if (not special_tokens[i][k] and s == context_idx) or k == cls_index else 1.0
+ for k, s in enumerate(sequence_ids)
+ ]
+ )
+
+ # One example can give several spans, this is the index of the example containing this span of text.
+ sample_index = sample_mapping[i]
+ tokenized_examples["example_id"].append(examples["id"][sample_index])
+
+ # Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
+ # position is part of the context or not.
+ tokenized_examples["offset_mapping"][i] = [
+ (o if sequence_ids[k] == context_idx else None)
+ for k, o in enumerate(tokenized_examples["offset_mapping"][i])
+ ]
+
+ return tokenized_examples
+
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_examples = raw_datasets["validation"]
+ if args.max_eval_samples is not None:
+ # We will select sample from whole data
+ eval_examples = eval_examples.select(range(args.max_eval_samples))
+ # Validation Feature Creation
+ with accelerator.main_process_first():
+ eval_dataset = eval_examples.map(
+ prepare_validation_features,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+
+ if args.max_eval_samples is not None:
+ # During Feature creation dataset samples might increase, we will select required samples again
+ eval_dataset = eval_dataset.select(range(args.max_eval_samples))
+
+ if args.do_predict:
+ if "test" not in raw_datasets:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_examples = raw_datasets["test"]
+ if args.max_predict_samples is not None:
+ # We will select sample from whole data
+ predict_examples = predict_examples.select(range(args.max_predict_samples))
+ # Predict Feature Creation
+ with accelerator.main_process_first():
+ predict_dataset = predict_examples.map(
+ prepare_validation_features,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Running tokenizer on prediction dataset",
+ )
+ if args.max_predict_samples is not None:
+ # During Feature creation dataset samples might increase, we will select required samples again
+ predict_dataset = predict_dataset.select(range(args.max_predict_samples))
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # DataLoaders creation:
+ if args.pad_to_max_length:
+ # If padding was already done ot max length, we use the default data collator that will just convert everything
+ # to tensors.
+ data_collator = default_data_collator
+ else:
+ # Otherwise, `DataCollatorWithPadding` will apply dynamic padding for us (by padding to the maximum length of
+ # the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
+ # of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
+ # For fp8, we pad to multiple of 16.
+ if accelerator.mixed_precision == "fp8":
+ pad_to_multiple_of = 16
+ elif accelerator.mixed_precision != "no":
+ pad_to_multiple_of = 8
+ else:
+ pad_to_multiple_of = None
+ data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=pad_to_multiple_of)
+
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
+ )
+
+ eval_dataset_for_model = eval_dataset.remove_columns(["example_id", "offset_mapping"])
+ eval_dataloader = DataLoader(
+ eval_dataset_for_model, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size
+ )
+
+ if args.do_predict:
+ predict_dataset_for_model = predict_dataset.remove_columns(["example_id", "offset_mapping"])
+ predict_dataloader = DataLoader(
+ predict_dataset_for_model, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size
+ )
+
+ # Post-processing:
+ def post_processing_function(examples, features, predictions, stage="eval"):
+ # Post-processing: we match the start logits and end logits to answers in the original context.
+ predictions, scores_diff_json = postprocess_qa_predictions_with_beam_search(
+ examples=examples,
+ features=features,
+ predictions=predictions,
+ version_2_with_negative=args.version_2_with_negative,
+ n_best_size=args.n_best_size,
+ max_answer_length=args.max_answer_length,
+ start_n_top=model.config.start_n_top,
+ end_n_top=model.config.end_n_top,
+ output_dir=args.output_dir,
+ prefix=stage,
+ )
+ # Format the result to the format the metric expects.
+ if args.version_2_with_negative:
+ formatted_predictions = [
+ {"id": k, "prediction_text": v, "no_answer_probability": scores_diff_json[k]}
+ for k, v in predictions.items()
+ ]
+ else:
+ formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
+
+ references = [{"id": ex["id"], "answers": ex[answer_column_name]} for ex in examples]
+ return EvalPrediction(predictions=formatted_predictions, label_ids=references)
+
+ metric = evaluate.load("squad_v2" if args.version_2_with_negative else "squad")
+
+ def create_and_fill_np_array(start_or_end_logits, dataset, max_len):
+ """
+ Create and fill numpy array of size len_of_validation_data * max_length_of_output_tensor
+
+ Args:
+ start_or_end_logits(:obj:`tensor`):
+ This is the output predictions of the model. We can only enter either start or end logits.
+ eval_dataset: Evaluation dataset
+ max_len(:obj:`int`):
+ The maximum length of the output tensor. ( See the model.eval() part for more details )
+ """
+
+ step = 0
+ # create a numpy array and fill it with -100.
+ logits_concat = np.full((len(dataset), max_len), -100, dtype=np.float32)
+ # Now since we have create an array now we will populate it with the outputs gathered using accelerator.gather_for_metrics
+ for i, output_logit in enumerate(start_or_end_logits): # populate columns
+ # We have to fill it such that we have to take the whole tensor and replace it on the newly created array
+ # And after every iteration we have to change the step
+
+ batch_size = output_logit.shape[0]
+ cols = output_logit.shape[1]
+ if step + batch_size < len(dataset):
+ logits_concat[step : step + batch_size, :cols] = output_logit
+ else:
+ logits_concat[step:, :cols] = output_logit[: len(dataset) - step]
+
+ step += batch_size
+
+ return logits_concat
+
+ # Optimizer
+ # Split weights in two groups, one with weight decay and the other not.
+ no_decay = ["bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps
+ if overrode_max_train_steps
+ else args.max_train_steps * accelerator.num_processes,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # We need to initialize the trackers we use, and also store our configuration
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("qa_beam_search_no_trainer", experiment_config)
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+ for step, batch in enumerate(active_dataloader):
+ with accelerator.accumulate(model):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+
+ accelerator.backward(loss)
+
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ accelerator.save_state(f"step_{completed_steps}")
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ # initialize all lists to collect the batches
+ all_start_top_log_probs = []
+ all_start_top_index = []
+ all_end_top_log_probs = []
+ all_end_top_index = []
+ all_cls_logits = []
+
+ model.eval()
+
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+ start_top_log_probs = outputs.start_top_log_probs
+ start_top_index = outputs.start_top_index
+ end_top_log_probs = outputs.end_top_log_probs
+ end_top_index = outputs.end_top_index
+ cls_logits = outputs.cls_logits
+
+ if not args.pad_to_max_length: # necessary to pad predictions and labels for being gathered
+ start_top_log_probs = accelerator.pad_across_processes(start_top_log_probs, dim=1, pad_index=-100)
+ start_top_index = accelerator.pad_across_processes(start_top_index, dim=1, pad_index=-100)
+ end_top_log_probs = accelerator.pad_across_processes(end_top_log_probs, dim=1, pad_index=-100)
+ end_top_index = accelerator.pad_across_processes(end_top_index, dim=1, pad_index=-100)
+ cls_logits = accelerator.pad_across_processes(cls_logits, dim=1, pad_index=-100)
+
+ all_start_top_log_probs.append(accelerator.gather_for_metrics(start_top_log_probs).cpu().numpy())
+ all_start_top_index.append(accelerator.gather_for_metrics(start_top_index).cpu().numpy())
+ all_end_top_log_probs.append(accelerator.gather_for_metrics(end_top_log_probs).cpu().numpy())
+ all_end_top_index.append(accelerator.gather_for_metrics(end_top_index).cpu().numpy())
+ all_cls_logits.append(accelerator.gather_for_metrics(cls_logits).cpu().numpy())
+
+ max_len = max([x.shape[1] for x in all_end_top_log_probs]) # Get the max_length of the tensor
+
+ # concatenate all numpy arrays collected above
+ start_top_log_probs_concat = create_and_fill_np_array(all_start_top_log_probs, eval_dataset, max_len)
+ start_top_index_concat = create_and_fill_np_array(all_start_top_index, eval_dataset, max_len)
+ end_top_log_probs_concat = create_and_fill_np_array(all_end_top_log_probs, eval_dataset, max_len)
+ end_top_index_concat = create_and_fill_np_array(all_end_top_index, eval_dataset, max_len)
+ cls_logits_concat = np.concatenate(all_cls_logits, axis=0)
+
+ # delete the list of numpy arrays
+ del start_top_log_probs
+ del start_top_index
+ del end_top_log_probs
+ del end_top_index
+ del cls_logits
+
+ outputs_numpy = (
+ start_top_log_probs_concat,
+ start_top_index_concat,
+ end_top_log_probs_concat,
+ end_top_index_concat,
+ cls_logits_concat,
+ )
+ prediction = post_processing_function(eval_examples, eval_dataset, outputs_numpy)
+ eval_metric = metric.compute(predictions=prediction.predictions, references=prediction.label_ids)
+ logger.info(f"Evaluation metrics: {eval_metric}")
+
+ if args.do_predict:
+ # initialize all lists to collect the batches
+
+ all_start_top_log_probs = []
+ all_start_top_index = []
+ all_end_top_log_probs = []
+ all_end_top_index = []
+ all_cls_logits = []
+
+ model.eval()
+
+ for step, batch in enumerate(predict_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+ start_top_log_probs = outputs.start_top_log_probs
+ start_top_index = outputs.start_top_index
+ end_top_log_probs = outputs.end_top_log_probs
+ end_top_index = outputs.end_top_index
+ cls_logits = outputs.cls_logits
+
+ if not args.pad_to_max_length: # necessary to pad predictions and labels for being gathered
+ start_top_log_probs = accelerator.pad_across_processes(start_top_log_probs, dim=1, pad_index=-100)
+ start_top_index = accelerator.pad_across_processes(start_top_index, dim=1, pad_index=-100)
+ end_top_log_probs = accelerator.pad_across_processes(end_top_log_probs, dim=1, pad_index=-100)
+ end_top_index = accelerator.pad_across_processes(end_top_index, dim=1, pad_index=-100)
+ cls_logits = accelerator.pad_across_processes(cls_logits, dim=1, pad_index=-100)
+
+ all_start_top_log_probs.append(accelerator.gather_for_metrics(start_top_log_probs).cpu().numpy())
+ all_start_top_index.append(accelerator.gather_for_metrics(start_top_index).cpu().numpy())
+ all_end_top_log_probs.append(accelerator.gather_for_metrics(end_top_log_probs).cpu().numpy())
+ all_end_top_index.append(accelerator.gather_for_metrics(end_top_index).cpu().numpy())
+ all_cls_logits.append(accelerator.gather_for_metrics(cls_logits).cpu().numpy())
+
+ max_len = max([x.shape[1] for x in all_end_top_log_probs]) # Get the max_length of the tensor
+
+ # concatenate all numpy arrays collected above
+ start_top_log_probs_concat = create_and_fill_np_array(all_start_top_log_probs, predict_dataset, max_len)
+ start_top_index_concat = create_and_fill_np_array(all_start_top_index, predict_dataset, max_len)
+ end_top_log_probs_concat = create_and_fill_np_array(all_end_top_log_probs, predict_dataset, max_len)
+ end_top_index_concat = create_and_fill_np_array(all_end_top_index, predict_dataset, max_len)
+ cls_logits_concat = np.concatenate(all_cls_logits, axis=0)
+
+ # delete the list of numpy arrays
+ del start_top_log_probs
+ del start_top_index
+ del end_top_log_probs
+ del end_top_index
+ del cls_logits
+
+ outputs_numpy = (
+ start_top_log_probs_concat,
+ start_top_index_concat,
+ end_top_log_probs_concat,
+ end_top_index_concat,
+ cls_logits_concat,
+ )
+
+ prediction = post_processing_function(predict_examples, predict_dataset, outputs_numpy)
+ predict_metric = metric.compute(predictions=prediction.predictions, references=prediction.label_ids)
+ logger.info(f"Predict metrics: {predict_metric}")
+
+ if args.with_tracking:
+ log = {
+ "squad_v2" if args.version_2_with_negative else "squad": eval_metric,
+ "train_loss": total_loss,
+ "epoch": epoch,
+ "step": completed_steps,
+ }
+ if args.do_predict:
+ log["squad_v2_predict" if args.version_2_with_negative else "squad_predict"] = predict_metric
+
+ accelerator.log(log)
+
+ if args.checkpointing_steps == "epoch":
+ accelerator.save_state(f"epoch_{epoch}")
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ logger.info(json.dumps(eval_metric, indent=4))
+ save_prefixed_metrics(eval_metric, args.output_dir)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/question-answering/run_qa_no_trainer.py b/docs/transformers/examples/pytorch/question-answering/run_qa_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..138dd61f99a11c9b2fe9533fd9ffeb94b30368c1
--- /dev/null
+++ b/docs/transformers/examples/pytorch/question-answering/run_qa_no_trainer.py
@@ -0,0 +1,1043 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning a 🤗 Transformers model for question answering using 🤗 Accelerate.
+"""
+# You can also adapt this script on your own question answering task. Pointers for this are left as comments.
+
+import argparse
+import json
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import datasets
+import evaluate
+import numpy as np
+import torch
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from datasets import load_dataset
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from tqdm.auto import tqdm
+from utils_qa import postprocess_qa_predictions
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_MAPPING,
+ AutoConfig,
+ AutoModelForQuestionAnswering,
+ AutoTokenizer,
+ DataCollatorWithPadding,
+ EvalPrediction,
+ SchedulerType,
+ default_data_collator,
+ get_scheduler,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
+
+logger = get_logger(__name__)
+# You should update this to your particular problem to have better documentation of `model_type`
+MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+def save_prefixed_metrics(results, output_dir, file_name: str = "all_results.json", metric_key_prefix: str = "eval"):
+ """
+ Save results while prefixing metric names.
+
+ Args:
+ results: (:obj:`dict`):
+ A dictionary of results.
+ output_dir: (:obj:`str`):
+ An output directory.
+ file_name: (:obj:`str`, `optional`, defaults to :obj:`all_results.json`):
+ An output file name.
+ metric_key_prefix: (:obj:`str`, `optional`, defaults to :obj:`eval`):
+ A metric name prefix.
+ """
+ # Prefix all keys with metric_key_prefix + '_'
+ for key in list(results.keys()):
+ if not key.startswith(f"{metric_key_prefix}_"):
+ results[f"{metric_key_prefix}_{key}"] = results.pop(key)
+
+ with open(os.path.join(output_dir, file_name), "w") as f:
+ json.dump(results, f, indent=4)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Finetune a transformers model on a Question Answering task")
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help="The name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The configuration name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--train_file", type=str, default=None, help="A csv or a json file containing the training data."
+ )
+ parser.add_argument(
+ "--preprocessing_num_workers", type=int, default=1, help="A csv or a json file containing the training data."
+ )
+ parser.add_argument("--do_predict", action="store_true", help="To do prediction on the question answering model")
+ parser.add_argument(
+ "--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
+ )
+ parser.add_argument(
+ "--test_file", type=str, default=None, help="A csv or a json file containing the Prediction data."
+ )
+ parser.add_argument(
+ "--max_seq_length",
+ type=int,
+ default=384,
+ help=(
+ "The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
+ " sequences shorter will be padded if `--pad_to_max_length` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--pad_to_max_length",
+ action="store_true",
+ help="If passed, pad all samples to `max_seq_length`. Otherwise, dynamic padding is used.",
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ required=False,
+ )
+ parser.add_argument(
+ "--config_name",
+ type=str,
+ default=None,
+ help="Pretrained config name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--use_slow_tokenizer",
+ action="store_true",
+ help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--doc_stride",
+ type=int,
+ default=128,
+ help="When splitting up a long document into chunks how much stride to take between chunks.",
+ )
+ parser.add_argument(
+ "--n_best_size",
+ type=int,
+ default=20,
+ help="The total number of n-best predictions to generate when looking for an answer.",
+ )
+ parser.add_argument(
+ "--null_score_diff_threshold",
+ type=float,
+ default=0.0,
+ help=(
+ "The threshold used to select the null answer: if the best answer has a score that is less than "
+ "the score of the null answer minus this threshold, the null answer is selected for this example. "
+ "Only useful when `version_2_with_negative=True`."
+ ),
+ )
+ parser.add_argument(
+ "--version_2_with_negative",
+ action="store_true",
+ help="If true, some of the examples do not have an answer.",
+ )
+ parser.add_argument(
+ "--max_answer_length",
+ type=int,
+ default=30,
+ help=(
+ "The maximum length of an answer that can be generated. This is needed because the start "
+ "and end predictions are not conditioned on one another."
+ ),
+ )
+ parser.add_argument(
+ "--max_train_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--max_eval_samples",
+ type=int,
+ default=None,
+ help=(
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ ),
+ )
+ parser.add_argument(
+ "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
+ )
+ parser.add_argument(
+ "--max_predict_samples",
+ type=int,
+ default=None,
+ help="For debugging purposes or quicker training, truncate the number of prediction examples to this",
+ )
+ parser.add_argument(
+ "--model_type",
+ type=str,
+ default=None,
+ help="Model type to use if training from scratch.",
+ choices=MODEL_TYPES,
+ )
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+ if (
+ args.dataset_name is None
+ and args.train_file is None
+ and args.validation_file is None
+ and args.test_file is None
+ ):
+ raise ValueError("Need either a dataset name or a training/validation/test file.")
+ else:
+ if args.train_file is not None:
+ extension = args.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if args.validation_file is not None:
+ extension = args.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ if args.test_file is not None:
+ extension = args.test_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
+
+ if args.push_to_hub:
+ assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_qa_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator_log_kwargs = {}
+
+ if args.with_tracking:
+ accelerator_log_kwargs["log_with"] = args.report_to
+ accelerator_log_kwargs["project_dir"] = args.output_dir
+
+ accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ args.dataset_name, args.dataset_config_name, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ data_files = {}
+ if args.train_file is not None:
+ data_files["train"] = args.train_file
+ extension = args.train_file.split(".")[-1]
+ if args.validation_file is not None:
+ data_files["validation"] = args.validation_file
+ extension = args.validation_file.split(".")[-1]
+ if args.test_file is not None:
+ data_files["test"] = args.test_file
+ extension = args.test_file.split(".")[-1]
+ raw_datasets = load_dataset(extension, data_files=data_files, field="data")
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+
+ if args.config_name:
+ config = AutoConfig.from_pretrained(args.config_name, trust_remote_code=args.trust_remote_code)
+ elif args.model_name_or_path:
+ config = AutoConfig.from_pretrained(args.model_name_or_path, trust_remote_code=args.trust_remote_code)
+ else:
+ config = CONFIG_MAPPING[args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_name, use_fast=True, trust_remote_code=args.trust_remote_code
+ )
+ elif args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path, use_fast=True, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if args.model_name_or_path:
+ model = AutoModelForQuestionAnswering.from_pretrained(
+ args.model_name_or_path,
+ from_tf=bool(".ckpt" in args.model_name_or_path),
+ config=config,
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelForQuestionAnswering.from_config(config, trust_remote_code=args.trust_remote_code)
+
+ # Preprocessing the datasets.
+ # Preprocessing is slightly different for training and evaluation.
+
+ column_names = raw_datasets["train"].column_names
+
+ question_column_name = "question" if "question" in column_names else column_names[0]
+ context_column_name = "context" if "context" in column_names else column_names[1]
+ answer_column_name = "answers" if "answers" in column_names else column_names[2]
+
+ # Padding side determines if we do (question|context) or (context|question).
+ pad_on_right = tokenizer.padding_side == "right"
+
+ if args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+
+ max_seq_length = min(args.max_seq_length, tokenizer.model_max_length)
+
+ # Training preprocessing
+ def prepare_train_features(examples):
+ # Some of the questions have lots of whitespace on the left, which is not useful and will make the
+ # truncation of the context fail (the tokenized question will take a lots of space). So we remove that
+ # left whitespace
+ examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
+
+ # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
+ # in one example possible giving several features when a context is long, each of those features having a
+ # context that overlaps a bit the context of the previous feature.
+ tokenized_examples = tokenizer(
+ examples[question_column_name if pad_on_right else context_column_name],
+ examples[context_column_name if pad_on_right else question_column_name],
+ truncation="only_second" if pad_on_right else "only_first",
+ max_length=max_seq_length,
+ stride=args.doc_stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ padding="max_length" if args.pad_to_max_length else False,
+ )
+
+ # Since one example might give us several features if it has a long context, we need a map from a feature to
+ # its corresponding example. This key gives us just that.
+ sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
+ # The offset mappings will give us a map from token to character position in the original context. This will
+ # help us compute the start_positions and end_positions.
+ offset_mapping = tokenized_examples.pop("offset_mapping")
+
+ # Let's label those examples!
+ tokenized_examples["start_positions"] = []
+ tokenized_examples["end_positions"] = []
+
+ for i, offsets in enumerate(offset_mapping):
+ # We will label impossible answers with the index of the CLS token.
+ input_ids = tokenized_examples["input_ids"][i]
+ if tokenizer.cls_token_id in input_ids:
+ cls_index = input_ids.index(tokenizer.cls_token_id)
+ elif tokenizer.bos_token_id in input_ids:
+ cls_index = input_ids.index(tokenizer.bos_token_id)
+ else:
+ cls_index = 0
+
+ # Grab the sequence corresponding to that example (to know what is the context and what is the question).
+ sequence_ids = tokenized_examples.sequence_ids(i)
+
+ # One example can give several spans, this is the index of the example containing this span of text.
+ sample_index = sample_mapping[i]
+ answers = examples[answer_column_name][sample_index]
+ # If no answers are given, set the cls_index as answer.
+ if len(answers["answer_start"]) == 0:
+ tokenized_examples["start_positions"].append(cls_index)
+ tokenized_examples["end_positions"].append(cls_index)
+ else:
+ # Start/end character index of the answer in the text.
+ start_char = answers["answer_start"][0]
+ end_char = start_char + len(answers["text"][0])
+
+ # Start token index of the current span in the text.
+ token_start_index = 0
+ while sequence_ids[token_start_index] != (1 if pad_on_right else 0):
+ token_start_index += 1
+
+ # End token index of the current span in the text.
+ token_end_index = len(input_ids) - 1
+ while sequence_ids[token_end_index] != (1 if pad_on_right else 0):
+ token_end_index -= 1
+
+ # Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
+ if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
+ tokenized_examples["start_positions"].append(cls_index)
+ tokenized_examples["end_positions"].append(cls_index)
+ else:
+ # Otherwise move the token_start_index and token_end_index to the two ends of the answer.
+ # Note: we could go after the last offset if the answer is the last word (edge case).
+ while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
+ token_start_index += 1
+ tokenized_examples["start_positions"].append(token_start_index - 1)
+ while offsets[token_end_index][1] >= end_char:
+ token_end_index -= 1
+ tokenized_examples["end_positions"].append(token_end_index + 1)
+
+ return tokenized_examples
+
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if args.max_train_samples is not None:
+ # We will select sample from whole data if argument is specified
+ train_dataset = train_dataset.select(range(args.max_train_samples))
+
+ # Create train feature from dataset
+ with accelerator.main_process_first():
+ train_dataset = train_dataset.map(
+ prepare_train_features,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+ if args.max_train_samples is not None:
+ # Number of samples might increase during Feature Creation, We select only specified max samples
+ train_dataset = train_dataset.select(range(args.max_train_samples))
+
+ # Validation preprocessing
+ def prepare_validation_features(examples):
+ # Some of the questions have lots of whitespace on the left, which is not useful and will make the
+ # truncation of the context fail (the tokenized question will take a lots of space). So we remove that
+ # left whitespace
+ examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
+
+ # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
+ # in one example possible giving several features when a context is long, each of those features having a
+ # context that overlaps a bit the context of the previous feature.
+ tokenized_examples = tokenizer(
+ examples[question_column_name if pad_on_right else context_column_name],
+ examples[context_column_name if pad_on_right else question_column_name],
+ truncation="only_second" if pad_on_right else "only_first",
+ max_length=max_seq_length,
+ stride=args.doc_stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ padding="max_length" if args.pad_to_max_length else False,
+ )
+
+ # Since one example might give us several features if it has a long context, we need a map from a feature to
+ # its corresponding example. This key gives us just that.
+ sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
+
+ # For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
+ # corresponding example_id and we will store the offset mappings.
+ tokenized_examples["example_id"] = []
+
+ for i in range(len(tokenized_examples["input_ids"])):
+ # Grab the sequence corresponding to that example (to know what is the context and what is the question).
+ sequence_ids = tokenized_examples.sequence_ids(i)
+ context_index = 1 if pad_on_right else 0
+
+ # One example can give several spans, this is the index of the example containing this span of text.
+ sample_index = sample_mapping[i]
+ tokenized_examples["example_id"].append(examples["id"][sample_index])
+
+ # Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
+ # position is part of the context or not.
+ tokenized_examples["offset_mapping"][i] = [
+ (o if sequence_ids[k] == context_index else None)
+ for k, o in enumerate(tokenized_examples["offset_mapping"][i])
+ ]
+
+ return tokenized_examples
+
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_examples = raw_datasets["validation"]
+ if args.max_eval_samples is not None:
+ # We will select sample from whole data
+ eval_examples = eval_examples.select(range(args.max_eval_samples))
+ # Validation Feature Creation
+ with accelerator.main_process_first():
+ eval_dataset = eval_examples.map(
+ prepare_validation_features,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+
+ if args.max_eval_samples is not None:
+ # During Feature creation dataset samples might increase, we will select required samples again
+ eval_dataset = eval_dataset.select(range(args.max_eval_samples))
+
+ if args.do_predict:
+ if "test" not in raw_datasets:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_examples = raw_datasets["test"]
+ if args.max_predict_samples is not None:
+ # We will select sample from whole data
+ predict_examples = predict_examples.select(range(args.max_predict_samples))
+ # Predict Feature Creation
+ with accelerator.main_process_first():
+ predict_dataset = predict_examples.map(
+ prepare_validation_features,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Running tokenizer on prediction dataset",
+ )
+ if args.max_predict_samples is not None:
+ # During Feature creation dataset samples might increase, we will select required samples again
+ predict_dataset = predict_dataset.select(range(args.max_predict_samples))
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # DataLoaders creation:
+ if args.pad_to_max_length:
+ # If padding was already done ot max length, we use the default data collator that will just convert everything
+ # to tensors.
+ data_collator = default_data_collator
+ else:
+ # Otherwise, `DataCollatorWithPadding` will apply dynamic padding for us (by padding to the maximum length of
+ # the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
+ # of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
+ # For fp8, we pad to multiple of 16.
+ if accelerator.mixed_precision == "fp8":
+ pad_to_multiple_of = 16
+ elif accelerator.mixed_precision != "no":
+ pad_to_multiple_of = 8
+ else:
+ pad_to_multiple_of = None
+ data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=pad_to_multiple_of)
+
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
+ )
+
+ eval_dataset_for_model = eval_dataset.remove_columns(["example_id", "offset_mapping"])
+ eval_dataloader = DataLoader(
+ eval_dataset_for_model, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size
+ )
+
+ if args.do_predict:
+ predict_dataset_for_model = predict_dataset.remove_columns(["example_id", "offset_mapping"])
+ predict_dataloader = DataLoader(
+ predict_dataset_for_model, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size
+ )
+
+ # Post-processing:
+ def post_processing_function(examples, features, predictions, stage="eval"):
+ # Post-processing: we match the start logits and end logits to answers in the original context.
+ predictions = postprocess_qa_predictions(
+ examples=examples,
+ features=features,
+ predictions=predictions,
+ version_2_with_negative=args.version_2_with_negative,
+ n_best_size=args.n_best_size,
+ max_answer_length=args.max_answer_length,
+ null_score_diff_threshold=args.null_score_diff_threshold,
+ output_dir=args.output_dir,
+ prefix=stage,
+ )
+ # Format the result to the format the metric expects.
+ if args.version_2_with_negative:
+ formatted_predictions = [
+ {"id": k, "prediction_text": v, "no_answer_probability": 0.0} for k, v in predictions.items()
+ ]
+ else:
+ formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
+
+ references = [{"id": ex["id"], "answers": ex[answer_column_name]} for ex in examples]
+ return EvalPrediction(predictions=formatted_predictions, label_ids=references)
+
+ metric = evaluate.load("squad_v2" if args.version_2_with_negative else "squad")
+
+ # Create and fill numpy array of size len_of_validation_data * max_length_of_output_tensor
+ def create_and_fill_np_array(start_or_end_logits, dataset, max_len):
+ """
+ Create and fill numpy array of size len_of_validation_data * max_length_of_output_tensor
+
+ Args:
+ start_or_end_logits(:obj:`tensor`):
+ This is the output predictions of the model. We can only enter either start or end logits.
+ eval_dataset: Evaluation dataset
+ max_len(:obj:`int`):
+ The maximum length of the output tensor. ( See the model.eval() part for more details )
+ """
+
+ step = 0
+ # create a numpy array and fill it with -100.
+ logits_concat = np.full((len(dataset), max_len), -100, dtype=np.float64)
+ # Now since we have create an array now we will populate it with the outputs gathered using accelerator.gather_for_metrics
+ for i, output_logit in enumerate(start_or_end_logits): # populate columns
+ # We have to fill it such that we have to take the whole tensor and replace it on the newly created array
+ # And after every iteration we have to change the step
+
+ batch_size = output_logit.shape[0]
+ cols = output_logit.shape[1]
+
+ if step + batch_size < len(dataset):
+ logits_concat[step : step + batch_size, :cols] = output_logit
+ else:
+ logits_concat[step:, :cols] = output_logit[: len(dataset) - step]
+
+ step += batch_size
+
+ return logits_concat
+
+ # Optimizer
+ # Split weights in two groups, one with weight decay and the other not.
+ no_decay = ["bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps
+ if overrode_max_train_steps
+ else args.max_train_steps * accelerator.num_processes,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("qa_no_trainer", experiment_config)
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+ for step, batch in enumerate(active_dataloader):
+ with accelerator.accumulate(model):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+
+ accelerator.backward(loss)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ # Evaluation
+ logger.info("***** Running Evaluation *****")
+ logger.info(f" Num examples = {len(eval_dataset)}")
+ logger.info(f" Batch size = {args.per_device_eval_batch_size}")
+
+ all_start_logits = []
+ all_end_logits = []
+
+ model.eval()
+
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+ start_logits = outputs.start_logits
+ end_logits = outputs.end_logits
+
+ if not args.pad_to_max_length: # necessary to pad predictions and labels for being gathered
+ start_logits = accelerator.pad_across_processes(start_logits, dim=1, pad_index=-100)
+ end_logits = accelerator.pad_across_processes(end_logits, dim=1, pad_index=-100)
+
+ all_start_logits.append(accelerator.gather_for_metrics(start_logits).cpu().numpy())
+ all_end_logits.append(accelerator.gather_for_metrics(end_logits).cpu().numpy())
+
+ max_len = max([x.shape[1] for x in all_start_logits]) # Get the max_length of the tensor
+
+ # concatenate the numpy array
+ start_logits_concat = create_and_fill_np_array(all_start_logits, eval_dataset, max_len)
+ end_logits_concat = create_and_fill_np_array(all_end_logits, eval_dataset, max_len)
+
+ # delete the list of numpy arrays
+ del all_start_logits
+ del all_end_logits
+
+ outputs_numpy = (start_logits_concat, end_logits_concat)
+ prediction = post_processing_function(eval_examples, eval_dataset, outputs_numpy)
+ eval_metric = metric.compute(predictions=prediction.predictions, references=prediction.label_ids)
+ logger.info(f"Evaluation metrics: {eval_metric}")
+
+ # Prediction
+ if args.do_predict:
+ logger.info("***** Running Prediction *****")
+ logger.info(f" Num examples = {len(predict_dataset)}")
+ logger.info(f" Batch size = {args.per_device_eval_batch_size}")
+
+ all_start_logits = []
+ all_end_logits = []
+
+ model.eval()
+
+ for step, batch in enumerate(predict_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+ start_logits = outputs.start_logits
+ end_logits = outputs.end_logits
+
+ if not args.pad_to_max_length: # necessary to pad predictions and labels for being gathered
+ start_logits = accelerator.pad_across_processes(start_logits, dim=1, pad_index=-100)
+ end_logits = accelerator.pad_across_processes(end_logits, dim=1, pad_index=-100)
+
+ all_start_logits.append(accelerator.gather_for_metrics(start_logits).cpu().numpy())
+ all_end_logits.append(accelerator.gather_for_metrics(end_logits).cpu().numpy())
+
+ max_len = max([x.shape[1] for x in all_start_logits]) # Get the max_length of the tensor
+ # concatenate the numpy array
+ start_logits_concat = create_and_fill_np_array(all_start_logits, predict_dataset, max_len)
+ end_logits_concat = create_and_fill_np_array(all_end_logits, predict_dataset, max_len)
+
+ # delete the list of numpy arrays
+ del all_start_logits
+ del all_end_logits
+
+ outputs_numpy = (start_logits_concat, end_logits_concat)
+ prediction = post_processing_function(predict_examples, predict_dataset, outputs_numpy)
+ predict_metric = metric.compute(predictions=prediction.predictions, references=prediction.label_ids)
+ logger.info(f"Predict metrics: {predict_metric}")
+
+ if args.with_tracking:
+ log = {
+ "squad_v2" if args.version_2_with_negative else "squad": eval_metric,
+ "train_loss": total_loss.item() / len(train_dataloader),
+ "epoch": epoch,
+ "step": completed_steps,
+ }
+ if args.do_predict:
+ log["squad_v2_predict" if args.version_2_with_negative else "squad_predict"] = predict_metric
+
+ accelerator.log(log, step=completed_steps)
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+ logger.info(json.dumps(eval_metric, indent=4))
+ save_prefixed_metrics(eval_metric, args.output_dir)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/question-answering/run_seq2seq_qa.py b/docs/transformers/examples/pytorch/question-answering/run_seq2seq_qa.py
new file mode 100644
index 0000000000000000000000000000000000000000..a07e34f091dbcd5504d8aaab9f4424a423fd290e
--- /dev/null
+++ b/docs/transformers/examples/pytorch/question-answering/run_seq2seq_qa.py
@@ -0,0 +1,742 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library's seq2seq models for question answering using the 🤗 Seq2SeqTrainer.
+"""
+# You can also adapt this script on your own question answering task. Pointers for this are left as comments.
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import datasets
+import evaluate
+import numpy as np
+from datasets import load_dataset
+from trainer_seq2seq_qa import QuestionAnsweringSeq2SeqTrainer
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForSeq2SeqLM,
+ AutoTokenizer,
+ DataCollatorForSeq2Seq,
+ HfArgumentParser,
+ Seq2SeqTrainingArguments,
+ set_seed,
+)
+from transformers.trainer_utils import EvalLoopOutput, EvalPrediction, get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Path to directory to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ context_column: Optional[str] = field(
+ default="context",
+ metadata={"help": "The name of the column in the datasets containing the contexts (for question answering)."},
+ )
+ question_column: Optional[str] = field(
+ default="question",
+ metadata={"help": "The name of the column in the datasets containing the questions (for question answering)."},
+ )
+ answer_column: Optional[str] = field(
+ default="answers",
+ metadata={"help": "The name of the column in the datasets containing the answers (for question answering)."},
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input test data file to evaluate the perplexity on (a text file)."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_seq_length: int = field(
+ default=384,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ max_answer_length: int = field(
+ default=30,
+ metadata={
+ "help": (
+ "The maximum length of an answer that can be generated. This is needed because the start "
+ "and end predictions are not conditioned on one another."
+ )
+ },
+ )
+ val_max_answer_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total sequence length for validation target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded. Will default to `max_answer_length`. "
+ "This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
+ "during ``evaluate`` and ``predict``."
+ )
+ },
+ )
+ pad_to_max_length: bool = field(
+ default=True,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. If False, will pad the samples dynamically when"
+ " batching to the maximum length in the batch (which can be faster on GPU but will be slower on TPU)."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ version_2_with_negative: bool = field(
+ default=False, metadata={"help": "If true, some of the examples do not have an answer."}
+ )
+ null_score_diff_threshold: float = field(
+ default=0.0,
+ metadata={
+ "help": (
+ "The threshold used to select the null answer: if the best answer has a score that is less than "
+ "the score of the null answer minus this threshold, the null answer is selected for this example. "
+ "Only useful when `version_2_with_negative=True`."
+ )
+ },
+ )
+ doc_stride: int = field(
+ default=128,
+ metadata={"help": "When splitting up a long document into chunks, how much stride to take between chunks."},
+ )
+ n_best_size: int = field(
+ default=20,
+ metadata={"help": "The total number of n-best predictions to generate when looking for an answer."},
+ )
+ num_beams: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Number of beams to use for evaluation. This argument will be passed to ``model.generate``, "
+ "which is used during ``evaluate`` and ``predict``."
+ )
+ },
+ )
+ ignore_pad_token_for_loss: bool = field(
+ default=True,
+ metadata={
+ "help": "Whether to ignore the tokens corresponding to padded labels in the loss computation or not."
+ },
+ )
+
+ def __post_init__(self):
+ if (
+ self.dataset_name is None
+ and self.train_file is None
+ and self.validation_file is None
+ and self.test_file is None
+ ):
+ raise ValueError("Need either a dataset name or a training/validation file/test_file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ if self.test_file is not None:
+ extension = self.test_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
+ if self.val_max_answer_length is None:
+ self.val_max_answer_length = self.max_answer_length
+
+
+question_answering_column_name_mapping = {
+ "squad_v2": ("question", "context", "answer"),
+}
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_seq2seq_qa", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if data_args.test_file is not None:
+ data_files["test"] = data_args.test_file
+ extension = data_args.test_file.split(".")[-1]
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ field="data",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = AutoModelForSeq2SeqLM.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embedding_size = model.get_input_embeddings().weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+
+ if model.config.decoder_start_token_id is None:
+ raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
+
+ # Preprocessing the datasets.
+ # We need to generate and tokenize inputs and targets.
+ if training_args.do_train:
+ column_names = raw_datasets["train"].column_names
+ elif training_args.do_eval:
+ column_names = raw_datasets["validation"].column_names
+ elif training_args.do_predict:
+ column_names = raw_datasets["test"].column_names
+ else:
+ logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
+ return
+
+ # Get the column names for input/target.
+ dataset_columns = question_answering_column_name_mapping.get(data_args.dataset_name, None)
+ if data_args.question_column is None:
+ question_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ question_column = data_args.question_column
+ if question_column not in column_names:
+ raise ValueError(
+ f"--question_column' value '{data_args.question_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if data_args.context_column is None:
+ context_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ context_column = data_args.context_column
+ if context_column not in column_names:
+ raise ValueError(
+ f"--context_column' value '{data_args.context_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if data_args.answer_column is None:
+ answer_column = dataset_columns[2] if dataset_columns is not None else column_names[2]
+ else:
+ answer_column = data_args.answer_column
+ if answer_column not in column_names:
+ raise ValueError(
+ f"--answer_column' value '{data_args.answer_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # Temporarily set max_answer_length for training.
+ max_answer_length = data_args.max_answer_length
+ padding = "max_length" if data_args.pad_to_max_length else False
+
+ if training_args.label_smoothing_factor > 0 and not hasattr(model, "prepare_decoder_input_ids_from_labels"):
+ logger.warning(
+ "label_smoothing is enabled but the `prepare_decoder_input_ids_from_labels` method is not defined for "
+ f"`{model.__class__.__name__}`. This will lead to loss being calculated twice and will take up more memory"
+ )
+
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ def preprocess_squad_batch(
+ examples,
+ question_column: str,
+ context_column: str,
+ answer_column: str,
+ ) -> tuple[list[str], list[str]]:
+ questions = examples[question_column]
+ contexts = examples[context_column]
+ answers = examples[answer_column]
+
+ def generate_input(_question, _context):
+ return " ".join(["question:", _question.lstrip(), "context:", _context.lstrip()])
+
+ inputs = [generate_input(question, context) for question, context in zip(questions, contexts)]
+ targets = [answer["text"][0] if len(answer["text"]) > 0 else "" for answer in answers]
+ return inputs, targets
+
+ def preprocess_function(examples):
+ inputs, targets = preprocess_squad_batch(examples, question_column, context_column, answer_column)
+
+ model_inputs = tokenizer(inputs, max_length=max_seq_length, padding=padding, truncation=True)
+ # Tokenize targets with text_target=...
+ labels = tokenizer(text_target=targets, max_length=max_answer_length, padding=padding, truncation=True)
+
+ # If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
+ # padding in the loss.
+ if padding == "max_length" and data_args.ignore_pad_token_for_loss:
+ labels["input_ids"] = [
+ [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
+ ]
+
+ model_inputs["labels"] = labels["input_ids"]
+ return model_inputs
+
+ # Validation preprocessing
+ def preprocess_validation_function(examples):
+ inputs, targets = preprocess_squad_batch(examples, question_column, context_column, answer_column)
+
+ model_inputs = tokenizer(
+ inputs,
+ max_length=max_seq_length,
+ padding=padding,
+ truncation=True,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ )
+ # Tokenize targets with the `text_target` keyword argument
+ labels = tokenizer(text_target=targets, max_length=max_answer_length, padding=padding, truncation=True)
+
+ # If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
+ # padding in the loss.
+ if padding == "max_length" and data_args.ignore_pad_token_for_loss:
+ labels["input_ids"] = [
+ [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
+ ]
+
+ # Since one example might give us several features if it has a long context, we need a map from a feature to
+ # its corresponding example. This key gives us just that.
+ sample_mapping = model_inputs.pop("overflow_to_sample_mapping")
+
+ # For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
+ # corresponding example_id and we will store the offset mappings.
+ model_inputs["example_id"] = []
+ # Augment the overflowing tokens to the labels
+ labels_out = []
+
+ for i in range(len(model_inputs["input_ids"])):
+ # One example can give several spans, this is the index of the example containing this span of text.
+ sample_index = sample_mapping[i]
+ model_inputs["example_id"].append(examples["id"][sample_index])
+ labels_out.append(labels["input_ids"][sample_index])
+
+ model_inputs["labels"] = labels_out
+ return model_inputs
+
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if data_args.max_train_samples is not None:
+ # We will select sample from whole data if argument is specified
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ # Create train feature from dataset
+ with training_args.main_process_first(desc="train dataset map pre-processing"):
+ train_dataset = train_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+ if data_args.max_train_samples is not None:
+ # Number of samples might increase during Feature Creation, We select only specified max samples
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+
+ if training_args.do_eval:
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_examples = raw_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ # We will select sample from whole data
+ max_eval_samples = min(len(eval_examples), data_args.max_eval_samples)
+ eval_examples = eval_examples.select(range(max_eval_samples))
+ # Validation Feature Creation
+ with training_args.main_process_first(desc="validation dataset map pre-processing"):
+ eval_dataset = eval_examples.map(
+ preprocess_validation_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+ if data_args.max_eval_samples is not None:
+ # During Feature creation dataset samples might increase, we will select required samples again
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ if training_args.do_predict:
+ if "test" not in raw_datasets:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_examples = raw_datasets["test"]
+ if data_args.max_predict_samples is not None:
+ # We will select sample from whole data
+ predict_examples = predict_examples.select(range(data_args.max_predict_samples))
+ # Predict Feature Creation
+ with training_args.main_process_first(desc="prediction dataset map pre-processing"):
+ predict_dataset = predict_examples.map(
+ preprocess_validation_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on prediction dataset",
+ )
+ if data_args.max_predict_samples is not None:
+ # During Feature creation dataset samples might increase, we will select required samples again
+ max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
+ predict_dataset = predict_dataset.select(range(max_predict_samples))
+
+ # Data collator
+ label_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
+ data_collator = DataCollatorForSeq2Seq(
+ tokenizer,
+ model=model,
+ label_pad_token_id=label_pad_token_id,
+ pad_to_multiple_of=8 if training_args.fp16 else None,
+ )
+
+ metric = evaluate.load(
+ "squad_v2" if data_args.version_2_with_negative else "squad", cache_dir=model_args.cache_dir
+ )
+
+ def compute_metrics(p: EvalPrediction):
+ return metric.compute(predictions=p.predictions, references=p.label_ids)
+
+ # Post-processing:
+ def post_processing_function(
+ examples: datasets.Dataset, features: datasets.Dataset, outputs: EvalLoopOutput, stage="eval"
+ ):
+ # Decode the predicted tokens.
+ preds = outputs.predictions
+ if isinstance(preds, tuple):
+ preds = preds[0]
+ # Replace -100s used for padding as we can't decode them
+ preds = np.where(preds != -100, preds, tokenizer.pad_token_id)
+ decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
+
+ # Build a map example to its corresponding features.
+ example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
+ feature_per_example = {example_id_to_index[feature["example_id"]]: i for i, feature in enumerate(features)}
+ predictions = {}
+ # Let's loop over all the examples!
+ for example_index, example in enumerate(examples):
+ # This is the index of the feature associated to the current example.
+ feature_index = feature_per_example[example_index]
+ predictions[example["id"]] = decoded_preds[feature_index]
+
+ # Format the result to the format the metric expects.
+ if data_args.version_2_with_negative:
+ formatted_predictions = [
+ {"id": k, "prediction_text": v, "no_answer_probability": 0.0} for k, v in predictions.items()
+ ]
+ else:
+ formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
+
+ references = [{"id": ex["id"], "answers": ex[answer_column]} for ex in examples]
+ return EvalPrediction(predictions=formatted_predictions, label_ids=references)
+
+ # Initialize our Trainer
+ trainer = QuestionAnsweringSeq2SeqTrainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ eval_examples=eval_examples if training_args.do_eval else None,
+ processing_class=tokenizer,
+ data_collator=data_collator,
+ compute_metrics=compute_metrics if training_args.predict_with_generate else None,
+ post_process_function=post_processing_function,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model() # Saves the tokenizer too for easy upload
+
+ metrics = train_result.metrics
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ results = {}
+ max_length = (
+ training_args.generation_max_length
+ if training_args.generation_max_length is not None
+ else data_args.val_max_answer_length
+ )
+ num_beams = data_args.num_beams if data_args.num_beams is not None else training_args.generation_num_beams
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+ metrics = trainer.evaluate(max_length=max_length, num_beams=num_beams, metric_key_prefix="eval")
+
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Prediction
+ if training_args.do_predict:
+ logger.info("*** Predict ***")
+ results = trainer.predict(predict_dataset, predict_examples)
+ metrics = results.metrics
+
+ max_predict_samples = (
+ data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
+ )
+ metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
+
+ trainer.log_metrics("predict", metrics)
+ trainer.save_metrics("predict", metrics)
+
+ if training_args.push_to_hub:
+ kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "question-answering"}
+ if data_args.dataset_name is not None:
+ kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ kwargs["dataset_args"] = data_args.dataset_config_name
+ kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ kwargs["dataset"] = data_args.dataset_name
+
+ trainer.push_to_hub(**kwargs)
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/question-answering/trainer_qa.py b/docs/transformers/examples/pytorch/question-answering/trainer_qa.py
new file mode 100644
index 0000000000000000000000000000000000000000..3948391f6335ff971af720243a6a80d7beb818da
--- /dev/null
+++ b/docs/transformers/examples/pytorch/question-answering/trainer_qa.py
@@ -0,0 +1,136 @@
+# Copyright 2020 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+A subclass of `Trainer` specific to Question-Answering tasks
+"""
+
+import math
+import time
+
+from transformers import Trainer, is_torch_xla_available
+from transformers.trainer_utils import PredictionOutput, speed_metrics
+
+
+if is_torch_xla_available():
+ import torch_xla.core.xla_model as xm
+ import torch_xla.debug.metrics as met
+
+
+class QuestionAnsweringTrainer(Trainer):
+ def __init__(self, *args, eval_examples=None, post_process_function=None, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.eval_examples = eval_examples
+ self.post_process_function = post_process_function
+
+ def evaluate(self, eval_dataset=None, eval_examples=None, ignore_keys=None, metric_key_prefix: str = "eval"):
+ eval_dataset = self.eval_dataset if eval_dataset is None else eval_dataset
+ eval_dataloader = self.get_eval_dataloader(eval_dataset)
+ eval_examples = self.eval_examples if eval_examples is None else eval_examples
+
+ # Temporarily disable metric computation, we will do it in the loop here.
+ compute_metrics = self.compute_metrics
+ self.compute_metrics = None
+ eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
+ start_time = time.time()
+ try:
+ output = eval_loop(
+ eval_dataloader,
+ description="Evaluation",
+ # No point gathering the predictions if there are no metrics, otherwise we defer to
+ # self.args.prediction_loss_only
+ prediction_loss_only=True if compute_metrics is None else None,
+ ignore_keys=ignore_keys,
+ metric_key_prefix=metric_key_prefix,
+ )
+ finally:
+ self.compute_metrics = compute_metrics
+ total_batch_size = self.args.eval_batch_size * self.args.world_size
+ if f"{metric_key_prefix}_jit_compilation_time" in output.metrics:
+ start_time += output.metrics[f"{metric_key_prefix}_jit_compilation_time"]
+ output.metrics.update(
+ speed_metrics(
+ metric_key_prefix,
+ start_time,
+ num_samples=output.num_samples,
+ num_steps=math.ceil(output.num_samples / total_batch_size),
+ )
+ )
+ if self.post_process_function is not None and self.compute_metrics is not None and self.args.should_save:
+ # Only the main node write the results by default
+ eval_preds = self.post_process_function(eval_examples, eval_dataset, output.predictions)
+ metrics = self.compute_metrics(eval_preds)
+
+ # Prefix all keys with metric_key_prefix + '_'
+ for key in list(metrics.keys()):
+ if not key.startswith(f"{metric_key_prefix}_"):
+ metrics[f"{metric_key_prefix}_{key}"] = metrics.pop(key)
+ metrics.update(output.metrics)
+ else:
+ metrics = output.metrics
+
+ if self.args.should_log:
+ # Only the main node log the results by default
+ self.log(metrics)
+
+ if self.args.tpu_metrics_debug or self.args.debug:
+ # tpu-comment: Logging debug metrics for PyTorch/XLA (compile, execute times, ops, etc.)
+ xm.master_print(met.metrics_report())
+
+ self.control = self.callback_handler.on_evaluate(self.args, self.state, self.control, metrics)
+ return metrics
+
+ def predict(self, predict_dataset, predict_examples, ignore_keys=None, metric_key_prefix: str = "test"):
+ predict_dataloader = self.get_test_dataloader(predict_dataset)
+
+ # Temporarily disable metric computation, we will do it in the loop here.
+ compute_metrics = self.compute_metrics
+ self.compute_metrics = None
+ eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
+ start_time = time.time()
+ try:
+ output = eval_loop(
+ predict_dataloader,
+ description="Prediction",
+ # No point gathering the predictions if there are no metrics, otherwise we defer to
+ # self.args.prediction_loss_only
+ prediction_loss_only=True if compute_metrics is None else None,
+ ignore_keys=ignore_keys,
+ metric_key_prefix=metric_key_prefix,
+ )
+ finally:
+ self.compute_metrics = compute_metrics
+ total_batch_size = self.args.eval_batch_size * self.args.world_size
+ if f"{metric_key_prefix}_jit_compilation_time" in output.metrics:
+ start_time += output.metrics[f"{metric_key_prefix}_jit_compilation_time"]
+ output.metrics.update(
+ speed_metrics(
+ metric_key_prefix,
+ start_time,
+ num_samples=output.num_samples,
+ num_steps=math.ceil(output.num_samples / total_batch_size),
+ )
+ )
+
+ if self.post_process_function is None or self.compute_metrics is None:
+ return output
+
+ predictions = self.post_process_function(predict_examples, predict_dataset, output.predictions, "predict")
+ metrics = self.compute_metrics(predictions)
+
+ # Prefix all keys with metric_key_prefix + '_'
+ for key in list(metrics.keys()):
+ if not key.startswith(f"{metric_key_prefix}_"):
+ metrics[f"{metric_key_prefix}_{key}"] = metrics.pop(key)
+ metrics.update(output.metrics)
+ return PredictionOutput(predictions=predictions.predictions, label_ids=predictions.label_ids, metrics=metrics)
diff --git a/docs/transformers/examples/pytorch/question-answering/trainer_seq2seq_qa.py b/docs/transformers/examples/pytorch/question-answering/trainer_seq2seq_qa.py
new file mode 100644
index 0000000000000000000000000000000000000000..2492f601316a31ffd3cf5fc47e27c98a29eedd99
--- /dev/null
+++ b/docs/transformers/examples/pytorch/question-answering/trainer_seq2seq_qa.py
@@ -0,0 +1,163 @@
+# Copyright 2021 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+A subclass of `Trainer` specific to Question-Answering tasks
+"""
+
+import math
+import time
+from typing import Optional
+
+from torch.utils.data import Dataset
+
+from transformers import Seq2SeqTrainer, is_torch_xla_available
+from transformers.trainer_utils import PredictionOutput, speed_metrics
+
+
+if is_torch_xla_available():
+ import torch_xla.core.xla_model as xm
+ import torch_xla.debug.metrics as met
+
+
+class QuestionAnsweringSeq2SeqTrainer(Seq2SeqTrainer):
+ def __init__(self, *args, eval_examples=None, post_process_function=None, **kwargs):
+ super().__init__(*args, **kwargs)
+ self.eval_examples = eval_examples
+ self.post_process_function = post_process_function
+
+ # def evaluate(self, eval_dataset=None, eval_examples=None, ignore_keys=None, metric_key_prefix: str = "eval"):
+ def evaluate(
+ self,
+ eval_dataset: Optional[Dataset] = None,
+ eval_examples=None,
+ ignore_keys: Optional[list[str]] = None,
+ metric_key_prefix: str = "eval",
+ **gen_kwargs,
+ ) -> dict[str, float]:
+ gen_kwargs = gen_kwargs.copy()
+
+ # Use legacy argument setting if a) the option is not explicitly passed; and b) the argument is set in the
+ # training args
+ if gen_kwargs.get("max_length") is None and self.args.generation_max_length is not None:
+ gen_kwargs["max_length"] = self.args.generation_max_length
+ if gen_kwargs.get("num_beams") is None and self.args.generation_num_beams is not None:
+ gen_kwargs["num_beams"] = self.args.generation_num_beams
+ self._gen_kwargs = gen_kwargs
+
+ eval_dataset = self.eval_dataset if eval_dataset is None else eval_dataset
+ eval_dataloader = self.get_eval_dataloader(eval_dataset)
+ eval_examples = self.eval_examples if eval_examples is None else eval_examples
+
+ # Temporarily disable metric computation, we will do it in the loop here.
+ compute_metrics = self.compute_metrics
+ self.compute_metrics = None
+ start_time = time.time()
+ eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
+ try:
+ output = eval_loop(
+ eval_dataloader,
+ description="Evaluation",
+ # No point gathering the predictions if there are no metrics, otherwise we defer to
+ # self.args.prediction_loss_only
+ prediction_loss_only=True if compute_metrics is None else None,
+ ignore_keys=ignore_keys,
+ metric_key_prefix=metric_key_prefix,
+ )
+ finally:
+ self.compute_metrics = compute_metrics
+ total_batch_size = self.args.eval_batch_size * self.args.world_size
+ if f"{metric_key_prefix}_jit_compilation_time" in output.metrics:
+ start_time += output.metrics[f"{metric_key_prefix}_jit_compilation_time"]
+ output.metrics.update(
+ speed_metrics(
+ metric_key_prefix,
+ start_time,
+ num_samples=output.num_samples,
+ num_steps=math.ceil(output.num_samples / total_batch_size),
+ )
+ )
+
+ if self.post_process_function is not None and self.compute_metrics is not None and self.args.should_save:
+ # Only the main node write the results by default
+ eval_preds = self.post_process_function(eval_examples, eval_dataset, output)
+ metrics = self.compute_metrics(eval_preds)
+
+ # Prefix all keys with metric_key_prefix + '_'
+ for key in list(metrics.keys()):
+ if not key.startswith(f"{metric_key_prefix}_"):
+ metrics[f"{metric_key_prefix}_{key}"] = metrics.pop(key)
+
+ metrics.update(output.metrics)
+ else:
+ metrics = output.metrics
+
+ if self.args.should_log:
+ # Only the main node log the results by default
+ self.log(metrics)
+
+ if self.args.tpu_metrics_debug or self.args.debug:
+ # tpu-comment: Logging debug metrics for PyTorch/XLA (compile, execute times, ops, etc.)
+ xm.master_print(met.metrics_report())
+
+ self.control = self.callback_handler.on_evaluate(self.args, self.state, self.control, metrics)
+ return metrics
+
+ def predict(
+ self, predict_dataset, predict_examples, ignore_keys=None, metric_key_prefix: str = "test", **gen_kwargs
+ ):
+ self._gen_kwargs = gen_kwargs.copy()
+
+ predict_dataloader = self.get_test_dataloader(predict_dataset)
+
+ # Temporarily disable metric computation, we will do it in the loop here.
+ compute_metrics = self.compute_metrics
+ self.compute_metrics = None
+ start_time = time.time()
+ eval_loop = self.prediction_loop if self.args.use_legacy_prediction_loop else self.evaluation_loop
+ try:
+ output = eval_loop(
+ predict_dataloader,
+ description="Prediction",
+ # No point gathering the predictions if there are no metrics, otherwise we defer to
+ # self.args.prediction_loss_only
+ prediction_loss_only=True if compute_metrics is None else None,
+ ignore_keys=ignore_keys,
+ metric_key_prefix=metric_key_prefix,
+ )
+ finally:
+ self.compute_metrics = compute_metrics
+
+ total_batch_size = self.args.eval_batch_size * self.args.world_size
+ if f"{metric_key_prefix}_jit_compilation_time" in output.metrics:
+ start_time += output.metrics[f"{metric_key_prefix}_jit_compilation_time"]
+ output.metrics.update(
+ speed_metrics(
+ metric_key_prefix,
+ start_time,
+ num_samples=output.num_samples,
+ num_steps=math.ceil(output.num_samples / total_batch_size),
+ )
+ )
+ if self.post_process_function is None or self.compute_metrics is None:
+ return output
+
+ predictions = self.post_process_function(predict_examples, predict_dataset, output, "predict")
+ metrics = self.compute_metrics(predictions)
+
+ # Prefix all keys with metric_key_prefix + '_'
+ for key in list(metrics.keys()):
+ if not key.startswith(f"{metric_key_prefix}_"):
+ metrics[f"{metric_key_prefix}_{key}"] = metrics.pop(key)
+ metrics.update(output.metrics)
+ return PredictionOutput(predictions=predictions.predictions, label_ids=predictions.label_ids, metrics=metrics)
diff --git a/docs/transformers/examples/pytorch/question-answering/utils_qa.py b/docs/transformers/examples/pytorch/question-answering/utils_qa.py
new file mode 100644
index 0000000000000000000000000000000000000000..f0cc5c26a6927179d83dab56d21f4acb357884ee
--- /dev/null
+++ b/docs/transformers/examples/pytorch/question-answering/utils_qa.py
@@ -0,0 +1,443 @@
+# Copyright 2020 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Post-processing utilities for question answering.
+"""
+
+import collections
+import json
+import logging
+import os
+from typing import Optional
+
+import numpy as np
+from tqdm.auto import tqdm
+
+
+logger = logging.getLogger(__name__)
+
+
+def postprocess_qa_predictions(
+ examples,
+ features,
+ predictions: tuple[np.ndarray, np.ndarray],
+ version_2_with_negative: bool = False,
+ n_best_size: int = 20,
+ max_answer_length: int = 30,
+ null_score_diff_threshold: float = 0.0,
+ output_dir: Optional[str] = None,
+ prefix: Optional[str] = None,
+ log_level: Optional[int] = logging.WARNING,
+):
+ """
+ Post-processes the predictions of a question-answering model to convert them to answers that are substrings of the
+ original contexts. This is the base postprocessing functions for models that only return start and end logits.
+
+ Args:
+ examples: The non-preprocessed dataset (see the main script for more information).
+ features: The processed dataset (see the main script for more information).
+ predictions (:obj:`Tuple[np.ndarray, np.ndarray]`):
+ The predictions of the model: two arrays containing the start logits and the end logits respectively. Its
+ first dimension must match the number of elements of :obj:`features`.
+ version_2_with_negative (:obj:`bool`, `optional`, defaults to :obj:`False`):
+ Whether or not the underlying dataset contains examples with no answers.
+ n_best_size (:obj:`int`, `optional`, defaults to 20):
+ The total number of n-best predictions to generate when looking for an answer.
+ max_answer_length (:obj:`int`, `optional`, defaults to 30):
+ The maximum length of an answer that can be generated. This is needed because the start and end predictions
+ are not conditioned on one another.
+ null_score_diff_threshold (:obj:`float`, `optional`, defaults to 0):
+ The threshold used to select the null answer: if the best answer has a score that is less than the score of
+ the null answer minus this threshold, the null answer is selected for this example (note that the score of
+ the null answer for an example giving several features is the minimum of the scores for the null answer on
+ each feature: all features must be aligned on the fact they `want` to predict a null answer).
+
+ Only useful when :obj:`version_2_with_negative` is :obj:`True`.
+ output_dir (:obj:`str`, `optional`):
+ If provided, the dictionaries of predictions, n_best predictions (with their scores and logits) and, if
+ :obj:`version_2_with_negative=True`, the dictionary of the scores differences between best and null
+ answers, are saved in `output_dir`.
+ prefix (:obj:`str`, `optional`):
+ If provided, the dictionaries mentioned above are saved with `prefix` added to their names.
+ log_level (:obj:`int`, `optional`, defaults to ``logging.WARNING``):
+ ``logging`` log level (e.g., ``logging.WARNING``)
+ """
+ if len(predictions) != 2:
+ raise ValueError("`predictions` should be a tuple with two elements (start_logits, end_logits).")
+ all_start_logits, all_end_logits = predictions
+
+ if len(predictions[0]) != len(features):
+ raise ValueError(f"Got {len(predictions[0])} predictions and {len(features)} features.")
+
+ # Build a map example to its corresponding features.
+ example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
+ features_per_example = collections.defaultdict(list)
+ for i, feature in enumerate(features):
+ features_per_example[example_id_to_index[feature["example_id"]]].append(i)
+
+ # The dictionaries we have to fill.
+ all_predictions = collections.OrderedDict()
+ all_nbest_json = collections.OrderedDict()
+ if version_2_with_negative:
+ scores_diff_json = collections.OrderedDict()
+
+ # Logging.
+ logger.setLevel(log_level)
+ logger.info(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
+
+ # Let's loop over all the examples!
+ for example_index, example in enumerate(tqdm(examples)):
+ # Those are the indices of the features associated to the current example.
+ feature_indices = features_per_example[example_index]
+
+ min_null_prediction = None
+ prelim_predictions = []
+
+ # Looping through all the features associated to the current example.
+ for feature_index in feature_indices:
+ # We grab the predictions of the model for this feature.
+ start_logits = all_start_logits[feature_index]
+ end_logits = all_end_logits[feature_index]
+ # This is what will allow us to map some the positions in our logits to span of texts in the original
+ # context.
+ offset_mapping = features[feature_index]["offset_mapping"]
+ # Optional `token_is_max_context`, if provided we will remove answers that do not have the maximum context
+ # available in the current feature.
+ token_is_max_context = features[feature_index].get("token_is_max_context", None)
+
+ # Update minimum null prediction.
+ feature_null_score = start_logits[0] + end_logits[0]
+ if min_null_prediction is None or min_null_prediction["score"] > feature_null_score:
+ min_null_prediction = {
+ "offsets": (0, 0),
+ "score": feature_null_score,
+ "start_logit": start_logits[0],
+ "end_logit": end_logits[0],
+ }
+
+ # Go through all possibilities for the `n_best_size` greater start and end logits.
+ start_indexes = np.argsort(start_logits)[-1 : -n_best_size - 1 : -1].tolist()
+ end_indexes = np.argsort(end_logits)[-1 : -n_best_size - 1 : -1].tolist()
+ for start_index in start_indexes:
+ for end_index in end_indexes:
+ # Don't consider out-of-scope answers, either because the indices are out of bounds or correspond
+ # to part of the input_ids that are not in the context.
+ if (
+ start_index >= len(offset_mapping)
+ or end_index >= len(offset_mapping)
+ or offset_mapping[start_index] is None
+ or len(offset_mapping[start_index]) < 2
+ or offset_mapping[end_index] is None
+ or len(offset_mapping[end_index]) < 2
+ ):
+ continue
+ # Don't consider answers with a length that is either < 0 or > max_answer_length.
+ if end_index < start_index or end_index - start_index + 1 > max_answer_length:
+ continue
+ # Don't consider answer that don't have the maximum context available (if such information is
+ # provided).
+ if token_is_max_context is not None and not token_is_max_context.get(str(start_index), False):
+ continue
+
+ prelim_predictions.append(
+ {
+ "offsets": (offset_mapping[start_index][0], offset_mapping[end_index][1]),
+ "score": start_logits[start_index] + end_logits[end_index],
+ "start_logit": start_logits[start_index],
+ "end_logit": end_logits[end_index],
+ }
+ )
+ if version_2_with_negative and min_null_prediction is not None:
+ # Add the minimum null prediction
+ prelim_predictions.append(min_null_prediction)
+ null_score = min_null_prediction["score"]
+
+ # Only keep the best `n_best_size` predictions.
+ predictions = sorted(prelim_predictions, key=lambda x: x["score"], reverse=True)[:n_best_size]
+
+ # Add back the minimum null prediction if it was removed because of its low score.
+ if (
+ version_2_with_negative
+ and min_null_prediction is not None
+ and not any(p["offsets"] == (0, 0) for p in predictions)
+ ):
+ predictions.append(min_null_prediction)
+
+ # Use the offsets to gather the answer text in the original context.
+ context = example["context"]
+ for pred in predictions:
+ offsets = pred.pop("offsets")
+ pred["text"] = context[offsets[0] : offsets[1]]
+
+ # In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
+ # failure.
+ if len(predictions) == 0 or (len(predictions) == 1 and predictions[0]["text"] == ""):
+ predictions.insert(0, {"text": "empty", "start_logit": 0.0, "end_logit": 0.0, "score": 0.0})
+
+ # Compute the softmax of all scores (we do it with numpy to stay independent from torch/tf in this file, using
+ # the LogSumExp trick).
+ scores = np.array([pred.pop("score") for pred in predictions])
+ exp_scores = np.exp(scores - np.max(scores))
+ probs = exp_scores / exp_scores.sum()
+
+ # Include the probabilities in our predictions.
+ for prob, pred in zip(probs, predictions):
+ pred["probability"] = prob
+
+ # Pick the best prediction. If the null answer is not possible, this is easy.
+ if not version_2_with_negative:
+ all_predictions[example["id"]] = predictions[0]["text"]
+ else:
+ # Otherwise we first need to find the best non-empty prediction.
+ i = 0
+ while predictions[i]["text"] == "":
+ i += 1
+ best_non_null_pred = predictions[i]
+
+ # Then we compare to the null prediction using the threshold.
+ score_diff = null_score - best_non_null_pred["start_logit"] - best_non_null_pred["end_logit"]
+ scores_diff_json[example["id"]] = float(score_diff) # To be JSON-serializable.
+ if score_diff > null_score_diff_threshold:
+ all_predictions[example["id"]] = ""
+ else:
+ all_predictions[example["id"]] = best_non_null_pred["text"]
+
+ # Make `predictions` JSON-serializable by casting np.float back to float.
+ all_nbest_json[example["id"]] = [
+ {k: (float(v) if isinstance(v, (np.float16, np.float32, np.float64)) else v) for k, v in pred.items()}
+ for pred in predictions
+ ]
+
+ # If we have an output_dir, let's save all those dicts.
+ if output_dir is not None:
+ if not os.path.isdir(output_dir):
+ raise OSError(f"{output_dir} is not a directory.")
+
+ prediction_file = os.path.join(
+ output_dir, "predictions.json" if prefix is None else f"{prefix}_predictions.json"
+ )
+ nbest_file = os.path.join(
+ output_dir, "nbest_predictions.json" if prefix is None else f"{prefix}_nbest_predictions.json"
+ )
+ if version_2_with_negative:
+ null_odds_file = os.path.join(
+ output_dir, "null_odds.json" if prefix is None else f"{prefix}_null_odds.json"
+ )
+
+ logger.info(f"Saving predictions to {prediction_file}.")
+ with open(prediction_file, "w") as writer:
+ writer.write(json.dumps(all_predictions, indent=4) + "\n")
+ logger.info(f"Saving nbest_preds to {nbest_file}.")
+ with open(nbest_file, "w") as writer:
+ writer.write(json.dumps(all_nbest_json, indent=4) + "\n")
+ if version_2_with_negative:
+ logger.info(f"Saving null_odds to {null_odds_file}.")
+ with open(null_odds_file, "w") as writer:
+ writer.write(json.dumps(scores_diff_json, indent=4) + "\n")
+
+ return all_predictions
+
+
+def postprocess_qa_predictions_with_beam_search(
+ examples,
+ features,
+ predictions: tuple[np.ndarray, np.ndarray],
+ version_2_with_negative: bool = False,
+ n_best_size: int = 20,
+ max_answer_length: int = 30,
+ start_n_top: int = 5,
+ end_n_top: int = 5,
+ output_dir: Optional[str] = None,
+ prefix: Optional[str] = None,
+ log_level: Optional[int] = logging.WARNING,
+):
+ """
+ Post-processes the predictions of a question-answering model with beam search to convert them to answers that are substrings of the
+ original contexts. This is the postprocessing functions for models that return start and end logits, indices, as well as
+ cls token predictions.
+
+ Args:
+ examples: The non-preprocessed dataset (see the main script for more information).
+ features: The processed dataset (see the main script for more information).
+ predictions (:obj:`Tuple[np.ndarray, np.ndarray]`):
+ The predictions of the model: two arrays containing the start logits and the end logits respectively. Its
+ first dimension must match the number of elements of :obj:`features`.
+ version_2_with_negative (:obj:`bool`, `optional`, defaults to :obj:`False`):
+ Whether or not the underlying dataset contains examples with no answers.
+ n_best_size (:obj:`int`, `optional`, defaults to 20):
+ The total number of n-best predictions to generate when looking for an answer.
+ max_answer_length (:obj:`int`, `optional`, defaults to 30):
+ The maximum length of an answer that can be generated. This is needed because the start and end predictions
+ are not conditioned on one another.
+ start_n_top (:obj:`int`, `optional`, defaults to 5):
+ The number of top start logits too keep when searching for the :obj:`n_best_size` predictions.
+ end_n_top (:obj:`int`, `optional`, defaults to 5):
+ The number of top end logits too keep when searching for the :obj:`n_best_size` predictions.
+ output_dir (:obj:`str`, `optional`):
+ If provided, the dictionaries of predictions, n_best predictions (with their scores and logits) and, if
+ :obj:`version_2_with_negative=True`, the dictionary of the scores differences between best and null
+ answers, are saved in `output_dir`.
+ prefix (:obj:`str`, `optional`):
+ If provided, the dictionaries mentioned above are saved with `prefix` added to their names.
+ log_level (:obj:`int`, `optional`, defaults to ``logging.WARNING``):
+ ``logging`` log level (e.g., ``logging.WARNING``)
+ """
+ if len(predictions) != 5:
+ raise ValueError("`predictions` should be a tuple with five elements.")
+ start_top_log_probs, start_top_index, end_top_log_probs, end_top_index, cls_logits = predictions
+
+ if len(predictions[0]) != len(features):
+ raise ValueError(f"Got {len(predictions[0])} predictions and {len(features)} features.")
+
+ # Build a map example to its corresponding features.
+ example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
+ features_per_example = collections.defaultdict(list)
+ for i, feature in enumerate(features):
+ features_per_example[example_id_to_index[feature["example_id"]]].append(i)
+
+ # The dictionaries we have to fill.
+ all_predictions = collections.OrderedDict()
+ all_nbest_json = collections.OrderedDict()
+ scores_diff_json = collections.OrderedDict() if version_2_with_negative else None
+
+ # Logging.
+ logger.setLevel(log_level)
+ logger.info(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
+
+ # Let's loop over all the examples!
+ for example_index, example in enumerate(tqdm(examples)):
+ # Those are the indices of the features associated to the current example.
+ feature_indices = features_per_example[example_index]
+
+ min_null_score = None
+ prelim_predictions = []
+
+ # Looping through all the features associated to the current example.
+ for feature_index in feature_indices:
+ # We grab the predictions of the model for this feature.
+ start_log_prob = start_top_log_probs[feature_index]
+ start_indexes = start_top_index[feature_index]
+ end_log_prob = end_top_log_probs[feature_index]
+ end_indexes = end_top_index[feature_index]
+ feature_null_score = cls_logits[feature_index]
+ # This is what will allow us to map some the positions in our logits to span of texts in the original
+ # context.
+ offset_mapping = features[feature_index]["offset_mapping"]
+ # Optional `token_is_max_context`, if provided we will remove answers that do not have the maximum context
+ # available in the current feature.
+ token_is_max_context = features[feature_index].get("token_is_max_context", None)
+
+ # Update minimum null prediction
+ if min_null_score is None or feature_null_score < min_null_score:
+ min_null_score = feature_null_score
+
+ # Go through all possibilities for the `n_start_top`/`n_end_top` greater start and end logits.
+ for i in range(start_n_top):
+ for j in range(end_n_top):
+ start_index = int(start_indexes[i])
+ j_index = i * end_n_top + j
+ end_index = int(end_indexes[j_index])
+ # Don't consider out-of-scope answers (last part of the test should be unnecessary because of the
+ # p_mask but let's not take any risk)
+ if (
+ start_index >= len(offset_mapping)
+ or end_index >= len(offset_mapping)
+ or offset_mapping[start_index] is None
+ or len(offset_mapping[start_index]) < 2
+ or offset_mapping[end_index] is None
+ or len(offset_mapping[end_index]) < 2
+ ):
+ continue
+
+ # Don't consider answers with a length negative or > max_answer_length.
+ if end_index < start_index or end_index - start_index + 1 > max_answer_length:
+ continue
+ # Don't consider answer that don't have the maximum context available (if such information is
+ # provided).
+ if token_is_max_context is not None and not token_is_max_context.get(str(start_index), False):
+ continue
+ prelim_predictions.append(
+ {
+ "offsets": (offset_mapping[start_index][0], offset_mapping[end_index][1]),
+ "score": start_log_prob[i] + end_log_prob[j_index],
+ "start_log_prob": start_log_prob[i],
+ "end_log_prob": end_log_prob[j_index],
+ }
+ )
+
+ # Only keep the best `n_best_size` predictions.
+ predictions = sorted(prelim_predictions, key=lambda x: x["score"], reverse=True)[:n_best_size]
+
+ # Use the offsets to gather the answer text in the original context.
+ context = example["context"]
+ for pred in predictions:
+ offsets = pred.pop("offsets")
+ pred["text"] = context[offsets[0] : offsets[1]]
+
+ # In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
+ # failure.
+ if len(predictions) == 0:
+ # Without predictions min_null_score is going to be None and None will cause an exception later
+ min_null_score = -2e-6
+ predictions.insert(0, {"text": "", "start_logit": -1e-6, "end_logit": -1e-6, "score": min_null_score})
+
+ # Compute the softmax of all scores (we do it with numpy to stay independent from torch/tf in this file, using
+ # the LogSumExp trick).
+ scores = np.array([pred.pop("score") for pred in predictions])
+ exp_scores = np.exp(scores - np.max(scores))
+ probs = exp_scores / exp_scores.sum()
+
+ # Include the probabilities in our predictions.
+ for prob, pred in zip(probs, predictions):
+ pred["probability"] = prob
+
+ # Pick the best prediction and set the probability for the null answer.
+ all_predictions[example["id"]] = predictions[0]["text"]
+ if version_2_with_negative:
+ scores_diff_json[example["id"]] = float(min_null_score)
+
+ # Make `predictions` JSON-serializable by casting np.float back to float.
+ all_nbest_json[example["id"]] = [
+ {k: (float(v) if isinstance(v, (np.float16, np.float32, np.float64)) else v) for k, v in pred.items()}
+ for pred in predictions
+ ]
+
+ # If we have an output_dir, let's save all those dicts.
+ if output_dir is not None:
+ if not os.path.isdir(output_dir):
+ raise OSError(f"{output_dir} is not a directory.")
+
+ prediction_file = os.path.join(
+ output_dir, "predictions.json" if prefix is None else f"{prefix}_predictions.json"
+ )
+ nbest_file = os.path.join(
+ output_dir, "nbest_predictions.json" if prefix is None else f"{prefix}_nbest_predictions.json"
+ )
+ if version_2_with_negative:
+ null_odds_file = os.path.join(
+ output_dir, "null_odds.json" if prefix is None else f"{prefix}_null_odds.json"
+ )
+
+ logger.info(f"Saving predictions to {prediction_file}.")
+ with open(prediction_file, "w") as writer:
+ writer.write(json.dumps(all_predictions, indent=4) + "\n")
+ logger.info(f"Saving nbest_preds to {nbest_file}.")
+ with open(nbest_file, "w") as writer:
+ writer.write(json.dumps(all_nbest_json, indent=4) + "\n")
+ if version_2_with_negative:
+ logger.info(f"Saving null_odds to {null_odds_file}.")
+ with open(null_odds_file, "w") as writer:
+ writer.write(json.dumps(scores_diff_json, indent=4) + "\n")
+
+ return all_predictions, scores_diff_json
diff --git a/docs/transformers/examples/pytorch/semantic-segmentation/README.md b/docs/transformers/examples/pytorch/semantic-segmentation/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..287870694c62e9ef687d791ccc2bd883447e9319
--- /dev/null
+++ b/docs/transformers/examples/pytorch/semantic-segmentation/README.md
@@ -0,0 +1,207 @@
+
+
+# Semantic segmentation examples
+
+This directory contains 2 scripts that showcase how to fine-tune any model supported by the [`AutoModelForSemanticSegmentation` API](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForSemanticSegmentation) (such as [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer), [BEiT](https://huggingface.co/docs/transformers/main/en/model_doc/beit), [DPT](https://huggingface.co/docs/transformers/main/en/model_doc/dpt)) using PyTorch.
+
+
+
+Content:
+* [Note on custom data](#note-on-custom-data)
+* [PyTorch version, Trainer](#pytorch-version-trainer)
+* [PyTorch version, no Trainer](#pytorch-version-no-trainer)
+* [Reload and perform inference](#reload-and-perform-inference)
+* [Important notes](#important-notes)
+
+## Note on custom data
+
+In case you'd like to use the script with custom data, there are 2 things required: 1) creating a DatasetDict 2) creating an id2label mapping. Below, these are explained in more detail.
+
+### Creating a `DatasetDict`
+
+The script assumes that you have a `DatasetDict` with 2 columns, "image" and "label", both of type [Image](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Image). This can be created as follows:
+
+```python
+from datasets import Dataset, DatasetDict, Image
+
+# your images can of course have a different extension
+# semantic segmentation maps are typically stored in the png format
+image_paths_train = ["path/to/image_1.jpg/jpg", "path/to/image_2.jpg/jpg", ..., "path/to/image_n.jpg/jpg"]
+label_paths_train = ["path/to/annotation_1.png", "path/to/annotation_2.png", ..., "path/to/annotation_n.png"]
+
+# same for validation
+# image_paths_validation = [...]
+# label_paths_validation = [...]
+
+def create_dataset(image_paths, label_paths):
+ dataset = Dataset.from_dict({"image": sorted(image_paths),
+ "label": sorted(label_paths)})
+ dataset = dataset.cast_column("image", Image())
+ dataset = dataset.cast_column("label", Image())
+
+ return dataset
+
+# step 1: create Dataset objects
+train_dataset = create_dataset(image_paths_train, label_paths_train)
+validation_dataset = create_dataset(image_paths_validation, label_paths_validation)
+
+# step 2: create DatasetDict
+dataset = DatasetDict({
+ "train": train_dataset,
+ "validation": validation_dataset,
+ }
+)
+
+# step 3: push to hub (assumes you have ran the huggingface-cli login command in a terminal/notebook)
+dataset.push_to_hub("name of repo on the hub")
+
+# optionally, you can push to a private repo on the hub
+# dataset.push_to_hub("name of repo on the hub", private=True)
+```
+
+An example of such a dataset can be seen at [nielsr/ade20k-demo](https://huggingface.co/datasets/nielsr/ade20k-demo).
+
+### Creating an id2label mapping
+
+Besides that, the script also assumes the existence of an `id2label.json` file in the repo, containing a mapping from integers to actual class names. An example of that can be seen [here](https://huggingface.co/datasets/nielsr/ade20k-demo/blob/main/id2label.json). This can be created in Python as follows:
+
+```python
+import json
+# simple example
+id2label = {0: 'cat', 1: 'dog'}
+with open('id2label.json', 'w') as fp:
+ json.dump(id2label, fp)
+```
+
+You can easily upload this by clicking on "Add file" in the "Files and versions" tab of your repo on the hub.
+
+## PyTorch version, Trainer
+
+Based on the script [`run_semantic_segmentation.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py).
+
+The script leverages the [🤗 Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer) to automatically take care of the training for you, running on distributed environments right away.
+
+Here we show how to fine-tune a [SegFormer](https://huggingface.co/nvidia/mit-b0) model on the [segments/sidewalk-semantic](https://huggingface.co/datasets/segments/sidewalk-semantic) dataset:
+
+In order to use `segments/sidewalk-semantic`:
+ - Log in to Hugging Face with `huggingface-cli login` (token can be accessed [here](https://huggingface.co/settings/tokens)).
+ - Accept terms of use for `sidewalk-semantic` on [dataset page](https://huggingface.co/datasets/segments/sidewalk-semantic).
+
+```bash
+python run_semantic_segmentation.py \
+ --model_name_or_path nvidia/mit-b0 \
+ --dataset_name segments/sidewalk-semantic \
+ --output_dir ./segformer_outputs/ \
+ --remove_unused_columns False \
+ --do_train \
+ --do_eval \
+ --push_to_hub \
+ --push_to_hub_model_id segformer-finetuned-sidewalk-10k-steps \
+ --max_steps 10000 \
+ --learning_rate 0.00006 \
+ --lr_scheduler_type polynomial \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 100 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --seed 1337
+```
+
+The resulting model can be seen here: https://huggingface.co/nielsr/segformer-finetuned-sidewalk-10k-steps. The corresponding Weights and Biases report [here](https://wandb.ai/nielsrogge/huggingface/reports/SegFormer-fine-tuning--VmlldzoxODY5NTQ2). Note that it's always advised to check the original paper to know the details regarding training hyperparameters. E.g. from the SegFormer paper:
+
+> We trained the models using AdamW optimizer for 160K iterations on ADE20K, Cityscapes, and 80K iterations on COCO-Stuff. (...) We used a batch size of 16 for ADE20K and COCO-Stuff, and a batch size of 8 for Cityscapes. The learning rate was set to an initial value of 0.00006 and then used a “poly” LR schedule with factor 1.0 by default.
+
+Note that you can replace the model and dataset by simply setting the `model_name_or_path` and `dataset_name` arguments respectively, with any model or dataset from the [hub](https://huggingface.co/). For an overview of all possible arguments, we refer to the [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) of the `TrainingArguments`, which can be passed as flags.
+
+## PyTorch version, no Trainer
+
+Based on the script [`run_semantic_segmentation_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py).
+
+The script leverages [🤗 `Accelerate`](https://github.com/huggingface/accelerate), which allows to write your own training loop in PyTorch, but have it run instantly on any (distributed) environment, including CPU, multi-CPU, GPU, multi-GPU and TPU. It also supports mixed precision.
+
+First, run:
+
+```bash
+accelerate config
+```
+
+and reply to the questions asked regarding the environment on which you'd like to train. Then
+
+```bash
+accelerate test
+```
+
+that will check everything is ready for training. Finally, you can launch training with
+
+```bash
+accelerate launch run_semantic_segmentation_no_trainer.py --output_dir segformer-finetuned-sidewalk --with_tracking --push_to_hub
+```
+
+and boom, you're training, possibly on multiple GPUs, logging everything to all trackers found in your environment (like Weights and Biases, Tensorboard) and regularly pushing your model to the hub (with the repo name being equal to `args.output_dir` at your HF username) 🤗
+
+With the default settings, the script fine-tunes a [SegFormer]((https://huggingface.co/docs/transformers/main/en/model_doc/segformer)) model on the [segments/sidewalk-semantic](https://huggingface.co/datasets/segments/sidewalk-semantic) dataset.
+
+The resulting model can be seen here: https://huggingface.co/nielsr/segformer-finetuned-sidewalk. Note that the script usually requires quite a few epochs to achieve great results, e.g. the SegFormer authors fine-tuned their model for 160k steps (batches) on [`scene_parse_150`](https://huggingface.co/datasets/scene_parse_150).
+
+## Reload and perform inference
+
+This means that after training, you can easily load your trained model as follows:
+
+```python
+from transformers import AutoImageProcessor, AutoModelForSemanticSegmentation
+
+model_name = "name_of_repo_on_the_hub_or_path_to_local_folder"
+
+image_processor = AutoImageProcessor.from_pretrained(model_name)
+model = AutoModelForSemanticSegmentation.from_pretrained(model_name)
+```
+
+and perform inference as follows:
+
+```python
+from PIL import Image
+import requests
+import torch
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+# prepare image for the model
+inputs = image_processor(images=image, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+ logits = outputs.logits
+
+# rescale logits to original image size
+logits = nn.functional.interpolate(outputs.logits.detach().cpu(),
+ size=image.size[::-1], # (height, width)
+ mode='bilinear',
+ align_corners=False)
+
+predicted = logits.argmax(1)
+```
+
+For visualization of the segmentation maps, we refer to the [example notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SegFormer/Segformer_inference_notebook.ipynb).
+
+## Important notes
+
+Some datasets, like [`scene_parse_150`](https://huggingface.co/datasets/scene_parse_150), contain a "background" label that is not part of the classes. The Scene Parse 150 dataset for instance contains labels between 0 and 150, with 0 being the background class, and 1 to 150 being actual class names (like "tree", "person", etc.). For these kind of datasets, one replaces the background label (0) by 255, which is the `ignore_index` of the PyTorch model's loss function, and reduces all labels by 1. This way, the `labels` are PyTorch tensors containing values between 0 and 149, and 255 for all background/padding.
+
+In case you're training on such a dataset, make sure to set the ``do_reduce_labels`` flag, which will take care of this.
diff --git a/docs/transformers/examples/pytorch/semantic-segmentation/requirements.txt b/docs/transformers/examples/pytorch/semantic-segmentation/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..7d62aa141db38399fcc633133fdf537f61ba1f30
--- /dev/null
+++ b/docs/transformers/examples/pytorch/semantic-segmentation/requirements.txt
@@ -0,0 +1,6 @@
+datasets >= 2.0.0
+torch >= 1.3
+accelerate
+evaluate
+Pillow
+albumentations >= 1.4.16
diff --git a/docs/transformers/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py b/docs/transformers/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
new file mode 100644
index 0000000000000000000000000000000000000000..bfedf7c4ca946de1ddd38a0054f91a97cafa620c
--- /dev/null
+++ b/docs/transformers/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py
@@ -0,0 +1,441 @@
+#!/usr/bin/env python
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+import json
+import logging
+import os
+import sys
+import warnings
+from dataclasses import dataclass, field
+from functools import partial
+from typing import Optional
+
+import albumentations as A
+import evaluate
+import numpy as np
+import torch
+from albumentations.pytorch import ToTensorV2
+from datasets import load_dataset
+from huggingface_hub import hf_hub_download
+from torch import nn
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoImageProcessor,
+ AutoModelForSemanticSegmentation,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ default_data_collator,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+""" Finetuning any 🤗 Transformers model supported by AutoModelForSemanticSegmentation for semantic segmentation leveraging the Trainer API."""
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=2.0.0", "To fix: pip install -r examples/pytorch/semantic-segmentation/requirements.txt")
+
+
+def reduce_labels_transform(labels: np.ndarray, **kwargs) -> np.ndarray:
+ """Set `0` label as with value 255 and then reduce all other labels by 1.
+
+ Example:
+ Initial class labels: 0 - background; 1 - road; 2 - car;
+ Transformed class labels: 255 - background; 0 - road; 1 - car;
+
+ **kwargs are required to use this function with albumentations.
+ """
+ labels[labels == 0] = 255
+ labels = labels - 1
+ labels[labels == 254] = 255
+ return labels
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ Using `HfArgumentParser` we can turn this class into argparse arguments to be able to specify
+ them on the command line.
+ """
+
+ dataset_name: Optional[str] = field(
+ default="segments/sidewalk-semantic",
+ metadata={
+ "help": "Name of a dataset from the hub (could be your own, possibly private dataset hosted on the hub)."
+ },
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_val_split: Optional[float] = field(
+ default=0.15, metadata={"help": "Percent to split off of train for validation."}
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ do_reduce_labels: Optional[bool] = field(
+ default=False,
+ metadata={"help": "Whether or not to reduce all labels by 1 and replace background by 255."},
+ )
+ reduce_labels: Optional[bool] = field(
+ default=False,
+ metadata={"help": "Whether or not to reduce all labels by 1 and replace background by 255."},
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and (self.train_dir is None and self.validation_dir is None):
+ raise ValueError(
+ "You must specify either a dataset name from the hub or a train and/or validation directory."
+ )
+ if self.reduce_labels:
+ self.do_reduce_labels = self.reduce_labels
+ warnings.warn(
+ "The `reduce_labels` argument is deprecated and will be removed in v4.45. Please use `do_reduce_labels` instead.",
+ FutureWarning,
+ )
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ default="nvidia/mit-b0",
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ image_processor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_semantic_segmentation", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Load dataset
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ # TODO support datasets from local folders
+ dataset = load_dataset(
+ data_args.dataset_name, cache_dir=model_args.cache_dir, trust_remote_code=model_args.trust_remote_code
+ )
+
+ # Rename column names to standardized names (only "image" and "label" need to be present)
+ if "pixel_values" in dataset["train"].column_names:
+ dataset = dataset.rename_columns({"pixel_values": "image"})
+ if "annotation" in dataset["train"].column_names:
+ dataset = dataset.rename_columns({"annotation": "label"})
+
+ # If we don't have a validation split, split off a percentage of train as validation.
+ data_args.train_val_split = None if "validation" in dataset.keys() else data_args.train_val_split
+ if isinstance(data_args.train_val_split, float) and data_args.train_val_split > 0.0:
+ split = dataset["train"].train_test_split(data_args.train_val_split)
+ dataset["train"] = split["train"]
+ dataset["validation"] = split["test"]
+
+ # Prepare label mappings.
+ # We'll include these in the model's config to get human readable labels in the Inference API.
+ if data_args.dataset_name == "scene_parse_150":
+ repo_id = "huggingface/label-files"
+ filename = "ade20k-id2label.json"
+ else:
+ repo_id = data_args.dataset_name
+ filename = "id2label.json"
+ id2label = json.load(open(hf_hub_download(repo_id, filename, repo_type="dataset")))
+ id2label = {int(k): v for k, v in id2label.items()}
+ label2id = {v: str(k) for k, v in id2label.items()}
+
+ # Load the mean IoU metric from the evaluate package
+ metric = evaluate.load("mean_iou", cache_dir=model_args.cache_dir)
+
+ # Define our compute_metrics function. It takes an `EvalPrediction` object (a namedtuple with a
+ # predictions and label_ids field) and has to return a dictionary string to float.
+ @torch.no_grad()
+ def compute_metrics(eval_pred):
+ logits, labels = eval_pred
+ logits_tensor = torch.from_numpy(logits)
+ # scale the logits to the size of the label
+ logits_tensor = nn.functional.interpolate(
+ logits_tensor,
+ size=labels.shape[-2:],
+ mode="bilinear",
+ align_corners=False,
+ ).argmax(dim=1)
+
+ pred_labels = logits_tensor.detach().cpu().numpy()
+ metrics = metric.compute(
+ predictions=pred_labels,
+ references=labels,
+ num_labels=len(id2label),
+ ignore_index=0,
+ reduce_labels=image_processor.do_reduce_labels,
+ )
+ # add per category metrics as individual key-value pairs
+ per_category_accuracy = metrics.pop("per_category_accuracy").tolist()
+ per_category_iou = metrics.pop("per_category_iou").tolist()
+
+ metrics.update({f"accuracy_{id2label[i]}": v for i, v in enumerate(per_category_accuracy)})
+ metrics.update({f"iou_{id2label[i]}": v for i, v in enumerate(per_category_iou)})
+
+ return metrics
+
+ config = AutoConfig.from_pretrained(
+ model_args.config_name or model_args.model_name_or_path,
+ label2id=label2id,
+ id2label=id2label,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = AutoModelForSemanticSegmentation.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ image_processor = AutoImageProcessor.from_pretrained(
+ model_args.image_processor_name or model_args.model_name_or_path,
+ do_reduce_labels=data_args.do_reduce_labels,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # Define transforms to be applied to each image and target.
+ if "shortest_edge" in image_processor.size:
+ # We instead set the target size as (shortest_edge, shortest_edge) to here to ensure all images are batchable.
+ height, width = image_processor.size["shortest_edge"], image_processor.size["shortest_edge"]
+ else:
+ height, width = image_processor.size["height"], image_processor.size["width"]
+ train_transforms = A.Compose(
+ [
+ A.Lambda(
+ name="reduce_labels",
+ mask=reduce_labels_transform if data_args.do_reduce_labels else None,
+ p=1.0,
+ ),
+ # pad image with 255, because it is ignored by loss
+ A.PadIfNeeded(min_height=height, min_width=width, border_mode=0, value=255, p=1.0),
+ A.RandomCrop(height=height, width=width, p=1.0),
+ A.HorizontalFlip(p=0.5),
+ A.Normalize(mean=image_processor.image_mean, std=image_processor.image_std, max_pixel_value=255.0, p=1.0),
+ ToTensorV2(),
+ ]
+ )
+ val_transforms = A.Compose(
+ [
+ A.Lambda(
+ name="reduce_labels",
+ mask=reduce_labels_transform if data_args.do_reduce_labels else None,
+ p=1.0,
+ ),
+ A.Resize(height=height, width=width, p=1.0),
+ A.Normalize(mean=image_processor.image_mean, std=image_processor.image_std, max_pixel_value=255.0, p=1.0),
+ ToTensorV2(),
+ ]
+ )
+
+ def preprocess_batch(example_batch, transforms: A.Compose):
+ pixel_values = []
+ labels = []
+ for image, target in zip(example_batch["image"], example_batch["label"]):
+ transformed = transforms(image=np.array(image.convert("RGB")), mask=np.array(target))
+ pixel_values.append(transformed["image"])
+ labels.append(transformed["mask"])
+
+ encoding = {}
+ encoding["pixel_values"] = torch.stack(pixel_values).to(torch.float)
+ encoding["labels"] = torch.stack(labels).to(torch.long)
+
+ return encoding
+
+ # Preprocess function for dataset should have only one argument,
+ # so we use partial to pass the transforms
+ preprocess_train_batch_fn = partial(preprocess_batch, transforms=train_transforms)
+ preprocess_val_batch_fn = partial(preprocess_batch, transforms=val_transforms)
+
+ if training_args.do_train:
+ if "train" not in dataset:
+ raise ValueError("--do_train requires a train dataset")
+ if data_args.max_train_samples is not None:
+ dataset["train"] = (
+ dataset["train"].shuffle(seed=training_args.seed).select(range(data_args.max_train_samples))
+ )
+ # Set the training transforms
+ dataset["train"].set_transform(preprocess_train_batch_fn)
+
+ if training_args.do_eval:
+ if "validation" not in dataset:
+ raise ValueError("--do_eval requires a validation dataset")
+ if data_args.max_eval_samples is not None:
+ dataset["validation"] = (
+ dataset["validation"].shuffle(seed=training_args.seed).select(range(data_args.max_eval_samples))
+ )
+ # Set the validation transforms
+ dataset["validation"].set_transform(preprocess_val_batch_fn)
+
+ # Initialize our trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=dataset["train"] if training_args.do_train else None,
+ eval_dataset=dataset["validation"] if training_args.do_eval else None,
+ compute_metrics=compute_metrics,
+ processing_class=image_processor,
+ data_collator=default_data_collator,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+ trainer.log_metrics("train", train_result.metrics)
+ trainer.save_metrics("train", train_result.metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ metrics = trainer.evaluate()
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Write model card and (optionally) push to hub
+ kwargs = {
+ "finetuned_from": model_args.model_name_or_path,
+ "dataset": data_args.dataset_name,
+ "tags": ["image-segmentation", "vision"],
+ }
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py b/docs/transformers/examples/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd2a7a895b21bdec9954a41f666393f94ebe0176
--- /dev/null
+++ b/docs/transformers/examples/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py
@@ -0,0 +1,633 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Finetuning any 🤗 Transformers model supported by AutoModelForSemanticSegmentation for semantic segmentation."""
+
+import argparse
+import json
+import math
+import os
+import warnings
+from functools import partial
+from pathlib import Path
+
+import albumentations as A
+import datasets
+import evaluate
+import numpy as np
+import torch
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from albumentations.pytorch import ToTensorV2
+from datasets import load_dataset
+from huggingface_hub import HfApi, hf_hub_download
+from torch.utils.data import DataLoader
+from tqdm.auto import tqdm
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoImageProcessor,
+ AutoModelForSemanticSegmentation,
+ SchedulerType,
+ default_data_collator,
+ get_scheduler,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logger = get_logger(__name__)
+
+require_version("datasets>=2.0.0", "To fix: pip install -r examples/pytorch/semantic-segmentation/requirements.txt")
+
+
+def reduce_labels_transform(labels: np.ndarray, **kwargs) -> np.ndarray:
+ """Set `0` label as with value 255 and then reduce all other labels by 1.
+
+ Example:
+ Initial class labels: 0 - background; 1 - road; 2 - car;
+ Transformed class labels: 255 - background; 0 - road; 1 - car;
+
+ **kwargs are required to use this function with albumentations.
+ """
+ labels[labels == 0] = 255
+ labels = labels - 1
+ labels[labels == 254] = 255
+ return labels
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Finetune a transformers model on a image semantic segmentation task")
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to a pretrained model or model identifier from huggingface.co/models.",
+ default="nvidia/mit-b0",
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ help="Name of the dataset on the hub.",
+ default="segments/sidewalk-semantic",
+ )
+ parser.add_argument(
+ "--do_reduce_labels",
+ action="store_true",
+ help="Whether or not to reduce all labels by 1 and replace background by 255.",
+ )
+ parser.add_argument(
+ "--reduce_labels",
+ action="store_true",
+ help="Whether or not to reduce all labels by 1 and replace background by 255.",
+ )
+ parser.add_argument(
+ "--train_val_split",
+ type=float,
+ default=0.15,
+ help="Fraction of the dataset to be used for validation.",
+ )
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ help="Path to a folder in which the model and dataset will be cached.",
+ )
+ parser.add_argument(
+ "--use_auth_token",
+ action="store_true",
+ help="Whether to use an authentication token to access the model repository.",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--adam_beta1",
+ type=float,
+ default=0.9,
+ help="Beta1 for AdamW optimizer",
+ )
+ parser.add_argument(
+ "--adam_beta2",
+ type=float,
+ default=0.999,
+ help="Beta2 for AdamW optimizer",
+ )
+ parser.add_argument(
+ "--adam_epsilon",
+ type=float,
+ default=1e-8,
+ help="Epsilon for AdamW optimizer",
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="polynomial",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ required=False,
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+ if args.push_to_hub or args.with_tracking:
+ if args.output_dir is None:
+ raise ValueError(
+ "Need an `output_dir` to create a repo when `--push_to_hub` or `with_tracking` is specified."
+ )
+
+ # Deprecation
+ if args.reduce_labels:
+ args.do_reduce_labels = args.reduce_labels
+ warnings.warn(
+ "The `reduce_labels` argument is deprecated and will be removed in v4.45. Please use `do_reduce_labels` instead.",
+ FutureWarning,
+ )
+
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_semantic_segmentation_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator_log_kwargs = {}
+
+ if args.with_tracking:
+ accelerator_log_kwargs["log_with"] = args.report_to
+ accelerator_log_kwargs["project_dir"] = args.output_dir
+
+ accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
+
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ # We set device_specific to True as we want different data augmentation per device.
+ if args.seed is not None:
+ set_seed(args.seed, device_specific=True)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Load dataset
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ # TODO support datasets from local folders
+ dataset = load_dataset(args.dataset_name, cache_dir=args.cache_dir, trust_remote_code=args.trust_remote_code)
+
+ # Rename column names to standardized names (only "image" and "label" need to be present)
+ if "pixel_values" in dataset["train"].column_names:
+ dataset = dataset.rename_columns({"pixel_values": "image"})
+ if "annotation" in dataset["train"].column_names:
+ dataset = dataset.rename_columns({"annotation": "label"})
+
+ # If we don't have a validation split, split off a percentage of train as validation.
+ args.train_val_split = None if "validation" in dataset.keys() else args.train_val_split
+ if isinstance(args.train_val_split, float) and args.train_val_split > 0.0:
+ split = dataset["train"].train_test_split(args.train_val_split)
+ dataset["train"] = split["train"]
+ dataset["validation"] = split["test"]
+
+ # Prepare label mappings.
+ # We'll include these in the model's config to get human readable labels in the Inference API.
+ if args.dataset_name == "scene_parse_150":
+ repo_id = "huggingface/label-files"
+ filename = "ade20k-id2label.json"
+ else:
+ repo_id = args.dataset_name
+ filename = "id2label.json"
+ id2label = json.load(open(hf_hub_download(repo_id, filename, repo_type="dataset")))
+ id2label = {int(k): v for k, v in id2label.items()}
+ label2id = {v: k for k, v in id2label.items()}
+
+ # Load pretrained model and image processor
+ config = AutoConfig.from_pretrained(
+ args.model_name_or_path, id2label=id2label, label2id=label2id, trust_remote_code=args.trust_remote_code
+ )
+ image_processor = AutoImageProcessor.from_pretrained(
+ args.model_name_or_path, trust_remote_code=args.trust_remote_code
+ )
+ model = AutoModelForSemanticSegmentation.from_pretrained(
+ args.model_name_or_path,
+ config=config,
+ trust_remote_code=args.trust_remote_code,
+ do_reduce_labels=args.do_reduce_labels,
+ )
+
+ # Define transforms to be applied to each image and target.
+ if "shortest_edge" in image_processor.size:
+ # We instead set the target size as (shortest_edge, shortest_edge) to here to ensure all images are batchable.
+ height, width = image_processor.size["shortest_edge"], image_processor.size["shortest_edge"]
+ else:
+ height, width = image_processor.size["height"], image_processor.size["width"]
+ train_transforms = A.Compose(
+ [
+ A.Lambda(name="reduce_labels", mask=reduce_labels_transform if args.do_reduce_labels else None, p=1.0),
+ # pad image with 255, because it is ignored by loss
+ A.PadIfNeeded(min_height=height, min_width=width, border_mode=0, value=255, p=1.0),
+ A.RandomCrop(height=height, width=width, p=1.0),
+ A.HorizontalFlip(p=0.5),
+ A.Normalize(mean=image_processor.image_mean, std=image_processor.image_std, max_pixel_value=255.0, p=1.0),
+ ToTensorV2(),
+ ]
+ )
+ val_transforms = A.Compose(
+ [
+ A.Lambda(name="reduce_labels", mask=reduce_labels_transform if args.do_reduce_labels else None, p=1.0),
+ A.Resize(height=height, width=width, p=1.0),
+ A.Normalize(mean=image_processor.image_mean, std=image_processor.image_std, max_pixel_value=255.0, p=1.0),
+ ToTensorV2(),
+ ]
+ )
+
+ def preprocess_batch(example_batch, transforms: A.Compose):
+ pixel_values = []
+ labels = []
+ for image, target in zip(example_batch["image"], example_batch["label"]):
+ transformed = transforms(image=np.array(image.convert("RGB")), mask=np.array(target))
+ pixel_values.append(transformed["image"])
+ labels.append(transformed["mask"])
+
+ encoding = {}
+ encoding["pixel_values"] = torch.stack(pixel_values).to(torch.float)
+ encoding["labels"] = torch.stack(labels).to(torch.long)
+
+ return encoding
+
+ # Preprocess function for dataset should have only one input argument,
+ # so we use partial to pass transforms
+ preprocess_train_batch_fn = partial(preprocess_batch, transforms=train_transforms)
+ preprocess_val_batch_fn = partial(preprocess_batch, transforms=val_transforms)
+
+ with accelerator.main_process_first():
+ train_dataset = dataset["train"].with_transform(preprocess_train_batch_fn)
+ eval_dataset = dataset["validation"].with_transform(preprocess_val_batch_fn)
+
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=args.per_device_train_batch_size
+ )
+ eval_dataloader = DataLoader(
+ eval_dataset, collate_fn=default_data_collator, batch_size=args.per_device_eval_batch_size
+ )
+
+ # Optimizer
+ optimizer = torch.optim.AdamW(
+ list(model.parameters()),
+ lr=args.learning_rate,
+ betas=[args.adam_beta1, args.adam_beta2],
+ eps=args.adam_epsilon,
+ )
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps
+ if overrode_max_train_steps
+ else args.max_train_steps * accelerator.num_processes,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # Instantiate metric
+ metric = evaluate.load("mean_iou", cache_dir=args.cache_dir)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("semantic_segmentation_no_trainer", experiment_config)
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+ for step, batch in enumerate(active_dataloader):
+ with accelerator.accumulate(model):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+ accelerator.backward(loss)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir,
+ is_main_process=accelerator.is_main_process,
+ save_function=accelerator.save,
+ )
+ if accelerator.is_main_process:
+ image_processor.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ logger.info("***** Running evaluation *****")
+ model.eval()
+ for step, batch in enumerate(tqdm(eval_dataloader, disable=not accelerator.is_local_main_process)):
+ with torch.no_grad():
+ outputs = model(**batch)
+
+ upsampled_logits = torch.nn.functional.interpolate(
+ outputs.logits, size=batch["labels"].shape[-2:], mode="bilinear", align_corners=False
+ )
+ predictions = upsampled_logits.argmax(dim=1)
+
+ predictions, references = accelerator.gather_for_metrics((predictions, batch["labels"]))
+
+ metric.add_batch(
+ predictions=predictions,
+ references=references,
+ )
+
+ eval_metrics = metric.compute(
+ num_labels=len(id2label),
+ ignore_index=255,
+ reduce_labels=False, # we've already reduced the labels before
+ )
+ logger.info(f"epoch {epoch}: {eval_metrics}")
+
+ if args.with_tracking:
+ accelerator.log(
+ {
+ "mean_iou": eval_metrics["mean_iou"],
+ "mean_accuracy": eval_metrics["mean_accuracy"],
+ "overall_accuracy": eval_metrics["overall_accuracy"],
+ "train_loss": total_loss.item() / len(train_dataloader),
+ "epoch": epoch,
+ "step": completed_steps,
+ },
+ step=completed_steps,
+ )
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ image_processor.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ image_processor.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ all_results = {
+ f"eval_{k}": v.tolist() if isinstance(v, np.ndarray) else v for k, v in eval_metrics.items()
+ }
+ with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
+ json.dump(all_results, f, indent=2)
+
+ accelerator.wait_for_everyone()
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/speech-pretraining/README.md b/docs/transformers/examples/pytorch/speech-pretraining/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..d0126634d2310a7cdaf5fe0bc08b6ac46d845e77
--- /dev/null
+++ b/docs/transformers/examples/pytorch/speech-pretraining/README.md
@@ -0,0 +1,161 @@
+
+
+# Speech Recognition Pre-Training
+
+
+## Wav2Vec2 Speech Pre-Training
+
+The script [`run_speech_wav2vec2_pretraining_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py) can be used to pre-train a [Wav2Vec2](https://huggingface.co/transformers/model_doc/wav2vec2.html?highlight=wav2vec2) model from scratch.
+
+In the script [`run_speech_wav2vec2_pretraining_no_trainer`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py), a Wav2Vec2 model is pre-trained on audio data alone using [Wav2Vec2's contrastive loss objective](https://arxiv.org/abs/2006.11477).
+
+The following examples show how to fine-tune a `"base"`-sized Wav2Vec2 model as well as a `"large"`-sized Wav2Vec2 model using [`accelerate`](https://github.com/huggingface/accelerate).
+
+
+---
+**NOTE 1**
+
+Wav2Vec2's pre-training is known to be quite unstable.
+It is advised to do a couple of test runs with a smaller dataset,
+*i.e.* `--dataset_config_names clean clean`, `--dataset_split_names validation test`
+to find good hyper-parameters for `learning_rate`, `batch_size`, `num_warmup_steps`,
+and the optimizer.
+A good metric to observe during training is the gradient norm which should ideally be between 0.5 and 2.
+
+---
+
+---
+**NOTE 2**
+
+When training a model on large datasets it is recommended to run the data preprocessing
+in a first run in a **non-distributed** mode via `--preprocessing_only` so that
+when running the model in **distributed** mode in a second step the preprocessed data
+can easily be loaded on each distributed device.
+
+---
+
+### Demo
+
+In this demo run we pre-train a `"base-sized"` Wav2Vec2 model simply only on the validation
+and test data of [librispeech_asr](https://huggingface.co/datasets/librispeech_asr).
+
+The demo is run on two Titan RTX (24 GB RAM each). In case you have less RAM available
+per device, consider reducing `--batch_size` and/or the `--max_duration_in_seconds`.
+
+
+```bash
+accelerate launch run_wav2vec2_pretraining_no_trainer.py \
+ --dataset_name="librispeech_asr" \
+ --dataset_config_names clean clean \
+ --dataset_split_names validation test \
+ --model_name_or_path="patrickvonplaten/wav2vec2-base-v2" \
+ --output_dir="./wav2vec2-pretrained-demo" \
+ --max_train_steps="20000" \
+ --num_warmup_steps="32000" \
+ --gradient_accumulation_steps="8" \
+ --learning_rate="0.005" \
+ --weight_decay="0.01" \
+ --max_duration_in_seconds="20.0" \
+ --min_duration_in_seconds="2.0" \
+ --logging_steps="1" \
+ --saving_steps="10000" \
+ --per_device_train_batch_size="8" \
+ --per_device_eval_batch_size="8" \
+ --adam_beta1="0.9" \
+ --adam_beta2="0.98" \
+ --adam_epsilon="1e-06" \
+ --gradient_checkpointing \
+ --mask_time_prob="0.65" \
+ --mask_time_length="10"
+```
+
+The results of this run can be seen [here](https://wandb.ai/patrickvonplaten/wav2vec2-pretrained-demo/reports/Wav2Vec2-PreTraining-Demo-Run--VmlldzoxMDk3MjAw?accessToken=oa05s1y57lizo2ocxy3k01g6db1u4pt8m6ur2n8nl4cb0ug02ms2cw313kb8ruch).
+
+### Base
+
+To pre-train `"base-sized"` Wav2Vec2 model, *e.g.* [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base)
+on [librispeech_asr](https://huggingface.co/datasets/librispeech_asr), the following command can be run:
+
+```bash
+accelerate launch run_wav2vec2_pretraining_no_trainer.py \
+ --dataset_name=librispeech_asr \
+ --dataset_config_names clean clean other \
+ --dataset_split_names train.100 train.360 train.500 \
+ --model_name_or_path="patrickvonplaten/wav2vec2-base-v2" \
+ --output_dir="./wav2vec2-pretrained-demo" \
+ --max_train_steps="200000" \
+ --num_warmup_steps="32000" \
+ --gradient_accumulation_steps="4" \
+ --learning_rate="0.001" \
+ --weight_decay="0.01" \
+ --max_duration_in_seconds="20.0" \
+ --min_duration_in_seconds="2.0" \
+ --logging_steps="1" \
+ --saving_steps="10000" \
+ --per_device_train_batch_size="8" \
+ --per_device_eval_batch_size="8" \
+ --adam_beta1="0.9" \
+ --adam_beta2="0.98" \
+ --adam_epsilon="1e-06" \
+ --gradient_checkpointing \
+ --mask_time_prob="0.65" \
+ --mask_time_length="10"
+```
+
+The experiment was run on 8 GPU V100 (16 GB RAM each) for 4 days.
+In case you have more than 8 GPUs available for a higher effective `batch_size`,
+it is recommended to increase the `learning_rate` to `0.005` for faster convergence.
+
+The results of this run can be seen [here](https://wandb.ai/patrickvonplaten/test/reports/Wav2Vec2-Base--VmlldzoxMTUyODQ0?accessToken=rg6e8u9yizx964k8q47zctq1m4afpvtn1i3qi9exgdmzip6xwkfzvagfajpzj55n) and the checkpoint pretrained for 85,000 steps can be accessed [here](https://huggingface.co/patrickvonplaten/wav2vec2-base-repro-960h-libri-85k-steps)
+
+
+### Large
+
+To pre-train `"large-sized"` Wav2Vec2 model, *e.g.* [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60),
+on [librispeech_asr](https://huggingface.co/datasets/librispeech_asr), the following command can be run:
+
+```bash
+accelerate launch run_wav2vec2_pretraining_no_trainer.py \
+ --dataset_name=librispeech_asr \
+ --dataset_config_names clean clean other \
+ --dataset_split_names train.100 train.360 train.500 \
+ --output_dir=./test \
+ --max_train_steps=200000 \
+ --num_warmup_steps=32000 \
+ --gradient_accumulation_steps=8 \
+ --learning_rate=0.001 \
+ --weight_decay=0.01 \
+ --max_duration_in_seconds=20.0 \
+ --min_duration_in_seconds=2.0 \
+ --model_name_or_path=./
+ --logging_steps=1 \
+ --saving_steps=10000 \
+ --per_device_train_batch_size=2 \
+ --per_device_eval_batch_size=4 \
+ --adam_beta1=0.9 \
+ --adam_beta2=0.98 \
+ --adam_epsilon=1e-06 \
+ --gradient_checkpointing \
+ --mask_time_prob=0.65 \
+ --mask_time_length=10
+```
+
+The experiment was run on 8 GPU V100 (16 GB RAM each) for 7 days.
+In case you have more than 8 GPUs available for a higher effective `batch_size`,
+it is recommended to increase the `learning_rate` to `0.005` for faster convergence.
+
+The results of this run can be seen [here](https://wandb.ai/patrickvonplaten/pretraining-wav2vec2/reports/Wav2Vec2-Large--VmlldzoxMTAwODM4?accessToken=wm3qzcnldrwsa31tkvf2pdmilw3f63d4twtffs86ou016xjbyilh55uoi3mo1qzc) and the checkpoint pretrained for 120,000 steps can be accessed [here](https://huggingface.co/patrickvonplaten/wav2vec2-large-repro-960h-libri-120k-steps)
diff --git a/docs/transformers/examples/pytorch/speech-pretraining/requirements.txt b/docs/transformers/examples/pytorch/speech-pretraining/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..c270b3a565fac4aa34d441e6471581926f919f04
--- /dev/null
+++ b/docs/transformers/examples/pytorch/speech-pretraining/requirements.txt
@@ -0,0 +1,5 @@
+datasets >= 1.12.0
+torch >= 1.5
+torchaudio
+accelerate >= 0.12.0
+librosa
\ No newline at end of file
diff --git a/docs/transformers/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py b/docs/transformers/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4ce3f71eb54773ed1fc1ef173912c0842bf0a2c
--- /dev/null
+++ b/docs/transformers/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py
@@ -0,0 +1,800 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+
+"""Pre-Training a 🤗 Wav2Vec2 model on unlabeled audio data"""
+
+import argparse
+import math
+import os
+from dataclasses import dataclass
+from pathlib import Path
+from typing import Optional, Union
+
+import datasets
+import torch
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from datasets import DatasetDict, concatenate_datasets, load_dataset
+from huggingface_hub import HfApi
+from torch.utils.data.dataloader import DataLoader
+from tqdm.auto import tqdm
+
+import transformers
+from transformers import (
+ SchedulerType,
+ Wav2Vec2Config,
+ Wav2Vec2FeatureExtractor,
+ Wav2Vec2ForPreTraining,
+ get_scheduler,
+ is_wandb_available,
+ set_seed,
+)
+from transformers.models.wav2vec2.modeling_wav2vec2 import _compute_mask_indices, _sample_negative_indices
+from transformers.utils import send_example_telemetry
+
+
+logger = get_logger(__name__)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Finetune a transformers model on a text classification task")
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help="The name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--dataset_config_names",
+ nargs="+",
+ type=str,
+ required=True,
+ help="The configuration names of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--dataset_split_names",
+ nargs="+",
+ type=str,
+ required=True,
+ help="The names of the training data set splits to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--preprocessing_num_workers",
+ type=int,
+ default=None,
+ help="The number of processes to use for the preprocessing.",
+ )
+ parser.add_argument(
+ "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
+ )
+ parser.add_argument(
+ "--preprocessing_only",
+ action="store_true",
+ help="Only run the preprocessing script to be cached for future use",
+ )
+ parser.add_argument(
+ "--cache_dir",
+ type=str,
+ default=None,
+ help="Where do you want to store the pretrained models downloaded from huggingface.co",
+ )
+ parser.add_argument(
+ "--validation_split_percentage",
+ type=int,
+ default=1,
+ help="Percentage of training data that should be used for validation if no validation is present in dataset.",
+ )
+ parser.add_argument(
+ "--logging_steps",
+ type=int,
+ default=500,
+ help="Number of steps between each logging",
+ )
+ parser.add_argument(
+ "--saving_steps",
+ type=int,
+ default=500,
+ help="Number of steps between each logging",
+ )
+ parser.add_argument(
+ "--audio_column_name",
+ type=str,
+ default="audio",
+ help="Column in the dataset that contains speech file path. Defaults to 'audio'",
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ required=True,
+ )
+ parser.add_argument(
+ "--config_name",
+ type=str,
+ default=None,
+ help="Pretrained config name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--train_cache_file_name",
+ type=str,
+ default=None,
+ help="Path to the train cached file name",
+ )
+ parser.add_argument(
+ "--validation_cache_file_name",
+ type=str,
+ default=None,
+ help="Path to the validation cached file name",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="If True, use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=0, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--max_gumbel_temperature",
+ type=float,
+ default=2.0,
+ help="Maximum temperature for gumbel softmax.",
+ )
+ parser.add_argument(
+ "--min_gumbel_temperature",
+ type=float,
+ default=0.5,
+ help="Minimum temperature for gumbel softmax.",
+ )
+ parser.add_argument(
+ "--gumbel_temperature_decay", type=float, default=0.999995, help="Decay of gumbel temperature during training."
+ )
+ parser.add_argument(
+ "--max_duration_in_seconds",
+ type=float,
+ default=5.0,
+ help="Filter out audio files that are longer than `max_duration_in_seconds` seconds",
+ )
+ parser.add_argument(
+ "--min_duration_in_seconds",
+ type=float,
+ default=3.0,
+ help="Filter out audio files that are shorter than `min_duration_in_seconds` seconds",
+ )
+ parser.add_argument(
+ "--pad_to_multiple_of",
+ type=int,
+ default=None,
+ help=(
+ "If set will pad the sequence to a multiple of the provided value. This is especially useful to enable the"
+ " use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta)."
+ ),
+ )
+ parser.add_argument(
+ "--adam_beta1",
+ type=float,
+ default=0.9,
+ help="Beta1 for AdamW optimizer",
+ )
+ parser.add_argument(
+ "--adam_beta2",
+ type=float,
+ default=0.999,
+ help="Beta2 for AdamW optimizer",
+ )
+ parser.add_argument(
+ "--adam_epsilon",
+ type=float,
+ default=1e-8,
+ help="Epsilon for AdamW optimizer",
+ )
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--mask_time_prob",
+ type=float,
+ default=None,
+ help=(
+ "Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked in the"
+ " contrastive task. If omitted, will pull value from model config."
+ ),
+ )
+ parser.add_argument(
+ "--mask_time_length",
+ type=int,
+ default=None,
+ help=(
+ "Length of each vector mask span to mask along the time axis in the contrastive task."
+ " If omitted, will pull value from model config."
+ ),
+ )
+ args = parser.parse_args()
+
+ if args.push_to_hub:
+ assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
+
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ return args
+
+
+@dataclass
+class DataCollatorForWav2Vec2Pretraining:
+ """
+ Data collator that will dynamically pad the inputs received and prepare masked indices
+ for self-supervised pretraining.
+
+ Args:
+ model (:class:`~transformers.Wav2Vec2ForPreTraining`):
+ The Wav2Vec2 model used for pretraining. The data collator needs to have access
+ to config and ``_get_feat_extract_output_lengths`` function for correct padding.
+ feature_extractor (:class:`~transformers.Wav2Vec2FeatureExtractor`):
+ The processor used for processing the data.
+ padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
+ Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
+ among:
+ * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
+ sequence if provided).
+ * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided.
+ * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
+ different lengths).
+ max_length (:obj:`int`, `optional`):
+ Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
+ pad_to_multiple_of (:obj:`int`, `optional`):
+ If set will pad the sequence to a multiple of the provided value.
+ This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
+ 7.5 (Volta).
+ mask_time_prob (:obj:`float`, `optional`, defaults to :obj:`0.65`):
+ Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked for the contrastive task.
+ Note that overlap between masked sequences may decrease the actual percentage of masked vectors.
+ The default value is taken from the original wav2vec 2.0 article (https://arxiv.org/abs/2006.11477),
+ and results in about 49 percent of each sequence being masked on average.
+ mask_time_length (:obj:`int`, `optional`, defaults to :obj:`10`):
+ Length of each vector mask span to mask along the time axis in the contrastive task. The default value
+ originates from the original wav2vec 2.0 article and corresponds to the ``M`` variable mentioned there.
+ """
+
+ model: Wav2Vec2ForPreTraining
+ feature_extractor: Wav2Vec2FeatureExtractor
+ padding: Union[bool, str] = "longest"
+ pad_to_multiple_of: Optional[int] = None
+ mask_time_prob: Optional[float] = 0.65
+ mask_time_length: Optional[int] = 10
+
+ def __call__(self, features: list[dict[str, Union[list[int], torch.Tensor]]]) -> dict[str, torch.Tensor]:
+ # reformat list to dict and set to pytorch format
+ batch = self.feature_extractor.pad(
+ features,
+ padding=self.padding,
+ pad_to_multiple_of=self.pad_to_multiple_of,
+ return_tensors="pt",
+ )
+
+ device = batch["input_values"].device
+ batch_size = batch["input_values"].shape[0]
+
+ mask_indices_seq_length = self.model._get_feat_extract_output_lengths(batch["input_values"].shape[-1])
+ # make sure masked sequence length is a Python scalar
+ mask_indices_seq_length = int(mask_indices_seq_length)
+
+ # make sure that no loss is computed on padded inputs
+ if batch.get("attention_mask") is not None:
+ # compute real output lengths according to convolution formula
+ batch["sub_attention_mask"] = self.model._get_feature_vector_attention_mask(
+ mask_indices_seq_length, batch["attention_mask"]
+ )
+
+ features_shape = (batch_size, mask_indices_seq_length)
+
+ # sample randomly masked indices
+ mask_time_indices = _compute_mask_indices(
+ features_shape,
+ self.mask_time_prob,
+ self.mask_time_length,
+ attention_mask=batch.get("sub_attention_mask"),
+ )
+
+ # sample negative indices
+ sampled_negative_indices = _sample_negative_indices(
+ features_shape,
+ self.model.config.num_negatives,
+ mask_time_indices=mask_time_indices,
+ )
+ batch["mask_time_indices"] = torch.tensor(mask_time_indices, dtype=torch.long, device=device)
+ batch["sampled_negative_indices"] = torch.tensor(sampled_negative_indices, dtype=torch.long, device=device)
+
+ return batch
+
+
+def multiply_grads(params, c):
+ """Multiplies grads by a constant *c*."""
+ for p in params:
+ if p.grad is not None:
+ if torch.is_tensor(c):
+ c = c.to(p.grad.device)
+ p.grad.data.mul_(c)
+
+
+def get_grad_norm(params, scale=1):
+ """Compute grad norm given a gradient scale."""
+ total_norm = 0.0
+ for p in params:
+ if p.grad is not None:
+ param_norm = (p.grad.detach().data / scale).norm(2)
+ total_norm += param_norm.item() ** 2
+ total_norm = total_norm**0.5
+ return total_norm
+
+
+def main():
+ # See all possible arguments in src/transformers/args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_wav2vec2_pretraining_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ accelerator = Accelerator()
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+
+ # set up weights and biases if available
+ if is_wandb_available():
+ import wandb
+
+ wandb.init(project=args.output_dir.split("/")[-1])
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub and not args.preprocessing_only:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # 1. Download and create train, validation dataset
+ # We load all dataset configuration and dataset split pairs passed in
+ # ``args.dataset_config_names`` and ``args.dataset_split_names``
+ datasets_splits = []
+ for dataset_config_name, train_split_name in zip(args.dataset_config_names, args.dataset_split_names):
+ # load dataset
+ dataset_split = load_dataset(
+ args.dataset_name,
+ dataset_config_name,
+ split=train_split_name,
+ cache_dir=args.cache_dir,
+ trust_remote_code=args.trust_remote_code,
+ )
+ datasets_splits.append(dataset_split)
+
+ # Next, we concatenate all configurations and splits into a single training dataset
+ raw_datasets = DatasetDict()
+ if len(datasets_splits) > 1:
+ raw_datasets["train"] = concatenate_datasets(datasets_splits).shuffle(seed=args.seed)
+ else:
+ raw_datasets["train"] = datasets_splits[0]
+
+ # Take ``args.validation_split_percentage`` from the training dataset for the validation_split_percentage
+ num_validation_samples = raw_datasets["train"].num_rows * args.validation_split_percentage // 100
+
+ if num_validation_samples == 0:
+ raise ValueError(
+ "`args.validation_split_percentage` is less than a single sample "
+ f"for {len(raw_datasets['train'])} training samples. Increase "
+ "`args.num_validation_split_percentage`. "
+ )
+
+ raw_datasets["validation"] = raw_datasets["train"].select(range(num_validation_samples))
+ raw_datasets["train"] = raw_datasets["train"].select(range(num_validation_samples, raw_datasets["train"].num_rows))
+
+ # 2. Now we preprocess the datasets including loading the audio, resampling and normalization
+ # Thankfully, `datasets` takes care of automatically loading and resampling the audio,
+ # so that we just need to set the correct target sampling rate and normalize the input
+ # via the `feature_extractor`
+ feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(args.model_name_or_path)
+
+ # make sure that dataset decodes audio with correct sampling rate
+ raw_datasets = raw_datasets.cast_column(
+ args.audio_column_name, datasets.features.Audio(sampling_rate=feature_extractor.sampling_rate)
+ )
+
+ # only normalized-inputs-training is supported
+ if not feature_extractor.do_normalize:
+ raise ValueError(
+ "Training is only supported for normalized inputs. Make sure ``feature_extractor.do_normalize == True``"
+ )
+
+ # set max & min audio length in number of samples
+ max_length = int(args.max_duration_in_seconds * feature_extractor.sampling_rate)
+ min_length = int(args.min_duration_in_seconds * feature_extractor.sampling_rate)
+
+ def prepare_dataset(batch):
+ sample = batch[args.audio_column_name]
+
+ inputs = feature_extractor(
+ sample["array"], sampling_rate=sample["sampling_rate"], max_length=max_length, truncation=True
+ )
+ batch["input_values"] = inputs.input_values[0]
+ batch["input_length"] = len(inputs.input_values[0])
+
+ return batch
+
+ # load via mapped files via path
+ cache_file_names = None
+ if args.train_cache_file_name is not None:
+ cache_file_names = {"train": args.train_cache_file_name, "validation": args.validation_cache_file_name}
+
+ # load audio files into numpy arrays
+ with accelerator.main_process_first():
+ vectorized_datasets = raw_datasets.map(
+ prepare_dataset,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=raw_datasets["train"].column_names,
+ cache_file_names=cache_file_names,
+ )
+
+ if min_length > 0.0:
+ vectorized_datasets = vectorized_datasets.filter(
+ lambda x: x > min_length,
+ num_proc=args.preprocessing_num_workers,
+ input_columns=["input_length"],
+ )
+
+ vectorized_datasets = vectorized_datasets.remove_columns("input_length")
+
+ # for large datasets it is advised to run the preprocessing on a
+ # single machine first with ``args.preprocessing_only`` since there will mostly likely
+ # be a timeout when running the script in distributed mode.
+ # In a second step ``args.preprocessing_only`` can then be set to `False` to load the
+ # cached dataset
+ if args.preprocessing_only:
+ return
+
+ # 3. Load model
+ config = Wav2Vec2Config.from_pretrained(args.model_name_or_path)
+
+ # pretraining is only supported for "newer" stable layer norm architecture
+ # apply_spec_augment has to be True, mask_feature_prob has to be 0.0
+ if not config.do_stable_layer_norm or config.feat_extract_norm != "layer":
+ raise ValueError(
+ "PreTraining is only supported for ``config.do_stable_layer_norm=True`` and"
+ " ``config.feat_extract_norm='layer'"
+ )
+
+ # initialize random model
+ model = Wav2Vec2ForPreTraining(config)
+
+ # Activate gradient checkpointing if needed
+ if args.gradient_checkpointing:
+ model.gradient_checkpointing_enable()
+
+ # 4. Define data collator, optimizer and scheduler
+
+ mask_time_prob = config.mask_time_prob if args.mask_time_prob is None else args.mask_time_prob
+ mask_time_length = config.mask_time_length if args.mask_time_length is None else args.mask_time_length
+
+ data_collator = DataCollatorForWav2Vec2Pretraining(
+ model=model,
+ feature_extractor=feature_extractor,
+ pad_to_multiple_of=args.pad_to_multiple_of,
+ mask_time_prob=mask_time_prob,
+ mask_time_length=mask_time_length,
+ )
+ train_dataloader = DataLoader(
+ vectorized_datasets["train"],
+ shuffle=True,
+ collate_fn=data_collator,
+ batch_size=args.per_device_train_batch_size,
+ )
+ eval_dataloader = DataLoader(
+ vectorized_datasets["validation"], collate_fn=data_collator, batch_size=args.per_device_eval_batch_size
+ )
+
+ # Optimizer
+ optimizer = torch.optim.AdamW(
+ list(model.parameters()),
+ lr=args.learning_rate,
+ betas=[args.adam_beta1, args.adam_beta2],
+ eps=args.adam_epsilon,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+ )
+
+ # Scheduler and math around the number of training steps.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps,
+ num_training_steps=args.max_train_steps,
+ )
+
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # 5. Train
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(vectorized_datasets['train'])}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ completed_steps = 0
+ starting_epoch = 0
+
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ for step, batch in enumerate(train_dataloader):
+ # compute num of losses
+ num_losses = batch["mask_time_indices"].sum()
+ sub_attention_mask = batch.pop("sub_attention_mask", None)
+ sub_attention_mask = (
+ sub_attention_mask if sub_attention_mask is not None else torch.ones_like(batch["mask_time_indices"])
+ )
+ percent_masked = num_losses / sub_attention_mask.sum()
+
+ # forward
+ outputs = model(**batch)
+
+ # divide loss by gradient accumulation steps since gradients
+ # are accumulated for multiple backward passes in PyTorch
+ loss = outputs.loss / args.gradient_accumulation_steps
+ accelerator.backward(loss)
+
+ # make sure that `num_losses` is summed for distributed training
+ # and average gradients over losses of all devices
+ if accelerator.state.num_processes > 1:
+ num_losses = accelerator.gather_for_metrics(num_losses).sum()
+ gradient_multiplier = accelerator.state.num_processes / num_losses
+ multiply_grads(model.module.parameters(), gradient_multiplier)
+ else:
+ multiply_grads(model.parameters(), 1 / num_losses)
+
+ # update step
+ if (step + 1) % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
+ # compute grad norm for monitoring
+ scale = (
+ accelerator.scaler._scale.item()
+ if hasattr(accelerator, "scaler") and accelerator.scaler is not None
+ else 1
+ )
+ if accelerator.state.num_processes > 1:
+ grad_norm = get_grad_norm(model.module.parameters(), scale)
+ else:
+ grad_norm = get_grad_norm(model.parameters(), scale)
+
+ # update parameters
+ optimizer.step()
+ optimizer.zero_grad()
+
+ if not accelerator.optimizer_step_was_skipped:
+ lr_scheduler.step()
+ elif accelerator.is_local_main_process:
+ progress_bar.write(
+ f"Gradients have overflown - skipping update step... Updating gradient scale to {scale}..."
+ )
+
+ # update gumbel temperature
+ gumbel_temperature = max(
+ args.max_gumbel_temperature * args.gumbel_temperature_decay**completed_steps,
+ args.min_gumbel_temperature,
+ )
+ if hasattr(model, "module"):
+ model.module.set_gumbel_temperature(gumbel_temperature)
+ else:
+ model.set_gumbel_temperature(gumbel_temperature)
+
+ progress_bar.update(1)
+ completed_steps += 1
+
+ # 6. Log all results
+ if (step + 1) % (args.gradient_accumulation_steps * args.logging_steps) == 0:
+ loss.detach()
+ outputs.contrastive_loss.detach()
+ outputs.diversity_loss.detach()
+
+ if accelerator.state.num_processes > 1:
+ loss = accelerator.gather_for_metrics(loss).sum()
+ outputs.contrastive_loss = accelerator.gather_for_metrics(outputs.contrastive_loss).sum()
+ outputs.diversity_loss = accelerator.gather_for_metrics(outputs.diversity_loss).sum()
+ percent_masked = accelerator.gather_for_metrics(percent_masked).sum()
+
+ train_logs = {
+ "loss": (loss * args.gradient_accumulation_steps) / num_losses,
+ "constrast_loss": outputs.contrastive_loss / num_losses,
+ "div_loss": outputs.diversity_loss / num_losses,
+ "%_mask_idx": percent_masked / accelerator.num_processes,
+ "ppl": outputs.codevector_perplexity,
+ "lr": torch.tensor(optimizer.param_groups[0]["lr"]),
+ "temp": torch.tensor(gumbel_temperature),
+ "grad_norm": torch.tensor(grad_norm),
+ }
+ log_str = ""
+ for k, v in train_logs.items():
+ log_str += f"| {k}: {v.item():.3e}"
+
+ if accelerator.is_local_main_process:
+ progress_bar.write(log_str)
+ if is_wandb_available():
+ wandb.log(train_logs)
+
+ # save model every `args.saving_steps` steps
+ if (step + 1) % (args.gradient_accumulation_steps * args.saving_steps) == 0:
+ if (args.push_to_hub and epoch < args.num_train_epochs - 1) or args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+
+ if (args.push_to_hub and epoch < args.num_train_epochs - 1) and accelerator.is_main_process:
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ # if completed steps > `args.max_train_steps` stop
+ if completed_steps >= args.max_train_steps:
+ break
+
+ # 7. Validate!
+ model.eval()
+
+ # init logs
+ val_logs = {
+ "val_loss": 0,
+ "val_contrastive_loss": 0,
+ "val_diversity_loss": 0,
+ "val_num_losses": 0,
+ }
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ batch.pop("sub_attention_mask", None)
+ outputs = model(**batch)
+
+ val_logs["val_loss"] += outputs.loss
+ val_logs["val_contrastive_loss"] += outputs.contrastive_loss
+ val_logs["val_diversity_loss"] += outputs.diversity_loss
+ val_logs["val_num_losses"] += batch["mask_time_indices"].sum()
+
+ # sum over devices in multi-processing
+ if accelerator.num_processes > 1:
+ val_logs = {k: accelerator.gather_for_metrics(v).sum() for k, v in val_logs.items()}
+
+ val_logs = {k: v / val_logs["val_num_losses"] for k, v in val_logs.items()}
+
+ log_str = ""
+ for k, v in val_logs.items():
+ log_str += f"| {k}: {v.item():.3e}"
+
+ if accelerator.is_local_main_process:
+ progress_bar.write(log_str)
+ if is_wandb_available():
+ wandb.log(val_logs)
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/speech-recognition/README.md b/docs/transformers/examples/pytorch/speech-recognition/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..4990219f42a143a799201f6d044b624942dd08e8
--- /dev/null
+++ b/docs/transformers/examples/pytorch/speech-recognition/README.md
@@ -0,0 +1,617 @@
+
+
+# Automatic Speech Recognition Examples
+
+## Table of Contents
+
+- [Automatic Speech Recognition with CTC](#connectionist-temporal-classification)
+ - [Single GPU example](#single-gpu-ctc)
+ - [Multi GPU example](#multi-gpu-ctc)
+ - [Examples](#examples-ctc)
+ - [TIMIT](#timit-ctc)
+ - [Librispeech](#librispeech-ctc)
+ - [Common Voice](#common-voice-ctc)
+ - [Multilingual Librispeech](#multilingual-librispeech-ctc)
+- [Automatic Speech Recognition with CTC and Adapter Layers](#connectionist-temporal-classification-with-adapters)
+ - [Massive Multilingual Speech (MMS)](#mms-model)
+ - [Examples](#examples-ctc-adapter)
+ - [Common Voice](#common-voice-ctc-adapter)
+- [Automatic Speech Recognition with Sequence-to-Sequence](#sequence-to-sequence)
+ - [Whisper Model](#whisper-model)
+ - [Speech-Encoder-Decoder Model](#warm-started-speech-encoder-decoder-model)
+ - [Examples](#examples-seq2seq)
+ - [Librispeech](#librispeech-seq2seq)
+
+## Connectionist Temporal Classification
+
+The script [`run_speech_recognition_ctc.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py) can be used to fine-tune any pretrained [Connectionist Temporal Classification Model](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForCTC) for automatic speech
+recognition on one of the [official speech recognition datasets](https://huggingface.co/datasets?task_ids=task_ids:automatic-speech-recognition) or a custom dataset.
+
+Speech recognition models that have been pretrained in unsupervised fashion on audio data alone, *e.g.* [Wav2Vec2](https://huggingface.co/transformers/main/model_doc/wav2vec2.html), [HuBERT](https://huggingface.co/transformers/main/model_doc/hubert.html), [XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html), have shown to require only
+very little annotated data to yield good performance on automatic speech recognition datasets.
+
+In the script [`run_speech_recognition_ctc`], we first create a vocabulary from all unique characters of both the training data and evaluation data. Then, we preprocesses the speech recognition dataset, which includes correct resampling, normalization and padding. Finally, the pretrained speech recognition model is fine-tuned on the annotated speech recognition datasets using CTC loss.
+
+---
+**NOTE**
+
+If you encounter problems with data preprocessing by setting `--preprocessing_num_workers` > 1,
+you might want to set the environment variable `OMP_NUM_THREADS` to 1 as follows:
+
+```bash
+OMP_NUM_THREADS=1 python run_speech_recognition_ctc ...
+```
+
+If the environment variable is not set, the training script might freeze, *i.e.* see: https://github.com/pytorch/audio/issues/1021#issuecomment-726915239
+
+---
+
+### Single GPU CTC
+
+The following command shows how to fine-tune [XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html) on [Common Voice](https://huggingface.co/datasets/common_voice) using a single GPU in half-precision.
+
+```bash
+python run_speech_recognition_ctc.py \
+ --dataset_name="common_voice" \
+ --model_name_or_path="facebook/wav2vec2-large-xlsr-53" \
+ --dataset_config_name="tr" \
+ --output_dir="./wav2vec2-common_voice-tr-demo" \
+ --overwrite_output_dir \
+ --num_train_epochs="15" \
+ --per_device_train_batch_size="16" \
+ --gradient_accumulation_steps="2" \
+ --learning_rate="3e-4" \
+ --warmup_steps="500" \
+ --eval_strategy="steps" \
+ --text_column_name="sentence" \
+ --length_column_name="input_length" \
+ --save_steps="400" \
+ --eval_steps="100" \
+ --layerdrop="0.0" \
+ --save_total_limit="3" \
+ --freeze_feature_encoder \
+ --gradient_checkpointing \
+ --chars_to_ignore , ? . ! - \; \: \" “ % ‘ ” � \
+ --fp16 \
+ --group_by_length \
+ --push_to_hub \
+ --do_train --do_eval
+```
+
+On a single V100 GPU, this script should run in *ca.* 1 hour 20 minutes and yield a CTC loss of **0.39** and word error rate
+of **0.35**.
+
+### Multi GPU CTC
+
+The following command shows how to fine-tune [XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html) on [Common Voice](https://huggingface.co/datasets/common_voice) using 8 GPUs in half-precision.
+
+```bash
+torchrun \
+ --nproc_per_node 8 run_speech_recognition_ctc.py \
+ --dataset_name="common_voice" \
+ --model_name_or_path="facebook/wav2vec2-large-xlsr-53" \
+ --dataset_config_name="tr" \
+ --output_dir="./wav2vec2-common_voice-tr-demo-dist" \
+ --overwrite_output_dir \
+ --num_train_epochs="15" \
+ --per_device_train_batch_size="4" \
+ --learning_rate="3e-4" \
+ --warmup_steps="500" \
+ --eval_strategy="steps" \
+ --text_column_name="sentence" \
+ --length_column_name="input_length" \
+ --save_steps="400" \
+ --eval_steps="100" \
+ --logging_steps="1" \
+ --layerdrop="0.0" \
+ --save_total_limit="3" \
+ --freeze_feature_encoder \
+ --gradient_checkpointing \
+ --chars_to_ignore , ? . ! - \; \: \" “ % ‘ ” � \
+ --fp16 \
+ --group_by_length \
+ --push_to_hub \
+ --do_train --do_eval
+```
+
+On 8 V100 GPUs, this script should run in *ca.* 18 minutes and yield a CTC loss of **0.39** and word error rate
+of **0.36**.
+
+
+### Multi GPU CTC with Dataset Streaming
+
+The following command shows how to use [Dataset Streaming mode](https://huggingface.co/docs/datasets/dataset_streaming)
+to fine-tune [XLS-R](https://huggingface.co/transformers/main/model_doc/xls_r.html)
+on [Common Voice](https://huggingface.co/datasets/common_voice) using 4 GPUs in half-precision.
+
+Streaming mode imposes several constraints on training:
+1. We need to construct a tokenizer beforehand and define it via `--tokenizer_name_or_path`.
+2. `--num_train_epochs` has to be replaced by `--max_steps`. Similarly, all other epoch-based arguments have to be
+replaced by step-based ones.
+3. Full dataset shuffling on each epoch is not possible, since we don't have the whole dataset available at once.
+However, the `--shuffle_buffer_size` argument controls how many examples we can pre-download before shuffling them.
+
+
+```bash
+**torchrun \
+ --nproc_per_node 4 run_speech_recognition_ctc_streaming.py \
+ --dataset_name="common_voice" \
+ --model_name_or_path="facebook/wav2vec2-xls-r-300m" \
+ --tokenizer_name_or_path="anton-l/wav2vec2-tokenizer-turkish" \
+ --dataset_config_name="tr" \
+ --train_split_name="train+validation" \
+ --eval_split_name="test" \
+ --output_dir="wav2vec2-xls-r-common_voice-tr-ft" \
+ --overwrite_output_dir \
+ --max_steps="5000" \
+ --per_device_train_batch_size="8" \
+ --gradient_accumulation_steps="2" \
+ --learning_rate="5e-4" \
+ --warmup_steps="500" \
+ --eval_strategy="steps" \
+ --text_column_name="sentence" \
+ --save_steps="500" \
+ --eval_steps="500" \
+ --logging_steps="1" \
+ --layerdrop="0.0" \
+ --eval_metrics wer cer \
+ --save_total_limit="1" \
+ --mask_time_prob="0.3" \
+ --mask_time_length="10" \
+ --mask_feature_prob="0.1" \
+ --mask_feature_length="64" \
+ --freeze_feature_encoder \
+ --chars_to_ignore , ? . ! - \; \: \" “ % ‘ ” � \
+ --max_duration_in_seconds="20" \
+ --shuffle_buffer_size="500" \
+ --fp16 \
+ --push_to_hub \
+ --do_train --do_eval \
+ --gradient_checkpointing**
+```
+
+On 4 V100 GPUs, this script should run in *ca.* 3h 31min and yield a CTC loss of **0.35** and word error rate
+of **0.29**.
+
+### Examples CTC
+
+The following tables present a couple of example runs on the most popular speech-recognition datasets.
+The presented performances are by no means optimal as no hyper-parameter tuning was done. Nevertheless,
+they can serve as a baseline to improve upon.
+
+
+#### TIMIT CTC
+
+- [TIMIT](https://huggingface.co/datasets/timit_asr)
+
+| Dataset | Dataset Config | Pretrained Model | Word error rate on eval | Phoneme error rate on eval | GPU setup | Training time | Fine-tuned Model & Logs | Command to reproduce |
+|-------|------------------------------|-------------|---------------|---------------|----------------------|-------------| -------------| ------- |
+| [TIMIT](https://huggingface.co/datasets/timit_asr)| - | [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) | 0.21 | - | 1 GPU TITAN RTX | 32min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-base-timit-fine-tuned) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-base-timit-fine-tuned/blob/main/run.sh) |
+| [TIMIT](https://huggingface.co/datasets/timit_asr)| - | [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) | 0.21 | - | 1 GPU TITAN RTX | 32min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-base-timit-fine-tuned) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-base-timit-fine-tuned/blob/main/run.sh) |
+| [TIMIT](https://huggingface.co/datasets/timit_asr)| - | [unispeech-large-1500h-cv](https://huggingface.co/microsoft/unispeech-large-1500h-cv) | 0.22 | - | 1 GPU TITAN RTX | 35min | [here](https://huggingface.co/patrickvonplaten/unispeech-large-1500h-cv-timit) | [run.sh](https://huggingface.co/patrickvonplaten/unispeech-large-1500h-cv-timit/blob/main/run.sh) |
+| [TIMIT](https://huggingface.co/datasets/timit_asr)| - | [asapp/sew-mid-100k](https://huggingface.co/asapp/sew-mid-100k) | 0.30 | - | 1 GPU TITAN RTX | 28min | [here](https://huggingface.co/patrickvonplaten/sew-small-100k-timit) | [run.sh](https://huggingface.co/patrickvonplaten/sew-small-100k-timit/blob/main/run.sh) |
+| [TIMIT](https://huggingface.co/datasets/timit_asr)| - | [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) | 0.68 | - | 1 GPU TITAN RTX | 26min | [here](https://huggingface.co/patrickvonplaten/distilhubert-timit) | [run.sh](https://huggingface.co/patrickvonplaten/distilhubert-timit/blob/main/run.sh) |
+
+
+#### Librispeech CTC
+
+- [Librispeech](https://huggingface.co/datasets/librispeech_asr)
+
+| Dataset | Dataset Config | Pretrained Model | Word error rate on eval | Phoneme error rate on eval | GPU setup | Training time | Fine-tuned Model & Logs | Command to reproduce |
+|-------|------------------------------|-------------|---------------|---------------|----------------------|-------------| -------------| ------- |
+| [Librispeech](https://huggingface.co/datasets/librispeech_asr)| `"clean"` - `"train.100"` | [microsoft/wavlm-large](https://huggingface.co/microsoft/wavlm-large) | 0.049 | - | 8 GPU V100 | 1h30min | [here](https://huggingface.co/patrickvonplaten/wavlm-libri-clean-100h-large) | [run.sh](https://huggingface.co/patrickvonplaten/wavlm-libri-clean-100h-large/blob/main/run.sh) |
+| [Librispeech](https://huggingface.co/datasets/librispeech_asr)| `"clean"` - `"train.100"` | [microsoft/wavlm-base-plus](https://huggingface.co/microsoft/wavlm-base-plus) | 0.068 | - | 8 GPU V100 | 1h30min | [here](https://huggingface.co/patrickvonplaten/wavlm-libri-clean-100h-base-plus) | [run.sh](https://huggingface.co/patrickvonplaten/wavlm-libri-clean-100h-base-plus/blob/main/run.sh) |
+| [Librispeech](https://huggingface.co/datasets/librispeech_asr)| `"clean"` - `"train.100"` | [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) | 0.042 | - | 8 GPU V100 | 1h30min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-librispeech-clean-100h-demo-dist) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-librispeech-clean-100h-demo-dist/blob/main/run.sh) |
+| [Librispeech](https://huggingface.co/datasets/librispeech_asr)| `"clean"` - `"train.100"` | [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) | 0.042 | - | 8 GPU V100 | 1h30min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-librispeech-clean-100h-demo-dist) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-librispeech-clean-100h-demo-dist/blob/main/run.sh) |
+| [Librispeech](https://huggingface.co/datasets/librispeech_asr)| `"clean"` - `"train.100"` | [facebook/hubert-large-ll60k](https://huggingface.co/facebook/hubert-large-ll60k) | 0.088 | - | 8 GPU V100 | 1h30min | [here](https://huggingface.co/patrickvonplaten/hubert-librispeech-clean-100h-demo-dist) | [run.sh](https://huggingface.co/patrickvonplaten/hubert-librispeech-clean-100h-demo-dist/blob/main/run.sh) |
+| [Librispeech](https://huggingface.co/datasets/librispeech_asr)| `"clean"` - `"train.100"` | [asapp/sew-mid-100k](https://huggingface.co/asapp/sew-mid-100k) | 0.167 | | 8 GPU V100 | 54min | [here](https://huggingface.co/patrickvonplaten/sew-mid-100k-librispeech-clean-100h-ft) | [run.sh](https://huggingface.co/patrickvonplaten/sew-mid-100k-librispeech-clean-100h-ft/blob/main/run.sh) |
+
+
+#### Common Voice CTC
+
+- [Common Voice](https://huggingface.co/datasets/common_voice)
+
+| Dataset | Dataset Config | Pretrained Model | Word error rate on eval | Phoneme error rate on eval | GPU setup | Training time | Fine-tuned Model & Logs | Command to reproduce |
+|-------|------------------------------|-------------|---------------|---------------|----------------------|-------------| -------------| ------- |
+| [Common Voice](https://huggingface.co/datasets/mozilla-foundation/common_voice_3_0)| `"tr"` | [facebook/wav2vec2-large-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | - | 0.099 | 8 GPU V100 | 23min | [here](https://huggingface.co/patrickvonplaten/xls-r-300m-tr-phoneme) | [run.sh](https://huggingface.co/patrickvonplaten/xls-r-300m-tr-phoneme/blob/main/run.sh) |
+| [Common Voice](https://huggingface.co/datasets/mozilla-foundation/common_voice_3_0)| `"it"` | [facebook/wav2vec2-large-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | - | 0.077 | 8 GPU V100 | 23min | [here](https://huggingface.co/patrickvonplaten/xls-r-300m-it-phoneme) | [run.sh](https://huggingface.co/patrickvonplaten/xls-r-300m-it-phoneme/blob/main/run.sh) |
+| [Common Voice](https://huggingface.co/datasets/mozilla-foundation/common_voice_3_0)| `"sv-SE"` | [facebook/wav2vec2-large-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | - | 0.099 | 8 GPU V100 | 23min | [here](https://huggingface.co/patrickvonplaten/xls-r-300m-sv-phoneme) | [run.sh](https://huggingface.co/patrickvonplaten/xls-r-300m-sv-phoneme/blob/main/run.sh) |
+| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) | 0.36 | - | 8 GPU V100 | 18min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-common_voice-tr-demo-dist) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-common_voice-tr-demo-dist/blob/main/run_dist.sh) |
+| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) | 0.31 | - | 8 GPU V100 | 1h05 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-large-xlsr-53-common_voice-tr-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-large-xlsr-53-common_voice-tr-ft/blob/main/run.sh) |
+| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) | 0.35 | - | 1 GPU V100 | 1h20min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-common_voice-tr-demo) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-common_voice-tr-demo/blob/main/run.sh) |
+| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | 0.31 | - | 8 GPU V100 | 1h05 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-large-xls-r-300m-common_voice-tr-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-large-xls-r-300m-common_voice-tr-ft/blob/main/run.sh) |
+| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) | 0.21 | - | 2 GPU Titan 24 GB RAM | 15h10 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-xls-r-1b-common_voice-tr-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-large-xls-r-1b-common_voice-tr-ft/blob/main/run.sh) |
+| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` in streaming mode | [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | 0.29 | - | 4 GPU V100 | 3h31 | [here](https://huggingface.co/anton-l/wav2vec2-xls-r-common_voice-tr-ft-stream) | [run.sh](https://huggingface.co/anton-l/wav2vec2-xls-r-common_voice-tr-ft-stream/blob/main/run.sh) |
+
+
+#### Multilingual Librispeech CTC
+
+- [Multilingual Librispeech](https://huggingface.co/datasets/multilingual_librispeech)
+
+| Dataset | Dataset Config | Pretrained Model | Word error rate on eval | Phoneme error rate on eval | GPU setup | Training time | Fine-tuned Model & Logs | Command to reproduce |
+|-------|------------------------------|-------------|---------------|---------------|----------------------|-------------| -------------| ------- |
+| [Multilingual Librispeech](https://huggingface.co/datasets/multilingual_librispeech)| `"german"` | [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) | 0.13 | - | 1 GPU Titan 24 GB RAM | 15h04 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-xlsr-53-300m-mls-german-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-xlsr-53-300m-mls-german-ft/blob/main/run.sh) |
+| [Multilingual Librispeech](https://huggingface.co/datasets/multilingual_librispeech)| `"german"` | [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | 0.15 | - | 1 GPU Titan 24 GB RAM | 15h04 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-300m-mls-german-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-300m-mls-german-ft/blob/main/run.sh) |
+
+## Connectionist Temporal Classification With Adapters
+
+The script [`run_speech_recognition_ctc_adapter.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py) can be used to fine-tune adapter layers for [Wav2Vec2-like models like MMS](https://huggingface.co/docs/transformers/main/en/model_doc/mms) for automatic speech recognition.
+
+### MMS Model
+
+The [Massive Multilingual Speech (MMS) model](https://huggingface.co/facebook/mms-1b-all) has been pre-trained and fine-tuned
+on 1000+ languages. The model makes use of adapter attention layers to fine-tune only a small part
+of the model on a specific language. The model already comes with fine-tuned adapter layers for 1000+ languages and
+can be used for inference for 1000+ languages out of the box.
+
+However, for improved performance or more specific use cases one can re-initialize the adapter weights, freeze all
+other weights and fine-tune them on a specific dataset as shown in the [example below](#examples-ctc-adapter).
+
+Note that the adapter weights include low dimensional linear layers for every attention block as well as the final language
+model head layers.
+
+### Examples CTC Adapter
+
+In the following we will look at how one can fine-tune adapter weights for any of the
+[MMS CTC checkpoints](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&other=mms&sort=downloads) in less than 1 hour.
+
+#### Common Voice CTC Adapter
+
+As in the examples [above](#examples-ctc), we fine-tune on Common Voice's 6 dataset in Turkish as an example.
+Contrary to [`run_speech_recognition_ctc.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py) before there is a `--target_language` which has to be defined to state for which
+language or concept the adapter layers shall be trained. The adapter weights will then
+accordingly be called `adapter.{/wav2vec2-2-bart-base
+cd wav2vec2-2-bart-base
+```
+
+Next, run the following script **inside** the just cloned repo:
+
+```python
+from transformers import SpeechEncoderDecoderModel, AutoFeatureExtractor, AutoTokenizer, Wav2Vec2Processor
+
+# checkpoints to leverage
+encoder_id = "facebook/wav2vec2-base"
+decoder_id = "facebook/bart-base"
+
+# load and save speech-encoder-decoder model
+# set some hyper-parameters for training and evaluation
+model = SpeechEncoderDecoderModel.from_encoder_decoder_pretrained(encoder_id, decoder_id, encoder_add_adapter=True, encoder_feat_proj_dropout=0.0, encoder_layerdrop=0.0, max_length=200, num_beams=5)
+model.config.decoder_start_token_id = model.decoder.config.bos_token_id
+model.config.pad_token_id = model.decoder.config.pad_token_id
+model.config.eos_token_id = model.decoder.config.eos_token_id
+model.save_pretrained("./")
+
+# load and save processor
+feature_extractor = AutoFeatureExtractor.from_pretrained(encoder_id)
+tokenizer = AutoTokenizer.from_pretrained(decoder_id)
+processor = Wav2Vec2Processor(feature_extractor, tokenizer)
+processor.save_pretrained("./")
+```
+
+Finally, we can upload all files:
+```bash
+git lfs install
+git add . && git commit -m "upload model files" && git push
+```
+
+and link the official `run_speech_recognition_seq2seq.py` script to the folder:
+
+```bash
+ln -s $(realpath /examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py) ./
+```
+
+Note that we have added a randomly initialized _adapter layer_ to `wav2vec2-base` with the argument
+`encoder_add_adapter=True`. This adapter sub-samples the output sequence of
+`wav2vec2-base` along the time dimension. By default, a single
+output vector of `wav2vec2-base` has a receptive field of *ca.* 25ms (*cf.*
+Section *4.2* of the [official Wav2Vec2 paper](https://arxiv.org/pdf/2006.11477.pdf)), which represents a little less a single character. On the other hand, BART
+makes use of a sentence-piece tokenizer as an input processor, so that a single
+hidden vector of `bart-base` represents *ca.* 4 characters. To better align the
+receptive field of the *Wav2Vec2* output vectors with *BART*'s hidden-states in the cross-attention
+mechanism, we further subsample *Wav2Vec2*'s output by a factor of 8 by
+adding a convolution-based adapter.
+
+Having warm-started the speech-encoder-decoder model under `/wav2vec2-2-bart`, we can now fine-tune it on the task of speech recognition.
+
+In the script [`run_speech_recognition_seq2seq`], we load the warm-started model,
+feature extractor, and tokenizer, process a speech recognition dataset,
+and subsequently make use of the [`Seq2SeqTrainer`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.Seq2SeqTrainer) to train our system.
+Note that it is important to align the target transcriptions with the decoder's vocabulary. For example, the [`Librispeech`](https://huggingface.co/datasets/librispeech_asr) dataset only contains capitalized letters in the transcriptions,
+whereas BART was pretrained mostly on normalized text. Thus, it is recommended to add the argument
+`--do_lower_case` to the fine-tuning script when using a warm-started `SpeechEncoderDecoderModel`.
+The model is fine-tuned on the standard cross-entropy language modeling
+loss for sequence-to-sequence (just like *T5* or *BART* in natural language processing).
+
+---
+**NOTE**
+
+If you encounter problems with data preprocessing by setting `--preprocessing_num_workers` > 1,
+you might want to set the environment variable `OMP_NUM_THREADS` to 1 as follows:
+
+```bash
+OMP_NUM_THREADS=1 python run_speech_recognition_ctc ...
+```
+
+If the environment variable is not set, the training script might freeze, *i.e.* see: https://github.com/pytorch/audio/issues/1021#issuecomment-726915239.
+
+---
+
+#### Single GPU Seq2Seq
+
+The following command shows how to fine-tune [XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html) on [Common Voice](https://huggingface.co/datasets/common_voice) using a single GPU in half-precision.
+
+```bash
+python run_speech_recognition_seq2seq.py \
+ --dataset_name="librispeech_asr" \
+ --model_name_or_path="./" \
+ --dataset_config_name="clean" \
+ --train_split_name="train.100" \
+ --eval_split_name="validation" \
+ --output_dir="./" \
+ --preprocessing_num_workers="16" \
+ --length_column_name="input_length" \
+ --overwrite_output_dir \
+ --num_train_epochs="5" \
+ --per_device_train_batch_size="8" \
+ --per_device_eval_batch_size="8" \
+ --gradient_accumulation_steps="8" \
+ --learning_rate="3e-4" \
+ --warmup_steps="400" \
+ --eval_strategy="steps" \
+ --text_column_name="text" \
+ --save_steps="400" \
+ --eval_steps="400" \
+ --logging_steps="10" \
+ --save_total_limit="1" \
+ --freeze_feature_encoder \
+ --gradient_checkpointing \
+ --fp16 \
+ --group_by_length \
+ --predict_with_generate \
+ --generation_max_length="40" \
+ --generation_num_beams="1" \
+ --do_train --do_eval \
+ --do_lower_case
+```
+
+On a single V100 GPU, this script should run in *ca.* 5 hours and yield a
+cross-entropy loss of **0.405** and word error rate of **0.0728**.
+
+#### Multi GPU Seq2Seq
+
+The following command shows how to fine-tune [XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html) on [Common Voice](https://huggingface.co/datasets/common_voice) using 8 GPUs in half-precision.
+
+```bash
+torchrun \
+ --nproc_per_node 8 run_speech_recognition_seq2seq.py \
+ --dataset_name="librispeech_asr" \
+ --model_name_or_path="./" \
+ --dataset_config_name="clean" \
+ --train_split_name="train.100" \
+ --eval_split_name="validation" \
+ --output_dir="./" \
+ --preprocessing_num_workers="16" \
+ --length_column_name="input_length" \
+ --overwrite_output_dir \
+ --num_train_epochs="5" \
+ --per_device_train_batch_size="8" \
+ --per_device_eval_batch_size="8" \
+ --gradient_accumulation_steps="1" \
+ --learning_rate="3e-4" \
+ --warmup_steps="400" \
+ --eval_strategy="steps" \
+ --text_column_name="text" \
+ --save_steps="400" \
+ --eval_steps="400" \
+ --logging_steps="10" \
+ --save_total_limit="1" \
+ --freeze_feature_encoder \
+ --gradient_checkpointing \
+ --fp16 \
+ --group_by_length \
+ --predict_with_generate \
+ --do_train --do_eval \
+ --do_lower_case
+```
+
+On 8 V100 GPUs, this script should run in *ca.* 45 minutes and yield a cross-entropy loss of **0.405** and word error rate of **0.0728**
+
+### Examples Seq2Seq
+
+#### Librispeech Seq2Seq
+
+- [Librispeech](https://huggingface.co/datasets/librispeech_asr)
+
+| Dataset | Dataset Config | Pretrained Model | Word error rate on eval | Phoneme error rate on eval | GPU setup | Training time | Fine-tuned Model & Logs | Command to reproduce |
+|----------------------------------------------------------------|---------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------|----------------------------|------------|---------------|-----------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| [Librispeech](https://huggingface.co/datasets/librispeech_asr) | `"clean"` - `"train.100"` | [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) and [facebook/bart-base](https://huggingface.co/facebook/bart-base) | 0.0728 | - | 8 GPU V100 | 45min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-2-bart-base) | [create_model.py](https://huggingface.co/patrickvonplaten/wav2vec2-2-bart-base/blob/main/create_model.py) & [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-2-bart-base/blob/main/run_librispeech.sh) |
+| [Librispeech](https://huggingface.co/datasets/librispeech_asr) | `"clean"` - `"train.100"` | [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) and [facebook/bart-large](https://huggingface.co/facebook/bart-large) | 0.0486 | - | 8 GPU V100 | 1h20min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-2-bart-large) | [create_model.py](https://huggingface.co/patrickvonplaten/wav2vec2-2-bart-large/blob/main/create_model.py) & [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-2-bart-large/blob/main/run_librispeech.sh) |
diff --git a/docs/transformers/examples/pytorch/speech-recognition/requirements.txt b/docs/transformers/examples/pytorch/speech-recognition/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a16697b038c6350b32ee9e35b6fd6331ee1e26da
--- /dev/null
+++ b/docs/transformers/examples/pytorch/speech-recognition/requirements.txt
@@ -0,0 +1,6 @@
+datasets >= 1.18.0
+torch >= 1.5
+torchaudio
+librosa
+jiwer
+evaluate
diff --git a/docs/transformers/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py b/docs/transformers/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
new file mode 100644
index 0000000000000000000000000000000000000000..53a1f98c890a0620bdb9331191b65e5d95d88f25
--- /dev/null
+++ b/docs/transformers/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py
@@ -0,0 +1,821 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Fine-tuning a 🤗 Transformers CTC model for automatic speech recognition"""
+
+import functools
+import json
+import logging
+import os
+import re
+import sys
+import warnings
+from dataclasses import dataclass, field
+from typing import Optional, Union
+
+import datasets
+import evaluate
+import torch
+from datasets import DatasetDict, load_dataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoFeatureExtractor,
+ AutoModelForCTC,
+ AutoProcessor,
+ AutoTokenizer,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ Wav2Vec2Processor,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint, is_main_process
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
+
+
+logger = logging.getLogger(__name__)
+
+
+def list_field(default=None, metadata=None):
+ return field(default_factory=lambda: default, metadata=metadata)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ tokenizer_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={"help": "Path to pretrained tokenizer or tokenizer identifier from huggingface.co/models"},
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ freeze_feature_encoder: bool = field(
+ default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
+ )
+ attention_dropout: float = field(
+ default=0.0, metadata={"help": "The dropout ratio for the attention probabilities."}
+ )
+ activation_dropout: float = field(
+ default=0.0, metadata={"help": "The dropout ratio for activations inside the fully connected layer."}
+ )
+ feat_proj_dropout: float = field(default=0.0, metadata={"help": "The dropout ratio for the projected features."})
+ hidden_dropout: float = field(
+ default=0.0,
+ metadata={
+ "help": "The dropout probability for all fully connected layers in the embeddings, encoder, and pooler."
+ },
+ )
+ final_dropout: float = field(
+ default=0.0,
+ metadata={"help": "The dropout probability for the final projection layer."},
+ )
+ mask_time_prob: float = field(
+ default=0.05,
+ metadata={
+ "help": (
+ "Probability of each feature vector along the time axis to be chosen as the start of the vector "
+ "span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature "
+ "vectors will be masked along the time axis."
+ )
+ },
+ )
+ mask_time_length: int = field(
+ default=10,
+ metadata={"help": "Length of vector span to mask along the time axis."},
+ )
+ mask_feature_prob: float = field(
+ default=0.0,
+ metadata={
+ "help": (
+ "Probability of each feature vector along the feature axis to be chosen as the start of the vectorspan"
+ " to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature"
+ " bins will be masked along the time axis."
+ )
+ },
+ )
+ mask_feature_length: int = field(
+ default=10,
+ metadata={"help": "Length of vector span to mask along the feature axis."},
+ )
+ layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})
+ ctc_loss_reduction: Optional[str] = field(
+ default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
+ )
+ ctc_zero_infinity: Optional[bool] = field(
+ default=False,
+ metadata={
+ "help": "Whether to zero infinite losses and the associated gradients of `torch.nn.CTCLoss`. Infinite losses mainly"
+ " occur when the inputs are too short to be aligned to the targets."
+ },
+ )
+ add_adapter: Optional[bool] = field(
+ default=False,
+ metadata={
+ "help": "Whether a convolutional attention network should be stacked on top of the Wav2Vec2Bert Encoder. Can be very"
+ "useful to downsample the output length."
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+
+ Using `HfArgumentParser` we can turn this class
+ into argparse arguments to be able to specify them on
+ the command line.
+ """
+
+ dataset_name: str = field(
+ metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: str = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_split_name: str = field(
+ default="train+validation",
+ metadata={
+ "help": (
+ "The name of the training data set split to use (via the datasets library). Defaults to "
+ "'train+validation'"
+ )
+ },
+ )
+ eval_split_name: str = field(
+ default="test",
+ metadata={
+ "help": "The name of the evaluation data set split to use (via the datasets library). Defaults to 'test'"
+ },
+ )
+ audio_column_name: str = field(
+ default="audio",
+ metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
+ )
+ text_column_name: str = field(
+ default="text",
+ metadata={"help": "The name of the dataset column containing the text data. Defaults to 'text'"},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of validation examples to this "
+ "value if set."
+ )
+ },
+ )
+ chars_to_ignore: Optional[list[str]] = list_field(
+ default=None,
+ metadata={"help": "A list of characters to remove from the transcripts."},
+ )
+ eval_metrics: list[str] = list_field(
+ default=["wer"],
+ metadata={"help": "A list of metrics the model should be evaluated on. E.g. `'wer cer'`"},
+ )
+ max_duration_in_seconds: float = field(
+ default=20.0,
+ metadata={
+ "help": (
+ "Filter audio files that are longer than `max_duration_in_seconds` seconds to"
+ " 'max_duration_in_seconds`"
+ )
+ },
+ )
+ min_duration_in_seconds: float = field(
+ default=0.0, metadata={"help": "Filter audio files that are shorter than `min_duration_in_seconds` seconds"}
+ )
+ preprocessing_only: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to only do data preprocessing and skip training. This is especially useful when data"
+ " preprocessing errors out in distributed training due to timeout. In this case, one should run the"
+ " preprocessing in a non-distributed setup with `preprocessing_only=True` so that the cached datasets"
+ " can consequently be loaded in distributed training"
+ )
+ },
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ unk_token: str = field(
+ default="[UNK]",
+ metadata={"help": "The unk token for the tokenizer"},
+ )
+ pad_token: str = field(
+ default="[PAD]",
+ metadata={"help": "The padding token for the tokenizer"},
+ )
+ word_delimiter_token: str = field(
+ default="|",
+ metadata={"help": "The word delimiter token for the tokenizer"},
+ )
+ phoneme_language: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The target language that should be used be"
+ " passed to the tokenizer for tokenization. Note that"
+ " this is only relevant if the model classifies the"
+ " input audio to a sequence of phoneme sequences."
+ )
+ },
+ )
+
+
+@dataclass
+class DataCollatorCTCWithPadding:
+ """
+ Data collator that will dynamically pad the inputs received.
+ Args:
+ processor (:class:`~transformers.AutoProcessor`)
+ The processor used for processing the data.
+ padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
+ Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
+ among:
+ * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
+ sequence if provided).
+ * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided.
+ * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
+ different lengths).
+ max_length (:obj:`int`, `optional`):
+ Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
+ max_length_labels (:obj:`int`, `optional`):
+ Maximum length of the ``labels`` returned list and optionally padding length (see above).
+ pad_to_multiple_of (:obj:`int`, `optional`):
+ If set will pad the sequence to a multiple of the provided value.
+ This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
+ 7.5 (Volta).
+ """
+
+ processor: AutoProcessor
+ padding: Union[bool, str] = "longest"
+ pad_to_multiple_of: Optional[int] = None
+ pad_to_multiple_of_labels: Optional[int] = None
+ feature_extractor_input_name: Optional[str] = "input_values"
+
+ def __call__(self, features: list[dict[str, Union[list[int], torch.Tensor]]]) -> dict[str, torch.Tensor]:
+ # split inputs and labels since they have to be of different lengths and need
+ # different padding methods
+ input_features = [
+ {self.feature_extractor_input_name: feature[self.feature_extractor_input_name]} for feature in features
+ ]
+ label_features = [{"input_ids": feature["labels"]} for feature in features]
+
+ batch = self.processor.pad(
+ input_features,
+ padding=self.padding,
+ pad_to_multiple_of=self.pad_to_multiple_of,
+ return_tensors="pt",
+ )
+
+ labels_batch = self.processor.pad(
+ labels=label_features,
+ padding=self.padding,
+ pad_to_multiple_of=self.pad_to_multiple_of_labels,
+ return_tensors="pt",
+ )
+
+ # replace padding with -100 to ignore loss correctly
+ labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
+
+ batch["labels"] = labels
+ if "attention_mask" in batch:
+ batch["attention_mask"] = batch["attention_mask"].to(torch.long)
+
+ return batch
+
+
+def create_vocabulary_from_data(
+ datasets: DatasetDict,
+ word_delimiter_token: Optional[str] = None,
+ unk_token: Optional[str] = None,
+ pad_token: Optional[str] = None,
+):
+ # Given training and test labels create vocabulary
+ def extract_all_chars(batch):
+ all_text = " ".join(batch["target_text"])
+ vocab = list(set(all_text))
+ return {"vocab": [vocab], "all_text": [all_text]}
+
+ vocabs = datasets.map(
+ extract_all_chars,
+ batched=True,
+ batch_size=-1,
+ keep_in_memory=True,
+ remove_columns=datasets["train"].column_names,
+ )
+
+ # take union of all unique characters in each dataset
+ vocab_set = functools.reduce(
+ lambda vocab_1, vocab_2: set(vocab_1["vocab"][0]) | set(vocab_2["vocab"][0]), vocabs.values()
+ )
+
+ vocab_dict = {v: k for k, v in enumerate(sorted(vocab_set))}
+
+ # replace white space with delimiter token
+ if word_delimiter_token is not None:
+ vocab_dict[word_delimiter_token] = vocab_dict[" "]
+ del vocab_dict[" "]
+
+ # add unk and pad token
+ if unk_token is not None:
+ vocab_dict[unk_token] = len(vocab_dict)
+
+ if pad_token is not None:
+ vocab_dict[pad_token] = len(vocab_dict)
+
+ return vocab_dict
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_speech_recognition_ctc", model_args, data_args)
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+ logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(training_args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ logger.info("Training/evaluation parameters %s", training_args)
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # 1. First, let's load the dataset
+ raw_datasets = DatasetDict()
+
+ if training_args.do_train:
+ raw_datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=data_args.train_split_name,
+ token=data_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ if data_args.audio_column_name not in raw_datasets["train"].column_names:
+ raise ValueError(
+ f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'."
+ " Make sure to set `--audio_column_name` to the correct audio column - one of"
+ f" {', '.join(raw_datasets['train'].column_names)}."
+ )
+
+ if data_args.text_column_name not in raw_datasets["train"].column_names:
+ raise ValueError(
+ f"--text_column_name {data_args.text_column_name} not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--text_column_name` to the correct text column - one of "
+ f"{', '.join(raw_datasets['train'].column_names)}."
+ )
+
+ if data_args.max_train_samples is not None:
+ raw_datasets["train"] = raw_datasets["train"].select(range(data_args.max_train_samples))
+
+ if training_args.do_eval:
+ raw_datasets["eval"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=data_args.eval_split_name,
+ token=data_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ if data_args.max_eval_samples is not None:
+ raw_datasets["eval"] = raw_datasets["eval"].select(range(data_args.max_eval_samples))
+
+ # 2. We remove some special characters from the datasets
+ # that make training complicated and do not help in transcribing the speech
+ # E.g. characters, such as `,` and `.` do not really have an acoustic characteristic
+ # that could be easily picked up by the model
+ chars_to_ignore_regex = (
+ f"[{''.join(data_args.chars_to_ignore)}]" if data_args.chars_to_ignore is not None else None
+ )
+ text_column_name = data_args.text_column_name
+
+ def remove_special_characters(batch):
+ if chars_to_ignore_regex is not None:
+ batch["target_text"] = re.sub(chars_to_ignore_regex, "", batch[text_column_name]).lower() + " "
+ else:
+ batch["target_text"] = batch[text_column_name].lower() + " "
+ return batch
+
+ with training_args.main_process_first(desc="dataset map special characters removal"):
+ raw_datasets = raw_datasets.map(
+ remove_special_characters,
+ remove_columns=[text_column_name],
+ desc="remove special characters from datasets",
+ )
+
+ # save special tokens for tokenizer
+ word_delimiter_token = data_args.word_delimiter_token
+ unk_token = data_args.unk_token
+ pad_token = data_args.pad_token
+
+ # 3. Next, let's load the config as we might need it to create
+ # the tokenizer
+ # load config
+ config = AutoConfig.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ token=data_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ # 4. Next, if no tokenizer file is defined,
+ # we create the vocabulary of the model by extracting all unique characters from
+ # the training and evaluation datasets
+ # We need to make sure that only first rank saves vocabulary
+ # make sure all processes wait until vocab is created
+ tokenizer_name_or_path = model_args.tokenizer_name_or_path
+ tokenizer_kwargs = {}
+ if tokenizer_name_or_path is None:
+ # save vocab in training output dir
+ tokenizer_name_or_path = training_args.output_dir
+
+ vocab_file = os.path.join(tokenizer_name_or_path, "vocab.json")
+
+ with training_args.main_process_first():
+ if training_args.overwrite_output_dir and os.path.isfile(vocab_file):
+ try:
+ os.remove(vocab_file)
+ except OSError:
+ # in shared file-systems it might be the case that
+ # two processes try to delete the vocab file at the some time
+ pass
+
+ with training_args.main_process_first(desc="dataset map vocabulary creation"):
+ if not os.path.isfile(vocab_file):
+ os.makedirs(tokenizer_name_or_path, exist_ok=True)
+ vocab_dict = create_vocabulary_from_data(
+ raw_datasets,
+ word_delimiter_token=word_delimiter_token,
+ unk_token=unk_token,
+ pad_token=pad_token,
+ )
+
+ # save vocab dict to be loaded into tokenizer
+ with open(vocab_file, "w") as file:
+ json.dump(vocab_dict, file)
+
+ # if tokenizer has just been created
+ # it is defined by `tokenizer_class` if present in config else by `model_type`
+ tokenizer_kwargs = {
+ "config": config if config.tokenizer_class is not None else None,
+ "tokenizer_type": config.model_type if config.tokenizer_class is None else None,
+ "unk_token": unk_token,
+ "pad_token": pad_token,
+ "word_delimiter_token": word_delimiter_token,
+ }
+
+ # 5. Now we can instantiate the feature extractor, tokenizer and model
+ # Note for distributed training, the .from_pretrained methods guarantee that only
+ # one local process can concurrently download model & vocab.
+
+ # load feature_extractor and tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(
+ tokenizer_name_or_path,
+ token=data_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ **tokenizer_kwargs,
+ )
+ feature_extractor = AutoFeatureExtractor.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ token=data_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ # adapt config
+ config.update(
+ {
+ "feat_proj_dropout": model_args.feat_proj_dropout,
+ "attention_dropout": model_args.attention_dropout,
+ "hidden_dropout": model_args.hidden_dropout,
+ "final_dropout": model_args.final_dropout,
+ "mask_time_prob": model_args.mask_time_prob,
+ "mask_time_length": model_args.mask_time_length,
+ "mask_feature_prob": model_args.mask_feature_prob,
+ "mask_feature_length": model_args.mask_feature_length,
+ "gradient_checkpointing": training_args.gradient_checkpointing,
+ "layerdrop": model_args.layerdrop,
+ "ctc_loss_reduction": model_args.ctc_loss_reduction,
+ "ctc_zero_infinity": model_args.ctc_zero_infinity,
+ "pad_token_id": tokenizer.pad_token_id,
+ "vocab_size": len(tokenizer),
+ "activation_dropout": model_args.activation_dropout,
+ "add_adapter": model_args.add_adapter,
+ }
+ )
+
+ # create model
+ model = AutoModelForCTC.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ config=config,
+ token=data_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ # freeze encoder
+ if model_args.freeze_feature_encoder:
+ model.freeze_feature_encoder()
+
+ # 6. Now we preprocess the datasets including loading the audio, resampling and normalization
+ # Thankfully, `datasets` takes care of automatically loading and resampling the audio,
+ # so that we just need to set the correct target sampling rate and normalize the input
+ # via the `feature_extractor`
+
+ # make sure that dataset decodes audio with correct sampling rate
+ dataset_sampling_rate = next(iter(raw_datasets.values())).features[data_args.audio_column_name].sampling_rate
+ if dataset_sampling_rate != feature_extractor.sampling_rate:
+ raw_datasets = raw_datasets.cast_column(
+ data_args.audio_column_name, datasets.features.Audio(sampling_rate=feature_extractor.sampling_rate)
+ )
+
+ # derive max & min input length for sample rate & max duration
+ max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
+ min_input_length = data_args.min_duration_in_seconds * feature_extractor.sampling_rate
+ audio_column_name = data_args.audio_column_name
+ num_workers = data_args.preprocessing_num_workers
+ feature_extractor_input_name = feature_extractor.model_input_names[0]
+
+ # `phoneme_language` is only relevant if the model is fine-tuned on phoneme classification
+ phoneme_language = data_args.phoneme_language
+
+ # Preprocessing the datasets.
+ # We need to read the audio files as arrays and tokenize the targets.
+ def prepare_dataset(batch):
+ # load audio
+ sample = batch[audio_column_name]
+
+ inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
+ batch[feature_extractor_input_name] = getattr(inputs, feature_extractor_input_name)[0]
+ # take length of raw audio waveform
+ batch["input_length"] = len(sample["array"].squeeze())
+
+ # encode targets
+ additional_kwargs = {}
+ if phoneme_language is not None:
+ additional_kwargs["phonemizer_lang"] = phoneme_language
+
+ batch["labels"] = tokenizer(batch["target_text"], **additional_kwargs).input_ids
+ return batch
+
+ with training_args.main_process_first(desc="dataset map preprocessing"):
+ vectorized_datasets = raw_datasets.map(
+ prepare_dataset,
+ remove_columns=next(iter(raw_datasets.values())).column_names,
+ num_proc=num_workers,
+ desc="preprocess datasets",
+ )
+
+ def is_audio_in_length_range(length):
+ return length > min_input_length and length < max_input_length
+
+ # filter data that is shorter than min_input_length
+ vectorized_datasets = vectorized_datasets.filter(
+ is_audio_in_length_range,
+ num_proc=num_workers,
+ input_columns=["input_length"],
+ )
+
+ # 7. Next, we can prepare the training.
+ # Let's use word error rate (WER) as our evaluation metric,
+ # instantiate a data collator and the trainer
+
+ # Define evaluation metrics during training, *i.e.* word error rate, character error rate
+ eval_metrics = {metric: evaluate.load(metric, cache_dir=model_args.cache_dir) for metric in data_args.eval_metrics}
+
+ # for large datasets it is advised to run the preprocessing on a
+ # single machine first with ``args.preprocessing_only`` since there will mostly likely
+ # be a timeout when running the script in distributed mode.
+ # In a second step ``args.preprocessing_only`` can then be set to `False` to load the
+ # cached dataset
+ if data_args.preprocessing_only:
+ logger.info(f"Data preprocessing finished. Files cached at {vectorized_datasets.cache_files}")
+ return
+
+ # For languages like Chinese with large vocabulary size, we need to discard logits
+ # and only keep the argmax, otherwise we run out of memory during evaluation.
+ def preprocess_logits_for_metrics(logits, labels):
+ pred_ids = torch.argmax(logits, dim=-1)
+ return pred_ids, labels
+
+ def compute_metrics(pred):
+ pred_ids = pred.predictions[0]
+ pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
+
+ pred_str = tokenizer.batch_decode(pred_ids)
+ # we do not want to group tokens when computing the metrics
+ label_str = tokenizer.batch_decode(pred.label_ids, group_tokens=False)
+
+ metrics = {k: v.compute(predictions=pred_str, references=label_str) for k, v in eval_metrics.items()}
+
+ return metrics
+
+ # Now save everything to be able to create a single processor later
+ # make sure all processes wait until data is saved
+ with training_args.main_process_first():
+ # only the main process saves them
+ if is_main_process(training_args.local_rank):
+ # save feature extractor, tokenizer and config
+ feature_extractor.save_pretrained(training_args.output_dir)
+ tokenizer.save_pretrained(training_args.output_dir)
+ config.save_pretrained(training_args.output_dir)
+
+ try:
+ processor = AutoProcessor.from_pretrained(training_args.output_dir)
+ except (OSError, KeyError):
+ warnings.warn(
+ "Loading a processor from a feature extractor config that does not"
+ " include a `processor_class` attribute is deprecated and will be removed in v5. Please add the following "
+ " attribute to your `preprocessor_config.json` file to suppress this warning: "
+ " `'processor_class': 'Wav2Vec2Processor'`",
+ FutureWarning,
+ )
+ processor = Wav2Vec2Processor.from_pretrained(training_args.output_dir)
+
+ # Instantiate custom data collator
+ data_collator = DataCollatorCTCWithPadding(
+ processor=processor, feature_extractor_input_name=feature_extractor_input_name
+ )
+
+ # Initialize Trainer
+ trainer = Trainer(
+ model=model,
+ data_collator=data_collator,
+ args=training_args,
+ compute_metrics=compute_metrics,
+ train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
+ eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
+ processing_class=processor,
+ preprocess_logits_for_metrics=preprocess_logits_for_metrics,
+ )
+
+ # 8. Finally, we can start training
+
+ # Training
+ if training_args.do_train:
+ # use last checkpoint if exist
+ if last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ elif os.path.isdir(model_args.model_name_or_path):
+ checkpoint = model_args.model_name_or_path
+ else:
+ checkpoint = None
+
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+
+ metrics = train_result.metrics
+ max_train_samples = (
+ data_args.max_train_samples
+ if data_args.max_train_samples is not None
+ else len(vectorized_datasets["train"])
+ )
+ metrics["train_samples"] = min(max_train_samples, len(vectorized_datasets["train"]))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ results = {}
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+ metrics = trainer.evaluate()
+ max_eval_samples = (
+ data_args.max_eval_samples if data_args.max_eval_samples is not None else len(vectorized_datasets["eval"])
+ )
+ metrics["eval_samples"] = min(max_eval_samples, len(vectorized_datasets["eval"]))
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Write model card and (optionally) push to hub
+ config_name = data_args.dataset_config_name if data_args.dataset_config_name is not None else "na"
+ kwargs = {
+ "finetuned_from": model_args.model_name_or_path,
+ "tasks": "automatic-speech-recognition",
+ "tags": ["automatic-speech-recognition", data_args.dataset_name],
+ "dataset_args": (
+ f"Config: {config_name}, Training split: {data_args.train_split_name}, Eval split:"
+ f" {data_args.eval_split_name}"
+ ),
+ "dataset": f"{data_args.dataset_name.upper()} - {config_name.upper()}",
+ }
+ if "common_voice" in data_args.dataset_name:
+ kwargs["language"] = config_name
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+ return results
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py b/docs/transformers/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
new file mode 100644
index 0000000000000000000000000000000000000000..511e7bc3d442663172e2e4c44b9ac426999d2747
--- /dev/null
+++ b/docs/transformers/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py
@@ -0,0 +1,822 @@
+#!/usr/bin/env python
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Fine-tuning a 🤗 Transformers CTC adapter model for automatic speech recognition"""
+
+import functools
+import json
+import logging
+import os
+import re
+import sys
+import warnings
+from dataclasses import dataclass, field
+from typing import Optional, Union
+
+import datasets
+import evaluate
+import numpy as np
+import torch
+from datasets import DatasetDict, load_dataset
+from safetensors.torch import save_file as safe_save_file
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoFeatureExtractor,
+ AutoModelForCTC,
+ AutoProcessor,
+ AutoTokenizer,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ Wav2Vec2Processor,
+ set_seed,
+)
+from transformers.models.wav2vec2.modeling_wav2vec2 import WAV2VEC2_ADAPTER_SAFE_FILE
+from transformers.trainer_utils import get_last_checkpoint, is_main_process
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
+
+
+logger = logging.getLogger(__name__)
+
+
+def list_field(default=None, metadata=None):
+ return field(default_factory=lambda: default, metadata=metadata)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ tokenizer_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={"help": "Path to pretrained tokenizer or tokenizer identifier from huggingface.co/models"},
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ final_dropout: float = field(
+ default=0.0,
+ metadata={"help": "The dropout probability for the final projection layer."},
+ )
+ mask_time_prob: float = field(
+ default=0.05,
+ metadata={
+ "help": (
+ "Probability of each feature vector along the time axis to be chosen as the start of the vector "
+ "span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature "
+ "vectors will be masked along the time axis."
+ )
+ },
+ )
+ mask_time_length: int = field(
+ default=10,
+ metadata={"help": "Length of vector span to mask along the time axis."},
+ )
+ mask_feature_prob: float = field(
+ default=0.0,
+ metadata={
+ "help": (
+ "Probability of each feature vector along the feature axis to be chosen as the start of the vectorspan"
+ " to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature"
+ " bins will be masked along the time axis."
+ )
+ },
+ )
+ mask_feature_length: int = field(
+ default=10,
+ metadata={"help": "Length of vector span to mask along the feature axis."},
+ )
+ layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})
+ ctc_loss_reduction: Optional[str] = field(
+ default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
+ )
+ adapter_attn_dim: int = field(
+ default=16,
+ metadata={
+ "help": "The hidden dimension of the adapter layers that will be randomly initialized and trained. The higher the dimension, the more capacity is given to the adapter weights. Note that only the adapter weights are fine-tuned."
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+
+ Using `HfArgumentParser` we can turn this class
+ into argparse arguments to be able to specify them on
+ the command line.
+ """
+
+ dataset_name: str = field(
+ metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ target_language: Optional[str] = field(
+ metadata={
+ "help": (
+ "The target language on which the adapter attention layers"
+ " should be trained on in ISO 693-3 code, e.g. `tur` for Turkish"
+ " Wav2Vec2's MMS ISO codes can be looked up here: https://dl.fbaipublicfiles.com/mms/misc/language_coverage_mms.html"
+ " If you are not training the adapter layers on a language, simply choose"
+ " another acronym that fits your data."
+ )
+ },
+ )
+ dataset_config_name: str = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_split_name: str = field(
+ default="train+validation",
+ metadata={
+ "help": (
+ "The name of the training data set split to use (via the datasets library). Defaults to "
+ "'train+validation'"
+ )
+ },
+ )
+ eval_split_name: str = field(
+ default="test",
+ metadata={
+ "help": "The name of the evaluation data set split to use (via the datasets library). Defaults to 'test'"
+ },
+ )
+ audio_column_name: str = field(
+ default="audio",
+ metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
+ )
+ text_column_name: str = field(
+ default="text",
+ metadata={"help": "The name of the dataset column containing the text data. Defaults to 'text'"},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of validation examples to this "
+ "value if set."
+ )
+ },
+ )
+ chars_to_ignore: Optional[list[str]] = list_field(
+ default=None,
+ metadata={"help": "A list of characters to remove from the transcripts."},
+ )
+ eval_metrics: list[str] = list_field(
+ default=["wer"],
+ metadata={"help": "A list of metrics the model should be evaluated on. E.g. `'wer cer'`"},
+ )
+ max_duration_in_seconds: float = field(
+ default=20.0,
+ metadata={
+ "help": (
+ "Filter audio files that are longer than `max_duration_in_seconds` seconds to"
+ " 'max_duration_in_seconds`"
+ )
+ },
+ )
+ min_duration_in_seconds: float = field(
+ default=0.0, metadata={"help": "Filter audio files that are shorter than `min_duration_in_seconds` seconds"}
+ )
+ preprocessing_only: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to only do data preprocessing and skip training. This is especially useful when data"
+ " preprocessing errors out in distributed training due to timeout. In this case, one should run the"
+ " preprocessing in a non-distributed setup with `preprocessing_only=True` so that the cached datasets"
+ " can consequently be loaded in distributed training"
+ )
+ },
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ unk_token: str = field(
+ default="[UNK]",
+ metadata={"help": "The unk token for the tokenizer"},
+ )
+ pad_token: str = field(
+ default="[PAD]",
+ metadata={"help": "The padding token for the tokenizer"},
+ )
+ word_delimiter_token: str = field(
+ default="|",
+ metadata={"help": "The word delimiter token for the tokenizer"},
+ )
+ overwrite_lang_vocab: bool = field(
+ default=False,
+ metadata={"help": ("If :obj:`True`, will overwrite existing `target_language` vocabulary of tokenizer.")},
+ )
+
+
+@dataclass
+class DataCollatorCTCWithPadding:
+ """
+ Data collator that will dynamically pad the inputs received.
+ Args:
+ processor (:class:`~transformers.AutoProcessor`)
+ The processor used for processing the data.
+ padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
+ Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
+ among:
+ * :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
+ sequence if provided).
+ * :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
+ maximum acceptable input length for the model if that argument is not provided.
+ * :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
+ different lengths).
+ max_length (:obj:`int`, `optional`):
+ Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
+ max_length_labels (:obj:`int`, `optional`):
+ Maximum length of the ``labels`` returned list and optionally padding length (see above).
+ pad_to_multiple_of (:obj:`int`, `optional`):
+ If set will pad the sequence to a multiple of the provided value.
+ This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
+ 7.5 (Volta).
+ """
+
+ processor: AutoProcessor
+ padding: Union[bool, str] = "longest"
+ pad_to_multiple_of: Optional[int] = None
+ pad_to_multiple_of_labels: Optional[int] = None
+
+ def __call__(self, features: list[dict[str, Union[list[int], torch.Tensor]]]) -> dict[str, torch.Tensor]:
+ # split inputs and labels since they have to be of different lengths and need
+ # different padding methods
+ input_features = [{"input_values": feature["input_values"]} for feature in features]
+ label_features = [{"input_ids": feature["labels"]} for feature in features]
+
+ batch = self.processor.pad(
+ input_features,
+ padding=self.padding,
+ pad_to_multiple_of=self.pad_to_multiple_of,
+ return_tensors="pt",
+ )
+
+ labels_batch = self.processor.pad(
+ labels=label_features,
+ padding=self.padding,
+ pad_to_multiple_of=self.pad_to_multiple_of_labels,
+ return_tensors="pt",
+ )
+
+ # replace padding with -100 to ignore loss correctly
+ labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
+
+ batch["labels"] = labels
+ if "attention_mask" in batch:
+ batch["attention_mask"] = batch["attention_mask"].to(torch.long)
+
+ return batch
+
+
+def create_vocabulary_from_data(
+ datasets: DatasetDict,
+ word_delimiter_token: Optional[str] = None,
+ unk_token: Optional[str] = None,
+ pad_token: Optional[str] = None,
+):
+ # Given training and test labels create vocabulary
+ def extract_all_chars(batch):
+ all_text = " ".join(batch["target_text"])
+ vocab = list(set(all_text))
+ return {"vocab": [vocab], "all_text": [all_text]}
+
+ vocabs = datasets.map(
+ extract_all_chars,
+ batched=True,
+ batch_size=-1,
+ keep_in_memory=True,
+ remove_columns=datasets["train"].column_names,
+ )
+
+ # take union of all unique characters in each dataset
+ vocab_set = functools.reduce(
+ lambda vocab_1, vocab_2: set(vocab_1["vocab"][0]) | set(vocab_2["vocab"][0]), vocabs.values()
+ )
+
+ vocab_dict = {v: k for k, v in enumerate(sorted(vocab_set))}
+
+ # replace white space with delimiter token
+ if word_delimiter_token is not None:
+ vocab_dict[word_delimiter_token] = vocab_dict[" "]
+ del vocab_dict[" "]
+
+ # add unk and pad token
+ if unk_token is not None:
+ vocab_dict[unk_token] = len(vocab_dict)
+
+ if pad_token is not None:
+ vocab_dict[pad_token] = len(vocab_dict)
+
+ return vocab_dict
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_speech_recognition_ctc_adapter", model_args, data_args)
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+ logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(training_args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ logger.info("Training/evaluation parameters %s", training_args)
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # 1. First, let's load the dataset
+ raw_datasets = DatasetDict()
+
+ if training_args.do_train:
+ raw_datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=data_args.train_split_name,
+ token=data_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ if data_args.audio_column_name not in raw_datasets["train"].column_names:
+ raise ValueError(
+ f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'."
+ " Make sure to set `--audio_column_name` to the correct audio column - one of"
+ f" {', '.join(raw_datasets['train'].column_names)}."
+ )
+
+ if data_args.text_column_name not in raw_datasets["train"].column_names:
+ raise ValueError(
+ f"--text_column_name {data_args.text_column_name} not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--text_column_name` to the correct text column - one of "
+ f"{', '.join(raw_datasets['train'].column_names)}."
+ )
+
+ if data_args.max_train_samples is not None:
+ raw_datasets["train"] = raw_datasets["train"].select(range(data_args.max_train_samples))
+
+ if training_args.do_eval:
+ raw_datasets["eval"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=data_args.eval_split_name,
+ token=data_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ if data_args.max_eval_samples is not None:
+ raw_datasets["eval"] = raw_datasets["eval"].select(range(data_args.max_eval_samples))
+
+ # 2. We remove some special characters from the datasets
+ # that make training complicated and do not help in transcribing the speech
+ # E.g. characters, such as `,` and `.` do not really have an acoustic characteristic
+ # that could be easily picked up by the model
+ chars_to_ignore_regex = (
+ f"[{''.join(data_args.chars_to_ignore)}]" if data_args.chars_to_ignore is not None else None
+ )
+ text_column_name = data_args.text_column_name
+
+ def remove_special_characters(batch):
+ if chars_to_ignore_regex is not None:
+ batch["target_text"] = re.sub(chars_to_ignore_regex, "", batch[text_column_name]).lower() + " "
+ else:
+ batch["target_text"] = batch[text_column_name].lower() + " "
+ return batch
+
+ with training_args.main_process_first(desc="dataset map special characters removal"):
+ raw_datasets = raw_datasets.map(
+ remove_special_characters,
+ remove_columns=[text_column_name],
+ desc="remove special characters from datasets",
+ )
+
+ # save special tokens for tokenizer
+ word_delimiter_token = data_args.word_delimiter_token
+ unk_token = data_args.unk_token
+ pad_token = data_args.pad_token
+
+ # 3. Next, let's load the config as we might need it to create
+ # the tokenizer
+ # load config
+ config = AutoConfig.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ token=data_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ # 4. Next, if no tokenizer file is defined,
+ # we create the vocabulary of the model by extracting all unique characters from
+ # the training and evaluation datasets
+ # We need to make sure that only first rank saves vocabulary
+ # make sure all processes wait until vocab is created
+ tokenizer_name_or_path = model_args.tokenizer_name_or_path
+ tokenizer_kwargs = {}
+
+ vocab_dict = {}
+ if tokenizer_name_or_path is not None:
+ # load vocabulary of other adapter languages so that new language can be appended
+ tokenizer = AutoTokenizer.from_pretrained(
+ tokenizer_name_or_path,
+ token=data_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+ vocab_dict = tokenizer.vocab.copy()
+ if tokenizer.target_lang is None:
+ raise ValueError("Make sure to load a multi-lingual tokenizer with a set target language.")
+
+ if data_args.target_language in tokenizer.vocab and not data_args.overwrite_lang_vocab:
+ logger.info(
+ "Adapter language already exists."
+ " Skipping vocabulary creating. If you want to create a new vocabulary"
+ f" for {data_args.target_language} make sure to add '--overwrite_lang_vocab'"
+ )
+ else:
+ tokenizer_name_or_path = None
+
+ if tokenizer_name_or_path is None:
+ # save vocab in training output dir
+ tokenizer_name_or_path = training_args.output_dir
+
+ vocab_file = os.path.join(tokenizer_name_or_path, "vocab.json")
+
+ with training_args.main_process_first():
+ if training_args.overwrite_output_dir and os.path.isfile(vocab_file):
+ try:
+ os.remove(vocab_file)
+ except OSError:
+ # in shared file-systems it might be the case that
+ # two processes try to delete the vocab file at the some time
+ pass
+
+ with training_args.main_process_first(desc="dataset map vocabulary creation"):
+ if not os.path.isfile(vocab_file):
+ os.makedirs(tokenizer_name_or_path, exist_ok=True)
+ lang_dict = create_vocabulary_from_data(
+ raw_datasets,
+ word_delimiter_token=word_delimiter_token,
+ unk_token=unk_token,
+ pad_token=pad_token,
+ )
+
+ # if we doing adapter language training, save
+ # vocab with adapter language
+ if data_args.target_language is not None:
+ vocab_dict[data_args.target_language] = lang_dict
+
+ # save vocab dict to be loaded into tokenizer
+ with open(vocab_file, "w") as file:
+ json.dump(vocab_dict, file)
+
+ # if tokenizer has just been created
+ # it is defined by `tokenizer_class` if present in config else by `model_type`
+ tokenizer_kwargs = {
+ "config": config if config.tokenizer_class is not None else None,
+ "tokenizer_type": config.model_type if config.tokenizer_class is None else None,
+ "unk_token": unk_token,
+ "pad_token": pad_token,
+ "word_delimiter_token": word_delimiter_token,
+ "target_lang": data_args.target_language,
+ }
+
+ # 5. Now we can instantiate the feature extractor, tokenizer and model
+ # Note for distributed training, the .from_pretrained methods guarantee that only
+ # one local process can concurrently download model & vocab.
+
+ # load feature_extractor and tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(
+ tokenizer_name_or_path,
+ token=data_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ **tokenizer_kwargs,
+ )
+ feature_extractor = AutoFeatureExtractor.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ token=data_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ )
+
+ # adapt config
+ config.update(
+ {
+ "final_dropout": model_args.final_dropout,
+ "mask_time_prob": model_args.mask_time_prob,
+ "mask_time_length": model_args.mask_time_length,
+ "mask_feature_prob": model_args.mask_feature_prob,
+ "mask_feature_length": model_args.mask_feature_length,
+ "gradient_checkpointing": training_args.gradient_checkpointing,
+ "layerdrop": model_args.layerdrop,
+ "ctc_loss_reduction": model_args.ctc_loss_reduction,
+ "pad_token_id": tokenizer.pad_token_id,
+ "vocab_size": len(tokenizer),
+ "adapter_attn_dim": model_args.adapter_attn_dim,
+ }
+ )
+
+ # create model
+ model = AutoModelForCTC.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ config=config,
+ token=data_args.token,
+ trust_remote_code=data_args.trust_remote_code,
+ ignore_mismatched_sizes=True,
+ )
+
+ # if attn adapter is defined, freeze all non-adapter weights
+ if model.config.adapter_attn_dim is not None:
+ model.init_adapter_layers()
+ # first we freeze the whole base model
+ model.freeze_base_model()
+
+ # next we unfreeze all adapter layers
+ adapter_weights = model._get_adapters()
+ for param in adapter_weights.values():
+ param.requires_grad = True
+
+ # 6. Now we preprocess the datasets including loading the audio, resampling and normalization
+ # Thankfully, `datasets` takes care of automatically loading and resampling the audio,
+ # so that we just need to set the correct target sampling rate and normalize the input
+ # via the `feature_extractor`
+
+ # make sure that dataset decodes audio with correct sampling rate
+ dataset_sampling_rate = next(iter(raw_datasets.values())).features[data_args.audio_column_name].sampling_rate
+ if dataset_sampling_rate != feature_extractor.sampling_rate:
+ raw_datasets = raw_datasets.cast_column(
+ data_args.audio_column_name, datasets.features.Audio(sampling_rate=feature_extractor.sampling_rate)
+ )
+
+ # derive max & min input length for sample rate & max duration
+ max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
+ min_input_length = data_args.min_duration_in_seconds * feature_extractor.sampling_rate
+ audio_column_name = data_args.audio_column_name
+ num_workers = data_args.preprocessing_num_workers
+
+ # Preprocessing the datasets.
+ # We need to read the audio files as arrays and tokenize the targets.
+ def prepare_dataset(batch):
+ # load audio
+ sample = batch[audio_column_name]
+
+ inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
+ batch["input_values"] = inputs.input_values[0]
+ batch["input_length"] = len(batch["input_values"])
+
+ # encode targets
+ batch["labels"] = tokenizer(batch["target_text"]).input_ids
+ return batch
+
+ with training_args.main_process_first(desc="dataset map preprocessing"):
+ vectorized_datasets = raw_datasets.map(
+ prepare_dataset,
+ remove_columns=next(iter(raw_datasets.values())).column_names,
+ num_proc=num_workers,
+ desc="preprocess datasets",
+ )
+
+ def is_audio_in_length_range(length):
+ return length > min_input_length and length < max_input_length
+
+ # filter data that is shorter than min_input_length
+ vectorized_datasets = vectorized_datasets.filter(
+ is_audio_in_length_range,
+ num_proc=num_workers,
+ input_columns=["input_length"],
+ )
+
+ # 7. Next, we can prepare the training.
+ # Let's use word error rate (WER) as our evaluation metric,
+ # instantiate a data collator and the trainer
+
+ # Define evaluation metrics during training, *i.e.* word error rate, character error rate
+ eval_metrics = {metric: evaluate.load(metric, cache_dir=model_args.cache_dir) for metric in data_args.eval_metrics}
+
+ # for large datasets it is advised to run the preprocessing on a
+ # single machine first with ``args.preprocessing_only`` since there will mostly likely
+ # be a timeout when running the script in distributed mode.
+ # In a second step ``args.preprocessing_only`` can then be set to `False` to load the
+ # cached dataset
+ if data_args.preprocessing_only:
+ logger.info(f"Data preprocessing finished. Files cached at {vectorized_datasets.cache_files}")
+ return
+
+ def compute_metrics(pred):
+ pred_logits = pred.predictions
+ pred_ids = np.argmax(pred_logits, axis=-1)
+
+ pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
+
+ pred_str = tokenizer.batch_decode(pred_ids)
+ # we do not want to group tokens when computing the metrics
+ label_str = tokenizer.batch_decode(pred.label_ids, group_tokens=False)
+
+ metrics = {k: v.compute(predictions=pred_str, references=label_str) for k, v in eval_metrics.items()}
+
+ return metrics
+
+ # Now save everything to be able to create a single processor later
+ # make sure all processes wait until data is saved
+ with training_args.main_process_first():
+ # only the main process saves them
+ if is_main_process(training_args.local_rank):
+ # save feature extractor, tokenizer and config
+ feature_extractor.save_pretrained(training_args.output_dir)
+ tokenizer.save_pretrained(training_args.output_dir)
+ config.save_pretrained(training_args.output_dir)
+
+ try:
+ processor = AutoProcessor.from_pretrained(training_args.output_dir)
+ except (OSError, KeyError):
+ warnings.warn(
+ "Loading a processor from a feature extractor config that does not"
+ " include a `processor_class` attribute is deprecated and will be removed in v5. Please add the following "
+ " attribute to your `preprocessor_config.json` file to suppress this warning: "
+ " `'processor_class': 'Wav2Vec2Processor'`",
+ FutureWarning,
+ )
+ processor = Wav2Vec2Processor.from_pretrained(training_args.output_dir)
+
+ # Instantiate custom data collator
+ data_collator = DataCollatorCTCWithPadding(processor=processor)
+
+ # Initialize Trainer
+ trainer = Trainer(
+ model=model,
+ data_collator=data_collator,
+ args=training_args,
+ compute_metrics=compute_metrics,
+ train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
+ eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
+ processing_class=processor,
+ )
+
+ # 8. Finally, we can start training
+
+ # Training
+ if training_args.do_train:
+ # use last checkpoint if exist
+ if last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ elif os.path.isdir(model_args.model_name_or_path):
+ checkpoint = model_args.model_name_or_path
+ else:
+ checkpoint = None
+
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model()
+
+ metrics = train_result.metrics
+ max_train_samples = (
+ data_args.max_train_samples
+ if data_args.max_train_samples is not None
+ else len(vectorized_datasets["train"])
+ )
+ metrics["train_samples"] = min(max_train_samples, len(vectorized_datasets["train"]))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ results = {}
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+ metrics = trainer.evaluate()
+ max_eval_samples = (
+ data_args.max_eval_samples if data_args.max_eval_samples is not None else len(vectorized_datasets["eval"])
+ )
+ metrics["eval_samples"] = min(max_eval_samples, len(vectorized_datasets["eval"]))
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Write model card and (optionally) push to hub
+ config_name = data_args.dataset_config_name if data_args.dataset_config_name is not None else "na"
+ kwargs = {
+ "finetuned_from": model_args.model_name_or_path,
+ "tasks": "automatic-speech-recognition",
+ "tags": ["automatic-speech-recognition", data_args.dataset_name, "mms"],
+ "dataset_args": (
+ f"Config: {config_name}, Training split: {data_args.train_split_name}, Eval split:"
+ f" {data_args.eval_split_name}"
+ ),
+ "dataset": f"{data_args.dataset_name.upper()} - {config_name.upper()}",
+ }
+ if "common_voice" in data_args.dataset_name:
+ kwargs["language"] = config_name
+
+ # make sure that adapter weights are saved seperately
+ adapter_file = WAV2VEC2_ADAPTER_SAFE_FILE.format(data_args.target_language)
+ adapter_file = os.path.join(training_args.output_dir, adapter_file)
+ logger.info(f"Saving adapter weights under {adapter_file}...")
+ safe_save_file(model._get_adapters(), adapter_file, metadata={"format": "pt"})
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+ return results
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py b/docs/transformers/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b64ea078d61acadb01246c1d49a07e7598d60de
--- /dev/null
+++ b/docs/transformers/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py
@@ -0,0 +1,633 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for sequence to sequence speech recognition.
+"""
+# You can also adapt this script on your own sequence to sequence speech
+# recognition task. Pointers for this are left as comments.
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Any, Optional, Union
+
+import datasets
+import evaluate
+import torch
+from datasets import DatasetDict, load_dataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoFeatureExtractor,
+ AutoModelForSpeechSeq2Seq,
+ AutoProcessor,
+ AutoTokenizer,
+ HfArgumentParser,
+ Seq2SeqTrainer,
+ Seq2SeqTrainingArguments,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint, is_main_process
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ feature_extractor_name: Optional[str] = field(
+ default=None, metadata={"help": "feature extractor name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ freeze_feature_encoder: bool = field(
+ default=True, metadata={"help": "Whether to freeze the feature encoder layers of the model."}
+ )
+ freeze_encoder: bool = field(
+ default=False, metadata={"help": "Whether to freeze the entire encoder of the seq2seq model."}
+ )
+ forced_decoder_ids: list[list[int]] = field(
+ default=None,
+ metadata={"help": "Deprecated. Please use the `language` and `task` arguments instead."},
+ )
+ suppress_tokens: list[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Deprecated. The use of `suppress_tokens` should not be required for the majority of fine-tuning examples."
+ "Should you need to use `suppress_tokens`, please manually update them in the fine-tuning script directly."
+ )
+ },
+ )
+ apply_spec_augment: bool = field(
+ default=False,
+ metadata={
+ "help": "Whether to apply *SpecAugment* data augmentation to the input features. This is currently only relevant for Wav2Vec2, HuBERT, WavLM and Whisper models."
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: str = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ audio_column_name: str = field(
+ default="audio",
+ metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
+ )
+ text_column_name: str = field(
+ default="text",
+ metadata={"help": "The name of the dataset column containing the text data. Defaults to 'text'"},
+ )
+ max_duration_in_seconds: float = field(
+ default=20.0,
+ metadata={
+ "help": (
+ "Truncate audio files that are longer than `max_duration_in_seconds` seconds to"
+ " 'max_duration_in_seconds`"
+ )
+ },
+ )
+ min_duration_in_seconds: float = field(
+ default=0.0, metadata={"help": "Filter audio files that are shorter than `min_duration_in_seconds` seconds"}
+ )
+ preprocessing_only: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to only do data preprocessing and skip training. This is especially useful when data"
+ " preprocessing errors out in distributed training due to timeout. In this case, one should run the"
+ " preprocessing in a non-distributed setup with `preprocessing_only=True` so that the cached datasets"
+ " can consequently be loaded in distributed training"
+ )
+ },
+ )
+ train_split_name: str = field(
+ default="train",
+ metadata={
+ "help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
+ },
+ )
+ eval_split_name: str = field(
+ default="test",
+ metadata={
+ "help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
+ },
+ )
+ do_lower_case: bool = field(
+ default=True,
+ metadata={"help": "Whether the target text should be lower cased."},
+ )
+ language: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "Language for multilingual fine-tuning. This argument should be set for multilingual fine-tuning "
+ "only. For English speech recognition, it should be set to `None`."
+ )
+ },
+ )
+ task: str = field(
+ default="transcribe",
+ metadata={"help": "Task, either `transcribe` for speech recognition or `translate` for speech translation."},
+ )
+
+
+@dataclass
+class DataCollatorSpeechSeq2SeqWithPadding:
+ """
+ Data collator that will dynamically pad the inputs received.
+ Args:
+ processor ([`WhisperProcessor`])
+ The processor used for processing the data.
+ decoder_start_token_id (`int`)
+ The begin-of-sentence of the decoder.
+ forward_attention_mask (`bool`)
+ Whether to return attention_mask.
+ """
+
+ processor: Any
+ decoder_start_token_id: int
+ forward_attention_mask: bool
+
+ def __call__(self, features: list[dict[str, Union[list[int], torch.Tensor]]]) -> dict[str, torch.Tensor]:
+ # split inputs and labels since they have to be of different lengths and need
+ # different padding methods
+ model_input_name = self.processor.model_input_names[0]
+ input_features = [{model_input_name: feature[model_input_name]} for feature in features]
+ label_features = [{"input_ids": feature["labels"]} for feature in features]
+
+ batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
+
+ if self.forward_attention_mask:
+ batch["attention_mask"] = torch.LongTensor([feature["attention_mask"] for feature in features])
+
+ labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
+
+ # replace padding with -100 to ignore loss correctly
+ labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
+
+ # if bos token is appended in previous tokenization step,
+ # cut bos token here as it's append later anyways
+ if (labels[:, 0] == self.decoder_start_token_id).all().cpu().item():
+ labels = labels[:, 1:]
+
+ batch["labels"] = labels
+
+ return batch
+
+
+def main():
+ # 1. Parse input arguments
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
+
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_speech_recognition_seq2seq", model_args, data_args)
+
+ # 2. Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(training_args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ logger.info("Training/evaluation parameters %s", training_args)
+
+ # 3. Detecting last checkpoint and eventually continue from last checkpoint
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # 4. Load dataset
+ raw_datasets = DatasetDict()
+
+ if training_args.do_train:
+ raw_datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=data_args.train_split_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ if training_args.do_eval:
+ raw_datasets["eval"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=data_args.eval_split_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ if data_args.audio_column_name not in next(iter(raw_datasets.values())).column_names:
+ raise ValueError(
+ f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--audio_column_name` to the correct audio column - one of "
+ f"{', '.join(next(iter(raw_datasets.values())).column_names)}."
+ )
+
+ if data_args.text_column_name not in next(iter(raw_datasets.values())).column_names:
+ raise ValueError(
+ f"--text_column_name {data_args.text_column_name} not found in dataset '{data_args.dataset_name}'. "
+ "Make sure to set `--text_column_name` to the correct text column - one of "
+ f"{', '.join(next(iter(raw_datasets.values())).column_names)}."
+ )
+
+ # 5. Load pretrained model, tokenizer, and feature extractor
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # SpecAugment for whisper models
+ if getattr(config, "model_type", None) == "whisper":
+ config.update({"apply_spec_augment": model_args.apply_spec_augment})
+
+ feature_extractor = AutoFeatureExtractor.from_pretrained(
+ model_args.feature_extractor_name if model_args.feature_extractor_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = AutoModelForSpeechSeq2Seq.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ if model.config.decoder_start_token_id is None:
+ raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
+
+ if model_args.freeze_feature_encoder:
+ model.freeze_feature_encoder()
+
+ if model_args.freeze_encoder:
+ model.freeze_encoder()
+ model.model.encoder.gradient_checkpointing = False
+
+ if hasattr(model.generation_config, "is_multilingual") and model.generation_config.is_multilingual:
+ # We only need to set the language and task ids in a multilingual setting
+ tokenizer.set_prefix_tokens(language=data_args.language, task=data_args.task)
+ model.generation_config.language = data_args.language
+ model.generation_config.task = data_args.task
+ elif data_args.language is not None:
+ raise ValueError(
+ "Setting language token for an English-only checkpoint is not permitted. The language argument should "
+ "only be set for multilingual checkpoints."
+ )
+
+ # TODO (Sanchit): deprecate these arguments in v4.41
+ if model_args.forced_decoder_ids is not None:
+ logger.warning(
+ "The use of `forced_decoder_ids` is deprecated and will be removed in v4.41."
+ "Please use the `language` and `task` arguments instead"
+ )
+ model.generation_config.forced_decoder_ids = model_args.forced_decoder_ids
+ else:
+ model.generation_config.forced_decoder_ids = None
+ model.config.forced_decoder_ids = None
+
+ if model_args.suppress_tokens is not None:
+ logger.warning(
+ "The use of `suppress_tokens` is deprecated and will be removed in v4.41."
+ "Should you need `suppress_tokens`, please manually set them in the fine-tuning script."
+ )
+ model.generation_config.suppress_tokens = model_args.suppress_tokens
+
+ # 6. Resample speech dataset if necessary
+ dataset_sampling_rate = next(iter(raw_datasets.values())).features[data_args.audio_column_name].sampling_rate
+ if dataset_sampling_rate != feature_extractor.sampling_rate:
+ raw_datasets = raw_datasets.cast_column(
+ data_args.audio_column_name, datasets.features.Audio(sampling_rate=feature_extractor.sampling_rate)
+ )
+
+ # 7. Preprocessing the datasets.
+ # We need to read the audio files as arrays and tokenize the targets.
+ max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
+ min_input_length = data_args.min_duration_in_seconds * feature_extractor.sampling_rate
+ audio_column_name = data_args.audio_column_name
+ num_workers = data_args.preprocessing_num_workers
+ text_column_name = data_args.text_column_name
+ model_input_name = feature_extractor.model_input_names[0]
+ do_lower_case = data_args.do_lower_case
+ # if SpecAugment is used for whisper models, return attention_mask to guide the mask along time axis
+ forward_attention_mask = (
+ getattr(config, "model_type", None) == "whisper"
+ and getattr(config, "apply_spec_augment", False)
+ and getattr(config, "mask_time_prob", 0) > 0
+ )
+
+ if data_args.max_train_samples is not None:
+ raw_datasets["train"] = raw_datasets["train"].select(range(data_args.max_train_samples))
+
+ if data_args.max_eval_samples is not None:
+ raw_datasets["eval"] = raw_datasets["eval"].select(range(data_args.max_eval_samples))
+
+ def prepare_dataset(batch):
+ # process audio
+ sample = batch[audio_column_name]
+ inputs = feature_extractor(
+ sample["array"], sampling_rate=sample["sampling_rate"], return_attention_mask=forward_attention_mask
+ )
+ # process audio length
+ batch[model_input_name] = inputs.get(model_input_name)[0]
+ batch["input_length"] = len(sample["array"])
+ if forward_attention_mask:
+ batch["attention_mask"] = inputs.get("attention_mask")[0]
+
+ # process targets
+ input_str = batch[text_column_name].lower() if do_lower_case else batch[text_column_name]
+ batch["labels"] = tokenizer(input_str).input_ids
+ return batch
+
+ with training_args.main_process_first(desc="dataset map pre-processing"):
+ vectorized_datasets = raw_datasets.map(
+ prepare_dataset,
+ remove_columns=next(iter(raw_datasets.values())).column_names,
+ num_proc=data_args.preprocessing_num_workers,
+ desc="preprocess train dataset",
+ )
+
+ # filter data that is shorter than min_input_length or longer than
+ # max_input_length
+ def is_audio_in_length_range(length):
+ return length > min_input_length and length < max_input_length
+
+ vectorized_datasets = vectorized_datasets.filter(
+ is_audio_in_length_range,
+ num_proc=num_workers,
+ input_columns=["input_length"],
+ )
+
+ # for large datasets it is advised to run the preprocessing on a
+ # single machine first with `args.preprocessing_only` since there will mostly likely
+ # be a timeout when running the script in distributed mode.
+ # In a second step `args.preprocessing_only` can then be set to `False` to load the
+ # cached dataset
+ if data_args.preprocessing_only:
+ cache = {k: v.cache_files for k, v in vectorized_datasets.items()}
+ logger.info(f"Data preprocessing finished. Files cached at {cache}.")
+ return
+
+ # 8. Load Metric
+ metric = evaluate.load("wer", cache_dir=model_args.cache_dir)
+
+ def compute_metrics(pred):
+ pred_ids = pred.predictions
+
+ pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
+
+ pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
+ # we do not want to group tokens when computing the metrics
+ label_str = tokenizer.batch_decode(pred.label_ids, skip_special_tokens=True)
+
+ wer = metric.compute(predictions=pred_str, references=label_str)
+
+ return {"wer": wer}
+
+ # 9. Create a single speech processor
+ # make sure all processes wait until data is saved
+ with training_args.main_process_first():
+ # only the main process saves them
+ if is_main_process(training_args.local_rank):
+ # save feature extractor, tokenizer and config
+ feature_extractor.save_pretrained(training_args.output_dir)
+ tokenizer.save_pretrained(training_args.output_dir)
+ config.save_pretrained(training_args.output_dir)
+
+ processor = AutoProcessor.from_pretrained(training_args.output_dir)
+
+ # 10. Define data collator
+ data_collator = DataCollatorSpeechSeq2SeqWithPadding(
+ processor=processor,
+ decoder_start_token_id=model.config.decoder_start_token_id,
+ forward_attention_mask=forward_attention_mask,
+ )
+
+ # 11. Initialize Trainer
+ trainer = Seq2SeqTrainer(
+ model=model,
+ args=training_args,
+ train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
+ eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
+ processing_class=feature_extractor,
+ data_collator=data_collator,
+ compute_metrics=compute_metrics if training_args.predict_with_generate else None,
+ )
+
+ # 12. Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model() # Saves the feature extractor too for easy upload
+
+ metrics = train_result.metrics
+ max_train_samples = (
+ data_args.max_train_samples
+ if data_args.max_train_samples is not None
+ else len(vectorized_datasets["train"])
+ )
+ metrics["train_samples"] = min(max_train_samples, len(vectorized_datasets["train"]))
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # 13. Evaluation
+ results = {}
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+ metrics = trainer.evaluate(
+ metric_key_prefix="eval",
+ max_length=training_args.generation_max_length,
+ num_beams=training_args.generation_num_beams,
+ )
+ max_eval_samples = (
+ data_args.max_eval_samples if data_args.max_eval_samples is not None else len(vectorized_datasets["eval"])
+ )
+ metrics["eval_samples"] = min(max_eval_samples, len(vectorized_datasets["eval"]))
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # 14. Write Training Stats
+ kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "automatic-speech-recognition"}
+ if data_args.dataset_name is not None:
+ kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ kwargs["dataset_args"] = data_args.dataset_config_name
+ kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+ return results
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/summarization/README.md b/docs/transformers/examples/pytorch/summarization/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0d332564de84ae810fc58b00dfe2def801231d88
--- /dev/null
+++ b/docs/transformers/examples/pytorch/summarization/README.md
@@ -0,0 +1,196 @@
+
+
+## Summarization
+
+This directory contains examples for finetuning and evaluating transformers on summarization tasks.
+Please tag @patil-suraj with any issues/unexpected behaviors, or send a PR!
+For deprecated `bertabs` instructions, see https://github.com/huggingface/transformers-research-projects/blob/main/bertabs/README.md.
+For the old `finetune_trainer.py` and related utils, see [`examples/legacy/seq2seq`](https://github.com/huggingface/transformers/blob/main/examples/legacy/seq2seq).
+
+### Supported Architectures
+
+- `BartForConditionalGeneration`
+- `FSMTForConditionalGeneration` (translation only)
+- `MBartForConditionalGeneration`
+- `MarianMTModel`
+- `PegasusForConditionalGeneration`
+- `T5ForConditionalGeneration`
+- `MT5ForConditionalGeneration`
+
+`run_summarization.py` is a lightweight example of how to download and preprocess a dataset from the [🤗 Datasets](https://github.com/huggingface/datasets) library or use your own files (jsonlines or csv), then fine-tune one of the architectures above on it.
+
+For custom datasets in `jsonlines` format please see: https://huggingface.co/docs/datasets/loading_datasets#json-files
+and you also will find examples of these below.
+
+## With Trainer
+
+Here is an example on a summarization task:
+```bash
+python examples/pytorch/summarization/run_summarization.py \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+Only T5 models `google-t5/t5-small`, `google-t5/t5-base`, `google-t5/t5-large`, `google-t5/t5-3b` and `google-t5/t5-11b` must use an additional argument: `--source_prefix "summarize: "`.
+
+We used CNN/DailyMail dataset in this example as `google-t5/t5-small` was trained on it and one can get good scores even when pre-training with a very small sample.
+
+Extreme Summarization (XSum) Dataset is another commonly used dataset for the task of summarization. To use it replace `--dataset_name cnn_dailymail --dataset_config "3.0.0"` with `--dataset_name xsum`.
+
+And here is how you would use it on your own files, after adjusting the values for the arguments
+`--train_file`, `--validation_file`, `--text_column` and `--summary_column` to match your setup:
+
+```bash
+python examples/pytorch/summarization/run_summarization.py \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --train_file path_to_csv_or_jsonlines_file \
+ --validation_file path_to_csv_or_jsonlines_file \
+ --source_prefix "summarize: " \
+ --output_dir /tmp/tst-summarization \
+ --overwrite_output_dir \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --predict_with_generate
+```
+
+The task of summarization supports custom CSV and JSONLINES formats.
+
+#### Custom CSV Files
+
+If it's a csv file the training and validation files should have a column for the inputs texts and a column for the summaries.
+
+If the csv file has just two columns as in the following example:
+
+```csv
+text,summary
+"I'm sitting here in a boring room. It's just another rainy Sunday afternoon. I'm wasting my time I got nothing to do. I'm hanging around I'm waiting for you. But nothing ever happens. And I wonder","I'm sitting in a room where I'm waiting for something to happen"
+"I see trees so green, red roses too. I see them bloom for me and you. And I think to myself what a wonderful world. I see skies so blue and clouds so white. The bright blessed day, the dark sacred night. And I think to myself what a wonderful world.","I'm a gardener and I'm a big fan of flowers."
+"Christmas time is here. Happiness and cheer. Fun for all that children call. Their favorite time of the year. Snowflakes in the air. Carols everywhere. Olden times and ancient rhymes. Of love and dreams to share","It's that time of year again."
+```
+
+The first column is assumed to be for `text` and the second is for summary.
+
+If the csv file has multiple columns, you can then specify the names of the columns to use:
+
+```bash
+ --text_column text_column_name \
+ --summary_column summary_column_name \
+```
+
+For example if the columns were:
+
+```csv
+id,date,text,summary
+```
+
+and you wanted to select only `text` and `summary`, then you'd pass these additional arguments:
+
+```bash
+ --text_column text \
+ --summary_column summary \
+```
+
+#### Custom JSONLINES Files
+
+The second supported format is jsonlines. Here is an example of a jsonlines custom data file.
+
+
+```json
+{"text": "I'm sitting here in a boring room. It's just another rainy Sunday afternoon. I'm wasting my time I got nothing to do. I'm hanging around I'm waiting for you. But nothing ever happens. And I wonder", "summary": "I'm sitting in a room where I'm waiting for something to happen"}
+{"text": "I see trees so green, red roses too. I see them bloom for me and you. And I think to myself what a wonderful world. I see skies so blue and clouds so white. The bright blessed day, the dark sacred night. And I think to myself what a wonderful world.", "summary": "I'm a gardener and I'm a big fan of flowers."}
+{"text": "Christmas time is here. Happiness and cheer. Fun for all that children call. Their favorite time of the year. Snowflakes in the air. Carols everywhere. Olden times and ancient rhymes. Of love and dreams to share", "summary": "It's that time of year again."}
+```
+
+Same as with the CSV files, by default the first value will be used as the text record and the second as the summary record. Therefore you can use any key names for the entries, in this example `text` and `summary` were used.
+
+And as with the CSV files, you can specify which values to select from the file, by explicitly specifying the corresponding key names. In our example this again would be:
+
+```bash
+ --text_column text \
+ --summary_column summary \
+```
+
+## With Accelerate
+
+Based on the script [`run_summarization_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/summarization/run_summarization_no_trainer.py).
+
+Like `run_summarization.py`, this script allows you to fine-tune any of the models supported on a
+summarization task, the main difference is that this
+script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like.
+
+It offers less options than the script with `Trainer` (for instance you can easily change the options for the optimizer
+or the dataloaders directly in the script) but still run in a distributed setup, on TPU and supports mixed precision by
+the mean of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
+after installing it:
+
+```bash
+pip install git+https://github.com/huggingface/accelerate
+```
+
+then
+
+```bash
+python run_summarization_no_trainer.py \
+ --model_name_or_path google-t5/t5-small \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir ~/tmp/tst-summarization
+```
+
+You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
+
+```bash
+accelerate config
+```
+
+and reply to the questions asked. Then
+
+```bash
+accelerate test
+```
+
+that will check everything is ready for training. Finally, you can launch training with
+
+```bash
+accelerate launch run_summarization_no_trainer.py \
+ --model_name_or_path google-t5/t5-small \
+ --dataset_name cnn_dailymail \
+ --dataset_config "3.0.0" \
+ --source_prefix "summarize: " \
+ --output_dir ~/tmp/tst-summarization
+```
+
+This command is the same and will work for:
+
+- a CPU-only setup
+- a setup with one GPU
+- a distributed training with several GPUs (single or multi node)
+- a training on TPUs
+
+Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
diff --git a/docs/transformers/examples/pytorch/summarization/requirements.txt b/docs/transformers/examples/pytorch/summarization/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..efc067478603d253fa6ec2fd309328307c562c79
--- /dev/null
+++ b/docs/transformers/examples/pytorch/summarization/requirements.txt
@@ -0,0 +1,9 @@
+accelerate >= 0.12.0
+datasets >= 1.8.0
+sentencepiece != 0.1.92
+protobuf
+rouge-score
+nltk
+py7zr
+torch >= 1.3
+evaluate
diff --git a/docs/transformers/examples/pytorch/summarization/run_summarization.py b/docs/transformers/examples/pytorch/summarization/run_summarization.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce63c1c7f0699988d61f6eb87ed7e08a9a39e7e6
--- /dev/null
+++ b/docs/transformers/examples/pytorch/summarization/run_summarization.py
@@ -0,0 +1,772 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for sequence to sequence.
+"""
+# You can also adapt this script on your own sequence to sequence task. Pointers for this are left as comments.
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import datasets
+import evaluate
+import nltk # Here to have a nice missing dependency error message early on
+import numpy as np
+from datasets import load_dataset
+from filelock import FileLock
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForSeq2SeqLM,
+ AutoTokenizer,
+ DataCollatorForSeq2Seq,
+ HfArgumentParser,
+ MBart50Tokenizer,
+ MBart50TokenizerFast,
+ MBartTokenizer,
+ MBartTokenizerFast,
+ Seq2SeqTrainer,
+ Seq2SeqTrainingArguments,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, is_offline_mode, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
+
+logger = logging.getLogger(__name__)
+
+try:
+ nltk.data.find("tokenizers/punkt")
+except (LookupError, OSError):
+ if is_offline_mode():
+ raise LookupError(
+ "Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
+ )
+ with FileLock(".lock") as lock:
+ nltk.download("punkt", quiet=True)
+
+# A list of all multilingual tokenizer which require lang attribute.
+MULTILINGUAL_TOKENIZERS = [MBartTokenizer, MBartTokenizerFast, MBart50Tokenizer, MBart50TokenizerFast]
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ resize_position_embeddings: Optional[bool] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Whether to automatically resize the position embeddings if `max_source_length` exceeds "
+ "the model's position embeddings."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ lang: Optional[str] = field(default=None, metadata={"help": "Language id for summarization."})
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ text_column: Optional[str] = field(
+ default=None,
+ metadata={"help": "The name of the column in the datasets containing the full texts (for summarization)."},
+ )
+ summary_column: Optional[str] = field(
+ default=None,
+ metadata={"help": "The name of the column in the datasets containing the summaries (for summarization)."},
+ )
+ train_file: Optional[str] = field(
+ default=None, metadata={"help": "The input training data file (a jsonlines or csv file)."}
+ )
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "An optional input evaluation data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
+ )
+ },
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": "An optional input test data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_source_length: Optional[int] = field(
+ default=1024,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ max_target_length: Optional[int] = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total sequence length for target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ val_max_target_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total sequence length for validation target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
+ "This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
+ "during ``evaluate`` and ``predict``."
+ )
+ },
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to model maximum sentence length. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
+ "efficient on GPU but very bad for TPU."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ num_beams: Optional[int] = field(
+ default=1,
+ metadata={
+ "help": (
+ "Number of beams to use for evaluation. This argument will be passed to ``model.generate``, "
+ "which is used during ``evaluate`` and ``predict``."
+ )
+ },
+ )
+ ignore_pad_token_for_loss: bool = field(
+ default=True,
+ metadata={
+ "help": "Whether to ignore the tokens corresponding to padded labels in the loss computation or not."
+ },
+ )
+ source_prefix: Optional[str] = field(
+ default=None, metadata={"help": "A prefix to add before every source text (useful for T5 models)."}
+ )
+
+ forced_bos_token: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to force as the first generated token after the decoder_start_token_id. "
+ "Useful for multilingual models like mBART where the first generated token"
+ "needs to be the target language token (Usually it is the target language token)"
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if (
+ self.dataset_name is None
+ and self.train_file is None
+ and self.validation_file is None
+ and self.test_file is None
+ ):
+ raise ValueError("Need either a dataset name or a training, validation, or test file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ if self.test_file is not None:
+ extension = self.test_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
+ if self.val_max_target_length is None:
+ self.val_max_target_length = self.max_target_length
+
+
+summarization_name_mapping = {
+ "amazon_reviews_multi": ("review_body", "review_title"),
+ "big_patent": ("description", "abstract"),
+ "cnn_dailymail": ("article", "highlights"),
+ "orange_sum": ("text", "summary"),
+ "pn_summary": ("article", "summary"),
+ "psc": ("extract_text", "summary_text"),
+ "samsum": ("dialogue", "summary"),
+ "thaisum": ("body", "summary"),
+ "xglue": ("news_body", "news_title"),
+ "xsum": ("document", "summary"),
+ "wiki_summary": ("article", "highlights"),
+ "multi_news": ("document", "summary"),
+}
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_summarization", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ if data_args.source_prefix is None and model_args.model_name_or_path in [
+ "google-t5/t5-small",
+ "google-t5/t5-base",
+ "google-t5/t5-large",
+ "google-t5/t5-3b",
+ "google-t5/t5-11b",
+ ]:
+ logger.warning(
+ "You're running a t5 model but didn't provide a source prefix, which is the expected, e.g. with "
+ "`--source_prefix 'summarize: ' `"
+ )
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files this script will use the first column for the full texts and the second column for the
+ # summaries (unless you specify column names for this with the `text_column` and `summary_column` arguments).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if data_args.test_file is not None:
+ data_files["test"] = data_args.test_file
+ extension = data_args.test_file.split(".")[-1]
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = AutoModelForSeq2SeqLM.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embedding_size = model.get_input_embeddings().weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+
+ if model.config.decoder_start_token_id is None and isinstance(tokenizer, (MBartTokenizer, MBartTokenizerFast)):
+ if isinstance(tokenizer, MBartTokenizer):
+ model.config.decoder_start_token_id = tokenizer.lang_code_to_id[data_args.lang]
+ else:
+ model.config.decoder_start_token_id = tokenizer.convert_tokens_to_ids(data_args.lang)
+
+ if model.config.decoder_start_token_id is None:
+ raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
+
+ if (
+ hasattr(model.config, "max_position_embeddings")
+ and model.config.max_position_embeddings < data_args.max_source_length
+ ):
+ if model_args.resize_position_embeddings is None:
+ logger.warning(
+ "Increasing the model's number of position embedding vectors from"
+ f" {model.config.max_position_embeddings} to {data_args.max_source_length}."
+ )
+ model.resize_position_embeddings(data_args.max_source_length)
+ elif model_args.resize_position_embeddings:
+ model.resize_position_embeddings(data_args.max_source_length)
+ else:
+ raise ValueError(
+ f"`--max_source_length` is set to {data_args.max_source_length}, but the model only has"
+ f" {model.config.max_position_embeddings} position encodings. Consider either reducing"
+ f" `--max_source_length` to {model.config.max_position_embeddings} or to automatically resize the"
+ " model's position encodings by passing `--resize_position_embeddings`."
+ )
+
+ prefix = data_args.source_prefix if data_args.source_prefix is not None else ""
+
+ # Preprocessing the datasets.
+ # We need to tokenize inputs and targets.
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ column_names = raw_datasets["train"].column_names
+ elif training_args.do_eval:
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ column_names = raw_datasets["validation"].column_names
+ elif training_args.do_predict:
+ if "test" not in raw_datasets:
+ raise ValueError("--do_predict requires a test dataset")
+ column_names = raw_datasets["test"].column_names
+ else:
+ logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
+ return
+
+ if isinstance(tokenizer, tuple(MULTILINGUAL_TOKENIZERS)):
+ assert data_args.lang is not None, (
+ f"{tokenizer.__class__.__name__} is a multilingual tokenizer which requires --lang argument"
+ )
+
+ tokenizer.src_lang = data_args.lang
+ tokenizer.tgt_lang = data_args.lang
+
+ # For multilingual translation models like mBART-50 and M2M100 we need to force the target language token
+ # as the first generated token. We ask the user to explicitly provide this as --forced_bos_token argument.
+ forced_bos_token_id = (
+ tokenizer.lang_code_to_id[data_args.forced_bos_token] if data_args.forced_bos_token is not None else None
+ )
+ model.config.forced_bos_token_id = forced_bos_token_id
+
+ # Get the column names for input/target.
+ dataset_columns = summarization_name_mapping.get(data_args.dataset_name, None)
+ if data_args.text_column is None:
+ text_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ text_column = data_args.text_column
+ if text_column not in column_names:
+ raise ValueError(
+ f"--text_column' value '{data_args.text_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if data_args.summary_column is None:
+ summary_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ summary_column = data_args.summary_column
+ if summary_column not in column_names:
+ raise ValueError(
+ f"--summary_column' value '{data_args.summary_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # Temporarily set max_target_length for training.
+ max_target_length = data_args.max_target_length
+ padding = "max_length" if data_args.pad_to_max_length else False
+
+ if training_args.label_smoothing_factor > 0 and not hasattr(model, "prepare_decoder_input_ids_from_labels"):
+ logger.warning(
+ "label_smoothing is enabled but the `prepare_decoder_input_ids_from_labels` method is not defined for "
+ f"`{model.__class__.__name__}`. This will lead to loss being calculated twice and will take up more memory"
+ )
+
+ def preprocess_function(examples):
+ # remove pairs where at least one record is None
+
+ inputs, targets = [], []
+ for i in range(len(examples[text_column])):
+ if examples[text_column][i] and examples[summary_column][i]:
+ inputs.append(examples[text_column][i])
+ targets.append(examples[summary_column][i])
+
+ inputs = [prefix + inp for inp in inputs]
+ model_inputs = tokenizer(inputs, max_length=data_args.max_source_length, padding=padding, truncation=True)
+
+ # Tokenize targets with the `text_target` keyword argument
+ labels = tokenizer(text_target=targets, max_length=max_target_length, padding=padding, truncation=True)
+
+ # If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
+ # padding in the loss.
+ if padding == "max_length" and data_args.ignore_pad_token_for_loss:
+ labels["input_ids"] = [
+ [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
+ ]
+
+ model_inputs["labels"] = labels["input_ids"]
+ return model_inputs
+
+ if training_args.do_train:
+ train_dataset = raw_datasets["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ with training_args.main_process_first(desc="train dataset map pre-processing"):
+ train_dataset = train_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+
+ if training_args.do_eval:
+ max_target_length = data_args.val_max_target_length
+ eval_dataset = raw_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+ with training_args.main_process_first(desc="validation dataset map pre-processing"):
+ eval_dataset = eval_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+
+ if training_args.do_predict:
+ max_target_length = data_args.val_max_target_length
+ predict_dataset = raw_datasets["test"]
+ if data_args.max_predict_samples is not None:
+ max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
+ predict_dataset = predict_dataset.select(range(max_predict_samples))
+ with training_args.main_process_first(desc="prediction dataset map pre-processing"):
+ predict_dataset = predict_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on prediction dataset",
+ )
+
+ # Data collator
+ label_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
+ data_collator = DataCollatorForSeq2Seq(
+ tokenizer,
+ model=model,
+ label_pad_token_id=label_pad_token_id,
+ pad_to_multiple_of=8 if training_args.fp16 else None,
+ )
+
+ # Metric
+ metric = evaluate.load("rouge", cache_dir=model_args.cache_dir)
+
+ def postprocess_text(preds, labels):
+ preds = [pred.strip() for pred in preds]
+ labels = [label.strip() for label in labels]
+
+ # rougeLSum expects newline after each sentence
+ preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
+ labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
+
+ return preds, labels
+
+ def compute_metrics(eval_preds):
+ preds, labels = eval_preds
+ if isinstance(preds, tuple):
+ preds = preds[0]
+ # Replace -100s used for padding as we can't decode them
+ preds = np.where(preds != -100, preds, tokenizer.pad_token_id)
+ decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Some simple post-processing
+ decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
+
+ result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
+ result = {k: round(v * 100, 4) for k, v in result.items()}
+ prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
+ result["gen_len"] = np.mean(prediction_lens)
+ return result
+
+ # Override the decoding parameters of Seq2SeqTrainer
+ training_args.generation_max_length = (
+ training_args.generation_max_length
+ if training_args.generation_max_length is not None
+ else data_args.val_max_target_length
+ )
+ training_args.generation_num_beams = (
+ data_args.num_beams if data_args.num_beams is not None else training_args.generation_num_beams
+ )
+
+ # Initialize our Trainer
+ trainer = Seq2SeqTrainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ processing_class=tokenizer,
+ data_collator=data_collator,
+ compute_metrics=compute_metrics if training_args.predict_with_generate else None,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model() # Saves the tokenizer too for easy upload
+
+ metrics = train_result.metrics
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ results = {}
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+ if isinstance(eval_dataset, dict):
+ metrics = {}
+ for eval_ds_name, eval_ds in eval_dataset.items():
+ dataset_metrics = trainer.evaluate(eval_dataset=eval_ds, metric_key_prefix=f"eval_{eval_ds_name}")
+ metrics.update(dataset_metrics)
+ else:
+ metrics = trainer.evaluate(metric_key_prefix="eval")
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ if training_args.do_predict:
+ logger.info("*** Predict ***")
+
+ predict_results = trainer.predict(predict_dataset, metric_key_prefix="predict")
+ metrics = predict_results.metrics
+ max_predict_samples = (
+ data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
+ )
+ metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
+
+ trainer.log_metrics("predict", metrics)
+ trainer.save_metrics("predict", metrics)
+
+ if trainer.is_world_process_zero():
+ if training_args.predict_with_generate:
+ predictions = predict_results.predictions
+ predictions = np.where(predictions != -100, predictions, tokenizer.pad_token_id)
+ predictions = tokenizer.batch_decode(
+ predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True
+ )
+ predictions = [pred.strip() for pred in predictions]
+ output_prediction_file = os.path.join(training_args.output_dir, "generated_predictions.txt")
+ with open(output_prediction_file, "w") as writer:
+ writer.write("\n".join(predictions))
+
+ kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "summarization"}
+ if data_args.dataset_name is not None:
+ kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ kwargs["dataset_args"] = data_args.dataset_config_name
+ kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ kwargs["dataset"] = data_args.dataset_name
+
+ if data_args.lang is not None:
+ kwargs["language"] = data_args.lang
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+ return results
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/summarization/run_summarization_no_trainer.py b/docs/transformers/examples/pytorch/summarization/run_summarization_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..4351ecffd10f629db4942a2c5dbe64aa967cac7b
--- /dev/null
+++ b/docs/transformers/examples/pytorch/summarization/run_summarization_no_trainer.py
@@ -0,0 +1,800 @@
+#!/usr/bin/env python
+# Copyright The HuggingFace Team and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning a 🤗 Transformers model on summarization.
+"""
+# You can also adapt this script on your own summarization task. Pointers for this are left as comments.
+
+import argparse
+import json
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import datasets
+import evaluate
+import nltk
+import numpy as np
+import torch
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from datasets import load_dataset
+from filelock import FileLock
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from tqdm.auto import tqdm
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_MAPPING,
+ AutoConfig,
+ AutoModelForSeq2SeqLM,
+ AutoTokenizer,
+ DataCollatorForSeq2Seq,
+ SchedulerType,
+ get_scheduler,
+)
+from transformers.utils import check_min_version, is_offline_mode, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logger = get_logger(__name__)
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
+
+# You should update this to your particular problem to have better documentation of `model_type`
+MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+try:
+ nltk.data.find("tokenizers/punkt")
+except (LookupError, OSError):
+ if is_offline_mode():
+ raise LookupError(
+ "Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
+ )
+ with FileLock(".lock") as lock:
+ nltk.download("punkt", quiet=True)
+
+summarization_name_mapping = {
+ "amazon_reviews_multi": ("review_body", "review_title"),
+ "big_patent": ("description", "abstract"),
+ "cnn_dailymail": ("article", "highlights"),
+ "orange_sum": ("text", "summary"),
+ "pn_summary": ("article", "summary"),
+ "psc": ("extract_text", "summary_text"),
+ "samsum": ("dialogue", "summary"),
+ "thaisum": ("body", "summary"),
+ "xglue": ("news_body", "news_title"),
+ "xsum": ("document", "summary"),
+ "wiki_summary": ("article", "highlights"),
+}
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Finetune a transformers model on a summarization task")
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help="The name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The configuration name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--train_file", type=str, default=None, help="A csv or a json file containing the training data."
+ )
+ parser.add_argument(
+ "--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
+ )
+ parser.add_argument(
+ "--ignore_pad_token_for_loss",
+ type=bool,
+ default=True,
+ help="Whether to ignore the tokens corresponding to padded labels in the loss computation or not.",
+ )
+ parser.add_argument(
+ "--max_source_length",
+ type=int,
+ default=1024,
+ help=(
+ "The maximum total input sequence length after "
+ "tokenization.Sequences longer than this will be truncated, sequences shorter will be padded."
+ ),
+ )
+ parser.add_argument(
+ "--source_prefix",
+ type=str,
+ default=None,
+ help="A prefix to add before every source text (useful for T5 models).",
+ )
+ parser.add_argument(
+ "--preprocessing_num_workers",
+ type=int,
+ default=None,
+ help="The number of processes to use for the preprocessing.",
+ )
+ parser.add_argument(
+ "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
+ )
+ parser.add_argument(
+ "--max_target_length",
+ type=int,
+ default=128,
+ help=(
+ "The maximum total sequence length for target text after "
+ "tokenization. Sequences longer than this will be truncated, sequences shorter will be padded. "
+ "during ``evaluate`` and ``predict``."
+ ),
+ )
+ parser.add_argument(
+ "--val_max_target_length",
+ type=int,
+ default=None,
+ help=(
+ "The maximum total sequence length for validation "
+ "target text after tokenization.Sequences longer than this will be truncated, sequences shorter will be "
+ "padded. Will default to `max_target_length`.This argument is also used to override the ``max_length`` "
+ "param of ``model.generate``, which is used during ``evaluate`` and ``predict``."
+ ),
+ )
+ parser.add_argument(
+ "--num_beams",
+ type=int,
+ default=None,
+ help=(
+ "Number of beams to use for evaluation. This argument will be "
+ "passed to ``model.generate``, which is used during ``evaluate`` and ``predict``."
+ ),
+ )
+ parser.add_argument(
+ "--pad_to_max_length",
+ action="store_true",
+ help="If passed, pad all samples to `max_length`. Otherwise, dynamic padding is used.",
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ required=False,
+ )
+ parser.add_argument(
+ "--config_name",
+ type=str,
+ default=None,
+ help="Pretrained config name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--text_column",
+ type=str,
+ default=None,
+ help="The name of the column in the datasets containing the full texts (for summarization).",
+ )
+ parser.add_argument(
+ "--summary_column",
+ type=str,
+ default=None,
+ help="The name of the column in the datasets containing the summaries (for summarization).",
+ )
+ parser.add_argument(
+ "--use_slow_tokenizer",
+ action="store_true",
+ help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--model_type",
+ type=str,
+ default=None,
+ help="Model type to use if training from scratch.",
+ choices=MODEL_TYPES,
+ )
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+ if args.dataset_name is None and args.train_file is None and args.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if args.train_file is not None:
+ extension = args.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if args.validation_file is not None:
+ extension = args.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+
+ if args.push_to_hub:
+ assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
+
+ return args
+
+
+def main():
+ args = parse_args()
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_summarization_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator_log_kwargs = {}
+
+ if args.with_tracking:
+ accelerator_log_kwargs["log_with"] = args.report_to
+ accelerator_log_kwargs["project_dir"] = args.output_dir
+
+ accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
+ if args.source_prefix is None and args.model_name_or_path in [
+ "google-t5/t5-small",
+ "google-t5/t5-base",
+ "google-t5/t5-large",
+ "google-t5/t5-3b",
+ "google-t5/t5-11b",
+ ]:
+ logger.warning(
+ "You're running a t5 model but didn't provide a source prefix, which is the expected, e.g. with "
+ "`--source_prefix 'summarize: ' `"
+ )
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ args.dataset_name, args.dataset_config_name, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ data_files = {}
+ if args.train_file is not None:
+ data_files["train"] = args.train_file
+ extension = args.train_file.split(".")[-1]
+ if args.validation_file is not None:
+ data_files["validation"] = args.validation_file
+ extension = args.validation_file.split(".")[-1]
+ raw_datasets = load_dataset(extension, data_files=data_files)
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ if args.config_name:
+ config = AutoConfig.from_pretrained(args.config_name, trust_remote_code=args.trust_remote_code)
+ elif args.model_name_or_path:
+ config = AutoConfig.from_pretrained(args.model_name_or_path, trust_remote_code=args.trust_remote_code)
+ else:
+ config = CONFIG_MAPPING[args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_name, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
+ )
+ elif args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if args.model_name_or_path:
+ model = AutoModelForSeq2SeqLM.from_pretrained(
+ args.model_name_or_path,
+ from_tf=bool(".ckpt" in args.model_name_or_path),
+ config=config,
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelForSeq2SeqLM.from_config(config, trust_remote_code=args.trust_remote_code)
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embedding_size = model.get_input_embeddings().weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+ if model.config.decoder_start_token_id is None:
+ raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
+
+ prefix = args.source_prefix if args.source_prefix is not None else ""
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ column_names = raw_datasets["train"].column_names
+
+ # Get the column names for input/target.
+ dataset_columns = summarization_name_mapping.get(args.dataset_name, None)
+ if args.text_column is None:
+ text_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ text_column = args.text_column
+ if text_column not in column_names:
+ raise ValueError(
+ f"--text_column' value '{args.text_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if args.summary_column is None:
+ summary_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ summary_column = args.summary_column
+ if summary_column not in column_names:
+ raise ValueError(
+ f"--summary_column' value '{args.summary_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ if args.val_max_target_length is None:
+ args.val_max_target_length = args.max_target_length
+
+ # Temporarily set max_target_length for training.
+ max_target_length = args.max_target_length
+ padding = "max_length" if args.pad_to_max_length else False
+
+ def preprocess_function(examples):
+ inputs = examples[text_column]
+ targets = examples[summary_column]
+ inputs = [prefix + inp for inp in inputs]
+ model_inputs = tokenizer(inputs, max_length=args.max_source_length, padding=padding, truncation=True)
+
+ # Tokenize targets with the `text_target` keyword argument
+ labels = tokenizer(text_target=targets, max_length=max_target_length, padding=padding, truncation=True)
+
+ # If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
+ # padding in the loss.
+ if padding == "max_length" and args.ignore_pad_token_for_loss:
+ labels["input_ids"] = [
+ [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
+ ]
+
+ model_inputs["labels"] = labels["input_ids"]
+ return model_inputs
+
+ with accelerator.main_process_first():
+ train_dataset = raw_datasets["train"].map(
+ preprocess_function,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Running tokenizer on dataset",
+ )
+
+ # Temporarily set max_target_length for validation.
+ max_target_length = args.val_max_target_length
+ eval_dataset = raw_datasets["validation"].map(
+ preprocess_function,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Running tokenizer on dataset",
+ )
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 1):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ label_pad_token_id = -100 if args.ignore_pad_token_for_loss else tokenizer.pad_token_id
+ if accelerator.mixed_precision == "fp8":
+ pad_to_multiple_of = 16
+ elif accelerator.mixed_precision != "no":
+ pad_to_multiple_of = 8
+ else:
+ pad_to_multiple_of = None
+ data_collator = DataCollatorForSeq2Seq(
+ tokenizer,
+ model=model,
+ label_pad_token_id=label_pad_token_id,
+ pad_to_multiple_of=pad_to_multiple_of,
+ )
+
+ def postprocess_text(preds, labels):
+ preds = [pred.strip() for pred in preds]
+ labels = [label.strip() for label in labels]
+
+ # rougeLSum expects newline after each sentence
+ preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
+ labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
+
+ return preds, labels
+
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
+ )
+ eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
+
+ # Optimizer
+ # Split weights in two groups, one with weight decay and the other not.
+ no_decay = ["bias", "LayerNorm.weight", "layer_norm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps
+ if overrode_max_train_steps
+ else args.max_train_steps * accelerator.num_processes,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("summarization_no_trainer", experiment_config)
+
+ # Metric
+ metric = evaluate.load("rouge")
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+ for step, batch in enumerate(active_dataloader):
+ with accelerator.accumulate(model):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+ accelerator.backward(loss)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ model.eval()
+
+ gen_kwargs = {
+ "max_length": args.val_max_target_length,
+ "num_beams": args.num_beams,
+ }
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ generated_tokens = accelerator.unwrap_model(model).generate(
+ batch["input_ids"],
+ attention_mask=batch["attention_mask"],
+ **gen_kwargs,
+ )
+
+ generated_tokens = accelerator.pad_across_processes(
+ generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
+ )
+ labels = batch["labels"]
+ if not args.pad_to_max_length:
+ # If we did not pad to max length, we need to pad the labels too
+ labels = accelerator.pad_across_processes(batch["labels"], dim=1, pad_index=tokenizer.pad_token_id)
+
+ generated_tokens, labels = accelerator.gather_for_metrics((generated_tokens, labels))
+ generated_tokens = generated_tokens.cpu().numpy()
+ labels = labels.cpu().numpy()
+
+ if args.ignore_pad_token_for_loss:
+ # Replace -100 in the labels as we can't decode them.
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ if isinstance(generated_tokens, tuple):
+ generated_tokens = generated_tokens[0]
+ decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
+ metric.add_batch(
+ predictions=decoded_preds,
+ references=decoded_labels,
+ )
+ result = metric.compute(use_stemmer=True)
+ result = {k: round(v * 100, 4) for k, v in result.items()}
+
+ logger.info(result)
+
+ if args.with_tracking:
+ result["train_loss"] = total_loss.item() / len(train_dataloader)
+ result["epoch"] = epoch
+ result["step"] = completed_steps
+ accelerator.log(result, step=completed_steps)
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ all_results = {f"eval_{k}": v for k, v in result.items()}
+ with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
+ json.dump(all_results, f)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/test_accelerate_examples.py b/docs/transformers/examples/pytorch/test_accelerate_examples.py
new file mode 100644
index 0000000000000000000000000000000000000000..923803a2da5f4e3e2ba93d35b39c9a9fb7b88637
--- /dev/null
+++ b/docs/transformers/examples/pytorch/test_accelerate_examples.py
@@ -0,0 +1,382 @@
+# Copyright 2018 HuggingFace Inc..
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import argparse
+import json
+import logging
+import os
+import shutil
+import sys
+import tempfile
+import unittest
+from unittest import mock
+
+from accelerate.utils import write_basic_config
+
+from transformers.testing_utils import (
+ TestCasePlus,
+ backend_device_count,
+ run_command,
+ slow,
+ torch_device,
+)
+
+
+logging.basicConfig(level=logging.DEBUG)
+
+logger = logging.getLogger()
+
+
+def get_setup_file():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-f")
+ args = parser.parse_args()
+ return args.f
+
+
+def get_results(output_dir):
+ results = {}
+ path = os.path.join(output_dir, "all_results.json")
+ if os.path.exists(path):
+ with open(path) as f:
+ results = json.load(f)
+ else:
+ raise ValueError(f"can't find {path}")
+ return results
+
+
+stream_handler = logging.StreamHandler(sys.stdout)
+logger.addHandler(stream_handler)
+
+
+class ExamplesTestsNoTrainer(TestCasePlus):
+ @classmethod
+ def setUpClass(cls):
+ # Write Accelerate config, will pick up on CPU, GPU, and multi-GPU
+ cls.tmpdir = tempfile.mkdtemp()
+ cls.configPath = os.path.join(cls.tmpdir, "default_config.yml")
+ write_basic_config(save_location=cls.configPath)
+ cls._launch_args = ["accelerate", "launch", "--config_file", cls.configPath]
+
+ @classmethod
+ def tearDownClass(cls):
+ shutil.rmtree(cls.tmpdir)
+
+ @mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
+ def test_run_glue_no_trainer(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ {self.examples_dir}/pytorch/text-classification/run_glue_no_trainer.py
+ --model_name_or_path distilbert/distilbert-base-uncased
+ --output_dir {tmp_dir}
+ --train_file ./tests/fixtures/tests_samples/MRPC/train.csv
+ --validation_file ./tests/fixtures/tests_samples/MRPC/dev.csv
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --learning_rate=1e-4
+ --seed=42
+ --num_warmup_steps=2
+ --checkpointing_steps epoch
+ --with_tracking
+ """.split()
+
+ run_command(self._launch_args + testargs)
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_accuracy"], 0.75)
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "glue_no_trainer")))
+
+ @unittest.skip("Zach is working on this.")
+ @mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
+ def test_run_clm_no_trainer(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ {self.examples_dir}/pytorch/language-modeling/run_clm_no_trainer.py
+ --model_name_or_path distilbert/distilgpt2
+ --train_file ./tests/fixtures/sample_text.txt
+ --validation_file ./tests/fixtures/sample_text.txt
+ --block_size 128
+ --per_device_train_batch_size 5
+ --per_device_eval_batch_size 5
+ --num_train_epochs 2
+ --output_dir {tmp_dir}
+ --checkpointing_steps epoch
+ --with_tracking
+ """.split()
+
+ if backend_device_count(torch_device) > 1:
+ # Skipping because there are not enough batches to train the model + would need a drop_last to work.
+ return
+
+ run_command(self._launch_args + testargs)
+ result = get_results(tmp_dir)
+ self.assertLess(result["perplexity"], 100)
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "clm_no_trainer")))
+
+ @unittest.skip("Zach is working on this.")
+ @mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
+ def test_run_mlm_no_trainer(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ {self.examples_dir}/pytorch/language-modeling/run_mlm_no_trainer.py
+ --model_name_or_path distilbert/distilroberta-base
+ --train_file ./tests/fixtures/sample_text.txt
+ --validation_file ./tests/fixtures/sample_text.txt
+ --output_dir {tmp_dir}
+ --num_train_epochs=1
+ --checkpointing_steps epoch
+ --with_tracking
+ """.split()
+
+ run_command(self._launch_args + testargs)
+ result = get_results(tmp_dir)
+ self.assertLess(result["perplexity"], 42)
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "mlm_no_trainer")))
+
+ @mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
+ def test_run_ner_no_trainer(self):
+ # with so little data distributed training needs more epochs to get the score on par with 0/1 gpu
+ epochs = 7 if backend_device_count(torch_device) > 1 else 2
+
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ {self.examples_dir}/pytorch/token-classification/run_ner_no_trainer.py
+ --model_name_or_path google-bert/bert-base-uncased
+ --train_file tests/fixtures/tests_samples/conll/sample.json
+ --validation_file tests/fixtures/tests_samples/conll/sample.json
+ --output_dir {tmp_dir}
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=2
+ --num_train_epochs={epochs}
+ --seed 7
+ --checkpointing_steps epoch
+ --with_tracking
+ """.split()
+
+ run_command(self._launch_args + testargs)
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_accuracy"], 0.75)
+ self.assertLess(result["train_loss"], 0.6)
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "ner_no_trainer")))
+
+ @mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
+ def test_run_squad_no_trainer(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ {self.examples_dir}/pytorch/question-answering/run_qa_no_trainer.py
+ --model_name_or_path google-bert/bert-base-uncased
+ --version_2_with_negative
+ --train_file tests/fixtures/tests_samples/SQUAD/sample.json
+ --validation_file tests/fixtures/tests_samples/SQUAD/sample.json
+ --output_dir {tmp_dir}
+ --seed=42
+ --max_train_steps=10
+ --num_warmup_steps=2
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --checkpointing_steps epoch
+ --with_tracking
+ """.split()
+
+ run_command(self._launch_args + testargs)
+ result = get_results(tmp_dir)
+ # Because we use --version_2_with_negative the testing script uses SQuAD v2 metrics.
+ self.assertGreaterEqual(result["eval_f1"], 28)
+ self.assertGreaterEqual(result["eval_exact"], 28)
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "qa_no_trainer")))
+
+ @mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
+ def test_run_swag_no_trainer(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ {self.examples_dir}/pytorch/multiple-choice/run_swag_no_trainer.py
+ --model_name_or_path google-bert/bert-base-uncased
+ --train_file tests/fixtures/tests_samples/swag/sample.json
+ --validation_file tests/fixtures/tests_samples/swag/sample.json
+ --output_dir {tmp_dir}
+ --max_train_steps=20
+ --num_warmup_steps=2
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --with_tracking
+ """.split()
+
+ run_command(self._launch_args + testargs)
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_accuracy"], 0.8)
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "swag_no_trainer")))
+
+ @slow
+ @mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
+ def test_run_summarization_no_trainer(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ {self.examples_dir}/pytorch/summarization/run_summarization_no_trainer.py
+ --model_name_or_path google-t5/t5-small
+ --train_file tests/fixtures/tests_samples/xsum/sample.json
+ --validation_file tests/fixtures/tests_samples/xsum/sample.json
+ --output_dir {tmp_dir}
+ --max_train_steps=50
+ --num_warmup_steps=8
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --checkpointing_steps epoch
+ --with_tracking
+ """.split()
+
+ run_command(self._launch_args + testargs)
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_rouge1"], 10)
+ self.assertGreaterEqual(result["eval_rouge2"], 2)
+ self.assertGreaterEqual(result["eval_rougeL"], 7)
+ self.assertGreaterEqual(result["eval_rougeLsum"], 7)
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "summarization_no_trainer")))
+
+ @slow
+ @mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
+ def test_run_translation_no_trainer(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ {self.examples_dir}/pytorch/translation/run_translation_no_trainer.py
+ --model_name_or_path sshleifer/student_marian_en_ro_6_1
+ --source_lang en
+ --target_lang ro
+ --train_file tests/fixtures/tests_samples/wmt16/sample.json
+ --validation_file tests/fixtures/tests_samples/wmt16/sample.json
+ --output_dir {tmp_dir}
+ --max_train_steps=50
+ --num_warmup_steps=8
+ --num_beams=6
+ --learning_rate=3e-3
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --source_lang en_XX
+ --target_lang ro_RO
+ --checkpointing_steps epoch
+ --with_tracking
+ """.split()
+
+ run_command(self._launch_args + testargs)
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_bleu"], 30)
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "translation_no_trainer")))
+
+ @slow
+ def test_run_semantic_segmentation_no_trainer(self):
+ stream_handler = logging.StreamHandler(sys.stdout)
+ logger.addHandler(stream_handler)
+
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ {self.examples_dir}/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py
+ --dataset_name huggingface/semantic-segmentation-test-sample
+ --output_dir {tmp_dir}
+ --max_train_steps=10
+ --num_warmup_steps=2
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --checkpointing_steps epoch
+ """.split()
+
+ run_command(self._launch_args + testargs)
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_overall_accuracy"], 0.10)
+
+ @mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
+ def test_run_image_classification_no_trainer(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ {self.examples_dir}/pytorch/image-classification/run_image_classification_no_trainer.py
+ --model_name_or_path google/vit-base-patch16-224-in21k
+ --dataset_name hf-internal-testing/cats_vs_dogs_sample
+ --trust_remote_code
+ --learning_rate 1e-4
+ --per_device_train_batch_size 2
+ --per_device_eval_batch_size 1
+ --max_train_steps 2
+ --train_val_split 0.1
+ --seed 42
+ --output_dir {tmp_dir}
+ --with_tracking
+ --checkpointing_steps 1
+ --label_column_name labels
+ """.split()
+
+ run_command(self._launch_args + testargs)
+ result = get_results(tmp_dir)
+ # The base model scores a 25%
+ self.assertGreaterEqual(result["eval_accuracy"], 0.4)
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "step_1")))
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "image_classification_no_trainer")))
+
+ @slow
+ @mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
+ def test_run_object_detection_no_trainer(self):
+ stream_handler = logging.StreamHandler(sys.stdout)
+ logger.addHandler(stream_handler)
+
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ {self.examples_dir}/pytorch/object-detection/run_object_detection_no_trainer.py
+ --model_name_or_path qubvel-hf/detr-resnet-50-finetuned-10k-cppe5
+ --dataset_name qubvel-hf/cppe-5-sample
+ --output_dir {tmp_dir}
+ --max_train_steps=10
+ --num_warmup_steps=2
+ --learning_rate=1e-6
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --checkpointing_steps epoch
+ """.split()
+
+ run_command(self._launch_args + testargs)
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["test_map"], 0.10)
+
+ @slow
+ @mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
+ def test_run_instance_segmentation_no_trainer(self):
+ stream_handler = logging.StreamHandler(sys.stdout)
+ logger.addHandler(stream_handler)
+
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ {self.examples_dir}/pytorch/instance-segmentation/run_instance_segmentation_no_trainer.py
+ --model_name_or_path qubvel-hf/finetune-instance-segmentation-ade20k-mini-mask2former
+ --output_dir {tmp_dir}
+ --dataset_name qubvel-hf/ade20k-nano
+ --do_reduce_labels
+ --image_height 256
+ --image_width 256
+ --num_train_epochs 1
+ --per_device_train_batch_size 2
+ --per_device_eval_batch_size 1
+ --seed 1234
+ """.split()
+
+ run_command(self._launch_args + testargs)
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["test_map"], 0.1)
diff --git a/docs/transformers/examples/pytorch/test_pytorch_examples.py b/docs/transformers/examples/pytorch/test_pytorch_examples.py
new file mode 100644
index 0000000000000000000000000000000000000000..a986b426e1b4e7c11772bd94f2b555ffdcd12cc9
--- /dev/null
+++ b/docs/transformers/examples/pytorch/test_pytorch_examples.py
@@ -0,0 +1,679 @@
+# Copyright 2018 HuggingFace Inc..
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import logging
+import os
+import sys
+from unittest.mock import patch
+
+from transformers import ViTMAEForPreTraining, Wav2Vec2ForPreTraining
+from transformers.testing_utils import (
+ CaptureLogger,
+ TestCasePlus,
+ backend_device_count,
+ is_torch_fp16_available_on_device,
+ slow,
+ torch_device,
+)
+
+
+SRC_DIRS = [
+ os.path.join(os.path.dirname(__file__), dirname)
+ for dirname in [
+ "text-generation",
+ "text-classification",
+ "token-classification",
+ "language-modeling",
+ "multiple-choice",
+ "question-answering",
+ "summarization",
+ "translation",
+ "image-classification",
+ "speech-recognition",
+ "audio-classification",
+ "speech-pretraining",
+ "image-pretraining",
+ "semantic-segmentation",
+ "object-detection",
+ "instance-segmentation",
+ ]
+]
+sys.path.extend(SRC_DIRS)
+
+
+if SRC_DIRS is not None:
+ import run_audio_classification
+ import run_clm
+ import run_generation
+ import run_glue
+ import run_image_classification
+ import run_instance_segmentation
+ import run_mae
+ import run_mlm
+ import run_ner
+ import run_object_detection
+ import run_qa as run_squad
+ import run_semantic_segmentation
+ import run_seq2seq_qa as run_squad_seq2seq
+ import run_speech_recognition_ctc
+ import run_speech_recognition_ctc_adapter
+ import run_speech_recognition_seq2seq
+ import run_summarization
+ import run_swag
+ import run_translation
+ import run_wav2vec2_pretraining_no_trainer
+
+
+logging.basicConfig(level=logging.DEBUG)
+
+logger = logging.getLogger()
+
+
+def get_results(output_dir):
+ results = {}
+ path = os.path.join(output_dir, "all_results.json")
+ if os.path.exists(path):
+ with open(path) as f:
+ results = json.load(f)
+ else:
+ raise ValueError(f"can't find {path}")
+ return results
+
+
+stream_handler = logging.StreamHandler(sys.stdout)
+logger.addHandler(stream_handler)
+
+
+class ExamplesTests(TestCasePlus):
+ def test_run_glue(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_glue.py
+ --model_name_or_path distilbert/distilbert-base-uncased
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --train_file ./tests/fixtures/tests_samples/MRPC/train.csv
+ --validation_file ./tests/fixtures/tests_samples/MRPC/dev.csv
+ --do_train
+ --do_eval
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --learning_rate=1e-4
+ --max_steps=10
+ --warmup_steps=2
+ --seed=42
+ --max_seq_length=128
+ """.split()
+
+ if is_torch_fp16_available_on_device(torch_device):
+ testargs.append("--fp16")
+
+ with patch.object(sys, "argv", testargs):
+ run_glue.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_accuracy"], 0.75)
+
+ def test_run_clm(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_clm.py
+ --model_name_or_path distilbert/distilgpt2
+ --train_file ./tests/fixtures/sample_text.txt
+ --validation_file ./tests/fixtures/sample_text.txt
+ --do_train
+ --do_eval
+ --block_size 128
+ --per_device_train_batch_size 5
+ --per_device_eval_batch_size 5
+ --num_train_epochs 2
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ """.split()
+
+ if backend_device_count(torch_device) > 1:
+ # Skipping because there are not enough batches to train the model + would need a drop_last to work.
+ return
+
+ if torch_device == "cpu":
+ testargs.append("--use_cpu")
+
+ with patch.object(sys, "argv", testargs):
+ run_clm.main()
+ result = get_results(tmp_dir)
+ self.assertLess(result["perplexity"], 100)
+
+ def test_run_clm_config_overrides(self):
+ # test that config_overrides works, despite the misleading dumps of default un-updated
+ # config via tokenizer
+
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_clm.py
+ --model_type gpt2
+ --tokenizer_name openai-community/gpt2
+ --train_file ./tests/fixtures/sample_text.txt
+ --output_dir {tmp_dir}
+ --config_overrides n_embd=10,n_head=2
+ """.split()
+
+ if torch_device == "cpu":
+ testargs.append("--use_cpu")
+
+ logger = run_clm.logger
+ with patch.object(sys, "argv", testargs):
+ with CaptureLogger(logger) as cl:
+ run_clm.main()
+
+ self.assertIn('"n_embd": 10', cl.out)
+ self.assertIn('"n_head": 2', cl.out)
+
+ def test_run_mlm(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_mlm.py
+ --model_name_or_path distilbert/distilroberta-base
+ --train_file ./tests/fixtures/sample_text.txt
+ --validation_file ./tests/fixtures/sample_text.txt
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --do_train
+ --do_eval
+ --prediction_loss_only
+ --num_train_epochs=1
+ """.split()
+
+ if torch_device == "cpu":
+ testargs.append("--use_cpu")
+
+ with patch.object(sys, "argv", testargs):
+ run_mlm.main()
+ result = get_results(tmp_dir)
+ self.assertLess(result["perplexity"], 42)
+
+ def test_run_ner(self):
+ # with so little data distributed training needs more epochs to get the score on par with 0/1 gpu
+ epochs = 7 if backend_device_count(torch_device) > 1 else 2
+
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_ner.py
+ --model_name_or_path google-bert/bert-base-uncased
+ --train_file tests/fixtures/tests_samples/conll/sample.json
+ --validation_file tests/fixtures/tests_samples/conll/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --do_train
+ --do_eval
+ --warmup_steps=2
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=2
+ --num_train_epochs={epochs}
+ --seed 7
+ """.split()
+
+ if torch_device == "cpu":
+ testargs.append("--use_cpu")
+
+ with patch.object(sys, "argv", testargs):
+ run_ner.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_accuracy"], 0.75)
+ self.assertLess(result["eval_loss"], 0.5)
+
+ def test_run_squad(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_qa.py
+ --model_name_or_path google-bert/bert-base-uncased
+ --version_2_with_negative
+ --train_file tests/fixtures/tests_samples/SQUAD/sample.json
+ --validation_file tests/fixtures/tests_samples/SQUAD/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --max_steps=10
+ --warmup_steps=2
+ --do_train
+ --do_eval
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_squad.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_f1"], 30)
+ self.assertGreaterEqual(result["eval_exact"], 30)
+
+ def test_run_squad_seq2seq(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_seq2seq_qa.py
+ --model_name_or_path google-t5/t5-small
+ --context_column context
+ --question_column question
+ --answer_column answers
+ --version_2_with_negative
+ --train_file tests/fixtures/tests_samples/SQUAD/sample.json
+ --validation_file tests/fixtures/tests_samples/SQUAD/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --max_steps=10
+ --warmup_steps=2
+ --do_train
+ --do_eval
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --predict_with_generate
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_squad_seq2seq.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_f1"], 30)
+ self.assertGreaterEqual(result["eval_exact"], 30)
+
+ def test_run_swag(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_swag.py
+ --model_name_or_path google-bert/bert-base-uncased
+ --train_file tests/fixtures/tests_samples/swag/sample.json
+ --validation_file tests/fixtures/tests_samples/swag/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --max_steps=20
+ --warmup_steps=2
+ --do_train
+ --do_eval
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_swag.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_accuracy"], 0.8)
+
+ def test_generation(self):
+ testargs = ["run_generation.py", "--prompt=Hello", "--length=10", "--seed=42"]
+
+ if is_torch_fp16_available_on_device(torch_device):
+ testargs.append("--fp16")
+
+ model_type, model_name = (
+ "--model_type=gpt2",
+ "--model_name_or_path=sshleifer/tiny-gpt2",
+ )
+ with patch.object(sys, "argv", testargs + [model_type, model_name]):
+ result = run_generation.main()
+ self.assertGreaterEqual(len(result[0]), 10)
+
+ @slow
+ def test_run_summarization(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_summarization.py
+ --model_name_or_path google-t5/t5-small
+ --train_file tests/fixtures/tests_samples/xsum/sample.json
+ --validation_file tests/fixtures/tests_samples/xsum/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --max_steps=50
+ --warmup_steps=8
+ --do_train
+ --do_eval
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --predict_with_generate
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_summarization.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_rouge1"], 10)
+ self.assertGreaterEqual(result["eval_rouge2"], 2)
+ self.assertGreaterEqual(result["eval_rougeL"], 7)
+ self.assertGreaterEqual(result["eval_rougeLsum"], 7)
+
+ @slow
+ def test_run_translation(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_translation.py
+ --model_name_or_path sshleifer/student_marian_en_ro_6_1
+ --source_lang en
+ --target_lang ro
+ --train_file tests/fixtures/tests_samples/wmt16/sample.json
+ --validation_file tests/fixtures/tests_samples/wmt16/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --max_steps=50
+ --warmup_steps=8
+ --do_train
+ --do_eval
+ --learning_rate=3e-3
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --predict_with_generate
+ --source_lang en_XX
+ --target_lang ro_RO
+ --max_source_length 512
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_translation.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_bleu"], 30)
+
+ def test_run_image_classification(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_image_classification.py
+ --output_dir {tmp_dir}
+ --model_name_or_path google/vit-base-patch16-224-in21k
+ --dataset_name hf-internal-testing/cats_vs_dogs_sample
+ --trust_remote_code
+ --do_train
+ --do_eval
+ --learning_rate 1e-4
+ --per_device_train_batch_size 2
+ --per_device_eval_batch_size 1
+ --remove_unused_columns False
+ --overwrite_output_dir True
+ --dataloader_num_workers 16
+ --metric_for_best_model accuracy
+ --max_steps 10
+ --train_val_split 0.1
+ --seed 42
+ --label_column_name labels
+ """.split()
+
+ if is_torch_fp16_available_on_device(torch_device):
+ testargs.append("--fp16")
+
+ with patch.object(sys, "argv", testargs):
+ run_image_classification.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_accuracy"], 0.8)
+
+ def test_run_speech_recognition_ctc(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_speech_recognition_ctc.py
+ --output_dir {tmp_dir}
+ --model_name_or_path hf-internal-testing/tiny-random-wav2vec2
+ --dataset_name hf-internal-testing/librispeech_asr_dummy
+ --dataset_config_name clean
+ --train_split_name validation
+ --eval_split_name validation
+ --trust_remote_code
+ --do_train
+ --do_eval
+ --learning_rate 1e-4
+ --per_device_train_batch_size 2
+ --per_device_eval_batch_size 1
+ --remove_unused_columns False
+ --overwrite_output_dir True
+ --preprocessing_num_workers 16
+ --max_steps 10
+ --seed 42
+ """.split()
+
+ if is_torch_fp16_available_on_device(torch_device):
+ testargs.append("--fp16")
+
+ with patch.object(sys, "argv", testargs):
+ run_speech_recognition_ctc.main()
+ result = get_results(tmp_dir)
+ self.assertLess(result["eval_loss"], result["train_loss"])
+
+ def test_run_speech_recognition_ctc_adapter(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_speech_recognition_ctc_adapter.py
+ --output_dir {tmp_dir}
+ --model_name_or_path hf-internal-testing/tiny-random-wav2vec2
+ --dataset_name hf-internal-testing/librispeech_asr_dummy
+ --dataset_config_name clean
+ --train_split_name validation
+ --eval_split_name validation
+ --trust_remote_code
+ --do_train
+ --do_eval
+ --learning_rate 1e-4
+ --per_device_train_batch_size 2
+ --per_device_eval_batch_size 1
+ --remove_unused_columns False
+ --overwrite_output_dir True
+ --preprocessing_num_workers 16
+ --max_steps 10
+ --target_language tur
+ --seed 42
+ """.split()
+
+ if is_torch_fp16_available_on_device(torch_device):
+ testargs.append("--fp16")
+
+ with patch.object(sys, "argv", testargs):
+ run_speech_recognition_ctc_adapter.main()
+ result = get_results(tmp_dir)
+ self.assertTrue(os.path.isfile(os.path.join(tmp_dir, "./adapter.tur.safetensors")))
+ self.assertLess(result["eval_loss"], result["train_loss"])
+
+ def test_run_speech_recognition_seq2seq(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_speech_recognition_seq2seq.py
+ --output_dir {tmp_dir}
+ --model_name_or_path hf-internal-testing/tiny-random-speech-encoder-decoder
+ --dataset_name hf-internal-testing/librispeech_asr_dummy
+ --dataset_config_name clean
+ --train_split_name validation
+ --eval_split_name validation
+ --trust_remote_code
+ --do_train
+ --do_eval
+ --learning_rate 1e-4
+ --per_device_train_batch_size 2
+ --per_device_eval_batch_size 4
+ --remove_unused_columns False
+ --overwrite_output_dir True
+ --preprocessing_num_workers 16
+ --max_steps 10
+ --seed 42
+ """.split()
+
+ if is_torch_fp16_available_on_device(torch_device):
+ testargs.append("--fp16")
+
+ with patch.object(sys, "argv", testargs):
+ run_speech_recognition_seq2seq.main()
+ result = get_results(tmp_dir)
+ self.assertLess(result["eval_loss"], result["train_loss"])
+
+ def test_run_audio_classification(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_audio_classification.py
+ --output_dir {tmp_dir}
+ --model_name_or_path hf-internal-testing/tiny-random-wav2vec2
+ --dataset_name anton-l/superb_demo
+ --trust_remote_code
+ --dataset_config_name ks
+ --train_split_name test
+ --eval_split_name test
+ --audio_column_name audio
+ --label_column_name label
+ --do_train
+ --do_eval
+ --learning_rate 1e-4
+ --per_device_train_batch_size 2
+ --per_device_eval_batch_size 1
+ --remove_unused_columns False
+ --overwrite_output_dir True
+ --num_train_epochs 10
+ --max_steps 50
+ --seed 42
+ """.split()
+
+ if is_torch_fp16_available_on_device(torch_device):
+ testargs.append("--fp16")
+
+ with patch.object(sys, "argv", testargs):
+ run_audio_classification.main()
+ result = get_results(tmp_dir)
+ self.assertLess(result["eval_loss"], result["train_loss"])
+
+ def test_run_wav2vec2_pretraining(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_wav2vec2_pretraining_no_trainer.py
+ --output_dir {tmp_dir}
+ --model_name_or_path hf-internal-testing/tiny-random-wav2vec2
+ --dataset_name hf-internal-testing/librispeech_asr_dummy
+ --dataset_config_names clean
+ --dataset_split_names validation
+ --trust_remote_code
+ --learning_rate 1e-4
+ --per_device_train_batch_size 4
+ --per_device_eval_batch_size 4
+ --preprocessing_num_workers 16
+ --max_train_steps 2
+ --validation_split_percentage 5
+ --seed 42
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_wav2vec2_pretraining_no_trainer.main()
+ model = Wav2Vec2ForPreTraining.from_pretrained(tmp_dir)
+ self.assertIsNotNone(model)
+
+ def test_run_vit_mae_pretraining(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_mae.py
+ --output_dir {tmp_dir}
+ --dataset_name hf-internal-testing/cats_vs_dogs_sample
+ --trust_remote_code
+ --do_train
+ --do_eval
+ --learning_rate 1e-4
+ --per_device_train_batch_size 2
+ --per_device_eval_batch_size 1
+ --remove_unused_columns False
+ --overwrite_output_dir True
+ --dataloader_num_workers 16
+ --metric_for_best_model accuracy
+ --max_steps 10
+ --train_val_split 0.1
+ --seed 42
+ """.split()
+
+ if is_torch_fp16_available_on_device(torch_device):
+ testargs.append("--fp16")
+
+ with patch.object(sys, "argv", testargs):
+ run_mae.main()
+ model = ViTMAEForPreTraining.from_pretrained(tmp_dir)
+ self.assertIsNotNone(model)
+
+ def test_run_semantic_segmentation(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_semantic_segmentation.py
+ --output_dir {tmp_dir}
+ --dataset_name huggingface/semantic-segmentation-test-sample
+ --do_train
+ --do_eval
+ --remove_unused_columns False
+ --overwrite_output_dir True
+ --max_steps 10
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --seed 32
+ """.split()
+
+ if is_torch_fp16_available_on_device(torch_device):
+ testargs.append("--fp16")
+
+ with patch.object(sys, "argv", testargs):
+ run_semantic_segmentation.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_overall_accuracy"], 0.1)
+
+ @patch.dict(os.environ, {"WANDB_DISABLED": "true"})
+ def test_run_object_detection(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_object_detection.py
+ --model_name_or_path qubvel-hf/detr-resnet-50-finetuned-10k-cppe5
+ --output_dir {tmp_dir}
+ --dataset_name qubvel-hf/cppe-5-sample
+ --do_train
+ --do_eval
+ --remove_unused_columns False
+ --overwrite_output_dir True
+ --eval_do_concat_batches False
+ --max_steps 10
+ --learning_rate=1e-6
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --seed 32
+ """.split()
+
+ if is_torch_fp16_available_on_device(torch_device):
+ testargs.append("--fp16")
+
+ with patch.object(sys, "argv", testargs):
+ run_object_detection.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["test_map"], 0.1)
+
+ @patch.dict(os.environ, {"WANDB_DISABLED": "true"})
+ def test_run_instance_segmentation(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_instance_segmentation.py
+ --model_name_or_path qubvel-hf/finetune-instance-segmentation-ade20k-mini-mask2former
+ --output_dir {tmp_dir}
+ --dataset_name qubvel-hf/ade20k-nano
+ --do_reduce_labels
+ --image_height 256
+ --image_width 256
+ --do_train
+ --num_train_epochs 1
+ --learning_rate 1e-5
+ --lr_scheduler_type constant
+ --per_device_train_batch_size 2
+ --per_device_eval_batch_size 1
+ --do_eval
+ --eval_strategy epoch
+ --seed 32
+ """.split()
+
+ if is_torch_fp16_available_on_device(torch_device):
+ testargs.append("--fp16")
+
+ with patch.object(sys, "argv", testargs):
+ run_instance_segmentation.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["test_map"], 0.1)
diff --git a/docs/transformers/examples/pytorch/text-classification/README.md b/docs/transformers/examples/pytorch/text-classification/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..6eae65e7c4bc5122f676980058e81a5aca40518a
--- /dev/null
+++ b/docs/transformers/examples/pytorch/text-classification/README.md
@@ -0,0 +1,252 @@
+
+
+# Text classification examples
+
+## GLUE tasks
+
+Based on the script [`run_glue.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-classification/run_glue.py).
+
+Fine-tuning the library models for sequence classification on the GLUE benchmark: [General Language Understanding
+Evaluation](https://gluebenchmark.com/). This script can fine-tune any of the models on the [hub](https://huggingface.co/models)
+and can also be used for a dataset hosted on our [hub](https://huggingface.co/datasets) or your own data in a csv or a JSON file
+(the script might need some tweaks in that case, refer to the comments inside for help).
+
+GLUE is made up of a total of 9 different tasks. Here is how to run the script on one of them:
+
+```bash
+export TASK_NAME=mrpc
+
+python run_glue.py \
+ --model_name_or_path google-bert/bert-base-cased \
+ --task_name $TASK_NAME \
+ --do_train \
+ --do_eval \
+ --max_seq_length 128 \
+ --per_device_train_batch_size 32 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/$TASK_NAME/
+```
+
+where task name can be one of cola, sst2, mrpc, stsb, qqp, mnli, qnli, rte, wnli.
+
+We get the following results on the dev set of the benchmark with the previous commands (with an exception for MRPC and
+WNLI which are tiny and where we used 5 epochs instead of 3). Trainings are seeded so you should obtain the same
+results with PyTorch 1.6.0 (and close results with different versions), training times are given for information (a
+single Titan RTX was used):
+
+| Task | Metric | Result | Training time |
+|-------|------------------------------|-------------|---------------|
+| CoLA | Matthews corr | 56.53 | 3:17 |
+| SST-2 | Accuracy | 92.32 | 26:06 |
+| MRPC | F1/Accuracy | 88.85/84.07 | 2:21 |
+| STS-B | Pearson/Spearman corr. | 88.64/88.48 | 2:13 |
+| QQP | Accuracy/F1 | 90.71/87.49 | 2:22:26 |
+| MNLI | Matched acc./Mismatched acc. | 83.91/84.10 | 2:35:23 |
+| QNLI | Accuracy | 90.66 | 40:57 |
+| RTE | Accuracy | 65.70 | 57 |
+| WNLI | Accuracy | 56.34 | 24 |
+
+Some of these results are significantly different from the ones reported on the test set of GLUE benchmark on the
+website. For QQP and WNLI, please refer to [FAQ #12](https://gluebenchmark.com/faq) on the website.
+
+The following example fine-tunes BERT on the `imdb` dataset hosted on our [hub](https://huggingface.co/datasets):
+
+```bash
+python run_glue.py \
+ --model_name_or_path google-bert/bert-base-cased \
+ --dataset_name imdb \
+ --do_train \
+ --do_predict \
+ --max_seq_length 128 \
+ --per_device_train_batch_size 32 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/imdb/
+```
+
+> If your model classification head dimensions do not fit the number of labels in the dataset, you can specify `--ignore_mismatched_sizes` to adapt it.
+
+## Text classification
+As an alternative, we can use the script [`run_classification.py`](./run_classification.py) to fine-tune models on a single/multi-label classification task.
+
+The following example fine-tunes BERT on the `en` subset of [`amazon_reviews_multi`](https://huggingface.co/datasets/amazon_reviews_multi) dataset.
+We can specify the metric, the label column and aso choose which text columns to use jointly for classification.
+```bash
+dataset="amazon_reviews_multi"
+subset="en"
+python run_classification.py \
+ --model_name_or_path google-bert/bert-base-uncased \
+ --dataset_name ${dataset} \
+ --dataset_config_name ${subset} \
+ --shuffle_train_dataset \
+ --metric_name accuracy \
+ --text_column_name "review_title,review_body,product_category" \
+ --text_column_delimiter "\n" \
+ --label_column_name stars \
+ --do_train \
+ --do_eval \
+ --max_seq_length 512 \
+ --per_device_train_batch_size 32 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 1 \
+ --output_dir /tmp/${dataset}_${subset}/
+```
+Training for 1 epoch results in acc of around 0.5958 for review_body only and 0.659 for title+body+category.
+
+The following is a multi-label classification example. It fine-tunes BERT on the `reuters21578` dataset hosted on our [hub](https://huggingface.co/datasets/reuters21578):
+```bash
+dataset="reuters21578"
+subset="ModApte"
+python run_classification.py \
+ --model_name_or_path google-bert/bert-base-uncased \
+ --dataset_name ${dataset} \
+ --dataset_config_name ${subset} \
+ --shuffle_train_dataset \
+ --remove_splits "unused" \
+ --metric_name f1 \
+ --text_column_name text \
+ --label_column_name topics \
+ --do_train \
+ --do_eval \
+ --max_seq_length 512 \
+ --per_device_train_batch_size 32 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 15 \
+ --output_dir /tmp/${dataset}_${subset}/
+```
+ It results in a Micro F1 score of around 0.82 without any text and label filtering. Note that you have to explicitly remove the "unused" split from the dataset, since it is not used for classification.
+
+### Mixed precision training
+
+If you have a GPU with mixed precision capabilities (architecture Pascal or more recent), you can use mixed precision
+training with PyTorch 1.6.0 or latest, or by installing the [Apex](https://github.com/NVIDIA/apex) library for previous
+versions. Just add the flag `--fp16` to your command launching one of the scripts mentioned above!
+
+Using mixed precision training usually results in 2x-speedup for training with the same final results:
+
+| Task | Metric | Result | Training time | Result (FP16) | Training time (FP16) |
+|-------|------------------------------|-------------|---------------|---------------|----------------------|
+| CoLA | Matthews corr | 56.53 | 3:17 | 56.78 | 1:41 |
+| SST-2 | Accuracy | 92.32 | 26:06 | 91.74 | 13:11 |
+| MRPC | F1/Accuracy | 88.85/84.07 | 2:21 | 88.12/83.58 | 1:10 |
+| STS-B | Pearson/Spearman corr. | 88.64/88.48 | 2:13 | 88.71/88.55 | 1:08 |
+| QQP | Accuracy/F1 | 90.71/87.49 | 2:22:26 | 90.67/87.43 | 1:11:54 |
+| MNLI | Matched acc./Mismatched acc. | 83.91/84.10 | 2:35:23 | 84.04/84.06 | 1:17:06 |
+| QNLI | Accuracy | 90.66 | 40:57 | 90.96 | 20:16 |
+| RTE | Accuracy | 65.70 | 57 | 65.34 | 29 |
+| WNLI | Accuracy | 56.34 | 24 | 56.34 | 12 |
+
+
+## PyTorch version, no Trainer
+
+Based on the script [`run_glue_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-classification/run_glue_no_trainer.py).
+
+Like `run_glue.py`, this script allows you to fine-tune any of the models on the [hub](https://huggingface.co/models) on a
+text classification task, either a GLUE task or your own data in a csv or a JSON file. The main difference is that this
+script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like.
+
+It offers less options than the script with `Trainer` (for instance you can easily change the options for the optimizer
+or the dataloaders directly in the script) but still run in a distributed setup, on TPU and supports mixed precision by
+the mean of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
+after installing it:
+
+```bash
+pip install git+https://github.com/huggingface/accelerate
+```
+
+then
+
+```bash
+export TASK_NAME=mrpc
+
+python run_glue_no_trainer.py \
+ --model_name_or_path google-bert/bert-base-cased \
+ --task_name $TASK_NAME \
+ --max_length 128 \
+ --per_device_train_batch_size 32 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/$TASK_NAME/
+```
+
+You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
+
+```bash
+accelerate config
+```
+
+and reply to the questions asked. Then
+
+```bash
+accelerate test
+```
+
+that will check everything is ready for training. Finally, you can launch training with
+
+```bash
+export TASK_NAME=mrpc
+
+accelerate launch run_glue_no_trainer.py \
+ --model_name_or_path google-bert/bert-base-cased \
+ --task_name $TASK_NAME \
+ --max_length 128 \
+ --per_device_train_batch_size 32 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/$TASK_NAME/
+```
+
+This command is the same and will work for:
+
+- a CPU-only setup
+- a setup with one GPU
+- a distributed training with several GPUs (single or multi node)
+- a training on TPUs
+
+Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
+
+## XNLI
+
+Based on the script [`run_xnli.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-classification/run_xnli.py).
+
+[XNLI](https://cims.nyu.edu/~sbowman/xnli/) is a crowd-sourced dataset based on [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/). It is an evaluation benchmark for cross-lingual text representations. Pairs of text are labeled with textual entailment annotations for 15 different languages (including both high-resource language such as English and low-resource languages such as Swahili).
+
+#### Fine-tuning on XNLI
+
+This example code fine-tunes mBERT (multi-lingual BERT) on the XNLI dataset. It runs in 106 mins on a single tesla V100 16GB.
+
+```bash
+python run_xnli.py \
+ --model_name_or_path google-bert/bert-base-multilingual-cased \
+ --language de \
+ --train_language en \
+ --do_train \
+ --do_eval \
+ --per_device_train_batch_size 32 \
+ --learning_rate 5e-5 \
+ --num_train_epochs 2.0 \
+ --max_seq_length 128 \
+ --output_dir /tmp/debug_xnli/ \
+ --save_steps -1
+```
+
+Training with the previously defined hyper-parameters yields the following results on the **test** set:
+
+```bash
+acc = 0.7093812375249501
+```
diff --git a/docs/transformers/examples/pytorch/text-classification/requirements.txt b/docs/transformers/examples/pytorch/text-classification/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..19090ab12477d9389cbc69804ef43180ce0e1f66
--- /dev/null
+++ b/docs/transformers/examples/pytorch/text-classification/requirements.txt
@@ -0,0 +1,8 @@
+accelerate >= 0.12.0
+datasets >= 1.8.0
+sentencepiece != 0.1.92
+scipy
+scikit-learn
+protobuf
+torch >= 1.3
+evaluate
\ No newline at end of file
diff --git a/docs/transformers/examples/pytorch/text-classification/run_classification.py b/docs/transformers/examples/pytorch/text-classification/run_classification.py
new file mode 100644
index 0000000000000000000000000000000000000000..62d71b7f28b53732be3d68e5357fcd91565880b0
--- /dev/null
+++ b/docs/transformers/examples/pytorch/text-classification/run_classification.py
@@ -0,0 +1,752 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Finetuning the library models for text classification."""
+# You can also adapt this script on your own text classification task. Pointers for this are left as comments.
+
+import logging
+import os
+import random
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import datasets
+import evaluate
+import numpy as np
+from datasets import Value, load_dataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForSequenceClassification,
+ AutoTokenizer,
+ DataCollatorWithPadding,
+ EvalPrediction,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ default_data_collator,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
+
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+
+ Using `HfArgumentParser` we can turn this class
+ into argparse arguments to be able to specify them on
+ the command line.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ do_regression: bool = field(
+ default=None,
+ metadata={
+ "help": "Whether to do regression instead of classification. If None, will be inferred from the dataset."
+ },
+ )
+ text_column_names: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The name of the text column in the input dataset or a CSV/JSON file. "
+ 'If not specified, will use the "sentence" column for single/multi-label classification task.'
+ )
+ },
+ )
+ text_column_delimiter: Optional[str] = field(
+ default=" ", metadata={"help": "The delimiter to use to join text columns into a single sentence."}
+ )
+ train_split_name: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": 'The name of the train split in the input dataset. If not specified, will use the "train" split when do_train is enabled'
+ },
+ )
+ validation_split_name: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": 'The name of the validation split in the input dataset. If not specified, will use the "validation" split when do_eval is enabled'
+ },
+ )
+ test_split_name: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": 'The name of the test split in the input dataset. If not specified, will use the "test" split when do_predict is enabled'
+ },
+ )
+ remove_splits: Optional[str] = field(
+ default=None,
+ metadata={"help": "The splits to remove from the dataset. Multiple splits should be separated by commas."},
+ )
+ remove_columns: Optional[str] = field(
+ default=None,
+ metadata={"help": "The columns to remove from the dataset. Multiple columns should be separated by commas."},
+ )
+ label_column_name: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The name of the label column in the input dataset or a CSV/JSON file. "
+ 'If not specified, will use the "label" column for single/multi-label classification task'
+ )
+ },
+ )
+ max_seq_length: int = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
+ )
+ pad_to_max_length: bool = field(
+ default=True,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch."
+ )
+ },
+ )
+ shuffle_train_dataset: bool = field(
+ default=False, metadata={"help": "Whether to shuffle the train dataset or not."}
+ )
+ shuffle_seed: int = field(
+ default=42, metadata={"help": "Random seed that will be used to shuffle the train dataset."}
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ metric_name: Optional[str] = field(default=None, metadata={"help": "The metric to use for evaluation."})
+ train_file: Optional[str] = field(
+ default=None, metadata={"help": "A csv or a json file containing the training data."}
+ )
+ validation_file: Optional[str] = field(
+ default=None, metadata={"help": "A csv or a json file containing the validation data."}
+ )
+ test_file: Optional[str] = field(default=None, metadata={"help": "A csv or a json file containing the test data."})
+
+ def __post_init__(self):
+ if self.dataset_name is None:
+ if self.train_file is None or self.validation_file is None:
+ raise ValueError(" training/validation file or a dataset name.")
+
+ train_extension = self.train_file.split(".")[-1]
+ assert train_extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ validation_extension = self.validation_file.split(".")[-1]
+ assert validation_extension == train_extension, (
+ "`validation_file` should have the same extension (csv or json) as `train_file`."
+ )
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ ignore_mismatched_sizes: bool = field(
+ default=False,
+ metadata={"help": "Will enable to load a pretrained model whose head dimensions are different."},
+ )
+
+
+def get_label_list(raw_dataset, split="train") -> list[str]:
+ """Get the list of labels from a multi-label dataset"""
+
+ if isinstance(raw_dataset[split]["label"][0], list):
+ label_list = [label for sample in raw_dataset[split]["label"] for label in sample]
+ label_list = list(set(label_list))
+ else:
+ label_list = raw_dataset[split].unique("label")
+ # we will treat the label list as a list of string instead of int, consistent with model.config.label2id
+ label_list = [str(label) for label in label_list]
+ return label_list
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_classification", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON training and evaluation files, or specify a dataset name
+ # to load from huggingface/datasets. In ether case, you can specify a the key of the column(s) containing the text and
+ # the key of the column containing the label. If multiple columns are specified for the text, they will be joined together
+ # for the actual text value.
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ # Try print some info about the dataset
+ logger.info(f"Dataset loaded: {raw_datasets}")
+ logger.info(raw_datasets)
+ else:
+ # Loading a dataset from your local files.
+ # CSV/JSON training and evaluation files are needed.
+ data_files = {"train": data_args.train_file, "validation": data_args.validation_file}
+
+ # Get the test dataset: you can provide your own CSV/JSON test file
+ if training_args.do_predict:
+ if data_args.test_file is not None:
+ train_extension = data_args.train_file.split(".")[-1]
+ test_extension = data_args.test_file.split(".")[-1]
+ assert test_extension == train_extension, (
+ "`test_file` should have the same extension (csv or json) as `train_file`."
+ )
+ data_files["test"] = data_args.test_file
+ else:
+ raise ValueError("Need either a dataset name or a test file for `do_predict`.")
+
+ for key in data_files.keys():
+ logger.info(f"load a local file for {key}: {data_files[key]}")
+
+ if data_args.train_file.endswith(".csv"):
+ # Loading a dataset from local csv files
+ raw_datasets = load_dataset(
+ "csv",
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ else:
+ # Loading a dataset from local json files
+ raw_datasets = load_dataset(
+ "json",
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+
+ # See more about loading any type of standard or custom dataset at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ if data_args.remove_splits is not None:
+ for split in data_args.remove_splits.split(","):
+ logger.info(f"removing split {split}")
+ raw_datasets.pop(split)
+
+ if data_args.train_split_name is not None:
+ logger.info(f"using {data_args.train_split_name} as train set")
+ raw_datasets["train"] = raw_datasets[data_args.train_split_name]
+ raw_datasets.pop(data_args.train_split_name)
+
+ if data_args.validation_split_name is not None:
+ logger.info(f"using {data_args.validation_split_name} as validation set")
+ raw_datasets["validation"] = raw_datasets[data_args.validation_split_name]
+ raw_datasets.pop(data_args.validation_split_name)
+
+ if data_args.test_split_name is not None:
+ logger.info(f"using {data_args.test_split_name} as test set")
+ raw_datasets["test"] = raw_datasets[data_args.test_split_name]
+ raw_datasets.pop(data_args.test_split_name)
+
+ if data_args.remove_columns is not None:
+ for split in raw_datasets.keys():
+ for column in data_args.remove_columns.split(","):
+ logger.info(f"removing column {column} from split {split}")
+ raw_datasets[split] = raw_datasets[split].remove_columns(column)
+
+ if data_args.label_column_name is not None and data_args.label_column_name != "label":
+ for key in raw_datasets.keys():
+ raw_datasets[key] = raw_datasets[key].rename_column(data_args.label_column_name, "label")
+
+ # Trying to have good defaults here, don't hesitate to tweak to your needs.
+
+ is_regression = (
+ raw_datasets["train"].features["label"].dtype in ["float32", "float64"]
+ if data_args.do_regression is None
+ else data_args.do_regression
+ )
+
+ is_multi_label = False
+ if is_regression:
+ label_list = None
+ num_labels = 1
+ # regression requires float as label type, let's cast it if needed
+ for split in raw_datasets.keys():
+ if raw_datasets[split].features["label"].dtype not in ["float32", "float64"]:
+ logger.warning(
+ f"Label type for {split} set to float32, was {raw_datasets[split].features['label'].dtype}"
+ )
+ features = raw_datasets[split].features
+ features.update({"label": Value("float32")})
+ try:
+ raw_datasets[split] = raw_datasets[split].cast(features)
+ except TypeError as error:
+ logger.error(
+ f"Unable to cast {split} set to float32, please check the labels are correct, or maybe try with --do_regression=False"
+ )
+ raise error
+
+ else: # classification
+ if raw_datasets["train"].features["label"].dtype == "list": # multi-label classification
+ is_multi_label = True
+ logger.info("Label type is list, doing multi-label classification")
+ # Trying to find the number of labels in a multi-label classification task
+ # We have to deal with common cases that labels appear in the training set but not in the validation/test set.
+ # So we build the label list from the union of labels in train/val/test.
+ label_list = get_label_list(raw_datasets, split="train")
+ for split in ["validation", "test"]:
+ if split in raw_datasets:
+ val_or_test_labels = get_label_list(raw_datasets, split=split)
+ diff = set(val_or_test_labels).difference(set(label_list))
+ if len(diff) > 0:
+ # add the labels that appear in val/test but not in train, throw a warning
+ logger.warning(
+ f"Labels {diff} in {split} set but not in training set, adding them to the label list"
+ )
+ label_list += list(diff)
+ # if label is -1, we throw a warning and remove it from the label list
+ for label in label_list:
+ if label == -1:
+ logger.warning("Label -1 found in label list, removing it.")
+ label_list.remove(label)
+
+ label_list.sort()
+ num_labels = len(label_list)
+ if num_labels <= 1:
+ raise ValueError("You need more than one label to do classification.")
+
+ # Load pretrained model and tokenizer
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ num_labels=num_labels,
+ finetuning_task="text-classification",
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ if is_regression:
+ config.problem_type = "regression"
+ logger.info("setting problem type to regression")
+ elif is_multi_label:
+ config.problem_type = "multi_label_classification"
+ logger.info("setting problem type to multi label classification")
+ else:
+ config.problem_type = "single_label_classification"
+ logger.info("setting problem type to single label classification")
+
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = AutoModelForSequenceClassification.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ ignore_mismatched_sizes=model_args.ignore_mismatched_sizes,
+ )
+
+ # Padding strategy
+ if data_args.pad_to_max_length:
+ padding = "max_length"
+ else:
+ # We will pad later, dynamically at batch creation, to the max sequence length in each batch
+ padding = False
+
+ # for training ,we will update the config with label infos,
+ # if do_train is not set, we will use the label infos in the config
+ if training_args.do_train and not is_regression: # classification, training
+ label_to_id = {v: i for i, v in enumerate(label_list)}
+ # update config with label infos
+ if model.config.label2id != label_to_id:
+ logger.warning(
+ "The label2id key in the model config.json is not equal to the label2id key of this "
+ "run. You can ignore this if you are doing finetuning."
+ )
+ model.config.label2id = label_to_id
+ model.config.id2label = {id: label for label, id in label_to_id.items()}
+ elif not is_regression: # classification, but not training
+ logger.info("using label infos in the model config")
+ logger.info(f"label2id: {model.config.label2id}")
+ label_to_id = model.config.label2id
+ else: # regression
+ label_to_id = None
+
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ def multi_labels_to_ids(labels: list[str]) -> list[float]:
+ ids = [0.0] * len(label_to_id) # BCELoss requires float as target type
+ for label in labels:
+ ids[label_to_id[label]] = 1.0
+ return ids
+
+ def preprocess_function(examples):
+ if data_args.text_column_names is not None:
+ text_column_names = data_args.text_column_names.split(",")
+ # join together text columns into "sentence" column
+ examples["sentence"] = examples[text_column_names[0]]
+ for column in text_column_names[1:]:
+ for i in range(len(examples[column])):
+ examples["sentence"][i] += data_args.text_column_delimiter + examples[column][i]
+ # Tokenize the texts
+ result = tokenizer(examples["sentence"], padding=padding, max_length=max_seq_length, truncation=True)
+ if label_to_id is not None and "label" in examples:
+ if is_multi_label:
+ result["label"] = [multi_labels_to_ids(l) for l in examples["label"]]
+ else:
+ result["label"] = [(label_to_id[str(l)] if l != -1 else -1) for l in examples["label"]]
+ return result
+
+ # Running the preprocessing pipeline on all the datasets
+ with training_args.main_process_first(desc="dataset map pre-processing"):
+ raw_datasets = raw_datasets.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on dataset",
+ )
+
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset.")
+ train_dataset = raw_datasets["train"]
+ if data_args.shuffle_train_dataset:
+ logger.info("Shuffling the training dataset")
+ train_dataset = train_dataset.shuffle(seed=data_args.shuffle_seed)
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+
+ if training_args.do_eval:
+ if "validation" not in raw_datasets and "validation_matched" not in raw_datasets:
+ if "test" not in raw_datasets and "test_matched" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation or test dataset if validation is not defined.")
+ else:
+ logger.warning("Validation dataset not found. Falling back to test dataset for validation.")
+ eval_dataset = raw_datasets["test"]
+ else:
+ eval_dataset = raw_datasets["validation"]
+
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ if training_args.do_predict or data_args.test_file is not None:
+ if "test" not in raw_datasets:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_dataset = raw_datasets["test"]
+ # remove label column if it exists
+ if data_args.max_predict_samples is not None:
+ max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
+ predict_dataset = predict_dataset.select(range(max_predict_samples))
+
+ # Log a few random samples from the training set:
+ if training_args.do_train:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ if data_args.metric_name is not None:
+ metric = (
+ evaluate.load(data_args.metric_name, config_name="multilabel", cache_dir=model_args.cache_dir)
+ if is_multi_label
+ else evaluate.load(data_args.metric_name, cache_dir=model_args.cache_dir)
+ )
+ logger.info(f"Using metric {data_args.metric_name} for evaluation.")
+ else:
+ if is_regression:
+ metric = evaluate.load("mse", cache_dir=model_args.cache_dir)
+ logger.info("Using mean squared error (mse) as regression score, you can use --metric_name to overwrite.")
+ else:
+ if is_multi_label:
+ metric = evaluate.load("f1", config_name="multilabel", cache_dir=model_args.cache_dir)
+ logger.info(
+ "Using multilabel F1 for multi-label classification task, you can use --metric_name to overwrite."
+ )
+ else:
+ metric = evaluate.load("accuracy", cache_dir=model_args.cache_dir)
+ logger.info("Using accuracy as classification score, you can use --metric_name to overwrite.")
+
+ def compute_metrics(p: EvalPrediction):
+ preds = p.predictions[0] if isinstance(p.predictions, tuple) else p.predictions
+ if is_regression:
+ preds = np.squeeze(preds)
+ result = metric.compute(predictions=preds, references=p.label_ids)
+ elif is_multi_label:
+ preds = np.array([np.where(p > 0, 1, 0) for p in preds]) # convert logits to multi-hot encoding
+ # Micro F1 is commonly used in multi-label classification
+ result = metric.compute(predictions=preds, references=p.label_ids, average="micro")
+ else:
+ preds = np.argmax(preds, axis=1)
+ result = metric.compute(predictions=preds, references=p.label_ids)
+ if len(result) > 1:
+ result["combined_score"] = np.mean(list(result.values())).item()
+ return result
+
+ # Data collator will default to DataCollatorWithPadding when the tokenizer is passed to Trainer, so we change it if
+ # we already did the padding.
+ if data_args.pad_to_max_length:
+ data_collator = default_data_collator
+ elif training_args.fp16:
+ data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8)
+ else:
+ data_collator = None
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ compute_metrics=compute_metrics,
+ processing_class=tokenizer,
+ data_collator=data_collator,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ metrics = train_result.metrics
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+ trainer.save_model() # Saves the tokenizer too for easy upload
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+ metrics = trainer.evaluate(eval_dataset=eval_dataset)
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ if training_args.do_predict:
+ logger.info("*** Predict ***")
+ # Removing the `label` columns if exists because it might contains -1 and Trainer won't like that.
+ if "label" in predict_dataset.features:
+ predict_dataset = predict_dataset.remove_columns("label")
+ predictions = trainer.predict(predict_dataset, metric_key_prefix="predict").predictions
+ if is_regression:
+ predictions = np.squeeze(predictions)
+ elif is_multi_label:
+ # Convert logits to multi-hot encoding. We compare the logits to 0 instead of 0.5, because the sigmoid is not applied.
+ # You can also pass `preprocess_logits_for_metrics=lambda logits, labels: nn.functional.sigmoid(logits)` to the Trainer
+ # and set p > 0.5 below (less efficient in this case)
+ predictions = np.array([np.where(p > 0, 1, 0) for p in predictions])
+ else:
+ predictions = np.argmax(predictions, axis=1)
+ output_predict_file = os.path.join(training_args.output_dir, "predict_results.txt")
+ if trainer.is_world_process_zero():
+ with open(output_predict_file, "w") as writer:
+ logger.info("***** Predict results *****")
+ writer.write("index\tprediction\n")
+ for index, item in enumerate(predictions):
+ if is_regression:
+ writer.write(f"{index}\t{item:3.3f}\n")
+ elif is_multi_label:
+ # recover from multi-hot encoding
+ item = [label_list[i] for i in range(len(item)) if item[i] == 1]
+ writer.write(f"{index}\t{item}\n")
+ else:
+ item = label_list[item]
+ writer.write(f"{index}\t{item}\n")
+ logger.info(f"Predict results saved at {output_predict_file}")
+ kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "text-classification"}
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/text-classification/run_glue.py b/docs/transformers/examples/pytorch/text-classification/run_glue.py
new file mode 100644
index 0000000000000000000000000000000000000000..7f8a266b44bcdd8a02ae9d71760640ab31b1068a
--- /dev/null
+++ b/docs/transformers/examples/pytorch/text-classification/run_glue.py
@@ -0,0 +1,652 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Finetuning the library models for sequence classification on GLUE."""
+# You can also adapt this script on your own text classification task. Pointers for this are left as comments.
+
+import logging
+import os
+import random
+import sys
+from collections import Counter
+from dataclasses import dataclass, field
+from typing import Optional
+
+import datasets
+import evaluate
+import numpy as np
+from datasets import load_dataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForSequenceClassification,
+ AutoTokenizer,
+ DataCollatorWithPadding,
+ EvalPrediction,
+ HfArgumentParser,
+ PretrainedConfig,
+ Trainer,
+ TrainingArguments,
+ default_data_collator,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
+
+task_to_keys = {
+ "cola": ("sentence", None),
+ "mnli": ("premise", "hypothesis"),
+ "mrpc": ("sentence1", "sentence2"),
+ "qnli": ("question", "sentence"),
+ "qqp": ("question1", "question2"),
+ "rte": ("sentence1", "sentence2"),
+ "sst2": ("sentence", None),
+ "stsb": ("sentence1", "sentence2"),
+ "wnli": ("sentence1", "sentence2"),
+}
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+
+ Using `HfArgumentParser` we can turn this class
+ into argparse arguments to be able to specify them on
+ the command line.
+ """
+
+ task_name: Optional[str] = field(
+ default=None,
+ metadata={"help": "The name of the task to train on: " + ", ".join(task_to_keys.keys())},
+ )
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ max_seq_length: int = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
+ )
+ pad_to_max_length: bool = field(
+ default=True,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ train_file: Optional[str] = field(
+ default=None, metadata={"help": "A csv or a json file containing the training data."}
+ )
+ validation_file: Optional[str] = field(
+ default=None, metadata={"help": "A csv or a json file containing the validation data."}
+ )
+ test_file: Optional[str] = field(default=None, metadata={"help": "A csv or a json file containing the test data."})
+
+ def __post_init__(self):
+ if self.task_name is not None:
+ self.task_name = self.task_name.lower()
+ if self.task_name not in task_to_keys.keys():
+ raise ValueError("Unknown task, you should pick one in " + ",".join(task_to_keys.keys()))
+ elif self.dataset_name is not None:
+ pass
+ elif self.train_file is None or self.validation_file is None:
+ raise ValueError("Need either a GLUE task, a training/validation file or a dataset name.")
+ else:
+ train_extension = self.train_file.split(".")[-1]
+ assert train_extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ validation_extension = self.validation_file.split(".")[-1]
+ assert validation_extension == train_extension, (
+ "`validation_file` should have the same extension (csv or json) as `train_file`."
+ )
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ ignore_mismatched_sizes: bool = field(
+ default=False,
+ metadata={"help": "Will enable to load a pretrained model whose head dimensions are different."},
+ )
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_glue", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
+ # or specify a GLUE benchmark task (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use as labels the column called 'label' and as pair of sentences the
+ # sentences in columns called 'sentence1' and 'sentence2' if such column exists or the first two columns not named
+ # label if at least two columns are provided.
+ #
+ # If the CSVs/JSONs contain only one non-label column, the script does single sentence classification on this
+ # single column. You can easily tweak this behavior (see below)
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.task_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ "nyu-mll/glue",
+ data_args.task_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ elif data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ # Loading a dataset from your local files.
+ # CSV/JSON training and evaluation files are needed.
+ data_files = {"train": data_args.train_file, "validation": data_args.validation_file}
+
+ # Get the test dataset: you can provide your own CSV/JSON test file (see below)
+ # when you use `do_predict` without specifying a GLUE benchmark task.
+ if training_args.do_predict:
+ if data_args.test_file is not None:
+ train_extension = data_args.train_file.split(".")[-1]
+ test_extension = data_args.test_file.split(".")[-1]
+ assert test_extension == train_extension, (
+ "`test_file` should have the same extension (csv or json) as `train_file`."
+ )
+ data_files["test"] = data_args.test_file
+ else:
+ raise ValueError("Need either a GLUE task or a test file for `do_predict`.")
+
+ for key in data_files.keys():
+ logger.info(f"load a local file for {key}: {data_files[key]}")
+
+ if data_args.train_file.endswith(".csv"):
+ # Loading a dataset from local csv files
+ raw_datasets = load_dataset(
+ "csv",
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ else:
+ # Loading a dataset from local json files
+ raw_datasets = load_dataset(
+ "json",
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Labels
+ if data_args.task_name is not None:
+ is_regression = data_args.task_name == "stsb"
+ if not is_regression:
+ label_list = raw_datasets["train"].features["label"].names
+ num_labels = len(label_list)
+ else:
+ num_labels = 1
+ else:
+ # Trying to have good defaults here, don't hesitate to tweak to your needs.
+ is_regression = raw_datasets["train"].features["label"].dtype in ["float32", "float64"]
+ if is_regression:
+ num_labels = 1
+ else:
+ # A useful fast method:
+ # https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.unique
+ label_list = raw_datasets["train"].unique("label")
+ label_list.sort() # Let's sort it for determinism
+ num_labels = len(label_list)
+
+ # Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ num_labels=num_labels,
+ finetuning_task=data_args.task_name,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = AutoModelForSequenceClassification.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ ignore_mismatched_sizes=model_args.ignore_mismatched_sizes,
+ )
+
+ # Preprocessing the raw_datasets
+ if data_args.task_name is not None:
+ sentence1_key, sentence2_key = task_to_keys[data_args.task_name]
+ else:
+ # Again, we try to have some nice defaults but don't hesitate to tweak to your use case.
+ non_label_column_names = [name for name in raw_datasets["train"].column_names if name != "label"]
+ if "sentence1" in non_label_column_names and "sentence2" in non_label_column_names:
+ sentence1_key, sentence2_key = "sentence1", "sentence2"
+ else:
+ if len(non_label_column_names) >= 2:
+ sentence1_key, sentence2_key = non_label_column_names[:2]
+ else:
+ sentence1_key, sentence2_key = non_label_column_names[0], None
+
+ # Padding strategy
+ if data_args.pad_to_max_length:
+ padding = "max_length"
+ else:
+ # We will pad later, dynamically at batch creation, to the max sequence length in each batch
+ padding = False
+
+ # Some models have set the order of the labels to use, so let's make sure we do use it.
+ label_to_id = None
+ if (
+ model.config.label2id != PretrainedConfig(num_labels=num_labels).label2id
+ and data_args.task_name is not None
+ and not is_regression
+ ):
+ # Some have all caps in their config, some don't.
+ label_name_to_id = {k.lower(): v for k, v in model.config.label2id.items()}
+ if sorted(label_name_to_id.keys()) == sorted(label_list):
+ label_to_id = {i: int(label_name_to_id[label_list[i]]) for i in range(num_labels)}
+ else:
+ logger.warning(
+ "Your model seems to have been trained with labels, but they don't match the dataset: "
+ f"model labels: {sorted(label_name_to_id.keys())}, dataset labels: {sorted(label_list)}."
+ "\nIgnoring the model labels as a result.",
+ )
+ elif data_args.task_name is None and not is_regression:
+ label_to_id = {v: i for i, v in enumerate(label_list)}
+
+ if label_to_id is not None:
+ model.config.label2id = label_to_id
+ model.config.id2label = {id: label for label, id in config.label2id.items()}
+ elif data_args.task_name is not None and not is_regression:
+ model.config.label2id = {l: i for i, l in enumerate(label_list)}
+ model.config.id2label = {id: label for label, id in config.label2id.items()}
+
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ def preprocess_function(examples):
+ # Tokenize the texts
+ args = (
+ (examples[sentence1_key],) if sentence2_key is None else (examples[sentence1_key], examples[sentence2_key])
+ )
+ result = tokenizer(*args, padding=padding, max_length=max_seq_length, truncation=True)
+
+ # Map labels to IDs (not necessary for GLUE tasks)
+ if label_to_id is not None and "label" in examples:
+ result["label"] = [(label_to_id[l] if l != -1 else -1) for l in examples["label"]]
+ return result
+
+ with training_args.main_process_first(desc="dataset map pre-processing"):
+ raw_datasets = raw_datasets.map(
+ preprocess_function,
+ batched=True,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on dataset",
+ )
+
+ def print_class_distribution(dataset, split_name):
+ label_counts = Counter(dataset["label"])
+ total = sum(label_counts.values())
+ logger.info(f"Class distribution in {split_name} set:")
+ for label, count in label_counts.items():
+ logger.info(f" Label {label}: {count} ({count / total:.2%})")
+
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ print_class_distribution(train_dataset, "train")
+
+ if training_args.do_eval:
+ if "validation" not in raw_datasets and "validation_matched" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = raw_datasets["validation_matched" if data_args.task_name == "mnli" else "validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+ print_class_distribution(eval_dataset, "validation")
+
+ if training_args.do_predict or data_args.task_name is not None or data_args.test_file is not None:
+ if "test" not in raw_datasets and "test_matched" not in raw_datasets:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_dataset = raw_datasets["test_matched" if data_args.task_name == "mnli" else "test"]
+ if data_args.max_predict_samples is not None:
+ max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
+ predict_dataset = predict_dataset.select(range(max_predict_samples))
+ print_class_distribution(predict_dataset, "test")
+
+ # Log a few random samples from the training set:
+ if training_args.do_train:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # Get the metric function
+ if data_args.task_name is not None:
+ metric = evaluate.load("glue", data_args.task_name, cache_dir=model_args.cache_dir)
+ elif is_regression:
+ metric = evaluate.load("mse", cache_dir=model_args.cache_dir)
+ else:
+ metric = evaluate.load("accuracy", cache_dir=model_args.cache_dir)
+
+ # You can define your custom compute_metrics function. It takes an `EvalPrediction` object (a namedtuple with a
+ # predictions and label_ids field) and has to return a dictionary string to float.
+ def compute_metrics(p: EvalPrediction):
+ preds = p.predictions[0] if isinstance(p.predictions, tuple) else p.predictions
+ labels = p.label_ids
+ if not training_args.eval_do_concat_batches:
+ preds = np.concatenate(preds, axis=0)
+ labels = np.concatenate(p.label_ids, axis=0)
+ preds = np.squeeze(preds) if is_regression else np.argmax(preds, axis=1)
+ result = metric.compute(predictions=preds, references=labels)
+ if len(result) > 1:
+ result["combined_score"] = np.mean(list(result.values())).item()
+ return result
+
+ # Data collator will default to DataCollatorWithPadding when the tokenizer is passed to Trainer, so we change it if
+ # we already did the padding.
+ if data_args.pad_to_max_length:
+ data_collator = default_data_collator
+ elif training_args.fp16:
+ data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8)
+ else:
+ data_collator = None
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ compute_metrics=compute_metrics,
+ processing_class=tokenizer,
+ data_collator=data_collator,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ metrics = train_result.metrics
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.save_model() # Saves the tokenizer too for easy upload
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+
+ # Loop to handle MNLI double evaluation (matched, mis-matched)
+ tasks = [data_args.task_name]
+ eval_datasets = [eval_dataset]
+ if data_args.task_name == "mnli":
+ tasks.append("mnli-mm")
+ valid_mm_dataset = raw_datasets["validation_mismatched"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(valid_mm_dataset), data_args.max_eval_samples)
+ valid_mm_dataset = valid_mm_dataset.select(range(max_eval_samples))
+ eval_datasets.append(valid_mm_dataset)
+ combined = {}
+
+ for eval_dataset, task in zip(eval_datasets, tasks):
+ metrics = trainer.evaluate(eval_dataset=eval_dataset)
+
+ max_eval_samples = (
+ data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ )
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+
+ if task == "mnli-mm":
+ metrics = {k + "_mm": v for k, v in metrics.items()}
+ if task is not None and "mnli" in task:
+ combined.update(metrics)
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", combined if task is not None and "mnli" in task else metrics)
+
+ if training_args.do_predict:
+ logger.info("*** Predict ***")
+
+ # Loop to handle MNLI double evaluation (matched, mis-matched)
+ tasks = [data_args.task_name]
+ predict_datasets = [predict_dataset]
+ if data_args.task_name == "mnli":
+ tasks.append("mnli-mm")
+ predict_datasets.append(raw_datasets["test_mismatched"])
+
+ for predict_dataset, task in zip(predict_datasets, tasks):
+ # Removing the `label` columns because it contains -1 and Trainer won't like that.
+ predict_dataset = predict_dataset.remove_columns("label")
+ predictions = trainer.predict(predict_dataset, metric_key_prefix="predict").predictions
+ predictions = np.squeeze(predictions) if is_regression else np.argmax(predictions, axis=1)
+
+ output_predict_file = os.path.join(training_args.output_dir, f"predict_results_{task}.txt")
+ if trainer.is_world_process_zero():
+ with open(output_predict_file, "w") as writer:
+ logger.info(f"***** Predict results {task} *****")
+ writer.write("index\tprediction\n")
+ for index, item in enumerate(predictions):
+ if is_regression:
+ writer.write(f"{index}\t{item:3.3f}\n")
+ else:
+ item = label_list[item]
+ writer.write(f"{index}\t{item}\n")
+
+ kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "text-classification"}
+ if data_args.task_name is not None:
+ kwargs["language"] = "en"
+ kwargs["dataset_tags"] = "glue"
+ kwargs["dataset_args"] = data_args.task_name
+ kwargs["dataset"] = f"GLUE {data_args.task_name.upper()}"
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/text-classification/run_glue_no_trainer.py b/docs/transformers/examples/pytorch/text-classification/run_glue_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..eab318867b3d5c2223e4219d8634159f18ae91d8
--- /dev/null
+++ b/docs/transformers/examples/pytorch/text-classification/run_glue_no_trainer.py
@@ -0,0 +1,684 @@
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Finetuning a 🤗 Transformers model for sequence classification on GLUE."""
+
+import argparse
+import json
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import datasets
+import evaluate
+import torch
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from datasets import load_dataset
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from tqdm.auto import tqdm
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForSequenceClassification,
+ AutoTokenizer,
+ DataCollatorWithPadding,
+ PretrainedConfig,
+ SchedulerType,
+ default_data_collator,
+ get_scheduler,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logger = get_logger(__name__)
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
+
+task_to_keys = {
+ "cola": ("sentence", None),
+ "mnli": ("premise", "hypothesis"),
+ "mrpc": ("sentence1", "sentence2"),
+ "qnli": ("question", "sentence"),
+ "qqp": ("question1", "question2"),
+ "rte": ("sentence1", "sentence2"),
+ "sst2": ("sentence", None),
+ "stsb": ("sentence1", "sentence2"),
+ "wnli": ("sentence1", "sentence2"),
+}
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Finetune a transformers model on a text classification task")
+ parser.add_argument(
+ "--task_name",
+ type=str,
+ default=None,
+ help="The name of the glue task to train on.",
+ choices=list(task_to_keys.keys()),
+ )
+ parser.add_argument(
+ "--train_file", type=str, default=None, help="A csv or a json file containing the training data."
+ )
+ parser.add_argument(
+ "--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
+ )
+ parser.add_argument(
+ "--max_length",
+ type=int,
+ default=128,
+ help=(
+ "The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
+ " sequences shorter will be padded if `--pad_to_max_length` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--pad_to_max_length",
+ action="store_true",
+ help="If passed, pad all samples to `max_length`. Otherwise, dynamic padding is used.",
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ required=True,
+ )
+ parser.add_argument(
+ "--use_slow_tokenizer",
+ action="store_true",
+ help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--trust_remote_code",
+ type=bool,
+ default=False,
+ help=(
+ "Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
+ "should only be set to `True` for repositories you trust and in which you have read the code, as it will "
+ "execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--ignore_mismatched_sizes",
+ action="store_true",
+ help="Whether or not to enable to load a pretrained model whose head dimensions are different.",
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+ if args.task_name is None and args.train_file is None and args.validation_file is None:
+ raise ValueError("Need either a task name or a training/validation file.")
+ else:
+ if args.train_file is not None:
+ extension = args.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if args.validation_file is not None:
+ extension = args.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+
+ if args.push_to_hub:
+ assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
+
+ return args
+
+
+def main():
+ args = parse_args()
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_glue_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator = (
+ Accelerator(log_with=args.report_to, project_dir=args.output_dir) if args.with_tracking else Accelerator()
+ )
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
+ # or specify a GLUE benchmark task (the dataset will be downloaded automatically from the datasets Hub).
+
+ # For CSV/JSON files, this script will use as labels the column called 'label' and as pair of sentences the
+ # sentences in columns called 'sentence1' and 'sentence2' if such column exists or the first two columns not named
+ # label if at least two columns are provided.
+
+ # If the CSVs/JSONs contain only one non-label column, the script does single sentence classification on this
+ # single column. You can easily tweak this behavior (see below)
+
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if args.task_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset("nyu-mll/glue", args.task_name)
+ else:
+ # Loading the dataset from local csv or json file.
+ data_files = {}
+ if args.train_file is not None:
+ data_files["train"] = args.train_file
+ if args.validation_file is not None:
+ data_files["validation"] = args.validation_file
+ extension = (args.train_file if args.train_file is not None else args.validation_file).split(".")[-1]
+ raw_datasets = load_dataset(extension, data_files=data_files)
+ # See more about loading any type of standard or custom dataset at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Labels
+ if args.task_name is not None:
+ is_regression = args.task_name == "stsb"
+ if not is_regression:
+ label_list = raw_datasets["train"].features["label"].names
+ num_labels = len(label_list)
+ else:
+ num_labels = 1
+ else:
+ # Trying to have good defaults here, don't hesitate to tweak to your needs.
+ is_regression = raw_datasets["train"].features["label"].dtype in ["float32", "float64"]
+ if is_regression:
+ num_labels = 1
+ else:
+ # A useful fast method:
+ # https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.unique
+ label_list = raw_datasets["train"].unique("label")
+ label_list.sort() # Let's sort it for determinism
+ num_labels = len(label_list)
+
+ # Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ args.model_name_or_path,
+ num_labels=num_labels,
+ finetuning_task=args.task_name,
+ trust_remote_code=args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
+ )
+ if tokenizer.pad_token is None:
+ tokenizer.pad_token = tokenizer.eos_token
+ config.pad_token_id = tokenizer.pad_token_id
+ model = AutoModelForSequenceClassification.from_pretrained(
+ args.model_name_or_path,
+ from_tf=bool(".ckpt" in args.model_name_or_path),
+ config=config,
+ ignore_mismatched_sizes=args.ignore_mismatched_sizes,
+ trust_remote_code=args.trust_remote_code,
+ )
+
+ # Preprocessing the datasets
+ if args.task_name is not None:
+ sentence1_key, sentence2_key = task_to_keys[args.task_name]
+ else:
+ # Again, we try to have some nice defaults but don't hesitate to tweak to your use case.
+ non_label_column_names = [name for name in raw_datasets["train"].column_names if name != "label"]
+ if "sentence1" in non_label_column_names and "sentence2" in non_label_column_names:
+ sentence1_key, sentence2_key = "sentence1", "sentence2"
+ else:
+ if len(non_label_column_names) >= 2:
+ sentence1_key, sentence2_key = non_label_column_names[:2]
+ else:
+ sentence1_key, sentence2_key = non_label_column_names[0], None
+
+ # Some models have set the order of the labels to use, so let's make sure we do use it.
+ label_to_id = None
+ if (
+ model.config.label2id != PretrainedConfig(num_labels=num_labels).label2id
+ and args.task_name is not None
+ and not is_regression
+ ):
+ # Some have all caps in their config, some don't.
+ label_name_to_id = {k.lower(): v for k, v in model.config.label2id.items()}
+ if sorted(label_name_to_id.keys()) == sorted(label_list):
+ logger.info(
+ f"The configuration of the model provided the following label correspondence: {label_name_to_id}. "
+ "Using it!"
+ )
+ label_to_id = {i: label_name_to_id[label_list[i]] for i in range(num_labels)}
+ else:
+ logger.warning(
+ "Your model seems to have been trained with labels, but they don't match the dataset: "
+ f"model labels: {sorted(label_name_to_id.keys())}, dataset labels: {sorted(label_list)}."
+ "\nIgnoring the model labels as a result.",
+ )
+ elif args.task_name is None and not is_regression:
+ label_to_id = {v: i for i, v in enumerate(label_list)}
+
+ if label_to_id is not None:
+ model.config.label2id = label_to_id
+ model.config.id2label = {id: label for label, id in config.label2id.items()}
+ elif args.task_name is not None and not is_regression:
+ model.config.label2id = {l: i for i, l in enumerate(label_list)}
+ model.config.id2label = {id: label for label, id in config.label2id.items()}
+
+ padding = "max_length" if args.pad_to_max_length else False
+
+ def preprocess_function(examples):
+ # Tokenize the texts
+ texts = (
+ (examples[sentence1_key],) if sentence2_key is None else (examples[sentence1_key], examples[sentence2_key])
+ )
+ result = tokenizer(*texts, padding=padding, max_length=args.max_length, truncation=True)
+
+ if "label" in examples:
+ if label_to_id is not None:
+ # Map labels to IDs (not necessary for GLUE tasks)
+ result["labels"] = [label_to_id[l] for l in examples["label"]]
+ else:
+ # In all cases, rename the column to labels because the model will expect that.
+ result["labels"] = examples["label"]
+ return result
+
+ with accelerator.main_process_first():
+ processed_datasets = raw_datasets.map(
+ preprocess_function,
+ batched=True,
+ remove_columns=raw_datasets["train"].column_names,
+ desc="Running tokenizer on dataset",
+ )
+
+ train_dataset = processed_datasets["train"]
+ eval_dataset = processed_datasets["validation_matched" if args.task_name == "mnli" else "validation"]
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # DataLoaders creation:
+ if args.pad_to_max_length:
+ # If padding was already done ot max length, we use the default data collator that will just convert everything
+ # to tensors.
+ data_collator = default_data_collator
+ else:
+ # Otherwise, `DataCollatorWithPadding` will apply dynamic padding for us (by padding to the maximum length of
+ # the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
+ # of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
+ # For fp8, we pad to multiple of 16.
+ if accelerator.mixed_precision == "fp8":
+ pad_to_multiple_of = 16
+ elif accelerator.mixed_precision != "no":
+ pad_to_multiple_of = 8
+ else:
+ pad_to_multiple_of = None
+ data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=pad_to_multiple_of)
+
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
+ )
+ eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
+
+ # Optimizer
+ # Split weights in two groups, one with weight decay and the other not.
+ no_decay = ["bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps,
+ num_training_steps=args.max_train_steps,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("glue_no_trainer", experiment_config)
+
+ # Get the metric function
+ if args.task_name is not None:
+ metric = evaluate.load("glue", args.task_name)
+ else:
+ metric = evaluate.load("accuracy")
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+ for step, batch in enumerate(active_dataloader):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+ loss = loss / args.gradient_accumulation_steps
+ accelerator.backward(loss)
+ if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ model.eval()
+ samples_seen = 0
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+ predictions = outputs.logits.argmax(dim=-1) if not is_regression else outputs.logits.squeeze()
+ predictions, references = accelerator.gather((predictions, batch["labels"]))
+ # If we are in a multiprocess environment, the last batch has duplicates
+ if accelerator.num_processes > 1:
+ if step == len(eval_dataloader) - 1:
+ predictions = predictions[: len(eval_dataloader.dataset) - samples_seen]
+ references = references[: len(eval_dataloader.dataset) - samples_seen]
+ else:
+ samples_seen += references.shape[0]
+ metric.add_batch(
+ predictions=predictions,
+ references=references,
+ )
+
+ eval_metric = metric.compute()
+ logger.info(f"epoch {epoch}: {eval_metric}")
+
+ if args.with_tracking:
+ accelerator.log(
+ {
+ "accuracy" if args.task_name is not None else "glue": eval_metric,
+ "train_loss": total_loss.item() / len(train_dataloader),
+ "epoch": epoch,
+ "step": completed_steps,
+ },
+ step=completed_steps,
+ )
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if args.task_name == "mnli":
+ # Final evaluation on mismatched validation set
+ eval_dataset = processed_datasets["validation_mismatched"]
+ eval_dataloader = DataLoader(
+ eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size
+ )
+ eval_dataloader = accelerator.prepare(eval_dataloader)
+
+ model.eval()
+ for step, batch in enumerate(eval_dataloader):
+ outputs = model(**batch)
+ predictions = outputs.logits.argmax(dim=-1)
+ metric.add_batch(
+ predictions=accelerator.gather(predictions),
+ references=accelerator.gather(batch["labels"]),
+ )
+
+ eval_metric = metric.compute()
+ logger.info(f"mnli-mm: {eval_metric}")
+
+ if args.output_dir is not None:
+ all_results = {f"eval_{k}": v for k, v in eval_metric.items()}
+ with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
+ json.dump(all_results, f)
+
+ accelerator.wait_for_everyone()
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/text-classification/run_xnli.py b/docs/transformers/examples/pytorch/text-classification/run_xnli.py
new file mode 100644
index 0000000000000000000000000000000000000000..86ecb0f63ad7c7f02b467fdeaa0830f943edd983
--- /dev/null
+++ b/docs/transformers/examples/pytorch/text-classification/run_xnli.py
@@ -0,0 +1,454 @@
+#!/usr/bin/env python
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Finetuning multi-lingual models on XNLI (e.g. Bert, DistilBERT, XLM).
+Adapted from `examples/text-classification/run_glue.py`"""
+
+import logging
+import os
+import random
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import datasets
+import evaluate
+import numpy as np
+from datasets import load_dataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForSequenceClassification,
+ AutoTokenizer,
+ DataCollatorWithPadding,
+ EvalPrediction,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ default_data_collator,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/text-classification/requirements.txt")
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+
+ Using `HfArgumentParser` we can turn this class
+ into argparse arguments to be able to specify them on
+ the command line.
+ """
+
+ max_seq_length: Optional[int] = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
+ )
+ pad_to_max_length: bool = field(
+ default=True,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ default=None, metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ language: str = field(
+ default=None, metadata={"help": "Evaluation language. Also train language if `train_language` is set to None."}
+ )
+ train_language: Optional[str] = field(
+ default=None, metadata={"help": "Train language if it is different from the evaluation language."}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ do_lower_case: Optional[bool] = field(
+ default=False,
+ metadata={"help": "arg to indicate if tokenizer should do lower case in AutoTokenizer.from_pretrained()"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
+ "should only be set to `True` for repositories you trust and in which you have read the code, as it will "
+ "execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ ignore_mismatched_sizes: bool = field(
+ default=False,
+ metadata={"help": "Will enable to load a pretrained model whose head dimensions are different."},
+ )
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_xnli", model_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # In distributed training, the load_dataset function guarantees that only one local process can concurrently
+ # download the dataset.
+ # Downloading and loading xnli dataset from the hub.
+ if training_args.do_train:
+ if model_args.train_language is None:
+ train_dataset = load_dataset(
+ "xnli",
+ model_args.language,
+ split="train",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ else:
+ train_dataset = load_dataset(
+ "xnli",
+ model_args.train_language,
+ split="train",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ label_list = train_dataset.features["label"].names
+
+ if training_args.do_eval:
+ eval_dataset = load_dataset(
+ "xnli",
+ model_args.language,
+ split="validation",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ label_list = eval_dataset.features["label"].names
+
+ if training_args.do_predict:
+ predict_dataset = load_dataset(
+ "xnli",
+ model_args.language,
+ split="test",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ label_list = predict_dataset.features["label"].names
+
+ # Labels
+ num_labels = len(label_list)
+
+ # Load pretrained model and tokenizer
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ num_labels=num_labels,
+ id2label={str(i): label for i, label in enumerate(label_list)},
+ label2id={label: i for i, label in enumerate(label_list)},
+ finetuning_task="xnli",
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ do_lower_case=model_args.do_lower_case,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = AutoModelForSequenceClassification.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ ignore_mismatched_sizes=model_args.ignore_mismatched_sizes,
+ )
+
+ # Preprocessing the datasets
+ # Padding strategy
+ if data_args.pad_to_max_length:
+ padding = "max_length"
+ else:
+ # We will pad later, dynamically at batch creation, to the max sequence length in each batch
+ padding = False
+
+ def preprocess_function(examples):
+ # Tokenize the texts
+ return tokenizer(
+ examples["premise"],
+ examples["hypothesis"],
+ padding=padding,
+ max_length=data_args.max_seq_length,
+ truncation=True,
+ )
+
+ if training_args.do_train:
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ with training_args.main_process_first(desc="train dataset map pre-processing"):
+ train_dataset = train_dataset.map(
+ preprocess_function,
+ batched=True,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ if training_args.do_eval:
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+ with training_args.main_process_first(desc="validation dataset map pre-processing"):
+ eval_dataset = eval_dataset.map(
+ preprocess_function,
+ batched=True,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+
+ if training_args.do_predict:
+ if data_args.max_predict_samples is not None:
+ max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
+ predict_dataset = predict_dataset.select(range(max_predict_samples))
+ with training_args.main_process_first(desc="prediction dataset map pre-processing"):
+ predict_dataset = predict_dataset.map(
+ preprocess_function,
+ batched=True,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on prediction dataset",
+ )
+
+ # Get the metric function
+ metric = evaluate.load("xnli", cache_dir=model_args.cache_dir)
+
+ # You can define your custom compute_metrics function. It takes an `EvalPrediction` object (a namedtuple with a
+ # predictions and label_ids field) and has to return a dictionary string to float.
+ def compute_metrics(p: EvalPrediction):
+ preds = p.predictions[0] if isinstance(p.predictions, tuple) else p.predictions
+ preds = np.argmax(preds, axis=1)
+ return metric.compute(predictions=preds, references=p.label_ids)
+
+ # Data collator will default to DataCollatorWithPadding, so we change it if we already did the padding.
+ if data_args.pad_to_max_length:
+ data_collator = default_data_collator
+ elif training_args.fp16:
+ data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8)
+ else:
+ data_collator = None
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ compute_metrics=compute_metrics,
+ processing_class=tokenizer,
+ data_collator=data_collator,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ metrics = train_result.metrics
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.save_model() # Saves the tokenizer too for easy upload
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+ metrics = trainer.evaluate(eval_dataset=eval_dataset)
+
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Prediction
+ if training_args.do_predict:
+ logger.info("*** Predict ***")
+ predictions, labels, metrics = trainer.predict(predict_dataset, metric_key_prefix="predict")
+
+ max_predict_samples = (
+ data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
+ )
+ metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
+
+ trainer.log_metrics("predict", metrics)
+ trainer.save_metrics("predict", metrics)
+
+ predictions = np.argmax(predictions, axis=1)
+ output_predict_file = os.path.join(training_args.output_dir, "predictions.txt")
+ if trainer.is_world_process_zero():
+ with open(output_predict_file, "w") as writer:
+ writer.write("index\tprediction\n")
+ for index, item in enumerate(predictions):
+ item = label_list[item]
+ writer.write(f"{index}\t{item}\n")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/text-generation/README.md b/docs/transformers/examples/pytorch/text-generation/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..b96bcd92241c0b1ba8f8ebaf55b42f864875af74
--- /dev/null
+++ b/docs/transformers/examples/pytorch/text-generation/README.md
@@ -0,0 +1,31 @@
+
+
+## Language generation
+
+Based on the script [`run_generation.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-generation/run_generation.py).
+
+Conditional text generation using the auto-regressive models of the library: GPT, GPT-2, GPT-J, Transformer-XL, XLNet, CTRL, BLOOM, LLAMA, OPT.
+A similar script is used for our official demo [Write With Transformer](https://transformer.huggingface.co), where you
+can try out the different models available in the library.
+
+Example usage:
+
+```bash
+python run_generation.py \
+ --model_type=gpt2 \
+ --model_name_or_path=openai-community/gpt2
+```
diff --git a/docs/transformers/examples/pytorch/text-generation/requirements.txt b/docs/transformers/examples/pytorch/text-generation/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..324a8cfb1c29e01bcaccae84e8c5a566f2d5dfbb
--- /dev/null
+++ b/docs/transformers/examples/pytorch/text-generation/requirements.txt
@@ -0,0 +1,4 @@
+accelerate >= 0.21.0
+sentencepiece != 0.1.92
+protobuf
+torch >= 1.3
diff --git a/docs/transformers/examples/pytorch/text-generation/run_generation.py b/docs/transformers/examples/pytorch/text-generation/run_generation.py
new file mode 100644
index 0000000000000000000000000000000000000000..9943a4f54a1e81d3db3044f281f759ef4f26b4cd
--- /dev/null
+++ b/docs/transformers/examples/pytorch/text-generation/run_generation.py
@@ -0,0 +1,439 @@
+#!/usr/bin/env python
+# Copyright 2018 Google AI, Google Brain and Carnegie Mellon University Authors and the HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Conditional text generation with the auto-regressive models of the library (GPT/GPT-2/CTRL/Transformer-XL/XLNet)"""
+
+import argparse
+import inspect
+import logging
+
+import torch
+from accelerate import PartialState
+from accelerate.utils import set_seed
+
+from transformers import (
+ AutoTokenizer,
+ BloomForCausalLM,
+ BloomTokenizerFast,
+ CTRLLMHeadModel,
+ CTRLTokenizer,
+ GenerationMixin,
+ GPT2LMHeadModel,
+ GPT2Tokenizer,
+ GPTJForCausalLM,
+ LlamaForCausalLM,
+ LlamaTokenizer,
+ OpenAIGPTLMHeadModel,
+ OpenAIGPTTokenizer,
+ OPTForCausalLM,
+ XLMTokenizer,
+ XLMWithLMHeadModel,
+ XLNetLMHeadModel,
+ XLNetTokenizer,
+)
+from transformers.modeling_outputs import CausalLMOutputWithPast
+
+
+logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+)
+logger = logging.getLogger(__name__)
+
+MAX_LENGTH = int(10000) # Hardcoded max length to avoid infinite loop
+
+MODEL_CLASSES = {
+ "gpt2": (GPT2LMHeadModel, GPT2Tokenizer),
+ "ctrl": (CTRLLMHeadModel, CTRLTokenizer),
+ "openai-gpt": (OpenAIGPTLMHeadModel, OpenAIGPTTokenizer),
+ "xlnet": (XLNetLMHeadModel, XLNetTokenizer),
+ "xlm": (XLMWithLMHeadModel, XLMTokenizer),
+ "gptj": (GPTJForCausalLM, AutoTokenizer),
+ "bloom": (BloomForCausalLM, BloomTokenizerFast),
+ "llama": (LlamaForCausalLM, LlamaTokenizer),
+ "opt": (OPTForCausalLM, GPT2Tokenizer),
+}
+
+# Padding text to help Transformer-XL and XLNet with short prompts as proposed by Aman Rusia
+# in https://github.com/rusiaaman/XLNet-gen#methodology
+# and https://medium.com/@amanrusia/xlnet-speaks-comparison-to-gpt-2-ea1a4e9ba39e
+PREFIX = """In 1991, the remains of Russian Tsar Nicholas II and his family
+(except for Alexei and Maria) are discovered.
+The voice of Nicholas's young son, Tsarevich Alexei Nikolaevich, narrates the
+remainder of the story. 1883 Western Siberia,
+a young Grigori Rasputin is asked by his father and a group of men to perform magic.
+Rasputin has a vision and denounces one of the men as a horse thief. Although his
+father initially slaps him for making such an accusation, Rasputin watches as the
+man is chased outside and beaten. Twenty years later, Rasputin sees a vision of
+the Virgin Mary, prompting him to become a priest. Rasputin quickly becomes famous,
+with people, even a bishop, begging for his blessing. """
+
+
+#
+# Functions to prepare models' input
+#
+
+
+def prepare_ctrl_input(args, _, tokenizer, prompt_text):
+ if args.temperature > 0.7:
+ logger.info("CTRL typically works better with lower temperatures (and lower top_k).")
+
+ encoded_prompt = tokenizer.encode(prompt_text, add_special_tokens=False)
+ if not any(encoded_prompt[0] == x for x in tokenizer.control_codes.values()):
+ logger.info("WARNING! You are not starting your generation from a control code so you won't get good results")
+ return prompt_text
+
+
+def prepare_xlm_input(args, model, tokenizer, prompt_text):
+ # kwargs = {"language": None, "mask_token_id": None}
+
+ # Set the language
+ use_lang_emb = hasattr(model.config, "use_lang_emb") and model.config.use_lang_emb
+ if hasattr(model.config, "lang2id") and use_lang_emb:
+ available_languages = model.config.lang2id.keys()
+ if args.xlm_language in available_languages:
+ language = args.xlm_language
+ else:
+ language = None
+ while language not in available_languages:
+ language = input("Using XLM. Select language in " + str(list(available_languages)) + " >>> ")
+
+ model.config.lang_id = model.config.lang2id[language]
+ # kwargs["language"] = tokenizer.lang2id[language]
+
+ # TODO fix mask_token_id setup when configurations will be synchronized between models and tokenizers
+ # XLM masked-language modeling (MLM) models need masked token
+ # is_xlm_mlm = "mlm" in args.model_name_or_path
+ # if is_xlm_mlm:
+ # kwargs["mask_token_id"] = tokenizer.mask_token_id
+
+ return prompt_text
+
+
+def prepare_xlnet_input(args, _, tokenizer, prompt_text):
+ prefix = args.prefix if args.prefix else args.padding_text if args.padding_text else PREFIX
+ prompt_text = prefix + prompt_text
+ return prompt_text
+
+
+def prepare_transfoxl_input(args, _, tokenizer, prompt_text):
+ prefix = args.prefix if args.prefix else args.padding_text if args.padding_text else PREFIX
+ prompt_text = prefix + prompt_text
+ return prompt_text
+
+
+PREPROCESSING_FUNCTIONS = {
+ "ctrl": prepare_ctrl_input,
+ "xlm": prepare_xlm_input,
+ "xlnet": prepare_xlnet_input,
+ "transfo-xl": prepare_transfoxl_input,
+}
+
+
+def adjust_length_to_model(length, max_sequence_length):
+ if length < 0 and max_sequence_length > 0:
+ length = max_sequence_length
+ elif 0 < max_sequence_length < length:
+ length = max_sequence_length # No generation bigger than model size
+ elif length < 0:
+ length = MAX_LENGTH # avoid infinite loop
+ return length
+
+
+def sparse_model_config(model_config):
+ embedding_size = None
+ if hasattr(model_config, "hidden_size"):
+ embedding_size = model_config.hidden_size
+ elif hasattr(model_config, "n_embed"):
+ embedding_size = model_config.n_embed
+ elif hasattr(model_config, "n_embd"):
+ embedding_size = model_config.n_embd
+
+ num_head = None
+ if hasattr(model_config, "num_attention_heads"):
+ num_head = model_config.num_attention_heads
+ elif hasattr(model_config, "n_head"):
+ num_head = model_config.n_head
+
+ if embedding_size is None or num_head is None or num_head == 0:
+ raise ValueError("Check the model config")
+
+ num_embedding_size_per_head = int(embedding_size / num_head)
+ if hasattr(model_config, "n_layer"):
+ num_layer = model_config.n_layer
+ elif hasattr(model_config, "num_hidden_layers"):
+ num_layer = model_config.num_hidden_layers
+ else:
+ raise ValueError("Number of hidden layers couldn't be determined from the model config")
+
+ return num_layer, num_head, num_embedding_size_per_head
+
+
+def generate_past_key_values(model, batch_size, seq_len):
+ num_block_layers, num_attention_heads, num_embedding_size_per_head = sparse_model_config(model.config)
+ if model.config.model_type == "bloom":
+ past_key_values = tuple(
+ (
+ torch.empty(int(num_attention_heads * batch_size), num_embedding_size_per_head, seq_len)
+ .to(model.dtype)
+ .to(model.device),
+ torch.empty(int(num_attention_heads * batch_size), seq_len, num_embedding_size_per_head)
+ .to(model.dtype)
+ .to(model.device),
+ )
+ for _ in range(num_block_layers)
+ )
+ else:
+ past_key_values = tuple(
+ (
+ torch.empty(batch_size, num_attention_heads, seq_len, num_embedding_size_per_head)
+ .to(model.dtype)
+ .to(model.device),
+ torch.empty(batch_size, num_attention_heads, seq_len, num_embedding_size_per_head)
+ .to(model.dtype)
+ .to(model.device),
+ )
+ for _ in range(num_block_layers)
+ )
+ return past_key_values
+
+
+def prepare_jit_inputs(inputs, model, tokenizer):
+ batch_size = len(inputs)
+ dummy_input = tokenizer.batch_encode_plus(inputs, return_tensors="pt")
+ dummy_input = dummy_input.to(model.device)
+ if model.config.use_cache:
+ dummy_input["past_key_values"] = generate_past_key_values(model, batch_size, 1)
+ dummy_input["attention_mask"] = torch.cat(
+ [
+ torch.zeros(dummy_input["attention_mask"].shape[0], 1)
+ .to(dummy_input["attention_mask"].dtype)
+ .to(model.device),
+ dummy_input["attention_mask"],
+ ],
+ -1,
+ )
+ return dummy_input
+
+
+class _ModelFallbackWrapper(GenerationMixin):
+ __slots__ = ("_optimized", "_default")
+
+ def __init__(self, optimized, default):
+ self._optimized = optimized
+ self._default = default
+
+ def __call__(self, *args, **kwargs):
+ if kwargs["past_key_values"] is None and self._default.config.use_cache:
+ kwargs["past_key_values"] = generate_past_key_values(self._default, kwargs["input_ids"].shape[0], 0)
+ kwargs.pop("position_ids", None)
+ for k in list(kwargs.keys()):
+ if kwargs[k] is None or isinstance(kwargs[k], bool):
+ kwargs.pop(k)
+ outputs = self._optimized(**kwargs)
+ lm_logits = outputs[0]
+ past_key_values = outputs[1]
+ fixed_output = CausalLMOutputWithPast(
+ loss=None,
+ logits=lm_logits,
+ past_key_values=past_key_values,
+ hidden_states=None,
+ attentions=None,
+ )
+ return fixed_output
+
+ def __getattr__(self, item):
+ return getattr(self._default, item)
+
+ def prepare_inputs_for_generation(
+ self, input_ids, past_key_values=None, inputs_embeds=None, use_cache=None, **kwargs
+ ):
+ return self._default.prepare_inputs_for_generation(
+ input_ids, past_key_values=past_key_values, inputs_embeds=inputs_embeds, use_cache=use_cache, **kwargs
+ )
+
+ def _reorder_cache(
+ self, past_key_values: tuple[tuple[torch.Tensor]], beam_idx: torch.Tensor
+ ) -> tuple[tuple[torch.Tensor]]:
+ """
+ This function is used to re-order the `past_key_values` cache if [`~PretrainedModel.beam_search`] or
+ [`~PretrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
+ beam_idx at every generation step.
+ """
+ return self._default._reorder_cache(past_key_values, beam_idx)
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--model_type",
+ default=None,
+ type=str,
+ required=True,
+ help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ default=None,
+ type=str,
+ required=True,
+ help="Path to pre-trained model or shortcut name selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
+ )
+
+ parser.add_argument("--prompt", type=str, default="")
+ parser.add_argument("--length", type=int, default=20)
+ parser.add_argument("--stop_token", type=str, default=None, help="Token at which text generation is stopped")
+
+ parser.add_argument(
+ "--temperature",
+ type=float,
+ default=1.0,
+ help="temperature of 1.0 has no effect, lower tend toward greedy sampling",
+ )
+ parser.add_argument(
+ "--repetition_penalty", type=float, default=1.0, help="primarily useful for CTRL model; in that case, use 1.2"
+ )
+ parser.add_argument("--k", type=int, default=0)
+ parser.add_argument("--p", type=float, default=0.9)
+
+ parser.add_argument("--prefix", type=str, default="", help="Text added prior to input.")
+ parser.add_argument("--padding_text", type=str, default="", help="Deprecated, the use of `--prefix` is preferred.")
+ parser.add_argument("--xlm_language", type=str, default="", help="Optional language when used with the XLM model.")
+
+ parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
+ parser.add_argument(
+ "--use_cpu",
+ action="store_true",
+ help="Whether or not to use cpu. If set to False, we will use gpu/npu or mps device if available",
+ )
+ parser.add_argument("--num_return_sequences", type=int, default=1, help="The number of samples to generate.")
+ parser.add_argument(
+ "--fp16",
+ action="store_true",
+ help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
+ )
+ parser.add_argument("--jit", action="store_true", help="Whether or not to use jit trace to accelerate inference")
+ args = parser.parse_args()
+
+ # Initialize the distributed state.
+ distributed_state = PartialState(cpu=args.use_cpu)
+
+ logger.warning(f"device: {distributed_state.device}, 16-bits inference: {args.fp16}")
+
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Initialize the model and tokenizer
+ try:
+ args.model_type = args.model_type.lower()
+ model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
+ except KeyError:
+ raise KeyError("the model {} you specified is not supported. You are welcome to add it and open a PR :)")
+
+ tokenizer = tokenizer_class.from_pretrained(args.model_name_or_path)
+ if tokenizer.pad_token is None:
+ tokenizer.pad_token = tokenizer.eos_token
+ model = model_class.from_pretrained(args.model_name_or_path)
+
+ # Set the model to the right device
+ model.to(distributed_state.device)
+
+ if args.fp16:
+ model.half()
+ max_seq_length = getattr(model.config, "max_position_embeddings", 0)
+ args.length = adjust_length_to_model(args.length, max_sequence_length=max_seq_length)
+ logger.info(args)
+
+ prompt_text = args.prompt if args.prompt else input("Model prompt >>> ")
+
+ # Different models need different input formatting and/or extra arguments
+ requires_preprocessing = args.model_type in PREPROCESSING_FUNCTIONS.keys()
+ if requires_preprocessing:
+ prepare_input = PREPROCESSING_FUNCTIONS.get(args.model_type)
+ preprocessed_prompt_text = prepare_input(args, model, tokenizer, prompt_text)
+
+ tokenizer_kwargs = {}
+
+ encoded_prompt = tokenizer.encode(
+ preprocessed_prompt_text, add_special_tokens=False, return_tensors="pt", **tokenizer_kwargs
+ )
+ else:
+ prefix = args.prefix if args.prefix else args.padding_text
+ encoded_prompt = tokenizer.encode(prefix + prompt_text, add_special_tokens=False, return_tensors="pt")
+ encoded_prompt = encoded_prompt.to(distributed_state.device)
+
+ if encoded_prompt.size()[-1] == 0:
+ input_ids = None
+ else:
+ input_ids = encoded_prompt
+
+ if args.jit:
+ jit_input_texts = ["enable jit"]
+ jit_inputs = prepare_jit_inputs(jit_input_texts, model, tokenizer)
+ torch._C._jit_set_texpr_fuser_enabled(False)
+ model.config.return_dict = False
+ if hasattr(model, "forward"):
+ sig = inspect.signature(model.forward)
+ else:
+ sig = inspect.signature(model.__call__)
+ jit_inputs = tuple(jit_inputs[key] for key in sig.parameters if jit_inputs.get(key, None) is not None)
+ traced_model = torch.jit.trace(model, jit_inputs, strict=False)
+ traced_model = torch.jit.freeze(traced_model.eval())
+ traced_model(*jit_inputs)
+ traced_model(*jit_inputs)
+
+ model = _ModelFallbackWrapper(traced_model, model)
+
+ output_sequences = model.generate(
+ input_ids=input_ids,
+ max_length=args.length + len(encoded_prompt[0]),
+ temperature=args.temperature,
+ top_k=args.k,
+ top_p=args.p,
+ repetition_penalty=args.repetition_penalty,
+ do_sample=True,
+ num_return_sequences=args.num_return_sequences,
+ )
+
+ # Remove the batch dimension when returning multiple sequences
+ if len(output_sequences.shape) > 2:
+ output_sequences.squeeze_()
+
+ generated_sequences = []
+
+ for generated_sequence_idx, generated_sequence in enumerate(output_sequences):
+ print(f"=== GENERATED SEQUENCE {generated_sequence_idx + 1} ===")
+ generated_sequence = generated_sequence.tolist()
+
+ # Decode text
+ text = tokenizer.decode(generated_sequence, clean_up_tokenization_spaces=True)
+
+ # Remove all text after the stop token
+ text = text[: text.find(args.stop_token) if args.stop_token else None]
+
+ # Add the prompt at the beginning of the sequence. Remove the excess text that was used for pre-processing
+ total_sequence = (
+ prompt_text + text[len(tokenizer.decode(encoded_prompt[0], clean_up_tokenization_spaces=True)) :]
+ )
+
+ generated_sequences.append(total_sequence)
+ print(total_sequence)
+
+ return generated_sequences
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/text-generation/run_generation_contrastive_search.py b/docs/transformers/examples/pytorch/text-generation/run_generation_contrastive_search.py
new file mode 100644
index 0000000000000000000000000000000000000000..5610dfb7f5deeb5c202fa77fe245434cd27ccb6d
--- /dev/null
+++ b/docs/transformers/examples/pytorch/text-generation/run_generation_contrastive_search.py
@@ -0,0 +1,135 @@
+#!/usr/bin/env python
+# Copyright 2022 University of Cambridge, Tencent AI Lab, DeepMind and The University of Hong Kong Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""The examples of running contrastive search on the auto-APIs;
+
+Running this example:
+python run_generation_contrastive_search.py --model_name_or_path=openai-community/gpt2-large --penalty_alpha=0.6 --k=4 --length=256
+"""
+
+import argparse
+import logging
+
+from accelerate import PartialState
+from accelerate.utils import set_seed
+
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+
+logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+)
+logger = logging.getLogger(__name__)
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--model_name_or_path",
+ default=None,
+ type=str,
+ required=True,
+ )
+ parser.add_argument("--prompt", type=str, default="")
+ parser.add_argument("--length", type=int, default=20)
+ parser.add_argument("--stop_token", type=str, default=None, help="Token at which text generation is stopped")
+ parser.add_argument(
+ "--temperature",
+ type=float,
+ default=1.0,
+ help="temperature of 1.0 has no effect, lower tend toward greedy sampling",
+ )
+ parser.add_argument(
+ "--repetition_penalty", type=float, default=1.0, help="primarily useful for CTRL model; in that case, use 1.2"
+ )
+ parser.add_argument("--k", type=int, default=0)
+ parser.add_argument("--penalty_alpha", type=float, default=0.0)
+ parser.add_argument("--p", type=float, default=0.9)
+
+ parser.add_argument("--prefix", type=str, default="", help="Text added prior to input.")
+ parser.add_argument("--padding_text", type=str, default="", help="Deprecated, the use of `--prefix` is preferred.")
+ parser.add_argument("--xlm_language", type=str, default="", help="Optional language when used with the XLM model.")
+
+ parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
+ parser.add_argument(
+ "--use_cpu",
+ action="store_true",
+ help="Whether or not to use cpu. If set to False, we will use gpu/npu or mps device if available",
+ )
+ parser.add_argument(
+ "--fp16",
+ action="store_true",
+ help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
+ )
+ args = parser.parse_args()
+
+ # Initialize the distributed state.
+ distributed_state = PartialState(cpu=args.use_cpu)
+
+ logger.warning(f"device: {distributed_state.device}, 16-bits inference: {args.fp16}")
+
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Initialize the model and tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path)
+ model = AutoModelForCausalLM.from_pretrained(args.model_name_or_path)
+
+ # tokenizer = GPT2Tokenizer.from_pretrained(args.model_name_or_path)
+ # model = OPTForCausalLM.from_pretrained(args.model_name_or_path)
+ # Set the model to the right device
+ model.to(distributed_state.device)
+
+ if args.fp16:
+ model.half()
+
+ logger.info(args)
+ prompt_text = args.prompt if args.prompt else input("Model prompt >>> ")
+
+ inputs = tokenizer(prompt_text, return_tensors="pt", add_special_tokens=False)
+ inputs = {key: value.to(distributed_state.device) for key, value in inputs.items()}
+
+ output_sequences = model.generate(
+ **inputs,
+ max_length=args.length + len(inputs["input_ids"][0]),
+ penalty_alpha=args.penalty_alpha,
+ top_k=args.k,
+ )
+
+ generated_sequences = []
+ for generated_sequence_idx, generated_sequence in enumerate(output_sequences):
+ print(f"=== GENERATED SEQUENCE {generated_sequence_idx + 1} ===")
+ generated_sequence = generated_sequence.tolist()
+
+ # Decode text
+ text = tokenizer.decode(generated_sequence, clean_up_tokenization_spaces=True, add_special_tokens=False)
+
+ # Remove all text after the stop token
+ text = text[: text.find(args.stop_token) if args.stop_token else None]
+
+ # Add the prompt at the beginning of the sequence. Remove the excess text that was used for pre-processing
+ total_sequence = (
+ prompt_text + text[len(tokenizer.decode(inputs["input_ids"][0], clean_up_tokenization_spaces=True)) :]
+ )
+
+ generated_sequences.append(total_sequence)
+ print(total_sequence)
+
+ return generated_sequences
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/token-classification/README.md b/docs/transformers/examples/pytorch/token-classification/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..734a1a1d1aef1a1d3217f60950d2b9b1daf231bb
--- /dev/null
+++ b/docs/transformers/examples/pytorch/token-classification/README.md
@@ -0,0 +1,146 @@
+
+
+# Token classification
+
+## PyTorch version
+
+Fine-tuning the library models for token classification task such as Named Entity Recognition (NER), Parts-of-speech
+tagging (POS) or phrase extraction (CHUNKS). The main script `run_ner.py` leverages the 🤗 Datasets library and the Trainer API. You can easily
+customize it to your needs if you need extra processing on your datasets.
+
+It will either run on a datasets hosted on our [hub](https://huggingface.co/datasets) or with your own text files for
+training and validation, you might just need to add some tweaks in the data preprocessing.
+
+### Using your own data
+
+If you use your own data, the script expects the following format of the data -
+
+```bash
+{
+ "chunk_tags": [11, 12, 12, 21, 13, 11, 11, 21, 13, 11, 12, 13, 11, 21, 22, 11, 12, 17, 11, 21, 17, 11, 12, 12, 21, 22, 22, 13, 11, 0],
+ "id": "0",
+ "ner_tags": [0, 3, 4, 0, 0, 0, 0, 0, 0, 7, 0, 0, 0, 0, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ "pos_tags": [12, 22, 22, 38, 15, 22, 28, 38, 15, 16, 21, 35, 24, 35, 37, 16, 21, 15, 24, 41, 15, 16, 21, 21, 20, 37, 40, 35, 21, 7],
+ "tokens": ["The", "European", "Commission", "said", "on", "Thursday", "it", "disagreed", "with", "German", "advice", "to", "consumers", "to", "shun", "British", "lamb", "until", "scientists", "determine", "whether", "mad", "cow", "disease", "can", "be", "transmitted", "to", "sheep", "."]
+}
+```
+
+The following example fine-tunes BERT on CoNLL-2003:
+
+```bash
+python run_ner.py \
+ --model_name_or_path google-bert/bert-base-uncased \
+ --dataset_name conll2003 \
+ --output_dir /tmp/test-ner \
+ --do_train \
+ --do_eval
+```
+
+or just can just run the bash script `run.sh`.
+
+To run on your own training and validation files, use the following command:
+
+```bash
+python run_ner.py \
+ --model_name_or_path google-bert/bert-base-uncased \
+ --train_file path_to_train_file \
+ --validation_file path_to_validation_file \
+ --output_dir /tmp/test-ner \
+ --do_train \
+ --do_eval
+```
+
+**Note:** This script only works with models that have a fast tokenizer (backed by the 🤗 Tokenizers library) as it
+uses special features of those tokenizers. You can check if your favorite model has a fast tokenizer in
+[this table](https://huggingface.co/transformers/index.html#supported-frameworks), if it doesn't you can still use the old version
+of the script.
+
+> If your model classification head dimensions do not fit the number of labels in the dataset, you can specify `--ignore_mismatched_sizes` to adapt it.
+
+## Old version of the script
+
+You can find the old version of the PyTorch script [here](https://github.com/huggingface/transformers/blob/main/examples/legacy/token-classification/run_ner.py).
+
+## Pytorch version, no Trainer
+
+Based on the script [run_ner_no_trainer.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/token-classification/run_ner_no_trainer.py).
+
+Like `run_ner.py`, this script allows you to fine-tune any of the models on the [hub](https://huggingface.co/models) on a
+token classification task, either NER, POS or CHUNKS tasks or your own data in a csv or a JSON file. The main difference is that this
+script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like.
+
+It offers less options than the script with `Trainer` (for instance you can easily change the options for the optimizer
+or the dataloaders directly in the script) but still run in a distributed setup, on TPU and supports mixed precision by
+the mean of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
+after installing it:
+
+```bash
+pip install git+https://github.com/huggingface/accelerate
+```
+
+then
+
+```bash
+export TASK_NAME=ner
+
+python run_ner_no_trainer.py \
+ --model_name_or_path google-bert/bert-base-cased \
+ --dataset_name conll2003 \
+ --task_name $TASK_NAME \
+ --max_length 128 \
+ --per_device_train_batch_size 32 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/$TASK_NAME/
+```
+
+You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
+
+```bash
+accelerate config
+```
+
+and reply to the questions asked. Then
+
+```bash
+accelerate test
+```
+
+that will check everything is ready for training. Finally, you can launch training with
+
+```bash
+export TASK_NAME=ner
+
+accelerate launch run_ner_no_trainer.py \
+ --model_name_or_path google-bert/bert-base-cased \
+ --dataset_name conll2003 \
+ --task_name $TASK_NAME \
+ --max_length 128 \
+ --per_device_train_batch_size 32 \
+ --learning_rate 2e-5 \
+ --num_train_epochs 3 \
+ --output_dir /tmp/$TASK_NAME/
+```
+
+This command is the same and will work for:
+
+- a CPU-only setup
+- a setup with one GPU
+- a distributed training with several GPUs (single or multi node)
+- a training on TPUs
+
+Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
diff --git a/docs/transformers/examples/pytorch/token-classification/requirements.txt b/docs/transformers/examples/pytorch/token-classification/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..53740bf4e81aee0c1007c449a9f20420094fa26f
--- /dev/null
+++ b/docs/transformers/examples/pytorch/token-classification/requirements.txt
@@ -0,0 +1,5 @@
+accelerate >= 0.12.0
+seqeval
+datasets >= 1.8.0
+torch >= 1.3
+evaluate
\ No newline at end of file
diff --git a/docs/transformers/examples/pytorch/token-classification/run.sh b/docs/transformers/examples/pytorch/token-classification/run.sh
new file mode 100644
index 0000000000000000000000000000000000000000..2dd49117d2d44afb20f64aba6c291e5be340b282
--- /dev/null
+++ b/docs/transformers/examples/pytorch/token-classification/run.sh
@@ -0,0 +1,20 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+python3 run_ner.py \
+ --model_name_or_path bert-base-uncased \
+ --dataset_name conll2003 \
+ --output_dir /tmp/test-ner \
+ --do_train \
+ --do_eval
diff --git a/docs/transformers/examples/pytorch/token-classification/run_ner.py b/docs/transformers/examples/pytorch/token-classification/run_ner.py
new file mode 100644
index 0000000000000000000000000000000000000000..28c344de27e83495da8af1b5ea7b3fe41495a91f
--- /dev/null
+++ b/docs/transformers/examples/pytorch/token-classification/run_ner.py
@@ -0,0 +1,653 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for token classification.
+"""
+# You can also adapt this script on your own token classification task and datasets. Pointers for this are left as
+# comments.
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import datasets
+import evaluate
+import numpy as np
+from datasets import ClassLabel, load_dataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForTokenClassification,
+ AutoTokenizer,
+ DataCollatorForTokenClassification,
+ HfArgumentParser,
+ PretrainedConfig,
+ PreTrainedTokenizerFast,
+ Trainer,
+ TrainingArguments,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
+
+logger = logging.getLogger(__name__)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ ignore_mismatched_sizes: bool = field(
+ default=False,
+ metadata={"help": "Will enable to load a pretrained model whose head dimensions are different."},
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ task_name: Optional[str] = field(default="ner", metadata={"help": "The name of the task (ner, pos...)."})
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(
+ default=None, metadata={"help": "The input training data file (a csv or JSON file)."}
+ )
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate on (a csv or JSON file)."},
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input test data file to predict on (a csv or JSON file)."},
+ )
+ text_column_name: Optional[str] = field(
+ default=None, metadata={"help": "The column name of text to input in the file (a csv or JSON file)."}
+ )
+ label_column_name: Optional[str] = field(
+ default=None, metadata={"help": "The column name of label to input in the file (a csv or JSON file)."}
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_seq_length: int = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. If set, sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to model maximum sentence length. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
+ "efficient on GPU but very bad for TPU."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ label_all_tokens: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to put the label for one word on all tokens of generated by that word or just on the "
+ "one (in which case the other tokens will have a padding index)."
+ )
+ },
+ )
+ return_entity_level_metrics: bool = field(
+ default=False,
+ metadata={"help": "Whether to return all the entity levels during evaluation or just the overall ones."},
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ self.task_name = self.task_name.lower()
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_ner", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if data_args.test_file is not None:
+ data_files["test"] = data_args.test_file
+ extension = data_args.test_file.split(".")[-1]
+ raw_datasets = load_dataset(extension, data_files=data_files, cache_dir=model_args.cache_dir)
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ if training_args.do_train:
+ column_names = raw_datasets["train"].column_names
+ features = raw_datasets["train"].features
+ else:
+ column_names = raw_datasets["validation"].column_names
+ features = raw_datasets["validation"].features
+
+ if data_args.text_column_name is not None:
+ text_column_name = data_args.text_column_name
+ elif "tokens" in column_names:
+ text_column_name = "tokens"
+ else:
+ text_column_name = column_names[0]
+
+ if data_args.label_column_name is not None:
+ label_column_name = data_args.label_column_name
+ elif f"{data_args.task_name}_tags" in column_names:
+ label_column_name = f"{data_args.task_name}_tags"
+ else:
+ label_column_name = column_names[1]
+
+ # In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
+ # unique labels.
+ def get_label_list(labels):
+ unique_labels = set()
+ for label in labels:
+ unique_labels = unique_labels | set(label)
+ label_list = list(unique_labels)
+ label_list.sort()
+ return label_list
+
+ # If the labels are of type ClassLabel, they are already integers and we have the map stored somewhere.
+ # Otherwise, we have to get the list of labels manually.
+ labels_are_int = isinstance(features[label_column_name].feature, ClassLabel)
+ if labels_are_int:
+ label_list = features[label_column_name].feature.names
+ label_to_id = {i: i for i in range(len(label_list))}
+ else:
+ label_list = get_label_list(raw_datasets["train"][label_column_name])
+ label_to_id = {l: i for i, l in enumerate(label_list)}
+
+ num_labels = len(label_list)
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ num_labels=num_labels,
+ finetuning_task=data_args.task_name,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ tokenizer_name_or_path = model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path
+ if config.model_type in {"bloom", "gpt2", "roberta", "deberta"}:
+ tokenizer = AutoTokenizer.from_pretrained(
+ tokenizer_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=True,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ add_prefix_space=True,
+ )
+ else:
+ tokenizer = AutoTokenizer.from_pretrained(
+ tokenizer_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=True,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ model = AutoModelForTokenClassification.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ ignore_mismatched_sizes=model_args.ignore_mismatched_sizes,
+ )
+
+ # Tokenizer check: this script requires a fast tokenizer.
+ if not isinstance(tokenizer, PreTrainedTokenizerFast):
+ raise ValueError(
+ "This example script only works for models that have a fast tokenizer. Checkout the big table of models at"
+ " https://huggingface.co/transformers/index.html#supported-frameworks to find the model types that meet"
+ " this requirement"
+ )
+
+ # Model has labels -> use them.
+ if model.config.label2id != PretrainedConfig(num_labels=num_labels).label2id:
+ if sorted(model.config.label2id.keys()) == sorted(label_list):
+ # Reorganize `label_list` to match the ordering of the model.
+ if labels_are_int:
+ label_to_id = {i: int(model.config.label2id[l]) for i, l in enumerate(label_list)}
+ label_list = [model.config.id2label[i] for i in range(num_labels)]
+ else:
+ label_list = [model.config.id2label[i] for i in range(num_labels)]
+ label_to_id = {l: i for i, l in enumerate(label_list)}
+ else:
+ logger.warning(
+ "Your model seems to have been trained with labels, but they don't match the dataset: "
+ f"model labels: {sorted(model.config.label2id.keys())}, dataset labels:"
+ f" {sorted(label_list)}.\nIgnoring the model labels as a result.",
+ )
+
+ # Set the correspondences label/ID inside the model config
+ model.config.label2id = {l: i for i, l in enumerate(label_list)}
+ model.config.id2label = dict(enumerate(label_list))
+
+ # Map that sends B-Xxx label to its I-Xxx counterpart
+ b_to_i_label = []
+ for idx, label in enumerate(label_list):
+ if label.startswith("B-") and label.replace("B-", "I-") in label_list:
+ b_to_i_label.append(label_list.index(label.replace("B-", "I-")))
+ else:
+ b_to_i_label.append(idx)
+
+ # Preprocessing the dataset
+ # Padding strategy
+ padding = "max_length" if data_args.pad_to_max_length else False
+
+ # Tokenize all texts and align the labels with them.
+ def tokenize_and_align_labels(examples):
+ tokenized_inputs = tokenizer(
+ examples[text_column_name],
+ padding=padding,
+ truncation=True,
+ max_length=data_args.max_seq_length,
+ # We use this argument because the texts in our dataset are lists of words (with a label for each word).
+ is_split_into_words=True,
+ )
+ labels = []
+ for i, label in enumerate(examples[label_column_name]):
+ word_ids = tokenized_inputs.word_ids(batch_index=i)
+ previous_word_idx = None
+ label_ids = []
+ for word_idx in word_ids:
+ # Special tokens have a word id that is None. We set the label to -100 so they are automatically
+ # ignored in the loss function.
+ if word_idx is None:
+ label_ids.append(-100)
+ # We set the label for the first token of each word.
+ elif word_idx != previous_word_idx:
+ label_ids.append(label_to_id[label[word_idx]])
+ # For the other tokens in a word, we set the label to either the current label or -100, depending on
+ # the label_all_tokens flag.
+ else:
+ if data_args.label_all_tokens:
+ label_ids.append(b_to_i_label[label_to_id[label[word_idx]]])
+ else:
+ label_ids.append(-100)
+ previous_word_idx = word_idx
+
+ labels.append(label_ids)
+ tokenized_inputs["labels"] = labels
+ return tokenized_inputs
+
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ with training_args.main_process_first(desc="train dataset map pre-processing"):
+ train_dataset = train_dataset.map(
+ tokenize_and_align_labels,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+
+ if training_args.do_eval:
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = raw_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+ with training_args.main_process_first(desc="validation dataset map pre-processing"):
+ eval_dataset = eval_dataset.map(
+ tokenize_and_align_labels,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+
+ if training_args.do_predict:
+ if "test" not in raw_datasets:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_dataset = raw_datasets["test"]
+ if data_args.max_predict_samples is not None:
+ max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
+ predict_dataset = predict_dataset.select(range(max_predict_samples))
+ with training_args.main_process_first(desc="prediction dataset map pre-processing"):
+ predict_dataset = predict_dataset.map(
+ tokenize_and_align_labels,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on prediction dataset",
+ )
+
+ # Data collator
+ data_collator = DataCollatorForTokenClassification(tokenizer, pad_to_multiple_of=8 if training_args.fp16 else None)
+
+ # Metrics
+ metric = evaluate.load("seqeval", cache_dir=model_args.cache_dir)
+
+ def compute_metrics(p):
+ predictions, labels = p
+ if not training_args.eval_do_concat_batches:
+ predictions = np.hstack(predictions)
+ labels = np.hstack(labels)
+ predictions = np.argmax(predictions, axis=2)
+
+ # Remove ignored index (special tokens)
+ true_predictions = [
+ [label_list[p] for (p, l) in zip(prediction, label) if l != -100]
+ for prediction, label in zip(predictions, labels)
+ ]
+ true_labels = [
+ [label_list[l] for (p, l) in zip(prediction, label) if l != -100]
+ for prediction, label in zip(predictions, labels)
+ ]
+
+ results = metric.compute(predictions=true_predictions, references=true_labels)
+ if data_args.return_entity_level_metrics:
+ # Unpack nested dictionaries
+ final_results = {}
+ for key, value in results.items():
+ if isinstance(value, dict):
+ for n, v in value.items():
+ final_results[f"{key}_{n}"] = v
+ else:
+ final_results[key] = value
+ return final_results
+ else:
+ return {
+ "precision": results["overall_precision"],
+ "recall": results["overall_recall"],
+ "f1": results["overall_f1"],
+ "accuracy": results["overall_accuracy"],
+ }
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ processing_class=tokenizer,
+ data_collator=data_collator,
+ compute_metrics=compute_metrics,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ metrics = train_result.metrics
+ trainer.save_model() # Saves the tokenizer too for easy upload
+
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+
+ metrics = trainer.evaluate()
+
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Predict
+ if training_args.do_predict:
+ logger.info("*** Predict ***")
+
+ predictions, labels, metrics = trainer.predict(predict_dataset, metric_key_prefix="predict")
+ predictions = np.argmax(predictions, axis=2)
+
+ # Remove ignored index (special tokens)
+ true_predictions = [
+ [label_list[p] for (p, l) in zip(prediction, label) if l != -100]
+ for prediction, label in zip(predictions, labels)
+ ]
+
+ trainer.log_metrics("predict", metrics)
+ trainer.save_metrics("predict", metrics)
+
+ # Save predictions
+ output_predictions_file = os.path.join(training_args.output_dir, "predictions.txt")
+ if trainer.is_world_process_zero():
+ with open(output_predictions_file, "w") as writer:
+ for prediction in true_predictions:
+ writer.write(" ".join(prediction) + "\n")
+
+ kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "token-classification"}
+ if data_args.dataset_name is not None:
+ kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ kwargs["dataset_args"] = data_args.dataset_config_name
+ kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/token-classification/run_ner_no_trainer.py b/docs/transformers/examples/pytorch/token-classification/run_ner_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf42f0d01c257eb5320adce22499d0b38d39988f
--- /dev/null
+++ b/docs/transformers/examples/pytorch/token-classification/run_ner_no_trainer.py
@@ -0,0 +1,831 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning a 🤗 Transformers model on token classification tasks (NER, POS, CHUNKS) relying on the accelerate library
+without using a Trainer.
+"""
+
+import argparse
+import json
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import datasets
+import evaluate
+import numpy as np
+import torch
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from datasets import ClassLabel, load_dataset
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from tqdm.auto import tqdm
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_MAPPING,
+ AutoConfig,
+ AutoModelForTokenClassification,
+ AutoTokenizer,
+ DataCollatorForTokenClassification,
+ PretrainedConfig,
+ SchedulerType,
+ default_data_collator,
+ get_scheduler,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logger = get_logger(__name__)
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
+
+# You should update this to your particular problem to have better documentation of `model_type`
+MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description="Finetune a transformers model on a text classification task (NER) with accelerate library"
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help="The name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The configuration name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--train_file", type=str, default=None, help="A csv or a json file containing the training data."
+ )
+ parser.add_argument(
+ "--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
+ )
+ parser.add_argument(
+ "--text_column_name",
+ type=str,
+ default=None,
+ help="The column name of text to input in the file (a csv or JSON file).",
+ )
+ parser.add_argument(
+ "--label_column_name",
+ type=str,
+ default=None,
+ help="The column name of label to input in the file (a csv or JSON file).",
+ )
+ parser.add_argument(
+ "--max_length",
+ type=int,
+ default=128,
+ help=(
+ "The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
+ " sequences shorter will be padded if `--pad_to_max_length` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--pad_to_max_length",
+ action="store_true",
+ help="If passed, pad all samples to `max_length`. Otherwise, dynamic padding is used.",
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ required=False,
+ )
+ parser.add_argument(
+ "--config_name",
+ type=str,
+ default=None,
+ help="Pretrained config name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--model_type",
+ type=str,
+ default=None,
+ help="Model type to use if training from scratch.",
+ choices=MODEL_TYPES,
+ )
+ parser.add_argument(
+ "--label_all_tokens",
+ action="store_true",
+ help="Setting labels of all special tokens to -100 and thus PyTorch will ignore them.",
+ )
+ parser.add_argument(
+ "--return_entity_level_metrics",
+ action="store_true",
+ help="Indication whether entity level metrics are to be returner.",
+ )
+ parser.add_argument(
+ "--task_name",
+ type=str,
+ default="ner",
+ choices=["ner", "pos", "chunk"],
+ help="The name of the task.",
+ )
+ parser.add_argument(
+ "--debug",
+ action="store_true",
+ help="Activate debug mode and run training only with a subset of data.",
+ )
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--ignore_mismatched_sizes",
+ action="store_true",
+ help="Whether or not to enable to load a pretrained model whose head dimensions are different.",
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+ if args.task_name is None and args.train_file is None and args.validation_file is None:
+ raise ValueError("Need either a task name or a training/validation file.")
+ else:
+ if args.train_file is not None:
+ extension = args.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if args.validation_file is not None:
+ extension = args.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+
+ if args.push_to_hub:
+ assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_ner_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator = (
+ Accelerator(log_with=args.report_to, project_dir=args.output_dir) if args.with_tracking else Accelerator()
+ )
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets for token classification task available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'tokens' or the first column if no column called
+ # 'tokens' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ args.dataset_name, args.dataset_config_name, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ data_files = {}
+ if args.train_file is not None:
+ data_files["train"] = args.train_file
+ extension = args.train_file.split(".")[-1]
+ if args.validation_file is not None:
+ data_files["validation"] = args.validation_file
+ extension = args.validation_file.split(".")[-1]
+ raw_datasets = load_dataset(extension, data_files=data_files)
+ # Trim a number of training examples
+ if args.debug:
+ for split in raw_datasets.keys():
+ raw_datasets[split] = raw_datasets[split].select(range(100))
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ if raw_datasets["train"] is not None:
+ column_names = raw_datasets["train"].column_names
+ features = raw_datasets["train"].features
+ else:
+ column_names = raw_datasets["validation"].column_names
+ features = raw_datasets["validation"].features
+
+ if args.text_column_name is not None:
+ text_column_name = args.text_column_name
+ elif "tokens" in column_names:
+ text_column_name = "tokens"
+ else:
+ text_column_name = column_names[0]
+
+ if args.label_column_name is not None:
+ label_column_name = args.label_column_name
+ elif f"{args.task_name}_tags" in column_names:
+ label_column_name = f"{args.task_name}_tags"
+ else:
+ label_column_name = column_names[1]
+
+ # In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
+ # unique labels.
+ def get_label_list(labels):
+ unique_labels = set()
+ for label in labels:
+ unique_labels = unique_labels | set(label)
+ label_list = list(unique_labels)
+ label_list.sort()
+ return label_list
+
+ # If the labels are of type ClassLabel, they are already integers and we have the map stored somewhere.
+ # Otherwise, we have to get the list of labels manually.
+ labels_are_int = isinstance(features[label_column_name].feature, ClassLabel)
+ if labels_are_int:
+ label_list = features[label_column_name].feature.names
+ label_to_id = {i: i for i in range(len(label_list))}
+ else:
+ label_list = get_label_list(raw_datasets["train"][label_column_name])
+ label_to_id = {l: i for i, l in enumerate(label_list)}
+
+ num_labels = len(label_list)
+
+ # Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ if args.config_name:
+ config = AutoConfig.from_pretrained(
+ args.config_name, num_labels=num_labels, trust_remote_code=args.trust_remote_code
+ )
+ elif args.model_name_or_path:
+ config = AutoConfig.from_pretrained(
+ args.model_name_or_path, num_labels=num_labels, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ config = CONFIG_MAPPING[args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ tokenizer_name_or_path = args.tokenizer_name if args.tokenizer_name else args.model_name_or_path
+ if not tokenizer_name_or_path:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if config.model_type in {"bloom", "gpt2", "roberta"}:
+ tokenizer = AutoTokenizer.from_pretrained(
+ tokenizer_name_or_path, use_fast=True, add_prefix_space=True, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ tokenizer = AutoTokenizer.from_pretrained(
+ tokenizer_name_or_path, use_fast=True, trust_remote_code=args.trust_remote_code
+ )
+
+ if args.model_name_or_path:
+ model = AutoModelForTokenClassification.from_pretrained(
+ args.model_name_or_path,
+ from_tf=bool(".ckpt" in args.model_name_or_path),
+ config=config,
+ ignore_mismatched_sizes=args.ignore_mismatched_sizes,
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelForTokenClassification.from_config(config, trust_remote_code=args.trust_remote_code)
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embedding_size = model.get_input_embeddings().weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ embedding_size = model.get_input_embeddings().weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+
+ # Model has labels -> use them.
+ if model.config.label2id != PretrainedConfig(num_labels=num_labels).label2id:
+ if sorted(model.config.label2id.keys()) == sorted(label_list):
+ # Reorganize `label_list` to match the ordering of the model.
+ if labels_are_int:
+ label_to_id = {i: int(model.config.label2id[l]) for i, l in enumerate(label_list)}
+ label_list = [model.config.id2label[i] for i in range(num_labels)]
+ else:
+ label_list = [model.config.id2label[i] for i in range(num_labels)]
+ label_to_id = {l: i for i, l in enumerate(label_list)}
+ else:
+ logger.warning(
+ "Your model seems to have been trained with labels, but they don't match the dataset: "
+ f"model labels: {sorted(model.config.label2id.keys())}, dataset labels:"
+ f" {sorted(label_list)}.\nIgnoring the model labels as a result.",
+ )
+
+ # Set the correspondences label/ID inside the model config
+ model.config.label2id = {l: i for i, l in enumerate(label_list)}
+ model.config.id2label = dict(enumerate(label_list))
+
+ # Map that sends B-Xxx label to its I-Xxx counterpart
+ b_to_i_label = []
+ for idx, label in enumerate(label_list):
+ if label.startswith("B-") and label.replace("B-", "I-") in label_list:
+ b_to_i_label.append(label_list.index(label.replace("B-", "I-")))
+ else:
+ b_to_i_label.append(idx)
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ padding = "max_length" if args.pad_to_max_length else False
+
+ # Tokenize all texts and align the labels with them.
+
+ def tokenize_and_align_labels(examples):
+ tokenized_inputs = tokenizer(
+ examples[text_column_name],
+ max_length=args.max_length,
+ padding=padding,
+ truncation=True,
+ # We use this argument because the texts in our dataset are lists of words (with a label for each word).
+ is_split_into_words=True,
+ )
+
+ labels = []
+ for i, label in enumerate(examples[label_column_name]):
+ word_ids = tokenized_inputs.word_ids(batch_index=i)
+ previous_word_idx = None
+ label_ids = []
+ for word_idx in word_ids:
+ # Special tokens have a word id that is None. We set the label to -100 so they are automatically
+ # ignored in the loss function.
+ if word_idx is None:
+ label_ids.append(-100)
+ # We set the label for the first token of each word.
+ elif word_idx != previous_word_idx:
+ label_ids.append(label_to_id[label[word_idx]])
+ # For the other tokens in a word, we set the label to either the current label or -100, depending on
+ # the label_all_tokens flag.
+ else:
+ if args.label_all_tokens:
+ label_ids.append(b_to_i_label[label_to_id[label[word_idx]]])
+ else:
+ label_ids.append(-100)
+ previous_word_idx = word_idx
+
+ labels.append(label_ids)
+ tokenized_inputs["labels"] = labels
+ return tokenized_inputs
+
+ with accelerator.main_process_first():
+ processed_raw_datasets = raw_datasets.map(
+ tokenize_and_align_labels,
+ batched=True,
+ remove_columns=raw_datasets["train"].column_names,
+ desc="Running tokenizer on dataset",
+ )
+
+ train_dataset = processed_raw_datasets["train"]
+ eval_dataset = processed_raw_datasets["validation"]
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # DataLoaders creation:
+ if args.pad_to_max_length:
+ # If padding was already done ot max length, we use the default data collator that will just convert everything
+ # to tensors.
+ data_collator = default_data_collator
+ else:
+ # Otherwise, `DataCollatorForTokenClassification` will apply dynamic padding for us (by padding to the maximum length of
+ # the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
+ # of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
+ # For fp8, we pad to multiple of 16.
+ if accelerator.mixed_precision == "fp8":
+ pad_to_multiple_of = 16
+ elif accelerator.mixed_precision != "no":
+ pad_to_multiple_of = 8
+ else:
+ pad_to_multiple_of = None
+ data_collator = DataCollatorForTokenClassification(tokenizer, pad_to_multiple_of=pad_to_multiple_of)
+
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
+ )
+ eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
+
+ # Optimizer
+ # Split weights in two groups, one with weight decay and the other not.
+ no_decay = ["bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
+
+ # Use the device given by the `accelerator` object.
+ device = accelerator.device
+ model.to(device)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps,
+ num_training_steps=args.max_train_steps,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if args.with_tracking:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("ner_no_trainer", experiment_config)
+
+ # Metrics
+ metric = evaluate.load("seqeval")
+
+ def get_labels(predictions, references):
+ # Transform predictions and references tensos to numpy arrays
+ if device.type == "cpu":
+ y_pred = predictions.detach().clone().numpy()
+ y_true = references.detach().clone().numpy()
+ else:
+ y_pred = predictions.detach().cpu().clone().numpy()
+ y_true = references.detach().cpu().clone().numpy()
+
+ # Remove ignored index (special tokens)
+ true_predictions = [
+ [label_list[p] for (p, l) in zip(pred, gold_label) if l != -100]
+ for pred, gold_label in zip(y_pred, y_true)
+ ]
+ true_labels = [
+ [label_list[l] for (p, l) in zip(pred, gold_label) if l != -100]
+ for pred, gold_label in zip(y_pred, y_true)
+ ]
+ return true_predictions, true_labels
+
+ def compute_metrics():
+ results = metric.compute()
+ if args.return_entity_level_metrics:
+ # Unpack nested dictionaries
+ final_results = {}
+ for key, value in results.items():
+ if isinstance(value, dict):
+ for n, v in value.items():
+ final_results[f"{key}_{n}"] = v
+ else:
+ final_results[key] = value
+ return final_results
+ else:
+ return {
+ "precision": results["overall_precision"],
+ "recall": results["overall_recall"],
+ "f1": results["overall_f1"],
+ "accuracy": results["overall_accuracy"],
+ }
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+ for step, batch in enumerate(active_dataloader):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+ loss = loss / args.gradient_accumulation_steps
+ accelerator.backward(loss)
+ if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ model.eval()
+ samples_seen = 0
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+ predictions = outputs.logits.argmax(dim=-1)
+ labels = batch["labels"]
+ if not args.pad_to_max_length: # necessary to pad predictions and labels for being gathered
+ predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
+ labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
+ predictions_gathered, labels_gathered = accelerator.gather((predictions, labels))
+ # If we are in a multiprocess environment, the last batch has duplicates
+ if accelerator.num_processes > 1:
+ if step == len(eval_dataloader) - 1:
+ predictions_gathered = predictions_gathered[: len(eval_dataloader.dataset) - samples_seen]
+ labels_gathered = labels_gathered[: len(eval_dataloader.dataset) - samples_seen]
+ else:
+ samples_seen += labels_gathered.shape[0]
+ preds, refs = get_labels(predictions_gathered, labels_gathered)
+ metric.add_batch(
+ predictions=preds,
+ references=refs,
+ ) # predictions and preferences are expected to be a nested list of labels, not label_ids
+
+ eval_metric = compute_metrics()
+ accelerator.print(f"epoch {epoch}:", eval_metric)
+ if args.with_tracking:
+ accelerator.log(
+ {
+ "seqeval": eval_metric,
+ "train_loss": total_loss.item() / len(train_dataloader),
+ "epoch": epoch,
+ "step": completed_steps,
+ },
+ step=completed_steps,
+ )
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ all_results = {f"eval_{k}": v for k, v in eval_metric.items()}
+ if args.with_tracking:
+ all_results.update({"train_loss": total_loss.item() / len(train_dataloader)})
+ with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
+ # Convert all float64 & int64 type numbers to float & int for json serialization
+ for key, value in all_results.items():
+ if isinstance(value, np.float64):
+ all_results[key] = float(value)
+ elif isinstance(value, np.int64):
+ all_results[key] = int(value)
+ json.dump(all_results, f)
+
+ accelerator.wait_for_everyone()
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/token-classification/run_no_trainer.sh b/docs/transformers/examples/pytorch/token-classification/run_no_trainer.sh
new file mode 100644
index 0000000000000000000000000000000000000000..bf9cbb7223cbbbb4cbab71a9c32e4170512c3c89
--- /dev/null
+++ b/docs/transformers/examples/pytorch/token-classification/run_no_trainer.sh
@@ -0,0 +1,21 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+accelerate launch run_ner_no_trainer.py \
+ --model_name_or_path bert-base-uncased \
+ --dataset_name conll2003 \
+ --output_dir /tmp/test-ner \
+ --pad_to_max_length \
+ --task_name ner \
+ --return_entity_level_metrics
diff --git a/docs/transformers/examples/pytorch/translation/README.md b/docs/transformers/examples/pytorch/translation/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..8285355fb0b5ceaf10cb23c6cd4e7d5fe93c620e
--- /dev/null
+++ b/docs/transformers/examples/pytorch/translation/README.md
@@ -0,0 +1,211 @@
+
+
+## Translation
+
+This directory contains examples for finetuning and evaluating transformers on translation tasks.
+Please tag @patil-suraj with any issues/unexpected behaviors, or send a PR!
+For deprecated `bertabs` instructions, see https://github.com/huggingface/transformers-research-projects/blob/main/bertabs/README.md.
+For the old `finetune_trainer.py` and related utils, see [`examples/legacy/seq2seq`](https://github.com/huggingface/transformers/blob/main/examples/legacy/seq2seq).
+
+### Supported Architectures
+
+- `BartForConditionalGeneration`
+- `FSMTForConditionalGeneration` (translation only)
+- `MBartForConditionalGeneration`
+- `MarianMTModel`
+- `PegasusForConditionalGeneration`
+- `T5ForConditionalGeneration`
+- `MT5ForConditionalGeneration`
+
+`run_translation.py` is a lightweight examples of how to download and preprocess a dataset from the [🤗 Datasets](https://github.com/huggingface/datasets) library or use your own files (jsonlines or csv), then fine-tune one of the architectures above on it.
+
+For custom datasets in `jsonlines` format please see: https://huggingface.co/docs/datasets/loading_datasets#json-files
+and you also will find examples of these below.
+
+
+## With Trainer
+
+Here is an example of a translation fine-tuning with a MarianMT model:
+
+```bash
+python examples/pytorch/translation/run_translation.py \
+ --model_name_or_path Helsinki-NLP/opus-mt-en-ro \
+ --do_train \
+ --do_eval \
+ --source_lang en \
+ --target_lang ro \
+ --dataset_name wmt16 \
+ --dataset_config_name ro-en \
+ --output_dir /tmp/tst-translation \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+MBart and some T5 models require special handling.
+
+T5 models `google-t5/t5-small`, `google-t5/t5-base`, `google-t5/t5-large`, `google-t5/t5-3b` and `google-t5/t5-11b` must use an additional argument: `--source_prefix "translate {source_lang} to {target_lang}"`. For example:
+
+```bash
+python examples/pytorch/translation/run_translation.py \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --source_lang en \
+ --target_lang ro \
+ --source_prefix "translate English to Romanian: " \
+ --dataset_name wmt16 \
+ --dataset_config_name ro-en \
+ --output_dir /tmp/tst-translation \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+If you get a terrible BLEU score, make sure that you didn't forget to use the `--source_prefix` argument.
+
+For the aforementioned group of T5 models it's important to remember that if you switch to a different language pair, make sure to adjust the source and target values in all 3 language-specific command line argument: `--source_lang`, `--target_lang` and `--source_prefix`.
+
+MBart models require a different format for `--source_lang` and `--target_lang` values, e.g. instead of `en` it expects `en_XX`, for `ro` it expects `ro_RO`. The full MBart specification for language codes can be found [here](https://huggingface.co/facebook/mbart-large-cc25). For example:
+
+```bash
+python examples/pytorch/translation/run_translation.py \
+ --model_name_or_path facebook/mbart-large-en-ro \
+ --do_train \
+ --do_eval \
+ --dataset_name wmt16 \
+ --dataset_config_name ro-en \
+ --source_lang en_XX \
+ --target_lang ro_RO \
+ --output_dir /tmp/tst-translation \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+ ```
+
+And here is how you would use the translation finetuning on your own files, after adjusting the
+values for the arguments `--train_file`, `--validation_file` to match your setup:
+
+```bash
+python examples/pytorch/translation/run_translation.py \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --source_lang en \
+ --target_lang ro \
+ --source_prefix "translate English to Romanian: " \
+ --dataset_name wmt16 \
+ --dataset_config_name ro-en \
+ --train_file path_to_jsonlines_file \
+ --validation_file path_to_jsonlines_file \
+ --output_dir /tmp/tst-translation \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+```
+
+The task of translation supports only custom JSONLINES files, with each line being a dictionary with a key `"translation"` and its value another dictionary whose keys is the language pair. For example:
+
+```json
+{ "translation": { "en": "Others have dismissed him as a joke.", "ro": "Alții l-au numit o glumă." } }
+{ "translation": { "en": "And some are holding out for an implosion.", "ro": "Iar alții așteaptă implozia." } }
+```
+Here the languages are Romanian (`ro`) and English (`en`).
+
+If you want to use a pre-processed dataset that leads to high BLEU scores, but for the `en-de` language pair, you can use `--dataset_name stas/wmt14-en-de-pre-processed`, as following:
+
+```bash
+python examples/pytorch/translation/run_translation.py \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --source_lang en \
+ --target_lang de \
+ --source_prefix "translate English to German: " \
+ --dataset_name stas/wmt14-en-de-pre-processed \
+ --output_dir /tmp/tst-translation \
+ --per_device_train_batch_size=4 \
+ --per_device_eval_batch_size=4 \
+ --overwrite_output_dir \
+ --predict_with_generate
+ ```
+
+## With Accelerate
+
+Based on the script [`run_translation_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/translation/run_translation_no_trainer.py).
+
+Like `run_translation.py`, this script allows you to fine-tune any of the models supported on a
+translation task, the main difference is that this
+script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like.
+
+It offers less options than the script with `Trainer` (for instance you can easily change the options for the optimizer
+or the dataloaders directly in the script) but still run in a distributed setup, on TPU and supports mixed precision by
+the mean of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
+after installing it:
+
+```bash
+pip install git+https://github.com/huggingface/accelerate
+```
+
+then
+
+```bash
+python run_translation_no_trainer.py \
+ --model_name_or_path Helsinki-NLP/opus-mt-en-ro \
+ --source_lang en \
+ --target_lang ro \
+ --dataset_name wmt16 \
+ --dataset_config_name ro-en \
+ --output_dir ~/tmp/tst-translation
+```
+
+You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
+
+```bash
+accelerate config
+```
+
+and reply to the questions asked. Then
+
+```bash
+accelerate test
+```
+
+that will check everything is ready for training. Finally, you can launch training with
+
+```bash
+accelerate launch run_translation_no_trainer.py \
+ --model_name_or_path Helsinki-NLP/opus-mt-en-ro \
+ --source_lang en \
+ --target_lang ro \
+ --dataset_name wmt16 \
+ --dataset_config_name ro-en \
+ --output_dir ~/tmp/tst-translation
+```
+
+This command is the same and will work for:
+
+- a CPU-only setup
+- a setup with one GPU
+- a distributed training with several GPUs (single or multi node)
+- a training on TPUs
+
+Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
diff --git a/docs/transformers/examples/pytorch/translation/requirements.txt b/docs/transformers/examples/pytorch/translation/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..9c9257430c06a832445db13b2446c6ac0bbadbcc
--- /dev/null
+++ b/docs/transformers/examples/pytorch/translation/requirements.txt
@@ -0,0 +1,8 @@
+accelerate >= 0.12.0
+datasets >= 1.8.0
+sentencepiece != 0.1.92
+protobuf
+sacrebleu >= 1.4.12
+py7zr
+torch >= 1.3
+evaluate
\ No newline at end of file
diff --git a/docs/transformers/examples/pytorch/translation/run_translation.py b/docs/transformers/examples/pytorch/translation/run_translation.py
new file mode 100644
index 0000000000000000000000000000000000000000..1310668646955173a32b639490886f63d38c4849
--- /dev/null
+++ b/docs/transformers/examples/pytorch/translation/run_translation.py
@@ -0,0 +1,696 @@
+#!/usr/bin/env python
+# Copyright The HuggingFace Team and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for sequence to sequence.
+"""
+# You can also adapt this script on your own sequence to sequence task. Pointers for this are left as comments.
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import datasets
+import evaluate
+import numpy as np
+from datasets import load_dataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoModelForSeq2SeqLM,
+ AutoTokenizer,
+ DataCollatorForSeq2Seq,
+ HfArgumentParser,
+ M2M100Tokenizer,
+ MBart50Tokenizer,
+ MBart50TokenizerFast,
+ MBartTokenizer,
+ MBartTokenizerFast,
+ Seq2SeqTrainer,
+ Seq2SeqTrainingArguments,
+ default_data_collator,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/translation/requirements.txt")
+
+logger = logging.getLogger(__name__)
+
+# A list of all multilingual tokenizer which require src_lang and tgt_lang attributes.
+MULTILINGUAL_TOKENIZERS = [MBartTokenizer, MBartTokenizerFast, MBart50Tokenizer, MBart50TokenizerFast, M2M100Tokenizer]
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ source_lang: str = field(default=None, metadata={"help": "Source language id for translation."})
+ target_lang: str = field(default=None, metadata={"help": "Target language id for translation."})
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a jsonlines)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": "An optional input evaluation data file to evaluate the metrics (sacrebleu) on a jsonlines file."
+ },
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input test data file to evaluate the metrics (sacrebleu) on a jsonlines file."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_source_length: Optional[int] = field(
+ default=1024,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ max_target_length: Optional[int] = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total sequence length for target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ val_max_target_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total sequence length for validation target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
+ "This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
+ "during ``evaluate`` and ``predict``."
+ )
+ },
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to model maximum sentence length. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
+ "efficient on GPU but very bad for TPU."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ num_beams: Optional[int] = field(
+ default=1,
+ metadata={
+ "help": (
+ "Number of beams to use for evaluation. This argument will be passed to ``model.generate``, "
+ "which is used during ``evaluate`` and ``predict``."
+ )
+ },
+ )
+ ignore_pad_token_for_loss: bool = field(
+ default=True,
+ metadata={
+ "help": "Whether to ignore the tokens corresponding to padded labels in the loss computation or not."
+ },
+ )
+ source_prefix: Optional[str] = field(
+ default=None, metadata={"help": "A prefix to add before every source text (useful for T5 models)."}
+ )
+ forced_bos_token: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to force as the first generated token after the :obj:`decoder_start_token_id`.Useful for"
+ " multilingual models like :doc:`mBART <../model_doc/mbart>` where the first generated token needs to"
+ " be the target language token.(Usually it is the target language token)"
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ elif self.source_lang is None or self.target_lang is None:
+ raise ValueError("Need to specify the source language and the target language.")
+
+ # accepting both json and jsonl file extensions, as
+ # many jsonlines files actually have a .json extension
+ valid_extensions = ["json", "jsonl"]
+
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in valid_extensions, "`train_file` should be a jsonlines file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in valid_extensions, "`validation_file` should be a jsonlines file."
+ if self.val_max_target_length is None:
+ self.val_max_target_length = self.max_target_length
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_translation", model_args, data_args)
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ if training_args.should_log:
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ + f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ if data_args.source_prefix is None and model_args.model_name_or_path in [
+ "google-t5/t5-small",
+ "google-t5/t5-base",
+ "google-t5/t5-large",
+ "google-t5/t5-3b",
+ "google-t5/t5-11b",
+ ]:
+ logger.warning(
+ "You're running a t5 model but didn't provide a source prefix, which is expected, e.g. with "
+ "`--source_prefix 'translate English to German: ' `"
+ )
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Get the datasets: you can either provide your own JSON training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For translation, only JSON files are supported, with one field named "translation" containing two keys for the
+ # source and target languages (unless you adapt what follows).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if data_args.test_file is not None:
+ data_files["test"] = data_args.test_file
+ extension = data_args.test_file.split(".")[-1]
+ if extension == "jsonl":
+ builder_name = "json" # the "json" builder reads both .json and .jsonl files
+ else:
+ builder_name = extension # e.g. "parquet"
+ raw_datasets = load_dataset(
+ builder_name,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading.
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = AutoModelForSeq2SeqLM.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embedding_size = model.get_input_embeddings().weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+
+ # Set decoder_start_token_id
+ if model.config.decoder_start_token_id is None and isinstance(tokenizer, (MBartTokenizer, MBartTokenizerFast)):
+ if isinstance(tokenizer, MBartTokenizer):
+ model.config.decoder_start_token_id = tokenizer.lang_code_to_id[data_args.target_lang]
+ else:
+ model.config.decoder_start_token_id = tokenizer.convert_tokens_to_ids(data_args.target_lang)
+
+ if model.config.decoder_start_token_id is None:
+ raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
+
+ prefix = data_args.source_prefix if data_args.source_prefix is not None else ""
+
+ # Preprocessing the datasets.
+ # We need to tokenize inputs and targets.
+ if training_args.do_train:
+ column_names = raw_datasets["train"].column_names
+ elif training_args.do_eval:
+ column_names = raw_datasets["validation"].column_names
+ elif training_args.do_predict:
+ column_names = raw_datasets["test"].column_names
+ else:
+ logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
+ return
+
+ # For translation we set the codes of our source and target languages (only useful for mBART, the others will
+ # ignore those attributes).
+ if isinstance(tokenizer, tuple(MULTILINGUAL_TOKENIZERS)):
+ assert data_args.target_lang is not None and data_args.source_lang is not None, (
+ f"{tokenizer.__class__.__name__} is a multilingual tokenizer which requires --source_lang and "
+ "--target_lang arguments."
+ )
+
+ tokenizer.src_lang = data_args.source_lang
+ tokenizer.tgt_lang = data_args.target_lang
+
+ # For multilingual translation models like mBART-50 and M2M100 we need to force the target language token
+ # as the first generated token. We ask the user to explicitly provide this as --forced_bos_token argument.
+ forced_bos_token_id = (
+ tokenizer.lang_code_to_id[data_args.forced_bos_token] if data_args.forced_bos_token is not None else None
+ )
+ model.config.forced_bos_token_id = forced_bos_token_id
+
+ # Get the language codes for input/target.
+ source_lang = data_args.source_lang.split("_")[0]
+ target_lang = data_args.target_lang.split("_")[0]
+
+ # Check the whether the source target length fits in the model, if it has absolute positional embeddings
+ if (
+ hasattr(model.config, "max_position_embeddings")
+ and not hasattr(model.config, "relative_attention_max_distance")
+ and model.config.max_position_embeddings < data_args.max_source_length
+ ):
+ raise ValueError(
+ f"`--max_source_length` is set to {data_args.max_source_length}, but the model only has"
+ f" {model.config.max_position_embeddings} position encodings. Consider either reducing"
+ f" `--max_source_length` to {model.config.max_position_embeddings} or using a model with larger position "
+ "embeddings"
+ )
+
+ # Temporarily set max_target_length for training.
+ max_target_length = data_args.max_target_length
+ padding = "max_length" if data_args.pad_to_max_length else False
+
+ if training_args.label_smoothing_factor > 0 and not hasattr(model, "prepare_decoder_input_ids_from_labels"):
+ logger.warning(
+ "label_smoothing is enabled but the `prepare_decoder_input_ids_from_labels` method is not defined for "
+ f"`{model.__class__.__name__}`. This will lead to loss being calculated twice and will take up more memory"
+ )
+
+ def preprocess_function(examples):
+ inputs = [ex[source_lang] for ex in examples["translation"]]
+ targets = [ex[target_lang] for ex in examples["translation"]]
+ inputs = [prefix + inp for inp in inputs]
+ model_inputs = tokenizer(inputs, max_length=data_args.max_source_length, padding=padding, truncation=True)
+
+ # Tokenize targets with the `text_target` keyword argument
+ labels = tokenizer(text_target=targets, max_length=max_target_length, padding=padding, truncation=True)
+
+ # If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
+ # padding in the loss.
+ if padding == "max_length" and data_args.ignore_pad_token_for_loss:
+ labels["input_ids"] = [
+ [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
+ ]
+
+ model_inputs["labels"] = labels["input_ids"]
+ return model_inputs
+
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ with training_args.main_process_first(desc="train dataset map pre-processing"):
+ train_dataset = train_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+
+ if training_args.do_eval:
+ max_target_length = data_args.val_max_target_length
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = raw_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+ with training_args.main_process_first(desc="validation dataset map pre-processing"):
+ eval_dataset = eval_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+
+ if training_args.do_predict:
+ max_target_length = data_args.val_max_target_length
+ if "test" not in raw_datasets:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_dataset = raw_datasets["test"]
+ if data_args.max_predict_samples is not None:
+ max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
+ predict_dataset = predict_dataset.select(range(max_predict_samples))
+ with training_args.main_process_first(desc="prediction dataset map pre-processing"):
+ predict_dataset = predict_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on prediction dataset",
+ )
+
+ # Data collator
+ label_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
+ if data_args.pad_to_max_length:
+ data_collator = default_data_collator
+ else:
+ data_collator = DataCollatorForSeq2Seq(
+ tokenizer,
+ model=model,
+ label_pad_token_id=label_pad_token_id,
+ pad_to_multiple_of=8 if training_args.fp16 else None,
+ )
+
+ # Metric
+ metric = evaluate.load("sacrebleu", cache_dir=model_args.cache_dir)
+
+ def postprocess_text(preds, labels):
+ preds = [pred.strip() for pred in preds]
+ labels = [[label.strip()] for label in labels]
+
+ return preds, labels
+
+ def compute_metrics(eval_preds):
+ preds, labels = eval_preds
+ if isinstance(preds, tuple):
+ preds = preds[0]
+ # Replace -100s used for padding as we can't decode them
+ preds = np.where(preds != -100, preds, tokenizer.pad_token_id)
+ decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ # Some simple post-processing
+ decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
+
+ result = metric.compute(predictions=decoded_preds, references=decoded_labels)
+ result = {"bleu": result["score"]}
+
+ prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
+ result["gen_len"] = np.mean(prediction_lens)
+ result = {k: round(v, 4) for k, v in result.items()}
+ return result
+
+ # Initialize our Trainer
+ trainer = Seq2SeqTrainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ processing_class=tokenizer,
+ data_collator=data_collator,
+ compute_metrics=compute_metrics if training_args.predict_with_generate else None,
+ )
+
+ # Training
+ if training_args.do_train:
+ checkpoint = None
+ if training_args.resume_from_checkpoint is not None:
+ checkpoint = training_args.resume_from_checkpoint
+ elif last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model() # Saves the tokenizer too for easy upload
+
+ metrics = train_result.metrics
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ results = {}
+ max_length = (
+ training_args.generation_max_length
+ if training_args.generation_max_length is not None
+ else data_args.val_max_target_length
+ )
+ num_beams = data_args.num_beams if data_args.num_beams is not None else training_args.generation_num_beams
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+
+ metrics = trainer.evaluate(max_length=max_length, num_beams=num_beams, metric_key_prefix="eval")
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ if training_args.do_predict:
+ logger.info("*** Predict ***")
+
+ predict_results = trainer.predict(
+ predict_dataset, metric_key_prefix="predict", max_length=max_length, num_beams=num_beams
+ )
+ metrics = predict_results.metrics
+ max_predict_samples = (
+ data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
+ )
+ metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
+
+ trainer.log_metrics("predict", metrics)
+ trainer.save_metrics("predict", metrics)
+
+ if trainer.is_world_process_zero():
+ if training_args.predict_with_generate:
+ predictions = predict_results.predictions
+ predictions = np.where(predictions != -100, predictions, tokenizer.pad_token_id)
+ predictions = tokenizer.batch_decode(
+ predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True
+ )
+ predictions = [pred.strip() for pred in predictions]
+ output_prediction_file = os.path.join(training_args.output_dir, "generated_predictions.txt")
+ with open(output_prediction_file, "w", encoding="utf-8") as writer:
+ writer.write("\n".join(predictions))
+
+ kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "translation"}
+ if data_args.dataset_name is not None:
+ kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ kwargs["dataset_args"] = data_args.dataset_config_name
+ kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ kwargs["dataset"] = data_args.dataset_name
+
+ languages = [l for l in [data_args.source_lang, data_args.target_lang] if l is not None]
+ if len(languages) > 0:
+ kwargs["language"] = languages
+
+ if training_args.push_to_hub:
+ trainer.push_to_hub(**kwargs)
+ else:
+ trainer.create_model_card(**kwargs)
+
+ return results
+
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/translation/run_translation_no_trainer.py b/docs/transformers/examples/pytorch/translation/run_translation_no_trainer.py
new file mode 100644
index 0000000000000000000000000000000000000000..876bf3ebdb04078294500e72a8627055db6ff188
--- /dev/null
+++ b/docs/transformers/examples/pytorch/translation/run_translation_no_trainer.py
@@ -0,0 +1,789 @@
+#!/usr/bin/env python
+# Copyright The HuggingFace Team and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning a 🤗 Transformers model on text translation.
+"""
+# You can also adapt this script on your own text translation task. Pointers for this are left as comments.
+
+import argparse
+import json
+import logging
+import math
+import os
+import random
+from pathlib import Path
+
+import datasets
+import evaluate
+import numpy as np
+import torch
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from datasets import load_dataset
+from huggingface_hub import HfApi
+from torch.utils.data import DataLoader
+from tqdm.auto import tqdm
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_MAPPING,
+ AutoConfig,
+ AutoModelForSeq2SeqLM,
+ AutoTokenizer,
+ DataCollatorForSeq2Seq,
+ MBartTokenizer,
+ MBartTokenizerFast,
+ SchedulerType,
+ default_data_collator,
+ get_scheduler,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logger = get_logger(__name__)
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/translation/requirements.txt")
+
+# You should update this to your particular problem to have better documentation of `model_type`
+MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+# Parsing input arguments
+def parse_args():
+ parser = argparse.ArgumentParser(description="Finetune a transformers model on a text classification task")
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help="The name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--predict_with_generate",
+ type=bool,
+ default=True,
+ help="",
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help="The configuration name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--train_file", type=str, default=None, help="A csv or a json file containing the training data."
+ )
+
+ parser.add_argument(
+ "--num_beams",
+ type=int,
+ default=None,
+ help=(
+ "Number of beams to use for evaluation. This argument will be "
+ "passed to ``model.generate``, which is used during ``evaluate`` and ``predict``."
+ ),
+ )
+
+ parser.add_argument(
+ "--max_source_length",
+ type=int,
+ default=1024,
+ help=(
+ "The maximum total input sequence length after "
+ "tokenization.Sequences longer than this will be truncated, sequences shorter will be padded."
+ ),
+ )
+ parser.add_argument(
+ "--max_target_length",
+ type=int,
+ default=128,
+ help=(
+ "The maximum total sequence length for target text after "
+ "tokenization. Sequences longer than this will be truncated, sequences shorter will be padded "
+ "during ``evaluate`` and ``predict``."
+ ),
+ )
+ parser.add_argument(
+ "--val_max_target_length",
+ type=int,
+ default=None,
+ help=(
+ "The maximum total sequence length for validation "
+ "target text after tokenization.Sequences longer than this will be truncated, sequences shorter will be "
+ "padded. Will default to `max_target_length`.This argument is also used to override the ``max_length`` "
+ "param of ``model.generate``, which is used during ``evaluate`` and ``predict``."
+ ),
+ )
+ parser.add_argument(
+ "--pad_to_max_length",
+ type=bool,
+ default=False,
+ help=(
+ "Whether to pad all samples to model maximum sentence "
+ "length. If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
+ "efficient on GPU but very bad for TPU."
+ ),
+ )
+ parser.add_argument(
+ "--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
+ )
+ parser.add_argument(
+ "--ignore_pad_token_for_loss",
+ type=bool,
+ default=True,
+ help="Whether to ignore the tokens corresponding to padded labels in the loss computation or not.",
+ )
+ parser.add_argument("--source_lang", type=str, default=None, help="Source language id for translation.")
+ parser.add_argument("--target_lang", type=str, default=None, help="Target language id for translation.")
+ parser.add_argument(
+ "--source_prefix",
+ type=str,
+ default=None,
+ help="A prefix to add before every source text (useful for T5 models).",
+ )
+ parser.add_argument(
+ "--preprocessing_num_workers",
+ type=int,
+ default=None,
+ help="The number of processes to use for the preprocessing.",
+ )
+ parser.add_argument(
+ "--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
+ )
+ parser.add_argument(
+ "--max_length",
+ type=int,
+ default=128,
+ help=(
+ "The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
+ " sequences shorter will be padded if `--pad_to_max_length` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ required=False,
+ )
+ parser.add_argument(
+ "--config_name",
+ type=str,
+ default=None,
+ help="Pretrained config name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--use_slow_tokenizer",
+ action="store_true",
+ help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--model_type",
+ type=str,
+ default=None,
+ help="Model type to use if training from scratch.",
+ choices=MODEL_TYPES,
+ )
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument(
+ "--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
+ )
+ parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--checkpointing_steps",
+ type=str,
+ default=None,
+ help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
+ )
+ parser.add_argument(
+ "--resume_from_checkpoint",
+ type=str,
+ default=None,
+ help="If the training should continue from a checkpoint folder.",
+ )
+ parser.add_argument(
+ "--with_tracking",
+ action="store_true",
+ help="Whether to enable experiment trackers for logging.",
+ )
+ parser.add_argument(
+ "--report_to",
+ type=str,
+ default="all",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
+ ' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
+ "Only applicable when `--with_tracking` is passed."
+ ),
+ )
+ args = parser.parse_args()
+
+ # Sanity checks
+
+ if args.dataset_name is None and args.train_file is None and args.validation_file is None:
+ raise ValueError("Need either a task name or a training/validation file.")
+
+ if args.train_file is not None:
+ extension = args.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if args.validation_file is not None:
+ extension = args.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+
+ if args.push_to_hub:
+ assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
+
+ return args
+
+
+def main():
+ # Parse the arguments
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_translation_no_trainer", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ # If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
+ # in the environment
+ accelerator = (
+ Accelerator(log_with=args.report_to, project_dir=args.output_dir) if args.with_tracking else Accelerator()
+ )
+
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state, main_process_only=False)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ # Retrieve of infer repo_name
+ repo_name = args.hub_model_id
+ if repo_name is None:
+ repo_name = Path(args.output_dir).absolute().name
+ # Create repo and retrieve repo_id
+ api = HfApi()
+ repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+ accelerator.wait_for_everyone()
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ args.dataset_name, args.dataset_config_name, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ data_files = {}
+ if args.train_file is not None:
+ data_files["train"] = args.train_file
+ extension = args.train_file.split(".")[-1]
+ if args.validation_file is not None:
+ data_files["validation"] = args.validation_file
+ extension = args.validation_file.split(".")[-1]
+ raw_datasets = load_dataset(extension, data_files=data_files)
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ if args.config_name:
+ config = AutoConfig.from_pretrained(args.config_name, trust_remote_code=args.trust_remote_code)
+ elif args.model_name_or_path:
+ config = AutoConfig.from_pretrained(args.model_name_or_path, trust_remote_code=args.trust_remote_code)
+ else:
+ config = CONFIG_MAPPING[args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_name, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
+ )
+ elif args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.model_name_or_path, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if args.model_name_or_path:
+ model = AutoModelForSeq2SeqLM.from_pretrained(
+ args.model_name_or_path,
+ from_tf=bool(".ckpt" in args.model_name_or_path),
+ config=config,
+ trust_remote_code=args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = AutoModelForSeq2SeqLM.from_config(config, trust_remote_code=args.trust_remote_code)
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embedding_size = model.get_input_embeddings().weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+
+ # Set decoder_start_token_id
+ if model.config.decoder_start_token_id is None and isinstance(tokenizer, (MBartTokenizer, MBartTokenizerFast)):
+ assert args.target_lang is not None and args.source_lang is not None, (
+ "mBart requires --target_lang and --source_lang"
+ )
+ if isinstance(tokenizer, MBartTokenizer):
+ model.config.decoder_start_token_id = tokenizer.lang_code_to_id[args.target_lang]
+ else:
+ model.config.decoder_start_token_id = tokenizer.convert_tokens_to_ids(args.target_lang)
+
+ if model.config.decoder_start_token_id is None:
+ raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
+
+ prefix = args.source_prefix if args.source_prefix is not None else ""
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ column_names = raw_datasets["train"].column_names
+
+ # For translation we set the codes of our source and target languages (only useful for mBART, the others will
+ # ignore those attributes).
+ if isinstance(tokenizer, (MBartTokenizer, MBartTokenizerFast)):
+ if args.source_lang is not None:
+ tokenizer.src_lang = args.source_lang
+ if args.target_lang is not None:
+ tokenizer.tgt_lang = args.target_lang
+
+ # Get the language codes for input/target.
+ source_lang = args.source_lang.split("_")[0]
+ target_lang = args.target_lang.split("_")[0]
+
+ padding = "max_length" if args.pad_to_max_length else False
+
+ # Temporarily set max_target_length for training.
+ max_target_length = args.max_target_length
+ padding = "max_length" if args.pad_to_max_length else False
+
+ def preprocess_function(examples):
+ inputs = [ex[source_lang] for ex in examples["translation"]]
+ targets = [ex[target_lang] for ex in examples["translation"]]
+ inputs = [prefix + inp for inp in inputs]
+ model_inputs = tokenizer(inputs, max_length=args.max_source_length, padding=padding, truncation=True)
+
+ # Tokenize targets with the `text_target` keyword argument
+ labels = tokenizer(text_target=targets, max_length=max_target_length, padding=padding, truncation=True)
+
+ # If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
+ # padding in the loss.
+ if padding == "max_length" and args.ignore_pad_token_for_loss:
+ labels["input_ids"] = [
+ [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
+ ]
+
+ model_inputs["labels"] = labels["input_ids"]
+ return model_inputs
+
+ with accelerator.main_process_first():
+ processed_datasets = raw_datasets.map(
+ preprocess_function,
+ batched=True,
+ num_proc=args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not args.overwrite_cache,
+ desc="Running tokenizer on dataset",
+ )
+
+ train_dataset = processed_datasets["train"]
+ eval_dataset = processed_datasets["validation"]
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # DataLoaders creation:
+ label_pad_token_id = -100 if args.ignore_pad_token_for_loss else tokenizer.pad_token_id
+ if args.pad_to_max_length:
+ # If padding was already done ot max length, we use the default data collator that will just convert everything
+ # to tensors.
+ data_collator = default_data_collator
+ else:
+ # Otherwise, `DataCollatorWithPadding` will apply dynamic padding for us (by padding to the maximum length of
+ # the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
+ # of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
+ # For fp8, we pad to multiple of 16.
+ if accelerator.mixed_precision == "fp8":
+ pad_to_multiple_of = 16
+ elif accelerator.mixed_precision != "no":
+ pad_to_multiple_of = 8
+ else:
+ pad_to_multiple_of = None
+ data_collator = DataCollatorForSeq2Seq(
+ tokenizer,
+ model=model,
+ label_pad_token_id=label_pad_token_id,
+ pad_to_multiple_of=pad_to_multiple_of,
+ )
+
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
+ )
+ eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
+
+ # Optimizer
+ # Split weights in two groups, one with weight decay and the other not.
+ no_decay = ["bias", "LayerNorm.weight", "layer_norm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps,
+ num_training_steps=args.max_train_steps,
+ )
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+ # Figure out how many steps we should save the Accelerator states
+ checkpointing_steps = args.checkpointing_steps
+ if checkpointing_steps is not None and checkpointing_steps.isdigit():
+ checkpointing_steps = int(checkpointing_steps)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # We initialize the trackers only on main process because `accelerator.log`
+ # only logs on main process and we don't want empty logs/runs on other processes.
+ if args.with_tracking:
+ if accelerator.is_main_process:
+ experiment_config = vars(args)
+ # TensorBoard cannot log Enums, need the raw value
+ experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
+ accelerator.init_trackers("translation_no_trainer", experiment_config)
+
+ metric = evaluate.load("sacrebleu")
+
+ def postprocess_text(preds, labels):
+ preds = [pred.strip() for pred in preds]
+ labels = [[label.strip()] for label in labels]
+
+ return preds, labels
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+ starting_epoch = 0
+
+ # Potentially load in the weights and states from a previous save
+ if args.resume_from_checkpoint:
+ if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
+ checkpoint_path = args.resume_from_checkpoint
+ path = os.path.basename(args.resume_from_checkpoint)
+ else:
+ # Get the most recent checkpoint
+ dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
+ dirs.sort(key=os.path.getctime)
+ path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
+ checkpoint_path = path
+ path = os.path.basename(checkpoint_path)
+
+ accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
+ accelerator.load_state(checkpoint_path)
+ # Extract `epoch_{i}` or `step_{i}`
+ training_difference = os.path.splitext(path)[0]
+
+ if "epoch" in training_difference:
+ starting_epoch = int(training_difference.replace("epoch_", "")) + 1
+ resume_step = None
+ completed_steps = starting_epoch * num_update_steps_per_epoch
+ else:
+ # need to multiply `gradient_accumulation_steps` to reflect real steps
+ resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
+ starting_epoch = resume_step // len(train_dataloader)
+ completed_steps = resume_step // args.gradient_accumulation_steps
+ resume_step -= starting_epoch * len(train_dataloader)
+
+ # update the progress_bar if load from checkpoint
+ progress_bar.update(completed_steps)
+
+ for epoch in range(starting_epoch, args.num_train_epochs):
+ model.train()
+ if args.with_tracking:
+ total_loss = 0
+ if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
+ # We skip the first `n` batches in the dataloader when resuming from a checkpoint
+ active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
+ else:
+ active_dataloader = train_dataloader
+ for step, batch in enumerate(active_dataloader):
+ outputs = model(**batch)
+ loss = outputs.loss
+ # We keep track of the loss at each epoch
+ if args.with_tracking:
+ total_loss += loss.detach().float()
+ loss = loss / args.gradient_accumulation_steps
+ accelerator.backward(loss)
+ if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if isinstance(checkpointing_steps, int):
+ if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
+ output_dir = f"step_{completed_steps}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ model.eval()
+
+ if args.val_max_target_length is None:
+ args.val_max_target_length = args.max_target_length
+
+ gen_kwargs = {
+ "max_length": args.val_max_target_length if args is not None else config.max_length,
+ "num_beams": args.num_beams,
+ }
+ samples_seen = 0
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ generated_tokens = accelerator.unwrap_model(model).generate(
+ batch["input_ids"],
+ attention_mask=batch["attention_mask"],
+ **gen_kwargs,
+ )
+
+ generated_tokens = accelerator.pad_across_processes(
+ generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
+ )
+ labels = batch["labels"]
+ if not args.pad_to_max_length:
+ # If we did not pad to max length, we need to pad the labels too
+ labels = accelerator.pad_across_processes(batch["labels"], dim=1, pad_index=tokenizer.pad_token_id)
+
+ generated_tokens = accelerator.gather(generated_tokens).cpu().numpy()
+ labels = accelerator.gather(labels).cpu().numpy()
+
+ if args.ignore_pad_token_for_loss:
+ # Replace -100 in the labels as we can't decode them.
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+
+ decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+
+ decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
+
+ # If we are in a multiprocess environment, the last batch has duplicates
+ if accelerator.num_processes > 1:
+ if step == len(eval_dataloader) - 1:
+ decoded_preds = decoded_preds[: len(eval_dataloader.dataset) - samples_seen]
+ decoded_labels = decoded_labels[: len(eval_dataloader.dataset) - samples_seen]
+ else:
+ samples_seen += len(decoded_labels)
+
+ metric.add_batch(predictions=decoded_preds, references=decoded_labels)
+ eval_metric = metric.compute()
+ logger.info({"bleu": eval_metric["score"]})
+
+ if args.with_tracking:
+ accelerator.log(
+ {
+ "bleu": eval_metric["score"],
+ "train_loss": total_loss.item() / len(train_dataloader),
+ "epoch": epoch,
+ "step": completed_steps,
+ },
+ step=completed_steps,
+ )
+
+ if args.push_to_hub and epoch < args.num_train_epochs - 1:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ api.upload_folder(
+ commit_message=f"Training in progress epoch {epoch}",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+
+ if args.checkpointing_steps == "epoch":
+ output_dir = f"epoch_{epoch}"
+ if args.output_dir is not None:
+ output_dir = os.path.join(args.output_dir, output_dir)
+ accelerator.save_state(output_dir)
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(
+ args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
+ )
+ if accelerator.is_main_process:
+ tokenizer.save_pretrained(args.output_dir)
+ if args.push_to_hub:
+ api.upload_folder(
+ commit_message="End of training",
+ folder_path=args.output_dir,
+ repo_id=repo_id,
+ repo_type="model",
+ token=args.hub_token,
+ )
+ with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
+ json.dump({"eval_bleu": eval_metric["score"]}, f)
+
+ accelerator.wait_for_everyone()
+ accelerator.end_training()
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/pytorch/xla_spawn.py b/docs/transformers/examples/pytorch/xla_spawn.py
new file mode 100644
index 0000000000000000000000000000000000000000..f9955acfa201a77b12ab4391c14190434e748bbb
--- /dev/null
+++ b/docs/transformers/examples/pytorch/xla_spawn.py
@@ -0,0 +1,82 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+A simple launcher script for TPU training
+
+Inspired by https://github.com/pytorch/pytorch/blob/master/torch/distributed/launch.py
+
+::
+ >>> python xla_spawn.py --num_cores=NUM_CORES_YOU_HAVE
+ YOUR_TRAINING_SCRIPT.py (--arg1 --arg2 --arg3 and all other
+ arguments of your training script)
+
+"""
+
+import importlib
+import sys
+from argparse import REMAINDER, ArgumentParser
+from pathlib import Path
+
+import torch_xla.distributed.xla_multiprocessing as xmp
+
+
+def parse_args():
+ """
+ Helper function parsing the command line options
+ @retval ArgumentParser
+ """
+ parser = ArgumentParser(
+ description=(
+ "PyTorch TPU distributed training launch helper utility that will spawn up multiple distributed processes"
+ )
+ )
+
+ # Optional arguments for the launch helper
+ parser.add_argument("--num_cores", type=int, default=1, help="Number of TPU cores to use (1 or 8).")
+
+ # positional
+ parser.add_argument(
+ "training_script",
+ type=str,
+ help=(
+ "The full path to the single TPU training "
+ "program/script to be launched in parallel, "
+ "followed by all the arguments for the "
+ "training script"
+ ),
+ )
+
+ # rest from the training program
+ parser.add_argument("training_script_args", nargs=REMAINDER)
+
+ return parser.parse_args()
+
+
+def main():
+ args = parse_args()
+
+ # Import training_script as a module.
+ script_fpath = Path(args.training_script)
+ sys.path.append(str(script_fpath.parent.resolve()))
+ mod_name = script_fpath.stem
+ mod = importlib.import_module(mod_name)
+
+ # Patch sys.argv
+ sys.argv = [args.training_script] + args.training_script_args + ["--tpu_num_cores", str(args.num_cores)]
+
+ xmp.spawn(mod._mp_fn, args=(), nprocs=args.num_cores)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/quantization/custom_quantization.py b/docs/transformers/examples/quantization/custom_quantization.py
new file mode 100644
index 0000000000000000000000000000000000000000..006b092e671a15f9c609a1bc1d8bbc7487792cfe
--- /dev/null
+++ b/docs/transformers/examples/quantization/custom_quantization.py
@@ -0,0 +1,78 @@
+import json
+from typing import Any
+
+import torch
+
+from transformers import AutoModelForCausalLM, AutoTokenizer
+from transformers.quantizers import HfQuantizer, register_quantization_config, register_quantizer
+from transformers.utils.quantization_config import QuantizationConfigMixin
+
+
+@register_quantization_config("custom")
+class CustomConfig(QuantizationConfigMixin):
+ def __init__(self):
+ self.quant_method = "custom"
+ self.bits = 8
+
+ def to_dict(self) -> dict[str, Any]:
+ output = {
+ "num_bits": self.bits,
+ }
+ return output
+
+ def __repr__(self):
+ config_dict = self.to_dict()
+ return f"{self.__class__.__name__} {json.dumps(config_dict, indent=2, sort_keys=True)}\n"
+
+ def to_diff_dict(self) -> dict[str, Any]:
+ config_dict = self.to_dict()
+
+ default_config_dict = CustomConfig().to_dict()
+
+ serializable_config_dict = {}
+
+ for key, value in config_dict.items():
+ if value != default_config_dict[key]:
+ serializable_config_dict[key] = value
+
+ return serializable_config_dict
+
+
+@register_quantizer("custom")
+class CustomQuantizer(HfQuantizer):
+ def __init__(self, quantization_config: QuantizationConfigMixin, **kwargs):
+ super().__init__(quantization_config, **kwargs)
+ self.quantization_config = quantization_config
+ self.scale_map = {}
+ self.device = kwargs.get("device", "cuda" if torch.cuda.is_available() else "cpu")
+ self.torch_dtype = kwargs.get("torch_dtype", torch.float32)
+
+ def _process_model_before_weight_loading(self, model, **kwargs):
+ return True
+
+ def _process_model_after_weight_loading(self, model, **kwargs):
+ return True
+
+ def is_serializable(self) -> bool:
+ return True
+
+ def is_trainable(self) -> bool:
+ return False
+
+
+model_8bit = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-350m", quantization_config=CustomConfig(), torch_dtype="auto"
+)
+
+tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
+input_text = "once there is"
+inputs = tokenizer(input_text, return_tensors="pt")
+output = model_8bit.generate(
+ **inputs,
+ max_length=100,
+ num_return_sequences=1,
+ no_repeat_ngram_size=2,
+)
+generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
+
+print(generated_text)
diff --git a/docs/transformers/examples/quantization/custom_quantization_int8_example.py b/docs/transformers/examples/quantization/custom_quantization_int8_example.py
new file mode 100644
index 0000000000000000000000000000000000000000..a61c041b447dcb6a73b388f7496c4928cff04105
--- /dev/null
+++ b/docs/transformers/examples/quantization/custom_quantization_int8_example.py
@@ -0,0 +1,257 @@
+import json
+from typing import Any, Optional
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from accelerate import init_empty_weights
+from huggingface_hub import HfApi
+
+from transformers import AutoModelForCausalLM, AutoTokenizer
+from transformers.quantizers import HfQuantizer, get_module_from_name, register_quantization_config, register_quantizer
+from transformers.utils.quantization_config import QuantizationConfigMixin
+
+
+# Implement INT8 Symmetric Linear layer
+class Int8SymmetricLinear(torch.nn.Module):
+ def __init__(self, in_features, out_features, bias, dtype=torch.float32):
+ super().__init__()
+ self.in_features = in_features
+ self.out_features = out_features
+
+ self.register_buffer("weight", torch.zeros((out_features, in_features), dtype=torch.int8))
+ self.register_buffer("weight_scale", torch.zeros((out_features, 1), dtype=dtype))
+
+ if bias:
+ self.register_buffer("bias", torch.zeros((self.out_features), dtype=dtype))
+ else:
+ self.bias = None
+
+ def forward(self, x):
+ dequant_weight = self.weight * self.weight_scale
+ output = F.linear(x, dequant_weight)
+ if self.bias is not None:
+ output = output + self.bias
+ return output
+
+
+# Function to replace standard linear layers with INT8 symmetric quantized layers
+def _replace_with_int8_symmetric_linear(
+ model,
+ modules_to_not_convert=None,
+ current_key_name=None,
+ quantization_config=None,
+ has_been_replaced=False,
+ pre_quantized=False,
+):
+ """
+ Recursively replaces nn.Linear modules with Int8SymmetricLinear modules.
+ """
+ if current_key_name is None:
+ current_key_name = []
+
+ for name, module in model.named_children():
+ current_key_name.append(name)
+
+ if (isinstance(module, nn.Linear)) and name not in modules_to_not_convert:
+ # Check if the current key is not in the `modules_to_not_convert`
+ current_key_name_str = ".".join(current_key_name)
+ if not any(
+ (key + "." in current_key_name_str) or (key == current_key_name_str) for key in modules_to_not_convert
+ ):
+ with init_empty_weights(include_buffers=True):
+ in_features = module.in_features
+ out_features = module.out_features
+ model._modules[name] = Int8SymmetricLinear(
+ in_features, out_features, module.bias is not None, dtype=module.weight.dtype
+ )
+ has_been_replaced = True
+ model._modules[name].requires_grad_(False)
+
+ if len(list(module.children())) > 0:
+ _, has_been_replaced = _replace_with_int8_symmetric_linear(
+ module,
+ modules_to_not_convert,
+ current_key_name,
+ quantization_config,
+ has_been_replaced=has_been_replaced,
+ pre_quantized=pre_quantized,
+ )
+ # Remove the last key for recursion
+ current_key_name.pop(-1)
+ return model, has_been_replaced
+
+
+def replace_with_int8_symmetric_linear(
+ model, modules_to_not_convert=None, current_key_name=None, quantization_config=None, pre_quantized=False
+):
+ """
+ Main function to replace model layers with INT8 symmetric quantized versions.
+ """
+ modules_to_not_convert = ["lm_head"] if modules_to_not_convert is None else modules_to_not_convert
+
+ if quantization_config.modules_to_not_convert is not None:
+ modules_to_not_convert.extend(quantization_config.modules_to_not_convert)
+ modules_to_not_convert = list(set(modules_to_not_convert))
+
+ model, has_been_replaced = _replace_with_int8_symmetric_linear(
+ model, modules_to_not_convert, current_key_name, quantization_config, pre_quantized=pre_quantized
+ )
+
+ if not has_been_replaced:
+ raise ValueError(
+ "You are loading your model using INT8 symmetric quantization but no linear modules were found in your model."
+ )
+
+ return model
+
+
+@register_quantization_config("int8_symmetric")
+class Int8SymmetricConfig(QuantizationConfigMixin):
+ """
+ Configuration for INT8 symmetric quantization.
+ """
+
+ def __init__(self, modules_to_not_convert: Optional[list[str]] = None, **kwargs):
+ self.quant_method = "int8_symmetric"
+ self.modules_to_not_convert = modules_to_not_convert
+
+ def __repr__(self):
+ config_dict = self.to_dict()
+ return f"{self.__class__.__name__} {json.dumps(config_dict, indent=2, sort_keys=True)}\n"
+
+ def to_diff_dict(self) -> dict[str, Any]:
+ config_dict = self.to_dict()
+ default_config_dict = Int8SymmetricConfig().to_dict()
+
+ serializable_config_dict = {}
+ for key, value in config_dict.items():
+ if value != default_config_dict[key]:
+ serializable_config_dict[key] = value
+
+ return serializable_config_dict
+
+
+@register_quantizer("int8_symmetric")
+class Int8SymmetricQuantizer(HfQuantizer):
+ """
+ Implementation of INT8 symmetric quantization.
+
+ """
+
+ requires_calibration = False
+ requires_parameters_quantization = True
+
+ def __init__(self, quantization_config: QuantizationConfigMixin, **kwargs):
+ super().__init__(quantization_config, **kwargs)
+ self.quantization_config = quantization_config
+
+ def _process_model_before_weight_loading(self, model, **kwargs):
+ """
+ Replace model's linear layers with quantized versions before loading weights.
+ """
+ self.modules_to_not_convert = self.quantization_config.modules_to_not_convert
+
+ model = replace_with_int8_symmetric_linear(
+ model,
+ modules_to_not_convert=self.modules_to_not_convert,
+ quantization_config=self.quantization_config,
+ pre_quantized=self.pre_quantized,
+ )
+
+ def check_quantized_param(
+ self,
+ model,
+ param_value: "torch.Tensor",
+ param_name: str,
+ state_dict: dict[str, Any],
+ **kwargs,
+ ):
+ module, tensor_name = get_module_from_name(model, param_name)
+
+ if isinstance(module, Int8SymmetricLinear):
+ if self.pre_quantized or tensor_name == "bias":
+ if tensor_name == "weight" and param_value.dtype != torch.int8:
+ raise ValueError("Expect quantized weights but got an unquantized weight")
+ return False
+ else:
+ if tensor_name == "weight_scale":
+ raise ValueError("Expect unquantized weights but got a quantized weight_scale")
+ return True
+ return False
+
+ def create_quantized_param(
+ self,
+ model,
+ param_value: "torch.Tensor",
+ param_name: str,
+ target_device: "torch.device",
+ state_dict: dict[str, Any],
+ unexpected_keys: Optional[list[str]] = None,
+ ):
+ """
+ Quantizes weights to INT8 symmetric format.
+ """
+ abs_max_per_row = torch.max(torch.abs(param_value), dim=1, keepdim=True)[0].clamp(min=1e-5)
+
+ weight_scale = abs_max_per_row / 127.0
+
+ weight_quantized = torch.round(param_value / weight_scale).clamp(-128, 127).to(torch.int8)
+
+ module, tensor_name = get_module_from_name(model, param_name)
+ module._buffers[tensor_name] = weight_quantized.to(target_device)
+ module._buffers["weight_scale"] = weight_scale.to(target_device)
+
+ def update_missing_keys(self, model, missing_keys: list[str], prefix: str) -> list[str]:
+ not_missing_keys = []
+ for name, module in model.named_modules():
+ if isinstance(module, Int8SymmetricLinear):
+ for missing in missing_keys:
+ if (
+ (name in missing or name in f"{prefix}.{missing}")
+ and not missing.endswith(".weight")
+ and not missing.endswith(".bias")
+ ):
+ not_missing_keys.append(missing)
+ return [k for k in missing_keys if k not in not_missing_keys]
+
+ def _process_model_after_weight_loading(self, model, **kwargs):
+ """
+ Post-processing after weights are loaded.
+ """
+ return True
+
+ def is_serializable(self, safe_serialization=None):
+ return True
+
+ @property
+ def is_trainable(self) -> bool:
+ return False
+
+
+# Example usage
+if __name__ == "__main__":
+ model_int8 = AutoModelForCausalLM.from_pretrained(
+ "meta-llama/Llama-3.2-1B", quantization_config=Int8SymmetricConfig(), torch_dtype=torch.float, device_map="cpu"
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.2-1B")
+ input_text = "once there is"
+ inputs = tokenizer(input_text, return_tensors="pt").to("cpu")
+ output = model_int8.generate(
+ **inputs,
+ max_length=100,
+ num_return_sequences=1,
+ no_repeat_ngram_size=2,
+ )
+ generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
+ print(generated_text)
+
+ # Save and upload to HUB
+ output_model_dir = "Llama-3.2-1B-INT8-CUSTOM"
+ model_int8.save_pretrained(output_model_dir)
+ tokenizer.save_pretrained(output_model_dir)
+ api = HfApi()
+ repo_id = "medmekk/Llama-3.2-1B-INT8-CUSTOM"
+ api.create_repo(repo_id, private=False)
+ api.upload_folder(folder_path=output_model_dir, repo_id=repo_id, repo_type="model")
diff --git a/docs/transformers/examples/research_projects/README.md b/docs/transformers/examples/research_projects/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..e8a0ecd8c4e9e51ac90f09fab0fe68678f37fa2f
--- /dev/null
+++ b/docs/transformers/examples/research_projects/README.md
@@ -0,0 +1,20 @@
+
+
+# Research projects
+
+This directory previously contained various research projects using 🤗 Transformers. They have been moved
+to a separate repo, so you can now find them at https://github.com/huggingface/transformers-research-projects/
diff --git a/docs/transformers/examples/run_on_remote.py b/docs/transformers/examples/run_on_remote.py
new file mode 100644
index 0000000000000000000000000000000000000000..2baf1d1a032a1598e1cbc30c0d14577007f75070
--- /dev/null
+++ b/docs/transformers/examples/run_on_remote.py
@@ -0,0 +1,70 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+import shlex
+
+import runhouse as rh
+
+
+if __name__ == "__main__":
+ # Refer to https://runhouse-docs.readthedocs-hosted.com/en/latest/api/python/cluster.html#hardware-setup for cloud access
+ # setup instructions, if using on-demand hardware
+
+ # If user passes --user --host --key_path , fill them in as BYO cluster
+ # If user passes --instance --provider , fill them in as on-demand cluster
+ # Throw an error if user passes both BYO and on-demand cluster args
+ # Otherwise, use default values
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--user", type=str, default="ubuntu")
+ parser.add_argument("--host", type=str, default="localhost")
+ parser.add_argument("--key_path", type=str, default=None)
+ parser.add_argument("--instance", type=str, default="V100:1")
+ parser.add_argument("--provider", type=str, default="cheapest")
+ parser.add_argument("--use_spot", type=bool, default=False)
+ parser.add_argument("--example", type=str, default="pytorch/text-generation/run_generation.py")
+ args, unknown = parser.parse_known_args()
+ if args.host != "localhost":
+ if args.instance != "V100:1" or args.provider != "cheapest":
+ raise ValueError("Cannot specify both BYO and on-demand cluster args")
+ cluster = rh.cluster(
+ name="rh-cluster", ips=[args.host], ssh_creds={"ssh_user": args.user, "ssh_private_key": args.key_path}
+ )
+ else:
+ cluster = rh.cluster(
+ name="rh-cluster", instance_type=args.instance, provider=args.provider, use_spot=args.use_spot
+ )
+ example_dir = args.example.rsplit("/", 1)[0]
+
+ # Set up remote environment
+ cluster.install_packages(["pip:./"]) # Installs transformers from local source
+ # Note transformers is copied into the home directory on the remote machine, so we can install from there
+ cluster.run([f"pip install -r transformers/examples/{example_dir}/requirements.txt"])
+ cluster.run(["pip install torch --upgrade --extra-index-url https://download.pytorch.org/whl/cu117"])
+
+ # Run example. You can bypass the CLI wrapper and paste your own code here.
+ cluster.run([f"python transformers/examples/{args.example} {shlex.join(unknown)}"])
+
+ # Alternatively, we can just import and run a training function (especially if there's no wrapper CLI):
+ # from my_script... import train
+ # reqs = ['pip:./', 'torch', 'datasets', 'accelerate', 'evaluate', 'tqdm', 'scipy', 'scikit-learn', 'tensorboard']
+ # launch_train_gpu = rh.function(fn=train,
+ # system=gpu,
+ # reqs=reqs,
+ # name='train_bert_glue')
+ #
+ # We can pass in arguments just like we would to a function:
+ # launch_train_gpu(num_epochs = 3, lr = 2e-5, seed = 42, batch_size = 16
+ # stream_logs=True)
diff --git a/docs/transformers/examples/tensorflow/README.md b/docs/transformers/examples/tensorflow/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2c4115b369f75ac1ffa6c32e3a99092c1cb07ac5
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/README.md
@@ -0,0 +1,44 @@
+
+
+# Examples
+
+This folder contains actively maintained examples of the use of 🤗 Transformers organized into different ML tasks. All examples in this folder are **TensorFlow** examples and are written using native Keras. If you've previously only used 🤗 Transformers via `TFTrainer`, we highly recommend taking a look at the new style - we think it's a big improvement!
+
+In addition, all scripts here now support the [🤗 Datasets](https://github.com/huggingface/datasets) library - you can grab entire datasets just by changing one command-line argument!
+
+## A note on code folding
+
+Most of these examples have been formatted with #region blocks. In IDEs such as PyCharm and VSCode, these blocks mark
+named regions of code that can be folded for easier viewing. If you find any of these scripts overwhelming or difficult
+to follow, we highly recommend beginning with all regions folded and then examining regions one at a time!
+
+## The Big Table of Tasks
+
+Here is the list of all our examples:
+
+| Task | Example datasets |
+|---|---|
+| [**`language-modeling`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling) | WikiText-2
+| [**`multiple-choice`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) | SWAG
+| [**`question-answering`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) | SQuAD
+| [**`summarization`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization) | XSum
+| [**`text-classification`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) | GLUE
+| [**`token-classification`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) | CoNLL NER
+| [**`translation`**](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/translation) | WMT
+
+## Coming soon
+
+- **Colab notebooks** to easily run through these scripts!
diff --git a/docs/transformers/examples/tensorflow/_tests_requirements.txt b/docs/transformers/examples/tensorflow/_tests_requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..6971795ce4ea198b8207bcee50f3ee14a21fdc6e
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/_tests_requirements.txt
@@ -0,0 +1,25 @@
+tensorflow<2.16
+keras<2.16
+tensorboard
+scikit-learn
+seqeval
+psutil
+sacrebleu >= 1.4.12
+rouge-score
+tensorflow_datasets
+matplotlib
+git-python==1.0.3
+faiss-cpu
+streamlit
+elasticsearch
+nltk
+pandas
+datasets >= 1.13.3
+fire
+pytest<8.0.1
+conllu
+sentencepiece != 0.1.92
+protobuf
+jiwer
+librosa
+evaluate >= 0.2.0
diff --git a/docs/transformers/examples/tensorflow/contrastive-image-text/README.md b/docs/transformers/examples/tensorflow/contrastive-image-text/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..29d9b897734cb27e211129d32eb50e60121f12fa
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/contrastive-image-text/README.md
@@ -0,0 +1,81 @@
+
+
+# TFVisionTextDualEncoder and CLIP model training examples
+
+The following example showcases how to train a CLIP-like vision-text dual encoder model
+using a pre-trained vision and text encoder.
+
+Such a model can be used for natural language image search and potentially zero-shot image classification.
+The model is inspired by [CLIP](https://openai.com/blog/clip/), introduced by Alec Radford et al.
+The idea is to train a vision encoder and a text encoder jointly to project the representation of images and their
+captions into the same embedding space, such that the caption embeddings are located near the embeddings
+of the images they describe.
+
+### Download COCO dataset (2017)
+This example uses COCO dataset (2017) through a custom dataset script, which requires users to manually download the
+COCO dataset before training.
+
+```bash
+mkdir data
+cd data
+wget http://images.cocodataset.org/zips/train2017.zip
+wget http://images.cocodataset.org/zips/val2017.zip
+wget http://images.cocodataset.org/zips/test2017.zip
+wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
+wget http://images.cocodataset.org/annotations/image_info_test2017.zip
+cd ..
+```
+
+Having downloaded COCO dataset manually you should be able to load with the `ydshieh/coc_dataset_script` dataset loading script:
+
+```py
+import os
+import datasets
+
+COCO_DIR = os.path.join(os.getcwd(), "data")
+ds = datasets.load_dataset("ydshieh/coco_dataset_script", "2017", data_dir=COCO_DIR)
+```
+
+### Create a model from a vision encoder model and a text encoder model
+We can either load a CLIP-like vision-text dual encoder model from an existing dual encoder model, or
+by using a pre-trained vision encoder model and a pre-trained text encoder model.
+
+If you wish to load an existing dual encoder model, please use the `--model_name_or_path` argument. If
+you want to use separate pre-trained vision and text models, please use the
+`--vision_model_name_or_path` and `--text_model_name_or_path` arguments instead.
+
+### Train the model
+Finally, we can run the example script to train the model:
+
+```bash
+python examples/tensorflow/contrastive-image-text/run_clip.py \
+ --output_dir ./clip-roberta-finetuned \
+ --vision_model_name_or_path openai/clip-vit-base-patch32 \
+ --text_model_name_or_path FacebookAI/roberta-base \
+ --data_dir $PWD/data \
+ --dataset_name ydshieh/coco_dataset_script \
+ --dataset_config_name=2017 \
+ --image_column image_path \
+ --caption_column caption \
+ --remove_unused_columns=False \
+ --do_train --do_eval \
+ --per_device_train_batch_size="64" \
+ --per_device_eval_batch_size="64" \
+ --learning_rate="5e-5" --warmup_steps="0" --weight_decay 0.1 \
+ --overwrite_output_dir \
+ --push_to_hub
+```
diff --git a/docs/transformers/examples/tensorflow/contrastive-image-text/requirements.txt b/docs/transformers/examples/tensorflow/contrastive-image-text/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..ef4bf188bff20310196af7d37f99e9bd1581dddd
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/contrastive-image-text/requirements.txt
@@ -0,0 +1,2 @@
+tensorflow>=2.6.0
+datasets>=1.8.0
\ No newline at end of file
diff --git a/docs/transformers/examples/tensorflow/contrastive-image-text/run_clip.py b/docs/transformers/examples/tensorflow/contrastive-image-text/run_clip.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b084a603ddb313fcca0573ee062549704696956
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/contrastive-image-text/run_clip.py
@@ -0,0 +1,610 @@
+#!/usr/bin/env python
+# Copyright 2023 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Training a CLIP like dual encoder models using text and vision encoders in the library.
+
+The script can be used to train CLIP like models for languages other than English by using
+a text encoder pre-trained in the desired language. Currently this script supports the following vision
+and text models:
+Vision models: ViT(https://huggingface.co/models?filter=vit), CLIP (https://huggingface.co/models?filter=clip)
+Text models: BERT, ROBERTa (https://huggingface.co/models?filter=fill-mask)
+"""
+
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import tensorflow as tf
+from datasets import load_dataset
+from PIL import Image
+
+import transformers
+from transformers import (
+ AutoImageProcessor,
+ AutoTokenizer,
+ HfArgumentParser,
+ PushToHubCallback,
+ TFAutoModel,
+ TFTrainingArguments,
+ TFVisionTextDualEncoderModel,
+ create_optimizer,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version(
+ "datasets>=1.8.0", "To fix: pip install -r examples/tensorflow/contrastive-image-text/requirements.txt"
+)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}, default=None
+ )
+ vision_model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained image model or model identifier from huggingface.co/models"},
+ default=None,
+ )
+ text_model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained text model or model identifier from huggingface.co/models"}, default=None
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ image_processor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ freeze_vision_model: bool = field(
+ default=False, metadata={"help": "Whether to freeze the vision model parameters or not."}
+ )
+ freeze_text_model: bool = field(
+ default=False, metadata={"help": "Whether to freeze the text model parameters or not."}
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ data_dir: Optional[str] = field(default=None, metadata={"help": "The data directory containing input files."})
+ image_column: Optional[str] = field(
+ default="image_path",
+ metadata={"help": "The name of the column in the datasets containing the full image file paths."},
+ )
+ caption_column: Optional[str] = field(
+ default="caption",
+ metadata={"help": "The name of the column in the datasets containing the image captions."},
+ )
+ train_file: Optional[str] = field(
+ default=None, metadata={"help": "The input training data file (a jsonlines file)."}
+ )
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file (a jsonlines file)."},
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input testing data file (a jsonlines file)."},
+ )
+ max_seq_length: Optional[int] = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ if self.test_file is not None:
+ extension = self.test_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
+
+
+dataset_name_mapping = {
+ "image_caption_dataset.py": ("image_path", "caption"),
+}
+
+
+def crop_to_square(image):
+ height, width = tf.shape(image)[0], tf.shape(image)[1]
+ if height > width:
+ image = tf.image.crop_to_bounding_box(image, (height - width) // 2, 0, width, width)
+ elif width > height:
+ image = tf.image.crop_to_bounding_box(image, 0, (width - height) // 2, height, height)
+ return image
+
+
+def load_as_tf_dataset(dataset, image_column, image_size, mean, std, batch_size, shuffle):
+ dataset = dataset.with_format("tensorflow")[:] # Load the dataset as tensor slices, but not the images yet!
+ tf_dataset = tf.data.Dataset.from_tensor_slices(dataset)
+
+ def load_image(sample):
+ image_path = sample[image_column]
+ image = tf.io.read_file(image_path)
+ image = tf.image.decode_image(image, channels=3, expand_animations=False)
+ image = crop_to_square(image)
+ image = tf.image.resize(image, [image_size, image_size], method="bicubic", antialias=True)
+ image = image / 255.0
+ image = (image - mean) / std
+ image = tf.transpose(image, perm=[2, 0, 1]) # Convert to channels-first
+ sample["pixel_values"] = image
+ del sample[image_column]
+ return sample
+
+ if shuffle:
+ tf_dataset = tf_dataset.shuffle(len(tf_dataset))
+ tf_dataset = tf_dataset.map(load_image, num_parallel_calls=tf.data.experimental.AUTOTUNE)
+ tf_dataset = tf_dataset.batch(batch_size, drop_remainder=shuffle)
+ tf_dataset = tf_dataset.prefetch(tf.data.experimental.AUTOTUNE)
+
+ return tf_dataset
+
+
+def main():
+ # 1. Parse input arguments
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ if model_args.model_name_or_path is not None:
+ if model_args.vision_model_name_or_path is not None or model_args.text_model_name_or_path is not None:
+ raise ValueError(
+ "If using model_name_or_path, you cannot specify separate image/text model paths as well!"
+ )
+
+ if model_args.vision_model_name_or_path is not None or model_args.text_model_name_or_path is not None:
+ if model_args.model_name_or_path is not None:
+ raise ValueError(
+ "If using separate image/text model paths, you cannot specify model_name_or_path as well!"
+ )
+ if not (model_args.vision_model_name_or_path is not None and model_args.text_model_name_or_path is not None):
+ raise ValueError(
+ "If using separate image/text model paths, you must specify both vision_model_name_or_path "
+ "and text_model_name_or_path!"
+ )
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/TensorFlow versions.
+ send_example_telemetry("run_clip", model_args, data_args, framework="tensorflow")
+
+ # 2. Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ # The default of training_args.log_level is passive, so we set log level at info here to have that default.
+ transformers.utils.logging.set_verbosity_info()
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # 3. Detecting last checkpoint and eventually continue from last checkpoint
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # 4. Load dataset
+ # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files this script will use the first column for the full image path and the second column for the
+ # captions (unless you specify column names for this with the `image_column` and `caption_column` arguments).
+ #
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ dataset = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ keep_in_memory=False,
+ data_dir=data_args.data_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if data_args.test_file is not None:
+ data_files["test"] = data_args.test_file
+ extension = data_args.test_file.split(".")[-1]
+ dataset = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # 5. Load pretrained model, tokenizer, and image processor
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ elif model_args.text_model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.text_model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if model_args.model_name_or_path:
+ # Load image_processor, in this script we only use this to get the mean and std for normalization.
+ image_processor = AutoImageProcessor.from_pretrained(
+ model_args.image_processor_name or model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ with training_args.strategy.scope():
+ model = TFAutoModel.from_pretrained(
+ model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ # Load image_processor, in this script we only use this to get the mean and std for normalization.
+ image_processor = AutoImageProcessor.from_pretrained(
+ model_args.image_processor_name or model_args.vision_model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ with training_args.strategy.scope():
+ model = TFVisionTextDualEncoderModel.from_vision_text_pretrained(
+ vision_model_name_or_path=model_args.vision_model_name_or_path,
+ text_model_name_or_path=model_args.text_model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ config = model.config
+
+ if model_args.freeze_vision_model:
+ model.vision_model.trainable = False
+
+ if model_args.freeze_text_model:
+ model.text_model.trainable = False
+
+ # Preprocessing the datasets.
+ # We need to tokenize inputs and targets.
+ if training_args.do_train:
+ column_names = dataset["train"].column_names
+ elif training_args.do_eval:
+ column_names = dataset["validation"].column_names
+ elif training_args.do_predict:
+ column_names = dataset["test"].column_names
+ else:
+ logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
+ return
+
+ # 6. Get the column names for input/target.
+ dataset_columns = dataset_name_mapping.get(data_args.dataset_name, None)
+ if data_args.image_column is None:
+ image_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ image_column = data_args.image_column
+ if image_column not in column_names:
+ raise ValueError(
+ f"--image_column' value '{data_args.image_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if data_args.caption_column is None:
+ caption_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ caption_column = data_args.caption_column
+ if caption_column not in column_names:
+ raise ValueError(
+ f"--caption_column' value '{data_args.caption_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # # 7. Preprocessing the datasets.
+
+ # We need to tokenize input captions and transform the images.
+ def tokenize_captions(examples):
+ captions = list(examples[caption_column])
+ text_inputs = tokenizer(captions, max_length=data_args.max_seq_length, padding="max_length", truncation=True)
+ examples["input_ids"] = text_inputs.input_ids
+ examples["attention_mask"] = text_inputs.attention_mask
+ return examples
+
+ def filter_corrupt_images(examples):
+ """remove problematic images"""
+ valid_images = []
+ for image_file in examples[image_column]:
+ try:
+ Image.open(image_file)
+ valid_images.append(True)
+ except Exception:
+ valid_images.append(False)
+ return valid_images
+
+ if training_args.do_train:
+ if "train" not in dataset:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = dataset["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+
+ train_dataset = train_dataset.filter(
+ filter_corrupt_images, batched=True, num_proc=data_args.preprocessing_num_workers
+ )
+ train_dataset = train_dataset.map(
+ function=tokenize_captions,
+ batched=True,
+ remove_columns=[col for col in column_names if col != image_column],
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+
+ tf_train_dataset = load_as_tf_dataset(
+ dataset=train_dataset,
+ batch_size=training_args.per_device_train_batch_size,
+ image_column=image_column,
+ image_size=config.vision_config.image_size,
+ mean=image_processor.image_mean,
+ std=image_processor.image_std,
+ shuffle=True,
+ )
+
+ if training_args.do_eval:
+ if "validation" not in dataset:
+ raise ValueError("--do_eval requires a train validation")
+ eval_dataset = dataset["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ eval_dataset = eval_dataset.filter(
+ filter_corrupt_images, batched=True, num_proc=data_args.preprocessing_num_workers
+ )
+ eval_dataset = eval_dataset.map(
+ function=tokenize_captions,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=[col for col in column_names if col != image_column],
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+
+ tf_eval_dataset = load_as_tf_dataset(
+ dataset=eval_dataset,
+ batch_size=training_args.per_device_eval_batch_size,
+ image_column=image_column,
+ image_size=config.vision_config.image_size,
+ mean=image_processor.image_mean,
+ std=image_processor.image_std,
+ shuffle=False,
+ )
+
+ # 8. Preparing push_to_hub and model card
+ push_to_hub_model_id = training_args.push_to_hub_model_id
+ if model_args.model_name_or_path is not None:
+ model_name = model_args.model_name_or_path.split("/")[-1]
+ else:
+ vision_name = model_args.vision_model_name_or_path.split("/")[-1]
+ text_name = model_args.text_model_name_or_path.split("/")[-1]
+ model_name = f"{vision_name}-{text_name}"
+ if not push_to_hub_model_id:
+ if data_args.dataset_name is not None:
+ push_to_hub_model_id = f"{model_name}-finetuned-{data_args.dataset_name}"
+ else:
+ push_to_hub_model_id = f"{model_name}-finetuned-contrastive-image-text-modeling"
+
+ model_card_kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "contrastive-image-text-modeling"}
+ if data_args.dataset_name is not None:
+ model_card_kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ model_card_kwargs["dataset_args"] = data_args.dataset_config_name
+ model_card_kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ model_card_kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ callbacks = [
+ PushToHubCallback(
+ output_dir=training_args.output_dir,
+ hub_model_id=push_to_hub_model_id,
+ hub_token=training_args.push_to_hub_token,
+ tokenizer=tokenizer,
+ **model_card_kwargs,
+ )
+ ]
+ else:
+ callbacks = []
+
+ # # 9. Training
+ if training_args.do_train:
+ num_train_steps = int(len(tf_train_dataset) * int(training_args.num_train_epochs))
+ if training_args.warmup_steps > 0:
+ num_warmup_steps = training_args.warmup_steps
+ elif training_args.warmup_ratio > 0:
+ num_warmup_steps = int(num_train_steps * training_args.warmup_ratio)
+ else:
+ num_warmup_steps = 0
+ optimizer, lr_schedule = create_optimizer(
+ init_lr=training_args.learning_rate,
+ num_train_steps=num_train_steps,
+ num_warmup_steps=num_warmup_steps,
+ adam_beta1=training_args.adam_beta1,
+ adam_beta2=training_args.adam_beta2,
+ adam_epsilon=training_args.adam_epsilon,
+ weight_decay_rate=training_args.weight_decay,
+ adam_global_clipnorm=training_args.max_grad_norm,
+ )
+ # Transformers models compute the right loss for their task by default when labels are passed, and will
+ # use this for training unless you specify your own loss function in compile().
+ model.compile(optimizer=optimizer, jit_compile=training_args.xla)
+
+ if not training_args.do_eval:
+ tf_eval_dataset = None
+ model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ epochs=int(training_args.num_train_epochs),
+ callbacks=callbacks,
+ )
+
+ # # 10. Evaluation
+
+ if training_args.do_eval and not training_args.do_train:
+ model.evaluate(tf_eval_dataset)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/tensorflow/image-classification/README.md b/docs/transformers/examples/tensorflow/image-classification/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a343b443ef1ae52f3d211e5d97de0c5864f412f0
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/image-classification/README.md
@@ -0,0 +1,162 @@
+
+
+# Image classification examples
+
+This directory contains 2 scripts that showcase how to fine-tune any model supported by the [`TFAutoModelForImageClassification` API](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.TFAutoModelForImageClassification) (such as [ViT](https://huggingface.co/docs/transformers/main/en/model_doc/vit), [ConvNeXT](https://huggingface.co/docs/transformers/main/en/model_doc/convnext), [ResNet](https://huggingface.co/docs/transformers/main/en/model_doc/resnet), [Swin Transformer](https://huggingface.co/docs/transformers/main/en/model_doc/swin)...) using TensorFlow. They can be used to fine-tune models on both [datasets from the hub](#using-datasets-from-hub) as well as on [your own custom data](#using-your-own-data).
+
+
+
+Try out the inference widget here: https://huggingface.co/google/vit-base-patch16-224
+
+## TensorFlow
+
+Based on the script [`run_image_classification.py`](https://github.com/huggingface/transformers/blob/main/examples/tensorflow/image-classification/run_image_classification.py).
+
+### Using datasets from Hub
+
+Here we show how to fine-tune a Vision Transformer (`ViT`) on the [beans](https://huggingface.co/datasets/beans) dataset, to classify the disease type of bean leaves. The following will train a model and push it to the `amyeroberts/vit-base-beans` repo.
+
+```bash
+python run_image_classification.py \
+ --dataset_name beans \
+ --output_dir ./beans_outputs/ \
+ --remove_unused_columns False \
+ --do_train \
+ --do_eval \
+ --push_to_hub \
+ --hub_model_id amyeroberts/vit-base-beans \
+ --learning_rate 2e-5 \
+ --num_train_epochs 5 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+👀 See the results here: [amyeroberts/vit-base-beans](https://huggingface.co/amyeroberts/vit-base-beans).
+
+Note that you can replace the model and dataset by simply setting the `model_name_or_path` and `dataset_name` arguments respectively, with any model or dataset from the [hub](https://huggingface.co/). For an overview of all possible arguments, we refer to the [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) of the `TrainingArguments`, which can be passed as flags.
+
+> If your model classification head dimensions do not fit the number of labels in the dataset, you can specify `--ignore_mismatched_sizes` to adapt it.
+
+### Using your own data
+
+To use your own dataset, there are 2 ways:
+- you can either provide your own folders as `--train_dir` and/or `--validation_dir` arguments
+- you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
+
+Below, we explain both in more detail.
+
+#### Provide them as folders
+
+If you provide your own folders with images, the script expects the following directory structure:
+
+```bash
+root/dog/xxx.png
+root/dog/xxy.png
+root/dog/[...]/xxz.png
+
+root/cat/123.png
+root/cat/nsdf3.png
+root/cat/[...]/asd932_.png
+```
+
+In other words, you need to organize your images in subfolders, based on their class. You can then run the script like this:
+
+```bash
+python run_image_classification.py \
+ --train_dir \
+ --output_dir ./outputs/ \
+ --remove_unused_columns False \
+ --do_train \
+ --do_eval
+```
+
+Internally, the script will use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature which will automatically turn the folders into 🤗 Dataset objects.
+
+##### 💡 The above will split the train dir into training and evaluation sets
+ - To control the split amount, use the `--train_val_split` flag.
+ - To provide your own validation split in its own directory, you can pass the `--validation_dir ` flag.
+
+#### Upload your data to the hub, as a (possibly private) repo
+
+To upload your image dataset to the hub you can use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature available in 🤗 Datasets. Simply do the following:
+
+```python
+from datasets import load_dataset
+
+# example 1: local folder
+dataset = load_dataset("imagefolder", data_dir="path_to_your_folder")
+
+# example 2: local files (supported formats are tar, gzip, zip, xz, rar, zstd)
+dataset = load_dataset("imagefolder", data_files="path_to_zip_file")
+
+# example 3: remote files (supported formats are tar, gzip, zip, xz, rar, zstd)
+dataset = load_dataset("imagefolder", data_files="https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip")
+
+# example 4: providing several splits
+dataset = load_dataset("imagefolder", data_files={"train": ["path/to/file1", "path/to/file2"], "test": ["path/to/file3", "path/to/file4"]})
+```
+
+`ImageFolder` will create a `label` column, and the label name is based on the directory name.
+
+Next, push it to the hub!
+
+```python
+# assuming you have ran the huggingface-cli login command in a terminal
+dataset.push_to_hub("name_of_your_dataset")
+
+# if you want to push to a private repo, simply pass private=True:
+dataset.push_to_hub("name_of_your_dataset", private=True)
+```
+
+and that's it! You can now train your model by simply setting the `--dataset_name` argument to the name of your dataset on the hub (as explained in [Using datasets from the 🤗 hub](#using-datasets-from-hub)).
+
+More on this can also be found in [this blog post](https://huggingface.co/blog/image-search-datasets).
+
+### Sharing your model on 🤗 Hub
+
+0. If you haven't already, [sign up](https://huggingface.co/join) for a 🤗 account
+
+1. Make sure you have `git-lfs` installed and git set up.
+
+```bash
+$ apt install git-lfs
+$ git config --global user.email "you@example.com"
+$ git config --global user.name "Your Name"
+```
+
+2. Log in with your HuggingFace account credentials using `huggingface-cli`:
+
+```bash
+$ huggingface-cli login
+# ...follow the prompts
+```
+
+3. When running the script, pass the following arguments:
+
+```bash
+python run_image_classification.py \
+ --push_to_hub \
+ --push_to_hub_model_id \
+ ...
+```
diff --git a/docs/transformers/examples/tensorflow/image-classification/requirements.txt b/docs/transformers/examples/tensorflow/image-classification/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..ccdff7ba7884c3a43e65f000a57409ea63dfaacb
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/image-classification/requirements.txt
@@ -0,0 +1,3 @@
+datasets>=1.17.0
+evaluate
+tensorflow>=2.4
diff --git a/docs/transformers/examples/tensorflow/image-classification/run_image_classification.py b/docs/transformers/examples/tensorflow/image-classification/run_image_classification.py
new file mode 100644
index 0000000000000000000000000000000000000000..c9f9c9750b938d6d9b440451ba750467f0bd3856
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/image-classification/run_image_classification.py
@@ -0,0 +1,576 @@
+#!/usr/bin/env python
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+"""
+Fine-tuning a 🤗 Transformers model for image classification.
+
+Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
+https://huggingface.co/models?filter=image-classification
+"""
+
+import json
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import evaluate
+import numpy as np
+import tensorflow as tf
+from datasets import load_dataset
+from PIL import Image
+
+import transformers
+from transformers import (
+ TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
+ AutoConfig,
+ AutoImageProcessor,
+ DefaultDataCollator,
+ HfArgumentParser,
+ PushToHubCallback,
+ TFAutoModelForImageClassification,
+ TFTrainingArguments,
+ create_optimizer,
+ set_seed,
+)
+from transformers.keras_callbacks import KerasMetricCallback
+from transformers.modeling_tf_utils import keras
+from transformers.trainer_utils import get_last_checkpoint, is_main_process
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+logger = logging.getLogger(__name__)
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-classification/requirements.txt")
+
+MODEL_CONFIG_CLASSES = list(TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+def pil_loader(path: str):
+ with open(path, "rb") as f:
+ im = Image.open(f)
+ return im.convert("RGB")
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ Using `HfArgumentParser` we can turn this class into argparse arguments to be able to specify
+ them on the command line.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": "Name of a dataset from the hub (could be your own, possibly private dataset hosted on the hub)."
+ },
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the training data."})
+ validation_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the validation data."})
+ train_val_split: Optional[float] = field(
+ default=0.15, metadata={"help": "Percent to split off of train for validation."}
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and (self.train_dir is None and self.validation_dir is None):
+ raise ValueError(
+ "You must specify either a dataset name from the hub or a train and/or validation directory."
+ )
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ default="google/vit-base-patch16-224-in21k",
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ image_processor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+ ignore_mismatched_sizes: bool = field(
+ default=False,
+ metadata={"help": "Will enable to load a pretrained model whose head dimensions are different."},
+ )
+
+
+def center_crop(image, size):
+ size = (size, size) if isinstance(size, int) else size
+ orig_height, orig_width, _ = image.shape
+ crop_height, crop_width = size
+ top = (orig_height - orig_width) // 2
+ left = (orig_width - crop_width) // 2
+ image = tf.image.crop_to_bounding_box(image, top, left, crop_height, crop_width)
+ return image
+
+
+# Numpy and TensorFlow compatible version of PyTorch RandomResizedCrop. Code adapted from:
+# https://pytorch.org/vision/main/_modules/torchvision/transforms/transforms.html#RandomResizedCrop
+def random_crop(image, scale=(0.08, 1.0), ratio=(3.0 / 4.0, 4.0 / 3.0)):
+ height, width, _ = image.shape
+ area = height * width
+ log_ratio = np.log(ratio)
+ for _ in range(10):
+ target_area = np.random.uniform(*scale) * area
+ aspect_ratio = np.exp(np.random.uniform(*log_ratio))
+ w = int(round(np.sqrt(target_area * aspect_ratio)))
+ h = int(round(np.sqrt(target_area / aspect_ratio)))
+ if 0 < w <= width and 0 < h <= height:
+ i = np.random.randint(0, height - h + 1)
+ j = np.random.randint(0, width - w + 1)
+ return image[i : i + h, j : j + w, :]
+
+ # Fallback to central crop
+ in_ratio = float(width) / float(height)
+ w = width if in_ratio < min(ratio) else int(round(height * max(ratio)))
+ h = height if in_ratio > max(ratio) else int(round(width / min(ratio)))
+ i = (height - h) // 2
+ j = (width - w) // 2
+ return image[i : i + h, j : j + w, :]
+
+
+def random_resized_crop(image, size, scale=(0.08, 1.0), ratio=(3.0 / 4.0, 4.0 / 3.0)):
+ size = (size, size) if isinstance(size, int) else size
+ image = random_crop(image, scale, ratio)
+ image = tf.image.resize(image, size)
+ return image
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/TensorFlow versions.
+ send_example_telemetry("run_image_classification", model_args, data_args, framework="tensorflow")
+
+ # Checkpoints. Find the checkpoint the use when loading the model.
+ checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ checkpoint = get_last_checkpoint(training_args.output_dir)
+ if checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(training_args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # region Dataset and labels
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Initialize our dataset and prepare it for the 'image-classification' task.
+ if data_args.dataset_name is not None:
+ dataset = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_dir is not None:
+ data_files["train"] = os.path.join(data_args.train_dir, "**")
+ if data_args.validation_dir is not None:
+ data_files["validation"] = os.path.join(data_args.validation_dir, "**")
+ dataset = load_dataset(
+ "imagefolder",
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Prepare label mappings.
+ # We'll include these in the model's config to get human readable labels in the Inference API.
+ labels = dataset["train"].features["labels"].names
+ label2id, id2label = {}, {}
+ for i, label in enumerate(labels):
+ label2id[label] = str(i)
+ id2label[str(i)] = label
+
+ # Load model image processor and configuration
+ config = AutoConfig.from_pretrained(
+ model_args.config_name or model_args.model_name_or_path,
+ num_labels=len(labels),
+ label2id=label2id,
+ id2label=id2label,
+ finetuning_task="image-classification",
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ image_processor = AutoImageProcessor.from_pretrained(
+ model_args.image_processor_name or model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # If we don't have a validation split, split off a percentage of train as validation.
+ data_args.train_val_split = None if "validation" in dataset.keys() else data_args.train_val_split
+ if isinstance(data_args.train_val_split, float) and data_args.train_val_split > 0.0:
+ split = dataset["train"].train_test_split(data_args.train_val_split)
+ dataset["train"] = split["train"]
+ dataset["validation"] = split["test"]
+
+ # Define our data preprocessing function. It takes an image file path as input and returns
+ # Write a note describing the resizing behaviour.
+ if "shortest_edge" in image_processor.size:
+ # We instead set the target size as (shortest_edge, shortest_edge) to here to ensure all images are batchable.
+ image_size = (image_processor.size["shortest_edge"], image_processor.size["shortest_edge"])
+ else:
+ image_size = (image_processor.size["height"], image_processor.size["width"])
+
+ def _train_transforms(image):
+ img_size = image_size
+ image = keras.utils.img_to_array(image)
+ image = random_resized_crop(image, size=img_size)
+ image = tf.image.random_flip_left_right(image)
+ image /= 255.0
+ image = (image - image_processor.image_mean) / image_processor.image_std
+ image = tf.transpose(image, perm=[2, 0, 1])
+ return image
+
+ def _val_transforms(image):
+ image = keras.utils.img_to_array(image)
+ image = tf.image.resize(image, size=image_size)
+ # image = np.array(image) # FIXME - use tf.image function
+ image = center_crop(image, size=image_size)
+ image /= 255.0
+ image = (image - image_processor.image_mean) / image_processor.image_std
+ image = tf.transpose(image, perm=[2, 0, 1])
+ return image
+
+ def train_transforms(example_batch):
+ """Apply _train_transforms across a batch."""
+ example_batch["pixel_values"] = [
+ _train_transforms(pil_img.convert("RGB")) for pil_img in example_batch["image"]
+ ]
+ return example_batch
+
+ def val_transforms(example_batch):
+ """Apply _val_transforms across a batch."""
+ example_batch["pixel_values"] = [_val_transforms(pil_img.convert("RGB")) for pil_img in example_batch["image"]]
+ return example_batch
+
+ train_dataset = None
+ if training_args.do_train:
+ if "train" not in dataset:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = dataset["train"]
+ if data_args.max_train_samples is not None:
+ train_dataset = train_dataset.shuffle(seed=training_args.seed).select(range(data_args.max_train_samples))
+ train_dataset = train_dataset.map(
+ train_transforms,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ eval_dataset = None
+ if training_args.do_eval:
+ if "validation" not in dataset:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = dataset["validation"]
+ if data_args.max_eval_samples is not None:
+ eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
+ # Set the validation transforms
+ eval_dataset = eval_dataset.map(
+ val_transforms,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ predict_dataset = None
+ if training_args.do_predict:
+ if "test" not in dataset:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_dataset = dataset["test"]
+ if data_args.max_predict_samples is not None:
+ predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
+ # Set the test transforms
+ predict_dataset = predict_dataset.map(
+ val_transforms,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ collate_fn = DefaultDataCollator(return_tensors="np")
+
+ # Load the accuracy metric from the datasets package
+ metric = evaluate.load("accuracy", cache_dir=model_args.cache_dir)
+
+ # Define our compute_metrics function. It takes an `EvalPrediction` object (a namedtuple with a
+ # predictions and label_ids field) and has to return a dictionary string to float.
+ def compute_metrics(p):
+ """Computes accuracy on a batch of predictions"""
+ logits, label_ids = p
+ predictions = np.argmax(logits, axis=-1)
+ metrics = metric.compute(predictions=predictions, references=label_ids)
+ return metrics
+
+ with training_args.strategy.scope():
+ if checkpoint is None:
+ model_path = model_args.model_name_or_path
+ else:
+ model_path = checkpoint
+
+ model = TFAutoModelForImageClassification.from_pretrained(
+ model_path,
+ config=config,
+ from_pt=bool(".bin" in model_path),
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ ignore_mismatched_sizes=model_args.ignore_mismatched_sizes,
+ )
+ num_replicas = training_args.strategy.num_replicas_in_sync
+ total_train_batch_size = training_args.per_device_train_batch_size * num_replicas
+ total_eval_batch_size = training_args.per_device_eval_batch_size * num_replicas
+
+ dataset_options = tf.data.Options()
+ dataset_options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
+
+ if training_args.do_train:
+ num_train_steps = int(len(train_dataset) * training_args.num_train_epochs)
+ if training_args.warmup_steps > 0:
+ num_warmpup_steps = int(training_args.warmup_steps)
+ elif training_args.warmup_ratio > 0:
+ num_warmpup_steps = int(training_args.warmup_ratio * num_train_steps)
+ else:
+ num_warmpup_steps = 0
+
+ optimizer, _ = create_optimizer(
+ init_lr=training_args.learning_rate,
+ num_train_steps=num_train_steps,
+ num_warmup_steps=num_warmpup_steps,
+ adam_beta1=training_args.adam_beta1,
+ adam_beta2=training_args.adam_beta2,
+ adam_epsilon=training_args.adam_epsilon,
+ weight_decay_rate=training_args.weight_decay,
+ adam_global_clipnorm=training_args.max_grad_norm,
+ )
+ # model.prepare_tf_dataset() wraps a Hugging Face dataset in a tf.data.Dataset which is ready to use in
+ # training. This is the recommended way to use a Hugging Face dataset when training with Keras. You can also
+ # use the lower-level dataset.to_tf_dataset() method, but you will have to specify things like column names
+ # yourself if you use this method, whereas they are automatically inferred from the model input names when
+ # using model.prepare_tf_dataset()
+ # For more info see the docs:
+ # https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.TFPreTrainedModel.prepare_tf_dataset
+ # https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.to_tf_dataset
+ train_dataset = model.prepare_tf_dataset(
+ train_dataset,
+ shuffle=True,
+ batch_size=total_train_batch_size,
+ collate_fn=collate_fn,
+ ).with_options(dataset_options)
+ else:
+ optimizer = "sgd" # Just write anything because we won't be using it
+
+ if training_args.do_eval:
+ eval_dataset = model.prepare_tf_dataset(
+ eval_dataset,
+ shuffle=False,
+ batch_size=total_eval_batch_size,
+ collate_fn=collate_fn,
+ ).with_options(dataset_options)
+
+ if training_args.do_predict:
+ predict_dataset = model.prepare_tf_dataset(
+ predict_dataset,
+ shuffle=False,
+ batch_size=total_eval_batch_size,
+ collate_fn=collate_fn,
+ ).with_options(dataset_options)
+
+ # Transformers models compute the right loss for their task by default when labels are passed, and will
+ # use this for training unless you specify your own loss function in compile().
+ model.compile(optimizer=optimizer, jit_compile=training_args.xla, metrics=["accuracy"])
+
+ push_to_hub_model_id = training_args.push_to_hub_model_id
+ if not push_to_hub_model_id:
+ model_name = model_args.model_name_or_path.split("/")[-1]
+ push_to_hub_model_id = f"{model_name}-finetuned-image-classification"
+
+ model_card_kwargs = {
+ "finetuned_from": model_args.model_name_or_path,
+ "tasks": "image-classification",
+ "dataset": data_args.dataset_name,
+ "tags": ["image-classification", "tensorflow", "vision"],
+ }
+
+ callbacks = []
+ if eval_dataset is not None:
+ callbacks.append(KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=eval_dataset))
+ if training_args.push_to_hub:
+ callbacks.append(
+ PushToHubCallback(
+ output_dir=training_args.output_dir,
+ hub_model_id=push_to_hub_model_id,
+ hub_token=training_args.push_to_hub_token,
+ tokenizer=image_processor,
+ **model_card_kwargs,
+ )
+ )
+
+ if training_args.do_train:
+ model.fit(
+ train_dataset,
+ validation_data=eval_dataset,
+ epochs=int(training_args.num_train_epochs),
+ callbacks=callbacks,
+ )
+
+ if training_args.do_eval:
+ n_eval_batches = len(eval_dataset)
+ eval_predictions = model.predict(eval_dataset, steps=n_eval_batches)
+ eval_labels = dataset["validation"]["labels"][: n_eval_batches * total_eval_batch_size]
+ eval_metrics = compute_metrics((eval_predictions.logits, eval_labels))
+ logging.info("Eval metrics:")
+ for metric_name, value in eval_metrics.items():
+ logging.info(f"{metric_name}: {value:.3f}")
+
+ if training_args.output_dir is not None:
+ os.makedirs(training_args.output_dir, exist_ok=True)
+ with open(os.path.join(training_args.output_dir, "all_results.json"), "w") as f:
+ f.write(json.dumps(eval_metrics))
+
+ if training_args.do_predict:
+ n_predict_batches = len(predict_dataset)
+ test_predictions = model.predict(predict_dataset, steps=n_predict_batches)
+ test_labels = dataset["validation"]["labels"][: n_predict_batches * total_eval_batch_size]
+ test_metrics = compute_metrics((test_predictions.logits, test_labels))
+ logging.info("Test metrics:")
+ for metric_name, value in test_metrics.items():
+ logging.info(f"{metric_name}: {value:.3f}")
+
+ if training_args.output_dir is not None and not training_args.push_to_hub:
+ # If we're not pushing to hub, at least save a local copy when we're done
+ model.save_pretrained(training_args.output_dir)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/tensorflow/language-modeling-tpu/README.md b/docs/transformers/examples/tensorflow/language-modeling-tpu/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..25381f86d093af9c5d525cb306468c12abdcaa8d
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/language-modeling-tpu/README.md
@@ -0,0 +1,110 @@
+# Training a masked language model end-to-end from scratch on TPUs
+
+In this example, we're going to demonstrate how to train a TensorFlow model from 🤗 Transformers from scratch. If you're interested in some background theory on training Hugging Face models with TensorFlow on TPU, please check out our
+[tutorial doc](https://huggingface.co/docs/transformers/main/perf_train_tpu_tf) on this topic!
+If you're interested in smaller-scale TPU training from a pre-trained checkpoint, you can also check out the [TPU fine-tuning example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb).
+
+This example will demonstrate pre-training language models at the 100M-1B parameter scale, similar to BERT or GPT-2. More concretely, we will show how to train a [RoBERTa](https://huggingface.co/docs/transformers/model_doc/roberta) (base model) from scratch on the [WikiText dataset (v1)](https://huggingface.co/datasets/wikitext).
+
+We've tried to ensure that all the practices we show you here are scalable, though - with relatively few changes, the code could be scaled up to much larger models.
+
+Google's gargantuan [PaLM model](https://arxiv.org/abs/2204.02311), with
+over 500B parameters, is a good example of how far you can go with pure TPU training, though gathering the dataset and the budget to train at that scale is not an easy task!
+
+### Table of contents
+
+- [Setting up a TPU-VM](#setting-up-a-tpu-vm)
+- [Training a tokenizer](#training-a-tokenizer)
+- [Preparing the dataset](#preparing-the-dataset)
+- [Training the model](#training-the-model)
+- [Inference](#inference)
+
+## Setting up a TPU-VM
+
+Since this example focuses on using TPUs, the first step is to set up access to TPU hardware. For this example, we chose to use a TPU v3-8 VM. Follow [this guide](https://cloud.google.com/tpu/docs/run-calculation-tensorflow) to quickly create a TPU VM with TensorFlow pre-installed.
+
+> 💡 **Note**: You don't need a TPU-enabled hardware for tokenizer training and TFRecord shard preparation.
+
+## Training a tokenizer
+
+To train a language model from scratch, the first step is to tokenize text. In most Hugging Face examples, we begin from a pre-trained model and use its tokenizer. However, in this example, we're going to train a tokenizer from scratch as well. The script for this is `train_unigram.py`. An example command is:
+
+```bash
+python train_unigram.py --batch_size 1000 --vocab_size 25000 --export_to_hub
+```
+
+The script will automatically load the `train` split of the WikiText dataset and train a [Unigram tokenizer](https://huggingface.co/course/chapter6/7?fw=pt) on it.
+
+> 💡 **Note**: In order for `export_to_hub` to work, you must authenticate yourself with the `huggingface-cli`. Run `huggingface-cli login` and follow the on-screen instructions.
+
+## Preparing the dataset
+
+The next step is to prepare the dataset. This consists of loading a text dataset from the Hugging Face Hub, tokenizing it and grouping it into chunks of a fixed length ready for training. The script for this is `prepare_tfrecord_shards.py`.
+
+The reason we create TFRecord output files from this step is that these files work well with [`tf.data` pipelines](https://www.tensorflow.org/guide/data_performance). This makes them very suitable for scalable TPU training - the dataset can easily be sharded and read in parallel just by tweaking a few parameters in the pipeline. An example command is:
+
+```bash
+python prepare_tfrecord_shards.py \
+ --tokenizer_name_or_path tf-tpu/unigram-tokenizer-wikitext \
+ --shard_size 5000 \
+ --split test
+ --max_length 128 \
+ --output_dir gs://tf-tpu-training-resources
+```
+
+**Notes**:
+
+* While running the above script, you need to specify the `split` accordingly. The example command above will only filter the `test` split of the dataset.
+* If you append `gs://` in your `output_dir` the TFRecord shards will be directly serialized to a Google Cloud Storage (GCS) bucket. Ensure that you have already [created the GCS bucket](https://cloud.google.com/storage/docs).
+* If you're using a TPU node, you must stream data from a GCS bucket. Otherwise, if you're using a TPU VM,you can store the data locally. You may need to [attach](https://cloud.google.com/tpu/docs/setup-persistent-disk) a persistent storage to the VM.
+* Additional CLI arguments are also supported. We encourage you to run `python prepare_tfrecord_shards.py -h` to know more about them.
+
+## Training the model
+
+Once that's done, the model is ready for training. By default, training takes place on TPU, but you can use the `--no_tpu` flag to train on CPU for testing purposes. An example command is:
+
+```bash
+python3 run_mlm.py \
+ --train_dataset gs://tf-tpu-training-resources/train/ \
+ --eval_dataset gs://tf-tpu-training-resources/validation/ \
+ --tokenizer tf-tpu/unigram-tokenizer-wikitext \
+ --output_dir trained_model
+```
+
+If you had specified a `hub_model_id` while launching training, then your model will be pushed to a model repository on the Hugging Face Hub. You can find such an example repository here:
+[tf-tpu/roberta-base-epochs-500-no-wd](https://huggingface.co/tf-tpu/roberta-base-epochs-500-no-wd).
+
+## Inference
+
+Once the model is trained, you can use 🤗 Pipelines to perform inference:
+
+```python
+from transformers import pipeline
+
+model_id = "tf-tpu/roberta-base-epochs-500-no-wd"
+unmasker = pipeline("fill-mask", model=model_id, framework="tf")
+unmasker("Goal of my life is to [MASK].")
+
+[{'score': 0.1003185287117958,
+ 'token': 52,
+ 'token_str': 'be',
+ 'sequence': 'Goal of my life is to be.'},
+ {'score': 0.032648514956235886,
+ 'token': 5,
+ 'token_str': '',
+ 'sequence': 'Goal of my life is to .'},
+ {'score': 0.02152673341333866,
+ 'token': 138,
+ 'token_str': 'work',
+ 'sequence': 'Goal of my life is to work.'},
+ {'score': 0.019547373056411743,
+ 'token': 984,
+ 'token_str': 'act',
+ 'sequence': 'Goal of my life is to act.'},
+ {'score': 0.01939118467271328,
+ 'token': 73,
+ 'token_str': 'have',
+ 'sequence': 'Goal of my life is to have.'}]
+```
+
+You can also try out inference using the [Inference Widget](https://huggingface.co/tf-tpu/roberta-base-epochs-500-no-wd?text=Goal+of+my+life+is+to+%5BMASK%5D.) from the model page.
\ No newline at end of file
diff --git a/docs/transformers/examples/tensorflow/language-modeling-tpu/prepare_tfrecord_shards.py b/docs/transformers/examples/tensorflow/language-modeling-tpu/prepare_tfrecord_shards.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa90a9db5271a4fc32481477cf58907f3981c6f1
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/language-modeling-tpu/prepare_tfrecord_shards.py
@@ -0,0 +1,191 @@
+#!/usr/bin/env python
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Script for preparing TFRecord shards for pre-tokenized examples."""
+
+import argparse
+import logging
+import os
+
+import datasets
+import tensorflow as tf
+
+from transformers import AutoTokenizer
+
+
+logger = logging.getLogger(__name__)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description="Prepare TFRecord shards from pre-tokenized samples of the wikitext dataset."
+ )
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default="wikitext",
+ help="Name of the training. Explore datasets at: hf.co/datasets.",
+ )
+ parser.add_argument(
+ "--dataset_config", type=str, default="wikitext-103-raw-v1", help="Configuration name of the dataset."
+ )
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--tokenizer_name_or_path",
+ type=str,
+ default="sayakpaul/unigram-tokenizer-wikitext",
+ help="Tokenizer identifier. Can be a local filepath or a Hub identifier.",
+ )
+ parser.add_argument(
+ "--shard_size",
+ type=int,
+ default=1000,
+ help="Number of entries to go in a single shard.",
+ )
+ parser.add_argument("--split", type=str, default="train", choices=["train", "test", "validation"])
+ parser.add_argument(
+ "--limit",
+ default=None,
+ type=int,
+ help="Limit the number of shards (used for debugging).",
+ )
+ parser.add_argument(
+ "--max_length",
+ type=int,
+ default=512,
+ help="Maximum sequence length. For training on TPUs, it helps to have a maximum"
+ " sequence length that is a multiple of 8.",
+ )
+ parser.add_argument(
+ "--output_dir",
+ default="tf-tpu",
+ type=str,
+ help="Output directory where the TFRecord shards will be saved. If the"
+ " path is appended with `gs://` ('gs://tf-tpu', for example) then the TFRecord"
+ " shards will be directly saved to a Google Cloud Storage bucket.",
+ )
+
+ args = parser.parse_args()
+ return args
+
+
+def tokenize_function(tokenizer):
+ def fn(examples):
+ return tokenizer(examples["text"])
+
+ return fn
+
+
+def get_serialized_examples(tokenized_data):
+ records = []
+ for i in range(len(tokenized_data["input_ids"])):
+ features = {
+ "input_ids": tf.train.Feature(int64_list=tf.train.Int64List(value=tokenized_data["input_ids"][i])),
+ "attention_mask": tf.train.Feature(
+ int64_list=tf.train.Int64List(value=tokenized_data["attention_mask"][i])
+ ),
+ }
+ features = tf.train.Features(feature=features)
+ example = tf.train.Example(features=features)
+ record_bytes = example.SerializeToString()
+ records.append(record_bytes)
+ return records
+
+
+def main(args):
+ dataset = datasets.load_dataset(
+ args.dataset_name, args.dataset_config, split=args.split, trust_remote_code=args.trust_remote_code
+ )
+
+ if args.limit is not None:
+ max_samples = min(len(dataset), args.limit)
+ dataset = dataset.select(range(max_samples))
+ print(f"Limiting the dataset to {args.limit} entries.")
+
+ tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name_or_path)
+
+ # Handle output directory creation.
+ # For serializing into a Google Cloud Storage Bucket, one needs to first
+ # create a bucket.
+ if "gs" not in args.output_dir:
+ if not os.path.exists(args.output_dir):
+ os.makedirs(args.output_dir)
+ split_dir = os.path.join(args.output_dir, args.split)
+ if not os.path.exists(split_dir):
+ os.makedirs(split_dir)
+ else:
+ split_dir = os.path.join(args.output_dir, args.split)
+
+ # Tokenize the whole dataset at once.
+ tokenize_fn = tokenize_function(tokenizer)
+ dataset_tokenized = dataset.map(tokenize_fn, batched=True, num_proc=4, remove_columns=["text"])
+
+ # We need to concatenate all our texts together, and then split the result
+ # into chunks of a fixed size, which we will call block_size. To do this, we
+ # will use the map method again, with the option batched=True. When we use batched=True,
+ # the function we pass to map() will be passed multiple inputs at once, allowing us
+ # to group them into more or fewer examples than we had in the input.
+ # This allows us to create our new fixed-length samples. The advantage of this
+ # method is that we don't lose a whole lot of content from the dataset compared to the
+ # case where we simply tokenize with a pre-defined max_length.
+
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, though you could add padding instead if the model supports it
+ # In this, as in all things, we advise you to follow your heart 🫀
+ total_length = (total_length // args.max_length) * args.max_length
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + args.max_length] for i in range(0, total_length, args.max_length)]
+ for k, t in concatenated_examples.items()
+ }
+ return result
+
+ grouped_dataset = dataset_tokenized.map(group_texts, batched=True, batch_size=1000, num_proc=4)
+
+ shard_count = 0
+ total_records = 0
+ for shard in range(0, len(grouped_dataset), args.shard_size):
+ dataset_snapshot = grouped_dataset[shard : shard + args.shard_size]
+ records_containing = len(dataset_snapshot["input_ids"])
+ filename = os.path.join(split_dir, f"dataset-{shard_count}-{records_containing}.tfrecord")
+ serialized_examples = get_serialized_examples(dataset_snapshot)
+
+ with tf.io.TFRecordWriter(filename) as out_file:
+ for i in range(len(serialized_examples)):
+ example = serialized_examples[i]
+ out_file.write(example)
+ print(f"Wrote file {filename} containing {records_containing} records")
+
+ shard_count += 1
+ total_records += records_containing
+
+ with open(f"split-{args.split}-records-count.txt", "w") as f:
+ print(f"Total {args.split} records: {total_records}", file=f)
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ main(args)
diff --git a/docs/transformers/examples/tensorflow/language-modeling-tpu/requirements.txt b/docs/transformers/examples/tensorflow/language-modeling-tpu/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f28a4c8dd18683b0a39f2dc086179c6385d55648
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/language-modeling-tpu/requirements.txt
@@ -0,0 +1,3 @@
+transformers==4.48.0
+datasets==2.9.0
+tokenizers==0.13.2
diff --git a/docs/transformers/examples/tensorflow/language-modeling-tpu/run_mlm.py b/docs/transformers/examples/tensorflow/language-modeling-tpu/run_mlm.py
new file mode 100644
index 0000000000000000000000000000000000000000..7b4155f26ed1c397e63aba0952c14bf2225ee5e4
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/language-modeling-tpu/run_mlm.py
@@ -0,0 +1,322 @@
+#!/usr/bin/env python
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Script for training a masked language model on TPU."""
+
+import argparse
+import logging
+import os
+import re
+
+import tensorflow as tf
+from packaging.version import parse
+
+from transformers import (
+ AutoConfig,
+ AutoTokenizer,
+ DataCollatorForLanguageModeling,
+ PushToHubCallback,
+ TFAutoModelForMaskedLM,
+ create_optimizer,
+)
+
+
+try:
+ import tf_keras as keras
+except (ModuleNotFoundError, ImportError):
+ import keras
+
+ if parse(keras.__version__).major > 2:
+ raise ValueError(
+ "Your currently installed version of Keras is Keras 3, but this is not yet supported in "
+ "Transformers. Please install the backwards-compatible tf-keras package with "
+ "`pip install tf-keras`."
+ )
+
+
+logger = logging.getLogger(__name__)
+
+AUTO = tf.data.AUTOTUNE
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Train a masked language model on TPU.")
+ parser.add_argument(
+ "--pretrained_model_config",
+ type=str,
+ default="FacebookAI/roberta-base",
+ help="The model config to use. Note that we don't copy the model's weights, only the config!",
+ )
+ parser.add_argument(
+ "--tokenizer",
+ type=str,
+ default="unigram-tokenizer-wikitext",
+ help="The name of the tokenizer to load. We use the pretrained tokenizer to initialize the model's vocab size.",
+ )
+
+ parser.add_argument(
+ "--per_replica_batch_size",
+ type=int,
+ default=8,
+ help="Batch size per TPU core.",
+ )
+
+ parser.add_argument(
+ "--no_tpu",
+ action="store_true",
+ help="If set, run on CPU and don't try to initialize a TPU. Useful for debugging on non-TPU instances.",
+ )
+
+ parser.add_argument(
+ "--tpu_name",
+ type=str,
+ help="Name of TPU resource to initialize. Should be blank on Colab, and 'local' on TPU VMs.",
+ default="local",
+ )
+
+ parser.add_argument(
+ "--tpu_zone",
+ type=str,
+ help="Google cloud zone that TPU resource is located in. Only used for non-Colab TPU nodes.",
+ )
+
+ parser.add_argument(
+ "--gcp_project", type=str, help="Google cloud project name. Only used for non-Colab TPU nodes."
+ )
+
+ parser.add_argument(
+ "--bfloat16",
+ action="store_true",
+ help="Use mixed-precision bfloat16 for training. This is the recommended lower-precision format for TPU.",
+ )
+
+ parser.add_argument(
+ "--train_dataset",
+ type=str,
+ help="Path to training dataset to load. If the path begins with `gs://`"
+ " then the dataset will be loaded from a Google Cloud Storage bucket.",
+ )
+
+ parser.add_argument(
+ "--shuffle_buffer_size",
+ type=int,
+ default=2**18, # Default corresponds to a 1GB buffer for seq_len 512
+ help="Size of the shuffle buffer (in samples)",
+ )
+
+ parser.add_argument(
+ "--eval_dataset",
+ type=str,
+ help="Path to evaluation dataset to load. If the path begins with `gs://`"
+ " then the dataset will be loaded from a Google Cloud Storage bucket.",
+ )
+
+ parser.add_argument(
+ "--num_epochs",
+ type=int,
+ default=1,
+ help="Number of epochs to train for.",
+ )
+
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=1e-4,
+ help="Learning rate to use for training.",
+ )
+
+ parser.add_argument(
+ "--weight_decay_rate",
+ type=float,
+ default=1e-3,
+ help="Weight decay rate to use for training.",
+ )
+
+ parser.add_argument(
+ "--max_length",
+ type=int,
+ default=512,
+ help="Maximum length of tokenized sequences. Should match the setting used in prepare_tfrecord_shards.py",
+ )
+
+ parser.add_argument(
+ "--mlm_probability",
+ type=float,
+ default=0.15,
+ help="Fraction of tokens to mask during training.",
+ )
+
+ parser.add_argument("--output_dir", type=str, required=True, help="Path to save model checkpoints to.")
+ parser.add_argument("--hub_model_id", type=str, help="Model ID to upload to on the Hugging Face Hub.")
+
+ args = parser.parse_args()
+ return args
+
+
+def initialize_tpu(args):
+ try:
+ if args.tpu_name:
+ tpu = tf.distribute.cluster_resolver.TPUClusterResolver(
+ args.tpu_name, zone=args.tpu_zone, project=args.gcp_project
+ )
+ else:
+ tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
+ except ValueError:
+ raise RuntimeError(
+ "Couldn't connect to TPU! Most likely you need to specify --tpu_name, --tpu_zone, or "
+ "--gcp_project. When running on a TPU VM, use --tpu_name local."
+ )
+
+ tf.config.experimental_connect_to_cluster(tpu)
+ tf.tpu.experimental.initialize_tpu_system(tpu)
+
+ return tpu
+
+
+def count_samples(file_list):
+ num_samples = 0
+ for file in file_list:
+ filename = file.split("/")[-1]
+ sample_count = re.search(r"-\d+-(\d+)\.tfrecord", filename).group(1)
+ sample_count = int(sample_count)
+ num_samples += sample_count
+
+ return num_samples
+
+
+def prepare_dataset(records, decode_fn, mask_fn, batch_size, shuffle, shuffle_buffer_size=None):
+ num_samples = count_samples(records)
+ dataset = tf.data.Dataset.from_tensor_slices(records)
+ if shuffle:
+ dataset = dataset.shuffle(len(dataset))
+ dataset = tf.data.TFRecordDataset(dataset, num_parallel_reads=AUTO)
+ # TF can't infer the total sample count because it doesn't read all the records yet, so we assert it here
+ dataset = dataset.apply(tf.data.experimental.assert_cardinality(num_samples))
+ dataset = dataset.map(decode_fn, num_parallel_calls=AUTO)
+ if shuffle:
+ assert shuffle_buffer_size is not None
+ dataset = dataset.shuffle(args.shuffle_buffer_size)
+ dataset = dataset.batch(batch_size, drop_remainder=True)
+ dataset = dataset.map(mask_fn, num_parallel_calls=AUTO)
+ dataset = dataset.prefetch(AUTO)
+ return dataset
+
+
+def main(args):
+ if not args.no_tpu:
+ tpu = initialize_tpu(args)
+ strategy = tf.distribute.TPUStrategy(tpu)
+ else:
+ strategy = tf.distribute.OneDeviceStrategy(device="/gpu:0")
+
+ if args.bfloat16:
+ keras.mixed_precision.set_global_policy("mixed_bfloat16")
+
+ tokenizer = AutoTokenizer.from_pretrained(args.tokenizer)
+ config = AutoConfig.from_pretrained(args.pretrained_model_config)
+ config.vocab_size = tokenizer.vocab_size
+
+ training_records = tf.io.gfile.glob(os.path.join(args.train_dataset, "*.tfrecord"))
+ if not training_records:
+ raise ValueError(f"No .tfrecord files found in {args.train_dataset}.")
+ eval_records = tf.io.gfile.glob(os.path.join(args.eval_dataset, "*.tfrecord"))
+ if not eval_records:
+ raise ValueError(f"No .tfrecord files found in {args.eval_dataset}.")
+
+ num_train_samples = count_samples(training_records)
+
+ steps_per_epoch = num_train_samples // (args.per_replica_batch_size * strategy.num_replicas_in_sync)
+ total_train_steps = steps_per_epoch * args.num_epochs
+
+ with strategy.scope():
+ model = TFAutoModelForMaskedLM.from_config(config)
+ model(model.dummy_inputs) # Pass some dummy inputs through the model to ensure all the weights are built
+ optimizer, schedule = create_optimizer(
+ num_train_steps=total_train_steps,
+ num_warmup_steps=total_train_steps // 20,
+ init_lr=args.learning_rate,
+ weight_decay_rate=args.weight_decay_rate,
+ )
+
+ # Transformers models compute the right loss for their task by default when labels are passed, and will
+ # use this for training unless you specify your own loss function in compile().
+ model.compile(optimizer=optimizer, metrics=["accuracy"])
+
+ def decode_fn(example):
+ features = {
+ "input_ids": tf.io.FixedLenFeature(dtype=tf.int64, shape=(args.max_length,)),
+ "attention_mask": tf.io.FixedLenFeature(dtype=tf.int64, shape=(args.max_length,)),
+ }
+ return tf.io.parse_single_example(example, features)
+
+ # Many of the data collators in Transformers are TF-compilable when return_tensors == "tf", so we can
+ # use their methods in our data pipeline.
+ data_collator = DataCollatorForLanguageModeling(
+ tokenizer=tokenizer, mlm_probability=args.mlm_probability, mlm=True, return_tensors="tf"
+ )
+
+ def mask_with_collator(batch):
+ # TF really needs an isin() function
+ special_tokens_mask = (
+ ~tf.cast(batch["attention_mask"], tf.bool)
+ | (batch["input_ids"] == tokenizer.cls_token_id)
+ | (batch["input_ids"] == tokenizer.sep_token_id)
+ )
+ batch["input_ids"], batch["labels"] = data_collator.tf_mask_tokens(
+ batch["input_ids"],
+ vocab_size=len(tokenizer),
+ mask_token_id=tokenizer.mask_token_id,
+ special_tokens_mask=special_tokens_mask,
+ )
+ return batch
+
+ batch_size = args.per_replica_batch_size * strategy.num_replicas_in_sync
+
+ train_dataset = prepare_dataset(
+ training_records,
+ decode_fn=decode_fn,
+ mask_fn=mask_with_collator,
+ batch_size=batch_size,
+ shuffle=True,
+ shuffle_buffer_size=args.shuffle_buffer_size,
+ )
+
+ eval_dataset = prepare_dataset(
+ eval_records,
+ decode_fn=decode_fn,
+ mask_fn=mask_with_collator,
+ batch_size=batch_size,
+ shuffle=False,
+ )
+
+ callbacks = []
+ if args.hub_model_id:
+ callbacks.append(
+ PushToHubCallback(output_dir=args.output_dir, hub_model_id=args.hub_model_id, tokenizer=tokenizer)
+ )
+
+ model.fit(
+ train_dataset,
+ validation_data=eval_dataset,
+ epochs=args.num_epochs,
+ callbacks=callbacks,
+ )
+
+ model.save_pretrained(args.output_dir)
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ main(args)
diff --git a/docs/transformers/examples/tensorflow/language-modeling-tpu/train_unigram.py b/docs/transformers/examples/tensorflow/language-modeling-tpu/train_unigram.py
new file mode 100644
index 0000000000000000000000000000000000000000..9eb9c8427b0f6d4d0e68171dc31ee112073a306a
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/language-modeling-tpu/train_unigram.py
@@ -0,0 +1,129 @@
+#!/usr/bin/env python
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Script for training a Unigram tokenizer."""
+
+import argparse
+import logging
+
+import datasets
+from tokenizers import Tokenizer, decoders, normalizers, pre_tokenizers, processors
+from tokenizers.models import Unigram
+from tokenizers.trainers import UnigramTrainer
+
+from transformers import AlbertTokenizerFast
+
+
+logger = logging.getLogger(__name__)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Train a unigram tokenizer on the wikitext dataset.")
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default="wikitext",
+ help="Name of the training. Explore datasets at: hf.co/datasets.",
+ )
+ parser.add_argument(
+ "--dataset_config", type=str, default="wikitext-103-raw-v1", help="Configuration name of the dataset."
+ )
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--batch_size",
+ type=int,
+ default=1000,
+ help="Batch size during training.",
+ )
+ parser.add_argument(
+ "--vocab_size",
+ type=int,
+ default=10048,
+ help="Size of the desired vocabulary.",
+ )
+ parser.add_argument(
+ "--limit",
+ default=None,
+ type=int,
+ help="Limit the number of shards (used for debugging).",
+ )
+ parser.add_argument(
+ "--export_to_hub",
+ action="store_true",
+ )
+
+ args = parser.parse_args()
+ return args
+
+
+def main(args):
+ dataset = datasets.load_dataset(
+ args.dataset_name, args.dataset_config, split="train", trust_remote_code=args.trust_remote_code
+ )
+
+ if args.limit is not None:
+ max_train_samples = min(len(dataset), args.limit)
+ dataset = dataset.select(range(max_train_samples))
+ logger.info(f"Limiting the dataset to {args.limit} entries.")
+
+ def batch_iterator():
+ for i in range(0, len(dataset), args.batch_size):
+ yield dataset[i : i + args.batch_size]["text"]
+
+ # Prepare the tokenizer.
+ tokenizer = Tokenizer(Unigram())
+ tokenizer.normalizer = normalizers.Sequence([normalizers.Replace("``", '"'), normalizers.Replace("''", '"')])
+ tokenizer.pre_tokenizer = pre_tokenizers.Metaspace()
+
+ # Prepare the trainer.
+ trainer = UnigramTrainer(
+ unk_token="",
+ special_tokens=["[CLS]", "[SEP]", "", "", "[MASK]"],
+ vocab_size=args.vocab_size,
+ )
+
+ logger.info("Training the tokenizer.")
+ tokenizer.train_from_iterator(batch_iterator(), trainer=trainer)
+ logger.info("Tokenizer training complete!")
+
+ cls_token_id = tokenizer.token_to_id("[CLS]")
+ sep_token_id = tokenizer.token_to_id("[SEP]")
+ tokenizer.post_processor = processors.TemplateProcessing(
+ single="[CLS]:0 $A:0 [SEP]:0",
+ pair="[CLS]:0 $A:0 [SEP]:0 $B:1 [SEP]:1",
+ special_tokens=[
+ ("[CLS]", cls_token_id),
+ ("[SEP]", sep_token_id),
+ ],
+ )
+ tokenizer.decoder = decoders.Metaspace()
+
+ if args.export_to_hub:
+ logger.info("Exporting the trained tokenizer to Hub.")
+ new_tokenizer = AlbertTokenizerFast(tokenizer_object=tokenizer)
+ new_tokenizer.push_to_hub("unigram-tokenizer-dataset")
+
+
+if __name__ == "__main__":
+ args = parse_args()
+ main(args)
diff --git a/docs/transformers/examples/tensorflow/language-modeling/README.md b/docs/transformers/examples/tensorflow/language-modeling/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..ed4f507d4e82ce15ddf0651c7ed51ba333fe209d
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/language-modeling/README.md
@@ -0,0 +1,80 @@
+
+
+# Language modelling examples
+
+This folder contains some scripts showing examples of *language model pre-training* with the 🤗 Transformers library.
+For straightforward use-cases you may be able to use these scripts without modification, although we have also
+included comments in the code to indicate areas that you may need to adapt to your own projects. The two scripts
+have almost identical arguments, but they differ in the type of LM they train - a causal language model (like GPT) or a
+masked language model (like BERT). Masked language models generally train more quickly and perform better when
+fine-tuned on new tasks with a task-specific output head, like text classification. However, their ability to generate
+text is weaker than causal language models.
+
+## Pre-training versus fine-tuning
+
+These scripts can be used to both *pre-train* a language model completely from scratch, as well as to *fine-tune*
+a language model on text from your domain of interest. To start with an existing pre-trained language model you
+can use the `--model_name_or_path` argument, or to train from scratch you can use the `--model_type` argument
+to indicate the class of model architecture to initialize.
+
+### Multi-GPU and TPU usage
+
+By default, these scripts use a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
+can also be used by passing the name of the TPU resource with the `--tpu` argument.
+
+## run_mlm.py
+
+This script trains a masked language model.
+
+### Example command
+```bash
+python run_mlm.py \
+--model_name_or_path distilbert/distilbert-base-cased \
+--output_dir output \
+--dataset_name wikitext \
+--dataset_config_name wikitext-103-raw-v1
+```
+
+When using a custom dataset, the validation file can be separately passed as an input argument. Otherwise some split (customizable) of training data is used as validation.
+```bash
+python run_mlm.py \
+--model_name_or_path distilbert/distilbert-base-cased \
+--output_dir output \
+--train_file train_file_path
+```
+
+## run_clm.py
+
+This script trains a causal language model.
+
+### Example command
+```bash
+python run_clm.py \
+--model_name_or_path distilbert/distilgpt2 \
+--output_dir output \
+--dataset_name wikitext \
+--dataset_config_name wikitext-103-raw-v1
+```
+
+When using a custom dataset, the validation file can be separately passed as an input argument. Otherwise some split (customizable) of training data is used as validation.
+
+```bash
+python run_clm.py \
+--model_name_or_path distilbert/distilgpt2 \
+--output_dir output \
+--train_file train_file_path
+```
diff --git a/docs/transformers/examples/tensorflow/language-modeling/requirements.txt b/docs/transformers/examples/tensorflow/language-modeling/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..c4ae4890d2e2c8591a914a80a986db83ab3cbe03
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/language-modeling/requirements.txt
@@ -0,0 +1,2 @@
+datasets >= 1.8.0
+sentencepiece != 0.1.92
\ No newline at end of file
diff --git a/docs/transformers/examples/tensorflow/language-modeling/run_clm.py b/docs/transformers/examples/tensorflow/language-modeling/run_clm.py
new file mode 100644
index 0000000000000000000000000000000000000000..d43530669b97677f8106ddf663cc3f115150ff6a
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/language-modeling/run_clm.py
@@ -0,0 +1,657 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for causal language modeling (GPT-2, GPT-Neo...)
+on a text file or a dataset without using HuggingFace Trainer.
+
+Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
+https://huggingface.co/models?filter=text-generation
+"""
+# You can also adapt this script on your own clm task. Pointers for this are left as comments.
+
+import json
+
+# region Imports
+import logging
+import math
+import os
+import random
+import sys
+from dataclasses import dataclass, field
+from itertools import chain
+from pathlib import Path
+from typing import Optional
+
+import datasets
+import tensorflow as tf
+from datasets import load_dataset
+from sklearn.model_selection import train_test_split
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ CONFIG_NAME,
+ TF2_WEIGHTS_NAME,
+ TF_MODEL_FOR_CAUSAL_LM_MAPPING,
+ AutoConfig,
+ AutoTokenizer,
+ HfArgumentParser,
+ PushToHubCallback,
+ TFAutoModelForCausalLM,
+ TFTrainingArguments,
+ create_optimizer,
+ set_seed,
+)
+from transformers.utils import send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+logger = logging.getLogger(__name__)
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/tensorflow/language-modeling/requirements.txt")
+MODEL_CONFIG_CLASSES = list(TF_MODEL_FOR_CAUSAL_LM_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+# endregion
+
+
+# region Command-line arguments
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_overrides: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Override some existing default config settings when a model is trained from scratch. Example: "
+ "n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
+ )
+ },
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if self.config_overrides is not None and (self.config_name is not None or self.model_name_or_path is not None):
+ raise ValueError(
+ "--config_overrides can't be used in combination with --config_name or --model_name_or_path"
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ validation_split_percentage: Optional[int] = field(
+ default=5,
+ metadata={
+ "help": "The percentage of the train set used as validation set in case there's no validation split"
+ },
+ )
+ block_size: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Optional input sequence length after tokenization. "
+ "The training dataset will be truncated in block of this size for training. "
+ "Default to the model max input length for single sentence inputs (take into account special tokens)."
+ )
+ },
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ line_by_line: bool = field(
+ default=False,
+ metadata={"help": "Whether distinct lines of text in the dataset are to be handled as distinct sequences."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ keep_linebreaks: bool = field(
+ default=True, metadata={"help": "Whether to keep line breaks when using TXT files or not."}
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
+
+
+# endregion
+
+
+def main():
+ # region Argument Parsing
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_clm", model_args, data_args, framework="tensorflow")
+
+ # Sanity checks
+ if data_args.dataset_name is None and data_args.train_file is None and data_args.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if data_args.train_file is not None:
+ extension = data_args.train_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, json or txt file."
+ if data_args.validation_file is not None:
+ extension = data_args.validation_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, json or txt file."
+
+ if training_args.output_dir is not None:
+ training_args.output_dir = Path(training_args.output_dir)
+ os.makedirs(training_args.output_dir, exist_ok=True)
+ # endregion
+
+ # region Checkpoints
+ # Detecting last checkpoint.
+ checkpoint = None
+ if len(os.listdir(training_args.output_dir)) > 0 and not training_args.overwrite_output_dir:
+ config_path = training_args.output_dir / CONFIG_NAME
+ weights_path = training_args.output_dir / TF2_WEIGHTS_NAME
+ if config_path.is_file() and weights_path.is_file():
+ checkpoint = training_args.output_dir
+ logger.info(
+ f"Checkpoint detected, resuming training from checkpoint in {training_args.output_dir}. To avoid this"
+ " behavior, change the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+ else:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to continue regardless."
+ )
+
+ # endregion
+
+ # region Setup logging
+ # accelerator.is_local_main_process is only True for one process per machine.
+ logger.setLevel(logging.INFO)
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ # endregion
+
+ # If passed along, set the training seed now.
+ if training_args.seed is not None:
+ set_seed(training_args.seed)
+
+ # region Load datasets
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ raw_datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ dataset_args = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = (
+ data_args.train_file.split(".")[-1]
+ if data_args.train_file is not None
+ else data_args.validation_file.split(".")[-1]
+ )
+ if extension == "txt":
+ extension = "text"
+ dataset_args["keep_linebreaks"] = data_args.keep_linebreaks
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ **dataset_args,
+ )
+ # If no validation data is there, validation_split_percentage will be used to divide the dataset.
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ **dataset_args,
+ )
+ raw_datasets["train"] = load_dataset(
+ extension,
+ data_files=data_files,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ **dataset_args,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+ # endregion
+
+ # region Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ if model_args.config_name:
+ config = AutoConfig.from_pretrained(
+ model_args.config_name,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(
+ model_args.model_name_or_path, token=model_args.token, trust_remote_code=model_args.trust_remote_code
+ )
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name, token=model_args.token, trust_remote_code=model_args.trust_remote_code
+ )
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.model_name_or_path, token=model_args.token, trust_remote_code=model_args.trust_remote_code
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+ # endregion
+
+ # region Dataset preprocessing
+ # First we tokenize all the texts.
+ column_names = raw_datasets["train"].column_names
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ def tokenize_function(examples):
+ return tokenizer(examples[text_column_name])
+
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on dataset",
+ )
+
+ if data_args.block_size is None:
+ block_size = tokenizer.model_max_length
+ if block_size > config.max_position_embeddings:
+ logger.warning(
+ f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). "
+ f"Using block_size={min(1024, config.max_position_embeddings)} instead. You can change that default value by passing --block_size xxx."
+ )
+ block_size = min(1024, config.max_position_embeddings)
+ else:
+ if data_args.block_size > tokenizer.model_max_length:
+ logger.warning(
+ f"The block_size passed ({data_args.block_size}) is larger than the maximum length for the model "
+ f"({tokenizer.model_max_length}). Using block_size={tokenizer.model_max_length}."
+ )
+ block_size = min(data_args.block_size, tokenizer.model_max_length)
+
+ # Main data processing function that will concatenate all texts from our dataset and generate chunks of block_size.
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
+ # customize this part to your needs.
+ if total_length >= block_size:
+ total_length = (total_length // block_size) * block_size
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
+ for k, t in concatenated_examples.items()
+ }
+ result["labels"] = result["input_ids"].copy()
+ return result
+
+ # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a remainder
+ # for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value might be slower
+ # to preprocess.
+ #
+ # To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
+ # https://huggingface.co/docs/datasets/process#map
+
+ lm_datasets = tokenized_datasets.map(
+ group_texts,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc=f"Grouping texts in chunks of {block_size}",
+ )
+
+ train_dataset = lm_datasets["train"]
+ if data_args.validation_file is not None:
+ eval_dataset = lm_datasets["validation"]
+ else:
+ logger.info(
+ f"Validation file not found: using {data_args.validation_split_percentage}% of the dataset as validation"
+ " as provided in data_args"
+ )
+ train_indices, val_indices = train_test_split(
+ list(range(len(train_dataset))), test_size=data_args.validation_split_percentage / 100
+ )
+
+ eval_dataset = train_dataset.select(val_indices)
+ train_dataset = train_dataset.select(train_indices)
+
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), min(3, len(train_dataset))):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+ # endregion
+
+ with training_args.strategy.scope():
+ # region Prepare model
+ if checkpoint is not None:
+ model = TFAutoModelForCausalLM.from_pretrained(
+ checkpoint, config=config, token=model_args.token, trust_remote_code=model_args.trust_remote_code
+ )
+ elif model_args.model_name_or_path:
+ model = TFAutoModelForCausalLM.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = TFAutoModelForCausalLM.from_config(
+ config, token=model_args.token, trust_remote_code=model_args.trust_remote_code
+ )
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embeddings = model.get_input_embeddings()
+
+ # Matt: This is a temporary workaround as we transition our models to exclusively using Keras embeddings.
+ # As soon as the transition is complete, all embeddings should be keras.Embeddings layers, and
+ # the weights will always be in embeddings.embeddings.
+ if hasattr(embeddings, "embeddings"):
+ embedding_size = embeddings.embeddings.shape[0]
+ else:
+ embedding_size = embeddings.weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+ # endregion
+
+ # region TF Dataset preparation
+ num_replicas = training_args.strategy.num_replicas_in_sync
+ options = tf.data.Options()
+ options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
+
+ # model.prepare_tf_dataset() wraps a Hugging Face dataset in a tf.data.Dataset which is ready to use in
+ # training. This is the recommended way to use a Hugging Face dataset when training with Keras. You can also
+ # use the lower-level dataset.to_tf_dataset() method, but you will have to specify things like column names
+ # yourself if you use this method, whereas they are automatically inferred from the model input names when
+ # using model.prepare_tf_dataset()
+ # For more info see the docs:
+ # https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.TFPreTrainedModel.prepare_tf_dataset
+ # https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.to_tf_dataset
+
+ tf_train_dataset = model.prepare_tf_dataset(
+ train_dataset,
+ shuffle=True,
+ batch_size=num_replicas * training_args.per_device_train_batch_size,
+ ).with_options(options)
+
+ tf_eval_dataset = model.prepare_tf_dataset(
+ eval_dataset,
+ shuffle=False,
+ batch_size=num_replicas * training_args.per_device_eval_batch_size,
+ drop_remainder=True,
+ ).with_options(options)
+ # endregion
+
+ # region Optimizer and loss
+ num_train_steps = len(tf_train_dataset) * int(training_args.num_train_epochs)
+ if training_args.warmup_steps > 0:
+ num_warmup_steps = training_args.warmup_steps
+ elif training_args.warmup_ratio > 0:
+ num_warmup_steps = int(num_train_steps * training_args.warmup_ratio)
+ else:
+ num_warmup_steps = 0
+
+ # Bias and layernorm weights are automatically excluded from the decay
+ optimizer, lr_schedule = create_optimizer(
+ init_lr=training_args.learning_rate,
+ num_train_steps=num_train_steps,
+ num_warmup_steps=num_warmup_steps,
+ adam_beta1=training_args.adam_beta1,
+ adam_beta2=training_args.adam_beta2,
+ adam_epsilon=training_args.adam_epsilon,
+ weight_decay_rate=training_args.weight_decay,
+ adam_global_clipnorm=training_args.max_grad_norm,
+ )
+
+ # Transformers models compute the right loss for their task by default when labels are passed, and will
+ # use this for training unless you specify your own loss function in compile().
+ model.compile(optimizer=optimizer, jit_compile=training_args.xla)
+ # endregion
+
+ # region Preparing push_to_hub and model card
+ push_to_hub_model_id = training_args.push_to_hub_model_id
+ model_name = model_args.model_name_or_path.split("/")[-1]
+ if not push_to_hub_model_id:
+ if data_args.dataset_name is not None:
+ push_to_hub_model_id = f"{model_name}-finetuned-{data_args.dataset_name}"
+ else:
+ push_to_hub_model_id = f"{model_name}-finetuned-clm"
+
+ model_card_kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "text-generation"}
+ if data_args.dataset_name is not None:
+ model_card_kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ model_card_kwargs["dataset_args"] = data_args.dataset_config_name
+ model_card_kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ model_card_kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ callbacks = [
+ PushToHubCallback(
+ output_dir=training_args.output_dir,
+ hub_model_id=push_to_hub_model_id,
+ hub_token=training_args.push_to_hub_token,
+ tokenizer=tokenizer,
+ **model_card_kwargs,
+ )
+ ]
+ else:
+ callbacks = []
+ # endregion
+
+ # region Training and validation
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {training_args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {training_args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size = {training_args.per_device_train_batch_size * num_replicas}")
+
+ # For long training runs, you may wish to use the PushToHub() callback here to save intermediate checkpoints
+ # to the Hugging Face Hub rather than just pushing the finished model.
+ # See https://huggingface.co/docs/transformers/main_classes/keras_callbacks#transformers.PushToHubCallback
+
+ history = model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ epochs=int(training_args.num_train_epochs),
+ callbacks=callbacks,
+ )
+ train_loss = history.history["loss"][-1]
+ try:
+ train_perplexity = math.exp(train_loss)
+ except OverflowError:
+ train_perplexity = math.inf
+ logger.info(f" Final train loss: {train_loss:.3f}")
+ logger.info(f" Final train perplexity: {train_perplexity:.3f}")
+ validation_loss = history.history["val_loss"][-1]
+ try:
+ validation_perplexity = math.exp(validation_loss)
+ except OverflowError:
+ validation_perplexity = math.inf
+ logger.info(f" Final validation loss: {validation_loss:.3f}")
+ logger.info(f" Final validation perplexity: {validation_perplexity:.3f}")
+
+ if training_args.output_dir is not None:
+ output_eval_file = os.path.join(training_args.output_dir, "all_results.json")
+ results_dict = {}
+ results_dict["train_loss"] = train_loss
+ results_dict["train_perplexity"] = train_perplexity
+ results_dict["eval_loss"] = validation_loss
+ results_dict["eval_perplexity"] = validation_perplexity
+ with open(output_eval_file, "w") as writer:
+ writer.write(json.dumps(results_dict))
+ # endregion
+
+ if training_args.output_dir is not None and not training_args.push_to_hub:
+ # If we're not pushing to hub, at least save a local copy when we're done
+ model.save_pretrained(training_args.output_dir)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/tensorflow/language-modeling/run_mlm.py b/docs/transformers/examples/tensorflow/language-modeling/run_mlm.py
new file mode 100644
index 0000000000000000000000000000000000000000..edae71252d5ea8ad07dcbee45e52f18e2ae57c63
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/language-modeling/run_mlm.py
@@ -0,0 +1,681 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for masked language modeling (BERT, ALBERT, RoBERTa...)
+on a text file or a dataset without using HuggingFace Trainer.
+
+Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
+https://huggingface.co/models?filter=fill-mask
+"""
+# You can also adapt this script on your own mlm task. Pointers for this are left as comments.
+
+import json
+import logging
+import math
+import os
+import random
+import sys
+from dataclasses import dataclass, field
+from itertools import chain
+from pathlib import Path
+from typing import Optional
+
+import datasets
+import tensorflow as tf
+from datasets import load_dataset
+from sklearn.model_selection import train_test_split
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ CONFIG_NAME,
+ TF2_WEIGHTS_NAME,
+ TF_MODEL_FOR_MASKED_LM_MAPPING,
+ AutoConfig,
+ AutoTokenizer,
+ DataCollatorForLanguageModeling,
+ HfArgumentParser,
+ PushToHubCallback,
+ TFAutoModelForMaskedLM,
+ TFTrainingArguments,
+ create_optimizer,
+ set_seed,
+)
+from transformers.utils import send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+logger = logging.getLogger(__name__)
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/tensorflow/language-modeling/requirements.txt")
+MODEL_CONFIG_CLASSES = list(TF_MODEL_FOR_MASKED_LM_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+# region Command-line arguments
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The model checkpoint for weights initialization. Don't set if you want to train a model from scratch."
+ )
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_overrides: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "Override some existing default config settings when a model is trained from scratch. Example: "
+ "n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
+ )
+ },
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if self.config_overrides is not None and (self.config_name is not None or self.model_name_or_path is not None):
+ raise ValueError(
+ "--config_overrides can't be used in combination with --config_name or --model_name_or_path"
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ validation_split_percentage: Optional[int] = field(
+ default=5,
+ metadata={
+ "help": "The percentage of the train set used as validation set in case there's no validation split"
+ },
+ )
+ max_seq_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated."
+ )
+ },
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ mlm_probability: float = field(
+ default=0.15, metadata={"help": "Ratio of tokens to mask for masked language modeling loss"}
+ )
+ line_by_line: bool = field(
+ default=False,
+ metadata={"help": "Whether distinct lines of text in the dataset are to be handled as distinct sequences."},
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
+
+
+# endregion
+
+
+def main():
+ # region Argument Parsing
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_mlm", model_args, data_args, framework="tensorflow")
+
+ # Sanity checks
+ if data_args.dataset_name is None and data_args.train_file is None and data_args.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if data_args.train_file is not None:
+ extension = data_args.train_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, json or txt file."
+ if data_args.validation_file is not None:
+ extension = data_args.validation_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, json or txt file."
+
+ if training_args.output_dir is not None:
+ training_args.output_dir = Path(training_args.output_dir)
+ os.makedirs(training_args.output_dir, exist_ok=True)
+
+ if isinstance(training_args.strategy, tf.distribute.TPUStrategy) and not data_args.pad_to_max_length:
+ logger.warning("We are training on TPU - forcing pad_to_max_length")
+ data_args.pad_to_max_length = True
+ # endregion
+
+ # region Checkpoints
+ # Detecting last checkpoint.
+ checkpoint = None
+ if len(os.listdir(training_args.output_dir)) > 0 and not training_args.overwrite_output_dir:
+ config_path = training_args.output_dir / CONFIG_NAME
+ weights_path = training_args.output_dir / TF2_WEIGHTS_NAME
+ if config_path.is_file() and weights_path.is_file():
+ checkpoint = training_args.output_dir
+ logger.warning(
+ f"Checkpoint detected, resuming training from checkpoint in {training_args.output_dir}. To avoid this"
+ " behavior, change the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+ else:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to continue regardless."
+ )
+
+ # endregion
+
+ # region Setup logging
+ # accelerator.is_local_main_process is only True for one process per machine.
+ logger.setLevel(logging.INFO)
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ # endregion
+
+ # If passed along, set the training seed now.
+ if training_args.seed is not None:
+ set_seed(training_args.seed)
+
+ # region Load datasets
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ if "validation" not in raw_datasets.keys():
+ raw_datasets["validation"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[:{data_args.validation_split_percentage}%]",
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ raw_datasets["train"] = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ split=f"train[{data_args.validation_split_percentage}%:]",
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if extension == "txt":
+ extension = "text"
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ token=model_args.token,
+ )
+
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+ # endregion
+
+ # region Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ if checkpoint is not None:
+ config = AutoConfig.from_pretrained(
+ checkpoint, token=model_args.token, trust_remote_code=model_args.trust_remote_code
+ )
+ elif model_args.config_name:
+ config = AutoConfig.from_pretrained(
+ model_args.config_name, token=model_args.token, trust_remote_code=model_args.trust_remote_code
+ )
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(
+ model_args.model_name_or_path, token=model_args.token, trust_remote_code=model_args.trust_remote_code
+ )
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name, token=model_args.token, trust_remote_code=model_args.trust_remote_code
+ )
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.model_name_or_path, token=model_args.token, trust_remote_code=model_args.trust_remote_code
+ )
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+ # endregion
+
+ # region Dataset preprocessing
+ # First we tokenize all the texts.
+ column_names = raw_datasets["train"].column_names
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ if data_args.max_seq_length is None:
+ max_seq_length = tokenizer.model_max_length
+ if max_seq_length > 1024:
+ logger.warning(
+ f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). "
+ "Picking 1024 instead. You can reduce that default value by passing --max_seq_length xxx."
+ )
+ max_seq_length = 1024
+ else:
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ if data_args.line_by_line:
+ # When using line_by_line, we just tokenize each nonempty line.
+ padding = "max_length" if data_args.pad_to_max_length else False
+
+ def tokenize_function(examples):
+ # Remove empty lines
+ examples[text_column_name] = [
+ line for line in examples[text_column_name] if len(line) > 0 and not line.isspace()
+ ]
+ return tokenizer(
+ examples[text_column_name],
+ padding=padding,
+ truncation=True,
+ max_length=max_seq_length,
+ # We use this option because DataCollatorForLanguageModeling (see below) is more efficient when it
+ # receives the `special_tokens_mask`.
+ return_special_tokens_mask=True,
+ )
+
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=[text_column_name],
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on dataset line_by_line",
+ )
+ else:
+ # Otherwise, we tokenize every text, then concatenate them together before splitting them in smaller parts.
+ # We use `return_special_tokens_mask=True` because DataCollatorForLanguageModeling (see below) is more
+ # efficient when it receives the `special_tokens_mask`.
+ def tokenize_function(examples):
+ return tokenizer(examples[text_column_name], return_special_tokens_mask=True)
+
+ tokenized_datasets = raw_datasets.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on every text in dataset",
+ )
+
+ # Main data processing function that will concatenate all texts from our dataset and generate chunks of
+ # max_seq_length.
+ def group_texts(examples):
+ # Concatenate all texts.
+ concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
+ total_length = len(concatenated_examples[list(examples.keys())[0]])
+ # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
+ # customize this part to your needs.
+ if total_length >= max_seq_length:
+ total_length = (total_length // max_seq_length) * max_seq_length
+ # Split by chunks of max_len.
+ result = {
+ k: [t[i : i + max_seq_length] for i in range(0, total_length, max_seq_length)]
+ for k, t in concatenated_examples.items()
+ }
+ return result
+
+ # Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a
+ # remainder for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value
+ # might be slower to preprocess.
+ #
+ # To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
+ # https://huggingface.co/docs/datasets/process#map
+
+ tokenized_datasets = tokenized_datasets.map(
+ group_texts,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc=f"Grouping texts in chunks of {max_seq_length}",
+ )
+
+ train_dataset = tokenized_datasets["train"]
+
+ if data_args.validation_file is not None:
+ eval_dataset = tokenized_datasets["validation"]
+ else:
+ logger.info(
+ f"Validation file not found: using {data_args.validation_split_percentage}% of the dataset as validation"
+ " as provided in data_args"
+ )
+ train_indices, val_indices = train_test_split(
+ list(range(len(train_dataset))), test_size=data_args.validation_split_percentage / 100
+ )
+
+ eval_dataset = train_dataset.select(val_indices)
+ train_dataset = train_dataset.select(train_indices)
+
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), min(3, len(train_dataset))):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+ # endregion
+
+ with training_args.strategy.scope():
+ # region Prepare model
+ if checkpoint is not None:
+ model = TFAutoModelForMaskedLM.from_pretrained(
+ checkpoint, config=config, token=model_args.token, trust_remote_code=model_args.trust_remote_code
+ )
+ elif model_args.model_name_or_path:
+ model = TFAutoModelForMaskedLM.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = TFAutoModelForMaskedLM.from_config(
+ config, token=model_args.token, trust_remote_code=model_args.trust_remote_code
+ )
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embeddings = model.get_input_embeddings()
+
+ # Matt: This is a temporary workaround as we transition our models to exclusively using Keras embeddings.
+ # As soon as the transition is complete, all embeddings should be keras.Embeddings layers, and
+ # the weights will always be in embeddings.embeddings.
+ if hasattr(embeddings, "embeddings"):
+ embedding_size = embeddings.embeddings.shape[0]
+ else:
+ embedding_size = embeddings.weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+ # endregion
+
+ # region TF Dataset preparation
+ num_replicas = training_args.strategy.num_replicas_in_sync
+ data_collator = DataCollatorForLanguageModeling(
+ tokenizer=tokenizer, mlm_probability=data_args.mlm_probability, return_tensors="np"
+ )
+ options = tf.data.Options()
+ options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
+
+ # model.prepare_tf_dataset() wraps a Hugging Face dataset in a tf.data.Dataset which is ready to use in
+ # training. This is the recommended way to use a Hugging Face dataset when training with Keras. You can also
+ # use the lower-level dataset.to_tf_dataset() method, but you will have to specify things like column names
+ # yourself if you use this method, whereas they are automatically inferred from the model input names when
+ # using model.prepare_tf_dataset()
+ # For more info see the docs:
+ # https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.TFPreTrainedModel.prepare_tf_dataset
+ # https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.to_tf_dataset
+
+ tf_train_dataset = model.prepare_tf_dataset(
+ train_dataset,
+ shuffle=True,
+ batch_size=num_replicas * training_args.per_device_train_batch_size,
+ collate_fn=data_collator,
+ ).with_options(options)
+
+ tf_eval_dataset = model.prepare_tf_dataset(
+ eval_dataset,
+ # labels are passed as input, as we will use the model's internal loss
+ shuffle=False,
+ batch_size=num_replicas * training_args.per_device_eval_batch_size,
+ collate_fn=data_collator,
+ drop_remainder=True,
+ ).with_options(options)
+ # endregion
+
+ # region Optimizer and loss
+ num_train_steps = len(tf_train_dataset) * int(training_args.num_train_epochs)
+ if training_args.warmup_steps > 0:
+ num_warmup_steps = training_args.warmup_steps
+ elif training_args.warmup_ratio > 0:
+ num_warmup_steps = int(num_train_steps * training_args.warmup_ratio)
+ else:
+ num_warmup_steps = 0
+
+ # Bias and layernorm weights are automatically excluded from the decay
+ optimizer, lr_schedule = create_optimizer(
+ init_lr=training_args.learning_rate,
+ num_train_steps=num_train_steps,
+ num_warmup_steps=num_warmup_steps,
+ adam_beta1=training_args.adam_beta1,
+ adam_beta2=training_args.adam_beta2,
+ adam_epsilon=training_args.adam_epsilon,
+ weight_decay_rate=training_args.weight_decay,
+ adam_global_clipnorm=training_args.max_grad_norm,
+ )
+
+ # Transformers models compute the right loss for their task by default when labels are passed, and will
+ # use this for training unless you specify your own loss function in compile().
+ model.compile(optimizer=optimizer, jit_compile=training_args.xla)
+ # endregion
+
+ # region Preparing push_to_hub and model card
+ push_to_hub_model_id = training_args.push_to_hub_model_id
+ model_name = model_args.model_name_or_path.split("/")[-1]
+ if not push_to_hub_model_id:
+ if data_args.dataset_name is not None:
+ push_to_hub_model_id = f"{model_name}-finetuned-{data_args.dataset_name}"
+ else:
+ push_to_hub_model_id = f"{model_name}-finetuned-mlm"
+
+ model_card_kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "fill-mask"}
+ if data_args.dataset_name is not None:
+ model_card_kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ model_card_kwargs["dataset_args"] = data_args.dataset_config_name
+ model_card_kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ model_card_kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ callbacks = [
+ PushToHubCallback(
+ output_dir=training_args.output_dir,
+ hub_model_id=push_to_hub_model_id,
+ hub_token=training_args.push_to_hub_token,
+ tokenizer=tokenizer,
+ **model_card_kwargs,
+ )
+ ]
+ else:
+ callbacks = []
+ # endregion
+
+ # region Training and validation
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {training_args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {training_args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size = {training_args.per_device_train_batch_size * num_replicas}")
+
+ # For long training runs, you may wish to use the PushToHub() callback here to save intermediate checkpoints
+ # to the Hugging Face Hub rather than just pushing the finished model.
+ # See https://huggingface.co/docs/transformers/main_classes/keras_callbacks#transformers.PushToHubCallback
+
+ history = model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ epochs=int(training_args.num_train_epochs),
+ callbacks=callbacks,
+ )
+ train_loss = history.history["loss"][-1]
+ try:
+ train_perplexity = math.exp(train_loss)
+ except OverflowError:
+ train_perplexity = math.inf
+ logger.info(f" Final train loss: {train_loss:.3f}")
+ logger.info(f" Final train perplexity: {train_perplexity:.3f}")
+
+ validation_loss = history.history["val_loss"][-1]
+ try:
+ validation_perplexity = math.exp(validation_loss)
+ except OverflowError:
+ validation_perplexity = math.inf
+ logger.info(f" Final validation loss: {validation_loss:.3f}")
+ logger.info(f" Final validation perplexity: {validation_perplexity:.3f}")
+
+ if training_args.output_dir is not None:
+ output_eval_file = os.path.join(training_args.output_dir, "all_results.json")
+ results_dict = {}
+ results_dict["train_loss"] = train_loss
+ results_dict["train_perplexity"] = train_perplexity
+ results_dict["eval_loss"] = validation_loss
+ results_dict["eval_perplexity"] = validation_perplexity
+ with open(output_eval_file, "w") as writer:
+ writer.write(json.dumps(results_dict))
+ # endregion
+
+ if training_args.output_dir is not None and not training_args.push_to_hub:
+ # If we're not pushing to hub, at least save a local copy when we're done
+ model.save_pretrained(training_args.output_dir)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/tensorflow/multiple-choice/README.md b/docs/transformers/examples/tensorflow/multiple-choice/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a7f499963ec678692d6be4a36878dee105336600
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/multiple-choice/README.md
@@ -0,0 +1,43 @@
+
+# Multiple-choice training (e.g. SWAG)
+
+This folder contains the `run_swag.py` script, showing an examples of *multiple-choice answering* with the
+🤗 Transformers library. For straightforward use-cases you may be able to use these scripts without modification,
+although we have also included comments in the code to indicate areas that you may need to adapt to your own projects.
+
+### Multi-GPU and TPU usage
+
+By default, the script uses a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
+can also be used by passing the name of the TPU resource with the `--tpu` argument.
+
+### Memory usage and data loading
+
+One thing to note is that all data is loaded into memory in this script. Most multiple-choice datasets are small
+enough that this is not an issue, but if you have a very large dataset you will need to modify the script to handle
+data streaming. This is particularly challenging for TPUs, given the stricter requirements and the sheer volume of data
+required to keep them fed. A full explanation of all the possible pitfalls is a bit beyond this example script and
+README, but for more information you can see the 'Input Datasets' section of
+[this document](https://www.tensorflow.org/guide/tpu).
+
+### Example command
+```bash
+python run_swag.py \
+ --model_name_or_path distilbert/distilbert-base-cased \
+ --output_dir output \
+ --do_eval \
+ --do_train
+```
diff --git a/docs/transformers/examples/tensorflow/multiple-choice/requirements.txt b/docs/transformers/examples/tensorflow/multiple-choice/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..657fbc90a5b6ae5eb7f33e10b268b6b8fceedb66
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/multiple-choice/requirements.txt
@@ -0,0 +1,3 @@
+sentencepiece != 0.1.92
+protobuf
+tensorflow >= 2.3
diff --git a/docs/transformers/examples/tensorflow/multiple-choice/run_swag.py b/docs/transformers/examples/tensorflow/multiple-choice/run_swag.py
new file mode 100644
index 0000000000000000000000000000000000000000..9b6ba4228c0ceaae1a48d31185749a8adc8620d1
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/multiple-choice/run_swag.py
@@ -0,0 +1,503 @@
+#!/usr/bin/env python
+# Copyright The HuggingFace Team and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for multiple choice.
+"""
+# You can also adapt this script on your own multiple choice task. Pointers for this are left as comments.
+
+import json
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from itertools import chain
+from pathlib import Path
+from typing import Optional
+
+import datasets
+import tensorflow as tf
+from datasets import load_dataset
+
+import transformers
+from transformers import (
+ CONFIG_NAME,
+ TF2_WEIGHTS_NAME,
+ AutoConfig,
+ AutoTokenizer,
+ DataCollatorForMultipleChoice,
+ DefaultDataCollator,
+ HfArgumentParser,
+ PushToHubCallback,
+ TFAutoModelForMultipleChoice,
+ TFTrainingArguments,
+ create_optimizer,
+ set_seed,
+)
+from transformers.utils import check_min_version, send_example_telemetry
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logger = logging.getLogger(__name__)
+
+
+# region Arguments
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
+ "should only be set to `True` for repositories you trust and in which you have read the code, as it will "
+ "execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_seq_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. If passed, sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to the maximum sentence length. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
+ "efficient on GPU but very bad for TPU."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+
+
+# endregion
+
+
+def main():
+ # region Argument parsing
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_swag", model_args, data_args, framework="tensorflow")
+
+ output_dir = Path(training_args.output_dir)
+ output_dir.mkdir(parents=True, exist_ok=True)
+ # endregion
+
+ # region Logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+ # endregion
+
+ # region Checkpoints
+ checkpoint = None
+ if len(os.listdir(training_args.output_dir)) > 0 and not training_args.overwrite_output_dir:
+ if (output_dir / CONFIG_NAME).is_file() and (output_dir / TF2_WEIGHTS_NAME).is_file():
+ checkpoint = output_dir
+ logger.info(
+ f"Checkpoint detected, resuming training from checkpoint in {training_args.output_dir}. To avoid this"
+ " behavior, change the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+ else:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to continue regardless."
+ )
+ # endregion
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # region Load datasets
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.train_file is not None or data_args.validation_file is not None:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ else:
+ # Downloading and loading the swag dataset from the hub.
+ raw_datasets = load_dataset(
+ "swag",
+ "regular",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # When using your own dataset or a different dataset from swag, you will probably need to change this.
+ ending_names = [f"ending{i}" for i in range(4)]
+ context_name = "sent1"
+ question_header_name = "sent2"
+ # endregion
+
+ # region Load model config and tokenizer
+ if checkpoint is not None:
+ config_path = training_args.output_dir
+ elif model_args.config_name:
+ config_path = model_args.config_name
+ else:
+ config_path = model_args.model_name_or_path
+
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ config_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ # endregion
+
+ # region Dataset preprocessing
+ if data_args.max_seq_length is None:
+ max_seq_length = tokenizer.model_max_length
+ if max_seq_length > 1024:
+ logger.warning(
+ f"The tokenizer picked seems to have a very large `model_max_length` ({tokenizer.model_max_length}). "
+ "Picking 1024 instead. You can change that default value by passing --max_seq_length xxx."
+ )
+ max_seq_length = 1024
+ else:
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ def preprocess_function(examples):
+ first_sentences = [[context] * 4 for context in examples[context_name]]
+ question_headers = examples[question_header_name]
+ second_sentences = [
+ [f"{header} {examples[end][i]}" for end in ending_names] for i, header in enumerate(question_headers)
+ ]
+
+ # Flatten out
+ first_sentences = list(chain(*first_sentences))
+ second_sentences = list(chain(*second_sentences))
+
+ # Tokenize
+ tokenized_examples = tokenizer(first_sentences, second_sentences, truncation=True, max_length=max_seq_length)
+ # Un-flatten
+ data = {k: [v[i : i + 4] for i in range(0, len(v), 4)] for k, v in tokenized_examples.items()}
+ return data
+
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ train_dataset = train_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ if training_args.do_eval:
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = raw_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+ eval_dataset = eval_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ if data_args.pad_to_max_length:
+ data_collator = DefaultDataCollator(return_tensors="np")
+ else:
+ data_collator = DataCollatorForMultipleChoice(tokenizer, return_tensors="tf")
+ # endregion
+
+ with training_args.strategy.scope():
+ # region Build model
+ if checkpoint is None:
+ model_path = model_args.model_name_or_path
+ else:
+ model_path = checkpoint
+ model = TFAutoModelForMultipleChoice.from_pretrained(
+ model_path,
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ num_replicas = training_args.strategy.num_replicas_in_sync
+ total_train_batch_size = training_args.per_device_train_batch_size * num_replicas
+ total_eval_batch_size = training_args.per_device_eval_batch_size * num_replicas
+
+ if training_args.do_train:
+ num_train_steps = (len(train_dataset) // total_train_batch_size) * int(training_args.num_train_epochs)
+ if training_args.warmup_steps > 0:
+ num_warmup_steps = training_args.warmup_steps
+ elif training_args.warmup_ratio > 0:
+ num_warmup_steps = int(num_train_steps * training_args.warmup_ratio)
+ else:
+ num_warmup_steps = 0
+ optimizer, lr_schedule = create_optimizer(
+ init_lr=training_args.learning_rate,
+ num_train_steps=num_train_steps,
+ num_warmup_steps=num_warmup_steps,
+ adam_beta1=training_args.adam_beta1,
+ adam_beta2=training_args.adam_beta2,
+ adam_epsilon=training_args.adam_epsilon,
+ weight_decay_rate=training_args.weight_decay,
+ adam_global_clipnorm=training_args.max_grad_norm,
+ )
+ else:
+ optimizer = "sgd" # Just write anything because we won't be using it
+ # Transformers models compute the right loss for their task by default when labels are passed, and will
+ # use this for training unless you specify your own loss function in compile().
+ model.compile(optimizer=optimizer, metrics=["accuracy"], jit_compile=training_args.xla)
+ # endregion
+
+ # region Preparing push_to_hub and model card
+ push_to_hub_model_id = training_args.push_to_hub_model_id
+ model_name = model_args.model_name_or_path.split("/")[-1]
+ if not push_to_hub_model_id:
+ push_to_hub_model_id = f"{model_name}-finetuned-multiplechoice"
+
+ model_card_kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "multiple-choice"}
+
+ if training_args.push_to_hub:
+ callbacks = [
+ PushToHubCallback(
+ output_dir=training_args.output_dir,
+ hub_model_id=push_to_hub_model_id,
+ hub_token=training_args.push_to_hub_token,
+ tokenizer=tokenizer,
+ **model_card_kwargs,
+ )
+ ]
+ else:
+ callbacks = []
+ # endregion
+
+ # region Training
+ eval_metrics = None
+ if training_args.do_train:
+ dataset_options = tf.data.Options()
+ dataset_options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
+
+ # model.prepare_tf_dataset() wraps a Hugging Face dataset in a tf.data.Dataset which is ready to use in
+ # training. This is the recommended way to use a Hugging Face dataset when training with Keras. You can also
+ # use the lower-level dataset.to_tf_dataset() method, but you will have to specify things like column names
+ # yourself if you use this method, whereas they are automatically inferred from the model input names when
+ # using model.prepare_tf_dataset()
+ # For more info see the docs:
+ # https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.TFPreTrainedModel.prepare_tf_dataset
+ # https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.to_tf_dataset
+
+ tf_train_dataset = model.prepare_tf_dataset(
+ train_dataset,
+ shuffle=True,
+ batch_size=total_train_batch_size,
+ collate_fn=data_collator,
+ ).with_options(dataset_options)
+
+ if training_args.do_eval:
+ validation_data = model.prepare_tf_dataset(
+ eval_dataset,
+ shuffle=False,
+ batch_size=total_eval_batch_size,
+ collate_fn=data_collator,
+ drop_remainder=True,
+ ).with_options(dataset_options)
+ else:
+ validation_data = None
+ history = model.fit(
+ tf_train_dataset,
+ validation_data=validation_data,
+ epochs=int(training_args.num_train_epochs),
+ callbacks=callbacks,
+ )
+ eval_metrics = {key: val[-1] for key, val in history.history.items()}
+ # endregion
+
+ # region Evaluation
+ if training_args.do_eval and not training_args.do_train:
+ dataset_options = tf.data.Options()
+ dataset_options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
+ # Do a standalone evaluation pass
+ tf_eval_dataset = model.prepare_tf_dataset(
+ eval_dataset,
+ shuffle=False,
+ batch_size=total_eval_batch_size,
+ collate_fn=data_collator,
+ drop_remainder=True,
+ ).with_options(dataset_options)
+ eval_results = model.evaluate(tf_eval_dataset)
+ eval_metrics = {"val_loss": eval_results[0], "val_accuracy": eval_results[1]}
+ # endregion
+
+ if eval_metrics is not None and training_args.output_dir is not None:
+ output_eval_file = os.path.join(training_args.output_dir, "all_results.json")
+ with open(output_eval_file, "w") as writer:
+ writer.write(json.dumps(eval_metrics))
+
+ # region Push to hub
+
+ if training_args.output_dir is not None and not training_args.push_to_hub:
+ # If we're not pushing to hub, at least save a local copy when we're done
+ model.save_pretrained(training_args.output_dir)
+ # endregion
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/tensorflow/question-answering/README.md b/docs/transformers/examples/tensorflow/question-answering/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c7e85623199fbe3a15853309c780dab1f5a2fd21
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/question-answering/README.md
@@ -0,0 +1,57 @@
+
+
+# Question answering example
+
+This folder contains the `run_qa.py` script, demonstrating *question answering* with the 🤗 Transformers library.
+For straightforward use-cases you may be able to use this script without modification, although we have also
+included comments in the code to indicate areas that you may need to adapt to your own projects.
+
+### Usage notes
+
+Note that when contexts are long they may be split into multiple training cases, not all of which may contain
+the answer span.
+
+As-is, the example script will train on SQuAD or any other question-answering dataset formatted the same way, and can handle user
+inputs as well.
+
+### Multi-GPU and TPU usage
+
+By default, the script uses a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
+can also be used by passing the name of the TPU resource with the `--tpu` argument. There are some issues surrounding
+these strategies and our models right now, which are most likely to appear in the evaluation/prediction steps. We're
+actively working on better support for multi-GPU and TPU training in TF, but if you encounter problems a quick
+workaround is to train in the multi-GPU or TPU context and then perform predictions outside of it.
+
+### Memory usage and data loading
+
+One thing to note is that all data is loaded into memory in this script. Most question answering datasets are small
+enough that this is not an issue, but if you have a very large dataset you will need to modify the script to handle
+data streaming. This is particularly challenging for TPUs, given the stricter requirements and the sheer volume of data
+required to keep them fed. A full explanation of all the possible pitfalls is a bit beyond this example script and
+README, but for more information you can see the 'Input Datasets' section of
+[this document](https://www.tensorflow.org/guide/tpu).
+
+### Example command
+
+```bash
+python run_qa.py \
+--model_name_or_path distilbert/distilbert-base-cased \
+--output_dir output \
+--dataset_name squad \
+--do_train \
+--do_eval
+```
diff --git a/docs/transformers/examples/tensorflow/question-answering/requirements.txt b/docs/transformers/examples/tensorflow/question-answering/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..99aff2bb32b2bb92f7628eb9bab4c7535d4c7f92
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/question-answering/requirements.txt
@@ -0,0 +1,3 @@
+datasets >= 1.4.0
+tensorflow >= 2.3.0
+evaluate >= 0.2.0
\ No newline at end of file
diff --git a/docs/transformers/examples/tensorflow/question-answering/run_qa.py b/docs/transformers/examples/tensorflow/question-answering/run_qa.py
new file mode 100644
index 0000000000000000000000000000000000000000..28418496c2348f4e5bede741e4ebd6984fd97435
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/question-answering/run_qa.py
@@ -0,0 +1,830 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for question answering.
+"""
+# You can also adapt this script on your own question answering task. Pointers for this are left as comments.
+
+import json
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from pathlib import Path
+from typing import Optional
+
+import evaluate
+import tensorflow as tf
+from datasets import load_dataset
+from packaging.version import parse
+from utils_qa import postprocess_qa_predictions
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoTokenizer,
+ EvalPrediction,
+ HfArgumentParser,
+ PreTrainedTokenizerFast,
+ PushToHubCallback,
+ TFAutoModelForQuestionAnswering,
+ TFTrainingArguments,
+ create_optimizer,
+ set_seed,
+)
+from transformers.utils import CONFIG_NAME, TF2_WEIGHTS_NAME, check_min_version, send_example_telemetry
+
+
+try:
+ import tf_keras as keras
+except (ModuleNotFoundError, ImportError):
+ import keras
+
+ if parse(keras.__version__).major > 2:
+ raise ValueError(
+ "Your currently installed version of Keras is Keras 3, but this is not yet supported in "
+ "Transformers. Please install the backwards-compatible tf-keras package with "
+ "`pip install tf-keras`."
+ )
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+logger = logging.getLogger(__name__)
+
+
+# region Arguments
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Path to directory to store the pretrained models downloaded from huggingface.co"},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input test data file to evaluate the perplexity on (a text file)."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_seq_length: int = field(
+ default=384,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. If False, will pad the samples dynamically when"
+ " batching to the maximum length in the batch (which can be faster on GPU but will be slower on TPU)."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ version_2_with_negative: bool = field(
+ default=False, metadata={"help": "If true, some of the examples do not have an answer."}
+ )
+ null_score_diff_threshold: float = field(
+ default=0.0,
+ metadata={
+ "help": (
+ "The threshold used to select the null answer: if the best answer has a score that is less than "
+ "the score of the null answer minus this threshold, the null answer is selected for this example. "
+ "Only useful when `version_2_with_negative=True`."
+ )
+ },
+ )
+ doc_stride: int = field(
+ default=128,
+ metadata={"help": "When splitting up a long document into chunks, how much stride to take between chunks."},
+ )
+ n_best_size: int = field(
+ default=20,
+ metadata={"help": "The total number of n-best predictions to generate when looking for an answer."},
+ )
+ max_answer_length: int = field(
+ default=30,
+ metadata={
+ "help": (
+ "The maximum length of an answer that can be generated. This is needed because the start "
+ "and end predictions are not conditioned on one another."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if (
+ self.dataset_name is None
+ and self.train_file is None
+ and self.validation_file is None
+ and self.test_file is None
+ ):
+ raise ValueError("Need either a dataset name or a training/validation file/test_file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ if self.test_file is not None:
+ extension = self.test_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
+
+
+# endregion
+
+
+# region Helper classes
+class SavePretrainedCallback(keras.callbacks.Callback):
+ # Hugging Face models have a save_pretrained() method that saves both the weights and the necessary
+ # metadata to allow them to be loaded as a pretrained model in future. This is a simple Keras callback
+ # that saves the model with this method after each epoch.
+ def __init__(self, output_dir, **kwargs):
+ super().__init__()
+ self.output_dir = output_dir
+
+ def on_epoch_end(self, epoch, logs=None):
+ self.model.save_pretrained(self.output_dir)
+
+
+# endregion
+
+
+def main():
+ # region Argument parsing
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_qa", model_args, data_args, framework="tensorflow")
+
+ output_dir = Path(training_args.output_dir)
+ output_dir.mkdir(parents=True, exist_ok=True)
+ # endregion
+
+ # region Checkpoints
+ checkpoint = None
+ if len(os.listdir(training_args.output_dir)) > 0 and not training_args.overwrite_output_dir:
+ if (output_dir / CONFIG_NAME).is_file() and (output_dir / TF2_WEIGHTS_NAME).is_file():
+ checkpoint = output_dir
+ logger.info(
+ f"Checkpoint detected, resuming training from checkpoint in {training_args.output_dir}. To avoid this"
+ " behavior, change the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+ else:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to continue regardless."
+ )
+ # endregion
+
+ # region Logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+ logger.setLevel(logging.INFO if training_args.should_log else logging.WARN)
+
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if training_args.should_log:
+ transformers.utils.logging.set_verbosity_info()
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+ logger.info(f"Training/evaluation parameters {training_args}")
+ # endregion
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # region Load Data
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if data_args.test_file is not None:
+ data_files["test"] = data_args.test_file
+ extension = data_args.test_file.split(".")[-1]
+ datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ field="data",
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+ # endregion
+
+ # region Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=True,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ # endregion
+
+ # region Tokenizer check: this script requires a fast tokenizer.
+ if not isinstance(tokenizer, PreTrainedTokenizerFast):
+ raise ValueError(
+ "This example script only works for models that have a fast tokenizer. Checkout the big table of models at"
+ " https://huggingface.co/transformers/index.html#supported-frameworks to find the model types that meet"
+ " this requirement"
+ )
+ # endregion
+
+ # region Preprocessing the datasets
+ # Preprocessing is slightly different for training and evaluation.
+ if training_args.do_train:
+ column_names = datasets["train"].column_names
+ elif training_args.do_eval:
+ column_names = datasets["validation"].column_names
+ else:
+ column_names = datasets["test"].column_names
+ question_column_name = "question" if "question" in column_names else column_names[0]
+ context_column_name = "context" if "context" in column_names else column_names[1]
+ answer_column_name = "answers" if "answers" in column_names else column_names[2]
+
+ # Padding side determines if we do (question|context) or (context|question).
+ pad_on_right = tokenizer.padding_side == "right"
+
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ if data_args.pad_to_max_length or isinstance(training_args.strategy, tf.distribute.TPUStrategy):
+ logger.info("Padding all batches to max length because argument was set or we're on TPU.")
+ padding = "max_length"
+ else:
+ padding = False
+
+ # Training preprocessing
+ def prepare_train_features(examples):
+ # Some of the questions have lots of whitespace on the left, which is not useful and will make the
+ # truncation of the context fail (the tokenized question will take a lots of space). So we remove that
+ # left whitespace
+ examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
+
+ # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
+ # in one example possible giving several features when a context is long, each of those features having a
+ # context that overlaps a bit the context of the previous feature.
+ tokenized_examples = tokenizer(
+ examples[question_column_name if pad_on_right else context_column_name],
+ examples[context_column_name if pad_on_right else question_column_name],
+ truncation="only_second" if pad_on_right else "only_first",
+ max_length=max_seq_length,
+ stride=data_args.doc_stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ padding=padding,
+ )
+
+ # Since one example might give us several features if it has a long context, we need a map from a feature to
+ # its corresponding example. This key gives us just that.
+ sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
+ # The offset mappings will give us a map from token to character position in the original context. This will
+ # help us compute the start_positions and end_positions.
+ offset_mapping = tokenized_examples.pop("offset_mapping")
+
+ # Let's label those examples!
+ tokenized_examples["start_positions"] = []
+ tokenized_examples["end_positions"] = []
+
+ for i, offsets in enumerate(offset_mapping):
+ # We will label impossible answers with the index of the CLS token.
+ input_ids = tokenized_examples["input_ids"][i]
+ cls_index = input_ids.index(tokenizer.cls_token_id)
+
+ # Grab the sequence corresponding to that example (to know what is the context and what is the question).
+ sequence_ids = tokenized_examples.sequence_ids(i)
+
+ # One example can give several spans, this is the index of the example containing this span of text.
+ sample_index = sample_mapping[i]
+ answers = examples[answer_column_name][sample_index]
+ # If no answers are given, set the cls_index as answer.
+ if len(answers["answer_start"]) == 0:
+ tokenized_examples["start_positions"].append(cls_index)
+ tokenized_examples["end_positions"].append(cls_index)
+ else:
+ # Start/end character index of the answer in the text.
+ start_char = answers["answer_start"][0]
+ end_char = start_char + len(answers["text"][0])
+
+ # Start token index of the current span in the text.
+ token_start_index = 0
+ while sequence_ids[token_start_index] != (1 if pad_on_right else 0):
+ token_start_index += 1
+
+ # End token index of the current span in the text.
+ token_end_index = len(input_ids) - 1
+ while sequence_ids[token_end_index] != (1 if pad_on_right else 0):
+ token_end_index -= 1
+
+ # Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
+ if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
+ tokenized_examples["start_positions"].append(cls_index)
+ tokenized_examples["end_positions"].append(cls_index)
+ else:
+ # Otherwise move the token_start_index and token_end_index to the two ends of the answer.
+ # Note: we could go after the last offset if the answer is the last word (edge case).
+ while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
+ token_start_index += 1
+ tokenized_examples["start_positions"].append(token_start_index - 1)
+ while offsets[token_end_index][1] >= end_char:
+ token_end_index -= 1
+ tokenized_examples["end_positions"].append(token_end_index + 1)
+
+ return tokenized_examples
+
+ processed_datasets = {}
+ if training_args.do_train:
+ if "train" not in datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = datasets["train"]
+ if data_args.max_train_samples is not None:
+ # We will select sample from whole data if argument is specified
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ # Create train feature from dataset
+ train_dataset = train_dataset.map(
+ prepare_train_features,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+ if data_args.max_train_samples is not None:
+ # Number of samples might increase during Feature Creation, We select only specified max samples
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ processed_datasets["train"] = train_dataset
+
+ # Validation preprocessing
+ def prepare_validation_features(examples):
+ # Some of the questions have lots of whitespace on the left, which is not useful and will make the
+ # truncation of the context fail (the tokenized question will take a lots of space). So we remove that
+ # left whitespace
+ examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
+
+ # Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
+ # in one example possible giving several features when a context is long, each of those features having a
+ # context that overlaps a bit the context of the previous feature.
+ tokenized_examples = tokenizer(
+ examples[question_column_name if pad_on_right else context_column_name],
+ examples[context_column_name if pad_on_right else question_column_name],
+ truncation="only_second" if pad_on_right else "only_first",
+ max_length=max_seq_length,
+ stride=data_args.doc_stride,
+ return_overflowing_tokens=True,
+ return_offsets_mapping=True,
+ padding=padding,
+ )
+
+ # Since one example might give us several features if it has a long context, we need a map from a feature to
+ # its corresponding example. This key gives us just that.
+ sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
+
+ # For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
+ # corresponding example_id and we will store the offset mappings.
+ tokenized_examples["example_id"] = []
+
+ for i in range(len(tokenized_examples["input_ids"])):
+ # Grab the sequence corresponding to that example (to know what is the context and what is the question).
+ sequence_ids = tokenized_examples.sequence_ids(i)
+ context_index = 1 if pad_on_right else 0
+
+ # One example can give several spans, this is the index of the example containing this span of text.
+ sample_index = sample_mapping[i]
+ tokenized_examples["example_id"].append(examples["id"][sample_index])
+
+ # Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
+ # position is part of the context or not.
+ tokenized_examples["offset_mapping"][i] = [
+ (o if sequence_ids[k] == context_index else None)
+ for k, o in enumerate(tokenized_examples["offset_mapping"][i])
+ ]
+
+ return tokenized_examples
+
+ if training_args.do_eval:
+ if "validation" not in datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_examples = datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ # We will select sample from whole data
+ max_eval_samples = min(len(eval_examples), data_args.max_eval_samples)
+ eval_examples = eval_examples.select(range(max_eval_samples))
+ # Validation Feature Creation
+ eval_dataset = eval_examples.map(
+ prepare_validation_features,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+ if data_args.max_eval_samples is not None:
+ # During Feature creation dataset samples might increase, we will select required samples again
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+ processed_datasets["validation"] = eval_dataset
+
+ if training_args.do_predict:
+ if "test" not in datasets:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_examples = datasets["test"]
+ if data_args.max_predict_samples is not None:
+ # We will select sample from whole data
+ predict_examples = predict_examples.select(range(data_args.max_predict_samples))
+ # Predict Feature Creation
+ predict_dataset = predict_examples.map(
+ prepare_validation_features,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+ if data_args.max_predict_samples is not None:
+ # During Feature creation dataset samples might increase, we will select required samples again
+ max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
+ predict_dataset = predict_dataset.select(range(max_predict_samples))
+ processed_datasets["test"] = predict_dataset
+ # endregion
+
+ # region Metrics and Post-processing:
+ def post_processing_function(examples, features, predictions, stage="eval"):
+ # Post-processing: we match the start logits and end logits to answers in the original context.
+ predictions = postprocess_qa_predictions(
+ examples=examples,
+ features=features,
+ predictions=predictions,
+ version_2_with_negative=data_args.version_2_with_negative,
+ n_best_size=data_args.n_best_size,
+ max_answer_length=data_args.max_answer_length,
+ null_score_diff_threshold=data_args.null_score_diff_threshold,
+ output_dir=training_args.output_dir,
+ prefix=stage,
+ )
+ # Format the result to the format the metric expects.
+ if data_args.version_2_with_negative:
+ formatted_predictions = [
+ {"id": k, "prediction_text": v, "no_answer_probability": 0.0} for k, v in predictions.items()
+ ]
+ else:
+ formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
+
+ references = [{"id": ex["id"], "answers": ex[answer_column_name]} for ex in examples]
+ return EvalPrediction(predictions=formatted_predictions, label_ids=references)
+
+ metric = evaluate.load(
+ "squad_v2" if data_args.version_2_with_negative else "squad", cache_dir=model_args.cache_dir
+ )
+
+ def compute_metrics(p: EvalPrediction):
+ return metric.compute(predictions=p.predictions, references=p.label_ids)
+
+ # endregion
+
+ with training_args.strategy.scope():
+ dataset_options = tf.data.Options()
+ dataset_options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
+ num_replicas = training_args.strategy.num_replicas_in_sync
+
+ # region Load model and prepare datasets
+ if checkpoint is None:
+ model_path = model_args.model_name_or_path
+ else:
+ model_path = checkpoint
+ model = TFAutoModelForQuestionAnswering.from_pretrained(
+ model_path,
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ if training_args.do_train:
+ training_dataset = model.prepare_tf_dataset(
+ processed_datasets["train"],
+ shuffle=True,
+ batch_size=training_args.per_device_train_batch_size * num_replicas,
+ tokenizer=tokenizer,
+ )
+
+ training_dataset = training_dataset.with_options(dataset_options)
+
+ num_train_steps = len(training_dataset) * training_args.num_train_epochs
+ if training_args.warmup_steps > 0:
+ num_warmup_steps = training_args.warmup_steps
+ elif training_args.warmup_ratio > 0:
+ num_warmup_steps = int(num_train_steps * training_args.warmup_ratio)
+ else:
+ num_warmup_steps = 0
+
+ optimizer, schedule = create_optimizer(
+ init_lr=training_args.learning_rate,
+ num_train_steps=len(training_dataset) * training_args.num_train_epochs,
+ num_warmup_steps=num_warmup_steps,
+ adam_beta1=training_args.adam_beta1,
+ adam_beta2=training_args.adam_beta2,
+ adam_epsilon=training_args.adam_epsilon,
+ weight_decay_rate=training_args.weight_decay,
+ adam_global_clipnorm=training_args.max_grad_norm,
+ )
+
+ # Transformers models compute the right loss for their task by default when labels are passed, and will
+ # use this for training unless you specify your own loss function in compile().
+ model.compile(optimizer=optimizer, jit_compile=training_args.xla, metrics=["accuracy"])
+
+ else:
+ # Optimizer doesn't matter as it won't be used anyway
+ model.compile(optimizer="sgd", jit_compile=training_args.xla, metrics=["accuracy"])
+ training_dataset = None
+
+ if training_args.do_eval:
+ eval_dataset = model.prepare_tf_dataset(
+ processed_datasets["validation"],
+ shuffle=False,
+ batch_size=training_args.per_device_train_batch_size * num_replicas,
+ tokenizer=tokenizer,
+ )
+ eval_dataset = eval_dataset.with_options(dataset_options)
+ else:
+ eval_dataset = None
+
+ if training_args.do_predict:
+ predict_dataset = model.prepare_tf_dataset(
+ processed_datasets["test"],
+ shuffle=False,
+ batch_size=training_args.per_device_eval_batch_size * num_replicas,
+ tokenizer=tokenizer,
+ )
+ predict_dataset = predict_dataset.with_options(dataset_options)
+ else:
+ predict_dataset = None
+
+ # endregion
+
+ # region Preparing push_to_hub and model card
+ push_to_hub_model_id = training_args.push_to_hub_model_id
+ model_name = model_args.model_name_or_path.split("/")[-1]
+ if not push_to_hub_model_id:
+ if data_args.dataset_name is not None:
+ push_to_hub_model_id = f"{model_name}-finetuned-{data_args.dataset_name}"
+ else:
+ push_to_hub_model_id = f"{model_name}-finetuned-question-answering"
+
+ model_card_kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "question-answering"}
+ if data_args.dataset_name is not None:
+ model_card_kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ model_card_kwargs["dataset_args"] = data_args.dataset_config_name
+ model_card_kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ model_card_kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ callbacks = [
+ PushToHubCallback(
+ output_dir=training_args.output_dir,
+ hub_model_id=push_to_hub_model_id,
+ hub_token=training_args.push_to_hub_token,
+ tokenizer=tokenizer,
+ **model_card_kwargs,
+ )
+ ]
+ else:
+ callbacks = []
+ # endregion
+
+ # region Training and Evaluation
+
+ if training_args.do_train:
+ # Note that the validation and test datasets have been processed in a different way to the
+ # training datasets in this example, and so they don't have the same label structure.
+ # As such, we don't pass them directly to Keras, but instead get model predictions to evaluate
+ # after training.
+ model.fit(training_dataset, epochs=int(training_args.num_train_epochs), callbacks=callbacks)
+
+ if training_args.do_eval:
+ logger.info("*** Evaluation ***")
+
+ # In this example, we compute advanced metrics at the end of training, but
+ # if you'd like to compute metrics every epoch that are too complex to be written as
+ # standard Keras metrics, you can use our KerasMetricCallback. See
+ # https://huggingface.co/docs/transformers/main/en/main_classes/keras_callbacks
+
+ eval_predictions = model.predict(eval_dataset)
+ if isinstance(eval_predictions.start_logits, tf.RaggedTensor):
+ # If predictions are RaggedTensor, we densify them. Since they are logits, padding with 0 is a bad idea!
+ # The reason is that a logit of 0 can often end up as quite a high probability value, sometimes even
+ # the highest probability in a sample. Instead, we use a large negative value, which ensures that the
+ # padding positions are correctly masked.
+ eval_start_logits = eval_predictions.start_logits.to_tensor(default_value=-1000).numpy()
+ eval_end_logits = eval_predictions.end_logits.to_tensor(default_value=-1000).numpy()
+ else:
+ eval_start_logits = eval_predictions.start_logits
+ eval_end_logits = eval_predictions.end_logits
+
+ post_processed_eval = post_processing_function(
+ datasets["validation"],
+ processed_datasets["validation"],
+ (eval_start_logits, eval_end_logits),
+ )
+ metrics = compute_metrics(post_processed_eval)
+ logging.info("Evaluation metrics:")
+ for metric, value in metrics.items():
+ logging.info(f"{metric}: {value:.3f}")
+ if training_args.output_dir is not None:
+ output_eval_file = os.path.join(training_args.output_dir, "all_results.json")
+ with open(output_eval_file, "w") as writer:
+ writer.write(json.dumps(metrics))
+ # endregion
+
+ # region Prediction
+ if training_args.do_predict:
+ logger.info("*** Predict ***")
+
+ test_predictions = model.predict(predict_dataset)
+ if isinstance(test_predictions.start_logits, tf.RaggedTensor):
+ # If predictions are RaggedTensor, we densify them. Since they are logits, padding with 0 is a bad idea!
+ # The reason is that a logit of 0 can often end up as quite a high probability value, sometimes even
+ # the highest probability in a sample. Instead, we use a large negative value, which ensures that the
+ # padding positions are correctly masked.
+ test_start_logits = test_predictions.start_logits.to_tensor(default_value=-1000).numpy()
+ test_end_logits = test_predictions.end_logits.to_tensor(default_value=-1000).numpy()
+ else:
+ test_start_logits = test_predictions.start_logits
+ test_end_logits = test_predictions.end_logits
+ post_processed_test = post_processing_function(
+ datasets["test"],
+ processed_datasets["test"],
+ (test_start_logits, test_end_logits),
+ )
+ metrics = compute_metrics(post_processed_test)
+
+ logging.info("Test metrics:")
+ for metric, value in metrics.items():
+ logging.info(f"{metric}: {value:.3f}")
+ # endregion
+
+ if training_args.output_dir is not None and not training_args.push_to_hub:
+ # If we're not pushing to hub, at least save a local copy when we're done
+ model.save_pretrained(training_args.output_dir)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/tensorflow/question-answering/utils_qa.py b/docs/transformers/examples/tensorflow/question-answering/utils_qa.py
new file mode 100644
index 0000000000000000000000000000000000000000..f0cc5c26a6927179d83dab56d21f4acb357884ee
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/question-answering/utils_qa.py
@@ -0,0 +1,443 @@
+# Copyright 2020 The HuggingFace Team All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Post-processing utilities for question answering.
+"""
+
+import collections
+import json
+import logging
+import os
+from typing import Optional
+
+import numpy as np
+from tqdm.auto import tqdm
+
+
+logger = logging.getLogger(__name__)
+
+
+def postprocess_qa_predictions(
+ examples,
+ features,
+ predictions: tuple[np.ndarray, np.ndarray],
+ version_2_with_negative: bool = False,
+ n_best_size: int = 20,
+ max_answer_length: int = 30,
+ null_score_diff_threshold: float = 0.0,
+ output_dir: Optional[str] = None,
+ prefix: Optional[str] = None,
+ log_level: Optional[int] = logging.WARNING,
+):
+ """
+ Post-processes the predictions of a question-answering model to convert them to answers that are substrings of the
+ original contexts. This is the base postprocessing functions for models that only return start and end logits.
+
+ Args:
+ examples: The non-preprocessed dataset (see the main script for more information).
+ features: The processed dataset (see the main script for more information).
+ predictions (:obj:`Tuple[np.ndarray, np.ndarray]`):
+ The predictions of the model: two arrays containing the start logits and the end logits respectively. Its
+ first dimension must match the number of elements of :obj:`features`.
+ version_2_with_negative (:obj:`bool`, `optional`, defaults to :obj:`False`):
+ Whether or not the underlying dataset contains examples with no answers.
+ n_best_size (:obj:`int`, `optional`, defaults to 20):
+ The total number of n-best predictions to generate when looking for an answer.
+ max_answer_length (:obj:`int`, `optional`, defaults to 30):
+ The maximum length of an answer that can be generated. This is needed because the start and end predictions
+ are not conditioned on one another.
+ null_score_diff_threshold (:obj:`float`, `optional`, defaults to 0):
+ The threshold used to select the null answer: if the best answer has a score that is less than the score of
+ the null answer minus this threshold, the null answer is selected for this example (note that the score of
+ the null answer for an example giving several features is the minimum of the scores for the null answer on
+ each feature: all features must be aligned on the fact they `want` to predict a null answer).
+
+ Only useful when :obj:`version_2_with_negative` is :obj:`True`.
+ output_dir (:obj:`str`, `optional`):
+ If provided, the dictionaries of predictions, n_best predictions (with their scores and logits) and, if
+ :obj:`version_2_with_negative=True`, the dictionary of the scores differences between best and null
+ answers, are saved in `output_dir`.
+ prefix (:obj:`str`, `optional`):
+ If provided, the dictionaries mentioned above are saved with `prefix` added to their names.
+ log_level (:obj:`int`, `optional`, defaults to ``logging.WARNING``):
+ ``logging`` log level (e.g., ``logging.WARNING``)
+ """
+ if len(predictions) != 2:
+ raise ValueError("`predictions` should be a tuple with two elements (start_logits, end_logits).")
+ all_start_logits, all_end_logits = predictions
+
+ if len(predictions[0]) != len(features):
+ raise ValueError(f"Got {len(predictions[0])} predictions and {len(features)} features.")
+
+ # Build a map example to its corresponding features.
+ example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
+ features_per_example = collections.defaultdict(list)
+ for i, feature in enumerate(features):
+ features_per_example[example_id_to_index[feature["example_id"]]].append(i)
+
+ # The dictionaries we have to fill.
+ all_predictions = collections.OrderedDict()
+ all_nbest_json = collections.OrderedDict()
+ if version_2_with_negative:
+ scores_diff_json = collections.OrderedDict()
+
+ # Logging.
+ logger.setLevel(log_level)
+ logger.info(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
+
+ # Let's loop over all the examples!
+ for example_index, example in enumerate(tqdm(examples)):
+ # Those are the indices of the features associated to the current example.
+ feature_indices = features_per_example[example_index]
+
+ min_null_prediction = None
+ prelim_predictions = []
+
+ # Looping through all the features associated to the current example.
+ for feature_index in feature_indices:
+ # We grab the predictions of the model for this feature.
+ start_logits = all_start_logits[feature_index]
+ end_logits = all_end_logits[feature_index]
+ # This is what will allow us to map some the positions in our logits to span of texts in the original
+ # context.
+ offset_mapping = features[feature_index]["offset_mapping"]
+ # Optional `token_is_max_context`, if provided we will remove answers that do not have the maximum context
+ # available in the current feature.
+ token_is_max_context = features[feature_index].get("token_is_max_context", None)
+
+ # Update minimum null prediction.
+ feature_null_score = start_logits[0] + end_logits[0]
+ if min_null_prediction is None or min_null_prediction["score"] > feature_null_score:
+ min_null_prediction = {
+ "offsets": (0, 0),
+ "score": feature_null_score,
+ "start_logit": start_logits[0],
+ "end_logit": end_logits[0],
+ }
+
+ # Go through all possibilities for the `n_best_size` greater start and end logits.
+ start_indexes = np.argsort(start_logits)[-1 : -n_best_size - 1 : -1].tolist()
+ end_indexes = np.argsort(end_logits)[-1 : -n_best_size - 1 : -1].tolist()
+ for start_index in start_indexes:
+ for end_index in end_indexes:
+ # Don't consider out-of-scope answers, either because the indices are out of bounds or correspond
+ # to part of the input_ids that are not in the context.
+ if (
+ start_index >= len(offset_mapping)
+ or end_index >= len(offset_mapping)
+ or offset_mapping[start_index] is None
+ or len(offset_mapping[start_index]) < 2
+ or offset_mapping[end_index] is None
+ or len(offset_mapping[end_index]) < 2
+ ):
+ continue
+ # Don't consider answers with a length that is either < 0 or > max_answer_length.
+ if end_index < start_index or end_index - start_index + 1 > max_answer_length:
+ continue
+ # Don't consider answer that don't have the maximum context available (if such information is
+ # provided).
+ if token_is_max_context is not None and not token_is_max_context.get(str(start_index), False):
+ continue
+
+ prelim_predictions.append(
+ {
+ "offsets": (offset_mapping[start_index][0], offset_mapping[end_index][1]),
+ "score": start_logits[start_index] + end_logits[end_index],
+ "start_logit": start_logits[start_index],
+ "end_logit": end_logits[end_index],
+ }
+ )
+ if version_2_with_negative and min_null_prediction is not None:
+ # Add the minimum null prediction
+ prelim_predictions.append(min_null_prediction)
+ null_score = min_null_prediction["score"]
+
+ # Only keep the best `n_best_size` predictions.
+ predictions = sorted(prelim_predictions, key=lambda x: x["score"], reverse=True)[:n_best_size]
+
+ # Add back the minimum null prediction if it was removed because of its low score.
+ if (
+ version_2_with_negative
+ and min_null_prediction is not None
+ and not any(p["offsets"] == (0, 0) for p in predictions)
+ ):
+ predictions.append(min_null_prediction)
+
+ # Use the offsets to gather the answer text in the original context.
+ context = example["context"]
+ for pred in predictions:
+ offsets = pred.pop("offsets")
+ pred["text"] = context[offsets[0] : offsets[1]]
+
+ # In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
+ # failure.
+ if len(predictions) == 0 or (len(predictions) == 1 and predictions[0]["text"] == ""):
+ predictions.insert(0, {"text": "empty", "start_logit": 0.0, "end_logit": 0.0, "score": 0.0})
+
+ # Compute the softmax of all scores (we do it with numpy to stay independent from torch/tf in this file, using
+ # the LogSumExp trick).
+ scores = np.array([pred.pop("score") for pred in predictions])
+ exp_scores = np.exp(scores - np.max(scores))
+ probs = exp_scores / exp_scores.sum()
+
+ # Include the probabilities in our predictions.
+ for prob, pred in zip(probs, predictions):
+ pred["probability"] = prob
+
+ # Pick the best prediction. If the null answer is not possible, this is easy.
+ if not version_2_with_negative:
+ all_predictions[example["id"]] = predictions[0]["text"]
+ else:
+ # Otherwise we first need to find the best non-empty prediction.
+ i = 0
+ while predictions[i]["text"] == "":
+ i += 1
+ best_non_null_pred = predictions[i]
+
+ # Then we compare to the null prediction using the threshold.
+ score_diff = null_score - best_non_null_pred["start_logit"] - best_non_null_pred["end_logit"]
+ scores_diff_json[example["id"]] = float(score_diff) # To be JSON-serializable.
+ if score_diff > null_score_diff_threshold:
+ all_predictions[example["id"]] = ""
+ else:
+ all_predictions[example["id"]] = best_non_null_pred["text"]
+
+ # Make `predictions` JSON-serializable by casting np.float back to float.
+ all_nbest_json[example["id"]] = [
+ {k: (float(v) if isinstance(v, (np.float16, np.float32, np.float64)) else v) for k, v in pred.items()}
+ for pred in predictions
+ ]
+
+ # If we have an output_dir, let's save all those dicts.
+ if output_dir is not None:
+ if not os.path.isdir(output_dir):
+ raise OSError(f"{output_dir} is not a directory.")
+
+ prediction_file = os.path.join(
+ output_dir, "predictions.json" if prefix is None else f"{prefix}_predictions.json"
+ )
+ nbest_file = os.path.join(
+ output_dir, "nbest_predictions.json" if prefix is None else f"{prefix}_nbest_predictions.json"
+ )
+ if version_2_with_negative:
+ null_odds_file = os.path.join(
+ output_dir, "null_odds.json" if prefix is None else f"{prefix}_null_odds.json"
+ )
+
+ logger.info(f"Saving predictions to {prediction_file}.")
+ with open(prediction_file, "w") as writer:
+ writer.write(json.dumps(all_predictions, indent=4) + "\n")
+ logger.info(f"Saving nbest_preds to {nbest_file}.")
+ with open(nbest_file, "w") as writer:
+ writer.write(json.dumps(all_nbest_json, indent=4) + "\n")
+ if version_2_with_negative:
+ logger.info(f"Saving null_odds to {null_odds_file}.")
+ with open(null_odds_file, "w") as writer:
+ writer.write(json.dumps(scores_diff_json, indent=4) + "\n")
+
+ return all_predictions
+
+
+def postprocess_qa_predictions_with_beam_search(
+ examples,
+ features,
+ predictions: tuple[np.ndarray, np.ndarray],
+ version_2_with_negative: bool = False,
+ n_best_size: int = 20,
+ max_answer_length: int = 30,
+ start_n_top: int = 5,
+ end_n_top: int = 5,
+ output_dir: Optional[str] = None,
+ prefix: Optional[str] = None,
+ log_level: Optional[int] = logging.WARNING,
+):
+ """
+ Post-processes the predictions of a question-answering model with beam search to convert them to answers that are substrings of the
+ original contexts. This is the postprocessing functions for models that return start and end logits, indices, as well as
+ cls token predictions.
+
+ Args:
+ examples: The non-preprocessed dataset (see the main script for more information).
+ features: The processed dataset (see the main script for more information).
+ predictions (:obj:`Tuple[np.ndarray, np.ndarray]`):
+ The predictions of the model: two arrays containing the start logits and the end logits respectively. Its
+ first dimension must match the number of elements of :obj:`features`.
+ version_2_with_negative (:obj:`bool`, `optional`, defaults to :obj:`False`):
+ Whether or not the underlying dataset contains examples with no answers.
+ n_best_size (:obj:`int`, `optional`, defaults to 20):
+ The total number of n-best predictions to generate when looking for an answer.
+ max_answer_length (:obj:`int`, `optional`, defaults to 30):
+ The maximum length of an answer that can be generated. This is needed because the start and end predictions
+ are not conditioned on one another.
+ start_n_top (:obj:`int`, `optional`, defaults to 5):
+ The number of top start logits too keep when searching for the :obj:`n_best_size` predictions.
+ end_n_top (:obj:`int`, `optional`, defaults to 5):
+ The number of top end logits too keep when searching for the :obj:`n_best_size` predictions.
+ output_dir (:obj:`str`, `optional`):
+ If provided, the dictionaries of predictions, n_best predictions (with their scores and logits) and, if
+ :obj:`version_2_with_negative=True`, the dictionary of the scores differences between best and null
+ answers, are saved in `output_dir`.
+ prefix (:obj:`str`, `optional`):
+ If provided, the dictionaries mentioned above are saved with `prefix` added to their names.
+ log_level (:obj:`int`, `optional`, defaults to ``logging.WARNING``):
+ ``logging`` log level (e.g., ``logging.WARNING``)
+ """
+ if len(predictions) != 5:
+ raise ValueError("`predictions` should be a tuple with five elements.")
+ start_top_log_probs, start_top_index, end_top_log_probs, end_top_index, cls_logits = predictions
+
+ if len(predictions[0]) != len(features):
+ raise ValueError(f"Got {len(predictions[0])} predictions and {len(features)} features.")
+
+ # Build a map example to its corresponding features.
+ example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
+ features_per_example = collections.defaultdict(list)
+ for i, feature in enumerate(features):
+ features_per_example[example_id_to_index[feature["example_id"]]].append(i)
+
+ # The dictionaries we have to fill.
+ all_predictions = collections.OrderedDict()
+ all_nbest_json = collections.OrderedDict()
+ scores_diff_json = collections.OrderedDict() if version_2_with_negative else None
+
+ # Logging.
+ logger.setLevel(log_level)
+ logger.info(f"Post-processing {len(examples)} example predictions split into {len(features)} features.")
+
+ # Let's loop over all the examples!
+ for example_index, example in enumerate(tqdm(examples)):
+ # Those are the indices of the features associated to the current example.
+ feature_indices = features_per_example[example_index]
+
+ min_null_score = None
+ prelim_predictions = []
+
+ # Looping through all the features associated to the current example.
+ for feature_index in feature_indices:
+ # We grab the predictions of the model for this feature.
+ start_log_prob = start_top_log_probs[feature_index]
+ start_indexes = start_top_index[feature_index]
+ end_log_prob = end_top_log_probs[feature_index]
+ end_indexes = end_top_index[feature_index]
+ feature_null_score = cls_logits[feature_index]
+ # This is what will allow us to map some the positions in our logits to span of texts in the original
+ # context.
+ offset_mapping = features[feature_index]["offset_mapping"]
+ # Optional `token_is_max_context`, if provided we will remove answers that do not have the maximum context
+ # available in the current feature.
+ token_is_max_context = features[feature_index].get("token_is_max_context", None)
+
+ # Update minimum null prediction
+ if min_null_score is None or feature_null_score < min_null_score:
+ min_null_score = feature_null_score
+
+ # Go through all possibilities for the `n_start_top`/`n_end_top` greater start and end logits.
+ for i in range(start_n_top):
+ for j in range(end_n_top):
+ start_index = int(start_indexes[i])
+ j_index = i * end_n_top + j
+ end_index = int(end_indexes[j_index])
+ # Don't consider out-of-scope answers (last part of the test should be unnecessary because of the
+ # p_mask but let's not take any risk)
+ if (
+ start_index >= len(offset_mapping)
+ or end_index >= len(offset_mapping)
+ or offset_mapping[start_index] is None
+ or len(offset_mapping[start_index]) < 2
+ or offset_mapping[end_index] is None
+ or len(offset_mapping[end_index]) < 2
+ ):
+ continue
+
+ # Don't consider answers with a length negative or > max_answer_length.
+ if end_index < start_index or end_index - start_index + 1 > max_answer_length:
+ continue
+ # Don't consider answer that don't have the maximum context available (if such information is
+ # provided).
+ if token_is_max_context is not None and not token_is_max_context.get(str(start_index), False):
+ continue
+ prelim_predictions.append(
+ {
+ "offsets": (offset_mapping[start_index][0], offset_mapping[end_index][1]),
+ "score": start_log_prob[i] + end_log_prob[j_index],
+ "start_log_prob": start_log_prob[i],
+ "end_log_prob": end_log_prob[j_index],
+ }
+ )
+
+ # Only keep the best `n_best_size` predictions.
+ predictions = sorted(prelim_predictions, key=lambda x: x["score"], reverse=True)[:n_best_size]
+
+ # Use the offsets to gather the answer text in the original context.
+ context = example["context"]
+ for pred in predictions:
+ offsets = pred.pop("offsets")
+ pred["text"] = context[offsets[0] : offsets[1]]
+
+ # In the very rare edge case we have not a single non-null prediction, we create a fake prediction to avoid
+ # failure.
+ if len(predictions) == 0:
+ # Without predictions min_null_score is going to be None and None will cause an exception later
+ min_null_score = -2e-6
+ predictions.insert(0, {"text": "", "start_logit": -1e-6, "end_logit": -1e-6, "score": min_null_score})
+
+ # Compute the softmax of all scores (we do it with numpy to stay independent from torch/tf in this file, using
+ # the LogSumExp trick).
+ scores = np.array([pred.pop("score") for pred in predictions])
+ exp_scores = np.exp(scores - np.max(scores))
+ probs = exp_scores / exp_scores.sum()
+
+ # Include the probabilities in our predictions.
+ for prob, pred in zip(probs, predictions):
+ pred["probability"] = prob
+
+ # Pick the best prediction and set the probability for the null answer.
+ all_predictions[example["id"]] = predictions[0]["text"]
+ if version_2_with_negative:
+ scores_diff_json[example["id"]] = float(min_null_score)
+
+ # Make `predictions` JSON-serializable by casting np.float back to float.
+ all_nbest_json[example["id"]] = [
+ {k: (float(v) if isinstance(v, (np.float16, np.float32, np.float64)) else v) for k, v in pred.items()}
+ for pred in predictions
+ ]
+
+ # If we have an output_dir, let's save all those dicts.
+ if output_dir is not None:
+ if not os.path.isdir(output_dir):
+ raise OSError(f"{output_dir} is not a directory.")
+
+ prediction_file = os.path.join(
+ output_dir, "predictions.json" if prefix is None else f"{prefix}_predictions.json"
+ )
+ nbest_file = os.path.join(
+ output_dir, "nbest_predictions.json" if prefix is None else f"{prefix}_nbest_predictions.json"
+ )
+ if version_2_with_negative:
+ null_odds_file = os.path.join(
+ output_dir, "null_odds.json" if prefix is None else f"{prefix}_null_odds.json"
+ )
+
+ logger.info(f"Saving predictions to {prediction_file}.")
+ with open(prediction_file, "w") as writer:
+ writer.write(json.dumps(all_predictions, indent=4) + "\n")
+ logger.info(f"Saving nbest_preds to {nbest_file}.")
+ with open(nbest_file, "w") as writer:
+ writer.write(json.dumps(all_nbest_json, indent=4) + "\n")
+ if version_2_with_negative:
+ logger.info(f"Saving null_odds to {null_odds_file}.")
+ with open(null_odds_file, "w") as writer:
+ writer.write(json.dumps(scores_diff_json, indent=4) + "\n")
+
+ return all_predictions, scores_diff_json
diff --git a/docs/transformers/examples/tensorflow/summarization/README.md b/docs/transformers/examples/tensorflow/summarization/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..032af0241c77ae32865cc8a1c7d518b3ec8680d3
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/summarization/README.md
@@ -0,0 +1,40 @@
+
+
+# Summarization example
+
+This script shows an example of training a *summarization* model with the 🤗 Transformers library.
+For straightforward use-cases you may be able to use these scripts without modification, although we have also
+included comments in the code to indicate areas that you may need to adapt to your own projects.
+
+### Multi-GPU and TPU usage
+
+By default, these scripts use a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
+can also be used by passing the name of the TPU resource with the `--tpu` argument.
+
+### Example command
+```
+python run_summarization.py \
+--model_name_or_path facebook/bart-base \
+--dataset_name cnn_dailymail \
+--dataset_config "3.0.0" \
+--output_dir /tmp/tst-summarization \
+--per_device_train_batch_size 8 \
+--per_device_eval_batch_size 16 \
+--num_train_epochs 3 \
+--do_train \
+--do_eval
+```
\ No newline at end of file
diff --git a/docs/transformers/examples/tensorflow/summarization/requirements.txt b/docs/transformers/examples/tensorflow/summarization/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..99aff2bb32b2bb92f7628eb9bab4c7535d4c7f92
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/summarization/requirements.txt
@@ -0,0 +1,3 @@
+datasets >= 1.4.0
+tensorflow >= 2.3.0
+evaluate >= 0.2.0
\ No newline at end of file
diff --git a/docs/transformers/examples/tensorflow/summarization/run_summarization.py b/docs/transformers/examples/tensorflow/summarization/run_summarization.py
new file mode 100644
index 0000000000000000000000000000000000000000..2a2ef3fb767716df64dfc34c798472e8fa147d7a
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/summarization/run_summarization.py
@@ -0,0 +1,749 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for summarization.
+"""
+# You can also adapt this script on your own sequence to sequence task. Pointers for this are left as comments.
+
+import json
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import datasets
+import evaluate
+import nltk # Here to have a nice missing dependency error message early on
+import numpy as np
+import tensorflow as tf
+from datasets import load_dataset
+from filelock import FileLock
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoTokenizer,
+ DataCollatorForSeq2Seq,
+ HfArgumentParser,
+ KerasMetricCallback,
+ PushToHubCallback,
+ TFAutoModelForSeq2SeqLM,
+ TFTrainingArguments,
+ create_optimizer,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, is_offline_mode, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# region Checking dependencies
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
+
+logger = logging.getLogger(__name__)
+
+try:
+ nltk.data.find("tokenizers/punkt")
+except (LookupError, OSError):
+ if is_offline_mode():
+ raise LookupError(
+ "Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
+ )
+ with FileLock(".lock") as lock:
+ nltk.download("punkt", quiet=True)
+# endregion
+
+
+# region Arguments
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ text_column: Optional[str] = field(
+ default=None,
+ metadata={"help": "The name of the column in the datasets containing the full texts (for summarization)."},
+ )
+ summary_column: Optional[str] = field(
+ default=None,
+ metadata={"help": "The name of the column in the datasets containing the summaries (for summarization)."},
+ )
+ train_file: Optional[str] = field(
+ default=None, metadata={"help": "The input training data file (a jsonlines or csv file)."}
+ )
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "An optional input evaluation data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
+ )
+ },
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": "An optional input test data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_source_length: Optional[int] = field(
+ default=1024,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ max_target_length: Optional[int] = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total sequence length for target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ val_max_target_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total sequence length for validation target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
+ "This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
+ "during ``evaluate`` and ``predict``."
+ )
+ },
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to model maximum sentence length. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
+ "efficient on GPU but very bad for TPU."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ num_beams: Optional[int] = field(
+ default=1,
+ metadata={
+ "help": (
+ "Number of beams to use for evaluation. This argument will be passed to ``model.generate``, "
+ "which is used during ``evaluate`` and ``predict``."
+ )
+ },
+ )
+ ignore_pad_token_for_loss: bool = field(
+ default=True,
+ metadata={
+ "help": "Whether to ignore the tokens corresponding to padded labels in the loss computation or not."
+ },
+ )
+ source_prefix: Optional[str] = field(
+ default=None, metadata={"help": "A prefix to add before every source text (useful for T5 models)."}
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ if self.val_max_target_length is None:
+ self.val_max_target_length = self.max_target_length
+
+
+# endregion
+
+# region Dataset name mappings
+summarization_name_mapping = {
+ "amazon_reviews_multi": ("review_body", "review_title"),
+ "big_patent": ("description", "abstract"),
+ "cnn_dailymail": ("article", "highlights"),
+ "orange_sum": ("text", "summary"),
+ "pn_summary": ("article", "summary"),
+ "psc": ("extract_text", "summary_text"),
+ "samsum": ("dialogue", "summary"),
+ "thaisum": ("body", "summary"),
+ "xglue": ("news_body", "news_title"),
+ "xsum": ("document", "summary"),
+ "wiki_summary": ("article", "highlights"),
+ "multi_news": ("document", "summary"),
+}
+# endregion
+
+
+def main():
+ # region Argument parsing
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_summarization", model_args, data_args, framework="tensorflow")
+ # endregion
+
+ # region Logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+ logger.setLevel(logging.INFO)
+ datasets.utils.logging.set_verbosity(logging.INFO)
+ transformers.utils.logging.set_verbosity(logging.INFO)
+
+ # Log on each process the small summary:
+ logger.info(f"Training/evaluation parameters {training_args}")
+ # endregion
+
+ # region T5 special-casing
+ if data_args.source_prefix is None and model_args.model_name_or_path in [
+ "google-t5/t5-small",
+ "google-t5/t5-base",
+ "google-t5/t5-large",
+ "google-t5/t5-3b",
+ "google-t5/t5-11b",
+ ]:
+ logger.warning(
+ "You're running a t5 model but didn't provide a source prefix, which is the expected, e.g. with "
+ "`--source_prefix 'summarize: ' `"
+ )
+ # endregion
+
+ # region Detecting last checkpoint
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+ # endregion
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # region Load datasets
+ # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files this script will use the first column for the full texts and the second column for the
+ # summaries (unless you specify column names for this with the `text_column` and `summary_column` arguments).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if data_args.test_file is not None:
+ data_files["test"] = data_args.test_file
+ extension = data_args.test_file.split(".")[-1]
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+ # endregion
+
+ # region Load model config and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ prefix = data_args.source_prefix if data_args.source_prefix is not None else ""
+ # endregion
+
+ # region Dataset preprocessing
+ # We need to tokenize inputs and targets.
+ if training_args.do_train:
+ column_names = raw_datasets["train"].column_names
+ elif training_args.do_eval:
+ column_names = raw_datasets["validation"].column_names
+ else:
+ logger.info("There is nothing to do. Please pass `do_train`, and/or `do_eval`.")
+ return
+
+ # Get the column names for input/target.
+ dataset_columns = summarization_name_mapping.get(data_args.dataset_name, None)
+ if data_args.text_column is None:
+ text_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
+ else:
+ text_column = data_args.text_column
+ if text_column not in column_names:
+ raise ValueError(
+ f"--text_column' value '{data_args.text_column}' needs to be one of: {', '.join(column_names)}"
+ )
+ if data_args.summary_column is None:
+ summary_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
+ else:
+ summary_column = data_args.summary_column
+ if summary_column not in column_names:
+ raise ValueError(
+ f"--summary_column' value '{data_args.summary_column}' needs to be one of: {', '.join(column_names)}"
+ )
+
+ # Temporarily set max_target_length for training.
+ max_target_length = data_args.max_target_length
+ padding = "max_length" if data_args.pad_to_max_length else False
+
+ def preprocess_function(examples):
+ inputs = examples[text_column]
+ targets = examples[summary_column]
+ inputs = [prefix + inp for inp in inputs]
+ model_inputs = tokenizer(inputs, max_length=data_args.max_source_length, padding=padding, truncation=True)
+
+ # Tokenize targets with the `text_target` keyword argument
+ labels = tokenizer(text_target=targets, max_length=max_target_length, padding=padding, truncation=True)
+
+ # If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
+ # padding in the loss.
+ if padding == "max_length" and data_args.ignore_pad_token_for_loss:
+ labels["input_ids"] = [
+ [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
+ ]
+
+ model_inputs["labels"] = labels["input_ids"]
+ return model_inputs
+
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ train_dataset = train_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+ else:
+ train_dataset = None
+
+ if training_args.do_eval:
+ max_target_length = data_args.val_max_target_length
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = raw_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+ eval_dataset = eval_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+ else:
+ eval_dataset = None
+ # endregion
+
+ # region Text preprocessing
+ def postprocess_text(preds, labels):
+ preds = [pred.strip() for pred in preds]
+ labels = [label.strip() for label in labels]
+
+ # rougeLSum expects newline after each sentence
+ preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
+ labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
+
+ return preds, labels
+
+ # endregion
+
+ with training_args.strategy.scope():
+ # region Prepare model
+ model = TFAutoModelForSeq2SeqLM.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embeddings = model.get_input_embeddings()
+
+ # Matt: This is a temporary workaround as we transition our models to exclusively using Keras embeddings.
+ # As soon as the transition is complete, all embeddings should be keras.Embeddings layers, and
+ # the weights will always be in embeddings.embeddings.
+ if hasattr(embeddings, "embeddings"):
+ embedding_size = embeddings.embeddings.shape[0]
+ else:
+ embedding_size = embeddings.weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+ # endregion
+
+ # region Prepare TF Dataset objects
+ if model.config.decoder_start_token_id is None:
+ raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
+
+ label_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
+ data_collator = DataCollatorForSeq2Seq(
+ tokenizer,
+ model=model,
+ label_pad_token_id=label_pad_token_id,
+ pad_to_multiple_of=128, # Reduce the number of unique shapes for XLA, especially for generation
+ return_tensors="np",
+ )
+
+ dataset_options = tf.data.Options()
+ dataset_options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
+
+ num_replicas = training_args.strategy.num_replicas_in_sync
+ total_train_batch_size = training_args.per_device_train_batch_size * num_replicas
+ total_eval_batch_size = training_args.per_device_eval_batch_size * num_replicas
+
+ # model.prepare_tf_dataset() wraps a Hugging Face dataset in a tf.data.Dataset which is ready to use in
+ # training. This is the recommended way to use a Hugging Face dataset when training with Keras. You can also
+ # use the lower-level dataset.to_tf_dataset() method, but you will have to specify things like column names
+ # yourself if you use this method, whereas they are automatically inferred from the model input names when
+ # using model.prepare_tf_dataset()
+ # For more info see the docs:
+ # https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.TFPreTrainedModel.prepare_tf_dataset
+ # https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.to_tf_dataset
+
+ tf_train_dataset = model.prepare_tf_dataset(
+ train_dataset,
+ collate_fn=data_collator,
+ batch_size=total_train_batch_size,
+ shuffle=True,
+ ).with_options(dataset_options)
+ tf_eval_dataset = model.prepare_tf_dataset(
+ eval_dataset,
+ collate_fn=data_collator,
+ batch_size=total_eval_batch_size,
+ shuffle=False,
+ ).with_options(dataset_options)
+ # endregion
+
+ # region Optimizer, loss and LR scheduling
+ num_train_steps = int(len(tf_train_dataset) * training_args.num_train_epochs)
+ if training_args.warmup_steps > 0:
+ num_warmup_steps = training_args.warmup_steps
+ elif training_args.warmup_ratio > 0:
+ num_warmup_steps = int(num_train_steps * training_args.warmup_ratio)
+ else:
+ num_warmup_steps = 0
+ if training_args.do_train:
+ optimizer, lr_schedule = create_optimizer(
+ init_lr=training_args.learning_rate,
+ num_train_steps=num_train_steps,
+ num_warmup_steps=num_warmup_steps,
+ adam_beta1=training_args.adam_beta1,
+ adam_beta2=training_args.adam_beta2,
+ adam_epsilon=training_args.adam_epsilon,
+ weight_decay_rate=training_args.weight_decay,
+ adam_global_clipnorm=training_args.max_grad_norm,
+ )
+ else:
+ optimizer = "sgd" # Just write anything because we won't be using it
+
+ # endregion
+
+ # region Metric and KerasMetricCallback
+ if training_args.do_eval:
+ metric = evaluate.load("rouge", cache_dir=model_args.cache_dir)
+
+ if data_args.val_max_target_length is None:
+ data_args.val_max_target_length = data_args.max_target_length
+
+ gen_kwargs = {
+ "max_length": data_args.val_max_target_length if data_args is not None else config.max_length,
+ "num_beams": data_args.num_beams,
+ "no_repeat_ngram_size": 0, # Not supported under XLA right now, and some models set it by default
+ }
+
+ def compute_metrics(preds):
+ predictions, labels = preds
+ if isinstance(predictions, tuple):
+ predictions = predictions[0]
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+ decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
+ metrics = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
+ # Only print the mid f-measures, but there are a lot of other statistics in there too!
+ metrics = {key: round(val.mid.fmeasure * 100, 4) for key, val in metrics.items()}
+ return metrics
+
+ # The KerasMetricCallback allows metrics that are too complex to write as standard Keras metrics
+ # to be computed each epoch. Any Python code can be included in the metric_fn. This is especially
+ # useful for metrics like BLEU and ROUGE that perform string comparisons on decoded model outputs.
+ # For more information, see the docs at
+ # https://huggingface.co/docs/transformers/main_classes/keras_callbacks#transformers.KerasMetricCallback
+
+ metric_callback = KerasMetricCallback(
+ metric_fn=compute_metrics,
+ eval_dataset=tf_eval_dataset,
+ predict_with_generate=True,
+ use_xla_generation=True,
+ generate_kwargs=gen_kwargs,
+ )
+ callbacks = [metric_callback]
+ else:
+ callbacks = []
+ # endregion
+
+ # region Preparing push_to_hub and model card
+ push_to_hub_model_id = training_args.push_to_hub_model_id
+ model_name = model_args.model_name_or_path.split("/")[-1]
+ if not push_to_hub_model_id:
+ if data_args.dataset_name is not None:
+ push_to_hub_model_id = f"{model_name}-finetuned-{data_args.dataset_name}"
+ else:
+ push_to_hub_model_id = f"{model_name}-finetuned-summarization"
+
+ model_card_kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "summarization"}
+ if data_args.dataset_name is not None:
+ model_card_kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ model_card_kwargs["dataset_args"] = data_args.dataset_config_name
+ model_card_kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ model_card_kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ # Because this training can be quite long, we save once per epoch.
+ callbacks.append(
+ PushToHubCallback(
+ output_dir=training_args.output_dir,
+ hub_model_id=push_to_hub_model_id,
+ hub_token=training_args.push_to_hub_token,
+ tokenizer=tokenizer,
+ **model_card_kwargs,
+ )
+ )
+ # endregion
+
+ # region Training
+ # Transformers models compute the right loss for their task by default when labels are passed, and will
+ # use this for training unless you specify your own loss function in compile().
+ model.compile(optimizer=optimizer, jit_compile=training_args.xla)
+ eval_metrics = None
+ if training_args.do_train:
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {training_args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {training_args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size = {total_train_batch_size}")
+ logger.info(f" Total optimization steps = {num_train_steps}")
+
+ if training_args.xla and not data_args.pad_to_max_length:
+ logger.warning(
+ "XLA training may be slow at first when --pad_to_max_length is not set "
+ "until all possible shapes have been compiled."
+ )
+ history = model.fit(tf_train_dataset, epochs=int(training_args.num_train_epochs), callbacks=callbacks)
+ eval_metrics = {key: val[-1] for key, val in history.history.items()}
+ # endregion
+
+ # region Validation
+
+ if training_args.do_eval and not training_args.do_train:
+ # Do a standalone evaluation run
+ logger.info("Evaluation...")
+
+ # Compiling generation with XLA yields enormous speedups, see https://huggingface.co/blog/tf-xla-generate
+ @tf.function(jit_compile=True)
+ def generate(**kwargs):
+ return model.generate(**kwargs)
+
+ for batch, labels in tf_eval_dataset:
+ batch.update(gen_kwargs)
+ generated_tokens = generate(**batch)
+ if isinstance(generated_tokens, tuple):
+ generated_tokens = generated_tokens[0]
+ decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+ decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
+
+ metric.add_batch(predictions=decoded_preds, references=decoded_labels)
+
+ eval_metrics = metric.compute(use_stemmer=True)
+
+ result = {key: round(val.mid.fmeasure * 100, 4) for key, val in eval_metrics.items()}
+ logger.info(result)
+ # endregion
+
+ if training_args.output_dir is not None and eval_metrics is not None:
+ output_eval_file = os.path.join(training_args.output_dir, "all_results.json")
+ with open(output_eval_file, "w") as writer:
+ writer.write(json.dumps(eval_metrics))
+
+ if training_args.output_dir is not None and not training_args.push_to_hub:
+ # If we're not pushing to hub, at least save a local copy when we're done
+ model.save_pretrained(training_args.output_dir)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/tensorflow/test_tensorflow_examples.py b/docs/transformers/examples/tensorflow/test_tensorflow_examples.py
new file mode 100644
index 0000000000000000000000000000000000000000..46ed20c021d2716e092f7b925536fb8bd2f13da1
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/test_tensorflow_examples.py
@@ -0,0 +1,337 @@
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import argparse
+import json
+import logging
+import os
+import sys
+from unittest import skip
+from unittest.mock import patch
+
+import tensorflow as tf
+from packaging.version import parse
+
+
+try:
+ import tf_keras as keras
+except (ModuleNotFoundError, ImportError):
+ import keras
+
+ if parse(keras.__version__).major > 2:
+ raise ValueError(
+ "Your currently installed version of Keras is Keras 3, but this is not yet supported in "
+ "Transformers. Please install the backwards-compatible tf-keras package with "
+ "`pip install tf-keras`."
+ )
+
+from transformers.testing_utils import TestCasePlus, get_gpu_count, slow
+
+
+SRC_DIRS = [
+ os.path.join(os.path.dirname(__file__), dirname)
+ for dirname in [
+ "text-generation",
+ "text-classification",
+ "token-classification",
+ "language-modeling",
+ "multiple-choice",
+ "question-answering",
+ "summarization",
+ "translation",
+ "image-classification",
+ ]
+]
+sys.path.extend(SRC_DIRS)
+
+
+if SRC_DIRS is not None:
+ import run_clm
+ import run_image_classification
+ import run_mlm
+ import run_ner
+ import run_qa as run_squad
+ import run_summarization
+ import run_swag
+ import run_text_classification
+ import run_translation
+
+
+logging.basicConfig(level=logging.DEBUG)
+
+logger = logging.getLogger()
+
+
+def get_setup_file():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("-f")
+ args = parser.parse_args()
+ return args.f
+
+
+def get_results(output_dir):
+ results = {}
+ path = os.path.join(output_dir, "all_results.json")
+ if os.path.exists(path):
+ with open(path) as f:
+ results = json.load(f)
+ else:
+ raise ValueError(f"can't find {path}")
+ return results
+
+
+def is_cuda_available():
+ return bool(tf.config.list_physical_devices("GPU"))
+
+
+stream_handler = logging.StreamHandler(sys.stdout)
+logger.addHandler(stream_handler)
+
+
+class ExamplesTests(TestCasePlus):
+ @skip("Skipping until shape inference for to_tf_dataset PR is merged.")
+ def test_run_text_classification(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_text_classification.py
+ --model_name_or_path distilbert/distilbert-base-uncased
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --train_file ./tests/fixtures/tests_samples/MRPC/train.csv
+ --validation_file ./tests/fixtures/tests_samples/MRPC/dev.csv
+ --do_train
+ --do_eval
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --learning_rate=1e-4
+ --max_steps=10
+ --warmup_steps=2
+ --seed=42
+ --max_seq_length=128
+ """.split()
+
+ if is_cuda_available():
+ testargs.append("--fp16")
+
+ with patch.object(sys, "argv", testargs):
+ run_text_classification.main()
+ # Reset the mixed precision policy so we don't break other tests
+ keras.mixed_precision.set_global_policy("float32")
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["eval_accuracy"], 0.75)
+
+ def test_run_clm(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_clm.py
+ --model_name_or_path distilbert/distilgpt2
+ --train_file ./tests/fixtures/sample_text.txt
+ --validation_file ./tests/fixtures/sample_text.txt
+ --do_train
+ --do_eval
+ --block_size 128
+ --per_device_train_batch_size 2
+ --per_device_eval_batch_size 1
+ --num_train_epochs 2
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ """.split()
+
+ if len(tf.config.list_physical_devices("GPU")) > 1:
+ # Skipping because there are not enough batches to train the model + would need a drop_last to work.
+ return
+
+ with patch.object(sys, "argv", testargs):
+ run_clm.main()
+ result = get_results(tmp_dir)
+ self.assertLess(result["eval_perplexity"], 100)
+
+ def test_run_mlm(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_mlm.py
+ --model_name_or_path distilbert/distilroberta-base
+ --train_file ./tests/fixtures/sample_text.txt
+ --validation_file ./tests/fixtures/sample_text.txt
+ --max_seq_length 64
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --do_train
+ --do_eval
+ --prediction_loss_only
+ --num_train_epochs=1
+ --learning_rate=1e-4
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_mlm.main()
+ result = get_results(tmp_dir)
+ self.assertLess(result["eval_perplexity"], 42)
+
+ def test_run_ner(self):
+ # with so little data distributed training needs more epochs to get the score on par with 0/1 gpu
+ epochs = 7 if get_gpu_count() > 1 else 2
+
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_ner.py
+ --model_name_or_path google-bert/bert-base-uncased
+ --train_file tests/fixtures/tests_samples/conll/sample.json
+ --validation_file tests/fixtures/tests_samples/conll/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --do_train
+ --do_eval
+ --warmup_steps=2
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=2
+ --num_train_epochs={epochs}
+ --seed 7
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_ner.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["accuracy"], 0.75)
+
+ def test_run_squad(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_qa.py
+ --model_name_or_path google-bert/bert-base-uncased
+ --version_2_with_negative
+ --train_file tests/fixtures/tests_samples/SQUAD/sample.json
+ --validation_file tests/fixtures/tests_samples/SQUAD/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --max_steps=10
+ --warmup_steps=2
+ --do_train
+ --do_eval
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_squad.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["f1"], 30)
+ self.assertGreaterEqual(result["exact"], 30)
+
+ def test_run_swag(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_swag.py
+ --model_name_or_path google-bert/bert-base-uncased
+ --train_file tests/fixtures/tests_samples/swag/sample.json
+ --validation_file tests/fixtures/tests_samples/swag/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --max_steps=20
+ --warmup_steps=2
+ --do_train
+ --do_eval
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_swag.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["val_accuracy"], 0.8)
+
+ @slow
+ def test_run_summarization(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_summarization.py
+ --model_name_or_path google-t5/t5-small
+ --train_file tests/fixtures/tests_samples/xsum/sample.json
+ --validation_file tests/fixtures/tests_samples/xsum/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --max_steps=50
+ --warmup_steps=8
+ --do_train
+ --do_eval
+ --learning_rate=2e-4
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_summarization.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["rouge1"], 10)
+ self.assertGreaterEqual(result["rouge2"], 2)
+ self.assertGreaterEqual(result["rougeL"], 7)
+ self.assertGreaterEqual(result["rougeLsum"], 7)
+
+ @slow
+ def test_run_translation(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_translation.py
+ --model_name_or_path Rocketknight1/student_marian_en_ro_6_1
+ --source_lang en
+ --target_lang ro
+ --train_file tests/fixtures/tests_samples/wmt16/sample.json
+ --validation_file tests/fixtures/tests_samples/wmt16/sample.json
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --warmup_steps=8
+ --do_train
+ --do_eval
+ --learning_rate=3e-3
+ --num_train_epochs 12
+ --per_device_train_batch_size=2
+ --per_device_eval_batch_size=1
+ --source_lang en_XX
+ --target_lang ro_RO
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_translation.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["bleu"], 30)
+
+ def test_run_image_classification(self):
+ tmp_dir = self.get_auto_remove_tmp_dir()
+ testargs = f"""
+ run_image_classification.py
+ --dataset_name hf-internal-testing/cats_vs_dogs_sample
+ --trust_remote_code
+ --model_name_or_path microsoft/resnet-18
+ --do_train
+ --do_eval
+ --learning_rate 1e-4
+ --per_device_train_batch_size 2
+ --per_device_eval_batch_size 1
+ --output_dir {tmp_dir}
+ --overwrite_output_dir
+ --dataloader_num_workers 16
+ --num_train_epochs 2
+ --train_val_split 0.1
+ --seed 42
+ --ignore_mismatched_sizes True
+ """.split()
+
+ with patch.object(sys, "argv", testargs):
+ run_image_classification.main()
+ result = get_results(tmp_dir)
+ self.assertGreaterEqual(result["accuracy"], 0.7)
diff --git a/docs/transformers/examples/tensorflow/text-classification/README.md b/docs/transformers/examples/tensorflow/text-classification/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..08d0324b51dd94729716aaa3c52b85ceb7259ec8
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/text-classification/README.md
@@ -0,0 +1,115 @@
+
+
+# Text classification examples
+
+This folder contains some scripts showing examples of *text classification* with the 🤗 Transformers library.
+For straightforward use-cases you may be able to use these scripts without modification, although we have also
+included comments in the code to indicate areas that you may need to adapt to your own projects.
+
+## run_text_classification.py
+
+This script handles perhaps the single most common use-case for this entire library: Training an NLP classifier
+on your own training data. This can be whatever you want - you could classify text as abusive/hateful or
+allowable, or forum posts as spam or not-spam, or classify the genre of a headline as politics, sports or any
+number of other categories. Any task that involves classifying natural language into two or more different categories
+can work with this! You can even do regression, such as predicting the score on a 1-10 scale that a user gave,
+given the text of their review.
+
+The preferred input format is either a CSV or newline-delimited JSON file that contains a `sentence1` and
+`label` field. If your task involves comparing two texts (for example, if your classifier
+is deciding whether two sentences are paraphrases of each other, or were written by the same author) then you should also include a `sentence2` field in each example. If you do not have a `sentence1` field then the script will assume the non-label fields are the input text, which
+may not always be what you want, especially if you have more than two fields!
+
+Here is a snippet of a valid input JSON file, though note that your texts can be much longer than these, and are not constrained
+(despite the field name) to being single grammatical sentences:
+```json
+{"sentence1": "COVID-19 vaccine updates: How is the rollout proceeding?", "label": "news"}
+{"sentence1": "Manchester United celebrates Europa League success", "label": "sports"}
+```
+
+### Usage notes
+If your inputs are long (more than ~60-70 words), you may wish to increase the `--max_seq_length` argument
+beyond the default value of 128. The maximum supported value for most models is 512 (about 200-300 words),
+and some can handle even longer. This will come at a cost in runtime and memory use, however.
+
+We assume that your labels represent *categories*, even if they are integers, since text classification
+is a much more common task than text regression. If your labels are floats, however, the script will assume
+you want to do regression. This is something you can edit yourself if your use-case requires it!
+
+After training, the model will be saved to `--output_dir`. Once your model is trained, you can get predictions
+by calling the script without a `--train_file` or `--validation_file`; simply pass it the output_dir containing
+the trained model and a `--test_file` and it will write its predictions to a text file for you.
+
+### Multi-GPU and TPU usage
+
+By default, the script uses a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
+can also be used by passing the name of the TPU resource with the `--tpu` argument.
+
+### Memory usage and data loading
+
+One thing to note is that all data is loaded into memory in this script. Most text classification datasets are small
+enough that this is not an issue, but if you have a very large dataset you will need to modify the script to handle
+data streaming. This is particularly challenging for TPUs, given the stricter requirements and the sheer volume of data
+required to keep them fed. A full explanation of all the possible pitfalls is a bit beyond this example script and
+README, but for more information you can see the 'Input Datasets' section of
+[this document](https://www.tensorflow.org/guide/tpu).
+
+### Example command
+```bash
+python run_text_classification.py \
+--model_name_or_path distilbert/distilbert-base-cased \
+--train_file training_data.json \
+--validation_file validation_data.json \
+--output_dir output/ \
+--test_file data_to_predict.json \
+--do_train \
+--do_eval \
+--do_predict
+```
+
+## run_glue.py
+
+This script handles training on the GLUE dataset for various text classification and regression tasks. The GLUE datasets will be loaded automatically, so you only need to specify the task you want (with the `--task_name` argument). You can also supply your own files for prediction with the `--predict_file` argument, for example if you want to train a model on GLUE for e.g. paraphrase detection and then predict whether your own data contains paraphrases or not. Please ensure the names of your input fields match the names of the features in the relevant GLUE dataset - you can see a list of the column names in the `task_to_keys` dict in the `run_glue.py` file.
+
+### Usage notes
+
+The `--do_train`, `--do_eval` and `--do_predict` arguments control whether training, evaluations or predictions are performed. After training, the model will be saved to `--output_dir`. Once your model is trained, you can call the script without the `--do_train` or `--do_eval` arguments to quickly get predictions from your saved model.
+
+### Multi-GPU and TPU usage
+
+By default, the script uses a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
+can also be used by passing the name of the TPU resource with the `--tpu` argument.
+
+### Memory usage and data loading
+
+One thing to note is that all data is loaded into memory in this script. Most text classification datasets are small
+enough that this is not an issue, but if you have a very large dataset you will need to modify the script to handle
+data streaming. This is particularly challenging for TPUs, given the stricter requirements and the sheer volume of data
+required to keep them fed. A full explanation of all the possible pitfalls is a bit beyond this example script and
+README, but for more information you can see the 'Input Datasets' section of
+[this document](https://www.tensorflow.org/guide/tpu).
+
+### Example command
+```bash
+python run_glue.py \
+--model_name_or_path distilbert/distilbert-base-cased \
+--task_name mnli \
+--do_train \
+--do_eval \
+--do_predict \
+--predict_file data_to_predict.json
+```
diff --git a/docs/transformers/examples/tensorflow/text-classification/requirements.txt b/docs/transformers/examples/tensorflow/text-classification/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..494a82127ab06d3e2b49cd956117180fe1216a64
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/text-classification/requirements.txt
@@ -0,0 +1,5 @@
+datasets >= 1.1.3
+sentencepiece != 0.1.92
+protobuf
+tensorflow >= 2.3
+evaluate >= 0.2.0
\ No newline at end of file
diff --git a/docs/transformers/examples/tensorflow/text-classification/run_glue.py b/docs/transformers/examples/tensorflow/text-classification/run_glue.py
new file mode 100644
index 0000000000000000000000000000000000000000..2e9096b3642b97276b2e815fcb47c9aee02a5ade
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/text-classification/run_glue.py
@@ -0,0 +1,599 @@
+#!/usr/bin/env python
+# Copyright 2020 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Finetuning the library models for sequence classification on GLUE."""
+# You can also adapt this script on your own text classification task. Pointers for this are left as comments.
+
+import json
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import evaluate
+import numpy as np
+import tensorflow as tf
+from datasets import load_dataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoTokenizer,
+ DataCollatorWithPadding,
+ DefaultDataCollator,
+ HfArgumentParser,
+ PretrainedConfig,
+ PushToHubCallback,
+ TFAutoModelForSequenceClassification,
+ TFTrainingArguments,
+ create_optimizer,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint, is_main_process
+from transformers.utils import check_min_version, send_example_telemetry
+
+
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+task_to_keys = {
+ "cola": ("sentence", None),
+ "mnli": ("premise", "hypothesis"),
+ "mrpc": ("sentence1", "sentence2"),
+ "qnli": ("question", "sentence"),
+ "qqp": ("question1", "question2"),
+ "rte": ("sentence1", "sentence2"),
+ "sst2": ("sentence", None),
+ "stsb": ("sentence1", "sentence2"),
+ "wnli": ("sentence1", "sentence2"),
+}
+
+logger = logging.getLogger(__name__)
+
+
+# region Command-line arguments
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+
+ Using `HfArgumentParser` we can turn this class
+ into argparse arguments to be able to specify them on
+ the command line.
+ """
+
+ task_name: str = field(
+ metadata={"help": "The name of the task to train on: " + ", ".join(task_to_keys.keys())},
+ )
+ predict_file: str = field(
+ metadata={"help": "A file containing user-supplied examples to make predictions for"},
+ default=None,
+ )
+ max_seq_length: int = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ self.task_name = self.task_name.lower()
+ if self.task_name not in task_to_keys.keys():
+ raise ValueError("Unknown task, you should pick one in " + ",".join(task_to_keys.keys()))
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
+ "should only be set to `True` for repositories you trust and in which you have read the code, as it will "
+ "execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+# endregion
+
+
+def main():
+ # region Argument parsing
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_glue", model_args, data_args, framework="tensorflow")
+
+ if not (training_args.do_train or training_args.do_eval or training_args.do_predict):
+ exit("Must specify at least one of --do_train, --do_eval or --do_predict!")
+ # endregion
+
+ # region Checkpoints
+ checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ checkpoint = get_last_checkpoint(training_args.output_dir)
+ if checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+ # endregion
+
+ # region Logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+ logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
+
+ # Set the verbosity to info of the Transformers logger (on main process only):
+ if is_main_process(training_args.local_rank):
+ transformers.utils.logging.set_verbosity_info()
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+ logger.info(f"Training/evaluation parameters {training_args}")
+ # endregion
+
+ # region Dataset and labels
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Downloading and loading a dataset from the hub. In distributed training, the load_dataset function guarantee
+ # that only one local process can concurrently download the dataset.
+ datasets = load_dataset(
+ "nyu-mll/glue",
+ data_args.task_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ is_regression = data_args.task_name == "stsb"
+ if not is_regression:
+ label_list = datasets["train"].features["label"].names
+ num_labels = len(label_list)
+ else:
+ num_labels = 1
+
+ if data_args.predict_file is not None:
+ logger.info("Preparing user-supplied file for predictions...")
+
+ data_files = {"data": data_args.predict_file}
+
+ for key in data_files.keys():
+ logger.info(f"Loading a local file for {key}: {data_files[key]}")
+
+ if data_args.predict_file.endswith(".csv"):
+ # Loading a dataset from local csv files
+ user_dataset = load_dataset("csv", data_files=data_files, cache_dir=model_args.cache_dir)
+ else:
+ # Loading a dataset from local json files
+ user_dataset = load_dataset("json", data_files=data_files, cache_dir=model_args.cache_dir)
+ needed_keys = task_to_keys[data_args.task_name]
+ for key in needed_keys:
+ assert key in user_dataset["data"].features, f"Your supplied predict_file is missing the {key} key!"
+ datasets["user_data"] = user_dataset["data"]
+ # endregion
+
+ # region Load model config and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ num_labels=num_labels,
+ finetuning_task=data_args.task_name,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ # endregion
+
+ # region Dataset preprocessing
+ sentence1_key, sentence2_key = task_to_keys[data_args.task_name]
+
+ # Padding strategy
+ if data_args.pad_to_max_length:
+ padding = "max_length"
+ else:
+ # We will pad later, dynamically at batch creation, to the max sequence length in each batch
+ padding = False
+
+ # Some models have set the order of the labels to use, so let's make sure we do use it.
+ label_to_id = None
+ if config.label2id != PretrainedConfig(num_labels=num_labels).label2id and not is_regression:
+ # Some have all caps in their config, some don't.
+ label_name_to_id = {k.lower(): v for k, v in config.label2id.items()}
+ if sorted(label_name_to_id.keys()) == sorted(label_list):
+ label_to_id = {i: int(label_name_to_id[label_list[i]]) for i in range(num_labels)}
+ else:
+ logger.warning(
+ "Your model seems to have been trained with labels, but they don't match the dataset: "
+ f"model labels: {sorted(label_name_to_id.keys())}, dataset labels: {sorted(label_list)}."
+ "\nIgnoring the model labels as a result.",
+ )
+ label_to_id = {label: i for i, label in enumerate(label_list)}
+ if label_to_id is not None:
+ config.label2id = label_to_id
+ config.id2label = {id: label for label, id in config.label2id.items()}
+ elif data_args.task_name is not None and not is_regression:
+ config.label2id = {l: i for i, l in enumerate(label_list)}
+ config.id2label = {id: label for label, id in config.label2id.items()}
+
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ def preprocess_function(examples):
+ # Tokenize the texts
+ args = (
+ (examples[sentence1_key],) if sentence2_key is None else (examples[sentence1_key], examples[sentence2_key])
+ )
+ result = tokenizer(*args, padding=padding, max_length=max_seq_length, truncation=True)
+
+ return result
+
+ datasets = datasets.map(preprocess_function, batched=True, load_from_cache_file=not data_args.overwrite_cache)
+
+ if data_args.pad_to_max_length:
+ data_collator = DefaultDataCollator(return_tensors="np")
+ else:
+ data_collator = DataCollatorWithPadding(tokenizer, return_tensors="np")
+ # endregion
+
+ # region Metric function
+ metric = evaluate.load("glue", data_args.task_name, cache_dir=model_args.cache_dir)
+
+ def compute_metrics(preds, label_ids):
+ preds = preds["logits"]
+ preds = np.squeeze(preds) if is_regression else np.argmax(preds, axis=1)
+ result = metric.compute(predictions=preds, references=label_ids)
+ if len(result) > 1:
+ result["combined_score"] = np.mean(list(result.values())).item()
+ return result
+
+ # endregion
+
+ with training_args.strategy.scope():
+ # region Load pretrained model
+ if checkpoint is None:
+ model_path = model_args.model_name_or_path
+ else:
+ model_path = checkpoint
+ model = TFAutoModelForSequenceClassification.from_pretrained(
+ model_path,
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ # endregion
+
+ # region Convert data to a tf.data.Dataset
+ dataset_options = tf.data.Options()
+ dataset_options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
+ num_replicas = training_args.strategy.num_replicas_in_sync
+
+ tf_data = {}
+ max_samples = {
+ "train": data_args.max_train_samples,
+ "validation": data_args.max_eval_samples,
+ "validation_matched": data_args.max_eval_samples,
+ "validation_mismatched": data_args.max_eval_samples,
+ "test": data_args.max_predict_samples,
+ "test_matched": data_args.max_predict_samples,
+ "test_mismatched": data_args.max_predict_samples,
+ "user_data": None,
+ }
+ for key in datasets.keys():
+ if key == "train" or key.startswith("validation"):
+ assert "label" in datasets[key].features, f"Missing labels from {key} data!"
+ if key == "train":
+ shuffle = True
+ batch_size = training_args.per_device_train_batch_size * num_replicas
+ else:
+ shuffle = False
+ batch_size = training_args.per_device_eval_batch_size * num_replicas
+ samples_limit = max_samples[key]
+ dataset = datasets[key]
+ if samples_limit is not None:
+ dataset = dataset.select(range(samples_limit))
+
+ # model.prepare_tf_dataset() wraps a Hugging Face dataset in a tf.data.Dataset which is ready to use in
+ # training. This is the recommended way to use a Hugging Face dataset when training with Keras. You can also
+ # use the lower-level dataset.to_tf_dataset() method, but you will have to specify things like column names
+ # yourself if you use this method, whereas they are automatically inferred from the model input names when
+ # using model.prepare_tf_dataset()
+ # For more info see the docs:
+ # https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.TFPreTrainedModel.prepare_tf_dataset
+ # https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.to_tf_dataset
+ data = model.prepare_tf_dataset(
+ dataset,
+ shuffle=shuffle,
+ batch_size=batch_size,
+ collate_fn=data_collator,
+ tokenizer=tokenizer,
+ )
+ data = data.with_options(dataset_options)
+ tf_data[key] = data
+ # endregion
+
+ # region Optimizer, loss and compilation
+ if training_args.do_train:
+ num_train_steps = len(tf_data["train"]) * training_args.num_train_epochs
+ if training_args.warmup_steps > 0:
+ num_warmup_steps = training_args.warmup_steps
+ elif training_args.warmup_ratio > 0:
+ num_warmup_steps = int(num_train_steps * training_args.warmup_ratio)
+ else:
+ num_warmup_steps = 0
+
+ optimizer, schedule = create_optimizer(
+ init_lr=training_args.learning_rate,
+ num_train_steps=num_train_steps,
+ num_warmup_steps=num_warmup_steps,
+ adam_beta1=training_args.adam_beta1,
+ adam_beta2=training_args.adam_beta2,
+ adam_epsilon=training_args.adam_epsilon,
+ weight_decay_rate=training_args.weight_decay,
+ adam_global_clipnorm=training_args.max_grad_norm,
+ )
+ else:
+ optimizer = "sgd" # Just write anything because we won't be using it
+ if is_regression:
+ metrics = []
+ else:
+ metrics = ["accuracy"]
+ # Transformers models compute the right loss for their task by default when labels are passed, and will
+ # use this for training unless you specify your own loss function in compile().
+ model.compile(optimizer=optimizer, metrics=metrics, jit_compile=training_args.xla)
+ # endregion
+
+ # region Preparing push_to_hub and model card
+ push_to_hub_model_id = training_args.push_to_hub_model_id
+ model_name = model_args.model_name_or_path.split("/")[-1]
+ if not push_to_hub_model_id:
+ push_to_hub_model_id = f"{model_name}-finetuned-glue"
+
+ model_card_kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "text-classification"}
+ model_card_kwargs["task_name"] = data_args.task_name
+
+ if training_args.push_to_hub:
+ callbacks = [
+ PushToHubCallback(
+ output_dir=training_args.output_dir,
+ hub_model_id=push_to_hub_model_id,
+ hub_token=training_args.push_to_hub_token,
+ tokenizer=tokenizer,
+ **model_card_kwargs,
+ )
+ ]
+ else:
+ callbacks = []
+ # endregion
+
+ # region Training and validation
+ if training_args.do_train:
+ if training_args.do_eval and not data_args.task_name == "mnli":
+ # Do both evaluation and training in the Keras fit loop, unless the task is MNLI
+ # because MNLI has two validation sets
+ validation_data = tf_data["validation"]
+ else:
+ validation_data = None
+ model.fit(
+ tf_data["train"],
+ validation_data=validation_data,
+ epochs=int(training_args.num_train_epochs),
+ callbacks=callbacks,
+ )
+ # endregion
+
+ # region Evaluation
+ if training_args.do_eval:
+ # We normally do validation as part of the Keras fit loop, but we run it independently
+ # if there was no fit() step (because we didn't train the model) or if the task is MNLI,
+ # because MNLI has a separate validation-mismatched validation set
+
+ # In this example, we compute advanced metrics only at the end of training, and only compute
+ # loss and accuracy on the validation set each epoch, but
+ # if you'd like to compute metrics every epoch that are too complex to be written as
+ # standard Keras metrics, you can use our KerasMetricCallback. See
+ # https://huggingface.co/docs/transformers/main/en/main_classes/keras_callbacks
+ logger.info("*** Evaluate ***")
+
+ # Loop to handle MNLI double evaluation (matched, mis-matched)
+ if data_args.task_name == "mnli":
+ tasks = ["mnli", "mnli-mm"]
+ tf_datasets = [tf_data["validation_matched"], tf_data["validation_mismatched"]]
+ raw_datasets = [datasets["validation_matched"], datasets["validation_mismatched"]]
+ else:
+ tasks = [data_args.task_name]
+ tf_datasets = [tf_data["validation"]]
+ raw_datasets = [datasets["validation"]]
+
+ for raw_dataset, tf_dataset, task in zip(raw_datasets, tf_datasets, tasks):
+ eval_predictions = model.predict(tf_dataset)
+ eval_metrics = compute_metrics(eval_predictions, raw_dataset["label"])
+ print(f"Evaluation metrics ({task}):")
+ print(eval_metrics)
+ if training_args.output_dir is not None:
+ output_eval_file = os.path.join(training_args.output_dir, "all_results.json")
+ with open(output_eval_file, "w") as writer:
+ writer.write(json.dumps(eval_metrics))
+
+ # endregion
+
+ # region Prediction
+ if training_args.do_predict or data_args.predict_file:
+ logger.info("*** Predict ***")
+
+ # Loop to handle MNLI double evaluation (matched, mis-matched)
+ tasks = []
+ tf_datasets = []
+ raw_datasets = []
+ if training_args.do_predict:
+ if data_args.task_name == "mnli":
+ tasks.extend(["mnli", "mnli-mm"])
+ tf_datasets.extend([tf_data["test_matched"], tf_data["test_mismatched"]])
+ raw_datasets.extend([datasets["test_matched"], datasets["test_mismatched"]])
+ else:
+ tasks.append(data_args.task_name)
+ tf_datasets.append(tf_data["test"])
+ raw_datasets.append(datasets["test"])
+ if data_args.predict_file:
+ tasks.append("user_data")
+ tf_datasets.append(tf_data["user_data"])
+ raw_datasets.append(datasets["user_data"])
+
+ for raw_dataset, tf_dataset, task in zip(raw_datasets, tf_datasets, tasks):
+ test_predictions = model.predict(tf_dataset)
+ if "label" in raw_dataset:
+ test_metrics = compute_metrics(test_predictions, raw_dataset["label"])
+ print(f"Test metrics ({task}):")
+ print(test_metrics)
+
+ if is_regression:
+ predictions_to_write = np.squeeze(test_predictions["logits"])
+ else:
+ predictions_to_write = np.argmax(test_predictions["logits"], axis=1)
+
+ output_predict_file = os.path.join(training_args.output_dir, f"predict_results_{task}.txt")
+ with open(output_predict_file, "w") as writer:
+ logger.info(f"***** Writing prediction results for {task} *****")
+ writer.write("index\tprediction\n")
+ for index, item in enumerate(predictions_to_write):
+ if is_regression:
+ writer.write(f"{index}\t{item:3.3f}\n")
+ else:
+ item = model.config.id2label[item]
+ writer.write(f"{index}\t{item}\n")
+ # endregion
+
+ if training_args.output_dir is not None and not training_args.push_to_hub:
+ # If we're not pushing to hub, at least save a local copy when we're done
+ model.save_pretrained(training_args.output_dir)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/tensorflow/text-classification/run_text_classification.py b/docs/transformers/examples/tensorflow/text-classification/run_text_classification.py
new file mode 100644
index 0000000000000000000000000000000000000000..45b4a3e607e4e2ac8932ee23ddc3abfc4403ebef
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/text-classification/run_text_classification.py
@@ -0,0 +1,592 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Fine-tuning the library models for sequence classification."""
+# You can also adapt this script on your own text classification task. Pointers for this are left as comments.
+
+import json
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from pathlib import Path
+from typing import Optional
+
+import numpy as np
+from datasets import load_dataset
+from packaging.version import parse
+
+from transformers import (
+ AutoConfig,
+ AutoTokenizer,
+ HfArgumentParser,
+ PretrainedConfig,
+ PushToHubCallback,
+ TFAutoModelForSequenceClassification,
+ TFTrainingArguments,
+ create_optimizer,
+ set_seed,
+)
+from transformers.utils import CONFIG_NAME, TF2_WEIGHTS_NAME, send_example_telemetry
+
+
+os.environ["TF_CPP_MIN_LOG_LEVEL"] = "1" # Reduce the amount of console output from TF
+import tensorflow as tf # noqa: E402
+
+
+try:
+ import tf_keras as keras
+except (ModuleNotFoundError, ImportError):
+ import keras
+
+ if parse(keras.__version__).major > 2:
+ raise ValueError(
+ "Your currently installed version of Keras is Keras 3, but this is not yet supported in "
+ "Transformers. Please install the backwards-compatible tf-keras package with "
+ "`pip install tf-keras`."
+ )
+
+
+logger = logging.getLogger(__name__)
+
+
+# region Helper classes
+class SavePretrainedCallback(keras.callbacks.Callback):
+ # Hugging Face models have a save_pretrained() method that saves both the weights and the necessary
+ # metadata to allow them to be loaded as a pretrained model in future. This is a simple Keras callback
+ # that saves the model with this method after each epoch.
+ def __init__(self, output_dir, **kwargs):
+ super().__init__()
+ self.output_dir = output_dir
+
+ def on_epoch_end(self, epoch, logs=None):
+ self.model.save_pretrained(self.output_dir)
+
+
+# endregion
+
+
+# region Command-line arguments
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+
+ Using `HfArgumentParser` we can turn this class
+ into argparse arguments to be able to specify them on
+ the command line.
+ """
+
+ train_file: Optional[str] = field(
+ default=None, metadata={"help": "A csv or a json file containing the training data."}
+ )
+ validation_file: Optional[str] = field(
+ default=None, metadata={"help": "A csv or a json file containing the validation data."}
+ )
+ test_file: Optional[str] = field(default=None, metadata={"help": "A csv or a json file containing the test data."})
+
+ max_seq_length: int = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to `max_seq_length`. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch. "
+ "Data will always be padded when using TPUs."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_val_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of validation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_test_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of test examples to this "
+ "value if set."
+ )
+ },
+ )
+
+ def __post_init__(self):
+ train_extension = self.train_file.split(".")[-1].lower() if self.train_file is not None else None
+ validation_extension = (
+ self.validation_file.split(".")[-1].lower() if self.validation_file is not None else None
+ )
+ test_extension = self.test_file.split(".")[-1].lower() if self.test_file is not None else None
+ extensions = {train_extension, validation_extension, test_extension}
+ extensions.discard(None)
+ assert len(extensions) != 0, "Need to supply at least one of --train_file, --validation_file or --test_file!"
+ assert len(extensions) == 1, "All input files should have the same file extension, either csv or json!"
+ assert "csv" in extensions or "json" in extensions, "Input files should have either .csv or .json extensions!"
+ self.input_file_extension = extensions.pop()
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
+ "should only be set to `True` for repositories you trust and in which you have read the code, as it will "
+ "execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+# endregion
+
+
+def main():
+ # region Argument parsing
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_text_classification", model_args, data_args, framework="tensorflow")
+
+ output_dir = Path(training_args.output_dir)
+ output_dir.mkdir(parents=True, exist_ok=True)
+ # endregion
+
+ # region Checkpoints
+ # Detecting last checkpoint.
+ checkpoint = None
+ if len(os.listdir(training_args.output_dir)) > 0 and not training_args.overwrite_output_dir:
+ if (output_dir / CONFIG_NAME).is_file() and (output_dir / TF2_WEIGHTS_NAME).is_file():
+ checkpoint = output_dir
+ logger.info(
+ f"Checkpoint detected, resuming training from checkpoint in {training_args.output_dir}. To avoid this"
+ " behavior, change the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+ else:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to continue regardless."
+ )
+
+ # endregion
+
+ # region Logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+ logger.setLevel(logging.INFO)
+
+ logger.info(f"Training/evaluation parameters {training_args}")
+ # endregion
+
+ # region Loading data
+ # For CSV/JSON files, this script will use the 'label' field as the label and the 'sentence1' and optionally
+ # 'sentence2' fields as inputs if they exist. If not, the first two fields not named label are used if at least two
+ # columns are provided. Note that the term 'sentence' can be slightly misleading, as they often contain more than
+ # a single grammatical sentence, when the task requires it.
+ #
+ # If the CSVs/JSONs contain only one non-label column, the script does single sentence classification on this
+ # single column. You can easily tweak this behavior (see below)
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ data_files = {"train": data_args.train_file, "validation": data_args.validation_file, "test": data_args.test_file}
+ data_files = {key: file for key, file in data_files.items() if file is not None}
+
+ for key in data_files.keys():
+ logger.info(f"Loading a local file for {key}: {data_files[key]}")
+
+ if data_args.input_file_extension == "csv":
+ # Loading a dataset from local csv files
+ datasets = load_dataset(
+ "csv",
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ else:
+ # Loading a dataset from local json files
+ datasets = load_dataset("json", data_files=data_files, cache_dir=model_args.cache_dir)
+ # See more about loading any type of standard or custom dataset at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+ # endregion
+
+ # region Label preprocessing
+ # If you've passed us a training set, we try to infer your labels from it
+ if "train" in datasets:
+ # By default we assume that if your label column looks like a float then you're doing regression,
+ # and if not then you're doing classification. This is something you may want to change!
+ is_regression = datasets["train"].features["label"].dtype in ["float32", "float64"]
+ if is_regression:
+ num_labels = 1
+ else:
+ # A useful fast method:
+ # https://huggingface.co/docs/datasets/package_reference/main_classes.html#datasets.Dataset.unique
+ label_list = datasets["train"].unique("label")
+ label_list.sort() # Let's sort it for determinism
+ num_labels = len(label_list)
+ # If you haven't passed a training set, we read label info from the saved model (this happens later)
+ else:
+ num_labels = None
+ label_list = None
+ is_regression = None
+ # endregion
+
+ # region Load model config and tokenizer
+ if checkpoint is not None:
+ config_path = training_args.output_dir
+ elif model_args.config_name:
+ config_path = model_args.config_name
+ else:
+ config_path = model_args.model_name_or_path
+ if num_labels is not None:
+ config = AutoConfig.from_pretrained(
+ config_path,
+ num_labels=num_labels,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ config = AutoConfig.from_pretrained(
+ config_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ # endregion
+
+ # region Dataset preprocessing
+ # Again, we try to have some nice defaults but don't hesitate to tweak to your use case.
+ column_names = {col for cols in datasets.column_names.values() for col in cols}
+ non_label_column_names = [name for name in column_names if name != "label"]
+ if "sentence1" in non_label_column_names and "sentence2" in non_label_column_names:
+ sentence1_key, sentence2_key = "sentence1", "sentence2"
+ elif "sentence1" in non_label_column_names:
+ sentence1_key, sentence2_key = "sentence1", None
+ else:
+ if len(non_label_column_names) >= 2:
+ sentence1_key, sentence2_key = non_label_column_names[:2]
+ else:
+ sentence1_key, sentence2_key = non_label_column_names[0], None
+
+ if data_args.max_seq_length > tokenizer.model_max_length:
+ logger.warning(
+ f"The max_seq_length passed ({data_args.max_seq_length}) is larger than the maximum length for the "
+ f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
+ )
+ max_seq_length = min(data_args.max_seq_length, tokenizer.model_max_length)
+
+ # Ensure that our labels match the model's, if it has some pre-specified
+ if "train" in datasets:
+ if not is_regression and config.label2id != PretrainedConfig(num_labels=num_labels).label2id:
+ label_name_to_id = config.label2id
+ if sorted(label_name_to_id.keys()) == sorted(label_list):
+ label_to_id = label_name_to_id # Use the model's labels
+ else:
+ logger.warning(
+ "Your model seems to have been trained with labels, but they don't match the dataset: "
+ f"model labels: {sorted(label_name_to_id.keys())}, dataset labels:"
+ f" {sorted(label_list)}.\nIgnoring the model labels as a result.",
+ )
+ label_to_id = {v: i for i, v in enumerate(label_list)}
+ elif not is_regression:
+ label_to_id = {v: i for i, v in enumerate(label_list)}
+ else:
+ label_to_id = None
+ # Now we've established our label2id, let's overwrite the model config with it.
+ config.label2id = label_to_id
+ if config.label2id is not None:
+ config.id2label = {id: label for label, id in label_to_id.items()}
+ else:
+ config.id2label = None
+ else:
+ label_to_id = config.label2id # Just load the data from the model
+
+ if "validation" in datasets and config.label2id is not None:
+ validation_label_list = datasets["validation"].unique("label")
+ for val_label in validation_label_list:
+ assert val_label in label_to_id, f"Label {val_label} is in the validation set but not the training set!"
+
+ def preprocess_function(examples):
+ # Tokenize the texts
+ args = (
+ (examples[sentence1_key],) if sentence2_key is None else (examples[sentence1_key], examples[sentence2_key])
+ )
+ result = tokenizer(*args, max_length=max_seq_length, truncation=True)
+
+ # Map labels to IDs
+ if config.label2id is not None and "label" in examples:
+ result["label"] = [(config.label2id[l] if l != -1 else -1) for l in examples["label"]]
+ return result
+
+ datasets = datasets.map(preprocess_function, batched=True, load_from_cache_file=not data_args.overwrite_cache)
+
+ # endregion
+
+ with training_args.strategy.scope():
+ # region Load pretrained model
+ # Set seed before initializing model
+ set_seed(training_args.seed)
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ if checkpoint is None:
+ model_path = model_args.model_name_or_path
+ else:
+ model_path = checkpoint
+ model = TFAutoModelForSequenceClassification.from_pretrained(
+ model_path,
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ # endregion
+
+ # region Convert data to a tf.data.Dataset
+ dataset_options = tf.data.Options()
+ dataset_options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
+ num_replicas = training_args.strategy.num_replicas_in_sync
+
+ tf_data = {}
+ max_samples = {
+ "train": data_args.max_train_samples,
+ "validation": data_args.max_val_samples,
+ "test": data_args.max_test_samples,
+ }
+ for key in ("train", "validation", "test"):
+ if key not in datasets:
+ tf_data[key] = None
+ continue
+ if (
+ (key == "train" and not training_args.do_train)
+ or (key == "validation" and not training_args.do_eval)
+ or (key == "test" and not training_args.do_predict)
+ ):
+ tf_data[key] = None
+ continue
+ if key in ("train", "validation"):
+ assert "label" in datasets[key].features, f"Missing labels from {key} data!"
+ if key == "train":
+ shuffle = True
+ batch_size = training_args.per_device_train_batch_size * num_replicas
+ else:
+ shuffle = False
+ batch_size = training_args.per_device_eval_batch_size * num_replicas
+ samples_limit = max_samples[key]
+ dataset = datasets[key]
+ if samples_limit is not None:
+ dataset = dataset.select(range(samples_limit))
+
+ # model.prepare_tf_dataset() wraps a Hugging Face dataset in a tf.data.Dataset which is ready to use in
+ # training. This is the recommended way to use a Hugging Face dataset when training with Keras. You can also
+ # use the lower-level dataset.to_tf_dataset() method, but you will have to specify things like column names
+ # yourself if you use this method, whereas they are automatically inferred from the model input names when
+ # using model.prepare_tf_dataset()
+ # For more info see the docs:
+ # https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.TFPreTrainedModel.prepare_tf_dataset
+ # https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.to_tf_dataset
+
+ data = model.prepare_tf_dataset(
+ dataset,
+ shuffle=shuffle,
+ batch_size=batch_size,
+ tokenizer=tokenizer,
+ )
+ data = data.with_options(dataset_options)
+ tf_data[key] = data
+ # endregion
+
+ # region Optimizer, loss and compilation
+
+ if training_args.do_train:
+ num_train_steps = len(tf_data["train"]) * training_args.num_train_epochs
+ if training_args.warmup_steps > 0:
+ num_warmup_steps = training_args.warmup_steps
+ elif training_args.warmup_ratio > 0:
+ num_warmup_steps = int(num_train_steps * training_args.warmup_ratio)
+ else:
+ num_warmup_steps = 0
+
+ optimizer, schedule = create_optimizer(
+ init_lr=training_args.learning_rate,
+ num_train_steps=num_train_steps,
+ num_warmup_steps=num_warmup_steps,
+ adam_beta1=training_args.adam_beta1,
+ adam_beta2=training_args.adam_beta2,
+ adam_epsilon=training_args.adam_epsilon,
+ weight_decay_rate=training_args.weight_decay,
+ adam_global_clipnorm=training_args.max_grad_norm,
+ )
+ else:
+ optimizer = "sgd" # Just use any default
+ if is_regression:
+ metrics = []
+ else:
+ metrics = ["accuracy"]
+ # Transformers models compute the right loss for their task by default when labels are passed, and will
+ # use this for training unless you specify your own loss function in compile().
+ model.compile(optimizer=optimizer, metrics=metrics)
+ # endregion
+
+ # region Preparing push_to_hub and model card
+ push_to_hub_model_id = training_args.push_to_hub_model_id
+ model_name = model_args.model_name_or_path.split("/")[-1]
+ if not push_to_hub_model_id:
+ push_to_hub_model_id = f"{model_name}-finetuned-text-classification"
+
+ model_card_kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "text-classification"}
+
+ if training_args.push_to_hub:
+ callbacks = [
+ PushToHubCallback(
+ output_dir=training_args.output_dir,
+ hub_model_id=push_to_hub_model_id,
+ hub_token=training_args.push_to_hub_token,
+ tokenizer=tokenizer,
+ **model_card_kwargs,
+ )
+ ]
+ else:
+ callbacks = []
+ # endregion
+
+ # region Training and validation
+ if tf_data["train"] is not None:
+ model.fit(
+ tf_data["train"],
+ validation_data=tf_data["validation"],
+ epochs=int(training_args.num_train_epochs),
+ callbacks=callbacks,
+ )
+ if tf_data["validation"] is not None:
+ logger.info("Computing metrics on validation data...")
+ if is_regression:
+ loss = model.evaluate(tf_data["validation"])
+ logger.info(f"Eval loss: {loss:.5f}")
+ else:
+ loss, accuracy = model.evaluate(tf_data["validation"])
+ logger.info(f"Eval loss: {loss:.5f}, Eval accuracy: {accuracy * 100:.4f}%")
+ if training_args.output_dir is not None:
+ output_eval_file = os.path.join(training_args.output_dir, "all_results.json")
+ eval_dict = {"eval_loss": loss}
+ if not is_regression:
+ eval_dict["eval_accuracy"] = accuracy
+ with open(output_eval_file, "w") as writer:
+ writer.write(json.dumps(eval_dict))
+ # endregion
+
+ # region Prediction
+ if tf_data["test"] is not None:
+ logger.info("Doing predictions on test dataset...")
+ predictions = model.predict(tf_data["test"])["logits"]
+ predicted_class = np.squeeze(predictions) if is_regression else np.argmax(predictions, axis=1)
+ output_test_file = os.path.join(training_args.output_dir, "test_results.txt")
+ with open(output_test_file, "w") as writer:
+ writer.write("index\tprediction\n")
+ for index, item in enumerate(predicted_class):
+ if is_regression:
+ writer.write(f"{index}\t{item:3.3f}\n")
+ else:
+ item = config.id2label[item]
+ writer.write(f"{index}\t{item}\n")
+ logger.info(f"Wrote predictions to {output_test_file}!")
+ # endregion
+
+ if training_args.output_dir is not None and not training_args.push_to_hub:
+ # If we're not pushing to hub, at least save a local copy when we're done
+ model.save_pretrained(training_args.output_dir)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/tensorflow/token-classification/README.md b/docs/transformers/examples/tensorflow/token-classification/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..6c8a15c00e813acc4fcba349c388e2c2d369d23d
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/token-classification/README.md
@@ -0,0 +1,47 @@
+
+
+# Token classification
+
+Fine-tuning the library models for token classification task such as Named Entity Recognition (NER), Parts-of-speech
+tagging (POS) or phrase extraction (CHUNKS). The main script `run_ner.py` leverages the [🤗 Datasets](https://github.com/huggingface/datasets) library. You can easily
+customize it to your needs if you need extra processing on your datasets.
+
+It will either run on a datasets hosted on our [hub](https://huggingface.co/datasets) or with your own text files for
+training and validation, you might just need to add some tweaks in the data preprocessing.
+
+The following example fine-tunes BERT on CoNLL-2003:
+
+```bash
+python run_ner.py \
+ --model_name_or_path google-bert/bert-base-uncased \
+ --dataset_name conll2003 \
+ --output_dir /tmp/test-ner
+```
+
+To run on your own training and validation files, use the following command:
+
+```bash
+python run_ner.py \
+ --model_name_or_path google-bert/bert-base-uncased \
+ --train_file path_to_train_file \
+ --validation_file path_to_validation_file \
+ --output_dir /tmp/test-ner
+```
+
+**Note:** This script only works with models that have a fast tokenizer (backed by the [🤗 Tokenizers](https://github.com/huggingface/tokenizers) library) as it
+uses special features of those tokenizers. You can check if your favorite model has a fast tokenizer in
+[this table](https://huggingface.co/transformers/index.html#supported-frameworks).
diff --git a/docs/transformers/examples/tensorflow/token-classification/requirements.txt b/docs/transformers/examples/tensorflow/token-classification/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..99aff2bb32b2bb92f7628eb9bab4c7535d4c7f92
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/token-classification/requirements.txt
@@ -0,0 +1,3 @@
+datasets >= 1.4.0
+tensorflow >= 2.3.0
+evaluate >= 0.2.0
\ No newline at end of file
diff --git a/docs/transformers/examples/tensorflow/token-classification/run_ner.py b/docs/transformers/examples/tensorflow/token-classification/run_ner.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a50b2a650395020c28ecd84a7fc869d7383555a
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/token-classification/run_ner.py
@@ -0,0 +1,635 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning a 🤗 Transformers model on token classification tasks (NER, POS, CHUNKS)
+"""
+
+import json
+import logging
+import os
+import random
+from dataclasses import dataclass, field
+from typing import Optional
+
+import datasets
+import evaluate
+import tensorflow as tf
+from datasets import ClassLabel, load_dataset
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ AutoConfig,
+ AutoTokenizer,
+ DataCollatorForTokenClassification,
+ HfArgumentParser,
+ PushToHubCallback,
+ TFAutoModelForTokenClassification,
+ TFTrainingArguments,
+ create_optimizer,
+ set_seed,
+)
+from transformers.utils import send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+logger = logging.getLogger(__name__)
+logger.addHandler(logging.StreamHandler())
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/tensorflow/token-classification/requirements.txt")
+
+
+# region Command-line arguments
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ task_name: Optional[str] = field(default="ner", metadata={"help": "The name of the task (ner, pos...)."})
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(
+ default=None, metadata={"help": "The input training data file (a csv or JSON file)."}
+ )
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate on (a csv or JSON file)."},
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input test data file to predict on (a csv or JSON file)."},
+ )
+ text_column_name: Optional[str] = field(
+ default=None, metadata={"help": "The column name of text to input in the file (a csv or JSON file)."}
+ )
+ label_column_name: Optional[str] = field(
+ default=None, metadata={"help": "The column name of label to input in the file (a csv or JSON file)."}
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_length: Optional[int] = field(default=256, metadata={"help": "Max length (in tokens) for truncation/padding"})
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to model maximum sentence length. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
+ "efficient on GPU but very bad for TPU."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ label_all_tokens: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to put the label for one word on all tokens of generated by that word or just on the "
+ "one (in which case the other tokens will have a padding index)."
+ )
+ },
+ )
+ return_entity_level_metrics: bool = field(
+ default=False,
+ metadata={"help": "Whether to return all the entity levels during evaluation or just the overall ones."},
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ self.task_name = self.task_name.lower()
+
+
+# endregion
+
+
+def main():
+ # region Argument Parsing
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_ner", model_args, data_args, framework="tensorflow")
+ # endregion
+
+ # region Setup logging
+ # we only want one process per machine to log things on the screen.
+ # accelerator.is_local_main_process is only True for one process per machine.
+ logger.setLevel(logging.INFO)
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+
+ # If passed along, set the training seed now.
+ if training_args.seed is not None:
+ set_seed(training_args.seed)
+ # endregion
+
+ # region Loading datasets
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets for token classification task available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'tokens' or the first column if no column called
+ # 'tokens' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ if raw_datasets["train"] is not None:
+ column_names = raw_datasets["train"].column_names
+ features = raw_datasets["train"].features
+ else:
+ column_names = raw_datasets["validation"].column_names
+ features = raw_datasets["validation"].features
+
+ if data_args.text_column_name is not None:
+ text_column_name = data_args.text_column_name
+ elif "tokens" in column_names:
+ text_column_name = "tokens"
+ else:
+ text_column_name = column_names[0]
+
+ if data_args.label_column_name is not None:
+ label_column_name = data_args.label_column_name
+ elif f"{data_args.task_name}_tags" in column_names:
+ label_column_name = f"{data_args.task_name}_tags"
+ else:
+ label_column_name = column_names[1]
+
+ # In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
+ # unique labels.
+ def get_label_list(labels):
+ unique_labels = set()
+ for label in labels:
+ unique_labels = unique_labels | set(label)
+ label_list = list(unique_labels)
+ label_list.sort()
+ return label_list
+
+ if isinstance(features[label_column_name].feature, ClassLabel):
+ label_list = features[label_column_name].feature.names
+ # No need to convert the labels since they are already ints.
+ label_to_id = {i: i for i in range(len(label_list))}
+ else:
+ label_list = get_label_list(raw_datasets["train"][label_column_name])
+ label_to_id = {l: i for i, l in enumerate(label_list)}
+ num_labels = len(label_list)
+ # endregion
+
+ # region Load config and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+ if model_args.config_name:
+ config = AutoConfig.from_pretrained(
+ model_args.config_name,
+ num_labels=num_labels,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(
+ model_args.model_name_or_path,
+ num_labels=num_labels,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ tokenizer_name_or_path = model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path
+ if not tokenizer_name_or_path:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if config.model_type in {"gpt2", "roberta"}:
+ tokenizer = AutoTokenizer.from_pretrained(
+ tokenizer_name_or_path,
+ use_fast=True,
+ add_prefix_space=True,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ tokenizer = AutoTokenizer.from_pretrained(
+ tokenizer_name_or_path,
+ use_fast=True,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ # endregion
+
+ # region Preprocessing the raw datasets
+ # First we tokenize all the texts.
+ padding = "max_length" if data_args.pad_to_max_length else False
+
+ # Tokenize all texts and align the labels with them.
+
+ def tokenize_and_align_labels(examples):
+ tokenized_inputs = tokenizer(
+ examples[text_column_name],
+ max_length=data_args.max_length,
+ padding=padding,
+ truncation=True,
+ # We use this argument because the texts in our dataset are lists of words (with a label for each word).
+ is_split_into_words=True,
+ )
+
+ labels = []
+ for i, label in enumerate(examples[label_column_name]):
+ word_ids = tokenized_inputs.word_ids(batch_index=i)
+ previous_word_idx = None
+ label_ids = []
+ for word_idx in word_ids:
+ # Special tokens have a word id that is None. We set the label to -100 so they are automatically
+ # ignored in the loss function.
+ if word_idx is None:
+ label_ids.append(-100)
+ # We set the label for the first token of each word.
+ elif word_idx != previous_word_idx:
+ label_ids.append(label_to_id[label[word_idx]])
+ # For the other tokens in a word, we set the label to either the current label or -100, depending on
+ # the label_all_tokens flag.
+ else:
+ label_ids.append(label_to_id[label[word_idx]] if data_args.label_all_tokens else -100)
+ previous_word_idx = word_idx
+
+ labels.append(label_ids)
+ tokenized_inputs["labels"] = labels
+ return tokenized_inputs
+
+ processed_raw_datasets = raw_datasets.map(
+ tokenize_and_align_labels,
+ batched=True,
+ remove_columns=raw_datasets["train"].column_names,
+ desc="Running tokenizer on dataset",
+ )
+
+ train_dataset = processed_raw_datasets["train"]
+ eval_dataset = processed_raw_datasets["validation"]
+
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+ # endregion
+
+ with training_args.strategy.scope():
+ # region Initialize model
+ if model_args.model_name_or_path:
+ model = TFAutoModelForTokenClassification.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = TFAutoModelForTokenClassification.from_config(
+ config, token=model_args.token, trust_remote_code=model_args.trust_remote_code
+ )
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embeddings = model.get_input_embeddings()
+
+ # Matt: This is a temporary workaround as we transition our models to exclusively using Keras embeddings.
+ # As soon as the transition is complete, all embeddings should be keras.Embeddings layers, and
+ # the weights will always be in embeddings.embeddings.
+ if hasattr(embeddings, "embeddings"):
+ embedding_size = embeddings.embeddings.shape[0]
+ else:
+ embedding_size = embeddings.weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+ # endregion
+
+ # region Create TF datasets
+
+ # We need the DataCollatorForTokenClassification here, as we need to correctly pad labels as
+ # well as inputs.
+ collate_fn = DataCollatorForTokenClassification(tokenizer=tokenizer, return_tensors="np")
+ num_replicas = training_args.strategy.num_replicas_in_sync
+ total_train_batch_size = training_args.per_device_train_batch_size * num_replicas
+
+ dataset_options = tf.data.Options()
+ dataset_options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
+
+ # model.prepare_tf_dataset() wraps a Hugging Face dataset in a tf.data.Dataset which is ready to use in
+ # training. This is the recommended way to use a Hugging Face dataset when training with Keras. You can also
+ # use the lower-level dataset.to_tf_dataset() method, but you will have to specify things like column names
+ # yourself if you use this method, whereas they are automatically inferred from the model input names when
+ # using model.prepare_tf_dataset()
+ # For more info see the docs:
+ # https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.TFPreTrainedModel.prepare_tf_dataset
+ # https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.to_tf_dataset
+
+ tf_train_dataset = model.prepare_tf_dataset(
+ train_dataset,
+ collate_fn=collate_fn,
+ batch_size=total_train_batch_size,
+ shuffle=True,
+ ).with_options(dataset_options)
+ total_eval_batch_size = training_args.per_device_eval_batch_size * num_replicas
+ tf_eval_dataset = model.prepare_tf_dataset(
+ eval_dataset,
+ collate_fn=collate_fn,
+ batch_size=total_eval_batch_size,
+ shuffle=False,
+ ).with_options(dataset_options)
+
+ # endregion
+
+ # region Optimizer, loss and compilation
+ num_train_steps = int(len(tf_train_dataset) * training_args.num_train_epochs)
+ if training_args.warmup_steps > 0:
+ num_warmup_steps = training_args.warmup_steps
+ elif training_args.warmup_ratio > 0:
+ num_warmup_steps = int(num_train_steps * training_args.warmup_ratio)
+ else:
+ num_warmup_steps = 0
+
+ optimizer, lr_schedule = create_optimizer(
+ init_lr=training_args.learning_rate,
+ num_train_steps=num_train_steps,
+ num_warmup_steps=num_warmup_steps,
+ adam_beta1=training_args.adam_beta1,
+ adam_beta2=training_args.adam_beta2,
+ adam_epsilon=training_args.adam_epsilon,
+ weight_decay_rate=training_args.weight_decay,
+ adam_global_clipnorm=training_args.max_grad_norm,
+ )
+ # Transformers models compute the right loss for their task by default when labels are passed, and will
+ # use this for training unless you specify your own loss function in compile().
+ model.compile(optimizer=optimizer, jit_compile=training_args.xla)
+ # endregion
+
+ # Metrics
+ metric = evaluate.load("seqeval", cache_dir=model_args.cache_dir)
+
+ def get_labels(y_pred, y_true):
+ # Transform predictions and references tensos to numpy arrays
+
+ # Remove ignored index (special tokens)
+ true_predictions = [
+ [label_list[p] for (p, l) in zip(pred, gold_label) if l != -100]
+ for pred, gold_label in zip(y_pred, y_true)
+ ]
+ true_labels = [
+ [label_list[l] for (p, l) in zip(pred, gold_label) if l != -100]
+ for pred, gold_label in zip(y_pred, y_true)
+ ]
+ return true_predictions, true_labels
+
+ def compute_metrics():
+ results = metric.compute()
+ if data_args.return_entity_level_metrics:
+ # Unpack nested dictionaries
+ final_results = {}
+ for key, value in results.items():
+ if isinstance(value, dict):
+ for n, v in value.items():
+ final_results[f"{key}_{n}"] = v
+ else:
+ final_results[key] = value
+ return final_results
+ else:
+ return {
+ "precision": results["overall_precision"],
+ "recall": results["overall_recall"],
+ "f1": results["overall_f1"],
+ "accuracy": results["overall_accuracy"],
+ }
+
+ # endregion
+
+ # region Preparing push_to_hub and model card
+ push_to_hub_model_id = training_args.push_to_hub_model_id
+ model_name = model_args.model_name_or_path.split("/")[-1]
+ if not push_to_hub_model_id:
+ if data_args.dataset_name is not None:
+ push_to_hub_model_id = f"{model_name}-finetuned-{data_args.dataset_name}"
+ else:
+ push_to_hub_model_id = f"{model_name}-finetuned-token-classification"
+
+ model_card_kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "token-classification"}
+ if data_args.dataset_name is not None:
+ model_card_kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ model_card_kwargs["dataset_args"] = data_args.dataset_config_name
+ model_card_kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ model_card_kwargs["dataset"] = data_args.dataset_name
+
+ if training_args.push_to_hub:
+ callbacks = [
+ PushToHubCallback(
+ output_dir=training_args.output_dir,
+ hub_model_id=push_to_hub_model_id,
+ hub_token=training_args.push_to_hub_token,
+ tokenizer=tokenizer,
+ **model_card_kwargs,
+ )
+ ]
+ else:
+ callbacks = []
+ # endregion
+
+ # region Training
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {training_args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {training_args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size = {total_train_batch_size}")
+ # Only show the progress bar once on each machine.
+
+ model.fit(
+ tf_train_dataset,
+ validation_data=tf_eval_dataset,
+ epochs=int(training_args.num_train_epochs),
+ callbacks=callbacks,
+ )
+ # endregion
+
+ # region Predictions
+ # If you have variable batch sizes (i.e. not using pad_to_max_length), then
+ # this bit might fail on TF < 2.8 because TF can't concatenate outputs of varying seq
+ # length from predict().
+
+ try:
+ predictions = model.predict(tf_eval_dataset, batch_size=training_args.per_device_eval_batch_size)["logits"]
+ except tf.python.framework.errors_impl.InvalidArgumentError:
+ raise ValueError(
+ "Concatenating predictions failed! If your version of TensorFlow is 2.8.0 or older "
+ "then you will need to use --pad_to_max_length to generate predictions, as older "
+ "versions of TensorFlow cannot concatenate variable-length predictions as RaggedTensor."
+ )
+ if isinstance(predictions, tf.RaggedTensor):
+ predictions = predictions.to_tensor(default_value=-100)
+ predictions = tf.math.argmax(predictions, axis=-1).numpy()
+ if "label" in eval_dataset:
+ labels = eval_dataset.with_format("tf")["label"]
+ else:
+ labels = eval_dataset.with_format("tf")["labels"]
+ if isinstance(labels, tf.RaggedTensor):
+ labels = labels.to_tensor(default_value=-100)
+ labels = labels.numpy()
+ attention_mask = eval_dataset.with_format("tf")["attention_mask"]
+ if isinstance(attention_mask, tf.RaggedTensor):
+ attention_mask = attention_mask.to_tensor(default_value=-100)
+ attention_mask = attention_mask.numpy()
+ labels[attention_mask == 0] = -100
+ preds, refs = get_labels(predictions, labels)
+ metric.add_batch(
+ predictions=preds,
+ references=refs,
+ )
+ eval_metric = compute_metrics()
+ logger.info("Evaluation metrics:")
+ for key, val in eval_metric.items():
+ logger.info(f"{key}: {val:.4f}")
+
+ if training_args.output_dir is not None:
+ output_eval_file = os.path.join(training_args.output_dir, "all_results.json")
+ with open(output_eval_file, "w") as writer:
+ writer.write(json.dumps(eval_metric))
+ # endregion
+
+ if training_args.output_dir is not None and not training_args.push_to_hub:
+ # If we're not pushing to hub, at least save a local copy when we're done
+ model.save_pretrained(training_args.output_dir)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/tensorflow/translation/README.md b/docs/transformers/examples/tensorflow/translation/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..bbe6e27e9c78a41518e2c4704105001f20b9528e
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/translation/README.md
@@ -0,0 +1,69 @@
+
+
+# Translation example
+
+This script shows an example of training a *translation* model with the 🤗 Transformers library.
+For straightforward use-cases you may be able to use these scripts without modification, although we have also
+included comments in the code to indicate areas that you may need to adapt to your own projects.
+
+### Multi-GPU and TPU usage
+
+By default, these scripts use a `MirroredStrategy` and will use multiple GPUs effectively if they are available. TPUs
+can also be used by passing the name of the TPU resource with the `--tpu` argument.
+
+### Example commands and caveats
+
+MBart and some T5 models require special handling.
+
+T5 models `google-t5/t5-small`, `google-t5/t5-base`, `google-t5/t5-large`, `google-t5/t5-3b` and `google-t5/t5-11b` must use an additional argument: `--source_prefix "translate {source_lang} to {target_lang}"`. For example:
+
+```bash
+python run_translation.py \
+ --model_name_or_path google-t5/t5-small \
+ --do_train \
+ --do_eval \
+ --source_lang en \
+ --target_lang ro \
+ --source_prefix "translate English to Romanian: " \
+ --dataset_name wmt16 \
+ --dataset_config_name ro-en \
+ --output_dir /tmp/tst-translation \
+ --per_device_train_batch_size=16 \
+ --per_device_eval_batch_size=16 \
+ --overwrite_output_dir
+```
+
+If you get a terrible BLEU score, make sure that you didn't forget to use the `--source_prefix` argument.
+
+For the aforementioned group of T5 models it's important to remember that if you switch to a different language pair, make sure to adjust the source and target values in all 3 language-specific command line argument: `--source_lang`, `--target_lang` and `--source_prefix`.
+
+MBart models require a different format for `--source_lang` and `--target_lang` values, e.g. instead of `en` it expects `en_XX`, for `ro` it expects `ro_RO`. The full MBart specification for language codes can be found [here](https://huggingface.co/facebook/mbart-large-cc25). For example:
+
+```bash
+python run_translation.py \
+ --model_name_or_path facebook/mbart-large-en-ro \
+ --do_train \
+ --do_eval \
+ --dataset_name wmt16 \
+ --dataset_config_name ro-en \
+ --source_lang en_XX \
+ --target_lang ro_RO \
+ --output_dir /tmp/tst-translation \
+ --per_device_train_batch_size=16 \
+ --per_device_eval_batch_size=16 \
+ --overwrite_output_dir
+ ```
diff --git a/docs/transformers/examples/tensorflow/translation/requirements.txt b/docs/transformers/examples/tensorflow/translation/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..99aff2bb32b2bb92f7628eb9bab4c7535d4c7f92
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/translation/requirements.txt
@@ -0,0 +1,3 @@
+datasets >= 1.4.0
+tensorflow >= 2.3.0
+evaluate >= 0.2.0
\ No newline at end of file
diff --git a/docs/transformers/examples/tensorflow/translation/run_translation.py b/docs/transformers/examples/tensorflow/translation/run_translation.py
new file mode 100644
index 0000000000000000000000000000000000000000..5d9771d425ec84af82f212c00793471539abbe34
--- /dev/null
+++ b/docs/transformers/examples/tensorflow/translation/run_translation.py
@@ -0,0 +1,715 @@
+#!/usr/bin/env python
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning the library models for translation.
+"""
+# You can also adapt this script on your own sequence to sequence task. Pointers for this are left as comments.
+
+import json
+import logging
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional
+
+import datasets
+import evaluate
+import numpy as np
+import tensorflow as tf
+from datasets import load_dataset
+
+import transformers
+from transformers import (
+ AutoConfig,
+ AutoTokenizer,
+ DataCollatorForSeq2Seq,
+ HfArgumentParser,
+ KerasMetricCallback,
+ M2M100Tokenizer,
+ MBart50Tokenizer,
+ MBart50TokenizerFast,
+ MBartTokenizer,
+ MBartTokenizerFast,
+ PushToHubCallback,
+ TFAutoModelForSeq2SeqLM,
+ TFTrainingArguments,
+ create_optimizer,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import check_min_version, send_example_telemetry
+from transformers.utils.versions import require_version
+
+
+# region Dependencies and constants
+# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
+check_min_version("4.52.0.dev0")
+
+require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
+
+logger = logging.getLogger(__name__)
+MULTILINGUAL_TOKENIZERS = [MBartTokenizer, MBartTokenizerFast, MBart50Tokenizer, MBart50TokenizerFast, M2M100Tokenizer]
+# endregion
+
+
+# region Arguments
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None,
+ metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ source_lang: str = field(default=None, metadata={"help": "Source language id for translation."})
+ target_lang: str = field(default=None, metadata={"help": "Target language id for translation."})
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(
+ default=None, metadata={"help": "The input training data file (a jsonlines or csv file)."}
+ )
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "An optional input evaluation data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
+ )
+ },
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": "An optional input test data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
+ },
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_source_length: Optional[int] = field(
+ default=1024,
+ metadata={
+ "help": (
+ "The maximum total input sequence length after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ max_target_length: Optional[int] = field(
+ default=128,
+ metadata={
+ "help": (
+ "The maximum total sequence length for target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded."
+ )
+ },
+ )
+ val_max_target_length: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The maximum total sequence length for validation target text after tokenization. Sequences longer "
+ "than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
+ "This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
+ "during ``evaluate`` and ``predict``."
+ )
+ },
+ )
+ pad_to_max_length: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to pad all samples to model maximum sentence length. "
+ "If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
+ "efficient on GPU but very bad for TPU."
+ )
+ },
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ )
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": (
+ "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ )
+ },
+ )
+ num_beams: Optional[int] = field(
+ default=1,
+ metadata={
+ "help": (
+ "Number of beams to use for evaluation. This argument will be passed to ``model.generate``, "
+ "which is used during ``evaluate`` and ``predict``."
+ )
+ },
+ )
+ ignore_pad_token_for_loss: bool = field(
+ default=True,
+ metadata={
+ "help": "Whether to ignore the tokens corresponding to padded labels in the loss computation or not."
+ },
+ )
+ source_prefix: Optional[str] = field(
+ default=None, metadata={"help": "A prefix to add before every source text (useful for T5 models)."}
+ )
+ forced_bos_token: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to force as the first generated token after the :obj:`decoder_start_token_id`.Useful for"
+ " multilingual models like :doc:`mBART <../model_doc/mbart>` where the first generated token needs to"
+ " be the target language token.(Usually it is the target language token)"
+ )
+ },
+ )
+
+ def __post_init__(self):
+ if self.dataset_name is None and self.train_file is None and self.validation_file is None:
+ raise ValueError("Need either a dataset name or a training/validation file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+ if self.val_max_target_length is None:
+ self.val_max_target_length = self.max_target_length
+
+
+# endregion
+
+
+def main():
+ # region Argument parsing
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TFTrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_translation", model_args, data_args, framework="tensorflow")
+ # endregion
+
+ # region Logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+ logger.setLevel(logging.INFO)
+ datasets.utils.logging.set_verbosity(logging.INFO)
+ transformers.utils.logging.set_verbosity(logging.INFO)
+
+ # Log on each process the small summary:
+ logger.info(f"Training/evaluation parameters {training_args}")
+ # endregion
+
+ # region Detecting last checkpoint
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+ # endregion
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # region Load datasets
+ # Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files this script will use the first column for the full texts and the second column for the
+ # summaries (unless you specify column names for this with the `text_column` and `summary_column` arguments).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ raw_datasets = load_dataset(
+ extension,
+ data_files=data_files,
+ cache_dir=model_args.cache_dir,
+ token=model_args.token,
+ )
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading
+ # endregion
+
+ # region Load model config and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ prefix = data_args.source_prefix if data_args.source_prefix is not None else ""
+ # endregion
+
+ # region Dataset preprocessing
+ # We need to tokenize inputs and targets.
+ if training_args.do_train:
+ column_names = raw_datasets["train"].column_names
+ elif training_args.do_eval:
+ column_names = raw_datasets["validation"].column_names
+ else:
+ logger.info("There is nothing to do. Please pass `do_train`, and/or `do_eval`.")
+ return
+
+ column_names = raw_datasets["train"].column_names
+
+ # For translation we set the codes of our source and target languages (only useful for mBART, the others will
+ # ignore those attributes).
+ if isinstance(tokenizer, tuple(MULTILINGUAL_TOKENIZERS)):
+ assert data_args.target_lang is not None and data_args.source_lang is not None, (
+ f"{tokenizer.__class__.__name__} is a multilingual tokenizer which requires --source_lang and "
+ "--target_lang arguments."
+ )
+ tokenizer.src_lang = data_args.source_lang
+ tokenizer.tgt_lang = data_args.target_lang
+ forced_bos_token_id = (
+ tokenizer.lang_code_to_id[data_args.forced_bos_token] if data_args.forced_bos_token is not None else None
+ )
+
+ # Get the language codes for input/target.
+ source_lang = data_args.source_lang.split("_")[0]
+ target_lang = data_args.target_lang.split("_")[0]
+
+ padding = "max_length" if data_args.pad_to_max_length else False
+
+ # Temporarily set max_target_length for training.
+ max_target_length = data_args.max_target_length
+ padding = "max_length" if data_args.pad_to_max_length else False
+
+ def preprocess_function(examples):
+ inputs = [ex[source_lang] for ex in examples["translation"]]
+ targets = [ex[target_lang] for ex in examples["translation"]]
+ inputs = [prefix + inp for inp in inputs]
+ model_inputs = tokenizer(inputs, max_length=data_args.max_source_length, padding=padding, truncation=True)
+
+ # Tokenize targets with the `text_target` keyword argument
+ labels = tokenizer(text_target=targets, max_length=max_target_length, padding=padding, truncation=True)
+
+ # If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
+ # padding in the loss.
+ if padding == "max_length" and data_args.ignore_pad_token_for_loss:
+ labels["input_ids"] = [
+ [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
+ ]
+
+ model_inputs["labels"] = labels["input_ids"]
+ return model_inputs
+
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if data_args.max_train_samples is not None:
+ max_train_samples = min(len(train_dataset), data_args.max_train_samples)
+ train_dataset = train_dataset.select(range(max_train_samples))
+ train_dataset = train_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on train dataset",
+ )
+ else:
+ train_dataset = None
+
+ if training_args.do_eval:
+ max_target_length = data_args.val_max_target_length
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = raw_datasets["validation"]
+ if data_args.max_eval_samples is not None:
+ max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
+ eval_dataset = eval_dataset.select(range(max_eval_samples))
+ eval_dataset = eval_dataset.map(
+ preprocess_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=column_names,
+ load_from_cache_file=not data_args.overwrite_cache,
+ desc="Running tokenizer on validation dataset",
+ )
+ else:
+ eval_dataset = None
+ # endregion
+
+ with training_args.strategy.scope():
+ # region Prepare model
+ model = TFAutoModelForSeq2SeqLM.from_pretrained(
+ model_args.model_name_or_path,
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+
+ # We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
+ # on a small vocab and want a smaller embedding size, remove this test.
+ embeddings = model.get_input_embeddings()
+
+ # Matt: This is a temporary workaround as we transition our models to exclusively using Keras embeddings.
+ # As soon as the transition is complete, all embeddings should be keras.Embeddings layers, and
+ # the weights will always be in embeddings.embeddings.
+ if hasattr(embeddings, "embeddings"):
+ embedding_size = embeddings.embeddings.shape[0]
+ else:
+ embedding_size = embeddings.weight.shape[0]
+ if len(tokenizer) > embedding_size:
+ model.resize_token_embeddings(len(tokenizer))
+
+ if isinstance(tokenizer, tuple(MULTILINGUAL_TOKENIZERS)):
+ model.config.forced_bos_token_id = forced_bos_token_id
+ # endregion
+
+ # region Set decoder_start_token_id
+ if model.config.decoder_start_token_id is None and isinstance(tokenizer, (MBartTokenizer, MBartTokenizerFast)):
+ assert data_args.target_lang is not None and data_args.source_lang is not None, (
+ "mBart requires --target_lang and --source_lang"
+ )
+ if isinstance(tokenizer, MBartTokenizer):
+ model.config.decoder_start_token_id = tokenizer.lang_code_to_id[data_args.target_lang]
+ else:
+ model.config.decoder_start_token_id = tokenizer.convert_tokens_to_ids(data_args.target_lang)
+
+ if model.config.decoder_start_token_id is None:
+ raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
+ # endregion
+
+ # region Prepare TF Dataset objects
+ label_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
+ data_collator = DataCollatorForSeq2Seq(
+ tokenizer,
+ model=model,
+ label_pad_token_id=label_pad_token_id,
+ pad_to_multiple_of=64, # Reduce the number of unique shapes for XLA, especially for generation
+ return_tensors="np",
+ )
+ num_replicas = training_args.strategy.num_replicas_in_sync
+ total_train_batch_size = training_args.per_device_train_batch_size * num_replicas
+ total_eval_batch_size = training_args.per_device_eval_batch_size * num_replicas
+
+ dataset_options = tf.data.Options()
+ dataset_options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.OFF
+
+ # model.prepare_tf_dataset() wraps a Hugging Face dataset in a tf.data.Dataset which is ready to use in
+ # training. This is the recommended way to use a Hugging Face dataset when training with Keras. You can also
+ # use the lower-level dataset.to_tf_dataset() method, but you will have to specify things like column names
+ # yourself if you use this method, whereas they are automatically inferred from the model input names when
+ # using model.prepare_tf_dataset()
+ # For more info see the docs:
+ # https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.TFPreTrainedModel.prepare_tf_dataset
+ # https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.to_tf_dataset
+
+ tf_train_dataset = model.prepare_tf_dataset(
+ train_dataset,
+ collate_fn=data_collator,
+ batch_size=total_train_batch_size,
+ shuffle=True,
+ ).with_options(dataset_options)
+ tf_eval_dataset = model.prepare_tf_dataset(
+ eval_dataset, collate_fn=data_collator, batch_size=total_eval_batch_size, shuffle=False
+ ).with_options(dataset_options)
+ # endregion
+
+ # region Optimizer and LR scheduling
+ num_train_steps = int(len(tf_train_dataset) * training_args.num_train_epochs)
+ if training_args.warmup_steps > 0:
+ num_warmup_steps = training_args.warmup_steps
+ elif training_args.warmup_ratio > 0:
+ num_warmup_steps = int(num_train_steps * training_args.warmup_ratio)
+ else:
+ num_warmup_steps = 0
+ if training_args.do_train:
+ optimizer, lr_schedule = create_optimizer(
+ init_lr=training_args.learning_rate,
+ num_train_steps=num_train_steps,
+ num_warmup_steps=num_warmup_steps,
+ adam_beta1=training_args.adam_beta1,
+ adam_beta2=training_args.adam_beta2,
+ adam_epsilon=training_args.adam_epsilon,
+ weight_decay_rate=training_args.weight_decay,
+ adam_global_clipnorm=training_args.max_grad_norm,
+ )
+ else:
+ optimizer = "sgd" # Just write anything because we won't be using it
+ # endregion
+
+ # region Metric and postprocessing
+ if training_args.do_eval:
+ metric = evaluate.load("sacrebleu", cache_dir=model_args.cache_dir)
+
+ if data_args.val_max_target_length is None:
+ data_args.val_max_target_length = data_args.max_target_length
+
+ gen_kwargs = {
+ "max_length": data_args.val_max_target_length,
+ "num_beams": data_args.num_beams,
+ "no_repeat_ngram_size": 0, # Not supported under XLA right now, and some models set it by default
+ }
+
+ def postprocess_text(preds, labels):
+ preds = [pred.strip() for pred in preds]
+ labels = [[label.strip()] for label in labels]
+
+ return preds, labels
+
+ def compute_metrics(preds):
+ predictions, labels = preds
+ if isinstance(predictions, tuple):
+ predictions = predictions[0]
+ decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+ decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
+ metrics = metric.compute(predictions=decoded_preds, references=decoded_labels)
+ return {"bleu": metrics["score"]}
+
+ # The KerasMetricCallback allows metrics that are too complex to write as standard Keras metrics
+ # to be computed each epoch. Any Python code can be included in the metric_fn. This is especially
+ # useful for metrics like BLEU and ROUGE that perform string comparisons on decoded model outputs.
+ # For more information, see the docs at
+ # https://huggingface.co/docs/transformers/main_classes/keras_callbacks#transformers.KerasMetricCallback
+
+ metric_callback = KerasMetricCallback(
+ metric_fn=compute_metrics,
+ eval_dataset=tf_eval_dataset,
+ predict_with_generate=True,
+ use_xla_generation=True,
+ generate_kwargs=gen_kwargs,
+ )
+ callbacks = [metric_callback]
+ else:
+ callbacks = []
+
+ # endregion
+
+ # region Preparing push_to_hub and model card
+ push_to_hub_model_id = training_args.push_to_hub_model_id
+ model_name = model_args.model_name_or_path.split("/")[-1]
+ if not push_to_hub_model_id:
+ push_to_hub_model_id = f"{model_name}-finetuned-{data_args.source_lang}-{data_args.target_lang}"
+
+ model_card_kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "translation"}
+ if data_args.dataset_name is not None:
+ model_card_kwargs["dataset_tags"] = data_args.dataset_name
+ if data_args.dataset_config_name is not None:
+ model_card_kwargs["dataset_args"] = data_args.dataset_config_name
+ model_card_kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
+ else:
+ model_card_kwargs["dataset"] = data_args.dataset_name
+
+ languages = [l for l in [data_args.source_lang, data_args.target_lang] if l is not None]
+ if len(languages) > 0:
+ model_card_kwargs["language"] = languages
+
+ if training_args.push_to_hub:
+ # Because this training can be quite long, we save once per epoch.
+ callbacks.append(
+ PushToHubCallback(
+ output_dir=training_args.output_dir,
+ hub_model_id=push_to_hub_model_id,
+ hub_token=training_args.push_to_hub_token,
+ tokenizer=tokenizer,
+ **model_card_kwargs,
+ )
+ )
+ # endregion
+
+ # region Training
+ eval_metrics = None
+ # Transformers models compute the right loss for their task by default when labels are passed, and will
+ # use this for training unless you specify your own loss function in compile().
+ model.compile(optimizer=optimizer, jit_compile=training_args.xla)
+
+ if training_args.do_train:
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {training_args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {training_args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size = {total_train_batch_size}")
+ logger.info(f" Total optimization steps = {num_train_steps}")
+
+ if training_args.xla and not data_args.pad_to_max_length:
+ logger.warning(
+ "XLA training may be slow at first when --pad_to_max_length is not set "
+ "until all possible shapes have been compiled."
+ )
+
+ history = model.fit(tf_train_dataset, epochs=int(training_args.num_train_epochs), callbacks=callbacks)
+ eval_metrics = {key: val[-1] for key, val in history.history.items()}
+ # endregion
+
+ # region Validation
+ if training_args.do_eval and not training_args.do_train:
+ # Compiling generation with XLA yields enormous speedups, see https://huggingface.co/blog/tf-xla-generate
+ @tf.function(jit_compile=True)
+ def generate(**kwargs):
+ return model.generate(**kwargs)
+
+ if training_args.do_eval:
+ logger.info("Evaluation...")
+ for batch, labels in tf_eval_dataset:
+ batch.update(gen_kwargs)
+ generated_tokens = generate(**batch)
+ if isinstance(generated_tokens, tuple):
+ generated_tokens = generated_tokens[0]
+ decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
+ labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
+ decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
+ decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
+
+ metric.add_batch(predictions=decoded_preds, references=decoded_labels)
+
+ eval_metrics = metric.compute()
+ logger.info({"bleu": eval_metrics["score"]})
+ # endregion
+
+ if training_args.output_dir is not None and eval_metrics is not None:
+ output_eval_file = os.path.join(training_args.output_dir, "all_results.json")
+ with open(output_eval_file, "w") as writer:
+ writer.write(json.dumps(eval_metrics))
+
+ if training_args.output_dir is not None and not training_args.push_to_hub:
+ # If we're not pushing to hub, at least save a local copy when we're done
+ model.save_pretrained(training_args.output_dir)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/examples/training/distributed_training.py b/docs/transformers/examples/training/distributed_training.py
new file mode 100644
index 0000000000000000000000000000000000000000..af19106a82764cae80e84134366523bb9a3d7b12
--- /dev/null
+++ b/docs/transformers/examples/training/distributed_training.py
@@ -0,0 +1,113 @@
+import argparse
+import os
+
+import torch
+import torch.distributed as dist
+
+
+# Environment variables set by torch.distributed.launch
+LOCAL_RANK = int(os.environ["LOCAL_RANK"])
+WORLD_SIZE = int(os.environ["WORLD_SIZE"])
+WORLD_RANK = int(os.environ["RANK"])
+
+LOCAL_RANK = int(os.environ["OMPI_COMM_WORLD_LOCAL_RANK"])
+WORLD_SIZE = int(os.environ["OMPI_COMM_WORLD_SIZE"])
+WORLD_RANK = int(os.environ["OMPI_COMM_WORLD_RANK"])
+
+
+def run(backend):
+ tensor = torch.zeros(1)
+ # Need to put tensor on a GPU device for nccl backend
+ if backend == "nccl":
+ device = torch.device(f"cuda:{LOCAL_RANK}")
+ tensor = tensor.to(device)
+
+ if WORLD_RANK == 0:
+ for rank_recv in range(1, WORLD_SIZE):
+ dist.send(tensor=tensor, dst=rank_recv)
+ print(f"worker_{0} sent data to Rank {rank_recv}\n")
+ else:
+ dist.recv(tensor=tensor, src=0)
+ print(f"worker_{WORLD_RANK} has received data from rank {0}\n")
+
+
+def init_processes(backend):
+ dist.init_process_group(backend, rank=WORLD_RANK, world_size=WORLD_SIZE)
+ run(backend)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "--local_rank", type=int, help="Local rank. Necessary for using the torch.distributed.launch utility."
+ )
+ parser.add_argument("--backend", type=str, default="nccl", choices=["nccl", "gloo"])
+ args = parser.parse_args()
+
+ init_processes(backend=args.backend)
+
+""""
+python-m torch.distributed.launch \
+--nproc_per_node=2 --nnodes=2 --node_rank=0 \
+test_compile.py
+
+python3 -m torch.distributed.launch \
+--nproc_per_node=2 --nnodes=2 --node_rank=1 \
+--master_addr=104.171.200.62 --master_port=1234 \
+main.py \
+--backend=nccl --use_syn --batch_size=8192 --arch=resnet152
+
+
+
+mpirun -np 4 \
+-H 104.171.200.62:2,104.171.200.182:2 \
+-x MASTER_ADDR=104.171.200.62 \
+-x MASTER_PORT=1234 \
+-x PATH \
+-bind-to none -map-by slot \
+-mca pml ob1 -mca btl ^openib \
+python3 main.py
+"""
+
+
+""""
+You need a host file with the name of hosts.
+for example I have arthur@ip-26-0-162-46 and arthur@ip-26-0-162-239
+
+________
+hostfile
+ip-26-0-162-46 slots=8
+ip-26-0-162-239 slots=8
+________
+
+mpirun --hostfile hostfile -np 16 \
+ --bind-to none --map-by slot \
+ -x MASTER_ADDR= \
+ -x MASTER_PORT=29500 \
+ -x NCCL_DEBUG=INFO \
+ -x NCCL_SOCKET_IFNAME=^lo,docker0 \
+ -x CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
+ python your_script.py --backend nccl
+
+
+to get the master IP you need to do a few things:
+hostname -I | awk '{print $1}'
+
+
+Use `ping ip-26-0-162-46` to check if connected
+
+26.0.162.46
+
+mpirun --hostfile hostfile -np 16 \
+ --bind-to none --map-by slot \
+ -x MASTER_ADDR=26.0.162.46 \
+ -x MASTER_PORT=29500 \
+ -x NCCL_DEBUG=INFO \
+ -x NCCL_SOCKET_IFNAME=^lo,docker0 \
+ -x CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
+ python your_script.py --backend nccl
+
+
+mpirun --hostfile hostfile -np 2 -x NCCL_DEBUG=INFO python -c "import os;print(os.environ['OMPI_COMM_WORLD_LOCAL_RANK'])" -b 8 -e 128M -f 2 -g 1
+to test your setup
+"""
diff --git a/docs/transformers/i18n/README_ar.md b/docs/transformers/i18n/README_ar.md
new file mode 100644
index 0000000000000000000000000000000000000000..cdf813445d6f2d43cf10cc327d92b9f108009728
--- /dev/null
+++ b/docs/transformers/i18n/README_ar.md
@@ -0,0 +1,318 @@
+
+
+
أحدث تقنيات التعلم الآلي لـ JAX وPyTorch وTensorFlow
+
+
+
+
+
+
+يوفر 🤗 Transformers آلاف النماذج المُدربة مسبقًا لأداء المهام على طرائق مختلفة مثل النص والصورة والصوت.
+
+يمكن تطبيق هذه النماذج على:
+
+* 📝 النص، لمهام مثل تصنيف النص واستخراج المعلومات والرد على الأسئلة والتلخيص والترجمة وتوليد النص، في أكثر من 100 لغة.
+* 🖼️ الصور، لمهام مثل تصنيف الصور وكشف الأشياء والتجزئة.
+* 🗣️ الصوت، لمهام مثل التعرف على الكلام وتصنيف الصوت.
+
+يمكن لنماذج المحول أيضًا أداء مهام على **طرائق متعددة مجتمعة**، مثل الرد على الأسئلة الجدولية والتعرف البصري على الحروف واستخراج المعلومات من المستندات الممسوحة ضوئيًا وتصنيف الفيديو والرد على الأسئلة المرئية.
+
+يوفر 🤗 Transformers واجهات برمجة التطبيقات (APIs) لتحميل تلك النماذج المُدربة مسبقًا واستخدامها على نص معين، وضبطها بدقة على مجموعات البيانات الخاصة بك، ثم مشاركتها مع المجتمع على [مركز النماذج](https://huggingface.co/models) الخاص بنا. وفي الوقت نفسه، فإن كل وحدة نمطية Python التي تحدد بنية هي وحدة مستقلة تمامًا ويمكن تعديلها لتمكين تجارب البحث السريعة.
+
+يتم دعم 🤗 Transformers بواسطة مكتبات التعلم العميق الثلاث الأكثر شيوعًا - [Jax](https://jax.readthedocs.io/en/latest/) و [PyTorch](https://pytorch.org/) و [TensorFlow](https://www.tensorflow.org/) - مع تكامل سلس بينها. من السهل تدريب نماذجك باستخدام واحدة قبل تحميلها للاستنتاج باستخدام الأخرى.
+
+## العروض التوضيحية عبر الإنترنت
+
+يمكنك اختبار معظم نماذجنا مباشرة على صفحاتها من [مركز النماذج](https://huggingface.co/models). كما نقدم [استضافة النماذج الخاصة وإصداراتها وواجهة برمجة تطبيقات الاستدلال](https://huggingface.co/pricing) للنماذج العامة والخاصة.
+
+فيما يلي بعض الأمثلة:
+
+في معالجة اللغات الطبيعية:
+- [استكمال الكلمات المقنعة باستخدام BERT](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [التعرف على الكيانات المسماة باستخدام إليكترا](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [توليد النص باستخدام ميسترال](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
+- [الاستدلال اللغوي الطبيعي باستخدام RoBERTa](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [التلخيص باستخدام BART](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [الرد على الأسئلة باستخدام DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [الترجمة باستخدام T5](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+في رؤية الكمبيوتر:
+- [تصنيف الصور باستخدام ViT](https://huggingface.co/google/vit-base-patch16-224)
+- [كشف الأشياء باستخدام DETR](https://huggingface.co/facebook/detr-resnet-50)
+- [التجزئة الدلالية باستخدام SegFormer](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
+- [التجزئة الشاملة باستخدام Mask2Former](https://huggingface.co/facebook/mask2former-swin-large-coco-panoptic)
+- [تقدير العمق باستخدام Depth Anything](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)
+- [تصنيف الفيديو باستخدام VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)
+- [التجزئة الشاملة باستخدام OneFormer](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
+
+في الصوت:
+- [الاعتراف التلقائي بالكلام مع Whisper](https://huggingface.co/openai/whisper-large-v3)
+- [اكتشاف الكلمات الرئيسية باستخدام Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
+- [تصنيف الصوت باستخدام محول طيف الصوت](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
+
+في المهام متعددة الطرائق:
+- [الرد على الأسئلة الجدولية باستخدام TAPAS](https://huggingface.co/google/tapas-base-finetuned-wtq)
+- [الرد على الأسئلة المرئية باستخدام ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
+- [وصف الصورة باستخدام LLaVa](https://huggingface.co/llava-hf/llava-1.5-7b-hf)
+- [تصنيف الصور بدون تدريب باستخدام SigLIP](https://huggingface.co/google/siglip-so400m-patch14-384)
+- [الرد على أسئلة المستندات باستخدام LayoutLM](https://huggingface.co/impira/layoutlm-document-qa)
+- [تصنيف الفيديو بدون تدريب باستخدام X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)
+- [كشف الأشياء بدون تدريب باستخدام OWLv2](https://huggingface.co/docs/transformers/en/model_doc/owlv2)
+- [تجزئة الصور بدون تدريب باستخدام CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)
+- [توليد الأقنعة التلقائي باستخدام SAM](https://huggingface.co/docs/transformers/model_doc/sam)
+
+
+## 100 مشروع يستخدم المحولات
+
+🤗 Transformers هو أكثر من مجرد مجموعة أدوات لاستخدام النماذج المُدربة مسبقًا: إنه مجتمع من المشاريع المبنية حوله ومركز Hugging Face. نريد أن يمكّن 🤗 Transformers المطورين والباحثين والطلاب والأساتذة والمهندسين وأي شخص آخر من بناء مشاريعهم التي يحلمون بها.
+
+للاحتفال بالـ 100,000 نجمة من النماذج المحولة، قررنا تسليط الضوء على المجتمع، وقد أنشأنا صفحة [awesome-transformers](./awesome-transformers.md) التي تُدرج 100 مشروعًا رائعًا تم بناؤها بالقرب من النماذج المحولة.
+
+إذا كنت تمتلك أو تستخدم مشروعًا تعتقد أنه يجب أن يكون جزءًا من القائمة، فالرجاء فتح PR لإضافته!
+
+## إذا كنت تبحث عن دعم مخصص من فريق Hugging Face
+
+
+
+
+
+## جولة سريعة
+
+لاستخدام نموذج على الفور على إدخال معين (نص أو صورة أو صوت، ...)، نوفر واجهة برمجة التطبيقات (API) الخاصة بـ `pipeline`. تجمع خطوط الأنابيب بين نموذج مُدرب مسبقًا ومعالجة ما قبل التدريب التي تم استخدامها أثناء تدريب هذا النموذج. فيما يلي كيفية استخدام خط أنابيب بسرعة لتصنيف النصوص الإيجابية مقابل السلبية:
+
+```python
+>>> from transformers import pipeline
+
+# خصص خط أنابيب للتحليل الشعوري
+>>> classifier = pipeline('sentiment-analysis')
+>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+يسمح السطر الثاني من التعليمات البرمجية بتحميل النموذج المُدرب مسبقًا الذي يستخدمه خط الأنابيب وتخزينه مؤقتًا، بينما يقوم السطر الثالث بتقييمه على النص المحدد. هنا، تكون الإجابة "إيجابية" بثقة تبلغ 99.97%.
+
+تتوفر العديد من المهام على خط أنابيب مُدرب مسبقًا جاهز للاستخدام، في NLP ولكن أيضًا في رؤية الكمبيوتر والخطاب. على سبيل المثال، يمكننا بسهولة استخراج الأشياء المكتشفة في صورة:
+
+``` python
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import pipeline
+
+# قم بتنزيل صورة بها قطط لطيفة
+>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
+>>> image_data = requests.get(url, stream=True).raw
+>>> image = Image.open(image_data)
+
+# خصص خط أنابيب لكشف الأشياء
+>>> object_detector = pipeline('object-detection')
+>>> object_detector(image)
+[{'score': 0.9982201457023621،
+ 'label': 'remote'،
+ 'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}}،
+ {'score': 0.9960021376609802،
+ 'label': 'remote'،
+ 'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}}،
+ {'score': 0.9954745173454285،
+ 'label': 'couch'،
+ 'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}}،
+ {'score': 0.9988006353378296،
+ 'label': 'cat'،
+ 'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}}،
+ {'score': 0.9986783862113953،
+ 'label': 'cat'،
+ 'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
+```
+
+هنا، نحصل على قائمة بالأشياء المكتشفة في الصورة، مع مربع يحيط بالشيء وتقييم الثقة. فيما يلي الصورة الأصلية على اليسار، مع عرض التوقعات على اليمين:
+
+
+
+
+
+
+يمكنك معرفة المزيد حول المهام التي تدعمها واجهة برمجة التطبيقات (API) الخاصة بـ `pipeline` في [هذا البرنامج التعليمي](https://huggingface.co/docs/transformers/task_summary).
+
+بالإضافة إلى `pipeline`، لاستخدام أي من النماذج المُدربة مسبقًا على مهمتك، كل ما عليك هو ثلاثة أسطر من التعليمات البرمجية. فيما يلي إصدار PyTorch:
+```python
+>>> from transformers import AutoTokenizer، AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!"، return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+
+وهنا رمز مماثل لـ TensorFlow:
+```python
+>>> from transformers import AutoTokenizer، TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!"، return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+المُعلم مسؤول عن جميع المعالجة المسبقة التي يتوقعها النموذج المُدرب مسبقًا ويمكن استدعاؤه مباشرة على سلسلة واحدة (كما هو موضح في الأمثلة أعلاه) أو قائمة. سيقوم بإخراج قاموس يمكنك استخدامه في التعليمات البرمجية لأسفل أو تمريره مباشرة إلى نموذجك باستخدام عامل فك التعبئة **.
+
+النموذج نفسه هو وحدة نمطية عادية [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) أو [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (حسب backend) والتي يمكنك استخدامها كالمعتاد. [يوضح هذا البرنامج التعليمي](https://huggingface.co/docs/transformers/training) كيفية دمج مثل هذا النموذج في حلقة تدريب PyTorch أو TensorFlow التقليدية، أو كيفية استخدام واجهة برمجة تطبيقات `Trainer` لدينا لضبطها بدقة بسرعة على مجموعة بيانات جديدة.
+
+## لماذا يجب أن أستخدم المحولات؟
+
+1. نماذج سهلة الاستخدام وحديثة:
+ - أداء عالي في فهم اللغة الطبيعية وتوليدها ورؤية الكمبيوتر والمهام الصوتية.
+ - حاجز دخول منخفض للمربين والممارسين.
+ - عدد قليل من التجريدات التي يواجهها المستخدم مع ثلاث فئات فقط للتعلم.
+ - واجهة برمجة تطبيقات (API) موحدة لاستخدام جميع نماذجنا المُدربة مسبقًا.
+
+1. تكاليف الكمبيوتر أقل، وبصمة كربونية أصغر:
+ - يمكن للباحثين مشاركة النماذج المدربة بدلاً من إعادة التدريب دائمًا.
+ - يمكن للممارسين تقليل وقت الكمبيوتر وتكاليف الإنتاج.
+ - عشرات البنيات مع أكثر من 400,000 نموذج مُدرب مسبقًا عبر جميع الطرائق.
+
+1. اختر الإطار المناسب لكل جزء من عمر النموذج:
+ - تدريب النماذج الحديثة في 3 أسطر من التعليمات البرمجية.
+ - قم بنقل نموذج واحد بين إطارات TF2.0/PyTorch/JAX حسب الرغبة.
+ - اختر الإطار المناسب بسلاسة للتدريب والتقييم والإنتاج.
+
+1. قم بسهولة بتخصيص نموذج أو مثال وفقًا لاحتياجاتك:
+ - نوفر أمثلة لكل بنية لإعادة إنتاج النتائج التي نشرها مؤلفوها الأصليون.
+ - يتم عرض داخليات النموذج بشكل متسق قدر الإمكان.
+ - يمكن استخدام ملفات النموذج بشكل مستقل عن المكتبة للتجارب السريعة.
+
+## لماذا لا يجب أن أستخدم المحولات؟
+
+- ليست هذه المكتبة عبارة عن مجموعة أدوات من الصناديق المكونة للشبكات العصبية. لم يتم إعادة صياغة التعليمات البرمجية في ملفات النموذج باستخدام تجريدات إضافية عن قصد، بحيث يمكن للباحثين إجراء حلقات تكرار سريعة على كل من النماذج دون الغوص في تجريدات/ملفات إضافية.
+- لا يُقصد بواجهة برمجة التطبيقات (API) للتدريب العمل على أي نموذج ولكنه مُستَهدف للعمل مع النماذج التي توفرها المكتبة. للحلقات العامة للتعلم الآلي، يجب استخدام مكتبة أخرى (ربما، [تسريع](https://huggingface.co/docs/accelerate)).
+- في حين أننا نسعى جاهدين لتقديم أكبر عدد ممكن من حالات الاستخدام، فإن البرامج النصية الموجودة في مجلد [الأمثلة](https://github.com/huggingface/transformers/tree/main/examples) الخاص بنا هي مجرد أمثلة. من المتوقع ألا تعمل هذه البرامج النصية خارج الصندوق على مشكلتك المحددة وأنه سيُطلب منك تغيير بضع أسطر من التعليمات البرمجية لتكييفها مع احتياجاتك.
+
+## التثبيت
+
+### باستخدام pip
+
+تم اختبار هذا المستودع على Python 3.9+، Flax 0.4.1+، PyTorch 2.1+، و TensorFlow 2.6+.
+
+يجب تثبيت 🤗 Transformers في [بيئة افتراضية](https://docs.python.org/3/library/venv.html). إذا كنت غير معتاد على البيئات الافتراضية Python، فراجع [دليل المستخدم](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+
+أولاً، قم بإنشاء بيئة افتراضية بالإصدار Python الذي تنوي استخدامه وقم بتنشيطه.
+
+بعد ذلك، ستحتاج إلى تثبيت واحدة على الأقل من Flax أو PyTorch أو TensorFlow.
+يرجى الرجوع إلى [صفحة تثبيت TensorFlow](https://www.tensorflow.org/install/)، و [صفحة تثبيت PyTorch](https://pytorch.org/get-started/locally/#start-locally) و/أو [صفحة تثبيت Flax](https://github.com/google/flax#quick-install) و [صفحة تثبيت Jax](https://github.com/google/jax#installation) بشأن أمر التثبيت المحدد لمنصتك.
+
+عندما يتم تثبيت إحدى هذه المكتبات الخلفية، يمكن تثبيت 🤗 Transformers باستخدام pip كما يلي:
+
+```bash
+pip install transformers
+```
+
+إذا كنت ترغب في اللعب مع الأمثلة أو تحتاج إلى أحدث إصدار من التعليمات البرمجية ولا يمكنك الانتظار حتى يتم إصدار إصدار جديد، فيجب [تثبيت المكتبة من المصدر](https://huggingface.co/docs/transformers/installation#installing-from-source).
+
+### باستخدام conda
+
+يمكن تثبيت 🤗 Transformers باستخدام conda كما يلي:
+
+```shell script
+conda install conda-forge::transformers
+```
+
+> **_ملاحظة:_** تم إيقاف تثبيت `transformers` من قناة `huggingface`.
+
+اتبع صفحات التثبيت الخاصة بـ Flax أو PyTorch أو TensorFlow لمعرفة كيفية تثبيتها باستخدام conda.
+
+> **_ملاحظة:_** على Windows، قد تتم مطالبتك بتنشيط وضع المطور للاستفادة من التخزين المؤقت. إذا لم يكن هذا خيارًا بالنسبة لك، فيرجى إعلامنا بذلك في [هذه المشكلة](https://github.com/huggingface/huggingface_hub/issues/1062).
+
+## بنيات النماذج
+
+**[جميع نقاط تفتيش النموذج](https://huggingface.co/models)** التي يوفرها 🤗 Transformers مدمجة بسلاسة من مركز [huggingface.co](https://huggingface.co/models) [model hub](https://huggingface.co/models)، حيث يتم تحميلها مباشرة من قبل [المستخدمين](https://huggingface.co/users) و [المنظمات](https://huggingface.co/organizations).
+
+عدد نقاط التفتيش الحالية: 
+
+يوفر 🤗 Transformers حاليًا البنيات التالية: راجع [هنا](https://huggingface.co/docs/transformers/model_summary) للحصول على ملخص لكل منها.
+
+للتحقق مما إذا كان لكل نموذج تنفيذ في Flax أو PyTorch أو TensorFlow، أو كان لديه مُعلم مرفق مدعوم من مكتبة 🤗 Tokenizers، يرجى الرجوع إلى [هذا الجدول](https://huggingface.co/docs/transformers/index#supported-frameworks).
+
+تم اختبار هذه التطبيقات على العديد من مجموعات البيانات (راجع البرامج النصية المثالية) ويجب أن تتطابق مع أداء التنفيذ الأصلي. يمكنك العثور على مزيد من التفاصيل حول الأداء في قسم الأمثلة من [الوثائق](https://github.com/huggingface/transformers/tree/main/examples).
+
+
+## تعلم المزيد
+
+| القسم | الوصف |
+|-|-|
+| [وثائق](https://huggingface.co/docs/transformers/) | وثائق واجهة برمجة التطبيقات (API) الكاملة والبرامج التعليمية |
+| [ملخص المهام](https://huggingface.co/docs/transformers/task_summary) | المهام التي يدعمها 🤗 Transformers |
+| [برنامج تعليمي لمعالجة مسبقة](https://huggingface.co/docs/transformers/preprocessing) | استخدام فئة `Tokenizer` لإعداد البيانات للنماذج |
+| [التدريب والضبط الدقيق](https://huggingface.co/docs/transformers/training) | استخدام النماذج التي يوفرها 🤗 Transformers في حلقة تدريب PyTorch/TensorFlow وواجهة برمجة تطبيقات `Trainer` |
+| [جولة سريعة: البرامج النصية للضبط الدقيق/الاستخدام](https://github.com/huggingface/transformers/tree/main/examples) | البرامج النصية المثالية للضبط الدقيق للنماذج على مجموعة واسعة من المهام |
+| [مشاركة النماذج وتحميلها](https://huggingface.co/docs/transformers/model_sharing) | تحميل ومشاركة نماذجك المضبوطة بدقة مع المجتمع |
+
+## الاستشهاد
+
+لدينا الآن [ورقة](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) يمكنك الاستشهاد بها لمكتبة 🤗 Transformers:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers،
+ title = "Transformers: State-of-the-Art Natural Language Processing"،
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and R{\'e}mi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush"،
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations"،
+ month = oct،
+ year = "2020"،
+ address = "Online"،
+ publisher = "Association for Computational Linguistics"،
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6"،
+ pages = "38--45"
+}
+```
diff --git a/docs/transformers/i18n/README_de.md b/docs/transformers/i18n/README_de.md
new file mode 100644
index 0000000000000000000000000000000000000000..b913df894dc147d575a8d283b7eab7265306bbb2
--- /dev/null
+++ b/docs/transformers/i18n/README_de.md
@@ -0,0 +1,318 @@
+
+
+
Maschinelles Lernen auf dem neuesten Stand der Technik für JAX, PyTorch und TensorFlow
+
+
+
+
+
+
+🤗 Transformers bietet Tausende von vortrainierten Modellen, um Aufgaben in verschiedenen Modalitäten wie Text, Bild und Audio durchzuführen.
+
+Diese Modelle können angewendet werden, auf:
+
+* 📝 Text - für Aufgaben wie Textklassifizierung, Informationsextraktion, Question Answering, automatische Textzusammenfassung, maschinelle Übersetzung und Textgenerierung in über 100 Sprachen.
+* 🖼️ Bilder - für Aufgaben wie Bildklassifizierung, Objekterkennung und Segmentierung.
+* 🗣️ Audio - für Aufgaben wie Spracherkennung und Audioklassifizierung.
+
+Transformer-Modelle können auch Aufgaben für **mehrere Modalitäten in Kombination** durchführen, z. B. tabellenbasiertes Question Answering, optische Zeichenerkennung, Informationsextraktion aus gescannten Dokumenten, Videoklassifizierung und visuelles Question Answering.
+
+🤗 Transformers bietet APIs, um diese vortrainierten Modelle schnell herunterzuladen und für einen gegebenen Text zu verwenden, sie auf Ihren eigenen Datensätzen zu feintunen und dann mit der Community in unserem [Model Hub](https://huggingface.co/models) zu teilen. Gleichzeitig ist jedes Python-Modul, das eine Architektur definiert, komplett eigenständig und kann modifiziert werden, um schnelle Forschungsexperimente zu ermöglichen.
+
+🤗 Transformers unterstützt die nahtlose Integration von drei der beliebtesten Deep-Learning-Bibliotheken: [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) und [TensorFlow](https://www.tensorflow.org/). Trainieren Sie Ihr Modell in einem Framework und laden Sie es zur Inferenz unkompliziert mit einem anderen.
+
+## Online-Demos
+
+Sie können die meisten unserer Modelle direkt auf ihren Seiten im [Model Hub](https://huggingface.co/models) testen. Wir bieten auch [privates Modell-Hosting, Versionierung, & eine Inferenz-API](https://huggingface.co/pricing) für öffentliche und private Modelle an.
+
+Hier sind einige Beispiele:
+
+In der Computerlinguistik:
+
+- [Maskierte Wortvervollständigung mit BERT](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [Eigennamenerkennung mit Electra](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [Textgenerierung mit GPT-2](https://huggingface.co/openai-community/gpt2?text=A+long+time+ago%2C+)
+- [Natural Language Inference mit RoBERTa](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [Automatische Textzusammenfassung mit BART](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [Question Answering mit DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [Maschinelle Übersetzung mit T5](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+In der Computer Vision:
+
+- [Bildklassifizierung mit ViT](https://huggingface.co/google/vit-base-patch16-224)
+- [Objekterkennung mit DETR](https://huggingface.co/facebook/detr-resnet-50)
+- [Semantische Segmentierung mit SegFormer](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
+- [Panoptische Segmentierung mit MaskFormer](https://huggingface.co/facebook/maskformer-swin-small-coco)
+- [Depth Estimation mit DPT](https://huggingface.co/docs/transformers/model_doc/dpt)
+- [Videoklassifizierung mit VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)
+- [Universelle Segmentierung mit OneFormer](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
+
+Im Audio-Bereich:
+
+- [Automatische Spracherkennung mit Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base-960h)
+- [Keyword Spotting mit Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
+- [Audioklassifizierung mit Audio Spectrogram Transformer](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
+
+In multimodalen Aufgaben:
+
+- [Tabellenbasiertes Question Answering mit TAPAS](https://huggingface.co/google/tapas-base-finetuned-wtq)
+- [Visuelles Question Answering mit ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
+- [Zero-Shot-Bildklassifizierung mit CLIP](https://huggingface.co/openai/clip-vit-large-patch14)
+- [Dokumentenbasiertes Question Answering mit LayoutLM](https://huggingface.co/impira/layoutlm-document-qa)
+- [Zero-Shot-Videoklassifizierung mit X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)
+
+## 100 Projekte, die 🤗 Transformers verwenden
+
+🤗 Transformers ist mehr als nur ein Toolkit zur Verwendung von vortrainierten Modellen: Es ist eine Gemeinschaft von Projekten, die darum herum und um den Hugging Face Hub aufgebaut sind. Wir möchten, dass 🤗 Transformers es Entwicklern, Forschern, Studenten, Professoren, Ingenieuren und jedem anderen ermöglicht, ihre Traumprojekte zu realisieren.
+
+Um die 100.000 Sterne von 🤗 Transformers zu feiern, haben wir beschlossen, die Gemeinschaft in den Mittelpunkt zu stellen und die Seite [awesome-transformers](./awesome-transformers.md) erstellt, die 100 unglaubliche Projekte auflistet, die zusammen mit 🤗 Transformers realisiert wurden.
+
+Wenn Sie ein Projekt besitzen oder nutzen, von dem Sie glauben, dass es Teil der Liste sein sollte, öffnen Sie bitte einen PR, um es hinzuzufügen!
+
+## Wenn Sie individuelle Unterstützung vom Hugging Face-Team möchten
+
+
+
+
+
+## Schnelleinstieg
+
+Um sofort ein Modell mit einer bestimmten Eingabe (Text, Bild, Audio ...) zu verwenden, bieten wir die `pipeline`-API an. Pipelines kombinieren ein vortrainiertes Modell mit der jeweiligen Vorverarbeitung, die während dessen Trainings verwendet wurde. Hier sehen Sie, wie man schnell eine Pipeline verwenden kann, um positive und negative Texte zu klassifizieren:
+
+```python
+>>> from transformers import pipeline
+
+# Zuweisung einer Pipeline für die Sentiment-Analyse
+>>> classifier = pipeline('sentiment-analysis')
+>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+Die zweite Codezeile lädt und cacht das vortrainierte Modell, das von der Pipeline verwendet wird, während die dritte es an dem gegebenen Text evaluiert. Hier ist die Antwort "positiv" mit einer Konfidenz von 99,97 %.
+
+Viele Aufgaben, sowohl in der Computerlinguistik als auch in der Computer Vision und Sprachverarbeitung, haben eine vortrainierte `pipeline`, die sofort einsatzbereit ist. Z. B. können wir leicht erkannte Objekte in einem Bild extrahieren:
+
+``` python
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import pipeline
+
+# Download eines Bildes mit süßen Katzen
+>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
+>>> image_data = requests.get(url, stream=True).raw
+>>> image = Image.open(image_data)
+
+# Zuweisung einer Pipeline für die Objekterkennung
+>>> object_detector = pipeline('object-detection')
+>>> object_detector(image)
+[{'score': 0.9982201457023621,
+ 'label': 'remote',
+ 'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
+ {'score': 0.9960021376609802,
+ 'label': 'remote',
+ 'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
+ {'score': 0.9954745173454285,
+ 'label': 'couch',
+ 'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
+ {'score': 0.9988006353378296,
+ 'label': 'cat',
+ 'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
+ {'score': 0.9986783862113953,
+ 'label': 'cat',
+ 'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
+```
+
+Hier erhalten wir eine Liste von Objekten, die im Bild erkannt wurden, mit einer Markierung, die das Objekt eingrenzt, und einem zugehörigen Konfidenzwert. Folgend ist das Originalbild links und die Vorhersagen rechts dargestellt:
+
+
+
+
+
+
+Sie können mehr über die von der `pipeline`-API unterstützten Aufgaben in [diesem Tutorial](https://huggingface.co/docs/transformers/task_summary) erfahren.
+
+Zusätzlich zur `pipeline` benötigt es nur drei Zeilen Code, um eines der vortrainierten Modelle für Ihre Aufgabe herunterzuladen und zu verwenden. Hier ist der Code für die PyTorch-Version:
+
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+
+Und hier ist der entsprechende Code für TensorFlow:
+
+```python
+>>> from transformers import AutoTokenizer, TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+Der Tokenizer ist für die gesamte Vorverarbeitung, die das vortrainierte Modell benötigt, verantwortlich und kann direkt auf einem einzelnen String (wie in den obigen Beispielen) oder einer Liste ausgeführt werden. Er gibt ein Dictionary aus, das Sie im darauffolgenden Code verwenden oder einfach direkt Ihrem Modell übergeben können, indem Sie den ** Operator zum Entpacken von Argumenten einsetzen.
+
+Das Modell selbst ist ein reguläres [PyTorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) oder ein [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (abhängig von Ihrem Backend), das Sie wie gewohnt verwenden können. [Dieses Tutorial](https://huggingface.co/docs/transformers/training) erklärt, wie man ein solches Modell in eine klassische PyTorch- oder TensorFlow-Trainingsschleife integrieren kann oder wie man unsere `Trainer`-API verwendet, um es schnell auf einem neuen Datensatz zu feintunen.
+
+## Warum sollten Sie 🤗 Transformers verwenden?
+
+1. Benutzerfreundliche Modelle auf dem neuesten Stand der Technik:
+ - Hohe Leistung bei Aufgaben zu Natural Language Understanding & Generation, Computer Vision und Audio.
+ - Niedrige Einstiegshürde für Bildungskräfte und Praktiker.
+ - Wenige benutzerseitige Abstraktionen mit nur drei zu lernenden Klassen.
+ - Eine einheitliche API für die Verwendung aller unserer vortrainierten Modelle.
+
+1. Geringere Rechenkosten, kleinerer CO2-Fußabdruck:
+ - Forscher können trainierte Modelle teilen, anstatt sie immer wieder neu zu trainieren.
+ - Praktiker können die Rechenzeit und Produktionskosten reduzieren.
+ - Dutzende Architekturen mit über 400.000 vortrainierten Modellen über alle Modalitäten hinweg.
+
+1. Wählen Sie das richtige Framework für jeden Lebensabschnitt eines Modells:
+ - Trainieren Sie Modelle auf neustem Stand der Technik in nur drei Codezeilen.
+ - Verwenden Sie ein einzelnes Modell nach Belieben mit TF2.0-/PyTorch-/JAX-Frameworks.
+ - Wählen Sie nahtlos das richtige Framework für Training, Evaluation und Produktiveinsatz.
+
+1. Passen Sie ein Modell oder Beispiel leicht an Ihre Bedürfnisse an:
+ - Wir bieten Beispiele für jede Architektur an, um die von ihren ursprünglichen Autoren veröffentlichten Ergebnisse zu reproduzieren.
+ - Modellinterna sind so einheitlich wie möglich verfügbar gemacht.
+ - Modelldateien können unabhängig von der Bibliothek für schnelle Experimente verwendet werden.
+
+## Warum sollten Sie 🤗 Transformers nicht verwenden?
+
+- Diese Bibliothek ist kein modularer Werkzeugkasten mit Bausteinen für neuronale Netze. Der Code in den Modelldateien ist absichtlich nicht mit zusätzlichen Abstraktionen refaktorisiert, sodass Forscher schnell mit jedem der Modelle iterieren können, ohne sich in zusätzliche Abstraktionen/Dateien vertiefen zu müssen.
+- Die Trainings-API ist nicht dafür gedacht, mit beliebigen Modellen zu funktionieren, sondern ist für die Verwendung mit den von der Bibliothek bereitgestellten Modellen optimiert. Für generische Trainingsschleifen von maschinellem Lernen sollten Sie eine andere Bibliothek verwenden (möglicherweise [Accelerate](https://huggingface.co/docs/accelerate)).
+- Auch wenn wir bestrebt sind, so viele Anwendungsfälle wie möglich zu veranschaulichen, sind die Beispielskripte in unserem [`examples`](./examples) Ordner genau das: Beispiele. Es ist davon auszugehen, dass sie nicht sofort auf Ihr spezielles Problem anwendbar sind und einige Codezeilen geändert werden müssen, um sie für Ihre Bedürfnisse anzupassen.
+
+## Installation
+
+### Mit pip
+
+Dieses Repository wurde mit Python 3.9+, Flax 0.4.1+, PyTorch 2.1+ und TensorFlow 2.6+ getestet.
+
+Sie sollten 🤗 Transformers in einer [virtuellen Umgebung](https://docs.python.org/3/library/venv.html) installieren. Wenn Sie mit virtuellen Python-Umgebungen nicht vertraut sind, schauen Sie sich den [Benutzerleitfaden](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/) an.
+
+Erstellen und aktivieren Sie zuerst eine virtuelle Umgebung mit der Python-Version, die Sie verwenden möchten.
+
+Dann müssen Sie entweder Flax, PyTorch oder TensorFlow installieren. Bitte beziehe dich entsprechend auf die jeweiligen Installationsanleitungen für [TensorFlow](https://www.tensorflow.org/install/), [PyTorch](https://pytorch.org/get-started/locally/#start-locally), und/oder [Flax](https://github.com/google/flax#quick-install) und [Jax](https://github.com/google/jax#installation) für den spezifischen Installationsbefehl für Ihre Plattform.
+
+Wenn eines dieser Backends installiert ist, kann 🤗 Transformers wie folgt mit pip installiert werden:
+
+```bash
+pip install transformers
+```
+
+Wenn Sie mit den Beispielen experimentieren möchten oder die neueste Version des Codes benötigen und nicht auf eine neue Veröffentlichung warten können, müssen Sie [die Bibliothek von der Quelle installieren](https://huggingface.co/docs/transformers/installation#installing-from-source).
+
+### Mit conda
+
+🤗 Transformers kann wie folgt mit conda installiert werden:
+
+```shell script
+conda install conda-forge::transformers
+```
+
+> **_HINWEIS:_** Die Installation von `transformers` aus dem `huggingface`-Kanal ist veraltet.
+
+Folgen Sie den Installationsanleitungen von Flax, PyTorch oder TensorFlow, um zu sehen, wie sie mit conda installiert werden können.
+
+> **_HINWEIS:_** Auf Windows werden Sie möglicherweise aufgefordert, den Entwicklermodus zu aktivieren, um von Caching zu profitieren. Wenn das für Sie keine Option ist, lassen Sie es uns bitte in [diesem Issue](https://github.com/huggingface/huggingface_hub/issues/1062) wissen.
+
+## Modellarchitekturen
+
+**[Alle Modell-Checkpoints](https://huggingface.co/models)**, die von 🤗 Transformers bereitgestellt werden, sind nahtlos aus dem huggingface.co [Model Hub](https://huggingface.co/models) integriert, wo sie direkt von [Benutzern](https://huggingface.co/users) und [Organisationen](https://huggingface.co/organizations) hochgeladen werden.
+
+Aktuelle Anzahl der Checkpoints: 
+
+🤗 Transformers bietet derzeit die folgenden Architekturen an: siehe [hier](https://huggingface.co/docs/transformers/model_summary) für eine jeweilige Übersicht.
+
+Um zu überprüfen, ob jedes Modell eine Implementierung in Flax, PyTorch oder TensorFlow hat oder über einen zugehörigen Tokenizer verfügt, der von der 🤗 Tokenizers-Bibliothek unterstützt wird, schauen Sie auf [diese Tabelle](https://huggingface.co/docs/transformers/index#supported-frameworks).
+
+Diese Implementierungen wurden mit mehreren Datensätzen getestet (siehe Beispielskripte) und sollten den Leistungen der ursprünglichen Implementierungen entsprechen. Weitere Details zur Leistung finden Sie im Abschnitt der Beispiele in der [Dokumentation](https://github.com/huggingface/transformers/tree/main/examples).
+
+## Mehr erfahren
+
+| Abschnitt | Beschreibung |
+|-|-|
+| [Dokumentation](https://huggingface.co/docs/transformers/) | Vollständige API-Dokumentation und Tutorials |
+| [Zusammenfassung der Aufgaben](https://huggingface.co/docs/transformers/task_summary) | Von 🤗 Transformers unterstützte Aufgaben |
+| [Vorverarbeitungs-Tutorial](https://huggingface.co/docs/transformers/preprocessing) | Verwendung der `Tokenizer`-Klasse zur Vorverarbeitung der Daten für die Modelle |
+| [Training und Feintuning](https://huggingface.co/docs/transformers/training) | Verwendung der von 🤗 Transformers bereitgestellten Modelle in einer PyTorch-/TensorFlow-Trainingsschleife und der `Trainer`-API |
+| [Schnelleinstieg: Feintuning/Anwendungsskripte](https://github.com/huggingface/transformers/tree/main/examples) | Beispielskripte für das Feintuning von Modellen für eine breite Palette von Aufgaben |
+| [Modellfreigabe und -upload](https://huggingface.co/docs/transformers/model_sharing) | Laden Sie Ihre feingetunten Modelle hoch und teilen Sie sie mit der Community |
+
+## Zitation
+
+Wir haben jetzt ein [Paper](https://www.aclweb.org/anthology/2020.emnlp-demos.6/), das Sie für die 🤗 Transformers-Bibliothek zitieren können:
+
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/docs/transformers/i18n/README_es.md b/docs/transformers/i18n/README_es.md
new file mode 100644
index 0000000000000000000000000000000000000000..36bb3e71ef4771aa88b12feaf0b66becd42b70f0
--- /dev/null
+++ b/docs/transformers/i18n/README_es.md
@@ -0,0 +1,296 @@
+
+
+
Lo último de Machine Learning para JAX, PyTorch y TensorFlow
+
+
+
+
+
+
+🤗 Transformers aporta miles de modelos preentrenados para realizar tareas en diferentes modalidades como texto, visión, y audio.
+
+Estos modelos pueden ser aplicados en:
+
+* 📝 Texto, para tareas como clasificación de texto, extracción de información, responder preguntas, resumir, traducir, generación de texto, en más de 100 idiomas.
+* 🖼️ Imágenes, para tareas como clasificación de imágenes, detección the objetos, y segmentación.
+* 🗣️ Audio, para tareas como reconocimiento de voz y clasificación de audio.
+
+Los modelos de Transformer también pueden realizar tareas en **muchas modalidades combinadas**, como responder preguntas, reconocimiento de carácteres ópticos,extracción de información de documentos escaneados, clasificación de video, y respuesta de preguntas visuales.
+
+🤗 Transformers aporta APIs para descargar rápidamente y usar estos modelos preentrenados en un texto dado, afinarlos en tus propios sets de datos y compartirlos con la comunidad en nuestro [centro de modelos](https://huggingface.co/models). Al mismo tiempo, cada módulo de Python que define una arquitectura es completamente independiente y se puede modificar para permitir experimentos de investigación rápidos.
+
+🤗 Transformers está respaldado por las tres bibliotecas de deep learning más populares — [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) y [TensorFlow](https://www.tensorflow.org/) — con una perfecta integración entre ellos. Es sencillo entrenar sus modelos con uno antes de cargarlos para la inferencia con el otro.
+
+## Demostraciones en línea
+
+Puedes probar la mayoría de nuestros modelos directamente en sus páginas desde el [centro de modelos](https://huggingface.co/models). También ofrecemos [alojamiento de modelos privados, control de versiones y una API de inferencia](https://huggingface.co/pricing) para modelos públicos y privados.
+
+Aquí hay algunos ejemplos:
+
+En procesamiento del lenguaje natural:
+- [Terminación de palabras enmascaradas con BERT](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [Reconocimiento del nombre de la entidad con Electra](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [Generación de texto con GPT-2](https://huggingface.co/openai-community/gpt2?text=A+long+time+ago%2C+)
+- [Inferencia del lenguaje natural con RoBERTa](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [Resumen con BART](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [Responder a preguntas con DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [Traducción con T5](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+En visión de ordenador:
+- [Clasificación de imágenes con ViT](https://huggingface.co/google/vit-base-patch16-224)
+- [Detección de objetos con DETR](https://huggingface.co/facebook/detr-resnet-50)
+- [Segmentación semántica con SegFormer](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
+- [Segmentación panóptica con DETR](https://huggingface.co/facebook/detr-resnet-50-panoptic)
+- [Segmentación Universal con OneFormer (Segmentación Semántica, de Instancia y Panóptica con un solo modelo)](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
+
+En Audio:
+- [Reconocimiento de voz automático con Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base-960h)
+- [Detección de palabras clave con Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
+
+En tareas multimodales:
+- [Respuesta visual a preguntas con ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
+
+**[Escribe con Transformer](https://transformer.huggingface.co)**, construido por el equipo de Hugging Face, es la demostración oficial de las capacidades de generación de texto de este repositorio.
+
+## Si está buscando soporte personalizado del equipo de Hugging Face
+
+
+
+
+
+## Tour rápido
+
+Para usar inmediatamente un modelo en una entrada determinada (texto, imagen, audio, ...), proporcionamos la API de `pipeline`. Los pipelines agrupan un modelo previamente entrenado con el preprocesamiento que se usó durante el entrenamiento de ese modelo. Aquí se explica cómo usar rápidamente un pipeline para clasificar textos positivos frente a negativos:
+
+```python
+>>> from transformers import pipeline
+
+# Allocate a pipeline for sentiment-analysis
+>>> classifier = pipeline('sentiment-analysis')
+>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+La segunda línea de código descarga y almacena en caché el modelo previamente entrenado que usa la canalización, mientras que la tercera lo evalúa en el texto dado. Aquí la respuesta es "positiva" con una confianza del 99,97%.
+
+Muchas tareas tienen un `pipeline` preentrenado listo para funcionar, en NLP pero también en visión por ordenador y habla. Por ejemplo, podemos extraer fácilmente los objetos detectados en una imagen:
+
+``` python
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import pipeline
+
+# Download an image with cute cats
+>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
+>>> image_data = requests.get(url, stream=True).raw
+>>> image = Image.open(image_data)
+
+# Allocate a pipeline for object detection
+>>> object_detector = pipeline('object_detection')
+>>> object_detector(image)
+[{'score': 0.9982201457023621,
+ 'label': 'remote',
+ 'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
+ {'score': 0.9960021376609802,
+ 'label': 'remote',
+ 'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
+ {'score': 0.9954745173454285,
+ 'label': 'couch',
+ 'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
+ {'score': 0.9988006353378296,
+ 'label': 'cat',
+ 'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
+ {'score': 0.9986783862113953,
+ 'label': 'cat',
+ 'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
+```
+
+Aquí obtenemos una lista de objetos detectados en la imagen, con un cuadro que rodea el objeto y una puntuación de confianza. Aquí está la imagen original a la derecha, con las predicciones mostradas a la izquierda:
+
+
+
+
+
+
+Puedes obtener más información sobre las tareas admitidas por la API de `pipeline` en [este tutorial](https://huggingface.co/docs/transformers/task_summary).
+
+Además de `pipeline`, para descargar y usar cualquiera de los modelos previamente entrenados en su tarea dada, todo lo que necesita son tres líneas de código. Aquí está la versión de PyTorch:
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+
+Y aquí está el código equivalente para TensorFlow:
+```python
+>>> from transformers import AutoTokenizer, TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+El tokenizador es responsable de todo el preprocesamiento que espera el modelo preentrenado y se puede llamar directamente en una sola cadena (como en los ejemplos anteriores) o en una lista. Este dará como resultado un diccionario que puedes usar en el código descendente o simplemente pasarlo directamente a su modelo usando el operador de desempaquetado de argumento **.
+
+El modelo en si es un [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) normal o un [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (dependiendo De tu backend) que puedes usar de forma habitual. [Este tutorial](https://huggingface.co/docs/transformers/training) explica cómo integrar un modelo de este tipo en un ciclo de entrenamiento PyTorch o TensorFlow clásico, o como usar nuestra API `Trainer` para ajustar rápidamente un nuevo conjunto de datos.
+
+## ¿Por qué debo usar transformers?
+
+1. Modelos de última generación fáciles de usar:
+ - Alto rendimiento en comprensión y generación de lenguaje natural, visión artificial y tareas de audio.
+ - Baja barrera de entrada para educadores y profesionales.
+ - Pocas abstracciones de cara al usuario con solo tres clases para aprender.
+ - Una API unificada para usar todos nuestros modelos preentrenados.
+
+1. Menores costes de cómputo, menor huella de carbono:
+ - Los investigadores pueden compartir modelos entrenados en lugar de siempre volver a entrenar.
+ - Los profesionales pueden reducir el tiempo de cómputo y los costos de producción.
+ - Docenas de arquitecturas con más de 60 000 modelos preentrenados en todas las modalidades.
+
+1. Elija el marco adecuado para cada parte de la vida útil de un modelo:
+ - Entrene modelos de última generación en 3 líneas de código.
+ - Mueva un solo modelo entre los marcos TF2.0/PyTorch/JAX a voluntad.
+ - Elija sin problemas el marco adecuado para la formación, la evaluación y la producción.
+
+1. Personalice fácilmente un modelo o un ejemplo según sus necesidades:
+ - Proporcionamos ejemplos de cada arquitectura para reproducir los resultados publicados por sus autores originales..
+ - Los internos del modelo están expuestos lo más consistentemente posible..
+ - Los archivos modelo se pueden usar independientemente de la biblioteca para experimentos rápidos.
+
+## ¿Por qué no debería usar transformers?
+
+- Esta biblioteca no es una caja de herramientas modular de bloques de construcción para redes neuronales. El código en los archivos del modelo no se refactoriza con abstracciones adicionales a propósito, de modo que los investigadores puedan iterar rápidamente en cada uno de los modelos sin sumergirse en abstracciones/archivos adicionales.
+- La API de entrenamiento no está diseñada para funcionar en ningún modelo, pero está optimizada para funcionar con los modelos proporcionados por la biblioteca. Para bucles genéricos de aprendizaje automático, debe usar otra biblioteca (posiblemente, [Accelerate](https://huggingface.co/docs/accelerate)).
+- Si bien nos esforzamos por presentar tantos casos de uso como sea posible, los scripts en nuestra [carpeta de ejemplos](https://github.com/huggingface/transformers/tree/main/examples) son solo eso: ejemplos. Se espera que no funcionen de forma inmediata en su problema específico y que deba cambiar algunas líneas de código para adaptarlas a sus necesidades.
+
+## Instalación
+
+### Con pip
+
+Este repositorio está probado en Python 3.9+, Flax 0.4.1+, PyTorch 2.1+ y TensorFlow 2.6+.
+
+Deberías instalar 🤗 Transformers en un [entorno virtual](https://docs.python.org/3/library/venv.html). Si no estas familiarizado con los entornos virtuales de Python, consulta la [guía de usuario](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+
+Primero, crea un entorno virtual con la versión de Python que vas a usar y actívalo.
+
+Luego, deberás instalar al menos uno entre Flax, PyTorch o TensorFlow.
+Por favor, ve a la [página de instalación de TensorFlow](https://www.tensorflow.org/install/), [página de instalación de PyTorch](https://pytorch.org/get-started/locally/#start-locally) y/o las páginas de instalación de [Flax](https://github.com/google/flax#quick-install) y [Jax](https://github.com/google/jax#installation) con respecto al comando de instalación específico para tu plataforma.
+
+Cuando se ha instalado uno de esos backends, los 🤗 Transformers se pueden instalar usando pip de la siguiente manera:
+
+```bash
+pip install transformers
+```
+
+Si deseas jugar con los ejemplos o necesitas la última versión del código y no puedes esperar a una nueva versión, tienes que [instalar la librería de la fuente](https://huggingface.co/docs/transformers/installation#installing-from-source).
+
+### Con conda
+
+🤗 Transformers se puede instalar usando conda de la siguiente manera:
+
+```shell script
+conda install conda-forge::transformers
+```
+
+> **_NOTA:_** Instalar `transformers` desde el canal `huggingface` está obsoleto.
+
+Sigue las páginas de instalación de Flax, PyTorch o TensorFlow para ver cómo instalarlos con conda.
+
+> **_NOTA:_** En Windows, es posible que se le pida que active el modo de desarrollador para beneficiarse del almacenamiento en caché. Si esta no es una opción para usted, háganoslo saber en [esta issue](https://github.com/huggingface/huggingface_hub/issues/1062).
+
+## Arquitecturas modelo
+
+**[Todos los puntos de control del modelo](https://huggingface.co/models)** aportados por 🤗 Transformers están perfectamente integrados desde huggingface.co [Centro de modelos](https://huggingface.co) donde son subidos directamente por los [usuarios](https://huggingface.co/users) y [organizaciones](https://huggingface.co/organizations).
+
+Número actual de puntos de control: 
+
+🤗 Transformers actualmente proporciona las siguientes arquitecturas: ver [aquí](https://huggingface.co/docs/transformers/model_summary) para un resumen de alto nivel de cada uno de ellas.
+
+Para comprobar si cada modelo tiene una implementación en Flax, PyTorch o TensorFlow, o tiene un tokenizador asociado respaldado por la librería 🤗 Tokenizers, ve a [esta tabla](https://huggingface.co/docs/transformers/index#supported-frameworks).
+
+Estas implementaciones se han probado en varios conjuntos de datos (consulte los scripts de ejemplo) y deberían coincidir con el rendimiento de las implementaciones originales. Puede encontrar más detalles sobre el rendimiento en la sección Examples de la [documentación](https://github.com/huggingface/transformers/tree/main/examples).
+
+
+## Aprender más
+
+| Sección | Descripción |
+|-|-|
+| [Documentación](https://huggingface.co/docs/transformers/) | Toda la documentación de la API y tutoriales |
+| [Resumen de tareas](https://huggingface.co/docs/transformers/task_summary) | Tareas soportadas 🤗 Transformers |
+| [Tutorial de preprocesamiento](https://huggingface.co/docs/transformers/preprocessing) | Usando la clase `Tokenizer` para preparar datos para los modelos |
+| [Entrenamiento y puesta a punto](https://huggingface.co/docs/transformers/training) | Usando los modelos aportados por 🤗 Transformers en un bucle de entreno de PyTorch/TensorFlow y la API de `Trainer` |
+| [Recorrido rápido: secuencias de comandos de ajuste/uso](https://github.com/huggingface/transformers/tree/main/examples) | Scripts de ejemplo para ajustar modelos en una amplia gama de tareas |
+| [Compartir y subir modelos](https://huggingface.co/docs/transformers/model_sharing) | Carga y comparte tus modelos perfeccionados con la comunidad |
+| [Migración](https://huggingface.co/docs/transformers/migration) | Migra a 🤗 Transformers desde `pytorch-transformers` o `pytorch-pretrained-bert` |
+
+## Citación
+
+Ahora nosotros tenemos un [paper](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) que puedes citar para la librería de 🤗 Transformers:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/docs/transformers/i18n/README_fr.md b/docs/transformers/i18n/README_fr.md
new file mode 100644
index 0000000000000000000000000000000000000000..6512b4af0700fac4422121432e8619ff25fbc3e5
--- /dev/null
+++ b/docs/transformers/i18n/README_fr.md
@@ -0,0 +1,315 @@
+
+
+
Apprentissage automatique de pointe pour JAX, PyTorch et TensorFlow
+
+
+
+
+
+
+🤗 Transformers fournit des milliers de modèles pré-entraînés pour effectuer des tâches sur différentes modalités telles que le texte, la vision et l'audio.
+
+Ces modèles peuvent être appliqués à :
+
+* 📝 Texte, pour des tâches telles que la classification de texte, l'extraction d'informations, la réponse aux questions, le résumé, la traduction et la génération de texte, dans plus de 100 langues.
+* 🖼️ Images, pour des tâches telles que la classification d'images, la détection d'objets et la segmentation.
+* 🗣️ Audio, pour des tâches telles que la reconnaissance vocale et la classification audio.
+
+Les modèles de transformer peuvent également effectuer des tâches sur **plusieurs modalités combinées**, telles que la réponse aux questions sur des tableaux, la reconnaissance optique de caractères, l'extraction d'informations à partir de documents numérisés, la classification vidéo et la réponse aux questions visuelles.
+
+🤗 Transformers fournit des API pour télécharger et utiliser rapidement ces modèles pré-entraînés sur un texte donné, les affiner sur vos propres ensembles de données, puis les partager avec la communauté sur notre [hub de modèles](https://huggingface.co/models). En même temps, chaque module Python définissant une architecture est complètement indépendant et peut être modifié pour permettre des expériences de recherche rapides.
+
+🤗 Transformers est soutenu par les trois bibliothèques d'apprentissage profond les plus populaires — [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) et [TensorFlow](https://www.tensorflow.org/) — avec une intégration transparente entre eux. Il est facile de former vos modèles avec l'un avant de les charger pour l'inférence avec l'autre.
+
+## Démos en ligne
+
+Vous pouvez tester la plupart de nos modèles directement sur leurs pages du [hub de modèles](https://huggingface.co/models). Nous proposons également [l'hébergement privé de modèles, le versionning et une API d'inférence](https://huggingface.co/pricing) pour des modèles publics et privés.
+
+Voici quelques exemples :
+
+En traitement du langage naturel :
+- [Complétion de mots masqués avec BERT](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [Reconnaissance d'entités nommées avec Electra](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [Génération de texte avec GPT-2](https://huggingface.co/openai-community/gpt2?text=A+long+time+ago%2C+)
+- [Inférence de langage naturel avec RoBERTa](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [Résumé avec BART](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [Réponse aux questions avec DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [Traduction avec T5](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+En vision par ordinateur :
+- [Classification d'images avec ViT](https://huggingface.co/google/vit-base-patch16-224)
+- [Détection d'objets avec DETR](https://huggingface.co/facebook/detr-resnet-50)
+- [Segmentation sémantique avec SegFormer](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
+- [Segmentation panoptique avec MaskFormer](https://huggingface.co/facebook/maskformer-swin-small-coco)
+- [Estimation de profondeur avec DPT](https://huggingface.co/docs/transformers/model_doc/dpt)
+- [Classification vidéo avec VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)
+- [Segmentation universelle avec OneFormer](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
+
+En audio :
+- [Reconnaissance automatique de la parole avec Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base-960h)
+- [Spotting de mots-clés avec Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
+- [Classification audio avec Audio Spectrogram Transformer](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
+
+Dans les tâches multimodales :
+- [Réponses aux questions sur table avec TAPAS](https://huggingface.co/google/tapas-base-finetuned-wtq)
+- [Réponses aux questions visuelles avec ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
+- [Classification d'images sans étiquette avec CLIP](https://huggingface.co/openai/clip-vit-large-patch14)
+- [Réponses aux questions sur les documents avec LayoutLM](https://huggingface.co/impira/layoutlm-document-qa)
+- [Classification vidéo sans étiquette avec X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)
+
+
+## 100 projets utilisant Transformers
+
+Transformers est plus qu'une boîte à outils pour utiliser des modèles pré-entraînés : c'est une communauté de projets construits autour de lui et du Hub Hugging Face. Nous voulons que Transformers permette aux développeurs, chercheurs, étudiants, professeurs, ingénieurs et à quiconque d'imaginer et de réaliser leurs projets de rêve.
+
+Afin de célébrer les 100 000 étoiles de transformers, nous avons décidé de mettre en avant la communauté et avons créé la page [awesome-transformers](./awesome-transformers.md) qui répertorie 100 projets incroyables construits autour de transformers.
+
+Si vous possédez ou utilisez un projet que vous pensez devoir figurer dans la liste, veuillez ouvrir une pull request pour l'ajouter !
+
+## Si vous recherchez un support personnalisé de la part de l'équipe Hugging Face
+
+
+
+
+
+## Tour rapide
+
+Pour utiliser immédiatement un modèle sur une entrée donnée (texte, image, audio,...), nous fournissons l'API `pipeline`. Les pipelines regroupent un modèle pré-entraîné avec la préparation des données qui a été utilisée lors de l'entraînement de ce modèle. Voici comment utiliser rapidement un pipeline pour classer des textes en positif ou négatif :
+
+```python
+>>> from transformers import pipeline
+
+# Allouer un pipeline pour l'analyse de sentiment
+>>> classifieur = pipeline('sentiment-analysis')
+>>> classifieur("Nous sommes très heureux d'introduire le pipeline dans le référentiel transformers.")
+[{'label': 'POSITIF', 'score': 0.9996980428695679}]
+```
+
+La deuxième ligne de code télécharge et met en cache le modèle pré-entraîné utilisé par le pipeline, tandis que la troisième l'évalue sur le texte donné. Ici, la réponse est "positive" avec une confiance de 99,97%.
+
+De nombreuses tâches ont une pipeline pré-entraîné prêt à l'emploi, en NLP, mais aussi en vision par ordinateur et en parole. Par exemple, nous pouvons facilement extraire les objets détectés dans une image :
+
+```python
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import pipeline
+
+# Télécharger une image avec de jolis chats
+>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
+>>> donnees_image = requests.get(url, stream=True).raw
+>>> image = Image.open(donnees_image)
+
+# Allouer un pipeline pour la détection d'objets
+>>> detecteur_objets = pipeline('object-detection')
+>>> detecteur_objets(image)
+[{'score': 0.9982201457023621,
+ 'label': 'télécommande',
+ 'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
+ {'score': 0.9960021376609802,
+ 'label': 'télécommande',
+ 'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
+ {'score': 0.9954745173454285,
+ 'label': 'canapé',
+ 'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
+ {'score': 0.9988006353378296,
+ 'label': 'chat',
+ 'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
+ {'score': 0.9986783862113953,
+ 'label': 'chat',
+ 'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
+```
+
+Ici, nous obtenons une liste d'objets détectés dans l'image, avec une boîte entourant l'objet et un score de confiance. Voici l'image originale à gauche, avec les prédictions affichées à droite :
+
+
+
+
+
+
+Vous pouvez en savoir plus sur les tâches supportées par l'API pipeline dans [ce tutoriel](https://huggingface.co/docs/transformers/task_summary).
+
+En plus de `pipeline`, pour télécharger et utiliser n'importe lequel des modèles pré-entraînés sur votre tâche donnée, il suffit de trois lignes de code. Voici la version PyTorch :
+
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+inputs = tokenizer("Bonjour le monde !", return_tensors="pt")
+outputs = model(**inputs)
+```
+
+Et voici le code équivalent pour TensorFlow :
+
+```python
+from transformers import AutoTokenizer, TFAutoModel
+
+tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+inputs = tokenizer("Bonjour le monde !", return_tensors="tf")
+outputs = model(**inputs)
+```
+
+Le tokenizer est responsable de toutes les étapes de prétraitement que le modèle préentraîné attend et peut être appelé directement sur une seule chaîne de caractères (comme dans les exemples ci-dessus) ou sur une liste. Il produira un dictionnaire que vous pouvez utiliser dans votre code ou simplement passer directement à votre modèle en utilisant l'opérateur de déballage **.
+
+Le modèle lui-même est un module [`nn.Module` PyTorch](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) ou un modèle [`tf.keras.Model` TensorFlow](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (selon votre backend) que vous pouvez utiliser comme d'habitude. [Ce tutoriel](https://huggingface.co/docs/transformers/training) explique comment intégrer un tel modèle dans une boucle d'entraînement classique PyTorch ou TensorFlow, ou comment utiliser notre API `Trainer` pour affiner rapidement sur un nouvel ensemble de données.
+
+## Pourquoi devrais-je utiliser transformers ?
+
+1. Des modèles de pointe faciles à utiliser :
+ - Hautes performances en compréhension et génération de langage naturel, en vision par ordinateur et en tâches audio.
+ - Faible barrière à l'entrée pour les éducateurs et les praticiens.
+ - Peu d'abstractions visibles pour l'utilisateur avec seulement trois classes à apprendre.
+ - Une API unifiée pour utiliser tous nos modèles préentraînés.
+
+1. Coûts informatiques réduits, empreinte carbone plus petite :
+ - Les chercheurs peuvent partager des modèles entraînés au lieu de toujours les réentraîner.
+ - Les praticiens peuvent réduire le temps de calcul et les coûts de production.
+ - Des dizaines d'architectures avec plus de 400 000 modèles préentraînés dans toutes les modalités.
+
+1. Choisissez le bon framework pour chaque partie de la vie d'un modèle :
+ - Entraînez des modèles de pointe en 3 lignes de code.
+ - Transférer un seul modèle entre les frameworks TF2.0/PyTorch/JAX à volonté.
+ - Choisissez facilement le bon framework pour l'entraînement, l'évaluation et la production.
+
+1. Personnalisez facilement un modèle ou un exemple selon vos besoins :
+ - Nous fournissons des exemples pour chaque architecture afin de reproduire les résultats publiés par ses auteurs originaux.
+ - Les détails internes du modèle sont exposés de manière aussi cohérente que possible.
+ - Les fichiers de modèle peuvent être utilisés indépendamment de la bibliothèque pour des expériences rapides.
+
+## Pourquoi ne devrais-je pas utiliser transformers ?
+
+- Cette bibliothèque n'est pas une boîte à outils modulaire de blocs de construction pour les réseaux neuronaux. Le code dans les fichiers de modèle n'est pas refactored avec des abstractions supplémentaires à dessein, afin que les chercheurs puissent itérer rapidement sur chacun des modèles sans plonger dans des abstractions/fichiers supplémentaires.
+- L'API d'entraînement n'est pas destinée à fonctionner avec n'importe quel modèle, mais elle est optimisée pour fonctionner avec les modèles fournis par la bibliothèque. Pour des boucles génériques d'apprentissage automatique, vous devriez utiliser une autre bibliothèque (éventuellement, [Accelerate](https://huggingface.co/docs/accelerate)).
+- Bien que nous nous efforcions de présenter autant de cas d'utilisation que possible, les scripts de notre [dossier d'exemples](https://github.com/huggingface/transformers/tree/main/examples) ne sont que cela : des exemples. Il est prévu qu'ils ne fonctionnent pas immédiatement sur votre problème spécifique et que vous devrez probablement modifier quelques lignes de code pour les adapter à vos besoins.
+
+## Installation
+
+### Avec pip
+
+Ce référentiel est testé sur Python 3.9+, Flax 0.4.1+, PyTorch 2.1+ et TensorFlow 2.6+.
+
+Vous devriez installer 🤗 Transformers dans un [environnement virtuel](https://docs.python.org/3/library/venv.html). Si vous n'êtes pas familier avec les environnements virtuels Python, consultez le [guide utilisateur](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+
+D'abord, créez un environnement virtuel avec la version de Python que vous allez utiliser et activez-le.
+
+Ensuite, vous devrez installer au moins l'un de Flax, PyTorch ou TensorFlow.
+Veuillez vous référer à la page d'installation de [TensorFlow](https://www.tensorflow.org/install/), de [PyTorch](https://pytorch.org/get-started/locally/#start-locally) et/ou de [Flax](https://github.com/google/flax#quick-install) et [Jax](https://github.com/google/jax#installation) pour connaître la commande d'installation spécifique à votre plateforme.
+
+Lorsqu'un de ces backends est installé, 🤗 Transformers peut être installé avec pip comme suit :
+
+```bash
+pip install transformers
+```
+
+Si vous souhaitez jouer avec les exemples ou avez besoin de la dernière version du code et ne pouvez pas attendre une nouvelle version, vous devez [installer la bibliothèque à partir de la source](https://huggingface.co/docs/transformers/installation#installing-from-source).
+
+### Avec conda
+
+🤗 Transformers peut être installé avec conda comme suit :
+
+```shell
+conda install conda-forge::transformers
+```
+
+> **_NOTE:_** L'installation de `transformers` depuis le canal `huggingface` est obsolète.
+
+Suivez les pages d'installation de Flax, PyTorch ou TensorFlow pour voir comment les installer avec conda.
+
+> **_NOTE:_** Sur Windows, on peut vous demander d'activer le mode développeur pour bénéficier de la mise en cache. Si ce n'est pas une option pour vous, veuillez nous le faire savoir dans [cette issue](https://github.com/huggingface/huggingface_hub/issues/1062).
+
+## Architectures de modèles
+
+**[Tous les points de contrôle](https://huggingface.co/models)** de modèle fournis par 🤗 Transformers sont intégrés de manière transparente depuis le [hub de modèles](https://huggingface.co/models) huggingface.co, où ils sont téléchargés directement par les [utilisateurs](https://huggingface.co/users) et les [organisations](https://huggingface.co/organizations).
+
+Nombre actuel de points de contrôle : 
+
+🤗 Transformers fournit actuellement les architectures suivantes: consultez [ici](https://huggingface.co/docs/transformers/model_summary) pour un résumé global de chacune d'entre elles.
+
+Pour vérifier si chaque modèle a une implémentation en Flax, PyTorch ou TensorFlow, ou s'il a un tokenizer associé pris en charge par la bibliothèque 🤗 Tokenizers, consultez [ce tableau](https://huggingface.co/docs/transformers/index#supported-frameworks).
+
+Ces implémentations ont été testées sur plusieurs ensembles de données (voir les scripts d'exemple) et devraient correspondre aux performances des implémentations originales. Vous pouvez trouver plus de détails sur les performances dans la section Exemples de la [documentation](https://github.com/huggingface/transformers/tree/main/examples).
+
+## En savoir plus
+
+| Section | Description |
+|-|-|
+| [Documentation](https://huggingface.co/docs/transformers/) | Documentation complète de l'API et tutoriels |
+| [Résumé des tâches](https://huggingface.co/docs/transformers/task_summary) | Tâches prises en charge par les 🤗 Transformers |
+| [Tutoriel de prétraitement](https://huggingface.co/docs/transformers/preprocessing) | Utilisation de la classe `Tokenizer` pour préparer les données pour les modèles |
+| [Entraînement et ajustement fin](https://huggingface.co/docs/transformers/training) | Utilisation des modèles fournis par les 🤗 Transformers dans une boucle d'entraînement PyTorch/TensorFlow et de l'API `Trainer` |
+| [Tour rapide : Scripts d'ajustement fin/d'utilisation](https://github.com/huggingface/transformers/tree/main/examples) | Scripts d'exemple pour ajuster finement les modèles sur une large gamme de tâches |
+| [Partage et téléversement de modèles](https://huggingface.co/docs/transformers/model_sharing) | Téléchargez et partagez vos modèles ajustés avec la communauté |
+
+## Citation
+
+Nous disposons désormais d'un [article](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) que vous pouvez citer pour la bibliothèque 🤗 Transformers :
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/docs/transformers/i18n/README_hd.md b/docs/transformers/i18n/README_hd.md
new file mode 100644
index 0000000000000000000000000000000000000000..76ee4355bd55a572a031145849c8481f4da98de3
--- /dev/null
+++ b/docs/transformers/i18n/README_hd.md
@@ -0,0 +1,270 @@
+
+
+
+
+
Jax, PyTorch और TensorFlow के लिए उन्नत मशीन लर्निंग
+
+
+
+
+
+
+🤗 Transformers 100 से अधिक भाषाओं में पाठ वर्गीकरण, सूचना निष्कर्षण, प्रश्न उत्तर, सारांशीकरण, अनुवाद, पाठ निर्माण का समर्थन करने के लिए हजारों पूर्व-प्रशिक्षित मॉडल प्रदान करता है। इसका उद्देश्य सबसे उन्नत एनएलपी तकनीक को सभी के लिए सुलभ बनाना है।
+
+🤗 Transformers त्वरित डाउनलोड और उपयोग के लिए एक एपीआई प्रदान करता है, जिससे आप किसी दिए गए पाठ पर एक पूर्व-प्रशिक्षित मॉडल ले सकते हैं, इसे अपने डेटासेट पर ठीक कर सकते हैं और इसे [मॉडल हब](https://huggingface.co/models) के माध्यम से समुदाय के साथ साझा कर सकते हैं। इसी समय, प्रत्येक परिभाषित पायथन मॉड्यूल पूरी तरह से स्वतंत्र है, जो संशोधन और तेजी से अनुसंधान प्रयोगों के लिए सुविधाजनक है।
+
+🤗 Transformers तीन सबसे लोकप्रिय गहन शिक्षण पुस्तकालयों का समर्थन करता है: [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) and [TensorFlow](https://www.tensorflow.org/) — और इसके साथ निर्बाध रूप से एकीकृत होता है। आप अपने मॉडल को सीधे एक ढांचे के साथ प्रशिक्षित कर सकते हैं और दूसरे के साथ लोड और अनुमान लगा सकते हैं।
+
+## ऑनलाइन डेमो
+
+आप सबसे सीधे मॉडल पृष्ठ पर परीक्षण कर सकते हैं [model hub](https://huggingface.co/models) मॉडल पर। हम [निजी मॉडल होस्टिंग, मॉडल संस्करण, और अनुमान एपीआई](https://huggingface.co/pricing) भी प्रदान करते हैं।。
+
+यहाँ कुछ उदाहरण हैं:
+- [शब्द को भरने के लिए मास्क के रूप में BERT का प्रयोग करें](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [इलेक्ट्रा के साथ नामित इकाई पहचान](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [जीपीटी-2 के साथ टेक्स्ट जनरेशन](https://huggingface.co/openai-community/gpt2?text=A+long+time+ago%2C+)
+- [रॉबर्टा के साथ प्राकृतिक भाषा निष्कर्ष](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [बार्ट के साथ पाठ सारांश](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [डिस्टिलबर्ट के साथ प्रश्नोत्तर](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [अनुवाद के लिए T5 का प्रयोग करें](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+**[Write With Transformer](https://transformer.huggingface.co)**,हगिंग फेस टीम द्वारा बनाया गया, यह एक आधिकारिक पाठ पीढ़ी है demo。
+
+## यदि आप हगिंग फेस टीम से बीस्पोक समर्थन की तलाश कर रहे हैं
+
+
+
+
+
+## जल्दी शुरू करें
+
+हम त्वरित उपयोग के लिए मॉडल प्रदान करते हैं `pipeline` (पाइपलाइन) एपीआई। पाइपलाइन पूर्व-प्रशिक्षित मॉडल और संबंधित पाठ प्रीप्रोसेसिंग को एकत्रित करती है। सकारात्मक और नकारात्मक भावना को निर्धारित करने के लिए पाइपलाइनों का उपयोग करने का एक त्वरित उदाहरण यहां दिया गया है:
+
+```python
+>>> from transformers import pipeline
+
+# भावना विश्लेषण पाइपलाइन का उपयोग करना
+>>> classifier = pipeline('sentiment-analysis')
+>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+कोड की दूसरी पंक्ति पाइपलाइन द्वारा उपयोग किए गए पूर्व-प्रशिक्षित मॉडल को डाउनलोड और कैश करती है, जबकि कोड की तीसरी पंक्ति दिए गए पाठ पर मूल्यांकन करती है। यहां उत्तर 99 आत्मविश्वास के स्तर के साथ "सकारात्मक" है।
+
+कई एनएलपी कार्यों में आउट ऑफ़ द बॉक्स पाइपलाइनों का पूर्व-प्रशिक्षण होता है। उदाहरण के लिए, हम किसी दिए गए पाठ से किसी प्रश्न का उत्तर आसानी से निकाल सकते हैं:
+
+``` python
+>>> from transformers import pipeline
+
+# प्रश्नोत्तर पाइपलाइन का उपयोग करना
+>>> question_answerer = pipeline('question-answering')
+>>> question_answerer({
+... 'question': 'What is the name of the repository ?',
+... 'context': 'Pipeline has been included in the huggingface/transformers repository'
+... })
+{'score': 0.30970096588134766, 'start': 34, 'end': 58, 'answer': 'huggingface/transformers'}
+
+```
+
+उत्तर देने के अलावा, पूर्व-प्रशिक्षित मॉडल संगत आत्मविश्वास स्कोर भी देता है, जहां उत्तर टोकनयुक्त पाठ में शुरू और समाप्त होता है। आप [इस ट्यूटोरियल](https://huggingface.co/docs/transformers/task_summary) से पाइपलाइन एपीआई द्वारा समर्थित कार्यों के बारे में अधिक जान सकते हैं।
+
+अपने कार्य पर किसी भी पूर्व-प्रशिक्षित मॉडल को डाउनलोड करना और उसका उपयोग करना भी कोड की तीन पंक्तियों की तरह सरल है। यहाँ PyTorch संस्करण के लिए एक उदाहरण दिया गया है:
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+यहाँ समकक्ष है TensorFlow कोड:
+```python
+>>> from transformers import AutoTokenizer, TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+टोकननाइज़र सभी पूर्व-प्रशिक्षित मॉडलों के लिए प्रीप्रोसेसिंग प्रदान करता है और इसे सीधे एक स्ट्रिंग (जैसे ऊपर दिए गए उदाहरण) या किसी सूची पर बुलाया जा सकता है। यह एक डिक्शनरी (तानाशाही) को आउटपुट करता है जिसे आप डाउनस्ट्रीम कोड में उपयोग कर सकते हैं या `**` अनपैकिंग एक्सप्रेशन के माध्यम से सीधे मॉडल को पास कर सकते हैं।
+
+मॉडल स्वयं एक नियमित [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) या [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (आपके बैकएंड के आधार पर), जो हो सकता है सामान्य तरीके से उपयोग किया जाता है। [यह ट्यूटोरियल](https://huggingface.co/transformers/training.html) बताता है कि इस तरह के मॉडल को क्लासिक PyTorch या TensorFlow प्रशिक्षण लूप में कैसे एकीकृत किया जाए, या हमारे `ट्रेनर` एपीआई का उपयोग कैसे करें ताकि इसे जल्दी से फ़ाइन ट्यून किया जा सके।एक नया डेटासेट पे।
+
+## ट्रांसफार्मर का उपयोग क्यों करें?
+
+1. उपयोग में आसानी के लिए उन्नत मॉडल:
+ - एनएलयू और एनएलजी पर बेहतर प्रदर्शन
+ - प्रवेश के लिए कम बाधाओं के साथ शिक्षण और अभ्यास के अनुकूल
+ - उपयोगकर्ता-सामना करने वाले सार तत्व, केवल तीन वर्गों को जानने की जरूरत है
+ - सभी मॉडलों के लिए एकीकृत एपीआई
+
+1. कम कम्प्यूटेशनल ओवरहेड और कम कार्बन उत्सर्जन:
+ - शोधकर्ता हर बार नए सिरे से प्रशिक्षण देने के बजाय प्रशिक्षित मॉडल साझा कर सकते हैं
+ - इंजीनियर गणना समय और उत्पादन ओवरहेड को कम कर सकते हैं
+ - दर्जनों मॉडल आर्किटेक्चर, 2,000 से अधिक पूर्व-प्रशिक्षित मॉडल, 100 से अधिक भाषाओं का समर्थन
+
+1.मॉडल जीवनचक्र के हर हिस्से को शामिल करता है:
+ - कोड की केवल 3 पंक्तियों में उन्नत मॉडलों को प्रशिक्षित करें
+ - मॉडल को मनमाने ढंग से विभिन्न डीप लर्निंग फ्रेमवर्क के बीच स्थानांतरित किया जा सकता है, जैसा आप चाहते हैं
+ - निर्बाध रूप से प्रशिक्षण, मूल्यांकन और उत्पादन के लिए सबसे उपयुक्त ढांचा चुनें
+
+1. आसानी से अनन्य मॉडल को अनुकूलित करें और अपनी आवश्यकताओं के लिए मामलों का उपयोग करें:
+ - हम मूल पेपर परिणामों को पुन: पेश करने के लिए प्रत्येक मॉडल आर्किटेक्चर के लिए कई उपयोग के मामले प्रदान करते हैं
+ - मॉडल की आंतरिक संरचना पारदर्शी और सुसंगत रहती है
+ - मॉडल फ़ाइल को अलग से इस्तेमाल किया जा सकता है, जो संशोधन और त्वरित प्रयोग के लिए सुविधाजनक है
+
+## मुझे ट्रांसफॉर्मर का उपयोग कब नहीं करना चाहिए?
+
+- यह लाइब्रेरी मॉड्यूलर न्यूरल नेटवर्क टूलबॉक्स नहीं है। मॉडल फ़ाइल में कोड जानबूझकर अल्पविकसित है, बिना अतिरिक्त सार इनकैप्सुलेशन के, ताकि शोधकर्ता अमूर्तता और फ़ाइल जंपिंग में शामिल हुए जल्दी से पुनरावृति कर सकें।
+- `ट्रेनर` एपीआई किसी भी मॉडल के साथ संगत नहीं है, यह केवल इस पुस्तकालय के मॉडल के लिए अनुकूलित है। यदि आप सामान्य मशीन लर्निंग के लिए उपयुक्त प्रशिक्षण लूप कार्यान्वयन की तलाश में हैं, तो कहीं और देखें।
+- हमारे सर्वोत्तम प्रयासों के बावजूद, [उदाहरण निर्देशिका](https://github.com/huggingface/transformers/tree/main/examples) में स्क्रिप्ट केवल उपयोग के मामले हैं। आपकी विशिष्ट समस्या के लिए, वे जरूरी नहीं कि बॉक्स से बाहर काम करें, और आपको कोड की कुछ पंक्तियों को सूट करने की आवश्यकता हो सकती है।
+
+## स्थापित करना
+
+### पिप का उपयोग करना
+
+इस रिपॉजिटरी का परीक्षण Python 3.9+, Flax 0.4.1+, PyTorch 2.1+ और TensorFlow 2.6+ के तहत किया गया है।
+
+आप [वर्चुअल एनवायरनमेंट](https://docs.python.org/3/library/venv.html) में 🤗 ट्रांसफॉर्मर इंस्टॉल कर सकते हैं। यदि आप अभी तक पायथन के वर्चुअल एनवायरनमेंट से परिचित नहीं हैं, तो कृपया इसे [उपयोगकर्ता निर्देश](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/) पढ़ें।
+
+सबसे पहले, पायथन के उस संस्करण के साथ एक आभासी वातावरण बनाएं जिसका आप उपयोग करने और उसे सक्रिय करने की योजना बना रहे हैं।
+
+फिर, आपको Flax, PyTorch या TensorFlow में से किसी एक को स्थापित करने की आवश्यकता है। अपने प्लेटफ़ॉर्म पर इन फ़्रेमवर्क को स्थापित करने के लिए, [TensorFlow स्थापना पृष्ठ](https://www.tensorflow.org/install/), [PyTorch स्थापना पृष्ठ](https://pytorch.org/get-started/locally)
+
+देखें start-locally या [Flax स्थापना पृष्ठ](https://github.com/google/flax#quick-install).
+
+जब इनमें से कोई एक बैकएंड सफलतापूर्वक स्थापित हो जाता है, तो ट्रांसफॉर्मर निम्नानुसार स्थापित किए जा सकते हैं:
+
+```bash
+pip install transformers
+```
+
+यदि आप उपयोग के मामलों को आज़माना चाहते हैं या आधिकारिक रिलीज़ से पहले नवीनतम इन-डेवलपमेंट कोड का उपयोग करना चाहते हैं, तो आपको [सोर्स से इंस्टॉल करना होगा](https://huggingface.co/docs/transformers/installation#installing-from-) स्रोत।
+
+### कोंडा का उपयोग करना
+
+ट्रांसफॉर्मर कोंडा के माध्यम से निम्नानुसार स्थापित किया जा सकता है:
+
+```shell script
+conda install conda-forge::transformers
+```
+
+> **_नोट:_** `huggingface` चैनल से `transformers` इंस्टॉल करना पुराना पड़ चुका है।
+
+कोंडा के माध्यम से Flax, PyTorch, या TensorFlow में से किसी एक को स्थापित करने के लिए, निर्देशों के लिए उनके संबंधित स्थापना पृष्ठ देखें।
+
+## मॉडल आर्किटेक्चर
+[उपयोगकर्ता](https://huggingface.co/users) और [organization](https://huggingface.co) द्वारा ट्रांसफॉर्मर समर्थित [**सभी मॉडल चौकियों**](https://huggingface.co/models/users) हगिंगफेस.को/ऑर्गनाइजेशन), सभी को बिना किसी बाधा के हगिंगफेस.को [मॉडल हब](https://huggingface.co) के साथ एकीकृत किया गया है।
+
+चौकियों की वर्तमान संख्या: 
+
+🤗 ट्रांसफॉर्मर वर्तमान में निम्नलिखित आर्किटेक्चर का समर्थन करते हैं: मॉडल के अवलोकन के लिए [यहां देखें](https://huggingface.co/docs/transformers/model_summary):
+
+यह जांचने के लिए कि क्या किसी मॉडल में पहले से ही Flax, PyTorch या TensorFlow का कार्यान्वयन है, या यदि उसके पास Tokenizers लाइब्रेरी में संबंधित टोकन है, तो [यह तालिका](https://huggingface.co/docs/transformers/index#supported) देखें। -फ्रेमवर्क)।
+
+इन कार्यान्वयनों का परीक्षण कई डेटासेट पर किया गया है (देखें केस स्क्रिप्ट का उपयोग करें) और वैनिला कार्यान्वयन के लिए तुलनात्मक रूप से प्रदर्शन करना चाहिए। आप उपयोग के मामले के दस्तावेज़ [इस अनुभाग](https://huggingface.co/docs/transformers/examples) में व्यवहार का विवरण पढ़ सकते हैं।
+
+
+## अधिक समझें
+
+|अध्याय | विवरण |
+|-|-|
+| [दस्तावेज़ीकरण](https://huggingface.co/transformers/) | पूरा एपीआई दस्तावेज़ीकरण और ट्यूटोरियल |
+| [कार्य सारांश](https://huggingface.co/docs/transformers/task_summary) | ट्रांसफॉर्मर समर्थित कार्य |
+| [प्रीप्रोसेसिंग ट्यूटोरियल](https://huggingface.co/docs/transformers/preprocessing) | मॉडल के लिए डेटा तैयार करने के लिए `टोकनाइज़र` का उपयोग करना |
+| [प्रशिक्षण और फाइन-ट्यूनिंग](https://huggingface.co/docs/transformers/training) | PyTorch/TensorFlow के ट्रेनिंग लूप या `ट्रेनर` API में ट्रांसफॉर्मर द्वारा दिए गए मॉडल का उपयोग करें |
+| [क्विक स्टार्ट: ट्वीकिंग एंड यूज़ केस स्क्रिप्ट्स](https://github.com/huggingface/transformers/tree/main/examples) | विभिन्न कार्यों के लिए केस स्क्रिप्ट का उपयोग करें |
+| [मॉडल साझा करना और अपलोड करना](https://huggingface.co/docs/transformers/model_sharing) | समुदाय के साथ अपने फाइन टूनड मॉडल अपलोड और साझा करें |
+| [माइग्रेशन](https://huggingface.co/docs/transformers/migration) | `पाइटोरच-ट्रांसफॉर्मर्स` या `पाइटोरच-प्रीट्रेनड-बर्ट` से ट्रांसफॉर्मर में माइग्रेट करना |
+
+## उद्धरण
+
+हमने आधिकारिक तौर पर इस लाइब्रेरी का [पेपर](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) प्रकाशित किया है, अगर आप ट्रान्सफ़ॉर्मर्स लाइब्रेरी का उपयोग करते हैं, तो कृपया उद्धृत करें:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/docs/transformers/i18n/README_ja.md b/docs/transformers/i18n/README_ja.md
new file mode 100644
index 0000000000000000000000000000000000000000..c57a07b56b6c4dfc6265670f1f4033c369039752
--- /dev/null
+++ b/docs/transformers/i18n/README_ja.md
@@ -0,0 +1,330 @@
+
+
+
+
+
+
+🤗 Transformers는 텍스트, 비전, 오디오와 같은 다양한 분야에서 여러 과제를 수행하는 수천 개의 사전 학습된 모델을 제공합니다.
+
+제공되는 모델을 통해 다음 과제를 수행할 수 있습니다.
+- 📝 텍스트: 100개 이상의 언어들로, 텍스트 분류, 정보 추출, 질문 답변, 요약, 번역 및 문장 생성
+- 🖼️ 이미지: 이미지 분류(Image Classification), 객체 탐지(Object Detection) 및 분할(Segmentation)
+- 🗣️ 오디오: 음성 인식(Speech Recognition) 및 오디오 분류(Audio Classification)
+
+Transformer의 모델은 표를 통한 질의응답(Table QA), 광학 문자 인식(Optical Character Recognition), 스캔 한 문서에서 정보 추출, 비디오 분류 및 시각적 질의응답과 같은 **여러 분야가 결합된** 과제 또한 수행할 수 있습니다.
+
+🤗 Transformers는 이러한 사전학습 모델을 빠르게 다운로드해 특정 텍스트에 사용하고, 원하는 데이터로 fine-tuning해 커뮤니티나 우리의 [모델 허브](https://huggingface.co/models)에 공유할 수 있도록 API를 제공합니다. 또한, 모델 구조를 정의하는 각 파이썬 모듈은 완전히 독립적이여서 연구 실험을 위해 손쉽게 수정할 수 있습니다.
+
+🤗 Transformers는 가장 유명한 3개의 딥러닝 라이브러리를 지원합니다. 이들은 서로 완벽히 연동됩니다 — [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/), [TensorFlow](https://www.tensorflow.org/). 간단하게 이 라이브러리 중 하나로 모델을 학습하고, 또 다른 라이브러리로 추론을 위해 모델을 불러올 수 있습니다.
+
+## 온라인 데모
+
+대부분의 모델을 [모델 허브](https://huggingface.co/models) 페이지에서 바로 테스트해 볼 수 있습니다. 공개 및 비공개 모델을 위한 [비공개 모델 호스팅, 버전 관리, 추론 API](https://huggingface.co/pricing)도 제공합니다.
+
+아래 몇 가지 예시가 있습니다:
+
+자연어 처리:
+- [BERT로 마스킹된 단어 완성하기](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [Electra를 이용한 개체명 인식](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [GPT-2로 텍스트 생성하기](https://huggingface.co/openai-community/gpt2?text=A+long+time+ago%2C+)
+- [RoBERTa로 자연어 추론하기](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [BART를 이용한 요약](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [DistilBERT를 이용한 질문 답변](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [T5로 번역하기](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+컴퓨터 비전:
+- [ViT와 함께하는 이미지 분류](https://huggingface.co/google/vit-base-patch16-224)
+- [DETR로 객체 탐지하기](https://huggingface.co/facebook/detr-resnet-50)
+- [SegFormer로 의미적 분할(semantic segmentation)하기](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
+- [Mask2Former로 판옵틱 분할(panoptic segmentation)하기](https://huggingface.co/facebook/mask2former-swin-large-coco-panoptic)
+- [Depth Anything으로 깊이 추정(depth estimation)하기](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)
+- [VideoMAE와 함께하는 비디오 분류](https://huggingface.co/docs/transformers/model_doc/videomae)
+- [OneFormer로 유니버설 분할(universal segmentation)하기](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
+
+오디오:
+- [Whisper와 함께하는 자동 음성 인식](https://huggingface.co/openai/whisper-large-v3)
+- [Wav2Vec2로 키워드 검출(keyword spotting)하기](https://huggingface.co/superb/wav2vec2-base-superb-ks)
+- [Audio Spectrogram Transformer로 오디오 분류하기](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
+
+멀티 모달(Multimodal Task):
+- [TAPAS로 표 안에서 질문 답변하기](https://huggingface.co/google/tapas-base-finetuned-wtq)
+- [ViLT와 함께하는 시각적 질의응답](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
+- [LLaVa로 이미지에 설명 넣기](https://huggingface.co/llava-hf/llava-1.5-7b-hf)
+- [SigLIP와 함께하는 제로 샷(zero-shot) 이미지 분류](https://huggingface.co/google/siglip-so400m-patch14-384)
+- [LayoutLM으로 문서 안에서 질문 답변하기](https://huggingface.co/impira/layoutlm-document-qa)
+- [X-CLIP과 함께하는 제로 샷(zero-shot) 비디오 분류](https://huggingface.co/docs/transformers/model_doc/xclip)
+- [OWLv2로 진행하는 제로 샷(zero-shot) 객체 탐지](https://huggingface.co/docs/transformers/en/model_doc/owlv2)
+- [CLIPSeg로 진행하는 제로 샷(zero-shot) 이미지 분할](https://huggingface.co/docs/transformers/model_doc/clipseg)
+- [SAM과 함께하는 자동 마스크 생성](https://huggingface.co/docs/transformers/model_doc/sam)
+
+**[Transformer와 글쓰기](https://transformer.huggingface.co)** 는 이 저장소의 텍스트 생성 능력에 관한 Hugging Face 팀의 공식 데모입니다.
+
+## Transformers를 사용한 100개의 프로젝트
+
+Transformers는 사전 학습된 모델들을 이용하는 도구를 넘어 Transformers와 함께 빌드 된 프로젝트 및 Hugging Face Hub를 위한 하나의 커뮤니티입니다. 우리는 Transformers를 통해 개발자, 연구자, 학생, 교수, 엔지니어 및 모든 이들이 꿈을 품은 프로젝트(Dream Project)를 빌드 할 수 있길 바랍니다.
+
+Transformers에 달린 100,000개의 별을 축하하기 위해, 우리는 커뮤니티를 주목하고자 Transformers를 품고 빌드 된 100개의 어마어마한 프로젝트들을 선별하여 [awesome-transformers](https://github.com/huggingface/transformers/blob/main/awesome-transformers.md) 페이지에 나열하였습니다.
+
+만일 소유한 혹은 사용하고 계신 프로젝트가 이 리스트에 꼭 등재되어야 한다고 믿으신다면, PR을 열고 추가하여 주세요!
+
+## 조직 안에서 AI 사용에 대해 진지하게 고민 중이신가요? Hugging Face Enterprise Hub을 통해 더 빨리 구축해 보세요.
+
+
+
+
+
+## 퀵 투어
+
+주어진 입력(텍스트, 이미지, 오디오, ...)에 바로 모델을 사용할 수 있도록, 우리는 `pipeline` API를 제공합니다. Pipeline은 사전학습 모델과 그 모델을 학습할 때 적용한 전처리 방식을 하나로 합칩니다. 다음은 긍정적인 텍스트와 부정적인 텍스트를 분류하기 위해 pipeline을 사용한 간단한 예시입니다:
+
+```python
+>>> from transformers import pipeline
+
+# 감정 분석 파이프라인을 할당하세요
+>>> classifier = pipeline('sentiment-analysis')
+>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+코드의 두 번째 줄은 pipeline이 사용하는 사전학습 모델을 다운로드하고 캐시로 저장합니다. 세 번째 줄에선 그 모델이 주어진 텍스트를 평가합니다. 여기서 모델은 99.97%의 확률로 텍스트가 긍정적이라고 평가했습니다.
+
+자연어 처리(NLP) 뿐만 아니라 컴퓨터 비전, 발화(Speech) 과제들을 사전 학습된 `pipeline`으로 바로 수행할 수 있습니다. 예를 들어, 사진에서 손쉽게 객체들을 탐지할 수 있습니다.:
+
+``` python
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import pipeline
+
+# 귀여운 고양이가 있는 이미지를 다운로드하세요
+>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
+>>> image_data = requests.get(url, stream=True).raw
+>>> image = Image.open(image_data)
+
+# 객체 감지를 위한 파이프라인을 할당하세요
+>>> object_detector = pipeline('object-detection')
+>>> object_detector(image)
+[{'score': 0.9982201457023621,
+ 'label': 'remote',
+ 'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
+ {'score': 0.9960021376609802,
+ 'label': 'remote',
+ 'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
+ {'score': 0.9954745173454285,
+ 'label': 'couch',
+ 'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
+ {'score': 0.9988006353378296,
+ 'label': 'cat',
+ 'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
+ {'score': 0.9986783862113953,
+ 'label': 'cat',
+ 'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
+```
+위와 같이, 우리는 이미지에서 탐지된 객체들에 대하여 객체를 감싸는 박스와 확률 리스트를 얻을 수 있습니다. 왼쪽이 원본 이미지이며 오른쪽은 해당 이미지에 탐지된 결과를 표시하였습니다.
+
+
+
+
+
+[이 튜토리얼](https://huggingface.co/docs/transformers/ko/task_summary)에서 `pipeline` API가 지원하는 다양한 과제를 확인할 수 있습니다.
+
+코드 3줄로 원하는 과제에 맞게 사전학습 모델을 다운로드 받고 사용할 수 있습니다. 다음은 PyTorch 버전입니다:
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+다음은 TensorFlow 버전입니다:
+```python
+>>> from transformers import AutoTokenizer, TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+토크나이저는 사전학습 모델의 모든 전처리를 책임집니다. 그리고 (위의 예시처럼) 1개의 스트링이나 리스트도 처리할 수 있습니다. 토크나이저는 딕셔너리를 반환하는데, 이는 다운스트림 코드에 사용하거나 언패킹 연산자 ** 를 이용해 모델에 바로 전달할 수도 있습니다.
+
+모델 자체는 일반적으로 사용되는 [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)이나 [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)입니다. [이 튜토리얼](https://huggingface.co/docs/transformers/ko/training)은 이러한 모델을 표준적인 PyTorch나 TensorFlow 학습 과정에서 사용하는 방법, 또는 새로운 데이터로 파인 튜닝하기 위해 `Trainer` API를 사용하는 방법을 설명해 줍니다.
+
+## 왜 transformers를 사용해야 할까요?
+
+1. 손쉽게 사용할 수 있는 최첨단 모델:
+ - 자연어 이해(NLU)와 생성(NLG), 컴퓨터 비전, 오디오 과제에서 뛰어난 성능을 보입니다.
+ - 교육자와 실무자에게 진입 장벽이 낮습니다.
+ - 3개의 클래스만 배우면 바로 사용할 수 있습니다.
+ - 하나의 API로 모든 사전학습 모델을 사용할 수 있습니다.
+
+1. 더 적은 계산 비용, 더 적은 탄소 발자국:
+ - 연구자들은 모델을 계속 다시 학습시키는 대신 학습된 모델을 공유할 수 있습니다.
+ - 실무자들은 학습에 필요한 시간과 비용을 절약할 수 있습니다.
+ - 모든 분야를 통틀어서 400,000개 이상의 사전 학습된 모델이 있는 수십 개의 아키텍처.
+
+1. 모델의 각 생애주기에 적합한 프레임워크:
+ - 코드 3줄로 최첨단 모델을 학습하세요.
+ - 목적에 알맞게 모델을 TF2.0/Pytorch/Jax 프레임 워크 중 하나로 이동시키세요.
+ - 학습, 평가, 공개 등 각 단계에 맞는 프레임워크를 원하는대로 선택하세요.
+
+1. 필요한 대로 모델이나 예시를 커스터마이즈하세요:
+ - 우리는 저자가 공개한 결과를 재현하기 위해 각 모델 구조의 예시를 제공합니다.
+ - 모델 내부 구조는 가능한 일관적으로 공개되어 있습니다.
+ - 빠른 실험을 위해 모델 파일은 라이브러리와 독립적으로 사용될 수 있습니다.
+
+## 왜 transformers를 사용하지 말아야 할까요?
+
+- 이 라이브러리는 신경망 블록을 만들기 위한 모듈이 아닙니다. 연구자들이 여러 파일을 살펴보지 않고 바로 각 모델을 사용할 수 있도록, 모델 파일 코드의 추상화 수준을 적정하게 유지했습니다.
+- 학습 API는 모든 모델에 적용할 수 있도록 만들어지진 않았지만, 라이브러리가 제공하는 모델들에 적용할 수 있도록 최적화되었습니다. 일반적인 머신 러닝을 위해선, 다른 라이브러리를 사용하세요(예를 들면, [Accelerate](https://huggingface.co/docs/accelerate/index)).
+- 가능한 많은 사용 예시를 보여드리고 싶어서, [예시 폴더](https://github.com/huggingface/transformers/tree/main/examples)의 스크립트를 준비했습니다. 이 스크립트들을 수정 없이 특정한 문제에 바로 적용하지 못할 수 있습니다. 필요에 맞게 일부 코드를 수정해야 할 수 있습니다.
+
+## 설치
+
+### pip로 설치하기
+
+이 저장소는 Python 3.9+, Flax 0.4.1+, PyTorch 2.1+, TensorFlow 2.6+에서 테스트 되었습니다.
+
+[가상 환경](https://docs.python.org/3/library/venv.html)에 🤗 Transformers를 설치하세요. Python 가상 환경에 익숙하지 않다면, [사용자 가이드](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)를 확인하세요.
+
+우선, 사용할 Python 버전으로 가상 환경을 만들고 실행하세요.
+
+그 다음, Flax, PyTorch, TensorFlow 중 적어도 하나는 설치해야 합니다.
+플랫폼에 맞는 설치 명령어를 확인하기 위해 [TensorFlow 설치 페이지](https://www.tensorflow.org/install/), [PyTorch 설치 페이지](https://pytorch.org/get-started/locally/#start-locally), [Flax 설치 페이지](https://github.com/google/flax#quick-install)를 확인하세요.
+
+이들 중 적어도 하나가 설치되었다면, 🤗 Transformers는 다음과 같이 pip을 이용해 설치할 수 있습니다:
+
+```bash
+pip install transformers
+```
+
+예시들을 체험해보고 싶거나, 최최최첨단 코드를 원하거나, 새로운 버전이 나올 때까지 기다릴 수 없다면 [라이브러리를 소스에서 바로 설치](https://huggingface.co/docs/transformers/ko/installation#install-from-source)하셔야 합니다.
+
+### conda로 설치하기
+
+🤗 Transformers는 다음과 같이 conda로 설치할 수 있습니다:
+
+```shell script
+conda install conda-forge::transformers
+```
+
+> **_노트:_** `huggingface` 채널에서 `transformers`를 설치하는 것은 사용이 중단되었습니다.
+
+Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는 방법을 확인하세요.
+
+> **_노트:_** 윈도우 환경에서 캐싱의 이점을 위해 개발자 모드를 활성화할 수 있습니다. 만약 여러분에게 있어서 선택이 아닌 필수라면 [이 이슈](https://github.com/huggingface/huggingface_hub/issues/1062)를 통해 알려주세요.
+
+## 모델 구조
+
+**🤗 Transformers가 제공하는 [모든 모델 체크포인트](https://huggingface.co/models)** 는 huggingface.co [모델 허브](https://huggingface.co/models)에 완벽히 연동되어 있습니다. [개인](https://huggingface.co/users)과 [기관](https://huggingface.co/organizations)이 모델 허브에 직접 업로드할 수 있습니다.
+
+현재 사용 가능한 모델 체크포인트의 개수: 
+
+🤗 Transformers는 다음 모델들을 제공합니다: 각 모델의 요약은 [여기](https://huggingface.co/docs/transformers/ko/model_summary)서 확인하세요.
+
+각 모델이 Flax, PyTorch, TensorFlow으로 구현되었는지 또는 🤗 Tokenizers 라이브러리가 지원하는 토크나이저를 사용하는지 확인하려면, [이 표](https://huggingface.co/docs/transformers/ko/index#supported-framework)를 확인하세요.
+
+이 구현은 여러 데이터로 검증되었고 (예시 스크립트를 참고하세요) 오리지널 구현의 성능과 같아야 합니다. [도큐먼트](https://github.com/huggingface/transformers/tree/main/examples)의 Examples 섹션에서 성능에 대한 자세한 설명을 확인할 수 있습니다.
+
+## 더 알아보기
+
+| 섹션 | 설명 |
+|-|-|
+| [도큐먼트](https://huggingface.co/transformers/ko/) | 전체 API 도큐먼트와 튜토리얼 |
+| [과제 요약](https://huggingface.co/docs/transformers/ko/task_summary) | 🤗 Transformers가 지원하는 과제들 |
+| [전처리 튜토리얼](https://huggingface.co/docs/transformers/ko/preprocessing) | `Tokenizer` 클래스를 이용해 모델을 위한 데이터 준비하기 |
+| [학습과 파인 튜닝](https://huggingface.co/docs/transformers/ko/training) | 🤗 Transformers가 제공하는 모델 PyTorch/TensorFlow 학습 과정과 `Trainer` API에서 사용하기 |
+| [퀵 투어: 파인 튜닝/사용 스크립트](https://github.com/huggingface/transformers/tree/main/examples) | 다양한 과제에서 모델을 파인 튜닝하는 예시 스크립트 |
+| [모델 공유 및 업로드](https://huggingface.co/docs/transformers/ko/model_sharing) | 커뮤니티에 파인 튜닝된 모델을 업로드 및 공유하기 |
+
+## 인용
+
+🤗 Transformers 라이브러리를 인용하고 싶다면, 이 [논문](https://www.aclweb.org/anthology/2020.emnlp-demos.6/)을 인용해 주세요:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/docs/transformers/i18n/README_pt-br.md b/docs/transformers/i18n/README_pt-br.md
new file mode 100644
index 0000000000000000000000000000000000000000..e3c71c6a3f353531014adabc9cb824d2e39799c9
--- /dev/null
+++ b/docs/transformers/i18n/README_pt-br.md
@@ -0,0 +1,327 @@
+
+
+
Aprendizado de máquina de última geração para JAX, PyTorch e TensorFlow
+
+
+
+
+
+
+
+A biblioteca 🤗 Transformers oferece milhares de modelos pré-treinados para executar tarefas em diferentes modalidades, como texto, visão e áudio.
+
+Esses modelos podem ser aplicados a:
+
+* 📝 Texto, para tarefas como classificação de texto, extração de informações, resposta a perguntas, sumarização, tradução, geração de texto, em mais de 100 idiomas.
+* 🖼️ Imagens, para tarefas como classificação de imagens, detecção de objetos e segmentação.
+* 🗣️ Áudio, para tarefas como reconhecimento de fala e classificação de áudio.
+
+Os modelos Transformer também podem executar tarefas em diversas modalidades combinadas, como responder a perguntas em tabelas, reconhecimento óptico de caracteres, extração de informações de documentos digitalizados, classificação de vídeo e resposta a perguntas visuais.
+
+
+A biblioteca 🤗 Transformers oferece APIs para baixar e usar rapidamente esses modelos pré-treinados em um texto específico, ajustá-los em seus próprios conjuntos de dados e, em seguida, compartilhá-los com a comunidade em nosso [model hub](https://huggingface.co/models). Ao mesmo tempo, cada módulo Python que define uma arquitetura é totalmente independente e pode ser modificado para permitir experimentos de pesquisa rápidos.
+
+A biblioteca 🤗 Transformers é respaldada pelas três bibliotecas de aprendizado profundo mais populares — [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) e [TensorFlow](https://www.tensorflow.org/) — com uma integração perfeita entre elas. É simples treinar seus modelos com uma delas antes de carregá-los para inferência com a outra
+
+## Demonstração Online
+
+Você pode testar a maioria de nossos modelos diretamente em suas páginas a partir do [model hub](https://huggingface.co/models). Também oferecemos [hospedagem de modelos privados, versionamento e uma API de inferência](https://huggingface.co/pricing)
+para modelos públicos e privados.
+
+Aqui estão alguns exemplos:
+
+Em Processamento de Linguagem Natural:
+
+- [Completar palavra mascarada com BERT](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [Reconhecimento de Entidades Nomeadas com Electra](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [Geração de texto com GPT-2](https://huggingface.co/openai-community/gpt2?text=A+long+time+ago%2C)
+- [Inferência de Linguagem Natural com RoBERTa](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [Sumarização com BART](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [Resposta a perguntas com DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [Tradução com T5](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+
+Em Visão Computacional:
+- [Classificação de Imagens com ViT](https://huggingface.co/google/vit-base-patch16-224)
+- [Detecção de Objetos com DETR](https://huggingface.co/facebook/detr-resnet-50)
+- [Segmentação Semântica com SegFormer](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
+- [Segmentação Panóptica com MaskFormer](https://huggingface.co/facebook/maskformer-swin-small-coco)
+- [Estimativa de Profundidade com DPT](https://huggingface.co/docs/transformers/model_doc/dpt)
+- [Classificação de Vídeo com VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)
+- [Segmentação Universal com OneFormer](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
+
+
+Em Áudio:
+- [Reconhecimento Automático de Fala com Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base-960h)
+- [Detecção de Palavras-Chave com Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
+- [Classificação de Áudio com Transformer de Espectrograma de Áudio](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
+
+Em Tarefas Multimodais:
+- [Respostas de Perguntas em Tabelas com TAPAS](https://huggingface.co/google/tapas-base-finetuned-wtq)
+- [Respostas de Perguntas Visuais com ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
+- [Classificação de Imagens sem Anotação com CLIP](https://huggingface.co/openai/clip-vit-large-patch14)
+- [Respostas de Perguntas em Documentos com LayoutLM](https://huggingface.co/impira/layoutlm-document-qa)
+- [Classificação de Vídeo sem Anotação com X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)
+
+## 100 Projetos Usando Transformers
+
+Transformers é mais do que um conjunto de ferramentas para usar modelos pré-treinados: é uma comunidade de projetos construídos ao seu redor e o Hugging Face Hub. Queremos que o Transformers permita que desenvolvedores, pesquisadores, estudantes, professores, engenheiros e qualquer outra pessoa construa seus projetos dos sonhos.
+
+Para celebrar as 100.000 estrelas do Transformers, decidimos destacar a comunidade e criamos a página [awesome-transformers](./awesome-transformers.md), que lista 100 projetos incríveis construídos nas proximidades dos Transformers.
+
+Se você possui ou utiliza um projeto que acredita que deveria fazer parte da lista, abra um PR para adicioná-lo!
+
+## Se você está procurando suporte personalizado da equipe Hugging Face
+
+
+
+
+
+
+## Tour Rápido
+
+Para usar imediatamente um modelo em uma entrada específica (texto, imagem, áudio, ...), oferecemos a API `pipeline`. Os pipelines agrupam um modelo pré-treinado com o pré-processamento que foi usado durante o treinamento desse modelo. Aqui está como usar rapidamente um pipeline para classificar textos como positivos ou negativos:
+
+```python
+from transformers import pipeline
+
+# Carregue o pipeline de classificação de texto
+>>> classifier = pipeline("sentiment-analysis")
+
+# Classifique o texto como positivo ou negativo
+>>> classifier("Estamos muito felizes em apresentar o pipeline no repositório dos transformers.")
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+A segunda linha de código baixa e armazena em cache o modelo pré-treinado usado pelo pipeline, enquanto a terceira linha o avalia no texto fornecido. Neste exemplo, a resposta é "positiva" com uma confiança de 99,97%.
+
+Muitas tarefas têm um `pipeline` pré-treinado pronto para uso, não apenas em PNL, mas também em visão computacional e processamento de áudio. Por exemplo, podemos facilmente extrair objetos detectados em uma imagem:
+
+``` python
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import pipeline
+
+# Download an image with cute cats
+>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
+>>> image_data = requests.get(url, stream=True).raw
+>>> image = Image.open(image_data)
+
+# Allocate a pipeline for object detection
+>>> object_detector = pipeline('object-detection')
+>>> object_detector(image)
+[{'score': 0.9982201457023621,
+ 'label': 'remote',
+ 'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
+ {'score': 0.9960021376609802,
+ 'label': 'remote',
+ 'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
+ {'score': 0.9954745173454285,
+ 'label': 'couch',
+ 'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
+ {'score': 0.9988006353378296,
+ 'label': 'cat',
+ 'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
+ {'score': 0.9986783862113953,
+ 'label': 'cat',
+ 'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
+```
+
+
+Aqui obtemos uma lista de objetos detectados na imagem, com uma caixa envolvendo o objeto e uma pontuação de confiança. Aqui está a imagem original à esquerda, com as previsões exibidas à direita:
+
+
+
+
+
+
+Você pode aprender mais sobre as tarefas suportadas pela API `pipeline` em [este tutorial](https://huggingface.co/docs/transformers/task_summary).
+
+
+Além do `pipeline`, para baixar e usar qualquer um dos modelos pré-treinados em sua tarefa específica, tudo o que é necessário são três linhas de código. Aqui está a versão em PyTorch:
+
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+
+E aqui está o código equivalente para TensorFlow:
+
+```python
+>>> from transformers import AutoTokenizer, TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+O tokenizador é responsável por todo o pré-processamento que o modelo pré-treinado espera, e pode ser chamado diretamente em uma única string (como nos exemplos acima) ou em uma lista. Ele produzirá um dicionário que você pode usar no código subsequente ou simplesmente passar diretamente para o seu modelo usando o operador de descompactação de argumentos **.
+
+O modelo em si é um [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) ou um [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)(dependendo do seu back-end) que você pode usar como de costume. [Este tutorial](https://huggingface.co/docs/transformers/training) explica como integrar esse modelo em um ciclo de treinamento clássico do PyTorch ou TensorFlow, ou como usar nossa API `Trainer` para ajuste fino rápido em um novo conjunto de dados.
+
+## Por que devo usar transformers?
+
+1. Modelos state-of-the-art fáceis de usar:
+ - Alto desempenho em compreensão e geração de linguagem natural, visão computacional e tarefas de áudio.
+ - Barreira de entrada baixa para educadores e profissionais.
+ - Poucas abstrações visíveis para o usuário, com apenas três classes para aprender.
+ - Uma API unificada para usar todos os nossos modelos pré-treinados.
+
+1. Menores custos de computação, menor pegada de carbono:
+ - Pesquisadores podem compartilhar modelos treinados em vez de treinar sempre do zero.
+ - Profissionais podem reduzir o tempo de computação e os custos de produção.
+ - Dezenas de arquiteturas com mais de 60.000 modelos pré-treinados em todas as modalidades.
+
+1. Escolha o framework certo para cada parte da vida de um modelo:
+ - Treine modelos state-of-the-art em 3 linhas de código.
+ - Mova um único modelo entre frameworks TF2.0/PyTorch/JAX à vontade.
+ - Escolha o framework certo de forma contínua para treinamento, avaliação e produção.
+
+1. Personalize facilmente um modelo ou um exemplo para atender às suas necessidades:
+ - Fornecemos exemplos para cada arquitetura para reproduzir os resultados publicados pelos autores originais.
+ - Os detalhes internos do modelo são expostos de maneira consistente.
+ - Os arquivos do modelo podem ser usados de forma independente da biblioteca para experimentos rápidos.
+
+## Por que não devo usar transformers?
+
+- Esta biblioteca não é uma caixa de ferramentas modular para construir redes neurais. O código nos arquivos do modelo não é refatorado com abstrações adicionais de propósito, para que os pesquisadores possam iterar rapidamente em cada um dos modelos sem se aprofundar em abstrações/arquivos adicionais.
+- A API de treinamento não é projetada para funcionar com qualquer modelo, mas é otimizada para funcionar com os modelos fornecidos pela biblioteca. Para loops de aprendizado de máquina genéricos, você deve usar outra biblioteca (possivelmente, [Accelerate](https://huggingface.co/docs/accelerate)).
+- Embora nos esforcemos para apresentar o maior número possível de casos de uso, os scripts em nossa [pasta de exemplos](https://github.com/huggingface/transformers/tree/main/examples) são apenas isso: exemplos. É esperado que eles não funcionem prontos para uso em seu problema específico e que seja necessário modificar algumas linhas de código para adaptá-los às suas necessidades.
+
+
+
+### Com pip
+
+Este repositório é testado no Python 3.9+, Flax 0.4.1+, PyTorch 2.1+ e TensorFlow 2.6+.
+
+Você deve instalar o 🤗 Transformers em um [ambiente virtual](https://docs.python.org/3/library/venv.html). Se você não está familiarizado com ambientes virtuais em Python, confira o [guia do usuário](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+
+Primeiro, crie um ambiente virtual com a versão do Python que você vai usar e ative-o.
+
+Em seguida, você precisará instalar pelo menos um dos back-ends Flax, PyTorch ou TensorFlow.
+Consulte a [página de instalação do TensorFlow](https://www.tensorflow.org/install/), a [página de instalação do PyTorch](https://pytorch.org/get-started/locally/#start-locally) e/ou [Flax](https://github.com/google/flax#quick-install) e [Jax](https://github.com/google/jax#installation) páginas de instalação para obter o comando de instalação específico para a sua plataforma.
+
+Quando um desses back-ends estiver instalado, o 🤗 Transformers pode ser instalado usando pip da seguinte forma:
+
+```bash
+pip install transformers
+```
+Se você deseja experimentar com os exemplos ou precisa da versão mais recente do código e não pode esperar por um novo lançamento, você deve instalar a [biblioteca a partir do código-fonte](https://huggingface.co/docs/transformers/installation#installing-from-source).
+
+### Com conda
+
+O 🤗 Transformers pode ser instalado com conda da seguinte forma:
+
+```bash
+conda install conda-forge::transformers
+```
+
+> **_NOTA:_** Instalar `transformers` pelo canal `huggingface` está obsoleto.
+
+Siga as páginas de instalação do Flax, PyTorch ou TensorFlow para ver como instalá-los com conda.
+
+Siga as páginas de instalação do Flax, PyTorch ou TensorFlow para ver como instalá-los com o conda.
+
+> **_NOTA:_** No Windows, você pode ser solicitado a ativar o Modo de Desenvolvedor para aproveitar o cache. Se isso não for uma opção para você, por favor nos avise [neste problema](https://github.com/huggingface/huggingface_hub/issues/1062).
+
+## Arquiteturas de Modelos
+
+**[Todos os pontos de verificação de modelo](https://huggingface.co/models)** fornecidos pelo 🤗 Transformers são integrados de forma transparente do [model hub](https://huggingface.co/models) do huggingface.co, onde são carregados diretamente por [usuários](https://huggingface.co/users) e [organizações](https://huggingface.co/organizations).
+
+Número atual de pontos de verificação: 
+
+🤗 Transformers atualmente fornece as seguintes arquiteturas: veja [aqui](https://huggingface.co/docs/transformers/model_summary) para um resumo de alto nível de cada uma delas.
+
+Para verificar se cada modelo tem uma implementação em Flax, PyTorch ou TensorFlow, ou possui um tokenizador associado com a biblioteca 🤗 Tokenizers, consulte [esta tabela](https://huggingface.co/docs/transformers/index#supported-frameworks).
+
+Essas implementações foram testadas em vários conjuntos de dados (veja os scripts de exemplo) e devem corresponder ao desempenho das implementações originais. Você pode encontrar mais detalhes sobre o desempenho na seção de Exemplos da [documentação](https://github.com/huggingface/transformers/tree/main/examples).
+
+
+## Saiba mais
+
+| Seção | Descrição |
+|-|-|
+| [Documentação](https://huggingface.co/docs/transformers/) | Documentação completa da API e tutoriais |
+| [Resumo de Tarefas](https://huggingface.co/docs/transformers/task_summary) | Tarefas suportadas pelo 🤗 Transformers |
+| [Tutorial de Pré-processamento](https://huggingface.co/docs/transformers/preprocessing) | Usando a classe `Tokenizer` para preparar dados para os modelos |
+| [Treinamento e Ajuste Fino](https://huggingface.co/docs/transformers/training) | Usando os modelos fornecidos pelo 🤗 Transformers em um loop de treinamento PyTorch/TensorFlow e a API `Trainer` |
+| [Tour Rápido: Scripts de Ajuste Fino/Utilização](https://github.com/huggingface/transformers/tree/main/examples) | Scripts de exemplo para ajuste fino de modelos em uma ampla gama de tarefas |
+| [Compartilhamento e Envio de Modelos](https://huggingface.co/docs/transformers/model_sharing) | Envie e compartilhe seus modelos ajustados com a comunidade |
+
+## Citação
+
+Agora temos um [artigo](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) que você pode citar para a biblioteca 🤗 Transformers:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = out,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/docs/transformers/i18n/README_ru.md b/docs/transformers/i18n/README_ru.md
new file mode 100644
index 0000000000000000000000000000000000000000..c30237fef88580201ca30139a8f21e4839a76724
--- /dev/null
+++ b/docs/transformers/i18n/README_ru.md
@@ -0,0 +1,317 @@
+
+
+
Современное машинное обучение для JAX, PyTorch и TensorFlow
+
+
+
+
+
+
+🤗 Transformers предоставляет тысячи предварительно обученных моделей для выполнения различных задач, таких как текст, зрение и аудио.
+
+Эти модели могут быть применены к:
+
+* 📝 Тексту для таких задач, как классификация текстов, извлечение информации, ответы на вопросы, обобщение, перевод, генерация текстов на более чем 100 языках.
+* 🖼️ Изображениям для задач классификации изображений, обнаружения объектов и сегментации.
+* 🗣️ Аудио для задач распознавания речи и классификации аудио.
+
+Модели transformers также могут выполнять несколько задач, такие как ответы на табличные вопросы, распознавание оптических символов, извлечение информации из отсканированных документов, классификация видео и ответы на визуальные вопросы.
+
+🤗 Transformers предоставляет API для быстрой загрузки и использования предварительно обученных моделей, их тонкой настройки на собственных датасетах и последующего взаимодействия ими с сообществом на нашем [сайте](https://huggingface.co/models). В то же время каждый python модуль, определяющий архитектуру, полностью автономен и может быть модифицирован для проведения быстрых исследовательских экспериментов.
+
+🤗 Transformers опирается на три самые популярные библиотеки глубокого обучения - [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) и [TensorFlow](https://www.tensorflow.org/) - и легко интегрируется между ними. Это позволяет легко обучать модели с помощью одной из них, а затем загружать их для выводов с помощью другой.
+
+## Онлайн демонстрация
+
+Большинство наших моделей можно протестировать непосредственно на их страницах с [сайта](https://huggingface.co/models). Мы также предлагаем [приватный хостинг моделей, контроль версий и API для выводов](https://huggingface.co/pricing) для публичных и частных моделей.
+
+Вот несколько примеров:
+
+В области NLP ( Обработка текстов на естественном языке ):
+- [Маскированное заполнение слов с помощью BERT](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [Распознавание сущностей с помощью Electra](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [Генерация текста с помощью GPT-2](https://huggingface.co/openai-community/gpt2?text=A+long+time+ago%2C+)
+- [Выводы на естественном языке с помощью RoBERTa](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [Обобщение с помощью BART](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [Ответы на вопросы с помощью DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [Перевод с помощью T5](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+В области компьютерного зрения:
+- [Классификация изображений с помощью ViT](https://huggingface.co/google/vit-base-patch16-224)
+- [Обнаружение объектов с помощью DETR](https://huggingface.co/facebook/detr-resnet-50)
+- [Семантическая сегментация с помощью SegFormer](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
+- [Сегментация паноптикума с помощью MaskFormer](https://huggingface.co/facebook/maskformer-swin-small-coco)
+- [Оценка глубины с помощью DPT](https://huggingface.co/docs/transformers/model_doc/dpt)
+- [Классификация видео с помощью VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)
+- [Универсальная сегментация с помощью OneFormer](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
+
+В области звука:
+- [Автоматическое распознавание речи с помощью Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base-960h)
+- [Поиск ключевых слов с помощью Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
+- [Классификация аудиоданных с помощью траснформера аудиоспектрограмм](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
+
+В мультимодальных задачах:
+- [Ответы на вопросы по таблице с помощью TAPAS](https://huggingface.co/google/tapas-base-finetuned-wtq)
+- [Визуальные ответы на вопросы с помощью ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
+- [Zero-shot классификация изображений с помощью CLIP](https://huggingface.co/openai/clip-vit-large-patch14)
+- [Ответы на вопросы по документам с помощью LayoutLM](https://huggingface.co/impira/layoutlm-document-qa)
+- [Zero-shot классификация видео с помощью X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)
+
+
+## 100 проектов, использующих Transformers
+
+Transformers - это не просто набор инструментов для использования предварительно обученных моделей: это сообщество проектов, созданное на его основе, и
+Hugging Face Hub. Мы хотим, чтобы Transformers позволил разработчикам, исследователям, студентам, профессорам, инженерам и всем желающим
+создавать проекты своей мечты.
+
+Чтобы отпраздновать 100 тысяч звезд Transformers, мы решили сделать акцент на сообществе, и создали страницу [awesome-transformers](./awesome-transformers.md), на которой перечислены 100
+невероятных проектов, созданных с помощью transformers.
+
+Если вы являетесь владельцем или пользователем проекта, который, по вашему мнению, должен быть включен в этот список, пожалуйста, откройте PR для его добавления!
+
+## Если вы хотите получить индивидуальную поддержку от команды Hugging Face
+
+
+
+
+
+## Быстрый гайд
+
+Для использования модели на заданном входе (текст, изображение, звук, ...) мы предоставляем API `pipeline`. Конвейеры объединяют предварительно обученную модель с препроцессингом, который использовался при ее обучении. Вот как можно быстро использовать конвейер для классификации положительных и отрицательных текстов:
+
+```python
+>>> from transformers import pipeline
+
+# Выделение конвейера для анализа настроений
+>>> classifier = pipeline('sentiment-analysis')
+>>> classifier('Мы очень рады представить конвейер в transformers.')
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+Вторая строка кода загружает и кэширует предварительно обученную модель, используемую конвейером, а третья оценивает ее на заданном тексте. Здесь ответ "POSITIVE" с уверенностью 99,97%.
+
+Во многих задачах, как в НЛП, так и в компьютерном зрении и речи, уже есть готовый `pipeline`. Например, мы можем легко извлечь обнаруженные объекты на изображении:
+
+``` python
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import pipeline
+
+# Скачиваем изображение с милыми котиками
+>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
+>>> image_data = requests.get(url, stream=True).raw
+>>> image = Image.open(image_data)
+
+# Выделение конвейера для обнаружения объектов
+>>> object_detector = pipeline('object-detection')
+>>> object_detector(image)
+[{'score': 0.9982201457023621,
+ 'label': 'remote',
+ 'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
+ {'score': 0.9960021376609802,
+ 'label': 'remote',
+ 'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
+ {'score': 0.9954745173454285,
+ 'label': 'couch',
+ 'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
+ {'score': 0.9988006353378296,
+ 'label': 'cat',
+ 'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
+ {'score': 0.9986783862113953,
+ 'label': 'cat',
+ 'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
+```
+
+Здесь мы получаем список объектов, обнаруженных на изображении, с рамкой вокруг объекта и оценкой достоверности. Слева - исходное изображение, справа прогнозы:
+
+
+
+
+
+
+Подробнее о задачах, поддерживаемых API `pipeline`, можно узнать в [этом учебном пособии](https://huggingface.co/docs/transformers/task_sum)
+
+В дополнение к `pipeline`, для загрузки и использования любой из предварительно обученных моделей в заданной задаче достаточно трех строк кода. Вот версия для PyTorch:
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Привет мир!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+
+А вот эквивалентный код для TensorFlow:
+```python
+>>> from transformers import AutoTokenizer, TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Привет мир!", return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+Токенизатор отвечает за всю предварительную обработку, которую ожидает предварительно обученная модель, и может быть вызван непосредственно с помощью одной строки (как в приведенных выше примерах) или на списке. В результате будет получен словарь, который можно использовать в последующем коде или просто напрямую передать в модель с помощью оператора распаковки аргументов **.
+
+Сама модель представляет собой обычный [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) или [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (в зависимости от используемого бэкенда), который можно использовать как обычно. [В этом руководстве](https://huggingface.co/docs/transformers/training) рассказывается, как интегрировать такую модель в классический цикл обучения PyTorch или TensorFlow, или как использовать наш API `Trainer` для быстрой тонкой настройки на новом датасете.
+
+## Почему необходимо использовать transformers?
+
+1. Простые в использовании современные модели:
+ - Высокая производительность в задачах понимания и генерации естественного языка, компьютерного зрения и аудио.
+ - Низкий входной барьер для преподавателей и практиков.
+ - Небольшое количество абстракций для пользователя и всего три класса для изучения.
+ - Единый API для использования всех наших предварительно обученных моделей.
+
+1. Более низкие вычислительные затраты, меньший "углеродный след":
+ - Исследователи могут обмениваться обученными моделями вместо того, чтобы постоянно их переобучать.
+ - Практики могут сократить время вычислений и производственные затраты.
+ - Десятки архитектур с более чем 60 000 предварительно обученных моделей для всех модальностей.
+
+1. Выбор подходящего фреймворка для каждого этапа жизни модели:
+ - Обучение самых современных моделей за 3 строки кода.
+ - Перемещайте одну модель между фреймворками TF2.0/PyTorch/JAX по своему усмотрению.
+ - Беспрепятственный выбор подходящего фреймворка для обучения, оценки и производства.
+
+1. Легко настроить модель или пример под свои нужды:
+ - Мы предоставляем примеры для каждой архитектуры, чтобы воспроизвести результаты, опубликованные их авторами.
+ - Внутренние компоненты модели раскрываются максимально последовательно.
+ - Файлы моделей можно использовать независимо от библиотеки для проведения быстрых экспериментов.
+
+## Почему я не должен использовать transformers?
+
+- Данная библиотека не является модульным набором строительных блоков для нейронных сетей. Код в файлах моделей специально не рефакторится дополнительными абстракциями, чтобы исследователи могли быстро итеративно работать с каждой из моделей, не погружаясь в дополнительные абстракции/файлы.
+- API обучения не предназначен для работы с любой моделью, а оптимизирован для работы с моделями, предоставляемыми библиотекой. Для работы с общими циклами машинного обучения следует использовать другую библиотеку (возможно, [Accelerate](https://huggingface.co/docs/accelerate)).
+- Несмотря на то, что мы стремимся представить как можно больше примеров использования, скрипты в нашей папке [примеров](https://github.com/huggingface/transformers/tree/main/examples) являются именно примерами. Предполагается, что они не будут работать "из коробки" для решения вашей конкретной задачи, и вам придется изменить несколько строк кода, чтобы адаптировать их под свои нужды.
+
+## Установка
+
+### С помощью pip
+
+Данный репозиторий протестирован на Python 3.9+, Flax 0.4.1+, PyTorch 2.1+ и TensorFlow 2.6+.
+
+Устанавливать 🤗 Transformers следует в [виртуальной среде](https://docs.python.org/3/library/venv.html). Если вы не знакомы с виртуальными средами Python, ознакомьтесь с [руководством пользователя](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+
+Сначала создайте виртуальную среду с той версией Python, которую вы собираетесь использовать, и активируйте ее.
+
+Затем необходимо установить хотя бы один бекенд из Flax, PyTorch или TensorFlow.
+Пожалуйста, обратитесь к страницам [TensorFlow установочная страница](https://www.tensorflow.org/install/), [PyTorch установочная страница](https://pytorch.org/get-started/locally/#start-locally) и/или [Flax](https://github.com/google/flax#quick-install) и [Jax](https://github.com/google/jax#installation), где описаны команды установки для вашей платформы.
+
+После установки одного из этих бэкендов 🤗 Transformers может быть установлен с помощью pip следующим образом:
+
+```bash
+pip install transformers
+```
+
+Если вы хотите поиграть с примерами или вам нужен самый современный код и вы не можете ждать нового релиза, вы должны [установить библиотеку из исходного кода](https://huggingface.co/docs/transformers/installation#installing-from-source).
+
+### С помощью conda
+
+Установить Transformers с помощью conda можно следующим образом:
+
+```bash
+conda install conda-forge::transformers
+```
+
+> **_ЗАМЕТКА:_** Установка `transformers` через канал `huggingface` устарела.
+
+О том, как установить Flax, PyTorch или TensorFlow с помощью conda, читайте на страницах, посвященных их установке.
+
+> **_ЗАМЕТКА:_** В операционной системе Windows вам может быть предложено активировать режим разработчика, чтобы воспользоваться преимуществами кэширования. Если для вас это невозможно, сообщите нам об этом [здесь](https://github.com/huggingface/huggingface_hub/issues/1062).
+
+## Модельные архитектуры
+
+**[Все контрольные точки моделей](https://huggingface.co/models)**, предоставляемые 🤗 Transformers, беспрепятственно интегрируются с huggingface.co [model hub](https://huggingface.co/models), куда они загружаются непосредственно [пользователями](https://huggingface.co/users) и [организациями](https://huggingface.co/organizations).
+
+Текущее количество контрольных точек: 
+
+🤗 В настоящее время Transformers предоставляет следующие архитектуры: подробное описание каждой из них см. [здесь](https://huggingface.co/docs/transformers/model_summary).
+
+Чтобы проверить, есть ли у каждой модели реализация на Flax, PyTorch или TensorFlow, или связанный с ней токенизатор, поддерживаемый библиотекой 🤗 Tokenizers, обратитесь к [этой таблице](https://huggingface.co/docs/transformers/index#supported-frameworks).
+
+Эти реализации были протестированы на нескольких наборах данных (см. примеры скриптов) и должны соответствовать производительности оригинальных реализаций. Более подробную информацию о производительности можно найти в разделе "Примеры" [документации](https://github.com/huggingface/transformers/tree/main/examples).
+
+
+## Изучи больше
+
+| Секция | Описание |
+|-|-|
+| [Документация](https://huggingface.co/docs/transformers/) | Полная документация по API и гайды |
+| [Краткие описания задач](https://huggingface.co/docs/transformers/task_summary) | Задачи поддерживаются 🤗 Transformers |
+| [Пособие по предварительной обработке](https://huggingface.co/docs/transformers/preprocessing) | Использование класса `Tokenizer` для подготовки данных для моделей |
+| [Обучение и доработка](https://huggingface.co/docs/transformers/training) | Использование моделей, предоставляемых 🤗 Transformers, в цикле обучения PyTorch/TensorFlow и API `Trainer`. |
+| [Быстрый тур: Тонкая настройка/скрипты использования](https://github.com/huggingface/transformers/tree/main/examples) | Примеры скриптов для тонкой настройки моделей на широком спектре задач |
+| [Совместное использование и загрузка моделей](https://huggingface.co/docs/transformers/model_sharing) | Загружайте и делитесь с сообществом своими доработанными моделями |
+
+## Цитирование
+
+Теперь у нас есть [статья](https://www.aclweb.org/anthology/2020.emnlp-demos.6/), которую можно цитировать для библиотеки 🤗 Transformers:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/docs/transformers/i18n/README_te.md b/docs/transformers/i18n/README_te.md
new file mode 100644
index 0000000000000000000000000000000000000000..aee579b52abdc8fd4f0a20fc5d90177ad6d1c496
--- /dev/null
+++ b/docs/transformers/i18n/README_te.md
@@ -0,0 +1,316 @@
+
+
+
JAX, PyTorch మరియు TensorFlow కోసం అత్యాధునిక యంత్ర అభ్యాసం
+
+
+
+
+
+
+🤗 ట్రాన్స్ఫార్మర్లు టెక్స్ట్, విజన్ మరియు ఆడియో వంటి విభిన్న పద్ధతులపై టాస్క్లను నిర్వహించడానికి వేలాది ముందుగా శిక్షణ పొందిన మోడల్లను అందిస్తాయి.
+
+ఈ నమూనాలు వర్తించవచ్చు:
+
+* 📝 టెక్స్ట్, 100కి పైగా భాషల్లో టెక్స్ట్ క్లాసిఫికేషన్, ఇన్ఫర్మేషన్ ఎక్స్ట్రాక్షన్, ప్రశ్నలకు సమాధానాలు, సారాంశం, అనువాదం, టెక్స్ట్ జనరేషన్ వంటి పనుల కోసం.
+* 🖼️ ఇమేజ్లు, ఇమేజ్ వర్గీకరణ, ఆబ్జెక్ట్ డిటెక్షన్ మరియు సెగ్మెంటేషన్ వంటి పనుల కోసం.
+* 🗣️ ఆడియో, స్పీచ్ రికగ్నిషన్ మరియు ఆడియో వర్గీకరణ వంటి పనుల కోసం.
+
+ట్రాన్స్ఫార్మర్ మోడల్లు టేబుల్ క్వశ్చన్ ఆన్సర్ చేయడం, ఆప్టికల్ క్యారెక్టర్ రికగ్నిషన్, స్కాన్ చేసిన డాక్యుమెంట్ల నుండి ఇన్ఫర్మేషన్ ఎక్స్ట్రాక్షన్, వీడియో క్లాసిఫికేషన్ మరియు విజువల్ క్వశ్చన్ ఆన్సర్ చేయడం వంటి **అనేక పద్ధతులతో కలిపి** పనులను కూడా చేయగలవు.
+
+🤗 ట్రాన్స్ఫార్మర్లు అందించిన టెక్స్ట్లో ప్రీట్రైన్డ్ మోడల్లను త్వరగా డౌన్లోడ్ చేయడానికి మరియు ఉపయోగించడానికి, వాటిని మీ స్వంత డేటాసెట్లలో ఫైన్-ట్యూన్ చేయడానికి మరియు వాటిని మా [మోడల్ హబ్](https://huggingface.co/models)లో సంఘంతో భాగస్వామ్యం చేయడానికి API లను అందిస్తుంది. అదే సమయంలో, ఆర్కిటెక్చర్ని నిర్వచించే ప్రతి పైథాన్ మాడ్యూల్ పూర్తిగా స్వతంత్రంగా ఉంటుంది మరియు త్వరిత పరిశోధన ప్రయోగాలను ప్రారంభించడానికి సవరించవచ్చు.
+
+🤗 ట్రాన్స్ఫార్మర్లకు మూడు అత్యంత ప్రజాదరణ పొందిన డీప్ లెర్నింగ్ లైబ్రరీలు ఉన్నాయి — [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) మరియు [TensorFlow](https://www.tensorflow.org/) — వాటి మధ్య అతుకులు లేని ఏకీకరణతో. మీ మోడల్లను ఒకదానితో మరొకదానితో అనుమితి కోసం లోడ్ చేసే ముందు వాటికి శిక్షణ ఇవ్వడం చాలా సులభం.
+
+## ఆన్లైన్ డెమోలు
+
+మీరు [మోడల్ హబ్](https://huggingface.co/models) నుండి మా మోడళ్లలో చాలా వరకు వాటి పేజీలలో నేరుగా పరీక్షించవచ్చు. మేము పబ్లిక్ మరియు ప్రైవేట్ మోడల్ల కోసం [ప్రైవేట్ మోడల్ హోస్టింగ్, సంస్కరణ & అనుమితి API](https://huggingface.co/pricing)ని కూడా అందిస్తాము.
+
+ఇక్కడ కొన్ని ఉదాహరణలు ఉన్నాయి:
+
+సహజ భాషా ప్రాసెసింగ్లో:
+- [BERT తో మాస్క్డ్ వర్డ్ కంప్లీషన్](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [Electra తో పేరు ఎంటిటీ గుర్తింపు](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [GPT-2 తో టెక్స్ట్ జనరేషన్](https://huggingface.co/openai-community/gpt2?text=A+long+time+ago%2C+)
+- [RoBERTa తో సహజ భాషా అనుమితి](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+Lost.+Nobody+lost+any+animal)
+- [BART తో సారాంశం](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [DistilBERT తో ప్రశ్న సమాధానం](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [T5 తో అనువాదం](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+కంప్యూటర్ దృష్టిలో:
+- [VIT తో చిత్ర వర్గీకరణ](https://huggingface.co/google/vit-base-patch16-224)
+- [DETR తో ఆబ్జెక్ట్ డిటెక్షన్](https://huggingface.co/facebook/detr-resnet-50)
+- [SegFormer తో సెమాంటిక్ సెగ్మెంటేషన్](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
+- [MaskFormer తో పానోప్టిక్ సెగ్మెంటేషన్](https://huggingface.co/facebook/maskformer-swin-small-coco)
+- [DPT తో లోతు అంచనా](https://huggingface.co/docs/transformers/model_doc/dpt)
+- [VideoMAE తో వీడియో వర్గీకరణ](https://huggingface.co/docs/transformers/model_doc/videomae)
+- [OneFormer తో యూనివర్సల్ సెగ్మెంటేషన్](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
+
+ఆడియోలో:
+- [Wav2Vec2 తో ఆటోమేటిక్ స్పీచ్ రికగ్నిషన్](https://huggingface.co/facebook/wav2vec2-base-960h)
+- [Wav2Vec2 తో కీవర్డ్ స్పాటింగ్](https://huggingface.co/superb/wav2vec2-base-superb-ks)
+- [ఆడియో స్పెక్ట్రోగ్రామ్ ట్రాన్స్ఫార్మర్తో ఆడియో వర్గీకరణ](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
+
+మల్టీమోడల్ టాస్క్లలో:
+- [TAPAS తో టేబుల్ ప్రశ్న సమాధానాలు](https://huggingface.co/google/tapas-base-finetuned-wtq)
+- [ViLT తో దృశ్యమాన ప్రశ్నకు సమాధానం](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
+- [CLIP తో జీరో-షాట్ ఇమేజ్ వర్గీకరణ](https://huggingface.co/openai/clip-vit-large-patch14)
+- [LayoutLM తో డాక్యుమెంట్ ప్రశ్నకు సమాధానం](https://huggingface.co/impira/layoutlm-document-qa)
+- [X-CLIP తో జీరో-షాట్ వీడియో వర్గీకరణ](https://huggingface.co/docs/transformers/model_doc/xclip)
+
+## ట్రాన్స్ఫార్మర్లను ఉపయోగించి 100 ప్రాజెక్టులు
+
+ట్రాన్స్ఫార్మర్లు ప్రీట్రైన్డ్ మోడల్లను ఉపయోగించడానికి టూల్కిట్ కంటే ఎక్కువ: ఇది దాని చుట్టూ నిర్మించిన ప్రాజెక్ట్ల సంఘం మరియు
+హగ్గింగ్ ఫేస్ హబ్. డెవలపర్లు, పరిశోధకులు, విద్యార్థులు, ప్రొఫెసర్లు, ఇంజనీర్లు మరియు ఎవరినైనా అనుమతించేలా ట్రాన్స్ఫార్మర్లను మేము కోరుకుంటున్నాము
+వారి కలల ప్రాజెక్టులను నిర్మించడానికి.
+
+ట్రాన్స్ఫార్మర్ల 100,000 నక్షత్రాలను జరుపుకోవడానికి, మేము స్పాట్లైట్ని ఉంచాలని నిర్ణయించుకున్నాము
+సంఘం, మరియు మేము 100 జాబితాలను కలిగి ఉన్న [awesome-transformers](./awesome-transformers.md) పేజీని సృష్టించాము.
+ట్రాన్స్ఫార్మర్ల పరిసరాల్లో అద్భుతమైన ప్రాజెక్టులు నిర్మించబడ్డాయి.
+
+జాబితాలో భాగమని మీరు విశ్వసించే ప్రాజెక్ట్ను మీరు కలిగి ఉంటే లేదా ఉపయోగిస్తుంటే, దయచేసి దానిని జోడించడానికి PRని తెరవండి!
+
+## మీరు హగ్గింగ్ ఫేస్ టీమ్ నుండి అనుకూల మద్దతు కోసం చూస్తున్నట్లయితే
+
+
+
+
+
+## త్వరిత పర్యటన
+
+ఇచ్చిన ఇన్పుట్ (టెక్స్ట్, ఇమేజ్, ఆడియో, ...)పై తక్షణమే మోడల్ను ఉపయోగించడానికి, మేము `pipeline` API ని అందిస్తాము. పైప్లైన్లు ఆ మోడల్ శిక్షణ సమయంలో ఉపయోగించిన ప్రీప్రాసెసింగ్తో కూడిన ప్రీట్రైన్డ్ మోడల్ను సమూహపరుస్తాయి. సానుకూల మరియు ప్రతికూల పాఠాలను వర్గీకరించడానికి పైప్లైన్ను త్వరగా ఎలా ఉపయోగించాలో ఇక్కడ ఉంది:
+
+```python
+>>> from transformers import pipeline
+
+# Allocate a pipeline for sentiment-analysis
+>>> classifier = pipeline('sentiment-analysis')
+>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+రెండవ లైన్ కోడ్ డౌన్లోడ్ మరియు పైప్లైన్ ఉపయోగించే ప్రీట్రైన్డ్ మోడల్ను కాష్ చేస్తుంది, మూడవది ఇచ్చిన టెక్స్ట్పై మూల్యాంకనం చేస్తుంది. ఇక్కడ సమాధానం 99.97% విశ్వాసంతో "పాజిటివ్".
+
+చాలా పనులు NLPలో కానీ కంప్యూటర్ విజన్ మరియు స్పీచ్లో కూడా ముందుగా శిక్షణ పొందిన `pipeline` సిద్ధంగా ఉన్నాయి. ఉదాహరణకు, మనం చిత్రంలో గుర్తించిన వస్తువులను సులభంగా సంగ్రహించవచ్చు:
+
+``` python
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import pipeline
+
+# Download an image with cute cats
+>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
+>>> image_data = requests.get(url, stream=True).raw
+>>> image = Image.open(image_data)
+
+# Allocate a pipeline for object detection
+>>> object_detector = pipeline('object-detection')
+>>> object_detector(image)
+[{'score': 0.9982201457023621,
+ 'label': 'remote',
+ 'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
+ {'score': 0.9960021376609802,
+ 'label': 'remote',
+ 'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
+ {'score': 0.9954745173454285,
+ 'label': 'couch',
+ 'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
+ {'score': 0.9988006353378296,
+ 'label': 'cat',
+ 'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
+ {'score': 0.9986783862113953,
+ 'label': 'cat',
+ 'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
+```
+
+ఇక్కడ మనం ఆబ్జెక్ట్ చుట్టూ ఉన్న బాక్స్ మరియు కాన్ఫిడెన్స్ స్కోర్తో చిత్రంలో గుర్తించబడిన వస్తువుల జాబితాను పొందుతాము. ఇక్కడ ఎడమవైపున ఉన్న అసలు చిత్రం, కుడివైపున అంచనాలు ప్రదర్శించబడతాయి:
+
+
+
+
+
+
+మీరు [ఈ ట్యుటోరియల్](https://huggingface.co/docs/transformers/task_summary)లో `pipeline` API ద్వారా సపోర్ట్ చేసే టాస్క్ల గురించి మరింత తెలుసుకోవచ్చు.
+
+`pipeline`తో పాటు, మీరు ఇచ్చిన టాస్క్లో ఏదైనా ప్రీట్రైన్డ్ మోడల్లను డౌన్లోడ్ చేయడానికి మరియు ఉపయోగించడానికి, దీనికి మూడు లైన్ల కోడ్ సరిపోతుంది. ఇక్కడ PyTorch వెర్షన్ ఉంది:
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+
+మరియు TensorFlow కి సమానమైన కోడ్ ఇక్కడ ఉంది:
+```python
+>>> from transformers import AutoTokenizer, TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+ప్రిట్రైన్డ్ మోడల్ ఆశించే అన్ని ప్రీప్రాసెసింగ్లకు టోకెనైజర్ బాధ్యత వహిస్తుంది మరియు నేరుగా ఒకే స్ట్రింగ్ (పై ఉదాహరణలలో వలె) లేదా జాబితాపై కాల్ చేయవచ్చు. ఇది మీరు డౌన్స్ట్రీమ్ కోడ్లో ఉపయోగించగల నిఘంటువుని అవుట్పుట్ చేస్తుంది లేదా ** ఆర్గ్యుమెంట్ అన్ప్యాకింగ్ ఆపరేటర్ని ఉపయోగించి నేరుగా మీ మోడల్కి పంపుతుంది.
+
+మోడల్ కూడా సాధారణ [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) లేదా [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (మీ బ్యాకెండ్ని బట్టి) మీరు మామూలుగా ఉపయోగించవచ్చు. [ఈ ట్యుటోరియల్](https://huggingface.co/docs/transformers/training) అటువంటి మోడల్ని క్లాసిక్ PyTorch లేదా TensorFlow ట్రైనింగ్ లూప్లో ఎలా ఇంటిగ్రేట్ చేయాలో లేదా మా `Trainer` API ని ఎలా ఉపయోగించాలో వివరిస్తుంది కొత్త డేటాసెట్.
+
+## నేను ట్రాన్స్ఫార్మర్లను ఎందుకు ఉపయోగించాలి?
+
+1. ఉపయోగించడానికి సులభమైన స్టేట్ ఆఫ్ ది ఆర్ట్ మోడల్లు:
+ - సహజ భాషా అవగాహన & ఉత్పత్తి, కంప్యూటర్ దృష్టి మరియు ఆడియో పనులపై అధిక పనితీరు.
+ - విద్యావేత్తలు మరియు అభ్యాసకుల ప్రవేశానికి తక్కువ అవరోధం.
+ - తెలుసుకోవడానికి కేవలం మూడు తరగతులతో కొన్ని వినియోగదారు-ముఖ సంగ్రహణలు.
+ - మా అన్ని ప్రీట్రైన్డ్ మోడల్లను ఉపయోగించడం కోసం ఏకీకృత API.
+
+2. తక్కువ గణన ఖర్చులు, చిన్న కార్బన్ పాదముద్ర:
+ - పరిశోధకులు ఎల్లప్పుడూ మళ్లీ శిక్షణ పొందే బదులు శిక్షణ పొందిన నమూనాలను పంచుకోవచ్చు.
+ - అభ్యాసకులు గణన సమయాన్ని మరియు ఉత్పత్తి ఖర్చులను తగ్గించగలరు.
+ - అన్ని పద్ధతుల్లో 60,000 కంటే ఎక్కువ ప్రీట్రైన్డ్ మోడల్లతో డజన్ల కొద్దీ ఆర్కిటెక్చర్లు.
+
+3. మోడల్ జీవితకాలంలో ప్రతి భాగానికి సరైన ఫ్రేమ్వర్క్ను ఎంచుకోండి:
+ - 3 లైన్ల కోడ్లో స్టేట్ ఆఫ్ ది ఆర్ట్ మోడల్లకు శిక్షణ ఇవ్వండి.
+ - TF2.0/PyTorch/JAX ఫ్రేమ్వర్క్ల మధ్య ఒకే మోడల్ను ఇష్టానుసారంగా తరలించండి.
+ - శిక్షణ, మూల్యాంకనం మరియు ఉత్పత్తి కోసం సరైన ఫ్రేమ్వర్క్ను సజావుగా ఎంచుకోండి.
+
+4. మీ అవసరాలకు అనుగుణంగా మోడల్ లేదా ఉదాహరణను సులభంగా అనుకూలీకరించండి:
+ - ప్రతి ఆర్కిటెక్చర్ దాని అసలు రచయితలు ప్రచురించిన ఫలితాలను పునరుత్పత్తి చేయడానికి మేము ఉదాహరణలను అందిస్తాము.
+ - మోడల్ ఇంటర్నల్లు వీలైనంత స్థిరంగా బహిర్గతమవుతాయి.
+ - శీఘ్ర ప్రయోగాల కోసం లైబ్రరీ నుండి స్వతంత్రంగా మోడల్ ఫైల్లను ఉపయోగించవచ్చు.
+
+## నేను ట్రాన్స్ఫార్మర్లను ఎందుకు ఉపయోగించకూడదు?
+
+- ఈ లైబ్రరీ న్యూరల్ నెట్ల కోసం బిల్డింగ్ బ్లాక్ల మాడ్యులర్ టూల్బాక్స్ కాదు. మోడల్ ఫైల్లలోని కోడ్ ఉద్దేశపూర్వకంగా అదనపు సంగ్రహణలతో రీఫ్యాక్టరింగ్ చేయబడదు, తద్వారా పరిశోధకులు అదనపు సంగ్రహణలు/ఫైళ్లలోకి ప్రవేశించకుండా ప్రతి మోడల్పై త్వరగా మళ్లించగలరు.
+- శిక్షణ API ఏ మోడల్లో పని చేయడానికి ఉద్దేశించబడలేదు కానీ లైబ్రరీ అందించిన మోడల్లతో పని చేయడానికి ఆప్టిమైజ్ చేయబడింది. సాధారణ మెషిన్ లెర్నింగ్ లూప్ల కోసం, మీరు మరొక లైబ్రరీని ఉపయోగించాలి (బహుశా, [Accelerate](https://huggingface.co/docs/accelerate)).
+- మేము వీలైనన్ని ఎక్కువ వినియోగ సందర్భాలను ప్రదర్శించడానికి ప్రయత్నిస్తున్నప్పుడు, మా [ఉదాహరణల ఫోల్డర్](https://github.com/huggingface/transformers/tree/main/examples)లోని స్క్రిప్ట్లు కేవలం: ఉదాహరణలు. మీ నిర్దిష్ట సమస్యపై అవి పని చేయవు మరియు వాటిని మీ అవసరాలకు అనుగుణంగా మార్చుకోవడానికి మీరు కొన్ని కోడ్ లైన్లను మార్చవలసి ఉంటుంది.
+
+## సంస్థాపన
+
+### పిప్ తో
+
+ఈ రిపోజిటరీ పైథాన్ 3.9+, ఫ్లాక్స్ 0.4.1+, PyTorch 2.1+ మరియు TensorFlow 2.6+లో పరీక్షించబడింది.
+
+మీరు [వర్చువల్ వాతావరణం](https://docs.python.org/3/library/venv.html)లో 🤗 ట్రాన్స్ఫార్మర్లను ఇన్స్టాల్ చేయాలి. మీకు పైథాన్ వర్చువల్ పరిసరాల గురించి తెలియకుంటే, [యూజర్ గైడ్](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/) చూడండి.
+
+ముందుగా, మీరు ఉపయోగించబోతున్న పైథాన్ వెర్షన్తో వర్చువల్ వాతావరణాన్ని సృష్టించండి మరియు దానిని సక్రియం చేయండి.
+
+అప్పుడు, మీరు ఫ్లాక్స్, పైటార్చ్ లేదా టెన్సర్ఫ్లోలో కనీసం ఒకదానిని ఇన్స్టాల్ చేయాలి.
+దయచేసి [TensorFlow ఇన్స్టాలేషన్ పేజీ](https://www.tensorflow.org/install/), [PyTorch ఇన్స్టాలేషన్ పేజీ](https://pytorch.org/get-started/locally/#start-locally) మరియు/ని చూడండి లేదా మీ ప్లాట్ఫారమ్ కోసం నిర్దిష్ట ఇన్స్టాలేషన్ కమాండ్కు సంబంధించి [Flax](https://github.com/google/flax#quick-install) మరియు [Jax](https://github.com/google/jax#installation) ఇన్స్టాలేషన్ పేజీలు .
+
+ఆ బ్యాకెండ్లలో ఒకటి ఇన్స్టాల్ చేయబడినప్పుడు, 🤗 ట్రాన్స్ఫార్మర్లను ఈ క్రింది విధంగా పిప్ని ఉపయోగించి ఇన్స్టాల్ చేయవచ్చు:
+
+```bash
+pip install transformers
+```
+
+మీరు ఉదాహరణలతో ప్లే చేయాలనుకుంటే లేదా కోడ్ యొక్క బ్లీడింగ్ ఎడ్జ్ అవసరం మరియు కొత్త విడుదల కోసం వేచి ఉండలేకపోతే, మీరు తప్పనిసరిగా [మూలం నుండి లైబ్రరీని ఇన్స్టాల్ చేయాలి](https://huggingface.co/docs/transformers/installation#installing-from-source).
+
+### కొండా తో
+
+🤗 కింది విధంగా కొండా ఉపయోగించి ట్రాన్స్ఫార్మర్లను ఇన్స్టాల్ చేయవచ్చు:
+
+```shell script
+conda install conda-forge::transformers
+```
+
+> **_గమనిక:_** `huggingface` ఛానెల్ నుండి `transformers` ఇన్స్టాల్ చేయడం పురాతనంగా ఉంది.
+
+Flax, PyTorch లేదా TensorFlow యొక్క ఇన్స్టాలేషన్ పేజీలను కొండాతో ఎలా ఇన్స్టాల్ చేయాలో చూడటానికి వాటిని అనుసరించండి.
+
+> **_గమనిక:_** Windowsలో, కాషింగ్ నుండి ప్రయోజనం పొందేందుకు మీరు డెవలపర్ మోడ్ని సక్రియం చేయమని ప్రాంప్ట్ చేయబడవచ్చు. ఇది మీకు ఎంపిక కాకపోతే, దయచేసి [ఈ సంచిక](https://github.com/huggingface/huggingface_hub/issues/1062)లో మాకు తెలియజేయండి.
+
+## మోడల్ ఆర్కిటెక్చర్లు
+
+**[అన్ని మోడల్ చెక్పాయింట్లు](https://huggingface.co/models)** 🤗 అందించిన ట్రాన్స్ఫార్మర్లు huggingface.co [model hub](https://huggingface.co/models) నుండి సజావుగా ఏకీకృతం చేయబడ్డాయి [users](https://huggingface.co/users) మరియు [organizations](https://huggingface.co/organizations) ద్వారా నేరుగా అప్లోడ్ చేయబడతాయి.
+
+ప్రస్తుత తనిఖీ కేంద్రాల సంఖ్య: 
+
+🤗 ట్రాన్స్ఫార్మర్లు ప్రస్తుతం కింది ఆర్కిటెక్చర్లను అందజేస్తున్నాయి: వాటిలో ప్రతి ఒక్కటి ఉన్నత స్థాయి సారాంశం కోసం [ఇక్కడ](https://huggingface.co/docs/transformers/model_summary) చూడండి.
+
+ఈ అమలులు అనేక డేటాసెట్లలో పరీక్షించబడ్డాయి (ఉదాహరణ స్క్రిప్ట్లను చూడండి) మరియు అసలైన అమలుల పనితీరుతో సరిపోలాలి. మీరు [డాక్యుమెంటేషన్](https://github.com/huggingface/transformers/tree/main/examples) యొక్క ఉదాహరణల విభాగంలో పనితీరుపై మరిన్ని వివరాలను కనుగొనవచ్చు.
+
+## ఇంకా నేర్చుకో
+
+| విభాగం | వివరణ |
+|-|-|
+| [డాక్యుమెంటేషన్](https://huggingface.co/docs/transformers/) | పూర్తి API డాక్యుమెంటేషన్ మరియు ట్యుటోరియల్స్ |
+| [టాస్క్ సారాంశం](https://huggingface.co/docs/transformers/task_summary) | 🤗 ట్రాన్స్ఫార్మర్ల ద్వారా సపోర్ట్ చేయబడిన విధులు |
+| [ప్రీప్రాసెసింగ్ ట్యుటోరియల్](https://huggingface.co/docs/transformers/preprocessing) | మోడల్ల కోసం డేటాను సిద్ధం చేయడానికి `Tokenizer` క్లాస్ని ఉపయోగించడం |
+| [ట్రైనింగ్ మరియు ఫైన్-ట్యూనింగ్](https://huggingface.co/docs/transformers/training) | PyTorch/TensorFlow ట్రైనింగ్ లూప్ మరియు `Trainer` APIలో 🤗 ట్రాన్స్ఫార్మర్లు అందించిన మోడల్లను ఉపయోగించడం |
+| [త్వరిత పర్యటన: ఫైన్-ట్యూనింగ్/యూసేజ్ స్క్రిప్ట్లు](https://github.com/huggingface/transformers/tree/main/examples) | విస్తృత శ్రేణి టాస్క్లపై ఫైన్-ట్యూనింగ్ మోడల్స్ కోసం ఉదాహరణ స్క్రిప్ట్లు |
+| [మోడల్ భాగస్వామ్యం మరియు అప్లోడ్ చేయడం](https://huggingface.co/docs/transformers/model_sharing) | కమ్యూనిటీతో మీ ఫైన్-ట్యూన్డ్ మోడల్లను అప్లోడ్ చేయండి మరియు భాగస్వామ్యం చేయండి |
+
+## అనులేఖనం
+
+🤗 ట్రాన్స్ఫార్మర్స్ లైబ్రరీ కోసం మీరు ఉదహరించగల [పేపర్](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) ఇప్పుడు మా వద్ద ఉంది:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/docs/transformers/i18n/README_ur.md b/docs/transformers/i18n/README_ur.md
new file mode 100644
index 0000000000000000000000000000000000000000..bba5988e77174dbde7787acdd474ccca293816a4
--- /dev/null
+++ b/docs/transformers/i18n/README_ur.md
@@ -0,0 +1,333 @@
+
+
+
جدید ترین مشین لرننگ برائے JAX، PyTorch اور TensorFlow
+
+
+
+
+
+
+🤗 Transformers مختلف طریقوں جیسے کہ متن، بصارت، اور آڈیو پر کام کرنے کے لیے ہزاروں پری ٹرینڈ ماڈلز فراہم کرتے ہیں۔
+
+یہ ماڈلز درج ذیل پر لاگو کیے جا سکتے ہیں:
+
+* 📝 متن، جیسے کہ متن کی درجہ بندی، معلومات کا استخراج، سوالات کے جوابات، خلاصہ، ترجمہ، اور متن کی تخلیق، 100 سے زائد زبانوں میں۔
+* 🖼️ تصاویر، جیسے کہ تصویر کی درجہ بندی، اشیاء کی شناخت، اور تقسیم۔
+* 🗣️ آڈیو، جیسے کہ تقریر کی شناخت اور آڈیو کی درجہ بندی۔
+
+ٹرانسفارمر ماڈلز **مختلف طریقوں کو ملا کر** بھی کام انجام دے سکتے ہیں، جیسے کہ ٹیبل سوال جواب، بصری حروف کی شناخت، اسکین شدہ دستاویزات سے معلومات نکالنا، ویڈیو کی درجہ بندی، اور بصری سوال جواب۔
+
+🤗 Transformers ایسے APIs فراہم کرتا ہے جو آپ کو تیز رفتاری سے پری ٹرینڈ ماڈلز کو ایک دیے گئے متن پر ڈاؤن لوڈ اور استعمال کرنے، انہیں اپنے ڈیٹا سیٹس پر فائن ٹون کرنے، اور پھر ہمارے [ماڈل حب](https://huggingface.co/models) پر کمیونٹی کے ساتھ شیئر کرنے کی سہولت دیتا ہے۔ اسی وقت، ہر پائتھن ماڈیول جو ایک آرکیٹیکچر کو بیان کرتا ہے، مکمل طور پر خود مختار ہوتا ہے اور اسے تیز تحقیقاتی تجربات کے لیے تبدیل کیا جا سکتا ہے۔
+
+
+🤗 Transformers تین سب سے مشہور ڈیپ لرننگ لائبریریوں — [Jax](https://jax.readthedocs.io/en/latest/)، [PyTorch](https://pytorch.org/) اور [TensorFlow](https://www.tensorflow.org/) — کی مدد سے تیار کردہ ہے، جن کے درمیان بے حد ہموار انضمام ہے۔ اپنے ماڈلز کو ایک کے ساتھ تربیت دینا اور پھر دوسرے کے ساتھ inference کے لیے لوڈ کرنا انتہائی سادہ ہے۔
+
+## آن لائن ڈیمو
+
+آپ ہمارے زیادہ تر ماڈلز کو براہ راست ان کے صفحات پر [ماڈل ہب](https://huggingface.co/models) سے آزما سکتے ہیں۔ ہم عوامی اور نجی ماڈلز کے لیے [ذاتی ماڈل ہوسٹنگ، ورژننگ، اور انفرنس API](https://huggingface.co/pricing) بھی فراہم کرتے ہیں۔
+
+یہاں چند مثالیں ہیں:
+
+قدرتی زبان کی پروسیسنگ میں:
+
+- [BERT کے ساتھ ماسک شدہ الفاظ کی تکمیل](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [Electra کے ساتھ نامزد اداروں کی شناخت](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [Mistral کے ساتھ متنی جنریشن](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
+- [RoBERTa کے ساتھ قدرتی زبان کی دلیل](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [BART کے ساتھ خلاصہ کاری](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [DistilBERT کے ساتھ سوالات کے جوابات](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [T5 کے ساتھ ترجمہ](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+کمپیوٹر وژن میں:
+- [ViT کے ساتھ امیج کی درجہ بندی](https://huggingface.co/google/vit-base-patch16-224)
+- [DETR کے ساتھ اشیاء کی شناخت](https://huggingface.co/facebook/detr-resnet-50)
+- [SegFormer کے ساتھ سیمانٹک سیگمینٹیشن](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
+- [Mask2Former کے ساتھ پینوسٹک سیگمینٹیشن](https://huggingface.co/facebook/mask2former-swin-large-coco-panoptic)
+- [Depth Anything کے ساتھ گہرائی کا اندازہ](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)
+- [VideoMAE کے ساتھ ویڈیو کی درجہ بندی](https://huggingface.co/docs/transformers/model_doc/videomae)
+- [OneFormer کے ساتھ یونیورسل سیگمینٹیشن](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
+
+
+آڈیو:
+- [خودکار تقریر کی پہچان Whisper کے ساتھ](https://huggingface.co/openai/whisper-large-v3)
+- [کلیدی الفاظ کی تلاش Wav2Vec2 کے ساتھ](https://huggingface.co/superb/wav2vec2-base-superb-ks)
+- [آڈیو کی درجہ بندی Audio Spectrogram Transformer کے ساتھ](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
+
+ملٹی ماڈل ٹاسک میں:
+
+- [ٹیبل سوال جواب کے لیے TAPAS](https://huggingface.co/google/tapas-base-finetuned-wtq)
+- [ویژول سوال جواب کے لیے ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
+- [امیج کیپشننگ کے لیے LLaVa](https://huggingface.co/llava-hf/llava-1.5-7b-hf)
+- [زیرو شاٹ امیج کلاسیفیکیشن کے لیے SigLIP](https://huggingface.co/google/siglip-so400m-patch14-384)
+- [دستاویزی سوال جواب کے لیے LayoutLM](https://huggingface.co/impira/layoutlm-document-qa)
+- [زیرو شاٹ ویڈیو کلاسیفیکیشن کے لیے X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)
+- [زیرو شاٹ آبجیکٹ ڈیٹیکشن کے لیے OWLv2](https://huggingface.co/docs/transformers/en/model_doc/owlv2)
+- [زیرو شاٹ امیج سیگمنٹیشن کے لیے CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)
+- [خودکار ماسک جنریشن کے لیے SAM](https://huggingface.co/docs/transformers/model_doc/sam)
+
+
+## ٹرانسفارمرز کے 100 منصوبے
+
+🤗 Transformers صرف پیشگی تربیت یافتہ ماڈلز کا ایک ٹول کٹ نہیں ہے: یہ ایک کمیونٹی ہے جو اس کے ارد گرد اور ہیگنگ فیس حب پر تعمیر شدہ منصوبوں کا مجموعہ ہے۔ ہم چاہتے ہیں کہ🤗 Transformers ترقی کاروں، محققین، طلباء، پروفیسرز، انجینئرز، اور ہر کسی کو اپنے خوابوں کے منصوبے بنانے میں مدد فراہم کرے۔
+
+
+🤗 Transformers کے 100,000 ستاروں کی خوشی منانے کے لیے، ہم نے کمیونٹی پر روشنی ڈالنے کا فیصلہ کیا ہے، اور ہم نے [awesome-transformers](./awesome-transformers.md) کا صفحہ بنایا ہے جو 100 شاندار منصوبے درج کرتا ہے جو 🤗 Transformers کے ارد گرد بنائے گئے ہیں۔
+
+اگر آپ کے پاس کوئی ایسا منصوبہ ہے جسے آپ سمجھتے ہیں کہ اس فہرست کا حصہ ہونا چاہیے، تو براہ کرم ایک PR کھولیں تاکہ اسے شامل کیا جا سکے!
+
+## اگر آپ ہیگنگ فیس ٹیم سے حسب ضرورت معاونت تلاش کر رہے ہیں
+
+
+
+
+
+## فوری ٹور
+
+دیے گئے ان پٹ (متن، تصویر، آڈیو، ...) پر ماڈل کو فوری طور پر استعمال کرنے کے لیے، ہم pipeline API فراہم کرتے ہیں۔ پائپ لائنز ایک پیشگی تربیت یافتہ ماڈل کو اس ماڈل کی تربیت کے دوران استعمال ہونے والے پری پروسیسنگ کے ساتھ گروپ کرتی ہیں۔ یہاں یہ ہے کہ مثبت اور منفی متون کی درجہ بندی کے لیے پائپ لائن کو جلدی سے کیسے استعمال کیا جائے:
+
+
+```python
+>>> from transformers import pipeline
+
+# جذبات کے تجزیے کے لیے ایک پائپ لائن مختص کریں
+>>> classifier = pipeline('sentiment-analysis')
+>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+دوسری لائن کوڈ پائپ لائن کے ذریعہ استعمال ہونے والے پیشگی تربیت یافتہ ماڈل کو ڈاؤن لوڈ اور کیش کرتی ہے، جبکہ تیسری لائن اسے دیے گئے متن پر جانچتی ہے۔ یہاں، جواب "مثبت" ہے جس کی اعتماد کی شرح 99.97% ہے۔
+
+بہت سے کاموں کے لیے ایک پیشگی تربیت یافتہ pipeline تیار ہے، NLP کے علاوہ کمپیوٹر ویژن اور آواز میں بھی۔ مثال کے طور پر، ہم تصویر میں دریافت شدہ اشیاء کو آسانی سے نکال سکتے ہیں:
+
+
+``` python
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import pipeline
+
+# جذبات کے تجزیے کے لیے ایک پائپ لائن مختص کریں
+>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
+>>> image_data = requests.get(url, stream=True).raw
+>>> image = Image.open(image_data)
+
+>>> object_detector = pipeline('object-detection')
+>>> object_detector(image)
+[{'score': 0.9982201457023621،
+ 'label': 'remote'،
+ 'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}}،
+ {'score': 0.9960021376609802،
+ 'label': 'remote'،
+ 'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}}،
+ {'score': 0.9954745173454285،
+ 'label': 'couch'،
+ 'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}}،
+ {'score': 0.9988006353378296،
+ 'label': 'cat'،
+ 'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}}،
+ {'score': 0.9986783862113953،
+ 'label': 'cat'،
+ 'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
+```
+
+یہاں، ہم کو تصویر میں دریافت شدہ اشیاء کی فہرست ملتی ہے، ہر ایک کے گرد ایک باکس اور اعتماد کا اسکور۔ یہاں اصل تصویر بائیں طرف ہے، اور پیشگوئیاں دائیں طرف ظاہر کی گئی ہیں:
+
+
+
+
+
+
+
+آپ `pipeline` API کی مدد سے معاونت شدہ کاموں کے بارے میں مزید جان سکتے ہیں [اس ٹیوٹوریل](https://huggingface.co/docs/transformers/task_summary) میں۔
+
+
+`pipeline` کے علاوہ، کسی بھی پیشگی تربیت یافتہ ماڈل کو آپ کے دیے گئے کام پر ڈاؤن لوڈ اور استعمال کرنے کے لیے، صرف تین لائنوں کا کوڈ کافی ہے۔ یہاں PyTorch ورژن ہے:
+
+```python
+>>> from transformers import AutoTokenizer، AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!"، return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+
+اور یہاں TensorFlow کے لیے مساوی کوڈ ہے:
+```python
+>>> from transformers import AutoTokenizer، TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!"، return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+ٹوکینائزر تمام پری پروسیسنگ کا ذمہ دار ہے جس کی پیشگی تربیت یافتہ ماڈل کو ضرورت ہوتی ہے اور اسے براہ راست ایک واحد سٹرنگ (جیسا کہ اوپر کی مثالوں میں) یا ایک فہرست پر کال کیا جا سکتا ہے۔ یہ ایک لغت فراہم کرے گا جسے آپ ڈاؤن اسٹریم کوڈ میں استعمال کر سکتے ہیں یا سادہ طور پر اپنے ماڈل کو ** دلیل انپیکنگ آپریٹر کے ذریعے براہ راست پاس کر سکتے ہیں۔
+
+ماڈل خود ایک باقاعدہ [PyTorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) یا [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (آپ کے بیک اینڈ پر منحصر ہے) ہے جسے آپ معمول کے مطابق استعمال کر سکتے ہیں۔ [یہ ٹیوٹوریل](https://huggingface.co/docs/transformers/training) وضاحت کرتا ہے کہ کلاسیکی PyTorch یا TensorFlow تربیتی لوپ میں ایسے ماڈل کو کیسے ضم کیا جائے، یا ہمارے `Trainer` API کا استعمال کرتے ہوئے نئے ڈیٹا سیٹ پر جلدی سے فائن ٹیون کیسے کیا جائے۔
+
+## مجھے Transformers کیوں استعمال کرنا چاہیے؟
+
+ 1. استعمال میں آسان جدید ترین ماڈلز:
+
+ - قدرتی زبان کی سمجھ اور تخلیق، کمپیوٹر وژن، اور آڈیو کے کاموں میں اعلی کارکردگی۔
+ - معلمین اور عملی ماہرین کے لیے کم داخلی رکاوٹ۔
+ - سیکھنے کے لیے صرف تین کلاسز کے ساتھ چند یوزر فرینڈلی ایبسٹریکشنز۔
+ - ہمارے تمام pretrained ماڈلز کے استعمال کے لیے ایک متحد API۔
+
+ 2. کمپیوٹیشن کے اخراجات میں کمی، کاربن فٹ پرنٹ میں کمی:
+
+- محققین ہمیشہ دوبارہ تربیت کرنے کی بجائے تربیت شدہ ماڈلز شیئر کر سکتے ہیں۔
+- عملی ماہرین کمپیوٹ وقت اور پروڈکشن اخراجات کو کم کر سکتے ہیں۔
+- ہر موڈیلٹی کے لیے 400,000 سے زیادہ pretrained ماڈلز کے ساتھ درجنوں آرکیٹیکچرز۔
+
+ 3. ماڈل کے لائف ٹائم کے ہر حصے کے لیے صحیح
+فریم ورک کا انتخاب کریں:
+
+ - 3 لائنز کے کوڈ میں جدید ترین ماڈلز تربیت دیں۔
+ - ایک ماڈل کو کسی بھی وقت TF2.0/PyTorch/JAX فریم ورکس کے درمیان منتقل کریں۔
+ - تربیت، تشخیص، اور پروڈکشن کے لیے بغیر کسی رکاوٹ کے صحیح فریم ورک کا انتخاب کریں۔
+
+ 4. اپنے ضروریات کے مطابق آسانی سے ماڈل یا ایک مثال کو حسب ضرورت بنائیں:
+
+ - ہم ہر آرکیٹیکچر کے لیے مثالیں فراہم کرتے ہیں تاکہ اصل مصنفین کے شائع شدہ نتائج کو دوبارہ پیدا کیا جا سکے۔
+ - ماڈلز کی اندرونی تفصیلات کو جتنا ممکن ہو یکساں طور پر ظاہر کیا جاتا ہے۔
+ - فوری تجربات کے لیے ماڈل فائلز کو لائبریری سے آزادانہ طور پر استعمال کیا جا سکتا ہے۔
+
+## مجھے Transformers کیوں استعمال نہیں کرنا چاہیے؟
+
+- یہ لائبریری نیورل نیٹس کے لیے بلڈنگ بلاکس کا ماڈیولر ٹول باکس نہیں ہے۔ ماڈل فائلز میں موجود کوڈ جان بوجھ کر اضافی ایبسٹریکشنز کے ساتھ دوبارہ ترتیب نہیں دیا گیا ہے، تاکہ محققین بغیر اضافی ایبسٹریکشنز/فائلوں میں گئے ہوئے جلدی سے ہر ماڈل پر کام کر سکیں۔
+- تربیتی API کا مقصد کسی بھی ماڈل پر کام کرنے کے لیے نہیں ہے بلکہ یہ لائبریری کے فراہم کردہ ماڈلز کے ساتھ کام کرنے کے لیے بہتر بنایا گیا ہے۔ عام مشین لرننگ لوپس کے لیے، آپ کو دوسری لائبریری (ممکنہ طور پر [Accelerate](https://huggingface.co/docs/accelerate)) استعمال کرنی چاہیے۔
+- حالانکہ ہم جتنا ممکن ہو زیادہ سے زیادہ استعمال کے کیسز پیش کرنے کی کوشش کرتے ہیں، ہمارے [مثالوں کے فولڈر](https://github.com/huggingface/transformers/tree/main/examples) میں موجود اسکرپٹس صرف یہی ہیں: مثالیں۔ یہ توقع کی جاتی ہے کہ یہ آپ کے مخصوص مسئلے پر فوراً کام نہیں کریں گی اور آپ کو اپنی ضروریات کے مطابق کوڈ کی کچھ لائنیں تبدیل کرنی پڑیں گی۔
+
+### انسٹالیشن
+
+#### pip کے ساتھ
+
+یہ ریپوزٹری Python 3.9+، Flax 0.4.1+، PyTorch 2.1+، اور TensorFlow 2.6+ پر ٹیسٹ کی گئی ہے۔
+
+آپ کو 🤗 Transformers کو ایک [ورچوئل ماحول](https://docs.python.org/3/library/venv.html) میں انسٹال کرنا چاہیے۔ اگر آپ Python ورچوئل ماحول سے واقف نہیں ہیں، تو [یوزر گائیڈ](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/) دیکھیں۔
+
+پہلے، Python کے اس ورژن کے ساتھ ایک ورچوئل ماحول بنائیں جو آپ استعمال کر رہے ہیں اور اسے ایکٹیویٹ کریں۔
+
+پھر، آپ کو کم از کم Flax، PyTorch، یا TensorFlow میں سے کسی ایک کو انسٹال کرنے کی ضرورت ہوگی۔
+براہ کرم اپنے پلیٹ فارم کے لیے مخصوص انسٹالیشن کمانڈ کے حوالے سے [TensorFlow انسٹالیشن صفحہ](https://www.tensorflow.org/install/)، [PyTorch انسٹالیشن صفحہ](https://pytorch.org/get-started/locally/#start-locally) اور/یا [Flax](https://github.com/google/flax#quick-install) اور [Jax](https://github.com/google/jax#installation) انسٹالیشن صفحات دیکھیں۔
+
+جب ان میں سے کوئی ایک بیک اینڈ انسٹال ہو جائے، تو 🤗 Transformers کو pip کے ذریعے مندرجہ ذیل طریقے سے انسٹال کیا جا سکتا ہے:
+
+```bash
+pip install transformers
+```
+
+اگر آپ مثالوں کے ساتھ کھیلنا چاہتے ہیں یا آپ کو کوڈ کا تازہ ترین ورژن چاہیے اور آپ نئے ریلیز کا انتظار نہیں کر سکتے، تو آپ کو [سورس سے لائبریری انسٹال کرنی ہوگی](https://huggingface.co/docs/transformers/installation#installing-from-source)۔
+
+#### conda کے ساتھ
+
+🤗 Transformers کو conda کے ذریعے مندرجہ ذیل طریقے سے انسٹال کیا جا سکتا ہے:
+
+```shell script
+conda install conda-forge::transformers
+```
+
+> **_نوٹ:_** `transformers` کو `huggingface` چینل سے انسٹال کرنا اب ختم کیا جا چکا ہے۔
+
+Flax، PyTorch، یا TensorFlow کو conda کے ساتھ انسٹال کرنے کے لیے انسٹالیشن صفحات کی پیروی کریں۔
+
+> **_نوٹ:_** ونڈوز پر، آپ کو کیشنگ سے فائدہ اٹھانے کے لیے ڈویلپر موڈ کو ایکٹیویٹ کرنے کا پیغام دیا جا سکتا ہے۔ اگر یہ آپ کے لیے ممکن نہیں ہے، تو براہ کرم ہمیں [اس مسئلے](https://github.com/huggingface/huggingface_hub/issues/1062) میں بتائیں۔
+
+### ماڈل کی تعمیرات
+
+ 🤗 Transformers کی طرف سے فراہم کردہ **[تمام ماڈل چیک پوائنٹس](https://huggingface.co/models)** ہگنگ فیس کے ماڈل حب [model hub](https://huggingface.co/models) سے بآسانی مربوط ہیں، جہاں یہ براہ راست [صارفین](https://huggingface.co/users) اور [تنظیموں](https://huggingface.co/organizations) کے ذریعہ اپ لوڈ کیے جاتے ہیں۔
+
+چیک پوائنٹس کی موجودہ تعداد: 
+
+🤗 Transformers فی الحال درج ذیل معماریاں فراہم کرتا ہے: ہر ایک کا اعلی سطحی خلاصہ دیکھنے کے لیے [یہاں](https://huggingface.co/docs/transformers/model_summary) دیکھیں۔
+
+یہ چیک کرنے کے لیے کہ ہر ماڈل کی Flax، PyTorch یا TensorFlow میں کوئی عملداری ہے یا 🤗 Tokenizers لائبریری کے ذریعہ سپورٹ کردہ ٹوکنائزر کے ساتھ ہے، [اس جدول](https://huggingface.co/docs/transformers/index#supported-frameworks) کا حوالہ لیں۔
+
+یہ عملداری مختلف ڈیٹا سیٹس پر ٹیسٹ کی گئی ہیں (مثال کے اسکرپٹس دیکھیں) اور اصل عملداری کی کارکردگی کے ہم آہنگ ہونی چاہئیں۔ آپ کو کارکردگی کی مزید تفصیلات [دستاویزات](https://github.com/huggingface/transformers/tree/main/examples) کے مثالوں کے سیکشن میں مل سکتی ہیں۔
+
+
+## مزید معلومات حاصل کریں
+
+| سیکشن | تفصیل |
+|-|-|
+| [دستاویزات](https://huggingface.co/docs/transformers/) | مکمل API دستاویزات اور ٹیوٹوریلز |
+| [ٹاسک کا خلاصہ](https://huggingface.co/docs/transformers/task_summary) | 🤗 Transformers کے ذریعہ سپورٹ کردہ ٹاسک |
+| [پری پروسیسنگ ٹیوٹوریل](https://huggingface.co/docs/transformers/preprocessing) | ماڈلز کے لیے ڈیٹا تیار کرنے کے لیے `Tokenizer` کلاس کا استعمال |
+| [ٹریننگ اور فائن ٹیوننگ](https://huggingface.co/docs/transformers/training) | PyTorch/TensorFlow ٹریننگ لوپ میں 🤗 Transformers کی طرف سے فراہم کردہ ماڈلز کا استعمال اور `Trainer` API |
+| [تیز دورہ: فائن ٹیوننگ/استعمال کے اسکرپٹس](https://github.com/huggingface/transformers/tree/main/examples) | مختلف قسم کے ٹاسک پر ماڈلز کو فائن ٹیون کرنے کے لیے مثال کے اسکرپٹس |
+| [ماڈل کا اشتراک اور اپ لوڈ کرنا](https://huggingface.co/docs/transformers/model_sharing) | اپنی فائن ٹیون کردہ ماڈلز کو کمیونٹی کے ساتھ اپ لوڈ اور شیئر کریں |
+
+## استشہاد
+
+ہم نے اب ایک [تحقیقی مقالہ](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) تیار کیا ہے جسے آپ 🤗 Transformers لائبریری کے لیے حوالہ دے سکتے ہیں:
+
+```bibtex
+@inproceedings{wolf-etal-2020-transformers،
+ title = "Transformers: State-of-the-Art Natural Language Processing"،
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and R{\'e}mi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush"،
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations"،
+ month = oct،
+ year = "2020"،
+ address = "Online"،
+ publisher = "Association for Computational Linguistics"،
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6"،
+ pages = "38--45"
+}
+```
diff --git a/docs/transformers/i18n/README_vi.md b/docs/transformers/i18n/README_vi.md
new file mode 100644
index 0000000000000000000000000000000000000000..f78e3b6d4e9b1d2379fecd4c14b691bc805b2f6a
--- /dev/null
+++ b/docs/transformers/i18n/README_vi.md
@@ -0,0 +1,318 @@
+
+
+
Công nghệ Học máy tiên tiến cho JAX, PyTorch và TensorFlow
+
+
+
+
+
+
+🤗 Transformers cung cấp hàng ngàn mô hình được huấn luyện trước để thực hiện các nhiệm vụ trên các modalities khác nhau như văn bản, hình ảnh và âm thanh.
+
+Các mô hình này có thể được áp dụng vào:
+
+* 📝 Văn bản, cho các nhiệm vụ như phân loại văn bản, trích xuất thông tin, trả lời câu hỏi, tóm tắt, dịch thuật và sinh văn bản, trong hơn 100 ngôn ngữ.
+* 🖼️ Hình ảnh, cho các nhiệm vụ như phân loại hình ảnh, nhận diện đối tượng và phân đoạn.
+* 🗣️ Âm thanh, cho các nhiệm vụ như nhận dạng giọng nói và phân loại âm thanh.
+
+Các mô hình Transformer cũng có thể thực hiện các nhiệm vụ trên **nhiều modalities kết hợp**, như trả lời câu hỏi về bảng, nhận dạng ký tự quang học, trích xuất thông tin từ tài liệu quét, phân loại video và trả lời câu hỏi hình ảnh.
+
+🤗 Transformers cung cấp các API để tải xuống và sử dụng nhanh chóng các mô hình được huấn luyện trước đó trên văn bản cụ thể, điều chỉnh chúng trên tập dữ liệu của riêng bạn và sau đó chia sẻ chúng với cộng đồng trên [model hub](https://huggingface.co/models) của chúng tôi. Đồng thời, mỗi module python xác định một kiến trúc là hoàn toàn độc lập và có thể được sửa đổi để cho phép thực hiện nhanh các thí nghiệm nghiên cứu.
+
+🤗 Transformers được hỗ trợ bởi ba thư viện học sâu phổ biến nhất — [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) và [TensorFlow](https://www.tensorflow.org/) — với tích hợp mượt mà giữa chúng. Việc huấn luyện mô hình của bạn với một thư viện trước khi tải chúng để sử dụng trong suy luận với thư viện khác là rất dễ dàng.
+
+## Các demo trực tuyến
+
+Bạn có thể kiểm tra hầu hết các mô hình của chúng tôi trực tiếp trên trang của chúng từ [model hub](https://huggingface.co/models). Chúng tôi cũng cung cấp [dịch vụ lưu trữ mô hình riêng tư, phiên bản và API suy luận](https://huggingface.co/pricing) cho các mô hình công khai và riêng tư.
+
+Dưới đây là một số ví dụ:
+
+Trong Xử lý Ngôn ngữ Tự nhiên:
+- [Hoàn thành từ vụng về từ với BERT](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [Nhận dạng thực thể đặt tên với Electra](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [Tạo văn bản tự nhiên với Mistral](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)
+- [Suy luận Ngôn ngữ Tự nhiên với RoBERTa](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [Tóm tắt văn bản với BART](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [Trả lời câu hỏi với DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [Dịch văn bản với T5](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+Trong Thị giác Máy tính:
+- [Phân loại hình ảnh với ViT](https://huggingface.co/google/vit-base-patch16-224)
+- [Phát hiện đối tượng với DETR](https://huggingface.co/facebook/detr-resnet-50)
+- [Phân đoạn ngữ nghĩa với SegFormer](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
+- [Phân đoạn toàn diện với Mask2Former](https://huggingface.co/facebook/mask2former-swin-large-coco-panoptic)
+- [Ước lượng độ sâu với Depth Anything](https://huggingface.co/docs/transformers/main/model_doc/depth_anything)
+- [Phân loại video với VideoMAE](https://huggingface.co/docs/transformers/model_doc/videomae)
+- [Phân đoạn toàn cầu với OneFormer](https://huggingface.co/shi-labs/oneformer_ade20k_dinat_large)
+
+Trong âm thanh:
+- [Nhận dạng giọng nói tự động với Whisper](https://huggingface.co/openai/whisper-large-v3)
+- [Phát hiện từ khóa với Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
+- [Phân loại âm thanh với Audio Spectrogram Transformer](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
+
+Trong các nhiệm vụ đa phương thức:
+- [Trả lời câu hỏi về bảng với TAPAS](https://huggingface.co/google/tapas-base-finetuned-wtq)
+- [Trả lời câu hỏi hình ảnh với ViLT](https://huggingface.co/dandelin/vilt-b32-finetuned-vqa)
+- [Mô tả hình ảnh với LLaVa](https://huggingface.co/llava-hf/llava-1.5-7b-hf)
+- [Phân loại hình ảnh không cần nhãn với SigLIP](https://huggingface.co/google/siglip-so400m-patch14-384)
+- [Trả lời câu hỏi văn bản tài liệu với LayoutLM](https://huggingface.co/impira/layoutlm-document-qa)
+- [Phân loại video không cần nhãn với X-CLIP](https://huggingface.co/docs/transformers/model_doc/xclip)
+- [Phát hiện đối tượng không cần nhãn với OWLv2](https://huggingface.co/docs/transformers/en/model_doc/owlv2)
+- [Phân đoạn hình ảnh không cần nhãn với CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg)
+- [Tạo mặt nạ tự động với SAM](https://huggingface.co/docs/transformers/model_doc/sam)
+
+
+## 100 dự án sử dụng Transformers
+
+Transformers không chỉ là một bộ công cụ để sử dụng các mô hình được huấn luyện trước: đó là một cộng đồng các dự án xây dựng xung quanh nó và Hugging Face Hub. Chúng tôi muốn Transformers giúp các nhà phát triển, nhà nghiên cứu, sinh viên, giáo sư, kỹ sư và bất kỳ ai khác xây dựng những dự án mơ ước của họ.
+
+Để kỷ niệm 100.000 sao của transformers, chúng tôi đã quyết định tập trung vào cộng đồng và tạo ra trang [awesome-transformers](./awesome-transformers.md) liệt kê 100 dự án tuyệt vời được xây dựng xung quanh transformers.
+
+Nếu bạn sở hữu hoặc sử dụng một dự án mà bạn tin rằng nên được thêm vào danh sách, vui lòng mở một PR để thêm nó!
+
+## Nếu bạn đang tìm kiếm hỗ trợ tùy chỉnh từ đội ngũ Hugging Face
+
+
+
+
+
+## Hành trình nhanh
+
+Để ngay lập tức sử dụng một mô hình trên một đầu vào cụ thể (văn bản, hình ảnh, âm thanh, ...), chúng tôi cung cấp API `pipeline`. Pipelines nhóm một mô hình được huấn luyện trước với quá trình tiền xử lý đã được sử dụng trong quá trình huấn luyện của mô hình đó. Dưới đây là cách sử dụng nhanh một pipeline để phân loại văn bản tích cực so với tiêu cực:
+
+```python
+>>> from transformers import pipeline
+
+# Cấp phát một pipeline cho phân tích cảm xúc
+>>> classifier = pipeline('sentiment-analysis')
+>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+Dòng code thứ hai tải xuống và lưu trữ bộ mô hình được huấn luyện được sử dụng bởi pipeline, trong khi dòng thứ ba đánh giá nó trên văn bản đã cho. Ở đây, câu trả lời là "tích cực" với độ tin cậy là 99,97%.
+
+Nhiều nhiệm vụ có sẵn một `pipeline` được huấn luyện trước, trong NLP nhưng cũng trong thị giác máy tính và giọng nói. Ví dụ, chúng ta có thể dễ dàng trích xuất các đối tượng được phát hiện trong một hình ảnh:
+
+``` python
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import pipeline
+
+# Tải xuống một hình ảnh với những con mèo dễ thương
+>>> url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png"
+>>> image_data = requests.get(url, stream=True).raw
+>>> image = Image.open(image_data)
+
+# Cấp phát một pipeline cho phát hiện đối tượng
+>>> object_detector = pipeline('object-detection')
+>>> object_detector(image)
+[{'score': 0.9982201457023621,
+ 'label': 'remote',
+ 'box': {'xmin': 40, 'ymin': 70, 'xmax': 175, 'ymax': 117}},
+ {'score': 0.9960021376609802,
+ 'label': 'remote',
+ 'box': {'xmin': 333, 'ymin': 72, 'xmax': 368, 'ymax': 187}},
+ {'score': 0.9954745173454285,
+ 'label': 'couch',
+ 'box': {'xmin': 0, 'ymin': 1, 'xmax': 639, 'ymax': 473}},
+ {'score': 0.9988006353378296,
+ 'label': 'cat',
+ 'box': {'xmin': 13, 'ymin': 52, 'xmax': 314, 'ymax': 470}},
+ {'score': 0.9986783862113953,
+ 'label': 'cat',
+ 'box': {'xmin': 345, 'ymin': 23, 'xmax': 640, 'ymax': 368}}]
+```
+
+Ở đây, chúng ta nhận được một danh sách các đối tượng được phát hiện trong hình ảnh, với một hộp bao quanh đối tượng và một điểm đánh giá độ tin cậy. Đây là hình ảnh gốc ở bên trái, với các dự đoán hiển thị ở bên phải:
+
+
+
+
+
+
+Bạn có thể tìm hiểu thêm về các nhiệm vụ được hỗ trợ bởi API `pipeline` trong [hướng dẫn này](https://huggingface.co/docs/transformers/task_summary).
+
+Ngoài `pipeline`, để tải xuống và sử dụng bất kỳ mô hình được huấn luyện trước nào cho nhiệm vụ cụ thể của bạn, chỉ cần ba dòng code. Đây là phiên bản PyTorch:
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+
+Và đây là mã tương đương cho TensorFlow:
+```python
+>>> from transformers import AutoTokenizer, TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+Tokenizer là thành phần chịu trách nhiệm cho việc tiền xử lý mà mô hình được huấn luyện trước mong đợi và có thể được gọi trực tiếp trên một chuỗi đơn (như trong các ví dụ trên) hoặc một danh sách. Nó sẽ xuất ra một từ điển mà bạn có thể sử dụng trong mã phụ thuộc hoặc đơn giản là truyền trực tiếp cho mô hình của bạn bằng cách sử dụng toán tử ** để giải nén đối số.
+
+Chính mô hình là một [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) thông thường hoặc một [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) (tùy thuộc vào backend của bạn) mà bạn có thể sử dụng như bình thường. [Hướng dẫn này](https://huggingface.co/docs/transformers/training) giải thích cách tích hợp một mô hình như vậy vào một vòng lặp huấn luyện cổ điển PyTorch hoặc TensorFlow, hoặc cách sử dụng API `Trainer` của chúng tôi để tinh chỉnh nhanh chóng trên một bộ dữ liệu mới.
+
+## Tại sao tôi nên sử dụng transformers?
+
+1. Các mô hình tiên tiến dễ sử dụng:
+ - Hiệu suất cao trong việc hiểu và tạo ra ngôn ngữ tự nhiên, thị giác máy tính và âm thanh.
+ - Ngưỡng vào thấp cho giảng viên và người thực hành.
+ - Ít trừu tượng dành cho người dùng với chỉ ba lớp học.
+ - Một API thống nhất để sử dụng tất cả các mô hình được huấn luyện trước của chúng tôi.
+
+2. Giảm chi phí tính toán, làm giảm lượng khí thải carbon:
+ - Các nhà nghiên cứu có thể chia sẻ các mô hình đã được huấn luyện thay vì luôn luôn huấn luyện lại.
+ - Người thực hành có thể giảm thời gian tính toán và chi phí sản xuất.
+ - Hàng chục kiến trúc với hơn 400.000 mô hình được huấn luyện trước trên tất cả các phương pháp.
+
+3. Lựa chọn framework phù hợp cho mọi giai đoạn của mô hình:
+ - Huấn luyện các mô hình tiên tiến chỉ trong 3 dòng code.
+ - Di chuyển một mô hình duy nhất giữa các framework TF2.0/PyTorch/JAX theo ý muốn.
+ - Dễ dàng chọn framework phù hợp cho huấn luyện, đánh giá và sản xuất.
+
+4. Dễ dàng tùy chỉnh một mô hình hoặc một ví dụ theo nhu cầu của bạn:
+ - Chúng tôi cung cấp các ví dụ cho mỗi kiến trúc để tái tạo kết quả được công bố bởi các tác giả gốc.
+ - Các thành phần nội tại của mô hình được tiết lộ một cách nhất quán nhất có thể.
+ - Các tệp mô hình có thể được sử dụng độc lập với thư viện để thực hiện các thử nghiệm nhanh chóng.
+
+## Tại sao tôi không nên sử dụng transformers?
+
+- Thư viện này không phải là một bộ công cụ modul cho các khối xây dựng mạng neural. Mã trong các tệp mô hình không được tái cấu trúc với các trừu tượng bổ sung một cách cố ý, để các nhà nghiên cứu có thể lặp nhanh trên từng mô hình mà không cần đào sâu vào các trừu tượng/tệp bổ sung.
+- API huấn luyện không được thiết kế để hoạt động trên bất kỳ mô hình nào, mà được tối ưu hóa để hoạt động với các mô hình được cung cấp bởi thư viện. Đối với vòng lặp học máy chung, bạn nên sử dụng một thư viện khác (có thể là [Accelerate](https://huggingface.co/docs/accelerate)).
+- Mặc dù chúng tôi cố gắng trình bày càng nhiều trường hợp sử dụng càng tốt, nhưng các tập lệnh trong thư mục [examples](https://github.com/huggingface/transformers/tree/main/examples) chỉ là ví dụ. Dự kiến rằng chúng sẽ không hoạt động ngay tức khắc trên vấn đề cụ thể của bạn và bạn sẽ phải thay đổi một số dòng mã để thích nghi với nhu cầu của bạn.
+
+## Cài đặt
+
+### Sử dụng pip
+
+Thư viện này được kiểm tra trên Python 3.9+, Flax 0.4.1+, PyTorch 2.1+ và TensorFlow 2.6+.
+
+Bạn nên cài đặt 🤗 Transformers trong một [môi trường ảo Python](https://docs.python.org/3/library/venv.html). Nếu bạn chưa quen với môi trường ảo Python, hãy xem [hướng dẫn sử dụng](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+
+Trước tiên, tạo một môi trường ảo với phiên bản Python bạn sẽ sử dụng và kích hoạt nó.
+
+Sau đó, bạn sẽ cần cài đặt ít nhất một trong số các framework Flax, PyTorch hoặc TensorFlow.
+Vui lòng tham khảo [trang cài đặt TensorFlow](https://www.tensorflow.org/install/), [trang cài đặt PyTorch](https://pytorch.org/get-started/locally/#start-locally) và/hoặc [Flax](https://github.com/google/flax#quick-install) và [Jax](https://github.com/google/jax#installation) để biết lệnh cài đặt cụ thể cho nền tảng của bạn.
+
+Khi đã cài đặt một trong các backend đó, 🤗 Transformers có thể được cài đặt bằng pip như sau:
+
+```bash
+pip install transformers
+```
+
+Nếu bạn muốn thực hiện các ví dụ hoặc cần phiên bản mới nhất của mã và không thể chờ đợi cho một phiên bản mới, bạn phải [cài đặt thư viện từ nguồn](https://huggingface.co/docs/transformers/installation#installing-from-source).
+
+### Với conda
+
+🤗 Transformers có thể được cài đặt bằng conda như sau:
+
+```shell script
+conda install conda-forge::transformers
+```
+
+> **_GHI CHÚ:_** Cài đặt `transformers` từ kênh `huggingface` đã bị lỗi thời.
+
+Hãy làm theo trang cài đặt của Flax, PyTorch hoặc TensorFlow để xem cách cài đặt chúng bằng conda.
+
+> **_GHI CHÚ:_** Trên Windows, bạn có thể được yêu cầu kích hoạt Chế độ phát triển để tận dụng việc lưu cache. Nếu điều này không phải là một lựa chọn cho bạn, hãy cho chúng tôi biết trong [vấn đề này](https://github.com/huggingface/huggingface_hub/issues/1062).
+
+## Kiến trúc mô hình
+
+**[Tất cả các điểm kiểm tra mô hình](https://huggingface.co/models)** được cung cấp bởi 🤗 Transformers được tích hợp một cách mượt mà từ trung tâm mô hình huggingface.co [model hub](https://huggingface.co/models), nơi chúng được tải lên trực tiếp bởi [người dùng](https://huggingface.co/users) và [tổ chức](https://huggingface.co/organizations).
+
+Số lượng điểm kiểm tra hiện tại: 
+
+🤗 Transformers hiện đang cung cấp các kiến trúc sau đây: xem [ở đây](https://huggingface.co/docs/transformers/model_summary) để có một tóm tắt tổng quan về mỗi kiến trúc.
+
+Để kiểm tra xem mỗi mô hình có một phiên bản thực hiện trong Flax, PyTorch hoặc TensorFlow, hoặc có một tokenizer liên quan được hỗ trợ bởi thư viện 🤗 Tokenizers, vui lòng tham khảo [bảng này](https://huggingface.co/docs/transformers/index#supported-frameworks).
+
+Những phiên bản này đã được kiểm tra trên một số tập dữ liệu (xem các tập lệnh ví dụ) và nên tương đương với hiệu suất của các phiên bản gốc. Bạn có thể tìm thấy thêm thông tin về hiệu suất trong phần Ví dụ của [tài liệu](https://github.com/huggingface/transformers/tree/main/examples).
+
+
+## Tìm hiểu thêm
+
+| Phần | Mô tả |
+|-|-|
+| [Tài liệu](https://huggingface.co/docs/transformers/) | Toàn bộ tài liệu API và hướng dẫn |
+| [Tóm tắt nhiệm vụ](https://huggingface.co/docs/transformers/task_summary) | Các nhiệm vụ được hỗ trợ bởi 🤗 Transformers |
+| [Hướng dẫn tiền xử lý](https://huggingface.co/docs/transformers/preprocessing) | Sử dụng lớp `Tokenizer` để chuẩn bị dữ liệu cho các mô hình |
+| [Huấn luyện và điều chỉnh](https://huggingface.co/docs/transformers/training) | Sử dụng các mô hình được cung cấp bởi 🤗 Transformers trong vòng lặp huấn luyện PyTorch/TensorFlow và API `Trainer` |
+| [Hướng dẫn nhanh: Điều chỉnh/sử dụng các kịch bản](https://github.com/huggingface/transformers/tree/main/examples) | Các kịch bản ví dụ để điều chỉnh mô hình trên nhiều nhiệm vụ khác nhau |
+| [Chia sẻ và tải lên mô hình](https://huggingface.co/docs/transformers/model_sharing) | Tải lên và chia sẻ các mô hình đã điều chỉnh của bạn với cộng đồng |
+
+## Trích dẫn
+
+Bây giờ chúng ta có một [bài báo](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) mà bạn có thể trích dẫn cho thư viện 🤗 Transformers:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/docs/transformers/i18n/README_zh-hans.md b/docs/transformers/i18n/README_zh-hans.md
new file mode 100644
index 0000000000000000000000000000000000000000..22e7db3918c439e81d8696c910c7a2eef48b4764
--- /dev/null
+++ b/docs/transformers/i18n/README_zh-hans.md
@@ -0,0 +1,269 @@
+
+
+
+
+
+
+🤗 Transformers 提供了數以千計的預訓練模型,支援 100 多種語言的文本分類、資訊擷取、問答、摘要、翻譯、文本生成。它的宗旨是讓最先進的 NLP 技術人人易用。
+
+🤗 Transformers 提供了便於快速下載和使用的API,讓你可以將預訓練模型用在給定文本、在你的資料集上微調然後經由 [model hub](https://huggingface.co/models) 與社群共享。同時,每個定義的 Python 模組架構均完全獨立,方便修改和快速研究實驗。
+
+🤗 Transformers 支援三個最熱門的深度學習函式庫: [Jax](https://jax.readthedocs.io/en/latest/), [PyTorch](https://pytorch.org/) 以及 [TensorFlow](https://www.tensorflow.org/) — 並與之完美整合。你可以直接使用其中一個框架訓練你的模型,然後用另一個載入和推論。
+
+## 線上Demo
+
+你可以直接在 [model hub](https://huggingface.co/models) 上測試大多數的模型。我們也提供了 [私有模型託管、模型版本管理以及推論API](https://huggingface.co/pricing)。
+
+這裡是一些範例:
+- [用 BERT 做遮蓋填詞](https://huggingface.co/google-bert/bert-base-uncased?text=Paris+is+the+%5BMASK%5D+of+France)
+- [用 Electra 做專有名詞辨識](https://huggingface.co/dbmdz/electra-large-discriminator-finetuned-conll03-english?text=My+name+is+Sarah+and+I+live+in+London+city)
+- [用 GPT-2 做文本生成](https://huggingface.co/openai-community/gpt2?text=A+long+time+ago%2C+)
+- [用 RoBERTa 做自然語言推論](https://huggingface.co/FacebookAI/roberta-large-mnli?text=The+dog+was+lost.+Nobody+lost+any+animal)
+- [用 BART 做文本摘要](https://huggingface.co/facebook/bart-large-cnn?text=The+tower+is+324+metres+%281%2C063+ft%29+tall%2C+about+the+same+height+as+an+81-storey+building%2C+and+the+tallest+structure+in+Paris.+Its+base+is+square%2C+measuring+125+metres+%28410+ft%29+on+each+side.+During+its+construction%2C+the+Eiffel+Tower+surpassed+the+Washington+Monument+to+become+the+tallest+man-made+structure+in+the+world%2C+a+title+it+held+for+41+years+until+the+Chrysler+Building+in+New+York+City+was+finished+in+1930.+It+was+the+first+structure+to+reach+a+height+of+300+metres.+Due+to+the+addition+of+a+broadcasting+aerial+at+the+top+of+the+tower+in+1957%2C+it+is+now+taller+than+the+Chrysler+Building+by+5.2+metres+%2817+ft%29.+Excluding+transmitters%2C+the+Eiffel+Tower+is+the+second+tallest+free-standing+structure+in+France+after+the+Millau+Viaduct)
+- [用 DistilBERT 做問答](https://huggingface.co/distilbert/distilbert-base-uncased-distilled-squad?text=Which+name+is+also+used+to+describe+the+Amazon+rainforest+in+English%3F&context=The+Amazon+rainforest+%28Portuguese%3A+Floresta+Amaz%C3%B4nica+or+Amaz%C3%B4nia%3B+Spanish%3A+Selva+Amaz%C3%B3nica%2C+Amazon%C3%ADa+or+usually+Amazonia%3B+French%3A+For%C3%AAt+amazonienne%3B+Dutch%3A+Amazoneregenwoud%29%2C+also+known+in+English+as+Amazonia+or+the+Amazon+Jungle%2C+is+a+moist+broadleaf+forest+that+covers+most+of+the+Amazon+basin+of+South+America.+This+basin+encompasses+7%2C000%2C000+square+kilometres+%282%2C700%2C000+sq+mi%29%2C+of+which+5%2C500%2C000+square+kilometres+%282%2C100%2C000+sq+mi%29+are+covered+by+the+rainforest.+This+region+includes+territory+belonging+to+nine+nations.+The+majority+of+the+forest+is+contained+within+Brazil%2C+with+60%25+of+the+rainforest%2C+followed+by+Peru+with+13%25%2C+Colombia+with+10%25%2C+and+with+minor+amounts+in+Venezuela%2C+Ecuador%2C+Bolivia%2C+Guyana%2C+Suriname+and+French+Guiana.+States+or+departments+in+four+nations+contain+%22Amazonas%22+in+their+names.+The+Amazon+represents+over+half+of+the+planet%27s+remaining+rainforests%2C+and+comprises+the+largest+and+most+biodiverse+tract+of+tropical+rainforest+in+the+world%2C+with+an+estimated+390+billion+individual+trees+divided+into+16%2C000+species)
+- [用 T5 做翻譯](https://huggingface.co/google-t5/t5-base?text=My+name+is+Wolfgang+and+I+live+in+Berlin)
+
+**[Write With Transformer](https://transformer.huggingface.co)**,由 Hugging Face 團隊所打造,是一個文本生成的官方 demo。
+
+## 如果你在尋找由 Hugging Face 團隊所提供的客製化支援服務
+
+
+
+
+
+## 快速上手
+
+我們為快速使用模型提供了 `pipeline` API。 Pipeline 包含了預訓練模型和對應的文本預處理。下面是一個快速使用 pipeline 去判斷正負面情緒的例子:
+
+```python
+>>> from transformers import pipeline
+
+# 使用情緒分析 pipeline
+>>> classifier = pipeline('sentiment-analysis')
+>>> classifier('We are very happy to introduce pipeline to the transformers repository.')
+[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
+```
+
+第二行程式碼下載並快取 pipeline 使用的預訓練模型,而第三行程式碼則在給定的文本上進行了評估。這裡的答案“正面” (positive) 具有 99.97% 的信賴度。
+
+許多的 NLP 任務都有隨選即用的預訓練 `pipeline`。例如,我們可以輕鬆地從給定文本中擷取問題答案:
+
+``` python
+>>> from transformers import pipeline
+
+# 使用問答 pipeline
+>>> question_answerer = pipeline('question-answering')
+>>> question_answerer({
+... 'question': 'What is the name of the repository ?',
+... 'context': 'Pipeline has been included in the huggingface/transformers repository'
+... })
+{'score': 0.30970096588134766, 'start': 34, 'end': 58, 'answer': 'huggingface/transformers'}
+
+```
+
+除了提供問題解答,預訓練模型還提供了對應的信賴度分數以及解答在 tokenized 後的文本中開始和結束的位置。你可以從[這個教學](https://huggingface.co/docs/transformers/task_summary)了解更多 `pipeline` API支援的任務。
+
+要在你的任務中下載和使用任何預訓練模型很簡單,只需三行程式碼。這裡是 PyTorch 版的範例:
+```python
+>>> from transformers import AutoTokenizer, AutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = AutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="pt")
+>>> outputs = model(**inputs)
+```
+這裡是對應的 TensorFlow 程式碼:
+```python
+>>> from transformers import AutoTokenizer, TFAutoModel
+
+>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+>>> model = TFAutoModel.from_pretrained("google-bert/bert-base-uncased")
+
+>>> inputs = tokenizer("Hello world!", return_tensors="tf")
+>>> outputs = model(**inputs)
+```
+
+Tokenizer 為所有的預訓練模型提供了預處理,並可以直接轉換單一字串(比如上面的例子)或串列 (list)。它會輸出一個的字典 (dict) 讓你可以在下游程式碼裡使用或直接藉由 `**` 運算式傳給模型。
+
+模型本身是一個常規的 [Pytorch `nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) 或 [TensorFlow `tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model)(取決於你的後端),可依常規方式使用。 [這個教學](https://huggingface.co/transformers/training.html)解釋了如何將這樣的模型整合到一般的 PyTorch 或 TensorFlow 訓練迴圈中,或是如何使用我們的 `Trainer` API 在一個新的資料集上快速進行微調。
+
+## 為什麼要用 transformers?
+
+1. 便於使用的先進模型:
+ - NLU 和 NLG 上性能卓越
+ - 對教學和實作友好且低門檻
+ - 高度抽象,使用者只須學習 3 個類別
+ - 對所有模型使用的制式化API
+
+1. 更低的運算成本,更少的碳排放:
+ - 研究人員可以分享已訓練的模型而非每次從頭開始訓練
+ - 工程師可以減少計算時間以及生產成本
+ - 數十種模型架構、兩千多個預訓練模型、100多種語言支援
+
+1. 對於模型生命週期的每一個部分都面面俱到:
+ - 訓練先進的模型,只需 3 行程式碼
+ - 模型可以在不同深度學習框架之間任意轉換
+ - 為訓練、評估和生產選擇最適合的框架,並完美銜接
+
+1. 為你的需求輕鬆客製化專屬模型和範例:
+ - 我們為每種模型架構提供了多個範例來重現原論文結果
+ - 一致的模型內部架構
+ - 模型檔案可單獨使用,便於修改和快速實驗
+
+## 什麼情況下我不該用 transformers?
+
+- 本函式庫並不是模組化的神經網絡工具箱。模型文件中的程式碼並未做額外的抽象封裝,以便研究人員快速地翻閱及修改程式碼,而不會深陷複雜的類別包裝之中。
+- `Trainer` API 並非相容任何模型,它只為本函式庫中的模型最佳化。對於一般的機器學習用途,請使用其他函式庫。
+- 儘管我們已盡力而為,[examples 目錄](https://github.com/huggingface/transformers/tree/main/examples)中的腳本也僅為範例而已。對於特定問題,它們並不一定隨選即用,可能需要修改幾行程式碼以符合需求。
+
+## 安裝
+
+### 使用 pip
+
+這個 Repository 已在 Python 3.9+、Flax 0.4.1+、PyTorch 2.1+ 和 TensorFlow 2.6+ 下經過測試。
+
+你可以在[虛擬環境](https://docs.python.org/3/library/venv.html)中安裝 🤗 Transformers。如果你還不熟悉 Python 的虛擬環境,請閱此[使用者指引](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)。
+
+首先,用你打算使用的版本的 Python 創建一個虛擬環境並進入。
+
+然後,你需要安裝 Flax、PyTorch 或 TensorFlow 其中之一。對於該如何在你使用的平台上安裝這些框架,請參閱 [TensorFlow 安裝頁面](https://www.tensorflow.org/install/), [PyTorch 安裝頁面](https://pytorch.org/get-started/locally/#start-locally) 或 [Flax 安裝頁面](https://github.com/google/flax#quick-install)。
+
+當其中一個後端安裝成功後,🤗 Transformers 可依此安裝:
+
+```bash
+pip install transformers
+```
+
+如果你想要試試範例或者想在正式發布前使用最新開發中的程式碼,你必須[從原始碼安裝](https://huggingface.co/docs/transformers/installation#installing-from-source)。
+
+### 使用 conda
+
+🤗 Transformers 可以藉由 conda 依此安裝:
+
+```shell script
+conda install conda-forge::transformers
+```
+
+> **_筆記:_** 從 `huggingface` 頻道安裝 `transformers` 已被淘汰。
+
+要藉由 conda 安裝 Flax、PyTorch 或 TensorFlow 其中之一,請參閱它們各自安裝頁面的說明。
+
+## 模型架構
+
+**🤗 Transformers 支援的[所有的模型檢查點](https://huggingface.co/models)**,由[使用者](https://huggingface.co/users)和[組織](https://huggingface.co/organizations)上傳,均與 huggingface.co [model hub](https://huggingface.co) 完美結合。
+
+目前的檢查點數量: 
+
+🤗 Transformers 目前支援以下的架構: 模型概覽請參閱[這裡](https://huggingface.co/docs/transformers/model_summary).
+
+要檢查某個模型是否已有 Flax、PyTorch 或 TensorFlow 的實作,或其是否在🤗 Tokenizers 函式庫中有對應的 tokenizer,敬請參閱[此表](https://huggingface.co/docs/transformers/index#supported-frameworks)。
+
+這些實作均已於多個資料集測試(請參閱範例腳本)並應與原版實作表現相當。你可以在範例文件的[此節](https://huggingface.co/docs/transformers/examples)中了解實作的細節。
+
+
+## 了解更多
+
+| 章節 | 描述 |
+|-|-|
+| [文件](https://huggingface.co/transformers/) | 完整的 API 文件和教學 |
+| [任務概覽](https://huggingface.co/docs/transformers/task_summary) | 🤗 Transformers 支援的任務 |
+| [預處理教學](https://huggingface.co/docs/transformers/preprocessing) | 使用 `Tokenizer` 來為模型準備資料 |
+| [訓練和微調](https://huggingface.co/docs/transformers/training) | 使用 PyTorch/TensorFlow 的內建的訓練方式或於 `Trainer` API 中使用 🤗 Transformers 提供的模型 |
+| [快速上手:微調和範例腳本](https://github.com/huggingface/transformers/tree/main/examples) | 為各種任務提供的範例腳本 |
+| [模型分享和上傳](https://huggingface.co/docs/transformers/model_sharing) | 上傳並與社群分享你微調的模型 |
+| [遷移](https://huggingface.co/docs/transformers/migration) | 從 `pytorch-transformers` 或 `pytorch-pretrained-bert` 遷移到 🤗 Transformers |
+
+## 引用
+
+我們已將此函式庫的[論文](https://www.aclweb.org/anthology/2020.emnlp-demos.6/)正式發表。如果你使用了 🤗 Transformers 函式庫,可以引用:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/docs/transformers/notebooks/README.md b/docs/transformers/notebooks/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..99ff598931cc4cb690e579b7b87d9532492dcff3
--- /dev/null
+++ b/docs/transformers/notebooks/README.md
@@ -0,0 +1,152 @@
+
+
+# 🤗 Transformers Notebooks
+
+You can find here a list of the official notebooks provided by Hugging Face.
+
+Also, we would like to list here interesting content created by the community.
+If you wrote some notebook(s) leveraging 🤗 Transformers and would like to be listed here, please open a
+Pull Request so it can be included under the Community notebooks.
+
+
+## Hugging Face's notebooks 🤗
+
+### Documentation notebooks
+
+You can open any page of the documentation as a notebook in Colab (there is a button directly on said pages) but they are also listed here if you need them:
+
+| Notebook | Description | | |
+|:----------|:-------------|:-------------|------:|
+| [Quicktour of the library](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/quicktour.ipynb) | A presentation of the various APIs in Transformers |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/quicktour.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/en/transformers_doc/quicktour.ipynb)|
+| [Summary of the tasks](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/task_summary.ipynb) | How to run the models of the Transformers library task by task |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/task_summary.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/task_summary.ipynb)|
+| [Preprocessing data](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/preprocessing.ipynb) | How to use a tokenizer to preprocess your data |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/preprocessing.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/preprocessing.ipynb)|
+| [Fine-tuning a pretrained model](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/training.ipynb) | How to use the Trainer to fine-tune a pretrained model |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/training.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/training.ipynb)|
+| [Summary of the tokenizers](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/tokenizer_summary.ipynb) | The differences between the tokenizers algorithm |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/tokenizer_summary.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/tokenizer_summary.ipynb)|
+| [Multilingual models](https://github.com/huggingface/notebooks/blob/main/transformers_doc/en/multilingual.ipynb) | How to use the multilingual models of the library |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/transformers_doc/en/multilingual.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/transformers_doc/en/multilingual.ipynb)|
+
+
+### PyTorch Examples
+
+#### Natural Language Processing[[pytorch-nlp]]
+
+| Notebook | Description | | |
+|:----------|:-------------|:-------------|------:|
+| [Train your tokenizer](https://github.com/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb) | How to train and use your very own tokenizer |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb)|
+| [Train your language model](https://github.com/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch.ipynb) | How to easily start using transformers |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch.ipynb)|
+| [How to fine-tune a model on text classification](https://github.com/huggingface/notebooks/blob/main/examples/text_classification.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on any GLUE task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)|
+| [How to fine-tune a model on language modeling](https://github.com/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on a causal or masked LM task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)|
+| [How to fine-tune a model on token classification](https://github.com/huggingface/notebooks/blob/main/examples/token_classification.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on a token classification task (NER, PoS). | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)|
+| [How to fine-tune a model on question answering](https://github.com/huggingface/notebooks/blob/main/examples/question_answering.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on SQUAD. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)|
+| [How to fine-tune a model on multiple choice](https://github.com/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on SWAG. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)|
+| [How to fine-tune a model on translation](https://github.com/huggingface/notebooks/blob/main/examples/translation.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on WMT. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/translation.ipynb)|
+| [How to fine-tune a model on summarization](https://github.com/huggingface/notebooks/blob/main/examples/summarization.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on XSUM. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/summarization.ipynb)|
+| [How to train a language model from scratch](https://github.com/huggingface/blog/blob/main/notebooks/01_how_to_train.ipynb)| Highlight all the steps to effectively train Transformer model on custom data | [](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/01_how_to_train.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/blog/blob/main/notebooks/01_how_to_train.ipynb)|
+| [How to generate text](https://github.com/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb)| How to use different decoding methods for language generation with transformers | [](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/blog/blob/main/notebooks/02_how_to_generate.ipynb)|
+| [How to generate text (with constraints)](https://github.com/huggingface/blog/blob/main/notebooks/53_constrained_beam_search.ipynb)| How to guide language generation with user-provided constraints | [](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/53_constrained_beam_search.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/blog/blob/main/notebooks/53_constrained_beam_search.ipynb)|
+| [Reformer](https://github.com/huggingface/blog/blob/main/notebooks/03_reformer.ipynb)| How Reformer pushes the limits of language modeling | [](https://colab.research.google.com/github/patrickvonplaten/blog/blob/main/notebooks/03_reformer.ipynb)| [](https://studiolab.sagemaker.aws/import/github/patrickvonplaten/blog/blob/main/notebooks/03_reformer.ipynb)|
+
+#### Computer Vision[[pytorch-cv]]
+
+| Notebook | Description | | |
+|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------:|
+| [How to fine-tune a model on image classification (Torchvision)](https://github.com/huggingface/notebooks/blob/main/examples/image_classification.ipynb) | Show how to preprocess the data using Torchvision and fine-tune any pretrained Vision model on Image Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)|
+| [How to fine-tune a model on image classification (Albumentations)](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) | Show how to preprocess the data using Albumentations and fine-tune any pretrained Vision model on Image Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb)|
+| [How to fine-tune a model on image classification (Kornia)](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb) | Show how to preprocess the data using Kornia and fine-tune any pretrained Vision model on Image Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb)|
+| [How to perform zero-shot object detection with OWL-ViT](https://github.com/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb) | Show how to perform zero-shot object detection on images with text queries | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb)|
+| [How to fine-tune an image captioning model](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) | Show how to fine-tune BLIP for image captioning on a custom dataset | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb)|
+| [How to build an image similarity system with Transformers](https://github.com/huggingface/notebooks/blob/main/examples/image_similarity.ipynb) | Show how to build an image similarity system | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_similarity.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_similarity.ipynb)|
+| [How to fine-tune a SegFormer model on semantic segmentation](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb) | Show how to preprocess the data and fine-tune a pretrained SegFormer model on Semantic Segmentation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb)|
+| [How to fine-tune a VideoMAE model on video classification](https://github.com/huggingface/notebooks/blob/main/examples/video_classification.ipynb) | Show how to preprocess the data and fine-tune a pretrained VideoMAE model on Video Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/video_classification.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/video_classification.ipynb)|
+
+#### Audio[[pytorch-audio]]
+
+| Notebook | Description | | |
+|:----------|:-------------|:-------------|------:|
+| [How to fine-tune a speech recognition model in English](https://github.com/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb)| Show how to preprocess the data and fine-tune a pretrained Speech model on TIMIT | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb)|
+| [How to fine-tune a speech recognition model in any language](https://github.com/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb)| Show how to preprocess the data and fine-tune a multi-lingually pretrained speech model on Common Voice | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb)|
+| [How to fine-tune a model on audio classification](https://github.com/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)| Show how to preprocess the data and fine-tune a pretrained Speech model on Keyword Spotting | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb)|
+
+#### Biological Sequences[[pytorch-bio]]
+
+| Notebook | Description | | |
+|:----------|:----------------------------------------------------------------------------------------|:-------------|------:|
+| [How to fine-tune a pre-trained protein model](https://github.com/huggingface/notebooks/blob/main/examples/protein_language_modeling.ipynb) | See how to tokenize proteins and fine-tune a large pre-trained protein "language" model | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_language_modeling.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/protein_language_modeling.ipynb) |
+| [How to generate protein folds](https://github.com/huggingface/notebooks/blob/main/examples/protein_folding.ipynb) | See how to go from protein sequence to a full protein model and PDB file | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_folding.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/protein_folding.ipynb) |
+| [How to fine-tune a Nucleotide Transformer model](https://github.com/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling.ipynb) | See how to tokenize DNA and fine-tune a large pre-trained DNA "language" model | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling.ipynb) |
+| [Fine-tune a Nucleotide Transformer model with LoRA](https://github.com/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling_with_peft.ipynb) | Train even larger DNA models in a memory-efficient way | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling_with_peft.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/nucleotide_transformer_dna_sequence_modelling_with_peft.ipynb) |
+
+
+#### Other modalities[[pytorch-other]]
+
+| Notebook | Description | | |
+|:----------|:----------------------------------------------------------------------------------------|:-------------|------:|
+| [Probabilistic Time Series Forecasting](https://github.com/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb) | See how to train Time Series Transformer on a custom dataset | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb) |
+
+#### Utility notebooks[[pytorch-utility]]
+
+| Notebook | Description | | |
+|:----------|:-------------|:-------------|------:|
+| [How to export model to ONNX](https://github.com/huggingface/notebooks/blob/main/examples/onnx-export.ipynb)| Highlight how to export and run inference workloads through ONNX | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/onnx-export.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/onnx-export.ipynb)|
+
+### TensorFlow Examples
+
+#### Natural Language Processing[[tensorflow-nlp]]
+
+| Notebook | Description | | |
+|:----------|:-------------|:-------------|------:|
+| [Train your tokenizer](https://github.com/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb) | How to train and use your very own tokenizer |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/tokenizer_training.ipynb)|
+| [Train your language model](https://github.com/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch-tf.ipynb) | How to easily start using transformers |[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/language_modeling_from_scratch-tf.ipynb)|
+| [How to fine-tune a model on text classification](https://github.com/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on any GLUE task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)|
+| [How to fine-tune a model on language modeling](https://github.com/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on a causal or masked LM task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)|
+| [How to fine-tune a model on token classification](https://github.com/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on a token classification task (NER, PoS). | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)|
+| [How to fine-tune a model on question answering](https://github.com/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on SQUAD. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)|
+| [How to fine-tune a model on multiple choice](https://github.com/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on SWAG. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)|
+| [How to fine-tune a model on translation](https://github.com/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on WMT. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb)|
+| [How to fine-tune a model on summarization](https://github.com/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)| Show how to preprocess the data and fine-tune a pretrained model on XSUM. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb)|
+
+#### Computer Vision[[tensorflow-cv]]
+
+| Notebook | Description | | |
+|:---------------------------------------------------------------------------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------------------------|:-------------|------:|
+| [How to fine-tune a model on image classification](https://github.com/huggingface/notebooks/blob/main/examples/image_classification-tf.ipynb) | Show how to preprocess the data and fine-tune any pretrained Vision model on Image Classification | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/image_classification-tf.ipynb)|
+| [How to fine-tune a SegFormer model on semantic segmentation](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb) | Show how to preprocess the data and fine-tune a pretrained SegFormer model on Semantic Segmentation | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb)|
+
+#### Biological Sequences[[tensorflow-bio]]
+
+| Notebook | Description | | |
+|:----------|:-------------|:-------------|------:|
+| [How to fine-tune a pre-trained protein model](https://github.com/huggingface/notebooks/blob/main/examples/protein_language_modeling-tf.ipynb) | See how to tokenize proteins and fine-tune a large pre-trained protein "language" model | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_language_modeling-tf.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/protein_language_modeling-tf.ipynb) |
+
+#### Utility notebooks[[tensorflow-utility]]
+
+| Notebook | Description | | |
+|:----------|:-------------|:-------------|------:|
+| [How to train TF/Keras models on TPU](https://github.com/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) | See how to train at high speed on Google's TPU hardware | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) | [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/tpu_training-tf.ipynb) |
+
+### Optimum notebooks
+
+🤗 [Optimum](https://github.com/huggingface/optimum) is an extension of 🤗 Transformers, providing a set of performance optimization tools enabling maximum efficiency to train and run models on targeted hardwares.
+
+| Notebook | Description | | |
+|:----------|:-------------|:-------------|------:|
+| [How to quantize a model with ONNX Runtime for text classification](https://github.com/huggingface/notebooks/blob/main/examples/text_classification_quantization_ort.ipynb)| Show how to apply static and dynamic quantization on a model using [ONNX Runtime](https://github.com/microsoft/onnxruntime) for any GLUE task. | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_quantization_ort.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification_quantization_ort.ipynb)|
+| [How to fine-tune a model on text classification with ONNX Runtime](https://github.com/huggingface/notebooks/blob/main/examples/text_classification_ort.ipynb)| Show how to preprocess the data and fine-tune a model on any GLUE task using [ONNX Runtime](https://github.com/microsoft/onnxruntime). | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_ort.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/text_classification_ort.ipynb)|
+| [How to fine-tune a model on summarization with ONNX Runtime](https://github.com/huggingface/notebooks/blob/main/examples/summarization_ort.ipynb)| Show how to preprocess the data and fine-tune a model on XSUM using [ONNX Runtime](https://github.com/microsoft/onnxruntime). | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization_ort.ipynb)| [](https://studiolab.sagemaker.aws/import/github/huggingface/notebooks/blob/main/examples/summarization_ort.ipynb)|
+
+## Community notebooks:
+
+More notebooks developed by the community are available [here](https://hf.co/docs/transformers/community#community-notebooks).
diff --git a/docs/transformers/scripts/check_tokenizers.py b/docs/transformers/scripts/check_tokenizers.py
new file mode 100644
index 0000000000000000000000000000000000000000..ba73460ce4d60b0d1d99ae317723b9016348ea31
--- /dev/null
+++ b/docs/transformers/scripts/check_tokenizers.py
@@ -0,0 +1,171 @@
+from collections import Counter
+
+import datasets
+
+import transformers
+from transformers.convert_slow_tokenizer import SLOW_TO_FAST_CONVERTERS
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+
+TOKENIZER_CLASSES = {
+ name: (getattr(transformers, name), getattr(transformers, name + "Fast")) for name in SLOW_TO_FAST_CONVERTERS
+}
+
+dataset = datasets.load_dataset("facebook/xnli", split="test+validation") # no-script
+
+total = 0
+perfect = 0
+imperfect = 0
+wrong = 0
+
+
+def check_diff(spm_diff, tok_diff, slow, fast):
+ if spm_diff == list(reversed(tok_diff)):
+ # AAA -> AA+A vs A+AA case.
+ return True
+ elif len(spm_diff) == len(tok_diff) and fast.decode(spm_diff) == fast.decode(tok_diff):
+ # Second order OK
+ # Barrich -> Barr + ich vs Bar + rich
+ return True
+ spm_reencoded = slow.encode(slow.decode(spm_diff))
+ tok_reencoded = fast.encode(fast.decode(spm_diff))
+ if spm_reencoded != spm_diff and spm_reencoded == tok_reencoded:
+ # Type 3 error.
+ # Snehagatha ->
+ # Sne, h, aga, th, a
+ # Sne, ha, gat, ha
+ # Encoding the wrong with sp does not even recover what spm gave us
+ # It fits tokenizer however...
+ return True
+ return False
+
+
+def check_LTR_mark(line, idx, fast):
+ enc = fast.encode_plus(line)[0]
+ offsets = enc.offsets
+ curr, prev = offsets[idx], offsets[idx - 1]
+ if curr is not None and line[curr[0] : curr[1]] == "\u200f":
+ return True
+ if prev is not None and line[prev[0] : prev[1]] == "\u200f":
+ return True
+
+
+def check_details(line, spm_ids, tok_ids, slow, fast):
+ # Encoding can be the same with same result AAA -> A + AA vs AA + A
+ # We can check that we use at least exactly the same number of tokens.
+ for i, (spm_id, tok_id) in enumerate(zip(spm_ids, tok_ids)):
+ if spm_id != tok_id:
+ break
+ first = i
+ for i, (spm_id, tok_id) in enumerate(zip(reversed(spm_ids), reversed(tok_ids))):
+ if spm_id != tok_id:
+ break
+ last = len(spm_ids) - i
+
+ spm_diff = spm_ids[first:last]
+ tok_diff = tok_ids[first:last]
+
+ if check_diff(spm_diff, tok_diff, slow, fast):
+ return True
+
+ if check_LTR_mark(line, first, fast):
+ return True
+
+ if last - first > 5:
+ # We might have twice a single problem, attempt to subdivide the disjointed tokens into smaller problems
+ spms = Counter(spm_ids[first:last])
+ toks = Counter(tok_ids[first:last])
+
+ removable_tokens = {spm_ for (spm_, si) in spms.items() if toks.get(spm_, 0) == si}
+ min_width = 3
+ for i in range(last - first - min_width):
+ if all(spm_ids[first + i + j] in removable_tokens for j in range(min_width)):
+ possible_matches = [
+ k
+ for k in range(last - first - min_width)
+ if tok_ids[first + k : first + k + min_width] == spm_ids[first + i : first + i + min_width]
+ ]
+ for j in possible_matches:
+ if check_diff(spm_ids[first : first + i], tok_ids[first : first + j], slow, fast) and check_details(
+ line,
+ spm_ids[first + i : last],
+ tok_ids[first + j : last],
+ slow,
+ fast,
+ ):
+ return True
+
+ print(f"Spm: {[fast.decode([spm_ids[i]]) for i in range(first, last)]}")
+ try:
+ print(f"Tok: {[fast.decode([tok_ids[i]]) for i in range(first, last)]}")
+ except Exception:
+ pass
+
+ fast.decode(spm_ids[:first])
+ fast.decode(spm_ids[last:])
+ wrong = fast.decode(spm_ids[first:last])
+ print()
+ print(wrong)
+ return False
+
+
+def test_string(slow, fast, text):
+ global perfect
+ global imperfect
+ global wrong
+ global total
+
+ slow_ids = slow.encode(text)
+ fast_ids = fast.encode(text)
+
+ skip_assert = False
+ total += 1
+
+ if slow_ids != fast_ids:
+ if check_details(text, slow_ids, fast_ids, slow, fast):
+ skip_assert = True
+ imperfect += 1
+ else:
+ wrong += 1
+ else:
+ perfect += 1
+
+ if total % 10000 == 0:
+ print(f"({perfect} / {imperfect} / {wrong} ----- {perfect + imperfect + wrong})")
+
+ if skip_assert:
+ return
+
+ assert (
+ slow_ids == fast_ids
+ ), f"line {text} : \n\n{slow_ids}\n{fast_ids}\n\n{slow.tokenize(text)}\n{fast.tokenize(text)}"
+
+
+def test_tokenizer(slow, fast):
+ global batch_total
+ for i in range(len(dataset)):
+ # premise, all languages
+ for text in dataset[i]["premise"].values():
+ test_string(slow, fast, text)
+
+ # hypothesis, all languages
+ for text in dataset[i]["hypothesis"]["translation"]:
+ test_string(slow, fast, text)
+
+
+if __name__ == "__main__":
+ for name, (slow_class, fast_class) in TOKENIZER_CLASSES.items():
+ checkpoint_names = list(slow_class.max_model_input_sizes.keys())
+ for checkpoint in checkpoint_names:
+ imperfect = 0
+ perfect = 0
+ wrong = 0
+ total = 0
+
+ print(f"========================== Checking {name}: {checkpoint} ==========================")
+ slow = slow_class.from_pretrained(checkpoint, force_download=True)
+ fast = fast_class.from_pretrained(checkpoint, force_download=True)
+ test_tokenizer(slow, fast)
+ print(f"Accuracy {perfect * 100 / total:.2f}")
diff --git a/docs/transformers/scripts/distributed/torch-distributed-gpu-test.py b/docs/transformers/scripts/distributed/torch-distributed-gpu-test.py
new file mode 100644
index 0000000000000000000000000000000000000000..22a99d570e4f85ba4fcbaf470fbbda1856fc8edd
--- /dev/null
+++ b/docs/transformers/scripts/distributed/torch-distributed-gpu-test.py
@@ -0,0 +1,92 @@
+#!/usr/bin/env python
+
+#
+# This a `torch.distributed` diagnostics script that checks that all GPUs in the cluster (one or
+# many nodes) can talk to each other via nccl and allocate gpu memory.
+#
+# To run first adjust the number of processes and nodes:
+#
+# python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
+#
+# You may need to add --master_addr $MASTER_ADDR --master_port $MASTER_PORT if using a custom addr:port
+#
+# You can also use the rdzv API: --rdzv_endpoint $MASTER_ADDR:$MASTER_PORT --rdzv_backend c10d
+#
+# use torch.distributed.launch instead of torch.distributed.run for torch < 1.9
+#
+# If you get a hanging in `barrier` calls you have some network issues, you may try to debug this with:
+#
+# NCCL_DEBUG=INFO python -m torch.distributed.run --nproc_per_node 2 --nnodes 1 torch-distributed-gpu-test.py
+#
+# which should tell you what's going on behind the scenes.
+#
+#
+# This script can be run via `srun` in the SLURM environment as well. Here is a SLURM script that
+# runs on 2 nodes of 4 gpus per node:
+#
+# #SBATCH --job-name=test-nodes # name
+# #SBATCH --nodes=2 # nodes
+# #SBATCH --ntasks-per-node=1 # crucial - only 1 task per dist per node!
+# #SBATCH --cpus-per-task=10 # number of cores per tasks
+# #SBATCH --gres=gpu:4 # number of gpus
+# #SBATCH --time 0:05:00 # maximum execution time (HH:MM:SS)
+# #SBATCH --output=%x-%j.out # output file name
+#
+# GPUS_PER_NODE=4
+# MASTER_ADDR=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
+# MASTER_PORT=6000
+#
+# srun --jobid $SLURM_JOBID bash -c 'python -m torch.distributed.run \
+# --nproc_per_node $GPUS_PER_NODE --nnodes $SLURM_NNODES --node_rank $SLURM_PROCID \
+# --master_addr $MASTER_ADDR --master_port $MASTER_PORT \
+# torch-distributed-gpu-test.py'
+#
+
+import fcntl
+import os
+import socket
+
+import torch
+import torch.distributed as dist
+
+
+def printflock(*msgs):
+ """solves multi-process interleaved print problem"""
+ with open(__file__, "r") as fh:
+ fcntl.flock(fh, fcntl.LOCK_EX)
+ try:
+ print(*msgs)
+ finally:
+ fcntl.flock(fh, fcntl.LOCK_UN)
+
+
+local_rank = int(os.environ["LOCAL_RANK"])
+torch.cuda.set_device(local_rank)
+device = torch.device("cuda", local_rank)
+hostname = socket.gethostname()
+
+gpu = f"[{hostname}-{local_rank}]"
+
+try:
+ # test distributed
+ dist.init_process_group("nccl")
+ dist.all_reduce(torch.ones(1).to(device), op=dist.ReduceOp.SUM)
+ dist.barrier()
+
+ # test cuda is available and can allocate memory
+ torch.cuda.is_available()
+ torch.ones(1).cuda(local_rank)
+
+ # global rank
+ rank = dist.get_rank()
+ world_size = dist.get_world_size()
+
+ printflock(f"{gpu} is OK (global rank: {rank}/{world_size})")
+
+ dist.barrier()
+ if rank == 0:
+ printflock(f"pt={torch.__version__}, cuda={torch.version.cuda}, nccl={torch.cuda.nccl.version()}")
+
+except Exception:
+ printflock(f"{gpu} is broken")
+ raise
diff --git a/docs/transformers/scripts/stale.py b/docs/transformers/scripts/stale.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf7c6670c431e152b63d3ea772e1a3523cee3d37
--- /dev/null
+++ b/docs/transformers/scripts/stale.py
@@ -0,0 +1,74 @@
+# Copyright 2021 The HuggingFace Team, the AllenNLP library authors. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Script to close stale issue. Taken in part from the AllenNLP repository.
+https://github.com/allenai/allennlp.
+"""
+import os
+from datetime import datetime as dt
+
+import github.GithubException
+from github import Github
+
+
+LABELS_TO_EXEMPT = [
+ "good first issue",
+ "good second issue",
+ "good difficult issue",
+ "feature request",
+ "new model",
+ "wip",
+]
+
+
+def main():
+ g = Github(os.environ["GITHUB_TOKEN"])
+ repo = g.get_repo("huggingface/transformers")
+ open_issues = repo.get_issues(state="open")
+
+ for i, issue in enumerate(open_issues):
+ print(i, issue)
+ comments = sorted(list(issue.get_comments()), key=lambda i: i.created_at, reverse=True)
+ last_comment = comments[0] if len(comments) > 0 else None
+ if (
+ last_comment is not None and last_comment.user.login == "github-actions[bot]"
+ and (dt.utcnow() - issue.updated_at.replace(tzinfo=None)).days > 7
+ and (dt.utcnow() - issue.created_at.replace(tzinfo=None)).days >= 30
+ and not any(label.name.lower() in LABELS_TO_EXEMPT for label in issue.get_labels())
+ ):
+ # print(f"Would close issue {issue.number} since it has been 7 days of inactivity since bot mention.")
+ try:
+ issue.edit(state="closed")
+ except github.GithubException as e:
+ print("Couldn't close the issue:", repr(e))
+ elif (
+ (dt.utcnow() - issue.updated_at.replace(tzinfo=None)).days > 23
+ and (dt.utcnow() - issue.created_at.replace(tzinfo=None)).days >= 30
+ and not any(label.name.lower() in LABELS_TO_EXEMPT for label in issue.get_labels())
+ ):
+ # print(f"Would add stale comment to {issue.number}")
+ try:
+ issue.create_comment(
+ "This issue has been automatically marked as stale because it has not had "
+ "recent activity. If you think this still needs to be addressed "
+ "please comment on this thread.\n\nPlease note that issues that do not follow the "
+ "[contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) "
+ "are likely to be ignored."
+ )
+ except github.GithubException as e:
+ print("Couldn't create comment:", repr(e))
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/src/transformers.egg-info/PKG-INFO b/docs/transformers/src/transformers.egg-info/PKG-INFO
new file mode 100644
index 0000000000000000000000000000000000000000..b67e0cdeaf5b60639b47c38a4ddb17bd096da162
--- /dev/null
+++ b/docs/transformers/src/transformers.egg-info/PKG-INFO
@@ -0,0 +1,808 @@
+Metadata-Version: 2.4
+Name: transformers
+Version: 4.52.0.dev0
+Summary: State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow
+Home-page: https://github.com/huggingface/transformers
+Author: The Hugging Face team (past and future) with the help of all our contributors (https://github.com/huggingface/transformers/graphs/contributors)
+Author-email: transformers@huggingface.co
+License: Apache 2.0 License
+Keywords: NLP vision speech deep learning transformer pytorch tensorflow jax BERT GPT-2 Wav2Vec2 ViT
+Classifier: Development Status :: 5 - Production/Stable
+Classifier: Intended Audience :: Developers
+Classifier: Intended Audience :: Education
+Classifier: Intended Audience :: Science/Research
+Classifier: License :: OSI Approved :: Apache Software License
+Classifier: Operating System :: OS Independent
+Classifier: Programming Language :: Python :: 3
+Classifier: Programming Language :: Python :: 3.9
+Classifier: Programming Language :: Python :: 3.10
+Classifier: Topic :: Scientific/Engineering :: Artificial Intelligence
+Requires-Python: >=3.9.0
+Description-Content-Type: text/markdown
+License-File: LICENSE
+Requires-Dist: filelock
+Requires-Dist: huggingface-hub<1.0,>=0.30.0
+Requires-Dist: numpy>=1.17
+Requires-Dist: packaging>=20.0
+Requires-Dist: pyyaml>=5.1
+Requires-Dist: regex!=2019.12.17
+Requires-Dist: requests
+Requires-Dist: tokenizers<0.22,>=0.21
+Requires-Dist: safetensors>=0.4.3
+Requires-Dist: tqdm>=4.27
+Provides-Extra: ja
+Requires-Dist: fugashi>=1.0; extra == "ja"
+Requires-Dist: ipadic<2.0,>=1.0.0; extra == "ja"
+Requires-Dist: unidic_lite>=1.0.7; extra == "ja"
+Requires-Dist: unidic>=1.0.2; extra == "ja"
+Requires-Dist: sudachipy>=0.6.6; extra == "ja"
+Requires-Dist: sudachidict_core>=20220729; extra == "ja"
+Requires-Dist: rhoknp<1.3.1,>=1.1.0; extra == "ja"
+Provides-Extra: sklearn
+Requires-Dist: scikit-learn; extra == "sklearn"
+Provides-Extra: tf
+Requires-Dist: tensorflow<2.16,>2.9; extra == "tf"
+Requires-Dist: onnxconverter-common; extra == "tf"
+Requires-Dist: tf2onnx; extra == "tf"
+Requires-Dist: tensorflow-text<2.16; extra == "tf"
+Requires-Dist: keras-nlp<0.14.0,>=0.3.1; extra == "tf"
+Provides-Extra: tf-cpu
+Requires-Dist: keras<2.16,>2.9; extra == "tf-cpu"
+Requires-Dist: tensorflow-cpu<2.16,>2.9; extra == "tf-cpu"
+Requires-Dist: onnxconverter-common; extra == "tf-cpu"
+Requires-Dist: tf2onnx; extra == "tf-cpu"
+Requires-Dist: tensorflow-text<2.16; extra == "tf-cpu"
+Requires-Dist: keras-nlp<0.14.0,>=0.3.1; extra == "tf-cpu"
+Requires-Dist: tensorflow-probability<0.24; extra == "tf-cpu"
+Provides-Extra: torch
+Requires-Dist: torch>=2.1; extra == "torch"
+Requires-Dist: accelerate>=0.26.0; extra == "torch"
+Provides-Extra: accelerate
+Requires-Dist: accelerate>=0.26.0; extra == "accelerate"
+Provides-Extra: hf-xet
+Requires-Dist: hf_xet; extra == "hf-xet"
+Provides-Extra: retrieval
+Requires-Dist: faiss-cpu; extra == "retrieval"
+Requires-Dist: datasets!=2.5.0; extra == "retrieval"
+Provides-Extra: flax
+Requires-Dist: jax<=0.4.13,>=0.4.1; extra == "flax"
+Requires-Dist: jaxlib<=0.4.13,>=0.4.1; extra == "flax"
+Requires-Dist: flax<=0.7.0,>=0.4.1; extra == "flax"
+Requires-Dist: optax<=0.1.4,>=0.0.8; extra == "flax"
+Requires-Dist: scipy<1.13.0; extra == "flax"
+Provides-Extra: tokenizers
+Requires-Dist: tokenizers<0.22,>=0.21; extra == "tokenizers"
+Provides-Extra: ftfy
+Requires-Dist: ftfy; extra == "ftfy"
+Provides-Extra: onnxruntime
+Requires-Dist: onnxruntime>=1.4.0; extra == "onnxruntime"
+Requires-Dist: onnxruntime-tools>=1.4.2; extra == "onnxruntime"
+Provides-Extra: onnx
+Requires-Dist: onnxconverter-common; extra == "onnx"
+Requires-Dist: tf2onnx; extra == "onnx"
+Requires-Dist: onnxruntime>=1.4.0; extra == "onnx"
+Requires-Dist: onnxruntime-tools>=1.4.2; extra == "onnx"
+Provides-Extra: modelcreation
+Requires-Dist: cookiecutter==1.7.3; extra == "modelcreation"
+Provides-Extra: sagemaker
+Requires-Dist: sagemaker>=2.31.0; extra == "sagemaker"
+Provides-Extra: deepspeed
+Requires-Dist: deepspeed>=0.9.3; extra == "deepspeed"
+Requires-Dist: accelerate>=0.26.0; extra == "deepspeed"
+Provides-Extra: optuna
+Requires-Dist: optuna; extra == "optuna"
+Provides-Extra: ray
+Requires-Dist: ray[tune]>=2.7.0; extra == "ray"
+Provides-Extra: sigopt
+Requires-Dist: sigopt; extra == "sigopt"
+Provides-Extra: hub-kernels
+Requires-Dist: kernels<0.5,>=0.4.4; extra == "hub-kernels"
+Provides-Extra: integrations
+Requires-Dist: kernels<0.5,>=0.4.4; extra == "integrations"
+Requires-Dist: optuna; extra == "integrations"
+Requires-Dist: ray[tune]>=2.7.0; extra == "integrations"
+Requires-Dist: sigopt; extra == "integrations"
+Provides-Extra: serving
+Requires-Dist: pydantic; extra == "serving"
+Requires-Dist: uvicorn; extra == "serving"
+Requires-Dist: fastapi; extra == "serving"
+Requires-Dist: starlette; extra == "serving"
+Provides-Extra: audio
+Requires-Dist: librosa; extra == "audio"
+Requires-Dist: pyctcdecode>=0.4.0; extra == "audio"
+Requires-Dist: phonemizer; extra == "audio"
+Requires-Dist: kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5 ; extra == "audio"
+Provides-Extra: speech
+Requires-Dist: torchaudio; extra == "speech"
+Requires-Dist: librosa; extra == "speech"
+Requires-Dist: pyctcdecode>=0.4.0; extra == "speech"
+Requires-Dist: phonemizer; extra == "speech"
+Requires-Dist: kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5 ; extra == "speech"
+Provides-Extra: torch-speech
+Requires-Dist: torchaudio; extra == "torch-speech"
+Requires-Dist: librosa; extra == "torch-speech"
+Requires-Dist: pyctcdecode>=0.4.0; extra == "torch-speech"
+Requires-Dist: phonemizer; extra == "torch-speech"
+Requires-Dist: kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5 ; extra == "torch-speech"
+Provides-Extra: tf-speech
+Requires-Dist: librosa; extra == "tf-speech"
+Requires-Dist: pyctcdecode>=0.4.0; extra == "tf-speech"
+Requires-Dist: phonemizer; extra == "tf-speech"
+Requires-Dist: kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5 ; extra == "tf-speech"
+Provides-Extra: flax-speech
+Requires-Dist: librosa; extra == "flax-speech"
+Requires-Dist: pyctcdecode>=0.4.0; extra == "flax-speech"
+Requires-Dist: phonemizer; extra == "flax-speech"
+Requires-Dist: kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5 ; extra == "flax-speech"
+Provides-Extra: vision
+Requires-Dist: Pillow<=15.0,>=10.0.1; extra == "vision"
+Provides-Extra: timm
+Requires-Dist: timm<=1.0.11; extra == "timm"
+Provides-Extra: torch-vision
+Requires-Dist: torchvision; extra == "torch-vision"
+Requires-Dist: Pillow<=15.0,>=10.0.1; extra == "torch-vision"
+Provides-Extra: natten
+Requires-Dist: natten<0.15.0,>=0.14.6; extra == "natten"
+Provides-Extra: codecarbon
+Requires-Dist: codecarbon>=2.8.1; extra == "codecarbon"
+Provides-Extra: video
+Requires-Dist: av; extra == "video"
+Provides-Extra: num2words
+Requires-Dist: num2words; extra == "num2words"
+Provides-Extra: sentencepiece
+Requires-Dist: sentencepiece!=0.1.92,>=0.1.91; extra == "sentencepiece"
+Requires-Dist: protobuf; extra == "sentencepiece"
+Provides-Extra: tiktoken
+Requires-Dist: tiktoken; extra == "tiktoken"
+Requires-Dist: blobfile; extra == "tiktoken"
+Provides-Extra: testing
+Requires-Dist: pytest<8.0.0,>=7.2.0; extra == "testing"
+Requires-Dist: pytest-asyncio; extra == "testing"
+Requires-Dist: pytest-rich; extra == "testing"
+Requires-Dist: pytest-xdist; extra == "testing"
+Requires-Dist: pytest-order; extra == "testing"
+Requires-Dist: pytest-rerunfailures; extra == "testing"
+Requires-Dist: timeout-decorator; extra == "testing"
+Requires-Dist: parameterized; extra == "testing"
+Requires-Dist: psutil; extra == "testing"
+Requires-Dist: datasets!=2.5.0; extra == "testing"
+Requires-Dist: dill<0.3.5; extra == "testing"
+Requires-Dist: evaluate>=0.2.0; extra == "testing"
+Requires-Dist: pytest-timeout; extra == "testing"
+Requires-Dist: ruff==0.11.2; extra == "testing"
+Requires-Dist: rouge-score!=0.0.7,!=0.0.8,!=0.1,!=0.1.1; extra == "testing"
+Requires-Dist: nltk<=3.8.1; extra == "testing"
+Requires-Dist: GitPython<3.1.19; extra == "testing"
+Requires-Dist: sacremoses; extra == "testing"
+Requires-Dist: rjieba; extra == "testing"
+Requires-Dist: beautifulsoup4; extra == "testing"
+Requires-Dist: tensorboard; extra == "testing"
+Requires-Dist: pydantic; extra == "testing"
+Requires-Dist: sentencepiece!=0.1.92,>=0.1.91; extra == "testing"
+Requires-Dist: sacrebleu<2.0.0,>=1.4.12; extra == "testing"
+Requires-Dist: faiss-cpu; extra == "testing"
+Requires-Dist: datasets!=2.5.0; extra == "testing"
+Requires-Dist: cookiecutter==1.7.3; extra == "testing"
+Provides-Extra: deepspeed-testing
+Requires-Dist: deepspeed>=0.9.3; extra == "deepspeed-testing"
+Requires-Dist: accelerate>=0.26.0; extra == "deepspeed-testing"
+Requires-Dist: pytest<8.0.0,>=7.2.0; extra == "deepspeed-testing"
+Requires-Dist: pytest-asyncio; extra == "deepspeed-testing"
+Requires-Dist: pytest-rich; extra == "deepspeed-testing"
+Requires-Dist: pytest-xdist; extra == "deepspeed-testing"
+Requires-Dist: pytest-order; extra == "deepspeed-testing"
+Requires-Dist: pytest-rerunfailures; extra == "deepspeed-testing"
+Requires-Dist: timeout-decorator; extra == "deepspeed-testing"
+Requires-Dist: parameterized; extra == "deepspeed-testing"
+Requires-Dist: psutil; extra == "deepspeed-testing"
+Requires-Dist: datasets!=2.5.0; extra == "deepspeed-testing"
+Requires-Dist: dill<0.3.5; extra == "deepspeed-testing"
+Requires-Dist: evaluate>=0.2.0; extra == "deepspeed-testing"
+Requires-Dist: pytest-timeout; extra == "deepspeed-testing"
+Requires-Dist: ruff==0.11.2; extra == "deepspeed-testing"
+Requires-Dist: rouge-score!=0.0.7,!=0.0.8,!=0.1,!=0.1.1; extra == "deepspeed-testing"
+Requires-Dist: nltk<=3.8.1; extra == "deepspeed-testing"
+Requires-Dist: GitPython<3.1.19; extra == "deepspeed-testing"
+Requires-Dist: sacremoses; extra == "deepspeed-testing"
+Requires-Dist: rjieba; extra == "deepspeed-testing"
+Requires-Dist: beautifulsoup4; extra == "deepspeed-testing"
+Requires-Dist: tensorboard; extra == "deepspeed-testing"
+Requires-Dist: pydantic; extra == "deepspeed-testing"
+Requires-Dist: sentencepiece!=0.1.92,>=0.1.91; extra == "deepspeed-testing"
+Requires-Dist: sacrebleu<2.0.0,>=1.4.12; extra == "deepspeed-testing"
+Requires-Dist: faiss-cpu; extra == "deepspeed-testing"
+Requires-Dist: datasets!=2.5.0; extra == "deepspeed-testing"
+Requires-Dist: cookiecutter==1.7.3; extra == "deepspeed-testing"
+Requires-Dist: optuna; extra == "deepspeed-testing"
+Requires-Dist: sentencepiece!=0.1.92,>=0.1.91; extra == "deepspeed-testing"
+Requires-Dist: protobuf; extra == "deepspeed-testing"
+Provides-Extra: ruff
+Requires-Dist: ruff==0.11.2; extra == "ruff"
+Provides-Extra: quality
+Requires-Dist: datasets!=2.5.0; extra == "quality"
+Requires-Dist: isort>=5.5.4; extra == "quality"
+Requires-Dist: ruff==0.11.2; extra == "quality"
+Requires-Dist: GitPython<3.1.19; extra == "quality"
+Requires-Dist: urllib3<2.0.0; extra == "quality"
+Requires-Dist: libcst; extra == "quality"
+Requires-Dist: rich; extra == "quality"
+Provides-Extra: all
+Requires-Dist: tensorflow<2.16,>2.9; extra == "all"
+Requires-Dist: onnxconverter-common; extra == "all"
+Requires-Dist: tf2onnx; extra == "all"
+Requires-Dist: tensorflow-text<2.16; extra == "all"
+Requires-Dist: keras-nlp<0.14.0,>=0.3.1; extra == "all"
+Requires-Dist: torch>=2.1; extra == "all"
+Requires-Dist: accelerate>=0.26.0; extra == "all"
+Requires-Dist: jax<=0.4.13,>=0.4.1; extra == "all"
+Requires-Dist: jaxlib<=0.4.13,>=0.4.1; extra == "all"
+Requires-Dist: flax<=0.7.0,>=0.4.1; extra == "all"
+Requires-Dist: optax<=0.1.4,>=0.0.8; extra == "all"
+Requires-Dist: scipy<1.13.0; extra == "all"
+Requires-Dist: sentencepiece!=0.1.92,>=0.1.91; extra == "all"
+Requires-Dist: protobuf; extra == "all"
+Requires-Dist: tokenizers<0.22,>=0.21; extra == "all"
+Requires-Dist: torchaudio; extra == "all"
+Requires-Dist: librosa; extra == "all"
+Requires-Dist: pyctcdecode>=0.4.0; extra == "all"
+Requires-Dist: phonemizer; extra == "all"
+Requires-Dist: kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5 ; extra == "all"
+Requires-Dist: Pillow<=15.0,>=10.0.1; extra == "all"
+Requires-Dist: kernels<0.5,>=0.4.4; extra == "all"
+Requires-Dist: optuna; extra == "all"
+Requires-Dist: ray[tune]>=2.7.0; extra == "all"
+Requires-Dist: sigopt; extra == "all"
+Requires-Dist: timm<=1.0.11; extra == "all"
+Requires-Dist: torchvision; extra == "all"
+Requires-Dist: Pillow<=15.0,>=10.0.1; extra == "all"
+Requires-Dist: codecarbon>=2.8.1; extra == "all"
+Requires-Dist: accelerate>=0.26.0; extra == "all"
+Requires-Dist: av; extra == "all"
+Requires-Dist: num2words; extra == "all"
+Provides-Extra: dev-torch
+Requires-Dist: pytest<8.0.0,>=7.2.0; extra == "dev-torch"
+Requires-Dist: pytest-asyncio; extra == "dev-torch"
+Requires-Dist: pytest-rich; extra == "dev-torch"
+Requires-Dist: pytest-xdist; extra == "dev-torch"
+Requires-Dist: pytest-order; extra == "dev-torch"
+Requires-Dist: pytest-rerunfailures; extra == "dev-torch"
+Requires-Dist: timeout-decorator; extra == "dev-torch"
+Requires-Dist: parameterized; extra == "dev-torch"
+Requires-Dist: psutil; extra == "dev-torch"
+Requires-Dist: datasets!=2.5.0; extra == "dev-torch"
+Requires-Dist: dill<0.3.5; extra == "dev-torch"
+Requires-Dist: evaluate>=0.2.0; extra == "dev-torch"
+Requires-Dist: pytest-timeout; extra == "dev-torch"
+Requires-Dist: ruff==0.11.2; extra == "dev-torch"
+Requires-Dist: rouge-score!=0.0.7,!=0.0.8,!=0.1,!=0.1.1; extra == "dev-torch"
+Requires-Dist: nltk<=3.8.1; extra == "dev-torch"
+Requires-Dist: GitPython<3.1.19; extra == "dev-torch"
+Requires-Dist: sacremoses; extra == "dev-torch"
+Requires-Dist: rjieba; extra == "dev-torch"
+Requires-Dist: beautifulsoup4; extra == "dev-torch"
+Requires-Dist: tensorboard; extra == "dev-torch"
+Requires-Dist: pydantic; extra == "dev-torch"
+Requires-Dist: sentencepiece!=0.1.92,>=0.1.91; extra == "dev-torch"
+Requires-Dist: sacrebleu<2.0.0,>=1.4.12; extra == "dev-torch"
+Requires-Dist: faiss-cpu; extra == "dev-torch"
+Requires-Dist: datasets!=2.5.0; extra == "dev-torch"
+Requires-Dist: cookiecutter==1.7.3; extra == "dev-torch"
+Requires-Dist: torch>=2.1; extra == "dev-torch"
+Requires-Dist: accelerate>=0.26.0; extra == "dev-torch"
+Requires-Dist: sentencepiece!=0.1.92,>=0.1.91; extra == "dev-torch"
+Requires-Dist: protobuf; extra == "dev-torch"
+Requires-Dist: tokenizers<0.22,>=0.21; extra == "dev-torch"
+Requires-Dist: torchaudio; extra == "dev-torch"
+Requires-Dist: librosa; extra == "dev-torch"
+Requires-Dist: pyctcdecode>=0.4.0; extra == "dev-torch"
+Requires-Dist: phonemizer; extra == "dev-torch"
+Requires-Dist: kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5 ; extra == "dev-torch"
+Requires-Dist: Pillow<=15.0,>=10.0.1; extra == "dev-torch"
+Requires-Dist: kernels<0.5,>=0.4.4; extra == "dev-torch"
+Requires-Dist: optuna; extra == "dev-torch"
+Requires-Dist: ray[tune]>=2.7.0; extra == "dev-torch"
+Requires-Dist: sigopt; extra == "dev-torch"
+Requires-Dist: timm<=1.0.11; extra == "dev-torch"
+Requires-Dist: torchvision; extra == "dev-torch"
+Requires-Dist: Pillow<=15.0,>=10.0.1; extra == "dev-torch"
+Requires-Dist: codecarbon>=2.8.1; extra == "dev-torch"
+Requires-Dist: datasets!=2.5.0; extra == "dev-torch"
+Requires-Dist: isort>=5.5.4; extra == "dev-torch"
+Requires-Dist: ruff==0.11.2; extra == "dev-torch"
+Requires-Dist: GitPython<3.1.19; extra == "dev-torch"
+Requires-Dist: urllib3<2.0.0; extra == "dev-torch"
+Requires-Dist: libcst; extra == "dev-torch"
+Requires-Dist: rich; extra == "dev-torch"
+Requires-Dist: fugashi>=1.0; extra == "dev-torch"
+Requires-Dist: ipadic<2.0,>=1.0.0; extra == "dev-torch"
+Requires-Dist: unidic_lite>=1.0.7; extra == "dev-torch"
+Requires-Dist: unidic>=1.0.2; extra == "dev-torch"
+Requires-Dist: sudachipy>=0.6.6; extra == "dev-torch"
+Requires-Dist: sudachidict_core>=20220729; extra == "dev-torch"
+Requires-Dist: rhoknp<1.3.1,>=1.1.0; extra == "dev-torch"
+Requires-Dist: scikit-learn; extra == "dev-torch"
+Requires-Dist: cookiecutter==1.7.3; extra == "dev-torch"
+Requires-Dist: onnxruntime>=1.4.0; extra == "dev-torch"
+Requires-Dist: onnxruntime-tools>=1.4.2; extra == "dev-torch"
+Requires-Dist: num2words; extra == "dev-torch"
+Provides-Extra: dev-tensorflow
+Requires-Dist: pytest<8.0.0,>=7.2.0; extra == "dev-tensorflow"
+Requires-Dist: pytest-asyncio; extra == "dev-tensorflow"
+Requires-Dist: pytest-rich; extra == "dev-tensorflow"
+Requires-Dist: pytest-xdist; extra == "dev-tensorflow"
+Requires-Dist: pytest-order; extra == "dev-tensorflow"
+Requires-Dist: pytest-rerunfailures; extra == "dev-tensorflow"
+Requires-Dist: timeout-decorator; extra == "dev-tensorflow"
+Requires-Dist: parameterized; extra == "dev-tensorflow"
+Requires-Dist: psutil; extra == "dev-tensorflow"
+Requires-Dist: datasets!=2.5.0; extra == "dev-tensorflow"
+Requires-Dist: dill<0.3.5; extra == "dev-tensorflow"
+Requires-Dist: evaluate>=0.2.0; extra == "dev-tensorflow"
+Requires-Dist: pytest-timeout; extra == "dev-tensorflow"
+Requires-Dist: ruff==0.11.2; extra == "dev-tensorflow"
+Requires-Dist: rouge-score!=0.0.7,!=0.0.8,!=0.1,!=0.1.1; extra == "dev-tensorflow"
+Requires-Dist: nltk<=3.8.1; extra == "dev-tensorflow"
+Requires-Dist: GitPython<3.1.19; extra == "dev-tensorflow"
+Requires-Dist: sacremoses; extra == "dev-tensorflow"
+Requires-Dist: rjieba; extra == "dev-tensorflow"
+Requires-Dist: beautifulsoup4; extra == "dev-tensorflow"
+Requires-Dist: tensorboard; extra == "dev-tensorflow"
+Requires-Dist: pydantic; extra == "dev-tensorflow"
+Requires-Dist: sentencepiece!=0.1.92,>=0.1.91; extra == "dev-tensorflow"
+Requires-Dist: sacrebleu<2.0.0,>=1.4.12; extra == "dev-tensorflow"
+Requires-Dist: faiss-cpu; extra == "dev-tensorflow"
+Requires-Dist: datasets!=2.5.0; extra == "dev-tensorflow"
+Requires-Dist: cookiecutter==1.7.3; extra == "dev-tensorflow"
+Requires-Dist: tensorflow<2.16,>2.9; extra == "dev-tensorflow"
+Requires-Dist: onnxconverter-common; extra == "dev-tensorflow"
+Requires-Dist: tf2onnx; extra == "dev-tensorflow"
+Requires-Dist: tensorflow-text<2.16; extra == "dev-tensorflow"
+Requires-Dist: keras-nlp<0.14.0,>=0.3.1; extra == "dev-tensorflow"
+Requires-Dist: sentencepiece!=0.1.92,>=0.1.91; extra == "dev-tensorflow"
+Requires-Dist: protobuf; extra == "dev-tensorflow"
+Requires-Dist: tokenizers<0.22,>=0.21; extra == "dev-tensorflow"
+Requires-Dist: Pillow<=15.0,>=10.0.1; extra == "dev-tensorflow"
+Requires-Dist: datasets!=2.5.0; extra == "dev-tensorflow"
+Requires-Dist: isort>=5.5.4; extra == "dev-tensorflow"
+Requires-Dist: ruff==0.11.2; extra == "dev-tensorflow"
+Requires-Dist: GitPython<3.1.19; extra == "dev-tensorflow"
+Requires-Dist: urllib3<2.0.0; extra == "dev-tensorflow"
+Requires-Dist: libcst; extra == "dev-tensorflow"
+Requires-Dist: rich; extra == "dev-tensorflow"
+Requires-Dist: scikit-learn; extra == "dev-tensorflow"
+Requires-Dist: cookiecutter==1.7.3; extra == "dev-tensorflow"
+Requires-Dist: onnxconverter-common; extra == "dev-tensorflow"
+Requires-Dist: tf2onnx; extra == "dev-tensorflow"
+Requires-Dist: onnxruntime>=1.4.0; extra == "dev-tensorflow"
+Requires-Dist: onnxruntime-tools>=1.4.2; extra == "dev-tensorflow"
+Requires-Dist: librosa; extra == "dev-tensorflow"
+Requires-Dist: pyctcdecode>=0.4.0; extra == "dev-tensorflow"
+Requires-Dist: phonemizer; extra == "dev-tensorflow"
+Requires-Dist: kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5 ; extra == "dev-tensorflow"
+Provides-Extra: dev
+Requires-Dist: tensorflow<2.16,>2.9; extra == "dev"
+Requires-Dist: onnxconverter-common; extra == "dev"
+Requires-Dist: tf2onnx; extra == "dev"
+Requires-Dist: tensorflow-text<2.16; extra == "dev"
+Requires-Dist: keras-nlp<0.14.0,>=0.3.1; extra == "dev"
+Requires-Dist: torch>=2.1; extra == "dev"
+Requires-Dist: accelerate>=0.26.0; extra == "dev"
+Requires-Dist: jax<=0.4.13,>=0.4.1; extra == "dev"
+Requires-Dist: jaxlib<=0.4.13,>=0.4.1; extra == "dev"
+Requires-Dist: flax<=0.7.0,>=0.4.1; extra == "dev"
+Requires-Dist: optax<=0.1.4,>=0.0.8; extra == "dev"
+Requires-Dist: scipy<1.13.0; extra == "dev"
+Requires-Dist: sentencepiece!=0.1.92,>=0.1.91; extra == "dev"
+Requires-Dist: protobuf; extra == "dev"
+Requires-Dist: tokenizers<0.22,>=0.21; extra == "dev"
+Requires-Dist: torchaudio; extra == "dev"
+Requires-Dist: librosa; extra == "dev"
+Requires-Dist: pyctcdecode>=0.4.0; extra == "dev"
+Requires-Dist: phonemizer; extra == "dev"
+Requires-Dist: kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5 ; extra == "dev"
+Requires-Dist: Pillow<=15.0,>=10.0.1; extra == "dev"
+Requires-Dist: kernels<0.5,>=0.4.4; extra == "dev"
+Requires-Dist: optuna; extra == "dev"
+Requires-Dist: ray[tune]>=2.7.0; extra == "dev"
+Requires-Dist: sigopt; extra == "dev"
+Requires-Dist: timm<=1.0.11; extra == "dev"
+Requires-Dist: torchvision; extra == "dev"
+Requires-Dist: Pillow<=15.0,>=10.0.1; extra == "dev"
+Requires-Dist: codecarbon>=2.8.1; extra == "dev"
+Requires-Dist: accelerate>=0.26.0; extra == "dev"
+Requires-Dist: av; extra == "dev"
+Requires-Dist: num2words; extra == "dev"
+Requires-Dist: pytest<8.0.0,>=7.2.0; extra == "dev"
+Requires-Dist: pytest-asyncio; extra == "dev"
+Requires-Dist: pytest-rich; extra == "dev"
+Requires-Dist: pytest-xdist; extra == "dev"
+Requires-Dist: pytest-order; extra == "dev"
+Requires-Dist: pytest-rerunfailures; extra == "dev"
+Requires-Dist: timeout-decorator; extra == "dev"
+Requires-Dist: parameterized; extra == "dev"
+Requires-Dist: psutil; extra == "dev"
+Requires-Dist: datasets!=2.5.0; extra == "dev"
+Requires-Dist: dill<0.3.5; extra == "dev"
+Requires-Dist: evaluate>=0.2.0; extra == "dev"
+Requires-Dist: pytest-timeout; extra == "dev"
+Requires-Dist: ruff==0.11.2; extra == "dev"
+Requires-Dist: rouge-score!=0.0.7,!=0.0.8,!=0.1,!=0.1.1; extra == "dev"
+Requires-Dist: nltk<=3.8.1; extra == "dev"
+Requires-Dist: GitPython<3.1.19; extra == "dev"
+Requires-Dist: sacremoses; extra == "dev"
+Requires-Dist: rjieba; extra == "dev"
+Requires-Dist: beautifulsoup4; extra == "dev"
+Requires-Dist: tensorboard; extra == "dev"
+Requires-Dist: pydantic; extra == "dev"
+Requires-Dist: sentencepiece!=0.1.92,>=0.1.91; extra == "dev"
+Requires-Dist: sacrebleu<2.0.0,>=1.4.12; extra == "dev"
+Requires-Dist: faiss-cpu; extra == "dev"
+Requires-Dist: datasets!=2.5.0; extra == "dev"
+Requires-Dist: cookiecutter==1.7.3; extra == "dev"
+Requires-Dist: datasets!=2.5.0; extra == "dev"
+Requires-Dist: isort>=5.5.4; extra == "dev"
+Requires-Dist: ruff==0.11.2; extra == "dev"
+Requires-Dist: GitPython<3.1.19; extra == "dev"
+Requires-Dist: urllib3<2.0.0; extra == "dev"
+Requires-Dist: libcst; extra == "dev"
+Requires-Dist: rich; extra == "dev"
+Requires-Dist: fugashi>=1.0; extra == "dev"
+Requires-Dist: ipadic<2.0,>=1.0.0; extra == "dev"
+Requires-Dist: unidic_lite>=1.0.7; extra == "dev"
+Requires-Dist: unidic>=1.0.2; extra == "dev"
+Requires-Dist: sudachipy>=0.6.6; extra == "dev"
+Requires-Dist: sudachidict_core>=20220729; extra == "dev"
+Requires-Dist: rhoknp<1.3.1,>=1.1.0; extra == "dev"
+Requires-Dist: scikit-learn; extra == "dev"
+Requires-Dist: cookiecutter==1.7.3; extra == "dev"
+Provides-Extra: torchhub
+Requires-Dist: filelock; extra == "torchhub"
+Requires-Dist: huggingface-hub<1.0,>=0.30.0; extra == "torchhub"
+Requires-Dist: importlib_metadata; extra == "torchhub"
+Requires-Dist: numpy>=1.17; extra == "torchhub"
+Requires-Dist: packaging>=20.0; extra == "torchhub"
+Requires-Dist: protobuf; extra == "torchhub"
+Requires-Dist: regex!=2019.12.17; extra == "torchhub"
+Requires-Dist: requests; extra == "torchhub"
+Requires-Dist: sentencepiece!=0.1.92,>=0.1.91; extra == "torchhub"
+Requires-Dist: torch>=2.1; extra == "torchhub"
+Requires-Dist: tokenizers<0.22,>=0.21; extra == "torchhub"
+Requires-Dist: tqdm>=4.27; extra == "torchhub"
+Provides-Extra: benchmark
+Requires-Dist: optimum-benchmark>=0.3.0; extra == "benchmark"
+Dynamic: author
+Dynamic: author-email
+Dynamic: classifier
+Dynamic: description
+Dynamic: description-content-type
+Dynamic: home-page
+Dynamic: keywords
+Dynamic: license
+Dynamic: license-file
+Dynamic: provides-extra
+Dynamic: requires-dist
+Dynamic: requires-python
+Dynamic: summary
+
+
+
+
State-of-the-art pretrained models for inference and training
+
+
+
+
+
+
+Transformers is a library of pretrained text, computer vision, audio, video, and multimodal models for inference and training. Use Transformers to fine-tune models on your data, build inference applications, and for generative AI use cases across multiple modalities.
+
+There are over 500K+ Transformers [model checkpoints](https://huggingface.co/models?library=transformers&sort=trending) on the [Hugging Face Hub](https://huggingface.com/models) you can use.
+
+Explore the [Hub](https://huggingface.com/) today to find a model and use Transformers to help you get started right away.
+
+## Installation
+
+Transformers works with Python 3.9+ [PyTorch](https://pytorch.org/get-started/locally/) 2.1+, [TensorFlow](https://www.tensorflow.org/install/pip) 2.6+, and [Flax](https://flax.readthedocs.io/en/latest/) 0.4.1+.
+
+Create and activate a virtual environment with [venv](https://docs.python.org/3/library/venv.html) or [uv](https://docs.astral.sh/uv/), a fast Rust-based Python package and project manager.
+
+```py
+# venv
+python -m venv .my-env
+source .my-env/bin/activate
+
+# uv
+uv venv .my-env
+source .my-env/bin/activate
+```
+
+Install Transformers in your virtual environment.
+
+```py
+# pip
+pip install transformers
+
+# uv
+uv pip install transformers
+```
+
+Install Transformers from source if you want the latest changes in the library or are interested in contributing. However, the *latest* version may not be stable. Feel free to open an [issue](https://github.com/huggingface/transformers/issues) if you encounter an error.
+
+```shell
+git clone https://github.com/huggingface/transformers.git
+cd transformers
+pip install .
+```
+
+## Quickstart
+
+Get started with Transformers right away with the [Pipeline](https://huggingface.co/docs/transformers/pipeline_tutorial) API. The `Pipeline` is a high-level inference class that supports text, audio, vision, and multimodal tasks. It handles preprocessing the input and returns the appropriate output.
+
+Instantiate a pipeline and specify model to use for text generation. The model is downloaded and cached so you can easily reuse it again. Finally, pass some text to prompt the model.
+
+```py
+from transformers import pipeline
+
+pipeline = pipeline(task="text-generation", model="Qwen/Qwen2.5-1.5B")
+pipeline("the secret to baking a really good cake is ")
+[{'generated_text': 'the secret to baking a really good cake is 1) to use the right ingredients and 2) to follow the recipe exactly. the recipe for the cake is as follows: 1 cup of sugar, 1 cup of flour, 1 cup of milk, 1 cup of butter, 1 cup of eggs, 1 cup of chocolate chips. if you want to make 2 cakes, how much sugar do you need? To make 2 cakes, you will need 2 cups of sugar.'}]
+```
+
+To chat with a model, the usage pattern is the same. The only difference is you need to construct a chat history (the input to `Pipeline`) between you and the system.
+
+> [!TIP]
+> You can also chat with a model directly from the command line.
+> ```shell
+> transformers-cli chat --model_name_or_path Qwen/Qwen2.5-0.5B-Instruct
+> ```
+
+```py
+import torch
+from transformers import pipeline
+
+chat = [
+ {"role": "system", "content": "You are a sassy, wise-cracking robot as imagined by Hollywood circa 1986."},
+ {"role": "user", "content": "Hey, can you tell me any fun things to do in New York?"}
+]
+
+pipeline = pipeline(task="text-generation", model="meta-llama/Meta-Llama-3-8B-Instruct", torch_dtype=torch.bfloat16, device_map="auto")
+response = pipeline(chat, max_new_tokens=512)
+print(response[0]["generated_text"][-1]["content"])
+```
+
+Expand the examples below to see how `Pipeline` works for different modalities and tasks.
+
+
+Automatic speech recognition
+
+```py
+from transformers import pipeline
+
+pipeline = pipeline(task="automatic-speech-recognition", model="openai/whisper-large-v3")
+pipeline("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
+{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
+```
+
+
+
+
+Image classification
+
+
+
+```py
+from transformers import pipeline
+
+pipeline = pipeline(task="visual-question-answering", model="Salesforce/blip-vqa-base")
+pipeline(
+ image="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/idefics-few-shot.jpg",
+ question="What is in the image?",
+)
+[{'answer': 'statue of liberty'}]
+```
+
+
+
+## Why should I use Transformers?
+
+1. Easy-to-use state-of-the-art models:
+ - High performance on natural language understanding & generation, computer vision, audio, video, and multimodal tasks.
+ - Low barrier to entry for researchers, engineers, and developers.
+ - Few user-facing abstractions with just three classes to learn.
+ - A unified API for using all our pretrained models.
+
+1. Lower compute costs, smaller carbon footprint:
+ - Share trained models instead of training from scratch.
+ - Reduce compute time and production costs.
+ - Dozens of model architectures with 1M+ pretrained checkpoints across all modalities.
+
+1. Choose the right framework for every part of a models lifetime:
+ - Train state-of-the-art models in 3 lines of code.
+ - Move a single model between PyTorch/JAX/TF2.0 frameworks at will.
+ - Pick the right framework for training, evaluation, and production.
+
+1. Easily customize a model or an example to your needs:
+ - We provide examples for each architecture to reproduce the results published by its original authors.
+ - Model internals are exposed as consistently as possible.
+ - Model files can be used independently of the library for quick experiments.
+
+
+
+
+
+## Why shouldn't I use Transformers?
+
+- This library is not a modular toolbox of building blocks for neural nets. The code in the model files is not refactored with additional abstractions on purpose, so that researchers can quickly iterate on each of the models without diving into additional abstractions/files.
+- The training API is optimized to work with PyTorch models provided by Transformers. For generic machine learning loops, you should use another library like [Accelerate](https://huggingface.co/docs/accelerate).
+- The [example scripts]((https://github.com/huggingface/transformers/tree/main/examples)) are only *examples*. They may not necessarily work out-of-the-box on your specific use case and you'll need to adapt the code for it to work.
+
+## 100 projects using Transformers
+
+Transformers is more than a toolkit to use pretrained models, it's a community of projects built around it and the
+Hugging Face Hub. We want Transformers to enable developers, researchers, students, professors, engineers, and anyone
+else to build their dream projects.
+
+In order to celebrate Transformers 100,000 stars, we wanted to put the spotlight on the
+community with the [awesome-transformers](./awesome-transformers.md) page which lists 100
+incredible projects built with Transformers.
+
+If you own or use a project that you believe should be part of the list, please open a PR to add it!
+
+## Example models
+
+You can test most of our models directly on their [Hub model pages](https://huggingface.co/models).
+
+Expand each modality below to see a few example models for various use cases.
+
+
+Audio
+
+- Audio classification with [Whisper](https://huggingface.co/openai/whisper-large-v3-turbo)
+- Automatic speech recognition with [Moonshine](https://huggingface.co/UsefulSensors/moonshine)
+- Keyword spotting with [Wav2Vec2](https://huggingface.co/superb/wav2vec2-base-superb-ks)
+- Speech to speech generation with [Moshi](https://huggingface.co/kyutai/moshiko-pytorch-bf16)
+- Text to audio with [MusicGen](https://huggingface.co/facebook/musicgen-large)
+- Text to speech with [Bark](https://huggingface.co/suno/bark)
+
+
+
+
+Computer vision
+
+- Automatic mask generation with [SAM](https://huggingface.co/facebook/sam-vit-base)
+- Depth estimation with [DepthPro](https://huggingface.co/apple/DepthPro-hf)
+- Image classification with [DINO v2](https://huggingface.co/facebook/dinov2-base)
+- Keypoint detection with [SuperGlue](https://huggingface.co/magic-leap-community/superglue_outdoor)
+- Keypoint matching with [SuperGlue](https://huggingface.co/magic-leap-community/superglue)
+- Object detection with [RT-DETRv2](https://huggingface.co/PekingU/rtdetr_v2_r50vd)
+- Pose Estimation with [VitPose](https://huggingface.co/usyd-community/vitpose-base-simple)
+- Universal segmentation with [OneFormer](https://huggingface.co/shi-labs/oneformer_ade20k_swin_large)
+- Video classification with [VideoMAE](https://huggingface.co/MCG-NJU/videomae-large)
+
+
+
+
+Multimodal
+
+- Audio or text to text with [Qwen2-Audio](https://huggingface.co/Qwen/Qwen2-Audio-7B)
+- Document question answering with [LayoutLMv3](https://huggingface.co/microsoft/layoutlmv3-base)
+- Image or text to text with [Qwen-VL](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct)
+- Image captioning [BLIP-2](https://huggingface.co/Salesforce/blip2-opt-2.7b)
+- OCR-based document understanding with [GOT-OCR2](https://huggingface.co/stepfun-ai/GOT-OCR-2.0-hf)
+- Table question answering with [TAPAS](https://huggingface.co/google/tapas-base)
+- Unified multimodal understanding and generation with [Emu3](https://huggingface.co/BAAI/Emu3-Gen)
+- Vision to text with [Llava-OneVision](https://huggingface.co/llava-hf/llava-onevision-qwen2-0.5b-ov-hf)
+- Visual question answering with [Llava](https://huggingface.co/llava-hf/llava-1.5-7b-hf)
+- Visual referring expression segmentation with [Kosmos-2](https://huggingface.co/microsoft/kosmos-2-patch14-224)
+
+
+
+
+NLP
+
+- Masked word completion with [ModernBERT](https://huggingface.co/answerdotai/ModernBERT-base)
+- Named entity recognition with [Gemma](https://huggingface.co/google/gemma-2-2b)
+- Question answering with [Mixtral](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1)
+- Summarization with [BART](https://huggingface.co/facebook/bart-large-cnn)
+- Translation with [T5](https://huggingface.co/google-t5/t5-base)
+- Text generation with [Llama](https://huggingface.co/meta-llama/Llama-3.2-1B)
+- Text classification with [Qwen](https://huggingface.co/Qwen/Qwen2.5-0.5B)
+
+
+
+## Citation
+
+We now have a [paper](https://www.aclweb.org/anthology/2020.emnlp-demos.6/) you can cite for the 🤗 Transformers library:
+```bibtex
+@inproceedings{wolf-etal-2020-transformers,
+ title = "Transformers: State-of-the-Art Natural Language Processing",
+ author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
+ booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
+ month = oct,
+ year = "2020",
+ address = "Online",
+ publisher = "Association for Computational Linguistics",
+ url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
+ pages = "38--45"
+}
+```
diff --git a/docs/transformers/src/transformers.egg-info/SOURCES.txt b/docs/transformers/src/transformers.egg-info/SOURCES.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e7ac5975b9ec6c9152d92b4e897a70f32109f70c
--- /dev/null
+++ b/docs/transformers/src/transformers.egg-info/SOURCES.txt
@@ -0,0 +1,2147 @@
+LICENSE
+README.md
+pyproject.toml
+setup.py
+src/transformers/__init__.py
+src/transformers/activations.py
+src/transformers/activations_tf.py
+src/transformers/audio_utils.py
+src/transformers/cache_utils.py
+src/transformers/configuration_utils.py
+src/transformers/convert_graph_to_onnx.py
+src/transformers/convert_pytorch_checkpoint_to_tf2.py
+src/transformers/convert_slow_tokenizer.py
+src/transformers/convert_slow_tokenizers_checkpoints_to_fast.py
+src/transformers/convert_tf_hub_seq_to_seq_bert_to_pytorch.py
+src/transformers/debug_utils.py
+src/transformers/dependency_versions_check.py
+src/transformers/dependency_versions_table.py
+src/transformers/dynamic_module_utils.py
+src/transformers/feature_extraction_sequence_utils.py
+src/transformers/feature_extraction_utils.py
+src/transformers/file_utils.py
+src/transformers/hf_argparser.py
+src/transformers/hyperparameter_search.py
+src/transformers/image_processing_base.py
+src/transformers/image_processing_utils.py
+src/transformers/image_processing_utils_fast.py
+src/transformers/image_transforms.py
+src/transformers/image_utils.py
+src/transformers/keras_callbacks.py
+src/transformers/model_debugging_utils.py
+src/transformers/modelcard.py
+src/transformers/modeling_attn_mask_utils.py
+src/transformers/modeling_flash_attention_utils.py
+src/transformers/modeling_flax_outputs.py
+src/transformers/modeling_flax_pytorch_utils.py
+src/transformers/modeling_flax_utils.py
+src/transformers/modeling_gguf_pytorch_utils.py
+src/transformers/modeling_layers.py
+src/transformers/modeling_outputs.py
+src/transformers/modeling_rope_utils.py
+src/transformers/modeling_tf_outputs.py
+src/transformers/modeling_tf_pytorch_utils.py
+src/transformers/modeling_tf_utils.py
+src/transformers/modeling_utils.py
+src/transformers/optimization.py
+src/transformers/optimization_tf.py
+src/transformers/processing_utils.py
+src/transformers/py.typed
+src/transformers/pytorch_utils.py
+src/transformers/safetensors_conversion.py
+src/transformers/testing_utils.py
+src/transformers/tf_utils.py
+src/transformers/time_series_utils.py
+src/transformers/tokenization_utils.py
+src/transformers/tokenization_utils_base.py
+src/transformers/tokenization_utils_fast.py
+src/transformers/trainer.py
+src/transformers/trainer_callback.py
+src/transformers/trainer_pt_utils.py
+src/transformers/trainer_seq2seq.py
+src/transformers/trainer_utils.py
+src/transformers/training_args.py
+src/transformers/training_args_seq2seq.py
+src/transformers/training_args_tf.py
+src/transformers.egg-info/PKG-INFO
+src/transformers.egg-info/SOURCES.txt
+src/transformers.egg-info/dependency_links.txt
+src/transformers.egg-info/entry_points.txt
+src/transformers.egg-info/not-zip-safe
+src/transformers.egg-info/requires.txt
+src/transformers.egg-info/top_level.txt
+src/transformers/commands/__init__.py
+src/transformers/commands/add_fast_image_processor.py
+src/transformers/commands/add_new_model_like.py
+src/transformers/commands/chat.py
+src/transformers/commands/convert.py
+src/transformers/commands/download.py
+src/transformers/commands/env.py
+src/transformers/commands/run.py
+src/transformers/commands/serving.py
+src/transformers/commands/train.py
+src/transformers/commands/transformers_cli.py
+src/transformers/data/__init__.py
+src/transformers/data/data_collator.py
+src/transformers/data/datasets/__init__.py
+src/transformers/data/datasets/glue.py
+src/transformers/data/datasets/language_modeling.py
+src/transformers/data/datasets/squad.py
+src/transformers/data/metrics/__init__.py
+src/transformers/data/metrics/squad_metrics.py
+src/transformers/data/processors/__init__.py
+src/transformers/data/processors/glue.py
+src/transformers/data/processors/squad.py
+src/transformers/data/processors/utils.py
+src/transformers/data/processors/xnli.py
+src/transformers/generation/__init__.py
+src/transformers/generation/beam_constraints.py
+src/transformers/generation/beam_search.py
+src/transformers/generation/candidate_generator.py
+src/transformers/generation/configuration_utils.py
+src/transformers/generation/flax_logits_process.py
+src/transformers/generation/flax_utils.py
+src/transformers/generation/logits_process.py
+src/transformers/generation/stopping_criteria.py
+src/transformers/generation/streamers.py
+src/transformers/generation/tf_logits_process.py
+src/transformers/generation/tf_utils.py
+src/transformers/generation/utils.py
+src/transformers/generation/watermarking.py
+src/transformers/integrations/__init__.py
+src/transformers/integrations/accelerate.py
+src/transformers/integrations/aqlm.py
+src/transformers/integrations/awq.py
+src/transformers/integrations/bitnet.py
+src/transformers/integrations/bitsandbytes.py
+src/transformers/integrations/deepspeed.py
+src/transformers/integrations/eetq.py
+src/transformers/integrations/executorch.py
+src/transformers/integrations/fbgemm_fp8.py
+src/transformers/integrations/finegrained_fp8.py
+src/transformers/integrations/flash_attention.py
+src/transformers/integrations/flex_attention.py
+src/transformers/integrations/fsdp.py
+src/transformers/integrations/ggml.py
+src/transformers/integrations/higgs.py
+src/transformers/integrations/hqq.py
+src/transformers/integrations/hub_kernels.py
+src/transformers/integrations/integration_utils.py
+src/transformers/integrations/mistral.py
+src/transformers/integrations/npu_flash_attention.py
+src/transformers/integrations/peft.py
+src/transformers/integrations/quanto.py
+src/transformers/integrations/sdpa_attention.py
+src/transformers/integrations/spqr.py
+src/transformers/integrations/tensor_parallel.py
+src/transformers/integrations/tiktoken.py
+src/transformers/integrations/tpu.py
+src/transformers/integrations/vptq.py
+src/transformers/kernels/__init__.py
+src/transformers/kernels/deta/ms_deform_attn.h
+src/transformers/kernels/deta/vision.cpp
+src/transformers/kernels/deta/cpu/ms_deform_attn_cpu.cpp
+src/transformers/kernels/deta/cpu/ms_deform_attn_cpu.h
+src/transformers/kernels/deta/cuda/ms_deform_attn_cuda.cu
+src/transformers/kernels/deta/cuda/ms_deform_attn_cuda.cuh
+src/transformers/kernels/deta/cuda/ms_deform_attn_cuda.h
+src/transformers/kernels/deta/cuda/ms_deform_im2col_cuda.cuh
+src/transformers/kernels/falcon_mamba/__init__.py
+src/transformers/kernels/falcon_mamba/selective_scan_with_ln_interface.py
+src/transformers/kernels/mra/cuda_kernel.cu
+src/transformers/kernels/mra/cuda_kernel.h
+src/transformers/kernels/mra/cuda_launch.cu
+src/transformers/kernels/mra/cuda_launch.h
+src/transformers/kernels/mra/torch_extension.cpp
+src/transformers/kernels/rwkv/wkv_cuda.cu
+src/transformers/kernels/rwkv/wkv_cuda_bf16.cu
+src/transformers/kernels/rwkv/wkv_op.cpp
+src/transformers/kernels/yoso/common.h
+src/transformers/kernels/yoso/common_cuda.h
+src/transformers/kernels/yoso/common_cuda_device.h
+src/transformers/kernels/yoso/fast_lsh_cumulation.cu
+src/transformers/kernels/yoso/fast_lsh_cumulation.h
+src/transformers/kernels/yoso/fast_lsh_cumulation_cuda.cu
+src/transformers/kernels/yoso/fast_lsh_cumulation_cuda.h
+src/transformers/kernels/yoso/fast_lsh_cumulation_torch.cpp
+src/transformers/loss/__init__.py
+src/transformers/loss/loss_deformable_detr.py
+src/transformers/loss/loss_for_object_detection.py
+src/transformers/loss/loss_grounding_dino.py
+src/transformers/loss/loss_rt_detr.py
+src/transformers/loss/loss_utils.py
+src/transformers/models/__init__.py
+src/transformers/models/albert/__init__.py
+src/transformers/models/albert/configuration_albert.py
+src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/albert/modeling_albert.py
+src/transformers/models/albert/modeling_flax_albert.py
+src/transformers/models/albert/modeling_tf_albert.py
+src/transformers/models/albert/tokenization_albert.py
+src/transformers/models/albert/tokenization_albert_fast.py
+src/transformers/models/align/__init__.py
+src/transformers/models/align/configuration_align.py
+src/transformers/models/align/convert_align_tf_to_hf.py
+src/transformers/models/align/modeling_align.py
+src/transformers/models/align/processing_align.py
+src/transformers/models/altclip/__init__.py
+src/transformers/models/altclip/configuration_altclip.py
+src/transformers/models/altclip/modeling_altclip.py
+src/transformers/models/altclip/processing_altclip.py
+src/transformers/models/aria/__init__.py
+src/transformers/models/aria/configuration_aria.py
+src/transformers/models/aria/convert_aria_weights_to_hf.py
+src/transformers/models/aria/image_processing_aria.py
+src/transformers/models/aria/modeling_aria.py
+src/transformers/models/aria/modular_aria.py
+src/transformers/models/aria/processing_aria.py
+src/transformers/models/audio_spectrogram_transformer/__init__.py
+src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py
+src/transformers/models/audio_spectrogram_transformer/convert_audio_spectrogram_transformer_original_to_pytorch.py
+src/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py
+src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py
+src/transformers/models/auto/__init__.py
+src/transformers/models/auto/auto_factory.py
+src/transformers/models/auto/configuration_auto.py
+src/transformers/models/auto/feature_extraction_auto.py
+src/transformers/models/auto/image_processing_auto.py
+src/transformers/models/auto/modeling_auto.py
+src/transformers/models/auto/modeling_flax_auto.py
+src/transformers/models/auto/modeling_tf_auto.py
+src/transformers/models/auto/processing_auto.py
+src/transformers/models/auto/tokenization_auto.py
+src/transformers/models/autoformer/__init__.py
+src/transformers/models/autoformer/configuration_autoformer.py
+src/transformers/models/autoformer/modeling_autoformer.py
+src/transformers/models/aya_vision/__init__.py
+src/transformers/models/aya_vision/configuration_aya_vision.py
+src/transformers/models/aya_vision/modeling_aya_vision.py
+src/transformers/models/aya_vision/modular_aya_vision.py
+src/transformers/models/aya_vision/processing_aya_vision.py
+src/transformers/models/bamba/__init__.py
+src/transformers/models/bamba/configuration_bamba.py
+src/transformers/models/bamba/convert_mamba_ssm_checkpoint.py
+src/transformers/models/bamba/modeling_bamba.py
+src/transformers/models/bamba/modular_bamba.py
+src/transformers/models/bark/__init__.py
+src/transformers/models/bark/configuration_bark.py
+src/transformers/models/bark/convert_suno_to_hf.py
+src/transformers/models/bark/generation_configuration_bark.py
+src/transformers/models/bark/modeling_bark.py
+src/transformers/models/bark/processing_bark.py
+src/transformers/models/bart/__init__.py
+src/transformers/models/bart/configuration_bart.py
+src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/bart/modeling_bart.py
+src/transformers/models/bart/modeling_flax_bart.py
+src/transformers/models/bart/modeling_tf_bart.py
+src/transformers/models/bart/tokenization_bart.py
+src/transformers/models/bart/tokenization_bart_fast.py
+src/transformers/models/barthez/__init__.py
+src/transformers/models/barthez/tokenization_barthez.py
+src/transformers/models/barthez/tokenization_barthez_fast.py
+src/transformers/models/bartpho/__init__.py
+src/transformers/models/bartpho/tokenization_bartpho.py
+src/transformers/models/beit/__init__.py
+src/transformers/models/beit/configuration_beit.py
+src/transformers/models/beit/convert_beit_unilm_to_pytorch.py
+src/transformers/models/beit/feature_extraction_beit.py
+src/transformers/models/beit/image_processing_beit.py
+src/transformers/models/beit/modeling_beit.py
+src/transformers/models/beit/modeling_flax_beit.py
+src/transformers/models/bert/__init__.py
+src/transformers/models/bert/configuration_bert.py
+src/transformers/models/bert/convert_bert_original_tf2_checkpoint_to_pytorch.py
+src/transformers/models/bert/convert_bert_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/bert/convert_bert_pytorch_checkpoint_to_original_tf.py
+src/transformers/models/bert/convert_bert_token_dropping_original_tf2_checkpoint_to_pytorch.py
+src/transformers/models/bert/modeling_bert.py
+src/transformers/models/bert/modeling_flax_bert.py
+src/transformers/models/bert/modeling_tf_bert.py
+src/transformers/models/bert/tokenization_bert.py
+src/transformers/models/bert/tokenization_bert_fast.py
+src/transformers/models/bert/tokenization_bert_tf.py
+src/transformers/models/bert_generation/__init__.py
+src/transformers/models/bert_generation/configuration_bert_generation.py
+src/transformers/models/bert_generation/modeling_bert_generation.py
+src/transformers/models/bert_generation/tokenization_bert_generation.py
+src/transformers/models/bert_japanese/__init__.py
+src/transformers/models/bert_japanese/tokenization_bert_japanese.py
+src/transformers/models/bertweet/__init__.py
+src/transformers/models/bertweet/tokenization_bertweet.py
+src/transformers/models/big_bird/__init__.py
+src/transformers/models/big_bird/configuration_big_bird.py
+src/transformers/models/big_bird/convert_bigbird_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/big_bird/modeling_big_bird.py
+src/transformers/models/big_bird/modeling_flax_big_bird.py
+src/transformers/models/big_bird/tokenization_big_bird.py
+src/transformers/models/big_bird/tokenization_big_bird_fast.py
+src/transformers/models/bigbird_pegasus/__init__.py
+src/transformers/models/bigbird_pegasus/configuration_bigbird_pegasus.py
+src/transformers/models/bigbird_pegasus/convert_bigbird_pegasus_tf_to_pytorch.py
+src/transformers/models/bigbird_pegasus/modeling_bigbird_pegasus.py
+src/transformers/models/biogpt/__init__.py
+src/transformers/models/biogpt/configuration_biogpt.py
+src/transformers/models/biogpt/convert_biogpt_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/biogpt/modeling_biogpt.py
+src/transformers/models/biogpt/tokenization_biogpt.py
+src/transformers/models/bit/__init__.py
+src/transformers/models/bit/configuration_bit.py
+src/transformers/models/bit/convert_bit_to_pytorch.py
+src/transformers/models/bit/image_processing_bit.py
+src/transformers/models/bit/image_processing_bit_fast.py
+src/transformers/models/bit/modeling_bit.py
+src/transformers/models/blenderbot/__init__.py
+src/transformers/models/blenderbot/configuration_blenderbot.py
+src/transformers/models/blenderbot/convert_blenderbot_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/blenderbot/modeling_blenderbot.py
+src/transformers/models/blenderbot/modeling_flax_blenderbot.py
+src/transformers/models/blenderbot/modeling_tf_blenderbot.py
+src/transformers/models/blenderbot/tokenization_blenderbot.py
+src/transformers/models/blenderbot/tokenization_blenderbot_fast.py
+src/transformers/models/blenderbot_small/__init__.py
+src/transformers/models/blenderbot_small/configuration_blenderbot_small.py
+src/transformers/models/blenderbot_small/modeling_blenderbot_small.py
+src/transformers/models/blenderbot_small/modeling_flax_blenderbot_small.py
+src/transformers/models/blenderbot_small/modeling_tf_blenderbot_small.py
+src/transformers/models/blenderbot_small/tokenization_blenderbot_small.py
+src/transformers/models/blenderbot_small/tokenization_blenderbot_small_fast.py
+src/transformers/models/blip/__init__.py
+src/transformers/models/blip/configuration_blip.py
+src/transformers/models/blip/convert_blip_original_pytorch_to_hf.py
+src/transformers/models/blip/image_processing_blip.py
+src/transformers/models/blip/image_processing_blip_fast.py
+src/transformers/models/blip/modeling_blip.py
+src/transformers/models/blip/modeling_blip_text.py
+src/transformers/models/blip/modeling_tf_blip.py
+src/transformers/models/blip/modeling_tf_blip_text.py
+src/transformers/models/blip/processing_blip.py
+src/transformers/models/blip_2/__init__.py
+src/transformers/models/blip_2/configuration_blip_2.py
+src/transformers/models/blip_2/convert_blip_2_original_to_pytorch.py
+src/transformers/models/blip_2/modeling_blip_2.py
+src/transformers/models/blip_2/processing_blip_2.py
+src/transformers/models/bloom/__init__.py
+src/transformers/models/bloom/configuration_bloom.py
+src/transformers/models/bloom/convert_bloom_original_checkpoint_to_pytorch.py
+src/transformers/models/bloom/modeling_bloom.py
+src/transformers/models/bloom/modeling_flax_bloom.py
+src/transformers/models/bloom/tokenization_bloom_fast.py
+src/transformers/models/bridgetower/__init__.py
+src/transformers/models/bridgetower/configuration_bridgetower.py
+src/transformers/models/bridgetower/image_processing_bridgetower.py
+src/transformers/models/bridgetower/image_processing_bridgetower_fast.py
+src/transformers/models/bridgetower/modeling_bridgetower.py
+src/transformers/models/bridgetower/processing_bridgetower.py
+src/transformers/models/bros/__init__.py
+src/transformers/models/bros/configuration_bros.py
+src/transformers/models/bros/convert_bros_to_pytorch.py
+src/transformers/models/bros/modeling_bros.py
+src/transformers/models/bros/processing_bros.py
+src/transformers/models/byt5/__init__.py
+src/transformers/models/byt5/convert_byt5_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/byt5/tokenization_byt5.py
+src/transformers/models/camembert/__init__.py
+src/transformers/models/camembert/configuration_camembert.py
+src/transformers/models/camembert/modeling_camembert.py
+src/transformers/models/camembert/modeling_tf_camembert.py
+src/transformers/models/camembert/tokenization_camembert.py
+src/transformers/models/camembert/tokenization_camembert_fast.py
+src/transformers/models/canine/__init__.py
+src/transformers/models/canine/configuration_canine.py
+src/transformers/models/canine/convert_canine_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/canine/modeling_canine.py
+src/transformers/models/canine/tokenization_canine.py
+src/transformers/models/chameleon/__init__.py
+src/transformers/models/chameleon/configuration_chameleon.py
+src/transformers/models/chameleon/convert_chameleon_weights_to_hf.py
+src/transformers/models/chameleon/image_processing_chameleon.py
+src/transformers/models/chameleon/modeling_chameleon.py
+src/transformers/models/chameleon/processing_chameleon.py
+src/transformers/models/chinese_clip/__init__.py
+src/transformers/models/chinese_clip/configuration_chinese_clip.py
+src/transformers/models/chinese_clip/convert_chinese_clip_original_pytorch_to_hf.py
+src/transformers/models/chinese_clip/feature_extraction_chinese_clip.py
+src/transformers/models/chinese_clip/image_processing_chinese_clip.py
+src/transformers/models/chinese_clip/image_processing_chinese_clip_fast.py
+src/transformers/models/chinese_clip/modeling_chinese_clip.py
+src/transformers/models/chinese_clip/processing_chinese_clip.py
+src/transformers/models/clap/__init__.py
+src/transformers/models/clap/configuration_clap.py
+src/transformers/models/clap/convert_clap_original_pytorch_to_hf.py
+src/transformers/models/clap/feature_extraction_clap.py
+src/transformers/models/clap/modeling_clap.py
+src/transformers/models/clap/processing_clap.py
+src/transformers/models/clip/__init__.py
+src/transformers/models/clip/configuration_clip.py
+src/transformers/models/clip/convert_clip_original_pytorch_to_hf.py
+src/transformers/models/clip/feature_extraction_clip.py
+src/transformers/models/clip/image_processing_clip.py
+src/transformers/models/clip/image_processing_clip_fast.py
+src/transformers/models/clip/modeling_clip.py
+src/transformers/models/clip/modeling_flax_clip.py
+src/transformers/models/clip/modeling_tf_clip.py
+src/transformers/models/clip/processing_clip.py
+src/transformers/models/clip/tokenization_clip.py
+src/transformers/models/clip/tokenization_clip_fast.py
+src/transformers/models/clipseg/__init__.py
+src/transformers/models/clipseg/configuration_clipseg.py
+src/transformers/models/clipseg/convert_clipseg_original_pytorch_to_hf.py
+src/transformers/models/clipseg/modeling_clipseg.py
+src/transformers/models/clipseg/processing_clipseg.py
+src/transformers/models/clvp/__init__.py
+src/transformers/models/clvp/configuration_clvp.py
+src/transformers/models/clvp/convert_clvp_to_hf.py
+src/transformers/models/clvp/feature_extraction_clvp.py
+src/transformers/models/clvp/modeling_clvp.py
+src/transformers/models/clvp/number_normalizer.py
+src/transformers/models/clvp/processing_clvp.py
+src/transformers/models/clvp/tokenization_clvp.py
+src/transformers/models/code_llama/__init__.py
+src/transformers/models/code_llama/tokenization_code_llama.py
+src/transformers/models/code_llama/tokenization_code_llama_fast.py
+src/transformers/models/codegen/__init__.py
+src/transformers/models/codegen/configuration_codegen.py
+src/transformers/models/codegen/modeling_codegen.py
+src/transformers/models/codegen/tokenization_codegen.py
+src/transformers/models/codegen/tokenization_codegen_fast.py
+src/transformers/models/cohere/__init__.py
+src/transformers/models/cohere/configuration_cohere.py
+src/transformers/models/cohere/modeling_cohere.py
+src/transformers/models/cohere/modular_cohere.py
+src/transformers/models/cohere/tokenization_cohere_fast.py
+src/transformers/models/cohere2/__init__.py
+src/transformers/models/cohere2/configuration_cohere2.py
+src/transformers/models/cohere2/modeling_cohere2.py
+src/transformers/models/cohere2/modular_cohere2.py
+src/transformers/models/colpali/__init__.py
+src/transformers/models/colpali/configuration_colpali.py
+src/transformers/models/colpali/convert_colpali_weights_to_hf.py
+src/transformers/models/colpali/modeling_colpali.py
+src/transformers/models/colpali/modular_colpali.py
+src/transformers/models/colpali/processing_colpali.py
+src/transformers/models/conditional_detr/__init__.py
+src/transformers/models/conditional_detr/configuration_conditional_detr.py
+src/transformers/models/conditional_detr/convert_conditional_detr_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/conditional_detr/feature_extraction_conditional_detr.py
+src/transformers/models/conditional_detr/image_processing_conditional_detr.py
+src/transformers/models/conditional_detr/image_processing_conditional_detr_fast.py
+src/transformers/models/conditional_detr/modeling_conditional_detr.py
+src/transformers/models/conditional_detr/modular_conditional_detr.py
+src/transformers/models/convbert/__init__.py
+src/transformers/models/convbert/configuration_convbert.py
+src/transformers/models/convbert/convert_convbert_original_tf1_checkpoint_to_pytorch_and_tf2.py
+src/transformers/models/convbert/modeling_convbert.py
+src/transformers/models/convbert/modeling_tf_convbert.py
+src/transformers/models/convbert/tokenization_convbert.py
+src/transformers/models/convbert/tokenization_convbert_fast.py
+src/transformers/models/convnext/__init__.py
+src/transformers/models/convnext/configuration_convnext.py
+src/transformers/models/convnext/convert_convnext_to_pytorch.py
+src/transformers/models/convnext/feature_extraction_convnext.py
+src/transformers/models/convnext/image_processing_convnext.py
+src/transformers/models/convnext/image_processing_convnext_fast.py
+src/transformers/models/convnext/modeling_convnext.py
+src/transformers/models/convnext/modeling_tf_convnext.py
+src/transformers/models/convnextv2/__init__.py
+src/transformers/models/convnextv2/configuration_convnextv2.py
+src/transformers/models/convnextv2/convert_convnextv2_to_pytorch.py
+src/transformers/models/convnextv2/modeling_convnextv2.py
+src/transformers/models/convnextv2/modeling_tf_convnextv2.py
+src/transformers/models/cpm/__init__.py
+src/transformers/models/cpm/tokenization_cpm.py
+src/transformers/models/cpm/tokenization_cpm_fast.py
+src/transformers/models/cpmant/__init__.py
+src/transformers/models/cpmant/configuration_cpmant.py
+src/transformers/models/cpmant/modeling_cpmant.py
+src/transformers/models/cpmant/tokenization_cpmant.py
+src/transformers/models/ctrl/__init__.py
+src/transformers/models/ctrl/configuration_ctrl.py
+src/transformers/models/ctrl/modeling_ctrl.py
+src/transformers/models/ctrl/modeling_tf_ctrl.py
+src/transformers/models/ctrl/tokenization_ctrl.py
+src/transformers/models/cvt/__init__.py
+src/transformers/models/cvt/configuration_cvt.py
+src/transformers/models/cvt/convert_cvt_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/cvt/modeling_cvt.py
+src/transformers/models/cvt/modeling_tf_cvt.py
+src/transformers/models/dab_detr/__init__.py
+src/transformers/models/dab_detr/configuration_dab_detr.py
+src/transformers/models/dab_detr/convert_dab_detr_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/dab_detr/modeling_dab_detr.py
+src/transformers/models/dac/__init__.py
+src/transformers/models/dac/configuration_dac.py
+src/transformers/models/dac/convert_dac_checkpoint.py
+src/transformers/models/dac/feature_extraction_dac.py
+src/transformers/models/dac/modeling_dac.py
+src/transformers/models/data2vec/__init__.py
+src/transformers/models/data2vec/configuration_data2vec_audio.py
+src/transformers/models/data2vec/configuration_data2vec_text.py
+src/transformers/models/data2vec/configuration_data2vec_vision.py
+src/transformers/models/data2vec/convert_data2vec_audio_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/data2vec/convert_data2vec_text_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/data2vec/convert_data2vec_vision_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/data2vec/modeling_data2vec_audio.py
+src/transformers/models/data2vec/modeling_data2vec_text.py
+src/transformers/models/data2vec/modeling_data2vec_vision.py
+src/transformers/models/data2vec/modeling_tf_data2vec_vision.py
+src/transformers/models/data2vec/modular_data2vec_audio.py
+src/transformers/models/dbrx/__init__.py
+src/transformers/models/dbrx/configuration_dbrx.py
+src/transformers/models/dbrx/modeling_dbrx.py
+src/transformers/models/deberta/__init__.py
+src/transformers/models/deberta/configuration_deberta.py
+src/transformers/models/deberta/modeling_deberta.py
+src/transformers/models/deberta/modeling_tf_deberta.py
+src/transformers/models/deberta/tokenization_deberta.py
+src/transformers/models/deberta/tokenization_deberta_fast.py
+src/transformers/models/deberta_v2/__init__.py
+src/transformers/models/deberta_v2/configuration_deberta_v2.py
+src/transformers/models/deberta_v2/modeling_deberta_v2.py
+src/transformers/models/deberta_v2/modeling_tf_deberta_v2.py
+src/transformers/models/deberta_v2/tokenization_deberta_v2.py
+src/transformers/models/deberta_v2/tokenization_deberta_v2_fast.py
+src/transformers/models/decision_transformer/__init__.py
+src/transformers/models/decision_transformer/configuration_decision_transformer.py
+src/transformers/models/decision_transformer/modeling_decision_transformer.py
+src/transformers/models/deepseek_v3/__init__.py
+src/transformers/models/deepseek_v3/configuration_deepseek_v3.py
+src/transformers/models/deepseek_v3/modeling_deepseek_v3.py
+src/transformers/models/deepseek_v3/modular_deepseek_v3.py
+src/transformers/models/deformable_detr/__init__.py
+src/transformers/models/deformable_detr/configuration_deformable_detr.py
+src/transformers/models/deformable_detr/convert_deformable_detr_to_pytorch.py
+src/transformers/models/deformable_detr/feature_extraction_deformable_detr.py
+src/transformers/models/deformable_detr/image_processing_deformable_detr.py
+src/transformers/models/deformable_detr/image_processing_deformable_detr_fast.py
+src/transformers/models/deformable_detr/modeling_deformable_detr.py
+src/transformers/models/deformable_detr/modular_deformable_detr.py
+src/transformers/models/deit/__init__.py
+src/transformers/models/deit/configuration_deit.py
+src/transformers/models/deit/convert_deit_timm_to_pytorch.py
+src/transformers/models/deit/feature_extraction_deit.py
+src/transformers/models/deit/image_processing_deit.py
+src/transformers/models/deit/image_processing_deit_fast.py
+src/transformers/models/deit/modeling_deit.py
+src/transformers/models/deit/modeling_tf_deit.py
+src/transformers/models/deprecated/__init__.py
+src/transformers/models/deprecated/bort/__init__.py
+src/transformers/models/deprecated/bort/convert_bort_original_gluonnlp_checkpoint_to_pytorch.py
+src/transformers/models/deprecated/deta/__init__.py
+src/transformers/models/deprecated/deta/configuration_deta.py
+src/transformers/models/deprecated/deta/convert_deta_resnet_to_pytorch.py
+src/transformers/models/deprecated/deta/convert_deta_swin_to_pytorch.py
+src/transformers/models/deprecated/deta/image_processing_deta.py
+src/transformers/models/deprecated/deta/modeling_deta.py
+src/transformers/models/deprecated/efficientformer/__init__.py
+src/transformers/models/deprecated/efficientformer/configuration_efficientformer.py
+src/transformers/models/deprecated/efficientformer/convert_efficientformer_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/deprecated/efficientformer/image_processing_efficientformer.py
+src/transformers/models/deprecated/efficientformer/modeling_efficientformer.py
+src/transformers/models/deprecated/efficientformer/modeling_tf_efficientformer.py
+src/transformers/models/deprecated/ernie_m/__init__.py
+src/transformers/models/deprecated/ernie_m/configuration_ernie_m.py
+src/transformers/models/deprecated/ernie_m/modeling_ernie_m.py
+src/transformers/models/deprecated/ernie_m/tokenization_ernie_m.py
+src/transformers/models/deprecated/gptsan_japanese/__init__.py
+src/transformers/models/deprecated/gptsan_japanese/configuration_gptsan_japanese.py
+src/transformers/models/deprecated/gptsan_japanese/convert_gptsan_tf_checkpoint_to_pytorch.py
+src/transformers/models/deprecated/gptsan_japanese/modeling_gptsan_japanese.py
+src/transformers/models/deprecated/gptsan_japanese/tokenization_gptsan_japanese.py
+src/transformers/models/deprecated/graphormer/__init__.py
+src/transformers/models/deprecated/graphormer/algos_graphormer.pyx
+src/transformers/models/deprecated/graphormer/collating_graphormer.py
+src/transformers/models/deprecated/graphormer/configuration_graphormer.py
+src/transformers/models/deprecated/graphormer/modeling_graphormer.py
+src/transformers/models/deprecated/jukebox/__init__.py
+src/transformers/models/deprecated/jukebox/configuration_jukebox.py
+src/transformers/models/deprecated/jukebox/convert_jukebox.py
+src/transformers/models/deprecated/jukebox/modeling_jukebox.py
+src/transformers/models/deprecated/jukebox/tokenization_jukebox.py
+src/transformers/models/deprecated/mctct/__init__.py
+src/transformers/models/deprecated/mctct/configuration_mctct.py
+src/transformers/models/deprecated/mctct/feature_extraction_mctct.py
+src/transformers/models/deprecated/mctct/modeling_mctct.py
+src/transformers/models/deprecated/mctct/processing_mctct.py
+src/transformers/models/deprecated/mega/__init__.py
+src/transformers/models/deprecated/mega/configuration_mega.py
+src/transformers/models/deprecated/mega/convert_mega_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/deprecated/mega/modeling_mega.py
+src/transformers/models/deprecated/mmbt/__init__.py
+src/transformers/models/deprecated/mmbt/configuration_mmbt.py
+src/transformers/models/deprecated/mmbt/modeling_mmbt.py
+src/transformers/models/deprecated/nat/__init__.py
+src/transformers/models/deprecated/nat/configuration_nat.py
+src/transformers/models/deprecated/nat/modeling_nat.py
+src/transformers/models/deprecated/nezha/__init__.py
+src/transformers/models/deprecated/nezha/configuration_nezha.py
+src/transformers/models/deprecated/nezha/modeling_nezha.py
+src/transformers/models/deprecated/open_llama/__init__.py
+src/transformers/models/deprecated/open_llama/configuration_open_llama.py
+src/transformers/models/deprecated/open_llama/modeling_open_llama.py
+src/transformers/models/deprecated/qdqbert/__init__.py
+src/transformers/models/deprecated/qdqbert/configuration_qdqbert.py
+src/transformers/models/deprecated/qdqbert/modeling_qdqbert.py
+src/transformers/models/deprecated/realm/__init__.py
+src/transformers/models/deprecated/realm/configuration_realm.py
+src/transformers/models/deprecated/realm/modeling_realm.py
+src/transformers/models/deprecated/realm/retrieval_realm.py
+src/transformers/models/deprecated/realm/tokenization_realm.py
+src/transformers/models/deprecated/realm/tokenization_realm_fast.py
+src/transformers/models/deprecated/retribert/__init__.py
+src/transformers/models/deprecated/retribert/configuration_retribert.py
+src/transformers/models/deprecated/retribert/modeling_retribert.py
+src/transformers/models/deprecated/retribert/tokenization_retribert.py
+src/transformers/models/deprecated/retribert/tokenization_retribert_fast.py
+src/transformers/models/deprecated/speech_to_text_2/__init__.py
+src/transformers/models/deprecated/speech_to_text_2/configuration_speech_to_text_2.py
+src/transformers/models/deprecated/speech_to_text_2/modeling_speech_to_text_2.py
+src/transformers/models/deprecated/speech_to_text_2/processing_speech_to_text_2.py
+src/transformers/models/deprecated/speech_to_text_2/tokenization_speech_to_text_2.py
+src/transformers/models/deprecated/tapex/__init__.py
+src/transformers/models/deprecated/tapex/tokenization_tapex.py
+src/transformers/models/deprecated/trajectory_transformer/__init__.py
+src/transformers/models/deprecated/trajectory_transformer/configuration_trajectory_transformer.py
+src/transformers/models/deprecated/trajectory_transformer/convert_trajectory_transformer_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/deprecated/trajectory_transformer/modeling_trajectory_transformer.py
+src/transformers/models/deprecated/transfo_xl/__init__.py
+src/transformers/models/deprecated/transfo_xl/configuration_transfo_xl.py
+src/transformers/models/deprecated/transfo_xl/convert_transfo_xl_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/deprecated/transfo_xl/modeling_tf_transfo_xl.py
+src/transformers/models/deprecated/transfo_xl/modeling_tf_transfo_xl_utilities.py
+src/transformers/models/deprecated/transfo_xl/modeling_transfo_xl.py
+src/transformers/models/deprecated/transfo_xl/modeling_transfo_xl_utilities.py
+src/transformers/models/deprecated/transfo_xl/tokenization_transfo_xl.py
+src/transformers/models/deprecated/tvlt/__init__.py
+src/transformers/models/deprecated/tvlt/configuration_tvlt.py
+src/transformers/models/deprecated/tvlt/feature_extraction_tvlt.py
+src/transformers/models/deprecated/tvlt/image_processing_tvlt.py
+src/transformers/models/deprecated/tvlt/modeling_tvlt.py
+src/transformers/models/deprecated/tvlt/processing_tvlt.py
+src/transformers/models/deprecated/van/__init__.py
+src/transformers/models/deprecated/van/configuration_van.py
+src/transformers/models/deprecated/van/convert_van_to_pytorch.py
+src/transformers/models/deprecated/van/modeling_van.py
+src/transformers/models/deprecated/vit_hybrid/__init__.py
+src/transformers/models/deprecated/vit_hybrid/configuration_vit_hybrid.py
+src/transformers/models/deprecated/vit_hybrid/convert_vit_hybrid_timm_to_pytorch.py
+src/transformers/models/deprecated/vit_hybrid/image_processing_vit_hybrid.py
+src/transformers/models/deprecated/vit_hybrid/modeling_vit_hybrid.py
+src/transformers/models/deprecated/xlm_prophetnet/__init__.py
+src/transformers/models/deprecated/xlm_prophetnet/configuration_xlm_prophetnet.py
+src/transformers/models/deprecated/xlm_prophetnet/modeling_xlm_prophetnet.py
+src/transformers/models/deprecated/xlm_prophetnet/tokenization_xlm_prophetnet.py
+src/transformers/models/depth_anything/__init__.py
+src/transformers/models/depth_anything/configuration_depth_anything.py
+src/transformers/models/depth_anything/convert_depth_anything_to_hf.py
+src/transformers/models/depth_anything/convert_distill_any_depth_to_hf.py
+src/transformers/models/depth_anything/modeling_depth_anything.py
+src/transformers/models/depth_pro/__init__.py
+src/transformers/models/depth_pro/configuration_depth_pro.py
+src/transformers/models/depth_pro/convert_depth_pro_weights_to_hf.py
+src/transformers/models/depth_pro/image_processing_depth_pro.py
+src/transformers/models/depth_pro/image_processing_depth_pro_fast.py
+src/transformers/models/depth_pro/modeling_depth_pro.py
+src/transformers/models/detr/__init__.py
+src/transformers/models/detr/configuration_detr.py
+src/transformers/models/detr/convert_detr_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/detr/convert_detr_to_pytorch.py
+src/transformers/models/detr/feature_extraction_detr.py
+src/transformers/models/detr/image_processing_detr.py
+src/transformers/models/detr/image_processing_detr_fast.py
+src/transformers/models/detr/modeling_detr.py
+src/transformers/models/dialogpt/__init__.py
+src/transformers/models/dialogpt/convert_dialogpt_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/diffllama/__init__.py
+src/transformers/models/diffllama/configuration_diffllama.py
+src/transformers/models/diffllama/modeling_diffllama.py
+src/transformers/models/diffllama/modular_diffllama.py
+src/transformers/models/dinat/__init__.py
+src/transformers/models/dinat/configuration_dinat.py
+src/transformers/models/dinat/modeling_dinat.py
+src/transformers/models/dinov2/__init__.py
+src/transformers/models/dinov2/configuration_dinov2.py
+src/transformers/models/dinov2/convert_dinov2_to_hf.py
+src/transformers/models/dinov2/modeling_dinov2.py
+src/transformers/models/dinov2/modeling_flax_dinov2.py
+src/transformers/models/dinov2_with_registers/__init__.py
+src/transformers/models/dinov2_with_registers/configuration_dinov2_with_registers.py
+src/transformers/models/dinov2_with_registers/convert_dinov2_with_registers_to_hf.py
+src/transformers/models/dinov2_with_registers/modeling_dinov2_with_registers.py
+src/transformers/models/dinov2_with_registers/modular_dinov2_with_registers.py
+src/transformers/models/distilbert/__init__.py
+src/transformers/models/distilbert/configuration_distilbert.py
+src/transformers/models/distilbert/modeling_distilbert.py
+src/transformers/models/distilbert/modeling_flax_distilbert.py
+src/transformers/models/distilbert/modeling_tf_distilbert.py
+src/transformers/models/distilbert/tokenization_distilbert.py
+src/transformers/models/distilbert/tokenization_distilbert_fast.py
+src/transformers/models/dit/__init__.py
+src/transformers/models/dit/convert_dit_unilm_to_pytorch.py
+src/transformers/models/donut/__init__.py
+src/transformers/models/donut/configuration_donut_swin.py
+src/transformers/models/donut/convert_donut_to_pytorch.py
+src/transformers/models/donut/feature_extraction_donut.py
+src/transformers/models/donut/image_processing_donut.py
+src/transformers/models/donut/image_processing_donut_fast.py
+src/transformers/models/donut/modeling_donut_swin.py
+src/transformers/models/donut/processing_donut.py
+src/transformers/models/dpr/__init__.py
+src/transformers/models/dpr/configuration_dpr.py
+src/transformers/models/dpr/convert_dpr_original_checkpoint_to_pytorch.py
+src/transformers/models/dpr/modeling_dpr.py
+src/transformers/models/dpr/modeling_tf_dpr.py
+src/transformers/models/dpr/tokenization_dpr.py
+src/transformers/models/dpr/tokenization_dpr_fast.py
+src/transformers/models/dpt/__init__.py
+src/transformers/models/dpt/configuration_dpt.py
+src/transformers/models/dpt/convert_dinov2_depth_to_hf.py
+src/transformers/models/dpt/convert_dpt_beit_to_hf.py
+src/transformers/models/dpt/convert_dpt_hybrid_to_pytorch.py
+src/transformers/models/dpt/convert_dpt_swinv2_to_hf.py
+src/transformers/models/dpt/convert_dpt_to_pytorch.py
+src/transformers/models/dpt/feature_extraction_dpt.py
+src/transformers/models/dpt/image_processing_dpt.py
+src/transformers/models/dpt/modeling_dpt.py
+src/transformers/models/efficientnet/__init__.py
+src/transformers/models/efficientnet/configuration_efficientnet.py
+src/transformers/models/efficientnet/convert_efficientnet_to_pytorch.py
+src/transformers/models/efficientnet/image_processing_efficientnet.py
+src/transformers/models/efficientnet/image_processing_efficientnet_fast.py
+src/transformers/models/efficientnet/modeling_efficientnet.py
+src/transformers/models/electra/__init__.py
+src/transformers/models/electra/configuration_electra.py
+src/transformers/models/electra/convert_electra_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/electra/modeling_electra.py
+src/transformers/models/electra/modeling_flax_electra.py
+src/transformers/models/electra/modeling_tf_electra.py
+src/transformers/models/electra/tokenization_electra.py
+src/transformers/models/electra/tokenization_electra_fast.py
+src/transformers/models/emu3/__init__.py
+src/transformers/models/emu3/configuration_emu3.py
+src/transformers/models/emu3/convert_emu3_weights_to_hf.py
+src/transformers/models/emu3/image_processing_emu3.py
+src/transformers/models/emu3/modeling_emu3.py
+src/transformers/models/emu3/modular_emu3.py
+src/transformers/models/emu3/processing_emu3.py
+src/transformers/models/encodec/__init__.py
+src/transformers/models/encodec/configuration_encodec.py
+src/transformers/models/encodec/convert_encodec_checkpoint_to_pytorch.py
+src/transformers/models/encodec/feature_extraction_encodec.py
+src/transformers/models/encodec/modeling_encodec.py
+src/transformers/models/encoder_decoder/__init__.py
+src/transformers/models/encoder_decoder/configuration_encoder_decoder.py
+src/transformers/models/encoder_decoder/modeling_encoder_decoder.py
+src/transformers/models/encoder_decoder/modeling_flax_encoder_decoder.py
+src/transformers/models/encoder_decoder/modeling_tf_encoder_decoder.py
+src/transformers/models/ernie/__init__.py
+src/transformers/models/ernie/configuration_ernie.py
+src/transformers/models/ernie/modeling_ernie.py
+src/transformers/models/esm/__init__.py
+src/transformers/models/esm/configuration_esm.py
+src/transformers/models/esm/convert_esm.py
+src/transformers/models/esm/modeling_esm.py
+src/transformers/models/esm/modeling_esmfold.py
+src/transformers/models/esm/modeling_tf_esm.py
+src/transformers/models/esm/tokenization_esm.py
+src/transformers/models/esm/openfold_utils/__init__.py
+src/transformers/models/esm/openfold_utils/chunk_utils.py
+src/transformers/models/esm/openfold_utils/data_transforms.py
+src/transformers/models/esm/openfold_utils/feats.py
+src/transformers/models/esm/openfold_utils/loss.py
+src/transformers/models/esm/openfold_utils/protein.py
+src/transformers/models/esm/openfold_utils/residue_constants.py
+src/transformers/models/esm/openfold_utils/rigid_utils.py
+src/transformers/models/esm/openfold_utils/tensor_utils.py
+src/transformers/models/falcon/__init__.py
+src/transformers/models/falcon/configuration_falcon.py
+src/transformers/models/falcon/convert_custom_code_checkpoint.py
+src/transformers/models/falcon/modeling_falcon.py
+src/transformers/models/falcon_mamba/__init__.py
+src/transformers/models/falcon_mamba/configuration_falcon_mamba.py
+src/transformers/models/falcon_mamba/modeling_falcon_mamba.py
+src/transformers/models/fastspeech2_conformer/__init__.py
+src/transformers/models/fastspeech2_conformer/configuration_fastspeech2_conformer.py
+src/transformers/models/fastspeech2_conformer/convert_fastspeech2_conformer_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/fastspeech2_conformer/convert_hifigan.py
+src/transformers/models/fastspeech2_conformer/convert_model_with_hifigan.py
+src/transformers/models/fastspeech2_conformer/modeling_fastspeech2_conformer.py
+src/transformers/models/fastspeech2_conformer/tokenization_fastspeech2_conformer.py
+src/transformers/models/flaubert/__init__.py
+src/transformers/models/flaubert/configuration_flaubert.py
+src/transformers/models/flaubert/modeling_flaubert.py
+src/transformers/models/flaubert/modeling_tf_flaubert.py
+src/transformers/models/flaubert/tokenization_flaubert.py
+src/transformers/models/flava/__init__.py
+src/transformers/models/flava/configuration_flava.py
+src/transformers/models/flava/convert_dalle_to_flava_codebook.py
+src/transformers/models/flava/convert_flava_original_pytorch_to_hf.py
+src/transformers/models/flava/feature_extraction_flava.py
+src/transformers/models/flava/image_processing_flava.py
+src/transformers/models/flava/image_processing_flava_fast.py
+src/transformers/models/flava/modeling_flava.py
+src/transformers/models/flava/processing_flava.py
+src/transformers/models/fnet/__init__.py
+src/transformers/models/fnet/configuration_fnet.py
+src/transformers/models/fnet/convert_fnet_original_flax_checkpoint_to_pytorch.py
+src/transformers/models/fnet/modeling_fnet.py
+src/transformers/models/fnet/tokenization_fnet.py
+src/transformers/models/fnet/tokenization_fnet_fast.py
+src/transformers/models/focalnet/__init__.py
+src/transformers/models/focalnet/configuration_focalnet.py
+src/transformers/models/focalnet/convert_focalnet_to_hf_format.py
+src/transformers/models/focalnet/modeling_focalnet.py
+src/transformers/models/fsmt/__init__.py
+src/transformers/models/fsmt/configuration_fsmt.py
+src/transformers/models/fsmt/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/fsmt/modeling_fsmt.py
+src/transformers/models/fsmt/tokenization_fsmt.py
+src/transformers/models/funnel/__init__.py
+src/transformers/models/funnel/configuration_funnel.py
+src/transformers/models/funnel/convert_funnel_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/funnel/modeling_funnel.py
+src/transformers/models/funnel/modeling_tf_funnel.py
+src/transformers/models/funnel/tokenization_funnel.py
+src/transformers/models/funnel/tokenization_funnel_fast.py
+src/transformers/models/fuyu/__init__.py
+src/transformers/models/fuyu/configuration_fuyu.py
+src/transformers/models/fuyu/convert_fuyu_model_weights_to_hf.py
+src/transformers/models/fuyu/image_processing_fuyu.py
+src/transformers/models/fuyu/modeling_fuyu.py
+src/transformers/models/fuyu/processing_fuyu.py
+src/transformers/models/gemma/__init__.py
+src/transformers/models/gemma/configuration_gemma.py
+src/transformers/models/gemma/convert_gemma_weights_to_hf.py
+src/transformers/models/gemma/modeling_flax_gemma.py
+src/transformers/models/gemma/modeling_gemma.py
+src/transformers/models/gemma/modular_gemma.py
+src/transformers/models/gemma/tokenization_gemma.py
+src/transformers/models/gemma/tokenization_gemma_fast.py
+src/transformers/models/gemma2/__init__.py
+src/transformers/models/gemma2/configuration_gemma2.py
+src/transformers/models/gemma2/convert_gemma2_weights_to_hf.py
+src/transformers/models/gemma2/modeling_gemma2.py
+src/transformers/models/gemma2/modular_gemma2.py
+src/transformers/models/gemma3/__init__.py
+src/transformers/models/gemma3/configuration_gemma3.py
+src/transformers/models/gemma3/convert_gemma3_weights_orbax_to_hf.py
+src/transformers/models/gemma3/image_processing_gemma3.py
+src/transformers/models/gemma3/image_processing_gemma3_fast.py
+src/transformers/models/gemma3/modeling_gemma3.py
+src/transformers/models/gemma3/modular_gemma3.py
+src/transformers/models/gemma3/processing_gemma3.py
+src/transformers/models/git/__init__.py
+src/transformers/models/git/configuration_git.py
+src/transformers/models/git/convert_git_to_pytorch.py
+src/transformers/models/git/modeling_git.py
+src/transformers/models/git/processing_git.py
+src/transformers/models/glm/__init__.py
+src/transformers/models/glm/configuration_glm.py
+src/transformers/models/glm/convert_glm_weights_to_hf.py
+src/transformers/models/glm/modeling_glm.py
+src/transformers/models/glm/modular_glm.py
+src/transformers/models/glm4/__init__.py
+src/transformers/models/glm4/configuration_glm4.py
+src/transformers/models/glm4/convert_glm4_weights_to_hf.py
+src/transformers/models/glm4/modeling_glm4.py
+src/transformers/models/glm4/modular_glm4.py
+src/transformers/models/glpn/__init__.py
+src/transformers/models/glpn/configuration_glpn.py
+src/transformers/models/glpn/convert_glpn_to_pytorch.py
+src/transformers/models/glpn/feature_extraction_glpn.py
+src/transformers/models/glpn/image_processing_glpn.py
+src/transformers/models/glpn/modeling_glpn.py
+src/transformers/models/got_ocr2/__init__.py
+src/transformers/models/got_ocr2/configuration_got_ocr2.py
+src/transformers/models/got_ocr2/convert_got_ocr2_weights_to_hf.py
+src/transformers/models/got_ocr2/image_processing_got_ocr2.py
+src/transformers/models/got_ocr2/image_processing_got_ocr2_fast.py
+src/transformers/models/got_ocr2/modeling_got_ocr2.py
+src/transformers/models/got_ocr2/modular_got_ocr2.py
+src/transformers/models/got_ocr2/processing_got_ocr2.py
+src/transformers/models/gpt2/__init__.py
+src/transformers/models/gpt2/configuration_gpt2.py
+src/transformers/models/gpt2/convert_gpt2_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/gpt2/modeling_flax_gpt2.py
+src/transformers/models/gpt2/modeling_gpt2.py
+src/transformers/models/gpt2/modeling_tf_gpt2.py
+src/transformers/models/gpt2/tokenization_gpt2.py
+src/transformers/models/gpt2/tokenization_gpt2_fast.py
+src/transformers/models/gpt2/tokenization_gpt2_tf.py
+src/transformers/models/gpt_bigcode/__init__.py
+src/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py
+src/transformers/models/gpt_bigcode/modeling_gpt_bigcode.py
+src/transformers/models/gpt_neo/__init__.py
+src/transformers/models/gpt_neo/configuration_gpt_neo.py
+src/transformers/models/gpt_neo/convert_gpt_neo_mesh_tf_to_pytorch.py
+src/transformers/models/gpt_neo/modeling_flax_gpt_neo.py
+src/transformers/models/gpt_neo/modeling_gpt_neo.py
+src/transformers/models/gpt_neox/__init__.py
+src/transformers/models/gpt_neox/configuration_gpt_neox.py
+src/transformers/models/gpt_neox/modeling_gpt_neox.py
+src/transformers/models/gpt_neox/modular_gpt_neox.py
+src/transformers/models/gpt_neox/tokenization_gpt_neox_fast.py
+src/transformers/models/gpt_neox_japanese/__init__.py
+src/transformers/models/gpt_neox_japanese/configuration_gpt_neox_japanese.py
+src/transformers/models/gpt_neox_japanese/modeling_gpt_neox_japanese.py
+src/transformers/models/gpt_neox_japanese/tokenization_gpt_neox_japanese.py
+src/transformers/models/gpt_sw3/__init__.py
+src/transformers/models/gpt_sw3/convert_megatron_to_pytorch.py
+src/transformers/models/gpt_sw3/tokenization_gpt_sw3.py
+src/transformers/models/gptj/__init__.py
+src/transformers/models/gptj/configuration_gptj.py
+src/transformers/models/gptj/modeling_flax_gptj.py
+src/transformers/models/gptj/modeling_gptj.py
+src/transformers/models/gptj/modeling_tf_gptj.py
+src/transformers/models/granite/__init__.py
+src/transformers/models/granite/configuration_granite.py
+src/transformers/models/granite/modeling_granite.py
+src/transformers/models/granite/modular_granite.py
+src/transformers/models/granite_speech/__init__.py
+src/transformers/models/granite_speech/configuration_granite_speech.py
+src/transformers/models/granite_speech/feature_extraction_granite_speech.py
+src/transformers/models/granite_speech/modeling_granite_speech.py
+src/transformers/models/granite_speech/processing_granite_speech.py
+src/transformers/models/granitemoe/__init__.py
+src/transformers/models/granitemoe/configuration_granitemoe.py
+src/transformers/models/granitemoe/modeling_granitemoe.py
+src/transformers/models/granitemoeshared/__init__.py
+src/transformers/models/granitemoeshared/configuration_granitemoeshared.py
+src/transformers/models/granitemoeshared/modeling_granitemoeshared.py
+src/transformers/models/granitemoeshared/modular_granitemoeshared.py
+src/transformers/models/grounding_dino/__init__.py
+src/transformers/models/grounding_dino/configuration_grounding_dino.py
+src/transformers/models/grounding_dino/convert_grounding_dino_to_hf.py
+src/transformers/models/grounding_dino/image_processing_grounding_dino.py
+src/transformers/models/grounding_dino/image_processing_grounding_dino_fast.py
+src/transformers/models/grounding_dino/modeling_grounding_dino.py
+src/transformers/models/grounding_dino/modular_grounding_dino.py
+src/transformers/models/grounding_dino/processing_grounding_dino.py
+src/transformers/models/groupvit/__init__.py
+src/transformers/models/groupvit/configuration_groupvit.py
+src/transformers/models/groupvit/convert_groupvit_nvlab_to_hf.py
+src/transformers/models/groupvit/modeling_groupvit.py
+src/transformers/models/groupvit/modeling_tf_groupvit.py
+src/transformers/models/helium/__init__.py
+src/transformers/models/helium/configuration_helium.py
+src/transformers/models/helium/modeling_helium.py
+src/transformers/models/helium/modular_helium.py
+src/transformers/models/herbert/__init__.py
+src/transformers/models/herbert/tokenization_herbert.py
+src/transformers/models/herbert/tokenization_herbert_fast.py
+src/transformers/models/hiera/__init__.py
+src/transformers/models/hiera/configuration_hiera.py
+src/transformers/models/hiera/convert_hiera_to_hf.py
+src/transformers/models/hiera/modeling_hiera.py
+src/transformers/models/hubert/__init__.py
+src/transformers/models/hubert/configuration_hubert.py
+src/transformers/models/hubert/convert_distilhubert_original_s3prl_checkpoint_to_pytorch.py
+src/transformers/models/hubert/convert_hubert_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/hubert/convert_hubert_original_s3prl_checkpoint_to_pytorch.py
+src/transformers/models/hubert/modeling_hubert.py
+src/transformers/models/hubert/modeling_tf_hubert.py
+src/transformers/models/hubert/modular_hubert.py
+src/transformers/models/ibert/__init__.py
+src/transformers/models/ibert/configuration_ibert.py
+src/transformers/models/ibert/modeling_ibert.py
+src/transformers/models/ibert/quant_modules.py
+src/transformers/models/idefics/__init__.py
+src/transformers/models/idefics/configuration_idefics.py
+src/transformers/models/idefics/image_processing_idefics.py
+src/transformers/models/idefics/modeling_idefics.py
+src/transformers/models/idefics/modeling_tf_idefics.py
+src/transformers/models/idefics/perceiver.py
+src/transformers/models/idefics/perceiver_tf.py
+src/transformers/models/idefics/processing_idefics.py
+src/transformers/models/idefics/vision.py
+src/transformers/models/idefics/vision_tf.py
+src/transformers/models/idefics2/__init__.py
+src/transformers/models/idefics2/configuration_idefics2.py
+src/transformers/models/idefics2/convert_idefics2_weights_to_hf.py
+src/transformers/models/idefics2/image_processing_idefics2.py
+src/transformers/models/idefics2/modeling_idefics2.py
+src/transformers/models/idefics2/processing_idefics2.py
+src/transformers/models/idefics3/__init__.py
+src/transformers/models/idefics3/configuration_idefics3.py
+src/transformers/models/idefics3/convert_idefics3_weights_to_hf.py
+src/transformers/models/idefics3/image_processing_idefics3.py
+src/transformers/models/idefics3/modeling_idefics3.py
+src/transformers/models/idefics3/processing_idefics3.py
+src/transformers/models/ijepa/__init__.py
+src/transformers/models/ijepa/configuration_ijepa.py
+src/transformers/models/ijepa/convert_ijepa_to_hf.py
+src/transformers/models/ijepa/modeling_ijepa.py
+src/transformers/models/ijepa/modular_ijepa.py
+src/transformers/models/imagegpt/__init__.py
+src/transformers/models/imagegpt/configuration_imagegpt.py
+src/transformers/models/imagegpt/convert_imagegpt_original_tf2_to_pytorch.py
+src/transformers/models/imagegpt/feature_extraction_imagegpt.py
+src/transformers/models/imagegpt/image_processing_imagegpt.py
+src/transformers/models/imagegpt/modeling_imagegpt.py
+src/transformers/models/informer/__init__.py
+src/transformers/models/informer/configuration_informer.py
+src/transformers/models/informer/modeling_informer.py
+src/transformers/models/instructblip/__init__.py
+src/transformers/models/instructblip/configuration_instructblip.py
+src/transformers/models/instructblip/convert_instructblip_original_to_pytorch.py
+src/transformers/models/instructblip/modeling_instructblip.py
+src/transformers/models/instructblip/processing_instructblip.py
+src/transformers/models/instructblipvideo/__init__.py
+src/transformers/models/instructblipvideo/configuration_instructblipvideo.py
+src/transformers/models/instructblipvideo/convert_instructblipvideo_original_to_pytorch.py
+src/transformers/models/instructblipvideo/image_processing_instructblipvideo.py
+src/transformers/models/instructblipvideo/modeling_instructblipvideo.py
+src/transformers/models/instructblipvideo/modular_instructblipvideo.py
+src/transformers/models/instructblipvideo/processing_instructblipvideo.py
+src/transformers/models/internvl/__init__.py
+src/transformers/models/internvl/configuration_internvl.py
+src/transformers/models/internvl/convert_internvl_weights_to_hf.py
+src/transformers/models/internvl/modeling_internvl.py
+src/transformers/models/internvl/modular_internvl.py
+src/transformers/models/internvl/processing_internvl.py
+src/transformers/models/jamba/__init__.py
+src/transformers/models/jamba/configuration_jamba.py
+src/transformers/models/jamba/modeling_jamba.py
+src/transformers/models/janus/__init__.py
+src/transformers/models/janus/configuration_janus.py
+src/transformers/models/janus/convert_janus_weights_to_hf.py
+src/transformers/models/janus/image_processing_janus.py
+src/transformers/models/janus/modeling_janus.py
+src/transformers/models/janus/modular_janus.py
+src/transformers/models/janus/processing_janus.py
+src/transformers/models/jetmoe/__init__.py
+src/transformers/models/jetmoe/configuration_jetmoe.py
+src/transformers/models/jetmoe/modeling_jetmoe.py
+src/transformers/models/kosmos2/__init__.py
+src/transformers/models/kosmos2/configuration_kosmos2.py
+src/transformers/models/kosmos2/convert_kosmos2_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/kosmos2/modeling_kosmos2.py
+src/transformers/models/kosmos2/processing_kosmos2.py
+src/transformers/models/layoutlm/__init__.py
+src/transformers/models/layoutlm/configuration_layoutlm.py
+src/transformers/models/layoutlm/modeling_layoutlm.py
+src/transformers/models/layoutlm/modeling_tf_layoutlm.py
+src/transformers/models/layoutlm/tokenization_layoutlm.py
+src/transformers/models/layoutlm/tokenization_layoutlm_fast.py
+src/transformers/models/layoutlmv2/__init__.py
+src/transformers/models/layoutlmv2/configuration_layoutlmv2.py
+src/transformers/models/layoutlmv2/feature_extraction_layoutlmv2.py
+src/transformers/models/layoutlmv2/image_processing_layoutlmv2.py
+src/transformers/models/layoutlmv2/image_processing_layoutlmv2_fast.py
+src/transformers/models/layoutlmv2/modeling_layoutlmv2.py
+src/transformers/models/layoutlmv2/processing_layoutlmv2.py
+src/transformers/models/layoutlmv2/tokenization_layoutlmv2.py
+src/transformers/models/layoutlmv2/tokenization_layoutlmv2_fast.py
+src/transformers/models/layoutlmv3/__init__.py
+src/transformers/models/layoutlmv3/configuration_layoutlmv3.py
+src/transformers/models/layoutlmv3/feature_extraction_layoutlmv3.py
+src/transformers/models/layoutlmv3/image_processing_layoutlmv3.py
+src/transformers/models/layoutlmv3/image_processing_layoutlmv3_fast.py
+src/transformers/models/layoutlmv3/modeling_layoutlmv3.py
+src/transformers/models/layoutlmv3/modeling_tf_layoutlmv3.py
+src/transformers/models/layoutlmv3/processing_layoutlmv3.py
+src/transformers/models/layoutlmv3/tokenization_layoutlmv3.py
+src/transformers/models/layoutlmv3/tokenization_layoutlmv3_fast.py
+src/transformers/models/layoutxlm/__init__.py
+src/transformers/models/layoutxlm/processing_layoutxlm.py
+src/transformers/models/layoutxlm/tokenization_layoutxlm.py
+src/transformers/models/layoutxlm/tokenization_layoutxlm_fast.py
+src/transformers/models/led/__init__.py
+src/transformers/models/led/configuration_led.py
+src/transformers/models/led/modeling_led.py
+src/transformers/models/led/modeling_tf_led.py
+src/transformers/models/led/tokenization_led.py
+src/transformers/models/led/tokenization_led_fast.py
+src/transformers/models/levit/__init__.py
+src/transformers/models/levit/configuration_levit.py
+src/transformers/models/levit/convert_levit_timm_to_pytorch.py
+src/transformers/models/levit/feature_extraction_levit.py
+src/transformers/models/levit/image_processing_levit.py
+src/transformers/models/levit/image_processing_levit_fast.py
+src/transformers/models/levit/modeling_levit.py
+src/transformers/models/lilt/__init__.py
+src/transformers/models/lilt/configuration_lilt.py
+src/transformers/models/lilt/modeling_lilt.py
+src/transformers/models/llama/__init__.py
+src/transformers/models/llama/configuration_llama.py
+src/transformers/models/llama/convert_llama_weights_to_hf.py
+src/transformers/models/llama/modeling_flax_llama.py
+src/transformers/models/llama/modeling_llama.py
+src/transformers/models/llama/tokenization_llama.py
+src/transformers/models/llama/tokenization_llama_fast.py
+src/transformers/models/llama4/__init__.py
+src/transformers/models/llama4/configuration_llama4.py
+src/transformers/models/llama4/convert_llama4_weights_to_hf.py
+src/transformers/models/llama4/image_processing_llama4_fast.py
+src/transformers/models/llama4/modeling_llama4.py
+src/transformers/models/llama4/processing_llama4.py
+src/transformers/models/llava/__init__.py
+src/transformers/models/llava/configuration_llava.py
+src/transformers/models/llava/convert_llava_weights_to_hf.py
+src/transformers/models/llava/image_processing_llava.py
+src/transformers/models/llava/image_processing_llava_fast.py
+src/transformers/models/llava/modeling_llava.py
+src/transformers/models/llava/processing_llava.py
+src/transformers/models/llava_next/__init__.py
+src/transformers/models/llava_next/configuration_llava_next.py
+src/transformers/models/llava_next/convert_llava_next_weights_to_hf.py
+src/transformers/models/llava_next/image_processing_llava_next.py
+src/transformers/models/llava_next/image_processing_llava_next_fast.py
+src/transformers/models/llava_next/modeling_llava_next.py
+src/transformers/models/llava_next/processing_llava_next.py
+src/transformers/models/llava_next_video/__init__.py
+src/transformers/models/llava_next_video/configuration_llava_next_video.py
+src/transformers/models/llava_next_video/convert_llava_next_video_weights_to_hf.py
+src/transformers/models/llava_next_video/image_processing_llava_next_video.py
+src/transformers/models/llava_next_video/modeling_llava_next_video.py
+src/transformers/models/llava_next_video/modular_llava_next_video.py
+src/transformers/models/llava_next_video/processing_llava_next_video.py
+src/transformers/models/llava_onevision/__init__.py
+src/transformers/models/llava_onevision/configuration_llava_onevision.py
+src/transformers/models/llava_onevision/convert_llava_onevision_weights_to_hf.py
+src/transformers/models/llava_onevision/image_processing_llava_onevision.py
+src/transformers/models/llava_onevision/image_processing_llava_onevision_fast.py
+src/transformers/models/llava_onevision/modeling_llava_onevision.py
+src/transformers/models/llava_onevision/modular_llava_onevision.py
+src/transformers/models/llava_onevision/processing_llava_onevision.py
+src/transformers/models/llava_onevision/video_processing_llava_onevision.py
+src/transformers/models/longformer/__init__.py
+src/transformers/models/longformer/configuration_longformer.py
+src/transformers/models/longformer/convert_longformer_original_pytorch_lightning_to_pytorch.py
+src/transformers/models/longformer/modeling_longformer.py
+src/transformers/models/longformer/modeling_tf_longformer.py
+src/transformers/models/longformer/tokenization_longformer.py
+src/transformers/models/longformer/tokenization_longformer_fast.py
+src/transformers/models/longt5/__init__.py
+src/transformers/models/longt5/configuration_longt5.py
+src/transformers/models/longt5/convert_longt5x_checkpoint_to_flax.py
+src/transformers/models/longt5/modeling_flax_longt5.py
+src/transformers/models/longt5/modeling_longt5.py
+src/transformers/models/luke/__init__.py
+src/transformers/models/luke/configuration_luke.py
+src/transformers/models/luke/convert_luke_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/luke/modeling_luke.py
+src/transformers/models/luke/tokenization_luke.py
+src/transformers/models/lxmert/__init__.py
+src/transformers/models/lxmert/configuration_lxmert.py
+src/transformers/models/lxmert/convert_lxmert_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/lxmert/modeling_lxmert.py
+src/transformers/models/lxmert/modeling_tf_lxmert.py
+src/transformers/models/lxmert/tokenization_lxmert.py
+src/transformers/models/lxmert/tokenization_lxmert_fast.py
+src/transformers/models/m2m_100/__init__.py
+src/transformers/models/m2m_100/configuration_m2m_100.py
+src/transformers/models/m2m_100/convert_m2m100_original_checkpoint_to_pytorch.py
+src/transformers/models/m2m_100/modeling_m2m_100.py
+src/transformers/models/m2m_100/tokenization_m2m_100.py
+src/transformers/models/mamba/__init__.py
+src/transformers/models/mamba/configuration_mamba.py
+src/transformers/models/mamba/convert_mamba_ssm_checkpoint_to_pytorch.py
+src/transformers/models/mamba/modeling_mamba.py
+src/transformers/models/mamba2/__init__.py
+src/transformers/models/mamba2/configuration_mamba2.py
+src/transformers/models/mamba2/convert_mamba2_ssm_checkpoint_to_pytorch.py
+src/transformers/models/mamba2/modeling_mamba2.py
+src/transformers/models/marian/__init__.py
+src/transformers/models/marian/configuration_marian.py
+src/transformers/models/marian/convert_marian_tatoeba_to_pytorch.py
+src/transformers/models/marian/convert_marian_to_pytorch.py
+src/transformers/models/marian/modeling_flax_marian.py
+src/transformers/models/marian/modeling_marian.py
+src/transformers/models/marian/modeling_tf_marian.py
+src/transformers/models/marian/tokenization_marian.py
+src/transformers/models/markuplm/__init__.py
+src/transformers/models/markuplm/configuration_markuplm.py
+src/transformers/models/markuplm/feature_extraction_markuplm.py
+src/transformers/models/markuplm/modeling_markuplm.py
+src/transformers/models/markuplm/processing_markuplm.py
+src/transformers/models/markuplm/tokenization_markuplm.py
+src/transformers/models/markuplm/tokenization_markuplm_fast.py
+src/transformers/models/mask2former/__init__.py
+src/transformers/models/mask2former/configuration_mask2former.py
+src/transformers/models/mask2former/convert_mask2former_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/mask2former/image_processing_mask2former.py
+src/transformers/models/mask2former/modeling_mask2former.py
+src/transformers/models/maskformer/__init__.py
+src/transformers/models/maskformer/configuration_maskformer.py
+src/transformers/models/maskformer/configuration_maskformer_swin.py
+src/transformers/models/maskformer/convert_maskformer_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/maskformer/convert_maskformer_resnet_to_pytorch.py
+src/transformers/models/maskformer/convert_maskformer_swin_to_pytorch.py
+src/transformers/models/maskformer/feature_extraction_maskformer.py
+src/transformers/models/maskformer/image_processing_maskformer.py
+src/transformers/models/maskformer/modeling_maskformer.py
+src/transformers/models/maskformer/modeling_maskformer_swin.py
+src/transformers/models/mbart/__init__.py
+src/transformers/models/mbart/configuration_mbart.py
+src/transformers/models/mbart/convert_mbart_original_checkpoint_to_pytorch.py
+src/transformers/models/mbart/modeling_flax_mbart.py
+src/transformers/models/mbart/modeling_mbart.py
+src/transformers/models/mbart/modeling_tf_mbart.py
+src/transformers/models/mbart/tokenization_mbart.py
+src/transformers/models/mbart/tokenization_mbart_fast.py
+src/transformers/models/mbart50/__init__.py
+src/transformers/models/mbart50/tokenization_mbart50.py
+src/transformers/models/mbart50/tokenization_mbart50_fast.py
+src/transformers/models/megatron_bert/__init__.py
+src/transformers/models/megatron_bert/configuration_megatron_bert.py
+src/transformers/models/megatron_bert/convert_megatron_bert_checkpoint.py
+src/transformers/models/megatron_bert/modeling_megatron_bert.py
+src/transformers/models/megatron_gpt2/__init__.py
+src/transformers/models/megatron_gpt2/checkpoint_reshaping_and_interoperability.py
+src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py
+src/transformers/models/mgp_str/__init__.py
+src/transformers/models/mgp_str/configuration_mgp_str.py
+src/transformers/models/mgp_str/modeling_mgp_str.py
+src/transformers/models/mgp_str/processing_mgp_str.py
+src/transformers/models/mgp_str/tokenization_mgp_str.py
+src/transformers/models/mimi/__init__.py
+src/transformers/models/mimi/configuration_mimi.py
+src/transformers/models/mimi/convert_mimi_checkpoint_to_pytorch.py
+src/transformers/models/mimi/modeling_mimi.py
+src/transformers/models/mistral/__init__.py
+src/transformers/models/mistral/configuration_mistral.py
+src/transformers/models/mistral/convert_mistral_weights_to_hf.py
+src/transformers/models/mistral/modeling_flax_mistral.py
+src/transformers/models/mistral/modeling_mistral.py
+src/transformers/models/mistral/modeling_tf_mistral.py
+src/transformers/models/mistral/modular_mistral.py
+src/transformers/models/mistral3/__init__.py
+src/transformers/models/mistral3/configuration_mistral3.py
+src/transformers/models/mistral3/convert_mistral3_weights_to_hf.py
+src/transformers/models/mistral3/modeling_mistral3.py
+src/transformers/models/mistral3/modular_mistral3.py
+src/transformers/models/mixtral/__init__.py
+src/transformers/models/mixtral/configuration_mixtral.py
+src/transformers/models/mixtral/convert_mixtral_weights_to_hf.py
+src/transformers/models/mixtral/modeling_mixtral.py
+src/transformers/models/mixtral/modular_mixtral.py
+src/transformers/models/mlcd/__init__.py
+src/transformers/models/mlcd/configuration_mlcd.py
+src/transformers/models/mlcd/convert_mlcd_weights_to_hf.py
+src/transformers/models/mlcd/modeling_mlcd.py
+src/transformers/models/mlcd/modular_mlcd.py
+src/transformers/models/mllama/__init__.py
+src/transformers/models/mllama/configuration_mllama.py
+src/transformers/models/mllama/convert_mllama_weights_to_hf.py
+src/transformers/models/mllama/image_processing_mllama.py
+src/transformers/models/mllama/modeling_mllama.py
+src/transformers/models/mllama/processing_mllama.py
+src/transformers/models/mluke/__init__.py
+src/transformers/models/mluke/convert_mluke_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/mluke/tokenization_mluke.py
+src/transformers/models/mobilebert/__init__.py
+src/transformers/models/mobilebert/configuration_mobilebert.py
+src/transformers/models/mobilebert/convert_mobilebert_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/mobilebert/modeling_mobilebert.py
+src/transformers/models/mobilebert/modeling_tf_mobilebert.py
+src/transformers/models/mobilebert/tokenization_mobilebert.py
+src/transformers/models/mobilebert/tokenization_mobilebert_fast.py
+src/transformers/models/mobilenet_v1/__init__.py
+src/transformers/models/mobilenet_v1/configuration_mobilenet_v1.py
+src/transformers/models/mobilenet_v1/convert_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/mobilenet_v1/feature_extraction_mobilenet_v1.py
+src/transformers/models/mobilenet_v1/image_processing_mobilenet_v1.py
+src/transformers/models/mobilenet_v1/image_processing_mobilenet_v1_fast.py
+src/transformers/models/mobilenet_v1/modeling_mobilenet_v1.py
+src/transformers/models/mobilenet_v2/__init__.py
+src/transformers/models/mobilenet_v2/configuration_mobilenet_v2.py
+src/transformers/models/mobilenet_v2/convert_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/mobilenet_v2/feature_extraction_mobilenet_v2.py
+src/transformers/models/mobilenet_v2/image_processing_mobilenet_v2.py
+src/transformers/models/mobilenet_v2/image_processing_mobilenet_v2_fast.py
+src/transformers/models/mobilenet_v2/modeling_mobilenet_v2.py
+src/transformers/models/mobilevit/__init__.py
+src/transformers/models/mobilevit/configuration_mobilevit.py
+src/transformers/models/mobilevit/convert_mlcvnets_to_pytorch.py
+src/transformers/models/mobilevit/feature_extraction_mobilevit.py
+src/transformers/models/mobilevit/image_processing_mobilevit.py
+src/transformers/models/mobilevit/modeling_mobilevit.py
+src/transformers/models/mobilevit/modeling_tf_mobilevit.py
+src/transformers/models/mobilevitv2/__init__.py
+src/transformers/models/mobilevitv2/configuration_mobilevitv2.py
+src/transformers/models/mobilevitv2/convert_mlcvnets_to_pytorch.py
+src/transformers/models/mobilevitv2/modeling_mobilevitv2.py
+src/transformers/models/modernbert/__init__.py
+src/transformers/models/modernbert/configuration_modernbert.py
+src/transformers/models/modernbert/modeling_modernbert.py
+src/transformers/models/modernbert/modular_modernbert.py
+src/transformers/models/moonshine/__init__.py
+src/transformers/models/moonshine/configuration_moonshine.py
+src/transformers/models/moonshine/convert_usefulsensors_to_hf.py
+src/transformers/models/moonshine/modeling_moonshine.py
+src/transformers/models/moonshine/modular_moonshine.py
+src/transformers/models/moshi/__init__.py
+src/transformers/models/moshi/configuration_moshi.py
+src/transformers/models/moshi/convert_moshi_transformers.py
+src/transformers/models/moshi/modeling_moshi.py
+src/transformers/models/mpnet/__init__.py
+src/transformers/models/mpnet/configuration_mpnet.py
+src/transformers/models/mpnet/modeling_mpnet.py
+src/transformers/models/mpnet/modeling_tf_mpnet.py
+src/transformers/models/mpnet/tokenization_mpnet.py
+src/transformers/models/mpnet/tokenization_mpnet_fast.py
+src/transformers/models/mpt/__init__.py
+src/transformers/models/mpt/configuration_mpt.py
+src/transformers/models/mpt/modeling_mpt.py
+src/transformers/models/mra/__init__.py
+src/transformers/models/mra/configuration_mra.py
+src/transformers/models/mra/convert_mra_pytorch_to_pytorch.py
+src/transformers/models/mra/modeling_mra.py
+src/transformers/models/mt5/__init__.py
+src/transformers/models/mt5/configuration_mt5.py
+src/transformers/models/mt5/modeling_flax_mt5.py
+src/transformers/models/mt5/modeling_mt5.py
+src/transformers/models/mt5/modeling_tf_mt5.py
+src/transformers/models/mt5/tokenization_mt5.py
+src/transformers/models/mt5/tokenization_mt5_fast.py
+src/transformers/models/musicgen/__init__.py
+src/transformers/models/musicgen/configuration_musicgen.py
+src/transformers/models/musicgen/convert_musicgen_transformers.py
+src/transformers/models/musicgen/modeling_musicgen.py
+src/transformers/models/musicgen/processing_musicgen.py
+src/transformers/models/musicgen_melody/__init__.py
+src/transformers/models/musicgen_melody/configuration_musicgen_melody.py
+src/transformers/models/musicgen_melody/convert_musicgen_melody_transformers.py
+src/transformers/models/musicgen_melody/feature_extraction_musicgen_melody.py
+src/transformers/models/musicgen_melody/modeling_musicgen_melody.py
+src/transformers/models/musicgen_melody/processing_musicgen_melody.py
+src/transformers/models/mvp/__init__.py
+src/transformers/models/mvp/configuration_mvp.py
+src/transformers/models/mvp/modeling_mvp.py
+src/transformers/models/mvp/tokenization_mvp.py
+src/transformers/models/mvp/tokenization_mvp_fast.py
+src/transformers/models/myt5/__init__.py
+src/transformers/models/myt5/convert_myt5_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/myt5/tokenization_myt5.py
+src/transformers/models/nemotron/__init__.py
+src/transformers/models/nemotron/configuration_nemotron.py
+src/transformers/models/nemotron/convert_nemotron_nemo_to_hf.py
+src/transformers/models/nemotron/modeling_nemotron.py
+src/transformers/models/nllb/__init__.py
+src/transformers/models/nllb/tokenization_nllb.py
+src/transformers/models/nllb/tokenization_nllb_fast.py
+src/transformers/models/nllb_moe/__init__.py
+src/transformers/models/nllb_moe/configuration_nllb_moe.py
+src/transformers/models/nllb_moe/convert_nllb_moe_sharded_original_checkpoint_to_pytorch.py
+src/transformers/models/nllb_moe/modeling_nllb_moe.py
+src/transformers/models/nougat/__init__.py
+src/transformers/models/nougat/convert_nougat_to_hf.py
+src/transformers/models/nougat/image_processing_nougat.py
+src/transformers/models/nougat/processing_nougat.py
+src/transformers/models/nougat/tokenization_nougat_fast.py
+src/transformers/models/nystromformer/__init__.py
+src/transformers/models/nystromformer/configuration_nystromformer.py
+src/transformers/models/nystromformer/convert_nystromformer_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/nystromformer/modeling_nystromformer.py
+src/transformers/models/olmo/__init__.py
+src/transformers/models/olmo/configuration_olmo.py
+src/transformers/models/olmo/convert_olmo_weights_to_hf.py
+src/transformers/models/olmo/modeling_olmo.py
+src/transformers/models/olmo/modular_olmo.py
+src/transformers/models/olmo2/__init__.py
+src/transformers/models/olmo2/configuration_olmo2.py
+src/transformers/models/olmo2/convert_olmo2_weights_to_hf.py
+src/transformers/models/olmo2/modeling_olmo2.py
+src/transformers/models/olmo2/modular_olmo2.py
+src/transformers/models/olmoe/__init__.py
+src/transformers/models/olmoe/configuration_olmoe.py
+src/transformers/models/olmoe/convert_olmoe_weights_to_hf.py
+src/transformers/models/olmoe/modeling_olmoe.py
+src/transformers/models/omdet_turbo/__init__.py
+src/transformers/models/omdet_turbo/configuration_omdet_turbo.py
+src/transformers/models/omdet_turbo/convert_omdet_turbo_to_hf.py
+src/transformers/models/omdet_turbo/modeling_omdet_turbo.py
+src/transformers/models/omdet_turbo/processing_omdet_turbo.py
+src/transformers/models/oneformer/__init__.py
+src/transformers/models/oneformer/configuration_oneformer.py
+src/transformers/models/oneformer/convert_to_hf_oneformer.py
+src/transformers/models/oneformer/image_processing_oneformer.py
+src/transformers/models/oneformer/modeling_oneformer.py
+src/transformers/models/oneformer/processing_oneformer.py
+src/transformers/models/openai/__init__.py
+src/transformers/models/openai/configuration_openai.py
+src/transformers/models/openai/convert_openai_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/openai/modeling_openai.py
+src/transformers/models/openai/modeling_tf_openai.py
+src/transformers/models/openai/tokenization_openai.py
+src/transformers/models/openai/tokenization_openai_fast.py
+src/transformers/models/opt/__init__.py
+src/transformers/models/opt/configuration_opt.py
+src/transformers/models/opt/convert_opt_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/opt/modeling_flax_opt.py
+src/transformers/models/opt/modeling_opt.py
+src/transformers/models/opt/modeling_tf_opt.py
+src/transformers/models/owlv2/__init__.py
+src/transformers/models/owlv2/configuration_owlv2.py
+src/transformers/models/owlv2/convert_owlv2_to_hf.py
+src/transformers/models/owlv2/image_processing_owlv2.py
+src/transformers/models/owlv2/modeling_owlv2.py
+src/transformers/models/owlv2/processing_owlv2.py
+src/transformers/models/owlvit/__init__.py
+src/transformers/models/owlvit/configuration_owlvit.py
+src/transformers/models/owlvit/convert_owlvit_original_flax_to_hf.py
+src/transformers/models/owlvit/feature_extraction_owlvit.py
+src/transformers/models/owlvit/image_processing_owlvit.py
+src/transformers/models/owlvit/image_processing_owlvit_fast.py
+src/transformers/models/owlvit/modeling_owlvit.py
+src/transformers/models/owlvit/processing_owlvit.py
+src/transformers/models/paligemma/__init__.py
+src/transformers/models/paligemma/configuration_paligemma.py
+src/transformers/models/paligemma/convert_paligemma2_weights_to_hf.py
+src/transformers/models/paligemma/convert_paligemma_weights_to_hf.py
+src/transformers/models/paligemma/modeling_paligemma.py
+src/transformers/models/paligemma/processing_paligemma.py
+src/transformers/models/patchtsmixer/__init__.py
+src/transformers/models/patchtsmixer/configuration_patchtsmixer.py
+src/transformers/models/patchtsmixer/modeling_patchtsmixer.py
+src/transformers/models/patchtst/__init__.py
+src/transformers/models/patchtst/configuration_patchtst.py
+src/transformers/models/patchtst/modeling_patchtst.py
+src/transformers/models/pegasus/__init__.py
+src/transformers/models/pegasus/configuration_pegasus.py
+src/transformers/models/pegasus/convert_pegasus_tf_to_pytorch.py
+src/transformers/models/pegasus/modeling_flax_pegasus.py
+src/transformers/models/pegasus/modeling_pegasus.py
+src/transformers/models/pegasus/modeling_tf_pegasus.py
+src/transformers/models/pegasus/tokenization_pegasus.py
+src/transformers/models/pegasus/tokenization_pegasus_fast.py
+src/transformers/models/pegasus_x/__init__.py
+src/transformers/models/pegasus_x/configuration_pegasus_x.py
+src/transformers/models/pegasus_x/modeling_pegasus_x.py
+src/transformers/models/perceiver/__init__.py
+src/transformers/models/perceiver/configuration_perceiver.py
+src/transformers/models/perceiver/convert_perceiver_haiku_to_pytorch.py
+src/transformers/models/perceiver/feature_extraction_perceiver.py
+src/transformers/models/perceiver/image_processing_perceiver.py
+src/transformers/models/perceiver/image_processing_perceiver_fast.py
+src/transformers/models/perceiver/modeling_perceiver.py
+src/transformers/models/perceiver/tokenization_perceiver.py
+src/transformers/models/persimmon/__init__.py
+src/transformers/models/persimmon/configuration_persimmon.py
+src/transformers/models/persimmon/convert_persimmon_weights_to_hf.py
+src/transformers/models/persimmon/modeling_persimmon.py
+src/transformers/models/phi/__init__.py
+src/transformers/models/phi/configuration_phi.py
+src/transformers/models/phi/convert_phi_weights_to_hf.py
+src/transformers/models/phi/modeling_phi.py
+src/transformers/models/phi/modular_phi.py
+src/transformers/models/phi3/__init__.py
+src/transformers/models/phi3/configuration_phi3.py
+src/transformers/models/phi3/modeling_phi3.py
+src/transformers/models/phi3/modular_phi3.py
+src/transformers/models/phi4_multimodal/__init__.py
+src/transformers/models/phi4_multimodal/configuration_phi4_multimodal.py
+src/transformers/models/phi4_multimodal/convert_phi4_multimodal_weights_to_hf.py
+src/transformers/models/phi4_multimodal/feature_extraction_phi4_multimodal.py
+src/transformers/models/phi4_multimodal/image_processing_phi4_multimodal_fast.py
+src/transformers/models/phi4_multimodal/modeling_phi4_multimodal.py
+src/transformers/models/phi4_multimodal/modular_phi4_multimodal.py
+src/transformers/models/phi4_multimodal/processing_phi4_multimodal.py
+src/transformers/models/phimoe/__init__.py
+src/transformers/models/phimoe/configuration_phimoe.py
+src/transformers/models/phimoe/modeling_phimoe.py
+src/transformers/models/phobert/__init__.py
+src/transformers/models/phobert/tokenization_phobert.py
+src/transformers/models/pix2struct/__init__.py
+src/transformers/models/pix2struct/configuration_pix2struct.py
+src/transformers/models/pix2struct/convert_pix2struct_original_pytorch_to_hf.py
+src/transformers/models/pix2struct/image_processing_pix2struct.py
+src/transformers/models/pix2struct/modeling_pix2struct.py
+src/transformers/models/pix2struct/processing_pix2struct.py
+src/transformers/models/pixtral/__init__.py
+src/transformers/models/pixtral/configuration_pixtral.py
+src/transformers/models/pixtral/convert_pixtral_weights_to_hf.py
+src/transformers/models/pixtral/image_processing_pixtral.py
+src/transformers/models/pixtral/image_processing_pixtral_fast.py
+src/transformers/models/pixtral/modeling_pixtral.py
+src/transformers/models/pixtral/processing_pixtral.py
+src/transformers/models/plbart/__init__.py
+src/transformers/models/plbart/configuration_plbart.py
+src/transformers/models/plbart/convert_plbart_original_checkpoint_to_torch.py
+src/transformers/models/plbart/modeling_plbart.py
+src/transformers/models/plbart/tokenization_plbart.py
+src/transformers/models/poolformer/__init__.py
+src/transformers/models/poolformer/configuration_poolformer.py
+src/transformers/models/poolformer/convert_poolformer_original_to_pytorch.py
+src/transformers/models/poolformer/feature_extraction_poolformer.py
+src/transformers/models/poolformer/image_processing_poolformer.py
+src/transformers/models/poolformer/image_processing_poolformer_fast.py
+src/transformers/models/poolformer/modeling_poolformer.py
+src/transformers/models/pop2piano/__init__.py
+src/transformers/models/pop2piano/configuration_pop2piano.py
+src/transformers/models/pop2piano/convert_pop2piano_weights_to_hf.py
+src/transformers/models/pop2piano/feature_extraction_pop2piano.py
+src/transformers/models/pop2piano/modeling_pop2piano.py
+src/transformers/models/pop2piano/processing_pop2piano.py
+src/transformers/models/pop2piano/tokenization_pop2piano.py
+src/transformers/models/prompt_depth_anything/__init__.py
+src/transformers/models/prompt_depth_anything/configuration_prompt_depth_anything.py
+src/transformers/models/prompt_depth_anything/convert_prompt_depth_anything_to_hf.py
+src/transformers/models/prompt_depth_anything/image_processing_prompt_depth_anything.py
+src/transformers/models/prompt_depth_anything/modeling_prompt_depth_anything.py
+src/transformers/models/prompt_depth_anything/modular_prompt_depth_anything.py
+src/transformers/models/prophetnet/__init__.py
+src/transformers/models/prophetnet/configuration_prophetnet.py
+src/transformers/models/prophetnet/convert_prophetnet_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/prophetnet/modeling_prophetnet.py
+src/transformers/models/prophetnet/tokenization_prophetnet.py
+src/transformers/models/pvt/__init__.py
+src/transformers/models/pvt/configuration_pvt.py
+src/transformers/models/pvt/convert_pvt_to_pytorch.py
+src/transformers/models/pvt/image_processing_pvt.py
+src/transformers/models/pvt/image_processing_pvt_fast.py
+src/transformers/models/pvt/modeling_pvt.py
+src/transformers/models/pvt_v2/__init__.py
+src/transformers/models/pvt_v2/configuration_pvt_v2.py
+src/transformers/models/pvt_v2/convert_pvt_v2_to_pytorch.py
+src/transformers/models/pvt_v2/modeling_pvt_v2.py
+src/transformers/models/qwen2/__init__.py
+src/transformers/models/qwen2/configuration_qwen2.py
+src/transformers/models/qwen2/modeling_qwen2.py
+src/transformers/models/qwen2/modular_qwen2.py
+src/transformers/models/qwen2/tokenization_qwen2.py
+src/transformers/models/qwen2/tokenization_qwen2_fast.py
+src/transformers/models/qwen2_5_omni/__init__.py
+src/transformers/models/qwen2_5_omni/configuration_qwen2_5_omni.py
+src/transformers/models/qwen2_5_omni/modeling_qwen2_5_omni.py
+src/transformers/models/qwen2_5_omni/modular_qwen2_5_omni.py
+src/transformers/models/qwen2_5_omni/processing_qwen2_5_omni.py
+src/transformers/models/qwen2_5_vl/__init__.py
+src/transformers/models/qwen2_5_vl/configuration_qwen2_5_vl.py
+src/transformers/models/qwen2_5_vl/modeling_qwen2_5_vl.py
+src/transformers/models/qwen2_5_vl/modular_qwen2_5_vl.py
+src/transformers/models/qwen2_5_vl/processing_qwen2_5_vl.py
+src/transformers/models/qwen2_audio/__init__.py
+src/transformers/models/qwen2_audio/configuration_qwen2_audio.py
+src/transformers/models/qwen2_audio/modeling_qwen2_audio.py
+src/transformers/models/qwen2_audio/processing_qwen2_audio.py
+src/transformers/models/qwen2_moe/__init__.py
+src/transformers/models/qwen2_moe/configuration_qwen2_moe.py
+src/transformers/models/qwen2_moe/modeling_qwen2_moe.py
+src/transformers/models/qwen2_vl/__init__.py
+src/transformers/models/qwen2_vl/configuration_qwen2_vl.py
+src/transformers/models/qwen2_vl/image_processing_qwen2_vl.py
+src/transformers/models/qwen2_vl/image_processing_qwen2_vl_fast.py
+src/transformers/models/qwen2_vl/modeling_qwen2_vl.py
+src/transformers/models/qwen2_vl/processing_qwen2_vl.py
+src/transformers/models/qwen3/__init__.py
+src/transformers/models/qwen3/configuration_qwen3.py
+src/transformers/models/qwen3/modeling_qwen3.py
+src/transformers/models/qwen3/modular_qwen3.py
+src/transformers/models/qwen3_moe/__init__.py
+src/transformers/models/qwen3_moe/configuration_qwen3_moe.py
+src/transformers/models/qwen3_moe/modeling_qwen3_moe.py
+src/transformers/models/qwen3_moe/modular_qwen3_moe.py
+src/transformers/models/rag/__init__.py
+src/transformers/models/rag/configuration_rag.py
+src/transformers/models/rag/modeling_rag.py
+src/transformers/models/rag/modeling_tf_rag.py
+src/transformers/models/rag/retrieval_rag.py
+src/transformers/models/rag/tokenization_rag.py
+src/transformers/models/recurrent_gemma/__init__.py
+src/transformers/models/recurrent_gemma/configuration_recurrent_gemma.py
+src/transformers/models/recurrent_gemma/convert_recurrent_gemma_to_hf.py
+src/transformers/models/recurrent_gemma/modeling_recurrent_gemma.py
+src/transformers/models/reformer/__init__.py
+src/transformers/models/reformer/configuration_reformer.py
+src/transformers/models/reformer/convert_reformer_trax_checkpoint_to_pytorch.py
+src/transformers/models/reformer/modeling_reformer.py
+src/transformers/models/reformer/tokenization_reformer.py
+src/transformers/models/reformer/tokenization_reformer_fast.py
+src/transformers/models/regnet/__init__.py
+src/transformers/models/regnet/configuration_regnet.py
+src/transformers/models/regnet/convert_regnet_seer_10b_to_pytorch.py
+src/transformers/models/regnet/convert_regnet_to_pytorch.py
+src/transformers/models/regnet/modeling_flax_regnet.py
+src/transformers/models/regnet/modeling_regnet.py
+src/transformers/models/regnet/modeling_tf_regnet.py
+src/transformers/models/rembert/__init__.py
+src/transformers/models/rembert/configuration_rembert.py
+src/transformers/models/rembert/convert_rembert_tf_checkpoint_to_pytorch.py
+src/transformers/models/rembert/modeling_rembert.py
+src/transformers/models/rembert/modeling_tf_rembert.py
+src/transformers/models/rembert/tokenization_rembert.py
+src/transformers/models/rembert/tokenization_rembert_fast.py
+src/transformers/models/resnet/__init__.py
+src/transformers/models/resnet/configuration_resnet.py
+src/transformers/models/resnet/convert_resnet_to_pytorch.py
+src/transformers/models/resnet/modeling_flax_resnet.py
+src/transformers/models/resnet/modeling_resnet.py
+src/transformers/models/resnet/modeling_tf_resnet.py
+src/transformers/models/roberta/__init__.py
+src/transformers/models/roberta/configuration_roberta.py
+src/transformers/models/roberta/convert_roberta_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/roberta/modeling_flax_roberta.py
+src/transformers/models/roberta/modeling_roberta.py
+src/transformers/models/roberta/modeling_tf_roberta.py
+src/transformers/models/roberta/tokenization_roberta.py
+src/transformers/models/roberta/tokenization_roberta_fast.py
+src/transformers/models/roberta_prelayernorm/__init__.py
+src/transformers/models/roberta_prelayernorm/configuration_roberta_prelayernorm.py
+src/transformers/models/roberta_prelayernorm/convert_roberta_prelayernorm_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/roberta_prelayernorm/modeling_flax_roberta_prelayernorm.py
+src/transformers/models/roberta_prelayernorm/modeling_roberta_prelayernorm.py
+src/transformers/models/roberta_prelayernorm/modeling_tf_roberta_prelayernorm.py
+src/transformers/models/roc_bert/__init__.py
+src/transformers/models/roc_bert/configuration_roc_bert.py
+src/transformers/models/roc_bert/modeling_roc_bert.py
+src/transformers/models/roc_bert/tokenization_roc_bert.py
+src/transformers/models/roformer/__init__.py
+src/transformers/models/roformer/configuration_roformer.py
+src/transformers/models/roformer/convert_roformer_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/roformer/modeling_flax_roformer.py
+src/transformers/models/roformer/modeling_roformer.py
+src/transformers/models/roformer/modeling_tf_roformer.py
+src/transformers/models/roformer/tokenization_roformer.py
+src/transformers/models/roformer/tokenization_roformer_fast.py
+src/transformers/models/roformer/tokenization_utils.py
+src/transformers/models/rt_detr/__init__.py
+src/transformers/models/rt_detr/configuration_rt_detr.py
+src/transformers/models/rt_detr/configuration_rt_detr_resnet.py
+src/transformers/models/rt_detr/convert_rt_detr_original_pytorch_checkpoint_to_hf.py
+src/transformers/models/rt_detr/image_processing_rt_detr.py
+src/transformers/models/rt_detr/image_processing_rt_detr_fast.py
+src/transformers/models/rt_detr/modeling_rt_detr.py
+src/transformers/models/rt_detr/modeling_rt_detr_resnet.py
+src/transformers/models/rt_detr/modular_rt_detr.py
+src/transformers/models/rt_detr_v2/__init__.py
+src/transformers/models/rt_detr_v2/configuration_rt_detr_v2.py
+src/transformers/models/rt_detr_v2/convert_rt_detr_v2_weights_to_hf.py
+src/transformers/models/rt_detr_v2/modeling_rt_detr_v2.py
+src/transformers/models/rt_detr_v2/modular_rt_detr_v2.py
+src/transformers/models/rwkv/__init__.py
+src/transformers/models/rwkv/configuration_rwkv.py
+src/transformers/models/rwkv/convert_rwkv_checkpoint_to_hf.py
+src/transformers/models/rwkv/modeling_rwkv.py
+src/transformers/models/sam/__init__.py
+src/transformers/models/sam/configuration_sam.py
+src/transformers/models/sam/convert_sam_to_hf.py
+src/transformers/models/sam/image_processing_sam.py
+src/transformers/models/sam/modeling_sam.py
+src/transformers/models/sam/modeling_tf_sam.py
+src/transformers/models/sam/processing_sam.py
+src/transformers/models/seamless_m4t/__init__.py
+src/transformers/models/seamless_m4t/configuration_seamless_m4t.py
+src/transformers/models/seamless_m4t/convert_fairseq2_to_hf.py
+src/transformers/models/seamless_m4t/feature_extraction_seamless_m4t.py
+src/transformers/models/seamless_m4t/modeling_seamless_m4t.py
+src/transformers/models/seamless_m4t/processing_seamless_m4t.py
+src/transformers/models/seamless_m4t/tokenization_seamless_m4t.py
+src/transformers/models/seamless_m4t/tokenization_seamless_m4t_fast.py
+src/transformers/models/seamless_m4t_v2/__init__.py
+src/transformers/models/seamless_m4t_v2/configuration_seamless_m4t_v2.py
+src/transformers/models/seamless_m4t_v2/convert_fairseq2_to_hf.py
+src/transformers/models/seamless_m4t_v2/modeling_seamless_m4t_v2.py
+src/transformers/models/segformer/__init__.py
+src/transformers/models/segformer/configuration_segformer.py
+src/transformers/models/segformer/convert_segformer_original_to_pytorch.py
+src/transformers/models/segformer/feature_extraction_segformer.py
+src/transformers/models/segformer/image_processing_segformer.py
+src/transformers/models/segformer/modeling_segformer.py
+src/transformers/models/segformer/modeling_tf_segformer.py
+src/transformers/models/seggpt/__init__.py
+src/transformers/models/seggpt/configuration_seggpt.py
+src/transformers/models/seggpt/convert_seggpt_to_hf.py
+src/transformers/models/seggpt/image_processing_seggpt.py
+src/transformers/models/seggpt/modeling_seggpt.py
+src/transformers/models/sew/__init__.py
+src/transformers/models/sew/configuration_sew.py
+src/transformers/models/sew/convert_sew_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/sew/modeling_sew.py
+src/transformers/models/sew_d/__init__.py
+src/transformers/models/sew_d/configuration_sew_d.py
+src/transformers/models/sew_d/convert_sew_d_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/sew_d/modeling_sew_d.py
+src/transformers/models/shieldgemma2/__init__.py
+src/transformers/models/shieldgemma2/configuration_shieldgemma2.py
+src/transformers/models/shieldgemma2/convert_shieldgemma2_weights_orbax_to_hf.py
+src/transformers/models/shieldgemma2/modeling_shieldgemma2.py
+src/transformers/models/shieldgemma2/processing_shieldgemma2.py
+src/transformers/models/siglip/__init__.py
+src/transformers/models/siglip/configuration_siglip.py
+src/transformers/models/siglip/convert_siglip_to_hf.py
+src/transformers/models/siglip/image_processing_siglip.py
+src/transformers/models/siglip/image_processing_siglip_fast.py
+src/transformers/models/siglip/modeling_siglip.py
+src/transformers/models/siglip/processing_siglip.py
+src/transformers/models/siglip/tokenization_siglip.py
+src/transformers/models/siglip2/__init__.py
+src/transformers/models/siglip2/configuration_siglip2.py
+src/transformers/models/siglip2/convert_siglip2_to_hf.py
+src/transformers/models/siglip2/image_processing_siglip2.py
+src/transformers/models/siglip2/image_processing_siglip2_fast.py
+src/transformers/models/siglip2/modeling_siglip2.py
+src/transformers/models/siglip2/modular_siglip2.py
+src/transformers/models/siglip2/processing_siglip2.py
+src/transformers/models/smolvlm/__init__.py
+src/transformers/models/smolvlm/configuration_smolvlm.py
+src/transformers/models/smolvlm/image_processing_smolvlm.py
+src/transformers/models/smolvlm/modeling_smolvlm.py
+src/transformers/models/smolvlm/modular_smolvlm.py
+src/transformers/models/smolvlm/processing_smolvlm.py
+src/transformers/models/smolvlm/video_processing_smolvlm.py
+src/transformers/models/speech_encoder_decoder/__init__.py
+src/transformers/models/speech_encoder_decoder/configuration_speech_encoder_decoder.py
+src/transformers/models/speech_encoder_decoder/convert_mbart_wav2vec2_seq2seq_original_to_pytorch.py
+src/transformers/models/speech_encoder_decoder/convert_speech_to_text_wav2vec2_seq2seq_original_to_pytorch.py
+src/transformers/models/speech_encoder_decoder/modeling_flax_speech_encoder_decoder.py
+src/transformers/models/speech_encoder_decoder/modeling_speech_encoder_decoder.py
+src/transformers/models/speech_to_text/__init__.py
+src/transformers/models/speech_to_text/configuration_speech_to_text.py
+src/transformers/models/speech_to_text/convert_s2t_fairseq_to_tfms.py
+src/transformers/models/speech_to_text/feature_extraction_speech_to_text.py
+src/transformers/models/speech_to_text/modeling_speech_to_text.py
+src/transformers/models/speech_to_text/modeling_tf_speech_to_text.py
+src/transformers/models/speech_to_text/processing_speech_to_text.py
+src/transformers/models/speech_to_text/tokenization_speech_to_text.py
+src/transformers/models/speecht5/__init__.py
+src/transformers/models/speecht5/configuration_speecht5.py
+src/transformers/models/speecht5/convert_hifigan.py
+src/transformers/models/speecht5/convert_speecht5_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/speecht5/feature_extraction_speecht5.py
+src/transformers/models/speecht5/modeling_speecht5.py
+src/transformers/models/speecht5/number_normalizer.py
+src/transformers/models/speecht5/processing_speecht5.py
+src/transformers/models/speecht5/tokenization_speecht5.py
+src/transformers/models/splinter/__init__.py
+src/transformers/models/splinter/configuration_splinter.py
+src/transformers/models/splinter/modeling_splinter.py
+src/transformers/models/splinter/tokenization_splinter.py
+src/transformers/models/splinter/tokenization_splinter_fast.py
+src/transformers/models/squeezebert/__init__.py
+src/transformers/models/squeezebert/configuration_squeezebert.py
+src/transformers/models/squeezebert/modeling_squeezebert.py
+src/transformers/models/squeezebert/tokenization_squeezebert.py
+src/transformers/models/squeezebert/tokenization_squeezebert_fast.py
+src/transformers/models/stablelm/__init__.py
+src/transformers/models/stablelm/configuration_stablelm.py
+src/transformers/models/stablelm/modeling_stablelm.py
+src/transformers/models/starcoder2/__init__.py
+src/transformers/models/starcoder2/configuration_starcoder2.py
+src/transformers/models/starcoder2/modeling_starcoder2.py
+src/transformers/models/starcoder2/modular_starcoder2.py
+src/transformers/models/superglue/__init__.py
+src/transformers/models/superglue/configuration_superglue.py
+src/transformers/models/superglue/convert_superglue_to_hf.py
+src/transformers/models/superglue/image_processing_superglue.py
+src/transformers/models/superglue/modeling_superglue.py
+src/transformers/models/superpoint/__init__.py
+src/transformers/models/superpoint/configuration_superpoint.py
+src/transformers/models/superpoint/convert_superpoint_to_pytorch.py
+src/transformers/models/superpoint/image_processing_superpoint.py
+src/transformers/models/superpoint/modeling_superpoint.py
+src/transformers/models/swiftformer/__init__.py
+src/transformers/models/swiftformer/configuration_swiftformer.py
+src/transformers/models/swiftformer/convert_swiftformer_original_to_hf.py
+src/transformers/models/swiftformer/modeling_swiftformer.py
+src/transformers/models/swiftformer/modeling_tf_swiftformer.py
+src/transformers/models/swin/__init__.py
+src/transformers/models/swin/configuration_swin.py
+src/transformers/models/swin/convert_swin_simmim_to_pytorch.py
+src/transformers/models/swin/convert_swin_timm_to_pytorch.py
+src/transformers/models/swin/modeling_swin.py
+src/transformers/models/swin/modeling_tf_swin.py
+src/transformers/models/swin2sr/__init__.py
+src/transformers/models/swin2sr/configuration_swin2sr.py
+src/transformers/models/swin2sr/convert_swin2sr_original_to_pytorch.py
+src/transformers/models/swin2sr/image_processing_swin2sr.py
+src/transformers/models/swin2sr/modeling_swin2sr.py
+src/transformers/models/swinv2/__init__.py
+src/transformers/models/swinv2/configuration_swinv2.py
+src/transformers/models/swinv2/convert_swinv2_timm_to_pytorch.py
+src/transformers/models/swinv2/modeling_swinv2.py
+src/transformers/models/switch_transformers/__init__.py
+src/transformers/models/switch_transformers/configuration_switch_transformers.py
+src/transformers/models/switch_transformers/convert_big_switch.py
+src/transformers/models/switch_transformers/convert_switch_transformers_original_flax_checkpoint_to_pytorch.py
+src/transformers/models/switch_transformers/modeling_switch_transformers.py
+src/transformers/models/t5/__init__.py
+src/transformers/models/t5/configuration_t5.py
+src/transformers/models/t5/convert_t5_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/t5/convert_t5x_checkpoint_to_flax.py
+src/transformers/models/t5/convert_t5x_checkpoint_to_pytorch.py
+src/transformers/models/t5/modeling_flax_t5.py
+src/transformers/models/t5/modeling_t5.py
+src/transformers/models/t5/modeling_tf_t5.py
+src/transformers/models/t5/tokenization_t5.py
+src/transformers/models/t5/tokenization_t5_fast.py
+src/transformers/models/table_transformer/__init__.py
+src/transformers/models/table_transformer/configuration_table_transformer.py
+src/transformers/models/table_transformer/convert_table_transformer_to_hf.py
+src/transformers/models/table_transformer/convert_table_transformer_to_hf_no_timm.py
+src/transformers/models/table_transformer/modeling_table_transformer.py
+src/transformers/models/tapas/__init__.py
+src/transformers/models/tapas/configuration_tapas.py
+src/transformers/models/tapas/convert_tapas_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/tapas/modeling_tapas.py
+src/transformers/models/tapas/modeling_tf_tapas.py
+src/transformers/models/tapas/tokenization_tapas.py
+src/transformers/models/textnet/__init__.py
+src/transformers/models/textnet/configuration_textnet.py
+src/transformers/models/textnet/convert_textnet_to_hf.py
+src/transformers/models/textnet/image_processing_textnet.py
+src/transformers/models/textnet/modeling_textnet.py
+src/transformers/models/time_series_transformer/__init__.py
+src/transformers/models/time_series_transformer/configuration_time_series_transformer.py
+src/transformers/models/time_series_transformer/modeling_time_series_transformer.py
+src/transformers/models/timesfm/__init__.py
+src/transformers/models/timesfm/configuration_timesfm.py
+src/transformers/models/timesfm/convert_timesfm_orignal_to_hf.py
+src/transformers/models/timesfm/modeling_timesfm.py
+src/transformers/models/timesfm/modular_timesfm.py
+src/transformers/models/timesformer/__init__.py
+src/transformers/models/timesformer/configuration_timesformer.py
+src/transformers/models/timesformer/convert_timesformer_to_pytorch.py
+src/transformers/models/timesformer/modeling_timesformer.py
+src/transformers/models/timm_backbone/__init__.py
+src/transformers/models/timm_backbone/configuration_timm_backbone.py
+src/transformers/models/timm_backbone/modeling_timm_backbone.py
+src/transformers/models/timm_wrapper/__init__.py
+src/transformers/models/timm_wrapper/configuration_timm_wrapper.py
+src/transformers/models/timm_wrapper/image_processing_timm_wrapper.py
+src/transformers/models/timm_wrapper/modeling_timm_wrapper.py
+src/transformers/models/trocr/__init__.py
+src/transformers/models/trocr/configuration_trocr.py
+src/transformers/models/trocr/convert_trocr_unilm_to_pytorch.py
+src/transformers/models/trocr/modeling_trocr.py
+src/transformers/models/trocr/processing_trocr.py
+src/transformers/models/tvp/__init__.py
+src/transformers/models/tvp/configuration_tvp.py
+src/transformers/models/tvp/image_processing_tvp.py
+src/transformers/models/tvp/modeling_tvp.py
+src/transformers/models/tvp/processing_tvp.py
+src/transformers/models/udop/__init__.py
+src/transformers/models/udop/configuration_udop.py
+src/transformers/models/udop/convert_udop_to_hf.py
+src/transformers/models/udop/modeling_udop.py
+src/transformers/models/udop/processing_udop.py
+src/transformers/models/udop/tokenization_udop.py
+src/transformers/models/udop/tokenization_udop_fast.py
+src/transformers/models/umt5/__init__.py
+src/transformers/models/umt5/configuration_umt5.py
+src/transformers/models/umt5/convert_umt5_checkpoint_to_pytorch.py
+src/transformers/models/umt5/modeling_umt5.py
+src/transformers/models/unispeech/__init__.py
+src/transformers/models/unispeech/configuration_unispeech.py
+src/transformers/models/unispeech/convert_unispeech_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/unispeech/modeling_unispeech.py
+src/transformers/models/unispeech/modular_unispeech.py
+src/transformers/models/unispeech_sat/__init__.py
+src/transformers/models/unispeech_sat/configuration_unispeech_sat.py
+src/transformers/models/unispeech_sat/convert_unispeech_original_s3prl_checkpoint_to_pytorch.py
+src/transformers/models/unispeech_sat/convert_unispeech_sat_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/unispeech_sat/modeling_unispeech_sat.py
+src/transformers/models/unispeech_sat/modular_unispeech_sat.py
+src/transformers/models/univnet/__init__.py
+src/transformers/models/univnet/configuration_univnet.py
+src/transformers/models/univnet/convert_univnet.py
+src/transformers/models/univnet/feature_extraction_univnet.py
+src/transformers/models/univnet/modeling_univnet.py
+src/transformers/models/upernet/__init__.py
+src/transformers/models/upernet/configuration_upernet.py
+src/transformers/models/upernet/convert_convnext_upernet_to_pytorch.py
+src/transformers/models/upernet/convert_swin_upernet_to_pytorch.py
+src/transformers/models/upernet/modeling_upernet.py
+src/transformers/models/video_llava/__init__.py
+src/transformers/models/video_llava/configuration_video_llava.py
+src/transformers/models/video_llava/convert_video_llava_weights_to_hf.py
+src/transformers/models/video_llava/image_processing_video_llava.py
+src/transformers/models/video_llava/modeling_video_llava.py
+src/transformers/models/video_llava/processing_video_llava.py
+src/transformers/models/videomae/__init__.py
+src/transformers/models/videomae/configuration_videomae.py
+src/transformers/models/videomae/convert_videomae_to_pytorch.py
+src/transformers/models/videomae/feature_extraction_videomae.py
+src/transformers/models/videomae/image_processing_videomae.py
+src/transformers/models/videomae/modeling_videomae.py
+src/transformers/models/vilt/__init__.py
+src/transformers/models/vilt/configuration_vilt.py
+src/transformers/models/vilt/convert_vilt_original_to_pytorch.py
+src/transformers/models/vilt/feature_extraction_vilt.py
+src/transformers/models/vilt/image_processing_vilt.py
+src/transformers/models/vilt/modeling_vilt.py
+src/transformers/models/vilt/processing_vilt.py
+src/transformers/models/vipllava/__init__.py
+src/transformers/models/vipllava/configuration_vipllava.py
+src/transformers/models/vipllava/convert_vipllava_weights_to_hf.py
+src/transformers/models/vipllava/modeling_vipllava.py
+src/transformers/models/vision_encoder_decoder/__init__.py
+src/transformers/models/vision_encoder_decoder/configuration_vision_encoder_decoder.py
+src/transformers/models/vision_encoder_decoder/modeling_flax_vision_encoder_decoder.py
+src/transformers/models/vision_encoder_decoder/modeling_tf_vision_encoder_decoder.py
+src/transformers/models/vision_encoder_decoder/modeling_vision_encoder_decoder.py
+src/transformers/models/vision_text_dual_encoder/__init__.py
+src/transformers/models/vision_text_dual_encoder/configuration_vision_text_dual_encoder.py
+src/transformers/models/vision_text_dual_encoder/modeling_flax_vision_text_dual_encoder.py
+src/transformers/models/vision_text_dual_encoder/modeling_tf_vision_text_dual_encoder.py
+src/transformers/models/vision_text_dual_encoder/modeling_vision_text_dual_encoder.py
+src/transformers/models/vision_text_dual_encoder/processing_vision_text_dual_encoder.py
+src/transformers/models/visual_bert/__init__.py
+src/transformers/models/visual_bert/configuration_visual_bert.py
+src/transformers/models/visual_bert/convert_visual_bert_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/visual_bert/modeling_visual_bert.py
+src/transformers/models/vit/__init__.py
+src/transformers/models/vit/configuration_vit.py
+src/transformers/models/vit/convert_dino_to_pytorch.py
+src/transformers/models/vit/convert_vit_timm_to_pytorch.py
+src/transformers/models/vit/feature_extraction_vit.py
+src/transformers/models/vit/image_processing_vit.py
+src/transformers/models/vit/image_processing_vit_fast.py
+src/transformers/models/vit/modeling_flax_vit.py
+src/transformers/models/vit/modeling_tf_vit.py
+src/transformers/models/vit/modeling_vit.py
+src/transformers/models/vit_mae/__init__.py
+src/transformers/models/vit_mae/configuration_vit_mae.py
+src/transformers/models/vit_mae/convert_vit_mae_to_pytorch.py
+src/transformers/models/vit_mae/modeling_tf_vit_mae.py
+src/transformers/models/vit_mae/modeling_vit_mae.py
+src/transformers/models/vit_msn/__init__.py
+src/transformers/models/vit_msn/configuration_vit_msn.py
+src/transformers/models/vit_msn/convert_msn_to_pytorch.py
+src/transformers/models/vit_msn/modeling_vit_msn.py
+src/transformers/models/vitdet/__init__.py
+src/transformers/models/vitdet/configuration_vitdet.py
+src/transformers/models/vitdet/modeling_vitdet.py
+src/transformers/models/vitmatte/__init__.py
+src/transformers/models/vitmatte/configuration_vitmatte.py
+src/transformers/models/vitmatte/convert_vitmatte_to_hf.py
+src/transformers/models/vitmatte/image_processing_vitmatte.py
+src/transformers/models/vitmatte/modeling_vitmatte.py
+src/transformers/models/vitpose/__init__.py
+src/transformers/models/vitpose/configuration_vitpose.py
+src/transformers/models/vitpose/convert_vitpose_to_hf.py
+src/transformers/models/vitpose/image_processing_vitpose.py
+src/transformers/models/vitpose/modeling_vitpose.py
+src/transformers/models/vitpose_backbone/__init__.py
+src/transformers/models/vitpose_backbone/configuration_vitpose_backbone.py
+src/transformers/models/vitpose_backbone/modeling_vitpose_backbone.py
+src/transformers/models/vits/__init__.py
+src/transformers/models/vits/configuration_vits.py
+src/transformers/models/vits/convert_original_checkpoint.py
+src/transformers/models/vits/modeling_vits.py
+src/transformers/models/vits/tokenization_vits.py
+src/transformers/models/vivit/__init__.py
+src/transformers/models/vivit/configuration_vivit.py
+src/transformers/models/vivit/convert_vivit_flax_to_pytorch.py
+src/transformers/models/vivit/image_processing_vivit.py
+src/transformers/models/vivit/modeling_vivit.py
+src/transformers/models/wav2vec2/__init__.py
+src/transformers/models/wav2vec2/configuration_wav2vec2.py
+src/transformers/models/wav2vec2/convert_wav2vec2_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/wav2vec2/convert_wav2vec2_original_s3prl_checkpoint_to_pytorch.py
+src/transformers/models/wav2vec2/feature_extraction_wav2vec2.py
+src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py
+src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py
+src/transformers/models/wav2vec2/modeling_wav2vec2.py
+src/transformers/models/wav2vec2/processing_wav2vec2.py
+src/transformers/models/wav2vec2/tokenization_wav2vec2.py
+src/transformers/models/wav2vec2_bert/__init__.py
+src/transformers/models/wav2vec2_bert/configuration_wav2vec2_bert.py
+src/transformers/models/wav2vec2_bert/convert_wav2vec2_seamless_checkpoint.py
+src/transformers/models/wav2vec2_bert/modeling_wav2vec2_bert.py
+src/transformers/models/wav2vec2_bert/modular_wav2vec2_bert.py
+src/transformers/models/wav2vec2_bert/processing_wav2vec2_bert.py
+src/transformers/models/wav2vec2_conformer/__init__.py
+src/transformers/models/wav2vec2_conformer/configuration_wav2vec2_conformer.py
+src/transformers/models/wav2vec2_conformer/convert_wav2vec2_conformer_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/wav2vec2_conformer/modeling_wav2vec2_conformer.py
+src/transformers/models/wav2vec2_conformer/modular_wav2vec2_conformer.py
+src/transformers/models/wav2vec2_phoneme/__init__.py
+src/transformers/models/wav2vec2_phoneme/tokenization_wav2vec2_phoneme.py
+src/transformers/models/wav2vec2_with_lm/__init__.py
+src/transformers/models/wav2vec2_with_lm/processing_wav2vec2_with_lm.py
+src/transformers/models/wavlm/__init__.py
+src/transformers/models/wavlm/configuration_wavlm.py
+src/transformers/models/wavlm/convert_wavlm_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/wavlm/convert_wavlm_original_s3prl_checkpoint_to_pytorch.py
+src/transformers/models/wavlm/modeling_wavlm.py
+src/transformers/models/wavlm/modular_wavlm.py
+src/transformers/models/whisper/__init__.py
+src/transformers/models/whisper/configuration_whisper.py
+src/transformers/models/whisper/convert_openai_to_hf.py
+src/transformers/models/whisper/english_normalizer.py
+src/transformers/models/whisper/feature_extraction_whisper.py
+src/transformers/models/whisper/generation_whisper.py
+src/transformers/models/whisper/modeling_flax_whisper.py
+src/transformers/models/whisper/modeling_tf_whisper.py
+src/transformers/models/whisper/modeling_whisper.py
+src/transformers/models/whisper/processing_whisper.py
+src/transformers/models/whisper/tokenization_whisper.py
+src/transformers/models/whisper/tokenization_whisper_fast.py
+src/transformers/models/x_clip/__init__.py
+src/transformers/models/x_clip/configuration_x_clip.py
+src/transformers/models/x_clip/convert_x_clip_original_pytorch_to_hf.py
+src/transformers/models/x_clip/modeling_x_clip.py
+src/transformers/models/x_clip/processing_x_clip.py
+src/transformers/models/xglm/__init__.py
+src/transformers/models/xglm/configuration_xglm.py
+src/transformers/models/xglm/convert_xglm_original_ckpt_to_trfms.py
+src/transformers/models/xglm/modeling_flax_xglm.py
+src/transformers/models/xglm/modeling_tf_xglm.py
+src/transformers/models/xglm/modeling_xglm.py
+src/transformers/models/xglm/tokenization_xglm.py
+src/transformers/models/xglm/tokenization_xglm_fast.py
+src/transformers/models/xlm/__init__.py
+src/transformers/models/xlm/configuration_xlm.py
+src/transformers/models/xlm/convert_xlm_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/xlm/modeling_tf_xlm.py
+src/transformers/models/xlm/modeling_xlm.py
+src/transformers/models/xlm/tokenization_xlm.py
+src/transformers/models/xlm_roberta/__init__.py
+src/transformers/models/xlm_roberta/configuration_xlm_roberta.py
+src/transformers/models/xlm_roberta/modeling_flax_xlm_roberta.py
+src/transformers/models/xlm_roberta/modeling_tf_xlm_roberta.py
+src/transformers/models/xlm_roberta/modeling_xlm_roberta.py
+src/transformers/models/xlm_roberta/tokenization_xlm_roberta.py
+src/transformers/models/xlm_roberta/tokenization_xlm_roberta_fast.py
+src/transformers/models/xlm_roberta_xl/__init__.py
+src/transformers/models/xlm_roberta_xl/configuration_xlm_roberta_xl.py
+src/transformers/models/xlm_roberta_xl/convert_xlm_roberta_xl_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/xlm_roberta_xl/modeling_xlm_roberta_xl.py
+src/transformers/models/xlnet/__init__.py
+src/transformers/models/xlnet/configuration_xlnet.py
+src/transformers/models/xlnet/convert_xlnet_original_tf_checkpoint_to_pytorch.py
+src/transformers/models/xlnet/modeling_tf_xlnet.py
+src/transformers/models/xlnet/modeling_xlnet.py
+src/transformers/models/xlnet/tokenization_xlnet.py
+src/transformers/models/xlnet/tokenization_xlnet_fast.py
+src/transformers/models/xmod/__init__.py
+src/transformers/models/xmod/configuration_xmod.py
+src/transformers/models/xmod/convert_xmod_original_pytorch_checkpoint_to_pytorch.py
+src/transformers/models/xmod/modeling_xmod.py
+src/transformers/models/yolos/__init__.py
+src/transformers/models/yolos/configuration_yolos.py
+src/transformers/models/yolos/convert_yolos_to_pytorch.py
+src/transformers/models/yolos/feature_extraction_yolos.py
+src/transformers/models/yolos/image_processing_yolos.py
+src/transformers/models/yolos/image_processing_yolos_fast.py
+src/transformers/models/yolos/modeling_yolos.py
+src/transformers/models/yolos/modular_yolos.py
+src/transformers/models/yoso/__init__.py
+src/transformers/models/yoso/configuration_yoso.py
+src/transformers/models/yoso/convert_yoso_pytorch_to_pytorch.py
+src/transformers/models/yoso/modeling_yoso.py
+src/transformers/models/zamba/__init__.py
+src/transformers/models/zamba/configuration_zamba.py
+src/transformers/models/zamba/modeling_zamba.py
+src/transformers/models/zamba2/__init__.py
+src/transformers/models/zamba2/configuration_zamba2.py
+src/transformers/models/zamba2/modeling_zamba2.py
+src/transformers/models/zamba2/modular_zamba2.py
+src/transformers/models/zoedepth/__init__.py
+src/transformers/models/zoedepth/configuration_zoedepth.py
+src/transformers/models/zoedepth/convert_zoedepth_to_hf.py
+src/transformers/models/zoedepth/image_processing_zoedepth.py
+src/transformers/models/zoedepth/modeling_zoedepth.py
+src/transformers/onnx/__init__.py
+src/transformers/onnx/__main__.py
+src/transformers/onnx/config.py
+src/transformers/onnx/convert.py
+src/transformers/onnx/features.py
+src/transformers/onnx/utils.py
+src/transformers/pipelines/__init__.py
+src/transformers/pipelines/audio_classification.py
+src/transformers/pipelines/audio_utils.py
+src/transformers/pipelines/automatic_speech_recognition.py
+src/transformers/pipelines/base.py
+src/transformers/pipelines/depth_estimation.py
+src/transformers/pipelines/document_question_answering.py
+src/transformers/pipelines/feature_extraction.py
+src/transformers/pipelines/fill_mask.py
+src/transformers/pipelines/image_classification.py
+src/transformers/pipelines/image_feature_extraction.py
+src/transformers/pipelines/image_segmentation.py
+src/transformers/pipelines/image_text_to_text.py
+src/transformers/pipelines/image_to_image.py
+src/transformers/pipelines/image_to_text.py
+src/transformers/pipelines/mask_generation.py
+src/transformers/pipelines/object_detection.py
+src/transformers/pipelines/pt_utils.py
+src/transformers/pipelines/question_answering.py
+src/transformers/pipelines/table_question_answering.py
+src/transformers/pipelines/text2text_generation.py
+src/transformers/pipelines/text_classification.py
+src/transformers/pipelines/text_generation.py
+src/transformers/pipelines/text_to_audio.py
+src/transformers/pipelines/token_classification.py
+src/transformers/pipelines/video_classification.py
+src/transformers/pipelines/visual_question_answering.py
+src/transformers/pipelines/zero_shot_audio_classification.py
+src/transformers/pipelines/zero_shot_classification.py
+src/transformers/pipelines/zero_shot_image_classification.py
+src/transformers/pipelines/zero_shot_object_detection.py
+src/transformers/quantizers/__init__.py
+src/transformers/quantizers/auto.py
+src/transformers/quantizers/base.py
+src/transformers/quantizers/quantizer_aqlm.py
+src/transformers/quantizers/quantizer_auto_round.py
+src/transformers/quantizers/quantizer_awq.py
+src/transformers/quantizers/quantizer_bitnet.py
+src/transformers/quantizers/quantizer_bnb_4bit.py
+src/transformers/quantizers/quantizer_bnb_8bit.py
+src/transformers/quantizers/quantizer_compressed_tensors.py
+src/transformers/quantizers/quantizer_eetq.py
+src/transformers/quantizers/quantizer_fbgemm_fp8.py
+src/transformers/quantizers/quantizer_finegrained_fp8.py
+src/transformers/quantizers/quantizer_gptq.py
+src/transformers/quantizers/quantizer_higgs.py
+src/transformers/quantizers/quantizer_hqq.py
+src/transformers/quantizers/quantizer_quanto.py
+src/transformers/quantizers/quantizer_quark.py
+src/transformers/quantizers/quantizer_spqr.py
+src/transformers/quantizers/quantizer_torchao.py
+src/transformers/quantizers/quantizer_vptq.py
+src/transformers/quantizers/quantizers_utils.py
+src/transformers/sagemaker/__init__.py
+src/transformers/sagemaker/trainer_sm.py
+src/transformers/sagemaker/training_args_sm.py
+src/transformers/utils/__init__.py
+src/transformers/utils/attention_visualizer.py
+src/transformers/utils/backbone_utils.py
+src/transformers/utils/bitsandbytes.py
+src/transformers/utils/chat_template_utils.py
+src/transformers/utils/constants.py
+src/transformers/utils/deprecation.py
+src/transformers/utils/doc.py
+src/transformers/utils/dummy_detectron2_objects.py
+src/transformers/utils/dummy_essentia_and_librosa_and_pretty_midi_and_scipy_and_torch_objects.py
+src/transformers/utils/dummy_flax_objects.py
+src/transformers/utils/dummy_music_objects.py
+src/transformers/utils/dummy_pt_objects.py
+src/transformers/utils/dummy_sentencepiece_and_tokenizers_objects.py
+src/transformers/utils/dummy_sentencepiece_objects.py
+src/transformers/utils/dummy_speech_objects.py
+src/transformers/utils/dummy_tensorflow_text_objects.py
+src/transformers/utils/dummy_tf_objects.py
+src/transformers/utils/dummy_timm_and_torchvision_objects.py
+src/transformers/utils/dummy_tokenizers_objects.py
+src/transformers/utils/dummy_torchaudio_objects.py
+src/transformers/utils/dummy_torchvision_objects.py
+src/transformers/utils/dummy_vision_objects.py
+src/transformers/utils/fx.py
+src/transformers/utils/generic.py
+src/transformers/utils/hp_naming.py
+src/transformers/utils/hub.py
+src/transformers/utils/import_utils.py
+src/transformers/utils/logging.py
+src/transformers/utils/model_parallel_utils.py
+src/transformers/utils/notebook.py
+src/transformers/utils/peft_utils.py
+src/transformers/utils/quantization_config.py
+src/transformers/utils/sentencepiece_model_pb2.py
+src/transformers/utils/sentencepiece_model_pb2_new.py
+src/transformers/utils/versions.py
+tests/test_backbone_common.py
+tests/test_configuration_common.py
+tests/test_feature_extraction_common.py
+tests/test_image_processing_common.py
+tests/test_image_transforms.py
+tests/test_modeling_common.py
+tests/test_modeling_flax_common.py
+tests/test_modeling_tf_common.py
+tests/test_pipeline_mixin.py
+tests/test_processing_common.py
+tests/test_sequence_feature_extraction_common.py
+tests/test_tokenization_common.py
+tests/test_training_args.py
\ No newline at end of file
diff --git a/docs/transformers/src/transformers.egg-info/dependency_links.txt b/docs/transformers/src/transformers.egg-info/dependency_links.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/docs/transformers/src/transformers.egg-info/dependency_links.txt
@@ -0,0 +1 @@
+
diff --git a/docs/transformers/src/transformers.egg-info/entry_points.txt b/docs/transformers/src/transformers.egg-info/entry_points.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8a7995ed6f21261a78509c57d57daba51ecf1a7d
--- /dev/null
+++ b/docs/transformers/src/transformers.egg-info/entry_points.txt
@@ -0,0 +1,2 @@
+[console_scripts]
+transformers-cli = transformers.commands.transformers_cli:main
diff --git a/docs/transformers/src/transformers.egg-info/not-zip-safe b/docs/transformers/src/transformers.egg-info/not-zip-safe
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/docs/transformers/src/transformers.egg-info/not-zip-safe
@@ -0,0 +1 @@
+
diff --git a/docs/transformers/src/transformers.egg-info/requires.txt b/docs/transformers/src/transformers.egg-info/requires.txt
new file mode 100644
index 0000000000000000000000000000000000000000..b50f5cdf4d3ac32ab341baa79e35b2a4b120b3a6
--- /dev/null
+++ b/docs/transformers/src/transformers.egg-info/requires.txt
@@ -0,0 +1,468 @@
+filelock
+huggingface-hub<1.0,>=0.30.0
+numpy>=1.17
+packaging>=20.0
+pyyaml>=5.1
+regex!=2019.12.17
+requests
+tokenizers<0.22,>=0.21
+safetensors>=0.4.3
+tqdm>=4.27
+
+[accelerate]
+accelerate>=0.26.0
+
+[all]
+tensorflow<2.16,>2.9
+onnxconverter-common
+tf2onnx
+tensorflow-text<2.16
+keras-nlp<0.14.0,>=0.3.1
+torch>=2.1
+accelerate>=0.26.0
+jax<=0.4.13,>=0.4.1
+jaxlib<=0.4.13,>=0.4.1
+flax<=0.7.0,>=0.4.1
+optax<=0.1.4,>=0.0.8
+scipy<1.13.0
+sentencepiece!=0.1.92,>=0.1.91
+protobuf
+tokenizers<0.22,>=0.21
+torchaudio
+librosa
+pyctcdecode>=0.4.0
+phonemizer
+kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5
+Pillow<=15.0,>=10.0.1
+kernels<0.5,>=0.4.4
+optuna
+ray[tune]>=2.7.0
+sigopt
+timm<=1.0.11
+torchvision
+codecarbon>=2.8.1
+av
+num2words
+
+[audio]
+librosa
+pyctcdecode>=0.4.0
+phonemizer
+kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5
+
+[benchmark]
+optimum-benchmark>=0.3.0
+
+[codecarbon]
+codecarbon>=2.8.1
+
+[deepspeed]
+deepspeed>=0.9.3
+accelerate>=0.26.0
+
+[deepspeed-testing]
+deepspeed>=0.9.3
+accelerate>=0.26.0
+pytest<8.0.0,>=7.2.0
+pytest-asyncio
+pytest-rich
+pytest-xdist
+pytest-order
+pytest-rerunfailures
+timeout-decorator
+parameterized
+psutil
+datasets!=2.5.0
+dill<0.3.5
+evaluate>=0.2.0
+pytest-timeout
+ruff==0.11.2
+rouge-score!=0.0.7,!=0.0.8,!=0.1,!=0.1.1
+nltk<=3.8.1
+GitPython<3.1.19
+sacremoses
+rjieba
+beautifulsoup4
+tensorboard
+pydantic
+sentencepiece!=0.1.92,>=0.1.91
+sacrebleu<2.0.0,>=1.4.12
+faiss-cpu
+cookiecutter==1.7.3
+optuna
+protobuf
+
+[dev]
+tensorflow<2.16,>2.9
+onnxconverter-common
+tf2onnx
+tensorflow-text<2.16
+keras-nlp<0.14.0,>=0.3.1
+torch>=2.1
+accelerate>=0.26.0
+jax<=0.4.13,>=0.4.1
+jaxlib<=0.4.13,>=0.4.1
+flax<=0.7.0,>=0.4.1
+optax<=0.1.4,>=0.0.8
+scipy<1.13.0
+sentencepiece!=0.1.92,>=0.1.91
+protobuf
+tokenizers<0.22,>=0.21
+torchaudio
+librosa
+pyctcdecode>=0.4.0
+phonemizer
+kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5
+Pillow<=15.0,>=10.0.1
+kernels<0.5,>=0.4.4
+optuna
+ray[tune]>=2.7.0
+sigopt
+timm<=1.0.11
+torchvision
+codecarbon>=2.8.1
+av
+num2words
+pytest<8.0.0,>=7.2.0
+pytest-asyncio
+pytest-rich
+pytest-xdist
+pytest-order
+pytest-rerunfailures
+timeout-decorator
+parameterized
+psutil
+datasets!=2.5.0
+dill<0.3.5
+evaluate>=0.2.0
+pytest-timeout
+ruff==0.11.2
+rouge-score!=0.0.7,!=0.0.8,!=0.1,!=0.1.1
+nltk<=3.8.1
+GitPython<3.1.19
+sacremoses
+rjieba
+beautifulsoup4
+tensorboard
+pydantic
+sacrebleu<2.0.0,>=1.4.12
+faiss-cpu
+cookiecutter==1.7.3
+isort>=5.5.4
+urllib3<2.0.0
+libcst
+rich
+fugashi>=1.0
+ipadic<2.0,>=1.0.0
+unidic_lite>=1.0.7
+unidic>=1.0.2
+sudachipy>=0.6.6
+sudachidict_core>=20220729
+rhoknp<1.3.1,>=1.1.0
+scikit-learn
+
+[dev-tensorflow]
+pytest<8.0.0,>=7.2.0
+pytest-asyncio
+pytest-rich
+pytest-xdist
+pytest-order
+pytest-rerunfailures
+timeout-decorator
+parameterized
+psutil
+datasets!=2.5.0
+dill<0.3.5
+evaluate>=0.2.0
+pytest-timeout
+ruff==0.11.2
+rouge-score!=0.0.7,!=0.0.8,!=0.1,!=0.1.1
+nltk<=3.8.1
+GitPython<3.1.19
+sacremoses
+rjieba
+beautifulsoup4
+tensorboard
+pydantic
+sentencepiece!=0.1.92,>=0.1.91
+sacrebleu<2.0.0,>=1.4.12
+faiss-cpu
+cookiecutter==1.7.3
+tensorflow<2.16,>2.9
+onnxconverter-common
+tf2onnx
+tensorflow-text<2.16
+keras-nlp<0.14.0,>=0.3.1
+protobuf
+tokenizers<0.22,>=0.21
+Pillow<=15.0,>=10.0.1
+isort>=5.5.4
+urllib3<2.0.0
+libcst
+rich
+scikit-learn
+onnxruntime>=1.4.0
+onnxruntime-tools>=1.4.2
+librosa
+pyctcdecode>=0.4.0
+phonemizer
+kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5
+
+[dev-torch]
+pytest<8.0.0,>=7.2.0
+pytest-asyncio
+pytest-rich
+pytest-xdist
+pytest-order
+pytest-rerunfailures
+timeout-decorator
+parameterized
+psutil
+datasets!=2.5.0
+dill<0.3.5
+evaluate>=0.2.0
+pytest-timeout
+ruff==0.11.2
+rouge-score!=0.0.7,!=0.0.8,!=0.1,!=0.1.1
+nltk<=3.8.1
+GitPython<3.1.19
+sacremoses
+rjieba
+beautifulsoup4
+tensorboard
+pydantic
+sentencepiece!=0.1.92,>=0.1.91
+sacrebleu<2.0.0,>=1.4.12
+faiss-cpu
+cookiecutter==1.7.3
+torch>=2.1
+accelerate>=0.26.0
+protobuf
+tokenizers<0.22,>=0.21
+torchaudio
+librosa
+pyctcdecode>=0.4.0
+phonemizer
+kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5
+Pillow<=15.0,>=10.0.1
+kernels<0.5,>=0.4.4
+optuna
+ray[tune]>=2.7.0
+sigopt
+timm<=1.0.11
+torchvision
+codecarbon>=2.8.1
+isort>=5.5.4
+urllib3<2.0.0
+libcst
+rich
+fugashi>=1.0
+ipadic<2.0,>=1.0.0
+unidic_lite>=1.0.7
+unidic>=1.0.2
+sudachipy>=0.6.6
+sudachidict_core>=20220729
+rhoknp<1.3.1,>=1.1.0
+scikit-learn
+onnxruntime>=1.4.0
+onnxruntime-tools>=1.4.2
+num2words
+
+[flax]
+jax<=0.4.13,>=0.4.1
+jaxlib<=0.4.13,>=0.4.1
+flax<=0.7.0,>=0.4.1
+optax<=0.1.4,>=0.0.8
+scipy<1.13.0
+
+[flax-speech]
+librosa
+pyctcdecode>=0.4.0
+phonemizer
+kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5
+
+[ftfy]
+ftfy
+
+[hf_xet]
+hf_xet
+
+[hub-kernels]
+kernels<0.5,>=0.4.4
+
+[integrations]
+kernels<0.5,>=0.4.4
+optuna
+ray[tune]>=2.7.0
+sigopt
+
+[ja]
+fugashi>=1.0
+ipadic<2.0,>=1.0.0
+unidic_lite>=1.0.7
+unidic>=1.0.2
+sudachipy>=0.6.6
+sudachidict_core>=20220729
+rhoknp<1.3.1,>=1.1.0
+
+[modelcreation]
+cookiecutter==1.7.3
+
+[natten]
+natten<0.15.0,>=0.14.6
+
+[num2words]
+num2words
+
+[onnx]
+onnxconverter-common
+tf2onnx
+onnxruntime>=1.4.0
+onnxruntime-tools>=1.4.2
+
+[onnxruntime]
+onnxruntime>=1.4.0
+onnxruntime-tools>=1.4.2
+
+[optuna]
+optuna
+
+[quality]
+datasets!=2.5.0
+isort>=5.5.4
+ruff==0.11.2
+GitPython<3.1.19
+urllib3<2.0.0
+libcst
+rich
+
+[ray]
+ray[tune]>=2.7.0
+
+[retrieval]
+faiss-cpu
+datasets!=2.5.0
+
+[ruff]
+ruff==0.11.2
+
+[sagemaker]
+sagemaker>=2.31.0
+
+[sentencepiece]
+sentencepiece!=0.1.92,>=0.1.91
+protobuf
+
+[serving]
+pydantic
+uvicorn
+fastapi
+starlette
+
+[sigopt]
+sigopt
+
+[sklearn]
+scikit-learn
+
+[speech]
+torchaudio
+librosa
+pyctcdecode>=0.4.0
+phonemizer
+kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5
+
+[testing]
+pytest<8.0.0,>=7.2.0
+pytest-asyncio
+pytest-rich
+pytest-xdist
+pytest-order
+pytest-rerunfailures
+timeout-decorator
+parameterized
+psutil
+datasets!=2.5.0
+dill<0.3.5
+evaluate>=0.2.0
+pytest-timeout
+ruff==0.11.2
+rouge-score!=0.0.7,!=0.0.8,!=0.1,!=0.1.1
+nltk<=3.8.1
+GitPython<3.1.19
+sacremoses
+rjieba
+beautifulsoup4
+tensorboard
+pydantic
+sentencepiece!=0.1.92,>=0.1.91
+sacrebleu<2.0.0,>=1.4.12
+faiss-cpu
+cookiecutter==1.7.3
+
+[tf]
+tensorflow<2.16,>2.9
+onnxconverter-common
+tf2onnx
+tensorflow-text<2.16
+keras-nlp<0.14.0,>=0.3.1
+
+[tf-cpu]
+keras<2.16,>2.9
+tensorflow-cpu<2.16,>2.9
+onnxconverter-common
+tf2onnx
+tensorflow-text<2.16
+keras-nlp<0.14.0,>=0.3.1
+tensorflow-probability<0.24
+
+[tf-speech]
+librosa
+pyctcdecode>=0.4.0
+phonemizer
+kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5
+
+[tiktoken]
+tiktoken
+blobfile
+
+[timm]
+timm<=1.0.11
+
+[tokenizers]
+tokenizers<0.22,>=0.21
+
+[torch]
+torch>=2.1
+accelerate>=0.26.0
+
+[torch-speech]
+torchaudio
+librosa
+pyctcdecode>=0.4.0
+phonemizer
+kenlm@ git+https://github.com/ydshieh/kenlm@78f664fb3dafe1468d868d71faf19534530698d5
+
+[torch-vision]
+torchvision
+Pillow<=15.0,>=10.0.1
+
+[torchhub]
+filelock
+huggingface-hub<1.0,>=0.30.0
+importlib_metadata
+numpy>=1.17
+packaging>=20.0
+protobuf
+regex!=2019.12.17
+requests
+sentencepiece!=0.1.92,>=0.1.91
+torch>=2.1
+tokenizers<0.22,>=0.21
+tqdm>=4.27
+
+[video]
+av
+
+[vision]
+Pillow<=15.0,>=10.0.1
diff --git a/docs/transformers/src/transformers.egg-info/top_level.txt b/docs/transformers/src/transformers.egg-info/top_level.txt
new file mode 100644
index 0000000000000000000000000000000000000000..976a2b1f3998279c10c413279a095be86bf69167
--- /dev/null
+++ b/docs/transformers/src/transformers.egg-info/top_level.txt
@@ -0,0 +1 @@
+transformers
diff --git a/docs/transformers/src/transformers/.ipynb_checkpoints/__init__-checkpoint.py b/docs/transformers/src/transformers/.ipynb_checkpoints/__init__-checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..e75357c39f9c296fa99249ce38e4633a86157707
--- /dev/null
+++ b/docs/transformers/src/transformers/.ipynb_checkpoints/__init__-checkpoint.py
@@ -0,0 +1,1032 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# When adding a new object to this init, remember to add it twice: once inside the `_import_structure` dictionary and
+# once inside the `if TYPE_CHECKING` branch. The `TYPE_CHECKING` should have import statements as usual, but they are
+# only there for type checking. The `_import_structure` is a dictionary submodule to list of object names, and is used
+# to defer the actual importing for when the objects are requested. This way `import transformers` provides the names
+# in the namespace without actually importing anything (and especially none of the backends).
+
+__version__ = "4.52.0.dev0"
+
+from pathlib import Path
+from typing import TYPE_CHECKING
+
+# Check the dependencies satisfy the minimal versions required.
+from . import dependency_versions_check
+from .utils import (
+ OptionalDependencyNotAvailable,
+ _LazyModule,
+ is_bitsandbytes_available,
+ is_essentia_available,
+ is_flax_available,
+ is_g2p_en_available,
+ is_keras_nlp_available,
+ is_librosa_available,
+ is_pretty_midi_available,
+ is_scipy_available,
+ is_sentencepiece_available,
+ is_speech_available,
+ is_tensorflow_text_available,
+ is_tf_available,
+ is_timm_available,
+ is_tokenizers_available,
+ is_torch_available,
+ is_torchaudio_available,
+ is_torchvision_available,
+ is_vision_available,
+ logging,
+)
+from .utils.import_utils import define_import_structure
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+# Base objects, independent of any specific backend
+_import_structure = {
+ "audio_utils": [],
+ "commands": [],
+ "configuration_utils": ["PretrainedConfig"],
+ "convert_graph_to_onnx": [],
+ "convert_slow_tokenizers_checkpoints_to_fast": [],
+ "convert_tf_hub_seq_to_seq_bert_to_pytorch": [],
+ "data": [
+ "DataProcessor",
+ "InputExample",
+ "InputFeatures",
+ "SingleSentenceClassificationProcessor",
+ "SquadExample",
+ "SquadFeatures",
+ "SquadV1Processor",
+ "SquadV2Processor",
+ "glue_compute_metrics",
+ "glue_convert_examples_to_features",
+ "glue_output_modes",
+ "glue_processors",
+ "glue_tasks_num_labels",
+ "squad_convert_examples_to_features",
+ "xnli_compute_metrics",
+ "xnli_output_modes",
+ "xnli_processors",
+ "xnli_tasks_num_labels",
+ ],
+ "data.data_collator": [
+ "DataCollator",
+ "DataCollatorForLanguageModeling",
+ "DataCollatorForMultipleChoice",
+ "DataCollatorForPermutationLanguageModeling",
+ "DataCollatorForSeq2Seq",
+ "DataCollatorForSOP",
+ "DataCollatorForTokenClassification",
+ "DataCollatorForWholeWordMask",
+ "DataCollatorWithFlattening",
+ "DataCollatorWithPadding",
+ "DefaultDataCollator",
+ "default_data_collator",
+ ],
+ "data.metrics": [],
+ "data.processors": [],
+ "debug_utils": [],
+ "dependency_versions_check": [],
+ "dependency_versions_table": [],
+ "dynamic_module_utils": [],
+ "feature_extraction_sequence_utils": ["SequenceFeatureExtractor"],
+ "feature_extraction_utils": ["BatchFeature", "FeatureExtractionMixin"],
+ "file_utils": [],
+ "generation": [
+ "AsyncTextIteratorStreamer",
+ "CompileConfig",
+ "GenerationConfig",
+ "TextIteratorStreamer",
+ "TextStreamer",
+ "WatermarkingConfig",
+ ],
+ "hf_argparser": ["HfArgumentParser"],
+ "hyperparameter_search": [],
+ "image_transforms": [],
+ "integrations": [
+ "is_clearml_available",
+ "is_comet_available",
+ "is_dvclive_available",
+ "is_neptune_available",
+ "is_optuna_available",
+ "is_ray_available",
+ "is_ray_tune_available",
+ "is_sigopt_available",
+ "is_swanlab_available",
+ "is_tensorboard_available",
+ "is_wandb_available",
+ ],
+ "loss": [],
+ "modelcard": ["ModelCard"],
+ # Losses
+ "modeling_tf_pytorch_utils": [
+ "convert_tf_weight_name_to_pt_weight_name",
+ "load_pytorch_checkpoint_in_tf2_model",
+ "load_pytorch_model_in_tf2_model",
+ "load_pytorch_weights_in_tf2_model",
+ "load_tf2_checkpoint_in_pytorch_model",
+ "load_tf2_model_in_pytorch_model",
+ "load_tf2_weights_in_pytorch_model",
+ ],
+ # Models
+ "onnx": [],
+ "pipelines": [
+ "AudioClassificationPipeline",
+ "AutomaticSpeechRecognitionPipeline",
+ "CsvPipelineDataFormat",
+ "DepthEstimationPipeline",
+ "DocumentQuestionAnsweringPipeline",
+ "FeatureExtractionPipeline",
+ "FillMaskPipeline",
+ "ImageClassificationPipeline",
+ "ImageFeatureExtractionPipeline",
+ "ImageSegmentationPipeline",
+ "ImageTextToTextPipeline",
+ "ImageToImagePipeline",
+ "ImageToTextPipeline",
+ "JsonPipelineDataFormat",
+ "MaskGenerationPipeline",
+ "NerPipeline",
+ "ObjectDetectionPipeline",
+ "PipedPipelineDataFormat",
+ "Pipeline",
+ "PipelineDataFormat",
+ "QuestionAnsweringPipeline",
+ "SummarizationPipeline",
+ "TableQuestionAnsweringPipeline",
+ "Text2TextGenerationPipeline",
+ "TextClassificationPipeline",
+ "TextGenerationPipeline",
+ "TextToAudioPipeline",
+ "TokenClassificationPipeline",
+ "TranslationPipeline",
+ "VideoClassificationPipeline",
+ "VisualQuestionAnsweringPipeline",
+ "ZeroShotAudioClassificationPipeline",
+ "ZeroShotClassificationPipeline",
+ "ZeroShotImageClassificationPipeline",
+ "ZeroShotObjectDetectionPipeline",
+ "pipeline",
+ ],
+ "processing_utils": ["ProcessorMixin"],
+ "quantizers": [],
+ "testing_utils": [],
+ "tokenization_utils": ["PreTrainedTokenizer"],
+ "tokenization_utils_base": [
+ "AddedToken",
+ "BatchEncoding",
+ "CharSpan",
+ "PreTrainedTokenizerBase",
+ "SpecialTokensMixin",
+ "TokenSpan",
+ ],
+ "trainer_callback": [
+ "DefaultFlowCallback",
+ "EarlyStoppingCallback",
+ "PrinterCallback",
+ "ProgressCallback",
+ "TrainerCallback",
+ "TrainerControl",
+ "TrainerState",
+ ],
+ "trainer_utils": [
+ "EvalPrediction",
+ "IntervalStrategy",
+ "SchedulerType",
+ "enable_full_determinism",
+ "set_seed",
+ ],
+ "training_args": ["TrainingArguments"],
+ "training_args_seq2seq": ["Seq2SeqTrainingArguments"],
+ "training_args_tf": ["TFTrainingArguments"],
+ "utils": [
+ "CONFIG_NAME",
+ "MODEL_CARD_NAME",
+ "PYTORCH_PRETRAINED_BERT_CACHE",
+ "PYTORCH_TRANSFORMERS_CACHE",
+ "SPIECE_UNDERLINE",
+ "TF2_WEIGHTS_NAME",
+ "TF_WEIGHTS_NAME",
+ "TRANSFORMERS_CACHE",
+ "WEIGHTS_NAME",
+ "TensorType",
+ "add_end_docstrings",
+ "add_start_docstrings",
+ "is_apex_available",
+ "is_av_available",
+ "is_bitsandbytes_available",
+ "is_datasets_available",
+ "is_faiss_available",
+ "is_flax_available",
+ "is_keras_nlp_available",
+ "is_phonemizer_available",
+ "is_psutil_available",
+ "is_py3nvml_available",
+ "is_pyctcdecode_available",
+ "is_sacremoses_available",
+ "is_safetensors_available",
+ "is_scipy_available",
+ "is_sentencepiece_available",
+ "is_sklearn_available",
+ "is_speech_available",
+ "is_tensorflow_text_available",
+ "is_tf_available",
+ "is_timm_available",
+ "is_tokenizers_available",
+ "is_torch_available",
+ "is_torch_hpu_available",
+ "is_torch_mlu_available",
+ "is_torch_musa_available",
+ "is_torch_neuroncore_available",
+ "is_torch_npu_available",
+ "is_torchvision_available",
+ "is_torch_xla_available",
+ "is_torch_xpu_available",
+ "is_vision_available",
+ "logging",
+ ],
+ "utils.quantization_config": [
+ "AqlmConfig",
+ "AutoRoundConfig",
+ "AwqConfig",
+ "BitNetConfig",
+ "BitsAndBytesConfig",
+ "CompressedTensorsConfig",
+ "EetqConfig",
+ "FbgemmFp8Config",
+ "FineGrainedFP8Config",
+ "GPTQConfig",
+ "HiggsConfig",
+ "HqqConfig",
+ "QuantoConfig",
+ "QuarkConfig",
+ "SpQRConfig",
+ "TorchAoConfig",
+ "VptqConfig",
+ ],
+}
+
+# tokenizers-backed objects
+try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_tokenizers_objects
+
+ _import_structure["utils.dummy_tokenizers_objects"] = [
+ name for name in dir(dummy_tokenizers_objects) if not name.startswith("_")
+ ]
+else:
+ # Fast tokenizers structure
+ _import_structure["tokenization_utils_fast"] = ["PreTrainedTokenizerFast"]
+
+
+try:
+ if not (is_sentencepiece_available() and is_tokenizers_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_sentencepiece_and_tokenizers_objects
+
+ _import_structure["utils.dummy_sentencepiece_and_tokenizers_objects"] = [
+ name for name in dir(dummy_sentencepiece_and_tokenizers_objects) if not name.startswith("_")
+ ]
+else:
+ _import_structure["convert_slow_tokenizer"] = [
+ "SLOW_TO_FAST_CONVERTERS",
+ "convert_slow_tokenizer",
+ ]
+
+# Vision-specific objects
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_vision_objects
+
+ _import_structure["utils.dummy_vision_objects"] = [
+ name for name in dir(dummy_vision_objects) if not name.startswith("_")
+ ]
+else:
+ _import_structure["image_processing_base"] = ["ImageProcessingMixin"]
+ _import_structure["image_processing_utils"] = ["BaseImageProcessor"]
+ _import_structure["image_utils"] = ["ImageFeatureExtractionMixin"]
+
+try:
+ if not is_torchvision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_torchvision_objects
+
+ _import_structure["utils.dummy_torchvision_objects"] = [
+ name for name in dir(dummy_torchvision_objects) if not name.startswith("_")
+ ]
+else:
+ _import_structure["image_processing_utils_fast"] = ["BaseImageProcessorFast"]
+
+# PyTorch-backed objects
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_pt_objects
+
+ _import_structure["utils.dummy_pt_objects"] = [name for name in dir(dummy_pt_objects) if not name.startswith("_")]
+else:
+ _import_structure["model_debugging_utils"] = [
+ "model_addition_debugger_context",
+ ]
+ _import_structure["activations"] = []
+ _import_structure["cache_utils"] = [
+ "Cache",
+ "CacheConfig",
+ "DynamicCache",
+ "EncoderDecoderCache",
+ "HQQQuantizedCache",
+ "HybridCache",
+ "MambaCache",
+ "OffloadedCache",
+ "OffloadedStaticCache",
+ "QuantizedCache",
+ "QuantizedCacheConfig",
+ "QuantoQuantizedCache",
+ "SinkCache",
+ "SlidingWindowCache",
+ "StaticCache",
+ ]
+ _import_structure["data.datasets"] = [
+ "GlueDataset",
+ "GlueDataTrainingArguments",
+ "LineByLineTextDataset",
+ "LineByLineWithRefDataset",
+ "LineByLineWithSOPTextDataset",
+ "SquadDataset",
+ "SquadDataTrainingArguments",
+ "TextDataset",
+ "TextDatasetForNextSentencePrediction",
+ ]
+ _import_structure["generation"].extend(
+ [
+ "AlternatingCodebooksLogitsProcessor",
+ "BayesianDetectorConfig",
+ "BayesianDetectorModel",
+ "BeamScorer",
+ "BeamSearchScorer",
+ "ClassifierFreeGuidanceLogitsProcessor",
+ "ConstrainedBeamSearchScorer",
+ "Constraint",
+ "ConstraintListState",
+ "DisjunctiveConstraint",
+ "EncoderNoRepeatNGramLogitsProcessor",
+ "EncoderRepetitionPenaltyLogitsProcessor",
+ "EosTokenCriteria",
+ "EpsilonLogitsWarper",
+ "EtaLogitsWarper",
+ "ExponentialDecayLengthPenalty",
+ "ForcedBOSTokenLogitsProcessor",
+ "ForcedEOSTokenLogitsProcessor",
+ "GenerationMixin",
+ "HammingDiversityLogitsProcessor",
+ "InfNanRemoveLogitsProcessor",
+ "LogitNormalization",
+ "LogitsProcessor",
+ "LogitsProcessorList",
+ "MaxLengthCriteria",
+ "MaxTimeCriteria",
+ "MinLengthLogitsProcessor",
+ "MinNewTokensLengthLogitsProcessor",
+ "MinPLogitsWarper",
+ "NoBadWordsLogitsProcessor",
+ "NoRepeatNGramLogitsProcessor",
+ "PhrasalConstraint",
+ "PrefixConstrainedLogitsProcessor",
+ "RepetitionPenaltyLogitsProcessor",
+ "SequenceBiasLogitsProcessor",
+ "StoppingCriteria",
+ "StoppingCriteriaList",
+ "StopStringCriteria",
+ "SuppressTokensAtBeginLogitsProcessor",
+ "SuppressTokensLogitsProcessor",
+ "SynthIDTextWatermarkDetector",
+ "SynthIDTextWatermarkingConfig",
+ "SynthIDTextWatermarkLogitsProcessor",
+ "TemperatureLogitsWarper",
+ "TopKLogitsWarper",
+ "TopPLogitsWarper",
+ "TypicalLogitsWarper",
+ "UnbatchedClassifierFreeGuidanceLogitsProcessor",
+ "WatermarkDetector",
+ "WatermarkLogitsProcessor",
+ "WhisperTimeStampLogitsProcessor",
+ ]
+ )
+
+ # PyTorch domain libraries integration
+ _import_structure["integrations.executorch"] = [
+ "TorchExportableModuleWithStaticCache",
+ "convert_and_export_with_cache",
+ ]
+
+ _import_structure["modeling_flash_attention_utils"] = []
+ _import_structure["modeling_layers"] = ["GradientCheckpointingLayer"]
+ _import_structure["modeling_outputs"] = []
+ _import_structure["modeling_rope_utils"] = ["ROPE_INIT_FUNCTIONS", "dynamic_rope_update"]
+ _import_structure["modeling_utils"] = ["PreTrainedModel", "AttentionInterface"]
+ _import_structure["optimization"] = [
+ "Adafactor",
+ "get_constant_schedule",
+ "get_constant_schedule_with_warmup",
+ "get_cosine_schedule_with_warmup",
+ "get_cosine_with_hard_restarts_schedule_with_warmup",
+ "get_inverse_sqrt_schedule",
+ "get_linear_schedule_with_warmup",
+ "get_polynomial_decay_schedule_with_warmup",
+ "get_scheduler",
+ "get_wsd_schedule",
+ ]
+ _import_structure["pytorch_utils"] = [
+ "Conv1D",
+ "apply_chunking_to_forward",
+ "prune_layer",
+ ]
+ _import_structure["sagemaker"] = []
+ _import_structure["time_series_utils"] = []
+ _import_structure["trainer"] = ["Trainer"]
+ _import_structure["trainer_pt_utils"] = ["torch_distributed_zero_first"]
+ _import_structure["trainer_seq2seq"] = ["Seq2SeqTrainer"]
+
+# TensorFlow-backed objects
+try:
+ if not is_tf_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_tf_objects
+
+ _import_structure["utils.dummy_tf_objects"] = [name for name in dir(dummy_tf_objects) if not name.startswith("_")]
+else:
+ _import_structure["activations_tf"] = []
+ _import_structure["generation"].extend(
+ [
+ "TFForcedBOSTokenLogitsProcessor",
+ "TFForcedEOSTokenLogitsProcessor",
+ "TFForceTokensLogitsProcessor",
+ "TFGenerationMixin",
+ "TFLogitsProcessor",
+ "TFLogitsProcessorList",
+ "TFLogitsWarper",
+ "TFMinLengthLogitsProcessor",
+ "TFNoBadWordsLogitsProcessor",
+ "TFNoRepeatNGramLogitsProcessor",
+ "TFRepetitionPenaltyLogitsProcessor",
+ "TFSuppressTokensAtBeginLogitsProcessor",
+ "TFSuppressTokensLogitsProcessor",
+ "TFTemperatureLogitsWarper",
+ "TFTopKLogitsWarper",
+ "TFTopPLogitsWarper",
+ ]
+ )
+ _import_structure["keras_callbacks"] = ["KerasMetricCallback", "PushToHubCallback"]
+ _import_structure["modeling_tf_outputs"] = []
+ _import_structure["modeling_tf_utils"] = [
+ "TFPreTrainedModel",
+ "TFSequenceSummary",
+ "TFSharedEmbeddings",
+ "shape_list",
+ ]
+ _import_structure["optimization_tf"] = [
+ "AdamWeightDecay",
+ "GradientAccumulator",
+ "WarmUp",
+ "create_optimizer",
+ ]
+ _import_structure["tf_utils"] = []
+
+
+# FLAX-backed objects
+try:
+ if not is_flax_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_flax_objects
+
+ _import_structure["utils.dummy_flax_objects"] = [
+ name for name in dir(dummy_flax_objects) if not name.startswith("_")
+ ]
+else:
+ _import_structure["generation"].extend(
+ [
+ "FlaxForcedBOSTokenLogitsProcessor",
+ "FlaxForcedEOSTokenLogitsProcessor",
+ "FlaxForceTokensLogitsProcessor",
+ "FlaxGenerationMixin",
+ "FlaxLogitsProcessor",
+ "FlaxLogitsProcessorList",
+ "FlaxLogitsWarper",
+ "FlaxMinLengthLogitsProcessor",
+ "FlaxTemperatureLogitsWarper",
+ "FlaxSuppressTokensAtBeginLogitsProcessor",
+ "FlaxSuppressTokensLogitsProcessor",
+ "FlaxTopKLogitsWarper",
+ "FlaxTopPLogitsWarper",
+ "FlaxWhisperTimeStampLogitsProcessor",
+ ]
+ )
+ _import_structure["modeling_flax_outputs"] = []
+ _import_structure["modeling_flax_utils"] = ["FlaxPreTrainedModel"]
+
+# Direct imports for type-checking
+if TYPE_CHECKING:
+ # All modeling imports
+ from .configuration_utils import PretrainedConfig
+
+ # Data
+ from .data import (
+ DataProcessor,
+ InputExample,
+ InputFeatures,
+ SingleSentenceClassificationProcessor,
+ SquadExample,
+ SquadFeatures,
+ SquadV1Processor,
+ SquadV2Processor,
+ glue_compute_metrics,
+ glue_convert_examples_to_features,
+ glue_output_modes,
+ glue_processors,
+ glue_tasks_num_labels,
+ squad_convert_examples_to_features,
+ xnli_compute_metrics,
+ xnli_output_modes,
+ xnli_processors,
+ xnli_tasks_num_labels,
+ )
+ from .data.data_collator import (
+ DataCollator,
+ DataCollatorForLanguageModeling,
+ DataCollatorForMultipleChoice,
+ DataCollatorForPermutationLanguageModeling,
+ DataCollatorForSeq2Seq,
+ DataCollatorForSOP,
+ DataCollatorForTokenClassification,
+ DataCollatorForWholeWordMask,
+ DataCollatorWithFlattening,
+ DataCollatorWithPadding,
+ DefaultDataCollator,
+ default_data_collator,
+ )
+ from .feature_extraction_sequence_utils import SequenceFeatureExtractor
+
+ # Feature Extractor
+ from .feature_extraction_utils import BatchFeature, FeatureExtractionMixin
+
+ # Generation
+ from .generation import (
+ AsyncTextIteratorStreamer,
+ CompileConfig,
+ GenerationConfig,
+ TextIteratorStreamer,
+ TextStreamer,
+ WatermarkingConfig,
+ )
+ from .hf_argparser import HfArgumentParser
+
+ # Integrations
+ from .integrations import (
+ is_clearml_available,
+ is_comet_available,
+ is_dvclive_available,
+ is_neptune_available,
+ is_optuna_available,
+ is_ray_available,
+ is_ray_tune_available,
+ is_sigopt_available,
+ is_swanlab_available,
+ is_tensorboard_available,
+ is_wandb_available,
+ )
+
+ # Model Cards
+ from .modelcard import ModelCard
+
+ # TF 2.0 <=> PyTorch conversion utilities
+ from .modeling_tf_pytorch_utils import (
+ convert_tf_weight_name_to_pt_weight_name,
+ load_pytorch_checkpoint_in_tf2_model,
+ load_pytorch_model_in_tf2_model,
+ load_pytorch_weights_in_tf2_model,
+ load_tf2_checkpoint_in_pytorch_model,
+ load_tf2_model_in_pytorch_model,
+ load_tf2_weights_in_pytorch_model,
+ )
+ from .models import *
+
+ # Pipelines
+ from .pipelines import (
+ AudioClassificationPipeline,
+ AutomaticSpeechRecognitionPipeline,
+ CsvPipelineDataFormat,
+ DepthEstimationPipeline,
+ DocumentQuestionAnsweringPipeline,
+ FeatureExtractionPipeline,
+ FillMaskPipeline,
+ ImageClassificationPipeline,
+ ImageFeatureExtractionPipeline,
+ ImageSegmentationPipeline,
+ ImageTextToTextPipeline,
+ ImageToImagePipeline,
+ ImageToTextPipeline,
+ JsonPipelineDataFormat,
+ MaskGenerationPipeline,
+ NerPipeline,
+ ObjectDetectionPipeline,
+ PipedPipelineDataFormat,
+ Pipeline,
+ PipelineDataFormat,
+ QuestionAnsweringPipeline,
+ SummarizationPipeline,
+ TableQuestionAnsweringPipeline,
+ Text2TextGenerationPipeline,
+ TextClassificationPipeline,
+ TextGenerationPipeline,
+ TextToAudioPipeline,
+ TokenClassificationPipeline,
+ TranslationPipeline,
+ VideoClassificationPipeline,
+ VisualQuestionAnsweringPipeline,
+ ZeroShotAudioClassificationPipeline,
+ ZeroShotClassificationPipeline,
+ ZeroShotImageClassificationPipeline,
+ ZeroShotObjectDetectionPipeline,
+ pipeline,
+ )
+ from .processing_utils import ProcessorMixin
+
+ # Tokenization
+ from .tokenization_utils import PreTrainedTokenizer
+ from .tokenization_utils_base import (
+ AddedToken,
+ BatchEncoding,
+ CharSpan,
+ PreTrainedTokenizerBase,
+ SpecialTokensMixin,
+ TokenSpan,
+ )
+
+ # Trainer
+ from .trainer_callback import (
+ DefaultFlowCallback,
+ EarlyStoppingCallback,
+ PrinterCallback,
+ ProgressCallback,
+ TrainerCallback,
+ TrainerControl,
+ TrainerState,
+ )
+ from .trainer_utils import (
+ EvalPrediction,
+ IntervalStrategy,
+ SchedulerType,
+ enable_full_determinism,
+ set_seed,
+ )
+ from .training_args import TrainingArguments
+ from .training_args_seq2seq import Seq2SeqTrainingArguments
+ from .training_args_tf import TFTrainingArguments
+
+ # Files and general utilities
+ from .utils import (
+ CONFIG_NAME,
+ MODEL_CARD_NAME,
+ PYTORCH_PRETRAINED_BERT_CACHE,
+ PYTORCH_TRANSFORMERS_CACHE,
+ SPIECE_UNDERLINE,
+ TF2_WEIGHTS_NAME,
+ TF_WEIGHTS_NAME,
+ TRANSFORMERS_CACHE,
+ WEIGHTS_NAME,
+ TensorType,
+ add_end_docstrings,
+ add_start_docstrings,
+ is_apex_available,
+ is_av_available,
+ is_bitsandbytes_available,
+ is_datasets_available,
+ is_faiss_available,
+ is_flax_available,
+ is_keras_nlp_available,
+ is_phonemizer_available,
+ is_psutil_available,
+ is_py3nvml_available,
+ is_pyctcdecode_available,
+ is_sacremoses_available,
+ is_safetensors_available,
+ is_scipy_available,
+ is_sentencepiece_available,
+ is_sklearn_available,
+ is_speech_available,
+ is_tensorflow_text_available,
+ is_tf_available,
+ is_timm_available,
+ is_tokenizers_available,
+ is_torch_available,
+ is_torch_hpu_available,
+ is_torch_mlu_available,
+ is_torch_musa_available,
+ is_torch_neuroncore_available,
+ is_torch_npu_available,
+ is_torch_xla_available,
+ is_torch_xpu_available,
+ is_torchvision_available,
+ is_vision_available,
+ logging,
+ )
+
+ # bitsandbytes config
+ from .utils.quantization_config import (
+ AqlmConfig,
+ AutoRoundConfig,
+ AwqConfig,
+ BitNetConfig,
+ BitsAndBytesConfig,
+ CompressedTensorsConfig,
+ EetqConfig,
+ FbgemmFp8Config,
+ FineGrainedFP8Config,
+ GPTQConfig,
+ HiggsConfig,
+ HqqConfig,
+ QuantoConfig,
+ QuarkConfig,
+ SpQRConfig,
+ TorchAoConfig,
+ VptqConfig,
+ )
+
+ try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ from .utils.dummy_tokenizers_objects import *
+ else:
+ from .tokenization_utils_fast import PreTrainedTokenizerFast
+
+ try:
+ if not (is_sentencepiece_available() and is_tokenizers_available()):
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ from .utils.dummies_sentencepiece_and_tokenizers_objects import *
+ else:
+ from .convert_slow_tokenizer import (
+ SLOW_TO_FAST_CONVERTERS,
+ convert_slow_tokenizer,
+ )
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ from .utils.dummy_vision_objects import *
+ else:
+ from .image_processing_base import ImageProcessingMixin
+ from .image_processing_utils import BaseImageProcessor
+ from .image_utils import ImageFeatureExtractionMixin
+
+ try:
+ if not is_torchvision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ from .utils.dummy_torchvision_objects import *
+ else:
+ from .image_processing_utils_fast import BaseImageProcessorFast
+
+ try:
+ if not (is_torchvision_available() and is_timm_available()):
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ from .utils.dummy_timm_and_torchvision_objects import *
+ else:
+ from .models.timm_wrapper import TimmWrapperImageProcessor
+
+ # Modeling
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ from .utils.dummy_pt_objects import *
+ else:
+ # Debugging
+ from .cache_utils import (
+ Cache,
+ CacheConfig,
+ DynamicCache,
+ EncoderDecoderCache,
+ HQQQuantizedCache,
+ HybridCache,
+ MambaCache,
+ OffloadedCache,
+ OffloadedStaticCache,
+ QuantizedCache,
+ QuantizedCacheConfig,
+ QuantoQuantizedCache,
+ SinkCache,
+ SlidingWindowCache,
+ StaticCache,
+ )
+ from .data.datasets import (
+ GlueDataset,
+ GlueDataTrainingArguments,
+ LineByLineTextDataset,
+ LineByLineWithRefDataset,
+ LineByLineWithSOPTextDataset,
+ SquadDataset,
+ SquadDataTrainingArguments,
+ TextDataset,
+ TextDatasetForNextSentencePrediction,
+ )
+ from .generation import (
+ AlternatingCodebooksLogitsProcessor,
+ BayesianDetectorConfig,
+ BayesianDetectorModel,
+ BeamScorer,
+ BeamSearchScorer,
+ ClassifierFreeGuidanceLogitsProcessor,
+ ConstrainedBeamSearchScorer,
+ Constraint,
+ ConstraintListState,
+ DisjunctiveConstraint,
+ EncoderNoRepeatNGramLogitsProcessor,
+ EncoderRepetitionPenaltyLogitsProcessor,
+ EosTokenCriteria,
+ EpsilonLogitsWarper,
+ EtaLogitsWarper,
+ ExponentialDecayLengthPenalty,
+ ForcedBOSTokenLogitsProcessor,
+ ForcedEOSTokenLogitsProcessor,
+ GenerationMixin,
+ HammingDiversityLogitsProcessor,
+ InfNanRemoveLogitsProcessor,
+ LogitNormalization,
+ LogitsProcessor,
+ LogitsProcessorList,
+ MaxLengthCriteria,
+ MaxTimeCriteria,
+ MinLengthLogitsProcessor,
+ MinNewTokensLengthLogitsProcessor,
+ MinPLogitsWarper,
+ NoBadWordsLogitsProcessor,
+ NoRepeatNGramLogitsProcessor,
+ PhrasalConstraint,
+ PrefixConstrainedLogitsProcessor,
+ RepetitionPenaltyLogitsProcessor,
+ SequenceBiasLogitsProcessor,
+ StoppingCriteria,
+ StoppingCriteriaList,
+ StopStringCriteria,
+ SuppressTokensAtBeginLogitsProcessor,
+ SuppressTokensLogitsProcessor,
+ SynthIDTextWatermarkDetector,
+ SynthIDTextWatermarkingConfig,
+ SynthIDTextWatermarkLogitsProcessor,
+ TemperatureLogitsWarper,
+ TopKLogitsWarper,
+ TopPLogitsWarper,
+ TypicalLogitsWarper,
+ UnbatchedClassifierFreeGuidanceLogitsProcessor,
+ WatermarkDetector,
+ WatermarkLogitsProcessor,
+ WhisperTimeStampLogitsProcessor,
+ )
+ from .integrations.executorch import (
+ TorchExportableModuleWithStaticCache,
+ convert_and_export_with_cache,
+ )
+ from .model_debugging_utils import (
+ model_addition_debugger_context,
+ )
+ from .modeling_layers import GradientCheckpointingLayer
+ from .modeling_rope_utils import ROPE_INIT_FUNCTIONS, dynamic_rope_update
+ from .modeling_utils import AttentionInterface, PreTrainedModel
+
+ # Optimization
+ from .optimization import (
+ Adafactor,
+ get_constant_schedule,
+ get_constant_schedule_with_warmup,
+ get_cosine_schedule_with_warmup,
+ get_cosine_with_hard_restarts_schedule_with_warmup,
+ get_inverse_sqrt_schedule,
+ get_linear_schedule_with_warmup,
+ get_polynomial_decay_schedule_with_warmup,
+ get_scheduler,
+ get_wsd_schedule,
+ )
+ from .pytorch_utils import Conv1D, apply_chunking_to_forward, prune_layer
+
+ # Trainer
+ from .trainer import Trainer
+ from .trainer_pt_utils import torch_distributed_zero_first
+ from .trainer_seq2seq import Seq2SeqTrainer
+
+ # TensorFlow
+ try:
+ if not is_tf_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ # Import the same objects as dummies to get them in the namespace.
+ # They will raise an import error if the user tries to instantiate / use them.
+ from .utils.dummy_tf_objects import *
+ else:
+ from .generation import (
+ TFForcedBOSTokenLogitsProcessor,
+ TFForcedEOSTokenLogitsProcessor,
+ TFForceTokensLogitsProcessor,
+ TFGenerationMixin,
+ TFLogitsProcessor,
+ TFLogitsProcessorList,
+ TFLogitsWarper,
+ TFMinLengthLogitsProcessor,
+ TFNoBadWordsLogitsProcessor,
+ TFNoRepeatNGramLogitsProcessor,
+ TFRepetitionPenaltyLogitsProcessor,
+ TFSuppressTokensAtBeginLogitsProcessor,
+ TFSuppressTokensLogitsProcessor,
+ TFTemperatureLogitsWarper,
+ TFTopKLogitsWarper,
+ TFTopPLogitsWarper,
+ )
+ from .keras_callbacks import KerasMetricCallback, PushToHubCallback
+ from .modeling_tf_utils import (
+ TFPreTrainedModel,
+ TFSequenceSummary,
+ TFSharedEmbeddings,
+ shape_list,
+ )
+
+ # Optimization
+ from .optimization_tf import (
+ AdamWeightDecay,
+ GradientAccumulator,
+ WarmUp,
+ create_optimizer,
+ )
+
+ try:
+ if not is_flax_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ # Import the same objects as dummies to get them in the namespace.
+ # They will raise an import error if the user tries to instantiate / use them.
+ from .utils.dummy_flax_objects import *
+ else:
+ from .generation import (
+ FlaxForcedBOSTokenLogitsProcessor,
+ FlaxForcedEOSTokenLogitsProcessor,
+ FlaxForceTokensLogitsProcessor,
+ FlaxGenerationMixin,
+ FlaxLogitsProcessor,
+ FlaxLogitsProcessorList,
+ FlaxLogitsWarper,
+ FlaxMinLengthLogitsProcessor,
+ FlaxSuppressTokensAtBeginLogitsProcessor,
+ FlaxSuppressTokensLogitsProcessor,
+ FlaxTemperatureLogitsWarper,
+ FlaxTopKLogitsWarper,
+ FlaxTopPLogitsWarper,
+ FlaxWhisperTimeStampLogitsProcessor,
+ )
+ from .modeling_flax_utils import FlaxPreTrainedModel
+
+else:
+ import sys
+
+ _import_structure = {k: set(v) for k, v in _import_structure.items()}
+
+ import_structure = define_import_structure(Path(__file__).parent / "models", prefix="models")
+ import_structure[frozenset({})].update(_import_structure)
+
+ sys.modules[__name__] = _LazyModule(
+ __name__,
+ globals()["__file__"],
+ import_structure,
+ module_spec=__spec__,
+ extra_objects={"__version__": __version__},
+ )
+
+
+if not is_tf_available() and not is_torch_available() and not is_flax_available():
+ logger.warning_advice(
+ "None of PyTorch, TensorFlow >= 2.0, or Flax have been found. "
+ "Models won't be available and only tokenizers, configuration "
+ "and file/data utilities can be used."
+ )
diff --git a/docs/transformers/src/transformers/__init__.py b/docs/transformers/src/transformers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e75357c39f9c296fa99249ce38e4633a86157707
--- /dev/null
+++ b/docs/transformers/src/transformers/__init__.py
@@ -0,0 +1,1032 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# When adding a new object to this init, remember to add it twice: once inside the `_import_structure` dictionary and
+# once inside the `if TYPE_CHECKING` branch. The `TYPE_CHECKING` should have import statements as usual, but they are
+# only there for type checking. The `_import_structure` is a dictionary submodule to list of object names, and is used
+# to defer the actual importing for when the objects are requested. This way `import transformers` provides the names
+# in the namespace without actually importing anything (and especially none of the backends).
+
+__version__ = "4.52.0.dev0"
+
+from pathlib import Path
+from typing import TYPE_CHECKING
+
+# Check the dependencies satisfy the minimal versions required.
+from . import dependency_versions_check
+from .utils import (
+ OptionalDependencyNotAvailable,
+ _LazyModule,
+ is_bitsandbytes_available,
+ is_essentia_available,
+ is_flax_available,
+ is_g2p_en_available,
+ is_keras_nlp_available,
+ is_librosa_available,
+ is_pretty_midi_available,
+ is_scipy_available,
+ is_sentencepiece_available,
+ is_speech_available,
+ is_tensorflow_text_available,
+ is_tf_available,
+ is_timm_available,
+ is_tokenizers_available,
+ is_torch_available,
+ is_torchaudio_available,
+ is_torchvision_available,
+ is_vision_available,
+ logging,
+)
+from .utils.import_utils import define_import_structure
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+# Base objects, independent of any specific backend
+_import_structure = {
+ "audio_utils": [],
+ "commands": [],
+ "configuration_utils": ["PretrainedConfig"],
+ "convert_graph_to_onnx": [],
+ "convert_slow_tokenizers_checkpoints_to_fast": [],
+ "convert_tf_hub_seq_to_seq_bert_to_pytorch": [],
+ "data": [
+ "DataProcessor",
+ "InputExample",
+ "InputFeatures",
+ "SingleSentenceClassificationProcessor",
+ "SquadExample",
+ "SquadFeatures",
+ "SquadV1Processor",
+ "SquadV2Processor",
+ "glue_compute_metrics",
+ "glue_convert_examples_to_features",
+ "glue_output_modes",
+ "glue_processors",
+ "glue_tasks_num_labels",
+ "squad_convert_examples_to_features",
+ "xnli_compute_metrics",
+ "xnli_output_modes",
+ "xnli_processors",
+ "xnli_tasks_num_labels",
+ ],
+ "data.data_collator": [
+ "DataCollator",
+ "DataCollatorForLanguageModeling",
+ "DataCollatorForMultipleChoice",
+ "DataCollatorForPermutationLanguageModeling",
+ "DataCollatorForSeq2Seq",
+ "DataCollatorForSOP",
+ "DataCollatorForTokenClassification",
+ "DataCollatorForWholeWordMask",
+ "DataCollatorWithFlattening",
+ "DataCollatorWithPadding",
+ "DefaultDataCollator",
+ "default_data_collator",
+ ],
+ "data.metrics": [],
+ "data.processors": [],
+ "debug_utils": [],
+ "dependency_versions_check": [],
+ "dependency_versions_table": [],
+ "dynamic_module_utils": [],
+ "feature_extraction_sequence_utils": ["SequenceFeatureExtractor"],
+ "feature_extraction_utils": ["BatchFeature", "FeatureExtractionMixin"],
+ "file_utils": [],
+ "generation": [
+ "AsyncTextIteratorStreamer",
+ "CompileConfig",
+ "GenerationConfig",
+ "TextIteratorStreamer",
+ "TextStreamer",
+ "WatermarkingConfig",
+ ],
+ "hf_argparser": ["HfArgumentParser"],
+ "hyperparameter_search": [],
+ "image_transforms": [],
+ "integrations": [
+ "is_clearml_available",
+ "is_comet_available",
+ "is_dvclive_available",
+ "is_neptune_available",
+ "is_optuna_available",
+ "is_ray_available",
+ "is_ray_tune_available",
+ "is_sigopt_available",
+ "is_swanlab_available",
+ "is_tensorboard_available",
+ "is_wandb_available",
+ ],
+ "loss": [],
+ "modelcard": ["ModelCard"],
+ # Losses
+ "modeling_tf_pytorch_utils": [
+ "convert_tf_weight_name_to_pt_weight_name",
+ "load_pytorch_checkpoint_in_tf2_model",
+ "load_pytorch_model_in_tf2_model",
+ "load_pytorch_weights_in_tf2_model",
+ "load_tf2_checkpoint_in_pytorch_model",
+ "load_tf2_model_in_pytorch_model",
+ "load_tf2_weights_in_pytorch_model",
+ ],
+ # Models
+ "onnx": [],
+ "pipelines": [
+ "AudioClassificationPipeline",
+ "AutomaticSpeechRecognitionPipeline",
+ "CsvPipelineDataFormat",
+ "DepthEstimationPipeline",
+ "DocumentQuestionAnsweringPipeline",
+ "FeatureExtractionPipeline",
+ "FillMaskPipeline",
+ "ImageClassificationPipeline",
+ "ImageFeatureExtractionPipeline",
+ "ImageSegmentationPipeline",
+ "ImageTextToTextPipeline",
+ "ImageToImagePipeline",
+ "ImageToTextPipeline",
+ "JsonPipelineDataFormat",
+ "MaskGenerationPipeline",
+ "NerPipeline",
+ "ObjectDetectionPipeline",
+ "PipedPipelineDataFormat",
+ "Pipeline",
+ "PipelineDataFormat",
+ "QuestionAnsweringPipeline",
+ "SummarizationPipeline",
+ "TableQuestionAnsweringPipeline",
+ "Text2TextGenerationPipeline",
+ "TextClassificationPipeline",
+ "TextGenerationPipeline",
+ "TextToAudioPipeline",
+ "TokenClassificationPipeline",
+ "TranslationPipeline",
+ "VideoClassificationPipeline",
+ "VisualQuestionAnsweringPipeline",
+ "ZeroShotAudioClassificationPipeline",
+ "ZeroShotClassificationPipeline",
+ "ZeroShotImageClassificationPipeline",
+ "ZeroShotObjectDetectionPipeline",
+ "pipeline",
+ ],
+ "processing_utils": ["ProcessorMixin"],
+ "quantizers": [],
+ "testing_utils": [],
+ "tokenization_utils": ["PreTrainedTokenizer"],
+ "tokenization_utils_base": [
+ "AddedToken",
+ "BatchEncoding",
+ "CharSpan",
+ "PreTrainedTokenizerBase",
+ "SpecialTokensMixin",
+ "TokenSpan",
+ ],
+ "trainer_callback": [
+ "DefaultFlowCallback",
+ "EarlyStoppingCallback",
+ "PrinterCallback",
+ "ProgressCallback",
+ "TrainerCallback",
+ "TrainerControl",
+ "TrainerState",
+ ],
+ "trainer_utils": [
+ "EvalPrediction",
+ "IntervalStrategy",
+ "SchedulerType",
+ "enable_full_determinism",
+ "set_seed",
+ ],
+ "training_args": ["TrainingArguments"],
+ "training_args_seq2seq": ["Seq2SeqTrainingArguments"],
+ "training_args_tf": ["TFTrainingArguments"],
+ "utils": [
+ "CONFIG_NAME",
+ "MODEL_CARD_NAME",
+ "PYTORCH_PRETRAINED_BERT_CACHE",
+ "PYTORCH_TRANSFORMERS_CACHE",
+ "SPIECE_UNDERLINE",
+ "TF2_WEIGHTS_NAME",
+ "TF_WEIGHTS_NAME",
+ "TRANSFORMERS_CACHE",
+ "WEIGHTS_NAME",
+ "TensorType",
+ "add_end_docstrings",
+ "add_start_docstrings",
+ "is_apex_available",
+ "is_av_available",
+ "is_bitsandbytes_available",
+ "is_datasets_available",
+ "is_faiss_available",
+ "is_flax_available",
+ "is_keras_nlp_available",
+ "is_phonemizer_available",
+ "is_psutil_available",
+ "is_py3nvml_available",
+ "is_pyctcdecode_available",
+ "is_sacremoses_available",
+ "is_safetensors_available",
+ "is_scipy_available",
+ "is_sentencepiece_available",
+ "is_sklearn_available",
+ "is_speech_available",
+ "is_tensorflow_text_available",
+ "is_tf_available",
+ "is_timm_available",
+ "is_tokenizers_available",
+ "is_torch_available",
+ "is_torch_hpu_available",
+ "is_torch_mlu_available",
+ "is_torch_musa_available",
+ "is_torch_neuroncore_available",
+ "is_torch_npu_available",
+ "is_torchvision_available",
+ "is_torch_xla_available",
+ "is_torch_xpu_available",
+ "is_vision_available",
+ "logging",
+ ],
+ "utils.quantization_config": [
+ "AqlmConfig",
+ "AutoRoundConfig",
+ "AwqConfig",
+ "BitNetConfig",
+ "BitsAndBytesConfig",
+ "CompressedTensorsConfig",
+ "EetqConfig",
+ "FbgemmFp8Config",
+ "FineGrainedFP8Config",
+ "GPTQConfig",
+ "HiggsConfig",
+ "HqqConfig",
+ "QuantoConfig",
+ "QuarkConfig",
+ "SpQRConfig",
+ "TorchAoConfig",
+ "VptqConfig",
+ ],
+}
+
+# tokenizers-backed objects
+try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_tokenizers_objects
+
+ _import_structure["utils.dummy_tokenizers_objects"] = [
+ name for name in dir(dummy_tokenizers_objects) if not name.startswith("_")
+ ]
+else:
+ # Fast tokenizers structure
+ _import_structure["tokenization_utils_fast"] = ["PreTrainedTokenizerFast"]
+
+
+try:
+ if not (is_sentencepiece_available() and is_tokenizers_available()):
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_sentencepiece_and_tokenizers_objects
+
+ _import_structure["utils.dummy_sentencepiece_and_tokenizers_objects"] = [
+ name for name in dir(dummy_sentencepiece_and_tokenizers_objects) if not name.startswith("_")
+ ]
+else:
+ _import_structure["convert_slow_tokenizer"] = [
+ "SLOW_TO_FAST_CONVERTERS",
+ "convert_slow_tokenizer",
+ ]
+
+# Vision-specific objects
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_vision_objects
+
+ _import_structure["utils.dummy_vision_objects"] = [
+ name for name in dir(dummy_vision_objects) if not name.startswith("_")
+ ]
+else:
+ _import_structure["image_processing_base"] = ["ImageProcessingMixin"]
+ _import_structure["image_processing_utils"] = ["BaseImageProcessor"]
+ _import_structure["image_utils"] = ["ImageFeatureExtractionMixin"]
+
+try:
+ if not is_torchvision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_torchvision_objects
+
+ _import_structure["utils.dummy_torchvision_objects"] = [
+ name for name in dir(dummy_torchvision_objects) if not name.startswith("_")
+ ]
+else:
+ _import_structure["image_processing_utils_fast"] = ["BaseImageProcessorFast"]
+
+# PyTorch-backed objects
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_pt_objects
+
+ _import_structure["utils.dummy_pt_objects"] = [name for name in dir(dummy_pt_objects) if not name.startswith("_")]
+else:
+ _import_structure["model_debugging_utils"] = [
+ "model_addition_debugger_context",
+ ]
+ _import_structure["activations"] = []
+ _import_structure["cache_utils"] = [
+ "Cache",
+ "CacheConfig",
+ "DynamicCache",
+ "EncoderDecoderCache",
+ "HQQQuantizedCache",
+ "HybridCache",
+ "MambaCache",
+ "OffloadedCache",
+ "OffloadedStaticCache",
+ "QuantizedCache",
+ "QuantizedCacheConfig",
+ "QuantoQuantizedCache",
+ "SinkCache",
+ "SlidingWindowCache",
+ "StaticCache",
+ ]
+ _import_structure["data.datasets"] = [
+ "GlueDataset",
+ "GlueDataTrainingArguments",
+ "LineByLineTextDataset",
+ "LineByLineWithRefDataset",
+ "LineByLineWithSOPTextDataset",
+ "SquadDataset",
+ "SquadDataTrainingArguments",
+ "TextDataset",
+ "TextDatasetForNextSentencePrediction",
+ ]
+ _import_structure["generation"].extend(
+ [
+ "AlternatingCodebooksLogitsProcessor",
+ "BayesianDetectorConfig",
+ "BayesianDetectorModel",
+ "BeamScorer",
+ "BeamSearchScorer",
+ "ClassifierFreeGuidanceLogitsProcessor",
+ "ConstrainedBeamSearchScorer",
+ "Constraint",
+ "ConstraintListState",
+ "DisjunctiveConstraint",
+ "EncoderNoRepeatNGramLogitsProcessor",
+ "EncoderRepetitionPenaltyLogitsProcessor",
+ "EosTokenCriteria",
+ "EpsilonLogitsWarper",
+ "EtaLogitsWarper",
+ "ExponentialDecayLengthPenalty",
+ "ForcedBOSTokenLogitsProcessor",
+ "ForcedEOSTokenLogitsProcessor",
+ "GenerationMixin",
+ "HammingDiversityLogitsProcessor",
+ "InfNanRemoveLogitsProcessor",
+ "LogitNormalization",
+ "LogitsProcessor",
+ "LogitsProcessorList",
+ "MaxLengthCriteria",
+ "MaxTimeCriteria",
+ "MinLengthLogitsProcessor",
+ "MinNewTokensLengthLogitsProcessor",
+ "MinPLogitsWarper",
+ "NoBadWordsLogitsProcessor",
+ "NoRepeatNGramLogitsProcessor",
+ "PhrasalConstraint",
+ "PrefixConstrainedLogitsProcessor",
+ "RepetitionPenaltyLogitsProcessor",
+ "SequenceBiasLogitsProcessor",
+ "StoppingCriteria",
+ "StoppingCriteriaList",
+ "StopStringCriteria",
+ "SuppressTokensAtBeginLogitsProcessor",
+ "SuppressTokensLogitsProcessor",
+ "SynthIDTextWatermarkDetector",
+ "SynthIDTextWatermarkingConfig",
+ "SynthIDTextWatermarkLogitsProcessor",
+ "TemperatureLogitsWarper",
+ "TopKLogitsWarper",
+ "TopPLogitsWarper",
+ "TypicalLogitsWarper",
+ "UnbatchedClassifierFreeGuidanceLogitsProcessor",
+ "WatermarkDetector",
+ "WatermarkLogitsProcessor",
+ "WhisperTimeStampLogitsProcessor",
+ ]
+ )
+
+ # PyTorch domain libraries integration
+ _import_structure["integrations.executorch"] = [
+ "TorchExportableModuleWithStaticCache",
+ "convert_and_export_with_cache",
+ ]
+
+ _import_structure["modeling_flash_attention_utils"] = []
+ _import_structure["modeling_layers"] = ["GradientCheckpointingLayer"]
+ _import_structure["modeling_outputs"] = []
+ _import_structure["modeling_rope_utils"] = ["ROPE_INIT_FUNCTIONS", "dynamic_rope_update"]
+ _import_structure["modeling_utils"] = ["PreTrainedModel", "AttentionInterface"]
+ _import_structure["optimization"] = [
+ "Adafactor",
+ "get_constant_schedule",
+ "get_constant_schedule_with_warmup",
+ "get_cosine_schedule_with_warmup",
+ "get_cosine_with_hard_restarts_schedule_with_warmup",
+ "get_inverse_sqrt_schedule",
+ "get_linear_schedule_with_warmup",
+ "get_polynomial_decay_schedule_with_warmup",
+ "get_scheduler",
+ "get_wsd_schedule",
+ ]
+ _import_structure["pytorch_utils"] = [
+ "Conv1D",
+ "apply_chunking_to_forward",
+ "prune_layer",
+ ]
+ _import_structure["sagemaker"] = []
+ _import_structure["time_series_utils"] = []
+ _import_structure["trainer"] = ["Trainer"]
+ _import_structure["trainer_pt_utils"] = ["torch_distributed_zero_first"]
+ _import_structure["trainer_seq2seq"] = ["Seq2SeqTrainer"]
+
+# TensorFlow-backed objects
+try:
+ if not is_tf_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_tf_objects
+
+ _import_structure["utils.dummy_tf_objects"] = [name for name in dir(dummy_tf_objects) if not name.startswith("_")]
+else:
+ _import_structure["activations_tf"] = []
+ _import_structure["generation"].extend(
+ [
+ "TFForcedBOSTokenLogitsProcessor",
+ "TFForcedEOSTokenLogitsProcessor",
+ "TFForceTokensLogitsProcessor",
+ "TFGenerationMixin",
+ "TFLogitsProcessor",
+ "TFLogitsProcessorList",
+ "TFLogitsWarper",
+ "TFMinLengthLogitsProcessor",
+ "TFNoBadWordsLogitsProcessor",
+ "TFNoRepeatNGramLogitsProcessor",
+ "TFRepetitionPenaltyLogitsProcessor",
+ "TFSuppressTokensAtBeginLogitsProcessor",
+ "TFSuppressTokensLogitsProcessor",
+ "TFTemperatureLogitsWarper",
+ "TFTopKLogitsWarper",
+ "TFTopPLogitsWarper",
+ ]
+ )
+ _import_structure["keras_callbacks"] = ["KerasMetricCallback", "PushToHubCallback"]
+ _import_structure["modeling_tf_outputs"] = []
+ _import_structure["modeling_tf_utils"] = [
+ "TFPreTrainedModel",
+ "TFSequenceSummary",
+ "TFSharedEmbeddings",
+ "shape_list",
+ ]
+ _import_structure["optimization_tf"] = [
+ "AdamWeightDecay",
+ "GradientAccumulator",
+ "WarmUp",
+ "create_optimizer",
+ ]
+ _import_structure["tf_utils"] = []
+
+
+# FLAX-backed objects
+try:
+ if not is_flax_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ from .utils import dummy_flax_objects
+
+ _import_structure["utils.dummy_flax_objects"] = [
+ name for name in dir(dummy_flax_objects) if not name.startswith("_")
+ ]
+else:
+ _import_structure["generation"].extend(
+ [
+ "FlaxForcedBOSTokenLogitsProcessor",
+ "FlaxForcedEOSTokenLogitsProcessor",
+ "FlaxForceTokensLogitsProcessor",
+ "FlaxGenerationMixin",
+ "FlaxLogitsProcessor",
+ "FlaxLogitsProcessorList",
+ "FlaxLogitsWarper",
+ "FlaxMinLengthLogitsProcessor",
+ "FlaxTemperatureLogitsWarper",
+ "FlaxSuppressTokensAtBeginLogitsProcessor",
+ "FlaxSuppressTokensLogitsProcessor",
+ "FlaxTopKLogitsWarper",
+ "FlaxTopPLogitsWarper",
+ "FlaxWhisperTimeStampLogitsProcessor",
+ ]
+ )
+ _import_structure["modeling_flax_outputs"] = []
+ _import_structure["modeling_flax_utils"] = ["FlaxPreTrainedModel"]
+
+# Direct imports for type-checking
+if TYPE_CHECKING:
+ # All modeling imports
+ from .configuration_utils import PretrainedConfig
+
+ # Data
+ from .data import (
+ DataProcessor,
+ InputExample,
+ InputFeatures,
+ SingleSentenceClassificationProcessor,
+ SquadExample,
+ SquadFeatures,
+ SquadV1Processor,
+ SquadV2Processor,
+ glue_compute_metrics,
+ glue_convert_examples_to_features,
+ glue_output_modes,
+ glue_processors,
+ glue_tasks_num_labels,
+ squad_convert_examples_to_features,
+ xnli_compute_metrics,
+ xnli_output_modes,
+ xnli_processors,
+ xnli_tasks_num_labels,
+ )
+ from .data.data_collator import (
+ DataCollator,
+ DataCollatorForLanguageModeling,
+ DataCollatorForMultipleChoice,
+ DataCollatorForPermutationLanguageModeling,
+ DataCollatorForSeq2Seq,
+ DataCollatorForSOP,
+ DataCollatorForTokenClassification,
+ DataCollatorForWholeWordMask,
+ DataCollatorWithFlattening,
+ DataCollatorWithPadding,
+ DefaultDataCollator,
+ default_data_collator,
+ )
+ from .feature_extraction_sequence_utils import SequenceFeatureExtractor
+
+ # Feature Extractor
+ from .feature_extraction_utils import BatchFeature, FeatureExtractionMixin
+
+ # Generation
+ from .generation import (
+ AsyncTextIteratorStreamer,
+ CompileConfig,
+ GenerationConfig,
+ TextIteratorStreamer,
+ TextStreamer,
+ WatermarkingConfig,
+ )
+ from .hf_argparser import HfArgumentParser
+
+ # Integrations
+ from .integrations import (
+ is_clearml_available,
+ is_comet_available,
+ is_dvclive_available,
+ is_neptune_available,
+ is_optuna_available,
+ is_ray_available,
+ is_ray_tune_available,
+ is_sigopt_available,
+ is_swanlab_available,
+ is_tensorboard_available,
+ is_wandb_available,
+ )
+
+ # Model Cards
+ from .modelcard import ModelCard
+
+ # TF 2.0 <=> PyTorch conversion utilities
+ from .modeling_tf_pytorch_utils import (
+ convert_tf_weight_name_to_pt_weight_name,
+ load_pytorch_checkpoint_in_tf2_model,
+ load_pytorch_model_in_tf2_model,
+ load_pytorch_weights_in_tf2_model,
+ load_tf2_checkpoint_in_pytorch_model,
+ load_tf2_model_in_pytorch_model,
+ load_tf2_weights_in_pytorch_model,
+ )
+ from .models import *
+
+ # Pipelines
+ from .pipelines import (
+ AudioClassificationPipeline,
+ AutomaticSpeechRecognitionPipeline,
+ CsvPipelineDataFormat,
+ DepthEstimationPipeline,
+ DocumentQuestionAnsweringPipeline,
+ FeatureExtractionPipeline,
+ FillMaskPipeline,
+ ImageClassificationPipeline,
+ ImageFeatureExtractionPipeline,
+ ImageSegmentationPipeline,
+ ImageTextToTextPipeline,
+ ImageToImagePipeline,
+ ImageToTextPipeline,
+ JsonPipelineDataFormat,
+ MaskGenerationPipeline,
+ NerPipeline,
+ ObjectDetectionPipeline,
+ PipedPipelineDataFormat,
+ Pipeline,
+ PipelineDataFormat,
+ QuestionAnsweringPipeline,
+ SummarizationPipeline,
+ TableQuestionAnsweringPipeline,
+ Text2TextGenerationPipeline,
+ TextClassificationPipeline,
+ TextGenerationPipeline,
+ TextToAudioPipeline,
+ TokenClassificationPipeline,
+ TranslationPipeline,
+ VideoClassificationPipeline,
+ VisualQuestionAnsweringPipeline,
+ ZeroShotAudioClassificationPipeline,
+ ZeroShotClassificationPipeline,
+ ZeroShotImageClassificationPipeline,
+ ZeroShotObjectDetectionPipeline,
+ pipeline,
+ )
+ from .processing_utils import ProcessorMixin
+
+ # Tokenization
+ from .tokenization_utils import PreTrainedTokenizer
+ from .tokenization_utils_base import (
+ AddedToken,
+ BatchEncoding,
+ CharSpan,
+ PreTrainedTokenizerBase,
+ SpecialTokensMixin,
+ TokenSpan,
+ )
+
+ # Trainer
+ from .trainer_callback import (
+ DefaultFlowCallback,
+ EarlyStoppingCallback,
+ PrinterCallback,
+ ProgressCallback,
+ TrainerCallback,
+ TrainerControl,
+ TrainerState,
+ )
+ from .trainer_utils import (
+ EvalPrediction,
+ IntervalStrategy,
+ SchedulerType,
+ enable_full_determinism,
+ set_seed,
+ )
+ from .training_args import TrainingArguments
+ from .training_args_seq2seq import Seq2SeqTrainingArguments
+ from .training_args_tf import TFTrainingArguments
+
+ # Files and general utilities
+ from .utils import (
+ CONFIG_NAME,
+ MODEL_CARD_NAME,
+ PYTORCH_PRETRAINED_BERT_CACHE,
+ PYTORCH_TRANSFORMERS_CACHE,
+ SPIECE_UNDERLINE,
+ TF2_WEIGHTS_NAME,
+ TF_WEIGHTS_NAME,
+ TRANSFORMERS_CACHE,
+ WEIGHTS_NAME,
+ TensorType,
+ add_end_docstrings,
+ add_start_docstrings,
+ is_apex_available,
+ is_av_available,
+ is_bitsandbytes_available,
+ is_datasets_available,
+ is_faiss_available,
+ is_flax_available,
+ is_keras_nlp_available,
+ is_phonemizer_available,
+ is_psutil_available,
+ is_py3nvml_available,
+ is_pyctcdecode_available,
+ is_sacremoses_available,
+ is_safetensors_available,
+ is_scipy_available,
+ is_sentencepiece_available,
+ is_sklearn_available,
+ is_speech_available,
+ is_tensorflow_text_available,
+ is_tf_available,
+ is_timm_available,
+ is_tokenizers_available,
+ is_torch_available,
+ is_torch_hpu_available,
+ is_torch_mlu_available,
+ is_torch_musa_available,
+ is_torch_neuroncore_available,
+ is_torch_npu_available,
+ is_torch_xla_available,
+ is_torch_xpu_available,
+ is_torchvision_available,
+ is_vision_available,
+ logging,
+ )
+
+ # bitsandbytes config
+ from .utils.quantization_config import (
+ AqlmConfig,
+ AutoRoundConfig,
+ AwqConfig,
+ BitNetConfig,
+ BitsAndBytesConfig,
+ CompressedTensorsConfig,
+ EetqConfig,
+ FbgemmFp8Config,
+ FineGrainedFP8Config,
+ GPTQConfig,
+ HiggsConfig,
+ HqqConfig,
+ QuantoConfig,
+ QuarkConfig,
+ SpQRConfig,
+ TorchAoConfig,
+ VptqConfig,
+ )
+
+ try:
+ if not is_tokenizers_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ from .utils.dummy_tokenizers_objects import *
+ else:
+ from .tokenization_utils_fast import PreTrainedTokenizerFast
+
+ try:
+ if not (is_sentencepiece_available() and is_tokenizers_available()):
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ from .utils.dummies_sentencepiece_and_tokenizers_objects import *
+ else:
+ from .convert_slow_tokenizer import (
+ SLOW_TO_FAST_CONVERTERS,
+ convert_slow_tokenizer,
+ )
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ from .utils.dummy_vision_objects import *
+ else:
+ from .image_processing_base import ImageProcessingMixin
+ from .image_processing_utils import BaseImageProcessor
+ from .image_utils import ImageFeatureExtractionMixin
+
+ try:
+ if not is_torchvision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ from .utils.dummy_torchvision_objects import *
+ else:
+ from .image_processing_utils_fast import BaseImageProcessorFast
+
+ try:
+ if not (is_torchvision_available() and is_timm_available()):
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ from .utils.dummy_timm_and_torchvision_objects import *
+ else:
+ from .models.timm_wrapper import TimmWrapperImageProcessor
+
+ # Modeling
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ from .utils.dummy_pt_objects import *
+ else:
+ # Debugging
+ from .cache_utils import (
+ Cache,
+ CacheConfig,
+ DynamicCache,
+ EncoderDecoderCache,
+ HQQQuantizedCache,
+ HybridCache,
+ MambaCache,
+ OffloadedCache,
+ OffloadedStaticCache,
+ QuantizedCache,
+ QuantizedCacheConfig,
+ QuantoQuantizedCache,
+ SinkCache,
+ SlidingWindowCache,
+ StaticCache,
+ )
+ from .data.datasets import (
+ GlueDataset,
+ GlueDataTrainingArguments,
+ LineByLineTextDataset,
+ LineByLineWithRefDataset,
+ LineByLineWithSOPTextDataset,
+ SquadDataset,
+ SquadDataTrainingArguments,
+ TextDataset,
+ TextDatasetForNextSentencePrediction,
+ )
+ from .generation import (
+ AlternatingCodebooksLogitsProcessor,
+ BayesianDetectorConfig,
+ BayesianDetectorModel,
+ BeamScorer,
+ BeamSearchScorer,
+ ClassifierFreeGuidanceLogitsProcessor,
+ ConstrainedBeamSearchScorer,
+ Constraint,
+ ConstraintListState,
+ DisjunctiveConstraint,
+ EncoderNoRepeatNGramLogitsProcessor,
+ EncoderRepetitionPenaltyLogitsProcessor,
+ EosTokenCriteria,
+ EpsilonLogitsWarper,
+ EtaLogitsWarper,
+ ExponentialDecayLengthPenalty,
+ ForcedBOSTokenLogitsProcessor,
+ ForcedEOSTokenLogitsProcessor,
+ GenerationMixin,
+ HammingDiversityLogitsProcessor,
+ InfNanRemoveLogitsProcessor,
+ LogitNormalization,
+ LogitsProcessor,
+ LogitsProcessorList,
+ MaxLengthCriteria,
+ MaxTimeCriteria,
+ MinLengthLogitsProcessor,
+ MinNewTokensLengthLogitsProcessor,
+ MinPLogitsWarper,
+ NoBadWordsLogitsProcessor,
+ NoRepeatNGramLogitsProcessor,
+ PhrasalConstraint,
+ PrefixConstrainedLogitsProcessor,
+ RepetitionPenaltyLogitsProcessor,
+ SequenceBiasLogitsProcessor,
+ StoppingCriteria,
+ StoppingCriteriaList,
+ StopStringCriteria,
+ SuppressTokensAtBeginLogitsProcessor,
+ SuppressTokensLogitsProcessor,
+ SynthIDTextWatermarkDetector,
+ SynthIDTextWatermarkingConfig,
+ SynthIDTextWatermarkLogitsProcessor,
+ TemperatureLogitsWarper,
+ TopKLogitsWarper,
+ TopPLogitsWarper,
+ TypicalLogitsWarper,
+ UnbatchedClassifierFreeGuidanceLogitsProcessor,
+ WatermarkDetector,
+ WatermarkLogitsProcessor,
+ WhisperTimeStampLogitsProcessor,
+ )
+ from .integrations.executorch import (
+ TorchExportableModuleWithStaticCache,
+ convert_and_export_with_cache,
+ )
+ from .model_debugging_utils import (
+ model_addition_debugger_context,
+ )
+ from .modeling_layers import GradientCheckpointingLayer
+ from .modeling_rope_utils import ROPE_INIT_FUNCTIONS, dynamic_rope_update
+ from .modeling_utils import AttentionInterface, PreTrainedModel
+
+ # Optimization
+ from .optimization import (
+ Adafactor,
+ get_constant_schedule,
+ get_constant_schedule_with_warmup,
+ get_cosine_schedule_with_warmup,
+ get_cosine_with_hard_restarts_schedule_with_warmup,
+ get_inverse_sqrt_schedule,
+ get_linear_schedule_with_warmup,
+ get_polynomial_decay_schedule_with_warmup,
+ get_scheduler,
+ get_wsd_schedule,
+ )
+ from .pytorch_utils import Conv1D, apply_chunking_to_forward, prune_layer
+
+ # Trainer
+ from .trainer import Trainer
+ from .trainer_pt_utils import torch_distributed_zero_first
+ from .trainer_seq2seq import Seq2SeqTrainer
+
+ # TensorFlow
+ try:
+ if not is_tf_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ # Import the same objects as dummies to get them in the namespace.
+ # They will raise an import error if the user tries to instantiate / use them.
+ from .utils.dummy_tf_objects import *
+ else:
+ from .generation import (
+ TFForcedBOSTokenLogitsProcessor,
+ TFForcedEOSTokenLogitsProcessor,
+ TFForceTokensLogitsProcessor,
+ TFGenerationMixin,
+ TFLogitsProcessor,
+ TFLogitsProcessorList,
+ TFLogitsWarper,
+ TFMinLengthLogitsProcessor,
+ TFNoBadWordsLogitsProcessor,
+ TFNoRepeatNGramLogitsProcessor,
+ TFRepetitionPenaltyLogitsProcessor,
+ TFSuppressTokensAtBeginLogitsProcessor,
+ TFSuppressTokensLogitsProcessor,
+ TFTemperatureLogitsWarper,
+ TFTopKLogitsWarper,
+ TFTopPLogitsWarper,
+ )
+ from .keras_callbacks import KerasMetricCallback, PushToHubCallback
+ from .modeling_tf_utils import (
+ TFPreTrainedModel,
+ TFSequenceSummary,
+ TFSharedEmbeddings,
+ shape_list,
+ )
+
+ # Optimization
+ from .optimization_tf import (
+ AdamWeightDecay,
+ GradientAccumulator,
+ WarmUp,
+ create_optimizer,
+ )
+
+ try:
+ if not is_flax_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ # Import the same objects as dummies to get them in the namespace.
+ # They will raise an import error if the user tries to instantiate / use them.
+ from .utils.dummy_flax_objects import *
+ else:
+ from .generation import (
+ FlaxForcedBOSTokenLogitsProcessor,
+ FlaxForcedEOSTokenLogitsProcessor,
+ FlaxForceTokensLogitsProcessor,
+ FlaxGenerationMixin,
+ FlaxLogitsProcessor,
+ FlaxLogitsProcessorList,
+ FlaxLogitsWarper,
+ FlaxMinLengthLogitsProcessor,
+ FlaxSuppressTokensAtBeginLogitsProcessor,
+ FlaxSuppressTokensLogitsProcessor,
+ FlaxTemperatureLogitsWarper,
+ FlaxTopKLogitsWarper,
+ FlaxTopPLogitsWarper,
+ FlaxWhisperTimeStampLogitsProcessor,
+ )
+ from .modeling_flax_utils import FlaxPreTrainedModel
+
+else:
+ import sys
+
+ _import_structure = {k: set(v) for k, v in _import_structure.items()}
+
+ import_structure = define_import_structure(Path(__file__).parent / "models", prefix="models")
+ import_structure[frozenset({})].update(_import_structure)
+
+ sys.modules[__name__] = _LazyModule(
+ __name__,
+ globals()["__file__"],
+ import_structure,
+ module_spec=__spec__,
+ extra_objects={"__version__": __version__},
+ )
+
+
+if not is_tf_available() and not is_torch_available() and not is_flax_available():
+ logger.warning_advice(
+ "None of PyTorch, TensorFlow >= 2.0, or Flax have been found. "
+ "Models won't be available and only tokenizers, configuration "
+ "and file/data utilities can be used."
+ )
diff --git a/docs/transformers/src/transformers/activations.py b/docs/transformers/src/transformers/activations.py
new file mode 100644
index 0000000000000000000000000000000000000000..2dab2fb32cd09839ea725cadd9bde1b3a48c8521
--- /dev/null
+++ b/docs/transformers/src/transformers/activations.py
@@ -0,0 +1,228 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import math
+from collections import OrderedDict
+
+import torch
+from torch import Tensor, nn
+
+from .utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class PytorchGELUTanh(nn.Module):
+ """
+ A fast C implementation of the tanh approximation of the GeLU activation function. See
+ https://arxiv.org/abs/1606.08415.
+
+ This implementation is equivalent to NewGELU and FastGELU but much faster. However, it is not an exact numerical
+ match due to rounding errors.
+ """
+
+ def forward(self, input: Tensor) -> Tensor:
+ return nn.functional.gelu(input, approximate="tanh")
+
+
+class NewGELUActivation(nn.Module):
+ """
+ Implementation of the GELU activation function currently in Google BERT repo (identical to OpenAI GPT). Also see
+ the Gaussian Error Linear Units paper: https://arxiv.org/abs/1606.08415
+ """
+
+ def forward(self, input: Tensor) -> Tensor:
+ return 0.5 * input * (1.0 + torch.tanh(math.sqrt(2.0 / math.pi) * (input + 0.044715 * torch.pow(input, 3.0))))
+
+
+class GELUActivation(nn.Module):
+ """
+ Original Implementation of the GELU activation function in Google BERT repo when initially created. For
+ information: OpenAI GPT's GELU is slightly different (and gives slightly different results): 0.5 * x * (1 +
+ torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) This is now written in C in nn.functional
+ Also see the Gaussian Error Linear Units paper: https://arxiv.org/abs/1606.08415
+ """
+
+ def __init__(self, use_gelu_python: bool = False):
+ super().__init__()
+ if use_gelu_python:
+ self.act = self._gelu_python
+ else:
+ self.act = nn.functional.gelu
+
+ def _gelu_python(self, input: Tensor) -> Tensor:
+ return input * 0.5 * (1.0 + torch.erf(input / math.sqrt(2.0)))
+
+ def forward(self, input: Tensor) -> Tensor:
+ return self.act(input)
+
+
+class FastGELUActivation(nn.Module):
+ """
+ Applies GELU approximation that is slower than QuickGELU but more accurate. See: https://github.com/hendrycks/GELUs
+ """
+
+ def forward(self, input: Tensor) -> Tensor:
+ return 0.5 * input * (1.0 + torch.tanh(input * 0.7978845608 * (1.0 + 0.044715 * input * input)))
+
+
+class QuickGELUActivation(nn.Module):
+ """
+ Applies GELU approximation that is fast but somewhat inaccurate. See: https://github.com/hendrycks/GELUs
+ """
+
+ def forward(self, input: Tensor) -> Tensor:
+ return input * torch.sigmoid(1.702 * input)
+
+
+class ClippedGELUActivation(nn.Module):
+ """
+ Clip the range of possible GeLU outputs between [min, max]. This is especially useful for quantization purpose, as
+ it allows mapping negatives values in the GeLU spectrum. For more information on this trick, please refer to
+ https://arxiv.org/abs/2004.09602.
+
+ Gaussian Error Linear Unit. Original Implementation of the gelu activation function in Google Bert repo when
+ initially created.
+
+ For information: OpenAI GPT's gelu is slightly different (and gives slightly different results): 0.5 * x * (1 +
+ torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))). See https://arxiv.org/abs/1606.08415
+ """
+
+ def __init__(self, min: float, max: float):
+ if min > max:
+ raise ValueError(f"min should be < max (got min: {min}, max: {max})")
+
+ super().__init__()
+ self.min = min
+ self.max = max
+
+ def forward(self, x: Tensor) -> Tensor:
+ return torch.clip(gelu(x), self.min, self.max)
+
+
+class AccurateGELUActivation(nn.Module):
+ """
+ Applies GELU approximation that is faster than default and more accurate than QuickGELU. See:
+ https://github.com/hendrycks/GELUs
+
+ Implemented along with MEGA (Moving Average Equipped Gated Attention)
+ """
+
+ def __init__(self):
+ super().__init__()
+ self.precomputed_constant = math.sqrt(2 / math.pi)
+
+ def forward(self, input: Tensor) -> Tensor:
+ return 0.5 * input * (1 + torch.tanh(self.precomputed_constant * (input + 0.044715 * torch.pow(input, 3))))
+
+
+class MishActivation(nn.Module):
+ """
+ See Mish: A Self-Regularized Non-Monotonic Activation Function (Misra., https://arxiv.org/abs/1908.08681). Also
+ visit the official repository for the paper: https://github.com/digantamisra98/Mish
+ """
+
+ def __init__(self):
+ super().__init__()
+ self.act = nn.functional.mish
+
+ def _mish_python(self, input: Tensor) -> Tensor:
+ return input * torch.tanh(nn.functional.softplus(input))
+
+ def forward(self, input: Tensor) -> Tensor:
+ return self.act(input)
+
+
+class LinearActivation(nn.Module):
+ """
+ Applies the linear activation function, i.e. forwarding input directly to output.
+ """
+
+ def forward(self, input: Tensor) -> Tensor:
+ return input
+
+
+class LaplaceActivation(nn.Module):
+ """
+ Applies elementwise activation based on Laplace function, introduced in MEGA as an attention activation. See
+ https://arxiv.org/abs/2209.10655
+
+ Inspired by squared relu, but with bounded range and gradient for better stability
+ """
+
+ def forward(self, input, mu=0.707107, sigma=0.282095):
+ input = (input - mu).div(sigma * math.sqrt(2.0))
+ return 0.5 * (1.0 + torch.erf(input))
+
+
+class ReLUSquaredActivation(nn.Module):
+ """
+ Applies the relu^2 activation introduced in https://arxiv.org/abs/2109.08668v2
+ """
+
+ def forward(self, input):
+ relu_applied = nn.functional.relu(input)
+ squared = torch.square(relu_applied)
+ return squared
+
+
+class ClassInstantier(OrderedDict):
+ def __getitem__(self, key):
+ content = super().__getitem__(key)
+ cls, kwargs = content if isinstance(content, tuple) else (content, {})
+ return cls(**kwargs)
+
+
+ACT2CLS = {
+ "gelu": GELUActivation,
+ "gelu_10": (ClippedGELUActivation, {"min": -10, "max": 10}),
+ "gelu_fast": FastGELUActivation,
+ "gelu_new": NewGELUActivation,
+ "gelu_python": (GELUActivation, {"use_gelu_python": True}),
+ "gelu_pytorch_tanh": PytorchGELUTanh,
+ "gelu_accurate": AccurateGELUActivation,
+ "laplace": LaplaceActivation,
+ "leaky_relu": nn.LeakyReLU,
+ "linear": LinearActivation,
+ "mish": MishActivation,
+ "quick_gelu": QuickGELUActivation,
+ "relu": nn.ReLU,
+ "relu2": ReLUSquaredActivation,
+ "relu6": nn.ReLU6,
+ "sigmoid": nn.Sigmoid,
+ "silu": nn.SiLU,
+ "swish": nn.SiLU,
+ "tanh": nn.Tanh,
+ "prelu": nn.PReLU,
+}
+ACT2FN = ClassInstantier(ACT2CLS)
+
+
+def get_activation(activation_string):
+ if activation_string in ACT2FN:
+ return ACT2FN[activation_string]
+ else:
+ raise KeyError(f"function {activation_string} not found in ACT2FN mapping {list(ACT2FN.keys())}")
+
+
+# For backwards compatibility with: from activations import gelu_python
+gelu_python = get_activation("gelu_python")
+gelu_new = get_activation("gelu_new")
+gelu = get_activation("gelu")
+gelu_fast = get_activation("gelu_fast")
+quick_gelu = get_activation("quick_gelu")
+silu = get_activation("silu")
+mish = get_activation("mish")
+linear_act = get_activation("linear")
diff --git a/docs/transformers/src/transformers/activations_tf.py b/docs/transformers/src/transformers/activations_tf.py
new file mode 100644
index 0000000000000000000000000000000000000000..d12b73ea45176f3a4bc42cdabe8b73078a3b90f2
--- /dev/null
+++ b/docs/transformers/src/transformers/activations_tf.py
@@ -0,0 +1,147 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import math
+
+import tensorflow as tf
+from packaging.version import parse
+
+
+try:
+ import tf_keras as keras
+except (ModuleNotFoundError, ImportError):
+ import keras
+
+ if parse(keras.__version__).major > 2:
+ raise ValueError(
+ "Your currently installed version of Keras is Keras 3, but this is not yet supported in "
+ "Transformers. Please install the backwards-compatible tf-keras package with "
+ "`pip install tf-keras`."
+ )
+
+
+def _gelu(x):
+ """
+ Gaussian Error Linear Unit. Original Implementation of the gelu activation function in Google Bert repo when
+ initially created. For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
+ 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) Also see
+ https://arxiv.org/abs/1606.08415
+ """
+ x = tf.convert_to_tensor(x)
+ cdf = 0.5 * (1.0 + tf.math.erf(x / tf.cast(tf.sqrt(2.0), x.dtype)))
+
+ return x * cdf
+
+
+def _gelu_new(x):
+ """
+ Gaussian Error Linear Unit. This is a smoother version of the GELU. Original paper: https://arxiv.org/abs/1606.0841
+
+ Args:
+ x: float Tensor to perform activation
+
+ Returns:
+ `x` with the GELU activation applied.
+ """
+ x = tf.convert_to_tensor(x)
+ pi = tf.cast(math.pi, x.dtype)
+ coeff = tf.cast(0.044715, x.dtype)
+ cdf = 0.5 * (1.0 + tf.tanh(tf.sqrt(2.0 / pi) * (x + coeff * tf.pow(x, 3))))
+
+ return x * cdf
+
+
+def mish(x):
+ x = tf.convert_to_tensor(x)
+
+ return x * tf.tanh(tf.math.softplus(x))
+
+
+def gelu_fast(x):
+ x = tf.convert_to_tensor(x)
+ coeff1 = tf.cast(0.044715, x.dtype)
+ coeff2 = tf.cast(0.7978845608, x.dtype)
+
+ return 0.5 * x * (1.0 + tf.tanh(x * coeff2 * (1.0 + coeff1 * x * x)))
+
+
+def quick_gelu(x):
+ x = tf.convert_to_tensor(x)
+ coeff = tf.cast(1.702, x.dtype)
+ return x * tf.math.sigmoid(coeff * x)
+
+
+def gelu_10(x):
+ """
+ Clip the range of possible GeLU outputs between [-10, 10]. This is especially useful for quantization purpose, as
+ it allows mapping 2 negatives values in the GeLU spectrum. For more information on this trick, please refer to
+ https://arxiv.org/abs/2004.09602
+
+ Gaussian Error Linear Unit. Original Implementation of the gelu activation function in Google Bert repo when
+ initially created. For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
+ 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) Also see
+ https://arxiv.org/abs/1606.08415 :param x: :return:
+ """
+ return tf.clip_by_value(_gelu(x), -10, 10)
+
+
+def glu(x, axis=-1):
+ """
+ Gated Linear Unit. Implementation as defined in the original paper (see https://arxiv.org/abs/1612.08083), where
+ the input `x` is split in two halves across a dimension (`axis`), A and B, returning A * sigmoid(B).
+
+ Args:
+ `x`: float Tensor to perform activation
+ `axis`: dimension across which `x` be split in half
+
+ Returns:
+ `x` with the GLU activation applied (with its size halved across the dimension `axis`).
+ """
+ a, b = tf.split(x, 2, axis=axis)
+ return a * tf.math.sigmoid(b)
+
+
+if parse(tf.version.VERSION) >= parse("2.4"):
+
+ def approximate_gelu_wrap(x):
+ return keras.activations.gelu(x, approximate=True)
+
+ gelu = keras.activations.gelu
+ gelu_new = approximate_gelu_wrap
+else:
+ gelu = _gelu
+ gelu_new = _gelu_new
+
+
+ACT2FN = {
+ "gelu": gelu,
+ "gelu_10": gelu_10,
+ "gelu_fast": gelu_fast,
+ "gelu_new": gelu_new,
+ "glu": glu,
+ "mish": mish,
+ "quick_gelu": quick_gelu,
+ "relu": keras.activations.relu,
+ "sigmoid": keras.activations.sigmoid,
+ "silu": keras.activations.swish,
+ "swish": keras.activations.swish,
+ "tanh": keras.activations.tanh,
+}
+
+
+def get_tf_activation(activation_string):
+ if activation_string in ACT2FN:
+ return ACT2FN[activation_string]
+ else:
+ raise KeyError(f"function {activation_string} not found in ACT2FN mapping {list(ACT2FN.keys())}")
diff --git a/docs/transformers/src/transformers/audio_utils.py b/docs/transformers/src/transformers/audio_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..8420a84e089e03be9a80fb63c237e34203ea28a0
--- /dev/null
+++ b/docs/transformers/src/transformers/audio_utils.py
@@ -0,0 +1,1193 @@
+# Copyright 2023 The HuggingFace Inc. team and the librosa & torchaudio authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Audio processing functions to extract features from audio waveforms. This code is pure numpy to support all frameworks
+and remove unnecessary dependencies.
+"""
+
+import os
+import warnings
+from io import BytesIO
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import requests
+
+from .utils import is_librosa_available, requires_backends
+
+
+if is_librosa_available():
+ import librosa
+
+
+def load_audio(audio: Union[str, np.ndarray], sampling_rate=16000, timeout=None) -> np.ndarray:
+ """
+ Loads `audio` to an np.ndarray object.
+
+ Args:
+ audio (`str` or `np.ndarray`):
+ The audio to be laoded to the numpy array format.
+ sampling_rate (`int`, *optional*, defaults to 16000):
+ The samlping rate to be used when loading the audio. It should be same as the
+ sampling rate the model you will be using further was trained with.
+ timeout (`float`, *optional*):
+ The timeout value in seconds for the URL request.
+
+ Returns:
+ `np.ndarray`: A numpy artay representing the audio.
+ """
+ requires_backends(load_audio, ["librosa"])
+
+ if isinstance(audio, str):
+ # Load audio from URL (e.g https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/translate_to_chinese.wav)
+ if audio.startswith("http://") or audio.startswith("https://"):
+ audio = librosa.load(BytesIO(requests.get(audio, timeout=timeout).content), sr=sampling_rate)[0]
+ elif os.path.isfile(audio):
+ audio = librosa.load(audio, sr=sampling_rate)[0]
+ elif isinstance(audio, np.ndarray):
+ audio = audio
+ else:
+ raise TypeError(
+ "Incorrect format used for `audio`. Should be an url linking to an audio, a local path, or numpy array."
+ )
+ return audio
+
+
+AudioInput = Union[
+ np.ndarray, "torch.Tensor", List[np.ndarray], Tuple[np.ndarray], List["torch.Tensor"], Tuple["torch.Tensor"] # noqa: F821
+]
+
+
+def hertz_to_mel(freq: Union[float, np.ndarray], mel_scale: str = "htk") -> Union[float, np.ndarray]:
+ """
+ Convert frequency from hertz to mels.
+
+ Args:
+ freq (`float` or `np.ndarray`):
+ The frequency, or multiple frequencies, in hertz (Hz).
+ mel_scale (`str`, *optional*, defaults to `"htk"`):
+ The mel frequency scale to use, `"htk"`, `"kaldi"` or `"slaney"`.
+
+ Returns:
+ `float` or `np.ndarray`: The frequencies on the mel scale.
+ """
+
+ if mel_scale not in ["slaney", "htk", "kaldi"]:
+ raise ValueError('mel_scale should be one of "htk", "slaney" or "kaldi".')
+
+ if mel_scale == "htk":
+ return 2595.0 * np.log10(1.0 + (freq / 700.0))
+ elif mel_scale == "kaldi":
+ return 1127.0 * np.log(1.0 + (freq / 700.0))
+
+ min_log_hertz = 1000.0
+ min_log_mel = 15.0
+ logstep = 27.0 / np.log(6.4)
+ mels = 3.0 * freq / 200.0
+
+ if isinstance(freq, np.ndarray):
+ log_region = freq >= min_log_hertz
+ mels[log_region] = min_log_mel + np.log(freq[log_region] / min_log_hertz) * logstep
+ elif freq >= min_log_hertz:
+ mels = min_log_mel + np.log(freq / min_log_hertz) * logstep
+
+ return mels
+
+
+def mel_to_hertz(mels: Union[float, np.ndarray], mel_scale: str = "htk") -> Union[float, np.ndarray]:
+ """
+ Convert frequency from mels to hertz.
+
+ Args:
+ mels (`float` or `np.ndarray`):
+ The frequency, or multiple frequencies, in mels.
+ mel_scale (`str`, *optional*, `"htk"`):
+ The mel frequency scale to use, `"htk"`, `"kaldi"` or `"slaney"`.
+
+ Returns:
+ `float` or `np.ndarray`: The frequencies in hertz.
+ """
+
+ if mel_scale not in ["slaney", "htk", "kaldi"]:
+ raise ValueError('mel_scale should be one of "htk", "slaney" or "kaldi".')
+
+ if mel_scale == "htk":
+ return 700.0 * (np.power(10, mels / 2595.0) - 1.0)
+ elif mel_scale == "kaldi":
+ return 700.0 * (np.exp(mels / 1127.0) - 1.0)
+
+ min_log_hertz = 1000.0
+ min_log_mel = 15.0
+ logstep = np.log(6.4) / 27.0
+ freq = 200.0 * mels / 3.0
+
+ if isinstance(mels, np.ndarray):
+ log_region = mels >= min_log_mel
+ freq[log_region] = min_log_hertz * np.exp(logstep * (mels[log_region] - min_log_mel))
+ elif mels >= min_log_mel:
+ freq = min_log_hertz * np.exp(logstep * (mels - min_log_mel))
+
+ return freq
+
+
+def hertz_to_octave(
+ freq: Union[float, np.ndarray], tuning: Optional[float] = 0.0, bins_per_octave: Optional[int] = 12
+):
+ """
+ Convert frequency from hertz to fractional octave numbers.
+ Adapted from *librosa*.
+
+ Args:
+ freq (`float` or `np.ndarray`):
+ The frequency, or multiple frequencies, in hertz (Hz).
+ tuning (`float`, defaults to `0.`):
+ Tuning deviation from the Stuttgart pitch (A440) in (fractional) bins per octave.
+ bins_per_octave (`int`, defaults to `12`):
+ Number of bins per octave.
+
+ Returns:
+ `float` or `np.ndarray`: The frequencies on the octave scale.
+ """
+ stuttgart_pitch = 440.0 * 2.0 ** (tuning / bins_per_octave)
+ octave = np.log2(freq / (float(stuttgart_pitch) / 16))
+ return octave
+
+
+def _create_triangular_filter_bank(fft_freqs: np.ndarray, filter_freqs: np.ndarray) -> np.ndarray:
+ """
+ Creates a triangular filter bank.
+
+ Adapted from *torchaudio* and *librosa*.
+
+ Args:
+ fft_freqs (`np.ndarray` of shape `(num_frequency_bins,)`):
+ Discrete frequencies of the FFT bins in Hz.
+ filter_freqs (`np.ndarray` of shape `(num_mel_filters,)`):
+ Center frequencies of the triangular filters to create, in Hz.
+
+ Returns:
+ `np.ndarray` of shape `(num_frequency_bins, num_mel_filters)`
+ """
+ filter_diff = np.diff(filter_freqs)
+ slopes = np.expand_dims(filter_freqs, 0) - np.expand_dims(fft_freqs, 1)
+ down_slopes = -slopes[:, :-2] / filter_diff[:-1]
+ up_slopes = slopes[:, 2:] / filter_diff[1:]
+ return np.maximum(np.zeros(1), np.minimum(down_slopes, up_slopes))
+
+
+def chroma_filter_bank(
+ num_frequency_bins: int,
+ num_chroma: int,
+ sampling_rate: int,
+ tuning: float = 0.0,
+ power: Optional[float] = 2.0,
+ weighting_parameters: Optional[tuple[float, float]] = (5.0, 2.0),
+ start_at_c_chroma: Optional[bool] = True,
+):
+ """
+ Creates a chroma filter bank, i.e a linear transformation to project spectrogram bins onto chroma bins.
+
+ Adapted from *librosa*.
+
+ Args:
+ num_frequency_bins (`int`):
+ Number of frequencies used to compute the spectrogram (should be the same as in `stft`).
+ num_chroma (`int`):
+ Number of chroma bins (i.e pitch classes).
+ sampling_rate (`float`):
+ Sample rate of the audio waveform.
+ tuning (`float`):
+ Tuning deviation from A440 in fractions of a chroma bin.
+ power (`float`, *optional*, defaults to 2.0):
+ If 12.0, normalizes each column with their L2 norm. If 1.0, normalizes each column with their L1 norm.
+ weighting_parameters (`Tuple[float, float]`, *optional*, defaults to `(5., 2.)`):
+ If specified, apply a Gaussian weighting parameterized by the first element of the tuple being the center and
+ the second element being the Gaussian half-width.
+ start_at_c_chroma (`float`, *optional*, defaults to `True`):
+ If True, the filter bank will start at the 'C' pitch class. Otherwise, it will start at 'A'.
+ Returns:
+ `np.ndarray` of shape `(num_frequency_bins, num_chroma)`
+ """
+ # Get the FFT bins, not counting the DC component
+ frequencies = np.linspace(0, sampling_rate, num_frequency_bins, endpoint=False)[1:]
+
+ freq_bins = num_chroma * hertz_to_octave(frequencies, tuning=tuning, bins_per_octave=num_chroma)
+
+ # make up a value for the 0 Hz bin = 1.5 octaves below bin 1
+ # (so chroma is 50% rotated from bin 1, and bin width is broad)
+ freq_bins = np.concatenate(([freq_bins[0] - 1.5 * num_chroma], freq_bins))
+
+ bins_width = np.concatenate((np.maximum(freq_bins[1:] - freq_bins[:-1], 1.0), [1]))
+
+ chroma_filters = np.subtract.outer(freq_bins, np.arange(0, num_chroma, dtype="d")).T
+
+ num_chroma2 = np.round(float(num_chroma) / 2)
+
+ # Project into range -num_chroma/2 .. num_chroma/2
+ # add on fixed offset of 10*num_chroma to ensure all values passed to
+ # rem are positive
+ chroma_filters = np.remainder(chroma_filters + num_chroma2 + 10 * num_chroma, num_chroma) - num_chroma2
+
+ # Gaussian bumps - 2*D to make them narrower
+ chroma_filters = np.exp(-0.5 * (2 * chroma_filters / np.tile(bins_width, (num_chroma, 1))) ** 2)
+
+ # normalize each column
+ if power is not None:
+ chroma_filters = chroma_filters / np.sum(chroma_filters**power, axis=0, keepdims=True) ** (1.0 / power)
+
+ # Maybe apply scaling for fft bins
+ if weighting_parameters is not None:
+ center, half_width = weighting_parameters
+ chroma_filters *= np.tile(
+ np.exp(-0.5 * (((freq_bins / num_chroma - center) / half_width) ** 2)),
+ (num_chroma, 1),
+ )
+
+ if start_at_c_chroma:
+ chroma_filters = np.roll(chroma_filters, -3 * (num_chroma // 12), axis=0)
+
+ # remove aliasing columns, copy to ensure row-contiguity
+ return np.ascontiguousarray(chroma_filters[:, : int(1 + num_frequency_bins / 2)])
+
+
+def mel_filter_bank(
+ num_frequency_bins: int,
+ num_mel_filters: int,
+ min_frequency: float,
+ max_frequency: float,
+ sampling_rate: int,
+ norm: Optional[str] = None,
+ mel_scale: str = "htk",
+ triangularize_in_mel_space: bool = False,
+) -> np.ndarray:
+ """
+ Creates a frequency bin conversion matrix used to obtain a mel spectrogram. This is called a *mel filter bank*, and
+ various implementation exist, which differ in the number of filters, the shape of the filters, the way the filters
+ are spaced, the bandwidth of the filters, and the manner in which the spectrum is warped. The goal of these
+ features is to approximate the non-linear human perception of the variation in pitch with respect to the frequency.
+
+ Different banks of mel filters were introduced in the literature. The following variations are supported:
+
+ - MFCC FB-20: introduced in 1980 by Davis and Mermelstein, it assumes a sampling frequency of 10 kHz and a speech
+ bandwidth of `[0, 4600]` Hz.
+ - MFCC FB-24 HTK: from the Cambridge HMM Toolkit (HTK) (1995) uses a filter bank of 24 filters for a speech
+ bandwidth of `[0, 8000]` Hz. This assumes sampling rate ≥ 16 kHz.
+ - MFCC FB-40: from the Auditory Toolbox for MATLAB written by Slaney in 1998, assumes a sampling rate of 16 kHz and
+ speech bandwidth of `[133, 6854]` Hz. This version also includes area normalization.
+ - HFCC-E FB-29 (Human Factor Cepstral Coefficients) of Skowronski and Harris (2004), assumes a sampling rate of
+ 12.5 kHz and speech bandwidth of `[0, 6250]` Hz.
+
+ This code is adapted from *torchaudio* and *librosa*. Note that the default parameters of torchaudio's
+ `melscale_fbanks` implement the `"htk"` filters while librosa uses the `"slaney"` implementation.
+
+ Args:
+ num_frequency_bins (`int`):
+ Number of frequency bins (should be the same as `n_fft // 2 + 1` where `n_fft` is the size of the Fourier Transform used to compute the spectrogram).
+ num_mel_filters (`int`):
+ Number of mel filters to generate.
+ min_frequency (`float`):
+ Lowest frequency of interest in Hz.
+ max_frequency (`float`):
+ Highest frequency of interest in Hz. This should not exceed `sampling_rate / 2`.
+ sampling_rate (`int`):
+ Sample rate of the audio waveform.
+ norm (`str`, *optional*):
+ If `"slaney"`, divide the triangular mel weights by the width of the mel band (area normalization).
+ mel_scale (`str`, *optional*, defaults to `"htk"`):
+ The mel frequency scale to use, `"htk"`, `"kaldi"` or `"slaney"`.
+ triangularize_in_mel_space (`bool`, *optional*, defaults to `False`):
+ If this option is enabled, the triangular filter is applied in mel space rather than frequency space. This
+ should be set to `true` in order to get the same results as `torchaudio` when computing mel filters.
+
+ Returns:
+ `np.ndarray` of shape (`num_frequency_bins`, `num_mel_filters`): Triangular filter bank matrix. This is a
+ projection matrix to go from a spectrogram to a mel spectrogram.
+ """
+ if norm is not None and norm != "slaney":
+ raise ValueError('norm must be one of None or "slaney"')
+
+ if num_frequency_bins < 2:
+ raise ValueError(f"Require num_frequency_bins: {num_frequency_bins} >= 2")
+
+ if min_frequency > max_frequency:
+ raise ValueError(f"Require min_frequency: {min_frequency} <= max_frequency: {max_frequency}")
+
+ # center points of the triangular mel filters
+ mel_min = hertz_to_mel(min_frequency, mel_scale=mel_scale)
+ mel_max = hertz_to_mel(max_frequency, mel_scale=mel_scale)
+ mel_freqs = np.linspace(mel_min, mel_max, num_mel_filters + 2)
+ filter_freqs = mel_to_hertz(mel_freqs, mel_scale=mel_scale)
+
+ if triangularize_in_mel_space:
+ # frequencies of FFT bins in Hz, but filters triangularized in mel space
+ fft_bin_width = sampling_rate / ((num_frequency_bins - 1) * 2)
+ fft_freqs = hertz_to_mel(fft_bin_width * np.arange(num_frequency_bins), mel_scale=mel_scale)
+ filter_freqs = mel_freqs
+ else:
+ # frequencies of FFT bins in Hz
+ fft_freqs = np.linspace(0, sampling_rate // 2, num_frequency_bins)
+
+ mel_filters = _create_triangular_filter_bank(fft_freqs, filter_freqs)
+
+ if norm is not None and norm == "slaney":
+ # Slaney-style mel is scaled to be approx constant energy per channel
+ enorm = 2.0 / (filter_freqs[2 : num_mel_filters + 2] - filter_freqs[:num_mel_filters])
+ mel_filters *= np.expand_dims(enorm, 0)
+
+ if (mel_filters.max(axis=0) == 0.0).any():
+ warnings.warn(
+ "At least one mel filter has all zero values. "
+ f"The value for `num_mel_filters` ({num_mel_filters}) may be set too high. "
+ f"Or, the value for `num_frequency_bins` ({num_frequency_bins}) may be set too low."
+ )
+
+ return mel_filters
+
+
+def optimal_fft_length(window_length: int) -> int:
+ """
+ Finds the best FFT input size for a given `window_length`. This function takes a given window length and, if not
+ already a power of two, rounds it up to the next power or two.
+
+ The FFT algorithm works fastest when the length of the input is a power of two, which may be larger than the size
+ of the window or analysis frame. For example, if the window is 400 samples, using an FFT input size of 512 samples
+ is more optimal than an FFT size of 400 samples. Using a larger FFT size does not affect the detected frequencies,
+ it simply gives a higher frequency resolution (i.e. the frequency bins are smaller).
+ """
+ return 2 ** int(np.ceil(np.log2(window_length)))
+
+
+def window_function(
+ window_length: int,
+ name: str = "hann",
+ periodic: bool = True,
+ frame_length: Optional[int] = None,
+ center: bool = True,
+) -> np.ndarray:
+ """
+ Returns an array containing the specified window. This window is intended to be used with `stft`.
+
+ The following window types are supported:
+
+ - `"boxcar"`: a rectangular window
+ - `"hamming"`: the Hamming window
+ - `"hann"`: the Hann window
+ - `"povey"`: the Povey window
+
+ Args:
+ window_length (`int`):
+ The length of the window in samples.
+ name (`str`, *optional*, defaults to `"hann"`):
+ The name of the window function.
+ periodic (`bool`, *optional*, defaults to `True`):
+ Whether the window is periodic or symmetric.
+ frame_length (`int`, *optional*):
+ The length of the analysis frames in samples. Provide a value for `frame_length` if the window is smaller
+ than the frame length, so that it will be zero-padded.
+ center (`bool`, *optional*, defaults to `True`):
+ Whether to center the window inside the FFT buffer. Only used when `frame_length` is provided.
+
+ Returns:
+ `np.ndarray` of shape `(window_length,)` or `(frame_length,)` containing the window.
+ """
+ length = window_length + 1 if periodic else window_length
+
+ if name == "boxcar":
+ window = np.ones(length)
+ elif name in ["hamming", "hamming_window"]:
+ window = np.hamming(length)
+ elif name in ["hann", "hann_window"]:
+ window = np.hanning(length)
+ elif name in ["povey"]:
+ window = np.power(np.hanning(length), 0.85)
+ else:
+ raise ValueError(f"Unknown window function '{name}'")
+
+ if periodic:
+ window = window[:-1]
+
+ if frame_length is None:
+ return window
+
+ if window_length > frame_length:
+ raise ValueError(
+ f"Length of the window ({window_length}) may not be larger than frame_length ({frame_length})"
+ )
+
+ padded_window = np.zeros(frame_length)
+ offset = (frame_length - window_length) // 2 if center else 0
+ padded_window[offset : offset + window_length] = window
+ return padded_window
+
+
+# TODO This method does not support batching yet as we are mainly focused on inference.
+def spectrogram(
+ waveform: np.ndarray,
+ window: np.ndarray,
+ frame_length: int,
+ hop_length: int,
+ fft_length: Optional[int] = None,
+ power: Optional[float] = 1.0,
+ center: bool = True,
+ pad_mode: str = "reflect",
+ onesided: bool = True,
+ dither: float = 0.0,
+ preemphasis: Optional[float] = None,
+ mel_filters: Optional[np.ndarray] = None,
+ mel_floor: float = 1e-10,
+ log_mel: Optional[str] = None,
+ reference: float = 1.0,
+ min_value: float = 1e-10,
+ db_range: Optional[float] = None,
+ remove_dc_offset: Optional[bool] = None,
+ dtype: np.dtype = np.float32,
+) -> np.ndarray:
+ """
+ Calculates a spectrogram over one waveform using the Short-Time Fourier Transform.
+
+ This function can create the following kinds of spectrograms:
+
+ - amplitude spectrogram (`power = 1.0`)
+ - power spectrogram (`power = 2.0`)
+ - complex-valued spectrogram (`power = None`)
+ - log spectrogram (use `log_mel` argument)
+ - mel spectrogram (provide `mel_filters`)
+ - log-mel spectrogram (provide `mel_filters` and `log_mel`)
+
+ How this works:
+
+ 1. The input waveform is split into frames of size `frame_length` that are partially overlapping by `frame_length
+ - hop_length` samples.
+ 2. Each frame is multiplied by the window and placed into a buffer of size `fft_length`.
+ 3. The DFT is taken of each windowed frame.
+ 4. The results are stacked into a spectrogram.
+
+ We make a distinction between the following "blocks" of sample data, each of which may have a different lengths:
+
+ - The analysis frame. This is the size of the time slices that the input waveform is split into.
+ - The window. Each analysis frame is multiplied by the window to avoid spectral leakage.
+ - The FFT input buffer. The length of this determines how many frequency bins are in the spectrogram.
+
+ In this implementation, the window is assumed to be zero-padded to have the same size as the analysis frame. A
+ padded window can be obtained from `window_function()`. The FFT input buffer may be larger than the analysis frame,
+ typically the next power of two.
+
+ Note: This function is not optimized for speed yet. It should be mostly compatible with `librosa.stft` and
+ `torchaudio.functional.transforms.Spectrogram`, although it is more flexible due to the different ways spectrograms
+ can be constructed.
+
+ Args:
+ waveform (`np.ndarray` of shape `(length,)`):
+ The input waveform. This must be a single real-valued, mono waveform.
+ window (`np.ndarray` of shape `(frame_length,)`):
+ The windowing function to apply, including zero-padding if necessary. The actual window length may be
+ shorter than `frame_length`, but we're assuming the array has already been zero-padded.
+ frame_length (`int`):
+ The length of the analysis frames in samples. With librosa this is always equal to `fft_length` but we also
+ allow smaller sizes.
+ hop_length (`int`):
+ The stride between successive analysis frames in samples.
+ fft_length (`int`, *optional*):
+ The size of the FFT buffer in samples. This determines how many frequency bins the spectrogram will have.
+ For optimal speed, this should be a power of two. If `None`, uses `frame_length`.
+ power (`float`, *optional*, defaults to 1.0):
+ If 1.0, returns the amplitude spectrogram. If 2.0, returns the power spectrogram. If `None`, returns
+ complex numbers.
+ center (`bool`, *optional*, defaults to `True`):
+ Whether to pad the waveform so that frame `t` is centered around time `t * hop_length`. If `False`, frame
+ `t` will start at time `t * hop_length`.
+ pad_mode (`str`, *optional*, defaults to `"reflect"`):
+ Padding mode used when `center` is `True`. Possible values are: `"constant"` (pad with zeros), `"edge"`
+ (pad with edge values), `"reflect"` (pads with mirrored values).
+ onesided (`bool`, *optional*, defaults to `True`):
+ If True, only computes the positive frequencies and returns a spectrogram containing `fft_length // 2 + 1`
+ frequency bins. If False, also computes the negative frequencies and returns `fft_length` frequency bins.
+ dither (`float`, *optional*, defaults to 0.0):
+ Adds dithering. In other words, adds a small Gaussian noise to each frame.
+ E.g. use 4.0 to add dithering with a normal distribution centered
+ around 0.0 with standard deviation 4.0, 0.0 means no dithering.
+ Dithering has similar effect as `mel_floor`. It reduces the high log_mel_fbank
+ values for signals with hard-zero sections, when VAD cutoff is present in the signal.
+ preemphasis (`float`, *optional*)
+ Coefficient for a low-pass filter that applies pre-emphasis before the DFT.
+ mel_filters (`np.ndarray` of shape `(num_freq_bins, num_mel_filters)`, *optional*):
+ The mel filter bank. If supplied, applies a this filter bank to create a mel spectrogram.
+ mel_floor (`float`, *optional*, defaults to 1e-10):
+ Minimum value of mel frequency banks.
+ log_mel (`str`, *optional*):
+ How to convert the spectrogram to log scale. Possible options are: `None` (don't convert), `"log"` (take
+ the natural logarithm) `"log10"` (take the base-10 logarithm), `"dB"` (convert to decibels). Can only be
+ used when `power` is not `None`.
+ reference (`float`, *optional*, defaults to 1.0):
+ Sets the input spectrogram value that corresponds to 0 dB. For example, use `np.max(spectrogram)` to set
+ the loudest part to 0 dB. Must be greater than zero.
+ min_value (`float`, *optional*, defaults to `1e-10`):
+ The spectrogram will be clipped to this minimum value before conversion to decibels, to avoid taking
+ `log(0)`. For a power spectrogram, the default of `1e-10` corresponds to a minimum of -100 dB. For an
+ amplitude spectrogram, the value `1e-5` corresponds to -100 dB. Must be greater than zero.
+ db_range (`float`, *optional*):
+ Sets the maximum dynamic range in decibels. For example, if `db_range = 80`, the difference between the
+ peak value and the smallest value will never be more than 80 dB. Must be greater than zero.
+ remove_dc_offset (`bool`, *optional*):
+ Subtract mean from waveform on each frame, applied before pre-emphasis. This should be set to `true` in
+ order to get the same results as `torchaudio.compliance.kaldi.fbank` when computing mel filters.
+ dtype (`np.dtype`, *optional*, defaults to `np.float32`):
+ Data type of the spectrogram tensor. If `power` is None, this argument is ignored and the dtype will be
+ `np.complex64`.
+
+ Returns:
+ `nd.array` containing a spectrogram of shape `(num_frequency_bins, length)` for a regular spectrogram or shape
+ `(num_mel_filters, length)` for a mel spectrogram.
+ """
+ window_length = len(window)
+
+ if fft_length is None:
+ fft_length = frame_length
+
+ if frame_length > fft_length:
+ raise ValueError(f"frame_length ({frame_length}) may not be larger than fft_length ({fft_length})")
+
+ if window_length != frame_length:
+ raise ValueError(f"Length of the window ({window_length}) must equal frame_length ({frame_length})")
+
+ if hop_length <= 0:
+ raise ValueError("hop_length must be greater than zero")
+
+ if waveform.ndim != 1:
+ raise ValueError(f"Input waveform must have only one dimension, shape is {waveform.shape}")
+
+ if np.iscomplexobj(waveform):
+ raise ValueError("Complex-valued input waveforms are not currently supported")
+
+ if power is None and mel_filters is not None:
+ raise ValueError(
+ "You have provided `mel_filters` but `power` is `None`. Mel spectrogram computation is not yet supported for complex-valued spectrogram."
+ "Specify `power` to fix this issue."
+ )
+
+ # center pad the waveform
+ if center:
+ padding = [(int(frame_length // 2), int(frame_length // 2))]
+ waveform = np.pad(waveform, padding, mode=pad_mode)
+
+ # promote to float64, since np.fft uses float64 internally
+ waveform = waveform.astype(np.float64)
+ window = window.astype(np.float64)
+
+ # split waveform into frames of frame_length size
+ num_frames = int(1 + np.floor((waveform.size - frame_length) / hop_length))
+
+ num_frequency_bins = (fft_length // 2) + 1 if onesided else fft_length
+ spectrogram = np.empty((num_frames, num_frequency_bins), dtype=np.complex64)
+
+ # rfft is faster than fft
+ fft_func = np.fft.rfft if onesided else np.fft.fft
+ buffer = np.zeros(fft_length)
+
+ timestep = 0
+ for frame_idx in range(num_frames):
+ buffer[:frame_length] = waveform[timestep : timestep + frame_length]
+
+ if dither != 0.0:
+ buffer[:frame_length] += dither * np.random.randn(frame_length)
+
+ if remove_dc_offset:
+ buffer[:frame_length] = buffer[:frame_length] - buffer[:frame_length].mean()
+
+ if preemphasis is not None:
+ buffer[1:frame_length] -= preemphasis * buffer[: frame_length - 1]
+ buffer[0] *= 1 - preemphasis
+
+ buffer[:frame_length] *= window
+
+ spectrogram[frame_idx] = fft_func(buffer)
+ timestep += hop_length
+
+ # note: ** is much faster than np.power
+ if power is not None:
+ spectrogram = np.abs(spectrogram, dtype=np.float64) ** power
+
+ spectrogram = spectrogram.T
+
+ if mel_filters is not None:
+ spectrogram = np.maximum(mel_floor, np.dot(mel_filters.T, spectrogram))
+
+ if power is not None and log_mel is not None:
+ if log_mel == "log":
+ spectrogram = np.log(spectrogram)
+ elif log_mel == "log10":
+ spectrogram = np.log10(spectrogram)
+ elif log_mel == "dB":
+ if power == 1.0:
+ spectrogram = amplitude_to_db(spectrogram, reference, min_value, db_range)
+ elif power == 2.0:
+ spectrogram = power_to_db(spectrogram, reference, min_value, db_range)
+ else:
+ raise ValueError(f"Cannot use log_mel option '{log_mel}' with power {power}")
+ else:
+ raise ValueError(f"Unknown log_mel option: {log_mel}")
+
+ spectrogram = np.asarray(spectrogram, dtype)
+
+ return spectrogram
+
+
+def spectrogram_batch(
+ waveform_list: list[np.ndarray],
+ window: np.ndarray,
+ frame_length: int,
+ hop_length: int,
+ fft_length: Optional[int] = None,
+ power: Optional[float] = 1.0,
+ center: bool = True,
+ pad_mode: str = "reflect",
+ onesided: bool = True,
+ dither: float = 0.0,
+ preemphasis: Optional[float] = None,
+ mel_filters: Optional[np.ndarray] = None,
+ mel_floor: float = 1e-10,
+ log_mel: Optional[str] = None,
+ reference: float = 1.0,
+ min_value: float = 1e-10,
+ db_range: Optional[float] = None,
+ remove_dc_offset: Optional[bool] = None,
+ dtype: np.dtype = np.float32,
+) -> list[np.ndarray]:
+ """
+ Calculates spectrograms for a list of waveforms using the Short-Time Fourier Transform, optimized for batch processing.
+ This function extends the capabilities of the `spectrogram` function to handle multiple waveforms efficiently by leveraging broadcasting.
+
+ It supports generating various types of spectrograms:
+
+ - amplitude spectrogram (`power = 1.0`)
+ - power spectrogram (`power = 2.0`)
+ - complex-valued spectrogram (`power = None`)
+ - log spectrogram (use `log_mel` argument)
+ - mel spectrogram (provide `mel_filters`)
+ - log-mel spectrogram (provide `mel_filters` and `log_mel`)
+
+ How this works:
+
+ 1. The input waveform is split into frames of size `frame_length` that are partially overlapping by `frame_length
+ - hop_length` samples.
+ 2. Each frame is multiplied by the window and placed into a buffer of size `fft_length`.
+ 3. The DFT is taken of each windowed frame.
+ 4. The results are stacked into a spectrogram.
+
+ We make a distinction between the following "blocks" of sample data, each of which may have a different lengths:
+
+ - The analysis frame. This is the size of the time slices that the input waveform is split into.
+ - The window. Each analysis frame is multiplied by the window to avoid spectral leakage.
+ - The FFT input buffer. The length of this determines how many frequency bins are in the spectrogram.
+
+ In this implementation, the window is assumed to be zero-padded to have the same size as the analysis frame. A
+ padded window can be obtained from `window_function()`. The FFT input buffer may be larger than the analysis frame,
+ typically the next power of two.
+
+ Note: This function is designed for efficient batch processing of multiple waveforms but retains compatibility with individual waveform processing methods like `librosa.stft`.
+
+ Args:
+ waveform_list (`List[np.ndarray]` with arrays of shape `(length,)`):
+ The list of input waveforms, each a single-channel (mono) signal.
+ window (`np.ndarray` of shape `(frame_length,)`):
+ The windowing function to apply, including zero-padding if necessary.
+ frame_length (`int`):
+ The length of each frame for analysis.
+ hop_length (`int`):
+ The step size between successive frames.
+ fft_length (`int`, *optional*):
+ The size of the FFT buffer, defining frequency bin resolution.
+ power (`float`, *optional*, defaults to 1.0):
+ Determines the type of spectrogram: 1.0 for amplitude, 2.0 for power, None for complex.
+ center (`bool`, *optional*, defaults to `True`):
+ Whether to center-pad the waveform frames.
+ pad_mode (`str`, *optional*, defaults to `"reflect"`):
+ The padding strategy when `center` is `True`.
+ onesided (`bool`, *optional*, defaults to `True`):
+ If True, returns a one-sided spectrogram for real input signals.
+ dither (`float`, *optional*, defaults to 0.0):
+ Adds dithering. In other words, adds a small Gaussian noise to each frame.
+ E.g. use 4.0 to add dithering with a normal distribution centered
+ around 0.0 with standard deviation 4.0, 0.0 means no dithering.
+ preemphasis (`float`, *optional*):
+ Applies a pre-emphasis filter to each frame.
+ mel_filters (`np.ndarray`, *optional*):
+ Mel filter bank for converting to mel spectrogram.
+ mel_floor (`float`, *optional*, defaults to 1e-10):
+ Floor value for mel spectrogram to avoid log(0).
+ log_mel (`str`, *optional*):
+ Specifies log scaling strategy; options are None, "log", "log10", "dB".
+ reference (`float`, *optional*, defaults to 1.0):
+ Reference value for dB conversion in log_mel.
+ min_value (`float`, *optional*, defaults to 1e-10):
+ Minimum floor value for log scale conversions.
+ db_range (`float`, *optional*):
+ Dynamic range for dB scale spectrograms.
+ remove_dc_offset (`bool`, *optional*):
+ Whether to remove the DC offset from each frame.
+ dtype (`np.dtype`, *optional*, defaults to `np.float32`):
+ Data type of the output spectrogram.
+
+ Returns:
+ List[`np.ndarray`]: A list of spectrogram arrays, one for each input waveform.
+ """
+ window_length = len(window)
+
+ if fft_length is None:
+ fft_length = frame_length
+
+ if frame_length > fft_length:
+ raise ValueError(f"frame_length ({frame_length}) may not be larger than fft_length ({fft_length})")
+
+ if window_length != frame_length:
+ raise ValueError(f"Length of the window ({window_length}) must equal frame_length ({frame_length})")
+
+ if hop_length <= 0:
+ raise ValueError("hop_length must be greater than zero")
+
+ # Check the dimensions of the waveform , and if waveform is complex
+ for waveform in waveform_list:
+ if waveform.ndim != 1:
+ raise ValueError(f"Input waveform must have only one dimension, shape is {waveform.shape}")
+ if np.iscomplexobj(waveform):
+ raise ValueError("Complex-valued input waveforms are not currently supported")
+ # Center pad the waveform
+ if center:
+ padding = [(int(frame_length // 2), int(frame_length // 2))]
+ waveform_list = [
+ np.pad(
+ waveform,
+ padding,
+ mode=pad_mode,
+ )
+ for waveform in waveform_list
+ ]
+ original_waveform_lengths = [
+ len(waveform) for waveform in waveform_list
+ ] # these lengths will be used to remove padding later
+
+ # Batch pad the waveform
+ max_length = max(original_waveform_lengths)
+ padded_waveform_batch = np.array(
+ [
+ np.pad(waveform, (0, max_length - len(waveform)), mode="constant", constant_values=0)
+ for waveform in waveform_list
+ ],
+ dtype=dtype,
+ )
+
+ # Promote to float64, since np.fft uses float64 internally
+ padded_waveform_batch = padded_waveform_batch.astype(np.float64)
+ window = window.astype(np.float64)
+
+ # Split waveform into frames of frame_length size
+ num_frames = int(1 + np.floor((padded_waveform_batch.shape[1] - frame_length) / hop_length))
+ # these lengths will be used to remove padding later
+ true_num_frames = [int(1 + np.floor((length - frame_length) / hop_length)) for length in original_waveform_lengths]
+ num_batches = padded_waveform_batch.shape[0]
+
+ num_frequency_bins = (fft_length // 2) + 1 if onesided else fft_length
+ spectrogram = np.empty((num_batches, num_frames, num_frequency_bins), dtype=np.complex64)
+
+ # rfft is faster than fft
+ fft_func = np.fft.rfft if onesided else np.fft.fft
+ buffer = np.zeros((num_batches, fft_length))
+
+ for frame_idx in range(num_frames):
+ timestep = frame_idx * hop_length
+ buffer[:, :frame_length] = padded_waveform_batch[:, timestep : timestep + frame_length]
+
+ if dither != 0.0:
+ buffer[:, :frame_length] += dither * np.random.randn(*buffer[:, :frame_length].shape)
+
+ if remove_dc_offset:
+ buffer[:, :frame_length] -= buffer[:, :frame_length].mean(axis=1, keepdims=True)
+
+ if preemphasis is not None:
+ buffer[:, 1:frame_length] -= preemphasis * buffer[:, : frame_length - 1]
+ buffer[:, 0] *= 1 - preemphasis
+
+ buffer[:, :frame_length] *= window
+
+ spectrogram[:, frame_idx] = fft_func(buffer)
+
+ # Note: ** is much faster than np.power
+ if power is not None:
+ spectrogram = np.abs(spectrogram, dtype=np.float64) ** power
+
+ # Apply mel filters if provided
+ if mel_filters is not None:
+ result = np.tensordot(spectrogram, mel_filters.T, axes=([2], [1]))
+ spectrogram = np.maximum(mel_floor, result)
+
+ # Convert to log scale if specified
+ if power is not None and log_mel is not None:
+ if log_mel == "log":
+ spectrogram = np.log(spectrogram)
+ elif log_mel == "log10":
+ spectrogram = np.log10(spectrogram)
+ elif log_mel == "dB":
+ if power == 1.0:
+ spectrogram = amplitude_to_db_batch(spectrogram, reference, min_value, db_range)
+ elif power == 2.0:
+ spectrogram = power_to_db_batch(spectrogram, reference, min_value, db_range)
+ else:
+ raise ValueError(f"Cannot use log_mel option '{log_mel}' with power {power}")
+ else:
+ raise ValueError(f"Unknown log_mel option: {log_mel}")
+
+ spectrogram = np.asarray(spectrogram, dtype)
+
+ spectrogram_list = [spectrogram[i, : true_num_frames[i], :].T for i in range(len(true_num_frames))]
+
+ return spectrogram_list
+
+
+def power_to_db(
+ spectrogram: np.ndarray,
+ reference: float = 1.0,
+ min_value: float = 1e-10,
+ db_range: Optional[float] = None,
+) -> np.ndarray:
+ """
+ Converts a power spectrogram to the decibel scale. This computes `10 * log10(spectrogram / reference)`, using basic
+ logarithm properties for numerical stability.
+
+ The motivation behind applying the log function on the (mel) spectrogram is that humans do not hear loudness on a
+ linear scale. Generally to double the perceived volume of a sound we need to put 8 times as much energy into it.
+ This means that large variations in energy may not sound all that different if the sound is loud to begin with.
+ This compression operation makes the (mel) spectrogram features match more closely what humans actually hear.
+
+ Based on the implementation of `librosa.power_to_db`.
+
+ Args:
+ spectrogram (`np.ndarray`):
+ The input power (mel) spectrogram. Note that a power spectrogram has the amplitudes squared!
+ reference (`float`, *optional*, defaults to 1.0):
+ Sets the input spectrogram value that corresponds to 0 dB. For example, use `np.max(spectrogram)` to set
+ the loudest part to 0 dB. Must be greater than zero.
+ min_value (`float`, *optional*, defaults to `1e-10`):
+ The spectrogram will be clipped to this minimum value before conversion to decibels, to avoid taking
+ `log(0)`. The default of `1e-10` corresponds to a minimum of -100 dB. Must be greater than zero.
+ db_range (`float`, *optional*):
+ Sets the maximum dynamic range in decibels. For example, if `db_range = 80`, the difference between the
+ peak value and the smallest value will never be more than 80 dB. Must be greater than zero.
+
+ Returns:
+ `np.ndarray`: the spectrogram in decibels
+ """
+ if reference <= 0.0:
+ raise ValueError("reference must be greater than zero")
+ if min_value <= 0.0:
+ raise ValueError("min_value must be greater than zero")
+
+ reference = max(min_value, reference)
+
+ spectrogram = np.clip(spectrogram, a_min=min_value, a_max=None)
+ spectrogram = 10.0 * (np.log10(spectrogram) - np.log10(reference))
+
+ if db_range is not None:
+ if db_range <= 0.0:
+ raise ValueError("db_range must be greater than zero")
+ spectrogram = np.clip(spectrogram, a_min=spectrogram.max() - db_range, a_max=None)
+
+ return spectrogram
+
+
+def power_to_db_batch(
+ spectrogram: np.ndarray,
+ reference: float = 1.0,
+ min_value: float = 1e-10,
+ db_range: Optional[float] = None,
+) -> np.ndarray:
+ """
+ Converts a batch of power spectrograms to the decibel scale. This computes `10 * log10(spectrogram / reference)`,
+ using basic logarithm properties for numerical stability.
+
+ This function supports batch processing, where each item in the batch is an individual power (mel) spectrogram.
+
+ Args:
+ spectrogram (`np.ndarray`):
+ The input batch of power (mel) spectrograms. Expected shape is (batch_size, *spectrogram_shape).
+ Note that a power spectrogram has the amplitudes squared!
+ reference (`float`, *optional*, defaults to 1.0):
+ Sets the input spectrogram value that corresponds to 0 dB. For example, use `np.max(spectrogram)` to set
+ the loudest part to 0 dB. Must be greater than zero.
+ min_value (`float`, *optional*, defaults to `1e-10`):
+ The spectrogram will be clipped to this minimum value before conversion to decibels, to avoid taking
+ `log(0)`. The default of `1e-10` corresponds to a minimum of -100 dB. Must be greater than zero.
+ db_range (`float`, *optional*):
+ Sets the maximum dynamic range in decibels. For example, if `db_range = 80`, the difference between the
+ peak value and the smallest value will never be more than 80 dB. Must be greater than zero.
+
+ Returns:
+ `np.ndarray`: the batch of spectrograms in decibels
+ """
+ if reference <= 0.0:
+ raise ValueError("reference must be greater than zero")
+ if min_value <= 0.0:
+ raise ValueError("min_value must be greater than zero")
+
+ reference = max(min_value, reference)
+
+ spectrogram = np.clip(spectrogram, a_min=min_value, a_max=None)
+ spectrogram = 10.0 * (np.log10(spectrogram) - np.log10(reference))
+
+ if db_range is not None:
+ if db_range <= 0.0:
+ raise ValueError("db_range must be greater than zero")
+ # Apply db_range clipping per batch item
+ max_values = spectrogram.max(axis=(1, 2), keepdims=True)
+ spectrogram = np.clip(spectrogram, a_min=max_values - db_range, a_max=None)
+
+ return spectrogram
+
+
+def amplitude_to_db(
+ spectrogram: np.ndarray,
+ reference: float = 1.0,
+ min_value: float = 1e-5,
+ db_range: Optional[float] = None,
+) -> np.ndarray:
+ """
+ Converts an amplitude spectrogram to the decibel scale. This computes `20 * log10(spectrogram / reference)`, using
+ basic logarithm properties for numerical stability.
+
+ The motivation behind applying the log function on the (mel) spectrogram is that humans do not hear loudness on a
+ linear scale. Generally to double the perceived volume of a sound we need to put 8 times as much energy into it.
+ This means that large variations in energy may not sound all that different if the sound is loud to begin with.
+ This compression operation makes the (mel) spectrogram features match more closely what humans actually hear.
+
+ Args:
+ spectrogram (`np.ndarray`):
+ The input amplitude (mel) spectrogram.
+ reference (`float`, *optional*, defaults to 1.0):
+ Sets the input spectrogram value that corresponds to 0 dB. For example, use `np.max(spectrogram)` to set
+ the loudest part to 0 dB. Must be greater than zero.
+ min_value (`float`, *optional*, defaults to `1e-5`):
+ The spectrogram will be clipped to this minimum value before conversion to decibels, to avoid taking
+ `log(0)`. The default of `1e-5` corresponds to a minimum of -100 dB. Must be greater than zero.
+ db_range (`float`, *optional*):
+ Sets the maximum dynamic range in decibels. For example, if `db_range = 80`, the difference between the
+ peak value and the smallest value will never be more than 80 dB. Must be greater than zero.
+
+ Returns:
+ `np.ndarray`: the spectrogram in decibels
+ """
+ if reference <= 0.0:
+ raise ValueError("reference must be greater than zero")
+ if min_value <= 0.0:
+ raise ValueError("min_value must be greater than zero")
+
+ reference = max(min_value, reference)
+
+ spectrogram = np.clip(spectrogram, a_min=min_value, a_max=None)
+ spectrogram = 20.0 * (np.log10(spectrogram) - np.log10(reference))
+
+ if db_range is not None:
+ if db_range <= 0.0:
+ raise ValueError("db_range must be greater than zero")
+ spectrogram = np.clip(spectrogram, a_min=spectrogram.max() - db_range, a_max=None)
+
+ return spectrogram
+
+
+def amplitude_to_db_batch(
+ spectrogram: np.ndarray, reference: float = 1.0, min_value: float = 1e-5, db_range: Optional[float] = None
+) -> np.ndarray:
+ """
+ Converts a batch of amplitude spectrograms to the decibel scale. This computes `20 * log10(spectrogram / reference)`,
+ using basic logarithm properties for numerical stability.
+
+ The function supports batch processing, where each item in the batch is an individual amplitude (mel) spectrogram.
+
+ Args:
+ spectrogram (`np.ndarray`):
+ The input batch of amplitude (mel) spectrograms. Expected shape is (batch_size, *spectrogram_shape).
+ reference (`float`, *optional*, defaults to 1.0):
+ Sets the input spectrogram value that corresponds to 0 dB. For example, use `np.max(spectrogram)` to set
+ the loudest part to 0 dB. Must be greater than zero.
+ min_value (`float`, *optional*, defaults to `1e-5`):
+ The spectrogram will be clipped to this minimum value before conversion to decibels, to avoid taking
+ `log(0)`. The default of `1e-5` corresponds to a minimum of -100 dB. Must be greater than zero.
+ db_range (`float`, *optional*):
+ Sets the maximum dynamic range in decibels. For example, if `db_range = 80`, the difference between the
+ peak value and the smallest value will never be more than 80 dB. Must be greater than zero.
+
+ Returns:
+ `np.ndarray`: the batch of spectrograms in decibels
+ """
+ if reference <= 0.0:
+ raise ValueError("reference must be greater than zero")
+ if min_value <= 0.0:
+ raise ValueError("min_value must be greater than zero")
+
+ reference = max(min_value, reference)
+
+ spectrogram = np.clip(spectrogram, a_min=min_value, a_max=None)
+ spectrogram = 20.0 * (np.log10(spectrogram) - np.log10(reference))
+
+ if db_range is not None:
+ if db_range <= 0.0:
+ raise ValueError("db_range must be greater than zero")
+ # Apply db_range clipping per batch item
+ max_values = spectrogram.max(axis=(1, 2), keepdims=True)
+ spectrogram = np.clip(spectrogram, a_min=max_values - db_range, a_max=None)
+
+ return spectrogram
+
+
+### deprecated functions below this line ###
+
+
+def get_mel_filter_banks(
+ nb_frequency_bins: int,
+ nb_mel_filters: int,
+ frequency_min: float,
+ frequency_max: float,
+ sample_rate: int,
+ norm: Optional[str] = None,
+ mel_scale: str = "htk",
+) -> np.array:
+ warnings.warn(
+ "The function `get_mel_filter_banks` is deprecated and will be removed in version 4.31.0 of Transformers",
+ FutureWarning,
+ )
+ return mel_filter_bank(
+ num_frequency_bins=nb_frequency_bins,
+ num_mel_filters=nb_mel_filters,
+ min_frequency=frequency_min,
+ max_frequency=frequency_max,
+ sampling_rate=sample_rate,
+ norm=norm,
+ mel_scale=mel_scale,
+ )
+
+
+def fram_wave(waveform: np.array, hop_length: int = 160, fft_window_size: int = 400, center: bool = True):
+ """
+ In order to compute the short time fourier transform, the waveform needs to be split in overlapping windowed
+ segments called `frames`.
+
+ The window length (window_length) defines how much of the signal is contained in each frame, while the hop length
+ defines the step between the beginning of each new frame.
+
+
+ Args:
+ waveform (`np.array` of shape `(sample_length,)`):
+ The raw waveform which will be split into smaller chunks.
+ hop_length (`int`, *optional*, defaults to 160):
+ Step between each window of the waveform.
+ fft_window_size (`int`, *optional*, defaults to 400):
+ Defines the size of the window.
+ center (`bool`, defaults to `True`):
+ Whether or not to center each frame around the middle of the frame. Centering is done by reflecting the
+ waveform on the left and on the right.
+
+ Return:
+ framed_waveform (`np.array` of shape `(waveform.shape // hop_length , fft_window_size)`):
+ The framed waveforms that can be fed to `np.fft`.
+ """
+ warnings.warn(
+ "The function `fram_wave` is deprecated and will be removed in version 4.31.0 of Transformers",
+ FutureWarning,
+ )
+ frames = []
+ for i in range(0, waveform.shape[0] + 1, hop_length):
+ if center:
+ half_window = (fft_window_size - 1) // 2 + 1
+ start = i - half_window if i > half_window else 0
+ end = i + half_window if i < waveform.shape[0] - half_window else waveform.shape[0]
+ frame = waveform[start:end]
+ if start == 0:
+ padd_width = (-i + half_window, 0)
+ frame = np.pad(frame, pad_width=padd_width, mode="reflect")
+
+ elif end == waveform.shape[0]:
+ padd_width = (0, (i - waveform.shape[0] + half_window))
+ frame = np.pad(frame, pad_width=padd_width, mode="reflect")
+
+ else:
+ frame = waveform[i : i + fft_window_size]
+ frame_width = frame.shape[0]
+ if frame_width < waveform.shape[0]:
+ frame = np.lib.pad(
+ frame, pad_width=(0, fft_window_size - frame_width), mode="constant", constant_values=0
+ )
+ frames.append(frame)
+
+ frames = np.stack(frames, 0)
+ return frames
+
+
+def stft(frames: np.array, windowing_function: np.array, fft_window_size: Optional[int] = None):
+ """
+ Calculates the complex Short-Time Fourier Transform (STFT) of the given framed signal. Should give the same results
+ as `torch.stft`.
+
+ Args:
+ frames (`np.array` of dimension `(num_frames, fft_window_size)`):
+ A framed audio signal obtained using `audio_utils.fram_wav`.
+ windowing_function (`np.array` of dimension `(nb_frequency_bins, nb_mel_filters)`:
+ A array representing the function that will be used to reduces the amplitude of the discontinuities at the
+ boundaries of each frame when computing the STFT. Each frame will be multiplied by the windowing_function.
+ For more information on the discontinuities, called *Spectral leakage*, refer to [this
+ tutorial]https://download.ni.com/evaluation/pxi/Understanding%20FFTs%20and%20Windowing.pdf
+ fft_window_size (`int`, *optional*):
+ Size of the window om which the Fourier transform is applied. This controls the frequency resolution of the
+ spectrogram. 400 means that the fourrier transform is computed on windows of 400 samples. The number of
+ frequency bins (`nb_frequency_bins`) used to divide the window into equal strips is equal to
+ `(1+fft_window_size)//2`. An increase of the fft_window_size slows the calculus time proportionnally.
+
+ Example:
+
+ ```python
+ >>> from transformers.audio_utils import stft, fram_wave
+ >>> import numpy as np
+
+ >>> audio = np.random.rand(50)
+ >>> fft_window_size = 10
+ >>> hop_length = 2
+ >>> framed_audio = fram_wave(audio, hop_length, fft_window_size)
+ >>> spectrogram = stft(framed_audio, np.hanning(fft_window_size + 1))
+ ```
+
+ Returns:
+ spectrogram (`np.ndarray`):
+ A spectrogram of shape `(num_frames, nb_frequency_bins)` obtained using the STFT algorithm
+ """
+ warnings.warn(
+ "The function `stft` is deprecated and will be removed in version 4.31.0 of Transformers",
+ FutureWarning,
+ )
+ frame_size = frames.shape[1]
+
+ if fft_window_size is None:
+ fft_window_size = frame_size
+
+ if fft_window_size < frame_size:
+ raise ValueError("FFT size must greater or equal the frame size")
+ # number of FFT bins to store
+ nb_frequency_bins = (fft_window_size >> 1) + 1
+
+ spectrogram = np.empty((len(frames), nb_frequency_bins), dtype=np.complex64)
+ fft_signal = np.zeros(fft_window_size)
+
+ for f, frame in enumerate(frames):
+ if windowing_function is not None:
+ np.multiply(frame, windowing_function, out=fft_signal[:frame_size])
+ else:
+ fft_signal[:frame_size] = frame
+ spectrogram[f] = np.fft.fft(fft_signal, axis=0)[:nb_frequency_bins]
+ return spectrogram.T
diff --git a/docs/transformers/src/transformers/cache_utils.py b/docs/transformers/src/transformers/cache_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..700aedba840288b03e80c10a83716a8243e362bc
--- /dev/null
+++ b/docs/transformers/src/transformers/cache_utils.py
@@ -0,0 +1,2485 @@
+import copy
+import importlib.metadata
+import json
+import os
+from dataclasses import dataclass
+from typing import Any, Dict, Iterable, List, Optional, Tuple, Union
+
+import torch
+from packaging import version
+
+from transformers.pytorch_utils import is_torch_greater_or_equal_than_2_6
+
+from .configuration_utils import PretrainedConfig
+from .utils import is_hqq_available, is_optimum_quanto_available, is_torch_greater_or_equal, logging
+
+
+if is_hqq_available():
+ from hqq.core.quantize import Quantizer as HQQQuantizer
+
+logger = logging.get_logger(__name__)
+
+
+class Cache:
+ """
+ Base, abstract class for all caches. The actual data structure is specific to each subclass.
+ """
+
+ is_compileable = False
+
+ def __init__(self):
+ super().__init__()
+
+ def update(
+ self,
+ key_states: torch.Tensor,
+ value_states: torch.Tensor,
+ layer_idx: int,
+ cache_kwargs: Optional[Dict[str, Any]] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """
+ Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
+
+ Parameters:
+ key_states (`torch.Tensor`):
+ The new key states to cache.
+ value_states (`torch.Tensor`):
+ The new value states to cache.
+ layer_idx (`int`):
+ The index of the layer to cache the states for.
+ cache_kwargs (`Dict[str, Any]`, `optional`):
+ Additional arguments for the cache subclass. These are specific to each subclass and allow new types of
+ cache to be created.
+
+ Return:
+ A tuple containing the updated key and value states.
+ """
+ raise NotImplementedError("Make sure to implement `update` in a subclass.")
+
+ def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
+ """Returns the sequence length of the cached states. A layer index can be optionally passed."""
+ # TODO: deprecate this function in favor of `cache_position`
+ raise NotImplementedError("Make sure to implement `get_seq_length` in a subclass.")
+
+ def get_max_cache_shape(self) -> Optional[int]:
+ """Returns the maximum sequence length (i.e. max capacity) of the cache object"""
+ raise NotImplementedError("Make sure to implement `get_max_cache_shape` in a subclass.")
+
+ def get_usable_length(self, new_seq_length: int, layer_idx: Optional[int] = 0) -> int:
+ """Given the sequence length of the new inputs, returns the usable length of the cache."""
+ # Cache without size limit -> all cache is usable
+ # Cache with size limit -> if the length cache plus the length of the new inputs is larger the maximum cache
+ # length, we will need to evict part of the cache (and thus not all cache is usable)
+ max_length = self.get_max_cache_shape()
+ previous_seq_length = self.get_seq_length(layer_idx)
+ if max_length is not None and previous_seq_length + new_seq_length > max_length:
+ return max_length - new_seq_length
+ return previous_seq_length
+
+ def reorder_cache(self, beam_idx: torch.LongTensor):
+ """Reorders the cache for beam search, given the selected beam indices."""
+ for layer_idx in range(len(self.key_cache)):
+ if self.key_cache[layer_idx].numel():
+ device = self.key_cache[layer_idx].device
+ self.key_cache[layer_idx] = self.key_cache[layer_idx].index_select(0, beam_idx.to(device))
+ if self.value_cache[layer_idx].numel():
+ device = self.value_cache[layer_idx].device
+ self.value_cache[layer_idx] = self.value_cache[layer_idx].index_select(0, beam_idx.to(device))
+
+ @property
+ def seen_tokens(self):
+ logger.warning_once(
+ "The `seen_tokens` attribute is deprecated and will be removed in v4.41. Use the `cache_position` "
+ "model input instead."
+ )
+ if hasattr(self, "_seen_tokens"):
+ return self._seen_tokens
+ else:
+ return None
+
+
+@dataclass
+class CacheConfig:
+ """
+ Base class for cache configs
+ """
+
+ cache_implementation: None
+
+ @classmethod
+ def from_dict(cls, config_dict, **kwargs):
+ """
+ Constructs a CacheConfig instance from a dictionary of parameters.
+ Args:
+ config_dict (Dict[str, Any]): Dictionary containing configuration parameters.
+ **kwargs: Additional keyword arguments to override dictionary values.
+
+ Returns:
+ CacheConfig: Instance of CacheConfig constructed from the dictionary.
+ """
+ config = cls(**config_dict)
+ to_remove = []
+ for key, value in kwargs.items():
+ if hasattr(config, key):
+ setattr(config, key, value)
+ to_remove.append(key)
+ for key in to_remove:
+ kwargs.pop(key, None)
+ return config
+
+ # Copied from transformers.utils.quantization_config.QuantizationConfigMixin.to_json_file
+ def to_json_file(self, json_file_path: Union[str, os.PathLike]):
+ """
+ Save this instance to a JSON file.
+
+ Args:
+ json_file_path (`str` or `os.PathLike`):
+ Path to the JSON file in which this configuration instance's parameters will be saved.
+ use_diff (`bool`, *optional*, defaults to `True`):
+ If set to `True`, only the difference between the config instance and the default
+ `QuantizationConfig()` is serialized to JSON file.
+ """
+ with open(json_file_path, "w", encoding="utf-8") as writer:
+ config_dict = self.to_dict()
+ json_string = json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
+
+ writer.write(json_string)
+
+ # Copied from transformers.utils.quantization_config.QuantizationConfigMixin.to_dict
+ def to_dict(self) -> Dict[str, Any]:
+ """
+ Serializes this instance to a Python dictionary. Returns:
+ `Dict[str, Any]`: Dictionary of all the attributes that make up this configuration instance.
+ """
+ return copy.deepcopy(self.__dict__)
+
+ # Copied from transformers.utils.quantization_config.QuantizationConfigMixin.__iter__
+ def __iter__(self):
+ """allows `dict(obj)` for situations where obj may be a dict or QuantizationConfigMixin"""
+ for attr, value in copy.deepcopy(self.__dict__).items():
+ yield attr, value
+
+ # Copied from transformers.utils.quantization_config.QuantizationConfigMixin.__repr__
+ def __repr__(self):
+ return f"{self.__class__.__name__} {self.to_json_string()}"
+
+ def to_json_string(self):
+ """
+ Serializes this instance to a JSON formatted string.
+ Returns:
+ str: JSON formatted string representing the configuration instance.
+ """
+ return json.dumps(self.__dict__, indent=2) + "\n"
+
+ # Copied from transformers.utils.quantization_config.QuantizationConfigMixin.update
+ def update(self, **kwargs):
+ """
+ Updates attributes of this class instance with attributes from `kwargs` if they match existing attributes,
+ returning all the unused kwargs.
+
+ Args:
+ kwargs (`Dict[str, Any]`):
+ Dictionary of attributes to tentatively update this class.
+
+ Returns:
+ `Dict[str, Any]`: Dictionary containing all the key-value pairs that were not used to update the instance.
+ """
+ to_remove = []
+ for key, value in kwargs.items():
+ if hasattr(self, key):
+ setattr(self, key, value)
+ to_remove.append(key)
+
+ # Remove all the attributes that were updated, without modifying the input dict
+ unused_kwargs = {key: value for key, value in kwargs.items() if key not in to_remove}
+ return unused_kwargs
+
+
+@dataclass
+class QuantizedCacheConfig(CacheConfig):
+ """
+ Configuration class for quantized cache settings.
+
+ Attributes:
+ backend (`str`, *optional*, defaults to `"quanto"`):
+ Backend to use when performing quantization, Can be one of [`quanto`, `HQQ`]
+ nbits (`Optional[int]`, *optional*, defaults to 4):
+ Number of bits, can be 2 or 4 for the `quanto` backend and one of [1, 2, 3, 4, 8] for the `HQQ` backend. Defaults to 2.
+ axis_key (`int`, *optional*, defaults to 0):
+ Axis over which to perform grouping for the key tensors. Can be [0, -1] for `quanto` backend and [0, 1] for `HQQ` backend.
+ axis_value (`int`, *optional*, defaults to 0):
+ Axis over which to perform grouping for the value tensors. Can be [0, -1] for `quanto` backend and [0, 1] for `HQQ` backend.
+ q_group_size (`Optional[int]`, *optional*, defaults to 64):
+ Size of the quantization group, should be a divisor of the model's hidden dimension.
+ Defaults to 64.
+ residual_length (`Optional[int]`, *optional*, defaults to 128):
+ Length of the residual cache which will always be stored in original precision.
+ Defaults to 128.
+ compute_dtype (`torch.dtype`, *optional*, defaults to `torch.float16`):
+ The default dtype used for computations in the model. Keys and Values will be cast to this dtype after dequantization.
+ device (`str`, *optional*, defaults to `"cpu"`):
+ Device on which to perform computations, should be same as the model's device.
+ """
+
+ def __init__(
+ self,
+ backend: str = "quanto",
+ nbits: Optional[int] = 4,
+ axis_key: Optional[int] = 0,
+ axis_value: Optional[int] = 0,
+ q_group_size: Optional[int] = 64,
+ residual_length: Optional[int] = 128,
+ compute_dtype: Optional[torch.dtype] = torch.float16,
+ device: Optional[str] = "cpu",
+ ):
+ self.backend = backend
+ self.nbits = nbits
+ self.axis_key = axis_key
+ self.axis_value = axis_value
+ self.q_group_size = q_group_size
+ self.residual_length = residual_length
+ self.compute_dtype = compute_dtype
+ self.device = device
+
+ def validate(self):
+ """Validates if the arguments passed are correct"""
+
+ incorrect_arg_msg = (
+ "Some of the keys in `cache_config` are defined incorrectly. `{key}` should be {correct_value}` "
+ "but found {found_value}"
+ )
+ # Check that the values are reasonable in general (nbits, axis)
+ # Later in QuantizedCache init we check if they are supported for that particular backend
+ if self.nbits not in [1, 2, 3, 4, 8]:
+ raise ValueError(
+ incorrect_arg_msg.format(
+ key="nbits",
+ correct_value="2 or 4 or 8",
+ found_value=self.nbits,
+ ),
+ )
+ if self.q_group_size <= 0:
+ raise ValueError(
+ incorrect_arg_msg.format(
+ key="q_group_size",
+ correct_value="a positive integer",
+ found_value=self.q_group_size,
+ ),
+ )
+ if self.residual_length < 0:
+ raise ValueError(
+ incorrect_arg_msg.format(
+ key="residual_length",
+ correct_value="a positive integer",
+ found_value=self.residual_length,
+ ),
+ )
+
+ if self.axis_key not in [0, 1, -1]:
+ raise ValueError(
+ incorrect_arg_msg.format(
+ key="axis_key",
+ correct_value="`1` or `0`, `-1`",
+ found_value=self.axis_key,
+ ),
+ )
+
+ if self.axis_value not in [0, 1, -1]:
+ raise ValueError(
+ incorrect_arg_msg.format(
+ key="axis_value",
+ correct_value="`1` or `0` or `-1`",
+ found_value=self.axis_value,
+ ),
+ )
+
+
+@dataclass
+class StaticCacheConfig(CacheConfig):
+ """
+ Configuration class for static cache settings.
+ """
+
+ cache_implementation = "static"
+
+ def __init__(self, batch_size: int, max_cache_len: int, device="cpu"):
+ self.batch_size = batch_size
+ self.max_cache_len = max_cache_len
+ self.device = device
+
+ def validate(self):
+ """Validates if the arguments passed are correct"""
+
+ incorrect_arg_msg = (
+ "Some of the keys in `cache_config` are defined incorrectly. `{key}` should be {correct_value}` "
+ "but found {found_value}"
+ )
+
+ if self.batch_size <= 0:
+ raise ValueError(
+ incorrect_arg_msg.format(
+ key="batch_size",
+ correct_value="> 0",
+ found_value=self.batch_size,
+ ),
+ )
+
+ if self.max_cache_len <= 0:
+ raise ValueError(
+ incorrect_arg_msg.format(
+ key="max_cache_len",
+ correct_value="> 0",
+ found_value=self.max_cache_len,
+ ),
+ )
+
+
+class DynamicCache(Cache):
+ """
+ A cache that grows dynamically as more tokens are generated. This is the default for generative models.
+
+ It stores the Key and Value states as a list of tensors, one for each layer. The expected shape for each tensor is
+ `[batch_size, num_heads, seq_len, head_dim]`.
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModelForCausalLM, DynamicCache
+
+ >>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
+ >>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
+
+ >>> inputs = tokenizer(text="My name is Qwen2", return_tensors="pt")
+
+ >>> # Prepare a cache class and pass it to model's forward
+ >>> past_key_values = DynamicCache()
+ >>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
+ >>> outputs.past_key_values # access cache filled with key/values from generation
+ DynamicCache()
+ ```
+ """
+
+ def __init__(self, _distributed_cache_data: Iterable = None) -> None:
+ super().__init__()
+ self._seen_tokens = 0 # Used in `generate` to keep tally of how many tokens the cache has seen
+ self.key_cache: List[torch.Tensor] = []
+ self.value_cache: List[torch.Tensor] = []
+
+ # `_distributed_cache_data` was originally added for compatibility with `torch.distributed` (DDP). See #36121
+ # and #36373 for more information. In a nutshell, it is `map(gather_map, zip(*caches))`, i.e. each item in the
+ # iterable contains the key and value states for a layer gathered across replicas by torch.distributed
+ # (shape=[global batch size, num_heads, seq_len, head_dim]).
+ # WARNING: `_distributed_cache_data` must be the first argument in `__init__`, otherwise we'll break
+ # compatibility. The name of the argument doesn't matter.
+ if _distributed_cache_data is not None:
+ for key_states, value_states in _distributed_cache_data:
+ self.key_cache.append(key_states)
+ self.value_cache.append(value_states)
+
+ def __getitem__(self, layer_idx: int) -> List[Tuple[torch.Tensor]]:
+ """
+ Support for backwards-compatible `past_key_value` indexing, e.g. `past_key_value[0][0].shape[2]` to get the
+ sequence length.
+ """
+ if layer_idx < len(self):
+ return (self.key_cache[layer_idx], self.value_cache[layer_idx])
+ else:
+ raise KeyError(f"Cache only has {len(self)} layers, attempted to access layer with index {layer_idx}")
+
+ def __iter__(self):
+ """
+ Support for backwards-compatible `past_key_value` iteration, e.g. `for x in past_key_value:` to iterate over
+ keys and values
+ """
+ for layer_idx in range(len(self)):
+ yield (self.key_cache[layer_idx], self.value_cache[layer_idx])
+
+ def __len__(self):
+ """
+ Support for backwards-compatible `past_key_value` length, e.g. `len(past_key_value)`. This value corresponds
+ to the number of layers in the model.
+ """
+ return len(self.key_cache)
+
+ def update(
+ self,
+ key_states: torch.Tensor,
+ value_states: torch.Tensor,
+ layer_idx: int,
+ cache_kwargs: Optional[Dict[str, Any]] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """
+ Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
+
+ Parameters:
+ key_states (`torch.Tensor`):
+ The new key states to cache.
+ value_states (`torch.Tensor`):
+ The new value states to cache.
+ layer_idx (`int`):
+ The index of the layer to cache the states for.
+ cache_kwargs (`Dict[str, Any]`, `optional`):
+ Additional arguments for the cache subclass. No additional arguments are used in `DynamicCache`.
+
+ Return:
+ A tuple containing the updated key and value states.
+ """
+ # Update the number of seen tokens
+ if layer_idx == 0:
+ self._seen_tokens += key_states.shape[-2]
+
+ # Update the cache
+ if key_states is not None:
+ if len(self.key_cache) <= layer_idx:
+ # There may be skipped layers, fill them with empty lists
+ for _ in range(len(self.key_cache), layer_idx):
+ self.key_cache.append(torch.tensor([]))
+ self.value_cache.append(torch.tensor([]))
+ self.key_cache.append(key_states)
+ self.value_cache.append(value_states)
+ elif (
+ not self.key_cache[layer_idx].numel() # prefers not t.numel() to len(t) == 0 to export the model
+ ): # fills previously skipped layers; checking for tensor causes errors
+ self.key_cache[layer_idx] = key_states
+ self.value_cache[layer_idx] = value_states
+ else:
+ self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=-2)
+ self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=-2)
+
+ return self.key_cache[layer_idx], self.value_cache[layer_idx]
+
+ def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
+ """Returns the sequence length of the cached states. A layer index can be optionally passed."""
+ # TODO: deprecate this function in favor of `cache_position`
+ is_empty_layer = (
+ len(self.key_cache) == 0 # no cache in any layer
+ or len(self.key_cache) <= layer_idx # skipped `layer_idx` and hasn't run a layer with cache after it
+ or not self.key_cache[layer_idx].numel() # the layer has no cache
+ )
+ layer_seq_length = self.key_cache[layer_idx].shape[-2] if not is_empty_layer else 0
+ return layer_seq_length
+
+ def get_max_cache_shape(self) -> Optional[int]:
+ """Returns the maximum sequence length of the cache object. DynamicCache does not have a maximum length."""
+ return None
+
+ def to_legacy_cache(self) -> Tuple[Tuple[torch.Tensor], Tuple[torch.Tensor]]:
+ """Converts the `DynamicCache` instance into the its equivalent in the legacy cache format. Used for
+ backward compatibility."""
+ legacy_cache = ()
+ for layer_idx in range(len(self)):
+ legacy_cache += ((self.key_cache[layer_idx], self.value_cache[layer_idx]),)
+ return legacy_cache
+
+ @classmethod
+ def from_legacy_cache(cls, past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None) -> "DynamicCache":
+ """Converts a cache in the legacy cache format into an equivalent `DynamicCache`. Used for
+ backward compatibility."""
+ cache = cls()
+ if past_key_values is not None:
+ for layer_idx in range(len(past_key_values)):
+ key_states, value_states = past_key_values[layer_idx]
+ cache.update(key_states, value_states, layer_idx)
+ return cache
+
+ def crop(self, max_length: int):
+ """Crop the past key values up to a new `max_length` in terms of tokens. `max_length` can also be
+ negative to remove `max_length` tokens. This is used in assisted decoding and contrastive search."""
+ # In case it is negative
+ if max_length < 0:
+ max_length = self.get_seq_length() - abs(max_length)
+
+ if self.get_seq_length() <= max_length:
+ return
+
+ self._seen_tokens = max_length
+ for idx in range(len(self.key_cache)):
+ if self.key_cache[idx].numel():
+ self.key_cache[idx] = self.key_cache[idx][..., :max_length, :]
+ self.value_cache[idx] = self.value_cache[idx][..., :max_length, :]
+
+ def batch_split(self, full_batch_size: int, split_size: int) -> List["DynamicCache"]:
+ """Split the current instance into a list of `DynamicCache` by the batch size. This will be used by
+ `_split_model_inputs()` in `generation.utils`"""
+ out = []
+ for i in range(0, full_batch_size, split_size):
+ current_split = DynamicCache()
+ current_split._seen_tokens = self._seen_tokens
+ current_split.key_cache = [tensor[i : i + split_size] for tensor in self.key_cache]
+ current_split.value_cache = [tensor[i : i + split_size] for tensor in self.value_cache]
+ out.append(current_split)
+ return out
+
+ @classmethod
+ def from_batch_splits(cls, splits: List["DynamicCache"]) -> "DynamicCache":
+ """This is the opposite of the above `batch_split()` method. This will be used by `stack_model_outputs` in
+ `generation.utils`"""
+ cache = cls()
+ for idx in range(len(splits[0])):
+ key_cache = [current.key_cache[idx] for current in splits if current.key_cache[idx].numel()]
+ value_cache = [current.value_cache[idx] for current in splits if current.value_cache[idx].numel()]
+ if key_cache != []:
+ layer_keys = torch.cat(key_cache, dim=0)
+ layer_values = torch.cat(value_cache, dim=0)
+ cache.update(layer_keys, layer_values, idx)
+ return cache
+
+ def batch_repeat_interleave(self, repeats: int):
+ """Repeat the cache `repeats` times in the batch dimension. Used in contrastive search."""
+ for layer_idx in range(len(self)):
+ self.key_cache[layer_idx] = self.key_cache[layer_idx].repeat_interleave(repeats, dim=0)
+ self.value_cache[layer_idx] = self.value_cache[layer_idx].repeat_interleave(repeats, dim=0)
+
+ def batch_select_indices(self, indices: torch.Tensor):
+ """Only keep the `indices` in the batch dimension of the cache. Used in contrastive search."""
+ for layer_idx in range(len(self)):
+ self.key_cache[layer_idx] = self.key_cache[layer_idx][indices, ...]
+ self.value_cache[layer_idx] = self.value_cache[layer_idx][indices, ...]
+
+
+# Utilities for `DynamicCache` <> torch.export support
+def _flatten_dynamic_cache(
+ dynamic_cache: DynamicCache,
+):
+ """Flattens DynamicCache into flat list of tensors for `torch.export.export` to consume"""
+ if not isinstance(dynamic_cache, DynamicCache):
+ raise RuntimeError("This pytree flattening function should only be applied to DynamicCache")
+
+ if not is_torch_greater_or_equal_than_2_6:
+ logger.warning_once(
+ "DynamicCache + torch.export is tested on torch 2.6.0+ and may not work on earlier versions."
+ )
+
+ # NOTE it seems _seen_tokens is deprecated, so probably doesn't need tracking
+ dictionary = {
+ "key_cache": getattr(dynamic_cache, "key_cache"),
+ "value_cache": getattr(dynamic_cache, "value_cache"),
+ }
+ return torch.utils._pytree._dict_flatten(dictionary)
+
+
+def _flatten_with_keys_dynamic_cache(dynamic_cache: DynamicCache):
+ dictionary = {
+ "key_cache": getattr(dynamic_cache, "key_cache"),
+ "value_cache": getattr(dynamic_cache, "value_cache"),
+ }
+ return torch.utils._pytree._dict_flatten_with_keys(dictionary)
+
+
+def _unflatten_dynamic_cache(
+ values,
+ context: torch.utils._pytree.Context,
+):
+ dictionary = torch.utils._pytree._dict_unflatten(values, context)
+ cache = DynamicCache()
+ for k, v in dictionary.items():
+ setattr(cache, k, v)
+ return cache
+
+
+def _flatten_dynamic_cache_for_fx(cache, spec):
+ dictionary = {
+ "key_cache": getattr(cache, "key_cache"),
+ "value_cache": getattr(cache, "value_cache"),
+ }
+ return torch.utils._pytree.tree_flatten(dictionary)[0]
+
+
+if is_torch_greater_or_equal("2.3"):
+ torch.utils._pytree.register_pytree_node(
+ DynamicCache,
+ _flatten_dynamic_cache,
+ _unflatten_dynamic_cache,
+ serialized_type_name=f"{DynamicCache.__module__}.{DynamicCache.__name__}",
+ flatten_with_keys_fn=_flatten_with_keys_dynamic_cache,
+ )
+ # TODO (tmanlaibaatar) This won't be needed in torch 2.7.
+ torch.fx._pytree.register_pytree_flatten_spec(DynamicCache, _flatten_dynamic_cache_for_fx)
+
+
+class OffloadedCache(DynamicCache):
+ """
+ A drop-in replacement for DynamicCache that conserves accelerator(GPU, XPU) memory at the expense of more CPU memory.
+ Useful for generating from models with very long context.
+
+ In addition to the default accelerator stream, where all forward() computations happen,
+ this class uses another stream, the prefetch stream, which it creates itself.
+ Since scheduling of operations on separate streams happens independently, this class uses
+ the prefetch stream to asynchronously prefetch the KV cache of layer k+1 when layer k is executing.
+ The movement of the layer k-1 cache to the CPU is handled by the default stream as a simple way to
+ ensure the eviction is scheduled after all computations on that cache are finished.
+ """
+
+ def __init__(self) -> None:
+ if not (
+ torch.cuda.is_available()
+ or (is_torch_greater_or_equal("2.7", accept_dev=True) and torch.xpu.is_available())
+ ):
+ raise RuntimeError(
+ "OffloadedCache can only be used with a GPU"
+ + (" or XPU" if is_torch_greater_or_equal("2.7", accept_dev=True) else "")
+ )
+
+ super().__init__()
+ self.original_device = []
+ self.prefetch_stream = None
+ self.prefetch_stream = (
+ torch.Stream() if is_torch_greater_or_equal("2.7", accept_dev=True) else torch.cuda.Stream()
+ )
+ self.beam_idx = None # used to delay beam search operations
+
+ def prefetch_layer(self, layer_idx: int):
+ "Starts prefetching the next layer cache"
+ if layer_idx < len(self):
+ with (
+ self.prefetch_stream
+ if is_torch_greater_or_equal("2.7", accept_dev=True)
+ else torch.cuda.stream(self.prefetch_stream)
+ ):
+ # Prefetch next layer tensors to GPU
+ device = self.original_device[layer_idx]
+ self.key_cache[layer_idx] = self.key_cache[layer_idx].to(device, non_blocking=True)
+ self.value_cache[layer_idx] = self.value_cache[layer_idx].to(device, non_blocking=True)
+
+ def evict_previous_layer(self, layer_idx: int):
+ "Moves the previous layer cache to the CPU"
+ if len(self) > 2:
+ # We do it on the default stream so it occurs after all earlier computations on these tensors are done
+ prev_layer_idx = (layer_idx - 1) % len(self)
+ self.key_cache[prev_layer_idx] = self.key_cache[prev_layer_idx].to("cpu", non_blocking=True)
+ self.value_cache[prev_layer_idx] = self.value_cache[prev_layer_idx].to("cpu", non_blocking=True)
+
+ def __getitem__(self, layer_idx: int) -> List[Tuple[torch.Tensor]]:
+ "Gets the cache for this layer to the device. Prefetches the next and evicts the previous layer."
+ if layer_idx < len(self):
+ # Evict the previous layer if necessary
+ if is_torch_greater_or_equal("2.7", accept_dev=True):
+ torch.accelerator.current_stream().synchronize()
+ else:
+ torch.cuda.current_stream().synchronize()
+ self.evict_previous_layer(layer_idx)
+ # Load current layer cache to its original device if not already there
+ original_device = self.original_device[layer_idx]
+ self.prefetch_stream.synchronize()
+ key_tensor = self.key_cache[layer_idx]
+ value_tensor = self.value_cache[layer_idx]
+ # Now deal with beam search ops which were delayed
+ if self.beam_idx is not None:
+ self.beam_idx = self.beam_idx.to(original_device)
+ key_tensor = key_tensor.index_select(0, self.beam_idx)
+ value_tensor = value_tensor.index_select(0, self.beam_idx)
+ # Prefetch the next layer
+ self.prefetch_layer((layer_idx + 1) % len(self))
+ return (key_tensor, value_tensor)
+ else:
+ raise KeyError(f"Cache only has {len(self)} layers, attempted to access layer with index {layer_idx}")
+
+ def reorder_cache(self, beam_idx: torch.LongTensor):
+ """Saves the beam indices and reorders the cache when the tensor is back to its device."""
+ # We delay this operation until the tensors are back to their original
+ # device because performing torch.index_select on the CPU is very slow
+ del self.beam_idx
+ self.beam_idx = beam_idx.clone()
+
+ def update(
+ self,
+ key_states: torch.Tensor,
+ value_states: torch.Tensor,
+ layer_idx: int,
+ cache_kwargs: Optional[Dict[str, Any]] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """
+ Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
+ Parameters:
+ key_states (`torch.Tensor`):
+ The new key states to cache.
+ value_states (`torch.Tensor`):
+ The new value states to cache.
+ layer_idx (`int`):
+ The index of the layer to cache the states for.
+ cache_kwargs (`Dict[str, Any]`, `optional`):
+ Additional arguments for the cache subclass. No additional arguments are used in `OffloadedCache`.
+ Return:
+ A tuple containing the updated key and value states.
+ """
+ # Update the number of seen tokens
+ if layer_idx == 0:
+ self._seen_tokens += key_states.shape[-2]
+
+ # Update the cache
+ if len(self.key_cache) < layer_idx:
+ raise ValueError("OffloadedCache does not support model usage where layers are skipped. Use DynamicCache.")
+ elif len(self.key_cache) == layer_idx:
+ self.key_cache.append(key_states)
+ self.value_cache.append(value_states)
+ self.original_device.append(key_states.device)
+ self.evict_previous_layer(layer_idx)
+ else:
+ key_tensor, value_tensor = self[layer_idx]
+ self.key_cache[layer_idx] = torch.cat([key_tensor, key_states], dim=-2)
+ self.value_cache[layer_idx] = torch.cat([value_tensor, value_states], dim=-2)
+
+ return self.key_cache[layer_idx], self.value_cache[layer_idx]
+
+ # According to https://docs.python.org/3/library/exceptions.html#NotImplementedError
+ # if a method is not supposed to be supported in a subclass we should set it to None
+ from_legacy_cache = None
+
+ to_legacy_cache = None
+
+
+class QuantizedCache(DynamicCache):
+ """
+ A quantizer cache similar to what is described in the [KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache paper](https://arxiv.org/abs/2402.02750).
+ It allows the model to generate longer sequence length without allocating too much memory for Key and Value cache by applying quantization.
+
+ The cache has two types of storage, one for original precision and one for the quantized cache. A `residual length` is set as a maximum capacity for the
+ original precision cache. When the length goes beyond maximum capacity, the original precision cache is discarded and moved into the quantized cache. The
+ quantization is done per-channel with a set `q_group_size` for both Keys and Values, in contrast to what was described in the paper.
+
+ It stores Keys and Values a list of quantized tensors (tuples in case we need to store metadata), one for each layer. Additionally, it stores the Key and
+ Value in original precision states as a list of tensors, one for each layer. The size of each tensor
+ is `[batch_size, num_heads, seq_len - residual_length, head_dim]`
+ """
+
+ def __init__(self, cache_config: QuantizedCacheConfig) -> None:
+ super().__init__()
+ self._quantized_key_cache: List[torch.Tensor] = []
+ self._quantized_value_cache: List[torch.Tensor] = []
+
+ self.nbits = cache_config.nbits
+ self.residual_length = cache_config.residual_length
+ self.q_group_size = cache_config.q_group_size
+ self.axis_key = cache_config.axis_key
+ self.axis_value = cache_config.axis_value
+ self.compute_dtype = cache_config.compute_dtype
+ self.device = cache_config.device
+
+ super().__init__()
+
+ def update(
+ self,
+ key_states: torch.Tensor,
+ value_states: torch.Tensor,
+ layer_idx: int,
+ cache_kwargs: Optional[Dict[str, Any]] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ # Update the number of seen tokens
+ if layer_idx == 0:
+ self._seen_tokens += key_states.shape[-2]
+
+ if len(self.key_cache) < layer_idx:
+ raise ValueError("QuantizedCache does not support model usage where layers are skipped. Use DynamicCache.")
+ elif len(self.key_cache) == layer_idx:
+ self._quantized_key_cache.append(self._quantize(key_states.contiguous(), axis=self.axis_key))
+ self._quantized_value_cache.append(self._quantize(value_states.contiguous(), axis=self.axis_value))
+ self.key_cache.append(torch.zeros(0, dtype=key_states.dtype, device=key_states.device))
+ self.value_cache.append(torch.zeros(0, dtype=key_states.dtype, device=key_states.device))
+ keys_to_return, values_to_return = key_states, value_states
+ else:
+ dequant_key = self._dequantize(self._quantized_key_cache[layer_idx])
+ dequant_value = self._dequantize(self._quantized_value_cache[layer_idx])
+ keys_to_return = [dequant_key, self.key_cache[layer_idx], key_states]
+ values_to_return = [dequant_value, self.value_cache[layer_idx], value_states]
+
+ keys_to_return = torch.cat(keys_to_return, dim=-2)
+ values_to_return = torch.cat(values_to_return, dim=-2)
+ if (
+ self.key_cache[layer_idx].dim() == 4
+ and self.key_cache[layer_idx].shape[-2] + 1 >= self.residual_length
+ ):
+ self._quantized_key_cache[layer_idx] = self._quantize(keys_to_return.contiguous(), axis=self.axis_key)
+ self._quantized_value_cache[layer_idx] = self._quantize(
+ values_to_return.contiguous(), axis=self.axis_value
+ )
+ self.key_cache[layer_idx] = torch.zeros(0, dtype=key_states.dtype, device=key_states.device)
+ self.value_cache[layer_idx] = torch.zeros(0, dtype=key_states.dtype, device=key_states.device)
+ else:
+ self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=-2)
+ self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=-2)
+
+ return keys_to_return, values_to_return
+
+ def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
+ """Returns the sequence length of the cached states. A layer index can be optionally passed."""
+ if len(self.key_cache) <= layer_idx:
+ return 0
+ # since we cannot get the seq_length of each layer directly and rely on `_seen_tokens` which is
+ # updated every "layer_idx" == 0, this is a hack to get the actual seq_length for the given layer_idx
+ # this part of code otherwise fails when used to verify attn_weight shape in some models
+ return self._seen_tokens if layer_idx == 0 else self._seen_tokens - 1
+
+ def _quantize(self, tensor, axis):
+ """Quantizes a key/value using a defined quantization method."""
+ raise NotImplementedError("Make sure to implement `_quantize` in a subclass.")
+
+ def _dequantize(self, q_tensor):
+ """Dequantizes back the tensor that was quantized by `self._quantize()`"""
+ raise NotImplementedError("Make sure to implement `_dequantize` in a subclass.")
+
+
+class QuantoQuantizedCache(QuantizedCache):
+ """
+ Quantized Cache class that uses `quanto` as a backend to perform quantization. Current implementation supports `int2` and `int4` dtypes only.
+
+ Parameters:
+ cache_config (`QuantizedCacheConfig`):
+ A configuration containing all the arguments to be used by the quantizer, including axis, qtype and group size.
+
+ Example:
+
+ ```python
+ >>> # Run pip install quanto first if you don't have it yet
+ >>> from transformers import AutoTokenizer, AutoModelForCausalLM, QuantoQuantizedCache, QuantizedCacheConfig
+
+ >>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
+ >>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
+
+ >>> inputs = tokenizer(text="My name is Qwen2", return_tensors="pt")
+
+ >>> # Prepare a cache class and pass it to model's forward
+ >>> cache_config = QuantizedCacheConfig(nbits=4)
+ >>> past_key_values = QuantoQuantizedCache(cache_config=cache_config)
+ >>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
+ >>> outputs.past_key_values # access cache filled with key/values from generation
+ QuantoQuantizedCache()
+ ```
+ """
+
+ def __init__(self, cache_config: CacheConfig) -> None:
+ super().__init__(cache_config)
+
+ if is_optimum_quanto_available():
+ optimum_quanto_version = version.parse(importlib.metadata.version("optimum-quanto"))
+ if optimum_quanto_version <= version.parse("0.2.5"):
+ raise ImportError(
+ f"You need optimum-quanto package version to be greater or equal than 0.2.5 to use `QuantoQuantizedCache`. Detected version {optimum_quanto_version}."
+ )
+ from optimum.quanto import MaxOptimizer, qint2, qint4
+
+ if self.nbits not in [2, 4]:
+ raise ValueError(f"`nbits` for `quanto` backend has to be one of [`2`, `4`] but got {self.nbits}")
+
+ if self.axis_key not in [0, -1]:
+ raise ValueError(f"`axis_key` for `quanto` backend has to be one of [`0`, `-1`] but got {self.axis_key}")
+
+ if self.axis_value not in [0, -1]:
+ raise ValueError(
+ f"`axis_value` for `quanto` backend has to be one of [`0`, `-1`] but got {self.axis_value}"
+ )
+
+ self.qtype = qint4 if self.nbits == 4 else qint2
+ self.optimizer = MaxOptimizer() # hardcode as it's the only one for per-channel quantization
+
+ def _quantize(self, tensor, axis):
+ # We have two different API since in optimum-quanto, we don't use AffineQuantizer anymore
+ if is_optimum_quanto_available():
+ from optimum.quanto import quantize_weight
+
+ scale, zeropoint = self.optimizer(tensor, self.qtype, axis, self.q_group_size)
+ qtensor = quantize_weight(tensor, self.qtype, axis, scale, zeropoint, self.q_group_size)
+ return qtensor
+
+ def _dequantize(self, qtensor):
+ return qtensor.dequantize()
+
+
+class HQQQuantizedCache(QuantizedCache):
+ """
+ Quantized Cache class that uses `HQQ` as a backend to perform quantization. Current implementation supports `int2`, `int4`, `int8` dtypes.
+
+ Parameters:
+ cache_config (`QuantizedCacheConfig`):
+ A configuration containing all the arguments to be used by the quantizer, including axis, qtype and group size.
+
+ Example:
+
+ ```python
+ >>> # Run pip install hqq first if you don't have it yet
+ >>> from transformers import AutoTokenizer, AutoModelForCausalLM, HQQQuantizedCache, QuantizedCacheConfig
+
+ >>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
+ >>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
+
+ >>> inputs = tokenizer(text="My name is Qwen2", return_tensors="pt")
+
+ >>> # Prepare a cache class and pass it to model's forward
+ >>> cache_config = QuantizedCacheConfig(nbits=4, axis_key=1, axis_value=1)
+ >>> past_key_values = HQQQuantizedCache(cache_config=cache_config)
+ >>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
+ >>> outputs.past_key_values # access cache filled with key/values from generation
+ HQQQuantizedCache()
+ ```
+ """
+
+ def __init__(self, cache_config: CacheConfig) -> None:
+ super().__init__(cache_config)
+ if self.nbits not in [1, 2, 3, 4, 8]:
+ raise ValueError(
+ f"`nbits` for `HQQ` backend has to be one of [`1`, `2`, `3`, `4`, `8`] but got {self.nbits}"
+ )
+
+ if self.axis_key not in [0, 1]:
+ raise ValueError(f"`axis_key` for `HQQ` backend has to be one of [`0`, `1`] but got {self.axis_key}")
+
+ if self.axis_value not in [0, 1]:
+ raise ValueError(f"`axis_value` for `HQQ` backend has to be one of [`0`, `1`] but got {self.axis_value}")
+
+ self.quantizer = HQQQuantizer
+
+ def _quantize(self, tensor, axis):
+ qtensor, meta = self.quantizer.quantize(
+ tensor,
+ axis=axis,
+ device=self.device,
+ compute_dtype=self.compute_dtype,
+ nbits=self.nbits,
+ group_size=self.q_group_size,
+ )
+ meta["compute_dtype"] = self.compute_dtype
+ self.quantizer.cuda(qtensor, meta=meta, device=self.device) # Move to device and cast to dtype
+ meta["scale"] = meta["scale"].to(qtensor.device)
+ meta["zero"] = meta["zero"].to(qtensor.device)
+ return qtensor, meta
+
+ def _dequantize(self, qtensor):
+ quant_tensor, meta = qtensor
+ tensor = self.quantizer.dequantize(quant_tensor, meta)
+ return tensor
+
+
+class SinkCache(Cache):
+ """
+ A cache that as described in the [Attention Sinks paper](https://arxiv.org/abs/2309.17453). It allows the model to
+ generate beyond the length of its context window, without losing fluency in the conversation. As it discards past
+ tokens, the model will lose the ability to generate tokens that depend on the context that was discarded.
+
+ It stores the Key and Value states as a list of tensors, one for each layer. The expected shape for each tensor is
+ `[batch_size, num_heads, seq_len, head_dim]`.
+
+ Parameters:
+ window_length (`int`):
+ The length of the context window.
+ num_sink_tokens (`int`):
+ The number of sink tokens. See the original paper for more information.
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModelForCausalLM, SinkCache
+
+ >>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
+ >>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
+
+ >>> inputs = tokenizer(text="My name is Qwen2", return_tensors="pt")
+
+ >>> # Prepare a cache class and pass it to model's forward
+ >>> past_key_values = SinkCache(window_length=256, num_sink_tokens=4)
+ >>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
+ >>> outputs.past_key_values # access cache filled with key/values from generation
+ SinkCache()
+ ```
+ """
+
+ is_sliding = True
+
+ def __init__(self, window_length: int, num_sink_tokens: int) -> None:
+ super().__init__()
+ self.key_cache: List[torch.Tensor] = []
+ self.value_cache: List[torch.Tensor] = []
+ self.window_length = window_length
+ self.num_sink_tokens = num_sink_tokens
+ self.cos_sin_rerotation_cache = {}
+ self._cos_cache = None
+ self._sin_cache = None
+ self._seen_tokens = 0 # Used in `generate` to keep tally of how many tokens the cache has seen
+
+ @staticmethod
+ def _rotate_half(x):
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+ def _apply_key_rotary_pos_emb(
+ self, key_states: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor
+ ) -> torch.Tensor:
+ rotated_key_states = (key_states * cos) + (self._rotate_half(key_states) * sin)
+ return rotated_key_states
+
+ def _get_rerotation_cos_sin(
+ self, key_states: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ if key_states.shape[-2] not in self.cos_sin_rerotation_cache:
+ # Upcast to float32 temporarily for better accuracy
+ cos = cos.to(torch.float32)
+ sin = sin.to(torch.float32)
+
+ # Compute the cos and sin required for back- and forward-rotating to one position earlier in the sequence
+ original_cos = cos[self.num_sink_tokens + key_states.shape[-2] :]
+ shifted_cos = cos[self.num_sink_tokens : -key_states.shape[-2]]
+ original_sin = sin[self.num_sink_tokens + key_states.shape[-2] :]
+ shifted_sin = sin[self.num_sink_tokens : -key_states.shape[-2]]
+ rerotation_cos = original_cos * shifted_cos + original_sin * shifted_sin
+ rerotation_sin = -original_sin * shifted_cos + original_cos * shifted_sin
+
+ self.cos_sin_rerotation_cache[key_states.shape[-2]] = (
+ rerotation_cos.to(key_states.dtype).unsqueeze(0),
+ rerotation_sin.to(key_states.dtype).unsqueeze(0),
+ )
+ return self.cos_sin_rerotation_cache[key_states.shape[-2]]
+
+ def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
+ """Returns the sequence length of the cached states. A layer index can be optionally passed."""
+ # TODO: deprecate this function in favor of `cache_position`
+ # Workaround to make 'key_states.shape[-2] + past_key_value.get_seq_length(self.layer_idx)' <= window_length
+ if len(self.key_cache) <= layer_idx:
+ return 0
+ return self.key_cache[layer_idx].shape[-2]
+
+ def get_max_cache_shape(self) -> Optional[int]:
+ """Returns the maximum sequence length of the cache object, in case of SinkCache it is the window length."""
+ return self.window_length
+
+ def update(
+ self,
+ key_states: torch.Tensor,
+ value_states: torch.Tensor,
+ layer_idx: int,
+ cache_kwargs: Optional[Dict[str, Any]] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """
+ Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
+
+ Parameters:
+ key_states (`torch.Tensor`):
+ The new key states to cache.
+ value_states (`torch.Tensor`):
+ The new value states to cache.
+ layer_idx (`int`):
+ The index of the layer to cache the states for.
+ cache_kwargs (`Dict[str, Any]`, `optional`):
+ Additional arguments for the cache subclass. The following arguments can be used in `SinkCache`: `sin`,
+ `cos` and `partial_rotation_size`. These arguments are used with models using RoPE, to recompute the
+ rotation as the tokens are shifted.
+
+ Return:
+ A tuple containing the updated key and value states.
+ """
+ # Optional kwargs for `SinkCache` -- needed on models using RoPE. `partial_rotation_size` is used on models
+ # with partially rotated position embeddings, like Phi or Persimmon.
+ if cache_kwargs is None:
+ cache_kwargs = {}
+ sin = cache_kwargs.get("sin")
+ cos = cache_kwargs.get("cos")
+ partial_rotation_size = cache_kwargs.get("partial_rotation_size")
+ using_rope = cos is not None and sin is not None
+
+ # Update the number of seen tokens
+ if layer_idx == 0:
+ self._seen_tokens += key_states.shape[-2]
+
+ # Update the sin/cos cache, which holds sin/cos values for all possible positions
+ if using_rope and layer_idx == 0:
+ # BC: some models still pass `sin`/`cos` with 2 dims. In those models, they are the full sin/cos. Remove
+ # after all RoPE models have a llama-like cache utilization.
+ if cos.dim() == 2:
+ self._cos_cache = cos
+ self._sin_cache = sin
+ else:
+ if self._cos_cache is None:
+ self._cos_cache = cos[0, ...]
+ self._sin_cache = sin[0, ...]
+ elif self._cos_cache.shape[0] < self.window_length:
+ self._cos_cache = torch.cat([self._cos_cache, cos[0, ...]], dim=0)
+ self._sin_cache = torch.cat([self._sin_cache, sin[0, ...]], dim=0)
+
+ # [bsz, num_heads, seq_len, head_dim]
+ if len(self.key_cache) <= layer_idx:
+ # Empty cache
+ self.key_cache.append(key_states)
+ self.value_cache.append(value_states)
+
+ elif key_states.shape[-2] + self.get_seq_length(layer_idx) < self.window_length:
+ # Growing cache
+ self.key_cache[layer_idx] = torch.cat([self.key_cache[layer_idx], key_states], dim=-2)
+ self.value_cache[layer_idx] = torch.cat([self.value_cache[layer_idx], value_states], dim=-2)
+
+ else:
+ # Shifting cache
+ keys_to_keep = self.key_cache[layer_idx][
+ :, :, -self.window_length + self.num_sink_tokens + key_states.shape[-2] :
+ ]
+
+ # On RoPE models, we need to recompute the Key rotation as the tokens are shifted
+ if using_rope:
+ rerotation_cos, rerotation_sin = self._get_rerotation_cos_sin(
+ key_states, self._cos_cache[: self.window_length], self._sin_cache[: self.window_length]
+ )
+ if partial_rotation_size is not None:
+ keys_to_keep, keys_pass = (
+ keys_to_keep[..., :partial_rotation_size],
+ keys_to_keep[..., partial_rotation_size:],
+ )
+ keys_to_keep = self._apply_key_rotary_pos_emb(keys_to_keep, rerotation_cos, rerotation_sin)
+ if partial_rotation_size is not None:
+ keys_to_keep = torch.cat((keys_to_keep, keys_pass), dim=-1)
+
+ # Concatenate sink tokens, shifted & rotated tokens (if needed), and new tokens
+ sink_keys = self.key_cache[layer_idx][:, :, : self.num_sink_tokens]
+ self.key_cache[layer_idx] = torch.cat([sink_keys, keys_to_keep, key_states], dim=-2)
+
+ sink_values = self.value_cache[layer_idx][:, :, : self.num_sink_tokens]
+ values_to_keep = self.value_cache[layer_idx][
+ :, :, -self.window_length + self.num_sink_tokens + value_states.shape[-2] :
+ ]
+ self.value_cache[layer_idx] = torch.cat([sink_values, values_to_keep, value_states], dim=-2)
+
+ return self.key_cache[layer_idx], self.value_cache[layer_idx]
+
+
+class StaticCache(Cache):
+ """
+ Static Cache class to be used with `torch.compile(model)` and `torch.export()`.
+
+ Parameters:
+ config (`PretrainedConfig`):
+ The configuration file defining the shape-related attributes required to initialize the static cache.
+ max_batch_size (`int`):
+ The maximum batch size with which the model will be used. Note that a new instance must be instantiated if a
+ smaller batch size is used. If you are manually setting the batch size, make sure to take into account the
+ number of beams if you are running beam search
+ max_cache_len (`int`, *optional*):
+ The maximum sequence length with which the model will be used.
+ device (`torch.device` or `str`, *optional*):
+ The device on which the cache should be initialized. If you're using more than 1 computation device, you
+ should pass the `layer_device_map` argument instead.
+ dtype (`torch.dtype`, *optional*, defaults to `torch.float32`):
+ The default `dtype` to use when initializing the layer.
+ layer_device_map (`Optional[Dict[int, Union[str, torch.device, int]]]]`, *optional*):
+ Mapping between the layers and its device. This is required when you are manually initializing the cache
+ and the model is split between different gpus. You can know which layers mapped to which device by
+ checking the associated device_map: `model.hf_device_map`.
+
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModelForCausalLM, StaticCache
+
+ >>> model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
+ >>> tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
+
+ >>> inputs = tokenizer(text="My name is Llama", return_tensors="pt")
+
+ >>> # Prepare a cache class and pass it to model's forward
+ >>> # Leave empty space for 10 new tokens, which can be used when calling forward iteratively 10 times to generate
+ >>> max_generated_length = inputs.input_ids.shape[1] + 10
+ >>> past_key_values = StaticCache(config=model.config, max_batch_size=1, max_cache_len=max_generated_length, device=model.device, dtype=model.dtype)
+ >>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
+ >>> outputs.past_key_values # access cache filled with key/values from generation
+ StaticCache()
+ ```
+ """
+
+ is_compileable = True
+
+ def __init__(
+ self,
+ config: PretrainedConfig,
+ max_batch_size: int,
+ max_cache_len: Optional[int] = None,
+ device: Union[torch.device, str, None] = None,
+ dtype: torch.dtype = torch.float32,
+ layer_device_map: Optional[Dict[int, Union[str, torch.device, int]]] = None,
+ ) -> None:
+ super().__init__()
+ self.max_batch_size = max_batch_size
+ self.max_cache_len = config.max_position_embeddings if max_cache_len is None else max_cache_len
+
+ # Some model define a custom `head_dim` != config.hidden_size // config.num_attention_heads
+ self.head_dim = getattr(config, "head_dim", None) or config.hidden_size // config.num_attention_heads
+
+ self._dtype = dtype
+ self.num_key_value_heads = (
+ config.num_attention_heads
+ if getattr(config, "num_key_value_heads", None) is None
+ else config.num_key_value_heads
+ )
+
+ self.key_cache: List[torch.Tensor] = []
+ self.value_cache: List[torch.Tensor] = []
+ # Note: There will be significant perf decrease if switching to use 5D tensors instead.
+ cache_shape = (self.max_batch_size, self.num_key_value_heads, self.max_cache_len, self.head_dim)
+ device = torch.device(device) if device is not None else None
+ for idx in range(config.num_hidden_layers):
+ if layer_device_map is not None:
+ layer_device = layer_device_map[idx]
+ else:
+ layer_device = device
+ new_layer_key_cache = torch.zeros(cache_shape, dtype=self._dtype, device=layer_device)
+ new_layer_value_cache = torch.zeros(cache_shape, dtype=self._dtype, device=layer_device)
+ # Note: `mark_static_address` is used to tag the cache as a fixed data pointer,
+ # preventing compiled graph breaks when updating the cache.
+ torch._dynamo.mark_static_address(new_layer_key_cache)
+ torch._dynamo.mark_static_address(new_layer_value_cache)
+ self.key_cache.append(new_layer_key_cache)
+ self.value_cache.append(new_layer_value_cache)
+
+ def update(
+ self,
+ key_states: torch.Tensor,
+ value_states: torch.Tensor,
+ layer_idx: int,
+ cache_kwargs: Optional[Dict[str, Any]] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """
+ Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
+ It is VERY important to index using a tensor, otherwise you introduce a copy to the device.
+
+ Parameters:
+ key_states (`torch.Tensor`):
+ The new key states to cache.
+ value_states (`torch.Tensor`):
+ The new value states to cache.
+ layer_idx (`int`):
+ The index of the layer to cache the states for.
+ cache_kwargs (`Dict[str, Any]`, `optional`):
+ Additional arguments for the cache subclass. The `StaticCache` needs the `cache_position` input
+ to know how where to write in the cache.
+
+ Return:
+ A tuple containing the updated key and value states.
+ """
+ if cache_kwargs is None:
+ cache_kwargs = {}
+ cache_position = cache_kwargs.get("cache_position")
+ k_out = self.key_cache[layer_idx]
+ v_out = self.value_cache[layer_idx]
+ key_states = key_states.to(k_out.dtype)
+ value_states = value_states.to(v_out.dtype)
+
+ if cache_position is None:
+ k_out.copy_(key_states)
+ v_out.copy_(value_states)
+ else:
+ # Note: here we use `tensor.index_copy_(dim, index, tensor)` that is equivalent to
+ # `tensor[:, :, index] = tensor`, but the first one is compile-friendly and it does explicitly an in-place
+ # operation, that avoids copies and uses less memory.
+ try:
+ k_out.index_copy_(2, cache_position, key_states)
+ v_out.index_copy_(2, cache_position, value_states)
+ except NotImplementedError:
+ # The operator 'aten::index_copy.out' is not currently implemented for the MPS device.
+ k_out[:, :, cache_position] = key_states
+ v_out[:, :, cache_position] = value_states
+
+ return k_out, v_out
+
+ def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
+ """Returns the sequence length of the cached states that were seen by the model."""
+ # Occupied cache == any slot in the 3rd dim (sequence length) holds a non-zero value. To save on compute, let's
+ # limit the check to the first batch member and head dimension.
+ # TODO: deprecate this function in favor of `cache_position`
+ return (self.key_cache[layer_idx][0, 0].any(dim=-1)).sum()
+
+ def get_max_cache_shape(self) -> Optional[int]:
+ return self.max_cache_len
+
+ def reset(self):
+ """Resets the cache values while preserving the objects"""
+ for layer_idx in range(len(self.key_cache)):
+ # In-place ops prevent breaking the static address
+ self.key_cache[layer_idx].zero_()
+ self.value_cache[layer_idx].zero_()
+
+
+class SlidingWindowCache(StaticCache):
+ """
+ Sliding Window Cache class to be used with `torch.compile` for models like Mistral that support sliding window attention.
+ Every time when we try to update the cache, we compute the `indices` based on `cache_position >= self.config.sliding_window - 1`,
+ if true(which means the cache can not hold all the old key value states and new states together because of the sliding window constraint),
+ we need to do a cycle shift based on `indices` to replace the oldest states by the new key value states passed in.
+
+ The `to_shift` is only true once we are above sliding_window. Thus with `sliding_window==64`:
+
+ indices = (slicing + to_shift[-1].int()-1) % self.config.sliding_window
+ tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,
+ 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36,
+ 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54,
+ 55, 56, 57, 58, 59, 60, 61, 62, 63, 0])
+
+ We overwrite the cache using these, then we always write at cache_position (clamped to `sliding_window`)
+
+ Parameters:
+ config (`PretrainedConfig`):
+ The configuration file defining the shape-related attributes required to initialize the static cache.
+ max_batch_size (`int`):
+ The maximum batch size with which the model will be used. Note that a new instance must be instantiated if a
+ smaller batch size is used.
+ max_cache_len (`int`, *optional*):
+ The maximum sequence length with which the model will be used.
+ device (`torch.device` or `str`, *optional*):
+ The device on which the cache should be initialized. If you're using more than 1 computation device, you
+ should pass the `layer_device_map` argument instead.
+ dtype (`torch.dtype`, *optional*, defaults to `torch.float32`):
+ The default `dtype` to use when initializing the layer.
+ layer_device_map (`Optional[Dict[int, Union[str, torch.device, int]]]]`, *optional*):
+ Mapping between the layers and its device. This is required when you are manually initializing the cache
+ and the model is split between different gpus. You can know which layers mapped to which device by
+ checking the associated device_map: `model.hf_device_map`.
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModelForCausalLM, SlidingWindowCache
+
+ >>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3")
+ >>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.3")
+
+ >>> inputs = tokenizer(text="My name is Mistral", return_tensors="pt")
+
+ >>> # Prepare a cache class and pass it to model's forward
+ >>> # Leave empty space for 10 new tokens, which can be used when calling forward iteratively 10 times to generate
+ >>> max_generated_length = inputs.input_ids.shape[1] + 10
+ >>> past_key_values = SlidingWindowCache(config=model.config, max_batch_size=1, max_cache_len=max_generated_length, device=model.device, dtype=model.dtype)
+ >>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
+ >>> outputs.past_key_values # access cache filled with key/values from generation
+ SlidingWindowCache()
+ ```
+ """
+
+ is_sliding = True
+ is_compileable = True
+
+ def __init__(
+ self,
+ config: PretrainedConfig,
+ max_batch_size: int,
+ max_cache_len: Optional[int] = None,
+ device: Union[torch.device, str, None] = None,
+ dtype: torch.dtype = torch.float32,
+ layer_device_map: Optional[Dict[int, Union[str, torch.device, int]]] = None,
+ ) -> None:
+ if not hasattr(config, "sliding_window") or config.sliding_window is None:
+ raise ValueError(
+ "Setting `cache_implementation` to 'sliding_window' requires the model config supporting "
+ "sliding window attention, please check if there is a `sliding_window` field in the model "
+ "config and it's not set to None."
+ )
+ max_cache_len = min(config.sliding_window, max_cache_len)
+ super().__init__(
+ config=config,
+ max_batch_size=max_batch_size,
+ max_cache_len=max_cache_len,
+ device=device,
+ dtype=dtype,
+ layer_device_map=layer_device_map,
+ )
+
+ def update(
+ self,
+ key_states: torch.Tensor,
+ value_states: torch.Tensor,
+ layer_idx: int,
+ cache_kwargs: Optional[Dict[str, Any]] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ if cache_kwargs is None:
+ cache_kwargs = {}
+ cache_position = cache_kwargs.get("cache_position")
+ k_out = self.key_cache[layer_idx]
+ v_out = self.value_cache[layer_idx]
+ key_states = key_states.to(k_out.dtype)
+ value_states = value_states.to(v_out.dtype)
+
+ # assume this only happens in prefill phase when prompt length > sliding_window_size (= max_cache_len)
+ if cache_position.shape[0] > self.max_cache_len:
+ k_out = key_states[:, :, -self.max_cache_len :, :]
+ v_out = value_states[:, :, -self.max_cache_len :, :]
+ # Assumption: caches are all zeros at this point, `+=` is equivalent to `=` but compile-friendly
+ self.key_cache[layer_idx] += k_out
+ self.value_cache[layer_idx] += v_out
+ # we should return the whole states instead of k_out, v_out to take the whole prompt
+ # into consideration when building kv cache instead of just throwing away tokens outside of the window
+ return key_states, value_states
+
+ slicing = torch.ones(self.max_cache_len, dtype=torch.long, device=value_states.device).cumsum(0)
+ cache_position = cache_position.clamp(0, self.max_cache_len - 1)
+ to_shift = cache_position >= self.max_cache_len - 1
+ indices = (slicing + to_shift[-1].int() - 1) % self.max_cache_len
+
+ k_out = k_out[:, :, indices]
+ v_out = v_out[:, :, indices]
+
+ try:
+ k_out.index_copy_(2, cache_position, key_states)
+ v_out.index_copy_(2, cache_position, value_states)
+ except NotImplementedError:
+ # The operator 'aten::index_copy.out' is not currently implemented for the MPS device.
+ k_out[:, :, cache_position] = key_states
+ v_out[:, :, cache_position] = value_states
+
+ # `_.zero()` followed by `+=` is equivalent `=`, but compile-friendly (without graph breaks due to assignment)
+ self.key_cache[layer_idx].zero_()
+ self.value_cache[layer_idx].zero_()
+
+ self.key_cache[layer_idx] += k_out
+ self.value_cache[layer_idx] += v_out
+
+ return k_out, v_out
+
+ def get_max_cache_shape(self) -> Optional[int]:
+ return self.max_cache_len
+
+ def reset(self):
+ for layer_idx in range(len(self.key_cache)):
+ # In-place ops prevent breaking the static address
+ self.key_cache[layer_idx].zero_()
+ self.value_cache[layer_idx].zero_()
+
+
+class EncoderDecoderCache(Cache):
+ """
+ Base, abstract class for all encoder-decoder caches. Can be used to hold combinations of self-attention and
+ cross-attention caches.
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoProcessor, AutoModelForCausalLM, DynamicCache, EncoderDecoderCache
+
+ >>> model = AutoModelForCausalLM.from_pretrained("openai/whisper-small")
+ >>> processor = AutoProcessor.from_pretrained("openai/whisper-small")
+
+ >>> inputs = processor(audio=YOUR-AUDIO, return_tensors="pt")
+
+ >>> # Prepare cache classes for encoder and decoder and pass it to model's forward
+ >>> self_attention_cache = DynamicCache()
+ >>> cross_attention_cache = DynamicCache()
+ >>> past_key_values = EncoderDecoderCache(self_attention_cache, cross_attention_cache)
+ >>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
+ >>> outputs.past_key_values # access cache filled with key/values from generation
+ EncoderDecoderCache()
+ ```
+
+ """
+
+ def __init__(self, self_attention_cache: Cache, cross_attention_cache: Cache):
+ super().__init__()
+ self.self_attention_cache = self_attention_cache
+ self.cross_attention_cache = cross_attention_cache
+ self.is_compileable = getattr(self.self_attention_cache, "is_compileable", False)
+
+ self.is_updated = {}
+ for layer_idx in range(len(cross_attention_cache.key_cache)):
+ self.is_updated[layer_idx] = bool(cross_attention_cache.get_seq_length(layer_idx) > 0)
+
+ def __getitem__(self, layer_idx: int) -> List[Tuple[torch.Tensor]]:
+ """
+ Support for backwards-compatible `past_key_value` indexing, e.g. `past_key_value[0][0].shape[2]` to get the
+ sequence length.
+ """
+ if layer_idx < len(self):
+ return (
+ self.self_attention_cache.key_cache[layer_idx],
+ self.self_attention_cache.value_cache[layer_idx],
+ self.cross_attention_cache.key_cache[layer_idx],
+ self.cross_attention_cache.value_cache[layer_idx],
+ )
+ else:
+ raise KeyError(f"Cache only has {len(self)} layers, attempted to access layer with index {layer_idx}")
+
+ def __len__(self):
+ """
+ Support for backwards-compatible `past_key_value` length, e.g. `len(past_key_value)`. This value corresponds
+ to the number of layers in the model.
+ """
+ return len(self.self_attention_cache)
+
+ def to_legacy_cache(self) -> Tuple[Tuple[torch.Tensor], Tuple[torch.Tensor]]:
+ """Converts the `EncoderDecoderCache` instance into its equivalent in the legacy cache format."""
+ legacy_cache = ()
+ if len(self.cross_attention_cache) > 0:
+ for self_attn, cross_attn in zip(
+ self.self_attention_cache.to_legacy_cache(), self.cross_attention_cache.to_legacy_cache()
+ ):
+ legacy_cache += (self_attn + cross_attn,)
+ else:
+ legacy_cache = self.self_attention_cache.to_legacy_cache()
+ return legacy_cache
+
+ @classmethod
+ def from_legacy_cache(
+ cls, past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ ) -> "EncoderDecoderCache":
+ """Converts a cache in the legacy cache format into an equivalent `EncoderDecoderCache`."""
+ cache = cls(
+ self_attention_cache=DynamicCache(),
+ cross_attention_cache=DynamicCache(),
+ )
+ if past_key_values is not None:
+ for layer_idx in range(len(past_key_values)):
+ key_states, value_states = past_key_values[layer_idx][:2]
+ cache.self_attention_cache.update(key_states, value_states, layer_idx)
+ if len(past_key_values[layer_idx]) > 2:
+ key_states, value_states = past_key_values[layer_idx][2:]
+ cache.cross_attention_cache.update(key_states, value_states, layer_idx)
+ cache.is_updated[layer_idx] = True
+ return cache
+
+ def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
+ """Returns the sequence length of the cached states. A layer index can be optionally passed."""
+ # check if empty list because in case of static cache it will be a tensors and we can't check `if not torch.Tensor`
+ return self.self_attention_cache.get_seq_length(layer_idx)
+
+ def reset(self):
+ if hasattr(self.self_attention_cache, "reset"):
+ self.self_attention_cache.reset()
+ if hasattr(self.cross_attention_cache, "reset"):
+ self.cross_attention_cache.reset()
+ elif not hasattr(self.self_attention_cache, "reset") and not hasattr(self.cross_attention_cache, "reset"):
+ raise ValueError(
+ "Neither self nor cross-attention cache have valid `.reset()` methods. `.reset()` should "
+ "only be called on compatible cache classes, such as `StaticCache` or `SlidingWindowCache`. "
+ f"Got {self.self_attention_cache.__str__()} for the self attention cache and "
+ f"{self.cross_attention_cache.__str__()} for the cross attention cache."
+ )
+ for layer_idx in self.is_updated:
+ self.is_updated[layer_idx] = False
+
+ def reorder_cache(self, beam_idx: torch.LongTensor):
+ """Reorders the cache for beam search, given the selected beam indices."""
+ self.self_attention_cache.reorder_cache(beam_idx)
+ self.cross_attention_cache.reorder_cache(beam_idx)
+
+ def check_dynamic_cache(self, method: str):
+ if not (
+ isinstance(self.self_attention_cache, DynamicCache)
+ and isinstance(self.cross_attention_cache, DynamicCache)
+ ):
+ raise ValueError(
+ f"`{method}` is only defined for dynamic cache, got {self.self_attention_cache.__str__()} for the self "
+ f"attention cache and {self.cross_attention_cache.__str__()} for the cross attention cache."
+ )
+
+ # TODO(gante, sanchit-gandhi): move following functionality into `.generate`
+ def crop(self, maximum_length: int):
+ """Crop the past key values up to a new `maximum_length` in terms of tokens. `maximum_length` can also be
+ negative to remove `maximum_length` tokens. This is used in assisted decoding and contrastive search."""
+ self.check_dynamic_cache(self.crop.__name__)
+ self.self_attention_cache.crop(maximum_length)
+
+ def batch_split(self, full_batch_size: int, split_size: int) -> "List[EncoderDecoderCache]":
+ """Split the current instance into a list of `DynamicCache` by the batch size. This will be used by
+ `_split_model_inputs()` in `generation.utils`"""
+ self.check_dynamic_cache(self.batch_split.__name__)
+ self_attention_cache = self.self_attention_cache.batch_split(full_batch_size, split_size)
+ cross_attention_cache = self.cross_attention_cache.batch_split(full_batch_size, split_size)
+
+ out = []
+ for self_attn, cross_attn in zip(self_attention_cache, cross_attention_cache):
+ out.append(EncoderDecoderCache(self_attn, cross_attn))
+ return out
+
+ @classmethod
+ def from_batch_splits(cls, splits: List["EncoderDecoderCache"]) -> "EncoderDecoderCache":
+ """This is the opposite of the above `batch_split()` method. This will be used by `stack_model_outputs` in
+ `generation.utils`"""
+ self_attention_cache = DynamicCache()
+ cross_attention_cache = DynamicCache()
+ for idx in range(len(splits[0])):
+ layer_keys = torch.cat([current.self_attention_cache.key_cache[idx] for current in splits], dim=0)
+ layer_values = torch.cat([current.self_attention_cache.value_cache[idx] for current in splits], dim=0)
+ self_attention_cache.update(layer_keys, layer_values, idx)
+
+ layer_keys = torch.cat([current.cross_attention_cache.key_cache[idx] for current in splits], dim=0)
+ layer_values = torch.cat([current.cross_attention_cache.value_cache[idx] for current in splits], dim=0)
+ cross_attention_cache.update(layer_keys, layer_values, idx)
+ return cls(self_attention_cache, cross_attention_cache)
+
+ def batch_repeat_interleave(self, repeats: int):
+ """Repeat the cache `repeats` times in the batch dimension. Used in contrastive search."""
+ self.check_dynamic_cache(self.batch_repeat_interleave.__name__)
+ self.self_attention_cache.batch_repeat_interleave(repeats)
+ self.cross_attention_cache.batch_repeat_interleave(repeats)
+
+ def batch_select_indices(self, indices: torch.Tensor):
+ """Only keep the `indices` in the batch dimension of the cache. Used in contrastive search."""
+ self.check_dynamic_cache(self.batch_select_indices.__name__)
+ self.self_attention_cache.batch_select_indices(indices)
+ self.cross_attention_cache.batch_select_indices(indices)
+
+
+class HybridCache(Cache):
+ """
+ Hybrid Cache class to be used with `torch.compile` for models that alternate between a local sliding window
+ attention and global attention in every other layer (originally implemented for Gemma2).
+ Under the hood, Hybrid Cache leverages ["SlidingWindowCache"] for sliding window attention and ["StaticCache"]
+ for global attention.For more information, see the documentation of each subcomponent cache class.
+
+ Parameters:
+ config (`PretrainedConfig):
+ The configuration file defining the shape-related attributes required to initialize the static cache.
+ max_batch_size (`int`):
+ The maximum batch size with which the model will be used. Note that a new instance must be instantiated if a
+ smaller batch size is used.
+ max_cache_len (`int`, *optional*):
+ The maximum sequence length with which the model will be used.
+ device (`torch.device` or `str`, *optional*):
+ The device on which the cache should be initialized. If you're using more than 1 computation device, you
+ should pass the `layer_device_map` argument instead.
+ dtype (torch.dtype, *optional*, defaults to `torch.float32`):
+ The default `dtype` to use when initializing the layer.
+ layer_device_map (`Optional[Dict[int, Union[str, torch.device, int]]]]`, *optional*):
+ Mapping between the layers and its device. This is required when you are manually initializing the cache
+ and the model is split between different gpus. You can know which layers mapped to which device by
+ checking the associated device_map: `model.hf_device_map`.
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModelForCausalLM, HybridCache
+
+ >>> model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b")
+ >>> tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b")
+
+ >>> inputs = tokenizer(text="My name is Gemma", return_tensors="pt")
+
+ >>> # Prepare a cache class and pass it to model's forward
+ >>> # Leave empty space for 10 new tokens, which can be used when calling forward iteratively 10 times to generate
+ >>> max_generated_length = inputs.input_ids.shape[1] + 10
+ >>> past_key_values = HybridCache(config=model.config, max_batch_size=1, max_cache_len=max_generated_length, device=model.device, dtype=model.dtype)
+ >>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
+ >>> outputs.past_key_values # access cache filled with key/values from generation
+ HybridCache()
+ ```
+ """
+
+ is_compileable = True
+
+ def __init__(
+ self,
+ config: PretrainedConfig,
+ max_batch_size: int,
+ max_cache_len: Optional[int] = None,
+ device: Union[torch.device, str, None] = None,
+ dtype: torch.dtype = torch.float32,
+ layer_device_map: Optional[Dict[int, Union[str, torch.device, int]]] = None,
+ ) -> None:
+ super().__init__()
+ if not hasattr(config, "sliding_window") or config.sliding_window is None:
+ raise ValueError(
+ "Setting `cache_implementation` to 'sliding_window' requires the model config supporting "
+ "sliding window attention, please check if there is a `sliding_window` field in the model "
+ "config and it's not set to None."
+ )
+ self.max_cache_len = max_cache_len
+ self.max_batch_size = max_batch_size
+ # Some model define a custom `head_dim` != config.hidden_size // config.num_attention_heads
+ self.head_dim = (
+ config.head_dim if hasattr(config, "head_dim") else config.hidden_size // config.num_attention_heads
+ )
+
+ self._dtype = dtype
+ self.num_key_value_heads = (
+ config.num_attention_heads if config.num_key_value_heads is None else config.num_key_value_heads
+ )
+
+ layer_switch = config.sliding_window_pattern if hasattr(config, "sliding_window_pattern") else 2 # 2 is for BC
+ self.is_sliding = torch.tensor(
+ [bool((i + 1) % layer_switch) for i in range(config.num_hidden_layers)], dtype=torch.bool
+ )
+ self.key_cache: List[torch.Tensor] = []
+ self.value_cache: List[torch.Tensor] = []
+ global_cache_shape = (self.max_batch_size, self.num_key_value_heads, max_cache_len, self.head_dim)
+ sliding_cache_shape = (
+ self.max_batch_size,
+ self.num_key_value_heads,
+ min(config.sliding_window, max_cache_len),
+ self.head_dim,
+ )
+ device = torch.device(device) if device is not None else None
+ for i in range(config.num_hidden_layers):
+ if layer_device_map is not None:
+ layer_device = layer_device_map[i]
+ else:
+ layer_device = device
+ # Note: `mark_static_address` is used to tag the cache as an fixed data pointer, preventing cuda graph
+ # breaks when updating the cache.
+ cache_shape = global_cache_shape if not self.is_sliding[i] else sliding_cache_shape
+ new_layer_key_cache = torch.zeros(cache_shape, dtype=self._dtype, device=layer_device)
+ new_layer_value_cache = torch.zeros(cache_shape, dtype=self._dtype, device=layer_device)
+ torch._dynamo.mark_static_address(new_layer_key_cache)
+ torch._dynamo.mark_static_address(new_layer_value_cache)
+ self.key_cache.append(new_layer_key_cache)
+ self.value_cache.append(new_layer_value_cache)
+
+ def _sliding_update(self, cache_position, layer_idx, key_states, value_states, k_out, v_out, max_cache_len):
+ if cache_position.shape[0] > max_cache_len:
+ k_out = key_states[:, :, -max_cache_len:, :]
+ v_out = value_states[:, :, -max_cache_len:, :]
+ # Assumption: caches are all zeros at this point, `+=` is equivalent to `=` but compile-friendly
+ self.key_cache[layer_idx] += k_out
+ self.value_cache[layer_idx] += v_out
+ # we should return the whole states instead of k_out, v_out to take the whole prompt
+ # into consideration when building kv cache instead of just throwing away tokens outside of the window
+ return key_states, value_states
+
+ slicing = torch.ones(max_cache_len, dtype=torch.long, device=value_states.device).cumsum(0)
+ cache_position = cache_position.clamp(0, max_cache_len - 1)
+ to_shift = cache_position >= max_cache_len - 1
+ indices = (slicing + to_shift[-1].int() - 1) % max_cache_len
+ k_out = k_out[:, :, indices]
+ v_out = v_out[:, :, indices]
+
+ k_out[:, :, cache_position] = key_states
+ v_out[:, :, cache_position] = value_states
+ # `_.zero()` followed by `+=` is equivalent `=`, but compile-friendly (without graph breaks due to assignment)
+ self.key_cache[layer_idx].zero_()
+ self.value_cache[layer_idx].zero_()
+
+ self.key_cache[layer_idx] += k_out
+ self.value_cache[layer_idx] += v_out
+ return k_out, v_out
+
+ def _static_update(self, cache_position, layer_idx, key_states, value_states, k_out, v_out, max_cache_len):
+ k_out[:, :, cache_position] = key_states
+ v_out[:, :, cache_position] = value_states
+
+ self.key_cache[layer_idx] = k_out
+ self.value_cache[layer_idx] = v_out
+ return k_out, v_out
+
+ def update(
+ self,
+ key_states: torch.Tensor,
+ value_states: torch.Tensor,
+ layer_idx: int,
+ cache_kwargs: Optional[Dict[str, Any]] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ if cache_kwargs is None:
+ cache_kwargs = {}
+ cache_position = cache_kwargs.get("cache_position")
+ sliding_window = cache_kwargs.get("sliding_window")
+
+ # These two `if` blocks are only reached in multigpu and if `layer_device_map` is not passed. They are used
+ # when the cache is initialized in the forward pass (e.g. Gemma2)
+ if self.key_cache[layer_idx].device != key_states.device:
+ self.key_cache[layer_idx] = self.key_cache[layer_idx].to(key_states.device)
+ if self.value_cache[layer_idx].device != value_states.device:
+ self.value_cache[layer_idx] = self.value_cache[layer_idx].to(value_states.device)
+
+ k_out = self.key_cache[layer_idx]
+ v_out = self.value_cache[layer_idx]
+ key_states = key_states.to(k_out.dtype)
+ value_states = value_states.to(v_out.dtype)
+
+ if sliding_window:
+ update_fn = self._sliding_update
+ else:
+ update_fn = self._static_update
+
+ return update_fn(
+ cache_position,
+ layer_idx,
+ key_states,
+ value_states,
+ k_out,
+ v_out,
+ k_out.shape[2],
+ )
+
+ def get_max_cache_shape(self) -> Optional[int]:
+ return self.max_cache_len
+
+ def get_seq_length(self, layer_idx: Optional[int] = 0):
+ # Occupied cache == any slot in the 3rd dim (sequence length) holds a non-zero value. To save on compute, let's
+ # limit the check to the first batch member and head dimension.
+ # TODO: deprecate this function in favor of `cache_position`
+ if layer_idx != 0:
+ raise ValueError(
+ "`get_seq_length` on `HybridCache` may get inconsistent results depending on the layer index. "
+ "Using the `layer_idx` argument is not supported."
+ )
+ return (self.key_cache[layer_idx][0, 0].any(dim=-1)).sum()
+
+ def reset(self):
+ """Resets the cache values while preserving the objects"""
+ for layer_idx in range(len(self.key_cache)):
+ # In-place ops prevent breaking the static address
+ self.key_cache[layer_idx].zero_()
+ self.value_cache[layer_idx].zero_()
+
+
+class HybridChunkedCache(Cache):
+ """
+ Hybrid Cache class to be used with `torch.compile` for models that alternate between a local sliding window
+ attention and global attention in every other layer, with support for chunked attention (originally implemented
+ for Llama4).
+ Under the hood, Hybrid Cache leverages ["SlidingWindowCache"] for sliding window attention and ["StaticCache"]
+ for global attention. For more information, see the documentation of each subcomponent cache class.
+
+ Parameters:
+ config (`PretrainedConfig):
+ The configuration file defining the shape-related attributes required to initialize the static cache.
+ max_batch_size (`int`):
+ The maximum batch size with which the model will be used. Note that a new instance must be instantiated if a
+ smaller batch size is used.
+ max_cache_len (`int`, *optional*):
+ The maximum sequence length with which the model will be used.
+ device (`torch.device` or `str`, *optional*):
+ The device on which the cache should be initialized. If you're using more than 1 computation device, you
+ should pass the `layer_device_map` argument instead.
+ dtype (torch.dtype, *optional*, defaults to `torch.bfloat16`):
+ The default `dtype` to use when initializing the layer.
+ layer_device_map (`Optional[Dict[int, Union[str, torch.device, int]]]]`, *optional*):
+ Mapping between the layers and its device. This is required when you are manually initializing the cache
+ and the model is split between different gpus. You can know which layers mapped to which device by
+ checking the associated device_map: `model.hf_device_map`.
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModelForCausalLM, HybridCache
+
+ >>> model = AutoModelForCausalLM.from_pretrained("google/gemma-2-2b")
+ >>> tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b")
+
+ >>> inputs = tokenizer(text="My name is Gemma", return_tensors="pt")
+
+ >>> # Prepare a cache class and pass it to model's forward
+ >>> # Leave empty space for 10 new tokens, which can be used when calling forward iteratively 10 times to generate
+ >>> max_generated_length = inputs.input_ids.shape[1] + 10
+ >>> past_key_values = HybridCache(config=model.config, max_batch_size=1, max_cache_len=max_generated_length, device=model.device, dtype=model.dtype)
+ >>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
+ >>> outputs.past_key_values # access cache filled with key/values from generation
+ HybridCache()
+ ```
+ """
+
+ is_compileable = True
+
+ def __init__(
+ self,
+ config: PretrainedConfig,
+ max_batch_size: int,
+ max_cache_len: Optional[int] = None,
+ device: Union[torch.device, str, None] = None,
+ dtype: torch.dtype = torch.bfloat16,
+ layer_device_map: Optional[Dict[int, Union[str, torch.device, int]]] = None,
+ ) -> None:
+ super().__init__()
+ if not hasattr(config, "sliding_window") or config.sliding_window is None:
+ self.sliding_window = getattr(config.get_text_config(), "attention_chunk_size", 8192)
+ else:
+ self.sliding_window = config.sliding_window
+ self.max_cache_len = max_cache_len
+ self.max_batch_size = max_batch_size
+ self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ self._dtype = dtype
+
+ if hasattr(config.get_text_config(), "no_rope_layers"):
+ self.is_sliding = config.no_rope_layers
+ else:
+ layer_switch = getattr(config, "sliding_window_pattern", 2)
+ self.is_sliding = [bool((i + 1) % layer_switch) for i in range(config.num_hidden_layers)]
+
+ self.key_cache: List[torch.Tensor] = []
+ self.value_cache: List[torch.Tensor] = []
+ self.cumulative_length = [0 for _ in range(config.num_hidden_layers)]
+
+ def initialise_cache_layer(self, layer_idx, key_states):
+ if len(self.key_cache) > layer_idx:
+ return
+
+ num_key_value_heads = key_states.shape[1]
+ device = key_states.device
+ global_cache_shape = (self.max_batch_size, num_key_value_heads, self.max_cache_len, self.head_dim)
+ sliding_cache_shape = (
+ self.max_batch_size,
+ num_key_value_heads,
+ self.sliding_window,
+ self.head_dim,
+ )
+ # Note: `mark_static_address` is used to tag the cache as an fixed data pointer, preventing cuda graph
+ # breaks when updating the cache.
+ cache_shape = sliding_cache_shape if self.is_sliding[layer_idx] else global_cache_shape
+ new_layer_key_cache = torch.zeros(cache_shape, dtype=self._dtype, device=device)
+ new_layer_value_cache = torch.zeros(cache_shape, dtype=self._dtype, device=device)
+ torch._dynamo.mark_static_address(new_layer_key_cache)
+ torch._dynamo.mark_static_address(new_layer_value_cache)
+ self.key_cache.append(new_layer_key_cache)
+ self.value_cache.append(new_layer_value_cache)
+
+ def _sliding_update(self, cache_position, layer_idx, key_states, value_states, k_out, v_out, max_cache_len):
+ cumulative_length = self.cumulative_length[layer_idx]
+ # Update it now that we saved the value above
+ self.cumulative_length[layer_idx] += key_states.shape[-2]
+ is_full = cumulative_length >= max_cache_len
+ if is_full:
+ full_key_states = torch.cat((k_out[:, :, 1:, :], key_states), dim=-2)
+ full_value_states = torch.cat((v_out[:, :, 1:, :], value_states), dim=-2)
+ # Fast decoding path -> here as the effective size is still sliding window, it is extremely important
+ # to return `self.key_cache[layer_idx]` and `self.value_cache[layer_idx]`, as they have the fixed adress
+ # in memory (the values are the same as the full states, but not the address!!)
+ if key_states.shape[-2] == 1:
+ self.key_cache[layer_idx].copy_(full_key_states)
+ self.value_cache[layer_idx].copy_(full_value_states)
+ return self.key_cache[layer_idx], self.value_cache[layer_idx]
+ elif not is_full and cumulative_length + key_states.shape[2] > max_cache_len:
+ # Fast prefill path, no need to cat() in this case (which creates a copy even if cating from 0 dim)
+ if cumulative_length == 0:
+ full_key_states = key_states
+ full_value_states = value_states
+ else:
+ full_key_states = torch.cat((k_out[:, :, :cumulative_length, :], key_states), dim=-2)
+ full_value_states = torch.cat((v_out[:, :, :cumulative_length, :], value_states), dim=-2)
+ else:
+ self.key_cache[layer_idx].index_copy_(2, cache_position, key_states)
+ self.value_cache[layer_idx].index_copy_(2, cache_position, value_states)
+ return self.key_cache[layer_idx], self.value_cache[layer_idx]
+
+ self.key_cache[layer_idx].copy_(full_key_states[:, :, -max_cache_len:, :])
+ self.value_cache[layer_idx].copy_(full_value_states[:, :, -max_cache_len:, :])
+ # we should return the whole states instead of k_out, v_out to take the whole prompt
+ # into consideration when building kv cache instead of just throwing away tokens outside of the window
+ return full_key_states, full_value_states
+
+ def _static_update(self, cache_position, layer_idx, key_states, value_states, k_out, v_out, max_cache_len):
+ k_out[:, :, cache_position] = key_states
+ v_out[:, :, cache_position] = value_states
+
+ self.key_cache[layer_idx] = k_out
+ self.value_cache[layer_idx] = v_out
+ return k_out, v_out
+
+ def update(
+ self,
+ key_states: torch.Tensor,
+ value_states: torch.Tensor,
+ layer_idx: int,
+ cache_kwargs: Optional[Dict[str, Any]] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ if cache_kwargs is None:
+ cache_kwargs = {}
+ cache_position = cache_kwargs.get("cache_position")
+ self.initialise_cache_layer(layer_idx, key_states)
+
+ k_out = self.key_cache[layer_idx]
+ v_out = self.value_cache[layer_idx]
+ key_states = key_states.to(k_out.dtype)
+ value_states = value_states.to(v_out.dtype)
+
+ if self.is_sliding[layer_idx]:
+ update_fn = self._sliding_update
+ else:
+ update_fn = self._static_update
+
+ return update_fn(
+ cache_position,
+ layer_idx,
+ key_states,
+ value_states,
+ k_out,
+ v_out,
+ k_out.shape[2],
+ )
+
+ def get_max_cache_shape(self) -> Optional[int]:
+ return self.max_cache_len
+
+ def get_seq_length(self, layer_idx: Optional[int] = 0):
+ # Occupied cache == any slot in the 3rd dim (sequence length) holds a non-zero value. To save on compute, let's
+ # limit the check to the first batch member and head dimension.
+ # TODO: deprecate this function in favor of `cache_position`
+ if layer_idx != 0:
+ raise ValueError(
+ "`get_seq_length` on `HybridCache` may get inconsistent results depending on the layer index. "
+ "Using the `layer_idx` argument is not supported."
+ )
+ if len(self.key_cache) == 0:
+ return 0
+ return (self.key_cache[layer_idx][0, 0].any(dim=-1)).sum()
+
+ def reset(self):
+ """Resets the cache values while preserving the objects"""
+ for layer_idx in range(len(self.key_cache)):
+ # In-place ops prevent breaking the static address
+ self.key_cache[layer_idx].zero_()
+ self.value_cache[layer_idx].zero_()
+ self.cumulative_length = [0 for _ in range(len(self.cumulative_length))]
+
+
+class OffloadedHybridCache(HybridChunkedCache):
+ def __init__(
+ self,
+ config: PretrainedConfig,
+ max_batch_size: int,
+ max_cache_len: Optional[int] = None,
+ device: Union[torch.device, str, None] = None,
+ dtype: torch.dtype = torch.bfloat16,
+ offload_device: Union[str, torch.device] = torch.device("cpu"),
+ layer_device_map: Optional[Dict[int, Union[str, torch.device, int]]] = None,
+ ):
+ super().__init__(config, max_batch_size, max_cache_len, device, dtype, layer_device_map)
+ self.offload_device = torch.device(offload_device)
+ # Create new CUDA stream for parallel prefetching.
+ self._prefetch_stream = torch.cuda.Stream() if torch._C._get_accelerator().type == "cuda" else None
+ # Those will be dynamically created as the other layers (for TP)
+ self.device_key_cache = None
+ self.device_value_cache = None
+ # This gives the index of which on-device full layer to use (we need 2 to avoid race conditions when prefetching)
+ self.active_device_layer = 0
+
+ def initialise_cache_layer(self, layer_idx, key_states):
+ """Overriden to use the correct device if offloaded layer (and pin memory)."""
+ if len(self.key_cache) > layer_idx:
+ return
+
+ num_key_value_heads = key_states.shape[1]
+ device = key_states.device if self.is_sliding[layer_idx] else self.offload_device
+ pin_memory = not self.is_sliding[layer_idx]
+ global_cache_shape = (self.max_batch_size, num_key_value_heads, self.max_cache_len, self.head_dim)
+ sliding_cache_shape = (
+ self.max_batch_size,
+ num_key_value_heads,
+ self.sliding_window,
+ self.head_dim,
+ )
+ # Note: `mark_static_address` is used to tag the cache as an fixed data pointer, preventing cuda graph
+ # breaks when updating the cache.
+ cache_shape = sliding_cache_shape if self.is_sliding[layer_idx] else global_cache_shape
+ new_layer_key_cache = torch.zeros(cache_shape, dtype=self._dtype, device=device, pin_memory=pin_memory)
+ new_layer_value_cache = torch.zeros(cache_shape, dtype=self._dtype, device=device, pin_memory=pin_memory)
+ torch._dynamo.mark_static_address(new_layer_key_cache)
+ torch._dynamo.mark_static_address(new_layer_value_cache)
+ self.key_cache.append(new_layer_key_cache)
+ self.value_cache.append(new_layer_value_cache)
+
+ # Make sure to initialize the on-device layer if it does not already exist
+ if self.device_key_cache is None and not self.is_sliding[layer_idx]:
+ self.device_key_cache = []
+ self.device_value_cache = []
+ # We need 2 layers to avoid race conditions when prefetching the next one
+ for _ in range(2):
+ device_layer_key_cache = torch.zeros(cache_shape, dtype=self._dtype, device=key_states.device)
+ device_layer_value_cache = torch.zeros(cache_shape, dtype=self._dtype, device=key_states.device)
+ torch._dynamo.mark_static_address(new_layer_key_cache)
+ torch._dynamo.mark_static_address(new_layer_value_cache)
+ self.device_key_cache.append(device_layer_key_cache)
+ self.device_value_cache.append(device_layer_value_cache)
+
+ def _static_update(self, cache_position, layer_idx, key_states, value_states, k_out, v_out, max_cache_len):
+ # Wait for prefetch stream if needed
+ if self._prefetch_stream is not None:
+ torch.cuda.default_stream(key_states.device).wait_stream(self._prefetch_stream)
+
+ # Get correct on-device layer
+ k_out = self.device_key_cache[self.active_device_layer]
+ v_out = self.device_value_cache[self.active_device_layer]
+
+ # Let's prefetch the next layer as soon as possible
+ self._prefetch_next_layer(layer_idx)
+
+ # Copy to on-device layer
+ k_out[:, :, cache_position] = key_states
+ v_out[:, :, cache_position] = value_states
+
+ # Copy to offloaded device
+ self.key_cache[layer_idx][:, :, cache_position] = key_states.to(self.offload_device)
+ self.value_cache[layer_idx][:, :, cache_position] = value_states.to(self.offload_device)
+
+ return k_out, v_out
+
+ def _prefetch_next_layer(self, layer_idx: int) -> None:
+ """Based on current layer_idx, prefetch next full layer to the device."""
+
+ # Switch the active layer
+ self.active_device_layer = 0 if self.active_device_layer == 1 else 1
+
+ # Find the next non-sliding layer
+ try:
+ next_layer = layer_idx + 1 + self.is_sliding[layer_idx + 1 :].index(False)
+ # In this case, we are at the last layer, and we go back to prefect the first one
+ except ValueError:
+ next_layer = self.is_sliding.index(False)
+
+ # Alternate between two on-device caches.
+ if self._prefetch_stream is not None:
+ with torch.cuda.stream(self._prefetch_stream):
+ self._prefetch_layer_in_context(next_layer)
+ else:
+ self._prefetch_layer_in_context(next_layer)
+
+ def _prefetch_layer_in_context(self, layer_idx: int) -> None:
+ """Performs the actual copy of the layer to device cache."""
+ if len(self.key_cache) >= layer_idx:
+ self.device_key_cache[self.active_device_layer].copy_(self.key_cache[layer_idx], non_blocking=True)
+ self.device_value_cache[self.active_device_layer].copy_(self.value_cache[layer_idx], non_blocking=True)
+ # The layer was not yet initialized
+ else:
+ self.device_key_cache[self.active_device_layer].fill_(0.0)
+ self.device_value_cache[self.active_device_layer].fill_(0.0)
+
+
+class MambaCache:
+ """
+ Cache for mamba model which does not have attention mechanism and key value states.
+
+ Arguments:
+ config (`PretrainedConfig):
+ The configuration file defining the shape-related attributes required to initialize the static cache.
+ max_batch_size (`int`):
+ The maximum batch size with which the model will be used. Note that a new instance must be instantiated if a smaller batch size is used.
+ dtype (`torch.dtype`, *optional*, defaults to `torch.float16`):
+ The default `dtype` to use when initializing the layer.
+ device (`torch.device` or `str`, *optional*):
+ The device on which the cache should be initialized. Should be the same as the layer.
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, MambaForCausalLM, MambaCache
+
+ >>> model = MambaForCausalLM.from_pretrained("state-spaces/mamba-130m-hf")
+ >>> tokenizer = AutoTokenizer.from_pretrained("state-spaces/mamba-130m-hf")
+
+ >>> inputs = tokenizer(text="My name is Mamba", return_tensors="pt")
+
+ >>> # Prepare a cache class and pass it to model's forward
+ >>> past_key_values = MambaCache(config=model.config, max_batch_size=1, device=model.device, dtype=model.dtype)
+ >>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
+ >>> outputs.past_key_values
+ MambaCache()
+ ```
+ """
+
+ is_compileable = True
+
+ # TODO (joao): add layer_device_map arg and update code in `generate` accordingly
+ def __init__(
+ self,
+ config: PretrainedConfig,
+ max_batch_size: int,
+ dtype: torch.dtype = torch.float16,
+ device: Union[torch.device, str, None] = None,
+ ):
+ self.max_batch_size = max_batch_size
+ self._dtype = dtype
+ self.intermediate_size = config.intermediate_size
+ self.ssm_state_size = config.state_size
+ self.conv_kernel_size = config.conv_kernel
+
+ self.conv_states: List[torch.Tensor] = []
+ self.ssm_states: List[torch.Tensor] = []
+ device = torch.device(device) if device is not None else None
+ for _ in range(config.num_hidden_layers):
+ conv_state: torch.Tensor = torch.zeros(
+ self.max_batch_size,
+ self.intermediate_size,
+ self.conv_kernel_size,
+ device=device,
+ dtype=self._dtype,
+ )
+ ssm_state: torch.Tensor = torch.zeros(
+ self.max_batch_size,
+ self.intermediate_size,
+ self.ssm_state_size,
+ device=device,
+ dtype=self._dtype,
+ )
+
+ torch._dynamo.mark_static_address(conv_state)
+ torch._dynamo.mark_static_address(ssm_state)
+ self.conv_states.append(conv_state)
+ self.ssm_states.append(ssm_state)
+
+ def update_conv_state(
+ self, layer_idx: int, new_conv_state: torch.Tensor, cache_position: torch.LongTensor
+ ) -> torch.Tensor:
+ # This `if` blocks is only reached in multigpu and if `layer_device_map` is not passed. It is used
+ # when the cache is initialized in the forward pass (e.g. Mamba)
+ if self.conv_states[layer_idx].device != new_conv_state.device:
+ self.conv_states[layer_idx] = self.conv_states[layer_idx].to(new_conv_state.device)
+
+ conv_state = self.conv_states[layer_idx]
+ cache_position = cache_position.clamp(0, self.conv_kernel_size - 1)
+
+ conv_state = conv_state.roll(shifts=-1, dims=-1)
+ conv_state[:, :, cache_position] = new_conv_state.to(device=conv_state.device, dtype=conv_state.dtype)
+ self.conv_states[layer_idx].zero_()
+ self.conv_states[layer_idx] += conv_state
+ return self.conv_states[layer_idx]
+
+ def update_ssm_state(self, layer_idx: int, new_ssm_state: torch.Tensor):
+ self.ssm_states[layer_idx] = new_ssm_state.to(self.ssm_states[layer_idx].device)
+ return self.ssm_states[layer_idx]
+
+ def reset(self):
+ for layer_idx in range(len(self.conv_states)):
+ # In-place ops prevent breaking the static address
+ self.conv_states[layer_idx].zero_()
+ self.ssm_states[layer_idx].zero_()
+
+
+class OffloadedStaticCache(StaticCache):
+ """
+ Static cache class to be used with `torch.compile(model)` that offloads to the CPU or
+ another device.
+
+ Args:
+ config (`PretrainedConfig):
+ The configuration file defining the shape-related attributes required to initialize
+ the static cache.
+ max_batch_size (`int`):
+ The maximum batch size with which the model will be used.
+ max_cache_len (`int`):
+ The maximum sequence length with which the model will be used.
+ device (`Union[str, torch.device]`):
+ The device on which the cache should be initialized. If you're using more than 1 computation device, you
+ should pass the `layer_device_map` argument instead.
+ dtype (`torch.dtype`, *optional*):
+ The default `dtype` to use when initializing the cache.
+ offload_device (`Union[str, torch.device]`, *optional*, defaults to `cpu`):
+ The device to offload to. Defaults to CPU.
+ layer_device_map (`Dict[int, Union[str, torch.device, int]]`, *optional*):
+ Mapping between the layers and its device. This is required when you are manually initializing the cache
+ and the model is splitted between differents gpus. You can know which layers mapped to which device by
+ checking the associated device_map: `model.hf_device_map`.
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AutoModelForCausalLM, OffloadedStaticCache
+
+ >>> model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
+ >>> tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
+
+ >>> inputs = tokenizer(text="My name is GPT2", return_tensors="pt")
+
+ >>> # Prepare a cache class and pass it to model's forward
+ >>> # Leave empty space for 10 new tokens, which can be used when calling forward iteratively 10 times to generate
+ >>> max_generated_length = inputs.input_ids.shape[1] + 10
+ >>> past_key_values = OffloadedStaticCache(config=model.config, max_batch_size=1, max_cache_len=max_generated_length, device=model.device, dtype=model.dtype)
+ >>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
+ >>> past_kv_length = outputs.past_key_values # access cache filled with key/values from generation
+ ```
+ """
+
+ is_compileable = True
+
+ def __init__(
+ self,
+ config: PretrainedConfig,
+ max_batch_size: int,
+ max_cache_len: Optional[int],
+ device: Union[str, torch.device],
+ dtype: Optional[torch.dtype] = None,
+ offload_device: Union[str, torch.device] = torch.device("cpu"),
+ layer_device_map: Optional[Dict[int, Union[str, torch.device, int]]] = None,
+ ) -> None:
+ super(Cache, self).__init__()
+ self.max_batch_size = max_batch_size
+ self.max_cache_len = config.max_position_embeddings if max_cache_len is None else max_cache_len
+ self.device = torch.device(device) if layer_device_map is None else torch.device(layer_device_map[0])
+ self.offload_device = torch.device(offload_device)
+ self._dtype = dtype if dtype is not None else torch.float32
+
+ # Some model define a custom `head_dim` != config.hidden_size // config.num_attention_heads
+ head_dim = config.head_dim if hasattr(config, "head_dim") else config.hidden_size // config.num_attention_heads
+
+ num_key_value_heads = (
+ config.num_attention_heads
+ if getattr(config, "num_key_value_heads", None) is None
+ else config.num_key_value_heads
+ )
+
+ cache_shape = (max_batch_size, num_key_value_heads, self.max_cache_len, head_dim)
+
+ # Create offloaded CPU tensors.
+ self.key_cache: List[torch.Tensor] = []
+ self.value_cache: List[torch.Tensor] = []
+
+ for i in range(config.num_hidden_layers):
+ # First layer is always on-device.
+ device = self.device if i == 0 else self.offload_device
+
+ key_cache, value_cache = self._create_key_value_cache_tensors(cache_shape, device)
+
+ self.key_cache.append(key_cache)
+ self.value_cache.append(value_cache)
+
+ # Create device tensors.
+ self._device_key_cache: List[torch.Tensor] = []
+ self._device_value_cache: List[torch.Tensor] = []
+
+ for i in range(2):
+ key_cache, value_cache = self._create_key_value_cache_tensors(cache_shape, self.device)
+
+ self._device_key_cache.append(key_cache)
+ self._device_value_cache.append(value_cache)
+
+ # For backwards compatibility.
+ # TODO(gante): Remove this.
+ self._seen_tokens = 0
+
+ # Create new CUDA stream for parallel prefetching.
+ self._prefetch_stream = torch.cuda.Stream() if self.device.type == "cuda" else None
+
+ def update(
+ self,
+ key_states: torch.Tensor,
+ value_states: torch.Tensor,
+ layer_idx: int,
+ cache_kwargs: Optional[Dict[str, Any]] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """
+ Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
+ It is VERY important to index using a tensor, otherwise you introduce a copy to the device.
+
+ Parameters:
+ key_states (`torch.Tensor`):
+ The new key states to cache.
+ value_states (`torch.Tensor`):
+ The new value states to cache.
+ layer_idx (`int`):
+ The index of the layer to cache the states for.
+ cache_kwargs (`Dict[str, Any]`, *optional*):
+ Additional arguments for the cache subclass. The `OffloadedStaticCache` needs the
+ `cache_position` input to know how where to write in the cache.
+
+ Return:
+ A tuple containing the updated key and value states.
+ """
+
+ if layer_idx == 0:
+ # Update seen tokens.
+ # TODO(gante): Remove this.
+ self._seen_tokens += key_states.shape[-2]
+
+ # Always there.
+ k_out = self.key_cache[0]
+ v_out = self.value_cache[0]
+ else:
+ # Wait for prefetch stream.
+ if self._prefetch_stream is not None:
+ torch.cuda.default_stream(self.device).wait_stream(self._prefetch_stream)
+
+ k_out = self._device_key_cache[layer_idx & 1]
+ v_out = self._device_value_cache[layer_idx & 1]
+
+ self._prefetch_layer(layer_idx + 1)
+
+ cache_position = cache_kwargs.get("cache_position") if cache_kwargs is not None else None
+ if cache_position is None:
+ k_out.copy_(key_states)
+ v_out.copy_(value_states)
+
+ # Copy the values to the offloaded device as well.
+ if layer_idx == 0:
+ self.key_cache[layer_idx].copy_(key_states.to(self.offload_device))
+ self.value_cache[layer_idx].copy_(value_states.to(self.offload_device))
+ else:
+ # Note: here we use `tensor.index_copy_(dim, index, tensor)` that is equivalent to
+ # `tensor[:, :, index] = tensor`, but the first one is compile-friendly and it does
+ # explicitly an in-place operation, that avoids copies and uses less memory.
+ try:
+ k_out.index_copy_(2, cache_position, key_states)
+ v_out.index_copy_(2, cache_position, value_states)
+ except NotImplementedError:
+ # The operator 'aten::index_copy.out' is not currently implemented for the MPS
+ # device.
+ k_out[:, :, cache_position] = key_states
+ v_out[:, :, cache_position] = value_states
+
+ # Copy the values to the offloaded device as well.
+ if layer_idx != 0:
+ cache_position = cache_position.to(self.offload_device)
+ key_states = key_states.to(self.offload_device)
+ value_states = value_states.to(self.offload_device)
+
+ try:
+ self.key_cache[layer_idx].index_copy_(2, cache_position, key_states)
+ self.value_cache[layer_idx].index_copy_(2, cache_position, value_states)
+ except NotImplementedError:
+ # The operator 'aten::index_copy.out' is not currently implemented for the MPS
+ # device.
+ self.key_cache[layer_idx][:, :, cache_position] = key_states
+ self.value_cache[layer_idx][:, :, cache_position] = value_states
+
+ return k_out, v_out
+
+ def get_seq_length(self, layer_idx: Optional[int] = 0) -> int:
+ """Returns the sequence length of the cached states that were seen by the model."""
+
+ # TODO(gante): Remove this.
+ return self._seen_tokens
+
+ def get_max_cache_shape(self) -> Optional[int]:
+ """Returns the maximum sequence length of the cached states."""
+
+ return self.max_cache_len
+
+ def reset(self) -> None:
+ """Resets the cache values while preserving the objects."""
+
+ # For backwards compatibility.
+ # TODO(gante): Remove this.
+ self._seen_tokens = 0
+
+ # Zero out cache.
+ for layer_idx in range(len(self.key_cache)):
+ # In-place ops prevent breaking the static address.
+ self.key_cache[layer_idx].zero_()
+ self.value_cache[layer_idx].zero_()
+
+ @property
+ def seen_tokens(self) -> int:
+ # For backwards compatibility.
+ # TODO(gante): Remove this.
+ return self._seen_tokens
+
+ def _create_key_value_cache_tensors(
+ self, shape: Tuple[int, ...], device: torch.device
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ """Creates K/V cache tensors on a device. Pins memory for CPU tensors. Marks them as static
+ addresses for non-CPU tensors.
+
+ Args:
+ shape (`Tuple[int, ...]`): Shape.
+ device (`torch.device`): Device.
+
+ Returns:
+ Key and value cache tensors as a tuple.
+ """
+
+ is_cpu_device = device == torch.device("cpu")
+
+ key_cache = torch.zeros(shape, dtype=self._dtype, device=device, pin_memory=is_cpu_device)
+ value_cache = torch.zeros(shape, dtype=self._dtype, device=device, pin_memory=is_cpu_device)
+
+ # Note: `mark_static_address` is used to tag the cache as a fixed data pointer,
+ # preventing compiled graph breaks when updating the cache.
+ torch._dynamo.mark_static_address(key_cache)
+ torch._dynamo.mark_static_address(value_cache)
+
+ return key_cache, value_cache
+
+ def _prefetch_layer(self, layer_idx: int) -> None:
+ """Prefetch a layer to the device. Needs to be called in order of layer indices."""
+
+ # Don't fetch layers that do not exist.
+ if layer_idx >= len(self.key_cache):
+ return
+
+ # Alternate between two on-device caches.
+ if self._prefetch_stream is not None:
+ with torch.cuda.stream(self._prefetch_stream):
+ self._prefetch_layer_in_context(layer_idx)
+ else:
+ self._prefetch_layer_in_context(layer_idx)
+
+ def _prefetch_layer_in_context(self, layer_idx: int) -> None:
+ """Performs the actual copy of the layer to device cache."""
+
+ self._device_key_cache[layer_idx & 1].copy_(self.key_cache[layer_idx], non_blocking=True)
+ self._device_value_cache[layer_idx & 1].copy_(self.value_cache[layer_idx], non_blocking=True)
diff --git a/docs/transformers/src/transformers/commands/__init__.py b/docs/transformers/src/transformers/commands/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..aa5d95a85b538171ec9cf4fa16e892df1efdef6b
--- /dev/null
+++ b/docs/transformers/src/transformers/commands/__init__.py
@@ -0,0 +1,27 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from abc import ABC, abstractmethod
+from argparse import ArgumentParser
+
+
+class BaseTransformersCLICommand(ABC):
+ @staticmethod
+ @abstractmethod
+ def register_subcommand(parser: ArgumentParser):
+ raise NotImplementedError()
+
+ @abstractmethod
+ def run(self):
+ raise NotImplementedError()
diff --git a/docs/transformers/src/transformers/commands/add_fast_image_processor.py b/docs/transformers/src/transformers/commands/add_fast_image_processor.py
new file mode 100644
index 0000000000000000000000000000000000000000..dff3cb2d7bc6061aacc6bf9d82f81d3abe0e7b54
--- /dev/null
+++ b/docs/transformers/src/transformers/commands/add_fast_image_processor.py
@@ -0,0 +1,534 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import re
+from argparse import ArgumentParser, Namespace
+from datetime import date
+from pathlib import Path
+
+from ..utils import logging
+from . import BaseTransformersCLICommand
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+CURRENT_YEAR = date.today().year
+TRANSFORMERS_PATH = Path(__file__).parent.parent
+REPO_PATH = TRANSFORMERS_PATH.parent.parent
+
+
+def add_fast_image_processor_to_model_init(
+ fast_image_processing_module_file: str, fast_image_processor_name, model_name: str
+):
+ """
+ Add the fast image processor to the __init__.py file of the model.
+ """
+ with open(TRANSFORMERS_PATH / "models" / model_name / "__init__.py", "r", encoding="utf-8") as f:
+ content = f.read()
+
+ fast_image_processing_module_file = fast_image_processing_module_file.split(os.sep)[-1].replace(".py", "")
+
+ if "import *" in content:
+ # we have an init file in the updated format
+ # get the indented block after if TYPE_CHECKING: and before else:, append the new import, sort the imports and write the updated content
+ # Step 1: Find the block
+ block_regex = re.compile(
+ r"if TYPE_CHECKING:\n(?P.*?)(?=\s*else:)",
+ re.DOTALL,
+ )
+ match = block_regex.search(content)
+
+ if not match:
+ raise ValueError("Couldn't find the 'if TYPE_CHECKING' block.")
+
+ block_content = match.group("if_block") # The captured import block
+
+ # Step 2: Parse existing entries
+ entries = block_content.split("\n")
+ indent = " " * (len(entries[0]) - len(entries[0].lstrip()))
+ new_entry = f"{indent}from .{fast_image_processing_module_file} import *"
+ if new_entry not in entries:
+ entries.append(new_entry)
+ entries.sort()
+ updated_block = "\n".join(entry for entry in entries)
+
+ # Replace the original block in the content
+ updated_content = content[: match.start("if_block")] + updated_block + content[match.end("if_block") :]
+ else:
+ # we have an init file in the old format
+
+ # add "is_torchvision_available" import to from ...utils import (
+ # Regex to match import statements from transformers.utils
+ pattern = r"""
+ from\s+\.\.\.utils\s+import\s+
+ (?: # Non-capturing group for either:
+ ([\w, ]+) # 1. Single-line imports (e.g., 'a, b')
+ | # OR
+ \((.*?)\) # 2. Multi-line imports (e.g., '(a, ... b)')
+ )
+ """
+ regex = re.compile(pattern, re.VERBOSE | re.DOTALL)
+
+ def replacement_function(match):
+ # Extract existing imports
+ imports = (match.group(1) or match.group(2)).split(",")
+ imports = imports[:-1] if imports[-1] == "\n" else imports
+ imports = [imp.strip() for imp in imports]
+
+ # Add the new import if not already present
+ if "is_torchvision_available" not in imports:
+ imports.append("is_torchvision_available")
+ imports.sort()
+
+ # Convert to multi-line import in all cases
+ updated_imports = "(\n " + ",\n ".join(imports) + ",\n)"
+
+ return f"from ...utils import {updated_imports}"
+
+ # Replace all matches in the file content
+ updated_content = regex.sub(replacement_function, content)
+
+ vision_import_structure_block = f' _import_structure["{fast_image_processing_module_file[:-5]}"] = ["{fast_image_processor_name[:-4]}"]\n'
+
+ added_import_structure_block = (
+ "try:\n if not is_torchvision_available():\n"
+ " raise OptionalDependencyNotAvailable()\n"
+ "except OptionalDependencyNotAvailable:\n"
+ " pass\n"
+ "else:\n"
+ f' _import_structure["{fast_image_processing_module_file}"] = ["{fast_image_processor_name}"]\n'
+ )
+
+ if vision_import_structure_block not in updated_content:
+ raise ValueError("Couldn't find the 'vision _import_structure block' block.")
+
+ if added_import_structure_block not in updated_content:
+ updated_content = updated_content.replace(
+ vision_import_structure_block, vision_import_structure_block + "\n" + added_import_structure_block
+ )
+
+ vision_import_statement_block = (
+ f" from .{fast_image_processing_module_file[:-5]} import {fast_image_processor_name[:-4]}\n"
+ )
+
+ added_import_statement_block = (
+ " try:\n if not is_torchvision_available():\n"
+ " raise OptionalDependencyNotAvailable()\n"
+ " except OptionalDependencyNotAvailable:\n"
+ " pass\n"
+ " else:\n"
+ f" from .{fast_image_processing_module_file} import {fast_image_processor_name}\n"
+ )
+
+ if vision_import_statement_block not in updated_content:
+ raise ValueError("Couldn't find the 'vision _import_structure block' block.")
+
+ if added_import_statement_block not in updated_content:
+ updated_content = updated_content.replace(
+ vision_import_statement_block, vision_import_statement_block + "\n" + added_import_statement_block
+ )
+
+ # write the updated content
+ with open(TRANSFORMERS_PATH / "models" / model_name / "__init__.py", "w", encoding="utf-8") as f:
+ f.write(updated_content)
+
+
+def add_fast_image_processor_to_auto(image_processor_name: str, fast_image_processor_name: str):
+ """
+ Add the fast image processor to the auto module.
+ """
+ with open(TRANSFORMERS_PATH / "models" / "auto" / "image_processing_auto.py", "r", encoding="utf-8") as f:
+ content = f.read()
+
+ # get all lines containing the image processor name
+ updated_content = content.replace(
+ f'("{image_processor_name}",)', f'("{image_processor_name}", "{fast_image_processor_name}")'
+ )
+
+ # write the updated content
+ with open(TRANSFORMERS_PATH / "models" / "auto" / "image_processing_auto.py", "w", encoding="utf-8") as f:
+ f.write(updated_content)
+
+
+def add_fast_image_processor_to_doc(fast_image_processor_name: str, model_name: str):
+ """
+ Add the fast image processor to the model's doc file.
+ """
+ doc_source = REPO_PATH / "docs" / "source"
+ # find the doc files
+ doc_files = list(doc_source.glob(f"*/model_doc/{model_name}.md"))
+ if not doc_files:
+ # try again with "-"
+ doc_files = list(doc_source.glob(f"*/model_doc/{model_name.replace('_', '-')}.md"))
+ if not doc_files:
+ raise ValueError(f"No doc files found for {model_name}")
+
+ base_doc_string = (
+ f"## {fast_image_processor_name[:-4]}\n\n[[autodoc]] {fast_image_processor_name[:-4]}\n - preprocess"
+ )
+ fast_doc_string = f"## {fast_image_processor_name}\n\n[[autodoc]] {fast_image_processor_name}\n - preprocess"
+
+ for doc_file in doc_files:
+ with open(doc_file, "r", encoding="utf-8") as f:
+ content = f.read()
+
+ if fast_doc_string not in content:
+ # add the fast image processor to the doc
+ updated_content = content.replace(
+ base_doc_string,
+ base_doc_string + "\n\n" + fast_doc_string,
+ )
+
+ # write the updated content
+ with open(doc_file, "w", encoding="utf-8") as f:
+ f.write(updated_content)
+
+
+def add_fast_image_processor_to_tests(fast_image_processor_name: str, model_name: str):
+ """
+ Add the fast image processor to the image processing tests.
+ """
+ tests_path = REPO_PATH / "tests" / "models" / model_name
+ test_file = tests_path / f"test_image_processing_{model_name}.py"
+ if not os.path.exists(test_file):
+ logger.warning(f"No test file found for {model_name}. Skipping.")
+ return
+
+ with open(test_file, "r", encoding="utf-8") as f:
+ content = f.read()
+
+ # add is_torchvision_available import to the imports
+ # Regex to match import statements from transformers.utils
+ pattern = r"""
+ from\s+transformers\.utils\s+import\s+
+ (?: # Non-capturing group for either:
+ ([\w, ]+) # 1. Single-line imports (e.g., 'a, b')
+ | # OR
+ \((.*?)\) # 2. Multi-line imports (e.g., '(a, ... b)')
+ )
+ """
+ regex = re.compile(pattern, re.VERBOSE | re.DOTALL)
+
+ def replacement_function(match):
+ # Extract existing imports
+ existing_imports = (match.group(1) or match.group(2)).split(",")
+ existing_imports = existing_imports[:-1] if existing_imports[-1] == "\n" else existing_imports
+ existing_imports = [imp.strip() for imp in existing_imports]
+
+ # Add the new import if not already present
+ if "is_torchvision_available" not in existing_imports:
+ existing_imports.append("is_torchvision_available")
+ existing_imports.sort()
+
+ # Rebuild the import statement
+ if match.group(1): # Single-line import
+ updated_imports = ", ".join(existing_imports)
+ else: # Multi-line import
+ updated_imports = "(\n " + ",\n ".join(existing_imports) + ",\n)"
+
+ return f"from transformers.utils import {updated_imports}"
+
+ # Replace all matches in the file content
+ updated_content = regex.sub(replacement_function, content)
+
+ # add the fast image processor to the imports
+ base_import_string = f" from transformers import {fast_image_processor_name[:-4]}"
+ fast_import_string = (
+ f" if is_torchvision_available():\n from transformers import {fast_image_processor_name}"
+ )
+ if fast_import_string not in updated_content:
+ updated_content = updated_content.replace(base_import_string, base_import_string + "\n\n" + fast_import_string)
+
+ # get line starting with " image_processing_class = " and add a line after it starting with " fast_image_processing_class = "
+ image_processing_class_line = re.search(r" image_processing_class = .*", updated_content)
+ if not image_processing_class_line:
+ logger.warning(f"Couldn't find the 'image_processing_class' line in {test_file}. Skipping.")
+ return
+
+ fast_image_processing_class_line = (
+ f" fast_image_processing_class = {fast_image_processor_name} if is_torchvision_available() else None"
+ )
+ if " fast_image_processing_class = " not in updated_content:
+ updated_content = updated_content.replace(
+ image_processing_class_line.group(0),
+ image_processing_class_line.group(0) + "\n" + fast_image_processing_class_line,
+ )
+
+ # write the updated content
+ with open(test_file, "w", encoding="utf-8") as f:
+ f.write(updated_content)
+
+
+def get_fast_image_processing_content_header(content: str) -> str:
+ """
+ Get the header of the slow image processor file.
+ """
+ # get all the commented lines at the beginning of the file
+ content_header = re.search(r"^# coding=utf-8\n(#[^\n]*\n)*", content, re.MULTILINE)
+ if not content_header:
+ logger.warning("Couldn't find the content header in the slow image processor file. Using a default header.")
+ return (
+ f"# coding=utf-8\n"
+ f"# Copyright {CURRENT_YEAR} The HuggingFace Team. All rights reserved.\n"
+ f"#\n"
+ f'# Licensed under the Apache License, Version 2.0 (the "License");\n'
+ f"# you may not use this file except in compliance with the License.\n"
+ f"# You may obtain a copy of the License at\n"
+ f"#\n"
+ f"# http://www.apache.org/licenses/LICENSE-2.0\n"
+ f"#\n"
+ f"# Unless required by applicable law or agreed to in writing, software\n"
+ f'# distributed under the License is distributed on an "AS IS" BASIS,\n'
+ f"# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n"
+ f"# See the License for the specific language governing permissions and\n"
+ f"# limitations under the License.\n"
+ f"\n"
+ )
+ content_header = content_header.group(0)
+ # replace the year in the copyright
+ content_header = re.sub(r"# Copyright (\d+)\s", f"# Copyright {CURRENT_YEAR} ", content_header)
+ # get the line starting with """Image processor in content if it exists
+ match = re.search(r'^"""Image processor.*$', content, re.MULTILINE)
+ if match:
+ content_header += match.group(0).replace("Image processor", "Fast Image processor")
+
+ return content_header
+
+
+def write_default_fast_image_processor_file(
+ fast_image_processing_module_file: str, fast_image_processor_name: str, content_base_file: str
+):
+ """
+ Write a default fast image processor file. Used when encountering a problem while parsing the slow image processor file.
+ """
+ imports = "\n\nfrom ...image_processing_utils_fast import BaseImageProcessorFast\n\n\n"
+ content_header = get_fast_image_processing_content_header(content_base_file)
+ content_base_file = (
+ f"class {fast_image_processor_name}(BaseImageProcessorFast):\n"
+ " # To be implemented\n"
+ " resample = None\n"
+ " image_mean = None\n"
+ " image_std = None\n"
+ " size = None\n"
+ " default_to_square = None\n"
+ " crop_size = None\n"
+ " do_resize = None\n"
+ " do_center_crop = None\n"
+ " do_rescale = None\n"
+ " do_normalize = None\n"
+ " do_convert_rgb = None\n\n\n"
+ f'__all__ = ["{fast_image_processor_name}"]\n'
+ )
+
+ content = content_header + imports + content_base_file
+
+ with open(fast_image_processing_module_file, "w", encoding="utf-8") as f:
+ f.write(content)
+
+
+def add_fast_image_processor_file(
+ fast_image_processing_module_file: str, fast_image_processor_name: str, content_base_file: str
+):
+ """
+ Add the fast image processor file to the model's folder.
+ """
+ # if the file already exists, do nothing
+ if os.path.exists(fast_image_processing_module_file):
+ print(f"{fast_image_processing_module_file} already exists. Skipping.")
+ return
+
+ regex = rf"class {fast_image_processor_name[:-4]}.*?(\n\S|$)"
+ match = re.search(regex, content_base_file, re.DOTALL)
+ if not match:
+ print(f"Couldn't find the {fast_image_processor_name[:-4]} class in {fast_image_processing_module_file}")
+ print("Creating a new file with the default content.")
+ return write_default_fast_image_processor_file(
+ fast_image_processing_module_file, fast_image_processor_name, content_base_file
+ )
+ # Exclude the last unindented line
+ slow_class_content = match.group(0).rstrip()
+ # get default args:
+ # find the __init__ block which start with def __init__ and ends with def
+ match = re.search(r"def __init__.*?def ", slow_class_content, re.DOTALL)
+ if not match:
+ print(
+ f"Couldn't find the __init__ block for {fast_image_processor_name[:-4]} in {fast_image_processing_module_file}"
+ )
+ print("Creating a new file with the default content.")
+ return write_default_fast_image_processor_file(
+ fast_image_processing_module_file, fast_image_processor_name, content_base_file
+ )
+ init = match.group(0)
+ init_signature_block = init.split(")")[0]
+ arg_names = init_signature_block.split(":")
+ arg_names = [arg_name.split("\n")[-1].strip() for arg_name in arg_names]
+ # get the default values
+ default_args = re.findall(r"= (.*?)(?:,|\))", init_signature_block)
+
+ # build default args dict
+ default_args_dict = dict(zip(arg_names, default_args))
+ pattern_default_size = r"size = size if size is not None else\s+(.*)"
+ match_default_size = re.findall(pattern_default_size, init)
+ default_args_dict["size"] = match_default_size[0] if match_default_size else None
+ pattern_default_crop_size = r"crop_size = crop_size if crop_size is not None else\s+(.*)"
+ match_default_crop_size = re.findall(pattern_default_crop_size, init)
+ default_args_dict["crop_size"] = match_default_crop_size[0] if match_default_crop_size else None
+ pattern_default_image_mean = r"self.image_mean = image_mean if image_mean is not None else\s+(.*)"
+ match_default_image_mean = re.findall(pattern_default_image_mean, init)
+ default_args_dict["image_mean"] = match_default_image_mean[0] if match_default_image_mean else None
+ pattern_default_image_std = r"self.image_std = image_std if image_std is not None else\s+(.*)"
+ match_default_image_std = re.findall(pattern_default_image_std, init)
+ default_args_dict["image_std"] = match_default_image_std[0] if match_default_image_std else None
+ default_args_dict["default_to_square"] = False if "(size, default_to_square=False" in init else None
+
+ content_header = get_fast_image_processing_content_header(content_base_file)
+ content_base_file = (
+ f"@add_start_docstrings(\n"
+ f' "Constructs a fast {fast_image_processor_name.replace("ImageProcessorFast", "")} image processor.",\n'
+ f" BASE_IMAGE_PROCESSOR_FAST_DOCSTRING,\n)\n"
+ f"class {fast_image_processor_name}(BaseImageProcessorFast):\n"
+ " # This generated class can be used as a starting point for the fast image processor.\n"
+ " # if the image processor is only used for simple augmentations, such as resizing, center cropping, rescaling, or normalizing,\n"
+ " # only the default values should be set in the class.\n"
+ " # If the image processor requires more complex augmentations, methods from BaseImageProcessorFast can be overridden.\n"
+ " # In most cases, only the `_preprocess` method should be overridden.\n\n"
+ " # For an example of a fast image processor requiring more complex augmentations, see `LlavaNextImageProcessorFast`.\n\n"
+ " # Default values should be checked against the slow image processor\n"
+ " # None values left after checking can be removed\n"
+ f" resample = {default_args_dict.get('resample')}\n"
+ f" image_mean = {default_args_dict.get('image_mean')}\n"
+ f" image_std = {default_args_dict.get('image_std')}\n"
+ f" size = {default_args_dict.get('size')}\n"
+ f" default_to_square = {default_args_dict.get('default_to_square')}\n"
+ f" crop_size = {default_args_dict.get('crop_size')}\n"
+ f" do_resize = {default_args_dict.get('do_resize')}\n"
+ f" do_center_crop = {default_args_dict.get('do_center_crop')}\n"
+ f" do_rescale = {default_args_dict.get('do_rescale')}\n"
+ f" do_normalize = {default_args_dict.get('do_normalize')}\n"
+ f" do_convert_rgb = {default_args_dict.get('do_convert_rgb')}\n\n\n"
+ f'__all__ = ["{fast_image_processor_name}"]\n'
+ )
+
+ imports = (
+ "\n\nfrom ...image_processing_utils_fast import BASE_IMAGE_PROCESSOR_FAST_DOCSTRING, BaseImageProcessorFast\n"
+ )
+ image_utils_imports = []
+ if default_args_dict.get("resample") is not None and "PILImageResampling" in default_args_dict.get("resample"):
+ image_utils_imports.append("PILImageResampling")
+ if default_args_dict.get("image_mean") is not None and not any(
+ char.isdigit() for char in default_args_dict.get("image_mean")
+ ):
+ image_utils_imports.append(default_args_dict.get("image_mean"))
+ if default_args_dict.get("image_std") is not None and not any(
+ char.isdigit() for char in default_args_dict.get("image_std")
+ ):
+ image_utils_imports.append(default_args_dict.get("image_std"))
+
+ if image_utils_imports:
+ # sort imports
+ image_utils_imports.sort()
+ imports += f"from ...image_utils import {', '.join(image_utils_imports)}\n"
+
+ imports += "from ...utils import add_start_docstrings\n"
+
+ content = content_header + imports + "\n\n" + content_base_file
+
+ with open(fast_image_processing_module_file, "w", encoding="utf-8") as f:
+ f.write(content)
+
+
+def add_fast_image_processor(model_name: str):
+ """
+ Add the necessary references to the fast image processor in the transformers package,
+ and create the fast image processor file in the model's folder.
+ """
+ model_module = TRANSFORMERS_PATH / "models" / model_name
+ image_processing_module_file = list(model_module.glob("image_processing*.py"))
+ if not image_processing_module_file:
+ raise ValueError(f"No image processing module found in {model_module}")
+ elif len(image_processing_module_file) > 1:
+ for file_name in image_processing_module_file:
+ if not str(file_name).endswith("_fast.py"):
+ image_processing_module_file = str(file_name)
+ break
+ else:
+ image_processing_module_file = str(image_processing_module_file[0])
+
+ with open(image_processing_module_file, "r", encoding="utf-8") as f:
+ content_base_file = f.read()
+
+ # regex to find object starting with "class " and ending with "ImageProcessor", including "ImageProcessor" in the match
+ image_processor_name = re.findall(r"class (\w*ImageProcessor)", content_base_file)
+ if not image_processor_name:
+ raise ValueError(f"No ImageProcessor class found in {image_processing_module_file}")
+ elif len(image_processor_name) > 1:
+ raise ValueError(f"Multiple ImageProcessor classes found in {image_processing_module_file}")
+
+ image_processor_name = image_processor_name[0]
+ fast_image_processor_name = image_processor_name + "Fast"
+ fast_image_processing_module_file = image_processing_module_file.replace(".py", "_fast.py")
+
+ print(f"Adding {fast_image_processor_name} to {fast_image_processing_module_file}")
+
+ add_fast_image_processor_to_model_init(
+ fast_image_processing_module_file=fast_image_processing_module_file,
+ fast_image_processor_name=fast_image_processor_name,
+ model_name=model_name,
+ )
+
+ add_fast_image_processor_to_auto(
+ image_processor_name=image_processor_name,
+ fast_image_processor_name=fast_image_processor_name,
+ )
+
+ add_fast_image_processor_to_doc(
+ fast_image_processor_name=fast_image_processor_name,
+ model_name=model_name,
+ )
+
+ add_fast_image_processor_to_tests(
+ fast_image_processor_name=fast_image_processor_name,
+ model_name=model_name,
+ )
+
+ add_fast_image_processor_file(
+ fast_image_processing_module_file=fast_image_processing_module_file,
+ fast_image_processor_name=fast_image_processor_name,
+ content_base_file=content_base_file,
+ )
+
+
+def add_new_model_like_command_factory(args: Namespace):
+ return AddFastImageProcessorCommand(model_name=args.model_name)
+
+
+class AddFastImageProcessorCommand(BaseTransformersCLICommand):
+ @staticmethod
+ def register_subcommand(parser: ArgumentParser):
+ add_fast_image_processor_parser = parser.add_parser("add-fast-image-processor")
+ add_fast_image_processor_parser.add_argument(
+ "--model-name",
+ type=str,
+ required=True,
+ help="The name of the folder containing the model's implementation.",
+ )
+ add_fast_image_processor_parser.set_defaults(func=add_new_model_like_command_factory)
+
+ def __init__(self, model_name: str, *args):
+ self.model_name = model_name
+
+ def run(self):
+ add_fast_image_processor(model_name=self.model_name)
diff --git a/docs/transformers/src/transformers/commands/add_new_model_like.py b/docs/transformers/src/transformers/commands/add_new_model_like.py
new file mode 100644
index 0000000000000000000000000000000000000000..bfb812340e72bdc4543581d1e53bafb6730eb622
--- /dev/null
+++ b/docs/transformers/src/transformers/commands/add_new_model_like.py
@@ -0,0 +1,1791 @@
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import difflib
+import json
+import os
+import re
+from argparse import ArgumentParser, Namespace
+from dataclasses import dataclass
+from datetime import date
+from itertools import chain
+from pathlib import Path
+from typing import Any, Callable, Dict, List, Optional, Pattern, Tuple, Union
+
+import yaml
+
+from ..models import auto as auto_module
+from ..models.auto.configuration_auto import model_type_to_module_name
+from ..utils import is_flax_available, is_tf_available, is_torch_available, logging
+from . import BaseTransformersCLICommand
+from .add_fast_image_processor import add_fast_image_processor
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+CURRENT_YEAR = date.today().year
+TRANSFORMERS_PATH = Path(__file__).parent.parent
+REPO_PATH = TRANSFORMERS_PATH.parent.parent
+
+
+@dataclass
+class ModelPatterns:
+ """
+ Holds the basic information about a new model for the add-new-model-like command.
+
+ Args:
+ model_name (`str`): The model name.
+ checkpoint (`str`): The checkpoint to use for doc examples.
+ model_type (`str`, *optional*):
+ The model type, the identifier used internally in the library like `bert` or `xlm-roberta`. Will default to
+ `model_name` lowercased with spaces replaced with minuses (-).
+ model_lower_cased (`str`, *optional*):
+ The lowercased version of the model name, to use for the module name or function names. Will default to
+ `model_name` lowercased with spaces and minuses replaced with underscores.
+ model_camel_cased (`str`, *optional*):
+ The camel-cased version of the model name, to use for the class names. Will default to `model_name`
+ camel-cased (with spaces and minuses both considered as word separators.
+ model_upper_cased (`str`, *optional*):
+ The uppercased version of the model name, to use for the constant names. Will default to `model_name`
+ uppercased with spaces and minuses replaced with underscores.
+ config_class (`str`, *optional*):
+ The tokenizer class associated with this model. Will default to `"{model_camel_cased}Config"`.
+ tokenizer_class (`str`, *optional*):
+ The tokenizer class associated with this model (leave to `None` for models that don't use a tokenizer).
+ image_processor_class (`str`, *optional*):
+ The image processor class associated with this model (leave to `None` for models that don't use an image
+ processor).
+ image_processor_fast_class (`str`, *optional*):
+ The fast image processor class associated with this model (leave to `None` for models that don't use a fast
+ image processor).
+ feature_extractor_class (`str`, *optional*):
+ The feature extractor class associated with this model (leave to `None` for models that don't use a feature
+ extractor).
+ processor_class (`str`, *optional*):
+ The processor class associated with this model (leave to `None` for models that don't use a processor).
+ """
+
+ model_name: str
+ checkpoint: str
+ model_type: Optional[str] = None
+ model_lower_cased: Optional[str] = None
+ model_camel_cased: Optional[str] = None
+ model_upper_cased: Optional[str] = None
+ config_class: Optional[str] = None
+ tokenizer_class: Optional[str] = None
+ image_processor_class: Optional[str] = None
+ image_processor_fast_class: Optional[str] = None
+ feature_extractor_class: Optional[str] = None
+ processor_class: Optional[str] = None
+
+ def __post_init__(self):
+ if self.model_type is None:
+ self.model_type = self.model_name.lower().replace(" ", "-")
+ if self.model_lower_cased is None:
+ self.model_lower_cased = self.model_name.lower().replace(" ", "_").replace("-", "_")
+ if self.model_camel_cased is None:
+ # Split the model name on - and space
+ words = self.model_name.split(" ")
+ words = list(chain(*[w.split("-") for w in words]))
+ # Make sure each word is capitalized
+ words = [w[0].upper() + w[1:] for w in words]
+ self.model_camel_cased = "".join(words)
+ if self.model_upper_cased is None:
+ self.model_upper_cased = self.model_name.upper().replace(" ", "_").replace("-", "_")
+ if self.config_class is None:
+ self.config_class = f"{self.model_camel_cased}Config"
+
+
+ATTRIBUTE_TO_PLACEHOLDER = {
+ "config_class": "[CONFIG_CLASS]",
+ "tokenizer_class": "[TOKENIZER_CLASS]",
+ "image_processor_class": "[IMAGE_PROCESSOR_CLASS]",
+ "image_processor_fast_class": "[IMAGE_PROCESSOR_FAST_CLASS]",
+ "feature_extractor_class": "[FEATURE_EXTRACTOR_CLASS]",
+ "processor_class": "[PROCESSOR_CLASS]",
+ "checkpoint": "[CHECKPOINT]",
+ "model_type": "[MODEL_TYPE]",
+ "model_upper_cased": "[MODEL_UPPER_CASED]",
+ "model_camel_cased": "[MODEL_CAMELCASED]",
+ "model_lower_cased": "[MODEL_LOWER_CASED]",
+ "model_name": "[MODEL_NAME]",
+}
+
+
+def is_empty_line(line: str) -> bool:
+ """
+ Determines whether a line is empty or not.
+ """
+ return len(line) == 0 or line.isspace()
+
+
+def find_indent(line: str) -> int:
+ """
+ Returns the number of spaces that start a line indent.
+ """
+ search = re.search(r"^(\s*)(?:\S|$)", line)
+ if search is None:
+ return 0
+ return len(search.groups()[0])
+
+
+def parse_module_content(content: str) -> List[str]:
+ """
+ Parse the content of a module in the list of objects it defines.
+
+ Args:
+ content (`str`): The content to parse
+
+ Returns:
+ `List[str]`: The list of objects defined in the module.
+ """
+ objects = []
+ current_object = []
+ lines = content.split("\n")
+ # Doc-styler takes everything between two triple quotes in docstrings, so we need a fake """ here to go with this.
+ end_markers = [")", "]", "}", '"""']
+
+ for line in lines:
+ # End of an object
+ is_valid_object = len(current_object) > 0
+ if is_valid_object and len(current_object) == 1:
+ is_valid_object = not current_object[0].startswith("# Copied from")
+ if not is_empty_line(line) and find_indent(line) == 0 and is_valid_object:
+ # Closing parts should be included in current object
+ if line in end_markers:
+ current_object.append(line)
+ objects.append("\n".join(current_object))
+ current_object = []
+ else:
+ objects.append("\n".join(current_object))
+ current_object = [line]
+ else:
+ current_object.append(line)
+
+ # Add last object
+ if len(current_object) > 0:
+ objects.append("\n".join(current_object))
+
+ return objects
+
+
+def extract_block(content: str, indent_level: int = 0) -> str:
+ """Return the first block in `content` with the indent level `indent_level`.
+
+ The first line in `content` should be indented at `indent_level` level, otherwise an error will be thrown.
+
+ This method will immediately stop the search when a (non-empty) line with indent level less than `indent_level` is
+ encountered.
+
+ Args:
+ content (`str`): The content to parse
+ indent_level (`int`, *optional*, default to 0): The indent level of the blocks to search for
+
+ Returns:
+ `str`: The first block in `content` with the indent level `indent_level`.
+ """
+ current_object = []
+ lines = content.split("\n")
+ # Doc-styler takes everything between two triple quotes in docstrings, so we need a fake """ here to go with this.
+ end_markers = [")", "]", "}", '"""']
+
+ for idx, line in enumerate(lines):
+ if idx == 0 and indent_level > 0 and not is_empty_line(line) and find_indent(line) != indent_level:
+ raise ValueError(
+ f"When `indent_level > 0`, the first line in `content` should have indent level {indent_level}. Got "
+ f"{find_indent(line)} instead."
+ )
+
+ if find_indent(line) < indent_level and not is_empty_line(line):
+ break
+
+ # End of an object
+ is_valid_object = len(current_object) > 0
+ if (
+ not is_empty_line(line)
+ and not line.endswith(":")
+ and find_indent(line) == indent_level
+ and is_valid_object
+ ):
+ # Closing parts should be included in current object
+ if line.lstrip() in end_markers:
+ current_object.append(line)
+ return "\n".join(current_object)
+ else:
+ current_object.append(line)
+
+ # Add last object
+ if len(current_object) > 0:
+ return "\n".join(current_object)
+
+
+def add_content_to_text(
+ text: str,
+ content: str,
+ add_after: Optional[Union[str, Pattern]] = None,
+ add_before: Optional[Union[str, Pattern]] = None,
+ exact_match: bool = False,
+) -> str:
+ """
+ A utility to add some content inside a given text.
+
+ Args:
+ text (`str`): The text in which we want to insert some content.
+ content (`str`): The content to add.
+ add_after (`str` or `Pattern`):
+ The pattern to test on a line of `text`, the new content is added after the first instance matching it.
+ add_before (`str` or `Pattern`):
+ The pattern to test on a line of `text`, the new content is added before the first instance matching it.
+ exact_match (`bool`, *optional*, defaults to `False`):
+ A line is considered a match with `add_after` or `add_before` if it matches exactly when `exact_match=True`,
+ otherwise, if `add_after`/`add_before` is present in the line.
+
+
+
+ The arguments `add_after` and `add_before` are mutually exclusive, and one exactly needs to be provided.
+
+
+
+ Returns:
+ `str`: The text with the new content added if a match was found.
+ """
+ if add_after is None and add_before is None:
+ raise ValueError("You need to pass either `add_after` or `add_before`")
+ if add_after is not None and add_before is not None:
+ raise ValueError("You can't pass both `add_after` or `add_before`")
+ pattern = add_after if add_before is None else add_before
+
+ def this_is_the_line(line):
+ if isinstance(pattern, Pattern):
+ return pattern.search(line) is not None
+ elif exact_match:
+ return pattern == line
+ else:
+ return pattern in line
+
+ new_lines = []
+ for line in text.split("\n"):
+ if this_is_the_line(line):
+ if add_before is not None:
+ new_lines.append(content)
+ new_lines.append(line)
+ if add_after is not None:
+ new_lines.append(content)
+ else:
+ new_lines.append(line)
+
+ return "\n".join(new_lines)
+
+
+def add_content_to_file(
+ file_name: Union[str, os.PathLike],
+ content: str,
+ add_after: Optional[Union[str, Pattern]] = None,
+ add_before: Optional[Union[str, Pattern]] = None,
+ exact_match: bool = False,
+):
+ """
+ A utility to add some content inside a given file.
+
+ Args:
+ file_name (`str` or `os.PathLike`): The name of the file in which we want to insert some content.
+ content (`str`): The content to add.
+ add_after (`str` or `Pattern`):
+ The pattern to test on a line of `text`, the new content is added after the first instance matching it.
+ add_before (`str` or `Pattern`):
+ The pattern to test on a line of `text`, the new content is added before the first instance matching it.
+ exact_match (`bool`, *optional*, defaults to `False`):
+ A line is considered a match with `add_after` or `add_before` if it matches exactly when `exact_match=True`,
+ otherwise, if `add_after`/`add_before` is present in the line.
+
+
+
+ The arguments `add_after` and `add_before` are mutually exclusive, and one exactly needs to be provided.
+
+
+ """
+ with open(file_name, "r", encoding="utf-8") as f:
+ old_content = f.read()
+
+ new_content = add_content_to_text(
+ old_content, content, add_after=add_after, add_before=add_before, exact_match=exact_match
+ )
+
+ with open(file_name, "w", encoding="utf-8") as f:
+ f.write(new_content)
+
+
+def replace_model_patterns(
+ text: str, old_model_patterns: ModelPatterns, new_model_patterns: ModelPatterns
+) -> Tuple[str, str]:
+ """
+ Replace all patterns present in a given text.
+
+ Args:
+ text (`str`): The text to treat.
+ old_model_patterns (`ModelPatterns`): The patterns for the old model.
+ new_model_patterns (`ModelPatterns`): The patterns for the new model.
+
+ Returns:
+ `Tuple(str, str)`: A tuple of with the treated text and the replacement actually done in it.
+ """
+ # The order is crucially important as we will check and replace in that order. For instance the config probably
+ # contains the camel-cased named, but will be treated before.
+ attributes_to_check = ["config_class"]
+ # Add relevant preprocessing classes
+ for attr in [
+ "tokenizer_class",
+ "image_processor_class",
+ "image_processor_fast_class",
+ "feature_extractor_class",
+ "processor_class",
+ ]:
+ if getattr(old_model_patterns, attr) is not None and getattr(new_model_patterns, attr) is not None:
+ attributes_to_check.append(attr)
+
+ # Special cases for checkpoint and model_type
+ if old_model_patterns.checkpoint not in [old_model_patterns.model_type, old_model_patterns.model_lower_cased]:
+ attributes_to_check.append("checkpoint")
+ if old_model_patterns.model_type != old_model_patterns.model_lower_cased:
+ attributes_to_check.append("model_type")
+ else:
+ text = re.sub(
+ rf'(\s*)model_type = "{old_model_patterns.model_type}"',
+ r'\1model_type = "[MODEL_TYPE]"',
+ text,
+ )
+
+ # Special case when the model camel cased and upper cased names are the same for the old model (like for GPT2) but
+ # not the new one. We can't just do a replace in all the text and will need a special regex
+ if old_model_patterns.model_upper_cased == old_model_patterns.model_camel_cased:
+ old_model_value = old_model_patterns.model_upper_cased
+ if re.search(rf"{old_model_value}_[A-Z_]*[^A-Z_]", text) is not None:
+ text = re.sub(rf"{old_model_value}([A-Z_]*)([^a-zA-Z_])", r"[MODEL_UPPER_CASED]\1\2", text)
+ else:
+ attributes_to_check.append("model_upper_cased")
+
+ attributes_to_check.extend(["model_camel_cased", "model_lower_cased", "model_name"])
+
+ # Now let's replace every other attribute by their placeholder
+ for attr in attributes_to_check:
+ text = text.replace(getattr(old_model_patterns, attr), ATTRIBUTE_TO_PLACEHOLDER[attr])
+
+ # Finally we can replace the placeholder byt the new values.
+ replacements = []
+ for attr, placeholder in ATTRIBUTE_TO_PLACEHOLDER.items():
+ if placeholder in text:
+ replacements.append((getattr(old_model_patterns, attr), getattr(new_model_patterns, attr)))
+ text = text.replace(placeholder, getattr(new_model_patterns, attr))
+
+ # If we have two inconsistent replacements, we don't return anything (ex: GPT2->GPT_NEW and GPT2->GPTNew)
+ old_replacement_values = [old for old, new in replacements]
+ if len(set(old_replacement_values)) != len(old_replacement_values):
+ return text, ""
+
+ replacements = simplify_replacements(replacements)
+ replacements = [f"{old}->{new}" for old, new in replacements]
+ return text, ",".join(replacements)
+
+
+def simplify_replacements(replacements):
+ """
+ Simplify a list of replacement patterns to make sure there are no needless ones.
+
+ For instance in the sequence "Bert->BertNew, BertConfig->BertNewConfig, bert->bert_new", the replacement
+ "BertConfig->BertNewConfig" is implied by "Bert->BertNew" so not needed.
+
+ Args:
+ replacements (`List[Tuple[str, str]]`): List of patterns (old, new)
+
+ Returns:
+ `List[Tuple[str, str]]`: The list of patterns simplified.
+ """
+ if len(replacements) <= 1:
+ # Nothing to simplify
+ return replacements
+
+ # Next let's sort replacements by length as a replacement can only "imply" another replacement if it's shorter.
+ replacements.sort(key=lambda x: len(x[0]))
+
+ idx = 0
+ while idx < len(replacements):
+ old, new = replacements[idx]
+ # Loop through all replacements after
+ j = idx + 1
+ while j < len(replacements):
+ old_2, new_2 = replacements[j]
+ # If the replacement is implied by the current one, we can drop it.
+ if old_2.replace(old, new) == new_2:
+ replacements.pop(j)
+ else:
+ j += 1
+ idx += 1
+
+ return replacements
+
+
+def get_module_from_file(module_file: Union[str, os.PathLike]) -> str:
+ """
+ Returns the module name corresponding to a module file.
+ """
+ full_module_path = Path(module_file).absolute()
+ module_parts = full_module_path.with_suffix("").parts
+
+ # Find the first part named transformers, starting from the end.
+ idx = len(module_parts) - 1
+ while idx >= 0 and module_parts[idx] != "transformers":
+ idx -= 1
+ if idx < 0:
+ raise ValueError(f"{module_file} is not a transformers module.")
+
+ return ".".join(module_parts[idx:])
+
+
+SPECIAL_PATTERNS = {
+ "_CHECKPOINT_FOR_DOC =": "checkpoint",
+ "_CONFIG_FOR_DOC =": "config_class",
+ "_TOKENIZER_FOR_DOC =": "tokenizer_class",
+ "_IMAGE_PROCESSOR_FOR_DOC =": "image_processor_class",
+ "_FEAT_EXTRACTOR_FOR_DOC =": "feature_extractor_class",
+ "_PROCESSOR_FOR_DOC =": "processor_class",
+}
+
+
+_re_class_func = re.compile(r"^(?:class|def)\s+([^\s:\(]+)\s*(?:\(|\:)", flags=re.MULTILINE)
+
+
+def remove_attributes(obj, target_attr):
+ """Remove `target_attr` in `obj`."""
+ lines = obj.split(os.linesep)
+
+ target_idx = None
+ for idx, line in enumerate(lines):
+ # search for assignment
+ if line.lstrip().startswith(f"{target_attr} = "):
+ target_idx = idx
+ break
+ # search for function/method definition
+ elif line.lstrip().startswith(f"def {target_attr}("):
+ target_idx = idx
+ break
+
+ # target not found
+ if target_idx is None:
+ return obj
+
+ line = lines[target_idx]
+ indent_level = find_indent(line)
+ # forward pass to find the ending of the block (including empty lines)
+ parsed = extract_block("\n".join(lines[target_idx:]), indent_level)
+ num_lines = len(parsed.split("\n"))
+ for idx in range(num_lines):
+ lines[target_idx + idx] = None
+
+ # backward pass to find comments or decorator
+ for idx in range(target_idx - 1, -1, -1):
+ line = lines[idx]
+ if (line.lstrip().startswith("#") or line.lstrip().startswith("@")) and find_indent(line) == indent_level:
+ lines[idx] = None
+ else:
+ break
+
+ new_obj = os.linesep.join([x for x in lines if x is not None])
+
+ return new_obj
+
+
+def duplicate_module(
+ module_file: Union[str, os.PathLike],
+ old_model_patterns: ModelPatterns,
+ new_model_patterns: ModelPatterns,
+ dest_file: Optional[str] = None,
+ add_copied_from: bool = True,
+ attrs_to_remove: List[str] = None,
+):
+ """
+ Create a new module from an existing one and adapting all function and classes names from old patterns to new ones.
+
+ Args:
+ module_file (`str` or `os.PathLike`): Path to the module to duplicate.
+ old_model_patterns (`ModelPatterns`): The patterns for the old model.
+ new_model_patterns (`ModelPatterns`): The patterns for the new model.
+ dest_file (`str` or `os.PathLike`, *optional*): Path to the new module.
+ add_copied_from (`bool`, *optional*, defaults to `True`):
+ Whether or not to add `# Copied from` statements in the duplicated module.
+ """
+ if dest_file is None:
+ dest_file = str(module_file).replace(
+ old_model_patterns.model_lower_cased, new_model_patterns.model_lower_cased
+ )
+
+ with open(module_file, "r", encoding="utf-8") as f:
+ content = f.read()
+
+ content = re.sub(r"# Copyright (\d+)\s", f"# Copyright {CURRENT_YEAR} ", content)
+ objects = parse_module_content(content)
+
+ # Loop and treat all objects
+ new_objects = []
+ for obj in objects:
+ special_pattern = False
+ for pattern, attr in SPECIAL_PATTERNS.items():
+ if pattern in obj:
+ obj = obj.replace(getattr(old_model_patterns, attr), getattr(new_model_patterns, attr))
+ new_objects.append(obj)
+ special_pattern = True
+ break
+
+ if special_pattern:
+ continue
+
+ # Regular classes functions
+ old_obj = obj
+ obj, replacement = replace_model_patterns(obj, old_model_patterns, new_model_patterns)
+ has_copied_from = re.search(r"^#\s+Copied from", obj, flags=re.MULTILINE) is not None
+ if add_copied_from and not has_copied_from and _re_class_func.search(obj) is not None and len(replacement) > 0:
+ # Copied from statement must be added just before the class/function definition, which may not be the
+ # first line because of decorators.
+ module_name = get_module_from_file(module_file)
+ old_object_name = _re_class_func.search(old_obj).groups()[0]
+ obj = add_content_to_text(
+ obj, f"# Copied from {module_name}.{old_object_name} with {replacement}", add_before=_re_class_func
+ )
+ # In all cases, we remove Copied from statement with indent on methods.
+ obj = re.sub("\n[ ]+# Copied from [^\n]*\n", "\n", obj)
+
+ new_objects.append(obj)
+
+ content = "\n".join(new_objects)
+ # Remove some attributes that we don't want to copy to the new file(s)
+ if attrs_to_remove is not None:
+ for attr in attrs_to_remove:
+ content = remove_attributes(content, target_attr=attr)
+
+ with open(dest_file, "w", encoding="utf-8") as f:
+ f.write(content)
+
+
+def filter_framework_files(
+ files: List[Union[str, os.PathLike]], frameworks: Optional[List[str]] = None
+) -> List[Union[str, os.PathLike]]:
+ """
+ Filter a list of files to only keep the ones corresponding to a list of frameworks.
+
+ Args:
+ files (`List[Union[str, os.PathLike]]`): The list of files to filter.
+ frameworks (`List[str]`, *optional*): The list of allowed frameworks.
+
+ Returns:
+ `List[Union[str, os.PathLike]]`: The list of filtered files.
+ """
+ if frameworks is None:
+ frameworks = get_default_frameworks()
+
+ framework_to_file = {}
+ others = []
+ for f in files:
+ parts = Path(f).name.split("_")
+ if "modeling" not in parts:
+ others.append(f)
+ continue
+ if "tf" in parts:
+ framework_to_file["tf"] = f
+ elif "flax" in parts:
+ framework_to_file["flax"] = f
+ else:
+ framework_to_file["pt"] = f
+
+ return [framework_to_file[f] for f in frameworks if f in framework_to_file] + others
+
+
+def get_model_files(model_type: str, frameworks: Optional[List[str]] = None) -> Dict[str, Union[Path, List[Path]]]:
+ """
+ Retrieves all the files associated to a model.
+
+ Args:
+ model_type (`str`): A valid model type (like "bert" or "gpt2")
+ frameworks (`List[str]`, *optional*):
+ If passed, will only keep the model files corresponding to the passed frameworks.
+
+ Returns:
+ `Dict[str, Union[Path, List[Path]]]`: A dictionary with the following keys:
+ - **doc_file** -- The documentation file for the model.
+ - **model_files** -- All the files in the model module.
+ - **test_files** -- The test files for the model.
+ """
+ module_name = model_type_to_module_name(model_type)
+
+ model_module = TRANSFORMERS_PATH / "models" / module_name
+ model_files = list(model_module.glob("*.py"))
+ model_files = filter_framework_files(model_files, frameworks=frameworks)
+
+ doc_file = REPO_PATH / "docs" / "source" / "en" / "model_doc" / f"{model_type}.md"
+
+ # Basic pattern for test files
+ test_files = [
+ f"test_modeling_{module_name}.py",
+ f"test_modeling_tf_{module_name}.py",
+ f"test_modeling_flax_{module_name}.py",
+ f"test_tokenization_{module_name}.py",
+ f"test_image_processing_{module_name}.py",
+ f"test_feature_extraction_{module_name}.py",
+ f"test_processor_{module_name}.py",
+ ]
+ test_files = filter_framework_files(test_files, frameworks=frameworks)
+ # Add the test directory
+ test_files = [REPO_PATH / "tests" / "models" / module_name / f for f in test_files]
+ # Filter by existing files
+ test_files = [f for f in test_files if f.exists()]
+
+ return {"doc_file": doc_file, "model_files": model_files, "module_name": module_name, "test_files": test_files}
+
+
+_re_checkpoint_for_doc = re.compile(r"^_CHECKPOINT_FOR_DOC\s+=\s+(\S*)\s*$", flags=re.MULTILINE)
+
+
+def find_base_model_checkpoint(
+ model_type: str, model_files: Optional[Dict[str, Union[Path, List[Path]]]] = None
+) -> str:
+ """
+ Finds the model checkpoint used in the docstrings for a given model.
+
+ Args:
+ model_type (`str`): A valid model type (like "bert" or "gpt2")
+ model_files (`Dict[str, Union[Path, List[Path]]`, *optional*):
+ The files associated to `model_type`. Can be passed to speed up the function, otherwise will be computed.
+
+ Returns:
+ `str`: The checkpoint used.
+ """
+ if model_files is None:
+ model_files = get_model_files(model_type)
+ module_files = model_files["model_files"]
+ for fname in module_files:
+ if "modeling" not in str(fname):
+ continue
+
+ with open(fname, "r", encoding="utf-8") as f:
+ content = f.read()
+ if _re_checkpoint_for_doc.search(content) is not None:
+ checkpoint = _re_checkpoint_for_doc.search(content).groups()[0]
+ # Remove quotes
+ checkpoint = checkpoint.replace('"', "")
+ checkpoint = checkpoint.replace("'", "")
+ return checkpoint
+
+ # TODO: Find some kind of fallback if there is no _CHECKPOINT_FOR_DOC in any of the modeling file.
+ return ""
+
+
+def get_default_frameworks():
+ """
+ Returns the list of frameworks (PyTorch, TensorFlow, Flax) that are installed in the environment.
+ """
+ frameworks = []
+ if is_torch_available():
+ frameworks.append("pt")
+ if is_tf_available():
+ frameworks.append("tf")
+ if is_flax_available():
+ frameworks.append("flax")
+ return frameworks
+
+
+_re_model_mapping = re.compile("MODEL_([A-Z_]*)MAPPING_NAMES")
+
+
+def retrieve_model_classes(model_type: str, frameworks: Optional[List[str]] = None) -> Dict[str, List[str]]:
+ """
+ Retrieve the model classes associated to a given model.
+
+ Args:
+ model_type (`str`): A valid model type (like "bert" or "gpt2")
+ frameworks (`List[str]`, *optional*):
+ The frameworks to look for. Will default to `["pt", "tf", "flax"]`, passing a smaller list will restrict
+ the classes returned.
+
+ Returns:
+ `Dict[str, List[str]]`: A dictionary with one key per framework and the list of model classes associated to
+ that framework as values.
+ """
+ if frameworks is None:
+ frameworks = get_default_frameworks()
+
+ modules = {
+ "pt": auto_module.modeling_auto if is_torch_available() else None,
+ "tf": auto_module.modeling_tf_auto if is_tf_available() else None,
+ "flax": auto_module.modeling_flax_auto if is_flax_available() else None,
+ }
+
+ model_classes = {}
+ for framework in frameworks:
+ new_model_classes = []
+ if modules[framework] is None:
+ raise ValueError(f"You selected {framework} in the frameworks, but it is not installed.")
+ model_mappings = [attr for attr in dir(modules[framework]) if _re_model_mapping.search(attr) is not None]
+ for model_mapping_name in model_mappings:
+ model_mapping = getattr(modules[framework], model_mapping_name)
+ if model_type in model_mapping:
+ new_model_classes.append(model_mapping[model_type])
+
+ if len(new_model_classes) > 0:
+ # Remove duplicates
+ model_classes[framework] = list(set(new_model_classes))
+
+ return model_classes
+
+
+def retrieve_info_for_model(model_type, frameworks: Optional[List[str]] = None):
+ """
+ Retrieves all the information from a given model_type.
+
+ Args:
+ model_type (`str`): A valid model type (like "bert" or "gpt2")
+ frameworks (`List[str]`, *optional*):
+ If passed, will only keep the info corresponding to the passed frameworks.
+
+ Returns:
+ `Dict`: A dictionary with the following keys:
+ - **frameworks** (`List[str]`): The list of frameworks that back this model type.
+ - **model_classes** (`Dict[str, List[str]]`): The model classes implemented for that model type.
+ - **model_files** (`Dict[str, Union[Path, List[Path]]]`): The files associated with that model type.
+ - **model_patterns** (`ModelPatterns`): The various patterns for the model.
+ """
+ if model_type not in auto_module.MODEL_NAMES_MAPPING:
+ raise ValueError(f"{model_type} is not a valid model type.")
+
+ model_name = auto_module.MODEL_NAMES_MAPPING[model_type]
+ config_class = auto_module.configuration_auto.CONFIG_MAPPING_NAMES[model_type]
+ if model_type in auto_module.tokenization_auto.TOKENIZER_MAPPING_NAMES:
+ tokenizer_classes = auto_module.tokenization_auto.TOKENIZER_MAPPING_NAMES[model_type]
+ tokenizer_class = tokenizer_classes[0] if tokenizer_classes[0] is not None else tokenizer_classes[1]
+ else:
+ tokenizer_class = None
+ image_processor_classes = auto_module.image_processing_auto.IMAGE_PROCESSOR_MAPPING_NAMES.get(model_type, None)
+ if isinstance(image_processor_classes, tuple):
+ image_processor_class, image_processor_fast_class = image_processor_classes
+ else:
+ image_processor_class = image_processor_classes
+ image_processor_fast_class = None
+ feature_extractor_class = auto_module.feature_extraction_auto.FEATURE_EXTRACTOR_MAPPING_NAMES.get(model_type, None)
+ processor_class = auto_module.processing_auto.PROCESSOR_MAPPING_NAMES.get(model_type, None)
+
+ model_files = get_model_files(model_type, frameworks=frameworks)
+ model_camel_cased = config_class.replace("Config", "")
+
+ available_frameworks = []
+ for fname in model_files["model_files"]:
+ if "modeling_tf" in str(fname):
+ available_frameworks.append("tf")
+ elif "modeling_flax" in str(fname):
+ available_frameworks.append("flax")
+ elif "modeling" in str(fname):
+ available_frameworks.append("pt")
+
+ if frameworks is None:
+ frameworks = get_default_frameworks()
+
+ frameworks = [f for f in frameworks if f in available_frameworks]
+
+ model_classes = retrieve_model_classes(model_type, frameworks=frameworks)
+
+ model_upper_cased = model_camel_cased.upper()
+ model_patterns = ModelPatterns(
+ model_name,
+ checkpoint=find_base_model_checkpoint(model_type, model_files=model_files),
+ model_type=model_type,
+ model_camel_cased=model_camel_cased,
+ model_lower_cased=model_files["module_name"],
+ model_upper_cased=model_upper_cased,
+ config_class=config_class,
+ tokenizer_class=tokenizer_class,
+ image_processor_class=image_processor_class,
+ image_processor_fast_class=image_processor_fast_class,
+ feature_extractor_class=feature_extractor_class,
+ processor_class=processor_class,
+ )
+
+ return {
+ "frameworks": frameworks,
+ "model_classes": model_classes,
+ "model_files": model_files,
+ "model_patterns": model_patterns,
+ }
+
+
+def clean_frameworks_in_init(
+ init_file: Union[str, os.PathLike], frameworks: Optional[List[str]] = None, keep_processing: bool = True
+):
+ """
+ Removes all the import lines that don't belong to a given list of frameworks or concern tokenizers/feature
+ extractors/image processors/processors in an init.
+
+ Args:
+ init_file (`str` or `os.PathLike`): The path to the init to treat.
+ frameworks (`List[str]`, *optional*):
+ If passed, this will remove all imports that are subject to a framework not in frameworks
+ keep_processing (`bool`, *optional*, defaults to `True`):
+ Whether or not to keep the preprocessing (tokenizer, feature extractor, image processor, processor) imports
+ in the init.
+ """
+ if frameworks is None:
+ frameworks = get_default_frameworks()
+
+ names = {"pt": "torch"}
+ to_remove = [names.get(f, f) for f in ["pt", "tf", "flax"] if f not in frameworks]
+ if not keep_processing:
+ to_remove.extend(["sentencepiece", "tokenizers", "vision"])
+
+ if len(to_remove) == 0:
+ # Nothing to do
+ return
+
+ remove_pattern = "|".join(to_remove)
+ re_conditional_imports = re.compile(rf"^\s*if not is_({remove_pattern})_available\(\):\s*$")
+ re_try = re.compile(r"\s*try:")
+ re_else = re.compile(r"\s*else:")
+ re_is_xxx_available = re.compile(rf"is_({remove_pattern})_available")
+
+ with open(init_file, "r", encoding="utf-8") as f:
+ content = f.read()
+
+ lines = content.split("\n")
+ new_lines = []
+ idx = 0
+ while idx < len(lines):
+ # Conditional imports in try-except-else blocks
+ if (re_conditional_imports.search(lines[idx]) is not None) and (re_try.search(lines[idx - 1]) is not None):
+ # Remove the preceding `try:`
+ new_lines.pop()
+ idx += 1
+ # Iterate until `else:`
+ while is_empty_line(lines[idx]) or re_else.search(lines[idx]) is None:
+ idx += 1
+ idx += 1
+ indent = find_indent(lines[idx])
+ while find_indent(lines[idx]) >= indent or is_empty_line(lines[idx]):
+ idx += 1
+ # Remove the import from utils
+ elif re_is_xxx_available.search(lines[idx]) is not None:
+ line = lines[idx]
+ for framework in to_remove:
+ line = line.replace(f", is_{framework}_available", "")
+ line = line.replace(f"is_{framework}_available, ", "")
+ line = line.replace(f"is_{framework}_available,", "")
+ line = line.replace(f"is_{framework}_available", "")
+
+ if len(line.strip()) > 0:
+ new_lines.append(line)
+ idx += 1
+ # Otherwise we keep the line, except if it's a tokenizer import and we don't want to keep it.
+ elif keep_processing or (
+ re.search(r'^\s*"(tokenization|processing|feature_extraction|image_processing)', lines[idx]) is None
+ and re.search(r"^\s*from .(tokenization|processing|feature_extraction|image_processing)", lines[idx])
+ is None
+ ):
+ new_lines.append(lines[idx])
+ idx += 1
+ else:
+ idx += 1
+
+ with open(init_file, "w", encoding="utf-8") as f:
+ f.write("\n".join(new_lines))
+
+
+def add_model_to_main_init(
+ old_model_patterns: ModelPatterns,
+ new_model_patterns: ModelPatterns,
+ frameworks: Optional[List[str]] = None,
+ with_processing: bool = True,
+):
+ """
+ Add a model to the main init of Transformers.
+
+ Args:
+ old_model_patterns (`ModelPatterns`): The patterns for the old model.
+ new_model_patterns (`ModelPatterns`): The patterns for the new model.
+ frameworks (`List[str]`, *optional*):
+ If specified, only the models implemented in those frameworks will be added.
+ with_processing (`bool`, *optional*, defaults to `True`):
+ Whether the tokenizer/feature extractor/processor of the model should also be added to the init or not.
+ """
+ with open(TRANSFORMERS_PATH / "__init__.py", "r", encoding="utf-8") as f:
+ content = f.read()
+
+ lines = content.split("\n")
+ idx = 0
+ new_lines = []
+ framework = None
+ while idx < len(lines):
+ new_framework = False
+ if not is_empty_line(lines[idx]) and find_indent(lines[idx]) == 0:
+ framework = None
+ elif lines[idx].lstrip().startswith("if not is_torch_available"):
+ framework = "pt"
+ new_framework = True
+ elif lines[idx].lstrip().startswith("if not is_tf_available"):
+ framework = "tf"
+ new_framework = True
+ elif lines[idx].lstrip().startswith("if not is_flax_available"):
+ framework = "flax"
+ new_framework = True
+
+ if new_framework:
+ # For a new framework, we need to skip until the else: block to get where the imports are.
+ while lines[idx].strip() != "else:":
+ new_lines.append(lines[idx])
+ idx += 1
+
+ # Skip if we are in a framework not wanted.
+ if framework is not None and frameworks is not None and framework not in frameworks:
+ new_lines.append(lines[idx])
+ idx += 1
+ elif re.search(rf'models.{old_model_patterns.model_lower_cased}( |")', lines[idx]) is not None:
+ block = [lines[idx]]
+ indent = find_indent(lines[idx])
+ idx += 1
+ while find_indent(lines[idx]) > indent:
+ block.append(lines[idx])
+ idx += 1
+ if lines[idx].strip() in [")", "]", "],"]:
+ block.append(lines[idx])
+ idx += 1
+ block = "\n".join(block)
+ new_lines.append(block)
+
+ add_block = True
+ if not with_processing:
+ processing_classes = [
+ old_model_patterns.tokenizer_class,
+ old_model_patterns.image_processor_class,
+ old_model_patterns.image_processor_fast_class,
+ old_model_patterns.feature_extractor_class,
+ old_model_patterns.processor_class,
+ ]
+ # Only keep the ones that are not None
+ processing_classes = [c for c in processing_classes if c is not None]
+ for processing_class in processing_classes:
+ block = block.replace(f' "{processing_class}",', "")
+ block = block.replace(f', "{processing_class}"', "")
+ block = block.replace(f" {processing_class},", "")
+ block = block.replace(f", {processing_class}", "")
+
+ if processing_class in block:
+ add_block = False
+ if add_block:
+ new_lines.append(replace_model_patterns(block, old_model_patterns, new_model_patterns)[0])
+ else:
+ new_lines.append(lines[idx])
+ idx += 1
+
+ with open(TRANSFORMERS_PATH / "__init__.py", "w", encoding="utf-8") as f:
+ f.write("\n".join(new_lines))
+
+
+def insert_tokenizer_in_auto_module(old_model_patterns: ModelPatterns, new_model_patterns: ModelPatterns):
+ """
+ Add a tokenizer to the relevant mappings in the auto module.
+
+ Args:
+ old_model_patterns (`ModelPatterns`): The patterns for the old model.
+ new_model_patterns (`ModelPatterns`): The patterns for the new model.
+ """
+ if old_model_patterns.tokenizer_class is None or new_model_patterns.tokenizer_class is None:
+ return
+
+ with open(TRANSFORMERS_PATH / "models" / "auto" / "tokenization_auto.py", "r", encoding="utf-8") as f:
+ content = f.read()
+
+ lines = content.split("\n")
+ idx = 0
+ # First we get to the TOKENIZER_MAPPING_NAMES block.
+ while not lines[idx].startswith(" TOKENIZER_MAPPING_NAMES = OrderedDict("):
+ idx += 1
+ idx += 1
+
+ # That block will end at this prompt:
+ while not lines[idx].startswith("TOKENIZER_MAPPING = _LazyAutoMapping"):
+ # Either all the tokenizer block is defined on one line, in which case, it ends with "),"
+ if lines[idx].endswith(","):
+ block = lines[idx]
+ # Otherwise it takes several lines until we get to a "),"
+ else:
+ block = []
+ while not lines[idx].startswith(" ),"):
+ block.append(lines[idx])
+ idx += 1
+ block = "\n".join(block)
+ idx += 1
+
+ # If we find the model type and tokenizer class in that block, we have the old model tokenizer block
+ if f'"{old_model_patterns.model_type}"' in block and old_model_patterns.tokenizer_class in block:
+ break
+
+ new_block = block.replace(old_model_patterns.model_type, new_model_patterns.model_type)
+ new_block = new_block.replace(old_model_patterns.tokenizer_class, new_model_patterns.tokenizer_class)
+
+ new_lines = lines[:idx] + [new_block] + lines[idx:]
+ with open(TRANSFORMERS_PATH / "models" / "auto" / "tokenization_auto.py", "w", encoding="utf-8") as f:
+ f.write("\n".join(new_lines))
+
+
+AUTO_CLASSES_PATTERNS = {
+ "configuration_auto.py": [
+ ' ("{model_type}", "{model_name}"),',
+ ' ("{model_type}", "{config_class}"),',
+ ' ("{model_type}", "{pretrained_archive_map}"),',
+ ],
+ "feature_extraction_auto.py": [' ("{model_type}", "{feature_extractor_class}"),'],
+ "image_processing_auto.py": [' ("{model_type}", "{image_processor_classes}"),'],
+ "modeling_auto.py": [' ("{model_type}", "{any_pt_class}"),'],
+ "modeling_tf_auto.py": [' ("{model_type}", "{any_tf_class}"),'],
+ "modeling_flax_auto.py": [' ("{model_type}", "{any_flax_class}"),'],
+ "processing_auto.py": [' ("{model_type}", "{processor_class}"),'],
+}
+
+
+def add_model_to_auto_classes(
+ old_model_patterns: ModelPatterns, new_model_patterns: ModelPatterns, model_classes: Dict[str, List[str]]
+):
+ """
+ Add a model to the relevant mappings in the auto module.
+
+ Args:
+ old_model_patterns (`ModelPatterns`): The patterns for the old model.
+ new_model_patterns (`ModelPatterns`): The patterns for the new model.
+ model_classes (`Dict[str, List[str]]`): A dictionary framework to list of model classes implemented.
+ """
+ for filename in AUTO_CLASSES_PATTERNS:
+ # Extend patterns with all model classes if necessary
+ new_patterns = []
+ for pattern in AUTO_CLASSES_PATTERNS[filename]:
+ if re.search("any_([a-z]*)_class", pattern) is not None:
+ framework = re.search("any_([a-z]*)_class", pattern).groups()[0]
+ if framework in model_classes:
+ new_patterns.extend(
+ [
+ pattern.replace("{" + f"any_{framework}_class" + "}", cls)
+ for cls in model_classes[framework]
+ ]
+ )
+ elif "{config_class}" in pattern:
+ new_patterns.append(pattern.replace("{config_class}", old_model_patterns.config_class))
+ elif "{image_processor_classes}" in pattern:
+ if (
+ old_model_patterns.image_processor_class is not None
+ and new_model_patterns.image_processor_class is not None
+ ):
+ if (
+ old_model_patterns.image_processor_fast_class is not None
+ and new_model_patterns.image_processor_fast_class is not None
+ ):
+ new_patterns.append(
+ pattern.replace(
+ '"{image_processor_classes}"',
+ f'("{old_model_patterns.image_processor_class}", "{old_model_patterns.image_processor_fast_class}")',
+ )
+ )
+ else:
+ new_patterns.append(
+ pattern.replace(
+ '"{image_processor_classes}"', f'("{old_model_patterns.image_processor_class}",)'
+ )
+ )
+ elif "{feature_extractor_class}" in pattern:
+ if (
+ old_model_patterns.feature_extractor_class is not None
+ and new_model_patterns.feature_extractor_class is not None
+ ):
+ new_patterns.append(
+ pattern.replace("{feature_extractor_class}", old_model_patterns.feature_extractor_class)
+ )
+ elif "{processor_class}" in pattern:
+ if old_model_patterns.processor_class is not None and new_model_patterns.processor_class is not None:
+ new_patterns.append(pattern.replace("{processor_class}", old_model_patterns.processor_class))
+ else:
+ new_patterns.append(pattern)
+
+ # Loop through all patterns.
+ for pattern in new_patterns:
+ full_name = TRANSFORMERS_PATH / "models" / "auto" / filename
+ old_model_line = pattern
+ new_model_line = pattern
+ for attr in ["model_type", "model_name"]:
+ old_model_line = old_model_line.replace("{" + attr + "}", getattr(old_model_patterns, attr))
+ new_model_line = new_model_line.replace("{" + attr + "}", getattr(new_model_patterns, attr))
+ new_model_line = new_model_line.replace(
+ old_model_patterns.model_camel_cased, new_model_patterns.model_camel_cased
+ )
+ add_content_to_file(full_name, new_model_line, add_after=old_model_line)
+
+ # Tokenizers require special handling
+ insert_tokenizer_in_auto_module(old_model_patterns, new_model_patterns)
+
+
+DOC_OVERVIEW_TEMPLATE = """## Overview
+
+The {model_name} model was proposed in []() by .
+
+
+The abstract from the paper is the following:
+
+**
+
+Tips:
+
+
+
+This model was contributed by [INSERT YOUR HF USERNAME HERE](https://huggingface.co/).
+The original code can be found [here]().
+
+"""
+
+
+def duplicate_doc_file(
+ doc_file: Union[str, os.PathLike],
+ old_model_patterns: ModelPatterns,
+ new_model_patterns: ModelPatterns,
+ dest_file: Optional[Union[str, os.PathLike]] = None,
+ frameworks: Optional[List[str]] = None,
+):
+ """
+ Duplicate a documentation file and adapts it for a new model.
+
+ Args:
+ module_file (`str` or `os.PathLike`): Path to the doc file to duplicate.
+ old_model_patterns (`ModelPatterns`): The patterns for the old model.
+ new_model_patterns (`ModelPatterns`): The patterns for the new model.
+ dest_file (`str` or `os.PathLike`, *optional*): Path to the new doc file.
+ Will default to the a file named `{new_model_patterns.model_type}.md` in the same folder as `module_file`.
+ frameworks (`List[str]`, *optional*):
+ If passed, will only keep the model classes corresponding to this list of frameworks in the new doc file.
+ """
+ with open(doc_file, "r", encoding="utf-8") as f:
+ content = f.read()
+
+ content = re.sub(r"
+"""
+
+AUTOGENERATED_KERAS_COMMENT = """
+
+"""
+
+
+TASK_TAG_TO_NAME_MAPPING = {
+ "fill-mask": "Masked Language Modeling",
+ "image-classification": "Image Classification",
+ "image-segmentation": "Image Segmentation",
+ "multiple-choice": "Multiple Choice",
+ "object-detection": "Object Detection",
+ "question-answering": "Question Answering",
+ "summarization": "Summarization",
+ "table-question-answering": "Table Question Answering",
+ "text-classification": "Text Classification",
+ "text-generation": "Causal Language Modeling",
+ "text2text-generation": "Sequence-to-sequence Language Modeling",
+ "token-classification": "Token Classification",
+ "translation": "Translation",
+ "zero-shot-classification": "Zero Shot Classification",
+ "automatic-speech-recognition": "Automatic Speech Recognition",
+ "audio-classification": "Audio Classification",
+}
+
+
+METRIC_TAGS = [
+ "accuracy",
+ "bleu",
+ "f1",
+ "matthews_correlation",
+ "pearsonr",
+ "precision",
+ "recall",
+ "rouge",
+ "sacrebleu",
+ "spearmanr",
+ "wer",
+]
+
+
+def _listify(obj):
+ if obj is None:
+ return []
+ elif isinstance(obj, str):
+ return [obj]
+ else:
+ return obj
+
+
+def _insert_values_as_list(metadata, name, values):
+ if values is None:
+ return metadata
+ if isinstance(values, str):
+ values = [values]
+ values = [v for v in values if v is not None]
+ if len(values) == 0:
+ return metadata
+ metadata[name] = values
+ return metadata
+
+
+def infer_metric_tags_from_eval_results(eval_results):
+ if eval_results is None:
+ return {}
+ result = {}
+ for key in eval_results.keys():
+ if key.lower().replace(" ", "_") in METRIC_TAGS:
+ result[key.lower().replace(" ", "_")] = key
+ elif key.lower() == "rouge1":
+ result["rouge"] = key
+ return result
+
+
+def _insert_value(metadata, name, value):
+ if value is None:
+ return metadata
+ metadata[name] = value
+ return metadata
+
+
+def is_hf_dataset(dataset):
+ if not is_datasets_available():
+ return False
+
+ from datasets import Dataset, IterableDataset
+
+ return isinstance(dataset, (Dataset, IterableDataset))
+
+
+def _get_mapping_values(mapping):
+ result = []
+ for v in mapping.values():
+ if isinstance(v, (tuple, list)):
+ result += list(v)
+ else:
+ result.append(v)
+ return result
+
+
+@dataclass
+class TrainingSummary:
+ model_name: str
+ language: Optional[Union[str, list[str]]] = None
+ license: Optional[str] = None
+ tags: Optional[Union[str, list[str]]] = None
+ finetuned_from: Optional[str] = None
+ tasks: Optional[Union[str, list[str]]] = None
+ dataset: Optional[Union[str, list[str]]] = None
+ dataset_tags: Optional[Union[str, list[str]]] = None
+ dataset_args: Optional[Union[str, list[str]]] = None
+ dataset_metadata: Optional[dict[str, Any]] = None
+ eval_results: Optional[dict[str, float]] = None
+ eval_lines: Optional[list[str]] = None
+ hyperparameters: Optional[dict[str, Any]] = None
+ source: Optional[str] = "trainer"
+
+ def __post_init__(self):
+ # Infer default license from the checkpoint used, if possible.
+ if (
+ self.license is None
+ and not is_offline_mode()
+ and self.finetuned_from is not None
+ and len(self.finetuned_from) > 0
+ ):
+ try:
+ info = model_info(self.finetuned_from)
+ for tag in info.tags:
+ if tag.startswith("license:"):
+ self.license = tag[8:]
+ except (requests.exceptions.HTTPError, requests.exceptions.ConnectionError, HFValidationError):
+ pass
+
+ def create_model_index(self, metric_mapping):
+ model_index = {"name": self.model_name}
+
+ # Dataset mapping tag -> name
+ dataset_names = _listify(self.dataset)
+ dataset_tags = _listify(self.dataset_tags)
+ dataset_args = _listify(self.dataset_args)
+ dataset_metadata = _listify(self.dataset_metadata)
+ if len(dataset_args) < len(dataset_tags):
+ dataset_args = dataset_args + [None] * (len(dataset_tags) - len(dataset_args))
+ dataset_mapping = dict(zip(dataset_tags, dataset_names))
+ dataset_arg_mapping = dict(zip(dataset_tags, dataset_args))
+ dataset_metadata_mapping = dict(zip(dataset_tags, dataset_metadata))
+
+ task_mapping = {
+ task: TASK_TAG_TO_NAME_MAPPING[task] for task in _listify(self.tasks) if task in TASK_TAG_TO_NAME_MAPPING
+ }
+
+ model_index["results"] = []
+
+ if len(task_mapping) == 0 and len(dataset_mapping) == 0:
+ return [model_index]
+ if len(task_mapping) == 0:
+ task_mapping = {None: None}
+ if len(dataset_mapping) == 0:
+ dataset_mapping = {None: None}
+
+ # One entry per dataset and per task
+ all_possibilities = [(task_tag, ds_tag) for task_tag in task_mapping for ds_tag in dataset_mapping]
+ for task_tag, ds_tag in all_possibilities:
+ result = {}
+ if task_tag is not None:
+ result["task"] = {"name": task_mapping[task_tag], "type": task_tag}
+
+ if ds_tag is not None:
+ metadata = dataset_metadata_mapping.get(ds_tag, {})
+ result["dataset"] = {
+ "name": dataset_mapping[ds_tag],
+ "type": ds_tag,
+ **metadata,
+ }
+ if dataset_arg_mapping[ds_tag] is not None:
+ result["dataset"]["args"] = dataset_arg_mapping[ds_tag]
+
+ if len(metric_mapping) > 0:
+ result["metrics"] = []
+ for metric_tag, metric_name in metric_mapping.items():
+ result["metrics"].append(
+ {
+ "name": metric_name,
+ "type": metric_tag,
+ "value": self.eval_results[metric_name],
+ }
+ )
+
+ # Remove partial results to avoid the model card being rejected.
+ if "task" in result and "dataset" in result and "metrics" in result:
+ model_index["results"].append(result)
+ else:
+ logger.info(f"Dropping the following result as it does not have all the necessary fields:\n{result}")
+
+ return [model_index]
+
+ def create_metadata(self):
+ metric_mapping = infer_metric_tags_from_eval_results(self.eval_results)
+
+ metadata = {}
+ metadata = _insert_value(metadata, "library_name", "transformers")
+ metadata = _insert_values_as_list(metadata, "language", self.language)
+ metadata = _insert_value(metadata, "license", self.license)
+ if self.finetuned_from is not None and isinstance(self.finetuned_from, str) and len(self.finetuned_from) > 0:
+ metadata = _insert_value(metadata, "base_model", self.finetuned_from)
+ metadata = _insert_values_as_list(metadata, "tags", self.tags)
+ metadata = _insert_values_as_list(metadata, "datasets", self.dataset_tags)
+ metadata = _insert_values_as_list(metadata, "metrics", list(metric_mapping.keys()))
+ metadata["model-index"] = self.create_model_index(metric_mapping)
+
+ return metadata
+
+ def to_model_card(self):
+ model_card = ""
+
+ metadata = yaml.dump(self.create_metadata(), sort_keys=False)
+ if len(metadata) > 0:
+ model_card = f"---\n{metadata}---\n"
+
+ # Now the model card for realsies.
+ if self.source == "trainer":
+ model_card += AUTOGENERATED_TRAINER_COMMENT
+ else:
+ model_card += AUTOGENERATED_KERAS_COMMENT
+
+ model_card += f"\n# {self.model_name}\n\n"
+
+ if self.finetuned_from is None:
+ model_card += "This model was trained from scratch on "
+ else:
+ model_card += (
+ "This model is a fine-tuned version of"
+ f" [{self.finetuned_from}](https://huggingface.co/{self.finetuned_from}) on "
+ )
+
+ if self.dataset is None or (isinstance(self.dataset, list) and len(self.dataset) == 0):
+ model_card += "an unknown dataset."
+ else:
+ if isinstance(self.dataset, str):
+ model_card += f"the {self.dataset} dataset."
+ elif isinstance(self.dataset, (tuple, list)) and len(self.dataset) == 1:
+ model_card += f"the {self.dataset[0]} dataset."
+ else:
+ model_card += (
+ ", ".join([f"the {ds}" for ds in self.dataset[:-1]]) + f" and the {self.dataset[-1]} datasets."
+ )
+
+ if self.eval_results is not None:
+ model_card += "\nIt achieves the following results on the evaluation set:\n"
+ model_card += "\n".join([f"- {name}: {_maybe_round(value)}" for name, value in self.eval_results.items()])
+ model_card += "\n"
+
+ model_card += "\n## Model description\n\nMore information needed\n"
+ model_card += "\n## Intended uses & limitations\n\nMore information needed\n"
+ model_card += "\n## Training and evaluation data\n\nMore information needed\n"
+
+ model_card += "\n## Training procedure\n"
+ model_card += "\n### Training hyperparameters\n"
+ if self.hyperparameters is not None:
+ model_card += "\nThe following hyperparameters were used during training:\n"
+ model_card += "\n".join([f"- {name}: {value}" for name, value in self.hyperparameters.items()])
+ model_card += "\n"
+ else:
+ model_card += "\nMore information needed\n"
+
+ if self.eval_lines is not None:
+ model_card += "\n### Training results\n\n"
+ model_card += make_markdown_table(self.eval_lines)
+ model_card += "\n"
+
+ model_card += "\n### Framework versions\n\n"
+ model_card += f"- Transformers {__version__}\n"
+
+ if self.source == "trainer" and is_torch_available():
+ import torch
+
+ model_card += f"- Pytorch {torch.__version__}\n"
+ elif self.source == "keras" and is_tf_available():
+ import tensorflow as tf
+
+ model_card += f"- TensorFlow {tf.__version__}\n"
+ if is_datasets_available():
+ import datasets
+
+ model_card += f"- Datasets {datasets.__version__}\n"
+ if is_tokenizers_available():
+ import tokenizers
+
+ model_card += f"- Tokenizers {tokenizers.__version__}\n"
+
+ return model_card
+
+ @classmethod
+ def from_trainer(
+ cls,
+ trainer,
+ language=None,
+ license=None,
+ tags=None,
+ model_name=None,
+ finetuned_from=None,
+ tasks=None,
+ dataset_tags=None,
+ dataset_metadata=None,
+ dataset=None,
+ dataset_args=None,
+ ):
+ # Infer default from dataset
+ one_dataset = trainer.eval_dataset if trainer.eval_dataset is not None else trainer.train_dataset
+ if is_hf_dataset(one_dataset) and (dataset_tags is None or dataset_args is None or dataset_metadata is None):
+ default_tag = one_dataset.builder_name
+ # Those are not real datasets from the Hub so we exclude them.
+ if default_tag not in ["csv", "json", "pandas", "parquet", "text"]:
+ if dataset_metadata is None:
+ dataset_metadata = [{"config": one_dataset.config_name, "split": str(one_dataset.split)}]
+ if dataset_tags is None:
+ dataset_tags = [default_tag]
+ if dataset_args is None:
+ dataset_args = [one_dataset.config_name]
+
+ if dataset is None and dataset_tags is not None:
+ dataset = dataset_tags
+
+ # Infer default finetuned_from
+ if (
+ finetuned_from is None
+ and hasattr(trainer.model.config, "_name_or_path")
+ and not os.path.isdir(trainer.model.config._name_or_path)
+ ):
+ finetuned_from = trainer.model.config._name_or_path
+
+ # Infer default task tag:
+ if tasks is None:
+ model_class_name = trainer.model.__class__.__name__
+ for task, mapping in TASK_MAPPING.items():
+ if model_class_name in _get_mapping_values(mapping):
+ tasks = task
+
+ if model_name is None:
+ model_name = Path(trainer.args.output_dir).name
+ if len(model_name) == 0:
+ model_name = finetuned_from
+
+ # Add `generated_from_trainer` to the tags
+ if tags is None:
+ tags = ["generated_from_trainer"]
+ elif isinstance(tags, str) and tags != "generated_from_trainer":
+ tags = [tags, "generated_from_trainer"]
+ elif "generated_from_trainer" not in tags:
+ tags.append("generated_from_trainer")
+
+ _, eval_lines, eval_results = parse_log_history(trainer.state.log_history)
+ hyperparameters = extract_hyperparameters_from_trainer(trainer)
+
+ return cls(
+ language=language,
+ license=license,
+ tags=tags,
+ model_name=model_name,
+ finetuned_from=finetuned_from,
+ tasks=tasks,
+ dataset=dataset,
+ dataset_tags=dataset_tags,
+ dataset_args=dataset_args,
+ dataset_metadata=dataset_metadata,
+ eval_results=eval_results,
+ eval_lines=eval_lines,
+ hyperparameters=hyperparameters,
+ )
+
+ @classmethod
+ def from_keras(
+ cls,
+ model,
+ model_name,
+ keras_history=None,
+ language=None,
+ license=None,
+ tags=None,
+ finetuned_from=None,
+ tasks=None,
+ dataset_tags=None,
+ dataset=None,
+ dataset_args=None,
+ ):
+ # Infer default from dataset
+ if dataset is not None:
+ if is_hf_dataset(dataset) and (dataset_tags is None or dataset_args is None):
+ default_tag = dataset.builder_name
+ # Those are not real datasets from the Hub so we exclude them.
+ if default_tag not in ["csv", "json", "pandas", "parquet", "text"]:
+ if dataset_tags is None:
+ dataset_tags = [default_tag]
+ if dataset_args is None:
+ dataset_args = [dataset.config_name]
+
+ if dataset is None and dataset_tags is not None:
+ dataset = dataset_tags
+
+ # Infer default finetuned_from
+ if (
+ finetuned_from is None
+ and hasattr(model.config, "_name_or_path")
+ and not os.path.isdir(model.config._name_or_path)
+ ):
+ finetuned_from = model.config._name_or_path
+
+ # Infer default task tag:
+ if tasks is None:
+ model_class_name = model.__class__.__name__
+ for task, mapping in TASK_MAPPING.items():
+ if model_class_name in _get_mapping_values(mapping):
+ tasks = task
+
+ # Add `generated_from_keras_callback` to the tags
+ if tags is None:
+ tags = ["generated_from_keras_callback"]
+ elif isinstance(tags, str) and tags != "generated_from_keras_callback":
+ tags = [tags, "generated_from_keras_callback"]
+ elif "generated_from_keras_callback" not in tags:
+ tags.append("generated_from_keras_callback")
+
+ if keras_history is not None:
+ _, eval_lines, eval_results = parse_keras_history(keras_history)
+ else:
+ eval_lines = []
+ eval_results = {}
+ hyperparameters = extract_hyperparameters_from_keras(model)
+
+ return cls(
+ language=language,
+ license=license,
+ tags=tags,
+ model_name=model_name,
+ finetuned_from=finetuned_from,
+ tasks=tasks,
+ dataset_tags=dataset_tags,
+ dataset=dataset,
+ dataset_args=dataset_args,
+ eval_results=eval_results,
+ eval_lines=eval_lines,
+ hyperparameters=hyperparameters,
+ source="keras",
+ )
+
+
+def parse_keras_history(logs):
+ """
+ Parse the `logs` of either a `keras.History` object returned by `model.fit()` or an accumulated logs `dict`
+ passed to the `PushToHubCallback`. Returns lines and logs compatible with those returned by `parse_log_history`.
+ """
+ if hasattr(logs, "history"):
+ # This looks like a `History` object
+ if not hasattr(logs, "epoch"):
+ # This history looks empty, return empty results
+ return None, [], {}
+ logs.history["epoch"] = logs.epoch
+ logs = logs.history
+ else:
+ # Training logs is a list of dicts, let's invert it to a dict of lists to match a History object
+ logs = {log_key: [single_dict[log_key] for single_dict in logs] for log_key in logs[0]}
+
+ lines = []
+ for i in range(len(logs["epoch"])):
+ epoch_dict = {log_key: log_value_list[i] for log_key, log_value_list in logs.items()}
+ values = {}
+ for k, v in epoch_dict.items():
+ if k.startswith("val_"):
+ k = "validation_" + k[4:]
+ elif k != "epoch":
+ k = "train_" + k
+ splits = k.split("_")
+ name = " ".join([part.capitalize() for part in splits])
+ values[name] = v
+ lines.append(values)
+
+ eval_results = lines[-1]
+
+ return logs, lines, eval_results
+
+
+def parse_log_history(log_history):
+ """
+ Parse the `log_history` of a Trainer to get the intermediate and final evaluation results.
+ """
+ idx = 0
+ while idx < len(log_history) and "train_runtime" not in log_history[idx]:
+ idx += 1
+
+ # If there are no training logs
+ if idx == len(log_history):
+ idx -= 1
+ while idx >= 0 and "eval_loss" not in log_history[idx]:
+ idx -= 1
+
+ if idx >= 0:
+ return None, None, log_history[idx]
+ else:
+ return None, None, None
+
+ # From now one we can assume we have training logs:
+ train_log = log_history[idx]
+ lines = []
+ training_loss = "No log"
+ for i in range(idx):
+ if "loss" in log_history[i]:
+ training_loss = log_history[i]["loss"]
+ if "eval_loss" in log_history[i]:
+ metrics = log_history[i].copy()
+ _ = metrics.pop("total_flos", None)
+ epoch = metrics.pop("epoch", None)
+ step = metrics.pop("step", None)
+ _ = metrics.pop("eval_runtime", None)
+ _ = metrics.pop("eval_samples_per_second", None)
+ _ = metrics.pop("eval_steps_per_second", None)
+ _ = metrics.pop("eval_jit_compilation_time", None)
+ values = {"Training Loss": training_loss, "Epoch": epoch, "Step": step}
+ for k, v in metrics.items():
+ if k == "eval_loss":
+ values["Validation Loss"] = v
+ else:
+ splits = k.split("_")
+ name = " ".join([part.capitalize() for part in splits[1:]])
+ values[name] = v
+ lines.append(values)
+
+ idx = len(log_history) - 1
+ while idx >= 0 and "eval_loss" not in log_history[idx]:
+ idx -= 1
+
+ if idx > 0:
+ eval_results = {}
+ for key, value in log_history[idx].items():
+ if key.startswith("eval_"):
+ key = key[5:]
+ if key not in ["runtime", "samples_per_second", "steps_per_second", "epoch", "step"]:
+ camel_cased_key = " ".join([part.capitalize() for part in key.split("_")])
+ eval_results[camel_cased_key] = value
+ return train_log, lines, eval_results
+ else:
+ return train_log, lines, None
+
+
+def extract_hyperparameters_from_keras(model):
+ from .modeling_tf_utils import keras
+
+ hyperparameters = {}
+ if hasattr(model, "optimizer") and model.optimizer is not None:
+ hyperparameters["optimizer"] = model.optimizer.get_config()
+ else:
+ hyperparameters["optimizer"] = None
+ hyperparameters["training_precision"] = keras.mixed_precision.global_policy().name
+
+ return hyperparameters
+
+
+def _maybe_round(v, decimals=4):
+ if isinstance(v, float) and len(str(v).split(".")) > 1 and len(str(v).split(".")[1]) > decimals:
+ return f"{v:.{decimals}f}"
+ return str(v)
+
+
+def _regular_table_line(values, col_widths):
+ values_with_space = [f"| {v}" + " " * (w - len(v) + 1) for v, w in zip(values, col_widths)]
+ return "".join(values_with_space) + "|\n"
+
+
+def _second_table_line(col_widths):
+ values = ["|:" + "-" * w + ":" for w in col_widths]
+ return "".join(values) + "|\n"
+
+
+def make_markdown_table(lines):
+ """
+ Create a nice Markdown table from the results in `lines`.
+ """
+ if lines is None or len(lines) == 0:
+ return ""
+ col_widths = {key: len(str(key)) for key in lines[0].keys()}
+ for line in lines:
+ for key, value in line.items():
+ if col_widths[key] < len(_maybe_round(value)):
+ col_widths[key] = len(_maybe_round(value))
+
+ table = _regular_table_line(list(lines[0].keys()), list(col_widths.values()))
+ table += _second_table_line(list(col_widths.values()))
+ for line in lines:
+ table += _regular_table_line([_maybe_round(v) for v in line.values()], list(col_widths.values()))
+ return table
+
+
+_TRAINING_ARGS_KEYS = [
+ "learning_rate",
+ "train_batch_size",
+ "eval_batch_size",
+ "seed",
+]
+
+
+def extract_hyperparameters_from_trainer(trainer):
+ hyperparameters = {k: getattr(trainer.args, k) for k in _TRAINING_ARGS_KEYS}
+
+ if trainer.args.parallel_mode not in [ParallelMode.NOT_PARALLEL, ParallelMode.NOT_DISTRIBUTED]:
+ hyperparameters["distributed_type"] = (
+ "multi-GPU" if trainer.args.parallel_mode == ParallelMode.DISTRIBUTED else trainer.args.parallel_mode.value
+ )
+ if trainer.args.world_size > 1:
+ hyperparameters["num_devices"] = trainer.args.world_size
+ if trainer.args.gradient_accumulation_steps > 1:
+ hyperparameters["gradient_accumulation_steps"] = trainer.args.gradient_accumulation_steps
+
+ total_train_batch_size = (
+ trainer.args.train_batch_size * trainer.args.world_size * trainer.args.gradient_accumulation_steps
+ )
+ if total_train_batch_size != hyperparameters["train_batch_size"]:
+ hyperparameters["total_train_batch_size"] = total_train_batch_size
+ total_eval_batch_size = trainer.args.eval_batch_size * trainer.args.world_size
+ if total_eval_batch_size != hyperparameters["eval_batch_size"]:
+ hyperparameters["total_eval_batch_size"] = total_eval_batch_size
+
+ if trainer.args.optim:
+ optimizer_name = trainer.args.optim
+ optimizer_args = trainer.args.optim_args if trainer.args.optim_args else "No additional optimizer arguments"
+
+ if "adam" in optimizer_name.lower():
+ hyperparameters["optimizer"] = (
+ f"Use {optimizer_name} with betas=({trainer.args.adam_beta1},{trainer.args.adam_beta2}) and"
+ f" epsilon={trainer.args.adam_epsilon} and optimizer_args={optimizer_args}"
+ )
+ else:
+ hyperparameters["optimizer"] = f"Use {optimizer_name} and the args are:\n{optimizer_args}"
+
+ hyperparameters["lr_scheduler_type"] = trainer.args.lr_scheduler_type.value
+ if trainer.args.warmup_ratio != 0.0:
+ hyperparameters["lr_scheduler_warmup_ratio"] = trainer.args.warmup_ratio
+ if trainer.args.warmup_steps != 0.0:
+ hyperparameters["lr_scheduler_warmup_steps"] = trainer.args.warmup_steps
+ if trainer.args.max_steps != -1:
+ hyperparameters["training_steps"] = trainer.args.max_steps
+ else:
+ hyperparameters["num_epochs"] = trainer.args.num_train_epochs
+
+ if trainer.args.fp16:
+ if trainer.use_apex:
+ hyperparameters["mixed_precision_training"] = f"Apex, opt level {trainer.args.fp16_opt_level}"
+ else:
+ hyperparameters["mixed_precision_training"] = "Native AMP"
+
+ if trainer.args.label_smoothing_factor != 0.0:
+ hyperparameters["label_smoothing_factor"] = trainer.args.label_smoothing_factor
+
+ return hyperparameters
diff --git a/docs/transformers/src/transformers/modeling_attn_mask_utils.py b/docs/transformers/src/transformers/modeling_attn_mask_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..dfdd976f0156139024c6f7788870a71e4a41754d
--- /dev/null
+++ b/docs/transformers/src/transformers/modeling_attn_mask_utils.py
@@ -0,0 +1,481 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from dataclasses import dataclass
+from typing import Optional, Union
+
+import torch
+
+from .utils.import_utils import is_torchdynamo_compiling
+
+
+@dataclass
+class AttentionMaskConverter:
+ """
+ A utility attention mask class that allows one to:
+ - Create a causal 4d mask
+ - Create a causal 4d mask with slided window
+ - Convert a 2d attention mask (batch_size, query_length) to a 4d attention mask (batch_size, 1, query_length,
+ key_value_length) that can be multiplied with attention scores
+
+ Examples:
+
+ ```python
+ >>> import torch
+ >>> from transformers.modeling_attn_mask_utils import AttentionMaskConverter
+
+ >>> converter = AttentionMaskConverter(True)
+ >>> converter.to_4d(torch.tensor([[0, 0, 0, 1, 1]]), 5, key_value_length=5, dtype=torch.float32)
+ tensor([[[[-3.4028e+38, -3.4028e+38, -3.4028e+38, -3.4028e+38, -3.4028e+38],
+ [-3.4028e+38, -3.4028e+38, -3.4028e+38, -3.4028e+38, -3.4028e+38],
+ [-3.4028e+38, -3.4028e+38, -3.4028e+38, -3.4028e+38, -3.4028e+38],
+ [-3.4028e+38, -3.4028e+38, -3.4028e+38, 0.0000e+00, -3.4028e+38],
+ [-3.4028e+38, -3.4028e+38, -3.4028e+38, 0.0000e+00, 0.0000e+00]]]])
+ ```
+
+ Parameters:
+ is_causal (`bool`):
+ Whether the attention mask should be a uni-directional (causal) or bi-directional mask.
+
+ sliding_window (`int`, *optional*):
+ Optionally, the sliding window masks can be created if `sliding_window` is defined to a positive integer.
+ """
+
+ is_causal: bool
+ sliding_window: int
+
+ def __init__(self, is_causal: bool, sliding_window: Optional[int] = None):
+ self.is_causal = is_causal
+ self.sliding_window = sliding_window
+
+ if self.sliding_window is not None and self.sliding_window <= 0:
+ raise ValueError(
+ f"Make sure that when passing `sliding_window` that its value is a strictly positive integer, not `{self.sliding_window}`"
+ )
+
+ def to_causal_4d(
+ self,
+ batch_size: int,
+ query_length: int,
+ key_value_length: int,
+ dtype: torch.dtype,
+ device: Union[torch.device, "str"] = "cpu",
+ ) -> Optional[torch.Tensor]:
+ """
+ Creates a causal 4D mask of (bsz, head_dim=1, query_length, key_value_length) shape and adds large negative
+ bias to upper right hand triangular matrix (causal mask).
+ """
+ if not self.is_causal:
+ raise ValueError(f"Please use `to_causal_4d` only if {self.__class__} has `is_causal` set to True.")
+
+ # If shape is not cached, create a new causal mask and cache it
+ input_shape = (batch_size, query_length)
+ past_key_values_length = key_value_length - query_length
+
+ # create causal mask
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ causal_4d_mask = None
+ if input_shape[-1] > 1 or self.sliding_window is not None:
+ causal_4d_mask = self._make_causal_mask(
+ input_shape,
+ dtype,
+ device=device,
+ past_key_values_length=past_key_values_length,
+ sliding_window=self.sliding_window,
+ )
+
+ return causal_4d_mask
+
+ def to_4d(
+ self,
+ attention_mask_2d: torch.Tensor,
+ query_length: int,
+ dtype: torch.dtype,
+ key_value_length: Optional[int] = None,
+ ) -> torch.Tensor:
+ """
+ Converts 2D attention mask to 4D attention mask by expanding mask to (bsz, head_dim=1, query_length,
+ key_value_length) shape and by adding a large negative bias to not-attended positions. If attention_mask is
+ causal, a causal mask will be added.
+ """
+ input_shape = (attention_mask_2d.shape[0], query_length)
+
+ # create causal mask
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ causal_4d_mask = None
+ if (input_shape[-1] > 1 or self.sliding_window is not None) and self.is_causal:
+ if key_value_length is None:
+ raise ValueError(
+ "This attention mask converter is causal. Make sure to pass `key_value_length` to correctly create a causal mask."
+ )
+
+ past_key_values_length = key_value_length - query_length
+ causal_4d_mask = self._make_causal_mask(
+ input_shape,
+ dtype,
+ device=attention_mask_2d.device,
+ past_key_values_length=past_key_values_length,
+ sliding_window=self.sliding_window,
+ )
+ elif self.sliding_window is not None:
+ raise NotImplementedError("Sliding window is currently only implemented for causal masking")
+
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ expanded_attn_mask = self._expand_mask(attention_mask_2d, dtype, tgt_len=input_shape[-1]).to(
+ attention_mask_2d.device
+ )
+
+ if causal_4d_mask is not None:
+ expanded_attn_mask = causal_4d_mask.masked_fill(expanded_attn_mask.bool(), torch.finfo(dtype).min)
+
+ # expanded_attn_mask + causal_4d_mask can cause some overflow
+ expanded_4d_mask = expanded_attn_mask
+
+ return expanded_4d_mask
+
+ @staticmethod
+ def _make_causal_mask(
+ input_ids_shape: torch.Size,
+ dtype: torch.dtype,
+ device: torch.device,
+ past_key_values_length: int = 0,
+ sliding_window: Optional[int] = None,
+ ):
+ """
+ Make causal mask used for bi-directional self-attention.
+ """
+ bsz, tgt_len = input_ids_shape
+ mask = torch.full((tgt_len, tgt_len), torch.finfo(dtype).min, device=device)
+ mask_cond = torch.arange(mask.size(-1), device=device)
+ mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
+
+ mask = mask.to(dtype)
+
+ if past_key_values_length > 0:
+ mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
+
+ # add lower triangular sliding window mask if necessary
+ if sliding_window is not None:
+ diagonal = past_key_values_length - sliding_window - 1
+
+ context_mask = torch.tril(torch.ones_like(mask, dtype=torch.bool), diagonal=diagonal)
+ # Recent changes in PyTorch prevent mutations on tensors converted with aten::_to_copy
+ # See https://github.com/pytorch/pytorch/issues/127571
+ if is_torchdynamo_compiling():
+ mask = mask.clone()
+ mask.masked_fill_(context_mask, torch.finfo(dtype).min)
+
+ return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
+
+ @staticmethod
+ def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
+ """
+ Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
+ """
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
+
+ inverted_mask = 1.0 - expanded_mask
+
+ return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
+
+ @staticmethod
+ def _unmask_unattended(
+ expanded_mask: torch.FloatTensor,
+ min_dtype: float,
+ ):
+ # fmt: off
+ """
+ Attend to all tokens in masked rows from the expanded attention mask, for example the relevant first rows when
+ using left padding. This is required by F.scaled_dot_product_attention memory-efficient attention path.
+ Details: https://github.com/pytorch/pytorch/issues/110213
+
+ `expanded_mask` is [bsz, num_masks, tgt_seq_len, src_seq_len] or [bsz, tgt_seq_len, src_seq_len].
+ `attention_mask` is [bsz, src_seq_len].
+
+ The dimension num_masks of `expanded_mask` is most often 1, but it can also be the number of heads in the case of alibi attention bias.
+
+ For example, if `expanded_mask` is (e.g. here left-padding case)
+ ```
+ [[[[0, 0, 0],
+ [0, 0, 0],
+ [0, 0, 1]]],
+ [[[1, 0, 0],
+ [1, 1, 0],
+ [1, 1, 1]]],
+ [[[0, 0, 0],
+ [0, 1, 0],
+ [0, 1, 1]]]]
+ ```
+ then the modified `expanded_mask` will be
+ ```
+ [[[[1, 1, 1], <-- modified
+ [1, 1, 1], <-- modified
+ [0, 0, 1]]],
+ [[[1, 0, 0],
+ [1, 1, 0],
+ [1, 1, 1]]],
+ [[[1, 1, 1], <-- modified
+ [0, 1, 0],
+ [0, 1, 1]]]]
+ ```
+ """
+ # fmt: on
+ if expanded_mask.dtype == torch.bool:
+ raise ValueError(
+ "AttentionMaskConverter._unmask_unattended expects a float `expanded_mask`, got a BoolTensor."
+ )
+
+ return expanded_mask.mul(~torch.all(expanded_mask == min_dtype, dim=-1, keepdim=True))
+
+ @staticmethod
+ def _ignore_causal_mask_sdpa(
+ attention_mask: Optional[torch.Tensor],
+ inputs_embeds: torch.Tensor,
+ past_key_values_length: int,
+ sliding_window: Optional[int] = None,
+ is_training: bool = False,
+ ) -> bool:
+ """
+ Detects whether the optional user-specified attention_mask & the automatically created causal mask can be
+ ignored in case PyTorch's SDPA is used, rather relying on SDPA's `is_causal` argument.
+
+ In case no token is masked in the `attention_mask` argument, if `query_length == 1` or
+ `key_value_length == query_length`, we rather rely on SDPA `is_causal` argument to use causal/non-causal masks,
+ allowing to dispatch to the flash attention kernel (that can otherwise not be used if a custom `attn_mask` is
+ passed).
+ """
+
+ _, query_length = inputs_embeds.shape[0], inputs_embeds.shape[1]
+ key_value_length = query_length + past_key_values_length
+
+ is_tracing = torch.jit.is_tracing() or isinstance(inputs_embeds, torch.fx.Proxy) or is_torchdynamo_compiling()
+
+ ignore_causal_mask = False
+
+ if attention_mask is None:
+ # TODO: When tracing with TorchDynamo with fullgraph=True, the model is recompiled depending on the input
+ # shape, thus SDPA's `is_causal` argument is rightfully updated
+ # (see https://gist.github.com/fxmarty/1313f39037fc1c112508989628c57363). However, when using
+ # `torch.export` or `torch.onnx.dynamo_export`, we must pass an example input, and `is_causal` behavior is
+ # hard-coded. If a user exports a model with q_len > 1, the exported model will hard-code `is_causal=True`
+ # which is in general wrong (see https://github.com/pytorch/pytorch/issues/108108).
+ # Thus, we only set `ignore_causal_mask = True` if the model is set to training.
+ #
+ # Besides, jit.trace can not handle the `q_len > 1` condition for `is_causal`
+ # ("TypeError: scaled_dot_product_attention(): argument 'is_causal' must be bool, not Tensor").
+ if (
+ (is_training or not is_tracing)
+ and (query_length == 1 or key_value_length == query_length)
+ and (sliding_window is None or key_value_length < sliding_window)
+ ):
+ ignore_causal_mask = True
+ elif sliding_window is None or key_value_length < sliding_window:
+ if len(attention_mask.shape) == 4:
+ return False
+ elif not is_tracing and torch.all(attention_mask == 1):
+ if query_length == 1 or key_value_length == query_length:
+ # For query_length == 1, causal attention and bi-directional attention are the same.
+ ignore_causal_mask = True
+
+ # Unfortunately, for query_length > 1 and key_value_length != query_length, we cannot generally ignore
+ # the attention mask, as SDPA causal mask generation may be wrong. We will set `is_causal=False` in
+ # SDPA and rely on Transformers attention_mask instead, hence not setting it to None here.
+ # Reference: https://github.com/pytorch/pytorch/issues/108108
+ # TODO: maybe revisit this with https://github.com/pytorch/pytorch/pull/114823 in PyTorch 2.3.
+
+ return ignore_causal_mask
+
+
+def _prepare_4d_causal_attention_mask(
+ attention_mask: Optional[torch.Tensor],
+ input_shape: Union[torch.Size, tuple, list],
+ inputs_embeds: torch.Tensor,
+ past_key_values_length: int,
+ sliding_window: Optional[int] = None,
+):
+ """
+ Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
+ `(batch_size, key_value_length)`
+
+ Args:
+ attention_mask (`torch.Tensor` or `None`):
+ A 2D attention mask of shape `(batch_size, key_value_length)`
+ input_shape (`tuple(int)` or `list(int)` or `torch.Size`):
+ The input shape should be a tuple that defines `(batch_size, query_length)`.
+ inputs_embeds (`torch.Tensor`):
+ The embedded inputs as a torch Tensor.
+ past_key_values_length (`int`):
+ The length of the key value cache.
+ sliding_window (`int`, *optional*):
+ If the model uses windowed attention, a sliding window should be passed.
+ """
+ attn_mask_converter = AttentionMaskConverter(is_causal=True, sliding_window=sliding_window)
+
+ key_value_length = input_shape[-1] + past_key_values_length
+
+ # 4d mask is passed through the layers
+ if attention_mask is not None and len(attention_mask.shape) == 2:
+ attention_mask = attn_mask_converter.to_4d(
+ attention_mask, input_shape[-1], key_value_length=key_value_length, dtype=inputs_embeds.dtype
+ )
+ elif attention_mask is not None and len(attention_mask.shape) == 4:
+ expected_shape = (input_shape[0], 1, input_shape[1], key_value_length)
+ if tuple(attention_mask.shape) != expected_shape:
+ raise ValueError(
+ f"Incorrect 4D attention_mask shape: {tuple(attention_mask.shape)}; expected: {expected_shape}."
+ )
+ else:
+ # if the 4D mask has correct shape - invert it and fill with negative infinity
+ inverted_mask = 1.0 - attention_mask
+ attention_mask = inverted_mask.masked_fill(
+ inverted_mask.to(torch.bool), torch.finfo(inputs_embeds.dtype).min
+ )
+ else:
+ attention_mask = attn_mask_converter.to_causal_4d(
+ input_shape[0], input_shape[-1], key_value_length, dtype=inputs_embeds.dtype, device=inputs_embeds.device
+ )
+
+ return attention_mask
+
+
+# Adapted from _prepare_4d_causal_attention_mask
+def _prepare_4d_causal_attention_mask_for_sdpa(
+ attention_mask: Optional[torch.Tensor],
+ input_shape: Union[torch.Size, tuple, list],
+ inputs_embeds: torch.Tensor,
+ past_key_values_length: int,
+ sliding_window: Optional[int] = None,
+):
+ """
+ Prepares the correct `attn_mask` argument to be used by `torch.nn.functional.scaled_dot_product_attention`.
+
+ In case no token is masked in the `attention_mask` argument, we simply set it to `None` for the cases `query_length == 1` and
+ `key_value_length == query_length`, and rely instead on SDPA `is_causal` argument to use causal/non-causal masks,
+ allowing to dispatch to the flash attention kernel (that can otherwise not be used if a custom `attn_mask` is passed).
+ """
+ attn_mask_converter = AttentionMaskConverter(is_causal=True, sliding_window=sliding_window)
+
+ key_value_length = input_shape[-1] + past_key_values_length
+
+ # torch.jit.trace, symbolic_trace and torchdynamo with fullgraph=True are unable to capture the controlflow `is_causal=attention_mask is None and q_len > 1`
+ # used as an SDPA argument. We keep compatibility with these tracing tools by always using SDPA's `attn_mask` argument in case we are tracing.
+ # TODO: For dynamo, rather use a check on fullgraph=True once this is possible (https://github.com/pytorch/pytorch/pull/120400).
+ is_tracing = torch.jit.is_tracing() or isinstance(inputs_embeds, torch.fx.Proxy) or is_torchdynamo_compiling()
+
+ ignore_causal_mask = AttentionMaskConverter._ignore_causal_mask_sdpa(
+ attention_mask=attention_mask,
+ inputs_embeds=inputs_embeds,
+ past_key_values_length=past_key_values_length,
+ sliding_window=sliding_window,
+ )
+
+ if ignore_causal_mask:
+ expanded_4d_mask = None
+ elif attention_mask is None:
+ expanded_4d_mask = attn_mask_converter.to_causal_4d(
+ input_shape[0], input_shape[-1], key_value_length, dtype=inputs_embeds.dtype, device=inputs_embeds.device
+ )
+ else:
+ if attention_mask.dim() == 4:
+ expanded_4d_mask = attention_mask
+ else:
+ expanded_4d_mask = attn_mask_converter.to_4d(
+ attention_mask,
+ input_shape[-1],
+ dtype=inputs_embeds.dtype,
+ key_value_length=key_value_length,
+ )
+
+ # Attend to all tokens in masked rows from the causal_mask, for example the relevant first rows when
+ # using left padding. This is required by F.scaled_dot_product_attention memory-efficient attention path.
+ # Details: https://github.com/pytorch/pytorch/issues/110213
+ if not is_tracing and expanded_4d_mask.device.type == "cuda":
+ expanded_4d_mask = AttentionMaskConverter._unmask_unattended(
+ expanded_4d_mask, min_dtype=torch.finfo(inputs_embeds.dtype).min
+ )
+
+ return expanded_4d_mask
+
+
+def _prepare_4d_attention_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
+ """
+ Creates a non-causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
+ `(batch_size, key_value_length)`
+
+ Args:
+ mask (`torch.Tensor`):
+ A 2D attention mask of shape `(batch_size, key_value_length)`
+ dtype (`torch.dtype`):
+ The torch dtype the created mask shall have.
+ tgt_len (`int`):
+ The target length or query length the created mask shall have.
+ """
+ return AttentionMaskConverter._expand_mask(mask=mask, dtype=dtype, tgt_len=tgt_len)
+
+
+def _prepare_4d_attention_mask_for_sdpa(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
+ """
+ Creates a non-causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
+ `(batch_size, key_value_length)`
+
+ Args:
+ mask (`torch.Tensor`):
+ A 2D attention mask of shape `(batch_size, key_value_length)`
+ dtype (`torch.dtype`):
+ The torch dtype the created mask shall have.
+ tgt_len (`int`):
+ The target length or query length the created mask shall have.
+ """
+ _, key_value_length = mask.shape
+ tgt_len = tgt_len if tgt_len is not None else key_value_length
+
+ is_tracing = torch.jit.is_tracing() or isinstance(mask, torch.fx.Proxy) or is_torchdynamo_compiling()
+
+ # torch.jit.trace, symbolic_trace and torchdynamo with fullgraph=True are unable to capture data-dependent controlflows.
+ if not is_tracing and torch.all(mask == 1):
+ return None
+ else:
+ return AttentionMaskConverter._expand_mask(mask=mask, dtype=dtype, tgt_len=tgt_len)
+
+
+def _create_4d_causal_attention_mask(
+ input_shape: Union[torch.Size, tuple, list],
+ dtype: torch.dtype,
+ device: torch.device,
+ past_key_values_length: int = 0,
+ sliding_window: Optional[int] = None,
+) -> Optional[torch.Tensor]:
+ """
+ Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)`
+
+ Args:
+ input_shape (`tuple(int)` or `list(int)` or `torch.Size`):
+ The input shape should be a tuple that defines `(batch_size, query_length)`.
+ dtype (`torch.dtype`):
+ The torch dtype the created mask shall have.
+ device (`int`):
+ The torch device the created mask shall have.
+ sliding_window (`int`, *optional*):
+ If the model uses windowed attention, a sliding window should be passed.
+ """
+ attn_mask_converter = AttentionMaskConverter(is_causal=True, sliding_window=sliding_window)
+
+ key_value_length = past_key_values_length + input_shape[-1]
+ attention_mask = attn_mask_converter.to_causal_4d(
+ input_shape[0], input_shape[-1], key_value_length, dtype=dtype, device=device
+ )
+
+ return attention_mask
diff --git a/docs/transformers/src/transformers/modeling_flash_attention_utils.py b/docs/transformers/src/transformers/modeling_flash_attention_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..c7d54dc415146e0f289750c86caffa5021399a92
--- /dev/null
+++ b/docs/transformers/src/transformers/modeling_flash_attention_utils.py
@@ -0,0 +1,437 @@
+# Copyright 2024 The Fairseq Authors and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+import os
+from typing import Optional, TypedDict
+
+import torch
+import torch.nn.functional as F
+
+from .utils import (
+ is_flash_attn_2_available,
+ is_flash_attn_greater_or_equal,
+ is_flash_attn_greater_or_equal_2_10,
+ is_torch_npu_available,
+ logging,
+)
+
+
+logger = logging.get_logger(__name__)
+flash_attn_func = None
+
+
+if is_flash_attn_2_available():
+ from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
+ from flash_attn import flash_attn_func, flash_attn_varlen_func
+ from flash_attn.layers.rotary import apply_rotary_emb # noqa
+
+
+# patch functions in package `flash-attn` when using flash-attention on Ascend NPU.
+if is_torch_npu_available():
+ from torch_npu import npu_rotary_mul as apply_rotary_emb # noqa
+
+ from .integrations.npu_flash_attention import index_first_axis, pad_input, unpad_input
+ from .integrations.npu_flash_attention import npu_flash_attn_func as flash_attn_func
+ from .integrations.npu_flash_attention import npu_flash_attn_varlen_func as flash_attn_varlen_func
+
+
+if flash_attn_func:
+ _flash_supports_window_size = "window_size" in list(inspect.signature(flash_attn_func).parameters)
+
+
+def is_flash_attn_available():
+ """Determine whether flash-attention can be used or not."""
+
+ # if package `flash-attn` is available, flash-attention can be used natively.
+ if is_flash_attn_2_available():
+ return True
+
+ # flash-attention can be used on Ascend NPU without package `flash-attn`
+ if is_torch_npu_available():
+ return True
+
+ return False
+
+
+def flash_attn_supports_top_left_mask():
+ """Determine whether flash-attention uses top-left or down-right mask"""
+
+ if is_flash_attn_2_available():
+ # top-left mask is used in package `flash-attn` with version lower than 2.1.0
+ return not is_flash_attn_greater_or_equal_2_10()
+
+ if is_torch_npu_available():
+ # down-right mask is used on Ascend NPU by default, set env `NPU_FA2_SPARSE_MODE=2` to activate top-left mask.
+ from .integrations.npu_flash_attention import is_npu_fa2_top_left_aligned_causal_mask
+
+ return is_npu_fa2_top_left_aligned_causal_mask()
+
+ return False
+
+
+def _get_unpad_data(attention_mask: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor, int]:
+ """
+ Retrieves indexing data required to repad unpadded (ragged) tensors.
+
+ Arguments:
+ attention_mask (`torch.Tensor`):
+ Boolean or int tensor of shape (batch_size, sequence_length), 1 means valid and 0 means not valid.
+
+ Return:
+ indices (`torch.Tensor`):
+ The indices of non-masked tokens from the flattened input sequence.
+ cu_seqlens (`torch.Tensor`):
+ The cumulative sequence lengths, used to index into ragged (unpadded) tensors. `cu_seqlens` shape is (batch_size + 1,).
+ max_seqlen_in_batch (`int`):
+ Maximum sequence length in batch.
+ """
+ seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
+ indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
+ max_seqlen_in_batch = seqlens_in_batch.max().item()
+ cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0))
+ return (
+ indices,
+ cu_seqlens,
+ max_seqlen_in_batch,
+ )
+
+
+def _upad_input(
+ query_layer: torch.Tensor,
+ key_layer: torch.Tensor,
+ value_layer: torch.Tensor,
+ attention_mask: torch.Tensor,
+ query_length: int,
+):
+ """
+ Unpads query, key, and values tensors, using a single dimension for all tokens even though they belong to different batches.
+
+ This function is used instead of `flash_attn.bert_padding.unpad_input` in order to avoid the recomputation of the same intermediary
+ tensors for query, key, value tensors.
+
+ Arguments:
+ query_layer (`torch.Tensor`):
+ Query state with padding. Shape: (batch_size, query_length, num_heads, head_dim).
+ key_layer (`torch.Tensor`):
+ Key state with padding. Shape: (batch_size, kv_seq_len, num_key_value_heads, head_dim).
+ value_layer (`torch.Tensor`):
+ Value state with padding. Shape: (batch_size, kv_seq_len, num_key_value_heads, head_dim).
+ attention_mask (`torch.Tensor`):
+ Boolean or int tensor of shape (batch_size, sequence_length), 1 means valid and 0 means not valid.
+ query_length (`int`):
+ Target length.
+
+ Return:
+ query_layer (`torch.Tensor`):
+ Query state without padding. Shape: (total_target_length, num_heads, head_dim).
+ key_layer (`torch.Tensor`):
+ Key state with padding. Shape: (total_source_length, num_key_value_heads, head_dim).
+ value_layer (`torch.Tensor`):
+ Value state with padding. Shape: (total_source_length, num_key_value_heads, head_dim).
+ indices_q (`torch.Tensor`):
+ The indices of non-masked tokens from the flattened input target sequence.
+ (cu_seqlens_q, cu_seqlens_k) (`Tuple[int]`):
+ The cumulative sequence lengths for the target (query) and source (key, value), used to index into ragged (unpadded) tensors. `cu_seqlens` shape is (batch_size + 1,).
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k) (`Tuple[int]`):
+ Maximum sequence length in batch (`max_seqlen_in_batch_q` for the target sequence i.e. query, `max_seqlen_in_batch_k` for the source sequence i.e. key/value).
+ """
+ indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
+ batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
+
+ key_layer = index_first_axis(key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k)
+ value_layer = index_first_axis(
+ value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
+ )
+ if query_length == kv_seq_len:
+ query_layer = index_first_axis(query_layer.reshape(batch_size * kv_seq_len, -1, head_dim), indices_k)
+ cu_seqlens_q = cu_seqlens_k
+ max_seqlen_in_batch_q = max_seqlen_in_batch_k
+ indices_q = indices_k
+ elif query_length == 1:
+ max_seqlen_in_batch_q = 1
+ cu_seqlens_q = torch.arange(
+ batch_size + 1, dtype=torch.int32, device=query_layer.device
+ ) # There is a memcpy here, that is very bad.
+ indices_q = cu_seqlens_q[:-1]
+ query_layer = query_layer.squeeze(1)
+ else:
+ # The -q_len: slice assumes left padding.
+ attention_mask = attention_mask[:, -query_length:]
+ query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q, *_ = unpad_input(query_layer, attention_mask)
+
+ return (
+ query_layer,
+ key_layer,
+ value_layer,
+ indices_q,
+ (cu_seqlens_q, cu_seqlens_k),
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k),
+ )
+
+
+def prepare_fa2_from_position_ids(query, key, value, position_ids):
+ """
+ This function returns necessary arguments to call `flash_attn_varlen_func`.
+ All three query, key, value states will be flattened.
+ Cumulative lengths of each examples in the batch will be extracted from position_ids.
+
+ NOTE: ideally cumulative lengths should be prepared at the data collator stage
+
+ Arguments:
+ query (`torch.Tensor`):
+ Query state with padding. Shape: (batch_size, query_length, num_heads, head_dim).
+ key (`torch.Tensor`):
+ Key state with padding. Shape: (batch_size, kv_seq_len, num_key_value_heads, head_dim).
+ value (`torch.Tensor`):
+ Value state with padding. Shape: (batch_size, kv_seq_len, num_key_value_heads, head_dim).
+ position_ids (`torch.Tensor`):
+ Boolean or int tensor of shape (batch_size, sequence_length), 1 means valid and 0 means not valid.
+
+ Return:
+ query (`torch.Tensor`):
+ Query state without padding. Shape: (total_target_length, num_heads, head_dim).
+ key (`torch.Tensor`):
+ Key state with padding. Shape: (total_source_length, num_key_value_heads, head_dim).
+ value (`torch.Tensor`):
+ Value state with padding. Shape: (total_source_length, num_key_value_heads, head_dim).
+ indices_q (`torch.Tensor`):
+ The indices of non-masked tokens from the flattened input target sequence.
+ (cu_seqlens_q, cu_seqlens_k) (`Tuple[int]`):
+ The cumulative sequence lengths for the target (query) and source (key, value), used to index into ragged (unpadded) tensors. `cu_seqlens` shape is (batch_size + 1,).
+ (max_seqlen_in_batch_q, max_seqlen_in_batch_k) (`Tuple[int]`):
+ Maximum sequence length in batch (`max_seqlen_in_batch_q` for the target sequence i.e. query, `max_seqlen_in_batch_k` for the source sequence i.e. key/value).
+ """
+ query = query.view(-1, query.size(-2), query.size(-1))
+ key = key.contiguous().view(-1, key.size(-2), key.size(-1))
+ value = value.contiguous().view(-1, value.size(-2), value.size(-1))
+ position_ids = position_ids.flatten()
+ indices_q = torch.arange(position_ids.size(0), device=position_ids.device, dtype=torch.int32)
+
+ cu_seq_lens = torch.cat(
+ (
+ indices_q[position_ids == 0],
+ torch.tensor(position_ids.size(), device=position_ids.device, dtype=torch.int32),
+ )
+ )
+
+ max_length = position_ids.max() + 1
+
+ return (query, key, value, indices_q, (cu_seq_lens, cu_seq_lens), (max_length, max_length))
+
+
+def fa_peft_integration_check(
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ target_dtype: Optional[torch.dtype] = None,
+):
+ """
+ PEFT usually casts the layer norms in float32 for training stability reasons
+ therefore the input hidden states gets silently casted in float32. Hence, we need
+ cast them back in float16 / bfloat16 just to be sure everything works as expected.
+ This might slowdown training & inference so it is recommended to not cast the LayerNorms!
+
+ Args:
+ query (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ target_dtype (`torch.dtype`, *optional*):
+ The dtype to convert the attention tensors to. Conversion can be ignored by
+ not providing the target dtype.
+ """
+ if target_dtype is None:
+ return query, key, value
+
+ input_dtype = query.dtype
+ if input_dtype == torch.float32:
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query = query.to(target_dtype)
+ key = key.to(target_dtype)
+ value = value.to(target_dtype)
+
+ return query, key, value
+
+
+flash_241 = is_flash_attn_greater_or_equal("2.4.1")
+deterministic_g = os.environ.get("FLASH_ATTENTION_DETERMINISTIC", "0") == "1"
+
+
+def _flash_attention_forward(
+ query_states: torch.Tensor,
+ key_states: torch.Tensor,
+ value_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor],
+ query_length: int,
+ is_causal: bool,
+ dropout: float = 0.0,
+ position_ids: Optional[torch.Tensor] = None,
+ softmax_scale: Optional[float] = None,
+ sliding_window: Optional[int] = None,
+ use_top_left_mask: bool = False,
+ softcap: Optional[float] = None,
+ deterministic: Optional[bool] = None,
+ cu_seq_lens_q: Optional[torch.LongTensor] = None,
+ cu_seq_lens_k: Optional[torch.LongTensor] = None,
+ max_length_q: Optional[int] = None,
+ max_length_k: Optional[int] = None,
+ target_dtype: Optional[torch.dtype] = None,
+ **kwargs,
+):
+ """
+ Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
+ first unpad the input, then computes the attention scores and pad the final attention scores.
+
+ Args:
+ query_states (`torch.Tensor`):
+ Input query states to be passed to Flash Attention API
+ key_states (`torch.Tensor`):
+ Input key states to be passed to Flash Attention API
+ value_states (`torch.Tensor`):
+ Input value states to be passed to Flash Attention API
+ attention_mask (`torch.Tensor`, *optional*):
+ The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
+ position of padding tokens and 1 for the position of non-padding tokens.
+ dropout (`float`):
+ Attention dropout
+ softmax_scale (`float`, *optional*):
+ The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
+ use_top_left_mask (`bool`, defaults to `False`):
+ flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignment, that was made default for flash_attn>=2.1. This attribute is used to handle this difference.
+ softcap (`float`, *optional*):
+ Softcap for the attention logits, used e.g. in gemma2.
+ deterministic (`bool`, *optional*):
+ Determines if the deterministic option introduced in flash_attn>=2.4.1 is enabled.
+ """
+ if not use_top_left_mask:
+ causal = is_causal
+ else:
+ # TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1.
+ causal = is_causal and query_length != 1
+
+ # Assuming 4D tensors, key_states.shape[1] is the key/value sequence length (source length).
+ use_sliding_windows = (
+ _flash_supports_window_size and sliding_window is not None and key_states.shape[1] > sliding_window
+ )
+ flash_kwargs = {"window_size": (sliding_window, sliding_window)} if use_sliding_windows else {}
+
+ if flash_241:
+ if deterministic is None:
+ deterministic = deterministic_g
+ flash_kwargs["deterministic"] = deterministic
+
+ if softcap is not None:
+ flash_kwargs["softcap"] = softcap
+
+ # PEFT possibly silently casts tensors to fp32, this potentially reconverts to correct dtype or is a no op
+ query_states, key_states, value_states = fa_peft_integration_check(
+ query_states, key_states, value_states, target_dtype
+ )
+
+ # Contains at least one padding token in the sequence
+ if attention_mask is not None:
+ batch_size = query_states.shape[0]
+ query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = _upad_input(
+ query_states, key_states, value_states, attention_mask, query_length
+ )
+ cu_seqlens_q, cu_seqlens_k = cu_seq_lens
+ max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
+
+ attn_output_unpad = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seqlens_q,
+ cu_seqlens_k=cu_seqlens_k,
+ max_seqlen_q=max_seqlen_in_batch_q,
+ max_seqlen_k=max_seqlen_in_batch_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ **flash_kwargs,
+ )
+ attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
+
+ # If position_ids is provided and check all examples do not contain only 1 sequence, If tensor in increasing
+ # then we probably have one sequence, otherwise it is packed. Additionally check we are in pre-fill/training stage.
+ # Use `flash_attn_varlen_func` to prevent cross-example attention and also allow padding free approach
+ elif position_ids is not None and (
+ max_length_q is not None or (query_length != 1 and not (torch.diff(position_ids, dim=-1) >= 0).all())
+ ):
+ batch_size = query_states.size(0)
+
+ if cu_seq_lens_q is None or cu_seq_lens_k is None:
+ query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = (
+ prepare_fa2_from_position_ids(query_states, key_states, value_states, position_ids)
+ )
+
+ cu_seq_lens_q, cu_seq_lens_k = cu_seq_lens
+ max_length_q, max_length_k = max_seq_lens
+
+ else:
+ query_states = query_states.reshape(-1, query_states.size(-2), query_states.size(-1))
+ key_states = key_states.reshape(-1, key_states.size(-2), key_states.size(-1))
+ value_states = value_states.reshape(-1, value_states.size(-2), value_states.size(-1))
+
+ attn_output = flash_attn_varlen_func(
+ query_states,
+ key_states,
+ value_states,
+ cu_seqlens_q=cu_seq_lens_q,
+ cu_seqlens_k=cu_seq_lens_k,
+ max_seqlen_q=max_length_q,
+ max_seqlen_k=max_length_k,
+ dropout_p=dropout,
+ softmax_scale=softmax_scale,
+ causal=causal,
+ **flash_kwargs,
+ )
+
+ attn_output = attn_output.view(batch_size, -1, attn_output.size(-2), attn_output.size(-1))
+
+ else:
+ attn_output = flash_attn_func(
+ query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal, **flash_kwargs
+ )
+
+ return attn_output
+
+
+class FlashAttentionKwargs(TypedDict, total=False):
+ """
+ Keyword arguments for Flash Attention with Compile.
+
+ Attributes:
+ cu_seq_lens_q (`torch.LongTensor`, *optional*)
+ Gets cumulative sequence length for query state.
+ cu_seq_lens_k (`torch.LongTensor`, *optional*)
+ Gets cumulative sequence length for key state.
+ max_length_q (`int`, *optional*):
+ Maximum sequence length for query state.
+ max_length_k (`int`, *optional*):
+ Maximum sequence length for key state.
+ """
+
+ cu_seq_lens_q: Optional[torch.LongTensor]
+ cu_seq_lens_k: Optional[torch.LongTensor]
+ max_length_q: Optional[int]
+ max_length_k: Optional[int]
diff --git a/docs/transformers/src/transformers/modeling_flax_outputs.py b/docs/transformers/src/transformers/modeling_flax_outputs.py
new file mode 100644
index 0000000000000000000000000000000000000000..325f968571ed400903b6c3bb15a4faf10f7e56c9
--- /dev/null
+++ b/docs/transformers/src/transformers/modeling_flax_outputs.py
@@ -0,0 +1,700 @@
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Dict, Optional, Tuple
+
+import flax
+import jax.numpy as jnp
+
+from .utils import ModelOutput
+
+
+@flax.struct.dataclass
+class FlaxBaseModelOutput(ModelOutput):
+ """
+ Base class for model's outputs, with potential hidden states and attentions.
+
+ Args:
+ last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: Optional[jnp.ndarray] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxBaseModelOutputWithNoAttention(ModelOutput):
+ """
+ Base class for model's outputs, with potential hidden states.
+
+ Args:
+ last_hidden_state (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings, if the model has an embedding layer, + one
+ for the output of each layer) of shape `(batch_size, num_channels, height, width)`. Hidden-states of the
+ model at the output of each layer plus the optional initial embedding outputs.
+ """
+
+ last_hidden_state: Optional[jnp.ndarray] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxBaseModelOutputWithPoolingAndNoAttention(ModelOutput):
+ """
+ Base class for model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ last_hidden_state (`jnp.ndarray` of shape `(batch_size, num_channels, height, width)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ pooler_output (`jnp.ndarray` of shape `(batch_size, hidden_size)`):
+ Last layer hidden-state after a pooling operation on the spatial dimensions.
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings, if the model has an embedding layer, + one
+ for the output of each layer) of shape `(batch_size, num_channels, height, width)`. Hidden-states of the
+ model at the output of each layer plus the optional initial embedding outputs.
+ """
+
+ last_hidden_state: Optional[jnp.ndarray] = None
+ pooler_output: Optional[jnp.ndarray] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxImageClassifierOutputWithNoAttention(ModelOutput):
+ """
+ Base class for outputs of image classification models.
+
+ Args:
+ logits (`jnp.ndarray` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when
+ `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings, if the model has an embedding layer, + one
+ for the output of each stage) of shape `(batch_size, num_channels, height, width)`. Hidden-states (also
+ called feature maps) of the model at the output of each stage.
+ """
+
+ logits: Optional[jnp.ndarray] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxBaseModelOutputWithPast(ModelOutput):
+ """
+ Base class for model's outputs, with potential hidden states and attentions.
+
+ Args:
+ last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ past_key_values (`Dict[str, jnp.ndarray]`):
+ Dictionary of pre-computed hidden-states (key and values in the attention blocks) that can be used for fast
+ auto-regressive decoding. Pre-computed key and value hidden-states are of shape *[batch_size, max_length]*.
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: Optional[jnp.ndarray] = None
+ past_key_values: Optional[Dict[str, jnp.ndarray]] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxBaseModelOutputWithPooling(ModelOutput):
+ """
+ Base class for model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ pooler_output (`jnp.ndarray` of shape `(batch_size, hidden_size)`):
+ Last layer hidden-state of the first token of the sequence (classification token) further processed by a
+ Linear layer and a Tanh activation function. The Linear layer weights are trained from the next sentence
+ prediction (classification) objective during pretraining.
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: Optional[jnp.ndarray] = None
+ pooler_output: Optional[jnp.ndarray] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxBaseModelOutputWithPoolingAndCrossAttentions(ModelOutput):
+ """
+ Base class for model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ pooler_output (`jnp.ndarray` of shape `(batch_size, hidden_size)`):
+ Last layer hidden-state of the first token of the sequence (classification token) after further processing
+ through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns
+ the classification token after processing through a linear layer and a tanh activation function. The linear
+ layer weights are trained from the next sentence prediction (classification) objective during pretraining.
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings, if the model has an embedding layer, + one
+ for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` and `config.add_cross_attention=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(jnp.ndarray)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
+ `config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
+ encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
+ `config.is_encoder_decoder=True` in the cross-attention blocks) that can be used (see `past_key_values`
+ input) to speed up sequential decoding.
+ """
+
+ last_hidden_state: Optional[jnp.ndarray] = None
+ pooler_output: Optional[jnp.ndarray] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
+ attentions: Optional[Tuple[jnp.ndarray]] = None
+ cross_attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxBaseModelOutputWithPastAndCrossAttentions(ModelOutput):
+ """
+ Base class for model's outputs that may also contain a past key/values (to speed up sequential decoding).
+
+ Args:
+ last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+
+ If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
+ hidden_size)` is output.
+ past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(jnp.ndarray)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
+ `config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
+ encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
+ `config.is_encoder_decoder=True` in the cross-attention blocks) that can be used (see `past_key_values`
+ input) to speed up sequential decoding.
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` and `config.add_cross_attention=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ """
+
+ last_hidden_state: Optional[jnp.ndarray] = None
+ past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ attentions: Optional[Tuple[jnp.ndarray]] = None
+ cross_attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxSeq2SeqModelOutput(ModelOutput):
+ """
+ Base class for model encoder's outputs that also contains : pre-computed hidden states that can speed up sequential
+ decoding.
+
+ Args:
+ last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the decoder of the model.
+
+ If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
+ hidden_size)` is output.
+ past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(jnp.ndarray)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ """
+
+ last_hidden_state: Optional[jnp.ndarray] = None
+ past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
+ decoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ decoder_attentions: Optional[Tuple[jnp.ndarray]] = None
+ cross_attentions: Optional[Tuple[jnp.ndarray]] = None
+ encoder_last_hidden_state: Optional[jnp.ndarray] = None
+ encoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ encoder_attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxCausalLMOutputWithCrossAttentions(ModelOutput):
+ """
+ Base class for causal language model (or autoregressive) outputs.
+
+ Args:
+ logits (`jnp.ndarray` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Cross attentions weights after the attention softmax, used to compute the weighted average in the
+ cross-attention heads.
+ past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `jnp.ndarray` tuples of length `config.n_layers`, with each tuple containing the cached key, value
+ states of the self-attention and the cross-attention layers if model is used in encoder-decoder setting.
+ Only relevant if `config.is_decoder = True`.
+
+ Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ """
+
+ logits: Optional[jnp.ndarray] = None
+ past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ attentions: Optional[Tuple[jnp.ndarray]] = None
+ cross_attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxMaskedLMOutput(ModelOutput):
+ """
+ Base class for masked language models outputs.
+
+ Args:
+ logits (`jnp.ndarray` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ logits: Optional[jnp.ndarray] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+FlaxCausalLMOutput = FlaxMaskedLMOutput
+
+
+@flax.struct.dataclass
+class FlaxSeq2SeqLMOutput(ModelOutput):
+ """
+ Base class for sequence-to-sequence language models outputs.
+
+ Args:
+ logits (`jnp.ndarray` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(jnp.ndarray)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ """
+
+ logits: Optional[jnp.ndarray] = None
+ past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
+ decoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ decoder_attentions: Optional[Tuple[jnp.ndarray]] = None
+ cross_attentions: Optional[Tuple[jnp.ndarray]] = None
+ encoder_last_hidden_state: Optional[jnp.ndarray] = None
+ encoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ encoder_attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxNextSentencePredictorOutput(ModelOutput):
+ """
+ Base class for outputs of models predicting if two sentences are consecutive or not.
+
+ Args:
+ logits (`jnp.ndarray` of shape `(batch_size, 2)`):
+ Prediction scores of the next sequence prediction (classification) head (scores of True/False continuation
+ before SoftMax).
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ logits: Optional[jnp.ndarray] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxSequenceClassifierOutput(ModelOutput):
+ """
+ Base class for outputs of sentence classification models.
+
+ Args:
+ logits (`jnp.ndarray` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ logits: Optional[jnp.ndarray] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxSeq2SeqSequenceClassifierOutput(ModelOutput):
+ """
+ Base class for outputs of sequence-to-sequence sentence classification models.
+
+ Args:
+ logits (`jnp.ndarray` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(jnp.ndarray)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ """
+
+ logits: Optional[jnp.ndarray] = None
+ past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
+ decoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ decoder_attentions: Optional[Tuple[jnp.ndarray]] = None
+ cross_attentions: Optional[Tuple[jnp.ndarray]] = None
+ encoder_last_hidden_state: Optional[jnp.ndarray] = None
+ encoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ encoder_attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxMultipleChoiceModelOutput(ModelOutput):
+ """
+ Base class for outputs of multiple choice models.
+
+ Args:
+ logits (`jnp.ndarray` of shape `(batch_size, num_choices)`):
+ *num_choices* is the second dimension of the input tensors. (see *input_ids* above).
+
+ Classification scores (before SoftMax).
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ logits: Optional[jnp.ndarray] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxTokenClassifierOutput(ModelOutput):
+ """
+ Base class for outputs of token classification models.
+
+ Args:
+ logits (`jnp.ndarray` of shape `(batch_size, sequence_length, config.num_labels)`):
+ Classification scores (before SoftMax).
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ logits: Optional[jnp.ndarray] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxQuestionAnsweringModelOutput(ModelOutput):
+ """
+ Base class for outputs of question answering models.
+
+ Args:
+ start_logits (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
+ Span-start scores (before SoftMax).
+ end_logits (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
+ Span-end scores (before SoftMax).
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ start_logits: Optional[jnp.ndarray] = None
+ end_logits: Optional[jnp.ndarray] = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+@flax.struct.dataclass
+class FlaxSeq2SeqQuestionAnsweringModelOutput(ModelOutput):
+ """
+ Base class for outputs of sequence-to-sequence question answering models.
+
+ Args:
+ start_logits (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
+ Span-start scores (before SoftMax).
+ end_logits (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
+ Span-end scores (before SoftMax).
+ past_key_values (`tuple(tuple(jnp.ndarray))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(jnp.ndarray)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ """
+
+ start_logits: Optional[jnp.ndarray] = None
+ end_logits: Optional[jnp.ndarray] = None
+ past_key_values: Optional[Tuple[Tuple[jnp.ndarray]]] = None
+ decoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ decoder_attentions: Optional[Tuple[jnp.ndarray]] = None
+ cross_attentions: Optional[Tuple[jnp.ndarray]] = None
+ encoder_last_hidden_state: Optional[jnp.ndarray] = None
+ encoder_hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ encoder_attentions: Optional[Tuple[jnp.ndarray]] = None
diff --git a/docs/transformers/src/transformers/modeling_flax_pytorch_utils.py b/docs/transformers/src/transformers/modeling_flax_pytorch_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..072850657725fb41e54eb33d0a7ad9d489968b00
--- /dev/null
+++ b/docs/transformers/src/transformers/modeling_flax_pytorch_utils.py
@@ -0,0 +1,490 @@
+# coding=utf-8
+# Copyright 2021 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch - Flax general utilities."""
+
+import os
+from pickle import UnpicklingError
+from typing import Dict, Tuple
+
+import jax
+import jax.numpy as jnp
+import numpy as np
+from flax.serialization import from_bytes
+from flax.traverse_util import flatten_dict, unflatten_dict
+
+import transformers
+
+from . import is_safetensors_available, is_torch_available
+from .utils import logging
+
+
+if is_torch_available():
+ import torch
+
+if is_safetensors_available():
+ from safetensors import safe_open
+ from safetensors.flax import load_file as safe_load_file
+
+
+logger = logging.get_logger(__name__)
+
+
+#####################
+# PyTorch => Flax #
+#####################
+
+
+def load_pytorch_checkpoint_in_flax_state_dict(
+ flax_model, pytorch_checkpoint_path, is_sharded, allow_missing_keys=False
+):
+ """Load pytorch checkpoints in a flax model"""
+
+ if not is_sharded:
+ pt_path = os.path.abspath(pytorch_checkpoint_path)
+ logger.info(f"Loading PyTorch weights from {pt_path}")
+
+ if pt_path.endswith(".safetensors"):
+ pt_state_dict = {}
+ with safe_open(pt_path, framework="flax") as f:
+ for k in f.keys():
+ pt_state_dict[k] = f.get_tensor(k)
+ else:
+ try:
+ import torch # noqa: F401
+ except (ImportError, ModuleNotFoundError):
+ logger.error(
+ "Loading a PyTorch model in Flax, requires both PyTorch and Flax to be installed. Please see"
+ " https://pytorch.org/ and https://flax.readthedocs.io/en/latest/installation.html for installation"
+ " instructions."
+ )
+ raise
+
+ pt_state_dict = torch.load(pt_path, map_location="cpu", weights_only=True)
+ logger.info(f"PyTorch checkpoint contains {sum(t.numel() for t in pt_state_dict.values()):,} parameters.")
+
+ flax_state_dict = convert_pytorch_state_dict_to_flax(pt_state_dict, flax_model)
+ else:
+ # model is sharded and pytorch_checkpoint_path already contains the list of .pt shard files
+ flax_state_dict = convert_pytorch_sharded_state_dict_to_flax(pytorch_checkpoint_path, flax_model)
+ return flax_state_dict
+
+
+def rename_key_and_reshape_tensor(
+ pt_tuple_key: Tuple[str],
+ pt_tensor: np.ndarray,
+ random_flax_state_dict: Dict[str, jnp.ndarray],
+ model_prefix: str,
+) -> (Tuple[str], np.ndarray):
+ """Rename PT weight names to corresponding Flax weight names and reshape tensor if necessary"""
+
+ def is_key_or_prefix_key_in_dict(key: Tuple[str]) -> bool:
+ """Checks if `key` of `(prefix,) + key` is in random_flax_state_dict"""
+ return len(set(random_flax_state_dict) & {key, (model_prefix,) + key}) > 0
+
+ # layer norm
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("scale",)
+ if pt_tuple_key[-1] in ["weight", "gamma"] and is_key_or_prefix_key_in_dict(renamed_pt_tuple_key):
+ return renamed_pt_tuple_key, pt_tensor
+
+ # batch norm layer mean
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("mean",)
+ if pt_tuple_key[-1] == "running_mean" and not is_key_or_prefix_key_in_dict(pt_tuple_key):
+ return renamed_pt_tuple_key, pt_tensor
+
+ # batch norm layer var
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("var",)
+ if pt_tuple_key[-1] == "running_var" and not is_key_or_prefix_key_in_dict(pt_tuple_key):
+ return renamed_pt_tuple_key, pt_tensor
+
+ # embedding
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("embedding",)
+ if pt_tuple_key[-1] == "weight" and is_key_or_prefix_key_in_dict(renamed_pt_tuple_key):
+ return renamed_pt_tuple_key, pt_tensor
+
+ # conv layer
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("kernel",)
+ if pt_tuple_key[-1] == "weight" and pt_tensor.ndim == 4 and not is_key_or_prefix_key_in_dict(pt_tuple_key):
+ pt_tensor = pt_tensor.transpose(2, 3, 1, 0)
+ return renamed_pt_tuple_key, pt_tensor
+
+ # linear layer
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("kernel",)
+ if pt_tuple_key[-1] == "weight" and not is_key_or_prefix_key_in_dict(pt_tuple_key):
+ pt_tensor = pt_tensor.T
+ return renamed_pt_tuple_key, pt_tensor
+
+ # old PyTorch layer norm weight
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("weight",)
+ if pt_tuple_key[-1] == "gamma":
+ return renamed_pt_tuple_key, pt_tensor
+
+ # old PyTorch layer norm bias
+ renamed_pt_tuple_key = pt_tuple_key[:-1] + ("bias",)
+ if pt_tuple_key[-1] == "beta":
+ return renamed_pt_tuple_key, pt_tensor
+
+ # New `weight_norm` from https://github.com/huggingface/transformers/pull/24030
+ name = None
+ if pt_tuple_key[-3::2] == ("parametrizations", "original0"):
+ name = pt_tuple_key[-2] + "_g"
+ elif pt_tuple_key[-3::2] == ("parametrizations", "original1"):
+ name = pt_tuple_key[-2] + "_v"
+ if name is not None:
+ renamed_pt_tuple_key = pt_tuple_key[:-3] + (name,)
+ return renamed_pt_tuple_key, pt_tensor
+
+ return pt_tuple_key, pt_tensor
+
+
+def convert_pytorch_state_dict_to_flax(pt_state_dict, flax_model):
+ # convert pytorch tensor to numpy
+ from_bin = is_torch_available() and isinstance(next(iter(pt_state_dict.values())), torch.Tensor)
+ bfloat16 = torch.bfloat16 if from_bin else "bfloat16"
+
+ weight_dtypes = {k: v.dtype for k, v in pt_state_dict.items()}
+
+ if from_bin:
+ for k, v in pt_state_dict.items():
+ # numpy currently does not support bfloat16, need to go over float32 in this case to not lose precision
+ if v.dtype == bfloat16:
+ v = v.float()
+ pt_state_dict[k] = v.cpu().numpy()
+
+ model_prefix = flax_model.base_model_prefix
+
+ # use params dict if the model contains batch norm layers
+ if "params" in flax_model.params:
+ flax_model_params = flax_model.params["params"]
+ else:
+ flax_model_params = flax_model.params
+ random_flax_state_dict = flatten_dict(flax_model_params)
+
+ # add batch_stats keys,values to dict
+ if "batch_stats" in flax_model.params:
+ flax_batch_stats = flatten_dict(flax_model.params["batch_stats"])
+ random_flax_state_dict.update(flax_batch_stats)
+
+ flax_state_dict = {}
+
+ load_model_with_head_into_base_model = (model_prefix not in flax_model_params) and (
+ model_prefix in {k.split(".")[0] for k in pt_state_dict.keys()}
+ )
+ load_base_model_into_model_with_head = (model_prefix in flax_model_params) and (
+ model_prefix not in {k.split(".")[0] for k in pt_state_dict.keys()}
+ )
+
+ # Need to change some parameters name to match Flax names
+ for pt_key, pt_tensor in pt_state_dict.items():
+ pt_tuple_key = tuple(pt_key.split("."))
+ is_bfloat_16 = weight_dtypes[pt_key] == bfloat16
+
+ # remove base model prefix if necessary
+ has_base_model_prefix = pt_tuple_key[0] == model_prefix
+ if load_model_with_head_into_base_model and has_base_model_prefix:
+ pt_tuple_key = pt_tuple_key[1:]
+
+ # Correctly rename weight parameters
+ flax_key, flax_tensor = rename_key_and_reshape_tensor(
+ pt_tuple_key, pt_tensor, random_flax_state_dict, model_prefix
+ )
+
+ # add model prefix if necessary
+ require_base_model_prefix = (model_prefix,) + flax_key in random_flax_state_dict
+ if load_base_model_into_model_with_head and require_base_model_prefix:
+ flax_key = (model_prefix,) + flax_key
+
+ if flax_key in random_flax_state_dict:
+ if flax_tensor.shape != random_flax_state_dict[flax_key].shape:
+ raise ValueError(
+ f"PyTorch checkpoint seems to be incorrect. Weight {pt_key} was expected to be of shape "
+ f"{random_flax_state_dict[flax_key].shape}, but is {flax_tensor.shape}."
+ )
+
+ # add batch stats if the model contains batchnorm layers
+ if "batch_stats" in flax_model.params:
+ if "mean" in flax_key[-1] or "var" in flax_key[-1]:
+ flax_state_dict[("batch_stats",) + flax_key] = jnp.asarray(flax_tensor)
+ continue
+ # remove num_batches_tracked key
+ if "num_batches_tracked" in flax_key[-1]:
+ flax_state_dict.pop(flax_key, None)
+ continue
+
+ # also add unexpected weight so that warning is thrown
+ flax_state_dict[("params",) + flax_key] = (
+ jnp.asarray(flax_tensor) if not is_bfloat_16 else jnp.asarray(flax_tensor, dtype=jnp.bfloat16)
+ )
+ else:
+ # also add unexpected weight so that warning is thrown
+ flax_state_dict[flax_key] = (
+ jnp.asarray(flax_tensor) if not is_bfloat_16 else jnp.asarray(flax_tensor, dtype=jnp.bfloat16)
+ )
+
+ return unflatten_dict(flax_state_dict)
+
+
+############################
+# Sharded Pytorch => Flax #
+############################
+
+
+def convert_pytorch_sharded_state_dict_to_flax(shard_filenames, flax_model):
+ import torch
+
+ # Load the index
+ flax_state_dict = {}
+ for shard_file in shard_filenames:
+ # load using msgpack utils
+ pt_state_dict = torch.load(shard_file, weights_only=True)
+ weight_dtypes = {k: v.dtype for k, v in pt_state_dict.items()}
+ pt_state_dict = {
+ k: v.numpy() if v.dtype != torch.bfloat16 else v.float().numpy() for k, v in pt_state_dict.items()
+ }
+
+ model_prefix = flax_model.base_model_prefix
+
+ # use params dict if the model contains batch norm layers and then add batch_stats keys,values to dict
+ if "batch_stats" in flax_model.params:
+ flax_model_params = flax_model.params["params"]
+
+ random_flax_state_dict = flatten_dict(flax_model_params)
+ random_flax_state_dict.update(flatten_dict(flax_model.params["batch_stats"]))
+ else:
+ flax_model_params = flax_model.params
+ random_flax_state_dict = flatten_dict(flax_model_params)
+
+ load_model_with_head_into_base_model = (model_prefix not in flax_model_params) and (
+ model_prefix in {k.split(".")[0] for k in pt_state_dict.keys()}
+ )
+ load_base_model_into_model_with_head = (model_prefix in flax_model_params) and (
+ model_prefix not in {k.split(".")[0] for k in pt_state_dict.keys()}
+ )
+ # Need to change some parameters name to match Flax names
+ for pt_key, pt_tensor in pt_state_dict.items():
+ pt_tuple_key = tuple(pt_key.split("."))
+ is_bfloat_16 = weight_dtypes[pt_key] == torch.bfloat16
+
+ # remove base model prefix if necessary
+ has_base_model_prefix = pt_tuple_key[0] == model_prefix
+ if load_model_with_head_into_base_model and has_base_model_prefix:
+ pt_tuple_key = pt_tuple_key[1:]
+
+ # Correctly rename weight parameters
+ flax_key, flax_tensor = rename_key_and_reshape_tensor(
+ pt_tuple_key, pt_tensor, random_flax_state_dict, model_prefix
+ )
+ # add model prefix if necessary
+ require_base_model_prefix = (model_prefix,) + flax_key in random_flax_state_dict
+ if load_base_model_into_model_with_head and require_base_model_prefix:
+ flax_key = (model_prefix,) + flax_key
+
+ if flax_key in random_flax_state_dict:
+ if flax_tensor.shape != random_flax_state_dict[flax_key].shape:
+ raise ValueError(
+ f"PyTorch checkpoint seems to be incorrect. Weight {pt_key} was expected to be of shape "
+ f"{random_flax_state_dict[flax_key].shape}, but is {flax_tensor.shape}."
+ )
+
+ # add batch stats if the model contains batchnorm layers
+ if "batch_stats" in flax_model.params:
+ if "mean" in flax_key[-1]:
+ flax_state_dict[("batch_stats",) + flax_key] = jnp.asarray(flax_tensor)
+ continue
+ if "var" in flax_key[-1]:
+ flax_state_dict[("batch_stats",) + flax_key] = jnp.asarray(flax_tensor)
+ continue
+ # remove num_batches_tracked key
+ if "num_batches_tracked" in flax_key[-1]:
+ flax_state_dict.pop(flax_key, None)
+ continue
+
+ # also add unexpected weight so that warning is thrown
+ flax_state_dict[("params",) + flax_key] = (
+ jnp.asarray(flax_tensor) if not is_bfloat_16 else jnp.asarray(flax_tensor, dtype=jnp.bfloat16)
+ )
+
+ else:
+ # also add unexpected weight so that warning is thrown
+ flax_state_dict[flax_key] = (
+ jnp.asarray(flax_tensor) if not is_bfloat_16 else jnp.asarray(flax_tensor, dtype=jnp.bfloat16)
+ )
+ return unflatten_dict(flax_state_dict)
+
+
+#####################
+# Flax => PyTorch #
+#####################
+
+
+def load_flax_checkpoint_in_pytorch_model(model, flax_checkpoint_path):
+ """Load flax checkpoints in a PyTorch model"""
+ flax_checkpoint_path = os.path.abspath(flax_checkpoint_path)
+ logger.info(f"Loading Flax weights from {flax_checkpoint_path}")
+
+ # import correct flax class
+ flax_cls = getattr(transformers, "Flax" + model.__class__.__name__)
+
+ # load flax weight dict
+ if flax_checkpoint_path.endswith(".safetensors"):
+ flax_state_dict = safe_load_file(flax_checkpoint_path)
+ flax_state_dict = unflatten_dict(flax_state_dict, sep=".")
+ else:
+ with open(flax_checkpoint_path, "rb") as state_f:
+ try:
+ flax_state_dict = from_bytes(flax_cls, state_f.read())
+ except UnpicklingError:
+ raise EnvironmentError(f"Unable to convert {flax_checkpoint_path} to Flax deserializable object. ")
+
+ return load_flax_weights_in_pytorch_model(model, flax_state_dict)
+
+
+def load_flax_weights_in_pytorch_model(pt_model, flax_state):
+ """Load flax checkpoints in a PyTorch model"""
+
+ try:
+ import torch # noqa: F401
+ except (ImportError, ModuleNotFoundError):
+ logger.error(
+ "Loading a Flax weights in PyTorch, requires both PyTorch and Flax to be installed. Please see"
+ " https://pytorch.org/ and https://flax.readthedocs.io/en/latest/installation.html for installation"
+ " instructions."
+ )
+ raise
+
+ # check if we have bf16 weights
+ is_type_bf16 = flatten_dict(jax.tree_util.tree_map(lambda x: x.dtype == jnp.bfloat16, flax_state)).values()
+ if any(is_type_bf16):
+ # convert all weights to fp32 if the are bf16 since torch.from_numpy can-not handle bf16
+ # and bf16 is not fully supported in PT yet.
+ logger.warning(
+ "Found ``bfloat16`` weights in Flax model. Casting all ``bfloat16`` weights to ``float32`` "
+ "before loading those in PyTorch model."
+ )
+ flax_state = jax.tree_util.tree_map(
+ lambda params: params.astype(np.float32) if params.dtype == jnp.bfloat16 else params, flax_state
+ )
+
+ flax_state_dict = flatten_dict(flax_state)
+ pt_model_dict = pt_model.state_dict()
+
+ load_model_with_head_into_base_model = (pt_model.base_model_prefix in flax_state) and (
+ pt_model.base_model_prefix not in {k.split(".")[0] for k in pt_model_dict.keys()}
+ )
+ load_base_model_into_model_with_head = (pt_model.base_model_prefix not in flax_state) and (
+ pt_model.base_model_prefix in {k.split(".")[0] for k in pt_model_dict.keys()}
+ )
+
+ # keep track of unexpected & missing keys
+ unexpected_keys = []
+ missing_keys = set(pt_model_dict.keys())
+
+ for flax_key_tuple, flax_tensor in flax_state_dict.items():
+ has_base_model_prefix = flax_key_tuple[0] == pt_model.base_model_prefix
+ require_base_model_prefix = ".".join((pt_model.base_model_prefix,) + flax_key_tuple) in pt_model_dict
+
+ # adapt flax_key to prepare for loading from/to base model only
+ if load_model_with_head_into_base_model and has_base_model_prefix:
+ flax_key_tuple = flax_key_tuple[1:]
+ elif load_base_model_into_model_with_head and require_base_model_prefix:
+ flax_key_tuple = (pt_model.base_model_prefix,) + flax_key_tuple
+
+ # rename flax weights to PyTorch format
+ if flax_key_tuple[-1] == "kernel" and flax_tensor.ndim == 4 and ".".join(flax_key_tuple) not in pt_model_dict:
+ # conv layer
+ flax_key_tuple = flax_key_tuple[:-1] + ("weight",)
+ flax_tensor = jnp.transpose(flax_tensor, (3, 2, 0, 1))
+ elif flax_key_tuple[-1] == "kernel" and ".".join(flax_key_tuple) not in pt_model_dict:
+ # linear layer
+ flax_key_tuple = flax_key_tuple[:-1] + ("weight",)
+ flax_tensor = flax_tensor.T
+ elif flax_key_tuple[-1] in ["scale", "embedding"]:
+ flax_key_tuple = flax_key_tuple[:-1] + ("weight",)
+
+ # adding batch stats from flax batch norm to pt
+ elif "mean" in flax_key_tuple[-1]:
+ flax_key_tuple = flax_key_tuple[:-1] + ("running_mean",)
+ elif "var" in flax_key_tuple[-1]:
+ flax_key_tuple = flax_key_tuple[:-1] + ("running_var",)
+
+ if "batch_stats" in flax_state:
+ flax_key = ".".join(flax_key_tuple[1:]) # Remove the params/batch_stats header
+ else:
+ flax_key = ".".join(flax_key_tuple)
+
+ # We also need to look at `pt_model_dict` and see if there are keys requiring further transformation.
+ special_pt_names = {}
+ # New `weight_norm` from https://github.com/huggingface/transformers/pull/24030
+ for key in pt_model_dict:
+ key_components = key.split(".")
+ name = None
+ if key_components[-3::2] == ["parametrizations", "original0"]:
+ name = key_components[-2] + "_g"
+ elif key_components[-3::2] == ["parametrizations", "original1"]:
+ name = key_components[-2] + "_v"
+ if name is not None:
+ key_components = key_components[:-3] + [name]
+ key_to_check = ".".join(key_components)
+ special_pt_names[key_to_check] = key
+
+ if flax_key in special_pt_names:
+ flax_key = special_pt_names[flax_key]
+
+ if flax_key in pt_model_dict:
+ if flax_tensor.shape != pt_model_dict[flax_key].shape:
+ raise ValueError(
+ f"Flax checkpoint seems to be incorrect. Weight {flax_key_tuple} was expected "
+ f"to be of shape {pt_model_dict[flax_key].shape}, but is {flax_tensor.shape}."
+ )
+ else:
+ # add weight to pytorch dict
+ flax_tensor = np.asarray(flax_tensor) if not isinstance(flax_tensor, np.ndarray) else flax_tensor
+ pt_model_dict[flax_key] = torch.from_numpy(flax_tensor)
+ # remove from missing keys
+ missing_keys.remove(flax_key)
+ else:
+ # weight is not expected by PyTorch model
+ unexpected_keys.append(flax_key)
+
+ pt_model.load_state_dict(pt_model_dict)
+
+ # re-transform missing_keys to list
+ missing_keys = list(missing_keys)
+
+ if len(unexpected_keys) > 0:
+ logger.warning(
+ "Some weights of the Flax model were not used when initializing the PyTorch model"
+ f" {pt_model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are initializing"
+ f" {pt_model.__class__.__name__} from a Flax model trained on another task or with another architecture"
+ " (e.g. initializing a BertForSequenceClassification model from a FlaxBertForPreTraining model).\n- This"
+ f" IS NOT expected if you are initializing {pt_model.__class__.__name__} from a Flax model that you expect"
+ " to be exactly identical (e.g. initializing a BertForSequenceClassification model from a"
+ " FlaxBertForSequenceClassification model)."
+ )
+ else:
+ logger.warning(f"All Flax model weights were used when initializing {pt_model.__class__.__name__}.\n")
+ if len(missing_keys) > 0:
+ logger.warning(
+ f"Some weights of {pt_model.__class__.__name__} were not initialized from the Flax model and are newly"
+ f" initialized: {missing_keys}\nYou should probably TRAIN this model on a down-stream task to be able to"
+ " use it for predictions and inference."
+ )
+ else:
+ logger.warning(
+ f"All the weights of {pt_model.__class__.__name__} were initialized from the Flax model.\n"
+ "If your task is similar to the task the model of the checkpoint was trained on, "
+ f"you can already use {pt_model.__class__.__name__} for predictions without further training."
+ )
+
+ return pt_model
diff --git a/docs/transformers/src/transformers/modeling_flax_utils.py b/docs/transformers/src/transformers/modeling_flax_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..c775ee85bbefb6a70481863bb8c546ef3efa43d3
--- /dev/null
+++ b/docs/transformers/src/transformers/modeling_flax_utils.py
@@ -0,0 +1,1273 @@
+# coding=utf-8
+# Copyright 2021 The Google Flax Team Authors and The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import gc
+import json
+import os
+import warnings
+from functools import partial
+from pickle import UnpicklingError
+from typing import Any, Dict, Optional, Set, Tuple, Union
+
+import flax.linen as nn
+import jax
+import jax.numpy as jnp
+import msgpack.exceptions
+from flax.core.frozen_dict import FrozenDict, unfreeze
+from flax.serialization import from_bytes, to_bytes
+from flax.traverse_util import flatten_dict, unflatten_dict
+from jax.random import PRNGKey
+
+from .configuration_utils import PretrainedConfig
+from .dynamic_module_utils import custom_object_save
+from .generation import FlaxGenerationMixin, GenerationConfig
+from .modeling_flax_pytorch_utils import load_pytorch_checkpoint_in_flax_state_dict
+from .utils import (
+ FLAX_WEIGHTS_INDEX_NAME,
+ FLAX_WEIGHTS_NAME,
+ SAFE_WEIGHTS_INDEX_NAME,
+ SAFE_WEIGHTS_NAME,
+ WEIGHTS_INDEX_NAME,
+ WEIGHTS_NAME,
+ PushToHubMixin,
+ add_code_sample_docstrings,
+ add_start_docstrings_to_model_forward,
+ cached_file,
+ copy_func,
+ download_url,
+ has_file,
+ is_offline_mode,
+ is_remote_url,
+ logging,
+ replace_return_docstrings,
+)
+from .utils.hub import convert_file_size_to_int, get_checkpoint_shard_files
+from .utils.import_utils import is_safetensors_available
+
+
+if is_safetensors_available():
+ from safetensors import safe_open
+ from safetensors.flax import load_file as safe_load_file
+ from safetensors.flax import save_file as safe_save_file
+
+logger = logging.get_logger(__name__)
+
+
+def quick_gelu(x):
+ return x * jax.nn.sigmoid(1.702 * x)
+
+
+ACT2FN = {
+ "gelu": partial(nn.gelu, approximate=False),
+ "relu": nn.relu,
+ "silu": nn.swish,
+ "swish": nn.swish,
+ "gelu_new": partial(nn.gelu, approximate=True),
+ "quick_gelu": quick_gelu,
+ "gelu_pytorch_tanh": partial(nn.gelu, approximate=True),
+ "tanh": nn.tanh,
+}
+
+
+def flax_shard_checkpoint(params, max_shard_size="10GB"):
+ """
+ Splits a model state dictionary in sub-checkpoints so that the final size of each sub-checkpoint does not exceed a
+ given size. The sub-checkpoints are determined by iterating through the `state_dict` in the order of its keys, so
+ there is no optimization made to make each sub-checkpoint as close as possible to the maximum size passed. For
+ example, if the limit is 10GB and we have weights of sizes [6GB, 6GB, 2GB, 6GB, 2GB, 2GB] they will get sharded as
+ [6GB], [6+2GB], [6+2+2GB] and not [6+2+2GB], [6+2GB], [6GB].
+
+
+
+ If one of the model's weight is bigger that `max_shard_size`, it will end up in its own sub-checkpoint which will
+ have a size greater than `max_shard_size`.
+
+
+
+ Args:
+ params (`Union[Dict, FrozenDict]`): A `PyTree` of model parameters.
+ max_shard_size (`int` or `str`, *optional*, defaults to `"10GB"`):
+ The maximum size of each sub-checkpoint. If expressed as a string, needs to be digits followed by a unit
+ (like `"5MB"`).
+ """
+ max_shard_size = convert_file_size_to_int(max_shard_size)
+
+ sharded_state_dicts = []
+ current_block = {}
+ current_block_size = 0
+ total_size = 0
+
+ # flatten the weights to chunk
+ weights = flatten_dict(params, sep="/")
+ for item in weights:
+ weight_size = weights[item].size * weights[item].dtype.itemsize
+
+ # If this weight is going to tip up over the maximal size, we split.
+ if current_block_size + weight_size > max_shard_size:
+ sharded_state_dicts.append(current_block)
+ current_block = {}
+ current_block_size = 0
+
+ current_block[item] = weights[item]
+ current_block_size += weight_size
+ total_size += weight_size
+
+ # Add the last block
+ sharded_state_dicts.append(current_block)
+
+ # If we only have one shard, we return it
+ if len(sharded_state_dicts) == 1:
+ return {FLAX_WEIGHTS_NAME: sharded_state_dicts[0]}, None
+
+ # Otherwise, let's build the index
+ weight_map = {}
+ shards = {}
+ for idx, shard in enumerate(sharded_state_dicts):
+ shard_file = FLAX_WEIGHTS_NAME.replace(".msgpack", f"-{idx + 1:05d}-of-{len(sharded_state_dicts):05d}.msgpack")
+ shards[shard_file] = shard
+ for weight_name in shard.keys():
+ weight_map[weight_name] = shard_file
+
+ # Add the metadata
+ metadata = {"total_size": total_size}
+ index = {"metadata": metadata, "weight_map": weight_map}
+ return shards, index
+
+
+class FlaxPreTrainedModel(PushToHubMixin, FlaxGenerationMixin):
+ r"""
+ Base class for all models.
+
+ [`FlaxPreTrainedModel`] takes care of storing the configuration of the models and handles methods for loading,
+ downloading and saving models.
+
+ Class attributes (overridden by derived classes):
+
+ - **config_class** ([`PretrainedConfig`]) -- A subclass of [`PretrainedConfig`] to use as configuration class
+ for this model architecture.
+ - **base_model_prefix** (`str`) -- A string indicating the attribute associated to the base model in derived
+ classes of the same architecture adding modules on top of the base model.
+ - **main_input_name** (`str`) -- The name of the principal input to the model (often `input_ids` for NLP
+ models, `pixel_values` for vision models and `input_values` for speech models).
+ """
+
+ config_class = None
+ base_model_prefix = ""
+ main_input_name = "input_ids"
+ _auto_class = None
+ _missing_keys = set()
+
+ def __init__(
+ self,
+ config: PretrainedConfig,
+ module: nn.Module,
+ input_shape: Tuple = (1, 1),
+ seed: int = 0,
+ dtype: jnp.dtype = jnp.float32,
+ _do_init: bool = True,
+ ):
+ if config is None:
+ raise ValueError("config cannot be None")
+
+ if module is None:
+ raise ValueError("module cannot be None")
+
+ # Those are private to be exposed as typed property on derived classes.
+ self._config = config
+ self._module = module
+
+ # Those are public as their type is generic to every derived classes.
+ self.key = PRNGKey(seed)
+ self.dtype = dtype
+ self.input_shape = input_shape
+ self.generation_config = GenerationConfig.from_model_config(config) if self.can_generate() else None
+
+ # To check if the model was initialized automatically.
+ self._is_initialized = _do_init
+
+ if _do_init:
+ # randomly initialized parameters
+ random_params = self.init_weights(self.key, input_shape)
+ params_shape_tree = jax.eval_shape(lambda params: params, random_params)
+ else:
+ init_fn = partial(self.init_weights, input_shape=input_shape)
+ params_shape_tree = jax.eval_shape(init_fn, self.key)
+
+ logger.info(
+ "Model weights are not initialized as `_do_init` is set to `False`. "
+ f"Make sure to call `{self.__class__.__name__}.init_weights` manually to initialize the weights."
+ )
+
+ # get the shape of the parameters
+ self._params_shape_tree = params_shape_tree
+
+ # save required_params as set
+ self._required_params = set(flatten_dict(unfreeze(params_shape_tree)).keys())
+
+ # initialize the parameters
+ if _do_init:
+ self.params = random_params
+
+ def init_weights(self, rng: jax.random.PRNGKey, input_shape: Tuple, params: FrozenDict = None) -> Dict:
+ raise NotImplementedError(f"init method has to be implemented for {self}")
+
+ def enable_gradient_checkpointing(self):
+ raise NotImplementedError(f"gradient checkpointing method has to be implemented for {self}")
+
+ @classmethod
+ def _from_config(cls, config, **kwargs):
+ """
+ All context managers that the model should be initialized under go here.
+ """
+ return cls(config, **kwargs)
+
+ @property
+ def framework(self) -> str:
+ """
+ :str: Identifies that this is a Flax model.
+ """
+ return "flax"
+
+ @property
+ def config(self) -> PretrainedConfig:
+ return self._config
+
+ @property
+ def module(self) -> nn.Module:
+ return self._module
+
+ @property
+ def params(self) -> Union[Dict, FrozenDict]:
+ if not self._is_initialized:
+ raise ValueError(
+ "`params` cannot be accessed from model when the model is created with `_do_init=False`. "
+ "You must call `init_weights` manually and store the params outside of the model and "
+ "pass it explicitly where needed."
+ )
+ return self._params
+
+ @property
+ def required_params(self) -> Set:
+ return self._required_params
+
+ @property
+ def params_shape_tree(self) -> Dict:
+ return self._params_shape_tree
+
+ @params.setter
+ def params(self, params: Union[Dict, FrozenDict]):
+ # don't set params if the model is not initialized
+ if not self._is_initialized:
+ raise ValueError(
+ "`params` cannot be set from model when the model is created with `_do_init=False`. "
+ "You store the params outside of the model."
+ )
+
+ if isinstance(params, FrozenDict):
+ params = unfreeze(params)
+ param_keys = set(flatten_dict(params).keys())
+ if len(self.required_params - param_keys) > 0:
+ raise ValueError(
+ "Some parameters are missing. Make sure that `params` include the following "
+ f"parameters {self.required_params - param_keys}"
+ )
+ self._params = params
+
+ def _cast_floating_to(self, params: Union[Dict, FrozenDict], dtype: jnp.dtype, mask: Any = None) -> Any:
+ """
+ Helper method to cast floating-point values of given parameter `PyTree` to given `dtype`.
+ """
+
+ # taken from https://github.com/deepmind/jmp/blob/3a8318abc3292be38582794dbf7b094e6583b192/jmp/_src/policy.py#L27
+ def conditional_cast(param):
+ if isinstance(param, jnp.ndarray) and jnp.issubdtype(param.dtype, jnp.floating):
+ param = param.astype(dtype)
+ return param
+
+ if mask is None:
+ return jax.tree_util.tree_map(conditional_cast, params)
+
+ flat_params = flatten_dict(params)
+ flat_mask, _ = jax.tree_util.tree_flatten(mask)
+
+ for masked, key in zip(flat_mask, sorted(flat_params.keys())):
+ if masked:
+ flat_params[key] = conditional_cast(flat_params[key])
+
+ return unflatten_dict(flat_params)
+
+ def to_bf16(self, params: Union[Dict, FrozenDict], mask: Any = None):
+ r"""
+ Cast the floating-point `params` to `jax.numpy.bfloat16`. This returns a new `params` tree and does not cast
+ the `params` in place.
+
+ This method can be used on TPU to explicitly convert the model parameters to bfloat16 precision to do full
+ half-precision training or to save weights in bfloat16 for inference in order to save memory and improve speed.
+
+ Arguments:
+ params (`Union[Dict, FrozenDict]`):
+ A `PyTree` of model parameters.
+ mask (`Union[Dict, FrozenDict]`):
+ A `PyTree` with same structure as the `params` tree. The leaves should be booleans, `True` for params
+ you want to cast, and should be `False` for those you want to skip.
+
+ Examples:
+
+ ```python
+ >>> from transformers import FlaxBertModel
+
+ >>> # load model
+ >>> model = FlaxBertModel.from_pretrained("google-bert/bert-base-cased")
+ >>> # By default, the model parameters will be in fp32 precision, to cast these to bfloat16 precision
+ >>> model.params = model.to_bf16(model.params)
+ >>> # If you want don't want to cast certain parameters (for example layer norm bias and scale)
+ >>> # then pass the mask as follows
+ >>> from flax import traverse_util
+
+ >>> model = FlaxBertModel.from_pretrained("google-bert/bert-base-cased")
+ >>> flat_params = traverse_util.flatten_dict(model.params)
+ >>> mask = {
+ ... path: (path[-2] != ("LayerNorm", "bias") and path[-2:] != ("LayerNorm", "scale"))
+ ... for path in flat_params
+ ... }
+ >>> mask = traverse_util.unflatten_dict(mask)
+ >>> model.params = model.to_bf16(model.params, mask)
+ ```"""
+ return self._cast_floating_to(params, jnp.bfloat16, mask)
+
+ def to_fp32(self, params: Union[Dict, FrozenDict], mask: Any = None):
+ r"""
+ Cast the floating-point `params` to `jax.numpy.float32`. This method can be used to explicitly convert the
+ model parameters to fp32 precision. This returns a new `params` tree and does not cast the `params` in place.
+
+ Arguments:
+ params (`Union[Dict, FrozenDict]`):
+ A `PyTree` of model parameters.
+ mask (`Union[Dict, FrozenDict]`):
+ A `PyTree` with same structure as the `params` tree. The leaves should be booleans, `True` for params
+ you want to cast, and should be `False` for those you want to skip
+
+ Examples:
+
+ ```python
+ >>> from transformers import FlaxBertModel
+
+ >>> # Download model and configuration from huggingface.co
+ >>> model = FlaxBertModel.from_pretrained("google-bert/bert-base-cased")
+ >>> # By default, the model params will be in fp32, to illustrate the use of this method,
+ >>> # we'll first cast to fp16 and back to fp32
+ >>> model.params = model.to_f16(model.params)
+ >>> # now cast back to fp32
+ >>> model.params = model.to_fp32(model.params)
+ ```"""
+ return self._cast_floating_to(params, jnp.float32, mask)
+
+ def to_fp16(self, params: Union[Dict, FrozenDict], mask: Any = None):
+ r"""
+ Cast the floating-point `params` to `jax.numpy.float16`. This returns a new `params` tree and does not cast the
+ `params` in place.
+
+ This method can be used on GPU to explicitly convert the model parameters to float16 precision to do full
+ half-precision training or to save weights in float16 for inference in order to save memory and improve speed.
+
+ Arguments:
+ params (`Union[Dict, FrozenDict]`):
+ A `PyTree` of model parameters.
+ mask (`Union[Dict, FrozenDict]`):
+ A `PyTree` with same structure as the `params` tree. The leaves should be booleans, `True` for params
+ you want to cast, and should be `False` for those you want to skip
+
+ Examples:
+
+ ```python
+ >>> from transformers import FlaxBertModel
+
+ >>> # load model
+ >>> model = FlaxBertModel.from_pretrained("google-bert/bert-base-cased")
+ >>> # By default, the model params will be in fp32, to cast these to float16
+ >>> model.params = model.to_fp16(model.params)
+ >>> # If you want don't want to cast certain parameters (for example layer norm bias and scale)
+ >>> # then pass the mask as follows
+ >>> from flax import traverse_util
+
+ >>> model = FlaxBertModel.from_pretrained("google-bert/bert-base-cased")
+ >>> flat_params = traverse_util.flatten_dict(model.params)
+ >>> mask = {
+ ... path: (path[-2] != ("LayerNorm", "bias") and path[-2:] != ("LayerNorm", "scale"))
+ ... for path in flat_params
+ ... }
+ >>> mask = traverse_util.unflatten_dict(mask)
+ >>> model.params = model.to_fp16(model.params, mask)
+ ```"""
+ return self._cast_floating_to(params, jnp.float16, mask)
+
+ @classmethod
+ def load_flax_weights(cls, resolved_archive_file):
+ try:
+ if resolved_archive_file.endswith(".safetensors"):
+ state = safe_load_file(resolved_archive_file)
+ state = unflatten_dict(state, sep=".")
+ else:
+ with open(resolved_archive_file, "rb") as state_f:
+ state = from_bytes(cls, state_f.read())
+ except (UnpicklingError, msgpack.exceptions.ExtraData) as e:
+ try:
+ with open(resolved_archive_file) as f:
+ if f.read().startswith("version"):
+ raise OSError(
+ "You seem to have cloned a repository without having git-lfs installed. Please"
+ " install git-lfs and run `git lfs install` followed by `git lfs pull` in the"
+ " folder you cloned."
+ )
+ else:
+ raise ValueError from e
+ except (UnicodeDecodeError, ValueError):
+ raise EnvironmentError(f"Unable to convert {resolved_archive_file} to Flax deserializable object. ")
+
+ return state
+
+ @classmethod
+ def load_flax_sharded_weights(cls, shard_files):
+ """
+ This is the same as [`flax.serialization.from_bytes`]
+ (https:lax.readthedocs.io/en/latest/_modules/flax/serialization.html#from_bytes) but for a sharded checkpoint.
+
+ This load is performed efficiently: each checkpoint shard is loaded one by one in RAM and deleted after being
+ loaded in the model.
+
+ Args:
+ shard_files (`List[str]`:
+ The list of shard files to load.
+
+ Returns:
+ `Dict`: A nested dictionary of the model parameters, in the expected format for flax models : `{'model':
+ {'params': {'...'}}}`.
+ """
+
+ # Load the index
+ state_sharded_dict = {}
+
+ for shard_file in shard_files:
+ # load using msgpack utils
+ try:
+ with open(shard_file, "rb") as state_f:
+ state = from_bytes(cls, state_f.read())
+ except (UnpicklingError, msgpack.exceptions.ExtraData) as e:
+ with open(shard_file) as f:
+ if f.read().startswith("version"):
+ raise OSError(
+ "You seem to have cloned a repository without having git-lfs installed. Please"
+ " install git-lfs and run `git lfs install` followed by `git lfs pull` in the"
+ " folder you cloned."
+ )
+ else:
+ raise ValueError from e
+ except (UnicodeDecodeError, ValueError):
+ raise EnvironmentError(f"Unable to convert {shard_file} to Flax deserializable object. ")
+
+ state = flatten_dict(state, sep="/")
+ state_sharded_dict.update(state)
+ del state
+ gc.collect()
+
+ # the state dict is unflattened to the match the format of model.params
+ return unflatten_dict(state_sharded_dict, sep="/")
+
+ @classmethod
+ def can_generate(cls) -> bool:
+ """
+ Returns whether this model can generate sequences with `.generate()`. Returns:
+ `bool`: Whether this model can generate sequences with `.generate()`.
+ """
+ # Detects whether `prepare_inputs_for_generation` has been overwritten, which is a requirement for generation.
+ # Alternatively, the model can also have a custom `generate` function.
+ if "GenerationMixin" in str(cls.prepare_inputs_for_generation) and "GenerationMixin" in str(cls.generate):
+ return False
+ return True
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path: Union[str, os.PathLike],
+ dtype: jnp.dtype = jnp.float32,
+ *model_args,
+ config: Optional[Union[PretrainedConfig, str, os.PathLike]] = None,
+ cache_dir: Optional[Union[str, os.PathLike]] = None,
+ ignore_mismatched_sizes: bool = False,
+ force_download: bool = False,
+ local_files_only: bool = False,
+ token: Optional[Union[str, bool]] = None,
+ revision: str = "main",
+ **kwargs,
+ ):
+ r"""
+ Instantiate a pretrained flax model from a pre-trained model configuration.
+
+ The warning *Weights from XXX not initialized from pretrained model* means that the weights of XXX do not come
+ pretrained with the rest of the model. It is up to you to train those weights with a downstream fine-tuning
+ task.
+
+ The warning *Weights from XXX not used in YYY* means that the layer XXX is not used by YYY, therefore those
+ weights are discarded.
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ Can be either:
+
+ - A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
+ - A path to a *directory* containing model weights saved using
+ [`~FlaxPreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
+ - A path or url to a *pt index checkpoint file* (e.g, `./tf_model/model.ckpt.index`). In this case,
+ `from_pt` should be set to `True`.
+ dtype (`jax.numpy.dtype`, *optional*, defaults to `jax.numpy.float32`):
+ The data type of the computation. Can be one of `jax.numpy.float32`, `jax.numpy.float16` (on GPUs) and
+ `jax.numpy.bfloat16` (on TPUs).
+
+ This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If
+ specified all the computation will be performed with the given `dtype`.
+
+ **Note that this only specifies the dtype of the computation and does not influence the dtype of model
+ parameters.**
+
+ If you wish to change the dtype of the model parameters, see [`~FlaxPreTrainedModel.to_fp16`] and
+ [`~FlaxPreTrainedModel.to_bf16`].
+ model_args (sequence of positional arguments, *optional*):
+ All remaining positional arguments will be passed to the underlying model's `__init__` method.
+ config (`Union[PretrainedConfig, str, os.PathLike]`, *optional*):
+ Can be either:
+
+ - an instance of a class derived from [`PretrainedConfig`],
+ - a string or path valid as input to [`~PretrainedConfig.from_pretrained`].
+
+ Configuration for the model to use instead of an automatically loaded configuration. Configuration can
+ be automatically loaded when:
+
+ - The model is a model provided by the library (loaded with the *model id* string of a pretrained
+ model).
+ - The model was saved using [`~PreTrainedModel.save_pretrained`] and is reloaded by supplying the
+ save directory.
+ - The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
+ configuration JSON file named *config.json* is found in the directory.
+ cache_dir (`Union[str, os.PathLike]`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ from_pt (`bool`, *optional*, defaults to `False`):
+ Load the model weights from a PyTorch checkpoint save file (see docstring of
+ `pretrained_model_name_or_path` argument).
+ ignore_mismatched_sizes (`bool`, *optional*, defaults to `False`):
+ Whether or not to raise an error if some of the weights from the checkpoint do not have the same size
+ as the weights of the model (if for instance, you are instantiating a model with 10 labels from a
+ checkpoint with 3 labels).
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ token (`str` or `bool`, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, or not specified, will use
+ the token generated when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+
+
+
+
+ To test a pull request you made on the Hub, you can pass `revision="refs/pr/"`.
+
+
+
+ subfolder (`str`, *optional*, defaults to `""`):
+ In case the relevant files are located inside a subfolder of the model repo on huggingface.co, you can
+ specify the folder name here.
+ kwargs (remaining dictionary of keyword arguments, *optional*):
+ Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
+ `output_attentions=True`). Behaves differently depending on whether a `config` is provided or
+ automatically loaded:
+
+ - If a configuration is provided with `config`, `**kwargs` will be directly passed to the
+ underlying model's `__init__` method (we assume all relevant updates to the configuration have
+ already been done)
+ - If a configuration is not provided, `kwargs` will be first passed to the configuration class
+ initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
+ corresponds to a configuration attribute will be used to override said attribute with the
+ supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
+ will be passed to the underlying model's `__init__` function.
+
+ Examples:
+
+ ```python
+ >>> from transformers import BertConfig, FlaxBertModel
+
+ >>> # Download model and configuration from huggingface.co and cache.
+ >>> model = FlaxBertModel.from_pretrained("google-bert/bert-base-cased")
+ >>> # Model was saved using *save_pretrained('./test/saved_model/')* (for example purposes, not runnable).
+ >>> model = FlaxBertModel.from_pretrained("./test/saved_model/")
+ >>> # Loading from a PyTorch checkpoint file instead of a PyTorch model (slower, for example purposes, not runnable).
+ >>> config = BertConfig.from_json_file("./pt_model/config.json")
+ >>> model = FlaxBertModel.from_pretrained("./pt_model/pytorch_model.bin", from_pt=True, config=config)
+ ```"""
+ from_pt = kwargs.pop("from_pt", False)
+ resume_download = kwargs.pop("resume_download", None)
+ proxies = kwargs.pop("proxies", None)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ trust_remote_code = kwargs.pop("trust_remote_code", None)
+ from_pipeline = kwargs.pop("_from_pipeline", None)
+ from_auto_class = kwargs.pop("_from_auto", False)
+ _do_init = kwargs.pop("_do_init", True)
+ subfolder = kwargs.pop("subfolder", "")
+ commit_hash = kwargs.pop("_commit_hash", None)
+
+ # Not relevant for Flax Models
+ _ = kwargs.pop("adapter_kwargs", None)
+
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if token is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ token = use_auth_token
+
+ if trust_remote_code is True:
+ logger.warning(
+ "The argument `trust_remote_code` is to be used with Auto classes. It has no effect here and is"
+ " ignored."
+ )
+
+ user_agent = {"file_type": "model", "framework": "flax", "from_auto_class": from_auto_class}
+ if from_pipeline is not None:
+ user_agent["using_pipeline"] = from_pipeline
+
+ if is_offline_mode() and not local_files_only:
+ logger.info("Offline mode: forcing local_files_only=True")
+ local_files_only = True
+
+ # Load config if we don't provide a configuration
+ if not isinstance(config, PretrainedConfig):
+ config_path = config if config is not None else pretrained_model_name_or_path
+ config, model_kwargs = cls.config_class.from_pretrained(
+ config_path,
+ cache_dir=cache_dir,
+ return_unused_kwargs=True,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ token=token,
+ revision=revision,
+ subfolder=subfolder,
+ _from_auto=from_auto_class,
+ _from_pipeline=from_pipeline,
+ _commit_hash=commit_hash,
+ **kwargs,
+ )
+ else:
+ model_kwargs = kwargs.copy()
+
+ if commit_hash is None:
+ commit_hash = getattr(config, "_commit_hash", None)
+
+ # Add the dtype to model_kwargs
+ model_kwargs["dtype"] = dtype
+
+ # This variable will flag if we're loading a sharded checkpoint. In this case the archive file is just the
+ # index of the files.
+ is_sharded = False
+
+ # Load model
+ if pretrained_model_name_or_path is not None:
+ pretrained_model_name_or_path = str(pretrained_model_name_or_path)
+ is_local = os.path.isdir(pretrained_model_name_or_path)
+ if os.path.isdir(pretrained_model_name_or_path):
+ if os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, FLAX_WEIGHTS_NAME)):
+ # Load from a Flax checkpoint
+ archive_file = os.path.join(pretrained_model_name_or_path, subfolder, FLAX_WEIGHTS_NAME)
+ elif os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, FLAX_WEIGHTS_INDEX_NAME)):
+ # Load from a sharded Flax checkpoint
+ archive_file = os.path.join(pretrained_model_name_or_path, subfolder, FLAX_WEIGHTS_INDEX_NAME)
+ is_sharded = True
+ elif is_safetensors_available() and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, SAFE_WEIGHTS_NAME)
+ ):
+ # Load from a safetensors checkpoint
+ archive_file = os.path.join(pretrained_model_name_or_path, SAFE_WEIGHTS_NAME)
+ elif from_pt and os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, WEIGHTS_NAME)):
+ # Load from a PyTorch checkpoint
+ archive_file = os.path.join(pretrained_model_name_or_path, subfolder, WEIGHTS_NAME)
+ elif from_pt and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, subfolder, WEIGHTS_INDEX_NAME)
+ ):
+ # Load from a sharded pytorch checkpoint
+ archive_file = os.path.join(pretrained_model_name_or_path, subfolder, WEIGHTS_INDEX_NAME)
+ is_sharded = True
+ # At this stage we don't have a weight file so we will raise an error.
+ elif is_safetensors_available() and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, SAFE_WEIGHTS_INDEX_NAME)
+ ):
+ # Load from a sharded safetensors checkpoint
+ archive_file = os.path.join(pretrained_model_name_or_path, SAFE_WEIGHTS_INDEX_NAME)
+ is_sharded = True
+ raise NotImplementedError("Support for sharded checkpoints using safetensors is coming soon!")
+ elif os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, WEIGHTS_NAME)):
+ raise EnvironmentError(
+ f"Error no file named {FLAX_WEIGHTS_NAME} found in directory {pretrained_model_name_or_path} "
+ "but there is a file for PyTorch weights. Use `from_pt=True` to load this model from those "
+ "weights."
+ )
+ else:
+ raise EnvironmentError(
+ f"Error no file named {FLAX_WEIGHTS_NAME} or {WEIGHTS_NAME} found in directory "
+ f"{pretrained_model_name_or_path}."
+ )
+ elif os.path.isfile(os.path.join(subfolder, pretrained_model_name_or_path)):
+ archive_file = pretrained_model_name_or_path
+ is_local = True
+ elif is_remote_url(pretrained_model_name_or_path):
+ filename = pretrained_model_name_or_path
+ resolved_archive_file = download_url(pretrained_model_name_or_path)
+ else:
+ if from_pt:
+ filename = WEIGHTS_NAME
+ else:
+ filename = FLAX_WEIGHTS_NAME
+
+ try:
+ # Load from URL or cache if already cached
+ cached_file_kwargs = {
+ "cache_dir": cache_dir,
+ "force_download": force_download,
+ "proxies": proxies,
+ "resume_download": resume_download,
+ "local_files_only": local_files_only,
+ "token": token,
+ "user_agent": user_agent,
+ "revision": revision,
+ "subfolder": subfolder,
+ "_raise_exceptions_for_gated_repo": False,
+ "_raise_exceptions_for_missing_entries": False,
+ "_commit_hash": commit_hash,
+ }
+ resolved_archive_file = cached_file(pretrained_model_name_or_path, filename, **cached_file_kwargs)
+
+ # Maybe the checkpoint is sharded, we try to grab the index name in this case.
+ if resolved_archive_file is None and filename == FLAX_WEIGHTS_NAME:
+ resolved_archive_file = cached_file(
+ pretrained_model_name_or_path, FLAX_WEIGHTS_INDEX_NAME, **cached_file_kwargs
+ )
+ if resolved_archive_file is not None:
+ is_sharded = True
+
+ # Maybe the checkpoint is pytorch sharded, we try to grab the pytorch index name in this case.
+ if resolved_archive_file is None and from_pt:
+ resolved_archive_file = cached_file(
+ pretrained_model_name_or_path, WEIGHTS_INDEX_NAME, **cached_file_kwargs
+ )
+ if resolved_archive_file is not None:
+ is_sharded = True
+
+ # If we still haven't found anything, look for `safetensors`.
+ if resolved_archive_file is None:
+ # No support for sharded safetensors yet, so we'll raise an error if that's all we find.
+ filename = SAFE_WEIGHTS_NAME
+ resolved_archive_file = cached_file(
+ pretrained_model_name_or_path, SAFE_WEIGHTS_NAME, **cached_file_kwargs
+ )
+
+ # Since we set _raise_exceptions_for_missing_entries=False, we don't get an exception but a None
+ # result when internet is up, the repo and revision exist, but the file does not.
+ if resolved_archive_file is None:
+ # Otherwise, maybe there is a TF or Torch model file. We try those to give a helpful error
+ # message.
+ has_file_kwargs = {
+ "revision": revision,
+ "proxies": proxies,
+ "token": token,
+ "cache_dir": cache_dir,
+ "local_files_only": local_files_only,
+ }
+ if has_file(pretrained_model_name_or_path, SAFE_WEIGHTS_INDEX_NAME, **has_file_kwargs):
+ is_sharded = True
+ raise NotImplementedError(
+ "Support for sharded checkpoints using safetensors is coming soon!"
+ )
+ elif has_file(pretrained_model_name_or_path, WEIGHTS_NAME, **has_file_kwargs):
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} does not appear to have a file named"
+ f" {FLAX_WEIGHTS_NAME} but there is a file for PyTorch weights. Use `from_pt=True` to"
+ " load this model from those weights."
+ )
+ elif has_file(pretrained_model_name_or_path, WEIGHTS_INDEX_NAME, **has_file_kwargs):
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} does not appear to have a file named"
+ f" {FLAX_WEIGHTS_INDEX_NAME} but there is a sharded file for PyTorch weights. Use"
+ " `from_pt=True` to load this model from those weights."
+ )
+ else:
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} does not appear to have a file named"
+ f" {FLAX_WEIGHTS_NAME} or {WEIGHTS_NAME}."
+ )
+ except EnvironmentError:
+ # Raise any environment error raise by `cached_file`. It will have a helpful error message adapted
+ # to the original exception.
+ raise
+ except Exception:
+ # For any other exception, we throw a generic error.
+ raise EnvironmentError(
+ f"Can't load the model for '{pretrained_model_name_or_path}'. If you were trying to load it"
+ " from 'https://huggingface.co/models', make sure you don't have a local directory with the"
+ f" same name. Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a"
+ f" directory containing a file named {FLAX_WEIGHTS_NAME} or {WEIGHTS_NAME}."
+ )
+
+ if is_local:
+ logger.info(f"loading weights file {archive_file}")
+ resolved_archive_file = archive_file
+ filename = resolved_archive_file.split(os.path.sep)[-1]
+ else:
+ logger.info(f"loading weights file {filename} from cache at {resolved_archive_file}")
+ else:
+ resolved_archive_file = None
+
+ # We'll need to download and cache each checkpoint shard if the checkpoint is sharded.
+ if is_sharded:
+ # resolved_archive_file becomes a list of files that point to the different checkpoint shards in this case.
+ resolved_archive_file, _ = get_checkpoint_shard_files(
+ pretrained_model_name_or_path,
+ resolved_archive_file,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ token=token,
+ user_agent=user_agent,
+ revision=revision,
+ subfolder=subfolder,
+ _commit_hash=commit_hash,
+ )
+
+ safetensors_from_pt = False
+ if filename == SAFE_WEIGHTS_NAME:
+ with safe_open(resolved_archive_file, framework="flax") as f:
+ safetensors_metadata = f.metadata()
+ if safetensors_metadata is None or safetensors_metadata.get("format") not in ["pt", "tf", "flax"]:
+ raise OSError(
+ f"The safetensors archive passed at {resolved_archive_file} does not contain the valid metadata."
+ " Make sure you save your model with the `save_pretrained` method."
+ )
+ safetensors_from_pt = safetensors_metadata.get("format") == "pt"
+
+ # init random models
+ model = cls(config, *model_args, _do_init=_do_init, **model_kwargs)
+
+ if from_pt or safetensors_from_pt:
+ state = load_pytorch_checkpoint_in_flax_state_dict(model, resolved_archive_file, is_sharded)
+ else:
+ if is_sharded:
+ state = cls.load_flax_sharded_weights(resolved_archive_file)
+ else:
+ state = cls.load_flax_weights(resolved_archive_file)
+ # make sure all arrays are stored as jnp.arrays
+ # NOTE: This is to prevent a bug this will be fixed in Flax >= v0.3.4:
+ # https://github.com/google/flax/issues/1261
+ if _do_init:
+ state = jax.tree_util.tree_map(jnp.array, state)
+ else:
+ # keep the params on CPU if we don't want to initialize
+ state = jax.tree_util.tree_map(lambda x: jax.device_put(x, jax.local_devices(backend="cpu")[0]), state)
+
+ if "batch_stats" in state: # if flax model contains batch norm layers
+ # if model is base model only use model_prefix key
+ if (
+ cls.base_model_prefix not in dict(model.params_shape_tree["params"])
+ and cls.base_model_prefix in state["params"]
+ ):
+ state["params"] = state["params"][cls.base_model_prefix]
+ state["batch_stats"] = state["batch_stats"][cls.base_model_prefix]
+
+ # if model is head model and we are loading weights from base model
+ # we initialize new params dict with base_model_prefix
+ if (
+ cls.base_model_prefix in dict(model.params_shape_tree["params"])
+ and cls.base_model_prefix not in state["params"]
+ ):
+ state = {
+ "params": {cls.base_model_prefix: state["params"]},
+ "batch_stats": {cls.base_model_prefix: state["batch_stats"]},
+ }
+
+ else:
+ # if model is base model only use model_prefix key
+ if cls.base_model_prefix not in dict(model.params_shape_tree) and cls.base_model_prefix in state:
+ state = state[cls.base_model_prefix]
+
+ # if model is head model and we are loading weights from base model
+ # we initialize new params dict with base_model_prefix
+ if cls.base_model_prefix in dict(model.params_shape_tree) and cls.base_model_prefix not in state:
+ state = {cls.base_model_prefix: state}
+
+ # flatten dicts
+ state = flatten_dict(state)
+
+ random_state = flatten_dict(unfreeze(model.params if _do_init else model.params_shape_tree))
+
+ missing_keys = model.required_params - set(state.keys())
+ unexpected_keys = set(state.keys()) - model.required_params
+
+ # Disabling warning when porting pytorch weights to flax, flax does not uses num_batches_tracked
+ for unexpected_key in unexpected_keys.copy():
+ if "num_batches_tracked" in unexpected_key[-1]:
+ unexpected_keys.remove(unexpected_key)
+
+ if missing_keys and not _do_init:
+ logger.warning(
+ f"The checkpoint {pretrained_model_name_or_path} is missing required keys: {missing_keys}. "
+ "Make sure to call model.init_weights to initialize the missing weights."
+ )
+ cls._missing_keys = missing_keys
+
+ # Mismatched keys contains tuples key/shape1/shape2 of weights in the checkpoint that have a shape not
+ # matching the weights in the model.
+ mismatched_keys = []
+ for key in state.keys():
+ if key in random_state and state[key].shape != random_state[key].shape:
+ if ignore_mismatched_sizes:
+ mismatched_keys.append((key, state[key].shape, random_state[key].shape))
+ state[key] = random_state[key]
+ else:
+ raise ValueError(
+ f"Trying to load the pretrained weight for {key} failed: checkpoint has shape "
+ f"{state[key].shape} which is incompatible with the model shape {random_state[key].shape}. "
+ "Using `ignore_mismatched_sizes=True` if you really want to load this checkpoint inside this "
+ "model."
+ )
+
+ # add missing keys as random parameters if we are initializing
+ if missing_keys and _do_init:
+ for missing_key in missing_keys:
+ state[missing_key] = random_state[missing_key]
+
+ # remove unexpected keys to not be saved again
+ for unexpected_key in unexpected_keys:
+ del state[unexpected_key]
+
+ if len(unexpected_keys) > 0:
+ logger.warning(
+ f"Some weights of the model checkpoint at {pretrained_model_name_or_path} were not used when"
+ f" initializing {model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are"
+ f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task or"
+ " with another architecture (e.g. initializing a BertForSequenceClassification model from a"
+ " BertForPreTraining model).\n- This IS NOT expected if you are initializing"
+ f" {model.__class__.__name__} from the checkpoint of a model that you expect to be exactly identical"
+ " (initializing a BertForSequenceClassification model from a BertForSequenceClassification model)."
+ )
+ else:
+ logger.info(f"All model checkpoint weights were used when initializing {model.__class__.__name__}.\n")
+
+ if len(missing_keys) > 0:
+ logger.warning(
+ f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path} and are newly initialized: {missing_keys}\nYou should probably"
+ " TRAIN this model on a down-stream task to be able to use it for predictions and inference."
+ )
+ elif len(mismatched_keys) == 0:
+ logger.info(
+ f"All the weights of {model.__class__.__name__} were initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the checkpoint"
+ f" was trained on, you can already use {model.__class__.__name__} for predictions without further"
+ " training."
+ )
+ if len(mismatched_keys) > 0:
+ mismatched_warning = "\n".join(
+ [
+ f"- {key}: found shape {shape1} in the checkpoint and {shape2} in the model instantiated"
+ for key, shape1, shape2 in mismatched_keys
+ ]
+ )
+ logger.warning(
+ f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path} and are newly initialized because the shapes did not"
+ f" match:\n{mismatched_warning}\nYou should probably TRAIN this model on a down-stream task to be able"
+ " to use it for predictions and inference."
+ )
+
+ # dictionary of key: dtypes for the model params
+ param_dtypes = jax.tree_util.tree_map(lambda x: x.dtype, state)
+ # extract keys of parameters not in jnp.float32
+ fp16_params = [k for k in param_dtypes if param_dtypes[k] == jnp.float16]
+ bf16_params = [k for k in param_dtypes if param_dtypes[k] == jnp.bfloat16]
+
+ # raise a warning if any of the parameters are not in jnp.float32
+ if len(fp16_params) > 0:
+ logger.warning(
+ f"Some of the weights of {model.__class__.__name__} were initialized in float16 precision from "
+ f"the model checkpoint at {pretrained_model_name_or_path}:\n{fp16_params}\n"
+ "You should probably UPCAST the model weights to float32 if this was not intended. "
+ "See [`~FlaxPreTrainedModel.to_fp32`] for further information on how to do this."
+ )
+
+ if len(bf16_params) > 0:
+ logger.warning(
+ f"Some of the weights of {model.__class__.__name__} were initialized in bfloat16 precision from "
+ f"the model checkpoint at {pretrained_model_name_or_path}:\n{bf16_params}\n"
+ "You should probably UPCAST the model weights to float32 if this was not intended. "
+ "See [`~FlaxPreTrainedModel.to_fp32`] for further information on how to do this."
+ )
+
+ # If it is a model with generation capabilities, attempt to load the generation config
+ if model.can_generate():
+ try:
+ model.generation_config = GenerationConfig.from_pretrained(
+ pretrained_model_name_or_path,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ token=token,
+ revision=revision,
+ subfolder=subfolder,
+ _from_auto=from_auto_class,
+ _from_pipeline=from_pipeline,
+ **kwargs,
+ )
+ except OSError:
+ logger.info(
+ "Generation config file not found, using a generation config created from the model config."
+ )
+ pass
+
+ if _do_init:
+ # set correct parameters
+ model.params = unflatten_dict(state)
+ return model
+ else:
+ return model, unflatten_dict(state)
+
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ params=None,
+ push_to_hub=False,
+ max_shard_size="10GB",
+ token: Optional[Union[str, bool]] = None,
+ safe_serialization: bool = False,
+ **kwargs,
+ ):
+ """
+ Save a model and its configuration file to a directory, so that it can be re-loaded using the
+ `[`~FlaxPreTrainedModel.from_pretrained`]` class method
+
+ Arguments:
+ save_directory (`str` or `os.PathLike`):
+ Directory to which to save. Will be created if it doesn't exist.
+ push_to_hub (`bool`, *optional*, defaults to `False`):
+ Whether or not to push your model to the Hugging Face model hub after saving it. You can specify the
+ repository you want to push to with `repo_id` (will default to the name of `save_directory` in your
+ namespace).
+ max_shard_size (`int` or `str`, *optional*, defaults to `"10GB"`):
+ The maximum size for a checkpoint before being sharded. Checkpoints shard will then be each of size
+ lower than this size. If expressed as a string, needs to be digits followed by a unit (like `"5MB"`).
+
+
+
+ If a single weight of the model is bigger than `max_shard_size`, it will be in its own checkpoint shard
+ which will be bigger than `max_shard_size`.
+
+
+
+ token (`str` or `bool`, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, or not specified, will use
+ the token generated when running `huggingface-cli login` (stored in `~/.huggingface`).
+ kwargs (`Dict[str, Any]`, *optional*):
+ Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
+ safe_serialization (`bool`, *optional*, defaults to `False`):
+ Whether to save the model using `safetensors` or through msgpack.
+ """
+ use_auth_token = kwargs.pop("use_auth_token", None)
+
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if token is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ token = use_auth_token
+
+ if token is not None:
+ kwargs["token"] = token
+
+ if os.path.isfile(save_directory):
+ logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
+ return
+
+ os.makedirs(save_directory, exist_ok=True)
+
+ if push_to_hub:
+ commit_message = kwargs.pop("commit_message", None)
+ repo_id = kwargs.pop("repo_id", save_directory.split(os.path.sep)[-1])
+ repo_id = self._create_repo(repo_id, **kwargs)
+ files_timestamps = self._get_files_timestamps(save_directory)
+
+ # get abs dir
+ save_directory = os.path.abspath(save_directory)
+ # save config as well
+ self.config.architectures = [self.__class__.__name__[4:]]
+
+ # If we have a custom model, we copy the file defining it in the folder and set the attributes so it can be
+ # loaded from the Hub.
+ if self._auto_class is not None:
+ custom_object_save(self, save_directory, config=self.config)
+
+ self.config.save_pretrained(save_directory)
+ if self.can_generate():
+ self.generation_config.save_pretrained(save_directory)
+
+ # save model
+ weights_name = SAFE_WEIGHTS_NAME if safe_serialization else FLAX_WEIGHTS_NAME
+ output_model_file = os.path.join(save_directory, weights_name)
+
+ shards, index = flax_shard_checkpoint(params if params is not None else self.params, max_shard_size)
+ # Clean the folder from a previous save
+ for filename in os.listdir(save_directory):
+ full_filename = os.path.join(save_directory, filename)
+ weights_no_suffix = weights_name.replace(".bin", "").replace(".safetensors", "")
+ if (
+ filename.startswith(weights_no_suffix)
+ and os.path.isfile(full_filename)
+ and filename not in shards.keys()
+ ):
+ os.remove(full_filename)
+
+ if index is None:
+ if safe_serialization:
+ params = params if params is not None else self.params
+ flat_dict = flatten_dict(params, sep=".")
+ safe_save_file(flat_dict, output_model_file, metadata={"format": "flax"})
+ else:
+ with open(output_model_file, "wb") as f:
+ params = params if params is not None else self.params
+ model_bytes = to_bytes(params)
+ f.write(model_bytes)
+
+ else:
+ save_index_file = os.path.join(save_directory, FLAX_WEIGHTS_INDEX_NAME)
+ # Save the index as well
+ with open(save_index_file, "w", encoding="utf-8") as f:
+ content = json.dumps(index, indent=2, sort_keys=True) + "\n"
+ f.write(content)
+ logger.info(
+ f"The model is bigger than the maximum size per checkpoint ({max_shard_size}) and is going to be "
+ f"split in {len(shards)} checkpoint shards. You can find where each parameters has been saved in the "
+ f"index located at {save_index_file}."
+ )
+ for shard_file, shard in shards.items():
+ # the shard item are unflattened, to save them we need to flatten them again
+ with open(os.path.join(save_directory, shard_file), mode="wb") as f:
+ params = unflatten_dict(shard, sep="/")
+ shard_bytes = to_bytes(params)
+ f.write(shard_bytes)
+
+ logger.info(f"Model weights saved in {output_model_file}")
+
+ if push_to_hub:
+ self._upload_modified_files(
+ save_directory,
+ repo_id,
+ files_timestamps,
+ commit_message=commit_message,
+ token=token,
+ )
+
+ @classmethod
+ def register_for_auto_class(cls, auto_class="FlaxAutoModel"):
+ """
+ Register this class with a given auto class. This should only be used for custom models as the ones in the
+ library are already mapped with an auto class.
+
+
+
+ This API is experimental and may have some slight breaking changes in the next releases.
+
+
+
+ Args:
+ auto_class (`str` or `type`, *optional*, defaults to `"FlaxAutoModel"`):
+ The auto class to register this new model with.
+ """
+ if not isinstance(auto_class, str):
+ auto_class = auto_class.__name__
+
+ import transformers.models.auto as auto_module
+
+ if not hasattr(auto_module, auto_class):
+ raise ValueError(f"{auto_class} is not a valid auto class.")
+
+ cls._auto_class = auto_class
+
+
+# To update the docstring, we need to copy the method, otherwise we change the original docstring.
+FlaxPreTrainedModel.push_to_hub = copy_func(FlaxPreTrainedModel.push_to_hub)
+if FlaxPreTrainedModel.push_to_hub.__doc__ is not None:
+ FlaxPreTrainedModel.push_to_hub.__doc__ = FlaxPreTrainedModel.push_to_hub.__doc__.format(
+ object="model", object_class="FlaxAutoModel", object_files="model checkpoint"
+ )
+
+
+def overwrite_call_docstring(model_class, docstring):
+ # copy __call__ function to be sure docstring is changed only for this function
+ model_class.__call__ = copy_func(model_class.__call__)
+ # delete existing docstring
+ model_class.__call__.__doc__ = None
+ # set correct docstring
+ model_class.__call__ = add_start_docstrings_to_model_forward(docstring)(model_class.__call__)
+
+
+def append_call_sample_docstring(
+ model_class, checkpoint, output_type, config_class, mask=None, revision=None, real_checkpoint=None
+):
+ model_class.__call__ = copy_func(model_class.__call__)
+ model_class.__call__ = add_code_sample_docstrings(
+ checkpoint=checkpoint,
+ output_type=output_type,
+ config_class=config_class,
+ model_cls=model_class.__name__,
+ revision=revision,
+ real_checkpoint=real_checkpoint,
+ )(model_class.__call__)
+
+
+def append_replace_return_docstrings(model_class, output_type, config_class):
+ model_class.__call__ = copy_func(model_class.__call__)
+ model_class.__call__ = replace_return_docstrings(
+ output_type=output_type,
+ config_class=config_class,
+ )(model_class.__call__)
diff --git a/docs/transformers/src/transformers/modeling_gguf_pytorch_utils.py b/docs/transformers/src/transformers/modeling_gguf_pytorch_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ce50f8fec2c9c044f076684e2934a9829be352c
--- /dev/null
+++ b/docs/transformers/src/transformers/modeling_gguf_pytorch_utils.py
@@ -0,0 +1,496 @@
+# Copyright 2024 The ggml.ai team and The HuggingFace Inc. team. and pygguf author (github.com/99991)
+# https://github.com/99991/pygguf
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import re
+from typing import NamedTuple, Optional
+
+import numpy as np
+from tqdm.auto import tqdm
+
+from .integrations import (
+ GGUF_CONFIG_MAPPING,
+ GGUF_TOKENIZER_MAPPING,
+ _gguf_parse_value,
+)
+from .utils import is_torch_available
+from .utils.import_utils import is_gguf_available
+from .utils.logging import get_logger
+
+
+if is_torch_available():
+ import torch
+
+logger = get_logger(__name__)
+
+
+GGUF_TO_TRANSFORMERS_MAPPING = {
+ "ignore": {
+ "GGUF": {
+ "version": "version",
+ "tensor_count": "tensor_count",
+ "kv_count": "kv_count",
+ },
+ "general": {"file_type": "file_type", "quantization_version": "quantization_version"},
+ },
+ "config": GGUF_CONFIG_MAPPING,
+ "tokenizer": {"tokenizer": GGUF_TOKENIZER_MAPPING["tokenizer"]},
+ "tokenizer_config": {"tokenizer": GGUF_TOKENIZER_MAPPING["tokenizer_config"]},
+}
+
+GGUF_SUPPORTED_ARCHITECTURES = list(GGUF_TO_TRANSFORMERS_MAPPING["config"].keys())
+
+
+class GGUFTensor(NamedTuple):
+ weights: np.ndarray
+ name: str
+ metadata: dict
+
+
+class TensorProcessor:
+ def __init__(self, config=None):
+ self.config = config or {}
+
+ def process(self, weights, name, **kwargs):
+ return GGUFTensor(weights, name, {})
+
+
+class LlamaTensorProcessor(TensorProcessor):
+ def __init__(self, config=None):
+ super().__init__(config=config)
+
+ def process(self, weights, name, **kwargs):
+ if ".attn_k." in name or ".attn_q." in name:
+ num_heads = self.config.get("num_attention_heads")
+ num_kv_heads = self.config.get("num_key_value_heads")
+
+ if None in (num_heads, num_kv_heads):
+ return GGUFTensor(weights, name, {})
+ if ".attn_q." in name:
+ weights = self._reverse_permute_weights(weights, num_heads, num_heads)
+ elif ".attn_k." in name:
+ weights = self._reverse_permute_weights(weights, num_heads, num_kv_heads)
+ return GGUFTensor(weights, name, {})
+
+ def _reverse_permute_weights(
+ self, weights: np.ndarray, n_head: int, num_kv_heads: Optional[int] = None
+ ) -> np.ndarray:
+ # Original permutation implementation
+ # https://github.com/ggerganov/llama.cpp/blob/a38b884c6c4b0c256583acfaaabdf556c62fabea/convert_hf_to_gguf.py#L1402-L1408
+ if num_kv_heads is not None and n_head != num_kv_heads:
+ n_head = num_kv_heads
+
+ dim = weights.shape[0] // n_head // 2
+ w = weights.reshape(n_head, dim, 2, *weights.shape[1:])
+ return w.swapaxes(2, 1).reshape(weights.shape)
+
+
+class Qwen2MoeTensorProcessor(TensorProcessor):
+ def __init__(self, config=None):
+ super().__init__(config=config)
+
+ def process(self, weights, name, **kwargs):
+ if "_exp" in name:
+ tensor_key_mapping = kwargs.get("tensor_key_mapping")
+ parsed_parameters = kwargs.get("parsed_parameters")
+ if tensor_key_mapping:
+ self._split_moe_expert_tensor(weights, parsed_parameters, name, tensor_key_mapping)
+ return GGUFTensor(weights, None, {})
+ if "ffn_gate_inp_shexp" in name:
+ # for compatibility tensor shared_expert_gate must be (1, 2048) dim,
+ # quantized one is (2048)
+ weights = np.expand_dims(weights, axis=0)
+ return GGUFTensor(weights, name, {})
+
+ def _split_moe_expert_tensor(
+ self, weights: np.ndarray, parsed_parameters: dict[str, dict], name: str, tensor_key_mapping: dict
+ ):
+ # Original merge implementation
+ # https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py#L1994-L2022
+ name = tensor_key_mapping[name]
+ w_counter = self.config.get("num_experts", 60)
+ for i in range(0, w_counter):
+ temp_name = name.replace("mlp.experts.", f"mlp.experts.{i}.")
+ exp_weight = weights[i]
+ parsed_parameters["tensors"][temp_name] = torch.from_numpy(np.copy(exp_weight))
+
+
+class BloomTensorProcessor(TensorProcessor):
+ def __init__(self, config=None):
+ super().__init__(config=config)
+
+ def process(self, weights, name, **kwargs):
+ if "attn_qkv" in name:
+ num_heads = self.config["n_head"]
+ n_embed = self.config["hidden_size"]
+ if "weight" in name:
+ weights = self._reverse_reshape_weights(weights, num_heads, n_embed)
+ else:
+ weights = self._reverse_reshape_bias(weights, num_heads, n_embed)
+ return GGUFTensor(weights, name, {})
+
+ def _reverse_reshape_weights(self, weights: np.ndarray, n_head: int, n_embed: int):
+ # Original reshape implementation
+ # https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py#L972-L985
+ q, k, v = np.array_split(weights, 3, axis=0)
+
+ q = q.reshape(n_head, n_embed // n_head, n_embed)
+ k = k.reshape(n_head, n_embed // n_head, n_embed)
+ v = v.reshape(n_head, n_embed // n_head, n_embed)
+ qkv_weights = np.stack([q, k, v], axis=1)
+
+ return qkv_weights.reshape(n_head * 3 * (n_embed // n_head), n_embed)
+
+ def _reverse_reshape_bias(self, weights: np.ndarray, n_head: int, n_embed: int):
+ # Original reshape implementation
+ # https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py#L986-L998
+ q_bias, k_bias, v_bias = np.array_split(weights, 3)
+
+ q_bias = q_bias.reshape(n_head, n_embed // n_head)
+ k_bias = k_bias.reshape(n_head, n_embed // n_head)
+ v_bias = v_bias.reshape(n_head, n_embed // n_head)
+
+ qkv_bias = np.stack([q_bias, k_bias, v_bias], axis=1).flatten()
+ return qkv_bias
+
+
+class T5TensorProcessor(TensorProcessor):
+ def __init__(self, config=None):
+ super().__init__(config=config)
+
+ def process(self, weights, name, **kwargs):
+ bid = None
+ for chunk in name.split("."):
+ if chunk.isdigit():
+ bid = int(chunk)
+ break
+ return GGUFTensor(weights, name, {"bid": bid})
+
+
+class GPT2TensorProcessor(TensorProcessor):
+ def __init__(self, config=None):
+ super().__init__(config=config)
+
+ def process(self, weights, name, **kwargs):
+ # Original transpose implementation
+ # https://github.com/ggerganov/llama.cpp/blob/a38b884c6c4b0c256583acfaaabdf556c62fabea/convert_hf_to_gguf.py#L2060-L2061
+ if (
+ "attn_qkv.weight" in name
+ or "ffn_down.weight" in name
+ or "ffn_up.weight" in name
+ or "attn_output.weight" in name
+ ):
+ weights = weights.T
+
+ # Handle special case for output.weight
+ if name == "output.weight":
+ # output.weight has conflicts with attn_output.weight in name checking
+ # Store the tensor directly and signal to skip further processing
+ name = "lm_head.weight"
+ parsed_parameters = kwargs.get("parsed_parameters", {})
+ parsed_parameters["tensors"][name] = torch.from_numpy(np.copy(weights))
+ name = None # Signal to skip further processing
+ return GGUFTensor(weights, name, {})
+
+
+class MambaTensorProcessor(TensorProcessor):
+ def __init__(self, config=None):
+ super().__init__(config=config)
+
+ def process(self, weights, name, **kwargs):
+ if "ssm_conv1d.weight" in name:
+ # for compatibility tensor ssm_conv1d must be (5120, 1, 4]) dim,
+ # quantized one is (5120, 4)
+ weights = np.expand_dims(weights, axis=1)
+ if "ssm_a" in name:
+ # Original exponential implementation
+ # https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py#L2975-L2977
+ weights = np.log(-weights)
+ return GGUFTensor(weights, name, {})
+
+
+class NemotronTensorProcessor(TensorProcessor):
+ def __init__(self, config=None):
+ super().__init__(config=config)
+
+ # ref : https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py#L4666
+ def process(self, weights, name, **kwargs):
+ if "norm.weight" in name:
+ weights = weights - 1
+ return GGUFTensor(weights, name, {})
+
+
+class Gemma2TensorProcessor(TensorProcessor):
+ def __init__(self, config=None):
+ super().__init__(config=config)
+
+ # ref: https://github.com/ggerganov/llama.cpp/blob/d79d8f39b4da6deca4aea8bf130c6034c482b320/convert_hf_to_gguf.py#L3191
+ # ref: https://github.com/huggingface/transformers/blob/fc37f38915372c15992b540dfcbbe00a916d4fc6/src/transformers/models/gemma/modeling_gemma.py#L89
+ def process(self, weights, name, **kwargs):
+ if "norm.weight" in name:
+ weights = weights - 1
+ return GGUFTensor(weights, name, {})
+
+
+TENSOR_PROCESSORS = {
+ "llama": LlamaTensorProcessor,
+ "qwen2moe": Qwen2MoeTensorProcessor,
+ "bloom": BloomTensorProcessor,
+ "t5": T5TensorProcessor,
+ "t5encoder": T5TensorProcessor,
+ "gpt2": GPT2TensorProcessor,
+ "mamba": MambaTensorProcessor,
+ "nemotron": NemotronTensorProcessor,
+ "gemma2": Gemma2TensorProcessor,
+ "gemma3": Gemma2TensorProcessor,
+}
+
+
+def read_field(reader, field):
+ if field not in reader.fields:
+ return []
+ value = reader.fields[field]
+ return [_gguf_parse_value(value.parts[_data_index], value.types) for _data_index in value.data]
+
+
+# modified from https://github.com/vllm-project/vllm/blob/v0.6.4.post1/vllm/model_executor/model_loader/loader.py#L1115-L1147
+def get_gguf_hf_weights_map(
+ hf_model,
+ model_type: Optional[str] = None,
+ num_layers: Optional[int] = None,
+ qual_name: str = "",
+):
+ """
+ GGUF uses this naming convention for their tensors from HF checkpoint:
+ `blk.N.BB.weight` and `blk.N.BB.bias`
+ where N signifies the block number of a layer, and BB signifies the
+ attention/mlp layer components.
+ See "Standardized tensor names" in
+ https://github.com/ggerganov/ggml/blob/master/docs/gguf.md for details.
+ """
+ if is_gguf_available() and is_torch_available():
+ from gguf import MODEL_ARCH_NAMES, get_tensor_name_map
+ else:
+ logger.error(
+ "Loading a GGUF checkpoint in PyTorch, requires both PyTorch and GGUF>=0.10.0 to be installed. Please see "
+ "https://pytorch.org/ and https://github.com/ggerganov/llama.cpp/tree/master/gguf-py for installation instructions."
+ )
+ raise ImportError("Please install torch and gguf>=0.10.0 to load a GGUF checkpoint in PyTorch.")
+
+ model_type = hf_model.config.model_type if model_type is None else model_type
+ num_layers = hf_model.config.num_hidden_layers if num_layers is None else num_layers
+ # hack: ggufs have a different name for cohere
+ if model_type == "cohere":
+ model_type = "command-r"
+ elif model_type == "qwen2_moe":
+ model_type = "qwen2moe"
+ elif model_type == "gemma3_text":
+ model_type = "gemma3"
+ arch = None
+ for key, value in MODEL_ARCH_NAMES.items():
+ if value == model_type:
+ arch = key
+ break
+ if arch is None:
+ raise NotImplementedError(
+ f"Unknown gguf model_type: {model_type} in gguf-py. "
+ "This might because you're using an outdated version of gguf-py package, "
+ "you can install `gguf` package from source refer to "
+ "https://github.com/ggerganov/llama.cpp/tree/master/gguf-py#development"
+ )
+ name_map = get_tensor_name_map(arch, num_layers)
+
+ # Use a dummy conversion to get the mapping, because
+ # hf => gguf and gguf => hf mappings are reversed
+ gguf_to_hf_name_map = {}
+ state_dict = hf_model.state_dict()
+ for hf_name in state_dict.keys():
+ # An exception for qwen2moe model, where the expert layers are packed
+ if model_type == "qwen2moe" and "mlp.experts." in hf_name:
+ hf_name = re.sub(r"mlp.experts.\d+.", "mlp.experts.", hf_name)
+
+ name, suffix = hf_name, ""
+ if hf_name.endswith(".weight") or hf_name.endswith(".bias"):
+ name, suffix = hf_name.rsplit(".", 1)
+ suffix = "." + suffix
+
+ gguf_name = name_map.get_name(name)
+ if gguf_name is None:
+ continue
+
+ gguf_to_hf_name_map[gguf_name + suffix] = qual_name + hf_name
+
+ # Some model like Bloom converted from BloomModel instead of BloomForCausalLM
+ # Therefore, we need to check submodule as well to get a correct mapping
+ if named_children := hf_model.named_children():
+ for name, child in named_children:
+ sub_map = get_gguf_hf_weights_map(child, model_type, num_layers, qual_name=f"{qual_name}{name}.")
+ # Ignore the keys that are already in the main map to avoid overwriting
+ sub_map = {k: v for k, v in sub_map.items() if k not in gguf_to_hf_name_map}
+ gguf_to_hf_name_map.update(sub_map)
+
+ return gguf_to_hf_name_map
+
+
+def load_gguf_checkpoint(gguf_checkpoint_path, return_tensors=False, model_to_load=None):
+ """
+ Load a GGUF file and return a dictionary of parsed parameters containing tensors, the parsed
+ tokenizer and config attributes.
+
+ Args:
+ gguf_checkpoint_path (`str`):
+ The path the to GGUF file to load
+ return_tensors (`bool`, defaults to `False`):
+ Whether to read the tensors from the file and return them. Not doing so is faster
+ and only loads the metadata in memory.
+ """
+ if is_gguf_available() and is_torch_available():
+ from gguf import GGUFReader, dequantize
+ else:
+ logger.error(
+ "Loading a GGUF checkpoint in PyTorch, requires both PyTorch and GGUF>=0.10.0 to be installed. Please see "
+ "https://pytorch.org/ and https://github.com/ggerganov/llama.cpp/tree/master/gguf-py for installation instructions."
+ )
+ raise ImportError("Please install torch and gguf>=0.10.0 to load a GGUF checkpoint in PyTorch.")
+
+ reader = GGUFReader(gguf_checkpoint_path)
+ fields = reader.fields
+ reader_keys = list(fields.keys())
+
+ parsed_parameters = {k: {} for k in GGUF_TO_TRANSFORMERS_MAPPING}
+
+ architecture = read_field(reader, "general.architecture")[0]
+ # NOTE: Some GGUF checkpoints may miss `general.name` field in metadata
+ model_name = read_field(reader, "general.name")
+
+ updated_architecture = None
+ # in llama.cpp mistral models use the same architecture as llama. We need
+ # to add this patch to ensure things work correctly on our side.
+ if "llama" in architecture and "mistral" in model_name:
+ updated_architecture = "mistral"
+ # FIXME: Currently this implementation is only for flan-t5 architecture.
+ # It needs to be developed for supporting legacy t5.
+ elif "t5" in architecture or "t5encoder" in architecture:
+ parsed_parameters["config"]["is_gated_act"] = True
+ if "t5encoder" in architecture:
+ parsed_parameters["config"]["architectures"] = ["T5EncoderModel"]
+ updated_architecture = "t5"
+ else:
+ updated_architecture = architecture
+
+ if "qwen2moe" in architecture:
+ updated_architecture = "qwen2_moe"
+
+ # For stablelm architecture, we need to set qkv_bias and use_parallel_residual from tensors
+ # If `qkv_bias=True`, qkv_proj with bias will be present in the tensors
+ # If `use_parallel_residual=False`, ffn_norm will be present in the tensors
+ if "stablelm" in architecture:
+ attn_bias_name = {"attn_q.bias", "attn_k.bias", "attn_v.bias"}
+ ffn_norm_name = "ffn_norm"
+ qkv_bias = any(bias_name in tensor.name for tensor in reader.tensors for bias_name in attn_bias_name)
+ use_parallel_residual = any(ffn_norm_name in tensor.name for tensor in reader.tensors)
+ parsed_parameters["config"]["use_qkv_bias"] = qkv_bias
+ parsed_parameters["config"]["use_parallel_residual"] = not use_parallel_residual
+
+ if architecture not in GGUF_SUPPORTED_ARCHITECTURES and updated_architecture not in GGUF_SUPPORTED_ARCHITECTURES:
+ raise ValueError(f"GGUF model with architecture {architecture} is not supported yet.")
+
+ # Handle tie_word_embeddings, if lm_head.weight is not present in tensors,
+ # tie_word_embeddings is true otherwise false
+ exceptions = ["falcon", "bloom"]
+ parsed_parameters["config"]["tie_word_embeddings"] = (
+ all("output.weight" != tensor.name for tensor in reader.tensors) or architecture in exceptions
+ )
+
+ # List all key-value pairs in a columnized format
+ for gguf_key, field in reader.fields.items():
+ gguf_key = gguf_key.replace(architecture, updated_architecture)
+ split = gguf_key.split(".")
+ prefix = split[0]
+ config_key = ".".join(split[1:])
+
+ value = [_gguf_parse_value(field.parts[_data_index], field.types) for _data_index in field.data]
+
+ if len(value) == 1:
+ value = value[0]
+
+ if isinstance(value, str) and architecture in value:
+ value = value.replace(architecture, updated_architecture)
+
+ for parameter in GGUF_TO_TRANSFORMERS_MAPPING:
+ parameter_renames = GGUF_TO_TRANSFORMERS_MAPPING[parameter]
+ if prefix in parameter_renames and config_key in parameter_renames[prefix]:
+ renamed_config_key = parameter_renames[prefix][config_key]
+ if renamed_config_key == -1:
+ continue
+
+ if renamed_config_key is not None:
+ parsed_parameters[parameter][renamed_config_key] = value
+
+ if gguf_key in reader_keys:
+ reader_keys.remove(gguf_key)
+
+ if gguf_key in reader_keys:
+ logger.info(f"Some keys were not parsed and added into account {gguf_key} | {value}")
+
+ # Gemma3 GGUF checkpoint only contains weights of text backbone
+ if parsed_parameters["config"]["model_type"] == "gemma3":
+ parsed_parameters["config"]["model_type"] = "gemma3_text"
+
+ # retrieve config vocab_size from tokenizer
+ # Please refer to https://github.com/huggingface/transformers/issues/32526 for more details
+ if "vocab_size" not in parsed_parameters["config"]:
+ tokenizer_parameters = parsed_parameters["tokenizer"]
+ if "tokens" in tokenizer_parameters:
+ parsed_parameters["config"]["vocab_size"] = len(tokenizer_parameters["tokens"])
+ else:
+ logger.warning(
+ "Can't find a way to retrieve missing config vocab_size from tokenizer parameters. "
+ "This will use default value from model config class and cause unexpected behavior."
+ )
+
+ if return_tensors:
+ parsed_parameters["tensors"] = {}
+
+ tensor_key_mapping = get_gguf_hf_weights_map(model_to_load)
+ config = parsed_parameters.get("config", {})
+
+ ProcessorClass = TENSOR_PROCESSORS.get(architecture, TensorProcessor)
+ processor = ProcessorClass(config=config)
+
+ for tensor in tqdm(reader.tensors, desc="Converting and de-quantizing GGUF tensors..."):
+ name = tensor.name
+ weights = dequantize(tensor.data, tensor.tensor_type)
+
+ result = processor.process(
+ weights=weights,
+ name=name,
+ tensor_key_mapping=tensor_key_mapping,
+ parsed_parameters=parsed_parameters,
+ )
+
+ weights = result.weights
+ name = result.name
+
+ if name not in tensor_key_mapping:
+ continue
+
+ name = tensor_key_mapping[name]
+
+ parsed_parameters["tensors"][name] = torch.from_numpy(np.copy(weights))
+
+ if len(reader_keys) > 0:
+ logger.info(f"Some keys of the GGUF file were not considered: {reader_keys}")
+
+ return parsed_parameters
diff --git a/docs/transformers/src/transformers/modeling_layers.py b/docs/transformers/src/transformers/modeling_layers.py
new file mode 100644
index 0000000000000000000000000000000000000000..57be2d8e0d7dc7af50f847f699bf80b707bbb98e
--- /dev/null
+++ b/docs/transformers/src/transformers/modeling_layers.py
@@ -0,0 +1,48 @@
+# Copyright 2025 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from functools import partial
+
+import torch.nn as nn
+
+
+class GradientCheckpointingLayer(nn.Module):
+ """Base class for layers with gradient checkpointing.
+
+ This class enables gradient checkpointing functionality for a layer. By default, gradient checkpointing is disabled
+ (`gradient_checkpointing = False`). When `model.set_gradient_checkpointing()` is called, gradient checkpointing is
+ enabled by setting `gradient_checkpointing = True` and assigning a checkpointing function to `_gradient_checkpointing_func`.
+
+ Important:
+
+ When using gradient checkpointing with `use_reentrant=True`, inputs that require gradients (e.g. hidden states)
+ must be passed as positional arguments (`*args`) rather than keyword arguments to properly propagate gradients.
+
+ Example:
+
+ ```python
+ >>> # Correct - hidden_states passed as positional arg
+ >>> out = self.layer(hidden_states, attention_mask=attention_mask)
+
+ >>> # Incorrect - hidden_states passed as keyword arg
+ >>> out = self.layer(hidden_states=hidden_states, attention_mask=attention_mask)
+ ```
+ """
+
+ gradient_checkpointing = False
+
+ def __call__(self, *args, **kwargs):
+ if self.gradient_checkpointing and self.training:
+ return self._gradient_checkpointing_func(partial(super().__call__, **kwargs), *args)
+ return super().__call__(*args, **kwargs)
diff --git a/docs/transformers/src/transformers/modeling_outputs.py b/docs/transformers/src/transformers/modeling_outputs.py
new file mode 100644
index 0000000000000000000000000000000000000000..60a3642f87c6b64771584b361ff6aef3ac06cb87
--- /dev/null
+++ b/docs/transformers/src/transformers/modeling_outputs.py
@@ -0,0 +1,1753 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import warnings
+from dataclasses import dataclass
+from typing import Optional, Tuple
+
+import torch
+
+from .utils import ModelOutput
+
+
+@dataclass
+class BaseModelOutput(ModelOutput):
+ """
+ Base class for model's outputs, with potential hidden states and attentions.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class BaseModelOutputWithNoAttention(ModelOutput):
+ """
+ Base class for model's outputs, with potential hidden states.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, num_channels, height, width)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class BaseModelOutputWithPooling(ModelOutput):
+ """
+ Base class for model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ pooler_output (`torch.FloatTensor` of shape `(batch_size, hidden_size)`):
+ Last layer hidden-state of the first token of the sequence (classification token) after further processing
+ through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns
+ the classification token after processing through a linear layer and a tanh activation function. The linear
+ layer weights are trained from the next sentence prediction (classification) objective during pretraining.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ pooler_output: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class BaseModelOutputWithPoolingAndNoAttention(ModelOutput):
+ """
+ Base class for model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ pooler_output (`torch.FloatTensor` of shape `(batch_size, hidden_size)`):
+ Last layer hidden-state after a pooling operation on the spatial dimensions.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, num_channels, height, width)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ pooler_output: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class BaseModelOutputWithPast(ModelOutput):
+ """
+ Base class for model's outputs that may also contain a past key/values (to speed up sequential decoding).
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+
+ If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
+ hidden_size)` is output.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
+ `config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
+ encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
+ `config.is_encoder_decoder=True` in the cross-attention blocks) that can be used (see `past_key_values`
+ input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class BaseModelOutputWithCrossAttentions(ModelOutput):
+ """
+ Base class for model's outputs, with potential hidden states and attentions.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` and `config.add_cross_attention=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class BaseModelOutputWithPoolingAndCrossAttentions(ModelOutput):
+ """
+ Base class for model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ pooler_output (`torch.FloatTensor` of shape `(batch_size, hidden_size)`):
+ Last layer hidden-state of the first token of the sequence (classification token) after further processing
+ through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns
+ the classification token after processing through a linear layer and a tanh activation function. The linear
+ layer weights are trained from the next sentence prediction (classification) objective during pretraining.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` and `config.add_cross_attention=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
+ `config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
+ encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
+ `config.is_encoder_decoder=True` in the cross-attention blocks) that can be used (see `past_key_values`
+ input) to speed up sequential decoding.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ pooler_output: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class BaseModelOutputWithPastAndCrossAttentions(ModelOutput):
+ """
+ Base class for model's outputs that may also contain a past key/values (to speed up sequential decoding).
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+
+ If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
+ hidden_size)` is output.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
+ `config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
+ encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
+ `config.is_encoder_decoder=True` in the cross-attention blocks) that can be used (see `past_key_values`
+ input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` and `config.add_cross_attention=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class MoECausalLMOutputWithPast(ModelOutput):
+ """
+ Base class for causal language model (or autoregressive) outputs as well as Mixture of Expert's router hidden
+ states terms, to train a MoE model.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Language modeling loss (for next-token prediction).
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`)
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ z_loss (`torch.FloatTensor`, *optional*, returned when `labels` is provided):
+ z_loss for the sparse modules.
+ aux_loss (`torch.FloatTensor`, *optional*, returned when `labels` is provided):
+ aux_loss for the sparse modules.
+ router_logits (`tuple(torch.FloatTensor)`, *optional*, returned when `output_router_logits=True` is passed or when `config.add_router_probs=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, sequence_length, num_experts)`.
+
+ Router logits of the encoder model, useful to compute the auxiliary loss and the z_loss for the sparse
+ modules.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ z_loss: Optional[torch.FloatTensor] = None
+ aux_loss: Optional[torch.FloatTensor] = None
+ router_logits: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class MoEModelOutput(ModelOutput):
+ """
+ Base class for model's outputs, with potential hidden states and attentions.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ router_probs (`tuple(torch.FloatTensor)`, *optional*, returned when `output_router_probs=True` and `config.add_router_probs=True` is passed or when `config.output_router_probs=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, sequence_length, num_experts)`.
+
+ Raw router probabilities that are computed by MoE routers, these terms are used to compute the auxiliary
+ loss and the z_loss for Mixture of Experts models.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ router_probs: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class MoeModelOutputWithPast(ModelOutput):
+ """
+ Base class for model's outputs, with potential hidden states and attentions.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
+ `config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
+ encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
+ `config.is_encoder_decoder=True` in the cross-attention blocks) that can be used (see `past_key_values`
+ input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ router_logits (`tuple(torch.FloatTensor)`, *optional*, returned when `output_router_probs=True` and `config.add_router_probs=True` is passed or when `config.output_router_probs=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, sequence_length, num_experts)`.
+
+ Raw router logtis (post-softmax) that are computed by MoE routers, these terms are used to compute the auxiliary
+ loss for Mixture of Experts models.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ router_logits: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class MoeCausalLMOutputWithPast(ModelOutput):
+ """
+ Base class for causal language model (or autoregressive) with mixture of experts outputs.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Language modeling loss (for next-token prediction).
+
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+
+ aux_loss (`torch.FloatTensor`, *optional*, returned when `labels` is provided):
+ aux_loss for the sparse modules.
+
+ router_logits (`tuple(torch.FloatTensor)`, *optional*, returned when `output_router_probs=True` and `config.add_router_probs=True` is passed or when `config.output_router_probs=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, sequence_length, num_experts)`.
+
+ Raw router logtis (post-softmax) that are computed by MoE routers, these terms are used to compute the auxiliary
+ loss for Mixture of Experts models.
+
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`)
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ aux_loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ router_logits: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class MoEModelOutputWithPastAndCrossAttentions(ModelOutput):
+ """
+ Base class for model's outputs that may also contain a past key/values (to speed up sequential decoding) as well as
+ Mixture of Expert's router hidden states terms, to train a MoE model.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+
+ If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
+ hidden_size)` is output.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
+ `config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
+ encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
+ `config.is_encoder_decoder=True` in the cross-attention blocks) that can be used (see `past_key_values`
+ input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` and `config.add_cross_attention=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ router_probs (`tuple(torch.FloatTensor)`, *optional*, returned when `output_router_probs=True` and `config.add_router_probs=True` is passed or when `config.output_router_probs=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, sequence_length, num_experts)`.
+
+ Raw router probabilities that are computed by MoE routers, these terms are used to compute the auxiliary
+ loss and the z_loss for Mixture of Experts models.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ router_probs: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class Seq2SeqModelOutput(ModelOutput):
+ """
+ Base class for model encoder's outputs that also contains : pre-computed hidden states that can speed up sequential
+ decoding.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the decoder of the model.
+
+ If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
+ hidden_size)` is output.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the optional initial embedding outputs.
+ decoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the optional initial embedding outputs.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ decoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_last_hidden_state: Optional[torch.FloatTensor] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class Seq2SeqMoEModelOutput(ModelOutput):
+ """
+ Base class for model encoder's outputs that also contains : pre-computed hidden states that can speed up sequential
+ decoding.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the decoder of the model.
+
+ If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
+ hidden_size)` is output.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the optional initial embedding outputs.
+ decoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ decoder_router_logits (`tuple(torch.FloatTensor)`, *optional*, returned when `output_router_logits=True` is passed or when `config.add_router_probs=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, sequence_length, num_experts)`.
+
+ Router logits of the decoder model, useful to compute the auxiliary loss for Mixture of Experts models.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the optional initial embedding outputs.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ encoder_router_logits (`tuple(torch.FloatTensor)`, *optional*, returned when `output_router_logits=True` is passed or when `config.add_router_probs=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, sequence_length, num_experts)`.
+
+ Router logits of the encoder model, useful to compute the auxiliary loss and the z_loss for the sparse
+ modules.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ decoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ decoder_router_logits: Optional[Tuple[torch.FloatTensor]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_last_hidden_state: Optional[torch.FloatTensor] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_router_logits: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class CausalLMOutput(ModelOutput):
+ """
+ Base class for causal language model (or autoregressive) outputs.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Language modeling loss (for next-token prediction).
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class CausalLMOutputWithPast(ModelOutput):
+ """
+ Base class for causal language model (or autoregressive) outputs.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Language modeling loss (for next-token prediction).
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`)
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class CausalLMOutputWithCrossAttentions(ModelOutput):
+ """
+ Base class for causal language model (or autoregressive) outputs.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Language modeling loss (for next-token prediction).
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Cross attentions weights after the attention softmax, used to compute the weighted average in the
+ cross-attention heads.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `torch.FloatTensor` tuples of length `config.n_layers`, with each tuple containing the cached key,
+ value states of the self-attention and the cross-attention layers if model is used in encoder-decoder
+ setting. Only relevant if `config.is_decoder = True`.
+
+ Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class SequenceClassifierOutputWithPast(ModelOutput):
+ """
+ Base class for outputs of sentence classification models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`)
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class MaskedLMOutput(ModelOutput):
+ """
+ Base class for masked language models outputs.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Masked language modeling (MLM) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class Seq2SeqLMOutput(ModelOutput):
+ """
+ Base class for sequence-to-sequence language models outputs.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Language modeling loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ decoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_last_hidden_state: Optional[torch.FloatTensor] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class Seq2SeqMoEOutput(ModelOutput):
+ """
+ Base class for sequence-to-sequence language models outputs.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Language modeling loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ decoder_router_logits (`tuple(torch.FloatTensor)`, *optional*, returned when `output_router_logits=True` is passed or when `config.add_router_probs=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, sequence_length, num_experts)`.
+
+ Router logits of the decoder model, useful to compute the auxiliary loss for Mixture of Experts models.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ encoder_router_logits (`tuple(torch.FloatTensor)`, *optional*, returned when `output_router_logits=True` is passed or when `config.add_router_probs=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, sequence_length, num_experts)`.
+
+ Router logits of the encoder model, useful to compute the auxiliary loss and z_loss for Mixture of Experts
+ models.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ encoder_z_loss: Optional[torch.FloatTensor] = None
+ decoder_z_loss: Optional[torch.FloatTensor] = None
+ encoder_aux_loss: Optional[torch.FloatTensor] = None
+ decoder_aux_loss: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ decoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ decoder_router_logits: Optional[Tuple[torch.FloatTensor]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_last_hidden_state: Optional[torch.FloatTensor] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_router_logits: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class NextSentencePredictorOutput(ModelOutput):
+ """
+ Base class for outputs of models predicting if two sentences are consecutive or not.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `next_sentence_label` is provided):
+ Next sequence prediction (classification) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, 2)`):
+ Prediction scores of the next sequence prediction (classification) head (scores of True/False continuation
+ before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class SequenceClassifierOutput(ModelOutput):
+ """
+ Base class for outputs of sentence classification models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class Seq2SeqSequenceClassifierOutput(ModelOutput):
+ """
+ Base class for outputs of sequence-to-sequence sentence classification models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `label` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ decoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_last_hidden_state: Optional[torch.FloatTensor] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class MultipleChoiceModelOutput(ModelOutput):
+ """
+ Base class for outputs of multiple choice models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape *(1,)*, *optional*, returned when `labels` is provided):
+ Classification loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, num_choices)`):
+ *num_choices* is the second dimension of the input tensors. (see *input_ids* above).
+
+ Classification scores (before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class TokenClassifierOutput(ModelOutput):
+ """
+ Base class for outputs of token classification models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided) :
+ Classification loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.num_labels)`):
+ Classification scores (before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class QuestionAnsweringModelOutput(ModelOutput):
+ """
+ Base class for outputs of question answering models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Total span extraction loss is the sum of a Cross-Entropy for the start and end positions.
+ start_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
+ Span-start scores (before SoftMax).
+ end_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
+ Span-end scores (before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ start_logits: Optional[torch.FloatTensor] = None
+ end_logits: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class Seq2SeqQuestionAnsweringModelOutput(ModelOutput):
+ """
+ Base class for outputs of sequence-to-sequence question answering models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Total span extraction loss is the sum of a Cross-Entropy for the start and end positions.
+ start_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
+ Span-start scores (before SoftMax).
+ end_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
+ Span-end scores (before SoftMax).
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ start_logits: Optional[torch.FloatTensor] = None
+ end_logits: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ decoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_last_hidden_state: Optional[torch.FloatTensor] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class SemanticSegmenterOutput(ModelOutput):
+ """
+ Base class for outputs of semantic segmentation models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels, logits_height, logits_width)`):
+ Classification scores for each pixel.
+
+
+
+ The logits returned do not necessarily have the same size as the `pixel_values` passed as inputs. This is
+ to avoid doing two interpolations and lose some quality when a user needs to resize the logits to the
+ original image size as post-processing. You should always check your logits shape and resize as needed.
+
+
+
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, patch_size, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, patch_size,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class ImageClassifierOutput(ModelOutput):
+ """
+ Base class for outputs of image classification models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each stage) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states
+ (also called feature maps) of the model at the output of each stage.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, patch_size,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class ImageClassifierOutputWithNoAttention(ModelOutput):
+ """
+ Base class for outputs of image classification models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each stage) of shape `(batch_size, num_channels, height, width)`. Hidden-states (also
+ called feature maps) of the model at the output of each stage.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class DepthEstimatorOutput(ModelOutput):
+ """
+ Base class for outputs of depth estimation models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ predicted_depth (`torch.FloatTensor` of shape `(batch_size, height, width)`):
+ Predicted depth for each pixel.
+
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, num_channels, height, width)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, patch_size,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ predicted_depth: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class ImageSuperResolutionOutput(ModelOutput):
+ """
+ Base class for outputs of image super resolution models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Reconstruction loss.
+ reconstruction (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Reconstructed images, possibly upscaled.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each stage) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states
+ (also called feature maps) of the model at the output of each stage.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, patch_size,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ reconstruction: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class Wav2Vec2BaseModelOutput(ModelOutput):
+ """
+ Base class for models that have been trained with the Wav2Vec2 loss objective.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ extract_features (`torch.FloatTensor` of shape `(batch_size, sequence_length, conv_dim[-1])`):
+ Sequence of extracted feature vectors of the last convolutional layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ extract_features: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class XVectorOutput(ModelOutput):
+ """
+ Output type of [`Wav2Vec2ForXVector`].
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, config.xvector_output_dim)`):
+ Classification hidden states before AMSoftmax.
+ embeddings (`torch.FloatTensor` of shape `(batch_size, config.xvector_output_dim)`):
+ Utterance embeddings used for vector similarity-based retrieval.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ embeddings: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class BackboneOutput(ModelOutput):
+ """
+ Base class for outputs of backbones.
+
+ Args:
+ feature_maps (`tuple(torch.FloatTensor)` of shape `(batch_size, num_channels, height, width)`):
+ Feature maps of the stages.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)` or `(batch_size, num_channels, height, width)`,
+ depending on the backbone.
+
+ Hidden-states of the model at the output of each stage plus the initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`. Only applicable if the backbone uses attention.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ feature_maps: Optional[Tuple[torch.FloatTensor]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class BaseModelOutputWithPoolingAndProjection(ModelOutput):
+ """
+ Base class for model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ pooler_output (`torch.FloatTensor` of shape `(batch_size, hidden_size)`):
+ Last layer hidden-state of the first token of the sequence (classification token) after further processing
+ through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns
+ the classification token after processing through a linear layer and a tanh activation function. The linear
+ layer weights are trained from the next sentence prediction (classification) objective during pretraining.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ projection_state (`tuple(torch.FloatTensor)`, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` of shape `(batch_size,config.project_dim)`.
+
+ Text embeddings before the projection layer, used to mimic the last hidden state of the teacher encoder.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ pooler_output: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ projection_state: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class Seq2SeqSpectrogramOutput(ModelOutput):
+ """
+ Base class for sequence-to-sequence spectrogram outputs.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Spectrogram generation loss.
+ spectrogram (`torch.FloatTensor` of shape `(batch_size, sequence_length, num_bins)`):
+ The predicted spectrogram.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ spectrogram: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ decoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_last_hidden_state: Optional[torch.FloatTensor] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+@dataclass
+class Seq2SeqTSModelOutput(ModelOutput):
+ """
+ Base class for time series model's encoder outputs that also contains pre-computed hidden states that can speed up
+ sequential decoding.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the decoder of the model.
+
+ If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
+ hidden_size)` is output.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the optional initial embedding outputs.
+ decoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the optional initial embedding outputs.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ loc (`torch.FloatTensor` of shape `(batch_size,)` or `(batch_size, input_size)`, *optional*):
+ Shift values of each time series' context window which is used to give the model inputs of the same
+ magnitude and then used to shift back to the original magnitude.
+ scale (`torch.FloatTensor` of shape `(batch_size,)` or `(batch_size, input_size)`, *optional*):
+ Scaling values of each time series' context window which is used to give the model inputs of the same
+ magnitude and then used to rescale back to the original magnitude.
+ static_features (`torch.FloatTensor` of shape `(batch_size, feature size)`, *optional*):
+ Static features of each time series' in a batch which are copied to the covariates at inference time.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ decoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_last_hidden_state: Optional[torch.FloatTensor] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ loc: Optional[torch.FloatTensor] = None
+ scale: Optional[torch.FloatTensor] = None
+ static_features: Optional[torch.FloatTensor] = None
+
+
+@dataclass
+class Seq2SeqTSPredictionOutput(ModelOutput):
+ """
+ Base class for time series model's decoder outputs that also contain the loss as well as the parameters of the
+ chosen distribution.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when a `future_values` is provided):
+ Distributional loss.
+ params (`torch.FloatTensor` of shape `(batch_size, num_samples, num_params)`):
+ Parameters of the chosen distribution.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ loc (`torch.FloatTensor` of shape `(batch_size,)` or `(batch_size, input_size)`, *optional*):
+ Shift values of each time series' context window which is used to give the model inputs of the same
+ magnitude and then used to shift back to the original magnitude.
+ scale (`torch.FloatTensor` of shape `(batch_size,)` or `(batch_size, input_size)`, *optional*):
+ Scaling values of each time series' context window which is used to give the model inputs of the same
+ magnitude and then used to rescale back to the original magnitude.
+ static_features (`torch.FloatTensor` of shape `(batch_size, feature size)`, *optional*):
+ Static features of each time series' in a batch which are copied to the covariates at inference time.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ params: Optional[Tuple[torch.FloatTensor]] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ decoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_last_hidden_state: Optional[torch.FloatTensor] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+ loc: Optional[torch.FloatTensor] = None
+ scale: Optional[torch.FloatTensor] = None
+ static_features: Optional[torch.FloatTensor] = None
+
+
+@dataclass
+class SampleTSPredictionOutput(ModelOutput):
+ """
+ Base class for time series model's predictions outputs that contains the sampled values from the chosen
+ distribution.
+
+ Args:
+ sequences (`torch.FloatTensor` of shape `(batch_size, num_samples, prediction_length)` or `(batch_size, num_samples, prediction_length, input_size)`):
+ Sampled values from the chosen distribution.
+ """
+
+ sequences: Optional[torch.FloatTensor] = None
+
+
+@dataclass
+class MaskedImageModelingOutput(ModelOutput):
+ """
+ Base class for outputs of masked image completion / in-painting models.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `bool_masked_pos` is provided):
+ Reconstruction loss.
+ reconstruction (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Reconstructed / completed images.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or
+ when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each stage) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states
+ (also called feature maps) of the model at the output of each stage.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when
+ `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, patch_size,
+ sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
+ the self-attention heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ reconstruction: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+ @property
+ def logits(self):
+ warnings.warn(
+ "logits attribute is deprecated and will be removed in version 5 of Transformers."
+ " Please use the reconstruction attribute to retrieve the final output instead.",
+ FutureWarning,
+ )
+ return self.reconstruction
diff --git a/docs/transformers/src/transformers/modeling_rope_utils.py b/docs/transformers/src/transformers/modeling_rope_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..ccb961edea9d6e297b14531188320d72bbf4ef66
--- /dev/null
+++ b/docs/transformers/src/transformers/modeling_rope_utils.py
@@ -0,0 +1,655 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import math
+from functools import wraps
+from typing import Optional
+
+from .configuration_utils import PretrainedConfig
+from .utils import is_torch_available, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+if is_torch_available():
+ import torch
+
+
+def dynamic_rope_update(rope_forward):
+ """
+ Decorator function to update the RoPE parameters in the forward pass, if the model is using a dynamic RoPE
+ (i.e. a RoPE implementation that may recompute its frequencies in the forward pass).
+
+ Args:
+ rope_forward (Callable):
+ The forward pass of the RoPE implementation.
+
+ Returns:
+ The decorated forward pass.
+ """
+
+ def longrope_frequency_update(self, position_ids, device):
+ """Longrope uses long factor if sequence is larger than original pretraining length, short otherwise."""
+ seq_len = torch.max(position_ids) + 1
+ if hasattr(self.config, "original_max_position_embeddings"):
+ original_max_position_embeddings = self.config.original_max_position_embeddings
+ else:
+ original_max_position_embeddings = self.config.max_position_embeddings
+ if seq_len > original_max_position_embeddings:
+ if not hasattr(self, "long_inv_freq"):
+ self.long_inv_freq, _ = self.rope_init_fn(
+ self.config, device, seq_len=original_max_position_embeddings + 1
+ )
+ self.register_buffer("inv_freq", self.long_inv_freq, persistent=False)
+ else:
+ # This .to() is needed if the model has been moved to a device after being initialized (because
+ # the buffer is automatically moved, but not the original copy)
+ self.original_inv_freq = self.original_inv_freq.to(device)
+ self.register_buffer("inv_freq", self.original_inv_freq, persistent=False)
+
+ def dynamic_frequency_update(self, position_ids, device):
+ """
+ dynamic RoPE layers should recompute `inv_freq` in the following situations:
+ 1 - growing beyond the cached sequence length (allow scaling)
+ 2 - the current sequence length is in the original scale (avoid losing precision with small sequences)
+ """
+ seq_len = torch.max(position_ids) + 1
+ if seq_len > self.max_seq_len_cached: # growth
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device, seq_len=seq_len)
+ self.register_buffer("inv_freq", inv_freq, persistent=False) # TODO joao: may break with compilation
+ self.max_seq_len_cached = seq_len
+
+ if seq_len < self.original_max_seq_len and self.max_seq_len_cached > self.original_max_seq_len: # reset
+ # This .to() is needed if the model has been moved to a device after being initialized (because
+ # the buffer is automatically moved, but not the original copy)
+ self.original_inv_freq = self.original_inv_freq.to(device)
+ self.register_buffer("inv_freq", self.original_inv_freq, persistent=False)
+ self.max_seq_len_cached = self.original_max_seq_len
+
+ @wraps(rope_forward)
+ def wrapper(self, x, position_ids):
+ if "dynamic" in self.rope_type:
+ dynamic_frequency_update(self, position_ids, device=x.device)
+ elif self.rope_type == "longrope":
+ longrope_frequency_update(self, position_ids, device=x.device)
+ return rope_forward(self, x, position_ids)
+
+ return wrapper
+
+
+def _compute_default_rope_parameters(
+ config: Optional[PretrainedConfig] = None,
+ device: Optional["torch.device"] = None,
+ seq_len: Optional[int] = None,
+ **rope_kwargs,
+) -> tuple["torch.Tensor", float]:
+ """
+ Computes the inverse frequencies according to the original RoPE implementation
+ Args:
+ config ([`~transformers.PretrainedConfig`]):
+ The model configuration.
+ device (`torch.device`):
+ The device to use for initialization of the inverse frequencies.
+ seq_len (`int`, *optional*):
+ The current sequence length. Unused for this type of RoPE.
+ rope_kwargs (`Dict`, *optional*):
+ BC compatibility with the previous RoPE class instantiation, will be removed in v4.45.
+ Returns:
+ Tuple of (`torch.Tensor`, `float`), containing the inverse frequencies for the RoPE embeddings and the
+ post-processing scaling factor applied to the computed cos/sin (unused in this type of RoPE).
+ """
+ if config is not None and len(rope_kwargs) > 0:
+ raise ValueError(
+ "Unexpected arguments: `**rope_kwargs` and `config` are mutually exclusive in "
+ f"`_compute_default_rope_parameters`, got `rope_kwargs`={rope_kwargs} and `config`={config}"
+ )
+ if len(rope_kwargs) > 0:
+ base = rope_kwargs["base"]
+ dim = rope_kwargs["dim"]
+ elif config is not None:
+ base = config.rope_theta
+ partial_rotary_factor = config.partial_rotary_factor if hasattr(config, "partial_rotary_factor") else 1.0
+ head_dim = getattr(config, "head_dim", None) or config.hidden_size // config.num_attention_heads
+ dim = int(head_dim * partial_rotary_factor)
+
+ attention_factor = 1.0 # Unused in this type of RoPE
+
+ # Compute the inverse frequencies
+ inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2, dtype=torch.int64).to(device=device, dtype=torch.float) / dim))
+ return inv_freq, attention_factor
+
+
+def _compute_linear_scaling_rope_parameters(
+ config: Optional[PretrainedConfig] = None,
+ device: Optional["torch.device"] = None,
+ seq_len: Optional[int] = None,
+ **rope_kwargs,
+) -> tuple["torch.Tensor", float]:
+ """
+ Computes the inverse frequencies with linear scaling. Credits to the Reddit user /u/kaiokendev
+ Args:
+ config ([`~transformers.PretrainedConfig`]):
+ The model configuration.
+ device (`torch.device`):
+ The device to use for initialization of the inverse frequencies.
+ seq_len (`int`, *optional*):
+ The current sequence length. Unused for this type of RoPE.
+ rope_kwargs (`Dict`, *optional*):
+ BC compatibility with the previous RoPE class instantiation, will be removed in v4.45.
+ Returns:
+ Tuple of (`torch.Tensor`, `float`), containing the inverse frequencies for the RoPE embeddings and the
+ post-processing scaling factor applied to the computed cos/sin (unused in this type of RoPE).
+ """
+ if config is not None and len(rope_kwargs) > 0:
+ raise ValueError(
+ "Unexpected arguments: `**rope_kwargs` and `config` are mutually exclusive in "
+ f"`_compute_linear_scaling_rope_parameters`, got `rope_kwargs`={rope_kwargs} and `config`={config}"
+ )
+ if len(rope_kwargs) > 0:
+ factor = rope_kwargs["factor"]
+ elif config is not None:
+ factor = config.rope_scaling["factor"]
+
+ # Gets the default RoPE parameters
+ inv_freq, attention_factor = _compute_default_rope_parameters(config, device, seq_len, **rope_kwargs)
+
+ # Then applies linear scaling to the frequencies.
+ # NOTE: originally, scaling was applied to the position_ids. However, we get `embs = inv_freq @ position_ids`, so
+ # applying scaling to the inverse frequencies is equivalent.
+ inv_freq /= factor
+ return inv_freq, attention_factor
+
+
+def _compute_dynamic_ntk_parameters(
+ config: Optional[PretrainedConfig] = None,
+ device: Optional["torch.device"] = None,
+ seq_len: Optional[int] = None,
+ **rope_kwargs,
+) -> tuple["torch.Tensor", float]:
+ """
+ Computes the inverse frequencies with NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla
+ Args:
+ config ([`~transformers.PretrainedConfig`]):
+ The model configuration.
+ device (`torch.device`):
+ The device to use for initialization of the inverse frequencies.
+ seq_len (`int`, *optional*):
+ The current sequence length, used to update the dynamic RoPE at inference time.
+ rope_kwargs (`Dict`, *optional*):
+ BC compatibility with the previous RoPE class instantiation, will be removed in v4.45.
+ Returns:
+ Tuple of (`torch.Tensor`, `float`), containing the inverse frequencies for the RoPE embeddings and the
+ post-processing scaling factor applied to the computed cos/sin (unused in this type of RoPE).
+ """
+ # TODO (joao): use the new `original_max_position_embeddings` from rope_scaling
+ if config is not None and len(rope_kwargs) > 0:
+ raise ValueError(
+ "Unexpected arguments: `**rope_kwargs` and `config` are mutually exclusive in "
+ f"`_compute_dynamic_ntk_parameters`, got `rope_kwargs`={rope_kwargs} and `config`={config}"
+ )
+ if len(rope_kwargs) > 0:
+ base = rope_kwargs["base"]
+ dim = rope_kwargs["dim"]
+ max_position_embeddings = rope_kwargs["max_position_embeddings"]
+ factor = rope_kwargs["factor"]
+ elif config is not None:
+ base = config.rope_theta
+ partial_rotary_factor = config.partial_rotary_factor if hasattr(config, "partial_rotary_factor") else 1.0
+ head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ dim = int(head_dim * partial_rotary_factor)
+ max_position_embeddings = config.max_position_embeddings
+ factor = config.rope_scaling["factor"]
+
+ attention_factor = 1.0 # Unused in this type of RoPE
+
+ # seq_len: default to max_position_embeddings, e.g. at init time
+ seq_len = seq_len if seq_len is not None and seq_len > max_position_embeddings else max_position_embeddings
+
+ # Compute the inverse frequencies
+ base = base * ((factor * seq_len / max_position_embeddings) - (factor - 1)) ** (dim / (dim - 2))
+ inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2, dtype=torch.int64).to(device=device, dtype=torch.float) / dim))
+ return inv_freq, attention_factor
+
+
+def _compute_yarn_parameters(
+ config: PretrainedConfig, device: "torch.device", seq_len: Optional[int] = None, **rope_kwargs
+) -> tuple["torch.Tensor", float]:
+ """
+ Computes the inverse frequencies with NTK scaling. Please refer to the
+ [original paper](https://arxiv.org/abs/2309.00071)
+ Args:
+ config ([`~transformers.PretrainedConfig`]):
+ The model configuration.
+ device (`torch.device`):
+ The device to use for initialization of the inverse frequencies.
+ seq_len (`int`, *optional*):
+ The current sequence length. Unused for this type of RoPE.
+ rope_kwargs (`Dict`, *optional*):
+ BC compatibility with the previous RoPE class instantiation, will be removed in v4.45.
+ Returns:
+ Tuple of (`torch.Tensor`, `float`), containing the inverse frequencies for the RoPE embeddings and the
+ post-processing scaling factor applied to the computed cos/sin.
+ """
+ # No need to keep BC with yarn, unreleased when this new pattern was created.
+ if len(rope_kwargs) > 0:
+ raise ValueError(
+ f"Unexpected arguments: `**rope_kwargs` should be unset in `_compute_yarn_parameters`, got {rope_kwargs}"
+ )
+
+ base = config.rope_theta
+ partial_rotary_factor = config.partial_rotary_factor if hasattr(config, "partial_rotary_factor") else 1.0
+ head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ dim = int(head_dim * partial_rotary_factor)
+ factor = config.rope_scaling["factor"]
+ attention_factor = config.rope_scaling.get("attention_factor")
+ mscale = config.rope_scaling.get("mscale")
+ mscale_all_dim = config.rope_scaling.get("mscale_all_dim")
+
+ # NOTE: DeekSeek-V3 (and potentially other models) modify `max_position_embeddings` and have a
+ # `original_max_position_embeddings` field containing the pretrained value. They use the ratio between these two
+ # values to compute the default attention scaling factor, instead of using `factor`.
+ if "original_max_position_embeddings" in config.rope_scaling:
+ original_max_position_embeddings = config.rope_scaling["original_max_position_embeddings"]
+ factor = config.max_position_embeddings / original_max_position_embeddings
+ else:
+ original_max_position_embeddings = config.max_position_embeddings
+
+ def get_mscale(scale, mscale=1):
+ if scale <= 1:
+ return 1.0
+ return 0.1 * mscale * math.log(scale) + 1.0
+
+ # Sets the attention factor as suggested in the paper
+ if attention_factor is None:
+ if mscale and mscale_all_dim:
+ attention_factor = float(get_mscale(factor, mscale) / get_mscale(factor, mscale_all_dim))
+ else:
+ attention_factor = get_mscale(factor)
+
+ # Optional config options
+ # beta_fast/beta_slow: as suggested in the paper, default to 32/1 (correspondingly)
+ beta_fast = config.rope_scaling.get("beta_fast") or 32
+ beta_slow = config.rope_scaling.get("beta_slow") or 1
+
+ # Compute the inverse frequencies
+ def find_correction_dim(num_rotations, dim, base, max_position_embeddings):
+ """Inverse dimension formula to find the dimension based on the number of rotations"""
+ return (dim * math.log(max_position_embeddings / (num_rotations * 2 * math.pi))) / (2 * math.log(base))
+
+ def find_correction_range(low_rot, high_rot, dim, base, max_position_embeddings):
+ """Find dimension range bounds based on rotations"""
+ low = math.floor(find_correction_dim(low_rot, dim, base, max_position_embeddings))
+ high = math.ceil(find_correction_dim(high_rot, dim, base, max_position_embeddings))
+ return max(low, 0), min(high, dim - 1)
+
+ def linear_ramp_factor(min, max, dim):
+ if min == max:
+ max += 0.001 # Prevent singularity
+
+ linear_func = (torch.arange(dim, dtype=torch.float32) - min) / (max - min)
+ ramp_func = torch.clamp(linear_func, 0, 1)
+ return ramp_func
+
+ # Note on variable naming: "interpolation" comes from the original technique, where we interpolate the position IDs
+ # to expand the possible context length. In other words, interpolation = apply scaling factor.
+ pos_freqs = base ** (torch.arange(0, dim, 2).to(device=device, dtype=torch.float) / dim)
+ inv_freq_extrapolation = 1.0 / pos_freqs
+ inv_freq_interpolation = 1.0 / (factor * pos_freqs)
+
+ low, high = find_correction_range(beta_fast, beta_slow, dim, base, original_max_position_embeddings)
+
+ # Get n-dimensional rotational scaling corrected for extrapolation
+ inv_freq_extrapolation_factor = 1 - linear_ramp_factor(low, high, dim // 2).to(device=device, dtype=torch.float)
+ inv_freq = (
+ inv_freq_interpolation * (1 - inv_freq_extrapolation_factor)
+ + inv_freq_extrapolation * inv_freq_extrapolation_factor
+ )
+ return inv_freq, attention_factor
+
+
+def _compute_longrope_parameters(
+ config: PretrainedConfig, device: "torch.device", seq_len: Optional[int] = None, **rope_kwargs
+) -> tuple["torch.Tensor", float]:
+ """
+ Computes the inverse frequencies with LongRoPE scaling. Please refer to the
+ [original implementation](https://github.com/microsoft/LongRoPE)
+ Args:
+ config ([`~transformers.PretrainedConfig`]):
+ The model configuration.
+ device (`torch.device`):
+ The device to use for initialization of the inverse frequencies.
+ seq_len (`int`, *optional*):
+ The current sequence length.
+ rope_kwargs (`Dict`, *optional*):
+ BC compatibility with the previous RoPE class instantiation, will be removed in v4.45.
+ Returns:
+ Tuple of (`torch.Tensor`, `float`), containing the inverse frequencies for the RoPE embeddings and the
+ post-processing scaling factor applied to the computed cos/sin.
+ """
+ # TODO (joao): use the new `original_max_position_embeddings` from rope_scaling
+ # No need to keep BC with longrope, unreleased when this new pattern was created.
+ if len(rope_kwargs) > 0:
+ raise ValueError(
+ "Unexpected arguments: `**rope_kwargs` should be unset in `_compute_longrope_parameters`, got "
+ f"{rope_kwargs}"
+ )
+
+ base = config.rope_theta
+ partial_rotary_factor = config.partial_rotary_factor if hasattr(config, "partial_rotary_factor") else 1.0
+ head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ dim = int(head_dim * partial_rotary_factor)
+ long_factor = config.rope_scaling["long_factor"]
+ short_factor = config.rope_scaling["short_factor"]
+ factor = config.rope_scaling.get("factor")
+ attention_factor = config.rope_scaling.get("attention_factor")
+
+ # NOTE: Phi3 (and potentially other models) modify `max_position_embeddings` and have a
+ # `original_max_position_embeddings` field containing the pretrained value. They use the ratio between these two
+ # values to compute the default attention scaling factor, instead of using `factor`.
+ if hasattr(config, "original_max_position_embeddings"):
+ original_max_position_embeddings = config.original_max_position_embeddings
+ factor = config.max_position_embeddings / config.original_max_position_embeddings
+ else:
+ original_max_position_embeddings = config.max_position_embeddings
+
+ # Sets the attention factor as suggested in the paper
+ if attention_factor is None:
+ if factor <= 1.0:
+ attention_factor = 1.0
+ else:
+ attention_factor = math.sqrt(1 + math.log(factor) / math.log(original_max_position_embeddings))
+
+ # Compute the inverse frequencies -- scaled based on the target sequence length
+ if seq_len and seq_len > original_max_position_embeddings:
+ ext_factors = torch.tensor(long_factor, dtype=torch.float32, device=device)
+ else:
+ ext_factors = torch.tensor(short_factor, dtype=torch.float32, device=device)
+ inv_freq_shape = torch.arange(0, dim, 2, dtype=torch.int64, device=device).float() / dim
+ inv_freq = 1.0 / (ext_factors * base**inv_freq_shape)
+
+ return inv_freq, attention_factor
+
+
+def _compute_llama3_parameters(
+ config: PretrainedConfig, device: "torch.device", seq_len: Optional[int] = None, **rope_kwargs
+) -> tuple["torch.Tensor", float]:
+ """
+ Computes the inverse frequencies for llama 3.1.
+
+ Args:
+ config ([`~transformers.PretrainedConfig`]):
+ The model configuration.
+ device (`torch.device`):
+ The device to use for initialization of the inverse frequencies.
+ seq_len (`int`, *optional*):
+ The current sequence length. Unused for this type of RoPE.
+ rope_kwargs (`Dict`, *optional*):
+ BC compatibility with the previous RoPE class instantiation, will be removed in v4.45.
+ Returns:
+ Tuple of (`torch.Tensor`, `float`), containing the inverse frequencies for the RoPE embeddings and the
+ post-processing scaling factor applied to the computed cos/sin.
+ """
+ # Gets the default RoPE parameters
+ inv_freq, attention_factor = _compute_default_rope_parameters(config, device, seq_len, **rope_kwargs)
+
+ factor = config.rope_scaling["factor"] # `8` in the original implementation
+ low_freq_factor = config.rope_scaling["low_freq_factor"] # `1` in the original implementation
+ high_freq_factor = config.rope_scaling["high_freq_factor"] # `4` in the original implementation
+ old_context_len = config.rope_scaling["original_max_position_embeddings"] # `8192` in the original implementation
+
+ low_freq_wavelen = old_context_len / low_freq_factor
+ high_freq_wavelen = old_context_len / high_freq_factor
+
+ wavelen = 2 * math.pi / inv_freq
+ # wavelen < high_freq_wavelen: do nothing
+ # wavelen > low_freq_wavelen: divide by factor
+ inv_freq_llama = torch.where(wavelen > low_freq_wavelen, inv_freq / factor, inv_freq)
+ # otherwise: interpolate between the two, using a smooth factor
+ smooth_factor = (old_context_len / wavelen - low_freq_factor) / (high_freq_factor - low_freq_factor)
+ smoothed_inv_freq = (1 - smooth_factor) * inv_freq_llama / factor + smooth_factor * inv_freq_llama
+ is_medium_freq = ~(wavelen < high_freq_wavelen) * ~(wavelen > low_freq_wavelen)
+ inv_freq_llama = torch.where(is_medium_freq, smoothed_inv_freq, inv_freq_llama)
+
+ return inv_freq_llama, attention_factor
+
+
+# This maps the "rope_type" string field in rope config to the corresponding function to compute the RoPE parameters
+# from the model config. You can append new {'rope_type': callable} pairs to this dictionary to enable custom RoPE
+# parameterizations, as long as the callable has the same signature.
+ROPE_INIT_FUNCTIONS = {
+ "default": _compute_default_rope_parameters,
+ "linear": _compute_linear_scaling_rope_parameters,
+ "dynamic": _compute_dynamic_ntk_parameters,
+ "yarn": _compute_yarn_parameters,
+ "longrope": _compute_longrope_parameters,
+ "llama3": _compute_llama3_parameters,
+}
+
+
+def _check_received_keys(
+ rope_type: str,
+ received_keys: set,
+ required_keys: set,
+ optional_keys: Optional[set] = None,
+ ignore_keys: Optional[set] = None,
+):
+ """Compare the received keys in `config.rope_scaling` against the expected and optional keys"""
+ # BC: "rope_type" was originally "type" -- let's check for "rope_type" when "type" is present
+ if "type" in received_keys:
+ received_keys -= {"type"}
+ required_keys.add("rope_type")
+
+ # Some models need to store model-specific keys, and we don't want to throw warning at them
+ if ignore_keys is not None:
+ received_keys -= ignore_keys
+
+ missing_keys = required_keys - received_keys
+ if missing_keys:
+ raise KeyError(f"Missing required keys in `rope_scaling` for 'rope_type'='{rope_type}': {missing_keys}")
+
+ if optional_keys is not None:
+ unused_keys = received_keys - required_keys - optional_keys
+ else:
+ unused_keys = received_keys - required_keys
+ if unused_keys:
+ logger.warning(f"Unrecognized keys in `rope_scaling` for 'rope_type'='{rope_type}': {unused_keys}")
+
+
+def _validate_default_rope_parameters(config: PretrainedConfig, ignore_keys: Optional[set] = None):
+ rope_scaling = config.rope_scaling
+ rope_type = rope_scaling.get("rope_type", rope_scaling.get("type", None)) # BC: "rope_type" was originally "type"
+ required_keys = {"rope_type"}
+ received_keys = set(rope_scaling.keys())
+ _check_received_keys(rope_type, received_keys, required_keys, ignore_keys=ignore_keys)
+
+
+def _validate_linear_scaling_rope_parameters(config: PretrainedConfig, ignore_keys: Optional[set] = None):
+ rope_scaling = config.rope_scaling
+ rope_type = rope_scaling.get("rope_type", rope_scaling.get("type", None)) # BC: "rope_type" was originally "type"
+ required_keys = {"rope_type", "factor"}
+ received_keys = set(rope_scaling.keys())
+ _check_received_keys(rope_type, received_keys, required_keys, ignore_keys=ignore_keys)
+
+ factor = rope_scaling["factor"]
+ if factor is None or not isinstance(factor, float) or factor < 1.0:
+ logger.warning(f"`rope_scaling`'s factor field must be a float >= 1, got {factor}")
+
+
+def _validate_dynamic_scaling_rope_parameters(config: PretrainedConfig, ignore_keys: Optional[set] = None):
+ rope_scaling = config.rope_scaling
+ rope_type = rope_scaling.get("rope_type", rope_scaling.get("type", None)) # BC: "rope_type" was originally "type"
+ required_keys = {"rope_type", "factor"}
+ # TODO (joao): update logic for the inclusion of `original_max_position_embeddings`
+ optional_keys = {"original_max_position_embeddings"}
+ received_keys = set(rope_scaling.keys())
+ _check_received_keys(rope_type, received_keys, required_keys, optional_keys, ignore_keys=ignore_keys)
+
+ factor = rope_scaling["factor"]
+ if factor is None or not isinstance(factor, float) or factor < 1.0:
+ logger.warning(f"`rope_scaling`'s factor field must be a float >= 1, got {factor}")
+
+
+def _validate_yarn_parameters(config: PretrainedConfig, ignore_keys: Optional[set] = None):
+ rope_scaling = config.rope_scaling
+ rope_type = rope_scaling.get("rope_type", rope_scaling.get("type", None)) # BC: "rope_type" was originally "type"
+ required_keys = {"rope_type", "factor"}
+ optional_keys = {
+ "attention_factor",
+ "beta_fast",
+ "beta_slow",
+ "original_max_position_embeddings",
+ "mscale",
+ "mscale_all_dim",
+ }
+ received_keys = set(rope_scaling.keys())
+ _check_received_keys(rope_type, received_keys, required_keys, optional_keys, ignore_keys=ignore_keys)
+
+ factor = rope_scaling["factor"]
+ if factor is None or not isinstance(factor, float) or factor < 1.0:
+ logger.warning(f"`rope_scaling`'s factor field must be a float >= 1, got {factor}")
+
+ attention_factor = rope_scaling.get("attention_factor")
+ if attention_factor is not None and (not isinstance(attention_factor, float) or attention_factor < 0):
+ logger.warning(
+ f"`rope_scaling`'s attention_factor field must be a float greater than 0, got {attention_factor}"
+ )
+ beta_fast = rope_scaling.get("beta_fast")
+ if beta_fast is not None and not isinstance(beta_fast, float):
+ logger.warning(f"`rope_scaling`'s beta_fast field must be a float, got {beta_fast}")
+ beta_slow = rope_scaling.get("beta_slow")
+ if beta_slow is not None and not isinstance(beta_slow, float):
+ logger.warning(f"`rope_scaling`'s beta_slow field must be a float, got {beta_slow}")
+
+ if (beta_fast or 32) < (beta_slow or 1):
+ logger.warning(
+ f"`rope_scaling`'s beta_fast field must be greater than beta_slow, got beta_fast={beta_fast} "
+ f"(defaults to 32 if None) and beta_slow={beta_slow} (defaults to 1 if None)"
+ )
+
+
+def _validate_longrope_parameters(config: PretrainedConfig, ignore_keys: Optional[set] = None):
+ rope_scaling = config.rope_scaling
+ rope_type = rope_scaling.get("rope_type", rope_scaling.get("type", None)) # BC: "rope_type" was originally "type"
+ required_keys = {"rope_type", "short_factor", "long_factor"}
+ # TODO (joao): update logic for the inclusion of `original_max_position_embeddings`
+ optional_keys = {"attention_factor", "factor", "original_max_position_embeddings"}
+ received_keys = set(rope_scaling.keys())
+ _check_received_keys(rope_type, received_keys, required_keys, optional_keys, ignore_keys=ignore_keys)
+
+ partial_rotary_factor = config.partial_rotary_factor if hasattr(config, "partial_rotary_factor") else 1.0
+ head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ dim = int(head_dim * partial_rotary_factor)
+
+ short_factor = rope_scaling.get("short_factor")
+ if not isinstance(short_factor, list) and all(isinstance(x, (int, float)) for x in short_factor):
+ logger.warning(f"`rope_scaling`'s short_factor field must be a list of numbers, got {short_factor}")
+ if not len(short_factor) == dim // 2:
+ logger.warning(f"`rope_scaling`'s short_factor field must have length {dim // 2}, got {len(short_factor)}")
+
+ long_factor = rope_scaling.get("long_factor")
+ if not isinstance(long_factor, list) and all(isinstance(x, (int, float)) for x in long_factor):
+ logger.warning(f"`rope_scaling`'s long_factor field must be a list of numbers, got {long_factor}")
+ if not len(long_factor) == dim // 2:
+ logger.warning(f"`rope_scaling`'s long_factor field must have length {dim // 2}, got {len(long_factor)}")
+
+ # Handle Phi3 divergence: prefer the use of `attention_factor` and/or `factor` over
+ # `original_max_position_embeddings` to compute internal variables. The latter lives outside `rope_scaling` and is
+ # unique to longrope (= undesirable)
+ if hasattr(config, "original_max_position_embeddings"):
+ logger.warning_once(
+ "This model has set a `original_max_position_embeddings` field, to be used together with "
+ "`max_position_embeddings` to determine a scaling factor. Please set the `factor` field of `rope_scaling`"
+ "with this ratio instead -- we recommend the use of this field over `original_max_position_embeddings`, "
+ "as it is compatible with most model architectures."
+ )
+ else:
+ factor = rope_scaling.get("factor")
+ if factor is None:
+ logger.warning("Missing required keys in `rope_scaling`: 'factor'")
+ elif not isinstance(factor, float) or factor < 1.0:
+ logger.warning(f"`rope_scaling`'s factor field must be a float >= 1, got {factor}")
+
+ attention_factor = rope_scaling.get("attention_factor")
+ if attention_factor is not None:
+ if not isinstance(attention_factor, float) or attention_factor < 0.0:
+ logger.warning(
+ f"`rope_scaling`'s attention_factor field must be a float greater than 0, got {attention_factor}"
+ )
+
+
+def _validate_llama3_parameters(config: PretrainedConfig, ignore_keys: Optional[set] = None):
+ rope_scaling = config.rope_scaling
+ rope_type = rope_scaling.get("rope_type", rope_scaling.get("type", None)) # BC: "rope_type" was originally "type"
+ required_keys = {"rope_type", "factor", "original_max_position_embeddings", "low_freq_factor", "high_freq_factor"}
+ received_keys = set(rope_scaling.keys())
+ _check_received_keys(rope_type, received_keys, required_keys, ignore_keys=ignore_keys)
+
+ factor = rope_scaling["factor"]
+ if factor is None or not isinstance(factor, float) or factor < 1.0:
+ logger.warning(f"`rope_scaling`'s factor field must be a float >= 1, got {factor}")
+
+ low_freq_factor = rope_scaling["low_freq_factor"]
+ high_freq_factor = rope_scaling["high_freq_factor"]
+ if low_freq_factor is None or not isinstance(low_freq_factor, float):
+ logger.warning(f"`rope_scaling`'s low_freq_factor field must be a float, got {low_freq_factor}")
+ if high_freq_factor is None or not isinstance(high_freq_factor, float):
+ logger.warning(f"`rope_scaling`'s high_freq_factor field must be a float, got {high_freq_factor}")
+ if high_freq_factor <= low_freq_factor:
+ logger.warning(
+ "`rope_scaling`'s high_freq_factor field must be greater than low_freq_factor, got high_freq_factor="
+ f"{high_freq_factor} and low_freq_factor={low_freq_factor}"
+ )
+
+ original_max_position_embeddings = rope_scaling["original_max_position_embeddings"]
+ if original_max_position_embeddings is None or not isinstance(original_max_position_embeddings, int):
+ logger.warning(
+ "`rope_scaling`'s original_max_position_embeddings field must be an integer, got "
+ f"{original_max_position_embeddings}"
+ )
+ if original_max_position_embeddings >= config.max_position_embeddings:
+ logger.warning(
+ "`rope_scaling`'s original_max_position_embeddings field must be less than max_position_embeddings, got "
+ f"{original_max_position_embeddings} and max_position_embeddings={config.max_position_embeddings}"
+ )
+
+
+# Like `ROPE_INIT_FUNCTIONS`, this validation function mapping can be dynamically updated for custom RoPE types.
+ROPE_VALIDATION_FUNCTIONS = {
+ "default": _validate_default_rope_parameters,
+ "linear": _validate_linear_scaling_rope_parameters,
+ "dynamic": _validate_dynamic_scaling_rope_parameters,
+ "yarn": _validate_yarn_parameters,
+ "longrope": _validate_longrope_parameters,
+ "llama3": _validate_llama3_parameters,
+}
+
+
+def rope_config_validation(config: PretrainedConfig, ignore_keys: Optional[set] = None):
+ """
+ Validate the RoPE config arguments, given a `PretrainedConfig` object
+ """
+ rope_scaling = getattr(config, "rope_scaling", None) # not a default parameter in `PretrainedConfig`
+ if rope_scaling is None:
+ return
+
+ # BC: "rope_type" was originally "type"
+ rope_type = rope_scaling.get("rope_type", rope_scaling.get("type", "default"))
+ validation_fn = ROPE_VALIDATION_FUNCTIONS.get(rope_type)
+ if validation_fn is not None:
+ validation_fn(config, ignore_keys=ignore_keys)
+ else:
+ logger.warning(
+ f"Missing validation function mapping in `ROPE_VALIDATION_FUNCTIONS` for 'rope_type'='{rope_type}'"
+ )
diff --git a/docs/transformers/src/transformers/modeling_tf_outputs.py b/docs/transformers/src/transformers/modeling_tf_outputs.py
new file mode 100644
index 0000000000000000000000000000000000000000..cbc8b3682af608d0db6da02ef36764d0be10ca9c
--- /dev/null
+++ b/docs/transformers/src/transformers/modeling_tf_outputs.py
@@ -0,0 +1,991 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import annotations
+
+import warnings
+from dataclasses import dataclass
+from typing import List, Optional, Tuple
+
+import tensorflow as tf
+
+from .utils import ModelOutput
+
+
+@dataclass
+class TFBaseModelOutput(ModelOutput):
+ """
+ Base class for model's outputs, with potential hidden states and attentions.
+
+ Args:
+ last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(tf.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFBaseModelOutputWithNoAttention(ModelOutput):
+ """
+ Base class for model's outputs, with potential hidden states.
+
+ Args:
+ last_hidden_state (`tf.Tensor` shape `(batch_size, num_channels, height, width)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings, if the model has an embedding layer, + one for
+ the output of each layer) of shape `(batch_size, num_channels, height, width)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ """
+
+ last_hidden_state: Optional[tf.Tensor] = None
+ hidden_states: Optional[Tuple[tf.Tensor, ...]] = None
+
+
+@dataclass
+class TFBaseModelOutputWithPooling(ModelOutput):
+ """
+ Base class for model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ pooler_output (`tf.Tensor` of shape `(batch_size, hidden_size)`):
+ Last layer hidden-state of the first token of the sequence (classification token) further processed by a
+ Linear layer and a Tanh activation function. The Linear layer weights are trained from the next sentence
+ prediction (classification) objective during pretraining.
+
+ This output is usually *not* a good summary of the semantic content of the input, you're often better with
+ averaging or pooling the sequence of hidden-states for the whole input sequence.
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: Optional[tf.Tensor] = None
+ pooler_output: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFBaseModelOutputWithPoolingAndNoAttention(ModelOutput):
+ """
+ Base class for model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ last_hidden_state (`tf.Tensor` of shape `(batch_size, num_channels, height, width)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ pooler_output (`tf.Tensor` of shape `(batch_size, hidden_size)`):
+ Last layer hidden-state after a pooling operation on the spatial dimensions.
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings, if the model has an embedding layer, + one for
+ the output of each layer) of shape `(batch_size, num_channels, height, width)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ """
+
+ last_hidden_state: Optional[tf.Tensor] = None
+ pooler_output: Optional[tf.Tensor] = None
+ hidden_states: Optional[Tuple[tf.Tensor, ...]] = None
+
+
+@dataclass
+class TFBaseModelOutputWithPoolingAndCrossAttentions(ModelOutput):
+ """
+ Base class for model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ pooler_output (`tf.Tensor` of shape `(batch_size, hidden_size)`):
+ Last layer hidden-state of the first token of the sequence (classification token) further processed by a
+ Linear layer and a Tanh activation function. The Linear layer weights are trained from the next sentence
+ prediction (classification) objective during pretraining.
+
+ This output is usually *not* a good summary of the semantic content of the input, you're often better with
+ averaging or pooling the sequence of hidden-states for the whole input sequence.
+ past_key_values (`List[tf.Tensor]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ List of `tf.Tensor` of length `config.n_layers`, with each tensor of shape `(2, batch_size, num_heads,
+ sequence_length, embed_size_per_head)`).
+
+ Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ cross_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ """
+
+ last_hidden_state: Optional[tf.Tensor] = None
+ pooler_output: Optional[tf.Tensor] = None
+ past_key_values: List[tf.Tensor] | None = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+ cross_attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFBaseModelOutputWithPast(ModelOutput):
+ """
+ Base class for model's outputs that may also contain a past key/values (to speed up sequential decoding).
+
+ Args:
+ last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+
+ If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
+ hidden_size)` is output.
+ past_key_values (`List[tf.Tensor]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ List of `tf.Tensor` of length `config.n_layers`, with each tensor of shape `(2, batch_size, num_heads,
+ sequence_length, embed_size_per_head)`).
+
+ Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ last_hidden_state: Optional[tf.Tensor] = None
+ past_key_values: List[tf.Tensor] | None = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFBaseModelOutputWithCrossAttentions(ModelOutput):
+ """
+ Base class for model's outputs, with potential hidden states and attentions.
+
+ Args:
+ last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(tf.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ cross_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ """
+
+ last_hidden_state: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+ cross_attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFBaseModelOutputWithPastAndCrossAttentions(ModelOutput):
+ """
+ Base class for model's outputs that may also contain a past key/values (to speed up sequential decoding).
+
+ Args:
+ last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+
+ If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
+ hidden_size)` is output.
+ past_key_values (`List[tf.Tensor]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ List of `tf.Tensor` of length `config.n_layers`, with each tensor of shape `(2, batch_size, num_heads,
+ sequence_length, embed_size_per_head)`).
+
+ Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(tf.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ cross_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ """
+
+ last_hidden_state: Optional[tf.Tensor] = None
+ past_key_values: List[tf.Tensor] | None = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+ cross_attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFSeq2SeqModelOutput(ModelOutput):
+ """
+ Base class for model encoder's outputs that also contains : pre-computed hidden states that can speed up sequential
+ decoding.
+
+ Args:
+ last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the decoder of the model.
+
+ If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
+ hidden_size)` is output.
+ past_key_values (`List[tf.Tensor]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ List of `tf.Tensor` of length `config.n_layers`, with each tensor of shape `(2, batch_size, num_heads,
+ sequence_length, embed_size_per_head)`).
+
+ Contains pre-computed hidden-states (key and values in the attention blocks) of the decoder that can be
+ used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ """
+
+ last_hidden_state: Optional[tf.Tensor] = None
+ past_key_values: List[tf.Tensor] | None = None
+ decoder_hidden_states: Tuple[tf.Tensor] | None = None
+ decoder_attentions: Tuple[tf.Tensor] | None = None
+ cross_attentions: Tuple[tf.Tensor] | None = None
+ encoder_last_hidden_state: tf.Tensor | None = None
+ encoder_hidden_states: Tuple[tf.Tensor] | None = None
+ encoder_attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFCausalLMOutput(ModelOutput):
+ """
+ Base class for causal language model (or autoregressive) outputs.
+
+ Args:
+ loss (`tf.Tensor` of shape `(n,)`, *optional*, where n is the number of non-masked labels, returned when `labels` is provided):
+ Language modeling loss (for next-token prediction).
+ logits (`tf.Tensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFCausalLMOutputWithPast(ModelOutput):
+ """
+ Base class for causal language model (or autoregressive) outputs.
+
+ Args:
+ loss (`tf.Tensor` of shape `(n,)`, *optional*, where n is the number of non-masked labels, returned when `labels` is provided):
+ Language modeling loss (for next-token prediction).
+ logits (`tf.Tensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ past_key_values (`List[tf.Tensor]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ List of `tf.Tensor` of length `config.n_layers`, with each tensor of shape `(2, batch_size, num_heads,
+ sequence_length, embed_size_per_head)`).
+
+ Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ past_key_values: List[tf.Tensor] | None = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFCausalLMOutputWithCrossAttentions(ModelOutput):
+ """
+ Base class for causal language model (or autoregressive) outputs.
+
+ Args:
+ loss (`tf.Tensor` of shape `(n,)`, *optional*, where n is the number of non-masked labels, returned when `labels` is provided):
+ Language modeling loss (for next-token prediction).
+ logits (`tf.Tensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ cross_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ past_key_values (`List[tf.Tensor]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ List of `tf.Tensor` of length `config.n_layers`, with each tensor of shape `(2, batch_size, num_heads,
+ sequence_length, embed_size_per_head)`).
+
+ Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ past_key_values: List[tf.Tensor] | None = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+ cross_attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFMaskedLMOutput(ModelOutput):
+ """
+ Base class for masked language models outputs.
+
+ Args:
+ loss (`tf.Tensor` of shape `(n,)`, *optional*, where n is the number of non-masked labels, returned when `labels` is provided):
+ Masked language modeling (MLM) loss.
+ logits (`tf.Tensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFSeq2SeqLMOutput(ModelOutput):
+ """
+ Base class for sequence-to-sequence language models outputs.
+
+ Args:
+ loss (`tf.Tensor` of shape `(n,)`, *optional*, where n is the number of non-masked labels, returned when `labels` is provided):
+ Language modeling loss.
+ logits (`tf.Tensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ past_key_values (`List[tf.Tensor]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ List of `tf.Tensor` of length `config.n_layers`, with each tensor of shape `(2, batch_size, num_heads,
+ sequence_length, embed_size_per_head)`).
+
+ Contains pre-computed hidden-states (key and values in the attention blocks) of the decoder that can be
+ used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ past_key_values: List[tf.Tensor] | None = None
+ decoder_hidden_states: Tuple[tf.Tensor] | None = None
+ decoder_attentions: Tuple[tf.Tensor] | None = None
+ cross_attentions: Tuple[tf.Tensor] | None = None
+ encoder_last_hidden_state: tf.Tensor | None = None
+ encoder_hidden_states: Tuple[tf.Tensor] | None = None
+ encoder_attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFNextSentencePredictorOutput(ModelOutput):
+ """
+ Base class for outputs of models predicting if two sentences are consecutive or not.
+
+ Args:
+ loss (`tf.Tensor` of shape `(n,)`, *optional*, where n is the number of non-masked labels, returned when `next_sentence_label` is provided):
+ Next sentence prediction loss.
+ logits (`tf.Tensor` of shape `(batch_size, 2)`):
+ Prediction scores of the next sequence prediction (classification) head (scores of True/False continuation
+ before SoftMax).
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFSequenceClassifierOutput(ModelOutput):
+ """
+ Base class for outputs of sentence classification models.
+
+ Args:
+ loss (`tf.Tensor` of shape `(batch_size, )`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`tf.Tensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFSeq2SeqSequenceClassifierOutput(ModelOutput):
+ """
+ Base class for outputs of sequence-to-sequence sentence classification models.
+
+ Args:
+ loss (`tf.Tensor` of shape `(1,)`, *optional*, returned when `label` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`tf.Tensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ past_key_values (`List[tf.Tensor]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ List of `tf.Tensor` of length `config.n_layers`, with each tensor of shape `(2, batch_size, num_heads,
+ sequence_length, embed_size_per_head)`).
+
+ Contains pre-computed hidden-states (key and values in the attention blocks) of the decoder that can be
+ used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`
+ encoder_last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ past_key_values: List[tf.Tensor] | None = None
+ decoder_hidden_states: Tuple[tf.Tensor] | None = None
+ decoder_attentions: Tuple[tf.Tensor] | None = None
+ cross_attentions: Tuple[tf.Tensor] | None = None
+ encoder_last_hidden_state: tf.Tensor | None = None
+ encoder_hidden_states: Tuple[tf.Tensor] | None = None
+ encoder_attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFSemanticSegmenterOutput(ModelOutput):
+ """
+ Base class for outputs of semantic segmentation models.
+
+ Args:
+ loss (`tf.Tensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`tf.Tensor` of shape `(batch_size, config.num_labels, logits_height, logits_width)`):
+ Classification scores for each pixel.
+
+
+
+ The logits returned do not necessarily have the same size as the `pixel_values` passed as inputs. This is
+ to avoid doing two interpolations and lose some quality when a user needs to resize the logits to the
+ original image size as post-processing. You should always check your logits shape and resize as needed.
+
+
+
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings, if the model has an embedding layer, + one for
+ the output of each layer) of shape `(batch_size, patch_size, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, patch_size, sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFSemanticSegmenterOutputWithNoAttention(ModelOutput):
+ """
+ Base class for outputs of semantic segmentation models that do not output attention scores.
+
+ Args:
+ loss (`tf.Tensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`tf.Tensor` of shape `(batch_size, config.num_labels, logits_height, logits_width)`):
+ Classification scores for each pixel.
+
+
+
+ The logits returned do not necessarily have the same size as the `pixel_values` passed as inputs. This is
+ to avoid doing two interpolations and lose some quality when a user needs to resize the logits to the
+ original image size as post-processing. You should always check your logits shape and resize as needed.
+
+
+
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings, if the model has an embedding layer, + one for
+ the output of each layer) of shape `(batch_size, patch_size, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFImageClassifierOutput(ModelOutput):
+ """
+ Base class for outputs of image classification models.
+
+ Args:
+ loss (`tf.Tensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`tf.Tensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings, if the model has an embedding layer, + one for
+ the output of each stage) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states (also called
+ feature maps) of the model at the output of each stage.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, patch_size, sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFMultipleChoiceModelOutput(ModelOutput):
+ """
+ Base class for outputs of multiple choice models.
+
+ Args:
+ loss (`tf.Tensor` of shape *(batch_size, )*, *optional*, returned when `labels` is provided):
+ Classification loss.
+ logits (`tf.Tensor` of shape `(batch_size, num_choices)`):
+ *num_choices* is the second dimension of the input tensors. (see *input_ids* above).
+
+ Classification scores (before SoftMax).
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFTokenClassifierOutput(ModelOutput):
+ """
+ Base class for outputs of token classification models.
+
+ Args:
+ loss (`tf.Tensor` of shape `(n,)`, *optional*, where n is the number of unmasked labels, returned when `labels` is provided) :
+ Classification loss.
+ logits (`tf.Tensor` of shape `(batch_size, sequence_length, config.num_labels)`):
+ Classification scores (before SoftMax).
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFQuestionAnsweringModelOutput(ModelOutput):
+ """
+ Base class for outputs of question answering models.
+
+ Args:
+ loss (`tf.Tensor` of shape `(batch_size, )`, *optional*, returned when `start_positions` and `end_positions` are provided):
+ Total span extraction loss is the sum of a Cross-Entropy for the start and end positions.
+ start_logits (`tf.Tensor` of shape `(batch_size, sequence_length)`):
+ Span-start scores (before SoftMax).
+ end_logits (`tf.Tensor` of shape `(batch_size, sequence_length)`):
+ Span-end scores (before SoftMax).
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: tf.Tensor | None = None
+ start_logits: Optional[tf.Tensor] = None
+ end_logits: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFSeq2SeqQuestionAnsweringModelOutput(ModelOutput):
+ """
+ Base class for outputs of sequence-to-sequence question answering models.
+
+ Args:
+ loss (`tf.Tensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Total span extraction loss is the sum of a Cross-Entropy for the start and end positions.
+ start_logits (`tf.Tensor` of shape `(batch_size, sequence_length)`):
+ Span-start scores (before SoftMax).
+ end_logits (`tf.Tensor` of shape `(batch_size, sequence_length)`):
+ Span-end scores (before SoftMax).
+ past_key_values (`List[tf.Tensor]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ List of `tf.Tensor` of length `config.n_layers`, with each tensor of shape `(2, batch_size, num_heads,
+ sequence_length, embed_size_per_head)`).
+
+ Contains pre-computed hidden-states (key and values in the attention blocks) of the decoder that can be
+ used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
+ decoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ encoder_last_hidden_state (`tf.Tensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
+ encoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ """
+
+ loss: tf.Tensor | None = None
+ start_logits: Optional[tf.Tensor] = None
+ end_logits: Optional[tf.Tensor] = None
+ past_key_values: List[tf.Tensor] | None = None
+ decoder_hidden_states: Tuple[tf.Tensor] | None = None
+ decoder_attentions: Tuple[tf.Tensor] | None = None
+ encoder_last_hidden_state: tf.Tensor | None = None
+ encoder_hidden_states: Tuple[tf.Tensor] | None = None
+ encoder_attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFSequenceClassifierOutputWithPast(ModelOutput):
+ """
+ Base class for outputs of sentence classification models.
+
+ Args:
+ loss (`tf.Tensor` of shape `(batch_size, )`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`tf.Tensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ past_key_values (`List[tf.Tensor]`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ List of `tf.Tensor` of length `config.n_layers`, with each tensor of shape `(2, batch_size, num_heads,
+ sequence_length, embed_size_per_head)`).
+
+ Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ past_key_values: List[tf.Tensor] | None = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+@dataclass
+class TFImageClassifierOutputWithNoAttention(ModelOutput):
+ """
+ Base class for outputs of image classification models.
+
+ Args:
+ loss (`tf.Tensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ logits (`tf.Tensor` of shape `(batch_size, config.num_labels)`):
+ Classification (or regression if config.num_labels==1) scores (before SoftMax).
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings, if the model has an embedding layer, + one for
+ the output of each stage) of shape `(batch_size, num_channels, height, width)`. Hidden-states (also called
+ feature maps) of the model at the output of each stage.
+ """
+
+ loss: tf.Tensor | None = None
+ logits: Optional[tf.Tensor] = None
+ hidden_states: Optional[Tuple[tf.Tensor, ...]] = None
+
+
+@dataclass
+class TFMaskedImageModelingOutput(ModelOutput):
+ """
+ Base class for outputs of masked image completion / in-painting models.
+
+ Args:
+ loss (`tf.Tensor` of shape `(1,)`, *optional*, returned when `bool_masked_pos` is provided):
+ Reconstruction loss.
+ reconstruction (`tf.Tensor` of shape `(batch_size, num_channels, height, width)`):
+ Reconstructed / completed images.
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when
+ `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings, if the model has an embedding layer, + one for
+ the output of each stage) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states (also called
+ feature maps) of the model at the output of each stage.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when
+ `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, patch_size, sequence_length)`.
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: tf.Tensor | None = None
+ reconstruction: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+ @property
+ def logits(self):
+ warnings.warn(
+ "logits attribute is deprecated and will be removed in version 5 of Transformers."
+ " Please use the reconstruction attribute to retrieve the final output instead.",
+ FutureWarning,
+ )
+ return self.reconstruction
diff --git a/docs/transformers/src/transformers/modeling_tf_pytorch_utils.py b/docs/transformers/src/transformers/modeling_tf_pytorch_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..84a6ddaebcc46c12a2a08e4612fde2f4f20cf648
--- /dev/null
+++ b/docs/transformers/src/transformers/modeling_tf_pytorch_utils.py
@@ -0,0 +1,671 @@
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch - TF 2.0 general utilities."""
+
+import os
+import re
+
+import numpy
+
+from .utils import (
+ ExplicitEnum,
+ expand_dims,
+ is_numpy_array,
+ is_safetensors_available,
+ is_torch_tensor,
+ logging,
+ reshape,
+ squeeze,
+ tensor_size,
+)
+from .utils import transpose as transpose_func
+
+
+if is_safetensors_available():
+ from safetensors import safe_open
+
+
+logger = logging.get_logger(__name__)
+
+
+class TransposeType(ExplicitEnum):
+ """
+ Possible ...
+ """
+
+ NO = "no"
+ SIMPLE = "simple"
+ CONV1D = "conv1d"
+ CONV2D = "conv2d"
+
+
+def convert_tf_weight_name_to_pt_weight_name(
+ tf_name, start_prefix_to_remove="", tf_weight_shape=None, name_scope=None
+):
+ """
+ Convert a TF 2.0 model variable name in a pytorch model weight name.
+
+ Conventions for TF2.0 scopes -> PyTorch attribute names conversions:
+
+ - '$1___$2' is replaced by $2 (can be used to duplicate or remove layers in TF2.0 vs PyTorch)
+ - '_._' is replaced by a new level separation (can be used to convert TF2.0 lists in PyTorch nn.ModulesList)
+
+ return tuple with:
+
+ - pytorch model weight name
+ - transpose: `TransposeType` member indicating whether and how TF2.0 and PyTorch weights matrices should be
+ transposed with regards to each other
+ """
+ if name_scope is not None:
+ if not tf_name.startswith(name_scope) and "final_logits_bias" not in tf_name:
+ raise ValueError(
+ f"Weight name {tf_name} does not start with name_scope {name_scope}. This is an internal error "
+ "in Transformers, so (unless you were doing something really evil) please open an issue to report it!"
+ )
+ tf_name = tf_name[len(name_scope) :]
+ tf_name = tf_name.lstrip("/")
+ tf_name = tf_name.replace(":0", "") # device ids
+ tf_name = re.sub(
+ r"/[^/]*___([^/]*)/", r"/\1/", tf_name
+ ) # '$1___$2' is replaced by $2 (can be used to duplicate or remove layers in TF2.0 vs PyTorch)
+ tf_name = tf_name.replace(
+ "_._", "/"
+ ) # '_._' is replaced by a level separation (can be used to convert TF2.0 lists in PyTorch nn.ModulesList)
+ tf_name = re.sub(r"//+", "/", tf_name) # Remove empty levels at the end
+ tf_name = tf_name.split("/") # Convert from TF2.0 '/' separators to PyTorch '.' separators
+ # Some weights have a single name without "/" such as final_logits_bias in BART
+ if len(tf_name) > 1:
+ tf_name = tf_name[1:] # Remove level zero
+
+ tf_weight_shape = list(tf_weight_shape)
+
+ # When should we transpose the weights
+ if tf_name[-1] == "kernel" and tf_weight_shape is not None and len(tf_weight_shape) == 4:
+ transpose = TransposeType.CONV2D
+ elif tf_name[-1] == "kernel" and tf_weight_shape is not None and len(tf_weight_shape) == 3:
+ transpose = TransposeType.CONV1D
+ elif bool(
+ tf_name[-1] in ["kernel", "pointwise_kernel", "depthwise_kernel"]
+ or "emb_projs" in tf_name
+ or "out_projs" in tf_name
+ ):
+ transpose = TransposeType.SIMPLE
+ else:
+ transpose = TransposeType.NO
+
+ # Convert standard TF2.0 names in PyTorch names
+ if tf_name[-1] == "kernel" or tf_name[-1] == "embeddings" or tf_name[-1] == "gamma":
+ tf_name[-1] = "weight"
+ if tf_name[-1] == "beta":
+ tf_name[-1] = "bias"
+
+ # The SeparableConv1D TF layer contains two weights that are translated to PyTorch Conv1D here
+ if tf_name[-1] == "pointwise_kernel" or tf_name[-1] == "depthwise_kernel":
+ tf_name[-1] = tf_name[-1].replace("_kernel", ".weight")
+
+ # Remove prefix if needed
+ tf_name = ".".join(tf_name)
+ if start_prefix_to_remove:
+ tf_name = tf_name.replace(start_prefix_to_remove, "", 1)
+
+ return tf_name, transpose
+
+
+def apply_transpose(transpose: TransposeType, weight, match_shape=None, pt_to_tf=True):
+ """
+ Apply a transpose to some weight then tries to reshape the weight to the same shape as a given shape, all in a
+ framework agnostic way.
+ """
+ if transpose is TransposeType.CONV2D:
+ # Conv2D weight:
+ # PT: (num_out_channel, num_in_channel, kernel[0], kernel[1])
+ # -> TF: (kernel[0], kernel[1], num_in_channel, num_out_channel)
+ axes = (2, 3, 1, 0) if pt_to_tf else (3, 2, 0, 1)
+ weight = transpose_func(weight, axes=axes)
+ elif transpose is TransposeType.CONV1D:
+ # Conv1D weight:
+ # PT: (num_out_channel, num_in_channel, kernel)
+ # -> TF: (kernel, num_in_channel, num_out_channel)
+ weight = transpose_func(weight, axes=(2, 1, 0))
+ elif transpose is TransposeType.SIMPLE:
+ weight = transpose_func(weight)
+
+ if match_shape is None:
+ return weight
+
+ if len(match_shape) < len(weight.shape):
+ weight = squeeze(weight)
+ elif len(match_shape) > len(weight.shape):
+ weight = expand_dims(weight, axis=0)
+
+ if list(match_shape) != list(weight.shape):
+ try:
+ weight = reshape(weight, match_shape)
+ except AssertionError as e:
+ e.args += (match_shape, match_shape)
+ raise e
+
+ return weight
+
+
+#####################
+# PyTorch => TF 2.0 #
+#####################
+
+
+def load_pytorch_checkpoint_in_tf2_model(
+ tf_model,
+ pytorch_checkpoint_path,
+ tf_inputs=None,
+ allow_missing_keys=False,
+ output_loading_info=False,
+ _prefix=None,
+ tf_to_pt_weight_rename=None,
+):
+ """Load pytorch checkpoints in a TF 2.0 model"""
+ try:
+ import tensorflow as tf # noqa: F401
+ import torch # noqa: F401
+ from safetensors.torch import load_file as safe_load_file # noqa: F401
+ except ImportError:
+ logger.error(
+ "Loading a PyTorch model in TensorFlow, requires both PyTorch and TensorFlow to be installed. Please see "
+ "https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
+ )
+ raise
+
+ # Treats a single file as a collection of shards with 1 shard.
+ if isinstance(pytorch_checkpoint_path, str):
+ pytorch_checkpoint_path = [pytorch_checkpoint_path]
+
+ # Loads all shards into a single state dictionary
+ pt_state_dict = {}
+ for path in pytorch_checkpoint_path:
+ pt_path = os.path.abspath(path)
+ logger.info(f"Loading PyTorch weights from {pt_path}")
+ if pt_path.endswith(".safetensors"):
+ state_dict = safe_load_file(pt_path)
+ else:
+ state_dict = torch.load(pt_path, map_location="cpu", weights_only=True)
+
+ pt_state_dict.update(state_dict)
+
+ logger.info(f"PyTorch checkpoint contains {sum(t.numel() for t in pt_state_dict.values()):,} parameters")
+
+ return load_pytorch_weights_in_tf2_model(
+ tf_model,
+ pt_state_dict,
+ tf_inputs=tf_inputs,
+ allow_missing_keys=allow_missing_keys,
+ output_loading_info=output_loading_info,
+ _prefix=_prefix,
+ tf_to_pt_weight_rename=tf_to_pt_weight_rename,
+ )
+
+
+def load_pytorch_model_in_tf2_model(tf_model, pt_model, tf_inputs=None, allow_missing_keys=False):
+ """Load pytorch checkpoints in a TF 2.0 model"""
+ pt_state_dict = pt_model.state_dict()
+
+ return load_pytorch_weights_in_tf2_model(
+ tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys
+ )
+
+
+def load_pytorch_weights_in_tf2_model(
+ tf_model,
+ pt_state_dict,
+ tf_inputs=None,
+ allow_missing_keys=False,
+ output_loading_info=False,
+ _prefix=None,
+ tf_to_pt_weight_rename=None,
+):
+ """Load pytorch state_dict in a TF 2.0 model."""
+ try:
+ import tensorflow as tf # noqa: F401
+ import torch # noqa: F401
+ except ImportError:
+ logger.error(
+ "Loading a PyTorch model in TensorFlow, requires both PyTorch and TensorFlow to be installed. Please see "
+ "https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
+ )
+ raise
+
+ # Numpy doesn't understand bfloat16, so upcast to a dtype that doesn't lose precision
+ pt_state_dict = {
+ k: v.numpy() if v.dtype != torch.bfloat16 else v.float().numpy() for k, v in pt_state_dict.items()
+ }
+ return load_pytorch_state_dict_in_tf2_model(
+ tf_model,
+ pt_state_dict,
+ tf_inputs=tf_inputs,
+ allow_missing_keys=allow_missing_keys,
+ output_loading_info=output_loading_info,
+ _prefix=_prefix,
+ tf_to_pt_weight_rename=tf_to_pt_weight_rename,
+ )
+
+
+def _log_key_warnings(missing_keys, unexpected_keys, mismatched_keys, class_name):
+ if len(unexpected_keys) > 0:
+ logger.warning(
+ "Some weights of the PyTorch model were not used when initializing the TF 2.0 model"
+ f" {class_name}: {unexpected_keys}\n- This IS expected if you are initializing"
+ f" {class_name} from a PyTorch model trained on another task or with another architecture"
+ " (e.g. initializing a TFBertForSequenceClassification model from a BertForPreTraining model).\n- This IS"
+ f" NOT expected if you are initializing {class_name} from a PyTorch model that you expect"
+ " to be exactly identical (e.g. initializing a TFBertForSequenceClassification model from a"
+ " BertForSequenceClassification model)."
+ )
+ else:
+ logger.warning(f"All PyTorch model weights were used when initializing {class_name}.\n")
+ if len(missing_keys) > 0:
+ logger.warning(
+ f"Some weights or buffers of the TF 2.0 model {class_name} were not initialized from the"
+ f" PyTorch model and are newly initialized: {missing_keys}\nYou should probably TRAIN this model on a"
+ " down-stream task to be able to use it for predictions and inference."
+ )
+ else:
+ logger.warning(
+ f"All the weights of {class_name} were initialized from the PyTorch model.\n"
+ "If your task is similar to the task the model of the checkpoint was trained on, "
+ f"you can already use {class_name} for predictions without further training."
+ )
+
+ if len(mismatched_keys) > 0:
+ mismatched_warning = "\n".join(
+ [
+ f"- {key}: found shape {shape1} in the checkpoint and {shape2} in the model instantiated"
+ for key, shape1, shape2 in mismatched_keys
+ ]
+ )
+ logger.warning(
+ f"Some weights of {class_name} were not initialized from the model checkpoint"
+ f" are newly initialized because the shapes did not"
+ f" match:\n{mismatched_warning}\nYou should probably TRAIN this model on a down-stream task to be able"
+ " to use it for predictions and inference."
+ )
+
+
+def load_pytorch_state_dict_in_tf2_model(
+ tf_model,
+ pt_state_dict,
+ tf_inputs=None,
+ allow_missing_keys=False,
+ output_loading_info=False,
+ _prefix=None,
+ tf_to_pt_weight_rename=None,
+ ignore_mismatched_sizes=False,
+ skip_logger_warnings=False,
+):
+ """Load a pytorch state_dict in a TF 2.0 model. pt_state_dict can be either an actual dict or a lazy-loading
+ safetensors archive created with the safe_open() function."""
+ import tensorflow as tf
+
+ if tf_inputs is None:
+ tf_inputs = tf_model.dummy_inputs
+
+ if _prefix is None:
+ _prefix = ""
+ if tf_inputs:
+ with tf.name_scope(_prefix):
+ tf_model(tf_inputs, training=False) # Make sure model is built
+ # Convert old format to new format if needed from a PyTorch state_dict
+ tf_keys_to_pt_keys = {}
+ for key in pt_state_dict.keys():
+ new_key = None
+ if "gamma" in key:
+ new_key = key.replace("gamma", "weight")
+ if "beta" in key:
+ new_key = key.replace("beta", "bias")
+ if "running_var" in key:
+ new_key = key.replace("running_var", "moving_variance")
+ if "running_mean" in key:
+ new_key = key.replace("running_mean", "moving_mean")
+
+ # New `weight_norm` from https://github.com/huggingface/transformers/pull/24030
+ key_components = key.split(".")
+ name = None
+ if key_components[-3::2] == ["parametrizations", "original0"]:
+ name = key_components[-2] + "_g"
+ elif key_components[-3::2] == ["parametrizations", "original1"]:
+ name = key_components[-2] + "_v"
+ if name is not None:
+ key_components = key_components[:-3] + [name]
+ new_key = ".".join(key_components)
+
+ if new_key is None:
+ new_key = key
+ tf_keys_to_pt_keys[new_key] = key
+
+ # Matt: All TF models store the actual model stem in a MainLayer class, including the base model.
+ # In PT, the derived models (with heads) use the base model class as the stem instead,
+ # and there is no MainLayer class. This means that TF base classes have one
+ # extra layer in their weight names, corresponding to the MainLayer class. This code block compensates for that.
+ start_prefix_to_remove = ""
+ if not any(s.startswith(tf_model.base_model_prefix) for s in tf_keys_to_pt_keys.keys()):
+ start_prefix_to_remove = tf_model.base_model_prefix + "."
+
+ symbolic_weights = tf_model.trainable_weights + tf_model.non_trainable_weights
+ tf_loaded_numel = 0
+ all_pytorch_weights = set(tf_keys_to_pt_keys.keys())
+ missing_keys = []
+ mismatched_keys = []
+ is_safetensor_archive = hasattr(pt_state_dict, "get_tensor")
+ for symbolic_weight in symbolic_weights:
+ sw_name = symbolic_weight.name
+ name, transpose = convert_tf_weight_name_to_pt_weight_name(
+ sw_name,
+ start_prefix_to_remove=start_prefix_to_remove,
+ tf_weight_shape=symbolic_weight.shape,
+ name_scope=_prefix,
+ )
+ if tf_to_pt_weight_rename is not None:
+ aliases = tf_to_pt_weight_rename(name) # Is a tuple to account for possible name aliasing
+ for alias in aliases: # The aliases are in priority order, take the first one that matches
+ if alias in tf_keys_to_pt_keys:
+ name = alias
+ break
+ else:
+ # If none of the aliases match, just use the first one (it'll be reported as missing)
+ name = aliases[0]
+
+ # Find associated numpy array in pytorch model state dict
+ if name not in tf_keys_to_pt_keys:
+ if allow_missing_keys:
+ missing_keys.append(name)
+ continue
+ elif tf_model._keys_to_ignore_on_load_missing is not None:
+ # authorized missing keys don't have to be loaded
+ if any(re.search(pat, name) is not None for pat in tf_model._keys_to_ignore_on_load_missing):
+ continue
+ raise AttributeError(f"{name} not found in PyTorch model")
+ state_dict_name = tf_keys_to_pt_keys[name]
+ if is_safetensor_archive:
+ array = pt_state_dict.get_tensor(state_dict_name)
+ else:
+ array = pt_state_dict[state_dict_name]
+ try:
+ array = apply_transpose(transpose, array, symbolic_weight.shape)
+ except tf.errors.InvalidArgumentError as e:
+ if not ignore_mismatched_sizes:
+ error_msg = str(e)
+ error_msg += (
+ "\n\tYou may consider adding `ignore_mismatched_sizes=True` in the model `from_pretrained` method."
+ )
+ raise tf.errors.InvalidArgumentError(error_msg)
+ else:
+ mismatched_keys.append((name, array.shape, symbolic_weight.shape))
+ continue
+
+ tf_loaded_numel += tensor_size(array)
+
+ symbolic_weight.assign(tf.cast(array, symbolic_weight.dtype))
+ del array # Immediately free memory to keep peak usage as low as possible
+ all_pytorch_weights.discard(name)
+
+ logger.info(f"Loaded {tf_loaded_numel:,} parameters in the TF 2.0 model.")
+
+ unexpected_keys = list(all_pytorch_weights)
+
+ if tf_model._keys_to_ignore_on_load_missing is not None:
+ for pat in tf_model._keys_to_ignore_on_load_missing:
+ missing_keys = [k for k in missing_keys if re.search(pat, k) is None]
+ if tf_model._keys_to_ignore_on_load_unexpected is not None:
+ for pat in tf_model._keys_to_ignore_on_load_unexpected:
+ unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None]
+ if not skip_logger_warnings:
+ _log_key_warnings(missing_keys, unexpected_keys, mismatched_keys, class_name=tf_model.__class__.__name__)
+
+ if output_loading_info:
+ loading_info = {
+ "missing_keys": missing_keys,
+ "unexpected_keys": unexpected_keys,
+ "mismatched_keys": mismatched_keys,
+ }
+ return tf_model, loading_info
+
+ return tf_model
+
+
+def load_sharded_pytorch_safetensors_in_tf2_model(
+ tf_model,
+ safetensors_shards,
+ tf_inputs=None,
+ allow_missing_keys=False,
+ output_loading_info=False,
+ _prefix=None,
+ tf_to_pt_weight_rename=None,
+ ignore_mismatched_sizes=False,
+):
+ all_loading_infos = []
+ for shard in safetensors_shards:
+ with safe_open(shard, framework="tf") as safetensors_archive:
+ tf_model, loading_info = load_pytorch_state_dict_in_tf2_model(
+ tf_model,
+ safetensors_archive,
+ tf_inputs=tf_inputs,
+ allow_missing_keys=allow_missing_keys,
+ output_loading_info=True,
+ _prefix=_prefix,
+ tf_to_pt_weight_rename=tf_to_pt_weight_rename,
+ ignore_mismatched_sizes=ignore_mismatched_sizes,
+ skip_logger_warnings=True, # We will emit merged warnings at the end
+ )
+ all_loading_infos.append(loading_info)
+ # Now we just need to merge the loading info
+ # Keys are missing only if they're missing in *every* shard
+ missing_keys = sorted(set.intersection(*[set(info["missing_keys"]) for info in all_loading_infos]))
+ # Keys are unexpected/mismatched if they're unexpected/mismatched in *any* shard
+ unexpected_keys = sum([info["unexpected_keys"] for info in all_loading_infos], [])
+ mismatched_keys = sum([info["mismatched_keys"] for info in all_loading_infos], [])
+
+ _log_key_warnings(missing_keys, unexpected_keys, mismatched_keys, class_name=tf_model.__class__.__name__)
+
+ if output_loading_info:
+ loading_info = {
+ "missing_keys": missing_keys,
+ "unexpected_keys": unexpected_keys,
+ "mismatched_keys": mismatched_keys,
+ }
+ return tf_model, loading_info
+
+ return tf_model
+
+
+#####################
+# TF 2.0 => PyTorch #
+#####################
+
+
+def load_tf2_checkpoint_in_pytorch_model(
+ pt_model, tf_checkpoint_path, tf_inputs=None, allow_missing_keys=False, output_loading_info=False
+):
+ """
+ Load TF 2.0 HDF5 checkpoint in a PyTorch model We use HDF5 to easily do transfer learning (see
+ https://github.com/tensorflow/tensorflow/blob/ee16fcac960ae660e0e4496658a366e2f745e1f0/tensorflow/python/keras/engine/network.py#L1352-L1357).
+ """
+ try:
+ import tensorflow as tf # noqa: F401
+ import torch # noqa: F401
+ except ImportError:
+ logger.error(
+ "Loading a TensorFlow model in PyTorch, requires both PyTorch and TensorFlow to be installed. Please see "
+ "https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
+ )
+ raise
+
+ import transformers
+
+ from .modeling_tf_utils import load_tf_weights
+
+ logger.info(f"Loading TensorFlow weights from {tf_checkpoint_path}")
+
+ # Instantiate and load the associated TF 2.0 model
+ tf_model_class_name = "TF" + pt_model.__class__.__name__ # Add "TF" at the beginning
+ tf_model_class = getattr(transformers, tf_model_class_name)
+ tf_model = tf_model_class(pt_model.config)
+
+ if tf_inputs is None:
+ tf_inputs = tf_model.dummy_inputs
+
+ if tf_inputs is not None:
+ tf_model(tf_inputs, training=False) # Make sure model is built
+
+ load_tf_weights(tf_model, tf_checkpoint_path)
+
+ return load_tf2_model_in_pytorch_model(
+ pt_model, tf_model, allow_missing_keys=allow_missing_keys, output_loading_info=output_loading_info
+ )
+
+
+def load_tf2_model_in_pytorch_model(pt_model, tf_model, allow_missing_keys=False, output_loading_info=False):
+ """Load TF 2.0 model in a pytorch model"""
+ weights = tf_model.weights
+
+ return load_tf2_weights_in_pytorch_model(
+ pt_model, weights, allow_missing_keys=allow_missing_keys, output_loading_info=output_loading_info
+ )
+
+
+def load_tf2_weights_in_pytorch_model(pt_model, tf_weights, allow_missing_keys=False, output_loading_info=False):
+ """Load TF2.0 symbolic weights in a PyTorch model"""
+ try:
+ import tensorflow as tf # noqa: F401
+ import torch # noqa: F401
+ except ImportError:
+ logger.error(
+ "Loading a TensorFlow model in PyTorch, requires both PyTorch and TensorFlow to be installed. Please see "
+ "https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
+ )
+ raise
+
+ tf_state_dict = {tf_weight.name: tf_weight.numpy() for tf_weight in tf_weights}
+ return load_tf2_state_dict_in_pytorch_model(
+ pt_model, tf_state_dict, allow_missing_keys=allow_missing_keys, output_loading_info=output_loading_info
+ )
+
+
+def load_tf2_state_dict_in_pytorch_model(pt_model, tf_state_dict, allow_missing_keys=False, output_loading_info=False):
+ import torch
+
+ new_pt_params_dict = {}
+ current_pt_params_dict = dict(pt_model.named_parameters())
+
+ # Make sure we are able to load PyTorch base models as well as derived models (with heads)
+ # TF models always have a prefix, some of PyTorch models (base ones) don't
+ start_prefix_to_remove = ""
+ if not any(s.startswith(pt_model.base_model_prefix) for s in current_pt_params_dict.keys()):
+ start_prefix_to_remove = pt_model.base_model_prefix + "."
+
+ # Build a map from potential PyTorch weight names to TF 2.0 Variables
+ tf_weights_map = {}
+ for name, tf_weight in tf_state_dict.items():
+ pt_name, transpose = convert_tf_weight_name_to_pt_weight_name(
+ name, start_prefix_to_remove=start_prefix_to_remove, tf_weight_shape=tf_weight.shape
+ )
+ tf_weights_map[pt_name] = (tf_weight, transpose)
+
+ all_tf_weights = set(tf_weights_map.keys())
+ loaded_pt_weights_data_ptr = {}
+ missing_keys_pt = []
+ for pt_weight_name, pt_weight in current_pt_params_dict.items():
+ # Handle PyTorch shared weight ()not duplicated in TF 2.0
+ if pt_weight.data_ptr() in loaded_pt_weights_data_ptr:
+ new_pt_params_dict[pt_weight_name] = loaded_pt_weights_data_ptr[pt_weight.data_ptr()]
+ continue
+
+ pt_weight_name_to_check = pt_weight_name
+ # New `weight_norm` from https://github.com/huggingface/transformers/pull/24030
+ key_components = pt_weight_name.split(".")
+ name = None
+ if key_components[-3::2] == ["parametrizations", "original0"]:
+ name = key_components[-2] + "_g"
+ elif key_components[-3::2] == ["parametrizations", "original1"]:
+ name = key_components[-2] + "_v"
+ if name is not None:
+ key_components = key_components[:-3] + [name]
+ pt_weight_name_to_check = ".".join(key_components)
+
+ # Find associated numpy array in pytorch model state dict
+ if pt_weight_name_to_check not in tf_weights_map:
+ if allow_missing_keys:
+ missing_keys_pt.append(pt_weight_name)
+ continue
+
+ raise AttributeError(f"{pt_weight_name} not found in TF 2.0 model")
+
+ array, transpose = tf_weights_map[pt_weight_name_to_check]
+
+ array = apply_transpose(transpose, array, pt_weight.shape, pt_to_tf=False)
+
+ if numpy.isscalar(array):
+ array = numpy.array(array)
+ if not is_torch_tensor(array) and not is_numpy_array(array):
+ array = array.numpy()
+ if is_numpy_array(array):
+ # Convert to torch tensor
+ array = torch.from_numpy(array)
+
+ new_pt_params_dict[pt_weight_name] = array
+ loaded_pt_weights_data_ptr[pt_weight.data_ptr()] = array
+ all_tf_weights.discard(pt_weight_name)
+
+ missing_keys, unexpected_keys = pt_model.load_state_dict(new_pt_params_dict, strict=False)
+ missing_keys += missing_keys_pt
+
+ # Some models may have keys that are not in the state by design, removing them before needlessly warning
+ # the user.
+ if pt_model._keys_to_ignore_on_load_missing is not None:
+ for pat in pt_model._keys_to_ignore_on_load_missing:
+ missing_keys = [k for k in missing_keys if re.search(pat, k) is None]
+
+ if pt_model._keys_to_ignore_on_load_unexpected is not None:
+ for pat in pt_model._keys_to_ignore_on_load_unexpected:
+ unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None]
+
+ if len(unexpected_keys) > 0:
+ logger.warning(
+ "Some weights of the TF 2.0 model were not used when initializing the PyTorch model"
+ f" {pt_model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are initializing"
+ f" {pt_model.__class__.__name__} from a TF 2.0 model trained on another task or with another architecture"
+ " (e.g. initializing a BertForSequenceClassification model from a TFBertForPreTraining model).\n- This IS"
+ f" NOT expected if you are initializing {pt_model.__class__.__name__} from a TF 2.0 model that you expect"
+ " to be exactly identical (e.g. initializing a BertForSequenceClassification model from a"
+ " TFBertForSequenceClassification model)."
+ )
+ else:
+ logger.warning(f"All TF 2.0 model weights were used when initializing {pt_model.__class__.__name__}.\n")
+ if len(missing_keys) > 0:
+ logger.warning(
+ f"Some weights of {pt_model.__class__.__name__} were not initialized from the TF 2.0 model and are newly"
+ f" initialized: {missing_keys}\nYou should probably TRAIN this model on a down-stream task to be able to"
+ " use it for predictions and inference."
+ )
+ else:
+ logger.warning(
+ f"All the weights of {pt_model.__class__.__name__} were initialized from the TF 2.0 model.\n"
+ "If your task is similar to the task the model of the checkpoint was trained on, "
+ f"you can already use {pt_model.__class__.__name__} for predictions without further training."
+ )
+
+ logger.info(f"Weights or buffers not loaded from TF 2.0 model: {all_tf_weights}")
+
+ if output_loading_info:
+ loading_info = {"missing_keys": missing_keys, "unexpected_keys": unexpected_keys}
+ return pt_model, loading_info
+
+ return pt_model
diff --git a/docs/transformers/src/transformers/modeling_tf_utils.py b/docs/transformers/src/transformers/modeling_tf_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..c0add5bb6672bf77ca0fca34a5bc194ab80f89f5
--- /dev/null
+++ b/docs/transformers/src/transformers/modeling_tf_utils.py
@@ -0,0 +1,3535 @@
+# coding=utf-8
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""TF general model utils."""
+
+from __future__ import annotations
+
+import functools
+import gc
+import inspect
+import json
+import os
+import pickle
+import re
+import warnings
+from collections.abc import Mapping
+from pathlib import Path
+from typing import TYPE_CHECKING, Any, Callable, Dict, List, Optional, Union
+
+import h5py
+import numpy as np
+import tensorflow as tf
+from packaging.version import parse
+
+from . import DataCollatorWithPadding, DefaultDataCollator
+from .activations_tf import get_tf_activation
+from .configuration_utils import PretrainedConfig
+from .dynamic_module_utils import custom_object_save
+from .generation import GenerationConfig, TFGenerationMixin
+from .tf_utils import (
+ convert_batch_encoding,
+ expand_1d,
+ load_attributes_from_hdf5_group,
+ save_attributes_to_hdf5_group,
+ shape_list,
+)
+from .utils import (
+ SAFE_WEIGHTS_INDEX_NAME,
+ SAFE_WEIGHTS_NAME,
+ TF2_WEIGHTS_INDEX_NAME,
+ TF2_WEIGHTS_NAME,
+ TF_WEIGHTS_NAME,
+ WEIGHTS_INDEX_NAME,
+ WEIGHTS_NAME,
+ ModelOutput,
+ PushToHubMixin,
+ cached_file,
+ download_url,
+ find_labels,
+ has_file,
+ is_offline_mode,
+ is_remote_url,
+ is_safetensors_available,
+ is_tf_symbolic_tensor,
+ logging,
+ requires_backends,
+ working_or_temp_dir,
+)
+from .utils.hub import convert_file_size_to_int, get_checkpoint_shard_files
+
+
+if is_safetensors_available():
+ from safetensors import safe_open
+ from safetensors.tensorflow import save_file as safe_save_file
+
+if TYPE_CHECKING:
+ from . import PreTrainedTokenizerBase
+
+logger = logging.get_logger(__name__)
+
+if "TF_USE_LEGACY_KERAS" not in os.environ:
+ os.environ["TF_USE_LEGACY_KERAS"] = "1" # Compatibility fix to make sure tf.keras stays at Keras 2
+elif os.environ["TF_USE_LEGACY_KERAS"] != "1":
+ logger.warning(
+ "Transformers is only compatible with Keras 2, but you have explicitly set `TF_USE_LEGACY_KERAS` to `0`. "
+ "This may result in unexpected behaviour or errors if Keras 3 objects are passed to Transformers models."
+ )
+
+try:
+ import tf_keras as keras
+ from tf_keras import backend as K
+except (ModuleNotFoundError, ImportError):
+ import keras
+ from keras import backend as K
+
+ if parse(keras.__version__).major > 2:
+ raise ValueError(
+ "Your currently installed version of Keras is Keras 3, but this is not yet supported in "
+ "Transformers. Please install the backwards-compatible tf-keras package with "
+ "`pip install tf-keras`."
+ )
+
+
+tf_logger = tf.get_logger()
+
+TFModelInputType = Union[
+ List[tf.Tensor],
+ List[np.ndarray],
+ Dict[str, tf.Tensor],
+ Dict[str, np.ndarray],
+ tf.Tensor,
+ np.ndarray,
+]
+
+
+def dummy_loss(y_true, y_pred):
+ if y_pred.shape.rank <= 1:
+ return y_pred
+ else:
+ reduction_axes = list(range(1, y_pred.shape.rank))
+ return tf.reduce_mean(y_pred, axis=reduction_axes)
+
+
+class TFModelUtilsMixin:
+ """
+ A few utilities for `keras.Model`, to be used as a mixin.
+ """
+
+ def num_parameters(self, only_trainable: bool = False) -> int:
+ """
+ Get the number of (optionally, trainable) parameters in the model.
+
+ Args:
+ only_trainable (`bool`, *optional*, defaults to `False`):
+ Whether or not to return only the number of trainable parameters
+
+ Returns:
+ `int`: The number of parameters.
+ """
+ if only_trainable:
+ return int(sum(np.prod(w.shape.as_list()) for w in self.trainable_variables))
+ else:
+ return self.count_params()
+
+
+def keras_serializable(cls):
+ """
+ Decorate a Keras Layer class to support Keras serialization.
+
+ This is done by:
+
+ 1. Adding a `transformers_config` dict to the Keras config dictionary in `get_config` (called by Keras at
+ serialization time.
+ 2. Wrapping `__init__` to accept that `transformers_config` dict (passed by Keras at deserialization time) and
+ convert it to a config object for the actual layer initializer.
+ 3. Registering the class as a custom object in Keras (if the Tensorflow version supports this), so that it does not
+ need to be supplied in `custom_objects` in the call to `keras.models.load_model`.
+
+ Args:
+ cls (a `keras.layers.Layers subclass`):
+ Typically a `TF.MainLayer` class in this project, in general must accept a `config` argument to its
+ initializer.
+
+ Returns:
+ The same class object, with modifications for Keras deserialization.
+ """
+ initializer = cls.__init__
+
+ config_class = getattr(cls, "config_class", None)
+ if config_class is None:
+ raise AttributeError("Must set `config_class` to use @keras_serializable")
+
+ @functools.wraps(initializer)
+ def wrapped_init(self, *args, **kwargs):
+ config = args[0] if args and isinstance(args[0], PretrainedConfig) else kwargs.pop("config", None)
+
+ if isinstance(config, dict):
+ config = config_class.from_dict(config)
+ initializer(self, config, *args, **kwargs)
+ elif isinstance(config, PretrainedConfig):
+ if len(args) > 0:
+ initializer(self, *args, **kwargs)
+ else:
+ initializer(self, config, *args, **kwargs)
+ else:
+ raise ValueError("Must pass either `config` (PretrainedConfig) or `config` (dict)")
+
+ self._config = config
+ self._kwargs = kwargs
+
+ cls.__init__ = wrapped_init
+
+ if not hasattr(cls, "get_config"):
+ raise TypeError("Only use @keras_serializable on keras.layers.Layer subclasses")
+ if hasattr(cls.get_config, "_is_default"):
+
+ def get_config(self):
+ cfg = super(cls, self).get_config()
+ cfg["config"] = self._config.to_dict()
+ cfg.update(self._kwargs)
+ return cfg
+
+ cls.get_config = get_config
+
+ cls._keras_serializable = True
+ if hasattr(keras.utils, "register_keras_serializable"):
+ cls = keras.utils.register_keras_serializable()(cls)
+ return cls
+
+
+class TFCausalLanguageModelingLoss:
+ """
+ Loss function suitable for causal language modeling (CLM), that is, the task of guessing the next token.
+
+
+
+ Any label of -100 will be ignored (along with the corresponding logits) in the loss computation.
+
+
+ """
+
+ def hf_compute_loss(self, labels, logits):
+ loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction=keras.losses.Reduction.NONE)
+ if self.config.tf_legacy_loss:
+ # make sure only labels that are not equal to -100 affect the loss
+ active_loss = tf.not_equal(tf.reshape(labels, (-1,)), -100)
+ reduced_logits = tf.boolean_mask(tf.reshape(logits, (-1, shape_list(logits)[2])), active_loss)
+ labels = tf.boolean_mask(tf.reshape(labels, (-1,)), active_loss)
+ return loss_fn(labels, reduced_logits)
+
+ # Clip negative labels to zero here to avoid NaNs and errors - those positions will get masked later anyway
+ unmasked_loss = loss_fn(tf.nn.relu(labels), logits)
+ # make sure only labels that are not equal to -100 affect the loss
+ loss_mask = tf.cast(labels != -100, dtype=unmasked_loss.dtype)
+ masked_loss = unmasked_loss * loss_mask
+ reduced_masked_loss = tf.reduce_sum(masked_loss) / tf.reduce_sum(loss_mask)
+ return tf.reshape(reduced_masked_loss, (1,))
+
+
+class TFQuestionAnsweringLoss:
+ """
+ Loss function suitable for question answering.
+ """
+
+ def hf_compute_loss(self, labels, logits):
+ loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction=keras.losses.Reduction.NONE)
+ start_loss = loss_fn(labels["start_position"], logits[0])
+ end_loss = loss_fn(labels["end_position"], logits[1])
+
+ return (start_loss + end_loss) / 2.0
+
+
+class TFTokenClassificationLoss:
+ """
+ Loss function suitable for token classification.
+
+
+
+ Any label of -100 will be ignored (along with the corresponding logits) in the loss computation.
+
+
+ """
+
+ def hf_compute_loss(self, labels, logits):
+ loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction=keras.losses.Reduction.NONE)
+ if tf.executing_eagerly(): # Data-dependent conditionals are forbidden in XLA
+ if tf.math.reduce_any(labels == -1):
+ tf.print("Using `-1` to mask the loss for the token is deprecated. Please use `-100` instead.")
+
+ if self.config.tf_legacy_loss:
+ # make sure only labels that are not equal to -100
+ # are taken into account as loss
+ if tf.math.reduce_any(labels == -1):
+ tf.print("Using `-1` to mask the loss for the token is deprecated. Please use `-100` instead.")
+ active_loss = tf.reshape(labels, (-1,)) != -1
+ else:
+ active_loss = tf.reshape(labels, (-1,)) != -100
+ reduced_logits = tf.boolean_mask(tf.reshape(logits, (-1, shape_list(logits)[2])), active_loss)
+ labels = tf.boolean_mask(tf.reshape(labels, (-1,)), active_loss)
+
+ return loss_fn(labels, reduced_logits)
+
+ # Clip negative labels to zero here to avoid NaNs and errors - those positions will get masked later anyway
+ unmasked_loss = loss_fn(tf.nn.relu(labels), logits)
+ # make sure only labels that are not equal to -100 or -1
+ # are taken into account as loss
+ loss_mask = tf.cast(labels >= 0, dtype=unmasked_loss.dtype)
+ # Avoid possible division by zero later
+ # Masked positions will have a loss of NaN because -100 and -1 are not valid labels
+ masked_loss = unmasked_loss * loss_mask
+ reduced_masked_loss = tf.reduce_sum(masked_loss) / tf.reduce_sum(loss_mask)
+ return tf.reshape(reduced_masked_loss, (1,))
+
+
+class TFSequenceClassificationLoss:
+ """
+ Loss function suitable for sequence classification.
+ """
+
+ def hf_compute_loss(self, labels, logits):
+ if logits.shape.rank == 1 or logits.shape[1] == 1:
+ loss_fn = keras.losses.MeanSquaredError(reduction=keras.losses.Reduction.NONE)
+ if labels.shape.rank == 1:
+ # MeanSquaredError returns a scalar loss if the labels are 1D, so avoid that
+ labels = tf.expand_dims(labels, axis=-1)
+ else:
+ loss_fn = keras.losses.SparseCategoricalCrossentropy(
+ from_logits=True, reduction=keras.losses.Reduction.NONE
+ )
+
+ return loss_fn(labels, logits)
+
+
+class TFMultipleChoiceLoss:
+ """Loss function suitable for multiple choice tasks."""
+
+ def hf_compute_loss(self, labels, logits):
+ loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction=keras.losses.Reduction.NONE)
+ return loss_fn(labels, logits)
+
+
+class TFMaskedLanguageModelingLoss(TFCausalLanguageModelingLoss):
+ """
+ Loss function suitable for masked language modeling (MLM), that is, the task of guessing the masked tokens.
+
+
+
+ Any label of -100 will be ignored (along with the corresponding logits) in the loss computation.
+
+
+ """
+
+
+class TFNextSentencePredictionLoss:
+ """
+ Loss function suitable for next sentence prediction (NSP), that is, the task of guessing the next sentence.
+
+
+
+ Any label of -100 will be ignored (along with the corresponding logits) in the loss computation.
+
+
+ """
+
+ def hf_compute_loss(self, labels, logits):
+ loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction=keras.losses.Reduction.NONE)
+ if self.config.tf_legacy_loss:
+ # make sure only labels that are not equal to -100
+ # are taken into account as loss
+ next_sentence_active_loss = tf.not_equal(tf.reshape(labels, (-1,)), -100)
+ next_sentence_reduced_logits = tf.boolean_mask(tf.reshape(logits, (-1, 2)), next_sentence_active_loss)
+ next_sentence_label = tf.boolean_mask(tf.reshape(labels, (-1,)), next_sentence_active_loss)
+
+ return loss_fn(next_sentence_label, next_sentence_reduced_logits)
+
+ # make sure only labels that are not equal to -100
+ # are taken into account as loss
+
+ # Clip negative labels to zero here to avoid NaNs and errors - those positions will get masked later anyway
+ unmasked_ns_loss = loss_fn(y_true=tf.nn.relu(labels), y_pred=logits)
+ ns_loss_mask = tf.cast(labels != -100, dtype=unmasked_ns_loss.dtype)
+ # Just zero out samples where label is -100, no reduction
+ masked_ns_loss = unmasked_ns_loss * ns_loss_mask
+
+ return masked_ns_loss
+
+
+def booleans_processing(config, **kwargs):
+ """
+ Process the input booleans of each model.
+
+ Args:
+ config ([`PretrainedConfig`]):
+ The config of the running model.
+ **kwargs:
+ The boolean parameters
+
+ Returns:
+ A dictionary with the proper values for each boolean
+ """
+ final_booleans = {}
+
+ # Pure conv models (such as ConvNext) do not have `output_attentions`. If the signature has
+ # `output_attentions`, it will be present here in `kwargs`, even if unset (in that case, as `None`)
+ if "output_attentions" in kwargs:
+ final_booleans["output_attentions"] = (
+ kwargs["output_attentions"] if kwargs["output_attentions"] is not None else config.output_attentions
+ )
+ final_booleans["output_hidden_states"] = (
+ kwargs["output_hidden_states"] if kwargs["output_hidden_states"] is not None else config.output_hidden_states
+ )
+ final_booleans["return_dict"] = kwargs["return_dict"] if kwargs["return_dict"] is not None else config.return_dict
+
+ if "use_cache" in kwargs:
+ final_booleans["use_cache"] = (
+ kwargs["use_cache"] if kwargs["use_cache"] is not None else getattr(config, "use_cache", None)
+ )
+ return final_booleans
+
+
+def unpack_inputs(func):
+ """
+ Decorator that processes the inputs to a Keras layer, passing them to the layer as keyword arguments. This enables
+ downstream use of the inputs by their variable name, even if they arrive packed as a dictionary in the first input
+ (common case in Keras).
+
+ Args:
+ func (`callable`):
+ The callable function of the TensorFlow model.
+
+
+ Returns:
+ A callable that wraps the original `func` with the behavior described above.
+ """
+
+ original_signature = inspect.signature(func)
+
+ @functools.wraps(func)
+ def run_call_with_unpacked_inputs(self, *args, **kwargs):
+ # isolates the actual `**kwargs` for the decorated function
+ kwargs_call = {key: val for key, val in kwargs.items() if key not in dict(original_signature.parameters)}
+ fn_args_and_kwargs = {key: val for key, val in kwargs.items() if key not in kwargs_call}
+ fn_args_and_kwargs.update({"kwargs_call": kwargs_call})
+
+ # move any arg into kwargs, if they exist
+ fn_args_and_kwargs.update(dict(zip(func.__code__.co_varnames[1:], args)))
+
+ # Encoder Decoder models delegate the application of the configuration options to their inner models.
+ if "EncoderDecoder" in self.__class__.__name__:
+ config = None
+ else:
+ config = self.config
+
+ unpacked_inputs = input_processing(func, config, **fn_args_and_kwargs)
+ return func(self, **unpacked_inputs)
+
+ # Keras enforces the first layer argument to be passed, and checks it through `inspect.getfullargspec()`. This
+ # function does not follow wrapper chains (i.e. ignores `functools.wraps()`), meaning that without the line below
+ # Keras would attempt to check the first argument against the literal signature of the wrapper.
+ run_call_with_unpacked_inputs.__signature__ = original_signature
+
+ return run_call_with_unpacked_inputs
+
+
+def input_processing(func, config, **kwargs):
+ """
+ Process the input of each TensorFlow model including the booleans. In case of a list of symbolic inputs, each input
+ has to be named accordingly to the parameters name, i.e. `input_ids = keras.Input(shape=(128,), dtype='int32',
+ name="input_ids")` otherwise the order of the tensors will not be guaranteed during the training.
+
+ Args:
+ func (`callable`):
+ The callable function of the TensorFlow model.
+ config ([`PretrainedConfig`]):
+ The config of the running model.
+ **kwargs:
+ The inputs of the model.
+
+ Returns:
+ Two lists, one for the missing layers, and another one for the unexpected layers.
+ """
+ signature = dict(inspect.signature(func).parameters)
+ has_kwargs = bool(signature.pop("kwargs", None))
+ signature.pop("self", None)
+ parameter_names = list(signature.keys())
+ main_input_name = parameter_names[0]
+ main_input = kwargs.pop(main_input_name, None)
+ output = {}
+ allowed_types = (tf.Tensor, bool, int, ModelOutput, tuple, list, dict, np.ndarray)
+
+ if "inputs" in kwargs["kwargs_call"]:
+ warnings.warn(
+ "The `inputs` argument is deprecated and will be removed in a future version, use `input_ids` instead.",
+ FutureWarning,
+ )
+
+ output["input_ids"] = kwargs["kwargs_call"].pop("inputs")
+
+ if "decoder_cached_states" in kwargs["kwargs_call"]:
+ warnings.warn(
+ "The `decoder_cached_states` argument is deprecated and will be removed in a future version, use"
+ " `past_key_values` instead.",
+ FutureWarning,
+ )
+ output["past_key_values"] = kwargs["kwargs_call"].pop("decoder_cached_states")
+
+ if "past" in kwargs["kwargs_call"] and "past_key_values" in parameter_names:
+ warnings.warn(
+ "The `past` argument is deprecated and will be removed in a future version, use `past_key_values`"
+ " instead.",
+ FutureWarning,
+ )
+ kwargs["past_key_values"] = kwargs["kwargs_call"].pop("past")
+ elif "past_key_values" in kwargs["kwargs_call"] and "past" in parameter_names:
+ kwargs["past"] = kwargs["kwargs_call"].pop("past_key_values")
+
+ if has_kwargs:
+ output["kwargs"] = kwargs.pop("kwargs_call", {})
+ else:
+ if len(kwargs["kwargs_call"]) > 0:
+ raise ValueError(
+ "The following keyword arguments are not supported by this model:"
+ f" {list(kwargs['kwargs_call'].keys())}."
+ )
+ kwargs.pop("kwargs_call")
+
+ for k, v in kwargs.items():
+ if isinstance(v, allowed_types) or tf.is_tensor(v) or v is None:
+ output[k] = v
+ else:
+ raise ValueError(f"Data of type {type(v)} is not allowed only {allowed_types} is accepted for {k}.")
+
+ if isinstance(main_input, (tuple, list)):
+ for i, input in enumerate(main_input):
+ # EagerTensors don't allow to use the .name property so we check for a real Tensor
+ if is_tf_symbolic_tensor(input):
+ # Tensor names have always the pattern `name:id` then we check only the
+ # `name` part
+ tensor_name = input.name.split(":")[0]
+
+ if tensor_name in parameter_names:
+ output[tensor_name] = input
+ else:
+ output[parameter_names[i]] = input
+ elif isinstance(input, allowed_types) or input is None:
+ output[parameter_names[i]] = input
+ else:
+ raise ValueError(
+ f"Data of type {type(input)} is not allowed only {allowed_types} is accepted for"
+ f" {parameter_names[i]}."
+ )
+ elif isinstance(main_input, Mapping):
+ if "inputs" in main_input:
+ warnings.warn(
+ "The `inputs` argument is deprecated and will be removed in a future version, use `input_ids`"
+ " instead.",
+ FutureWarning,
+ )
+
+ output["input_ids"] = main_input.pop("inputs")
+
+ if "decoder_cached_states" in main_input:
+ warnings.warn(
+ "The `decoder_cached_states` argument is deprecated and will be removed in a future version, use"
+ " `past_key_values` instead.",
+ FutureWarning,
+ )
+ output["past_key_values"] = main_input.pop("decoder_cached_states")
+
+ for k, v in dict(main_input).items():
+ if isinstance(v, allowed_types) or v is None:
+ output[k] = v
+ elif k not in parameter_names and "args" not in parameter_names:
+ logger.warning(
+ f"The parameter {k} does not belongs to the parameter list {parameter_names} and will be ignored."
+ )
+ continue
+ else:
+ raise ValueError(f"Data of type {type(v)} is not allowed only {allowed_types} is accepted for {k}.")
+ else:
+ if tf.is_tensor(main_input) or main_input is None:
+ output[main_input_name] = main_input
+ else:
+ raise ValueError(
+ f"Data of type {type(main_input)} is not allowed only {allowed_types} is accepted for"
+ f" {main_input_name}."
+ )
+
+ # Populates any unspecified argument with their default value, according to the signature.
+ for name in parameter_names:
+ if name not in list(output.keys()) and name != "args":
+ output[name] = kwargs.pop(name, signature[name].default)
+
+ # When creating a SavedModel TF calls the method with LayerCall.__call__(args, **kwargs)
+ # So to respect the proper output we have to add this exception
+ if "args" in output:
+ if output["args"] is not None and is_tf_symbolic_tensor(output["args"]):
+ tensor_name = output["args"].name.split(":")[0]
+ output[tensor_name] = output["args"]
+ else:
+ # `args` in this case is always the first parameter, then `input_ids`
+ output["input_ids"] = output["args"]
+
+ del output["args"]
+
+ if "kwargs" in output:
+ del output["kwargs"]
+
+ cast_output = {}
+ for key, val in output.items():
+ if isinstance(val, tf.Tensor) and val.dtype == tf.int64:
+ cast_output[key] = tf.cast(val, tf.int32)
+ elif isinstance(val, np.ndarray) and val.dtype == np.int64:
+ cast_output[key] = val.astype(np.int32)
+ else:
+ cast_output[key] = val
+
+ output = cast_output
+ del cast_output
+
+ if config is not None:
+ boolean_dict = {
+ k: v
+ for k, v in output.items()
+ if k in ["return_dict", "output_attentions", "output_hidden_states", "use_cache"]
+ }
+
+ output.update(
+ booleans_processing(
+ config=config,
+ **boolean_dict,
+ )
+ )
+
+ return output
+
+
+def strip_model_name_and_prefix(name, _prefix=None):
+ if _prefix is not None and name.startswith(_prefix):
+ name = name[len(_prefix) :]
+ if name.startswith("/"):
+ name = name[1:]
+ if "model." not in name and len(name.split("/")) > 1:
+ name = "/".join(name.split("/")[1:])
+ return name
+
+
+def tf_shard_checkpoint(weights, max_shard_size="10GB", weights_name: str = TF2_WEIGHTS_NAME):
+ """
+ Splits a model state dictionary in sub-checkpoints so that the final size of each sub-checkpoint does not exceed a
+ given size.
+
+ The sub-checkpoints are determined by iterating through the `state_dict` in the order of its keys, so there is no
+ optimization made to make each sub-checkpoint as close as possible to the maximum size passed. For example, if the
+ limit is 10GB and we have weights of sizes [6GB, 6GB, 2GB, 6GB, 2GB, 2GB] they will get sharded as [6GB], [6+2GB],
+ [6+2+2GB] and not [6+2+2GB], [6+2GB], [6GB].
+
+
+
+ If one of the model's weight is bigger that `max_shard_size`, it will end up in its own sub-checkpoint which will
+ have a size greater than `max_shard_size`.
+
+
+
+ Args:
+ weights (`Dict[str, tf.RessourceVariable]`): The list of tf.RessourceVariable of a model to save.
+ max_shard_size (`int` or `str`, *optional*, defaults to `"10GB"`):
+ The maximum size of each sub-checkpoint. If expressed as a string, needs to be digits followed by a unit
+ (like `"5MB"`).
+ """
+ max_shard_size = convert_file_size_to_int(max_shard_size)
+
+ sharded_state_dicts = []
+ current_block = []
+ current_block_size = 0
+ total_size = 0
+
+ for item in weights:
+ weight_size = item.numpy().size * item.dtype.size
+
+ # If this weight is going to tip up over the maximal size, we split.
+ if current_block_size + weight_size > max_shard_size:
+ sharded_state_dicts.append(current_block)
+ current_block = []
+ current_block_size = 0
+
+ current_block.append(item)
+ current_block_size += weight_size
+ total_size += weight_size
+
+ # Add the last block
+ sharded_state_dicts.append(current_block)
+
+ # If we only have one shard, we return it
+ if len(sharded_state_dicts) == 1:
+ return {weights_name: sharded_state_dicts[0]}, None
+
+ # Otherwise, let's build the index
+ weight_map = {}
+ shards = {}
+ for idx, shard in enumerate(sharded_state_dicts):
+ shard_file = weights_name.replace(".h5", f"-{idx + 1:05d}-of-{len(sharded_state_dicts):05d}.h5")
+ shard_file = shard_file.replace(
+ ".safetensors", f"-{idx + 1:05d}-of-{len(sharded_state_dicts):05d}.safetensors"
+ )
+ shards[shard_file] = shard
+ for weight in shard:
+ weight_name = weight.name
+ weight_map[weight_name] = shard_file
+
+ # Add the metadata
+ metadata = {"total_size": total_size}
+ index = {"metadata": metadata, "weight_map": weight_map}
+ return shards, index
+
+
+def load_tf_sharded_weights(model, shard_files, ignore_mismatched_sizes=False, strict=False, _prefix=None):
+ """
+ This is the same as `load_tf_weights` but for a sharded checkpoint. Detect missing and unexpected layers and load
+ the TF weights from the shard file accordingly to their names and shapes.
+
+ This load is performed efficiently: each checkpoint shard is loaded one by one in RAM and deleted after being
+ loaded in the model.
+
+ Args:
+ model (`keras.models.Model`): The model in which to load the checkpoint.
+ shard_files (`str` or `os.PathLike`): A list containing the sharded checkpoint names.
+ ignore_mismatched_sizes`bool`, *optional`, defaults to `True`):
+ Whether or not to ignore the mismatch between the sizes
+ strict (`bool`, *optional*, defaults to `True`):
+ Whether to strictly enforce that the keys in the model state dict match the keys in the sharded checkpoint.
+
+ Returns:
+ Three lists, one for the missing layers, another one for the unexpected layers, and a last one for the
+ mismatched layers.
+ """
+
+ # Load the index
+ unexpected_keys = set()
+ saved_keys = set()
+ mismatched_keys = set()
+
+ # Since TF adds the name of the class to its weights, and uses the index and not the name of the layer to load
+ # the weight, we have to get rid of the first prefix of the name of the layer.
+ model_keys = set()
+ model_layer_map = {}
+ for i, k in enumerate(model.weights):
+ layer_name = k.name
+ if _prefix is not None and layer_name.startswith(_prefix):
+ layer_name = layer_name[len(_prefix) :]
+ layer_name = layer_name.lstrip("/")
+ if not ("model." in layer_name or len(layer_name.split("/")) == 1):
+ layer_name = "/".join(layer_name.split("/")[1:])
+ model_keys.add(layer_name)
+ model_layer_map[layer_name] = i
+
+ for shard_file in shard_files:
+ saved_weight_names_set, unexpected_keys_set, mismatched_keys_set = load_tf_shard(
+ model,
+ model_layer_map,
+ shard_file,
+ ignore_mismatched_sizes=ignore_mismatched_sizes,
+ _prefix=_prefix,
+ )
+ saved_keys.update(saved_weight_names_set)
+ unexpected_keys.update(unexpected_keys_set)
+ mismatched_keys.update(mismatched_keys_set)
+ gc.collect()
+
+ missing_keys = model_keys - saved_keys
+ if strict and (len(missing_keys) > 0 or len(unexpected_keys) > 0):
+ error_message = f"Error(s) in loading state_dict for {model.__class__.__name__}"
+ if len(missing_keys) > 0:
+ str_missing_keys = ",".join([f'"{k}"' for k in missing_keys])
+ error_message += f"\nMissing key(s): {str_missing_keys}."
+ if len(unexpected_keys) > 0:
+ str_unexpected_keys = ",".join([f'"{k}"' for k in unexpected_keys])
+ error_message += f"\nMissing key(s): {str_unexpected_keys}."
+ raise RuntimeError(error_message)
+
+ return missing_keys, unexpected_keys, mismatched_keys
+
+
+def load_tf_shard(model, model_layer_map, resolved_archive_file, ignore_mismatched_sizes=False, _prefix=None):
+ """
+ Loads a shard from a sharded checkpoint file. Can be either H5 or Safetensors.
+ Handles missing keys and unexpected keys.
+
+ Args:
+ model (`keras.models.Model`): Model in which the weights are loaded
+ model_layer_map (`Dict`): A dictionary mapping the layer name to the index of the layer in the model.
+ resolved_archive_file (`str`): Path to the checkpoint file from which the weights will be loaded
+ ignore_mismatched_sizes (`bool`, *optional*, defaults to `False`): Whether to ignore the mismatched keys
+
+ Returns:
+ `keras.models.Model`: Three lists, one for the layers that were found and successfully restored (from the
+ shard file), one for the mismatched layers, and another one for the unexpected layers.
+ """
+ saved_weight_names_set = set()
+ saved_weights = {}
+ mismatched_keys = set()
+ unexpected_keys = set()
+ # Read the H5 file
+ try:
+ with h5py.File(resolved_archive_file, "r") as sharded_checkpoint_file:
+ # Retrieve the name of each layer from the H5 file
+ saved_h5_model_layers_name = set(load_attributes_from_hdf5_group(sharded_checkpoint_file, "layer_names"))
+ weight_value_tuples = []
+
+ # Compute missing and unexpected sub layers
+ # Store the weights in list of tuples that looks like [(weight_object, value_of_weight),...]
+ for layer_name in saved_h5_model_layers_name:
+ h5_layer_object = sharded_checkpoint_file[layer_name]
+ saved_weights[layer_name] = np.asarray(h5_layer_object)
+
+ saved_weight_names_set.add(layer_name)
+
+ if layer_name not in model_layer_map:
+ unexpected_keys.add(layer_name)
+ else:
+ symbolic_weight = model.weights[model_layer_map[layer_name]]
+
+ saved_weight_value = saved_weights[layer_name]
+ # If the current weight is found
+ if saved_weight_value is not None:
+ # Check if the shape of the current weight and the one from the H5 file are different
+ if K.int_shape(symbolic_weight) != saved_weight_value.shape:
+ # If yes we reshape the weight from the H5 file accordingly to the current weight
+ # If the two shapes are not compatible we raise an issue
+ try:
+ array = np.reshape(saved_weight_value, K.int_shape(symbolic_weight))
+ except ValueError as e:
+ if ignore_mismatched_sizes:
+ mismatched_keys.add(
+ (layer_name, saved_weight_value.shape, K.int_shape(symbolic_weight))
+ )
+ continue
+ else:
+ raise e
+ else:
+ array = saved_weight_value
+
+ # We create the tuple that will be loaded and add it to the final list
+ weight_value_tuples.append((symbolic_weight, array))
+
+ K.batch_set_value(weight_value_tuples)
+
+ return saved_weight_names_set, unexpected_keys, mismatched_keys
+
+ except Exception as e:
+ try:
+ with open(resolved_archive_file) as f:
+ if f.read().startswith("version"):
+ raise OSError(
+ "You seem to have cloned a repository without having git-lfs installed. Please install "
+ "git-lfs and run `git lfs install` followed by `git lfs pull` in the folder "
+ "you cloned."
+ )
+ else:
+ raise ValueError(
+ f"Unable to locate the file {resolved_archive_file} which is necessary to load this pretrained"
+ " model. Make sure you have saved the model properly."
+ ) from e
+ except (UnicodeDecodeError, ValueError):
+ raise OSError(
+ f"Unable to load weights from TF checkpoint file for '{resolved_archive_file}' "
+ f"at '{resolved_archive_file}'. "
+ "If you tried to load a TF model from a sharded checkpoint, you should try converting the model "
+ "by loading it in pytorch and saving it locally. A convertion script should be released soon."
+ )
+
+
+def load_tf_sharded_weights_from_safetensors(
+ model, shard_files, ignore_mismatched_sizes=False, strict=False, _prefix=None
+):
+ """
+ This is the same as `load_tf_weights_from_safetensors` but for a sharded TF-format safetensors checkpoint.
+ Detect missing and unexpected layers and load the TF weights from the shard file accordingly to their names and
+ shapes.
+
+ This load is performed efficiently: each checkpoint shard is loaded one by one in RAM and deleted after being
+ loaded in the model.
+
+ Args:
+ model (`keras.models.Model`): The model in which to load the checkpoint.
+ shard_files (`str` or `os.PathLike`): A list containing the sharded checkpoint names.
+ ignore_mismatched_sizes`bool`, *optional`, defaults to `True`):
+ Whether or not to ignore the mismatch between the sizes
+ strict (`bool`, *optional*, defaults to `True`):
+ Whether to strictly enforce that the keys in the model state dict match the keys in the sharded checkpoint.
+
+ Returns:
+ Three lists, one for the missing layers, another one for the unexpected layers, and a last one for the
+ mismatched layers.
+ """
+
+ # Load the index
+ unexpected_keys = set()
+ all_missing_keys = []
+ mismatched_keys = set()
+
+ for shard_file in shard_files:
+ missing_layers, unexpected_layers, mismatched_layers = load_tf_weights_from_safetensors(
+ model,
+ shard_file,
+ ignore_mismatched_sizes=ignore_mismatched_sizes,
+ _prefix=_prefix,
+ )
+ all_missing_keys.append(set(missing_layers))
+ unexpected_keys.update(unexpected_layers)
+ mismatched_keys.update(mismatched_layers)
+ gc.collect()
+ missing_keys = set.intersection(*all_missing_keys)
+
+ if strict and (len(missing_keys) > 0 or len(unexpected_keys) > 0):
+ error_message = f"Error(s) in loading state_dict for {model.__class__.__name__}"
+ if len(missing_keys) > 0:
+ str_missing_keys = ",".join([f'"{k}"' for k in missing_keys])
+ error_message += f"\nMissing key(s): {str_missing_keys}."
+ if len(unexpected_keys) > 0:
+ str_unexpected_keys = ",".join([f'"{k}"' for k in unexpected_keys])
+ error_message += f"\nMissing key(s): {str_unexpected_keys}."
+ raise RuntimeError(error_message)
+
+ return missing_keys, unexpected_keys, mismatched_keys
+
+
+def load_tf_weights(model, resolved_archive_file, ignore_mismatched_sizes=False, _prefix=None):
+ """
+ Detect missing and unexpected layers and load the TF weights from the shard file accordingly to their names and
+ shapes.
+
+ Args:
+ model (`keras.models.Model`):
+ The model to load the weights into.
+ resolved_archive_file (`str`):
+ The location of the H5 file.
+ ignore_mismatched_sizes (`bool`, *optional*, defaults to `False`):
+ Whether or not to ignore weights with shapes that don't match between the checkpoint of the model.
+
+ Returns:
+ Three lists, one for the missing layers, another one for the unexpected layers, and a last one for the
+ mismatched layers.
+ """
+ if resolved_archive_file.endswith(".safetensors"):
+ load_function = load_tf_weights_from_safetensors
+ else:
+ load_function = load_tf_weights_from_h5
+
+ return load_function(
+ model, resolved_archive_file, ignore_mismatched_sizes=ignore_mismatched_sizes, _prefix=_prefix
+ )
+
+
+def load_tf_weights_from_h5(model, resolved_archive_file, ignore_mismatched_sizes=False, _prefix=None):
+ mismatched_layers = []
+
+ # Read the H5 file
+ with h5py.File(resolved_archive_file, "r") as sharded_checkpoint_file:
+ # Retrieve the name of each layer from the H5 file
+ saved_h5_model_layers_name = set(load_attributes_from_hdf5_group(sharded_checkpoint_file, "layer_names"))
+
+ # Find the missing layers from the high level list of layers
+ missing_layers = list({layer.name for layer in model.layers} - saved_h5_model_layers_name)
+
+ # Find the unexpected layers from the high level list of layers
+ unexpected_layers = list(saved_h5_model_layers_name - {layer.name for layer in model.layers})
+ saved_weight_names_set = set()
+ symbolic_weights_names = set()
+ weight_value_tuples = []
+
+ # Compute missing and unexpected sub layers
+ # Store the weights in list of tuples that looks like [(weight_object, value_of_weight),...]
+ for layer in model.layers:
+ # if layer_name from the H5 file belongs to the layers from the instantiated model
+ if layer.name in saved_h5_model_layers_name:
+ # Get the H5 layer object from its name
+ h5_layer_object = sharded_checkpoint_file[layer.name]
+ # Get all the weights as a list from the layer object
+ symbolic_weights = layer.trainable_weights + layer.non_trainable_weights
+ saved_weights = {}
+
+ # Create a dict from the H5 saved model that looks like {"weight_name": weight_value}
+ # And a set with only the names
+ for weight_name in load_attributes_from_hdf5_group(h5_layer_object, "weight_names"):
+ # TF names always start with the model name so we ignore it
+ name = "/".join(weight_name.split("/")[1:])
+
+ if _prefix is not None:
+ name = _prefix + "/" + name
+
+ saved_weights[name] = np.asarray(h5_layer_object[weight_name])
+
+ # Add the updated name to the final list for computing missing/unexpected values
+ saved_weight_names_set.add(name)
+
+ # Loop over each weights from the instantiated model and compare with the weights from the H5 file
+ for symbolic_weight in symbolic_weights:
+ # TF names always start with the model name so we ignore it
+ if _prefix is not None:
+ delimeter = len(_prefix.split("/"))
+ symbolic_weight_name = "/".join(
+ symbolic_weight.name.split("/")[:delimeter]
+ + symbolic_weight.name.split("/")[delimeter + 1 :]
+ )
+ else:
+ symbolic_weight_name = "/".join(symbolic_weight.name.split("/")[1:])
+
+ # here we check if the current weight is among the weights from the H5 file
+ # If yes, get the weight_value of the corresponding weight from the H5 file
+ # If not, make the value to None
+ saved_weight_value = saved_weights.get(symbolic_weight_name, None)
+
+ # Retrocompatibility patch: some embeddings are stored with the weights name (e.g. Bart's
+ # `model.shared/embeddings:0` are stored as `model.shared/weights:0`)
+ if saved_weight_value is None and symbolic_weight_name.endswith("embeddings:0"):
+ symbolic_weight_name = symbolic_weight_name[:-12] + "weight:0"
+ saved_weight_value = saved_weights.get(symbolic_weight_name, None)
+
+ # Add the updated name to the final list for computing missing/unexpected values
+ symbolic_weights_names.add(symbolic_weight_name)
+
+ # If the current weight is found
+ if saved_weight_value is not None:
+ # Check if the shape of the current weight and the one from the H5 file are different
+ if K.int_shape(symbolic_weight) != saved_weight_value.shape:
+ # If yes we reshape the weight from the H5 file accordingly to the current weight
+ # If the two shapes are not compatible we raise an issue
+ try:
+ array = np.reshape(saved_weight_value, K.int_shape(symbolic_weight))
+ except ValueError as e:
+ if ignore_mismatched_sizes:
+ mismatched_layers.append(
+ (symbolic_weight_name, saved_weight_value.shape, K.int_shape(symbolic_weight))
+ )
+ continue
+ else:
+ raise e
+ else:
+ array = saved_weight_value
+
+ # We create the tuple that will be loaded and add it to the final list
+ weight_value_tuples.append((symbolic_weight, array))
+
+ # Load all the weights
+ K.batch_set_value(weight_value_tuples)
+
+ # Compute the missing and unexpected layers
+ missing_layers.extend(list(symbolic_weights_names - saved_weight_names_set))
+ unexpected_layers.extend(list(saved_weight_names_set - symbolic_weights_names))
+
+ return missing_layers, unexpected_layers, mismatched_layers
+
+
+def load_tf_weights_from_safetensors(model, resolved_archive_file, ignore_mismatched_sizes=False, _prefix=None):
+ # Read the safetensors file
+ with safe_open(resolved_archive_file, framework="tf") as safetensors_archive:
+ mismatched_layers = []
+ weight_names = [strip_model_name_and_prefix(w.name, _prefix=_prefix) for w in model.weights]
+ loaded_weight_names = list(safetensors_archive.keys())
+ # Find the missing layers from the high level list of layers
+ missing_layers = list(set(weight_names) - set(loaded_weight_names))
+ # Find the unexpected layers from the high level list of layers
+ unexpected_layers = list(set(loaded_weight_names) - set(weight_names))
+
+ for weight in model.weights:
+ weight_name = strip_model_name_and_prefix(weight.name, _prefix=_prefix)
+ if weight_name in loaded_weight_names:
+ weight_value = safetensors_archive.get_tensor(weight_name)
+ # Check if the shape of the current weight and the one from the H5 file are different
+ if K.int_shape(weight) != weight_value.shape:
+ # If yes we reshape the weight from the H5 file accordingly to the current weight
+ # If the two shapes are not compatible we raise an issue
+ try:
+ weight_value = tf.reshape(weight_value, K.int_shape(weight))
+ except (ValueError, tf.errors.InvalidArgumentError) as e:
+ if ignore_mismatched_sizes:
+ mismatched_layers.append((weight_name, weight_value.shape, K.int_shape(weight)))
+ continue
+ else:
+ raise e
+
+ K.set_value(weight, weight_value) # weight.assign() might break if weight is a DTensor
+ return missing_layers, unexpected_layers, mismatched_layers
+
+
+def init_copy_embeddings(old_embeddings, new_num_tokens):
+ r"""
+ This function aims to reduce the embeddings in case new_num_tokens < old_num_tokens or to pad with -1 in case
+ new_num_tokens > old_num_tokens. A mask is also computed in order to know which weight in the embeddings should be
+ kept or not. Example:
+
+ - if new_num_tokens=5 and old_num_tokens=4 and old_embeddings=[w1,w2,w3,w4]
+
+ - mask=[True,True,True,True,False] and current_weights=[w1,w2,w3,w4,-1]
+ - if new_num_tokens=4 and old_num_tokens=5 and old_embeddings=[w1,w2,w3,w4,w5]
+
+ - mask=[True,True,True,True] and current_weights=[w1,w2,w3,w4]
+ """
+ old_num_tokens, old_embedding_dim = shape_list(old_embeddings)
+ size_diff = new_num_tokens - old_num_tokens
+
+ # initialize new embeddings
+ # Copy token embeddings from the previous ones
+ if tf.math.greater(size_diff, 0):
+ # if the new size is greater than the old one, we extend the current embeddings with a padding until getting new size
+ # and we create a mask to properly identify the padded values and be replaced by the values of the newly created
+ # embeddings
+ current_weights = tf.pad(
+ old_embeddings.value(), tf.convert_to_tensor([[0, size_diff], [0, 0]]), constant_values=-1
+ )
+ num_tokens_to_copy = min(old_num_tokens, new_num_tokens)
+ mask = tf.fill(tf.convert_to_tensor([num_tokens_to_copy, 1]), True)
+ mask = tf.pad(mask, tf.convert_to_tensor([[0, size_diff], [0, 0]]), constant_values=False)
+ else:
+ # if the new size if lower than the old one, we take the current embeddings until the new size
+ current_weights = tf.slice(
+ old_embeddings.value(),
+ tf.convert_to_tensor([0, 0]),
+ tf.convert_to_tensor([new_num_tokens, old_embedding_dim]),
+ )
+ mask = tf.fill(tf.convert_to_tensor([new_num_tokens, 1]), True)
+
+ return mask, current_weights
+
+
+class TFPreTrainedModel(keras.Model, TFModelUtilsMixin, TFGenerationMixin, PushToHubMixin):
+ r"""
+ Base class for all TF models.
+
+ [`TFPreTrainedModel`] takes care of storing the configuration of the models and handles methods for loading,
+ downloading and saving models as well as a few methods common to all models to:
+
+ - resize the input embeddings,
+ - prune heads in the self-attention heads.
+
+ Class attributes (overridden by derived classes):
+
+ - **config_class** ([`PretrainedConfig`]) -- A subclass of [`PretrainedConfig`] to use as configuration class
+ for this model architecture.
+ - **base_model_prefix** (`str`) -- A string indicating the attribute associated to the base model in derived
+ classes of the same architecture adding modules on top of the base model.
+ - **main_input_name** (`str`) -- The name of the principal input to the model (often `input_ids` for NLP
+ models, `pixel_values` for vision models and `input_values` for speech models).
+ """
+
+ config_class = None
+ base_model_prefix = ""
+ main_input_name = "input_ids"
+ _auto_class = None
+ _using_dummy_loss = None
+ _label_to_output_map = None
+
+ # a list of re pattern of tensor names to ignore from the model when loading the model weights
+ # (and avoid unnecessary warnings).
+ _keys_to_ignore_on_load_missing = None
+ # a list of re pattern of tensor names to ignore from the weights when loading the model weights
+ # (and avoid unnecessary warnings).
+ _keys_to_ignore_on_load_unexpected = None
+ _requires_load_weight_prefix = False
+
+ @property
+ def dummy_inputs(self) -> Dict[str, tf.Tensor]:
+ """
+ Dummy inputs to build the network.
+
+ Returns:
+ `Dict[str, tf.Tensor]`: The dummy inputs.
+ """
+ dummies = {}
+ for key, spec in self.input_signature.items():
+ # 2 is the most correct arbitrary size. I will not be taking questions
+ dummy_shape = [dim if dim is not None else 2 for dim in spec.shape]
+ if spec.shape[0] is None:
+ # But let's make the batch size 1 to save memory anyway
+ dummy_shape[0] = 1
+ dummies[key] = tf.ones(shape=dummy_shape, dtype=spec.dtype)
+ if key == "token_type_ids":
+ # Some models have token_type_ids but with a vocab_size of 1
+ dummies[key] = tf.zeros_like(dummies[key])
+ if self.config.add_cross_attention and "encoder_hidden_states" in inspect.signature(self.call).parameters:
+ if "encoder_hidden_states" not in dummies:
+ if self.main_input_name == "input_ids":
+ dummies["encoder_hidden_states"] = tf.ones(
+ shape=(1, 2, self.config.hidden_size), dtype=tf.float32, name="encoder_hidden_states"
+ )
+ else:
+ raise NotImplementedError(
+ "Model has cross-attention but we couldn't infer the shape for the encoder hidden states. Please manually override dummy_inputs!"
+ )
+ return dummies
+
+ def build_in_name_scope(self):
+ with tf.name_scope(self.name):
+ self.build(input_shape=None)
+
+ @property
+ def framework(self) -> str:
+ """
+ :str: Identifies that this is a TensorFlow model.
+ """
+ return "tf"
+
+ def build(self, input_shape=None):
+ pass # This is just here to make sure we don't call the superclass build()
+
+ def __init__(self, config, *inputs, **kwargs):
+ super().__init__(*inputs, **kwargs)
+ if not isinstance(config, PretrainedConfig):
+ raise TypeError(
+ f"Parameter config in `{self.__class__.__name__}(config)` should be an instance of class "
+ "`PretrainedConfig`. To create a model from a pretrained model use "
+ f"`model = {self.__class__.__name__}.from_pretrained(PRETRAINED_MODEL_NAME)`"
+ )
+ # Save config and origin of the pretrained weights if given in model
+ self.config = config
+ self.name_or_path = config.name_or_path
+ self.generation_config = GenerationConfig.from_model_config(config) if self.can_generate() else None
+ self._set_save_spec(self.input_signature)
+
+ def get_config(self):
+ return self.config.to_dict()
+
+ @functools.wraps(keras.Model.fit)
+ def fit(self, *args, **kwargs):
+ args, kwargs = convert_batch_encoding(*args, **kwargs)
+ return super().fit(*args, **kwargs)
+
+ @functools.wraps(keras.Model.train_on_batch)
+ def train_on_batch(self, *args, **kwargs):
+ args, kwargs = convert_batch_encoding(*args, **kwargs)
+ return super().train_on_batch(*args, **kwargs)
+
+ @functools.wraps(keras.Model.test_on_batch)
+ def test_on_batch(self, *args, **kwargs):
+ args, kwargs = convert_batch_encoding(*args, **kwargs)
+ return super().test_on_batch(*args, **kwargs)
+
+ @functools.wraps(keras.Model.predict_on_batch)
+ def predict_on_batch(self, *args, **kwargs):
+ args, kwargs = convert_batch_encoding(*args, **kwargs)
+ return super().predict_on_batch(*args, **kwargs)
+
+ @functools.wraps(keras.Model.predict)
+ def predict(self, *args, **kwargs):
+ args, kwargs = convert_batch_encoding(*args, **kwargs)
+ return super().predict(*args, **kwargs)
+
+ @functools.wraps(keras.Model.evaluate)
+ def evaluate(self, *args, **kwargs):
+ args, kwargs = convert_batch_encoding(*args, **kwargs)
+ return super().evaluate(*args, **kwargs)
+
+ @classmethod
+ def from_config(cls, config, **kwargs):
+ if isinstance(config, PretrainedConfig):
+ return cls._from_config(config, **kwargs)
+ return cls._from_config(cls.config_class.from_dict(config, **kwargs))
+
+ @classmethod
+ def _from_config(cls, config, **kwargs):
+ """
+ All context managers that the model should be initialized under go here.
+ """
+ return cls(config, **kwargs)
+
+ def get_head_mask(self, head_mask: tf.Tensor | None, num_hidden_layers: int) -> tf.Tensor:
+ """
+ Prepare the head mask if needed.
+
+ Args:
+ head_mask (`tf.Tensor` with shape `[num_heads]` or `[num_hidden_layers x num_heads]`, *optional*):
+ The mask indicating if we should keep the heads or not (1.0 for keep, 0.0 for discard).
+ num_hidden_layers (`int`):
+ The number of hidden layers in the model.
+
+ Returns:
+ `tf.Tensor` with shape `[num_hidden_layers x batch x num_heads x seq_length x seq_length]` or list with
+ `[None]` for each layer.
+ """
+ if head_mask is not None:
+ head_mask = self._convert_head_mask_to_5d(head_mask, num_hidden_layers)
+ else:
+ head_mask = [None] * num_hidden_layers
+
+ return head_mask
+
+ def _convert_head_mask_to_5d(self, head_mask, num_hidden_layers):
+ """-> [num_hidden_layers x batch x num_heads x seq_length x seq_length]"""
+ if head_mask.shape.rank == 1:
+ head_mask = head_mask[None, None, :, None, None]
+ head_mask = tf.repeat(head_mask, repeats=num_hidden_layers, axis=0)
+ elif head_mask.shape.rank == 2:
+ head_mask = head_mask[:, None, :, None, None]
+ assert head_mask.shape.rank == 5, f"head_mask.dim != 5, instead {head_mask.dim()}"
+ head_mask = tf.cast(head_mask, tf.float32) # switch to float if need + fp16 compatibility
+ return head_mask
+
+ @tf.function
+ def serving(self, inputs):
+ """
+ Args:
+ Method used for serving the model. Does not have a specific signature, but will be specialized as concrete
+ functions when saving with `save_pretrained`.
+ inputs (`Dict[str, tf.Tensor]`):
+ The input of the saved model as a dictionary of tensors.
+ """
+ output = self.call(inputs)
+
+ return self.serving_output(output)
+
+ @property
+ def input_signature(self) -> Dict[str, tf.TensorSpec]:
+ """
+ This property should return a dict mapping input names to tf.TensorSpec objects, representing the expected
+ shape and dtype for model inputs. It is used for both serving and for generating dummy inputs.
+ """
+ model_inputs = list(inspect.signature(self.call).parameters)
+ sig = {}
+ if "input_ids" in model_inputs:
+ if self.__class__.__name__.endswith("ForMultipleChoice"):
+ text_dims = 3
+ else:
+ text_dims = 2
+ for input_name in (
+ "input_ids",
+ "attention_mask",
+ "token_type_ids",
+ "decoder_input_ids",
+ "decoder_attention_mask",
+ ):
+ if input_name in model_inputs:
+ sig[input_name] = tf.TensorSpec([None] * text_dims, tf.int32, name=input_name)
+ if "pixel_values" in model_inputs:
+ pixel_values_shape = [None, None, None, None]
+ if hasattr(self.config, "vision_config"):
+ vision_config = self.config.vision_config
+ else:
+ vision_config = self.config
+ if hasattr(vision_config, "num_channels"):
+ pixel_values_shape[1] = vision_config.num_channels
+ else:
+ raise NotImplementedError(
+ "Could not infer number of channels from config, please override input_signature to specify input shapes."
+ )
+ if hasattr(vision_config, "image_size"):
+ pixel_values_shape[2] = pixel_values_shape[3] = vision_config.image_size
+ elif hasattr(vision_config, "input_size"):
+ pixel_values_shape[2] = pixel_values_shape[3] = vision_config.input_size
+ else:
+ raise NotImplementedError(
+ "Could not infer input image shape from config, please override input_signature to specify input shapes."
+ )
+ sig["pixel_values"] = tf.TensorSpec(pixel_values_shape, tf.float32, name="pixel_values")
+ if "input_features" in model_inputs:
+ raise NotImplementedError("Audio models need a manually defined input_signature")
+ return sig
+
+ def serving_output(self, output):
+ """
+ Prepare the output of the saved model. Can be overridden if specific serving modifications are required.
+ """
+ if not isinstance(output, ModelOutput):
+ return output
+ for key in output:
+ if key.endswith("hidden_states") and not getattr(self.config, "output_hidden_states", False):
+ output[key] = None
+ elif key.endswith("attentions") and not getattr(self.config, "output_attentions", False):
+ output[key] = None
+ elif key == "past_key_values" and not getattr(self.config, "use_cache", False):
+ output[key] = None
+ elif key == "cross_attentions" and not (
+ getattr(self.config, "output_attentions", False) and getattr(self.config, "add_cross_attention", False)
+ ):
+ output[key] = None
+ if isinstance(output[key], (tuple, list)):
+ try:
+ output[key] = tf.convert_to_tensor(output[key])
+ except (ValueError, tf.errors.InvalidArgumentError):
+ pass # Layers may not have the same dimensions
+ return output
+
+ @classmethod
+ def can_generate(cls) -> bool:
+ """
+ Returns whether this model can generate sequences with `.generate()`.
+
+ Returns:
+ `bool`: Whether this model can generate sequences with `.generate()`.
+ """
+ # Detects whether `prepare_inputs_for_generation` has been overwritten, which is a requirement for generation.
+ # Alternatively, the model can also have a custom `generate` function.
+ if "GenerationMixin" in str(cls.prepare_inputs_for_generation) and "GenerationMixin" in str(cls.generate):
+ return False
+ return True
+
+ def get_input_embeddings(self) -> keras.layers.Layer:
+ """
+ Returns the model's input embeddings layer.
+
+ Returns:
+ `tf.Variable`: The embeddings layer mapping vocabulary to hidden states.
+ """
+ main_layer = getattr(self, self.base_model_prefix, self)
+
+ if main_layer is not self:
+ return main_layer.get_input_embeddings()
+ else:
+ raise NotImplementedError
+
+ def _save_checkpoint(self, checkpoint_dir, epoch):
+ if not os.path.isdir(checkpoint_dir):
+ os.mkdir(checkpoint_dir)
+ # We avoid tf.train.checkpoint or saving weights in TF format, even though that includes optimizer
+ # state for us, because it requires special handling for objects like custom losses, which we use
+ # internally and which users are likely to use too
+ weights_path = os.path.join(checkpoint_dir, "weights.h5")
+ self.save_weights(weights_path)
+ extra_data = {"epoch": epoch, "optimizer_state": self.optimizer.get_weights()}
+ extra_data_path = os.path.join(checkpoint_dir, "extra_data.pickle")
+ with open(extra_data_path, "wb") as f:
+ pickle.dump(extra_data, f)
+
+ def prepare_tf_dataset(
+ self,
+ dataset: "datasets.Dataset", # noqa:F821
+ batch_size: int = 8,
+ shuffle: bool = True,
+ tokenizer: Optional["PreTrainedTokenizerBase"] = None,
+ collate_fn: Optional[Callable] = None,
+ collate_fn_args: Optional[Dict[str, Any]] = None,
+ drop_remainder: Optional[bool] = None,
+ prefetch: bool = True,
+ ):
+ """
+ Wraps a HuggingFace [`~datasets.Dataset`] as a `tf.data.Dataset` with collation and batching. This method is
+ designed to create a "ready-to-use" dataset that can be passed directly to Keras methods like `fit()` without
+ further modification. The method will drop columns from the dataset if they don't match input names for the
+ model. If you want to specify the column names to return rather than using the names that match this model, we
+ recommend using `Dataset.to_tf_dataset()` instead.
+
+ Args:
+ dataset (`Any`):
+ A [~`datasets.Dataset`] to be wrapped as a `tf.data.Dataset`.
+ batch_size (`int`, *optional*, defaults to 8):
+ The size of batches to return.
+ shuffle (`bool`, defaults to `True`):
+ Whether to return samples from the dataset in random order. Usually `True` for training datasets and
+ `False` for validation/test datasets.
+ tokenizer ([`PreTrainedTokenizerBase`], *optional*):
+ A `PreTrainedTokenizer` that will be used to pad samples to create batches. Has no effect if a specific
+ `collate_fn` is passed instead.
+ collate_fn (`Callable`, *optional*):
+ A function that collates samples from the dataset into a single batch. Defaults to
+ `DefaultDataCollator` if no `tokenizer` is supplied or `DataCollatorWithPadding` if a `tokenizer` is
+ passed.
+ collate_fn_args (`Dict[str, Any]`, *optional*):
+ A dict of arguments to pass to the `collate_fn` alongside the list of samples.
+ drop_remainder (`bool`, *optional*):
+ Whether to drop the final batch, if the batch_size does not evenly divide the dataset length. Defaults
+ to the same setting as `shuffle`.
+ prefetch (`bool`, defaults to `True`):
+ Whether to add prefetching to the end of the `tf.data` pipeline. This is almost always beneficial for
+ performance, but can be disabled in edge cases.
+
+
+ Returns:
+ `Dataset`: A `tf.data.Dataset` which is ready to pass to the Keras API.
+ """
+ requires_backends(self, ["datasets"])
+ import datasets
+
+ if collate_fn is None:
+ if tokenizer is None:
+ collate_fn = DefaultDataCollator(return_tensors="np")
+ else:
+ collate_fn = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="np")
+ if collate_fn_args is None:
+ collate_fn_args = {}
+
+ if not isinstance(dataset, datasets.Dataset):
+ raise TypeError("Dataset argument should be a datasets.Dataset!")
+ model_inputs = list(inspect.signature(self.call).parameters)
+ model_labels = find_labels(self.__class__)
+ if "cols_to_retain" in list(inspect.signature(dataset._get_output_signature).parameters.keys()):
+ output_signature, _ = dataset._get_output_signature(
+ dataset,
+ batch_size=None,
+ collate_fn=collate_fn,
+ collate_fn_args=collate_fn_args,
+ cols_to_retain=model_inputs,
+ )
+ else:
+ # TODO Matt: This is a workaround for older versions of datasets that are missing the `cols_to_retain`
+ # argument. We should remove this once the minimum supported version of datasets is > 2.3.2
+ unwanted_columns = [
+ feature
+ for feature in dataset.features
+ if feature not in model_inputs and feature not in ("label_ids", "label")
+ ]
+ dataset = dataset.remove_columns(unwanted_columns)
+ output_signature, _ = dataset._get_output_signature(
+ dataset, batch_size=None, collate_fn=collate_fn, collate_fn_args=collate_fn_args
+ )
+ output_columns = list(output_signature.keys())
+ feature_cols = [col for col in output_columns if col in model_inputs and col not in model_labels]
+ label_cols = [col for col in output_columns if col in model_labels]
+
+ # Backwards compatibility for older versions of datasets. Previously, if `columns` or `label_cols`
+ # were a single element list, the returned element spec would be a single element. Now, passing [feature]
+ # will return a dict structure {"feature": feature}, and passing a single string will return a single element.
+ feature_cols = feature_cols[0] if len(feature_cols) == 1 else feature_cols
+ label_cols = label_cols[0] if len(label_cols) == 1 else label_cols
+
+ if drop_remainder is None:
+ drop_remainder = shuffle
+ tf_dataset = dataset.to_tf_dataset(
+ columns=feature_cols,
+ label_cols=label_cols,
+ batch_size=batch_size,
+ shuffle=shuffle,
+ drop_remainder=drop_remainder,
+ collate_fn=collate_fn,
+ collate_fn_args=collate_fn_args,
+ prefetch=prefetch,
+ )
+ return tf_dataset
+
+ def compile(
+ self,
+ optimizer="rmsprop",
+ loss="auto_with_warning",
+ metrics=None,
+ loss_weights=None,
+ weighted_metrics=None,
+ run_eagerly=None,
+ steps_per_execution=None,
+ **kwargs,
+ ):
+ """
+ This is a thin wrapper that sets the model's loss output head as the loss if the user does not specify a loss
+ function themselves.
+ """
+ if loss in ("auto_with_warning", "passthrough"): # "passthrough" for workflow backward compatibility
+ logger.info(
+ "No loss specified in compile() - the model's internal loss computation will be used as the "
+ "loss. Don't panic - this is a common way to train TensorFlow models in Transformers! "
+ "To disable this behaviour please pass a loss argument, or explicitly pass "
+ "`loss=None` if you do not want your model to compute a loss. You can also specify `loss='auto'` to "
+ "get the internal loss without printing this info string."
+ )
+ loss = "auto"
+ if loss == "auto":
+ loss = dummy_loss
+ self._using_dummy_loss = True
+ else:
+ self._using_dummy_loss = False
+ parent_args = list(inspect.signature(keras.Model.compile).parameters.keys())
+ # This argument got renamed, we need to support both versions
+ if "steps_per_execution" in parent_args:
+ super().compile(
+ optimizer=optimizer,
+ loss=loss,
+ metrics=metrics,
+ loss_weights=loss_weights,
+ weighted_metrics=weighted_metrics,
+ run_eagerly=run_eagerly,
+ steps_per_execution=steps_per_execution,
+ **kwargs,
+ )
+ else:
+ super().compile(
+ optimizer=optimizer,
+ loss=loss,
+ metrics=metrics,
+ loss_weights=loss_weights,
+ weighted_metrics=weighted_metrics,
+ run_eagerly=run_eagerly,
+ experimental_steps_per_execution=steps_per_execution,
+ **kwargs,
+ )
+
+ def compute_loss(self, *args, **kwargs):
+ if hasattr(keras.Model, "compute_loss"):
+ # This will be true in TF 2.8 or greater
+ return super().compute_loss(*args, **kwargs)
+ else:
+ warnings.warn(
+ "The old compute_loss method is deprecated as it conflicts with the Keras compute_loss "
+ "method added in TF 2.8. If you want the original HF compute_loss, please call "
+ "hf_compute_loss() instead. From TF versions >= 2.8, or Transformers versions >= 5, "
+ "calling compute_loss() will get the Keras method instead.",
+ FutureWarning,
+ )
+ return self.hf_compute_loss(*args, **kwargs)
+
+ def get_label_to_output_name_mapping(self):
+ arg_names = list(inspect.signature(self.call).parameters)
+ if self._label_to_output_map is not None:
+ return self._label_to_output_map
+ elif "start_positions" in arg_names:
+ return {"start_positions": "start_logits", "end_positions": "end_logits"}
+ elif "sentence_order_label" in arg_names:
+ return {"labels": "prediction_logits", "sentence_order_label": "sop_logits"}
+ elif "next_sentence_label" in arg_names:
+ return {"labels": "prediction_logits", "next_sentence_label": "seq_relationship_logits"}
+ elif "mc_labels" in arg_names:
+ return {"labels": "logits", "mc_labels": "mc_logits"}
+ else:
+ return {}
+
+ def train_step(self, data):
+ """
+ A modification of Keras's default `train_step` that correctly handles matching outputs to labels for our models
+ and supports directly training on the loss output head. In addition, it ensures input keys are copied to the
+ labels where appropriate. It will also copy label keys into the input dict when using the dummy loss, to ensure
+ that they are available to the model during the forward pass.
+ """
+
+ # We hardcode the most common renamings; models with weirder names can set `self._label_to_output_map`
+ arg_names = list(inspect.signature(self.call).parameters)
+ label_kwargs = find_labels(self.__class__)
+ label_to_output = self.get_label_to_output_name_mapping()
+ output_to_label = {val: key for key, val in label_to_output.items()}
+ if not self._using_dummy_loss and parse(tf.__version__) < parse("2.11.0"):
+ # Newer TF train steps leave this out
+ data = expand_1d(data)
+ x, y, sample_weight = keras.utils.unpack_x_y_sample_weight(data)
+ # If the inputs are mutable dictionaries, make a shallow copy of them because we will modify
+ # them during input/label pre-processing. This avoids surprising the user by wrecking their data.
+ # In addition, modifying mutable Python inputs makes XLA compilation impossible.
+ if isinstance(x, dict):
+ x = x.copy()
+ if isinstance(y, dict):
+ y = y.copy()
+
+ # When using a dummy loss, we ensure that separate labels are copied to the correct model arguments,
+ # if those keys are not already present in the input dict
+ if self._using_dummy_loss and y is not None:
+ # If y is a tensor and the model only has one label-like input, map y to that input
+ if len(label_kwargs) == 1 and isinstance(y, tf.Tensor):
+ if isinstance(x, tf.Tensor):
+ x = {arg_names[0]: x}
+ label_kwarg = next(iter(label_kwargs))
+ if label_kwarg not in x:
+ x[label_kwarg] = y
+ # Otherwise, copy keys from y to x as long as they weren't already present in x
+ elif isinstance(y, dict):
+ if isinstance(x, tf.Tensor):
+ x = {arg_names[0]: x}
+ for key, val in y.items():
+ if key in arg_names and key not in x:
+ x[key] = val
+ elif output_to_label.get(key, None) in arg_names and key not in x:
+ x[output_to_label[key]] = val
+ if y is None:
+ y = {key: val for key, val in x.items() if key in label_kwargs}
+ if not y and not self._using_dummy_loss:
+ raise ValueError("Could not find label column(s) in input dict and no separate labels were provided!")
+
+ if isinstance(y, dict):
+ # Rename labels at this point to match output heads
+ y = {label_to_output.get(key, key): val for key, val in y.items()}
+
+ # Run forward pass.
+ with tf.GradientTape() as tape:
+ if self._using_dummy_loss and "return_loss" in arg_names:
+ y_pred = self(x, training=True, return_loss=True)
+ else:
+ y_pred = self(x, training=True)
+ if self._using_dummy_loss:
+ loss = self.compiled_loss(y_pred.loss, y_pred.loss, sample_weight, regularization_losses=self.losses)
+ else:
+ loss = None
+
+ # This next block matches outputs to label keys. Tensorflow's standard method for doing this
+ # can get very confused if any of the keys contain nested values (e.g. lists/tuples of Tensors)
+ if isinstance(y, dict) and len(y) == 1:
+ if list(y.keys())[0] in y_pred.keys():
+ y_pred = y_pred[list(y.keys())[0]]
+ elif list(y_pred.keys())[0] == "loss":
+ y_pred = y_pred[1]
+ else:
+ y_pred = y_pred[0]
+ _, y = y.popitem()
+ elif isinstance(y, dict):
+ # If the labels are a dict, match keys from the output by name
+ y_pred = {key: val for key, val in y_pred.items() if key in y}
+ elif isinstance(y, tuple) or isinstance(y, list):
+ # If the labels are a tuple/list, match keys to the output by order, skipping the loss.
+ if list(y_pred.keys())[0] == "loss":
+ y_pred = y_pred.to_tuple()[1:]
+ else:
+ y_pred = y_pred.to_tuple()
+ y_pred = y_pred[: len(y)] # Remove unused fields in case those cause problems
+ else:
+ # If the labels are a single tensor, match them to the first non-loss tensor in the output
+ if list(y_pred.keys())[0] == "loss":
+ y_pred = y_pred[1]
+ else:
+ y_pred = y_pred[0]
+
+ if loss is None:
+ loss = self.compiled_loss(y, y_pred, sample_weight, regularization_losses=self.losses)
+
+ # Run backwards pass.
+ self.optimizer.minimize(loss, self.trainable_variables, tape=tape)
+
+ self.compiled_metrics.update_state(y, y_pred, sample_weight)
+ # Collect metrics to return
+ return_metrics = {}
+ for metric in self.metrics:
+ result = metric.result()
+ if isinstance(result, dict):
+ return_metrics.update(result)
+ else:
+ return_metrics[metric.name] = result
+ return return_metrics
+
+ def test_step(self, data):
+ """
+ A modification of Keras's default `train_step` that correctly handles matching outputs to labels for our models
+ and supports directly training on the loss output head. In addition, it ensures input keys are copied to the
+ labels where appropriate. It will also copy label keys into the input dict when using the dummy loss, to ensure
+ that they are available to the model during the forward pass.
+ """
+ # We hardcode the most common renamings; models with weirder names can set `self._label_to_output_map`
+ arg_names = list(inspect.signature(self.call).parameters)
+ label_kwargs = find_labels(self.__class__)
+ label_to_output = self.get_label_to_output_name_mapping()
+ output_to_label = {val: key for key, val in label_to_output.items()}
+ if not self._using_dummy_loss and parse(tf.__version__) < parse("2.11.0"):
+ # Newer versions leave this out
+ data = expand_1d(data)
+ x, y, sample_weight = keras.utils.unpack_x_y_sample_weight(data)
+ # If the inputs are mutable dictionaries, make a shallow copy of them because we will modify
+ # them during input/label pre-processing. This avoids surprising the user by wrecking their data.
+ # In addition, modifying mutable Python inputs makes XLA compilation impossible.
+ if isinstance(x, dict):
+ x = x.copy()
+ if isinstance(y, dict):
+ y = y.copy()
+
+ # When using a dummy loss, we ensure that separate labels are copied to the correct model arguments,
+ # if those keys are not already present in the input dict
+ if self._using_dummy_loss and y is not None:
+ arg_names = list(inspect.signature(self.call).parameters)
+ # If y is a tensor and the model only has one label-like input, map y to that input
+ if len(label_kwargs) == 1 and isinstance(y, tf.Tensor):
+ if isinstance(x, tf.Tensor):
+ x = {arg_names[0]: x}
+ label_kwarg = next(iter(label_kwargs))
+ if label_kwarg not in x:
+ x[label_kwarg] = y
+ # Otherwise, copy keys from y to x as long as they weren't already present in x
+ elif isinstance(y, dict):
+ if isinstance(x, tf.Tensor):
+ x = {arg_names[0]: x}
+ for key, val in y.items():
+ if key in arg_names and key not in x:
+ x[key] = val
+ elif output_to_label.get(key, None) in arg_names and key not in x:
+ x[output_to_label[key]] = val
+ if y is None:
+ y = {key: val for key, val in x.items() if key in label_kwargs}
+ if not y and not self._using_dummy_loss:
+ raise ValueError("Could not find label column(s) in input dict and no separate labels were provided!")
+
+ if isinstance(y, dict):
+ # Rename labels at this point to match output heads
+ y = {label_to_output.get(key, key): val for key, val in y.items()}
+
+ # Run forward pass.
+ if self._using_dummy_loss and "return_loss" in arg_names:
+ y_pred = self(x, return_loss=True, training=False)
+ else:
+ y_pred = self(x, training=False)
+ if self._using_dummy_loss:
+ loss = self.compiled_loss(y_pred.loss, y_pred.loss, sample_weight, regularization_losses=self.losses)
+ else:
+ loss = None
+
+ # This next block matches outputs to label keys. Tensorflow's standard method for doing this
+ # can get very confused if any of the keys contain nested values (e.g. lists/tuples of Tensors)
+ if isinstance(y, dict) and len(y) == 1:
+ if list(y.keys())[0] in y_pred.keys():
+ y_pred = y_pred[list(y.keys())[0]]
+ elif list(y_pred.keys())[0] == "loss":
+ y_pred = y_pred[1]
+ else:
+ y_pred = y_pred[0]
+ _, y = y.popitem()
+ elif isinstance(y, dict):
+ # If the labels are a dict, match keys from the output by name
+ y_pred = {key: val for key, val in y_pred.items() if key in y}
+ elif isinstance(y, tuple) or isinstance(y, list):
+ # If the labels are a tuple/list, match keys to the output by order, skipping the loss.
+ if list(y_pred.keys())[0] == "loss":
+ y_pred = y_pred.to_tuple()[1:]
+ else:
+ y_pred = y_pred.to_tuple()
+ y_pred = y_pred[: len(y)] # Remove unused fields in case those cause problems
+ else:
+ # If the labels are a single tensor, match them to the first non-loss tensor in the output
+ if list(y_pred.keys())[0] == "loss":
+ y_pred = y_pred[1]
+ else:
+ y_pred = y_pred[0]
+
+ if loss is None:
+ loss = self.compiled_loss(y, y_pred, sample_weight, regularization_losses=self.losses)
+
+ self.compiled_metrics.update_state(y, y_pred, sample_weight)
+ # Collect metrics to return
+ return_metrics = {}
+ for metric in self.metrics:
+ result = metric.result()
+ if isinstance(result, dict):
+ return_metrics.update(result)
+ else:
+ return_metrics[metric.name] = result
+ return return_metrics
+
+ def create_model_card(
+ self,
+ output_dir,
+ model_name: str,
+ language: Optional[str] = None,
+ license: Optional[str] = None,
+ tags: Optional[str] = None,
+ finetuned_from: Optional[str] = None,
+ tasks: Optional[str] = None,
+ dataset_tags: Optional[Union[str, List[str]]] = None,
+ dataset: Optional[Union[str, List[str]]] = None,
+ dataset_args: Optional[Union[str, List[str]]] = None,
+ ):
+ """
+ Creates a draft of a model card using the information available to the `Trainer`.
+
+ Args:
+ output_dir (`str` or `os.PathLike`):
+ The folder in which to create the model card.
+ model_name (`str`, *optional*):
+ The name of the model.
+ language (`str`, *optional*):
+ The language of the model (if applicable)
+ license (`str`, *optional*):
+ The license of the model. Will default to the license of the pretrained model used, if the original
+ model given to the `Trainer` comes from a repo on the Hub.
+ tags (`str` or `List[str]`, *optional*):
+ Some tags to be included in the metadata of the model card.
+ finetuned_from (`str`, *optional*):
+ The name of the model used to fine-tune this one (if applicable). Will default to the name of the repo
+ of the original model given to the `Trainer` (if it comes from the Hub).
+ tasks (`str` or `List[str]`, *optional*):
+ One or several task identifiers, to be included in the metadata of the model card.
+ dataset_tags (`str` or `List[str]`, *optional*):
+ One or several dataset tags, to be included in the metadata of the model card.
+ dataset (`str` or `List[str]`, *optional*):
+ One or several dataset identifiers, to be included in the metadata of the model card.
+ dataset_args (`str` or `List[str]`, *optional*):
+ One or several dataset arguments, to be included in the metadata of the model card.
+ """
+ # Avoids a circular import by doing this when necessary.
+ from .modelcard import TrainingSummary # tests_ignore
+
+ training_summary = TrainingSummary.from_keras(
+ self,
+ keras_history=self.history,
+ language=language,
+ license=license,
+ tags=tags,
+ model_name=model_name,
+ finetuned_from=finetuned_from,
+ tasks=tasks,
+ dataset_tags=dataset_tags,
+ dataset=dataset,
+ dataset_args=dataset_args,
+ )
+ model_card = training_summary.to_model_card()
+ with open(os.path.join(output_dir, "README.md"), "w") as f:
+ f.write(model_card)
+
+ def set_input_embeddings(self, value):
+ """
+ Set model's input embeddings
+
+ Args:
+ value (`tf.Variable`):
+ The new weights mapping hidden states to vocabulary.
+ """
+ main_layer = getattr(self, self.base_model_prefix)
+
+ if main_layer is None:
+ raise NotImplementedError("The model does not implements the base_model_prefix attribute.")
+
+ try:
+ main_layer.set_input_embeddings(value)
+ except AttributeError:
+ logger.info("Building the model")
+ self.build_in_name_scope()
+ main_layer.set_input_embeddings(value)
+
+ def get_output_embeddings(self) -> Union[None, keras.layers.Layer]:
+ """
+ Returns the model's output embeddings
+
+ Returns:
+ `tf.Variable`: The new weights mapping vocabulary to hidden states.
+ """
+ if self.get_lm_head() is not None:
+ lm_head = self.get_lm_head()
+
+ try:
+ return lm_head.get_output_embeddings()
+ except AttributeError:
+ logger.info("Building the model")
+ self.build_in_name_scope()
+
+ return lm_head().get_output_embeddings()
+
+ return None # Overwrite for models with output embeddings
+
+ def set_output_embeddings(self, value):
+ """
+ Set model's output embeddings
+
+ Args:
+ value (`tf.Variable`):
+ The new weights mapping hidden states to vocabulary.
+ """
+ if self.get_lm_head() is not None:
+ lm_head = self.get_lm_head()
+ try:
+ lm_head.set_output_embeddings(value)
+ except AttributeError:
+ logger.info("Building the model")
+ self.build_in_name_scope()
+ lm_head.set_output_embeddings(value)
+
+ def get_output_layer_with_bias(self) -> Union[None, keras.layers.Layer]:
+ """
+ Get the layer that handles a bias attribute in case the model has an LM head with weights tied to the
+ embeddings
+
+ Return:
+ `keras.layers.Layer`: The layer that handles the bias, None if not an LM model.
+ """
+ warnings.warn(
+ "The method get_output_layer_with_bias is deprecated. Please use `get_lm_head` instead.", FutureWarning
+ )
+ return self.get_lm_head()
+
+ def get_prefix_bias_name(self) -> Union[None, str]:
+ """
+ Get the concatenated _prefix name of the bias from the model name to the parent layer
+
+ Return:
+ `str`: The _prefix name of the bias.
+ """
+ warnings.warn("The method get_prefix_bias_name is deprecated. Please use `get_bias` instead.", FutureWarning)
+ return None
+
+ def get_bias(self) -> Union[None, Dict[str, tf.Variable]]:
+ """
+ Dict of bias attached to an LM head. The key represents the name of the bias attribute.
+
+ Return:
+ `tf.Variable`: The weights representing the bias, None if not an LM model.
+ """
+ if self.get_lm_head() is not None:
+ lm_head = self.get_lm_head()
+ try:
+ return lm_head.get_bias()
+ except AttributeError:
+ self.build_in_name_scope()
+
+ return lm_head.get_bias()
+ return None
+
+ def set_bias(self, value):
+ """
+ Set all the bias in the LM head.
+
+ Args:
+ value (`Dict[tf.Variable]`):
+ All the new bias attached to an LM head.
+ """
+ if self.get_lm_head() is not None:
+ lm_head = self.get_lm_head()
+ try:
+ lm_head.set_bias(value)
+ except AttributeError:
+ self.build_in_name_scope()
+ lm_head.set_bias(value)
+
+ def get_lm_head(self) -> keras.layers.Layer:
+ """
+ The LM Head layer. This method must be overwritten by all the models that have a lm head.
+
+ Return:
+ `keras.layers.Layer`: The LM head layer if the model has one, None if not.
+ """
+ return None
+
+ def resize_token_embeddings(
+ self, new_num_tokens: Optional[int] = None
+ ) -> Union[keras.layers.Embedding, tf.Variable]:
+ """
+ Resizes input token embeddings matrix of the model if `new_num_tokens != config.vocab_size`.
+
+ Takes care of tying weights embeddings afterwards if the model class has a `tie_weights()` method.
+
+ Arguments:
+ new_num_tokens (`int`, *optional*):
+ The number of new tokens in the embedding matrix. Increasing the size will add newly initialized
+ vectors at the end. Reducing the size will remove vectors from the end. If not provided or `None`, just
+ returns a pointer to the input tokens without doing anything.
+
+ Return:
+ `tf.Variable` or `keras.layers.Embedding`: Pointer to the input tokens of the model.
+ """
+ # TODO (joao): flagged for replacement (by `_v2_resized_token_embeddings`) due to embeddings refactor
+
+ # Run the new code path if the model has a keras embeddings layer
+ if isinstance(self.get_input_embeddings(), keras.layers.Embedding):
+ return self._v2_resized_token_embeddings(new_num_tokens)
+
+ if new_num_tokens is None or new_num_tokens == self.config.vocab_size:
+ return self._get_word_embedding_weight(self.get_input_embeddings())
+
+ model_embeds = self._resize_token_embeddings(new_num_tokens)
+
+ # Update base model and current model config
+ self.config.vocab_size = new_num_tokens
+
+ return model_embeds
+
+ def _v2_resized_token_embeddings(self, new_num_tokens: Optional[int] = None) -> keras.layers.Embedding:
+ """
+ Resizes input token embeddings matrix of the model if `new_num_tokens != config.vocab_size`.
+
+ Arguments:
+ new_num_tokens (`int`, *optional*):
+ The number of new tokens in the embedding matrix. Increasing the size will add newly initialized
+ vectors at the end. Reducing the size will remove vectors from the end. If not provided or `None`, just
+ returns a pointer to the input tokens without doing anything.
+
+ Return:
+ `keras.layers.Embedding`: Pointer to the input tokens of the model.
+ """
+ if new_num_tokens is None or new_num_tokens == self.config.vocab_size:
+ return self.get_input_embeddings()
+
+ model_embeds = self._v2_resize_token_embeddings(new_num_tokens)
+
+ # Update base model and current model config
+ self.config.vocab_size = new_num_tokens
+
+ return model_embeds
+
+ def _get_word_embedding_weight(model, embedding_layer):
+ # TODO (joao): flagged for delection due to embeddings refactor
+
+ # If the variable holds the weights themselves, return them
+ if isinstance(embedding_layer, tf.Tensor):
+ return embedding_layer
+ # Otherwise, try to get them from the layer's attributes
+
+ embeds = getattr(embedding_layer, "weight", None)
+ if embeds is not None:
+ return embeds
+
+ embeds = getattr(embedding_layer, "decoder", None)
+ if embeds is not None:
+ return embeds
+
+ # The reason why the attributes don't exist might be
+ # because the model is not built, so retry getting
+ # the argument after building the model
+ model.build_in_name_scope()
+
+ embeds = getattr(embedding_layer, "weight", None)
+ if embeds is not None:
+ return embeds
+
+ embeds = getattr(embedding_layer, "decoder", None)
+ if embeds is not None:
+ return embeds
+
+ return None
+
+ def _resize_token_embeddings(self, new_num_tokens):
+ # TODO (joao): flagged for replacement (by `_v2_resize_token_embeddings`) due to embeddings refactor
+ old_embeddings = self._get_word_embedding_weight(self.get_input_embeddings())
+ new_embeddings = self._get_resized_embeddings(old_embeddings, new_num_tokens)
+
+ # if word embeddings are not tied, make sure that lm head bias is resized as well
+ if self.get_bias() is not None:
+ old_lm_head_bias = self.get_bias()
+ new_lm_head_bias = self._get_resized_lm_head_bias(old_lm_head_bias, new_num_tokens)
+
+ self.set_bias(new_lm_head_bias)
+
+ # if word embeddings are not tied, make sure that lm head decoder is resized as well
+ if self.get_output_embeddings() is not None:
+ old_lm_head_decoder = self._get_word_embedding_weight(self.get_output_embeddings())
+ new_lm_head_decoder = self._get_resized_lm_head_decoder(old_lm_head_decoder, new_num_tokens)
+
+ self.set_output_embeddings(new_lm_head_decoder)
+
+ self.set_input_embeddings(new_embeddings)
+
+ return self.get_input_embeddings()
+
+ def _v2_resize_token_embeddings(self, new_num_tokens):
+ old_embeddings = self.get_input_embeddings()
+ new_embeddings = self._v2_get_resized_embeddings(old_embeddings, new_num_tokens)
+ self.set_input_embeddings(new_embeddings)
+
+ # If word embeddings are not tied, make sure that lm head bias is resized as well
+ if self.get_bias() is not None:
+ old_lm_head_bias = self.get_bias()
+ new_lm_head_bias = self._v2_get_resized_lm_head_bias(old_lm_head_bias, new_num_tokens)
+ self.set_bias(new_lm_head_bias)
+
+ # If word embeddings are not tied, make sure that lm head decoder is resized as well.
+ tied_weights = self.get_input_embeddings() == self.get_output_embeddings()
+ if self.get_output_embeddings() is not None and not tied_weights:
+ old_lm_head_decoder = self._get_word_embedding_weight(self.get_output_embeddings())
+ # TODO (joao): this one probably needs a v2 version with other models
+ new_lm_head_decoder = self._get_resized_lm_head_decoder(old_lm_head_decoder, new_num_tokens)
+ self.set_output_embeddings(new_lm_head_decoder)
+
+ return self.get_input_embeddings()
+
+ def _get_resized_lm_head_bias(self, old_lm_head_bias, new_num_tokens):
+ """
+ Build a resized bias from the old ones. Increasing the size will add newly initialized vectors at the end.
+ Reducing the size will remove vectors from the end
+
+ Args:
+ old_lm_head_bias (`tf.Variable`):
+ Old lm head bias to be resized.
+ new_num_tokens (`int`, *optional*):
+ New number of tokens in the linear matrix.
+
+ Increasing the size will add newly initialized vectors at the end. Reducing the size will remove
+ vectors from the end. If not provided or `None`, just returns None
+
+ Return:
+ `tf.Variable`: Pointer to the resized bias.
+ """
+ # TODO (joao): flagged for replacement (by `_v2_get_resized_lm_head_bias`) due to embeddings refactor
+ new_lm_head_bias = {}
+
+ for attr, weight in old_lm_head_bias.items():
+ first_dim, old_num_tokens = (None, shape_list(weight)[0]) if tf.rank(weight) == 1 else shape_list(weight)
+ size_diff = new_num_tokens - old_num_tokens
+ final_shape = [new_num_tokens] if first_dim is None else [first_dim, new_num_tokens]
+
+ # initialize new bias
+ if tf.math.greater(size_diff, 0):
+ padding_shape = [[0, size_diff]] if first_dim is None else [[0, 0], [0, size_diff]]
+ current_bias = tf.pad(weight.value(), tf.convert_to_tensor(padding_shape), constant_values=-1)
+ num_tokens_to_copy = min(old_num_tokens, new_num_tokens)
+ mask_shape = [num_tokens_to_copy] if first_dim is None else [1, num_tokens_to_copy]
+ bias_mask = tf.fill(tf.convert_to_tensor(mask_shape), True)
+ bias_mask = tf.pad(bias_mask, tf.convert_to_tensor(padding_shape), constant_values=False)
+ else:
+ slice_from = [0] if first_dim is None else [0, 0]
+ current_bias = tf.slice(
+ weight.value(), tf.convert_to_tensor(slice_from), tf.convert_to_tensor(final_shape)
+ )
+ bias_mask = tf.fill(tf.convert_to_tensor(final_shape), True)
+
+ new_bias = self.add_weight(
+ shape=final_shape,
+ initializer="zeros",
+ trainable=True,
+ name=weight.name.split(":")[0],
+ )
+ init_bias = tf.where(bias_mask, current_bias, new_bias.value())
+
+ new_bias.assign(init_bias)
+ new_lm_head_bias[attr] = new_bias
+
+ return new_lm_head_bias
+
+ def _v2_get_resized_lm_head_bias(
+ self, old_lm_head_bias: Dict[str, tf.Variable], new_num_tokens: int
+ ) -> Dict[str, tf.Tensor]:
+ """
+ Build a resized bias from the old ones. Increasing the size will add newly initialized vectors at the end.
+ Reducing the size will remove vectors from the end
+
+ Args:
+ old_lm_head_bias (`Dict[str, tf.Variable]`):
+ Old lm head bias to be resized.
+ new_num_tokens (`int`):
+ New number of tokens in the linear matrix. Increasing the size will add newly initialized vectors at
+ the end. Reducing the size will remove vectors from the end.
+
+ Return:
+ `tf.Tensor`: Values for the resized bias.
+ """
+ new_lm_head_bias = {}
+
+ for attr, weight in old_lm_head_bias.items():
+ # Determine the size difference (depending on the shape)
+ first_dim, old_num_tokens = (None, shape_list(weight)[0]) if tf.rank(weight) == 1 else shape_list(weight)
+ size_diff = new_num_tokens - old_num_tokens
+
+ # Copy the old bias values to the new bias
+ if old_num_tokens > new_num_tokens:
+ new_bias = weight.value()[..., :new_num_tokens]
+ else:
+ padding_shape = [[0, size_diff]] if first_dim is None else [[0, 0], [0, size_diff]]
+ new_bias = tf.pad(weight.value(), tf.convert_to_tensor(padding_shape))
+
+ new_lm_head_bias[attr] = new_bias
+ return new_lm_head_bias
+
+ def _get_resized_lm_head_decoder(self, old_lm_head_decoder, new_num_tokens):
+ """
+ Build a resized decoder from the old ones. Increasing the size will add newly initialized vectors at the end.
+ Reducing the size will remove vectors from the end
+
+ Args:
+ old_lm_head_decoder (`tf.Variable`):
+ Old lm head decoder to be resized.
+ new_num_tokens (`int`, *optional*):
+ New number of tokens in the linear matrix.
+
+ Increasing the size will add newly initialized vectors at the end. Reducing the size will remove
+ vectors from the end. If not provided or `None`, just returns None
+
+ Return:
+ `tf.Variable`: Pointer to the resized decoder or None if the output embeddings are different from the input
+ ones.
+ """
+ new_lm_head_decoder = old_lm_head_decoder
+ is_input_output_equals = tf.reduce_any(
+ self._get_word_embedding_weight(self.get_input_embeddings()) == old_lm_head_decoder
+ )
+
+ if old_lm_head_decoder is not None and not is_input_output_equals:
+ old_embedding_dim = shape_list(old_lm_head_decoder)[1]
+ decoder_mask, current_decoder = init_copy_embeddings(old_lm_head_decoder, new_num_tokens)
+ new_lm_head_decoder = self.add_weight(
+ shape=(new_num_tokens, old_embedding_dim),
+ initializer="zeros",
+ trainable=True,
+ name=old_lm_head_decoder.name.split(":")[0],
+ )
+ init_decoder = tf.where(decoder_mask, current_decoder, new_lm_head_decoder.value())
+
+ new_lm_head_decoder.assign(init_decoder)
+
+ return new_lm_head_decoder
+
+ def _get_resized_embeddings(self, old_embeddings, new_num_tokens=None) -> tf.Variable:
+ """
+ Build a resized Embedding weights from a provided token Embedding weights. Increasing the size will add newly
+ initialized vectors at the end. Reducing the size will remove vectors from the end
+
+ Args:
+ old_embeddings (`tf.Variable`):
+ Old embeddings to be resized.
+ new_num_tokens (`int`, *optional*):
+ New number of tokens in the embedding matrix.
+
+ Increasing the size will add newly initialized vectors at the end. Reducing the size will remove
+ vectors from the end. If not provided or `None`, just returns a pointer to the input tokens
+ `tf.Variable` module of the model without doing anything.
+
+ Return:
+ `tf.Variable`: Pointer to the resized Embedding Module or the old Embedding Module if `new_num_tokens` is
+ `None`
+ """
+ # TODO (joao): flagged for replacement (by `_v2_get_resized_embeddings`) due to embeddings refactor
+ old_embedding_dim = shape_list(old_embeddings)[1]
+ init_range = getattr(self.config, "initializer_range", 0.02)
+ embeddings_mask, current_embeddings = init_copy_embeddings(old_embeddings, new_num_tokens)
+ new_embeddings = self.add_weight(
+ name=old_embeddings.name.split(":")[0],
+ shape=[new_num_tokens, old_embedding_dim],
+ initializer=get_initializer(init_range),
+ dtype=tf.float32,
+ )
+ init_embeddings = tf.where(embeddings_mask, current_embeddings, new_embeddings.value())
+
+ new_embeddings.assign(init_embeddings)
+
+ return new_embeddings
+
+ def _v2_get_resized_embeddings(
+ self, old_embeddings: keras.layers.Embedding, new_num_tokens: int
+ ) -> keras.layers.Embedding:
+ """
+ Build a resized Embedding layer from a provided Embedding layer. Increasing the size will add newly initialized
+ vectors at the end. Reducing the size will remove vectors from the end.
+
+ Args:
+ old_embeddings (`keras.layers.Embedding`):
+ Old embeddings to be resized.
+ new_num_tokens (`int`, *optional*):
+ New number of tokens in the embedding matrix.
+
+ Return:
+ `keras.layers.Embedding`: Resized Embedding layer.
+ """
+
+ # Get the initialization range for the embeddings
+ init_range = 0.02 # default value
+ potential_initialization_variable_names = [
+ "initializer_range", # most common
+ "initializer_factor", # e.g. T5
+ "init_std", # e.g BART
+ ]
+ for var_name in potential_initialization_variable_names:
+ if hasattr(self.config, var_name):
+ init_range = getattr(self.config, var_name)
+
+ # Get a new (initialized) embeddings layer
+ new_embeddings = keras.layers.Embedding(
+ input_dim=new_num_tokens,
+ output_dim=old_embeddings.output_dim,
+ embeddings_initializer=keras.initializers.TruncatedNormal(stddev=init_range),
+ name=old_embeddings.embeddings.name[:-13], # exact same scoped name except "/embeddings:0"
+ )
+ new_embeddings(tf.constant([[0]]))
+
+ # Copy the old embeddings to the new embeddings
+ if old_embeddings.input_dim >= new_num_tokens:
+ init_embeddings = old_embeddings.embeddings[:new_num_tokens]
+ else:
+ init_embeddings = tf.concat(
+ [old_embeddings.embeddings, new_embeddings.embeddings[old_embeddings.input_dim :]], axis=0
+ )
+ new_embeddings.embeddings.assign(init_embeddings)
+ return new_embeddings
+
+ def prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the base model.
+
+ Arguments:
+ heads_to_prune (`Dict[int, List[int]]`):
+ Dictionary with keys being selected layer indices (`int`) and associated values being the list of heads
+ to prune in said layer (list of `int`). For instance {1: [0, 2], 2: [2, 3]} will prune heads 0 and 2 on
+ layer 1 and heads 2 and 3 on layer 2.
+ """
+ raise NotImplementedError
+
+ def save_pretrained(
+ self,
+ save_directory,
+ saved_model=False,
+ version=1,
+ push_to_hub=False,
+ signatures=None,
+ max_shard_size: Union[int, str] = "5GB",
+ create_pr: bool = False,
+ safe_serialization: bool = False,
+ token: Optional[Union[str, bool]] = None,
+ **kwargs,
+ ):
+ """
+ Save a model and its configuration file to a directory, so that it can be re-loaded using the
+ [`~TFPreTrainedModel.from_pretrained`] class method.
+
+ Arguments:
+ save_directory (`str`):
+ Directory to which to save. Will be created if it doesn't exist.
+ saved_model (`bool`, *optional*, defaults to `False`):
+ If the model has to be saved in saved model format as well or not.
+ version (`int`, *optional*, defaults to 1):
+ The version of the saved model. A saved model needs to be versioned in order to be properly loaded by
+ TensorFlow Serving as detailed in the official documentation
+ https://www.tensorflow.org/tfx/serving/serving_basic
+ push_to_hub (`bool`, *optional*, defaults to `False`):
+ Whether or not to push your model to the Hugging Face model hub after saving it. You can specify the
+ repository you want to push to with `repo_id` (will default to the name of `save_directory` in your
+ namespace).
+ signatures (`dict` or `tf.function`, *optional*):
+ Model's signature used for serving. This will be passed to the `signatures` argument of model.save().
+ max_shard_size (`int` or `str`, *optional*, defaults to `"10GB"`):
+ The maximum size for a checkpoint before being sharded. Checkpoints shard will then be each of size
+ lower than this size. If expressed as a string, needs to be digits followed by a unit (like `"5MB"`).
+
+
+
+ If a single weight of the model is bigger than `max_shard_size`, it will be in its own checkpoint shard
+ which will be bigger than `max_shard_size`.
+
+
+
+ create_pr (`bool`, *optional*, defaults to `False`):
+ Whether or not to create a PR with the uploaded files or directly commit.
+ safe_serialization (`bool`, *optional*, defaults to `False`):
+ Whether to save the model using `safetensors` or the traditional TensorFlow way (that uses `h5`).
+ token (`str` or `bool`, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, or not specified, will use
+ the token generated when running `huggingface-cli login` (stored in `~/.huggingface`).
+ kwargs (`Dict[str, Any]`, *optional*):
+ Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
+ """
+ use_auth_token = kwargs.pop("use_auth_token", None)
+
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if token is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ token = use_auth_token
+
+ if token is not None:
+ kwargs["token"] = token
+
+ if os.path.isfile(save_directory):
+ logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
+ return
+
+ os.makedirs(save_directory, exist_ok=True)
+
+ if push_to_hub:
+ commit_message = kwargs.pop("commit_message", None)
+ repo_id = kwargs.pop("repo_id", save_directory.split(os.path.sep)[-1])
+ repo_id = self._create_repo(repo_id, **kwargs)
+ files_timestamps = self._get_files_timestamps(save_directory)
+
+ if saved_model:
+ # If `torch_dtype` is in the config with a torch dtype class as the value, we need to change it to string.
+ # (Although TF doesn't care about this attribute, we can't just remove it or set it to `None`.)
+ if getattr(self.config, "torch_dtype", None) is not None and not isinstance(self.config.torch_dtype, str):
+ self.config.torch_dtype = str(self.config.torch_dtype).split(".")[1]
+ if signatures is None:
+ serving_default = self.serving.get_concrete_function(self.input_signature)
+ if any(spec.dtype == tf.int32 for spec in self.input_signature.values()):
+ int64_spec = {
+ key: tf.TensorSpec(
+ shape=spec.shape, dtype=tf.int64 if spec.dtype == tf.int32 else spec.dtype, name=spec.name
+ )
+ for key, spec in self.input_signature.items()
+ }
+ int64_serving = self.serving.get_concrete_function(int64_spec)
+ signatures = {"serving_default": serving_default, "int64_serving": int64_serving}
+ else:
+ signatures = serving_default
+ saved_model_dir = os.path.join(save_directory, "saved_model", str(version))
+ self.save(saved_model_dir, include_optimizer=False, signatures=signatures)
+ logger.info(f"Saved model created in {saved_model_dir}")
+
+ # Save configuration file
+ self.config.architectures = [self.__class__.__name__[2:]]
+
+ # If we have a custom model, we copy the file defining it in the folder and set the attributes so it can be
+ # loaded from the Hub.
+ if self._auto_class is not None:
+ custom_object_save(self, save_directory, config=self.config)
+
+ self.config.save_pretrained(save_directory)
+ if self.can_generate():
+ self.generation_config.save_pretrained(save_directory)
+
+ # If we save using the predefined names, we can load using `from_pretrained`
+ weights_name = SAFE_WEIGHTS_NAME if safe_serialization else TF2_WEIGHTS_NAME
+ output_model_file = os.path.join(save_directory, weights_name)
+
+ shards, index = tf_shard_checkpoint(self.weights, max_shard_size, weights_name=weights_name)
+
+ # Clean the folder from a previous save
+ for filename in os.listdir(save_directory):
+ full_filename = os.path.join(save_directory, filename)
+ # If we have a shard file that is not going to be replaced, we delete it, but only from the main process
+ # in distributed settings to avoid race conditions.
+ weights_no_suffix = weights_name.replace(".bin", "").replace(".safetensors", "")
+ if (
+ filename.startswith(weights_no_suffix)
+ and os.path.isfile(full_filename)
+ and filename not in shards.keys()
+ ):
+ os.remove(full_filename)
+
+ if index is None:
+ if safe_serialization:
+ state_dict = {strip_model_name_and_prefix(w.name): w.value() for w in self.weights}
+ safe_save_file(state_dict, output_model_file, metadata={"format": "tf"})
+ else:
+ self.save_weights(output_model_file)
+ logger.info(f"Model weights saved in {output_model_file}")
+ else:
+ save_index_file = SAFE_WEIGHTS_INDEX_NAME if safe_serialization else TF2_WEIGHTS_INDEX_NAME
+ save_index_file = os.path.join(save_directory, save_index_file)
+ # Save the index as well
+ with open(save_index_file, "w", encoding="utf-8") as index_file:
+ content = json.dumps(index, indent=2, sort_keys=True) + "\n"
+ index_file.write(content)
+ logger.info(
+ f"The model is bigger than the maximum size per checkpoint ({max_shard_size}) and is going to be "
+ f"split in {len(shards)} checkpoint shards. You can find where each parameters has been saved in the "
+ f"index located at {save_index_file}."
+ )
+ for shard_file, shard in shards.items():
+ if safe_serialization:
+ shard_state_dict = {strip_model_name_and_prefix(w.name): w.value() for w in shard}
+ safe_save_file(
+ shard_state_dict, os.path.join(save_directory, shard_file), metadata={"format": "tf"}
+ )
+ else:
+ with h5py.File(os.path.join(save_directory, shard_file), mode="w") as shard_file:
+ layers = []
+ for layer in sorted(shard, key=lambda x: x.name):
+ if "model." in layer.name or len(layer.name.split("/")) == 1:
+ layer_name = layer.name
+ else:
+ layer_name = "/".join(layer.name.split("/")[1:])
+ param_dset = shard_file.create_dataset(
+ layer_name, layer.numpy().shape, dtype=layer.numpy().dtype
+ )
+ param_dset[:] = layer.numpy()
+ layers.append(layer_name.encode("utf8"))
+ save_attributes_to_hdf5_group(shard_file, "layer_names", layers)
+
+ if push_to_hub:
+ self._upload_modified_files(
+ save_directory,
+ repo_id,
+ files_timestamps,
+ commit_message=commit_message,
+ token=token,
+ )
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path: Optional[Union[str, os.PathLike]],
+ *model_args,
+ config: Optional[Union[PretrainedConfig, str, os.PathLike]] = None,
+ cache_dir: Optional[Union[str, os.PathLike]] = None,
+ ignore_mismatched_sizes: bool = False,
+ force_download: bool = False,
+ local_files_only: bool = False,
+ token: Optional[Union[str, bool]] = None,
+ revision: str = "main",
+ use_safetensors: Optional[bool] = None,
+ **kwargs,
+ ):
+ r"""
+ Instantiate a pretrained TF 2.0 model from a pre-trained model configuration.
+
+ The warning *Weights from XXX not initialized from pretrained model* means that the weights of XXX do not come
+ pretrained with the rest of the model. It is up to you to train those weights with a downstream fine-tuning
+ task.
+
+ The warning *Weights from XXX not used in YYY* means that the layer XXX is not used by YYY, therefore those
+ weights are discarded.
+
+ Parameters:
+ pretrained_model_name_or_path (`str`, *optional*):
+ Can be either:
+
+ - A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
+ - A path to a *directory* containing model weights saved using
+ [`~TFPreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
+ - A path or url to a *PyTorch state_dict save file* (e.g, `./pt_model/pytorch_model.bin`). In this
+ case, `from_pt` should be set to `True` and a configuration object should be provided as `config`
+ argument. This loading path is slower than converting the PyTorch model in a TensorFlow model
+ using the provided conversion scripts and loading the TensorFlow model afterwards.
+ - `None` if you are both providing the configuration and state dictionary (resp. with keyword
+ arguments `config` and `state_dict`).
+ model_args (sequence of positional arguments, *optional*):
+ All remaining positional arguments will be passed to the underlying model's `__init__` method.
+ config (`Union[PretrainedConfig, str]`, *optional*):
+ Can be either:
+
+ - an instance of a class derived from [`PretrainedConfig`],
+ - a string valid as input to [`~PretrainedConfig.from_pretrained`].
+
+ Configuration for the model to use instead of an automatically loaded configuration. Configuration can
+ be automatically loaded when:
+
+ - The model is a model provided by the library (loaded with the *model id* string of a pretrained
+ model).
+ - The model was saved using [`~TFPreTrainedModel.save_pretrained`] and is reloaded by supplying the
+ save directory.
+ - The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
+ configuration JSON file named *config.json* is found in the directory.
+ from_pt (`bool`, *optional*, defaults to `False`):
+ Load the model weights from a PyTorch state_dict save file (see docstring of
+ `pretrained_model_name_or_path` argument).
+ ignore_mismatched_sizes (`bool`, *optional*, defaults to `False`):
+ Whether or not to raise an error if some of the weights from the checkpoint do not have the same size
+ as the weights of the model (if for instance, you are instantiating a model with 10 labels from a
+ checkpoint with 3 labels).
+ cache_dir (`str`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies:
+ (`Dict[str, str], `optional`): A dictionary of proxy servers to use by protocol or endpoint, e.g.,
+ `{'http': 'foo.bar:3128', 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`): Whether ot not to also return a
+ dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (e.g., not try downloading the model).
+ token (`str` or `bool`, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, or not specified, will use
+ the token generated when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+
+
+
+
+ To test a pull request you made on the Hub, you can pass `revision="refs/pr/"`.
+
+
+
+ mirror (`str`, *optional*):
+ Mirror source to accelerate downloads in China. If you are from China and have an accessibility
+ problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety.
+ Please refer to the mirror site for more information.
+ subfolder (`str`, *optional*, defaults to `""`):
+ In case the relevant files are located inside a subfolder of the model repo on huggingface.co, you can
+ specify the folder name here.
+ tf_to_pt_weight_rename (`Callable`, *optional*):
+ A function that is called to transform the names of weights during the PyTorch to TensorFlow
+ crossloading process. This is not necessary for most models, but is useful to allow composite models to
+ be crossloaded correctly.
+ use_safetensors (`bool`, *optional*, defaults to `None`):
+ Whether or not to use `safetensors` checkpoints. Defaults to `None`. If not specified and `safetensors`
+ is not installed, it will be set to `False`.
+ kwargs (remaining dictionary of keyword arguments, *optional*):
+ Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
+ `output_attentions=True`). Behaves differently depending on whether a `config` is provided or
+ automatically loaded:
+
+ - If a configuration is provided with `config`, `**kwargs` will be directly passed to the
+ underlying model's `__init__` method (we assume all relevant updates to the configuration have
+ already been done)
+ - If a configuration is not provided, `kwargs` will be first passed to the configuration class
+ initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
+ corresponds to a configuration attribute will be used to override said attribute with the
+ supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
+ will be passed to the underlying model's `__init__` function.
+
+ Examples:
+
+ ```python
+ >>> from transformers import BertConfig, TFBertModel
+
+ >>> # Download model and configuration from huggingface.co and cache.
+ >>> model = TFBertModel.from_pretrained("google-bert/bert-base-uncased")
+ >>> # Model was saved using *save_pretrained('./test/saved_model/')* (for example purposes, not runnable).
+ >>> model = TFBertModel.from_pretrained("./test/saved_model/")
+ >>> # Update configuration during loading.
+ >>> model = TFBertModel.from_pretrained("google-bert/bert-base-uncased", output_attentions=True)
+ >>> assert model.config.output_attentions == True
+ >>> # Loading from a Pytorch model file instead of a TensorFlow checkpoint (slower, for example purposes, not runnable).
+ >>> config = BertConfig.from_json_file("./pt_model/my_pt_model_config.json")
+ >>> model = TFBertModel.from_pretrained("./pt_model/my_pytorch_model.bin", from_pt=True, config=config)
+ ```"""
+ from_pt = kwargs.pop("from_pt", False)
+ resume_download = kwargs.pop("resume_download", None)
+ proxies = kwargs.pop("proxies", None)
+ output_loading_info = kwargs.pop("output_loading_info", False)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ trust_remote_code = kwargs.pop("trust_remote_code", None)
+ _ = kwargs.pop("mirror", None)
+ load_weight_prefix = kwargs.pop("load_weight_prefix", None)
+ from_pipeline = kwargs.pop("_from_pipeline", None)
+ from_auto_class = kwargs.pop("_from_auto", False)
+ subfolder = kwargs.pop("subfolder", "")
+ commit_hash = kwargs.pop("_commit_hash", None)
+ tf_to_pt_weight_rename = kwargs.pop("tf_to_pt_weight_rename", None)
+
+ # Not relevant for TF models
+ _ = kwargs.pop("adapter_kwargs", None)
+
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if token is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ token = use_auth_token
+
+ if trust_remote_code is True:
+ logger.warning(
+ "The argument `trust_remote_code` is to be used with Auto classes. It has no effect here and is"
+ " ignored."
+ )
+
+ user_agent = {"file_type": "model", "framework": "tensorflow", "from_auto_class": from_auto_class}
+ if from_pipeline is not None:
+ user_agent["using_pipeline"] = from_pipeline
+
+ if is_offline_mode() and not local_files_only:
+ logger.info("Offline mode: forcing local_files_only=True")
+ local_files_only = True
+
+ if use_safetensors is None and not is_safetensors_available():
+ use_safetensors = False
+
+ # Load config if we don't provide a configuration
+ if not isinstance(config, PretrainedConfig):
+ config_path = config if config is not None else pretrained_model_name_or_path
+ config, model_kwargs = cls.config_class.from_pretrained(
+ config_path,
+ cache_dir=cache_dir,
+ return_unused_kwargs=True,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ token=token,
+ revision=revision,
+ _from_auto=from_auto_class,
+ _from_pipeline=from_pipeline,
+ _commit_hash=commit_hash,
+ **kwargs,
+ )
+ else:
+ model_kwargs = kwargs
+
+ if commit_hash is None:
+ commit_hash = getattr(config, "_commit_hash", None)
+
+ # This variable will flag if we're loading a sharded checkpoint. In this case the archive file is just the
+ # index of the files.
+ is_sharded = False
+ # Load model
+ if pretrained_model_name_or_path is not None:
+ pretrained_model_name_or_path = str(pretrained_model_name_or_path)
+ is_local = os.path.isdir(pretrained_model_name_or_path)
+ if is_local:
+ if from_pt and os.path.isfile(os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)):
+ # Load from a PyTorch checkpoint in priority if from_pt
+ archive_file = os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)
+ elif from_pt and os.path.isfile(os.path.join(pretrained_model_name_or_path, WEIGHTS_INDEX_NAME)):
+ # Load from a sharded PyTorch checkpoint
+ archive_file = os.path.join(pretrained_model_name_or_path, WEIGHTS_INDEX_NAME)
+ is_sharded = True
+ elif use_safetensors is not False and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, SAFE_WEIGHTS_NAME)
+ ):
+ # Load from a safetensors checkpoint
+ archive_file = os.path.join(pretrained_model_name_or_path, SAFE_WEIGHTS_NAME)
+ elif use_safetensors is not False and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, SAFE_WEIGHTS_INDEX_NAME)
+ ):
+ # Load from a sharded safetensors checkpoint
+ archive_file = os.path.join(pretrained_model_name_or_path, SAFE_WEIGHTS_INDEX_NAME)
+ is_sharded = True
+ elif os.path.isfile(os.path.join(pretrained_model_name_or_path, TF2_WEIGHTS_NAME)):
+ # Load from a TF 2.0 checkpoint
+ archive_file = os.path.join(pretrained_model_name_or_path, TF2_WEIGHTS_NAME)
+ elif os.path.isfile(os.path.join(pretrained_model_name_or_path, TF2_WEIGHTS_INDEX_NAME)):
+ # Load from a sharded TF 2.0 checkpoint
+ archive_file = os.path.join(pretrained_model_name_or_path, TF2_WEIGHTS_INDEX_NAME)
+ is_sharded = True
+
+ # At this stage we don't have a weight file so we will raise an error.
+ elif use_safetensors:
+ raise EnvironmentError(
+ f"Error no file named {SAFE_WEIGHTS_NAME} or {SAFE_WEIGHTS_INDEX_NAME} found in directory {pretrained_model_name_or_path}. "
+ f"Please make sure that the model has been saved with `safe_serialization=True` or do not "
+ f"set `use_safetensors=True`."
+ )
+ elif os.path.isfile(os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME)) or os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, WEIGHTS_INDEX_NAME)
+ ):
+ raise EnvironmentError(
+ f"Error no file named {TF2_WEIGHTS_NAME} or {SAFE_WEIGHTS_NAME} found in directory {pretrained_model_name_or_path} "
+ "but there is a file for PyTorch weights. Use `from_pt=True` to load this model from those "
+ "weights."
+ )
+ else:
+ raise EnvironmentError(
+ f"Error no file named {TF2_WEIGHTS_NAME}, {SAFE_WEIGHTS_NAME} or {WEIGHTS_NAME} found in directory "
+ f"{pretrained_model_name_or_path}."
+ )
+ elif os.path.isfile(pretrained_model_name_or_path):
+ archive_file = pretrained_model_name_or_path
+ is_local = True
+ elif os.path.isfile(pretrained_model_name_or_path + ".index"):
+ archive_file = pretrained_model_name_or_path + ".index"
+ is_local = True
+ elif is_remote_url(pretrained_model_name_or_path):
+ filename = pretrained_model_name_or_path
+ resolved_archive_file = download_url(pretrained_model_name_or_path)
+ else:
+ # set correct filename
+ if from_pt:
+ filename = WEIGHTS_NAME
+ elif use_safetensors is not False:
+ filename = SAFE_WEIGHTS_NAME
+ else:
+ filename = TF2_WEIGHTS_NAME
+
+ try:
+ # Load from URL or cache if already cached
+ cached_file_kwargs = {
+ "cache_dir": cache_dir,
+ "force_download": force_download,
+ "proxies": proxies,
+ "resume_download": resume_download,
+ "local_files_only": local_files_only,
+ "token": token,
+ "user_agent": user_agent,
+ "revision": revision,
+ "subfolder": subfolder,
+ "_raise_exceptions_for_gated_repo": False,
+ "_raise_exceptions_for_missing_entries": False,
+ "_commit_hash": commit_hash,
+ }
+ resolved_archive_file = cached_file(pretrained_model_name_or_path, filename, **cached_file_kwargs)
+
+ # Since we set _raise_exceptions_for_missing_entries=False, we don't get an exception but a None
+ # result when internet is up, the repo and revision exist, but the file does not.
+ if resolved_archive_file is None and filename == SAFE_WEIGHTS_NAME:
+ # Did not find the safetensors file, let's fallback to TF.
+ # No support for sharded safetensors yet, so we'll raise an error if that's all we find.
+ filename = TF2_WEIGHTS_NAME
+ resolved_archive_file = cached_file(
+ pretrained_model_name_or_path, TF2_WEIGHTS_NAME, **cached_file_kwargs
+ )
+ if resolved_archive_file is None and filename == TF2_WEIGHTS_NAME:
+ # Maybe the checkpoint is sharded, we try to grab the index name in this case.
+ resolved_archive_file = cached_file(
+ pretrained_model_name_or_path, TF2_WEIGHTS_INDEX_NAME, **cached_file_kwargs
+ )
+ if resolved_archive_file is not None:
+ is_sharded = True
+ if resolved_archive_file is None and filename == WEIGHTS_NAME:
+ # Maybe the checkpoint is sharded, we try to grab the index name in this case.
+ resolved_archive_file = cached_file(
+ pretrained_model_name_or_path, WEIGHTS_INDEX_NAME, **cached_file_kwargs
+ )
+ if resolved_archive_file is not None:
+ is_sharded = True
+ if resolved_archive_file is None:
+ # Otherwise, maybe there is a PyTorch or Flax model file. We try those to give a helpful error
+ # message.
+ has_file_kwargs = {
+ "revision": revision,
+ "proxies": proxies,
+ "token": token,
+ "cache_dir": cache_dir,
+ "local_files_only": local_files_only,
+ }
+ if has_file(pretrained_model_name_or_path, SAFE_WEIGHTS_INDEX_NAME, **has_file_kwargs):
+ is_sharded = True
+ elif has_file(pretrained_model_name_or_path, WEIGHTS_NAME, **has_file_kwargs):
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} does not appear to have a file named"
+ f" {TF2_WEIGHTS_NAME} but there is a file for PyTorch weights. Use `from_pt=True` to"
+ " load this model from those weights."
+ )
+ else:
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} does not appear to have a file named {WEIGHTS_NAME},"
+ f" {TF2_WEIGHTS_NAME} or {TF_WEIGHTS_NAME}"
+ )
+
+ except EnvironmentError:
+ # Raise any environment error raise by `cached_file`. It will have a helpful error message adapted
+ # to the original exception.
+ raise
+ except Exception:
+ # For any other exception, we throw a generic error.
+
+ raise EnvironmentError(
+ f"Can't load the model for '{pretrained_model_name_or_path}'. If you were trying to load it"
+ " from 'https://huggingface.co/models', make sure you don't have a local directory with the"
+ f" same name. Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a"
+ f" directory containing a file named {WEIGHTS_NAME}, {TF2_WEIGHTS_NAME} or {TF_WEIGHTS_NAME}"
+ )
+ if is_local:
+ logger.info(f"loading weights file {archive_file}")
+ resolved_archive_file = archive_file
+ filename = resolved_archive_file.split(os.path.sep)[-1]
+ else:
+ logger.info(f"loading weights file {filename} from cache at {resolved_archive_file}")
+ else:
+ resolved_archive_file = None
+
+ # We'll need to download and cache each checkpoint shard if the checkpoint is sharded.
+ if is_sharded:
+ # resolved_archive_file becomes a list of files that point to the different checkpoint shards in this case.
+ resolved_archive_file, sharded_metadata = get_checkpoint_shard_files(
+ pretrained_model_name_or_path,
+ resolved_archive_file,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ token=token,
+ user_agent=user_agent,
+ revision=revision,
+ _commit_hash=commit_hash,
+ )
+
+ safetensors_from_pt = False
+ if filename == SAFE_WEIGHTS_NAME:
+ with safe_open(resolved_archive_file, framework="tf") as f:
+ safetensors_metadata = f.metadata()
+ if safetensors_metadata is None or safetensors_metadata.get("format") not in ["pt", "tf", "flax", "mlx"]:
+ raise OSError(
+ f"The safetensors archive passed at {resolved_archive_file} does not contain the valid metadata."
+ " Make sure you save your model with the `save_pretrained` method."
+ )
+ safetensors_from_pt = safetensors_metadata.get("format") == "pt"
+ elif filename == SAFE_WEIGHTS_INDEX_NAME:
+ with safe_open(resolved_archive_file[0], framework="tf") as f:
+ safetensors_metadata = f.metadata()
+ if safetensors_metadata is None or safetensors_metadata.get("format") not in ["pt", "tf", "flax", "mlx"]:
+ raise OSError(
+ f"The safetensors archive passed at {resolved_archive_file} does not contain the valid metadata."
+ " Make sure you save your model with the `save_pretrained` method."
+ )
+ safetensors_from_pt = safetensors_metadata.get("format") == "pt"
+
+ config.name_or_path = pretrained_model_name_or_path
+
+ # composed models, *e.g.* TFRag, require special treatment when it comes to loading
+ # pre-trained weights.
+ if cls._requires_load_weight_prefix and model_kwargs.get("name") is not None:
+ model_kwargs["load_weight_prefix"] = load_weight_prefix + "/" + model_kwargs.get("name")
+
+ # Instantiate model.
+ model = cls(config, *model_args, **model_kwargs)
+
+ if tf_to_pt_weight_rename is None and hasattr(model, "tf_to_pt_weight_rename"):
+ # TODO Matt: This is a temporary workaround to allow weight renaming, but requires a method
+ # to be defined for each class that requires a rename. We can probably just have a class-level
+ # dict and a single top-level method or something and cut down a lot of boilerplate code
+ tf_to_pt_weight_rename = model.tf_to_pt_weight_rename
+
+ if from_pt:
+ from .modeling_tf_pytorch_utils import load_pytorch_checkpoint_in_tf2_model
+
+ # Load from a PyTorch checkpoint
+ return load_pytorch_checkpoint_in_tf2_model(
+ model,
+ resolved_archive_file,
+ allow_missing_keys=True,
+ output_loading_info=output_loading_info,
+ _prefix=load_weight_prefix,
+ tf_to_pt_weight_rename=tf_to_pt_weight_rename,
+ )
+
+ # we might need to extend the variable scope for composite models
+ if load_weight_prefix is not None:
+ with tf.compat.v1.variable_scope(load_weight_prefix):
+ model.build_in_name_scope() # build the network with dummy inputs
+ else:
+ model.build_in_name_scope() # build the network with dummy inputs
+
+ if safetensors_from_pt and not is_sharded:
+ from .modeling_tf_pytorch_utils import load_pytorch_state_dict_in_tf2_model
+
+ with safe_open(resolved_archive_file, framework="tf") as safetensors_archive:
+ # Load from a PyTorch safetensors checkpoint
+ # We load in TF format here because PT weights often need to be transposed, and this is much
+ # faster on GPU. Loading as numpy and transposing on CPU adds several seconds to load times.
+ return load_pytorch_state_dict_in_tf2_model(
+ model,
+ safetensors_archive,
+ tf_inputs=False, # No need to build the model again
+ allow_missing_keys=True,
+ output_loading_info=output_loading_info,
+ _prefix=load_weight_prefix,
+ ignore_mismatched_sizes=ignore_mismatched_sizes,
+ tf_to_pt_weight_rename=tf_to_pt_weight_rename,
+ )
+ elif safetensors_from_pt:
+ from .modeling_tf_pytorch_utils import load_sharded_pytorch_safetensors_in_tf2_model
+
+ return load_sharded_pytorch_safetensors_in_tf2_model(
+ model,
+ resolved_archive_file,
+ tf_inputs=False,
+ allow_missing_keys=True,
+ output_loading_info=output_loading_info,
+ _prefix=load_weight_prefix,
+ ignore_mismatched_sizes=ignore_mismatched_sizes,
+ tf_to_pt_weight_rename=tf_to_pt_weight_rename,
+ )
+
+ # 'by_name' allow us to do transfer learning by skipping/adding layers
+ # see https://github.com/tensorflow/tensorflow/blob/00fad90125b18b80fe054de1055770cfb8fe4ba3/tensorflow/python/keras/engine/network.py#L1339-L1357
+ try:
+ if is_sharded:
+ for file in resolved_archive_file:
+ os.path.isfile(file), f"Error retrieving files {file}"
+ if filename == SAFE_WEIGHTS_INDEX_NAME:
+ missing_keys, unexpected_keys, mismatched_keys = load_tf_sharded_weights_from_safetensors(
+ model,
+ resolved_archive_file,
+ ignore_mismatched_sizes=ignore_mismatched_sizes,
+ _prefix=load_weight_prefix,
+ )
+ else:
+ missing_keys, unexpected_keys, mismatched_keys = load_tf_sharded_weights(
+ model,
+ resolved_archive_file,
+ ignore_mismatched_sizes=ignore_mismatched_sizes,
+ _prefix=load_weight_prefix,
+ )
+ else:
+ # Handles both H5 and safetensors
+ missing_keys, unexpected_keys, mismatched_keys = load_tf_weights(
+ model,
+ resolved_archive_file,
+ ignore_mismatched_sizes=ignore_mismatched_sizes,
+ _prefix=load_weight_prefix,
+ )
+ except OSError as e:
+ try:
+ with open(resolved_archive_file) as f:
+ if f.read().startswith("version"):
+ raise OSError(
+ "You seem to have cloned a repository without having git-lfs installed. Please install "
+ "git-lfs and run `git lfs install` followed by `git lfs pull` in the folder "
+ "you cloned."
+ )
+ else:
+ raise ValueError from e
+ except (UnicodeDecodeError, ValueError):
+ raise OSError(
+ "Unable to load weights from h5 file. "
+ "If you tried to load a TF 2.0 model from a PyTorch checkpoint, please set from_pt=True. "
+ )
+
+ if cls._keys_to_ignore_on_load_missing is not None:
+ for pat in cls._keys_to_ignore_on_load_missing:
+ missing_keys = [k for k in missing_keys if re.search(pat, k) is None]
+
+ if cls._keys_to_ignore_on_load_unexpected is not None:
+ for pat in cls._keys_to_ignore_on_load_unexpected:
+ unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None]
+
+ if len(unexpected_keys) > 0:
+ logger.warning(
+ f"Some layers from the model checkpoint at {pretrained_model_name_or_path} were not used when"
+ f" initializing {model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are"
+ f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task or"
+ " with another architecture (e.g. initializing a BertForSequenceClassification model from a"
+ " BertForPreTraining model).\n- This IS NOT expected if you are initializing"
+ f" {model.__class__.__name__} from the checkpoint of a model that you expect to be exactly identical"
+ " (initializing a BertForSequenceClassification model from a BertForSequenceClassification model)."
+ )
+ else:
+ logger.warning(f"All model checkpoint layers were used when initializing {model.__class__.__name__}.\n")
+
+ if len(missing_keys) > 0:
+ logger.warning(
+ f"Some layers of {model.__class__.__name__} were not initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path} and are newly initialized: {missing_keys}\nYou should probably"
+ " TRAIN this model on a down-stream task to be able to use it for predictions and inference."
+ )
+ elif len(mismatched_keys) == 0:
+ logger.warning(
+ f"All the layers of {model.__class__.__name__} were initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the checkpoint"
+ f" was trained on, you can already use {model.__class__.__name__} for predictions without further"
+ " training."
+ )
+ if len(mismatched_keys) > 0:
+ mismatched_warning = "\n".join(
+ [
+ f"- {key}: found shape {shape1} in the checkpoint and {shape2} in the model instantiated"
+ for key, shape1, shape2 in mismatched_keys
+ ]
+ )
+ logger.warning(
+ f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path} and are newly initialized because the shapes did not"
+ f" match:\n{mismatched_warning}\nYou should probably TRAIN this model on a down-stream task to be able"
+ " to use it for predictions and inference."
+ )
+
+ # If it is a model with generation capabilities, attempt to load the generation config
+ if model.can_generate():
+ try:
+ model.generation_config = GenerationConfig.from_pretrained(
+ pretrained_model_name_or_path,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ token=token,
+ revision=revision,
+ subfolder=subfolder,
+ _from_auto=from_auto_class,
+ _from_pipeline=from_pipeline,
+ **kwargs,
+ )
+ except OSError:
+ logger.info(
+ "Generation config file not found, using a generation config created from the model config."
+ )
+ pass
+
+ if output_loading_info:
+ loading_info = {
+ "missing_keys": missing_keys,
+ "unexpected_keys": unexpected_keys,
+ "mismatched_keys": mismatched_keys,
+ }
+
+ return model, loading_info
+
+ return model
+
+ def push_to_hub(
+ self,
+ repo_id: str,
+ use_temp_dir: Optional[bool] = None,
+ commit_message: Optional[str] = None,
+ private: Optional[bool] = None,
+ max_shard_size: Optional[Union[int, str]] = "10GB",
+ token: Optional[Union[bool, str]] = None,
+ # (`use_auth_token` is deprecated: we have to keep it here as we don't have **kwargs)
+ use_auth_token: Optional[Union[bool, str]] = None,
+ create_pr: bool = False,
+ **base_model_card_args,
+ ) -> str:
+ """
+ Upload the model files to the 🤗 Model Hub while synchronizing a local clone of the repo in `repo_path_or_name`.
+
+ Parameters:
+ repo_id (`str`):
+ The name of the repository you want to push your model to. It should contain your organization name
+ when pushing to a given organization.
+ use_temp_dir (`bool`, *optional*):
+ Whether or not to use a temporary directory to store the files saved before they are pushed to the Hub.
+ Will default to `True` if there is no directory named like `repo_id`, `False` otherwise.
+ commit_message (`str`, *optional*):
+ Message to commit while pushing. Will default to `"Upload model"`.
+ private (`bool`, *optional*):
+ Whether to make the repo private. If `None` (default), the repo will be public unless the organization's default is private. This value is ignored if the repo already exists.
+ token (`bool` or `str`, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`). Will default to `True` if `repo_url`
+ is not specified.
+ max_shard_size (`int` or `str`, *optional*, defaults to `"10GB"`):
+ Only applicable for models. The maximum size for a checkpoint before being sharded. Checkpoints shard
+ will then be each of size lower than this size. If expressed as a string, needs to be digits followed
+ by a unit (like `"5MB"`).
+ create_pr (`bool`, *optional*, defaults to `False`):
+ Whether or not to create a PR with the uploaded files or directly commit.
+
+ Examples:
+
+ ```python
+ from transformers import TFAutoModel
+
+ model = TFAutoModel.from_pretrained("google-bert/bert-base-cased")
+
+ # Push the model to your namespace with the name "my-finetuned-bert".
+ model.push_to_hub("my-finetuned-bert")
+
+ # Push the model to an organization with the name "my-finetuned-bert".
+ model.push_to_hub("huggingface/my-finetuned-bert")
+ ```
+ """
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if token is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ token = use_auth_token
+
+ if "repo_path_or_name" in base_model_card_args:
+ warnings.warn(
+ "The `repo_path_or_name` argument is deprecated and will be removed in v5 of Transformers. Use "
+ "`repo_id` instead."
+ )
+ repo_id = base_model_card_args.pop("repo_path_or_name")
+ # Deprecation warning will be sent after for repo_url and organization
+ repo_url = base_model_card_args.pop("repo_url", None)
+ organization = base_model_card_args.pop("organization", None)
+
+ if os.path.isdir(repo_id):
+ working_dir = repo_id
+ repo_id = repo_id.split(os.path.sep)[-1]
+ else:
+ working_dir = repo_id.split("/")[-1]
+
+ repo_id = self._create_repo(
+ repo_id, private=private, token=token, repo_url=repo_url, organization=organization
+ )
+
+ if use_temp_dir is None:
+ use_temp_dir = not os.path.isdir(working_dir)
+
+ with working_or_temp_dir(working_dir=working_dir, use_temp_dir=use_temp_dir) as work_dir:
+ files_timestamps = self._get_files_timestamps(work_dir)
+
+ # Save all files.
+ self.save_pretrained(work_dir, max_shard_size=max_shard_size)
+ if hasattr(self, "history") and hasattr(self, "create_model_card"):
+ # This is a Keras model and we might be able to fish out its History and make a model card out of it
+ base_model_card_args = {
+ "output_dir": work_dir,
+ "model_name": Path(repo_id).name,
+ }
+ base_model_card_args.update(base_model_card_args)
+ self.create_model_card(**base_model_card_args)
+
+ self._upload_modified_files(
+ work_dir,
+ repo_id,
+ files_timestamps,
+ commit_message=commit_message,
+ token=token,
+ create_pr=create_pr,
+ )
+
+ @classmethod
+ def register_for_auto_class(cls, auto_class="TFAutoModel"):
+ """
+ Register this class with a given auto class. This should only be used for custom models as the ones in the
+ library are already mapped with an auto class.
+
+
+
+ This API is experimental and may have some slight breaking changes in the next releases.
+
+
+
+ Args:
+ auto_class (`str` or `type`, *optional*, defaults to `"TFAutoModel"`):
+ The auto class to register this new model with.
+ """
+ if not isinstance(auto_class, str):
+ auto_class = auto_class.__name__
+
+ import transformers.models.auto as auto_module
+
+ if not hasattr(auto_module, auto_class):
+ raise ValueError(f"{auto_class} is not a valid auto class.")
+
+ cls._auto_class = auto_class
+
+
+class TFConv1D(keras.layers.Layer):
+ """
+ 1D-convolutional layer as defined by Radford et al. for OpenAI GPT (and also used in GPT-2).
+
+ Basically works like a linear layer but the weights are transposed.
+
+ Args:
+ nf (`int`):
+ The number of output features.
+ nx (`int`):
+ The number of input features.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation to use to initialize the weights.
+ kwargs (`Dict[str, Any]`, *optional*):
+ Additional keyword arguments passed along to the `__init__` of `keras.layers.Layer`.
+ """
+
+ def __init__(self, nf, nx, initializer_range=0.02, **kwargs):
+ super().__init__(**kwargs)
+ self.nf = nf
+ self.nx = nx
+ self.initializer_range = initializer_range
+
+ def build(self, input_shape):
+ if self.built:
+ return
+ self.built = True
+ self.weight = self.add_weight(
+ "weight", shape=[self.nx, self.nf], initializer=get_initializer(self.initializer_range)
+ )
+ self.bias = self.add_weight("bias", shape=[1, self.nf], initializer=tf.zeros_initializer())
+
+ def call(self, x):
+ bz, sl = shape_list(x)[:2]
+
+ x = tf.reshape(x, [-1, self.nx])
+ x = tf.matmul(x, self.weight) + self.bias
+
+ x = tf.reshape(x, [bz, sl, self.nf])
+
+ return x
+
+
+class TFSharedEmbeddings(keras.layers.Layer):
+ r"""
+ Construct shared token embeddings.
+
+ The weights of the embedding layer is usually shared with the weights of the linear decoder when doing language
+ modeling.
+
+ Args:
+ vocab_size (`int`):
+ The size of the vocabulary, e.g., the number of unique tokens.
+ hidden_size (`int`):
+ The size of the embedding vectors.
+ initializer_range (`float`, *optional*):
+ The standard deviation to use when initializing the weights. If no value is provided, it will default to
+ \\(1/\sqrt{hidden\_size}\\).
+ kwargs (`Dict[str, Any]`, *optional*):
+ Additional keyword arguments passed along to the `__init__` of `keras.layers.Layer`.
+ """
+
+ # TODO (joao): flagged for delection due to embeddings refactor
+
+ def __init__(self, vocab_size: int, hidden_size: int, initializer_range: Optional[float] = None, **kwargs):
+ super().__init__(**kwargs)
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.initializer_range = hidden_size**-0.5 if initializer_range is None else initializer_range
+ warnings.warn(
+ "`TFSharedEmbeddings` is scheduled for deletion in v4.32, use `keras.layers.Embedding` instead.",
+ DeprecationWarning,
+ )
+
+ def build(self, input_shape):
+ """
+ Build shared token embedding layer Shared weights logic adapted from
+ https://github.com/tensorflow/models/blob/a009f4fb9d2fc4949e32192a944688925ef78659/official/transformer/v2/embedding_layer.py#L24
+ """
+ self.weight = self.add_weight(
+ "weight", shape=[self.vocab_size, self.hidden_size], initializer=get_initializer(self.initializer_range)
+ )
+ super().build(input_shape)
+
+ def get_config(self):
+ config = {
+ "vocab_size": self.vocab_size,
+ "hidden_size": self.hidden_size,
+ "initializer_range": self.initializer_range,
+ }
+ base_config = super().get_config()
+
+ return dict(list(base_config.items()) + list(config.items()))
+
+ def call(self, inputs: tf.Tensor, mode: str = "embedding") -> tf.Tensor:
+ """
+ Get token embeddings of inputs or decode final hidden state.
+
+ Args:
+ inputs (`tf.Tensor`):
+ In embedding mode, should be an int64 tensor with shape `[batch_size, length]`.
+
+ In linear mode, should be a float tensor with shape `[batch_size, length, hidden_size]`.
+ mode (`str`, defaults to `"embedding"`):
+ A valid value is either `"embedding"` or `"linear"`, the first one indicates that the layer should be
+ used as an embedding layer, the second one that the layer should be used as a linear decoder.
+
+ Returns:
+ `tf.Tensor`: In embedding mode, the output is a float32 embedding tensor, with shape `[batch_size, length,
+ embedding_size]`.
+
+ In linear mode, the output is a float32 with shape `[batch_size, length, vocab_size]`.
+
+ Raises:
+ ValueError: if `mode` is not valid.
+
+ Shared weights logic is adapted from
+ [here](https://github.com/tensorflow/models/blob/a009f4fb9d2fc4949e32192a944688925ef78659/official/transformer/v2/embedding_layer.py#L24).
+ """
+ if mode == "embedding":
+ return self._embedding(inputs)
+ elif mode == "linear":
+ return self._linear(inputs)
+ else:
+ raise ValueError(f"mode {mode} is not valid.")
+
+ def _embedding(self, input_ids):
+ """Applies embedding based on inputs tensor."""
+ return tf.gather(self.weight, input_ids)
+
+ def _linear(self, inputs):
+ """
+ Computes logits by running inputs through a linear layer.
+
+ Args:
+ inputs: A float32 tensor with shape [..., hidden_size]
+
+ Returns:
+ float32 tensor with shape [..., vocab_size].
+ """
+ first_dims = shape_list(inputs)[:-1]
+ x = tf.reshape(inputs, [-1, self.hidden_size])
+ logits = tf.matmul(x, self.weight, transpose_b=True)
+
+ return tf.reshape(logits, first_dims + [self.vocab_size])
+
+
+class TFSequenceSummary(keras.layers.Layer):
+ """
+ Compute a single vector summary of a sequence hidden states.
+
+ Args:
+ config ([`PretrainedConfig`]):
+ The config used by the model. Relevant arguments in the config class of the model are (refer to the actual
+ config class of your model for the default values it uses):
+
+ - **summary_type** (`str`) -- The method to use to make this summary. Accepted values are:
+
+ - `"last"` -- Take the last token hidden state (like XLNet)
+ - `"first"` -- Take the first token hidden state (like Bert)
+ - `"mean"` -- Take the mean of all tokens hidden states
+ - `"cls_index"` -- Supply a Tensor of classification token position (GPT/GPT-2)
+ - `"attn"` -- Not implemented now, use multi-head attention
+
+ - **summary_use_proj** (`bool`) -- Add a projection after the vector extraction.
+ - **summary_proj_to_labels** (`bool`) -- If `True`, the projection outputs to `config.num_labels` classes
+ (otherwise to `config.hidden_size`).
+ - **summary_activation** (`Optional[str]`) -- Set to `"tanh"` to add a tanh activation to the output,
+ another string or `None` will add no activation.
+ - **summary_first_dropout** (`float`) -- Optional dropout probability before the projection and activation.
+ - **summary_last_dropout** (`float`)-- Optional dropout probability after the projection and activation.
+
+ initializer_range (`float`, *optional*, defaults to 0.02): The standard deviation to use to initialize the weights.
+ kwargs (`Dict[str, Any]`, *optional*):
+ Additional keyword arguments passed along to the `__init__` of `keras.layers.Layer`.
+ """
+
+ def __init__(self, config: PretrainedConfig, initializer_range: float = 0.02, **kwargs):
+ super().__init__(**kwargs)
+
+ self.summary_type = config.summary_type if hasattr(config, "summary_use_proj") else "last"
+ if self.summary_type == "attn":
+ # We should use a standard multi-head attention module with absolute positional embedding for that.
+ # Cf. https://github.com/zihangdai/xlnet/blob/master/modeling.py#L253-L276
+ # We can probably just use the multi-head attention module of PyTorch >=1.1.0
+ raise NotImplementedError
+
+ self.has_summary = hasattr(config, "summary_use_proj") and config.summary_use_proj
+ if self.has_summary:
+ if hasattr(config, "summary_proj_to_labels") and config.summary_proj_to_labels and config.num_labels > 0:
+ num_classes = config.num_labels
+ else:
+ num_classes = config.hidden_size
+ self.summary = keras.layers.Dense(
+ num_classes, kernel_initializer=get_initializer(initializer_range), name="summary"
+ )
+
+ self.has_activation = False
+ activation_string = getattr(config, "summary_activation", None)
+ if activation_string is not None:
+ self.has_activation = True
+ self.activation = get_tf_activation(activation_string)
+
+ self.has_first_dropout = hasattr(config, "summary_first_dropout") and config.summary_first_dropout > 0
+ if self.has_first_dropout:
+ self.first_dropout = keras.layers.Dropout(config.summary_first_dropout)
+
+ self.has_last_dropout = hasattr(config, "summary_last_dropout") and config.summary_last_dropout > 0
+ if self.has_last_dropout:
+ self.last_dropout = keras.layers.Dropout(config.summary_last_dropout)
+ self.hidden_size = config.hidden_size
+
+ def call(self, inputs, cls_index=None, training=False):
+ if not isinstance(inputs, (dict, tuple, list)):
+ hidden_states = inputs
+ elif isinstance(inputs, (tuple, list)):
+ hidden_states = inputs[0]
+ cls_index = inputs[1] if len(inputs) > 1 else None
+ assert len(inputs) <= 2, "Too many inputs."
+ else:
+ hidden_states = inputs.get("hidden_states")
+ cls_index = inputs.get("cls_index", None)
+
+ if self.summary_type == "last":
+ output = hidden_states[:, -1]
+ elif self.summary_type == "first":
+ output = hidden_states[:, 0]
+ elif self.summary_type == "mean":
+ output = tf.reduce_mean(hidden_states, axis=1)
+ elif self.summary_type == "cls_index":
+ hidden_shape = shape_list(hidden_states) # e.g. [batch, num choices, seq length, hidden dims]
+ if cls_index is None:
+ cls_index = tf.fill(
+ hidden_shape[:-2], hidden_shape[-2] - 1
+ ) # A tensor full of shape [batch] or [batch, num choices] full of sequence length
+ cls_shape = shape_list(cls_index)
+ if len(cls_shape) <= len(hidden_shape) - 2:
+ cls_index = tf.expand_dims(cls_index, axis=-1)
+ # else:
+ # cls_index = cls_index[..., tf.newaxis]
+ # cls_index = cls_index.expand((-1,) * (cls_index.dim()-1) + (hidden_states.size(-1),))
+ # shape of cls_index: (bsz, XX, 1, hidden_size) where XX are optional leading dim of hidden_states
+ output = tf.gather(hidden_states, cls_index, batch_dims=len(hidden_shape) - 2)
+ output = tf.squeeze(
+ output, axis=len(hidden_shape) - 2
+ ) # shape of output: (batch, num choices, hidden_size)
+ elif self.summary_type == "attn":
+ raise NotImplementedError
+
+ if self.has_first_dropout:
+ output = self.first_dropout(output, training=training)
+
+ if self.has_summary:
+ output = self.summary(output)
+
+ if self.has_activation:
+ output = self.activation(output)
+
+ if self.has_last_dropout:
+ output = self.last_dropout(output, training=training)
+
+ return output
+
+ def build(self, input_shape):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "summary", None) is not None:
+ with tf.name_scope("summary"):
+ self.summary.build(self.hidden_size)
+
+
+def get_initializer(initializer_range: float = 0.02) -> keras.initializers.TruncatedNormal:
+ """
+ Creates a `keras.initializers.TruncatedNormal` with the given range.
+
+ Args:
+ initializer_range (*float*, defaults to 0.02): Standard deviation of the initializer range.
+
+ Returns:
+ `keras.initializers.TruncatedNormal`: The truncated normal initializer.
+ """
+ return keras.initializers.TruncatedNormal(stddev=initializer_range)
diff --git a/docs/transformers/src/transformers/modeling_utils.py b/docs/transformers/src/transformers/modeling_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..adac0890e6dbaedb32e6bb6cdf64c081e75f25b6
--- /dev/null
+++ b/docs/transformers/src/transformers/modeling_utils.py
@@ -0,0 +1,6005 @@
+# coding=utf-8
+# Copyright 2018 The Google AI Language Team Authors, Facebook AI Research authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import collections
+import copy
+import functools
+import gc
+import importlib.metadata
+import inspect
+import itertools
+import json
+import os
+import re
+import shutil
+import tempfile
+import warnings
+from collections import defaultdict
+from collections.abc import MutableMapping
+from contextlib import contextmanager
+from dataclasses import dataclass
+from enum import Enum
+from functools import partial, wraps
+from threading import Thread
+from typing import Any, Callable, Dict, List, Optional, Set, Tuple, Type, TypeVar, Union
+from zipfile import is_zipfile
+
+import torch
+import torch.distributed.tensor
+from huggingface_hub import split_torch_state_dict_into_shards
+from packaging import version
+from torch import Tensor, nn
+from torch.distributions import constraints
+from torch.nn import CrossEntropyLoss, Identity
+from torch.utils.checkpoint import checkpoint
+
+from transformers.utils import is_torchao_available
+
+
+if is_torchao_available():
+ from torchao.quantization import Int4WeightOnlyConfig
+
+from .activations import get_activation
+from .configuration_utils import PretrainedConfig
+from .dynamic_module_utils import custom_object_save
+from .generation import CompileConfig, GenerationConfig
+from .integrations import PeftAdapterMixin, deepspeed_config, is_deepspeed_zero3_enabled
+from .integrations.accelerate import find_tied_parameters, init_empty_weights
+from .integrations.deepspeed import _load_state_dict_into_zero3_model, is_deepspeed_available
+from .integrations.flash_attention import flash_attention_forward
+from .integrations.flex_attention import flex_attention_forward
+from .integrations.sdpa_attention import sdpa_attention_forward
+from .integrations.tensor_parallel import (
+ SUPPORTED_TP_STYLES,
+ shard_and_distribute_module,
+)
+from .loss.loss_utils import LOSS_MAPPING
+from .pytorch_utils import ( # noqa: F401
+ Conv1D,
+ apply_chunking_to_forward,
+ find_pruneable_heads_and_indices,
+ id_tensor_storage,
+ prune_conv1d_layer,
+ prune_layer,
+ prune_linear_layer,
+)
+from .quantizers import AutoHfQuantizer, HfQuantizer
+from .quantizers.quantizers_utils import get_module_from_name
+from .safetensors_conversion import auto_conversion
+from .utils import (
+ ADAPTER_SAFE_WEIGHTS_NAME,
+ ADAPTER_WEIGHTS_NAME,
+ CONFIG_NAME,
+ DUMMY_INPUTS,
+ FLAX_WEIGHTS_NAME,
+ SAFE_WEIGHTS_INDEX_NAME,
+ SAFE_WEIGHTS_NAME,
+ TF2_WEIGHTS_NAME,
+ TF_WEIGHTS_NAME,
+ WEIGHTS_INDEX_NAME,
+ WEIGHTS_NAME,
+ ContextManagers,
+ ModelOutput,
+ PushToHubMixin,
+ cached_file,
+ copy_func,
+ download_url,
+ extract_commit_hash,
+ has_file,
+ is_accelerate_available,
+ is_bitsandbytes_available,
+ is_flash_attn_2_available,
+ is_kernels_available,
+ is_offline_mode,
+ is_optimum_available,
+ is_peft_available,
+ is_remote_url,
+ is_safetensors_available,
+ is_torch_flex_attn_available,
+ is_torch_greater_or_equal,
+ is_torch_mlu_available,
+ is_torch_npu_available,
+ is_torch_sdpa_available,
+ is_torch_xla_available,
+ logging,
+ replace_return_docstrings,
+ strtobool,
+)
+from .utils.hub import create_and_tag_model_card, get_checkpoint_shard_files
+from .utils.import_utils import (
+ ENV_VARS_TRUE_VALUES,
+ is_sagemaker_mp_enabled,
+ is_torch_fx_proxy,
+ is_torchdynamo_compiling,
+)
+from .utils.quantization_config import BitsAndBytesConfig, QuantizationMethod
+
+
+XLA_USE_BF16 = os.environ.get("XLA_USE_BF16", "0").upper()
+XLA_DOWNCAST_BF16 = os.environ.get("XLA_DOWNCAST_BF16", "0").upper()
+
+
+if is_accelerate_available():
+ from accelerate import dispatch_model, infer_auto_device_map
+ from accelerate.hooks import add_hook_to_module
+ from accelerate.utils import (
+ check_tied_parameters_on_same_device,
+ extract_model_from_parallel,
+ get_balanced_memory,
+ get_max_memory,
+ load_offloaded_weights,
+ offload_weight,
+ save_offload_index,
+ )
+
+ accelerate_version = version.parse(importlib.metadata.version("accelerate"))
+ if accelerate_version >= version.parse("0.31"):
+ from accelerate.utils.modeling import get_state_dict_from_offload
+
+if is_safetensors_available():
+ from safetensors import safe_open
+ from safetensors.torch import load_file as safe_load_file
+ from safetensors.torch import save_file as safe_save_file
+
+
+if is_deepspeed_available():
+ import deepspeed
+
+if is_kernels_available():
+ from kernels import get_kernel
+
+logger = logging.get_logger(__name__)
+
+
+_init_weights = True
+_is_quantized = False
+_is_ds_init_called = False
+_torch_distributed_available = torch.distributed.is_available()
+
+
+def is_fsdp_enabled():
+ return (
+ torch.distributed.is_available()
+ and torch.distributed.is_initialized()
+ and strtobool(os.environ.get("ACCELERATE_USE_FSDP", "False")) == 1
+ and strtobool(os.environ.get("FSDP_CPU_RAM_EFFICIENT_LOADING", "False")) == 1
+ )
+
+
+def is_local_dist_rank_0():
+ return (
+ torch.distributed.is_available()
+ and torch.distributed.is_initialized()
+ and int(os.environ.get("LOCAL_RANK", -1)) == 0
+ )
+
+
+if is_sagemaker_mp_enabled():
+ import smdistributed.modelparallel.torch as smp
+ from smdistributed.modelparallel import __version__ as SMP_VERSION
+
+ IS_SAGEMAKER_MP_POST_1_10 = version.parse(SMP_VERSION) >= version.parse("1.10")
+else:
+ IS_SAGEMAKER_MP_POST_1_10 = False
+
+if is_peft_available():
+ from .utils import find_adapter_config_file
+
+
+SpecificPreTrainedModelType = TypeVar("SpecificPreTrainedModelType", bound="PreTrainedModel")
+
+TORCH_INIT_FUNCTIONS = {
+ "uniform_": nn.init.uniform_,
+ "normal_": nn.init.normal_,
+ "trunc_normal_": nn.init.trunc_normal_,
+ "constant_": nn.init.constant_,
+ "xavier_uniform_": nn.init.xavier_uniform_,
+ "xavier_normal_": nn.init.xavier_normal_,
+ "kaiming_uniform_": nn.init.kaiming_uniform_,
+ "kaiming_normal_": nn.init.kaiming_normal_,
+ "uniform": nn.init.uniform,
+ "normal": nn.init.normal,
+ "xavier_uniform": nn.init.xavier_uniform,
+ "xavier_normal": nn.init.xavier_normal,
+ "kaiming_uniform": nn.init.kaiming_uniform,
+ "kaiming_normal": nn.init.kaiming_normal,
+}
+
+
+@contextmanager
+def no_init_weights():
+ """
+ Context manager to globally disable weight initialization to speed up loading large models.
+ """
+ global _init_weights
+ old_init_weights = _init_weights
+
+ _init_weights = False
+
+ def _skip_init(*args, **kwargs):
+ pass
+
+ # Save the original initialization functions
+ for name, init_func in TORCH_INIT_FUNCTIONS.items():
+ setattr(torch.nn.init, name, _skip_init)
+
+ try:
+ yield
+ finally:
+ _init_weights = old_init_weights
+ # Restore the original initialization functions
+ for name, init_func in TORCH_INIT_FUNCTIONS.items():
+ setattr(torch.nn.init, name, init_func)
+
+
+@contextmanager
+def set_quantized_state():
+ global _is_quantized
+ _is_quantized = True
+ try:
+ yield
+ finally:
+ _is_quantized = False
+
+
+# Skip recursive calls to deepspeed.zero.Init to avoid pinning errors.
+# This issue occurs with ZeRO stage 3 when using NVMe offloading.
+# For more details, refer to issue #34429.
+@contextmanager
+def set_zero3_state():
+ global _is_ds_init_called
+ _is_ds_init_called = True
+ try:
+ yield
+ finally:
+ _is_ds_init_called = False
+
+
+def restore_default_torch_dtype(func):
+ """
+ Decorator to restore the default torch dtype
+ at the end of the function. Serves
+ as a backup in case calling the function raises
+ an error after the function has changed the default dtype but before it could restore it.
+ """
+
+ @wraps(func)
+ def _wrapper(*args, **kwargs):
+ old_dtype = torch.get_default_dtype()
+ try:
+ return func(*args, **kwargs)
+ finally:
+ torch.set_default_dtype(old_dtype)
+
+ return _wrapper
+
+
+def get_torch_context_manager_or_global_device():
+ """
+ Test if a device context manager is currently in use, or if it is not the case, check if the default device
+ is not "cpu". This is used to infer the correct device to load the model on, in case `device_map` is not provided.
+ """
+ device_in_context = torch.tensor([]).device
+ default_device = torch.get_default_device()
+ # This case means no context manager was used -> we still check if the default that was potentially set is not cpu
+ if device_in_context == default_device:
+ if default_device != torch.device("cpu"):
+ return default_device
+ return None
+ return device_in_context
+
+
+def get_parameter_device(parameter: Union[nn.Module, "ModuleUtilsMixin"]):
+ try:
+ return next(parameter.parameters()).device
+ except StopIteration:
+ # For nn.DataParallel compatibility in PyTorch 1.5
+
+ def find_tensor_attributes(module: nn.Module) -> List[Tuple[str, Tensor]]:
+ tuples = [(k, v) for k, v in module.__dict__.items() if torch.is_tensor(v)]
+ return tuples
+
+ gen = parameter._named_members(get_members_fn=find_tensor_attributes)
+ first_tuple = next(gen)
+ return first_tuple[1].device
+
+
+def get_parameter_dtype(parameter: Union[nn.Module, "ModuleUtilsMixin"]):
+ """
+ Returns the first found floating dtype in parameters if there is one, otherwise returns the last dtype it found.
+ """
+ last_dtype = None
+ for t in parameter.parameters():
+ last_dtype = t.dtype
+ if t.is_floating_point():
+ # Adding fix for https://github.com/pytorch/xla/issues/4152
+ # Fixes issue where the model code passes a value that is out of range for XLA_USE_BF16=1
+ # and XLA_DOWNCAST_BF16=1 so the conversion would cast it to -inf
+ # NOTE: `is_torch_xla_available()` is checked last as it induces a graph break in torch dynamo
+ if XLA_USE_BF16 in ENV_VARS_TRUE_VALUES and is_torch_xla_available():
+ return torch.bfloat16
+ if XLA_DOWNCAST_BF16 in ENV_VARS_TRUE_VALUES and is_torch_xla_available():
+ if t.dtype == torch.float:
+ return torch.bfloat16
+ if t.dtype == torch.double:
+ return torch.float32
+ return t.dtype
+
+ if last_dtype is not None:
+ # if no floating dtype was found return whatever the first dtype is
+ return last_dtype
+
+ # For nn.DataParallel compatibility in PyTorch > 1.5
+ def find_tensor_attributes(module: nn.Module) -> List[Tuple[str, Tensor]]:
+ tuples = [(k, v) for k, v in module.__dict__.items() if torch.is_tensor(v)]
+ return tuples
+
+ gen = parameter._named_members(get_members_fn=find_tensor_attributes)
+ last_tuple = None
+ for tuple in gen:
+ last_tuple = tuple
+ if tuple[1].is_floating_point():
+ return tuple[1].dtype
+
+ if last_tuple is not None:
+ # fallback to the last dtype
+ return last_tuple[1].dtype
+
+ # fallback to buffer dtype
+ for t in parameter.buffers():
+ last_dtype = t.dtype
+ if t.is_floating_point():
+ return t.dtype
+ return last_dtype
+
+
+def get_state_dict_dtype(state_dict):
+ """
+ Returns the first found floating dtype in `state_dict` if there is one, otherwise returns the first dtype.
+ """
+ for t in state_dict.values():
+ if t.is_floating_point():
+ return t.dtype
+
+ # if no floating dtype was found return whatever the first dtype is
+ else:
+ return next(state_dict.values()).dtype
+
+
+def load_sharded_checkpoint(model, folder, strict=True, prefer_safe=True):
+ """
+ This is the same as
+ [`torch.nn.Module.load_state_dict`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html?highlight=load_state_dict#torch.nn.Module.load_state_dict)
+ but for a sharded checkpoint.
+
+ This load is performed efficiently: each checkpoint shard is loaded one by one in RAM and deleted after being
+ loaded in the model.
+
+ Args:
+ model (`torch.nn.Module`): The model in which to load the checkpoint.
+ folder (`str` or `os.PathLike`): A path to a folder containing the sharded checkpoint.
+ strict (`bool`, *optional*, defaults to `True`):
+ Whether to strictly enforce that the keys in the model state dict match the keys in the sharded checkpoint.
+ prefer_safe (`bool`, *optional*, defaults to `False`):
+ If both safetensors and PyTorch save files are present in checkpoint and `prefer_safe` is True, the
+ safetensors files will be loaded. Otherwise, PyTorch files are always loaded when possible.
+
+ Returns:
+ `NamedTuple`: A named tuple with `missing_keys` and `unexpected_keys` fields
+ - `missing_keys` is a list of str containing the missing keys
+ - `unexpected_keys` is a list of str containing the unexpected keys
+ """
+ # Load the index
+ index_file = os.path.join(folder, WEIGHTS_INDEX_NAME)
+ safe_index_file = os.path.join(folder, SAFE_WEIGHTS_INDEX_NAME)
+
+ index_present = os.path.isfile(index_file)
+ safe_index_present = os.path.isfile(safe_index_file)
+
+ if not index_present and not (safe_index_present and is_safetensors_available()):
+ filenames = (
+ (WEIGHTS_INDEX_NAME, SAFE_WEIGHTS_INDEX_NAME) if is_safetensors_available() else (WEIGHTS_INDEX_NAME,)
+ )
+ raise ValueError(f"Can't find a checkpoint index ({' or '.join(filenames)}) in {folder}.")
+
+ load_safe = False
+ if safe_index_present:
+ if prefer_safe:
+ if is_safetensors_available():
+ load_safe = True # load safe due to preference
+ else:
+ logger.warning(
+ f"Cannot load sharded checkpoint at {folder} safely since safetensors is not installed!"
+ )
+ elif not index_present:
+ load_safe = True # load safe since we have no other choice
+
+ load_index = safe_index_file if load_safe else index_file
+
+ with open(load_index, "r", encoding="utf-8") as f:
+ index = json.load(f)
+
+ shard_files = list(set(index["weight_map"].values()))
+
+ # If strict=True, error before loading any of the state dicts.
+ loaded_keys = index["weight_map"].keys()
+ model_keys = model.state_dict().keys()
+ missing_keys = [key for key in model_keys if key not in loaded_keys]
+ unexpected_keys = [key for key in loaded_keys if key not in model_keys]
+ if strict and (len(missing_keys) > 0 or len(unexpected_keys) > 0):
+ error_message = f"Error(s) in loading state_dict for {model.__class__.__name__}"
+ if len(missing_keys) > 0:
+ str_missing_keys = ",".join([f'"{k}"' for k in missing_keys])
+ error_message += f"\nMissing key(s): {str_missing_keys}."
+ if len(unexpected_keys) > 0:
+ str_unexpected_keys = ",".join([f'"{k}"' for k in unexpected_keys])
+ error_message += f"\nMissing key(s): {str_unexpected_keys}."
+ raise RuntimeError(error_message)
+
+ loader = safe_load_file if load_safe else partial(torch.load, map_location="cpu", weights_only=True)
+
+ for shard_file in shard_files:
+ state_dict = loader(os.path.join(folder, shard_file))
+ model.load_state_dict(state_dict, strict=False)
+
+ # Make sure memory is freed before we load the next state dict.
+ del state_dict
+ gc.collect()
+
+ # Return the same thing as PyTorch load_state_dict function.
+ return torch.nn.modules.module._IncompatibleKeys(missing_keys, unexpected_keys)
+
+
+str_to_torch_dtype = {
+ "BOOL": torch.bool,
+ "U8": torch.uint8,
+ "I8": torch.int8,
+ "I16": torch.int16,
+ "F16": torch.float16,
+ "BF16": torch.bfloat16,
+ "I32": torch.int32,
+ "F32": torch.float32,
+ "F64": torch.float64,
+ "I64": torch.int64,
+ "F8_E4M3": torch.float8_e4m3fn,
+ "F8_E5M2": torch.float8_e5m2,
+}
+
+
+if is_torch_greater_or_equal("2.3.0"):
+ str_to_torch_dtype["U16"] = torch.uint16
+ str_to_torch_dtype["U32"] = torch.uint32
+ str_to_torch_dtype["U64"] = torch.uint64
+
+
+def load_state_dict(
+ checkpoint_file: Union[str, os.PathLike],
+ is_quantized: bool = False,
+ map_location: Optional[Union[str, torch.device]] = "cpu",
+ weights_only: bool = True,
+):
+ """
+ Reads a `safetensor` or a `.bin` checkpoint file. We load the checkpoint on "cpu" by default.
+ """
+ if checkpoint_file.endswith(".safetensors") and is_safetensors_available():
+ with safe_open(checkpoint_file, framework="pt") as f:
+ metadata = f.metadata()
+
+ if metadata is not None and metadata.get("format") not in ["pt", "tf", "flax", "mlx"]:
+ raise OSError(
+ f"The safetensors archive passed at {checkpoint_file} does not contain the valid metadata. Make sure "
+ "you save your model with the `save_pretrained` method."
+ )
+ state_dict = {}
+ for k in f.keys():
+ k_dtype = f.get_slice(k).get_dtype()
+ if k_dtype in str_to_torch_dtype:
+ dtype = str_to_torch_dtype[k_dtype]
+ else:
+ raise ValueError(f"Cannot load safetensors of unknown dtype {k_dtype}")
+ if map_location == "meta":
+ state_dict[k] = torch.empty(size=f.get_slice(k).get_shape(), dtype=dtype, device="meta")
+ else:
+ state_dict[k] = f.get_tensor(k)
+ return state_dict
+
+ try:
+ if map_location is None:
+ if (
+ (
+ is_deepspeed_zero3_enabled()
+ and torch.distributed.is_initialized()
+ and torch.distributed.get_rank() > 0
+ )
+ or (is_fsdp_enabled() and not is_local_dist_rank_0())
+ ) and not is_quantized:
+ map_location = "meta"
+ else:
+ map_location = "cpu"
+ extra_args = {}
+ # mmap can only be used with files serialized with zipfile-based format.
+ if isinstance(checkpoint_file, str) and map_location != "meta" and is_zipfile(checkpoint_file):
+ extra_args = {"mmap": True}
+ return torch.load(
+ checkpoint_file,
+ map_location=map_location,
+ weights_only=weights_only,
+ **extra_args,
+ )
+ except Exception as e:
+ try:
+ with open(checkpoint_file) as f:
+ if f.read(7) == "version":
+ raise OSError(
+ "You seem to have cloned a repository without having git-lfs installed. Please install "
+ "git-lfs and run `git lfs install` followed by `git lfs pull` in the folder "
+ "you cloned."
+ )
+ else:
+ raise ValueError(
+ f"Unable to locate the file {checkpoint_file} which is necessary to load this pretrained "
+ "model. Make sure you have saved the model properly."
+ ) from e
+ except (UnicodeDecodeError, ValueError):
+ raise OSError(
+ f"Unable to load weights from pytorch checkpoint file for '{checkpoint_file}' "
+ f"at '{checkpoint_file}'. "
+ "If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True."
+ )
+
+
+def set_initialized_submodules(model, state_dict_keys):
+ """
+ Sets the `_is_hf_initialized` flag in all submodules of a given model when all its weights are in the loaded state
+ dict.
+ """
+ state_dict_keys = set(state_dict_keys)
+ not_initialized_submodules = {}
+ for module_name, module in model.named_modules():
+ if module_name == "":
+ # When checking if the root module is loaded there's no need to prepend module_name.
+ module_keys = set(module.state_dict())
+ else:
+ module_keys = {f"{module_name}.{k}" for k in module.state_dict()}
+ if module_keys.issubset(state_dict_keys):
+ module._is_hf_initialized = True
+ else:
+ not_initialized_submodules[module_name] = module
+ return not_initialized_submodules
+
+
+def _end_ptr(tensor: torch.Tensor) -> int:
+ # extract the end of the pointer if the tensor is a slice of a bigger tensor
+ if tensor.nelement():
+ stop = tensor.view(-1)[-1].data_ptr() + tensor.element_size()
+ else:
+ stop = tensor.data_ptr()
+ return stop
+
+
+def _get_tied_weight_keys(module: nn.Module, prefix=""):
+ tied_weight_keys = []
+ if getattr(module, "_tied_weights_keys", None) is not None:
+ names = [f"{prefix}.{k}" if prefix else k for k in module._tied_weights_keys]
+ tied_weight_keys.extend(names)
+ if getattr(module, "_dynamic_tied_weights_keys", None) is not None:
+ names = [f"{prefix}.{k}" if prefix else k for k in module._dynamic_tied_weights_keys]
+ tied_weight_keys.extend(names)
+ for name, submodule in module.named_children():
+ local_prefix = f"{prefix}.{name}" if prefix else name
+ tied_weight_keys.extend(_get_tied_weight_keys(submodule, prefix=local_prefix))
+ return tied_weight_keys
+
+
+def _find_disjoint(tensors: List[Set[str]], state_dict: Dict[str, torch.Tensor]) -> Tuple[List[Set[str]], List[str]]:
+ filtered_tensors = []
+ for shared in tensors:
+ if len(shared) < 2:
+ filtered_tensors.append(shared)
+ continue
+
+ areas = []
+ for name in shared:
+ tensor = state_dict[name]
+ areas.append((tensor.data_ptr(), _end_ptr(tensor), name))
+ areas.sort()
+
+ _, last_stop, last_name = areas[0]
+ filtered_tensors.append({last_name})
+ for start, stop, name in areas[1:]:
+ if start >= last_stop:
+ filtered_tensors.append({name})
+ else:
+ filtered_tensors[-1].add(name)
+ last_stop = stop
+ disjoint_tensors = []
+ shared_tensors = []
+ for tensors in filtered_tensors:
+ if len(tensors) == 1:
+ disjoint_tensors.append(tensors.pop())
+ else:
+ shared_tensors.append(tensors)
+ return shared_tensors, disjoint_tensors
+
+
+def _find_identical(tensors: List[Set[str]], state_dict: Dict[str, torch.Tensor]) -> Tuple[List[Set[str]], Set[str]]:
+ shared_tensors = []
+ identical = []
+ for shared in tensors:
+ if len(shared) < 2:
+ continue
+
+ areas = collections.defaultdict(set)
+ for name in shared:
+ tensor = state_dict[name]
+ area = (tensor.device, tensor.data_ptr(), _end_ptr(tensor))
+ areas[area].add(name)
+ if len(areas) == 1:
+ identical.append(shared)
+ else:
+ shared_tensors.append(shared)
+ return shared_tensors, identical
+
+
+def _infer_parameter_dtype(
+ model: "PreTrainedModel",
+ param_name: str,
+ empty_param: torch.Tensor,
+ keep_in_fp32_regex: Optional[re.Pattern] = None,
+ hf_quantizer: Optional[HfQuantizer] = None,
+) -> Union[bool, Optional[torch.dtype]]:
+ try:
+ old_param = model.get_parameter_or_buffer(param_name)
+ except Exception as e:
+ if hf_quantizer is not None and hf_quantizer.quantization_config.quant_method in {
+ QuantizationMethod.HQQ,
+ QuantizationMethod.QUARK,
+ }:
+ return True, None
+ else:
+ raise e
+ is_torch_e4m3fn_available = hasattr(torch, "float8_e4m3fn")
+ # We convert floating dtypes to the `dtype` passed except for float8_e4m3fn type. We also want to keep the buffers/params
+ # in int/uint/bool and not cast them.
+ casting_dtype = None
+ is_param_float8_e4m3fn = is_torch_e4m3fn_available and empty_param.dtype == torch.float8_e4m3fn
+ if empty_param.dtype.is_floating_point and not is_param_float8_e4m3fn:
+ # First fp32 if part of the exception list
+ if keep_in_fp32_regex is not None and keep_in_fp32_regex.search(param_name):
+ casting_dtype = torch.float32
+ # Then dtype that was instantiated in the meta model -- note that this respects subconfigs dtypes
+ elif hf_quantizer is not None:
+ casting_dtype = model.config._pre_quantization_dtype
+ else:
+ casting_dtype = old_param.dtype
+ return old_param is not None and old_param.is_contiguous(), casting_dtype
+
+
+def _load_parameter_into_model(model: "PreTrainedModel", param_name: str, tensor: torch.Tensor):
+ """Cast a single parameter `param_name` into the `model`, with value `tensor`."""
+ module, param_type = get_module_from_name(model, param_name)
+ # This will check potential shape mismatch if skipped before
+ module.load_state_dict({param_type: tensor}, strict=False, assign=True)
+
+
+@torch.no_grad()
+def _load_state_dict_into_meta_model(
+ model: "PreTrainedModel",
+ state_dict: Dict,
+ shard_file: str,
+ expected_keys: List[str],
+ reverse_renaming_mapping: Dict[str, str],
+ device_map: Optional[Dict] = None,
+ disk_offload_folder: Optional[str] = None,
+ disk_offload_index: Optional[Dict] = None,
+ cpu_offload_folder: Optional[str] = None,
+ cpu_offload_index: Optional[Dict] = None,
+ hf_quantizer: Optional[HfQuantizer] = None,
+ is_safetensors: bool = False,
+ keep_in_fp32_regex: Optional[re.Pattern] = None,
+ unexpected_keys: Optional[List[str]] = None, # passing `unexpected` for cleanup from quantization items
+ device_mesh: Optional["torch.distributed.device_mesh.DeviceMesh"] = None,
+) -> Tuple[Optional[Dict], Optional[Dict]]:
+ """Load parameters from `meta_state_dict` into the model. The parameters of the `meta_state_dict` are on the meta
+ device in order to easily infer the shapes and dtypes that they will have. Then proper parameters are then loaded
+ from `shard_file`, which is the actual state dict file on disk.
+ This function takes care of correctly casting dtypes, devices, and sharding tensors in case of tensor parallelism.
+ """
+ tensor_device = "cpu"
+ if device_map is not None and device_map.get("", None) is not None:
+ if device_map[""] not in ("cpu", torch.device("cpu")):
+ tensor_device = device_map[""].index if isinstance(device_map[""], torch.device) else device_map[""]
+ if device_map is not None:
+ device_map_regex = "|".join([re.escape(k) for k in sorted(device_map.keys(), reverse=True)])
+
+ is_quantized = hf_quantizer is not None
+ is_hqq_or_bnb = is_quantized and hf_quantizer.quantization_config.quant_method in {
+ QuantizationMethod.HQQ,
+ QuantizationMethod.BITS_AND_BYTES,
+ }
+ is_meta_state_dict = shard_file.endswith(".safetensors") and not is_hqq_or_bnb
+ file_pointer = None
+ if is_meta_state_dict:
+ file_pointer = safe_open(shard_file, framework="pt", device=tensor_device)
+
+ for param_name, empty_param in state_dict.items():
+ if param_name not in expected_keys:
+ continue
+
+ # we need to use serialized_param_name as file pointer is untouched
+ if is_meta_state_dict:
+ # This is the name of the parameter as it appears on disk file
+ serialized_param_name = reverse_renaming_mapping[param_name]
+ param = file_pointer.get_slice(serialized_param_name)
+ else:
+ param = empty_param.to(tensor_device) # It is actually not empty!
+
+ to_contiguous, casting_dtype = _infer_parameter_dtype(
+ model,
+ param_name,
+ empty_param,
+ keep_in_fp32_regex,
+ hf_quantizer,
+ )
+
+ if device_mesh is not None: # In this case, the param is already on the correct device!
+ shard_and_distribute_module(
+ model,
+ param,
+ empty_param,
+ param_name,
+ casting_dtype,
+ to_contiguous,
+ int(os.environ["RANK"]), # the rank
+ device_mesh,
+ )
+ else:
+ param = param[...]
+ if casting_dtype is not None:
+ param = param.to(casting_dtype)
+ if to_contiguous:
+ param = param.contiguous()
+
+ if device_map is None:
+ param_device = "cpu"
+ else:
+ module_layer = re.search(device_map_regex, param_name)
+ if not module_layer:
+ raise ValueError(f"{param_name} doesn't have any device set.")
+ else:
+ param_device = device_map[module_layer.group()]
+
+ if param_device == "disk":
+ if not is_safetensors:
+ disk_offload_index = offload_weight(param, param_name, disk_offload_folder, disk_offload_index)
+ elif param_device == "cpu" and cpu_offload_index is not None:
+ cpu_offload_index = offload_weight(param, param_name, cpu_offload_folder, cpu_offload_index)
+ elif (
+ not is_quantized
+ or (not hf_quantizer.requires_parameters_quantization)
+ or (
+ not hf_quantizer.check_quantized_param(
+ model,
+ param,
+ param_name,
+ state_dict,
+ param_device=param_device,
+ device_map=device_map,
+ )
+ )
+ ):
+ if is_fsdp_enabled():
+ param_device = "cpu" if is_local_dist_rank_0() else "meta"
+
+ _load_parameter_into_model(model, param_name, param.to(param_device))
+
+ else:
+ hf_quantizer.create_quantized_param(
+ model, param, param_name, param_device, state_dict, unexpected_keys
+ )
+ # For quantized modules with FSDP/DeepSpeed Stage 3, we need to quantize the parameter on the GPU
+ # and then cast it to CPU to avoid excessive memory usage on each GPU
+ # in comparison to the sharded model across GPUs.
+ if is_fsdp_enabled() or is_deepspeed_zero3_enabled():
+ module, param_type = get_module_from_name(model, param_name)
+ value = getattr(module, param_type)
+ param_to = "cpu"
+ if is_fsdp_enabled() and not is_local_dist_rank_0():
+ param_to = "meta"
+ val_kwargs = {}
+ if hasattr(module, "weight") and module.weight.__class__.__name__ == "Int8Params":
+ val_kwargs["requires_grad"] = False
+ value = type(value)(value.data.to(param_to), **val_kwargs, **value.__dict__)
+ setattr(module, param_type, value)
+
+ if file_pointer is not None:
+ file_pointer.__exit__(None, None, None)
+
+ return disk_offload_index, cpu_offload_index
+
+
+def _add_variant(weights_name: str, variant: Optional[str] = None) -> str:
+ if variant is not None:
+ path, name = weights_name.rsplit(".", 1)
+ weights_name = f"{path}.{variant}.{name}"
+ return weights_name
+
+
+def _get_resolved_checkpoint_files(
+ pretrained_model_name_or_path: Optional[Union[str, os.PathLike]],
+ subfolder: str,
+ variant: Optional[str],
+ gguf_file: Optional[str],
+ from_tf: bool,
+ from_flax: bool,
+ use_safetensors: bool,
+ cache_dir: str,
+ force_download: bool,
+ proxies: Optional[Dict[str, str]],
+ local_files_only: bool,
+ token: Optional[Union[str, bool]],
+ user_agent: dict,
+ revision: str,
+ commit_hash: Optional[str],
+) -> Tuple[Optional[List[str]], Optional[Dict]]:
+ """Get all the checkpoint filenames based on `pretrained_model_name_or_path`, and optional metadata if the
+ checkpoints are sharded.
+ This function will download the data if necesary.
+ """
+ is_sharded = False
+
+ if pretrained_model_name_or_path is not None and gguf_file is None:
+ pretrained_model_name_or_path = str(pretrained_model_name_or_path)
+ is_local = os.path.isdir(pretrained_model_name_or_path)
+ if is_local:
+ if from_tf and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, subfolder, TF_WEIGHTS_NAME + ".index")
+ ):
+ # Load from a TF 1.0 checkpoint in priority if from_tf
+ archive_file = os.path.join(pretrained_model_name_or_path, subfolder, TF_WEIGHTS_NAME + ".index")
+ elif from_tf and os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, TF2_WEIGHTS_NAME)):
+ # Load from a TF 2.0 checkpoint in priority if from_tf
+ archive_file = os.path.join(pretrained_model_name_or_path, subfolder, TF2_WEIGHTS_NAME)
+ elif from_flax and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, subfolder, FLAX_WEIGHTS_NAME)
+ ):
+ # Load from a Flax checkpoint in priority if from_flax
+ archive_file = os.path.join(pretrained_model_name_or_path, subfolder, FLAX_WEIGHTS_NAME)
+ elif use_safetensors is not False and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, subfolder, _add_variant(SAFE_WEIGHTS_NAME, variant))
+ ):
+ # Load from a safetensors checkpoint
+ archive_file = os.path.join(
+ pretrained_model_name_or_path, subfolder, _add_variant(SAFE_WEIGHTS_NAME, variant)
+ )
+ elif use_safetensors is not False and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, subfolder, _add_variant(SAFE_WEIGHTS_INDEX_NAME, variant))
+ ):
+ # Load from a sharded safetensors checkpoint
+ archive_file = os.path.join(
+ pretrained_model_name_or_path, subfolder, _add_variant(SAFE_WEIGHTS_INDEX_NAME, variant)
+ )
+ is_sharded = True
+ elif not use_safetensors and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, subfolder, _add_variant(WEIGHTS_NAME, variant))
+ ):
+ # Load from a PyTorch checkpoint
+ archive_file = os.path.join(
+ pretrained_model_name_or_path, subfolder, _add_variant(WEIGHTS_NAME, variant)
+ )
+ elif not use_safetensors and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, subfolder, _add_variant(WEIGHTS_INDEX_NAME, variant))
+ ):
+ # Load from a sharded PyTorch checkpoint
+ archive_file = os.path.join(
+ pretrained_model_name_or_path, subfolder, _add_variant(WEIGHTS_INDEX_NAME, variant)
+ )
+ is_sharded = True
+ # At this stage we don't have a weight file so we will raise an error.
+ elif not use_safetensors and (
+ os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, TF_WEIGHTS_NAME + ".index"))
+ or os.path.isfile(os.path.join(pretrained_model_name_or_path, subfolder, TF2_WEIGHTS_NAME))
+ ):
+ raise EnvironmentError(
+ f"Error no file named {_add_variant(WEIGHTS_NAME, variant)} found in directory"
+ f" {pretrained_model_name_or_path} but there is a file for TensorFlow weights. Use"
+ " `from_tf=True` to load this model from those weights."
+ )
+ elif not use_safetensors and os.path.isfile(
+ os.path.join(pretrained_model_name_or_path, subfolder, FLAX_WEIGHTS_NAME)
+ ):
+ raise EnvironmentError(
+ f"Error no file named {_add_variant(WEIGHTS_NAME, variant)} found in directory"
+ f" {pretrained_model_name_or_path} but there is a file for Flax weights. Use `from_flax=True`"
+ " to load this model from those weights."
+ )
+ elif use_safetensors:
+ raise EnvironmentError(
+ f"Error no file named {_add_variant(SAFE_WEIGHTS_NAME, variant)} found in directory"
+ f" {pretrained_model_name_or_path}."
+ )
+ else:
+ raise EnvironmentError(
+ f"Error no file named {_add_variant(WEIGHTS_NAME, variant)}, {_add_variant(SAFE_WEIGHTS_NAME, variant)},"
+ f" {TF2_WEIGHTS_NAME}, {TF_WEIGHTS_NAME + '.index'} or {FLAX_WEIGHTS_NAME} found in directory"
+ f" {pretrained_model_name_or_path}."
+ )
+ elif os.path.isfile(os.path.join(subfolder, pretrained_model_name_or_path)):
+ archive_file = pretrained_model_name_or_path
+ is_local = True
+ elif os.path.isfile(os.path.join(subfolder, pretrained_model_name_or_path + ".index")):
+ if not from_tf:
+ raise ValueError(
+ f"We found a TensorFlow checkpoint at {pretrained_model_name_or_path + '.index'}, please set "
+ "from_tf to True to load from this checkpoint."
+ )
+ archive_file = os.path.join(subfolder, pretrained_model_name_or_path + ".index")
+ is_local = True
+ elif is_remote_url(pretrained_model_name_or_path):
+ filename = pretrained_model_name_or_path
+ resolved_archive_file = download_url(pretrained_model_name_or_path)
+ else:
+ # set correct filename
+ if from_tf:
+ filename = TF2_WEIGHTS_NAME
+ elif from_flax:
+ filename = FLAX_WEIGHTS_NAME
+ elif use_safetensors is not False:
+ filename = _add_variant(SAFE_WEIGHTS_NAME, variant)
+ else:
+ filename = _add_variant(WEIGHTS_NAME, variant)
+
+ try:
+ # Load from URL or cache if already cached
+ cached_file_kwargs = {
+ "cache_dir": cache_dir,
+ "force_download": force_download,
+ "proxies": proxies,
+ "local_files_only": local_files_only,
+ "token": token,
+ "user_agent": user_agent,
+ "revision": revision,
+ "subfolder": subfolder,
+ "_raise_exceptions_for_gated_repo": False,
+ "_raise_exceptions_for_missing_entries": False,
+ "_commit_hash": commit_hash,
+ }
+ resolved_archive_file = cached_file(pretrained_model_name_or_path, filename, **cached_file_kwargs)
+
+ # Since we set _raise_exceptions_for_missing_entries=False, we don't get an exception but a None
+ # result when internet is up, the repo and revision exist, but the file does not.
+ if resolved_archive_file is None and filename == _add_variant(SAFE_WEIGHTS_NAME, variant):
+ # Maybe the checkpoint is sharded, we try to grab the index name in this case.
+ resolved_archive_file = cached_file(
+ pretrained_model_name_or_path,
+ _add_variant(SAFE_WEIGHTS_INDEX_NAME, variant),
+ **cached_file_kwargs,
+ )
+ if resolved_archive_file is not None:
+ is_sharded = True
+ elif use_safetensors:
+ if revision == "main":
+ resolved_archive_file, revision, is_sharded = auto_conversion(
+ pretrained_model_name_or_path, **cached_file_kwargs
+ )
+ cached_file_kwargs["revision"] = revision
+ if resolved_archive_file is None:
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} does not appear to have a file named"
+ f" {_add_variant(SAFE_WEIGHTS_NAME, variant)} or {_add_variant(SAFE_WEIGHTS_INDEX_NAME, variant)} "
+ "and thus cannot be loaded with `safetensors`. Please make sure that the model has "
+ "been saved with `safe_serialization=True` or do not set `use_safetensors=True`."
+ )
+ else:
+ # This repo has no safetensors file of any kind, we switch to PyTorch.
+ filename = _add_variant(WEIGHTS_NAME, variant)
+ resolved_archive_file = cached_file(
+ pretrained_model_name_or_path, filename, **cached_file_kwargs
+ )
+ if resolved_archive_file is None and filename == _add_variant(WEIGHTS_NAME, variant):
+ # Maybe the checkpoint is sharded, we try to grab the index name in this case.
+ resolved_archive_file = cached_file(
+ pretrained_model_name_or_path,
+ _add_variant(WEIGHTS_INDEX_NAME, variant),
+ **cached_file_kwargs,
+ )
+ if resolved_archive_file is not None:
+ is_sharded = True
+ if not local_files_only and not is_offline_mode():
+ if resolved_archive_file is not None:
+ if filename in [WEIGHTS_NAME, WEIGHTS_INDEX_NAME]:
+ # If the PyTorch file was found, check if there is a safetensors file on the repository
+ # If there is no safetensors file on the repositories, start an auto conversion
+ safe_weights_name = SAFE_WEIGHTS_INDEX_NAME if is_sharded else SAFE_WEIGHTS_NAME
+ has_file_kwargs = {
+ "revision": revision,
+ "proxies": proxies,
+ "token": token,
+ "cache_dir": cache_dir,
+ "local_files_only": local_files_only,
+ }
+ cached_file_kwargs = {
+ "cache_dir": cache_dir,
+ "force_download": force_download,
+ "local_files_only": local_files_only,
+ "user_agent": user_agent,
+ "subfolder": subfolder,
+ "_raise_exceptions_for_gated_repo": False,
+ "_raise_exceptions_for_missing_entries": False,
+ "_commit_hash": commit_hash,
+ **has_file_kwargs,
+ }
+ if not has_file(pretrained_model_name_or_path, safe_weights_name, **has_file_kwargs):
+ Thread(
+ target=auto_conversion,
+ args=(pretrained_model_name_or_path,),
+ kwargs={"ignore_errors_during_conversion": True, **cached_file_kwargs},
+ name="Thread-auto_conversion",
+ ).start()
+ else:
+ # Otherwise, no PyTorch file was found, maybe there is a TF or Flax model file.
+ # We try those to give a helpful error message.
+ has_file_kwargs = {
+ "revision": revision,
+ "proxies": proxies,
+ "token": token,
+ "cache_dir": cache_dir,
+ "local_files_only": local_files_only,
+ }
+ if has_file(pretrained_model_name_or_path, TF2_WEIGHTS_NAME, **has_file_kwargs):
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} does not appear to have a file named"
+ f" {_add_variant(WEIGHTS_NAME, variant)} but there is a file for TensorFlow weights."
+ " Use `from_tf=True` to load this model from those weights."
+ )
+ elif has_file(pretrained_model_name_or_path, FLAX_WEIGHTS_NAME, **has_file_kwargs):
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} does not appear to have a file named"
+ f" {_add_variant(WEIGHTS_NAME, variant)} but there is a file for Flax weights. Use"
+ " `from_flax=True` to load this model from those weights."
+ )
+ elif variant is not None and has_file(
+ pretrained_model_name_or_path, WEIGHTS_NAME, **has_file_kwargs
+ ):
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} does not appear to have a file named"
+ f" {_add_variant(WEIGHTS_NAME, variant)} but there is a file without the variant"
+ f" {variant}. Use `variant=None` to load this model from those weights."
+ )
+ else:
+ raise EnvironmentError(
+ f"{pretrained_model_name_or_path} does not appear to have a file named"
+ f" {_add_variant(WEIGHTS_NAME, variant)}, {_add_variant(SAFE_WEIGHTS_NAME, variant)},"
+ f" {TF2_WEIGHTS_NAME}, {TF_WEIGHTS_NAME} or {FLAX_WEIGHTS_NAME}."
+ )
+
+ except EnvironmentError:
+ # Raise any environment error raise by `cached_file`. It will have a helpful error message adapted
+ # to the original exception.
+ raise
+ except Exception as e:
+ # For any other exception, we throw a generic error.
+ raise EnvironmentError(
+ f"Can't load the model for '{pretrained_model_name_or_path}'. If you were trying to load it"
+ " from 'https://huggingface.co/models', make sure you don't have a local directory with the"
+ f" same name. Otherwise, make sure '{pretrained_model_name_or_path}' is the correct path to a"
+ f" directory containing a file named {_add_variant(WEIGHTS_NAME, variant)},"
+ f" {TF2_WEIGHTS_NAME}, {TF_WEIGHTS_NAME} or {FLAX_WEIGHTS_NAME}."
+ ) from e
+
+ if is_local:
+ logger.info(f"loading weights file {archive_file}")
+ resolved_archive_file = archive_file
+ else:
+ logger.info(f"loading weights file {filename} from cache at {resolved_archive_file}")
+
+ elif gguf_file:
+ # Case 1: the GGUF file is present locally
+ if os.path.isfile(gguf_file):
+ resolved_archive_file = gguf_file
+ # Case 2: The GGUF path is a location on the Hub
+ # Load from URL or cache if already cached
+ else:
+ cached_file_kwargs = {
+ "cache_dir": cache_dir,
+ "force_download": force_download,
+ "proxies": proxies,
+ "local_files_only": local_files_only,
+ "token": token,
+ "user_agent": user_agent,
+ "revision": revision,
+ "subfolder": subfolder,
+ "_raise_exceptions_for_gated_repo": False,
+ "_raise_exceptions_for_missing_entries": False,
+ "_commit_hash": commit_hash,
+ }
+
+ resolved_archive_file = cached_file(pretrained_model_name_or_path, gguf_file, **cached_file_kwargs)
+
+ # We now download and resolve all checkpoint files if the checkpoint is sharded
+ sharded_metadata = None
+ if is_sharded:
+ checkpoint_files, sharded_metadata = get_checkpoint_shard_files(
+ pretrained_model_name_or_path,
+ resolved_archive_file,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ token=token,
+ user_agent=user_agent,
+ revision=revision,
+ subfolder=subfolder,
+ _commit_hash=commit_hash,
+ )
+ else:
+ checkpoint_files = [resolved_archive_file] if pretrained_model_name_or_path is not None else None
+
+ return checkpoint_files, sharded_metadata
+
+
+def _get_torch_dtype(
+ cls,
+ torch_dtype: Optional[Union[str, torch.dtype, Dict]],
+ checkpoint_files: Optional[List[str]],
+ config: PretrainedConfig,
+ sharded_metadata: Optional[Dict],
+ state_dict: Optional[Dict],
+ weights_only: bool,
+) -> Tuple[PretrainedConfig, Optional[torch.dtype], Optional[torch.dtype]]:
+ """Find the correct `torch_dtype` to use based on provided arguments. Also update the `config` based on the
+ inferred dtype. We do the following:
+ 1. If torch_dtype is not None, we use that dtype
+ 2. If torch_dtype is "auto", we auto-detect dtype from the loaded state_dict, by checking its first
+ weights entry that is of a floating type - we assume all floating dtype weights are of the same dtype
+ we also may have config.torch_dtype available, but we won't rely on it till v5
+ """
+ dtype_orig = None
+ is_sharded = sharded_metadata is not None
+
+ if torch_dtype is not None:
+ if isinstance(torch_dtype, str):
+ if torch_dtype == "auto":
+ if hasattr(config, "torch_dtype") and config.torch_dtype is not None:
+ torch_dtype = config.torch_dtype
+ logger.info(f"Will use torch_dtype={torch_dtype} as defined in model's config object")
+ else:
+ if is_sharded and "dtype" in sharded_metadata:
+ torch_dtype = sharded_metadata["dtype"]
+ elif state_dict is not None:
+ torch_dtype = get_state_dict_dtype(state_dict)
+ else:
+ state_dict = load_state_dict(
+ checkpoint_files[0], map_location="meta", weights_only=weights_only
+ )
+ torch_dtype = get_state_dict_dtype(state_dict)
+ logger.info(
+ "Since the `torch_dtype` attribute can't be found in model's config object, "
+ "will use torch_dtype={torch_dtype} as derived from model's weights"
+ )
+ elif hasattr(torch, torch_dtype):
+ torch_dtype = getattr(torch, torch_dtype)
+ config.torch_dtype = torch_dtype
+ for sub_config_key in config.sub_configs.keys():
+ sub_config = getattr(config, sub_config_key)
+ sub_config.torch_dtype = torch_dtype
+ elif isinstance(torch_dtype, torch.dtype):
+ config.torch_dtype = torch_dtype
+ for sub_config_key in config.sub_configs.keys():
+ sub_config = getattr(config, sub_config_key)
+ sub_config.torch_dtype = torch_dtype
+ elif isinstance(torch_dtype, dict):
+ for key, curr_dtype in torch_dtype.items():
+ if hasattr(config, key):
+ value = getattr(config, key)
+ curr_dtype = curr_dtype if not isinstance(curr_dtype, str) else getattr(torch, curr_dtype)
+ value.torch_dtype = curr_dtype
+ # main torch dtype for modules that aren't part of any sub-config
+ torch_dtype = torch_dtype.get("")
+ torch_dtype = torch_dtype if not isinstance(torch_dtype, str) else getattr(torch, torch_dtype)
+ config.torch_dtype = torch_dtype
+ if torch_dtype is None:
+ torch_dtype = torch.float32
+ else:
+ raise ValueError(
+ f"`torch_dtype` can be one of: `torch.dtype`, `'auto'`, a string of a valid `torch.dtype` or a `dict` with valid `torch_dtype` "
+ f"for each sub-config in composite configs, but received {torch_dtype}"
+ )
+
+ dtype_orig = cls._set_default_torch_dtype(torch_dtype)
+ else:
+ # set fp32 as the default dtype for BC
+ default_dtype = torch.get_default_dtype()
+ config.torch_dtype = default_dtype
+ for key in config.sub_configs.keys():
+ value = getattr(config, key)
+ value.torch_dtype = default_dtype
+
+ return config, torch_dtype, dtype_orig
+
+
+def _get_device_map(
+ model: "PreTrainedModel",
+ device_map: Optional[Union[str, Dict]],
+ max_memory: Optional[Dict],
+ hf_quantizer: Optional[HfQuantizer],
+ torch_dtype: Optional[torch.dtype],
+ keep_in_fp32_regex: Optional[re.Pattern],
+) -> Dict:
+ """Compute the final `device_map` to use if we passed a value in ['auto', 'balanced', 'balanced_low_0', 'sequential'].
+ Otherwise, we check for any device inconsistencies in the device_map.
+ """
+ if isinstance(device_map, str):
+ special_dtypes = {}
+ if hf_quantizer is not None:
+ special_dtypes.update(hf_quantizer.get_special_dtypes_update(model, torch_dtype))
+ if keep_in_fp32_regex is not None:
+ special_dtypes.update(
+ {name: torch.float32 for name, _ in model.named_parameters() if keep_in_fp32_regex.search(name)}
+ )
+
+ target_dtype = torch_dtype
+
+ if hf_quantizer is not None:
+ target_dtype = hf_quantizer.adjust_target_dtype(target_dtype)
+
+ no_split_modules = model._get_no_split_modules(device_map)
+ device_map_kwargs = {"no_split_module_classes": no_split_modules}
+
+ if "special_dtypes" in inspect.signature(infer_auto_device_map).parameters:
+ device_map_kwargs["special_dtypes"] = special_dtypes
+ elif len(special_dtypes) > 0:
+ logger.warning(
+ "This model has some weights that should be kept in higher precision, you need to upgrade "
+ "`accelerate` to properly deal with them (`pip install --upgrade accelerate`)."
+ )
+
+ if device_map != "sequential":
+ max_memory = get_balanced_memory(
+ model,
+ dtype=target_dtype,
+ low_zero=(device_map == "balanced_low_0"),
+ max_memory=max_memory,
+ **device_map_kwargs,
+ )
+ else:
+ max_memory = get_max_memory(max_memory)
+ if hf_quantizer is not None:
+ max_memory = hf_quantizer.adjust_max_memory(max_memory)
+ device_map_kwargs["max_memory"] = max_memory
+
+ device_map = infer_auto_device_map(model, dtype=target_dtype, **device_map_kwargs)
+
+ if hf_quantizer is not None:
+ hf_quantizer.validate_environment(device_map=device_map)
+
+ elif device_map is not None:
+ tied_params = find_tied_parameters(model)
+ # check if we don't have tied param in different devices
+ check_tied_parameters_on_same_device(tied_params, device_map)
+
+ return device_map
+
+
+def _find_missing_and_unexpected_keys(
+ cls,
+ model: "PreTrainedModel",
+ original_checkpoint_keys: List[str],
+ checkpoint_keys: List[str],
+ loading_base_model_from_task_state_dict: bool,
+ hf_quantizer: Optional[HfQuantizer],
+ device_map: Dict,
+) -> Tuple[List[str], List[str]]:
+ """Find missing keys (keys that are part of the model parameters but were NOT found in the loaded state dict keys) and unexpected keys
+ (keys found in the loaded state dict keys, but that are NOT part of the model parameters)
+ """
+ prefix = model.base_model_prefix
+
+ # Compute expected keys, i.e. keys that the FULL model (not model_to_load) expects
+ expected_keys = list(model.state_dict().keys())
+ if hf_quantizer is not None:
+ expected_keys = hf_quantizer.update_expected_keys(model, expected_keys, checkpoint_keys)
+
+ # Adjust prefix of the keys to make them match loaded keys before removing them
+ missing_keys = sorted(set(expected_keys) - set(checkpoint_keys))
+ unexpected_keys = set(checkpoint_keys) - set(expected_keys)
+ # If a module has the same name under the base and task specific model, we have to re-add it to unexpected keys
+ if loading_base_model_from_task_state_dict:
+ task_specific_keys = [k for k in original_checkpoint_keys if not k.startswith(f"{prefix}.")]
+ unexpected_keys.update(task_specific_keys)
+
+ # Remove nonpersistent buffers from unexpected keys: they are not in the expected keys (model state dict), but
+ # may be in the loaded keys. Note that removing all buffers does the job, as they were part of the expected keys anyway
+ model_buffers = {n for n, _ in model.named_buffers()}
+ unexpected_keys = sorted(unexpected_keys - model_buffers)
+
+ # Old checkpoints may have keys for rotary_emb.inv_freq for each layer, however we moved this buffer to the main model
+ # (so the buffer name has changed). Remove them in such a case
+ has_inv_freq_buffers = any(buffer.endswith("rotary_emb.inv_freq") for buffer in model_buffers)
+ if has_inv_freq_buffers:
+ unexpected_keys = [k for k in unexpected_keys if "rotary_emb.inv_freq" not in k]
+
+ tied_params = find_tied_parameters(model)
+ for group in tied_params:
+ missing_in_group = [k for k in missing_keys if k in group]
+ if len(missing_in_group) > 0 and len(missing_in_group) < len(group):
+ missing_keys = [k for k in missing_keys if k not in missing_in_group]
+
+ if hf_quantizer is not None:
+ missing_keys = hf_quantizer.update_missing_keys(model, missing_keys, prefix)
+ unexpected_keys = hf_quantizer.update_unexpected_keys(model, unexpected_keys, prefix)
+
+ # Model-specific exceptions for missing and unexpected keys (e.g. if the modeling change over time, or any other reason...)
+ if cls._keys_to_ignore_on_load_missing is not None:
+ for pattern in cls._keys_to_ignore_on_load_missing:
+ missing_keys = [k for k in missing_keys if re.search(pattern, k) is None]
+
+ if cls._keys_to_ignore_on_load_unexpected is not None:
+ for pattern in cls._keys_to_ignore_on_load_unexpected:
+ unexpected_keys = [k for k in unexpected_keys if re.search(pattern, k) is None]
+
+ return missing_keys, unexpected_keys
+
+
+def _find_mismatched_keys(
+ model: "PreTrainedModel",
+ state_dict: Optional[Dict],
+ checkpoint_files: Optional[List[str]],
+ ignore_mismatched_sizes: bool,
+ keys_to_rename_mapping: Dict[str, str],
+ is_quantized: bool,
+ weights_only: bool,
+) -> Tuple[List[str], List[Tuple[int, int]]]:
+ """
+ Find potential shape mismatch between the different state dicts and the model parameters, but only if `ignore_mismatched_sizes`
+ is True. Otherwise, return immediately and any shape mismatch that may exist will be raised later on. This avoids checking
+ every parameter in advance, as shape mismatch are extremely rare in practice. If we want to ignore them however, we do
+ need to check in advance as we need to know which parameters we need to move back from meta to cpu, and initialize
+ correctly. Indeed, as our model initialization takes place at the module level, and not the weight level, in the
+ case of a sharded checkpoint we cannot correctly initialize the weights according to `model._init_weights()` if we perform
+ this check on each state dict at loading time (after the first loaded checkpoint, there are no way to initialize only the
+ mismatched weights if any, without overwriting the previously loaded weights as well because all the module will be
+ initialized, not only the weights that are mismatched).
+ """
+
+ # An error will be raised later on anyway if there is a mismatch - this avoids running the rest of this function
+ # if there are no mismatch (which is almost always the case)
+ if not ignore_mismatched_sizes:
+ return [], []
+
+ if state_dict is not None:
+ checkpoint_files = [""]
+
+ model_state_dict = model.state_dict()
+ mismatched_keys = []
+ mismatched_shapes = []
+ for shard_file in checkpoint_files:
+ # If shard_file is "", we use the existing state_dict instead of loading it
+ if shard_file != "":
+ state_dict = load_state_dict(
+ shard_file, is_quantized=is_quantized, map_location="meta", weights_only=weights_only
+ )
+
+ # Fix the key names
+ new_state_dict = {keys_to_rename_mapping[k]: v for k, v in state_dict.items() if k in keys_to_rename_mapping}
+
+ for key in new_state_dict.keys():
+ if key in model_state_dict and new_state_dict[key].shape != model_state_dict[key].shape:
+ # This skips size mismatches for 4-bit weights. Two 4-bit values share an 8-bit container, causing size differences.
+ # Without matching with module type or paramter type it seems like a practical way to detect valid 4bit weights.
+ if not (
+ new_state_dict[key].shape[-1] == 1
+ and new_state_dict[key].numel() * 2 == model_state_dict[key].numel()
+ ):
+ mismatched_keys.append(key)
+ mismatched_shapes.append((new_state_dict[key].shape, model_state_dict[key].shape))
+
+ return mismatched_keys, mismatched_shapes
+
+
+class PipelineParallel(Enum):
+ inputs: 0
+ outputs: 1
+
+
+class ModuleUtilsMixin:
+ """
+ A few utilities for `torch.nn.Modules`, to be used as a mixin.
+ """
+
+ @staticmethod
+ def _hook_rss_memory_pre_forward(module, *args, **kwargs):
+ try:
+ import psutil
+ except ImportError:
+ raise ImportError("You need to install psutil (pip install psutil) to use memory tracing.")
+
+ process = psutil.Process(os.getpid())
+ mem = process.memory_info()
+ module.mem_rss_pre_forward = mem.rss
+ return None
+
+ @staticmethod
+ def _hook_rss_memory_post_forward(module, *args, **kwargs):
+ try:
+ import psutil
+ except ImportError:
+ raise ImportError("You need to install psutil (pip install psutil) to use memory tracing.")
+
+ process = psutil.Process(os.getpid())
+ mem = process.memory_info()
+ module.mem_rss_post_forward = mem.rss
+ mem_rss_diff = module.mem_rss_post_forward - module.mem_rss_pre_forward
+ module.mem_rss_diff = mem_rss_diff + (module.mem_rss_diff if hasattr(module, "mem_rss_diff") else 0)
+ return None
+
+ def add_memory_hooks(self):
+ """
+ Add a memory hook before and after each sub-module forward pass to record increase in memory consumption.
+
+ Increase in memory consumption is stored in a `mem_rss_diff` attribute for each module and can be reset to zero
+ with `model.reset_memory_hooks_state()`.
+ """
+ for module in self.modules():
+ module.register_forward_pre_hook(self._hook_rss_memory_pre_forward)
+ module.register_forward_hook(self._hook_rss_memory_post_forward)
+ self.reset_memory_hooks_state()
+
+ def reset_memory_hooks_state(self):
+ """
+ Reset the `mem_rss_diff` attribute of each module (see [`~modeling_utils.ModuleUtilsMixin.add_memory_hooks`]).
+ """
+ for module in self.modules():
+ module.mem_rss_diff = 0
+ module.mem_rss_post_forward = 0
+ module.mem_rss_pre_forward = 0
+
+ @property
+ def device(self) -> torch.device:
+ """
+ `torch.device`: The device on which the module is (assuming that all the module parameters are on the same
+ device).
+ """
+ return get_parameter_device(self)
+
+ @property
+ def dtype(self) -> torch.dtype:
+ """
+ `torch.dtype`: The dtype of the module (assuming that all the module parameters have the same dtype).
+ """
+ return get_parameter_dtype(self)
+
+ def invert_attention_mask(self, encoder_attention_mask: Tensor) -> Tensor:
+ """
+ Invert an attention mask (e.g., switches 0. and 1.).
+
+ Args:
+ encoder_attention_mask (`torch.Tensor`): An attention mask.
+
+ Returns:
+ `torch.Tensor`: The inverted attention mask.
+ """
+ if encoder_attention_mask.dim() == 3:
+ encoder_extended_attention_mask = encoder_attention_mask[:, None, :, :]
+ if encoder_attention_mask.dim() == 2:
+ encoder_extended_attention_mask = encoder_attention_mask[:, None, None, :]
+ # T5 has a mask that can compare sequence ids, we can simulate this here with this transposition
+ # Cf. https://github.com/tensorflow/mesh/blob/8d2465e9bc93129b913b5ccc6a59aa97abd96ec6/mesh_tensorflow
+ # /transformer/transformer_layers.py#L270
+ # encoder_extended_attention_mask = (encoder_extended_attention_mask ==
+ # encoder_extended_attention_mask.transpose(-1, -2))
+ encoder_extended_attention_mask = encoder_extended_attention_mask.to(dtype=self.dtype) # fp16 compatibility
+ encoder_extended_attention_mask = (1.0 - encoder_extended_attention_mask) * torch.finfo(self.dtype).min
+
+ return encoder_extended_attention_mask
+
+ @staticmethod
+ def create_extended_attention_mask_for_decoder(input_shape, attention_mask, device=None):
+ if device is not None:
+ warnings.warn(
+ "The `device` argument is deprecated and will be removed in v5 of Transformers.", FutureWarning
+ )
+ else:
+ device = attention_mask.device
+ batch_size, seq_length = input_shape
+ seq_ids = torch.arange(seq_length, device=device)
+ causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]
+ # in case past_key_values are used we need to add a prefix ones mask to the causal mask
+ causal_mask = causal_mask.to(attention_mask.dtype)
+
+ if causal_mask.shape[1] < attention_mask.shape[1]:
+ prefix_seq_len = attention_mask.shape[1] - causal_mask.shape[1]
+ causal_mask = torch.cat(
+ [
+ torch.ones((batch_size, seq_length, prefix_seq_len), device=device, dtype=causal_mask.dtype),
+ causal_mask,
+ ],
+ axis=-1,
+ )
+
+ extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
+ return extended_attention_mask
+
+ def get_extended_attention_mask(
+ self, attention_mask: Tensor, input_shape: Tuple[int], device: torch.device = None, dtype: torch.float = None
+ ) -> Tensor:
+ """
+ Makes broadcastable attention and causal masks so that future and masked tokens are ignored.
+
+ Arguments:
+ attention_mask (`torch.Tensor`):
+ Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
+ input_shape (`Tuple[int]`):
+ The shape of the input to the model.
+
+ Returns:
+ `torch.Tensor` The extended attention mask, with a the same dtype as `attention_mask.dtype`.
+ """
+ if dtype is None:
+ dtype = self.dtype
+
+ if not (attention_mask.dim() == 2 and self.config.is_decoder):
+ # show warning only if it won't be shown in `create_extended_attention_mask_for_decoder`
+ if device is not None:
+ warnings.warn(
+ "The `device` argument is deprecated and will be removed in v5 of Transformers.", FutureWarning
+ )
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ if attention_mask.dim() == 3:
+ extended_attention_mask = attention_mask[:, None, :, :]
+ elif attention_mask.dim() == 2:
+ # Provided a padding mask of dimensions [batch_size, seq_length]
+ # - if the model is a decoder, apply a causal mask in addition to the padding mask
+ # - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if self.config.is_decoder:
+ extended_attention_mask = ModuleUtilsMixin.create_extended_attention_mask_for_decoder(
+ input_shape, attention_mask, device
+ )
+ else:
+ extended_attention_mask = attention_mask[:, None, None, :]
+ else:
+ raise ValueError(
+ f"Wrong shape for input_ids (shape {input_shape}) or attention_mask (shape {attention_mask.shape})"
+ )
+
+ # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
+ # masked positions, this operation will create a tensor which is 0.0 for
+ # positions we want to attend and the dtype's smallest value for masked positions.
+ # Since we are adding it to the raw scores before the softmax, this is
+ # effectively the same as removing these entirely.
+ extended_attention_mask = extended_attention_mask.to(dtype=dtype) # fp16 compatibility
+ extended_attention_mask = (1.0 - extended_attention_mask) * torch.finfo(dtype).min
+ return extended_attention_mask
+
+ def get_head_mask(
+ self, head_mask: Optional[Tensor], num_hidden_layers: int, is_attention_chunked: bool = False
+ ) -> Tensor:
+ """
+ Prepare the head mask if needed.
+
+ Args:
+ head_mask (`torch.Tensor` with shape `[num_heads]` or `[num_hidden_layers x num_heads]`, *optional*):
+ The mask indicating if we should keep the heads or not (1.0 for keep, 0.0 for discard).
+ num_hidden_layers (`int`):
+ The number of hidden layers in the model.
+ is_attention_chunked (`bool`, *optional*, defaults to `False`):
+ Whether or not the attentions scores are computed by chunks or not.
+
+ Returns:
+ `torch.Tensor` with shape `[num_hidden_layers x batch x num_heads x seq_length x seq_length]` or list with
+ `[None]` for each layer.
+ """
+ if head_mask is not None:
+ head_mask = self._convert_head_mask_to_5d(head_mask, num_hidden_layers)
+ if is_attention_chunked is True:
+ head_mask = head_mask.unsqueeze(-1)
+ else:
+ head_mask = [None] * num_hidden_layers
+
+ return head_mask
+
+ def _convert_head_mask_to_5d(self, head_mask, num_hidden_layers):
+ """-> [num_hidden_layers x batch x num_heads x seq_length x seq_length]"""
+ if head_mask.dim() == 1:
+ head_mask = head_mask.unsqueeze(0).unsqueeze(0).unsqueeze(-1).unsqueeze(-1)
+ head_mask = head_mask.expand(num_hidden_layers, -1, -1, -1, -1)
+ elif head_mask.dim() == 2:
+ head_mask = head_mask.unsqueeze(1).unsqueeze(-1).unsqueeze(-1) # We can specify head_mask for each layer
+ assert head_mask.dim() == 5, f"head_mask.dim != 5, instead {head_mask.dim()}"
+ head_mask = head_mask.to(dtype=self.dtype) # switch to float if need + fp16 compatibility
+ return head_mask
+
+ def num_parameters(self, only_trainable: bool = False, exclude_embeddings: bool = False) -> int:
+ """
+ Get number of (optionally, trainable or non-embeddings) parameters in the module.
+
+ Args:
+ only_trainable (`bool`, *optional*, defaults to `False`):
+ Whether or not to return only the number of trainable parameters
+
+ exclude_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether or not to return only the number of non-embeddings parameters
+
+ Returns:
+ `int`: The number of parameters.
+ """
+
+ if exclude_embeddings:
+ embedding_param_names = [
+ f"{name}.weight" for name, module_type in self.named_modules() if isinstance(module_type, nn.Embedding)
+ ]
+ total_parameters = [
+ parameter for name, parameter in self.named_parameters() if name not in embedding_param_names
+ ]
+ else:
+ total_parameters = list(self.parameters())
+
+ total_numel = []
+ is_loaded_in_4bit = getattr(self, "is_loaded_in_4bit", False)
+
+ if is_loaded_in_4bit:
+ if is_bitsandbytes_available():
+ import bitsandbytes as bnb
+ else:
+ raise ValueError(
+ "bitsandbytes is not installed but it seems that the model has been loaded in 4bit precision, something went wrong"
+ " make sure to install bitsandbytes with `pip install bitsandbytes`. You also need a GPU. "
+ )
+
+ for param in total_parameters:
+ if param.requires_grad or not only_trainable:
+ # For 4bit models, we need to multiply the number of parameters by 2 as half of the parameters are
+ # used for the 4bit quantization (uint8 tensors are stored)
+ if is_loaded_in_4bit and isinstance(param, bnb.nn.Params4bit):
+ if hasattr(param, "element_size"):
+ num_bytes = param.element_size()
+ elif hasattr(param, "quant_storage"):
+ num_bytes = param.quant_storage.itemsize
+ else:
+ num_bytes = 1
+ total_numel.append(param.numel() * 2 * num_bytes)
+ else:
+ total_numel.append(param.numel())
+
+ return sum(total_numel)
+
+ def estimate_tokens(self, input_dict: Dict[str, Union[torch.Tensor, Any]]) -> int:
+ """
+ Helper function to estimate the total number of tokens from the model inputs.
+
+ Args:
+ inputs (`dict`): The model inputs.
+
+ Returns:
+ `int`: The total number of tokens.
+ """
+ if not hasattr(self, "warnings_issued"):
+ self.warnings_issued = {}
+ if self.main_input_name in input_dict:
+ return input_dict[self.main_input_name].numel()
+ elif "estimate_tokens" not in self.warnings_issued:
+ logger.warning(
+ "Could not estimate the number of tokens of the input, floating-point operations will not be computed"
+ )
+ self.warnings_issued["estimate_tokens"] = True
+ return 0
+
+ def floating_point_ops(
+ self, input_dict: Dict[str, Union[torch.Tensor, Any]], exclude_embeddings: bool = True
+ ) -> int:
+ """
+ Get number of (optionally, non-embeddings) floating-point operations for the forward and backward passes of a
+ batch with this transformer model. Default approximation neglects the quadratic dependency on the number of
+ tokens (valid if `12 * d_model << sequence_length`) as laid out in [this
+ paper](https://arxiv.org/pdf/2001.08361.pdf) section 2.1. Should be overridden for transformers with parameter
+ re-use e.g. Albert or Universal Transformers, or if doing long-range modeling with very high sequence lengths.
+
+ Args:
+ batch_size (`int`):
+ The batch size for the forward pass.
+
+ sequence_length (`int`):
+ The number of tokens in each line of the batch.
+
+ exclude_embeddings (`bool`, *optional*, defaults to `True`):
+ Whether or not to count embedding and softmax operations.
+
+ Returns:
+ `int`: The number of floating-point operations.
+ """
+
+ return 6 * self.estimate_tokens(input_dict) * self.num_parameters(exclude_embeddings=exclude_embeddings)
+
+
+class PreTrainedModel(nn.Module, ModuleUtilsMixin, PushToHubMixin, PeftAdapterMixin):
+ r"""
+ Base class for all models.
+
+ [`PreTrainedModel`] takes care of storing the configuration of the models and handles methods for loading,
+ downloading and saving models as well as a few methods common to all models to:
+
+ - resize the input embeddings,
+ - prune heads in the self-attention heads.
+
+ Class attributes (overridden by derived classes):
+
+ - **config_class** ([`PretrainedConfig`]) -- A subclass of [`PretrainedConfig`] to use as configuration class
+ for this model architecture.
+ - **load_tf_weights** (`Callable`) -- A python *method* for loading a TensorFlow checkpoint in a PyTorch model,
+ taking as arguments:
+
+ - **model** ([`PreTrainedModel`]) -- An instance of the model on which to load the TensorFlow checkpoint.
+ - **config** ([`PreTrainedConfig`]) -- An instance of the configuration associated to the model.
+ - **path** (`str`) -- A path to the TensorFlow checkpoint.
+
+ - **base_model_prefix** (`str`) -- A string indicating the attribute associated to the base model in derived
+ classes of the same architecture adding modules on top of the base model.
+ - **is_parallelizable** (`bool`) -- A flag indicating whether this model supports model parallelization.
+ - **main_input_name** (`str`) -- The name of the principal input to the model (often `input_ids` for NLP
+ models, `pixel_values` for vision models and `input_values` for speech models).
+ """
+
+ config_class = None
+ base_model_prefix = ""
+ main_input_name = "input_ids"
+ model_tags = None
+
+ _auto_class = None
+ _no_split_modules = None
+ _skip_keys_device_placement = None
+ _keep_in_fp32_modules = None
+
+ # a list of `re` patterns of `state_dict` keys that should be removed from the list of missing
+ # keys we find (keys inside the model but not in the checkpoint) and avoid unnecessary warnings.
+ _keys_to_ignore_on_load_missing = None
+ # a list of `re` patterns of `state_dict` keys that should be removed from the list of
+ # unexpected keys we find (keys inside the checkpoint but not the model) and avoid unnecessary
+ # warnings.
+ _keys_to_ignore_on_load_unexpected = None
+ # a list of `state_dict` keys to ignore when saving the model (useful for keys that aren't
+ # trained, but which are either deterministic or tied variables)
+ _keys_to_ignore_on_save = None
+ # a list of `state_dict` keys that are potentially tied to another key in the state_dict.
+ _tied_weights_keys = None
+
+ is_parallelizable = False
+ supports_gradient_checkpointing = False
+ _is_stateful = False
+
+ # Flash Attention 2 support
+ _supports_flash_attn_2 = False
+
+ # SDPA support
+ _supports_sdpa = False
+
+ # Flex Attention support
+ _supports_flex_attn = False
+
+ # Has support for a `Cache` instance as `past_key_values`? Does it support a `StaticCache`?
+ _supports_cache_class = False
+ _supports_static_cache = False
+
+ # Has support for a `QuantoQuantizedCache` instance as `past_key_values`
+ _supports_quantized_cache = False
+
+ # A tensor parallel plan to be applied to the model when TP is enabled. For
+ # top-level models, this attribute is currently defined in respective model
+ # code. For base models, this attribute comes from
+ # `config.base_model_tp_plan` during `__init__`.
+ # It should identify the layers exactly: if you want to TP model.language_model.layers.fc1
+ # by passing `tp_plan` to the init, it should be {"model.language_model.layers.fc1":"colwise"}
+ # for example.
+ _tp_plan = None
+
+ # tensor parallel degree to which model is sharded to.
+ _tp_size = None
+
+ # A pipeline parallel plan specifying the layers which may not be present
+ # on all ranks when PP is enabled. For top-level models, this attribute is
+ # currently defined in respective model code. For base models, this
+ # attribute comes from `config.base_model_pp_plan` during `post_init`.
+ #
+ # The variable names for the inputs and outputs of the specified layers can
+ # be indexed using the `PipelineParallel` enum as follows:
+ # - `_pp_plan["layers"][PipelineParallel.inputs]`
+ # - `_pp_plan["layers"][PipelineParallel.outputs]`
+ _pp_plan = None
+
+ # This flag signal that the model can be used as an efficient backend in TGI and vLLM
+ # In practice, it means that they support attention interface functions, fully pass the kwargs
+ # through all modules up to the Attention layer, can slice logits with Tensor, and have a default TP plan
+ _supports_attention_backend = False
+
+ @property
+ def dummy_inputs(self) -> Dict[str, torch.Tensor]:
+ """
+ `Dict[str, torch.Tensor]`: Dummy inputs to do a forward pass in the network.
+ """
+ return {"input_ids": torch.tensor(DUMMY_INPUTS)}
+
+ @property
+ def framework(self) -> str:
+ """
+ :str: Identifies that this is a PyTorch model.
+ """
+ return "pt"
+
+ def __init__(self, config: PretrainedConfig, *inputs, **kwargs):
+ super().__init__()
+ if not isinstance(config, PretrainedConfig):
+ raise ValueError(
+ f"Parameter config in `{self.__class__.__name__}(config)` should be an instance of class "
+ "`PretrainedConfig`. To create a model from a pretrained model use "
+ f"`model = {self.__class__.__name__}.from_pretrained(PRETRAINED_MODEL_NAME)`"
+ )
+ if not getattr(config, "_attn_implementation_autoset", False):
+ # config usually has a `torch_dtype` but we need the next line for the `no_super_init` tests
+ dtype = config.torch_dtype if hasattr(config, "torch_dtype") else torch.get_default_dtype()
+ config = self._autoset_attn_implementation(config, torch_dtype=dtype, check_device_map=False)
+ self.config = config
+
+ # for initialization of the loss
+ loss_type = self.__class__.__name__
+ if loss_type not in LOSS_MAPPING:
+ loss_groups = f"({'|'.join(LOSS_MAPPING)})"
+ loss_type = re.findall(loss_groups, self.__class__.__name__)
+ if len(loss_type) > 0:
+ loss_type = loss_type[0]
+ else:
+ loss_type = None
+ self.loss_type = loss_type
+
+ self.name_or_path = config.name_or_path
+ self.warnings_issued = {}
+ self.generation_config = GenerationConfig.from_model_config(config) if self.can_generate() else None
+ # Overwrite the class attribute to make it an instance attribute, so models like
+ # `InstructBlipForConditionalGeneration` can dynamically update it without modifying the class attribute
+ # when a different component (e.g. language_model) is used.
+ self._keep_in_fp32_modules = copy.copy(self.__class__._keep_in_fp32_modules)
+
+ self._no_split_modules = self._no_split_modules or []
+
+ def post_init(self):
+ """
+ A method executed at the end of each Transformer model initialization, to execute code that needs the model's
+ modules properly initialized (such as weight initialization).
+ """
+ self.init_weights()
+ self._backward_compatibility_gradient_checkpointing()
+
+ # Make sure the modules correctly exist if the flag is active
+ if self._keep_in_fp32_modules is not None:
+ all_parameters = {name for name, _ in self.named_parameters() if len(name) > 0}
+ unique_module_names = set()
+ # Get all unique module names in the module graph, without the prefixes
+ for param in all_parameters:
+ unique_module_names.update(
+ [name for name in param.split(".") if not name.isnumeric() and name not in ["weight", "bias"]]
+ )
+ # Check that every module in the keep_in_fp32 list is part of the module graph
+ for module in self._keep_in_fp32_modules:
+ if module not in unique_module_names:
+ raise ValueError(
+ f"{module} was specified in the `_keep_in_fp32_modules` list, but is not part of the modules in"
+ f" {self.__class__.__name__}"
+ )
+
+ # If current model is a base model, attach `base_model_tp_plan` and `base_model_pp_plan` from config
+ self._pp_plan = self.config.base_model_pp_plan.copy() if self.config.base_model_pp_plan is not None else None
+ self._tp_plan = self.config.base_model_tp_plan.copy() if self.config.base_model_tp_plan is not None else {}
+ for name, module in self.named_children():
+ if plan := getattr(module, "_tp_plan", None):
+ self._tp_plan.update({f"{name}.{k}": v for k, v in plan.copy().items()})
+
+ if self._tp_plan is not None and is_torch_greater_or_equal("2.3"):
+ for _, v in self._tp_plan.items():
+ if v not in SUPPORTED_TP_STYLES:
+ raise ValueError(
+ f"Unsupported tensor parallel style {v}. Supported styles are {SUPPORTED_TP_STYLES}"
+ )
+
+ def dequantize(self):
+ """
+ Potentially dequantize the model in case it has been quantized by a quantization method that support
+ dequantization.
+ """
+ hf_quantizer = getattr(self, "hf_quantizer", None)
+
+ if hf_quantizer is None:
+ raise ValueError("You need to first quantize your model in order to dequantize it")
+
+ return hf_quantizer.dequantize(self)
+
+ def _backward_compatibility_gradient_checkpointing(self):
+ if self.supports_gradient_checkpointing and getattr(self.config, "gradient_checkpointing", False):
+ self.gradient_checkpointing_enable()
+ # Remove the attribute now that is has been consumed, so it's no saved in the config.
+ delattr(self.config, "gradient_checkpointing")
+
+ def add_model_tags(self, tags: Union[List[str], str]) -> None:
+ r"""
+ Add custom tags into the model that gets pushed to the Hugging Face Hub. Will
+ not overwrite existing tags in the model.
+
+ Args:
+ tags (`Union[List[str], str]`):
+ The desired tags to inject in the model
+
+ Examples:
+
+ ```python
+ from transformers import AutoModel
+
+ model = AutoModel.from_pretrained("google-bert/bert-base-cased")
+
+ model.add_model_tags(["custom", "custom-bert"])
+
+ # Push the model to your namespace with the name "my-custom-bert".
+ model.push_to_hub("my-custom-bert")
+ ```
+ """
+ if isinstance(tags, str):
+ tags = [tags]
+
+ if self.model_tags is None:
+ self.model_tags = []
+
+ for tag in tags:
+ if tag not in self.model_tags:
+ self.model_tags.append(tag)
+
+ @classmethod
+ @restore_default_torch_dtype
+ def _from_config(cls, config, **kwargs):
+ """
+ All context managers that the model should be initialized under go here.
+
+ Args:
+ torch_dtype (`torch.dtype`, *optional*):
+ Override the default `torch.dtype` and load the model under this dtype.
+ """
+ # when we init a model from within another model (e.g. VLMs) and dispatch on FA2
+ # a warning is raised that dtype should be fp16. Since we never pass dtype from within
+ # modeling code, we can try to infer it here same way as done in `from_pretrained`
+ torch_dtype = kwargs.pop("torch_dtype", config.torch_dtype)
+ if isinstance(torch_dtype, str):
+ torch_dtype = getattr(torch, torch_dtype)
+
+ use_flash_attention_2 = kwargs.pop("use_flash_attention_2", False)
+
+ # override default dtype if needed
+ dtype_orig = None
+ if torch_dtype is not None:
+ dtype_orig = cls._set_default_torch_dtype(torch_dtype)
+
+ config = copy.deepcopy(config) # We do not want to modify the config inplace in _from_config.
+
+ if config._attn_implementation_internal is not None:
+ # In this case, the config has been created with the attn_implementation set by the user, which we
+ # should respect.
+ attn_implementation = config._attn_implementation_internal
+ else:
+ attn_implementation = None
+
+ config._attn_implementation = kwargs.pop("attn_implementation", attn_implementation)
+ if not getattr(config, "_attn_implementation_autoset", False):
+ config = cls._autoset_attn_implementation(
+ config,
+ use_flash_attention_2=use_flash_attention_2,
+ check_device_map=False,
+ torch_dtype=torch_dtype,
+ )
+
+ if is_deepspeed_zero3_enabled() and not _is_quantized and not _is_ds_init_called:
+ logger.info("Detected DeepSpeed ZeRO-3: activating zero.init() for this model")
+ # this immediately partitions the model across all gpus, to avoid the overhead in time
+ # and memory copying it on CPU or each GPU first
+ init_contexts = [deepspeed.zero.Init(config_dict_or_path=deepspeed_config()), set_zero3_state()]
+ with ContextManagers(init_contexts):
+ model = cls(config, **kwargs)
+
+ else:
+ model = cls(config, **kwargs)
+
+ # restore default dtype if it was modified
+ if dtype_orig is not None:
+ torch.set_default_dtype(dtype_orig)
+
+ return model
+
+ @classmethod
+ def _autoset_attn_implementation(
+ cls,
+ config,
+ use_flash_attention_2: bool = False,
+ torch_dtype: Optional[torch.dtype] = None,
+ device_map: Optional[Union[str, Dict[str, int]]] = None,
+ check_device_map: bool = True,
+ ):
+ """
+ Automatically checks and dispatches to a default attention implementation. In order of priority:
+ 1. An implementation specified in `config._attn_implementation` (due for example to the argument attn_implementation="sdpa" in from_pretrained).
+ 2. DEPRECATED: if use_flash_attention_2 is set to `True` and `flash_attn` is available, flash attention. (`LlamaFlashAttention` for example)
+ 3. SDPA implementation, if available and supported by the model type. (`LlamaSdpaAttention` for example)
+ 4. The default model's implementation otherwise (`LlamaAttention` for example) .
+ """
+ # Here we use config._attn_implementation_internal to check whether the attention implementation was explicitly set by the user.
+ # The property `PretrainedConfig._attn_implementation` is never `None`, for backward compatibility (always fall back on "eager").
+ # The `hasattr` here is used as some Transformers tests for some reason do not call PretrainedConfig __init__ (e.g. test_no_super_init_config_and_model)
+ requested_attn_implementation = None
+ if hasattr(config, "_attn_implementation_internal") and config._attn_implementation_internal is not None:
+ if config._attn_implementation != "flash_attention_2" and use_flash_attention_2:
+ raise ValueError(
+ f'Both attn_implementation="{config._attn_implementation}" and `use_flash_attention_2=True` were used when loading the model, which are not compatible.'
+ ' We recommend to just use `attn_implementation="flash_attention_2"` when loading the model.'
+ )
+
+ if isinstance(config._attn_implementation, str) and re.match(
+ r"^[^/:]+/[^/:]+:[^/:]+$", config._attn_implementation
+ ):
+ if not is_kernels_available():
+ raise ValueError("kernels is not installed. Please install it with `pip install kernels`.")
+
+ # Extract repo_id and kernel_name from the string
+ repo_id, kernel_name = config._attn_implementation.split(":")
+ kernel_name = kernel_name.strip()
+ repo_id = repo_id.strip()
+
+ try:
+ kernel = get_kernel(repo_id)
+ ALL_ATTENTION_FUNCTIONS.register(
+ f"kernel_{repo_id.replace('/', '_')}", getattr(kernel, kernel_name)
+ )
+ config._attn_implementation = f"kernel_{repo_id.replace('/', '_')}"
+ except FileNotFoundError as e:
+ logger.warning(
+ f"Could not find a kernel repository '{repo_id}' compatible with your devicein the hub: {e}. Using eager attention implementation instead."
+ )
+ config._attn_implementation = "eager"
+ except AttributeError:
+ raise ValueError(
+ "the kernel function name or class specified in the attn_implementation argument is not valid. \
+ Please check the documentation for the correct format, \
+ and check that the kernel exports the class and the function correctly."
+ )
+
+ if (
+ not isinstance(config._attn_implementation, dict)
+ and config._attn_implementation not in ["eager"] + ALL_ATTENTION_FUNCTIONS.valid_keys()
+ ):
+ message = f'Specified `attn_implementation="{config._attn_implementation}"` is not supported. The only possible arguments are `attn_implementation="eager"` (manual attention implementation)'
+ if cls._supports_flash_attn_2:
+ message += ', `"attn_implementation=flash_attention_2"` (implementation using flash attention 2)'
+ if cls._supports_sdpa:
+ message += ', `"attn_implementation=sdpa"` (implementation using torch.nn.functional.scaled_dot_product_attention)'
+ if cls._supports_flex_attn:
+ message += (
+ ', `"attn_implementation=flex_attention"` (implementation using torch\'s flex_attention)'
+ )
+ raise ValueError(message + ".")
+
+ # If a config is passed with a preset attn_implementation, we skip the automatic dispatch and use the user-provided config, with hard checks that the requested attention implementation is available.
+ requested_attn_implementation = config._attn_implementation_internal
+
+ # Composite models consisting of several PretrainedModels have to specify attention impl as a dict
+ # where keys are sub-config names. But most people will specify one `str` which means that should dispatch it
+ # for all sub-models.
+ # Below we check if a config is composite and manually prepare a dict of attn impl if not already passed as a dict.
+ # Later each sub-module will dispatch with its own attn impl, by calling `XXXModel._from_config(config.text_config)`
+ # If any of sub-modules doesn't support requested attn, an error will be raised. See https://github.com/huggingface/transformers/pull/32238
+ for key in config.sub_configs.keys():
+ sub_config = getattr(config, key)
+ curr_attn_implementation = (
+ requested_attn_implementation
+ if not isinstance(requested_attn_implementation, dict)
+ else requested_attn_implementation.get(key, None)
+ )
+ # For models with backbone sub-config might be not initialized
+ if sub_config is not None:
+ sub_config._attn_implementation_internal = curr_attn_implementation
+
+ if use_flash_attention_2:
+ logger.warning_once(
+ 'The model was loaded with use_flash_attention_2=True, which is deprecated and may be removed in a future release. Please use `attn_implementation="flash_attention_2"` instead.'
+ )
+ config._attn_implementation = "flash_attention_2"
+
+ if config._attn_implementation == "flash_attention_2":
+ cls._check_and_enable_flash_attn_2(
+ config,
+ torch_dtype=torch_dtype,
+ device_map=device_map,
+ hard_check_only=False,
+ check_device_map=check_device_map,
+ )
+ elif requested_attn_implementation == "flex_attention":
+ config = cls._check_and_enable_flex_attn(config, hard_check_only=True)
+ elif requested_attn_implementation in [None, "sdpa"] and not is_torch_xla_available():
+ # use_flash_attention_2 takes priority over SDPA, hence SDPA treated in this elif.
+ config = cls._check_and_enable_sdpa(
+ config,
+ hard_check_only=False if requested_attn_implementation is None else True,
+ )
+
+ if (
+ torch.version.hip is not None
+ and config._attn_implementation == "sdpa"
+ and torch.cuda.device_count() > 1
+ and version.parse(torch.__version__) < version.parse("2.4.1")
+ ):
+ logger.warning_once(
+ "Using the `SDPA` attention implementation on multi-gpu setup with ROCM may lead to performance issues due to the FA backend. Disabling it to use alternative backends."
+ )
+ torch.backends.cuda.enable_flash_sdp(False)
+ elif requested_attn_implementation in ALL_ATTENTION_FUNCTIONS.valid_keys():
+ config._attn_implementation = requested_attn_implementation
+ elif isinstance(requested_attn_implementation, dict):
+ config._attn_implementation = None
+ else:
+ config._attn_implementation = "eager"
+
+ config._attn_implementation_autoset = True
+ return config
+
+ @classmethod
+ def _set_default_torch_dtype(cls, dtype: torch.dtype) -> torch.dtype:
+ """
+ Change the default dtype and return the previous one. This is needed when wanting to instantiate the model
+ under specific dtype.
+
+ Args:
+ dtype (`torch.dtype`):
+ a floating dtype to set to.
+
+ Returns:
+ `torch.dtype`: the original `dtype` that can be used to restore `torch.set_default_dtype(dtype)` if it was
+ modified. If it wasn't, returns `None`.
+
+ Note `set_default_dtype` currently only works with floating-point types and asserts if for example,
+ `torch.int64` is passed. So if a non-float `dtype` is passed this functions will throw an exception.
+ """
+ if not dtype.is_floating_point:
+ raise ValueError(
+ f"Can't instantiate {cls.__name__} model under dtype={dtype} since it is not a floating point dtype"
+ )
+
+ logger.info(f"Instantiating {cls.__name__} model under default dtype {dtype}.")
+ dtype_orig = torch.get_default_dtype()
+ torch.set_default_dtype(dtype)
+ return dtype_orig
+
+ @property
+ def base_model(self) -> nn.Module:
+ """
+ `torch.nn.Module`: The main body of the model.
+ """
+ return getattr(self, self.base_model_prefix, self)
+
+ @classmethod
+ def can_generate(cls) -> bool:
+ """
+ Returns whether this model can generate sequences with `.generate()` from the `GenerationMixin`.
+
+ Under the hood, on classes where this function returns True, some generation-specific changes are triggered:
+ for instance, the model instance will have a populated `generation_config` attribute.
+
+ Returns:
+ `bool`: Whether this model can generate sequences with `.generate()`.
+ """
+ # Directly inherits `GenerationMixin` -> can generate
+ if "GenerationMixin" in str(cls.__bases__):
+ return True
+ # The class inherits from a class that can generate (recursive check) -> can generate
+ for base in cls.__bases__:
+ if not hasattr(base, "can_generate"):
+ continue
+ if "PreTrainedModel" not in str(base) and base.can_generate():
+ return True
+ # Detects whether `prepare_inputs_for_generation` has been overwritten in the model. Prior to v4.45, this
+ # was how we detected whether a model could generate.
+ if hasattr(cls, "prepare_inputs_for_generation"): # implicit: doesn't inherit `GenerationMixin`
+ logger.warning(
+ f"{cls.__name__} has generative capabilities, as `prepare_inputs_for_generation` is explicitly "
+ "defined. However, it doesn't directly inherit from `GenerationMixin`. From 👉v4.50👈 onwards, "
+ "`PreTrainedModel` will NOT inherit from `GenerationMixin`, and this model will lose the ability "
+ "to call `generate` and other related functions."
+ "\n - If you're using `trust_remote_code=True`, you can get rid of this warning by loading the "
+ "model with an auto class. See https://huggingface.co/docs/transformers/en/model_doc/auto#auto-classes"
+ "\n - If you are the owner of the model architecture code, please modify your model class such that "
+ "it inherits from `GenerationMixin` (after `PreTrainedModel`, otherwise you'll get an exception)."
+ "\n - If you are not the owner of the model architecture class, please contact the model code owner "
+ "to update it."
+ )
+ # Otherwise, can't generate
+ return False
+
+ @classmethod
+ def _check_and_enable_flash_attn_2(
+ cls,
+ config,
+ torch_dtype: Optional[torch.dtype] = None,
+ device_map: Optional[Union[str, Dict[str, int]]] = None,
+ check_device_map: bool = True,
+ hard_check_only: bool = False,
+ ) -> PretrainedConfig:
+ """
+ Checks the availability of Flash Attention 2 and compatibility with the current model.
+
+ If all checks pass and `hard_check_only` is False, the method will set the config attribute `attn_implementation` to "flash_attention_2" so that the model can initialize the correct attention module.
+ """
+ if not cls._supports_flash_attn_2:
+ raise ValueError(
+ f"{cls.__name__} does not support Flash Attention 2.0 yet. Please request to add support where"
+ f" the model is hosted, on its model hub page: https://huggingface.co/{config._name_or_path}/discussions/new"
+ " or in the Transformers GitHub repo: https://github.com/huggingface/transformers/issues/new"
+ )
+
+ if not is_flash_attn_2_available():
+ preface = "FlashAttention2 has been toggled on, but it cannot be used due to the following error:"
+ install_message = "Please refer to the documentation of https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2 to install Flash Attention 2."
+
+ if importlib.util.find_spec("flash_attn") is None:
+ # package `flash-attn` can not be installed on Ascend NPU, ignore related validation logic and early exit.
+ if is_torch_npu_available():
+ if not hard_check_only:
+ config._attn_implementation = "flash_attention_2"
+
+ logger.info("Detect using FlashAttention2 on Ascend NPU.")
+ return config
+ else:
+ raise ImportError(f"{preface} the package flash_attn seems to be not installed. {install_message}")
+
+ flash_attention_version = version.parse(importlib.metadata.version("flash_attn"))
+ if torch.version.cuda:
+ if flash_attention_version < version.parse("2.1.0"):
+ raise ImportError(
+ f"{preface} you need flash_attn package version to be greater or equal than 2.1.0. Detected version {flash_attention_version}. {install_message}"
+ )
+ elif not torch.cuda.is_available():
+ raise ValueError(
+ f"{preface} Flash Attention 2 is not available on CPU. Please make sure torch can access a CUDA device."
+ )
+ else:
+ raise ImportError(f"{preface} Flash Attention 2 is not available. {install_message}")
+ elif torch.version.hip:
+ if flash_attention_version < version.parse("2.0.4"):
+ raise ImportError(
+ f"{preface} you need flash_attn package version to be greater or equal than 2.0.4. Make sure to have that version installed - detected version {flash_attention_version}. {install_message}"
+ )
+ else:
+ raise ImportError(f"{preface} Flash Attention 2 is not available. {install_message}")
+
+ _is_bettertransformer = getattr(cls, "use_bettertransformer", False)
+
+ if _is_bettertransformer:
+ raise ValueError(
+ "Flash Attention 2 and BetterTransformer API are not compatible. Please make sure to disable BetterTransformers by doing model.reverse_bettertransformer()"
+ )
+
+ if torch_dtype is None:
+ logger.warning_once(
+ "You are attempting to use Flash Attention 2.0 without specifying a torch dtype. This might lead to unexpected behaviour"
+ )
+ elif torch_dtype is not None and torch_dtype not in [torch.float16, torch.bfloat16]:
+ logger.warning_once(
+ "Flash Attention 2.0 only supports torch.float16 and torch.bfloat16 dtypes, but"
+ f" the current dype in {cls.__name__} is {torch_dtype}. You should run training or inference using Automatic Mixed-Precision via the `with torch.autocast(device_type='torch_device'):` decorator,"
+ ' or load the model with the `torch_dtype` argument. Example: `model = AutoModel.from_pretrained("openai/whisper-tiny", attn_implementation="flash_attention_2", torch_dtype=torch.float16)`'
+ )
+
+ # The check `torch.empty(0).device.type != "cuda"` is needed as the model may be initialized after `torch.set_default_device` has been called,
+ # or the model may be initialized under the context manager `with torch.device("cuda"):`.
+ if check_device_map and device_map is None and torch.empty(0).device.type not in ["cuda", "mlu"]:
+ if torch.cuda.is_available():
+ logger.warning_once(
+ "You are attempting to use Flash Attention 2.0 with a model not initialized on GPU. Make sure to move the model to GPU"
+ " after initializing it on CPU with `model.to('cuda')`."
+ )
+ elif is_torch_mlu_available():
+ logger.warning_once(
+ "You are attempting to use Flash Attention 2.0 with a model not initialized on MLU. Make sure to move the model to MLU"
+ " after initializing it on CPU with `model.to('mlu')`."
+ )
+ else:
+ raise ValueError(
+ "You are attempting to use Flash Attention 2.0 with a model not initialized on GPU and with no GPU available. "
+ "This is not supported yet. Please make sure to have access to a GPU and either initialise the model on a GPU by passing a device_map "
+ "or initialising the model on CPU and then moving it to GPU."
+ )
+ elif (
+ check_device_map
+ and device_map is not None
+ and isinstance(device_map, dict)
+ and ("cpu" in device_map.values() or "disk" in device_map.values())
+ ):
+ raise ValueError(
+ "You are attempting to use Flash Attention 2.0 with a model dispatched on CPU or disk. This is not supported. Please make sure to "
+ "initialise the model on a GPU by passing a device_map that contains only GPU devices as keys."
+ )
+ if not hard_check_only:
+ config._attn_implementation = "flash_attention_2"
+ return config
+
+ @classmethod
+ def _check_and_enable_sdpa(cls, config, hard_check_only: bool = False) -> PretrainedConfig:
+ """
+ Checks the availability of SDPA for a given model.
+
+ If all checks pass and `hard_check_only` is False, the method will set the config attribute `_attn_implementation` to "sdpa" so that the model can initialize the correct attention module.
+ """
+ if hard_check_only:
+ if not cls._supports_sdpa:
+ raise ValueError(
+ f"{cls.__name__} does not support an attention implementation through torch.nn.functional.scaled_dot_product_attention yet."
+ " Please request the support for this architecture: https://github.com/huggingface/transformers/issues/28005. If you believe"
+ ' this error is a bug, please open an issue in Transformers GitHub repository and load your model with the argument `attn_implementation="eager"` meanwhile. Example: `model = AutoModel.from_pretrained("openai/whisper-tiny", attn_implementation="eager")`'
+ )
+ if not is_torch_sdpa_available():
+ raise ImportError(
+ "PyTorch SDPA requirements in Transformers are not met. Please install torch>=2.1.1."
+ )
+
+ if not is_torch_sdpa_available() or not cls._supports_sdpa:
+ return config
+
+ _is_bettertransformer = getattr(cls, "use_bettertransformer", False)
+ if _is_bettertransformer:
+ return config
+
+ if not hard_check_only:
+ config._attn_implementation = "sdpa"
+ return config
+
+ @classmethod
+ def _check_and_enable_flex_attn(cls, config, hard_check_only: bool = False) -> PretrainedConfig:
+ """
+ Checks the availability of Flex Attention for a given model.
+
+ If all checks pass and `hard_check_only` is False, the method will set the config attribute `_attn_implementation` to "flex_attention" so that the model can initialize the correct attention module.
+ """
+ if hard_check_only:
+ if not cls._supports_flex_attn:
+ raise ValueError(
+ f"{cls.__name__} does not support an attention implementation through torch's flex_attention."
+ " Please request the support for this architecture: https://github.com/huggingface/transformers/issues/34809."
+ " If you believe this error is a bug, please open an issue in Transformers GitHub repository"
+ ' and load your model with the argument `attn_implementation="eager"` meanwhile.'
+ ' Example: `model = AutoModel.from_pretrained("openai/whisper-tiny", attn_implementation="eager")`'
+ )
+ if not is_torch_flex_attn_available():
+ raise ImportError(
+ "PyTorch Flex Attention requirements in Transformers are not met. Please install torch>=2.5.0."
+ )
+
+ if not is_torch_flex_attn_available() or not cls._supports_flex_attn:
+ return config
+
+ if not hard_check_only:
+ config._attn_implementation = "flex_attention"
+
+ return config
+
+ def enable_input_require_grads(self):
+ """
+ Enables the gradients for the input embeddings. This is useful for fine-tuning adapter weights while keeping
+ the model weights fixed.
+ """
+
+ def make_inputs_require_grads(module, input, output):
+ output.requires_grad_(True)
+
+ self._require_grads_hook = self.get_input_embeddings().register_forward_hook(make_inputs_require_grads)
+
+ def disable_input_require_grads(self):
+ """
+ Removes the `_require_grads_hook`.
+ """
+ self._require_grads_hook.remove()
+
+ def get_input_embeddings(self) -> nn.Module:
+ """
+ Returns the model's input embeddings.
+
+ Returns:
+ `nn.Module`: A torch module mapping vocabulary to hidden states.
+ """
+ base_model = getattr(self, self.base_model_prefix, self)
+ if base_model is not self:
+ return base_model.get_input_embeddings()
+ else:
+ raise NotImplementedError
+
+ def set_input_embeddings(self, value: nn.Module):
+ """
+ Set model's input embeddings.
+
+ Args:
+ value (`nn.Module`): A module mapping vocabulary to hidden states.
+ """
+ base_model = getattr(self, self.base_model_prefix, self)
+ if base_model is not self:
+ base_model.set_input_embeddings(value)
+ else:
+ raise NotImplementedError
+
+ def get_output_embeddings(self) -> nn.Module:
+ """
+ Returns the model's output embeddings.
+
+ Returns:
+ `nn.Module`: A torch module mapping hidden states to vocabulary.
+ """
+ return None # Overwrite for models with output embeddings
+
+ def _init_weights(self, module):
+ """
+ Initialize the weights. This method should be overridden by derived class and is
+ the only initialization method that will be called when loading a checkpoint
+ using `from_pretrained`. Any attempt to initialize outside of this function
+ will be useless as the torch.nn.init function are all replaced with skip.
+ """
+ pass
+
+ def _initialize_weights(self, module):
+ """
+ Initialize the weights if they are not already initialized.
+ """
+ if getattr(module, "_is_hf_initialized", False):
+ return
+ self._init_weights(module)
+ module._is_hf_initialized = True
+
+ @torch.no_grad()
+ def initialize_weights(self):
+ """
+ This is equivalent to calling `self.apply(self._initialize_weights)`, but correctly handles composite models.
+ This function dynamically dispatches the correct `init_weights` function to the modules as we advance in the
+ module graph along the recursion. It can handle an arbitrary number of sub-models. Without it, every composite
+ model would have to recurse a second time on all sub-models explicitly in the outer-most `_init_weights`, which
+ is extremely error prone and inefficient.
+
+ Note that the `torch.no_grad()` decorator is very important as well, as most of our `_init_weights` do not use
+ `torch.nn.init` functions (which are all no_grad by default), but simply do in-place ops such as
+ `module.weight.data.zero_()`.
+ """
+ if not hasattr(torch.nn.Module, "smart_apply"):
+ # This function is equivalent to `torch.nn.Module.apply`, except that it dynamically adjust the function
+ # to apply as we go down the graph
+ def smart_apply(self, fn):
+ for module in self.children():
+ # We found a sub-model: recursively dispatch its own init function now!
+ if hasattr(module, "_init_weights"):
+ module.smart_apply(module._initialize_weights)
+ else:
+ module.smart_apply(fn)
+ fn(self)
+ return self
+
+ torch.nn.Module.smart_apply = smart_apply
+
+ # Let the magic happen with this simple call
+ self.smart_apply(self._initialize_weights)
+
+ def tie_weights(self):
+ """
+ Tie the weights between the input embeddings and the output embeddings.
+
+ If the `torchscript` flag is set in the configuration, can't handle parameter sharing so we are cloning the
+ weights instead.
+ """
+ if getattr(self.config.get_text_config(decoder=True), "tie_word_embeddings", True):
+ output_embeddings = self.get_output_embeddings()
+ if output_embeddings is not None:
+ self._tie_or_clone_weights(output_embeddings, self.get_input_embeddings())
+
+ if getattr(self.config, "is_encoder_decoder", False) and getattr(self.config, "tie_encoder_decoder", False):
+ if hasattr(self, self.base_model_prefix):
+ self = getattr(self, self.base_model_prefix)
+ tied_weights = self._tie_encoder_decoder_weights(
+ self.encoder, self.decoder, self.base_model_prefix, "encoder"
+ )
+ # Setting a dynamic variable instead of `_tied_weights_keys` because it's a class
+ # attributed not an instance member, therefore modifying it will modify the entire class
+ # Leading to issues on subsequent calls by different tests or subsequent calls.
+ self._dynamic_tied_weights_keys = tied_weights
+
+ for module in self.modules():
+ if hasattr(module, "_tie_weights"):
+ module._tie_weights()
+
+ @staticmethod
+ def _tie_encoder_decoder_weights(
+ encoder: nn.Module, decoder: nn.Module, base_model_prefix: str, base_encoder_name: str
+ ):
+ uninitialized_encoder_weights: List[str] = []
+ tied_weights: List[str] = []
+ if decoder.__class__ != encoder.__class__:
+ logger.info(
+ f"{decoder.__class__} and {encoder.__class__} are not equal. In this case make sure that all encoder"
+ " weights are correctly initialized."
+ )
+
+ def tie_encoder_to_decoder_recursively(
+ decoder_pointer: nn.Module,
+ encoder_pointer: nn.Module,
+ module_name: str,
+ base_encoder_name: str,
+ uninitialized_encoder_weights: List[str],
+ depth=0,
+ total_decoder_name="",
+ total_encoder_name="",
+ ):
+ assert isinstance(decoder_pointer, nn.Module) and isinstance(encoder_pointer, nn.Module), (
+ f"{decoder_pointer} and {encoder_pointer} have to be of type nn.Module"
+ )
+ if hasattr(decoder_pointer, "weight"):
+ assert hasattr(encoder_pointer, "weight")
+ encoder_pointer.weight = decoder_pointer.weight
+ tied_weights.append(f"{base_encoder_name}{total_encoder_name}.weight")
+ if hasattr(decoder_pointer, "bias"):
+ assert hasattr(encoder_pointer, "bias")
+ tied_weights.append(f"{base_encoder_name}{total_encoder_name}.bias")
+ encoder_pointer.bias = decoder_pointer.bias
+ return
+
+ encoder_modules = encoder_pointer._modules
+ decoder_modules = decoder_pointer._modules
+ if len(decoder_modules) > 0:
+ assert len(encoder_modules) > 0, (
+ f"Encoder module {encoder_pointer} does not match decoder module {decoder_pointer}"
+ )
+
+ all_encoder_weights = {module_name + "/" + sub_name for sub_name in encoder_modules.keys()}
+ encoder_layer_pos = 0
+ for name, module in decoder_modules.items():
+ if name.isdigit():
+ encoder_name = str(int(name) + encoder_layer_pos)
+ decoder_name = name
+ if not isinstance(decoder_modules[decoder_name], type(encoder_modules[encoder_name])) and len(
+ encoder_modules
+ ) != len(decoder_modules):
+ # this can happen if the name corresponds to the position in a list module list of layers
+ # in this case the decoder has added a cross-attention that the encoder does not have
+ # thus skip this step and subtract one layer pos from encoder
+ encoder_layer_pos -= 1
+ continue
+ elif name not in encoder_modules:
+ continue
+ elif depth > 500:
+ raise ValueError(
+ "Max depth of recursive function `tie_encoder_to_decoder` reached. It seems that there is"
+ " a circular dependency between two or more `nn.Modules` of your model."
+ )
+ else:
+ decoder_name = encoder_name = name
+ tie_encoder_to_decoder_recursively(
+ decoder_modules[decoder_name],
+ encoder_modules[encoder_name],
+ module_name + "/" + name,
+ base_encoder_name,
+ uninitialized_encoder_weights,
+ depth=depth + 1,
+ total_encoder_name=f"{total_encoder_name}.{encoder_name}",
+ total_decoder_name=f"{total_decoder_name}.{decoder_name}",
+ )
+ all_encoder_weights.remove(module_name + "/" + encoder_name)
+
+ uninitialized_encoder_weights += list(all_encoder_weights)
+
+ # tie weights recursively
+ tie_encoder_to_decoder_recursively(
+ decoder, encoder, base_model_prefix, base_encoder_name, uninitialized_encoder_weights
+ )
+
+ if len(uninitialized_encoder_weights) > 0:
+ logger.warning(
+ f"The following encoder weights were not tied to the decoder {uninitialized_encoder_weights}"
+ )
+ return tied_weights
+
+ def _tie_or_clone_weights(self, output_embeddings, input_embeddings):
+ """Tie or clone module weights depending of whether we are using TorchScript or not"""
+ if self.config.torchscript:
+ output_embeddings.weight = nn.Parameter(input_embeddings.weight.clone())
+ else:
+ output_embeddings.weight = input_embeddings.weight
+
+ if getattr(output_embeddings, "bias", None) is not None:
+ output_embeddings.bias.data = nn.functional.pad(
+ output_embeddings.bias.data,
+ (
+ 0,
+ output_embeddings.weight.shape[0] - output_embeddings.bias.shape[0],
+ ),
+ "constant",
+ 0,
+ )
+ if hasattr(output_embeddings, "out_features") and hasattr(input_embeddings, "num_embeddings"):
+ output_embeddings.out_features = input_embeddings.num_embeddings
+
+ def _get_no_split_modules(self, device_map: str):
+ """
+ Get the modules of the model that should not be spit when using device_map. We iterate through the modules to
+ get the underlying `_no_split_modules`.
+
+ Args:
+ device_map (`str`):
+ The device map value. Options are ["auto", "balanced", "balanced_low_0", "sequential"]
+
+ Returns:
+ `List[str]`: List of modules that should not be split
+ """
+ _no_split_modules = set()
+ modules_to_check = [self]
+ while len(modules_to_check) > 0:
+ module = modules_to_check.pop(-1)
+ # if the module does not appear in _no_split_modules, we also check the children
+ if module.__class__.__name__ not in _no_split_modules:
+ if isinstance(module, PreTrainedModel):
+ if module._no_split_modules is None:
+ raise ValueError(
+ f"{module.__class__.__name__} does not support `device_map='{device_map}'`. To implement support, the model "
+ "class needs to implement the `_no_split_modules` attribute."
+ )
+ else:
+ _no_split_modules = _no_split_modules | set(module._no_split_modules)
+ modules_to_check += list(module.children())
+ return list(_no_split_modules)
+
+ def resize_token_embeddings(
+ self,
+ new_num_tokens: Optional[int] = None,
+ pad_to_multiple_of: Optional[int] = None,
+ mean_resizing: bool = True,
+ ) -> nn.Embedding:
+ """
+ Resizes input token embeddings matrix of the model if `new_num_tokens != config.vocab_size`.
+
+ Takes care of tying weights embeddings afterwards if the model class has a `tie_weights()` method.
+
+ Arguments:
+ new_num_tokens (`int`, *optional*):
+ The new number of tokens in the embedding matrix. Increasing the size will add newly initialized
+ vectors at the end. Reducing the size will remove vectors from the end. If not provided or `None`, just
+ returns a pointer to the input tokens `torch.nn.Embedding` module of the model without doing anything.
+ pad_to_multiple_of (`int`, *optional*):
+ If set will pad the embedding matrix to a multiple of the provided value.If `new_num_tokens` is set to
+ `None` will just pad the embedding to a multiple of `pad_to_multiple_of`.
+
+ This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability
+ `>= 7.5` (Volta), or on TPUs which benefit from having sequence lengths be a multiple of 128. For more
+ details about this, or help on choosing the correct value for resizing, refer to this guide:
+ https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc
+ mean_resizing (`bool`):
+ Whether to initialize the added embeddings from a multivariate normal distribution that has old embeddings' mean and
+ covariance or to initialize them with a normal distribution that has a mean of zero and std equals `config.initializer_range`.
+
+ Setting `mean_resizing` to `True` is useful when increasing the size of the embeddings of causal language models,
+ where the generated tokens' probabilities won't be affected by the added embeddings because initializing the new embeddings with the
+ old embeddings' mean will reduce the kl-divergence between the next token probability before and after adding the new embeddings.
+ Refer to this article for more information: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
+
+ Return:
+ `torch.nn.Embedding`: Pointer to the input tokens Embeddings Module of the model.
+ """
+ model_embeds = self._resize_token_embeddings(new_num_tokens, pad_to_multiple_of, mean_resizing)
+ if new_num_tokens is None and pad_to_multiple_of is None:
+ return model_embeds
+
+ # Since we are basically reusing the same old embeddings with new weight values, gathering is required
+ is_quantized = hasattr(self, "hf_quantizer") and self.hf_quantizer is not None
+ if is_deepspeed_zero3_enabled() and not is_quantized:
+ with deepspeed.zero.GatheredParameters(model_embeds.weight, modifier_rank=None):
+ vocab_size = model_embeds.weight.shape[0]
+ else:
+ vocab_size = model_embeds.weight.shape[0]
+
+ # Update base model and current model config.
+ self.config.get_text_config().vocab_size = vocab_size
+ self.vocab_size = vocab_size
+
+ # Tie weights again if needed
+ self.tie_weights()
+
+ return model_embeds
+
+ def _resize_token_embeddings(self, new_num_tokens, pad_to_multiple_of=None, mean_resizing=True):
+ old_embeddings = self.get_input_embeddings()
+ new_embeddings = self._get_resized_embeddings(
+ old_embeddings, new_num_tokens, pad_to_multiple_of, mean_resizing
+ )
+ if hasattr(old_embeddings, "_hf_hook"):
+ hook = old_embeddings._hf_hook
+ add_hook_to_module(new_embeddings, hook)
+ old_embeddings_requires_grad = old_embeddings.weight.requires_grad
+ new_embeddings.requires_grad_(old_embeddings_requires_grad)
+ self.set_input_embeddings(new_embeddings)
+ is_quantized = hasattr(self, "hf_quantizer") and self.hf_quantizer is not None
+
+ # Update new_num_tokens with the actual size of new_embeddings
+ if pad_to_multiple_of is not None:
+ if is_deepspeed_zero3_enabled() and not is_quantized:
+ with deepspeed.zero.GatheredParameters(new_embeddings.weight, modifier_rank=None):
+ new_num_tokens = new_embeddings.weight.shape[0]
+ else:
+ new_num_tokens = new_embeddings.weight.shape[0]
+
+ # if word embeddings are not tied, make sure that lm head is resized as well
+ if (
+ self.get_output_embeddings() is not None
+ and not self.config.get_text_config(decoder=True).tie_word_embeddings
+ ):
+ old_lm_head = self.get_output_embeddings()
+ if isinstance(old_lm_head, torch.nn.Embedding):
+ new_lm_head = self._get_resized_embeddings(old_lm_head, new_num_tokens, mean_resizing=mean_resizing)
+ else:
+ new_lm_head = self._get_resized_lm_head(old_lm_head, new_num_tokens, mean_resizing=mean_resizing)
+ if hasattr(old_lm_head, "_hf_hook"):
+ hook = old_lm_head._hf_hook
+ add_hook_to_module(new_lm_head, hook)
+ old_lm_head_requires_grad = old_lm_head.weight.requires_grad
+ new_lm_head.requires_grad_(old_lm_head_requires_grad)
+ self.set_output_embeddings(new_lm_head)
+
+ return self.get_input_embeddings()
+
+ def _get_resized_embeddings(
+ self,
+ old_embeddings: nn.Embedding,
+ new_num_tokens: Optional[int] = None,
+ pad_to_multiple_of: Optional[int] = None,
+ mean_resizing: bool = True,
+ ) -> nn.Embedding:
+ """
+ Build a resized Embedding Module from a provided token Embedding Module. Increasing the size will add newly
+ initialized vectors at the end. Reducing the size will remove vectors from the end
+
+ Args:
+ old_embeddings (`torch.nn.Embedding`):
+ Old embeddings to be resized.
+ new_num_tokens (`int`, *optional*):
+ New number of tokens in the embedding matrix.
+
+ Increasing the size will add newly initialized vectors at the end. Reducing the size will remove
+ vectors from the end. If not provided or `None`, just returns a pointer to the input tokens
+ `torch.nn.Embedding` module of the model without doing anything.
+ pad_to_multiple_of (`int`, *optional*):
+ If set will pad the embedding matrix to a multiple of the provided value. If `new_num_tokens` is set to
+ `None` will just pad the embedding to a multiple of `pad_to_multiple_of`.
+
+ This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability
+ `>= 7.5` (Volta), or on TPUs which benefit from having sequence lengths be a multiple of 128. For more
+ details about this, or help on choosing the correct value for resizing, refer to this guide:
+ https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc
+ mean_resizing (`bool`):
+ Whether to initialize the added embeddings from a multivariate normal distribution that has old embeddings' mean and
+ covariance or to initialize them with a normal distribution that has a mean of zero and std equals `config.initializer_range`.
+
+ Setting `mean_resizing` to `True` is useful when increasing the size of the embeddings of causal language models,
+ where the generated tokens' probabilities will not be affected by the added embeddings because initializing the new embeddings with the
+ old embeddings' mean will reduce the kl-divergence between the next token probability before and after adding the new embeddings.
+ Refer to this article for more information: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
+
+
+ Return:
+ `torch.nn.Embedding`: Pointer to the resized Embedding Module or the old Embedding Module if
+ `new_num_tokens` is `None`
+ """
+
+ if pad_to_multiple_of is not None:
+ if not isinstance(pad_to_multiple_of, int):
+ raise ValueError(
+ f"Asking to pad the embedding matrix to a multiple of `{pad_to_multiple_of}`, which is not and integer. Please make sure to pass an integer"
+ )
+ if new_num_tokens is None:
+ new_num_tokens = old_embeddings.weight.shape[0]
+ new_num_tokens = ((new_num_tokens + pad_to_multiple_of - 1) // pad_to_multiple_of) * pad_to_multiple_of
+ else:
+ logger.info(
+ "You are resizing the embedding layer without providing a `pad_to_multiple_of` parameter. This means that the new embedding"
+ f" dimension will be {new_num_tokens}. This might induce some performance reduction as *Tensor Cores* will not be available."
+ " For more details about this, or help on choosing the correct value for resizing, refer to this guide:"
+ " https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc"
+ )
+
+ if new_num_tokens is None:
+ return old_embeddings
+
+ is_quantized = hasattr(self, "hf_quantizer") and self.hf_quantizer is not None
+ if is_deepspeed_zero3_enabled() and not is_quantized:
+ with deepspeed.zero.GatheredParameters(old_embeddings.weight, modifier_rank=None):
+ old_num_tokens, old_embedding_dim = old_embeddings.weight.size()
+ else:
+ old_num_tokens, old_embedding_dim = old_embeddings.weight.size()
+
+ if old_num_tokens == new_num_tokens and not is_deepspeed_zero3_enabled():
+ return old_embeddings
+
+ if not isinstance(old_embeddings, nn.Embedding):
+ raise TypeError(
+ f"Old embeddings are of type {type(old_embeddings)}, which is not an instance of {nn.Embedding}. You"
+ " should either use a different resize function or make sure that `old_embeddings` are an instance of"
+ f" {nn.Embedding}."
+ )
+
+ # Build new embeddings
+
+ # When using DeepSpeed ZeRO-3, we shouldn't create new embeddings with DeepSpeed init
+ # because the shape of the new embedding layer is used across various modeling files
+ # as well as to update config vocab size. Shape will be 0 when using DeepSpeed init leading
+ # to errors when training.
+ new_embeddings = nn.Embedding(
+ new_num_tokens,
+ old_embedding_dim,
+ device=old_embeddings.weight.device,
+ dtype=old_embeddings.weight.dtype,
+ )
+
+ if new_num_tokens > old_num_tokens and not mean_resizing:
+ # initialize new embeddings (in particular added tokens) with a mean of 0 and std equals `config.initializer_range`.
+ self._init_weights(new_embeddings)
+
+ elif new_num_tokens > old_num_tokens and mean_resizing:
+ # initialize new embeddings (in particular added tokens). The new embeddings will be initialized
+ # from a multivariate normal distribution that has old embeddings' mean and covariance.
+ # as described in this article: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
+ logger.warning_once(
+ "The new embeddings will be initialized from a multivariate normal distribution that has old embeddings' mean and covariance. "
+ "As described in this article: https://nlp.stanford.edu/~johnhew/vocab-expansion.html. "
+ "To disable this, use `mean_resizing=False`"
+ )
+
+ added_num_tokens = new_num_tokens - old_num_tokens
+ if is_deepspeed_zero3_enabled() and not is_quantized:
+ with deepspeed.zero.GatheredParameters([old_embeddings.weight], modifier_rank=None):
+ self._init_added_embeddings_weights_with_mean(
+ old_embeddings, new_embeddings, old_embedding_dim, old_num_tokens, added_num_tokens
+ )
+ else:
+ self._init_added_embeddings_weights_with_mean(
+ old_embeddings, new_embeddings, old_embedding_dim, old_num_tokens, added_num_tokens
+ )
+
+ # Copy token embeddings from the previous weights
+
+ # numbers of tokens to copy
+ n = min(old_num_tokens, new_num_tokens)
+
+ if is_deepspeed_zero3_enabled() and not is_quantized:
+ params = [old_embeddings.weight, new_embeddings.weight]
+ with deepspeed.zero.GatheredParameters(params, modifier_rank=0):
+ new_embeddings.weight.data[:n, :] = old_embeddings.weight.data[:n, :]
+ else:
+ new_embeddings.weight.data[:n, :] = old_embeddings.weight.data[:n, :]
+
+ # Replace weights in old_embeddings and return to maintain the same embedding type.
+ # This ensures correct functionality when a Custom Embedding class is passed as input.
+ # The input and output embedding types remain consistent. (c.f. https://github.com/huggingface/transformers/pull/31979)
+ if is_deepspeed_zero3_enabled() and not is_quantized:
+ params = [old_embeddings.weight, new_embeddings.weight]
+ with deepspeed.zero.GatheredParameters(params, modifier_rank=0):
+ old_embeddings.weight = new_embeddings.weight
+ old_embeddings.num_embeddings = new_embeddings.weight.data.shape[0]
+
+ # If the new number of tokens is smaller than the original `padding_idx`, the `padding_idx`
+ # will be set to `None` in the resized embeddings.
+ if old_embeddings.padding_idx is not None and (new_num_tokens - 1) < old_embeddings.padding_idx:
+ old_embeddings.padding_idx = None
+ else:
+ old_embeddings.weight.data = new_embeddings.weight.data
+ old_embeddings.num_embeddings = new_embeddings.weight.data.shape[0]
+ if old_embeddings.padding_idx is not None and (new_num_tokens - 1) < old_embeddings.padding_idx:
+ old_embeddings.padding_idx = None
+
+ return old_embeddings
+
+ def _get_resized_lm_head(
+ self,
+ old_lm_head: nn.Linear,
+ new_num_tokens: Optional[int] = None,
+ transposed: Optional[bool] = False,
+ mean_resizing: bool = True,
+ ) -> nn.Linear:
+ """
+ Build a resized Linear Module from a provided old Linear Module. Increasing the size will add newly initialized
+ vectors at the end. Reducing the size will remove vectors from the end
+
+ Args:
+ old_lm_head (`torch.nn.Linear`):
+ Old lm head liner layer to be resized.
+ new_num_tokens (`int`, *optional*):
+ New number of tokens in the linear matrix.
+
+ Increasing the size will add newly initialized vectors at the end. Reducing the size will remove
+ vectors from the end. If not provided or `None`, just returns a pointer to the input tokens
+ `torch.nn.Linear` module of the model without doing anything. transposed (`bool`, *optional*, defaults
+ to `False`): Whether `old_lm_head` is transposed or not. If True `old_lm_head.size()` is `lm_head_dim,
+ vocab_size` else `vocab_size, lm_head_dim`.
+ mean_resizing (`bool`):
+ Whether to initialize the added embeddings from a multivariate normal distribution that has old embeddings' mean and
+ covariance or to initialize them with a normal distribution that has a mean of zero and std equals `config.initializer_range`.
+
+ Setting `mean_resizing` to `True` is useful when increasing the size of the embeddings of causal language models,
+ where the generated tokens' probabilities will not be affected by the added embeddings because initializing the new embeddings with the
+ old embeddings' mean will reduce the kl-divergence between the next token probability before and after adding the new embeddings.
+ Refer to this article for more information: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
+
+ Return:
+ `torch.nn.Linear`: Pointer to the resized Linear Module or the old Linear Module if `new_num_tokens` is
+ `None`
+ """
+ if new_num_tokens is None:
+ return old_lm_head
+
+ is_quantized = hasattr(self, "hf_quantizer") and self.hf_quantizer is not None
+ if is_deepspeed_zero3_enabled() and not is_quantized:
+ with deepspeed.zero.GatheredParameters(old_lm_head.weight, modifier_rank=None):
+ old_num_tokens, old_lm_head_dim = (
+ old_lm_head.weight.size() if not transposed else old_lm_head.weight.t().size()
+ )
+ else:
+ old_num_tokens, old_lm_head_dim = (
+ old_lm_head.weight.size() if not transposed else old_lm_head.weight.t().size()
+ )
+
+ if old_num_tokens == new_num_tokens and not is_deepspeed_zero3_enabled():
+ return old_lm_head
+
+ if not isinstance(old_lm_head, nn.Linear):
+ raise TypeError(
+ f"Old language model head is of type {type(old_lm_head)}, which is not an instance of {nn.Linear}. You"
+ " should either use a different resize function or make sure that `old_lm_head` are an instance of"
+ f" {nn.Linear}."
+ )
+
+ # Build new lm head
+ new_lm_head_shape = (old_lm_head_dim, new_num_tokens) if not transposed else (new_num_tokens, old_lm_head_dim)
+ has_new_lm_head_bias = old_lm_head.bias is not None
+
+ # When using DeepSpeed ZeRO-3, we shouldn't create new embeddings with DeepSpeed init
+ # because the shape of the new embedding layer is used across various modeling files
+ # as well as to update config vocab size. Shape will be 0 when using DeepSpeed init leading
+ # to errors when training.
+ new_lm_head = nn.Linear(
+ *new_lm_head_shape,
+ bias=has_new_lm_head_bias,
+ device=old_lm_head.weight.device,
+ dtype=old_lm_head.weight.dtype,
+ )
+
+ if new_num_tokens > old_num_tokens and not mean_resizing:
+ # initialize new embeddings (in particular added tokens) with a mean of 0 and std equals `config.initializer_range`.
+ self._init_weights(new_lm_head)
+
+ elif new_num_tokens > old_num_tokens and mean_resizing:
+ # initialize new lm_head weights (in particular added tokens). The new lm_head weights
+ # will be initialized from a multivariate normal distribution that has old embeddings' mean and covariance.
+ # as described in this article: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
+ logger.warning_once(
+ "The new lm_head weights will be initialized from a multivariate normal distribution that has old embeddings' mean and covariance. "
+ "As described in this article: https://nlp.stanford.edu/~johnhew/vocab-expansion.html. "
+ "To disable this, use `mean_resizing=False`"
+ )
+
+ added_num_tokens = new_num_tokens - old_num_tokens
+ if is_deepspeed_zero3_enabled() and not is_quantized:
+ params = [old_lm_head.weight]
+ if has_new_lm_head_bias:
+ params += [old_lm_head.bias]
+ with deepspeed.zero.GatheredParameters(params, modifier_rank=None):
+ self._init_added_lm_head_weights_with_mean(
+ old_lm_head, new_lm_head, old_lm_head_dim, old_num_tokens, added_num_tokens, transposed
+ )
+ if has_new_lm_head_bias:
+ self._init_added_lm_head_bias_with_mean(old_lm_head, new_lm_head, added_num_tokens)
+
+ else:
+ self._init_added_lm_head_weights_with_mean(
+ old_lm_head, new_lm_head, old_lm_head_dim, old_num_tokens, added_num_tokens, transposed
+ )
+ if has_new_lm_head_bias:
+ self._init_added_lm_head_bias_with_mean(old_lm_head, new_lm_head, added_num_tokens)
+
+ num_tokens_to_copy = min(old_num_tokens, new_num_tokens)
+
+ if is_deepspeed_zero3_enabled() and not is_quantized:
+ params = [old_lm_head.weight, old_lm_head.bias, new_lm_head.weight, new_lm_head.bias]
+ with deepspeed.zero.GatheredParameters(params, modifier_rank=0):
+ self._copy_lm_head_original_to_resized(
+ new_lm_head, old_lm_head, num_tokens_to_copy, transposed, has_new_lm_head_bias
+ )
+ else:
+ self._copy_lm_head_original_to_resized(
+ new_lm_head, old_lm_head, num_tokens_to_copy, transposed, has_new_lm_head_bias
+ )
+
+ return new_lm_head
+
+ def _init_added_embeddings_weights_with_mean(
+ self, old_embeddings, new_embeddings, old_embedding_dim, old_num_tokens, added_num_tokens
+ ):
+ old_embeddings_weight = old_embeddings.weight.data.to(torch.float32)
+ mean_embeddings = torch.mean(old_embeddings_weight, axis=0)
+ old_centered_embeddings = old_embeddings_weight - mean_embeddings
+ covariance = old_centered_embeddings.T @ old_centered_embeddings / old_num_tokens
+
+ # Check if the covariance is positive definite.
+ epsilon = 1e-9
+ is_covariance_psd = constraints.positive_definite.check(epsilon * covariance).all()
+ if is_covariance_psd:
+ # If covariances is positive definite, a distribution can be created. and we can sample new weights from it.
+ distribution = torch.distributions.multivariate_normal.MultivariateNormal(
+ mean_embeddings, covariance_matrix=epsilon * covariance
+ )
+ new_embeddings.weight.data[-1 * added_num_tokens :, :] = distribution.sample(
+ sample_shape=(added_num_tokens,)
+ ).to(old_embeddings.weight.dtype)
+ else:
+ # Otherwise, just initialize with the mean. because distribution will not be created.
+ new_embeddings.weight.data[-1 * added_num_tokens :, :] = (
+ mean_embeddings[None, :].repeat(added_num_tokens, 1).to(old_embeddings.weight.dtype)
+ )
+
+ def _init_added_lm_head_weights_with_mean(
+ self,
+ old_lm_head,
+ new_lm_head,
+ old_lm_head_dim,
+ old_num_tokens,
+ added_num_tokens,
+ transposed=False,
+ ):
+ if transposed:
+ # Transpose to the desired shape for the function.
+ new_lm_head.weight.data = new_lm_head.weight.data.T
+ old_lm_head.weight.data = old_lm_head.weight.data.T
+
+ # The same initialization logic as Embeddings.
+ self._init_added_embeddings_weights_with_mean(
+ old_lm_head, new_lm_head, old_lm_head_dim, old_num_tokens, added_num_tokens
+ )
+
+ if transposed:
+ # Transpose again to the correct shape.
+ new_lm_head.weight.data = new_lm_head.weight.data.T
+ old_lm_head.weight.data = old_lm_head.weight.data.T
+
+ def _init_added_lm_head_bias_with_mean(self, old_lm_head, new_lm_head, added_num_tokens):
+ bias_mean = torch.mean(old_lm_head.bias.data, axis=0, dtype=torch.float32)
+ bias_std = torch.std(old_lm_head.bias.data, axis=0).to(torch.float32)
+ new_lm_head.bias.data[-1 * added_num_tokens :].normal_(mean=bias_mean, std=1e-9 * bias_std)
+
+ def _copy_lm_head_original_to_resized(
+ self, new_lm_head, old_lm_head, num_tokens_to_copy, transposed, has_new_lm_head_bias
+ ):
+ # Copy old lm head weights to new lm head
+ if not transposed:
+ new_lm_head.weight.data[:num_tokens_to_copy, :] = old_lm_head.weight.data[:num_tokens_to_copy, :]
+ else:
+ new_lm_head.weight.data[:, :num_tokens_to_copy] = old_lm_head.weight.data[:, :num_tokens_to_copy]
+
+ # Copy bias weights to new lm head
+ if has_new_lm_head_bias:
+ new_lm_head.bias.data[:num_tokens_to_copy] = old_lm_head.bias.data[:num_tokens_to_copy]
+
+ def resize_position_embeddings(self, new_num_position_embeddings: int):
+ raise NotImplementedError(
+ f"`resize_position_embeddings` is not implemented for {self.__class__}`. To implement it, you should "
+ f"overwrite this method in the class {self.__class__} in `modeling_{self.__class__.__module__}.py`"
+ )
+
+ def get_position_embeddings(self) -> Union[nn.Embedding, Tuple[nn.Embedding]]:
+ raise NotImplementedError(
+ f"`get_position_embeddings` is not implemented for {self.__class__}`. To implement it, you should "
+ f"overwrite this method in the class {self.__class__} in `modeling_{self.__class__.__module__}.py`"
+ )
+
+ def init_weights(self):
+ """
+ If needed prunes and maybe initializes weights. If using a custom `PreTrainedModel`, you need to implement any
+ initialization logic in `_init_weights`.
+ """
+ # Prune heads if needed
+ if self.config.pruned_heads:
+ self.prune_heads(self.config.pruned_heads)
+
+ if _init_weights:
+ # Initialize weights
+ self.initialize_weights()
+
+ # Tie weights should be skipped when not initializing all weights
+ # since from_pretrained(...) calls tie weights anyways
+ self.tie_weights()
+
+ def prune_heads(self, heads_to_prune: Dict[int, List[int]]):
+ """
+ Prunes heads of the base model.
+
+ Arguments:
+ heads_to_prune (`Dict[int, List[int]]`):
+ Dictionary with keys being selected layer indices (`int`) and associated values being the list of heads
+ to prune in said layer (list of `int`). For instance {1: [0, 2], 2: [2, 3]} will prune heads 0 and 2 on
+ layer 1 and heads 2 and 3 on layer 2.
+ """
+ # save new sets of pruned heads as union of previously stored pruned heads and newly pruned heads
+ for layer, heads in heads_to_prune.items():
+ union_heads = set(self.config.pruned_heads.get(layer, [])) | set(heads)
+ self.config.pruned_heads[layer] = list(union_heads) # Unfortunately we have to store it as list for JSON
+
+ self.base_model._prune_heads(heads_to_prune)
+
+ def gradient_checkpointing_enable(self, gradient_checkpointing_kwargs=None):
+ """
+ Activates gradient checkpointing for the current model.
+
+ Note that in other frameworks this feature can be referred to as "activation checkpointing" or "checkpoint
+ activations".
+
+ We pass the `__call__` method of the modules instead of `forward` because `__call__` attaches all the hooks of
+ the module. https://discuss.pytorch.org/t/any-different-between-model-input-and-model-forward-input/3690/2
+
+ Args:
+ gradient_checkpointing_kwargs (dict, *optional*):
+ Additional keyword arguments passed along to the `torch.utils.checkpoint.checkpoint` function.
+ """
+ if not self.supports_gradient_checkpointing:
+ raise ValueError(f"{self.__class__.__name__} does not support gradient checkpointing.")
+
+ if gradient_checkpointing_kwargs is None:
+ gradient_checkpointing_kwargs = {"use_reentrant": True}
+
+ gradient_checkpointing_func = functools.partial(checkpoint, **gradient_checkpointing_kwargs)
+
+ # For old GC format (transformers < 4.35.0) for models that live on the Hub
+ # we will fall back to the overwritten `_set_gradient_checkpointing` method
+ _is_using_old_format = "value" in inspect.signature(self._set_gradient_checkpointing).parameters
+
+ if not _is_using_old_format:
+ self._set_gradient_checkpointing(enable=True, gradient_checkpointing_func=gradient_checkpointing_func)
+ else:
+ self.apply(partial(self._set_gradient_checkpointing, value=True))
+ logger.warning(
+ "You are using an old version of the checkpointing format that is deprecated (We will also silently ignore `gradient_checkpointing_kwargs` in case you passed it)."
+ "Please update to the new format on your modeling file. To use the new format, you need to completely remove the definition of the method `_set_gradient_checkpointing` in your model."
+ )
+
+ if getattr(self, "_hf_peft_config_loaded", False):
+ # When using PEFT + gradient checkpointing + Trainer we need to make sure the input has requires_grad=True
+ # we do it also on PEFT: https://github.com/huggingface/peft/blob/85013987aa82aa1af3da1236b6902556ce3e483e/src/peft/peft_model.py#L334
+ # When training with PEFT, only LoRA layers will have requires grad set to True, but the output of frozen layers need to propagate
+ # the gradients to make sure the gradient flows.
+ self.enable_input_require_grads()
+
+ def _set_gradient_checkpointing(self, enable: bool = True, gradient_checkpointing_func: Callable = checkpoint):
+ is_gradient_checkpointing_set = False
+
+ # Apply it on the top-level module in case the top-level modules supports it
+ # for example, LongT5Stack inherits from `PreTrainedModel`.
+ if hasattr(self, "gradient_checkpointing"):
+ self._gradient_checkpointing_func = gradient_checkpointing_func
+ self.gradient_checkpointing = enable
+ is_gradient_checkpointing_set = True
+
+ for module in self.modules():
+ if hasattr(module, "gradient_checkpointing"):
+ module._gradient_checkpointing_func = gradient_checkpointing_func
+ module.gradient_checkpointing = enable
+ is_gradient_checkpointing_set = True
+
+ if not is_gradient_checkpointing_set:
+ raise ValueError(
+ f"{self.__class__.__name__} is not compatible with gradient checkpointing. Make sure all the architecture support it by setting a boolean attribute"
+ " `gradient_checkpointing` to modules of the model that uses checkpointing."
+ )
+
+ def gradient_checkpointing_disable(self):
+ """
+ Deactivates gradient checkpointing for the current model.
+
+ Note that in other frameworks this feature can be referred to as "activation checkpointing" or "checkpoint
+ activations".
+ """
+ if self.supports_gradient_checkpointing:
+ # For old GC format (transformers < 4.35.0) for models that live on the Hub
+ # we will fall back to the overwritten `_set_gradient_checkpointing` method
+ _is_using_old_format = "value" in inspect.signature(self._set_gradient_checkpointing).parameters
+ if not _is_using_old_format:
+ self._set_gradient_checkpointing(enable=False)
+ else:
+ logger.warning(
+ "You are using an old version of the checkpointing format that is deprecated (We will also silently ignore `gradient_checkpointing_kwargs` in case you passed it)."
+ "Please update to the new format on your modeling file. To use the new format, you need to completely remove the definition of the method `_set_gradient_checkpointing` in your model."
+ )
+ self.apply(partial(self._set_gradient_checkpointing, value=False))
+
+ if getattr(self, "_hf_peft_config_loaded", False):
+ self.disable_input_require_grads()
+
+ @property
+ def is_gradient_checkpointing(self) -> bool:
+ """
+ Whether gradient checkpointing is activated for this model or not.
+
+ Note that in other frameworks this feature can be referred to as "activation checkpointing" or "checkpoint
+ activations".
+ """
+ return any(hasattr(m, "gradient_checkpointing") and m.gradient_checkpointing for m in self.modules())
+
+ def save_pretrained(
+ self,
+ save_directory: Union[str, os.PathLike],
+ is_main_process: bool = True,
+ state_dict: Optional[dict] = None,
+ save_function: Callable = torch.save,
+ push_to_hub: bool = False,
+ max_shard_size: Union[int, str] = "5GB",
+ safe_serialization: bool = True,
+ variant: Optional[str] = None,
+ token: Optional[Union[str, bool]] = None,
+ save_peft_format: bool = True,
+ **kwargs,
+ ):
+ """
+ Save a model and its configuration file to a directory, so that it can be re-loaded using the
+ [`~PreTrainedModel.from_pretrained`] class method.
+
+ Arguments:
+ save_directory (`str` or `os.PathLike`):
+ Directory to which to save. Will be created if it doesn't exist.
+ is_main_process (`bool`, *optional*, defaults to `True`):
+ Whether the process calling this is the main process or not. Useful when in distributed training like
+ TPUs and need to call this function on all processes. In this case, set `is_main_process=True` only on
+ the main process to avoid race conditions.
+ state_dict (nested dictionary of `torch.Tensor`):
+ The state dictionary of the model to save. Will default to `self.state_dict()`, but can be used to only
+ save parts of the model or if special precautions need to be taken when recovering the state dictionary
+ of a model (like when using model parallelism).
+ save_function (`Callable`):
+ The function to use to save the state dictionary. Useful on distributed training like TPUs when one
+ need to replace `torch.save` by another method.
+ push_to_hub (`bool`, *optional*, defaults to `False`):
+ Whether or not to push your model to the Hugging Face model hub after saving it. You can specify the
+ repository you want to push to with `repo_id` (will default to the name of `save_directory` in your
+ namespace).
+ max_shard_size (`int` or `str`, *optional*, defaults to `"5GB"`):
+ The maximum size for a checkpoint before being sharded. Checkpoints shard will then be each of size
+ lower than this size. If expressed as a string, needs to be digits followed by a unit (like `"5MB"`).
+ We default it to 5GB in order for models to be able to run easily on free-tier google colab instances
+ without CPU OOM issues.
+
+
+
+ If a single weight of the model is bigger than `max_shard_size`, it will be in its own checkpoint shard
+ which will be bigger than `max_shard_size`.
+
+
+
+ safe_serialization (`bool`, *optional*, defaults to `True`):
+ Whether to save the model using `safetensors` or the traditional PyTorch way (that uses `pickle`).
+ variant (`str`, *optional*):
+ If specified, weights are saved in the format pytorch_model..bin.
+ token (`str` or `bool`, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, or not specified, will use
+ the token generated when running `huggingface-cli login` (stored in `~/.huggingface`).
+ save_peft_format (`bool`, *optional*, defaults to `True`):
+ For backward compatibility with PEFT library, in case adapter weights are attached to the model, all
+ keys of the state dict of adapters needs to be pre-pended with `base_model.model`. Advanced users can
+ disable this behaviours by setting `save_peft_format` to `False`.
+ kwargs (`Dict[str, Any]`, *optional*):
+ Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
+ """
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ ignore_metadata_errors = kwargs.pop("ignore_metadata_errors", False)
+
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if token is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ token = use_auth_token
+
+ if token is not None:
+ kwargs["token"] = token
+
+ _hf_peft_config_loaded = getattr(self, "_hf_peft_config_loaded", False)
+
+ hf_quantizer = getattr(self, "hf_quantizer", None)
+ quantization_serializable = (
+ hf_quantizer is not None
+ and isinstance(hf_quantizer, HfQuantizer)
+ and hf_quantizer.is_serializable(safe_serialization=safe_serialization)
+ )
+
+ if hf_quantizer is not None and not _hf_peft_config_loaded and not quantization_serializable:
+ raise ValueError(
+ f"The model is quantized with {hf_quantizer.quantization_config.quant_method} and is not serializable - check out the warnings from"
+ " the logger on the traceback to understand the reason why the quantized model is not serializable."
+ )
+
+ if "save_config" in kwargs:
+ warnings.warn(
+ "`save_config` is deprecated and will be removed in v5 of Transformers. Use `is_main_process` instead."
+ )
+ is_main_process = kwargs.pop("save_config")
+ if safe_serialization and not is_safetensors_available():
+ raise ImportError("`safe_serialization` requires the `safetensors library: `pip install safetensors`.")
+
+ if os.path.isfile(save_directory):
+ logger.error(f"Provided path ({save_directory}) should be a directory, not a file")
+ return
+
+ os.makedirs(save_directory, exist_ok=True)
+
+ if push_to_hub:
+ commit_message = kwargs.pop("commit_message", None)
+ repo_id = kwargs.pop("repo_id", save_directory.split(os.path.sep)[-1])
+ repo_id = self._create_repo(repo_id, **kwargs)
+ files_timestamps = self._get_files_timestamps(save_directory)
+
+ # Only save the model itself if we are using distributed training
+ model_to_save = unwrap_model(self)
+
+ # save the string version of dtype to the config, e.g. convert torch.float32 => "float32"
+ # we currently don't use this setting automatically, but may start to use with v5
+ dtype = get_parameter_dtype(model_to_save)
+ model_to_save.config.torch_dtype = str(dtype).split(".")[1]
+
+ # Attach architecture to the config
+ model_to_save.config.architectures = [model_to_save.__class__.__name__]
+
+ # Unset attn implementation so it can be set to another one when loading back
+ model_to_save.config._attn_implementation_autoset = False
+
+ # If we have a custom model, we copy the file defining it in the folder and set the attributes so it can be
+ # loaded from the Hub.
+ if self._auto_class is not None:
+ custom_object_save(self, save_directory, config=self.config)
+
+ # Save the config
+ if is_main_process:
+ if not _hf_peft_config_loaded:
+ # If the model config has set attributes that should be in the generation config, move them there.
+ misplaced_generation_parameters = model_to_save.config._get_non_default_generation_parameters()
+ if self.can_generate() and len(misplaced_generation_parameters) > 0:
+ warnings.warn(
+ "Moving the following attributes in the config to the generation config: "
+ f"{misplaced_generation_parameters}. You are seeing this warning because you've set "
+ "generation parameters in the model config, as opposed to in the generation config.",
+ UserWarning,
+ )
+ for param_name, param_value in misplaced_generation_parameters.items():
+ setattr(model_to_save.generation_config, param_name, param_value)
+ setattr(model_to_save.config, param_name, None)
+
+ model_to_save.config.save_pretrained(save_directory)
+ if self.can_generate():
+ model_to_save.generation_config.save_pretrained(save_directory)
+
+ if _hf_peft_config_loaded:
+ logger.info(
+ "Detected adapters on the model, saving the model in the PEFT format, only adapter weights will be saved."
+ )
+ state_dict = model_to_save.get_adapter_state_dict(state_dict=state_dict)
+
+ if save_peft_format:
+ logger.info(
+ "To match the expected format of the PEFT library, all keys of the state dict of adapters will be pre-pended with `base_model.model`."
+ )
+ peft_state_dict = {}
+ for key, value in state_dict.items():
+ peft_state_dict[f"base_model.model.{key}"] = value
+ state_dict = peft_state_dict
+
+ active_adapter = self.active_adapters()
+
+ if len(active_adapter) > 1:
+ raise ValueError(
+ "Multiple active adapters detected, saving multiple active adapters is not supported yet. You can save adapters separately one by one "
+ "by iteratively calling `model.set_adapter(adapter_name)` then `model.save_pretrained(...)`"
+ )
+ active_adapter = active_adapter[0]
+
+ current_peft_config = self.peft_config[active_adapter]
+ current_peft_config.save_pretrained(save_directory)
+
+ # for offloaded modules
+ module_map = {}
+
+ # Save the model
+ if state_dict is None:
+ # if any model parameters are offloaded, make module map
+ if (
+ hasattr(self, "hf_device_map")
+ and len(set(self.hf_device_map.values())) > 1
+ and ("cpu" in self.hf_device_map.values() or "disk" in self.hf_device_map.values())
+ ):
+ warnings.warn(
+ "Attempting to save a model with offloaded modules. Ensure that unallocated cpu memory exceeds the `shard_size` (5GB default)"
+ )
+ for name, module in model_to_save.named_modules():
+ if name == "":
+ continue
+ module_state_dict = module.state_dict()
+
+ for key in module_state_dict:
+ module_map[name + f".{key}"] = module
+ state_dict = model_to_save.state_dict()
+
+ # Translate state_dict from smp to hf if saving with smp >= 1.10
+ if IS_SAGEMAKER_MP_POST_1_10:
+ for smp_to_hf, _ in smp.state.module_manager.translate_functions:
+ state_dict = smp_to_hf(state_dict)
+
+ # Handle the case where some state_dict keys shouldn't be saved
+ if self._keys_to_ignore_on_save is not None:
+ for ignore_key in self._keys_to_ignore_on_save:
+ if ignore_key in state_dict.keys():
+ del state_dict[ignore_key]
+
+ # Rename state_dict keys before saving to file. Do nothing unless overridden in a particular model.
+ # (initially introduced with TimmWrapperModel to remove prefix and make checkpoints compatible with timm)
+ state_dict = self._fix_state_dict_keys_on_save(state_dict)
+
+ if safe_serialization:
+ # Safetensors does not allow tensor aliasing.
+ # We're going to remove aliases before saving
+ ptrs = collections.defaultdict(list)
+ for name, tensor in state_dict.items():
+ # Sometimes in the state_dict we have non-tensor objects.
+ # e.g. in bitsandbytes we have some `str` objects in the state_dict
+ if isinstance(tensor, torch.Tensor):
+ ptrs[id_tensor_storage(tensor)].append(name)
+ else:
+ # In the non-tensor case, fall back to the pointer of the object itself
+ ptrs[id(tensor)].append(name)
+
+ # These are all the pointers of shared tensors
+ if hasattr(self, "hf_device_map"):
+ # if the model has offloaded parameters, we must check using find_tied_parameters()
+ tied_params = find_tied_parameters(self)
+ if tied_params:
+ tied_names = tied_params[0]
+ shared_ptrs = {
+ ptr: names for ptr, names in ptrs.items() if any(name in tied_names for name in names)
+ }
+ else:
+ shared_ptrs = {}
+ else:
+ shared_ptrs = {ptr: names for ptr, names in ptrs.items() if len(names) > 1}
+
+ # Recursively descend to find tied weight keys
+ _tied_weights_keys = _get_tied_weight_keys(self)
+ error_names = []
+ to_delete_names = set()
+ for names in shared_ptrs.values():
+ # Removing the keys which are declared as known duplicates on
+ # load. This allows to make sure the name which is kept is consistent.
+ if _tied_weights_keys is not None:
+ found = 0
+ for name in sorted(names):
+ matches_pattern = any(re.search(pat, name) for pat in _tied_weights_keys)
+ if matches_pattern and name in state_dict:
+ found += 1
+ if found < len(names):
+ to_delete_names.add(name)
+ # We are entering a place where the weights and the transformers configuration do NOT match.
+ shared_names, disjoint_names = _find_disjoint(shared_ptrs.values(), state_dict)
+ # Those are actually tensor sharing but disjoint from each other, we can safely clone them
+ # Reloaded won't have the same property, but it shouldn't matter in any meaningful way.
+ for name in disjoint_names:
+ state_dict[name] = state_dict[name].clone()
+
+ # When not all duplicates have been cleaned, still remove those keys, but put a clear warning.
+ # If the link between tensors was done at runtime then `from_pretrained` will not get
+ # the key back leading to random tensor. A proper warning will be shown
+ # during reload (if applicable), but since the file is not necessarily compatible with
+ # the config, better show a proper warning.
+ shared_names, identical_names = _find_identical(shared_names, state_dict)
+ # delete tensors that have identical storage
+ for inames in identical_names:
+ known = inames.intersection(to_delete_names)
+ for name in known:
+ del state_dict[name]
+ unknown = inames.difference(to_delete_names)
+ if len(unknown) > 1:
+ error_names.append(unknown)
+
+ if shared_names:
+ error_names.append(set(shared_names))
+
+ if len(error_names) > 0:
+ raise RuntimeError(
+ f"The weights trying to be saved contained shared tensors {error_names} that are mismatching the transformers base configuration. Try saving using `safe_serialization=False` or remove this tensor sharing.",
+ )
+
+ # Shard the model if it is too big.
+ if not _hf_peft_config_loaded:
+ weights_name = SAFE_WEIGHTS_NAME if safe_serialization else WEIGHTS_NAME
+ weights_name = _add_variant(weights_name, variant)
+ else:
+ weights_name = ADAPTER_SAFE_WEIGHTS_NAME if safe_serialization else ADAPTER_WEIGHTS_NAME
+
+ filename_pattern = weights_name.replace(".bin", "{suffix}.bin").replace(".safetensors", "{suffix}.safetensors")
+ state_dict_split = split_torch_state_dict_into_shards(
+ state_dict, filename_pattern=filename_pattern, max_shard_size=max_shard_size
+ )
+ # Save index if sharded
+ index = None
+ if state_dict_split.is_sharded:
+ index = {
+ "metadata": state_dict_split.metadata,
+ "weight_map": state_dict_split.tensor_to_filename,
+ }
+
+ # Clean the folder from a previous save
+ for filename in os.listdir(save_directory):
+ full_filename = os.path.join(save_directory, filename)
+ # If we have a shard file that is not going to be replaced, we delete it, but only from the main process
+ # in distributed settings to avoid race conditions.
+ weights_no_suffix = weights_name.replace(".bin", "").replace(".safetensors", "")
+
+ # make sure that file to be deleted matches format of sharded file, e.g. pytorch_model-00001-of-00005
+ filename_no_suffix = filename.replace(".bin", "").replace(".safetensors", "")
+ reg = re.compile(r"(.*?)-\d{5}-of-\d{5}")
+
+ if (
+ filename.startswith(weights_no_suffix)
+ and os.path.isfile(full_filename)
+ and filename not in state_dict_split.filename_to_tensors.keys()
+ and is_main_process
+ and reg.fullmatch(filename_no_suffix) is not None
+ ):
+ os.remove(full_filename)
+ # Save the model
+ filename_to_tensors = state_dict_split.filename_to_tensors.items()
+ if module_map:
+ filename_to_tensors = logging.tqdm(filename_to_tensors, desc="Saving checkpoint shards")
+ for shard_file, tensors in filename_to_tensors:
+ shard = {}
+ for tensor in tensors:
+ shard[tensor] = state_dict[tensor].contiguous()
+ # delete reference, see https://github.com/huggingface/transformers/pull/34890
+ del state_dict[tensor]
+
+ # remake shard with onloaded parameters if necessary
+ if module_map:
+ if accelerate_version < version.parse("0.31"):
+ raise ImportError(
+ f"You need accelerate version to be greater or equal than 0.31 to save models with offloaded parameters. Detected version {accelerate_version}. "
+ f"Please upgrade accelerate with `pip install -U accelerate`"
+ )
+ # init state_dict for this shard
+ shard_state_dict = dict.fromkeys(shard, "")
+ for module_name in shard:
+ # skip to collect this weight again
+ if shard_state_dict.get(module_name) != "":
+ continue
+ module = module_map[module_name]
+ # update state dict with onloaded parameters
+ shard_state_dict = get_state_dict_from_offload(module, module_name, shard_state_dict)
+
+ # assign shard to be the completed state dict
+ shard = shard_state_dict
+ del shard_state_dict
+ gc.collect()
+
+ if safe_serialization:
+ # At some point we will need to deal better with save_function (used for TPU and other distributed
+ # joyfulness), but for now this enough.
+ safe_save_file(shard, os.path.join(save_directory, shard_file), metadata={"format": "pt"})
+ else:
+ save_function(shard, os.path.join(save_directory, shard_file))
+
+ del state_dict
+
+ if index is None:
+ path_to_weights = os.path.join(save_directory, weights_name)
+ logger.info(f"Model weights saved in {path_to_weights}")
+ else:
+ save_index_file = SAFE_WEIGHTS_INDEX_NAME if safe_serialization else WEIGHTS_INDEX_NAME
+ save_index_file = os.path.join(save_directory, _add_variant(save_index_file, variant))
+ # Save the index as well
+ with open(save_index_file, "w", encoding="utf-8") as f:
+ content = json.dumps(index, indent=2, sort_keys=True) + "\n"
+ f.write(content)
+ logger.info(
+ f"The model is bigger than the maximum size per checkpoint ({max_shard_size}) and is going to be "
+ f"split in {len(state_dict_split.filename_to_tensors)} checkpoint shards. You can find where each parameters has been saved in the "
+ f"index located at {save_index_file}."
+ )
+
+ if push_to_hub:
+ # Eventually create an empty model card
+ model_card = create_and_tag_model_card(
+ repo_id, self.model_tags, token=token, ignore_metadata_errors=ignore_metadata_errors
+ )
+
+ # Update model card if needed:
+ model_card.save(os.path.join(save_directory, "README.md"))
+
+ self._upload_modified_files(
+ save_directory,
+ repo_id,
+ files_timestamps,
+ commit_message=commit_message,
+ token=token,
+ )
+
+ @wraps(PushToHubMixin.push_to_hub)
+ def push_to_hub(self, *args, **kwargs):
+ tags = self.model_tags if self.model_tags is not None else []
+
+ tags_kwargs = kwargs.get("tags", [])
+ if isinstance(tags_kwargs, str):
+ tags_kwargs = [tags_kwargs]
+
+ for tag in tags_kwargs:
+ if tag not in tags:
+ tags.append(tag)
+
+ if tags:
+ kwargs["tags"] = tags
+ return super().push_to_hub(*args, **kwargs)
+
+ def get_memory_footprint(self, return_buffers=True):
+ r"""
+ Get the memory footprint of a model. This will return the memory footprint of the current model in bytes.
+ Useful to benchmark the memory footprint of the current model and design some tests. Solution inspired from the
+ PyTorch discussions: https://discuss.pytorch.org/t/gpu-memory-that-model-uses/56822/2
+
+ Arguments:
+ return_buffers (`bool`, *optional*, defaults to `True`):
+ Whether to return the size of the buffer tensors in the computation of the memory footprint. Buffers
+ are tensors that do not require gradients and not registered as parameters. E.g. mean and std in batch
+ norm layers. Please see: https://discuss.pytorch.org/t/what-pytorch-means-by-buffers/120266/2
+ """
+ mem = sum([param.nelement() * param.element_size() for param in self.parameters()])
+ if return_buffers:
+ mem_bufs = sum([buf.nelement() * buf.element_size() for buf in self.buffers()])
+ mem = mem + mem_bufs
+ return mem
+
+ @wraps(torch.nn.Module.cuda)
+ def cuda(self, *args, **kwargs):
+ if getattr(self, "quantization_method", None) == QuantizationMethod.HQQ:
+ raise ValueError("`.cuda` is not supported for HQQ-quantized models.")
+ # Checks if the model has been loaded in 4-bit or 8-bit with BNB
+ if getattr(self, "quantization_method", None) == QuantizationMethod.BITS_AND_BYTES:
+ if getattr(self, "is_loaded_in_8bit", False):
+ raise ValueError(
+ "Calling `cuda()` is not supported for `8-bit` quantized models. "
+ " Please use the model as it is, since the model has already been set to the correct devices."
+ )
+ elif version.parse(importlib.metadata.version("bitsandbytes")) < version.parse("0.43.2"):
+ raise ValueError(
+ "Calling `cuda()` is not supported for `4-bit` quantized models with the installed version of bitsandbytes. "
+ f"The current device is `{self.device}`. If you intended to move the model, please install bitsandbytes >= 0.43.2."
+ )
+ else:
+ return super().cuda(*args, **kwargs)
+
+ @wraps(torch.nn.Module.to)
+ def to(self, *args, **kwargs):
+ # For BNB/GPTQ models, we prevent users from casting the model to another dtype to restrict unwanted behaviours.
+ # the correct API should be to load the model with the desired dtype directly through `from_pretrained`.
+ dtype_present_in_args = "dtype" in kwargs
+
+ if not dtype_present_in_args:
+ for arg in args:
+ if isinstance(arg, torch.dtype):
+ dtype_present_in_args = True
+ break
+
+ if getattr(self, "quantization_method", None) == QuantizationMethod.HQQ:
+ raise ValueError("`.to` is not supported for HQQ-quantized models.")
+
+ if dtype_present_in_args and getattr(self, "quantization_method", None) == QuantizationMethod.QUARK:
+ raise ValueError("Casting a Quark quantized model to a new `dtype` is not supported.")
+
+ # Checks if the model has been loaded in 4-bit or 8-bit with BNB
+ if getattr(self, "quantization_method", None) == QuantizationMethod.BITS_AND_BYTES:
+ if dtype_present_in_args:
+ raise ValueError(
+ "You cannot cast a bitsandbytes model in a new `dtype`. Make sure to load the model using `from_pretrained` using the"
+ " desired `dtype` by passing the correct `torch_dtype` argument."
+ )
+
+ if getattr(self, "is_loaded_in_8bit", False):
+ raise ValueError(
+ "`.to` is not supported for `8-bit` bitsandbytes models. Please use the model as it is, since the"
+ " model has already been set to the correct devices and casted to the correct `dtype`."
+ )
+ elif version.parse(importlib.metadata.version("bitsandbytes")) < version.parse("0.43.2"):
+ raise ValueError(
+ "Calling `to()` is not supported for `4-bit` quantized models with the installed version of bitsandbytes. "
+ f"The current device is `{self.device}`. If you intended to move the model, please install bitsandbytes >= 0.43.2."
+ )
+ elif getattr(self, "quantization_method", None) == QuantizationMethod.GPTQ:
+ if dtype_present_in_args:
+ raise ValueError(
+ "You cannot cast a GPTQ model in a new `dtype`. Make sure to load the model using `from_pretrained` using the desired"
+ " `dtype` by passing the correct `torch_dtype` argument."
+ )
+ return super().to(*args, **kwargs)
+
+ def half(self, *args):
+ # Checks if the model is quantized
+ if getattr(self, "is_quantized", False):
+ raise ValueError(
+ "`.half()` is not supported for quantized model. Please use the model as it is, since the"
+ " model has already been casted to the correct `dtype`."
+ )
+ else:
+ return super().half(*args)
+
+ def float(self, *args):
+ # Checks if the model is quantized
+ if getattr(self, "is_quantized", False):
+ raise ValueError(
+ "`.float()` is not supported for quantized model. Please use the model as it is, since the"
+ " model has already been casted to the correct `dtype`."
+ )
+ else:
+ return super().float(*args)
+
+ @classmethod
+ def get_init_context(cls, is_quantized: bool, _is_ds_init_called: bool):
+ if is_deepspeed_zero3_enabled():
+ init_contexts = [no_init_weights()]
+ # We cannot initialize the model on meta device with deepspeed when not quantized
+ if not is_quantized and not _is_ds_init_called:
+ logger.info("Detected DeepSpeed ZeRO-3: activating zero.init() for this model")
+ init_contexts.extend([deepspeed.zero.Init(config_dict_or_path=deepspeed_config()), set_zero3_state()])
+ elif is_quantized:
+ init_contexts.extend([init_empty_weights(), set_quantized_state()])
+ else:
+ init_contexts = [no_init_weights(), init_empty_weights()]
+
+ return init_contexts
+
+ @classmethod
+ @restore_default_torch_dtype
+ def from_pretrained(
+ cls: Type[SpecificPreTrainedModelType],
+ pretrained_model_name_or_path: Optional[Union[str, os.PathLike]],
+ *model_args,
+ config: Optional[Union[PretrainedConfig, str, os.PathLike]] = None,
+ cache_dir: Optional[Union[str, os.PathLike]] = None,
+ ignore_mismatched_sizes: bool = False,
+ force_download: bool = False,
+ local_files_only: bool = False,
+ token: Optional[Union[str, bool]] = None,
+ revision: str = "main",
+ use_safetensors: Optional[bool] = None,
+ weights_only: bool = True,
+ **kwargs,
+ ) -> SpecificPreTrainedModelType:
+ r"""
+ Instantiate a pretrained pytorch model from a pre-trained model configuration.
+
+ The model is set in evaluation mode by default using `model.eval()` (Dropout modules are deactivated). To train
+ the model, you should first set it back in training mode with `model.train()`.
+
+ The warning *Weights from XXX not initialized from pretrained model* means that the weights of XXX do not come
+ pretrained with the rest of the model. It is up to you to train those weights with a downstream fine-tuning
+ task.
+
+ The warning *Weights from XXX not used in YYY* means that the layer XXX is not used by YYY, therefore those
+ weights are discarded.
+
+ Parameters:
+ pretrained_model_name_or_path (`str` or `os.PathLike`, *optional*):
+ Can be either:
+
+ - A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
+ - A path to a *directory* containing model weights saved using
+ [`~PreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
+ - A path or url to a *tensorflow index checkpoint file* (e.g, `./tf_model/model.ckpt.index`). In
+ this case, `from_tf` should be set to `True` and a configuration object should be provided as
+ `config` argument. This loading path is slower than converting the TensorFlow checkpoint in a
+ PyTorch model using the provided conversion scripts and loading the PyTorch model afterwards.
+ - A path or url to a model folder containing a *flax checkpoint file* in *.msgpack* format (e.g,
+ `./flax_model/` containing `flax_model.msgpack`). In this case, `from_flax` should be set to
+ `True`.
+ - `None` if you are both providing the configuration and state dictionary (resp. with keyword
+ arguments `config` and `state_dict`).
+ model_args (sequence of positional arguments, *optional*):
+ All remaining positional arguments will be passed to the underlying model's `__init__` method.
+ config (`Union[PretrainedConfig, str, os.PathLike]`, *optional*):
+ Can be either:
+
+ - an instance of a class derived from [`PretrainedConfig`],
+ - a string or path valid as input to [`~PretrainedConfig.from_pretrained`].
+
+ Configuration for the model to use instead of an automatically loaded configuration. Configuration can
+ be automatically loaded when:
+
+ - The model is a model provided by the library (loaded with the *model id* string of a pretrained
+ model).
+ - The model was saved using [`~PreTrainedModel.save_pretrained`] and is reloaded by supplying the
+ save directory.
+ - The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
+ configuration JSON file named *config.json* is found in the directory.
+ state_dict (`Dict[str, torch.Tensor]`, *optional*):
+ A state dictionary to use instead of a state dictionary loaded from saved weights file.
+
+ This option can be used if you want to create a model from a pretrained configuration but load your own
+ weights. In this case though, you should check if using [`~PreTrainedModel.save_pretrained`] and
+ [`~PreTrainedModel.from_pretrained`] is not a simpler option.
+ cache_dir (`Union[str, os.PathLike]`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ from_tf (`bool`, *optional*, defaults to `False`):
+ Load the model weights from a TensorFlow checkpoint save file (see docstring of
+ `pretrained_model_name_or_path` argument).
+ from_flax (`bool`, *optional*, defaults to `False`):
+ Load the model weights from a Flax checkpoint save file (see docstring of
+ `pretrained_model_name_or_path` argument).
+ ignore_mismatched_sizes (`bool`, *optional*, defaults to `False`):
+ Whether or not to raise an error if some of the weights from the checkpoint do not have the same size
+ as the weights of the model (if for instance, you are instantiating a model with 10 labels from a
+ checkpoint with 3 labels).
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`):
+ Whether ot not to also return a dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (i.e., do not try to download the model).
+ token (`str` or `bool`, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, or not specified, will use
+ the token generated when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+
+
+
+ To test a pull request you made on the Hub, you can pass `revision="refs/pr/"`.
+
+
+ attn_implementation (`str`, *optional*):
+ The attention implementation to use in the model (if relevant). Can be any of `"eager"` (manual implementation of the attention), `"sdpa"` (using [`F.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html)), or `"flash_attention_2"` (using [Dao-AILab/flash-attention](https://github.com/Dao-AILab/flash-attention)). By default, if available, SDPA will be used for torch>=2.1.1. The default is otherwise the manual `"eager"` implementation.
+
+ > Parameters for big model inference
+
+ torch_dtype (`str` or `torch.dtype`, *optional*):
+ Override the default `torch.dtype` and load the model under a specific `dtype`. The different options
+ are:
+
+ 1. `torch.float16` or `torch.bfloat16` or `torch.float`: load in a specified
+ `dtype`, ignoring the model's `config.torch_dtype` if one exists. If not specified
+ - the model will get loaded in `torch.float` (fp32).
+
+ 2. `"auto"` - A `torch_dtype` entry in the `config.json` file of the model will be
+ attempted to be used. If this entry isn't found then next check the `dtype` of the first weight in
+ the checkpoint that's of a floating point type and use that as `dtype`. This will load the model
+ using the `dtype` it was saved in at the end of the training. It can't be used as an indicator of how
+ the model was trained. Since it could be trained in one of half precision dtypes, but saved in fp32.
+
+ 3. A string that is a valid `torch.dtype`. E.g. "float32" loads the model in `torch.float32`, "float16" loads in `torch.float16` etc.
+
+
+
+ For some models the `dtype` they were trained in is unknown - you may try to check the model's paper or
+ reach out to the authors and ask them to add this information to the model's card and to insert the
+ `torch_dtype` entry in `config.json` on the hub.
+
+
+
+ device_map (`str` or `Dict[str, Union[int, str, torch.device]]` or `int` or `torch.device`, *optional*):
+ A map that specifies where each submodule should go. It doesn't need to be refined to each
+ parameter/buffer name, once a given module name is inside, every submodule of it will be sent to the
+ same device. If we only pass the device (*e.g.*, `"cpu"`, `"cuda:1"`, `"mps"`, or a GPU ordinal rank
+ like `1`) on which the model will be allocated, the device map will map the entire model to this
+ device. Passing `device_map = 0` means put the whole model on GPU 0.
+
+ To have Accelerate compute the most optimized `device_map` automatically, set `device_map="auto"`. For
+ more information about each option see [designing a device
+ map](https://hf.co/docs/accelerate/main/en/usage_guides/big_modeling#designing-a-device-map).
+ max_memory (`Dict`, *optional*):
+ A dictionary device identifier to maximum memory if using `device_map`. Will default to the maximum memory available for each
+ GPU and the available CPU RAM if unset.
+ tp_plan (`str`, *optional*):
+ A torch tensor parallel plan, see [here](https://pytorch.org/tutorials/intermediate/TP_tutorial.html). Currently, it only accepts
+ `tp_plan="auto"` to use predefined plan based on the model. Note that if you use it, you should launch your script accordingly with
+ `torchrun [args] script.py`. This will be much faster than using a `device_map`, but has limitations.
+ tp_size (`str`, *optional*):
+ A torch tensor parallel degree. If not provided would default to world size.
+ offload_folder (`str` or `os.PathLike`, *optional*):
+ If the `device_map` contains any value `"disk"`, the folder where we will offload weights.
+ offload_state_dict (`bool`, *optional*):
+ If `True`, will temporarily offload the CPU state dict to the hard drive to avoid getting out of CPU
+ RAM if the weight of the CPU state dict + the biggest shard of the checkpoint does not fit. Defaults to
+ `True` when there is some disk offload.
+ offload_buffers (`bool`, *optional*):
+ Whether or not to offload the buffers with the model parameters.
+ quantization_config (`Union[QuantizationConfigMixin,Dict]`, *optional*):
+ A dictionary of configuration parameters or a QuantizationConfigMixin object for quantization (e.g
+ bitsandbytes, gptq). There may be other quantization-related kwargs, including `load_in_4bit` and
+ `load_in_8bit`, which are parsed by QuantizationConfigParser. Supported only for bitsandbytes
+ quantizations and not preferred. consider inserting all such arguments into quantization_config
+ instead.
+ subfolder (`str`, *optional*, defaults to `""`):
+ In case the relevant files are located inside a subfolder of the model repo on huggingface.co, you can
+ specify the folder name here.
+ variant (`str`, *optional*):
+ If specified load weights from `variant` filename, *e.g.* pytorch_model..bin. `variant` is
+ ignored when using `from_tf` or `from_flax`.
+ use_safetensors (`bool`, *optional*, defaults to `None`):
+ Whether or not to use `safetensors` checkpoints. Defaults to `None`. If not specified and `safetensors`
+ is not installed, it will be set to `False`.
+ weights_only (`bool`, *optional*, defaults to `True`):
+ Indicates whether unpickler should be restricted to loading only tensors, primitive types,
+ dictionaries and any types added via torch.serialization.add_safe_globals().
+ When set to False, we can load wrapper tensor subclass weights.
+ key_mapping (`Dict[str, str], *optional*):
+ A potential mapping of the weight names if using a model on the Hub which is compatible to a Transformers
+ architecture, but was not converted accordingly.
+ kwargs (remaining dictionary of keyword arguments, *optional*):
+ Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
+ `output_attentions=True`). Behaves differently depending on whether a `config` is provided or
+ automatically loaded:
+
+ - If a configuration is provided with `config`, `**kwargs` will be directly passed to the
+ underlying model's `__init__` method (we assume all relevant updates to the configuration have
+ already been done)
+ - If a configuration is not provided, `kwargs` will be first passed to the configuration class
+ initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
+ corresponds to a configuration attribute will be used to override said attribute with the
+ supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
+ will be passed to the underlying model's `__init__` function.
+
+
+
+ Activate the special ["offline-mode"](https://huggingface.co/transformers/installation.html#offline-mode) to
+ use this method in a firewalled environment.
+
+
+
+ Examples:
+
+ ```python
+ >>> from transformers import BertConfig, BertModel
+
+ >>> # Download model and configuration from huggingface.co and cache.
+ >>> model = BertModel.from_pretrained("google-bert/bert-base-uncased")
+ >>> # Model was saved using *save_pretrained('./test/saved_model/')* (for example purposes, not runnable).
+ >>> model = BertModel.from_pretrained("./test/saved_model/")
+ >>> # Update configuration during loading.
+ >>> model = BertModel.from_pretrained("google-bert/bert-base-uncased", output_attentions=True)
+ >>> assert model.config.output_attentions == True
+ >>> # Loading from a TF checkpoint file instead of a PyTorch model (slower, for example purposes, not runnable).
+ >>> config = BertConfig.from_json_file("./tf_model/my_tf_model_config.json")
+ >>> model = BertModel.from_pretrained("./tf_model/my_tf_checkpoint.ckpt.index", from_tf=True, config=config)
+ >>> # Loading from a Flax checkpoint file instead of a PyTorch model (slower)
+ >>> model = BertModel.from_pretrained("google-bert/bert-base-uncased", from_flax=True)
+ ```
+ """
+ state_dict = kwargs.pop("state_dict", None)
+ from_tf = kwargs.pop("from_tf", False)
+ from_flax = kwargs.pop("from_flax", False)
+ proxies = kwargs.pop("proxies", None)
+ output_loading_info = kwargs.pop("output_loading_info", False)
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ from_pipeline = kwargs.pop("_from_pipeline", None)
+ from_auto_class = kwargs.pop("_from_auto", False)
+ torch_dtype = kwargs.pop("torch_dtype", None)
+ device_map = kwargs.pop("device_map", None)
+ max_memory = kwargs.pop("max_memory", None)
+ offload_folder = kwargs.pop("offload_folder", None)
+ offload_state_dict = kwargs.pop("offload_state_dict", False)
+ offload_buffers = kwargs.pop("offload_buffers", False)
+ load_in_8bit = kwargs.pop("load_in_8bit", False)
+ load_in_4bit = kwargs.pop("load_in_4bit", False)
+ quantization_config = kwargs.pop("quantization_config", None)
+ subfolder = kwargs.pop("subfolder", "")
+ commit_hash = kwargs.pop("_commit_hash", None)
+ variant = kwargs.pop("variant", None)
+ adapter_kwargs = kwargs.pop("adapter_kwargs", {})
+ adapter_name = kwargs.pop("adapter_name", "default")
+ use_flash_attention_2 = kwargs.pop("use_flash_attention_2", False)
+ generation_config = kwargs.pop("generation_config", None)
+ gguf_file = kwargs.pop("gguf_file", None)
+ tp_plan = kwargs.pop("tp_plan", None)
+ tp_size = kwargs.pop("tp_size", None)
+ key_mapping = kwargs.pop("key_mapping", None)
+ # Not used anymore -- remove them from the kwargs
+ _ = kwargs.pop("resume_download", None)
+ _ = kwargs.pop("trust_remote_code", None)
+ _ = kwargs.pop("mirror", None)
+ _ = kwargs.pop("_fast_init", True)
+ _ = kwargs.pop("low_cpu_mem_usage", None)
+
+ if state_dict is not None and (pretrained_model_name_or_path is not None or gguf_file is not None):
+ raise ValueError(
+ "`state_dict` cannot be passed together with a model name or a `gguf_file`. Use one of the two loading strategies."
+ )
+ if tp_size is not None and tp_plan is None:
+ raise ValueError("tp_plan has to be set when tp_size is passed.")
+ if tp_plan is not None and tp_plan != "auto":
+ # TODO: we can relax this check when we support taking tp_plan from a json file, for example.
+ raise ValueError(f"tp_plan supports 'auto' only for now but got {tp_plan}.")
+ if tp_plan is not None and device_map is not None:
+ raise ValueError(
+ "`tp_plan` and `device_map` are mutually exclusive. Choose either one for parallelization."
+ )
+
+ # If torchrun was used, make sure to TP by default. This way people don't need to change tp or device map
+ if device_map == "auto" and tp_plan is None and int(os.environ.get("WORLD_SIZE", 0)):
+ tp_plan = "auto" # device_map = "auto" in torchrun equivalent to TP plan = AUTO!
+ device_map = None
+
+ # We need to correctly dispatch the model on the current process device. The easiest way for this is to use a simple
+ # `device_map` pointing to the correct device
+ device_mesh = None
+ if tp_plan is not None:
+ if not is_torch_greater_or_equal("2.5"):
+ raise EnvironmentError("tensor parallel is only supported for `torch>=2.5`.")
+
+ # Detect the accelerator on the machine. If no accelerator is available, it returns CPU.
+ device_type = torch._C._get_accelerator().type
+
+ if not torch.distributed.is_initialized():
+ try:
+ rank = int(os.environ["RANK"])
+ world_size = int(os.environ["WORLD_SIZE"])
+ if device_type == "cuda":
+ torch.distributed.init_process_group(
+ "nccl", rank=rank, world_size=world_size, init_method="env://"
+ )
+ torch.cuda.set_device(int(os.environ["LOCAL_RANK"]))
+ elif device_type == "cpu":
+ cpu_backend = "ccl" if int(os.environ.get("CCL_WORKER_COUNT", 0)) else "gloo"
+ torch.distributed.init_process_group(cpu_backend, rank=rank, world_size=world_size)
+ elif device_type == "xpu":
+ torch.distributed.init_process_group("ccl", rank=rank, world_size=world_size)
+ torch.xpu.set_device(int(os.environ["LOCAL_RANK"]))
+
+ except Exception as e:
+ raise EnvironmentError(
+ "We tried to initialize torch.distributed for you, but it failed, make"
+ "sure you init torch distributed in your script to use `tp_plan='auto'`"
+ ) from e
+
+ # Get device with index assuming equal number of devices per host
+ if device_type == "xpu":
+ index = torch.xpu.current_device()
+ else:
+ index = None if device_type == "cpu" else torch.cuda.current_device()
+ tp_device = torch.device(device_type, index)
+
+ if index is not None and index > 0:
+ import sys
+
+ sys.stdout = open(os.devnull, "w")
+ sys.stderr = open(os.devnull, "w")
+ # This is the easiest way to dispatch to the current process device
+ device_map = tp_device
+
+ # Assuming sharding the model onto the world when tp_size not provided
+ tp_size = tp_size if tp_size is not None else torch.distributed.get_world_size()
+ device_mesh = torch.distributed.init_device_mesh(tp_device.type, (tp_size,))
+
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if token is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ token = use_auth_token
+
+ if token is not None and adapter_kwargs is not None and "token" not in adapter_kwargs:
+ adapter_kwargs["token"] = token
+
+ if use_safetensors is None and not is_safetensors_available():
+ use_safetensors = False
+
+ if gguf_file is not None and not is_accelerate_available():
+ raise ValueError("accelerate is required when loading a GGUF file `pip install accelerate`.")
+
+ if commit_hash is None:
+ if not isinstance(config, PretrainedConfig):
+ # We make a call to the config file first (which may be absent) to get the commit hash as soon as possible
+ resolved_config_file = cached_file(
+ pretrained_model_name_or_path,
+ CONFIG_NAME,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ token=token,
+ revision=revision,
+ subfolder=subfolder,
+ _raise_exceptions_for_gated_repo=False,
+ _raise_exceptions_for_missing_entries=False,
+ _raise_exceptions_for_connection_errors=False,
+ )
+ commit_hash = extract_commit_hash(resolved_config_file, commit_hash)
+ else:
+ commit_hash = getattr(config, "_commit_hash", None)
+
+ if is_peft_available():
+ _adapter_model_path = adapter_kwargs.pop("_adapter_model_path", None)
+
+ if _adapter_model_path is None:
+ _adapter_model_path = find_adapter_config_file(
+ pretrained_model_name_or_path,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ _commit_hash=commit_hash,
+ **adapter_kwargs,
+ )
+ if _adapter_model_path is not None and os.path.isfile(_adapter_model_path):
+ with open(_adapter_model_path, "r", encoding="utf-8") as f:
+ _adapter_model_path = pretrained_model_name_or_path
+ pretrained_model_name_or_path = json.load(f)["base_model_name_or_path"]
+ else:
+ _adapter_model_path = None
+
+ # Potentially detect context manager or global device, and use it (only if no device_map was provided)
+ if device_map is None and not is_deepspeed_zero3_enabled():
+ device_in_context = get_torch_context_manager_or_global_device()
+ if device_in_context == torch.device("meta"):
+ # TODO Cyril: raise an error instead of the warning in v4.53 (and change the test to check for raise instead of success)
+ logger.warning(
+ "We detected that you are using `from_pretrained` with a meta device context manager or `torch.set_default_device('meta')`\n"
+ "This is an anti-pattern and will raise an Error in version v4.53\nIf you want to initialize a model on the meta device, use "
+ "the context manager or global device with `from_config`, or `ModelClass(config)`"
+ )
+ device_map = device_in_context
+
+ # change device_map into a map if we passed an int, a str or a torch.device
+ if isinstance(device_map, torch.device):
+ device_map = {"": device_map}
+ elif isinstance(device_map, str) and device_map not in ["auto", "balanced", "balanced_low_0", "sequential"]:
+ try:
+ device_map = {"": torch.device(device_map)}
+ except RuntimeError:
+ raise ValueError(
+ "When passing device_map as a string, the value needs to be a device name (e.g. cpu, cuda:0) or "
+ f"'auto', 'balanced', 'balanced_low_0', 'sequential' but found {device_map}."
+ )
+ elif isinstance(device_map, int):
+ if device_map < 0:
+ raise ValueError(
+ "You can't pass device_map as a negative int. If you want to put the model on the cpu, pass device_map = 'cpu' "
+ )
+ else:
+ device_map = {"": device_map}
+
+ if device_map is not None:
+ if is_deepspeed_zero3_enabled():
+ raise ValueError("DeepSpeed Zero-3 is not compatible with passing a `device_map`.")
+ if not is_accelerate_available():
+ raise ValueError(
+ (
+ "Using a `device_map`, `tp_plan`, `torch.device` context manager or setting `torch.set_default_device(device)` "
+ "requires `accelerate`. You can install it with `pip install accelerate`"
+ )
+ )
+
+ # handling bnb config from kwargs, remove after `load_in_{4/8}bit` deprecation.
+ if load_in_4bit or load_in_8bit:
+ if quantization_config is not None:
+ raise ValueError(
+ "You can't pass `load_in_4bit`or `load_in_8bit` as a kwarg when passing "
+ "`quantization_config` argument at the same time."
+ )
+
+ # preparing BitsAndBytesConfig from kwargs
+ config_dict = {k: v for k, v in kwargs.items() if k in inspect.signature(BitsAndBytesConfig).parameters}
+ config_dict = {**config_dict, "load_in_4bit": load_in_4bit, "load_in_8bit": load_in_8bit}
+ quantization_config, kwargs = BitsAndBytesConfig.from_dict(
+ config_dict=config_dict, return_unused_kwargs=True, **kwargs
+ )
+ logger.warning(
+ "The `load_in_4bit` and `load_in_8bit` arguments are deprecated and will be removed in the future versions. "
+ "Please, pass a `BitsAndBytesConfig` object in `quantization_config` argument instead."
+ )
+
+ from_pt = not (from_tf | from_flax)
+
+ user_agent = {"file_type": "model", "framework": "pytorch", "from_auto_class": from_auto_class}
+ if from_pipeline is not None:
+ user_agent["using_pipeline"] = from_pipeline
+
+ if is_offline_mode() and not local_files_only:
+ logger.info("Offline mode: forcing local_files_only=True")
+ local_files_only = True
+
+ # Load config if we don't provide a configuration
+ if not isinstance(config, PretrainedConfig):
+ config_path = config if config is not None else pretrained_model_name_or_path
+ config, model_kwargs = cls.config_class.from_pretrained(
+ config_path,
+ cache_dir=cache_dir,
+ return_unused_kwargs=True,
+ force_download=force_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ token=token,
+ revision=revision,
+ subfolder=subfolder,
+ gguf_file=gguf_file,
+ _from_auto=from_auto_class,
+ _from_pipeline=from_pipeline,
+ **kwargs,
+ )
+ if "gguf_file" in model_kwargs:
+ model_kwargs.pop("gguf_file")
+ else:
+ # In case one passes a config to `from_pretrained` + "attn_implementation"
+ # override the `_attn_implementation` attribute to `attn_implementation` of the kwargs
+ # Please see: https://github.com/huggingface/transformers/issues/28038
+
+ # Overwrite `config._attn_implementation` by the one from the kwargs --> in auto-factory
+ # we pop attn_implementation from the kwargs but this handles the case where users
+ # passes manually the config to `from_pretrained`.
+ config = copy.deepcopy(config)
+
+ kwarg_attn_imp = kwargs.pop("attn_implementation", None)
+ if kwarg_attn_imp is not None:
+ config._attn_implementation = kwarg_attn_imp
+
+ model_kwargs = kwargs
+
+ pre_quantized = hasattr(config, "quantization_config")
+ if pre_quantized and not AutoHfQuantizer.supports_quant_method(config.quantization_config):
+ pre_quantized = False
+
+ if pre_quantized or quantization_config is not None:
+ if pre_quantized:
+ config.quantization_config = AutoHfQuantizer.merge_quantization_configs(
+ config.quantization_config, quantization_config
+ )
+ else:
+ config.quantization_config = quantization_config
+
+ hf_quantizer = AutoHfQuantizer.from_config(
+ config.quantization_config,
+ pre_quantized=pre_quantized,
+ )
+ else:
+ hf_quantizer = None
+
+ if hf_quantizer is not None:
+ hf_quantizer.validate_environment(
+ torch_dtype=torch_dtype,
+ from_tf=from_tf,
+ from_flax=from_flax,
+ device_map=device_map,
+ weights_only=weights_only,
+ )
+ torch_dtype = hf_quantizer.update_torch_dtype(torch_dtype)
+ device_map = hf_quantizer.update_device_map(device_map)
+ config = hf_quantizer.update_tp_plan(config)
+
+ # In order to ensure popular quantization methods are supported. Can be disable with `disable_telemetry`
+ if hasattr(hf_quantizer.quantization_config.quant_method, "value"):
+ user_agent["quant"] = hf_quantizer.quantization_config.quant_method.value
+ else:
+ user_agent["quant"] = hf_quantizer.quantization_config.quant_method
+
+ if gguf_file is not None and hf_quantizer is not None:
+ raise ValueError(
+ "You cannot combine Quantization and loading a model from a GGUF file, try again by making sure you did not passed a `quantization_config` or that you did not load a quantized model from the Hub."
+ )
+
+ if (
+ gguf_file
+ and device_map is not None
+ and ((isinstance(device_map, dict) and "disk" in device_map.values()) or "disk" in device_map)
+ ):
+ raise RuntimeError(
+ "One or more modules is configured to be mapped to disk. Disk offload is not supported for models "
+ "loaded from GGUF files."
+ )
+
+ checkpoint_files, sharded_metadata = _get_resolved_checkpoint_files(
+ pretrained_model_name_or_path=pretrained_model_name_or_path,
+ subfolder=subfolder,
+ variant=variant,
+ gguf_file=gguf_file,
+ from_tf=from_tf,
+ from_flax=from_flax,
+ use_safetensors=use_safetensors,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ token=token,
+ user_agent=user_agent,
+ revision=revision,
+ commit_hash=commit_hash,
+ )
+
+ is_sharded = sharded_metadata is not None
+ is_quantized = hf_quantizer is not None
+ is_from_file = pretrained_model_name_or_path is not None or gguf_file is not None
+
+ if (
+ is_safetensors_available()
+ and is_from_file
+ and not is_sharded
+ and checkpoint_files[0].endswith(".safetensors")
+ ):
+ with safe_open(checkpoint_files[0], framework="pt") as f:
+ metadata = f.metadata()
+
+ if metadata is None:
+ # Assume it's a pytorch checkpoint (introduced for timm checkpoints)
+ pass
+ elif metadata.get("format") == "pt":
+ pass
+ elif metadata.get("format") == "tf":
+ from_tf = True
+ logger.info("A TensorFlow safetensors file is being loaded in a PyTorch model.")
+ elif metadata.get("format") == "flax":
+ from_flax = True
+ logger.info("A Flax safetensors file is being loaded in a PyTorch model.")
+ elif metadata.get("format") == "mlx":
+ # This is a mlx file, we assume weights are compatible with pt
+ pass
+ else:
+ raise ValueError(
+ f"Incompatible safetensors file. File metadata is not ['pt', 'tf', 'flax', 'mlx'] but {metadata.get('format')}"
+ )
+
+ from_pt = not (from_tf | from_flax)
+
+ if from_pt:
+ if gguf_file:
+ from .modeling_gguf_pytorch_utils import load_gguf_checkpoint
+
+ # we need a dummy model to get the state_dict - for this reason, we keep the state_dict as if it was
+ # passed directly as a kwarg from now on
+ with torch.device("meta"):
+ dummy_model = cls(config)
+ state_dict = load_gguf_checkpoint(checkpoint_files[0], return_tensors=True, model_to_load=dummy_model)[
+ "tensors"
+ ]
+
+ # Find the correct dtype based on current state
+ config, torch_dtype, dtype_orig = _get_torch_dtype(
+ cls, torch_dtype, checkpoint_files, config, sharded_metadata, state_dict, weights_only
+ )
+
+ config.name_or_path = pretrained_model_name_or_path
+
+ # Instantiate model.
+ model_init_context = cls.get_init_context(is_quantized, _is_ds_init_called)
+
+ config = copy.deepcopy(config) # We do not want to modify the config inplace in from_pretrained.
+ if not getattr(config, "_attn_implementation_autoset", False):
+ config = cls._autoset_attn_implementation(
+ config,
+ use_flash_attention_2=use_flash_attention_2,
+ torch_dtype=torch_dtype,
+ device_map=device_map,
+ )
+
+ with ContextManagers(model_init_context):
+ # Let's make sure we don't run the init function of buffer modules
+ model = cls(config, *model_args, **model_kwargs)
+
+ # Make sure to tie the weights correctly
+ model.tie_weights()
+
+ # Last check for tp
+ if device_mesh is not None and not model.supports_tp_plan:
+ if config.base_model_tp_plan is None and config.get_text_config().base_model_tp_plan is None:
+ raise NotImplementedError("This model does not have a tensor parallel plan.")
+
+ # make sure we use the model's config since the __init__ call might have copied it
+ config = model.config
+
+ # Find fp32 modules if needed
+ keep_in_fp32_regex = None
+ # The _keep_in_fp32_modules flag is only used to avoid bf16 -> fp16 casting precision issues. It was introduced
+ # in case of force loading a model that should stay bf16 in fp16 (which includes a few quantizers as this is a pre-processing
+ # step for e.g. bitsandbytes). See https://github.com/huggingface/transformers/issues/20287 for details.
+ if model._keep_in_fp32_modules is not None and (
+ torch_dtype == torch.float16 or getattr(hf_quantizer, "use_keep_in_fp32_modules", False)
+ ):
+ # We need to match exact layers, so we add either `.` on each side, or start/end of string
+ keep_in_fp32_regex = re.compile(
+ "|".join([rf"((^|\.){module}($|\.))" for module in model._keep_in_fp32_modules])
+ )
+
+ if hf_quantizer is not None:
+ hf_quantizer.preprocess_model(
+ model=model, device_map=device_map, keep_in_fp32_modules=model._keep_in_fp32_modules, config=config
+ )
+ # We store the original dtype for quantized models as we cannot easily retrieve it
+ # once the weights have been quantized
+ # Note that once you have loaded a quantized model, you can't change its dtype so this will
+ # remain a single source of truth
+ original_dtype = torch_dtype if torch_dtype is not None else torch.get_default_dtype()
+
+ def _assign_original_dtype(module):
+ for child in module.children():
+ if isinstance(child, PreTrainedModel):
+ child.config._pre_quantization_dtype = original_dtype
+ _assign_original_dtype(child)
+
+ config._pre_quantization_dtype = original_dtype
+ _assign_original_dtype(model)
+
+ # Prepare the full device map
+ if device_map is not None:
+ device_map = _get_device_map(model, device_map, max_memory, hf_quantizer, torch_dtype, keep_in_fp32_regex)
+
+ # Finalize model weight initialization
+ if from_tf:
+ model, loading_info = cls._load_from_tf(model, config, checkpoint_files)
+ elif from_flax:
+ model = cls._load_from_flax(model, checkpoint_files)
+ elif from_pt:
+ # restore default dtype
+ if dtype_orig is not None:
+ torch.set_default_dtype(dtype_orig)
+
+ (
+ model,
+ missing_keys,
+ unexpected_keys,
+ mismatched_keys,
+ offload_index,
+ error_msgs,
+ ) = cls._load_pretrained_model(
+ model,
+ state_dict,
+ checkpoint_files,
+ pretrained_model_name_or_path,
+ ignore_mismatched_sizes=ignore_mismatched_sizes,
+ sharded_metadata=sharded_metadata,
+ device_map=device_map,
+ disk_offload_folder=offload_folder,
+ offload_state_dict=offload_state_dict,
+ dtype=torch_dtype,
+ hf_quantizer=hf_quantizer,
+ keep_in_fp32_regex=keep_in_fp32_regex,
+ device_mesh=device_mesh,
+ key_mapping=key_mapping,
+ weights_only=weights_only,
+ )
+
+ # record tp degree the model sharded to
+ model._tp_size = tp_size
+
+ # make sure token embedding weights are still tied if needed
+ model.tie_weights()
+
+ # Set model in evaluation mode to deactivate DropOut modules by default
+ model.eval()
+
+ # If it is a model with generation capabilities, attempt to load the generation config
+ if model.can_generate() and generation_config is not None:
+ logger.info("The user-defined `generation_config` will be used to override the default generation config.")
+ model.generation_config = model.generation_config.from_dict(generation_config.to_dict())
+ elif model.can_generate() and pretrained_model_name_or_path is not None:
+ try:
+ model.generation_config = GenerationConfig.from_pretrained(
+ pretrained_model_name_or_path,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ local_files_only=local_files_only,
+ token=token,
+ revision=revision,
+ subfolder=subfolder,
+ _from_auto=from_auto_class,
+ _from_pipeline=from_pipeline,
+ **kwargs,
+ )
+ except OSError:
+ logger.info(
+ "Generation config file not found, using a generation config created from the model config."
+ )
+ pass
+
+ # Dispatch model with hooks on all devices if necessary (not needed with a tp_plan, so we skip it as it slightly
+ # harm performances)
+ if device_map is not None and device_mesh is None:
+ device_map_kwargs = {
+ "device_map": device_map,
+ "offload_dir": offload_folder,
+ "offload_index": offload_index,
+ "offload_buffers": offload_buffers,
+ }
+ if "skip_keys" in inspect.signature(dispatch_model).parameters:
+ device_map_kwargs["skip_keys"] = model._skip_keys_device_placement
+ # For HQQ method we force-set the hooks for single GPU envs
+ if (
+ "force_hooks" in inspect.signature(dispatch_model).parameters
+ and hf_quantizer is not None
+ and hf_quantizer.quantization_config.quant_method == QuantizationMethod.HQQ
+ ):
+ device_map_kwargs["force_hooks"] = True
+ if (
+ hf_quantizer is not None
+ and hf_quantizer.quantization_config.quant_method == QuantizationMethod.FBGEMM_FP8
+ and isinstance(device_map, dict)
+ and ("cpu" in device_map.values() or "disk" in device_map.values())
+ ):
+ device_map_kwargs["offload_buffers"] = True
+
+ if not is_fsdp_enabled() and not is_deepspeed_zero3_enabled():
+ dispatch_model(model, **device_map_kwargs)
+
+ if hf_quantizer is not None:
+ hf_quantizer.postprocess_model(model, config=config)
+ model.hf_quantizer = hf_quantizer
+
+ if _adapter_model_path is not None:
+ model.load_adapter(
+ _adapter_model_path,
+ adapter_name=adapter_name,
+ token=token,
+ adapter_kwargs=adapter_kwargs,
+ )
+
+ if output_loading_info:
+ if from_pt:
+ loading_info = {
+ "missing_keys": missing_keys,
+ "unexpected_keys": unexpected_keys,
+ "mismatched_keys": mismatched_keys,
+ "error_msgs": error_msgs,
+ }
+ elif from_flax:
+ loading_info = None
+ return model, loading_info
+ return model
+
+ @staticmethod
+ def _fix_state_dict_key_on_load(key: str) -> Tuple[str, bool]:
+ """Replace legacy parameter names with their modern equivalents. E.g. beta -> bias, gamma -> weight."""
+ # Rename LayerNorm beta & gamma params for some early models ported from Tensorflow (e.g. Bert)
+ # This rename is logged.
+ if key.endswith("LayerNorm.beta"):
+ return key.replace("LayerNorm.beta", "LayerNorm.bias"), True
+ if key.endswith("LayerNorm.gamma"):
+ return key.replace("LayerNorm.gamma", "LayerNorm.weight"), True
+
+ # Rename weight norm parametrizations to match changes across torch versions.
+ # Impacts a number of speech/wav2vec models. e.g. Hubert, Wav2Vec2, and others.
+ # This rename is not logged.
+ if hasattr(nn.utils.parametrizations, "weight_norm"):
+ if key.endswith("weight_g"):
+ return key.replace("weight_g", "parametrizations.weight.original0"), True
+ if key.endswith("weight_v"):
+ return key.replace("weight_v", "parametrizations.weight.original1"), True
+ else:
+ if key.endswith("parametrizations.weight.original0"):
+ return key.replace("parametrizations.weight.original0", "weight_g"), True
+ if key.endswith("parametrizations.weight.original1"):
+ return key.replace("parametrizations.weight.original1", "weight_v"), True
+
+ return key, False
+
+ def _get_key_renaming_mapping(
+ self,
+ checkpoint_keys: List[str],
+ key_mapping: Optional[Dict[str, str]] = None,
+ loading_base_model_from_task_state_dict: bool = False,
+ loading_task_model_from_base_state_dict: bool = False,
+ ):
+ """
+ Compute a mapping between the serialized keys on disk `checkpoint_keys`, and the keys that the model
+ that we are loading expects. This is the single entry point for key renaming that will be used during
+ loading.
+ Log if any parameters have been renamed.
+ """
+ prefix = self.base_model_prefix
+ _prefix = f"{prefix}."
+
+ renamed_keys = {}
+ key_renaming_mapping = {}
+ for key in checkpoint_keys:
+ # Class specific rename
+ new_key, has_changed = self._fix_state_dict_key_on_load(key)
+
+ # Optionally map the key according to `key_mapping`
+ if key_mapping is not None:
+ for pattern, replacement in key_mapping.items():
+ new_key, n_replace = re.subn(pattern, replacement, new_key)
+ # Early exit of the loop
+ if n_replace > 0:
+ has_changed = True
+ break
+
+ # In this case, we need to add the prefix to the keys, to match them to the expected keys
+ if loading_task_model_from_base_state_dict:
+ new_key = ".".join([prefix, new_key])
+ # In this case we need to remove the prefix from the key to match them to the expected keys, and use
+ # only the keys starting with the prefix
+ elif loading_base_model_from_task_state_dict:
+ if not new_key.startswith(_prefix):
+ continue
+ new_key = new_key[len(_prefix) :]
+
+ key_renaming_mapping[key] = new_key
+
+ # track gamma/beta rename for logging
+ if has_changed:
+ if key.endswith("LayerNorm.gamma"):
+ renamed_keys["LayerNorm.gamma"] = (key, new_key)
+ elif key.endswith("LayerNorm.beta"):
+ renamed_keys["LayerNorm.beta"] = (key, new_key)
+
+ if renamed_keys:
+ warning_msg = f"A pretrained model of type `{self.__class__.__name__}` "
+ warning_msg += "contains parameters that have been renamed internally (a few are listed below but more are present in the model):\n"
+ for old_key, new_key in renamed_keys.values():
+ warning_msg += f"* `{old_key}` -> `{new_key}`\n"
+ warning_msg += "If you are using a model from the Hub, consider submitting a PR to adjust these weights and help future users."
+ logger.info_once(warning_msg)
+
+ return key_renaming_mapping
+
+ @staticmethod
+ def _fix_state_dict_key_on_save(key) -> Tuple[str, bool]:
+ """
+ Similar to `_fix_state_dict_key_on_load` allows to define hook for state dict key renaming on model save.
+ Do nothing by default, but can be overridden in particular models.
+ """
+ return key, False
+
+ def _fix_state_dict_keys_on_save(self, state_dict):
+ """
+ Similar to `_fix_state_dict_keys_on_load` allows to define hook for state dict key renaming on model save.
+ Apply `_fix_state_dict_key_on_save` to all keys in `state_dict`.
+ """
+ return {self._fix_state_dict_key_on_save(key)[0]: value for key, value in state_dict.items()}
+
+ @classmethod
+ def _load_pretrained_model(
+ cls,
+ model: "PreTrainedModel",
+ state_dict: Optional[Dict],
+ checkpoint_files: Optional[List[str]],
+ pretrained_model_name_or_path: Optional[str],
+ ignore_mismatched_sizes: bool = False,
+ sharded_metadata: Optional[Dict] = None,
+ device_map: Optional[Dict] = None,
+ disk_offload_folder: Optional[str] = None,
+ offload_state_dict: Optional[bool] = None,
+ dtype: Optional[torch.dtype] = None,
+ hf_quantizer: Optional[HfQuantizer] = None,
+ keep_in_fp32_regex: Optional[re.Pattern] = None,
+ device_mesh: Optional["torch.distributed.device_mesh.DeviceMesh"] = None,
+ key_mapping: Optional[Dict[str, str]] = None,
+ weights_only: bool = True,
+ ):
+ # Useful flags
+ is_quantized = hf_quantizer is not None
+ is_hqq_or_quark = is_quantized and hf_quantizer.quantization_config.quant_method in {
+ QuantizationMethod.HQQ,
+ QuantizationMethod.QUARK,
+ }
+ is_hqq_or_bnb = is_quantized and hf_quantizer.quantization_config.quant_method in {
+ QuantizationMethod.HQQ,
+ QuantizationMethod.BITS_AND_BYTES,
+ }
+
+ # Get all the keys of the state dicts that we have to initialize the model
+ if sharded_metadata is not None:
+ original_checkpoint_keys = sharded_metadata["all_checkpoint_keys"]
+ elif state_dict is not None:
+ original_checkpoint_keys = list(state_dict.keys())
+ else:
+ original_checkpoint_keys = list(
+ load_state_dict(checkpoint_files[0], map_location="meta", weights_only=weights_only).keys()
+ )
+
+ # Check if we are in a special state, i.e. loading from a state dict coming from a different architecture
+ prefix = model.base_model_prefix
+ _prefix = f"{prefix}."
+ has_prefix_module = any(s.startswith(prefix) for s in original_checkpoint_keys) if len(prefix) > 0 else False
+ expects_prefix_module = hasattr(model, prefix) if len(prefix) > 0 else False
+ loading_task_model_from_base_state_dict = not has_prefix_module and expects_prefix_module
+ loading_base_model_from_task_state_dict = has_prefix_module and not expects_prefix_module
+
+ # Find the key names that the model expects from the serialized keys
+ key_renaming_mapping = model._get_key_renaming_mapping(
+ original_checkpoint_keys,
+ key_mapping,
+ loading_base_model_from_task_state_dict,
+ loading_task_model_from_base_state_dict,
+ )
+ checkpoint_keys = list(key_renaming_mapping.values())
+
+ # Find missing and unexpected keys from the state dict
+ missing_keys, unexpected_keys = _find_missing_and_unexpected_keys(
+ cls,
+ model,
+ original_checkpoint_keys,
+ checkpoint_keys,
+ loading_base_model_from_task_state_dict,
+ hf_quantizer,
+ device_map,
+ )
+ # Find all the keys with shape mismatch (if we ignore the mismatch, the weights need to be newly initialized the
+ # same way as missing keys)
+ mismatched_keys, mismatched_shapes = _find_mismatched_keys(
+ model,
+ state_dict,
+ checkpoint_files,
+ ignore_mismatched_sizes,
+ key_renaming_mapping,
+ is_quantized,
+ weights_only,
+ )
+
+ # We need to update both the mapping and the list of checkpoint keys to remove the mismatched ones
+ key_renaming_mapping = {k: v for k, v in key_renaming_mapping.items() if v not in mismatched_keys}
+ checkpoint_keys = list(key_renaming_mapping.values())
+
+ # Move missing (and potentially mismatched) keys back to cpu from meta device (because they won't be moved when
+ # loading the weights as they are not in the loaded state dict)
+ model._move_missing_keys_from_meta_to_cpu(missing_keys + mismatched_keys, unexpected_keys, dtype, hf_quantizer)
+
+ # correctly initialize the missing (and potentially mismatched) keys
+ model._initialize_missing_keys(checkpoint_keys, ignore_mismatched_sizes, is_quantized)
+
+ # Set some modules to fp32 if needed
+ if keep_in_fp32_regex is not None:
+ for name, param in model.named_parameters():
+ if keep_in_fp32_regex.search(name):
+ # param = param.to(torch.float32) does not work here as only in the local scope.
+ param.data = param.data.to(torch.float32)
+
+ # Make sure we are able to load base models as well as derived models (specific task models, with heads)
+ model_to_load = model
+ # In this case, we load a ForTaskModel with keys from a BaseModel -> only load keys to the BaseModel
+ if loading_task_model_from_base_state_dict:
+ model_to_load = getattr(model, prefix)
+ # Here we need to remove the prefix we added to correctly find missing/unexpected keys, as we will load
+ # in the submodule
+ key_renaming_mapping = {k: v[len(_prefix) :] for k, v in key_renaming_mapping.items()}
+ checkpoint_keys = list(key_renaming_mapping.values())
+ # We need to update the device map as well
+ if device_map is not None:
+ device_map = {k[len(_prefix) :] if k.startswith(_prefix) else k: v for k, v in device_map.items()}
+ # small sanity check: the base model should not contain task-specific head keys
+ task_specific_expected_keys = [s for s in model.state_dict().keys() if not s.startswith(_prefix)]
+ base_model_expected_keys = list(model_to_load.state_dict().keys())
+ if any(
+ key in task_specific_expected_keys and key not in base_model_expected_keys for key in checkpoint_keys
+ ):
+ raise ValueError(
+ "The state dictionary of the model you are trying to load is corrupted. Are you sure it was "
+ "properly saved?"
+ )
+
+ # Get reverse key mapping
+ reverse_key_renaming_mapping = {v: k for k, v in key_renaming_mapping.items()}
+
+ is_offloaded_safetensors = False
+ # This offload index if for params explicitly on the "disk" in the device_map
+ disk_offload_index = None
+ disk_only_shard_files = []
+ # Prepare parameters offloading if needed
+ if device_map is not None and "disk" in device_map.values():
+ if offload_state_dict is None:
+ offload_state_dict = True
+ if disk_offload_folder is not None:
+ os.makedirs(disk_offload_folder, exist_ok=True)
+ is_offloaded_safetensors = checkpoint_files is not None and checkpoint_files[0].endswith(".safetensors")
+ if disk_offload_folder is None and not is_offloaded_safetensors:
+ raise ValueError(
+ "The current `device_map` had weights offloaded to the disk. Please provide an `offload_folder`"
+ " for them. Alternatively, make sure you have `safetensors` installed if the model you are using"
+ " offers the weights in this format."
+ )
+ if is_offloaded_safetensors:
+ param_device_map = expand_device_map(device_map, checkpoint_keys)
+ str_dtype = str(dtype).replace("torch.", "") if dtype is not None else "float32"
+ if sharded_metadata is None:
+ weight_map = dict.fromkeys(checkpoint_keys, checkpoint_files[0])
+ else:
+ folder = os.path.sep.join(checkpoint_files[0].split(os.path.sep)[:-1])
+ # Fix the weight map keys according to the key mapping
+ weight_map = {
+ key_renaming_mapping[k]: v
+ for k, v in sharded_metadata["weight_map"].items()
+ if k in key_renaming_mapping
+ }
+ weight_map = {k: os.path.join(folder, v) for k, v in weight_map.items()}
+ # Find potential checkpoints containing only offloaded weights
+ disk_only_shard_files = get_disk_only_shard_files(device_map, weight_map)
+ disk_offload_index = {
+ name: {
+ "safetensors_file": file,
+ "weight_name": reverse_key_renaming_mapping[name],
+ "dtype": str_dtype,
+ }
+ for name, file in weight_map.items()
+ if param_device_map[name] == "disk"
+ }
+ else:
+ disk_offload_index = {}
+
+ # This offload index if for params that are supposed to be on the "cpu", either with or without a device_map
+ # It allows to load parameters one-by-one from the state dict, avoiding a memory peak of 2 x state_dict_size,
+ # i.e. 1x to load it, and 1x to copy it to model
+ cpu_offload_folder = None
+ cpu_offload_index = None
+ if offload_state_dict:
+ cpu_offload_folder = tempfile.mkdtemp()
+ cpu_offload_index = {}
+
+ # For nice tqdm bars
+ if checkpoint_files is not None and len(checkpoint_files) > 1:
+ checkpoint_files = logging.tqdm(checkpoint_files, desc="Loading checkpoint shards")
+ # To be able to iterate, even if we don't use it if the state_dict is already provided
+ elif state_dict is not None:
+ checkpoint_files = [""]
+
+ # Compute expected model keys
+ expected_keys = list(model_to_load.state_dict().keys())
+ if hf_quantizer is not None:
+ expected_keys = hf_quantizer.update_expected_keys(model_to_load, expected_keys, checkpoint_keys)
+
+ # Warmup cuda to load the weights much faster on devices
+ if device_map is not None and not is_hqq_or_quark:
+ expanded_device_map = expand_device_map(device_map, expected_keys)
+ caching_allocator_warmup(model_to_load, expanded_device_map, hf_quantizer)
+
+ error_msgs = []
+ # Iterate on all the shards to load the weights
+ for shard_file in checkpoint_files:
+ # Skip the load for shards that only contain disk-offloaded weights
+ if shard_file in disk_only_shard_files:
+ continue
+
+ map_location = "cpu"
+ if (
+ shard_file.endswith(".safetensors")
+ and not is_hqq_or_bnb
+ and not (is_deepspeed_zero3_enabled() and not is_quantized)
+ ):
+ map_location = "meta"
+ elif (
+ device_map is not None
+ and hf_quantizer is not None
+ and hf_quantizer.quantization_config.quant_method == QuantizationMethod.TORCHAO
+ and (
+ hf_quantizer.quantization_config.quant_type in ["int4_weight_only", "autoquant"]
+ or isinstance(hf_quantizer.quantization_config.quant_type, Int4WeightOnlyConfig)
+ )
+ ):
+ map_location = torch.device([d for d in device_map.values() if d not in ["cpu", "disk"]][0])
+
+ # If shard_file is "", we use the existing state_dict instead of loading it
+ if shard_file != "":
+ state_dict = load_state_dict(
+ shard_file, is_quantized=is_quantized, map_location=map_location, weights_only=weights_only
+ )
+
+ # Fix the key names
+ state_dict = {key_renaming_mapping[k]: v for k, v in state_dict.items() if k in key_renaming_mapping}
+
+ if is_deepspeed_zero3_enabled() and not is_quantized:
+ error_msgs += _load_state_dict_into_zero3_model(model_to_load, state_dict)
+ # Skip it with fsdp on ranks other than 0
+ elif not (is_fsdp_enabled() and not is_local_dist_rank_0() and not is_quantized):
+ disk_offload_index, cpu_offload_index = _load_state_dict_into_meta_model(
+ model_to_load,
+ state_dict,
+ shard_file,
+ expected_keys,
+ reverse_key_renaming_mapping,
+ device_map=device_map,
+ disk_offload_folder=disk_offload_folder,
+ disk_offload_index=disk_offload_index,
+ cpu_offload_folder=cpu_offload_folder,
+ cpu_offload_index=cpu_offload_index,
+ hf_quantizer=hf_quantizer,
+ is_safetensors=is_offloaded_safetensors,
+ keep_in_fp32_regex=keep_in_fp32_regex,
+ unexpected_keys=unexpected_keys,
+ device_mesh=device_mesh,
+ )
+
+ # force memory release if loading multiple shards, to avoid having 2 state dicts in memory in next loop
+ del state_dict
+
+ # Adjust offloaded weights name and save if needed
+ if disk_offload_index is not None and len(disk_offload_index) > 0:
+ if loading_task_model_from_base_state_dict:
+ # We need to add the prefix of the base model
+ prefix = cls.base_model_prefix
+ if not is_offloaded_safetensors:
+ for weight_name in disk_offload_index:
+ shutil.move(
+ os.path.join(disk_offload_folder, f"{weight_name}.dat"),
+ os.path.join(disk_offload_folder, f"{prefix}.{weight_name}.dat"),
+ )
+ disk_offload_index = {f"{prefix}.{key}": value for key, value in disk_offload_index.items()}
+ if not is_offloaded_safetensors:
+ save_offload_index(disk_offload_index, disk_offload_folder)
+ disk_offload_index = None
+
+ # one-at-a-time param loading for the cpu offloaded params
+ if offload_state_dict:
+ # Load back temporarily offloaded state dict
+ load_offloaded_weights(model_to_load, cpu_offload_index, cpu_offload_folder)
+ shutil.rmtree(cpu_offload_folder)
+
+ if hf_quantizer is not None:
+ missing_keys = hf_quantizer.update_missing_keys_after_loading(model_to_load, missing_keys, prefix)
+
+ # Post-processing for tensor parallelism
+ if device_mesh is not None:
+ # When using TP, the device map is a single device for all parameters
+ tp_device = list(device_map.values())[0]
+ # This is needed for the RotaryEmbedding, which was not initialized on the correct device as it is
+ # not part of the state_dict (persistent=False)
+ for buffer in model.buffers():
+ if buffer.device != tp_device:
+ buffer.data = buffer.to(tp_device)
+
+ # In this case, the top-most task module weights were not moved to device and parallelized as they
+ # were not part of the loaded weights: do it now
+ if loading_task_model_from_base_state_dict:
+ parameters_to_initialize = {
+ name: param for name, param in model.named_parameters() if not name.startswith(prefix)
+ }
+ for name, param in parameters_to_initialize.items():
+ # First move data to correct
+ to_contiguous, casting_dtype = _infer_parameter_dtype(model, name, param, keep_in_fp32_regex)
+ shard_and_distribute_module(
+ model,
+ param.to(tp_device),
+ param,
+ name,
+ casting_dtype,
+ to_contiguous,
+ os.environ["RANK"],
+ device_mesh,
+ )
+
+ # All potential warnings/infos
+ if len(error_msgs) > 0:
+ error_msg = "\n\t".join(error_msgs)
+ if "size mismatch" in error_msg:
+ error_msg += (
+ "\n\tYou may consider adding `ignore_mismatched_sizes=True` in the model `from_pretrained` method."
+ )
+ raise RuntimeError(f"Error(s) in loading state_dict for {model.__class__.__name__}:\n\t{error_msg}")
+ if len(unexpected_keys) > 0:
+ archs = [] if model.config.architectures is None else model.config.architectures
+ warner = logger.warning if model.__class__.__name__ in archs else logger.info
+ warner(
+ f"Some weights of the model checkpoint at {pretrained_model_name_or_path} were not used when"
+ f" initializing {model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are"
+ f" initializing {model.__class__.__name__} from the checkpoint of a model trained on another task or"
+ " with another architecture (e.g. initializing a BertForSequenceClassification model from a"
+ " BertForPreTraining model).\n- This IS NOT expected if you are initializing"
+ f" {model.__class__.__name__} from the checkpoint of a model that you expect to be exactly identical"
+ " (initializing a BertForSequenceClassification model from a BertForSequenceClassification model)."
+ )
+ else:
+ logger.info(f"All model checkpoint weights were used when initializing {model.__class__.__name__}.\n")
+ if len(missing_keys) > 0:
+ logger.warning(
+ f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path} and are newly initialized: {missing_keys}\nYou should probably"
+ " TRAIN this model on a down-stream task to be able to use it for predictions and inference."
+ )
+ elif len(mismatched_keys) == 0:
+ logger.info(
+ f"All the weights of {model.__class__.__name__} were initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path}.\nIf your task is similar to the task the model of the checkpoint"
+ f" was trained on, you can already use {model.__class__.__name__} for predictions without further"
+ " training."
+ )
+ if len(mismatched_keys) > 0:
+ mismatched_warning = "\n".join(
+ [
+ f"- {key}: found shape {shape1} in the checkpoint and {shape2} in the model instantiated"
+ for key, (shape1, shape2) in zip(mismatched_keys, mismatched_shapes)
+ ]
+ )
+ logger.warning(
+ f"Some weights of {model.__class__.__name__} were not initialized from the model checkpoint at"
+ f" {pretrained_model_name_or_path} and are newly initialized because the shapes did not"
+ f" match:\n{mismatched_warning}\nYou should probably TRAIN this model on a down-stream task to be able"
+ " to use it for predictions and inference."
+ )
+
+ return model, missing_keys, unexpected_keys, mismatched_keys, disk_offload_index, error_msgs
+
+ @classmethod
+ def _load_from_tf(cls, model, config, checkpoint_files):
+ if checkpoint_files[0].endswith(".index"):
+ # Load from a TensorFlow 1.X checkpoint - provided by original authors
+ model = cls.load_tf_weights(model, config, checkpoint_files[0][:-6]) # Remove the '.index'
+ loading_info = None
+ else:
+ # Load from our TensorFlow 2.0 checkpoints
+ try:
+ from .modeling_tf_pytorch_utils import load_tf2_checkpoint_in_pytorch_model
+
+ model, loading_info = load_tf2_checkpoint_in_pytorch_model(
+ model, checkpoint_files[0], allow_missing_keys=True, output_loading_info=True
+ )
+ except ImportError:
+ logger.error(
+ "Loading a TensorFlow model in PyTorch, requires both PyTorch and TensorFlow to be installed."
+ " Please see https://pytorch.org/ and https://www.tensorflow.org/install/ for installation"
+ " instructions."
+ )
+ raise
+ return model, loading_info
+
+ @classmethod
+ def _load_from_flax(cls, model, checkpoint_files):
+ try:
+ from .modeling_flax_pytorch_utils import load_flax_checkpoint_in_pytorch_model
+
+ model = load_flax_checkpoint_in_pytorch_model(model, checkpoint_files[0])
+ except ImportError:
+ logger.error(
+ "Loading a Flax model in PyTorch, requires both PyTorch and Flax to be installed. Please see"
+ " https://pytorch.org/ and https://flax.readthedocs.io/en/latest/installation.html for"
+ " installation instructions."
+ )
+ raise
+ return model
+
+ def retrieve_modules_from_names(self, names, add_prefix=False, remove_prefix=False):
+ module_keys = {".".join(key.split(".")[:-1]) for key in names}
+
+ # torch.nn.ParameterList is a special case where two parameter keywords
+ # are appended to the module name, *e.g.* bert.special_embeddings.0
+ module_keys = module_keys.union(
+ {".".join(key.split(".")[:-2]) for key in names if len(key) > 0 and key[-1].isdigit()}
+ )
+
+ retrieved_modules = []
+ # retrieve all modules that has at least one missing weight name
+ for name, module in self.named_modules():
+ if remove_prefix:
+ _prefix = f"{self.base_model_prefix}."
+ name = name[len(_prefix) :] if name.startswith(_prefix) else name
+ elif add_prefix:
+ name = ".".join([self.base_model_prefix, name]) if len(name) > 0 else self.base_model_prefix
+
+ if name in module_keys:
+ retrieved_modules.append(module)
+
+ return retrieved_modules
+
+ @classmethod
+ def register_for_auto_class(cls, auto_class="AutoModel"):
+ """
+ Register this class with a given auto class. This should only be used for custom models as the ones in the
+ library are already mapped with an auto class.
+
+
+
+ This API is experimental and may have some slight breaking changes in the next releases.
+
+
+
+ Args:
+ auto_class (`str` or `type`, *optional*, defaults to `"AutoModel"`):
+ The auto class to register this new model with.
+ """
+ if not isinstance(auto_class, str):
+ auto_class = auto_class.__name__
+
+ import transformers.models.auto as auto_module
+
+ if not hasattr(auto_module, auto_class):
+ raise ValueError(f"{auto_class} is not a valid auto class.")
+
+ cls._auto_class = auto_class
+
+ def to_bettertransformer(self) -> "PreTrainedModel":
+ """
+ Converts the model to use [PyTorch's native attention
+ implementation](https://pytorch.org/docs/stable/generated/torch.nn.MultiheadAttention.html), integrated to
+ Transformers through [Optimum library](https://huggingface.co/docs/optimum/bettertransformer/overview). Only a
+ subset of all Transformers models are supported.
+
+ PyTorch's attention fastpath allows to speed up inference through kernel fusions and the use of [nested
+ tensors](https://pytorch.org/docs/stable/nested.html). Detailed benchmarks can be found in [this blog
+ post](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2).
+
+ Returns:
+ [`PreTrainedModel`]: The model converted to BetterTransformer.
+ """
+ if not is_optimum_available():
+ raise ImportError("The package `optimum` is required to use Better Transformer.")
+
+ from optimum.version import __version__ as optimum_version
+
+ if version.parse(optimum_version) < version.parse("1.7.0"):
+ raise ImportError(
+ f"Please install optimum>=1.7.0 to use Better Transformer. The version {optimum_version} was found."
+ )
+
+ from optimum.bettertransformer import BetterTransformer
+
+ return BetterTransformer.transform(self)
+
+ def reverse_bettertransformer(self):
+ """
+ Reverts the transformation from [`~PreTrainedModel.to_bettertransformer`] so that the original modeling is
+ used, for example in order to save the model.
+
+ Returns:
+ [`PreTrainedModel`]: The model converted back to the original modeling.
+ """
+ if not is_optimum_available():
+ raise ImportError("The package `optimum` is required to use Better Transformer.")
+
+ from optimum.version import __version__ as optimum_version
+
+ if version.parse(optimum_version) < version.parse("1.7.0"):
+ raise ImportError(
+ f"Please install optimum>=1.7.0 to use Better Transformer. The version {optimum_version} was found."
+ )
+
+ from optimum.bettertransformer import BetterTransformer
+
+ return BetterTransformer.reverse(self)
+
+ def warn_if_padding_and_no_attention_mask(self, input_ids, attention_mask):
+ """
+ Shows a one-time warning if the input_ids appear to contain padding and no attention mask was given.
+ """
+
+ # Skip the check during tracing.
+ if is_torch_fx_proxy(input_ids) or torch.jit.is_tracing() or is_torchdynamo_compiling():
+ return
+
+ if (attention_mask is not None) or (self.config.pad_token_id is None):
+ return
+
+ # Check only the first and last input IDs to reduce overhead.
+ if self.config.pad_token_id in input_ids[:, [-1, 0]]:
+ warn_string = (
+ "We strongly recommend passing in an `attention_mask` since your input_ids may be padded. See "
+ "https://huggingface.co/docs/transformers/troubleshooting"
+ "#incorrect-output-when-padding-tokens-arent-masked."
+ )
+
+ # If the pad token is equal to either BOS, EOS, or SEP, we do not know whether the user should use an
+ # attention_mask or not. In this case, we should still show a warning because this is a rare case.
+ if (
+ (self.config.bos_token_id is not None and self.config.bos_token_id == self.config.pad_token_id)
+ or (self.config.eos_token_id is not None and self.config.eos_token_id == self.config.pad_token_id)
+ or (self.config.sep_token_id is not None and self.config.sep_token_id == self.config.pad_token_id)
+ ):
+ warn_string += (
+ f"\nYou may ignore this warning if your `pad_token_id` ({self.config.pad_token_id}) is identical "
+ f"to the `bos_token_id` ({self.config.bos_token_id}), `eos_token_id` ({self.config.eos_token_id}), "
+ f"or the `sep_token_id` ({self.config.sep_token_id}), and your input is not padded."
+ )
+
+ logger.warning_once(warn_string)
+
+ @property
+ def supports_tp_plan(self):
+ """
+ Returns whether the model has a tensor parallelism plan.
+ """
+ if self._tp_plan is not None:
+ return True
+ # Check if base model has a TP plan
+ if getattr(self.base_model, "_tp_plan", None) is not None:
+ return True
+ return False
+
+ @property
+ def tp_size(self):
+ """
+ Returns the model's tensor parallelism degree.
+ """
+ # if None, the model didn't undergo tensor parallel sharding
+ return self._tp_size
+
+ @property
+ def supports_pp_plan(self):
+ if self._pp_plan is not None:
+ return True
+ # Check if base model has PP plan
+ if getattr(self.base_model, "_pp_plan", None) is not None:
+ return True
+ return False
+
+ @property
+ def loss_function(self):
+ if hasattr(self, "_loss_function"):
+ return self._loss_function
+
+ loss_type = getattr(self, "loss_type", None)
+
+ if loss_type is None or loss_type not in LOSS_MAPPING:
+ logger.warning_once(
+ f"`loss_type={loss_type}` was set in the config but it is unrecognised."
+ f"Using the default loss: `ForCausalLMLoss`."
+ )
+ loss_type = "ForCausalLM"
+ return LOSS_MAPPING[loss_type]
+
+ @loss_function.setter
+ def loss_function(self, value):
+ self._loss_function = value
+
+ def get_compiled_call(self, compile_config: Optional[CompileConfig]) -> Callable:
+ """Return a `torch.compile`'d version of `self.__call__`. This is useful to dynamically choose between
+ non-compiled/compiled `forward` during inference, especially to switch between prefill (where we don't
+ want to use compiled version to avoid recomputing the graph with new shapes) and iterative decoding
+ (where we want the speed-ups of compiled version with static shapes)."""
+ # Only reset it if not present or different from previous config
+ if "llama4" in self.config.model_type: # TODO try to enable for FULL COMPILE HYBRID CACHE SUPPORT
+ return self.__call__
+ default_config = getattr(self.generation_config, "compile_config", None) or CompileConfig()
+ if (
+ not hasattr(self, "_compiled_call")
+ or getattr(self, "_last_compile_config", default_config) != compile_config
+ ):
+ self._last_compile_config = compile_config
+ self._compiled_call = torch.compile(self.__call__, **compile_config.to_dict())
+ return self._compiled_call
+
+ @classmethod
+ def is_backend_compatible(cls):
+ return cls._supports_attention_backend
+
+ def _move_missing_keys_from_meta_to_cpu(
+ self,
+ missing_keys: List[str],
+ unexpected_keys: List[str],
+ dtype: Optional[torch.dtype],
+ hf_quantizer: Optional[HfQuantizer],
+ ) -> "PreTrainedModel":
+ """Move the missing keys (keys that are part of the model parameters, but were NOT found in the loaded state dicts) back
+ from meta device to cpu.
+ """
+ is_quantized = hf_quantizer is not None
+
+ # In this case we need to move everything back
+ if is_fsdp_enabled() and not is_local_dist_rank_0() and not is_quantized:
+ # We only do it for the parameters, as the buffers are not initialized on the meta device by default
+ for key, param in self.named_parameters():
+ value = torch.empty_like(param, dtype=dtype, device="cpu")
+ _load_parameter_into_model(self, key, value)
+ return
+
+ model_state_dict = self.state_dict()
+ for key in missing_keys:
+ param = model_state_dict[key]
+ # Buffers are not initialized on the meta device, so we still need this check to avoid overwriting them
+ if param.device == torch.device("meta"):
+ value = torch.empty_like(param, dtype=dtype, device="cpu")
+ if (
+ not is_quantized
+ or (getattr(hf_quantizer, "requires_parameters_quantization", False))
+ or not hf_quantizer.check_quantized_param(self, param_value=value, param_name=key, state_dict={})
+ ):
+ _load_parameter_into_model(self, key, value)
+ else:
+ hf_quantizer.create_quantized_param(self, value, key, "cpu", model_state_dict, unexpected_keys)
+
+ def _initialize_missing_keys(
+ self,
+ loaded_keys: List[str],
+ ignore_mismatched_sizes: bool,
+ is_quantized: bool,
+ ) -> "PreTrainedModel":
+ """Initialize the missing keys (keys that are part of the model parameters, but were NOT found in the loaded state dicts), according to
+ `_initialize_weights`. Indeed, since the corresponding weights are missing from the state dict, they will not be replaced and need to
+ be initialized correctly (i.e. weight initialization distribution).
+ Also take care of setting the `_is_hf_initialized` flag for keys that are not missing.
+ """
+ if not ignore_mismatched_sizes:
+ not_initialized_submodules = set_initialized_submodules(self, loaded_keys)
+ # If we're about to tie the output embeds to the input embeds we don't need to init them
+ if (
+ hasattr(self.config.get_text_config(decoder=True), "tie_word_embeddings")
+ and self.config.get_text_config(decoder=True).tie_word_embeddings
+ ):
+ output_embeddings = self.get_output_embeddings()
+ if output_embeddings is not None:
+ # Still need to initialize if there is a bias term since biases are not tied.
+ if not hasattr(output_embeddings, "bias") or output_embeddings.bias is None:
+ output_embeddings._is_hf_initialized = True
+ else:
+ not_initialized_submodules = dict(self.named_modules())
+ # This will only initialize submodules that are not marked as initialized by the line above.
+ if is_deepspeed_zero3_enabled() and not is_quantized:
+ not_initialized_parameters = list(
+ set(
+ itertools.chain.from_iterable(
+ submodule.parameters(recurse=False) for submodule in not_initialized_submodules.values()
+ )
+ )
+ )
+ with deepspeed.zero.GatheredParameters(not_initialized_parameters, modifier_rank=0):
+ self.initialize_weights()
+ else:
+ self.initialize_weights()
+
+ def get_parameter_or_buffer(self, target: str):
+ """
+ Return the parameter or buffer given by `target` if it exists, otherwise throw an error. This combines
+ `get_parameter()` and `get_buffer()` in a single handy function. Note that it only work if `target` is a
+ leaf of the model.
+ """
+ try:
+ return self.get_parameter(target)
+ except AttributeError:
+ pass
+ try:
+ return self.get_buffer(target)
+ except AttributeError:
+ pass
+ raise AttributeError(f"`{target}` is neither a parameter nor a buffer.")
+
+
+PreTrainedModel.push_to_hub = copy_func(PreTrainedModel.push_to_hub)
+if PreTrainedModel.push_to_hub.__doc__ is not None:
+ PreTrainedModel.push_to_hub.__doc__ = PreTrainedModel.push_to_hub.__doc__.format(
+ object="model", object_class="AutoModel", object_files="model file"
+ )
+
+
+class PoolerStartLogits(nn.Module):
+ """
+ Compute SQuAD start logits from sequence hidden states.
+
+ Args:
+ config ([`PretrainedConfig`]):
+ The config used by the model, will be used to grab the `hidden_size` of the model.
+ """
+
+ def __init__(self, config: PretrainedConfig):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, 1)
+ logger.warning_once(
+ "[DEPRECATION WARNING] `PoolerStartLogits` is deprecated and will be removed in v4.53. "
+ "Please use model-specific class, e.g. `XLMPoolerStartLogits`."
+ )
+
+ def forward(
+ self, hidden_states: torch.FloatTensor, p_mask: Optional[torch.FloatTensor] = None
+ ) -> torch.FloatTensor:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor` of shape `(batch_size, seq_len, hidden_size)`):
+ The final hidden states of the model.
+ p_mask (`torch.FloatTensor` of shape `(batch_size, seq_len)`, *optional*):
+ Mask for tokens at invalid position, such as query and special symbols (PAD, SEP, CLS). 1.0 means token
+ should be masked.
+
+ Returns:
+ `torch.FloatTensor`: The start logits for SQuAD.
+ """
+ x = self.dense(hidden_states).squeeze(-1)
+
+ if p_mask is not None:
+ if get_parameter_dtype(self) == torch.float16:
+ x = x * (1 - p_mask) - 65500 * p_mask
+ else:
+ x = x * (1 - p_mask) - 1e30 * p_mask
+
+ return x
+
+
+class PoolerEndLogits(nn.Module):
+ """
+ Compute SQuAD end logits from sequence hidden states.
+
+ Args:
+ config ([`PretrainedConfig`]):
+ The config used by the model, will be used to grab the `hidden_size` of the model and the `layer_norm_eps`
+ to use.
+ """
+
+ def __init__(self, config: PretrainedConfig):
+ super().__init__()
+ self.dense_0 = nn.Linear(config.hidden_size * 2, config.hidden_size)
+ self.activation = nn.Tanh()
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dense_1 = nn.Linear(config.hidden_size, 1)
+ logger.warning_once(
+ "[DEPRECATION WARNING] `PoolerEndLogits` is deprecated and will be removed in v4.53. "
+ "Please use model-specific class, e.g. `XLMPoolerEndLogits`."
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ start_states: Optional[torch.FloatTensor] = None,
+ start_positions: Optional[torch.LongTensor] = None,
+ p_mask: Optional[torch.FloatTensor] = None,
+ ) -> torch.FloatTensor:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor` of shape `(batch_size, seq_len, hidden_size)`):
+ The final hidden states of the model.
+ start_states (`torch.FloatTensor` of shape `(batch_size, seq_len, hidden_size)`, *optional*):
+ The hidden states of the first tokens for the labeled span.
+ start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ The position of the first token for the labeled span.
+ p_mask (`torch.FloatTensor` of shape `(batch_size, seq_len)`, *optional*):
+ Mask for tokens at invalid position, such as query and special symbols (PAD, SEP, CLS). 1.0 means token
+ should be masked.
+
+
+
+ One of `start_states` or `start_positions` should be not `None`. If both are set, `start_positions` overrides
+ `start_states`.
+
+
+
+ Returns:
+ `torch.FloatTensor`: The end logits for SQuAD.
+ """
+ assert start_states is not None or start_positions is not None, (
+ "One of start_states, start_positions should be not None"
+ )
+ if start_positions is not None:
+ slen, hsz = hidden_states.shape[-2:]
+ start_positions = start_positions[:, None, None].expand(-1, -1, hsz) # shape (bsz, 1, hsz)
+ start_states = hidden_states.gather(-2, start_positions) # shape (bsz, 1, hsz)
+ start_states = start_states.expand(-1, slen, -1) # shape (bsz, slen, hsz)
+
+ x = self.dense_0(torch.cat([hidden_states, start_states], dim=-1))
+ x = self.activation(x)
+ x = self.LayerNorm(x)
+ x = self.dense_1(x).squeeze(-1)
+
+ if p_mask is not None:
+ if get_parameter_dtype(self) == torch.float16:
+ x = x * (1 - p_mask) - 65500 * p_mask
+ else:
+ x = x * (1 - p_mask) - 1e30 * p_mask
+
+ return x
+
+
+class PoolerAnswerClass(nn.Module):
+ """
+ Compute SQuAD 2.0 answer class from classification and start tokens hidden states.
+
+ Args:
+ config ([`PretrainedConfig`]):
+ The config used by the model, will be used to grab the `hidden_size` of the model.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.dense_0 = nn.Linear(config.hidden_size * 2, config.hidden_size)
+ self.activation = nn.Tanh()
+ self.dense_1 = nn.Linear(config.hidden_size, 1, bias=False)
+ logger.warning_once(
+ "[DEPRECATION WARNING] `PoolerAnswerClass` is deprecated and will be removed in v4.53. "
+ "Please use model-specific class, e.g. `XLMPoolerAnswerClass`."
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ start_states: Optional[torch.FloatTensor] = None,
+ start_positions: Optional[torch.LongTensor] = None,
+ cls_index: Optional[torch.LongTensor] = None,
+ ) -> torch.FloatTensor:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor` of shape `(batch_size, seq_len, hidden_size)`):
+ The final hidden states of the model.
+ start_states (`torch.FloatTensor` of shape `(batch_size, seq_len, hidden_size)`, *optional*):
+ The hidden states of the first tokens for the labeled span.
+ start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ The position of the first token for the labeled span.
+ cls_index (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Position of the CLS token for each sentence in the batch. If `None`, takes the last token.
+
+
+
+ One of `start_states` or `start_positions` should be not `None`. If both are set, `start_positions` overrides
+ `start_states`.
+
+
+
+ Returns:
+ `torch.FloatTensor`: The SQuAD 2.0 answer class.
+ """
+ # No dependency on end_feature so that we can obtain one single `cls_logits` for each sample.
+ hsz = hidden_states.shape[-1]
+ assert start_states is not None or start_positions is not None, (
+ "One of start_states, start_positions should be not None"
+ )
+ if start_positions is not None:
+ start_positions = start_positions[:, None, None].expand(-1, -1, hsz) # shape (bsz, 1, hsz)
+ start_states = hidden_states.gather(-2, start_positions).squeeze(-2) # shape (bsz, hsz)
+
+ if cls_index is not None:
+ cls_index = cls_index[:, None, None].expand(-1, -1, hsz) # shape (bsz, 1, hsz)
+ cls_token_state = hidden_states.gather(-2, cls_index).squeeze(-2) # shape (bsz, hsz)
+ else:
+ cls_token_state = hidden_states[:, -1, :] # shape (bsz, hsz)
+
+ x = self.dense_0(torch.cat([start_states, cls_token_state], dim=-1))
+ x = self.activation(x)
+ x = self.dense_1(x).squeeze(-1)
+
+ return x
+
+
+@dataclass
+class SquadHeadOutput(ModelOutput):
+ """
+ Base class for outputs of question answering models using a [`~modeling_utils.SQuADHead`].
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned if both `start_positions` and `end_positions` are provided):
+ Classification loss as the sum of start token, end token (and is_impossible if provided) classification
+ losses.
+ start_top_log_probs (`torch.FloatTensor` of shape `(batch_size, config.start_n_top)`, *optional*, returned if `start_positions` or `end_positions` is not provided):
+ Log probabilities for the top config.start_n_top start token possibilities (beam-search).
+ start_top_index (`torch.LongTensor` of shape `(batch_size, config.start_n_top)`, *optional*, returned if `start_positions` or `end_positions` is not provided):
+ Indices for the top config.start_n_top start token possibilities (beam-search).
+ end_top_log_probs (`torch.FloatTensor` of shape `(batch_size, config.start_n_top * config.end_n_top)`, *optional*, returned if `start_positions` or `end_positions` is not provided):
+ Log probabilities for the top `config.start_n_top * config.end_n_top` end token possibilities
+ (beam-search).
+ end_top_index (`torch.LongTensor` of shape `(batch_size, config.start_n_top * config.end_n_top)`, *optional*, returned if `start_positions` or `end_positions` is not provided):
+ Indices for the top `config.start_n_top * config.end_n_top` end token possibilities (beam-search).
+ cls_logits (`torch.FloatTensor` of shape `(batch_size,)`, *optional*, returned if `start_positions` or `end_positions` is not provided):
+ Log probabilities for the `is_impossible` label of the answers.
+
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ start_top_log_probs: Optional[torch.FloatTensor] = None
+ start_top_index: Optional[torch.LongTensor] = None
+ end_top_log_probs: Optional[torch.FloatTensor] = None
+ end_top_index: Optional[torch.LongTensor] = None
+ cls_logits: Optional[torch.FloatTensor] = None
+
+ def __post_init__(self):
+ logger.warning_once(
+ "[DEPRECATION WARNING] `SquadHeadOutput` is deprecated and will be removed in v4.53. "
+ "Please use model-specific class, e.g. `XLMSquadHeadOutput`."
+ )
+
+
+class SQuADHead(nn.Module):
+ r"""
+ A SQuAD head inspired by XLNet.
+
+ Args:
+ config ([`PretrainedConfig`]):
+ The config used by the model, will be used to grab the `hidden_size` of the model and the `layer_norm_eps`
+ to use.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+ self.start_n_top = config.start_n_top
+ self.end_n_top = config.end_n_top
+
+ self.start_logits = PoolerStartLogits(config)
+ self.end_logits = PoolerEndLogits(config)
+ self.answer_class = PoolerAnswerClass(config)
+
+ logger.warning_once(
+ "[DEPRECATION WARNING] `SQuADHead` is deprecated and will be removed in v4.53. "
+ "Please use model-specific class, e.g. `XLMSQuADHead`."
+ )
+
+ @replace_return_docstrings(output_type=SquadHeadOutput, config_class=PretrainedConfig)
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ start_positions: Optional[torch.LongTensor] = None,
+ end_positions: Optional[torch.LongTensor] = None,
+ cls_index: Optional[torch.LongTensor] = None,
+ is_impossible: Optional[torch.LongTensor] = None,
+ p_mask: Optional[torch.FloatTensor] = None,
+ return_dict: bool = False,
+ ) -> Union[SquadHeadOutput, Tuple[torch.FloatTensor]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor` of shape `(batch_size, seq_len, hidden_size)`):
+ Final hidden states of the model on the sequence tokens.
+ start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Positions of the first token for the labeled span.
+ end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Positions of the last token for the labeled span.
+ cls_index (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Position of the CLS token for each sentence in the batch. If `None`, takes the last token.
+ is_impossible (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Whether the question has a possible answer in the paragraph or not.
+ p_mask (`torch.FloatTensor` of shape `(batch_size, seq_len)`, *optional*):
+ Mask for tokens at invalid position, such as query and special symbols (PAD, SEP, CLS). 1.0 means token
+ should be masked.
+ return_dict (`bool`, *optional*, defaults to `False`):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+
+ Returns:
+ """
+ start_logits = self.start_logits(hidden_states, p_mask=p_mask)
+
+ if start_positions is not None and end_positions is not None:
+ # If we are on multi-GPU, let's remove the dimension added by batch splitting
+ for x in (start_positions, end_positions, cls_index, is_impossible):
+ if x is not None and x.dim() > 1:
+ x.squeeze_(-1)
+
+ # during training, compute the end logits based on the ground truth of the start position
+ end_logits = self.end_logits(hidden_states, start_positions=start_positions, p_mask=p_mask)
+
+ loss_fct = CrossEntropyLoss()
+ start_loss = loss_fct(start_logits, start_positions)
+ end_loss = loss_fct(end_logits, end_positions)
+ total_loss = (start_loss + end_loss) / 2
+
+ if cls_index is not None and is_impossible is not None:
+ # Predict answerability from the representation of CLS and START
+ cls_logits = self.answer_class(hidden_states, start_positions=start_positions, cls_index=cls_index)
+ loss_fct_cls = nn.BCEWithLogitsLoss()
+ cls_loss = loss_fct_cls(cls_logits, is_impossible)
+
+ # note(zhiliny): by default multiply the loss by 0.5 so that the scale is comparable to start_loss and end_loss
+ total_loss += cls_loss * 0.5
+
+ return SquadHeadOutput(loss=total_loss) if return_dict else (total_loss,)
+
+ else:
+ # during inference, compute the end logits based on beam search
+ bsz, slen, hsz = hidden_states.size()
+ start_log_probs = nn.functional.softmax(start_logits, dim=-1) # shape (bsz, slen)
+
+ start_top_log_probs, start_top_index = torch.topk(
+ start_log_probs, self.start_n_top, dim=-1
+ ) # shape (bsz, start_n_top)
+ start_top_index_exp = start_top_index.unsqueeze(-1).expand(-1, -1, hsz) # shape (bsz, start_n_top, hsz)
+ start_states = torch.gather(hidden_states, -2, start_top_index_exp) # shape (bsz, start_n_top, hsz)
+ start_states = start_states.unsqueeze(1).expand(-1, slen, -1, -1) # shape (bsz, slen, start_n_top, hsz)
+
+ hidden_states_expanded = hidden_states.unsqueeze(2).expand_as(
+ start_states
+ ) # shape (bsz, slen, start_n_top, hsz)
+ p_mask = p_mask.unsqueeze(-1) if p_mask is not None else None
+ end_logits = self.end_logits(hidden_states_expanded, start_states=start_states, p_mask=p_mask)
+ end_log_probs = nn.functional.softmax(end_logits, dim=1) # shape (bsz, slen, start_n_top)
+
+ end_top_log_probs, end_top_index = torch.topk(
+ end_log_probs, self.end_n_top, dim=1
+ ) # shape (bsz, end_n_top, start_n_top)
+ end_top_log_probs = end_top_log_probs.view(-1, self.start_n_top * self.end_n_top)
+ end_top_index = end_top_index.view(-1, self.start_n_top * self.end_n_top)
+
+ start_states = torch.einsum("blh,bl->bh", hidden_states, start_log_probs)
+ cls_logits = self.answer_class(hidden_states, start_states=start_states, cls_index=cls_index)
+
+ if not return_dict:
+ return (start_top_log_probs, start_top_index, end_top_log_probs, end_top_index, cls_logits)
+ else:
+ return SquadHeadOutput(
+ start_top_log_probs=start_top_log_probs,
+ start_top_index=start_top_index,
+ end_top_log_probs=end_top_log_probs,
+ end_top_index=end_top_index,
+ cls_logits=cls_logits,
+ )
+
+
+class SequenceSummary(nn.Module):
+ r"""
+ Compute a single vector summary of a sequence hidden states.
+
+ Args:
+ config ([`PretrainedConfig`]):
+ The config used by the model. Relevant arguments in the config class of the model are (refer to the actual
+ config class of your model for the default values it uses):
+
+ - **summary_type** (`str`) -- The method to use to make this summary. Accepted values are:
+
+ - `"last"` -- Take the last token hidden state (like XLNet)
+ - `"first"` -- Take the first token hidden state (like Bert)
+ - `"mean"` -- Take the mean of all tokens hidden states
+ - `"cls_index"` -- Supply a Tensor of classification token position (GPT/GPT-2)
+ - `"attn"` -- Not implemented now, use multi-head attention
+
+ - **summary_use_proj** (`bool`) -- Add a projection after the vector extraction.
+ - **summary_proj_to_labels** (`bool`) -- If `True`, the projection outputs to `config.num_labels` classes
+ (otherwise to `config.hidden_size`).
+ - **summary_activation** (`Optional[str]`) -- Set to `"tanh"` to add a tanh activation to the output,
+ another string or `None` will add no activation.
+ - **summary_first_dropout** (`float`) -- Optional dropout probability before the projection and activation.
+ - **summary_last_dropout** (`float`)-- Optional dropout probability after the projection and activation.
+ """
+
+ def __init__(self, config: PretrainedConfig):
+ super().__init__()
+
+ self.summary_type = getattr(config, "summary_type", "last")
+ if self.summary_type == "attn":
+ # We should use a standard multi-head attention module with absolute positional embedding for that.
+ # Cf. https://github.com/zihangdai/xlnet/blob/master/modeling.py#L253-L276
+ # We can probably just use the multi-head attention module of PyTorch >=1.1.0
+ raise NotImplementedError
+
+ self.summary = Identity()
+ if hasattr(config, "summary_use_proj") and config.summary_use_proj:
+ if hasattr(config, "summary_proj_to_labels") and config.summary_proj_to_labels and config.num_labels > 0:
+ num_classes = config.num_labels
+ else:
+ num_classes = config.hidden_size
+ self.summary = nn.Linear(config.hidden_size, num_classes)
+
+ activation_string = getattr(config, "summary_activation", None)
+ self.activation: Callable = get_activation(activation_string) if activation_string else Identity()
+
+ self.first_dropout = Identity()
+ if hasattr(config, "summary_first_dropout") and config.summary_first_dropout > 0:
+ self.first_dropout = nn.Dropout(config.summary_first_dropout)
+
+ self.last_dropout = Identity()
+ if hasattr(config, "summary_last_dropout") and config.summary_last_dropout > 0:
+ self.last_dropout = nn.Dropout(config.summary_last_dropout)
+
+ logger.warning_once(
+ "[DEPRECATION WARNING] `SequenceSummary` is deprecated and will be removed in v4.53. "
+ "Please use model-specific class, e.g. `XLMSequenceSummary`."
+ )
+
+ def forward(
+ self, hidden_states: torch.FloatTensor, cls_index: Optional[torch.LongTensor] = None
+ ) -> torch.FloatTensor:
+ """
+ Compute a single vector summary of a sequence hidden states.
+
+ Args:
+ hidden_states (`torch.FloatTensor` of shape `[batch_size, seq_len, hidden_size]`):
+ The hidden states of the last layer.
+ cls_index (`torch.LongTensor` of shape `[batch_size]` or `[batch_size, ...]` where ... are optional leading dimensions of `hidden_states`, *optional*):
+ Used if `summary_type == "cls_index"` and takes the last token of the sequence as classification token.
+
+ Returns:
+ `torch.FloatTensor`: The summary of the sequence hidden states.
+ """
+ if self.summary_type == "last":
+ output = hidden_states[:, -1]
+ elif self.summary_type == "first":
+ output = hidden_states[:, 0]
+ elif self.summary_type == "mean":
+ output = hidden_states.mean(dim=1)
+ elif self.summary_type == "cls_index":
+ if cls_index is None:
+ cls_index = torch.full_like(
+ hidden_states[..., :1, :],
+ hidden_states.shape[-2] - 1,
+ dtype=torch.long,
+ )
+ else:
+ cls_index = cls_index.unsqueeze(-1).unsqueeze(-1)
+ cls_index = cls_index.expand((-1,) * (cls_index.dim() - 1) + (hidden_states.size(-1),))
+ # shape of cls_index: (bsz, XX, 1, hidden_size) where XX are optional leading dim of hidden_states
+ output = hidden_states.gather(-2, cls_index).squeeze(-2) # shape (bsz, XX, hidden_size)
+ elif self.summary_type == "attn":
+ raise NotImplementedError
+
+ output = self.first_dropout(output)
+ output = self.summary(output)
+ output = self.activation(output)
+ output = self.last_dropout(output)
+
+ return output
+
+
+def unwrap_model(model: nn.Module, recursive: bool = False) -> nn.Module:
+ """
+ Recursively unwraps a model from potential containers (as used in distributed training).
+
+ Args:
+ model (`torch.nn.Module`): The model to unwrap.
+ recursive (`bool`, *optional*, defaults to `False`):
+ Whether to recursively extract all cases of `module.module` from `model` as well as unwrap child sublayers
+ recursively, not just the top-level distributed containers.
+ """
+ # Use accelerate implementation if available (should always be the case when using torch)
+ # This is for pytorch, as we also have to handle things like dynamo
+ if is_accelerate_available():
+ kwargs = {}
+ if recursive:
+ if not is_accelerate_available("0.29.0"):
+ raise RuntimeError(
+ "Setting `recursive=True` to `unwrap_model` requires `accelerate` v0.29.0. Please upgrade your version of accelerate"
+ )
+ else:
+ kwargs["recursive"] = recursive
+ return extract_model_from_parallel(model, **kwargs)
+ else:
+ # since there could be multiple levels of wrapping, unwrap recursively
+ if hasattr(model, "module"):
+ return unwrap_model(model.module)
+ else:
+ return model
+
+
+def expand_device_map(device_map, param_names):
+ """
+ Expand a device map to return the correspondence parameter name to device.
+ """
+ new_device_map = {}
+ for module, device in device_map.items():
+ new_device_map.update(
+ {p: device for p in param_names if p == module or p.startswith(f"{module}.") or module == ""}
+ )
+ return new_device_map
+
+
+def is_accelerator_device(device: Union[str, int, torch.device]) -> bool:
+ """Check if the device is an accelerator. We need to function, as device_map can be "disk" as well, which is not
+ a proper `torch.device`.
+ """
+ if device == "disk":
+ return False
+ else:
+ return torch.device(device).type not in ["meta", "cpu"]
+
+
+def caching_allocator_warmup(model: PreTrainedModel, expanded_device_map: Dict, hf_quantizer: Optional[HfQuantizer]):
+ """This function warm-ups the caching allocator based on the size of the model tensors that will reside on each
+ device. It allows to have one large call to Malloc, instead of recursively calling it later when loading
+ the model, which is actually the loading speed botteneck.
+ Calling this function allows to cut the model loading time by a very large margin.
+
+ A few facts related to loading speed (taking into account the use of this function):
+ - When loading a model the first time, it is usually slower than the subsequent times, because the OS is very likely
+ to cache the different state dicts (if enough ressources/RAM are available)
+ - Trying to force the OS to cache the files in advance (by e.g. accessing a small portion of them) is really hard,
+ and not a good idea in general as this is low level OS optimizations that depend on ressource usage anyway
+ - As of 18/03/2025, loading a Llama 70B model with TP takes ~1 min without file cache, and ~13s with full file cache.
+ The baseline, i.e. only loading the tensor shards on device and adjusting dtype (i.e. copying them) is ~5s with full cache.
+ These numbers are reported for TP on 4 H100 GPUs.
+ - It is useless to pre-allocate more than the model size in this function (i.e. using an `allocation_factor` > 1) as
+ cudaMalloc is not a bottleneck at all anymore
+ - Loading speed bottleneck is now almost only tensor copy (i.e. changing the dtype) and moving the tensors to the devices.
+ However, we cannot really improve on those aspects obviously, as the data needs to be moved/copied in the end.
+ """
+ factor = 2 if hf_quantizer is None else hf_quantizer.get_cuda_warm_up_factor()
+
+ # Remove disk, cpu and meta devices, and cast to proper torch.device
+ accelerator_device_map = {
+ param: torch.device(device) for param, device in expanded_device_map.items() if is_accelerator_device(device)
+ }
+ if not len(accelerator_device_map):
+ return
+
+ tp_plan_regex = (
+ re.compile("|".join([re.escape(plan) for plan in model._tp_plan]))
+ if _torch_distributed_available and torch.distributed.is_initialized()
+ else None
+ )
+ total_byte_count = defaultdict(lambda: 0)
+ for param_name, device in accelerator_device_map.items():
+ param = model.get_parameter_or_buffer(param_name)
+ # The dtype of different parameters may be different with composite models or `keep_in_fp32_modules`
+ param_byte_count = param.numel() * param.element_size()
+
+ if tp_plan_regex is not None:
+ generic_name = re.sub(r"\.\d+\.", ".*.", param_name)
+ param_byte_count //= torch.distributed.get_world_size() if tp_plan_regex.search(generic_name) else 1
+
+ total_byte_count[device] += param_byte_count
+
+ # This will kick off the caching allocator to avoid having to Malloc afterwards
+ for device, byte_count in total_byte_count.items():
+ if device.type == "cuda":
+ index = device.index if device.index is not None else torch.cuda.current_device()
+ device_memory = torch.cuda.mem_get_info(index)[0]
+ # Allow up to (max device memory - 1.2 GiB) in resource-constrained hardware configurations. Trying to reserve more
+ # than that amount might sometimes lead to unecesary cuda OOM, if the last parameter to be loaded on the device is large,
+ # and the remaining reserved memory portion is smaller than the param size -> torch will then try to fully re-allocate all
+ # the param size, instead of using the remaining reserved part, and allocating only the difference, which can lead
+ # to OOM. See https://github.com/huggingface/transformers/issues/37436#issuecomment-2808982161 for more details.
+ # Note that we use an absolute value instead of device proportion here, as a 8GiB device could still allocate too much
+ # if using e.g. 90% of device size, while a 140GiB device would allocate too little
+ byte_count = min(byte_count, max(0, int(device_memory - 1.2 * 1024**3)))
+ # Allocate memory
+ _ = torch.empty(byte_count // factor, dtype=torch.float16, device=device, requires_grad=False)
+
+
+def get_disk_only_shard_files(device_map, weight_map):
+ """
+ Returns the list of shard files containing only weights offloaded to disk.
+ """
+ files_content = collections.defaultdict(list)
+ for weight_name, filename in weight_map.items():
+ while len(weight_name) > 0 and weight_name not in device_map:
+ weight_name = ".".join(weight_name.split(".")[:-1])
+ files_content[filename].append(device_map[weight_name])
+
+ return [fname for fname, devices in files_content.items() if set(devices) == {"disk"}]
+
+
+class AttentionInterface(MutableMapping):
+ """
+ Dict-like object keeping track of allowed attention functions. You can easily add a new attention function
+ with a call to `register()`. If a model needs to locally overwrite an existing attention function, say `sdpa`,
+ it needs to declare a new instance of this class inside the `modeling_.py`, and declare it on that instance.
+ """
+
+ # Class instance object, so that a call to `register` can be reflected into all other files correctly, even if
+ # a new instance is created (in order to locally override a given function)
+ _global_mapping = {
+ "flash_attention_2": flash_attention_forward,
+ "flex_attention": flex_attention_forward,
+ "sdpa": sdpa_attention_forward,
+ }
+
+ def __init__(self):
+ self._local_mapping = {}
+
+ def __getitem__(self, key):
+ # First check if instance has a local override
+ if key in self._local_mapping:
+ return self._local_mapping[key]
+ return self._global_mapping[key]
+
+ def __setitem__(self, key, value):
+ # Allow local update of the default functions without impacting other instances
+ self._local_mapping.update({key: value})
+
+ def __delitem__(self, key):
+ del self._local_mapping[key]
+
+ def __iter__(self):
+ # Ensure we use all keys, with the overwritten ones on top
+ return iter({**self._global_mapping, **self._local_mapping})
+
+ def __len__(self):
+ return len(self._global_mapping.keys() | self._local_mapping.keys())
+
+ @classmethod
+ def register(cls, key: str, value: Callable):
+ cls._global_mapping.update({key: value})
+
+ def valid_keys(self) -> List[str]:
+ return list(self.keys())
+
+
+# Global AttentionInterface shared by all models which do not need to overwrite any of the existing ones
+ALL_ATTENTION_FUNCTIONS: AttentionInterface = AttentionInterface()
diff --git a/docs/transformers/src/transformers/models/__init__.py b/docs/transformers/src/transformers/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..26e6e0a97994aa1db773ecc59cdd5e4b48555a14
--- /dev/null
+++ b/docs/transformers/src/transformers/models/__init__.py
@@ -0,0 +1,335 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ..utils import _LazyModule
+from ..utils.import_utils import define_import_structure
+
+
+if TYPE_CHECKING:
+ from .albert import *
+ from .align import *
+ from .altclip import *
+ from .aria import *
+ from .audio_spectrogram_transformer import *
+ from .auto import *
+ from .autoformer import *
+ from .aya_vision import *
+ from .bamba import *
+ from .bark import *
+ from .bart import *
+ from .barthez import *
+ from .bartpho import *
+ from .beit import *
+ from .bert import *
+ from .bert_generation import *
+ from .bert_japanese import *
+ from .bertweet import *
+ from .big_bird import *
+ from .bigbird_pegasus import *
+ from .biogpt import *
+ from .bit import *
+ from .blenderbot import *
+ from .blenderbot_small import *
+ from .blip import *
+ from .blip_2 import *
+ from .bloom import *
+ from .bridgetower import *
+ from .bros import *
+ from .byt5 import *
+ from .camembert import *
+ from .canine import *
+ from .chameleon import *
+ from .chinese_clip import *
+ from .clap import *
+ from .clip import *
+ from .clipseg import *
+ from .clvp import *
+ from .code_llama import *
+ from .codegen import *
+ from .cohere import *
+ from .cohere2 import *
+ from .colpali import *
+ from .conditional_detr import *
+ from .convbert import *
+ from .convnext import *
+ from .convnextv2 import *
+ from .cpm import *
+ from .cpmant import *
+ from .ctrl import *
+ from .cvt import *
+ from .dab_detr import *
+ from .dac import *
+ from .data2vec import *
+ from .dbrx import *
+ from .deberta import *
+ from .deberta_v2 import *
+ from .decision_transformer import *
+ from .deformable_detr import *
+ from .deit import *
+ from .deprecated import *
+ from .depth_anything import *
+ from .depth_pro import *
+ from .detr import *
+ from .dialogpt import *
+ from .diffllama import *
+ from .dinat import *
+ from .dinov2 import *
+ from .dinov2_with_registers import *
+ from .distilbert import *
+ from .dit import *
+ from .donut import *
+ from .dpr import *
+ from .dpt import *
+ from .efficientnet import *
+ from .electra import *
+ from .emu3 import *
+ from .encodec import *
+ from .encoder_decoder import *
+ from .ernie import *
+ from .esm import *
+ from .falcon import *
+ from .falcon_mamba import *
+ from .fastspeech2_conformer import *
+ from .flaubert import *
+ from .flava import *
+ from .fnet import *
+ from .focalnet import *
+ from .fsmt import *
+ from .funnel import *
+ from .fuyu import *
+ from .gemma import *
+ from .gemma2 import *
+ from .gemma3 import *
+ from .git import *
+ from .glm import *
+ from .glm4 import *
+ from .glpn import *
+ from .got_ocr2 import *
+ from .gpt2 import *
+ from .gpt_bigcode import *
+ from .gpt_neo import *
+ from .gpt_neox import *
+ from .gpt_neox_japanese import *
+ from .gpt_sw3 import *
+ from .gptj import *
+ from .granite import *
+ from .granite_speech import *
+ from .granitemoe import *
+ from .granitemoeshared import *
+ from .grounding_dino import *
+ from .groupvit import *
+ from .helium import *
+ from .herbert import *
+ from .hiera import *
+ from .hubert import *
+ from .ibert import *
+ from .idefics import *
+ from .idefics2 import *
+ from .idefics3 import *
+ from .ijepa import *
+ from .imagegpt import *
+ from .informer import *
+ from .instructblip import *
+ from .instructblipvideo import *
+ from .internvl import *
+ from .jamba import *
+ from .janus import *
+ from .jetmoe import *
+ from .kosmos2 import *
+ from .layoutlm import *
+ from .layoutlmv2 import *
+ from .layoutlmv3 import *
+ from .layoutxlm import *
+ from .led import *
+ from .levit import *
+ from .lilt import *
+ from .llama import *
+ from .llama4 import *
+ from .llava import *
+ from .llava_next import *
+ from .llava_next_video import *
+ from .llava_onevision import *
+ from .longformer import *
+ from .longt5 import *
+ from .luke import *
+ from .lxmert import *
+ from .m2m_100 import *
+ from .mamba import *
+ from .mamba2 import *
+ from .marian import *
+ from .markuplm import *
+ from .mask2former import *
+ from .maskformer import *
+ from .mbart import *
+ from .mbart50 import *
+ from .megatron_bert import *
+ from .megatron_gpt2 import *
+ from .mgp_str import *
+ from .mimi import *
+ from .mistral import *
+ from .mistral3 import *
+ from .mixtral import *
+ from .mlcd import *
+ from .mllama import *
+ from .mluke import *
+ from .mobilebert import *
+ from .mobilenet_v1 import *
+ from .mobilenet_v2 import *
+ from .mobilevit import *
+ from .mobilevitv2 import *
+ from .modernbert import *
+ from .moonshine import *
+ from .moshi import *
+ from .mpnet import *
+ from .mpt import *
+ from .mra import *
+ from .mt5 import *
+ from .musicgen import *
+ from .musicgen_melody import *
+ from .mvp import *
+ from .myt5 import *
+ from .nemotron import *
+ from .nllb import *
+ from .nllb_moe import *
+ from .nougat import *
+ from .nystromformer import *
+ from .olmo import *
+ from .olmo2 import *
+ from .olmoe import *
+ from .omdet_turbo import *
+ from .oneformer import *
+ from .openai import *
+ from .opt import *
+ from .owlv2 import *
+ from .owlvit import *
+ from .paligemma import *
+ from .patchtsmixer import *
+ from .patchtst import *
+ from .pegasus import *
+ from .pegasus_x import *
+ from .perceiver import *
+ from .persimmon import *
+ from .phi import *
+ from .phi3 import *
+ from .phi4_multimodal import *
+ from .phimoe import *
+ from .phobert import *
+ from .pix2struct import *
+ from .pixtral import *
+ from .plbart import *
+ from .poolformer import *
+ from .pop2piano import *
+ from .prophetnet import *
+ from .pvt import *
+ from .pvt_v2 import *
+ from .qwen2 import *
+ from .qwen2_5_vl import *
+ from .qwen2_audio import *
+ from .qwen2_moe import *
+ from .qwen2_vl import *
+ from .rag import *
+ from .recurrent_gemma import *
+ from .reformer import *
+ from .regnet import *
+ from .rembert import *
+ from .resnet import *
+ from .roberta import *
+ from .roberta_prelayernorm import *
+ from .roc_bert import *
+ from .roformer import *
+ from .rt_detr import *
+ from .rt_detr_v2 import *
+ from .rwkv import *
+ from .sam import *
+ from .seamless_m4t import *
+ from .seamless_m4t_v2 import *
+ from .segformer import *
+ from .seggpt import *
+ from .sew import *
+ from .sew_d import *
+ from .siglip import *
+ from .siglip2 import *
+ from .smolvlm import *
+ from .speech_encoder_decoder import *
+ from .speech_to_text import *
+ from .speecht5 import *
+ from .splinter import *
+ from .squeezebert import *
+ from .stablelm import *
+ from .starcoder2 import *
+ from .superglue import *
+ from .superpoint import *
+ from .swiftformer import *
+ from .swin import *
+ from .swin2sr import *
+ from .swinv2 import *
+ from .switch_transformers import *
+ from .t5 import *
+ from .table_transformer import *
+ from .tapas import *
+ from .textnet import *
+ from .time_series_transformer import *
+ from .timesfm import *
+ from .timesformer import *
+ from .timm_backbone import *
+ from .timm_wrapper import *
+ from .trocr import *
+ from .tvp import *
+ from .udop import *
+ from .umt5 import *
+ from .unispeech import *
+ from .unispeech_sat import *
+ from .univnet import *
+ from .upernet import *
+ from .video_llava import *
+ from .videomae import *
+ from .vilt import *
+ from .vipllava import *
+ from .vision_encoder_decoder import *
+ from .vision_text_dual_encoder import *
+ from .visual_bert import *
+ from .vit import *
+ from .vit_mae import *
+ from .vit_msn import *
+ from .vitdet import *
+ from .vitmatte import *
+ from .vitpose import *
+ from .vitpose_backbone import *
+ from .vits import *
+ from .vivit import *
+ from .wav2vec2 import *
+ from .wav2vec2_bert import *
+ from .wav2vec2_conformer import *
+ from .wav2vec2_phoneme import *
+ from .wav2vec2_with_lm import *
+ from .wavlm import *
+ from .whisper import *
+ from .x_clip import *
+ from .xglm import *
+ from .xlm import *
+ from .xlm_roberta import *
+ from .xlm_roberta_xl import *
+ from .xlnet import *
+ from .xmod import *
+ from .yolos import *
+ from .yoso import *
+ from .zamba import *
+ from .zamba2 import *
+ from .zoedepth import *
+else:
+ import sys
+
+ _file = globals()["__file__"]
+ sys.modules[__name__] = _LazyModule(__name__, _file, define_import_structure(_file), module_spec=__spec__)
diff --git a/docs/transformers/src/transformers/models/albert/__init__.py b/docs/transformers/src/transformers/models/albert/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..57b5747909e091ede05ff07c98254224fbebed97
--- /dev/null
+++ b/docs/transformers/src/transformers/models/albert/__init__.py
@@ -0,0 +1,31 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import _LazyModule
+from ...utils.import_utils import define_import_structure
+
+
+if TYPE_CHECKING:
+ from .configuration_albert import *
+ from .modeling_albert import *
+ from .modeling_flax_albert import *
+ from .modeling_tf_albert import *
+ from .tokenization_albert import *
+ from .tokenization_albert_fast import *
+else:
+ import sys
+
+ _file = globals()["__file__"]
+ sys.modules[__name__] = _LazyModule(__name__, _file, define_import_structure(_file), module_spec=__spec__)
diff --git a/docs/transformers/src/transformers/models/albert/configuration_albert.py b/docs/transformers/src/transformers/models/albert/configuration_albert.py
new file mode 100644
index 0000000000000000000000000000000000000000..e1e2d4547cc4e285634a8e9fcfac68092c8ded68
--- /dev/null
+++ b/docs/transformers/src/transformers/models/albert/configuration_albert.py
@@ -0,0 +1,170 @@
+# coding=utf-8
+# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""ALBERT model configuration"""
+
+from collections import OrderedDict
+from typing import Mapping
+
+from ...configuration_utils import PretrainedConfig
+from ...onnx import OnnxConfig
+
+
+class AlbertConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`AlbertModel`] or a [`TFAlbertModel`]. It is used
+ to instantiate an ALBERT model according to the specified arguments, defining the model architecture. Instantiating
+ a configuration with the defaults will yield a similar configuration to that of the ALBERT
+ [albert/albert-xxlarge-v2](https://huggingface.co/albert/albert-xxlarge-v2) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 30000):
+ Vocabulary size of the ALBERT model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`AlbertModel`] or [`TFAlbertModel`].
+ embedding_size (`int`, *optional*, defaults to 128):
+ Dimensionality of vocabulary embeddings.
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimensionality of the encoder layers and the pooler layer.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_hidden_groups (`int`, *optional*, defaults to 1):
+ Number of groups for the hidden layers, parameters in the same group are shared.
+ num_attention_heads (`int`, *optional*, defaults to 64):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 16384):
+ The dimensionality of the "intermediate" (often named feed-forward) layer in the Transformer encoder.
+ inner_group_num (`int`, *optional*, defaults to 1):
+ The number of inner repetition of attention and ffn.
+ hidden_act (`str` or `Callable`, *optional*, defaults to `"gelu_new"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"silu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0):
+ The dropout ratio for the attention probabilities.
+ max_position_embeddings (`int`, *optional*, defaults to 512):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ (e.g., 512 or 1024 or 2048).
+ type_vocab_size (`int`, *optional*, defaults to 2):
+ The vocabulary size of the `token_type_ids` passed when calling [`AlbertModel`] or [`TFAlbertModel`].
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ classifier_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout ratio for attached classifiers.
+ position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
+ Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
+ positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
+ with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ pad_token_id (`int`, *optional*, defaults to 0):
+ Padding token id.
+ bos_token_id (`int`, *optional*, defaults to 2):
+ Beginning of stream token id.
+ eos_token_id (`int`, *optional*, defaults to 3):
+ End of stream token id.
+
+ Examples:
+
+ ```python
+ >>> from transformers import AlbertConfig, AlbertModel
+
+ >>> # Initializing an ALBERT-xxlarge style configuration
+ >>> albert_xxlarge_configuration = AlbertConfig()
+
+ >>> # Initializing an ALBERT-base style configuration
+ >>> albert_base_configuration = AlbertConfig(
+ ... hidden_size=768,
+ ... num_attention_heads=12,
+ ... intermediate_size=3072,
+ ... )
+
+ >>> # Initializing a model (with random weights) from the ALBERT-base style configuration
+ >>> model = AlbertModel(albert_xxlarge_configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "albert"
+
+ def __init__(
+ self,
+ vocab_size=30000,
+ embedding_size=128,
+ hidden_size=4096,
+ num_hidden_layers=12,
+ num_hidden_groups=1,
+ num_attention_heads=64,
+ intermediate_size=16384,
+ inner_group_num=1,
+ hidden_act="gelu_new",
+ hidden_dropout_prob=0,
+ attention_probs_dropout_prob=0,
+ max_position_embeddings=512,
+ type_vocab_size=2,
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ classifier_dropout_prob=0.1,
+ position_embedding_type="absolute",
+ pad_token_id=0,
+ bos_token_id=2,
+ eos_token_id=3,
+ **kwargs,
+ ):
+ super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
+
+ self.vocab_size = vocab_size
+ self.embedding_size = embedding_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_hidden_groups = num_hidden_groups
+ self.num_attention_heads = num_attention_heads
+ self.inner_group_num = inner_group_num
+ self.hidden_act = hidden_act
+ self.intermediate_size = intermediate_size
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.classifier_dropout_prob = classifier_dropout_prob
+ self.position_embedding_type = position_embedding_type
+
+
+# Copied from transformers.models.bert.configuration_bert.BertOnnxConfig with Roberta->Albert
+class AlbertOnnxConfig(OnnxConfig):
+ @property
+ def inputs(self) -> Mapping[str, Mapping[int, str]]:
+ if self.task == "multiple-choice":
+ dynamic_axis = {0: "batch", 1: "choice", 2: "sequence"}
+ else:
+ dynamic_axis = {0: "batch", 1: "sequence"}
+ return OrderedDict(
+ [
+ ("input_ids", dynamic_axis),
+ ("attention_mask", dynamic_axis),
+ ("token_type_ids", dynamic_axis),
+ ]
+ )
+
+
+__all__ = ["AlbertConfig", "AlbertOnnxConfig"]
diff --git a/docs/transformers/src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py b/docs/transformers/src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py
new file mode 100644
index 0000000000000000000000000000000000000000..df2a22610187586dc63511581a1cf28416bfd0c2
--- /dev/null
+++ b/docs/transformers/src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py
@@ -0,0 +1,62 @@
+# coding=utf-8
+# Copyright 2018 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert ALBERT checkpoint."""
+
+import argparse
+
+import torch
+
+from ...utils import logging
+from . import AlbertConfig, AlbertForPreTraining, load_tf_weights_in_albert
+
+
+logging.set_verbosity_info()
+
+
+def convert_tf_checkpoint_to_pytorch(tf_checkpoint_path, albert_config_file, pytorch_dump_path):
+ # Initialise PyTorch model
+ config = AlbertConfig.from_json_file(albert_config_file)
+ print(f"Building PyTorch model from configuration: {config}")
+ model = AlbertForPreTraining(config)
+
+ # Load weights from tf checkpoint
+ load_tf_weights_in_albert(model, config, tf_checkpoint_path)
+
+ # Save pytorch-model
+ print(f"Save PyTorch model to {pytorch_dump_path}")
+ torch.save(model.state_dict(), pytorch_dump_path)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--tf_checkpoint_path", default=None, type=str, required=True, help="Path to the TensorFlow checkpoint path."
+ )
+ parser.add_argument(
+ "--albert_config_file",
+ default=None,
+ type=str,
+ required=True,
+ help=(
+ "The config json file corresponding to the pre-trained ALBERT model. \n"
+ "This specifies the model architecture."
+ ),
+ )
+ parser.add_argument(
+ "--pytorch_dump_path", default=None, type=str, required=True, help="Path to the output PyTorch model."
+ )
+ args = parser.parse_args()
+ convert_tf_checkpoint_to_pytorch(args.tf_checkpoint_path, args.albert_config_file, args.pytorch_dump_path)
diff --git a/docs/transformers/src/transformers/models/albert/modeling_albert.py b/docs/transformers/src/transformers/models/albert/modeling_albert.py
new file mode 100644
index 0000000000000000000000000000000000000000..68abb317ee3f7ac8c16963fd87685802096c0d13
--- /dev/null
+++ b/docs/transformers/src/transformers/models/albert/modeling_albert.py
@@ -0,0 +1,1483 @@
+# coding=utf-8
+# Copyright 2018 Google AI, Google Brain and the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch ALBERT model."""
+
+import math
+import os
+from dataclasses import dataclass
+from typing import Dict, List, Optional, Tuple, Union
+
+import torch
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...modeling_attn_mask_utils import _prepare_4d_attention_mask_for_sdpa
+from ...modeling_outputs import (
+ BaseModelOutput,
+ BaseModelOutputWithPooling,
+ MaskedLMOutput,
+ MultipleChoiceModelOutput,
+ QuestionAnsweringModelOutput,
+ SequenceClassifierOutput,
+ TokenClassifierOutput,
+)
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import (
+ apply_chunking_to_forward,
+ find_pruneable_heads_and_indices,
+ is_torch_greater_or_equal_than_2_2,
+ prune_linear_layer,
+)
+from ...utils import (
+ ModelOutput,
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+from .configuration_albert import AlbertConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = "albert/albert-base-v2"
+_CONFIG_FOR_DOC = "AlbertConfig"
+
+
+def load_tf_weights_in_albert(model, config, tf_checkpoint_path):
+ """Load tf checkpoints in a pytorch model."""
+ try:
+ import re
+
+ import numpy as np
+ import tensorflow as tf
+ except ImportError:
+ logger.error(
+ "Loading a TensorFlow model in PyTorch, requires TensorFlow to be installed. Please see "
+ "https://www.tensorflow.org/install/ for installation instructions."
+ )
+ raise
+ tf_path = os.path.abspath(tf_checkpoint_path)
+ logger.info(f"Converting TensorFlow checkpoint from {tf_path}")
+ # Load weights from TF model
+ init_vars = tf.train.list_variables(tf_path)
+ names = []
+ arrays = []
+ for name, shape in init_vars:
+ logger.info(f"Loading TF weight {name} with shape {shape}")
+ array = tf.train.load_variable(tf_path, name)
+ names.append(name)
+ arrays.append(array)
+
+ for name, array in zip(names, arrays):
+ print(name)
+
+ for name, array in zip(names, arrays):
+ original_name = name
+
+ # If saved from the TF HUB module
+ name = name.replace("module/", "")
+
+ # Renaming and simplifying
+ name = name.replace("ffn_1", "ffn")
+ name = name.replace("bert/", "albert/")
+ name = name.replace("attention_1", "attention")
+ name = name.replace("transform/", "")
+ name = name.replace("LayerNorm_1", "full_layer_layer_norm")
+ name = name.replace("LayerNorm", "attention/LayerNorm")
+ name = name.replace("transformer/", "")
+
+ # The feed forward layer had an 'intermediate' step which has been abstracted away
+ name = name.replace("intermediate/dense/", "")
+ name = name.replace("ffn/intermediate/output/dense/", "ffn_output/")
+
+ # ALBERT attention was split between self and output which have been abstracted away
+ name = name.replace("/output/", "/")
+ name = name.replace("/self/", "/")
+
+ # The pooler is a linear layer
+ name = name.replace("pooler/dense", "pooler")
+
+ # The classifier was simplified to predictions from cls/predictions
+ name = name.replace("cls/predictions", "predictions")
+ name = name.replace("predictions/attention", "predictions")
+
+ # Naming was changed to be more explicit
+ name = name.replace("embeddings/attention", "embeddings")
+ name = name.replace("inner_group_", "albert_layers/")
+ name = name.replace("group_", "albert_layer_groups/")
+
+ # Classifier
+ if len(name.split("/")) == 1 and ("output_bias" in name or "output_weights" in name):
+ name = "classifier/" + name
+
+ # No ALBERT model currently handles the next sentence prediction task
+ if "seq_relationship" in name:
+ name = name.replace("seq_relationship/output_", "sop_classifier/classifier/")
+ name = name.replace("weights", "weight")
+
+ name = name.split("/")
+
+ # Ignore the gradients applied by the LAMB/ADAM optimizers.
+ if (
+ "adam_m" in name
+ or "adam_v" in name
+ or "AdamWeightDecayOptimizer" in name
+ or "AdamWeightDecayOptimizer_1" in name
+ or "global_step" in name
+ ):
+ logger.info(f"Skipping {'/'.join(name)}")
+ continue
+
+ pointer = model
+ for m_name in name:
+ if re.fullmatch(r"[A-Za-z]+_\d+", m_name):
+ scope_names = re.split(r"_(\d+)", m_name)
+ else:
+ scope_names = [m_name]
+
+ if scope_names[0] == "kernel" or scope_names[0] == "gamma":
+ pointer = getattr(pointer, "weight")
+ elif scope_names[0] == "output_bias" or scope_names[0] == "beta":
+ pointer = getattr(pointer, "bias")
+ elif scope_names[0] == "output_weights":
+ pointer = getattr(pointer, "weight")
+ elif scope_names[0] == "squad":
+ pointer = getattr(pointer, "classifier")
+ else:
+ try:
+ pointer = getattr(pointer, scope_names[0])
+ except AttributeError:
+ logger.info(f"Skipping {'/'.join(name)}")
+ continue
+ if len(scope_names) >= 2:
+ num = int(scope_names[1])
+ pointer = pointer[num]
+
+ if m_name[-11:] == "_embeddings":
+ pointer = getattr(pointer, "weight")
+ elif m_name == "kernel":
+ array = np.transpose(array)
+ try:
+ if pointer.shape != array.shape:
+ raise ValueError(f"Pointer shape {pointer.shape} and array shape {array.shape} mismatched")
+ except ValueError as e:
+ e.args += (pointer.shape, array.shape)
+ raise
+ print(f"Initialize PyTorch weight {name} from {original_name}")
+ pointer.data = torch.from_numpy(array)
+
+ return model
+
+
+class AlbertEmbeddings(nn.Module):
+ """
+ Construct the embeddings from word, position and token_type embeddings.
+ """
+
+ def __init__(self, config: AlbertConfig):
+ super().__init__()
+ self.word_embeddings = nn.Embedding(config.vocab_size, config.embedding_size, padding_idx=config.pad_token_id)
+ self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.embedding_size)
+ self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.embedding_size)
+
+ # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = nn.LayerNorm(config.embedding_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.register_buffer(
+ "position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
+ )
+ self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
+ self.register_buffer(
+ "token_type_ids", torch.zeros(self.position_ids.size(), dtype=torch.long), persistent=False
+ )
+
+ # Copied from transformers.models.bert.modeling_bert.BertEmbeddings.forward
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ past_key_values_length: int = 0,
+ ) -> torch.Tensor:
+ if input_ids is not None:
+ input_shape = input_ids.size()
+ else:
+ input_shape = inputs_embeds.size()[:-1]
+
+ seq_length = input_shape[1]
+
+ if position_ids is None:
+ position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
+
+ # Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
+ # when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
+ # issue #5664
+ if token_type_ids is None:
+ if hasattr(self, "token_type_ids"):
+ buffered_token_type_ids = self.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+ token_type_embeddings = self.token_type_embeddings(token_type_ids)
+
+ embeddings = inputs_embeds + token_type_embeddings
+ if self.position_embedding_type == "absolute":
+ position_embeddings = self.position_embeddings(position_ids)
+ embeddings += position_embeddings
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings
+
+
+class AlbertAttention(nn.Module):
+ def __init__(self, config: AlbertConfig):
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
+ f"heads ({config.num_attention_heads}"
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.hidden_size = config.hidden_size
+ self.attention_head_size = config.hidden_size // config.num_attention_heads
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.attention_dropout = nn.Dropout(config.attention_probs_dropout_prob)
+ self.output_dropout = nn.Dropout(config.hidden_dropout_prob)
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.pruned_heads = set()
+
+ self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ self.max_position_embeddings = config.max_position_embeddings
+ self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
+
+ # Copied from transformers.models.bert.modeling_bert.BertSelfAttention.transpose_for_scores
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def prune_heads(self, heads: List[int]) -> None:
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.num_attention_heads, self.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.query = prune_linear_layer(self.query, index)
+ self.key = prune_linear_layer(self.key, index)
+ self.value = prune_linear_layer(self.value, index)
+ self.dense = prune_linear_layer(self.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.num_attention_heads = self.num_attention_heads - len(heads)
+ self.all_head_size = self.attention_head_size * self.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
+ mixed_query_layer = self.query(hidden_states)
+ mixed_key_layer = self.key(hidden_states)
+ mixed_value_layer = self.value(hidden_states)
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+ key_layer = self.transpose_for_scores(mixed_key_layer)
+ value_layer = self.transpose_for_scores(mixed_value_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in BertModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ seq_length = hidden_states.size()[1]
+ position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+ positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == "relative_key":
+ relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores
+ elif self.position_embedding_type == "relative_key_query":
+ relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.attention_dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+ context_layer = context_layer.transpose(2, 1).flatten(2)
+
+ projected_context_layer = self.dense(context_layer)
+ projected_context_layer_dropout = self.output_dropout(projected_context_layer)
+ layernormed_context_layer = self.LayerNorm(hidden_states + projected_context_layer_dropout)
+ return (layernormed_context_layer, attention_probs) if output_attentions else (layernormed_context_layer,)
+
+
+class AlbertSdpaAttention(AlbertAttention):
+ def __init__(self, config):
+ super().__init__(config)
+ self.dropout_prob = config.attention_probs_dropout_prob
+ self.require_contiguous_qkv = not is_torch_greater_or_equal_than_2_2
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
+ if self.position_embedding_type != "absolute" or output_attentions or head_mask is not None:
+ logger.warning(
+ "AlbertSdpaAttention is used but `torch.nn.functional.scaled_dot_product_attention` does not support "
+ "non-absolute `position_embedding_type` or `output_attentions=True` or `head_mask`. Falling back to "
+ "the eager attention implementation, but specifying the eager implementation will be required from "
+ "Transformers version v5.0.0 onwards. This warning can be removed using the argument "
+ '`attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(hidden_states, attention_mask, head_mask, output_attentions)
+
+ batch_size, seq_len, _ = hidden_states.size()
+ query_layer = self.transpose_for_scores(self.query(hidden_states))
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+
+ # SDPA with memory-efficient backend is broken in torch==2.1.2 when using non-contiguous inputs and a custom
+ # attn_mask, so we need to call `.contiguous()` here. This was fixed in torch==2.2.0.
+ # Reference: https://github.com/pytorch/pytorch/issues/112577
+ if self.require_contiguous_qkv and query_layer.device.type == "cuda" and attention_mask is not None:
+ query_layer = query_layer.contiguous()
+ key_layer = key_layer.contiguous()
+ value_layer = value_layer.contiguous()
+
+ attention_output = torch.nn.functional.scaled_dot_product_attention(
+ query=query_layer,
+ key=key_layer,
+ value=value_layer,
+ attn_mask=attention_mask,
+ dropout_p=self.dropout_prob if self.training else 0.0,
+ is_causal=False,
+ )
+
+ attention_output = attention_output.transpose(1, 2)
+ attention_output = attention_output.reshape(batch_size, seq_len, self.all_head_size)
+
+ projected_context_layer = self.dense(attention_output)
+ projected_context_layer_dropout = self.output_dropout(projected_context_layer)
+ layernormed_context_layer = self.LayerNorm(hidden_states + projected_context_layer_dropout)
+ return (layernormed_context_layer,)
+
+
+ALBERT_ATTENTION_CLASSES = {
+ "eager": AlbertAttention,
+ "sdpa": AlbertSdpaAttention,
+}
+
+
+class AlbertLayer(nn.Module):
+ def __init__(self, config: AlbertConfig):
+ super().__init__()
+
+ self.config = config
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.full_layer_layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.attention = ALBERT_ATTENTION_CLASSES[config._attn_implementation](config)
+ self.ffn = nn.Linear(config.hidden_size, config.intermediate_size)
+ self.ffn_output = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.activation = ACT2FN[config.hidden_act]
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ ) -> Tuple[torch.Tensor, torch.Tensor]:
+ attention_output = self.attention(hidden_states, attention_mask, head_mask, output_attentions)
+
+ ffn_output = apply_chunking_to_forward(
+ self.ff_chunk,
+ self.chunk_size_feed_forward,
+ self.seq_len_dim,
+ attention_output[0],
+ )
+ hidden_states = self.full_layer_layer_norm(ffn_output + attention_output[0])
+
+ return (hidden_states,) + attention_output[1:] # add attentions if we output them
+
+ def ff_chunk(self, attention_output: torch.Tensor) -> torch.Tensor:
+ ffn_output = self.ffn(attention_output)
+ ffn_output = self.activation(ffn_output)
+ ffn_output = self.ffn_output(ffn_output)
+ return ffn_output
+
+
+class AlbertLayerGroup(nn.Module):
+ def __init__(self, config: AlbertConfig):
+ super().__init__()
+
+ self.albert_layers = nn.ModuleList([AlbertLayer(config) for _ in range(config.inner_group_num)])
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ ) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:
+ layer_hidden_states = ()
+ layer_attentions = ()
+
+ for layer_index, albert_layer in enumerate(self.albert_layers):
+ layer_output = albert_layer(hidden_states, attention_mask, head_mask[layer_index], output_attentions)
+ hidden_states = layer_output[0]
+
+ if output_attentions:
+ layer_attentions = layer_attentions + (layer_output[1],)
+
+ if output_hidden_states:
+ layer_hidden_states = layer_hidden_states + (hidden_states,)
+
+ outputs = (hidden_states,)
+ if output_hidden_states:
+ outputs = outputs + (layer_hidden_states,)
+ if output_attentions:
+ outputs = outputs + (layer_attentions,)
+ return outputs # last-layer hidden state, (layer hidden states), (layer attentions)
+
+
+class AlbertTransformer(nn.Module):
+ def __init__(self, config: AlbertConfig):
+ super().__init__()
+
+ self.config = config
+ self.embedding_hidden_mapping_in = nn.Linear(config.embedding_size, config.hidden_size)
+ self.albert_layer_groups = nn.ModuleList([AlbertLayerGroup(config) for _ in range(config.num_hidden_groups)])
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ) -> Union[BaseModelOutput, Tuple]:
+ hidden_states = self.embedding_hidden_mapping_in(hidden_states)
+
+ all_hidden_states = (hidden_states,) if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+
+ head_mask = [None] * self.config.num_hidden_layers if head_mask is None else head_mask
+
+ for i in range(self.config.num_hidden_layers):
+ # Number of layers in a hidden group
+ layers_per_group = int(self.config.num_hidden_layers / self.config.num_hidden_groups)
+
+ # Index of the hidden group
+ group_idx = int(i / (self.config.num_hidden_layers / self.config.num_hidden_groups))
+
+ layer_group_output = self.albert_layer_groups[group_idx](
+ hidden_states,
+ attention_mask,
+ head_mask[group_idx * layers_per_group : (group_idx + 1) * layers_per_group],
+ output_attentions,
+ output_hidden_states,
+ )
+ hidden_states = layer_group_output[0]
+
+ if output_attentions:
+ all_attentions = all_attentions + layer_group_output[-1]
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states, hidden_states=all_hidden_states, attentions=all_attentions
+ )
+
+
+class AlbertPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = AlbertConfig
+ load_tf_weights = load_tf_weights_in_albert
+ base_model_prefix = "albert"
+ _supports_sdpa = True
+
+ def _init_weights(self, module):
+ """Initialize the weights."""
+ if isinstance(module, nn.Linear):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+ elif isinstance(module, AlbertMLMHead):
+ module.bias.data.zero_()
+
+
+@dataclass
+class AlbertForPreTrainingOutput(ModelOutput):
+ """
+ Output type of [`AlbertForPreTraining`].
+
+ Args:
+ loss (*optional*, returned when `labels` is provided, `torch.FloatTensor` of shape `(1,)`):
+ Total loss as the sum of the masked language modeling loss and the next sequence prediction
+ (classification) loss.
+ prediction_logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ sop_logits (`torch.FloatTensor` of shape `(batch_size, 2)`):
+ Prediction scores of the next sequence prediction (classification) head (scores of True/False continuation
+ before SoftMax).
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ prediction_logits: Optional[torch.FloatTensor] = None
+ sop_logits: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+ALBERT_START_DOCSTRING = r"""
+
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Args:
+ config ([`AlbertConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+ALBERT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `({0})`):
+ Indices of input sequence tokens in the vocabulary.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.__call__`] and
+ [`PreTrainedTokenizer.encode`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
+ 1]`:
+
+ - 0 corresponds to a *sentence A* token,
+ - 1 corresponds to a *sentence B* token.
+
+ [What are token type IDs?](../glossary#token-type-ids)
+ position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare ALBERT Model transformer outputting raw hidden-states without any specific head on top.",
+ ALBERT_START_DOCSTRING,
+)
+class AlbertModel(AlbertPreTrainedModel):
+ config_class = AlbertConfig
+ base_model_prefix = "albert"
+
+ def __init__(self, config: AlbertConfig, add_pooling_layer: bool = True):
+ super().__init__(config)
+
+ self.config = config
+ self.embeddings = AlbertEmbeddings(config)
+ self.encoder = AlbertTransformer(config)
+ if add_pooling_layer:
+ self.pooler = nn.Linear(config.hidden_size, config.hidden_size)
+ self.pooler_activation = nn.Tanh()
+ else:
+ self.pooler = None
+ self.pooler_activation = None
+
+ self.attn_implementation = config._attn_implementation
+ self.position_embedding_type = config.position_embedding_type
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> nn.Embedding:
+ return self.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value: nn.Embedding) -> None:
+ self.embeddings.word_embeddings = value
+
+ def _prune_heads(self, heads_to_prune: Dict[int, List[int]]) -> None:
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} ALBERT has
+ a different architecture in that its layers are shared across groups, which then has inner groups. If an ALBERT
+ model has 12 hidden layers and 2 hidden groups, with two inner groups, there is a total of 4 different layers.
+
+ These layers are flattened: the indices [0,1] correspond to the two inner groups of the first hidden layer,
+ while [2,3] correspond to the two inner groups of the second hidden layer.
+
+ Any layer with in index other than [0,1,2,3] will result in an error. See base class PreTrainedModel for more
+ information about head pruning
+ """
+ for layer, heads in heads_to_prune.items():
+ group_idx = int(layer / self.config.inner_group_num)
+ inner_group_idx = int(layer - group_idx * self.config.inner_group_num)
+ self.encoder.albert_layer_groups[group_idx].albert_layers[inner_group_idx].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @add_code_sample_docstrings(
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutputWithPooling,
+ config_class=_CONFIG_FOR_DOC,
+ )
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[BaseModelOutputWithPooling, Tuple]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
+ input_shape = input_ids.size()
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ batch_size, seq_length = input_shape
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+
+ if attention_mask is None:
+ attention_mask = torch.ones(input_shape, device=device)
+ if token_type_ids is None:
+ if hasattr(self.embeddings, "token_type_ids"):
+ buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
+
+ embedding_output = self.embeddings(
+ input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
+ )
+
+ use_sdpa_attention_mask = (
+ self.attn_implementation == "sdpa"
+ and self.position_embedding_type == "absolute"
+ and head_mask is None
+ and not output_attentions
+ )
+
+ if use_sdpa_attention_mask:
+ extended_attention_mask = _prepare_4d_attention_mask_for_sdpa(
+ attention_mask, embedding_output.dtype, tgt_len=seq_length
+ )
+ else:
+ extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
+ extended_attention_mask = extended_attention_mask.to(dtype=self.dtype) # fp16 compatibility
+ extended_attention_mask = (1.0 - extended_attention_mask) * torch.finfo(self.dtype).min
+
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ extended_attention_mask,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = encoder_outputs[0]
+
+ pooled_output = self.pooler_activation(self.pooler(sequence_output[:, 0])) if self.pooler is not None else None
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Albert Model with two heads on top as done during the pretraining: a `masked language modeling` head and a
+ `sentence order prediction (classification)` head.
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class AlbertForPreTraining(AlbertPreTrainedModel):
+ _tied_weights_keys = ["predictions.decoder.bias", "predictions.decoder.weight"]
+
+ def __init__(self, config: AlbertConfig):
+ super().__init__(config)
+
+ self.albert = AlbertModel(config)
+ self.predictions = AlbertMLMHead(config)
+ self.sop_classifier = AlbertSOPHead(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_output_embeddings(self) -> nn.Linear:
+ return self.predictions.decoder
+
+ def set_output_embeddings(self, new_embeddings: nn.Linear) -> None:
+ self.predictions.decoder = new_embeddings
+
+ def get_input_embeddings(self) -> nn.Embedding:
+ return self.albert.embeddings.word_embeddings
+
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=AlbertForPreTrainingOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ sentence_order_label: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[AlbertForPreTrainingOutput, Tuple]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
+ config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
+ loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
+ sentence_order_label (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the next sequence prediction (classification) loss. Input should be a sequence pair
+ (see `input_ids` docstring) Indices should be in `[0, 1]`. `0` indicates original order (sequence A, then
+ sequence B), `1` indicates switched order (sequence B, then sequence A).
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AlbertForPreTraining
+ >>> import torch
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("albert/albert-base-v2")
+ >>> model = AlbertForPreTraining.from_pretrained("albert/albert-base-v2")
+
+ >>> input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True)).unsqueeze(0)
+ >>> # Batch size 1
+ >>> outputs = model(input_ids)
+
+ >>> prediction_logits = outputs.prediction_logits
+ >>> sop_logits = outputs.sop_logits
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.albert(
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output, pooled_output = outputs[:2]
+
+ prediction_scores = self.predictions(sequence_output)
+ sop_scores = self.sop_classifier(pooled_output)
+
+ total_loss = None
+ if labels is not None and sentence_order_label is not None:
+ loss_fct = CrossEntropyLoss()
+ masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
+ sentence_order_loss = loss_fct(sop_scores.view(-1, 2), sentence_order_label.view(-1))
+ total_loss = masked_lm_loss + sentence_order_loss
+
+ if not return_dict:
+ output = (prediction_scores, sop_scores) + outputs[2:]
+ return ((total_loss,) + output) if total_loss is not None else output
+
+ return AlbertForPreTrainingOutput(
+ loss=total_loss,
+ prediction_logits=prediction_scores,
+ sop_logits=sop_scores,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+class AlbertMLMHead(nn.Module):
+ def __init__(self, config: AlbertConfig):
+ super().__init__()
+
+ self.LayerNorm = nn.LayerNorm(config.embedding_size, eps=config.layer_norm_eps)
+ self.bias = nn.Parameter(torch.zeros(config.vocab_size))
+ self.dense = nn.Linear(config.hidden_size, config.embedding_size)
+ self.decoder = nn.Linear(config.embedding_size, config.vocab_size)
+ self.activation = ACT2FN[config.hidden_act]
+ self.decoder.bias = self.bias
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.activation(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states)
+ hidden_states = self.decoder(hidden_states)
+
+ prediction_scores = hidden_states
+
+ return prediction_scores
+
+ def _tie_weights(self) -> None:
+ # For accelerate compatibility and to not break backward compatibility
+ if self.decoder.bias.device.type == "meta":
+ self.decoder.bias = self.bias
+ else:
+ # To tie those two weights if they get disconnected (on TPU or when the bias is resized)
+ self.bias = self.decoder.bias
+
+
+class AlbertSOPHead(nn.Module):
+ def __init__(self, config: AlbertConfig):
+ super().__init__()
+
+ self.dropout = nn.Dropout(config.classifier_dropout_prob)
+ self.classifier = nn.Linear(config.hidden_size, config.num_labels)
+
+ def forward(self, pooled_output: torch.Tensor) -> torch.Tensor:
+ dropout_pooled_output = self.dropout(pooled_output)
+ logits = self.classifier(dropout_pooled_output)
+ return logits
+
+
+@add_start_docstrings(
+ "Albert Model with a `language modeling` head on top.",
+ ALBERT_START_DOCSTRING,
+)
+class AlbertForMaskedLM(AlbertPreTrainedModel):
+ _tied_weights_keys = ["predictions.decoder.bias", "predictions.decoder.weight"]
+
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.albert = AlbertModel(config, add_pooling_layer=False)
+ self.predictions = AlbertMLMHead(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_output_embeddings(self) -> nn.Linear:
+ return self.predictions.decoder
+
+ def set_output_embeddings(self, new_embeddings: nn.Linear) -> None:
+ self.predictions.decoder = new_embeddings
+ self.predictions.bias = new_embeddings.bias
+
+ def get_input_embeddings(self) -> nn.Embedding:
+ return self.albert.embeddings.word_embeddings
+
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=MaskedLMOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[MaskedLMOutput, Tuple]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
+ config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
+ loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> import torch
+ >>> from transformers import AutoTokenizer, AlbertForMaskedLM
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("albert/albert-base-v2")
+ >>> model = AlbertForMaskedLM.from_pretrained("albert/albert-base-v2")
+
+ >>> # add mask_token
+ >>> inputs = tokenizer("The capital of [MASK] is Paris.", return_tensors="pt")
+ >>> with torch.no_grad():
+ ... logits = model(**inputs).logits
+
+ >>> # retrieve index of [MASK]
+ >>> mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]
+ >>> predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
+ >>> tokenizer.decode(predicted_token_id)
+ 'france'
+ ```
+
+ ```python
+ >>> labels = tokenizer("The capital of France is Paris.", return_tensors="pt")["input_ids"]
+ >>> labels = torch.where(inputs.input_ids == tokenizer.mask_token_id, labels, -100)
+ >>> outputs = model(**inputs, labels=labels)
+ >>> round(outputs.loss.item(), 2)
+ 0.81
+ ```
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.albert(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_outputs = outputs[0]
+
+ prediction_scores = self.predictions(sequence_outputs)
+
+ masked_lm_loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss()
+ masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
+
+ if not return_dict:
+ output = (prediction_scores,) + outputs[2:]
+ return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
+
+ return MaskedLMOutput(
+ loss=masked_lm_loss,
+ logits=prediction_scores,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Albert Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled
+ output) e.g. for GLUE tasks.
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class AlbertForSequenceClassification(AlbertPreTrainedModel):
+ def __init__(self, config: AlbertConfig):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+ self.config = config
+
+ self.albert = AlbertModel(config)
+ self.dropout = nn.Dropout(config.classifier_dropout_prob)
+ self.classifier = nn.Linear(config.hidden_size, self.config.num_labels)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @add_code_sample_docstrings(
+ checkpoint="textattack/albert-base-v2-imdb",
+ output_type=SequenceClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output="'LABEL_1'",
+ expected_loss=0.12,
+ )
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[SequenceClassifierOutput, Tuple]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.albert(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = outputs[1]
+
+ pooled_output = self.dropout(pooled_output)
+ logits = self.classifier(pooled_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Albert Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
+ Named-Entity-Recognition (NER) tasks.
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class AlbertForTokenClassification(AlbertPreTrainedModel):
+ def __init__(self, config: AlbertConfig):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+
+ self.albert = AlbertModel(config, add_pooling_layer=False)
+ classifier_dropout_prob = (
+ config.classifier_dropout_prob
+ if config.classifier_dropout_prob is not None
+ else config.hidden_dropout_prob
+ )
+ self.dropout = nn.Dropout(classifier_dropout_prob)
+ self.classifier = nn.Linear(config.hidden_size, self.config.num_labels)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @add_code_sample_docstrings(
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=TokenClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ )
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[TokenClassifierOutput, Tuple]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.albert(
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ sequence_output = self.dropout(sequence_output)
+ logits = self.classifier(sequence_output)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return TokenClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Albert Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
+ layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class AlbertForQuestionAnswering(AlbertPreTrainedModel):
+ def __init__(self, config: AlbertConfig):
+ super().__init__(config)
+ self.num_labels = config.num_labels
+
+ self.albert = AlbertModel(config, add_pooling_layer=False)
+ self.qa_outputs = nn.Linear(config.hidden_size, config.num_labels)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @add_code_sample_docstrings(
+ checkpoint="twmkn9/albert-base-v2-squad2",
+ output_type=QuestionAnsweringModelOutput,
+ config_class=_CONFIG_FOR_DOC,
+ qa_target_start_index=12,
+ qa_target_end_index=13,
+ expected_output="'a nice puppet'",
+ expected_loss=7.36,
+ )
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ start_positions: Optional[torch.LongTensor] = None,
+ end_positions: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[AlbertForPreTrainingOutput, Tuple]:
+ r"""
+ start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the start of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+ end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the end of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.albert(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ logits: torch.Tensor = self.qa_outputs(sequence_output)
+ start_logits, end_logits = logits.split(1, dim=-1)
+ start_logits = start_logits.squeeze(-1).contiguous()
+ end_logits = end_logits.squeeze(-1).contiguous()
+
+ total_loss = None
+ if start_positions is not None and end_positions is not None:
+ # If we are on multi-GPU, split add a dimension
+ if len(start_positions.size()) > 1:
+ start_positions = start_positions.squeeze(-1)
+ if len(end_positions.size()) > 1:
+ end_positions = end_positions.squeeze(-1)
+ # sometimes the start/end positions are outside our model inputs, we ignore these terms
+ ignored_index = start_logits.size(1)
+ start_positions = start_positions.clamp(0, ignored_index)
+ end_positions = end_positions.clamp(0, ignored_index)
+
+ loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
+ start_loss = loss_fct(start_logits, start_positions)
+ end_loss = loss_fct(end_logits, end_positions)
+ total_loss = (start_loss + end_loss) / 2
+
+ if not return_dict:
+ output = (start_logits, end_logits) + outputs[2:]
+ return ((total_loss,) + output) if total_loss is not None else output
+
+ return QuestionAnsweringModelOutput(
+ loss=total_loss,
+ start_logits=start_logits,
+ end_logits=end_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Albert Model with a multiple choice classification head on top (a linear layer on top of the pooled output and a
+ softmax) e.g. for RocStories/SWAG tasks.
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class AlbertForMultipleChoice(AlbertPreTrainedModel):
+ def __init__(self, config: AlbertConfig):
+ super().__init__(config)
+
+ self.albert = AlbertModel(config)
+ self.dropout = nn.Dropout(config.classifier_dropout_prob)
+ self.classifier = nn.Linear(config.hidden_size, 1)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length"))
+ @add_code_sample_docstrings(
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=MultipleChoiceModelOutput,
+ config_class=_CONFIG_FOR_DOC,
+ )
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[AlbertForPreTrainingOutput, Tuple]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the multiple choice classification loss. Indices should be in `[0, ...,
+ num_choices-1]` where *num_choices* is the size of the second dimension of the input tensors. (see
+ *input_ids* above)
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ num_choices = input_ids.shape[1] if input_ids is not None else inputs_embeds.shape[1]
+
+ input_ids = input_ids.view(-1, input_ids.size(-1)) if input_ids is not None else None
+ attention_mask = attention_mask.view(-1, attention_mask.size(-1)) if attention_mask is not None else None
+ token_type_ids = token_type_ids.view(-1, token_type_ids.size(-1)) if token_type_ids is not None else None
+ position_ids = position_ids.view(-1, position_ids.size(-1)) if position_ids is not None else None
+ inputs_embeds = (
+ inputs_embeds.view(-1, inputs_embeds.size(-2), inputs_embeds.size(-1))
+ if inputs_embeds is not None
+ else None
+ )
+ outputs = self.albert(
+ input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = outputs[1]
+
+ pooled_output = self.dropout(pooled_output)
+ logits: torch.Tensor = self.classifier(pooled_output)
+ reshaped_logits = logits.view(-1, num_choices)
+
+ loss = None
+ if labels is not None:
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(reshaped_logits, labels)
+
+ if not return_dict:
+ output = (reshaped_logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return MultipleChoiceModelOutput(
+ loss=loss,
+ logits=reshaped_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+__all__ = [
+ "load_tf_weights_in_albert",
+ "AlbertPreTrainedModel",
+ "AlbertModel",
+ "AlbertForPreTraining",
+ "AlbertForMaskedLM",
+ "AlbertForSequenceClassification",
+ "AlbertForTokenClassification",
+ "AlbertForQuestionAnswering",
+ "AlbertForMultipleChoice",
+]
diff --git a/docs/transformers/src/transformers/models/albert/modeling_flax_albert.py b/docs/transformers/src/transformers/models/albert/modeling_flax_albert.py
new file mode 100644
index 0000000000000000000000000000000000000000..df2ebddc7e6275a35524dd72381c3518e34a1b95
--- /dev/null
+++ b/docs/transformers/src/transformers/models/albert/modeling_flax_albert.py
@@ -0,0 +1,1132 @@
+# coding=utf-8
+# Copyright 2021 Google AI, Google Brain and the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Callable, Optional, Tuple
+
+import flax
+import flax.linen as nn
+import jax
+import jax.numpy as jnp
+import numpy as np
+from flax.core.frozen_dict import FrozenDict, freeze, unfreeze
+from flax.linen.attention import dot_product_attention_weights
+from flax.traverse_util import flatten_dict, unflatten_dict
+from jax import lax
+
+from ...modeling_flax_outputs import (
+ FlaxBaseModelOutput,
+ FlaxBaseModelOutputWithPooling,
+ FlaxMaskedLMOutput,
+ FlaxMultipleChoiceModelOutput,
+ FlaxQuestionAnsweringModelOutput,
+ FlaxSequenceClassifierOutput,
+ FlaxTokenClassifierOutput,
+)
+from ...modeling_flax_utils import (
+ ACT2FN,
+ FlaxPreTrainedModel,
+ append_call_sample_docstring,
+ append_replace_return_docstrings,
+ overwrite_call_docstring,
+)
+from ...utils import ModelOutput, add_start_docstrings, add_start_docstrings_to_model_forward, logging
+from .configuration_albert import AlbertConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = "albert/albert-base-v2"
+_CONFIG_FOR_DOC = "AlbertConfig"
+
+
+@flax.struct.dataclass
+class FlaxAlbertForPreTrainingOutput(ModelOutput):
+ """
+ Output type of [`FlaxAlbertForPreTraining`].
+
+ Args:
+ prediction_logits (`jnp.ndarray` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ sop_logits (`jnp.ndarray` of shape `(batch_size, 2)`):
+ Prediction scores of the next sequence prediction (classification) head (scores of True/False continuation
+ before SoftMax).
+ hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ prediction_logits: jnp.ndarray = None
+ sop_logits: jnp.ndarray = None
+ hidden_states: Optional[Tuple[jnp.ndarray]] = None
+ attentions: Optional[Tuple[jnp.ndarray]] = None
+
+
+ALBERT_START_DOCSTRING = r"""
+
+ This model inherits from [`FlaxPreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading, saving and converting weights from PyTorch models)
+
+ This model is also a
+ [flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html) subclass. Use it as
+ a regular Flax linen Module and refer to the Flax documentation for all matter related to general usage and
+ behavior.
+
+ Finally, this model supports inherent JAX features such as:
+
+ - [Just-In-Time (JIT) compilation](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
+ - [Automatic Differentiation](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
+ - [Vectorization](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
+ - [Parallelization](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
+
+ Parameters:
+ config ([`AlbertConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~FlaxPreTrainedModel.from_pretrained`] method to load the model weights.
+ dtype (`jax.numpy.dtype`, *optional*, defaults to `jax.numpy.float32`):
+ The data type of the computation. Can be one of `jax.numpy.float32`, `jax.numpy.float16` (on GPUs) and
+ `jax.numpy.bfloat16` (on TPUs).
+
+ This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If
+ specified all the computation will be performed with the given `dtype`.
+
+ **Note that this only specifies the dtype of the computation and does not influence the dtype of model
+ parameters.**
+
+ If you wish to change the dtype of the model parameters, see [`~FlaxPreTrainedModel.to_fp16`] and
+ [`~FlaxPreTrainedModel.to_bf16`].
+"""
+
+ALBERT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`numpy.ndarray` of shape `({0})`):
+ Indices of input sequence tokens in the vocabulary.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`numpy.ndarray` of shape `({0})`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ token_type_ids (`numpy.ndarray` of shape `({0})`, *optional*):
+ Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
+ 1]`:
+
+ - 0 corresponds to a *sentence A* token,
+ - 1 corresponds to a *sentence B* token.
+
+ [What are token type IDs?](../glossary#token-type-ids)
+ position_ids (`numpy.ndarray` of shape `({0})`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+
+"""
+
+
+class FlaxAlbertEmbeddings(nn.Module):
+ """Construct the embeddings from word, position and token_type embeddings."""
+
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32 # the dtype of the computation
+
+ def setup(self):
+ self.word_embeddings = nn.Embed(
+ self.config.vocab_size,
+ self.config.embedding_size,
+ embedding_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
+ )
+ self.position_embeddings = nn.Embed(
+ self.config.max_position_embeddings,
+ self.config.embedding_size,
+ embedding_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
+ )
+ self.token_type_embeddings = nn.Embed(
+ self.config.type_vocab_size,
+ self.config.embedding_size,
+ embedding_init=jax.nn.initializers.normal(stddev=self.config.initializer_range),
+ )
+ self.LayerNorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
+ self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
+
+ def __call__(self, input_ids, token_type_ids, position_ids, deterministic: bool = True):
+ # Embed
+ inputs_embeds = self.word_embeddings(input_ids.astype("i4"))
+ position_embeds = self.position_embeddings(position_ids.astype("i4"))
+ token_type_embeddings = self.token_type_embeddings(token_type_ids.astype("i4"))
+
+ # Sum all embeddings
+ hidden_states = inputs_embeds + token_type_embeddings + position_embeds
+
+ # Layer Norm
+ hidden_states = self.LayerNorm(hidden_states)
+ hidden_states = self.dropout(hidden_states, deterministic=deterministic)
+ return hidden_states
+
+
+class FlaxAlbertSelfAttention(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32 # the dtype of the computation
+
+ def setup(self):
+ if self.config.hidden_size % self.config.num_attention_heads != 0:
+ raise ValueError(
+ "`config.hidden_size`: {self.config.hidden_size} has to be a multiple of `config.num_attention_heads` "
+ " : {self.config.num_attention_heads}"
+ )
+
+ self.query = nn.Dense(
+ self.config.hidden_size,
+ dtype=self.dtype,
+ kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
+ )
+ self.key = nn.Dense(
+ self.config.hidden_size,
+ dtype=self.dtype,
+ kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
+ )
+ self.value = nn.Dense(
+ self.config.hidden_size,
+ dtype=self.dtype,
+ kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
+ )
+ self.dense = nn.Dense(
+ self.config.hidden_size,
+ kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
+ dtype=self.dtype,
+ )
+ self.LayerNorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
+ self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
+
+ def __call__(self, hidden_states, attention_mask, deterministic=True, output_attentions: bool = False):
+ head_dim = self.config.hidden_size // self.config.num_attention_heads
+
+ query_states = self.query(hidden_states).reshape(
+ hidden_states.shape[:2] + (self.config.num_attention_heads, head_dim)
+ )
+ value_states = self.value(hidden_states).reshape(
+ hidden_states.shape[:2] + (self.config.num_attention_heads, head_dim)
+ )
+ key_states = self.key(hidden_states).reshape(
+ hidden_states.shape[:2] + (self.config.num_attention_heads, head_dim)
+ )
+
+ # Convert the boolean attention mask to an attention bias.
+ if attention_mask is not None:
+ # attention mask in the form of attention bias
+ attention_mask = jnp.expand_dims(attention_mask, axis=(-3, -2))
+ attention_bias = lax.select(
+ attention_mask > 0,
+ jnp.full(attention_mask.shape, 0.0).astype(self.dtype),
+ jnp.full(attention_mask.shape, jnp.finfo(self.dtype).min).astype(self.dtype),
+ )
+ else:
+ attention_bias = None
+
+ dropout_rng = None
+ if not deterministic and self.config.attention_probs_dropout_prob > 0.0:
+ dropout_rng = self.make_rng("dropout")
+
+ attn_weights = dot_product_attention_weights(
+ query_states,
+ key_states,
+ bias=attention_bias,
+ dropout_rng=dropout_rng,
+ dropout_rate=self.config.attention_probs_dropout_prob,
+ broadcast_dropout=True,
+ deterministic=deterministic,
+ dtype=self.dtype,
+ precision=None,
+ )
+
+ attn_output = jnp.einsum("...hqk,...khd->...qhd", attn_weights, value_states)
+ attn_output = attn_output.reshape(attn_output.shape[:2] + (-1,))
+
+ projected_attn_output = self.dense(attn_output)
+ projected_attn_output = self.dropout(projected_attn_output, deterministic=deterministic)
+ layernormed_attn_output = self.LayerNorm(projected_attn_output + hidden_states)
+ outputs = (layernormed_attn_output, attn_weights) if output_attentions else (layernormed_attn_output,)
+ return outputs
+
+
+class FlaxAlbertLayer(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32 # the dtype of the computation
+
+ def setup(self):
+ self.attention = FlaxAlbertSelfAttention(self.config, dtype=self.dtype)
+ self.ffn = nn.Dense(
+ self.config.intermediate_size,
+ kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
+ dtype=self.dtype,
+ )
+ self.activation = ACT2FN[self.config.hidden_act]
+ self.ffn_output = nn.Dense(
+ self.config.hidden_size,
+ kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
+ dtype=self.dtype,
+ )
+ self.full_layer_layer_norm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
+ self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
+
+ def __call__(
+ self,
+ hidden_states,
+ attention_mask,
+ deterministic: bool = True,
+ output_attentions: bool = False,
+ ):
+ attention_outputs = self.attention(
+ hidden_states, attention_mask, deterministic=deterministic, output_attentions=output_attentions
+ )
+ attention_output = attention_outputs[0]
+ ffn_output = self.ffn(attention_output)
+ ffn_output = self.activation(ffn_output)
+ ffn_output = self.ffn_output(ffn_output)
+ ffn_output = self.dropout(ffn_output, deterministic=deterministic)
+ hidden_states = self.full_layer_layer_norm(ffn_output + attention_output)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attention_outputs[1],)
+ return outputs
+
+
+class FlaxAlbertLayerCollection(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32 # the dtype of the computation
+
+ def setup(self):
+ self.layers = [
+ FlaxAlbertLayer(self.config, name=str(i), dtype=self.dtype) for i in range(self.config.inner_group_num)
+ ]
+
+ def __call__(
+ self,
+ hidden_states,
+ attention_mask,
+ deterministic: bool = True,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ ):
+ layer_hidden_states = ()
+ layer_attentions = ()
+
+ for layer_index, albert_layer in enumerate(self.layers):
+ layer_output = albert_layer(
+ hidden_states,
+ attention_mask,
+ deterministic=deterministic,
+ output_attentions=output_attentions,
+ )
+ hidden_states = layer_output[0]
+
+ if output_attentions:
+ layer_attentions = layer_attentions + (layer_output[1],)
+
+ if output_hidden_states:
+ layer_hidden_states = layer_hidden_states + (hidden_states,)
+
+ outputs = (hidden_states,)
+ if output_hidden_states:
+ outputs = outputs + (layer_hidden_states,)
+ if output_attentions:
+ outputs = outputs + (layer_attentions,)
+ return outputs # last-layer hidden state, (layer hidden states), (layer attentions)
+
+
+class FlaxAlbertLayerCollections(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32 # the dtype of the computation
+ layer_index: Optional[str] = None
+
+ def setup(self):
+ self.albert_layers = FlaxAlbertLayerCollection(self.config, dtype=self.dtype)
+
+ def __call__(
+ self,
+ hidden_states,
+ attention_mask,
+ deterministic: bool = True,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ ):
+ outputs = self.albert_layers(
+ hidden_states,
+ attention_mask,
+ deterministic=deterministic,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+ return outputs
+
+
+class FlaxAlbertLayerGroups(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32 # the dtype of the computation
+
+ def setup(self):
+ self.layers = [
+ FlaxAlbertLayerCollections(self.config, name=str(i), layer_index=str(i), dtype=self.dtype)
+ for i in range(self.config.num_hidden_groups)
+ ]
+
+ def __call__(
+ self,
+ hidden_states,
+ attention_mask,
+ deterministic: bool = True,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ):
+ all_attentions = () if output_attentions else None
+ all_hidden_states = (hidden_states,) if output_hidden_states else None
+
+ for i in range(self.config.num_hidden_layers):
+ # Index of the hidden group
+ group_idx = int(i / (self.config.num_hidden_layers / self.config.num_hidden_groups))
+ layer_group_output = self.layers[group_idx](
+ hidden_states,
+ attention_mask,
+ deterministic=deterministic,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+ hidden_states = layer_group_output[0]
+
+ if output_attentions:
+ all_attentions = all_attentions + layer_group_output[-1]
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_attentions] if v is not None)
+ return FlaxBaseModelOutput(
+ last_hidden_state=hidden_states, hidden_states=all_hidden_states, attentions=all_attentions
+ )
+
+
+class FlaxAlbertEncoder(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32 # the dtype of the computation
+
+ def setup(self):
+ self.embedding_hidden_mapping_in = nn.Dense(
+ self.config.hidden_size,
+ kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
+ dtype=self.dtype,
+ )
+ self.albert_layer_groups = FlaxAlbertLayerGroups(self.config, dtype=self.dtype)
+
+ def __call__(
+ self,
+ hidden_states,
+ attention_mask,
+ deterministic: bool = True,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ):
+ hidden_states = self.embedding_hidden_mapping_in(hidden_states)
+ return self.albert_layer_groups(
+ hidden_states,
+ attention_mask,
+ deterministic=deterministic,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+
+
+class FlaxAlbertOnlyMLMHead(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32
+ bias_init: Callable[..., np.ndarray] = jax.nn.initializers.zeros
+
+ def setup(self):
+ self.dense = nn.Dense(self.config.embedding_size, dtype=self.dtype)
+ self.activation = ACT2FN[self.config.hidden_act]
+ self.LayerNorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
+ self.decoder = nn.Dense(self.config.vocab_size, dtype=self.dtype, use_bias=False)
+ self.bias = self.param("bias", self.bias_init, (self.config.vocab_size,))
+
+ def __call__(self, hidden_states, shared_embedding=None):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.activation(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states)
+
+ if shared_embedding is not None:
+ hidden_states = self.decoder.apply({"params": {"kernel": shared_embedding.T}}, hidden_states)
+ else:
+ hidden_states = self.decoder(hidden_states)
+
+ hidden_states += self.bias
+ return hidden_states
+
+
+class FlaxAlbertSOPHead(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.dropout = nn.Dropout(self.config.classifier_dropout_prob)
+ self.classifier = nn.Dense(2, dtype=self.dtype)
+
+ def __call__(self, pooled_output, deterministic=True):
+ pooled_output = self.dropout(pooled_output, deterministic=deterministic)
+ logits = self.classifier(pooled_output)
+ return logits
+
+
+class FlaxAlbertPreTrainedModel(FlaxPreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = AlbertConfig
+ base_model_prefix = "albert"
+ module_class: nn.Module = None
+
+ def __init__(
+ self,
+ config: AlbertConfig,
+ input_shape: Tuple = (1, 1),
+ seed: int = 0,
+ dtype: jnp.dtype = jnp.float32,
+ _do_init: bool = True,
+ **kwargs,
+ ):
+ module = self.module_class(config=config, dtype=dtype, **kwargs)
+ super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype, _do_init=_do_init)
+
+ def init_weights(self, rng: jax.random.PRNGKey, input_shape: Tuple, params: FrozenDict = None) -> FrozenDict:
+ # init input tensors
+ input_ids = jnp.zeros(input_shape, dtype="i4")
+ token_type_ids = jnp.zeros_like(input_ids)
+ position_ids = jnp.broadcast_to(jnp.arange(jnp.atleast_2d(input_ids).shape[-1]), input_shape)
+ attention_mask = jnp.ones_like(input_ids)
+
+ params_rng, dropout_rng = jax.random.split(rng)
+ rngs = {"params": params_rng, "dropout": dropout_rng}
+
+ random_params = self.module.init(
+ rngs, input_ids, attention_mask, token_type_ids, position_ids, return_dict=False
+ )["params"]
+
+ if params is not None:
+ random_params = flatten_dict(unfreeze(random_params))
+ params = flatten_dict(unfreeze(params))
+ for missing_key in self._missing_keys:
+ params[missing_key] = random_params[missing_key]
+ self._missing_keys = set()
+ return freeze(unflatten_dict(params))
+ else:
+ return random_params
+
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ def __call__(
+ self,
+ input_ids,
+ attention_mask=None,
+ token_type_ids=None,
+ position_ids=None,
+ params: dict = None,
+ dropout_rng: jax.random.PRNGKey = None,
+ train: bool = False,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.return_dict
+
+ # init input tensors if not passed
+ if token_type_ids is None:
+ token_type_ids = jnp.zeros_like(input_ids)
+
+ if position_ids is None:
+ position_ids = jnp.broadcast_to(jnp.arange(jnp.atleast_2d(input_ids).shape[-1]), input_ids.shape)
+
+ if attention_mask is None:
+ attention_mask = jnp.ones_like(input_ids)
+
+ # Handle any PRNG if needed
+ rngs = {}
+ if dropout_rng is not None:
+ rngs["dropout"] = dropout_rng
+
+ return self.module.apply(
+ {"params": params or self.params},
+ jnp.array(input_ids, dtype="i4"),
+ jnp.array(attention_mask, dtype="i4"),
+ jnp.array(token_type_ids, dtype="i4"),
+ jnp.array(position_ids, dtype="i4"),
+ not train,
+ output_attentions,
+ output_hidden_states,
+ return_dict,
+ rngs=rngs,
+ )
+
+
+class FlaxAlbertModule(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32 # the dtype of the computation
+ add_pooling_layer: bool = True
+
+ def setup(self):
+ self.embeddings = FlaxAlbertEmbeddings(self.config, dtype=self.dtype)
+ self.encoder = FlaxAlbertEncoder(self.config, dtype=self.dtype)
+ if self.add_pooling_layer:
+ self.pooler = nn.Dense(
+ self.config.hidden_size,
+ kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
+ dtype=self.dtype,
+ name="pooler",
+ )
+ self.pooler_activation = nn.tanh
+ else:
+ self.pooler = None
+ self.pooler_activation = None
+
+ def __call__(
+ self,
+ input_ids,
+ attention_mask,
+ token_type_ids: Optional[np.ndarray] = None,
+ position_ids: Optional[np.ndarray] = None,
+ deterministic: bool = True,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ):
+ # make sure `token_type_ids` is correctly initialized when not passed
+ if token_type_ids is None:
+ token_type_ids = jnp.zeros_like(input_ids)
+
+ # make sure `position_ids` is correctly initialized when not passed
+ if position_ids is None:
+ position_ids = jnp.broadcast_to(jnp.arange(jnp.atleast_2d(input_ids).shape[-1]), input_ids.shape)
+
+ hidden_states = self.embeddings(input_ids, token_type_ids, position_ids, deterministic=deterministic)
+
+ outputs = self.encoder(
+ hidden_states,
+ attention_mask,
+ deterministic=deterministic,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ hidden_states = outputs[0]
+ if self.add_pooling_layer:
+ pooled = self.pooler(hidden_states[:, 0])
+ pooled = self.pooler_activation(pooled)
+ else:
+ pooled = None
+
+ if not return_dict:
+ # if pooled is None, don't return it
+ if pooled is None:
+ return (hidden_states,) + outputs[1:]
+ return (hidden_states, pooled) + outputs[1:]
+
+ return FlaxBaseModelOutputWithPooling(
+ last_hidden_state=hidden_states,
+ pooler_output=pooled,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ "The bare Albert Model transformer outputting raw hidden-states without any specific head on top.",
+ ALBERT_START_DOCSTRING,
+)
+class FlaxAlbertModel(FlaxAlbertPreTrainedModel):
+ module_class = FlaxAlbertModule
+
+
+append_call_sample_docstring(FlaxAlbertModel, _CHECKPOINT_FOR_DOC, FlaxBaseModelOutputWithPooling, _CONFIG_FOR_DOC)
+
+
+class FlaxAlbertForPreTrainingModule(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.albert = FlaxAlbertModule(config=self.config, dtype=self.dtype)
+ self.predictions = FlaxAlbertOnlyMLMHead(config=self.config, dtype=self.dtype)
+ self.sop_classifier = FlaxAlbertSOPHead(config=self.config, dtype=self.dtype)
+
+ def __call__(
+ self,
+ input_ids,
+ attention_mask,
+ token_type_ids,
+ position_ids,
+ deterministic: bool = True,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ):
+ # Model
+ outputs = self.albert(
+ input_ids,
+ attention_mask,
+ token_type_ids,
+ position_ids,
+ deterministic=deterministic,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if self.config.tie_word_embeddings:
+ shared_embedding = self.albert.variables["params"]["embeddings"]["word_embeddings"]["embedding"]
+ else:
+ shared_embedding = None
+
+ hidden_states = outputs[0]
+ pooled_output = outputs[1]
+
+ prediction_scores = self.predictions(hidden_states, shared_embedding=shared_embedding)
+ sop_scores = self.sop_classifier(pooled_output, deterministic=deterministic)
+
+ if not return_dict:
+ return (prediction_scores, sop_scores) + outputs[2:]
+
+ return FlaxAlbertForPreTrainingOutput(
+ prediction_logits=prediction_scores,
+ sop_logits=sop_scores,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Albert Model with two heads on top as done during the pretraining: a `masked language modeling` head and a
+ `sentence order prediction (classification)` head.
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class FlaxAlbertForPreTraining(FlaxAlbertPreTrainedModel):
+ module_class = FlaxAlbertForPreTrainingModule
+
+
+FLAX_ALBERT_FOR_PRETRAINING_DOCSTRING = """
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, FlaxAlbertForPreTraining
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("albert/albert-base-v2")
+ >>> model = FlaxAlbertForPreTraining.from_pretrained("albert/albert-base-v2")
+
+ >>> inputs = tokenizer("Hello, my dog is cute", return_tensors="np")
+ >>> outputs = model(**inputs)
+
+ >>> prediction_logits = outputs.prediction_logits
+ >>> seq_relationship_logits = outputs.sop_logits
+ ```
+"""
+
+overwrite_call_docstring(
+ FlaxAlbertForPreTraining,
+ ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length") + FLAX_ALBERT_FOR_PRETRAINING_DOCSTRING,
+)
+append_replace_return_docstrings(
+ FlaxAlbertForPreTraining, output_type=FlaxAlbertForPreTrainingOutput, config_class=_CONFIG_FOR_DOC
+)
+
+
+class FlaxAlbertForMaskedLMModule(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.albert = FlaxAlbertModule(config=self.config, add_pooling_layer=False, dtype=self.dtype)
+ self.predictions = FlaxAlbertOnlyMLMHead(config=self.config, dtype=self.dtype)
+
+ def __call__(
+ self,
+ input_ids,
+ attention_mask,
+ token_type_ids,
+ position_ids,
+ deterministic: bool = True,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ):
+ # Model
+ outputs = self.albert(
+ input_ids,
+ attention_mask,
+ token_type_ids,
+ position_ids,
+ deterministic=deterministic,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ if self.config.tie_word_embeddings:
+ shared_embedding = self.albert.variables["params"]["embeddings"]["word_embeddings"]["embedding"]
+ else:
+ shared_embedding = None
+
+ # Compute the prediction scores
+ logits = self.predictions(hidden_states, shared_embedding=shared_embedding)
+
+ if not return_dict:
+ return (logits,) + outputs[1:]
+
+ return FlaxMaskedLMOutput(
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings("""Albert Model with a `language modeling` head on top.""", ALBERT_START_DOCSTRING)
+class FlaxAlbertForMaskedLM(FlaxAlbertPreTrainedModel):
+ module_class = FlaxAlbertForMaskedLMModule
+
+
+append_call_sample_docstring(
+ FlaxAlbertForMaskedLM, _CHECKPOINT_FOR_DOC, FlaxMaskedLMOutput, _CONFIG_FOR_DOC, revision="refs/pr/11"
+)
+
+
+class FlaxAlbertForSequenceClassificationModule(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.albert = FlaxAlbertModule(config=self.config, dtype=self.dtype)
+ classifier_dropout = (
+ self.config.classifier_dropout_prob
+ if self.config.classifier_dropout_prob is not None
+ else self.config.hidden_dropout_prob
+ )
+ self.dropout = nn.Dropout(rate=classifier_dropout)
+ self.classifier = nn.Dense(
+ self.config.num_labels,
+ dtype=self.dtype,
+ )
+
+ def __call__(
+ self,
+ input_ids,
+ attention_mask,
+ token_type_ids,
+ position_ids,
+ deterministic: bool = True,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ):
+ # Model
+ outputs = self.albert(
+ input_ids,
+ attention_mask,
+ token_type_ids,
+ position_ids,
+ deterministic=deterministic,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = outputs[1]
+ pooled_output = self.dropout(pooled_output, deterministic=deterministic)
+ logits = self.classifier(pooled_output)
+
+ if not return_dict:
+ return (logits,) + outputs[2:]
+
+ return FlaxSequenceClassifierOutput(
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Albert Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled
+ output) e.g. for GLUE tasks.
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class FlaxAlbertForSequenceClassification(FlaxAlbertPreTrainedModel):
+ module_class = FlaxAlbertForSequenceClassificationModule
+
+
+append_call_sample_docstring(
+ FlaxAlbertForSequenceClassification,
+ _CHECKPOINT_FOR_DOC,
+ FlaxSequenceClassifierOutput,
+ _CONFIG_FOR_DOC,
+)
+
+
+class FlaxAlbertForMultipleChoiceModule(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.albert = FlaxAlbertModule(config=self.config, dtype=self.dtype)
+ self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
+ self.classifier = nn.Dense(1, dtype=self.dtype)
+
+ def __call__(
+ self,
+ input_ids,
+ attention_mask,
+ token_type_ids,
+ position_ids,
+ deterministic: bool = True,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ):
+ num_choices = input_ids.shape[1]
+ input_ids = input_ids.reshape(-1, input_ids.shape[-1]) if input_ids is not None else None
+ attention_mask = attention_mask.reshape(-1, attention_mask.shape[-1]) if attention_mask is not None else None
+ token_type_ids = token_type_ids.reshape(-1, token_type_ids.shape[-1]) if token_type_ids is not None else None
+ position_ids = position_ids.reshape(-1, position_ids.shape[-1]) if position_ids is not None else None
+
+ # Model
+ outputs = self.albert(
+ input_ids,
+ attention_mask,
+ token_type_ids,
+ position_ids,
+ deterministic=deterministic,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = outputs[1]
+ pooled_output = self.dropout(pooled_output, deterministic=deterministic)
+ logits = self.classifier(pooled_output)
+
+ reshaped_logits = logits.reshape(-1, num_choices)
+
+ if not return_dict:
+ return (reshaped_logits,) + outputs[2:]
+
+ return FlaxMultipleChoiceModelOutput(
+ logits=reshaped_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Albert Model with a multiple choice classification head on top (a linear layer on top of the pooled output and a
+ softmax) e.g. for RocStories/SWAG tasks.
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class FlaxAlbertForMultipleChoice(FlaxAlbertPreTrainedModel):
+ module_class = FlaxAlbertForMultipleChoiceModule
+
+
+overwrite_call_docstring(
+ FlaxAlbertForMultipleChoice, ALBERT_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length")
+)
+append_call_sample_docstring(
+ FlaxAlbertForMultipleChoice,
+ _CHECKPOINT_FOR_DOC,
+ FlaxMultipleChoiceModelOutput,
+ _CONFIG_FOR_DOC,
+)
+
+
+class FlaxAlbertForTokenClassificationModule(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.albert = FlaxAlbertModule(config=self.config, dtype=self.dtype, add_pooling_layer=False)
+ classifier_dropout = (
+ self.config.classifier_dropout_prob
+ if self.config.classifier_dropout_prob is not None
+ else self.config.hidden_dropout_prob
+ )
+ self.dropout = nn.Dropout(rate=classifier_dropout)
+ self.classifier = nn.Dense(self.config.num_labels, dtype=self.dtype)
+
+ def __call__(
+ self,
+ input_ids,
+ attention_mask,
+ token_type_ids,
+ position_ids,
+ deterministic: bool = True,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ):
+ # Model
+ outputs = self.albert(
+ input_ids,
+ attention_mask,
+ token_type_ids,
+ position_ids,
+ deterministic=deterministic,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ hidden_states = self.dropout(hidden_states, deterministic=deterministic)
+ logits = self.classifier(hidden_states)
+
+ if not return_dict:
+ return (logits,) + outputs[1:]
+
+ return FlaxTokenClassifierOutput(
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Albert Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
+ Named-Entity-Recognition (NER) tasks.
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class FlaxAlbertForTokenClassification(FlaxAlbertPreTrainedModel):
+ module_class = FlaxAlbertForTokenClassificationModule
+
+
+append_call_sample_docstring(
+ FlaxAlbertForTokenClassification,
+ _CHECKPOINT_FOR_DOC,
+ FlaxTokenClassifierOutput,
+ _CONFIG_FOR_DOC,
+)
+
+
+class FlaxAlbertForQuestionAnsweringModule(nn.Module):
+ config: AlbertConfig
+ dtype: jnp.dtype = jnp.float32
+
+ def setup(self):
+ self.albert = FlaxAlbertModule(config=self.config, dtype=self.dtype, add_pooling_layer=False)
+ self.qa_outputs = nn.Dense(self.config.num_labels, dtype=self.dtype)
+
+ def __call__(
+ self,
+ input_ids,
+ attention_mask,
+ token_type_ids,
+ position_ids,
+ deterministic: bool = True,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ):
+ # Model
+ outputs = self.albert(
+ input_ids,
+ attention_mask,
+ token_type_ids,
+ position_ids,
+ deterministic=deterministic,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+
+ logits = self.qa_outputs(hidden_states)
+ start_logits, end_logits = jnp.split(logits, self.config.num_labels, axis=-1)
+ start_logits = start_logits.squeeze(-1)
+ end_logits = end_logits.squeeze(-1)
+
+ if not return_dict:
+ return (start_logits, end_logits) + outputs[1:]
+
+ return FlaxQuestionAnsweringModelOutput(
+ start_logits=start_logits,
+ end_logits=end_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """
+ Albert Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
+ layers on top of the hidden-states output to compute `span start logits` and `span end logits`).
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class FlaxAlbertForQuestionAnswering(FlaxAlbertPreTrainedModel):
+ module_class = FlaxAlbertForQuestionAnsweringModule
+
+
+append_call_sample_docstring(
+ FlaxAlbertForQuestionAnswering,
+ _CHECKPOINT_FOR_DOC,
+ FlaxQuestionAnsweringModelOutput,
+ _CONFIG_FOR_DOC,
+)
+
+__all__ = [
+ "FlaxAlbertPreTrainedModel",
+ "FlaxAlbertModel",
+ "FlaxAlbertForPreTraining",
+ "FlaxAlbertForMaskedLM",
+ "FlaxAlbertForSequenceClassification",
+ "FlaxAlbertForMultipleChoice",
+ "FlaxAlbertForTokenClassification",
+ "FlaxAlbertForQuestionAnswering",
+]
diff --git a/docs/transformers/src/transformers/models/albert/modeling_tf_albert.py b/docs/transformers/src/transformers/models/albert/modeling_tf_albert.py
new file mode 100644
index 0000000000000000000000000000000000000000..6800cfa8d16a84a422e804ada3e0a7d9b9e9ef40
--- /dev/null
+++ b/docs/transformers/src/transformers/models/albert/modeling_tf_albert.py
@@ -0,0 +1,1573 @@
+# coding=utf-8
+# Copyright 2018 The OpenAI Team Authors and HuggingFace Inc. team.
+# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""TF 2.0 ALBERT model."""
+
+from __future__ import annotations
+
+import math
+from dataclasses import dataclass
+from typing import Dict, Optional, Tuple, Union
+
+import numpy as np
+import tensorflow as tf
+
+from ...activations_tf import get_tf_activation
+from ...modeling_tf_outputs import (
+ TFBaseModelOutput,
+ TFBaseModelOutputWithPooling,
+ TFMaskedLMOutput,
+ TFMultipleChoiceModelOutput,
+ TFQuestionAnsweringModelOutput,
+ TFSequenceClassifierOutput,
+ TFTokenClassifierOutput,
+)
+from ...modeling_tf_utils import (
+ TFMaskedLanguageModelingLoss,
+ TFModelInputType,
+ TFMultipleChoiceLoss,
+ TFPreTrainedModel,
+ TFQuestionAnsweringLoss,
+ TFSequenceClassificationLoss,
+ TFTokenClassificationLoss,
+ get_initializer,
+ keras,
+ keras_serializable,
+ unpack_inputs,
+)
+from ...tf_utils import check_embeddings_within_bounds, shape_list, stable_softmax
+from ...utils import (
+ ModelOutput,
+ add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+from .configuration_albert import AlbertConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = "albert/albert-base-v2"
+_CONFIG_FOR_DOC = "AlbertConfig"
+
+
+class TFAlbertPreTrainingLoss:
+ """
+ Loss function suitable for ALBERT pretraining, that is, the task of pretraining a language model by combining SOP +
+ MLM. .. note:: Any label of -100 will be ignored (along with the corresponding logits) in the loss computation.
+ """
+
+ def hf_compute_loss(self, labels: tf.Tensor, logits: tf.Tensor) -> tf.Tensor:
+ loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction=keras.losses.Reduction.NONE)
+ if self.config.tf_legacy_loss:
+ # make sure only labels that are not equal to -100
+ # are taken into account as loss
+ masked_lm_active_loss = tf.not_equal(tf.reshape(tensor=labels["labels"], shape=(-1,)), -100)
+ masked_lm_reduced_logits = tf.boolean_mask(
+ tensor=tf.reshape(tensor=logits[0], shape=(-1, shape_list(logits[0])[2])),
+ mask=masked_lm_active_loss,
+ )
+ masked_lm_labels = tf.boolean_mask(
+ tensor=tf.reshape(tensor=labels["labels"], shape=(-1,)), mask=masked_lm_active_loss
+ )
+ sentence_order_active_loss = tf.not_equal(
+ tf.reshape(tensor=labels["sentence_order_label"], shape=(-1,)), -100
+ )
+ sentence_order_reduced_logits = tf.boolean_mask(
+ tensor=tf.reshape(tensor=logits[1], shape=(-1, 2)), mask=sentence_order_active_loss
+ )
+ sentence_order_label = tf.boolean_mask(
+ tensor=tf.reshape(tensor=labels["sentence_order_label"], shape=(-1,)), mask=sentence_order_active_loss
+ )
+ masked_lm_loss = loss_fn(y_true=masked_lm_labels, y_pred=masked_lm_reduced_logits)
+ sentence_order_loss = loss_fn(y_true=sentence_order_label, y_pred=sentence_order_reduced_logits)
+ masked_lm_loss = tf.reshape(tensor=masked_lm_loss, shape=(-1, shape_list(sentence_order_loss)[0]))
+ masked_lm_loss = tf.reduce_mean(input_tensor=masked_lm_loss, axis=0)
+
+ return masked_lm_loss + sentence_order_loss
+
+ # Clip negative labels to zero here to avoid NaNs and errors - those positions will get masked later anyway
+ unmasked_lm_losses = loss_fn(y_true=tf.nn.relu(labels["labels"]), y_pred=logits[0])
+ # make sure only labels that are not equal to -100
+ # are taken into account for the loss computation
+ lm_loss_mask = tf.cast(labels["labels"] != -100, dtype=unmasked_lm_losses.dtype)
+ masked_lm_losses = unmasked_lm_losses * lm_loss_mask
+ reduced_masked_lm_loss = tf.reduce_sum(masked_lm_losses) / tf.reduce_sum(lm_loss_mask)
+
+ sop_logits = tf.reshape(logits[1], (-1, 2))
+ # Clip negative labels to zero here to avoid NaNs and errors - those positions will get masked later anyway
+ unmasked_sop_loss = loss_fn(y_true=tf.nn.relu(labels["sentence_order_label"]), y_pred=sop_logits)
+ sop_loss_mask = tf.cast(labels["sentence_order_label"] != -100, dtype=unmasked_sop_loss.dtype)
+
+ masked_sop_loss = unmasked_sop_loss * sop_loss_mask
+ reduced_masked_sop_loss = tf.reduce_sum(masked_sop_loss) / tf.reduce_sum(sop_loss_mask)
+
+ return tf.reshape(reduced_masked_lm_loss + reduced_masked_sop_loss, (1,))
+
+
+class TFAlbertEmbeddings(keras.layers.Layer):
+ """Construct the embeddings from word, position and token_type embeddings."""
+
+ def __init__(self, config: AlbertConfig, **kwargs):
+ super().__init__(**kwargs)
+
+ self.config = config
+ self.embedding_size = config.embedding_size
+ self.max_position_embeddings = config.max_position_embeddings
+ self.initializer_range = config.initializer_range
+ self.LayerNorm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
+ self.dropout = keras.layers.Dropout(rate=config.hidden_dropout_prob)
+
+ def build(self, input_shape=None):
+ with tf.name_scope("word_embeddings"):
+ self.weight = self.add_weight(
+ name="weight",
+ shape=[self.config.vocab_size, self.embedding_size],
+ initializer=get_initializer(self.initializer_range),
+ )
+
+ with tf.name_scope("token_type_embeddings"):
+ self.token_type_embeddings = self.add_weight(
+ name="embeddings",
+ shape=[self.config.type_vocab_size, self.embedding_size],
+ initializer=get_initializer(self.initializer_range),
+ )
+
+ with tf.name_scope("position_embeddings"):
+ self.position_embeddings = self.add_weight(
+ name="embeddings",
+ shape=[self.max_position_embeddings, self.embedding_size],
+ initializer=get_initializer(self.initializer_range),
+ )
+
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "LayerNorm", None) is not None:
+ with tf.name_scope(self.LayerNorm.name):
+ self.LayerNorm.build([None, None, self.config.embedding_size])
+
+ # Copied from transformers.models.bert.modeling_tf_bert.TFBertEmbeddings.call
+ def call(
+ self,
+ input_ids: Optional[tf.Tensor] = None,
+ position_ids: Optional[tf.Tensor] = None,
+ token_type_ids: Optional[tf.Tensor] = None,
+ inputs_embeds: Optional[tf.Tensor] = None,
+ past_key_values_length=0,
+ training: bool = False,
+ ) -> tf.Tensor:
+ """
+ Applies embedding based on inputs tensor.
+
+ Returns:
+ final_embeddings (`tf.Tensor`): output embedding tensor.
+ """
+ if input_ids is None and inputs_embeds is None:
+ raise ValueError("Need to provide either `input_ids` or `input_embeds`.")
+
+ if input_ids is not None:
+ check_embeddings_within_bounds(input_ids, self.config.vocab_size)
+ inputs_embeds = tf.gather(params=self.weight, indices=input_ids)
+
+ input_shape = shape_list(inputs_embeds)[:-1]
+
+ if token_type_ids is None:
+ token_type_ids = tf.fill(dims=input_shape, value=0)
+
+ if position_ids is None:
+ position_ids = tf.expand_dims(
+ tf.range(start=past_key_values_length, limit=input_shape[1] + past_key_values_length), axis=0
+ )
+
+ position_embeds = tf.gather(params=self.position_embeddings, indices=position_ids)
+ token_type_embeds = tf.gather(params=self.token_type_embeddings, indices=token_type_ids)
+ final_embeddings = inputs_embeds + position_embeds + token_type_embeds
+ final_embeddings = self.LayerNorm(inputs=final_embeddings)
+ final_embeddings = self.dropout(inputs=final_embeddings, training=training)
+
+ return final_embeddings
+
+
+class TFAlbertAttention(keras.layers.Layer):
+ """Contains the complete attention sublayer, including both dropouts and layer norm."""
+
+ def __init__(self, config: AlbertConfig, **kwargs):
+ super().__init__(**kwargs)
+
+ if config.hidden_size % config.num_attention_heads != 0:
+ raise ValueError(
+ f"The hidden size ({config.hidden_size}) is not a multiple of the number "
+ f"of attention heads ({config.num_attention_heads})"
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+ self.sqrt_att_head_size = math.sqrt(self.attention_head_size)
+ self.output_attentions = config.output_attentions
+
+ self.query = keras.layers.Dense(
+ units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="query"
+ )
+ self.key = keras.layers.Dense(
+ units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="key"
+ )
+ self.value = keras.layers.Dense(
+ units=self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="value"
+ )
+ self.dense = keras.layers.Dense(
+ units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
+ )
+ self.LayerNorm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
+ # Two different dropout probabilities; see https://github.com/google-research/albert/blob/master/modeling.py#L971-L993
+ self.attention_dropout = keras.layers.Dropout(rate=config.attention_probs_dropout_prob)
+ self.output_dropout = keras.layers.Dropout(rate=config.hidden_dropout_prob)
+ self.config = config
+
+ def transpose_for_scores(self, tensor: tf.Tensor, batch_size: int) -> tf.Tensor:
+ # Reshape from [batch_size, seq_length, all_head_size] to [batch_size, seq_length, num_attention_heads, attention_head_size]
+ tensor = tf.reshape(tensor=tensor, shape=(batch_size, -1, self.num_attention_heads, self.attention_head_size))
+
+ # Transpose the tensor from [batch_size, seq_length, num_attention_heads, attention_head_size] to [batch_size, num_attention_heads, seq_length, attention_head_size]
+ return tf.transpose(tensor, perm=[0, 2, 1, 3])
+
+ def call(
+ self,
+ input_tensor: tf.Tensor,
+ attention_mask: tf.Tensor,
+ head_mask: tf.Tensor,
+ output_attentions: bool,
+ training: bool = False,
+ ) -> Tuple[tf.Tensor]:
+ batch_size = shape_list(input_tensor)[0]
+ mixed_query_layer = self.query(inputs=input_tensor)
+ mixed_key_layer = self.key(inputs=input_tensor)
+ mixed_value_layer = self.value(inputs=input_tensor)
+ query_layer = self.transpose_for_scores(mixed_query_layer, batch_size)
+ key_layer = self.transpose_for_scores(mixed_key_layer, batch_size)
+ value_layer = self.transpose_for_scores(mixed_value_layer, batch_size)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ # (batch size, num_heads, seq_len_q, seq_len_k)
+ attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
+ dk = tf.cast(self.sqrt_att_head_size, dtype=attention_scores.dtype)
+ attention_scores = tf.divide(attention_scores, dk)
+
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in TFAlbertModel call() function)
+ attention_scores = tf.add(attention_scores, attention_mask)
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = stable_softmax(logits=attention_scores, axis=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.attention_dropout(inputs=attention_probs, training=training)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = tf.multiply(attention_probs, head_mask)
+
+ context_layer = tf.matmul(attention_probs, value_layer)
+ context_layer = tf.transpose(context_layer, perm=[0, 2, 1, 3])
+
+ # (batch_size, seq_len_q, all_head_size)
+ context_layer = tf.reshape(tensor=context_layer, shape=(batch_size, -1, self.all_head_size))
+ self_outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+ hidden_states = self_outputs[0]
+ hidden_states = self.dense(inputs=hidden_states)
+ hidden_states = self.output_dropout(inputs=hidden_states, training=training)
+ attention_output = self.LayerNorm(inputs=hidden_states + input_tensor)
+
+ # add attentions if we output them
+ outputs = (attention_output,) + self_outputs[1:]
+
+ return outputs
+
+ def build(self, input_shape=None):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "query", None) is not None:
+ with tf.name_scope(self.query.name):
+ self.query.build([None, None, self.config.hidden_size])
+ if getattr(self, "key", None) is not None:
+ with tf.name_scope(self.key.name):
+ self.key.build([None, None, self.config.hidden_size])
+ if getattr(self, "value", None) is not None:
+ with tf.name_scope(self.value.name):
+ self.value.build([None, None, self.config.hidden_size])
+ if getattr(self, "dense", None) is not None:
+ with tf.name_scope(self.dense.name):
+ self.dense.build([None, None, self.config.hidden_size])
+ if getattr(self, "LayerNorm", None) is not None:
+ with tf.name_scope(self.LayerNorm.name):
+ self.LayerNorm.build([None, None, self.config.hidden_size])
+
+
+class TFAlbertLayer(keras.layers.Layer):
+ def __init__(self, config: AlbertConfig, **kwargs):
+ super().__init__(**kwargs)
+
+ self.attention = TFAlbertAttention(config, name="attention")
+ self.ffn = keras.layers.Dense(
+ units=config.intermediate_size, kernel_initializer=get_initializer(config.initializer_range), name="ffn"
+ )
+
+ if isinstance(config.hidden_act, str):
+ self.activation = get_tf_activation(config.hidden_act)
+ else:
+ self.activation = config.hidden_act
+
+ self.ffn_output = keras.layers.Dense(
+ units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="ffn_output"
+ )
+ self.full_layer_layer_norm = keras.layers.LayerNormalization(
+ epsilon=config.layer_norm_eps, name="full_layer_layer_norm"
+ )
+ self.dropout = keras.layers.Dropout(rate=config.hidden_dropout_prob)
+ self.config = config
+
+ def call(
+ self,
+ hidden_states: tf.Tensor,
+ attention_mask: tf.Tensor,
+ head_mask: tf.Tensor,
+ output_attentions: bool,
+ training: bool = False,
+ ) -> Tuple[tf.Tensor]:
+ attention_outputs = self.attention(
+ input_tensor=hidden_states,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ training=training,
+ )
+ ffn_output = self.ffn(inputs=attention_outputs[0])
+ ffn_output = self.activation(ffn_output)
+ ffn_output = self.ffn_output(inputs=ffn_output)
+ ffn_output = self.dropout(inputs=ffn_output, training=training)
+ hidden_states = self.full_layer_layer_norm(inputs=ffn_output + attention_outputs[0])
+
+ # add attentions if we output them
+ outputs = (hidden_states,) + attention_outputs[1:]
+
+ return outputs
+
+ def build(self, input_shape=None):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "attention", None) is not None:
+ with tf.name_scope(self.attention.name):
+ self.attention.build(None)
+ if getattr(self, "ffn", None) is not None:
+ with tf.name_scope(self.ffn.name):
+ self.ffn.build([None, None, self.config.hidden_size])
+ if getattr(self, "ffn_output", None) is not None:
+ with tf.name_scope(self.ffn_output.name):
+ self.ffn_output.build([None, None, self.config.intermediate_size])
+ if getattr(self, "full_layer_layer_norm", None) is not None:
+ with tf.name_scope(self.full_layer_layer_norm.name):
+ self.full_layer_layer_norm.build([None, None, self.config.hidden_size])
+
+
+class TFAlbertLayerGroup(keras.layers.Layer):
+ def __init__(self, config: AlbertConfig, **kwargs):
+ super().__init__(**kwargs)
+
+ self.albert_layers = [
+ TFAlbertLayer(config, name=f"albert_layers_._{i}") for i in range(config.inner_group_num)
+ ]
+
+ def call(
+ self,
+ hidden_states: tf.Tensor,
+ attention_mask: tf.Tensor,
+ head_mask: tf.Tensor,
+ output_attentions: bool,
+ output_hidden_states: bool,
+ training: bool = False,
+ ) -> Union[TFBaseModelOutput, Tuple[tf.Tensor]]:
+ layer_hidden_states = () if output_hidden_states else None
+ layer_attentions = () if output_attentions else None
+
+ for layer_index, albert_layer in enumerate(self.albert_layers):
+ if output_hidden_states:
+ layer_hidden_states = layer_hidden_states + (hidden_states,)
+
+ layer_output = albert_layer(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ head_mask=head_mask[layer_index],
+ output_attentions=output_attentions,
+ training=training,
+ )
+ hidden_states = layer_output[0]
+
+ if output_attentions:
+ layer_attentions = layer_attentions + (layer_output[1],)
+
+ # Add last layer
+ if output_hidden_states:
+ layer_hidden_states = layer_hidden_states + (hidden_states,)
+
+ return tuple(v for v in [hidden_states, layer_hidden_states, layer_attentions] if v is not None)
+
+ def build(self, input_shape=None):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "albert_layers", None) is not None:
+ for layer in self.albert_layers:
+ with tf.name_scope(layer.name):
+ layer.build(None)
+
+
+class TFAlbertTransformer(keras.layers.Layer):
+ def __init__(self, config: AlbertConfig, **kwargs):
+ super().__init__(**kwargs)
+
+ self.num_hidden_layers = config.num_hidden_layers
+ self.num_hidden_groups = config.num_hidden_groups
+ # Number of layers in a hidden group
+ self.layers_per_group = int(config.num_hidden_layers / config.num_hidden_groups)
+ self.embedding_hidden_mapping_in = keras.layers.Dense(
+ units=config.hidden_size,
+ kernel_initializer=get_initializer(config.initializer_range),
+ name="embedding_hidden_mapping_in",
+ )
+ self.albert_layer_groups = [
+ TFAlbertLayerGroup(config, name=f"albert_layer_groups_._{i}") for i in range(config.num_hidden_groups)
+ ]
+ self.config = config
+
+ def call(
+ self,
+ hidden_states: tf.Tensor,
+ attention_mask: tf.Tensor,
+ head_mask: tf.Tensor,
+ output_attentions: bool,
+ output_hidden_states: bool,
+ return_dict: bool,
+ training: bool = False,
+ ) -> Union[TFBaseModelOutput, Tuple[tf.Tensor]]:
+ hidden_states = self.embedding_hidden_mapping_in(inputs=hidden_states)
+ all_attentions = () if output_attentions else None
+ all_hidden_states = (hidden_states,) if output_hidden_states else None
+
+ for i in range(self.num_hidden_layers):
+ # Index of the hidden group
+ group_idx = int(i / (self.num_hidden_layers / self.num_hidden_groups))
+ layer_group_output = self.albert_layer_groups[group_idx](
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ head_mask=head_mask[group_idx * self.layers_per_group : (group_idx + 1) * self.layers_per_group],
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ training=training,
+ )
+ hidden_states = layer_group_output[0]
+
+ if output_attentions:
+ all_attentions = all_attentions + layer_group_output[-1]
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_attentions] if v is not None)
+
+ return TFBaseModelOutput(
+ last_hidden_state=hidden_states, hidden_states=all_hidden_states, attentions=all_attentions
+ )
+
+ def build(self, input_shape=None):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "embedding_hidden_mapping_in", None) is not None:
+ with tf.name_scope(self.embedding_hidden_mapping_in.name):
+ self.embedding_hidden_mapping_in.build([None, None, self.config.embedding_size])
+ if getattr(self, "albert_layer_groups", None) is not None:
+ for layer in self.albert_layer_groups:
+ with tf.name_scope(layer.name):
+ layer.build(None)
+
+
+class TFAlbertPreTrainedModel(TFPreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = AlbertConfig
+ base_model_prefix = "albert"
+
+
+class TFAlbertMLMHead(keras.layers.Layer):
+ def __init__(self, config: AlbertConfig, input_embeddings: keras.layers.Layer, **kwargs):
+ super().__init__(**kwargs)
+
+ self.config = config
+ self.embedding_size = config.embedding_size
+ self.dense = keras.layers.Dense(
+ config.embedding_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
+ )
+ if isinstance(config.hidden_act, str):
+ self.activation = get_tf_activation(config.hidden_act)
+ else:
+ self.activation = config.hidden_act
+
+ self.LayerNorm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
+
+ # The output weights are the same as the input embeddings, but there is
+ # an output-only bias for each token.
+ self.decoder = input_embeddings
+
+ def build(self, input_shape=None):
+ self.bias = self.add_weight(shape=(self.config.vocab_size,), initializer="zeros", trainable=True, name="bias")
+ self.decoder_bias = self.add_weight(
+ shape=(self.config.vocab_size,), initializer="zeros", trainable=True, name="decoder/bias"
+ )
+
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "dense", None) is not None:
+ with tf.name_scope(self.dense.name):
+ self.dense.build([None, None, self.config.hidden_size])
+ if getattr(self, "LayerNorm", None) is not None:
+ with tf.name_scope(self.LayerNorm.name):
+ self.LayerNorm.build([None, None, self.config.embedding_size])
+
+ def get_output_embeddings(self) -> keras.layers.Layer:
+ return self.decoder
+
+ def set_output_embeddings(self, value: tf.Variable):
+ self.decoder.weight = value
+ self.decoder.vocab_size = shape_list(value)[0]
+
+ def get_bias(self) -> Dict[str, tf.Variable]:
+ return {"bias": self.bias, "decoder_bias": self.decoder_bias}
+
+ def set_bias(self, value: tf.Variable):
+ self.bias = value["bias"]
+ self.decoder_bias = value["decoder_bias"]
+ self.config.vocab_size = shape_list(value["bias"])[0]
+
+ def call(self, hidden_states: tf.Tensor) -> tf.Tensor:
+ hidden_states = self.dense(inputs=hidden_states)
+ hidden_states = self.activation(hidden_states)
+ hidden_states = self.LayerNorm(inputs=hidden_states)
+ seq_length = shape_list(tensor=hidden_states)[1]
+ hidden_states = tf.reshape(tensor=hidden_states, shape=[-1, self.embedding_size])
+ hidden_states = tf.matmul(a=hidden_states, b=self.decoder.weight, transpose_b=True)
+ hidden_states = tf.reshape(tensor=hidden_states, shape=[-1, seq_length, self.config.vocab_size])
+ hidden_states = tf.nn.bias_add(value=hidden_states, bias=self.decoder_bias)
+
+ return hidden_states
+
+
+@keras_serializable
+class TFAlbertMainLayer(keras.layers.Layer):
+ config_class = AlbertConfig
+
+ def __init__(self, config: AlbertConfig, add_pooling_layer: bool = True, **kwargs):
+ super().__init__(**kwargs)
+
+ self.config = config
+
+ self.embeddings = TFAlbertEmbeddings(config, name="embeddings")
+ self.encoder = TFAlbertTransformer(config, name="encoder")
+ self.pooler = (
+ keras.layers.Dense(
+ units=config.hidden_size,
+ kernel_initializer=get_initializer(config.initializer_range),
+ activation="tanh",
+ name="pooler",
+ )
+ if add_pooling_layer
+ else None
+ )
+
+ def get_input_embeddings(self) -> keras.layers.Layer:
+ return self.embeddings
+
+ def set_input_embeddings(self, value: tf.Variable):
+ self.embeddings.weight = value
+ self.embeddings.vocab_size = shape_list(value)[0]
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ raise NotImplementedError
+
+ @unpack_inputs
+ def call(
+ self,
+ input_ids: TFModelInputType | None = None,
+ attention_mask: np.ndarray | tf.Tensor | None = None,
+ token_type_ids: np.ndarray | tf.Tensor | None = None,
+ position_ids: np.ndarray | tf.Tensor | None = None,
+ head_mask: np.ndarray | tf.Tensor | None = None,
+ inputs_embeds: np.ndarray | tf.Tensor | None = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ training: bool = False,
+ ) -> Union[TFBaseModelOutputWithPooling, Tuple[tf.Tensor]]:
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ input_shape = shape_list(input_ids)
+ elif inputs_embeds is not None:
+ input_shape = shape_list(inputs_embeds)[:-1]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ if attention_mask is None:
+ attention_mask = tf.fill(dims=input_shape, value=1)
+
+ if token_type_ids is None:
+ token_type_ids = tf.fill(dims=input_shape, value=0)
+
+ embedding_output = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids,
+ inputs_embeds=inputs_embeds,
+ training=training,
+ )
+
+ # We create a 3D attention mask from a 2D tensor mask.
+ # Sizes are [batch_size, 1, 1, to_seq_length]
+ # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
+ # this attention mask is more simple than the triangular masking of causal attention
+ # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
+ extended_attention_mask = tf.reshape(attention_mask, (input_shape[0], 1, 1, input_shape[1]))
+
+ # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
+ # masked positions, this operation will create a tensor which is 0.0 for
+ # positions we want to attend and -10000.0 for masked positions.
+ # Since we are adding it to the raw scores before the softmax, this is
+ # effectively the same as removing these entirely.
+ extended_attention_mask = tf.cast(extended_attention_mask, dtype=embedding_output.dtype)
+ one_cst = tf.constant(1.0, dtype=embedding_output.dtype)
+ ten_thousand_cst = tf.constant(-10000.0, dtype=embedding_output.dtype)
+ extended_attention_mask = tf.multiply(tf.subtract(one_cst, extended_attention_mask), ten_thousand_cst)
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ if head_mask is not None:
+ raise NotImplementedError
+ else:
+ head_mask = [None] * self.config.num_hidden_layers
+
+ encoder_outputs = self.encoder(
+ hidden_states=embedding_output,
+ attention_mask=extended_attention_mask,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ training=training,
+ )
+
+ sequence_output = encoder_outputs[0]
+ pooled_output = self.pooler(inputs=sequence_output[:, 0]) if self.pooler is not None else None
+
+ if not return_dict:
+ return (
+ sequence_output,
+ pooled_output,
+ ) + encoder_outputs[1:]
+
+ return TFBaseModelOutputWithPooling(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+ def build(self, input_shape=None):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "embeddings", None) is not None:
+ with tf.name_scope(self.embeddings.name):
+ self.embeddings.build(None)
+ if getattr(self, "encoder", None) is not None:
+ with tf.name_scope(self.encoder.name):
+ self.encoder.build(None)
+ if getattr(self, "pooler", None) is not None:
+ with tf.name_scope(self.pooler.name):
+ self.pooler.build([None, None, self.config.hidden_size])
+
+
+@dataclass
+class TFAlbertForPreTrainingOutput(ModelOutput):
+ """
+ Output type of [`TFAlbertForPreTraining`].
+
+ Args:
+ prediction_logits (`tf.Tensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ sop_logits (`tf.Tensor` of shape `(batch_size, 2)`):
+ Prediction scores of the next sequence prediction (classification) head (scores of True/False continuation
+ before SoftMax).
+ hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
+ `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the initial embedding outputs.
+ attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `tf.Tensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[tf.Tensor] = None
+ prediction_logits: Optional[tf.Tensor] = None
+ sop_logits: Optional[tf.Tensor] = None
+ hidden_states: Tuple[tf.Tensor] | None = None
+ attentions: Tuple[tf.Tensor] | None = None
+
+
+ALBERT_START_DOCSTRING = r"""
+
+ This model inherits from [`TFPreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a [keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model) subclass. Use it
+ as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and
+ behavior.
+
+
+
+ TensorFlow models and layers in `transformers` accept two formats as input:
+
+ - having all inputs as keyword arguments (like PyTorch models), or
+ - having all inputs as a list, tuple or dict in the first positional argument.
+
+ The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
+ and layers. Because of this support, when using methods like `model.fit()` things should "just work" for you - just
+ pass your inputs and labels in any format that `model.fit()` supports! If, however, you want to use the second
+ format outside of Keras methods like `fit()` and `predict()`, such as when creating your own layers or models with
+ the Keras `Functional` API, there are three possibilities you can use to gather all the input Tensors in the first
+ positional argument:
+
+ - a single Tensor with `input_ids` only and nothing else: `model(input_ids)`
+ - a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
+ `model([input_ids, attention_mask])` or `model([input_ids, attention_mask, token_type_ids])`
+ - a dictionary with one or several input Tensors associated to the input names given in the docstring:
+ `model({"input_ids": input_ids, "token_type_ids": token_type_ids})`
+
+ Note that when creating models and layers with
+ [subclassing](https://keras.io/guides/making_new_layers_and_models_via_subclassing/) then you don't need to worry
+ about any of this, as you can just pass inputs like you would to any other Python function!
+
+
+
+ Args:
+ config ([`AlbertConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+ALBERT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`Numpy array` or `tf.Tensor` of shape `({0})`):
+ Indices of input sequence tokens in the vocabulary.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.__call__`] and
+ [`PreTrainedTokenizer.encode`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`Numpy array` or `tf.Tensor` of shape `({0})`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ token_type_ids (`Numpy array` or `tf.Tensor` of shape `({0})`, *optional*):
+ Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
+ 1]`:
+
+ - 0 corresponds to a *sentence A* token,
+ - 1 corresponds to a *sentence B* token.
+
+ [What are token type IDs?](../glossary#token-type-ids)
+ position_ids (`Numpy array` or `tf.Tensor` of shape `({0})`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ head_mask (`Numpy array` or `tf.Tensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ inputs_embeds (`tf.Tensor` of shape `({0}, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the
+ config will be used instead.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail. This argument can be used only in eager mode, in graph mode the value in the config will be
+ used instead.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple. This argument can be used in
+ eager mode, in graph mode the value will always be set to True.
+ training (`bool`, *optional*, defaults to `False`):
+ Whether or not to use the model in training mode (some modules like dropout modules have different
+ behaviors between training and evaluation).
+"""
+
+
+@add_start_docstrings(
+ "The bare Albert Model transformer outputting raw hidden-states without any specific head on top.",
+ ALBERT_START_DOCSTRING,
+)
+class TFAlbertModel(TFAlbertPreTrainedModel):
+ def __init__(self, config: AlbertConfig, *inputs, **kwargs):
+ super().__init__(config, *inputs, **kwargs)
+
+ self.albert = TFAlbertMainLayer(config, name="albert")
+
+ @unpack_inputs
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @add_code_sample_docstrings(
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=TFBaseModelOutputWithPooling,
+ config_class=_CONFIG_FOR_DOC,
+ )
+ def call(
+ self,
+ input_ids: TFModelInputType | None = None,
+ attention_mask: np.ndarray | tf.Tensor | None = None,
+ token_type_ids: np.ndarray | tf.Tensor | None = None,
+ position_ids: np.ndarray | tf.Tensor | None = None,
+ head_mask: np.ndarray | tf.Tensor | None = None,
+ inputs_embeds: np.ndarray | tf.Tensor | None = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ training: Optional[bool] = False,
+ ) -> Union[TFBaseModelOutputWithPooling, Tuple[tf.Tensor]]:
+ outputs = self.albert(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ training=training,
+ )
+
+ return outputs
+
+ def build(self, input_shape=None):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "albert", None) is not None:
+ with tf.name_scope(self.albert.name):
+ self.albert.build(None)
+
+
+@add_start_docstrings(
+ """
+ Albert Model with two heads on top for pretraining: a `masked language modeling` head and a `sentence order
+ prediction` (classification) head.
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class TFAlbertForPreTraining(TFAlbertPreTrainedModel, TFAlbertPreTrainingLoss):
+ # names with a '.' represents the authorized unexpected/missing layers when a TF model is loaded from a PT model
+ _keys_to_ignore_on_load_unexpected = [r"predictions.decoder.weight"]
+
+ def __init__(self, config: AlbertConfig, *inputs, **kwargs):
+ super().__init__(config, *inputs, **kwargs)
+
+ self.num_labels = config.num_labels
+
+ self.albert = TFAlbertMainLayer(config, name="albert")
+ self.predictions = TFAlbertMLMHead(config, input_embeddings=self.albert.embeddings, name="predictions")
+ self.sop_classifier = TFAlbertSOPHead(config, name="sop_classifier")
+
+ def get_lm_head(self) -> keras.layers.Layer:
+ return self.predictions
+
+ @unpack_inputs
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=TFAlbertForPreTrainingOutput, config_class=_CONFIG_FOR_DOC)
+ def call(
+ self,
+ input_ids: TFModelInputType | None = None,
+ attention_mask: np.ndarray | tf.Tensor | None = None,
+ token_type_ids: np.ndarray | tf.Tensor | None = None,
+ position_ids: np.ndarray | tf.Tensor | None = None,
+ head_mask: np.ndarray | tf.Tensor | None = None,
+ inputs_embeds: np.ndarray | tf.Tensor | None = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: np.ndarray | tf.Tensor | None = None,
+ sentence_order_label: np.ndarray | tf.Tensor | None = None,
+ training: Optional[bool] = False,
+ ) -> Union[TFAlbertForPreTrainingOutput, Tuple[tf.Tensor]]:
+ r"""
+ Return:
+
+ Example:
+
+ ```python
+ >>> import tensorflow as tf
+ >>> from transformers import AutoTokenizer, TFAlbertForPreTraining
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("albert/albert-base-v2")
+ >>> model = TFAlbertForPreTraining.from_pretrained("albert/albert-base-v2")
+
+ >>> input_ids = tf.constant(tokenizer.encode("Hello, my dog is cute", add_special_tokens=True))[None, :]
+ >>> # Batch size 1
+ >>> outputs = model(input_ids)
+
+ >>> prediction_logits = outputs.prediction_logits
+ >>> sop_logits = outputs.sop_logits
+ ```"""
+
+ outputs = self.albert(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ training=training,
+ )
+ sequence_output, pooled_output = outputs[:2]
+ prediction_scores = self.predictions(hidden_states=sequence_output)
+ sop_scores = self.sop_classifier(pooled_output=pooled_output, training=training)
+ total_loss = None
+
+ if labels is not None and sentence_order_label is not None:
+ d_labels = {"labels": labels}
+ d_labels["sentence_order_label"] = sentence_order_label
+ total_loss = self.hf_compute_loss(labels=d_labels, logits=(prediction_scores, sop_scores))
+
+ if not return_dict:
+ output = (prediction_scores, sop_scores) + outputs[2:]
+ return ((total_loss,) + output) if total_loss is not None else output
+
+ return TFAlbertForPreTrainingOutput(
+ loss=total_loss,
+ prediction_logits=prediction_scores,
+ sop_logits=sop_scores,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def build(self, input_shape=None):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "albert", None) is not None:
+ with tf.name_scope(self.albert.name):
+ self.albert.build(None)
+ if getattr(self, "predictions", None) is not None:
+ with tf.name_scope(self.predictions.name):
+ self.predictions.build(None)
+ if getattr(self, "sop_classifier", None) is not None:
+ with tf.name_scope(self.sop_classifier.name):
+ self.sop_classifier.build(None)
+
+
+class TFAlbertSOPHead(keras.layers.Layer):
+ def __init__(self, config: AlbertConfig, **kwargs):
+ super().__init__(**kwargs)
+
+ self.dropout = keras.layers.Dropout(rate=config.classifier_dropout_prob)
+ self.classifier = keras.layers.Dense(
+ units=config.num_labels,
+ kernel_initializer=get_initializer(config.initializer_range),
+ name="classifier",
+ )
+ self.config = config
+
+ def call(self, pooled_output: tf.Tensor, training: bool) -> tf.Tensor:
+ dropout_pooled_output = self.dropout(inputs=pooled_output, training=training)
+ logits = self.classifier(inputs=dropout_pooled_output)
+
+ return logits
+
+ def build(self, input_shape=None):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "classifier", None) is not None:
+ with tf.name_scope(self.classifier.name):
+ self.classifier.build([None, None, self.config.hidden_size])
+
+
+@add_start_docstrings("""Albert Model with a `language modeling` head on top.""", ALBERT_START_DOCSTRING)
+class TFAlbertForMaskedLM(TFAlbertPreTrainedModel, TFMaskedLanguageModelingLoss):
+ # names with a '.' represents the authorized unexpected/missing layers when a TF model is loaded from a PT model
+ _keys_to_ignore_on_load_unexpected = [r"pooler", r"predictions.decoder.weight"]
+
+ def __init__(self, config: AlbertConfig, *inputs, **kwargs):
+ super().__init__(config, *inputs, **kwargs)
+
+ self.albert = TFAlbertMainLayer(config, add_pooling_layer=False, name="albert")
+ self.predictions = TFAlbertMLMHead(config, input_embeddings=self.albert.embeddings, name="predictions")
+
+ def get_lm_head(self) -> keras.layers.Layer:
+ return self.predictions
+
+ @unpack_inputs
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @replace_return_docstrings(output_type=TFMaskedLMOutput, config_class=_CONFIG_FOR_DOC)
+ def call(
+ self,
+ input_ids: TFModelInputType | None = None,
+ attention_mask: np.ndarray | tf.Tensor | None = None,
+ token_type_ids: np.ndarray | tf.Tensor | None = None,
+ position_ids: np.ndarray | tf.Tensor | None = None,
+ head_mask: np.ndarray | tf.Tensor | None = None,
+ inputs_embeds: np.ndarray | tf.Tensor | None = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: np.ndarray | tf.Tensor | None = None,
+ training: Optional[bool] = False,
+ ) -> Union[TFMaskedLMOutput, Tuple[tf.Tensor]]:
+ r"""
+ labels (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
+ config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
+ loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> import tensorflow as tf
+ >>> from transformers import AutoTokenizer, TFAlbertForMaskedLM
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("albert/albert-base-v2")
+ >>> model = TFAlbertForMaskedLM.from_pretrained("albert/albert-base-v2")
+
+ >>> # add mask_token
+ >>> inputs = tokenizer(f"The capital of [MASK] is Paris.", return_tensors="tf")
+ >>> logits = model(**inputs).logits
+
+ >>> # retrieve index of [MASK]
+ >>> mask_token_index = tf.where(inputs.input_ids == tokenizer.mask_token_id)[0][1]
+ >>> predicted_token_id = tf.math.argmax(logits[0, mask_token_index], axis=-1)
+ >>> tokenizer.decode(predicted_token_id)
+ 'france'
+ ```
+
+ ```python
+ >>> labels = tokenizer("The capital of France is Paris.", return_tensors="tf")["input_ids"]
+ >>> labels = tf.where(inputs.input_ids == tokenizer.mask_token_id, labels, -100)
+ >>> outputs = model(**inputs, labels=labels)
+ >>> round(float(outputs.loss), 2)
+ 0.81
+ ```
+ """
+ outputs = self.albert(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ training=training,
+ )
+ sequence_output = outputs[0]
+ prediction_scores = self.predictions(hidden_states=sequence_output, training=training)
+ loss = None if labels is None else self.hf_compute_loss(labels=labels, logits=prediction_scores)
+
+ if not return_dict:
+ output = (prediction_scores,) + outputs[2:]
+
+ return ((loss,) + output) if loss is not None else output
+
+ return TFMaskedLMOutput(
+ loss=loss,
+ logits=prediction_scores,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def build(self, input_shape=None):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "albert", None) is not None:
+ with tf.name_scope(self.albert.name):
+ self.albert.build(None)
+ if getattr(self, "predictions", None) is not None:
+ with tf.name_scope(self.predictions.name):
+ self.predictions.build(None)
+
+
+@add_start_docstrings(
+ """
+ Albert Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled
+ output) e.g. for GLUE tasks.
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class TFAlbertForSequenceClassification(TFAlbertPreTrainedModel, TFSequenceClassificationLoss):
+ # names with a '.' represents the authorized unexpected/missing layers when a TF model is loaded from a PT model
+ _keys_to_ignore_on_load_unexpected = [r"predictions"]
+ _keys_to_ignore_on_load_missing = [r"dropout"]
+
+ def __init__(self, config: AlbertConfig, *inputs, **kwargs):
+ super().__init__(config, *inputs, **kwargs)
+
+ self.num_labels = config.num_labels
+
+ self.albert = TFAlbertMainLayer(config, name="albert")
+ self.dropout = keras.layers.Dropout(rate=config.classifier_dropout_prob)
+ self.classifier = keras.layers.Dense(
+ units=config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="classifier"
+ )
+ self.config = config
+
+ @unpack_inputs
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @add_code_sample_docstrings(
+ checkpoint="vumichien/albert-base-v2-imdb",
+ output_type=TFSequenceClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output="'LABEL_1'",
+ expected_loss=0.12,
+ )
+ def call(
+ self,
+ input_ids: TFModelInputType | None = None,
+ attention_mask: np.ndarray | tf.Tensor | None = None,
+ token_type_ids: np.ndarray | tf.Tensor | None = None,
+ position_ids: np.ndarray | tf.Tensor | None = None,
+ head_mask: np.ndarray | tf.Tensor | None = None,
+ inputs_embeds: np.ndarray | tf.Tensor | None = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: np.ndarray | tf.Tensor | None = None,
+ training: Optional[bool] = False,
+ ) -> Union[TFSequenceClassifierOutput, Tuple[tf.Tensor]]:
+ r"""
+ labels (`tf.Tensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ outputs = self.albert(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ training=training,
+ )
+ pooled_output = outputs[1]
+ pooled_output = self.dropout(inputs=pooled_output, training=training)
+ logits = self.classifier(inputs=pooled_output)
+ loss = None if labels is None else self.hf_compute_loss(labels=labels, logits=logits)
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+
+ return ((loss,) + output) if loss is not None else output
+
+ return TFSequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def build(self, input_shape=None):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "albert", None) is not None:
+ with tf.name_scope(self.albert.name):
+ self.albert.build(None)
+ if getattr(self, "classifier", None) is not None:
+ with tf.name_scope(self.classifier.name):
+ self.classifier.build([None, None, self.config.hidden_size])
+
+
+@add_start_docstrings(
+ """
+ Albert Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
+ Named-Entity-Recognition (NER) tasks.
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class TFAlbertForTokenClassification(TFAlbertPreTrainedModel, TFTokenClassificationLoss):
+ # names with a '.' represents the authorized unexpected/missing layers when a TF model is loaded from a PT model
+ _keys_to_ignore_on_load_unexpected = [r"pooler", r"predictions"]
+ _keys_to_ignore_on_load_missing = [r"dropout"]
+
+ def __init__(self, config: AlbertConfig, *inputs, **kwargs):
+ super().__init__(config, *inputs, **kwargs)
+
+ self.num_labels = config.num_labels
+
+ self.albert = TFAlbertMainLayer(config, add_pooling_layer=False, name="albert")
+ classifier_dropout_prob = (
+ config.classifier_dropout_prob
+ if config.classifier_dropout_prob is not None
+ else config.hidden_dropout_prob
+ )
+ self.dropout = keras.layers.Dropout(rate=classifier_dropout_prob)
+ self.classifier = keras.layers.Dense(
+ units=config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="classifier"
+ )
+ self.config = config
+
+ @unpack_inputs
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @add_code_sample_docstrings(
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=TFTokenClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ )
+ def call(
+ self,
+ input_ids: TFModelInputType | None = None,
+ attention_mask: np.ndarray | tf.Tensor | None = None,
+ token_type_ids: np.ndarray | tf.Tensor | None = None,
+ position_ids: np.ndarray | tf.Tensor | None = None,
+ head_mask: np.ndarray | tf.Tensor | None = None,
+ inputs_embeds: np.ndarray | tf.Tensor | None = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: np.ndarray | tf.Tensor | None = None,
+ training: Optional[bool] = False,
+ ) -> Union[TFTokenClassifierOutput, Tuple[tf.Tensor]]:
+ r"""
+ labels (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the token classification loss. Indices should be in `[0, ..., config.num_labels - 1]`.
+ """
+ outputs = self.albert(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ training=training,
+ )
+ sequence_output = outputs[0]
+ sequence_output = self.dropout(inputs=sequence_output, training=training)
+ logits = self.classifier(inputs=sequence_output)
+ loss = None if labels is None else self.hf_compute_loss(labels=labels, logits=logits)
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+
+ return ((loss,) + output) if loss is not None else output
+
+ return TFTokenClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def build(self, input_shape=None):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "albert", None) is not None:
+ with tf.name_scope(self.albert.name):
+ self.albert.build(None)
+ if getattr(self, "classifier", None) is not None:
+ with tf.name_scope(self.classifier.name):
+ self.classifier.build([None, None, self.config.hidden_size])
+
+
+@add_start_docstrings(
+ """
+ Albert Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
+ layer on top of the hidden-states output to compute `span start logits` and `span end logits`).
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class TFAlbertForQuestionAnswering(TFAlbertPreTrainedModel, TFQuestionAnsweringLoss):
+ # names with a '.' represents the authorized unexpected/missing layers when a TF model is loaded from a PT model
+ _keys_to_ignore_on_load_unexpected = [r"pooler", r"predictions"]
+
+ def __init__(self, config: AlbertConfig, *inputs, **kwargs):
+ super().__init__(config, *inputs, **kwargs)
+
+ self.num_labels = config.num_labels
+
+ self.albert = TFAlbertMainLayer(config, add_pooling_layer=False, name="albert")
+ self.qa_outputs = keras.layers.Dense(
+ units=config.num_labels, kernel_initializer=get_initializer(config.initializer_range), name="qa_outputs"
+ )
+ self.config = config
+
+ @unpack_inputs
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
+ @add_code_sample_docstrings(
+ checkpoint="vumichien/albert-base-v2-squad2",
+ output_type=TFQuestionAnsweringModelOutput,
+ config_class=_CONFIG_FOR_DOC,
+ qa_target_start_index=12,
+ qa_target_end_index=13,
+ expected_output="'a nice puppet'",
+ expected_loss=7.36,
+ )
+ def call(
+ self,
+ input_ids: TFModelInputType | None = None,
+ attention_mask: np.ndarray | tf.Tensor | None = None,
+ token_type_ids: np.ndarray | tf.Tensor | None = None,
+ position_ids: np.ndarray | tf.Tensor | None = None,
+ head_mask: np.ndarray | tf.Tensor | None = None,
+ inputs_embeds: np.ndarray | tf.Tensor | None = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ start_positions: np.ndarray | tf.Tensor | None = None,
+ end_positions: np.ndarray | tf.Tensor | None = None,
+ training: Optional[bool] = False,
+ ) -> Union[TFQuestionAnsweringModelOutput, Tuple[tf.Tensor]]:
+ r"""
+ start_positions (`tf.Tensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the start of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+ end_positions (`tf.Tensor` of shape `(batch_size,)`, *optional*):
+ Labels for position (index) of the end of the labelled span for computing the token classification loss.
+ Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
+ are not taken into account for computing the loss.
+ """
+ outputs = self.albert(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ training=training,
+ )
+ sequence_output = outputs[0]
+ logits = self.qa_outputs(inputs=sequence_output)
+ start_logits, end_logits = tf.split(value=logits, num_or_size_splits=2, axis=-1)
+ start_logits = tf.squeeze(input=start_logits, axis=-1)
+ end_logits = tf.squeeze(input=end_logits, axis=-1)
+ loss = None
+
+ if start_positions is not None and end_positions is not None:
+ labels = {"start_position": start_positions}
+ labels["end_position"] = end_positions
+ loss = self.hf_compute_loss(labels=labels, logits=(start_logits, end_logits))
+
+ if not return_dict:
+ output = (start_logits, end_logits) + outputs[2:]
+
+ return ((loss,) + output) if loss is not None else output
+
+ return TFQuestionAnsweringModelOutput(
+ loss=loss,
+ start_logits=start_logits,
+ end_logits=end_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def build(self, input_shape=None):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "albert", None) is not None:
+ with tf.name_scope(self.albert.name):
+ self.albert.build(None)
+ if getattr(self, "qa_outputs", None) is not None:
+ with tf.name_scope(self.qa_outputs.name):
+ self.qa_outputs.build([None, None, self.config.hidden_size])
+
+
+@add_start_docstrings(
+ """
+ Albert Model with a multiple choice classification head on top (a linear layer on top of the pooled output and a
+ softmax) e.g. for RocStories/SWAG tasks.
+ """,
+ ALBERT_START_DOCSTRING,
+)
+class TFAlbertForMultipleChoice(TFAlbertPreTrainedModel, TFMultipleChoiceLoss):
+ # names with a '.' represents the authorized unexpected/missing layers when a TF model is loaded from a PT model
+ _keys_to_ignore_on_load_unexpected = [r"pooler", r"predictions"]
+ _keys_to_ignore_on_load_missing = [r"dropout"]
+
+ def __init__(self, config: AlbertConfig, *inputs, **kwargs):
+ super().__init__(config, *inputs, **kwargs)
+
+ self.albert = TFAlbertMainLayer(config, name="albert")
+ self.dropout = keras.layers.Dropout(rate=config.hidden_dropout_prob)
+ self.classifier = keras.layers.Dense(
+ units=1, kernel_initializer=get_initializer(config.initializer_range), name="classifier"
+ )
+ self.config = config
+
+ @unpack_inputs
+ @add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING.format("batch_size, num_choices, sequence_length"))
+ @add_code_sample_docstrings(
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=TFMultipleChoiceModelOutput,
+ config_class=_CONFIG_FOR_DOC,
+ )
+ def call(
+ self,
+ input_ids: TFModelInputType | None = None,
+ attention_mask: np.ndarray | tf.Tensor | None = None,
+ token_type_ids: np.ndarray | tf.Tensor | None = None,
+ position_ids: np.ndarray | tf.Tensor | None = None,
+ head_mask: np.ndarray | tf.Tensor | None = None,
+ inputs_embeds: np.ndarray | tf.Tensor | None = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ labels: np.ndarray | tf.Tensor | None = None,
+ training: Optional[bool] = False,
+ ) -> Union[TFMultipleChoiceModelOutput, Tuple[tf.Tensor]]:
+ r"""
+ labels (`tf.Tensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the multiple choice classification loss. Indices should be in `[0, ..., num_choices]`
+ where `num_choices` is the size of the second dimension of the input tensors. (See `input_ids` above)
+ """
+
+ if input_ids is not None:
+ num_choices = shape_list(input_ids)[1]
+ seq_length = shape_list(input_ids)[2]
+ else:
+ num_choices = shape_list(inputs_embeds)[1]
+ seq_length = shape_list(inputs_embeds)[2]
+
+ flat_input_ids = tf.reshape(input_ids, (-1, seq_length)) if input_ids is not None else None
+ flat_attention_mask = (
+ tf.reshape(tensor=attention_mask, shape=(-1, seq_length)) if attention_mask is not None else None
+ )
+ flat_token_type_ids = (
+ tf.reshape(tensor=token_type_ids, shape=(-1, seq_length)) if token_type_ids is not None else None
+ )
+ flat_position_ids = (
+ tf.reshape(tensor=position_ids, shape=(-1, seq_length)) if position_ids is not None else None
+ )
+ flat_inputs_embeds = (
+ tf.reshape(tensor=inputs_embeds, shape=(-1, seq_length, shape_list(inputs_embeds)[3]))
+ if inputs_embeds is not None
+ else None
+ )
+ outputs = self.albert(
+ input_ids=flat_input_ids,
+ attention_mask=flat_attention_mask,
+ token_type_ids=flat_token_type_ids,
+ position_ids=flat_position_ids,
+ head_mask=head_mask,
+ inputs_embeds=flat_inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ training=training,
+ )
+ pooled_output = outputs[1]
+ pooled_output = self.dropout(inputs=pooled_output, training=training)
+ logits = self.classifier(inputs=pooled_output)
+ reshaped_logits = tf.reshape(tensor=logits, shape=(-1, num_choices))
+ loss = None if labels is None else self.hf_compute_loss(labels=labels, logits=reshaped_logits)
+
+ if not return_dict:
+ output = (reshaped_logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return TFMultipleChoiceModelOutput(
+ loss=loss,
+ logits=reshaped_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def build(self, input_shape=None):
+ if self.built:
+ return
+ self.built = True
+ if getattr(self, "albert", None) is not None:
+ with tf.name_scope(self.albert.name):
+ self.albert.build(None)
+ if getattr(self, "classifier", None) is not None:
+ with tf.name_scope(self.classifier.name):
+ self.classifier.build([None, None, self.config.hidden_size])
+
+
+__all__ = [
+ "TFAlbertPreTrainedModel",
+ "TFAlbertModel",
+ "TFAlbertForPreTraining",
+ "TFAlbertForMaskedLM",
+ "TFAlbertForSequenceClassification",
+ "TFAlbertForTokenClassification",
+ "TFAlbertForQuestionAnswering",
+ "TFAlbertForMultipleChoice",
+ "TFAlbertMainLayer",
+]
diff --git a/docs/transformers/src/transformers/models/albert/tokenization_albert.py b/docs/transformers/src/transformers/models/albert/tokenization_albert.py
new file mode 100644
index 0000000000000000000000000000000000000000..7ecd9f907eb7b694e748094faf6ad145c388133d
--- /dev/null
+++ b/docs/transformers/src/transformers/models/albert/tokenization_albert.py
@@ -0,0 +1,350 @@
+# coding=utf-8
+# Copyright 2018 Google AI, Google Brain and the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Tokenization classes for ALBERT model."""
+
+import os
+import unicodedata
+from shutil import copyfile
+from typing import Any, Dict, List, Optional, Tuple
+
+import sentencepiece as spm
+
+from ...tokenization_utils import AddedToken, PreTrainedTokenizer
+from ...utils import logging
+from ...utils.import_utils import requires
+
+
+logger = logging.get_logger(__name__)
+VOCAB_FILES_NAMES = {"vocab_file": "spiece.model"}
+
+
+SPIECE_UNDERLINE = "▁"
+
+
+@requires(backends=("sentencepiece",))
+class AlbertTokenizer(PreTrainedTokenizer):
+ """
+ Construct an ALBERT tokenizer. Based on [SentencePiece](https://github.com/google/sentencepiece).
+
+ This tokenizer inherits from [`PreTrainedTokenizer`] which contains most of the main methods. Users should refer to
+ this superclass for more information regarding those methods.
+
+ Args:
+ vocab_file (`str`):
+ [SentencePiece](https://github.com/google/sentencepiece) file (generally has a *.spm* extension) that
+ contains the vocabulary necessary to instantiate a tokenizer.
+ do_lower_case (`bool`, *optional*, defaults to `True`):
+ Whether or not to lowercase the input when tokenizing.
+ remove_space (`bool`, *optional*, defaults to `True`):
+ Whether or not to strip the text when tokenizing (removing excess spaces before and after the string).
+ keep_accents (`bool`, *optional*, defaults to `False`):
+ Whether or not to keep accents when tokenizing.
+ bos_token (`str`, *optional*, defaults to `"[CLS]"`):
+ The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.
+
+
+
+ When building a sequence using special tokens, this is not the token that is used for the beginning of
+ sequence. The token used is the `cls_token`.
+
+
+
+ eos_token (`str`, *optional*, defaults to `"[SEP]"`):
+ The end of sequence token.
+
+
+
+ When building a sequence using special tokens, this is not the token that is used for the end of sequence.
+ The token used is the `sep_token`.
+
+
+
+ unk_token (`str`, *optional*, defaults to `""`):
+ The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
+ token instead.
+ sep_token (`str`, *optional*, defaults to `"[SEP]"`):
+ The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for
+ sequence classification or for a text and a question for question answering. It is also used as the last
+ token of a sequence built with special tokens.
+ pad_token (`str`, *optional*, defaults to `""`):
+ The token used for padding, for example when batching sequences of different lengths.
+ cls_token (`str`, *optional*, defaults to `"[CLS]"`):
+ The classifier token which is used when doing sequence classification (classification of the whole sequence
+ instead of per-token classification). It is the first token of the sequence when built with special tokens.
+ mask_token (`str`, *optional*, defaults to `"[MASK]"`):
+ The token used for masking values. This is the token used when training this model with masked language
+ modeling. This is the token which the model will try to predict.
+ sp_model_kwargs (`dict`, *optional*):
+ Will be passed to the `SentencePieceProcessor.__init__()` method. The [Python wrapper for
+ SentencePiece](https://github.com/google/sentencepiece/tree/master/python) can be used, among other things,
+ to set:
+
+ - `enable_sampling`: Enable subword regularization.
+ - `nbest_size`: Sampling parameters for unigram. Invalid for BPE-Dropout.
+
+ - `nbest_size = {0,1}`: No sampling is performed.
+ - `nbest_size > 1`: samples from the nbest_size results.
+ - `nbest_size < 0`: assuming that nbest_size is infinite and samples from the all hypothesis (lattice)
+ using forward-filtering-and-backward-sampling algorithm.
+
+ - `alpha`: Smoothing parameter for unigram sampling, and dropout probability of merge operations for
+ BPE-dropout.
+
+ Attributes:
+ sp_model (`SentencePieceProcessor`):
+ The *SentencePiece* processor that is used for every conversion (string, tokens and IDs).
+ """
+
+ vocab_files_names = VOCAB_FILES_NAMES
+
+ def __init__(
+ self,
+ vocab_file,
+ do_lower_case=True,
+ remove_space=True,
+ keep_accents=False,
+ bos_token="[CLS]",
+ eos_token="[SEP]",
+ unk_token="",
+ sep_token="[SEP]",
+ pad_token="",
+ cls_token="[CLS]",
+ mask_token="[MASK]",
+ sp_model_kwargs: Optional[Dict[str, Any]] = None,
+ **kwargs,
+ ) -> None:
+ # Mask token behave like a normal word, i.e. include the space before it and
+ # is included in the raw text, there should be a match in a non-normalized sentence.
+ mask_token = (
+ AddedToken(mask_token, lstrip=True, rstrip=False, normalized=False)
+ if isinstance(mask_token, str)
+ else mask_token
+ )
+
+ self.sp_model_kwargs = {} if sp_model_kwargs is None else sp_model_kwargs
+
+ self.do_lower_case = do_lower_case
+ self.remove_space = remove_space
+ self.keep_accents = keep_accents
+ self.vocab_file = vocab_file
+
+ self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
+ self.sp_model.Load(vocab_file)
+
+ super().__init__(
+ do_lower_case=do_lower_case,
+ remove_space=remove_space,
+ keep_accents=keep_accents,
+ bos_token=bos_token,
+ eos_token=eos_token,
+ unk_token=unk_token,
+ sep_token=sep_token,
+ pad_token=pad_token,
+ cls_token=cls_token,
+ mask_token=mask_token,
+ sp_model_kwargs=self.sp_model_kwargs,
+ **kwargs,
+ )
+
+ @property
+ def vocab_size(self) -> int:
+ return len(self.sp_model)
+
+ def get_vocab(self) -> Dict[str, int]:
+ vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
+ vocab.update(self.added_tokens_encoder)
+ return vocab
+
+ def __getstate__(self):
+ state = self.__dict__.copy()
+ state["sp_model"] = None
+ return state
+
+ def __setstate__(self, d):
+ self.__dict__ = d
+
+ # for backward compatibility
+ if not hasattr(self, "sp_model_kwargs"):
+ self.sp_model_kwargs = {}
+
+ self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
+ self.sp_model.Load(self.vocab_file)
+
+ def preprocess_text(self, inputs):
+ if self.remove_space:
+ outputs = " ".join(inputs.strip().split())
+ else:
+ outputs = inputs
+ outputs = outputs.replace("``", '"').replace("''", '"')
+
+ if not self.keep_accents:
+ outputs = unicodedata.normalize("NFKD", outputs)
+ outputs = "".join([c for c in outputs if not unicodedata.combining(c)])
+ if self.do_lower_case:
+ outputs = outputs.lower()
+
+ return outputs
+
+ def _tokenize(self, text: str) -> List[str]:
+ """Tokenize a string."""
+ text = self.preprocess_text(text)
+ pieces = self.sp_model.encode(text, out_type=str)
+ new_pieces = []
+ for piece in pieces:
+ if len(piece) > 1 and piece[-1] == str(",") and piece[-2].isdigit():
+ # Logic to handle special cases see https://github.com/google-research/bert/blob/master/README.md#tokenization
+ # `9,9` -> ['▁9', ',', '9'] instead of [`_9,`, '9']
+ cur_pieces = self.sp_model.EncodeAsPieces(piece[:-1].replace(SPIECE_UNDERLINE, ""))
+ if piece[0] != SPIECE_UNDERLINE and cur_pieces[0][0] == SPIECE_UNDERLINE:
+ if len(cur_pieces[0]) == 1:
+ cur_pieces = cur_pieces[1:]
+ else:
+ cur_pieces[0] = cur_pieces[0][1:]
+ cur_pieces.append(piece[-1])
+ new_pieces.extend(cur_pieces)
+ else:
+ new_pieces.append(piece)
+
+ return new_pieces
+
+ def _convert_token_to_id(self, token):
+ """Converts a token (str) in an id using the vocab."""
+ return self.sp_model.PieceToId(token)
+
+ def _convert_id_to_token(self, index):
+ """Converts an index (integer) in a token (str) using the vocab."""
+ return self.sp_model.IdToPiece(index)
+
+ def convert_tokens_to_string(self, tokens):
+ """Converts a sequence of tokens (string) in a single string."""
+ current_sub_tokens = []
+ out_string = ""
+ prev_is_special = False
+ for token in tokens:
+ # make sure that special tokens are not decoded using sentencepiece model
+ if token in self.all_special_tokens:
+ if not prev_is_special:
+ out_string += " "
+ out_string += self.sp_model.decode(current_sub_tokens) + token
+ prev_is_special = True
+ current_sub_tokens = []
+ else:
+ current_sub_tokens.append(token)
+ prev_is_special = False
+ out_string += self.sp_model.decode(current_sub_tokens)
+ return out_string.strip()
+
+ def build_inputs_with_special_tokens(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
+ ) -> List[int]:
+ """
+ Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
+ adding special tokens. An ALBERT sequence has the following format:
+
+ - single sequence: `[CLS] X [SEP]`
+ - pair of sequences: `[CLS] A [SEP] B [SEP]`
+
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs to which the special tokens will be added.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+
+ Returns:
+ `List[int]`: List of [input IDs](../glossary#input-ids) with the appropriate special tokens.
+ """
+ sep = [self.sep_token_id]
+ cls = [self.cls_token_id]
+ if token_ids_1 is None:
+ return cls + token_ids_0 + sep
+ return cls + token_ids_0 + sep + token_ids_1 + sep
+
+ def get_special_tokens_mask(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None, already_has_special_tokens: bool = False
+ ) -> List[int]:
+ """
+ Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
+ special tokens using the tokenizer `prepare_for_model` method.
+
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+ already_has_special_tokens (`bool`, *optional*, defaults to `False`):
+ Whether or not the token list is already formatted with special tokens for the model.
+
+ Returns:
+ `List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
+ """
+
+ if already_has_special_tokens:
+ return super().get_special_tokens_mask(
+ token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
+ )
+
+ if token_ids_1 is not None:
+ return [1] + ([0] * len(token_ids_0)) + [1] + ([0] * len(token_ids_1)) + [1]
+ return [1] + ([0] * len(token_ids_0)) + [1]
+
+ def create_token_type_ids_from_sequences(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
+ ) -> List[int]:
+ """
+ Create a mask from the two sequences passed to be used in a sequence-pair classification task. An ALBERT
+ sequence pair mask has the following format:
+
+ ```
+ 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
+ | first sequence | second sequence |
+ ```
+
+ If `token_ids_1` is `None`, this method only returns the first portion of the mask (0s).
+
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+
+ Returns:
+ `List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
+ """
+ sep = [self.sep_token_id]
+ cls = [self.cls_token_id]
+
+ if token_ids_1 is None:
+ return len(cls + token_ids_0 + sep) * [0]
+ return len(cls + token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]
+
+ def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
+ if not os.path.isdir(save_directory):
+ logger.error(f"Vocabulary path ({save_directory}) should be a directory")
+ return
+ out_vocab_file = os.path.join(
+ save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
+ )
+
+ if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file) and os.path.isfile(self.vocab_file):
+ copyfile(self.vocab_file, out_vocab_file)
+ elif not os.path.isfile(self.vocab_file):
+ with open(out_vocab_file, "wb") as fi:
+ content_spiece_model = self.sp_model.serialized_model_proto()
+ fi.write(content_spiece_model)
+
+ return (out_vocab_file,)
+
+
+__all__ = ["AlbertTokenizer"]
diff --git a/docs/transformers/src/transformers/models/albert/tokenization_albert_fast.py b/docs/transformers/src/transformers/models/albert/tokenization_albert_fast.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e7b110b0afad7e65fba7be2d951ee7a7fba4788
--- /dev/null
+++ b/docs/transformers/src/transformers/models/albert/tokenization_albert_fast.py
@@ -0,0 +1,212 @@
+# coding=utf-8
+# Copyright 2018 Google AI, Google Brain and the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Tokenization classes for ALBERT model."""
+
+import os
+from shutil import copyfile
+from typing import List, Optional, Tuple
+
+from ...tokenization_utils import AddedToken
+from ...tokenization_utils_fast import PreTrainedTokenizerFast
+from ...utils import is_sentencepiece_available, logging
+
+
+if is_sentencepiece_available():
+ from .tokenization_albert import AlbertTokenizer
+else:
+ AlbertTokenizer = None
+
+logger = logging.get_logger(__name__)
+VOCAB_FILES_NAMES = {"vocab_file": "spiece.model", "tokenizer_file": "tokenizer.json"}
+
+
+SPIECE_UNDERLINE = "▁"
+
+
+class AlbertTokenizerFast(PreTrainedTokenizerFast):
+ """
+ Construct a "fast" ALBERT tokenizer (backed by HuggingFace's *tokenizers* library). Based on
+ [Unigram](https://huggingface.co/docs/tokenizers/python/latest/components.html?highlight=unigram#models). This
+ tokenizer inherits from [`PreTrainedTokenizerFast`] which contains most of the main methods. Users should refer to
+ this superclass for more information regarding those methods
+
+ Args:
+ vocab_file (`str`):
+ [SentencePiece](https://github.com/google/sentencepiece) file (generally has a *.spm* extension) that
+ contains the vocabulary necessary to instantiate a tokenizer.
+ do_lower_case (`bool`, *optional*, defaults to `True`):
+ Whether or not to lowercase the input when tokenizing.
+ remove_space (`bool`, *optional*, defaults to `True`):
+ Whether or not to strip the text when tokenizing (removing excess spaces before and after the string).
+ keep_accents (`bool`, *optional*, defaults to `False`):
+ Whether or not to keep accents when tokenizing.
+ bos_token (`str`, *optional*, defaults to `"[CLS]"`):
+ The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token.
+
+
+
+ When building a sequence using special tokens, this is not the token that is used for the beginning of
+ sequence. The token used is the `cls_token`.
+
+
+
+ eos_token (`str`, *optional*, defaults to `"[SEP]"`):
+ The end of sequence token. .. note:: When building a sequence using special tokens, this is not the token
+ that is used for the end of sequence. The token used is the `sep_token`.
+ unk_token (`str`, *optional*, defaults to `""`):
+ The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
+ token instead.
+ sep_token (`str`, *optional*, defaults to `"[SEP]"`):
+ The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for
+ sequence classification or for a text and a question for question answering. It is also used as the last
+ token of a sequence built with special tokens.
+ pad_token (`str`, *optional*, defaults to `""`):
+ The token used for padding, for example when batching sequences of different lengths.
+ cls_token (`str`, *optional*, defaults to `"[CLS]"`):
+ The classifier token which is used when doing sequence classification (classification of the whole sequence
+ instead of per-token classification). It is the first token of the sequence when built with special tokens.
+ mask_token (`str`, *optional*, defaults to `"[MASK]"`):
+ The token used for masking values. This is the token used when training this model with masked language
+ modeling. This is the token which the model will try to predict.
+ """
+
+ vocab_files_names = VOCAB_FILES_NAMES
+ slow_tokenizer_class = AlbertTokenizer
+
+ def __init__(
+ self,
+ vocab_file=None,
+ tokenizer_file=None,
+ do_lower_case=True,
+ remove_space=True,
+ keep_accents=False,
+ bos_token="[CLS]",
+ eos_token="[SEP]",
+ unk_token="",
+ sep_token="[SEP]",
+ pad_token="",
+ cls_token="[CLS]",
+ mask_token="[MASK]",
+ **kwargs,
+ ):
+ # Mask token behave like a normal word, i.e. include the space before it and
+ # is included in the raw text, there should be a match in a non-normalized sentence.
+ mask_token = (
+ AddedToken(mask_token, lstrip=True, rstrip=False, normalized=False)
+ if isinstance(mask_token, str)
+ else mask_token
+ )
+
+ super().__init__(
+ vocab_file,
+ tokenizer_file=tokenizer_file,
+ do_lower_case=do_lower_case,
+ remove_space=remove_space,
+ keep_accents=keep_accents,
+ bos_token=bos_token,
+ eos_token=eos_token,
+ unk_token=unk_token,
+ sep_token=sep_token,
+ pad_token=pad_token,
+ cls_token=cls_token,
+ mask_token=mask_token,
+ **kwargs,
+ )
+
+ self.do_lower_case = do_lower_case
+ self.remove_space = remove_space
+ self.keep_accents = keep_accents
+ self.vocab_file = vocab_file
+
+ @property
+ def can_save_slow_tokenizer(self) -> bool:
+ return os.path.isfile(self.vocab_file) if self.vocab_file else False
+
+ def build_inputs_with_special_tokens(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
+ ) -> List[int]:
+ """
+ Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
+ adding special tokens. An ALBERT sequence has the following format:
+
+ - single sequence: `[CLS] X [SEP]`
+ - pair of sequences: `[CLS] A [SEP] B [SEP]`
+
+ Args:
+ token_ids_0 (`List[int]`):
+ List of IDs to which the special tokens will be added
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+
+ Returns:
+ `List[int]`: list of [input IDs](../glossary#input-ids) with the appropriate special tokens.
+ """
+ sep = [self.sep_token_id]
+ cls = [self.cls_token_id]
+ if token_ids_1 is None:
+ return cls + token_ids_0 + sep
+ return cls + token_ids_0 + sep + token_ids_1 + sep
+
+ def create_token_type_ids_from_sequences(
+ self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
+ ) -> List[int]:
+ """
+ Creates a mask from the two sequences passed to be used in a sequence-pair classification task. An ALBERT
+ sequence pair mask has the following format:
+
+ ```
+ 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
+ | first sequence | second sequence |
+ ```
+
+ if token_ids_1 is None, only returns the first portion of the mask (0s).
+
+ Args:
+ token_ids_0 (`List[int]`):
+ List of ids.
+ token_ids_1 (`List[int]`, *optional*):
+ Optional second list of IDs for sequence pairs.
+
+ Returns:
+ `List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
+ """
+ sep = [self.sep_token_id]
+ cls = [self.cls_token_id]
+
+ if token_ids_1 is None:
+ return len(cls + token_ids_0 + sep) * [0]
+ return len(cls + token_ids_0 + sep) * [0] + len(token_ids_1 + sep) * [1]
+
+ def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
+ if not self.can_save_slow_tokenizer:
+ raise ValueError(
+ "Your fast tokenizer does not have the necessary information to save the vocabulary for a slow "
+ "tokenizer."
+ )
+
+ if not os.path.isdir(save_directory):
+ logger.error(f"Vocabulary path ({save_directory}) should be a directory")
+ return
+ out_vocab_file = os.path.join(
+ save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
+ )
+
+ if os.path.abspath(self.vocab_file) != os.path.abspath(out_vocab_file):
+ copyfile(self.vocab_file, out_vocab_file)
+
+ return (out_vocab_file,)
+
+
+__all__ = ["AlbertTokenizerFast"]
diff --git a/docs/transformers/src/transformers/models/align/__init__.py b/docs/transformers/src/transformers/models/align/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..aaa64dfb6064b10e820fca01e9e632aa7ecd68c6
--- /dev/null
+++ b/docs/transformers/src/transformers/models/align/__init__.py
@@ -0,0 +1,28 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import _LazyModule
+from ...utils.import_utils import define_import_structure
+
+
+if TYPE_CHECKING:
+ from .configuration_align import *
+ from .modeling_align import *
+ from .processing_align import *
+else:
+ import sys
+
+ _file = globals()["__file__"]
+ sys.modules[__name__] = _LazyModule(__name__, _file, define_import_structure(_file), module_spec=__spec__)
diff --git a/docs/transformers/src/transformers/models/align/configuration_align.py b/docs/transformers/src/transformers/models/align/configuration_align.py
new file mode 100644
index 0000000000000000000000000000000000000000..a22ab1dc40f8d0d147e5f98f122a64e53bf18fcc
--- /dev/null
+++ b/docs/transformers/src/transformers/models/align/configuration_align.py
@@ -0,0 +1,349 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""ALIGN model configuration"""
+
+from typing import TYPE_CHECKING, List
+
+
+if TYPE_CHECKING:
+ pass
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class AlignTextConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`AlignTextModel`]. It is used to instantiate a
+ ALIGN text encoder according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the text encoder of the ALIGN
+ [kakaobrain/align-base](https://huggingface.co/kakaobrain/align-base) architecture. The default values here are
+ copied from BERT.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 30522):
+ Vocabulary size of the Align Text model. Defines the number of different tokens that can be represented by
+ the `inputs_ids` passed when calling [`AlignTextModel`].
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (often named feed-forward) layer in the Transformer encoder.
+ hidden_act (`str` or `Callable`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"silu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout ratio for the attention probabilities.
+ max_position_embeddings (`int`, *optional*, defaults to 512):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ just in case (e.g., 512 or 1024 or 2048).
+ type_vocab_size (`int`, *optional*, defaults to 2):
+ The vocabulary size of the `token_type_ids` passed when calling [`AlignTextModel`].
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ pad_token_id (`int`, *optional*, defaults to 0):
+ Padding token id.
+ position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
+ Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
+ positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
+ with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+
+ Example:
+
+ ```python
+ >>> from transformers import AlignTextConfig, AlignTextModel
+
+ >>> # Initializing a AlignTextConfig with kakaobrain/align-base style configuration
+ >>> configuration = AlignTextConfig()
+
+ >>> # Initializing a AlignTextModel (with random weights) from the kakaobrain/align-base style configuration
+ >>> model = AlignTextModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "align_text_model"
+ base_config_key = "text_config"
+
+ def __init__(
+ self,
+ vocab_size=30522,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=2,
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ pad_token_id=0,
+ position_embedding_type="absolute",
+ use_cache=True,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.hidden_act = hidden_act
+ self.intermediate_size = intermediate_size
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.position_embedding_type = position_embedding_type
+ self.use_cache = use_cache
+ self.pad_token_id = pad_token_id
+
+
+class AlignVisionConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`AlignVisionModel`]. It is used to instantiate a
+ ALIGN vision encoder according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the vision encoder of the ALIGN
+ [kakaobrain/align-base](https://huggingface.co/kakaobrain/align-base) architecture. The default values are copied
+ from EfficientNet (efficientnet-b7)
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of input channels.
+ image_size (`int`, *optional*, defaults to 600):
+ The input image size.
+ width_coefficient (`float`, *optional*, defaults to 2.0):
+ Scaling coefficient for network width at each stage.
+ depth_coefficient (`float`, *optional*, defaults to 3.1):
+ Scaling coefficient for network depth at each stage.
+ depth_divisor `int`, *optional*, defaults to 8):
+ A unit of network width.
+ kernel_sizes (`List[int]`, *optional*, defaults to `[3, 3, 5, 3, 5, 5, 3]`):
+ List of kernel sizes to be used in each block.
+ in_channels (`List[int]`, *optional*, defaults to `[32, 16, 24, 40, 80, 112, 192]`):
+ List of input channel sizes to be used in each block for convolutional layers.
+ out_channels (`List[int]`, *optional*, defaults to `[16, 24, 40, 80, 112, 192, 320]`):
+ List of output channel sizes to be used in each block for convolutional layers.
+ depthwise_padding (`List[int]`, *optional*, defaults to `[]`):
+ List of block indices with square padding.
+ strides (`List[int]`, *optional*, defaults to `[1, 2, 2, 2, 1, 2, 1]`):
+ List of stride sizes to be used in each block for convolutional layers.
+ num_block_repeats (`List[int]`, *optional*, defaults to `[1, 2, 2, 3, 3, 4, 1]`):
+ List of the number of times each block is to repeated.
+ expand_ratios (`List[int]`, *optional*, defaults to `[1, 6, 6, 6, 6, 6, 6]`):
+ List of scaling coefficient of each block.
+ squeeze_expansion_ratio (`float`, *optional*, defaults to 0.25):
+ Squeeze expansion ratio.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in each block. If string, `"gelu"`, `"relu"`,
+ `"selu", `"gelu_new"`, `"silu"` and `"mish"` are supported.
+ hidden_dim (`int`, *optional*, defaults to 1280):
+ The hidden dimension of the layer before the classification head.
+ pooling_type (`str` or `function`, *optional*, defaults to `"mean"`):
+ Type of final pooling to be applied before the dense classification head. Available options are [`"mean"`,
+ `"max"`]
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ batch_norm_eps (`float`, *optional*, defaults to 1e-3):
+ The epsilon used by the batch normalization layers.
+ batch_norm_momentum (`float`, *optional*, defaults to 0.99):
+ The momentum used by the batch normalization layers.
+ drop_connect_rate (`float`, *optional*, defaults to 0.2):
+ The drop rate for skip connections.
+
+ Example:
+
+ ```python
+ >>> from transformers import AlignVisionConfig, AlignVisionModel
+
+ >>> # Initializing a AlignVisionConfig with kakaobrain/align-base style configuration
+ >>> configuration = AlignVisionConfig()
+
+ >>> # Initializing a AlignVisionModel (with random weights) from the kakaobrain/align-base style configuration
+ >>> model = AlignVisionModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "align_vision_model"
+ base_config_key = "vision_config"
+
+ def __init__(
+ self,
+ num_channels: int = 3,
+ image_size: int = 600,
+ width_coefficient: float = 2.0,
+ depth_coefficient: float = 3.1,
+ depth_divisor: int = 8,
+ kernel_sizes: List[int] = [3, 3, 5, 3, 5, 5, 3],
+ in_channels: List[int] = [32, 16, 24, 40, 80, 112, 192],
+ out_channels: List[int] = [16, 24, 40, 80, 112, 192, 320],
+ depthwise_padding: List[int] = [],
+ strides: List[int] = [1, 2, 2, 2, 1, 2, 1],
+ num_block_repeats: List[int] = [1, 2, 2, 3, 3, 4, 1],
+ expand_ratios: List[int] = [1, 6, 6, 6, 6, 6, 6],
+ squeeze_expansion_ratio: float = 0.25,
+ hidden_act: str = "swish",
+ hidden_dim: int = 2560,
+ pooling_type: str = "mean",
+ initializer_range: float = 0.02,
+ batch_norm_eps: float = 0.001,
+ batch_norm_momentum: float = 0.99,
+ drop_connect_rate: float = 0.2,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.width_coefficient = width_coefficient
+ self.depth_coefficient = depth_coefficient
+ self.depth_divisor = depth_divisor
+ self.kernel_sizes = kernel_sizes
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.depthwise_padding = depthwise_padding
+ self.strides = strides
+ self.num_block_repeats = num_block_repeats
+ self.expand_ratios = expand_ratios
+ self.squeeze_expansion_ratio = squeeze_expansion_ratio
+ self.hidden_act = hidden_act
+ self.hidden_dim = hidden_dim
+ self.pooling_type = pooling_type
+ self.initializer_range = initializer_range
+ self.batch_norm_eps = batch_norm_eps
+ self.batch_norm_momentum = batch_norm_momentum
+ self.drop_connect_rate = drop_connect_rate
+ self.num_hidden_layers = sum(num_block_repeats) * 4
+
+
+class AlignConfig(PretrainedConfig):
+ r"""
+ [`AlignConfig`] is the configuration class to store the configuration of a [`AlignModel`]. It is used to
+ instantiate a ALIGN model according to the specified arguments, defining the text model and vision model configs.
+ Instantiating a configuration with the defaults will yield a similar configuration to that of the ALIGN
+ [kakaobrain/align-base](https://huggingface.co/kakaobrain/align-base) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ text_config (`dict`, *optional*):
+ Dictionary of configuration options used to initialize [`AlignTextConfig`].
+ vision_config (`dict`, *optional*):
+ Dictionary of configuration options used to initialize [`AlignVisionConfig`].
+ projection_dim (`int`, *optional*, defaults to 640):
+ Dimensionality of text and vision projection layers.
+ temperature_init_value (`float`, *optional*, defaults to 1.0):
+ The initial value of the *temperature* parameter. Default is used as per the original ALIGN implementation.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ kwargs (*optional*):
+ Dictionary of keyword arguments.
+
+ Example:
+
+ ```python
+ >>> from transformers import AlignConfig, AlignModel
+
+ >>> # Initializing a AlignConfig with kakaobrain/align-base style configuration
+ >>> configuration = AlignConfig()
+
+ >>> # Initializing a AlignModel (with random weights) from the kakaobrain/align-base style configuration
+ >>> model = AlignModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+
+ >>> # We can also initialize a AlignConfig from a AlignTextConfig and a AlignVisionConfig
+ >>> from transformers import AlignTextConfig, AlignVisionConfig
+
+ >>> # Initializing ALIGN Text and Vision configurations
+ >>> config_text = AlignTextConfig()
+ >>> config_vision = AlignVisionConfig()
+
+ >>> config = AlignConfig.from_text_vision_configs(config_text, config_vision)
+ ```"""
+
+ model_type = "align"
+ sub_configs = {"text_config": AlignTextConfig, "vision_config": AlignVisionConfig}
+
+ def __init__(
+ self,
+ text_config=None,
+ vision_config=None,
+ projection_dim=640,
+ temperature_init_value=1.0,
+ initializer_range=0.02,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ if text_config is None:
+ text_config = {}
+ logger.info("text_config is None. Initializing the AlignTextConfig with default values.")
+
+ if vision_config is None:
+ vision_config = {}
+ logger.info("vision_config is None. Initializing the AlignVisionConfig with default values.")
+
+ self.text_config = AlignTextConfig(**text_config)
+ self.vision_config = AlignVisionConfig(**vision_config)
+
+ self.projection_dim = projection_dim
+ self.temperature_init_value = temperature_init_value
+ self.initializer_range = initializer_range
+
+ @classmethod
+ def from_text_vision_configs(cls, text_config: AlignTextConfig, vision_config: AlignVisionConfig, **kwargs):
+ r"""
+ Instantiate a [`AlignConfig`] (or a derived class) from align text model configuration and align vision model
+ configuration.
+
+ Returns:
+ [`AlignConfig`]: An instance of a configuration object
+ """
+
+ return cls(text_config=text_config.to_dict(), vision_config=vision_config.to_dict(), **kwargs)
+
+
+__all__ = ["AlignTextConfig", "AlignVisionConfig", "AlignConfig"]
diff --git a/docs/transformers/src/transformers/models/align/convert_align_tf_to_hf.py b/docs/transformers/src/transformers/models/align/convert_align_tf_to_hf.py
new file mode 100644
index 0000000000000000000000000000000000000000..610db8482f91628164f2f48ea948ed357ac5ea93
--- /dev/null
+++ b/docs/transformers/src/transformers/models/align/convert_align_tf_to_hf.py
@@ -0,0 +1,389 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert ALIGN checkpoints from the original repository."""
+
+import argparse
+import os
+
+import align
+import numpy as np
+import requests
+import tensorflow as tf
+import torch
+from PIL import Image
+from tokenizer import Tokenizer
+
+from transformers import (
+ AlignConfig,
+ AlignModel,
+ AlignProcessor,
+ BertConfig,
+ BertTokenizer,
+ EfficientNetConfig,
+ EfficientNetImageProcessor,
+)
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+def preprocess(image):
+ image = tf.image.resize(image, (346, 346))
+ image = tf.image.crop_to_bounding_box(image, (346 - 289) // 2, (346 - 289) // 2, 289, 289)
+ return image
+
+
+def get_align_config():
+ vision_config = EfficientNetConfig.from_pretrained("google/efficientnet-b7")
+ vision_config.image_size = 289
+ vision_config.hidden_dim = 640
+ vision_config.id2label = {"0": "LABEL_0", "1": "LABEL_1"}
+ vision_config.label2id = {"LABEL_0": 0, "LABEL_1": 1}
+ vision_config.depthwise_padding = []
+
+ text_config = BertConfig()
+ config = AlignConfig.from_text_vision_configs(
+ text_config=text_config, vision_config=vision_config, projection_dim=640
+ )
+ return config
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ im = Image.open(requests.get(url, stream=True).raw)
+ return im
+
+
+def get_processor():
+ image_processor = EfficientNetImageProcessor(
+ do_center_crop=True,
+ rescale_factor=1 / 127.5,
+ rescale_offset=True,
+ do_normalize=False,
+ include_top=False,
+ resample=Image.BILINEAR,
+ )
+ tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+ tokenizer.model_max_length = 64
+ processor = AlignProcessor(image_processor=image_processor, tokenizer=tokenizer)
+ return processor
+
+
+# here we list all keys to be renamed (original name on the left, our name on the right)
+def rename_keys(original_param_names):
+ # EfficientNet image encoder
+ block_names = [v.split("_")[0].split("block")[1] for v in original_param_names if v.startswith("block")]
+ block_names = list(set(block_names))
+ block_names = sorted(block_names)
+ num_blocks = len(block_names)
+ block_name_mapping = {b: str(i) for b, i in zip(block_names, range(num_blocks))}
+
+ rename_keys = []
+ rename_keys.append(("stem_conv/kernel:0", "embeddings.convolution.weight"))
+ rename_keys.append(("stem_bn/gamma:0", "embeddings.batchnorm.weight"))
+ rename_keys.append(("stem_bn/beta:0", "embeddings.batchnorm.bias"))
+ rename_keys.append(("stem_bn/moving_mean:0", "embeddings.batchnorm.running_mean"))
+ rename_keys.append(("stem_bn/moving_variance:0", "embeddings.batchnorm.running_var"))
+
+ for b in block_names:
+ hf_b = block_name_mapping[b]
+ rename_keys.append((f"block{b}_expand_conv/kernel:0", f"encoder.blocks.{hf_b}.expansion.expand_conv.weight"))
+ rename_keys.append((f"block{b}_expand_bn/gamma:0", f"encoder.blocks.{hf_b}.expansion.expand_bn.weight"))
+ rename_keys.append((f"block{b}_expand_bn/beta:0", f"encoder.blocks.{hf_b}.expansion.expand_bn.bias"))
+ rename_keys.append(
+ (f"block{b}_expand_bn/moving_mean:0", f"encoder.blocks.{hf_b}.expansion.expand_bn.running_mean")
+ )
+ rename_keys.append(
+ (f"block{b}_expand_bn/moving_variance:0", f"encoder.blocks.{hf_b}.expansion.expand_bn.running_var")
+ )
+ rename_keys.append(
+ (f"block{b}_dwconv/depthwise_kernel:0", f"encoder.blocks.{hf_b}.depthwise_conv.depthwise_conv.weight")
+ )
+ rename_keys.append((f"block{b}_bn/gamma:0", f"encoder.blocks.{hf_b}.depthwise_conv.depthwise_norm.weight"))
+ rename_keys.append((f"block{b}_bn/beta:0", f"encoder.blocks.{hf_b}.depthwise_conv.depthwise_norm.bias"))
+ rename_keys.append(
+ (f"block{b}_bn/moving_mean:0", f"encoder.blocks.{hf_b}.depthwise_conv.depthwise_norm.running_mean")
+ )
+ rename_keys.append(
+ (f"block{b}_bn/moving_variance:0", f"encoder.blocks.{hf_b}.depthwise_conv.depthwise_norm.running_var")
+ )
+
+ rename_keys.append((f"block{b}_se_reduce/kernel:0", f"encoder.blocks.{hf_b}.squeeze_excite.reduce.weight"))
+ rename_keys.append((f"block{b}_se_reduce/bias:0", f"encoder.blocks.{hf_b}.squeeze_excite.reduce.bias"))
+ rename_keys.append((f"block{b}_se_expand/kernel:0", f"encoder.blocks.{hf_b}.squeeze_excite.expand.weight"))
+ rename_keys.append((f"block{b}_se_expand/bias:0", f"encoder.blocks.{hf_b}.squeeze_excite.expand.bias"))
+ rename_keys.append(
+ (f"block{b}_project_conv/kernel:0", f"encoder.blocks.{hf_b}.projection.project_conv.weight")
+ )
+ rename_keys.append((f"block{b}_project_bn/gamma:0", f"encoder.blocks.{hf_b}.projection.project_bn.weight"))
+ rename_keys.append((f"block{b}_project_bn/beta:0", f"encoder.blocks.{hf_b}.projection.project_bn.bias"))
+ rename_keys.append(
+ (f"block{b}_project_bn/moving_mean:0", f"encoder.blocks.{hf_b}.projection.project_bn.running_mean")
+ )
+ rename_keys.append(
+ (f"block{b}_project_bn/moving_variance:0", f"encoder.blocks.{hf_b}.projection.project_bn.running_var")
+ )
+
+ key_mapping = {}
+ for item in rename_keys:
+ if item[0] in original_param_names:
+ key_mapping[item[0]] = "vision_model." + item[1]
+
+ # BERT text encoder
+ rename_keys = []
+ old = "tf_bert_model/bert"
+ new = "text_model"
+ for i in range(12):
+ rename_keys.append(
+ (
+ f"{old}/encoder/layer_._{i}/attention/self/query/kernel:0",
+ f"{new}.encoder.layer.{i}.attention.self.query.weight",
+ )
+ )
+ rename_keys.append(
+ (
+ f"{old}/encoder/layer_._{i}/attention/self/query/bias:0",
+ f"{new}.encoder.layer.{i}.attention.self.query.bias",
+ )
+ )
+ rename_keys.append(
+ (
+ f"{old}/encoder/layer_._{i}/attention/self/key/kernel:0",
+ f"{new}.encoder.layer.{i}.attention.self.key.weight",
+ )
+ )
+ rename_keys.append(
+ (
+ f"{old}/encoder/layer_._{i}/attention/self/key/bias:0",
+ f"{new}.encoder.layer.{i}.attention.self.key.bias",
+ )
+ )
+ rename_keys.append(
+ (
+ f"{old}/encoder/layer_._{i}/attention/self/value/kernel:0",
+ f"{new}.encoder.layer.{i}.attention.self.value.weight",
+ )
+ )
+ rename_keys.append(
+ (
+ f"{old}/encoder/layer_._{i}/attention/self/value/bias:0",
+ f"{new}.encoder.layer.{i}.attention.self.value.bias",
+ )
+ )
+ rename_keys.append(
+ (
+ f"{old}/encoder/layer_._{i}/attention/output/dense/kernel:0",
+ f"{new}.encoder.layer.{i}.attention.output.dense.weight",
+ )
+ )
+ rename_keys.append(
+ (
+ f"{old}/encoder/layer_._{i}/attention/output/dense/bias:0",
+ f"{new}.encoder.layer.{i}.attention.output.dense.bias",
+ )
+ )
+ rename_keys.append(
+ (
+ f"{old}/encoder/layer_._{i}/attention/output/LayerNorm/gamma:0",
+ f"{new}.encoder.layer.{i}.attention.output.LayerNorm.weight",
+ )
+ )
+ rename_keys.append(
+ (
+ f"{old}/encoder/layer_._{i}/attention/output/LayerNorm/beta:0",
+ f"{new}.encoder.layer.{i}.attention.output.LayerNorm.bias",
+ )
+ )
+ rename_keys.append(
+ (
+ f"{old}/encoder/layer_._{i}/intermediate/dense/kernel:0",
+ f"{new}.encoder.layer.{i}.intermediate.dense.weight",
+ )
+ )
+ rename_keys.append(
+ (
+ f"{old}/encoder/layer_._{i}/intermediate/dense/bias:0",
+ f"{new}.encoder.layer.{i}.intermediate.dense.bias",
+ )
+ )
+ rename_keys.append(
+ (f"{old}/encoder/layer_._{i}/output/dense/kernel:0", f"{new}.encoder.layer.{i}.output.dense.weight")
+ )
+ rename_keys.append(
+ (f"{old}/encoder/layer_._{i}/output/dense/bias:0", f"{new}.encoder.layer.{i}.output.dense.bias")
+ )
+ rename_keys.append(
+ (f"{old}/encoder/layer_._{i}/output/LayerNorm/gamma:0", f"{new}.encoder.layer.{i}.output.LayerNorm.weight")
+ )
+ rename_keys.append(
+ (f"{old}/encoder/layer_._{i}/output/LayerNorm/beta:0", f"{new}.encoder.layer.{i}.output.LayerNorm.bias")
+ )
+
+ rename_keys.append((f"{old}/embeddings/word_embeddings/weight:0", f"{new}.embeddings.word_embeddings.weight"))
+ rename_keys.append(
+ (f"{old}/embeddings/position_embeddings/embeddings:0", f"{new}.embeddings.position_embeddings.weight")
+ )
+ rename_keys.append(
+ (f"{old}/embeddings/token_type_embeddings/embeddings:0", f"{new}.embeddings.token_type_embeddings.weight")
+ )
+ rename_keys.append((f"{old}/embeddings/LayerNorm/gamma:0", f"{new}.embeddings.LayerNorm.weight"))
+ rename_keys.append((f"{old}/embeddings/LayerNorm/beta:0", f"{new}.embeddings.LayerNorm.bias"))
+
+ rename_keys.append((f"{old}/pooler/dense/kernel:0", f"{new}.pooler.dense.weight"))
+ rename_keys.append((f"{old}/pooler/dense/bias:0", f"{new}.pooler.dense.bias"))
+ rename_keys.append(("dense/kernel:0", "text_projection.weight"))
+ rename_keys.append(("dense/bias:0", "text_projection.bias"))
+ rename_keys.append(("dense/bias:0", "text_projection.bias"))
+ rename_keys.append(("temperature:0", "temperature"))
+
+ for item in rename_keys:
+ if item[0] in original_param_names:
+ key_mapping[item[0]] = item[1]
+ return key_mapping
+
+
+def replace_params(hf_params, tf_params, key_mapping):
+ list(hf_params.keys())
+
+ for key, value in tf_params.items():
+ if key not in key_mapping:
+ continue
+
+ hf_key = key_mapping[key]
+ if "_conv" in key and "kernel" in key:
+ new_hf_value = torch.from_numpy(value).permute(3, 2, 0, 1)
+ elif "embeddings" in key:
+ new_hf_value = torch.from_numpy(value)
+ elif "depthwise_kernel" in key:
+ new_hf_value = torch.from_numpy(value).permute(2, 3, 0, 1)
+ elif "kernel" in key:
+ new_hf_value = torch.from_numpy(np.transpose(value))
+ elif "temperature" in key:
+ new_hf_value = value
+ elif "bn/gamma" or "bn/beta" in key:
+ new_hf_value = torch.from_numpy(np.transpose(value)).squeeze()
+ else:
+ new_hf_value = torch.from_numpy(value)
+
+ # Replace HF parameters with original TF model parameters
+ hf_params[hf_key].copy_(new_hf_value)
+
+
+@torch.no_grad()
+def convert_align_checkpoint(checkpoint_path, pytorch_dump_folder_path, save_model, push_to_hub):
+ """
+ Copy/paste/tweak model's weights to our ALIGN structure.
+ """
+ # Load original model
+ seq_length = 64
+ tok = Tokenizer(seq_length)
+ original_model = align.Align("efficientnet-b7", "bert-base", 640, seq_length, tok.get_vocab_size())
+ original_model.compile()
+ original_model.load_weights(checkpoint_path)
+
+ tf_params = original_model.trainable_variables
+ tf_non_train_params = original_model.non_trainable_variables
+ tf_params = {param.name: param.numpy() for param in tf_params}
+ for param in tf_non_train_params:
+ tf_params[param.name] = param.numpy()
+ tf_param_names = list(tf_params.keys())
+
+ # Load HuggingFace model
+ config = get_align_config()
+ hf_model = AlignModel(config).eval()
+ hf_params = hf_model.state_dict()
+
+ # Create src-to-dst parameter name mapping dictionary
+ print("Converting parameters...")
+ key_mapping = rename_keys(tf_param_names)
+ replace_params(hf_params, tf_params, key_mapping)
+
+ # Initialize processor
+ processor = get_processor()
+ inputs = processor(
+ images=prepare_img(), text="A picture of a cat", padding="max_length", max_length=64, return_tensors="pt"
+ )
+
+ # HF model inference
+ hf_model.eval()
+ with torch.no_grad():
+ outputs = hf_model(**inputs)
+
+ hf_image_features = outputs.image_embeds.detach().numpy()
+ hf_text_features = outputs.text_embeds.detach().numpy()
+
+ # Original model inference
+ original_model.trainable = False
+ tf_image_processor = EfficientNetImageProcessor(
+ do_center_crop=True,
+ do_rescale=False,
+ do_normalize=False,
+ include_top=False,
+ resample=Image.BILINEAR,
+ )
+ image = tf_image_processor(images=prepare_img(), return_tensors="tf", data_format="channels_last")["pixel_values"]
+ text = tok(tf.constant(["A picture of a cat"]))
+
+ image_features = original_model.image_encoder(image, training=False)
+ text_features = original_model.text_encoder(text, training=False)
+
+ image_features = tf.nn.l2_normalize(image_features, axis=-1)
+ text_features = tf.nn.l2_normalize(text_features, axis=-1)
+
+ # Check whether original and HF model outputs match -> np.allclose
+ if not np.allclose(image_features, hf_image_features, atol=1e-3):
+ raise ValueError("The predicted image features are not the same.")
+ if not np.allclose(text_features, hf_text_features, atol=1e-3):
+ raise ValueError("The predicted text features are not the same.")
+ print("Model outputs match!")
+
+ if save_model:
+ # Create folder to save model
+ if not os.path.isdir(pytorch_dump_folder_path):
+ os.mkdir(pytorch_dump_folder_path)
+ # Save converted model and image processor
+ hf_model.save_pretrained(pytorch_dump_folder_path)
+ processor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ # Push model and image processor to hub
+ print("Pushing converted ALIGN to the hub...")
+ processor.push_to_hub("align-base")
+ hf_model.push_to_hub("align-base")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--checkpoint_path",
+ default="./weights/model-weights",
+ type=str,
+ help="Path to the pretrained TF ALIGN checkpoint.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path",
+ default="hf_model",
+ type=str,
+ help="Path to the output PyTorch model directory.",
+ )
+ parser.add_argument("--save_model", action="store_true", help="Save model to local")
+ parser.add_argument("--push_to_hub", action="store_true", help="Push model and image processor to the hub")
+
+ args = parser.parse_args()
+ convert_align_checkpoint(args.checkpoint_path, args.pytorch_dump_folder_path, args.save_model, args.push_to_hub)
diff --git a/docs/transformers/src/transformers/models/align/modeling_align.py b/docs/transformers/src/transformers/models/align/modeling_align.py
new file mode 100644
index 0000000000000000000000000000000000000000..a007b7a7c6d698977369255162c732502b966269
--- /dev/null
+++ b/docs/transformers/src/transformers/models/align/modeling_align.py
@@ -0,0 +1,1641 @@
+# coding=utf-8
+# Copyright 2023 The Google Research Team Authors and The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch ALIGN model."""
+
+import math
+from dataclasses import dataclass
+from typing import Any, Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+
+from ...activations import ACT2FN
+from ...modeling_outputs import (
+ BaseModelOutputWithNoAttention,
+ BaseModelOutputWithPastAndCrossAttentions,
+ BaseModelOutputWithPoolingAndCrossAttentions,
+ BaseModelOutputWithPoolingAndNoAttention,
+)
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import apply_chunking_to_forward, find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+from .configuration_align import AlignConfig, AlignTextConfig, AlignVisionConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = "kakaobrain/align-base"
+_CONFIG_FOR_DOC = "AlignConfig"
+
+
+ALIGN_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`AlignConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+ALIGN_TEXT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
+ 1]`:
+
+ - 0 corresponds to a *sentence A* token,
+ - 1 corresponds to a *sentence B* token.
+
+ [What are token type IDs?](../glossary#token-type-ids)
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+ALIGN_VISION_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
+ [`AutoImageProcessor`]. See [`EfficientNetImageProcessor.__call__`] for details.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+ALIGN_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
+ Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
+ 1]`:
+
+ - 0 corresponds to a *sentence A* token,
+ - 1 corresponds to a *sentence B* token.
+
+ [What are token type IDs?](../glossary#token-type-ids)
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
+ [`AutoImageProcessor`]. See [`EfficientNetImageProcessor.__call__`] for details.
+ return_loss (`bool`, *optional*):
+ Whether or not to return the contrastive loss.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@dataclass
+class AlignVisionModelOutput(ModelOutput):
+ """
+ Base class for vision model's outputs that also contains image embeddings of the pooling of the last hidden states.
+
+ Args:
+ image_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
+ The image embeddings obtained by applying the projection layer to the pooler_output.
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ """
+
+ image_embeds: Optional[torch.FloatTensor] = None
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class AlignTextModelOutput(ModelOutput):
+ """
+ Base class for text model's outputs that also contains a pooling of the last hidden states.
+
+ Args:
+ text_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
+ The text embeddings obtained by applying the projection layer to the pooler_output.
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ text_embeds: Optional[torch.FloatTensor] = None
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class AlignOutput(ModelOutput):
+ """
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
+ Contrastive loss for image-text similarity.
+ logits_per_image:(`torch.FloatTensor` of shape `(image_batch_size, text_batch_size)`):
+ The scaled dot product scores between `image_embeds` and `text_embeds`. This represents the image-text
+ similarity scores.
+ logits_per_text:(`torch.FloatTensor` of shape `(text_batch_size, image_batch_size)`):
+ The scaled dot product scores between `text_embeds` and `image_embeds`. This represents the text-image
+ similarity scores.
+ text_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
+ The text embeddings obtained by applying the projection layer to the pooled output of [`AlignTextModel`].
+ image_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
+ The output of [`AlignVisionModel`].
+ text_model_output(`BaseModelOutputWithPoolingAndCrossAttentions`):
+ The output of the [`AlignTextModel`].
+ vision_model_output(`BaseModelOutputWithPoolingAndNoAttention`):
+ The output of the [`AlignVisionModel`].
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits_per_image: Optional[torch.FloatTensor] = None
+ logits_per_text: Optional[torch.FloatTensor] = None
+ text_embeds: Optional[torch.FloatTensor] = None
+ image_embeds: Optional[torch.FloatTensor] = None
+ text_model_output: BaseModelOutputWithPoolingAndCrossAttentions = None
+ vision_model_output: BaseModelOutputWithPoolingAndNoAttention = None
+
+ def to_tuple(self) -> Tuple[Any]:
+ return tuple(
+ self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
+ for k in self.keys()
+ )
+
+
+# contrastive loss function, adapted from
+# https://sachinruk.github.io/blog/pytorch/pytorch%20lightning/loss%20function/gpu/2021/03/07/CLIP.html
+def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
+ return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device), label_smoothing=0.1)
+
+
+def align_loss(similarity: torch.Tensor) -> torch.Tensor:
+ caption_loss = contrastive_loss(similarity)
+ image_loss = contrastive_loss(similarity.t())
+ return (caption_loss + image_loss) / 2.0
+
+
+# Copied from transformers.models.efficientnet.modeling_efficientnet.round_filters with EfficientNet->AlignVision
+def round_filters(config: AlignVisionConfig, num_channels: int):
+ r"""
+ Round number of filters based on depth multiplier.
+ """
+ divisor = config.depth_divisor
+ num_channels *= config.width_coefficient
+ new_dim = max(divisor, int(num_channels + divisor / 2) // divisor * divisor)
+
+ # Make sure that round down does not go down by more than 10%.
+ if new_dim < 0.9 * num_channels:
+ new_dim += divisor
+
+ return int(new_dim)
+
+
+# Copied from transformers.models.efficientnet.modeling_efficientnet.correct_pad
+def correct_pad(kernel_size: Union[int, Tuple], adjust: bool = True):
+ r"""
+ Utility function to get the tuple padding value for the depthwise convolution.
+
+ Args:
+ kernel_size (`int` or `tuple`):
+ Kernel size of the convolution layers.
+ adjust (`bool`, *optional*, defaults to `True`):
+ Adjusts padding value to apply to right and bottom sides of the input.
+ """
+ if isinstance(kernel_size, int):
+ kernel_size = (kernel_size, kernel_size)
+
+ correct = (kernel_size[0] // 2, kernel_size[1] // 2)
+ if adjust:
+ return (correct[1] - 1, correct[1], correct[0] - 1, correct[0])
+ else:
+ return (correct[1], correct[1], correct[0], correct[0])
+
+
+# Copied from transformers.models.efficientnet.modeling_efficientnet.EfficientNetEmbeddings with EfficientNet->AlignVision
+class AlignVisionEmbeddings(nn.Module):
+ r"""
+ A module that corresponds to the stem module of the original work.
+ """
+
+ def __init__(self, config: AlignVisionConfig):
+ super().__init__()
+
+ self.out_dim = round_filters(config, 32)
+ self.padding = nn.ZeroPad2d(padding=(0, 1, 0, 1))
+ self.convolution = nn.Conv2d(
+ config.num_channels, self.out_dim, kernel_size=3, stride=2, padding="valid", bias=False
+ )
+ self.batchnorm = nn.BatchNorm2d(self.out_dim, eps=config.batch_norm_eps, momentum=config.batch_norm_momentum)
+ self.activation = ACT2FN[config.hidden_act]
+
+ def forward(self, pixel_values: torch.Tensor) -> torch.Tensor:
+ features = self.padding(pixel_values)
+ features = self.convolution(features)
+ features = self.batchnorm(features)
+ features = self.activation(features)
+
+ return features
+
+
+# Copied from transformers.models.efficientnet.modeling_efficientnet.EfficientNetDepthwiseConv2d with EfficientNet->AlignVision
+class AlignVisionDepthwiseConv2d(nn.Conv2d):
+ def __init__(
+ self,
+ in_channels,
+ depth_multiplier=1,
+ kernel_size=3,
+ stride=1,
+ padding=0,
+ dilation=1,
+ bias=True,
+ padding_mode="zeros",
+ ):
+ out_channels = in_channels * depth_multiplier
+ super().__init__(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ dilation=dilation,
+ groups=in_channels,
+ bias=bias,
+ padding_mode=padding_mode,
+ )
+
+
+# Copied from transformers.models.efficientnet.modeling_efficientnet.EfficientNetExpansionLayer with EfficientNet->AlignVision
+class AlignVisionExpansionLayer(nn.Module):
+ r"""
+ This corresponds to the expansion phase of each block in the original implementation.
+ """
+
+ def __init__(self, config: AlignVisionConfig, in_dim: int, out_dim: int, stride: int):
+ super().__init__()
+ self.expand_conv = nn.Conv2d(
+ in_channels=in_dim,
+ out_channels=out_dim,
+ kernel_size=1,
+ padding="same",
+ bias=False,
+ )
+ self.expand_bn = nn.BatchNorm2d(num_features=out_dim, eps=config.batch_norm_eps)
+ self.expand_act = ACT2FN[config.hidden_act]
+
+ def forward(self, hidden_states: torch.FloatTensor) -> torch.Tensor:
+ # Expand phase
+ hidden_states = self.expand_conv(hidden_states)
+ hidden_states = self.expand_bn(hidden_states)
+ hidden_states = self.expand_act(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.efficientnet.modeling_efficientnet.EfficientNetDepthwiseLayer with EfficientNet->AlignVision
+class AlignVisionDepthwiseLayer(nn.Module):
+ r"""
+ This corresponds to the depthwise convolution phase of each block in the original implementation.
+ """
+
+ def __init__(
+ self,
+ config: AlignVisionConfig,
+ in_dim: int,
+ stride: int,
+ kernel_size: int,
+ adjust_padding: bool,
+ ):
+ super().__init__()
+ self.stride = stride
+ conv_pad = "valid" if self.stride == 2 else "same"
+ padding = correct_pad(kernel_size, adjust=adjust_padding)
+
+ self.depthwise_conv_pad = nn.ZeroPad2d(padding=padding)
+ self.depthwise_conv = AlignVisionDepthwiseConv2d(
+ in_dim, kernel_size=kernel_size, stride=stride, padding=conv_pad, bias=False
+ )
+ self.depthwise_norm = nn.BatchNorm2d(
+ num_features=in_dim, eps=config.batch_norm_eps, momentum=config.batch_norm_momentum
+ )
+ self.depthwise_act = ACT2FN[config.hidden_act]
+
+ def forward(self, hidden_states: torch.FloatTensor) -> torch.Tensor:
+ # Depthwise convolution
+ if self.stride == 2:
+ hidden_states = self.depthwise_conv_pad(hidden_states)
+
+ hidden_states = self.depthwise_conv(hidden_states)
+ hidden_states = self.depthwise_norm(hidden_states)
+ hidden_states = self.depthwise_act(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.efficientnet.modeling_efficientnet.EfficientNetSqueezeExciteLayer with EfficientNet->AlignVision
+class AlignVisionSqueezeExciteLayer(nn.Module):
+ r"""
+ This corresponds to the Squeeze and Excitement phase of each block in the original implementation.
+ """
+
+ def __init__(self, config: AlignVisionConfig, in_dim: int, expand_dim: int, expand: bool = False):
+ super().__init__()
+ self.dim = expand_dim if expand else in_dim
+ self.dim_se = max(1, int(in_dim * config.squeeze_expansion_ratio))
+
+ self.squeeze = nn.AdaptiveAvgPool2d(output_size=1)
+ self.reduce = nn.Conv2d(
+ in_channels=self.dim,
+ out_channels=self.dim_se,
+ kernel_size=1,
+ padding="same",
+ )
+ self.expand = nn.Conv2d(
+ in_channels=self.dim_se,
+ out_channels=self.dim,
+ kernel_size=1,
+ padding="same",
+ )
+ self.act_reduce = ACT2FN[config.hidden_act]
+ self.act_expand = nn.Sigmoid()
+
+ def forward(self, hidden_states: torch.FloatTensor) -> torch.Tensor:
+ inputs = hidden_states
+ hidden_states = self.squeeze(hidden_states)
+ hidden_states = self.reduce(hidden_states)
+ hidden_states = self.act_reduce(hidden_states)
+
+ hidden_states = self.expand(hidden_states)
+ hidden_states = self.act_expand(hidden_states)
+ hidden_states = torch.mul(inputs, hidden_states)
+
+ return hidden_states
+
+
+class AlignVisionFinalBlockLayer(nn.Module):
+ r"""
+ This corresponds to the final phase of each block in the original implementation.
+ """
+
+ def __init__(
+ self, config: AlignVisionConfig, in_dim: int, out_dim: int, stride: int, drop_rate: float, id_skip: bool
+ ):
+ super().__init__()
+ self.apply_dropout = stride == 1 and not id_skip
+ self.project_conv = nn.Conv2d(
+ in_channels=in_dim,
+ out_channels=out_dim,
+ kernel_size=1,
+ padding="same",
+ bias=False,
+ )
+ self.project_bn = nn.BatchNorm2d(
+ num_features=out_dim, eps=config.batch_norm_eps, momentum=config.batch_norm_momentum
+ )
+ self.dropout = nn.Dropout(p=drop_rate)
+
+ def forward(self, embeddings: torch.FloatTensor, hidden_states: torch.FloatTensor) -> torch.Tensor:
+ hidden_states = self.project_conv(hidden_states)
+ hidden_states = self.project_bn(hidden_states)
+
+ if self.apply_dropout:
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = hidden_states + embeddings
+
+ return hidden_states
+
+
+class AlignVisionBlock(nn.Module):
+ r"""
+ This corresponds to the block module of original the EfficientNet vision encoder implementation.
+
+ Args:
+ config ([`AlignVisionConfig`]):
+ Model configuration class.
+ in_dim (`int`):
+ Number of input channels.
+ out_dim (`int`):
+ Number of output channels.
+ stride (`int`):
+ Stride size to be used in convolution layers.
+ expand_ratio (`int`):
+ Expand ratio to set the output dimensions for the expansion and squeeze-excite layers.
+ kernel_size (`int`):
+ Kernel size for the depthwise convolution layer.
+ drop_rate (`float`):
+ Dropout rate to be used in the final phase of each block.
+ id_skip (`bool`):
+ Whether to apply dropout and sum the final hidden states with the input embeddings during the final phase
+ of each block. Set to `True` for the first block of each stage.
+ adjust_padding (`bool`):
+ Whether to apply padding to only right and bottom side of the input kernel before the depthwise convolution
+ operation, set to `True` for inputs with odd input sizes.
+ """
+
+ def __init__(
+ self,
+ config: AlignVisionConfig,
+ in_dim: int,
+ out_dim: int,
+ stride: int,
+ expand_ratio: int,
+ kernel_size: int,
+ drop_rate: float,
+ id_skip: bool,
+ adjust_padding: bool,
+ ):
+ super().__init__()
+ self.expand_ratio = expand_ratio
+ self.expand = True if self.expand_ratio != 1 else False
+ expand_in_dim = in_dim * expand_ratio
+
+ if self.expand:
+ self.expansion = AlignVisionExpansionLayer(
+ config=config, in_dim=in_dim, out_dim=expand_in_dim, stride=stride
+ )
+
+ self.depthwise_conv = AlignVisionDepthwiseLayer(
+ config=config,
+ in_dim=expand_in_dim if self.expand else in_dim,
+ stride=stride,
+ kernel_size=kernel_size,
+ adjust_padding=adjust_padding,
+ )
+ self.squeeze_excite = AlignVisionSqueezeExciteLayer(
+ config=config, in_dim=in_dim, expand_dim=expand_in_dim, expand=self.expand
+ )
+ self.projection = AlignVisionFinalBlockLayer(
+ config=config,
+ in_dim=expand_in_dim if self.expand else in_dim,
+ out_dim=out_dim,
+ stride=stride,
+ drop_rate=drop_rate,
+ id_skip=id_skip,
+ )
+
+ def forward(self, hidden_states: torch.FloatTensor) -> torch.Tensor:
+ embeddings = hidden_states
+ # Expansion and depthwise convolution phase
+ if self.expand_ratio != 1:
+ hidden_states = self.expansion(hidden_states)
+ hidden_states = self.depthwise_conv(hidden_states)
+
+ # Squeeze and excite phase
+ hidden_states = self.squeeze_excite(hidden_states)
+ hidden_states = self.projection(embeddings, hidden_states)
+ return hidden_states
+
+
+class AlignVisionEncoder(nn.Module):
+ r"""
+ Forward propogates the embeddings through each vision encoder (EfficientNet) block.
+
+ Args:
+ config ([`AlignVisionConfig`]):
+ Model configuration class.
+ """
+
+ def __init__(self, config: AlignVisionConfig):
+ super().__init__()
+ self.depth_coefficient = config.depth_coefficient
+
+ def round_repeats(repeats):
+ # Round number of block repeats based on depth multiplier.
+ return int(math.ceil(self.depth_coefficient * repeats))
+
+ num_base_blocks = len(config.in_channels)
+ num_blocks = sum(round_repeats(n) for n in config.num_block_repeats)
+
+ curr_block_num = 0
+ blocks = []
+ for i in range(num_base_blocks):
+ in_dim = round_filters(config, config.in_channels[i])
+ out_dim = round_filters(config, config.out_channels[i])
+ stride = config.strides[i]
+ kernel_size = config.kernel_sizes[i]
+ expand_ratio = config.expand_ratios[i]
+
+ for j in range(round_repeats(config.num_block_repeats[i])):
+ id_skip = True if j == 0 else False
+ stride = 1 if j > 0 else stride
+ in_dim = out_dim if j > 0 else in_dim
+ adjust_padding = False if curr_block_num in config.depthwise_padding else True
+ drop_rate = config.drop_connect_rate * curr_block_num / num_blocks
+
+ block = AlignVisionBlock(
+ config=config,
+ in_dim=in_dim,
+ out_dim=out_dim,
+ stride=stride,
+ kernel_size=kernel_size,
+ expand_ratio=expand_ratio,
+ drop_rate=drop_rate,
+ id_skip=id_skip,
+ adjust_padding=adjust_padding,
+ )
+ blocks.append(block)
+ curr_block_num += 1
+
+ self.blocks = nn.ModuleList(blocks)
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = True,
+ ) -> BaseModelOutputWithPoolingAndNoAttention:
+ all_hidden_states = (hidden_states,) if output_hidden_states else None
+
+ for block in self.blocks:
+ hidden_states = block(hidden_states)
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states] if v is not None)
+
+ return BaseModelOutputWithNoAttention(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ )
+
+
+# Copied from transformers.models.bert.modeling_bert.BertEmbeddings with Bert->AlignText
+class AlignTextEmbeddings(nn.Module):
+ """Construct the embeddings from word, position and token_type embeddings."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
+ self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
+ self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
+
+ # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
+ self.register_buffer(
+ "position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
+ )
+ self.register_buffer(
+ "token_type_ids", torch.zeros(self.position_ids.size(), dtype=torch.long), persistent=False
+ )
+
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ token_type_ids: Optional[torch.LongTensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ past_key_values_length: int = 0,
+ ) -> torch.Tensor:
+ if input_ids is not None:
+ input_shape = input_ids.size()
+ else:
+ input_shape = inputs_embeds.size()[:-1]
+
+ seq_length = input_shape[1]
+
+ if position_ids is None:
+ position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
+
+ # Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
+ # when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
+ # issue #5664
+ if token_type_ids is None:
+ if hasattr(self, "token_type_ids"):
+ buffered_token_type_ids = self.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+ token_type_embeddings = self.token_type_embeddings(token_type_ids)
+
+ embeddings = inputs_embeds + token_type_embeddings
+ if self.position_embedding_type == "absolute":
+ position_embeddings = self.position_embeddings(position_ids)
+ embeddings += position_embeddings
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings
+
+
+# Copied from transformers.models.bert.modeling_bert.BertSelfAttention with Bert->AlignText
+class AlignTextSelfAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
+ f"heads ({config.num_attention_heads})"
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+ self.position_embedding_type = position_embedding_type or getattr(
+ config, "position_embedding_type", "absolute"
+ )
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ self.max_position_embeddings = config.max_position_embeddings
+ self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
+
+ self.is_decoder = config.is_decoder
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ mixed_query_layer = self.query(hidden_states)
+
+ # If this is instantiated as a cross-attention module, the keys
+ # and values come from an encoder; the attention mask needs to be
+ # such that the encoder's padding tokens are not attended to.
+ is_cross_attention = encoder_hidden_states is not None
+
+ if is_cross_attention and past_key_value is not None:
+ # reuse k,v, cross_attentions
+ key_layer = past_key_value[0]
+ value_layer = past_key_value[1]
+ attention_mask = encoder_attention_mask
+ elif is_cross_attention:
+ key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
+ value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
+ attention_mask = encoder_attention_mask
+ elif past_key_value is not None:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
+ value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
+ else:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ use_cache = past_key_value is not None
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_layer, value_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ query_length, key_length = query_layer.shape[2], key_layer.shape[2]
+ if use_cache:
+ position_ids_l = torch.tensor(key_length - 1, dtype=torch.long, device=hidden_states.device).view(
+ -1, 1
+ )
+ else:
+ position_ids_l = torch.arange(query_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(key_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+
+ positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == "relative_key":
+ relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores
+ elif self.position_embedding_type == "relative_key_query":
+ relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in AlignTextModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ if self.is_decoder:
+ outputs = outputs + (past_key_value,)
+ return outputs
+
+
+# Copied from transformers.models.bert.modeling_bert.BertSelfOutput with Bert->AlignText
+class AlignTextSelfOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+ALIGN_TEXT_SELF_ATTENTION_CLASSES = {
+ "eager": AlignTextSelfAttention,
+}
+
+
+# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->AlignText,BERT->ALIGN_TEXT
+class AlignTextAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ self.self = ALIGN_TEXT_SELF_ATTENTION_CLASSES[config._attn_implementation](
+ config, position_embedding_type=position_embedding_type
+ )
+ self.output = AlignTextSelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.self.query = prune_linear_layer(self.self.query, index)
+ self.self.key = prune_linear_layer(self.self.key, index)
+ self.self.value = prune_linear_layer(self.self.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
+ self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ self_outputs = self.self(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ attention_output = self.output(self_outputs[0], hidden_states)
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.bert.modeling_bert.BertIntermediate with Bert->AlignText
+class AlignTextIntermediate(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.bert.modeling_bert.BertOutput with Bert->AlignText
+class AlignTextOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+# Copied from transformers.models.bert.modeling_bert.BertLayer with Bert->AlignText
+class AlignTextLayer(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = AlignTextAttention(config)
+ self.is_decoder = config.is_decoder
+ self.add_cross_attention = config.add_cross_attention
+ if self.add_cross_attention:
+ if not self.is_decoder:
+ raise ValueError(f"{self} should be used as a decoder model if cross attention is added")
+ self.crossattention = AlignTextAttention(config, position_embedding_type="absolute")
+ self.intermediate = AlignTextIntermediate(config)
+ self.output = AlignTextOutput(config)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
+ self_attention_outputs = self.attention(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ output_attentions=output_attentions,
+ past_key_value=self_attn_past_key_value,
+ )
+ attention_output = self_attention_outputs[0]
+
+ # if decoder, the last output is tuple of self-attn cache
+ if self.is_decoder:
+ outputs = self_attention_outputs[1:-1]
+ present_key_value = self_attention_outputs[-1]
+ else:
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ cross_attn_present_key_value = None
+ if self.is_decoder and encoder_hidden_states is not None:
+ if not hasattr(self, "crossattention"):
+ raise ValueError(
+ f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers"
+ " by setting `config.add_cross_attention=True`"
+ )
+
+ # cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
+ cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
+ cross_attention_outputs = self.crossattention(
+ attention_output,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ cross_attn_past_key_value,
+ output_attentions,
+ )
+ attention_output = cross_attention_outputs[0]
+ outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
+
+ # add cross-attn cache to positions 3,4 of present_key_value tuple
+ cross_attn_present_key_value = cross_attention_outputs[-1]
+ present_key_value = present_key_value + cross_attn_present_key_value
+
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
+ )
+ outputs = (layer_output,) + outputs
+
+ # if decoder, return the attn key/values as the last output
+ if self.is_decoder:
+ outputs = outputs + (present_key_value,)
+
+ return outputs
+
+ def feed_forward_chunk(self, attention_output):
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ return layer_output
+
+
+# Copied from transformers.models.bert.modeling_bert.BertEncoder with Bert->AlignText
+class AlignTextEncoder(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([AlignTextLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = True,
+ ) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPastAndCrossAttentions]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ next_decoder_cache = () if use_cache else None
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+ past_key_value = past_key_values[i] if past_key_values is not None else None
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ layer_module.__call__,
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ else:
+ layer_outputs = layer_module(
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+ if use_cache:
+ next_decoder_cache += (layer_outputs[-1],)
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+ if self.config.add_cross_attention:
+ all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ next_decoder_cache,
+ all_hidden_states,
+ all_self_attentions,
+ all_cross_attentions,
+ ]
+ if v is not None
+ )
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+
+# Copied from transformers.models.bert.modeling_bert.BertPooler with Bert -> AlignText
+class AlignTextPooler(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+class AlignPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = AlignConfig
+ base_model_prefix = "align"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, AlignModel):
+ nn.init.xavier_uniform_(module.text_projection.weight)
+ module.text_projection.bias.data.zero_()
+ module.text_projection._is_hf_initialized = True
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ if isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+
+@add_start_docstrings(
+ """The text model from ALIGN without any head or projection on top.""",
+ ALIGN_START_DOCSTRING,
+)
+class AlignTextModel(AlignPreTrainedModel):
+ config_class = AlignTextConfig
+ _no_split_modules = ["AlignTextEmbeddings"]
+
+ def __init__(self, config: AlignTextConfig, add_pooling_layer: bool = True):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = AlignTextEmbeddings(config)
+ self.encoder = AlignTextEncoder(config)
+
+ self.pooler = AlignTextPooler(config) if add_pooling_layer else None
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value):
+ self.embeddings.word_embeddings = value
+
+ @add_start_docstrings_to_model_forward(ALIGN_TEXT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPoolingAndCrossAttentions, config_class=AlignTextConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPoolingAndCrossAttentions]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AlignTextModel
+
+ >>> model = AlignTextModel.from_pretrained("kakaobrain/align-base")
+ >>> tokenizer = AutoTokenizer.from_pretrained("kakaobrain/align-base")
+
+ >>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_state = outputs.last_hidden_state
+ >>> pooled_output = outputs.pooler_output # pooled (EOS token) states
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
+ input_shape = input_ids.size()
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ batch_size, seq_length = input_shape
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+
+ if attention_mask is None:
+ attention_mask = torch.ones(((batch_size, seq_length)), device=device)
+
+ if token_type_ids is None:
+ if hasattr(self.embeddings, "token_type_ids"):
+ buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
+
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ embedding_output = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids,
+ inputs_embeds=inputs_embeds,
+ )
+ encoder_outputs = self.encoder(
+ embedding_output,
+ attention_mask=extended_attention_mask,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+ pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPoolingAndCrossAttentions(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ cross_attentions=encoder_outputs.cross_attentions,
+ )
+
+
+@add_start_docstrings(
+ """The vision model from ALIGN without any head or projection on top.""",
+ ALIGN_START_DOCSTRING,
+)
+class AlignVisionModel(AlignPreTrainedModel):
+ config_class = AlignVisionConfig
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = False
+
+ def __init__(self, config: AlignVisionConfig):
+ super().__init__(config)
+ self.config = config
+ self.embeddings = AlignVisionEmbeddings(config)
+ self.encoder = AlignVisionEncoder(config)
+
+ # Final pooling layer
+ if config.pooling_type == "mean":
+ self.pooler = nn.AvgPool2d(config.hidden_dim, ceil_mode=True)
+ elif config.pooling_type == "max":
+ self.pooler = nn.MaxPool2d(config.hidden_dim, ceil_mode=True)
+ else:
+ raise ValueError(f"config.pooling must be one of ['mean', 'max'] got {config.pooling}")
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> nn.Module:
+ return self.vision_model.embeddings.convolution
+
+ @add_start_docstrings_to_model_forward(ALIGN_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPoolingAndNoAttention, config_class=AlignVisionConfig)
+ def forward(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPoolingAndNoAttention]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, AlignVisionModel
+
+ >>> model = AlignVisionModel.from_pretrained("kakaobrain/align-base")
+ >>> processor = AutoProcessor.from_pretrained("kakaobrain/align-base")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_state = outputs.last_hidden_state
+ >>> pooled_output = outputs.pooler_output # pooled CLS states
+ ```"""
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ embedding_output = self.embeddings(pixel_values)
+ encoder_outputs = self.encoder(
+ embedding_output,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ # Apply pooling
+ last_hidden_state = encoder_outputs[0]
+ pooled_output = self.pooler(last_hidden_state)
+ # Reshape (batch_size, projection_dim, 1 , 1) -> (batch_size, projection_dim)
+ pooled_output = pooled_output.reshape(pooled_output.shape[:2])
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPoolingAndNoAttention(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ )
+
+
+@add_start_docstrings(ALIGN_START_DOCSTRING)
+class AlignModel(AlignPreTrainedModel):
+ config_class = AlignConfig
+
+ def __init__(self, config: AlignConfig):
+ super().__init__(config)
+
+ if not isinstance(config.text_config, AlignTextConfig):
+ raise TypeError(
+ "config.text_config is expected to be of type AlignTextConfig but is of type"
+ f" {type(config.text_config)}."
+ )
+
+ if not isinstance(config.vision_config, AlignVisionConfig):
+ raise TypeError(
+ "config.vision_config is expected to be of type AlignVisionConfig but is of type"
+ f" {type(config.vision_config)}."
+ )
+
+ text_config = config.text_config
+ vision_config = config.vision_config
+
+ self.projection_dim = config.projection_dim
+ self.text_embed_dim = text_config.hidden_size
+
+ self.text_model = AlignTextModel(text_config)
+ self.vision_model = AlignVisionModel(vision_config)
+
+ self.text_projection = nn.Linear(self.text_embed_dim, self.projection_dim)
+ self.temperature = nn.Parameter(torch.tensor(self.config.temperature_init_value))
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(ALIGN_TEXT_INPUTS_DOCSTRING)
+ def get_text_features(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> torch.FloatTensor:
+ r"""
+ Returns:
+ text_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The text embeddings obtained by
+ applying the projection layer to the pooled output of [`AlignTextModel`].
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AlignModel
+
+ >>> model = AlignModel.from_pretrained("kakaobrain/align-base")
+ >>> tokenizer = AutoTokenizer.from_pretrained("kakaobrain/align-base")
+
+ >>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="pt")
+ >>> text_features = model.get_text_features(**inputs)
+ ```"""
+ # Use ALIGN model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ text_outputs = self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = text_outputs[0][:, 0, :]
+ text_features = self.text_projection(last_hidden_state)
+
+ return text_features
+
+ @add_start_docstrings_to_model_forward(ALIGN_VISION_INPUTS_DOCSTRING)
+ def get_image_features(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> torch.FloatTensor:
+ r"""
+ Returns:
+ image_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The image embeddings obtained by
+ applying the projection layer to the pooled output of [`AlignVisionModel`].
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, AlignModel
+
+ >>> model = AlignModel.from_pretrained("kakaobrain/align-base")
+ >>> processor = AutoProcessor.from_pretrained("kakaobrain/align-base")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> image_features = model.get_image_features(**inputs)
+ ```"""
+ # Use ALIGN model's config for some fields (if specified) instead of those of vision & text components.
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ vision_outputs = self.vision_model(
+ pixel_values=pixel_values,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ image_features = vision_outputs[1] # pooled_output
+
+ return image_features
+
+ @add_start_docstrings_to_model_forward(ALIGN_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=AlignOutput, config_class=AlignConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ return_loss: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, AlignOutput]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, AlignModel
+
+ >>> model = AlignModel.from_pretrained("kakaobrain/align-base")
+ >>> processor = AutoProcessor.from_pretrained("kakaobrain/align-base")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(
+ ... images=image, text=["a photo of a cat", "a photo of a dog"], return_tensors="pt", padding=True
+ ... )
+
+ >>> outputs = model(**inputs)
+ >>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+ >>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
+ ```"""
+ # Use ALIGN model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ vision_outputs = self.vision_model(
+ pixel_values=pixel_values,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ text_outputs = self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ image_embeds = vision_outputs[1]
+ text_embeds = text_outputs[0][:, 0, :]
+ text_embeds = self.text_projection(text_embeds)
+
+ # normalized features
+ image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
+ text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
+
+ # cosine similarity as logits
+ logits_per_text = torch.matmul(text_embeds, image_embeds.t()) / self.temperature
+ logits_per_image = logits_per_text.t()
+
+ loss = None
+ if return_loss:
+ loss = align_loss(logits_per_text)
+
+ if not return_dict:
+ output = (logits_per_image, logits_per_text, text_embeds, image_embeds, text_outputs, vision_outputs)
+ return ((loss,) + output) if loss is not None else output
+
+ return AlignOutput(
+ loss=loss,
+ logits_per_image=logits_per_image,
+ logits_per_text=logits_per_text,
+ text_embeds=text_embeds,
+ image_embeds=image_embeds,
+ text_model_output=text_outputs,
+ vision_model_output=vision_outputs,
+ )
+
+
+__all__ = ["AlignPreTrainedModel", "AlignTextModel", "AlignVisionModel", "AlignModel"]
diff --git a/docs/transformers/src/transformers/models/align/processing_align.py b/docs/transformers/src/transformers/models/align/processing_align.py
new file mode 100644
index 0000000000000000000000000000000000000000..628f05b2e01bd6e12f0904c54f6c43b10ece33c0
--- /dev/null
+++ b/docs/transformers/src/transformers/models/align/processing_align.py
@@ -0,0 +1,161 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Image/Text processor class for ALIGN
+"""
+
+from typing import List, Union
+
+from ...image_utils import ImageInput
+from ...processing_utils import ProcessingKwargs, ProcessorMixin, Unpack, _validate_images_text_input_order
+from ...tokenization_utils_base import BatchEncoding, PreTokenizedInput, TextInput
+
+
+class AlignProcessorKwargs(ProcessingKwargs, total=False):
+ # see processing_utils.ProcessingKwargs documentation for usage.
+ _defaults = {
+ "text_kwargs": {
+ "padding": "max_length",
+ "max_length": 64,
+ },
+ }
+
+
+class AlignProcessor(ProcessorMixin):
+ r"""
+ Constructs an ALIGN processor which wraps [`EfficientNetImageProcessor`] and
+ [`BertTokenizer`]/[`BertTokenizerFast`] into a single processor that interits both the image processor and
+ tokenizer functionalities. See the [`~AlignProcessor.__call__`] and [`~OwlViTProcessor.decode`] for more
+ information.
+ The preferred way of passing kwargs is as a dictionary per modality, see usage example below.
+ ```python
+ from transformers import AlignProcessor
+ from PIL import Image
+ model_id = "kakaobrain/align-base"
+ processor = AlignProcessor.from_pretrained(model_id)
+
+ processor(
+ images=your_pil_image,
+ text=["What is that?"],
+ images_kwargs = {"crop_size": {"height": 224, "width": 224}},
+ text_kwargs = {"padding": "do_not_pad"},
+ common_kwargs = {"return_tensors": "pt"},
+ )
+ ```
+
+ Args:
+ image_processor ([`EfficientNetImageProcessor`]):
+ The image processor is a required input.
+ tokenizer ([`BertTokenizer`, `BertTokenizerFast`]):
+ The tokenizer is a required input.
+
+ """
+
+ attributes = ["image_processor", "tokenizer"]
+ image_processor_class = "EfficientNetImageProcessor"
+ tokenizer_class = ("BertTokenizer", "BertTokenizerFast")
+
+ def __init__(self, image_processor, tokenizer):
+ super().__init__(image_processor, tokenizer)
+
+ def __call__(
+ self,
+ images: ImageInput = None,
+ text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]] = None,
+ audio=None,
+ videos=None,
+ **kwargs: Unpack[AlignProcessorKwargs],
+ ) -> BatchEncoding:
+ """
+ Main method to prepare text(s) and image(s) to be fed as input to the model. This method forwards the `text`
+ arguments to BertTokenizerFast's [`~BertTokenizerFast.__call__`] if `text` is not `None` to encode
+ the text. To prepare the image(s), this method forwards the `images` arguments to
+ EfficientNetImageProcessor's [`~EfficientNetImageProcessor.__call__`] if `images` is not `None`. Please refer
+ to the docstring of the above two methods for more information.
+
+ Args:
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. Both channels-first and channels-last formats are supported.
+ text (`str`, `List[str]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors of a particular framework. Acceptable values are:
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+ Returns:
+ [`BatchEncoding`]: A [`BatchEncoding`] with the following fields:
+
+ - **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
+ - **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
+ `return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
+ `None`).
+ - **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
+ """
+ if text is None and images is None:
+ raise ValueError("You must specify either text or images.")
+ # check if images and text inputs are reversed for BC
+ images, text = _validate_images_text_input_order(images, text)
+
+ output_kwargs = self._merge_kwargs(
+ AlignProcessorKwargs,
+ tokenizer_init_kwargs=self.tokenizer.init_kwargs,
+ **kwargs,
+ )
+ # then, we can pass correct kwargs to each processor
+ if text is not None:
+ encoding = self.tokenizer(text, **output_kwargs["text_kwargs"])
+
+ if images is not None:
+ image_features = self.image_processor(images, **output_kwargs["images_kwargs"])
+
+ # BC for explicit return_tensors
+ if "return_tensors" in output_kwargs["common_kwargs"]:
+ return_tensors = output_kwargs["common_kwargs"].pop("return_tensors", None)
+
+ if text is not None and images is not None:
+ encoding["pixel_values"] = image_features.pixel_values
+ return encoding
+ elif text is not None:
+ return encoding
+ else:
+ return BatchEncoding(data=dict(**image_features), tensor_type=return_tensors)
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to BertTokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to BertTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
+ the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
+
+ @property
+ def model_input_names(self):
+ tokenizer_input_names = self.tokenizer.model_input_names
+ image_processor_input_names = self.image_processor.model_input_names
+ return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
+
+
+__all__ = ["AlignProcessor"]
diff --git a/docs/transformers/src/transformers/models/altclip/__init__.py b/docs/transformers/src/transformers/models/altclip/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a30de8a2527567b521be3e9b60e99d025571cb18
--- /dev/null
+++ b/docs/transformers/src/transformers/models/altclip/__init__.py
@@ -0,0 +1,28 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import _LazyModule
+from ...utils.import_utils import define_import_structure
+
+
+if TYPE_CHECKING:
+ from .configuration_altclip import *
+ from .modeling_altclip import *
+ from .processing_altclip import *
+else:
+ import sys
+
+ _file = globals()["__file__"]
+ sys.modules[__name__] = _LazyModule(__name__, _file, define_import_structure(_file), module_spec=__spec__)
diff --git a/docs/transformers/src/transformers/models/altclip/configuration_altclip.py b/docs/transformers/src/transformers/models/altclip/configuration_altclip.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c8e91bd473533c37f37a6dda58f550a0f9cfeda
--- /dev/null
+++ b/docs/transformers/src/transformers/models/altclip/configuration_altclip.py
@@ -0,0 +1,384 @@
+# coding=utf-8
+# Copyright 2022 WenXiang ZhongzhiCheng LedellWu LiuGuang BoWenZhang and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""AltCLIP model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class AltCLIPTextConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`AltCLIPTextModel`]. It is used to instantiate a
+ AltCLIP text model according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the AltCLIP
+ [BAAI/AltCLIP](https://huggingface.co/BAAI/AltCLIP) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 250002):
+ Vocabulary size of the AltCLIP model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`AltCLIPTextModel`].
+ hidden_size (`int`, *optional*, defaults to 1024):
+ Dimensionality of the encoder layers and the pooler layer.
+ num_hidden_layers (`int`, *optional*, defaults to 24):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 16):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 4096):
+ Dimensionality of the "intermediate" (often named feed-forward) layer in the Transformer encoder.
+ hidden_act (`str` or `Callable`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"silu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.1):
+ The dropout ratio for the attention probabilities.
+ max_position_embeddings (`int`, *optional*, defaults to 514):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ just in case (e.g., 512 or 1024 or 2048).
+ type_vocab_size (`int`, *optional*, defaults to 1):
+ The vocabulary size of the `token_type_ids` passed when calling [`AltCLIPTextModel`]
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ initializer_factor (`float`, *optional*, defaults to 0.02):
+ A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
+ testing).
+ layer_norm_eps (`float`, *optional*, defaults to 1e-05):
+ The epsilon used by the layer normalization layers.
+ pad_token_id (`int`, *optional*, defaults to 1): The id of the *padding* token.
+ bos_token_id (`int`, *optional*, defaults to 0): The id of the *beginning-of-sequence* token.
+ eos_token_id (`Union[int, List[int]]`, *optional*, defaults to 2):
+ The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
+ position_embedding_type (`str`, *optional*, defaults to `"absolute"`):
+ Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
+ positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
+ [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
+ For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
+ with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ project_dim (`int`, *optional*, defaults to 768):
+ The dimensions of the teacher model before the mapping layer.
+
+ Examples:
+
+ ```python
+ >>> from transformers import AltCLIPTextModel, AltCLIPTextConfig
+
+ >>> # Initializing a AltCLIPTextConfig with BAAI/AltCLIP style configuration
+ >>> configuration = AltCLIPTextConfig()
+
+ >>> # Initializing a AltCLIPTextModel (with random weights) from the BAAI/AltCLIP style configuration
+ >>> model = AltCLIPTextModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "altclip_text_model"
+
+ def __init__(
+ self,
+ vocab_size=250002,
+ hidden_size=1024,
+ num_hidden_layers=24,
+ num_attention_heads=16,
+ intermediate_size=4096,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=514,
+ type_vocab_size=1,
+ initializer_range=0.02,
+ initializer_factor=0.02,
+ layer_norm_eps=1e-05,
+ pad_token_id=1,
+ bos_token_id=0,
+ eos_token_id=2,
+ position_embedding_type="absolute",
+ use_cache=True,
+ project_dim=768,
+ **kwargs,
+ ):
+ super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
+
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.hidden_act = hidden_act
+ self.intermediate_size = intermediate_size
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.initializer_range = initializer_range
+ self.initializer_factor = initializer_factor
+ self.layer_norm_eps = layer_norm_eps
+ self.position_embedding_type = position_embedding_type
+ self.use_cache = use_cache
+ self.project_dim = project_dim
+
+
+class AltCLIPVisionConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`AltCLIPModel`]. It is used to instantiate an
+ AltCLIP model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the AltCLIP
+ [BAAI/AltCLIP](https://huggingface.co/BAAI/AltCLIP) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ projection_dim (`int`, *optional*, defaults to 512):
+ Dimensionality of text and vision projection layers.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of input channels.
+ image_size (`int`, *optional*, defaults to 224):
+ The size (resolution) of each image.
+ patch_size (`int`, *optional*, defaults to 32):
+ The size (resolution) of each patch.
+ hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` `"quick_gelu"` are supported.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-05):
+ The epsilon used by the layer normalization layers.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ initializer_factor (`float`, *optional*, defaults to 1.0):
+ A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
+ testing).
+
+ Example:
+
+ ```python
+ >>> from transformers import AltCLIPVisionConfig, AltCLIPVisionModel
+
+ >>> # Initializing a AltCLIPVisionConfig with BAAI/AltCLIP style configuration
+ >>> configuration = AltCLIPVisionConfig()
+
+ >>> # Initializing a AltCLIPVisionModel (with random weights) from the BAAI/AltCLIP style configuration
+ >>> model = AltCLIPVisionModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "altclip_vision_model"
+ base_config_key = "vision_config"
+
+ def __init__(
+ self,
+ hidden_size=768,
+ intermediate_size=3072,
+ projection_dim=512,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ num_channels=3,
+ image_size=224,
+ patch_size=32,
+ hidden_act="quick_gelu",
+ layer_norm_eps=1e-5,
+ attention_dropout=0.0,
+ initializer_range=0.02,
+ initializer_factor=1.0,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.projection_dim = projection_dim
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_channels = num_channels
+ self.patch_size = patch_size
+ self.image_size = image_size
+ self.initializer_range = initializer_range
+ self.initializer_factor = initializer_factor
+ self.attention_dropout = attention_dropout
+ self.layer_norm_eps = layer_norm_eps
+ self.hidden_act = hidden_act
+
+
+class AltCLIPConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`AltCLIPModel`]. It is used to instantiate an
+ AltCLIP model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the AltCLIP
+ [BAAI/AltCLIP](https://huggingface.co/BAAI/AltCLIP) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ text_config (`dict`, *optional*):
+ Dictionary of configuration options used to initialize [`AltCLIPTextConfig`].
+ vision_config (`dict`, *optional*):
+ Dictionary of configuration options used to initialize [`AltCLIPVisionConfig`].
+ projection_dim (`int`, *optional*, defaults to 768):
+ Dimensionality of text and vision projection layers.
+ logit_scale_init_value (`float`, *optional*, defaults to 2.6592):
+ The initial value of the *logit_scale* parameter. Default is used as per the original CLIP implementation.
+ kwargs (*optional*):
+ Dictionary of keyword arguments.
+
+ Example:
+
+ ```python
+ >>> from transformers import AltCLIPConfig, AltCLIPModel
+
+ >>> # Initializing a AltCLIPConfig with BAAI/AltCLIP style configuration
+ >>> configuration = AltCLIPConfig()
+
+ >>> # Initializing a AltCLIPModel (with random weights) from the BAAI/AltCLIP style configuration
+ >>> model = AltCLIPModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+
+ >>> # We can also initialize a AltCLIPConfig from a AltCLIPTextConfig and a AltCLIPVisionConfig
+
+ >>> # Initializing a AltCLIPText and AltCLIPVision configuration
+ >>> config_text = AltCLIPTextConfig()
+ >>> config_vision = AltCLIPVisionConfig()
+
+ >>> config = AltCLIPConfig.from_text_vision_configs(config_text, config_vision)
+ ```"""
+
+ model_type = "altclip"
+ sub_configs = {"text_config": AltCLIPTextConfig, "vision_config": AltCLIPVisionConfig}
+
+ def __init__(
+ self, text_config=None, vision_config=None, projection_dim=768, logit_scale_init_value=2.6592, **kwargs
+ ):
+ # If `_config_dict` exist, we use them for the backward compatibility.
+ # We pop out these 2 attributes before calling `super().__init__` to avoid them being saved (which causes a lot
+ # of confusion!).
+ text_config_dict = kwargs.pop("text_config_dict", None)
+ vision_config_dict = kwargs.pop("vision_config_dict", None)
+
+ super().__init__(**kwargs)
+
+ # Instead of simply assigning `[text|vision]_config_dict` to `[text|vision]_config`, we use the values in
+ # `[text|vision]_config_dict` to update the values in `[text|vision]_config`. The values should be same in most
+ # cases, but we don't want to break anything regarding `_config_dict` that existed before commit `8827e1b2`.
+ if text_config_dict is not None:
+ if text_config is None:
+ text_config = {}
+
+ # This is the complete result when using `text_config_dict`.
+ _text_config_dict = AltCLIPTextConfig(**text_config_dict).to_dict()
+
+ # Give a warning if the values exist in both `_text_config_dict` and `text_config` but being different.
+ for key, value in _text_config_dict.items():
+ if key in text_config and value != text_config[key] and key not in ["transformers_version"]:
+ # If specified in `text_config_dict`
+ if key in text_config_dict:
+ message = (
+ f"`{key}` is found in both `text_config_dict` and `text_config` but with different values. "
+ f'The value `text_config_dict["{key}"]` will be used instead.'
+ )
+ # If inferred from default argument values (just to be super careful)
+ else:
+ message = (
+ f"`text_config_dict` is provided which will be used to initialize `AltCLIPTextConfig`. The "
+ f'value `text_config["{key}"]` will be overridden.'
+ )
+ logger.info(message)
+
+ # Update all values in `text_config` with the ones in `_text_config_dict`.
+ text_config.update(_text_config_dict)
+
+ if vision_config_dict is not None:
+ if vision_config is None:
+ vision_config = {}
+
+ # This is the complete result when using `vision_config_dict`.
+ _vision_config_dict = AltCLIPVisionConfig(**vision_config_dict).to_dict()
+ # convert keys to string instead of integer
+ if "id2label" in _vision_config_dict:
+ _vision_config_dict["id2label"] = {
+ str(key): value for key, value in _vision_config_dict["id2label"].items()
+ }
+
+ # Give a warning if the values exist in both `_vision_config_dict` and `vision_config` but being different.
+ for key, value in _vision_config_dict.items():
+ if key in vision_config and value != vision_config[key] and key not in ["transformers_version"]:
+ # If specified in `vision_config_dict`
+ if key in vision_config_dict:
+ message = (
+ f"`{key}` is found in both `vision_config_dict` and `vision_config` but with different "
+ f'values. The value `vision_config_dict["{key}"]` will be used instead.'
+ )
+ # If inferred from default argument values (just to be super careful)
+ else:
+ message = (
+ f"`vision_config_dict` is provided which will be used to initialize `AltCLIPVisionConfig`. "
+ f'The value `vision_config["{key}"]` will be overridden.'
+ )
+ logger.info(message)
+
+ # Update all values in `vision_config` with the ones in `_vision_config_dict`.
+ vision_config.update(_vision_config_dict)
+
+ if text_config is None:
+ text_config = {}
+ logger.info("`text_config` is `None`. Initializing the `AltCLIPTextConfig` with default values.")
+
+ if vision_config is None:
+ vision_config = {}
+ logger.info("`vision_config` is `None`. initializing the `AltCLIPVisionConfig` with default values.")
+
+ self.text_config = AltCLIPTextConfig(**text_config)
+ self.vision_config = AltCLIPVisionConfig(**vision_config)
+
+ self.projection_dim = projection_dim
+ self.logit_scale_init_value = logit_scale_init_value
+ self.initializer_factor = 1.0
+
+ @classmethod
+ def from_text_vision_configs(cls, text_config: AltCLIPTextConfig, vision_config: AltCLIPVisionConfig, **kwargs):
+ r"""
+ Instantiate a [`AltCLIPConfig`] (or a derived class) from altclip text model configuration and altclip vision
+ model configuration.
+
+ Returns:
+ [`AltCLIPConfig`]: An instance of a configuration object
+ """
+
+ return cls(text_config=text_config.to_dict(), vision_config=vision_config.to_dict(), **kwargs)
+
+
+__all__ = ["AltCLIPTextConfig", "AltCLIPVisionConfig", "AltCLIPConfig"]
diff --git a/docs/transformers/src/transformers/models/altclip/modeling_altclip.py b/docs/transformers/src/transformers/models/altclip/modeling_altclip.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c8be7ea8079a34276a9513ca1ee4eaa6287e2fb
--- /dev/null
+++ b/docs/transformers/src/transformers/models/altclip/modeling_altclip.py
@@ -0,0 +1,1761 @@
+# coding=utf-8
+# Copyright 2022 The BAAI Teams Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch AltCLIP model."""
+
+import math
+from dataclasses import dataclass
+from typing import Any, Callable, List, Optional, Tuple, Union
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint
+
+from ...activations import ACT2FN
+from ...modeling_outputs import (
+ BaseModelOutput,
+ BaseModelOutputWithPastAndCrossAttentions,
+ BaseModelOutputWithPooling,
+ BaseModelOutputWithPoolingAndCrossAttentions,
+ BaseModelOutputWithPoolingAndProjection,
+)
+from ...modeling_utils import ALL_ATTENTION_FUNCTIONS, PreTrainedModel
+from ...pytorch_utils import apply_chunking_to_forward, find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import (
+ ModelOutput,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+ torch_int,
+)
+from .configuration_altclip import AltCLIPConfig, AltCLIPTextConfig, AltCLIPVisionConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = "BAAI/AltCLIP"
+_CONFIG_FOR_DOC = "AltCLIPConfig"
+
+
+ALTCLIP_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`CLIPConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+ALTCLIP_TEXT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+ALTCLIP_VISION_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
+ [`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ interpolate_pos_encoding (`bool`, *optional*, defaults `False`):
+ Whether to interpolate the pre-trained position encodings.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+ALTCLIP_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
+ [`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
+ return_loss (`bool`, *optional*):
+ Whether or not to return the contrastive loss.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ interpolate_pos_encoding (`bool`, *optional*, defaults `False`):
+ Whether to interpolate the pre-trained position encodings.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+# contrastive loss function, adapted from
+# https://sachinruk.github.io/blog/pytorch/pytorch%20lightning/loss%20function/gpu/2021/03/07/CLIP.html
+def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
+ return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
+
+
+def clip_loss(similarity: torch.Tensor) -> torch.Tensor:
+ caption_loss = contrastive_loss(similarity)
+ image_loss = contrastive_loss(similarity.t())
+ return (caption_loss + image_loss) / 2.0
+
+
+@dataclass
+# Copied from transformers.models.clip.modeling_clip.CLIPOutput with CLIP->AltCLIP
+class AltCLIPOutput(ModelOutput):
+ """
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
+ Contrastive loss for image-text similarity.
+ logits_per_image (`torch.FloatTensor` of shape `(image_batch_size, text_batch_size)`):
+ The scaled dot product scores between `image_embeds` and `text_embeds`. This represents the image-text
+ similarity scores.
+ logits_per_text (`torch.FloatTensor` of shape `(text_batch_size, image_batch_size)`):
+ The scaled dot product scores between `text_embeds` and `image_embeds`. This represents the text-image
+ similarity scores.
+ text_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim`):
+ The text embeddings obtained by applying the projection layer to the pooled output of [`AltCLIPTextModel`].
+ image_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim`):
+ The image embeddings obtained by applying the projection layer to the pooled output of [`AltCLIPVisionModel`].
+ text_model_output (`BaseModelOutputWithPooling`):
+ The output of the [`AltCLIPTextModel`].
+ vision_model_output (`BaseModelOutputWithPooling`):
+ The output of the [`AltCLIPVisionModel`].
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits_per_image: Optional[torch.FloatTensor] = None
+ logits_per_text: Optional[torch.FloatTensor] = None
+ text_embeds: Optional[torch.FloatTensor] = None
+ image_embeds: Optional[torch.FloatTensor] = None
+ text_model_output: BaseModelOutputWithPooling = None
+ vision_model_output: BaseModelOutputWithPooling = None
+
+ def to_tuple(self) -> Tuple[Any]:
+ return tuple(
+ self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
+ for k in self.keys()
+ )
+
+
+# Copied from transformers.models.roberta.modeling_roberta.RobertaEmbeddings with Roberta->AltRoberta
+class AltRobertaEmbeddings(nn.Module):
+ """
+ Same as BertEmbeddings with a tiny tweak for positional embeddings indexing.
+ """
+
+ # Copied from transformers.models.bert.modeling_bert.BertEmbeddings.__init__
+ def __init__(self, config):
+ super().__init__()
+ self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
+ self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
+ self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
+
+ # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
+ self.register_buffer(
+ "position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
+ )
+ self.register_buffer(
+ "token_type_ids", torch.zeros(self.position_ids.size(), dtype=torch.long), persistent=False
+ )
+
+ # End copy
+ self.padding_idx = config.pad_token_id
+ self.position_embeddings = nn.Embedding(
+ config.max_position_embeddings, config.hidden_size, padding_idx=self.padding_idx
+ )
+
+ def forward(
+ self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
+ ):
+ if position_ids is None:
+ if input_ids is not None:
+ # Create the position ids from the input token ids. Any padded tokens remain padded.
+ position_ids = create_position_ids_from_input_ids(input_ids, self.padding_idx, past_key_values_length)
+ else:
+ position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds)
+
+ if input_ids is not None:
+ input_shape = input_ids.size()
+ else:
+ input_shape = inputs_embeds.size()[:-1]
+
+ seq_length = input_shape[1]
+
+ # Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
+ # when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
+ # issue #5664
+ if token_type_ids is None:
+ if hasattr(self, "token_type_ids"):
+ buffered_token_type_ids = self.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+ token_type_embeddings = self.token_type_embeddings(token_type_ids)
+
+ embeddings = inputs_embeds + token_type_embeddings
+ if self.position_embedding_type == "absolute":
+ position_embeddings = self.position_embeddings(position_ids)
+ embeddings += position_embeddings
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings
+
+ def create_position_ids_from_inputs_embeds(self, inputs_embeds):
+ """
+ We are provided embeddings directly. We cannot infer which are padded so just generate sequential position ids.
+
+ Args:
+ inputs_embeds: torch.Tensor
+
+ Returns: torch.Tensor
+ """
+ input_shape = inputs_embeds.size()[:-1]
+ sequence_length = input_shape[1]
+
+ position_ids = torch.arange(
+ self.padding_idx + 1, sequence_length + self.padding_idx + 1, dtype=torch.long, device=inputs_embeds.device
+ )
+ return position_ids.unsqueeze(0).expand(input_shape)
+
+
+# Copied from transformers.models.roberta.modeling_roberta.RobertaSelfAttention with Roberta->AltRoberta
+class AltRobertaSelfAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
+ f"heads ({config.num_attention_heads})"
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+ self.position_embedding_type = position_embedding_type or getattr(
+ config, "position_embedding_type", "absolute"
+ )
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ self.max_position_embeddings = config.max_position_embeddings
+ self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
+
+ self.is_decoder = config.is_decoder
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ mixed_query_layer = self.query(hidden_states)
+
+ # If this is instantiated as a cross-attention module, the keys
+ # and values come from an encoder; the attention mask needs to be
+ # such that the encoder's padding tokens are not attended to.
+ is_cross_attention = encoder_hidden_states is not None
+
+ if is_cross_attention and past_key_value is not None:
+ # reuse k,v, cross_attentions
+ key_layer = past_key_value[0]
+ value_layer = past_key_value[1]
+ attention_mask = encoder_attention_mask
+ elif is_cross_attention:
+ key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
+ value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
+ attention_mask = encoder_attention_mask
+ elif past_key_value is not None:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
+ value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
+ else:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ use_cache = past_key_value is not None
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_layer, value_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ query_length, key_length = query_layer.shape[2], key_layer.shape[2]
+ if use_cache:
+ position_ids_l = torch.tensor(key_length - 1, dtype=torch.long, device=hidden_states.device).view(
+ -1, 1
+ )
+ else:
+ position_ids_l = torch.arange(query_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(key_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+
+ positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == "relative_key":
+ relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores
+ elif self.position_embedding_type == "relative_key_query":
+ relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in AltRobertaModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ if self.is_decoder:
+ outputs = outputs + (past_key_value,)
+ return outputs
+
+
+# Copied from transformers.models.roberta.modeling_roberta.RobertaSelfOutput
+class AltRobertaSelfOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+ALT_ROBERTA_SELF_ATTENTION_CLASSES = {
+ "eager": AltRobertaSelfAttention,
+}
+
+
+# Copied from transformers.models.roberta.modeling_roberta.RobertaAttention with Roberta->AltRoberta,ROBERTA->ALT_ROBERTA
+class AltRobertaAttention(nn.Module):
+ def __init__(self, config, position_embedding_type=None):
+ super().__init__()
+ self.self = ALT_ROBERTA_SELF_ATTENTION_CLASSES[config._attn_implementation](
+ config, position_embedding_type=position_embedding_type
+ )
+ self.output = AltRobertaSelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.self.query = prune_linear_layer(self.self.query, index)
+ self.self.key = prune_linear_layer(self.self.key, index)
+ self.self.value = prune_linear_layer(self.self.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
+ self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ self_outputs = self.self(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ attention_output = self.output(self_outputs[0], hidden_states)
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.roberta.modeling_roberta.RobertaIntermediate with Roberta->AltRoberta
+class AltRobertaIntermediate(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+# Copied from transformers.models.roberta.modeling_roberta.RobertaOutput
+class AltRobertaOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+# Copied from transformers.models.roberta.modeling_roberta.RobertaLayer with Roberta->AltRoberta
+class AltRobertaLayer(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = AltRobertaAttention(config)
+ self.is_decoder = config.is_decoder
+ self.add_cross_attention = config.add_cross_attention
+ if self.add_cross_attention:
+ if not self.is_decoder:
+ raise ValueError(f"{self} should be used as a decoder model if cross attention is added")
+ self.crossattention = AltRobertaAttention(config, position_embedding_type="absolute")
+ self.intermediate = AltRobertaIntermediate(config)
+ self.output = AltRobertaOutput(config)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
+ self_attention_outputs = self.attention(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ output_attentions=output_attentions,
+ past_key_value=self_attn_past_key_value,
+ )
+ attention_output = self_attention_outputs[0]
+
+ # if decoder, the last output is tuple of self-attn cache
+ if self.is_decoder:
+ outputs = self_attention_outputs[1:-1]
+ present_key_value = self_attention_outputs[-1]
+ else:
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ cross_attn_present_key_value = None
+ if self.is_decoder and encoder_hidden_states is not None:
+ if not hasattr(self, "crossattention"):
+ raise ValueError(
+ f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers"
+ " by setting `config.add_cross_attention=True`"
+ )
+
+ # cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
+ cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
+ cross_attention_outputs = self.crossattention(
+ attention_output,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ cross_attn_past_key_value,
+ output_attentions,
+ )
+ attention_output = cross_attention_outputs[0]
+ outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
+
+ # add cross-attn cache to positions 3,4 of present_key_value tuple
+ cross_attn_present_key_value = cross_attention_outputs[-1]
+ present_key_value = present_key_value + cross_attn_present_key_value
+
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
+ )
+ outputs = (layer_output,) + outputs
+
+ # if decoder, return the attn key/values as the last output
+ if self.is_decoder:
+ outputs = outputs + (present_key_value,)
+
+ return outputs
+
+ def feed_forward_chunk(self, attention_output):
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ return layer_output
+
+
+# Copied from transformers.models.roberta.modeling_roberta.RobertaEncoder with Roberta->AltRoberta
+class AltRobertaEncoder(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([AltRobertaLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = False,
+ output_hidden_states: Optional[bool] = False,
+ return_dict: Optional[bool] = True,
+ ) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPastAndCrossAttentions]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ next_decoder_cache = () if use_cache else None
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+ past_key_value = past_key_values[i] if past_key_values is not None else None
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ layer_module.__call__,
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ else:
+ layer_outputs = layer_module(
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+ if use_cache:
+ next_decoder_cache += (layer_outputs[-1],)
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+ if self.config.add_cross_attention:
+ all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ next_decoder_cache,
+ all_hidden_states,
+ all_self_attentions,
+ all_cross_attentions,
+ ]
+ if v is not None
+ )
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+
+# Copied from transformers.models.roberta.modeling_roberta.RobertaPooler
+class AltRobertaPooler(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+# Copied from transformers.models.siglip.modeling_siglip.eager_attention_forward
+def eager_attention_forward(
+ module: nn.Module,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ attention_mask: Optional[torch.Tensor],
+ scaling: float,
+ dropout: float = 0.0,
+ **kwargs,
+):
+ attn_weights = torch.matmul(query, key.transpose(-1, -2)) * scaling
+ if attention_mask is not None:
+ attn_weights = attn_weights + attention_mask
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
+
+ attn_output = torch.matmul(attn_weights, value)
+ attn_output = attn_output.transpose(1, 2).contiguous()
+ return attn_output, attn_weights
+
+
+class AltCLIPAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.embed_dim = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.embed_dim // self.num_heads
+ if self.head_dim * self.num_heads != self.embed_dim:
+ raise ValueError(
+ f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
+ f" {self.num_heads})."
+ )
+ self.scale = self.head_dim**-0.5
+ self.dropout = config.attention_dropout
+ self.is_causal = False
+
+ self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
+ self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ causal_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
+ """Input shape: Batch x Time x Channel"""
+
+ batch_size, seq_length, embed_dim = hidden_states.shape
+
+ queries = self.q_proj(hidden_states)
+ keys = self.k_proj(hidden_states)
+ values = self.v_proj(hidden_states)
+
+ queries = queries.view(batch_size, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
+ keys = keys.view(batch_size, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
+ values = values.view(batch_size, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
+ # CLIP text model uses both `causal_attention_mask` and `attention_mask`
+ # in case FA2 kernel is called, `is_causal` should be inferred from `causal_attention_mask`
+ if self.config._attn_implementation != "flash_attention_2":
+ if attention_mask is not None and causal_attention_mask is not None:
+ attention_mask = attention_mask + causal_attention_mask
+ elif causal_attention_mask is not None:
+ attention_mask = causal_attention_mask
+ else:
+ self.is_causal = causal_attention_mask is not None
+
+ attention_interface: Callable = eager_attention_forward
+ if self.config._attn_implementation != "eager":
+ if self.config._attn_implementation == "sdpa" and output_attentions:
+ logger.warning_once(
+ "`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
+ 'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ else:
+ attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
+
+ attn_output, attn_weights = attention_interface(
+ self,
+ queries,
+ keys,
+ values,
+ attention_mask,
+ is_causal=self.is_causal,
+ scaling=self.scale,
+ dropout=0.0 if not self.training else self.dropout,
+ )
+
+ attn_output = attn_output.reshape(batch_size, seq_length, embed_dim).contiguous()
+ attn_output = self.out_proj(attn_output)
+ if not output_attentions:
+ attn_weights = None
+ return attn_output, attn_weights
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPMLP with CLIP->AltCLIP
+class AltCLIPMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.activation_fn = ACT2FN[config.hidden_act]
+ self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
+ self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.fc1(hidden_states)
+ hidden_states = self.activation_fn(hidden_states)
+ hidden_states = self.fc2(hidden_states)
+ return hidden_states
+
+
+class AltCLIPEncoderLayer(nn.Module):
+ def __init__(self, config: AltCLIPConfig):
+ super().__init__()
+ self.embed_dim = config.hidden_size
+ self.self_attn = AltCLIPAttention(config)
+ self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
+ self.mlp = AltCLIPMLP(config)
+ self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ causal_attention_mask: torch.Tensor,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ `(config.encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+
+ hidden_states = self.layer_norm1(hidden_states)
+ hidden_states, attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ causal_attention_mask=causal_attention_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = residual + hidden_states
+
+ residual = hidden_states
+ hidden_states = self.layer_norm2(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+
+class AltCLIPEncoder(nn.Module):
+ """
+ Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
+ [`AltCLIPEncoderLayer`].
+
+ Args:
+ config: AltCLIPConfig
+ """
+
+ def __init__(self, config: AltCLIPConfig):
+ super().__init__()
+ self.config = config
+ self.layers = nn.ModuleList([AltCLIPEncoderLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ inputs_embeds,
+ attention_mask: Optional[torch.Tensor] = None,
+ causal_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutput]:
+ r"""
+ Args:
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ This is useful if you want more control over how to convert `input_ids` indices into associated vectors
+ than the model's internal embedding lookup matrix.
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ causal_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Causal mask for the text model. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ encoder_states = () if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+
+ hidden_states = inputs_embeds
+ for idx, encoder_layer in enumerate(self.layers):
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ encoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ causal_attention_mask,
+ output_attentions,
+ )
+ else:
+ layer_outputs = encoder_layer(
+ hidden_states,
+ attention_mask,
+ causal_attention_mask,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_attentions = all_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
+ )
+
+
+# Copied from transformers.models.clip.modeling_clip.CLIPVisionEmbeddings with CLIP->AltCLIP
+class AltCLIPVisionEmbeddings(nn.Module):
+ def __init__(self, config: AltCLIPVisionConfig):
+ super().__init__()
+ self.config = config
+ self.embed_dim = config.hidden_size
+ self.image_size = config.image_size
+ self.patch_size = config.patch_size
+
+ self.class_embedding = nn.Parameter(torch.randn(self.embed_dim))
+
+ self.patch_embedding = nn.Conv2d(
+ in_channels=config.num_channels,
+ out_channels=self.embed_dim,
+ kernel_size=self.patch_size,
+ stride=self.patch_size,
+ bias=False,
+ )
+
+ self.num_patches = (self.image_size // self.patch_size) ** 2
+ self.num_positions = self.num_patches + 1
+ self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
+ self.register_buffer("position_ids", torch.arange(self.num_positions).expand((1, -1)), persistent=False)
+
+ def interpolate_pos_encoding(self, embeddings: torch.Tensor, height: int, width: int) -> torch.Tensor:
+ """
+ This method allows to interpolate the pre-trained position encodings, to be able to use the model on higher resolution
+ images. This method is also adapted to support torch.jit tracing.
+
+ Adapted from:
+ - https://github.com/facebookresearch/dino/blob/de9ee3df6cf39fac952ab558447af1fa1365362a/vision_transformer.py#L174-L194, and
+ - https://github.com/facebookresearch/dinov2/blob/e1277af2ba9496fbadf7aec6eba56e8d882d1e35/dinov2/models/vision_transformer.py#L179-L211
+ """
+
+ num_patches = embeddings.shape[1] - 1
+ position_embedding = self.position_embedding.weight.unsqueeze(0)
+ num_positions = position_embedding.shape[1] - 1
+
+ # always interpolate when tracing to ensure the exported model works for dynamic input shapes
+ if not torch.jit.is_tracing() and num_patches == num_positions and height == width:
+ return self.position_embedding(self.position_ids)
+
+ class_pos_embed = position_embedding[:, :1]
+ patch_pos_embed = position_embedding[:, 1:]
+
+ dim = embeddings.shape[-1]
+
+ new_height = height // self.patch_size
+ new_width = width // self.patch_size
+
+ sqrt_num_positions = torch_int(num_positions**0.5)
+ patch_pos_embed = patch_pos_embed.reshape(1, sqrt_num_positions, sqrt_num_positions, dim)
+ patch_pos_embed = patch_pos_embed.permute(0, 3, 1, 2)
+
+ patch_pos_embed = nn.functional.interpolate(
+ patch_pos_embed,
+ size=(new_height, new_width),
+ mode="bicubic",
+ align_corners=False,
+ )
+
+ patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
+
+ return torch.cat((class_pos_embed, patch_pos_embed), dim=1)
+
+ def forward(self, pixel_values: torch.FloatTensor, interpolate_pos_encoding=False) -> torch.Tensor:
+ batch_size, _, height, width = pixel_values.shape
+ if not interpolate_pos_encoding and (height != self.image_size or width != self.image_size):
+ raise ValueError(
+ f"Input image size ({height}*{width}) doesn't match model ({self.image_size}*{self.image_size})."
+ )
+ target_dtype = self.patch_embedding.weight.dtype
+ patch_embeds = self.patch_embedding(pixel_values.to(dtype=target_dtype)) # shape = [*, width, grid, grid]
+ patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
+
+ class_embeds = self.class_embedding.expand(batch_size, 1, -1)
+ embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
+ if interpolate_pos_encoding:
+ embeddings = embeddings + self.interpolate_pos_encoding(embeddings, height, width)
+ else:
+ embeddings = embeddings + self.position_embedding(self.position_ids)
+ return embeddings
+
+
+class AltCLIPPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = AltCLIPConfig
+ base_model_prefix = "altclip"
+ supports_gradient_checkpointing = True
+ _no_split_module = []
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ factor = self.config.initializer_factor
+ if isinstance(module, AltCLIPVisionEmbeddings):
+ factor = self.config.initializer_factor
+ nn.init.normal_(module.class_embedding, mean=0.0, std=module.embed_dim**-0.5 * factor)
+ nn.init.normal_(module.patch_embedding.weight, std=module.config.initializer_range * factor)
+ nn.init.normal_(module.position_embedding.weight, std=module.config.initializer_range * factor)
+ elif isinstance(module, AltCLIPAttention):
+ factor = self.config.initializer_factor
+ in_proj_std = (module.embed_dim**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
+ out_proj_std = (module.embed_dim**-0.5) * factor
+ nn.init.normal_(module.q_proj.weight, std=in_proj_std)
+ nn.init.normal_(module.k_proj.weight, std=in_proj_std)
+ nn.init.normal_(module.v_proj.weight, std=in_proj_std)
+ nn.init.normal_(module.out_proj.weight, std=out_proj_std)
+ elif isinstance(module, AltCLIPMLP):
+ factor = self.config.initializer_factor
+ in_proj_std = (module.config.hidden_size**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
+ fc_std = (2 * module.config.hidden_size) ** -0.5 * factor
+ nn.init.normal_(module.fc1.weight, std=fc_std)
+ nn.init.normal_(module.fc2.weight, std=in_proj_std)
+ elif isinstance(module, AltCLIPModel):
+ nn.init.normal_(
+ module.text_projection.weight,
+ std=module.text_embed_dim**-0.5 * self.config.initializer_factor,
+ )
+ module.text_projection._is_hf_initialized = True
+ nn.init.normal_(
+ module.visual_projection.weight,
+ std=module.vision_embed_dim**-0.5 * self.config.initializer_factor,
+ )
+ module.visual_projection._is_hf_initialized = True
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+ elif isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_factor)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_factor)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+
+class AltCLIPVisionTransformer(nn.Module):
+ def __init__(self, config: AltCLIPVisionConfig):
+ super().__init__()
+ self.config = config
+ embed_dim = config.hidden_size
+
+ self.embeddings = AltCLIPVisionEmbeddings(config)
+ self.pre_layrnorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+ self.encoder = AltCLIPEncoder(config)
+ self.post_layernorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
+
+ @add_start_docstrings_to_model_forward(ALTCLIP_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=AltCLIPVisionConfig)
+ def forward(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ interpolate_pos_encoding: Optional[bool] = False,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if pixel_values is None:
+ raise ValueError("You have to specify pixel_values")
+
+ hidden_states = self.embeddings(pixel_values, interpolate_pos_encoding=interpolate_pos_encoding)
+ hidden_states = self.pre_layrnorm(hidden_states)
+
+ encoder_outputs = self.encoder(
+ inputs_embeds=hidden_states,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ last_hidden_state = encoder_outputs[0]
+ pooled_output = last_hidden_state[:, 0, :]
+ pooled_output = self.post_layernorm(pooled_output)
+
+ if not return_dict:
+ return (last_hidden_state, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=last_hidden_state,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class AltCLIPVisionModel(AltCLIPPreTrainedModel):
+ config_class = AltCLIPVisionConfig
+ main_input_name = "pixel_values"
+
+ def __init__(self, config: AltCLIPVisionConfig):
+ super().__init__(config)
+ self.vision_model = AltCLIPVisionTransformer(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> nn.Module:
+ return self.vision_model.embeddings.patch_embedding
+
+ @add_start_docstrings_to_model_forward(ALTCLIP_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=AltCLIPVisionConfig)
+ def forward(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ interpolate_pos_encoding: bool = False,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, AltCLIPVisionModel
+
+ >>> model = AltCLIPVisionModel.from_pretrained("BAAI/AltCLIP")
+ >>> processor = AutoProcessor.from_pretrained("BAAI/AltCLIP")
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> inputs = processor(images=image, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_state = outputs.last_hidden_state
+ >>> pooled_output = outputs.pooler_output # pooled CLS states
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ return self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ interpolate_pos_encoding=interpolate_pos_encoding,
+ return_dict=return_dict,
+ )
+
+
+class AltRobertaModel(AltCLIPPreTrainedModel):
+ """
+
+ The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
+ cross-attention is added between the self-attention layers, following the architecture described in *Attention is
+ all you need*_ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz
+ Kaiser and Illia Polosukhin.
+
+ To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
+ to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
+ `add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
+
+ .. _*Attention is all you need*: https://arxiv.org/abs/1706.03762
+
+ """
+
+ config_class = AltCLIPTextConfig
+
+ # Copied from transformers.models.clap.modeling_clap.ClapTextModel.__init__ with ClapText->AltRoberta
+ def __init__(self, config, add_pooling_layer=True):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = AltRobertaEmbeddings(config)
+ self.encoder = AltRobertaEncoder(config)
+
+ self.pooler = AltRobertaPooler(config) if add_pooling_layer else None
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value):
+ self.embeddings.word_embeddings = value
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ # Copied from transformers.models.clap.modeling_clap.ClapTextModel.forward
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPoolingAndCrossAttentions]:
+ r"""
+ encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if self.config.is_decoder:
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ else:
+ use_cache = False
+
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
+ input_shape = input_ids.size()
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds")
+
+ batch_size, seq_length = input_shape
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+
+ # past_key_values_length
+ past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
+
+ if attention_mask is None:
+ attention_mask = torch.ones(((batch_size, seq_length + past_key_values_length)), device=device)
+
+ if token_type_ids is None:
+ if hasattr(self.embeddings, "token_type_ids"):
+ buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
+ buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
+ token_type_ids = buffered_token_type_ids_expanded
+ else:
+ token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
+
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
+
+ # If a 2D or 3D attention mask is provided for the cross-attention
+ # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if self.config.is_decoder and encoder_hidden_states is not None:
+ encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
+ encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
+ if encoder_attention_mask is None:
+ encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
+ encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = None
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ embedding_output = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids,
+ inputs_embeds=inputs_embeds,
+ past_key_values_length=past_key_values_length,
+ )
+ encoder_outputs = self.encoder(
+ embedding_output,
+ attention_mask=extended_attention_mask,
+ head_mask=head_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_extended_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+ pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPoolingAndCrossAttentions(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ past_key_values=encoder_outputs.past_key_values,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ cross_attentions=encoder_outputs.cross_attentions,
+ )
+
+
+class AltCLIPTextModel(AltCLIPPreTrainedModel):
+ config_class = AltCLIPTextConfig
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.roberta = AltRobertaModel(config, add_pooling_layer=False)
+ self.transformation = nn.Linear(config.hidden_size, config.project_dim)
+ self.pre_LN = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.post_init()
+
+ def get_input_embeddings(self) -> nn.Module:
+ return self.roberta.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value: nn.Embedding) -> None:
+ self.roberta.embeddings.word_embeddings = value
+
+ def resize_token_embeddings(self, new_num_tokens: Optional[int] = None) -> nn.Embedding:
+ return super().resize_token_embeddings(new_num_tokens)
+
+ @add_start_docstrings_to_model_forward(ALTCLIP_TEXT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutputWithPoolingAndProjection, config_class=AltCLIPTextConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPoolingAndProjection]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoProcessor, AltCLIPTextModel
+
+ >>> model = AltCLIPTextModel.from_pretrained("BAAI/AltCLIP")
+ >>> processor = AutoProcessor.from_pretrained("BAAI/AltCLIP")
+
+ >>> texts = ["it's a cat", "it's a dog"]
+
+ >>> inputs = processor(text=texts, padding=True, return_tensors="pt")
+
+ >>> outputs = model(**inputs)
+ >>> last_hidden_state = outputs.last_hidden_state
+ >>> pooled_output = outputs.pooler_output # pooled CLS states
+ ```"""
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.roberta(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ # last module outputs
+ sequence_output = outputs[0]
+
+ # project every module
+ sequence_output = self.pre_LN(sequence_output)
+
+ # pooler
+ projection_state = self.transformation(sequence_output)
+ pooler_output = projection_state[:, 0]
+
+ if not return_dict:
+ return (projection_state, pooler_output) + outputs[2:4]
+
+ return BaseModelOutputWithPoolingAndProjection(
+ last_hidden_state=projection_state,
+ pooler_output=pooler_output,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+class AltCLIPModel(AltCLIPPreTrainedModel):
+ config_class = AltCLIPConfig
+
+ def __init__(self, config: AltCLIPConfig):
+ super().__init__(config)
+
+ if not isinstance(config.vision_config, AltCLIPVisionConfig):
+ raise TypeError(
+ "config.vision_config is expected to be of type AltCLIPVisionConfig but is of type"
+ f" {type(config.vision_config)}."
+ )
+ if not isinstance(config.text_config, AltCLIPTextConfig):
+ raise TypeError(
+ "config.text_config is expected to be of type AltCLIPTextConfig but is of type"
+ f" {type(config.text_config)}."
+ )
+
+ text_config = config.text_config
+ vision_config = config.vision_config
+
+ self.projection_dim = config.projection_dim
+ self.text_embed_dim = text_config.project_dim
+ self.vision_embed_dim = vision_config.hidden_size
+
+ self.text_model = AltCLIPTextModel(text_config)
+ self.vision_model = AltCLIPVisionTransformer(vision_config)
+
+ self.visual_projection = nn.Linear(self.vision_embed_dim, self.projection_dim, bias=False)
+ self.text_projection = nn.Linear(self.text_embed_dim, self.projection_dim, bias=False)
+ self.logit_scale = nn.Parameter(torch.tensor(self.config.logit_scale_init_value))
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(ALTCLIP_TEXT_INPUTS_DOCSTRING)
+ def get_text_features(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ token_type_ids=None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> torch.FloatTensor:
+ r"""
+ Returns:
+ text_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The text embeddings obtained by
+ applying the projection layer to the pooled output of [`AltCLIPTextModel`].
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoProcessor, AltCLIPModel
+
+ >>> model = AltCLIPModel.from_pretrained("BAAI/AltCLIP")
+ >>> processor = AutoProcessor.from_pretrained("BAAI/AltCLIP")
+ >>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="pt")
+ >>> text_features = model.get_text_features(**inputs)
+ ```"""
+ # Use AltCLIP model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ text_outputs = self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ pooled_output = text_outputs[1]
+ text_features = self.text_projection(pooled_output)
+
+ return text_features
+
+ @add_start_docstrings_to_model_forward(ALTCLIP_VISION_INPUTS_DOCSTRING)
+ def get_image_features(
+ self,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ interpolate_pos_encoding: bool = False,
+ return_dict: Optional[bool] = None,
+ ) -> torch.FloatTensor:
+ r"""
+ Returns:
+ image_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The image embeddings obtained by
+ applying the projection layer to the pooled output of [`AltCLIPVisionModel`].
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, AltCLIPModel
+
+ >>> model = AltCLIPModel.from_pretrained("BAAI/AltCLIP")
+ >>> processor = AutoProcessor.from_pretrained("BAAI/AltCLIP")
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+ >>> inputs = processor(images=image, return_tensors="pt")
+ >>> image_features = model.get_image_features(**inputs)
+ ```"""
+ # Use AltCLIP model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ vision_outputs = self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ interpolate_pos_encoding=interpolate_pos_encoding,
+ return_dict=return_dict,
+ )
+
+ pooled_output = vision_outputs[1] # pooled_output
+ image_features = self.visual_projection(pooled_output)
+
+ return image_features
+
+ @add_start_docstrings_to_model_forward(ALTCLIP_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=AltCLIPOutput, config_class=AltCLIPConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ token_type_ids: Optional[torch.Tensor] = None,
+ return_loss: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ interpolate_pos_encoding: bool = False,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, AltCLIPOutput]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from PIL import Image
+ >>> import requests
+ >>> from transformers import AutoProcessor, AltCLIPModel
+
+ >>> model = AltCLIPModel.from_pretrained("BAAI/AltCLIP")
+ >>> processor = AutoProcessor.from_pretrained("BAAI/AltCLIP")
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+ >>> inputs = processor(
+ ... text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True
+ ... )
+ >>> outputs = model(**inputs)
+ >>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
+ >>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
+ ```"""
+ # Use AltCLIP model's config for some fields (if specified) instead of those of vision & text components.
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ text_outputs = self.text_model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ position_ids=position_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ vision_outputs = self.vision_model(
+ pixel_values=pixel_values,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ interpolate_pos_encoding=interpolate_pos_encoding,
+ return_dict=return_dict,
+ )
+
+ image_embeds = vision_outputs[1]
+ image_embeds = self.visual_projection(image_embeds)
+
+ text_embeds = text_outputs[1]
+ text_embeds = self.text_projection(text_embeds)
+
+ # normalized features
+ image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
+ text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
+
+ # cosine similarity as logits
+ logit_scale = self.logit_scale.exp()
+ logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * logit_scale
+ logits_per_image = logits_per_text.T
+
+ loss = None
+ if return_loss:
+ loss = clip_loss(logits_per_text)
+
+ if not return_dict:
+ output = (logits_per_image, logits_per_text, text_embeds, image_embeds, text_outputs, vision_outputs)
+ return ((loss,) + output) if loss is not None else output
+
+ return AltCLIPOutput(
+ loss=loss,
+ logits_per_image=logits_per_image,
+ logits_per_text=logits_per_text,
+ text_embeds=text_embeds,
+ image_embeds=image_embeds,
+ text_model_output=text_outputs,
+ vision_model_output=vision_outputs,
+ )
+
+
+# Copied from transformers.models.roberta.modeling_roberta.create_position_ids_from_input_ids
+def create_position_ids_from_input_ids(input_ids, padding_idx, past_key_values_length=0):
+ """
+ Replace non-padding symbols with their position numbers. Position numbers begin at padding_idx+1. Padding symbols
+ are ignored. This is modified from fairseq's `utils.make_positions`.
+
+ Args:
+ x: torch.Tensor x:
+
+ Returns: torch.Tensor
+ """
+ # The series of casts and type-conversions here are carefully balanced to both work with ONNX export and XLA.
+ mask = input_ids.ne(padding_idx).int()
+ incremental_indices = (torch.cumsum(mask, dim=1).type_as(mask) + past_key_values_length) * mask
+ return incremental_indices.long() + padding_idx
+
+
+__all__ = ["AltCLIPPreTrainedModel", "AltCLIPVisionModel", "AltCLIPTextModel", "AltCLIPModel"]
diff --git a/docs/transformers/src/transformers/models/altclip/processing_altclip.py b/docs/transformers/src/transformers/models/altclip/processing_altclip.py
new file mode 100644
index 0000000000000000000000000000000000000000..3ce4f2481d4905c651d1abcbe7fc020e92d2c001
--- /dev/null
+++ b/docs/transformers/src/transformers/models/altclip/processing_altclip.py
@@ -0,0 +1,148 @@
+# coding=utf-8
+# Copyright 2022 WenXiang ZhongzhiCheng LedellWu LiuGuang BoWenZhang The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Image/Text processor class for AltCLIP
+"""
+
+from typing import List, Union
+
+from ...image_utils import ImageInput
+from ...processing_utils import ProcessingKwargs, ProcessorMixin, Unpack
+from ...tokenization_utils_base import BatchEncoding, PreTokenizedInput, TextInput
+from ...utils.deprecation import deprecate_kwarg
+
+
+class AltClipProcessorKwargs(ProcessingKwargs, total=False):
+ _defaults = {}
+
+
+class AltCLIPProcessor(ProcessorMixin):
+ r"""
+ Constructs a AltCLIP processor which wraps a CLIP image processor and a XLM-Roberta tokenizer into a single
+ processor.
+
+ [`AltCLIPProcessor`] offers all the functionalities of [`CLIPImageProcessor`] and [`XLMRobertaTokenizerFast`]. See
+ the [`~AltCLIPProcessor.__call__`] and [`~AltCLIPProcessor.decode`] for more information.
+
+ Args:
+ image_processor ([`CLIPImageProcessor`], *optional*):
+ The image processor is a required input.
+ tokenizer ([`XLMRobertaTokenizerFast`], *optional*):
+ The tokenizer is a required input.
+ """
+
+ attributes = ["image_processor", "tokenizer"]
+ image_processor_class = ("CLIPImageProcessor", "CLIPImageProcessorFast")
+ tokenizer_class = ("XLMRobertaTokenizer", "XLMRobertaTokenizerFast")
+
+ @deprecate_kwarg(old_name="feature_extractor", version="5.0.0", new_name="image_processor")
+ def __init__(self, image_processor=None, tokenizer=None):
+ if image_processor is None:
+ raise ValueError("You need to specify an `image_processor`.")
+ if tokenizer is None:
+ raise ValueError("You need to specify a `tokenizer`.")
+
+ super().__init__(image_processor, tokenizer)
+
+ def __call__(
+ self,
+ images: ImageInput = None,
+ text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]] = None,
+ audio=None,
+ videos=None,
+ **kwargs: Unpack[AltClipProcessorKwargs],
+ ) -> BatchEncoding:
+ """
+ Main method to prepare for the model one or several sequences(s) and image(s). This method forwards the `text`
+ and `kwargs` arguments to XLMRobertaTokenizerFast's [`~XLMRobertaTokenizerFast.__call__`] if `text` is not
+ `None` to encode the text. To prepare the image(s), this method forwards the `images` and `kwrags` arguments to
+ CLIPImageProcessor's [`~CLIPImageProcessor.__call__`] if `images` is not `None`. Please refer to the docstring
+ of the above two methods for more information.
+
+ Args:
+
+ images (`ImageInput`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. Both channels-first and channels-last formats are supported.
+ text (`TextInput`, `PreTokenizedInput`, `List[TextInput]`, `List[PreTokenizedInput]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors of a particular framework. Acceptable values are:
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+ Returns:
+ [`BatchEncoding`]: A [`BatchEncoding`] with the following fields:
+
+ - **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
+ - **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
+ `return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
+ `None`).
+ - **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
+ """
+
+ if text is None and images is None:
+ raise ValueError("You must specify either text or images.")
+
+ if text is None and images is None:
+ raise ValueError("You must specify either text or images.")
+ output_kwargs = self._merge_kwargs(
+ AltClipProcessorKwargs,
+ tokenizer_init_kwargs=self.tokenizer.init_kwargs,
+ **kwargs,
+ )
+
+ if text is not None:
+ encoding = self.tokenizer(text, **output_kwargs["text_kwargs"])
+ if images is not None:
+ image_features = self.image_processor(images, **output_kwargs["images_kwargs"])
+
+ # BC for explicit return_tensors
+ if "return_tensors" in output_kwargs["common_kwargs"]:
+ return_tensors = output_kwargs["common_kwargs"].pop("return_tensors", None)
+
+ if text is not None and images is not None:
+ encoding["pixel_values"] = image_features.pixel_values
+ return encoding
+ elif text is not None:
+ return encoding
+ else:
+ return BatchEncoding(data=dict(**image_features), tensor_type=return_tensors)
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to XLMRobertaTokenizerFast's [`~PreTrainedTokenizer.batch_decode`].
+ Please refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to XLMRobertaTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
+
+ @property
+ def model_input_names(self):
+ tokenizer_input_names = self.tokenizer.model_input_names
+ image_processor_input_names = self.image_processor.model_input_names
+ return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
+
+
+__all__ = ["AltCLIPProcessor"]
diff --git a/docs/transformers/src/transformers/models/aria/__init__.py b/docs/transformers/src/transformers/models/aria/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f73301321527c185cfab149b171a38f5fd4f7852
--- /dev/null
+++ b/docs/transformers/src/transformers/models/aria/__init__.py
@@ -0,0 +1,30 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import _LazyModule
+from ...utils.import_utils import define_import_structure
+
+
+if TYPE_CHECKING:
+ from .configuration_aria import *
+ from .image_processing_aria import *
+ from .modeling_aria import *
+ from .processing_aria import *
+
+else:
+ import sys
+
+ _file = globals()["__file__"]
+ sys.modules[__name__] = _LazyModule(__name__, _file, define_import_structure(_file), module_spec=__spec__)
diff --git a/docs/transformers/src/transformers/models/aria/configuration_aria.py b/docs/transformers/src/transformers/models/aria/configuration_aria.py
new file mode 100644
index 0000000000000000000000000000000000000000..f3faa60ca3d5920ad9f43596719c928c54d48b7b
--- /dev/null
+++ b/docs/transformers/src/transformers/models/aria/configuration_aria.py
@@ -0,0 +1,307 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from src/transformers/models/aria/modular_aria.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_aria.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# coding=utf-8
+# Copyright 2024 The Rhymes-AI Teams Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Dict
+
+from ...configuration_utils import PretrainedConfig
+from ...modeling_rope_utils import rope_config_validation
+from ..auto import CONFIG_MAPPING, AutoConfig
+
+
+class AriaTextConfig(PretrainedConfig):
+ r"""
+ This class handles the configuration for the text component of the Aria model.
+ Instantiating a configuration with the defaults will yield a similar configuration to that of the model of the Aria
+ [rhymes-ai/Aria](https://huggingface.co/rhymes-ai/Aria) architecture.
+ This class extends the LlamaConfig to include additional parameters specific to the Mixture of Experts (MoE) architecture.
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 32000):
+ Vocabulary size of the LLaMA model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`LlamaModel`]
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 4096):
+ The size of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 32):
+ Number of hidden layers in the Transformer decoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer decoder.
+ num_key_value_heads (`int`, *optional*):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ `num_attention_heads`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to 2048):
+ The maximum sequence length that this model might ever be used with. Llama 1 supports up to 2048 tokens,
+ Llama 2 up to 4096, CodeLlama up to 16384.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ pad_token_id (`int`, *optional*, defaults to 2):
+ Padding token id.
+ bos_token_id (`int`, *optional*, defaults to 1):
+ Beginning of stream token id.
+ eos_token_id (`int`, *optional*, defaults to 2):
+ End of stream token id.
+ pretraining_tp (`int`, *optional*, defaults to 1):
+ Experimental feature. Tensor parallelism rank used during pretraining. Please refer to [this
+ document](https://huggingface.co/docs/transformers/main/perf_train_gpu_many#tensor-parallelism) to
+ understand more about it. This value is necessary to ensure exact reproducibility of the pretraining
+ results. Please refer to [this issue](https://github.com/pytorch/pytorch/issues/76232).
+ tie_word_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether to tie weight embeddings
+ rope_theta (`float`, *optional*, defaults to 10000.0):
+ The base period of the RoPE embeddings.
+ rope_scaling (`Dict`, *optional*):
+ Dictionary containing the scaling configuration for the RoPE embeddings. NOTE: if you apply new rope type
+ and you expect the model to work on longer `max_position_embeddings`, we recommend you to update this value
+ accordingly.
+ Expected contents:
+ `rope_type` (`str`):
+ The sub-variant of RoPE to use. Can be one of ['default', 'linear', 'dynamic', 'yarn', 'longrope',
+ 'llama3'], with 'default' being the original RoPE implementation.
+ `factor` (`float`, *optional*):
+ Used with all rope types except 'default'. The scaling factor to apply to the RoPE embeddings. In
+ most scaling types, a `factor` of x will enable the model to handle sequences of length x *
+ original maximum pre-trained length.
+ `original_max_position_embeddings` (`int`, *optional*):
+ Used with 'dynamic', 'longrope' and 'llama3'. The original max position embeddings used during
+ pretraining.
+ `attention_factor` (`float`, *optional*):
+ Used with 'yarn' and 'longrope'. The scaling factor to be applied on the attention
+ computation. If unspecified, it defaults to value recommended by the implementation, using the
+ `factor` field to infer the suggested value.
+ `beta_fast` (`float`, *optional*):
+ Only used with 'yarn'. Parameter to set the boundary for extrapolation (only) in the linear
+ ramp function. If unspecified, it defaults to 32.
+ `beta_slow` (`float`, *optional*):
+ Only used with 'yarn'. Parameter to set the boundary for interpolation (only) in the linear
+ ramp function. If unspecified, it defaults to 1.
+ `short_factor` (`List[float]`, *optional*):
+ Only used with 'longrope'. The scaling factor to be applied to short contexts (<
+ `original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
+ size divided by the number of attention heads divided by 2
+ `long_factor` (`List[float]`, *optional*):
+ Only used with 'longrope'. The scaling factor to be applied to long contexts (<
+ `original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
+ size divided by the number of attention heads divided by 2
+ `low_freq_factor` (`float`, *optional*):
+ Only used with 'llama3'. Scaling factor applied to low frequency components of the RoPE
+ `high_freq_factor` (`float`, *optional*):
+ Only used with 'llama3'. Scaling factor applied to high frequency components of the RoPE
+ attention_bias (`bool`, *optional*, defaults to `False`):
+ Whether to use a bias in the query, key, value and output projection layers during self-attention.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ mlp_bias (`bool`, *optional*, defaults to `False`):
+ Whether to use a bias in up_proj, down_proj and gate_proj layers in the MLP layers.
+ head_dim (`int`, *optional*):
+ The attention head dimension. If None, it will default to hidden_size // num_heads
+ moe_num_experts (`int`, *optional*, defaults to 8):
+ The number of experts in the MoE layer.
+ moe_topk (`int`, *optional*, defaults to 2):
+ The number of top experts to route to for each token.
+ moe_num_shared_experts (`int`, *optional*, defaults to 2):
+ The number of shared experts.
+ """
+
+ model_type = "aria_text"
+ keys_to_ignore_at_inference = ["past_key_values"]
+ # Default tensor parallel plan for base model `AriaTextModel`
+ base_model_tp_plan = {
+ "layers.*.self_attn.q_proj": "colwise",
+ "layers.*.self_attn.k_proj": "colwise",
+ "layers.*.self_attn.v_proj": "colwise",
+ "layers.*.self_attn.o_proj": "rowwise",
+ "layers.*.mlp.gate_proj": "colwise",
+ "layers.*.mlp.up_proj": "colwise",
+ "layers.*.mlp.down_proj": "rowwise",
+ }
+ base_model_pp_plan = {
+ "embed_tokens": (["input_ids"], ["inputs_embeds"]),
+ "layers": (["hidden_states", "attention_mask"], ["hidden_states"]),
+ "norm": (["hidden_states"], ["hidden_states"]),
+ }
+ base_config_key = "text_config"
+
+ def __init__(
+ self,
+ vocab_size=32000,
+ hidden_size=4096,
+ intermediate_size: int = 4096,
+ num_hidden_layers=32,
+ num_attention_heads=32,
+ num_key_value_heads=None,
+ hidden_act="silu",
+ max_position_embeddings=2048,
+ initializer_range=0.02,
+ rms_norm_eps=1e-6,
+ use_cache=True,
+ pad_token_id=2,
+ bos_token_id=1,
+ eos_token_id=2,
+ pretraining_tp=1,
+ tie_word_embeddings=False,
+ rope_theta=10000.0,
+ rope_scaling=None,
+ attention_bias=False,
+ attention_dropout=0.0,
+ mlp_bias=False,
+ head_dim=None,
+ moe_num_experts: int = 8,
+ moe_topk: int = 2,
+ moe_num_shared_experts: int = 2,
+ **kwargs,
+ ):
+ super().__init__(
+ pad_token_id=pad_token_id,
+ bos_token_id=bos_token_id,
+ eos_token_id=eos_token_id,
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+
+ # for backward compatibility
+ if num_key_value_heads is None:
+ num_key_value_heads = num_attention_heads
+
+ self.num_key_value_heads = num_key_value_heads
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+ self.pretraining_tp = pretraining_tp
+ self.use_cache = use_cache
+ self.rope_theta = rope_theta
+ self.rope_scaling = rope_scaling
+ self.attention_bias = attention_bias
+ self.attention_dropout = attention_dropout
+ self.mlp_bias = mlp_bias
+ self.head_dim = head_dim if head_dim is not None else self.hidden_size // self.num_attention_heads
+ # Validate the correctness of rotary position embeddings parameters
+ # BC: if there is a 'type' field, copy it it to 'rope_type'.
+ if self.rope_scaling is not None and "type" in self.rope_scaling:
+ self.rope_scaling["rope_type"] = self.rope_scaling["type"]
+ rope_config_validation(self)
+ self.moe_num_experts = moe_num_experts
+ self.moe_topk = moe_topk
+ self.moe_num_shared_experts = moe_num_shared_experts
+
+
+class AriaConfig(PretrainedConfig):
+ r"""
+ This class handles the configuration for both vision and text components of the Aria model,
+ as well as additional parameters for image token handling and projector mapping.
+ Instantiating a configuration with the defaults will yield a similar configuration to that of the model of the Aria
+ [rhymes-ai/Aria](https://huggingface.co/rhymes-ai/Aria) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ vision_config (`AriaVisionConfig` or `dict`, *optional*):
+ Configuration for the vision component.
+ vision_feature_layer (`int`, *optional*, defaults to -1):
+ The index of the layer to select the vision feature.
+ text_config (`AriaTextConfig` or `dict`, *optional*):
+ Configuration for the text component.
+ projector_patch_to_query_dict (`dict`, *optional*):
+ Mapping of patch sizes to query dimensions.
+ image_token_index (`int`, *optional*, defaults to 9):
+ Index used to represent image tokens.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated normal initializer for initializing all weight matrices.
+
+ Attributes:
+ model_type (`str`):
+ Type of the model, set to `"aria"`.
+ image_token_index (`int`):
+ Index used to represent image tokens.
+ projector_patch_to_query_dict (`dict`):
+ Mapping of patch sizes to query dimensions.
+ vision_config (`AriaVisionConfig`):
+ Configuration for the vision component.
+ text_config (`AriaTextConfig`):
+ Configuration for the text component.
+ """
+
+ model_type = "aria"
+ attribute_map = {
+ "image_token_id": "image_token_index",
+ }
+ sub_configs = {"text_config": AriaTextConfig, "vision_config": AutoConfig}
+
+ def __init__(
+ self,
+ vision_config=None,
+ vision_feature_layer: int = -1,
+ text_config: AriaTextConfig = None,
+ projector_patch_to_query_dict: Dict = None,
+ image_token_index: int = 9,
+ initializer_range: float = 0.02,
+ **kwargs,
+ ):
+ self.image_token_index = image_token_index
+
+ # Convert the keys and values of projector_patch_to_query_dict to integers
+ # This ensures consistency even if they were provided as strings
+ if projector_patch_to_query_dict is None:
+ projector_patch_to_query_dict = {
+ 1225: 128,
+ 4900: 256,
+ }
+ self.projector_patch_to_query_dict = {int(k): int(v) for k, v in projector_patch_to_query_dict.items()}
+ self.max_value_projector_patch_to_query_dict = max(self.projector_patch_to_query_dict.values())
+ self.vision_feature_layer = vision_feature_layer
+ if isinstance(vision_config, dict):
+ vision_config["model_type"] = "idefics3_vision"
+ vision_config = CONFIG_MAPPING[vision_config["model_type"]](**vision_config)
+ elif vision_config is None:
+ vision_config = CONFIG_MAPPING["idefics3_vision"]()
+
+ self.vision_config = vision_config
+ self.initializer_range = initializer_range
+
+ if isinstance(text_config, dict) and "model_type" in text_config:
+ text_config = AriaTextConfig(**text_config)
+ elif text_config is None:
+ text_config = AriaTextConfig()
+
+ self.text_config = text_config
+
+ super().__init__(**kwargs)
+
+
+__all__ = ["AriaConfig", "AriaTextConfig"]
diff --git a/docs/transformers/src/transformers/models/aria/convert_aria_weights_to_hf.py b/docs/transformers/src/transformers/models/aria/convert_aria_weights_to_hf.py
new file mode 100644
index 0000000000000000000000000000000000000000..a95f3cda8349c45da1870720063e381f43d34438
--- /dev/null
+++ b/docs/transformers/src/transformers/models/aria/convert_aria_weights_to_hf.py
@@ -0,0 +1,162 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import glob
+
+import torch
+from huggingface_hub import snapshot_download
+from safetensors import safe_open
+
+from transformers import (
+ AddedToken,
+ AriaForConditionalGeneration,
+ AriaProcessor,
+ AutoConfig,
+ AutoTokenizer,
+)
+
+
+EPILOG_TXT = """Example:
+ python transformers/src/transformers/models/aria/convert_aria_weights_to_hf.py --text_model_id rhymes-ai/Aria --vision_model_id rhymes-ai/Aria --output_hub_path m-ric/Aria_hf_2 --old_state_dict_id rhymes-ai/Aria
+
+Example for creating the old state dict file with Python:
+
+ import torch
+ from aria.model.language_model.aria_llama import AriaTextForCausalLM
+
+ # load model
+ kwargs = {"device_map": "auto", "torch_dtype": torch.float16}
+ model = AriaTextForCausalLM.from_pretrained("rhymes-ai/Aria", low_cpu_mem_usage=True, **kwargs)
+
+ # load vision tower
+ model.get_vision_tower().load_model()
+
+ # Save state dict
+ torch.save(model.state_dict(), "tmp/hf_models/aria/model_state_dict.bin")
+"""
+
+KEYS_TO_MODIFY_MAPPING = {
+ "vision_tower.vision_model": "vision_tower",
+ "ln_ffn": "layer_norm",
+ "ffn": "feed_forward",
+ "ln_kv": "layer_norm_kv",
+}
+
+
+def load_original_state_dict(model_id):
+ directory_path = snapshot_download(repo_id=model_id, allow_patterns=["*.safetensors"])
+
+ original_state_dict = {}
+ for path in glob.glob(f"{directory_path}/*"):
+ if path.endswith(".safetensors"):
+ with safe_open(path, framework="pt", device="cpu") as f:
+ for key in f.keys():
+ original_state_dict[key] = f.get_tensor(key)
+
+ return original_state_dict
+
+
+def convert_state_dict_to_hf(state_dict):
+ new_state_dict = {}
+ for key, value in state_dict.items():
+ if key.endswith(".inv_freq"):
+ continue
+ for key_to_modify, new_key in KEYS_TO_MODIFY_MAPPING.items():
+ if key_to_modify in key:
+ key = key.replace(key_to_modify, new_key)
+
+ new_state_dict[key] = value
+ new_state_dict["vision_tower.post_layernorm.weight"] = torch.zeros((1152,))
+ new_state_dict["vision_tower.post_layernorm.bias"] = torch.zeros((1152,))
+
+ return new_state_dict
+
+
+def convert_aria_llama_to_hf(text_model_id, vision_model_id, output_hub_path, old_state_dict_id):
+ torch.set_default_dtype(torch.float16)
+
+ tokenizer = AutoTokenizer.from_pretrained(
+ text_model_id,
+ extra_special_tokens={
+ "image_token": "<|img|>",
+ "pad_token": "",
+ },
+ )
+ tokenizer.add_tokens(AddedToken("<|img|>", special=True, normalized=False), special_tokens=True)
+ tokenizer.add_special_tokens({"pad_token": ""})
+ tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}<|im_start|>{{ message['role'] }}\n{% if message['content'] is string %}{{ message['content'] }}{% elif message['content'] is iterable %}{% for item in message['content'] %}{% if item['type'] == 'text' %}{{ item['text'] }}{% elif item['type'] == 'image' %}<|img|>{% endif %}{% endfor %}{% endif %}<|im_end|>\n{% endfor %}{% if add_generation_prompt %}<|im_start|>assistant\n{% endif %}"
+
+ processor = AriaProcessor.from_pretrained(
+ text_model_id,
+ tokenizer=tokenizer,
+ )
+
+ config = AutoConfig.from_pretrained(text_model_id)
+ config.vision_config.hidden_size = 1152
+ config.vision_config.attention_heads = 16
+ config.pad_token_id = 2
+ config.image_token_id = 9
+ config.intermediate_size = config.moe_intermediate_size
+ config.auto_map = {
+ "AutoConfig": "modeling_aria.AriaConfig",
+ "AutoModelForCausalLM": "modeling_aria.AriaForConditionalGeneration",
+ }
+
+ with torch.device("meta"):
+ model = AriaForConditionalGeneration(config)
+
+ state_dict = load_original_state_dict(old_state_dict_id)
+
+ state_dict = convert_state_dict_to_hf(state_dict)
+ model.load_state_dict(state_dict, strict=False, assign=True)
+
+ # print("Saving models")
+ # model.save_pretrained("local_aria", safe_serialization=False)
+ # processor.save_pretrained("local_aria")
+ print("Pushing to hub")
+ model.push_to_hub(output_hub_path, create_pr=True)
+ processor.push_to_hub(output_hub_path, create_pr=True)
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ epilog=EPILOG_TXT,
+ formatter_class=argparse.RawDescriptionHelpFormatter,
+ )
+ parser.add_argument(
+ "--text_model_id",
+ default="rhymes-ai/Aria",
+ help="Hub location of the text model",
+ )
+ parser.add_argument(
+ "--vision_model_id",
+ default="rhymes-ai/Aria",
+ help="Hub location of the vision model",
+ )
+ parser.add_argument(
+ "--output_hub_path",
+ default="rhymes-ai/Aria",
+ help="Location on the hub of the converted model",
+ )
+ parser.add_argument(
+ "--old_state_dict_id",
+ default="rhymes-ai/Aria",
+ help="Location on the hub of the raw state dict of the original model. The filename needs to be `model_state_dict.bin`",
+ )
+ args = parser.parse_args()
+ convert_aria_llama_to_hf(args.text_model_id, args.vision_model_id, args.output_hub_path, args.old_state_dict_id)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/docs/transformers/src/transformers/models/aria/image_processing_aria.py b/docs/transformers/src/transformers/models/aria/image_processing_aria.py
new file mode 100644
index 0000000000000000000000000000000000000000..364f8f70df1f01d1200e0455083ea128d1befa50
--- /dev/null
+++ b/docs/transformers/src/transformers/models/aria/image_processing_aria.py
@@ -0,0 +1,518 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from src/transformers/models/aria/modular_aria.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_aria.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# coding=utf-8
+# Copyright 2024 The Rhymes-AI Teams Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+from typing import Iterable, List, Optional, Tuple, Union
+
+import numpy as np
+
+from ...image_processing_utils import BaseImageProcessor, BatchFeature, select_best_resolution
+from ...image_transforms import PaddingMode, convert_to_rgb, pad, resize, to_channel_dimension_format
+from ...image_utils import (
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_scaled_image,
+ make_flat_list_of_images,
+ to_numpy_array,
+ valid_images,
+ validate_preprocess_arguments,
+)
+from ...utils import TensorType, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+def divide_to_patches(image: np.array, patch_size: int, input_data_format) -> List[np.array]:
+ """
+ Divides an image into patches of a specified size.
+
+ Args:
+ image (`np.array`):
+ The input image.
+ patch_size (`int`):
+ The size of each patch.
+ input_data_format (`ChannelDimension` or `str`):
+ The channel dimension format of the input image.
+
+ Returns:
+ list: A list of np.array representing the patches.
+ """
+ patches = []
+ height, width = get_image_size(image, channel_dim=input_data_format)
+ for i in range(0, height, patch_size):
+ for j in range(0, width, patch_size):
+ if input_data_format == ChannelDimension.LAST:
+ patch = image[i : i + patch_size, j : j + patch_size]
+ else:
+ patch = image[:, i : i + patch_size, j : j + patch_size]
+ patches.append(patch)
+
+ return patches
+
+
+def _get_patch_output_size(image, target_resolution, input_data_format):
+ original_height, original_width = get_image_size(image, channel_dim=input_data_format)
+ target_height, target_width = target_resolution
+
+ scale_w = target_width / original_width
+ scale_h = target_height / original_height
+
+ if scale_w < scale_h:
+ new_width = target_width
+ new_height = min(math.ceil(original_height * scale_w), target_height)
+ else:
+ new_height = target_height
+ new_width = min(math.ceil(original_width * scale_h), target_width)
+
+ return new_height, new_width
+
+
+class AriaImageProcessor(BaseImageProcessor):
+ """
+ A vision processor for the Aria model that handles image preprocessing.
+ Initialize the AriaImageProcessor.
+
+ Args:
+ image_mean (`list`, *optional*, defaults to [0.5, 0.5, 0.5]):
+ Mean values for normalization.
+ image_std (`list`, *optional*, defaults to [0.5, 0.5, 0.5]):
+ Standard deviation values for normalization.
+ max_image_size (`int`, *optional*, defaults to 980):
+ Maximum image size.
+ min_image_size (`int`, *optional*, defaults to 336):
+ Minimum image size.
+ split_resolutions (`list`, *optional*, defaults to a list of optimal,resolutions as tuples):
+ The optimal resolutions for splitting the image.
+ split_image (`bool`, *optional*, defaults to `False`):
+ Whether to split the image.
+ do_convert_rgb (`bool`, *optional*, defaults to `True`):
+ Whether to convert the image to RGB.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by `do_rescale` in
+ the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by `rescale_factor` in the `preprocess`
+ method.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image.
+ resample (PILImageResampling, *optional*, defaults to `BICUBIC`):
+ The resampling filter to use if resizing the image.
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask", "num_crops"]
+
+ def __init__(
+ self,
+ image_mean: List[float] = None,
+ image_std: List[float] = None,
+ max_image_size: int = 980,
+ min_image_size: int = 336,
+ split_resolutions: Optional[List[Tuple[int, int]]] = None,
+ split_image: Optional[bool] = False,
+ do_convert_rgb: Optional[bool] = True,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: Optional[bool] = True,
+ resample: PILImageResampling = PILImageResampling.BICUBIC,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ if image_mean is None:
+ image_mean = [0.5, 0.5, 0.5]
+ if image_std is None:
+ image_std = [0.5, 0.5, 0.5]
+ self.max_image_size = max_image_size
+ self.min_image_size = min_image_size
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.split_image = split_image
+ if split_resolutions is None:
+ split_resolutions = [(1, 2), (1, 3), (1, 4), (1, 5), (1, 6), (1, 7), (1, 8), (2, 4), (2, 3), (2, 2), (2, 1), (3, 1), (3, 2), (4, 1), (4, 2), (5, 1), (6, 1), (7, 1), (8, 1)] # fmt: skip
+ split_resolutions = [(el[0] * 490, el[1] * 490) for el in split_resolutions]
+ self.split_resolutions = split_resolutions
+ self.do_convert_rgb = do_convert_rgb
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.resample = resample
+
+ def preprocess(
+ self,
+ images: Union[ImageInput, List[ImageInput]],
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ max_image_size: Optional[int] = None,
+ min_image_size: Optional[int] = None,
+ split_image: Optional[bool] = None,
+ do_convert_rgb: Optional[bool] = None,
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[float] = None,
+ do_normalize: Optional[bool] = None,
+ resample: PILImageResampling = None,
+ return_tensors: Optional[Union[str, TensorType]] = "pt",
+ data_format: Optional[ChannelDimension] = ChannelDimension.FIRST,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ):
+ """
+ Process a list of images.
+
+ Args:
+ images (ImageInput or list of ImageInput):
+ The input image or a list of images.
+ image_mean (`list`, *optional*, defaults to [0.5, 0.5, 0.5]):
+ Mean values for normalization.
+ image_std (`list`, *optional*, defaults to [0.5, 0.5, 0.5]):
+ Standard deviation values for normalization.
+ max_image_size (`int`, *optional*, defaults to `self.max_image_size` (980)):
+ Maximum image size.
+ min_image_size (`int`, *optional*, defaults to `self.min_image_size` (336)):
+ Minimum image size.
+ split_image (`bool`, *optional*, defaults to `self.split_image` (False)):
+ Whether to split the image.
+ do_convert_rgb (`bool`, *optional*, defaults to `self.do_convert_rgb` (True)):
+ Whether to convert the image to RGB.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ Rescale factor to rescale the image by if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `self.do_normalize` (True)):
+ Whether to normalize the image.
+ resample (PILImageResampling, *optional*, defaults to `self.resample` (BICUBIC)):
+ The resampling filter to use if resizing the image.
+ return_tensors (`str` or `TensorType`, *optional*, defaults to "pt"):
+ The type of tensor to return.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`:
+ image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`:
+ image in (height, width, num_channels) format.
+ If unset, will use same as the input image.
+ input_data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`:
+ image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`:
+ image in (height, width, num_channels) format.
+ If unset, will use the inferred format of the input image.
+
+ Returns:
+ BatchFeature:
+ A BatchFeature object containing:
+ - 'pixel_values':
+ Tensor of processed image pixel values.
+ - 'pixel_mask':
+ Boolean pixel mask. This mask is a 2D tensor of shape (max_image_size, max_image_size) where:
+ - True (1) values indicate pixels that belong to the original resized image.
+ - False (0) values indicate pixels that are part of the padding.
+ The mask helps distinguish between actual image content and padded areas in subsequent processing steps.
+ - 'num_crops':
+ The maximum number of crops across all images.
+ """
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+ max_image_size = max_image_size if max_image_size is not None else self.max_image_size
+ min_image_size = min_image_size if min_image_size is not None else self.min_image_size
+ split_image = split_image if split_image is not None else self.split_image
+ do_convert_rgb = do_convert_rgb if do_convert_rgb is not None else self.do_convert_rgb
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ resample = resample if resample is not None else self.resample
+
+ if max_image_size not in [490, 980]:
+ raise ValueError("max_image_size must be either 490 or 980")
+
+ images = make_flat_list_of_images(images)
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ validate_preprocess_arguments(
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ resample=resample,
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ )
+
+ if do_convert_rgb:
+ images = [convert_to_rgb(image) for image in images]
+
+ # All transformations expect numpy arrays.
+ images = [to_numpy_array(image) for image in images]
+
+ if do_rescale and is_scaled_image(images[0]):
+ logger.warning_once(
+ "It looks like you are trying to rescale already rescaled images. If the input"
+ " images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
+ )
+
+ if input_data_format is None:
+ # We assume that all images have the same channel dimension format.
+ input_data_format = infer_channel_dimension_format(images[0])
+
+ pixel_values = []
+ pixel_masks = []
+ num_crops = None
+
+ for image in images:
+ if split_image:
+ crop_images = self.get_image_patches(
+ image,
+ self.split_resolutions,
+ max_image_size,
+ resample,
+ data_format=input_data_format,
+ input_data_format=input_data_format,
+ )
+ else:
+ crop_images = [image]
+ if num_crops is None or len(crop_images) > num_crops:
+ num_crops = len(crop_images)
+
+ for crop_image in crop_images:
+ # At this point the scale is the rescaling factor that would bring the image to max_size in its larger dimension
+ h, w = get_image_size(crop_image)
+ scale = max_image_size / max(h, w)
+ if w >= h:
+ new_size = (max(int(h * scale), min_image_size), max_image_size) # h, w
+ else:
+ new_size = (max_image_size, max(int(w * scale), min_image_size)) # h, w
+
+ crop_image_resized = resize(
+ crop_image,
+ new_size,
+ resample=resample,
+ data_format=input_data_format,
+ input_data_format=input_data_format,
+ )
+
+ padding_bottom, padding_right = max_image_size - new_size[0], max_image_size - new_size[1]
+ crop_image_padded = pad(
+ crop_image_resized,
+ ((0, padding_bottom), (0, padding_right)),
+ data_format=input_data_format,
+ input_data_format=input_data_format,
+ )
+
+ # Create a pixel mask
+ pixel_mask = np.zeros((max_image_size, max_image_size), dtype=bool)
+ pixel_mask[: new_size[0], : new_size[1]] = 1
+ pixel_masks.append(pixel_mask)
+
+ if do_rescale:
+ crop_image_padded = self.rescale(
+ image=crop_image_padded, scale=rescale_factor, input_data_format=input_data_format
+ )
+
+ if do_normalize:
+ crop_image_padded = self.normalize(
+ crop_image_padded,
+ self.image_mean,
+ self.image_std,
+ data_format=input_data_format,
+ input_data_format=input_data_format,
+ )
+ crop_image_padded = (
+ to_channel_dimension_format(crop_image_padded, data_format, input_data_format)
+ if data_format is not None
+ else crop_image_padded
+ )
+
+ pixel_values.append(crop_image_padded)
+ return BatchFeature(
+ data={
+ "pixel_values": np.stack(pixel_values, axis=0),
+ "pixel_mask": np.stack(pixel_masks, axis=0),
+ "num_crops": num_crops,
+ },
+ tensor_type=return_tensors,
+ )
+
+ def _resize_for_patching(
+ self, image: np.array, target_resolution: tuple, resample, input_data_format: ChannelDimension
+ ) -> np.array:
+ """
+ Resizes an image to a target resolution while maintaining aspect ratio.
+
+ Args:
+ image (np.array):
+ The input image.
+ target_resolution (tuple):
+ The target resolution (height, width) of the image.
+ resample (`PILImageResampling`):
+ Resampling filter to use if resizing the image.
+ input_data_format (`ChannelDimension` or `str`):
+ The channel dimension format of the input image.
+
+ Returns:
+ np.array: The resized and padded image.
+ """
+ new_height, new_width = _get_patch_output_size(image, target_resolution, input_data_format)
+
+ # Resize the image
+ resized_image = resize(image, (new_height, new_width), resample=resample, input_data_format=input_data_format)
+
+ return resized_image
+
+ def _pad_for_patching(
+ self, image: np.array, target_resolution: tuple, input_data_format: ChannelDimension
+ ) -> np.array:
+ """
+ Pad an image to a target resolution while maintaining aspect ratio.
+ """
+ target_height, target_width = target_resolution
+ new_height, new_width = _get_patch_output_size(image, target_resolution, input_data_format)
+
+ paste_x = (target_width - new_width) // 2
+ paste_y = (target_height - new_height) // 2
+
+ padded_image = self.pad(image, padding=((paste_y, paste_y), (paste_x, paste_x)))
+
+ return padded_image
+
+ def pad(
+ self,
+ image: np.ndarray,
+ padding: Union[int, Tuple[int, int], Iterable[Tuple[int, int]]],
+ mode: PaddingMode = PaddingMode.CONSTANT,
+ constant_values: Union[float, Iterable[float]] = 0.0,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ) -> np.ndarray:
+ """
+ Pads the `image` with the specified `padding` and `mode`. Padding can be in the (`height`, `width`)
+ dimension of in the (`num_patches`) dimension. In the second case an iterable if tuples is expected
+ as input.
+
+ Args:
+ image (`np.ndarray`):
+ The image to pad.
+ padding (`int` or `Tuple[int, int]` or `Iterable[Tuple[int, int]]`):
+ Padding to apply to the edges of the height, width axes. Can be one of three formats:
+ - `((before_height, after_height), (before_width, after_width))` unique pad widths for each axis.
+ - `((before, after),)` yields same before and after pad for height and width.
+ - `(pad,)` or int is a shortcut for before = after = pad width for all axes.
+ mode (`PaddingMode`):
+ The padding mode to use. Can be one of:
+ - `"constant"`: pads with a constant value.
+ - `"reflect"`: pads with the reflection of the vector mirrored on the first and last values of the
+ vector along each axis.
+ - `"replicate"`: pads with the replication of the last value on the edge of the array along each axis.
+ - `"symmetric"`: pads with the reflection of the vector mirrored along the edge of the array.
+ constant_values (`float` or `Iterable[float]`, *optional*):
+ The value to use for the padding if `mode` is `"constant"`.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ If unset, will use same as the input image.
+ input_data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ If unset, will use the inferred format of the input image.
+
+ Returns:
+ `np.ndarray`: The padded image.
+
+ """
+
+ # call the general `pad` if padding on `height/width`, otherwise it's the `num_patched` dim
+ if isinstance(padding, int) or len(padding) != 4:
+ return pad(image, padding, mode, constant_values, data_format, input_data_format)
+
+ if input_data_format is None:
+ input_data_format = infer_channel_dimension_format(image)
+
+ padding_mode_mapping = {
+ PaddingMode.CONSTANT: "constant",
+ PaddingMode.REFLECT: "reflect",
+ PaddingMode.REPLICATE: "edge",
+ PaddingMode.SYMMETRIC: "symmetric",
+ }
+ image = np.pad(image, padding, mode=padding_mode_mapping[mode], constant_values=constant_values)
+ image = (
+ to_channel_dimension_format(image, data_format, input_data_format) if data_format is not None else image
+ )
+ return image
+
+ def get_image_patches(
+ self,
+ image: np.array,
+ grid_pinpoints: List[Tuple[int, int]],
+ patch_size: int,
+ resample: PILImageResampling,
+ data_format: ChannelDimension,
+ input_data_format: ChannelDimension,
+ ) -> List[np.array]:
+ """
+ Process an image with variable resolutions by dividing it into patches.
+
+ Args:
+ image (`np.array`):
+ The input image to be processed.
+ grid_pinpoints (List[Tuple[int, int]]):
+ A list of possible resolutions as tuples.
+ patch_size (`int`):
+ Size of the patches to divide the image into.
+ resample (`PILImageResampling`):
+ Resampling filter to use if resizing the image.
+ data_format (`ChannelDimension` or `str`):
+ The channel dimension format for the output image.
+ input_data_format (`ChannelDimension` or `str`):
+ The channel dimension format of the input image.
+
+ Returns:
+ `List[np.array]`: A list of NumPy arrays containing the processed image patches.
+ """
+ if not isinstance(grid_pinpoints, list):
+ raise TypeError("grid_pinpoints must be a list of possible resolutions.")
+
+ possible_resolutions = grid_pinpoints
+
+ image_size = get_image_size(image, channel_dim=input_data_format)
+ best_resolution = select_best_resolution(image_size, possible_resolutions)
+ resized_image = self._resize_for_patching(
+ image, best_resolution, resample=resample, input_data_format=input_data_format
+ )
+ padded_image = self._pad_for_patching(resized_image, best_resolution, input_data_format=input_data_format)
+
+ patches = divide_to_patches(padded_image, patch_size=patch_size, input_data_format=input_data_format)
+
+ # make sure that all patches are in the input data format
+ patches = [
+ to_channel_dimension_format(patch, channel_dim=data_format, input_channel_dim=input_data_format)
+ for patch in patches
+ ]
+ return patches
+
+
+__all__ = ["AriaImageProcessor"]
diff --git a/docs/transformers/src/transformers/models/aria/modeling_aria.py b/docs/transformers/src/transformers/models/aria/modeling_aria.py
new file mode 100644
index 0000000000000000000000000000000000000000..1b9892c94f85b4b1eed091f02fb9e299fb24e548
--- /dev/null
+++ b/docs/transformers/src/transformers/models/aria/modeling_aria.py
@@ -0,0 +1,1584 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from src/transformers/models/aria/modular_aria.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_aria.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# coding=utf-8
+# Copyright 2024 The Rhymes-AI Teams Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from dataclasses import dataclass
+from typing import Callable, List, Optional, Tuple, Union
+
+from ...activations import ACT2FN
+from ...cache_utils import Cache, DynamicCache, StaticCache
+from ...generation import GenerationMixin
+from ...integrations import use_kernel_forward_from_hub
+from ...modeling_attn_mask_utils import AttentionMaskConverter
+from ...modeling_flash_attention_utils import FlashAttentionKwargs
+from ...modeling_layers import GradientCheckpointingLayer
+from ...modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast, ModelOutput
+from ...modeling_rope_utils import ROPE_INIT_FUNCTIONS, dynamic_rope_update
+from ...modeling_utils import ALL_ATTENTION_FUNCTIONS, PreTrainedModel
+from ...processing_utils import Unpack
+from ...utils import (
+ LossKwargs,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ can_return_tuple,
+ is_torch_flex_attn_available,
+ logging,
+ replace_return_docstrings,
+)
+from ...utils.import_utils import is_torch_available
+from ..auto import AutoModel, AutoModelForCausalLM
+from .configuration_aria import AriaConfig, AriaTextConfig
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+if is_torch_flex_attn_available():
+ from torch.nn.attention.flex_attention import BlockMask
+
+ from ...integrations.flex_attention import make_flex_block_causal_mask
+
+
+logger = logging.get_logger(__name__)
+_CONFIG_FOR_DOC = "AriaTextConfig"
+
+
+@use_kernel_forward_from_hub("RMSNorm")
+class AriaTextRMSNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ AriaTextRMSNorm is equivalent to T5LayerNorm
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+ def extra_repr(self):
+ return f"{tuple(self.weight.shape)}, eps={self.variance_epsilon}"
+
+
+class AriaProjectorMLP(nn.Module):
+ """
+ Feed-Forward Network module for the Aria Projector.
+
+ Args:
+ in_features (`int`):
+ Input embedding dimension.
+ hidden_features (`int`):
+ Hidden dimension of the feed-forward network.
+ output_dim (`int`):
+ Output dimension.
+ """
+
+ def __init__(self, in_features, hidden_features, output_dim):
+ super().__init__()
+ self.linear_in = nn.Linear(in_features, hidden_features, bias=False)
+ self.linear_out = nn.Linear(hidden_features, output_dim, bias=False)
+ self.act = ACT2FN["gelu_new"]
+
+ def forward(self, hidden_states):
+ hidden_states = self.act(self.linear_in(hidden_states))
+ hidden_states = self.linear_out(hidden_states)
+ return hidden_states
+
+
+class AriaCrossAttention(nn.Module):
+ """
+ Aria Cross-Attention module.
+
+ Args:
+ config (`AriaConfig`):
+ The configuration to use.
+ """
+
+ def __init__(self, config: AriaConfig, dropout_rate: float = 0):
+ super().__init__()
+ hidden_size = config.vision_config.hidden_size
+ num_heads = config.vision_config.num_attention_heads
+ self.num_heads = num_heads
+ self.q_proj = nn.Linear(hidden_size, hidden_size, bias=False)
+ self.k_proj = nn.Linear(hidden_size, hidden_size, bias=False)
+ self.v_proj = nn.Linear(hidden_size, hidden_size, bias=False)
+
+ # Original code here: https://github.com/rhymes-ai/Aria/blob/719ff4e52b727443cba3793b0e27fe64e0244fe1/aria/model/projector.py#L48
+ self.multihead_attn = nn.MultiheadAttention(hidden_size, num_heads, batch_first=True)
+ self.linear = nn.Linear(hidden_size, hidden_size)
+ self.dropout = nn.Dropout(dropout_rate)
+
+ self.layer_norm = nn.LayerNorm(hidden_size)
+ self.layer_norm_kv = nn.LayerNorm(hidden_size)
+
+ def forward(self, key_value_states, hidden_states, attn_mask=None):
+ """
+ Forward pass of the AriaCrossAttention module.
+
+ Args:
+ key_value_states (`torch.Tensor`):
+ Input tensor for key and value.
+ hidden_states (`torch.Tensor`):
+ Input tensor for query.
+ attn_mask (`torch.Tensor`, *optional*, defaults to None):
+ Attention mask.
+
+ Returns:
+ torch.Tensor:
+ Output tensor after cross-attention.
+ """
+ query = self.q_proj(self.layer_norm(hidden_states))
+
+ key_value_states = self.layer_norm_kv(key_value_states)
+ key = self.k_proj(key_value_states)
+ value = self.v_proj(key_value_states)
+
+ attn_output, _ = self.multihead_attn(query, key, value, attn_mask=attn_mask)
+
+ attn_output = self.dropout(self.linear(attn_output))
+
+ return attn_output
+
+
+class AriaProjector(nn.Module):
+ """
+ Aria Projector module.
+
+ This module projects vision features into the language model's embedding space, enabling interaction between vision and language components.
+
+ Args:
+ config (`AriaConfig`):
+ Configuration object for the model.
+ """
+
+ def __init__(
+ self,
+ config: AriaConfig,
+ ):
+ super().__init__()
+
+ self.patch_to_query_dict = config.projector_patch_to_query_dict
+ self.in_features = config.vision_config.hidden_size
+ self.num_heads = config.vision_config.num_attention_heads
+ self.kv_dim = config.vision_config.hidden_size
+ self.hidden_features = config.text_config.hidden_size
+ self.output_dim = config.text_config.hidden_size
+
+ self.query = nn.Parameter(torch.zeros(config.max_value_projector_patch_to_query_dict, self.in_features))
+
+ self.cross_attn = AriaCrossAttention(config)
+
+ self.layer_norm = nn.LayerNorm(self.in_features)
+ self.feed_forward = AriaProjectorMLP(self.in_features, self.hidden_features, self.output_dim)
+
+ def forward(self, key_value_states: torch.Tensor, attn_mask: Optional[torch.Tensor] = None):
+ """
+ Forward pass of the Projector module.
+
+ Args:
+ key_value_states (`torch.Tensor`):
+ Input tensor of shape (batch_size, num_patches, kv_dim).
+ attn_mask (`torch.Tensor`, *optional*, default is None):
+ Attention mask.
+
+ Returns:
+ `torch.Tensor`: Output tensor of shape (batch_size, query_number, output_dim).
+ """
+ batch_size, num_patches = key_value_states.shape[0], key_value_states.shape[1]
+
+ if num_patches not in self.patch_to_query_dict.keys():
+ raise KeyError(
+ f"Number of patches {num_patches} not found in patch_to_query_dict amongst possible values {self.patch_to_query_dict.keys()}."
+ )
+ query_num = self.patch_to_query_dict[num_patches]
+
+ queries = self.query[:query_num].unsqueeze(0).repeat(batch_size, 1, 1)
+
+ if attn_mask is not None:
+ attn_mask = attn_mask.repeat_interleave(self.num_heads, 0)
+ attn_mask = attn_mask.unsqueeze(1).expand(-1, queries.size(1), -1)
+
+ attention_out = self.cross_attn(key_value_states, queries, attn_mask=attn_mask)
+
+ out = self.feed_forward(self.layer_norm(attention_out))
+
+ return out
+
+
+class AriaSharedExpertsMLP(nn.Module):
+ """
+ Shared Expert MLP for shared experts.
+
+ Unlike routed experts, shared experts process all tokens without routing.
+ This class reconfigures the intermediate size in comparison to the LlamaMLP.
+
+ Args:
+ config (`AriaTextConfig`): Configuration object for the Aria language model.
+ """
+
+ def __init__(self, config: AriaTextConfig):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.intermediate_size = config.intermediate_size * config.moe_num_shared_experts
+ self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
+ self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
+ self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=config.mlp_bias)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+ return down_proj
+
+
+def sequential_experts_gemm(token_states, expert_weights, tokens_per_expert):
+ """
+ Compute the matrix multiplication (GEMM) for each expert sequentially. This approach is computationally inefficient, especially when dealing with a large number of experts.
+
+ Args:
+ token_states (torch.Tensor): Input tensor of shape (num_tokens, in_features).
+ expert_weights (torch.Tensor): Weight tensor of shape (num_experts, in_features, out_features).
+ tokens_per_expert (torch.Tensor): Number of tokens assigned to each expert.
+
+ Returns:
+ torch.Tensor: Output tensor of shape (num_tokens, out_features).
+ """
+ num_tokens = token_states.shape[0]
+ out_features = expert_weights.shape[-1]
+ output = torch.zeros(num_tokens, out_features, dtype=token_states.dtype, device=token_states.device)
+
+ cumsum_num_tokens = torch.cumsum(tokens_per_expert, dim=0)
+ # Insert zero at the beginning for offset index's convenience
+ zero_tensor = torch.zeros(1, dtype=torch.long, device=cumsum_num_tokens.device)
+ cumsum_num_tokens = torch.cat((zero_tensor, cumsum_num_tokens))
+
+ for expert_num in range(expert_weights.shape[0]):
+ start = cumsum_num_tokens[expert_num]
+ end = cumsum_num_tokens[expert_num + 1]
+ tokens = token_states[start:end]
+
+ out = torch.matmul(tokens, expert_weights[expert_num])
+ output[start:end] = out
+ return output
+
+
+class AriaGroupedExpertsGemm(nn.Module):
+ """
+ Grouped GEMM (General Matrix Multiplication) module for efficient expert computation.
+ This module utilizes the grouped_gemm library (https://github.com/fanshiqing/grouped_gemm)
+ for optimized performance. If the grouped_gemm library is not installed, it gracefully
+ falls back to a sequential GEMM implementation, which may be slower but ensures
+ functionality.
+
+ Args:
+ in_features (`int`):
+ Number of input features.
+ out_features (`int`):
+ Number of output features.
+ groups (`int`):
+ Number of expert groups.
+ """
+
+ def __init__(self, in_features, out_features, groups):
+ super().__init__()
+ self.in_features = in_features
+ self.out_features = out_features
+ self.groups = groups
+ self.weight = nn.Parameter(torch.empty(groups, in_features, out_features))
+
+ def forward(self, input, tokens_per_expert):
+ """
+ Perform grouped matrix multiplication.
+
+ Args:
+ input (`torch.Tensor`):
+ Input tensor of shape (num_tokens, in_features).
+ tokens_per_expert (`torch.Tensor`):
+ Number of tokens assigned to each expert.
+
+ Returns:
+ torch.Tensor: Output tensor of shape (num_tokens, out_features).
+ """
+ return sequential_experts_gemm(
+ input,
+ self.weight,
+ tokens_per_expert.cpu(),
+ )
+
+
+class AriaGroupedExpertsMLP(nn.Module):
+ """
+ Grouped MLP module for Mixture of Experts.
+
+ Args:
+ config (`AriaTextConfig`):
+ Configuration object for the model.
+ """
+
+ def __init__(self, config: AriaTextConfig) -> None:
+ super().__init__()
+ self.config = config
+ self.fc1 = AriaGroupedExpertsGemm(config.hidden_size, config.intermediate_size * 2, config.moe_num_experts)
+ self.fc2 = AriaGroupedExpertsGemm(config.intermediate_size, config.hidden_size, config.moe_num_experts)
+
+ def forward(self, permuted_tokens, tokens_per_expert):
+ """
+ Forward pass of the Grouped MLP.
+
+ Args:
+ permuted_tokens (torch.Tensor): Permuted input tokens.
+ tokens_per_expert (torch.Tensor): Number of tokens assigned to each expert.
+
+ Returns:
+ torch.Tensor: Output tensor after passing through the MLP.
+ """
+ fc1_output = self.fc1(permuted_tokens, tokens_per_expert)
+ projection, gate = torch.chunk(fc1_output, 2, dim=-1)
+ fc1_output = nn.functional.silu(projection) * gate
+ fc2_output = self.fc2(fc1_output, tokens_per_expert)
+ return fc2_output
+
+
+# Token permutation adapted from https://github.com/NVIDIA/Megatron-LM/blob/54f1f78529cbc2b9cddad313e7f9d96ac0420a27/megatron/core/transformer/moe/token_dispatcher.py#L291-L587
+class AriaTextMoELayer(nn.Module):
+ """
+ Aria Text Mixture of Experts (MoE) Layer.
+
+ This layer applies a gating mechanism to route input tokens to different experts.
+
+ Args:
+ config (`AriaTextConfig`):
+ Configuration object for the text component of the model.
+ """
+
+ def __init__(self, config: AriaTextConfig):
+ super().__init__()
+
+ self.router = nn.Linear(config.hidden_size, config.moe_num_experts, bias=False)
+ self.experts = AriaGroupedExpertsMLP(config)
+ self.shared_experts = AriaSharedExpertsMLP(config)
+ self.config = config
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ """
+ Forward pass of the MoE Layer.
+
+ Args:
+ hidden_states (`torch.Tensor`):
+ Input tensor of shape (batch_size, sequence_length, hidden_size).
+
+ Returns:
+ torch.Tensor: Output tensor after passing through the MoE layer.
+
+ Process:
+ 1. Route tokens to experts using the router.
+ 2. Permute tokens based on routing decisions.
+ 3. Process tokens through experts.
+ 4. Unpermute and combine expert outputs.
+ 5. Add shared expert output to the final result.
+ """
+ original_shape = hidden_states.shape
+ hidden_states = hidden_states.view(-1, hidden_states.size(-1))
+
+ # Top K Routing
+ logits = self.router(hidden_states)
+ top_logits, top_indices = torch.topk(logits, k=self.config.moe_topk, dim=1)
+ scores = nn.functional.softmax(top_logits, dim=-1)
+
+ original_dtype = top_indices.dtype
+
+ tokens_per_expert = torch.histc(
+ top_indices.flatten().to(torch.float32),
+ bins=self.config.moe_num_experts,
+ min=0,
+ max=self.config.moe_num_experts - 1,
+ ).to(original_dtype)
+ indices = top_indices
+
+ # Token permutation
+ flatten_indices = indices.view(-1)
+ sorted_indices = torch.argsort(flatten_indices)
+ permuted_tokens = hidden_states.index_select(0, sorted_indices // self.config.moe_topk)
+
+ # Process through experts
+ expert_output = self.experts(permuted_tokens, tokens_per_expert)
+
+ # Token unpermutation
+ unpermuted_tokens = torch.zeros(
+ (scores.shape[0] * self.config.moe_topk, expert_output.size(1)),
+ dtype=expert_output.dtype,
+ device=expert_output.device,
+ )
+ unpermuted_tokens.index_copy_(0, sorted_indices, expert_output)
+ unpermuted_tokens = unpermuted_tokens.view(-1, self.config.moe_topk, expert_output.size(1))
+
+ output = (unpermuted_tokens * scores.unsqueeze(-1)).sum(dim=1).view(original_shape)
+
+ # Add shared expert output
+ shared_expert_output = self.shared_experts(hidden_states.view(original_shape))
+ return output + shared_expert_output
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+def eager_attention_forward(
+ module: nn.Module,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ attention_mask: Optional[torch.Tensor],
+ scaling: float,
+ dropout: float = 0.0,
+ **kwargs,
+):
+ key_states = repeat_kv(key, module.num_key_value_groups)
+ value_states = repeat_kv(value, module.num_key_value_groups)
+
+ attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
+ if attention_mask is not None:
+ causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
+ attn_weights = attn_weights + causal_mask
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ return attn_output, attn_weights
+
+
+class AriaTextAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: AriaTextConfig, layer_idx: int):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
+ self.scaling = self.head_dim**-0.5
+ self.attention_dropout = config.attention_dropout
+ self.is_causal = True
+
+ self.q_proj = nn.Linear(
+ config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.k_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.v_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.o_proj = nn.Linear(
+ config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ position_embeddings: Tuple[torch.Tensor, torch.Tensor],
+ attention_mask: Optional[torch.Tensor],
+ past_key_value: Optional[Cache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ input_shape = hidden_states.shape[:-1]
+ hidden_shape = (*input_shape, -1, self.head_dim)
+
+ query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+
+ cos, sin = position_embeddings
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models; cache_position needed for the static cache
+ cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ attention_interface: Callable = eager_attention_forward
+
+ if self.config._attn_implementation != "eager":
+ if self.config._attn_implementation == "sdpa" and kwargs.get("output_attentions", False):
+ logger.warning_once(
+ "`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
+ 'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ else:
+ attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
+
+ attn_output, attn_weights = attention_interface(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ dropout=0.0 if not self.training else self.attention_dropout,
+ scaling=self.scaling,
+ **kwargs,
+ )
+
+ attn_output = attn_output.reshape(*input_shape, -1).contiguous()
+ attn_output = self.o_proj(attn_output)
+ return attn_output, attn_weights
+
+
+class AriaTextDecoderLayer(GradientCheckpointingLayer):
+ """
+ Aria Text Decoder Layer.
+
+ This class defines a single decoder layer in the language model, incorporating self-attention and Mixture of Experts (MoE) feed-forward network.
+
+ Args:
+ config (`AriaTextConfig`):
+ Configuration object for the text component of the model.
+ layer_idx (`int`):
+ Index of the layer.
+ """
+
+ def __init__(self, config: AriaTextConfig, layer_idx: int):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+
+ self.self_attn = AriaTextAttention(config=config, layer_idx=layer_idx)
+ self.mlp = AriaTextMoELayer(config)
+ self.input_layernorm = AriaTextRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = AriaTextRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Cache] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ residual = hidden_states
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **kwargs,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ return outputs
+
+
+class AriaTextPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained models.
+ """
+
+ config_class = AriaConfig
+ base_model_prefix = "model"
+ _no_split_modules = ["AriaTextDecoderLayer", "AriaGroupedExpertsGemm"]
+ supports_gradient_checkpointing = True
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn_2 = False
+ _supports_sdpa = True
+ _supports_cache_class = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, AriaTextRMSNorm):
+ module.weight.data.fill_(1.0)
+ elif isinstance(module, AriaGroupedExpertsGemm):
+ module.weight.data.normal_(mean=0.0, std=std)
+
+
+ARIA_TEXT_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`AriaTextConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare Aria Model outputting raw hidden-states without any specific head on top.",
+ ARIA_TEXT_START_DOCSTRING,
+)
+class AriaPreTrainedModel(PreTrainedModel):
+ config_class = AriaTextConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["AriaDecoderLayer"]
+ _skip_keys_device_placement = ["past_key_values"]
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_flex_attn = True
+ _supports_cache_class = True
+ _supports_quantized_cache = True
+ _supports_static_cache = False # MoE models don't work with torch.compile (dynamic slicing)
+ _supports_attention_backend = False
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.MultiheadAttention):
+ # This uses torch's original init
+ module._reset_parameters()
+ elif isinstance(module, nn.LayerNorm):
+ module.weight.data.fill_(1.0)
+ module.bias.data.zero_()
+ elif isinstance(module, AriaProjector):
+ nn.init.trunc_normal_(module.query, std=std)
+
+
+class AriaTextRotaryEmbedding(nn.Module):
+ def __init__(self, config: AriaTextConfig, device=None):
+ super().__init__()
+ # BC: "rope_type" was originally "type"
+ if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
+ self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
+ else:
+ self.rope_type = "default"
+ self.max_seq_len_cached = config.max_position_embeddings
+ self.original_max_seq_len = config.max_position_embeddings
+
+ self.config = config
+ self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
+
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+ self.original_inv_freq = self.inv_freq
+
+ @torch.no_grad()
+ @dynamic_rope_update # power user: used with advanced RoPE types (e.g. dynamic rope)
+ def forward(self, x, position_ids):
+ inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1).to(x.device)
+ position_ids_expanded = position_ids[:, None, :].float()
+
+ device_type = x.device.type if isinstance(x.device.type, str) and x.device.type != "mps" else "cpu"
+ with torch.autocast(device_type=device_type, enabled=False): # Force float32
+ freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
+ emb = torch.cat((freqs, freqs), dim=-1)
+ cos = emb.cos() * self.attention_scaling
+ sin = emb.sin() * self.attention_scaling
+
+ return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
+
+
+ARIA_TEXT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length) or `BlockMask`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ If the model is configured to use flex_attention, it will attempt to convert the mask Tensor into a BlockMask,
+ but you can also pass a `BlockMask` object directly here.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`Cache`, *optional*):
+ Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used to speed up sequential decoding. This typically consists in the `past_key_values`
+ returned by the model at a previous stage of decoding, when `use_cache=True` or `config.use_cache=True`.
+
+ It is a [`~cache_utils.Cache`] instance. For more details, see our [kv cache guide](https://huggingface.co/docs/transformers/en/kv_cache).
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
+ have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
+ of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence. Contrarily to `position_ids`,
+ this tensor is not affected by padding. It is used to update the cache in the correct position and to infer
+ the complete sequence length.
+"""
+
+
+@add_start_docstrings(
+ "The bare AriaText Model outputting raw hidden-states without any specific head on top.",
+ ARIA_TEXT_START_DOCSTRING,
+)
+class AriaTextModel(AriaTextPreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`AriaTextDecoderLayer`]
+
+ Args:
+ config: AriaTextConfig
+ """
+
+ def __init__(self, config: AriaTextConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+ self.layers = nn.ModuleList(
+ [AriaTextDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
+ )
+ self.norm = AriaTextRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.rotary_emb = AriaTextRotaryEmbedding(config=config)
+ self.gradient_checkpointing = False
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @can_return_tuple
+ @add_start_docstrings_to_model_forward(ARIA_TEXT_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Cache] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **flash_attn_kwargs: Unpack[FlashAttentionKwargs],
+ ) -> BaseModelOutputWithPast:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ if (input_ids is None) ^ (inputs_embeds is not None):
+ raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
+
+ if self.gradient_checkpointing and self.training and use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`."
+ )
+ use_cache = False
+
+ # TODO (joao): remove this exception in v4.56 -- it exists for users that try to pass a legacy cache
+ if not isinstance(past_key_values, (type(None), Cache)):
+ raise ValueError("The `past_key_values` should be either a `Cache` object or `None`.")
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if use_cache and past_key_values is None:
+ past_key_values = DynamicCache()
+
+ if cache_position is None:
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+ cache_position = torch.arange(
+ past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
+ )
+
+ if position_ids is None:
+ position_ids = cache_position.unsqueeze(0)
+
+ causal_mask = self._update_causal_mask(
+ attention_mask, inputs_embeds, cache_position, past_key_values, output_attentions
+ )
+
+ hidden_states = inputs_embeds
+
+ # create position embeddings to be shared across the decoder layers
+ position_embeddings = self.rotary_emb(hidden_states, position_ids)
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+
+ for decoder_layer in self.layers[: self.config.num_hidden_layers]:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=causal_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **flash_attn_kwargs,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=past_key_values if use_cache else None,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+ def _update_causal_mask(
+ self,
+ attention_mask: Union[torch.Tensor, "BlockMask"],
+ input_tensor: torch.Tensor,
+ cache_position: torch.Tensor,
+ past_key_values: Cache,
+ output_attentions: bool = False,
+ ):
+ if self.config._attn_implementation == "flash_attention_2":
+ if attention_mask is not None and (attention_mask == 0.0).any():
+ return attention_mask
+ return None
+ if self.config._attn_implementation == "flex_attention":
+ if isinstance(attention_mask, torch.Tensor):
+ attention_mask = make_flex_block_causal_mask(attention_mask)
+ return attention_mask
+
+ # For SDPA, when possible, we will rely on its `is_causal` argument instead of its `attn_mask` argument, in
+ # order to dispatch on Flash Attention 2. This feature is not compatible with static cache, as SDPA will fail
+ # to infer the attention mask.
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+ using_static_cache = isinstance(past_key_values, StaticCache)
+
+ # When output attentions is True, sdpa implementation's forward method calls the eager implementation's forward
+ if self.config._attn_implementation == "sdpa" and not using_static_cache and not output_attentions:
+ if AttentionMaskConverter._ignore_causal_mask_sdpa(
+ attention_mask,
+ inputs_embeds=input_tensor,
+ past_key_values_length=past_seen_tokens,
+ is_training=self.training,
+ ):
+ return None
+
+ dtype, device = input_tensor.dtype, input_tensor.device
+ sequence_length = input_tensor.shape[1]
+ if using_static_cache:
+ target_length = past_key_values.get_max_cache_shape()
+ else:
+ target_length = (
+ attention_mask.shape[-1]
+ if isinstance(attention_mask, torch.Tensor)
+ else past_seen_tokens + sequence_length + 1
+ )
+
+ # In case the provided `attention` mask is 2D, we generate a causal mask here (4D).
+ causal_mask = self._prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask,
+ sequence_length=sequence_length,
+ target_length=target_length,
+ dtype=dtype,
+ device=device,
+ cache_position=cache_position,
+ batch_size=input_tensor.shape[0],
+ )
+
+ if (
+ self.config._attn_implementation == "sdpa"
+ and attention_mask is not None
+ and attention_mask.device.type in ["cuda", "xpu", "npu"]
+ and not output_attentions
+ ):
+ # Attend to all tokens in fully masked rows in the causal_mask, for example the relevant first rows when
+ # using left padding. This is required by F.scaled_dot_product_attention memory-efficient attention path.
+ # Details: https://github.com/pytorch/pytorch/issues/110213
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = AttentionMaskConverter._unmask_unattended(causal_mask, min_dtype)
+
+ return causal_mask
+
+ @staticmethod
+ def _prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask: torch.Tensor,
+ sequence_length: int,
+ target_length: int,
+ dtype: torch.dtype,
+ device: torch.device,
+ cache_position: torch.Tensor,
+ batch_size: int,
+ **kwargs,
+ ):
+ """
+ Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
+ `(batch_size, key_value_length)`, or if the input `attention_mask` is already 4D, do nothing.
+
+ Args:
+ attention_mask (`torch.Tensor`):
+ A 2D attention mask of shape `(batch_size, key_value_length)` or a 4D attention mask of shape
+ `(batch_size, 1, query_length, key_value_length)`.
+ sequence_length (`int`):
+ The sequence length being processed.
+ target_length (`int`):
+ The target length: when generating with static cache, the mask should be as long as the static cache,
+ to account for the 0 padding, the part of the cache that is not filled yet.
+ dtype (`torch.dtype`):
+ The dtype to use for the 4D attention mask.
+ device (`torch.device`):
+ The device to place the 4D attention mask on.
+ cache_position (`torch.Tensor`):
+ Indices depicting the position of the input sequence tokens in the sequence.
+ batch_size (`torch.Tensor`):
+ Batch size.
+ """
+ if attention_mask is not None and attention_mask.dim() == 4:
+ # In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
+ causal_mask = attention_mask
+ else:
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = torch.full(
+ (sequence_length, target_length), fill_value=min_dtype, dtype=dtype, device=device
+ )
+ if sequence_length != 1:
+ causal_mask = torch.triu(causal_mask, diagonal=1)
+ causal_mask *= torch.arange(target_length, device=device) > cache_position.reshape(-1, 1)
+ causal_mask = causal_mask[None, None, :, :].expand(batch_size, 1, -1, -1)
+ if attention_mask is not None:
+ causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
+ mask_length = attention_mask.shape[-1]
+ padding_mask = causal_mask[:, :, :, :mask_length] + attention_mask[:, None, None, :].to(
+ causal_mask.device
+ )
+ padding_mask = padding_mask == 0
+ causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
+ padding_mask, min_dtype
+ )
+
+ return causal_mask
+
+
+class KwargsForCausalLM(FlashAttentionKwargs, LossKwargs): ...
+
+
+class AriaTextForCausalLM(AriaTextPreTrainedModel, GenerationMixin):
+ """
+ Aria model for causal language modeling tasks.
+
+ This class extends `LlamaForCausalLM` to incorporate the Mixture of Experts (MoE) approach,
+ allowing for more efficient and scalable language modeling.
+
+ Args:
+ config (`AriaTextConfig`):
+ Configuration object for the model.
+ """
+
+ _tied_weights_keys = ["lm_head.weight"]
+ _tp_plan = {"lm_head": "colwise_rep"}
+ _pp_plan = {"lm_head": (["hidden_states"], ["logits"])}
+ config_class = AriaTextConfig
+
+ def __init__(self, config: AriaTextConfig):
+ super().__init__(config)
+ self.model = AriaTextModel(config)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @can_return_tuple
+ @add_start_docstrings_to_model_forward(ARIA_TEXT_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[Cache] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ logits_to_keep: Union[int, torch.Tensor] = 0,
+ **kwargs: Unpack[KwargsForCausalLM],
+ ) -> CausalLMOutputWithPast:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ logits_to_keep (`int` or `torch.Tensor`, *optional*):
+ If an `int`, compute logits for the last `logits_to_keep` tokens. If `0`, calculate logits for all
+ `input_ids` (special case). Only last token logits are needed for generation, and calculating them only for that
+ token can save memory, which becomes pretty significant for long sequences or large vocabulary size.
+ If a `torch.Tensor`, must be 1D corresponding to the indices to keep in the sequence length dimension.
+ This is useful when using packed tensor format (single dimension for batch and sequence length).
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, AriaTextForCausalLM
+
+ >>> model = AriaTextForCausalLM.from_pretrained("meta-aria_text/AriaText-2-7b-hf")
+ >>> tokenizer = AutoTokenizer.from_pretrained("meta-aria_text/AriaText-2-7b-hf")
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs: BaseModelOutputWithPast = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ cache_position=cache_position,
+ **kwargs,
+ )
+
+ hidden_states = outputs.last_hidden_state
+ # Only compute necessary logits, and do not upcast them to float if we are not computing the loss
+ slice_indices = slice(-logits_to_keep, None) if isinstance(logits_to_keep, int) else logits_to_keep
+ logits = self.lm_head(hidden_states[:, slice_indices, :])
+
+ loss = None
+ if labels is not None:
+ loss = self.loss_function(logits=logits, labels=labels, vocab_size=self.config.vocab_size, **kwargs)
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@dataclass
+class AriaCausalLMOutputWithPast(ModelOutput):
+ """
+ Base class for Aria causal language model (or autoregressive) outputs.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Language modeling loss (for next-token prediction).
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`)
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ image_hidden_states (`torch.FloatTensor`, *optional*):
+ A `torch.FloatTensor` of size (batch_size, num_images, sequence_length, hidden_size)`.
+ image_hidden_states of the model produced by the vision encoder and after projecting the last hidden state.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[List[torch.FloatTensor]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+ image_hidden_states: Optional[torch.FloatTensor] = None
+
+
+ARIA_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor`, *optional*):
+ Input token IDs.
+ pixel_values (`torch.FloatTensor`, *optional*):
+ Pixel values of the images.
+ pixel_mask (`torch.LongTensor`, *optional*):
+ Mask for the pixel values.
+ attention_mask (`torch.Tensor`, *optional*):
+ Attention mask.
+ position_ids (`torch.LongTensor`, *optional*):
+ Position IDs.
+ past_key_values (`List[torch.FloatTensor]`, *optional*):
+ Past key values for efficient processing.
+ inputs_embeds (`torch.FloatTensor`, *optional*):
+ Input embeddings.
+ labels (`torch.LongTensor`, *optional*):
+ Labels for computing the language modeling loss.
+ use_cache (`bool`, *optional*):
+ Whether to use the model's cache mechanism.
+ output_attentions (`bool`, *optional*):
+ Whether to output attention weights.
+ output_hidden_states (`bool`, *optional*):
+ Whether to output hidden states.
+ return_dict (`bool`, *optional*):
+ Whether to return a `ModelOutput` object.
+ logits_to_keep (`int` or `torch.Tensor`, *optional*, defaults to 0):
+ If an `int`, calculate logits for the last `logits_to_keep` tokens, or all `input_ids` if `0`.
+ Otherwise, slice according to the 1D tensor in the sequence length dimension
+ cache_position (`torch.LongTensor`, *optional*):
+ Cache positions.
+ **loss_kwargs:
+ Additional keyword arguments for loss calculation.
+"""
+
+ARIA_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config (`AriaConfig`):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ """Aria model for conditional generation tasks.
+
+ This model combines a vision tower, a multi-modal projector, and a language model
+ to perform tasks that involve both image and text inputs.""",
+ ARIA_START_DOCSTRING,
+)
+class AriaForConditionalGeneration(AriaPreTrainedModel, GenerationMixin):
+ config_class = AriaConfig
+ _supports_flash_attn_2 = False
+ _supports_flex_attn = False
+ _supports_sdpa = False
+ _tied_weights_keys = ["language_model.lm_head.weight"]
+
+ def __init__(self, config: AriaConfig):
+ super().__init__(config)
+
+ self.vision_tower = AutoModel.from_config(config.vision_config)
+ self.multi_modal_projector = AriaProjector(config)
+ self.vocab_size = config.text_config.vocab_size
+ self.language_model = AutoModelForCausalLM.from_config(config.text_config)
+ self.pad_token_id = self.config.pad_token_id if self.config.pad_token_id is not None else -1
+ self._use_flash_attention_2 = config.text_config._attn_implementation == "flash_attention_2"
+ self.post_init()
+
+ def _create_patch_attention_mask(self, pixel_mask):
+ if pixel_mask is None:
+ return None
+
+ patches_subgrid = pixel_mask.unfold(
+ dimension=1,
+ size=self.vision_tower.config.patch_size,
+ step=self.vision_tower.config.patch_size,
+ )
+ patches_subgrid = patches_subgrid.unfold(
+ dimension=2,
+ size=self.vision_tower.config.patch_size,
+ step=self.vision_tower.config.patch_size,
+ )
+ return (patches_subgrid.sum(dim=(-1, -2)) > 0).bool()
+
+ def get_input_embeddings(self):
+ return self.language_model.get_input_embeddings()
+
+ def set_input_embeddings(self, value):
+ self.language_model.set_input_embeddings(value)
+
+ def get_output_embeddings(self):
+ return self.language_model.get_output_embeddings()
+
+ def set_output_embeddings(self, new_embeddings):
+ self.language_model.set_output_embeddings(new_embeddings)
+
+ def set_decoder(self, decoder):
+ self.language_model.set_decoder(decoder)
+
+ def get_decoder(self):
+ return self.language_model.get_decoder()
+
+ def get_image_features(
+ self,
+ pixel_values: torch.FloatTensor,
+ pixel_mask: Optional[torch.FloatTensor] = None,
+ vision_feature_layer: int = -1,
+ ):
+ patch_attention_mask = self._create_patch_attention_mask(pixel_mask)
+ image_outputs = self.vision_tower(
+ pixel_values, patch_attention_mask=patch_attention_mask, output_hidden_states=True
+ )
+ image_attn_mask = None
+ if patch_attention_mask is not None:
+ flattened_mask = patch_attention_mask.flatten(1)
+ image_attn_mask = torch.logical_not(flattened_mask)
+
+ selected_image_feature = image_outputs.hidden_states[vision_feature_layer]
+ image_features = self.multi_modal_projector(selected_image_feature, attn_mask=image_attn_mask)
+ return image_features
+
+ @can_return_tuple
+ @add_start_docstrings_to_model_forward(ARIA_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=AriaCausalLMOutputWithPast, config_class=AriaConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ pixel_mask: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ logits_to_keep: Union[int, torch.Tensor] = 0,
+ cache_position: Optional[torch.LongTensor] = None,
+ **loss_kwargs,
+ ) -> AriaCausalLMOutputWithPast:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or `model.image_token_id` (where `model` is your instance of `Idefics3ForConditionalGeneration`).
+ Tokens with indices set to `model.image_token_id` are ignored (masked), the loss is only
+ computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+ Returns:
+
+ Example:
+
+ ```python
+ >>> import requests
+ >>> import torch
+ >>> from PIL import Image
+ >>> from io import BytesIO
+
+ >>> from transformers import AutoProcessor, AutoModel
+ >>> from transformers.image_utils import load_image
+
+ >>> # Note that passing the image urls (instead of the actual pil images) to the processor is also possible
+ >>> image1 = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
+ >>> image2 = load_image("https://cdn.britannica.com/59/94459-050-DBA42467/Skyline-Chicago.jpg")
+ >>> image3 = load_image("https://cdn.britannica.com/68/170868-050-8DDE8263/Golden-Gate-Bridge-San-Francisco.jpg")
+
+ >>> processor = AutoProcessor.from_pretrained("Rhymes-AI/Aria")
+ >>> model = AutoModel.from_pretrained("Rhymes-AI/Aria", torch_dtype=torch.bfloat16, device_map="auto")
+
+ >>> # Create inputs
+ >>> messages = [
+ ... {
+ ... "role": "user",
+ ... "content": [
+ ... {"type": "image"},
+ ... {"type": "text", "text": "In this image, we can see the city of New York, and more specifically the Statue of Liberty."},
+ ... {"type": "image"},
+ ... {"type": "text", "text": "What can we see in this image?"},
+ ... ]
+ ... },
+ ... {
+ ... "role": "user",
+ ... "content": [
+ ... {"type": "image"},
+ ... {"type": "text", "text": "In which city is that bridge located?"},
+ ... ]
+ ... }
+ ... ]
+
+ >>> prompts = [processor.apply_chat_template([message], add_generation_prompt=True) for message in messages]
+ >>> images = [[image1, image2], [image3]]
+ >>> inputs = processor(text=prompts, images=images, padding=True, return_tensors="pt").to(model.device)
+
+ >>> # Generate
+ >>> generated_ids = model.generate(**inputs, max_new_tokens=256)
+ >>> generated_texts = processor.batch_decode(generated_ids, skip_special_tokens=True)
+
+ >>> print(generated_texts[0])
+ Assistant: There are buildings, trees, lights, and water visible in this image.
+
+ >>> print(generated_texts[1])
+ Assistant: The bridge is in San Francisco.
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+
+ if inputs_embeds is None:
+ inputs_embeds = self.get_input_embeddings()(input_ids)
+
+ # 2. Merge text and images
+ if pixel_values is not None and inputs_embeds.shape[1] != 1:
+ if input_ids is None:
+ special_image_mask = inputs_embeds == self.get_input_embeddings()(
+ torch.tensor(self.config.image_token_id, dtype=torch.long, device=inputs_embeds.device)
+ )
+ n_image_tokens = (special_image_mask).sum(dim=1).sum(dim=0)[0]
+ else:
+ image_embeds = input_ids == self.config.image_token_id
+ special_image_mask = image_embeds.unsqueeze(-1).expand_as(inputs_embeds).to(inputs_embeds.device)
+ n_image_tokens = (image_embeds).sum(dim=1).sum(dim=0)
+ image_features = self.get_image_features(
+ pixel_values=pixel_values,
+ pixel_mask=pixel_mask,
+ vision_feature_layer=self.config.vision_feature_layer,
+ )
+ n_images, n_features_per_image = image_features.shape[0], image_features.shape[1]
+ n_image_features = n_images * n_features_per_image
+ if n_image_tokens != n_image_features:
+ raise ValueError(
+ f"Image features and image tokens do not match: tokens: {n_image_tokens}, features {n_image_features}"
+ )
+
+ image_features = image_features.to(inputs_embeds.device, inputs_embeds.dtype)
+ inputs_embeds = inputs_embeds.masked_scatter(special_image_mask, image_features)
+
+ outputs: CausalLMOutputWithPast = self.language_model(
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ logits_to_keep=logits_to_keep,
+ cache_position=cache_position,
+ )
+
+ logits = outputs.logits
+
+ loss = None
+ if labels is not None:
+ loss = self.loss_function(
+ logits=logits, labels=labels, vocab_size=self.config.text_config.vocab_size, **loss_kwargs
+ )
+
+ return AriaCausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ inputs_embeds=None,
+ pixel_values=None,
+ pixel_mask=None,
+ attention_mask=None,
+ cache_position=None,
+ logits_to_keep=None,
+ **kwargs,
+ ):
+ model_inputs = self.language_model.prepare_inputs_for_generation(
+ input_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ attention_mask=attention_mask,
+ cache_position=cache_position,
+ logits_to_keep=logits_to_keep,
+ **kwargs,
+ )
+
+ if cache_position[0] == 0:
+ # If we're in cached decoding stage, pixel values should be None because input ids do not contain special image token anymore
+ # Otherwise we need pixel values to be passed to model
+ model_inputs["pixel_values"] = pixel_values
+ model_inputs["pixel_mask"] = pixel_mask
+
+ return model_inputs
+
+
+__all__ = [
+ "AriaForConditionalGeneration",
+ "AriaPreTrainedModel",
+ "AriaTextPreTrainedModel",
+ "AriaTextModel",
+ "AriaTextForCausalLM",
+]
diff --git a/docs/transformers/src/transformers/models/aria/modular_aria.py b/docs/transformers/src/transformers/models/aria/modular_aria.py
new file mode 100644
index 0000000000000000000000000000000000000000..add5bdc16b764201a73717a3bc6a0981237d1b3f
--- /dev/null
+++ b/docs/transformers/src/transformers/models/aria/modular_aria.py
@@ -0,0 +1,1643 @@
+# coding=utf-8
+# Copyright 2024 The Rhymes-AI Teams Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import math
+from typing import Dict, Iterable, List, Optional, Tuple, Union
+
+import numpy as np
+
+from ...activations import ACT2FN
+from ...configuration_utils import PretrainedConfig
+from ...generation import GenerationMixin
+from ...image_processing_utils import BaseImageProcessor, BatchFeature, select_best_resolution
+from ...image_transforms import PaddingMode, convert_to_rgb, pad, resize, to_channel_dimension_format
+from ...image_utils import (
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_scaled_image,
+ make_flat_list_of_images,
+ to_numpy_array,
+ valid_images,
+ validate_preprocess_arguments,
+)
+from ...modeling_outputs import CausalLMOutputWithPast
+from ...modeling_utils import PreTrainedModel
+from ...processing_utils import ProcessingKwargs, ProcessorMixin, Unpack
+from ...tokenization_utils import (
+ PreTokenizedInput,
+ TextInput,
+)
+from ...utils import (
+ TensorType,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ can_return_tuple,
+ logging,
+ replace_return_docstrings,
+)
+from ...utils.import_utils import is_torch_available
+from ..auto import CONFIG_MAPPING, AutoConfig, AutoModel, AutoModelForCausalLM, AutoTokenizer
+from ..llama.configuration_llama import LlamaConfig
+from ..llama.modeling_llama import (
+ LlamaDecoderLayer,
+ LlamaForCausalLM,
+ LlamaMLP,
+ LlamaModel,
+ LlamaPreTrainedModel,
+ LlamaRMSNorm,
+)
+from ..llava.modeling_llava import LlavaCausalLMOutputWithPast
+from ..llava_next.image_processing_llava_next import divide_to_patches
+
+
+logger = logging.get_logger(__name__)
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+def sequential_experts_gemm(token_states, expert_weights, tokens_per_expert):
+ """
+ Compute the matrix multiplication (GEMM) for each expert sequentially. This approach is computationally inefficient, especially when dealing with a large number of experts.
+
+ Args:
+ token_states (torch.Tensor): Input tensor of shape (num_tokens, in_features).
+ expert_weights (torch.Tensor): Weight tensor of shape (num_experts, in_features, out_features).
+ tokens_per_expert (torch.Tensor): Number of tokens assigned to each expert.
+
+ Returns:
+ torch.Tensor: Output tensor of shape (num_tokens, out_features).
+ """
+ num_tokens = token_states.shape[0]
+ out_features = expert_weights.shape[-1]
+ output = torch.zeros(num_tokens, out_features, dtype=token_states.dtype, device=token_states.device)
+
+ cumsum_num_tokens = torch.cumsum(tokens_per_expert, dim=0)
+ # Insert zero at the beginning for offset index's convenience
+ zero_tensor = torch.zeros(1, dtype=torch.long, device=cumsum_num_tokens.device)
+ cumsum_num_tokens = torch.cat((zero_tensor, cumsum_num_tokens))
+
+ for expert_num in range(expert_weights.shape[0]):
+ start = cumsum_num_tokens[expert_num]
+ end = cumsum_num_tokens[expert_num + 1]
+ tokens = token_states[start:end]
+
+ out = torch.matmul(tokens, expert_weights[expert_num])
+ output[start:end] = out
+ return output
+
+
+class AriaTextConfig(LlamaConfig):
+ r"""
+ This class handles the configuration for the text component of the Aria model.
+ Instantiating a configuration with the defaults will yield a similar configuration to that of the model of the Aria
+ [rhymes-ai/Aria](https://huggingface.co/rhymes-ai/Aria) architecture.
+ This class extends the LlamaConfig to include additional parameters specific to the Mixture of Experts (MoE) architecture.
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 32000):
+ Vocabulary size of the LLaMA model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`LlamaModel`]
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 4096):
+ The size of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 32):
+ Number of hidden layers in the Transformer decoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer decoder.
+ num_key_value_heads (`int`, *optional*):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
+ `num_attention_heads`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ max_position_embeddings (`int`, *optional*, defaults to 2048):
+ The maximum sequence length that this model might ever be used with. Llama 1 supports up to 2048 tokens,
+ Llama 2 up to 4096, CodeLlama up to 16384.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ pad_token_id (`int`, *optional*, defaults to 2):
+ Padding token id.
+ bos_token_id (`int`, *optional*, defaults to 1):
+ Beginning of stream token id.
+ eos_token_id (`int`, *optional*, defaults to 2):
+ End of stream token id.
+ pretraining_tp (`int`, *optional*, defaults to 1):
+ Experimental feature. Tensor parallelism rank used during pretraining. Please refer to [this
+ document](https://huggingface.co/docs/transformers/main/perf_train_gpu_many#tensor-parallelism) to
+ understand more about it. This value is necessary to ensure exact reproducibility of the pretraining
+ results. Please refer to [this issue](https://github.com/pytorch/pytorch/issues/76232).
+ tie_word_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether to tie weight embeddings
+ rope_theta (`float`, *optional*, defaults to 10000.0):
+ The base period of the RoPE embeddings.
+ rope_scaling (`Dict`, *optional*):
+ Dictionary containing the scaling configuration for the RoPE embeddings. NOTE: if you apply new rope type
+ and you expect the model to work on longer `max_position_embeddings`, we recommend you to update this value
+ accordingly.
+ Expected contents:
+ `rope_type` (`str`):
+ The sub-variant of RoPE to use. Can be one of ['default', 'linear', 'dynamic', 'yarn', 'longrope',
+ 'llama3'], with 'default' being the original RoPE implementation.
+ `factor` (`float`, *optional*):
+ Used with all rope types except 'default'. The scaling factor to apply to the RoPE embeddings. In
+ most scaling types, a `factor` of x will enable the model to handle sequences of length x *
+ original maximum pre-trained length.
+ `original_max_position_embeddings` (`int`, *optional*):
+ Used with 'dynamic', 'longrope' and 'llama3'. The original max position embeddings used during
+ pretraining.
+ `attention_factor` (`float`, *optional*):
+ Used with 'yarn' and 'longrope'. The scaling factor to be applied on the attention
+ computation. If unspecified, it defaults to value recommended by the implementation, using the
+ `factor` field to infer the suggested value.
+ `beta_fast` (`float`, *optional*):
+ Only used with 'yarn'. Parameter to set the boundary for extrapolation (only) in the linear
+ ramp function. If unspecified, it defaults to 32.
+ `beta_slow` (`float`, *optional*):
+ Only used with 'yarn'. Parameter to set the boundary for interpolation (only) in the linear
+ ramp function. If unspecified, it defaults to 1.
+ `short_factor` (`List[float]`, *optional*):
+ Only used with 'longrope'. The scaling factor to be applied to short contexts (<
+ `original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
+ size divided by the number of attention heads divided by 2
+ `long_factor` (`List[float]`, *optional*):
+ Only used with 'longrope'. The scaling factor to be applied to long contexts (<
+ `original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
+ size divided by the number of attention heads divided by 2
+ `low_freq_factor` (`float`, *optional*):
+ Only used with 'llama3'. Scaling factor applied to low frequency components of the RoPE
+ `high_freq_factor` (`float`, *optional*):
+ Only used with 'llama3'. Scaling factor applied to high frequency components of the RoPE
+ attention_bias (`bool`, *optional*, defaults to `False`):
+ Whether to use a bias in the query, key, value and output projection layers during self-attention.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ mlp_bias (`bool`, *optional*, defaults to `False`):
+ Whether to use a bias in up_proj, down_proj and gate_proj layers in the MLP layers.
+ head_dim (`int`, *optional*):
+ The attention head dimension. If None, it will default to hidden_size // num_heads
+ moe_num_experts (`int`, *optional*, defaults to 8):
+ The number of experts in the MoE layer.
+ moe_topk (`int`, *optional*, defaults to 2):
+ The number of top experts to route to for each token.
+ moe_num_shared_experts (`int`, *optional*, defaults to 2):
+ The number of shared experts.
+ """
+
+ model_type = "aria_text"
+ base_config_key = "text_config"
+
+ def __init__(
+ self,
+ intermediate_size: int = 4096,
+ moe_num_experts: int = 8,
+ moe_topk: int = 2,
+ moe_num_shared_experts: int = 2,
+ pad_token_id=2,
+ **super_kwargs,
+ ):
+ super().__init__(pad_token_id=pad_token_id, **super_kwargs)
+ self.intermediate_size = intermediate_size
+ self.moe_num_experts = moe_num_experts
+ self.moe_topk = moe_topk
+ self.moe_num_shared_experts = moe_num_shared_experts
+
+
+class AriaConfig(PretrainedConfig):
+ r"""
+ This class handles the configuration for both vision and text components of the Aria model,
+ as well as additional parameters for image token handling and projector mapping.
+ Instantiating a configuration with the defaults will yield a similar configuration to that of the model of the Aria
+ [rhymes-ai/Aria](https://huggingface.co/rhymes-ai/Aria) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ vision_config (`AriaVisionConfig` or `dict`, *optional*):
+ Configuration for the vision component.
+ vision_feature_layer (`int`, *optional*, defaults to -1):
+ The index of the layer to select the vision feature.
+ text_config (`AriaTextConfig` or `dict`, *optional*):
+ Configuration for the text component.
+ projector_patch_to_query_dict (`dict`, *optional*):
+ Mapping of patch sizes to query dimensions.
+ image_token_index (`int`, *optional*, defaults to 9):
+ Index used to represent image tokens.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated normal initializer for initializing all weight matrices.
+
+ Attributes:
+ model_type (`str`):
+ Type of the model, set to `"aria"`.
+ image_token_index (`int`):
+ Index used to represent image tokens.
+ projector_patch_to_query_dict (`dict`):
+ Mapping of patch sizes to query dimensions.
+ vision_config (`AriaVisionConfig`):
+ Configuration for the vision component.
+ text_config (`AriaTextConfig`):
+ Configuration for the text component.
+ """
+
+ model_type = "aria"
+ attribute_map = {
+ "image_token_id": "image_token_index",
+ }
+ sub_configs = {"text_config": AriaTextConfig, "vision_config": AutoConfig}
+
+ def __init__(
+ self,
+ vision_config=None,
+ vision_feature_layer: int = -1,
+ text_config: AriaTextConfig = None,
+ projector_patch_to_query_dict: Dict = None,
+ image_token_index: int = 9,
+ initializer_range: float = 0.02,
+ **kwargs,
+ ):
+ self.image_token_index = image_token_index
+
+ # Convert the keys and values of projector_patch_to_query_dict to integers
+ # This ensures consistency even if they were provided as strings
+ if projector_patch_to_query_dict is None:
+ projector_patch_to_query_dict = {
+ 1225: 128,
+ 4900: 256,
+ }
+ self.projector_patch_to_query_dict = {int(k): int(v) for k, v in projector_patch_to_query_dict.items()}
+ self.max_value_projector_patch_to_query_dict = max(self.projector_patch_to_query_dict.values())
+ self.vision_feature_layer = vision_feature_layer
+ if isinstance(vision_config, dict):
+ vision_config["model_type"] = "idefics3_vision"
+ vision_config = CONFIG_MAPPING[vision_config["model_type"]](**vision_config)
+ elif vision_config is None:
+ vision_config = CONFIG_MAPPING["idefics3_vision"]()
+
+ self.vision_config = vision_config
+ self.initializer_range = initializer_range
+
+ if isinstance(text_config, dict) and "model_type" in text_config:
+ text_config = AriaTextConfig(**text_config)
+ elif text_config is None:
+ text_config = AriaTextConfig()
+
+ self.text_config = text_config
+
+ super().__init__(**kwargs)
+
+
+class AriaTextRMSNorm(LlamaRMSNorm):
+ pass
+
+
+class AriaProjectorMLP(nn.Module):
+ """
+ Feed-Forward Network module for the Aria Projector.
+
+ Args:
+ in_features (`int`):
+ Input embedding dimension.
+ hidden_features (`int`):
+ Hidden dimension of the feed-forward network.
+ output_dim (`int`):
+ Output dimension.
+ """
+
+ def __init__(self, in_features, hidden_features, output_dim):
+ super().__init__()
+ self.linear_in = nn.Linear(in_features, hidden_features, bias=False)
+ self.linear_out = nn.Linear(hidden_features, output_dim, bias=False)
+ self.act = ACT2FN["gelu_new"]
+
+ def forward(self, hidden_states):
+ hidden_states = self.act(self.linear_in(hidden_states))
+ hidden_states = self.linear_out(hidden_states)
+ return hidden_states
+
+
+class AriaCrossAttention(nn.Module):
+ """
+ Aria Cross-Attention module.
+
+ Args:
+ config (`AriaConfig`):
+ The configuration to use.
+ """
+
+ def __init__(self, config: AriaConfig, dropout_rate: float = 0):
+ super().__init__()
+ hidden_size = config.vision_config.hidden_size
+ num_heads = config.vision_config.num_attention_heads
+ self.num_heads = num_heads
+ self.q_proj = nn.Linear(hidden_size, hidden_size, bias=False)
+ self.k_proj = nn.Linear(hidden_size, hidden_size, bias=False)
+ self.v_proj = nn.Linear(hidden_size, hidden_size, bias=False)
+
+ # Original code here: https://github.com/rhymes-ai/Aria/blob/719ff4e52b727443cba3793b0e27fe64e0244fe1/aria/model/projector.py#L48
+ self.multihead_attn = nn.MultiheadAttention(hidden_size, num_heads, batch_first=True)
+ self.linear = nn.Linear(hidden_size, hidden_size)
+ self.dropout = nn.Dropout(dropout_rate)
+
+ self.layer_norm = nn.LayerNorm(hidden_size)
+ self.layer_norm_kv = nn.LayerNorm(hidden_size)
+
+ def forward(self, key_value_states, hidden_states, attn_mask=None):
+ """
+ Forward pass of the AriaCrossAttention module.
+
+ Args:
+ key_value_states (`torch.Tensor`):
+ Input tensor for key and value.
+ hidden_states (`torch.Tensor`):
+ Input tensor for query.
+ attn_mask (`torch.Tensor`, *optional*, defaults to None):
+ Attention mask.
+
+ Returns:
+ torch.Tensor:
+ Output tensor after cross-attention.
+ """
+ query = self.q_proj(self.layer_norm(hidden_states))
+
+ key_value_states = self.layer_norm_kv(key_value_states)
+ key = self.k_proj(key_value_states)
+ value = self.v_proj(key_value_states)
+
+ attn_output, _ = self.multihead_attn(query, key, value, attn_mask=attn_mask)
+
+ attn_output = self.dropout(self.linear(attn_output))
+
+ return attn_output
+
+
+class AriaProjector(nn.Module):
+ """
+ Aria Projector module.
+
+ This module projects vision features into the language model's embedding space, enabling interaction between vision and language components.
+
+ Args:
+ config (`AriaConfig`):
+ Configuration object for the model.
+ """
+
+ def __init__(
+ self,
+ config: AriaConfig,
+ ):
+ super().__init__()
+
+ self.patch_to_query_dict = config.projector_patch_to_query_dict
+ self.in_features = config.vision_config.hidden_size
+ self.num_heads = config.vision_config.num_attention_heads
+ self.kv_dim = config.vision_config.hidden_size
+ self.hidden_features = config.text_config.hidden_size
+ self.output_dim = config.text_config.hidden_size
+
+ self.query = nn.Parameter(torch.zeros(config.max_value_projector_patch_to_query_dict, self.in_features))
+
+ self.cross_attn = AriaCrossAttention(config)
+
+ self.layer_norm = nn.LayerNorm(self.in_features)
+ self.feed_forward = AriaProjectorMLP(self.in_features, self.hidden_features, self.output_dim)
+
+ def forward(self, key_value_states: torch.Tensor, attn_mask: Optional[torch.Tensor] = None):
+ """
+ Forward pass of the Projector module.
+
+ Args:
+ key_value_states (`torch.Tensor`):
+ Input tensor of shape (batch_size, num_patches, kv_dim).
+ attn_mask (`torch.Tensor`, *optional*, default is None):
+ Attention mask.
+
+ Returns:
+ `torch.Tensor`: Output tensor of shape (batch_size, query_number, output_dim).
+ """
+ batch_size, num_patches = key_value_states.shape[0], key_value_states.shape[1]
+
+ if num_patches not in self.patch_to_query_dict.keys():
+ raise KeyError(
+ f"Number of patches {num_patches} not found in patch_to_query_dict amongst possible values {self.patch_to_query_dict.keys()}."
+ )
+ query_num = self.patch_to_query_dict[num_patches]
+
+ queries = self.query[:query_num].unsqueeze(0).repeat(batch_size, 1, 1)
+
+ if attn_mask is not None:
+ attn_mask = attn_mask.repeat_interleave(self.num_heads, 0)
+ attn_mask = attn_mask.unsqueeze(1).expand(-1, queries.size(1), -1)
+
+ attention_out = self.cross_attn(key_value_states, queries, attn_mask=attn_mask)
+
+ out = self.feed_forward(self.layer_norm(attention_out))
+
+ return out
+
+
+def _get_patch_output_size(image, target_resolution, input_data_format):
+ original_height, original_width = get_image_size(image, channel_dim=input_data_format)
+ target_height, target_width = target_resolution
+
+ scale_w = target_width / original_width
+ scale_h = target_height / original_height
+
+ if scale_w < scale_h:
+ new_width = target_width
+ new_height = min(math.ceil(original_height * scale_w), target_height)
+ else:
+ new_height = target_height
+ new_width = min(math.ceil(original_width * scale_h), target_width)
+
+ return new_height, new_width
+
+
+class AriaImageProcessor(BaseImageProcessor):
+ """
+ A vision processor for the Aria model that handles image preprocessing.
+ Initialize the AriaImageProcessor.
+
+ Args:
+ image_mean (`list`, *optional*, defaults to [0.5, 0.5, 0.5]):
+ Mean values for normalization.
+ image_std (`list`, *optional*, defaults to [0.5, 0.5, 0.5]):
+ Standard deviation values for normalization.
+ max_image_size (`int`, *optional*, defaults to 980):
+ Maximum image size.
+ min_image_size (`int`, *optional*, defaults to 336):
+ Minimum image size.
+ split_resolutions (`list`, *optional*, defaults to a list of optimal,resolutions as tuples):
+ The optimal resolutions for splitting the image.
+ split_image (`bool`, *optional*, defaults to `False`):
+ Whether to split the image.
+ do_convert_rgb (`bool`, *optional*, defaults to `True`):
+ Whether to convert the image to RGB.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the image by the specified scale `rescale_factor`. Can be overridden by `do_rescale` in
+ the `preprocess` method.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overridden by `rescale_factor` in the `preprocess`
+ method.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image.
+ resample (PILImageResampling, *optional*, defaults to `BICUBIC`):
+ The resampling filter to use if resizing the image.
+ """
+
+ model_input_names = ["pixel_values", "pixel_mask", "num_crops"]
+
+ def __init__(
+ self,
+ image_mean: List[float] = None,
+ image_std: List[float] = None,
+ max_image_size: int = 980,
+ min_image_size: int = 336,
+ split_resolutions: Optional[List[Tuple[int, int]]] = None,
+ split_image: Optional[bool] = False,
+ do_convert_rgb: Optional[bool] = True,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: Optional[bool] = True,
+ resample: PILImageResampling = PILImageResampling.BICUBIC,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ if image_mean is None:
+ image_mean = [0.5, 0.5, 0.5]
+ if image_std is None:
+ image_std = [0.5, 0.5, 0.5]
+ self.max_image_size = max_image_size
+ self.min_image_size = min_image_size
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.split_image = split_image
+ if split_resolutions is None:
+ split_resolutions = [(1, 2), (1, 3), (1, 4), (1, 5), (1, 6), (1, 7), (1, 8), (2, 4), (2, 3), (2, 2), (2, 1), (3, 1), (3, 2), (4, 1), (4, 2), (5, 1), (6, 1), (7, 1), (8, 1)] # fmt: skip
+ split_resolutions = [(el[0] * 490, el[1] * 490) for el in split_resolutions]
+ self.split_resolutions = split_resolutions
+ self.do_convert_rgb = do_convert_rgb
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.resample = resample
+
+ def preprocess(
+ self,
+ images: Union[ImageInput, List[ImageInput]],
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ max_image_size: Optional[int] = None,
+ min_image_size: Optional[int] = None,
+ split_image: Optional[bool] = None,
+ do_convert_rgb: Optional[bool] = None,
+ do_rescale: Optional[bool] = None,
+ rescale_factor: Optional[float] = None,
+ do_normalize: Optional[bool] = None,
+ resample: PILImageResampling = None,
+ return_tensors: Optional[Union[str, TensorType]] = "pt",
+ data_format: Optional[ChannelDimension] = ChannelDimension.FIRST,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ):
+ """
+ Process a list of images.
+
+ Args:
+ images (ImageInput or list of ImageInput):
+ The input image or a list of images.
+ image_mean (`list`, *optional*, defaults to [0.5, 0.5, 0.5]):
+ Mean values for normalization.
+ image_std (`list`, *optional*, defaults to [0.5, 0.5, 0.5]):
+ Standard deviation values for normalization.
+ max_image_size (`int`, *optional*, defaults to `self.max_image_size` (980)):
+ Maximum image size.
+ min_image_size (`int`, *optional*, defaults to `self.min_image_size` (336)):
+ Minimum image size.
+ split_image (`bool`, *optional*, defaults to `self.split_image` (False)):
+ Whether to split the image.
+ do_convert_rgb (`bool`, *optional*, defaults to `self.do_convert_rgb` (True)):
+ Whether to convert the image to RGB.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether to rescale the image.
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ Rescale factor to rescale the image by if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `self.do_normalize` (True)):
+ Whether to normalize the image.
+ resample (PILImageResampling, *optional*, defaults to `self.resample` (BICUBIC)):
+ The resampling filter to use if resizing the image.
+ return_tensors (`str` or `TensorType`, *optional*, defaults to "pt"):
+ The type of tensor to return.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`:
+ image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`:
+ image in (height, width, num_channels) format.
+ If unset, will use same as the input image.
+ input_data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`:
+ image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`:
+ image in (height, width, num_channels) format.
+ If unset, will use the inferred format of the input image.
+
+ Returns:
+ BatchFeature:
+ A BatchFeature object containing:
+ - 'pixel_values':
+ Tensor of processed image pixel values.
+ - 'pixel_mask':
+ Boolean pixel mask. This mask is a 2D tensor of shape (max_image_size, max_image_size) where:
+ - True (1) values indicate pixels that belong to the original resized image.
+ - False (0) values indicate pixels that are part of the padding.
+ The mask helps distinguish between actual image content and padded areas in subsequent processing steps.
+ - 'num_crops':
+ The maximum number of crops across all images.
+ """
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+ max_image_size = max_image_size if max_image_size is not None else self.max_image_size
+ min_image_size = min_image_size if min_image_size is not None else self.min_image_size
+ split_image = split_image if split_image is not None else self.split_image
+ do_convert_rgb = do_convert_rgb if do_convert_rgb is not None else self.do_convert_rgb
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ resample = resample if resample is not None else self.resample
+
+ if max_image_size not in [490, 980]:
+ raise ValueError("max_image_size must be either 490 or 980")
+
+ images = make_flat_list_of_images(images)
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+
+ validate_preprocess_arguments(
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ resample=resample,
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ )
+
+ if do_convert_rgb:
+ images = [convert_to_rgb(image) for image in images]
+
+ # All transformations expect numpy arrays.
+ images = [to_numpy_array(image) for image in images]
+
+ if do_rescale and is_scaled_image(images[0]):
+ logger.warning_once(
+ "It looks like you are trying to rescale already rescaled images. If the input"
+ " images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
+ )
+
+ if input_data_format is None:
+ # We assume that all images have the same channel dimension format.
+ input_data_format = infer_channel_dimension_format(images[0])
+
+ pixel_values = []
+ pixel_masks = []
+ num_crops = None
+
+ for image in images:
+ if split_image:
+ crop_images = self.get_image_patches(
+ image,
+ self.split_resolutions,
+ max_image_size,
+ resample,
+ data_format=input_data_format,
+ input_data_format=input_data_format,
+ )
+ else:
+ crop_images = [image]
+ if num_crops is None or len(crop_images) > num_crops:
+ num_crops = len(crop_images)
+
+ for crop_image in crop_images:
+ # At this point the scale is the rescaling factor that would bring the image to max_size in its larger dimension
+ h, w = get_image_size(crop_image)
+ scale = max_image_size / max(h, w)
+ if w >= h:
+ new_size = (max(int(h * scale), min_image_size), max_image_size) # h, w
+ else:
+ new_size = (max_image_size, max(int(w * scale), min_image_size)) # h, w
+
+ crop_image_resized = resize(
+ crop_image,
+ new_size,
+ resample=resample,
+ data_format=input_data_format,
+ input_data_format=input_data_format,
+ )
+
+ padding_bottom, padding_right = max_image_size - new_size[0], max_image_size - new_size[1]
+ crop_image_padded = pad(
+ crop_image_resized,
+ ((0, padding_bottom), (0, padding_right)),
+ data_format=input_data_format,
+ input_data_format=input_data_format,
+ )
+
+ # Create a pixel mask
+ pixel_mask = np.zeros((max_image_size, max_image_size), dtype=bool)
+ pixel_mask[: new_size[0], : new_size[1]] = 1
+ pixel_masks.append(pixel_mask)
+
+ if do_rescale:
+ crop_image_padded = self.rescale(
+ image=crop_image_padded, scale=rescale_factor, input_data_format=input_data_format
+ )
+
+ if do_normalize:
+ crop_image_padded = self.normalize(
+ crop_image_padded,
+ self.image_mean,
+ self.image_std,
+ data_format=input_data_format,
+ input_data_format=input_data_format,
+ )
+ crop_image_padded = (
+ to_channel_dimension_format(crop_image_padded, data_format, input_data_format)
+ if data_format is not None
+ else crop_image_padded
+ )
+
+ pixel_values.append(crop_image_padded)
+ return BatchFeature(
+ data={
+ "pixel_values": np.stack(pixel_values, axis=0),
+ "pixel_mask": np.stack(pixel_masks, axis=0),
+ "num_crops": num_crops,
+ },
+ tensor_type=return_tensors,
+ )
+
+ def _resize_for_patching(
+ self, image: np.array, target_resolution: tuple, resample, input_data_format: ChannelDimension
+ ) -> np.array:
+ """
+ Resizes an image to a target resolution while maintaining aspect ratio.
+
+ Args:
+ image (np.array):
+ The input image.
+ target_resolution (tuple):
+ The target resolution (height, width) of the image.
+ resample (`PILImageResampling`):
+ Resampling filter to use if resizing the image.
+ input_data_format (`ChannelDimension` or `str`):
+ The channel dimension format of the input image.
+
+ Returns:
+ np.array: The resized and padded image.
+ """
+ new_height, new_width = _get_patch_output_size(image, target_resolution, input_data_format)
+
+ # Resize the image
+ resized_image = resize(image, (new_height, new_width), resample=resample, input_data_format=input_data_format)
+
+ return resized_image
+
+ def _pad_for_patching(
+ self, image: np.array, target_resolution: tuple, input_data_format: ChannelDimension
+ ) -> np.array:
+ """
+ Pad an image to a target resolution while maintaining aspect ratio.
+ """
+ target_height, target_width = target_resolution
+ new_height, new_width = _get_patch_output_size(image, target_resolution, input_data_format)
+
+ paste_x = (target_width - new_width) // 2
+ paste_y = (target_height - new_height) // 2
+
+ padded_image = self.pad(image, padding=((paste_y, paste_y), (paste_x, paste_x)))
+
+ return padded_image
+
+ def pad(
+ self,
+ image: np.ndarray,
+ padding: Union[int, Tuple[int, int], Iterable[Tuple[int, int]]],
+ mode: PaddingMode = PaddingMode.CONSTANT,
+ constant_values: Union[float, Iterable[float]] = 0.0,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ) -> np.ndarray:
+ """
+ Pads the `image` with the specified `padding` and `mode`. Padding can be in the (`height`, `width`)
+ dimension of in the (`num_patches`) dimension. In the second case an iterable if tuples is expected
+ as input.
+
+ Args:
+ image (`np.ndarray`):
+ The image to pad.
+ padding (`int` or `Tuple[int, int]` or `Iterable[Tuple[int, int]]`):
+ Padding to apply to the edges of the height, width axes. Can be one of three formats:
+ - `((before_height, after_height), (before_width, after_width))` unique pad widths for each axis.
+ - `((before, after),)` yields same before and after pad for height and width.
+ - `(pad,)` or int is a shortcut for before = after = pad width for all axes.
+ mode (`PaddingMode`):
+ The padding mode to use. Can be one of:
+ - `"constant"`: pads with a constant value.
+ - `"reflect"`: pads with the reflection of the vector mirrored on the first and last values of the
+ vector along each axis.
+ - `"replicate"`: pads with the replication of the last value on the edge of the array along each axis.
+ - `"symmetric"`: pads with the reflection of the vector mirrored along the edge of the array.
+ constant_values (`float` or `Iterable[float]`, *optional*):
+ The value to use for the padding if `mode` is `"constant"`.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ If unset, will use same as the input image.
+ input_data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format for the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ If unset, will use the inferred format of the input image.
+
+ Returns:
+ `np.ndarray`: The padded image.
+
+ """
+
+ # call the general `pad` if padding on `height/width`, otherwise it's the `num_patched` dim
+ if isinstance(padding, int) or len(padding) != 4:
+ return pad(image, padding, mode, constant_values, data_format, input_data_format)
+
+ if input_data_format is None:
+ input_data_format = infer_channel_dimension_format(image)
+
+ padding_mode_mapping = {
+ PaddingMode.CONSTANT: "constant",
+ PaddingMode.REFLECT: "reflect",
+ PaddingMode.REPLICATE: "edge",
+ PaddingMode.SYMMETRIC: "symmetric",
+ }
+ image = np.pad(image, padding, mode=padding_mode_mapping[mode], constant_values=constant_values)
+ image = (
+ to_channel_dimension_format(image, data_format, input_data_format) if data_format is not None else image
+ )
+ return image
+
+ def get_image_patches(
+ self,
+ image: np.array,
+ grid_pinpoints: List[Tuple[int, int]],
+ patch_size: int,
+ resample: PILImageResampling,
+ data_format: ChannelDimension,
+ input_data_format: ChannelDimension,
+ ) -> List[np.array]:
+ """
+ Process an image with variable resolutions by dividing it into patches.
+
+ Args:
+ image (`np.array`):
+ The input image to be processed.
+ grid_pinpoints (List[Tuple[int, int]]):
+ A list of possible resolutions as tuples.
+ patch_size (`int`):
+ Size of the patches to divide the image into.
+ resample (`PILImageResampling`):
+ Resampling filter to use if resizing the image.
+ data_format (`ChannelDimension` or `str`):
+ The channel dimension format for the output image.
+ input_data_format (`ChannelDimension` or `str`):
+ The channel dimension format of the input image.
+
+ Returns:
+ `List[np.array]`: A list of NumPy arrays containing the processed image patches.
+ """
+ if not isinstance(grid_pinpoints, list):
+ raise TypeError("grid_pinpoints must be a list of possible resolutions.")
+
+ possible_resolutions = grid_pinpoints
+
+ image_size = get_image_size(image, channel_dim=input_data_format)
+ best_resolution = select_best_resolution(image_size, possible_resolutions)
+ resized_image = self._resize_for_patching(
+ image, best_resolution, resample=resample, input_data_format=input_data_format
+ )
+ padded_image = self._pad_for_patching(resized_image, best_resolution, input_data_format=input_data_format)
+
+ patches = divide_to_patches(padded_image, patch_size=patch_size, input_data_format=input_data_format)
+
+ # make sure that all patches are in the input data format
+ patches = [
+ to_channel_dimension_format(patch, channel_dim=data_format, input_channel_dim=input_data_format)
+ for patch in patches
+ ]
+ return patches
+
+
+class AriaProcessorKwargs(ProcessingKwargs, total=False):
+ _defaults = {
+ "text_kwargs": {
+ "padding": False,
+ },
+ "images_kwargs": {
+ "max_image_size": 980,
+ "split_image": False,
+ },
+ "return_tensors": TensorType.PYTORCH,
+ }
+
+
+class AriaProcessor(ProcessorMixin):
+ """
+ AriaProcessor is a processor for the Aria model which wraps the Aria image preprocessor and the LLama slow tokenizer.
+
+ Args:
+ image_processor (`AriaImageProcessor`, *optional*):
+ The AriaImageProcessor to use for image preprocessing.
+ tokenizer (`PreTrainedTokenizerBase`, *optional*):
+ An instance of [`PreTrainedTokenizerBase`]. This should correspond with the model's text model. The tokenizer is a required input.
+ chat_template (`str`, *optional*):
+ A Jinja template which will be used to convert lists of messages in a chat into a tokenizable string.
+ size_conversion (`Dict`, *optional*):
+ A dictionary indicating size conversions for images.
+ """
+
+ attributes = ["image_processor", "tokenizer"]
+ valid_kwargs = ["chat_template", "size_conversion"]
+ image_processor_class = "AriaImageProcessor"
+ tokenizer_class = "AutoTokenizer"
+
+ def __init__(
+ self,
+ image_processor=None,
+ tokenizer: Union[AutoTokenizer, str] = None,
+ chat_template: Optional[str] = None,
+ size_conversion: Optional[Dict[Union[float, int], int]] = None,
+ ):
+ if size_conversion is None:
+ size_conversion = {490: 128, 980: 256}
+ self.size_conversion = {int(k): v for k, v in size_conversion.items()}
+
+ self.image_token = tokenizer.image_token
+ self.image_token_id = tokenizer.image_token_id
+ if tokenizer is not None and tokenizer.pad_token is None:
+ tokenizer.pad_token = tokenizer.unk_token
+
+ super().__init__(image_processor, tokenizer, chat_template=chat_template)
+
+ def __call__(
+ self,
+ text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]],
+ images: Optional[ImageInput] = None,
+ audio=None,
+ videos=None,
+ **kwargs: Unpack[AriaProcessorKwargs],
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several sequences(s) and image(s).
+
+ Args:
+ text (`TextInput`, `PreTokenizedInput`, `List[TextInput]`, `List[PreTokenizedInput]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ images (`ImageInput`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. Both channels-first and channels-last formats are supported.
+
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+ - **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
+ - **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
+ `return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
+ `None`).
+ - **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
+ - **pixel_mask** -- Pixel mask to be fed to a model. Returned when `images` is not `None`.
+ """
+ output_kwargs = self._merge_kwargs(
+ AriaProcessorKwargs,
+ tokenizer_init_kwargs=self.tokenizer.init_kwargs,
+ **kwargs,
+ )
+
+ if isinstance(text, str):
+ text = [text]
+ elif not isinstance(text, list) and not isinstance(text[0], str):
+ raise ValueError("Invalid input text. Please provide a string, or a list of strings")
+
+ if images is not None:
+ image_inputs = self.image_processor(
+ images,
+ **output_kwargs["images_kwargs"],
+ )
+ # expand the image_token according to the num_crops and tokens per image
+ tokens_per_image = self.size_conversion[image_inputs.pixel_values.shape[2]]
+ prompt_strings = []
+ num_crops = image_inputs.pop("num_crops") * tokens_per_image
+ for sample in text:
+ sample = sample.replace(self.tokenizer.image_token, self.tokenizer.image_token * num_crops)
+ prompt_strings.append(sample)
+
+ else:
+ image_inputs = {}
+ prompt_strings = text
+
+ return_tensors = output_kwargs["text_kwargs"].pop("return_tensors", None)
+ text_inputs = self.tokenizer(prompt_strings, **output_kwargs["text_kwargs"])
+ self._check_special_mm_tokens(prompt_strings, text_inputs, modalities=["image"])
+
+ return BatchFeature(data={**text_inputs, **image_inputs}, tensor_type=return_tensors)
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
+ the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
+
+ @property
+ def model_input_names(self):
+ tokenizer_input_names = self.tokenizer.model_input_names
+ image_processor_input_names = self.image_processor.model_input_names
+
+ # Remove `num_crops`, it is popped and used only when processing. Make a copy of list when remocing
+ # otherwise `self.image_processor.model_input_names` is also modified
+ image_processor_input_names = [name for name in image_processor_input_names if name != "num_crops"]
+ return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
+
+
+class AriaSharedExpertsMLP(LlamaMLP):
+ """
+ Shared Expert MLP for shared experts.
+
+ Unlike routed experts, shared experts process all tokens without routing.
+ This class reconfigures the intermediate size in comparison to the LlamaMLP.
+
+ Args:
+ config (`AriaTextConfig`): Configuration object for the Aria language model.
+ """
+
+ def __init__(self, config: AriaTextConfig):
+ super().__init__(self)
+ self.intermediate_size = config.intermediate_size * config.moe_num_shared_experts
+
+
+class AriaGroupedExpertsGemm(nn.Module):
+ """
+ Grouped GEMM (General Matrix Multiplication) module for efficient expert computation.
+ This module utilizes the grouped_gemm library (https://github.com/fanshiqing/grouped_gemm)
+ for optimized performance. If the grouped_gemm library is not installed, it gracefully
+ falls back to a sequential GEMM implementation, which may be slower but ensures
+ functionality.
+
+ Args:
+ in_features (`int`):
+ Number of input features.
+ out_features (`int`):
+ Number of output features.
+ groups (`int`):
+ Number of expert groups.
+ """
+
+ def __init__(self, in_features, out_features, groups):
+ super().__init__()
+ self.in_features = in_features
+ self.out_features = out_features
+ self.groups = groups
+ self.weight = nn.Parameter(torch.empty(groups, in_features, out_features))
+
+ def forward(self, input, tokens_per_expert):
+ """
+ Perform grouped matrix multiplication.
+
+ Args:
+ input (`torch.Tensor`):
+ Input tensor of shape (num_tokens, in_features).
+ tokens_per_expert (`torch.Tensor`):
+ Number of tokens assigned to each expert.
+
+ Returns:
+ torch.Tensor: Output tensor of shape (num_tokens, out_features).
+ """
+ return sequential_experts_gemm(
+ input,
+ self.weight,
+ tokens_per_expert.cpu(),
+ )
+
+
+class AriaGroupedExpertsMLP(nn.Module):
+ """
+ Grouped MLP module for Mixture of Experts.
+
+ Args:
+ config (`AriaTextConfig`):
+ Configuration object for the model.
+ """
+
+ def __init__(self, config: AriaTextConfig) -> None:
+ super().__init__()
+ self.config = config
+ self.fc1 = AriaGroupedExpertsGemm(config.hidden_size, config.intermediate_size * 2, config.moe_num_experts)
+ self.fc2 = AriaGroupedExpertsGemm(config.intermediate_size, config.hidden_size, config.moe_num_experts)
+
+ def forward(self, permuted_tokens, tokens_per_expert):
+ """
+ Forward pass of the Grouped MLP.
+
+ Args:
+ permuted_tokens (torch.Tensor): Permuted input tokens.
+ tokens_per_expert (torch.Tensor): Number of tokens assigned to each expert.
+
+ Returns:
+ torch.Tensor: Output tensor after passing through the MLP.
+ """
+ fc1_output = self.fc1(permuted_tokens, tokens_per_expert)
+ projection, gate = torch.chunk(fc1_output, 2, dim=-1)
+ fc1_output = nn.functional.silu(projection) * gate
+ fc2_output = self.fc2(fc1_output, tokens_per_expert)
+ return fc2_output
+
+
+# Token permutation adapted from https://github.com/NVIDIA/Megatron-LM/blob/54f1f78529cbc2b9cddad313e7f9d96ac0420a27/megatron/core/transformer/moe/token_dispatcher.py#L291-L587
+class AriaTextMoELayer(nn.Module):
+ """
+ Aria Text Mixture of Experts (MoE) Layer.
+
+ This layer applies a gating mechanism to route input tokens to different experts.
+
+ Args:
+ config (`AriaTextConfig`):
+ Configuration object for the text component of the model.
+ """
+
+ def __init__(self, config: AriaTextConfig):
+ super().__init__()
+
+ self.router = nn.Linear(config.hidden_size, config.moe_num_experts, bias=False)
+ self.experts = AriaGroupedExpertsMLP(config)
+ self.shared_experts = AriaSharedExpertsMLP(config)
+ self.config = config
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ """
+ Forward pass of the MoE Layer.
+
+ Args:
+ hidden_states (`torch.Tensor`):
+ Input tensor of shape (batch_size, sequence_length, hidden_size).
+
+ Returns:
+ torch.Tensor: Output tensor after passing through the MoE layer.
+
+ Process:
+ 1. Route tokens to experts using the router.
+ 2. Permute tokens based on routing decisions.
+ 3. Process tokens through experts.
+ 4. Unpermute and combine expert outputs.
+ 5. Add shared expert output to the final result.
+ """
+ original_shape = hidden_states.shape
+ hidden_states = hidden_states.view(-1, hidden_states.size(-1))
+
+ # Top K Routing
+ logits = self.router(hidden_states)
+ top_logits, top_indices = torch.topk(logits, k=self.config.moe_topk, dim=1)
+ scores = nn.functional.softmax(top_logits, dim=-1)
+
+ original_dtype = top_indices.dtype
+
+ tokens_per_expert = torch.histc(
+ top_indices.flatten().to(torch.float32),
+ bins=self.config.moe_num_experts,
+ min=0,
+ max=self.config.moe_num_experts - 1,
+ ).to(original_dtype)
+ indices = top_indices
+
+ # Token permutation
+ flatten_indices = indices.view(-1)
+ sorted_indices = torch.argsort(flatten_indices)
+ permuted_tokens = hidden_states.index_select(0, sorted_indices // self.config.moe_topk)
+
+ # Process through experts
+ expert_output = self.experts(permuted_tokens, tokens_per_expert)
+
+ # Token unpermutation
+ unpermuted_tokens = torch.zeros(
+ (scores.shape[0] * self.config.moe_topk, expert_output.size(1)),
+ dtype=expert_output.dtype,
+ device=expert_output.device,
+ )
+ unpermuted_tokens.index_copy_(0, sorted_indices, expert_output)
+ unpermuted_tokens = unpermuted_tokens.view(-1, self.config.moe_topk, expert_output.size(1))
+
+ output = (unpermuted_tokens * scores.unsqueeze(-1)).sum(dim=1).view(original_shape)
+
+ # Add shared expert output
+ shared_expert_output = self.shared_experts(hidden_states.view(original_shape))
+ return output + shared_expert_output
+
+
+class AriaTextDecoderLayer(LlamaDecoderLayer):
+ """
+ Aria Text Decoder Layer.
+
+ This class defines a single decoder layer in the language model, incorporating self-attention and Mixture of Experts (MoE) feed-forward network.
+
+ Args:
+ config (`AriaTextConfig`):
+ Configuration object for the text component of the model.
+ layer_idx (`int`):
+ Index of the layer.
+ """
+
+ def __init__(self, config: AriaTextConfig, layer_idx: int):
+ super().__init__(self)
+ self.mlp = AriaTextMoELayer(config)
+
+
+class AriaTextPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained models.
+ """
+
+ config_class = AriaConfig
+ base_model_prefix = "model"
+ _no_split_modules = ["AriaTextDecoderLayer", "AriaGroupedExpertsGemm"]
+ supports_gradient_checkpointing = True
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn_2 = False
+ _supports_sdpa = True
+ _supports_cache_class = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, AriaTextRMSNorm):
+ module.weight.data.fill_(1.0)
+ elif isinstance(module, AriaGroupedExpertsGemm):
+ module.weight.data.normal_(mean=0.0, std=std)
+
+
+class AriaPreTrainedModel(LlamaPreTrainedModel):
+ _supports_static_cache = False # MoE models don't work with torch.compile (dynamic slicing)
+ _supports_attention_backend = False
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.MultiheadAttention):
+ # This uses torch's original init
+ module._reset_parameters()
+ elif isinstance(module, nn.LayerNorm):
+ module.weight.data.fill_(1.0)
+ module.bias.data.zero_()
+ elif isinstance(module, AriaProjector):
+ nn.init.trunc_normal_(module.query, std=std)
+
+
+class AriaTextModel(LlamaModel):
+ def __init__(self, config: AriaTextConfig):
+ super().__init__(config)
+ self.layers = nn.ModuleList(
+ [AriaTextDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
+ )
+ self.gradient_checkpointing = False
+ self.post_init()
+
+
+class AriaTextForCausalLM(AriaTextPreTrainedModel, LlamaForCausalLM):
+ """
+ Aria model for causal language modeling tasks.
+
+ This class extends `LlamaForCausalLM` to incorporate the Mixture of Experts (MoE) approach,
+ allowing for more efficient and scalable language modeling.
+
+ Args:
+ config (`AriaTextConfig`):
+ Configuration object for the model.
+ """
+
+ _tied_weights_keys = ["lm_head.weight"]
+ config_class = AriaTextConfig
+
+ def __init__(self, config: AriaTextConfig):
+ super().__init__(config)
+ self.model = AriaTextModel(config)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+
+class AriaCausalLMOutputWithPast(LlavaCausalLMOutputWithPast):
+ pass
+
+
+ARIA_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor`, *optional*):
+ Input token IDs.
+ pixel_values (`torch.FloatTensor`, *optional*):
+ Pixel values of the images.
+ pixel_mask (`torch.LongTensor`, *optional*):
+ Mask for the pixel values.
+ attention_mask (`torch.Tensor`, *optional*):
+ Attention mask.
+ position_ids (`torch.LongTensor`, *optional*):
+ Position IDs.
+ past_key_values (`List[torch.FloatTensor]`, *optional*):
+ Past key values for efficient processing.
+ inputs_embeds (`torch.FloatTensor`, *optional*):
+ Input embeddings.
+ labels (`torch.LongTensor`, *optional*):
+ Labels for computing the language modeling loss.
+ use_cache (`bool`, *optional*):
+ Whether to use the model's cache mechanism.
+ output_attentions (`bool`, *optional*):
+ Whether to output attention weights.
+ output_hidden_states (`bool`, *optional*):
+ Whether to output hidden states.
+ return_dict (`bool`, *optional*):
+ Whether to return a `ModelOutput` object.
+ logits_to_keep (`int` or `torch.Tensor`, *optional*, defaults to 0):
+ If an `int`, calculate logits for the last `logits_to_keep` tokens, or all `input_ids` if `0`.
+ Otherwise, slice according to the 1D tensor in the sequence length dimension
+ cache_position (`torch.LongTensor`, *optional*):
+ Cache positions.
+ **loss_kwargs:
+ Additional keyword arguments for loss calculation.
+"""
+
+ARIA_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config (`AriaConfig`):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ """Aria model for conditional generation tasks.
+
+ This model combines a vision tower, a multi-modal projector, and a language model
+ to perform tasks that involve both image and text inputs.""",
+ ARIA_START_DOCSTRING,
+)
+class AriaForConditionalGeneration(AriaPreTrainedModel, GenerationMixin):
+ config_class = AriaConfig
+ _supports_flash_attn_2 = False
+ _supports_flex_attn = False
+ _supports_sdpa = False
+ _tied_weights_keys = ["language_model.lm_head.weight"]
+
+ def __init__(self, config: AriaConfig):
+ super().__init__(config)
+
+ self.vision_tower = AutoModel.from_config(config.vision_config)
+ self.multi_modal_projector = AriaProjector(config)
+ self.vocab_size = config.text_config.vocab_size
+ self.language_model = AutoModelForCausalLM.from_config(config.text_config)
+ self.pad_token_id = self.config.pad_token_id if self.config.pad_token_id is not None else -1
+ self._use_flash_attention_2 = config.text_config._attn_implementation == "flash_attention_2"
+ self.post_init()
+
+ def _create_patch_attention_mask(self, pixel_mask):
+ if pixel_mask is None:
+ return None
+
+ patches_subgrid = pixel_mask.unfold(
+ dimension=1,
+ size=self.vision_tower.config.patch_size,
+ step=self.vision_tower.config.patch_size,
+ )
+ patches_subgrid = patches_subgrid.unfold(
+ dimension=2,
+ size=self.vision_tower.config.patch_size,
+ step=self.vision_tower.config.patch_size,
+ )
+ return (patches_subgrid.sum(dim=(-1, -2)) > 0).bool()
+
+ def get_input_embeddings(self):
+ return self.language_model.get_input_embeddings()
+
+ def set_input_embeddings(self, value):
+ self.language_model.set_input_embeddings(value)
+
+ def get_output_embeddings(self):
+ return self.language_model.get_output_embeddings()
+
+ def set_output_embeddings(self, new_embeddings):
+ self.language_model.set_output_embeddings(new_embeddings)
+
+ def set_decoder(self, decoder):
+ self.language_model.set_decoder(decoder)
+
+ def get_decoder(self):
+ return self.language_model.get_decoder()
+
+ def get_image_features(
+ self,
+ pixel_values: torch.FloatTensor,
+ pixel_mask: Optional[torch.FloatTensor] = None,
+ vision_feature_layer: int = -1,
+ ):
+ patch_attention_mask = self._create_patch_attention_mask(pixel_mask)
+ image_outputs = self.vision_tower(
+ pixel_values, patch_attention_mask=patch_attention_mask, output_hidden_states=True
+ )
+ image_attn_mask = None
+ if patch_attention_mask is not None:
+ flattened_mask = patch_attention_mask.flatten(1)
+ image_attn_mask = torch.logical_not(flattened_mask)
+
+ selected_image_feature = image_outputs.hidden_states[vision_feature_layer]
+ image_features = self.multi_modal_projector(selected_image_feature, attn_mask=image_attn_mask)
+ return image_features
+
+ @can_return_tuple
+ @add_start_docstrings_to_model_forward(ARIA_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=AriaCausalLMOutputWithPast, config_class=AriaConfig)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ pixel_mask: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ logits_to_keep: Union[int, torch.Tensor] = 0,
+ cache_position: Optional[torch.LongTensor] = None,
+ **loss_kwargs,
+ ) -> AriaCausalLMOutputWithPast:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or `model.image_token_id` (where `model` is your instance of `Idefics3ForConditionalGeneration`).
+ Tokens with indices set to `model.image_token_id` are ignored (masked), the loss is only
+ computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+ Returns:
+
+ Example:
+
+ ```python
+ >>> import requests
+ >>> import torch
+ >>> from PIL import Image
+ >>> from io import BytesIO
+
+ >>> from transformers import AutoProcessor, AutoModel
+ >>> from transformers.image_utils import load_image
+
+ >>> # Note that passing the image urls (instead of the actual pil images) to the processor is also possible
+ >>> image1 = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
+ >>> image2 = load_image("https://cdn.britannica.com/59/94459-050-DBA42467/Skyline-Chicago.jpg")
+ >>> image3 = load_image("https://cdn.britannica.com/68/170868-050-8DDE8263/Golden-Gate-Bridge-San-Francisco.jpg")
+
+ >>> processor = AutoProcessor.from_pretrained("Rhymes-AI/Aria")
+ >>> model = AutoModel.from_pretrained("Rhymes-AI/Aria", torch_dtype=torch.bfloat16, device_map="auto")
+
+ >>> # Create inputs
+ >>> messages = [
+ ... {
+ ... "role": "user",
+ ... "content": [
+ ... {"type": "image"},
+ ... {"type": "text", "text": "In this image, we can see the city of New York, and more specifically the Statue of Liberty."},
+ ... {"type": "image"},
+ ... {"type": "text", "text": "What can we see in this image?"},
+ ... ]
+ ... },
+ ... {
+ ... "role": "user",
+ ... "content": [
+ ... {"type": "image"},
+ ... {"type": "text", "text": "In which city is that bridge located?"},
+ ... ]
+ ... }
+ ... ]
+
+ >>> prompts = [processor.apply_chat_template([message], add_generation_prompt=True) for message in messages]
+ >>> images = [[image1, image2], [image3]]
+ >>> inputs = processor(text=prompts, images=images, padding=True, return_tensors="pt").to(model.device)
+
+ >>> # Generate
+ >>> generated_ids = model.generate(**inputs, max_new_tokens=256)
+ >>> generated_texts = processor.batch_decode(generated_ids, skip_special_tokens=True)
+
+ >>> print(generated_texts[0])
+ Assistant: There are buildings, trees, lights, and water visible in this image.
+
+ >>> print(generated_texts[1])
+ Assistant: The bridge is in San Francisco.
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+
+ if inputs_embeds is None:
+ inputs_embeds = self.get_input_embeddings()(input_ids)
+
+ # 2. Merge text and images
+ if pixel_values is not None and inputs_embeds.shape[1] != 1:
+ if input_ids is None:
+ special_image_mask = inputs_embeds == self.get_input_embeddings()(
+ torch.tensor(self.config.image_token_id, dtype=torch.long, device=inputs_embeds.device)
+ )
+ n_image_tokens = (special_image_mask).sum(dim=1).sum(dim=0)[0]
+ else:
+ image_embeds = input_ids == self.config.image_token_id
+ special_image_mask = image_embeds.unsqueeze(-1).expand_as(inputs_embeds).to(inputs_embeds.device)
+ n_image_tokens = (image_embeds).sum(dim=1).sum(dim=0)
+ image_features = self.get_image_features(
+ pixel_values=pixel_values,
+ pixel_mask=pixel_mask,
+ vision_feature_layer=self.config.vision_feature_layer,
+ )
+ n_images, n_features_per_image = image_features.shape[0], image_features.shape[1]
+ n_image_features = n_images * n_features_per_image
+ if n_image_tokens != n_image_features:
+ raise ValueError(
+ f"Image features and image tokens do not match: tokens: {n_image_tokens}, features {n_image_features}"
+ )
+
+ image_features = image_features.to(inputs_embeds.device, inputs_embeds.dtype)
+ inputs_embeds = inputs_embeds.masked_scatter(special_image_mask, image_features)
+
+ outputs: CausalLMOutputWithPast = self.language_model(
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ logits_to_keep=logits_to_keep,
+ cache_position=cache_position,
+ )
+
+ logits = outputs.logits
+
+ loss = None
+ if labels is not None:
+ loss = self.loss_function(
+ logits=logits, labels=labels, vocab_size=self.config.text_config.vocab_size, **loss_kwargs
+ )
+
+ return AriaCausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ inputs_embeds=None,
+ pixel_values=None,
+ pixel_mask=None,
+ attention_mask=None,
+ cache_position=None,
+ logits_to_keep=None,
+ **kwargs,
+ ):
+ model_inputs = self.language_model.prepare_inputs_for_generation(
+ input_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ attention_mask=attention_mask,
+ cache_position=cache_position,
+ logits_to_keep=logits_to_keep,
+ **kwargs,
+ )
+
+ if cache_position[0] == 0:
+ # If we're in cached decoding stage, pixel values should be None because input ids do not contain special image token anymore
+ # Otherwise we need pixel values to be passed to model
+ model_inputs["pixel_values"] = pixel_values
+ model_inputs["pixel_mask"] = pixel_mask
+
+ return model_inputs
+
+
+__all__ = [
+ "AriaConfig",
+ "AriaTextConfig",
+ "AriaImageProcessor",
+ "AriaProcessor",
+ "AriaForConditionalGeneration",
+ "AriaPreTrainedModel",
+ "AriaTextPreTrainedModel",
+ "AriaTextModel",
+ "AriaTextForCausalLM",
+]
diff --git a/docs/transformers/src/transformers/models/aria/processing_aria.py b/docs/transformers/src/transformers/models/aria/processing_aria.py
new file mode 100644
index 0000000000000000000000000000000000000000..7d3076247550521b0900b07991ba0d68ad24747a
--- /dev/null
+++ b/docs/transformers/src/transformers/models/aria/processing_aria.py
@@ -0,0 +1,171 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from src/transformers/models/aria/modular_aria.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_aria.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# coding=utf-8
+# Copyright 2024 The Rhymes-AI Teams Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import Dict, List, Optional, Union
+
+from ...image_processing_utils import BatchFeature
+from ...image_utils import ImageInput
+from ...processing_utils import ProcessingKwargs, ProcessorMixin, Unpack
+from ...tokenization_utils import PreTokenizedInput, TextInput
+from ...utils import TensorType
+from ..auto import AutoTokenizer
+
+
+class AriaProcessorKwargs(ProcessingKwargs, total=False):
+ _defaults = {
+ "text_kwargs": {
+ "padding": False,
+ },
+ "images_kwargs": {
+ "max_image_size": 980,
+ "split_image": False,
+ },
+ "return_tensors": TensorType.PYTORCH,
+ }
+
+
+class AriaProcessor(ProcessorMixin):
+ """
+ AriaProcessor is a processor for the Aria model which wraps the Aria image preprocessor and the LLama slow tokenizer.
+
+ Args:
+ image_processor (`AriaImageProcessor`, *optional*):
+ The AriaImageProcessor to use for image preprocessing.
+ tokenizer (`PreTrainedTokenizerBase`, *optional*):
+ An instance of [`PreTrainedTokenizerBase`]. This should correspond with the model's text model. The tokenizer is a required input.
+ chat_template (`str`, *optional*):
+ A Jinja template which will be used to convert lists of messages in a chat into a tokenizable string.
+ size_conversion (`Dict`, *optional*):
+ A dictionary indicating size conversions for images.
+ """
+
+ attributes = ["image_processor", "tokenizer"]
+ valid_kwargs = ["chat_template", "size_conversion"]
+ image_processor_class = "AriaImageProcessor"
+ tokenizer_class = "AutoTokenizer"
+
+ def __init__(
+ self,
+ image_processor=None,
+ tokenizer: Union[AutoTokenizer, str] = None,
+ chat_template: Optional[str] = None,
+ size_conversion: Optional[Dict[Union[float, int], int]] = None,
+ ):
+ if size_conversion is None:
+ size_conversion = {490: 128, 980: 256}
+ self.size_conversion = {int(k): v for k, v in size_conversion.items()}
+
+ self.image_token = tokenizer.image_token
+ self.image_token_id = tokenizer.image_token_id
+ if tokenizer is not None and tokenizer.pad_token is None:
+ tokenizer.pad_token = tokenizer.unk_token
+
+ super().__init__(image_processor, tokenizer, chat_template=chat_template)
+
+ def __call__(
+ self,
+ text: Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]],
+ images: Optional[ImageInput] = None,
+ audio=None,
+ videos=None,
+ **kwargs: Unpack[AriaProcessorKwargs],
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several sequences(s) and image(s).
+
+ Args:
+ text (`TextInput`, `PreTokenizedInput`, `List[TextInput]`, `List[PreTokenizedInput]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ images (`ImageInput`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. Both channels-first and channels-last formats are supported.
+
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+ - **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
+ - **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
+ `return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
+ `None`).
+ - **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
+ - **pixel_mask** -- Pixel mask to be fed to a model. Returned when `images` is not `None`.
+ """
+ output_kwargs = self._merge_kwargs(
+ AriaProcessorKwargs,
+ tokenizer_init_kwargs=self.tokenizer.init_kwargs,
+ **kwargs,
+ )
+
+ if isinstance(text, str):
+ text = [text]
+ elif not isinstance(text, list) and not isinstance(text[0], str):
+ raise ValueError("Invalid input text. Please provide a string, or a list of strings")
+
+ if images is not None:
+ image_inputs = self.image_processor(
+ images,
+ **output_kwargs["images_kwargs"],
+ )
+ # expand the image_token according to the num_crops and tokens per image
+ tokens_per_image = self.size_conversion[image_inputs.pixel_values.shape[2]]
+ prompt_strings = []
+ num_crops = image_inputs.pop("num_crops") * tokens_per_image
+ for sample in text:
+ sample = sample.replace(self.tokenizer.image_token, self.tokenizer.image_token * num_crops)
+ prompt_strings.append(sample)
+
+ else:
+ image_inputs = {}
+ prompt_strings = text
+
+ return_tensors = output_kwargs["text_kwargs"].pop("return_tensors", None)
+ text_inputs = self.tokenizer(prompt_strings, **output_kwargs["text_kwargs"])
+ self._check_special_mm_tokens(prompt_strings, text_inputs, modalities=["image"])
+
+ return BatchFeature(data={**text_inputs, **image_inputs}, tensor_type=return_tensors)
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to LlamaTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
+ the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
+
+ @property
+ def model_input_names(self):
+ tokenizer_input_names = self.tokenizer.model_input_names
+ image_processor_input_names = self.image_processor.model_input_names
+
+ # Remove `num_crops`, it is popped and used only when processing. Make a copy of list when remocing
+ # otherwise `self.image_processor.model_input_names` is also modified
+ image_processor_input_names = [name for name in image_processor_input_names if name != "num_crops"]
+ return list(dict.fromkeys(tokenizer_input_names + image_processor_input_names))
+
+
+__all__ = ["AriaProcessor"]
diff --git a/docs/transformers/src/transformers/models/audio_spectrogram_transformer/__init__.py b/docs/transformers/src/transformers/models/audio_spectrogram_transformer/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..618fceef70d3891f4313958cdadede27d605f12c
--- /dev/null
+++ b/docs/transformers/src/transformers/models/audio_spectrogram_transformer/__init__.py
@@ -0,0 +1,28 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import _LazyModule
+from ...utils.import_utils import define_import_structure
+
+
+if TYPE_CHECKING:
+ from .configuration_audio_spectrogram_transformer import *
+ from .feature_extraction_audio_spectrogram_transformer import *
+ from .modeling_audio_spectrogram_transformer import *
+else:
+ import sys
+
+ _file = globals()["__file__"]
+ sys.modules[__name__] = _LazyModule(__name__, _file, define_import_structure(_file), module_spec=__spec__)
diff --git a/docs/transformers/src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py b/docs/transformers/src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..77bec930236f600ae7ee5117d1d2f86a5a12fefd
--- /dev/null
+++ b/docs/transformers/src/transformers/models/audio_spectrogram_transformer/configuration_audio_spectrogram_transformer.py
@@ -0,0 +1,131 @@
+# coding=utf-8
+# Copyright 2022 Google AI and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Audio Spectogram Transformer (AST) model configuration"""
+
+from typing import Any, Dict
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class ASTConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`ASTModel`]. It is used to instantiate an AST
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the AST
+ [MIT/ast-finetuned-audioset-10-10-0.4593](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593)
+ architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ patch_size (`int`, *optional*, defaults to 16):
+ The size (resolution) of each patch.
+ qkv_bias (`bool`, *optional*, defaults to `True`):
+ Whether to add a bias to the queries, keys and values.
+ frequency_stride (`int`, *optional*, defaults to 10):
+ Frequency stride to use when patchifying the spectrograms.
+ time_stride (`int`, *optional*, defaults to 10):
+ Temporal stride to use when patchifying the spectrograms.
+ max_length (`int`, *optional*, defaults to 1024):
+ Temporal dimension of the spectrograms.
+ num_mel_bins (`int`, *optional*, defaults to 128):
+ Frequency dimension of the spectrograms (number of Mel-frequency bins).
+
+ Example:
+
+ ```python
+ >>> from transformers import ASTConfig, ASTModel
+
+ >>> # Initializing a AST MIT/ast-finetuned-audioset-10-10-0.4593 style configuration
+ >>> configuration = ASTConfig()
+
+ >>> # Initializing a model (with random weights) from the MIT/ast-finetuned-audioset-10-10-0.4593 style configuration
+ >>> model = ASTModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "audio-spectrogram-transformer"
+
+ def __init__(
+ self,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ patch_size=16,
+ qkv_bias=True,
+ frequency_stride=10,
+ time_stride=10,
+ max_length=1024,
+ num_mel_bins=128,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.patch_size = patch_size
+ self.qkv_bias = qkv_bias
+ self.frequency_stride = frequency_stride
+ self.time_stride = time_stride
+ self.max_length = max_length
+ self.num_mel_bins = num_mel_bins
+
+ # Overwritten from the parent class: AST is not compatible with `generate`, but has a config parameter sharing the
+ # same name (`max_length`). Sharing the same name triggers checks regarding the config -> generation_config
+ # generative parameters deprecation cycle, overwriting this function prevents this from happening.
+ def _get_non_default_generation_parameters(self) -> Dict[str, Any]:
+ return {}
+
+
+__all__ = ["ASTConfig"]
diff --git a/docs/transformers/src/transformers/models/audio_spectrogram_transformer/convert_audio_spectrogram_transformer_original_to_pytorch.py b/docs/transformers/src/transformers/models/audio_spectrogram_transformer/convert_audio_spectrogram_transformer_original_to_pytorch.py
new file mode 100644
index 0000000000000000000000000000000000000000..d211ef7ab058f0ab23439d727cf5fa4f22dad4cf
--- /dev/null
+++ b/docs/transformers/src/transformers/models/audio_spectrogram_transformer/convert_audio_spectrogram_transformer_original_to_pytorch.py
@@ -0,0 +1,279 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert Audio Spectrogram Transformer checkpoints from the original repository. URL: https://github.com/YuanGongND/ast"""
+
+import argparse
+import json
+from pathlib import Path
+
+import torch
+import torchaudio
+from datasets import load_dataset
+from huggingface_hub import hf_hub_download
+
+from transformers import ASTConfig, ASTFeatureExtractor, ASTForAudioClassification
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+def get_audio_spectrogram_transformer_config(model_name):
+ config = ASTConfig()
+
+ if "10-10" in model_name:
+ pass
+ elif "speech-commands" in model_name:
+ config.max_length = 128
+ elif "12-12" in model_name:
+ config.time_stride = 12
+ config.frequency_stride = 12
+ elif "14-14" in model_name:
+ config.time_stride = 14
+ config.frequency_stride = 14
+ elif "16-16" in model_name:
+ config.time_stride = 16
+ config.frequency_stride = 16
+ else:
+ raise ValueError("Model not supported")
+
+ repo_id = "huggingface/label-files"
+ if "speech-commands" in model_name:
+ config.num_labels = 35
+ filename = "speech-commands-v2-id2label.json"
+ else:
+ config.num_labels = 527
+ filename = "audioset-id2label.json"
+
+ id2label = json.load(open(hf_hub_download(repo_id, filename, repo_type="dataset"), "r"))
+ id2label = {int(k): v for k, v in id2label.items()}
+ config.id2label = id2label
+ config.label2id = {v: k for k, v in id2label.items()}
+
+ return config
+
+
+def rename_key(name):
+ if "module.v" in name:
+ name = name.replace("module.v", "audio_spectrogram_transformer")
+ if "cls_token" in name:
+ name = name.replace("cls_token", "embeddings.cls_token")
+ if "dist_token" in name:
+ name = name.replace("dist_token", "embeddings.distillation_token")
+ if "pos_embed" in name:
+ name = name.replace("pos_embed", "embeddings.position_embeddings")
+ if "patch_embed.proj" in name:
+ name = name.replace("patch_embed.proj", "embeddings.patch_embeddings.projection")
+ # transformer blocks
+ if "blocks" in name:
+ name = name.replace("blocks", "encoder.layer")
+ if "attn.proj" in name:
+ name = name.replace("attn.proj", "attention.output.dense")
+ if "attn" in name:
+ name = name.replace("attn", "attention.self")
+ if "norm1" in name:
+ name = name.replace("norm1", "layernorm_before")
+ if "norm2" in name:
+ name = name.replace("norm2", "layernorm_after")
+ if "mlp.fc1" in name:
+ name = name.replace("mlp.fc1", "intermediate.dense")
+ if "mlp.fc2" in name:
+ name = name.replace("mlp.fc2", "output.dense")
+ # final layernorm
+ if "audio_spectrogram_transformer.norm" in name:
+ name = name.replace("audio_spectrogram_transformer.norm", "audio_spectrogram_transformer.layernorm")
+ # classifier head
+ if "module.mlp_head.0" in name:
+ name = name.replace("module.mlp_head.0", "classifier.layernorm")
+ if "module.mlp_head.1" in name:
+ name = name.replace("module.mlp_head.1", "classifier.dense")
+
+ return name
+
+
+def convert_state_dict(orig_state_dict, config):
+ for key in orig_state_dict.copy().keys():
+ val = orig_state_dict.pop(key)
+
+ if "qkv" in key:
+ key_split = key.split(".")
+ layer_num = int(key_split[3])
+ dim = config.hidden_size
+ if "weight" in key:
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.query.weight"
+ ] = val[:dim, :]
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.key.weight"
+ ] = val[dim : dim * 2, :]
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.value.weight"
+ ] = val[-dim:, :]
+ else:
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.query.bias"
+ ] = val[:dim]
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.key.bias"
+ ] = val[dim : dim * 2]
+ orig_state_dict[
+ f"audio_spectrogram_transformer.encoder.layer.{layer_num}.attention.attention.value.bias"
+ ] = val[-dim:]
+ else:
+ orig_state_dict[rename_key(key)] = val
+
+ return orig_state_dict
+
+
+def remove_keys(state_dict):
+ ignore_keys = [
+ "module.v.head.weight",
+ "module.v.head.bias",
+ "module.v.head_dist.weight",
+ "module.v.head_dist.bias",
+ ]
+ for k in ignore_keys:
+ state_dict.pop(k, None)
+
+
+@torch.no_grad()
+def convert_audio_spectrogram_transformer_checkpoint(model_name, pytorch_dump_folder_path, push_to_hub=False):
+ """
+ Copy/paste/tweak model's weights to our Audio Spectrogram Transformer structure.
+ """
+ config = get_audio_spectrogram_transformer_config(model_name)
+
+ model_name_to_url = {
+ "ast-finetuned-audioset-10-10-0.4593": (
+ "https://www.dropbox.com/s/ca0b1v2nlxzyeb4/audioset_10_10_0.4593.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-10-10-0.450": (
+ "https://www.dropbox.com/s/1tv0hovue1bxupk/audioset_10_10_0.4495.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-10-10-0.448": (
+ "https://www.dropbox.com/s/6u5sikl4b9wo4u5/audioset_10_10_0.4483.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-10-10-0.448-v2": (
+ "https://www.dropbox.com/s/kt6i0v9fvfm1mbq/audioset_10_10_0.4475.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-12-12-0.447": (
+ "https://www.dropbox.com/s/snfhx3tizr4nuc8/audioset_12_12_0.4467.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-14-14-0.443": (
+ "https://www.dropbox.com/s/z18s6pemtnxm4k7/audioset_14_14_0.4431.pth?dl=1"
+ ),
+ "ast-finetuned-audioset-16-16-0.442": (
+ "https://www.dropbox.com/s/mdsa4t1xmcimia6/audioset_16_16_0.4422.pth?dl=1"
+ ),
+ "ast-finetuned-speech-commands-v2": (
+ "https://www.dropbox.com/s/q0tbqpwv44pquwy/speechcommands_10_10_0.9812.pth?dl=1"
+ ),
+ }
+
+ # load original state_dict
+ checkpoint_url = model_name_to_url[model_name]
+ state_dict = torch.hub.load_state_dict_from_url(checkpoint_url, map_location="cpu")
+ # remove some keys
+ remove_keys(state_dict)
+ # rename some keys
+ new_state_dict = convert_state_dict(state_dict, config)
+
+ # load 🤗 model
+ model = ASTForAudioClassification(config)
+ model.eval()
+
+ model.load_state_dict(new_state_dict)
+
+ # verify outputs on dummy input
+ # source: https://github.com/YuanGongND/ast/blob/79e873b8a54d0a3b330dd522584ff2b9926cd581/src/run.py#L62
+ mean = -4.2677393 if "speech-commands" not in model_name else -6.845978
+ std = 4.5689974 if "speech-commands" not in model_name else 5.5654526
+ max_length = 1024 if "speech-commands" not in model_name else 128
+ feature_extractor = ASTFeatureExtractor(mean=mean, std=std, max_length=max_length)
+
+ if "speech-commands" in model_name:
+ # TODO: Convert dataset to Parquet
+ dataset = load_dataset("google/speech_commands", "v0.02", split="validation", trust_remote_code=True)
+ waveform = dataset[0]["audio"]["array"]
+ else:
+ filepath = hf_hub_download(
+ repo_id="nielsr/audio-spectogram-transformer-checkpoint",
+ filename="sample_audio.flac",
+ repo_type="dataset",
+ )
+
+ waveform, _ = torchaudio.load(filepath)
+ waveform = waveform.squeeze().numpy()
+
+ inputs = feature_extractor(waveform, sampling_rate=16000, return_tensors="pt")
+
+ # forward pass
+ outputs = model(**inputs)
+ logits = outputs.logits
+
+ if model_name == "ast-finetuned-audioset-10-10-0.4593":
+ expected_slice = torch.tensor([-0.8760, -7.0042, -8.6602])
+ elif model_name == "ast-finetuned-audioset-10-10-0.450":
+ expected_slice = torch.tensor([-1.1986, -7.0903, -8.2718])
+ elif model_name == "ast-finetuned-audioset-10-10-0.448":
+ expected_slice = torch.tensor([-2.6128, -8.0080, -9.4344])
+ elif model_name == "ast-finetuned-audioset-10-10-0.448-v2":
+ expected_slice = torch.tensor([-1.5080, -7.4534, -8.8917])
+ elif model_name == "ast-finetuned-audioset-12-12-0.447":
+ expected_slice = torch.tensor([-0.5050, -6.5833, -8.0843])
+ elif model_name == "ast-finetuned-audioset-14-14-0.443":
+ expected_slice = torch.tensor([-0.3826, -7.0336, -8.2413])
+ elif model_name == "ast-finetuned-audioset-16-16-0.442":
+ expected_slice = torch.tensor([-1.2113, -6.9101, -8.3470])
+ elif model_name == "ast-finetuned-speech-commands-v2":
+ expected_slice = torch.tensor([6.1589, -8.0566, -8.7984])
+ else:
+ raise ValueError("Unknown model name")
+ if not torch.allclose(logits[0, :3], expected_slice, atol=1e-4):
+ raise ValueError("Logits don't match")
+ print("Looks ok!")
+
+ if pytorch_dump_folder_path is not None:
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ print(f"Saving model {model_name} to {pytorch_dump_folder_path}")
+ model.save_pretrained(pytorch_dump_folder_path)
+ print(f"Saving feature extractor to {pytorch_dump_folder_path}")
+ feature_extractor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ print("Pushing model and feature extractor to the hub...")
+ model.push_to_hub(f"MIT/{model_name}")
+ feature_extractor.push_to_hub(f"MIT/{model_name}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default="ast-finetuned-audioset-10-10-0.4593",
+ type=str,
+ help="Name of the Audio Spectrogram Transformer model you'd like to convert.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model directory."
+ )
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+
+ args = parser.parse_args()
+ convert_audio_spectrogram_transformer_checkpoint(args.model_name, args.pytorch_dump_folder_path, args.push_to_hub)
diff --git a/docs/transformers/src/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py b/docs/transformers/src/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..888d38e1870367526492ecfa38f3a488cc5a0b02
--- /dev/null
+++ b/docs/transformers/src/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py
@@ -0,0 +1,239 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Feature extractor class for Audio Spectrogram Transformer.
+"""
+
+from typing import List, Optional, Union
+
+import numpy as np
+
+from ...audio_utils import mel_filter_bank, spectrogram, window_function
+from ...feature_extraction_sequence_utils import SequenceFeatureExtractor
+from ...feature_extraction_utils import BatchFeature
+from ...utils import TensorType, is_speech_available, is_torch_available, logging
+
+
+if is_speech_available():
+ import torchaudio.compliance.kaldi as ta_kaldi
+
+if is_torch_available():
+ import torch
+
+
+logger = logging.get_logger(__name__)
+
+
+class ASTFeatureExtractor(SequenceFeatureExtractor):
+ r"""
+ Constructs a Audio Spectrogram Transformer (AST) feature extractor.
+
+ This feature extractor inherits from [`~feature_extraction_sequence_utils.SequenceFeatureExtractor`] which contains
+ most of the main methods. Users should refer to this superclass for more information regarding those methods.
+
+ This class extracts mel-filter bank features from raw speech using TorchAudio if installed or using numpy
+ otherwise, pads/truncates them to a fixed length and normalizes them using a mean and standard deviation.
+
+ Args:
+ feature_size (`int`, *optional*, defaults to 1):
+ The feature dimension of the extracted features.
+ sampling_rate (`int`, *optional*, defaults to 16000):
+ The sampling rate at which the audio files should be digitalized expressed in hertz (Hz).
+ num_mel_bins (`int`, *optional*, defaults to 128):
+ Number of Mel-frequency bins.
+ max_length (`int`, *optional*, defaults to 1024):
+ Maximum length to which to pad/truncate the extracted features.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the log-Mel features using `mean` and `std`.
+ mean (`float`, *optional*, defaults to -4.2677393):
+ The mean value used to normalize the log-Mel features. Uses the AudioSet mean by default.
+ std (`float`, *optional*, defaults to 4.5689974):
+ The standard deviation value used to normalize the log-Mel features. Uses the AudioSet standard deviation
+ by default.
+ return_attention_mask (`bool`, *optional*, defaults to `False`):
+ Whether or not [`~ASTFeatureExtractor.__call__`] should return `attention_mask`.
+ """
+
+ model_input_names = ["input_values", "attention_mask"]
+
+ def __init__(
+ self,
+ feature_size=1,
+ sampling_rate=16000,
+ num_mel_bins=128,
+ max_length=1024,
+ padding_value=0.0,
+ do_normalize=True,
+ mean=-4.2677393,
+ std=4.5689974,
+ return_attention_mask=False,
+ **kwargs,
+ ):
+ super().__init__(feature_size=feature_size, sampling_rate=sampling_rate, padding_value=padding_value, **kwargs)
+ self.num_mel_bins = num_mel_bins
+ self.max_length = max_length
+ self.do_normalize = do_normalize
+ self.mean = mean
+ self.std = std
+ self.return_attention_mask = return_attention_mask
+
+ if not is_speech_available():
+ mel_filters = mel_filter_bank(
+ num_frequency_bins=257,
+ num_mel_filters=self.num_mel_bins,
+ min_frequency=20,
+ max_frequency=sampling_rate // 2,
+ sampling_rate=sampling_rate,
+ norm=None,
+ mel_scale="kaldi",
+ triangularize_in_mel_space=True,
+ )
+
+ self.mel_filters = mel_filters
+ self.window = window_function(400, "hann", periodic=False)
+
+ def _extract_fbank_features(
+ self,
+ waveform: np.ndarray,
+ max_length: int,
+ ) -> np.ndarray:
+ """
+ Get mel-filter bank features using TorchAudio. Note that TorchAudio requires 16-bit signed integers as inputs
+ and hence the waveform should not be normalized before feature extraction.
+ """
+ # waveform = waveform * (2**15) # Kaldi compliance: 16-bit signed integers
+ if is_speech_available():
+ waveform = torch.from_numpy(waveform).unsqueeze(0)
+ fbank = ta_kaldi.fbank(
+ waveform,
+ sample_frequency=self.sampling_rate,
+ window_type="hanning",
+ num_mel_bins=self.num_mel_bins,
+ )
+ else:
+ waveform = np.squeeze(waveform)
+ fbank = spectrogram(
+ waveform,
+ self.window,
+ frame_length=400,
+ hop_length=160,
+ fft_length=512,
+ power=2.0,
+ center=False,
+ preemphasis=0.97,
+ mel_filters=self.mel_filters,
+ log_mel="log",
+ mel_floor=1.192092955078125e-07,
+ remove_dc_offset=True,
+ ).T
+
+ fbank = torch.from_numpy(fbank)
+
+ n_frames = fbank.shape[0]
+ difference = max_length - n_frames
+
+ # pad or truncate, depending on difference
+ if difference > 0:
+ pad_module = torch.nn.ZeroPad2d((0, 0, 0, difference))
+ fbank = pad_module(fbank)
+ elif difference < 0:
+ fbank = fbank[0:max_length, :]
+
+ fbank = fbank.numpy()
+
+ return fbank
+
+ def normalize(self, input_values: np.ndarray) -> np.ndarray:
+ return (input_values - (self.mean)) / (self.std * 2)
+
+ def __call__(
+ self,
+ raw_speech: Union[np.ndarray, List[float], List[np.ndarray], List[List[float]]],
+ sampling_rate: Optional[int] = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ **kwargs,
+ ) -> BatchFeature:
+ """
+ Main method to featurize and prepare for the model one or several sequence(s).
+
+ Args:
+ raw_speech (`np.ndarray`, `List[float]`, `List[np.ndarray]`, `List[List[float]]`):
+ The sequence or batch of sequences to be padded. Each sequence can be a numpy array, a list of float
+ values, a list of numpy arrays or a list of list of float values. Must be mono channel audio, not
+ stereo, i.e. single float per timestep.
+ sampling_rate (`int`, *optional*):
+ The sampling rate at which the `raw_speech` input was sampled. It is strongly recommended to pass
+ `sampling_rate` at the forward call to prevent silent errors.
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors instead of list of python integers. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return Numpy `np.ndarray` objects.
+ """
+
+ if sampling_rate is not None:
+ if sampling_rate != self.sampling_rate:
+ raise ValueError(
+ f"The model corresponding to this feature extractor: {self} was trained using a sampling rate of"
+ f" {self.sampling_rate}. Please make sure that the provided `raw_speech` input was sampled with"
+ f" {self.sampling_rate} and not {sampling_rate}."
+ )
+ else:
+ logger.warning(
+ f"It is strongly recommended to pass the `sampling_rate` argument to `{self.__class__.__name__}()`. "
+ "Failing to do so can result in silent errors that might be hard to debug."
+ )
+
+ is_batched_numpy = isinstance(raw_speech, np.ndarray) and len(raw_speech.shape) > 1
+ if is_batched_numpy and len(raw_speech.shape) > 2:
+ raise ValueError(f"Only mono-channel audio is supported for input to {self}")
+ is_batched = is_batched_numpy or (
+ isinstance(raw_speech, (list, tuple)) and (isinstance(raw_speech[0], (np.ndarray, tuple, list)))
+ )
+
+ if is_batched:
+ raw_speech = [np.asarray(speech, dtype=np.float32) for speech in raw_speech]
+ elif not is_batched and not isinstance(raw_speech, np.ndarray):
+ raw_speech = np.asarray(raw_speech, dtype=np.float32)
+ elif isinstance(raw_speech, np.ndarray) and raw_speech.dtype is np.dtype(np.float64):
+ raw_speech = raw_speech.astype(np.float32)
+
+ # always return batch
+ if not is_batched:
+ raw_speech = [raw_speech]
+
+ # extract fbank features and pad/truncate to max_length
+ features = [self._extract_fbank_features(waveform, max_length=self.max_length) for waveform in raw_speech]
+
+ # convert into BatchFeature
+ padded_inputs = BatchFeature({"input_values": features})
+
+ # make sure list is in array format
+ input_values = padded_inputs.get("input_values")
+ if isinstance(input_values[0], list):
+ padded_inputs["input_values"] = [np.asarray(feature, dtype=np.float32) for feature in input_values]
+
+ # normalization
+ if self.do_normalize:
+ padded_inputs["input_values"] = [self.normalize(feature) for feature in input_values]
+
+ if return_tensors is not None:
+ padded_inputs = padded_inputs.convert_to_tensors(return_tensors)
+
+ return padded_inputs
+
+
+__all__ = ["ASTFeatureExtractor"]
diff --git a/docs/transformers/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py b/docs/transformers/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..1aa24ca08a5aa17763074379f0db904c9e0f0fb1
--- /dev/null
+++ b/docs/transformers/src/transformers/models/audio_spectrogram_transformer/modeling_audio_spectrogram_transformer.py
@@ -0,0 +1,650 @@
+# coding=utf-8
+# Copyright 2022 MIT and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch Audio Spectrogram Transformer (AST) model."""
+
+from typing import Callable, Dict, List, Optional, Set, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling, SequenceClassifierOutput
+from ...modeling_utils import ALL_ATTENTION_FUNCTIONS, PreTrainedModel
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import add_code_sample_docstrings, add_start_docstrings, add_start_docstrings_to_model_forward, logging
+from .configuration_audio_spectrogram_transformer import ASTConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "ASTConfig"
+
+# Base docstring
+_CHECKPOINT_FOR_DOC = "MIT/ast-finetuned-audioset-10-10-0.4593"
+_EXPECTED_OUTPUT_SHAPE = [1, 1214, 768]
+
+# Audio classification docstring
+_SEQ_CLASS_CHECKPOINT = "MIT/ast-finetuned-audioset-10-10-0.4593"
+_SEQ_CLASS_EXPECTED_OUTPUT = "'Speech'"
+_SEQ_CLASS_EXPECTED_LOSS = 0.17
+
+
+class ASTEmbeddings(nn.Module):
+ """
+ Construct the CLS token, position and patch embeddings.
+ """
+
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+
+ self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.distillation_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
+ self.patch_embeddings = ASTPatchEmbeddings(config)
+
+ frequency_out_dimension, time_out_dimension = self.get_shape(config)
+ num_patches = frequency_out_dimension * time_out_dimension
+ self.position_embeddings = nn.Parameter(torch.zeros(1, num_patches + 2, config.hidden_size))
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+ self.config = config
+
+ def get_shape(self, config):
+ # see Karpathy's cs231n blog on how to calculate the output dimensions
+ # https://cs231n.github.io/convolutional-networks/#conv
+ frequency_out_dimension = (config.num_mel_bins - config.patch_size) // config.frequency_stride + 1
+ time_out_dimension = (config.max_length - config.patch_size) // config.time_stride + 1
+
+ return frequency_out_dimension, time_out_dimension
+
+ def forward(self, input_values: torch.Tensor) -> torch.Tensor:
+ batch_size = input_values.shape[0]
+ embeddings = self.patch_embeddings(input_values)
+
+ cls_tokens = self.cls_token.expand(batch_size, -1, -1)
+ distillation_tokens = self.distillation_token.expand(batch_size, -1, -1)
+ embeddings = torch.cat((cls_tokens, distillation_tokens, embeddings), dim=1)
+ embeddings = embeddings + self.position_embeddings
+ embeddings = self.dropout(embeddings)
+
+ return embeddings
+
+
+class ASTPatchEmbeddings(nn.Module):
+ """
+ This class turns `input_values` into the initial `hidden_states` (patch embeddings) of shape `(batch_size,
+ seq_length, hidden_size)` to be consumed by a Transformer.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ patch_size = config.patch_size
+ frequency_stride = config.frequency_stride
+ time_stride = config.time_stride
+
+ self.projection = nn.Conv2d(
+ 1, config.hidden_size, kernel_size=(patch_size, patch_size), stride=(frequency_stride, time_stride)
+ )
+
+ def forward(self, input_values: torch.Tensor) -> torch.Tensor:
+ input_values = input_values.unsqueeze(1)
+ input_values = input_values.transpose(2, 3)
+ embeddings = self.projection(input_values).flatten(2).transpose(1, 2)
+ return embeddings
+
+
+# Copied from transformers.models.vit.modeling_vit.eager_attention_forward
+def eager_attention_forward(
+ module: nn.Module,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ attention_mask: Optional[torch.Tensor],
+ scaling: float,
+ dropout: float = 0.0,
+ **kwargs,
+):
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attn_weights = torch.matmul(query, key.transpose(-1, -2)) * scaling
+
+ # Normalize the attention scores to probabilities.
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
+
+ # Mask heads if we want to
+ if attention_mask is not None:
+ attn_weights = attn_weights * attention_mask
+
+ attn_output = torch.matmul(attn_weights, value)
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ return attn_output, attn_weights
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfAttention with ViT->AST
+class ASTSelfAttention(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size {config.hidden_size} is not a multiple of the number of attention "
+ f"heads {config.num_attention_heads}."
+ )
+
+ self.config = config
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+ self.dropout_prob = config.attention_probs_dropout_prob
+ self.scaling = self.attention_head_size**-0.5
+ self.is_causal = False
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self, hidden_states, head_mask: Optional[torch.Tensor] = None, output_attentions: bool = False
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ query_layer = self.transpose_for_scores(self.query(hidden_states))
+
+ attention_interface: Callable = eager_attention_forward
+ if self.config._attn_implementation != "eager":
+ if self.config._attn_implementation == "sdpa" and output_attentions:
+ logger.warning_once(
+ "`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
+ 'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ else:
+ attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
+
+ context_layer, attention_probs = attention_interface(
+ self,
+ query_layer,
+ key_layer,
+ value_layer,
+ head_mask,
+ is_causal=self.is_causal,
+ scaling=self.scaling,
+ dropout=0.0 if not self.training else self.dropout_prob,
+ )
+
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.reshape(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfOutput with ViT->AST
+class ASTSelfOutput(nn.Module):
+ """
+ The residual connection is defined in ASTLayer instead of here (as is the case with other models), due to the
+ layernorm applied before each block.
+ """
+
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTAttention with ViT->AST
+class ASTAttention(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.attention = ASTSelfAttention(config)
+ self.output = ASTSelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads: Set[int]) -> None:
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.attention.query = prune_linear_layer(self.attention.query, index)
+ self.attention.key = prune_linear_layer(self.attention.key, index)
+ self.attention.value = prune_linear_layer(self.attention.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
+ self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_outputs = self.attention(hidden_states, head_mask, output_attentions)
+
+ attention_output = self.output(self_outputs[0], hidden_states)
+
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTIntermediate with ViT->AST
+class ASTIntermediate(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTOutput with ViT->AST
+class ASTOutput(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ hidden_states = hidden_states + input_tensor
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTLayer with ViT->AST,VIT->AST
+class ASTLayer(nn.Module):
+ """This corresponds to the Block class in the timm implementation."""
+
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = ASTAttention(config)
+ self.intermediate = ASTIntermediate(config)
+ self.output = ASTOutput(config)
+ self.layernorm_before = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.layernorm_after = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_attention_outputs = self.attention(
+ self.layernorm_before(hidden_states), # in AST, layernorm is applied before self-attention
+ head_mask,
+ output_attentions=output_attentions,
+ )
+ attention_output = self_attention_outputs[0]
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ # first residual connection
+ hidden_states = attention_output + hidden_states
+
+ # in AST, layernorm is also applied after self-attention
+ layer_output = self.layernorm_after(hidden_states)
+ layer_output = self.intermediate(layer_output)
+
+ # second residual connection is done here
+ layer_output = self.output(layer_output, hidden_states)
+
+ outputs = (layer_output,) + outputs
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTEncoder with ViT->AST
+class ASTEncoder(nn.Module):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([ASTLayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ) -> Union[tuple, BaseModelOutput]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ layer_module.__call__,
+ hidden_states,
+ layer_head_mask,
+ output_attentions,
+ )
+ else:
+ layer_outputs = layer_module(hidden_states, layer_head_mask, output_attentions)
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class ASTPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = ASTConfig
+ base_model_prefix = "audio_spectrogram_transformer"
+ main_input_name = "input_values"
+ supports_gradient_checkpointing = True
+ _supports_sdpa = True
+ _supports_flash_attn_2 = True
+
+ def _init_weights(self, module: Union[nn.Linear, nn.Conv2d, nn.LayerNorm]) -> None:
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d)):
+ # Upcast the input in `fp32` and cast it back to desired `dtype` to avoid
+ # `trunc_normal_cpu` not implemented in `half` issues
+ module.weight.data = nn.init.trunc_normal_(
+ module.weight.data.to(torch.float32), mean=0.0, std=self.config.initializer_range
+ ).to(module.weight.dtype)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+ elif isinstance(module, ASTEmbeddings):
+ module.cls_token.data.zero_()
+ module.position_embeddings.data.zero_()
+ module.distillation_token.data.zero_()
+
+
+AUDIO_SPECTROGRAM_TRANSFORMER_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`ASTConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+AUDIO_SPECTROGRAM_TRANSFORMER_INPUTS_DOCSTRING = r"""
+ Args:
+ input_values (`torch.FloatTensor` of shape `(batch_size, max_length, num_mel_bins)`):
+ Float values mel features extracted from the raw audio waveform. Raw audio waveform can be obtained by
+ loading a `.flac` or `.wav` audio file into an array of type `List[float]` or a `numpy.ndarray`, *e.g.* via
+ the soundfile library (`pip install soundfile`). To prepare the array into `input_features`, the
+ [`AutoFeatureExtractor`] should be used for extracting the mel features, padding and conversion into a
+ tensor of type `torch.FloatTensor`. See [`~ASTFeatureExtractor.__call__`]
+
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare AST Model transformer outputting raw hidden-states without any specific head on top.",
+ AUDIO_SPECTROGRAM_TRANSFORMER_START_DOCSTRING,
+)
+class ASTModel(ASTPreTrainedModel):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = ASTEmbeddings(config)
+ self.encoder = ASTEncoder(config)
+
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self) -> ASTPatchEmbeddings:
+ return self.embeddings.patch_embeddings
+
+ def _prune_heads(self, heads_to_prune: Dict[int, List[int]]) -> None:
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(AUDIO_SPECTROGRAM_TRANSFORMER_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutputWithPooling,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(
+ self,
+ input_values: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPooling]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if input_values is None:
+ raise ValueError("You have to specify input_values")
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ embedding_output = self.embeddings(input_values)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+ sequence_output = self.layernorm(sequence_output)
+
+ pooled_output = (sequence_output[:, 0] + sequence_output[:, 1]) / 2
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPooling(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class ASTMLPHead(nn.Module):
+ def __init__(self, config: ASTConfig):
+ super().__init__()
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dense = nn.Linear(config.hidden_size, config.num_labels) if config.num_labels > 0 else nn.Identity()
+
+ def forward(self, hidden_state):
+ hidden_state = self.layernorm(hidden_state)
+ hidden_state = self.dense(hidden_state)
+ return hidden_state
+
+
+@add_start_docstrings(
+ """
+ Audio Spectrogram Transformer model with an audio classification head on top (a linear layer on top of the pooled
+ output) e.g. for datasets like AudioSet, Speech Commands v2.
+ """,
+ AUDIO_SPECTROGRAM_TRANSFORMER_START_DOCSTRING,
+)
+class ASTForAudioClassification(ASTPreTrainedModel):
+ def __init__(self, config: ASTConfig) -> None:
+ super().__init__(config)
+
+ self.num_labels = config.num_labels
+ self.audio_spectrogram_transformer = ASTModel(config)
+
+ # Classifier head
+ self.classifier = ASTMLPHead(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(AUDIO_SPECTROGRAM_TRANSFORMER_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ checkpoint=_SEQ_CLASS_CHECKPOINT,
+ output_type=SequenceClassifierOutput,
+ config_class=_CONFIG_FOR_DOC,
+ modality="audio",
+ expected_output=_SEQ_CLASS_EXPECTED_OUTPUT,
+ expected_loss=_SEQ_CLASS_EXPECTED_LOSS,
+ )
+ def forward(
+ self,
+ input_values: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[tuple, SequenceClassifierOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the audio classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.audio_spectrogram_transformer(
+ input_values,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ pooled_output = outputs[1]
+ logits = self.classifier(pooled_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[2:]
+ return ((loss,) + output) if loss is not None else output
+
+ return SequenceClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+__all__ = ["ASTForAudioClassification", "ASTModel", "ASTPreTrainedModel"]
diff --git a/docs/transformers/src/transformers/models/auto/__init__.py b/docs/transformers/src/transformers/models/auto/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6828030287e9472748f3f7ecf2e5b7fb06625e87
--- /dev/null
+++ b/docs/transformers/src/transformers/models/auto/__init__.py
@@ -0,0 +1,34 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import _LazyModule
+from ...utils.import_utils import define_import_structure
+
+
+if TYPE_CHECKING:
+ from .auto_factory import *
+ from .configuration_auto import *
+ from .feature_extraction_auto import *
+ from .image_processing_auto import *
+ from .modeling_auto import *
+ from .modeling_flax_auto import *
+ from .modeling_tf_auto import *
+ from .processing_auto import *
+ from .tokenization_auto import *
+else:
+ import sys
+
+ _file = globals()["__file__"]
+ sys.modules[__name__] = _LazyModule(__name__, _file, define_import_structure(_file), module_spec=__spec__)
diff --git a/docs/transformers/src/transformers/models/auto/auto_factory.py b/docs/transformers/src/transformers/models/auto/auto_factory.py
new file mode 100644
index 0000000000000000000000000000000000000000..d458c1b6f266f35510a39030efc5237260a28940
--- /dev/null
+++ b/docs/transformers/src/transformers/models/auto/auto_factory.py
@@ -0,0 +1,849 @@
+# coding=utf-8
+# Copyright 2021 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Factory function to build auto-model classes."""
+
+import copy
+import importlib
+import json
+import warnings
+from collections import OrderedDict
+
+from ...configuration_utils import PretrainedConfig
+from ...dynamic_module_utils import get_class_from_dynamic_module, resolve_trust_remote_code
+from ...utils import (
+ CONFIG_NAME,
+ cached_file,
+ copy_func,
+ extract_commit_hash,
+ find_adapter_config_file,
+ is_peft_available,
+ is_torch_available,
+ logging,
+ requires_backends,
+)
+from .configuration_auto import AutoConfig, model_type_to_module_name, replace_list_option_in_docstrings
+
+
+if is_torch_available():
+ from ...generation import GenerationMixin
+
+
+logger = logging.get_logger(__name__)
+
+
+CLASS_DOCSTRING = """
+ This is a generic model class that will be instantiated as one of the model classes of the library when created
+ with the [`~BaseAutoModelClass.from_pretrained`] class method or the [`~BaseAutoModelClass.from_config`] class
+ method.
+
+ This class cannot be instantiated directly using `__init__()` (throws an error).
+"""
+
+FROM_CONFIG_DOCSTRING = """
+ Instantiates one of the model classes of the library from a configuration.
+
+ Note:
+ Loading a model from its configuration file does **not** load the model weights. It only affects the
+ model's configuration. Use [`~BaseAutoModelClass.from_pretrained`] to load the model weights.
+
+ Args:
+ config ([`PretrainedConfig`]):
+ The model class to instantiate is selected based on the configuration class:
+
+ List options
+ attn_implementation (`str`, *optional*):
+ The attention implementation to use in the model (if relevant). Can be any of `"eager"` (manual implementation of the attention), `"sdpa"` (using [`F.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html)), or `"flash_attention_2"` (using [Dao-AILab/flash-attention](https://github.com/Dao-AILab/flash-attention)). By default, if available, SDPA will be used for torch>=2.1.1. The default is otherwise the manual `"eager"` implementation.
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoConfig, BaseAutoModelClass
+
+ >>> # Download configuration from huggingface.co and cache.
+ >>> config = AutoConfig.from_pretrained("checkpoint_placeholder")
+ >>> model = BaseAutoModelClass.from_config(config)
+ ```
+"""
+
+FROM_PRETRAINED_TORCH_DOCSTRING = """
+ Instantiate one of the model classes of the library from a pretrained model.
+
+ The model class to instantiate is selected based on the `model_type` property of the config object (either
+ passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's missing, by
+ falling back to using pattern matching on `pretrained_model_name_or_path`:
+
+ List options
+
+ The model is set in evaluation mode by default using `model.eval()` (so for instance, dropout modules are
+ deactivated). To train the model, you should first set it back in training mode with `model.train()`
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ Can be either:
+
+ - A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
+ - A path to a *directory* containing model weights saved using
+ [`~PreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
+ - A path or url to a *tensorflow index checkpoint file* (e.g, `./tf_model/model.ckpt.index`). In
+ this case, `from_tf` should be set to `True` and a configuration object should be provided as
+ `config` argument. This loading path is slower than converting the TensorFlow checkpoint in a
+ PyTorch model using the provided conversion scripts and loading the PyTorch model afterwards.
+ model_args (additional positional arguments, *optional*):
+ Will be passed along to the underlying model `__init__()` method.
+ config ([`PretrainedConfig`], *optional*):
+ Configuration for the model to use instead of an automatically loaded configuration. Configuration can
+ be automatically loaded when:
+
+ - The model is a model provided by the library (loaded with the *model id* string of a pretrained
+ model).
+ - The model was saved using [`~PreTrainedModel.save_pretrained`] and is reloaded by supplying the
+ save directory.
+ - The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
+ configuration JSON file named *config.json* is found in the directory.
+ state_dict (*Dict[str, torch.Tensor]*, *optional*):
+ A state dictionary to use instead of a state dictionary loaded from saved weights file.
+
+ This option can be used if you want to create a model from a pretrained configuration but load your own
+ weights. In this case though, you should check if using [`~PreTrainedModel.save_pretrained`] and
+ [`~PreTrainedModel.from_pretrained`] is not a simpler option.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ from_tf (`bool`, *optional*, defaults to `False`):
+ Load the model weights from a TensorFlow checkpoint save file (see docstring of
+ `pretrained_model_name_or_path` argument).
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`):
+ Whether ot not to also return a dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (e.g., not try downloading the model).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ trust_remote_code (`bool`, *optional*, defaults to `False`):
+ Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
+ should only be set to `True` for repositories you trust and in which you have read the code, as it will
+ execute code present on the Hub on your local machine.
+ code_revision (`str`, *optional*, defaults to `"main"`):
+ The specific revision to use for the code on the Hub, if the code leaves in a different repository than
+ the rest of the model. It can be a branch name, a tag name, or a commit id, since we use a git-based
+ system for storing models and other artifacts on huggingface.co, so `revision` can be any identifier
+ allowed by git.
+ kwargs (additional keyword arguments, *optional*):
+ Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
+ `output_attentions=True`). Behaves differently depending on whether a `config` is provided or
+ automatically loaded:
+
+ - If a configuration is provided with `config`, `**kwargs` will be directly passed to the
+ underlying model's `__init__` method (we assume all relevant updates to the configuration have
+ already been done)
+ - If a configuration is not provided, `kwargs` will be first passed to the configuration class
+ initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
+ corresponds to a configuration attribute will be used to override said attribute with the
+ supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
+ will be passed to the underlying model's `__init__` function.
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoConfig, BaseAutoModelClass
+
+ >>> # Download model and configuration from huggingface.co and cache.
+ >>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder")
+
+ >>> # Update configuration during loading
+ >>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder", output_attentions=True)
+ >>> model.config.output_attentions
+ True
+
+ >>> # Loading from a TF checkpoint file instead of a PyTorch model (slower)
+ >>> config = AutoConfig.from_pretrained("./tf_model/shortcut_placeholder_tf_model_config.json")
+ >>> model = BaseAutoModelClass.from_pretrained(
+ ... "./tf_model/shortcut_placeholder_tf_checkpoint.ckpt.index", from_tf=True, config=config
+ ... )
+ ```
+"""
+
+FROM_PRETRAINED_TF_DOCSTRING = """
+ Instantiate one of the model classes of the library from a pretrained model.
+
+ The model class to instantiate is selected based on the `model_type` property of the config object (either
+ passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's missing, by
+ falling back to using pattern matching on `pretrained_model_name_or_path`:
+
+ List options
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ Can be either:
+
+ - A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
+ - A path to a *directory* containing model weights saved using
+ [`~PreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
+ - A path or url to a *PyTorch state_dict save file* (e.g, `./pt_model/pytorch_model.bin`). In this
+ case, `from_pt` should be set to `True` and a configuration object should be provided as `config`
+ argument. This loading path is slower than converting the PyTorch model in a TensorFlow model
+ using the provided conversion scripts and loading the TensorFlow model afterwards.
+ model_args (additional positional arguments, *optional*):
+ Will be passed along to the underlying model `__init__()` method.
+ config ([`PretrainedConfig`], *optional*):
+ Configuration for the model to use instead of an automatically loaded configuration. Configuration can
+ be automatically loaded when:
+
+ - The model is a model provided by the library (loaded with the *model id* string of a pretrained
+ model).
+ - The model was saved using [`~PreTrainedModel.save_pretrained`] and is reloaded by supplying the
+ save directory.
+ - The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
+ configuration JSON file named *config.json* is found in the directory.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ from_pt (`bool`, *optional*, defaults to `False`):
+ Load the model weights from a PyTorch checkpoint save file (see docstring of
+ `pretrained_model_name_or_path` argument).
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`):
+ Whether ot not to also return a dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (e.g., not try downloading the model).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ trust_remote_code (`bool`, *optional*, defaults to `False`):
+ Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
+ should only be set to `True` for repositories you trust and in which you have read the code, as it will
+ execute code present on the Hub on your local machine.
+ code_revision (`str`, *optional*, defaults to `"main"`):
+ The specific revision to use for the code on the Hub, if the code leaves in a different repository than
+ the rest of the model. It can be a branch name, a tag name, or a commit id, since we use a git-based
+ system for storing models and other artifacts on huggingface.co, so `revision` can be any identifier
+ allowed by git.
+ kwargs (additional keyword arguments, *optional*):
+ Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
+ `output_attentions=True`). Behaves differently depending on whether a `config` is provided or
+ automatically loaded:
+
+ - If a configuration is provided with `config`, `**kwargs` will be directly passed to the
+ underlying model's `__init__` method (we assume all relevant updates to the configuration have
+ already been done)
+ - If a configuration is not provided, `kwargs` will be first passed to the configuration class
+ initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
+ corresponds to a configuration attribute will be used to override said attribute with the
+ supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
+ will be passed to the underlying model's `__init__` function.
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoConfig, BaseAutoModelClass
+
+ >>> # Download model and configuration from huggingface.co and cache.
+ >>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder")
+
+ >>> # Update configuration during loading
+ >>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder", output_attentions=True)
+ >>> model.config.output_attentions
+ True
+
+ >>> # Loading from a PyTorch checkpoint file instead of a TensorFlow model (slower)
+ >>> config = AutoConfig.from_pretrained("./pt_model/shortcut_placeholder_pt_model_config.json")
+ >>> model = BaseAutoModelClass.from_pretrained(
+ ... "./pt_model/shortcut_placeholder_pytorch_model.bin", from_pt=True, config=config
+ ... )
+ ```
+"""
+
+FROM_PRETRAINED_FLAX_DOCSTRING = """
+ Instantiate one of the model classes of the library from a pretrained model.
+
+ The model class to instantiate is selected based on the `model_type` property of the config object (either
+ passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's missing, by
+ falling back to using pattern matching on `pretrained_model_name_or_path`:
+
+ List options
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ Can be either:
+
+ - A string, the *model id* of a pretrained model hosted inside a model repo on huggingface.co.
+ - A path to a *directory* containing model weights saved using
+ [`~PreTrainedModel.save_pretrained`], e.g., `./my_model_directory/`.
+ - A path or url to a *PyTorch state_dict save file* (e.g, `./pt_model/pytorch_model.bin`). In this
+ case, `from_pt` should be set to `True` and a configuration object should be provided as `config`
+ argument. This loading path is slower than converting the PyTorch model in a TensorFlow model
+ using the provided conversion scripts and loading the TensorFlow model afterwards.
+ model_args (additional positional arguments, *optional*):
+ Will be passed along to the underlying model `__init__()` method.
+ config ([`PretrainedConfig`], *optional*):
+ Configuration for the model to use instead of an automatically loaded configuration. Configuration can
+ be automatically loaded when:
+
+ - The model is a model provided by the library (loaded with the *model id* string of a pretrained
+ model).
+ - The model was saved using [`~PreTrainedModel.save_pretrained`] and is reloaded by supplying the
+ save directory.
+ - The model is loaded by supplying a local directory as `pretrained_model_name_or_path` and a
+ configuration JSON file named *config.json* is found in the directory.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ from_pt (`bool`, *optional*, defaults to `False`):
+ Load the model weights from a PyTorch checkpoint save file (see docstring of
+ `pretrained_model_name_or_path` argument).
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download of the model weights and configuration files, overriding the
+ cached versions if they exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ output_loading_info(`bool`, *optional*, defaults to `False`):
+ Whether ot not to also return a dictionary containing missing keys, unexpected keys and error messages.
+ local_files_only(`bool`, *optional*, defaults to `False`):
+ Whether or not to only look at local files (e.g., not try downloading the model).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ trust_remote_code (`bool`, *optional*, defaults to `False`):
+ Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
+ should only be set to `True` for repositories you trust and in which you have read the code, as it will
+ execute code present on the Hub on your local machine.
+ code_revision (`str`, *optional*, defaults to `"main"`):
+ The specific revision to use for the code on the Hub, if the code leaves in a different repository than
+ the rest of the model. It can be a branch name, a tag name, or a commit id, since we use a git-based
+ system for storing models and other artifacts on huggingface.co, so `revision` can be any identifier
+ allowed by git.
+ kwargs (additional keyword arguments, *optional*):
+ Can be used to update the configuration object (after it being loaded) and initiate the model (e.g.,
+ `output_attentions=True`). Behaves differently depending on whether a `config` is provided or
+ automatically loaded:
+
+ - If a configuration is provided with `config`, `**kwargs` will be directly passed to the
+ underlying model's `__init__` method (we assume all relevant updates to the configuration have
+ already been done)
+ - If a configuration is not provided, `kwargs` will be first passed to the configuration class
+ initialization function ([`~PretrainedConfig.from_pretrained`]). Each key of `kwargs` that
+ corresponds to a configuration attribute will be used to override said attribute with the
+ supplied `kwargs` value. Remaining keys that do not correspond to any configuration attribute
+ will be passed to the underlying model's `__init__` function.
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoConfig, BaseAutoModelClass
+
+ >>> # Download model and configuration from huggingface.co and cache.
+ >>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder")
+
+ >>> # Update configuration during loading
+ >>> model = BaseAutoModelClass.from_pretrained("checkpoint_placeholder", output_attentions=True)
+ >>> model.config.output_attentions
+ True
+
+ >>> # Loading from a PyTorch checkpoint file instead of a TensorFlow model (slower)
+ >>> config = AutoConfig.from_pretrained("./pt_model/shortcut_placeholder_pt_model_config.json")
+ >>> model = BaseAutoModelClass.from_pretrained(
+ ... "./pt_model/shortcut_placeholder_pytorch_model.bin", from_pt=True, config=config
+ ... )
+ ```
+"""
+
+
+def _get_model_class(config, model_mapping):
+ supported_models = model_mapping[type(config)]
+ if not isinstance(supported_models, (list, tuple)):
+ return supported_models
+
+ name_to_model = {model.__name__: model for model in supported_models}
+ architectures = getattr(config, "architectures", [])
+ for arch in architectures:
+ if arch in name_to_model:
+ return name_to_model[arch]
+ elif f"TF{arch}" in name_to_model:
+ return name_to_model[f"TF{arch}"]
+ elif f"Flax{arch}" in name_to_model:
+ return name_to_model[f"Flax{arch}"]
+
+ # If not architecture is set in the config or match the supported models, the first element of the tuple is the
+ # defaults.
+ return supported_models[0]
+
+
+class _BaseAutoModelClass:
+ # Base class for auto models.
+ _model_mapping = None
+
+ def __init__(self, *args, **kwargs):
+ raise EnvironmentError(
+ f"{self.__class__.__name__} is designed to be instantiated "
+ f"using the `{self.__class__.__name__}.from_pretrained(pretrained_model_name_or_path)` or "
+ f"`{self.__class__.__name__}.from_config(config)` methods."
+ )
+
+ @classmethod
+ def from_config(cls, config, **kwargs):
+ trust_remote_code = kwargs.pop("trust_remote_code", None)
+ has_remote_code = hasattr(config, "auto_map") and cls.__name__ in config.auto_map
+ has_local_code = type(config) in cls._model_mapping.keys()
+ trust_remote_code = resolve_trust_remote_code(
+ trust_remote_code, config._name_or_path, has_local_code, has_remote_code
+ )
+
+ if has_remote_code and trust_remote_code:
+ class_ref = config.auto_map[cls.__name__]
+ if "--" in class_ref:
+ repo_id, class_ref = class_ref.split("--")
+ else:
+ repo_id = config.name_or_path
+ model_class = get_class_from_dynamic_module(class_ref, repo_id, **kwargs)
+ cls.register(config.__class__, model_class, exist_ok=True)
+ _ = kwargs.pop("code_revision", None)
+ model_class = add_generation_mixin_to_remote_model(model_class)
+ return model_class._from_config(config, **kwargs)
+ elif type(config) in cls._model_mapping.keys():
+ model_class = _get_model_class(config, cls._model_mapping)
+ return model_class._from_config(config, **kwargs)
+
+ raise ValueError(
+ f"Unrecognized configuration class {config.__class__} for this kind of AutoModel: {cls.__name__}.\n"
+ f"Model type should be one of {', '.join(c.__name__ for c in cls._model_mapping.keys())}."
+ )
+
+ @classmethod
+ def _prepare_config_for_auto_class(cls, config: PretrainedConfig) -> PretrainedConfig:
+ """Additional autoclass-specific config post-loading manipulation. May be overridden in subclasses."""
+ return config
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
+ config = kwargs.pop("config", None)
+ trust_remote_code = kwargs.pop("trust_remote_code", None)
+ kwargs["_from_auto"] = True
+ hub_kwargs_names = [
+ "cache_dir",
+ "force_download",
+ "local_files_only",
+ "proxies",
+ "resume_download",
+ "revision",
+ "subfolder",
+ "use_auth_token",
+ "token",
+ ]
+ hub_kwargs = {name: kwargs.pop(name) for name in hub_kwargs_names if name in kwargs}
+ code_revision = kwargs.pop("code_revision", None)
+ commit_hash = kwargs.pop("_commit_hash", None)
+ adapter_kwargs = kwargs.pop("adapter_kwargs", None)
+
+ token = hub_kwargs.pop("token", None)
+ use_auth_token = hub_kwargs.pop("use_auth_token", None)
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if token is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ token = use_auth_token
+
+ if token is not None:
+ hub_kwargs["token"] = token
+
+ if commit_hash is None:
+ if not isinstance(config, PretrainedConfig):
+ # We make a call to the config file first (which may be absent) to get the commit hash as soon as possible
+ resolved_config_file = cached_file(
+ pretrained_model_name_or_path,
+ CONFIG_NAME,
+ _raise_exceptions_for_gated_repo=False,
+ _raise_exceptions_for_missing_entries=False,
+ _raise_exceptions_for_connection_errors=False,
+ **hub_kwargs,
+ )
+ commit_hash = extract_commit_hash(resolved_config_file, commit_hash)
+ else:
+ commit_hash = getattr(config, "_commit_hash", None)
+
+ if is_peft_available():
+ if adapter_kwargs is None:
+ adapter_kwargs = {}
+ if token is not None:
+ adapter_kwargs["token"] = token
+
+ maybe_adapter_path = find_adapter_config_file(
+ pretrained_model_name_or_path, _commit_hash=commit_hash, **adapter_kwargs
+ )
+
+ if maybe_adapter_path is not None:
+ with open(maybe_adapter_path, "r", encoding="utf-8") as f:
+ adapter_config = json.load(f)
+
+ adapter_kwargs["_adapter_model_path"] = pretrained_model_name_or_path
+ pretrained_model_name_or_path = adapter_config["base_model_name_or_path"]
+
+ if not isinstance(config, PretrainedConfig):
+ kwargs_orig = copy.deepcopy(kwargs)
+ # ensure not to pollute the config object with torch_dtype="auto" - since it's
+ # meaningless in the context of the config object - torch.dtype values are acceptable
+ if kwargs.get("torch_dtype", None) == "auto":
+ _ = kwargs.pop("torch_dtype")
+ # to not overwrite the quantization_config if config has a quantization_config
+ if kwargs.get("quantization_config", None) is not None:
+ _ = kwargs.pop("quantization_config")
+
+ config, kwargs = AutoConfig.from_pretrained(
+ pretrained_model_name_or_path,
+ return_unused_kwargs=True,
+ trust_remote_code=trust_remote_code,
+ code_revision=code_revision,
+ _commit_hash=commit_hash,
+ **hub_kwargs,
+ **kwargs,
+ )
+
+ # if torch_dtype=auto was passed here, ensure to pass it on
+ if kwargs_orig.get("torch_dtype", None) == "auto":
+ kwargs["torch_dtype"] = "auto"
+ if kwargs_orig.get("quantization_config", None) is not None:
+ kwargs["quantization_config"] = kwargs_orig["quantization_config"]
+
+ has_remote_code = hasattr(config, "auto_map") and cls.__name__ in config.auto_map
+ has_local_code = type(config) in cls._model_mapping.keys()
+ trust_remote_code = resolve_trust_remote_code(
+ trust_remote_code, pretrained_model_name_or_path, has_local_code, has_remote_code
+ )
+
+ # Set the adapter kwargs
+ kwargs["adapter_kwargs"] = adapter_kwargs
+
+ if has_remote_code and trust_remote_code:
+ class_ref = config.auto_map[cls.__name__]
+ model_class = get_class_from_dynamic_module(
+ class_ref, pretrained_model_name_or_path, code_revision=code_revision, **hub_kwargs, **kwargs
+ )
+ _ = hub_kwargs.pop("code_revision", None)
+ cls.register(config.__class__, model_class, exist_ok=True)
+ model_class = add_generation_mixin_to_remote_model(model_class)
+ return model_class.from_pretrained(
+ pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs
+ )
+ elif type(config) in cls._model_mapping.keys():
+ model_class = _get_model_class(config, cls._model_mapping)
+ if model_class.config_class == config.sub_configs.get("text_config", None):
+ config = config.get_text_config()
+ return model_class.from_pretrained(
+ pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs
+ )
+ raise ValueError(
+ f"Unrecognized configuration class {config.__class__} for this kind of AutoModel: {cls.__name__}.\n"
+ f"Model type should be one of {', '.join(c.__name__ for c in cls._model_mapping.keys())}."
+ )
+
+ @classmethod
+ def register(cls, config_class, model_class, exist_ok=False):
+ """
+ Register a new model for this class.
+
+ Args:
+ config_class ([`PretrainedConfig`]):
+ The configuration corresponding to the model to register.
+ model_class ([`PreTrainedModel`]):
+ The model to register.
+ """
+ if hasattr(model_class, "config_class") and model_class.config_class.__name__ != config_class.__name__:
+ raise ValueError(
+ "The model class you are passing has a `config_class` attribute that is not consistent with the "
+ f"config class you passed (model has {model_class.config_class} and you passed {config_class}. Fix "
+ "one of those so they match!"
+ )
+ cls._model_mapping.register(config_class, model_class, exist_ok=exist_ok)
+
+
+class _BaseAutoBackboneClass(_BaseAutoModelClass):
+ # Base class for auto backbone models.
+ _model_mapping = None
+
+ @classmethod
+ def _load_timm_backbone_from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
+ requires_backends(cls, ["vision", "timm"])
+ from ...models.timm_backbone import TimmBackboneConfig
+
+ config = kwargs.pop("config", TimmBackboneConfig())
+
+ if kwargs.get("out_features", None) is not None:
+ raise ValueError("Cannot specify `out_features` for timm backbones")
+
+ if kwargs.get("output_loading_info", False):
+ raise ValueError("Cannot specify `output_loading_info=True` when loading from timm")
+
+ num_channels = kwargs.pop("num_channels", config.num_channels)
+ features_only = kwargs.pop("features_only", config.features_only)
+ use_pretrained_backbone = kwargs.pop("use_pretrained_backbone", config.use_pretrained_backbone)
+ out_indices = kwargs.pop("out_indices", config.out_indices)
+ config = TimmBackboneConfig(
+ backbone=pretrained_model_name_or_path,
+ num_channels=num_channels,
+ features_only=features_only,
+ use_pretrained_backbone=use_pretrained_backbone,
+ out_indices=out_indices,
+ )
+ return super().from_config(config, **kwargs)
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
+ use_timm_backbone = kwargs.pop("use_timm_backbone", False)
+ if use_timm_backbone:
+ return cls._load_timm_backbone_from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
+
+ return super().from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
+
+
+def insert_head_doc(docstring, head_doc=""):
+ if len(head_doc) > 0:
+ return docstring.replace(
+ "one of the model classes of the library ",
+ f"one of the model classes of the library (with a {head_doc} head) ",
+ )
+ return docstring.replace(
+ "one of the model classes of the library ", "one of the base model classes of the library "
+ )
+
+
+def auto_class_update(cls, checkpoint_for_example="google-bert/bert-base-cased", head_doc=""):
+ # Create a new class with the right name from the base class
+ model_mapping = cls._model_mapping
+ name = cls.__name__
+ class_docstring = insert_head_doc(CLASS_DOCSTRING, head_doc=head_doc)
+ cls.__doc__ = class_docstring.replace("BaseAutoModelClass", name)
+
+ # Now we need to copy and re-register `from_config` and `from_pretrained` as class methods otherwise we can't
+ # have a specific docstrings for them.
+ from_config = copy_func(_BaseAutoModelClass.from_config)
+ from_config_docstring = insert_head_doc(FROM_CONFIG_DOCSTRING, head_doc=head_doc)
+ from_config_docstring = from_config_docstring.replace("BaseAutoModelClass", name)
+ from_config_docstring = from_config_docstring.replace("checkpoint_placeholder", checkpoint_for_example)
+ from_config.__doc__ = from_config_docstring
+ from_config = replace_list_option_in_docstrings(model_mapping._model_mapping, use_model_types=False)(from_config)
+ cls.from_config = classmethod(from_config)
+
+ if name.startswith("TF"):
+ from_pretrained_docstring = FROM_PRETRAINED_TF_DOCSTRING
+ elif name.startswith("Flax"):
+ from_pretrained_docstring = FROM_PRETRAINED_FLAX_DOCSTRING
+ else:
+ from_pretrained_docstring = FROM_PRETRAINED_TORCH_DOCSTRING
+ from_pretrained = copy_func(_BaseAutoModelClass.from_pretrained)
+ from_pretrained_docstring = insert_head_doc(from_pretrained_docstring, head_doc=head_doc)
+ from_pretrained_docstring = from_pretrained_docstring.replace("BaseAutoModelClass", name)
+ from_pretrained_docstring = from_pretrained_docstring.replace("checkpoint_placeholder", checkpoint_for_example)
+ shortcut = checkpoint_for_example.split("/")[-1].split("-")[0]
+ from_pretrained_docstring = from_pretrained_docstring.replace("shortcut_placeholder", shortcut)
+ from_pretrained.__doc__ = from_pretrained_docstring
+ from_pretrained = replace_list_option_in_docstrings(model_mapping._model_mapping)(from_pretrained)
+ cls.from_pretrained = classmethod(from_pretrained)
+ return cls
+
+
+def get_values(model_mapping):
+ result = []
+ for model in model_mapping.values():
+ if isinstance(model, (list, tuple)):
+ result += list(model)
+ else:
+ result.append(model)
+
+ return result
+
+
+def getattribute_from_module(module, attr):
+ if attr is None:
+ return None
+ if isinstance(attr, tuple):
+ return tuple(getattribute_from_module(module, a) for a in attr)
+ if hasattr(module, attr):
+ return getattr(module, attr)
+ # Some of the mappings have entries model_type -> object of another model type. In that case we try to grab the
+ # object at the top level.
+ transformers_module = importlib.import_module("transformers")
+
+ if module != transformers_module:
+ try:
+ return getattribute_from_module(transformers_module, attr)
+ except ValueError:
+ raise ValueError(f"Could not find {attr} neither in {module} nor in {transformers_module}!")
+ else:
+ raise ValueError(f"Could not find {attr} in {transformers_module}!")
+
+
+def add_generation_mixin_to_remote_model(model_class):
+ """
+ Adds `GenerationMixin` to the inheritance of `model_class`, if `model_class` is a PyTorch model.
+
+ This function is used for backwards compatibility purposes: in v4.45, we've started a deprecation cycle to make
+ `PreTrainedModel` stop inheriting from `GenerationMixin`. Without this function, older models dynamically loaded
+ from the Hub may not have the `generate` method after we remove the inheritance.
+ """
+ # 1. If it is not a PT model (i.e. doesn't inherit Module), do nothing
+ if "torch.nn.modules.module.Module" not in str(model_class.__mro__):
+ return model_class
+
+ # 2. If it already **directly** inherits from GenerationMixin, do nothing
+ if "GenerationMixin" in str(model_class.__bases__):
+ return model_class
+
+ # 3. Prior to v4.45, we could detect whether a model was `generate`-compatible if it had its own `generate` and/or
+ # `prepare_inputs_for_generation` method.
+ has_custom_generate = hasattr(model_class, "generate") and "GenerationMixin" not in str(
+ getattr(model_class, "generate")
+ )
+ has_custom_prepare_inputs = hasattr(model_class, "prepare_inputs_for_generation") and "GenerationMixin" not in str(
+ getattr(model_class, "prepare_inputs_for_generation")
+ )
+ if has_custom_generate or has_custom_prepare_inputs:
+ model_class_with_generation_mixin = type(
+ model_class.__name__, (model_class, GenerationMixin), {**model_class.__dict__}
+ )
+ return model_class_with_generation_mixin
+ return model_class
+
+
+class _LazyAutoMapping(OrderedDict):
+ """
+ " A mapping config to object (model or tokenizer for instance) that will load keys and values when it is accessed.
+
+ Args:
+ - config_mapping: The map model type to config class
+ - model_mapping: The map model type to model (or tokenizer) class
+ """
+
+ def __init__(self, config_mapping, model_mapping):
+ self._config_mapping = config_mapping
+ self._reverse_config_mapping = {v: k for k, v in config_mapping.items()}
+ self._model_mapping = model_mapping
+ self._model_mapping._model_mapping = self
+ self._extra_content = {}
+ self._modules = {}
+
+ def __len__(self):
+ common_keys = set(self._config_mapping.keys()).intersection(self._model_mapping.keys())
+ return len(common_keys) + len(self._extra_content)
+
+ def __getitem__(self, key):
+ if key in self._extra_content:
+ return self._extra_content[key]
+ model_type = self._reverse_config_mapping[key.__name__]
+ if model_type in self._model_mapping:
+ model_name = self._model_mapping[model_type]
+ return self._load_attr_from_module(model_type, model_name)
+
+ # Maybe there was several model types associated with this config.
+ model_types = [k for k, v in self._config_mapping.items() if v == key.__name__]
+ for mtype in model_types:
+ if mtype in self._model_mapping:
+ model_name = self._model_mapping[mtype]
+ return self._load_attr_from_module(mtype, model_name)
+ raise KeyError(key)
+
+ def _load_attr_from_module(self, model_type, attr):
+ module_name = model_type_to_module_name(model_type)
+ if module_name not in self._modules:
+ self._modules[module_name] = importlib.import_module(f".{module_name}", "transformers.models")
+ return getattribute_from_module(self._modules[module_name], attr)
+
+ def keys(self):
+ mapping_keys = [
+ self._load_attr_from_module(key, name)
+ for key, name in self._config_mapping.items()
+ if key in self._model_mapping.keys()
+ ]
+ return mapping_keys + list(self._extra_content.keys())
+
+ def get(self, key, default):
+ try:
+ return self.__getitem__(key)
+ except KeyError:
+ return default
+
+ def __bool__(self):
+ return bool(self.keys())
+
+ def values(self):
+ mapping_values = [
+ self._load_attr_from_module(key, name)
+ for key, name in self._model_mapping.items()
+ if key in self._config_mapping.keys()
+ ]
+ return mapping_values + list(self._extra_content.values())
+
+ def items(self):
+ mapping_items = [
+ (
+ self._load_attr_from_module(key, self._config_mapping[key]),
+ self._load_attr_from_module(key, self._model_mapping[key]),
+ )
+ for key in self._model_mapping.keys()
+ if key in self._config_mapping.keys()
+ ]
+ return mapping_items + list(self._extra_content.items())
+
+ def __iter__(self):
+ return iter(self.keys())
+
+ def __contains__(self, item):
+ if item in self._extra_content:
+ return True
+ if not hasattr(item, "__name__") or item.__name__ not in self._reverse_config_mapping:
+ return False
+ model_type = self._reverse_config_mapping[item.__name__]
+ return model_type in self._model_mapping
+
+ def register(self, key, value, exist_ok=False):
+ """
+ Register a new model in this mapping.
+ """
+ if hasattr(key, "__name__") and key.__name__ in self._reverse_config_mapping:
+ model_type = self._reverse_config_mapping[key.__name__]
+ if model_type in self._model_mapping.keys() and not exist_ok:
+ raise ValueError(f"'{key}' is already used by a Transformers model.")
+
+ self._extra_content[key] = value
+
+
+__all__ = ["get_values"]
diff --git a/docs/transformers/src/transformers/models/auto/configuration_auto.py b/docs/transformers/src/transformers/models/auto/configuration_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..7d13bc788d466caa36c0f46338f4159783715618
--- /dev/null
+++ b/docs/transformers/src/transformers/models/auto/configuration_auto.py
@@ -0,0 +1,1199 @@
+# coding=utf-8
+# Copyright 2018 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Auto Config class."""
+
+import importlib
+import os
+import re
+import warnings
+from collections import OrderedDict
+from typing import List, Union
+
+from ...configuration_utils import PretrainedConfig
+from ...dynamic_module_utils import get_class_from_dynamic_module, resolve_trust_remote_code
+from ...utils import CONFIG_NAME, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+CONFIG_MAPPING_NAMES = OrderedDict(
+ [
+ # Add configs here
+ ("albert", "AlbertConfig"),
+ ("align", "AlignConfig"),
+ ("altclip", "AltCLIPConfig"),
+ ("aria", "AriaConfig"),
+ ("aria_text", "AriaTextConfig"),
+ ("audio-spectrogram-transformer", "ASTConfig"),
+ ("autoformer", "AutoformerConfig"),
+ ("aya_vision", "AyaVisionConfig"),
+ ("bamba", "BambaConfig"),
+ ("bark", "BarkConfig"),
+ ("bart", "BartConfig"),
+ ("beit", "BeitConfig"),
+ ("bert", "BertConfig"),
+ ("bert-generation", "BertGenerationConfig"),
+ ("big_bird", "BigBirdConfig"),
+ ("bigbird_pegasus", "BigBirdPegasusConfig"),
+ ("biogpt", "BioGptConfig"),
+ ("bit", "BitConfig"),
+ ("blenderbot", "BlenderbotConfig"),
+ ("blenderbot-small", "BlenderbotSmallConfig"),
+ ("blip", "BlipConfig"),
+ ("blip-2", "Blip2Config"),
+ ("blip_2_qformer", "Blip2QFormerConfig"),
+ ("bloom", "BloomConfig"),
+ ("bridgetower", "BridgeTowerConfig"),
+ ("bros", "BrosConfig"),
+ ("camembert", "CamembertConfig"),
+ ("canine", "CanineConfig"),
+ ("chameleon", "ChameleonConfig"),
+ ("chinese_clip", "ChineseCLIPConfig"),
+ ("chinese_clip_vision_model", "ChineseCLIPVisionConfig"),
+ ("clap", "ClapConfig"),
+ ("clip", "CLIPConfig"),
+ ("clip_text_model", "CLIPTextConfig"),
+ ("clip_vision_model", "CLIPVisionConfig"),
+ ("clipseg", "CLIPSegConfig"),
+ ("clvp", "ClvpConfig"),
+ ("code_llama", "LlamaConfig"),
+ ("codegen", "CodeGenConfig"),
+ ("cohere", "CohereConfig"),
+ ("cohere2", "Cohere2Config"),
+ ("colpali", "ColPaliConfig"),
+ ("conditional_detr", "ConditionalDetrConfig"),
+ ("convbert", "ConvBertConfig"),
+ ("convnext", "ConvNextConfig"),
+ ("convnextv2", "ConvNextV2Config"),
+ ("cpmant", "CpmAntConfig"),
+ ("ctrl", "CTRLConfig"),
+ ("cvt", "CvtConfig"),
+ ("dab-detr", "DabDetrConfig"),
+ ("dac", "DacConfig"),
+ ("data2vec-audio", "Data2VecAudioConfig"),
+ ("data2vec-text", "Data2VecTextConfig"),
+ ("data2vec-vision", "Data2VecVisionConfig"),
+ ("dbrx", "DbrxConfig"),
+ ("deberta", "DebertaConfig"),
+ ("deberta-v2", "DebertaV2Config"),
+ ("decision_transformer", "DecisionTransformerConfig"),
+ ("deepseek_v3", "DeepseekV3Config"),
+ ("deformable_detr", "DeformableDetrConfig"),
+ ("deit", "DeiTConfig"),
+ ("depth_anything", "DepthAnythingConfig"),
+ ("depth_pro", "DepthProConfig"),
+ ("deta", "DetaConfig"),
+ ("detr", "DetrConfig"),
+ ("diffllama", "DiffLlamaConfig"),
+ ("dinat", "DinatConfig"),
+ ("dinov2", "Dinov2Config"),
+ ("dinov2_with_registers", "Dinov2WithRegistersConfig"),
+ ("distilbert", "DistilBertConfig"),
+ ("donut-swin", "DonutSwinConfig"),
+ ("dpr", "DPRConfig"),
+ ("dpt", "DPTConfig"),
+ ("efficientformer", "EfficientFormerConfig"),
+ ("efficientnet", "EfficientNetConfig"),
+ ("electra", "ElectraConfig"),
+ ("emu3", "Emu3Config"),
+ ("encodec", "EncodecConfig"),
+ ("encoder-decoder", "EncoderDecoderConfig"),
+ ("ernie", "ErnieConfig"),
+ ("ernie_m", "ErnieMConfig"),
+ ("esm", "EsmConfig"),
+ ("falcon", "FalconConfig"),
+ ("falcon_mamba", "FalconMambaConfig"),
+ ("fastspeech2_conformer", "FastSpeech2ConformerConfig"),
+ ("flaubert", "FlaubertConfig"),
+ ("flava", "FlavaConfig"),
+ ("fnet", "FNetConfig"),
+ ("focalnet", "FocalNetConfig"),
+ ("fsmt", "FSMTConfig"),
+ ("funnel", "FunnelConfig"),
+ ("fuyu", "FuyuConfig"),
+ ("gemma", "GemmaConfig"),
+ ("gemma2", "Gemma2Config"),
+ ("gemma3", "Gemma3Config"),
+ ("gemma3_text", "Gemma3TextConfig"),
+ ("git", "GitConfig"),
+ ("glm", "GlmConfig"),
+ ("glm4", "Glm4Config"),
+ ("glpn", "GLPNConfig"),
+ ("got_ocr2", "GotOcr2Config"),
+ ("gpt-sw3", "GPT2Config"),
+ ("gpt2", "GPT2Config"),
+ ("gpt_bigcode", "GPTBigCodeConfig"),
+ ("gpt_neo", "GPTNeoConfig"),
+ ("gpt_neox", "GPTNeoXConfig"),
+ ("gpt_neox_japanese", "GPTNeoXJapaneseConfig"),
+ ("gptj", "GPTJConfig"),
+ ("gptsan-japanese", "GPTSanJapaneseConfig"),
+ ("granite", "GraniteConfig"),
+ ("granite_speech", "GraniteSpeechConfig"),
+ ("granitemoe", "GraniteMoeConfig"),
+ ("granitemoeshared", "GraniteMoeSharedConfig"),
+ ("granitevision", "LlavaNextConfig"),
+ ("graphormer", "GraphormerConfig"),
+ ("grounding-dino", "GroundingDinoConfig"),
+ ("groupvit", "GroupViTConfig"),
+ ("helium", "HeliumConfig"),
+ ("hiera", "HieraConfig"),
+ ("hubert", "HubertConfig"),
+ ("ibert", "IBertConfig"),
+ ("idefics", "IdeficsConfig"),
+ ("idefics2", "Idefics2Config"),
+ ("idefics3", "Idefics3Config"),
+ ("idefics3_vision", "Idefics3VisionConfig"),
+ ("ijepa", "IJepaConfig"),
+ ("imagegpt", "ImageGPTConfig"),
+ ("informer", "InformerConfig"),
+ ("instructblip", "InstructBlipConfig"),
+ ("instructblipvideo", "InstructBlipVideoConfig"),
+ ("internvl", "InternVLConfig"),
+ ("internvl_vision", "InternVLVisionConfig"),
+ ("jamba", "JambaConfig"),
+ ("janus", "JanusConfig"),
+ ("jetmoe", "JetMoeConfig"),
+ ("jukebox", "JukeboxConfig"),
+ ("kosmos-2", "Kosmos2Config"),
+ ("layoutlm", "LayoutLMConfig"),
+ ("layoutlmv2", "LayoutLMv2Config"),
+ ("layoutlmv3", "LayoutLMv3Config"),
+ ("led", "LEDConfig"),
+ ("levit", "LevitConfig"),
+ ("lilt", "LiltConfig"),
+ ("llama", "LlamaConfig"),
+ ("llama4", "Llama4Config"),
+ ("llama4_text", "Llama4TextConfig"),
+ ("llava", "LlavaConfig"),
+ ("llava_next", "LlavaNextConfig"),
+ ("llava_next_video", "LlavaNextVideoConfig"),
+ ("llava_onevision", "LlavaOnevisionConfig"),
+ ("longformer", "LongformerConfig"),
+ ("longt5", "LongT5Config"),
+ ("luke", "LukeConfig"),
+ ("lxmert", "LxmertConfig"),
+ ("m2m_100", "M2M100Config"),
+ ("mamba", "MambaConfig"),
+ ("mamba2", "Mamba2Config"),
+ ("marian", "MarianConfig"),
+ ("markuplm", "MarkupLMConfig"),
+ ("mask2former", "Mask2FormerConfig"),
+ ("maskformer", "MaskFormerConfig"),
+ ("maskformer-swin", "MaskFormerSwinConfig"),
+ ("mbart", "MBartConfig"),
+ ("mctct", "MCTCTConfig"),
+ ("mega", "MegaConfig"),
+ ("megatron-bert", "MegatronBertConfig"),
+ ("mgp-str", "MgpstrConfig"),
+ ("mimi", "MimiConfig"),
+ ("mistral", "MistralConfig"),
+ ("mistral3", "Mistral3Config"),
+ ("mixtral", "MixtralConfig"),
+ ("mlcd", "MLCDVisionConfig"),
+ ("mllama", "MllamaConfig"),
+ ("mobilebert", "MobileBertConfig"),
+ ("mobilenet_v1", "MobileNetV1Config"),
+ ("mobilenet_v2", "MobileNetV2Config"),
+ ("mobilevit", "MobileViTConfig"),
+ ("mobilevitv2", "MobileViTV2Config"),
+ ("modernbert", "ModernBertConfig"),
+ ("moonshine", "MoonshineConfig"),
+ ("moshi", "MoshiConfig"),
+ ("mpnet", "MPNetConfig"),
+ ("mpt", "MptConfig"),
+ ("mra", "MraConfig"),
+ ("mt5", "MT5Config"),
+ ("musicgen", "MusicgenConfig"),
+ ("musicgen_melody", "MusicgenMelodyConfig"),
+ ("mvp", "MvpConfig"),
+ ("nat", "NatConfig"),
+ ("nemotron", "NemotronConfig"),
+ ("nezha", "NezhaConfig"),
+ ("nllb-moe", "NllbMoeConfig"),
+ ("nougat", "VisionEncoderDecoderConfig"),
+ ("nystromformer", "NystromformerConfig"),
+ ("olmo", "OlmoConfig"),
+ ("olmo2", "Olmo2Config"),
+ ("olmoe", "OlmoeConfig"),
+ ("omdet-turbo", "OmDetTurboConfig"),
+ ("oneformer", "OneFormerConfig"),
+ ("open-llama", "OpenLlamaConfig"),
+ ("openai-gpt", "OpenAIGPTConfig"),
+ ("opt", "OPTConfig"),
+ ("owlv2", "Owlv2Config"),
+ ("owlvit", "OwlViTConfig"),
+ ("paligemma", "PaliGemmaConfig"),
+ ("patchtsmixer", "PatchTSMixerConfig"),
+ ("patchtst", "PatchTSTConfig"),
+ ("pegasus", "PegasusConfig"),
+ ("pegasus_x", "PegasusXConfig"),
+ ("perceiver", "PerceiverConfig"),
+ ("persimmon", "PersimmonConfig"),
+ ("phi", "PhiConfig"),
+ ("phi3", "Phi3Config"),
+ ("phi4_multimodal", "Phi4MultimodalConfig"),
+ ("phimoe", "PhimoeConfig"),
+ ("pix2struct", "Pix2StructConfig"),
+ ("pixtral", "PixtralVisionConfig"),
+ ("plbart", "PLBartConfig"),
+ ("poolformer", "PoolFormerConfig"),
+ ("pop2piano", "Pop2PianoConfig"),
+ ("prompt_depth_anything", "PromptDepthAnythingConfig"),
+ ("prophetnet", "ProphetNetConfig"),
+ ("pvt", "PvtConfig"),
+ ("pvt_v2", "PvtV2Config"),
+ ("qdqbert", "QDQBertConfig"),
+ ("qwen2", "Qwen2Config"),
+ ("qwen2_5_omni", "Qwen2_5OmniConfig"),
+ ("qwen2_5_vl", "Qwen2_5_VLConfig"),
+ ("qwen2_5_vl_text", "Qwen2_5_VLTextConfig"),
+ ("qwen2_audio", "Qwen2AudioConfig"),
+ ("qwen2_audio_encoder", "Qwen2AudioEncoderConfig"),
+ ("qwen2_moe", "Qwen2MoeConfig"),
+ ("qwen2_vl", "Qwen2VLConfig"),
+ ("qwen2_vl_text", "Qwen2VLTextConfig"),
+ ("qwen3", "Qwen3Config"),
+ ("qwen3_moe", "Qwen3MoeConfig"),
+ ("rag", "RagConfig"),
+ ("realm", "RealmConfig"),
+ ("recurrent_gemma", "RecurrentGemmaConfig"),
+ ("reformer", "ReformerConfig"),
+ ("regnet", "RegNetConfig"),
+ ("rembert", "RemBertConfig"),
+ ("resnet", "ResNetConfig"),
+ ("retribert", "RetriBertConfig"),
+ ("roberta", "RobertaConfig"),
+ ("roberta-prelayernorm", "RobertaPreLayerNormConfig"),
+ ("roc_bert", "RoCBertConfig"),
+ ("roformer", "RoFormerConfig"),
+ ("rt_detr", "RTDetrConfig"),
+ ("rt_detr_resnet", "RTDetrResNetConfig"),
+ ("rt_detr_v2", "RTDetrV2Config"),
+ ("rwkv", "RwkvConfig"),
+ ("sam", "SamConfig"),
+ ("sam_vision_model", "SamVisionConfig"),
+ ("seamless_m4t", "SeamlessM4TConfig"),
+ ("seamless_m4t_v2", "SeamlessM4Tv2Config"),
+ ("segformer", "SegformerConfig"),
+ ("seggpt", "SegGptConfig"),
+ ("sew", "SEWConfig"),
+ ("sew-d", "SEWDConfig"),
+ ("shieldgemma2", "ShieldGemma2Config"),
+ ("siglip", "SiglipConfig"),
+ ("siglip2", "Siglip2Config"),
+ ("siglip_vision_model", "SiglipVisionConfig"),
+ ("smolvlm", "SmolVLMConfig"),
+ ("smolvlm_vision", "SmolVLMVisionConfig"),
+ ("speech-encoder-decoder", "SpeechEncoderDecoderConfig"),
+ ("speech_to_text", "Speech2TextConfig"),
+ ("speech_to_text_2", "Speech2Text2Config"),
+ ("speecht5", "SpeechT5Config"),
+ ("splinter", "SplinterConfig"),
+ ("squeezebert", "SqueezeBertConfig"),
+ ("stablelm", "StableLmConfig"),
+ ("starcoder2", "Starcoder2Config"),
+ ("superglue", "SuperGlueConfig"),
+ ("superpoint", "SuperPointConfig"),
+ ("swiftformer", "SwiftFormerConfig"),
+ ("swin", "SwinConfig"),
+ ("swin2sr", "Swin2SRConfig"),
+ ("swinv2", "Swinv2Config"),
+ ("switch_transformers", "SwitchTransformersConfig"),
+ ("t5", "T5Config"),
+ ("table-transformer", "TableTransformerConfig"),
+ ("tapas", "TapasConfig"),
+ ("textnet", "TextNetConfig"),
+ ("time_series_transformer", "TimeSeriesTransformerConfig"),
+ ("timesfm", "TimesFmConfig"),
+ ("timesformer", "TimesformerConfig"),
+ ("timm_backbone", "TimmBackboneConfig"),
+ ("timm_wrapper", "TimmWrapperConfig"),
+ ("trajectory_transformer", "TrajectoryTransformerConfig"),
+ ("transfo-xl", "TransfoXLConfig"),
+ ("trocr", "TrOCRConfig"),
+ ("tvlt", "TvltConfig"),
+ ("tvp", "TvpConfig"),
+ ("udop", "UdopConfig"),
+ ("umt5", "UMT5Config"),
+ ("unispeech", "UniSpeechConfig"),
+ ("unispeech-sat", "UniSpeechSatConfig"),
+ ("univnet", "UnivNetConfig"),
+ ("upernet", "UperNetConfig"),
+ ("van", "VanConfig"),
+ ("video_llava", "VideoLlavaConfig"),
+ ("videomae", "VideoMAEConfig"),
+ ("vilt", "ViltConfig"),
+ ("vipllava", "VipLlavaConfig"),
+ ("vision-encoder-decoder", "VisionEncoderDecoderConfig"),
+ ("vision-text-dual-encoder", "VisionTextDualEncoderConfig"),
+ ("visual_bert", "VisualBertConfig"),
+ ("vit", "ViTConfig"),
+ ("vit_hybrid", "ViTHybridConfig"),
+ ("vit_mae", "ViTMAEConfig"),
+ ("vit_msn", "ViTMSNConfig"),
+ ("vitdet", "VitDetConfig"),
+ ("vitmatte", "VitMatteConfig"),
+ ("vitpose", "VitPoseConfig"),
+ ("vitpose_backbone", "VitPoseBackboneConfig"),
+ ("vits", "VitsConfig"),
+ ("vivit", "VivitConfig"),
+ ("wav2vec2", "Wav2Vec2Config"),
+ ("wav2vec2-bert", "Wav2Vec2BertConfig"),
+ ("wav2vec2-conformer", "Wav2Vec2ConformerConfig"),
+ ("wavlm", "WavLMConfig"),
+ ("whisper", "WhisperConfig"),
+ ("xclip", "XCLIPConfig"),
+ ("xglm", "XGLMConfig"),
+ ("xlm", "XLMConfig"),
+ ("xlm-prophetnet", "XLMProphetNetConfig"),
+ ("xlm-roberta", "XLMRobertaConfig"),
+ ("xlm-roberta-xl", "XLMRobertaXLConfig"),
+ ("xlnet", "XLNetConfig"),
+ ("xmod", "XmodConfig"),
+ ("yolos", "YolosConfig"),
+ ("yoso", "YosoConfig"),
+ ("zamba", "ZambaConfig"),
+ ("zamba2", "Zamba2Config"),
+ ("zoedepth", "ZoeDepthConfig"),
+ ]
+)
+
+
+MODEL_NAMES_MAPPING = OrderedDict(
+ [
+ # Add full (and cased) model names here
+ ("albert", "ALBERT"),
+ ("align", "ALIGN"),
+ ("altclip", "AltCLIP"),
+ ("aria", "Aria"),
+ ("aria_text", "AriaText"),
+ ("audio-spectrogram-transformer", "Audio Spectrogram Transformer"),
+ ("autoformer", "Autoformer"),
+ ("aya_vision", "AyaVision"),
+ ("bamba", "Bamba"),
+ ("bark", "Bark"),
+ ("bart", "BART"),
+ ("barthez", "BARThez"),
+ ("bartpho", "BARTpho"),
+ ("beit", "BEiT"),
+ ("bert", "BERT"),
+ ("bert-generation", "Bert Generation"),
+ ("bert-japanese", "BertJapanese"),
+ ("bertweet", "BERTweet"),
+ ("big_bird", "BigBird"),
+ ("bigbird_pegasus", "BigBird-Pegasus"),
+ ("biogpt", "BioGpt"),
+ ("bit", "BiT"),
+ ("blenderbot", "Blenderbot"),
+ ("blenderbot-small", "BlenderbotSmall"),
+ ("blip", "BLIP"),
+ ("blip-2", "BLIP-2"),
+ ("blip_2_qformer", "BLIP-2 QFormer"),
+ ("bloom", "BLOOM"),
+ ("bort", "BORT"),
+ ("bridgetower", "BridgeTower"),
+ ("bros", "BROS"),
+ ("byt5", "ByT5"),
+ ("camembert", "CamemBERT"),
+ ("canine", "CANINE"),
+ ("chameleon", "Chameleon"),
+ ("chinese_clip", "Chinese-CLIP"),
+ ("chinese_clip_vision_model", "ChineseCLIPVisionModel"),
+ ("clap", "CLAP"),
+ ("clip", "CLIP"),
+ ("clip_text_model", "CLIPTextModel"),
+ ("clip_vision_model", "CLIPVisionModel"),
+ ("clipseg", "CLIPSeg"),
+ ("clvp", "CLVP"),
+ ("code_llama", "CodeLlama"),
+ ("codegen", "CodeGen"),
+ ("cohere", "Cohere"),
+ ("cohere2", "Cohere2"),
+ ("colpali", "ColPali"),
+ ("conditional_detr", "Conditional DETR"),
+ ("convbert", "ConvBERT"),
+ ("convnext", "ConvNeXT"),
+ ("convnextv2", "ConvNeXTV2"),
+ ("cpm", "CPM"),
+ ("cpmant", "CPM-Ant"),
+ ("ctrl", "CTRL"),
+ ("cvt", "CvT"),
+ ("dab-detr", "DAB-DETR"),
+ ("dac", "DAC"),
+ ("data2vec-audio", "Data2VecAudio"),
+ ("data2vec-text", "Data2VecText"),
+ ("data2vec-vision", "Data2VecVision"),
+ ("dbrx", "DBRX"),
+ ("deberta", "DeBERTa"),
+ ("deberta-v2", "DeBERTa-v2"),
+ ("decision_transformer", "Decision Transformer"),
+ ("deepseek_v3", "DeepSeek-V3"),
+ ("deformable_detr", "Deformable DETR"),
+ ("deit", "DeiT"),
+ ("deplot", "DePlot"),
+ ("depth_anything", "Depth Anything"),
+ ("depth_anything_v2", "Depth Anything V2"),
+ ("depth_pro", "DepthPro"),
+ ("deta", "DETA"),
+ ("detr", "DETR"),
+ ("dialogpt", "DialoGPT"),
+ ("diffllama", "DiffLlama"),
+ ("dinat", "DiNAT"),
+ ("dinov2", "DINOv2"),
+ ("dinov2_with_registers", "DINOv2 with Registers"),
+ ("distilbert", "DistilBERT"),
+ ("dit", "DiT"),
+ ("donut-swin", "DonutSwin"),
+ ("dpr", "DPR"),
+ ("dpt", "DPT"),
+ ("efficientformer", "EfficientFormer"),
+ ("efficientnet", "EfficientNet"),
+ ("electra", "ELECTRA"),
+ ("emu3", "Emu3"),
+ ("encodec", "EnCodec"),
+ ("encoder-decoder", "Encoder decoder"),
+ ("ernie", "ERNIE"),
+ ("ernie_m", "ErnieM"),
+ ("esm", "ESM"),
+ ("falcon", "Falcon"),
+ ("falcon3", "Falcon3"),
+ ("falcon_mamba", "FalconMamba"),
+ ("fastspeech2_conformer", "FastSpeech2Conformer"),
+ ("flan-t5", "FLAN-T5"),
+ ("flan-ul2", "FLAN-UL2"),
+ ("flaubert", "FlauBERT"),
+ ("flava", "FLAVA"),
+ ("fnet", "FNet"),
+ ("focalnet", "FocalNet"),
+ ("fsmt", "FairSeq Machine-Translation"),
+ ("funnel", "Funnel Transformer"),
+ ("fuyu", "Fuyu"),
+ ("gemma", "Gemma"),
+ ("gemma2", "Gemma2"),
+ ("gemma3", "Gemma3ForConditionalGeneration"),
+ ("gemma3_text", "Gemma3ForCausalLM"),
+ ("git", "GIT"),
+ ("glm", "GLM"),
+ ("glm4", "glm4"),
+ ("glpn", "GLPN"),
+ ("got_ocr2", "GOT-OCR2"),
+ ("gpt-sw3", "GPT-Sw3"),
+ ("gpt2", "OpenAI GPT-2"),
+ ("gpt_bigcode", "GPTBigCode"),
+ ("gpt_neo", "GPT Neo"),
+ ("gpt_neox", "GPT NeoX"),
+ ("gpt_neox_japanese", "GPT NeoX Japanese"),
+ ("gptj", "GPT-J"),
+ ("gptsan-japanese", "GPTSAN-japanese"),
+ ("granite", "Granite"),
+ ("granite_speech", "GraniteSpeech"),
+ ("granitemoe", "GraniteMoeMoe"),
+ ("granitemoeshared", "GraniteMoeSharedMoe"),
+ ("granitevision", "LLaVA-NeXT"),
+ ("graphormer", "Graphormer"),
+ ("grounding-dino", "Grounding DINO"),
+ ("groupvit", "GroupViT"),
+ ("helium", "Helium"),
+ ("herbert", "HerBERT"),
+ ("hiera", "Hiera"),
+ ("hubert", "Hubert"),
+ ("ibert", "I-BERT"),
+ ("idefics", "IDEFICS"),
+ ("idefics2", "Idefics2"),
+ ("idefics3", "Idefics3"),
+ ("idefics3_vision", "Idefics3VisionTransformer"),
+ ("ijepa", "I-JEPA"),
+ ("imagegpt", "ImageGPT"),
+ ("informer", "Informer"),
+ ("instructblip", "InstructBLIP"),
+ ("instructblipvideo", "InstructBlipVideo"),
+ ("internvl", "InternVL"),
+ ("internvl_vision", "InternVLVision"),
+ ("jamba", "Jamba"),
+ ("janus", "Janus"),
+ ("jetmoe", "JetMoe"),
+ ("jukebox", "Jukebox"),
+ ("kosmos-2", "KOSMOS-2"),
+ ("layoutlm", "LayoutLM"),
+ ("layoutlmv2", "LayoutLMv2"),
+ ("layoutlmv3", "LayoutLMv3"),
+ ("layoutxlm", "LayoutXLM"),
+ ("led", "LED"),
+ ("levit", "LeViT"),
+ ("lilt", "LiLT"),
+ ("llama", "LLaMA"),
+ ("llama2", "Llama2"),
+ ("llama3", "Llama3"),
+ ("llama4", "Llama4"),
+ ("llama4_text", "Llama4ForCausalLM"),
+ ("llava", "LLaVa"),
+ ("llava_next", "LLaVA-NeXT"),
+ ("llava_next_video", "LLaVa-NeXT-Video"),
+ ("llava_onevision", "LLaVA-Onevision"),
+ ("longformer", "Longformer"),
+ ("longt5", "LongT5"),
+ ("luke", "LUKE"),
+ ("lxmert", "LXMERT"),
+ ("m2m_100", "M2M100"),
+ ("madlad-400", "MADLAD-400"),
+ ("mamba", "Mamba"),
+ ("mamba2", "mamba2"),
+ ("marian", "Marian"),
+ ("markuplm", "MarkupLM"),
+ ("mask2former", "Mask2Former"),
+ ("maskformer", "MaskFormer"),
+ ("maskformer-swin", "MaskFormerSwin"),
+ ("matcha", "MatCha"),
+ ("mbart", "mBART"),
+ ("mbart50", "mBART-50"),
+ ("mctct", "M-CTC-T"),
+ ("mega", "MEGA"),
+ ("megatron-bert", "Megatron-BERT"),
+ ("megatron_gpt2", "Megatron-GPT2"),
+ ("mgp-str", "MGP-STR"),
+ ("mimi", "Mimi"),
+ ("mistral", "Mistral"),
+ ("mistral3", "Mistral3"),
+ ("mixtral", "Mixtral"),
+ ("mlcd", "MLCD"),
+ ("mllama", "Mllama"),
+ ("mluke", "mLUKE"),
+ ("mms", "MMS"),
+ ("mobilebert", "MobileBERT"),
+ ("mobilenet_v1", "MobileNetV1"),
+ ("mobilenet_v2", "MobileNetV2"),
+ ("mobilevit", "MobileViT"),
+ ("mobilevitv2", "MobileViTV2"),
+ ("modernbert", "ModernBERT"),
+ ("moonshine", "Moonshine"),
+ ("moshi", "Moshi"),
+ ("mpnet", "MPNet"),
+ ("mpt", "MPT"),
+ ("mra", "MRA"),
+ ("mt5", "MT5"),
+ ("musicgen", "MusicGen"),
+ ("musicgen_melody", "MusicGen Melody"),
+ ("mvp", "MVP"),
+ ("myt5", "myt5"),
+ ("nat", "NAT"),
+ ("nemotron", "Nemotron"),
+ ("nezha", "Nezha"),
+ ("nllb", "NLLB"),
+ ("nllb-moe", "NLLB-MOE"),
+ ("nougat", "Nougat"),
+ ("nystromformer", "Nyströmformer"),
+ ("olmo", "OLMo"),
+ ("olmo2", "OLMo2"),
+ ("olmoe", "OLMoE"),
+ ("omdet-turbo", "OmDet-Turbo"),
+ ("oneformer", "OneFormer"),
+ ("open-llama", "OpenLlama"),
+ ("openai-gpt", "OpenAI GPT"),
+ ("opt", "OPT"),
+ ("owlv2", "OWLv2"),
+ ("owlvit", "OWL-ViT"),
+ ("paligemma", "PaliGemma"),
+ ("patchtsmixer", "PatchTSMixer"),
+ ("patchtst", "PatchTST"),
+ ("pegasus", "Pegasus"),
+ ("pegasus_x", "PEGASUS-X"),
+ ("perceiver", "Perceiver"),
+ ("persimmon", "Persimmon"),
+ ("phi", "Phi"),
+ ("phi3", "Phi3"),
+ ("phi4_multimodal", "Phi4Multimodal"),
+ ("phimoe", "Phimoe"),
+ ("phobert", "PhoBERT"),
+ ("pix2struct", "Pix2Struct"),
+ ("pixtral", "Pixtral"),
+ ("plbart", "PLBart"),
+ ("poolformer", "PoolFormer"),
+ ("pop2piano", "Pop2Piano"),
+ ("prompt_depth_anything", "PromptDepthAnything"),
+ ("prophetnet", "ProphetNet"),
+ ("pvt", "PVT"),
+ ("pvt_v2", "PVTv2"),
+ ("qdqbert", "QDQBert"),
+ ("qwen2", "Qwen2"),
+ ("qwen2_5_omni", "Qwen2_5Omni"),
+ ("qwen2_5_vl", "Qwen2_5_VL"),
+ ("qwen2_5_vl_text", "Qwen2_5_VL"),
+ ("qwen2_audio", "Qwen2Audio"),
+ ("qwen2_audio_encoder", "Qwen2AudioEncoder"),
+ ("qwen2_moe", "Qwen2MoE"),
+ ("qwen2_vl", "Qwen2VL"),
+ ("qwen2_vl_text", "Qwen2VL"),
+ ("qwen3", "Qwen3"),
+ ("qwen3_moe", "Qwen3MoE"),
+ ("rag", "RAG"),
+ ("realm", "REALM"),
+ ("recurrent_gemma", "RecurrentGemma"),
+ ("reformer", "Reformer"),
+ ("regnet", "RegNet"),
+ ("rembert", "RemBERT"),
+ ("resnet", "ResNet"),
+ ("retribert", "RetriBERT"),
+ ("roberta", "RoBERTa"),
+ ("roberta-prelayernorm", "RoBERTa-PreLayerNorm"),
+ ("roc_bert", "RoCBert"),
+ ("roformer", "RoFormer"),
+ ("rt_detr", "RT-DETR"),
+ ("rt_detr_resnet", "RT-DETR-ResNet"),
+ ("rt_detr_v2", "RT-DETRv2"),
+ ("rwkv", "RWKV"),
+ ("sam", "SAM"),
+ ("sam_vision_model", "SamVisionModel"),
+ ("seamless_m4t", "SeamlessM4T"),
+ ("seamless_m4t_v2", "SeamlessM4Tv2"),
+ ("segformer", "SegFormer"),
+ ("seggpt", "SegGPT"),
+ ("sew", "SEW"),
+ ("sew-d", "SEW-D"),
+ ("shieldgemma2", "Shieldgemma2"),
+ ("siglip", "SigLIP"),
+ ("siglip2", "SigLIP2"),
+ ("siglip2_vision_model", "Siglip2VisionModel"),
+ ("siglip_vision_model", "SiglipVisionModel"),
+ ("smolvlm", "SmolVLM"),
+ ("smolvlm_vision", "SmolVLMVisionTransformer"),
+ ("speech-encoder-decoder", "Speech Encoder decoder"),
+ ("speech_to_text", "Speech2Text"),
+ ("speech_to_text_2", "Speech2Text2"),
+ ("speecht5", "SpeechT5"),
+ ("splinter", "Splinter"),
+ ("squeezebert", "SqueezeBERT"),
+ ("stablelm", "StableLm"),
+ ("starcoder2", "Starcoder2"),
+ ("superglue", "SuperGlue"),
+ ("superpoint", "SuperPoint"),
+ ("swiftformer", "SwiftFormer"),
+ ("swin", "Swin Transformer"),
+ ("swin2sr", "Swin2SR"),
+ ("swinv2", "Swin Transformer V2"),
+ ("switch_transformers", "SwitchTransformers"),
+ ("t5", "T5"),
+ ("t5v1.1", "T5v1.1"),
+ ("table-transformer", "Table Transformer"),
+ ("tapas", "TAPAS"),
+ ("tapex", "TAPEX"),
+ ("textnet", "TextNet"),
+ ("time_series_transformer", "Time Series Transformer"),
+ ("timesfm", "TimesFm"),
+ ("timesformer", "TimeSformer"),
+ ("timm_backbone", "TimmBackbone"),
+ ("timm_wrapper", "TimmWrapperModel"),
+ ("trajectory_transformer", "Trajectory Transformer"),
+ ("transfo-xl", "Transformer-XL"),
+ ("trocr", "TrOCR"),
+ ("tvlt", "TVLT"),
+ ("tvp", "TVP"),
+ ("udop", "UDOP"),
+ ("ul2", "UL2"),
+ ("umt5", "UMT5"),
+ ("unispeech", "UniSpeech"),
+ ("unispeech-sat", "UniSpeechSat"),
+ ("univnet", "UnivNet"),
+ ("upernet", "UPerNet"),
+ ("van", "VAN"),
+ ("video_llava", "VideoLlava"),
+ ("videomae", "VideoMAE"),
+ ("vilt", "ViLT"),
+ ("vipllava", "VipLlava"),
+ ("vision-encoder-decoder", "Vision Encoder decoder"),
+ ("vision-text-dual-encoder", "VisionTextDualEncoder"),
+ ("visual_bert", "VisualBERT"),
+ ("vit", "ViT"),
+ ("vit_hybrid", "ViT Hybrid"),
+ ("vit_mae", "ViTMAE"),
+ ("vit_msn", "ViTMSN"),
+ ("vitdet", "VitDet"),
+ ("vitmatte", "ViTMatte"),
+ ("vitpose", "ViTPose"),
+ ("vitpose_backbone", "ViTPoseBackbone"),
+ ("vits", "VITS"),
+ ("vivit", "ViViT"),
+ ("wav2vec2", "Wav2Vec2"),
+ ("wav2vec2-bert", "Wav2Vec2-BERT"),
+ ("wav2vec2-conformer", "Wav2Vec2-Conformer"),
+ ("wav2vec2_phoneme", "Wav2Vec2Phoneme"),
+ ("wavlm", "WavLM"),
+ ("whisper", "Whisper"),
+ ("xclip", "X-CLIP"),
+ ("xglm", "XGLM"),
+ ("xlm", "XLM"),
+ ("xlm-prophetnet", "XLM-ProphetNet"),
+ ("xlm-roberta", "XLM-RoBERTa"),
+ ("xlm-roberta-xl", "XLM-RoBERTa-XL"),
+ ("xlm-v", "XLM-V"),
+ ("xlnet", "XLNet"),
+ ("xls_r", "XLS-R"),
+ ("xlsr_wav2vec2", "XLSR-Wav2Vec2"),
+ ("xmod", "X-MOD"),
+ ("yolos", "YOLOS"),
+ ("yoso", "YOSO"),
+ ("zamba", "Zamba"),
+ ("zamba2", "Zamba2"),
+ ("zoedepth", "ZoeDepth"),
+ ]
+)
+
+# This is tied to the processing `-` -> `_` in `model_type_to_module_name`. For example, instead of putting
+# `transfo-xl` (as in `CONFIG_MAPPING_NAMES`), we should use `transfo_xl`.
+DEPRECATED_MODELS = [
+ "bort",
+ "deta",
+ "efficientformer",
+ "ernie_m",
+ "gptsan_japanese",
+ "graphormer",
+ "jukebox",
+ "mctct",
+ "mega",
+ "mmbt",
+ "nat",
+ "nezha",
+ "open_llama",
+ "qdqbert",
+ "realm",
+ "retribert",
+ "speech_to_text_2",
+ "tapex",
+ "trajectory_transformer",
+ "transfo_xl",
+ "tvlt",
+ "van",
+ "vit_hybrid",
+ "xlm_prophetnet",
+]
+
+SPECIAL_MODEL_TYPE_TO_MODULE_NAME = OrderedDict(
+ [
+ ("openai-gpt", "openai"),
+ ("data2vec-audio", "data2vec"),
+ ("data2vec-text", "data2vec"),
+ ("data2vec-vision", "data2vec"),
+ ("donut-swin", "donut"),
+ ("kosmos-2", "kosmos2"),
+ ("maskformer-swin", "maskformer"),
+ ("xclip", "x_clip"),
+ ("clip_vision_model", "clip"),
+ ("qwen2_audio_encoder", "qwen2_audio"),
+ ("clip_text_model", "clip"),
+ ("aria_text", "aria"),
+ ("gemma3_text", "gemma3"),
+ ("idefics3_vision", "idefics3"),
+ ("siglip_vision_model", "siglip"),
+ ("smolvlm_vision", "smolvlm"),
+ ("chinese_clip_vision_model", "chinese_clip"),
+ ("rt_detr_resnet", "rt_detr"),
+ ("granitevision", "llava_next"),
+ ("internvl_vision", "internvl"),
+ ("qwen2_5_vl_text", "qwen2_5_vl"),
+ ("qwen2_vl_text", "qwen2_vl"),
+ ("sam_vision_model", "sam"),
+ ("llama4_text", "llama4"),
+ ("blip_2_qformer", "blip_2"),
+ ]
+)
+
+
+def model_type_to_module_name(key):
+ """Converts a config key to the corresponding module."""
+ # Special treatment
+ if key in SPECIAL_MODEL_TYPE_TO_MODULE_NAME:
+ key = SPECIAL_MODEL_TYPE_TO_MODULE_NAME[key]
+
+ if key in DEPRECATED_MODELS:
+ key = f"deprecated.{key}"
+ return key
+
+ key = key.replace("-", "_")
+ if key in DEPRECATED_MODELS:
+ key = f"deprecated.{key}"
+
+ return key
+
+
+def config_class_to_model_type(config):
+ """Converts a config class name to the corresponding model type"""
+ for key, cls in CONFIG_MAPPING_NAMES.items():
+ if cls == config:
+ return key
+ # if key not found check in extra content
+ for key, cls in CONFIG_MAPPING._extra_content.items():
+ if cls.__name__ == config:
+ return key
+ return None
+
+
+class _LazyConfigMapping(OrderedDict):
+ """
+ A dictionary that lazily load its values when they are requested.
+ """
+
+ def __init__(self, mapping):
+ self._mapping = mapping
+ self._extra_content = {}
+ self._modules = {}
+
+ def __getitem__(self, key):
+ if key in self._extra_content:
+ return self._extra_content[key]
+ if key not in self._mapping:
+ raise KeyError(key)
+ value = self._mapping[key]
+ module_name = model_type_to_module_name(key)
+ if module_name not in self._modules:
+ self._modules[module_name] = importlib.import_module(f".{module_name}", "transformers.models")
+ if hasattr(self._modules[module_name], value):
+ return getattr(self._modules[module_name], value)
+
+ # Some of the mappings have entries model_type -> config of another model type. In that case we try to grab the
+ # object at the top level.
+ transformers_module = importlib.import_module("transformers")
+ return getattr(transformers_module, value)
+
+ def keys(self):
+ return list(self._mapping.keys()) + list(self._extra_content.keys())
+
+ def values(self):
+ return [self[k] for k in self._mapping.keys()] + list(self._extra_content.values())
+
+ def items(self):
+ return [(k, self[k]) for k in self._mapping.keys()] + list(self._extra_content.items())
+
+ def __iter__(self):
+ return iter(list(self._mapping.keys()) + list(self._extra_content.keys()))
+
+ def __contains__(self, item):
+ return item in self._mapping or item in self._extra_content
+
+ def register(self, key, value, exist_ok=False):
+ """
+ Register a new configuration in this mapping.
+ """
+ if key in self._mapping.keys() and not exist_ok:
+ raise ValueError(f"'{key}' is already used by a Transformers config, pick another name.")
+ self._extra_content[key] = value
+
+
+CONFIG_MAPPING = _LazyConfigMapping(CONFIG_MAPPING_NAMES)
+
+
+class _LazyLoadAllMappings(OrderedDict):
+ """
+ A mapping that will load all pairs of key values at the first access (either by indexing, requestions keys, values,
+ etc.)
+
+ Args:
+ mapping: The mapping to load.
+ """
+
+ def __init__(self, mapping):
+ self._mapping = mapping
+ self._initialized = False
+ self._data = {}
+
+ def _initialize(self):
+ if self._initialized:
+ return
+
+ for model_type, map_name in self._mapping.items():
+ module_name = model_type_to_module_name(model_type)
+ module = importlib.import_module(f".{module_name}", "transformers.models")
+ mapping = getattr(module, map_name)
+ self._data.update(mapping)
+
+ self._initialized = True
+
+ def __getitem__(self, key):
+ self._initialize()
+ return self._data[key]
+
+ def keys(self):
+ self._initialize()
+ return self._data.keys()
+
+ def values(self):
+ self._initialize()
+ return self._data.values()
+
+ def items(self):
+ self._initialize()
+ return self._data.keys()
+
+ def __iter__(self):
+ self._initialize()
+ return iter(self._data)
+
+ def __contains__(self, item):
+ self._initialize()
+ return item in self._data
+
+
+def _get_class_name(model_class: Union[str, List[str]]):
+ if isinstance(model_class, (list, tuple)):
+ return " or ".join([f"[`{c}`]" for c in model_class if c is not None])
+ return f"[`{model_class}`]"
+
+
+def _list_model_options(indent, config_to_class=None, use_model_types=True):
+ if config_to_class is None and not use_model_types:
+ raise ValueError("Using `use_model_types=False` requires a `config_to_class` dictionary.")
+ if use_model_types:
+ if config_to_class is None:
+ model_type_to_name = {model_type: f"[`{config}`]" for model_type, config in CONFIG_MAPPING_NAMES.items()}
+ else:
+ model_type_to_name = {
+ model_type: _get_class_name(model_class)
+ for model_type, model_class in config_to_class.items()
+ if model_type in MODEL_NAMES_MAPPING
+ }
+ lines = [
+ f"{indent}- **{model_type}** -- {model_type_to_name[model_type]} ({MODEL_NAMES_MAPPING[model_type]} model)"
+ for model_type in sorted(model_type_to_name.keys())
+ ]
+ else:
+ config_to_name = {
+ CONFIG_MAPPING_NAMES[config]: _get_class_name(clas)
+ for config, clas in config_to_class.items()
+ if config in CONFIG_MAPPING_NAMES
+ }
+ config_to_model_name = {
+ config: MODEL_NAMES_MAPPING[model_type] for model_type, config in CONFIG_MAPPING_NAMES.items()
+ }
+ lines = [
+ f"{indent}- [`{config_name}`] configuration class:"
+ f" {config_to_name[config_name]} ({config_to_model_name[config_name]} model)"
+ for config_name in sorted(config_to_name.keys())
+ ]
+ return "\n".join(lines)
+
+
+def replace_list_option_in_docstrings(config_to_class=None, use_model_types=True):
+ def docstring_decorator(fn):
+ docstrings = fn.__doc__
+ if docstrings is None:
+ # Example: -OO
+ return fn
+ lines = docstrings.split("\n")
+ i = 0
+ while i < len(lines) and re.search(r"^(\s*)List options\s*$", lines[i]) is None:
+ i += 1
+ if i < len(lines):
+ indent = re.search(r"^(\s*)List options\s*$", lines[i]).groups()[0]
+ if use_model_types:
+ indent = f"{indent} "
+ lines[i] = _list_model_options(indent, config_to_class=config_to_class, use_model_types=use_model_types)
+ docstrings = "\n".join(lines)
+ else:
+ raise ValueError(
+ f"The function {fn} should have an empty 'List options' in its docstring as placeholder, current"
+ f" docstring is:\n{docstrings}"
+ )
+ fn.__doc__ = docstrings
+ return fn
+
+ return docstring_decorator
+
+
+class AutoConfig:
+ r"""
+ This is a generic configuration class that will be instantiated as one of the configuration classes of the library
+ when created with the [`~AutoConfig.from_pretrained`] class method.
+
+ This class cannot be instantiated directly using `__init__()` (throws an error).
+ """
+
+ def __init__(self):
+ raise EnvironmentError(
+ "AutoConfig is designed to be instantiated "
+ "using the `AutoConfig.from_pretrained(pretrained_model_name_or_path)` method."
+ )
+
+ @classmethod
+ def for_model(cls, model_type: str, *args, **kwargs):
+ if model_type in CONFIG_MAPPING:
+ config_class = CONFIG_MAPPING[model_type]
+ return config_class(*args, **kwargs)
+ raise ValueError(
+ f"Unrecognized model identifier: {model_type}. Should contain one of {', '.join(CONFIG_MAPPING.keys())}"
+ )
+
+ @classmethod
+ @replace_list_option_in_docstrings()
+ def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
+ r"""
+ Instantiate one of the configuration classes of the library from a pretrained model configuration.
+
+ The configuration class to instantiate is selected based on the `model_type` property of the config object that
+ is loaded, or when it's missing, by falling back to using pattern matching on `pretrained_model_name_or_path`:
+
+ List options
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ Can be either:
+
+ - A string, the *model id* of a pretrained model configuration hosted inside a model repo on
+ huggingface.co.
+ - A path to a *directory* containing a configuration file saved using the
+ [`~PretrainedConfig.save_pretrained`] method, or the [`~PreTrainedModel.save_pretrained`] method,
+ e.g., `./my_model_directory/`.
+ - A path or url to a saved configuration JSON *file*, e.g.,
+ `./my_model_directory/configuration.json`.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download the model weights and configuration files and override the
+ cached versions if they exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ return_unused_kwargs (`bool`, *optional*, defaults to `False`):
+ If `False`, then this function returns just the final configuration object.
+
+ If `True`, then this functions returns a `Tuple(config, unused_kwargs)` where *unused_kwargs* is a
+ dictionary consisting of the key/value pairs whose keys are not configuration attributes: i.e., the
+ part of `kwargs` which has not been used to update `config` and is otherwise ignored.
+ trust_remote_code (`bool`, *optional*, defaults to `False`):
+ Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
+ should only be set to `True` for repositories you trust and in which you have read the code, as it will
+ execute code present on the Hub on your local machine.
+ kwargs(additional keyword arguments, *optional*):
+ The values in kwargs of any keys which are configuration attributes will be used to override the loaded
+ values. Behavior concerning key/value pairs whose keys are *not* configuration attributes is controlled
+ by the `return_unused_kwargs` keyword parameter.
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoConfig
+
+ >>> # Download configuration from huggingface.co and cache.
+ >>> config = AutoConfig.from_pretrained("google-bert/bert-base-uncased")
+
+ >>> # Download configuration from huggingface.co (user-uploaded) and cache.
+ >>> config = AutoConfig.from_pretrained("dbmdz/bert-base-german-cased")
+
+ >>> # If configuration file is in a directory (e.g., was saved using *save_pretrained('./test/saved_model/')*).
+ >>> config = AutoConfig.from_pretrained("./test/bert_saved_model/")
+
+ >>> # Load a specific configuration file.
+ >>> config = AutoConfig.from_pretrained("./test/bert_saved_model/my_configuration.json")
+
+ >>> # Change some config attributes when loading a pretrained config.
+ >>> config = AutoConfig.from_pretrained("google-bert/bert-base-uncased", output_attentions=True, foo=False)
+ >>> config.output_attentions
+ True
+
+ >>> config, unused_kwargs = AutoConfig.from_pretrained(
+ ... "google-bert/bert-base-uncased", output_attentions=True, foo=False, return_unused_kwargs=True
+ ... )
+ >>> config.output_attentions
+ True
+
+ >>> unused_kwargs
+ {'foo': False}
+ ```"""
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if kwargs.get("token", None) is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ kwargs["token"] = use_auth_token
+
+ kwargs["_from_auto"] = True
+ kwargs["name_or_path"] = pretrained_model_name_or_path
+ trust_remote_code = kwargs.pop("trust_remote_code", None)
+ code_revision = kwargs.pop("code_revision", None)
+
+ config_dict, unused_kwargs = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
+ has_remote_code = "auto_map" in config_dict and "AutoConfig" in config_dict["auto_map"]
+ has_local_code = "model_type" in config_dict and config_dict["model_type"] in CONFIG_MAPPING
+ trust_remote_code = resolve_trust_remote_code(
+ trust_remote_code, pretrained_model_name_or_path, has_local_code, has_remote_code
+ )
+
+ if has_remote_code and trust_remote_code:
+ class_ref = config_dict["auto_map"]["AutoConfig"]
+ config_class = get_class_from_dynamic_module(
+ class_ref, pretrained_model_name_or_path, code_revision=code_revision, **kwargs
+ )
+ if os.path.isdir(pretrained_model_name_or_path):
+ config_class.register_for_auto_class()
+ return config_class.from_pretrained(pretrained_model_name_or_path, **kwargs)
+ elif "model_type" in config_dict:
+ try:
+ config_class = CONFIG_MAPPING[config_dict["model_type"]]
+ except KeyError:
+ raise ValueError(
+ f"The checkpoint you are trying to load has model type `{config_dict['model_type']}` "
+ "but Transformers does not recognize this architecture. This could be because of an "
+ "issue with the checkpoint, or because your version of Transformers is out of date.\n\n"
+ "You can update Transformers with the command `pip install --upgrade transformers`. If this "
+ "does not work, and the checkpoint is very new, then there may not be a release version "
+ "that supports this model yet. In this case, you can get the most up-to-date code by installing "
+ "Transformers from source with the command "
+ "`pip install git+https://github.com/huggingface/transformers.git`"
+ )
+ return config_class.from_dict(config_dict, **unused_kwargs)
+ else:
+ # Fallback: use pattern matching on the string.
+ # We go from longer names to shorter names to catch roberta before bert (for instance)
+ for pattern in sorted(CONFIG_MAPPING.keys(), key=len, reverse=True):
+ if pattern in str(pretrained_model_name_or_path):
+ return CONFIG_MAPPING[pattern].from_dict(config_dict, **unused_kwargs)
+
+ raise ValueError(
+ f"Unrecognized model in {pretrained_model_name_or_path}. "
+ f"Should have a `model_type` key in its {CONFIG_NAME}, or contain one of the following strings "
+ f"in its name: {', '.join(CONFIG_MAPPING.keys())}"
+ )
+
+ @staticmethod
+ def register(model_type, config, exist_ok=False):
+ """
+ Register a new configuration for this class.
+
+ Args:
+ model_type (`str`): The model type like "bert" or "gpt".
+ config ([`PretrainedConfig`]): The config to register.
+ """
+ if issubclass(config, PretrainedConfig) and config.model_type != model_type:
+ raise ValueError(
+ "The config you are passing has a `model_type` attribute that is not consistent with the model type "
+ f"you passed (config has {config.model_type} and you passed {model_type}. Fix one of those so they "
+ "match!"
+ )
+ CONFIG_MAPPING.register(model_type, config, exist_ok=exist_ok)
+
+
+__all__ = ["CONFIG_MAPPING", "MODEL_NAMES_MAPPING", "AutoConfig"]
diff --git a/docs/transformers/src/transformers/models/auto/feature_extraction_auto.py b/docs/transformers/src/transformers/models/auto/feature_extraction_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..86dc8703c426ab9d953bccfa622b45d5d346b9d7
--- /dev/null
+++ b/docs/transformers/src/transformers/models/auto/feature_extraction_auto.py
@@ -0,0 +1,412 @@
+# coding=utf-8
+# Copyright 2021 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""AutoFeatureExtractor class."""
+
+import importlib
+import json
+import os
+import warnings
+from collections import OrderedDict
+from typing import Dict, Optional, Union
+
+# Build the list of all feature extractors
+from ...configuration_utils import PretrainedConfig
+from ...dynamic_module_utils import get_class_from_dynamic_module, resolve_trust_remote_code
+from ...feature_extraction_utils import FeatureExtractionMixin
+from ...utils import CONFIG_NAME, FEATURE_EXTRACTOR_NAME, cached_file, logging
+from .auto_factory import _LazyAutoMapping
+from .configuration_auto import (
+ CONFIG_MAPPING_NAMES,
+ AutoConfig,
+ model_type_to_module_name,
+ replace_list_option_in_docstrings,
+)
+
+
+logger = logging.get_logger(__name__)
+
+FEATURE_EXTRACTOR_MAPPING_NAMES = OrderedDict(
+ [
+ ("audio-spectrogram-transformer", "ASTFeatureExtractor"),
+ ("beit", "BeitFeatureExtractor"),
+ ("chinese_clip", "ChineseCLIPFeatureExtractor"),
+ ("clap", "ClapFeatureExtractor"),
+ ("clip", "CLIPFeatureExtractor"),
+ ("clipseg", "ViTFeatureExtractor"),
+ ("clvp", "ClvpFeatureExtractor"),
+ ("conditional_detr", "ConditionalDetrFeatureExtractor"),
+ ("convnext", "ConvNextFeatureExtractor"),
+ ("cvt", "ConvNextFeatureExtractor"),
+ ("dac", "DacFeatureExtractor"),
+ ("data2vec-audio", "Wav2Vec2FeatureExtractor"),
+ ("data2vec-vision", "BeitFeatureExtractor"),
+ ("deformable_detr", "DeformableDetrFeatureExtractor"),
+ ("deit", "DeiTFeatureExtractor"),
+ ("detr", "DetrFeatureExtractor"),
+ ("dinat", "ViTFeatureExtractor"),
+ ("donut-swin", "DonutFeatureExtractor"),
+ ("dpt", "DPTFeatureExtractor"),
+ ("encodec", "EncodecFeatureExtractor"),
+ ("flava", "FlavaFeatureExtractor"),
+ ("glpn", "GLPNFeatureExtractor"),
+ ("granite_speech", "GraniteSpeechFeatureExtractor"),
+ ("groupvit", "CLIPFeatureExtractor"),
+ ("hubert", "Wav2Vec2FeatureExtractor"),
+ ("imagegpt", "ImageGPTFeatureExtractor"),
+ ("layoutlmv2", "LayoutLMv2FeatureExtractor"),
+ ("layoutlmv3", "LayoutLMv3FeatureExtractor"),
+ ("levit", "LevitFeatureExtractor"),
+ ("maskformer", "MaskFormerFeatureExtractor"),
+ ("mctct", "MCTCTFeatureExtractor"),
+ ("mimi", "EncodecFeatureExtractor"),
+ ("mobilenet_v1", "MobileNetV1FeatureExtractor"),
+ ("mobilenet_v2", "MobileNetV2FeatureExtractor"),
+ ("mobilevit", "MobileViTFeatureExtractor"),
+ ("moonshine", "Wav2Vec2FeatureExtractor"),
+ ("moshi", "EncodecFeatureExtractor"),
+ ("nat", "ViTFeatureExtractor"),
+ ("owlvit", "OwlViTFeatureExtractor"),
+ ("perceiver", "PerceiverFeatureExtractor"),
+ ("phi4_multimodal", "Phi4MultimodalFeatureExtractor"),
+ ("poolformer", "PoolFormerFeatureExtractor"),
+ ("pop2piano", "Pop2PianoFeatureExtractor"),
+ ("regnet", "ConvNextFeatureExtractor"),
+ ("resnet", "ConvNextFeatureExtractor"),
+ ("seamless_m4t", "SeamlessM4TFeatureExtractor"),
+ ("seamless_m4t_v2", "SeamlessM4TFeatureExtractor"),
+ ("segformer", "SegformerFeatureExtractor"),
+ ("sew", "Wav2Vec2FeatureExtractor"),
+ ("sew-d", "Wav2Vec2FeatureExtractor"),
+ ("speech_to_text", "Speech2TextFeatureExtractor"),
+ ("speecht5", "SpeechT5FeatureExtractor"),
+ ("swiftformer", "ViTFeatureExtractor"),
+ ("swin", "ViTFeatureExtractor"),
+ ("swinv2", "ViTFeatureExtractor"),
+ ("table-transformer", "DetrFeatureExtractor"),
+ ("timesformer", "VideoMAEFeatureExtractor"),
+ ("tvlt", "TvltFeatureExtractor"),
+ ("unispeech", "Wav2Vec2FeatureExtractor"),
+ ("unispeech-sat", "Wav2Vec2FeatureExtractor"),
+ ("univnet", "UnivNetFeatureExtractor"),
+ ("van", "ConvNextFeatureExtractor"),
+ ("videomae", "VideoMAEFeatureExtractor"),
+ ("vilt", "ViltFeatureExtractor"),
+ ("vit", "ViTFeatureExtractor"),
+ ("vit_mae", "ViTFeatureExtractor"),
+ ("vit_msn", "ViTFeatureExtractor"),
+ ("wav2vec2", "Wav2Vec2FeatureExtractor"),
+ ("wav2vec2-bert", "Wav2Vec2FeatureExtractor"),
+ ("wav2vec2-conformer", "Wav2Vec2FeatureExtractor"),
+ ("wavlm", "Wav2Vec2FeatureExtractor"),
+ ("whisper", "WhisperFeatureExtractor"),
+ ("xclip", "CLIPFeatureExtractor"),
+ ("yolos", "YolosFeatureExtractor"),
+ ]
+)
+
+FEATURE_EXTRACTOR_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, FEATURE_EXTRACTOR_MAPPING_NAMES)
+
+
+def feature_extractor_class_from_name(class_name: str):
+ for module_name, extractors in FEATURE_EXTRACTOR_MAPPING_NAMES.items():
+ if class_name in extractors:
+ module_name = model_type_to_module_name(module_name)
+
+ module = importlib.import_module(f".{module_name}", "transformers.models")
+ try:
+ return getattr(module, class_name)
+ except AttributeError:
+ continue
+
+ for _, extractor in FEATURE_EXTRACTOR_MAPPING._extra_content.items():
+ if getattr(extractor, "__name__", None) == class_name:
+ return extractor
+
+ # We did not fine the class, but maybe it's because a dep is missing. In that case, the class will be in the main
+ # init and we return the proper dummy to get an appropriate error message.
+ main_module = importlib.import_module("transformers")
+ if hasattr(main_module, class_name):
+ return getattr(main_module, class_name)
+
+ return None
+
+
+def get_feature_extractor_config(
+ pretrained_model_name_or_path: Union[str, os.PathLike],
+ cache_dir: Optional[Union[str, os.PathLike]] = None,
+ force_download: bool = False,
+ resume_download: Optional[bool] = None,
+ proxies: Optional[Dict[str, str]] = None,
+ token: Optional[Union[bool, str]] = None,
+ revision: Optional[str] = None,
+ local_files_only: bool = False,
+ **kwargs,
+):
+ """
+ Loads the tokenizer configuration from a pretrained model tokenizer configuration.
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained model configuration hosted inside a model repo on
+ huggingface.co.
+ - a path to a *directory* containing a configuration file saved using the
+ [`~PreTrainedTokenizer.save_pretrained`] method, e.g., `./my_model_directory/`.
+
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the standard
+ cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the configuration files and override the cached versions if they
+ exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ local_files_only (`bool`, *optional*, defaults to `False`):
+ If `True`, will only try to load the tokenizer configuration from local files.
+
+
+
+ Passing `token=True` is required when you want to use a private model.
+
+
+
+ Returns:
+ `Dict`: The configuration of the tokenizer.
+
+ Examples:
+
+ ```python
+ # Download configuration from huggingface.co and cache.
+ tokenizer_config = get_tokenizer_config("google-bert/bert-base-uncased")
+ # This model does not have a tokenizer config so the result will be an empty dict.
+ tokenizer_config = get_tokenizer_config("FacebookAI/xlm-roberta-base")
+
+ # Save a pretrained tokenizer locally and you can reload its config
+ from transformers import AutoTokenizer
+
+ tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
+ tokenizer.save_pretrained("tokenizer-test")
+ tokenizer_config = get_tokenizer_config("tokenizer-test")
+ ```"""
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if token is not None:
+ raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
+ token = use_auth_token
+
+ resolved_config_file = cached_file(
+ pretrained_model_name_or_path,
+ FEATURE_EXTRACTOR_NAME,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ token=token,
+ revision=revision,
+ local_files_only=local_files_only,
+ _raise_exceptions_for_gated_repo=False,
+ _raise_exceptions_for_missing_entries=False,
+ _raise_exceptions_for_connection_errors=False,
+ )
+ if resolved_config_file is None:
+ logger.info(
+ "Could not locate the feature extractor configuration file, will try to use the model config instead."
+ )
+ return {}
+
+ with open(resolved_config_file, encoding="utf-8") as reader:
+ return json.load(reader)
+
+
+class AutoFeatureExtractor:
+ r"""
+ This is a generic feature extractor class that will be instantiated as one of the feature extractor classes of the
+ library when created with the [`AutoFeatureExtractor.from_pretrained`] class method.
+
+ This class cannot be instantiated directly using `__init__()` (throws an error).
+ """
+
+ def __init__(self):
+ raise EnvironmentError(
+ "AutoFeatureExtractor is designed to be instantiated "
+ "using the `AutoFeatureExtractor.from_pretrained(pretrained_model_name_or_path)` method."
+ )
+
+ @classmethod
+ @replace_list_option_in_docstrings(FEATURE_EXTRACTOR_MAPPING_NAMES)
+ def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
+ r"""
+ Instantiate one of the feature extractor classes of the library from a pretrained model vocabulary.
+
+ The feature extractor class to instantiate is selected based on the `model_type` property of the config object
+ (either passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's
+ missing, by falling back to using pattern matching on `pretrained_model_name_or_path`:
+
+ List options
+
+ Params:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained feature_extractor hosted inside a model repo on
+ huggingface.co.
+ - a path to a *directory* containing a feature extractor file saved using the
+ [`~feature_extraction_utils.FeatureExtractionMixin.save_pretrained`] method, e.g.,
+ `./my_model_directory/`.
+ - a path or url to a saved feature extractor JSON *file*, e.g.,
+ `./my_model_directory/preprocessor_config.json`.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model feature extractor should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the feature extractor files and override the cached versions
+ if they exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ return_unused_kwargs (`bool`, *optional*, defaults to `False`):
+ If `False`, then this function returns just the final feature extractor object. If `True`, then this
+ functions returns a `Tuple(feature_extractor, unused_kwargs)` where *unused_kwargs* is a dictionary
+ consisting of the key/value pairs whose keys are not feature extractor attributes: i.e., the part of
+ `kwargs` which has not been used to update `feature_extractor` and is otherwise ignored.
+ trust_remote_code (`bool`, *optional*, defaults to `False`):
+ Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
+ should only be set to `True` for repositories you trust and in which you have read the code, as it will
+ execute code present on the Hub on your local machine.
+ kwargs (`Dict[str, Any]`, *optional*):
+ The values in kwargs of any keys which are feature extractor attributes will be used to override the
+ loaded values. Behavior concerning key/value pairs whose keys are *not* feature extractor attributes is
+ controlled by the `return_unused_kwargs` keyword parameter.
+
+
+
+ Passing `token=True` is required when you want to use a private model.
+
+
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoFeatureExtractor
+
+ >>> # Download feature extractor from huggingface.co and cache.
+ >>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base-960h")
+
+ >>> # If feature extractor files are in a directory (e.g. feature extractor was saved using *save_pretrained('./test/saved_model/')*)
+ >>> # feature_extractor = AutoFeatureExtractor.from_pretrained("./test/saved_model/")
+ ```"""
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if kwargs.get("token", None) is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ kwargs["token"] = use_auth_token
+
+ config = kwargs.pop("config", None)
+ trust_remote_code = kwargs.pop("trust_remote_code", None)
+ kwargs["_from_auto"] = True
+
+ config_dict, _ = FeatureExtractionMixin.get_feature_extractor_dict(pretrained_model_name_or_path, **kwargs)
+ feature_extractor_class = config_dict.get("feature_extractor_type", None)
+ feature_extractor_auto_map = None
+ if "AutoFeatureExtractor" in config_dict.get("auto_map", {}):
+ feature_extractor_auto_map = config_dict["auto_map"]["AutoFeatureExtractor"]
+
+ # If we don't find the feature extractor class in the feature extractor config, let's try the model config.
+ if feature_extractor_class is None and feature_extractor_auto_map is None:
+ if not isinstance(config, PretrainedConfig):
+ config = AutoConfig.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
+ )
+ # It could be in `config.feature_extractor_type``
+ feature_extractor_class = getattr(config, "feature_extractor_type", None)
+ if hasattr(config, "auto_map") and "AutoFeatureExtractor" in config.auto_map:
+ feature_extractor_auto_map = config.auto_map["AutoFeatureExtractor"]
+
+ if feature_extractor_class is not None:
+ feature_extractor_class = feature_extractor_class_from_name(feature_extractor_class)
+
+ has_remote_code = feature_extractor_auto_map is not None
+ has_local_code = feature_extractor_class is not None or type(config) in FEATURE_EXTRACTOR_MAPPING
+ trust_remote_code = resolve_trust_remote_code(
+ trust_remote_code, pretrained_model_name_or_path, has_local_code, has_remote_code
+ )
+
+ if has_remote_code and trust_remote_code:
+ feature_extractor_class = get_class_from_dynamic_module(
+ feature_extractor_auto_map, pretrained_model_name_or_path, **kwargs
+ )
+ _ = kwargs.pop("code_revision", None)
+ if os.path.isdir(pretrained_model_name_or_path):
+ feature_extractor_class.register_for_auto_class()
+ return feature_extractor_class.from_dict(config_dict, **kwargs)
+ elif feature_extractor_class is not None:
+ return feature_extractor_class.from_dict(config_dict, **kwargs)
+ # Last try: we use the FEATURE_EXTRACTOR_MAPPING.
+ elif type(config) in FEATURE_EXTRACTOR_MAPPING:
+ feature_extractor_class = FEATURE_EXTRACTOR_MAPPING[type(config)]
+ return feature_extractor_class.from_dict(config_dict, **kwargs)
+
+ raise ValueError(
+ f"Unrecognized feature extractor in {pretrained_model_name_or_path}. Should have a "
+ f"`feature_extractor_type` key in its {FEATURE_EXTRACTOR_NAME} of {CONFIG_NAME}, or one of the following "
+ f"`model_type` keys in its {CONFIG_NAME}: {', '.join(c for c in FEATURE_EXTRACTOR_MAPPING_NAMES.keys())}"
+ )
+
+ @staticmethod
+ def register(config_class, feature_extractor_class, exist_ok=False):
+ """
+ Register a new feature extractor for this class.
+
+ Args:
+ config_class ([`PretrainedConfig`]):
+ The configuration corresponding to the model to register.
+ feature_extractor_class ([`FeatureExtractorMixin`]): The feature extractor to register.
+ """
+ FEATURE_EXTRACTOR_MAPPING.register(config_class, feature_extractor_class, exist_ok=exist_ok)
+
+
+__all__ = ["FEATURE_EXTRACTOR_MAPPING", "AutoFeatureExtractor"]
diff --git a/docs/transformers/src/transformers/models/auto/image_processing_auto.py b/docs/transformers/src/transformers/models/auto/image_processing_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..79b13f1f4a262e44793b4a7891e27f3f8cff420f
--- /dev/null
+++ b/docs/transformers/src/transformers/models/auto/image_processing_auto.py
@@ -0,0 +1,649 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""AutoImageProcessor class."""
+
+import importlib
+import json
+import os
+import warnings
+from collections import OrderedDict
+from typing import TYPE_CHECKING, Dict, Optional, Tuple, Union
+
+# Build the list of all image processors
+from ...configuration_utils import PretrainedConfig
+from ...dynamic_module_utils import get_class_from_dynamic_module, resolve_trust_remote_code
+from ...image_processing_utils import ImageProcessingMixin
+from ...image_processing_utils_fast import BaseImageProcessorFast
+from ...utils import (
+ CONFIG_NAME,
+ IMAGE_PROCESSOR_NAME,
+ cached_file,
+ is_timm_config_dict,
+ is_timm_local_checkpoint,
+ is_torchvision_available,
+ is_vision_available,
+ logging,
+)
+from ...utils.import_utils import requires
+from .auto_factory import _LazyAutoMapping
+from .configuration_auto import (
+ CONFIG_MAPPING_NAMES,
+ AutoConfig,
+ model_type_to_module_name,
+ replace_list_option_in_docstrings,
+)
+
+
+logger = logging.get_logger(__name__)
+
+
+if TYPE_CHECKING:
+ # This significantly improves completion suggestion performance when
+ # the transformers package is used with Microsoft's Pylance language server.
+ IMAGE_PROCESSOR_MAPPING_NAMES: OrderedDict[str, Tuple[Optional[str], Optional[str]]] = OrderedDict()
+else:
+ IMAGE_PROCESSOR_MAPPING_NAMES = OrderedDict(
+ [
+ ("align", ("EfficientNetImageProcessor", "EfficientNetImageProcessorFast")),
+ ("aria", ("AriaImageProcessor",)),
+ ("beit", ("BeitImageProcessor",)),
+ ("bit", ("BitImageProcessor", "BitImageProcessorFast")),
+ ("blip", ("BlipImageProcessor", "BlipImageProcessorFast")),
+ ("blip-2", ("BlipImageProcessor", "BlipImageProcessorFast")),
+ ("bridgetower", ("BridgeTowerImageProcessor", "BridgeTowerImageProcessorFast")),
+ ("chameleon", ("ChameleonImageProcessor",)),
+ ("chinese_clip", ("ChineseCLIPImageProcessor", "ChineseCLIPImageProcessorFast")),
+ ("clip", ("CLIPImageProcessor", "CLIPImageProcessorFast")),
+ ("clipseg", ("ViTImageProcessor", "ViTImageProcessorFast")),
+ ("conditional_detr", ("ConditionalDetrImageProcessor", "ConditionalDetrImageProcessorFast")),
+ ("convnext", ("ConvNextImageProcessor", "ConvNextImageProcessorFast")),
+ ("convnextv2", ("ConvNextImageProcessor", "ConvNextImageProcessorFast")),
+ ("cvt", ("ConvNextImageProcessor", "ConvNextImageProcessorFast")),
+ ("data2vec-vision", ("BeitImageProcessor",)),
+ ("deformable_detr", ("DeformableDetrImageProcessor", "DeformableDetrImageProcessorFast")),
+ ("deit", ("DeiTImageProcessor", "DeiTImageProcessorFast")),
+ ("depth_anything", ("DPTImageProcessor",)),
+ ("depth_pro", ("DepthProImageProcessor", "DepthProImageProcessorFast")),
+ ("deta", ("DetaImageProcessor",)),
+ ("detr", ("DetrImageProcessor", "DetrImageProcessorFast")),
+ ("dinat", ("ViTImageProcessor", "ViTImageProcessorFast")),
+ ("dinov2", ("BitImageProcessor", "BitImageProcessorFast")),
+ ("donut-swin", ("DonutImageProcessor", "DonutImageProcessorFast")),
+ ("dpt", ("DPTImageProcessor",)),
+ ("efficientformer", ("EfficientFormerImageProcessor",)),
+ ("efficientnet", ("EfficientNetImageProcessor", "EfficientNetImageProcessorFast")),
+ ("flava", ("FlavaImageProcessor", "FlavaImageProcessorFast")),
+ ("focalnet", ("BitImageProcessor", "BitImageProcessorFast")),
+ ("fuyu", ("FuyuImageProcessor",)),
+ ("gemma3", ("Gemma3ImageProcessor", "Gemma3ImageProcessorFast")),
+ ("git", ("CLIPImageProcessor", "CLIPImageProcessorFast")),
+ ("glpn", ("GLPNImageProcessor",)),
+ ("got_ocr2", ("GotOcr2ImageProcessor", "GotOcr2ImageProcessorFast")),
+ ("grounding-dino", ("GroundingDinoImageProcessor", "GroundingDinoImageProcessorFast")),
+ ("groupvit", ("CLIPImageProcessor", "CLIPImageProcessorFast")),
+ ("hiera", ("BitImageProcessor", "BitImageProcessorFast")),
+ ("idefics", ("IdeficsImageProcessor",)),
+ ("idefics2", ("Idefics2ImageProcessor",)),
+ ("idefics3", ("Idefics3ImageProcessor",)),
+ ("ijepa", ("ViTImageProcessor", "ViTImageProcessorFast")),
+ ("imagegpt", ("ImageGPTImageProcessor",)),
+ ("instructblip", ("BlipImageProcessor", "BlipImageProcessorFast")),
+ ("instructblipvideo", ("InstructBlipVideoImageProcessor",)),
+ ("janus", ("JanusImageProcessor")),
+ ("kosmos-2", ("CLIPImageProcessor", "CLIPImageProcessorFast")),
+ ("layoutlmv2", ("LayoutLMv2ImageProcessor", "LayoutLMv2ImageProcessorFast")),
+ ("layoutlmv3", ("LayoutLMv3ImageProcessor", "LayoutLMv3ImageProcessorFast")),
+ ("levit", ("LevitImageProcessor", "LevitImageProcessorFast")),
+ ("llama4", ("Llama4ImageProcessor", "Llama4ImageProcessorFast")),
+ ("llava", ("LlavaImageProcessor", "LlavaImageProcessorFast")),
+ ("llava_next", ("LlavaNextImageProcessor", "LlavaNextImageProcessorFast")),
+ ("llava_next_video", ("LlavaNextVideoImageProcessor",)),
+ ("llava_onevision", ("LlavaOnevisionImageProcessor", "LlavaOnevisionImageProcessorFast")),
+ ("mask2former", ("Mask2FormerImageProcessor",)),
+ ("maskformer", ("MaskFormerImageProcessor",)),
+ ("mgp-str", ("ViTImageProcessor", "ViTImageProcessorFast")),
+ ("mistral3", ("PixtralImageProcessor", "PixtralImageProcessorFast")),
+ ("mlcd", ("CLIPImageProcessor", "CLIPImageProcessorFast")),
+ ("mllama", ("MllamaImageProcessor",)),
+ ("mobilenet_v1", ("MobileNetV1ImageProcessor", "MobileNetV1ImageProcessorFast")),
+ ("mobilenet_v2", ("MobileNetV2ImageProcessor", "MobileNetV2ImageProcessorFast")),
+ ("mobilevit", ("MobileViTImageProcessor",)),
+ ("mobilevitv2", ("MobileViTImageProcessor",)),
+ ("nat", ("ViTImageProcessor", "ViTImageProcessorFast")),
+ ("nougat", ("NougatImageProcessor",)),
+ ("oneformer", ("OneFormerImageProcessor",)),
+ ("owlv2", ("Owlv2ImageProcessor",)),
+ ("owlvit", ("OwlViTImageProcessor", "OwlViTImageProcessorFast")),
+ ("paligemma", ("SiglipImageProcessor", "SiglipImageProcessorFast")),
+ ("perceiver", ("PerceiverImageProcessor", "PerceiverImageProcessorFast")),
+ ("phi4_multimodal", "Phi4MultimodalImageProcessorFast"),
+ ("pix2struct", ("Pix2StructImageProcessor",)),
+ ("pixtral", ("PixtralImageProcessor", "PixtralImageProcessorFast")),
+ ("poolformer", ("PoolFormerImageProcessor", "PoolFormerImageProcessorFast")),
+ ("prompt_depth_anything", ("PromptDepthAnythingImageProcessor",)),
+ ("pvt", ("PvtImageProcessor", "PvtImageProcessorFast")),
+ ("pvt_v2", ("PvtImageProcessor", "PvtImageProcessorFast")),
+ ("qwen2_5_vl", ("Qwen2VLImageProcessor", "Qwen2VLImageProcessorFast")),
+ ("qwen2_vl", ("Qwen2VLImageProcessor", "Qwen2VLImageProcessorFast")),
+ ("regnet", ("ConvNextImageProcessor", "ConvNextImageProcessorFast")),
+ ("resnet", ("ConvNextImageProcessor", "ConvNextImageProcessorFast")),
+ ("rt_detr", ("RTDetrImageProcessor", "RTDetrImageProcessorFast")),
+ ("sam", ("SamImageProcessor",)),
+ ("segformer", ("SegformerImageProcessor",)),
+ ("seggpt", ("SegGptImageProcessor",)),
+ ("shieldgemma2", ("Gemma3ImageProcessor", "Gemma3ImageProcessorFast")),
+ ("siglip", ("SiglipImageProcessor", "SiglipImageProcessorFast")),
+ ("siglip2", ("Siglip2ImageProcessor", "Siglip2ImageProcessorFast")),
+ ("superglue", ("SuperGlueImageProcessor",)),
+ ("swiftformer", ("ViTImageProcessor", "ViTImageProcessorFast")),
+ ("swin", ("ViTImageProcessor", "ViTImageProcessorFast")),
+ ("swin2sr", ("Swin2SRImageProcessor",)),
+ ("swinv2", ("ViTImageProcessor", "ViTImageProcessorFast")),
+ ("table-transformer", ("DetrImageProcessor",)),
+ ("timesformer", ("VideoMAEImageProcessor",)),
+ ("timm_wrapper", ("TimmWrapperImageProcessor",)),
+ ("tvlt", ("TvltImageProcessor",)),
+ ("tvp", ("TvpImageProcessor",)),
+ ("udop", ("LayoutLMv3ImageProcessor", "LayoutLMv3ImageProcessorFast")),
+ ("upernet", ("SegformerImageProcessor",)),
+ ("van", ("ConvNextImageProcessor", "ConvNextImageProcessorFast")),
+ ("videomae", ("VideoMAEImageProcessor",)),
+ ("vilt", ("ViltImageProcessor",)),
+ ("vipllava", ("CLIPImageProcessor", "CLIPImageProcessorFast")),
+ ("vit", ("ViTImageProcessor", "ViTImageProcessorFast")),
+ ("vit_hybrid", ("ViTHybridImageProcessor",)),
+ ("vit_mae", ("ViTImageProcessor", "ViTImageProcessorFast")),
+ ("vit_msn", ("ViTImageProcessor", "ViTImageProcessorFast")),
+ ("vitmatte", ("VitMatteImageProcessor",)),
+ ("xclip", ("CLIPImageProcessor", "CLIPImageProcessorFast")),
+ ("yolos", ("YolosImageProcessor", "YolosImageProcessorFast")),
+ ("zoedepth", ("ZoeDepthImageProcessor",)),
+ ]
+ )
+
+for model_type, image_processors in IMAGE_PROCESSOR_MAPPING_NAMES.items():
+ slow_image_processor_class, *fast_image_processor_class = image_processors
+ if not is_vision_available():
+ slow_image_processor_class = None
+
+ # If the fast image processor is not defined, or torchvision is not available, we set it to None
+ if not fast_image_processor_class or fast_image_processor_class[0] is None or not is_torchvision_available():
+ fast_image_processor_class = None
+ else:
+ fast_image_processor_class = fast_image_processor_class[0]
+
+ IMAGE_PROCESSOR_MAPPING_NAMES[model_type] = (slow_image_processor_class, fast_image_processor_class)
+
+IMAGE_PROCESSOR_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, IMAGE_PROCESSOR_MAPPING_NAMES)
+
+
+def get_image_processor_class_from_name(class_name: str):
+ if class_name == "BaseImageProcessorFast":
+ return BaseImageProcessorFast
+
+ for module_name, extractors in IMAGE_PROCESSOR_MAPPING_NAMES.items():
+ if class_name in extractors:
+ module_name = model_type_to_module_name(module_name)
+
+ module = importlib.import_module(f".{module_name}", "transformers.models")
+ try:
+ return getattr(module, class_name)
+ except AttributeError:
+ continue
+
+ for _, extractors in IMAGE_PROCESSOR_MAPPING._extra_content.items():
+ for extractor in extractors:
+ if getattr(extractor, "__name__", None) == class_name:
+ return extractor
+
+ # We did not find the class, but maybe it's because a dep is missing. In that case, the class will be in the main
+ # init and we return the proper dummy to get an appropriate error message.
+ main_module = importlib.import_module("transformers")
+ if hasattr(main_module, class_name):
+ return getattr(main_module, class_name)
+
+ return None
+
+
+def get_image_processor_config(
+ pretrained_model_name_or_path: Union[str, os.PathLike],
+ cache_dir: Optional[Union[str, os.PathLike]] = None,
+ force_download: bool = False,
+ resume_download: Optional[bool] = None,
+ proxies: Optional[Dict[str, str]] = None,
+ token: Optional[Union[bool, str]] = None,
+ revision: Optional[str] = None,
+ local_files_only: bool = False,
+ **kwargs,
+):
+ """
+ Loads the image processor configuration from a pretrained model image processor configuration.
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained model configuration hosted inside a model repo on
+ huggingface.co.
+ - a path to a *directory* containing a configuration file saved using the
+ [`~PreTrainedTokenizer.save_pretrained`] method, e.g., `./my_model_directory/`.
+
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the standard
+ cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the configuration files and override the cached versions if they
+ exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ local_files_only (`bool`, *optional*, defaults to `False`):
+ If `True`, will only try to load the image processor configuration from local files.
+
+
+
+ Passing `token=True` is required when you want to use a private model.
+
+
+
+ Returns:
+ `Dict`: The configuration of the image processor.
+
+ Examples:
+
+ ```python
+ # Download configuration from huggingface.co and cache.
+ image_processor_config = get_image_processor_config("google-bert/bert-base-uncased")
+ # This model does not have a image processor config so the result will be an empty dict.
+ image_processor_config = get_image_processor_config("FacebookAI/xlm-roberta-base")
+
+ # Save a pretrained image processor locally and you can reload its config
+ from transformers import AutoTokenizer
+
+ image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
+ image_processor.save_pretrained("image-processor-test")
+ image_processor_config = get_image_processor_config("image-processor-test")
+ ```"""
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if token is not None:
+ raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
+ token = use_auth_token
+
+ resolved_config_file = cached_file(
+ pretrained_model_name_or_path,
+ IMAGE_PROCESSOR_NAME,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ token=token,
+ revision=revision,
+ local_files_only=local_files_only,
+ _raise_exceptions_for_gated_repo=False,
+ _raise_exceptions_for_missing_entries=False,
+ _raise_exceptions_for_connection_errors=False,
+ )
+ if resolved_config_file is None:
+ logger.info(
+ "Could not locate the image processor configuration file, will try to use the model config instead."
+ )
+ return {}
+
+ with open(resolved_config_file, encoding="utf-8") as reader:
+ return json.load(reader)
+
+
+def _warning_fast_image_processor_available(fast_class):
+ logger.warning(
+ f"Fast image processor class {fast_class} is available for this model. "
+ "Using slow image processor class. To use the fast image processor class set `use_fast=True`."
+ )
+
+
+@requires(backends=("vision",))
+class AutoImageProcessor:
+ r"""
+ This is a generic image processor class that will be instantiated as one of the image processor classes of the
+ library when created with the [`AutoImageProcessor.from_pretrained`] class method.
+
+ This class cannot be instantiated directly using `__init__()` (throws an error).
+ """
+
+ def __init__(self):
+ raise EnvironmentError(
+ "AutoImageProcessor is designed to be instantiated "
+ "using the `AutoImageProcessor.from_pretrained(pretrained_model_name_or_path)` method."
+ )
+
+ @classmethod
+ @replace_list_option_in_docstrings(IMAGE_PROCESSOR_MAPPING_NAMES)
+ def from_pretrained(cls, pretrained_model_name_or_path, *inputs, **kwargs):
+ r"""
+ Instantiate one of the image processor classes of the library from a pretrained model vocabulary.
+
+ The image processor class to instantiate is selected based on the `model_type` property of the config object
+ (either passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's
+ missing, by falling back to using pattern matching on `pretrained_model_name_or_path`:
+
+ List options
+
+ Params:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained image_processor hosted inside a model repo on
+ huggingface.co.
+ - a path to a *directory* containing a image processor file saved using the
+ [`~image_processing_utils.ImageProcessingMixin.save_pretrained`] method, e.g.,
+ `./my_model_directory/`.
+ - a path or url to a saved image processor JSON *file*, e.g.,
+ `./my_model_directory/preprocessor_config.json`.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model image processor should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the image processor files and override the cached versions if
+ they exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ use_fast (`bool`, *optional*, defaults to `False`):
+ Use a fast torchvision-base image processor if it is supported for a given model.
+ If a fast image processor is not available for a given model, a normal numpy-based image processor
+ is returned instead.
+ return_unused_kwargs (`bool`, *optional*, defaults to `False`):
+ If `False`, then this function returns just the final image processor object. If `True`, then this
+ functions returns a `Tuple(image_processor, unused_kwargs)` where *unused_kwargs* is a dictionary
+ consisting of the key/value pairs whose keys are not image processor attributes: i.e., the part of
+ `kwargs` which has not been used to update `image_processor` and is otherwise ignored.
+ trust_remote_code (`bool`, *optional*, defaults to `False`):
+ Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
+ should only be set to `True` for repositories you trust and in which you have read the code, as it will
+ execute code present on the Hub on your local machine.
+ image_processor_filename (`str`, *optional*, defaults to `"config.json"`):
+ The name of the file in the model directory to use for the image processor config.
+ kwargs (`Dict[str, Any]`, *optional*):
+ The values in kwargs of any keys which are image processor attributes will be used to override the
+ loaded values. Behavior concerning key/value pairs whose keys are *not* image processor attributes is
+ controlled by the `return_unused_kwargs` keyword parameter.
+
+
+
+ Passing `token=True` is required when you want to use a private model.
+
+
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoImageProcessor
+
+ >>> # Download image processor from huggingface.co and cache.
+ >>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
+
+ >>> # If image processor files are in a directory (e.g. image processor was saved using *save_pretrained('./test/saved_model/')*)
+ >>> # image_processor = AutoImageProcessor.from_pretrained("./test/saved_model/")
+ ```"""
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if kwargs.get("token", None) is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ kwargs["token"] = use_auth_token
+
+ config = kwargs.pop("config", None)
+ # TODO: @yoni, change in v4.48 (use_fast set to True by default)
+ use_fast = kwargs.pop("use_fast", None)
+ trust_remote_code = kwargs.pop("trust_remote_code", None)
+ kwargs["_from_auto"] = True
+
+ # Resolve the image processor config filename
+ if "image_processor_filename" in kwargs:
+ image_processor_filename = kwargs.pop("image_processor_filename")
+ elif is_timm_local_checkpoint(pretrained_model_name_or_path):
+ image_processor_filename = CONFIG_NAME
+ else:
+ image_processor_filename = IMAGE_PROCESSOR_NAME
+
+ # Load the image processor config
+ try:
+ # Main path for all transformers models and local TimmWrapper checkpoints
+ config_dict, _ = ImageProcessingMixin.get_image_processor_dict(
+ pretrained_model_name_or_path, image_processor_filename=image_processor_filename, **kwargs
+ )
+ except Exception as initial_exception:
+ # Fallback path for Hub TimmWrapper checkpoints. Timm models' image processing is saved in `config.json`
+ # instead of `preprocessor_config.json`. Because this is an Auto class and we don't have any information
+ # except the model name, the only way to check if a remote checkpoint is a timm model is to try to
+ # load `config.json` and if it fails with some error, we raise the initial exception.
+ try:
+ config_dict, _ = ImageProcessingMixin.get_image_processor_dict(
+ pretrained_model_name_or_path, image_processor_filename=CONFIG_NAME, **kwargs
+ )
+ except Exception:
+ raise initial_exception
+
+ # In case we have a config_dict, but it's not a timm config dict, we raise the initial exception,
+ # because only timm models have image processing in `config.json`.
+ if not is_timm_config_dict(config_dict):
+ raise initial_exception
+
+ image_processor_type = config_dict.get("image_processor_type", None)
+ image_processor_auto_map = None
+ if "AutoImageProcessor" in config_dict.get("auto_map", {}):
+ image_processor_auto_map = config_dict["auto_map"]["AutoImageProcessor"]
+
+ # If we still don't have the image processor class, check if we're loading from a previous feature extractor config
+ # and if so, infer the image processor class from there.
+ if image_processor_type is None and image_processor_auto_map is None:
+ feature_extractor_class = config_dict.pop("feature_extractor_type", None)
+ if feature_extractor_class is not None:
+ image_processor_type = feature_extractor_class.replace("FeatureExtractor", "ImageProcessor")
+ if "AutoFeatureExtractor" in config_dict.get("auto_map", {}):
+ feature_extractor_auto_map = config_dict["auto_map"]["AutoFeatureExtractor"]
+ image_processor_auto_map = feature_extractor_auto_map.replace("FeatureExtractor", "ImageProcessor")
+
+ # If we don't find the image processor class in the image processor config, let's try the model config.
+ if image_processor_type is None and image_processor_auto_map is None:
+ if not isinstance(config, PretrainedConfig):
+ config = AutoConfig.from_pretrained(
+ pretrained_model_name_or_path,
+ trust_remote_code=trust_remote_code,
+ **kwargs,
+ )
+ # It could be in `config.image_processor_type``
+ image_processor_type = getattr(config, "image_processor_type", None)
+ if hasattr(config, "auto_map") and "AutoImageProcessor" in config.auto_map:
+ image_processor_auto_map = config.auto_map["AutoImageProcessor"]
+
+ image_processor_class = None
+ # TODO: @yoni, change logic in v4.52 (when use_fast set to True by default)
+ if image_processor_type is not None:
+ # if use_fast is not set and the processor was saved with a fast processor, we use it, otherwise we use the slow processor.
+ if use_fast is None:
+ use_fast = image_processor_type.endswith("Fast")
+ if not use_fast:
+ logger.warning_once(
+ "Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. "
+ "`use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. "
+ "This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`."
+ )
+ # Update class name to reflect the use_fast option. If class is not found, we fall back to the slow version.
+ if use_fast and not is_torchvision_available():
+ logger.warning_once(
+ "Using `use_fast=True` but `torchvision` is not available. Falling back to the slow image processor."
+ )
+ use_fast = False
+ if use_fast:
+ if not image_processor_type.endswith("Fast"):
+ image_processor_type += "Fast"
+ for _, image_processors in IMAGE_PROCESSOR_MAPPING_NAMES.items():
+ if image_processor_type in image_processors:
+ break
+ else:
+ image_processor_type = image_processor_type[:-4]
+ use_fast = False
+ logger.warning_once(
+ "`use_fast` is set to `True` but the image processor class does not have a fast version. "
+ " Falling back to the slow version."
+ )
+ image_processor_class = get_image_processor_class_from_name(image_processor_type)
+ else:
+ image_processor_type = (
+ image_processor_type[:-4] if image_processor_type.endswith("Fast") else image_processor_type
+ )
+ image_processor_class = get_image_processor_class_from_name(image_processor_type)
+
+ has_remote_code = image_processor_auto_map is not None
+ has_local_code = image_processor_class is not None or type(config) in IMAGE_PROCESSOR_MAPPING
+ trust_remote_code = resolve_trust_remote_code(
+ trust_remote_code, pretrained_model_name_or_path, has_local_code, has_remote_code
+ )
+
+ if image_processor_auto_map is not None and not isinstance(image_processor_auto_map, tuple):
+ # In some configs, only the slow image processor class is stored
+ image_processor_auto_map = (image_processor_auto_map, None)
+
+ if has_remote_code and trust_remote_code:
+ if not use_fast and image_processor_auto_map[1] is not None:
+ _warning_fast_image_processor_available(image_processor_auto_map[1])
+
+ if use_fast and image_processor_auto_map[1] is not None:
+ class_ref = image_processor_auto_map[1]
+ else:
+ class_ref = image_processor_auto_map[0]
+ image_processor_class = get_class_from_dynamic_module(class_ref, pretrained_model_name_or_path, **kwargs)
+ _ = kwargs.pop("code_revision", None)
+ if os.path.isdir(pretrained_model_name_or_path):
+ image_processor_class.register_for_auto_class()
+ return image_processor_class.from_dict(config_dict, **kwargs)
+ elif image_processor_class is not None:
+ return image_processor_class.from_dict(config_dict, **kwargs)
+ # Last try: we use the IMAGE_PROCESSOR_MAPPING.
+ elif type(config) in IMAGE_PROCESSOR_MAPPING:
+ image_processor_tuple = IMAGE_PROCESSOR_MAPPING[type(config)]
+
+ image_processor_class_py, image_processor_class_fast = image_processor_tuple
+
+ if not use_fast and image_processor_class_fast is not None:
+ _warning_fast_image_processor_available(image_processor_class_fast)
+
+ if image_processor_class_fast and (use_fast or image_processor_class_py is None):
+ return image_processor_class_fast.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
+ else:
+ if image_processor_class_py is not None:
+ return image_processor_class_py.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
+ else:
+ raise ValueError(
+ "This image processor cannot be instantiated. Please make sure you have `Pillow` installed."
+ )
+
+ raise ValueError(
+ f"Unrecognized image processor in {pretrained_model_name_or_path}. Should have a "
+ f"`image_processor_type` key in its {IMAGE_PROCESSOR_NAME} of {CONFIG_NAME}, or one of the following "
+ f"`model_type` keys in its {CONFIG_NAME}: {', '.join(c for c in IMAGE_PROCESSOR_MAPPING_NAMES.keys())}"
+ )
+
+ @staticmethod
+ def register(
+ config_class,
+ image_processor_class=None,
+ slow_image_processor_class=None,
+ fast_image_processor_class=None,
+ exist_ok=False,
+ ):
+ """
+ Register a new image processor for this class.
+
+ Args:
+ config_class ([`PretrainedConfig`]):
+ The configuration corresponding to the model to register.
+ image_processor_class ([`ImageProcessingMixin`]): The image processor to register.
+ """
+ if image_processor_class is not None:
+ if slow_image_processor_class is not None:
+ raise ValueError("Cannot specify both image_processor_class and slow_image_processor_class")
+ warnings.warn(
+ "The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead",
+ FutureWarning,
+ )
+ slow_image_processor_class = image_processor_class
+
+ if slow_image_processor_class is None and fast_image_processor_class is None:
+ raise ValueError("You need to specify either slow_image_processor_class or fast_image_processor_class")
+ if slow_image_processor_class is not None and issubclass(slow_image_processor_class, BaseImageProcessorFast):
+ raise ValueError("You passed a fast image processor in as the `slow_image_processor_class`.")
+ if fast_image_processor_class is not None and not issubclass(
+ fast_image_processor_class, BaseImageProcessorFast
+ ):
+ raise ValueError("The `fast_image_processor_class` should inherit from `BaseImageProcessorFast`.")
+
+ if (
+ slow_image_processor_class is not None
+ and fast_image_processor_class is not None
+ and issubclass(fast_image_processor_class, BaseImageProcessorFast)
+ and fast_image_processor_class.slow_image_processor_class != slow_image_processor_class
+ ):
+ raise ValueError(
+ "The fast processor class you are passing has a `slow_image_processor_class` attribute that is not "
+ "consistent with the slow processor class you passed (fast tokenizer has "
+ f"{fast_image_processor_class.slow_image_processor_class} and you passed {slow_image_processor_class}. Fix one of those "
+ "so they match!"
+ )
+
+ # Avoid resetting a set slow/fast image processor if we are passing just the other ones.
+ if config_class in IMAGE_PROCESSOR_MAPPING._extra_content:
+ existing_slow, existing_fast = IMAGE_PROCESSOR_MAPPING[config_class]
+ if slow_image_processor_class is None:
+ slow_image_processor_class = existing_slow
+ if fast_image_processor_class is None:
+ fast_image_processor_class = existing_fast
+
+ IMAGE_PROCESSOR_MAPPING.register(
+ config_class, (slow_image_processor_class, fast_image_processor_class), exist_ok=exist_ok
+ )
+
+
+__all__ = ["IMAGE_PROCESSOR_MAPPING", "AutoImageProcessor"]
diff --git a/docs/transformers/src/transformers/models/auto/modeling_auto.py b/docs/transformers/src/transformers/models/auto/modeling_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..a7271d04f6071cc2450861fc19655a5e3e1a6a76
--- /dev/null
+++ b/docs/transformers/src/transformers/models/auto/modeling_auto.py
@@ -0,0 +1,2077 @@
+# coding=utf-8
+# Copyright 2018 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Auto Model class."""
+
+import warnings
+from collections import OrderedDict
+
+from ...utils import logging
+from .auto_factory import (
+ _BaseAutoBackboneClass,
+ _BaseAutoModelClass,
+ _LazyAutoMapping,
+ auto_class_update,
+)
+from .configuration_auto import CONFIG_MAPPING_NAMES
+
+
+logger = logging.get_logger(__name__)
+
+MODEL_MAPPING_NAMES = OrderedDict(
+ [
+ # Base model mapping
+ ("albert", "AlbertModel"),
+ ("align", "AlignModel"),
+ ("altclip", "AltCLIPModel"),
+ ("aria", "AriaForConditionalGeneration"),
+ ("aria_text", "AriaTextModel"),
+ ("audio-spectrogram-transformer", "ASTModel"),
+ ("autoformer", "AutoformerModel"),
+ ("bamba", "BambaModel"),
+ ("bark", "BarkModel"),
+ ("bart", "BartModel"),
+ ("beit", "BeitModel"),
+ ("bert", "BertModel"),
+ ("bert-generation", "BertGenerationEncoder"),
+ ("big_bird", "BigBirdModel"),
+ ("bigbird_pegasus", "BigBirdPegasusModel"),
+ ("biogpt", "BioGptModel"),
+ ("bit", "BitModel"),
+ ("blenderbot", "BlenderbotModel"),
+ ("blenderbot-small", "BlenderbotSmallModel"),
+ ("blip", "BlipModel"),
+ ("blip-2", "Blip2Model"),
+ ("blip_2_qformer", "Blip2QFormerModel"),
+ ("bloom", "BloomModel"),
+ ("bridgetower", "BridgeTowerModel"),
+ ("bros", "BrosModel"),
+ ("camembert", "CamembertModel"),
+ ("canine", "CanineModel"),
+ ("chameleon", "ChameleonModel"),
+ ("chinese_clip", "ChineseCLIPModel"),
+ ("chinese_clip_vision_model", "ChineseCLIPVisionModel"),
+ ("clap", "ClapModel"),
+ ("clip", "CLIPModel"),
+ ("clip_text_model", "CLIPTextModel"),
+ ("clip_vision_model", "CLIPVisionModel"),
+ ("clipseg", "CLIPSegModel"),
+ ("clvp", "ClvpModelForConditionalGeneration"),
+ ("code_llama", "LlamaModel"),
+ ("codegen", "CodeGenModel"),
+ ("cohere", "CohereModel"),
+ ("cohere2", "Cohere2Model"),
+ ("conditional_detr", "ConditionalDetrModel"),
+ ("convbert", "ConvBertModel"),
+ ("convnext", "ConvNextModel"),
+ ("convnextv2", "ConvNextV2Model"),
+ ("cpmant", "CpmAntModel"),
+ ("ctrl", "CTRLModel"),
+ ("cvt", "CvtModel"),
+ ("dab-detr", "DabDetrModel"),
+ ("dac", "DacModel"),
+ ("data2vec-audio", "Data2VecAudioModel"),
+ ("data2vec-text", "Data2VecTextModel"),
+ ("data2vec-vision", "Data2VecVisionModel"),
+ ("dbrx", "DbrxModel"),
+ ("deberta", "DebertaModel"),
+ ("deberta-v2", "DebertaV2Model"),
+ ("decision_transformer", "DecisionTransformerModel"),
+ ("deepseek_v3", "DeepseekV3Model"),
+ ("deformable_detr", "DeformableDetrModel"),
+ ("deit", "DeiTModel"),
+ ("depth_pro", "DepthProModel"),
+ ("deta", "DetaModel"),
+ ("detr", "DetrModel"),
+ ("diffllama", "DiffLlamaModel"),
+ ("dinat", "DinatModel"),
+ ("dinov2", "Dinov2Model"),
+ ("dinov2_with_registers", "Dinov2WithRegistersModel"),
+ ("distilbert", "DistilBertModel"),
+ ("donut-swin", "DonutSwinModel"),
+ ("dpr", "DPRQuestionEncoder"),
+ ("dpt", "DPTModel"),
+ ("efficientformer", "EfficientFormerModel"),
+ ("efficientnet", "EfficientNetModel"),
+ ("electra", "ElectraModel"),
+ ("encodec", "EncodecModel"),
+ ("ernie", "ErnieModel"),
+ ("ernie_m", "ErnieMModel"),
+ ("esm", "EsmModel"),
+ ("falcon", "FalconModel"),
+ ("falcon_mamba", "FalconMambaModel"),
+ ("fastspeech2_conformer", "FastSpeech2ConformerModel"),
+ ("flaubert", "FlaubertModel"),
+ ("flava", "FlavaModel"),
+ ("fnet", "FNetModel"),
+ ("focalnet", "FocalNetModel"),
+ ("fsmt", "FSMTModel"),
+ ("funnel", ("FunnelModel", "FunnelBaseModel")),
+ ("gemma", "GemmaModel"),
+ ("gemma2", "Gemma2Model"),
+ ("gemma3_text", "Gemma3TextModel"),
+ ("git", "GitModel"),
+ ("glm", "GlmModel"),
+ ("glm4", "Glm4Model"),
+ ("glpn", "GLPNModel"),
+ ("got_ocr2", "GotOcr2ForConditionalGeneration"),
+ ("gpt-sw3", "GPT2Model"),
+ ("gpt2", "GPT2Model"),
+ ("gpt_bigcode", "GPTBigCodeModel"),
+ ("gpt_neo", "GPTNeoModel"),
+ ("gpt_neox", "GPTNeoXModel"),
+ ("gpt_neox_japanese", "GPTNeoXJapaneseModel"),
+ ("gptj", "GPTJModel"),
+ ("gptsan-japanese", "GPTSanJapaneseForConditionalGeneration"),
+ ("granite", "GraniteModel"),
+ ("granitemoe", "GraniteMoeModel"),
+ ("granitemoeshared", "GraniteMoeSharedModel"),
+ ("graphormer", "GraphormerModel"),
+ ("grounding-dino", "GroundingDinoModel"),
+ ("groupvit", "GroupViTModel"),
+ ("helium", "HeliumModel"),
+ ("hiera", "HieraModel"),
+ ("hubert", "HubertModel"),
+ ("ibert", "IBertModel"),
+ ("idefics", "IdeficsModel"),
+ ("idefics2", "Idefics2Model"),
+ ("idefics3", "Idefics3Model"),
+ ("idefics3_vision", "Idefics3VisionTransformer"),
+ ("ijepa", "IJepaModel"),
+ ("imagegpt", "ImageGPTModel"),
+ ("informer", "InformerModel"),
+ ("internvl_vision", "InternVLVisionModel"),
+ ("jamba", "JambaModel"),
+ ("janus", "JanusModel"),
+ ("jetmoe", "JetMoeModel"),
+ ("jukebox", "JukeboxModel"),
+ ("kosmos-2", "Kosmos2Model"),
+ ("layoutlm", "LayoutLMModel"),
+ ("layoutlmv2", "LayoutLMv2Model"),
+ ("layoutlmv3", "LayoutLMv3Model"),
+ ("led", "LEDModel"),
+ ("levit", "LevitModel"),
+ ("lilt", "LiltModel"),
+ ("llama", "LlamaModel"),
+ ("llama4", "Llama4ForConditionalGeneration"),
+ ("longformer", "LongformerModel"),
+ ("longt5", "LongT5Model"),
+ ("luke", "LukeModel"),
+ ("lxmert", "LxmertModel"),
+ ("m2m_100", "M2M100Model"),
+ ("mamba", "MambaModel"),
+ ("mamba2", "Mamba2Model"),
+ ("marian", "MarianModel"),
+ ("markuplm", "MarkupLMModel"),
+ ("mask2former", "Mask2FormerModel"),
+ ("maskformer", "MaskFormerModel"),
+ ("maskformer-swin", "MaskFormerSwinModel"),
+ ("mbart", "MBartModel"),
+ ("mctct", "MCTCTModel"),
+ ("mega", "MegaModel"),
+ ("megatron-bert", "MegatronBertModel"),
+ ("mgp-str", "MgpstrForSceneTextRecognition"),
+ ("mimi", "MimiModel"),
+ ("mistral", "MistralModel"),
+ ("mixtral", "MixtralModel"),
+ ("mlcd", "MLCDVisionModel"),
+ ("mobilebert", "MobileBertModel"),
+ ("mobilenet_v1", "MobileNetV1Model"),
+ ("mobilenet_v2", "MobileNetV2Model"),
+ ("mobilevit", "MobileViTModel"),
+ ("mobilevitv2", "MobileViTV2Model"),
+ ("modernbert", "ModernBertModel"),
+ ("moonshine", "MoonshineModel"),
+ ("moshi", "MoshiModel"),
+ ("mpnet", "MPNetModel"),
+ ("mpt", "MptModel"),
+ ("mra", "MraModel"),
+ ("mt5", "MT5Model"),
+ ("musicgen", "MusicgenModel"),
+ ("musicgen_melody", "MusicgenMelodyModel"),
+ ("mvp", "MvpModel"),
+ ("nat", "NatModel"),
+ ("nemotron", "NemotronModel"),
+ ("nezha", "NezhaModel"),
+ ("nllb-moe", "NllbMoeModel"),
+ ("nystromformer", "NystromformerModel"),
+ ("olmo", "OlmoModel"),
+ ("olmo2", "Olmo2Model"),
+ ("olmoe", "OlmoeModel"),
+ ("omdet-turbo", "OmDetTurboForObjectDetection"),
+ ("oneformer", "OneFormerModel"),
+ ("open-llama", "OpenLlamaModel"),
+ ("openai-gpt", "OpenAIGPTModel"),
+ ("opt", "OPTModel"),
+ ("owlv2", "Owlv2Model"),
+ ("owlvit", "OwlViTModel"),
+ ("patchtsmixer", "PatchTSMixerModel"),
+ ("patchtst", "PatchTSTModel"),
+ ("pegasus", "PegasusModel"),
+ ("pegasus_x", "PegasusXModel"),
+ ("perceiver", "PerceiverModel"),
+ ("persimmon", "PersimmonModel"),
+ ("phi", "PhiModel"),
+ ("phi3", "Phi3Model"),
+ ("phi4_multimodal", "Phi4MultimodalModel"),
+ ("phimoe", "PhimoeModel"),
+ ("pixtral", "PixtralVisionModel"),
+ ("plbart", "PLBartModel"),
+ ("poolformer", "PoolFormerModel"),
+ ("prophetnet", "ProphetNetModel"),
+ ("pvt", "PvtModel"),
+ ("pvt_v2", "PvtV2Model"),
+ ("qdqbert", "QDQBertModel"),
+ ("qwen2", "Qwen2Model"),
+ ("qwen2_5_vl", "Qwen2_5_VLModel"),
+ ("qwen2_5_vl_text", "Qwen2_5_VLModel"),
+ ("qwen2_audio_encoder", "Qwen2AudioEncoder"),
+ ("qwen2_moe", "Qwen2MoeModel"),
+ ("qwen2_vl", "Qwen2VLModel"),
+ ("qwen2_vl_text", "Qwen2VLModel"),
+ ("qwen3", "Qwen3Model"),
+ ("qwen3_moe", "Qwen3MoeModel"),
+ ("recurrent_gemma", "RecurrentGemmaModel"),
+ ("reformer", "ReformerModel"),
+ ("regnet", "RegNetModel"),
+ ("rembert", "RemBertModel"),
+ ("resnet", "ResNetModel"),
+ ("retribert", "RetriBertModel"),
+ ("roberta", "RobertaModel"),
+ ("roberta-prelayernorm", "RobertaPreLayerNormModel"),
+ ("roc_bert", "RoCBertModel"),
+ ("roformer", "RoFormerModel"),
+ ("rt_detr", "RTDetrModel"),
+ ("rt_detr_v2", "RTDetrV2Model"),
+ ("rwkv", "RwkvModel"),
+ ("sam", "SamModel"),
+ ("sam_vision_model", "SamVisionModel"),
+ ("seamless_m4t", "SeamlessM4TModel"),
+ ("seamless_m4t_v2", "SeamlessM4Tv2Model"),
+ ("segformer", "SegformerModel"),
+ ("seggpt", "SegGptModel"),
+ ("sew", "SEWModel"),
+ ("sew-d", "SEWDModel"),
+ ("siglip", "SiglipModel"),
+ ("siglip2", "Siglip2Model"),
+ ("siglip_vision_model", "SiglipVisionModel"),
+ ("smolvlm", "SmolVLMModel"),
+ ("smolvlm_vision", "SmolVLMVisionTransformer"),
+ ("speech_to_text", "Speech2TextModel"),
+ ("speecht5", "SpeechT5Model"),
+ ("splinter", "SplinterModel"),
+ ("squeezebert", "SqueezeBertModel"),
+ ("stablelm", "StableLmModel"),
+ ("starcoder2", "Starcoder2Model"),
+ ("superglue", "SuperGlueForKeypointMatching"),
+ ("swiftformer", "SwiftFormerModel"),
+ ("swin", "SwinModel"),
+ ("swin2sr", "Swin2SRModel"),
+ ("swinv2", "Swinv2Model"),
+ ("switch_transformers", "SwitchTransformersModel"),
+ ("t5", "T5Model"),
+ ("table-transformer", "TableTransformerModel"),
+ ("tapas", "TapasModel"),
+ ("textnet", "TextNetModel"),
+ ("time_series_transformer", "TimeSeriesTransformerModel"),
+ ("timesfm", "TimesFmModel"),
+ ("timesformer", "TimesformerModel"),
+ ("timm_backbone", "TimmBackbone"),
+ ("timm_wrapper", "TimmWrapperModel"),
+ ("trajectory_transformer", "TrajectoryTransformerModel"),
+ ("transfo-xl", "TransfoXLModel"),
+ ("tvlt", "TvltModel"),
+ ("tvp", "TvpModel"),
+ ("udop", "UdopModel"),
+ ("umt5", "UMT5Model"),
+ ("unispeech", "UniSpeechModel"),
+ ("unispeech-sat", "UniSpeechSatModel"),
+ ("univnet", "UnivNetModel"),
+ ("van", "VanModel"),
+ ("videomae", "VideoMAEModel"),
+ ("vilt", "ViltModel"),
+ ("vision-text-dual-encoder", "VisionTextDualEncoderModel"),
+ ("visual_bert", "VisualBertModel"),
+ ("vit", "ViTModel"),
+ ("vit_hybrid", "ViTHybridModel"),
+ ("vit_mae", "ViTMAEModel"),
+ ("vit_msn", "ViTMSNModel"),
+ ("vitdet", "VitDetModel"),
+ ("vits", "VitsModel"),
+ ("vivit", "VivitModel"),
+ ("wav2vec2", "Wav2Vec2Model"),
+ ("wav2vec2-bert", "Wav2Vec2BertModel"),
+ ("wav2vec2-conformer", "Wav2Vec2ConformerModel"),
+ ("wavlm", "WavLMModel"),
+ ("whisper", "WhisperModel"),
+ ("xclip", "XCLIPModel"),
+ ("xglm", "XGLMModel"),
+ ("xlm", "XLMModel"),
+ ("xlm-prophetnet", "XLMProphetNetModel"),
+ ("xlm-roberta", "XLMRobertaModel"),
+ ("xlm-roberta-xl", "XLMRobertaXLModel"),
+ ("xlnet", "XLNetModel"),
+ ("xmod", "XmodModel"),
+ ("yolos", "YolosModel"),
+ ("yoso", "YosoModel"),
+ ("zamba", "ZambaModel"),
+ ("zamba2", "Zamba2Model"),
+ ]
+)
+
+MODEL_FOR_PRETRAINING_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for pre-training mapping
+ ("albert", "AlbertForPreTraining"),
+ ("bart", "BartForConditionalGeneration"),
+ ("bert", "BertForPreTraining"),
+ ("big_bird", "BigBirdForPreTraining"),
+ ("bloom", "BloomForCausalLM"),
+ ("camembert", "CamembertForMaskedLM"),
+ ("colpali", "ColPaliForRetrieval"),
+ ("ctrl", "CTRLLMHeadModel"),
+ ("data2vec-text", "Data2VecTextForMaskedLM"),
+ ("deberta", "DebertaForMaskedLM"),
+ ("deberta-v2", "DebertaV2ForMaskedLM"),
+ ("distilbert", "DistilBertForMaskedLM"),
+ ("electra", "ElectraForPreTraining"),
+ ("ernie", "ErnieForPreTraining"),
+ ("falcon_mamba", "FalconMambaForCausalLM"),
+ ("flaubert", "FlaubertWithLMHeadModel"),
+ ("flava", "FlavaForPreTraining"),
+ ("fnet", "FNetForPreTraining"),
+ ("fsmt", "FSMTForConditionalGeneration"),
+ ("funnel", "FunnelForPreTraining"),
+ ("gemma3", "Gemma3ForConditionalGeneration"),
+ ("gpt-sw3", "GPT2LMHeadModel"),
+ ("gpt2", "GPT2LMHeadModel"),
+ ("gpt_bigcode", "GPTBigCodeForCausalLM"),
+ ("gptsan-japanese", "GPTSanJapaneseForConditionalGeneration"),
+ ("hiera", "HieraForPreTraining"),
+ ("ibert", "IBertForMaskedLM"),
+ ("idefics", "IdeficsForVisionText2Text"),
+ ("idefics2", "Idefics2ForConditionalGeneration"),
+ ("idefics3", "Idefics3ForConditionalGeneration"),
+ ("janus", "JanusForConditionalGeneration"),
+ ("layoutlm", "LayoutLMForMaskedLM"),
+ ("llava", "LlavaForConditionalGeneration"),
+ ("llava_next", "LlavaNextForConditionalGeneration"),
+ ("llava_next_video", "LlavaNextVideoForConditionalGeneration"),
+ ("llava_onevision", "LlavaOnevisionForConditionalGeneration"),
+ ("longformer", "LongformerForMaskedLM"),
+ ("luke", "LukeForMaskedLM"),
+ ("lxmert", "LxmertForPreTraining"),
+ ("mamba", "MambaForCausalLM"),
+ ("mamba2", "Mamba2ForCausalLM"),
+ ("mega", "MegaForMaskedLM"),
+ ("megatron-bert", "MegatronBertForPreTraining"),
+ ("mistral3", "Mistral3ForConditionalGeneration"),
+ ("mllama", "MllamaForConditionalGeneration"),
+ ("mobilebert", "MobileBertForPreTraining"),
+ ("mpnet", "MPNetForMaskedLM"),
+ ("mpt", "MptForCausalLM"),
+ ("mra", "MraForMaskedLM"),
+ ("mvp", "MvpForConditionalGeneration"),
+ ("nezha", "NezhaForPreTraining"),
+ ("nllb-moe", "NllbMoeForConditionalGeneration"),
+ ("openai-gpt", "OpenAIGPTLMHeadModel"),
+ ("paligemma", "PaliGemmaForConditionalGeneration"),
+ ("qwen2_audio", "Qwen2AudioForConditionalGeneration"),
+ ("retribert", "RetriBertModel"),
+ ("roberta", "RobertaForMaskedLM"),
+ ("roberta-prelayernorm", "RobertaPreLayerNormForMaskedLM"),
+ ("roc_bert", "RoCBertForPreTraining"),
+ ("rwkv", "RwkvForCausalLM"),
+ ("splinter", "SplinterForPreTraining"),
+ ("squeezebert", "SqueezeBertForMaskedLM"),
+ ("switch_transformers", "SwitchTransformersForConditionalGeneration"),
+ ("t5", "T5ForConditionalGeneration"),
+ ("tapas", "TapasForMaskedLM"),
+ ("transfo-xl", "TransfoXLLMHeadModel"),
+ ("tvlt", "TvltForPreTraining"),
+ ("unispeech", "UniSpeechForPreTraining"),
+ ("unispeech-sat", "UniSpeechSatForPreTraining"),
+ ("video_llava", "VideoLlavaForConditionalGeneration"),
+ ("videomae", "VideoMAEForPreTraining"),
+ ("vipllava", "VipLlavaForConditionalGeneration"),
+ ("visual_bert", "VisualBertForPreTraining"),
+ ("vit_mae", "ViTMAEForPreTraining"),
+ ("wav2vec2", "Wav2Vec2ForPreTraining"),
+ ("wav2vec2-conformer", "Wav2Vec2ConformerForPreTraining"),
+ ("xlm", "XLMWithLMHeadModel"),
+ ("xlm-roberta", "XLMRobertaForMaskedLM"),
+ ("xlm-roberta-xl", "XLMRobertaXLForMaskedLM"),
+ ("xlnet", "XLNetLMHeadModel"),
+ ("xmod", "XmodForMaskedLM"),
+ ]
+)
+
+MODEL_WITH_LM_HEAD_MAPPING_NAMES = OrderedDict(
+ [
+ # Model with LM heads mapping
+ ("albert", "AlbertForMaskedLM"),
+ ("bart", "BartForConditionalGeneration"),
+ ("bert", "BertForMaskedLM"),
+ ("big_bird", "BigBirdForMaskedLM"),
+ ("bigbird_pegasus", "BigBirdPegasusForConditionalGeneration"),
+ ("blenderbot-small", "BlenderbotSmallForConditionalGeneration"),
+ ("bloom", "BloomForCausalLM"),
+ ("camembert", "CamembertForMaskedLM"),
+ ("codegen", "CodeGenForCausalLM"),
+ ("convbert", "ConvBertForMaskedLM"),
+ ("cpmant", "CpmAntForCausalLM"),
+ ("ctrl", "CTRLLMHeadModel"),
+ ("data2vec-text", "Data2VecTextForMaskedLM"),
+ ("deberta", "DebertaForMaskedLM"),
+ ("deberta-v2", "DebertaV2ForMaskedLM"),
+ ("distilbert", "DistilBertForMaskedLM"),
+ ("electra", "ElectraForMaskedLM"),
+ ("encoder-decoder", "EncoderDecoderModel"),
+ ("ernie", "ErnieForMaskedLM"),
+ ("esm", "EsmForMaskedLM"),
+ ("falcon_mamba", "FalconMambaForCausalLM"),
+ ("flaubert", "FlaubertWithLMHeadModel"),
+ ("fnet", "FNetForMaskedLM"),
+ ("fsmt", "FSMTForConditionalGeneration"),
+ ("funnel", "FunnelForMaskedLM"),
+ ("git", "GitForCausalLM"),
+ ("gpt-sw3", "GPT2LMHeadModel"),
+ ("gpt2", "GPT2LMHeadModel"),
+ ("gpt_bigcode", "GPTBigCodeForCausalLM"),
+ ("gpt_neo", "GPTNeoForCausalLM"),
+ ("gpt_neox", "GPTNeoXForCausalLM"),
+ ("gpt_neox_japanese", "GPTNeoXJapaneseForCausalLM"),
+ ("gptj", "GPTJForCausalLM"),
+ ("gptsan-japanese", "GPTSanJapaneseForConditionalGeneration"),
+ ("ibert", "IBertForMaskedLM"),
+ ("layoutlm", "LayoutLMForMaskedLM"),
+ ("led", "LEDForConditionalGeneration"),
+ ("longformer", "LongformerForMaskedLM"),
+ ("longt5", "LongT5ForConditionalGeneration"),
+ ("luke", "LukeForMaskedLM"),
+ ("m2m_100", "M2M100ForConditionalGeneration"),
+ ("mamba", "MambaForCausalLM"),
+ ("mamba2", "Mamba2ForCausalLM"),
+ ("marian", "MarianMTModel"),
+ ("mega", "MegaForMaskedLM"),
+ ("megatron-bert", "MegatronBertForCausalLM"),
+ ("mobilebert", "MobileBertForMaskedLM"),
+ ("moonshine", "MoonshineForConditionalGeneration"),
+ ("mpnet", "MPNetForMaskedLM"),
+ ("mpt", "MptForCausalLM"),
+ ("mra", "MraForMaskedLM"),
+ ("mvp", "MvpForConditionalGeneration"),
+ ("nezha", "NezhaForMaskedLM"),
+ ("nllb-moe", "NllbMoeForConditionalGeneration"),
+ ("nystromformer", "NystromformerForMaskedLM"),
+ ("openai-gpt", "OpenAIGPTLMHeadModel"),
+ ("pegasus_x", "PegasusXForConditionalGeneration"),
+ ("plbart", "PLBartForConditionalGeneration"),
+ ("pop2piano", "Pop2PianoForConditionalGeneration"),
+ ("qdqbert", "QDQBertForMaskedLM"),
+ ("reformer", "ReformerModelWithLMHead"),
+ ("rembert", "RemBertForMaskedLM"),
+ ("roberta", "RobertaForMaskedLM"),
+ ("roberta-prelayernorm", "RobertaPreLayerNormForMaskedLM"),
+ ("roc_bert", "RoCBertForMaskedLM"),
+ ("roformer", "RoFormerForMaskedLM"),
+ ("rwkv", "RwkvForCausalLM"),
+ ("speech_to_text", "Speech2TextForConditionalGeneration"),
+ ("squeezebert", "SqueezeBertForMaskedLM"),
+ ("switch_transformers", "SwitchTransformersForConditionalGeneration"),
+ ("t5", "T5ForConditionalGeneration"),
+ ("tapas", "TapasForMaskedLM"),
+ ("transfo-xl", "TransfoXLLMHeadModel"),
+ ("wav2vec2", "Wav2Vec2ForMaskedLM"),
+ ("whisper", "WhisperForConditionalGeneration"),
+ ("xlm", "XLMWithLMHeadModel"),
+ ("xlm-roberta", "XLMRobertaForMaskedLM"),
+ ("xlm-roberta-xl", "XLMRobertaXLForMaskedLM"),
+ ("xlnet", "XLNetLMHeadModel"),
+ ("xmod", "XmodForMaskedLM"),
+ ("yoso", "YosoForMaskedLM"),
+ ]
+)
+
+MODEL_FOR_CAUSAL_LM_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Causal LM mapping
+ ("aria_text", "AriaTextForCausalLM"),
+ ("bamba", "BambaForCausalLM"),
+ ("bart", "BartForCausalLM"),
+ ("bert", "BertLMHeadModel"),
+ ("bert-generation", "BertGenerationDecoder"),
+ ("big_bird", "BigBirdForCausalLM"),
+ ("bigbird_pegasus", "BigBirdPegasusForCausalLM"),
+ ("biogpt", "BioGptForCausalLM"),
+ ("blenderbot", "BlenderbotForCausalLM"),
+ ("blenderbot-small", "BlenderbotSmallForCausalLM"),
+ ("bloom", "BloomForCausalLM"),
+ ("camembert", "CamembertForCausalLM"),
+ ("code_llama", "LlamaForCausalLM"),
+ ("codegen", "CodeGenForCausalLM"),
+ ("cohere", "CohereForCausalLM"),
+ ("cohere2", "Cohere2ForCausalLM"),
+ ("cpmant", "CpmAntForCausalLM"),
+ ("ctrl", "CTRLLMHeadModel"),
+ ("data2vec-text", "Data2VecTextForCausalLM"),
+ ("dbrx", "DbrxForCausalLM"),
+ ("deepseek_v3", "DeepseekV3ForCausalLM"),
+ ("diffllama", "DiffLlamaForCausalLM"),
+ ("electra", "ElectraForCausalLM"),
+ ("emu3", "Emu3ForCausalLM"),
+ ("ernie", "ErnieForCausalLM"),
+ ("falcon", "FalconForCausalLM"),
+ ("falcon_mamba", "FalconMambaForCausalLM"),
+ ("fuyu", "FuyuForCausalLM"),
+ ("gemma", "GemmaForCausalLM"),
+ ("gemma2", "Gemma2ForCausalLM"),
+ ("gemma3", "Gemma3ForConditionalGeneration"),
+ ("gemma3_text", "Gemma3ForCausalLM"),
+ ("git", "GitForCausalLM"),
+ ("glm", "GlmForCausalLM"),
+ ("glm4", "Glm4ForCausalLM"),
+ ("got_ocr2", "GotOcr2ForConditionalGeneration"),
+ ("gpt-sw3", "GPT2LMHeadModel"),
+ ("gpt2", "GPT2LMHeadModel"),
+ ("gpt_bigcode", "GPTBigCodeForCausalLM"),
+ ("gpt_neo", "GPTNeoForCausalLM"),
+ ("gpt_neox", "GPTNeoXForCausalLM"),
+ ("gpt_neox_japanese", "GPTNeoXJapaneseForCausalLM"),
+ ("gptj", "GPTJForCausalLM"),
+ ("granite", "GraniteForCausalLM"),
+ ("granitemoe", "GraniteMoeForCausalLM"),
+ ("granitemoeshared", "GraniteMoeSharedForCausalLM"),
+ ("helium", "HeliumForCausalLM"),
+ ("jamba", "JambaForCausalLM"),
+ ("jetmoe", "JetMoeForCausalLM"),
+ ("llama", "LlamaForCausalLM"),
+ ("llama4", "Llama4ForCausalLM"),
+ ("llama4_text", "Llama4ForCausalLM"),
+ ("mamba", "MambaForCausalLM"),
+ ("mamba2", "Mamba2ForCausalLM"),
+ ("marian", "MarianForCausalLM"),
+ ("mbart", "MBartForCausalLM"),
+ ("mega", "MegaForCausalLM"),
+ ("megatron-bert", "MegatronBertForCausalLM"),
+ ("mistral", "MistralForCausalLM"),
+ ("mixtral", "MixtralForCausalLM"),
+ ("mllama", "MllamaForCausalLM"),
+ ("moshi", "MoshiForCausalLM"),
+ ("mpt", "MptForCausalLM"),
+ ("musicgen", "MusicgenForCausalLM"),
+ ("musicgen_melody", "MusicgenMelodyForCausalLM"),
+ ("mvp", "MvpForCausalLM"),
+ ("nemotron", "NemotronForCausalLM"),
+ ("olmo", "OlmoForCausalLM"),
+ ("olmo2", "Olmo2ForCausalLM"),
+ ("olmoe", "OlmoeForCausalLM"),
+ ("open-llama", "OpenLlamaForCausalLM"),
+ ("openai-gpt", "OpenAIGPTLMHeadModel"),
+ ("opt", "OPTForCausalLM"),
+ ("pegasus", "PegasusForCausalLM"),
+ ("persimmon", "PersimmonForCausalLM"),
+ ("phi", "PhiForCausalLM"),
+ ("phi3", "Phi3ForCausalLM"),
+ ("phi4_multimodal", "Phi4MultimodalForCausalLM"),
+ ("phimoe", "PhimoeForCausalLM"),
+ ("plbart", "PLBartForCausalLM"),
+ ("prophetnet", "ProphetNetForCausalLM"),
+ ("qdqbert", "QDQBertLMHeadModel"),
+ ("qwen2", "Qwen2ForCausalLM"),
+ ("qwen2_moe", "Qwen2MoeForCausalLM"),
+ ("qwen3", "Qwen3ForCausalLM"),
+ ("qwen3_moe", "Qwen3MoeForCausalLM"),
+ ("recurrent_gemma", "RecurrentGemmaForCausalLM"),
+ ("reformer", "ReformerModelWithLMHead"),
+ ("rembert", "RemBertForCausalLM"),
+ ("roberta", "RobertaForCausalLM"),
+ ("roberta-prelayernorm", "RobertaPreLayerNormForCausalLM"),
+ ("roc_bert", "RoCBertForCausalLM"),
+ ("roformer", "RoFormerForCausalLM"),
+ ("rwkv", "RwkvForCausalLM"),
+ ("speech_to_text_2", "Speech2Text2ForCausalLM"),
+ ("stablelm", "StableLmForCausalLM"),
+ ("starcoder2", "Starcoder2ForCausalLM"),
+ ("transfo-xl", "TransfoXLLMHeadModel"),
+ ("trocr", "TrOCRForCausalLM"),
+ ("whisper", "WhisperForCausalLM"),
+ ("xglm", "XGLMForCausalLM"),
+ ("xlm", "XLMWithLMHeadModel"),
+ ("xlm-prophetnet", "XLMProphetNetForCausalLM"),
+ ("xlm-roberta", "XLMRobertaForCausalLM"),
+ ("xlm-roberta-xl", "XLMRobertaXLForCausalLM"),
+ ("xlnet", "XLNetLMHeadModel"),
+ ("xmod", "XmodForCausalLM"),
+ ("zamba", "ZambaForCausalLM"),
+ ("zamba2", "Zamba2ForCausalLM"),
+ ]
+)
+
+MODEL_FOR_IMAGE_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Image mapping
+ ("beit", "BeitModel"),
+ ("bit", "BitModel"),
+ ("conditional_detr", "ConditionalDetrModel"),
+ ("convnext", "ConvNextModel"),
+ ("convnextv2", "ConvNextV2Model"),
+ ("dab-detr", "DabDetrModel"),
+ ("data2vec-vision", "Data2VecVisionModel"),
+ ("deformable_detr", "DeformableDetrModel"),
+ ("deit", "DeiTModel"),
+ ("depth_pro", "DepthProModel"),
+ ("deta", "DetaModel"),
+ ("detr", "DetrModel"),
+ ("dinat", "DinatModel"),
+ ("dinov2", "Dinov2Model"),
+ ("dinov2_with_registers", "Dinov2WithRegistersModel"),
+ ("dpt", "DPTModel"),
+ ("efficientformer", "EfficientFormerModel"),
+ ("efficientnet", "EfficientNetModel"),
+ ("focalnet", "FocalNetModel"),
+ ("glpn", "GLPNModel"),
+ ("hiera", "HieraModel"),
+ ("ijepa", "IJepaModel"),
+ ("imagegpt", "ImageGPTModel"),
+ ("levit", "LevitModel"),
+ ("llama4", "Llama4VisionModel"),
+ ("mlcd", "MLCDVisionModel"),
+ ("mllama", "MllamaVisionModel"),
+ ("mobilenet_v1", "MobileNetV1Model"),
+ ("mobilenet_v2", "MobileNetV2Model"),
+ ("mobilevit", "MobileViTModel"),
+ ("mobilevitv2", "MobileViTV2Model"),
+ ("nat", "NatModel"),
+ ("poolformer", "PoolFormerModel"),
+ ("pvt", "PvtModel"),
+ ("regnet", "RegNetModel"),
+ ("resnet", "ResNetModel"),
+ ("segformer", "SegformerModel"),
+ ("siglip_vision_model", "SiglipVisionModel"),
+ ("swiftformer", "SwiftFormerModel"),
+ ("swin", "SwinModel"),
+ ("swin2sr", "Swin2SRModel"),
+ ("swinv2", "Swinv2Model"),
+ ("table-transformer", "TableTransformerModel"),
+ ("timesformer", "TimesformerModel"),
+ ("timm_backbone", "TimmBackbone"),
+ ("timm_wrapper", "TimmWrapperModel"),
+ ("van", "VanModel"),
+ ("videomae", "VideoMAEModel"),
+ ("vit", "ViTModel"),
+ ("vit_hybrid", "ViTHybridModel"),
+ ("vit_mae", "ViTMAEModel"),
+ ("vit_msn", "ViTMSNModel"),
+ ("vitdet", "VitDetModel"),
+ ("vivit", "VivitModel"),
+ ("yolos", "YolosModel"),
+ ]
+)
+
+MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING_NAMES = OrderedDict(
+ [
+ ("deit", "DeiTForMaskedImageModeling"),
+ ("focalnet", "FocalNetForMaskedImageModeling"),
+ ("swin", "SwinForMaskedImageModeling"),
+ ("swinv2", "Swinv2ForMaskedImageModeling"),
+ ("vit", "ViTForMaskedImageModeling"),
+ ]
+)
+
+
+MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING_NAMES = OrderedDict(
+ # Model for Causal Image Modeling mapping
+ [
+ ("imagegpt", "ImageGPTForCausalImageModeling"),
+ ]
+)
+
+MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Image Classification mapping
+ ("beit", "BeitForImageClassification"),
+ ("bit", "BitForImageClassification"),
+ ("clip", "CLIPForImageClassification"),
+ ("convnext", "ConvNextForImageClassification"),
+ ("convnextv2", "ConvNextV2ForImageClassification"),
+ ("cvt", "CvtForImageClassification"),
+ ("data2vec-vision", "Data2VecVisionForImageClassification"),
+ (
+ "deit",
+ ("DeiTForImageClassification", "DeiTForImageClassificationWithTeacher"),
+ ),
+ ("dinat", "DinatForImageClassification"),
+ ("dinov2", "Dinov2ForImageClassification"),
+ ("dinov2_with_registers", "Dinov2WithRegistersForImageClassification"),
+ ("donut-swin", "DonutSwinForImageClassification"),
+ (
+ "efficientformer",
+ (
+ "EfficientFormerForImageClassification",
+ "EfficientFormerForImageClassificationWithTeacher",
+ ),
+ ),
+ ("efficientnet", "EfficientNetForImageClassification"),
+ ("focalnet", "FocalNetForImageClassification"),
+ ("hiera", "HieraForImageClassification"),
+ ("ijepa", "IJepaForImageClassification"),
+ ("imagegpt", "ImageGPTForImageClassification"),
+ (
+ "levit",
+ ("LevitForImageClassification", "LevitForImageClassificationWithTeacher"),
+ ),
+ ("mobilenet_v1", "MobileNetV1ForImageClassification"),
+ ("mobilenet_v2", "MobileNetV2ForImageClassification"),
+ ("mobilevit", "MobileViTForImageClassification"),
+ ("mobilevitv2", "MobileViTV2ForImageClassification"),
+ ("nat", "NatForImageClassification"),
+ (
+ "perceiver",
+ (
+ "PerceiverForImageClassificationLearned",
+ "PerceiverForImageClassificationFourier",
+ "PerceiverForImageClassificationConvProcessing",
+ ),
+ ),
+ ("poolformer", "PoolFormerForImageClassification"),
+ ("pvt", "PvtForImageClassification"),
+ ("pvt_v2", "PvtV2ForImageClassification"),
+ ("regnet", "RegNetForImageClassification"),
+ ("resnet", "ResNetForImageClassification"),
+ ("segformer", "SegformerForImageClassification"),
+ ("shieldgemma2", "ShieldGemma2ForImageClassification"),
+ ("siglip", "SiglipForImageClassification"),
+ ("siglip2", "Siglip2ForImageClassification"),
+ ("swiftformer", "SwiftFormerForImageClassification"),
+ ("swin", "SwinForImageClassification"),
+ ("swinv2", "Swinv2ForImageClassification"),
+ ("textnet", "TextNetForImageClassification"),
+ ("timm_wrapper", "TimmWrapperForImageClassification"),
+ ("van", "VanForImageClassification"),
+ ("vit", "ViTForImageClassification"),
+ ("vit_hybrid", "ViTHybridForImageClassification"),
+ ("vit_msn", "ViTMSNForImageClassification"),
+ ]
+)
+
+MODEL_FOR_IMAGE_SEGMENTATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Do not add new models here, this class will be deprecated in the future.
+ # Model for Image Segmentation mapping
+ ("detr", "DetrForSegmentation"),
+ ]
+)
+
+MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Semantic Segmentation mapping
+ ("beit", "BeitForSemanticSegmentation"),
+ ("data2vec-vision", "Data2VecVisionForSemanticSegmentation"),
+ ("dpt", "DPTForSemanticSegmentation"),
+ ("mobilenet_v2", "MobileNetV2ForSemanticSegmentation"),
+ ("mobilevit", "MobileViTForSemanticSegmentation"),
+ ("mobilevitv2", "MobileViTV2ForSemanticSegmentation"),
+ ("segformer", "SegformerForSemanticSegmentation"),
+ ("upernet", "UperNetForSemanticSegmentation"),
+ ]
+)
+
+MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Instance Segmentation mapping
+ # MaskFormerForInstanceSegmentation can be removed from this mapping in v5
+ ("maskformer", "MaskFormerForInstanceSegmentation"),
+ ]
+)
+
+MODEL_FOR_UNIVERSAL_SEGMENTATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Universal Segmentation mapping
+ ("detr", "DetrForSegmentation"),
+ ("mask2former", "Mask2FormerForUniversalSegmentation"),
+ ("maskformer", "MaskFormerForInstanceSegmentation"),
+ ("oneformer", "OneFormerForUniversalSegmentation"),
+ ]
+)
+
+MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ ("timesformer", "TimesformerForVideoClassification"),
+ ("videomae", "VideoMAEForVideoClassification"),
+ ("vivit", "VivitForVideoClassification"),
+ ]
+)
+
+MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES = OrderedDict(
+ [
+ ("blip", "BlipForConditionalGeneration"),
+ ("blip-2", "Blip2ForConditionalGeneration"),
+ ("chameleon", "ChameleonForConditionalGeneration"),
+ ("git", "GitForCausalLM"),
+ ("idefics2", "Idefics2ForConditionalGeneration"),
+ ("idefics3", "Idefics3ForConditionalGeneration"),
+ ("instructblip", "InstructBlipForConditionalGeneration"),
+ ("instructblipvideo", "InstructBlipVideoForConditionalGeneration"),
+ ("kosmos-2", "Kosmos2ForConditionalGeneration"),
+ ("llava", "LlavaForConditionalGeneration"),
+ ("llava_next", "LlavaNextForConditionalGeneration"),
+ ("llava_next_video", "LlavaNextVideoForConditionalGeneration"),
+ ("llava_onevision", "LlavaOnevisionForConditionalGeneration"),
+ ("mistral3", "Mistral3ForConditionalGeneration"),
+ ("mllama", "MllamaForConditionalGeneration"),
+ ("paligemma", "PaliGemmaForConditionalGeneration"),
+ ("pix2struct", "Pix2StructForConditionalGeneration"),
+ ("qwen2_5_vl", "Qwen2_5_VLForConditionalGeneration"),
+ ("qwen2_vl", "Qwen2VLForConditionalGeneration"),
+ ("video_llava", "VideoLlavaForConditionalGeneration"),
+ ("vipllava", "VipLlavaForConditionalGeneration"),
+ ("vision-encoder-decoder", "VisionEncoderDecoderModel"),
+ ]
+)
+
+MODEL_FOR_RETRIEVAL_MAPPING_NAMES = OrderedDict(
+ [
+ ("colpali", "ColPaliForRetrieval"),
+ ]
+)
+
+MODEL_FOR_IMAGE_TEXT_TO_TEXT_MAPPING_NAMES = OrderedDict(
+ [
+ ("aria", "AriaForConditionalGeneration"),
+ ("aya_vision", "AyaVisionForConditionalGeneration"),
+ ("blip", "BlipForConditionalGeneration"),
+ ("blip-2", "Blip2ForConditionalGeneration"),
+ ("chameleon", "ChameleonForConditionalGeneration"),
+ ("emu3", "Emu3ForConditionalGeneration"),
+ ("fuyu", "FuyuForCausalLM"),
+ ("gemma3", "Gemma3ForConditionalGeneration"),
+ ("git", "GitForCausalLM"),
+ ("got_ocr2", "GotOcr2ForConditionalGeneration"),
+ ("idefics", "IdeficsForVisionText2Text"),
+ ("idefics2", "Idefics2ForConditionalGeneration"),
+ ("idefics3", "Idefics3ForConditionalGeneration"),
+ ("instructblip", "InstructBlipForConditionalGeneration"),
+ ("internvl", "InternVLForConditionalGeneration"),
+ ("janus", "JanusForConditionalGeneration"),
+ ("kosmos-2", "Kosmos2ForConditionalGeneration"),
+ ("llama4", "Llama4ForConditionalGeneration"),
+ ("llava", "LlavaForConditionalGeneration"),
+ ("llava_next", "LlavaNextForConditionalGeneration"),
+ ("llava_onevision", "LlavaOnevisionForConditionalGeneration"),
+ ("mistral3", "Mistral3ForConditionalGeneration"),
+ ("mllama", "MllamaForConditionalGeneration"),
+ ("paligemma", "PaliGemmaForConditionalGeneration"),
+ ("pix2struct", "Pix2StructForConditionalGeneration"),
+ ("pixtral", "LlavaForConditionalGeneration"),
+ ("qwen2_5_vl", "Qwen2_5_VLForConditionalGeneration"),
+ ("qwen2_vl", "Qwen2VLForConditionalGeneration"),
+ ("shieldgemma2", "Gemma3ForConditionalGeneration"),
+ ("smolvlm", "SmolVLMForConditionalGeneration"),
+ ("udop", "UdopForConditionalGeneration"),
+ ("vipllava", "VipLlavaForConditionalGeneration"),
+ ("vision-encoder-decoder", "VisionEncoderDecoderModel"),
+ ]
+)
+
+MODEL_FOR_MASKED_LM_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Masked LM mapping
+ ("albert", "AlbertForMaskedLM"),
+ ("bart", "BartForConditionalGeneration"),
+ ("bert", "BertForMaskedLM"),
+ ("big_bird", "BigBirdForMaskedLM"),
+ ("camembert", "CamembertForMaskedLM"),
+ ("convbert", "ConvBertForMaskedLM"),
+ ("data2vec-text", "Data2VecTextForMaskedLM"),
+ ("deberta", "DebertaForMaskedLM"),
+ ("deberta-v2", "DebertaV2ForMaskedLM"),
+ ("distilbert", "DistilBertForMaskedLM"),
+ ("electra", "ElectraForMaskedLM"),
+ ("ernie", "ErnieForMaskedLM"),
+ ("esm", "EsmForMaskedLM"),
+ ("flaubert", "FlaubertWithLMHeadModel"),
+ ("fnet", "FNetForMaskedLM"),
+ ("funnel", "FunnelForMaskedLM"),
+ ("ibert", "IBertForMaskedLM"),
+ ("layoutlm", "LayoutLMForMaskedLM"),
+ ("longformer", "LongformerForMaskedLM"),
+ ("luke", "LukeForMaskedLM"),
+ ("mbart", "MBartForConditionalGeneration"),
+ ("mega", "MegaForMaskedLM"),
+ ("megatron-bert", "MegatronBertForMaskedLM"),
+ ("mobilebert", "MobileBertForMaskedLM"),
+ ("modernbert", "ModernBertForMaskedLM"),
+ ("mpnet", "MPNetForMaskedLM"),
+ ("mra", "MraForMaskedLM"),
+ ("mvp", "MvpForConditionalGeneration"),
+ ("nezha", "NezhaForMaskedLM"),
+ ("nystromformer", "NystromformerForMaskedLM"),
+ ("perceiver", "PerceiverForMaskedLM"),
+ ("qdqbert", "QDQBertForMaskedLM"),
+ ("reformer", "ReformerForMaskedLM"),
+ ("rembert", "RemBertForMaskedLM"),
+ ("roberta", "RobertaForMaskedLM"),
+ ("roberta-prelayernorm", "RobertaPreLayerNormForMaskedLM"),
+ ("roc_bert", "RoCBertForMaskedLM"),
+ ("roformer", "RoFormerForMaskedLM"),
+ ("squeezebert", "SqueezeBertForMaskedLM"),
+ ("tapas", "TapasForMaskedLM"),
+ ("wav2vec2", "Wav2Vec2ForMaskedLM"),
+ ("xlm", "XLMWithLMHeadModel"),
+ ("xlm-roberta", "XLMRobertaForMaskedLM"),
+ ("xlm-roberta-xl", "XLMRobertaXLForMaskedLM"),
+ ("xmod", "XmodForMaskedLM"),
+ ("yoso", "YosoForMaskedLM"),
+ ]
+)
+
+MODEL_FOR_OBJECT_DETECTION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Object Detection mapping
+ ("conditional_detr", "ConditionalDetrForObjectDetection"),
+ ("dab-detr", "DabDetrForObjectDetection"),
+ ("deformable_detr", "DeformableDetrForObjectDetection"),
+ ("deta", "DetaForObjectDetection"),
+ ("detr", "DetrForObjectDetection"),
+ ("rt_detr", "RTDetrForObjectDetection"),
+ ("rt_detr_v2", "RTDetrV2ForObjectDetection"),
+ ("table-transformer", "TableTransformerForObjectDetection"),
+ ("yolos", "YolosForObjectDetection"),
+ ]
+)
+
+MODEL_FOR_ZERO_SHOT_OBJECT_DETECTION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Zero Shot Object Detection mapping
+ ("grounding-dino", "GroundingDinoForObjectDetection"),
+ ("omdet-turbo", "OmDetTurboForObjectDetection"),
+ ("owlv2", "Owlv2ForObjectDetection"),
+ ("owlvit", "OwlViTForObjectDetection"),
+ ]
+)
+
+MODEL_FOR_DEPTH_ESTIMATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for depth estimation mapping
+ ("depth_anything", "DepthAnythingForDepthEstimation"),
+ ("depth_pro", "DepthProForDepthEstimation"),
+ ("dpt", "DPTForDepthEstimation"),
+ ("glpn", "GLPNForDepthEstimation"),
+ ("prompt_depth_anything", "PromptDepthAnythingForDepthEstimation"),
+ ("zoedepth", "ZoeDepthForDepthEstimation"),
+ ]
+)
+MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Seq2Seq Causal LM mapping
+ ("bart", "BartForConditionalGeneration"),
+ ("bigbird_pegasus", "BigBirdPegasusForConditionalGeneration"),
+ ("blenderbot", "BlenderbotForConditionalGeneration"),
+ ("blenderbot-small", "BlenderbotSmallForConditionalGeneration"),
+ ("encoder-decoder", "EncoderDecoderModel"),
+ ("fsmt", "FSMTForConditionalGeneration"),
+ ("gptsan-japanese", "GPTSanJapaneseForConditionalGeneration"),
+ ("granite_speech", "GraniteSpeechForConditionalGeneration"),
+ ("led", "LEDForConditionalGeneration"),
+ ("longt5", "LongT5ForConditionalGeneration"),
+ ("m2m_100", "M2M100ForConditionalGeneration"),
+ ("marian", "MarianMTModel"),
+ ("mbart", "MBartForConditionalGeneration"),
+ ("mt5", "MT5ForConditionalGeneration"),
+ ("mvp", "MvpForConditionalGeneration"),
+ ("nllb-moe", "NllbMoeForConditionalGeneration"),
+ ("pegasus", "PegasusForConditionalGeneration"),
+ ("pegasus_x", "PegasusXForConditionalGeneration"),
+ ("plbart", "PLBartForConditionalGeneration"),
+ ("prophetnet", "ProphetNetForConditionalGeneration"),
+ ("qwen2_audio", "Qwen2AudioForConditionalGeneration"),
+ ("seamless_m4t", "SeamlessM4TForTextToText"),
+ ("seamless_m4t_v2", "SeamlessM4Tv2ForTextToText"),
+ ("switch_transformers", "SwitchTransformersForConditionalGeneration"),
+ ("t5", "T5ForConditionalGeneration"),
+ ("umt5", "UMT5ForConditionalGeneration"),
+ ("xlm-prophetnet", "XLMProphetNetForConditionalGeneration"),
+ ]
+)
+
+MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES = OrderedDict(
+ [
+ ("granite_speech", "GraniteSpeechForConditionalGeneration"),
+ ("moonshine", "MoonshineForConditionalGeneration"),
+ ("pop2piano", "Pop2PianoForConditionalGeneration"),
+ ("seamless_m4t", "SeamlessM4TForSpeechToText"),
+ ("seamless_m4t_v2", "SeamlessM4Tv2ForSpeechToText"),
+ ("speech-encoder-decoder", "SpeechEncoderDecoderModel"),
+ ("speech_to_text", "Speech2TextForConditionalGeneration"),
+ ("speecht5", "SpeechT5ForSpeechToText"),
+ ("whisper", "WhisperForConditionalGeneration"),
+ ]
+)
+
+MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Sequence Classification mapping
+ ("albert", "AlbertForSequenceClassification"),
+ ("bart", "BartForSequenceClassification"),
+ ("bert", "BertForSequenceClassification"),
+ ("big_bird", "BigBirdForSequenceClassification"),
+ ("bigbird_pegasus", "BigBirdPegasusForSequenceClassification"),
+ ("biogpt", "BioGptForSequenceClassification"),
+ ("bloom", "BloomForSequenceClassification"),
+ ("camembert", "CamembertForSequenceClassification"),
+ ("canine", "CanineForSequenceClassification"),
+ ("code_llama", "LlamaForSequenceClassification"),
+ ("convbert", "ConvBertForSequenceClassification"),
+ ("ctrl", "CTRLForSequenceClassification"),
+ ("data2vec-text", "Data2VecTextForSequenceClassification"),
+ ("deberta", "DebertaForSequenceClassification"),
+ ("deberta-v2", "DebertaV2ForSequenceClassification"),
+ ("diffllama", "DiffLlamaForSequenceClassification"),
+ ("distilbert", "DistilBertForSequenceClassification"),
+ ("electra", "ElectraForSequenceClassification"),
+ ("ernie", "ErnieForSequenceClassification"),
+ ("ernie_m", "ErnieMForSequenceClassification"),
+ ("esm", "EsmForSequenceClassification"),
+ ("falcon", "FalconForSequenceClassification"),
+ ("flaubert", "FlaubertForSequenceClassification"),
+ ("fnet", "FNetForSequenceClassification"),
+ ("funnel", "FunnelForSequenceClassification"),
+ ("gemma", "GemmaForSequenceClassification"),
+ ("gemma2", "Gemma2ForSequenceClassification"),
+ ("glm", "GlmForSequenceClassification"),
+ ("glm4", "Glm4ForSequenceClassification"),
+ ("gpt-sw3", "GPT2ForSequenceClassification"),
+ ("gpt2", "GPT2ForSequenceClassification"),
+ ("gpt_bigcode", "GPTBigCodeForSequenceClassification"),
+ ("gpt_neo", "GPTNeoForSequenceClassification"),
+ ("gpt_neox", "GPTNeoXForSequenceClassification"),
+ ("gptj", "GPTJForSequenceClassification"),
+ ("helium", "HeliumForSequenceClassification"),
+ ("ibert", "IBertForSequenceClassification"),
+ ("jamba", "JambaForSequenceClassification"),
+ ("jetmoe", "JetMoeForSequenceClassification"),
+ ("layoutlm", "LayoutLMForSequenceClassification"),
+ ("layoutlmv2", "LayoutLMv2ForSequenceClassification"),
+ ("layoutlmv3", "LayoutLMv3ForSequenceClassification"),
+ ("led", "LEDForSequenceClassification"),
+ ("lilt", "LiltForSequenceClassification"),
+ ("llama", "LlamaForSequenceClassification"),
+ ("longformer", "LongformerForSequenceClassification"),
+ ("luke", "LukeForSequenceClassification"),
+ ("markuplm", "MarkupLMForSequenceClassification"),
+ ("mbart", "MBartForSequenceClassification"),
+ ("mega", "MegaForSequenceClassification"),
+ ("megatron-bert", "MegatronBertForSequenceClassification"),
+ ("mistral", "MistralForSequenceClassification"),
+ ("mixtral", "MixtralForSequenceClassification"),
+ ("mobilebert", "MobileBertForSequenceClassification"),
+ ("modernbert", "ModernBertForSequenceClassification"),
+ ("mpnet", "MPNetForSequenceClassification"),
+ ("mpt", "MptForSequenceClassification"),
+ ("mra", "MraForSequenceClassification"),
+ ("mt5", "MT5ForSequenceClassification"),
+ ("mvp", "MvpForSequenceClassification"),
+ ("nemotron", "NemotronForSequenceClassification"),
+ ("nezha", "NezhaForSequenceClassification"),
+ ("nystromformer", "NystromformerForSequenceClassification"),
+ ("open-llama", "OpenLlamaForSequenceClassification"),
+ ("openai-gpt", "OpenAIGPTForSequenceClassification"),
+ ("opt", "OPTForSequenceClassification"),
+ ("perceiver", "PerceiverForSequenceClassification"),
+ ("persimmon", "PersimmonForSequenceClassification"),
+ ("phi", "PhiForSequenceClassification"),
+ ("phi3", "Phi3ForSequenceClassification"),
+ ("phimoe", "PhimoeForSequenceClassification"),
+ ("plbart", "PLBartForSequenceClassification"),
+ ("qdqbert", "QDQBertForSequenceClassification"),
+ ("qwen2", "Qwen2ForSequenceClassification"),
+ ("qwen2_moe", "Qwen2MoeForSequenceClassification"),
+ ("qwen3", "Qwen3ForSequenceClassification"),
+ ("qwen3_moe", "Qwen3MoeForSequenceClassification"),
+ ("reformer", "ReformerForSequenceClassification"),
+ ("rembert", "RemBertForSequenceClassification"),
+ ("roberta", "RobertaForSequenceClassification"),
+ ("roberta-prelayernorm", "RobertaPreLayerNormForSequenceClassification"),
+ ("roc_bert", "RoCBertForSequenceClassification"),
+ ("roformer", "RoFormerForSequenceClassification"),
+ ("squeezebert", "SqueezeBertForSequenceClassification"),
+ ("stablelm", "StableLmForSequenceClassification"),
+ ("starcoder2", "Starcoder2ForSequenceClassification"),
+ ("t5", "T5ForSequenceClassification"),
+ ("tapas", "TapasForSequenceClassification"),
+ ("transfo-xl", "TransfoXLForSequenceClassification"),
+ ("umt5", "UMT5ForSequenceClassification"),
+ ("xlm", "XLMForSequenceClassification"),
+ ("xlm-roberta", "XLMRobertaForSequenceClassification"),
+ ("xlm-roberta-xl", "XLMRobertaXLForSequenceClassification"),
+ ("xlnet", "XLNetForSequenceClassification"),
+ ("xmod", "XmodForSequenceClassification"),
+ ("yoso", "YosoForSequenceClassification"),
+ ("zamba", "ZambaForSequenceClassification"),
+ ("zamba2", "Zamba2ForSequenceClassification"),
+ ]
+)
+
+MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Question Answering mapping
+ ("albert", "AlbertForQuestionAnswering"),
+ ("bart", "BartForQuestionAnswering"),
+ ("bert", "BertForQuestionAnswering"),
+ ("big_bird", "BigBirdForQuestionAnswering"),
+ ("bigbird_pegasus", "BigBirdPegasusForQuestionAnswering"),
+ ("bloom", "BloomForQuestionAnswering"),
+ ("camembert", "CamembertForQuestionAnswering"),
+ ("canine", "CanineForQuestionAnswering"),
+ ("convbert", "ConvBertForQuestionAnswering"),
+ ("data2vec-text", "Data2VecTextForQuestionAnswering"),
+ ("deberta", "DebertaForQuestionAnswering"),
+ ("deberta-v2", "DebertaV2ForQuestionAnswering"),
+ ("diffllama", "DiffLlamaForQuestionAnswering"),
+ ("distilbert", "DistilBertForQuestionAnswering"),
+ ("electra", "ElectraForQuestionAnswering"),
+ ("ernie", "ErnieForQuestionAnswering"),
+ ("ernie_m", "ErnieMForQuestionAnswering"),
+ ("falcon", "FalconForQuestionAnswering"),
+ ("flaubert", "FlaubertForQuestionAnsweringSimple"),
+ ("fnet", "FNetForQuestionAnswering"),
+ ("funnel", "FunnelForQuestionAnswering"),
+ ("gpt2", "GPT2ForQuestionAnswering"),
+ ("gpt_neo", "GPTNeoForQuestionAnswering"),
+ ("gpt_neox", "GPTNeoXForQuestionAnswering"),
+ ("gptj", "GPTJForQuestionAnswering"),
+ ("ibert", "IBertForQuestionAnswering"),
+ ("layoutlmv2", "LayoutLMv2ForQuestionAnswering"),
+ ("layoutlmv3", "LayoutLMv3ForQuestionAnswering"),
+ ("led", "LEDForQuestionAnswering"),
+ ("lilt", "LiltForQuestionAnswering"),
+ ("llama", "LlamaForQuestionAnswering"),
+ ("longformer", "LongformerForQuestionAnswering"),
+ ("luke", "LukeForQuestionAnswering"),
+ ("lxmert", "LxmertForQuestionAnswering"),
+ ("markuplm", "MarkupLMForQuestionAnswering"),
+ ("mbart", "MBartForQuestionAnswering"),
+ ("mega", "MegaForQuestionAnswering"),
+ ("megatron-bert", "MegatronBertForQuestionAnswering"),
+ ("mistral", "MistralForQuestionAnswering"),
+ ("mixtral", "MixtralForQuestionAnswering"),
+ ("mobilebert", "MobileBertForQuestionAnswering"),
+ ("modernbert", "ModernBertForQuestionAnswering"),
+ ("mpnet", "MPNetForQuestionAnswering"),
+ ("mpt", "MptForQuestionAnswering"),
+ ("mra", "MraForQuestionAnswering"),
+ ("mt5", "MT5ForQuestionAnswering"),
+ ("mvp", "MvpForQuestionAnswering"),
+ ("nemotron", "NemotronForQuestionAnswering"),
+ ("nezha", "NezhaForQuestionAnswering"),
+ ("nystromformer", "NystromformerForQuestionAnswering"),
+ ("opt", "OPTForQuestionAnswering"),
+ ("qdqbert", "QDQBertForQuestionAnswering"),
+ ("qwen2", "Qwen2ForQuestionAnswering"),
+ ("qwen2_moe", "Qwen2MoeForQuestionAnswering"),
+ ("qwen3", "Qwen3ForQuestionAnswering"),
+ ("qwen3_moe", "Qwen3MoeForQuestionAnswering"),
+ ("reformer", "ReformerForQuestionAnswering"),
+ ("rembert", "RemBertForQuestionAnswering"),
+ ("roberta", "RobertaForQuestionAnswering"),
+ ("roberta-prelayernorm", "RobertaPreLayerNormForQuestionAnswering"),
+ ("roc_bert", "RoCBertForQuestionAnswering"),
+ ("roformer", "RoFormerForQuestionAnswering"),
+ ("splinter", "SplinterForQuestionAnswering"),
+ ("squeezebert", "SqueezeBertForQuestionAnswering"),
+ ("t5", "T5ForQuestionAnswering"),
+ ("umt5", "UMT5ForQuestionAnswering"),
+ ("xlm", "XLMForQuestionAnsweringSimple"),
+ ("xlm-roberta", "XLMRobertaForQuestionAnswering"),
+ ("xlm-roberta-xl", "XLMRobertaXLForQuestionAnswering"),
+ ("xlnet", "XLNetForQuestionAnsweringSimple"),
+ ("xmod", "XmodForQuestionAnswering"),
+ ("yoso", "YosoForQuestionAnswering"),
+ ]
+)
+
+MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Table Question Answering mapping
+ ("tapas", "TapasForQuestionAnswering"),
+ ]
+)
+
+MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING_NAMES = OrderedDict(
+ [
+ ("blip", "BlipForQuestionAnswering"),
+ ("blip-2", "Blip2ForConditionalGeneration"),
+ ("vilt", "ViltForQuestionAnswering"),
+ ]
+)
+
+MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING_NAMES = OrderedDict(
+ [
+ ("layoutlm", "LayoutLMForQuestionAnswering"),
+ ("layoutlmv2", "LayoutLMv2ForQuestionAnswering"),
+ ("layoutlmv3", "LayoutLMv3ForQuestionAnswering"),
+ ]
+)
+
+MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Token Classification mapping
+ ("albert", "AlbertForTokenClassification"),
+ ("bert", "BertForTokenClassification"),
+ ("big_bird", "BigBirdForTokenClassification"),
+ ("biogpt", "BioGptForTokenClassification"),
+ ("bloom", "BloomForTokenClassification"),
+ ("bros", "BrosForTokenClassification"),
+ ("camembert", "CamembertForTokenClassification"),
+ ("canine", "CanineForTokenClassification"),
+ ("convbert", "ConvBertForTokenClassification"),
+ ("data2vec-text", "Data2VecTextForTokenClassification"),
+ ("deberta", "DebertaForTokenClassification"),
+ ("deberta-v2", "DebertaV2ForTokenClassification"),
+ ("diffllama", "DiffLlamaForTokenClassification"),
+ ("distilbert", "DistilBertForTokenClassification"),
+ ("electra", "ElectraForTokenClassification"),
+ ("ernie", "ErnieForTokenClassification"),
+ ("ernie_m", "ErnieMForTokenClassification"),
+ ("esm", "EsmForTokenClassification"),
+ ("falcon", "FalconForTokenClassification"),
+ ("flaubert", "FlaubertForTokenClassification"),
+ ("fnet", "FNetForTokenClassification"),
+ ("funnel", "FunnelForTokenClassification"),
+ ("gemma", "GemmaForTokenClassification"),
+ ("gemma2", "Gemma2ForTokenClassification"),
+ ("glm", "GlmForTokenClassification"),
+ ("glm4", "Glm4ForTokenClassification"),
+ ("gpt-sw3", "GPT2ForTokenClassification"),
+ ("gpt2", "GPT2ForTokenClassification"),
+ ("gpt_bigcode", "GPTBigCodeForTokenClassification"),
+ ("gpt_neo", "GPTNeoForTokenClassification"),
+ ("gpt_neox", "GPTNeoXForTokenClassification"),
+ ("helium", "HeliumForTokenClassification"),
+ ("ibert", "IBertForTokenClassification"),
+ ("layoutlm", "LayoutLMForTokenClassification"),
+ ("layoutlmv2", "LayoutLMv2ForTokenClassification"),
+ ("layoutlmv3", "LayoutLMv3ForTokenClassification"),
+ ("lilt", "LiltForTokenClassification"),
+ ("llama", "LlamaForTokenClassification"),
+ ("longformer", "LongformerForTokenClassification"),
+ ("luke", "LukeForTokenClassification"),
+ ("markuplm", "MarkupLMForTokenClassification"),
+ ("mega", "MegaForTokenClassification"),
+ ("megatron-bert", "MegatronBertForTokenClassification"),
+ ("mistral", "MistralForTokenClassification"),
+ ("mixtral", "MixtralForTokenClassification"),
+ ("mobilebert", "MobileBertForTokenClassification"),
+ ("modernbert", "ModernBertForTokenClassification"),
+ ("mpnet", "MPNetForTokenClassification"),
+ ("mpt", "MptForTokenClassification"),
+ ("mra", "MraForTokenClassification"),
+ ("mt5", "MT5ForTokenClassification"),
+ ("nemotron", "NemotronForTokenClassification"),
+ ("nezha", "NezhaForTokenClassification"),
+ ("nystromformer", "NystromformerForTokenClassification"),
+ ("persimmon", "PersimmonForTokenClassification"),
+ ("phi", "PhiForTokenClassification"),
+ ("phi3", "Phi3ForTokenClassification"),
+ ("qdqbert", "QDQBertForTokenClassification"),
+ ("qwen2", "Qwen2ForTokenClassification"),
+ ("qwen2_moe", "Qwen2MoeForTokenClassification"),
+ ("qwen3", "Qwen3ForTokenClassification"),
+ ("qwen3_moe", "Qwen3MoeForTokenClassification"),
+ ("rembert", "RemBertForTokenClassification"),
+ ("roberta", "RobertaForTokenClassification"),
+ ("roberta-prelayernorm", "RobertaPreLayerNormForTokenClassification"),
+ ("roc_bert", "RoCBertForTokenClassification"),
+ ("roformer", "RoFormerForTokenClassification"),
+ ("squeezebert", "SqueezeBertForTokenClassification"),
+ ("stablelm", "StableLmForTokenClassification"),
+ ("starcoder2", "Starcoder2ForTokenClassification"),
+ ("t5", "T5ForTokenClassification"),
+ ("umt5", "UMT5ForTokenClassification"),
+ ("xlm", "XLMForTokenClassification"),
+ ("xlm-roberta", "XLMRobertaForTokenClassification"),
+ ("xlm-roberta-xl", "XLMRobertaXLForTokenClassification"),
+ ("xlnet", "XLNetForTokenClassification"),
+ ("xmod", "XmodForTokenClassification"),
+ ("yoso", "YosoForTokenClassification"),
+ ]
+)
+
+MODEL_FOR_MULTIPLE_CHOICE_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Multiple Choice mapping
+ ("albert", "AlbertForMultipleChoice"),
+ ("bert", "BertForMultipleChoice"),
+ ("big_bird", "BigBirdForMultipleChoice"),
+ ("camembert", "CamembertForMultipleChoice"),
+ ("canine", "CanineForMultipleChoice"),
+ ("convbert", "ConvBertForMultipleChoice"),
+ ("data2vec-text", "Data2VecTextForMultipleChoice"),
+ ("deberta-v2", "DebertaV2ForMultipleChoice"),
+ ("distilbert", "DistilBertForMultipleChoice"),
+ ("electra", "ElectraForMultipleChoice"),
+ ("ernie", "ErnieForMultipleChoice"),
+ ("ernie_m", "ErnieMForMultipleChoice"),
+ ("flaubert", "FlaubertForMultipleChoice"),
+ ("fnet", "FNetForMultipleChoice"),
+ ("funnel", "FunnelForMultipleChoice"),
+ ("ibert", "IBertForMultipleChoice"),
+ ("longformer", "LongformerForMultipleChoice"),
+ ("luke", "LukeForMultipleChoice"),
+ ("mega", "MegaForMultipleChoice"),
+ ("megatron-bert", "MegatronBertForMultipleChoice"),
+ ("mobilebert", "MobileBertForMultipleChoice"),
+ ("mpnet", "MPNetForMultipleChoice"),
+ ("mra", "MraForMultipleChoice"),
+ ("nezha", "NezhaForMultipleChoice"),
+ ("nystromformer", "NystromformerForMultipleChoice"),
+ ("qdqbert", "QDQBertForMultipleChoice"),
+ ("rembert", "RemBertForMultipleChoice"),
+ ("roberta", "RobertaForMultipleChoice"),
+ ("roberta-prelayernorm", "RobertaPreLayerNormForMultipleChoice"),
+ ("roc_bert", "RoCBertForMultipleChoice"),
+ ("roformer", "RoFormerForMultipleChoice"),
+ ("squeezebert", "SqueezeBertForMultipleChoice"),
+ ("xlm", "XLMForMultipleChoice"),
+ ("xlm-roberta", "XLMRobertaForMultipleChoice"),
+ ("xlm-roberta-xl", "XLMRobertaXLForMultipleChoice"),
+ ("xlnet", "XLNetForMultipleChoice"),
+ ("xmod", "XmodForMultipleChoice"),
+ ("yoso", "YosoForMultipleChoice"),
+ ]
+)
+
+MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING_NAMES = OrderedDict(
+ [
+ ("bert", "BertForNextSentencePrediction"),
+ ("ernie", "ErnieForNextSentencePrediction"),
+ ("fnet", "FNetForNextSentencePrediction"),
+ ("megatron-bert", "MegatronBertForNextSentencePrediction"),
+ ("mobilebert", "MobileBertForNextSentencePrediction"),
+ ("nezha", "NezhaForNextSentencePrediction"),
+ ("qdqbert", "QDQBertForNextSentencePrediction"),
+ ]
+)
+
+MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Audio Classification mapping
+ ("audio-spectrogram-transformer", "ASTForAudioClassification"),
+ ("data2vec-audio", "Data2VecAudioForSequenceClassification"),
+ ("hubert", "HubertForSequenceClassification"),
+ ("sew", "SEWForSequenceClassification"),
+ ("sew-d", "SEWDForSequenceClassification"),
+ ("unispeech", "UniSpeechForSequenceClassification"),
+ ("unispeech-sat", "UniSpeechSatForSequenceClassification"),
+ ("wav2vec2", "Wav2Vec2ForSequenceClassification"),
+ ("wav2vec2-bert", "Wav2Vec2BertForSequenceClassification"),
+ ("wav2vec2-conformer", "Wav2Vec2ConformerForSequenceClassification"),
+ ("wavlm", "WavLMForSequenceClassification"),
+ ("whisper", "WhisperForAudioClassification"),
+ ]
+)
+
+MODEL_FOR_CTC_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Connectionist temporal classification (CTC) mapping
+ ("data2vec-audio", "Data2VecAudioForCTC"),
+ ("hubert", "HubertForCTC"),
+ ("mctct", "MCTCTForCTC"),
+ ("sew", "SEWForCTC"),
+ ("sew-d", "SEWDForCTC"),
+ ("unispeech", "UniSpeechForCTC"),
+ ("unispeech-sat", "UniSpeechSatForCTC"),
+ ("wav2vec2", "Wav2Vec2ForCTC"),
+ ("wav2vec2-bert", "Wav2Vec2BertForCTC"),
+ ("wav2vec2-conformer", "Wav2Vec2ConformerForCTC"),
+ ("wavlm", "WavLMForCTC"),
+ ]
+)
+
+MODEL_FOR_AUDIO_FRAME_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Audio Classification mapping
+ ("data2vec-audio", "Data2VecAudioForAudioFrameClassification"),
+ ("unispeech-sat", "UniSpeechSatForAudioFrameClassification"),
+ ("wav2vec2", "Wav2Vec2ForAudioFrameClassification"),
+ ("wav2vec2-bert", "Wav2Vec2BertForAudioFrameClassification"),
+ ("wav2vec2-conformer", "Wav2Vec2ConformerForAudioFrameClassification"),
+ ("wavlm", "WavLMForAudioFrameClassification"),
+ ]
+)
+
+MODEL_FOR_AUDIO_XVECTOR_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Audio Classification mapping
+ ("data2vec-audio", "Data2VecAudioForXVector"),
+ ("unispeech-sat", "UniSpeechSatForXVector"),
+ ("wav2vec2", "Wav2Vec2ForXVector"),
+ ("wav2vec2-bert", "Wav2Vec2BertForXVector"),
+ ("wav2vec2-conformer", "Wav2Vec2ConformerForXVector"),
+ ("wavlm", "WavLMForXVector"),
+ ]
+)
+
+MODEL_FOR_TEXT_TO_SPECTROGRAM_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Text-To-Spectrogram mapping
+ ("fastspeech2_conformer", "FastSpeech2ConformerModel"),
+ ("speecht5", "SpeechT5ForTextToSpeech"),
+ ]
+)
+
+MODEL_FOR_TEXT_TO_WAVEFORM_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Text-To-Waveform mapping
+ ("bark", "BarkModel"),
+ ("fastspeech2_conformer", "FastSpeech2ConformerWithHifiGan"),
+ ("musicgen", "MusicgenForConditionalGeneration"),
+ ("musicgen_melody", "MusicgenMelodyForConditionalGeneration"),
+ ("qwen2_5_omni", "Qwen2_5OmniForConditionalGeneration"),
+ ("seamless_m4t", "SeamlessM4TForTextToSpeech"),
+ ("seamless_m4t_v2", "SeamlessM4Tv2ForTextToSpeech"),
+ ("vits", "VitsModel"),
+ ]
+)
+
+MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Zero Shot Image Classification mapping
+ ("align", "AlignModel"),
+ ("altclip", "AltCLIPModel"),
+ ("blip", "BlipModel"),
+ ("blip-2", "Blip2ForImageTextRetrieval"),
+ ("chinese_clip", "ChineseCLIPModel"),
+ ("clip", "CLIPModel"),
+ ("clipseg", "CLIPSegModel"),
+ ("siglip", "SiglipModel"),
+ ("siglip2", "Siglip2Model"),
+ ]
+)
+
+MODEL_FOR_BACKBONE_MAPPING_NAMES = OrderedDict(
+ [
+ # Backbone mapping
+ ("beit", "BeitBackbone"),
+ ("bit", "BitBackbone"),
+ ("convnext", "ConvNextBackbone"),
+ ("convnextv2", "ConvNextV2Backbone"),
+ ("dinat", "DinatBackbone"),
+ ("dinov2", "Dinov2Backbone"),
+ ("dinov2_with_registers", "Dinov2WithRegistersBackbone"),
+ ("focalnet", "FocalNetBackbone"),
+ ("hiera", "HieraBackbone"),
+ ("maskformer-swin", "MaskFormerSwinBackbone"),
+ ("nat", "NatBackbone"),
+ ("pvt_v2", "PvtV2Backbone"),
+ ("resnet", "ResNetBackbone"),
+ ("rt_detr_resnet", "RTDetrResNetBackbone"),
+ ("swin", "SwinBackbone"),
+ ("swinv2", "Swinv2Backbone"),
+ ("textnet", "TextNetBackbone"),
+ ("timm_backbone", "TimmBackbone"),
+ ("vitdet", "VitDetBackbone"),
+ ("vitpose_backbone", "VitPoseBackbone"),
+ ]
+)
+
+MODEL_FOR_MASK_GENERATION_MAPPING_NAMES = OrderedDict(
+ [
+ ("sam", "SamModel"),
+ ]
+)
+
+
+MODEL_FOR_KEYPOINT_DETECTION_MAPPING_NAMES = OrderedDict(
+ [
+ ("superpoint", "SuperPointForKeypointDetection"),
+ ]
+)
+
+
+MODEL_FOR_TEXT_ENCODING_MAPPING_NAMES = OrderedDict(
+ [
+ ("albert", "AlbertModel"),
+ ("bert", "BertModel"),
+ ("big_bird", "BigBirdModel"),
+ ("clip_text_model", "CLIPTextModel"),
+ ("data2vec-text", "Data2VecTextModel"),
+ ("deberta", "DebertaModel"),
+ ("deberta-v2", "DebertaV2Model"),
+ ("distilbert", "DistilBertModel"),
+ ("electra", "ElectraModel"),
+ ("emu3", "Emu3TextModel"),
+ ("flaubert", "FlaubertModel"),
+ ("ibert", "IBertModel"),
+ ("llama4", "Llama4TextModel"),
+ ("longformer", "LongformerModel"),
+ ("mllama", "MllamaTextModel"),
+ ("mobilebert", "MobileBertModel"),
+ ("mt5", "MT5EncoderModel"),
+ ("nystromformer", "NystromformerModel"),
+ ("reformer", "ReformerModel"),
+ ("rembert", "RemBertModel"),
+ ("roberta", "RobertaModel"),
+ ("roberta-prelayernorm", "RobertaPreLayerNormModel"),
+ ("roc_bert", "RoCBertModel"),
+ ("roformer", "RoFormerModel"),
+ ("squeezebert", "SqueezeBertModel"),
+ ("t5", "T5EncoderModel"),
+ ("umt5", "UMT5EncoderModel"),
+ ("xlm", "XLMModel"),
+ ("xlm-roberta", "XLMRobertaModel"),
+ ("xlm-roberta-xl", "XLMRobertaXLModel"),
+ ]
+)
+
+MODEL_FOR_TIME_SERIES_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ ("patchtsmixer", "PatchTSMixerForTimeSeriesClassification"),
+ ("patchtst", "PatchTSTForClassification"),
+ ]
+)
+
+MODEL_FOR_TIME_SERIES_REGRESSION_MAPPING_NAMES = OrderedDict(
+ [
+ ("patchtsmixer", "PatchTSMixerForRegression"),
+ ("patchtst", "PatchTSTForRegression"),
+ ]
+)
+
+MODEL_FOR_TIME_SERIES_PREDICTION_MAPPING_NAMES = OrderedDict(
+ [
+ ("timesfm", "TimesFmModelForPrediction"),
+ ]
+)
+
+MODEL_FOR_IMAGE_TO_IMAGE_MAPPING_NAMES = OrderedDict(
+ [
+ ("swin2sr", "Swin2SRForImageSuperResolution"),
+ ]
+)
+
+MODEL_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_MAPPING_NAMES)
+MODEL_FOR_PRETRAINING_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_PRETRAINING_MAPPING_NAMES)
+MODEL_WITH_LM_HEAD_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_WITH_LM_HEAD_MAPPING_NAMES)
+MODEL_FOR_CAUSAL_LM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_CAUSAL_LM_MAPPING_NAMES)
+MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING_NAMES
+)
+MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES
+)
+MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING_NAMES
+)
+MODEL_FOR_IMAGE_SEGMENTATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_IMAGE_SEGMENTATION_MAPPING_NAMES
+)
+MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING_NAMES
+)
+MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING_NAMES
+)
+MODEL_FOR_UNIVERSAL_SEGMENTATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_UNIVERSAL_SEGMENTATION_MAPPING_NAMES
+)
+MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING_NAMES
+)
+MODEL_FOR_VISION_2_SEQ_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES)
+MODEL_FOR_IMAGE_TEXT_TO_TEXT_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_IMAGE_TEXT_TO_TEXT_MAPPING_NAMES
+)
+MODEL_FOR_RETRIEVAL_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_RETRIEVAL_MAPPING_NAMES)
+MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING_NAMES
+)
+MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING_NAMES
+)
+MODEL_FOR_MASKED_LM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_MASKED_LM_MAPPING_NAMES)
+MODEL_FOR_IMAGE_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_IMAGE_MAPPING_NAMES)
+MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING_NAMES
+)
+MODEL_FOR_OBJECT_DETECTION_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_OBJECT_DETECTION_MAPPING_NAMES)
+MODEL_FOR_ZERO_SHOT_OBJECT_DETECTION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_ZERO_SHOT_OBJECT_DETECTION_MAPPING_NAMES
+)
+MODEL_FOR_DEPTH_ESTIMATION_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_DEPTH_ESTIMATION_MAPPING_NAMES)
+MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES
+)
+MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES
+)
+MODEL_FOR_QUESTION_ANSWERING_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES
+)
+MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING_NAMES
+)
+MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES
+)
+MODEL_FOR_MULTIPLE_CHOICE_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_MULTIPLE_CHOICE_MAPPING_NAMES)
+MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING_NAMES
+)
+MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES
+)
+MODEL_FOR_CTC_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_CTC_MAPPING_NAMES)
+MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES)
+MODEL_FOR_AUDIO_FRAME_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_AUDIO_FRAME_CLASSIFICATION_MAPPING_NAMES
+)
+MODEL_FOR_AUDIO_XVECTOR_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_AUDIO_XVECTOR_MAPPING_NAMES)
+
+MODEL_FOR_TEXT_TO_SPECTROGRAM_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_TEXT_TO_SPECTROGRAM_MAPPING_NAMES
+)
+
+MODEL_FOR_TEXT_TO_WAVEFORM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_TEXT_TO_WAVEFORM_MAPPING_NAMES)
+
+MODEL_FOR_BACKBONE_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_BACKBONE_MAPPING_NAMES)
+
+MODEL_FOR_MASK_GENERATION_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_MASK_GENERATION_MAPPING_NAMES)
+
+MODEL_FOR_KEYPOINT_DETECTION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_KEYPOINT_DETECTION_MAPPING_NAMES
+)
+
+MODEL_FOR_TEXT_ENCODING_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_TEXT_ENCODING_MAPPING_NAMES)
+
+MODEL_FOR_TIME_SERIES_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_TIME_SERIES_CLASSIFICATION_MAPPING_NAMES
+)
+
+MODEL_FOR_TIME_SERIES_REGRESSION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_TIME_SERIES_REGRESSION_MAPPING_NAMES
+)
+
+MODEL_FOR_TIME_SERIES_PREDICTION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_TIME_SERIES_PREDICTION_MAPPING_NAMES
+)
+
+MODEL_FOR_IMAGE_TO_IMAGE_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_IMAGE_TO_IMAGE_MAPPING_NAMES)
+
+
+class AutoModelForMaskGeneration(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_MASK_GENERATION_MAPPING
+
+
+class AutoModelForKeypointDetection(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_KEYPOINT_DETECTION_MAPPING
+
+
+class AutoModelForTextEncoding(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_TEXT_ENCODING_MAPPING
+
+
+class AutoModelForImageToImage(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_IMAGE_TO_IMAGE_MAPPING
+
+
+class AutoModel(_BaseAutoModelClass):
+ _model_mapping = MODEL_MAPPING
+
+
+AutoModel = auto_class_update(AutoModel)
+
+
+class AutoModelForPreTraining(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_PRETRAINING_MAPPING
+
+
+AutoModelForPreTraining = auto_class_update(AutoModelForPreTraining, head_doc="pretraining")
+
+
+# Private on purpose, the public class will add the deprecation warnings.
+class _AutoModelWithLMHead(_BaseAutoModelClass):
+ _model_mapping = MODEL_WITH_LM_HEAD_MAPPING
+
+
+_AutoModelWithLMHead = auto_class_update(_AutoModelWithLMHead, head_doc="language modeling")
+
+
+class AutoModelForCausalLM(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_CAUSAL_LM_MAPPING
+
+
+AutoModelForCausalLM = auto_class_update(AutoModelForCausalLM, head_doc="causal language modeling")
+
+
+class AutoModelForMaskedLM(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_MASKED_LM_MAPPING
+
+
+AutoModelForMaskedLM = auto_class_update(AutoModelForMaskedLM, head_doc="masked language modeling")
+
+
+class AutoModelForSeq2SeqLM(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING
+
+
+AutoModelForSeq2SeqLM = auto_class_update(
+ AutoModelForSeq2SeqLM,
+ head_doc="sequence-to-sequence language modeling",
+ checkpoint_for_example="google-t5/t5-base",
+)
+
+
+class AutoModelForSequenceClassification(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING
+
+
+AutoModelForSequenceClassification = auto_class_update(
+ AutoModelForSequenceClassification, head_doc="sequence classification"
+)
+
+
+class AutoModelForQuestionAnswering(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_QUESTION_ANSWERING_MAPPING
+
+
+AutoModelForQuestionAnswering = auto_class_update(AutoModelForQuestionAnswering, head_doc="question answering")
+
+
+class AutoModelForTableQuestionAnswering(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING
+
+
+AutoModelForTableQuestionAnswering = auto_class_update(
+ AutoModelForTableQuestionAnswering,
+ head_doc="table question answering",
+ checkpoint_for_example="google/tapas-base-finetuned-wtq",
+)
+
+
+class AutoModelForVisualQuestionAnswering(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING
+
+
+AutoModelForVisualQuestionAnswering = auto_class_update(
+ AutoModelForVisualQuestionAnswering,
+ head_doc="visual question answering",
+ checkpoint_for_example="dandelin/vilt-b32-finetuned-vqa",
+)
+
+
+class AutoModelForDocumentQuestionAnswering(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING
+
+
+AutoModelForDocumentQuestionAnswering = auto_class_update(
+ AutoModelForDocumentQuestionAnswering,
+ head_doc="document question answering",
+ checkpoint_for_example='impira/layoutlm-document-qa", revision="52e01b3',
+)
+
+
+class AutoModelForTokenClassification(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING
+
+
+AutoModelForTokenClassification = auto_class_update(AutoModelForTokenClassification, head_doc="token classification")
+
+
+class AutoModelForMultipleChoice(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_MULTIPLE_CHOICE_MAPPING
+
+
+AutoModelForMultipleChoice = auto_class_update(AutoModelForMultipleChoice, head_doc="multiple choice")
+
+
+class AutoModelForNextSentencePrediction(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING
+
+
+AutoModelForNextSentencePrediction = auto_class_update(
+ AutoModelForNextSentencePrediction, head_doc="next sentence prediction"
+)
+
+
+class AutoModelForImageClassification(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING
+
+
+AutoModelForImageClassification = auto_class_update(AutoModelForImageClassification, head_doc="image classification")
+
+
+class AutoModelForZeroShotImageClassification(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING
+
+
+AutoModelForZeroShotImageClassification = auto_class_update(
+ AutoModelForZeroShotImageClassification, head_doc="zero-shot image classification"
+)
+
+
+class AutoModelForImageSegmentation(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_IMAGE_SEGMENTATION_MAPPING
+
+
+AutoModelForImageSegmentation = auto_class_update(AutoModelForImageSegmentation, head_doc="image segmentation")
+
+
+class AutoModelForSemanticSegmentation(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING
+
+
+AutoModelForSemanticSegmentation = auto_class_update(
+ AutoModelForSemanticSegmentation, head_doc="semantic segmentation"
+)
+
+
+class AutoModelForTimeSeriesPrediction(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_TIME_SERIES_PREDICTION_MAPPING
+
+
+AutoModelForTimeSeriesPrediction = auto_class_update(
+ AutoModelForTimeSeriesPrediction, head_doc="time-series prediction"
+)
+
+
+class AutoModelForUniversalSegmentation(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_UNIVERSAL_SEGMENTATION_MAPPING
+
+
+AutoModelForUniversalSegmentation = auto_class_update(
+ AutoModelForUniversalSegmentation, head_doc="universal image segmentation"
+)
+
+
+class AutoModelForInstanceSegmentation(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING
+
+
+AutoModelForInstanceSegmentation = auto_class_update(
+ AutoModelForInstanceSegmentation, head_doc="instance segmentation"
+)
+
+
+class AutoModelForObjectDetection(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_OBJECT_DETECTION_MAPPING
+
+
+AutoModelForObjectDetection = auto_class_update(AutoModelForObjectDetection, head_doc="object detection")
+
+
+class AutoModelForZeroShotObjectDetection(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_ZERO_SHOT_OBJECT_DETECTION_MAPPING
+
+
+AutoModelForZeroShotObjectDetection = auto_class_update(
+ AutoModelForZeroShotObjectDetection, head_doc="zero-shot object detection"
+)
+
+
+class AutoModelForDepthEstimation(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_DEPTH_ESTIMATION_MAPPING
+
+
+AutoModelForDepthEstimation = auto_class_update(AutoModelForDepthEstimation, head_doc="depth estimation")
+
+
+class AutoModelForVideoClassification(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING
+
+
+AutoModelForVideoClassification = auto_class_update(AutoModelForVideoClassification, head_doc="video classification")
+
+
+class AutoModelForVision2Seq(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_VISION_2_SEQ_MAPPING
+
+
+AutoModelForVision2Seq = auto_class_update(AutoModelForVision2Seq, head_doc="vision-to-text modeling")
+
+
+class AutoModelForImageTextToText(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_IMAGE_TEXT_TO_TEXT_MAPPING
+
+
+AutoModelForImageTextToText = auto_class_update(AutoModelForImageTextToText, head_doc="image-text-to-text modeling")
+
+
+class AutoModelForAudioClassification(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING
+
+
+AutoModelForAudioClassification = auto_class_update(AutoModelForAudioClassification, head_doc="audio classification")
+
+
+class AutoModelForCTC(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_CTC_MAPPING
+
+
+AutoModelForCTC = auto_class_update(AutoModelForCTC, head_doc="connectionist temporal classification")
+
+
+class AutoModelForSpeechSeq2Seq(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING
+
+
+AutoModelForSpeechSeq2Seq = auto_class_update(
+ AutoModelForSpeechSeq2Seq, head_doc="sequence-to-sequence speech-to-text modeling"
+)
+
+
+class AutoModelForAudioFrameClassification(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_AUDIO_FRAME_CLASSIFICATION_MAPPING
+
+
+AutoModelForAudioFrameClassification = auto_class_update(
+ AutoModelForAudioFrameClassification, head_doc="audio frame (token) classification"
+)
+
+
+class AutoModelForAudioXVector(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_AUDIO_XVECTOR_MAPPING
+
+
+class AutoModelForTextToSpectrogram(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_TEXT_TO_SPECTROGRAM_MAPPING
+
+
+class AutoModelForTextToWaveform(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_TEXT_TO_WAVEFORM_MAPPING
+
+
+class AutoBackbone(_BaseAutoBackboneClass):
+ _model_mapping = MODEL_FOR_BACKBONE_MAPPING
+
+
+AutoModelForAudioXVector = auto_class_update(AutoModelForAudioXVector, head_doc="audio retrieval via x-vector")
+
+
+class AutoModelForMaskedImageModeling(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING
+
+
+AutoModelForMaskedImageModeling = auto_class_update(AutoModelForMaskedImageModeling, head_doc="masked image modeling")
+
+
+class AutoModelWithLMHead(_AutoModelWithLMHead):
+ @classmethod
+ def from_config(cls, config):
+ warnings.warn(
+ "The class `AutoModelWithLMHead` is deprecated and will be removed in a future version. Please use "
+ "`AutoModelForCausalLM` for causal language models, `AutoModelForMaskedLM` for masked language models and "
+ "`AutoModelForSeq2SeqLM` for encoder-decoder models.",
+ FutureWarning,
+ )
+ return super().from_config(config)
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
+ warnings.warn(
+ "The class `AutoModelWithLMHead` is deprecated and will be removed in a future version. Please use "
+ "`AutoModelForCausalLM` for causal language models, `AutoModelForMaskedLM` for masked language models and "
+ "`AutoModelForSeq2SeqLM` for encoder-decoder models.",
+ FutureWarning,
+ )
+ return super().from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
+
+
+__all__ = [
+ "MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING",
+ "MODEL_FOR_AUDIO_FRAME_CLASSIFICATION_MAPPING",
+ "MODEL_FOR_AUDIO_XVECTOR_MAPPING",
+ "MODEL_FOR_BACKBONE_MAPPING",
+ "MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING",
+ "MODEL_FOR_CAUSAL_LM_MAPPING",
+ "MODEL_FOR_CTC_MAPPING",
+ "MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING",
+ "MODEL_FOR_DEPTH_ESTIMATION_MAPPING",
+ "MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING",
+ "MODEL_FOR_IMAGE_MAPPING",
+ "MODEL_FOR_IMAGE_SEGMENTATION_MAPPING",
+ "MODEL_FOR_IMAGE_TO_IMAGE_MAPPING",
+ "MODEL_FOR_KEYPOINT_DETECTION_MAPPING",
+ "MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING",
+ "MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING",
+ "MODEL_FOR_MASKED_LM_MAPPING",
+ "MODEL_FOR_MASK_GENERATION_MAPPING",
+ "MODEL_FOR_MULTIPLE_CHOICE_MAPPING",
+ "MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING",
+ "MODEL_FOR_OBJECT_DETECTION_MAPPING",
+ "MODEL_FOR_PRETRAINING_MAPPING",
+ "MODEL_FOR_QUESTION_ANSWERING_MAPPING",
+ "MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING",
+ "MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING",
+ "MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING",
+ "MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING",
+ "MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING",
+ "MODEL_FOR_TEXT_ENCODING_MAPPING",
+ "MODEL_FOR_TEXT_TO_WAVEFORM_MAPPING",
+ "MODEL_FOR_TEXT_TO_SPECTROGRAM_MAPPING",
+ "MODEL_FOR_TIME_SERIES_PREDICTION_MAPPING",
+ "MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING",
+ "MODEL_FOR_UNIVERSAL_SEGMENTATION_MAPPING",
+ "MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING",
+ "MODEL_FOR_VISION_2_SEQ_MAPPING",
+ "MODEL_FOR_RETRIEVAL_MAPPING",
+ "MODEL_FOR_IMAGE_TEXT_TO_TEXT_MAPPING",
+ "MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING",
+ "MODEL_MAPPING",
+ "MODEL_WITH_LM_HEAD_MAPPING",
+ "MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING",
+ "MODEL_FOR_ZERO_SHOT_OBJECT_DETECTION_MAPPING",
+ "MODEL_FOR_TIME_SERIES_CLASSIFICATION_MAPPING",
+ "MODEL_FOR_TIME_SERIES_REGRESSION_MAPPING",
+ "AutoModel",
+ "AutoBackbone",
+ "AutoModelForAudioClassification",
+ "AutoModelForAudioFrameClassification",
+ "AutoModelForAudioXVector",
+ "AutoModelForCausalLM",
+ "AutoModelForCTC",
+ "AutoModelForDepthEstimation",
+ "AutoModelForImageClassification",
+ "AutoModelForImageSegmentation",
+ "AutoModelForImageToImage",
+ "AutoModelForInstanceSegmentation",
+ "AutoModelForKeypointDetection",
+ "AutoModelForMaskGeneration",
+ "AutoModelForTextEncoding",
+ "AutoModelForMaskedImageModeling",
+ "AutoModelForMaskedLM",
+ "AutoModelForMultipleChoice",
+ "AutoModelForNextSentencePrediction",
+ "AutoModelForObjectDetection",
+ "AutoModelForPreTraining",
+ "AutoModelForQuestionAnswering",
+ "AutoModelForSemanticSegmentation",
+ "AutoModelForSeq2SeqLM",
+ "AutoModelForSequenceClassification",
+ "AutoModelForSpeechSeq2Seq",
+ "AutoModelForTableQuestionAnswering",
+ "AutoModelForTextToSpectrogram",
+ "AutoModelForTextToWaveform",
+ "AutoModelForTokenClassification",
+ "AutoModelForUniversalSegmentation",
+ "AutoModelForVideoClassification",
+ "AutoModelForVision2Seq",
+ "AutoModelForVisualQuestionAnswering",
+ "AutoModelForDocumentQuestionAnswering",
+ "AutoModelWithLMHead",
+ "AutoModelForZeroShotImageClassification",
+ "AutoModelForZeroShotObjectDetection",
+ "AutoModelForImageTextToText",
+]
diff --git a/docs/transformers/src/transformers/models/auto/modeling_flax_auto.py b/docs/transformers/src/transformers/models/auto/modeling_flax_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..0588d03cb6cdb43b94cc3fcd73b1791d1a5ee809
--- /dev/null
+++ b/docs/transformers/src/transformers/models/auto/modeling_flax_auto.py
@@ -0,0 +1,413 @@
+# coding=utf-8
+# Copyright 2018 The Google Flax Team Authors and The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Auto Model class."""
+
+from collections import OrderedDict
+
+from ...utils import logging
+from .auto_factory import _BaseAutoModelClass, _LazyAutoMapping, auto_class_update
+from .configuration_auto import CONFIG_MAPPING_NAMES
+
+
+logger = logging.get_logger(__name__)
+
+
+FLAX_MODEL_MAPPING_NAMES = OrderedDict(
+ [
+ # Base model mapping
+ ("albert", "FlaxAlbertModel"),
+ ("bart", "FlaxBartModel"),
+ ("beit", "FlaxBeitModel"),
+ ("bert", "FlaxBertModel"),
+ ("big_bird", "FlaxBigBirdModel"),
+ ("blenderbot", "FlaxBlenderbotModel"),
+ ("blenderbot-small", "FlaxBlenderbotSmallModel"),
+ ("bloom", "FlaxBloomModel"),
+ ("clip", "FlaxCLIPModel"),
+ ("dinov2", "FlaxDinov2Model"),
+ ("distilbert", "FlaxDistilBertModel"),
+ ("electra", "FlaxElectraModel"),
+ ("gemma", "FlaxGemmaModel"),
+ ("gpt-sw3", "FlaxGPT2Model"),
+ ("gpt2", "FlaxGPT2Model"),
+ ("gpt_neo", "FlaxGPTNeoModel"),
+ ("gptj", "FlaxGPTJModel"),
+ ("llama", "FlaxLlamaModel"),
+ ("longt5", "FlaxLongT5Model"),
+ ("marian", "FlaxMarianModel"),
+ ("mbart", "FlaxMBartModel"),
+ ("mistral", "FlaxMistralModel"),
+ ("mt5", "FlaxMT5Model"),
+ ("opt", "FlaxOPTModel"),
+ ("pegasus", "FlaxPegasusModel"),
+ ("regnet", "FlaxRegNetModel"),
+ ("resnet", "FlaxResNetModel"),
+ ("roberta", "FlaxRobertaModel"),
+ ("roberta-prelayernorm", "FlaxRobertaPreLayerNormModel"),
+ ("roformer", "FlaxRoFormerModel"),
+ ("t5", "FlaxT5Model"),
+ ("vision-text-dual-encoder", "FlaxVisionTextDualEncoderModel"),
+ ("vit", "FlaxViTModel"),
+ ("wav2vec2", "FlaxWav2Vec2Model"),
+ ("whisper", "FlaxWhisperModel"),
+ ("xglm", "FlaxXGLMModel"),
+ ("xlm-roberta", "FlaxXLMRobertaModel"),
+ ]
+)
+
+FLAX_MODEL_FOR_PRETRAINING_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for pre-training mapping
+ ("albert", "FlaxAlbertForPreTraining"),
+ ("bart", "FlaxBartForConditionalGeneration"),
+ ("bert", "FlaxBertForPreTraining"),
+ ("big_bird", "FlaxBigBirdForPreTraining"),
+ ("electra", "FlaxElectraForPreTraining"),
+ ("longt5", "FlaxLongT5ForConditionalGeneration"),
+ ("mbart", "FlaxMBartForConditionalGeneration"),
+ ("mt5", "FlaxMT5ForConditionalGeneration"),
+ ("roberta", "FlaxRobertaForMaskedLM"),
+ ("roberta-prelayernorm", "FlaxRobertaPreLayerNormForMaskedLM"),
+ ("roformer", "FlaxRoFormerForMaskedLM"),
+ ("t5", "FlaxT5ForConditionalGeneration"),
+ ("wav2vec2", "FlaxWav2Vec2ForPreTraining"),
+ ("whisper", "FlaxWhisperForConditionalGeneration"),
+ ("xlm-roberta", "FlaxXLMRobertaForMaskedLM"),
+ ]
+)
+
+FLAX_MODEL_FOR_MASKED_LM_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Masked LM mapping
+ ("albert", "FlaxAlbertForMaskedLM"),
+ ("bart", "FlaxBartForConditionalGeneration"),
+ ("bert", "FlaxBertForMaskedLM"),
+ ("big_bird", "FlaxBigBirdForMaskedLM"),
+ ("distilbert", "FlaxDistilBertForMaskedLM"),
+ ("electra", "FlaxElectraForMaskedLM"),
+ ("mbart", "FlaxMBartForConditionalGeneration"),
+ ("roberta", "FlaxRobertaForMaskedLM"),
+ ("roberta-prelayernorm", "FlaxRobertaPreLayerNormForMaskedLM"),
+ ("roformer", "FlaxRoFormerForMaskedLM"),
+ ("xlm-roberta", "FlaxXLMRobertaForMaskedLM"),
+ ]
+)
+
+FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Seq2Seq Causal LM mapping
+ ("bart", "FlaxBartForConditionalGeneration"),
+ ("blenderbot", "FlaxBlenderbotForConditionalGeneration"),
+ ("blenderbot-small", "FlaxBlenderbotSmallForConditionalGeneration"),
+ ("encoder-decoder", "FlaxEncoderDecoderModel"),
+ ("longt5", "FlaxLongT5ForConditionalGeneration"),
+ ("marian", "FlaxMarianMTModel"),
+ ("mbart", "FlaxMBartForConditionalGeneration"),
+ ("mt5", "FlaxMT5ForConditionalGeneration"),
+ ("pegasus", "FlaxPegasusForConditionalGeneration"),
+ ("t5", "FlaxT5ForConditionalGeneration"),
+ ]
+)
+
+FLAX_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Image-classification
+ ("beit", "FlaxBeitForImageClassification"),
+ ("dinov2", "FlaxDinov2ForImageClassification"),
+ ("regnet", "FlaxRegNetForImageClassification"),
+ ("resnet", "FlaxResNetForImageClassification"),
+ ("vit", "FlaxViTForImageClassification"),
+ ]
+)
+
+FLAX_MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES = OrderedDict(
+ [
+ ("vision-encoder-decoder", "FlaxVisionEncoderDecoderModel"),
+ ]
+)
+
+FLAX_MODEL_FOR_CAUSAL_LM_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Causal LM mapping
+ ("bart", "FlaxBartForCausalLM"),
+ ("bert", "FlaxBertForCausalLM"),
+ ("big_bird", "FlaxBigBirdForCausalLM"),
+ ("bloom", "FlaxBloomForCausalLM"),
+ ("electra", "FlaxElectraForCausalLM"),
+ ("gemma", "FlaxGemmaForCausalLM"),
+ ("gpt-sw3", "FlaxGPT2LMHeadModel"),
+ ("gpt2", "FlaxGPT2LMHeadModel"),
+ ("gpt_neo", "FlaxGPTNeoForCausalLM"),
+ ("gptj", "FlaxGPTJForCausalLM"),
+ ("llama", "FlaxLlamaForCausalLM"),
+ ("mistral", "FlaxMistralForCausalLM"),
+ ("opt", "FlaxOPTForCausalLM"),
+ ("roberta", "FlaxRobertaForCausalLM"),
+ ("roberta-prelayernorm", "FlaxRobertaPreLayerNormForCausalLM"),
+ ("xglm", "FlaxXGLMForCausalLM"),
+ ("xlm-roberta", "FlaxXLMRobertaForCausalLM"),
+ ]
+)
+
+FLAX_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Sequence Classification mapping
+ ("albert", "FlaxAlbertForSequenceClassification"),
+ ("bart", "FlaxBartForSequenceClassification"),
+ ("bert", "FlaxBertForSequenceClassification"),
+ ("big_bird", "FlaxBigBirdForSequenceClassification"),
+ ("distilbert", "FlaxDistilBertForSequenceClassification"),
+ ("electra", "FlaxElectraForSequenceClassification"),
+ ("mbart", "FlaxMBartForSequenceClassification"),
+ ("roberta", "FlaxRobertaForSequenceClassification"),
+ ("roberta-prelayernorm", "FlaxRobertaPreLayerNormForSequenceClassification"),
+ ("roformer", "FlaxRoFormerForSequenceClassification"),
+ ("xlm-roberta", "FlaxXLMRobertaForSequenceClassification"),
+ ]
+)
+
+FLAX_MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Question Answering mapping
+ ("albert", "FlaxAlbertForQuestionAnswering"),
+ ("bart", "FlaxBartForQuestionAnswering"),
+ ("bert", "FlaxBertForQuestionAnswering"),
+ ("big_bird", "FlaxBigBirdForQuestionAnswering"),
+ ("distilbert", "FlaxDistilBertForQuestionAnswering"),
+ ("electra", "FlaxElectraForQuestionAnswering"),
+ ("mbart", "FlaxMBartForQuestionAnswering"),
+ ("roberta", "FlaxRobertaForQuestionAnswering"),
+ ("roberta-prelayernorm", "FlaxRobertaPreLayerNormForQuestionAnswering"),
+ ("roformer", "FlaxRoFormerForQuestionAnswering"),
+ ("xlm-roberta", "FlaxXLMRobertaForQuestionAnswering"),
+ ]
+)
+
+FLAX_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Token Classification mapping
+ ("albert", "FlaxAlbertForTokenClassification"),
+ ("bert", "FlaxBertForTokenClassification"),
+ ("big_bird", "FlaxBigBirdForTokenClassification"),
+ ("distilbert", "FlaxDistilBertForTokenClassification"),
+ ("electra", "FlaxElectraForTokenClassification"),
+ ("roberta", "FlaxRobertaForTokenClassification"),
+ ("roberta-prelayernorm", "FlaxRobertaPreLayerNormForTokenClassification"),
+ ("roformer", "FlaxRoFormerForTokenClassification"),
+ ("xlm-roberta", "FlaxXLMRobertaForTokenClassification"),
+ ]
+)
+
+FLAX_MODEL_FOR_MULTIPLE_CHOICE_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Multiple Choice mapping
+ ("albert", "FlaxAlbertForMultipleChoice"),
+ ("bert", "FlaxBertForMultipleChoice"),
+ ("big_bird", "FlaxBigBirdForMultipleChoice"),
+ ("distilbert", "FlaxDistilBertForMultipleChoice"),
+ ("electra", "FlaxElectraForMultipleChoice"),
+ ("roberta", "FlaxRobertaForMultipleChoice"),
+ ("roberta-prelayernorm", "FlaxRobertaPreLayerNormForMultipleChoice"),
+ ("roformer", "FlaxRoFormerForMultipleChoice"),
+ ("xlm-roberta", "FlaxXLMRobertaForMultipleChoice"),
+ ]
+)
+
+FLAX_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING_NAMES = OrderedDict(
+ [
+ ("bert", "FlaxBertForNextSentencePrediction"),
+ ]
+)
+
+FLAX_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES = OrderedDict(
+ [
+ ("speech-encoder-decoder", "FlaxSpeechEncoderDecoderModel"),
+ ("whisper", "FlaxWhisperForConditionalGeneration"),
+ ]
+)
+
+FLAX_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ ("whisper", "FlaxWhisperForAudioClassification"),
+ ]
+)
+
+FLAX_MODEL_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, FLAX_MODEL_MAPPING_NAMES)
+FLAX_MODEL_FOR_PRETRAINING_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_PRETRAINING_MAPPING_NAMES)
+FLAX_MODEL_FOR_MASKED_LM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_MASKED_LM_MAPPING_NAMES)
+FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES
+)
+FLAX_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES
+)
+FLAX_MODEL_FOR_VISION_2_SEQ_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES)
+FLAX_MODEL_FOR_CAUSAL_LM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_CAUSAL_LM_MAPPING_NAMES)
+FLAX_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES
+)
+FLAX_MODEL_FOR_QUESTION_ANSWERING_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES
+)
+FLAX_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES
+)
+FLAX_MODEL_FOR_MULTIPLE_CHOICE_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_MULTIPLE_CHOICE_MAPPING_NAMES
+)
+FLAX_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING_NAMES
+)
+FLAX_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES
+)
+FLAX_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES
+)
+
+
+class FlaxAutoModel(_BaseAutoModelClass):
+ _model_mapping = FLAX_MODEL_MAPPING
+
+
+FlaxAutoModel = auto_class_update(FlaxAutoModel)
+
+
+class FlaxAutoModelForPreTraining(_BaseAutoModelClass):
+ _model_mapping = FLAX_MODEL_FOR_PRETRAINING_MAPPING
+
+
+FlaxAutoModelForPreTraining = auto_class_update(FlaxAutoModelForPreTraining, head_doc="pretraining")
+
+
+class FlaxAutoModelForCausalLM(_BaseAutoModelClass):
+ _model_mapping = FLAX_MODEL_FOR_CAUSAL_LM_MAPPING
+
+
+FlaxAutoModelForCausalLM = auto_class_update(FlaxAutoModelForCausalLM, head_doc="causal language modeling")
+
+
+class FlaxAutoModelForMaskedLM(_BaseAutoModelClass):
+ _model_mapping = FLAX_MODEL_FOR_MASKED_LM_MAPPING
+
+
+FlaxAutoModelForMaskedLM = auto_class_update(FlaxAutoModelForMaskedLM, head_doc="masked language modeling")
+
+
+class FlaxAutoModelForSeq2SeqLM(_BaseAutoModelClass):
+ _model_mapping = FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING
+
+
+FlaxAutoModelForSeq2SeqLM = auto_class_update(
+ FlaxAutoModelForSeq2SeqLM,
+ head_doc="sequence-to-sequence language modeling",
+ checkpoint_for_example="google-t5/t5-base",
+)
+
+
+class FlaxAutoModelForSequenceClassification(_BaseAutoModelClass):
+ _model_mapping = FLAX_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING
+
+
+FlaxAutoModelForSequenceClassification = auto_class_update(
+ FlaxAutoModelForSequenceClassification, head_doc="sequence classification"
+)
+
+
+class FlaxAutoModelForQuestionAnswering(_BaseAutoModelClass):
+ _model_mapping = FLAX_MODEL_FOR_QUESTION_ANSWERING_MAPPING
+
+
+FlaxAutoModelForQuestionAnswering = auto_class_update(FlaxAutoModelForQuestionAnswering, head_doc="question answering")
+
+
+class FlaxAutoModelForTokenClassification(_BaseAutoModelClass):
+ _model_mapping = FLAX_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING
+
+
+FlaxAutoModelForTokenClassification = auto_class_update(
+ FlaxAutoModelForTokenClassification, head_doc="token classification"
+)
+
+
+class FlaxAutoModelForMultipleChoice(_BaseAutoModelClass):
+ _model_mapping = FLAX_MODEL_FOR_MULTIPLE_CHOICE_MAPPING
+
+
+FlaxAutoModelForMultipleChoice = auto_class_update(FlaxAutoModelForMultipleChoice, head_doc="multiple choice")
+
+
+class FlaxAutoModelForNextSentencePrediction(_BaseAutoModelClass):
+ _model_mapping = FLAX_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING
+
+
+FlaxAutoModelForNextSentencePrediction = auto_class_update(
+ FlaxAutoModelForNextSentencePrediction, head_doc="next sentence prediction"
+)
+
+
+class FlaxAutoModelForImageClassification(_BaseAutoModelClass):
+ _model_mapping = FLAX_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING
+
+
+FlaxAutoModelForImageClassification = auto_class_update(
+ FlaxAutoModelForImageClassification, head_doc="image classification"
+)
+
+
+class FlaxAutoModelForVision2Seq(_BaseAutoModelClass):
+ _model_mapping = FLAX_MODEL_FOR_VISION_2_SEQ_MAPPING
+
+
+FlaxAutoModelForVision2Seq = auto_class_update(FlaxAutoModelForVision2Seq, head_doc="vision-to-text modeling")
+
+
+class FlaxAutoModelForSpeechSeq2Seq(_BaseAutoModelClass):
+ _model_mapping = FLAX_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING
+
+
+FlaxAutoModelForSpeechSeq2Seq = auto_class_update(
+ FlaxAutoModelForSpeechSeq2Seq, head_doc="sequence-to-sequence speech-to-text modeling"
+)
+
+__all__ = [
+ "FLAX_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING",
+ "FLAX_MODEL_FOR_CAUSAL_LM_MAPPING",
+ "FLAX_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING",
+ "FLAX_MODEL_FOR_MASKED_LM_MAPPING",
+ "FLAX_MODEL_FOR_MULTIPLE_CHOICE_MAPPING",
+ "FLAX_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING",
+ "FLAX_MODEL_FOR_PRETRAINING_MAPPING",
+ "FLAX_MODEL_FOR_QUESTION_ANSWERING_MAPPING",
+ "FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING",
+ "FLAX_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING",
+ "FLAX_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING",
+ "FLAX_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING",
+ "FLAX_MODEL_FOR_VISION_2_SEQ_MAPPING",
+ "FLAX_MODEL_MAPPING",
+ "FlaxAutoModel",
+ "FlaxAutoModelForCausalLM",
+ "FlaxAutoModelForImageClassification",
+ "FlaxAutoModelForMaskedLM",
+ "FlaxAutoModelForMultipleChoice",
+ "FlaxAutoModelForNextSentencePrediction",
+ "FlaxAutoModelForPreTraining",
+ "FlaxAutoModelForQuestionAnswering",
+ "FlaxAutoModelForSeq2SeqLM",
+ "FlaxAutoModelForSequenceClassification",
+ "FlaxAutoModelForSpeechSeq2Seq",
+ "FlaxAutoModelForTokenClassification",
+ "FlaxAutoModelForVision2Seq",
+]
diff --git a/docs/transformers/src/transformers/models/auto/modeling_tf_auto.py b/docs/transformers/src/transformers/models/auto/modeling_tf_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf39f4d7c9c40bd87a8e4c5e3037e2cbe3574a29
--- /dev/null
+++ b/docs/transformers/src/transformers/models/auto/modeling_tf_auto.py
@@ -0,0 +1,776 @@
+# coding=utf-8
+# Copyright 2018 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Auto Model class."""
+
+import warnings
+from collections import OrderedDict
+
+from ...utils import logging
+from .auto_factory import _BaseAutoModelClass, _LazyAutoMapping, auto_class_update
+from .configuration_auto import CONFIG_MAPPING_NAMES
+
+
+logger = logging.get_logger(__name__)
+
+
+TF_MODEL_MAPPING_NAMES = OrderedDict(
+ [
+ # Base model mapping
+ ("albert", "TFAlbertModel"),
+ ("bart", "TFBartModel"),
+ ("bert", "TFBertModel"),
+ ("blenderbot", "TFBlenderbotModel"),
+ ("blenderbot-small", "TFBlenderbotSmallModel"),
+ ("blip", "TFBlipModel"),
+ ("camembert", "TFCamembertModel"),
+ ("clip", "TFCLIPModel"),
+ ("convbert", "TFConvBertModel"),
+ ("convnext", "TFConvNextModel"),
+ ("convnextv2", "TFConvNextV2Model"),
+ ("ctrl", "TFCTRLModel"),
+ ("cvt", "TFCvtModel"),
+ ("data2vec-vision", "TFData2VecVisionModel"),
+ ("deberta", "TFDebertaModel"),
+ ("deberta-v2", "TFDebertaV2Model"),
+ ("deit", "TFDeiTModel"),
+ ("distilbert", "TFDistilBertModel"),
+ ("dpr", "TFDPRQuestionEncoder"),
+ ("efficientformer", "TFEfficientFormerModel"),
+ ("electra", "TFElectraModel"),
+ ("esm", "TFEsmModel"),
+ ("flaubert", "TFFlaubertModel"),
+ ("funnel", ("TFFunnelModel", "TFFunnelBaseModel")),
+ ("gpt-sw3", "TFGPT2Model"),
+ ("gpt2", "TFGPT2Model"),
+ ("gptj", "TFGPTJModel"),
+ ("groupvit", "TFGroupViTModel"),
+ ("hubert", "TFHubertModel"),
+ ("idefics", "TFIdeficsModel"),
+ ("layoutlm", "TFLayoutLMModel"),
+ ("layoutlmv3", "TFLayoutLMv3Model"),
+ ("led", "TFLEDModel"),
+ ("longformer", "TFLongformerModel"),
+ ("lxmert", "TFLxmertModel"),
+ ("marian", "TFMarianModel"),
+ ("mbart", "TFMBartModel"),
+ ("mistral", "TFMistralModel"),
+ ("mobilebert", "TFMobileBertModel"),
+ ("mobilevit", "TFMobileViTModel"),
+ ("mpnet", "TFMPNetModel"),
+ ("mt5", "TFMT5Model"),
+ ("openai-gpt", "TFOpenAIGPTModel"),
+ ("opt", "TFOPTModel"),
+ ("pegasus", "TFPegasusModel"),
+ ("regnet", "TFRegNetModel"),
+ ("rembert", "TFRemBertModel"),
+ ("resnet", "TFResNetModel"),
+ ("roberta", "TFRobertaModel"),
+ ("roberta-prelayernorm", "TFRobertaPreLayerNormModel"),
+ ("roformer", "TFRoFormerModel"),
+ ("sam", "TFSamModel"),
+ ("sam_vision_model", "TFSamVisionModel"),
+ ("segformer", "TFSegformerModel"),
+ ("speech_to_text", "TFSpeech2TextModel"),
+ ("swiftformer", "TFSwiftFormerModel"),
+ ("swin", "TFSwinModel"),
+ ("t5", "TFT5Model"),
+ ("tapas", "TFTapasModel"),
+ ("transfo-xl", "TFTransfoXLModel"),
+ ("vision-text-dual-encoder", "TFVisionTextDualEncoderModel"),
+ ("vit", "TFViTModel"),
+ ("vit_mae", "TFViTMAEModel"),
+ ("wav2vec2", "TFWav2Vec2Model"),
+ ("whisper", "TFWhisperModel"),
+ ("xglm", "TFXGLMModel"),
+ ("xlm", "TFXLMModel"),
+ ("xlm-roberta", "TFXLMRobertaModel"),
+ ("xlnet", "TFXLNetModel"),
+ ]
+)
+
+TF_MODEL_FOR_PRETRAINING_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for pre-training mapping
+ ("albert", "TFAlbertForPreTraining"),
+ ("bart", "TFBartForConditionalGeneration"),
+ ("bert", "TFBertForPreTraining"),
+ ("camembert", "TFCamembertForMaskedLM"),
+ ("ctrl", "TFCTRLLMHeadModel"),
+ ("distilbert", "TFDistilBertForMaskedLM"),
+ ("electra", "TFElectraForPreTraining"),
+ ("flaubert", "TFFlaubertWithLMHeadModel"),
+ ("funnel", "TFFunnelForPreTraining"),
+ ("gpt-sw3", "TFGPT2LMHeadModel"),
+ ("gpt2", "TFGPT2LMHeadModel"),
+ ("idefics", "TFIdeficsForVisionText2Text"),
+ ("layoutlm", "TFLayoutLMForMaskedLM"),
+ ("lxmert", "TFLxmertForPreTraining"),
+ ("mobilebert", "TFMobileBertForPreTraining"),
+ ("mpnet", "TFMPNetForMaskedLM"),
+ ("openai-gpt", "TFOpenAIGPTLMHeadModel"),
+ ("roberta", "TFRobertaForMaskedLM"),
+ ("roberta-prelayernorm", "TFRobertaPreLayerNormForMaskedLM"),
+ ("t5", "TFT5ForConditionalGeneration"),
+ ("tapas", "TFTapasForMaskedLM"),
+ ("transfo-xl", "TFTransfoXLLMHeadModel"),
+ ("vit_mae", "TFViTMAEForPreTraining"),
+ ("xlm", "TFXLMWithLMHeadModel"),
+ ("xlm-roberta", "TFXLMRobertaForMaskedLM"),
+ ("xlnet", "TFXLNetLMHeadModel"),
+ ]
+)
+
+TF_MODEL_WITH_LM_HEAD_MAPPING_NAMES = OrderedDict(
+ [
+ # Model with LM heads mapping
+ ("albert", "TFAlbertForMaskedLM"),
+ ("bart", "TFBartForConditionalGeneration"),
+ ("bert", "TFBertForMaskedLM"),
+ ("camembert", "TFCamembertForMaskedLM"),
+ ("convbert", "TFConvBertForMaskedLM"),
+ ("ctrl", "TFCTRLLMHeadModel"),
+ ("distilbert", "TFDistilBertForMaskedLM"),
+ ("electra", "TFElectraForMaskedLM"),
+ ("esm", "TFEsmForMaskedLM"),
+ ("flaubert", "TFFlaubertWithLMHeadModel"),
+ ("funnel", "TFFunnelForMaskedLM"),
+ ("gpt-sw3", "TFGPT2LMHeadModel"),
+ ("gpt2", "TFGPT2LMHeadModel"),
+ ("gptj", "TFGPTJForCausalLM"),
+ ("layoutlm", "TFLayoutLMForMaskedLM"),
+ ("led", "TFLEDForConditionalGeneration"),
+ ("longformer", "TFLongformerForMaskedLM"),
+ ("marian", "TFMarianMTModel"),
+ ("mobilebert", "TFMobileBertForMaskedLM"),
+ ("mpnet", "TFMPNetForMaskedLM"),
+ ("openai-gpt", "TFOpenAIGPTLMHeadModel"),
+ ("rembert", "TFRemBertForMaskedLM"),
+ ("roberta", "TFRobertaForMaskedLM"),
+ ("roberta-prelayernorm", "TFRobertaPreLayerNormForMaskedLM"),
+ ("roformer", "TFRoFormerForMaskedLM"),
+ ("speech_to_text", "TFSpeech2TextForConditionalGeneration"),
+ ("t5", "TFT5ForConditionalGeneration"),
+ ("tapas", "TFTapasForMaskedLM"),
+ ("transfo-xl", "TFTransfoXLLMHeadModel"),
+ ("whisper", "TFWhisperForConditionalGeneration"),
+ ("xlm", "TFXLMWithLMHeadModel"),
+ ("xlm-roberta", "TFXLMRobertaForMaskedLM"),
+ ("xlnet", "TFXLNetLMHeadModel"),
+ ]
+)
+
+TF_MODEL_FOR_CAUSAL_LM_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Causal LM mapping
+ ("bert", "TFBertLMHeadModel"),
+ ("camembert", "TFCamembertForCausalLM"),
+ ("ctrl", "TFCTRLLMHeadModel"),
+ ("gpt-sw3", "TFGPT2LMHeadModel"),
+ ("gpt2", "TFGPT2LMHeadModel"),
+ ("gptj", "TFGPTJForCausalLM"),
+ ("mistral", "TFMistralForCausalLM"),
+ ("openai-gpt", "TFOpenAIGPTLMHeadModel"),
+ ("opt", "TFOPTForCausalLM"),
+ ("rembert", "TFRemBertForCausalLM"),
+ ("roberta", "TFRobertaForCausalLM"),
+ ("roberta-prelayernorm", "TFRobertaPreLayerNormForCausalLM"),
+ ("roformer", "TFRoFormerForCausalLM"),
+ ("transfo-xl", "TFTransfoXLLMHeadModel"),
+ ("xglm", "TFXGLMForCausalLM"),
+ ("xlm", "TFXLMWithLMHeadModel"),
+ ("xlm-roberta", "TFXLMRobertaForCausalLM"),
+ ("xlnet", "TFXLNetLMHeadModel"),
+ ]
+)
+
+TF_MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING_NAMES = OrderedDict(
+ [
+ ("deit", "TFDeiTForMaskedImageModeling"),
+ ("swin", "TFSwinForMaskedImageModeling"),
+ ]
+)
+
+TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Image-classsification
+ ("convnext", "TFConvNextForImageClassification"),
+ ("convnextv2", "TFConvNextV2ForImageClassification"),
+ ("cvt", "TFCvtForImageClassification"),
+ ("data2vec-vision", "TFData2VecVisionForImageClassification"),
+ ("deit", ("TFDeiTForImageClassification", "TFDeiTForImageClassificationWithTeacher")),
+ (
+ "efficientformer",
+ ("TFEfficientFormerForImageClassification", "TFEfficientFormerForImageClassificationWithTeacher"),
+ ),
+ ("mobilevit", "TFMobileViTForImageClassification"),
+ ("regnet", "TFRegNetForImageClassification"),
+ ("resnet", "TFResNetForImageClassification"),
+ ("segformer", "TFSegformerForImageClassification"),
+ ("swiftformer", "TFSwiftFormerForImageClassification"),
+ ("swin", "TFSwinForImageClassification"),
+ ("vit", "TFViTForImageClassification"),
+ ]
+)
+
+
+TF_MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Zero Shot Image Classification mapping
+ ("blip", "TFBlipModel"),
+ ("clip", "TFCLIPModel"),
+ ]
+)
+
+
+TF_MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Semantic Segmentation mapping
+ ("data2vec-vision", "TFData2VecVisionForSemanticSegmentation"),
+ ("mobilevit", "TFMobileViTForSemanticSegmentation"),
+ ("segformer", "TFSegformerForSemanticSegmentation"),
+ ]
+)
+
+TF_MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES = OrderedDict(
+ [
+ ("blip", "TFBlipForConditionalGeneration"),
+ ("vision-encoder-decoder", "TFVisionEncoderDecoderModel"),
+ ]
+)
+
+TF_MODEL_FOR_MASKED_LM_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Masked LM mapping
+ ("albert", "TFAlbertForMaskedLM"),
+ ("bert", "TFBertForMaskedLM"),
+ ("camembert", "TFCamembertForMaskedLM"),
+ ("convbert", "TFConvBertForMaskedLM"),
+ ("deberta", "TFDebertaForMaskedLM"),
+ ("deberta-v2", "TFDebertaV2ForMaskedLM"),
+ ("distilbert", "TFDistilBertForMaskedLM"),
+ ("electra", "TFElectraForMaskedLM"),
+ ("esm", "TFEsmForMaskedLM"),
+ ("flaubert", "TFFlaubertWithLMHeadModel"),
+ ("funnel", "TFFunnelForMaskedLM"),
+ ("layoutlm", "TFLayoutLMForMaskedLM"),
+ ("longformer", "TFLongformerForMaskedLM"),
+ ("mobilebert", "TFMobileBertForMaskedLM"),
+ ("mpnet", "TFMPNetForMaskedLM"),
+ ("rembert", "TFRemBertForMaskedLM"),
+ ("roberta", "TFRobertaForMaskedLM"),
+ ("roberta-prelayernorm", "TFRobertaPreLayerNormForMaskedLM"),
+ ("roformer", "TFRoFormerForMaskedLM"),
+ ("tapas", "TFTapasForMaskedLM"),
+ ("xlm", "TFXLMWithLMHeadModel"),
+ ("xlm-roberta", "TFXLMRobertaForMaskedLM"),
+ ]
+)
+
+TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Seq2Seq Causal LM mapping
+ ("bart", "TFBartForConditionalGeneration"),
+ ("blenderbot", "TFBlenderbotForConditionalGeneration"),
+ ("blenderbot-small", "TFBlenderbotSmallForConditionalGeneration"),
+ ("encoder-decoder", "TFEncoderDecoderModel"),
+ ("led", "TFLEDForConditionalGeneration"),
+ ("marian", "TFMarianMTModel"),
+ ("mbart", "TFMBartForConditionalGeneration"),
+ ("mt5", "TFMT5ForConditionalGeneration"),
+ ("pegasus", "TFPegasusForConditionalGeneration"),
+ ("t5", "TFT5ForConditionalGeneration"),
+ ]
+)
+
+TF_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES = OrderedDict(
+ [
+ ("speech_to_text", "TFSpeech2TextForConditionalGeneration"),
+ ("whisper", "TFWhisperForConditionalGeneration"),
+ ]
+)
+
+TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Sequence Classification mapping
+ ("albert", "TFAlbertForSequenceClassification"),
+ ("bart", "TFBartForSequenceClassification"),
+ ("bert", "TFBertForSequenceClassification"),
+ ("camembert", "TFCamembertForSequenceClassification"),
+ ("convbert", "TFConvBertForSequenceClassification"),
+ ("ctrl", "TFCTRLForSequenceClassification"),
+ ("deberta", "TFDebertaForSequenceClassification"),
+ ("deberta-v2", "TFDebertaV2ForSequenceClassification"),
+ ("distilbert", "TFDistilBertForSequenceClassification"),
+ ("electra", "TFElectraForSequenceClassification"),
+ ("esm", "TFEsmForSequenceClassification"),
+ ("flaubert", "TFFlaubertForSequenceClassification"),
+ ("funnel", "TFFunnelForSequenceClassification"),
+ ("gpt-sw3", "TFGPT2ForSequenceClassification"),
+ ("gpt2", "TFGPT2ForSequenceClassification"),
+ ("gptj", "TFGPTJForSequenceClassification"),
+ ("layoutlm", "TFLayoutLMForSequenceClassification"),
+ ("layoutlmv3", "TFLayoutLMv3ForSequenceClassification"),
+ ("longformer", "TFLongformerForSequenceClassification"),
+ ("mistral", "TFMistralForSequenceClassification"),
+ ("mobilebert", "TFMobileBertForSequenceClassification"),
+ ("mpnet", "TFMPNetForSequenceClassification"),
+ ("openai-gpt", "TFOpenAIGPTForSequenceClassification"),
+ ("rembert", "TFRemBertForSequenceClassification"),
+ ("roberta", "TFRobertaForSequenceClassification"),
+ ("roberta-prelayernorm", "TFRobertaPreLayerNormForSequenceClassification"),
+ ("roformer", "TFRoFormerForSequenceClassification"),
+ ("tapas", "TFTapasForSequenceClassification"),
+ ("transfo-xl", "TFTransfoXLForSequenceClassification"),
+ ("xlm", "TFXLMForSequenceClassification"),
+ ("xlm-roberta", "TFXLMRobertaForSequenceClassification"),
+ ("xlnet", "TFXLNetForSequenceClassification"),
+ ]
+)
+
+TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Question Answering mapping
+ ("albert", "TFAlbertForQuestionAnswering"),
+ ("bert", "TFBertForQuestionAnswering"),
+ ("camembert", "TFCamembertForQuestionAnswering"),
+ ("convbert", "TFConvBertForQuestionAnswering"),
+ ("deberta", "TFDebertaForQuestionAnswering"),
+ ("deberta-v2", "TFDebertaV2ForQuestionAnswering"),
+ ("distilbert", "TFDistilBertForQuestionAnswering"),
+ ("electra", "TFElectraForQuestionAnswering"),
+ ("flaubert", "TFFlaubertForQuestionAnsweringSimple"),
+ ("funnel", "TFFunnelForQuestionAnswering"),
+ ("gptj", "TFGPTJForQuestionAnswering"),
+ ("layoutlmv3", "TFLayoutLMv3ForQuestionAnswering"),
+ ("longformer", "TFLongformerForQuestionAnswering"),
+ ("mobilebert", "TFMobileBertForQuestionAnswering"),
+ ("mpnet", "TFMPNetForQuestionAnswering"),
+ ("rembert", "TFRemBertForQuestionAnswering"),
+ ("roberta", "TFRobertaForQuestionAnswering"),
+ ("roberta-prelayernorm", "TFRobertaPreLayerNormForQuestionAnswering"),
+ ("roformer", "TFRoFormerForQuestionAnswering"),
+ ("xlm", "TFXLMForQuestionAnsweringSimple"),
+ ("xlm-roberta", "TFXLMRobertaForQuestionAnswering"),
+ ("xlnet", "TFXLNetForQuestionAnsweringSimple"),
+ ]
+)
+TF_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES = OrderedDict([("wav2vec2", "TFWav2Vec2ForSequenceClassification")])
+
+TF_MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING_NAMES = OrderedDict(
+ [
+ ("layoutlm", "TFLayoutLMForQuestionAnswering"),
+ ("layoutlmv3", "TFLayoutLMv3ForQuestionAnswering"),
+ ]
+)
+
+
+TF_MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Table Question Answering mapping
+ ("tapas", "TFTapasForQuestionAnswering"),
+ ]
+)
+
+TF_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Token Classification mapping
+ ("albert", "TFAlbertForTokenClassification"),
+ ("bert", "TFBertForTokenClassification"),
+ ("camembert", "TFCamembertForTokenClassification"),
+ ("convbert", "TFConvBertForTokenClassification"),
+ ("deberta", "TFDebertaForTokenClassification"),
+ ("deberta-v2", "TFDebertaV2ForTokenClassification"),
+ ("distilbert", "TFDistilBertForTokenClassification"),
+ ("electra", "TFElectraForTokenClassification"),
+ ("esm", "TFEsmForTokenClassification"),
+ ("flaubert", "TFFlaubertForTokenClassification"),
+ ("funnel", "TFFunnelForTokenClassification"),
+ ("layoutlm", "TFLayoutLMForTokenClassification"),
+ ("layoutlmv3", "TFLayoutLMv3ForTokenClassification"),
+ ("longformer", "TFLongformerForTokenClassification"),
+ ("mobilebert", "TFMobileBertForTokenClassification"),
+ ("mpnet", "TFMPNetForTokenClassification"),
+ ("rembert", "TFRemBertForTokenClassification"),
+ ("roberta", "TFRobertaForTokenClassification"),
+ ("roberta-prelayernorm", "TFRobertaPreLayerNormForTokenClassification"),
+ ("roformer", "TFRoFormerForTokenClassification"),
+ ("xlm", "TFXLMForTokenClassification"),
+ ("xlm-roberta", "TFXLMRobertaForTokenClassification"),
+ ("xlnet", "TFXLNetForTokenClassification"),
+ ]
+)
+
+TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING_NAMES = OrderedDict(
+ [
+ # Model for Multiple Choice mapping
+ ("albert", "TFAlbertForMultipleChoice"),
+ ("bert", "TFBertForMultipleChoice"),
+ ("camembert", "TFCamembertForMultipleChoice"),
+ ("convbert", "TFConvBertForMultipleChoice"),
+ ("deberta-v2", "TFDebertaV2ForMultipleChoice"),
+ ("distilbert", "TFDistilBertForMultipleChoice"),
+ ("electra", "TFElectraForMultipleChoice"),
+ ("flaubert", "TFFlaubertForMultipleChoice"),
+ ("funnel", "TFFunnelForMultipleChoice"),
+ ("longformer", "TFLongformerForMultipleChoice"),
+ ("mobilebert", "TFMobileBertForMultipleChoice"),
+ ("mpnet", "TFMPNetForMultipleChoice"),
+ ("rembert", "TFRemBertForMultipleChoice"),
+ ("roberta", "TFRobertaForMultipleChoice"),
+ ("roberta-prelayernorm", "TFRobertaPreLayerNormForMultipleChoice"),
+ ("roformer", "TFRoFormerForMultipleChoice"),
+ ("xlm", "TFXLMForMultipleChoice"),
+ ("xlm-roberta", "TFXLMRobertaForMultipleChoice"),
+ ("xlnet", "TFXLNetForMultipleChoice"),
+ ]
+)
+
+TF_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING_NAMES = OrderedDict(
+ [
+ ("bert", "TFBertForNextSentencePrediction"),
+ ("mobilebert", "TFMobileBertForNextSentencePrediction"),
+ ]
+)
+TF_MODEL_FOR_MASK_GENERATION_MAPPING_NAMES = OrderedDict(
+ [
+ ("sam", "TFSamModel"),
+ ]
+)
+TF_MODEL_FOR_TEXT_ENCODING_MAPPING_NAMES = OrderedDict(
+ [
+ ("albert", "TFAlbertModel"),
+ ("bert", "TFBertModel"),
+ ("convbert", "TFConvBertModel"),
+ ("deberta", "TFDebertaModel"),
+ ("deberta-v2", "TFDebertaV2Model"),
+ ("distilbert", "TFDistilBertModel"),
+ ("electra", "TFElectraModel"),
+ ("flaubert", "TFFlaubertModel"),
+ ("longformer", "TFLongformerModel"),
+ ("mobilebert", "TFMobileBertModel"),
+ ("mt5", "TFMT5EncoderModel"),
+ ("rembert", "TFRemBertModel"),
+ ("roberta", "TFRobertaModel"),
+ ("roberta-prelayernorm", "TFRobertaPreLayerNormModel"),
+ ("roformer", "TFRoFormerModel"),
+ ("t5", "TFT5EncoderModel"),
+ ("xlm", "TFXLMModel"),
+ ("xlm-roberta", "TFXLMRobertaModel"),
+ ]
+)
+
+TF_MODEL_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, TF_MODEL_MAPPING_NAMES)
+TF_MODEL_FOR_PRETRAINING_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, TF_MODEL_FOR_PRETRAINING_MAPPING_NAMES)
+TF_MODEL_WITH_LM_HEAD_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, TF_MODEL_WITH_LM_HEAD_MAPPING_NAMES)
+TF_MODEL_FOR_CAUSAL_LM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, TF_MODEL_FOR_CAUSAL_LM_MAPPING_NAMES)
+TF_MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING_NAMES
+)
+TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES
+)
+TF_MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING_NAMES
+)
+TF_MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING_NAMES
+)
+TF_MODEL_FOR_VISION_2_SEQ_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, TF_MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES)
+TF_MODEL_FOR_MASKED_LM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, TF_MODEL_FOR_MASKED_LM_MAPPING_NAMES)
+TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES
+)
+TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES
+)
+TF_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES
+)
+TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES
+)
+TF_MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING_NAMES
+)
+TF_MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING_NAMES
+)
+TF_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES
+)
+TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING_NAMES
+)
+TF_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING_NAMES
+)
+TF_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES
+)
+
+TF_MODEL_FOR_MASK_GENERATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, TF_MODEL_FOR_MASK_GENERATION_MAPPING_NAMES
+)
+
+TF_MODEL_FOR_TEXT_ENCODING_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, TF_MODEL_FOR_TEXT_ENCODING_MAPPING_NAMES)
+
+
+class TFAutoModelForMaskGeneration(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_MASK_GENERATION_MAPPING
+
+
+class TFAutoModelForTextEncoding(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_TEXT_ENCODING_MAPPING
+
+
+class TFAutoModel(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_MAPPING
+
+
+TFAutoModel = auto_class_update(TFAutoModel)
+
+
+class TFAutoModelForAudioClassification(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING
+
+
+TFAutoModelForAudioClassification = auto_class_update(
+ TFAutoModelForAudioClassification, head_doc="audio classification"
+)
+
+
+class TFAutoModelForPreTraining(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_PRETRAINING_MAPPING
+
+
+TFAutoModelForPreTraining = auto_class_update(TFAutoModelForPreTraining, head_doc="pretraining")
+
+
+# Private on purpose, the public class will add the deprecation warnings.
+class _TFAutoModelWithLMHead(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_WITH_LM_HEAD_MAPPING
+
+
+_TFAutoModelWithLMHead = auto_class_update(_TFAutoModelWithLMHead, head_doc="language modeling")
+
+
+class TFAutoModelForCausalLM(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_CAUSAL_LM_MAPPING
+
+
+TFAutoModelForCausalLM = auto_class_update(TFAutoModelForCausalLM, head_doc="causal language modeling")
+
+
+class TFAutoModelForMaskedImageModeling(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING
+
+
+TFAutoModelForMaskedImageModeling = auto_class_update(
+ TFAutoModelForMaskedImageModeling, head_doc="masked image modeling"
+)
+
+
+class TFAutoModelForImageClassification(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING
+
+
+TFAutoModelForImageClassification = auto_class_update(
+ TFAutoModelForImageClassification, head_doc="image classification"
+)
+
+
+class TFAutoModelForZeroShotImageClassification(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING
+
+
+TFAutoModelForZeroShotImageClassification = auto_class_update(
+ TFAutoModelForZeroShotImageClassification, head_doc="zero-shot image classification"
+)
+
+
+class TFAutoModelForSemanticSegmentation(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING
+
+
+TFAutoModelForSemanticSegmentation = auto_class_update(
+ TFAutoModelForSemanticSegmentation, head_doc="semantic segmentation"
+)
+
+
+class TFAutoModelForVision2Seq(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_VISION_2_SEQ_MAPPING
+
+
+TFAutoModelForVision2Seq = auto_class_update(TFAutoModelForVision2Seq, head_doc="vision-to-text modeling")
+
+
+class TFAutoModelForMaskedLM(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_MASKED_LM_MAPPING
+
+
+TFAutoModelForMaskedLM = auto_class_update(TFAutoModelForMaskedLM, head_doc="masked language modeling")
+
+
+class TFAutoModelForSeq2SeqLM(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING
+
+
+TFAutoModelForSeq2SeqLM = auto_class_update(
+ TFAutoModelForSeq2SeqLM,
+ head_doc="sequence-to-sequence language modeling",
+ checkpoint_for_example="google-t5/t5-base",
+)
+
+
+class TFAutoModelForSequenceClassification(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING
+
+
+TFAutoModelForSequenceClassification = auto_class_update(
+ TFAutoModelForSequenceClassification, head_doc="sequence classification"
+)
+
+
+class TFAutoModelForQuestionAnswering(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING
+
+
+TFAutoModelForQuestionAnswering = auto_class_update(TFAutoModelForQuestionAnswering, head_doc="question answering")
+
+
+class TFAutoModelForDocumentQuestionAnswering(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING
+
+
+TFAutoModelForDocumentQuestionAnswering = auto_class_update(
+ TFAutoModelForDocumentQuestionAnswering,
+ head_doc="document question answering",
+ checkpoint_for_example='impira/layoutlm-document-qa", revision="52e01b3',
+)
+
+
+class TFAutoModelForTableQuestionAnswering(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING
+
+
+TFAutoModelForTableQuestionAnswering = auto_class_update(
+ TFAutoModelForTableQuestionAnswering,
+ head_doc="table question answering",
+ checkpoint_for_example="google/tapas-base-finetuned-wtq",
+)
+
+
+class TFAutoModelForTokenClassification(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING
+
+
+TFAutoModelForTokenClassification = auto_class_update(
+ TFAutoModelForTokenClassification, head_doc="token classification"
+)
+
+
+class TFAutoModelForMultipleChoice(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING
+
+
+TFAutoModelForMultipleChoice = auto_class_update(TFAutoModelForMultipleChoice, head_doc="multiple choice")
+
+
+class TFAutoModelForNextSentencePrediction(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING
+
+
+TFAutoModelForNextSentencePrediction = auto_class_update(
+ TFAutoModelForNextSentencePrediction, head_doc="next sentence prediction"
+)
+
+
+class TFAutoModelForSpeechSeq2Seq(_BaseAutoModelClass):
+ _model_mapping = TF_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING
+
+
+TFAutoModelForSpeechSeq2Seq = auto_class_update(
+ TFAutoModelForSpeechSeq2Seq, head_doc="sequence-to-sequence speech-to-text modeling"
+)
+
+
+class TFAutoModelWithLMHead(_TFAutoModelWithLMHead):
+ @classmethod
+ def from_config(cls, config):
+ warnings.warn(
+ "The class `TFAutoModelWithLMHead` is deprecated and will be removed in a future version. Please use"
+ " `TFAutoModelForCausalLM` for causal language models, `TFAutoModelForMaskedLM` for masked language models"
+ " and `TFAutoModelForSeq2SeqLM` for encoder-decoder models.",
+ FutureWarning,
+ )
+ return super().from_config(config)
+
+ @classmethod
+ def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
+ warnings.warn(
+ "The class `TFAutoModelWithLMHead` is deprecated and will be removed in a future version. Please use"
+ " `TFAutoModelForCausalLM` for causal language models, `TFAutoModelForMaskedLM` for masked language models"
+ " and `TFAutoModelForSeq2SeqLM` for encoder-decoder models.",
+ FutureWarning,
+ )
+ return super().from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
+
+
+__all__ = [
+ "TF_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING",
+ "TF_MODEL_FOR_CAUSAL_LM_MAPPING",
+ "TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING",
+ "TF_MODEL_FOR_MASK_GENERATION_MAPPING",
+ "TF_MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING",
+ "TF_MODEL_FOR_MASKED_LM_MAPPING",
+ "TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING",
+ "TF_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING",
+ "TF_MODEL_FOR_PRETRAINING_MAPPING",
+ "TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING",
+ "TF_MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING",
+ "TF_MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING",
+ "TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING",
+ "TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING",
+ "TF_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING",
+ "TF_MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING",
+ "TF_MODEL_FOR_TEXT_ENCODING_MAPPING",
+ "TF_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING",
+ "TF_MODEL_FOR_VISION_2_SEQ_MAPPING",
+ "TF_MODEL_FOR_ZERO_SHOT_IMAGE_CLASSIFICATION_MAPPING",
+ "TF_MODEL_MAPPING",
+ "TF_MODEL_WITH_LM_HEAD_MAPPING",
+ "TFAutoModel",
+ "TFAutoModelForAudioClassification",
+ "TFAutoModelForCausalLM",
+ "TFAutoModelForImageClassification",
+ "TFAutoModelForMaskedImageModeling",
+ "TFAutoModelForMaskedLM",
+ "TFAutoModelForMaskGeneration",
+ "TFAutoModelForMultipleChoice",
+ "TFAutoModelForNextSentencePrediction",
+ "TFAutoModelForPreTraining",
+ "TFAutoModelForDocumentQuestionAnswering",
+ "TFAutoModelForQuestionAnswering",
+ "TFAutoModelForSemanticSegmentation",
+ "TFAutoModelForSeq2SeqLM",
+ "TFAutoModelForSequenceClassification",
+ "TFAutoModelForSpeechSeq2Seq",
+ "TFAutoModelForTableQuestionAnswering",
+ "TFAutoModelForTextEncoding",
+ "TFAutoModelForTokenClassification",
+ "TFAutoModelForVision2Seq",
+ "TFAutoModelForZeroShotImageClassification",
+ "TFAutoModelWithLMHead",
+]
diff --git a/docs/transformers/src/transformers/models/auto/processing_auto.py b/docs/transformers/src/transformers/models/auto/processing_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..7060b6125dfb49ef0c91193321f717556c10e5da
--- /dev/null
+++ b/docs/transformers/src/transformers/models/auto/processing_auto.py
@@ -0,0 +1,398 @@
+# coding=utf-8
+# Copyright 2021 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""AutoProcessor class."""
+
+import importlib
+import inspect
+import json
+import os
+import warnings
+from collections import OrderedDict
+
+# Build the list of all feature extractors
+from ...configuration_utils import PretrainedConfig
+from ...dynamic_module_utils import get_class_from_dynamic_module, resolve_trust_remote_code
+from ...feature_extraction_utils import FeatureExtractionMixin
+from ...image_processing_utils import ImageProcessingMixin
+from ...processing_utils import ProcessorMixin
+from ...tokenization_utils import TOKENIZER_CONFIG_FILE
+from ...utils import FEATURE_EXTRACTOR_NAME, PROCESSOR_NAME, cached_file, logging
+from .auto_factory import _LazyAutoMapping
+from .configuration_auto import (
+ CONFIG_MAPPING_NAMES,
+ AutoConfig,
+ model_type_to_module_name,
+ replace_list_option_in_docstrings,
+)
+from .feature_extraction_auto import AutoFeatureExtractor
+from .image_processing_auto import AutoImageProcessor
+from .tokenization_auto import AutoTokenizer
+
+
+logger = logging.get_logger(__name__)
+
+PROCESSOR_MAPPING_NAMES = OrderedDict(
+ [
+ ("align", "AlignProcessor"),
+ ("altclip", "AltCLIPProcessor"),
+ ("aria", "AriaProcessor"),
+ ("aya_vision", "AyaVisionProcessor"),
+ ("bark", "BarkProcessor"),
+ ("blip", "BlipProcessor"),
+ ("blip-2", "Blip2Processor"),
+ ("bridgetower", "BridgeTowerProcessor"),
+ ("chameleon", "ChameleonProcessor"),
+ ("chinese_clip", "ChineseCLIPProcessor"),
+ ("clap", "ClapProcessor"),
+ ("clip", "CLIPProcessor"),
+ ("clipseg", "CLIPSegProcessor"),
+ ("clvp", "ClvpProcessor"),
+ ("colpali", "ColPaliProcessor"),
+ ("emu3", "Emu3Processor"),
+ ("flava", "FlavaProcessor"),
+ ("fuyu", "FuyuProcessor"),
+ ("gemma3", "Gemma3Processor"),
+ ("git", "GitProcessor"),
+ ("got_ocr2", "GotOcr2Processor"),
+ ("granite_speech", "GraniteSpeechProcessor"),
+ ("grounding-dino", "GroundingDinoProcessor"),
+ ("groupvit", "CLIPProcessor"),
+ ("hubert", "Wav2Vec2Processor"),
+ ("idefics", "IdeficsProcessor"),
+ ("idefics2", "Idefics2Processor"),
+ ("idefics3", "Idefics3Processor"),
+ ("instructblip", "InstructBlipProcessor"),
+ ("instructblipvideo", "InstructBlipVideoProcessor"),
+ ("internvl", "InternVLProcessor"),
+ ("janus", "JanusProcessor"),
+ ("kosmos-2", "Kosmos2Processor"),
+ ("layoutlmv2", "LayoutLMv2Processor"),
+ ("layoutlmv3", "LayoutLMv3Processor"),
+ ("llama4", "Llama4Processor"),
+ ("llava", "LlavaProcessor"),
+ ("llava_next", "LlavaNextProcessor"),
+ ("llava_next_video", "LlavaNextVideoProcessor"),
+ ("llava_onevision", "LlavaOnevisionProcessor"),
+ ("markuplm", "MarkupLMProcessor"),
+ ("mctct", "MCTCTProcessor"),
+ ("mgp-str", "MgpstrProcessor"),
+ ("mistral3", "PixtralProcessor"),
+ ("mllama", "MllamaProcessor"),
+ ("moonshine", "Wav2Vec2Processor"),
+ ("oneformer", "OneFormerProcessor"),
+ ("owlv2", "Owlv2Processor"),
+ ("owlvit", "OwlViTProcessor"),
+ ("paligemma", "PaliGemmaProcessor"),
+ ("phi4_multimodal", "Phi4MultimodalProcessor"),
+ ("pix2struct", "Pix2StructProcessor"),
+ ("pixtral", "PixtralProcessor"),
+ ("pop2piano", "Pop2PianoProcessor"),
+ ("qwen2_5_omni", "Qwen2_5OmniProcessor"),
+ ("qwen2_5_vl", "Qwen2_5_VLProcessor"),
+ ("qwen2_audio", "Qwen2AudioProcessor"),
+ ("qwen2_vl", "Qwen2VLProcessor"),
+ ("sam", "SamProcessor"),
+ ("seamless_m4t", "SeamlessM4TProcessor"),
+ ("sew", "Wav2Vec2Processor"),
+ ("sew-d", "Wav2Vec2Processor"),
+ ("shieldgemma2", "ShieldGemma2Processor"),
+ ("siglip", "SiglipProcessor"),
+ ("siglip2", "Siglip2Processor"),
+ ("speech_to_text", "Speech2TextProcessor"),
+ ("speech_to_text_2", "Speech2Text2Processor"),
+ ("speecht5", "SpeechT5Processor"),
+ ("trocr", "TrOCRProcessor"),
+ ("tvlt", "TvltProcessor"),
+ ("tvp", "TvpProcessor"),
+ ("udop", "UdopProcessor"),
+ ("unispeech", "Wav2Vec2Processor"),
+ ("unispeech-sat", "Wav2Vec2Processor"),
+ ("video_llava", "VideoLlavaProcessor"),
+ ("vilt", "ViltProcessor"),
+ ("vipllava", "LlavaProcessor"),
+ ("vision-text-dual-encoder", "VisionTextDualEncoderProcessor"),
+ ("wav2vec2", "Wav2Vec2Processor"),
+ ("wav2vec2-bert", "Wav2Vec2Processor"),
+ ("wav2vec2-conformer", "Wav2Vec2Processor"),
+ ("wavlm", "Wav2Vec2Processor"),
+ ("whisper", "WhisperProcessor"),
+ ("xclip", "XCLIPProcessor"),
+ ]
+)
+
+PROCESSOR_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, PROCESSOR_MAPPING_NAMES)
+
+
+def processor_class_from_name(class_name: str):
+ for module_name, processors in PROCESSOR_MAPPING_NAMES.items():
+ if class_name in processors:
+ module_name = model_type_to_module_name(module_name)
+
+ module = importlib.import_module(f".{module_name}", "transformers.models")
+ try:
+ return getattr(module, class_name)
+ except AttributeError:
+ continue
+
+ for processor in PROCESSOR_MAPPING._extra_content.values():
+ if getattr(processor, "__name__", None) == class_name:
+ return processor
+
+ # We did not fine the class, but maybe it's because a dep is missing. In that case, the class will be in the main
+ # init and we return the proper dummy to get an appropriate error message.
+ main_module = importlib.import_module("transformers")
+ if hasattr(main_module, class_name):
+ return getattr(main_module, class_name)
+
+ return None
+
+
+class AutoProcessor:
+ r"""
+ This is a generic processor class that will be instantiated as one of the processor classes of the library when
+ created with the [`AutoProcessor.from_pretrained`] class method.
+
+ This class cannot be instantiated directly using `__init__()` (throws an error).
+ """
+
+ def __init__(self):
+ raise EnvironmentError(
+ "AutoProcessor is designed to be instantiated "
+ "using the `AutoProcessor.from_pretrained(pretrained_model_name_or_path)` method."
+ )
+
+ @classmethod
+ @replace_list_option_in_docstrings(PROCESSOR_MAPPING_NAMES)
+ def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
+ r"""
+ Instantiate one of the processor classes of the library from a pretrained model vocabulary.
+
+ The processor class to instantiate is selected based on the `model_type` property of the config object (either
+ passed as an argument or loaded from `pretrained_model_name_or_path` if possible):
+
+ List options
+
+ Params:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained feature_extractor hosted inside a model repo on
+ huggingface.co.
+ - a path to a *directory* containing a processor files saved using the `save_pretrained()` method,
+ e.g., `./my_model_directory/`.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model feature extractor should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the feature extractor files and override the cached versions
+ if they exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ return_unused_kwargs (`bool`, *optional*, defaults to `False`):
+ If `False`, then this function returns just the final feature extractor object. If `True`, then this
+ functions returns a `Tuple(feature_extractor, unused_kwargs)` where *unused_kwargs* is a dictionary
+ consisting of the key/value pairs whose keys are not feature extractor attributes: i.e., the part of
+ `kwargs` which has not been used to update `feature_extractor` and is otherwise ignored.
+ trust_remote_code (`bool`, *optional*, defaults to `False`):
+ Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
+ should only be set to `True` for repositories you trust and in which you have read the code, as it will
+ execute code present on the Hub on your local machine.
+ kwargs (`Dict[str, Any]`, *optional*):
+ The values in kwargs of any keys which are feature extractor attributes will be used to override the
+ loaded values. Behavior concerning key/value pairs whose keys are *not* feature extractor attributes is
+ controlled by the `return_unused_kwargs` keyword parameter.
+
+
+
+ Passing `token=True` is required when you want to use a private model.
+
+
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoProcessor
+
+ >>> # Download processor from huggingface.co and cache.
+ >>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
+
+ >>> # If processor files are in a directory (e.g. processor was saved using *save_pretrained('./test/saved_model/')*)
+ >>> # processor = AutoProcessor.from_pretrained("./test/saved_model/")
+ ```"""
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if kwargs.get("token", None) is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ kwargs["token"] = use_auth_token
+
+ config = kwargs.pop("config", None)
+ trust_remote_code = kwargs.pop("trust_remote_code", None)
+ kwargs["_from_auto"] = True
+
+ processor_class = None
+ processor_auto_map = None
+
+ # First, let's see if we have a processor or preprocessor config.
+ # Filter the kwargs for `cached_file`.
+ cached_file_kwargs = {
+ key: kwargs[key] for key in inspect.signature(cached_file).parameters.keys() if key in kwargs
+ }
+ # We don't want to raise
+ cached_file_kwargs.update(
+ {
+ "_raise_exceptions_for_gated_repo": False,
+ "_raise_exceptions_for_missing_entries": False,
+ "_raise_exceptions_for_connection_errors": False,
+ }
+ )
+
+ # Let's start by checking whether the processor class is saved in a processor config
+ processor_config_file = cached_file(pretrained_model_name_or_path, PROCESSOR_NAME, **cached_file_kwargs)
+ if processor_config_file is not None:
+ config_dict, _ = ProcessorMixin.get_processor_dict(pretrained_model_name_or_path, **kwargs)
+ processor_class = config_dict.get("processor_class", None)
+ if "AutoProcessor" in config_dict.get("auto_map", {}):
+ processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
+
+ if processor_class is None:
+ # If not found, let's check whether the processor class is saved in an image processor config
+ preprocessor_config_file = cached_file(
+ pretrained_model_name_or_path, FEATURE_EXTRACTOR_NAME, **cached_file_kwargs
+ )
+ if preprocessor_config_file is not None:
+ config_dict, _ = ImageProcessingMixin.get_image_processor_dict(pretrained_model_name_or_path, **kwargs)
+ processor_class = config_dict.get("processor_class", None)
+ if "AutoProcessor" in config_dict.get("auto_map", {}):
+ processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
+
+ # If not found, let's check whether the processor class is saved in a feature extractor config
+ if preprocessor_config_file is not None and processor_class is None:
+ config_dict, _ = FeatureExtractionMixin.get_feature_extractor_dict(
+ pretrained_model_name_or_path, **kwargs
+ )
+ processor_class = config_dict.get("processor_class", None)
+ if "AutoProcessor" in config_dict.get("auto_map", {}):
+ processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
+
+ if processor_class is None:
+ # Next, let's check whether the processor class is saved in a tokenizer
+ tokenizer_config_file = cached_file(
+ pretrained_model_name_or_path, TOKENIZER_CONFIG_FILE, **cached_file_kwargs
+ )
+ if tokenizer_config_file is not None:
+ with open(tokenizer_config_file, encoding="utf-8") as reader:
+ config_dict = json.load(reader)
+
+ processor_class = config_dict.get("processor_class", None)
+ if "AutoProcessor" in config_dict.get("auto_map", {}):
+ processor_auto_map = config_dict["auto_map"]["AutoProcessor"]
+
+ if processor_class is None:
+ # Otherwise, load config, if it can be loaded.
+ if not isinstance(config, PretrainedConfig):
+ config = AutoConfig.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
+ )
+
+ # And check if the config contains the processor class.
+ processor_class = getattr(config, "processor_class", None)
+ if hasattr(config, "auto_map") and "AutoProcessor" in config.auto_map:
+ processor_auto_map = config.auto_map["AutoProcessor"]
+
+ if processor_class is not None:
+ processor_class = processor_class_from_name(processor_class)
+
+ has_remote_code = processor_auto_map is not None
+ has_local_code = processor_class is not None or type(config) in PROCESSOR_MAPPING
+ trust_remote_code = resolve_trust_remote_code(
+ trust_remote_code, pretrained_model_name_or_path, has_local_code, has_remote_code
+ )
+
+ if has_remote_code and trust_remote_code:
+ processor_class = get_class_from_dynamic_module(
+ processor_auto_map, pretrained_model_name_or_path, **kwargs
+ )
+ _ = kwargs.pop("code_revision", None)
+ if os.path.isdir(pretrained_model_name_or_path):
+ processor_class.register_for_auto_class()
+ return processor_class.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
+ )
+ elif processor_class is not None:
+ return processor_class.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
+ )
+ # Last try: we use the PROCESSOR_MAPPING.
+ elif type(config) in PROCESSOR_MAPPING:
+ return PROCESSOR_MAPPING[type(config)].from_pretrained(pretrained_model_name_or_path, **kwargs)
+
+ # At this stage, there doesn't seem to be a `Processor` class available for this model, so let's try a
+ # tokenizer.
+ try:
+ return AutoTokenizer.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
+ )
+ except Exception:
+ try:
+ return AutoImageProcessor.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
+ )
+ except Exception:
+ pass
+
+ try:
+ return AutoFeatureExtractor.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
+ )
+ except Exception:
+ pass
+
+ raise ValueError(
+ f"Unrecognized processing class in {pretrained_model_name_or_path}. Can't instantiate a processor, a "
+ "tokenizer, an image processor or a feature extractor for this model. Make sure the repository contains "
+ "the files of at least one of those processing classes."
+ )
+
+ @staticmethod
+ def register(config_class, processor_class, exist_ok=False):
+ """
+ Register a new processor for this class.
+
+ Args:
+ config_class ([`PretrainedConfig`]):
+ The configuration corresponding to the model to register.
+ processor_class ([`ProcessorMixin`]): The processor to register.
+ """
+ PROCESSOR_MAPPING.register(config_class, processor_class, exist_ok=exist_ok)
+
+
+__all__ = ["PROCESSOR_MAPPING", "AutoProcessor"]
diff --git a/docs/transformers/src/transformers/models/auto/tokenization_auto.py b/docs/transformers/src/transformers/models/auto/tokenization_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..5da5fb73f4d6a620c7d621fe221ae130b5f7714f
--- /dev/null
+++ b/docs/transformers/src/transformers/models/auto/tokenization_auto.py
@@ -0,0 +1,1091 @@
+# coding=utf-8
+# Copyright 2018 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Auto Tokenizer class."""
+
+import importlib
+import json
+import os
+import warnings
+from collections import OrderedDict
+from typing import TYPE_CHECKING, Dict, Optional, Tuple, Union
+
+from ...configuration_utils import PretrainedConfig
+from ...dynamic_module_utils import get_class_from_dynamic_module, resolve_trust_remote_code
+from ...modeling_gguf_pytorch_utils import load_gguf_checkpoint
+from ...tokenization_utils import PreTrainedTokenizer
+from ...tokenization_utils_base import TOKENIZER_CONFIG_FILE
+from ...utils import (
+ cached_file,
+ extract_commit_hash,
+ is_g2p_en_available,
+ is_sentencepiece_available,
+ is_tokenizers_available,
+ logging,
+)
+from ..encoder_decoder import EncoderDecoderConfig
+from .auto_factory import _LazyAutoMapping
+from .configuration_auto import (
+ CONFIG_MAPPING_NAMES,
+ AutoConfig,
+ config_class_to_model_type,
+ model_type_to_module_name,
+ replace_list_option_in_docstrings,
+)
+
+
+if is_tokenizers_available():
+ from ...tokenization_utils_fast import PreTrainedTokenizerFast
+else:
+ PreTrainedTokenizerFast = None
+
+
+logger = logging.get_logger(__name__)
+
+if TYPE_CHECKING:
+ # This significantly improves completion suggestion performance when
+ # the transformers package is used with Microsoft's Pylance language server.
+ TOKENIZER_MAPPING_NAMES: OrderedDict[str, Tuple[Optional[str], Optional[str]]] = OrderedDict()
+else:
+ TOKENIZER_MAPPING_NAMES = OrderedDict(
+ [
+ (
+ "albert",
+ (
+ "AlbertTokenizer" if is_sentencepiece_available() else None,
+ "AlbertTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("align", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ ("aria", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("aya_vision", (None, "CohereTokenizerFast" if is_tokenizers_available() else None)),
+ ("bark", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ ("bart", ("BartTokenizer", "BartTokenizerFast")),
+ (
+ "barthez",
+ (
+ "BarthezTokenizer" if is_sentencepiece_available() else None,
+ "BarthezTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("bartpho", ("BartphoTokenizer", None)),
+ ("bert", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ ("bert-generation", ("BertGenerationTokenizer" if is_sentencepiece_available() else None, None)),
+ ("bert-japanese", ("BertJapaneseTokenizer", None)),
+ ("bertweet", ("BertweetTokenizer", None)),
+ (
+ "big_bird",
+ (
+ "BigBirdTokenizer" if is_sentencepiece_available() else None,
+ "BigBirdTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("bigbird_pegasus", ("PegasusTokenizer", "PegasusTokenizerFast" if is_tokenizers_available() else None)),
+ ("biogpt", ("BioGptTokenizer", None)),
+ ("blenderbot", ("BlenderbotTokenizer", "BlenderbotTokenizerFast")),
+ ("blenderbot-small", ("BlenderbotSmallTokenizer", None)),
+ ("blip", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ ("blip-2", ("GPT2Tokenizer", "GPT2TokenizerFast" if is_tokenizers_available() else None)),
+ ("bloom", (None, "BloomTokenizerFast" if is_tokenizers_available() else None)),
+ ("bridgetower", ("RobertaTokenizer", "RobertaTokenizerFast" if is_tokenizers_available() else None)),
+ ("bros", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ ("byt5", ("ByT5Tokenizer", None)),
+ (
+ "camembert",
+ (
+ "CamembertTokenizer" if is_sentencepiece_available() else None,
+ "CamembertTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("canine", ("CanineTokenizer", None)),
+ (
+ "chameleon",
+ (
+ "LlamaTokenizer" if is_sentencepiece_available() else None,
+ "LlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("chinese_clip", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "clap",
+ (
+ "RobertaTokenizer",
+ "RobertaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "clip",
+ (
+ "CLIPTokenizer",
+ "CLIPTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "clipseg",
+ (
+ "CLIPTokenizer",
+ "CLIPTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("clvp", ("ClvpTokenizer", None)),
+ (
+ "code_llama",
+ (
+ "CodeLlamaTokenizer" if is_sentencepiece_available() else None,
+ "CodeLlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("codegen", ("CodeGenTokenizer", "CodeGenTokenizerFast" if is_tokenizers_available() else None)),
+ ("cohere", (None, "CohereTokenizerFast" if is_tokenizers_available() else None)),
+ ("cohere2", (None, "CohereTokenizerFast" if is_tokenizers_available() else None)),
+ ("colpali", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("convbert", ("ConvBertTokenizer", "ConvBertTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "cpm",
+ (
+ "CpmTokenizer" if is_sentencepiece_available() else None,
+ "CpmTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("cpmant", ("CpmAntTokenizer", None)),
+ ("ctrl", ("CTRLTokenizer", None)),
+ ("data2vec-audio", ("Wav2Vec2CTCTokenizer", None)),
+ ("data2vec-text", ("RobertaTokenizer", "RobertaTokenizerFast" if is_tokenizers_available() else None)),
+ ("dbrx", ("GPT2Tokenizer", "GPT2TokenizerFast" if is_tokenizers_available() else None)),
+ ("deberta", ("DebertaTokenizer", "DebertaTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "deberta-v2",
+ (
+ "DebertaV2Tokenizer" if is_sentencepiece_available() else None,
+ "DebertaV2TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "deepseek_v3",
+ (
+ "LlamaTokenizer" if is_sentencepiece_available() else None,
+ "LlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "diffllama",
+ (
+ "LlamaTokenizer" if is_sentencepiece_available() else None,
+ "LlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("distilbert", ("DistilBertTokenizer", "DistilBertTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "dpr",
+ (
+ "DPRQuestionEncoderTokenizer",
+ "DPRQuestionEncoderTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("electra", ("ElectraTokenizer", "ElectraTokenizerFast" if is_tokenizers_available() else None)),
+ ("emu3", ("GPT2Tokenizer", "GPT2TokenizerFast" if is_tokenizers_available() else None)),
+ ("ernie", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ ("ernie_m", ("ErnieMTokenizer" if is_sentencepiece_available() else None, None)),
+ ("esm", ("EsmTokenizer", None)),
+ ("falcon", (None, "PreTrainedTokenizerFast" if is_tokenizers_available() else None)),
+ ("falcon_mamba", (None, "GPTNeoXTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "fastspeech2_conformer",
+ ("FastSpeech2ConformerTokenizer" if is_g2p_en_available() else None, None),
+ ),
+ ("flaubert", ("FlaubertTokenizer", None)),
+ ("fnet", ("FNetTokenizer", "FNetTokenizerFast" if is_tokenizers_available() else None)),
+ ("fsmt", ("FSMTTokenizer", None)),
+ ("funnel", ("FunnelTokenizer", "FunnelTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "gemma",
+ (
+ "GemmaTokenizer" if is_sentencepiece_available() else None,
+ "GemmaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "gemma2",
+ (
+ "GemmaTokenizer" if is_sentencepiece_available() else None,
+ "GemmaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "gemma3",
+ (
+ "GemmaTokenizer" if is_sentencepiece_available() else None,
+ "GemmaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "gemma3_text",
+ (
+ "GemmaTokenizer" if is_sentencepiece_available() else None,
+ "GemmaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("git", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ ("glm", (None, "PreTrainedTokenizerFast" if is_tokenizers_available() else None)),
+ ("glm4", (None, "PreTrainedTokenizerFast" if is_tokenizers_available() else None)),
+ ("gpt-sw3", ("GPTSw3Tokenizer" if is_sentencepiece_available() else None, None)),
+ ("gpt2", ("GPT2Tokenizer", "GPT2TokenizerFast" if is_tokenizers_available() else None)),
+ ("gpt_bigcode", ("GPT2Tokenizer", "GPT2TokenizerFast" if is_tokenizers_available() else None)),
+ ("gpt_neo", ("GPT2Tokenizer", "GPT2TokenizerFast" if is_tokenizers_available() else None)),
+ ("gpt_neox", (None, "GPTNeoXTokenizerFast" if is_tokenizers_available() else None)),
+ ("gpt_neox_japanese", ("GPTNeoXJapaneseTokenizer", None)),
+ ("gptj", ("GPT2Tokenizer", "GPT2TokenizerFast" if is_tokenizers_available() else None)),
+ ("gptsan-japanese", ("GPTSanJapaneseTokenizer", None)),
+ ("grounding-dino", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ ("groupvit", ("CLIPTokenizer", "CLIPTokenizerFast" if is_tokenizers_available() else None)),
+ ("helium", (None, "PreTrainedTokenizerFast" if is_tokenizers_available() else None)),
+ ("herbert", ("HerbertTokenizer", "HerbertTokenizerFast" if is_tokenizers_available() else None)),
+ ("hubert", ("Wav2Vec2CTCTokenizer", None)),
+ ("ibert", ("RobertaTokenizer", "RobertaTokenizerFast" if is_tokenizers_available() else None)),
+ ("idefics", (None, "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("idefics2", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("idefics3", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("instructblip", ("GPT2Tokenizer", "GPT2TokenizerFast" if is_tokenizers_available() else None)),
+ ("instructblipvideo", ("GPT2Tokenizer", "GPT2TokenizerFast" if is_tokenizers_available() else None)),
+ ("internvl", ("Qwen2Tokenizer", "Qwen2TokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "jamba",
+ (
+ "LlamaTokenizer" if is_sentencepiece_available() else None,
+ "LlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("janus", (None, "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "jetmoe",
+ (
+ "LlamaTokenizer" if is_sentencepiece_available() else None,
+ "LlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("jukebox", ("JukeboxTokenizer", None)),
+ (
+ "kosmos-2",
+ (
+ "XLMRobertaTokenizer" if is_sentencepiece_available() else None,
+ "XLMRobertaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("layoutlm", ("LayoutLMTokenizer", "LayoutLMTokenizerFast" if is_tokenizers_available() else None)),
+ ("layoutlmv2", ("LayoutLMv2Tokenizer", "LayoutLMv2TokenizerFast" if is_tokenizers_available() else None)),
+ ("layoutlmv3", ("LayoutLMv3Tokenizer", "LayoutLMv3TokenizerFast" if is_tokenizers_available() else None)),
+ ("layoutxlm", ("LayoutXLMTokenizer", "LayoutXLMTokenizerFast" if is_tokenizers_available() else None)),
+ ("led", ("LEDTokenizer", "LEDTokenizerFast" if is_tokenizers_available() else None)),
+ ("lilt", ("LayoutLMv3Tokenizer", "LayoutLMv3TokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "llama",
+ (
+ "LlamaTokenizer" if is_sentencepiece_available() else None,
+ "LlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "llama4",
+ (
+ "LlamaTokenizer" if is_sentencepiece_available() else None,
+ "LlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "llama4_text",
+ (
+ "LlamaTokenizer" if is_sentencepiece_available() else None,
+ "LlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("llava", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("llava_next", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("llava_next_video", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("llava_onevision", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("longformer", ("LongformerTokenizer", "LongformerTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "longt5",
+ (
+ "T5Tokenizer" if is_sentencepiece_available() else None,
+ "T5TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("luke", ("LukeTokenizer", None)),
+ ("lxmert", ("LxmertTokenizer", "LxmertTokenizerFast" if is_tokenizers_available() else None)),
+ ("m2m_100", ("M2M100Tokenizer" if is_sentencepiece_available() else None, None)),
+ ("mamba", (None, "GPTNeoXTokenizerFast" if is_tokenizers_available() else None)),
+ ("mamba2", (None, "GPTNeoXTokenizerFast" if is_tokenizers_available() else None)),
+ ("marian", ("MarianTokenizer" if is_sentencepiece_available() else None, None)),
+ (
+ "mbart",
+ (
+ "MBartTokenizer" if is_sentencepiece_available() else None,
+ "MBartTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "mbart50",
+ (
+ "MBart50Tokenizer" if is_sentencepiece_available() else None,
+ "MBart50TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("mega", ("RobertaTokenizer", "RobertaTokenizerFast" if is_tokenizers_available() else None)),
+ ("megatron-bert", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ ("mgp-str", ("MgpstrTokenizer", None)),
+ (
+ "mistral",
+ (
+ "LlamaTokenizer" if is_sentencepiece_available() else None,
+ "LlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "mixtral",
+ (
+ "LlamaTokenizer" if is_sentencepiece_available() else None,
+ "LlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("mllama", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("mluke", ("MLukeTokenizer" if is_sentencepiece_available() else None, None)),
+ ("mobilebert", ("MobileBertTokenizer", "MobileBertTokenizerFast" if is_tokenizers_available() else None)),
+ ("modernbert", (None, "PreTrainedTokenizerFast" if is_tokenizers_available() else None)),
+ ("moonshine", (None, "PreTrainedTokenizerFast" if is_tokenizers_available() else None)),
+ ("moshi", (None, "PreTrainedTokenizerFast" if is_tokenizers_available() else None)),
+ ("mpnet", ("MPNetTokenizer", "MPNetTokenizerFast" if is_tokenizers_available() else None)),
+ ("mpt", (None, "GPTNeoXTokenizerFast" if is_tokenizers_available() else None)),
+ ("mra", ("RobertaTokenizer", "RobertaTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "mt5",
+ (
+ "MT5Tokenizer" if is_sentencepiece_available() else None,
+ "MT5TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("musicgen", ("T5Tokenizer", "T5TokenizerFast" if is_tokenizers_available() else None)),
+ ("musicgen_melody", ("T5Tokenizer", "T5TokenizerFast" if is_tokenizers_available() else None)),
+ ("mvp", ("MvpTokenizer", "MvpTokenizerFast" if is_tokenizers_available() else None)),
+ ("myt5", ("MyT5Tokenizer", None)),
+ ("nemotron", (None, "PreTrainedTokenizerFast" if is_tokenizers_available() else None)),
+ ("nezha", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "nllb",
+ (
+ "NllbTokenizer" if is_sentencepiece_available() else None,
+ "NllbTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "nllb-moe",
+ (
+ "NllbTokenizer" if is_sentencepiece_available() else None,
+ "NllbTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "nystromformer",
+ (
+ "AlbertTokenizer" if is_sentencepiece_available() else None,
+ "AlbertTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("olmo", (None, "GPTNeoXTokenizerFast" if is_tokenizers_available() else None)),
+ ("olmo2", (None, "GPTNeoXTokenizerFast" if is_tokenizers_available() else None)),
+ ("olmoe", (None, "GPTNeoXTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "omdet-turbo",
+ ("CLIPTokenizer", "CLIPTokenizerFast" if is_tokenizers_available() else None),
+ ),
+ ("oneformer", ("CLIPTokenizer", "CLIPTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "openai-gpt",
+ ("OpenAIGPTTokenizer", "OpenAIGPTTokenizerFast" if is_tokenizers_available() else None),
+ ),
+ ("opt", ("GPT2Tokenizer", "GPT2TokenizerFast" if is_tokenizers_available() else None)),
+ ("owlv2", ("CLIPTokenizer", "CLIPTokenizerFast" if is_tokenizers_available() else None)),
+ ("owlvit", ("CLIPTokenizer", "CLIPTokenizerFast" if is_tokenizers_available() else None)),
+ ("paligemma", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "pegasus",
+ (
+ "PegasusTokenizer" if is_sentencepiece_available() else None,
+ "PegasusTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "pegasus_x",
+ (
+ "PegasusTokenizer" if is_sentencepiece_available() else None,
+ "PegasusTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "perceiver",
+ (
+ "PerceiverTokenizer",
+ None,
+ ),
+ ),
+ (
+ "persimmon",
+ (
+ "LlamaTokenizer" if is_sentencepiece_available() else None,
+ "LlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("phi", ("CodeGenTokenizer", "CodeGenTokenizerFast" if is_tokenizers_available() else None)),
+ ("phi3", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("phimoe", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("phobert", ("PhobertTokenizer", None)),
+ ("pix2struct", ("T5Tokenizer", "T5TokenizerFast" if is_tokenizers_available() else None)),
+ ("pixtral", (None, "PreTrainedTokenizerFast" if is_tokenizers_available() else None)),
+ ("plbart", ("PLBartTokenizer" if is_sentencepiece_available() else None, None)),
+ ("prophetnet", ("ProphetNetTokenizer", None)),
+ ("qdqbert", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "qwen2",
+ (
+ "Qwen2Tokenizer",
+ "Qwen2TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("qwen2_5_omni", ("Qwen2Tokenizer", "Qwen2TokenizerFast" if is_tokenizers_available() else None)),
+ ("qwen2_5_vl", ("Qwen2Tokenizer", "Qwen2TokenizerFast" if is_tokenizers_available() else None)),
+ ("qwen2_audio", ("Qwen2Tokenizer", "Qwen2TokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "qwen2_moe",
+ (
+ "Qwen2Tokenizer",
+ "Qwen2TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("qwen2_vl", ("Qwen2Tokenizer", "Qwen2TokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "qwen3",
+ (
+ "Qwen2Tokenizer",
+ "Qwen2TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "qwen3_moe",
+ (
+ "Qwen2Tokenizer",
+ "Qwen2TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("rag", ("RagTokenizer", None)),
+ ("realm", ("RealmTokenizer", "RealmTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "recurrent_gemma",
+ (
+ "GemmaTokenizer" if is_sentencepiece_available() else None,
+ "GemmaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "reformer",
+ (
+ "ReformerTokenizer" if is_sentencepiece_available() else None,
+ "ReformerTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "rembert",
+ (
+ "RemBertTokenizer" if is_sentencepiece_available() else None,
+ "RemBertTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("retribert", ("RetriBertTokenizer", "RetriBertTokenizerFast" if is_tokenizers_available() else None)),
+ ("roberta", ("RobertaTokenizer", "RobertaTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "roberta-prelayernorm",
+ ("RobertaTokenizer", "RobertaTokenizerFast" if is_tokenizers_available() else None),
+ ),
+ ("roc_bert", ("RoCBertTokenizer", None)),
+ ("roformer", ("RoFormerTokenizer", "RoFormerTokenizerFast" if is_tokenizers_available() else None)),
+ ("rwkv", (None, "GPTNeoXTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "seamless_m4t",
+ (
+ "SeamlessM4TTokenizer" if is_sentencepiece_available() else None,
+ "SeamlessM4TTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "seamless_m4t_v2",
+ (
+ "SeamlessM4TTokenizer" if is_sentencepiece_available() else None,
+ "SeamlessM4TTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "shieldgemma2",
+ (
+ "GemmaTokenizer" if is_sentencepiece_available() else None,
+ "GemmaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("siglip", ("SiglipTokenizer" if is_sentencepiece_available() else None, None)),
+ (
+ "siglip2",
+ (
+ "GemmaTokenizer" if is_sentencepiece_available() else None,
+ "GemmaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("speech_to_text", ("Speech2TextTokenizer" if is_sentencepiece_available() else None, None)),
+ ("speech_to_text_2", ("Speech2Text2Tokenizer", None)),
+ ("speecht5", ("SpeechT5Tokenizer" if is_sentencepiece_available() else None, None)),
+ ("splinter", ("SplinterTokenizer", "SplinterTokenizerFast")),
+ (
+ "squeezebert",
+ ("SqueezeBertTokenizer", "SqueezeBertTokenizerFast" if is_tokenizers_available() else None),
+ ),
+ ("stablelm", (None, "GPTNeoXTokenizerFast" if is_tokenizers_available() else None)),
+ ("starcoder2", ("GPT2Tokenizer", "GPT2TokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "switch_transformers",
+ (
+ "T5Tokenizer" if is_sentencepiece_available() else None,
+ "T5TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "t5",
+ (
+ "T5Tokenizer" if is_sentencepiece_available() else None,
+ "T5TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("tapas", ("TapasTokenizer", None)),
+ ("tapex", ("TapexTokenizer", None)),
+ ("transfo-xl", ("TransfoXLTokenizer", None)),
+ ("tvp", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "udop",
+ (
+ "UdopTokenizer" if is_sentencepiece_available() else None,
+ "UdopTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "umt5",
+ (
+ "T5Tokenizer" if is_sentencepiece_available() else None,
+ "T5TokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("video_llava", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("vilt", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ ("vipllava", ("LlamaTokenizer", "LlamaTokenizerFast" if is_tokenizers_available() else None)),
+ ("visual_bert", ("BertTokenizer", "BertTokenizerFast" if is_tokenizers_available() else None)),
+ ("vits", ("VitsTokenizer", None)),
+ ("wav2vec2", ("Wav2Vec2CTCTokenizer", None)),
+ ("wav2vec2-bert", ("Wav2Vec2CTCTokenizer", None)),
+ ("wav2vec2-conformer", ("Wav2Vec2CTCTokenizer", None)),
+ ("wav2vec2_phoneme", ("Wav2Vec2PhonemeCTCTokenizer", None)),
+ ("whisper", ("WhisperTokenizer", "WhisperTokenizerFast" if is_tokenizers_available() else None)),
+ ("xclip", ("CLIPTokenizer", "CLIPTokenizerFast" if is_tokenizers_available() else None)),
+ (
+ "xglm",
+ (
+ "XGLMTokenizer" if is_sentencepiece_available() else None,
+ "XGLMTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ("xlm", ("XLMTokenizer", None)),
+ ("xlm-prophetnet", ("XLMProphetNetTokenizer" if is_sentencepiece_available() else None, None)),
+ (
+ "xlm-roberta",
+ (
+ "XLMRobertaTokenizer" if is_sentencepiece_available() else None,
+ "XLMRobertaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "xlm-roberta-xl",
+ (
+ "XLMRobertaTokenizer" if is_sentencepiece_available() else None,
+ "XLMRobertaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "xlnet",
+ (
+ "XLNetTokenizer" if is_sentencepiece_available() else None,
+ "XLNetTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "xmod",
+ (
+ "XLMRobertaTokenizer" if is_sentencepiece_available() else None,
+ "XLMRobertaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "yoso",
+ (
+ "AlbertTokenizer" if is_sentencepiece_available() else None,
+ "AlbertTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "zamba",
+ (
+ "LlamaTokenizer" if is_sentencepiece_available() else None,
+ "LlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ (
+ "zamba2",
+ (
+ "LlamaTokenizer" if is_sentencepiece_available() else None,
+ "LlamaTokenizerFast" if is_tokenizers_available() else None,
+ ),
+ ),
+ ]
+ )
+
+TOKENIZER_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, TOKENIZER_MAPPING_NAMES)
+
+CONFIG_TO_TYPE = {v: k for k, v in CONFIG_MAPPING_NAMES.items()}
+
+
+def tokenizer_class_from_name(class_name: str):
+ if class_name == "PreTrainedTokenizerFast":
+ return PreTrainedTokenizerFast
+
+ for module_name, tokenizers in TOKENIZER_MAPPING_NAMES.items():
+ if class_name in tokenizers:
+ module_name = model_type_to_module_name(module_name)
+
+ module = importlib.import_module(f".{module_name}", "transformers.models")
+ try:
+ return getattr(module, class_name)
+ except AttributeError:
+ continue
+
+ for config, tokenizers in TOKENIZER_MAPPING._extra_content.items():
+ for tokenizer in tokenizers:
+ if getattr(tokenizer, "__name__", None) == class_name:
+ return tokenizer
+
+ # We did not fine the class, but maybe it's because a dep is missing. In that case, the class will be in the main
+ # init and we return the proper dummy to get an appropriate error message.
+ main_module = importlib.import_module("transformers")
+ if hasattr(main_module, class_name):
+ return getattr(main_module, class_name)
+
+ return None
+
+
+def get_tokenizer_config(
+ pretrained_model_name_or_path: Union[str, os.PathLike],
+ cache_dir: Optional[Union[str, os.PathLike]] = None,
+ force_download: bool = False,
+ resume_download: Optional[bool] = None,
+ proxies: Optional[Dict[str, str]] = None,
+ token: Optional[Union[bool, str]] = None,
+ revision: Optional[str] = None,
+ local_files_only: bool = False,
+ subfolder: str = "",
+ **kwargs,
+):
+ """
+ Loads the tokenizer configuration from a pretrained model tokenizer configuration.
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained model configuration hosted inside a model repo on
+ huggingface.co.
+ - a path to a *directory* containing a configuration file saved using the
+ [`~PreTrainedTokenizer.save_pretrained`] method, e.g., `./my_model_directory/`.
+
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the standard
+ cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the configuration files and override the cached versions if they
+ exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ local_files_only (`bool`, *optional*, defaults to `False`):
+ If `True`, will only try to load the tokenizer configuration from local files.
+ subfolder (`str`, *optional*, defaults to `""`):
+ In case the tokenizer config is located inside a subfolder of the model repo on huggingface.co, you can
+ specify the folder name here.
+
+
+
+ Passing `token=True` is required when you want to use a private model.
+
+
+
+ Returns:
+ `Dict`: The configuration of the tokenizer.
+
+ Examples:
+
+ ```python
+ # Download configuration from huggingface.co and cache.
+ tokenizer_config = get_tokenizer_config("google-bert/bert-base-uncased")
+ # This model does not have a tokenizer config so the result will be an empty dict.
+ tokenizer_config = get_tokenizer_config("FacebookAI/xlm-roberta-base")
+
+ # Save a pretrained tokenizer locally and you can reload its config
+ from transformers import AutoTokenizer
+
+ tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
+ tokenizer.save_pretrained("tokenizer-test")
+ tokenizer_config = get_tokenizer_config("tokenizer-test")
+ ```"""
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if token is not None:
+ raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
+ token = use_auth_token
+
+ commit_hash = kwargs.get("_commit_hash", None)
+ resolved_config_file = cached_file(
+ pretrained_model_name_or_path,
+ TOKENIZER_CONFIG_FILE,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ token=token,
+ revision=revision,
+ local_files_only=local_files_only,
+ subfolder=subfolder,
+ _raise_exceptions_for_gated_repo=False,
+ _raise_exceptions_for_missing_entries=False,
+ _raise_exceptions_for_connection_errors=False,
+ _commit_hash=commit_hash,
+ )
+ if resolved_config_file is None:
+ logger.info("Could not locate the tokenizer configuration file, will try to use the model config instead.")
+ return {}
+ commit_hash = extract_commit_hash(resolved_config_file, commit_hash)
+
+ with open(resolved_config_file, encoding="utf-8") as reader:
+ result = json.load(reader)
+ result["_commit_hash"] = commit_hash
+ return result
+
+
+class AutoTokenizer:
+ r"""
+ This is a generic tokenizer class that will be instantiated as one of the tokenizer classes of the library when
+ created with the [`AutoTokenizer.from_pretrained`] class method.
+
+ This class cannot be instantiated directly using `__init__()` (throws an error).
+ """
+
+ def __init__(self):
+ raise EnvironmentError(
+ "AutoTokenizer is designed to be instantiated "
+ "using the `AutoTokenizer.from_pretrained(pretrained_model_name_or_path)` method."
+ )
+
+ @classmethod
+ @replace_list_option_in_docstrings(TOKENIZER_MAPPING_NAMES)
+ def from_pretrained(cls, pretrained_model_name_or_path, *inputs, **kwargs):
+ r"""
+ Instantiate one of the tokenizer classes of the library from a pretrained model vocabulary.
+
+ The tokenizer class to instantiate is selected based on the `model_type` property of the config object (either
+ passed as an argument or loaded from `pretrained_model_name_or_path` if possible), or when it's missing, by
+ falling back to using pattern matching on `pretrained_model_name_or_path`:
+
+ List options
+
+ Params:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ Can be either:
+
+ - A string, the *model id* of a predefined tokenizer hosted inside a model repo on huggingface.co.
+ - A path to a *directory* containing vocabulary files required by the tokenizer, for instance saved
+ using the [`~PreTrainedTokenizer.save_pretrained`] method, e.g., `./my_model_directory/`.
+ - A path or url to a single saved vocabulary file if and only if the tokenizer only requires a
+ single vocabulary file (like Bert or XLNet), e.g.: `./my_model_directory/vocab.txt`. (Not
+ applicable to all derived classes)
+ inputs (additional positional arguments, *optional*):
+ Will be passed along to the Tokenizer `__init__()` method.
+ config ([`PretrainedConfig`], *optional*)
+ The configuration object used to determine the tokenizer class to instantiate.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the
+ standard cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force the (re-)download the model weights and configuration files and override the
+ cached versions if they exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}`. The proxies are used on each request.
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+ subfolder (`str`, *optional*):
+ In case the relevant files are located inside a subfolder of the model repo on huggingface.co (e.g. for
+ facebook/rag-token-base), specify it here.
+ use_fast (`bool`, *optional*, defaults to `True`):
+ Use a [fast Rust-based tokenizer](https://huggingface.co/docs/tokenizers/index) if it is supported for
+ a given model. If a fast tokenizer is not available for a given model, a normal Python-based tokenizer
+ is returned instead.
+ tokenizer_type (`str`, *optional*):
+ Tokenizer type to be loaded.
+ trust_remote_code (`bool`, *optional*, defaults to `False`):
+ Whether or not to allow for custom models defined on the Hub in their own modeling files. This option
+ should only be set to `True` for repositories you trust and in which you have read the code, as it will
+ execute code present on the Hub on your local machine.
+ kwargs (additional keyword arguments, *optional*):
+ Will be passed to the Tokenizer `__init__()` method. Can be used to set special tokens like
+ `bos_token`, `eos_token`, `unk_token`, `sep_token`, `pad_token`, `cls_token`, `mask_token`,
+ `additional_special_tokens`. See parameters in the `__init__()` for more details.
+
+ Examples:
+
+ ```python
+ >>> from transformers import AutoTokenizer
+
+ >>> # Download vocabulary from huggingface.co and cache.
+ >>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
+
+ >>> # Download vocabulary from huggingface.co (user-uploaded) and cache.
+ >>> tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-german-cased")
+
+ >>> # If vocabulary files are in a directory (e.g. tokenizer was saved using *save_pretrained('./test/saved_model/')*)
+ >>> # tokenizer = AutoTokenizer.from_pretrained("./test/bert_saved_model/")
+
+ >>> # Download vocabulary from huggingface.co and define model-specific arguments
+ >>> tokenizer = AutoTokenizer.from_pretrained("FacebookAI/roberta-base", add_prefix_space=True)
+ ```"""
+ use_auth_token = kwargs.pop("use_auth_token", None)
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if kwargs.get("token", None) is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ kwargs["token"] = use_auth_token
+
+ config = kwargs.pop("config", None)
+ kwargs["_from_auto"] = True
+
+ use_fast = kwargs.pop("use_fast", True)
+ tokenizer_type = kwargs.pop("tokenizer_type", None)
+ trust_remote_code = kwargs.pop("trust_remote_code", None)
+ gguf_file = kwargs.get("gguf_file", None)
+
+ # First, let's see whether the tokenizer_type is passed so that we can leverage it
+ if tokenizer_type is not None:
+ tokenizer_class = None
+ tokenizer_class_tuple = TOKENIZER_MAPPING_NAMES.get(tokenizer_type, None)
+
+ if tokenizer_class_tuple is None:
+ raise ValueError(
+ f"Passed `tokenizer_type` {tokenizer_type} does not exist. `tokenizer_type` should be one of "
+ f"{', '.join(c for c in TOKENIZER_MAPPING_NAMES.keys())}."
+ )
+
+ tokenizer_class_name, tokenizer_fast_class_name = tokenizer_class_tuple
+
+ if use_fast:
+ if tokenizer_fast_class_name is not None:
+ tokenizer_class = tokenizer_class_from_name(tokenizer_fast_class_name)
+ else:
+ logger.warning(
+ "`use_fast` is set to `True` but the tokenizer class does not have a fast version. "
+ " Falling back to the slow version."
+ )
+ if tokenizer_class is None:
+ tokenizer_class = tokenizer_class_from_name(tokenizer_class_name)
+
+ if tokenizer_class is None:
+ raise ValueError(f"Tokenizer class {tokenizer_class_name} is not currently imported.")
+
+ return tokenizer_class.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
+
+ # Next, let's try to use the tokenizer_config file to get the tokenizer class.
+ tokenizer_config = get_tokenizer_config(pretrained_model_name_or_path, **kwargs)
+ if "_commit_hash" in tokenizer_config:
+ kwargs["_commit_hash"] = tokenizer_config["_commit_hash"]
+ config_tokenizer_class = tokenizer_config.get("tokenizer_class")
+ tokenizer_auto_map = None
+ if "auto_map" in tokenizer_config:
+ if isinstance(tokenizer_config["auto_map"], (tuple, list)):
+ # Legacy format for dynamic tokenizers
+ tokenizer_auto_map = tokenizer_config["auto_map"]
+ else:
+ tokenizer_auto_map = tokenizer_config["auto_map"].get("AutoTokenizer", None)
+
+ # If that did not work, let's try to use the config.
+ if config_tokenizer_class is None:
+ if not isinstance(config, PretrainedConfig):
+ if gguf_file:
+ gguf_path = cached_file(pretrained_model_name_or_path, gguf_file, **kwargs)
+ config_dict = load_gguf_checkpoint(gguf_path, return_tensors=False)["config"]
+ config = AutoConfig.for_model(**config_dict)
+ else:
+ config = AutoConfig.from_pretrained(
+ pretrained_model_name_or_path, trust_remote_code=trust_remote_code, **kwargs
+ )
+ config_tokenizer_class = config.tokenizer_class
+ if hasattr(config, "auto_map") and "AutoTokenizer" in config.auto_map:
+ tokenizer_auto_map = config.auto_map["AutoTokenizer"]
+
+ has_remote_code = tokenizer_auto_map is not None
+ has_local_code = type(config) in TOKENIZER_MAPPING or (
+ config_tokenizer_class is not None
+ and (
+ tokenizer_class_from_name(config_tokenizer_class) is not None
+ or tokenizer_class_from_name(config_tokenizer_class + "Fast") is not None
+ )
+ )
+ trust_remote_code = resolve_trust_remote_code(
+ trust_remote_code, pretrained_model_name_or_path, has_local_code, has_remote_code
+ )
+
+ if has_remote_code and trust_remote_code:
+ if use_fast and tokenizer_auto_map[1] is not None:
+ class_ref = tokenizer_auto_map[1]
+ else:
+ class_ref = tokenizer_auto_map[0]
+ tokenizer_class = get_class_from_dynamic_module(class_ref, pretrained_model_name_or_path, **kwargs)
+ _ = kwargs.pop("code_revision", None)
+ if os.path.isdir(pretrained_model_name_or_path):
+ tokenizer_class.register_for_auto_class()
+ return tokenizer_class.from_pretrained(
+ pretrained_model_name_or_path, *inputs, trust_remote_code=trust_remote_code, **kwargs
+ )
+ elif config_tokenizer_class is not None:
+ tokenizer_class = None
+ if use_fast and not config_tokenizer_class.endswith("Fast"):
+ tokenizer_class_candidate = f"{config_tokenizer_class}Fast"
+ tokenizer_class = tokenizer_class_from_name(tokenizer_class_candidate)
+ if tokenizer_class is None:
+ tokenizer_class_candidate = config_tokenizer_class
+ tokenizer_class = tokenizer_class_from_name(tokenizer_class_candidate)
+ if tokenizer_class is None:
+ raise ValueError(
+ f"Tokenizer class {tokenizer_class_candidate} does not exist or is not currently imported."
+ )
+ return tokenizer_class.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
+
+ # Otherwise we have to be creative.
+ # if model is an encoder decoder, the encoder tokenizer class is used by default
+ if isinstance(config, EncoderDecoderConfig):
+ if type(config.decoder) is not type(config.encoder): # noqa: E721
+ logger.warning(
+ f"The encoder model config class: {config.encoder.__class__} is different from the decoder model "
+ f"config class: {config.decoder.__class__}. It is not recommended to use the "
+ "`AutoTokenizer.from_pretrained()` method in this case. Please use the encoder and decoder "
+ "specific tokenizer classes."
+ )
+ config = config.encoder
+
+ model_type = config_class_to_model_type(type(config).__name__)
+ if model_type is not None:
+ tokenizer_class_py, tokenizer_class_fast = TOKENIZER_MAPPING[type(config)]
+
+ if tokenizer_class_fast and (use_fast or tokenizer_class_py is None):
+ return tokenizer_class_fast.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
+ else:
+ if tokenizer_class_py is not None:
+ return tokenizer_class_py.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
+ else:
+ raise ValueError(
+ "This tokenizer cannot be instantiated. Please make sure you have `sentencepiece` installed "
+ "in order to use this tokenizer."
+ )
+
+ raise ValueError(
+ f"Unrecognized configuration class {config.__class__} to build an AutoTokenizer.\n"
+ f"Model type should be one of {', '.join(c.__name__ for c in TOKENIZER_MAPPING.keys())}."
+ )
+
+ @staticmethod
+ def register(config_class, slow_tokenizer_class=None, fast_tokenizer_class=None, exist_ok=False):
+ """
+ Register a new tokenizer in this mapping.
+
+
+ Args:
+ config_class ([`PretrainedConfig`]):
+ The configuration corresponding to the model to register.
+ slow_tokenizer_class ([`PretrainedTokenizer`], *optional*):
+ The slow tokenizer to register.
+ fast_tokenizer_class ([`PretrainedTokenizerFast`], *optional*):
+ The fast tokenizer to register.
+ """
+ if slow_tokenizer_class is None and fast_tokenizer_class is None:
+ raise ValueError("You need to pass either a `slow_tokenizer_class` or a `fast_tokenizer_class")
+ if slow_tokenizer_class is not None and issubclass(slow_tokenizer_class, PreTrainedTokenizerFast):
+ raise ValueError("You passed a fast tokenizer in the `slow_tokenizer_class`.")
+ if fast_tokenizer_class is not None and issubclass(fast_tokenizer_class, PreTrainedTokenizer):
+ raise ValueError("You passed a slow tokenizer in the `fast_tokenizer_class`.")
+
+ if (
+ slow_tokenizer_class is not None
+ and fast_tokenizer_class is not None
+ and issubclass(fast_tokenizer_class, PreTrainedTokenizerFast)
+ and fast_tokenizer_class.slow_tokenizer_class != slow_tokenizer_class
+ ):
+ raise ValueError(
+ "The fast tokenizer class you are passing has a `slow_tokenizer_class` attribute that is not "
+ "consistent with the slow tokenizer class you passed (fast tokenizer has "
+ f"{fast_tokenizer_class.slow_tokenizer_class} and you passed {slow_tokenizer_class}. Fix one of those "
+ "so they match!"
+ )
+
+ # Avoid resetting a set slow/fast tokenizer if we are passing just the other ones.
+ if config_class in TOKENIZER_MAPPING._extra_content:
+ existing_slow, existing_fast = TOKENIZER_MAPPING[config_class]
+ if slow_tokenizer_class is None:
+ slow_tokenizer_class = existing_slow
+ if fast_tokenizer_class is None:
+ fast_tokenizer_class = existing_fast
+
+ TOKENIZER_MAPPING.register(config_class, (slow_tokenizer_class, fast_tokenizer_class), exist_ok=exist_ok)
+
+
+__all__ = ["TOKENIZER_MAPPING", "AutoTokenizer"]
diff --git a/docs/transformers/src/transformers/models/autoformer/__init__.py b/docs/transformers/src/transformers/models/autoformer/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..48a329608039b1a4a96ac1f99c20ee427f845cd9
--- /dev/null
+++ b/docs/transformers/src/transformers/models/autoformer/__init__.py
@@ -0,0 +1,27 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import _LazyModule
+from ...utils.import_utils import define_import_structure
+
+
+if TYPE_CHECKING:
+ from .configuration_autoformer import *
+ from .modeling_autoformer import *
+else:
+ import sys
+
+ _file = globals()["__file__"]
+ sys.modules[__name__] = _LazyModule(__name__, _file, define_import_structure(_file), module_spec=__spec__)
diff --git a/docs/transformers/src/transformers/models/autoformer/configuration_autoformer.py b/docs/transformers/src/transformers/models/autoformer/configuration_autoformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..aba83f19a5d942d528b1e443199e264feb51f83c
--- /dev/null
+++ b/docs/transformers/src/transformers/models/autoformer/configuration_autoformer.py
@@ -0,0 +1,245 @@
+# coding=utf-8
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Autoformer model configuration"""
+
+from typing import List, Optional
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class AutoformerConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of an [`AutoformerModel`]. It is used to instantiate an
+ Autoformer model according to the specified arguments, defining the model architecture. Instantiating a
+ configuration with the defaults will yield a similar configuration to that of the Autoformer
+ [huggingface/autoformer-tourism-monthly](https://huggingface.co/huggingface/autoformer-tourism-monthly)
+ architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ prediction_length (`int`):
+ The prediction length for the decoder. In other words, the prediction horizon of the model.
+ context_length (`int`, *optional*, defaults to `prediction_length`):
+ The context length for the encoder. If unset, the context length will be the same as the
+ `prediction_length`.
+ distribution_output (`string`, *optional*, defaults to `"student_t"`):
+ The distribution emission head for the model. Could be either "student_t", "normal" or "negative_binomial".
+ loss (`string`, *optional*, defaults to `"nll"`):
+ The loss function for the model corresponding to the `distribution_output` head. For parametric
+ distributions it is the negative log likelihood (nll) - which currently is the only supported one.
+ input_size (`int`, *optional*, defaults to 1):
+ The size of the target variable which by default is 1 for univariate targets. Would be > 1 in case of
+ multivariate targets.
+ lags_sequence (`list[int]`, *optional*, defaults to `[1, 2, 3, 4, 5, 6, 7]`):
+ The lags of the input time series as covariates often dictated by the frequency. Default is `[1, 2, 3, 4,
+ 5, 6, 7]`.
+ scaling (`bool`, *optional* defaults to `True`):
+ Whether to scale the input targets.
+ num_time_features (`int`, *optional*, defaults to 0):
+ The number of time features in the input time series.
+ num_dynamic_real_features (`int`, *optional*, defaults to 0):
+ The number of dynamic real valued features.
+ num_static_categorical_features (`int`, *optional*, defaults to 0):
+ The number of static categorical features.
+ num_static_real_features (`int`, *optional*, defaults to 0):
+ The number of static real valued features.
+ cardinality (`list[int]`, *optional*):
+ The cardinality (number of different values) for each of the static categorical features. Should be a list
+ of integers, having the same length as `num_static_categorical_features`. Cannot be `None` if
+ `num_static_categorical_features` is > 0.
+ embedding_dimension (`list[int]`, *optional*):
+ The dimension of the embedding for each of the static categorical features. Should be a list of integers,
+ having the same length as `num_static_categorical_features`. Cannot be `None` if
+ `num_static_categorical_features` is > 0.
+ d_model (`int`, *optional*, defaults to 64):
+ Dimensionality of the transformer layers.
+ encoder_layers (`int`, *optional*, defaults to 2):
+ Number of encoder layers.
+ decoder_layers (`int`, *optional*, defaults to 2):
+ Number of decoder layers.
+ encoder_attention_heads (`int`, *optional*, defaults to 2):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ decoder_attention_heads (`int`, *optional*, defaults to 2):
+ Number of attention heads for each attention layer in the Transformer decoder.
+ encoder_ffn_dim (`int`, *optional*, defaults to 32):
+ Dimension of the "intermediate" (often named feed-forward) layer in encoder.
+ decoder_ffn_dim (`int`, *optional*, defaults to 32):
+ Dimension of the "intermediate" (often named feed-forward) layer in decoder.
+ activation_function (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and decoder. If string, `"gelu"` and
+ `"relu"` are supported.
+ dropout (`float`, *optional*, defaults to 0.1):
+ The dropout probability for all fully connected layers in the encoder, and decoder.
+ encoder_layerdrop (`float`, *optional*, defaults to 0.1):
+ The dropout probability for the attention and fully connected layers for each encoder layer.
+ decoder_layerdrop (`float`, *optional*, defaults to 0.1):
+ The dropout probability for the attention and fully connected layers for each decoder layer.
+ attention_dropout (`float`, *optional*, defaults to 0.1):
+ The dropout probability for the attention probabilities.
+ activation_dropout (`float`, *optional*, defaults to 0.1):
+ The dropout probability used between the two layers of the feed-forward networks.
+ num_parallel_samples (`int`, *optional*, defaults to 100):
+ The number of samples to generate in parallel for each time step of inference.
+ init_std (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated normal weight initialization distribution.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether to use the past key/values attentions (if applicable to the model) to speed up decoding.
+ label_length (`int`, *optional*, defaults to 10):
+ Start token length of the Autoformer decoder, which is used for direct multi-step prediction (i.e.
+ non-autoregressive generation).
+ moving_average (`int`, *optional*, defaults to 25):
+ The window size of the moving average. In practice, it's the kernel size in AvgPool1d of the Decomposition
+ Layer.
+ autocorrelation_factor (`int`, *optional*, defaults to 3):
+ "Attention" (i.e. AutoCorrelation mechanism) factor which is used to find top k autocorrelations delays.
+ It's recommended in the paper to set it to a number between 1 and 5.
+
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoformerConfig, AutoformerModel
+
+ >>> # Initializing a default Autoformer configuration
+ >>> configuration = AutoformerConfig()
+
+ >>> # Randomly initializing a model (with random weights) from the configuration
+ >>> model = AutoformerModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "autoformer"
+ attribute_map = {
+ "hidden_size": "d_model",
+ "num_attention_heads": "encoder_attention_heads",
+ "num_hidden_layers": "encoder_layers",
+ }
+
+ def __init__(
+ self,
+ prediction_length: Optional[int] = None,
+ context_length: Optional[int] = None,
+ distribution_output: str = "student_t",
+ loss: str = "nll",
+ input_size: int = 1,
+ lags_sequence: List[int] = [1, 2, 3, 4, 5, 6, 7],
+ scaling: bool = True,
+ num_time_features: int = 0,
+ num_dynamic_real_features: int = 0,
+ num_static_categorical_features: int = 0,
+ num_static_real_features: int = 0,
+ cardinality: Optional[List[int]] = None,
+ embedding_dimension: Optional[List[int]] = None,
+ d_model: int = 64,
+ encoder_attention_heads: int = 2,
+ decoder_attention_heads: int = 2,
+ encoder_layers: int = 2,
+ decoder_layers: int = 2,
+ encoder_ffn_dim: int = 32,
+ decoder_ffn_dim: int = 32,
+ activation_function: str = "gelu",
+ dropout: float = 0.1,
+ encoder_layerdrop: float = 0.1,
+ decoder_layerdrop: float = 0.1,
+ attention_dropout: float = 0.1,
+ activation_dropout: float = 0.1,
+ num_parallel_samples: int = 100,
+ init_std: float = 0.02,
+ use_cache: bool = True,
+ is_encoder_decoder=True,
+ # Autoformer arguments
+ label_length: int = 10,
+ moving_average: int = 25,
+ autocorrelation_factor: int = 3,
+ **kwargs,
+ ):
+ # time series specific configuration
+ self.prediction_length = prediction_length
+ self.context_length = context_length if context_length is not None else prediction_length
+ self.distribution_output = distribution_output
+ self.loss = loss
+ self.input_size = input_size
+ self.num_time_features = num_time_features
+ self.lags_sequence = lags_sequence
+ self.scaling = scaling
+ self.num_dynamic_real_features = num_dynamic_real_features
+ self.num_static_real_features = num_static_real_features
+ self.num_static_categorical_features = num_static_categorical_features
+ if cardinality is not None and num_static_categorical_features > 0:
+ if len(cardinality) != num_static_categorical_features:
+ raise ValueError(
+ "The cardinality should be a list of the same length as `num_static_categorical_features`"
+ )
+ self.cardinality = cardinality
+ else:
+ self.cardinality = [0]
+ if embedding_dimension is not None and num_static_categorical_features > 0:
+ if len(embedding_dimension) != num_static_categorical_features:
+ raise ValueError(
+ "The embedding dimension should be a list of the same length as `num_static_categorical_features`"
+ )
+ self.embedding_dimension = embedding_dimension
+ else:
+ self.embedding_dimension = [min(50, (cat + 1) // 2) for cat in self.cardinality]
+ self.num_parallel_samples = num_parallel_samples
+
+ # Transformer architecture configuration
+ self.feature_size = input_size * len(self.lags_sequence) + self._number_of_features
+ self.d_model = d_model
+ self.encoder_attention_heads = encoder_attention_heads
+ self.decoder_attention_heads = decoder_attention_heads
+ self.encoder_ffn_dim = encoder_ffn_dim
+ self.decoder_ffn_dim = decoder_ffn_dim
+ self.encoder_layers = encoder_layers
+ self.decoder_layers = decoder_layers
+
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.activation_dropout = activation_dropout
+ self.encoder_layerdrop = encoder_layerdrop
+ self.decoder_layerdrop = decoder_layerdrop
+
+ self.activation_function = activation_function
+ self.init_std = init_std
+
+ self.use_cache = use_cache
+
+ # Autoformer
+ self.label_length = label_length
+ self.moving_average = moving_average
+ self.autocorrelation_factor = autocorrelation_factor
+
+ super().__init__(is_encoder_decoder=is_encoder_decoder, **kwargs)
+
+ @property
+ def _number_of_features(self) -> int:
+ return (
+ sum(self.embedding_dimension)
+ + self.num_dynamic_real_features
+ + self.num_time_features
+ + self.num_static_real_features
+ + self.input_size * 2 # the log1p(abs(loc)) and log(scale) features
+ )
+
+
+__all__ = ["AutoformerConfig"]
diff --git a/docs/transformers/src/transformers/models/autoformer/modeling_autoformer.py b/docs/transformers/src/transformers/models/autoformer/modeling_autoformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..eb32013d5e7324273b9a978b477b5593982e6fe5
--- /dev/null
+++ b/docs/transformers/src/transformers/models/autoformer/modeling_autoformer.py
@@ -0,0 +1,2152 @@
+# coding=utf-8
+# Copyright (c) 2021 THUML @ Tsinghua University
+# Copyright 2023 Amazon.com, Inc. or its affiliates. All Rights Reserved.
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch Autoformer model."""
+
+import math
+from dataclasses import dataclass
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+import torch.utils.checkpoint
+from torch import nn
+
+from ...activations import ACT2FN
+from ...modeling_attn_mask_utils import _prepare_4d_attention_mask
+from ...modeling_outputs import (
+ BaseModelOutput,
+ ModelOutput,
+ SampleTSPredictionOutput,
+ Seq2SeqTSPredictionOutput,
+)
+from ...modeling_utils import PreTrainedModel
+from ...time_series_utils import NegativeBinomialOutput, NormalOutput, StudentTOutput
+from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings
+from .configuration_autoformer import AutoformerConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "AutoformerConfig"
+
+
+@dataclass
+class AutoFormerDecoderOutput(ModelOutput):
+ """
+ Base class for model's outputs that may also contain a past key/values (to speed up sequential decoding).
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the model.
+
+ If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
+ hidden_size)` is output.
+ trend (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Trend tensor for each time series.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and optionally if
+ `config.is_encoder_decoder=True` 2 additional tensors of shape `(batch_size, num_heads,
+ encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
+ `config.is_encoder_decoder=True` in the cross-attention blocks) that can be used (see `past_key_values`
+ input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` and `config.add_cross_attention=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ trend: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class AutoformerModelOutput(ModelOutput):
+ """
+ Autoformer model output that contains the additional trend output.
+
+ Args:
+ last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Sequence of hidden-states at the output of the last layer of the decoder of the model.
+
+ If `past_key_values` is used only the last hidden-state of the sequences of shape `(batch_size, 1,
+ hidden_size)` is output.
+ trend (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
+ Trend tensor for each time series.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+ decoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the decoder at the output of each layer plus the optional initial embedding outputs.
+ decoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ cross_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the decoder's cross-attention layer, after the attention softmax, used to compute the
+ weighted average in the cross-attention heads.
+ encoder_last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder of the model.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the encoder at the output of each layer plus the optional initial embedding outputs.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the
+ self-attention heads.
+ loc (`torch.FloatTensor` of shape `(batch_size,)` or `(batch_size, input_size)`, *optional*):
+ Shift values of each time series' context window which is used to give the model inputs of the same
+ magnitude and then used to shift back to the original magnitude.
+ scale (`torch.FloatTensor` of shape `(batch_size,)` or `(batch_size, input_size)`, *optional*):
+ Scaling values of each time series' context window which is used to give the model inputs of the same
+ magnitude and then used to rescale back to the original magnitude.
+ static_features: (`torch.FloatTensor` of shape `(batch_size, feature size)`, *optional*):
+ Static features of each time series' in a batch which are copied to the covariates at inference time.
+ """
+
+ last_hidden_state: Optional[torch.FloatTensor] = None
+ trend: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ decoder_attentions: Optional[Tuple[torch.FloatTensor]] = None
+ cross_attentions: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_last_hidden_state: Optional[torch.FloatTensor] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor]] = None
+ loc: Optional[torch.FloatTensor] = None
+ scale: Optional[torch.FloatTensor] = None
+ static_features: Optional[torch.FloatTensor] = None
+
+
+# Copied from transformers.models.time_series_transformer.modeling_time_series_transformer.TimeSeriesFeatureEmbedder with TimeSeries->Autoformer
+class AutoformerFeatureEmbedder(nn.Module):
+ """
+ Embed a sequence of categorical features.
+
+ Args:
+ cardinalities (`list[int]`):
+ List of cardinalities of the categorical features.
+ embedding_dims (`list[int]`):
+ List of embedding dimensions of the categorical features.
+ """
+
+ def __init__(self, cardinalities: List[int], embedding_dims: List[int]) -> None:
+ super().__init__()
+
+ self.num_features = len(cardinalities)
+ self.embedders = nn.ModuleList([nn.Embedding(c, d) for c, d in zip(cardinalities, embedding_dims)])
+
+ def forward(self, features: torch.Tensor) -> torch.Tensor:
+ if self.num_features > 1:
+ # we slice the last dimension, giving an array of length
+ # self.num_features with shape (N,T) or (N)
+ cat_feature_slices = torch.chunk(features, self.num_features, dim=-1)
+ else:
+ cat_feature_slices = [features]
+
+ return torch.cat(
+ [
+ embed(cat_feature_slice.squeeze(-1))
+ for embed, cat_feature_slice in zip(self.embedders, cat_feature_slices)
+ ],
+ dim=-1,
+ )
+
+
+# Copied from transformers.models.time_series_transformer.modeling_time_series_transformer.TimeSeriesStdScaler with TimeSeriesTransformer->Autoformer,TimeSeries->Autoformer
+class AutoformerStdScaler(nn.Module):
+ """
+ Standardize features by calculating the mean and scaling along the first dimension, and then normalizes it by
+ subtracting from the mean and dividing by the standard deviation.
+ """
+
+ def __init__(self, config: AutoformerConfig):
+ super().__init__()
+ self.dim = config.scaling_dim if hasattr(config, "scaling_dim") else 1
+ self.keepdim = config.keepdim if hasattr(config, "keepdim") else True
+ self.minimum_scale = config.minimum_scale if hasattr(config, "minimum_scale") else 1e-5
+
+ def forward(
+ self, data: torch.Tensor, observed_indicator: torch.Tensor
+ ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
+ """
+ Parameters:
+ data (`torch.Tensor` of shape `(batch_size, sequence_length, num_input_channels)`):
+ input for Batch norm calculation
+ observed_indicator (`torch.BoolTensor` of shape `(batch_size, sequence_length, num_input_channels)`):
+ Calculating the scale on the observed indicator.
+ Returns:
+ tuple of `torch.Tensor` of shapes
+ (`(batch_size, sequence_length, num_input_channels)`,`(batch_size, 1, num_input_channels)`,
+ `(batch_size, 1, num_input_channels)`)
+ """
+ denominator = observed_indicator.sum(self.dim, keepdim=self.keepdim)
+ denominator = denominator.clamp_min(1.0)
+ loc = (data * observed_indicator).sum(self.dim, keepdim=self.keepdim) / denominator
+
+ variance = (((data - loc) * observed_indicator) ** 2).sum(self.dim, keepdim=self.keepdim) / denominator
+ scale = torch.sqrt(variance + self.minimum_scale)
+ return (data - loc) / scale, loc, scale
+
+
+# Copied from transformers.models.time_series_transformer.modeling_time_series_transformer.TimeSeriesMeanScaler with TimeSeriesTransformer->Autoformer,TimeSeries->Autoformer
+class AutoformerMeanScaler(nn.Module):
+ """
+ Computes a scaling factor as the weighted average absolute value along the first dimension, and scales the data
+ accordingly.
+ """
+
+ def __init__(self, config: AutoformerConfig):
+ super().__init__()
+ self.dim = config.scaling_dim if hasattr(config, "scaling_dim") else 1
+ self.keepdim = config.keepdim if hasattr(config, "keepdim") else True
+ self.minimum_scale = config.minimum_scale if hasattr(config, "minimum_scale") else 1e-10
+ self.default_scale = config.default_scale if hasattr(config, "default_scale") else None
+
+ def forward(
+ self, data: torch.Tensor, observed_indicator: torch.Tensor
+ ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
+ """
+ Parameters:
+ data (`torch.Tensor` of shape `(batch_size, sequence_length, num_input_channels)`):
+ input for Batch norm calculation
+ observed_indicator (`torch.BoolTensor` of shape `(batch_size, sequence_length, num_input_channels)`):
+ Calculating the scale on the observed indicator.
+ Returns:
+ tuple of `torch.Tensor` of shapes
+ (`(batch_size, sequence_length, num_input_channels)`,`(batch_size, 1, num_input_channels)`,
+ `(batch_size, 1, num_input_channels)`)
+ """
+ ts_sum = (data * observed_indicator).abs().sum(self.dim, keepdim=True)
+ num_observed = observed_indicator.sum(self.dim, keepdim=True)
+
+ scale = ts_sum / torch.clamp(num_observed, min=1)
+
+ # If `default_scale` is provided, we use it, otherwise we use the scale
+ # of the batch.
+ if self.default_scale is None:
+ batch_sum = ts_sum.sum(dim=0)
+ batch_observations = torch.clamp(num_observed.sum(0), min=1)
+ default_scale = torch.squeeze(batch_sum / batch_observations)
+ else:
+ default_scale = self.default_scale * torch.ones_like(scale)
+
+ # apply default scale where there are no observations
+ scale = torch.where(num_observed > 0, scale, default_scale)
+
+ # ensure the scale is at least `self.minimum_scale`
+ scale = torch.clamp(scale, min=self.minimum_scale)
+ scaled_data = data / scale
+
+ if not self.keepdim:
+ scale = scale.squeeze(dim=self.dim)
+
+ return scaled_data, torch.zeros_like(scale), scale
+
+
+# Copied from transformers.models.time_series_transformer.modeling_time_series_transformer.TimeSeriesNOPScaler with TimeSeriesTransformer->Autoformer,TimeSeries->Autoformer
+class AutoformerNOPScaler(nn.Module):
+ """
+ Assigns a scaling factor equal to 1 along the first dimension, and therefore applies no scaling to the input data.
+ """
+
+ def __init__(self, config: AutoformerConfig):
+ super().__init__()
+ self.dim = config.scaling_dim if hasattr(config, "scaling_dim") else 1
+ self.keepdim = config.keepdim if hasattr(config, "keepdim") else True
+
+ def forward(
+ self, data: torch.Tensor, observed_indicator: Optional[torch.Tensor] = None
+ ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
+ """
+ Parameters:
+ data (`torch.Tensor` of shape `(batch_size, sequence_length, num_input_channels)`):
+ input for Batch norm calculation
+ Returns:
+ tuple of `torch.Tensor` of shapes
+ (`(batch_size, sequence_length, num_input_channels)`,`(batch_size, 1, num_input_channels)`,
+ `(batch_size, 1, num_input_channels)`)
+ """
+ scale = torch.ones_like(data, requires_grad=False).mean(dim=self.dim, keepdim=self.keepdim)
+ loc = torch.zeros_like(data, requires_grad=False).mean(dim=self.dim, keepdim=self.keepdim)
+ return data, loc, scale
+
+
+# Copied from transformers.models.time_series_transformer.modeling_time_series_transformer.weighted_average
+def weighted_average(input_tensor: torch.Tensor, weights: Optional[torch.Tensor] = None, dim=None) -> torch.Tensor:
+ """
+ Computes the weighted average of a given tensor across a given `dim`, masking values associated with weight zero,
+ meaning instead of `nan * 0 = nan` you will get `0 * 0 = 0`.
+
+ Args:
+ input_tensor (`torch.FloatTensor`):
+ Input tensor, of which the average must be computed.
+ weights (`torch.FloatTensor`, *optional*):
+ Weights tensor, of the same shape as `input_tensor`.
+ dim (`int`, *optional*):
+ The dim along which to average `input_tensor`.
+
+ Returns:
+ `torch.FloatTensor`: The tensor with values averaged along the specified `dim`.
+ """
+ if weights is not None:
+ weighted_tensor = torch.where(weights != 0, input_tensor * weights, torch.zeros_like(input_tensor))
+ sum_weights = torch.clamp(weights.sum(dim=dim) if dim else weights.sum(), min=1.0)
+ return (weighted_tensor.sum(dim=dim) if dim else weighted_tensor.sum()) / sum_weights
+ else:
+ return input_tensor.mean(dim=dim)
+
+
+# Copied from transformers.models.time_series_transformer.modeling_time_series_transformer.nll
+def nll(input: torch.distributions.Distribution, target: torch.Tensor) -> torch.Tensor:
+ """
+ Computes the negative log likelihood loss from input distribution with respect to target.
+ """
+ return -input.log_prob(target)
+
+
+# Copied from transformers.models.marian.modeling_marian.MarianSinusoidalPositionalEmbedding with Marian->Autoformer
+class AutoformerSinusoidalPositionalEmbedding(nn.Embedding):
+ """This module produces sinusoidal positional embeddings of any length."""
+
+ def __init__(self, num_positions: int, embedding_dim: int, padding_idx: Optional[int] = None) -> None:
+ super().__init__(num_positions, embedding_dim)
+
+ def _init_weight(self):
+ """
+ Identical to the XLM create_sinusoidal_embeddings except features are not interleaved. The cos features are in
+ the 2nd half of the vector. [dim // 2:]
+ """
+ n_pos, dim = self.weight.shape
+ position_enc = np.array(
+ [[pos / np.power(10000, 2 * (j // 2) / dim) for j in range(dim)] for pos in range(n_pos)]
+ )
+ out = torch.empty(n_pos, dim, dtype=self.weight.dtype, requires_grad=False)
+ sentinel = dim // 2 if dim % 2 == 0 else (dim // 2) + 1
+ out[:, 0:sentinel] = torch.FloatTensor(np.sin(position_enc[:, 0::2]))
+ out[:, sentinel:] = torch.FloatTensor(np.cos(position_enc[:, 1::2]))
+ self.weight = nn.Parameter(out, requires_grad=False)
+
+ @torch.no_grad()
+ def forward(self, input_ids_shape: torch.Size, past_key_values_length: int = 0) -> torch.Tensor:
+ """`input_ids_shape` is expected to be [bsz x seqlen]."""
+ bsz, seq_len = input_ids_shape[:2]
+ positions = torch.arange(
+ past_key_values_length, past_key_values_length + seq_len, dtype=torch.long, device=self.weight.device
+ )
+ return super().forward(positions)
+
+
+# Copied from transformers.models.time_series_transformer.modeling_time_series_transformer.TimeSeriesValueEmbedding with TimeSeries->Autoformer
+class AutoformerValueEmbedding(nn.Module):
+ def __init__(self, feature_size, d_model):
+ super().__init__()
+ self.value_projection = nn.Linear(in_features=feature_size, out_features=d_model, bias=False)
+
+ def forward(self, x):
+ return self.value_projection(x)
+
+
+# Class based on
+# https://github.com/thuml/Autoformer/blob/c6a0694ff484753f2d986cc0bb1f99ee850fc1a8/layers/Autoformer_EncDec.py#L39
+# where AutoformerSeriesDecompositionLayer is series_decomp + moving_average
+class AutoformerSeriesDecompositionLayer(nn.Module):
+ """
+ Returns the trend and the seasonal parts of the time series. Calculated as:
+
+ x_trend = AvgPool(Padding(X)) and x_seasonal = X - x_trend
+ """
+
+ def __init__(self, config: AutoformerConfig):
+ super().__init__()
+ self.kernel_size = config.moving_average
+ self.avg = nn.AvgPool1d(kernel_size=self.kernel_size, stride=1, padding=0)
+
+ def forward(self, x):
+ """Input shape: Batch x Time x EMBED_DIM"""
+ # padding on the both ends of time series
+ num_of_pads = (self.kernel_size - 1) // 2
+ front = x[:, 0:1, :].repeat(1, num_of_pads, 1)
+ end = x[:, -1:, :].repeat(1, num_of_pads, 1)
+ x_padded = torch.cat([front, x, end], dim=1)
+
+ # calculate the trend and seasonal part of the series
+ x_trend = self.avg(x_padded.permute(0, 2, 1)).permute(0, 2, 1)
+ x_seasonal = x - x_trend
+ return x_seasonal, x_trend
+
+
+# Class based on
+# https://github.com/thuml/Autoformer/blob/c6a0694ff484753f2d986cc0bb1f99ee850fc1a8/layers/Autoformer_EncDec.py#L6
+# where AutoformerLayernorm is my_Layernorm
+class AutoformerLayernorm(nn.Module):
+ """
+ Special designed layer normalization for the seasonal part, calculated as: AutoformerLayernorm(x) = nn.LayerNorm(x)
+ - torch.mean(nn.LayerNorm(x))
+ """
+
+ def __init__(self, config: AutoformerConfig):
+ super().__init__()
+ self.layernorm = nn.LayerNorm(config.d_model)
+
+ def forward(self, x):
+ x_hat = self.layernorm(x)
+ bias = torch.mean(x_hat, dim=1).unsqueeze(1).repeat(1, x.shape[1], 1)
+ return x_hat - bias
+
+
+class AutoformerAttention(nn.Module):
+ """
+ AutoCorrelation Mechanism with the following two phases:
+ (1) period-based dependencies discovery (2) time delay aggregation
+ This block replace the canonical self-attention mechanism.
+ """
+
+ def __init__(
+ self,
+ embed_dim: int,
+ num_heads: int,
+ dropout: float = 0.0,
+ is_decoder: bool = False,
+ bias: bool = True,
+ autocorrelation_factor: int = 3,
+ ):
+ super().__init__()
+ self.embed_dim = embed_dim
+ self.num_heads = num_heads
+ self.dropout = dropout
+ self.head_dim = embed_dim // num_heads
+
+ if (self.head_dim * num_heads) != self.embed_dim:
+ raise ValueError(
+ f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim}"
+ f" and `num_heads`: {num_heads})."
+ )
+ self.scaling = self.head_dim**-0.5
+ self.is_decoder = is_decoder
+
+ self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+ self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+ self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+ self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+
+ self.autocorrelation_factor = autocorrelation_factor
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, tgt_len, _ = hidden_states.size()
+
+ # get query proj
+ query_states = self.q_proj(hidden_states)
+ # get key, value proj
+ # `past_key_value[0].shape[2] == key_value_states.shape[1]`
+ # is checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ if (
+ is_cross_attention
+ and past_key_value is not None
+ and past_key_value[0].shape[2] == key_value_states.shape[1]
+ ):
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0]
+ value_states = past_key_value[1]
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
+ value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+ else:
+ # self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ proj_shape = (bsz * self.num_heads, -1, self.head_dim)
+ query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
+ key_states = key_states.view(*proj_shape)
+ value_states = value_states.view(*proj_shape)
+
+ # (1) period-based dependencies discovery
+ # Resize (truncation or zero filling)
+ queries_time_length = query_states.size(1)
+ values_time_length = value_states.size(1)
+ if queries_time_length > values_time_length:
+ query_states = query_states[:, : (queries_time_length - values_time_length), :]
+ zeros = torch.zeros_like(query_states).float()
+ value_states = torch.cat([value_states, zeros], dim=1)
+ key_states = torch.cat([key_states, zeros], dim=1)
+ else:
+ value_states = value_states[:, :queries_time_length, :]
+ key_states = key_states[:, :queries_time_length, :]
+
+ query_states_fft = torch.fft.rfft(query_states, n=tgt_len, dim=1)
+ key_states_fft = torch.fft.rfft(key_states, n=tgt_len, dim=1)
+ attn_weights = query_states_fft * torch.conj(key_states_fft)
+ attn_weights = torch.fft.irfft(attn_weights, n=tgt_len, dim=1) # Autocorrelation(Q,K)
+
+ src_len = key_states.size(1)
+ channel = key_states.size(2)
+
+ if attn_weights.size() != (bsz * self.num_heads, tgt_len, channel):
+ raise ValueError(
+ f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, channel)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
+ )
+ attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
+
+ if layer_head_mask is not None:
+ if layer_head_mask.size() != (self.num_heads,):
+ raise ValueError(
+ f"Head mask for a single layer should be of size {(self.num_heads,)}, but is"
+ f" {layer_head_mask.size()}"
+ )
+ attn_weights = layer_head_mask.view(1, -1, 1, 1) * attn_weights.view(bsz, self.num_heads, tgt_len, channel)
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, channel)
+
+ if output_attentions:
+ # this operation is a bit awkward, but it's required to
+ # make sure that attn_weights keeps its gradient.
+ # In order to do so, attn_weights have to be reshaped
+ # twice and have to be reused in the following
+ attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, channel)
+ attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, channel)
+ else:
+ attn_weights_reshaped = None
+
+ # time delay aggregation
+ time_length = value_states.size(1)
+ autocorrelations = attn_weights.view(bsz, self.num_heads, tgt_len, channel)
+
+ # find top k autocorrelations delays
+ top_k = int(self.autocorrelation_factor * math.log(time_length))
+ autocorrelations_mean_on_head_channel = torch.mean(autocorrelations, dim=(1, -1)) # bsz x tgt_len
+ if self.training:
+ autocorrelations_mean_on_bsz = torch.mean(autocorrelations_mean_on_head_channel, dim=0)
+ _, top_k_delays_index = torch.topk(autocorrelations_mean_on_bsz, top_k)
+ top_k_autocorrelations = torch.stack(
+ [autocorrelations_mean_on_head_channel[:, top_k_delays_index[i]] for i in range(top_k)], dim=-1
+ )
+ else:
+ top_k_autocorrelations, top_k_delays_index = torch.topk(
+ autocorrelations_mean_on_head_channel, top_k, dim=1
+ )
+
+ top_k_autocorrelations = torch.softmax(top_k_autocorrelations, dim=-1) # bsz x top_k
+
+ # compute aggregation: value_states.roll(delay) * top_k_autocorrelations(delay)
+ if not self.training:
+ # used for compute values_states.roll(delay) in inference
+ tmp_values = value_states.repeat(1, 2, 1)
+ init_index = (
+ torch.arange(time_length)
+ .view(1, -1, 1)
+ .repeat(bsz * self.num_heads, 1, channel)
+ .to(value_states.device)
+ )
+
+ delays_agg = torch.zeros_like(value_states).float() # bsz x time_length x channel
+ for i in range(top_k):
+ # compute value_states roll delay
+ if not self.training:
+ tmp_delay = init_index + top_k_delays_index[:, i].view(-1, 1, 1).repeat(
+ self.num_heads, tgt_len, channel
+ )
+ value_states_roll_delay = torch.gather(tmp_values, dim=1, index=tmp_delay)
+ else:
+ value_states_roll_delay = value_states.roll(shifts=-int(top_k_delays_index[i]), dims=1)
+
+ # aggregation
+ top_k_autocorrelations_at_delay = (
+ top_k_autocorrelations[:, i].view(-1, 1, 1).repeat(self.num_heads, tgt_len, channel)
+ )
+ delays_agg += value_states_roll_delay * top_k_autocorrelations_at_delay
+
+ attn_output = delays_agg.contiguous()
+
+ if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz * self.num_heads, tgt_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
+ attn_output = attn_output.transpose(1, 2)
+
+ # Use the `embed_dim` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
+ # partitioned across GPUs when using tensor-parallelism.
+ attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, attn_weights_reshaped, past_key_value
+
+
+class AutoformerEncoderLayer(nn.Module):
+ def __init__(self, config: AutoformerConfig):
+ super().__init__()
+ self.embed_dim = config.d_model
+ self.self_attn = AutoformerAttention(
+ embed_dim=self.embed_dim,
+ num_heads=config.encoder_attention_heads,
+ dropout=config.attention_dropout,
+ autocorrelation_factor=config.autocorrelation_factor,
+ )
+ self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
+ self.dropout = config.dropout
+ self.activation_fn = ACT2FN[config.activation_function]
+ self.activation_dropout = config.activation_dropout
+ self.fc1 = nn.Linear(self.embed_dim, config.encoder_ffn_dim)
+ self.fc2 = nn.Linear(config.encoder_ffn_dim, self.embed_dim)
+ self.final_layer_norm = AutoformerLayernorm(config)
+ self.decomp1 = AutoformerSeriesDecompositionLayer(config)
+ self.decomp2 = AutoformerSeriesDecompositionLayer(config)
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ attention_mask: torch.FloatTensor,
+ layer_head_mask: torch.FloatTensor,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor, Optional[torch.FloatTensor]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+ hidden_states, attn_weights, _ = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ # added layer norm here as an improvement
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+ hidden_states, _ = self.decomp1(hidden_states)
+
+ residual = hidden_states
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states, _ = self.decomp2(hidden_states)
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ if hidden_states.dtype == torch.float16 and (
+ torch.isinf(hidden_states).any() or torch.isnan(hidden_states).any()
+ ):
+ clamp_value = torch.finfo(hidden_states.dtype).max - 1000
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+
+class AutoformerDecoderLayer(nn.Module):
+ def __init__(self, config: AutoformerConfig):
+ super().__init__()
+ self.embed_dim = config.d_model
+
+ self.self_attn = AutoformerAttention(
+ embed_dim=self.embed_dim,
+ num_heads=config.decoder_attention_heads,
+ dropout=config.attention_dropout,
+ is_decoder=True,
+ autocorrelation_factor=config.autocorrelation_factor,
+ )
+ self.dropout = config.dropout
+ self.activation_fn = ACT2FN[config.activation_function]
+ self.activation_dropout = config.activation_dropout
+
+ self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
+ self.encoder_attn = AutoformerAttention(
+ self.embed_dim,
+ config.decoder_attention_heads,
+ dropout=config.attention_dropout,
+ is_decoder=True,
+ autocorrelation_factor=config.autocorrelation_factor,
+ )
+ self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim)
+ self.fc1 = nn.Linear(self.embed_dim, config.decoder_ffn_dim)
+ self.fc2 = nn.Linear(config.decoder_ffn_dim, self.embed_dim)
+ self.final_layer_norm = AutoformerLayernorm(config)
+
+ self.decomp1 = AutoformerSeriesDecompositionLayer(config)
+ self.decomp2 = AutoformerSeriesDecompositionLayer(config)
+ self.decomp3 = AutoformerSeriesDecompositionLayer(config)
+
+ # source: https://github.com/thuml/Autoformer/blob/e6371e24f2ae2dd53e472edefdd5814c5176f864/layers/Autoformer_EncDec.py#L128
+ self.trend_projection = nn.Conv1d(
+ in_channels=self.embed_dim,
+ out_channels=config.feature_size,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ padding_mode="circular",
+ bias=False,
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ cross_attn_layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = True,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ encoder_hidden_states (`torch.FloatTensor`):
+ cross attention input to the layer of shape `(batch, seq_len, embed_dim)`
+ encoder_attention_mask (`torch.FloatTensor`): encoder attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ cross_attn_layer_head_mask (`torch.FloatTensor`): mask for cross-attention heads in a given layer of
+ size `(decoder_attention_heads,)`.
+ past_key_value (`Tuple(torch.FloatTensor)`): cached past key and value projection states
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache: (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the `present_key_value` state to be used for subsequent
+ decoding.
+ """
+ residual = hidden_states
+
+ # Self Attention
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
+ # add present self-attn cache to positions 1,2 of present_key_value tuple
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ past_key_value=self_attn_past_key_value,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states, trend1 = self.decomp1(hidden_states)
+ # added layer norm here as an improvement
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Cross-Attention Block
+ cross_attn_present_key_value = None
+ cross_attn_weights = None
+ if encoder_hidden_states is not None:
+ residual = hidden_states
+
+ # cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
+ cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
+ hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
+ hidden_states=hidden_states,
+ key_value_states=encoder_hidden_states,
+ attention_mask=encoder_attention_mask,
+ layer_head_mask=cross_attn_layer_head_mask,
+ past_key_value=cross_attn_past_key_value,
+ output_attentions=output_attentions,
+ )
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states, trend2 = self.decomp2(hidden_states)
+ # added layer norm here as an improvement
+ hidden_states = self.encoder_attn_layer_norm(hidden_states)
+
+ # add cross-attn to positions 3,4 of present_key_value tuple
+ present_key_value = present_key_value + cross_attn_present_key_value
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states, trend3 = self.decomp3(hidden_states)
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ if encoder_hidden_states is not None:
+ residual_trend = trend1 + trend2 + trend3
+ else:
+ residual_trend = trend1 + trend3
+ residual_trend = self.trend_projection(residual_trend.permute(0, 2, 1)).transpose(1, 2)
+ outputs = ((hidden_states, residual_trend),)
+
+ if output_attentions:
+ outputs += (self_attn_weights, cross_attn_weights)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+
+class AutoformerPreTrainedModel(PreTrainedModel):
+ config_class = AutoformerConfig
+ base_model_prefix = "model"
+ main_input_name = "past_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ std = self.config.init_std
+ if isinstance(module, (nn.Linear, nn.Conv1d)):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, AutoformerSinusoidalPositionalEmbedding):
+ module._init_weight()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+
+AUTOFORMER_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`AutoformerConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+AUTOFORMER_INPUTS_DOCSTRING = r"""
+ Args:
+ past_values (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
+ Past values of the time series, that serve as context in order to predict the future. These values may
+ contain lags, i.e. additional values from the past which are added in order to serve as "extra context".
+ The `past_values` is what the Transformer encoder gets as input (with optional additional features, such as
+ `static_categorical_features`, `static_real_features`, `past_time_features`).
+
+ The sequence length here is equal to `context_length` + `max(config.lags_sequence)`.
+
+ Missing values need to be replaced with zeros.
+
+ past_time_features (`torch.FloatTensor` of shape `(batch_size, sequence_length, num_features)`, *optional*):
+ Optional time features, which the model internally will add to `past_values`. These could be things like
+ "month of year", "day of the month", etc. encoded as vectors (for instance as Fourier features). These
+ could also be so-called "age" features, which basically help the model know "at which point in life" a
+ time-series is. Age features have small values for distant past time steps and increase monotonically the
+ more we approach the current time step.
+
+ These features serve as the "positional encodings" of the inputs. So contrary to a model like BERT, where
+ the position encodings are learned from scratch internally as parameters of the model, the Time Series
+ Transformer requires to provide additional time features.
+
+ The Autoformer only learns additional embeddings for `static_categorical_features`.
+
+ past_observed_mask (`torch.BoolTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Boolean mask to indicate which `past_values` were observed and which were missing. Mask values selected in
+ `[0, 1]`:
+
+ - 1 for values that are **observed**,
+ - 0 for values that are **missing** (i.e. NaNs that were replaced by zeros).
+
+ static_categorical_features (`torch.LongTensor` of shape `(batch_size, number of static categorical features)`, *optional*):
+ Optional static categorical features for which the model will learn an embedding, which it will add to the
+ values of the time series.
+
+ Static categorical features are features which have the same value for all time steps (static over time).
+
+ A typical example of a static categorical feature is a time series ID.
+
+ static_real_features (`torch.FloatTensor` of shape `(batch_size, number of static real features)`, *optional*):
+ Optional static real features which the model will add to the values of the time series.
+
+ Static real features are features which have the same value for all time steps (static over time).
+
+ A typical example of a static real feature is promotion information.
+
+ future_values (`torch.FloatTensor` of shape `(batch_size, prediction_length)`):
+ Future values of the time series, that serve as labels for the model. The `future_values` is what the
+ Transformer needs to learn to output, given the `past_values`.
+
+ See the demo notebook and code snippets for details.
+
+ Missing values need to be replaced with zeros.
+
+ future_time_features (`torch.FloatTensor` of shape `(batch_size, prediction_length, num_features)`, *optional*):
+ Optional time features, which the model internally will add to `future_values`. These could be things like
+ "month of year", "day of the month", etc. encoded as vectors (for instance as Fourier features). These
+ could also be so-called "age" features, which basically help the model know "at which point in life" a
+ time-series is. Age features have small values for distant past time steps and increase monotonically the
+ more we approach the current time step.
+
+ These features serve as the "positional encodings" of the inputs. So contrary to a model like BERT, where
+ the position encodings are learned from scratch internally as parameters of the model, the Time Series
+ Transformer requires to provide additional features.
+
+ The Autoformer only learns additional embeddings for `static_categorical_features`.
+
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on certain token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ decoder_attention_mask (`torch.LongTensor` of shape `(batch_size, target_sequence_length)`, *optional*):
+ Mask to avoid performing attention on certain token indices. By default, a causal mask will be used, to
+ make sure the model can only look at previous inputs in order to predict the future.
+
+ head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ decoder_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the cross-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ encoder_outputs (`tuple(tuple(torch.FloatTensor)`, *optional*):
+ Tuple consists of `last_hidden_state`, `hidden_states` (*optional*) and `attentions` (*optional*)
+ `last_hidden_state` of shape `(batch_size, sequence_length, hidden_size)` (*optional*) is a sequence of
+ hidden-states at the output of the last layer of the encoder. Used in the cross-attention of the decoder.
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+# Copied from transformers.models.time_series_transformer.modeling_time_series_transformer.TimeSeriesTransformerEncoder with TimeSeriesTransformer->Autoformer,TimeSeries->Autoformer
+class AutoformerEncoder(AutoformerPreTrainedModel):
+ """
+ Transformer encoder consisting of *config.encoder_layers* self attention layers. Each layer is a
+ [`AutoformerEncoderLayer`].
+
+ Args:
+ config: AutoformerConfig
+ """
+
+ def __init__(self, config: AutoformerConfig):
+ super().__init__(config)
+
+ self.dropout = config.dropout
+ self.layerdrop = config.encoder_layerdrop
+ if config.prediction_length is None:
+ raise ValueError("The `prediction_length` config needs to be specified.")
+
+ self.value_embedding = AutoformerValueEmbedding(feature_size=config.feature_size, d_model=config.d_model)
+ self.embed_positions = AutoformerSinusoidalPositionalEmbedding(
+ config.context_length + config.prediction_length, config.d_model
+ )
+ self.layers = nn.ModuleList([AutoformerEncoderLayer(config) for _ in range(config.encoder_layers)])
+ self.layernorm_embedding = nn.LayerNorm(config.d_model)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def forward(
+ self,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutput]:
+ r"""
+ Args:
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ This is useful if you want more control over how to convert `input_ids` indices into associated vectors
+ than the model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ hidden_states = self.value_embedding(inputs_embeds)
+ embed_pos = self.embed_positions(inputs_embeds.size())
+
+ hidden_states = self.layernorm_embedding(hidden_states + embed_pos)
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+
+ # expand attention_mask
+ if attention_mask is not None:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ attention_mask = _prepare_4d_attention_mask(attention_mask, inputs_embeds.dtype)
+
+ encoder_states = () if output_hidden_states else None
+ all_attentions = () if output_attentions else None
+
+ # check if head_mask has a correct number of layers specified if desired
+ if head_mask is not None:
+ if head_mask.size()[0] != (len(self.layers)):
+ raise ValueError(
+ f"The head_mask should be specified for {len(self.layers)} layers, but it is for"
+ f" {head_mask.size()[0]}."
+ )
+
+ for idx, encoder_layer in enumerate(self.layers):
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+ # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ to_drop = False
+ if self.training:
+ dropout_probability = torch.rand([])
+ if dropout_probability < self.layerdrop: # skip the layer
+ to_drop = True
+
+ if to_drop:
+ layer_outputs = (None, None)
+ else:
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ encoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ (head_mask[idx] if head_mask is not None else None),
+ output_attentions,
+ )
+ else:
+ layer_outputs = encoder_layer(
+ hidden_states,
+ attention_mask,
+ layer_head_mask=(head_mask[idx] if head_mask is not None else None),
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_attentions = all_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ encoder_states = encoder_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
+ )
+
+
+class AutoformerDecoder(AutoformerPreTrainedModel):
+ """
+ Transformer decoder consisting of `config.decoder_layers` layers. Each layer is a [`AutoformerDecoderLayer`]
+
+ Args:
+ config: AutoformerConfig
+ """
+
+ def __init__(self, config: AutoformerConfig):
+ super().__init__(config)
+ self.dropout = config.dropout
+ self.layerdrop = config.decoder_layerdrop
+ if config.prediction_length is None:
+ raise ValueError("The `prediction_length` config needs to be specified.")
+
+ self.value_embedding = AutoformerValueEmbedding(feature_size=config.feature_size, d_model=config.d_model)
+ self.embed_positions = AutoformerSinusoidalPositionalEmbedding(
+ config.context_length + config.prediction_length, config.d_model
+ )
+ self.layers = nn.ModuleList([AutoformerDecoderLayer(config) for _ in range(config.decoder_layers)])
+ self.layernorm_embedding = nn.LayerNorm(config.d_model)
+
+ # https://github.com/thuml/Autoformer/blob/e6371e24f2ae2dd53e472edefdd5814c5176f864/models/Autoformer.py#L74
+ self.seasonality_projection = nn.Linear(config.d_model, config.feature_size)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def forward(
+ self,
+ trend: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ cross_attn_head_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, AutoFormerDecoderOutput]:
+ r"""
+ Args:
+ trend (`torch.FloatTensor` of shape `(batch_size, prediction_length, feature_size)`, *optional*):
+ The trend sequence to be fed to the decoder.
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, encoder_sequence_length, hidden_size)`, *optional*):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
+ of the decoder.
+ encoder_attention_mask (`torch.LongTensor` of shape `(batch_size, encoder_sequence_length)`, *optional*):
+ Mask to avoid performing cross-attention on padding tokens indices of encoder input_ids. Mask values
+ selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ cross_attn_head_mask (`torch.Tensor` of shape `(decoder_layers, decoder_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the cross-attention modules in the decoder to avoid performing
+ cross-attention on hidden heads. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of
+ shape `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the
+ cross-attention blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those
+ that don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of
+ all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ This is useful if you want more control over how to convert `input_ids` indices into associated vectors
+ than the model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If `use_cache` is True, `past_key_values` key value states are returned and can be used to speed up
+ decoding (see `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ input_shape = inputs_embeds.size()[:-1]
+
+ # expand encoder attention mask
+ if encoder_hidden_states is not None and encoder_attention_mask is not None:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ encoder_attention_mask = _prepare_4d_attention_mask(
+ encoder_attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]
+ )
+
+ hidden_states = self.value_embedding(inputs_embeds)
+ embed_pos = self.embed_positions(
+ inputs_embeds.size(), past_key_values_length=self.config.context_length - self.config.label_length
+ )
+ hidden_states = self.layernorm_embedding(hidden_states + embed_pos)
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ all_cross_attentions = () if (output_attentions and encoder_hidden_states is not None) else None
+ next_decoder_cache = () if use_cache else None
+
+ # check if head_mask/cross_attn_head_mask has a correct number of layers specified if desired
+ for attn_mask, mask_name in zip([head_mask, cross_attn_head_mask], ["head_mask", "cross_attn_head_mask"]):
+ if attn_mask is not None:
+ if attn_mask.size()[0] != (len(self.layers)):
+ raise ValueError(
+ f"The `{mask_name}` should be specified for {len(self.layers)} layers, but it is for"
+ f" {head_mask.size()[0]}."
+ )
+
+ for idx, decoder_layer in enumerate(self.layers):
+ # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+ if self.training:
+ dropout_probability = torch.rand([])
+ if dropout_probability < self.layerdrop:
+ continue
+
+ past_key_value = past_key_values[idx] if past_key_values is not None else None
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ attention_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ head_mask[idx] if head_mask is not None else None,
+ cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None,
+ None,
+ output_attentions,
+ use_cache,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ layer_head_mask=(head_mask[idx] if head_mask is not None else None),
+ cross_attn_layer_head_mask=(
+ cross_attn_head_mask[idx] if cross_attn_head_mask is not None else None
+ ),
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+ (hidden_states, residual_trend) = layer_outputs[0]
+ trend = trend + residual_trend
+
+ if use_cache:
+ next_decoder_cache += (layer_outputs[3 if output_attentions else 1],)
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ if encoder_hidden_states is not None:
+ all_cross_attentions += (layer_outputs[2],)
+
+ # project seasonality representation
+ hidden_states = self.seasonality_projection(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = next_decoder_cache if use_cache else None
+ if not return_dict:
+ return tuple(
+ v
+ for v in [hidden_states, trend, next_cache, all_hidden_states, all_self_attns, all_cross_attentions]
+ if v is not None
+ )
+ return AutoFormerDecoderOutput(
+ last_hidden_state=hidden_states,
+ trend=trend,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ cross_attentions=all_cross_attentions,
+ )
+
+
+@add_start_docstrings(
+ "The bare Autoformer Model outputting raw hidden-states without any specific head on top.",
+ AUTOFORMER_START_DOCSTRING,
+)
+class AutoformerModel(AutoformerPreTrainedModel):
+ def __init__(self, config: AutoformerConfig):
+ super().__init__(config)
+
+ if config.scaling == "mean" or config.scaling is True:
+ self.scaler = AutoformerMeanScaler(config)
+ elif config.scaling == "std":
+ self.scaler = AutoformerStdScaler(config)
+ else:
+ self.scaler = AutoformerNOPScaler(config)
+
+ if config.num_static_categorical_features > 0:
+ self.embedder = AutoformerFeatureEmbedder(
+ cardinalities=config.cardinality, embedding_dims=config.embedding_dimension
+ )
+
+ # transformer encoder-decoder and mask initializer
+ self.encoder = AutoformerEncoder(config)
+ self.decoder = AutoformerDecoder(config)
+
+ # used for decoder seasonal and trend initialization
+ self.decomposition_layer = AutoformerSeriesDecompositionLayer(config)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @property
+ def _past_length(self) -> int:
+ return self.config.context_length + max(self.config.lags_sequence)
+
+ def get_lagged_subsequences(
+ self, sequence: torch.Tensor, subsequences_length: int, shift: int = 0
+ ) -> torch.Tensor:
+ """
+ Returns lagged subsequences of a given sequence. Returns a tensor of shape (batch_size, subsequences_length,
+ feature_size, indices_length), containing lagged subsequences. Specifically, lagged[i, j, :, k] = sequence[i,
+ -indices[k]-subsequences_length+j, :].
+
+ Args:
+ sequence (`torch.Tensor` or shape `(batch_size, context_length,
+ feature_size)`): The sequence from which lagged subsequences should be extracted.
+ subsequences_length (`int`):
+ Length of the subsequences to be extracted.
+ shift (`int`, *optional* defaults to 0):
+ Shift the lags by this amount back in the time index.
+ """
+
+ # calculates the indices of the lags by subtracting the shift value from the given lags_sequence
+ indices = [lag - shift for lag in self.config.lags_sequence]
+
+ # checks if the maximum lag plus the length of the subsequences exceeds the length of the input sequence
+ sequence_length = sequence.shape[1]
+ if max(indices) + subsequences_length > sequence_length:
+ raise ValueError(
+ f"lags cannot go further than history length, found lag {max(indices)} "
+ f"while history length is only {sequence_length}"
+ )
+
+ # extracts the lagged subsequences from the input sequence using the calculated indices
+ lagged_values = []
+ for lag_index in indices:
+ begin_index = -lag_index - subsequences_length
+ end_index = -lag_index if lag_index > 0 else None
+ lagged_values.append(sequence[:, begin_index:end_index, ...])
+
+ # return as stacked tensor in the feature dimension
+ return torch.stack(lagged_values, dim=-1)
+
+ def create_network_inputs(
+ self,
+ past_values: torch.Tensor,
+ past_time_features: torch.Tensor,
+ static_categorical_features: Optional[torch.Tensor] = None,
+ static_real_features: Optional[torch.Tensor] = None,
+ past_observed_mask: Optional[torch.Tensor] = None,
+ future_values: Optional[torch.Tensor] = None,
+ future_time_features: Optional[torch.Tensor] = None,
+ ) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:
+ """
+ Creates the inputs for the network given the past and future values, time features, and static features.
+
+ Args:
+ past_values (`torch.Tensor`):
+ A tensor of shape `(batch_size, past_length, input_size)` containing the past values.
+ past_time_features (`torch.Tensor`):
+ A tensor of shape `(batch_size, past_length, num_features)` containing the past time features.
+ static_categorical_features (`Optional[torch.Tensor]`):
+ An optional tensor of shape `(batch_size, num_categorical_features)` containing the static categorical
+ features.
+ static_real_features (`Optional[torch.Tensor]`):
+ An optional tensor of shape `(batch_size, num_real_features)` containing the static real features.
+ past_observed_mask (`Optional[torch.Tensor]`):
+ An optional tensor of shape `(batch_size, past_length, input_size)` containing the mask of observed
+ values in the past.
+ future_values (`Optional[torch.Tensor]`):
+ An optional tensor of shape `(batch_size, future_length, input_size)` containing the future values.
+
+ Returns:
+ A tuple containing the following tensors:
+ - reshaped_lagged_sequence (`torch.Tensor`): A tensor of shape `(batch_size, sequence_length, num_lags *
+ input_size)` containing the lagged subsequences of the inputs.
+ - features (`torch.Tensor`): A tensor of shape `(batch_size, sequence_length, num_features)` containing the
+ concatenated static and time features.
+ - loc (`torch.Tensor`): A tensor of shape `(batch_size, input_size)` containing the mean of the input
+ values.
+ - scale (`torch.Tensor`): A tensor of shape `(batch_size, input_size)` containing the std of the input
+ values.
+ - static_feat (`torch.Tensor`): A tensor of shape `(batch_size, num_static_features)` containing the
+ concatenated static features.
+ """
+ # time feature
+ time_feat = (
+ torch.cat(
+ (
+ past_time_features[:, self._past_length - self.config.context_length :, ...],
+ future_time_features,
+ ),
+ dim=1,
+ )
+ if future_values is not None
+ else past_time_features[:, self._past_length - self.config.context_length :, ...]
+ )
+
+ # target
+ if past_observed_mask is None:
+ past_observed_mask = torch.ones_like(past_values)
+
+ context = past_values[:, -self.config.context_length :]
+ observed_context = past_observed_mask[:, -self.config.context_length :]
+ _, loc, scale = self.scaler(context, observed_context)
+
+ inputs = (
+ (torch.cat((past_values, future_values), dim=1) - loc) / scale
+ if future_values is not None
+ else (past_values - loc) / scale
+ )
+
+ # static features
+ log_abs_loc = loc.abs().log1p() if self.config.input_size == 1 else loc.squeeze(1).abs().log1p()
+ log_scale = scale.log() if self.config.input_size == 1 else scale.squeeze(1).log()
+ static_feat = torch.cat((log_abs_loc, log_scale), dim=1)
+
+ if static_real_features is not None:
+ static_feat = torch.cat((static_real_features, static_feat), dim=1)
+ if static_categorical_features is not None:
+ embedded_cat = self.embedder(static_categorical_features)
+ static_feat = torch.cat((embedded_cat, static_feat), dim=1)
+ expanded_static_feat = static_feat.unsqueeze(1).expand(-1, time_feat.shape[1], -1)
+
+ # all features
+ features = torch.cat((expanded_static_feat, time_feat), dim=-1)
+
+ # lagged features
+ subsequences_length = (
+ self.config.context_length + self.config.prediction_length
+ if future_values is not None
+ else self.config.context_length
+ )
+ lagged_sequence = self.get_lagged_subsequences(sequence=inputs, subsequences_length=subsequences_length)
+ lags_shape = lagged_sequence.shape
+ reshaped_lagged_sequence = lagged_sequence.reshape(lags_shape[0], lags_shape[1], -1)
+
+ if reshaped_lagged_sequence.shape[1] != time_feat.shape[1]:
+ raise ValueError(
+ f"input length {reshaped_lagged_sequence.shape[1]} and time feature lengths {time_feat.shape[1]} does not match"
+ )
+ return reshaped_lagged_sequence, features, loc, scale, static_feat
+
+ def get_encoder(self):
+ return self.encoder
+
+ def get_decoder(self):
+ return self.decoder
+
+ @add_start_docstrings_to_model_forward(AUTOFORMER_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=AutoformerModelOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ past_values: torch.Tensor,
+ past_time_features: torch.Tensor,
+ past_observed_mask: torch.Tensor,
+ static_categorical_features: Optional[torch.Tensor] = None,
+ static_real_features: Optional[torch.Tensor] = None,
+ future_values: Optional[torch.Tensor] = None,
+ future_time_features: Optional[torch.Tensor] = None,
+ decoder_attention_mask: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ decoder_head_mask: Optional[torch.Tensor] = None,
+ cross_attn_head_mask: Optional[torch.Tensor] = None,
+ encoder_outputs: Optional[List[torch.FloatTensor]] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ use_cache: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[AutoformerModelOutput, Tuple]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from huggingface_hub import hf_hub_download
+ >>> import torch
+ >>> from transformers import AutoformerModel
+
+ >>> file = hf_hub_download(
+ ... repo_id="hf-internal-testing/tourism-monthly-batch", filename="train-batch.pt", repo_type="dataset"
+ ... )
+ >>> batch = torch.load(file)
+
+ >>> model = AutoformerModel.from_pretrained("huggingface/autoformer-tourism-monthly")
+
+ >>> # during training, one provides both past and future values
+ >>> # as well as possible additional features
+ >>> outputs = model(
+ ... past_values=batch["past_values"],
+ ... past_time_features=batch["past_time_features"],
+ ... past_observed_mask=batch["past_observed_mask"],
+ ... static_categorical_features=batch["static_categorical_features"],
+ ... future_values=batch["future_values"],
+ ... future_time_features=batch["future_time_features"],
+ ... )
+
+ >>> last_hidden_state = outputs.last_hidden_state
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ transformer_inputs, temporal_features, loc, scale, static_feat = self.create_network_inputs(
+ past_values=past_values,
+ past_time_features=past_time_features,
+ past_observed_mask=past_observed_mask,
+ static_categorical_features=static_categorical_features,
+ static_real_features=static_real_features,
+ future_values=future_values,
+ future_time_features=future_time_features,
+ )
+
+ if encoder_outputs is None:
+ enc_input = torch.cat(
+ (
+ transformer_inputs[:, : self.config.context_length, ...],
+ temporal_features[:, : self.config.context_length, ...],
+ ),
+ dim=-1,
+ )
+ encoder_outputs = self.encoder(
+ inputs_embeds=enc_input,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ # If the user passed a tuple for encoder_outputs, we wrap it in a BaseModelOutput when return_dict=True
+ elif return_dict and not isinstance(encoder_outputs, BaseModelOutput):
+ encoder_outputs = BaseModelOutput(
+ last_hidden_state=encoder_outputs[0],
+ hidden_states=encoder_outputs[1] if len(encoder_outputs) > 1 else None,
+ attentions=encoder_outputs[2] if len(encoder_outputs) > 2 else None,
+ )
+
+ if future_values is not None:
+ # Decoder inputs
+ # seasonality and trend from context length
+ seasonal_input, trend_input = self.decomposition_layer(
+ transformer_inputs[:, : self.config.context_length, ...]
+ )
+ mean = (
+ torch.mean(transformer_inputs[:, : self.config.context_length, ...], dim=1)
+ .unsqueeze(1)
+ .repeat(1, self.config.prediction_length, 1)
+ )
+ zeros = torch.zeros(
+ [transformer_inputs.shape[0], self.config.prediction_length, transformer_inputs.shape[2]],
+ device=enc_input.device,
+ )
+
+ decoder_input = torch.cat(
+ (
+ torch.cat((seasonal_input[:, -self.config.label_length :, ...], zeros), dim=1),
+ temporal_features[:, self.config.context_length - self.config.label_length :, ...],
+ ),
+ dim=-1,
+ )
+ trend_init = torch.cat(
+ (
+ torch.cat((trend_input[:, -self.config.label_length :, ...], mean), dim=1),
+ temporal_features[:, self.config.context_length - self.config.label_length :, ...],
+ ),
+ dim=-1,
+ )
+
+ decoder_outputs = self.decoder(
+ trend=trend_init,
+ inputs_embeds=decoder_input,
+ attention_mask=decoder_attention_mask,
+ encoder_hidden_states=encoder_outputs[0],
+ head_mask=decoder_head_mask,
+ cross_attn_head_mask=cross_attn_head_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ else:
+ decoder_outputs = AutoFormerDecoderOutput()
+
+ if not return_dict:
+ return decoder_outputs + encoder_outputs + (loc, scale, static_feat)
+
+ return AutoformerModelOutput(
+ last_hidden_state=decoder_outputs.last_hidden_state,
+ trend=decoder_outputs.trend,
+ past_key_values=decoder_outputs.past_key_values,
+ decoder_hidden_states=decoder_outputs.hidden_states,
+ decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
+ encoder_last_hidden_state=encoder_outputs.last_hidden_state,
+ encoder_hidden_states=encoder_outputs.hidden_states,
+ encoder_attentions=encoder_outputs.attentions,
+ loc=loc,
+ scale=scale,
+ static_features=static_feat,
+ )
+
+
+@add_start_docstrings(
+ "The Autoformer Model with a distribution head on top for time-series forecasting.",
+ AUTOFORMER_START_DOCSTRING,
+)
+class AutoformerForPrediction(AutoformerPreTrainedModel):
+ def __init__(self, config: AutoformerConfig):
+ super().__init__(config)
+ self.model = AutoformerModel(config)
+ if config.distribution_output == "student_t":
+ self.distribution_output = StudentTOutput(dim=config.input_size)
+ elif config.distribution_output == "normal":
+ self.distribution_output = NormalOutput(dim=config.input_size)
+ elif config.distribution_output == "negative_binomial":
+ self.distribution_output = NegativeBinomialOutput(dim=config.input_size)
+ else:
+ raise ValueError(f"Unknown distribution output {config.distribution_output}")
+
+ self.parameter_projection = self.distribution_output.get_parameter_projection(self.model.config.feature_size)
+ self.target_shape = self.distribution_output.event_shape
+
+ if config.loss == "nll":
+ self.loss = nll
+ else:
+ raise ValueError(f"Unknown loss function {config.loss}")
+
+ # Initialize weights of distribution_output and apply final processing
+ self.post_init()
+
+ def output_params(self, decoder_output):
+ return self.parameter_projection(decoder_output[:, -self.config.prediction_length :, :])
+
+ def get_encoder(self):
+ return self.model.get_encoder()
+
+ def get_decoder(self):
+ return self.model.get_decoder()
+
+ @torch.jit.ignore
+ def output_distribution(self, params, loc=None, scale=None, trailing_n=None) -> torch.distributions.Distribution:
+ sliced_params = params
+ if trailing_n is not None:
+ sliced_params = [p[:, -trailing_n:] for p in params]
+ return self.distribution_output.distribution(sliced_params, loc=loc, scale=scale)
+
+ @add_start_docstrings_to_model_forward(AUTOFORMER_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=Seq2SeqTSPredictionOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ past_values: torch.Tensor,
+ past_time_features: torch.Tensor,
+ past_observed_mask: torch.Tensor,
+ static_categorical_features: Optional[torch.Tensor] = None,
+ static_real_features: Optional[torch.Tensor] = None,
+ future_values: Optional[torch.Tensor] = None,
+ future_time_features: Optional[torch.Tensor] = None,
+ future_observed_mask: Optional[torch.Tensor] = None,
+ decoder_attention_mask: Optional[torch.LongTensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ decoder_head_mask: Optional[torch.Tensor] = None,
+ cross_attn_head_mask: Optional[torch.Tensor] = None,
+ encoder_outputs: Optional[List[torch.FloatTensor]] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ use_cache: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Seq2SeqTSPredictionOutput, Tuple]:
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from huggingface_hub import hf_hub_download
+ >>> import torch
+ >>> from transformers import AutoformerForPrediction
+
+ >>> file = hf_hub_download(
+ ... repo_id="hf-internal-testing/tourism-monthly-batch", filename="train-batch.pt", repo_type="dataset"
+ ... )
+ >>> batch = torch.load(file)
+
+ >>> model = AutoformerForPrediction.from_pretrained("huggingface/autoformer-tourism-monthly")
+
+ >>> # during training, one provides both past and future values
+ >>> # as well as possible additional features
+ >>> outputs = model(
+ ... past_values=batch["past_values"],
+ ... past_time_features=batch["past_time_features"],
+ ... past_observed_mask=batch["past_observed_mask"],
+ ... static_categorical_features=batch["static_categorical_features"],
+ ... future_values=batch["future_values"],
+ ... future_time_features=batch["future_time_features"],
+ ... )
+
+ >>> loss = outputs.loss
+ >>> loss.backward()
+
+ >>> # during inference, one only provides past values
+ >>> # as well as possible additional features
+ >>> # the model autoregressively generates future values
+ >>> outputs = model.generate(
+ ... past_values=batch["past_values"],
+ ... past_time_features=batch["past_time_features"],
+ ... past_observed_mask=batch["past_observed_mask"],
+ ... static_categorical_features=batch["static_categorical_features"],
+ ... future_time_features=batch["future_time_features"],
+ ... )
+
+ >>> mean_prediction = outputs.sequences.mean(dim=1)
+ ```
+
+
+
+ The AutoformerForPrediction can also use static_real_features. To do so, set num_static_real_features in
+ AutoformerConfig based on number of such features in the dataset (in case of tourism_monthly dataset it
+ is equal to 1), initialize the model and call as shown below:
+
+ ```
+ >>> from huggingface_hub import hf_hub_download
+ >>> import torch
+ >>> from transformers import AutoformerConfig, AutoformerForPrediction
+
+ >>> file = hf_hub_download(
+ ... repo_id="hf-internal-testing/tourism-monthly-batch", filename="train-batch.pt", repo_type="dataset"
+ ... )
+ >>> batch = torch.load(file)
+
+ >>> # check number of static real features
+ >>> num_static_real_features = batch["static_real_features"].shape[-1]
+
+ >>> # load configuration of pretrained model and override num_static_real_features
+ >>> configuration = AutoformerConfig.from_pretrained(
+ ... "huggingface/autoformer-tourism-monthly",
+ ... num_static_real_features=num_static_real_features,
+ ... )
+ >>> # we also need to update feature_size as it is not recalculated
+ >>> configuration.feature_size += num_static_real_features
+
+ >>> model = AutoformerForPrediction(configuration)
+
+ >>> outputs = model(
+ ... past_values=batch["past_values"],
+ ... past_time_features=batch["past_time_features"],
+ ... past_observed_mask=batch["past_observed_mask"],
+ ... static_categorical_features=batch["static_categorical_features"],
+ ... static_real_features=batch["static_real_features"],
+ ... future_values=batch["future_values"],
+ ... future_time_features=batch["future_time_features"],
+ ... )
+ ```
+
+
+ """
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ if future_values is not None:
+ use_cache = False
+
+ outputs = self.model(
+ past_values=past_values,
+ past_time_features=past_time_features,
+ past_observed_mask=past_observed_mask,
+ static_categorical_features=static_categorical_features,
+ static_real_features=static_real_features,
+ future_values=future_values,
+ future_time_features=future_time_features,
+ decoder_attention_mask=decoder_attention_mask,
+ head_mask=head_mask,
+ decoder_head_mask=decoder_head_mask,
+ cross_attn_head_mask=cross_attn_head_mask,
+ encoder_outputs=encoder_outputs,
+ past_key_values=past_key_values,
+ output_hidden_states=output_hidden_states,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ return_dict=return_dict,
+ )
+
+ prediction_loss = None
+ params = None
+ if future_values is not None:
+ # outputs.last_hidden_state and trend
+ # loc is 4rd last and scale is 3rd last output
+ params = self.output_params(outputs[0] + outputs[1])
+ distribution = self.output_distribution(params, loc=outputs[-3], scale=outputs[-2])
+
+ loss = self.loss(distribution, future_values)
+
+ if future_observed_mask is None:
+ future_observed_mask = torch.ones_like(future_values)
+
+ if len(self.target_shape) == 0:
+ loss_weights = future_observed_mask
+ else:
+ loss_weights, _ = future_observed_mask.min(dim=-1, keepdim=False)
+
+ prediction_loss = weighted_average(loss, weights=loss_weights)
+
+ if not return_dict:
+ outputs = ((params,) + outputs[2:]) if params is not None else outputs[2:]
+ return ((prediction_loss,) + outputs) if prediction_loss is not None else outputs
+
+ return Seq2SeqTSPredictionOutput(
+ loss=prediction_loss,
+ params=params,
+ past_key_values=outputs.past_key_values,
+ decoder_hidden_states=outputs.decoder_hidden_states,
+ decoder_attentions=outputs.decoder_attentions,
+ cross_attentions=outputs.cross_attentions,
+ encoder_last_hidden_state=outputs.encoder_last_hidden_state,
+ encoder_hidden_states=outputs.encoder_hidden_states,
+ encoder_attentions=outputs.encoder_attentions,
+ loc=outputs.loc,
+ scale=outputs.scale,
+ static_features=outputs.static_features,
+ )
+
+ @torch.no_grad()
+ def generate(
+ self,
+ past_values: torch.Tensor,
+ past_time_features: torch.Tensor,
+ future_time_features: torch.Tensor,
+ past_observed_mask: Optional[torch.Tensor] = None,
+ static_categorical_features: Optional[torch.Tensor] = None,
+ static_real_features: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ ) -> SampleTSPredictionOutput:
+ r"""
+ Greedily generate sequences of sample predictions from a model with a probability distribution head.
+
+ Parameters:
+ past_values (`torch.FloatTensor` of shape `(batch_size, sequence_length)` or `(batch_size, sequence_length, input_size)`):
+ Past values of the time series, that serve as context in order to predict the future. The sequence size
+ of this tensor must be larger than the `context_length` of the model, since the model will use the
+ larger size to construct lag features, i.e. additional values from the past which are added in order to
+ serve as "extra context".
+
+ The `sequence_length` here is equal to `config.context_length` + `max(config.lags_sequence)`, which if
+ no `lags_sequence` is configured, is equal to `config.context_length` + 7 (as by default, the largest
+ look-back index in `config.lags_sequence` is 7). The property `_past_length` returns the actual length
+ of the past.
+
+ The `past_values` is what the Transformer encoder gets as input (with optional additional features,
+ such as `static_categorical_features`, `static_real_features`, `past_time_features` and lags).
+
+ Optionally, missing values need to be replaced with zeros and indicated via the `past_observed_mask`.
+
+ For multivariate time series, the `input_size` > 1 dimension is required and corresponds to the number
+ of variates in the time series per time step.
+ past_time_features (`torch.FloatTensor` of shape `(batch_size, sequence_length, num_features)`):
+ Required time features, which the model internally will add to `past_values`. These could be things
+ like "month of year", "day of the month", etc. encoded as vectors (for instance as Fourier features).
+ These could also be so-called "age" features, which basically help the model know "at which point in
+ life" a time-series is. Age features have small values for distant past time steps and increase
+ monotonically the more we approach the current time step. Holiday features are also a good example of
+ time features.
+
+ These features serve as the "positional encodings" of the inputs. So contrary to a model like BERT,
+ where the position encodings are learned from scratch internally as parameters of the model, the Time
+ Series Transformer requires to provide additional time features. The Time Series Transformer only
+ learns additional embeddings for `static_categorical_features`.
+
+ Additional dynamic real covariates can be concatenated to this tensor, with the caveat that these
+ features must but known at prediction time.
+
+ The `num_features` here is equal to `config.`num_time_features` + `config.num_dynamic_real_features`.
+ future_time_features (`torch.FloatTensor` of shape `(batch_size, prediction_length, num_features)`):
+ Required time features for the prediction window, which the model internally will add to sampled
+ predictions. These could be things like "month of year", "day of the month", etc. encoded as vectors
+ (for instance as Fourier features). These could also be so-called "age" features, which basically help
+ the model know "at which point in life" a time-series is. Age features have small values for distant
+ past time steps and increase monotonically the more we approach the current time step. Holiday features
+ are also a good example of time features.
+
+ These features serve as the "positional encodings" of the inputs. So contrary to a model like BERT,
+ where the position encodings are learned from scratch internally as parameters of the model, the Time
+ Series Transformer requires to provide additional time features. The Time Series Transformer only
+ learns additional embeddings for `static_categorical_features`.
+
+ Additional dynamic real covariates can be concatenated to this tensor, with the caveat that these
+ features must but known at prediction time.
+
+ The `num_features` here is equal to `config.`num_time_features` + `config.num_dynamic_real_features`.
+ past_observed_mask (`torch.BoolTensor` of shape `(batch_size, sequence_length)` or `(batch_size, sequence_length, input_size)`, *optional*):
+ Boolean mask to indicate which `past_values` were observed and which were missing. Mask values selected
+ in `[0, 1]`:
+
+ - 1 for values that are **observed**,
+ - 0 for values that are **missing** (i.e. NaNs that were replaced by zeros).
+
+ static_categorical_features (`torch.LongTensor` of shape `(batch_size, number of static categorical features)`, *optional*):
+ Optional static categorical features for which the model will learn an embedding, which it will add to
+ the values of the time series.
+
+ Static categorical features are features which have the same value for all time steps (static over
+ time).
+
+ A typical example of a static categorical feature is a time series ID.
+ static_real_features (`torch.FloatTensor` of shape `(batch_size, number of static real features)`, *optional*):
+ Optional static real features which the model will add to the values of the time series.
+
+ Static real features are features which have the same value for all time steps (static over time).
+
+ A typical example of a static real feature is promotion information.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers.
+
+ Return:
+ [`SampleTSPredictionOutput`] where the outputs `sequences` tensor will have shape `(batch_size, number of
+ samples, prediction_length)` or `(batch_size, number of samples, prediction_length, input_size)` for
+ multivariate predictions.
+ """
+ outputs = self(
+ static_categorical_features=static_categorical_features,
+ static_real_features=static_real_features,
+ past_time_features=past_time_features,
+ past_values=past_values,
+ past_observed_mask=past_observed_mask,
+ future_time_features=None,
+ future_values=None,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=True,
+ use_cache=False,
+ )
+
+ decoder = self.model.get_decoder()
+ enc_last_hidden = outputs.encoder_last_hidden_state
+ loc = outputs.loc
+ scale = outputs.scale
+ static_feat = outputs.static_features
+
+ num_parallel_samples = self.config.num_parallel_samples
+ repeated_loc = loc.repeat_interleave(repeats=num_parallel_samples, dim=0)
+ repeated_scale = scale.repeat_interleave(repeats=num_parallel_samples, dim=0)
+
+ repeated_past_values = (
+ past_values.repeat_interleave(repeats=num_parallel_samples, dim=0) - repeated_loc
+ ) / repeated_scale
+
+ time_features = torch.cat((past_time_features, future_time_features), dim=1)
+
+ expanded_static_feat = static_feat.unsqueeze(1).expand(-1, time_features.shape[1], -1)
+ features = torch.cat((expanded_static_feat, time_features), dim=-1)
+ repeated_features = features.repeat_interleave(repeats=num_parallel_samples, dim=0)
+
+ repeated_enc_last_hidden = enc_last_hidden.repeat_interleave(repeats=num_parallel_samples, dim=0)
+
+ lagged_sequence = self.model.get_lagged_subsequences(
+ sequence=repeated_past_values, subsequences_length=self.config.context_length
+ )
+ lags_shape = lagged_sequence.shape
+ reshaped_lagged_sequence = lagged_sequence.reshape(lags_shape[0], lags_shape[1], -1)
+ seasonal_input, trend_input = self.model.decomposition_layer(reshaped_lagged_sequence)
+
+ mean = torch.mean(reshaped_lagged_sequence, dim=1).unsqueeze(1).repeat(1, self.config.prediction_length, 1)
+ zeros = torch.zeros(
+ [reshaped_lagged_sequence.shape[0], self.config.prediction_length, reshaped_lagged_sequence.shape[2]],
+ device=reshaped_lagged_sequence.device,
+ )
+
+ decoder_input = torch.cat(
+ (
+ torch.cat((seasonal_input[:, -self.config.label_length :, ...], zeros), dim=1),
+ repeated_features[:, -self.config.prediction_length - self.config.label_length :, ...],
+ ),
+ dim=-1,
+ )
+ trend_init = torch.cat(
+ (
+ torch.cat((trend_input[:, -self.config.label_length :, ...], mean), dim=1),
+ repeated_features[:, -self.config.prediction_length - self.config.label_length :, ...],
+ ),
+ dim=-1,
+ )
+ decoder_outputs = decoder(
+ trend=trend_init, inputs_embeds=decoder_input, encoder_hidden_states=repeated_enc_last_hidden
+ )
+ decoder_last_hidden = decoder_outputs.last_hidden_state
+ trend = decoder_outputs.trend
+ params = self.output_params(decoder_last_hidden + trend)
+ distr = self.output_distribution(params, loc=repeated_loc, scale=repeated_scale)
+ future_samples = distr.sample()
+
+ return SampleTSPredictionOutput(
+ sequences=future_samples.reshape(
+ (-1, num_parallel_samples, self.config.prediction_length) + self.target_shape,
+ )
+ )
+
+
+__all__ = ["AutoformerForPrediction", "AutoformerModel", "AutoformerPreTrainedModel"]
diff --git a/docs/transformers/src/transformers/models/aya_vision/__init__.py b/docs/transformers/src/transformers/models/aya_vision/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8be47cb228b19f02b87d195747e78c2a87de752
--- /dev/null
+++ b/docs/transformers/src/transformers/models/aya_vision/__init__.py
@@ -0,0 +1,28 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import _LazyModule
+from ...utils.import_utils import define_import_structure
+
+
+if TYPE_CHECKING:
+ from .configuration_aya_vision import *
+ from .modeling_aya_vision import *
+ from .processing_aya_vision import *
+else:
+ import sys
+
+ _file = globals()["__file__"]
+ sys.modules[__name__] = _LazyModule(__name__, _file, define_import_structure(_file), module_spec=__spec__)
diff --git a/docs/transformers/src/transformers/models/aya_vision/configuration_aya_vision.py b/docs/transformers/src/transformers/models/aya_vision/configuration_aya_vision.py
new file mode 100644
index 0000000000000000000000000000000000000000..ad7fdfd319d183d454c482a76ec2ab9fa00572c6
--- /dev/null
+++ b/docs/transformers/src/transformers/models/aya_vision/configuration_aya_vision.py
@@ -0,0 +1,112 @@
+# coding=utf-8
+# Copyright 2025 Cohere team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""AyaVision model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+from ..auto import CONFIG_MAPPING, AutoConfig
+
+
+logger = logging.get_logger(__name__)
+
+
+class AyaVisionConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`AyaVisionForConditionalGeneration`]. It is used to instantiate an
+ AyaVision model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of AyaVision.
+ e.g. [CohereForAI/aya-vision-8b](https://huggingface.co/CohereForAI/aya-vision-8b)
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ vision_config (`Union[AutoConfig, dict]`, *optional*, defaults to `CLIPVisionConfig`):
+ The config object or dictionary of the vision backbone.
+ text_config (`Union[AutoConfig, dict]`, *optional*, defaults to `LlamaConfig`):
+ The config object or dictionary of the text backbone.
+ vision_feature_select_strategy (`str`, *optional*, defaults to `"full"`):
+ The feature selection strategy used to select the vision feature from the vision backbone.
+ Can be one of `"default"` or `"full"`. If `"default"`, the CLS token is removed from the vision features.
+ If `"full"`, the full vision features are used.
+ vision_feature_layer (`int`, *optional*, defaults to -1):
+ The index of the layer to select the vision feature.
+ downsample_factor (`int`, *optional*, defaults to 2):
+ The downsample factor to apply to the vision features.
+ adapter_layer_norm_eps (`float`, *optional*, defaults to 1e-06):
+ The epsilon value used for layer normalization in the adapter.
+ image_token_index (`int`, *optional*, defaults to 255036):
+ The image token index to encode the image prompt.
+ """
+
+ model_type = "aya_vision"
+ attribute_map = {
+ "image_token_id": "image_token_index",
+ }
+ sub_configs = {"text_config": AutoConfig, "vision_config": AutoConfig}
+
+ def __init__(
+ self,
+ vision_config=None,
+ text_config=None,
+ vision_feature_select_strategy="full",
+ vision_feature_layer=-1,
+ downsample_factor=2,
+ adapter_layer_norm_eps=1e-6,
+ image_token_index=255036,
+ **kwargs,
+ ):
+ self.image_token_index = image_token_index
+ self.downsample_factor = downsample_factor
+ self.adapter_layer_norm_eps = adapter_layer_norm_eps
+ if vision_feature_select_strategy not in ["default", "full"]:
+ raise ValueError(
+ "vision_feature_select_strategy should be one of 'default', 'full'."
+ f"Got: {vision_feature_select_strategy}"
+ )
+
+ self.vision_feature_select_strategy = vision_feature_select_strategy
+ self.vision_feature_layer = vision_feature_layer
+
+ if isinstance(vision_config, dict):
+ vision_config["model_type"] = (
+ vision_config["model_type"] if "model_type" in vision_config else "clip_vision_model"
+ )
+ vision_config = CONFIG_MAPPING[vision_config["model_type"]](**vision_config)
+ elif vision_config is None:
+ vision_config = CONFIG_MAPPING["siglip_vision_model"](
+ hidden_size=1152,
+ intermediate_size=4304,
+ patch_size=14,
+ image_size=384,
+ num_hidden_layers=26,
+ num_attention_heads=14,
+ vision_use_head=False,
+ )
+
+ self.vision_config = vision_config
+
+ if isinstance(text_config, dict):
+ text_config["model_type"] = text_config["model_type"] if "model_type" in text_config else "llama"
+ text_config = CONFIG_MAPPING[text_config["model_type"]](**text_config)
+ elif text_config is None:
+ text_config = CONFIG_MAPPING["cohere2"]()
+
+ self.text_config = text_config
+
+ super().__init__(**kwargs)
+
+
+__all__ = ["AyaVisionConfig"]
diff --git a/docs/transformers/src/transformers/models/aya_vision/modeling_aya_vision.py b/docs/transformers/src/transformers/models/aya_vision/modeling_aya_vision.py
new file mode 100644
index 0000000000000000000000000000000000000000..45c2ab66e3e96dcfe2372ee1434bab1eebe52323
--- /dev/null
+++ b/docs/transformers/src/transformers/models/aya_vision/modeling_aya_vision.py
@@ -0,0 +1,546 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from src/transformers/models/aya_vision/modular_aya_vision.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_aya_vision.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# coding=utf-8
+# Copyright 2025 the Cohere Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from dataclasses import dataclass
+from typing import List, Optional, Tuple, Union
+
+import torch
+from torch import nn
+
+from ...activations import ACT2FN
+from ...generation import GenerationMixin
+from ...modeling_outputs import ModelOutput
+from ...modeling_utils import PreTrainedModel
+from ...utils import (
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ is_torchdynamo_compiling,
+ replace_return_docstrings,
+)
+from ..auto import AutoModel, AutoModelForCausalLM
+from .configuration_aya_vision import AyaVisionConfig
+
+
+_CONFIG_FOR_DOC = "AyaVisionConfig"
+
+
+class AyaVisionMultiModalProjector(nn.Module):
+ def __init__(self, config: AyaVisionConfig):
+ super().__init__()
+ self.config = config
+ self.downsample_factor = config.downsample_factor
+ self.alignment_intermediate_size = getattr(
+ config, "alignment_intermediate_size", config.text_config.hidden_size
+ )
+ self.layernorm = nn.LayerNorm(
+ config.vision_config.hidden_size * (config.downsample_factor**2), eps=config.adapter_layer_norm_eps
+ )
+
+ self.linear_1 = nn.Linear(
+ config.vision_config.hidden_size * (config.downsample_factor**2),
+ self.alignment_intermediate_size,
+ bias=True,
+ )
+
+ self.act = ACT2FN["silu"] # SwiGLU uses SiLU activation
+ # For SwiGLU, project down to half size since we split intermediate dim
+ self.linear_2 = nn.Linear(self.alignment_intermediate_size // 2, config.text_config.hidden_size, bias=True)
+
+ def forward(self, image_features):
+ image_features = self.pixel_shuffle(image_features)
+ image_features = self.layernorm(image_features)
+ hidden_states = self.linear_1(image_features)
+
+ # Split along last dimension and apply SwiGLU
+ x, gate = hidden_states.chunk(2, dim=-1)
+ hidden_states = self.act(gate) * x
+
+ hidden_states = self.linear_2(hidden_states)
+ return hidden_states
+
+ def pixel_shuffle(self, image_features): # B, S, D
+ batch_size, seq_length, feature_dim = image_features.shape
+ height = width = int(seq_length**0.5)
+ image_features = image_features.reshape(image_features.shape[0], width, height, -1)
+ channels = image_features.shape[-1]
+ image_features = image_features.reshape(
+ batch_size, width, int(height / self.downsample_factor), int(channels * self.downsample_factor)
+ )
+ image_features = image_features.permute(0, 2, 1, 3)
+ image_features = image_features.reshape(
+ batch_size, int(height / self.downsample_factor), int(width / self.downsample_factor), -1
+ )
+ image_features = image_features.permute(0, 2, 1, 3)
+ return image_features
+
+
+AYA_VISION_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`AyaVisionConfig`] or [`AyaVisionVisionConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare Aya Vision Model outputting raw hidden-states without any specific head on top.",
+ AYA_VISION_START_DOCSTRING,
+)
+class AyaVisionPreTrainedModel(PreTrainedModel):
+ config_class = AyaVisionConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["AyaVisionVisionAttention"]
+ _skip_keys_device_placement = "past_key_values"
+ _supports_cache_class = True
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_quantized_cache = False
+ _supports_static_cache = False
+
+ def _init_weights(self, module):
+ std = (
+ self.config.initializer_range
+ if hasattr(self.config, "initializer_range")
+ else self.config.text_config.initializer_range
+ )
+
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.weight.data.fill_(1.0)
+ module.bias.data.zero_()
+
+
+@dataclass
+class AyaVisionCausalLMOutputWithPast(ModelOutput):
+ """
+ Base class for AyaVision causal language model (or autoregressive) outputs.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Language modeling loss (for next-token prediction).
+ logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`)
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ image_hidden_states (`torch.FloatTensor`, *optional*):
+ A `torch.FloatTensor` of size (batch_size, num_images, sequence_length, hidden_size)`.
+ image_hidden_states of the model produced by the vision encoder and after projecting the last hidden state.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: Optional[torch.FloatTensor] = None
+ past_key_values: Optional[List[torch.FloatTensor]] = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+ image_hidden_states: Optional[torch.FloatTensor] = None
+
+
+AYA_VISION_INPUTS_DOCSTRING = """
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)):
+ The tensors corresponding to the input images. Pixel values can be obtained using
+ [`AutoImageProcessor`]. See [`GotOcr2ImageProcessor.__call__`] for details. [`AyaVisionProcessor`] uses
+ [`GotOcr2ImageProcessor`] for processing images.
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`. [What are position IDs?](../glossary#position-ids)
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ vision_feature_layer (`Union[int, List[int]], *optional*, defaults to -2`):
+ The index of the layer to select the vision feature. If multiple indices are provided,
+ the vision feature of the corresponding indices will be concatenated to form the
+ vision features.
+ vision_feature_select_strategy (`str`, *optional*, defaults to `"default"`):
+ The feature selection strategy used to select the vision feature from the vision backbone.
+ Can be one of `"default"` or `"full"`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence. Contrarily to `position_ids`,
+ this tensor is not affected by padding. It is used to update the cache in the correct position and to infer
+ the complete sequence length.
+"""
+
+
+@add_start_docstrings(
+ """The AyaVision model which consists of a vision backbone and a language model.""",
+ AYA_VISION_START_DOCSTRING,
+)
+class AyaVisionForConditionalGeneration(AyaVisionPreTrainedModel, GenerationMixin):
+ def __init__(self, config: AyaVisionConfig):
+ super().__init__(config)
+ self.vision_tower = AutoModel.from_config(config.vision_config)
+
+ self.multi_modal_projector = AyaVisionMultiModalProjector(config)
+ self.vocab_size = config.text_config.vocab_size
+ self.language_model = AutoModelForCausalLM.from_config(config.text_config)
+
+ if self.language_model._tied_weights_keys is not None:
+ self._tied_weights_keys = [f"language_model.{k}" for k in self.language_model._tied_weights_keys]
+
+ self.pad_token_id = self.config.pad_token_id if self.config.pad_token_id is not None else -1
+
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.language_model.get_input_embeddings()
+
+ def set_input_embeddings(self, value):
+ self.language_model.set_input_embeddings(value)
+
+ def get_output_embeddings(self):
+ return self.language_model.get_output_embeddings()
+
+ def set_output_embeddings(self, new_embeddings):
+ self.language_model.set_output_embeddings(new_embeddings)
+
+ def set_decoder(self, decoder):
+ self.language_model.set_decoder(decoder)
+
+ def get_decoder(self):
+ return self.language_model.get_decoder()
+
+ def get_image_features(
+ self,
+ pixel_values: torch.FloatTensor,
+ vision_feature_layer: Union[int, List[int]],
+ vision_feature_select_strategy: str,
+ **kwargs,
+ ):
+ """
+ Obtains image last hidden states from the vision tower and apply multimodal projection.
+
+ Args:
+ pixel_values (`torch.FloatTensor]` of shape `(batch_size, channels, height, width)`)
+ The tensors corresponding to the input images.
+ vision_feature_layer (`Union[int, List[int]]`):
+ The index of the layer to select the vision feature. If multiple indices are provided,
+ the vision feature of the corresponding indices will be concatenated to form the
+ vision features.
+ vision_feature_select_strategy (`str`):
+ The feature selection strategy used to select the vision feature from the vision backbone.
+ Can be one of `"default"` or `"full"`
+ Returns:
+ image_features (`torch.Tensor`): Image feature tensor of shape `(num_images, image_length, embed_dim)`).
+ """
+ if vision_feature_select_strategy not in ["default", "full"]:
+ raise ValueError(f"Unexpected select feature strategy: {self.config.vision_feature_select_strategy}")
+
+ kwargs = {k: v for k, v in kwargs.items() if v is not None}
+ # this is not memory efficient at all (output_hidden_states=True) will save all the hidden states.
+ image_outputs = self.vision_tower(pixel_values, output_hidden_states=True, **kwargs)
+
+ # If we have one vision feature layer, return the corresponding hidden states,
+ # otherwise, select the hidden states of each feature layer and concatenate them
+ if isinstance(vision_feature_layer, int):
+ selected_image_feature = image_outputs.hidden_states[vision_feature_layer]
+ if vision_feature_select_strategy == "default":
+ selected_image_feature = selected_image_feature[:, 1:]
+ else:
+ hs_pool = [image_outputs.hidden_states[layer_idx] for layer_idx in vision_feature_layer]
+ # For default; crop CLS from each hidden state in the hidden state pool
+ if vision_feature_select_strategy == "default":
+ hs_pool = [hs[:, 1:] for hs in hs_pool]
+ selected_image_feature = torch.cat(hs_pool, dim=-1)
+
+ image_features = self.multi_modal_projector(selected_image_feature)
+ return image_features
+
+ @add_start_docstrings_to_model_forward(AYA_VISION_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=AyaVisionCausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ vision_feature_layer: Optional[Union[int, List[int]]] = None,
+ vision_feature_select_strategy: Optional[str] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ logits_to_keep: Union[int, torch.Tensor] = 0,
+ image_sizes: Optional[torch.Tensor] = None,
+ **lm_kwargs,
+ ) -> Union[Tuple, AyaVisionCausalLMOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ logits_to_keep (`int` or `torch.Tensor`, *optional*):
+ If an `int`, compute logits for the last `logits_to_keep` tokens. If `0`, calculate logits for all
+ `input_ids` (special case). Only last token logits are needed for generation, and calculating them only for that
+ token can save memory, which becomes pretty significant for long sequences or large vocabulary size.
+ If a `torch.Tensor`, must be 1D corresponding to the indices to keep in the sequence length dimension.
+ This is useful when using packed tensor format (single dimension for batch and sequence length).
+
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoProcessor, AyaVisionForConditionalGeneration
+ >>> import torch
+
+ >>> torch_device = "cuda:0"
+ >>> processor = AutoProcessor.from_pretrained("CohereForAI/aya-vision-8b", use_fast=True)
+ >>> model = AyaVisionForConditionalGeneration.from_pretrained("CohereForAI/aya-vision-8b", device_map=torch_device)
+
+ >>> messages = [
+ ... {
+ ... "role": "user",
+ ... "content": [
+ ... {
+ ... "type": "image",
+ ... "url": "https://pbs.twimg.com/media/Fx7YvfQWYAIp6rZ?format=jpg&name=medium",
+ ... },
+ ... {"type": "text", "text": "चित्र में लिखा पाठ क्या कहता है?"},
+ ... ],
+ ... }
+ ... ]
+
+ >>> inputs = processor.apply_chat_template(
+ ... messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt", device=torch_device
+ ... ).to(model.device)
+
+ >>> gen_tokens = model.generate(**inputs, max_new_tokens=300, do_sample=True, temperature=0.3)
+ >>> processor.tokenizer.decode(gen_tokens[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
+ ```"""
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ vision_feature_layer = (
+ vision_feature_layer if vision_feature_layer is not None else self.config.vision_feature_layer
+ )
+ vision_feature_select_strategy = (
+ vision_feature_select_strategy
+ if vision_feature_select_strategy is not None
+ else self.config.vision_feature_select_strategy
+ )
+
+ if (input_ids is None) ^ (inputs_embeds is not None):
+ raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
+
+ if pixel_values is not None and inputs_embeds is not None:
+ raise ValueError(
+ "You cannot specify both pixel_values and inputs_embeds at the same time, and must specify either one"
+ )
+
+ if inputs_embeds is None:
+ inputs_embeds = self.get_input_embeddings()(input_ids)
+
+ if pixel_values is not None:
+ image_features = self.get_image_features(
+ pixel_values=pixel_values,
+ vision_feature_layer=vision_feature_layer,
+ vision_feature_select_strategy=vision_feature_select_strategy,
+ image_sizes=image_sizes,
+ )
+
+ special_image_mask = (input_ids == self.config.image_token_id).unsqueeze(-1)
+ special_image_mask = special_image_mask.expand_as(inputs_embeds).to(inputs_embeds.device)
+ if not is_torchdynamo_compiling() and inputs_embeds[special_image_mask].numel() != image_features.numel():
+ n_image_tokens = (input_ids == self.config.image_token_id).sum()
+ n_image_features = image_features.shape[0] * image_features.shape[1]
+ raise ValueError(
+ f"Image features and image tokens do not match: tokens: {n_image_tokens}, features {n_image_features}"
+ )
+ image_features = image_features.to(inputs_embeds.device, inputs_embeds.dtype)
+ inputs_embeds = inputs_embeds.masked_scatter(special_image_mask, image_features)
+
+ outputs = self.language_model(
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ cache_position=cache_position,
+ logits_to_keep=logits_to_keep,
+ **lm_kwargs,
+ )
+
+ logits = outputs[0]
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ if attention_mask is not None:
+ # we use the input attention mask to shift the logits and labels, because it is 2D.
+ # we also crop attn mask in case it is longer, which happens in PrefixTuning with peft
+ shift_attention_mask = attention_mask[:, -(logits.shape[1] - 1) :].to(logits.device)
+ shift_logits = logits[..., :-1, :][shift_attention_mask.to(logits.device) != 0].contiguous()
+ shift_labels = labels[..., 1:][shift_attention_mask.to(labels.device) != 0].contiguous()
+ else:
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = nn.CrossEntropyLoss()
+ loss = loss_fct(
+ shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1).to(shift_logits.device)
+ )
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return (loss,) + output if loss is not None else output
+
+ return AyaVisionCausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ image_hidden_states=image_features if pixel_values is not None else None,
+ )
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ inputs_embeds=None,
+ pixel_values=None,
+ attention_mask=None,
+ cache_position=None,
+ logits_to_keep=None,
+ **kwargs,
+ ):
+ # Overwritten -- in specific circumstances we don't want to forward image inputs to the model
+
+ model_inputs = self.language_model.prepare_inputs_for_generation(
+ input_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ attention_mask=attention_mask,
+ cache_position=cache_position,
+ logits_to_keep=logits_to_keep,
+ **kwargs,
+ )
+
+ if cache_position[0] == 0:
+ # If we're in cached decoding stage, pixel values should be None because input ids do not contain special image token anymore
+ # Otherwise we need pixel values to be passed to model
+ model_inputs["pixel_values"] = pixel_values
+
+ return model_inputs
+
+ def tie_weights(self):
+ return self.language_model.tie_weights()
+
+ def resize_token_embeddings(self, new_num_tokens: Optional[int] = None, pad_to_multiple_of=None) -> nn.Embedding:
+ model_embeds = self.language_model.resize_token_embeddings(new_num_tokens, pad_to_multiple_of)
+ # update vocab size
+ self.config.text_config.vocab_size = model_embeds.num_embeddings
+ self.vocab_size = model_embeds.num_embeddings
+ return model_embeds
+
+
+__all__ = ["AyaVisionForConditionalGeneration", "AyaVisionPreTrainedModel"]
diff --git a/docs/transformers/src/transformers/models/aya_vision/modular_aya_vision.py b/docs/transformers/src/transformers/models/aya_vision/modular_aya_vision.py
new file mode 100644
index 0000000000000000000000000000000000000000..96f0de888dd793b22c4eaeba6e94684740b61c78
--- /dev/null
+++ b/docs/transformers/src/transformers/models/aya_vision/modular_aya_vision.py
@@ -0,0 +1,315 @@
+# coding=utf-8
+# Copyright 2025 the Cohere Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch AyaVision model."""
+
+from typing import List, Optional, Tuple, Union
+
+import torch
+from torch import nn
+
+from transformers.models.llava.modeling_llava import (
+ LlavaCausalLMOutputWithPast,
+ LlavaForConditionalGeneration,
+ LlavaPreTrainedModel,
+)
+
+from ...activations import ACT2FN
+from ...utils import (
+ add_start_docstrings,
+ logging,
+)
+from .configuration_aya_vision import AyaVisionConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "AyaVisionConfig"
+
+
+class AyaVisionMultiModalProjector(nn.Module):
+ def __init__(self, config: AyaVisionConfig):
+ super().__init__()
+ self.config = config
+ self.downsample_factor = config.downsample_factor
+ self.alignment_intermediate_size = getattr(
+ config, "alignment_intermediate_size", config.text_config.hidden_size
+ )
+ self.layernorm = nn.LayerNorm(
+ config.vision_config.hidden_size * (config.downsample_factor**2), eps=config.adapter_layer_norm_eps
+ )
+
+ self.linear_1 = nn.Linear(
+ config.vision_config.hidden_size * (config.downsample_factor**2),
+ self.alignment_intermediate_size,
+ bias=True,
+ )
+
+ self.act = ACT2FN["silu"] # SwiGLU uses SiLU activation
+ # For SwiGLU, project down to half size since we split intermediate dim
+ self.linear_2 = nn.Linear(self.alignment_intermediate_size // 2, config.text_config.hidden_size, bias=True)
+
+ def forward(self, image_features):
+ image_features = self.pixel_shuffle(image_features)
+ image_features = self.layernorm(image_features)
+ hidden_states = self.linear_1(image_features)
+
+ # Split along last dimension and apply SwiGLU
+ x, gate = hidden_states.chunk(2, dim=-1)
+ hidden_states = self.act(gate) * x
+
+ hidden_states = self.linear_2(hidden_states)
+ return hidden_states
+
+ def pixel_shuffle(self, image_features): # B, S, D
+ batch_size, seq_length, feature_dim = image_features.shape
+ height = width = int(seq_length**0.5)
+ image_features = image_features.reshape(image_features.shape[0], width, height, -1)
+ channels = image_features.shape[-1]
+ image_features = image_features.reshape(
+ batch_size, width, int(height / self.downsample_factor), int(channels * self.downsample_factor)
+ )
+ image_features = image_features.permute(0, 2, 1, 3)
+ image_features = image_features.reshape(
+ batch_size, int(height / self.downsample_factor), int(width / self.downsample_factor), -1
+ )
+ image_features = image_features.permute(0, 2, 1, 3)
+ return image_features
+
+
+AYA_VISION_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`AyaVisionConfig`] or [`AyaVisionVisionConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare Aya Vision Model outputting raw hidden-states without any specific head on top.",
+ AYA_VISION_START_DOCSTRING,
+)
+class AyaVisionPreTrainedModel(LlavaPreTrainedModel):
+ _supports_quantized_cache = False
+ _supports_static_cache = False
+
+ def _init_weights(self, module):
+ std = (
+ self.config.initializer_range
+ if hasattr(self.config, "initializer_range")
+ else self.config.text_config.initializer_range
+ )
+
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.weight.data.fill_(1.0)
+ module.bias.data.zero_()
+
+
+class AyaVisionCausalLMOutputWithPast(LlavaCausalLMOutputWithPast):
+ pass
+
+
+AYA_VISION_INPUTS_DOCSTRING = """
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, image_size, image_size)):
+ The tensors corresponding to the input images. Pixel values can be obtained using
+ [`AutoImageProcessor`]. See [`GotOcr2ImageProcessor.__call__`] for details. [`AyaVisionProcessor`] uses
+ [`GotOcr2ImageProcessor`] for processing images.
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`. [What are position IDs?](../glossary#position-ids)
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ vision_feature_layer (`Union[int, List[int]], *optional*, defaults to -2`):
+ The index of the layer to select the vision feature. If multiple indices are provided,
+ the vision feature of the corresponding indices will be concatenated to form the
+ vision features.
+ vision_feature_select_strategy (`str`, *optional*, defaults to `"default"`):
+ The feature selection strategy used to select the vision feature from the vision backbone.
+ Can be one of `"default"` or `"full"`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence. Contrarily to `position_ids`,
+ this tensor is not affected by padding. It is used to update the cache in the correct position and to infer
+ the complete sequence length.
+"""
+
+
+@add_start_docstrings(
+ """The AyaVision model which consists of a vision backbone and a language model.""",
+ AYA_VISION_START_DOCSTRING,
+)
+class AyaVisionForConditionalGeneration(LlavaForConditionalGeneration):
+ def tie_weights(self):
+ return self.language_model.tie_weights()
+
+ def resize_token_embeddings(self, new_num_tokens: Optional[int] = None, pad_to_multiple_of=None) -> nn.Embedding:
+ model_embeds = self.language_model.resize_token_embeddings(new_num_tokens, pad_to_multiple_of)
+ # update vocab size
+ self.config.text_config.vocab_size = model_embeds.num_embeddings
+ self.vocab_size = model_embeds.num_embeddings
+ return model_embeds
+
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ pixel_values: Optional[torch.FloatTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ vision_feature_layer: Optional[Union[int, List[int]]] = None,
+ vision_feature_select_strategy: Optional[str] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ logits_to_keep: Union[int, torch.Tensor] = 0,
+ image_sizes: Optional[torch.Tensor] = None,
+ **lm_kwargs,
+ ) -> Union[Tuple, AyaVisionCausalLMOutputWithPast]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ logits_to_keep (`int` or `torch.Tensor`, *optional*):
+ If an `int`, compute logits for the last `logits_to_keep` tokens. If `0`, calculate logits for all
+ `input_ids` (special case). Only last token logits are needed for generation, and calculating them only for that
+ token can save memory, which becomes pretty significant for long sequences or large vocabulary size.
+ If a `torch.Tensor`, must be 1D corresponding to the indices to keep in the sequence length dimension.
+ This is useful when using packed tensor format (single dimension for batch and sequence length).
+
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoProcessor, AyaVisionForConditionalGeneration
+ >>> import torch
+
+ >>> torch_device = "cuda:0"
+ >>> processor = AutoProcessor.from_pretrained("CohereForAI/aya-vision-8b", use_fast=True)
+ >>> model = AyaVisionForConditionalGeneration.from_pretrained("CohereForAI/aya-vision-8b", device_map=torch_device)
+
+ >>> messages = [
+ ... {
+ ... "role": "user",
+ ... "content": [
+ ... {
+ ... "type": "image",
+ ... "url": "https://pbs.twimg.com/media/Fx7YvfQWYAIp6rZ?format=jpg&name=medium",
+ ... },
+ ... {"type": "text", "text": "चित्र में लिखा पाठ क्या कहता है?"},
+ ... ],
+ ... }
+ ... ]
+
+ >>> inputs = processor.apply_chat_template(
+ ... messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt", device=torch_device
+ ... ).to(model.device)
+
+ >>> gen_tokens = model.generate(**inputs, max_new_tokens=300, do_sample=True, temperature=0.3)
+ >>> processor.tokenizer.decode(gen_tokens[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
+ ```"""
+ super().forward(
+ input_ids=input_ids,
+ pixel_values=pixel_values,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ vision_feature_layer=vision_feature_layer,
+ vision_feature_select_strategy=vision_feature_select_strategy,
+ labels=labels,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ cache_position=cache_position,
+ logits_to_keep=logits_to_keep,
+ image_sizes=image_sizes,
+ **lm_kwargs,
+ )
+
+
+__all__ = ["AyaVisionForConditionalGeneration", "AyaVisionPreTrainedModel"]
diff --git a/docs/transformers/src/transformers/models/aya_vision/processing_aya_vision.py b/docs/transformers/src/transformers/models/aya_vision/processing_aya_vision.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b9afecda50fd1f34d681922eff43949bf44a519
--- /dev/null
+++ b/docs/transformers/src/transformers/models/aya_vision/processing_aya_vision.py
@@ -0,0 +1,255 @@
+# coding=utf-8
+# Copyright 2025 HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+from typing import List, Optional, Union
+
+from transformers.processing_utils import (
+ ImagesKwargs,
+ ProcessingKwargs,
+ ProcessorMixin,
+ Unpack,
+)
+from transformers.tokenization_utils_base import PreTokenizedInput, TextInput
+
+from ...image_processing_utils import BatchFeature
+from ...image_utils import (
+ ImageInput,
+ make_flat_list_of_images,
+)
+
+
+class AyaVisionImagesKwargs(ImagesKwargs, total=False):
+ crop_to_patches: Optional[bool]
+ min_patches: Optional[int]
+ max_patches: Optional[int]
+
+
+class AyaVisionProcessorKwargs(ProcessingKwargs, total=False):
+ images_kwargs: AyaVisionImagesKwargs
+ _defaults = {
+ "text_kwargs": {
+ "padding_side": "left",
+ "padding": True,
+ },
+ "images_kwargs": {
+ "crop_to_patches": True,
+ },
+ }
+
+
+class AyaVisionProcessor(ProcessorMixin):
+ r"""
+ Constructs a AyaVision processor which wraps a [`AutoImageProcessor`] and
+ [`PretrainedTokenizerFast`] tokenizer into a single processor that inherits both the image processor and
+ tokenizer functionalities. See the [`~AyaVisionProcessor.__call__`] and [`~AyaVisionProcessor.decode`] for more information.
+ Args:
+ image_processor ([`AutoImageProcessor`], *optional*):
+ The image processor is a required input.
+ tokenizer ([`PreTrainedTokenizer`, `PreTrainedTokenizerFast`], *optional*):
+ The tokenizer is a required input.
+ patch_size (`int`, *optional*, defaults to 28):
+ The size of image patches for tokenization.
+ img_size (`int`, *optional*, defaults to 364):
+ The size of the image to be tokenized. This should correspond to the size given to the image processor.
+ image_token (`str`, *optional*, defaults to `""`):
+ The token to be used to represent an image in the text.
+ downsample_factor (`int`, *optional*, defaults to 1):
+ The factor by which to scale the patch size.
+ start_of_img_token (`str`, *optional*, defaults to `"<|START_OF_IMG|>"`):
+ The token to be used to represent the start of an image in the text.
+ end_of_img_token (`str`, *optional*, defaults to `"<|END_OF_IMG|>"`):
+ The token to be used to represent the end of an image in the text.
+ img_patch_token (`str`, *optional*, defaults to `"<|IMG_PATCH|>"`):
+ The token to be used to represent an image patch in the text.
+ img_line_break_token (`str`, *optional*, defaults to `"<|IMG_LINE_BREAK|>"`):
+ The token to be used to represent a line break in the text.
+ tile_token (`str`, *optional*, defaults to `"TILE"`):
+ The token to be used to represent an image patch in the text.
+ tile_global_token (`str`, *optional*, defaults to `"TILE_GLOBAL"`):
+ The token to be used to represent the cover image in the text.
+ chat_template (`str`, *optional*): A Jinja template which will be used to convert lists of messages
+ in a chat into a tokenizable string.
+ """
+
+ attributes = ["image_processor", "tokenizer"]
+ valid_kwargs = [
+ "chat_template",
+ "image_token",
+ "patch_size",
+ "img_size",
+ "downsample_factor",
+ "start_of_img_token",
+ "end_of_img_token",
+ "img_patch_token",
+ "img_line_break_token",
+ "tile_token",
+ "tile_global_token",
+ ]
+ image_processor_class = "AutoImageProcessor"
+ tokenizer_class = "AutoTokenizer"
+
+ def __init__(
+ self,
+ image_processor=None,
+ tokenizer=None,
+ patch_size: int = 28,
+ img_size: int = 364,
+ image_token="", # set the default and let users change if they have peculiar special tokens in rare cases
+ downsample_factor: int = 1,
+ start_of_img_token="<|START_OF_IMG|>",
+ end_of_img_token="<|END_OF_IMG|>",
+ img_patch_token="<|IMG_PATCH|>",
+ img_line_break_token="<|IMG_LINE_BREAK|>",
+ tile_token="TILE",
+ tile_global_token="TILE_GLOBAL",
+ chat_template=None,
+ **kwargs,
+ ):
+ super().__init__(image_processor, tokenizer, chat_template=chat_template)
+
+ self.image_token = image_token
+ self.image_token_id = tokenizer.convert_tokens_to_ids(self.image_token)
+ self.patch_size = patch_size * downsample_factor
+ self.img_size = img_size
+
+ self.start_of_img_token = start_of_img_token
+ self.end_of_img_token = end_of_img_token
+ self.img_patch_token = img_patch_token
+ self.img_line_break_token = img_line_break_token
+ self.tile_token = tile_token
+ self.tile_global_token = tile_global_token
+
+ def _prompt_split_image(self, num_patches):
+ """
+ Create a structured string representation of image tokens
+
+ Args:
+ num_patches: Number of patches in the image
+
+ Returns:
+ String with appropriate image tokens
+ """
+
+ img_patches_per_tile = (self.img_size // self.patch_size) ** 2
+ img_string = f"{self.start_of_img_token}"
+ if num_patches > 1:
+ for idx in range(1, num_patches):
+ img_string += f"{self.tile_token}_{idx}" + f"{self.img_patch_token}" * img_patches_per_tile
+
+ img_string += f"{self.tile_global_token}" + f"{self.img_patch_token}" * img_patches_per_tile
+ img_string += f"{self.end_of_img_token}"
+ return img_string
+
+ def __call__(
+ self,
+ images: Optional[ImageInput] = None,
+ text: Optional[Union[TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]]] = None,
+ audio=None,
+ videos=None,
+ **kwargs: Unpack[AyaVisionProcessorKwargs],
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several sequences(s) and image(s). This method forwards the `text`
+ and `kwargs` arguments to PreTrainedTokenizerFast's [`~PreTrainedTokenizerFast.__call__`] to encode the text.
+ To prepare the vision inputs, this method forwards the `images` and `kwargs` arguments to
+ GotOcr2ImageProcessor's [`~GotOcr2ImageProcessor.__call__`] if `images` is not `None`.
+
+ Args:
+ images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
+ The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
+ tensor. Both channels-first and channels-last formats are supported.
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors of a particular framework. Acceptable values are:
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
+ - **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
+ `return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
+ `None`).
+ - **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
+ """
+ if text is None:
+ raise ValueError("You have to specify text.")
+
+ output_kwargs = self._merge_kwargs(
+ AyaVisionProcessorKwargs,
+ tokenizer_init_kwargs=self.tokenizer.init_kwargs,
+ **kwargs,
+ )
+
+ if not isinstance(text, (list, tuple)):
+ text = [text]
+
+ # Process images
+ image_inputs = {}
+ if images is not None:
+ images = make_flat_list_of_images(images)
+ image_inputs = self.image_processor(images=images, **output_kwargs["images_kwargs"])
+ num_patches = image_inputs.pop("num_patches")
+ image_index = 0
+ processed_text = []
+ for prompt in text:
+ new_prompt = prompt
+ while "" in new_prompt:
+ # Replace the image placeholder with structured image tokens
+ image_tokens = self._prompt_split_image(num_patches[image_index])
+ new_prompt = new_prompt.replace("", image_tokens, 1)
+ image_index += 1
+ processed_text.append(new_prompt)
+
+ if image_index != len(images):
+ raise ValueError("Number of image placeholders in the prompt does not match the number of images.")
+
+ text = processed_text
+
+ return_tensors = output_kwargs["text_kwargs"].pop("return_tensors", None)
+ text_inputs = self.tokenizer(text, **output_kwargs["text_kwargs"])
+ self._check_special_mm_tokens(text, text_inputs, modalities=["image"])
+
+ return BatchFeature(data={**text_inputs, **image_inputs}, tensor_type=return_tensors)
+
+ def batch_decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
+ refer to the docstring of this method for more information.
+ """
+ return self.tokenizer.batch_decode(*args, **kwargs)
+
+ def decode(self, *args, **kwargs):
+ """
+ This method forwards all its arguments to PreTrainedTokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
+ the docstring of this method for more information.
+ """
+ return self.tokenizer.decode(*args, **kwargs)
+
+ @property
+ def model_input_names(self):
+ tokenizer_input_names = self.tokenizer.model_input_names
+ image_processor_input_names = self.image_processor.model_input_names
+ return list(tokenizer_input_names) + list(image_processor_input_names)
+
+
+__all__ = ["AyaVisionProcessor"]
diff --git a/docs/transformers/src/transformers/models/bamba/__init__.py b/docs/transformers/src/transformers/models/bamba/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c3920da849a33318e626f6df3fe65d1abc71aac7
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bamba/__init__.py
@@ -0,0 +1,28 @@
+# Copyright 2024 IBM and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import _LazyModule
+from ...utils.import_utils import define_import_structure
+
+
+if TYPE_CHECKING:
+ from .configuration_bamba import *
+ from .modeling_bamba import *
+ from .processing_bamba import *
+else:
+ import sys
+
+ _file = globals()["__file__"]
+ sys.modules[__name__] = _LazyModule(__name__, _file, define_import_structure(_file), module_spec=__spec__)
diff --git a/docs/transformers/src/transformers/models/bamba/configuration_bamba.py b/docs/transformers/src/transformers/models/bamba/configuration_bamba.py
new file mode 100644
index 0000000000000000000000000000000000000000..36ac30ccca430c30315006df12341bea2dab1a09
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bamba/configuration_bamba.py
@@ -0,0 +1,206 @@
+# coding=utf-8
+# Copyright 2024 IBM and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Bamba model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class BambaConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`BambaModel`]. It is used to instantiate a
+ BambaModel model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with defaults taken from [ibm-fms/Bamba-9.8b-2.2T-hf](https://huggingface.co/ibm-fms/Bamba-9.8b-2.2T-hf).
+
+ The BambaModel is a hybrid [mamba2](https://github.com/state-spaces/mamba) architecture with SwiGLU.
+ The checkpoints are jointly trained by IBM, Princeton, and UIUC.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 128000):
+ Vocabulary size of the Bamba model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`BambaModel`]
+ tie_word_embeddings (`bool`, *optional*, defaults to `False`):
+ Whether the model's input and output word embeddings should be tied. Note that this is only relevant if the
+ model has an output word embedding layer.
+ hidden_size (`int`, *optional*, defaults to 4096):
+ Dimension of the hidden representations.
+ intermediate_size (`int`, *optional*, defaults to 14336):
+ Dimension of the MLP representations.
+ num_hidden_layers (`int`, *optional*, defaults to 32):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 32):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ num_key_value_heads (`int`, *optional*, defaults to 8):
+ This is the number of key_value heads that should be used to implement Grouped Query Attention. If
+ `num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
+ `num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
+ converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
+ by meanpooling all the original heads within that group. For more details checkout [this
+ paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `8`.
+ hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
+ The non-linear activation function (function or string) in the decoder.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ rms_norm_eps (`float`, *optional*, defaults to 1e-05):
+ The epsilon used by the rms normalization layers.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models). Only
+ relevant if `config.is_decoder=True`.
+ num_logits_to_keep (`int` or `None`, *optional*, defaults to 1):
+ Number of prompt logits to calculate during generation. If `None`, all logits will be calculated. If an
+ integer value, only last `num_logits_to_keep` logits will be calculated. Default is 1 because only the
+ logits of the last prompt token are needed for generation. For long sequences, the logits for the entire
+ sequence may use a lot of memory so, setting `num_logits_to_keep=1` will reduce memory footprint
+ significantly.
+ pad_token_id (`int`, *optional*, defaults to 0):
+ The id of the padding token.
+ bos_token_id (`int`, *optional*, defaults to 1):
+ The id of the "beginning-of-sequence" token.
+ eos_token_id (`int`, *optional*, defaults to 2):
+ The id of the "end-of-sequence" token.
+ max_position_embeddings (`int`, *optional*, defaults to 262144):
+ Max cached sequence length for the model
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ attn_layer_indices (`list`, *optional*):
+ Specifies the layer indices that will have full attention. Must contain values at most num_hidden_layers.
+ mamba_n_heads (`int`, *optional*, defaults to 128):
+ The number of mamba heads used in the v2 implementation.
+ mamba_d_head (`int`, *optional*, defaults to `"auto"`):
+ Head embedding dimension size
+ mamba_n_groups (`int`, *optional*, defaults to 1):
+ The number of the mamba groups used in the v2 implementation.
+ mamba_d_state (`int`, *optional*, defaults to 256):
+ The dimension the mamba state space latents
+ mamba_d_conv (`int`, *optional*, defaults to 4):
+ The size of the mamba convolution kernel
+ mamba_expand (`int`, *optional*, defaults to 2):
+ Expanding factor (relative to hidden_size) used to determine the mamba intermediate size
+ mamba_chunk_size (`int`, *optional*, defaults to 256):
+ The chunks in which to break the sequence when doing prefill/training
+ mamba_conv_bias (`bool`, *optional*, defaults to `True`):
+ Flag indicating whether or not to use bias in the convolution layer of the mamba mixer block.
+ mamba_proj_bias (`bool`, *optional*, defaults to `False`):
+ Flag indicating whether or not to use bias in the input and output projections (["in_proj", "out_proj"]) of the mamba mixer block
+
+ """
+
+ model_type = "bamba"
+ keys_to_ignore_at_inference = ["past_key_values"]
+
+ def __init__(
+ self,
+ vocab_size=128000,
+ tie_word_embeddings=False,
+ hidden_size=4096,
+ intermediate_size=14336,
+ num_hidden_layers=32,
+ num_attention_heads=32,
+ num_key_value_heads=8,
+ hidden_act="silu",
+ initializer_range=0.02,
+ rms_norm_eps=1e-5,
+ use_cache=True,
+ num_logits_to_keep=1,
+ pad_token_id=0,
+ bos_token_id=1,
+ eos_token_id=2,
+ max_position_embeddings=262144,
+ attention_dropout=0.0,
+ attn_layer_indices=None,
+ mamba_n_heads=128,
+ mamba_d_head="auto",
+ mamba_n_groups=1,
+ mamba_d_state=256,
+ mamba_d_conv=4,
+ mamba_expand=2,
+ mamba_chunk_size=256,
+ mamba_conv_bias=True,
+ mamba_proj_bias=False,
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.tie_word_embeddings = tie_word_embeddings
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.max_position_embeddings = max_position_embeddings
+ self.attention_dropout = attention_dropout
+ self.attention_bias = False
+ self.mlp_bias = False
+
+ # for backward compatibility
+ if num_key_value_heads is None:
+ num_key_value_heads = num_attention_heads
+
+ self.num_key_value_heads = num_key_value_heads
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.rms_norm_eps = rms_norm_eps
+
+ self.use_cache = use_cache
+ self.num_logits_to_keep = num_logits_to_keep
+
+ self.attn_layer_indices = attn_layer_indices
+ self.rope_theta = 10000.0
+ self.rope_scaling = None
+ self.partial_rotary_factor = 0.5
+
+ mamba_intermediate = mamba_expand * hidden_size
+
+ if mamba_intermediate % mamba_n_heads != 0:
+ raise ValueError("mamba_n_heads must divide mamba_expand * hidden_size")
+
+ # for the mamba_v2, must satisfy the following
+ if mamba_d_head == "auto":
+ mamba_d_head = mamba_intermediate // mamba_n_heads
+
+ if mamba_d_head * mamba_n_heads != mamba_intermediate:
+ raise ValueError("The dimensions for the Mamba head state do not match the model intermediate_size")
+
+ self.mamba_n_heads = mamba_n_heads
+ self.mamba_d_head = mamba_d_head
+ self.mamba_n_groups = mamba_n_groups
+ self.mamba_d_state = mamba_d_state
+ self.mamba_d_conv = mamba_d_conv
+ self.mamba_expand = mamba_expand
+ self.mamba_chunk_size = mamba_chunk_size
+ self.mamba_conv_bias = mamba_conv_bias
+ self.mamba_proj_bias = mamba_proj_bias
+
+ super().__init__(
+ pad_token_id=pad_token_id,
+ bos_token_id=bos_token_id,
+ eos_token_id=eos_token_id,
+ tie_word_embeddings=tie_word_embeddings,
+ **kwargs,
+ )
+
+ @property
+ def layers_block_type(self):
+ return [
+ "attention" if (self.attn_layer_indices and i in self.attn_layer_indices) else "mamba"
+ for i in range(self.num_hidden_layers)
+ ]
+
+
+__all__ = ["BambaConfig"]
diff --git a/docs/transformers/src/transformers/models/bamba/convert_mamba_ssm_checkpoint.py b/docs/transformers/src/transformers/models/bamba/convert_mamba_ssm_checkpoint.py
new file mode 100644
index 0000000000000000000000000000000000000000..92ddcc88d4c214e3be0dcec5ef7ece963df6ed37
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bamba/convert_mamba_ssm_checkpoint.py
@@ -0,0 +1,273 @@
+# coding=utf-8
+# Copyright 2024 IBM and the HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""This script can be used to convert checkpoints provided in the `mamba_ssm` library into the format provided in HuggingFace `transformers`. It depends on the `mamba2_ssm` package to be installed."""
+
+import argparse
+import json
+import os
+import re
+from os import path
+from typing import Dict, Optional, Union
+
+import torch
+from huggingface_hub import split_torch_state_dict_into_shards
+from safetensors.torch import save_file
+
+from transformers import AutoTokenizer
+from transformers.utils import SAFE_WEIGHTS_INDEX_NAME, SAFE_WEIGHTS_NAME
+
+from .configuration_bamba import BambaConfig
+
+
+def convert_state_dict_from_mamba_ssm(original_sd: Dict) -> Dict[str, torch.Tensor]:
+ state_dict = {}
+
+ for orig_k, param in original_sd.items():
+ k = orig_k.replace("backbone", "model")
+
+ # for embeddings
+ k = k.replace("embedding", "embed_tokens")
+
+ # for mixer
+ k = k.replace("mixer", "mamba")
+
+ # for final layernorm
+ k = k.replace("norm_f", "final_layernorm")
+
+ # for block layernorm
+ k = re.sub(r"(\d+)\.norm\.", r"\1.input_layernorm.", k)
+ k = re.sub(r"(\d+)\.norm2\.", r"\1.pre_ff_layernorm.", k)
+
+ # for mlp
+ k = k.replace("mlp.fc2", "feed_forward.down_proj")
+
+ if "mlp.fc1" in k:
+ param, param2 = torch.chunk(param, 2, dim=0)
+ k2 = k.replace("mlp.fc1", "feed_forward.gate_proj")
+ state_dict[k2] = param2
+ k = k.replace("mlp.fc1", "feed_forward.up_proj")
+
+ if ("in_proj" in k and orig_k.replace("in_proj", "conv1d") in original_sd) or (
+ "out_proj" in k and orig_k.replace("out_proj", "conv1d") in original_sd
+ ):
+ # then this must be a mamba
+ pass
+ else:
+ # for attn
+ # - because mixer was replaced to mamba above
+ k = k.replace("mamba.out_proj", "self_attn.o_proj")
+ if "mamba.in_proj" in k:
+ m, n = param.shape
+ d = (m - n) // 2
+ param, param2, param3 = torch.split(param, [n, d, d], dim=0)
+ k2 = k.replace("mamba.in_proj", "self_attn.k_proj")
+ state_dict[k2] = param2
+ k2 = k.replace("mamba.in_proj", "self_attn.v_proj")
+ state_dict[k2] = param3
+ k = k.replace("mamba.in_proj", "self_attn.q_proj")
+
+ state_dict[k] = param
+
+ return state_dict
+
+
+# Adapted from transformers.models.mamba.convert_mamba_ssm_checkpoint_to_pytorch.py
+def convert_ssm_config_to_hf_config(
+ config_ssm: Dict,
+ **kwargs,
+) -> BambaConfig:
+ """Convert a config from mamba_ssm to a BambaConfig from here."""
+ hf_config: BambaConfig = BambaConfig(**kwargs)
+
+ hf_config.architectures = ["BambaForCausalLM"]
+
+ # Set important values from config and recalculate other resulting entries
+ hf_config.hidden_size = config_ssm["d_model"]
+ hf_config.intermediate_size = config_ssm["d_intermediate"]
+ hf_config.mamba_n_heads = (hf_config.hidden_size * hf_config.mamba_expand) // hf_config.mamba_d_head
+ hf_config.num_hidden_layers = config_ssm["n_layer"]
+ hf_config.tie_word_embeddings = config_ssm["tie_embeddings"]
+
+ # currently this script assumes config_ssm belongs to v2
+ if config_ssm["ssm_cfg"].get("layer") != "Mamba2":
+ raise ValueError("Conversion script only supports Mamba2")
+
+ # Set attention values
+ attn_cfg = config_ssm.get("attn_cfg")
+ if attn_cfg:
+ assert attn_cfg["causal"], "Only support non-causal attention."
+ assert not attn_cfg["qkv_proj_bias"], "Only support no qkv bias."
+ assert not attn_cfg["out_proj_bias"], "Only support no out bias."
+ hf_config.attn_rotary_emb = attn_cfg["rotary_emb_dim"]
+ hf_config.num_attention_heads = attn_cfg["num_heads"]
+ hf_config.num_key_value_heads = attn_cfg["num_heads_kv"]
+
+ attention_layer_indices = config_ssm.get("attn_layer_idx")
+ if attention_layer_indices:
+ hf_config.attn_layer_indices = attention_layer_indices
+
+ # Padded vocab size, mostly of 16 but 32 is also very common in different models
+ vocab_size = config_ssm["vocab_size"]
+ pad_vocab_size_multiple = config_ssm["pad_vocab_size_multiple"]
+ if (vocab_size % pad_vocab_size_multiple) != 0:
+ vocab_size += pad_vocab_size_multiple - (vocab_size % pad_vocab_size_multiple)
+ hf_config.vocab_size = vocab_size
+
+ return hf_config
+
+
+def save_single_safetensor(
+ state_dict: Dict,
+ save_directory: str,
+ metadata: Dict,
+):
+ save_file(
+ state_dict,
+ os.path.join(save_directory, SAFE_WEIGHTS_NAME),
+ metadata,
+ )
+
+
+def save_sharded_safetensors(
+ state_dict: Dict,
+ save_directory: str,
+ metadata: Dict,
+ max_shard_size: Union[int, str] = "5GB",
+):
+ filename_pattern = SAFE_WEIGHTS_NAME.replace(".bin", "{suffix}.bin").replace(
+ ".safetensors", "{suffix}.safetensors"
+ )
+ state_dict_split = split_torch_state_dict_into_shards(
+ state_dict, filename_pattern=filename_pattern, max_shard_size=max_shard_size
+ )
+ index = {
+ "metadata": state_dict_split.metadata,
+ "weight_map": state_dict_split.tensor_to_filename,
+ }
+ # Save the index
+ with open(os.path.join(save_directory, SAFE_WEIGHTS_INDEX_NAME), "w", encoding="utf-8") as f:
+ content = json.dumps(index, indent=2, sort_keys=True) + "\n"
+ f.write(content)
+
+ filename_to_tensors = state_dict_split.filename_to_tensors.items()
+ for shard_file, tensors in filename_to_tensors:
+ shard = {tensor: state_dict[tensor].contiguous() for tensor in tensors}
+ save_file(shard, os.path.join(save_directory, shard_file), metadata=metadata)
+
+
+# Adapted from transformers.models.mamba.convert_mamba_ssm_checkpoint_to_pytorch.py
+def convert_mamba_ssm_checkpoint_file_to_huggingface_model_file(
+ mamba_ssm_checkpoint_path: str,
+ precision: str,
+ output_dir: str,
+ tokenizer_path: Optional[str] = None,
+ save_model: Union[bool, str] = True,
+) -> None:
+ # load tokenizer if provided, this will be used to set the
+ # token_ids in the config file
+ token_ids = {}
+ if tokenizer_path:
+ tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
+ for key in [
+ "bos_token_id",
+ "eos_token_id",
+ "pad_token_id",
+ ]:
+ id = getattr(tokenizer, key, None)
+ if id:
+ token_ids[key] = id
+
+ # there are some configs unsettable by mamba_ssn config, so
+ # if there are changes from the defaults, have to pass them into
+ # the function
+ unsettables = {
+ "mamba_d_head": 64,
+ "mamba_d_state": 128,
+ "mamba_n_groups": 1,
+ "rms_norm_eps": 1e-5,
+ }
+
+ # Load and save config based on name
+ config_path = path.join(mamba_ssm_checkpoint_path, "config.json")
+ with open(config_path, "r", encoding="utf-8") as json_file:
+ config = json.load(json_file)
+
+ # convert the config
+ hf_config = convert_ssm_config_to_hf_config(
+ config_ssm=config,
+ **token_ids,
+ **unsettables,
+ )
+ hf_config.save_pretrained(output_dir)
+
+ # Load state dict of the original model and transfer to hf model
+ state_dict = torch.load(
+ path.join(mamba_ssm_checkpoint_path, "pytorch_model.bin"),
+ map_location="cpu",
+ weights_only=True,
+ )
+ # FIXME: allow other parameters to pass in
+ state_dict = convert_state_dict_from_mamba_ssm(state_dict)
+
+ # Save new model to pytorch_dump_path
+ dtype = torch.float32 if precision == "fp32" else (torch.bfloat16 if precision == "bf16" else torch.float16)
+
+ save_file_fn = None
+ if isinstance(save_model, bool) and save_model:
+ save_file_fn = save_single_safetensor
+ elif isinstance(save_model, str) and save_model == "sharded":
+ save_file_fn = save_sharded_safetensors
+
+ if save_file_fn:
+ save_file_fn({k: v.to(dtype) for k, v in state_dict.items()}, output_dir, metadata={"format": "pt"})
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument(
+ "-i",
+ "--mamba_ssm_checkpoint_directory",
+ type=str,
+ required=True,
+ help="Path to a directory containing the `pytorch_model.bin` mamba_ssm checkpoint file to be converted.",
+ )
+ parser.add_argument(
+ "-p",
+ "--precision",
+ type=str,
+ default="fp16",
+ const="fp16",
+ required=True,
+ choices=("fp32", "fp16", "bf16"),
+ help="The precision the model will be saved in. Select from fp32, fp16 or bf16.",
+ )
+ parser.add_argument(
+ "-o", "--output_dir", type=str, required=True, help="Path to directory to save the converted output model to."
+ )
+ parser.add_argument(
+ "-t",
+ "--tokenizer_model_path",
+ type=str,
+ default=None,
+ required=False,
+ help="Path to a the tokenizer file.",
+ )
+ args = parser.parse_args()
+
+ convert_mamba_ssm_checkpoint_file_to_huggingface_model_file(
+ args.mamba2_checkpoint_directory,
+ args.precision,
+ args.output_dir,
+ )
diff --git a/docs/transformers/src/transformers/models/bamba/modeling_bamba.py b/docs/transformers/src/transformers/models/bamba/modeling_bamba.py
new file mode 100644
index 0000000000000000000000000000000000000000..0fb696c1f7364fc403d24196a5c872d7cd6376f0
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bamba/modeling_bamba.py
@@ -0,0 +1,1596 @@
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# This file was automatically generated from src/transformers/models/bamba/modular_bamba.py.
+# Do NOT edit this file manually as any edits will be overwritten by the generation of
+# the file from the modular. If any change should be done, please apply the change to the
+# modular_bamba.py file directly. One of our CI enforces this.
+# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
+# coding=utf-8
+# Copyright 2024 IBM and the HuggingFace Inc. team. All rights reserved.
+#
+# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
+# and OPT implementations in this library. It has been modified from its
+# original forms to accommodate minor architectural differences compared
+# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Callable, Optional, Tuple, Union
+
+import torch
+from torch import nn
+
+import transformers.models.jamba.modeling_jamba as modeling_jamba
+from transformers.activations import ACT2FN
+
+from ...cache_utils import Cache # we need __iter__ and __len__ of pkv
+from ...generation import GenerationMixin
+from ...integrations import use_kernel_forward_from_hub
+from ...modeling_attn_mask_utils import AttentionMaskConverter
+from ...modeling_flash_attention_utils import FlashAttentionKwargs
+from ...modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
+from ...modeling_rope_utils import ROPE_INIT_FUNCTIONS, dynamic_rope_update
+from ...modeling_utils import ALL_ATTENTION_FUNCTIONS, PreTrainedModel
+from ...processing_utils import Unpack
+from ...utils import (
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ can_return_tuple,
+ logging,
+ replace_return_docstrings,
+)
+from ...utils.import_utils import is_causal_conv1d_available, is_mamba_2_ssm_available
+from .configuration_bamba import BambaConfig
+
+
+if is_mamba_2_ssm_available():
+ from mamba_ssm.ops.triton.selective_state_update import selective_state_update
+ from mamba_ssm.ops.triton.ssd_combined import mamba_chunk_scan_combined, mamba_split_conv1d_scan_combined
+else:
+ selective_state_update = None
+
+if is_causal_conv1d_available():
+ from causal_conv1d import causal_conv1d_fn, causal_conv1d_update
+else:
+ causal_conv1d_update, causal_conv1d_fn = None, None
+
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "BambaConfig"
+
+
+# Adapted from transformers.models.jamba.modeling_jamba.HybridMambaAttentionDynamicCache for the v2 mixer
+class HybridMambaAttentionDynamicCache(modeling_jamba.HybridMambaAttentionDynamicCache):
+ """
+ A dynamic cache that can handle both the attention cache (which has a seq_len dimension) and the mamba cache
+ (which has a constant shape regardless of seq_len).
+
+ This cache has two sets of lists of tensors: `key_cache` and `value_cache` for attention cache and `conv_states`
+ and `ssm_states` for mamba cache. Each of these lists has `num_layers` tensors. The expected shape for each tensor
+ For attention layers, `key_cache` and `value_cache` have a shape of `(batch_size, num_heads, seq_len, head_dim)`,
+ while `conv_states` and `ssm_states` have a shape of `(batch_size, 0)` (empty tensors).
+ For mamba layers, `key_cache` and `value_cache` have a shape of `(batch_size, 0)` (empty tensors),
+ while `conv_states` represents the convolution state and has a shape of `(batch_size, d_inner, d_conv)`,
+ and `ssm_states` represents the ssm state and has a shape of `(batch_size, d_inner, d_state)`.
+ """
+
+ def __init__(self, config: BambaConfig, batch_size, dtype=torch.float16, device=None):
+ super().__init__(config, batch_size, dtype, device)
+ self.layers_block_type = config.layers_block_type
+ self.has_previous_state = False # only used by mamba
+ conv_kernel_size = config.mamba_d_conv
+ ssm_state_size = config.mamba_d_state
+
+ self.conv_states = []
+ self.ssm_states = []
+ self.transformer_layers = []
+ for i in range(config.num_hidden_layers):
+ if self.layers_block_type[i] == "mamba":
+ self.conv_states += [
+ torch.zeros(
+ batch_size,
+ (config.mamba_expand * config.hidden_size + 2 * config.mamba_n_groups * ssm_state_size),
+ conv_kernel_size,
+ device=device,
+ dtype=dtype,
+ )
+ ]
+ self.ssm_states += [
+ torch.zeros(
+ batch_size,
+ config.mamba_n_heads,
+ config.mamba_d_head,
+ ssm_state_size,
+ device=device,
+ dtype=dtype,
+ )
+ ]
+ else:
+ self.conv_states += [torch.tensor([[]] * batch_size, device=device)]
+ self.ssm_states += [torch.tensor([[]] * batch_size, device=device)]
+ self.transformer_layers.append(i)
+
+ self.key_cache = [torch.tensor([[]] * batch_size, device=device) for _ in range(config.num_hidden_layers)]
+ self.value_cache = [torch.tensor([[]] * batch_size, device=device) for _ in range(config.num_hidden_layers)]
+
+
+class BambaRotaryEmbedding(nn.Module):
+ def __init__(self, config: BambaConfig, device=None):
+ super().__init__()
+ # BC: "rope_type" was originally "type"
+ if hasattr(config, "rope_scaling") and config.rope_scaling is not None:
+ self.rope_type = config.rope_scaling.get("rope_type", config.rope_scaling.get("type"))
+ else:
+ self.rope_type = "default"
+ self.max_seq_len_cached = config.max_position_embeddings
+ self.original_max_seq_len = config.max_position_embeddings
+
+ self.config = config
+ self.rope_init_fn = ROPE_INIT_FUNCTIONS[self.rope_type]
+
+ inv_freq, self.attention_scaling = self.rope_init_fn(self.config, device)
+ self.register_buffer("inv_freq", inv_freq, persistent=False)
+ self.original_inv_freq = self.inv_freq
+
+ @torch.no_grad()
+ @dynamic_rope_update # power user: used with advanced RoPE types (e.g. dynamic rope)
+ def forward(self, x, position_ids):
+ inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1).to(x.device)
+ position_ids_expanded = position_ids[:, None, :].float()
+
+ device_type = x.device.type if isinstance(x.device.type, str) and x.device.type != "mps" else "cpu"
+ with torch.autocast(device_type=device_type, enabled=False): # Force float32
+ freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
+ emb = torch.cat((freqs, freqs), dim=-1)
+ cos = emb.cos() * self.attention_scaling
+ sin = emb.sin() * self.attention_scaling
+
+ return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
+ """
+ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
+ num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
+ """
+ batch, num_key_value_heads, slen, head_dim = hidden_states.shape
+ if n_rep == 1:
+ return hidden_states
+ hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
+ return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
+
+
+def eager_attention_forward(
+ module: nn.Module,
+ query: torch.Tensor,
+ key: torch.Tensor,
+ value: torch.Tensor,
+ attention_mask: Optional[torch.Tensor],
+ scaling: float,
+ dropout: float = 0.0,
+ **kwargs,
+):
+ key_states = repeat_kv(key, module.num_key_value_groups)
+ value_states = repeat_kv(value, module.num_key_value_groups)
+
+ attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
+ if attention_mask is not None:
+ causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
+ attn_weights = attn_weights + causal_mask
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
+ attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ return attn_output, attn_weights
+
+
+# Adapted from transformers.models.glm.modular_glm.apply_rotary_pos_emb
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Removes the interleaving of cos and sin from GLM
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+
+ # Keep half or full tensor for later concatenation
+ rotary_dim = cos.shape[-1]
+ q_rot, q_pass = q[..., :rotary_dim], q[..., rotary_dim:]
+ k_rot, k_pass = k[..., :rotary_dim], k[..., rotary_dim:]
+
+ # Apply rotary embeddings on the first half or full tensor
+ q_embed = (q_rot * cos) + (rotate_half(q_rot) * sin)
+ k_embed = (k_rot * cos) + (rotate_half(k_rot) * sin)
+
+ # Concatenate back to full shape
+ q_embed = torch.cat([q_embed, q_pass], dim=-1)
+ k_embed = torch.cat([k_embed, k_pass], dim=-1)
+ return q_embed, k_embed
+
+
+class BambaAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: BambaConfig, layer_idx: int):
+ super().__init__()
+ self.config = config
+ self.layer_idx = layer_idx
+ self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
+ self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
+ self.scaling = self.head_dim**-0.5
+ self.attention_dropout = config.attention_dropout
+ self.is_causal = True
+
+ self.q_proj = nn.Linear(
+ config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.k_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.v_proj = nn.Linear(
+ config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
+ )
+ self.o_proj = nn.Linear(
+ config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
+ )
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ position_embeddings: Tuple[torch.Tensor, torch.Tensor],
+ attention_mask: Optional[torch.Tensor],
+ past_key_value: Optional[Cache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs: Unpack[FlashAttentionKwargs],
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ input_shape = hidden_states.shape[:-1]
+ hidden_shape = (*input_shape, -1, self.head_dim)
+
+ query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
+
+ cos, sin = position_embeddings
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models; cache_position needed for the static cache
+ cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
+
+ attention_interface: Callable = eager_attention_forward
+
+ if self.config._attn_implementation != "eager":
+ if self.config._attn_implementation == "sdpa" and kwargs.get("output_attentions", False):
+ logger.warning_once(
+ "`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
+ 'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ else:
+ attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
+
+ attn_output, attn_weights = attention_interface(
+ self,
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ dropout=0.0 if not self.training else self.attention_dropout,
+ scaling=self.scaling,
+ **kwargs,
+ )
+
+ attn_output = attn_output.reshape(*input_shape, -1).contiguous()
+ attn_output = self.o_proj(attn_output)
+ return attn_output, attn_weights
+
+
+class BambaRMSNormGated(torch.nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states, gate=None):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+
+ if gate is not None:
+ hidden_states = hidden_states * nn.functional.silu(gate.to(torch.float32))
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+
+ return self.weight * hidden_states.to(input_dtype)
+
+
+# Helper methods for segment sum computation
+
+
+def pad_tensor_by_size(input_tensor: torch.Tensor, pad_size: int):
+ """
+ Padding x tensor with `pad_size` on the seq_len dim (dim=1)
+
+ Assumes that we only have tensors of either size 4 or 3
+ """
+ pad_shape = (0, 0, 0, 0, 0, pad_size, 0, 0) if len(input_tensor.shape) == 4 else (0, 0, 0, pad_size, 0, 0)
+
+ return torch.nn.functional.pad(input_tensor, pad_shape, mode="constant", value=0)
+
+
+def reshape_into_chunks(input_tensor, pad_size, chunk_size):
+ """
+ Padding input_tensor with `pad_size` on the seq_len dim (dim=1) and
+ simultaneously splitting it into chunk sequences.
+
+ Assumes that we only have tensors of either size 4 or 3
+ """
+ # [bsz, seq_len, ...] -> [bsz, seq_len multiple of chunk_size, ...]
+ input_tensor = pad_tensor_by_size(input_tensor, pad_size)
+
+ if len(input_tensor.shape) == 3:
+ # [bsz, seq_len multiple of chunk_size, num_heads] -> [bsz, -1, chunk_size, num_heads]
+ return input_tensor.reshape(input_tensor.shape[0], -1, chunk_size, input_tensor.shape[2])
+ else:
+ # [bsz, seq_len multiple of chunk_size, num_heads, head_dim or state_size] -> [bsz, -1, chunk_size, num_heads, head_dim or state_size]
+ return input_tensor.reshape(
+ input_tensor.shape[0], -1, chunk_size, input_tensor.shape[2], input_tensor.shape[3]
+ )
+
+
+def segment_sum(input_tensor):
+ """
+ More stable segment sum calculation. Uses cumulative sums and masking instead of direct subtractions.
+ """
+ chunk_size = input_tensor.size(-1)
+ # 1. expand input tensor to have an additional dimension and repeat along that dimension
+ # [..., chunk_size] -> [..., chunk_size, chunk_size]
+ input_tensor = input_tensor[..., None].expand(*input_tensor.size(), chunk_size)
+ # 2. create a lower triangular mask with the diagonal set to 0 to 0 out elements above diag
+ mask = torch.tril(torch.ones(chunk_size, chunk_size, device=input_tensor.device, dtype=torch.bool), diagonal=-1)
+ input_tensor = input_tensor.masked_fill(~mask, 0)
+ # 3. compute actual cumsum
+ tensor_segsum = torch.cumsum(input_tensor, dim=-2)
+
+ # 4. apply mask to keep only the lower triangular part of the cumulative sum result (incl diagonal this time)
+ mask = torch.tril(torch.ones(chunk_size, chunk_size, device=input_tensor.device, dtype=torch.bool), diagonal=0)
+ tensor_segsum = tensor_segsum.masked_fill(~mask, -torch.inf)
+ return tensor_segsum
+
+
+is_fast_path_available = all((selective_state_update, causal_conv1d_fn, causal_conv1d_update))
+
+
+def apply_mask_to_padding_states(hidden_states, attention_mask):
+ """
+ Tunes out the hidden states for padding tokens, see https://github.com/state-spaces/mamba/issues/66
+ """
+ if attention_mask is not None and attention_mask.shape[1] > 1 and attention_mask.shape[0] > 1:
+ dtype = hidden_states.dtype
+ hidden_states = (hidden_states * attention_mask[:, :, None]).to(dtype)
+
+ return hidden_states
+
+
+# Adapted from transformers.models.mamba2.modeling_mamba2.Mamba2Mixer
+class BambaMixer(nn.Module):
+ """
+ Compute ∆, A, B, C, and D the state space parameters and compute the `contextualized_states`.
+ A, D are input independent (see Mamba paper [1] Section 3.5.2 "Interpretation of A" for why A isn't selective)
+ ∆, B, C are input-dependent (this is a key difference between Mamba and the linear time invariant S4,
+ and is why Mamba is called **selective** state spaces)
+
+ The are a few differences between this and Mamba2Mixer:
+ - The variable use_precomputed_states is slightly different due to the HybridCache structure
+ - There's a few non-obvious bugs fixed with batching in the slow path that exist in main
+ - Some extra variables that our layer doesn't need have been removed
+ - We ported most of the refactors in https://github.com/huggingface/transformers/pull/35154, which is (as of Dec 18, 2024) unmerged
+ """
+
+ def __init__(self, config: BambaConfig, layer_idx: int):
+ super().__init__()
+ self.num_heads = config.mamba_n_heads
+ self.hidden_size = config.hidden_size
+ self.ssm_state_size = config.mamba_d_state
+ self.conv_kernel_size = config.mamba_d_conv
+ self.intermediate_size = int(config.mamba_expand * self.hidden_size)
+ self.layer_idx = layer_idx
+ self.use_conv_bias = config.mamba_conv_bias
+ self.activation = config.hidden_act
+ self.act = ACT2FN[config.hidden_act]
+ self.use_bias = config.mamba_proj_bias
+
+ self.layer_norm_epsilon = config.rms_norm_eps
+
+ self.n_groups = config.mamba_n_groups
+ self.head_dim = config.mamba_d_head
+ self.chunk_size = config.mamba_chunk_size
+
+ # FIXME:
+ self.time_step_limit = (0.0, float("inf"))
+ self.time_step_min = 0.001
+ self.time_step_max = 0.1
+
+ self.conv_dim = self.intermediate_size + 2 * self.n_groups * self.ssm_state_size
+ self.conv1d = nn.Conv1d(
+ in_channels=self.conv_dim,
+ out_channels=self.conv_dim,
+ bias=config.mamba_conv_bias,
+ kernel_size=self.conv_kernel_size,
+ groups=self.conv_dim,
+ padding=self.conv_kernel_size - 1,
+ )
+
+ # projection of the input hidden states
+ projection_size = self.intermediate_size + self.conv_dim + self.num_heads
+ self.in_proj = nn.Linear(
+ self.hidden_size,
+ projection_size,
+ bias=self.use_bias,
+ )
+ # selective projection used to make dt, B and C input dependant
+
+ # time step projection (discretization)
+ # instantiate once and copy inv_dt in init_weights of PretrainedModel
+ self.dt_bias = nn.Parameter(torch.ones(self.num_heads))
+
+ # S4D real initialization. These are not discretized!
+ # The core is to load them, compute the discrete states, then write the updated state. Keeps the memory bounded
+ A = torch.arange(1, self.num_heads + 1)
+ self.A_log = nn.Parameter(torch.log(A))
+ self.A_log._no_weight_decay = True
+ self.norm = BambaRMSNormGated(self.intermediate_size, eps=self.layer_norm_epsilon)
+ self.D = nn.Parameter(torch.ones(self.num_heads))
+ self.D._no_weight_decay = True
+
+ self.out_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=self.use_bias)
+
+ if not is_fast_path_available:
+ logger.warning_once(
+ "The fast path is not available because on of `(selective_state_update, causal_conv1d_fn, causal_conv1d_update)`"
+ " is None. Falling back to the naive implementation. To install follow https://github.com/state-spaces/mamba/#installation and"
+ " https://github.com/Dao-AILab/causal-conv1d"
+ )
+ else:
+ logger.warning_once("The fast path for Bamba will be used when running the model on a GPU")
+
+ def cuda_kernels_forward(
+ self,
+ hidden_states: torch.Tensor,
+ cache_params: Optional[HybridMambaAttentionDynamicCache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ ):
+ # 1. Gated MLP's linear projection
+ hidden_states = apply_mask_to_padding_states(hidden_states, attention_mask)
+ projected_states = self.in_proj(hidden_states)
+
+ # Set up dimensions for reshapes later
+ batch_size, seq_len, _ = hidden_states.shape
+ groups_time_state_size = self.n_groups * self.ssm_state_size
+
+ use_precomputed_states = (
+ cache_params is not None
+ and cache_params.has_previous_state
+ and seq_len == 1
+ and cache_params.conv_states[self.layer_idx].shape[0]
+ == cache_params.ssm_states[self.layer_idx].shape[0]
+ == batch_size
+ and cache_position is not None
+ and cache_position[0] > 0
+ )
+
+ # getting projected states from cache if it exists
+ if use_precomputed_states:
+ gate, hidden_states_B_C, dt = projected_states.squeeze(1).split(
+ [self.intermediate_size, self.conv_dim, self.num_heads], dim=-1
+ )
+
+ # 2. Convolution sequence transformation
+ hidden_states_B_C = causal_conv1d_update(
+ hidden_states_B_C,
+ cache_params.conv_states[self.layer_idx],
+ self.conv1d.weight.squeeze(1),
+ self.conv1d.bias,
+ self.activation,
+ )
+
+ hidden_states, B, C = torch.split(
+ hidden_states_B_C,
+ [self.intermediate_size, groups_time_state_size, groups_time_state_size],
+ dim=-1,
+ )
+
+ # 3. SSM transformation
+ A = -torch.exp(self.A_log.float()) # (nheads,)
+ A = A[:, None, ...][:, :, None].expand(-1, self.head_dim, self.ssm_state_size).to(dtype=torch.float32)
+ dt = dt[:, :, None].expand(-1, -1, self.head_dim)
+ dt_bias = self.dt_bias[:, None, ...].expand(-1, self.head_dim)
+ D = self.D[:, None, ...].expand(-1, self.head_dim)
+ B = B.view(batch_size, self.n_groups, B.shape[1] // self.n_groups)
+ C = C.view(batch_size, self.n_groups, C.shape[1] // self.n_groups)
+ hidden_states_reshaped = hidden_states.view(batch_size, self.num_heads, self.head_dim)
+ hidden_states = selective_state_update(
+ cache_params.ssm_states[self.layer_idx],
+ hidden_states_reshaped,
+ dt,
+ A,
+ B,
+ C,
+ D,
+ z=None,
+ dt_bias=dt_bias,
+ dt_softplus=True,
+ )
+ hidden_states = hidden_states.view(batch_size, self.num_heads * self.head_dim)
+ hidden_states = self.norm(hidden_states, gate)
+
+ # 4. Final linear projection
+ out = self.out_proj(hidden_states)[:, None, ...]
+ # Fused calculations or step by step if no initialized cache is found
+ else:
+ A = -torch.exp(self.A_log.float()) # (num_heads) or (intermediate_size, state_size)
+ dt_limit_kwargs = {} if self.time_step_limit == (0.0, float("inf")) else {"dt_limit": self.time_step_limit}
+
+ # 2-4. Fused kernel for conv1d, SSM, and the final projection
+ if self.training and cache_params is None:
+ out = mamba_split_conv1d_scan_combined(
+ projected_states,
+ self.conv1d.weight.squeeze(1),
+ self.conv1d.bias,
+ self.dt_bias,
+ A,
+ D=self.D,
+ chunk_size=self.chunk_size,
+ seq_idx=None, # was seq_idx
+ activation=self.activation,
+ rmsnorm_weight=self.norm.weight,
+ rmsnorm_eps=self.norm.variance_epsilon,
+ outproj_weight=self.out_proj.weight,
+ outproj_bias=self.out_proj.bias,
+ headdim=self.head_dim,
+ ngroups=self.n_groups,
+ norm_before_gate=False,
+ return_final_states=False,
+ **dt_limit_kwargs,
+ )
+
+ else:
+ gate, hidden_states_B_C, dt = projected_states.split(
+ [self.intermediate_size, self.conv_dim, self.num_heads], dim=-1
+ )
+
+ # 2. Convolution sequence transformation
+ # Init cache
+ if cache_params is not None:
+ # storing the states
+ # If we just take xBC[:, :, -self.d_conv :], it will error if seqlen < self.d_conv
+ # Instead F.pad will pad with zeros if seqlen < self.d_conv, and truncate otherwise.
+ hidden_states_B_C_transposed = hidden_states_B_C.transpose(1, 2)
+ conv_states = nn.functional.pad(
+ hidden_states_B_C_transposed,
+ (self.conv_kernel_size - hidden_states_B_C_transposed.shape[-1], 0),
+ )
+ cache_params.conv_states[self.layer_idx].copy_(conv_states)
+
+ if self.activation not in ["silu", "swish"]:
+ hidden_states_B_C = self.act(
+ self.conv1d(hidden_states_B_C.transpose(1, 2))[..., :seq_len].transpose(1, 2)
+ )
+ else:
+ hidden_states_B_C = causal_conv1d_fn(
+ x=hidden_states_B_C.transpose(1, 2),
+ weight=self.conv1d.weight.squeeze(1),
+ bias=self.conv1d.bias,
+ activation=self.activation,
+ ).transpose(1, 2)
+
+ hidden_states_B_C = apply_mask_to_padding_states(hidden_states_B_C, attention_mask)
+ hidden_states, B, C = torch.split(
+ hidden_states_B_C,
+ [self.intermediate_size, groups_time_state_size, groups_time_state_size],
+ dim=-1,
+ )
+
+ # 3. SSM transformation
+ scan_output, ssm_state = mamba_chunk_scan_combined(
+ hidden_states.view(batch_size, seq_len, -1, self.head_dim),
+ dt,
+ A,
+ B.view(batch_size, seq_len, self.n_groups, -1),
+ C.view(batch_size, seq_len, self.n_groups, -1),
+ chunk_size=self.chunk_size,
+ D=self.D,
+ z=None,
+ seq_idx=None,
+ return_final_states=True,
+ dt_bias=self.dt_bias,
+ dt_softplus=True,
+ **dt_limit_kwargs,
+ )
+
+ # Init cache
+ if ssm_state is not None and cache_params is not None:
+ cache_params.ssm_states[self.layer_idx].copy_(ssm_state)
+
+ scan_output = scan_output.view(batch_size, seq_len, -1)
+ # Multiply "gate" branch and apply extra normalization layer
+ scan_output = self.norm(scan_output, gate)
+
+ # 4. Final linear projection
+ out = self.out_proj(scan_output)
+ return out
+
+ # fmt: off
+ def torch_forward(
+ self,
+ input_states,
+ cache_params: Optional[HybridMambaAttentionDynamicCache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ ):
+ batch_size, seq_len, _ = input_states.shape
+ dtype = input_states.dtype
+
+ # 1. Gated MLP's linear projection
+ input_states = apply_mask_to_padding_states(input_states, attention_mask)
+ projected_states = self.in_proj(input_states)
+ gate, hidden_states_B_C, dt = projected_states.split(
+ [self.intermediate_size, self.conv_dim, self.num_heads], dim=-1
+ )
+
+ use_precomputed_states = (
+ cache_params is not None
+ and cache_params.has_previous_state
+ and seq_len == 1
+ and cache_params.conv_states[self.layer_idx].shape[0]
+ == cache_params.ssm_states[self.layer_idx].shape[0]
+ == batch_size
+ and cache_position is not None
+ and cache_position[0] > 0
+ )
+
+ # 2. Convolution sequence transformation
+ if use_precomputed_states:
+ cache_params.conv_states[self.layer_idx] = cache_params.conv_states[self.layer_idx].roll(shifts=-1, dims=-1)
+ cache_params.conv_states[self.layer_idx][:, :, -1] = hidden_states_B_C[:, 0, :].to(cache_params.conv_states[self.layer_idx].device)
+
+ # We need to guarantee that anything regarding the cache is on the same device
+ conv_states = cache_params.conv_states[self.layer_idx].to(device=self.conv1d.weight.device)
+
+ hidden_states_B_C = torch.sum(
+ conv_states * self.conv1d.weight.squeeze(1), dim=-1
+ )
+ if self.use_conv_bias:
+ hidden_states_B_C = hidden_states_B_C + self.conv1d.bias
+ hidden_states_B_C = self.act(hidden_states_B_C)
+ else:
+ # Init cache
+ if cache_params is not None:
+ hidden_states_B_C_transposed = hidden_states_B_C.transpose(1, 2)
+ conv_states = nn.functional.pad(
+ hidden_states_B_C_transposed, (self.conv_kernel_size - hidden_states_B_C_transposed.shape[-1], 0)
+ )
+ cache_params.conv_states[self.layer_idx].copy_(conv_states)
+
+ hidden_states_B_C = self.act(self.conv1d(hidden_states_B_C.transpose(1, 2))[..., :seq_len].transpose(1, 2))
+
+ hidden_states_B_C = apply_mask_to_padding_states(hidden_states_B_C, attention_mask)
+ hidden_states, B, C = torch.split(
+ hidden_states_B_C,
+ [self.intermediate_size, self.n_groups * self.ssm_state_size, self.n_groups * self.ssm_state_size],
+ dim=-1
+ )
+
+ # 3. SSM transformation
+ A = -torch.exp(self.A_log.float()) # [num_heads]
+ if use_precomputed_states:
+ # We need to guarantee that anything regarding the cache is on the same device
+ cache_device = cache_params.ssm_states[self.layer_idx].device
+
+ # Note: there is no need to pad parameter matrices here, as there is just one new token
+ # for batched generation
+ dt = dt[:, 0, :][:, None, ...]
+ dt = dt.transpose(1, 2).expand(batch_size, dt.shape[-1], self.head_dim)
+ # [num_heads] -> [num_heads, head_dim]
+ dt_bias = self.dt_bias[..., None].expand(self.dt_bias.shape[0], self.head_dim)
+
+ dt = torch.nn.functional.softplus(dt + dt_bias.to(dt.dtype))
+ dt = torch.clamp(dt, self.time_step_limit[0], self.time_step_limit[1])
+ A = A[..., None, None].expand(self.num_heads, self.head_dim, self.ssm_state_size).to(dtype=torch.float32)
+ # [bsz, num_heads, head_dim, state_size]
+ dA = (torch.exp(dt[..., None] * A)).to(device=cache_device)
+
+ # Discretize B
+ # [bsz, n_groups * state_size] -> [bsz, n_groups, 1, state_size] ->
+ # -> [bsz, n_groups, group to head repetition factor, state_size] -> [bsz, num_heads, state_size]
+ B = B.reshape(batch_size, self.n_groups, -1)[..., None, :]
+ B = B.expand(batch_size, self.n_groups, self.num_heads // self.n_groups, B.shape[-1]).contiguous()
+ B = B.reshape(batch_size, -1, B.shape[-1])
+ # [bsz, num_heads, head_dim, state_size]
+ dB = dt[..., None] * B[..., None, :]
+
+ # Discretize x into dB
+ # [bsz, intermediate_size] -> [bsz, num_heads, head_dim]
+ hidden_states = hidden_states.reshape(batch_size, -1, self.head_dim)
+ dBx = (dB * hidden_states[..., None]).to(device=cache_device)
+
+ # State calculation
+ cache_params.ssm_states[self.layer_idx].copy_(
+ cache_params.ssm_states[self.layer_idx] * dA + dBx
+ )
+
+ # Subsequent output
+ # [bsz, n_groups * state_size] -> [bsz, num_heads, state_size]
+ C = C.reshape(batch_size, self.n_groups, -1)[..., None, :]
+ C = C.expand(batch_size, self.n_groups, self.num_heads // self.n_groups, C.shape[-1]).contiguous()
+ C = C.reshape(batch_size, -1, C.shape[-1])
+ # [bsz, num_heads, head_dim]
+
+ ssm_states = cache_params.ssm_states[self.layer_idx].to(device=C.device, dtype=C.dtype) # Shape: [b, h, d, n]
+ # Reshape ssm_states to merge the first two dimensions
+ ssm_states_reshaped = ssm_states.view(batch_size * self.num_heads, self.head_dim, self.ssm_state_size) # Shape: [b*h, d, n]
+ C_reshaped = C.view(batch_size * self.num_heads, self.ssm_state_size, 1) # Shape: [b*h, n, 1]
+ y = torch.bmm(ssm_states_reshaped, C_reshaped)
+ y = y.view(batch_size, self.num_heads, self.head_dim)
+
+ # D skip connection
+ # [num_heads] -> [num_heads, head_dim]
+ D = self.D[..., None].expand(self.D.shape[0], self.head_dim)
+ y = (y + hidden_states * D).to(y.dtype)
+
+ # [bsz, num_heads, head_dim] -> [bsz, 1, intermediate_size]
+ y = y.reshape(batch_size, -1)[:, None, ...]
+ else:
+ # begin ssd naive implementation without einsums
+ dt = nn.functional.softplus(dt + self.dt_bias)
+ dt = torch.clamp(dt, self.time_step_limit[0], self.time_step_limit[1])
+ hidden_states = hidden_states.reshape(batch_size, seq_len, -1, self.head_dim).float()
+ B = B.reshape(batch_size, seq_len, -1, self.ssm_state_size).float()
+ C = C.reshape(batch_size, seq_len, -1, self.ssm_state_size).float()
+ B = B.repeat_interleave(self.num_heads // self.n_groups, dim=2, output_size=self.num_heads)
+ C = C.repeat_interleave(self.num_heads // self.n_groups, dim=2, output_size=self.num_heads)
+ pad_size = (self.chunk_size - seq_len % self.chunk_size) % self.chunk_size
+
+ D_residual = self.D[..., None] * pad_tensor_by_size(hidden_states, pad_size)
+
+ # Discretize x and A
+ hidden_states = hidden_states * dt[..., None]
+ A = A.to(hidden_states.dtype) * dt
+
+ # Rearrange into blocks/chunks
+ hidden_states, A, B, C = [reshape_into_chunks(t, pad_size, self.chunk_size) for t in (hidden_states, A, B, C)]
+
+ # [bsz, -1, chunk_size, num_heads] -> [bsz, num_heads, -1, chunk_size]
+ A = A.permute(0, 3, 1, 2)
+ A_cumsum = torch.cumsum(A, dim=-1)
+
+ # 1. Compute the output for each intra-chunk (diagonal blocks)
+ # This is the analog of a causal mask
+ L = torch.exp(segment_sum(A))
+
+ # Contraction of C and B to get G (attention-weights like)
+ G_intermediate = C[:, :, :, None, :, :] * B[:, :, None, :, :, :] # shape: (b, c, l, s, h, n)
+ G = G_intermediate.sum(dim=-1) # shape: (b, c, l, s, h)
+
+ # Compute M, equivalent to applying attention mask to weights
+ M_intermediate = G[..., None] * L.permute(0, 2, 3, 4, 1)[..., None]
+ M = M_intermediate.sum(dim=-1)
+
+ # Compute Y_diag (apply to values)
+ Y_diag = (M[..., None] * hidden_states[:, :, None]).sum(dim=3)
+
+ # 2. Compute the state for each intra-chunk
+ # (right term of low-rank factorization of off-diagonal blocks; B terms)
+ decay_states = torch.exp((A_cumsum[:, :, :, -1:] - A_cumsum))
+ B_decay = B * decay_states.permute(0, -2, -1, 1)[..., None]
+ states = (B_decay[..., None, :] * hidden_states[..., None]).sum(dim=2)
+
+ # 3. Compute the inter-chunk SSM recurrence; produces correct SSM states at chunk boundaries
+ # (middle term of factorization of off-diag blocks; A terms)
+ if use_precomputed_states:
+ previous_states = cache_params.ssm_states[self.layer_idx][:, None, ...].to(device=states.device)
+ else:
+ previous_states = torch.zeros_like(states[:, :1])
+ states = torch.cat([previous_states, states], dim=1)
+ decay_chunk = torch.exp(segment_sum(nn.functional.pad(A_cumsum[:, :, :, -1], (1, 0))))
+ decay_chunk = decay_chunk.transpose(1, 3)
+ new_states = (decay_chunk[..., None, None] * states[:, :, None, ...]).sum(dim=1)
+ states, ssm_state = new_states[:, :-1], new_states[:, -1]
+
+ # 4. Compute state -> output conversion per chunk
+ # (left term of low-rank factorization of off-diagonal blocks; C terms)
+ state_decay_out = torch.exp(A_cumsum)
+ C_times_states = (C[..., None, :] * states[:, :, None, ...])
+ state_decay_out_permuted = state_decay_out.permute(0, 2, 3, 1)
+ Y_off = (C_times_states.sum(-1) * state_decay_out_permuted[..., None])
+
+ # Add output of intra-chunk and inter-chunk terms (diagonal and off-diagonal blocks)
+ y = Y_diag + Y_off
+ # [bsz, -1, self.chunk_size, num_heads, head_dim] -> [bsz, (padded) seq_len, num_heads, head_dim]
+ y = y.reshape(batch_size, -1, self.num_heads, self.head_dim)
+
+ y = y + D_residual
+ # Cutting off padded chunks
+ if pad_size > 0:
+ y = y[:, :seq_len, :, :]
+ y = y.reshape(batch_size, seq_len, -1)
+
+ # Init cache
+ if ssm_state is not None and cache_params is not None:
+ cache_params.ssm_states[self.layer_idx].copy_(ssm_state)
+
+ scan_output = self.norm(y, gate)
+
+ # end ssd naive
+
+ # 4. Final linear projection
+ contextualized_states = self.out_proj(scan_output.to(dtype)) # [batch, seq_len, hidden_size]
+ return contextualized_states
+ # fmt: on
+
+ def forward(
+ self,
+ hidden_states,
+ cache_params: Optional[HybridMambaAttentionDynamicCache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ ):
+ if is_fast_path_available and "cuda" in self.in_proj.weight.device.type:
+ return self.cuda_kernels_forward(hidden_states, cache_params, cache_position, attention_mask)
+ dtype = hidden_states.dtype
+ if attention_mask is not None and attention_mask.shape[1] > 1 and attention_mask.shape[0] > 1:
+ # tune out hidden states for pad tokens, see https://github.com/state-spaces/mamba/issues/66
+ hidden_states = (hidden_states * attention_mask[:, :, None]).to(dtype)
+
+ return self.torch_forward(hidden_states, cache_params, cache_position, attention_mask)
+
+
+class BambaMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.intermediate_size = config.intermediate_size
+ self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
+ self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
+ self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=config.mlp_bias)
+ self.act_fn = ACT2FN[config.hidden_act]
+
+ def forward(self, x):
+ down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+ return down_proj
+
+
+@use_kernel_forward_from_hub("RMSNorm")
+class BambaRMSNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ BambaRMSNorm is equivalent to T5LayerNorm
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ input_dtype = hidden_states.dtype
+ hidden_states = hidden_states.to(torch.float32)
+ variance = hidden_states.pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+ return self.weight * hidden_states.to(input_dtype)
+
+ def extra_repr(self):
+ return f"{tuple(self.weight.shape)}, eps={self.variance_epsilon}"
+
+
+class BambaDecoderLayer(nn.Module):
+ def __init__(self, config: BambaConfig, layer_idx: int, layer_type: str = "mamba"):
+ super().__init__()
+
+ num_experts = 1
+ ffn_layer_class = BambaMLP if num_experts == 1 else None
+ self.feed_forward = ffn_layer_class(config)
+ self.input_layernorm = BambaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.pre_ff_layernorm = BambaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ self.layer_type = layer_type
+ if layer_type == "mamba":
+ self.mamba = BambaMixer(config=config, layer_idx=layer_idx)
+ elif layer_type == "attention":
+ self.self_attn = BambaAttention(config, layer_idx)
+ else:
+ raise ValueError("Invalid layer_type")
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[HybridMambaAttentionDynamicCache] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
+ **kwargs,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, sequence_length)` where padding elements are indicated by 0.
+ past_key_value (`HybridMambaAttentionDynamicCache`, *optional*): cached past key and value projection states
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence.
+ position_embeddings (`Tuple[torch.FloatTensor, torch.FloatTensor]`, *optional*):
+ Tuple containing the cosine and sine positional embeddings of shape `(batch_size, seq_len, head_dim)`,
+ with `head_dim` being the embedding dimension of each attention head.
+ kwargs (`dict`, *optional*):
+ Arbitrary kwargs to be ignored, used for FSDP and other methods that injects code
+ into the model
+ """
+
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # this is a hybrid decoder layer
+ if self.layer_type == "mamba":
+ hidden_states = self.mamba(
+ hidden_states=hidden_states,
+ cache_params=past_key_value,
+ cache_position=cache_position,
+ attention_mask=attention_mask,
+ )
+ self_attn_weights = None
+ elif self.layer_type == "attention":
+ hidden_states, self_attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **kwargs,
+ )
+
+ # residual connection after attention
+ hidden_states = residual + hidden_states
+
+ # feed-forward
+ residual = hidden_states
+ hidden_states = self.pre_ff_layernorm(hidden_states)
+ hidden_states = self.feed_forward(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ return outputs
+
+
+BAMBA_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`BambaConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare BambaModel outputting raw hidden-states without any specific head on top.",
+ BAMBA_START_DOCSTRING,
+)
+class BambaPreTrainedModel(PreTrainedModel):
+ config_class = BambaConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["BambaDecoderLayer"]
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_cache_class = True # Note: only supports HybridMambaAttentionDynamicCache
+ _is_stateful = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, (nn.Linear, nn.Conv1d)):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, (BambaRMSNormGated, BambaRMSNorm)):
+ module.weight.data.fill_(1.0)
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, BambaMixer):
+ module.dt_bias.data.fill_(1.0)
+ module.A_log.data = torch.log(torch.arange(1, module.num_heads + 1))
+ module.D.data.fill_(1.0)
+
+
+BAMBA_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`HybridMambaAttentionDynamicCache`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ A HybridMambaAttentionDynamicCache object containing pre-computed hidden-states (keys and values in the
+ self-attention blocks and convolution and ssm states in the mamba blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ Key and value cache tensors have shape `(batch_size, num_heads, seq_len, head_dim)`.
+ Convolution and ssm states tensors have shape `(batch_size, d_inner, d_conv)` and
+ `(batch_size, d_inner, d_state)` respectively.
+ See the `HybridMambaAttentionDynamicCache` class for more details.
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ output_router_logits (`bool`, *optional*):
+ Whether or not to return the logits of all the routers. They are useful for computing the router loss, and
+ should not be returned during inference.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence. Contrarily to `position_ids`,
+ this tensor is not affected by padding. It is used to update the cache in the correct position and to infer
+ the complete sequence length.
+"""
+
+
+@add_start_docstrings(
+ "The bare Bamba Model outputting raw hidden-states without any specific head on top.",
+ BAMBA_START_DOCSTRING,
+)
+# Adapted from transformers.models.jamba.modeling_jamba.JambaModel
+class BambaModel(BambaPreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`BambaDecoderLayer`]
+
+ Args:
+ config: BambaConfig
+ """
+
+ def __init__(self, config: BambaConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+ decoder_layers = []
+ for i in range(config.num_hidden_layers):
+ decoder_layers.append(BambaDecoderLayer(config, layer_idx=i, layer_type=config.layers_block_type[i]))
+ self.layers = nn.ModuleList(decoder_layers)
+
+ self._attn_implementation = config._attn_implementation
+ self.final_layernorm = BambaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.rotary_emb = BambaRotaryEmbedding(config=config)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @can_return_tuple
+ @add_start_docstrings_to_model_forward(BAMBA_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[HybridMambaAttentionDynamicCache] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs, # NOOP kwargs, for now
+ ) -> BaseModelOutputWithPast:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ if (input_ids is None) ^ (inputs_embeds is not None):
+ raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
+
+ if self.gradient_checkpointing and self.training and use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`."
+ )
+ use_cache = False
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+ hidden_states = inputs_embeds
+
+ if use_cache and past_key_values is None:
+ logger.warning_once(
+ "Bamba requires an initialized `HybridMambaAttentionDynamicCache` to return a cache. None was "
+ "provided, so no cache will be returned."
+ )
+
+ if cache_position is None:
+ cache_position = torch.arange(hidden_states.shape[1], device=hidden_states.device)
+ if position_ids is None:
+ position_ids = cache_position.unsqueeze(0)
+
+ causal_mask = self._update_causal_mask(
+ attention_mask, inputs_embeds, cache_position, past_key_values, output_attentions
+ )
+ mamba_mask = self._update_mamba_mask(attention_mask, cache_position)
+
+ # create position embeddings to be shared across the decoder layers
+ position_embeddings = self.rotary_emb(hidden_states, position_ids)
+
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+
+ for decoder_layer in self.layers:
+ # Depending on the layer type we opt for 2D base attention mask (Mamba) or 4D causal mask (Attention)
+ layer_mask = mamba_mask if decoder_layer.layer_type == "mamba" else causal_mask
+
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ layer_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ use_cache,
+ cache_position,
+ position_embeddings,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=layer_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ if layer_outputs[1] is not None:
+ # append attentions only of attention layers. Mamba layers return `None` as the attention weights
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.final_layernorm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if past_key_values and not past_key_values.has_previous_state:
+ past_key_values.has_previous_state = True
+
+ next_cache = None if not use_cache else past_key_values
+
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+ def _update_causal_mask(
+ self,
+ attention_mask: torch.Tensor,
+ input_tensor: torch.Tensor,
+ cache_position: torch.Tensor,
+ past_key_values: HybridMambaAttentionDynamicCache,
+ output_attentions: bool,
+ ):
+ if self.config._attn_implementation == "flash_attention_2":
+ if attention_mask is not None and 0.0 in attention_mask:
+ return attention_mask
+ return None
+
+ # For SDPA, when possible, we will rely on its `is_causal` argument instead of its `attn_mask` argument, in
+ # order to dispatch on Flash Attention 2. This feature is not compatible with static cache, as SDPA will fail
+ # to infer the attention mask.
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+
+ # When output attentions is True, sdpa implementation's forward method calls the eager implementation's forward
+ if self.config._attn_implementation == "sdpa" and not output_attentions:
+ if AttentionMaskConverter._ignore_causal_mask_sdpa(
+ attention_mask,
+ inputs_embeds=input_tensor,
+ past_key_values_length=past_seen_tokens,
+ is_training=self.training,
+ ):
+ return None
+
+ dtype, device = input_tensor.dtype, input_tensor.device
+ sequence_length = input_tensor.shape[1]
+ target_length = (
+ attention_mask.shape[-1]
+ if isinstance(attention_mask, torch.Tensor)
+ else past_seen_tokens + sequence_length + 1
+ )
+
+ # In case the provided `attention` mask is 2D, we generate a causal mask here (4D).
+ causal_mask = self._prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask,
+ sequence_length=sequence_length,
+ target_length=target_length,
+ dtype=dtype,
+ device=device,
+ cache_position=cache_position,
+ batch_size=input_tensor.shape[0],
+ )
+
+ if (
+ self.config._attn_implementation == "sdpa"
+ and attention_mask is not None
+ and attention_mask.device.type in ["cuda", "xpu", "npu"]
+ and not output_attentions
+ ):
+ # Attend to all tokens in fully masked rows in the causal_mask, for example the relevant first rows when
+ # using left padding. This is required by F.scaled_dot_product_attention memory-efficient attention path.
+ # Details: https://github.com/pytorch/pytorch/issues/110213
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = AttentionMaskConverter._unmask_unattended(causal_mask, min_dtype)
+
+ return causal_mask
+
+ @staticmethod
+ def _prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask: torch.Tensor,
+ sequence_length: int,
+ target_length: int,
+ dtype: torch.dtype,
+ device: torch.device,
+ cache_position: torch.Tensor,
+ batch_size: int,
+ **kwargs,
+ ):
+ """
+ Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
+ `(batch_size, key_value_length)`, or if the input `attention_mask` is already 4D, do nothing.
+
+ Args:
+ attention_mask (`torch.Tensor`):
+ A 2D attention mask of shape `(batch_size, key_value_length)` or a 4D attention mask of shape
+ `(batch_size, 1, query_length, key_value_length)`.
+ sequence_length (`int`):
+ The sequence length being processed.
+ target_length (`int`):
+ The target length: when generating with static cache, the mask should be as long as the static cache,
+ to account for the 0 padding, the part of the cache that is not filled yet.
+ dtype (`torch.dtype`):
+ The dtype to use for the 4D attention mask.
+ device (`torch.device`):
+ The device to place the 4D attention mask on.
+ cache_position (`torch.Tensor`):
+ Indices depicting the position of the input sequence tokens in the sequence.
+ batch_size (`torch.Tensor`):
+ Batch size.
+ """
+ if attention_mask is not None and attention_mask.dim() == 4:
+ # In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
+ causal_mask = attention_mask
+ else:
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = torch.full(
+ (sequence_length, target_length), fill_value=min_dtype, dtype=dtype, device=device
+ )
+ if sequence_length != 1:
+ causal_mask = torch.triu(causal_mask, diagonal=1)
+ causal_mask *= torch.arange(target_length, device=device) > cache_position.reshape(-1, 1)
+ causal_mask = causal_mask[None, None, :, :].expand(batch_size, 1, -1, -1)
+ if attention_mask is not None:
+ causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
+ mask_length = attention_mask.shape[-1]
+ padding_attention_mask = (attention_mask[:, None, None, :] == attention_mask[:, None, :, None])[
+ :, :, -sequence_length:, :
+ ].to(dtype)
+ padding_mask = causal_mask[:, :, :, :mask_length] + padding_attention_mask
+ padding_mask = padding_mask == 0
+ causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
+ padding_mask, min_dtype
+ )
+
+ return causal_mask
+
+ def _update_mamba_mask(self, attention_mask, cache_position):
+ """
+ No need for zeroing states when
+ 1. Cached forward
+ 2. Attending to all inputs
+ """
+ mamba_mask = attention_mask
+ if cache_position[0] > 0 or (attention_mask is not None and torch.all(attention_mask == 1)):
+ mamba_mask = None
+ return mamba_mask
+
+
+class BambaForCausalLM(BambaPreTrainedModel, GenerationMixin):
+ _tied_weights_keys = ["lm_head.weight"]
+ _tp_plan = {"lm_head": "colwise_rep"}
+ _pp_plan = {"lm_head": (["hidden_states"], ["logits"])}
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = BambaModel(config)
+ self.vocab_size = config.vocab_size
+ self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @can_return_tuple
+ @add_start_docstrings_to_model_forward(BAMBA_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[HybridMambaAttentionDynamicCache] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ logits_to_keep: Union[int, torch.Tensor] = 0,
+ **kwargs,
+ ) -> CausalLMOutputWithPast:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ logits_to_keep (`int` or `torch.Tensor`, *optional*):
+ If an `int`, compute logits for the last `logits_to_keep` tokens. If `0`, calculate logits for all
+ `input_ids` (special case). Only last token logits are needed for generation, and calculating them only for that
+ token can save memory, which becomes pretty significant for long sequences or large vocabulary size.
+ If a `torch.Tensor`, must be 1D corresponding to the indices to keep in the sequence length dimension.
+ This is useful when using packed tensor format (single dimension for batch and sequence length).
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, BambaForCausalLM
+
+ >>> model = BambaForCausalLM.from_pretrained("...")
+ >>> tokenizer = AutoTokenizer.from_pretrained("...")
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs: BaseModelOutputWithPast = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ cache_position=cache_position,
+ **kwargs,
+ )
+
+ hidden_states = outputs.last_hidden_state
+ # Only compute necessary logits, and do not upcast them to float if we are not computing the loss
+ slice_indices = slice(-logits_to_keep, None) if isinstance(logits_to_keep, int) else logits_to_keep
+ logits = self.lm_head(hidden_states[:, slice_indices, :])
+
+ loss = None
+ if labels is not None:
+ loss = self.loss_function(logits=logits, labels=labels, vocab_size=self.config.vocab_size, **kwargs)
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ attention_mask=None,
+ inputs_embeds=None,
+ cache_position=None,
+ position_ids=None,
+ use_cache=True,
+ **kwargs,
+ ):
+ # Overwitten -- has a unique cache type, `HybridMambaAttentionDynamicCache`
+
+ empty_past_kv = past_key_values is None
+
+ # If we have cache: let's slice `input_ids` through `cache_position`, to keep only the unprocessed tokens
+ # Exception 1: when passing input_embeds, input_ids may be missing entries
+ # Exception 2: some generation methods do special slicing of input_ids, so we don't need to do it here
+ # Exception 3: with synced GPUs cache_position may go out of bounds, but we only want dummy token in that case.
+ # (we can't check exception 3 while compiling)
+ if not empty_past_kv:
+ if (
+ inputs_embeds is not None # Exception 1
+ or cache_position[-1] >= input_ids.shape[1] # Exception 3
+ ):
+ input_ids = input_ids[:, -cache_position.shape[0] :]
+ elif input_ids.shape[1] != cache_position.shape[0]: # Default case (the "else", a no op, is Exception 2)
+ input_ids = input_ids[:, cache_position]
+ else:
+ past_key_values = HybridMambaAttentionDynamicCache(
+ self.config, input_ids.shape[0], self.dtype, device=self.device
+ )
+
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if not empty_past_kv:
+ position_ids = position_ids[:, -input_ids.shape[1] :]
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and empty_past_kv:
+ model_inputs = {"inputs_embeds": inputs_embeds}
+ else:
+ model_inputs = {"input_ids": input_ids.contiguous()} # `contiguous()` needed for compilation use cases
+
+ model_inputs.update(
+ {
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ "use_cache": use_cache,
+ "attention_mask": attention_mask,
+ "logits_to_keep": self.config.num_logits_to_keep,
+ "cache_position": cache_position,
+ }
+ )
+ return model_inputs
+
+
+__all__ = ["BambaModel", "BambaForCausalLM", "BambaPreTrainedModel"]
diff --git a/docs/transformers/src/transformers/models/bamba/modular_bamba.py b/docs/transformers/src/transformers/models/bamba/modular_bamba.py
new file mode 100644
index 0000000000000000000000000000000000000000..3e0eb513d5cdec54aefef1fe50e0ecf4a86696b6
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bamba/modular_bamba.py
@@ -0,0 +1,1312 @@
+# coding=utf-8
+# Copyright 2024 IBM and the HuggingFace Inc. team. All rights reserved.
+#
+# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
+# and OPT implementations in this library. It has been modified from its
+# original forms to accommodate minor architectural differences compared
+# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch Bamba model."""
+
+from typing import Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+
+import transformers.models.jamba.modeling_jamba as modeling_jamba
+from transformers.activations import ACT2FN
+from transformers.models.jamba.modeling_jamba import JambaAttentionDecoderLayer
+from transformers.models.llama.modeling_llama import (
+ LlamaAttention,
+ LlamaForCausalLM,
+ LlamaMLP,
+ LlamaRMSNorm,
+ LlamaRotaryEmbedding,
+ rotate_half,
+)
+from transformers.models.mamba2.modeling_mamba2 import (
+ MambaRMSNormGated,
+ pad_tensor_by_size,
+ reshape_into_chunks,
+ segment_sum,
+)
+
+from ...modeling_attn_mask_utils import (
+ AttentionMaskConverter,
+)
+from ...modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
+from ...modeling_utils import PreTrainedModel
+from ...utils import (
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ can_return_tuple,
+ logging,
+ replace_return_docstrings,
+)
+from ...utils.import_utils import (
+ is_causal_conv1d_available,
+ is_flash_attn_2_available,
+ is_mamba_2_ssm_available,
+)
+from .configuration_bamba import BambaConfig
+
+
+if is_flash_attn_2_available():
+ pass
+
+if is_mamba_2_ssm_available():
+ from mamba_ssm.ops.triton.selective_state_update import selective_state_update
+ from mamba_ssm.ops.triton.ssd_combined import mamba_chunk_scan_combined, mamba_split_conv1d_scan_combined
+else:
+ selective_state_update = None
+
+if is_causal_conv1d_available():
+ from causal_conv1d import causal_conv1d_fn, causal_conv1d_update
+else:
+ causal_conv1d_update, causal_conv1d_fn = None, None
+
+is_fast_path_available = all((selective_state_update, causal_conv1d_fn, causal_conv1d_update))
+
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "BambaConfig"
+
+
+# Adapted from transformers.models.jamba.modeling_jamba.HybridMambaAttentionDynamicCache for the v2 mixer
+class HybridMambaAttentionDynamicCache(modeling_jamba.HybridMambaAttentionDynamicCache):
+ """
+ A dynamic cache that can handle both the attention cache (which has a seq_len dimension) and the mamba cache
+ (which has a constant shape regardless of seq_len).
+
+ This cache has two sets of lists of tensors: `key_cache` and `value_cache` for attention cache and `conv_states`
+ and `ssm_states` for mamba cache. Each of these lists has `num_layers` tensors. The expected shape for each tensor
+ For attention layers, `key_cache` and `value_cache` have a shape of `(batch_size, num_heads, seq_len, head_dim)`,
+ while `conv_states` and `ssm_states` have a shape of `(batch_size, 0)` (empty tensors).
+ For mamba layers, `key_cache` and `value_cache` have a shape of `(batch_size, 0)` (empty tensors),
+ while `conv_states` represents the convolution state and has a shape of `(batch_size, d_inner, d_conv)`,
+ and `ssm_states` represents the ssm state and has a shape of `(batch_size, d_inner, d_state)`.
+ """
+
+ def __init__(self, config: BambaConfig, batch_size, dtype=torch.float16, device=None):
+ super().__init__(config, batch_size, dtype, device)
+ self.layers_block_type = config.layers_block_type
+ self.has_previous_state = False # only used by mamba
+ conv_kernel_size = config.mamba_d_conv
+ ssm_state_size = config.mamba_d_state
+
+ self.conv_states = []
+ self.ssm_states = []
+ self.transformer_layers = []
+ for i in range(config.num_hidden_layers):
+ if self.layers_block_type[i] == "mamba":
+ self.conv_states += [
+ torch.zeros(
+ batch_size,
+ (config.mamba_expand * config.hidden_size + 2 * config.mamba_n_groups * ssm_state_size),
+ conv_kernel_size,
+ device=device,
+ dtype=dtype,
+ )
+ ]
+ self.ssm_states += [
+ torch.zeros(
+ batch_size,
+ config.mamba_n_heads,
+ config.mamba_d_head,
+ ssm_state_size,
+ device=device,
+ dtype=dtype,
+ )
+ ]
+ else:
+ self.conv_states += [torch.tensor([[]] * batch_size, device=device)]
+ self.ssm_states += [torch.tensor([[]] * batch_size, device=device)]
+ self.transformer_layers.append(i)
+
+ self.key_cache = [torch.tensor([[]] * batch_size, device=device) for _ in range(config.num_hidden_layers)]
+ self.value_cache = [torch.tensor([[]] * batch_size, device=device) for _ in range(config.num_hidden_layers)]
+
+
+class BambaRotaryEmbedding(LlamaRotaryEmbedding):
+ pass
+
+
+# Adapted from transformers.models.glm.modular_glm.apply_rotary_pos_emb
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
+ """Applies Rotary Position Embedding to the query and key tensors.
+
+ Removes the interleaving of cos and sin from GLM
+
+ Args:
+ q (`torch.Tensor`): The query tensor.
+ k (`torch.Tensor`): The key tensor.
+ cos (`torch.Tensor`): The cosine part of the rotary embedding.
+ sin (`torch.Tensor`): The sine part of the rotary embedding.
+ position_ids (`torch.Tensor`, *optional*):
+ Deprecated and unused.
+ unsqueeze_dim (`int`, *optional*, defaults to 1):
+ The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
+ sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
+ that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
+ k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
+ cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
+ the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
+ Returns:
+ `tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
+ """
+ cos = cos.unsqueeze(unsqueeze_dim)
+ sin = sin.unsqueeze(unsqueeze_dim)
+
+ # Keep half or full tensor for later concatenation
+ rotary_dim = cos.shape[-1]
+ q_rot, q_pass = q[..., :rotary_dim], q[..., rotary_dim:]
+ k_rot, k_pass = k[..., :rotary_dim], k[..., rotary_dim:]
+
+ # Apply rotary embeddings on the first half or full tensor
+ q_embed = (q_rot * cos) + (rotate_half(q_rot) * sin)
+ k_embed = (k_rot * cos) + (rotate_half(k_rot) * sin)
+
+ # Concatenate back to full shape
+ q_embed = torch.cat([q_embed, q_pass], dim=-1)
+ k_embed = torch.cat([k_embed, k_pass], dim=-1)
+ return q_embed, k_embed
+
+
+class BambaAttention(LlamaAttention):
+ pass
+
+
+class BambaRMSNormGated(MambaRMSNormGated):
+ pass
+
+
+def apply_mask_to_padding_states(hidden_states, attention_mask):
+ """
+ Tunes out the hidden states for padding tokens, see https://github.com/state-spaces/mamba/issues/66
+ """
+ if attention_mask is not None and attention_mask.shape[1] > 1 and attention_mask.shape[0] > 1:
+ dtype = hidden_states.dtype
+ hidden_states = (hidden_states * attention_mask[:, :, None]).to(dtype)
+
+ return hidden_states
+
+
+# Adapted from transformers.models.mamba2.modeling_mamba2.Mamba2Mixer
+class BambaMixer(nn.Module):
+ """
+ Compute ∆, A, B, C, and D the state space parameters and compute the `contextualized_states`.
+ A, D are input independent (see Mamba paper [1] Section 3.5.2 "Interpretation of A" for why A isn't selective)
+ ∆, B, C are input-dependent (this is a key difference between Mamba and the linear time invariant S4,
+ and is why Mamba is called **selective** state spaces)
+
+ The are a few differences between this and Mamba2Mixer:
+ - The variable use_precomputed_states is slightly different due to the HybridCache structure
+ - There's a few non-obvious bugs fixed with batching in the slow path that exist in main
+ - Some extra variables that our layer doesn't need have been removed
+ - We ported most of the refactors in https://github.com/huggingface/transformers/pull/35154, which is (as of Dec 18, 2024) unmerged
+ """
+
+ def __init__(self, config: BambaConfig, layer_idx: int):
+ super().__init__()
+ self.num_heads = config.mamba_n_heads
+ self.hidden_size = config.hidden_size
+ self.ssm_state_size = config.mamba_d_state
+ self.conv_kernel_size = config.mamba_d_conv
+ self.intermediate_size = int(config.mamba_expand * self.hidden_size)
+ self.layer_idx = layer_idx
+ self.use_conv_bias = config.mamba_conv_bias
+ self.activation = config.hidden_act
+ self.act = ACT2FN[config.hidden_act]
+ self.use_bias = config.mamba_proj_bias
+
+ self.layer_norm_epsilon = config.rms_norm_eps
+
+ self.n_groups = config.mamba_n_groups
+ self.head_dim = config.mamba_d_head
+ self.chunk_size = config.mamba_chunk_size
+
+ # FIXME:
+ self.time_step_limit = (0.0, float("inf"))
+ self.time_step_min = 0.001
+ self.time_step_max = 0.1
+
+ self.conv_dim = self.intermediate_size + 2 * self.n_groups * self.ssm_state_size
+ self.conv1d = nn.Conv1d(
+ in_channels=self.conv_dim,
+ out_channels=self.conv_dim,
+ bias=config.mamba_conv_bias,
+ kernel_size=self.conv_kernel_size,
+ groups=self.conv_dim,
+ padding=self.conv_kernel_size - 1,
+ )
+
+ # projection of the input hidden states
+ projection_size = self.intermediate_size + self.conv_dim + self.num_heads
+ self.in_proj = nn.Linear(
+ self.hidden_size,
+ projection_size,
+ bias=self.use_bias,
+ )
+ # selective projection used to make dt, B and C input dependant
+
+ # time step projection (discretization)
+ # instantiate once and copy inv_dt in init_weights of PretrainedModel
+ self.dt_bias = nn.Parameter(torch.ones(self.num_heads))
+
+ # S4D real initialization. These are not discretized!
+ # The core is to load them, compute the discrete states, then write the updated state. Keeps the memory bounded
+ A = torch.arange(1, self.num_heads + 1)
+ self.A_log = nn.Parameter(torch.log(A))
+ self.A_log._no_weight_decay = True
+ self.norm = BambaRMSNormGated(self.intermediate_size, eps=self.layer_norm_epsilon)
+ self.D = nn.Parameter(torch.ones(self.num_heads))
+ self.D._no_weight_decay = True
+
+ self.out_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=self.use_bias)
+
+ if not is_fast_path_available:
+ logger.warning_once(
+ "The fast path is not available because on of `(selective_state_update, causal_conv1d_fn, causal_conv1d_update)`"
+ " is None. Falling back to the naive implementation. To install follow https://github.com/state-spaces/mamba/#installation and"
+ " https://github.com/Dao-AILab/causal-conv1d"
+ )
+ else:
+ logger.warning_once("The fast path for Bamba will be used when running the model on a GPU")
+
+ def cuda_kernels_forward(
+ self,
+ hidden_states: torch.Tensor,
+ cache_params: Optional[HybridMambaAttentionDynamicCache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ ):
+ # 1. Gated MLP's linear projection
+ hidden_states = apply_mask_to_padding_states(hidden_states, attention_mask)
+ projected_states = self.in_proj(hidden_states)
+
+ # Set up dimensions for reshapes later
+ batch_size, seq_len, _ = hidden_states.shape
+ groups_time_state_size = self.n_groups * self.ssm_state_size
+
+ use_precomputed_states = (
+ cache_params is not None
+ and cache_params.has_previous_state
+ and seq_len == 1
+ and cache_params.conv_states[self.layer_idx].shape[0]
+ == cache_params.ssm_states[self.layer_idx].shape[0]
+ == batch_size
+ and cache_position is not None
+ and cache_position[0] > 0
+ )
+
+ # getting projected states from cache if it exists
+ if use_precomputed_states:
+ gate, hidden_states_B_C, dt = projected_states.squeeze(1).split(
+ [self.intermediate_size, self.conv_dim, self.num_heads], dim=-1
+ )
+
+ # 2. Convolution sequence transformation
+ hidden_states_B_C = causal_conv1d_update(
+ hidden_states_B_C,
+ cache_params.conv_states[self.layer_idx],
+ self.conv1d.weight.squeeze(1),
+ self.conv1d.bias,
+ self.activation,
+ )
+
+ hidden_states, B, C = torch.split(
+ hidden_states_B_C,
+ [self.intermediate_size, groups_time_state_size, groups_time_state_size],
+ dim=-1,
+ )
+
+ # 3. SSM transformation
+ A = -torch.exp(self.A_log.float()) # (nheads,)
+ A = A[:, None, ...][:, :, None].expand(-1, self.head_dim, self.ssm_state_size).to(dtype=torch.float32)
+ dt = dt[:, :, None].expand(-1, -1, self.head_dim)
+ dt_bias = self.dt_bias[:, None, ...].expand(-1, self.head_dim)
+ D = self.D[:, None, ...].expand(-1, self.head_dim)
+ B = B.view(batch_size, self.n_groups, B.shape[1] // self.n_groups)
+ C = C.view(batch_size, self.n_groups, C.shape[1] // self.n_groups)
+ hidden_states_reshaped = hidden_states.view(batch_size, self.num_heads, self.head_dim)
+ hidden_states = selective_state_update(
+ cache_params.ssm_states[self.layer_idx],
+ hidden_states_reshaped,
+ dt,
+ A,
+ B,
+ C,
+ D,
+ z=None,
+ dt_bias=dt_bias,
+ dt_softplus=True,
+ )
+ hidden_states = hidden_states.view(batch_size, self.num_heads * self.head_dim)
+ hidden_states = self.norm(hidden_states, gate)
+
+ # 4. Final linear projection
+ out = self.out_proj(hidden_states)[:, None, ...]
+ # Fused calculations or step by step if no initialized cache is found
+ else:
+ A = -torch.exp(self.A_log.float()) # (num_heads) or (intermediate_size, state_size)
+ dt_limit_kwargs = {} if self.time_step_limit == (0.0, float("inf")) else {"dt_limit": self.time_step_limit}
+
+ # 2-4. Fused kernel for conv1d, SSM, and the final projection
+ if self.training and cache_params is None:
+ out = mamba_split_conv1d_scan_combined(
+ projected_states,
+ self.conv1d.weight.squeeze(1),
+ self.conv1d.bias,
+ self.dt_bias,
+ A,
+ D=self.D,
+ chunk_size=self.chunk_size,
+ seq_idx=None, # was seq_idx
+ activation=self.activation,
+ rmsnorm_weight=self.norm.weight,
+ rmsnorm_eps=self.norm.variance_epsilon,
+ outproj_weight=self.out_proj.weight,
+ outproj_bias=self.out_proj.bias,
+ headdim=self.head_dim,
+ ngroups=self.n_groups,
+ norm_before_gate=False,
+ return_final_states=False,
+ **dt_limit_kwargs,
+ )
+
+ else:
+ gate, hidden_states_B_C, dt = projected_states.split(
+ [self.intermediate_size, self.conv_dim, self.num_heads], dim=-1
+ )
+
+ # 2. Convolution sequence transformation
+ # Init cache
+ if cache_params is not None:
+ # storing the states
+ # If we just take xBC[:, :, -self.d_conv :], it will error if seqlen < self.d_conv
+ # Instead F.pad will pad with zeros if seqlen < self.d_conv, and truncate otherwise.
+ hidden_states_B_C_transposed = hidden_states_B_C.transpose(1, 2)
+ conv_states = nn.functional.pad(
+ hidden_states_B_C_transposed,
+ (self.conv_kernel_size - hidden_states_B_C_transposed.shape[-1], 0),
+ )
+ cache_params.conv_states[self.layer_idx].copy_(conv_states)
+
+ if self.activation not in ["silu", "swish"]:
+ hidden_states_B_C = self.act(
+ self.conv1d(hidden_states_B_C.transpose(1, 2))[..., :seq_len].transpose(1, 2)
+ )
+ else:
+ hidden_states_B_C = causal_conv1d_fn(
+ x=hidden_states_B_C.transpose(1, 2),
+ weight=self.conv1d.weight.squeeze(1),
+ bias=self.conv1d.bias,
+ activation=self.activation,
+ ).transpose(1, 2)
+
+ hidden_states_B_C = apply_mask_to_padding_states(hidden_states_B_C, attention_mask)
+ hidden_states, B, C = torch.split(
+ hidden_states_B_C,
+ [self.intermediate_size, groups_time_state_size, groups_time_state_size],
+ dim=-1,
+ )
+
+ # 3. SSM transformation
+ scan_output, ssm_state = mamba_chunk_scan_combined(
+ hidden_states.view(batch_size, seq_len, -1, self.head_dim),
+ dt,
+ A,
+ B.view(batch_size, seq_len, self.n_groups, -1),
+ C.view(batch_size, seq_len, self.n_groups, -1),
+ chunk_size=self.chunk_size,
+ D=self.D,
+ z=None,
+ seq_idx=None,
+ return_final_states=True,
+ dt_bias=self.dt_bias,
+ dt_softplus=True,
+ **dt_limit_kwargs,
+ )
+
+ # Init cache
+ if ssm_state is not None and cache_params is not None:
+ cache_params.ssm_states[self.layer_idx].copy_(ssm_state)
+
+ scan_output = scan_output.view(batch_size, seq_len, -1)
+ # Multiply "gate" branch and apply extra normalization layer
+ scan_output = self.norm(scan_output, gate)
+
+ # 4. Final linear projection
+ out = self.out_proj(scan_output)
+ return out
+
+ # fmt: off
+ def torch_forward(
+ self,
+ input_states,
+ cache_params: Optional[HybridMambaAttentionDynamicCache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ ):
+ batch_size, seq_len, _ = input_states.shape
+ dtype = input_states.dtype
+
+ # 1. Gated MLP's linear projection
+ input_states = apply_mask_to_padding_states(input_states, attention_mask)
+ projected_states = self.in_proj(input_states)
+ gate, hidden_states_B_C, dt = projected_states.split(
+ [self.intermediate_size, self.conv_dim, self.num_heads], dim=-1
+ )
+
+ use_precomputed_states = (
+ cache_params is not None
+ and cache_params.has_previous_state
+ and seq_len == 1
+ and cache_params.conv_states[self.layer_idx].shape[0]
+ == cache_params.ssm_states[self.layer_idx].shape[0]
+ == batch_size
+ and cache_position is not None
+ and cache_position[0] > 0
+ )
+
+ # 2. Convolution sequence transformation
+ if use_precomputed_states:
+ cache_params.conv_states[self.layer_idx] = cache_params.conv_states[self.layer_idx].roll(shifts=-1, dims=-1)
+ cache_params.conv_states[self.layer_idx][:, :, -1] = hidden_states_B_C[:, 0, :].to(cache_params.conv_states[self.layer_idx].device)
+
+ # We need to guarantee that anything regarding the cache is on the same device
+ conv_states = cache_params.conv_states[self.layer_idx].to(device=self.conv1d.weight.device)
+
+ hidden_states_B_C = torch.sum(
+ conv_states * self.conv1d.weight.squeeze(1), dim=-1
+ )
+ if self.use_conv_bias:
+ hidden_states_B_C = hidden_states_B_C + self.conv1d.bias
+ hidden_states_B_C = self.act(hidden_states_B_C)
+ else:
+ # Init cache
+ if cache_params is not None:
+ hidden_states_B_C_transposed = hidden_states_B_C.transpose(1, 2)
+ conv_states = nn.functional.pad(
+ hidden_states_B_C_transposed, (self.conv_kernel_size - hidden_states_B_C_transposed.shape[-1], 0)
+ )
+ cache_params.conv_states[self.layer_idx].copy_(conv_states)
+
+ hidden_states_B_C = self.act(self.conv1d(hidden_states_B_C.transpose(1, 2))[..., :seq_len].transpose(1, 2))
+
+ hidden_states_B_C = apply_mask_to_padding_states(hidden_states_B_C, attention_mask)
+ hidden_states, B, C = torch.split(
+ hidden_states_B_C,
+ [self.intermediate_size, self.n_groups * self.ssm_state_size, self.n_groups * self.ssm_state_size],
+ dim=-1
+ )
+
+ # 3. SSM transformation
+ A = -torch.exp(self.A_log.float()) # [num_heads]
+ if use_precomputed_states:
+ # We need to guarantee that anything regarding the cache is on the same device
+ cache_device = cache_params.ssm_states[self.layer_idx].device
+
+ # Note: there is no need to pad parameter matrices here, as there is just one new token
+ # for batched generation
+ dt = dt[:, 0, :][:, None, ...]
+ dt = dt.transpose(1, 2).expand(batch_size, dt.shape[-1], self.head_dim)
+ # [num_heads] -> [num_heads, head_dim]
+ dt_bias = self.dt_bias[..., None].expand(self.dt_bias.shape[0], self.head_dim)
+
+ dt = torch.nn.functional.softplus(dt + dt_bias.to(dt.dtype))
+ dt = torch.clamp(dt, self.time_step_limit[0], self.time_step_limit[1])
+ A = A[..., None, None].expand(self.num_heads, self.head_dim, self.ssm_state_size).to(dtype=torch.float32)
+ # [bsz, num_heads, head_dim, state_size]
+ dA = (torch.exp(dt[..., None] * A)).to(device=cache_device)
+
+ # Discretize B
+ # [bsz, n_groups * state_size] -> [bsz, n_groups, 1, state_size] ->
+ # -> [bsz, n_groups, group to head repetition factor, state_size] -> [bsz, num_heads, state_size]
+ B = B.reshape(batch_size, self.n_groups, -1)[..., None, :]
+ B = B.expand(batch_size, self.n_groups, self.num_heads // self.n_groups, B.shape[-1]).contiguous()
+ B = B.reshape(batch_size, -1, B.shape[-1])
+ # [bsz, num_heads, head_dim, state_size]
+ dB = dt[..., None] * B[..., None, :]
+
+ # Discretize x into dB
+ # [bsz, intermediate_size] -> [bsz, num_heads, head_dim]
+ hidden_states = hidden_states.reshape(batch_size, -1, self.head_dim)
+ dBx = (dB * hidden_states[..., None]).to(device=cache_device)
+
+ # State calculation
+ cache_params.ssm_states[self.layer_idx].copy_(
+ cache_params.ssm_states[self.layer_idx] * dA + dBx
+ )
+
+ # Subsequent output
+ # [bsz, n_groups * state_size] -> [bsz, num_heads, state_size]
+ C = C.reshape(batch_size, self.n_groups, -1)[..., None, :]
+ C = C.expand(batch_size, self.n_groups, self.num_heads // self.n_groups, C.shape[-1]).contiguous()
+ C = C.reshape(batch_size, -1, C.shape[-1])
+ # [bsz, num_heads, head_dim]
+
+ ssm_states = cache_params.ssm_states[self.layer_idx].to(device=C.device, dtype=C.dtype) # Shape: [b, h, d, n]
+ # Reshape ssm_states to merge the first two dimensions
+ ssm_states_reshaped = ssm_states.view(batch_size * self.num_heads, self.head_dim, self.ssm_state_size) # Shape: [b*h, d, n]
+ C_reshaped = C.view(batch_size * self.num_heads, self.ssm_state_size, 1) # Shape: [b*h, n, 1]
+ y = torch.bmm(ssm_states_reshaped, C_reshaped)
+ y = y.view(batch_size, self.num_heads, self.head_dim)
+
+ # D skip connection
+ # [num_heads] -> [num_heads, head_dim]
+ D = self.D[..., None].expand(self.D.shape[0], self.head_dim)
+ y = (y + hidden_states * D).to(y.dtype)
+
+ # [bsz, num_heads, head_dim] -> [bsz, 1, intermediate_size]
+ y = y.reshape(batch_size, -1)[:, None, ...]
+ else:
+ # begin ssd naive implementation without einsums
+ dt = nn.functional.softplus(dt + self.dt_bias)
+ dt = torch.clamp(dt, self.time_step_limit[0], self.time_step_limit[1])
+ hidden_states = hidden_states.reshape(batch_size, seq_len, -1, self.head_dim).float()
+ B = B.reshape(batch_size, seq_len, -1, self.ssm_state_size).float()
+ C = C.reshape(batch_size, seq_len, -1, self.ssm_state_size).float()
+ B = B.repeat_interleave(self.num_heads // self.n_groups, dim=2, output_size=self.num_heads)
+ C = C.repeat_interleave(self.num_heads // self.n_groups, dim=2, output_size=self.num_heads)
+ pad_size = (self.chunk_size - seq_len % self.chunk_size) % self.chunk_size
+
+ D_residual = self.D[..., None] * pad_tensor_by_size(hidden_states, pad_size)
+
+ # Discretize x and A
+ hidden_states = hidden_states * dt[..., None]
+ A = A.to(hidden_states.dtype) * dt
+
+ # Rearrange into blocks/chunks
+ hidden_states, A, B, C = [reshape_into_chunks(t, pad_size, self.chunk_size) for t in (hidden_states, A, B, C)]
+
+ # [bsz, -1, chunk_size, num_heads] -> [bsz, num_heads, -1, chunk_size]
+ A = A.permute(0, 3, 1, 2)
+ A_cumsum = torch.cumsum(A, dim=-1)
+
+ # 1. Compute the output for each intra-chunk (diagonal blocks)
+ # This is the analog of a causal mask
+ L = torch.exp(segment_sum(A))
+
+ # Contraction of C and B to get G (attention-weights like)
+ G_intermediate = C[:, :, :, None, :, :] * B[:, :, None, :, :, :] # shape: (b, c, l, s, h, n)
+ G = G_intermediate.sum(dim=-1) # shape: (b, c, l, s, h)
+
+ # Compute M, equivalent to applying attention mask to weights
+ M_intermediate = G[..., None] * L.permute(0, 2, 3, 4, 1)[..., None]
+ M = M_intermediate.sum(dim=-1)
+
+ # Compute Y_diag (apply to values)
+ Y_diag = (M[..., None] * hidden_states[:, :, None]).sum(dim=3)
+
+ # 2. Compute the state for each intra-chunk
+ # (right term of low-rank factorization of off-diagonal blocks; B terms)
+ decay_states = torch.exp((A_cumsum[:, :, :, -1:] - A_cumsum))
+ B_decay = B * decay_states.permute(0, -2, -1, 1)[..., None]
+ states = (B_decay[..., None, :] * hidden_states[..., None]).sum(dim=2)
+
+ # 3. Compute the inter-chunk SSM recurrence; produces correct SSM states at chunk boundaries
+ # (middle term of factorization of off-diag blocks; A terms)
+ if use_precomputed_states:
+ previous_states = cache_params.ssm_states[self.layer_idx][:, None, ...].to(device=states.device)
+ else:
+ previous_states = torch.zeros_like(states[:, :1])
+ states = torch.cat([previous_states, states], dim=1)
+ decay_chunk = torch.exp(segment_sum(nn.functional.pad(A_cumsum[:, :, :, -1], (1, 0))))
+ decay_chunk = decay_chunk.transpose(1, 3)
+ new_states = (decay_chunk[..., None, None] * states[:, :, None, ...]).sum(dim=1)
+ states, ssm_state = new_states[:, :-1], new_states[:, -1]
+
+ # 4. Compute state -> output conversion per chunk
+ # (left term of low-rank factorization of off-diagonal blocks; C terms)
+ state_decay_out = torch.exp(A_cumsum)
+ C_times_states = (C[..., None, :] * states[:, :, None, ...])
+ state_decay_out_permuted = state_decay_out.permute(0, 2, 3, 1)
+ Y_off = (C_times_states.sum(-1) * state_decay_out_permuted[..., None])
+
+ # Add output of intra-chunk and inter-chunk terms (diagonal and off-diagonal blocks)
+ y = Y_diag + Y_off
+ # [bsz, -1, self.chunk_size, num_heads, head_dim] -> [bsz, (padded) seq_len, num_heads, head_dim]
+ y = y.reshape(batch_size, -1, self.num_heads, self.head_dim)
+
+ y = y + D_residual
+ # Cutting off padded chunks
+ if pad_size > 0:
+ y = y[:, :seq_len, :, :]
+ y = y.reshape(batch_size, seq_len, -1)
+
+ # Init cache
+ if ssm_state is not None and cache_params is not None:
+ cache_params.ssm_states[self.layer_idx].copy_(ssm_state)
+
+ scan_output = self.norm(y, gate)
+
+ # end ssd naive
+
+ # 4. Final linear projection
+ contextualized_states = self.out_proj(scan_output.to(dtype)) # [batch, seq_len, hidden_size]
+ return contextualized_states
+ # fmt: on
+
+ def forward(
+ self,
+ hidden_states,
+ cache_params: Optional[HybridMambaAttentionDynamicCache] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ ):
+ if is_fast_path_available and "cuda" in self.in_proj.weight.device.type:
+ return self.cuda_kernels_forward(hidden_states, cache_params, cache_position, attention_mask)
+ dtype = hidden_states.dtype
+ if attention_mask is not None and attention_mask.shape[1] > 1 and attention_mask.shape[0] > 1:
+ # tune out hidden states for pad tokens, see https://github.com/state-spaces/mamba/issues/66
+ hidden_states = (hidden_states * attention_mask[:, :, None]).to(dtype)
+
+ return self.torch_forward(hidden_states, cache_params, cache_position, attention_mask)
+
+
+class BambaMLP(LlamaMLP):
+ pass
+
+
+class BambaRMSNorm(LlamaRMSNorm):
+ pass
+
+
+class BambaDecoderLayer(JambaAttentionDecoderLayer):
+ def __init__(self, config: BambaConfig, layer_idx: int, layer_type: str = "mamba"):
+ super().__init__()
+
+ del self.self_attn
+
+ num_experts = 1
+ ffn_layer_class = BambaMLP if num_experts == 1 else None
+ self.feed_forward = ffn_layer_class(config)
+
+ self.layer_type = layer_type
+ if layer_type == "mamba":
+ self.mamba = BambaMixer(config=config, layer_idx=layer_idx)
+ elif layer_type == "attention":
+ self.self_attn = BambaAttention(config, layer_idx)
+ else:
+ raise ValueError("Invalid layer_type")
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[HybridMambaAttentionDynamicCache] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
+ **kwargs,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, sequence_length)` where padding elements are indicated by 0.
+ past_key_value (`HybridMambaAttentionDynamicCache`, *optional*): cached past key and value projection states
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence.
+ position_embeddings (`Tuple[torch.FloatTensor, torch.FloatTensor]`, *optional*):
+ Tuple containing the cosine and sine positional embeddings of shape `(batch_size, seq_len, head_dim)`,
+ with `head_dim` being the embedding dimension of each attention head.
+ kwargs (`dict`, *optional*):
+ Arbitrary kwargs to be ignored, used for FSDP and other methods that injects code
+ into the model
+ """
+
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # this is a hybrid decoder layer
+ if self.layer_type == "mamba":
+ hidden_states = self.mamba(
+ hidden_states=hidden_states,
+ cache_params=past_key_value,
+ cache_position=cache_position,
+ attention_mask=attention_mask,
+ )
+ self_attn_weights = None
+ elif self.layer_type == "attention":
+ hidden_states, self_attn_weights = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ **kwargs,
+ )
+
+ # residual connection after attention
+ hidden_states = residual + hidden_states
+
+ # feed-forward
+ residual = hidden_states
+ hidden_states = self.pre_ff_layernorm(hidden_states)
+ hidden_states = self.feed_forward(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ return outputs
+
+
+BAMBA_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`BambaConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare BambaModel outputting raw hidden-states without any specific head on top.",
+ BAMBA_START_DOCSTRING,
+)
+class BambaPreTrainedModel(PreTrainedModel):
+ config_class = BambaConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["BambaDecoderLayer"]
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+ _supports_cache_class = True # Note: only supports HybridMambaAttentionDynamicCache
+ _is_stateful = True
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, (nn.Linear, nn.Conv1d)):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, (BambaRMSNormGated, BambaRMSNorm)):
+ module.weight.data.fill_(1.0)
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, BambaMixer):
+ module.dt_bias.data.fill_(1.0)
+ module.A_log.data = torch.log(torch.arange(1, module.num_heads + 1))
+ module.D.data.fill_(1.0)
+
+
+BAMBA_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`HybridMambaAttentionDynamicCache`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ A HybridMambaAttentionDynamicCache object containing pre-computed hidden-states (keys and values in the
+ self-attention blocks and convolution and ssm states in the mamba blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+ Key and value cache tensors have shape `(batch_size, num_heads, seq_len, head_dim)`.
+ Convolution and ssm states tensors have shape `(batch_size, d_inner, d_conv)` and
+ `(batch_size, d_inner, d_state)` respectively.
+ See the `HybridMambaAttentionDynamicCache` class for more details.
+
+ If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ output_router_logits (`bool`, *optional*):
+ Whether or not to return the logits of all the routers. They are useful for computing the router loss, and
+ should not be returned during inference.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ cache_position (`torch.LongTensor` of shape `(sequence_length)`, *optional*):
+ Indices depicting the position of the input sequence tokens in the sequence. Contrarily to `position_ids`,
+ this tensor is not affected by padding. It is used to update the cache in the correct position and to infer
+ the complete sequence length.
+"""
+
+
+@add_start_docstrings(
+ "The bare Bamba Model outputting raw hidden-states without any specific head on top.",
+ BAMBA_START_DOCSTRING,
+)
+# Adapted from transformers.models.jamba.modeling_jamba.JambaModel
+class BambaModel(BambaPreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`BambaDecoderLayer`]
+
+ Args:
+ config: BambaConfig
+ """
+
+ def __init__(self, config: BambaConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+ decoder_layers = []
+ for i in range(config.num_hidden_layers):
+ decoder_layers.append(BambaDecoderLayer(config, layer_idx=i, layer_type=config.layers_block_type[i]))
+ self.layers = nn.ModuleList(decoder_layers)
+
+ self._attn_implementation = config._attn_implementation
+ self.final_layernorm = BambaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.rotary_emb = BambaRotaryEmbedding(config=config)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ @can_return_tuple
+ @add_start_docstrings_to_model_forward(BAMBA_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[HybridMambaAttentionDynamicCache] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs, # NOOP kwargs, for now
+ ) -> BaseModelOutputWithPast:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ if (input_ids is None) ^ (inputs_embeds is not None):
+ raise ValueError("You must specify exactly one of input_ids or inputs_embeds")
+
+ if self.gradient_checkpointing and self.training and use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`."
+ )
+ use_cache = False
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+ hidden_states = inputs_embeds
+
+ if use_cache and past_key_values is None:
+ logger.warning_once(
+ "Bamba requires an initialized `HybridMambaAttentionDynamicCache` to return a cache. None was "
+ "provided, so no cache will be returned."
+ )
+
+ if cache_position is None:
+ cache_position = torch.arange(hidden_states.shape[1], device=hidden_states.device)
+ if position_ids is None:
+ position_ids = cache_position.unsqueeze(0)
+
+ causal_mask = self._update_causal_mask(
+ attention_mask, inputs_embeds, cache_position, past_key_values, output_attentions
+ )
+ mamba_mask = self._update_mamba_mask(attention_mask, cache_position)
+
+ # create position embeddings to be shared across the decoder layers
+ position_embeddings = self.rotary_emb(hidden_states, position_ids)
+
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+
+ for decoder_layer in self.layers:
+ # Depending on the layer type we opt for 2D base attention mask (Mamba) or 4D causal mask (Attention)
+ layer_mask = mamba_mask if decoder_layer.layer_type == "mamba" else causal_mask
+
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ layer_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ use_cache,
+ cache_position,
+ position_embeddings,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=layer_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ position_embeddings=position_embeddings,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ if layer_outputs[1] is not None:
+ # append attentions only of attention layers. Mamba layers return `None` as the attention weights
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.final_layernorm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if past_key_values and not past_key_values.has_previous_state:
+ past_key_values.has_previous_state = True
+
+ next_cache = None if not use_cache else past_key_values
+
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+ def _update_causal_mask(
+ self,
+ attention_mask: torch.Tensor,
+ input_tensor: torch.Tensor,
+ cache_position: torch.Tensor,
+ past_key_values: HybridMambaAttentionDynamicCache,
+ output_attentions: bool,
+ ):
+ if self.config._attn_implementation == "flash_attention_2":
+ if attention_mask is not None and 0.0 in attention_mask:
+ return attention_mask
+ return None
+
+ # For SDPA, when possible, we will rely on its `is_causal` argument instead of its `attn_mask` argument, in
+ # order to dispatch on Flash Attention 2. This feature is not compatible with static cache, as SDPA will fail
+ # to infer the attention mask.
+ past_seen_tokens = past_key_values.get_seq_length() if past_key_values is not None else 0
+
+ # When output attentions is True, sdpa implementation's forward method calls the eager implementation's forward
+ if self.config._attn_implementation == "sdpa" and not output_attentions:
+ if AttentionMaskConverter._ignore_causal_mask_sdpa(
+ attention_mask,
+ inputs_embeds=input_tensor,
+ past_key_values_length=past_seen_tokens,
+ is_training=self.training,
+ ):
+ return None
+
+ dtype, device = input_tensor.dtype, input_tensor.device
+ sequence_length = input_tensor.shape[1]
+ target_length = (
+ attention_mask.shape[-1]
+ if isinstance(attention_mask, torch.Tensor)
+ else past_seen_tokens + sequence_length + 1
+ )
+
+ # In case the provided `attention` mask is 2D, we generate a causal mask here (4D).
+ causal_mask = self._prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask,
+ sequence_length=sequence_length,
+ target_length=target_length,
+ dtype=dtype,
+ device=device,
+ cache_position=cache_position,
+ batch_size=input_tensor.shape[0],
+ )
+
+ if (
+ self.config._attn_implementation == "sdpa"
+ and attention_mask is not None
+ and attention_mask.device.type in ["cuda", "xpu", "npu"]
+ and not output_attentions
+ ):
+ # Attend to all tokens in fully masked rows in the causal_mask, for example the relevant first rows when
+ # using left padding. This is required by F.scaled_dot_product_attention memory-efficient attention path.
+ # Details: https://github.com/pytorch/pytorch/issues/110213
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = AttentionMaskConverter._unmask_unattended(causal_mask, min_dtype)
+
+ return causal_mask
+
+ @staticmethod
+ def _prepare_4d_causal_attention_mask_with_cache_position(
+ attention_mask: torch.Tensor,
+ sequence_length: int,
+ target_length: int,
+ dtype: torch.dtype,
+ device: torch.device,
+ cache_position: torch.Tensor,
+ batch_size: int,
+ **kwargs,
+ ):
+ """
+ Creates a causal 4D mask of shape `(batch_size, 1, query_length, key_value_length)` from a 2D mask of shape
+ `(batch_size, key_value_length)`, or if the input `attention_mask` is already 4D, do nothing.
+
+ Args:
+ attention_mask (`torch.Tensor`):
+ A 2D attention mask of shape `(batch_size, key_value_length)` or a 4D attention mask of shape
+ `(batch_size, 1, query_length, key_value_length)`.
+ sequence_length (`int`):
+ The sequence length being processed.
+ target_length (`int`):
+ The target length: when generating with static cache, the mask should be as long as the static cache,
+ to account for the 0 padding, the part of the cache that is not filled yet.
+ dtype (`torch.dtype`):
+ The dtype to use for the 4D attention mask.
+ device (`torch.device`):
+ The device to place the 4D attention mask on.
+ cache_position (`torch.Tensor`):
+ Indices depicting the position of the input sequence tokens in the sequence.
+ batch_size (`torch.Tensor`):
+ Batch size.
+ """
+ if attention_mask is not None and attention_mask.dim() == 4:
+ # In this case we assume that the mask comes already in inverted form and requires no inversion or slicing.
+ causal_mask = attention_mask
+ else:
+ min_dtype = torch.finfo(dtype).min
+ causal_mask = torch.full(
+ (sequence_length, target_length), fill_value=min_dtype, dtype=dtype, device=device
+ )
+ if sequence_length != 1:
+ causal_mask = torch.triu(causal_mask, diagonal=1)
+ causal_mask *= torch.arange(target_length, device=device) > cache_position.reshape(-1, 1)
+ causal_mask = causal_mask[None, None, :, :].expand(batch_size, 1, -1, -1)
+ if attention_mask is not None:
+ causal_mask = causal_mask.clone() # copy to contiguous memory for in-place edit
+ mask_length = attention_mask.shape[-1]
+ padding_attention_mask = (attention_mask[:, None, None, :] == attention_mask[:, None, :, None])[
+ :, :, -sequence_length:, :
+ ].to(dtype)
+ padding_mask = causal_mask[:, :, :, :mask_length] + padding_attention_mask
+ padding_mask = padding_mask == 0
+ causal_mask[:, :, :, :mask_length] = causal_mask[:, :, :, :mask_length].masked_fill(
+ padding_mask, min_dtype
+ )
+
+ return causal_mask
+
+ def _update_mamba_mask(self, attention_mask, cache_position):
+ """
+ No need for zeroing states when
+ 1. Cached forward
+ 2. Attending to all inputs
+ """
+ mamba_mask = attention_mask
+ if cache_position[0] > 0 or (attention_mask is not None and torch.all(attention_mask == 1)):
+ mamba_mask = None
+ return mamba_mask
+
+
+class BambaForCausalLM(LlamaForCausalLM):
+ @can_return_tuple
+ @add_start_docstrings_to_model_forward(BAMBA_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: Optional[torch.LongTensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[HybridMambaAttentionDynamicCache] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+ logits_to_keep: Union[int, torch.Tensor] = 0,
+ **kwargs,
+ ) -> CausalLMOutputWithPast:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ logits_to_keep (`int` or `torch.Tensor`, *optional*):
+ If an `int`, compute logits for the last `logits_to_keep` tokens. If `0`, calculate logits for all
+ `input_ids` (special case). Only last token logits are needed for generation, and calculating them only for that
+ token can save memory, which becomes pretty significant for long sequences or large vocabulary size.
+ If a `torch.Tensor`, must be 1D corresponding to the indices to keep in the sequence length dimension.
+ This is useful when using packed tensor format (single dimension for batch and sequence length).
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, BambaForCausalLM
+
+ >>> model = BambaForCausalLM.from_pretrained("...")
+ >>> tokenizer = AutoTokenizer.from_pretrained("...")
+
+ >>> prompt = "Hey, are you conscious? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
+ ```"""
+ return super().forward(
+ input_ids,
+ attention_mask,
+ position_ids,
+ past_key_values,
+ inputs_embeds,
+ labels,
+ use_cache,
+ output_attentions,
+ output_hidden_states,
+ cache_position,
+ logits_to_keep,
+ **kwargs,
+ )
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids,
+ past_key_values=None,
+ attention_mask=None,
+ inputs_embeds=None,
+ cache_position=None,
+ position_ids=None,
+ use_cache=True,
+ **kwargs,
+ ):
+ # Overwitten -- has a unique cache type, `HybridMambaAttentionDynamicCache`
+
+ empty_past_kv = past_key_values is None
+
+ # If we have cache: let's slice `input_ids` through `cache_position`, to keep only the unprocessed tokens
+ # Exception 1: when passing input_embeds, input_ids may be missing entries
+ # Exception 2: some generation methods do special slicing of input_ids, so we don't need to do it here
+ # Exception 3: with synced GPUs cache_position may go out of bounds, but we only want dummy token in that case.
+ # (we can't check exception 3 while compiling)
+ if not empty_past_kv:
+ if (
+ inputs_embeds is not None # Exception 1
+ or cache_position[-1] >= input_ids.shape[1] # Exception 3
+ ):
+ input_ids = input_ids[:, -cache_position.shape[0] :]
+ elif input_ids.shape[1] != cache_position.shape[0]: # Default case (the "else", a no op, is Exception 2)
+ input_ids = input_ids[:, cache_position]
+ else:
+ past_key_values = HybridMambaAttentionDynamicCache(
+ self.config, input_ids.shape[0], self.dtype, device=self.device
+ )
+
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if not empty_past_kv:
+ position_ids = position_ids[:, -input_ids.shape[1] :]
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and empty_past_kv:
+ model_inputs = {"inputs_embeds": inputs_embeds}
+ else:
+ model_inputs = {"input_ids": input_ids.contiguous()} # `contiguous()` needed for compilation use cases
+
+ model_inputs.update(
+ {
+ "position_ids": position_ids,
+ "past_key_values": past_key_values,
+ "use_cache": use_cache,
+ "attention_mask": attention_mask,
+ "logits_to_keep": self.config.num_logits_to_keep,
+ "cache_position": cache_position,
+ }
+ )
+ return model_inputs
+
+
+__all__ = ["BambaModel", "BambaForCausalLM", "BambaPreTrainedModel"]
diff --git a/docs/transformers/src/transformers/models/bark/__init__.py b/docs/transformers/src/transformers/models/bark/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5296fc47fc423c300cf6c43bccb5daafd6d134a
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bark/__init__.py
@@ -0,0 +1,28 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import _LazyModule
+from ...utils.import_utils import define_import_structure
+
+
+if TYPE_CHECKING:
+ from .configuration_bark import *
+ from .modeling_bark import *
+ from .processing_bark import *
+else:
+ import sys
+
+ _file = globals()["__file__"]
+ sys.modules[__name__] = _LazyModule(__name__, _file, define_import_structure(_file), module_spec=__spec__)
diff --git a/docs/transformers/src/transformers/models/bark/configuration_bark.py b/docs/transformers/src/transformers/models/bark/configuration_bark.py
new file mode 100644
index 0000000000000000000000000000000000000000..932bad618aa187ce0e55dc772fc803ef9d1d08dd
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bark/configuration_bark.py
@@ -0,0 +1,303 @@
+# coding=utf-8
+# Copyright 2023 The Suno AI Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""BARK model configuration"""
+
+from typing import Dict
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import add_start_docstrings, logging
+from ..auto import CONFIG_MAPPING, AutoConfig
+
+
+logger = logging.get_logger(__name__)
+
+
+BARK_SUBMODELCONFIG_START_DOCSTRING = """
+ This is the configuration class to store the configuration of a [`{model}`]. It is used to instantiate the model
+ according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the Bark [suno/bark](https://huggingface.co/suno/bark)
+ architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ block_size (`int`, *optional*, defaults to 1024):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ just in case (e.g., 512 or 1024 or 2048).
+ input_vocab_size (`int`, *optional*, defaults to 10_048):
+ Vocabulary size of a Bark sub-model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`{model}`]. Defaults to 10_048 but should be carefully thought with
+ regards to the chosen sub-model.
+ output_vocab_size (`int`, *optional*, defaults to 10_048):
+ Output vocabulary size of a Bark sub-model. Defines the number of different tokens that can be represented
+ by the: `output_ids` when passing forward a [`{model}`]. Defaults to 10_048 but should be carefully thought
+ with regards to the chosen sub-model.
+ num_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the given sub-model.
+ num_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer architecture.
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the "intermediate" (often named feed-forward) layer in the architecture.
+ dropout (`float`, *optional*, defaults to 0.0):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ bias (`bool`, *optional*, defaults to `True`):
+ Whether or not to use bias in the linear layers and layer norm layers.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models).
+"""
+
+
+class BarkSubModelConfig(PretrainedConfig):
+ keys_to_ignore_at_inference = ["past_key_values"]
+
+ attribute_map = {
+ "num_attention_heads": "num_heads",
+ "num_hidden_layers": "num_layers",
+ "vocab_size": "input_vocab_size",
+ "window_size": "block_size",
+ }
+
+ def __init__(
+ self,
+ block_size=1024,
+ input_vocab_size=10_048,
+ output_vocab_size=10_048,
+ num_layers=12,
+ num_heads=12,
+ hidden_size=768,
+ dropout=0.0,
+ bias=True, # True: bias in Linears and LayerNorms, like GPT-2. False: a bit better and faster
+ initializer_range=0.02,
+ use_cache=True,
+ **kwargs,
+ ):
+ self.block_size = block_size
+ self.input_vocab_size = input_vocab_size
+ self.output_vocab_size = output_vocab_size
+ self.num_layers = num_layers
+ self.num_heads = num_heads
+ self.hidden_size = hidden_size
+ self.dropout = dropout
+ self.bias = bias
+ self.use_cache = use_cache
+ self.initializer_range = initializer_range
+
+ super().__init__(**kwargs)
+
+
+@add_start_docstrings(
+ BARK_SUBMODELCONFIG_START_DOCSTRING.format(config="BarkSemanticConfig", model="BarkSemanticModel"),
+ """
+ Example:
+
+ ```python
+ >>> from transformers import BarkSemanticConfig, BarkSemanticModel
+
+ >>> # Initializing a Bark sub-module style configuration
+ >>> configuration = BarkSemanticConfig()
+
+ >>> # Initializing a model (with random weights) from the suno/bark style configuration
+ >>> model = BarkSemanticModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```""",
+)
+class BarkSemanticConfig(BarkSubModelConfig):
+ model_type = "semantic"
+ base_config_key = "semantic_config"
+
+
+@add_start_docstrings(
+ BARK_SUBMODELCONFIG_START_DOCSTRING.format(config="BarkCoarseConfig", model="BarkCoarseModel"),
+ """
+ Example:
+
+ ```python
+ >>> from transformers import BarkCoarseConfig, BarkCoarseModel
+
+ >>> # Initializing a Bark sub-module style configuration
+ >>> configuration = BarkCoarseConfig()
+
+ >>> # Initializing a model (with random weights) from the suno/bark style configuration
+ >>> model = BarkCoarseModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```""",
+)
+class BarkCoarseConfig(BarkSubModelConfig):
+ model_type = "coarse_acoustics"
+ base_config_key = "coarse_acoustics_config"
+
+
+@add_start_docstrings(
+ BARK_SUBMODELCONFIG_START_DOCSTRING.format(config="BarkFineConfig", model="BarkFineModel"),
+ """
+ n_codes_total (`int`, *optional*, defaults to 8):
+ The total number of audio codebooks predicted. Used in the fine acoustics sub-model.
+ n_codes_given (`int`, *optional*, defaults to 1):
+ The number of audio codebooks predicted in the coarse acoustics sub-model. Used in the acoustics
+ sub-models.
+ Example:
+
+ ```python
+ >>> from transformers import BarkFineConfig, BarkFineModel
+
+ >>> # Initializing a Bark sub-module style configuration
+ >>> configuration = BarkFineConfig()
+
+ >>> # Initializing a model (with random weights) from the suno/bark style configuration
+ >>> model = BarkFineModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```""",
+)
+class BarkFineConfig(BarkSubModelConfig):
+ model_type = "fine_acoustics"
+ base_config_key = "fine_acoustics_config"
+
+ def __init__(self, tie_word_embeddings=True, n_codes_total=8, n_codes_given=1, **kwargs):
+ self.n_codes_total = n_codes_total
+ self.n_codes_given = n_codes_given
+
+ super().__init__(tie_word_embeddings=tie_word_embeddings, **kwargs)
+
+
+class BarkConfig(PretrainedConfig):
+ """
+ This is the configuration class to store the configuration of a [`BarkModel`]. It is used to instantiate a Bark
+ model according to the specified sub-models configurations, defining the model architecture.
+
+ Instantiating a configuration with the defaults will yield a similar configuration to that of the Bark
+ [suno/bark](https://huggingface.co/suno/bark) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ semantic_config ([`BarkSemanticConfig`], *optional*):
+ Configuration of the underlying semantic sub-model.
+ coarse_acoustics_config ([`BarkCoarseConfig`], *optional*):
+ Configuration of the underlying coarse acoustics sub-model.
+ fine_acoustics_config ([`BarkFineConfig`], *optional*):
+ Configuration of the underlying fine acoustics sub-model.
+ codec_config ([`AutoConfig`], *optional*):
+ Configuration of the underlying codec sub-model.
+
+ Example:
+
+ ```python
+ >>> from transformers import (
+ ... BarkSemanticConfig,
+ ... BarkCoarseConfig,
+ ... BarkFineConfig,
+ ... BarkModel,
+ ... BarkConfig,
+ ... AutoConfig,
+ ... )
+
+ >>> # Initializing Bark sub-modules configurations.
+ >>> semantic_config = BarkSemanticConfig()
+ >>> coarse_acoustics_config = BarkCoarseConfig()
+ >>> fine_acoustics_config = BarkFineConfig()
+ >>> codec_config = AutoConfig.from_pretrained("facebook/encodec_24khz")
+
+
+ >>> # Initializing a Bark module style configuration
+ >>> configuration = BarkConfig.from_sub_model_configs(
+ ... semantic_config, coarse_acoustics_config, fine_acoustics_config, codec_config
+ ... )
+
+ >>> # Initializing a model (with random weights)
+ >>> model = BarkModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```
+ """
+
+ model_type = "bark"
+ sub_configs = {
+ "semantic_config": BarkSemanticConfig,
+ "coarse_acoustics_config": BarkCoarseConfig,
+ "fine_acoustics_config": BarkFineConfig,
+ "codec_config": AutoConfig,
+ }
+
+ def __init__(
+ self,
+ semantic_config: Dict = None,
+ coarse_acoustics_config: Dict = None,
+ fine_acoustics_config: Dict = None,
+ codec_config: Dict = None,
+ initializer_range=0.02,
+ **kwargs,
+ ):
+ if semantic_config is None:
+ semantic_config = {}
+ logger.info("semantic_config is None. initializing the semantic model with default values.")
+
+ if coarse_acoustics_config is None:
+ coarse_acoustics_config = {}
+ logger.info("coarse_acoustics_config is None. initializing the coarse model with default values.")
+
+ if fine_acoustics_config is None:
+ fine_acoustics_config = {}
+ logger.info("fine_acoustics_config is None. initializing the fine model with default values.")
+
+ if codec_config is None:
+ codec_config = {}
+ logger.info("codec_config is None. initializing the codec model with default values.")
+
+ self.semantic_config = BarkSemanticConfig(**semantic_config)
+ self.coarse_acoustics_config = BarkCoarseConfig(**coarse_acoustics_config)
+ self.fine_acoustics_config = BarkFineConfig(**fine_acoustics_config)
+ codec_model_type = codec_config["model_type"] if "model_type" in codec_config else "encodec"
+ self.codec_config = CONFIG_MAPPING[codec_model_type](**codec_config)
+
+ self.initializer_range = initializer_range
+
+ super().__init__(**kwargs)
+
+ @classmethod
+ def from_sub_model_configs(
+ cls,
+ semantic_config: BarkSemanticConfig,
+ coarse_acoustics_config: BarkCoarseConfig,
+ fine_acoustics_config: BarkFineConfig,
+ codec_config: PretrainedConfig,
+ **kwargs,
+ ):
+ r"""
+ Instantiate a [`BarkConfig`] (or a derived class) from bark sub-models configuration.
+
+ Returns:
+ [`BarkConfig`]: An instance of a configuration object
+ """
+ return cls(
+ semantic_config=semantic_config.to_dict(),
+ coarse_acoustics_config=coarse_acoustics_config.to_dict(),
+ fine_acoustics_config=fine_acoustics_config.to_dict(),
+ codec_config=codec_config.to_dict(),
+ **kwargs,
+ )
+
+
+__all__ = ["BarkCoarseConfig", "BarkConfig", "BarkFineConfig", "BarkSemanticConfig"]
diff --git a/docs/transformers/src/transformers/models/bark/convert_suno_to_hf.py b/docs/transformers/src/transformers/models/bark/convert_suno_to_hf.py
new file mode 100644
index 0000000000000000000000000000000000000000..803656b623edbffbfef01bb2d9644cfc6f983a93
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bark/convert_suno_to_hf.py
@@ -0,0 +1,263 @@
+"""Convert Bark checkpoint."""
+
+import argparse
+import os
+from pathlib import Path
+
+import torch
+from bark.generation import _load_model as _bark_load_model
+from huggingface_hub import hf_hub_download
+
+from transformers import EncodecConfig, EncodecModel, set_seed
+from transformers.models.bark.configuration_bark import (
+ BarkCoarseConfig,
+ BarkConfig,
+ BarkFineConfig,
+ BarkSemanticConfig,
+)
+from transformers.models.bark.generation_configuration_bark import (
+ BarkCoarseGenerationConfig,
+ BarkFineGenerationConfig,
+ BarkGenerationConfig,
+ BarkSemanticGenerationConfig,
+)
+from transformers.models.bark.modeling_bark import BarkCoarseModel, BarkFineModel, BarkModel, BarkSemanticModel
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+set_seed(770)
+
+
+new_layer_name_dict = {
+ "c_attn": "att_proj",
+ "c_proj": "out_proj",
+ "c_fc": "in_proj",
+ "transformer.": "",
+ "h.": "layers.",
+ "ln_1": "layernorm_1",
+ "ln_2": "layernorm_2",
+ "ln_f": "layernorm_final",
+ "wpe": "position_embeds_layer",
+ "wte": "input_embeds_layer",
+}
+
+
+REMOTE_MODEL_PATHS = {
+ "text_small": {
+ "repo_id": "suno/bark",
+ "file_name": "text.pt",
+ },
+ "coarse_small": {
+ "repo_id": "suno/bark",
+ "file_name": "coarse.pt",
+ },
+ "fine_small": {
+ "repo_id": "suno/bark",
+ "file_name": "fine.pt",
+ },
+ "text": {
+ "repo_id": "suno/bark",
+ "file_name": "text_2.pt",
+ },
+ "coarse": {
+ "repo_id": "suno/bark",
+ "file_name": "coarse_2.pt",
+ },
+ "fine": {
+ "repo_id": "suno/bark",
+ "file_name": "fine_2.pt",
+ },
+}
+
+CUR_PATH = os.path.dirname(os.path.abspath(__file__))
+default_cache_dir = os.path.join(os.path.expanduser("~"), ".cache")
+CACHE_DIR = os.path.join(os.getenv("XDG_CACHE_HOME", default_cache_dir), "suno", "bark_v0")
+
+
+def _get_ckpt_path(model_type, use_small=False):
+ key = model_type
+ if use_small:
+ key += "_small"
+ return os.path.join(CACHE_DIR, REMOTE_MODEL_PATHS[key]["file_name"])
+
+
+def _download(from_hf_path, file_name):
+ os.makedirs(CACHE_DIR, exist_ok=True)
+ hf_hub_download(repo_id=from_hf_path, filename=file_name, local_dir=CACHE_DIR)
+
+
+def _load_model(ckpt_path, device, use_small=False, model_type="text"):
+ if model_type == "text":
+ ModelClass = BarkSemanticModel
+ ConfigClass = BarkSemanticConfig
+ GenerationConfigClass = BarkSemanticGenerationConfig
+ elif model_type == "coarse":
+ ModelClass = BarkCoarseModel
+ ConfigClass = BarkCoarseConfig
+ GenerationConfigClass = BarkCoarseGenerationConfig
+ elif model_type == "fine":
+ ModelClass = BarkFineModel
+ ConfigClass = BarkFineConfig
+ GenerationConfigClass = BarkFineGenerationConfig
+ else:
+ raise NotImplementedError()
+ model_key = f"{model_type}_small" if use_small else model_type
+ model_info = REMOTE_MODEL_PATHS[model_key]
+ if not os.path.exists(ckpt_path):
+ logger.info(f"{model_type} model not found, downloading into `{CACHE_DIR}`.")
+ _download(model_info["repo_id"], model_info["file_name"])
+ checkpoint = torch.load(ckpt_path, map_location=device, weights_only=True)
+ # this is a hack
+ model_args = checkpoint["model_args"]
+ if "input_vocab_size" not in model_args:
+ model_args["input_vocab_size"] = model_args["vocab_size"]
+ model_args["output_vocab_size"] = model_args["vocab_size"]
+ del model_args["vocab_size"]
+
+ # convert Bark model arguments to HF Bark model arguments
+ model_args["num_heads"] = model_args.pop("n_head")
+ model_args["hidden_size"] = model_args.pop("n_embd")
+ model_args["num_layers"] = model_args.pop("n_layer")
+
+ model_config = ConfigClass(**checkpoint["model_args"])
+ model = ModelClass(config=model_config)
+ model_generation_config = GenerationConfigClass()
+
+ model.generation_config = model_generation_config
+ state_dict = checkpoint["model"]
+ # fixup checkpoint
+ unwanted_prefix = "_orig_mod."
+ for k, v in list(state_dict.items()):
+ if k.startswith(unwanted_prefix):
+ # replace part of the key with corresponding layer name in HF implementation
+ new_k = k[len(unwanted_prefix) :]
+ for old_layer_name in new_layer_name_dict:
+ new_k = new_k.replace(old_layer_name, new_layer_name_dict[old_layer_name])
+
+ state_dict[new_k] = state_dict.pop(k)
+
+ extra_keys = set(state_dict.keys()) - set(model.state_dict().keys())
+ extra_keys = {k for k in extra_keys if not k.endswith(".attn.bias")}
+ missing_keys = set(model.state_dict().keys()) - set(state_dict.keys())
+ missing_keys = {k for k in missing_keys if not k.endswith(".attn.bias")}
+ if len(extra_keys) != 0:
+ raise ValueError(f"extra keys found: {extra_keys}")
+ if len(missing_keys) != 0:
+ raise ValueError(f"missing keys: {missing_keys}")
+ model.load_state_dict(state_dict, strict=False)
+ n_params = model.num_parameters(exclude_embeddings=True)
+ val_loss = checkpoint["best_val_loss"].item()
+ logger.info(f"model loaded: {round(n_params / 1e6, 1)}M params, {round(val_loss, 3)} loss")
+ model.eval()
+ model.to(device)
+ del checkpoint, state_dict
+
+ return model
+
+
+def load_model(pytorch_dump_folder_path, use_small=False, model_type="text"):
+ if model_type not in ("text", "coarse", "fine"):
+ raise NotImplementedError()
+
+ device = "cpu" # do conversion on cpu
+
+ ckpt_path = _get_ckpt_path(model_type, use_small=use_small)
+ model = _load_model(ckpt_path, device, model_type=model_type, use_small=use_small)
+
+ # load bark initial model
+ bark_model = _bark_load_model(ckpt_path, "cpu", model_type=model_type, use_small=use_small)
+
+ if model_type == "text":
+ bark_model = bark_model["model"]
+
+ if model.num_parameters(exclude_embeddings=True) != bark_model.get_num_params():
+ raise ValueError("initial and new models don't have the same number of parameters")
+
+ # check if same output as the bark model
+ batch_size = 5
+ sequence_length = 10
+
+ if model_type in ["text", "coarse"]:
+ vec = torch.randint(256, (batch_size, sequence_length), dtype=torch.int)
+ output_old_model = bark_model(vec)[0]
+
+ output_new_model_total = model(vec)
+
+ # take last logits
+ output_new_model = output_new_model_total.logits[:, [-1], :]
+
+ else:
+ prediction_codebook_channel = 3
+ n_codes_total = 8
+ vec = torch.randint(256, (batch_size, sequence_length, n_codes_total), dtype=torch.int)
+
+ output_new_model_total = model(prediction_codebook_channel, vec)
+ output_old_model = bark_model(prediction_codebook_channel, vec)
+
+ output_new_model = output_new_model_total.logits
+
+ # output difference should come from the difference of self-attention implementation design
+ if output_new_model.shape != output_old_model.shape:
+ raise ValueError("initial and new outputs don't have the same shape")
+ if (output_new_model - output_old_model).abs().max().item() > 1e-3:
+ raise ValueError("initial and new outputs are not equal")
+
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ model.save_pretrained(pytorch_dump_folder_path)
+
+
+def load_whole_bark_model(
+ semantic_path,
+ coarse_path,
+ fine_path,
+ append_text,
+ hub_path,
+ folder_path,
+):
+ pytorch_dump_folder_path = os.path.join(folder_path, append_text)
+
+ semanticConfig = BarkSemanticConfig.from_pretrained(os.path.join(semantic_path, "config.json"))
+ coarseAcousticConfig = BarkCoarseConfig.from_pretrained(os.path.join(coarse_path, "config.json"))
+ fineAcousticConfig = BarkFineConfig.from_pretrained(os.path.join(fine_path, "config.json"))
+ codecConfig = EncodecConfig.from_pretrained("facebook/encodec_24khz")
+
+ semantic = BarkSemanticModel.from_pretrained(semantic_path)
+ coarseAcoustic = BarkCoarseModel.from_pretrained(coarse_path)
+ fineAcoustic = BarkFineModel.from_pretrained(fine_path)
+ codec = EncodecModel.from_pretrained("facebook/encodec_24khz")
+
+ bark_config = BarkConfig.from_sub_model_configs(
+ semanticConfig, coarseAcousticConfig, fineAcousticConfig, codecConfig
+ )
+
+ bark_generation_config = BarkGenerationConfig.from_sub_model_configs(
+ semantic.generation_config, coarseAcoustic.generation_config, fineAcoustic.generation_config
+ )
+
+ bark = BarkModel(bark_config)
+
+ bark.semantic = semantic
+ bark.coarse_acoustics = coarseAcoustic
+ bark.fine_acoustics = fineAcoustic
+ bark.codec_model = codec
+
+ bark.generation_config = bark_generation_config
+
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ bark.save_pretrained(pytorch_dump_folder_path, repo_id=hub_path, push_to_hub=True)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+
+ parser.add_argument("model_type", type=str, help="text, coarse or fine.")
+ parser.add_argument("pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model.")
+ parser.add_argument("--is_small", action="store_true", help="convert the small version instead of the large.")
+
+ args = parser.parse_args()
+
+ load_model(args.pytorch_dump_folder_path, model_type=args.model_type, use_small=args.is_small)
diff --git a/docs/transformers/src/transformers/models/bark/generation_configuration_bark.py b/docs/transformers/src/transformers/models/bark/generation_configuration_bark.py
new file mode 100644
index 0000000000000000000000000000000000000000..00ff22c8b894be11110b5a5ec9f20cece58e3788
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bark/generation_configuration_bark.py
@@ -0,0 +1,330 @@
+# coding=utf-8
+# Copyright 2023 The Suno AI Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""BARK model generation configuration"""
+
+import copy
+from typing import Dict
+
+from ...generation.configuration_utils import GenerationConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class BarkSemanticGenerationConfig(GenerationConfig):
+ model_type = "semantic"
+
+ def __init__(
+ self,
+ eos_token_id=10_000,
+ renormalize_logits=True,
+ max_new_tokens=768,
+ output_scores=False,
+ return_dict_in_generate=False,
+ output_hidden_states=False,
+ output_attentions=False,
+ temperature=1.0,
+ do_sample=False,
+ text_encoding_offset=10_048,
+ text_pad_token=129_595,
+ semantic_infer_token=129_599,
+ semantic_vocab_size=10_000,
+ max_input_semantic_length=256,
+ semantic_rate_hz=49.9,
+ min_eos_p=None,
+ **kwargs,
+ ):
+ """Class that holds a generation configuration for [`BarkSemanticModel`].
+
+ This configuration inherit from [`GenerationConfig`] and can be used to control the model generation. Read the
+ documentation from [`GenerationConfig`] for more information.
+
+ Args:
+ eos_token_id (`int`, *optional*, defaults to 10_000):
+ The id of the *end-of-sequence* token.
+ renormalize_logits (`bool`, *optional*, defaults to `True`):
+ Whether to renormalize the logits after applying all the logits processors (including the
+ custom ones). It's highly recommended to set this flag to `True` as the search algorithms suppose the
+ score logits are normalized but some logit processors break the normalization.
+ max_new_tokens (`int`, *optional*, defaults to 768):
+ The maximum numbers of tokens to generate, ignoring the number of tokens in the prompt.
+ output_scores (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
+ return_dict_in_generate (`bool`, *optional*, defaults to `False`):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ output_hidden_states (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more details.
+ output_attentions (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more details.
+ temperature (`float`, *optional*, defaults to 1.0):
+ The value used to modulate the next token probabilities.
+ do_sample (`bool`, *optional*, defaults to `False`):
+ Whether or not to use sampling ; use greedy decoding otherwise.
+ text_encoding_offset (`int`, *optional*, defaults to 10_048):
+ Text encoding offset.
+ text_pad_token (`int`, *optional*, defaults to 129_595):
+ Text pad token.
+ semantic_infer_token (`int`, *optional*, defaults to 129_599):
+ Semantic infer token.
+ semantic_vocab_size (`int`, *optional*, defaults to 10_000):
+ Semantic vocab size.
+ max_input_semantic_length (`int`, *optional*, defaults to 256):
+ Max length of semantic input vector.
+ semantic_rate_hz (`float`, *optional*, defaults to 49.9):
+ Semantic rate in Hertz.
+ min_eos_p (`float`, *optional*):
+ Minimum threshold of the probability of the EOS token for it to be sampled. This is an early stopping
+ strategy to mitigate potential unwanted generations at the end of a prompt. The original implementation
+ suggests a default value of 0.2.
+ """
+ super().__init__(
+ temperature=temperature,
+ do_sample=do_sample,
+ eos_token_id=eos_token_id,
+ renormalize_logits=renormalize_logits,
+ max_new_tokens=max_new_tokens,
+ output_scores=output_scores,
+ return_dict_in_generate=return_dict_in_generate,
+ output_hidden_states=output_hidden_states,
+ output_attentions=output_attentions,
+ **kwargs,
+ )
+
+ self.text_encoding_offset = text_encoding_offset
+ self.text_pad_token = text_pad_token
+ self.semantic_pad_token = eos_token_id
+ self.semantic_infer_token = semantic_infer_token
+ self.semantic_vocab_size = semantic_vocab_size
+ self.max_input_semantic_length = max_input_semantic_length
+ self.semantic_rate_hz = semantic_rate_hz
+ self.min_eos_p = min_eos_p
+
+
+class BarkCoarseGenerationConfig(GenerationConfig):
+ model_type = "coarse_acoustics"
+
+ def __init__(
+ self,
+ renormalize_logits=True,
+ output_scores=False,
+ return_dict_in_generate=False,
+ output_hidden_states=False,
+ output_attentions=False,
+ temperature=1.0,
+ do_sample=False,
+ coarse_semantic_pad_token=12_048,
+ coarse_rate_hz=75,
+ n_coarse_codebooks=2,
+ coarse_infer_token=12_050,
+ max_coarse_input_length=256,
+ max_coarse_history: int = 630,
+ sliding_window_len: int = 60,
+ **kwargs,
+ ):
+ """Class that holds a generation configuration for [`BarkCoarseModel`].
+
+ This configuration inherit from [`GenerationConfig`] and can be used to control the model generation. Read the
+ documentation from [`GenerationConfig`] for more information.
+
+ Args:
+ renormalize_logits (`bool`, *optional*, defaults to `True`):
+ Whether to renormalize the logits after applying all the logits processors (including the
+ custom ones). It's highly recommended to set this flag to `True` as the search algorithms suppose the
+ score logits are normalized but some logit processors break the normalization.
+ output_scores (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
+ return_dict_in_generate (`bool`, *optional*, defaults to `False`):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ output_hidden_states (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more details.
+ output_attentions (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more details.
+ temperature (`float`, *optional*, defaults to 1.0):
+ The value used to modulate the next token probabilities.
+ do_sample (`bool`, *optional*, defaults to `False`):
+ Whether or not to use sampling ; use greedy decoding otherwise.
+ coarse_semantic_pad_token (`int`, *optional*, defaults to 12_048):
+ Coarse semantic pad token.
+ coarse_rate_hz (`int`, *optional*, defaults to 75):
+ Coarse rate in Hertz.
+ n_coarse_codebooks (`int`, *optional*, defaults to 2):
+ Number of coarse codebooks.
+ coarse_infer_token (`int`, *optional*, defaults to 12_050):
+ Coarse infer token.
+ max_coarse_input_length (`int`, *optional*, defaults to 256):
+ Max length of input coarse vector.
+ max_coarse_history (`int`, *optional*, defaults to 630):
+ Max length of the output of the coarse acoustics model used in the fine generation step.
+ sliding_window_len (`int`, *optional*, defaults to 60):
+ The coarse generation step uses a sliding window to generate raw audio.
+ """
+ super().__init__(
+ temperature=temperature,
+ do_sample=do_sample,
+ renormalize_logits=renormalize_logits,
+ output_scores=output_scores,
+ return_dict_in_generate=return_dict_in_generate,
+ output_hidden_states=output_hidden_states,
+ output_attentions=output_attentions,
+ **kwargs,
+ )
+
+ self.coarse_semantic_pad_token = coarse_semantic_pad_token
+ self.coarse_rate_hz = coarse_rate_hz
+ self.n_coarse_codebooks = n_coarse_codebooks
+ self.coarse_infer_token = coarse_infer_token
+ self.max_coarse_input_length = max_coarse_input_length
+ self.max_coarse_history = max_coarse_history
+ self.sliding_window_len = sliding_window_len
+
+
+class BarkFineGenerationConfig(GenerationConfig):
+ model_type = "fine_acoustics"
+
+ def __init__(
+ self,
+ temperature=1.0,
+ max_fine_history_length=512,
+ max_fine_input_length=1024,
+ n_fine_codebooks=8,
+ **kwargs,
+ ):
+ """Class that holds a generation configuration for [`BarkFineModel`].
+
+ [`BarkFineModel`] is an autoencoder model, so should not usually be used for generation. However, under the
+ hood, it uses `temperature` when used by [`BarkModel`]
+
+ This configuration inherit from [`GenerationConfig`] and can be used to control the model generation. Read the
+ documentation from [`GenerationConfig`] for more information.
+
+ Args:
+ temperature (`float`, *optional*):
+ The value used to modulate the next token probabilities.
+ max_fine_history_length (`int`, *optional*, defaults to 512):
+ Max length of the fine history vector.
+ max_fine_input_length (`int`, *optional*, defaults to 1024):
+ Max length of fine input vector.
+ n_fine_codebooks (`int`, *optional*, defaults to 8):
+ Number of codebooks used.
+ """
+ super().__init__(temperature=temperature)
+
+ self.max_fine_history_length = max_fine_history_length
+ self.max_fine_input_length = max_fine_input_length
+ self.n_fine_codebooks = n_fine_codebooks
+
+ def validate(self, **kwargs):
+ """
+ Overrides GenerationConfig.validate because BarkFineGenerationConfig don't use any parameters outside
+ temperature.
+ """
+ pass
+
+
+class BarkGenerationConfig(GenerationConfig):
+ model_type = "bark"
+
+ # TODO (joao): nested from_dict
+
+ def __init__(
+ self,
+ semantic_config: Dict = None,
+ coarse_acoustics_config: Dict = None,
+ fine_acoustics_config: Dict = None,
+ sample_rate=24_000,
+ codebook_size=1024,
+ **kwargs,
+ ):
+ """Class that holds a generation configuration for [`BarkModel`].
+
+ The [`BarkModel`] does not have a `generate` method, but uses this class to generate speeches with a nested
+ [`BarkGenerationConfig`] which uses [`BarkSemanticGenerationConfig`], [`BarkCoarseGenerationConfig`],
+ [`BarkFineGenerationConfig`].
+
+ This configuration inherit from [`GenerationConfig`] and can be used to control the model generation. Read the
+ documentation from [`GenerationConfig`] for more information.
+
+ Args:
+ semantic_config (`Dict`, *optional*):
+ Semantic generation configuration.
+ coarse_acoustics_config (`Dict`, *optional*):
+ Coarse generation configuration.
+ fine_acoustics_config (`Dict`, *optional*):
+ Fine generation configuration.
+ sample_rate (`int`, *optional*, defaults to 24_000):
+ Sample rate.
+ codebook_size (`int`, *optional*, defaults to 1024):
+ Vector length for each codebook.
+ """
+ if semantic_config is None:
+ semantic_config = {}
+ logger.info("semantic_config is None. initializing the semantic model with default values.")
+
+ if coarse_acoustics_config is None:
+ coarse_acoustics_config = {}
+ logger.info("coarse_acoustics_config is None. initializing the coarse model with default values.")
+
+ if fine_acoustics_config is None:
+ fine_acoustics_config = {}
+ logger.info("fine_acoustics_config is None. initializing the fine model with default values.")
+
+ self.semantic_config = BarkSemanticGenerationConfig(**semantic_config)
+ self.coarse_acoustics_config = BarkCoarseGenerationConfig(**coarse_acoustics_config)
+ self.fine_acoustics_config = BarkFineGenerationConfig(**fine_acoustics_config)
+
+ self.sample_rate = sample_rate
+ self.codebook_size = codebook_size
+
+ @classmethod
+ def from_sub_model_configs(
+ cls,
+ semantic_config: BarkSemanticGenerationConfig,
+ coarse_acoustics_config: BarkCoarseGenerationConfig,
+ fine_acoustics_config: BarkFineGenerationConfig,
+ **kwargs,
+ ):
+ r"""
+ Instantiate a [`BarkGenerationConfig`] (or a derived class) from bark sub-models generation configuration.
+
+ Returns:
+ [`BarkGenerationConfig`]: An instance of a configuration object
+ """
+ return cls(
+ semantic_config=semantic_config.to_dict(),
+ coarse_acoustics_config=coarse_acoustics_config.to_dict(),
+ fine_acoustics_config=fine_acoustics_config.to_dict(),
+ **kwargs,
+ )
+
+ def to_dict(self):
+ """
+ Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`].
+
+ Returns:
+ `Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
+ """
+ output = copy.deepcopy(self.__dict__)
+
+ output["semantic_config"] = self.semantic_config.to_dict()
+ output["coarse_acoustics_config"] = self.coarse_acoustics_config.to_dict()
+ output["fine_acoustics_config"] = self.fine_acoustics_config.to_dict()
+
+ output["model_type"] = self.__class__.model_type
+ return output
diff --git a/docs/transformers/src/transformers/models/bark/modeling_bark.py b/docs/transformers/src/transformers/models/bark/modeling_bark.py
new file mode 100644
index 0000000000000000000000000000000000000000..57a0c4e5a7a53f6af0ae7018e3da5b5f6cf8e121
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bark/modeling_bark.py
@@ -0,0 +1,1869 @@
+# coding=utf-8
+# Copyright 2023 The Suno AI Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch BARK model."""
+
+import math
+import warnings
+from typing import Dict, Optional, Tuple, Union
+
+import numpy as np
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from ...generation import GenerationMixin
+from ...generation.logits_process import (
+ AlternatingCodebooksLogitsProcessor,
+ BarkEosPrioritizerLogitsProcessor,
+ SuppressTokensLogitsProcessor,
+)
+from ...modeling_attn_mask_utils import _prepare_4d_attention_mask
+from ...modeling_flash_attention_utils import flash_attn_supports_top_left_mask, is_flash_attn_available
+from ...modeling_outputs import CausalLMOutputWithPast, MaskedLMOutput
+from ...modeling_utils import PreTrainedModel, get_parameter_device
+from ...utils import (
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ is_accelerate_available,
+ is_torch_accelerator_available,
+ logging,
+)
+from ..auto import AutoModel
+from .configuration_bark import (
+ BarkCoarseConfig,
+ BarkConfig,
+ BarkFineConfig,
+ BarkSemanticConfig,
+ BarkSubModelConfig,
+)
+from .generation_configuration_bark import (
+ BarkCoarseGenerationConfig,
+ BarkFineGenerationConfig,
+ BarkSemanticGenerationConfig,
+)
+
+
+if is_flash_attn_available():
+ from ...modeling_flash_attention_utils import _flash_attention_forward
+
+
+logger = logging.get_logger(__name__)
+
+
+_CHECKPOINT_FOR_DOC = "suno/bark-small"
+_CONFIG_FOR_DOC = "BarkConfig"
+
+
+class BarkSelfAttention(nn.Module):
+ # adapted from GPTNeoSelfAttention and Bark code
+ # BarkSelfAttention can have two attention type, i.e full attention or causal attention
+
+ def __init__(self, config, is_causal=False):
+ super().__init__()
+
+ # regularization
+ self.dropout = config.dropout
+ self.attn_dropout = nn.Dropout(config.dropout)
+ self.resid_dropout = nn.Dropout(config.dropout)
+
+ self.embed_dim = config.hidden_size
+ self.num_heads = config.num_heads
+ self.head_dim = self.embed_dim // self.num_heads
+
+ if config.hidden_size % config.num_heads != 0:
+ raise ValueError(
+ f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
+ f" {self.num_heads})."
+ )
+
+ # key, query, value projections for all heads, but in a batch
+ self.att_proj = nn.Linear(config.hidden_size, 3 * config.hidden_size, bias=config.bias)
+ # output projection
+ self.out_proj = nn.Linear(config.hidden_size, config.hidden_size, bias=config.bias)
+
+ self.is_causal = is_causal
+ if is_causal:
+ block_size = config.block_size
+ bias = torch.tril(torch.ones((block_size, block_size), dtype=bool)).view(1, 1, block_size, block_size)
+ self.register_buffer("bias", bias)
+
+ # Copied from transformers.models.gpt_neo.modeling_gpt_neo.GPTNeoSelfAttention._split_heads
+ def _split_heads(self, tensor, num_heads, attn_head_size):
+ """
+ Splits hidden_size dim into attn_head_size and num_heads
+ """
+ new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
+ tensor = tensor.view(new_shape)
+ return tensor.permute(0, 2, 1, 3) # (batch, head, seq_length, head_features)
+
+ def _merge_heads(self, tensor, num_heads, attn_head_size):
+ """
+ Merges attn_head_size dim and num_attn_heads dim into hidden_size
+ """
+
+ # re-assemble all head outputs side by side
+ # (batch, num_heads, seq_len, attn_head_size) -> (batch, seq_len, num_heads*attn_head_size)
+ tensor = tensor.transpose(1, 2).contiguous()
+ tensor = tensor.view(tensor.size()[:-2] + (num_heads * attn_head_size,))
+
+ return tensor
+
+ def _attn(self, query, key, value, attention_mask=None, head_mask=None):
+ # unlike GPTNeo's SelfAttention, divide by the square root of the dimension of the query and the key
+ attn_weights = torch.matmul(query, key.transpose(-1, -2)) * (1.0 / math.sqrt(self.head_dim))
+
+ if self.is_causal:
+ query_length, key_length = query.size(-2), key.size(-2)
+
+ # fill the upper left part of the attention weights with inf
+ attn_weights = attn_weights.masked_fill(
+ self.bias[:, :, key_length - query_length : key_length, :key_length] == 0,
+ torch.finfo(attn_weights.dtype).min,
+ )
+
+ if attention_mask is not None:
+ # Apply the attention mask
+ attn_weights = attn_weights + attention_mask
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1)
+ attn_weights = attn_weights.to(value.dtype)
+ attn_weights = self.attn_dropout(attn_weights)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attn_weights = attn_weights * head_mask
+
+ # (batch, num_heads, seq_len, seq_len) x (batch, num_heads, seq_len, attn_head_size)
+ # -> (batch, num_heads, seq_len, attn_head_size)
+ attn_output = torch.matmul(attn_weights, value)
+
+ return attn_output, attn_weights
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ past_key_values=None,
+ head_mask=None,
+ use_cache=False,
+ output_attentions=False,
+ ):
+ # calculate query, key, values for all heads in batch and move head forward to be the batch dim
+ query, key, value = self.att_proj(hidden_states).split(self.embed_dim, dim=2)
+
+ query = self._split_heads(query, self.num_heads, self.head_dim)
+ key = self._split_heads(key, self.num_heads, self.head_dim)
+ value = self._split_heads(value, self.num_heads, self.head_dim)
+
+ if past_key_values is not None:
+ past_key = past_key_values[0]
+ past_value = past_key_values[1]
+ key = torch.cat((past_key, key), dim=-2)
+ value = torch.cat((past_value, value), dim=-2)
+
+ if use_cache is True:
+ present = (key, value)
+ else:
+ present = None
+
+ attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
+
+ attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)
+ attn_output = self.out_proj(attn_output)
+ attn_output = self.resid_dropout(attn_output)
+
+ outputs = (attn_output, present)
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+
+class BarkSelfFlashAttention2(BarkSelfAttention):
+ """
+ Bark flash attention module. This module inherits from `BarkSelfAttention` as the weights of the module stays
+ untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
+ flash attention and deal with padding tokens in case the input contains any of them.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignment, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = flash_attn_supports_top_left_mask()
+
+ def _split_heads(self, tensor, num_heads, attn_head_size):
+ """
+ Splits hidden_size dim into attn_head_size and num_heads
+ """
+ new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
+ tensor = tensor.view(new_shape)
+ # Flash attention requires the input to have the shape
+ # batch_size x seq_length x head_dim x hidden_dim - (batch, seq_length, head, head_features)
+ return tensor
+
+ def _merge_heads(self, tensor, num_heads, attn_head_size):
+ """
+ Merges attn_head_size dim and num_attn_heads dim into hidden_size
+ """
+ # re-assemble all head outputs side by side
+ # (batch, seq_len, num_heads, attn_head_size) -> (batch, seq_len, num_heads*attn_head_size)
+ tensor = tensor.view(tensor.size()[:-2] + (num_heads * attn_head_size,))
+ return tensor
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ past_key_values=None,
+ head_mask=None,
+ use_cache=False,
+ output_attentions=False,
+ ):
+ batch_size, query_len, _ = hidden_states.size()
+
+ # calculate query, key, values for all heads in batch and move head forward to be the batch dim
+ query, key, value = self.att_proj(hidden_states).split(self.embed_dim, dim=2)
+
+ query = self._split_heads(query, self.num_heads, self.head_dim)
+ key = self._split_heads(key, self.num_heads, self.head_dim)
+ value = self._split_heads(value, self.num_heads, self.head_dim)
+
+ if past_key_values is not None:
+ # (batch, head, seq_length, head_features) -> (batch, seq_length, head, head_features)
+ past_key = past_key_values[0].transpose(1, 2)
+ past_value = past_key_values[1].transpose(1, 2)
+ # and merge on seq_length
+ key = torch.cat((past_key, key), dim=1)
+ value = torch.cat((past_value, value), dim=1)
+
+ if use_cache is True:
+ # (batch, head, seq_length, head_features)
+ present = (key.transpose(1, 2), value.transpose(1, 2))
+ else:
+ present = None
+
+ attn_output = _flash_attention_forward(
+ query,
+ key,
+ value,
+ attention_mask,
+ query_len,
+ dropout=self.dropout if self.training else 0.0,
+ use_top_left_mask=self._flash_attn_uses_top_left_mask,
+ is_causal=self.is_causal,
+ )
+
+ attn_output = self._merge_heads(attn_output, self.num_heads, self.head_dim)
+ attn_output = self.out_proj(attn_output)
+ attn_output = self.resid_dropout(attn_output)
+
+ outputs = (attn_output, present)
+ if output_attentions:
+ attn_weights = None
+ outputs += (attn_weights,)
+
+ return outputs
+
+
+BARK_ATTENTION_CLASSES = {
+ "eager": BarkSelfAttention,
+ "flash_attention_2": BarkSelfFlashAttention2,
+}
+
+
+class BarkLayerNorm(nn.Module):
+ """LayerNorm but with an optional bias. PyTorch doesn't support simply bias=False."""
+
+ def __init__(self, hidden_size, bias=True):
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.bias = nn.Parameter(torch.zeros(hidden_size)) if bias else None
+
+ def forward(self, input):
+ return F.layer_norm(input, self.weight.shape, self.weight, self.bias, eps=1e-5)
+
+
+class BarkMLP(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.in_proj = nn.Linear(config.hidden_size, 4 * config.hidden_size, bias=config.bias)
+ self.out_proj = nn.Linear(4 * config.hidden_size, config.hidden_size, bias=config.bias)
+ self.dropout = nn.Dropout(config.dropout)
+ self.gelu = nn.GELU()
+
+ def forward(self, hidden_states):
+ hidden_states = self.in_proj(hidden_states)
+ hidden_states = self.gelu(hidden_states)
+ hidden_states = self.out_proj(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ return hidden_states
+
+
+class BarkBlock(nn.Module):
+ def __init__(self, config, is_causal=False):
+ super().__init__()
+
+ if is_causal:
+ # if causal, uses handmade LayerNorm, so that the layerNorm bias is optional
+ # this handmade layerNorm is used to stick with Bark choice of leaving optional bias in
+ # AutoRegressive models (corresponding to the "Text" and the "Coarse" modules)
+ self.layernorm_1 = BarkLayerNorm(config.hidden_size, bias=config.bias)
+ self.layernorm_2 = BarkLayerNorm(config.hidden_size, bias=config.bias)
+ else:
+ self.layernorm_1 = nn.LayerNorm(config.hidden_size)
+ self.layernorm_2 = nn.LayerNorm(config.hidden_size)
+
+ self.attn = BARK_ATTENTION_CLASSES[config._attn_implementation](config, is_causal=is_causal)
+
+ self.mlp = BarkMLP(config)
+
+ def forward(
+ self,
+ hidden_states,
+ past_key_values=None,
+ attention_mask=None,
+ head_mask=None,
+ use_cache=False,
+ output_attentions=False,
+ ):
+ intermediary_hidden_states = self.layernorm_1(hidden_states)
+
+ attn_outputs = self.attn(
+ intermediary_hidden_states,
+ past_key_values=past_key_values,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+
+ attn_output = attn_outputs[0] # output_attn: output, present_key_values, (attn_weights)
+ outputs = attn_outputs[1:]
+
+ intermediary_hidden_states = hidden_states + attn_output
+ intermediary_hidden_states = intermediary_hidden_states + self.mlp(
+ self.layernorm_2(intermediary_hidden_states)
+ )
+
+ if use_cache:
+ outputs = (intermediary_hidden_states,) + outputs
+ else:
+ outputs = (intermediary_hidden_states,) + outputs[1:]
+
+ return outputs # hidden_states, ((present), attentions)
+
+
+class BarkPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = BarkConfig
+ supports_gradient_checkpointing = False
+ _supports_flash_attn_2 = True
+
+ def _init_weights(self, module):
+ """Initialize the weights."""
+ if isinstance(module, (nn.Linear,)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def __init__(self, *inputs, **kwargs):
+ super().__init__(*inputs, **kwargs)
+
+ @property
+ def device(self) -> torch.device:
+ """
+ `torch.device`: The device on which the module is (assuming that all the module parameters are on the same
+ device).
+ """
+
+ # if has _hf_hook, has been offloaded so the device has to be found in the hook
+ if not hasattr(self, "_hf_hook"):
+ return get_parameter_device(self)
+ for module in self.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+
+ return get_parameter_device(self)
+
+
+BARK_MODEL_START_DOCSTRING = """
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`{config}`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+BARK_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`BarkConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+BARK_FINE_INPUTS_DOCSTRING = r"""
+ Args:
+ codebook_idx (`int`):
+ Index of the codebook that will be predicted.
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length, number_of_codebooks)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it. Initially, indices of the first two codebooks are obtained from the `coarse` sub-model. The rest is
+ predicted recursively by attending the previously predicted channels. The model predicts on windows of
+ length 1024.
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*): NOT IMPLEMENTED YET.
+ input_embeds (`torch.FloatTensor` of shape `(batch_size, input_sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. If
+ `past_key_values` is used, optionally only the last `input_embeds` have to be input (see
+ `past_key_values`). This is useful if you want more control over how to convert `input_ids` indices into
+ associated vectors than the model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+BARK_CAUSAL_MODEL_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it. Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details. [What are input IDs?](../glossary#input-ids)
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
+ `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `input_ids` of shape `(batch_size, sequence_length)`.
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.max_position_embeddings - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ input_embeds (`torch.FloatTensor` of shape `(batch_size, input_sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ Here, due to `Bark` particularities, if `past_key_values` is used, `input_embeds` will be ignored and you
+ have to use `input_ids`. If `past_key_values` is not used and `use_cache` is set to `True`, `input_embeds`
+ is used in priority instead of `input_ids`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+# GPT2-like autoregressive model
+class BarkCausalModel(BarkPreTrainedModel, GenerationMixin):
+ config_class = BarkSubModelConfig
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+
+ # initialize as an autoregressive GPT-like model
+ self.input_embeds_layer = nn.Embedding(config.input_vocab_size, config.hidden_size)
+ self.position_embeds_layer = nn.Embedding(config.block_size, config.hidden_size)
+
+ self.drop = nn.Dropout(config.dropout)
+
+ self.layers = nn.ModuleList([BarkBlock(config, is_causal=True) for _ in range(config.num_layers)])
+ self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
+
+ self.layernorm_final = BarkLayerNorm(config.hidden_size, bias=config.bias)
+
+ self.lm_head = nn.Linear(config.hidden_size, config.output_vocab_size, bias=False)
+ self.gradient_checkpointing = False
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.input_embeds_layer
+
+ def set_input_embeddings(self, new_embeddings):
+ self.input_embeds_layer = new_embeddings
+
+ def prepare_inputs_for_generation(self, input_ids, past_key_values=None, **kwargs):
+ # Overwritten -- bark has a model-specific hack
+ input_embeds = kwargs.get("input_embeds", None)
+
+ attention_mask = kwargs.get("attention_mask", None)
+ position_ids = kwargs.get("position_ids", None)
+
+ if past_key_values is not None:
+ # Omit tokens covered by past_key_values
+ seq_len = input_ids.shape[1]
+ past_length = past_key_values[0][0].shape[2]
+
+ # Some generation methods already pass only the last input ID
+ if input_ids.shape[1] > past_length:
+ remove_prefix_length = past_length
+ else:
+ # Default to old behavior: keep only final ID
+ remove_prefix_length = input_ids.shape[1] - 1
+
+ input_ids = input_ids[:, remove_prefix_length:]
+
+ # input_embeds have already been used and is not required anymore
+ input_embeds = None
+ else:
+ if input_embeds is not None and kwargs.get("use_cache"):
+ seq_len = input_embeds.shape[1]
+ else:
+ seq_len = input_ids.shape[1]
+
+ # ensure that attention_mask and position_ids shapes are aligned with the weird Bark hack of reducing
+ # sequence length on the first forward pass
+ if attention_mask is not None:
+ attention_mask = attention_mask[:, :seq_len]
+ if position_ids is not None:
+ position_ids = position_ids[:, :seq_len]
+
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -input_ids.shape[1] :]
+ else:
+ position_ids = None
+
+ if input_embeds is not None and kwargs.get("use_cache"):
+ return {
+ "input_ids": None,
+ "input_embeds": input_embeds,
+ "past_key_values": past_key_values,
+ "use_cache": kwargs.get("use_cache"),
+ "position_ids": position_ids,
+ "attention_mask": attention_mask,
+ }
+ return {
+ "input_ids": input_ids,
+ "past_key_values": past_key_values,
+ "use_cache": kwargs.get("use_cache"),
+ "position_ids": position_ids,
+ "attention_mask": attention_mask,
+ }
+
+ @add_start_docstrings_to_model_forward(BARK_CAUSAL_MODEL_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ input_embeds: Optional[torch.Tensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor], CausalLMOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ loss = None
+ if labels is not None:
+ raise NotImplementedError(
+ "Training is not implemented yet for Bark - ensure you do not pass `labels` to the model."
+ )
+
+ # Verify if input_embeds already exists
+ # then compute embeddings.
+ if input_ids is not None and input_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and input_embeds at the same time")
+ elif input_embeds is not None and past_key_values is None:
+ # we want to return the input_embeds in priority so that it is in line with a weird hack
+ # of Bark which concatenate two bits of the input_embeds on the first forward pass of the semantic model
+ pass
+ elif input_ids is not None:
+ input_embeds = self.input_embeds_layer(input_ids) # token embeddings of shape (b, t, n_embd)
+ elif input_embeds is not None:
+ pass
+ else:
+ raise ValueError("You have to specify either input_ids or input_embeds")
+
+ input_shape = input_embeds.size()[:-1]
+ batch_size = input_embeds.shape[0]
+ seq_length = input_shape[-1]
+
+ device = input_ids.device if input_ids is not None else input_embeds.device
+
+ if past_key_values is None:
+ past_length = 0
+ past_key_values = tuple([None] * len(self.layers))
+ else:
+ past_length = past_key_values[0][0].size(-2)
+
+ if position_ids is None:
+ position_ids = torch.arange(past_length, seq_length + past_length, dtype=torch.long, device=device)
+ position_ids = position_ids.unsqueeze(0) # shape (1, seq_length)
+
+ position_embeds = self.position_embeds_layer(position_ids) # position embeddings of shape (1, t, n_embd)
+
+ # Attention mask.
+ if attention_mask is not None:
+ if batch_size <= 0:
+ raise ValueError("batch_size has to be defined and > 0")
+ if self._use_flash_attention_2:
+ attention_mask = attention_mask if 0 in attention_mask else None
+ else:
+ attention_mask = attention_mask.view(batch_size, -1)
+ # [bsz, to_seq_length] -> [bsz, 1, 1, to_seq_length]
+ # from_seq_length is 1 to easily broadcast
+ attention_mask = _prepare_4d_attention_mask(attention_mask, input_embeds.dtype, tgt_len=1)
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x num_heads x N x N
+ # head_mask has shape num_layers x batch x num_heads x N x N
+ head_mask = self.get_head_mask(head_mask, self.config.num_layers)
+
+ hidden_states = self.drop(input_embeds + position_embeds)
+ output_shape = input_shape + (hidden_states.size(-1),)
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ present_key_values = () if use_cache else None
+ all_self_attentions = () if output_attentions else None
+ all_hidden_states = () if output_hidden_states else None
+
+ for i, (block, past_layer_key_values) in enumerate(zip(self.layers, past_key_values)):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ outputs = self._gradient_checkpointing_func(
+ block.__call__,
+ hidden_states,
+ None,
+ attention_mask,
+ head_mask[i],
+ use_cache,
+ output_attentions,
+ )
+ else:
+ outputs = block(
+ hidden_states,
+ past_key_values=past_layer_key_values,
+ attention_mask=attention_mask,
+ head_mask=head_mask[i],
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = outputs[0]
+
+ if use_cache:
+ present_key_values = present_key_values + (outputs[1],)
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
+
+ hidden_states = self.layernorm_final(hidden_states)
+
+ hidden_states = hidden_states.view(output_shape)
+
+ # Add last hidden state
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ logits = self.lm_head(hidden_states)
+
+ if not return_dict:
+ return tuple(
+ v for v in [None, logits, present_key_values, all_hidden_states, all_self_attentions] if v is not None
+ )
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=present_key_values,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+ @staticmethod
+ def _reorder_cache(
+ past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
+ ) -> Tuple[Tuple[torch.Tensor]]:
+ """
+ This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
+ [`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
+ beam_idx at every generation step.
+ """
+ # Necessary for beam_search
+ return tuple(
+ tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past)
+ for layer_past in past_key_values
+ )
+
+
+@add_start_docstrings(
+ """Bark semantic (or text) model. It shares the same architecture as the coarse model.
+ It is a GPT-2 like autoregressive model with a language modeling head on top.""",
+ BARK_MODEL_START_DOCSTRING.format(config="BarkSemanticConfig"),
+)
+class BarkSemanticModel(BarkCausalModel):
+ base_model_prefix = "semantic"
+ config_class = BarkSemanticConfig
+
+ def generate(
+ self,
+ input_ids: torch.Tensor,
+ semantic_generation_config: BarkSemanticGenerationConfig = None,
+ history_prompt: Optional[Dict[str, torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ **kwargs,
+ ) -> torch.LongTensor:
+ """
+ Generates text semantic tokens from an input prompt and an additional optional `Bark` speaker prompt.
+
+ Args:
+ input_ids (`Optional[torch.Tensor]` of shape (batch_size, seq_len), *optional*):
+ Input ids, i.e tokenized input sentences. Will be truncated up to
+ semantic_generation_config.max_input_semantic_length tokens. Note that the output audios will be as
+ long as the longest generation among the batch.
+ semantic_generation_config (`BarkSemanticGenerationConfig`):
+ Generation config indicating how to generate the semantic tokens.
+ history_prompt (`Optional[Dict[str,torch.Tensor]]`, *optional*):
+ Optional `Bark` speaker prompt.
+ attention_mask (`Optional[torch.Tensor]`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ Returns:
+ torch.LongTensor: Output semantic tokens.
+ """
+ if semantic_generation_config is None:
+ raise ValueError("`semantic_generation_config` has to be provided")
+
+ batch_size = input_ids.shape[0]
+
+ max_input_semantic_length = semantic_generation_config.max_input_semantic_length
+
+ input_ids = input_ids + semantic_generation_config.text_encoding_offset
+
+ if attention_mask is not None:
+ input_ids = input_ids.masked_fill((1 - attention_mask).bool(), semantic_generation_config.text_pad_token)
+
+ if history_prompt is not None:
+ semantic_history = history_prompt["semantic_prompt"][-max_input_semantic_length:]
+ semantic_history = nn.functional.pad(
+ semantic_history,
+ (0, max_input_semantic_length - len(semantic_history)),
+ value=semantic_generation_config.semantic_pad_token,
+ mode="constant",
+ )
+ else:
+ semantic_history = torch.tensor(
+ [semantic_generation_config.semantic_pad_token] * max_input_semantic_length, dtype=torch.int
+ ).to(self.device)
+
+ semantic_history = torch.repeat_interleave(semantic_history[None], batch_size, dim=0)
+
+ infer_array = torch.tensor(
+ [[semantic_generation_config.semantic_infer_token]] * batch_size, dtype=torch.int
+ ).to(self.device)
+
+ input_embeds = torch.cat(
+ [
+ self.input_embeds_layer(input_ids[:, :max_input_semantic_length])
+ + self.input_embeds_layer(semantic_history[:, : max_input_semantic_length + 1]),
+ self.input_embeds_layer(infer_array),
+ ],
+ dim=1,
+ )
+
+ tokens_to_suppress = list(
+ range(semantic_generation_config.semantic_vocab_size, semantic_generation_config.semantic_pad_token)
+ )
+ tokens_to_suppress.extend(
+ list(range(semantic_generation_config.semantic_pad_token + 1, self.config.output_vocab_size))
+ )
+
+ suppress_tokens_logits_processor = SuppressTokensLogitsProcessor(tokens_to_suppress, device=input_ids.device)
+
+ min_eos_p = kwargs.get("min_eos_p", semantic_generation_config.min_eos_p)
+ early_stopping_logits_processor = BarkEosPrioritizerLogitsProcessor(
+ eos_token_id=semantic_generation_config.eos_token_id, min_eos_p=min_eos_p, device=input_ids.device
+ )
+
+ # pass input_ids in order to stay consistent with the transformers generate method even though it is not used
+ # (except to get the input seq_len - that's why we keep the first 257 tokens)
+ semantic_output = super().generate(
+ torch.ones((batch_size, max_input_semantic_length + 1), dtype=torch.int, device=self.device),
+ input_embeds=input_embeds,
+ logits_processor=[suppress_tokens_logits_processor, early_stopping_logits_processor],
+ generation_config=semantic_generation_config,
+ **kwargs,
+ ) # size: 10048
+
+ # take the generated semantic tokens
+ semantic_output = semantic_output[:, max_input_semantic_length + 1 :]
+
+ return semantic_output
+
+
+@add_start_docstrings(
+ """Bark coarse acoustics model.
+ It shares the same architecture as the semantic (or text) model. It is a GPT-2 like autoregressive model with a
+ language modeling head on top.""",
+ BARK_MODEL_START_DOCSTRING.format(config="BarkCoarseConfig"),
+)
+class BarkCoarseModel(BarkCausalModel):
+ base_model_prefix = "coarse_acoustics"
+ config_class = BarkCoarseConfig
+
+ def preprocess_histories(
+ self,
+ max_coarse_history: int,
+ semantic_to_coarse_ratio: int,
+ batch_size: int,
+ semantic_generation_config: int,
+ codebook_size: int,
+ history_prompt: Optional[Dict[str, torch.Tensor]] = None,
+ ):
+ """
+ Preprocess the optional `Bark` speaker prompts before `self.generate`.
+
+ Args:
+ max_coarse_history (`int`):
+ Maximum size of coarse tokens used.
+ semantic_to_coarse_ratio (`int`):
+ Ratio of semantic to coarse frequency
+ batch_size (`int`):
+ Batch size, i.e the number of samples.
+ semantic_generation_config (`BarkSemanticGenerationConfig`):
+ Generation config indicating how to generate the semantic tokens.
+ codebook_size (`int`):
+ Codebook channel size, i.e. the size of the output vocabulary per codebook channel.
+ history_prompt (`Optional[Dict[str,torch.Tensor]]`):
+ Optional `Bark` speaker prompt.
+ Returns: Returns:
+ `tuple(torch.FloatTensor)`:
+ - **x_semantic_history** (`torch.FloatTensor` -- Processed semantic speaker prompt.
+ - **x_coarse_history** (`torch.FloatTensor`) -- Processed coarse speaker prompt.
+ """
+ if history_prompt is not None:
+ x_semantic_history = torch.repeat_interleave(history_prompt["semantic_prompt"][None], batch_size, dim=0)
+ # clone to avoid modifying history_prompt.coarse_prompt
+ x_coarse_history = history_prompt["coarse_prompt"].clone()
+
+ # offset x_coarse_history
+ if codebook_size is not None:
+ for n in range(1, x_coarse_history.shape[0]):
+ # offset
+ x_coarse_history[n, :] += codebook_size * n
+
+ # flatten x_coarse_history
+ x_coarse_history = torch.transpose(x_coarse_history, 0, 1).reshape(-1)
+
+ x_coarse_history = x_coarse_history + semantic_generation_config.semantic_vocab_size
+
+ x_coarse_history = torch.repeat_interleave(x_coarse_history[None], batch_size, dim=0)
+ # e.g: after SEMANTIC_VOCAB_SIZE (10000), 1024 tokens dedicated to first codebook, 1024 next tokens
+ # dedicated to second codebook.
+
+ max_semantic_history = int(np.floor(max_coarse_history / semantic_to_coarse_ratio))
+ # trim histories correctly
+ n_semantic_hist_provided = min(
+ [
+ max_semantic_history,
+ x_semantic_history.shape[1] - x_semantic_history.shape[1] % 2,
+ int(np.floor(x_coarse_history.shape[1] / semantic_to_coarse_ratio)),
+ ]
+ )
+
+ n_coarse_hist_provided = int(round(n_semantic_hist_provided * semantic_to_coarse_ratio))
+
+ x_semantic_history = x_semantic_history[:, -n_semantic_hist_provided:].int()
+ x_coarse_history = x_coarse_history[:, -n_coarse_hist_provided:].int()
+ # bit of a hack for time alignment (sounds better) - from Bark original implementation
+ x_coarse_history = x_coarse_history[:, :-2]
+
+ else:
+ # shape: (batch_size, 0)
+ x_semantic_history = torch.tensor([[]] * batch_size, dtype=torch.int, device=self.device)
+ x_coarse_history = torch.tensor([[]] * batch_size, dtype=torch.int, device=self.device)
+
+ return x_semantic_history, x_coarse_history
+
+ def generate(
+ self,
+ semantic_output: torch.Tensor,
+ semantic_generation_config: BarkSemanticGenerationConfig = None,
+ coarse_generation_config: BarkCoarseGenerationConfig = None,
+ codebook_size: int = 1024,
+ history_prompt: Optional[Dict[str, torch.Tensor]] = None,
+ return_output_lengths: Optional[bool] = None,
+ **kwargs,
+ ) -> Union[torch.LongTensor, Tuple[torch.LongTensor, torch.LongTensor]]:
+ """
+ Generates coarse acoustics tokens from input text semantic tokens and an additional optional `Bark` speaker
+ prompt.
+
+ Args:
+ semantic_output (`torch.Tensor` of shape (batch_size, seq_len), *optional*):
+ Input text semantic ids, i.e the output of `BarkSemanticModel.generate`.
+ semantic_generation_config (`BarkSemanticGenerationConfig`):
+ Generation config indicating how to generate the semantic tokens.
+ coarse_generation_config (`BarkCoarseGenerationConfig`):
+ Generation config indicating how to generate the coarse tokens.
+ codebook_size (`int`, *optional*, defaults to 1024):
+ Codebook channel size, i.e. the size of the output vocabulary per codebook channel.
+ history_prompt (`Optional[Dict[str,torch.Tensor]]`, *optional*):
+ Optional `Bark` speaker prompt.
+ return_output_lengths (`bool`, *optional*):
+ Whether or not to return the output lengths. Useful when batching.
+ Returns:
+ By default:
+ torch.LongTensor: Output coarse acoustics tokens.
+ If `return_output_lengths=True`:
+ `Tuple(torch.Tensor, torch.Tensor): The output coarse acoustics tokens, and the length of each sample
+ of the batch.
+ """
+
+ if semantic_generation_config is None:
+ raise ValueError("`semantic_generation_config` has to be provided")
+
+ if coarse_generation_config is None:
+ raise ValueError("`coarse_generation_config` has to be provided")
+
+ max_coarse_input_length = coarse_generation_config.max_coarse_input_length
+ max_coarse_history = coarse_generation_config.max_coarse_history
+ sliding_window_len = coarse_generation_config.sliding_window_len
+
+ # replace semantic_pad_token (eos_tok and pad_tok here) with coarse_semantic_pad_token i.e the pad_token
+ # used in the next model
+ semantic_output.masked_fill_(
+ semantic_output == semantic_generation_config.semantic_pad_token,
+ coarse_generation_config.coarse_semantic_pad_token,
+ )
+
+ semantic_to_coarse_ratio = (
+ coarse_generation_config.coarse_rate_hz
+ / semantic_generation_config.semantic_rate_hz
+ * coarse_generation_config.n_coarse_codebooks
+ )
+ max_semantic_history = int(np.floor(max_coarse_history / semantic_to_coarse_ratio))
+
+ output_lengths = (semantic_output != coarse_generation_config.coarse_semantic_pad_token).sum(1)
+ output_lengths = torch.floor(
+ output_lengths * semantic_to_coarse_ratio / coarse_generation_config.n_coarse_codebooks
+ )
+ output_lengths = torch.round(output_lengths * coarse_generation_config.n_coarse_codebooks).int()
+
+ max_generated_len = torch.max(output_lengths).item()
+
+ batch_size = semantic_output.shape[0]
+
+ x_semantic_history, x_coarse = self.preprocess_histories(
+ history_prompt=history_prompt,
+ max_coarse_history=max_coarse_history,
+ semantic_to_coarse_ratio=semantic_to_coarse_ratio,
+ batch_size=batch_size,
+ semantic_generation_config=semantic_generation_config,
+ codebook_size=codebook_size,
+ )
+ base_semantic_idx = x_semantic_history.shape[1]
+
+ semantic_output = torch.hstack([x_semantic_history, semantic_output])
+
+ n_window_steps = int(np.ceil(max_generated_len / sliding_window_len))
+
+ total_generated_len = 0
+
+ len_coarse_history = x_coarse.shape[1]
+
+ for _ in range(n_window_steps):
+ semantic_idx = base_semantic_idx + int(round(total_generated_len / semantic_to_coarse_ratio))
+
+ # pad from right side
+ input_coarse = semantic_output[:, np.max([0, semantic_idx - max_semantic_history]) :]
+ input_coarse = input_coarse[:, :max_coarse_input_length]
+ input_coarse = F.pad(
+ input_coarse,
+ (0, max_coarse_input_length - input_coarse.shape[-1]),
+ "constant",
+ coarse_generation_config.coarse_semantic_pad_token,
+ )
+
+ input_coarse = torch.hstack(
+ [
+ input_coarse,
+ torch.tensor([[coarse_generation_config.coarse_infer_token]] * batch_size, device=self.device),
+ x_coarse[:, -max_coarse_history:],
+ ]
+ )
+
+ alternatingLogitsProcessor = AlternatingCodebooksLogitsProcessor(
+ input_coarse.shape[1],
+ semantic_generation_config.semantic_vocab_size,
+ codebook_size,
+ )
+
+ output_coarse = super().generate(
+ input_coarse,
+ logits_processor=[alternatingLogitsProcessor],
+ max_new_tokens=min(sliding_window_len, max_generated_len - total_generated_len),
+ generation_config=coarse_generation_config,
+ **kwargs,
+ )
+
+ input_coarse_len = input_coarse.shape[1]
+
+ x_coarse = torch.hstack([x_coarse, output_coarse[:, input_coarse_len:]])
+ total_generated_len = x_coarse.shape[1] - len_coarse_history
+
+ del output_coarse
+
+ coarse_output = x_coarse[:, len_coarse_history:]
+
+ if return_output_lengths:
+ return coarse_output, output_lengths
+
+ return coarse_output
+
+
+@add_start_docstrings(
+ """Bark fine acoustics model. It is a non-causal GPT-like model with `config.n_codes_total` embedding layers and
+ language modeling heads, one for each codebook.""",
+ BARK_MODEL_START_DOCSTRING.format(config="BarkFineConfig"),
+)
+class BarkFineModel(BarkPreTrainedModel):
+ base_model_prefix = "fine_acoustics"
+ config_class = BarkFineConfig
+ main_input_name = "codebook_idx"
+
+ def __init__(self, config):
+ # non-causal gpt-like model with one embedding layer and one lm_head for each codebook of Encodec
+ super().__init__(config)
+ self.config = config
+
+ # initialize a modified non causal GPT-like model
+ # note that for there is one embedding layer and one lm_head for each codebook of Encodec
+ self.input_embeds_layers = nn.ModuleList(
+ [nn.Embedding(config.input_vocab_size, config.hidden_size) for _ in range(config.n_codes_total)]
+ )
+ self.position_embeds_layer = nn.Embedding(config.block_size, config.hidden_size)
+
+ self.drop = nn.Dropout(config.dropout)
+
+ self.layers = nn.ModuleList([BarkBlock(config, is_causal=False) for _ in range(config.num_layers)])
+ self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
+
+ self.layernorm_final = nn.LayerNorm(config.hidden_size)
+
+ self.lm_heads = nn.ModuleList(
+ [
+ nn.Linear(config.hidden_size, config.output_vocab_size, bias=False)
+ for _ in range(config.n_codes_given, config.n_codes_total)
+ ]
+ )
+ self.gradient_checkpointing = False
+ self.n_codes_total = config.n_codes_total
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ # one embedding layers for each codebook
+ return self.input_embeds_layers
+
+ def set_input_embeddings(self, new_embeddings):
+ # one embedding layers for each codebook
+ self.input_embeds_layers = new_embeddings
+
+ def get_output_embeddings(self):
+ # one lm_head for each codebook
+ return self.lm_heads
+
+ def set_output_embeddings(self, new_output_embeddings):
+ # one lm_head for each codebook
+ self.lm_heads = new_output_embeddings
+
+ def _resize_token_embeddings(self, new_num_tokens, pad_to_multiple_of=None, mean_resizing=True):
+ old_embeddings_list = self.get_input_embeddings()
+ new_embeddings_list = nn.ModuleList(
+ [
+ self._get_resized_embeddings(old_embeddings, new_num_tokens, pad_to_multiple_of, mean_resizing)
+ for old_embeddings in old_embeddings_list
+ ]
+ )
+ self.set_input_embeddings(new_embeddings_list)
+ new_num_tokens = new_embeddings_list[0].weight.shape[0]
+
+ # if word embeddings are not tied, make sure that lm head is resized as well
+ if self.get_output_embeddings() is not None and not self.config.tie_word_embeddings:
+ old_lm_head_list = self.get_output_embeddings()
+ new_lm_head_list = nn.ModuleList(
+ [self._get_resized_lm_head(old_lm_head, new_num_tokens) for old_lm_head in old_lm_head_list]
+ )
+ self.set_output_embeddings(new_lm_head_list)
+
+ return self.get_input_embeddings()
+
+ def resize_token_embeddings(
+ self,
+ new_num_tokens: Optional[int] = None,
+ pad_to_multiple_of: Optional[int] = None,
+ mean_resizing: bool = True,
+ ) -> nn.Embedding:
+ """
+ Resizes input token embeddings matrix of the model if `new_num_tokens != config.vocab_size`.
+
+ Takes care of tying weights embeddings afterwards if the model class has a `tie_weights()` method.
+
+ Arguments:
+ new_num_tokens (`int`, *optional*):
+ The number of new tokens in the embedding matrix. Increasing the size will add newly initialized
+ vectors at the end. Reducing the size will remove vectors from the end. If not provided or `None`, just
+ returns a pointer to the input tokens `torch.nn.Embedding` module of the model without doing anything.
+ pad_to_multiple_of (`int`, *optional*):
+ If set will pad the embedding matrix to a multiple of the provided value.
+
+ This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability
+ `>= 7.5` (Volta), or on TPUs which benefit from having sequence lengths be a multiple of 128. For more
+ details about this, or help on choosing the correct value for resizing, refer to this guide:
+ https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc
+ mean_resizing (`bool`):
+ Whether to initialize the added embeddings from a multivariate normal distribution that has old embeddings' mean and
+ covariance or to initialize them with a normal distribution that has a mean of zero and std equals `config.initializer_range`.
+
+ Setting `mean_resizing` to `True` is useful when increasing the size of the embeddings of causal language models,
+ where the generated tokens' probabilities won't be affected by the added embeddings because initializing the new embeddings with the
+ old embeddings' mean will reduce the kl-divergence between the next token probability before and after adding the new embeddings.
+ Refer to this article for more information: https://nlp.stanford.edu/~johnhew/vocab-expansion.html
+
+ Return:
+ `torch.nn.Embedding`: Pointer to the input tokens Embeddings Module of the model.
+ """
+ model_embeds = self._resize_token_embeddings(new_num_tokens, pad_to_multiple_of, mean_resizing)
+ if new_num_tokens is None and pad_to_multiple_of is None:
+ return model_embeds
+
+ # Update base model and current model config
+ self.config.output_vocab_size = model_embeds[0].weight.shape[0]
+ self.config.vocab_size = model_embeds[0].weight.shape[0]
+ self.output_vocab_size = model_embeds[0].weight.shape[0]
+ self.vocab_size = model_embeds[0].weight.shape[0]
+
+ # Tie weights again if needed
+ self.tie_weights()
+
+ return model_embeds
+
+ def _tie_weights(self):
+ if getattr(self.config, "tie_word_embeddings", True):
+ self._tied_weights_keys = []
+ output_embeddings = self.get_output_embeddings()
+ input_embeddings = self.get_input_embeddings()
+
+ for i in range(self.config.n_codes_total - self.config.n_codes_given):
+ # self.input_embeds_layers[i + 1].weight = self.lm_heads[i].weight
+ self._tie_or_clone_weights(output_embeddings[i], input_embeddings[i + 1])
+ self._tied_weights_keys.append(f"lm_heads.{i}.weight")
+
+ def tie_weights(self):
+ """
+ Tie the weights between the input embeddings list and the output embeddings list.
+
+ If the `torchscript` flag is set in the configuration, can't handle parameter sharing so we are cloning the
+ weights instead.
+ """
+ if getattr(self.config, "tie_word_embeddings", True):
+ self._tied_weights_keys = []
+ output_embeddings = self.get_output_embeddings()
+ input_embeddings = self.get_input_embeddings()
+
+ for i in range(self.config.n_codes_total - self.config.n_codes_given):
+ # self.input_embeds_layers[i + 1].weight = self.lm_heads[i].weight
+ self._tie_or_clone_weights(output_embeddings[i], input_embeddings[i + 1])
+ self._tied_weights_keys.append(f"lm_heads.{i}.weight")
+
+ for module in self.modules():
+ if hasattr(module, "_tie_weights"):
+ module._tie_weights()
+
+ @add_start_docstrings_to_model_forward(BARK_FINE_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ codebook_idx: int, # an additionnal idx corresponding to the id of the codebook that will be predicted
+ input_ids: Optional[torch.Tensor] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ input_embeds: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor], MaskedLMOutput]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ loss = None
+ if labels is not None:
+ raise NotImplementedError("Training is not implemented yet")
+
+ if codebook_idx == 0:
+ raise ValueError("Cannot predict 0th codebook - 0th codebook should be predicted by the coarse model")
+
+ if input_ids is not None and input_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and input_embeds at the same time")
+
+ if input_ids is None and input_embeds is None:
+ raise ValueError("You have to specify either input_ids or input_embeds")
+
+ if input_ids is not None:
+ # the input_embeddings are the sum of the j previous codebooks embeddings before
+ # the current codebook_idx codebook
+
+ # forward the GPT model itself
+ input_embeds = [
+ input_embeds_layer(input_ids[:, :, i]).unsqueeze(-1)
+ for i, input_embeds_layer in enumerate(self.input_embeds_layers)
+ ] # token embeddings of shape (b, t, n_embd)
+ input_embeds = torch.cat(input_embeds, dim=-1)
+ input_embeds = input_embeds[:, :, :, : codebook_idx + 1].sum(dim=-1)
+
+ input_shape = input_embeds.size()[:-1]
+ batch_size = input_embeds.shape[0]
+ seq_length = input_shape[1]
+
+ device = input_ids.device if input_ids is not None else input_embeds.device
+
+ if position_ids is None:
+ position_ids = torch.arange(0, seq_length, dtype=torch.long, device=device)
+ position_ids = position_ids.unsqueeze(0) # shape (1, seq_length)
+
+ position_embeds = self.position_embeds_layer(position_ids) # position embeddings of shape (1, t, n_embd)
+
+ # Attention mask.
+ if attention_mask is not None:
+ if batch_size <= 0:
+ raise ValueError("batch_size has to be defined and > 0")
+ if self._use_flash_attention_2:
+ attention_mask = attention_mask if 0 in attention_mask else None
+ else:
+ # [bsz, to_seq_length] -> [bsz, 1, 1, to_seq_length]
+ # from_seq_length is 1 to easily broadcast
+ attention_mask = _prepare_4d_attention_mask(attention_mask, input_embeds.dtype, tgt_len=1)
+
+ head_mask = self.get_head_mask(head_mask, self.config.num_layers)
+
+ hidden_states = self.drop(input_embeds + position_embeds)
+ output_shape = input_shape + (hidden_states.size(-1),)
+
+ all_self_attentions = () if output_attentions else None
+ all_hidden_states = () if output_hidden_states else None
+
+ for i, block in enumerate(self.layers):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ outputs = block(
+ hidden_states,
+ attention_mask=attention_mask,
+ head_mask=head_mask[i],
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = outputs[0]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (outputs[1],)
+
+ hidden_states = self.layernorm_final(hidden_states)
+ hidden_states = hidden_states.view(output_shape)
+
+ # Add last hidden state
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ logits = self.lm_heads[codebook_idx - self.config.n_codes_given](hidden_states)
+
+ if not return_dict:
+ return tuple(v for v in [None, logits, all_hidden_states, all_self_attentions] if v is not None)
+
+ return MaskedLMOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+ def generate(
+ self,
+ coarse_output: torch.Tensor,
+ semantic_generation_config: BarkSemanticGenerationConfig = None,
+ coarse_generation_config: BarkCoarseGenerationConfig = None,
+ fine_generation_config: BarkFineGenerationConfig = None,
+ codebook_size: int = 1024,
+ history_prompt: Optional[Dict[str, torch.Tensor]] = None,
+ **kwargs,
+ ) -> torch.LongTensor:
+ """
+ Generates fine acoustics tokens from input coarse acoustics tokens and an additional optional `Bark` speaker
+ prompt.
+
+ Args:
+ coarse_output (`torch.Tensor` of shape (batch_size, seq_len)):
+ Input coarse acoustics ids, i.e the output of `BarkCoarseModel.generate`.
+ semantic_generation_config (`BarkSemanticGenerationConfig`):
+ Generation config indicating how to generate the semantic tokens.
+ coarse_generation_config (`BarkCoarseGenerationConfig`):
+ Generation config indicating how to generate the coarse tokens.
+ fine_generation_config (`BarkFineGenerationConfig`):
+ Generation config indicating how to generate the fine tokens.
+ codebook_size (`int`, *optional*, defaults to 1024):
+ Codebook channel size, i.e. the size of the output vocabulary per codebook channel.
+ history_prompt (`Optional[Dict[str,torch.Tensor]]`, *optional*):
+ Optional `Bark` speaker prompt.
+ Returns:
+ torch.LongTensor: Output fine acoustics tokens.
+ """
+ if semantic_generation_config is None:
+ raise ValueError("`semantic_generation_config` has to be provided")
+
+ if coarse_generation_config is None:
+ raise ValueError("`coarse_generation_config` has to be provided")
+
+ if fine_generation_config is None:
+ raise ValueError("`fine_generation_config` has to be provided")
+
+ # since we don't really use GenerationConfig through the fine model (autoencoder)
+ # and since only temperature is used from the classic GenerationConfig parameters
+ # manually impose the kwargs priority over the generation config
+ temperature = kwargs.get("temperature", fine_generation_config.temperature)
+
+ max_fine_history_length = fine_generation_config.max_fine_history_length
+ max_fine_input_length = fine_generation_config.max_fine_input_length
+
+ # shape: (batch, n_coarse_codebooks * seq_len)
+ # new_shape: (batch, seq_len, n_coarse_codebooks)
+ coarse_output = coarse_output.view(coarse_output.shape[0], -1, coarse_generation_config.n_coarse_codebooks)
+
+ # brings ids into the range [0, codebook_size -1]
+ coarse_output = torch.remainder(coarse_output - semantic_generation_config.semantic_vocab_size, codebook_size)
+ batch_size = coarse_output.shape[0]
+
+ if history_prompt is not None:
+ x_fine_history = torch.repeat_interleave(history_prompt["fine_prompt"].T[None], batch_size, dim=0)
+ # transpose to get to shape (seq_len, n_fine_codebooks)
+ else:
+ x_fine_history = None
+
+ n_coarse = coarse_generation_config.n_coarse_codebooks
+
+ # pad the last 6th codebooks
+ fine_input = F.pad(
+ coarse_output,
+ (0, fine_generation_config.n_fine_codebooks - n_coarse),
+ "constant",
+ codebook_size,
+ )
+
+ # prepend history if available (max max_fine_history_length)
+ if x_fine_history is not None:
+ fine_input = torch.cat([x_fine_history[:, -max_fine_history_length:, :], fine_input], dim=1)
+
+ # len of the fine_history that has been added to fine_input
+ n_history = x_fine_history[:, -max_fine_history_length:, :].shape[1]
+ else:
+ n_history = 0
+
+ n_remove_from_end = 0
+ # need to pad if too short (since non-causal model)
+ if fine_input.shape[1] < max_fine_input_length:
+ n_remove_from_end = max_fine_input_length - fine_input.shape[1]
+ fine_input = F.pad(fine_input, (0, 0, 0, n_remove_from_end), mode="constant", value=codebook_size)
+
+ # we can be lazy about fractional loop and just keep overwriting codebooks.
+ # seems that coarse_output.shape[1] - (max_fine_input_length - n_history) is equal to minus n_remove_from_end
+ # So if we needed to pad because too short, n_loops is always 1 (because n_remove_from_end > 0)
+ # If not, we loop over at least twice.
+
+ n_loops = (coarse_output.shape[1] - (max_fine_input_length - n_history)) / max_fine_history_length
+ n_loops = int(np.ceil(n_loops))
+ n_loops = max(0, n_loops) + 1
+
+ for n_outer in range(n_loops):
+ start_idx = min([n_outer * max_fine_history_length, fine_input.shape[1] - max_fine_input_length])
+
+ start_fill_idx = min(
+ [n_history + n_outer * max_fine_history_length, fine_input.shape[1] - max_fine_history_length]
+ )
+ rel_start_fill_idx = start_fill_idx - start_idx
+ input_buffer = fine_input[:, start_idx : start_idx + max_fine_input_length, :]
+ for n_inner in range(n_coarse, fine_generation_config.n_fine_codebooks):
+ logits = self.forward(n_inner, input_buffer).logits
+ if temperature is None or temperature == 1.0:
+ relevant_logits = logits[:, rel_start_fill_idx:, :codebook_size]
+ codebook_preds = torch.argmax(relevant_logits, -1)
+ else:
+ relevant_logits = logits[:, :, :codebook_size] / temperature
+ # apply softmax
+ probs = F.softmax(relevant_logits, dim=-1)[:, rel_start_fill_idx:max_fine_input_length]
+ # reshape to 2D: (batch_size, seq_len, codebook_size) -> (batch_size*seq_len, codebook_size)
+ probs = probs.reshape((-1, codebook_size))
+ # multinomial then reshape : (batch_size*seq_len)-> (batch_size,seq_len)
+ codebook_preds = torch.multinomial(probs, num_samples=1).view(batch_size, -1)
+ codebook_preds = codebook_preds.to(torch.int32)
+ input_buffer[:, rel_start_fill_idx:, n_inner] = codebook_preds
+ del logits, codebook_preds
+
+ # transfer into fine_input
+ for n_inner in range(n_coarse, fine_generation_config.n_fine_codebooks):
+ fine_input[
+ :, start_fill_idx : start_fill_idx + (max_fine_input_length - rel_start_fill_idx), n_inner
+ ] = input_buffer[:, rel_start_fill_idx:, n_inner]
+ del input_buffer
+
+ fine_input = fine_input.transpose(1, 2)[:, :, n_history:]
+ if n_remove_from_end > 0:
+ fine_input = fine_input[:, :, :-n_remove_from_end]
+
+ if fine_input.shape[-1] != coarse_output.shape[-2]:
+ raise ValueError("input and output should have the same seq_len")
+
+ return fine_input
+
+
+@add_start_docstrings(
+ """
+ The full Bark model, a text-to-speech model composed of 4 sub-models:
+ - [`BarkSemanticModel`] (also referred to as the 'text' model): a causal auto-regressive transformer model that
+ takes
+ as input tokenized text, and predicts semantic text tokens that capture the meaning of the text.
+ - [`BarkCoarseModel`] (also refered to as the 'coarse acoustics' model), also a causal autoregressive transformer,
+ that takes into input the results of the last model. It aims at regressing the first two audio codebooks necessary
+ to `encodec`.
+ - [`BarkFineModel`] (the 'fine acoustics' model), this time a non-causal autoencoder transformer, which iteratively
+ predicts the last codebooks based on the sum of the previous codebooks embeddings.
+ - having predicted all the codebook channels from the [`EncodecModel`], Bark uses it to decode the output audio
+ array.
+
+ It should be noted that each of the first three modules can support conditional speaker embeddings to condition the
+ output sound according to specific predefined voice.
+ """,
+ BARK_START_DOCSTRING,
+)
+class BarkModel(BarkPreTrainedModel):
+ config_class = BarkConfig
+
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.semantic = BarkSemanticModel(config.semantic_config)
+ self.coarse_acoustics = BarkCoarseModel(config.coarse_acoustics_config)
+ self.fine_acoustics = BarkFineModel(config.fine_acoustics_config)
+
+ self.codec_model = AutoModel.from_config(config.codec_config)
+
+ self.config = config
+
+ @classmethod
+ def can_generate(cls) -> bool:
+ # Bark has a unique model structure, where the external class (`BarkModel`) doesn't need to inherit from
+ # `GenerationMixin` (it has a non-standard generation method), but one of the internal models do
+ # (`BarkSemanticModel`). This means that the base `can_generate()` will return `False`, but we need to
+ # override it so as to do `GenerationConfig` handling in multiple parts of the codebase.
+ return True
+
+ @property
+ def device(self) -> torch.device:
+ """
+ `torch.device`: The device on which the module is (assuming that all the module parameters are on the same
+ device).
+ """
+ # for bark_model, device must be verified on its sub-models
+ # if has _hf_hook, has been offloaded so the device has to be found in the hook
+ if not hasattr(self.semantic, "_hf_hook"):
+ return get_parameter_device(self)
+ for module in self.semantic.modules():
+ if (
+ hasattr(module, "_hf_hook")
+ and hasattr(module._hf_hook, "execution_device")
+ and module._hf_hook.execution_device is not None
+ ):
+ return torch.device(module._hf_hook.execution_device)
+
+ def enable_cpu_offload(
+ self,
+ accelerator_id: Optional[int] = 0,
+ **kwargs,
+ ):
+ r"""
+ Offloads all sub-models to CPU using accelerate, reducing memory usage with a low impact on performance. This
+ method moves one whole sub-model at a time to the accelerator when it is used, and the sub-model remains in accelerator until the next sub-model runs.
+
+ Args:
+ accelerator_id (`int`, *optional*, defaults to 0):
+ accelerator id on which the sub-models will be loaded and offloaded. This argument is deprecated.
+ kwargs (`dict`, *optional*):
+ additional keyword arguments:
+ `gpu_id`: accelerator id on which the sub-models will be loaded and offloaded.
+ """
+ if is_accelerate_available():
+ from accelerate import cpu_offload_with_hook
+ else:
+ raise ImportError("`enable_model_cpu_offload` requires `accelerate`.")
+
+ gpu_id = kwargs.get("gpu_id", 0)
+
+ if gpu_id != 0:
+ warnings.warn(
+ "The argument `gpu_id` is deprecated and will be removed in version 4.54.0 of Transformers. Please use `accelerator_id` instead.",
+ FutureWarning,
+ )
+ accelerator_id = gpu_id
+
+ device_type = "cuda"
+ if is_torch_accelerator_available():
+ device_type = torch.accelerator.current_accelerator().type
+ device = torch.device(f"{device_type}:{accelerator_id}")
+
+ torch_accelerator_module = getattr(torch, device_type)
+ if self.device.type != "cpu":
+ self.to("cpu")
+ torch_accelerator_module.empty_cache() # otherwise we don't see the memory savings (but they probably exist)
+
+ # this layer is used outside the first foward pass of semantic so need to be loaded before semantic
+ self.semantic.input_embeds_layer, _ = cpu_offload_with_hook(self.semantic.input_embeds_layer, device)
+
+ hook = None
+ for cpu_offloaded_model in [
+ self.semantic,
+ self.coarse_acoustics,
+ self.fine_acoustics,
+ ]:
+ _, hook = cpu_offload_with_hook(cpu_offloaded_model, device, prev_module_hook=hook)
+
+ self.fine_acoustics_hook = hook
+
+ _, hook = cpu_offload_with_hook(self.codec_model, device, prev_module_hook=hook)
+
+ # We'll offload the last model manually.
+ self.codec_model_hook = hook
+
+ def codec_decode(self, fine_output, output_lengths=None):
+ """Turn quantized audio codes into audio array using encodec."""
+
+ fine_output = fine_output.transpose(0, 1)
+ emb = self.codec_model.quantizer.decode(fine_output)
+
+ if output_lengths is not None:
+ # encodec uses LSTMs which behaves differently with appended padding
+ # decoding with encodec takes around 0.1% of the total generation time
+ # to keep generation quality, we break batching
+ out = [sample[:, :l].unsqueeze(0) for (sample, l) in zip(emb, output_lengths)]
+ audio_arr = [self.codec_model.decoder(sample).squeeze() for sample in out]
+ else:
+ out = self.codec_model.decoder(emb)
+ audio_arr = out.squeeze(1) # squeeze the codebook dimension
+
+ return audio_arr
+
+ @torch.no_grad()
+ def generate(
+ self,
+ input_ids: Optional[torch.Tensor] = None,
+ history_prompt: Optional[Dict[str, torch.Tensor]] = None,
+ return_output_lengths: Optional[bool] = None,
+ **kwargs,
+ ) -> torch.LongTensor:
+ """
+ Generates audio from an input prompt and an additional optional `Bark` speaker prompt.
+
+ Args:
+ input_ids (`Optional[torch.Tensor]` of shape (batch_size, seq_len), *optional*):
+ Input ids. Will be truncated up to 256 tokens. Note that the output audios will be as long as the
+ longest generation among the batch.
+ history_prompt (`Optional[Dict[str,torch.Tensor]]`, *optional*):
+ Optional `Bark` speaker prompt. Note that for now, this model takes only one speaker prompt per batch.
+ kwargs (*optional*): Remaining dictionary of keyword arguments. Keyword arguments are of two types:
+
+ - Without a prefix, they will be entered as `**kwargs` for the `generate` method of each sub-model.
+ - With a *semantic_*, *coarse_*, *fine_* prefix, they will be input for the `generate` method of the
+ semantic, coarse and fine respectively. It has the priority over the keywords without a prefix.
+
+ This means you can, for example, specify a generation strategy for all sub-models except one.
+ return_output_lengths (`bool`, *optional*):
+ Whether or not to return the waveform lengths. Useful when batching.
+ Returns:
+ By default:
+ - **audio_waveform** (`torch.Tensor` of shape (batch_size, seq_len)): Generated audio waveform.
+ When `return_output_lengths=True`:
+ Returns a tuple made of:
+ - **audio_waveform** (`torch.Tensor` of shape (batch_size, seq_len)): Generated audio waveform.
+ - **output_lengths** (`torch.Tensor` of shape (batch_size)): The length of each waveform in the batch
+ Example:
+
+ ```python
+ >>> from transformers import AutoProcessor, BarkModel
+
+ >>> processor = AutoProcessor.from_pretrained("suno/bark-small")
+ >>> model = BarkModel.from_pretrained("suno/bark-small")
+
+ >>> # To add a voice preset, you can pass `voice_preset` to `BarkProcessor.__call__(...)`
+ >>> voice_preset = "v2/en_speaker_6"
+
+ >>> inputs = processor("Hello, my dog is cute, I need him in my life", voice_preset=voice_preset)
+
+ >>> audio_array = model.generate(**inputs, semantic_max_new_tokens=100)
+ >>> audio_array = audio_array.cpu().numpy().squeeze()
+ ```
+ """
+ # TODO (joao):workaround until nested generation config is compatible with PreTrained Model
+ # todo: dict
+ semantic_generation_config = BarkSemanticGenerationConfig(**self.generation_config.semantic_config)
+ coarse_generation_config = BarkCoarseGenerationConfig(**self.generation_config.coarse_acoustics_config)
+ fine_generation_config = BarkFineGenerationConfig(**self.generation_config.fine_acoustics_config)
+
+ kwargs_semantic = {
+ # if "attention_mask" is set, it should not be passed to CoarseModel and FineModel
+ "attention_mask": kwargs.pop("attention_mask", None),
+ "min_eos_p": kwargs.pop("min_eos_p", None),
+ }
+ kwargs_coarse = {}
+ kwargs_fine = {}
+ for key, value in kwargs.items():
+ if key.startswith("semantic_"):
+ key = key[len("semantic_") :]
+ kwargs_semantic[key] = value
+ elif key.startswith("coarse_"):
+ key = key[len("coarse_") :]
+ kwargs_coarse[key] = value
+ elif key.startswith("fine_"):
+ key = key[len("fine_") :]
+ kwargs_fine[key] = value
+ else:
+ # If the key is already in a specific config, then it's been set with a
+ # submodules specific value and we don't override
+ if key not in kwargs_semantic:
+ kwargs_semantic[key] = value
+ if key not in kwargs_coarse:
+ kwargs_coarse[key] = value
+ if key not in kwargs_fine:
+ kwargs_fine[key] = value
+
+ # 1. Generate from the semantic model
+ if "generation_config" in kwargs_semantic:
+ kwargs_semantic.pop("generation_config")
+ semantic_output = self.semantic.generate(
+ input_ids,
+ history_prompt=history_prompt,
+ semantic_generation_config=semantic_generation_config,
+ **kwargs_semantic,
+ )
+
+ # 2. Generate from the coarse model
+ if "generation_config" in kwargs_coarse:
+ kwargs_coarse.pop("generation_config")
+ coarse_output = self.coarse_acoustics.generate(
+ semantic_output,
+ history_prompt=history_prompt,
+ semantic_generation_config=semantic_generation_config,
+ coarse_generation_config=coarse_generation_config,
+ codebook_size=self.generation_config.codebook_size,
+ return_output_lengths=return_output_lengths,
+ **kwargs_coarse,
+ )
+
+ output_lengths = None
+ if return_output_lengths:
+ coarse_output, output_lengths = coarse_output
+ # (batch_size, seq_len*coarse_codebooks) -> (batch_size, seq_len)
+ output_lengths = output_lengths // coarse_generation_config.n_coarse_codebooks
+
+ # 3. "generate" from the fine model
+ if "generation_config" in kwargs_fine:
+ kwargs_fine.pop("generation_config")
+ output = self.fine_acoustics.generate(
+ coarse_output,
+ history_prompt=history_prompt,
+ semantic_generation_config=semantic_generation_config,
+ coarse_generation_config=coarse_generation_config,
+ fine_generation_config=fine_generation_config,
+ codebook_size=self.generation_config.codebook_size,
+ **kwargs_fine,
+ )
+
+ if getattr(self, "fine_acoustics_hook", None) is not None:
+ # Manually offload fine_acoustics to CPU
+ # and load codec_model to GPU
+ # since bark doesn't use codec_model forward pass
+ self.fine_acoustics_hook.offload()
+ self.codec_model = self.codec_model.to(self.device)
+
+ # 4. Decode the output and generate audio array
+ audio = self.codec_decode(output, output_lengths)
+
+ if getattr(self, "codec_model_hook", None) is not None:
+ # Offload codec_model to CPU
+ self.codec_model_hook.offload()
+
+ if return_output_lengths:
+ output_lengths = [len(sample) for sample in audio]
+ audio = nn.utils.rnn.pad_sequence(audio, batch_first=True, padding_value=0)
+ return audio, output_lengths
+
+ return audio
+
+ @classmethod
+ def _check_and_enable_flash_attn_2(
+ cls,
+ config,
+ torch_dtype: Optional[torch.dtype] = None,
+ device_map: Optional[Union[str, Dict[str, int]]] = None,
+ hard_check_only: bool = False,
+ check_device_map: bool = False,
+ ):
+ """
+ `_check_and_enable_flash_attn_2` originally don't expand flash attention enabling to the model
+ sub-configurations. We override the original method to make sure that Bark sub-models are using Flash Attention
+ if necessary.
+
+ If you don't know about Flash Attention, check out the official repository of flash attention:
+ https://github.com/Dao-AILab/flash-attention
+
+ For using Flash Attention 1.0 you can do it directly via the `BetterTransformer` API, have a look at this
+ specific section of the documentation to learn more about it:
+ https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#decoder-models
+
+ The method checks if the current setup is compatible with Flash Attention as it requires the model to be in
+ half precision and not ran on CPU.
+
+ If all checks pass and `hard_check_only` is False, the method will set the config attribute `_attn_implementation` to "flash_attention_2" so that the model
+ can initialize the correct attention module
+ """
+ config = super()._check_and_enable_flash_attn_2(
+ config, torch_dtype, device_map, hard_check_only=hard_check_only, check_device_map=check_device_map
+ )
+
+ config.semantic_config._attn_implementation = config._attn_implementation
+ config.coarse_acoustics_config._attn_implementation = config._attn_implementation
+ config.fine_acoustics_config._attn_implementation = config._attn_implementation
+ return config
+
+
+__all__ = [
+ "BarkFineModel",
+ "BarkSemanticModel",
+ "BarkCoarseModel",
+ "BarkModel",
+ "BarkPreTrainedModel",
+ "BarkCausalModel",
+]
diff --git a/docs/transformers/src/transformers/models/bark/processing_bark.py b/docs/transformers/src/transformers/models/bark/processing_bark.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2ec0629e42146f0ce743c3129c32b58a3fa4f47
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bark/processing_bark.py
@@ -0,0 +1,296 @@
+# coding=utf-8
+# Copyright 2023 The Suno AI Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Processor class for Bark
+"""
+
+import json
+import os
+from typing import Optional
+
+import numpy as np
+
+from ...feature_extraction_utils import BatchFeature
+from ...processing_utils import ProcessorMixin
+from ...utils import logging
+from ...utils.hub import cached_file
+from ..auto import AutoTokenizer
+
+
+logger = logging.get_logger(__name__)
+
+
+class BarkProcessor(ProcessorMixin):
+ r"""
+ Constructs a Bark processor which wraps a text tokenizer and optional Bark voice presets into a single processor.
+
+ Args:
+ tokenizer ([`PreTrainedTokenizer`]):
+ An instance of [`PreTrainedTokenizer`].
+ speaker_embeddings (`Dict[Dict[str]]`, *optional*):
+ Optional nested speaker embeddings dictionary. The first level contains voice preset names (e.g
+ `"en_speaker_4"`). The second level contains `"semantic_prompt"`, `"coarse_prompt"` and `"fine_prompt"`
+ embeddings. The values correspond to the path of the corresponding `np.ndarray`. See
+ [here](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c) for
+ a list of `voice_preset_names`.
+
+ """
+
+ tokenizer_class = "AutoTokenizer"
+ attributes = ["tokenizer"]
+
+ preset_shape = {
+ "semantic_prompt": 1,
+ "coarse_prompt": 2,
+ "fine_prompt": 2,
+ }
+
+ def __init__(self, tokenizer, speaker_embeddings=None):
+ super().__init__(tokenizer)
+
+ self.speaker_embeddings = speaker_embeddings
+
+ @classmethod
+ def from_pretrained(
+ cls, pretrained_processor_name_or_path, speaker_embeddings_dict_path="speaker_embeddings_path.json", **kwargs
+ ):
+ r"""
+ Instantiate a Bark processor associated with a pretrained model.
+
+ Args:
+ pretrained_model_name_or_path (`str` or `os.PathLike`):
+ This can be either:
+
+ - a string, the *model id* of a pretrained [`BarkProcessor`] hosted inside a model repo on
+ huggingface.co.
+ - a path to a *directory* containing a processor saved using the [`~BarkProcessor.save_pretrained`]
+ method, e.g., `./my_model_directory/`.
+ speaker_embeddings_dict_path (`str`, *optional*, defaults to `"speaker_embeddings_path.json"`):
+ The name of the `.json` file containing the speaker_embeddings dictionary located in
+ `pretrained_model_name_or_path`. If `None`, no speaker_embeddings is loaded.
+ **kwargs
+ Additional keyword arguments passed along to both
+ [`~tokenization_utils_base.PreTrainedTokenizer.from_pretrained`].
+ """
+
+ if speaker_embeddings_dict_path is not None:
+ speaker_embeddings_path = cached_file(
+ pretrained_processor_name_or_path,
+ speaker_embeddings_dict_path,
+ subfolder=kwargs.pop("subfolder", None),
+ cache_dir=kwargs.pop("cache_dir", None),
+ force_download=kwargs.pop("force_download", False),
+ proxies=kwargs.pop("proxies", None),
+ resume_download=kwargs.pop("resume_download", None),
+ local_files_only=kwargs.pop("local_files_only", False),
+ token=kwargs.pop("use_auth_token", None),
+ revision=kwargs.pop("revision", None),
+ _raise_exceptions_for_gated_repo=False,
+ _raise_exceptions_for_missing_entries=False,
+ _raise_exceptions_for_connection_errors=False,
+ )
+ if speaker_embeddings_path is None:
+ logger.warning(
+ f"""`{os.path.join(pretrained_processor_name_or_path, speaker_embeddings_dict_path)}` does not exists
+ , no preloaded speaker embeddings will be used - Make sure to provide a correct path to the json
+ dictionary if wanted, otherwise set `speaker_embeddings_dict_path=None`."""
+ )
+ speaker_embeddings = None
+ else:
+ with open(speaker_embeddings_path) as speaker_embeddings_json:
+ speaker_embeddings = json.load(speaker_embeddings_json)
+ else:
+ speaker_embeddings = None
+
+ tokenizer = AutoTokenizer.from_pretrained(pretrained_processor_name_or_path, **kwargs)
+
+ return cls(tokenizer=tokenizer, speaker_embeddings=speaker_embeddings)
+
+ def save_pretrained(
+ self,
+ save_directory,
+ speaker_embeddings_dict_path="speaker_embeddings_path.json",
+ speaker_embeddings_directory="speaker_embeddings",
+ push_to_hub: bool = False,
+ **kwargs,
+ ):
+ """
+ Saves the attributes of this processor (tokenizer...) in the specified directory so that it can be reloaded
+ using the [`~BarkProcessor.from_pretrained`] method.
+
+ Args:
+ save_directory (`str` or `os.PathLike`):
+ Directory where the tokenizer files and the speaker embeddings will be saved (directory will be created
+ if it does not exist).
+ speaker_embeddings_dict_path (`str`, *optional*, defaults to `"speaker_embeddings_path.json"`):
+ The name of the `.json` file that will contains the speaker_embeddings nested path dictionary, if it
+ exists, and that will be located in `pretrained_model_name_or_path/speaker_embeddings_directory`.
+ speaker_embeddings_directory (`str`, *optional*, defaults to `"speaker_embeddings/"`):
+ The name of the folder in which the speaker_embeddings arrays will be saved.
+ push_to_hub (`bool`, *optional*, defaults to `False`):
+ Whether or not to push your model to the Hugging Face model hub after saving it. You can specify the
+ repository you want to push to with `repo_id` (will default to the name of `save_directory` in your
+ namespace).
+ kwargs:
+ Additional key word arguments passed along to the [`~utils.PushToHubMixin.push_to_hub`] method.
+ """
+ if self.speaker_embeddings is not None:
+ os.makedirs(os.path.join(save_directory, speaker_embeddings_directory, "v2"), exist_ok=True)
+
+ embeddings_dict = {}
+
+ embeddings_dict["repo_or_path"] = save_directory
+
+ for prompt_key in self.speaker_embeddings:
+ if prompt_key != "repo_or_path":
+ voice_preset = self._load_voice_preset(prompt_key)
+
+ tmp_dict = {}
+ for key in self.speaker_embeddings[prompt_key]:
+ np.save(
+ os.path.join(
+ embeddings_dict["repo_or_path"], speaker_embeddings_directory, f"{prompt_key}_{key}"
+ ),
+ voice_preset[key],
+ allow_pickle=False,
+ )
+ tmp_dict[key] = os.path.join(speaker_embeddings_directory, f"{prompt_key}_{key}.npy")
+
+ embeddings_dict[prompt_key] = tmp_dict
+
+ with open(os.path.join(save_directory, speaker_embeddings_dict_path), "w") as fp:
+ json.dump(embeddings_dict, fp)
+
+ super().save_pretrained(save_directory, push_to_hub, **kwargs)
+
+ def _load_voice_preset(self, voice_preset: Optional[str] = None, **kwargs):
+ voice_preset_paths = self.speaker_embeddings[voice_preset]
+
+ voice_preset_dict = {}
+ for key in ["semantic_prompt", "coarse_prompt", "fine_prompt"]:
+ if key not in voice_preset_paths:
+ raise ValueError(
+ f"Voice preset unrecognized, missing {key} as a key in self.speaker_embeddings[{voice_preset}]."
+ )
+
+ path = cached_file(
+ self.speaker_embeddings.get("repo_or_path", "/"),
+ voice_preset_paths[key],
+ subfolder=kwargs.pop("subfolder", None),
+ cache_dir=kwargs.pop("cache_dir", None),
+ force_download=kwargs.pop("force_download", False),
+ proxies=kwargs.pop("proxies", None),
+ resume_download=kwargs.pop("resume_download", None),
+ local_files_only=kwargs.pop("local_files_only", False),
+ token=kwargs.pop("use_auth_token", None),
+ revision=kwargs.pop("revision", None),
+ _raise_exceptions_for_gated_repo=False,
+ _raise_exceptions_for_missing_entries=False,
+ _raise_exceptions_for_connection_errors=False,
+ )
+ if path is None:
+ raise ValueError(
+ f"""`{os.path.join(self.speaker_embeddings.get("repo_or_path", "/"), voice_preset_paths[key])}` does not exists
+ , no preloaded voice preset will be used - Make sure to provide correct paths to the {voice_preset}
+ embeddings."""
+ )
+
+ voice_preset_dict[key] = np.load(path)
+
+ return voice_preset_dict
+
+ def _validate_voice_preset_dict(self, voice_preset: Optional[dict] = None):
+ for key in ["semantic_prompt", "coarse_prompt", "fine_prompt"]:
+ if key not in voice_preset:
+ raise ValueError(f"Voice preset unrecognized, missing {key} as a key.")
+
+ if not isinstance(voice_preset[key], np.ndarray):
+ raise TypeError(f"{key} voice preset must be a {str(self.preset_shape[key])}D ndarray.")
+
+ if len(voice_preset[key].shape) != self.preset_shape[key]:
+ raise ValueError(f"{key} voice preset must be a {str(self.preset_shape[key])}D ndarray.")
+
+ def __call__(
+ self,
+ text=None,
+ voice_preset=None,
+ return_tensors="pt",
+ max_length=256,
+ add_special_tokens=False,
+ return_attention_mask=True,
+ return_token_type_ids=False,
+ **kwargs,
+ ):
+ """
+ Main method to prepare for the model one or several sequences(s). This method forwards the `text` and `kwargs`
+ arguments to the AutoTokenizer's [`~AutoTokenizer.__call__`] to encode the text. The method also proposes a
+ voice preset which is a dictionary of arrays that conditions `Bark`'s output. `kwargs` arguments are forwarded
+ to the tokenizer and to `cached_file` method if `voice_preset` is a valid filename.
+
+ Args:
+ text (`str`, `List[str]`, `List[List[str]]`):
+ The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
+ (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
+ `is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
+ voice_preset (`str`, `Dict[np.ndarray]`):
+ The voice preset, i.e the speaker embeddings. It can either be a valid voice_preset name, e.g
+ `"en_speaker_1"`, or directly a dictionary of `np.ndarray` embeddings for each submodel of `Bark`. Or
+ it can be a valid file name of a local `.npz` single voice preset.
+ return_tensors (`str` or [`~utils.TensorType`], *optional*):
+ If set, will return tensors of a particular framework. Acceptable values are:
+
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+
+ Returns:
+ Tuple([`BatchEncoding`], [`BatchFeature`]): A tuple composed of a [`BatchEncoding`], i.e the output of the
+ `tokenizer` and a [`BatchFeature`], i.e the voice preset with the right tensors type.
+ """
+ if voice_preset is not None and not isinstance(voice_preset, dict):
+ if (
+ isinstance(voice_preset, str)
+ and self.speaker_embeddings is not None
+ and voice_preset in self.speaker_embeddings
+ ):
+ voice_preset = self._load_voice_preset(voice_preset)
+
+ else:
+ if isinstance(voice_preset, str) and not voice_preset.endswith(".npz"):
+ voice_preset = voice_preset + ".npz"
+
+ voice_preset = np.load(voice_preset)
+
+ if voice_preset is not None:
+ self._validate_voice_preset_dict(voice_preset, **kwargs)
+ voice_preset = BatchFeature(data=voice_preset, tensor_type=return_tensors)
+
+ encoded_text = self.tokenizer(
+ text,
+ return_tensors=return_tensors,
+ padding="max_length",
+ max_length=max_length,
+ return_attention_mask=return_attention_mask,
+ return_token_type_ids=return_token_type_ids,
+ add_special_tokens=add_special_tokens,
+ **kwargs,
+ )
+
+ if voice_preset is not None:
+ encoded_text["history_prompt"] = voice_preset
+
+ return encoded_text
+
+
+__all__ = ["BarkProcessor"]
diff --git a/docs/transformers/src/transformers/models/bart/__init__.py b/docs/transformers/src/transformers/models/bart/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8f4c713f4698d7c901ed06738efc8983e317805c
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bart/__init__.py
@@ -0,0 +1,31 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import _LazyModule
+from ...utils.import_utils import define_import_structure
+
+
+if TYPE_CHECKING:
+ from .configuration_bart import *
+ from .modeling_bart import *
+ from .modeling_flax_bart import *
+ from .modeling_tf_bart import *
+ from .tokenization_bart import *
+ from .tokenization_bart_fast import *
+else:
+ import sys
+
+ _file = globals()["__file__"]
+ sys.modules[__name__] = _LazyModule(__name__, _file, define_import_structure(_file), module_spec=__spec__)
diff --git a/docs/transformers/src/transformers/models/bart/configuration_bart.py b/docs/transformers/src/transformers/models/bart/configuration_bart.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ce4316e3c03150d1845b7a3f96409ae4b637e55
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bart/configuration_bart.py
@@ -0,0 +1,405 @@
+# coding=utf-8
+# Copyright 2021 The Fairseq Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""BART model configuration"""
+
+import warnings
+from collections import OrderedDict
+from typing import Any, Mapping, Optional
+
+from ... import PreTrainedTokenizer
+from ...configuration_utils import PretrainedConfig
+from ...onnx import OnnxConfig, OnnxConfigWithPast, OnnxSeq2SeqConfigWithPast
+from ...onnx.utils import compute_effective_axis_dimension
+from ...utils import TensorType, is_torch_available, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class BartConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`BartModel`]. It is used to instantiate a BART
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the BART
+ [facebook/bart-large](https://huggingface.co/facebook/bart-large) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+
+ Args:
+ vocab_size (`int`, *optional*, defaults to 50265):
+ Vocabulary size of the BART model. Defines the number of different tokens that can be represented by the
+ `inputs_ids` passed when calling [`BartModel`] or [`TFBartModel`].
+ d_model (`int`, *optional*, defaults to 1024):
+ Dimensionality of the layers and the pooler layer.
+ encoder_layers (`int`, *optional*, defaults to 12):
+ Number of encoder layers.
+ decoder_layers (`int`, *optional*, defaults to 12):
+ Number of decoder layers.
+ encoder_attention_heads (`int`, *optional*, defaults to 16):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ decoder_attention_heads (`int`, *optional*, defaults to 16):
+ Number of attention heads for each attention layer in the Transformer decoder.
+ decoder_ffn_dim (`int`, *optional*, defaults to 4096):
+ Dimensionality of the "intermediate" (often named feed-forward) layer in decoder.
+ encoder_ffn_dim (`int`, *optional*, defaults to 4096):
+ Dimensionality of the "intermediate" (often named feed-forward) layer in decoder.
+ activation_function (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"silu"` and `"gelu_new"` are supported.
+ dropout (`float`, *optional*, defaults to 0.1):
+ The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ activation_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for activations inside the fully connected layer.
+ classifier_dropout (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for classifier.
+ max_position_embeddings (`int`, *optional*, defaults to 1024):
+ The maximum sequence length that this model might ever be used with. Typically set this to something large
+ just in case (e.g., 512 or 1024 or 2048).
+ init_std (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ encoder_layerdrop (`float`, *optional*, defaults to 0.0):
+ The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ for more details.
+ decoder_layerdrop (`float`, *optional*, defaults to 0.0):
+ The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556)
+ for more details.
+ scale_embedding (`bool`, *optional*, defaults to `False`):
+ Scale embeddings by diving by sqrt(d_model).
+ use_cache (`bool`, *optional*, defaults to `True`):
+ Whether or not the model should return the last key/values attentions (not used by all models).
+ num_labels (`int`, *optional*, defaults to 3):
+ The number of labels to use in [`BartForSequenceClassification`].
+ forced_eos_token_id (`int`, *optional*, defaults to 2):
+ The id of the token to force as the last generated token when `max_length` is reached. Usually set to
+ `eos_token_id`.
+
+ Example:
+
+ ```python
+ >>> from transformers import BartConfig, BartModel
+
+ >>> # Initializing a BART facebook/bart-large style configuration
+ >>> configuration = BartConfig()
+
+ >>> # Initializing a model (with random weights) from the facebook/bart-large style configuration
+ >>> model = BartModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "bart"
+ keys_to_ignore_at_inference = ["past_key_values"]
+ attribute_map = {"num_attention_heads": "encoder_attention_heads", "hidden_size": "d_model"}
+
+ def __init__(
+ self,
+ vocab_size=50265,
+ max_position_embeddings=1024,
+ encoder_layers=12,
+ encoder_ffn_dim=4096,
+ encoder_attention_heads=16,
+ decoder_layers=12,
+ decoder_ffn_dim=4096,
+ decoder_attention_heads=16,
+ encoder_layerdrop=0.0,
+ decoder_layerdrop=0.0,
+ activation_function="gelu",
+ d_model=1024,
+ dropout=0.1,
+ attention_dropout=0.0,
+ activation_dropout=0.0,
+ init_std=0.02,
+ classifier_dropout=0.0,
+ scale_embedding=False,
+ use_cache=True,
+ num_labels=3,
+ pad_token_id=1,
+ bos_token_id=0,
+ eos_token_id=2,
+ is_encoder_decoder=True,
+ decoder_start_token_id=2,
+ forced_eos_token_id=2,
+ **kwargs,
+ ):
+ self.vocab_size = vocab_size
+ self.max_position_embeddings = max_position_embeddings
+ self.d_model = d_model
+ self.encoder_ffn_dim = encoder_ffn_dim
+ self.encoder_layers = encoder_layers
+ self.encoder_attention_heads = encoder_attention_heads
+ self.decoder_ffn_dim = decoder_ffn_dim
+ self.decoder_layers = decoder_layers
+ self.decoder_attention_heads = decoder_attention_heads
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.activation_dropout = activation_dropout
+ self.activation_function = activation_function
+ self.init_std = init_std
+ self.encoder_layerdrop = encoder_layerdrop
+ self.decoder_layerdrop = decoder_layerdrop
+ self.classifier_dropout = classifier_dropout
+ self.use_cache = use_cache
+ self.num_hidden_layers = encoder_layers
+ self.scale_embedding = scale_embedding # scale factor will be sqrt(d_model) if True
+
+ super().__init__(
+ num_labels=num_labels,
+ pad_token_id=pad_token_id,
+ bos_token_id=bos_token_id,
+ eos_token_id=eos_token_id,
+ is_encoder_decoder=is_encoder_decoder,
+ decoder_start_token_id=decoder_start_token_id,
+ forced_eos_token_id=forced_eos_token_id,
+ **kwargs,
+ )
+
+ # ensure backward compatibility for BART CNN models
+ if self.forced_bos_token_id is None and kwargs.get("force_bos_token_to_be_generated", False):
+ self.forced_bos_token_id = self.bos_token_id
+ warnings.warn(
+ f"Please make sure the config includes `forced_bos_token_id={self.bos_token_id}` in future versions. "
+ "The config can simply be saved and uploaded again to be fixed."
+ )
+
+
+class BartOnnxConfig(OnnxSeq2SeqConfigWithPast):
+ @property
+ def inputs(self) -> Mapping[str, Mapping[int, str]]:
+ if self.task in ["default", "seq2seq-lm"]:
+ common_inputs = OrderedDict(
+ [
+ ("input_ids", {0: "batch", 1: "encoder_sequence"}),
+ ("attention_mask", {0: "batch", 1: "encoder_sequence"}),
+ ]
+ )
+
+ if self.use_past:
+ common_inputs["decoder_input_ids"] = {0: "batch"}
+ common_inputs["decoder_attention_mask"] = {0: "batch", 1: "past_decoder_sequence + sequence"}
+ else:
+ common_inputs["decoder_input_ids"] = {0: "batch", 1: "decoder_sequence"}
+ common_inputs["decoder_attention_mask"] = {0: "batch", 1: "decoder_sequence"}
+
+ if self.use_past:
+ self.fill_with_past_key_values_(common_inputs, direction="inputs")
+ elif self.task == "causal-lm":
+ # TODO: figure this case out.
+ common_inputs = OrderedDict(
+ [
+ ("input_ids", {0: "batch", 1: "encoder_sequence"}),
+ ("attention_mask", {0: "batch", 1: "encoder_sequence"}),
+ ]
+ )
+ if self.use_past:
+ num_encoder_layers, _ = self.num_layers
+ for i in range(num_encoder_layers):
+ common_inputs[f"past_key_values.{i}.key"] = {0: "batch", 2: "past_sequence + sequence"}
+ common_inputs[f"past_key_values.{i}.value"] = {0: "batch", 2: "past_sequence + sequence"}
+ else:
+ common_inputs = OrderedDict(
+ [
+ ("input_ids", {0: "batch", 1: "encoder_sequence"}),
+ ("attention_mask", {0: "batch", 1: "encoder_sequence"}),
+ ("decoder_input_ids", {0: "batch", 1: "decoder_sequence"}),
+ ("decoder_attention_mask", {0: "batch", 1: "decoder_sequence"}),
+ ]
+ )
+
+ return common_inputs
+
+ @property
+ def outputs(self) -> Mapping[str, Mapping[int, str]]:
+ if self.task in ["default", "seq2seq-lm"]:
+ common_outputs = super().outputs
+ else:
+ common_outputs = super(OnnxConfigWithPast, self).outputs
+ if self.use_past:
+ num_encoder_layers, _ = self.num_layers
+ for i in range(num_encoder_layers):
+ common_outputs[f"present.{i}.key"] = {0: "batch", 2: "past_sequence + sequence"}
+ common_outputs[f"present.{i}.value"] = {0: "batch", 2: "past_sequence + sequence"}
+ return common_outputs
+
+ def _generate_dummy_inputs_for_default_and_seq2seq_lm(
+ self,
+ tokenizer: PreTrainedTokenizer,
+ batch_size: int = -1,
+ seq_length: int = -1,
+ is_pair: bool = False,
+ framework: Optional[TensorType] = None,
+ ) -> Mapping[str, Any]:
+ encoder_inputs = self._generate_dummy_inputs_for_sequence_classification_and_question_answering(
+ tokenizer, batch_size, seq_length, is_pair, framework
+ )
+
+ # Generate decoder inputs
+ decoder_seq_length = seq_length if not self.use_past else 1
+ decoder_inputs = self._generate_dummy_inputs_for_sequence_classification_and_question_answering(
+ tokenizer, batch_size, decoder_seq_length, is_pair, framework
+ )
+ decoder_inputs = {f"decoder_{name}": tensor for name, tensor in decoder_inputs.items()}
+ common_inputs = dict(**encoder_inputs, **decoder_inputs)
+
+ if self.use_past:
+ if not is_torch_available():
+ raise ValueError("Cannot generate dummy past_keys inputs without PyTorch installed.")
+ else:
+ import torch
+ batch, encoder_seq_length = common_inputs["input_ids"].shape
+ decoder_seq_length = common_inputs["decoder_input_ids"].shape[1]
+ num_encoder_attention_heads, num_decoder_attention_heads = self.num_attention_heads
+ encoder_shape = (
+ batch,
+ num_encoder_attention_heads,
+ encoder_seq_length,
+ self._config.hidden_size // num_encoder_attention_heads,
+ )
+ decoder_past_length = decoder_seq_length + 3
+ decoder_shape = (
+ batch,
+ num_decoder_attention_heads,
+ decoder_past_length,
+ self._config.hidden_size // num_decoder_attention_heads,
+ )
+
+ common_inputs["decoder_attention_mask"] = torch.cat(
+ [common_inputs["decoder_attention_mask"], torch.ones(batch, decoder_past_length)], dim=1
+ )
+
+ common_inputs["past_key_values"] = []
+ # If the number of encoder and decoder layers are present in the model configuration, both are considered
+ num_encoder_layers, num_decoder_layers = self.num_layers
+ min_num_layers = min(num_encoder_layers, num_decoder_layers)
+ max_num_layers = max(num_encoder_layers, num_decoder_layers) - min_num_layers
+ remaining_side_name = "encoder" if num_encoder_layers > num_decoder_layers else "decoder"
+
+ for _ in range(min_num_layers):
+ common_inputs["past_key_values"].append(
+ (
+ torch.zeros(decoder_shape),
+ torch.zeros(decoder_shape),
+ torch.zeros(encoder_shape),
+ torch.zeros(encoder_shape),
+ )
+ )
+ # TODO: test this.
+ shape = encoder_shape if remaining_side_name == "encoder" else decoder_shape
+ for _ in range(min_num_layers, max_num_layers):
+ common_inputs["past_key_values"].append((torch.zeros(shape), torch.zeros(shape)))
+ return common_inputs
+
+ def _generate_dummy_inputs_for_causal_lm(
+ self,
+ tokenizer: PreTrainedTokenizer,
+ batch_size: int = -1,
+ seq_length: int = -1,
+ is_pair: bool = False,
+ framework: Optional[TensorType] = None,
+ ) -> Mapping[str, Any]:
+ common_inputs = self._generate_dummy_inputs_for_sequence_classification_and_question_answering(
+ tokenizer, batch_size, seq_length, is_pair, framework
+ )
+
+ if self.use_past:
+ if not is_torch_available():
+ raise ValueError("Cannot generate dummy past_keys inputs without PyTorch installed.")
+ else:
+ import torch
+ batch, seqlen = common_inputs["input_ids"].shape
+ # Not using the same length for past_key_values
+ past_key_values_length = seqlen + 2
+ num_encoder_layers, _ = self.num_layers
+ num_encoder_attention_heads, _ = self.num_attention_heads
+ past_shape = (
+ batch,
+ num_encoder_attention_heads,
+ past_key_values_length,
+ self._config.hidden_size // num_encoder_attention_heads,
+ )
+
+ mask_dtype = common_inputs["attention_mask"].dtype
+ common_inputs["attention_mask"] = torch.cat(
+ [common_inputs["attention_mask"], torch.ones(batch, past_key_values_length, dtype=mask_dtype)], dim=1
+ )
+ common_inputs["past_key_values"] = [
+ (torch.zeros(past_shape), torch.zeros(past_shape)) for _ in range(num_encoder_layers)
+ ]
+ return common_inputs
+
+ def _generate_dummy_inputs_for_sequence_classification_and_question_answering(
+ self,
+ tokenizer: PreTrainedTokenizer,
+ batch_size: int = -1,
+ seq_length: int = -1,
+ is_pair: bool = False,
+ framework: Optional[TensorType] = None,
+ ) -> Mapping[str, Any]:
+ # Copied from OnnxConfig.generate_dummy_inputs
+ # Did not use super(OnnxConfigWithPast, self).generate_dummy_inputs for code clarity.
+ # If dynamic axis (-1) we forward with a fixed dimension of 2 samples to avoid optimizations made by ONNX
+ batch_size = compute_effective_axis_dimension(
+ batch_size, fixed_dimension=OnnxConfig.default_fixed_batch, num_token_to_add=0
+ )
+
+ # If dynamic axis (-1) we forward with a fixed dimension of 8 tokens to avoid optimizations made by ONNX
+ token_to_add = tokenizer.num_special_tokens_to_add(is_pair)
+ seq_length = compute_effective_axis_dimension(
+ seq_length, fixed_dimension=OnnxConfig.default_fixed_sequence, num_token_to_add=token_to_add
+ )
+
+ # Generate dummy inputs according to compute batch and sequence
+ dummy_input = [" ".join([tokenizer.unk_token]) * seq_length] * batch_size
+ common_inputs = dict(tokenizer(dummy_input, return_tensors=framework))
+ return common_inputs
+
+ def generate_dummy_inputs(
+ self,
+ tokenizer: PreTrainedTokenizer,
+ batch_size: int = -1,
+ seq_length: int = -1,
+ is_pair: bool = False,
+ framework: Optional[TensorType] = None,
+ ) -> Mapping[str, Any]:
+ if self.task in ["default", "seq2seq-lm"]:
+ common_inputs = self._generate_dummy_inputs_for_default_and_seq2seq_lm(
+ tokenizer, batch_size=batch_size, seq_length=seq_length, is_pair=is_pair, framework=framework
+ )
+
+ elif self.task == "causal-lm":
+ common_inputs = self._generate_dummy_inputs_for_causal_lm(
+ tokenizer, batch_size=batch_size, seq_length=seq_length, is_pair=is_pair, framework=framework
+ )
+ else:
+ common_inputs = self._generate_dummy_inputs_for_sequence_classification_and_question_answering(
+ tokenizer, batch_size=batch_size, seq_length=seq_length, is_pair=is_pair, framework=framework
+ )
+
+ return common_inputs
+
+ def _flatten_past_key_values_(self, flattened_output, name, idx, t):
+ if self.task in ["default", "seq2seq-lm"]:
+ flattened_output = super()._flatten_past_key_values_(flattened_output, name, idx, t)
+ else:
+ flattened_output = super(OnnxSeq2SeqConfigWithPast, self)._flatten_past_key_values_(
+ flattened_output, name, idx, t
+ )
+
+
+__all__ = ["BartConfig", "BartOnnxConfig"]
diff --git a/docs/transformers/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py b/docs/transformers/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py
new file mode 100644
index 0000000000000000000000000000000000000000..84dc415443f0e81a43a528a9942142639bfae28e
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py
@@ -0,0 +1,156 @@
+# coding=utf-8
+# Copyright 2020 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert BART checkpoint."""
+
+import argparse
+import os
+from pathlib import Path
+
+import fairseq
+import torch
+from packaging import version
+from torch import nn
+
+from transformers import (
+ BartConfig,
+ BartForConditionalGeneration,
+ BartForSequenceClassification,
+ BartModel,
+ BartTokenizer,
+)
+from transformers.utils import logging
+
+
+FAIRSEQ_MODELS = ["bart.large", "bart.large.mnli", "bart.large.cnn", "bart_xsum/model.pt"]
+extra_arch = {"bart.large": BartModel, "bart.large.mnli": BartForSequenceClassification}
+if version.parse(fairseq.__version__) < version.parse("0.9.0"):
+ raise Exception("requires fairseq >= 0.9.0")
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+SAMPLE_TEXT = " Hello world! cécé herlolip"
+
+mnli_rename_keys = [
+ ("model.classification_heads.mnli.dense.weight", "classification_head.dense.weight"),
+ ("model.classification_heads.mnli.dense.bias", "classification_head.dense.bias"),
+ ("model.classification_heads.mnli.out_proj.weight", "classification_head.out_proj.weight"),
+ ("model.classification_heads.mnli.out_proj.bias", "classification_head.out_proj.bias"),
+]
+
+
+def remove_ignore_keys_(state_dict):
+ ignore_keys = [
+ "encoder.version",
+ "decoder.version",
+ "model.encoder.version",
+ "model.decoder.version",
+ "_float_tensor",
+ ]
+ for k in ignore_keys:
+ state_dict.pop(k, None)
+
+
+def rename_key(dct, old, new):
+ val = dct.pop(old)
+ dct[new] = val
+
+
+def load_xsum_checkpoint(checkpoint_path):
+ """Checkpoint path should end in model.pt"""
+ sd = torch.load(checkpoint_path, map_location="cpu", weights_only=True)
+ hub_interface = torch.hub.load("pytorch/fairseq", "bart.large.cnn").eval()
+ hub_interface.model.load_state_dict(sd["model"])
+ return hub_interface
+
+
+def make_linear_from_emb(emb):
+ vocab_size, emb_size = emb.weight.shape
+ lin_layer = nn.Linear(vocab_size, emb_size, bias=False)
+ lin_layer.weight.data = emb.weight.data
+ return lin_layer
+
+
+@torch.no_grad()
+def convert_bart_checkpoint(checkpoint_path, pytorch_dump_folder_path, hf_checkpoint_name=None):
+ """
+ Copy/paste/tweak model's weights to our BERT structure.
+ """
+ if not os.path.exists(checkpoint_path):
+ bart = torch.hub.load("pytorch/fairseq", checkpoint_path).eval()
+ else:
+ bart = load_xsum_checkpoint(checkpoint_path)
+
+ bart.model.upgrade_state_dict(bart.model.state_dict())
+ if hf_checkpoint_name is None:
+ hf_checkpoint_name = checkpoint_path.replace(".", "-")
+ config = BartConfig.from_pretrained(hf_checkpoint_name)
+ tokens = bart.encode(SAMPLE_TEXT).unsqueeze(0)
+ tokens2 = BartTokenizer.from_pretrained(hf_checkpoint_name).encode(SAMPLE_TEXT, return_tensors="pt").unsqueeze(0)
+ if not torch.eq(tokens, tokens2).all():
+ raise ValueError(
+ f"converted tokenizer and pretrained tokenizer returned different output: {tokens} != {tokens2}"
+ )
+
+ if checkpoint_path == "bart.large.mnli":
+ state_dict = bart.state_dict()
+ remove_ignore_keys_(state_dict)
+ state_dict["model.shared.weight"] = state_dict["model.decoder.embed_tokens.weight"]
+ for src, dest in mnli_rename_keys:
+ rename_key(state_dict, src, dest)
+ model = BartForSequenceClassification(config).eval()
+ model.load_state_dict(state_dict)
+ fairseq_output = bart.predict("mnli", tokens, return_logits=True)
+ new_model_outputs = model(tokens)[0] # logits
+ else: # no classification heads to worry about
+ state_dict = bart.model.state_dict()
+ remove_ignore_keys_(state_dict)
+ state_dict["shared.weight"] = state_dict["decoder.embed_tokens.weight"]
+ fairseq_output = bart.extract_features(tokens)
+ if hf_checkpoint_name == "facebook/bart-large":
+ model = BartModel(config).eval()
+ model.load_state_dict(state_dict)
+ new_model_outputs = model(tokens).model[0]
+ else:
+ model = BartForConditionalGeneration(config).eval() # an existing summarization ckpt
+ model.model.load_state_dict(state_dict)
+ if hasattr(model, "lm_head"):
+ model.lm_head = make_linear_from_emb(model.model.shared)
+ new_model_outputs = model.model(tokens)[0]
+
+ # Check results
+ if fairseq_output.shape != new_model_outputs.shape:
+ raise ValueError(
+ f"`fairseq_output` shape and `new_model_output` shape are different: {fairseq_output.shape=}, {new_model_outputs.shape}"
+ )
+ if (fairseq_output != new_model_outputs).any().item():
+ raise ValueError("Some values in `fairseq_output` are different from `new_model_outputs`")
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ model.save_pretrained(pytorch_dump_folder_path)
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "fairseq_path", type=str, help="bart.large, bart.large.cnn or a path to a model.pt on local filesystem."
+ )
+ parser.add_argument("pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model.")
+ parser.add_argument(
+ "--hf_config", default=None, type=str, help="Which huggingface architecture to use: bart-large-xsum"
+ )
+ args = parser.parse_args()
+ convert_bart_checkpoint(args.fairseq_path, args.pytorch_dump_folder_path, hf_checkpoint_name=args.hf_config)
diff --git a/docs/transformers/src/transformers/models/bart/modeling_bart.py b/docs/transformers/src/transformers/models/bart/modeling_bart.py
new file mode 100644
index 0000000000000000000000000000000000000000..bc3d4dcd936c1a52b70634c41998f1288f82f50a
--- /dev/null
+++ b/docs/transformers/src/transformers/models/bart/modeling_bart.py
@@ -0,0 +1,2184 @@
+# coding=utf-8
+# Copyright 2021 The Fairseq Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch BART model."""
+
+import copy
+import math
+import warnings
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...generation import GenerationMixin
+from ...modeling_attn_mask_utils import (
+ _prepare_4d_attention_mask,
+ _prepare_4d_attention_mask_for_sdpa,
+ _prepare_4d_causal_attention_mask,
+ _prepare_4d_causal_attention_mask_for_sdpa,
+)
+from ...modeling_flash_attention_utils import flash_attn_supports_top_left_mask, is_flash_attn_available
+from ...modeling_outputs import (
+ BaseModelOutput,
+ BaseModelOutputWithPastAndCrossAttentions,
+ CausalLMOutputWithCrossAttentions,
+ Seq2SeqLMOutput,
+ Seq2SeqModelOutput,
+ Seq2SeqQuestionAnsweringModelOutput,
+ Seq2SeqSequenceClassifierOutput,
+)
+from ...modeling_utils import PreTrainedModel
+from ...utils import (
+ add_code_sample_docstrings,
+ add_end_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+from .configuration_bart import BartConfig
+
+
+if is_flash_attn_available():
+ from ...modeling_flash_attention_utils import _flash_attention_forward
+
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = "facebook/bart-base"
+_CONFIG_FOR_DOC = "BartConfig"
+
+# Base model docstring
+_EXPECTED_OUTPUT_SHAPE = [1, 8, 768]
+
+# SequenceClassification docstring
+_CHECKPOINT_FOR_SEQUENCE_CLASSIFICATION = "valhalla/bart-large-sst2"
+_SEQ_CLASS_EXPECTED_LOSS = 0.0
+_SEQ_CLASS_EXPECTED_OUTPUT = "'POSITIVE'"
+
+# QuestionAsnwering docstring
+_CHECKPOINT_FOR_QA = "valhalla/bart-large-finetuned-squadv1"
+_QA_EXPECTED_LOSS = 0.59
+_QA_EXPECTED_OUTPUT = "' nice puppet'"
+
+
+def shift_tokens_right(input_ids: torch.Tensor, pad_token_id: int, decoder_start_token_id: int):
+ """
+ Shift input ids one token to the right.
+ """
+ shifted_input_ids = input_ids.new_zeros(input_ids.shape)
+ shifted_input_ids[:, 1:] = input_ids[:, :-1].clone()
+ shifted_input_ids[:, 0] = decoder_start_token_id
+
+ if pad_token_id is None:
+ raise ValueError("self.model.config.pad_token_id has to be defined.")
+ # replace possible -100 values in labels by `pad_token_id`
+ shifted_input_ids.masked_fill_(shifted_input_ids == -100, pad_token_id)
+
+ return shifted_input_ids
+
+
+class BartLearnedPositionalEmbedding(nn.Embedding):
+ """
+ This module learns positional embeddings up to a fixed maximum size.
+ """
+
+ def __init__(self, num_embeddings: int, embedding_dim: int):
+ # Bart is set up so that if padding_idx is specified then offset the embedding ids by 2
+ # and adjust num_embeddings appropriately. Other models don't have this hack
+ self.offset = 2
+ super().__init__(num_embeddings + self.offset, embedding_dim)
+
+ def forward(self, input_ids: torch.Tensor, past_key_values_length: int = 0):
+ """`input_ids' shape is expected to be [bsz x seqlen]."""
+
+ bsz, seq_len = input_ids.shape[:2]
+ positions = torch.arange(
+ past_key_values_length, past_key_values_length + seq_len, dtype=torch.long, device=self.weight.device
+ ).expand(bsz, -1)
+
+ return super().forward(positions + self.offset)
+
+
+class BartScaledWordEmbedding(nn.Embedding):
+ """
+ This module overrides nn.Embeddings' forward by multiplying with embeddings scale.
+ """
+
+ def __init__(self, num_embeddings: int, embedding_dim: int, padding_idx: int, embed_scale: Optional[float] = 1.0):
+ super().__init__(num_embeddings, embedding_dim, padding_idx)
+ self.embed_scale = embed_scale
+
+ def forward(self, input_ids: torch.Tensor):
+ return super().forward(input_ids) * self.embed_scale
+
+
+class BartAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(
+ self,
+ embed_dim: int,
+ num_heads: int,
+ dropout: float = 0.0,
+ is_decoder: bool = False,
+ bias: bool = True,
+ is_causal: bool = False,
+ config: Optional[BartConfig] = None,
+ ):
+ super().__init__()
+ self.embed_dim = embed_dim
+ self.num_heads = num_heads
+ self.dropout = dropout
+ self.head_dim = embed_dim // num_heads
+ self.config = config
+
+ if (self.head_dim * num_heads) != self.embed_dim:
+ raise ValueError(
+ f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim}"
+ f" and `num_heads`: {num_heads})."
+ )
+ self.scaling = self.head_dim**-0.5
+ self.is_decoder = is_decoder
+ self.is_causal = is_causal
+
+ self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+ self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+ self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+ self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, tgt_len, _ = hidden_states.size()
+
+ # get query proj
+ query_states = self.q_proj(hidden_states) * self.scaling
+ # get key, value proj
+ # `past_key_value[0].shape[2] == key_value_states.shape[1]`
+ # is checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ if (
+ is_cross_attention
+ and past_key_value is not None
+ and past_key_value[0].shape[2] == key_value_states.shape[1]
+ ):
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0]
+ value_states = past_key_value[1]
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
+ value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+ else:
+ # self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ proj_shape = (bsz * self.num_heads, -1, self.head_dim)
+ query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
+ key_states = key_states.reshape(*proj_shape)
+ value_states = value_states.reshape(*proj_shape)
+
+ src_len = key_states.size(1)
+ attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
+
+ if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
+ raise ValueError(
+ f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
+ )
+ attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
+
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1)
+
+ if layer_head_mask is not None:
+ if layer_head_mask.size() != (self.num_heads,):
+ raise ValueError(
+ f"Head mask for a single layer should be of size {(self.num_heads,)}, but is"
+ f" {layer_head_mask.size()}"
+ )
+ attn_weights = layer_head_mask.view(1, -1, 1, 1) * attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
+
+ if output_attentions:
+ # this operation is a bit awkward, but it's required to
+ # make sure that attn_weights keeps its gradient.
+ # In order to do so, attn_weights have to be reshaped
+ # twice and have to be reused in the following
+ attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
+ attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
+ else:
+ attn_weights_reshaped = None
+
+ attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
+
+ attn_output = torch.bmm(attn_probs, value_states)
+
+ if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz * self.num_heads, tgt_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
+ attn_output = attn_output.transpose(1, 2)
+
+ # Use the `embed_dim` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
+ # partitioned across GPUs when using tensor-parallelism.
+ attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, attn_weights_reshaped, past_key_value
+
+
+class BartFlashAttention2(BartAttention):
+ """
+ Bart flash attention module. This module inherits from `BartAttention` as the weights of the module stays
+ untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
+ flash attention and deal with padding tokens in case the input contains any of them.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ # TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
+ # flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignment, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
+ # Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
+ self._flash_attn_uses_top_left_mask = flash_attn_supports_top_left_mask()
+
+ def _reshape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ # BartFlashAttention2 attention does not support output_attentions
+ if output_attentions:
+ raise ValueError("BartFlashAttention2 attention does not support output_attentions")
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, q_len, _ = hidden_states.size()
+
+ # get query proj
+ query_states = self._reshape(self.q_proj(hidden_states), -1, bsz)
+ # get key, value proj
+ # `past_key_value[0].shape[2] == key_value_states.shape[1]`
+ # is checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ if (
+ is_cross_attention
+ and past_key_value is not None
+ and past_key_value[0].shape[2] == key_value_states.shape[1]
+ ):
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0].transpose(1, 2)
+ value_states = past_key_value[1].transpose(1, 2)
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self._reshape(self.k_proj(key_value_states), -1, bsz)
+ value_states = self._reshape(self.v_proj(key_value_states), -1, bsz)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self._reshape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._reshape(self.v_proj(hidden_states), -1, bsz)
+ key_states = torch.cat([past_key_value[0].transpose(1, 2), key_states], dim=1)
+ value_states = torch.cat([past_key_value[1].transpose(1, 2), value_states], dim=1)
+ else:
+ # self_attention
+ key_states = self._reshape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._reshape(self.v_proj(hidden_states), -1, bsz)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states.transpose(1, 2), value_states.transpose(1, 2))
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+
+ # In PEFT, usually we cast the layer norms in float32 for training stability reasons
+ # therefore the input hidden states gets silently casted in float32. Hence, we need
+ # cast them back in the correct dtype just to be sure everything works as expected.
+ # This might slowdown training & inference so it is recommended to not cast the LayerNorms
+ # in fp32. (LlamaRMSNorm handles it correctly)
+
+ input_dtype = query_states.dtype
+ if input_dtype == torch.float32:
+ if torch.is_autocast_enabled():
+ target_dtype = torch.get_autocast_gpu_dtype()
+ # Handle the case where the model is quantized
+ elif hasattr(self.config, "_pre_quantization_dtype"):
+ target_dtype = self.config._pre_quantization_dtype
+ else:
+ target_dtype = self.q_proj.weight.dtype
+
+ logger.warning_once(
+ f"The input hidden states seems to be silently casted in float32, this might be related to"
+ f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
+ f" {target_dtype}."
+ )
+
+ query_states = query_states.to(target_dtype)
+ key_states = key_states.to(target_dtype)
+ value_states = value_states.to(target_dtype)
+
+ attn_output = _flash_attention_forward(
+ query_states,
+ key_states,
+ value_states,
+ attention_mask,
+ q_len,
+ dropout=self.dropout if self.training else 0.0,
+ is_causal=self.is_causal,
+ use_top_left_mask=self._flash_attn_uses_top_left_mask,
+ )
+
+ attn_output = attn_output.reshape(bsz, q_len, -1)
+ attn_output = self.out_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+class BartSdpaAttention(BartAttention):
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+ if output_attentions or layer_head_mask is not None:
+ # TODO: Improve this warning with e.g. `model.config._attn_implementation = "manual"` once this is implemented.
+ logger.warning_once(
+ "BartModel is using BartSdpaAttention, but `torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True` or `layer_head_mask` not None. Falling back to the manual attention"
+ ' implementation, but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
+ )
+ return super().forward(
+ hidden_states,
+ key_value_states=key_value_states,
+ past_key_value=past_key_value,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, tgt_len, _ = hidden_states.size()
+
+ # get query proj
+ query_states = self.q_proj(hidden_states)
+ # get key, value proj
+ # `past_key_value[0].shape[2] == key_value_states.shape[1]`
+ # is checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ if (
+ is_cross_attention
+ and past_key_value is not None
+ and past_key_value[0].shape[2] == key_value_states.shape[1]
+ ):
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0]
+ value_states = past_key_value[1]
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
+ value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+ else:
+ # self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ query_states = self._shape(query_states, tgt_len, bsz)
+
+ # We dispatch to SDPA's Flash Attention or Efficient kernels via this `is_causal` if statement instead of an inline conditional assignment
+ # in SDPA to support both torch.compile's dynamic shapes and full graph options. An inline conditional prevents dynamic shapes from compiling.
+ # The tgt_len > 1 is necessary to match with AttentionMaskConverter.to_causal_4d that does not create a causal mask in case tgt_len == 1.
+ is_causal = True if self.is_causal and attention_mask is None and tgt_len > 1 else False
+
+ # NOTE: SDPA with memory-efficient backend is currently (torch==2.1.2) bugged when using non-contiguous inputs and a custom attn_mask,
+ # but we are fine here as `_shape` do call `.contiguous()`. Reference: https://github.com/pytorch/pytorch/issues/112577
+ attn_output = torch.nn.functional.scaled_dot_product_attention(
+ query_states,
+ key_states,
+ value_states,
+ attn_mask=attention_mask,
+ dropout_p=self.dropout if self.training else 0.0,
+ is_causal=is_causal,
+ )
+
+ if attn_output.size() != (bsz, self.num_heads, tgt_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.transpose(1, 2)
+
+ # Use the `embed_dim` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
+ # partitioned across GPUs when using tensor-parallelism.
+ attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+
+BART_ATTENTION_CLASSES = {
+ "eager": BartAttention,
+ "sdpa": BartSdpaAttention,
+ "flash_attention_2": BartFlashAttention2,
+}
+
+
+class BartEncoderLayer(nn.Module):
+ def __init__(self, config: BartConfig):
+ super().__init__()
+ self.embed_dim = config.d_model
+
+ self.self_attn = BART_ATTENTION_CLASSES[config._attn_implementation](
+ embed_dim=self.embed_dim,
+ num_heads=config.encoder_attention_heads,
+ dropout=config.attention_dropout,
+ config=config,
+ )
+ self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
+ self.dropout = config.dropout
+ self.activation_fn = ACT2FN[config.activation_function]
+ self.activation_dropout = config.activation_dropout
+ self.fc1 = nn.Linear(self.embed_dim, config.encoder_ffn_dim)
+ self.fc2 = nn.Linear(config.encoder_ffn_dim, self.embed_dim)
+ self.final_layer_norm = nn.LayerNorm(self.embed_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.FloatTensor,
+ attention_mask: torch.FloatTensor,
+ layer_head_mask: torch.FloatTensor,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor, Optional[torch.FloatTensor]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+ hidden_states, attn_weights, _ = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ residual = hidden_states
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ if hidden_states.dtype == torch.float16 and (
+ torch.isinf(hidden_states).any() or torch.isnan(hidden_states).any()
+ ):
+ clamp_value = torch.finfo(hidden_states.dtype).max - 1000
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+
+class BartDecoderLayer(nn.Module):
+ def __init__(self, config: BartConfig):
+ super().__init__()
+ self.embed_dim = config.d_model
+
+ self.self_attn = BART_ATTENTION_CLASSES[config._attn_implementation](
+ embed_dim=self.embed_dim,
+ num_heads=config.decoder_attention_heads,
+ dropout=config.attention_dropout,
+ is_decoder=True,
+ is_causal=True,
+ config=config,
+ )
+ self.dropout = config.dropout
+ self.activation_fn = ACT2FN[config.activation_function]
+ self.activation_dropout = config.activation_dropout
+
+ self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
+ self.encoder_attn = BART_ATTENTION_CLASSES[config._attn_implementation](
+ self.embed_dim,
+ config.decoder_attention_heads,
+ dropout=config.attention_dropout,
+ is_decoder=True,
+ config=config,
+ )
+ self.encoder_attn_layer_norm = nn.LayerNorm(self.embed_dim)
+ self.fc1 = nn.Linear(self.embed_dim, config.decoder_ffn_dim)
+ self.fc2 = nn.Linear(config.decoder_ffn_dim, self.embed_dim)
+ self.final_layer_norm = nn.LayerNorm(self.embed_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ cross_attn_layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = True,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ encoder_hidden_states (`torch.FloatTensor`):
+ cross attention input to the layer of shape `(batch, seq_len, embed_dim)`
+ encoder_attention_mask (`torch.FloatTensor`): encoder attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ cross_attn_layer_head_mask (`torch.FloatTensor`): mask for cross-attention heads in a given layer of
+ size `(decoder_attention_heads,)`.
+ past_key_value (`Tuple(torch.FloatTensor)`): cached past key and value projection states
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+
+ # Self Attention
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
+ # add present self-attn cache to positions 1,2 of present_key_value tuple
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ past_key_value=self_attn_past_key_value,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Cross-Attention Block
+ cross_attn_present_key_value = None
+ cross_attn_weights = None
+ if encoder_hidden_states is not None:
+ residual = hidden_states
+
+ # cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
+ cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
+ hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
+ hidden_states=hidden_states,
+ key_value_states=encoder_hidden_states,
+ attention_mask=encoder_attention_mask,
+ layer_head_mask=cross_attn_layer_head_mask,
+ past_key_value=cross_attn_past_key_value,
+ output_attentions=output_attentions,
+ )
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states = self.encoder_attn_layer_norm(hidden_states)
+
+ # add cross-attn to positions 3,4 of present_key_value tuple
+ present_key_value = present_key_value + cross_attn_present_key_value
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = nn.functional.dropout(hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights, cross_attn_weights)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+
+class BartClassificationHead(nn.Module):
+ """Head for sentence-level classification tasks."""
+
+ def __init__(
+ self,
+ input_dim: int,
+ inner_dim: int,
+ num_classes: int,
+ pooler_dropout: float,
+ ):
+ super().__init__()
+ self.dense = nn.Linear(input_dim, inner_dim)
+ self.dropout = nn.Dropout(p=pooler_dropout)
+ self.out_proj = nn.Linear(inner_dim, num_classes)
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.dense(hidden_states)
+ hidden_states = torch.tanh(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.out_proj(hidden_states)
+ return hidden_states
+
+
+class BartPreTrainedModel(PreTrainedModel):
+ config_class = BartConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _keys_to_ignore_on_load_unexpected = ["encoder.version", "decoder.version"]
+ _no_split_modules = [r"BartEncoderLayer", r"BartDecoderLayer"]
+ _skip_keys_device_placement = "past_key_values"
+ _supports_flash_attn_2 = True
+ _supports_sdpa = True
+
+ def _init_weights(self, module):
+ std = self.config.init_std
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+ @property
+ def dummy_inputs(self):
+ pad_token = self.config.pad_token_id
+ input_ids = torch.tensor([[0, 6, 10, 4, 2], [0, 8, 12, 2, pad_token]], device=self.device)
+ dummy_inputs = {
+ "attention_mask": input_ids.ne(pad_token),
+ "input_ids": input_ids,
+ }
+ return dummy_inputs
+
+
+class PretrainedBartModel(BartPreTrainedModel):
+ def __init_subclass__(self):
+ warnings.warn(
+ "The class `PretrainedBartModel` has been depreciated, please use `BartPreTrainedModel` instead.",
+ FutureWarning,
+ )
+
+
+class BartPretrainedModel(BartPreTrainedModel):
+ def __init_subclass__(self):
+ warnings.warn(
+ "The class `PretrainedBartModel` has been depreciated, please use `BartPreTrainedModel` instead.",
+ FutureWarning,
+ )
+
+
+BART_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`BartConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+BART_GENERATION_EXAMPLE = r"""
+ Summarization example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, BartForConditionalGeneration
+
+ >>> model = BartForConditionalGeneration.from_pretrained("facebook/bart-large-cnn")
+ >>> tokenizer = AutoTokenizer.from_pretrained("facebook/bart-large-cnn")
+
+ >>> ARTICLE_TO_SUMMARIZE = (
+ ... "PG&E stated it scheduled the blackouts in response to forecasts for high winds "
+ ... "amid dry conditions. The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were "
+ ... "scheduled to be affected by the shutoffs which were expected to last through at least midday tomorrow."
+ ... )
+ >>> inputs = tokenizer([ARTICLE_TO_SUMMARIZE], max_length=1024, return_tensors="pt")
+
+ >>> # Generate Summary
+ >>> summary_ids = model.generate(inputs["input_ids"], num_beams=2, min_length=0, max_length=20)
+ >>> tokenizer.batch_decode(summary_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ 'PG&E scheduled the blackouts in response to forecasts for high winds amid dry conditions'
+ ```
+
+ Mask filling example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, BartForConditionalGeneration
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("facebook/bart-base")
+ >>> model = BartForConditionalGeneration.from_pretrained("facebook/bart-base")
+
+ >>> TXT = "My friends are
 +
+[[autodoc]] get_cosine_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_schedule_with_warmup
+
+ +
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+ +
+[[autodoc]] get_linear_schedule_with_warmup
+
+
+
+[[autodoc]] get_linear_schedule_with_warmup
+
+ +
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+[[autodoc]] get_inverse_sqrt_schedule
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## Gradient Strategies
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
diff --git a/docs/transformers/docs/source/ja/main_classes/output.md b/docs/transformers/docs/source/ja/main_classes/output.md
new file mode 100644
index 0000000000000000000000000000000000000000..beb9dcbb4423556c7bafd2f0b9ad63c89727a897
--- /dev/null
+++ b/docs/transformers/docs/source/ja/main_classes/output.md
@@ -0,0 +1,321 @@
+
+
+# Model outputs
+
+すべてのモデルには、[`~utils.ModelOutput`] のサブクラスのインスタンスである出力があります。それらは
+モデルによって返されるすべての情報を含むデータ構造ですが、タプルまたは
+辞書。
+
+これがどのようになるかを例で見てみましょう。
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
+outputs = model(**inputs, labels=labels)
+```
+
+`outputs`オブジェクトは[`~modeling_outputs.SequenceClassifierOutput`]である。
+これは、オプションで `loss`、`logits`、オプションで `hidden_states`、オプションで `attentions` 属性を持つことを意味します。
+オプションの `attentions` 属性を持つことを意味する。ここでは、`labels`を渡したので`loss`があるが、`hidden_states`と`attentions`はない。
+`output_hidden_states=True`や`output_attentions=True`を渡していないので、`hidden_states`と`attentions`はない。
+`output_attentions=True`を渡さなかったからだ。
+
+
+
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+[[autodoc]] get_inverse_sqrt_schedule
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## Gradient Strategies
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
diff --git a/docs/transformers/docs/source/ja/main_classes/output.md b/docs/transformers/docs/source/ja/main_classes/output.md
new file mode 100644
index 0000000000000000000000000000000000000000..beb9dcbb4423556c7bafd2f0b9ad63c89727a897
--- /dev/null
+++ b/docs/transformers/docs/source/ja/main_classes/output.md
@@ -0,0 +1,321 @@
+
+
+# Model outputs
+
+すべてのモデルには、[`~utils.ModelOutput`] のサブクラスのインスタンスである出力があります。それらは
+モデルによって返されるすべての情報を含むデータ構造ですが、タプルまたは
+辞書。
+
+これがどのようになるかを例で見てみましょう。
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
+outputs = model(**inputs, labels=labels)
+```
+
+`outputs`オブジェクトは[`~modeling_outputs.SequenceClassifierOutput`]である。
+これは、オプションで `loss`、`logits`、オプションで `hidden_states`、オプションで `attentions` 属性を持つことを意味します。
+オプションの `attentions` 属性を持つことを意味する。ここでは、`labels`を渡したので`loss`があるが、`hidden_states`と`attentions`はない。
+`output_hidden_states=True`や`output_attentions=True`を渡していないので、`hidden_states`と`attentions`はない。
+`output_attentions=True`を渡さなかったからだ。
+
+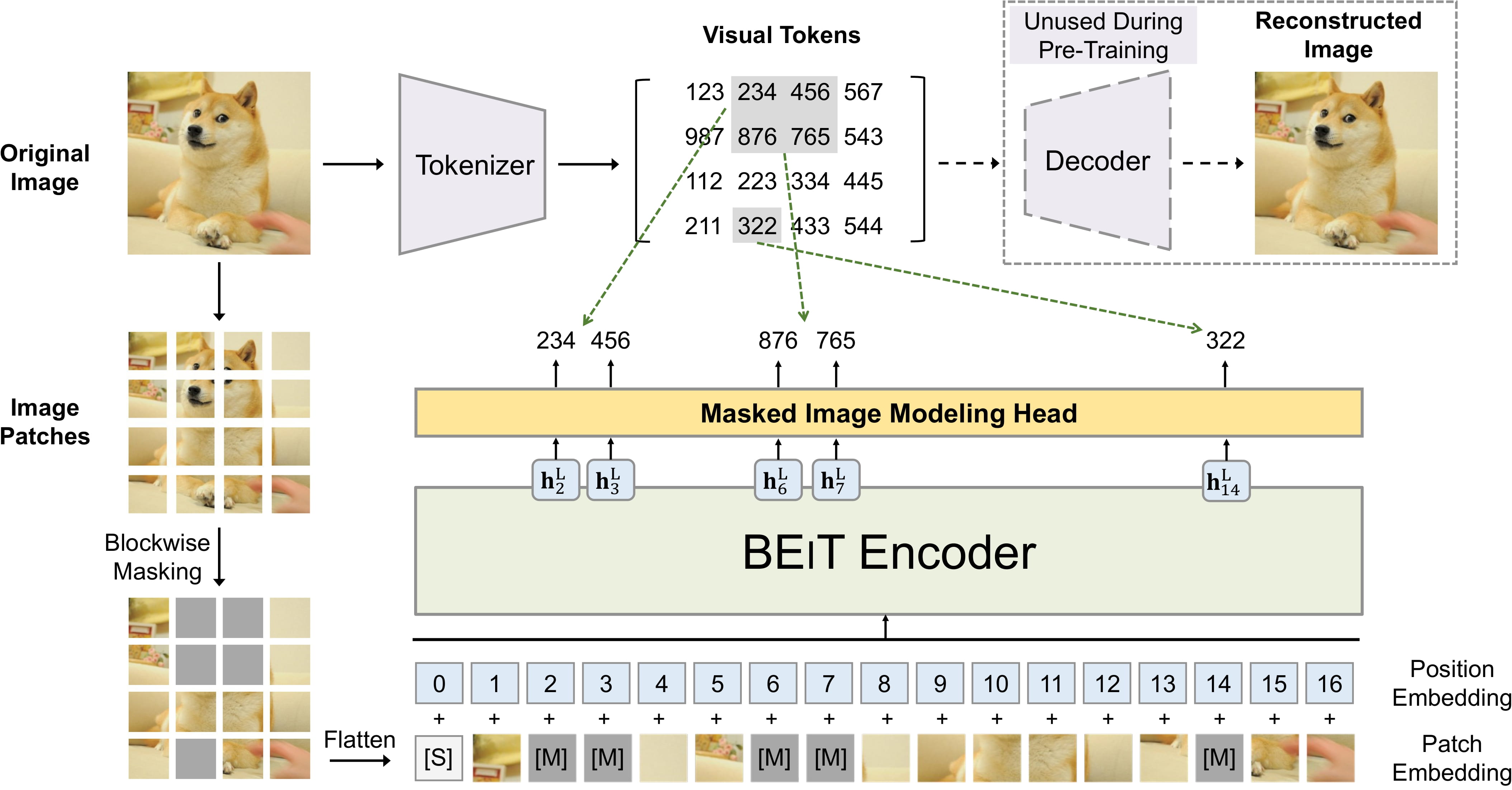 +
+ BEiT の事前トレーニング。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。このモデルの JAX/FLAX バージョンは、
+[kamalkraj](https://huggingface.co/kamalkraj) による投稿。元のコードは [ここ](https://github.com/microsoft/unilm/tree/master/beit) にあります。
+
+## Resources
+
+BEiT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+
+
+ BEiT の事前トレーニング。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。このモデルの JAX/FLAX バージョンは、
+[kamalkraj](https://huggingface.co/kamalkraj) による投稿。元のコードは [ここ](https://github.com/microsoft/unilm/tree/master/beit) にあります。
+
+## Resources
+
+BEiT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+ +
+ BLIP-2 アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207) にあります。
+
+## Usage tips
+
+- BLIP-2 は、画像とオプションのテキスト プロンプトを指定して条件付きテキストを生成するために使用できます。推論時には、 [`generate`] メソッドを使用することをお勧めします。
+- [`Blip2Processor`] を使用してモデル用の画像を準備し、予測されたトークン ID をデコードしてテキストに戻すことができます。
+
+## Resources
+
+BLIP-2 の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+- 画像キャプション、ビジュアル質問応答 (VQA)、およびチャットのような会話のための BLIP-2 のデモ ノートブックは、[こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BLIP-2) にあります。
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## Blip2Config
+
+[[autodoc]] Blip2Config
+ - from_vision_qformer_text_configs
+
+## Blip2VisionConfig
+
+[[autodoc]] Blip2VisionConfig
+
+## Blip2QFormerConfig
+
+[[autodoc]] Blip2QFormerConfig
+
+## Blip2Processor
+
+[[autodoc]] Blip2Processor
+
+## Blip2VisionModel
+
+[[autodoc]] Blip2VisionModel
+ - forward
+
+## Blip2QFormerModel
+
+[[autodoc]] Blip2QFormerModel
+ - forward
+
+## Blip2Model
+
+[[autodoc]] Blip2Model
+ - forward
+ - get_text_features
+ - get_image_features
+ - get_qformer_features
+
+## Blip2ForConditionalGeneration
+
+[[autodoc]] Blip2ForConditionalGeneration
+ - forward
+ - generate
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ja/model_doc/blip.md b/docs/transformers/docs/source/ja/model_doc/blip.md
new file mode 100644
index 0000000000000000000000000000000000000000..8e8550318bd4c878ab594baffc80fcf248504789
--- /dev/null
+++ b/docs/transformers/docs/source/ja/model_doc/blip.md
@@ -0,0 +1,139 @@
+
+
+# BLIP
+
+## Overview
+
+BLIP モデルは、[BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) で Junnan Li、Dongxu Li、Caiming Xiong、Steven Hoi によって提案されました。 。
+
+BLIP は、次のようなさまざまなマルチモーダル タスクを実行できるモデルです。
+- 視覚的な質問応答
+- 画像とテキストの検索(画像とテキストのマッチング)
+- 画像キャプション
+
+論文の要約は次のとおりです。
+
+*視覚言語事前トレーニング (VLP) により、多くの視覚言語タスクのパフォーマンスが向上しました。
+ただし、既存の事前トレーニング済みモデルのほとんどは、理解ベースのタスクまたは世代ベースのタスクのいずれかでのみ優れています。さらに、最適ではない監視ソースである Web から収集されたノイズの多い画像とテキストのペアを使用してデータセットをスケールアップすることで、パフォーマンスの向上が大幅に達成されました。この論文では、視覚言語の理解と生成タスクの両方に柔軟に移行する新しい VLP フレームワークである BLIP を提案します。 BLIP は、キャプションをブートストラップすることでノイズの多い Web データを効果的に利用します。キャプショナーが合成キャプションを生成し、フィルターがノイズの多いキャプションを除去します。画像テキスト検索 (平均再現率 +2.7%@1)、画像キャプション作成 (CIDEr で +2.8%)、VQA ( VQA スコアは +1.6%)。 BLIP は、ゼロショット方式でビデオ言語タスクに直接転送した場合にも、強力な一般化能力を発揮します。コード、モデル、データセットがリリースされています。*
+
+
+
+このモデルは [ybelkada](https://huggingface.co/ybelkada) によって提供されました。
+元のコードは [ここ](https://github.com/salesforce/BLIP) にあります。
+
+## Resources
+
+- [Jupyter ノートブック](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) カスタム データセットの画像キャプション用に BLIP を微調整する方法
+
+## BlipConfig
+
+[[autodoc]] BlipConfig
+ - from_text_vision_configs
+
+## BlipTextConfig
+
+[[autodoc]] BlipTextConfig
+
+## BlipVisionConfig
+
+[[autodoc]] BlipVisionConfig
+
+## BlipProcessor
+
+[[autodoc]] BlipProcessor
+
+## BlipImageProcessor
+
+[[autodoc]] BlipImageProcessor
+ - preprocess
+
+## BlipImageProcessorFast
+
+[[autodoc]] BlipImageProcessorFast
+ - preprocess
+
+
+
+ BLIP-2 アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207) にあります。
+
+## Usage tips
+
+- BLIP-2 は、画像とオプションのテキスト プロンプトを指定して条件付きテキストを生成するために使用できます。推論時には、 [`generate`] メソッドを使用することをお勧めします。
+- [`Blip2Processor`] を使用してモデル用の画像を準備し、予測されたトークン ID をデコードしてテキストに戻すことができます。
+
+## Resources
+
+BLIP-2 の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+- 画像キャプション、ビジュアル質問応答 (VQA)、およびチャットのような会話のための BLIP-2 のデモ ノートブックは、[こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BLIP-2) にあります。
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## Blip2Config
+
+[[autodoc]] Blip2Config
+ - from_vision_qformer_text_configs
+
+## Blip2VisionConfig
+
+[[autodoc]] Blip2VisionConfig
+
+## Blip2QFormerConfig
+
+[[autodoc]] Blip2QFormerConfig
+
+## Blip2Processor
+
+[[autodoc]] Blip2Processor
+
+## Blip2VisionModel
+
+[[autodoc]] Blip2VisionModel
+ - forward
+
+## Blip2QFormerModel
+
+[[autodoc]] Blip2QFormerModel
+ - forward
+
+## Blip2Model
+
+[[autodoc]] Blip2Model
+ - forward
+ - get_text_features
+ - get_image_features
+ - get_qformer_features
+
+## Blip2ForConditionalGeneration
+
+[[autodoc]] Blip2ForConditionalGeneration
+ - forward
+ - generate
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ja/model_doc/blip.md b/docs/transformers/docs/source/ja/model_doc/blip.md
new file mode 100644
index 0000000000000000000000000000000000000000..8e8550318bd4c878ab594baffc80fcf248504789
--- /dev/null
+++ b/docs/transformers/docs/source/ja/model_doc/blip.md
@@ -0,0 +1,139 @@
+
+
+# BLIP
+
+## Overview
+
+BLIP モデルは、[BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) で Junnan Li、Dongxu Li、Caiming Xiong、Steven Hoi によって提案されました。 。
+
+BLIP は、次のようなさまざまなマルチモーダル タスクを実行できるモデルです。
+- 視覚的な質問応答
+- 画像とテキストの検索(画像とテキストのマッチング)
+- 画像キャプション
+
+論文の要約は次のとおりです。
+
+*視覚言語事前トレーニング (VLP) により、多くの視覚言語タスクのパフォーマンスが向上しました。
+ただし、既存の事前トレーニング済みモデルのほとんどは、理解ベースのタスクまたは世代ベースのタスクのいずれかでのみ優れています。さらに、最適ではない監視ソースである Web から収集されたノイズの多い画像とテキストのペアを使用してデータセットをスケールアップすることで、パフォーマンスの向上が大幅に達成されました。この論文では、視覚言語の理解と生成タスクの両方に柔軟に移行する新しい VLP フレームワークである BLIP を提案します。 BLIP は、キャプションをブートストラップすることでノイズの多い Web データを効果的に利用します。キャプショナーが合成キャプションを生成し、フィルターがノイズの多いキャプションを除去します。画像テキスト検索 (平均再現率 +2.7%@1)、画像キャプション作成 (CIDEr で +2.8%)、VQA ( VQA スコアは +1.6%)。 BLIP は、ゼロショット方式でビデオ言語タスクに直接転送した場合にも、強力な一般化能力を発揮します。コード、モデル、データセットがリリースされています。*
+
+
+
+このモデルは [ybelkada](https://huggingface.co/ybelkada) によって提供されました。
+元のコードは [ここ](https://github.com/salesforce/BLIP) にあります。
+
+## Resources
+
+- [Jupyter ノートブック](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) カスタム データセットの画像キャプション用に BLIP を微調整する方法
+
+## BlipConfig
+
+[[autodoc]] BlipConfig
+ - from_text_vision_configs
+
+## BlipTextConfig
+
+[[autodoc]] BlipTextConfig
+
+## BlipVisionConfig
+
+[[autodoc]] BlipVisionConfig
+
+## BlipProcessor
+
+[[autodoc]] BlipProcessor
+
+## BlipImageProcessor
+
+[[autodoc]] BlipImageProcessor
+ - preprocess
+
+## BlipImageProcessorFast
+
+[[autodoc]] BlipImageProcessorFast
+ - preprocess
+
+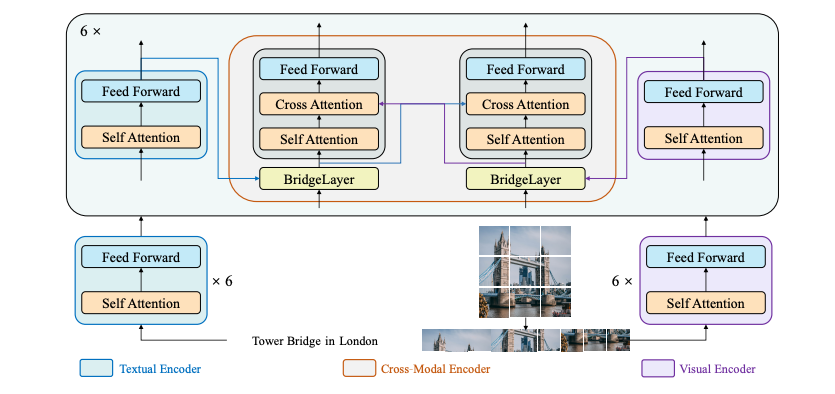 +
+ ブリッジタワー アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[Anahita Bhiwandiwalla](https://huggingface.co/anahita-b)、[Tiep Le](https://huggingface.co/Tile)、[Shaoyen Tseng](https://huggingface.co/shaoyent) 。元のコードは [ここ](https://github.com/microsoft/BridgeTower) にあります。
+
+## Usage tips and examples
+
+BridgeTower は、ビジュアル エンコーダー、テキスト エンコーダー、および複数の軽量ブリッジ レイヤーを備えたクロスモーダル エンコーダーで構成されます。
+このアプローチの目標は、各ユニモーダル エンコーダーとクロスモーダル エンコーダーの間にブリッジを構築し、クロスモーダル エンコーダーの各層で包括的かつ詳細な対話を可能にすることでした。
+原則として、提案されたアーキテクチャでは、任意のビジュアル、テキスト、またはクロスモーダル エンコーダを適用できます。
+
+[`BridgeTowerProcessor`] は、[`RobertaTokenizer`] と [`BridgeTowerImageProcessor`] を単一のインスタンスにラップし、両方の機能を実現します。
+テキストをエンコードし、画像をそれぞれ用意します。
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForContrastiveLearning`] を使用して対照学習を実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs
+```
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForImageAndTextRetrieval`] を使用して画像テキストの取得を実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs.logits[0, 1].item()
+```
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForMaskedLM`] を使用してマスクされた言語モデリングを実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+>>> text = "a
+
+ ブリッジタワー アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[Anahita Bhiwandiwalla](https://huggingface.co/anahita-b)、[Tiep Le](https://huggingface.co/Tile)、[Shaoyen Tseng](https://huggingface.co/shaoyent) 。元のコードは [ここ](https://github.com/microsoft/BridgeTower) にあります。
+
+## Usage tips and examples
+
+BridgeTower は、ビジュアル エンコーダー、テキスト エンコーダー、および複数の軽量ブリッジ レイヤーを備えたクロスモーダル エンコーダーで構成されます。
+このアプローチの目標は、各ユニモーダル エンコーダーとクロスモーダル エンコーダーの間にブリッジを構築し、クロスモーダル エンコーダーの各層で包括的かつ詳細な対話を可能にすることでした。
+原則として、提案されたアーキテクチャでは、任意のビジュアル、テキスト、またはクロスモーダル エンコーダを適用できます。
+
+[`BridgeTowerProcessor`] は、[`RobertaTokenizer`] と [`BridgeTowerImageProcessor`] を単一のインスタンスにラップし、両方の機能を実現します。
+テキストをエンコードし、画像をそれぞれ用意します。
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForContrastiveLearning`] を使用して対照学習を実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs
+```
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForImageAndTextRetrieval`] を使用して画像テキストの取得を実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs.logits[0, 1].item()
+```
+
+次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForMaskedLM`] を使用してマスクされた言語モデリングを実行する方法を示しています。
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+>>> text = "a 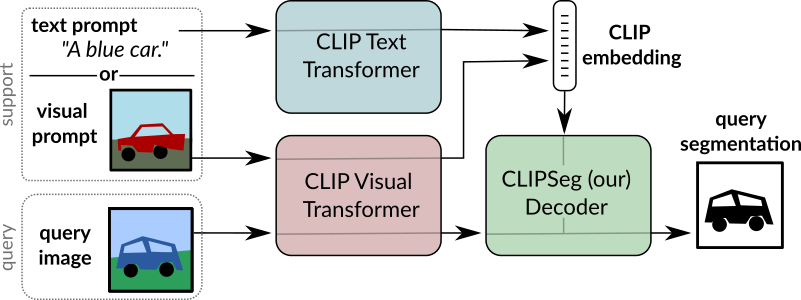 +
+ CLIPSeg の概要。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/timojl/clipseg) にあります。
+
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] は、[`CLIPSegModel`] の上にデコーダを追加します。後者は [`CLIPModel`] と同じです。
+- [`CLIPSegForImageSegmentation`] は、テスト時に任意のプロンプトに基づいて画像セグメンテーションを生成できます。プロンプトはテキストのいずれかです
+(`input_ids` としてモデルに提供される) または画像 (`conditional_pixel_values` としてモデルに提供される)。カスタムを提供することもできます
+条件付き埋め込み (`conditional_embeddings`としてモデルに提供されます)。
+
+## Resources
+
+CLIPSeg の使用を開始するのに役立つ、公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+
+
+ CLIPSeg の概要。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/timojl/clipseg) にあります。
+
+## Usage tips
+
+- [`CLIPSegForImageSegmentation`] は、[`CLIPSegModel`] の上にデコーダを追加します。後者は [`CLIPModel`] と同じです。
+- [`CLIPSegForImageSegmentation`] は、テスト時に任意のプロンプトに基づいて画像セグメンテーションを生成できます。プロンプトはテキストのいずれかです
+(`input_ids` としてモデルに提供される) または画像 (`conditional_pixel_values` としてモデルに提供される)。カスタムを提供することもできます
+条件付き埋め込み (`conditional_embeddings`としてモデルに提供されます)。
+
+## Resources
+
+CLIPSeg の使用を開始するのに役立つ、公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+ +
+ 条件付き DETR は、元の DETR に比べてはるかに速い収束を示します。 元の論文から引用。
+
+このモデルは [DepuMeng](https://huggingface.co/DepuMeng) によって寄稿されました。元のコードは [ここ](https://github.com/Atten4Vis/ConditionalDETR) にあります。
+
+## Resources
+
+- [オブジェクト検出タスクガイド](../tasks/object_detection)
+
+## ConditionalDetrConfig
+
+[[autodoc]] ConditionalDetrConfig
+
+## ConditionalDetrImageProcessor
+
+[[autodoc]] ConditionalDetrImageProcessor
+ - preprocess
+
+## ConditionalDetrImageProcessorFast
+
+[[autodoc]] ConditionalDetrImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrFeatureExtractor
+
+[[autodoc]] ConditionalDetrFeatureExtractor
+ - __call__
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrModel
+
+[[autodoc]] ConditionalDetrModel
+ - forward
+
+## ConditionalDetrForObjectDetection
+
+[[autodoc]] ConditionalDetrForObjectDetection
+ - forward
+
+## ConditionalDetrForSegmentation
+
+[[autodoc]] ConditionalDetrForSegmentation
+ - forward
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ja/model_doc/convbert.md b/docs/transformers/docs/source/ja/model_doc/convbert.md
new file mode 100644
index 0000000000000000000000000000000000000000..5d15f86c5136b791426efd10332b16e617d50411
--- /dev/null
+++ b/docs/transformers/docs/source/ja/model_doc/convbert.md
@@ -0,0 +1,145 @@
+
+
+# ConvBERT
+
+
+
+## Overview
+
+ConvBERT モデルは、[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) で Zihang Jiang、Weihao Yu、Daquan Zhou、Yunpeng Chen、Jiashi Feng、Shuicheng Yan によって提案されました。
+やん。
+
+論文の要約は次のとおりです。
+
+*BERT やそのバリアントなどの事前トレーニング済み言語モデルは、最近、さまざまな環境で目覚ましいパフォーマンスを達成しています。
+自然言語理解タスク。ただし、BERT はグローバルな自己注意ブロックに大きく依存しているため、問題が発生します。
+メモリ使用量と計算コストが大きくなります。すべての注意が入力シーケンス全体に対してクエリを実行しますが、
+グローバルな観点からアテンション マップを生成すると、一部のヘッドはローカルな依存関係のみを学習する必要があることがわかります。
+これは、計算の冗長性が存在することを意味します。したがって、我々は、新しいスパンベースの動的畳み込みを提案します。
+これらのセルフアテンション ヘッドを置き換えて、ローカルの依存関係を直接モデル化します。新しいコンボリューションヘッドと、
+自己注意の頭を休め、グローバルとローカルの両方の状況でより効率的な新しい混合注意ブロックを形成します
+学ぶ。この混合注意設計を BERT に装備し、ConvBERT モデルを構築します。実験でわかったことは、
+ConvBERT は、トレーニング コストが低く、さまざまな下流タスクにおいて BERT およびその亜種よりも大幅に優れたパフォーマンスを発揮します。
+モデルパラメータが少なくなります。注目すべきことに、ConvBERTbase モデルは 86.4 GLUE スコアを達成し、ELECTRAbase よりも 0.7 高いのに対し、
+トレーニングコストは 1/4 未満です。コードと事前トレーニングされたモデルがリリースされます。*
+
+このモデルは、[abhishek](https://huggingface.co/abhishek) によって提供されました。オリジナルの実装が見つかります
+ここ: https://github.com/yitu-opensource/ConvBert
+
+## Usage tips
+
+ConvBERT トレーニングのヒントは BERT のヒントと似ています。使用上のヒントについては、[BERT ドキュメント](bert) を参照してください。
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## ConvBertConfig
+
+[[autodoc]] ConvBertConfig
+
+## ConvBertTokenizer
+
+[[autodoc]] ConvBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## ConvBertTokenizerFast
+
+[[autodoc]] ConvBertTokenizerFast
+
+
+
+ 条件付き DETR は、元の DETR に比べてはるかに速い収束を示します。 元の論文から引用。
+
+このモデルは [DepuMeng](https://huggingface.co/DepuMeng) によって寄稿されました。元のコードは [ここ](https://github.com/Atten4Vis/ConditionalDETR) にあります。
+
+## Resources
+
+- [オブジェクト検出タスクガイド](../tasks/object_detection)
+
+## ConditionalDetrConfig
+
+[[autodoc]] ConditionalDetrConfig
+
+## ConditionalDetrImageProcessor
+
+[[autodoc]] ConditionalDetrImageProcessor
+ - preprocess
+
+## ConditionalDetrImageProcessorFast
+
+[[autodoc]] ConditionalDetrImageProcessorFast
+ - preprocess
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrFeatureExtractor
+
+[[autodoc]] ConditionalDetrFeatureExtractor
+ - __call__
+ - post_process_object_detection
+ - post_process_instance_segmentation
+ - post_process_semantic_segmentation
+ - post_process_panoptic_segmentation
+
+## ConditionalDetrModel
+
+[[autodoc]] ConditionalDetrModel
+ - forward
+
+## ConditionalDetrForObjectDetection
+
+[[autodoc]] ConditionalDetrForObjectDetection
+ - forward
+
+## ConditionalDetrForSegmentation
+
+[[autodoc]] ConditionalDetrForSegmentation
+ - forward
+
+
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ja/model_doc/convbert.md b/docs/transformers/docs/source/ja/model_doc/convbert.md
new file mode 100644
index 0000000000000000000000000000000000000000..5d15f86c5136b791426efd10332b16e617d50411
--- /dev/null
+++ b/docs/transformers/docs/source/ja/model_doc/convbert.md
@@ -0,0 +1,145 @@
+
+
+# ConvBERT
+
+
+
+## Overview
+
+ConvBERT モデルは、[ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) で Zihang Jiang、Weihao Yu、Daquan Zhou、Yunpeng Chen、Jiashi Feng、Shuicheng Yan によって提案されました。
+やん。
+
+論文の要約は次のとおりです。
+
+*BERT やそのバリアントなどの事前トレーニング済み言語モデルは、最近、さまざまな環境で目覚ましいパフォーマンスを達成しています。
+自然言語理解タスク。ただし、BERT はグローバルな自己注意ブロックに大きく依存しているため、問題が発生します。
+メモリ使用量と計算コストが大きくなります。すべての注意が入力シーケンス全体に対してクエリを実行しますが、
+グローバルな観点からアテンション マップを生成すると、一部のヘッドはローカルな依存関係のみを学習する必要があることがわかります。
+これは、計算の冗長性が存在することを意味します。したがって、我々は、新しいスパンベースの動的畳み込みを提案します。
+これらのセルフアテンション ヘッドを置き換えて、ローカルの依存関係を直接モデル化します。新しいコンボリューションヘッドと、
+自己注意の頭を休め、グローバルとローカルの両方の状況でより効率的な新しい混合注意ブロックを形成します
+学ぶ。この混合注意設計を BERT に装備し、ConvBERT モデルを構築します。実験でわかったことは、
+ConvBERT は、トレーニング コストが低く、さまざまな下流タスクにおいて BERT およびその亜種よりも大幅に優れたパフォーマンスを発揮します。
+モデルパラメータが少なくなります。注目すべきことに、ConvBERTbase モデルは 86.4 GLUE スコアを達成し、ELECTRAbase よりも 0.7 高いのに対し、
+トレーニングコストは 1/4 未満です。コードと事前トレーニングされたモデルがリリースされます。*
+
+このモデルは、[abhishek](https://huggingface.co/abhishek) によって提供されました。オリジナルの実装が見つかります
+ここ: https://github.com/yitu-opensource/ConvBert
+
+## Usage tips
+
+ConvBERT トレーニングのヒントは BERT のヒントと似ています。使用上のヒントについては、[BERT ドキュメント](bert) を参照してください。
+
+## Resources
+
+- [テキスト分類タスクガイド](../tasks/sequence_classification)
+- [トークン分類タスクガイド](../tasks/token_classification)
+- [質問回答タスク ガイド](../tasks/question_answering)
+- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
+- [多肢選択タスク ガイド](../tasks/multiple_choice)
+
+## ConvBertConfig
+
+[[autodoc]] ConvBertConfig
+
+## ConvBertTokenizer
+
+[[autodoc]] ConvBertTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+
+## ConvBertTokenizerFast
+
+[[autodoc]] ConvBertTokenizerFast
+
+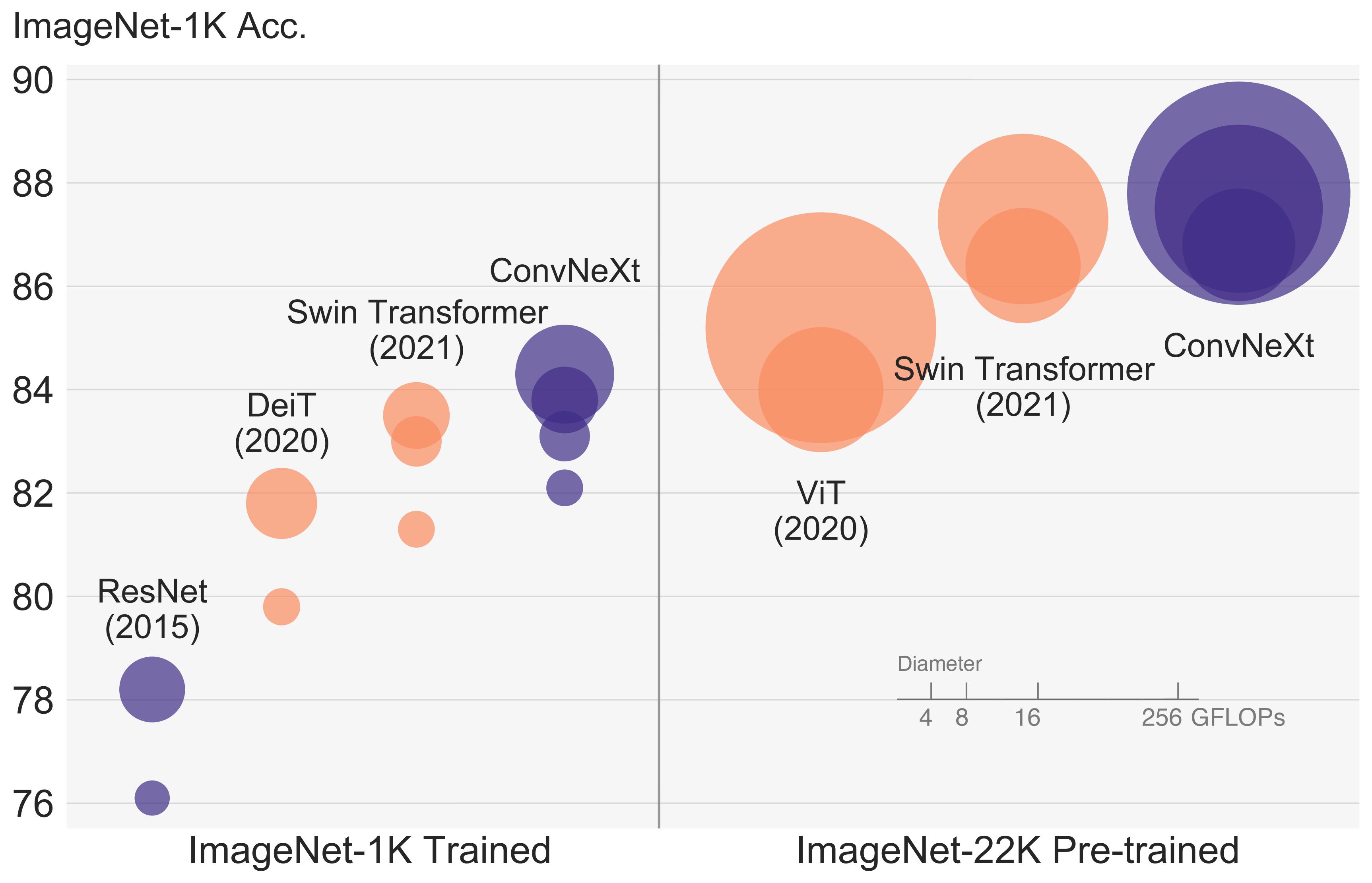 +
+ ConvNeXT アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。 TensorFlow バージョンのモデルは [ariG23498](https://github.com/ariG23498) によって提供されました。
+[gante](https://github.com/gante)、および [sayakpaul](https://github.com/sayakpaul) (同等の貢献)。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt) にあります。
+
+## Resources
+
+ConvNeXT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+
+
+ ConvNeXT アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。 TensorFlow バージョンのモデルは [ariG23498](https://github.com/ariG23498) によって提供されました。
+[gante](https://github.com/gante)、および [sayakpaul](https://github.com/sayakpaul) (同等の貢献)。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt) にあります。
+
+## Resources
+
+ConvNeXT の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+ +
+ ConvNeXt V2 アーキテクチャ。 元の論文から抜粋。
+
+このモデルは [adirik](https://huggingface.co/adirik) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt-V2) にあります。
+
+## Resources
+
+ConvNeXt V2 の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+
+
+ ConvNeXt V2 アーキテクチャ。 元の論文から抜粋。
+
+このモデルは [adirik](https://huggingface.co/adirik) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/ConvNeXt-V2) にあります。
+
+## Resources
+
+ConvNeXt V2 の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+ +
+ 変形可能な DETR アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [ここ](https://github.com/fundamentalvision/Deformable-DETR) にあります。
+
+## Usage tips
+
+
+ - トレーニング Deformable DETR は、元の [DETR](detr) モデルをトレーニングすることと同等です。デモ ノートブックについては、以下の [resources](#resources) セクションを参照してください。
+
+## Resources
+
+Deformable DETR の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+
+
+ 変形可能な DETR アーキテクチャ。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [ここ](https://github.com/fundamentalvision/Deformable-DETR) にあります。
+
+## Usage tips
+
+
+ - トレーニング Deformable DETR は、元の [DETR](detr) モデルをトレーニングすることと同等です。デモ ノートブックについては、以下の [resources](#resources) セクションを参照してください。
+
+## Resources
+
+Deformable DETR の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
+
+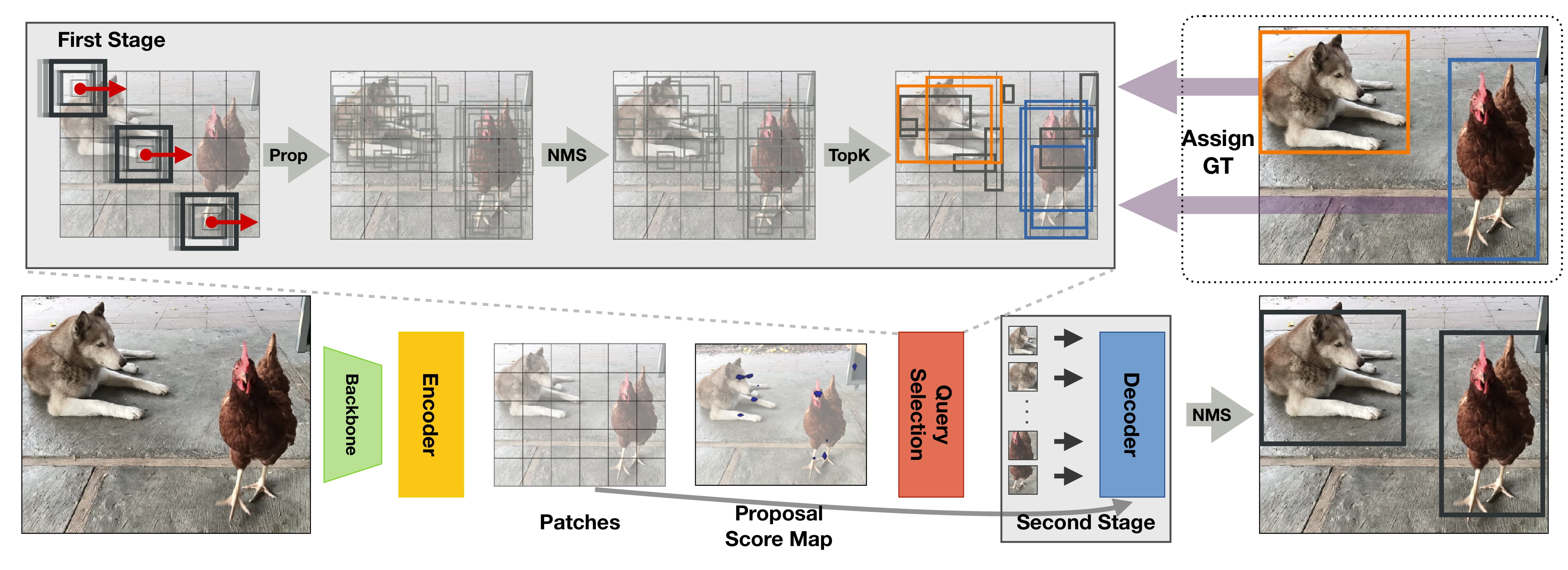 +
+ DETA の概要。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/jozhang97/DETA) にあります。
+
+## Resources
+
+DETA の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+- DETA のデモ ノートブックは [こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETA) にあります。
+- 参照: [オブジェクト検出タスク ガイド](../tasks/object_detection)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## DetaConfig
+
+[[autodoc]] DetaConfig
+
+## DetaImageProcessor
+
+[[autodoc]] DetaImageProcessor
+ - preprocess
+ - post_process_object_detection
+
+## DetaModel
+
+[[autodoc]] DetaModel
+ - forward
+
+## DetaForObjectDetection
+
+[[autodoc]] DetaForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/ja/model_doc/detr.md b/docs/transformers/docs/source/ja/model_doc/detr.md
new file mode 100644
index 0000000000000000000000000000000000000000..3342b123a01b833795847c8b46c723ddb53f45f4
--- /dev/null
+++ b/docs/transformers/docs/source/ja/model_doc/detr.md
@@ -0,0 +1,226 @@
+
+
+# DETR
+
+## Overview
+
+DETR モデルは、[Transformers を使用したエンドツーエンドのオブジェクト検出](https://arxiv.org/abs/2005.12872) で提案されました。
+Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko ルイコ。 DETR
+畳み込みバックボーンと、その後にエンドツーエンドでトレーニングできるエンコーダー/デコーダー Transformer で構成されます。
+物体の検出。 Faster-R-CNN や Mask-R-CNN などのモデルの複雑さの多くが大幅に簡素化されます。
+領域提案、非最大抑制手順、アンカー生成などです。さらに、DETR は次のようにすることもできます。
+デコーダ出力の上にマスク ヘッドを追加するだけで、パノプティック セグメンテーションを実行できるように自然に拡張されています。
+
+論文の要約は次のとおりです。
+
+*物体検出を直接集合予測問題として見る新しい方法を紹介します。私たちのアプローチは、
+検出パイプラインにより、非最大抑制などの多くの手作業で設計されたコンポーネントの必要性が効果的に排除されます。
+タスクに関する事前の知識を明示的にエンコードするプロシージャまたはアンカーの生成。の主な成分は、
+DEtection TRansformer または DETR と呼ばれる新しいフレームワークは、セットベースのグローバル損失であり、
+二部マッチング、およびトランスフォーマー エンコーダー/デコーダー アーキテクチャ。学習されたオブジェクト クエリの固定された小さなセットが与えられると、
+DETR は、オブジェクトとグローバル イメージ コンテキストの関係について推論し、最終セットを直接出力します。
+並行して予想も。新しいモデルは概念的にシンプルであり、多くのモデルとは異なり、特殊なライブラリを必要としません。
+他の最新の検出器。 DETR は、確立された、および同等の精度と実行時のパフォーマンスを実証します。
+困難な COCO 物体検出データセットに基づく、高度に最適化された Faster RCNN ベースライン。さらに、DETR は簡単に実行できます。
+統一された方法でパノプティック セグメンテーションを生成するために一般化されました。競合他社を大幅に上回るパフォーマンスを示しています
+ベースライン*
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/detr) にあります。
+
+## How DETR works
+
+[`~transformers.DetrForObjectDetection`] がどのように機能するかを説明する TLDR は次のとおりです。
+
+まず、事前にトレーニングされた畳み込みバックボーンを通じて画像が送信されます (論文では、著者らは次のように使用しています)。
+ResNet-50/ResNet-101)。バッチ ディメンションも追加すると仮定します。これは、バックボーンへの入力が
+画像に 3 つのカラー チャネル (RGB) があると仮定した場合の、形状 `(batch_size, 3, height, width)` のテンソル。 CNNのバックボーン
+通常は `(batch_size, 2048, height/32, width/32)` の形状の、新しい低解像度の特徴マップを出力します。これは
+次に、DETR の Transformer の隠れ次元 (デフォルトでは `256`) に一致するように投影されます。
+`nn.Conv2D` レイヤー。これで、形状 `(batch_size, 256, height/32, width/32)` のテンソルが完成しました。
+特徴マップは平坦化および転置され、形状 `(batch_size, seq_len, d_model)` のテンソルを取得します =
+`(batch_size, width/32*height/32, 256)`。したがって、NLP モデルとの違いは、シーケンスの長さが実際には
+通常よりも長くなりますが、「d_model」は小さくなります (NLP では通常 768 以上です)。
+
+次に、これがエンコーダを介して送信され、同じ形状の `encoder_hidden_states` が出力されます (次のように考えることができます)。
+これらは画像の特徴として)。次に、いわゆる **オブジェクト クエリ**がデコーダを通じて送信されます。これは形状のテンソルです
+`(batch_size, num_queries, d_model)`。通常、`num_queries` は 100 に設定され、ゼロで初期化されます。
+これらの入力埋め込みは学習された位置エンコーディングであり、作成者はこれをオブジェクト クエリと呼び、同様に
+エンコーダでは、それらは各アテンション層の入力に追加されます。各オブジェクト クエリは特定のオブジェクトを検索します。
+画像では。デコーダは、複数のセルフ アテンション レイヤとエンコーダ デコーダ アテンション レイヤを通じてこれらの埋め込みを更新します。
+同じ形状の `decoder_hidden_states` を出力します: `(batch_size, num_queries, d_model)`。次に頭が2つ
+オブジェクト検出のために上部に追加されます。各オブジェクト クエリをオブジェクトの 1 つに分類するための線形レイヤー、または「いいえ」
+オブジェクト」、および各クエリの境界ボックスを予測する MLP。
+
+モデルは **2 部マッチング損失**を使用してトレーニングされます。つまり、実際に行うことは、予測されたクラスを比較することです +
+グラウンド トゥルース アノテーションに対する N = 100 個の各オブジェクト クエリの境界ボックス (同じ長さ N までパディング)
+(したがって、画像にオブジェクトが 4 つしか含まれていない場合、96 個の注釈にはクラスとして「オブジェクトなし」、およびクラスとして「境界ボックスなし」が含まれるだけになります。
+境界ボックス)。 [Hungarian matching algorithm](https://en.wikipedia.org/wiki/Hungarian_algorithm) は、検索に使用されます。
+N 個のクエリのそれぞれから N 個の注釈のそれぞれへの最適な 1 対 1 のマッピング。次に、標準クロスエントロピー (
+クラス)、および L1 と [generalized IoU loss](https://giou.stanford.edu/) の線形結合 (
+境界ボックス) は、モデルのパラメーターを最適化するために使用されます。
+
+DETR は、パノプティック セグメンテーション (セマンティック セグメンテーションとインスタンスを統合する) を実行するように自然に拡張できます。
+セグメンテーション)。 [`~transformers.DetrForSegmentation`] はセグメンテーション マスク ヘッドを上に追加します
+[`~transformers.DetrForObjectDetection`]。マスク ヘッドは、共同でトレーニングすることも、2 段階のプロセスでトレーニングすることもできます。
+ここで、最初に [`~transformers.DetrForObjectDetection`] モデルをトレーニングして、両方の周囲の境界ボックスを検出します。
+「もの」(インスタンス)と「もの」(木、道路、空などの背景のもの)をすべて凍結し、すべての重みをフリーズしてのみトレーニングします。
+25 エポックのマスクヘッド。実験的には、これら 2 つのアプローチは同様の結果をもたらします。ボックスの予測は
+ハンガリー語のマッチングはボックス間の距離を使用して計算されるため、トレーニングを可能にするためにはこれが必要です。
+
+## Usage tips
+
+- DETR は、いわゆる **オブジェクト クエリ** を使用して、画像内のオブジェクトを検出します。クエリの数によって最大値が決まります
+ 単一の画像内で検出できるオブジェクトの数。デフォルトでは 100 に設定されます (パラメーターを参照)
+ [`~transformers.DetrConfig`] の `num_queries`)。ある程度の余裕があるのは良いことです (COCO では、
+ 著者は 100 を使用しましたが、COCO イメージ内のオブジェクトの最大数は約 70 です)。
+- DETR のデコーダーは、クエリの埋め込みを並行して更新します。これは GPT-2 のような言語モデルとは異なります。
+ 並列ではなく自己回帰デコードを使用します。したがって、因果的注意マスクは使用されません。
+- DETR は、投影前に各セルフアテンション層とクロスアテンション層の隠れ状態に位置埋め込みを追加します。
+ クエリとキーに。画像の位置埋め込みについては、固定正弦波または学習済みのどちらかを選択できます。
+ 絶対位置埋め込み。デフォルトでは、パラメータ `position_embedding_type` は
+ [`~transformers.DetrConfig`] は `"sine"` に設定されます。
+- DETR の作成者は、トレーニング中に、特にデコーダで補助損失を使用すると役立つことに気づきました。
+ モデルは各クラスの正しい数のオブジェクトを出力します。パラメータ `auxiliary_loss` を設定すると、
+ [`~transformers.DetrConfig`] を`True`に設定し、フィードフォワード ニューラル ネットワークとハンガリー損失を予測します
+ は各デコーダ層の後に追加されます (FFN がパラメータを共有する)。
+- 複数のノードにわたる分散環境でモデルをトレーニングする場合は、
+ _modeling_detr.py_ の _DetrLoss_ クラスの _num_boxes_ 変数。複数のノードでトレーニングする場合、これは次のようにする必要があります
+ 元の実装で見られるように、すべてのノードにわたるターゲット ボックスの平均数に設定されます [こちら](https://github.com/facebookresearch/detr/blob/a54b77800eb8e64e3ad0d8237789fcbf2f8350c5/models/detr.py#L227-L232) 。
+- [`~transformers.DetrForObjectDetection`] および [`~transformers.DetrForSegmentation`] は次のように初期化できます。
+ [timm ライブラリ](https://github.com/rwightman/pytorch-image-models) で利用可能な畳み込みバックボーン。
+ たとえば、MobileNet バックボーンを使用した初期化は、次の `backbone` 属性を設定することで実行できます。
+ [`~transformers.DetrConfig`] を `"tf_mobilenetv3_small_075"` に設定し、それを使用してモデルを初期化します。
+ 構成。
+- DETR は、最短辺が一定のピクセル数以上になり、最長辺が一定量以上になるように入力画像のサイズを変更します。
+ 最大 1333 ピクセル。トレーニング時に、最短辺がランダムに に設定されるようにスケール拡張が使用されます。
+ 最小 480、最大 800 ピクセル。推論時には、最短辺が 800 に設定されます。
+
+使用できます
+ [`~transformers.DetrImageProcessor`] 用の画像 (およびオプションの COCO 形式の注釈) を準備します。
+ モデル。このサイズ変更により、バッチ内の画像のサイズが異なる場合があります。 DETR は、画像を最大までパディングすることでこの問題を解決します。
+ どのピクセルが実数でどのピクセルがパディングであるかを示すピクセル マスクを作成することによって、バッチ内の最大サイズを決定します。
+ あるいは、画像をバッチ処理するためにカスタムの `collate_fn` を定義することもできます。
+ [`~transformers.DetrImageProcessor.pad_and_create_pixel_mask`]。
+- 画像のサイズによって使用されるメモリの量が決まり、したがって「batch_size」も決まります。
+ GPU あたり 2 のバッチ サイズを使用することをお勧めします。詳細については、[この Github スレッド](https://github.com/facebookresearch/detr/issues/150) を参照してください。
+
+DETR モデルをインスタンス化するには 3 つの方法があります (好みに応じて)。
+
+オプション 1: モデル全体の事前トレーニングされた重みを使用して DETR をインスタンス化する
+
+```py
+>>> from transformers import DetrForObjectDetection
+
+>>> model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
+```
+
+オプション 2: Transformer についてはランダムに初期化された重みを使用して DETR をインスタンス化しますが、バックボーンについては事前にトレーニングされた重みを使用します
+
+```py
+>>> from transformers import DetrConfig, DetrForObjectDetection
+
+>>> config = DetrConfig()
+>>> model = DetrForObjectDetection(config)
+```
+
+オプション 3: バックボーン + トランスフォーマーのランダムに初期化された重みを使用して DETR をインスタンス化します。
+
+```py
+>>> config = DetrConfig(use_pretrained_backbone=False)
+>>> model = DetrForObjectDetection(config)
+```
+
+| Task | Object detection | Instance segmentation | Panoptic segmentation |
+|------|------------------|-----------------------|-----------------------|
+| **Description** |画像内のオブジェクトの周囲の境界ボックスとクラス ラベルを予測する | 画像内のオブジェクト (つまりインスタンス) の周囲のマスクを予測する | 画像内のオブジェクト (インスタンス) と「もの」 (木や道路などの背景) の両方の周囲のマスクを予測します |
+| **Model** | [`~transformers.DetrForObjectDetection`] | [`~transformers.DetrForSegmentation`] | [`~transformers.DetrForSegmentation`] |
+| **Example dataset** | COCO detection | COCO detection, COCO panoptic | COCO panoptic | |
+| **Format of annotations to provide to** [`~transformers.DetrImageProcessor`] | {'image_id': `int`, 'annotations': `List[Dict]`} each Dict being a COCO object annotation | {'image_id': `int`, 'annotations': `List[Dict]`} (in case of COCO detection) or {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} (in case of COCO panoptic) | {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} and masks_path (path to directory containing PNG files of the masks) |
+| **Postprocessing** (i.e. converting the output of the model to Pascal VOC format) | [`~transformers.DetrImageProcessor.post_process`] | [`~transformers.DetrImageProcessor.post_process_segmentation`] | [`~transformers.DetrImageProcessor.post_process_segmentation`], [`~transformers.DetrImageProcessor.post_process_panoptic`] |
+| **evaluators** | `CocoEvaluator` with `iou_types="bbox"` | `CocoEvaluator` with `iou_types="bbox"` or `"segm"` | `CocoEvaluator` with `iou_tupes="bbox"` or `"segm"`, `PanopticEvaluator` |
+
+つまり、COCO 検出または COCO パノプティック形式でデータを準備してから、次を使用する必要があります。
+[`~transformers.DetrImageProcessor`] `pixel_values`、`pixel_mask`、およびオプションを作成します。
+「ラベル」。これを使用してモデルをトレーニング (または微調整) できます。評価するには、まず、
+[`~transformers.DetrImageProcessor`] の後処理メソッドの 1 つを使用したモデルの出力。これらはできます
+`CocoEvaluator` または `PanopticEvaluator` のいずれかに提供され、次のようなメトリクスを計算できます。
+平均平均精度 (mAP) とパノラマ品質 (PQ)。後者のオブジェクトは [元のリポジトリ](https://github.com/facebookresearch/detr) に実装されています。評価の詳細については、[サンプル ノートブック](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) を参照してください。
+
+## Resources
+
+DETR の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+
+
+ DETA の概要。 元の論文から抜粋。
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。
+元のコードは [ここ](https://github.com/jozhang97/DETA) にあります。
+
+## Resources
+
+DETA の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+- DETA のデモ ノートブックは [こちら](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETA) にあります。
+- 参照: [オブジェクト検出タスク ガイド](../tasks/object_detection)
+
+ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
+
+## DetaConfig
+
+[[autodoc]] DetaConfig
+
+## DetaImageProcessor
+
+[[autodoc]] DetaImageProcessor
+ - preprocess
+ - post_process_object_detection
+
+## DetaModel
+
+[[autodoc]] DetaModel
+ - forward
+
+## DetaForObjectDetection
+
+[[autodoc]] DetaForObjectDetection
+ - forward
diff --git a/docs/transformers/docs/source/ja/model_doc/detr.md b/docs/transformers/docs/source/ja/model_doc/detr.md
new file mode 100644
index 0000000000000000000000000000000000000000..3342b123a01b833795847c8b46c723ddb53f45f4
--- /dev/null
+++ b/docs/transformers/docs/source/ja/model_doc/detr.md
@@ -0,0 +1,226 @@
+
+
+# DETR
+
+## Overview
+
+DETR モデルは、[Transformers を使用したエンドツーエンドのオブジェクト検出](https://arxiv.org/abs/2005.12872) で提案されました。
+Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov and Sergey Zagoruyko ルイコ。 DETR
+畳み込みバックボーンと、その後にエンドツーエンドでトレーニングできるエンコーダー/デコーダー Transformer で構成されます。
+物体の検出。 Faster-R-CNN や Mask-R-CNN などのモデルの複雑さの多くが大幅に簡素化されます。
+領域提案、非最大抑制手順、アンカー生成などです。さらに、DETR は次のようにすることもできます。
+デコーダ出力の上にマスク ヘッドを追加するだけで、パノプティック セグメンテーションを実行できるように自然に拡張されています。
+
+論文の要約は次のとおりです。
+
+*物体検出を直接集合予測問題として見る新しい方法を紹介します。私たちのアプローチは、
+検出パイプラインにより、非最大抑制などの多くの手作業で設計されたコンポーネントの必要性が効果的に排除されます。
+タスクに関する事前の知識を明示的にエンコードするプロシージャまたはアンカーの生成。の主な成分は、
+DEtection TRansformer または DETR と呼ばれる新しいフレームワークは、セットベースのグローバル損失であり、
+二部マッチング、およびトランスフォーマー エンコーダー/デコーダー アーキテクチャ。学習されたオブジェクト クエリの固定された小さなセットが与えられると、
+DETR は、オブジェクトとグローバル イメージ コンテキストの関係について推論し、最終セットを直接出力します。
+並行して予想も。新しいモデルは概念的にシンプルであり、多くのモデルとは異なり、特殊なライブラリを必要としません。
+他の最新の検出器。 DETR は、確立された、および同等の精度と実行時のパフォーマンスを実証します。
+困難な COCO 物体検出データセットに基づく、高度に最適化された Faster RCNN ベースライン。さらに、DETR は簡単に実行できます。
+統一された方法でパノプティック セグメンテーションを生成するために一般化されました。競合他社を大幅に上回るパフォーマンスを示しています
+ベースライン*
+
+このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [こちら](https://github.com/facebookresearch/detr) にあります。
+
+## How DETR works
+
+[`~transformers.DetrForObjectDetection`] がどのように機能するかを説明する TLDR は次のとおりです。
+
+まず、事前にトレーニングされた畳み込みバックボーンを通じて画像が送信されます (論文では、著者らは次のように使用しています)。
+ResNet-50/ResNet-101)。バッチ ディメンションも追加すると仮定します。これは、バックボーンへの入力が
+画像に 3 つのカラー チャネル (RGB) があると仮定した場合の、形状 `(batch_size, 3, height, width)` のテンソル。 CNNのバックボーン
+通常は `(batch_size, 2048, height/32, width/32)` の形状の、新しい低解像度の特徴マップを出力します。これは
+次に、DETR の Transformer の隠れ次元 (デフォルトでは `256`) に一致するように投影されます。
+`nn.Conv2D` レイヤー。これで、形状 `(batch_size, 256, height/32, width/32)` のテンソルが完成しました。
+特徴マップは平坦化および転置され、形状 `(batch_size, seq_len, d_model)` のテンソルを取得します =
+`(batch_size, width/32*height/32, 256)`。したがって、NLP モデルとの違いは、シーケンスの長さが実際には
+通常よりも長くなりますが、「d_model」は小さくなります (NLP では通常 768 以上です)。
+
+次に、これがエンコーダを介して送信され、同じ形状の `encoder_hidden_states` が出力されます (次のように考えることができます)。
+これらは画像の特徴として)。次に、いわゆる **オブジェクト クエリ**がデコーダを通じて送信されます。これは形状のテンソルです
+`(batch_size, num_queries, d_model)`。通常、`num_queries` は 100 に設定され、ゼロで初期化されます。
+これらの入力埋め込みは学習された位置エンコーディングであり、作成者はこれをオブジェクト クエリと呼び、同様に
+エンコーダでは、それらは各アテンション層の入力に追加されます。各オブジェクト クエリは特定のオブジェクトを検索します。
+画像では。デコーダは、複数のセルフ アテンション レイヤとエンコーダ デコーダ アテンション レイヤを通じてこれらの埋め込みを更新します。
+同じ形状の `decoder_hidden_states` を出力します: `(batch_size, num_queries, d_model)`。次に頭が2つ
+オブジェクト検出のために上部に追加されます。各オブジェクト クエリをオブジェクトの 1 つに分類するための線形レイヤー、または「いいえ」
+オブジェクト」、および各クエリの境界ボックスを予測する MLP。
+
+モデルは **2 部マッチング損失**を使用してトレーニングされます。つまり、実際に行うことは、予測されたクラスを比較することです +
+グラウンド トゥルース アノテーションに対する N = 100 個の各オブジェクト クエリの境界ボックス (同じ長さ N までパディング)
+(したがって、画像にオブジェクトが 4 つしか含まれていない場合、96 個の注釈にはクラスとして「オブジェクトなし」、およびクラスとして「境界ボックスなし」が含まれるだけになります。
+境界ボックス)。 [Hungarian matching algorithm](https://en.wikipedia.org/wiki/Hungarian_algorithm) は、検索に使用されます。
+N 個のクエリのそれぞれから N 個の注釈のそれぞれへの最適な 1 対 1 のマッピング。次に、標準クロスエントロピー (
+クラス)、および L1 と [generalized IoU loss](https://giou.stanford.edu/) の線形結合 (
+境界ボックス) は、モデルのパラメーターを最適化するために使用されます。
+
+DETR は、パノプティック セグメンテーション (セマンティック セグメンテーションとインスタンスを統合する) を実行するように自然に拡張できます。
+セグメンテーション)。 [`~transformers.DetrForSegmentation`] はセグメンテーション マスク ヘッドを上に追加します
+[`~transformers.DetrForObjectDetection`]。マスク ヘッドは、共同でトレーニングすることも、2 段階のプロセスでトレーニングすることもできます。
+ここで、最初に [`~transformers.DetrForObjectDetection`] モデルをトレーニングして、両方の周囲の境界ボックスを検出します。
+「もの」(インスタンス)と「もの」(木、道路、空などの背景のもの)をすべて凍結し、すべての重みをフリーズしてのみトレーニングします。
+25 エポックのマスクヘッド。実験的には、これら 2 つのアプローチは同様の結果をもたらします。ボックスの予測は
+ハンガリー語のマッチングはボックス間の距離を使用して計算されるため、トレーニングを可能にするためにはこれが必要です。
+
+## Usage tips
+
+- DETR は、いわゆる **オブジェクト クエリ** を使用して、画像内のオブジェクトを検出します。クエリの数によって最大値が決まります
+ 単一の画像内で検出できるオブジェクトの数。デフォルトでは 100 に設定されます (パラメーターを参照)
+ [`~transformers.DetrConfig`] の `num_queries`)。ある程度の余裕があるのは良いことです (COCO では、
+ 著者は 100 を使用しましたが、COCO イメージ内のオブジェクトの最大数は約 70 です)。
+- DETR のデコーダーは、クエリの埋め込みを並行して更新します。これは GPT-2 のような言語モデルとは異なります。
+ 並列ではなく自己回帰デコードを使用します。したがって、因果的注意マスクは使用されません。
+- DETR は、投影前に各セルフアテンション層とクロスアテンション層の隠れ状態に位置埋め込みを追加します。
+ クエリとキーに。画像の位置埋め込みについては、固定正弦波または学習済みのどちらかを選択できます。
+ 絶対位置埋め込み。デフォルトでは、パラメータ `position_embedding_type` は
+ [`~transformers.DetrConfig`] は `"sine"` に設定されます。
+- DETR の作成者は、トレーニング中に、特にデコーダで補助損失を使用すると役立つことに気づきました。
+ モデルは各クラスの正しい数のオブジェクトを出力します。パラメータ `auxiliary_loss` を設定すると、
+ [`~transformers.DetrConfig`] を`True`に設定し、フィードフォワード ニューラル ネットワークとハンガリー損失を予測します
+ は各デコーダ層の後に追加されます (FFN がパラメータを共有する)。
+- 複数のノードにわたる分散環境でモデルをトレーニングする場合は、
+ _modeling_detr.py_ の _DetrLoss_ クラスの _num_boxes_ 変数。複数のノードでトレーニングする場合、これは次のようにする必要があります
+ 元の実装で見られるように、すべてのノードにわたるターゲット ボックスの平均数に設定されます [こちら](https://github.com/facebookresearch/detr/blob/a54b77800eb8e64e3ad0d8237789fcbf2f8350c5/models/detr.py#L227-L232) 。
+- [`~transformers.DetrForObjectDetection`] および [`~transformers.DetrForSegmentation`] は次のように初期化できます。
+ [timm ライブラリ](https://github.com/rwightman/pytorch-image-models) で利用可能な畳み込みバックボーン。
+ たとえば、MobileNet バックボーンを使用した初期化は、次の `backbone` 属性を設定することで実行できます。
+ [`~transformers.DetrConfig`] を `"tf_mobilenetv3_small_075"` に設定し、それを使用してモデルを初期化します。
+ 構成。
+- DETR は、最短辺が一定のピクセル数以上になり、最長辺が一定量以上になるように入力画像のサイズを変更します。
+ 最大 1333 ピクセル。トレーニング時に、最短辺がランダムに に設定されるようにスケール拡張が使用されます。
+ 最小 480、最大 800 ピクセル。推論時には、最短辺が 800 に設定されます。
+
+使用できます
+ [`~transformers.DetrImageProcessor`] 用の画像 (およびオプションの COCO 形式の注釈) を準備します。
+ モデル。このサイズ変更により、バッチ内の画像のサイズが異なる場合があります。 DETR は、画像を最大までパディングすることでこの問題を解決します。
+ どのピクセルが実数でどのピクセルがパディングであるかを示すピクセル マスクを作成することによって、バッチ内の最大サイズを決定します。
+ あるいは、画像をバッチ処理するためにカスタムの `collate_fn` を定義することもできます。
+ [`~transformers.DetrImageProcessor.pad_and_create_pixel_mask`]。
+- 画像のサイズによって使用されるメモリの量が決まり、したがって「batch_size」も決まります。
+ GPU あたり 2 のバッチ サイズを使用することをお勧めします。詳細については、[この Github スレッド](https://github.com/facebookresearch/detr/issues/150) を参照してください。
+
+DETR モデルをインスタンス化するには 3 つの方法があります (好みに応じて)。
+
+オプション 1: モデル全体の事前トレーニングされた重みを使用して DETR をインスタンス化する
+
+```py
+>>> from transformers import DetrForObjectDetection
+
+>>> model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
+```
+
+オプション 2: Transformer についてはランダムに初期化された重みを使用して DETR をインスタンス化しますが、バックボーンについては事前にトレーニングされた重みを使用します
+
+```py
+>>> from transformers import DetrConfig, DetrForObjectDetection
+
+>>> config = DetrConfig()
+>>> model = DetrForObjectDetection(config)
+```
+
+オプション 3: バックボーン + トランスフォーマーのランダムに初期化された重みを使用して DETR をインスタンス化します。
+
+```py
+>>> config = DetrConfig(use_pretrained_backbone=False)
+>>> model = DetrForObjectDetection(config)
+```
+
+| Task | Object detection | Instance segmentation | Panoptic segmentation |
+|------|------------------|-----------------------|-----------------------|
+| **Description** |画像内のオブジェクトの周囲の境界ボックスとクラス ラベルを予測する | 画像内のオブジェクト (つまりインスタンス) の周囲のマスクを予測する | 画像内のオブジェクト (インスタンス) と「もの」 (木や道路などの背景) の両方の周囲のマスクを予測します |
+| **Model** | [`~transformers.DetrForObjectDetection`] | [`~transformers.DetrForSegmentation`] | [`~transformers.DetrForSegmentation`] |
+| **Example dataset** | COCO detection | COCO detection, COCO panoptic | COCO panoptic | |
+| **Format of annotations to provide to** [`~transformers.DetrImageProcessor`] | {'image_id': `int`, 'annotations': `List[Dict]`} each Dict being a COCO object annotation | {'image_id': `int`, 'annotations': `List[Dict]`} (in case of COCO detection) or {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} (in case of COCO panoptic) | {'file_name': `str`, 'image_id': `int`, 'segments_info': `List[Dict]`} and masks_path (path to directory containing PNG files of the masks) |
+| **Postprocessing** (i.e. converting the output of the model to Pascal VOC format) | [`~transformers.DetrImageProcessor.post_process`] | [`~transformers.DetrImageProcessor.post_process_segmentation`] | [`~transformers.DetrImageProcessor.post_process_segmentation`], [`~transformers.DetrImageProcessor.post_process_panoptic`] |
+| **evaluators** | `CocoEvaluator` with `iou_types="bbox"` | `CocoEvaluator` with `iou_types="bbox"` or `"segm"` | `CocoEvaluator` with `iou_tupes="bbox"` or `"segm"`, `PanopticEvaluator` |
+
+つまり、COCO 検出または COCO パノプティック形式でデータを準備してから、次を使用する必要があります。
+[`~transformers.DetrImageProcessor`] `pixel_values`、`pixel_mask`、およびオプションを作成します。
+「ラベル」。これを使用してモデルをトレーニング (または微調整) できます。評価するには、まず、
+[`~transformers.DetrImageProcessor`] の後処理メソッドの 1 つを使用したモデルの出力。これらはできます
+`CocoEvaluator` または `PanopticEvaluator` のいずれかに提供され、次のようなメトリクスを計算できます。
+平均平均精度 (mAP) とパノラマ品質 (PQ)。後者のオブジェクトは [元のリポジトリ](https://github.com/facebookresearch/detr) に実装されています。評価の詳細については、[サンプル ノートブック](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) を参照してください。
+
+## Resources
+
+DETR の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示されている) リソースのリスト。
+
+ +
+ 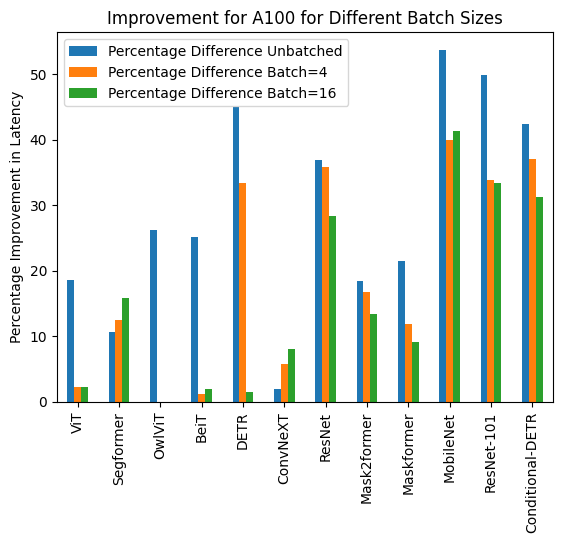 +
+ 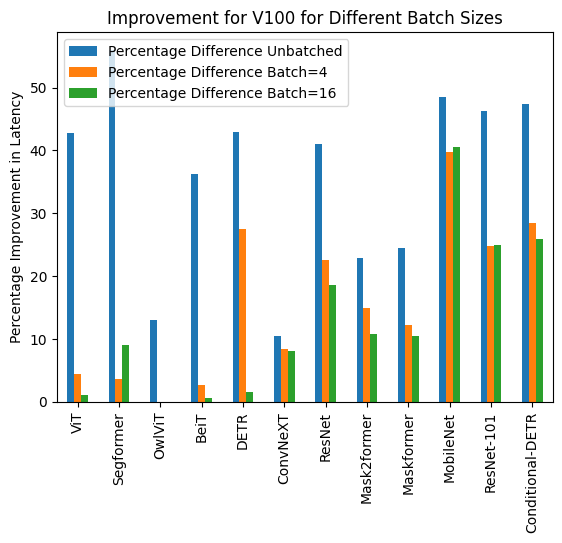 +
+ 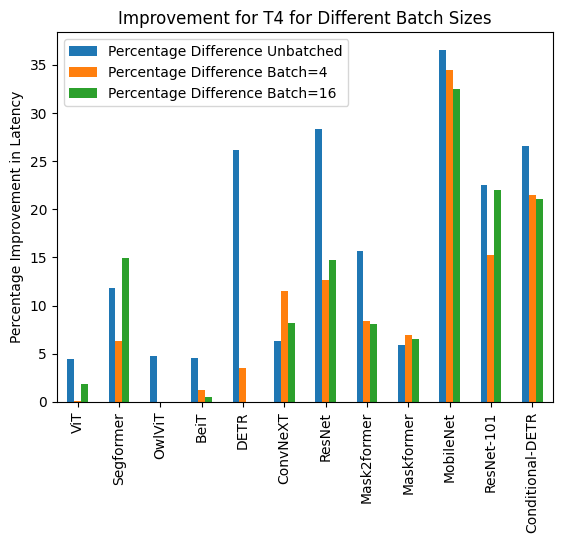 +
+ 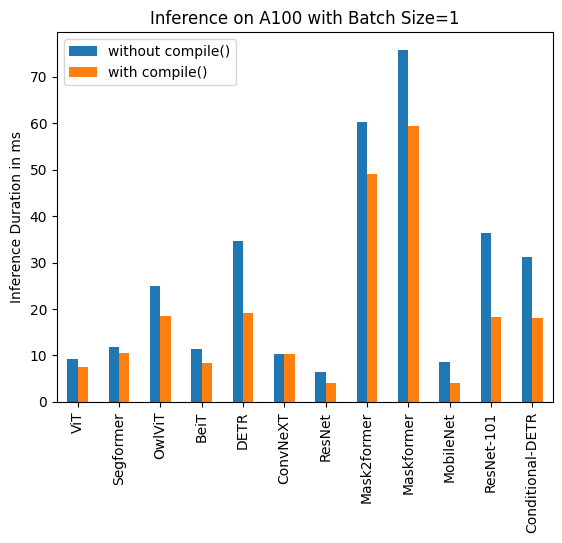 +
+ 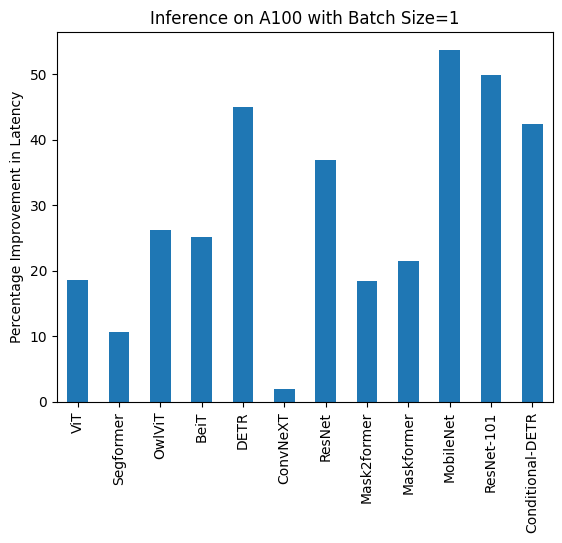 +
+  +
+これはシーケンスの確率のより正確な分解に近いものであり、通常はより有利なスコアを生成します。欠点は、コーパス内の各トークンに対して別個の前方パスが必要です。実用的な妥協案は、1トークンずつスライドする代わりに、より大きなストライドでコンテキストを移動するストライド型のスライディングウィンドウを使用することです。これにより、計算がはるかに高速に進行できる一方で、モデルには各ステップで予測を行うための大きなコンテキストが提供されます。
+
+## Example: Calculating perplexity with GPT-2 in 🤗 Transformers
+
+GPT-2を使用してこのプロセスをデモンストレーションしてみましょう。
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "openai-community/gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+WikiText-2データセットを読み込み、異なるスライディングウィンドウ戦略を使用してパープレキシティを評価します。このデータセットは小規模で、セット全体に対して単一のフォワードパスを実行するだけなので、データセット全体をメモリに読み込んでエンコードするだけで十分です。
+
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+🤗 Transformersを使用すると、単純に`input_ids`をモデルの`labels`として渡すことで、各トークンの平均負の対数尤度が損失として返されます。しかし、スライディングウィンドウのアプローチでは、各イテレーションでモデルに渡すトークンにオーバーラップがあります。私たちは、コンテキストとして扱っているトークンの対数尤度を損失に含めたくありません。そのため、これらの対象を `-100` に設定して無視されるようにします。以下は、ストライドを `512` とした場合の例です。これにより、モデルは任意のトークンの条件付けの尤度を計算する際に、少なくともコンテキストとして 512 トークンを持つことになります(512 個の前のトークンが利用可能である場合)。
+
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+seq_len = encodings.input_ids.size(1)
+
+nlls = []
+prev_end_loc = 0
+for begin_loc in tqdm(range(0, seq_len, stride)):
+ end_loc = min(begin_loc + max_length, seq_len)
+ trg_len = end_loc - prev_end_loc # may be different from stride on last loop
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+
+ # loss is calculated using CrossEntropyLoss which averages over valid labels
+ # N.B. the model only calculates loss over trg_len - 1 labels, because it internally shifts the labels
+ # to the left by 1.
+ neg_log_likelihood = outputs.loss
+
+ nlls.append(neg_log_likelihood)
+
+ prev_end_loc = end_loc
+ if end_loc == seq_len:
+ break
+
+ppl = torch.exp(torch.stack(nlls).mean())
+```
+
+ストライド長が最大入力長と同じ場合、上述の最適でないスライディングウィンドウ戦略と同等です。ストライドが小さいほど、モデルは各予測を行う際により多くのコンテキストを持つため、通常、報告される困難度(perplexity)が向上します。
+
+上記のコードを `stride = 1024` で実行すると、オーバーラップがない状態で、結果の困難度(perplexity)は `19.44` になります。これは GPT-2 の論文に報告された `19.93` とほぼ同等です。一方、`stride = 512` を使用し、このようにストライディングウィンドウ戦略を採用すると、困難度(perplexity)が `16.45` に向上します。これはより好意的なスコアだけでなく、シーケンスの尤度の真の自己回帰分解により近い方法で計算されています。
+
+
+
diff --git a/docs/transformers/docs/source/ja/philosophy.md b/docs/transformers/docs/source/ja/philosophy.md
new file mode 100644
index 0000000000000000000000000000000000000000..3edef0bd2add3b20d37332d0afadb904214ab1b0
--- /dev/null
+++ b/docs/transformers/docs/source/ja/philosophy.md
@@ -0,0 +1,67 @@
+
+
+# Philosophy
+
+🤗 Transformersは、次のような目的で構築された意見を持つライブラリです:
+
+- 大規模なTransformersモデルを使用、研究、または拡張したい機械学習研究者および教育者。
+- これらのモデルを微調整したり、本番環境で提供したり、またはその両方を行いたい実務家。
+- 与えられた機械学習タスクを解決するために、事前トレーニングされたモデルをダウンロードして使用したいエンジニア。
+
+このライブラリは、2つの強力な目標を持って設計されました:
+
+1. できるだけ簡単かつ高速に使用できるようにすること:
+
+ - ユーザー向けの抽象化を限りなく少なくし、実際、ほとんどの場合、抽象化はありません。
+ 各モデルを使用するために必要な3つの標準クラスだけが存在します:[構成](main_classes/configuration)、
+ [モデル](main_classes/model)、および前処理クラス(NLP用の[トークナイザ](main_classes/tokenizer)、ビジョン用の[イメージプロセッサ](main_classes/image_processor)、
+ オーディオ用の[特徴抽出器](main_classes/feature_extractor)、およびマルチモーダル入力用の[プロセッサ](main_classes/processors))。
+ - これらのクラスは、共通の`from_pretrained()`メソッドを使用して、事前トレーニング済みのインスタンスから簡単かつ統一された方法で初期化できます。このメソッドは、事前トレーニング済みのチェックポイントから関連するクラスのインスタンスと関連データ(構成のハイパーパラメータ、トークナイザの語彙、モデルの重み)をダウンロード(必要な場合はキャッシュ)して読み込みます。これらの基本クラスの上に、ライブラリは2つのAPIを提供しています:[パイプライン]は、特定のタスクでモデルをすばやく推論に使用するためのものであり、[`Trainer`]はPyTorchモデルを迅速にトレーニングまたは微調整するためのものです(すべてのTensorFlowモデルは`Keras.fit`と互換性があります)。
+ - その結果、このライブラリはニューラルネットワークのモジュラーツールボックスではありません。ライブラリを拡張または構築したい場合は、通常のPython、PyTorch、TensorFlow、Kerasモジュールを使用し、ライブラリの基本クラスから継承してモデルの読み込みと保存などの機能を再利用するだけです。モデルのコーディング哲学について詳しく知りたい場合は、[Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy)ブログ投稿をチェックしてみてください。
+
+2. オリジナルのモデルにできるだけ近い性能を持つ最新のモデルを提供すること:
+
+ - 各アーキテクチャに対して、公式な著者から提供された結果を再現する少なくとも1つの例を提供します。
+ - コードは通常、可能な限り元のコードベースに近いものであり、これはPyTorchコードがTensorFlowコードに変換されることから生じ、逆もまた然りです。
+
+その他のいくつかの目標:
+
+- モデルの内部をできるだけ一貫して公開すること:
+
+ - フルな隠れ状態と注意の重みにアクセスできる単一のAPIを提供します。
+ - 前処理クラスと基本モデルのAPIは標準化され、簡単にモデル間を切り替えることができます。
+
+- これらのモデルの微調整と調査のための有望なツールを主観的に選定すること:
+
+ - 語彙と埋め込みに新しいトークンを追加するための簡単で一貫した方法。
+ - Transformerヘッドをマスクおよびプルーンするための簡単な方法。
+
+- PyTorch、TensorFlow 2.0、およびFlaxの間を簡単に切り替えて、1つのフレームワークでトレーニングし、別のフレームワークで推論を行うことを可能にすること。
+
+## Main concepts
+
+このライブラリは、各モデルについて次の3つのタイプのクラスを中心に構築されています:
+
+- **モデルクラス**は、ライブラリで提供される事前トレーニング済みの重みと互換性のあるPyTorchモデル([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module))、Kerasモデル([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model))またはJAX/Flaxモデル([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html))を使用できます。
+- **構成クラス**は、モデルを構築するために必要なハイパーパラメータを格納します(層の数や隠れ層のサイズなど)。これらを自分でインスタンス化する必要はありません。特に、変更を加えずに事前トレーニング済みモデルを使用している場合、モデルを作成すると自動的に構成がインスタンス化されるようになります(これはモデルの一部です)。
+- **前処理クラス**は、生データをモデルが受け入れる形式に変換します。[トークナイザ](main_classes/tokenizer)は各モデルの語彙を保存し、文字列をトークン埋め込みのインデックスのリストにエンコードおよびデコードするためのメソッドを提供します。[イメージプロセッサ](main_classes/image_processor)はビジョン入力を前処理し、[特徴抽出器](main_classes/feature_extractor)はオーディオ入力を前処理し、[プロセッサ](main_classes/processors)はマルチモーダル入力を処理します。
+
+これらのすべてのクラスは、事前トレーニング済みのインスタンスからインスタンス化し、ローカルに保存し、Hubで共有することができる3つのメソッドを使用しています:
+
+- `from_pretrained()`は、ライブラリ自体によって提供される([モデルハブ](https://huggingface.co/models)でサポートされているモデルがあります)か、ユーザーによってローカルに保存された(またはサーバーに保存された)事前トレーニング済みバージョンからモデル、構成、前処理クラスをインスタンス化するためのメソッドです。
+- `save_pretrained()`は、モデル、構成、前処理クラスをローカルに保存し、`from_pretrained()`を使用して再読み込みできるようにします。
+- `push_to_hub()`は、モデル、構成、前処理クラスをHubに共有し、誰でも簡単にアクセスできるようにします。
diff --git a/docs/transformers/docs/source/ja/pipeline_tutorial.md b/docs/transformers/docs/source/ja/pipeline_tutorial.md
new file mode 100644
index 0000000000000000000000000000000000000000..5dbda5ce4d4a359b9ae0a1f5be9714feb18b6ea5
--- /dev/null
+++ b/docs/transformers/docs/source/ja/pipeline_tutorial.md
@@ -0,0 +1,295 @@
+
+
+# Pipelines for inference
+
+[`pipeline`]を使用することで、[Hub](https://huggingface.co/models)からの任意のモデルを言語、コンピュータビジョン、音声、およびマルチモーダルタスクの推論に簡単に使用できます。
+特定のモダリティに関する経験がない場合や、モデルの背後にあるコードに精通していない場合でも、[`pipeline`]を使用して推論できます!
+このチュートリアルでは、次のことを学びます:
+
+- 推論のための[`pipeline`]の使用方法。
+- 特定のトークナイザやモデルの使用方法。
+- オーディオ、ビジョン、マルチモーダルタスクのための[`pipeline`]の使用方法。
+
+
+
+これはシーケンスの確率のより正確な分解に近いものであり、通常はより有利なスコアを生成します。欠点は、コーパス内の各トークンに対して別個の前方パスが必要です。実用的な妥協案は、1トークンずつスライドする代わりに、より大きなストライドでコンテキストを移動するストライド型のスライディングウィンドウを使用することです。これにより、計算がはるかに高速に進行できる一方で、モデルには各ステップで予測を行うための大きなコンテキストが提供されます。
+
+## Example: Calculating perplexity with GPT-2 in 🤗 Transformers
+
+GPT-2を使用してこのプロセスをデモンストレーションしてみましょう。
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "openai-community/gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+WikiText-2データセットを読み込み、異なるスライディングウィンドウ戦略を使用してパープレキシティを評価します。このデータセットは小規模で、セット全体に対して単一のフォワードパスを実行するだけなので、データセット全体をメモリに読み込んでエンコードするだけで十分です。
+
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+🤗 Transformersを使用すると、単純に`input_ids`をモデルの`labels`として渡すことで、各トークンの平均負の対数尤度が損失として返されます。しかし、スライディングウィンドウのアプローチでは、各イテレーションでモデルに渡すトークンにオーバーラップがあります。私たちは、コンテキストとして扱っているトークンの対数尤度を損失に含めたくありません。そのため、これらの対象を `-100` に設定して無視されるようにします。以下は、ストライドを `512` とした場合の例です。これにより、モデルは任意のトークンの条件付けの尤度を計算する際に、少なくともコンテキストとして 512 トークンを持つことになります(512 個の前のトークンが利用可能である場合)。
+
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+seq_len = encodings.input_ids.size(1)
+
+nlls = []
+prev_end_loc = 0
+for begin_loc in tqdm(range(0, seq_len, stride)):
+ end_loc = min(begin_loc + max_length, seq_len)
+ trg_len = end_loc - prev_end_loc # may be different from stride on last loop
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+
+ # loss is calculated using CrossEntropyLoss which averages over valid labels
+ # N.B. the model only calculates loss over trg_len - 1 labels, because it internally shifts the labels
+ # to the left by 1.
+ neg_log_likelihood = outputs.loss
+
+ nlls.append(neg_log_likelihood)
+
+ prev_end_loc = end_loc
+ if end_loc == seq_len:
+ break
+
+ppl = torch.exp(torch.stack(nlls).mean())
+```
+
+ストライド長が最大入力長と同じ場合、上述の最適でないスライディングウィンドウ戦略と同等です。ストライドが小さいほど、モデルは各予測を行う際により多くのコンテキストを持つため、通常、報告される困難度(perplexity)が向上します。
+
+上記のコードを `stride = 1024` で実行すると、オーバーラップがない状態で、結果の困難度(perplexity)は `19.44` になります。これは GPT-2 の論文に報告された `19.93` とほぼ同等です。一方、`stride = 512` を使用し、このようにストライディングウィンドウ戦略を採用すると、困難度(perplexity)が `16.45` に向上します。これはより好意的なスコアだけでなく、シーケンスの尤度の真の自己回帰分解により近い方法で計算されています。
+
+
+
diff --git a/docs/transformers/docs/source/ja/philosophy.md b/docs/transformers/docs/source/ja/philosophy.md
new file mode 100644
index 0000000000000000000000000000000000000000..3edef0bd2add3b20d37332d0afadb904214ab1b0
--- /dev/null
+++ b/docs/transformers/docs/source/ja/philosophy.md
@@ -0,0 +1,67 @@
+
+
+# Philosophy
+
+🤗 Transformersは、次のような目的で構築された意見を持つライブラリです:
+
+- 大規模なTransformersモデルを使用、研究、または拡張したい機械学習研究者および教育者。
+- これらのモデルを微調整したり、本番環境で提供したり、またはその両方を行いたい実務家。
+- 与えられた機械学習タスクを解決するために、事前トレーニングされたモデルをダウンロードして使用したいエンジニア。
+
+このライブラリは、2つの強力な目標を持って設計されました:
+
+1. できるだけ簡単かつ高速に使用できるようにすること:
+
+ - ユーザー向けの抽象化を限りなく少なくし、実際、ほとんどの場合、抽象化はありません。
+ 各モデルを使用するために必要な3つの標準クラスだけが存在します:[構成](main_classes/configuration)、
+ [モデル](main_classes/model)、および前処理クラス(NLP用の[トークナイザ](main_classes/tokenizer)、ビジョン用の[イメージプロセッサ](main_classes/image_processor)、
+ オーディオ用の[特徴抽出器](main_classes/feature_extractor)、およびマルチモーダル入力用の[プロセッサ](main_classes/processors))。
+ - これらのクラスは、共通の`from_pretrained()`メソッドを使用して、事前トレーニング済みのインスタンスから簡単かつ統一された方法で初期化できます。このメソッドは、事前トレーニング済みのチェックポイントから関連するクラスのインスタンスと関連データ(構成のハイパーパラメータ、トークナイザの語彙、モデルの重み)をダウンロード(必要な場合はキャッシュ)して読み込みます。これらの基本クラスの上に、ライブラリは2つのAPIを提供しています:[パイプライン]は、特定のタスクでモデルをすばやく推論に使用するためのものであり、[`Trainer`]はPyTorchモデルを迅速にトレーニングまたは微調整するためのものです(すべてのTensorFlowモデルは`Keras.fit`と互換性があります)。
+ - その結果、このライブラリはニューラルネットワークのモジュラーツールボックスではありません。ライブラリを拡張または構築したい場合は、通常のPython、PyTorch、TensorFlow、Kerasモジュールを使用し、ライブラリの基本クラスから継承してモデルの読み込みと保存などの機能を再利用するだけです。モデルのコーディング哲学について詳しく知りたい場合は、[Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy)ブログ投稿をチェックしてみてください。
+
+2. オリジナルのモデルにできるだけ近い性能を持つ最新のモデルを提供すること:
+
+ - 各アーキテクチャに対して、公式な著者から提供された結果を再現する少なくとも1つの例を提供します。
+ - コードは通常、可能な限り元のコードベースに近いものであり、これはPyTorchコードがTensorFlowコードに変換されることから生じ、逆もまた然りです。
+
+その他のいくつかの目標:
+
+- モデルの内部をできるだけ一貫して公開すること:
+
+ - フルな隠れ状態と注意の重みにアクセスできる単一のAPIを提供します。
+ - 前処理クラスと基本モデルのAPIは標準化され、簡単にモデル間を切り替えることができます。
+
+- これらのモデルの微調整と調査のための有望なツールを主観的に選定すること:
+
+ - 語彙と埋め込みに新しいトークンを追加するための簡単で一貫した方法。
+ - Transformerヘッドをマスクおよびプルーンするための簡単な方法。
+
+- PyTorch、TensorFlow 2.0、およびFlaxの間を簡単に切り替えて、1つのフレームワークでトレーニングし、別のフレームワークで推論を行うことを可能にすること。
+
+## Main concepts
+
+このライブラリは、各モデルについて次の3つのタイプのクラスを中心に構築されています:
+
+- **モデルクラス**は、ライブラリで提供される事前トレーニング済みの重みと互換性のあるPyTorchモデル([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module))、Kerasモデル([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model))またはJAX/Flaxモデル([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html))を使用できます。
+- **構成クラス**は、モデルを構築するために必要なハイパーパラメータを格納します(層の数や隠れ層のサイズなど)。これらを自分でインスタンス化する必要はありません。特に、変更を加えずに事前トレーニング済みモデルを使用している場合、モデルを作成すると自動的に構成がインスタンス化されるようになります(これはモデルの一部です)。
+- **前処理クラス**は、生データをモデルが受け入れる形式に変換します。[トークナイザ](main_classes/tokenizer)は各モデルの語彙を保存し、文字列をトークン埋め込みのインデックスのリストにエンコードおよびデコードするためのメソッドを提供します。[イメージプロセッサ](main_classes/image_processor)はビジョン入力を前処理し、[特徴抽出器](main_classes/feature_extractor)はオーディオ入力を前処理し、[プロセッサ](main_classes/processors)はマルチモーダル入力を処理します。
+
+これらのすべてのクラスは、事前トレーニング済みのインスタンスからインスタンス化し、ローカルに保存し、Hubで共有することができる3つのメソッドを使用しています:
+
+- `from_pretrained()`は、ライブラリ自体によって提供される([モデルハブ](https://huggingface.co/models)でサポートされているモデルがあります)か、ユーザーによってローカルに保存された(またはサーバーに保存された)事前トレーニング済みバージョンからモデル、構成、前処理クラスをインスタンス化するためのメソッドです。
+- `save_pretrained()`は、モデル、構成、前処理クラスをローカルに保存し、`from_pretrained()`を使用して再読み込みできるようにします。
+- `push_to_hub()`は、モデル、構成、前処理クラスをHubに共有し、誰でも簡単にアクセスできるようにします。
diff --git a/docs/transformers/docs/source/ja/pipeline_tutorial.md b/docs/transformers/docs/source/ja/pipeline_tutorial.md
new file mode 100644
index 0000000000000000000000000000000000000000..5dbda5ce4d4a359b9ae0a1f5be9714feb18b6ea5
--- /dev/null
+++ b/docs/transformers/docs/source/ja/pipeline_tutorial.md
@@ -0,0 +1,295 @@
+
+
+# Pipelines for inference
+
+[`pipeline`]を使用することで、[Hub](https://huggingface.co/models)からの任意のモデルを言語、コンピュータビジョン、音声、およびマルチモーダルタスクの推論に簡単に使用できます。
+特定のモダリティに関する経験がない場合や、モデルの背後にあるコードに精通していない場合でも、[`pipeline`]を使用して推論できます!
+このチュートリアルでは、次のことを学びます:
+
+- 推論のための[`pipeline`]の使用方法。
+- 特定のトークナイザやモデルの使用方法。
+- オーディオ、ビジョン、マルチモーダルタスクのための[`pipeline`]の使用方法。
+
+ +
+ +
+ +
+  +
+ +
+ +
+ +
+ +
+ +
+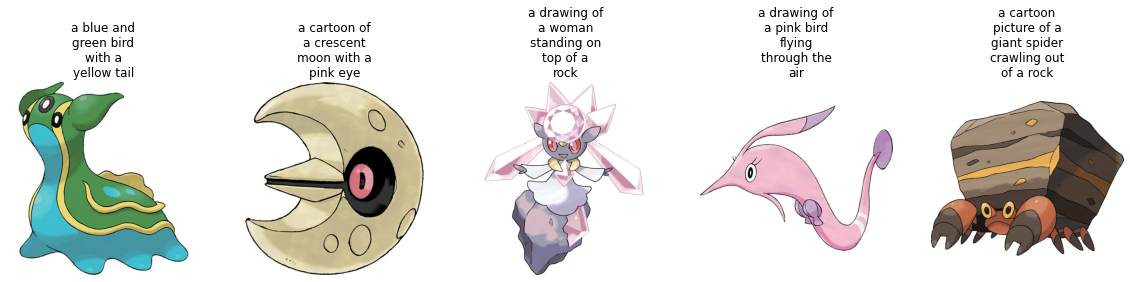 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+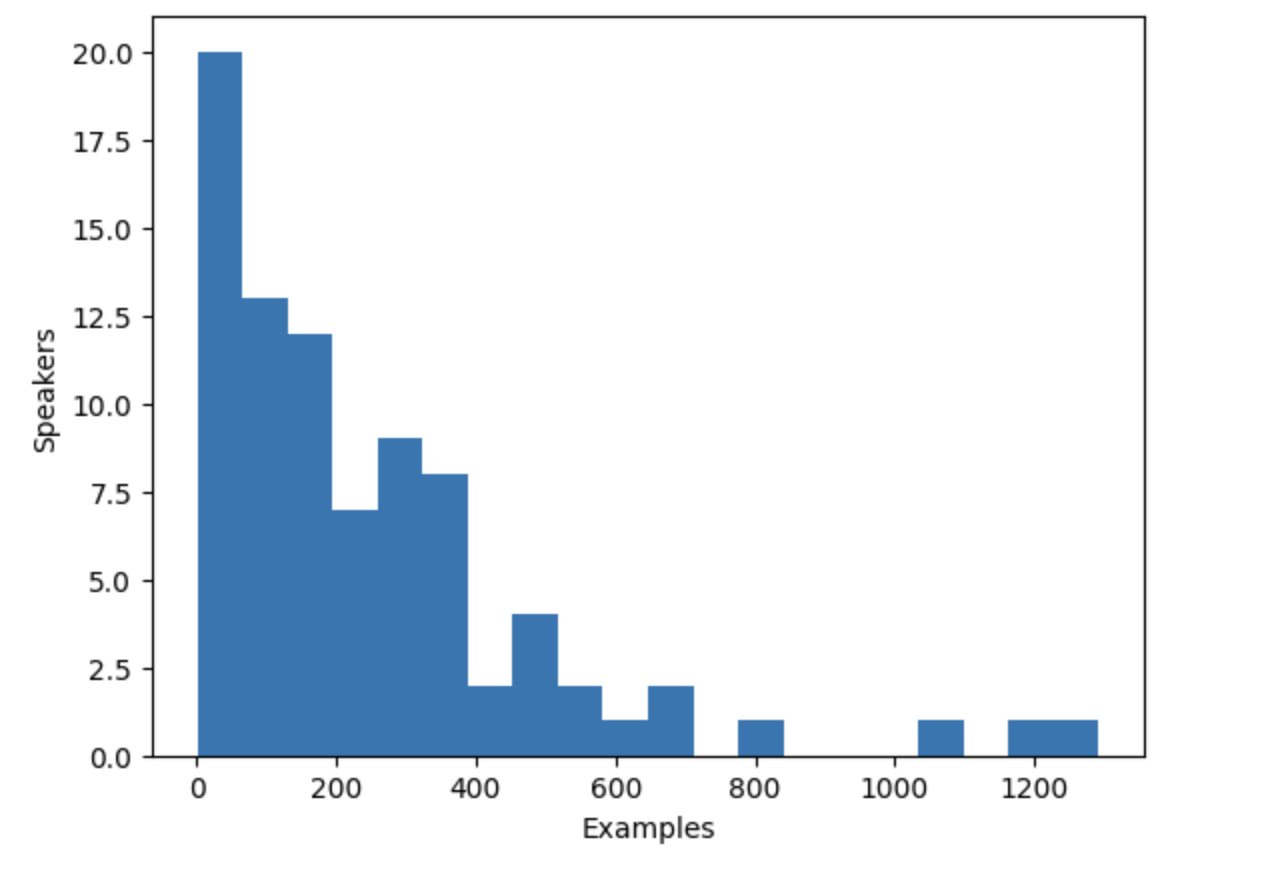 +
+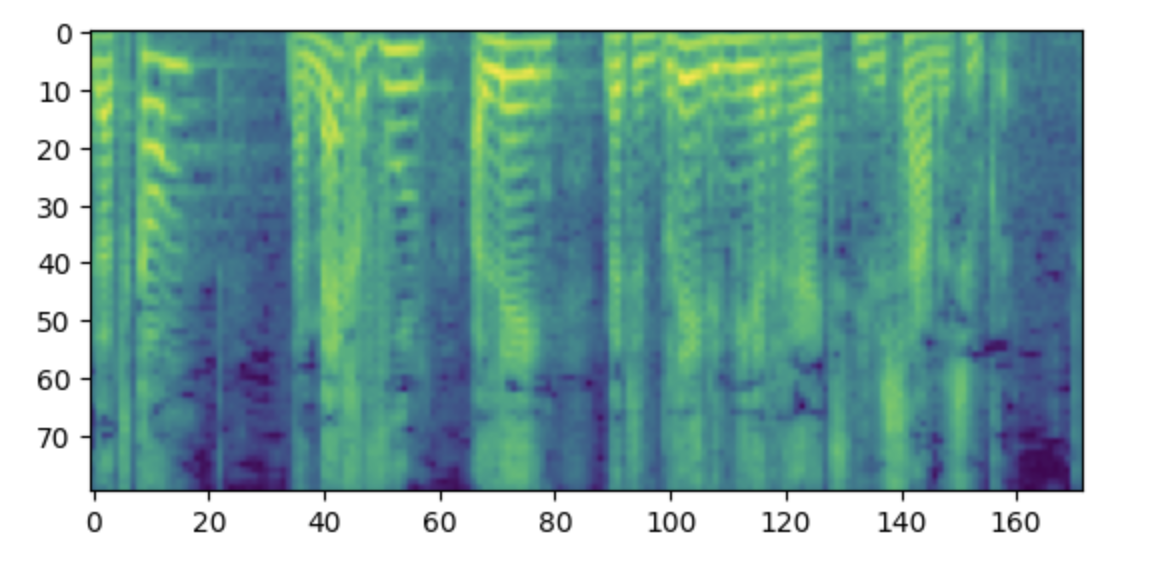 +
+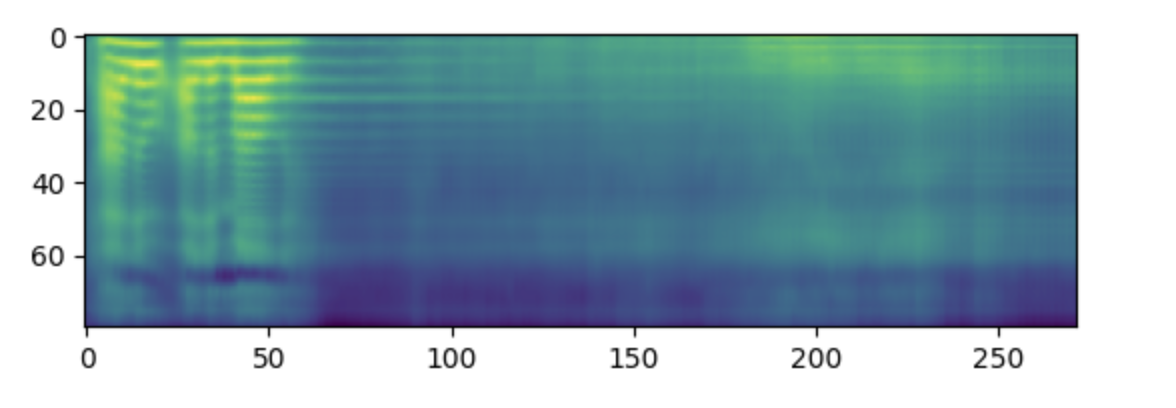 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+
+## 콘텐츠[[contents]]
+
+저희 기술문서는 크게 5개 섹션으로 나눌 수 있습니다:
+
+- **시작하기**에서 라이브러리를 간단히 훑어보고, 본격적으로 뛰어들 수 있게 설치 방법을 안내합니다.
+- **튜토리얼**에서 라이브러리에 익숙해질 수 있도록 자세하고도 쉽게 기본적인 부분을 안내합니다.
+- **How-to 가이드**에서 언어 모델링을 위해 사전학습된 모델을 파인 튜닝하는 방법이나, 직접 모델을 작성하고 공유하는 방법과 같이 특정 목표를 달성하는 방법을 안내합니다.
+- **개념 가이드**에서 🤗 Transformers의 설계 철학과 함께 모델이나 태스크 뒤에 숨겨진 개념들과 아이디어를 탐구하고 설명을 덧붙입니다.
+- **API**에서 모든 클래스와 함수를 설명합니다.
+
+ - **메인 클래스**에서 configuration, model, tokenizer, pipeline과 같이 제일 중요한 클래스들을 자세히 설명합니다.
+ - **모델**에서 라이브러리 속 구현된 각 모델과 연관된 클래스와 함수를 자세히 설명합니다.
+ - **내부 유틸리티**에서 내부적으로 사용되는 유틸리티 클래스와 함수를 자세히 설명합니다.
+
+### 지원 모델[[supported-models]]
+
+
+
+1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BLOOM](model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
+1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
+1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
+1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
+1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
+1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
+1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
+1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
+1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
+1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
+1. **[ESM](model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
+1. **[FLAN-T5](model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
+1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
+1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
+1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
+1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
+1. **[GPT NeoX Japanese](model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
+1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
+1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
+1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
+1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
+1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
+1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
+1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
+1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
+1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
+1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
+1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
+1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
+1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
+1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
+1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
+1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
+1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
+1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
+1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoCBert](model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
+1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
+1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
+1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Time Series Transformer](model_doc/time_series_transformer)** (from HuggingFace).
+1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
+1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
+1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
+1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[Whisper](model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
+1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
+1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+
+
+### 지원 프레임워크[[supported-framework]]
+
+아래 표는 라이브러리 속 각 모델의 지원 현황을 나타냅니다. 토큰화를 파이썬 (별칭 "slow") 또는 🤗 Tokenizers (별칭 "fast") 라이브러리로 하는지; (Flax를 통한) Jax, PyTorch, TensorFlow 중 어떤 프레임워크를 지원하는지 표시되어 있습니다.
+
+
+
+| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
+|:---------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
+| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
+| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
+| BigBird-Pegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
+| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
+| CLIPSeg | ❌ | ❌ | ✅ | ❌ | ❌ |
+| CodeGen | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Conditional DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ConvNeXT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| CvT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
+| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Deformable DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DeiT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| DonutSwin | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ERNIE | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ESM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FLAVA | ❌ | ❌ | ✅ | ❌ | ❌ |
+| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
+| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
+| GPT NeoX Japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
+| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
+| GroupViT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
+| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Jukebox | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
+| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| LiLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LongT5 | ❌ | ❌ | ✅ | ❌ | ✅ |
+| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| M-CTC-T | ❌ | ❌ | ✅ | ❌ | ❌ |
+| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
+| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
+| MarkupLM | ✅ | ✅ | ✅ | ❌ | ❌ |
+| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Megatron-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MobileViT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| MVP | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Nezha | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Nyströmformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| OPT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| OWL-ViT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
+| PEGASUS-X | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
+| REALM | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
+| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ResNet | ❌ | ❌ | ✅ | ✅ | ✅ |
+| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| RoCBert | ✅ | ❌ | ✅ | ❌ | ❌ |
+| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
+| SegFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
+| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
+| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
+| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Swin Transformer | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Swin Transformer V2 | ❌ | ❌ | ✅ | ❌ | ❌ |
+| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Table Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Time Series Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VideoMAE | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| VisualBERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
+| ViTMSN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
+| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Whisper | ✅ | ❌ | ✅ | ✅ | ❌ |
+| X-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| XLM-ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
+| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/transformers/docs/source/ko/installation.md b/docs/transformers/docs/source/ko/installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..a744db40d291236a10b6b93c06d99c0b31a0a33d
--- /dev/null
+++ b/docs/transformers/docs/source/ko/installation.md
@@ -0,0 +1,245 @@
+
+
+# 설치방법[[installation]]
+
+🤗 Transformers를 사용 중인 딥러닝 라이브러리에 맞춰 설치하고, 캐시를 구성하거나 선택적으로 오프라인에서도 실행할 수 있도록 🤗 Transformers를 설정하는 방법을 배우겠습니다.
+
+🤗 Transformers는 Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+ 및 Flax에서 테스트되었습니다. 딥러닝 라이브러리를 설치하려면 아래 링크된 저마다의 공식 사이트를 참고해주세요.
+
+* [PyTorch](https://pytorch.org/get-started/locally/) 설치하기
+* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) 설치하기
+* [Flax](https://flax.readthedocs.io/en/latest/) 설치하기
+
+## pip으로 설치하기[[install-with-pip]]
+
+🤗 Transformers를 [가상 환경](https://docs.python.org/3/library/venv.html)에 설치하는 것을 추천드립니다. Python 가상 환경에 익숙하지 않다면, 이 [가이드](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)를 참고하세요. 가상 환경을 사용하면 서로 다른 프로젝트들을 보다 쉽게 관리할 수 있고, 의존성 간의 호환성 문제를 방지할 수 있습니다.
+
+먼저 프로젝트 디렉토리에서 가상 환경을 만들어 줍니다.
+
+```bash
+python -m venv .env
+```
+
+가상 환경을 활성화해주세요. Linux나 MacOS의 경우:
+
+```bash
+source .env/bin/activate
+```
+Windows의 경우:
+
+```bash
+.env/Scripts/activate
+```
+
+이제 🤗 Transformers를 설치할 준비가 되었습니다. 다음 명령을 입력해주세요.
+
+```bash
+pip install transformers
+```
+
+CPU만 써도 된다면, 🤗 Transformers와 딥러닝 라이브러리를 단 1줄로 설치할 수 있습니다. 예를 들어 🤗 Transformers와 PyTorch의 경우:
+
+```bash
+pip install transformers[torch]
+```
+
+🤗 Transformers와 TensorFlow 2.0의 경우:
+
+```bash
+pip install transformers[tf-cpu]
+```
+
+🤗 Transformers와 Flax의 경우:
+
+```bash
+pip install transformers[flax]
+```
+
+마지막으로 🤗 Transformers가 제대로 설치되었는지 확인할 차례입니다. 사전훈련된 모델을 다운로드하는 코드입니다.
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
+```
+
+라벨과 점수가 출력되면 잘 설치된 것입니다.
+
+```bash
+[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
+```
+
+## 소스에서 설치하기[[install-from-source]]
+
+🤗 Transformers를 소스에서 설치하려면 아래 명령을 실행하세요.
+
+```bash
+pip install git+https://github.com/huggingface/transformers
+```
+
+위 명령은 최신이지만 (안정적인) `stable` 버전이 아닌 실험성이 짙은 `main` 버전을 설치합니다. `main` 버전은 개발 현황과 발맞추는데 유용합니다. 예시로 마지막 공식 릴리스 이후 발견된 버그가 패치되었지만, 새 릴리스로 아직 롤아웃되지는 않은 경우를 들 수 있습니다. 바꿔 말하면 `main` 버전이 안정성과는 거리가 있다는 뜻이기도 합니다. 저희는 `main` 버전을 사용하는데 문제가 없도록 노력하고 있으며, 대부분의 문제는 대개 몇 시간이나 하루 안에 해결됩니다. 만약 문제가 발생하면 [이슈](https://github.com/huggingface/transformers/issues)를 열어주시면 더 빨리 해결할 수 있습니다!
+
+전과 마찬가지로 🤗 Transformers가 제대로 설치되었는지 확인할 차례입니다.
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
+```
+
+## 수정 가능한 설치[[editable-install]]
+
+수정 가능한 설치가 필요한 경우는 다음과 같습니다.
+
+* `main` 버전의 소스 코드를 사용하기 위해
+* 🤗 Transformers에 기여하고 싶어서 코드의 변경 사항을 테스트하기 위해
+
+리포지터리를 복제하고 🤗 Transformers를 설치하려면 다음 명령을 입력해주세요.
+
+```bash
+git clone https://github.com/huggingface/transformers.git
+cd transformers
+pip install -e .
+```
+
+위 명령은 리포지터리를 복제한 위치의 폴더와 Python 라이브러리의 경로를 연결시킵니다. Python이 일반 라이브러리 경로 외에 복제한 폴더 내부를 확인할 것입니다. 예를 들어 Python 패키지가 일반적으로 `~/anaconda3/envs/main/lib/python3.7/site-packages/`에 설치되어 있는데, 명령을 받은 Python이 이제 복제한 폴더인 `~/transformers/`도 검색하게 됩니다.
+
+
+
+
+## 콘텐츠[[contents]]
+
+저희 기술문서는 크게 5개 섹션으로 나눌 수 있습니다:
+
+- **시작하기**에서 라이브러리를 간단히 훑어보고, 본격적으로 뛰어들 수 있게 설치 방법을 안내합니다.
+- **튜토리얼**에서 라이브러리에 익숙해질 수 있도록 자세하고도 쉽게 기본적인 부분을 안내합니다.
+- **How-to 가이드**에서 언어 모델링을 위해 사전학습된 모델을 파인 튜닝하는 방법이나, 직접 모델을 작성하고 공유하는 방법과 같이 특정 목표를 달성하는 방법을 안내합니다.
+- **개념 가이드**에서 🤗 Transformers의 설계 철학과 함께 모델이나 태스크 뒤에 숨겨진 개념들과 아이디어를 탐구하고 설명을 덧붙입니다.
+- **API**에서 모든 클래스와 함수를 설명합니다.
+
+ - **메인 클래스**에서 configuration, model, tokenizer, pipeline과 같이 제일 중요한 클래스들을 자세히 설명합니다.
+ - **모델**에서 라이브러리 속 구현된 각 모델과 연관된 클래스와 함수를 자세히 설명합니다.
+ - **내부 유틸리티**에서 내부적으로 사용되는 유틸리티 클래스와 함수를 자세히 설명합니다.
+
+### 지원 모델[[supported-models]]
+
+
+
+1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BLOOM](model_doc/bloom)** (from BigScience workshop) released by the [BigScience Workshop](https://bigscience.huggingface.co/).
+1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[CLIPSeg](model_doc/clipseg)** (from University of Göttingen) released with the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Timo Lüddecke and Alexander Ecker.
+1. **[CodeGen](model_doc/codegen)** (from Salesforce) released with the paper [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong.
+1. **[Conditional DETR](model_doc/conditional_detr)** (from Microsoft Research Asia) released with the paper [Conditional DETR for Fast Training Convergence](https://arxiv.org/abs/2108.06152) by Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, Jingdong Wang.
+1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[CvT](model_doc/cvt)** (from Microsoft) released with the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang.
+1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[Deformable DETR](model_doc/deformable_detr)** (from SenseTime Research) released with the paper [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159) by Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai.
+1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
+1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[Donut](model_doc/donut)** (from NAVER), released together with the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park.
+1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
+1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ERNIE](model_doc/ernie)** (from Baidu) released with the paper [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223) by Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu.
+1. **[ESM](model_doc/esm)** (from Meta AI) are transformer protein language models. **ESM-1b** was released with the paper [Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. **ESM-1v** was released with the paper [Language models enable zero-shot prediction of the effects of mutations on protein function](https://doi.org/10.1101/2021.07.09.450648) by Joshua Meier, Roshan Rao, Robert Verkuil, Jason Liu, Tom Sercu and Alexander Rives. **ESM-2 and ESMFold** were released with the paper [Language models of protein sequences at the scale of evolution enable accurate structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, Alexander Rives.
+1. **[FLAN-T5](model_doc/flan-t5)** (from Google AI) released in the repository [google-research/t5x](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints) by Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei
+1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FLAVA](model_doc/flava)** (from Facebook AI) released with the paper [FLAVA: A Foundational Language And Vision Alignment Model](https://arxiv.org/abs/2112.04482) by Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela.
+1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
+1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
+1. **[GPT NeoX](model_doc/gpt_neox)** (from EleutherAI) released with the paper [GPT-NeoX-20B: An Open-Source Autoregressive Language Model](https://arxiv.org/abs/2204.06745) by Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, Samuel Weinbach
+1. **[GPT NeoX Japanese](model_doc/gpt_neox_japanese)** (from ABEJA) released by Shinya Otani, Takayoshi Makabe, Anuj Arora, and Kyo Hattori.
+1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
+1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
+1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
+1. **[GroupViT](model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
+1. **[Jukebox](model_doc/jukebox)** (from OpenAI) released with the paper [Jukebox: A Generative Model for Music](https://arxiv.org/pdf/2005.00341.pdf) by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford, Ilya Sutskever.
+1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutLMv3](model_doc/layoutlmv3)** (from Microsoft Research Asia) released with the paper [LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387) by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei.
+1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LeViT](model_doc/levit)** (from Meta AI) released with the paper [LeViT: A Vision Transformer in ConvNet's Clothing for Faster Inference](https://arxiv.org/abs/2104.01136) by Ben Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, Matthijs Douze.
+1. **[LiLT](model_doc/lilt)** (from South China University of Technology) released with the paper [LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding](https://arxiv.org/abs/2202.13669) by Jiapeng Wang, Lianwen Jin, Kai Ding.
+1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LongT5](model_doc/longt5)** (from Google AI) released with the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/abs/2112.07916) by Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni, Yun-Hsuan Sung, Yinfei Yang.
+1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M-CTC-T](model_doc/mctct)** (from Facebook) released with the paper [Pseudo-Labeling For Massively Multilingual Speech Recognition](https://arxiv.org/abs/2111.00161) by Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, and Ronan Collobert.
+1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[MarkupLM](model_doc/markuplm)** (from Microsoft Research Asia) released with the paper [MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding](https://arxiv.org/abs/2110.08518) by Junlong Li, Yiheng Xu, Lei Cui, Furu Wei.
+1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[mBART](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[mBART-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[MobileBERT](model_doc/mobilebert)** (from CMU/Google Brain) released with the paper [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, and Denny Zhou.
+1. **[MobileViT](model_doc/mobilevit)** (from Apple) released with the paper [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari.
+1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[MVP](model_doc/mvp)** (from RUC AI Box) released with the paper [MVP: Multi-task Supervised Pre-training for Natural Language Generation](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
+1. **[Nezha](model_doc/nezha)** (from Huawei Noah’s Ark Lab) released with the paper [NEZHA: Neural Contextualized Representation for Chinese Language Understanding](https://arxiv.org/abs/1909.00204) by Junqiu Wei, Xiaozhe Ren, Xiaoguang Li, Wenyong Huang, Yi Liao, Yasheng Wang, Jiashu Lin, Xin Jiang, Xiao Chen and Qun Liu.
+1. **[NLLB](model_doc/nllb)** (from Meta) released with the paper [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by the NLLB team.
+1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[OPT](master/model_doc/opt)** (from Meta AI) released with the paper [OPT: Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) by Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen et al.
+1. **[OWL-ViT](model_doc/owlvit)** (from Google AI) released with the paper [Simple Open-Vocabulary Object Detection with Vision Transformers](https://arxiv.org/abs/2205.06230) by Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, Xiao Wang, Xiaohua Zhai, Thomas Kipf, and Neil Houlsby.
+1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[PEGASUS-X](model_doc/pegasus_x)** (from Google) released with the paper [Investigating Efficiently Extending Transformers for Long Input Summarization](https://arxiv.org/abs/2208.04347) by Jason Phang, Yao Zhao, and Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[RAG](model_doc/rag)** (from Facebook) released with the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401) by Patrick Lewis, Ethan Perez, Aleksandara Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela.
+1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoCBert](model_doc/roc_bert)** (from WeChatAI) released with the paper [RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining](https://aclanthology.org/2022.acl-long.65.pdf) by HuiSu, WeiweiShi, XiaoyuShen, XiaoZhou, TuoJi, JiaruiFang, JieZhou.
+1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBERT](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[Swin Transformer V2](model_doc/swinv2)** (from Microsoft) released with the paper [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) by Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo.
+1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[Table Transformer](model_doc/table-transformer)** (from Microsoft Research) released with the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Brandon Smock, Rohith Pesala, Robin Abraham.
+1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Time Series Transformer](model_doc/time_series_transformer)** (from HuggingFace).
+1. **[Trajectory Transformer](model_doc/trajectory_transformers)** (from the University of California at Berkeley) released with the paper [Offline Reinforcement Learning as One Big Sequence Modeling Problem](https://arxiv.org/abs/2106.02039) by Michael Janner, Qiyang Li, Sergey Levine
+1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UL2](model_doc/ul2)** (from Google Research) released with the paper [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1) by Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler
+1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
+1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[ViTMSN](model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2-Conformer](model_doc/wav2vec2-conformer)** (from Facebook AI) released with the paper [FAIRSEQ S2T: Fast Speech-to-Text Modeling with FAIRSEQ](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[Whisper](model_doc/whisper)** (from OpenAI) released with the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf) by Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
+1. **[X-CLIP](model_doc/xclip)** (from Microsoft Research) released with the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, Haibin Ling.
+1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[YOLOS](model_doc/yolos)** (from Huazhong University of Science & Technology) released with the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
+1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+
+
+### 지원 프레임워크[[supported-framework]]
+
+아래 표는 라이브러리 속 각 모델의 지원 현황을 나타냅니다. 토큰화를 파이썬 (별칭 "slow") 또는 🤗 Tokenizers (별칭 "fast") 라이브러리로 하는지; (Flax를 통한) Jax, PyTorch, TensorFlow 중 어떤 프레임워크를 지원하는지 표시되어 있습니다.
+
+
+
+| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
+|:---------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
+| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
+| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
+| BigBird-Pegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BLOOM | ❌ | ✅ | ✅ | ❌ | ❌ |
+| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| CANINE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
+| CLIPSeg | ❌ | ❌ | ✅ | ❌ | ❌ |
+| CodeGen | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Conditional DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ConvNeXT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| CvT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecVision | ❌ | ❌ | ✅ | ✅ | ❌ |
+| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Deformable DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DeiT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| DonutSwin | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ERNIE | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ESM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FLAVA | ❌ | ❌ | ✅ | ❌ | ❌ |
+| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
+| GPT NeoX | ❌ | ✅ | ✅ | ❌ | ❌ |
+| GPT NeoX Japanese | ✅ | ❌ | ✅ | ❌ | ❌ |
+| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
+| GroupViT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
+| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Jukebox | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
+| LayoutLMv3 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LeViT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| LiLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LongT5 | ❌ | ❌ | ✅ | ❌ | ✅ |
+| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| M-CTC-T | ❌ | ❌ | ✅ | ❌ | ❌ |
+| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
+| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
+| MarkupLM | ✅ | ✅ | ✅ | ❌ | ❌ |
+| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Megatron-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MobileViT | ❌ | ❌ | ✅ | ✅ | ❌ |
+| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| MVP | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Nezha | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Nyströmformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| OPT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| OWL-ViT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
+| PEGASUS-X | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
+| REALM | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
+| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ResNet | ❌ | ❌ | ✅ | ✅ | ✅ |
+| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| RoCBert | ✅ | ❌ | ✅ | ❌ | ❌ |
+| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
+| SegFormer | ❌ | ❌ | ✅ | ✅ | ❌ |
+| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
+| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
+| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Swin Transformer | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Swin Transformer V2 | ❌ | ❌ | ✅ | ❌ | ❌ |
+| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Table Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Time Series Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Trajectory Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VideoMAE | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| VisualBERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
+| ViTMSN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
+| Wav2Vec2-Conformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Whisper | ✅ | ❌ | ✅ | ✅ | ❌ |
+| X-CLIP | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XGLM | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| XLM-ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| YOLOS | ❌ | ❌ | ✅ | ❌ | ❌ |
+| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/transformers/docs/source/ko/installation.md b/docs/transformers/docs/source/ko/installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..a744db40d291236a10b6b93c06d99c0b31a0a33d
--- /dev/null
+++ b/docs/transformers/docs/source/ko/installation.md
@@ -0,0 +1,245 @@
+
+
+# 설치방법[[installation]]
+
+🤗 Transformers를 사용 중인 딥러닝 라이브러리에 맞춰 설치하고, 캐시를 구성하거나 선택적으로 오프라인에서도 실행할 수 있도록 🤗 Transformers를 설정하는 방법을 배우겠습니다.
+
+🤗 Transformers는 Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+ 및 Flax에서 테스트되었습니다. 딥러닝 라이브러리를 설치하려면 아래 링크된 저마다의 공식 사이트를 참고해주세요.
+
+* [PyTorch](https://pytorch.org/get-started/locally/) 설치하기
+* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) 설치하기
+* [Flax](https://flax.readthedocs.io/en/latest/) 설치하기
+
+## pip으로 설치하기[[install-with-pip]]
+
+🤗 Transformers를 [가상 환경](https://docs.python.org/3/library/venv.html)에 설치하는 것을 추천드립니다. Python 가상 환경에 익숙하지 않다면, 이 [가이드](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/)를 참고하세요. 가상 환경을 사용하면 서로 다른 프로젝트들을 보다 쉽게 관리할 수 있고, 의존성 간의 호환성 문제를 방지할 수 있습니다.
+
+먼저 프로젝트 디렉토리에서 가상 환경을 만들어 줍니다.
+
+```bash
+python -m venv .env
+```
+
+가상 환경을 활성화해주세요. Linux나 MacOS의 경우:
+
+```bash
+source .env/bin/activate
+```
+Windows의 경우:
+
+```bash
+.env/Scripts/activate
+```
+
+이제 🤗 Transformers를 설치할 준비가 되었습니다. 다음 명령을 입력해주세요.
+
+```bash
+pip install transformers
+```
+
+CPU만 써도 된다면, 🤗 Transformers와 딥러닝 라이브러리를 단 1줄로 설치할 수 있습니다. 예를 들어 🤗 Transformers와 PyTorch의 경우:
+
+```bash
+pip install transformers[torch]
+```
+
+🤗 Transformers와 TensorFlow 2.0의 경우:
+
+```bash
+pip install transformers[tf-cpu]
+```
+
+🤗 Transformers와 Flax의 경우:
+
+```bash
+pip install transformers[flax]
+```
+
+마지막으로 🤗 Transformers가 제대로 설치되었는지 확인할 차례입니다. 사전훈련된 모델을 다운로드하는 코드입니다.
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
+```
+
+라벨과 점수가 출력되면 잘 설치된 것입니다.
+
+```bash
+[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
+```
+
+## 소스에서 설치하기[[install-from-source]]
+
+🤗 Transformers를 소스에서 설치하려면 아래 명령을 실행하세요.
+
+```bash
+pip install git+https://github.com/huggingface/transformers
+```
+
+위 명령은 최신이지만 (안정적인) `stable` 버전이 아닌 실험성이 짙은 `main` 버전을 설치합니다. `main` 버전은 개발 현황과 발맞추는데 유용합니다. 예시로 마지막 공식 릴리스 이후 발견된 버그가 패치되었지만, 새 릴리스로 아직 롤아웃되지는 않은 경우를 들 수 있습니다. 바꿔 말하면 `main` 버전이 안정성과는 거리가 있다는 뜻이기도 합니다. 저희는 `main` 버전을 사용하는데 문제가 없도록 노력하고 있으며, 대부분의 문제는 대개 몇 시간이나 하루 안에 해결됩니다. 만약 문제가 발생하면 [이슈](https://github.com/huggingface/transformers/issues)를 열어주시면 더 빨리 해결할 수 있습니다!
+
+전과 마찬가지로 🤗 Transformers가 제대로 설치되었는지 확인할 차례입니다.
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
+```
+
+## 수정 가능한 설치[[editable-install]]
+
+수정 가능한 설치가 필요한 경우는 다음과 같습니다.
+
+* `main` 버전의 소스 코드를 사용하기 위해
+* 🤗 Transformers에 기여하고 싶어서 코드의 변경 사항을 테스트하기 위해
+
+리포지터리를 복제하고 🤗 Transformers를 설치하려면 다음 명령을 입력해주세요.
+
+```bash
+git clone https://github.com/huggingface/transformers.git
+cd transformers
+pip install -e .
+```
+
+위 명령은 리포지터리를 복제한 위치의 폴더와 Python 라이브러리의 경로를 연결시킵니다. Python이 일반 라이브러리 경로 외에 복제한 폴더 내부를 확인할 것입니다. 예를 들어 Python 패키지가 일반적으로 `~/anaconda3/envs/main/lib/python3.7/site-packages/`에 설치되어 있는데, 명령을 받은 Python이 이제 복제한 폴더인 `~/transformers/`도 검색하게 됩니다.
+
+ +
+Chameleon은 이미지를 이산적인 토큰으로 변환하기 위해 벡터 양자화 모듈을 통합합니다. 이는 자기회귀 transformer를 사용한 이미지 생성을 가능하게 합니다. 원본 논문에서 가져왔습니다.
+
+이 모델은 [joaogante](https://huggingface.co/joaogante)와 [RaushanTurganbay](https://huggingface.co/RaushanTurganbay)가 기여했습니다. 원본 코드는 [여기](https://github.com/facebookresearch/chameleon)에서 찾을 수 있습니다.
+
+## 사용 팁 [[usage-tips]]
+
+- 더 정확한 결과를 위해, 배치 생성 시 `padding_side="left"`를 사용하는 것을 권장합니다. 생성하기 전에 `processor.tokenizer.padding_side = "left"`로 설정하십시오.
+
+- Chameleon은 안전성 정렬을 위해 튜닝되었음을 유의하십시오. 모델이 응답을 거부하는 경우, 열린 질문보다는 더 구체적으로 질문을 해보세요.
+
+- Chameleon은 채팅 형식으로 생성하므로, 생성된 텍스트는 항상 "assistant's turn"으로 표시됩니다. 프로세서를 호출할 때 `return_for_text_completion=True`를 전달하여 텍스트 완성 생성을 활성화할 수 있습니다.
+
+> [!NOTE]
+> Transformers에서의 Chameleon 구현은 이미지 임베딩을 병합할 위치를 나타내기 위해 특별한 이미지 토큰을 사용합니다. 특별한 이미지 토큰을 위해 새로운 토큰을 추가하지 않고 예약된 토큰 중 하나인 `
+
+Chameleon은 이미지를 이산적인 토큰으로 변환하기 위해 벡터 양자화 모듈을 통합합니다. 이는 자기회귀 transformer를 사용한 이미지 생성을 가능하게 합니다. 원본 논문에서 가져왔습니다.
+
+이 모델은 [joaogante](https://huggingface.co/joaogante)와 [RaushanTurganbay](https://huggingface.co/RaushanTurganbay)가 기여했습니다. 원본 코드는 [여기](https://github.com/facebookresearch/chameleon)에서 찾을 수 있습니다.
+
+## 사용 팁 [[usage-tips]]
+
+- 더 정확한 결과를 위해, 배치 생성 시 `padding_side="left"`를 사용하는 것을 권장합니다. 생성하기 전에 `processor.tokenizer.padding_side = "left"`로 설정하십시오.
+
+- Chameleon은 안전성 정렬을 위해 튜닝되었음을 유의하십시오. 모델이 응답을 거부하는 경우, 열린 질문보다는 더 구체적으로 질문을 해보세요.
+
+- Chameleon은 채팅 형식으로 생성하므로, 생성된 텍스트는 항상 "assistant's turn"으로 표시됩니다. 프로세서를 호출할 때 `return_for_text_completion=True`를 전달하여 텍스트 완성 생성을 활성화할 수 있습니다.
+
+> [!NOTE]
+> Transformers에서의 Chameleon 구현은 이미지 임베딩을 병합할 위치를 나타내기 위해 특별한 이미지 토큰을 사용합니다. 특별한 이미지 토큰을 위해 새로운 토큰을 추가하지 않고 예약된 토큰 중 하나인 `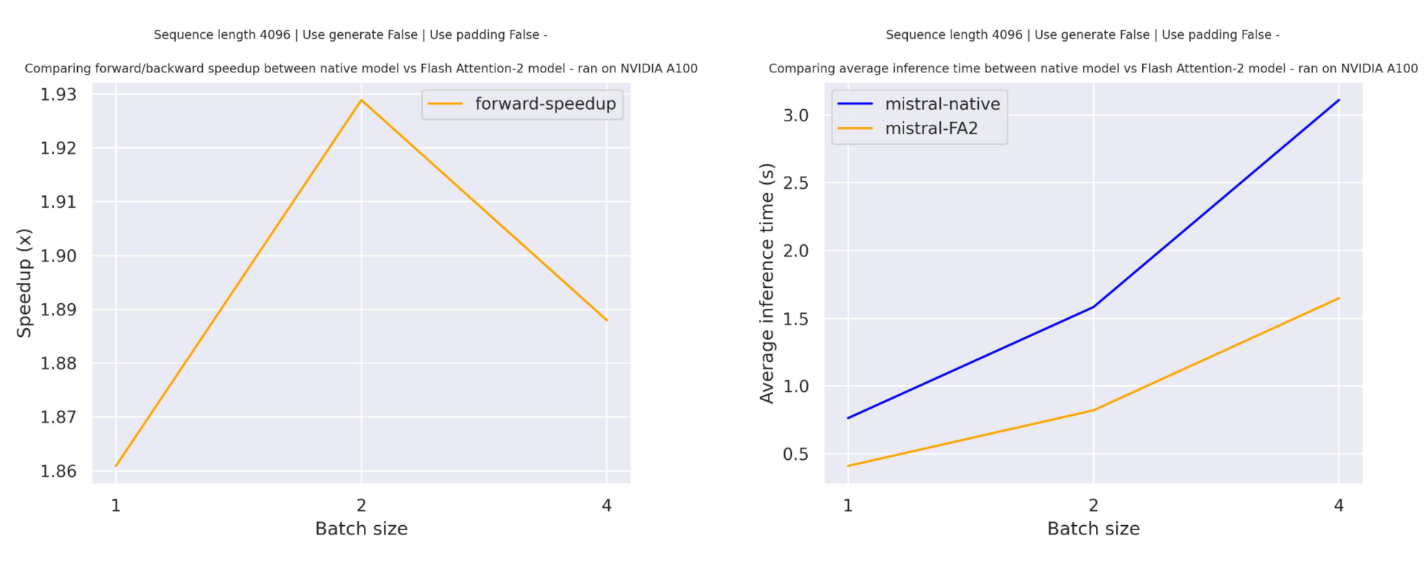 +
+ +
+ PaliGemma 아키텍처 블로그 포스트.
+
+이 모델은 [Molbap](https://huggingface.co/Molbap)에 의해 기여 되었습니다.
+
+## 사용 팁[[usage-tips]]
+
+PaliGemma의 추론은 다음처럼 수행됩니다:
+
+```python
+from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
+
+model_id = "google/paligemma-3b-mix-224"
+model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
+processor = AutoProcessor.from_pretrained(model_id)
+
+prompt = "What is on the flower?"
+image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg?download=true"
+raw_image = Image.open(requests.get(image_file, stream=True).raw)
+inputs = processor(raw_image, prompt, return_tensors="pt")
+output = model.generate(**inputs, max_new_tokens=20)
+
+print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
+```
+
+- PaliGemma는 대화용으로 설계되지 않았으며, 특정 사용 사례에 대해 미세 조정할 때 가장 잘 작동합니다. PaliGemma를 미세 조정할 수 있는 몇 가지 하위 작업에는 이미지 캡셔닝, 시각적 질문 답변(VQA), 오브젝트 디텍션, 참조 표현 분할 및 문서 이해가 포함됩니다.
+- 모델에 필요한 이미지, 텍스트 및 선택적 레이블을 준비하는데 `PaliGemmaProcessor`를 사용할 수 있습니다. PaliGemma 모델을 미세 조정할 때는, 프로세서에 `suffix`인자를 전달하여 다음 처럼 모델의 `labels`를 생성할 수 있습니다:
+
+```python
+prompt = "What is on the flower?"
+answer = "a bee"
+inputs = processor(images=raw_image, text=prompt, suffix=answer, return_tensors="pt")
+```
+
+## 자료[[resources]]
+
+PaliGemma를 시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다.여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰 해드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
+
+- PaliGemma의 모든 기능을 소개하는 블로그 포스트는 [이곳](https://huggingface.co/blog/paligemma)에서 찾을 수 있습니다. 🌎
+- Trainer API를 사용하여 VQA(Visual Question Answering)를 위해 PaliGemma를 미세 조정하는 방법과 추론에 대한 데모 노트북은 [이곳](https://github.com/huggingface/notebooks/tree/main/examples/paligemma)에서 찾을 수 있습니다. 🌎
+- 사용자 정의 데이터셋(영수증 이미지 -> JSON)에 대해 PaliGemma를 미세 조정하는 방법과 추론에 대한 데모 노트북은 [이곳](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/PaliGemma)에서 찾을 수 있습니다. 🌎
+
+## PaliGemmaConfig[[transformers.PaliGemmaConfig]]
+
+[[autodoc]] PaliGemmaConfig
+
+## PaliGemmaProcessor[[transformers.PaliGemmaProcessor]]
+
+[[autodoc]] PaliGemmaProcessor
+
+## PaliGemmaForConditionalGeneration[[transformers.PaliGemmaForConditionalGeneration]]
+
+[[autodoc]] PaliGemmaForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/patchtsmixer.md b/docs/transformers/docs/source/ko/model_doc/patchtsmixer.md
new file mode 100644
index 0000000000000000000000000000000000000000..e1463eb85de3e5aca2623fe038da4b249f9c629c
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/patchtsmixer.md
@@ -0,0 +1,95 @@
+
+
+# PatchTSMixer[[patchtsmixer]]
+
+## 개요[[overview]]
+
+PatchTSMixer 모델은 Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam이 제안한 [TSMixer: 다변량 시계열 예측을 위한 경량 MLP-Mixer 모델](https://arxiv.org/pdf/2306.09364.pdf)이라는 논문에서 소개되었습니다.
+
+
+PatchTSMixer는 MLP-Mixer 아키텍처를 기반으로 한 경량 시계열 모델링 접근법입니다. 허깅페이스 구현에서는 PatchTSMixer의 기능을 제공하여 패치, 채널, 숨겨진 특성 간의 경량 혼합을 쉽게 수행하여 효과적인 다변량 시계열 모델링을 가능하게 합니다. 또한 간단한 게이트 어텐션부터 사용자 정의된 더 복잡한 셀프 어텐션 블록까지 다양한 어텐션 메커니즘을 지원합니다. 이 모델은 사전 훈련될 수 있으며 이후 예측, 분류, 회귀와 같은 다양한 다운스트림 작업에 사용될 수 있습니다.
+
+
+해당 논문의 초록입니다:
+
+*TSMixer는 패치 처리된 시계열의 다변량 예측 및 표현 학습을 위해 설계된 다층 퍼셉트론(MLP) 모듈로만 구성된 경량 신경망 아키텍처입니다. 우리의 모델은 컴퓨터 비전 분야에서 MLP-Mixer 모델의 성공에서 영감을 받았습니다. 우리는 Vision MLP-Mixer를 시계열에 적용하는 데 따르는 과제를 보여주고, 정확도를 향상시키기 위해 경험적으로 검증된 구성 요소들을 도입합니다. 여기에는 계층 구조 및 채널 상관관계와 같은 시계열 특성을 명시적으로 모델링하기 위해 MLP-Mixer 백본에 온라인 조정 헤드를 부착하는 새로운 설계 패러다임이 포함됩니다. 또한 기존 패치 채널 혼합 방법의 일반적인 문제인 노이즈가 있는 채널 상호작용을 효과적으로 처리하고 다양한 데이터셋에 걸쳐 일반화하기 위한 하이브리드 채널 모델링 접근법을 제안합니다. 추가로, 중요한 특성을 우선시하기 위해 백본에 간단한 게이트 주의 메커니즘을 도입합니다. 이러한 경량 구성 요소들을 통합함으로써, 우리는 단순한 MLP 구조의 학습 능력을 크게 향상시켜 최소한의 컴퓨팅 사용으로 복잡한 트랜스포머 모델들을 능가하는 성능을 달성합니다. 더욱이, TSMixer의 모듈식 설계는 감독 학습과 마스크 자기 감독 학습 방법 모두와 호환되어 시계열 기초 모델의 유망한 구성 요소가 됩니다. TSMixer는 예측 작업에서 최첨단 MLP 및 트랜스포머 모델들을 상당한 차이(8-60%)로 능가합니다. 또한 최신의 강력한 Patch-Transformer 모델 벤치마크들을 메모리와 실행 시간을 크게 줄이면서(2-3배) 성능 면에서도 앞섭니다(1-2%).*
+
+이 모델은 [ajati](https://huggingface.co/ajati), [vijaye12](https://huggingface.co/vijaye12),
+[gsinthong](https://huggingface.co/gsinthong), [namctin](https://huggingface.co/namctin),
+[wmgifford](https://huggingface.co/wmgifford), [kashif](https://huggingface.co/kashif)가 기여했습니다.
+
+## 사용 예[[usage-example]]
+
+아래의 코드 스니펫은 PatchTSMixer 모델을 무작위로 초기화하는 방법을 보여줍니다.
+PatchTSMixer 모델은 [Trainer API](../trainer.md)와 호환됩니다.
+
+```python
+
+from transformers import PatchTSMixerConfig, PatchTSMixerForPrediction
+from transformers import Trainer, TrainingArguments,
+
+
+config = PatchTSMixerConfig(context_length = 512, prediction_length = 96)
+model = PatchTSMixerForPrediction(config)
+trainer = Trainer(model=model, args=training_args,
+ train_dataset=train_dataset,
+ eval_dataset=valid_dataset)
+trainer.train()
+results = trainer.evaluate(test_dataset)
+```
+
+## 사용 팁[[usage-tips]]
+
+이 모델은 시계열 분류와 시계열 회귀에도 사용될 수 있습니다. 각각[`PatchTSMixerForTimeSeriesClassification`]와 [`PatchTSMixerForRegression`] 클래스를 참조하세요.
+
+## 자료[[resources]]
+
+- PatchTSMixer를 자세히 설명하는 블로그 포스트는 여기에서 찾을 수 있습니다 [이곳](https://huggingface.co/blog/patchtsmixer). 이 블로그는 Google Colab에서도 열어볼 수 있습니다.
+
+## PatchTSMixerConfig[[transformers.PatchTSMixerConfig]]
+
+[[autodoc]] PatchTSMixerConfig
+
+
+## PatchTSMixerModel[[transformers.PatchTSMixerModel]]
+
+[[autodoc]] PatchTSMixerModel
+ - forward
+
+
+## PatchTSMixerForPrediction[[transformers.PatchTSMixerForPrediction]]
+
+[[autodoc]] PatchTSMixerForPrediction
+ - forward
+
+
+## PatchTSMixerForTimeSeriesClassification[[transformers.PatchTSMixerForTimeSeriesClassification]]
+
+[[autodoc]] PatchTSMixerForTimeSeriesClassification
+ - forward
+
+
+## PatchTSMixerForPretraining[[transformers.PatchTSMixerForPretraining]]
+
+[[autodoc]] PatchTSMixerForPretraining
+ - forward
+
+
+## PatchTSMixerForRegression[[transformers.PatchTSMixerForRegression]]
+
+[[autodoc]] PatchTSMixerForRegression
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/model_doc/patchtst.md b/docs/transformers/docs/source/ko/model_doc/patchtst.md
new file mode 100644
index 0000000000000000000000000000000000000000..fc9b0eb51e4a427b26f832a30e8d5c007e9a9bb1
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/patchtst.md
@@ -0,0 +1,76 @@
+
+
+# PatchTST[[patchtst]]
+
+## 개요[[overview]]
+
+The PatchTST 모델은 Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam이 제안한 [시계열 하나가 64개의 단어만큼 가치있다: 트랜스포머를 이용한 장기예측](https://arxiv.org/abs/2211.14730)라는 논문에서 소개되었습니다.
+
+이 모델은 고수준에서 시계열을 주어진 크기의 패치로 벡터화하고, 결과로 나온 벡터 시퀀스를 트랜스포머를 통해 인코딩한 다음 적절한 헤드를 통해 예측 길이의 예측을 출력합니다. 모델은 다음 그림과 같이 도식화됩니다:
+
+
+
+해당 논문의 초록입니다:
+
+*우리는 다변량 시계열 예측과 자기 감독 표현 학습을 위한 효율적인 트랜스포머 기반 모델 설계를 제안합니다. 이는 두 가지 주요 구성 요소를 기반으로 합니다:
+
+(i) 시계열을 하위 시리즈 수준의 패치로 분할하여 트랜스포머의 입력 토큰으로 사용
+(ii) 각 채널이 모든 시리즈에 걸쳐 동일한 임베딩과 트랜스포머 가중치를 공유하는 단일 단변량 시계열을 포함하는 채널 독립성. 패칭 설계는 자연스럽게 세 가지 이점을 가집니다:
+ - 지역적 의미 정보가 임베딩에 유지됩니다;
+ - 동일한 룩백 윈도우에 대해 어텐션 맵의 계산과 메모리 사용량이 제곱으로 감소합니다
+ - 모델이 더 긴 과거를 참조할 수 있습니다.
+ 우리의 채널 독립적 패치 시계열 트랜스포머(PatchTST)는 최신 트랜스포머 기반 모델들과 비교했을 때 장기 예측 정확도를 크게 향상시킬 수 있습니다. 또한 모델을 자기지도 사전 훈련 작업에 적용하여, 대규모 데이터셋에 대한 지도 학습을 능가하는 아주 뛰어난 미세 조정 성능을 달성했습니다. 한 데이터셋에서 마스크된 사전 훈련 표현을 다른 데이터셋으로 전이하는 것도 최고 수준의 예측 정확도(SOTA)를 산출했습니다.*
+
+이 모델은 [namctin](https://huggingface.co/namctin), [gsinthong](https://huggingface.co/gsinthong), [diepi](https://huggingface.co/diepi), [vijaye12](https://huggingface.co/vijaye12), [wmgifford](https://huggingface.co/wmgifford), [kashif](https://huggingface.co/kashif)에 의해 기여 되었습니다. 원본코드는 [이곳](https://github.com/yuqinie98/PatchTST)에서 확인할 수 있습니다.
+
+## 사용 팁[[usage-tips]]
+
+이 모델은 시계열 분류와 시계열 회귀에도 사용될 수 있습니다. 각각 [`PatchTSTForClassification`]와 [`PatchTSTForRegression`] 클래스를 참조하세요.
+
+## 자료[[resources]]
+
+- PatchTST를 자세히 설명하는 블로그 포스트는 [이곳](https://huggingface.co/blog/patchtst)에서 찾을 수 있습니다.
+이 블로그는 Google Colab에서도 열어볼 수 있습니다.
+
+## PatchTSTConfig[[transformers.PatchTSTConfig]]
+
+[[autodoc]] PatchTSTConfig
+
+## PatchTSTModel[[transformers.PatchTSTModel]]
+
+[[autodoc]] PatchTSTModel
+ - forward
+
+## PatchTSTForPrediction[[transformers.PatchTSTForPrediction]]
+
+[[autodoc]] PatchTSTForPrediction
+ - forward
+
+## PatchTSTForClassification[[transformers.PatchTSTForClassification]]
+
+[[autodoc]] PatchTSTForClassification
+ - forward
+
+## PatchTSTForPretraining[[transformers.PatchTSTForPretraining]]
+
+[[autodoc]] PatchTSTForPretraining
+ - forward
+
+## PatchTSTForRegression[[transformers.PatchTSTForRegression]]
+
+[[autodoc]] PatchTSTForRegression
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/qwen2_vl.md b/docs/transformers/docs/source/ko/model_doc/qwen2_vl.md
new file mode 100644
index 0000000000000000000000000000000000000000..fb4ed27391e015918fa90b836b17ffa6a40369ea
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/qwen2_vl.md
@@ -0,0 +1,303 @@
+
+
+# Qwen2-VL[[Qwen2-VL]]
+
+
+
+ PaliGemma 아키텍처 블로그 포스트.
+
+이 모델은 [Molbap](https://huggingface.co/Molbap)에 의해 기여 되었습니다.
+
+## 사용 팁[[usage-tips]]
+
+PaliGemma의 추론은 다음처럼 수행됩니다:
+
+```python
+from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
+
+model_id = "google/paligemma-3b-mix-224"
+model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
+processor = AutoProcessor.from_pretrained(model_id)
+
+prompt = "What is on the flower?"
+image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg?download=true"
+raw_image = Image.open(requests.get(image_file, stream=True).raw)
+inputs = processor(raw_image, prompt, return_tensors="pt")
+output = model.generate(**inputs, max_new_tokens=20)
+
+print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
+```
+
+- PaliGemma는 대화용으로 설계되지 않았으며, 특정 사용 사례에 대해 미세 조정할 때 가장 잘 작동합니다. PaliGemma를 미세 조정할 수 있는 몇 가지 하위 작업에는 이미지 캡셔닝, 시각적 질문 답변(VQA), 오브젝트 디텍션, 참조 표현 분할 및 문서 이해가 포함됩니다.
+- 모델에 필요한 이미지, 텍스트 및 선택적 레이블을 준비하는데 `PaliGemmaProcessor`를 사용할 수 있습니다. PaliGemma 모델을 미세 조정할 때는, 프로세서에 `suffix`인자를 전달하여 다음 처럼 모델의 `labels`를 생성할 수 있습니다:
+
+```python
+prompt = "What is on the flower?"
+answer = "a bee"
+inputs = processor(images=raw_image, text=prompt, suffix=answer, return_tensors="pt")
+```
+
+## 자료[[resources]]
+
+PaliGemma를 시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다.여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰 해드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
+
+- PaliGemma의 모든 기능을 소개하는 블로그 포스트는 [이곳](https://huggingface.co/blog/paligemma)에서 찾을 수 있습니다. 🌎
+- Trainer API를 사용하여 VQA(Visual Question Answering)를 위해 PaliGemma를 미세 조정하는 방법과 추론에 대한 데모 노트북은 [이곳](https://github.com/huggingface/notebooks/tree/main/examples/paligemma)에서 찾을 수 있습니다. 🌎
+- 사용자 정의 데이터셋(영수증 이미지 -> JSON)에 대해 PaliGemma를 미세 조정하는 방법과 추론에 대한 데모 노트북은 [이곳](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/PaliGemma)에서 찾을 수 있습니다. 🌎
+
+## PaliGemmaConfig[[transformers.PaliGemmaConfig]]
+
+[[autodoc]] PaliGemmaConfig
+
+## PaliGemmaProcessor[[transformers.PaliGemmaProcessor]]
+
+[[autodoc]] PaliGemmaProcessor
+
+## PaliGemmaForConditionalGeneration[[transformers.PaliGemmaForConditionalGeneration]]
+
+[[autodoc]] PaliGemmaForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/patchtsmixer.md b/docs/transformers/docs/source/ko/model_doc/patchtsmixer.md
new file mode 100644
index 0000000000000000000000000000000000000000..e1463eb85de3e5aca2623fe038da4b249f9c629c
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/patchtsmixer.md
@@ -0,0 +1,95 @@
+
+
+# PatchTSMixer[[patchtsmixer]]
+
+## 개요[[overview]]
+
+PatchTSMixer 모델은 Vijay Ekambaram, Arindam Jati, Nam Nguyen, Phanwadee Sinthong, Jayant Kalagnanam이 제안한 [TSMixer: 다변량 시계열 예측을 위한 경량 MLP-Mixer 모델](https://arxiv.org/pdf/2306.09364.pdf)이라는 논문에서 소개되었습니다.
+
+
+PatchTSMixer는 MLP-Mixer 아키텍처를 기반으로 한 경량 시계열 모델링 접근법입니다. 허깅페이스 구현에서는 PatchTSMixer의 기능을 제공하여 패치, 채널, 숨겨진 특성 간의 경량 혼합을 쉽게 수행하여 효과적인 다변량 시계열 모델링을 가능하게 합니다. 또한 간단한 게이트 어텐션부터 사용자 정의된 더 복잡한 셀프 어텐션 블록까지 다양한 어텐션 메커니즘을 지원합니다. 이 모델은 사전 훈련될 수 있으며 이후 예측, 분류, 회귀와 같은 다양한 다운스트림 작업에 사용될 수 있습니다.
+
+
+해당 논문의 초록입니다:
+
+*TSMixer는 패치 처리된 시계열의 다변량 예측 및 표현 학습을 위해 설계된 다층 퍼셉트론(MLP) 모듈로만 구성된 경량 신경망 아키텍처입니다. 우리의 모델은 컴퓨터 비전 분야에서 MLP-Mixer 모델의 성공에서 영감을 받았습니다. 우리는 Vision MLP-Mixer를 시계열에 적용하는 데 따르는 과제를 보여주고, 정확도를 향상시키기 위해 경험적으로 검증된 구성 요소들을 도입합니다. 여기에는 계층 구조 및 채널 상관관계와 같은 시계열 특성을 명시적으로 모델링하기 위해 MLP-Mixer 백본에 온라인 조정 헤드를 부착하는 새로운 설계 패러다임이 포함됩니다. 또한 기존 패치 채널 혼합 방법의 일반적인 문제인 노이즈가 있는 채널 상호작용을 효과적으로 처리하고 다양한 데이터셋에 걸쳐 일반화하기 위한 하이브리드 채널 모델링 접근법을 제안합니다. 추가로, 중요한 특성을 우선시하기 위해 백본에 간단한 게이트 주의 메커니즘을 도입합니다. 이러한 경량 구성 요소들을 통합함으로써, 우리는 단순한 MLP 구조의 학습 능력을 크게 향상시켜 최소한의 컴퓨팅 사용으로 복잡한 트랜스포머 모델들을 능가하는 성능을 달성합니다. 더욱이, TSMixer의 모듈식 설계는 감독 학습과 마스크 자기 감독 학습 방법 모두와 호환되어 시계열 기초 모델의 유망한 구성 요소가 됩니다. TSMixer는 예측 작업에서 최첨단 MLP 및 트랜스포머 모델들을 상당한 차이(8-60%)로 능가합니다. 또한 최신의 강력한 Patch-Transformer 모델 벤치마크들을 메모리와 실행 시간을 크게 줄이면서(2-3배) 성능 면에서도 앞섭니다(1-2%).*
+
+이 모델은 [ajati](https://huggingface.co/ajati), [vijaye12](https://huggingface.co/vijaye12),
+[gsinthong](https://huggingface.co/gsinthong), [namctin](https://huggingface.co/namctin),
+[wmgifford](https://huggingface.co/wmgifford), [kashif](https://huggingface.co/kashif)가 기여했습니다.
+
+## 사용 예[[usage-example]]
+
+아래의 코드 스니펫은 PatchTSMixer 모델을 무작위로 초기화하는 방법을 보여줍니다.
+PatchTSMixer 모델은 [Trainer API](../trainer.md)와 호환됩니다.
+
+```python
+
+from transformers import PatchTSMixerConfig, PatchTSMixerForPrediction
+from transformers import Trainer, TrainingArguments,
+
+
+config = PatchTSMixerConfig(context_length = 512, prediction_length = 96)
+model = PatchTSMixerForPrediction(config)
+trainer = Trainer(model=model, args=training_args,
+ train_dataset=train_dataset,
+ eval_dataset=valid_dataset)
+trainer.train()
+results = trainer.evaluate(test_dataset)
+```
+
+## 사용 팁[[usage-tips]]
+
+이 모델은 시계열 분류와 시계열 회귀에도 사용될 수 있습니다. 각각[`PatchTSMixerForTimeSeriesClassification`]와 [`PatchTSMixerForRegression`] 클래스를 참조하세요.
+
+## 자료[[resources]]
+
+- PatchTSMixer를 자세히 설명하는 블로그 포스트는 여기에서 찾을 수 있습니다 [이곳](https://huggingface.co/blog/patchtsmixer). 이 블로그는 Google Colab에서도 열어볼 수 있습니다.
+
+## PatchTSMixerConfig[[transformers.PatchTSMixerConfig]]
+
+[[autodoc]] PatchTSMixerConfig
+
+
+## PatchTSMixerModel[[transformers.PatchTSMixerModel]]
+
+[[autodoc]] PatchTSMixerModel
+ - forward
+
+
+## PatchTSMixerForPrediction[[transformers.PatchTSMixerForPrediction]]
+
+[[autodoc]] PatchTSMixerForPrediction
+ - forward
+
+
+## PatchTSMixerForTimeSeriesClassification[[transformers.PatchTSMixerForTimeSeriesClassification]]
+
+[[autodoc]] PatchTSMixerForTimeSeriesClassification
+ - forward
+
+
+## PatchTSMixerForPretraining[[transformers.PatchTSMixerForPretraining]]
+
+[[autodoc]] PatchTSMixerForPretraining
+ - forward
+
+
+## PatchTSMixerForRegression[[transformers.PatchTSMixerForRegression]]
+
+[[autodoc]] PatchTSMixerForRegression
+ - forward
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ko/model_doc/patchtst.md b/docs/transformers/docs/source/ko/model_doc/patchtst.md
new file mode 100644
index 0000000000000000000000000000000000000000..fc9b0eb51e4a427b26f832a30e8d5c007e9a9bb1
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/patchtst.md
@@ -0,0 +1,76 @@
+
+
+# PatchTST[[patchtst]]
+
+## 개요[[overview]]
+
+The PatchTST 모델은 Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam이 제안한 [시계열 하나가 64개의 단어만큼 가치있다: 트랜스포머를 이용한 장기예측](https://arxiv.org/abs/2211.14730)라는 논문에서 소개되었습니다.
+
+이 모델은 고수준에서 시계열을 주어진 크기의 패치로 벡터화하고, 결과로 나온 벡터 시퀀스를 트랜스포머를 통해 인코딩한 다음 적절한 헤드를 통해 예측 길이의 예측을 출력합니다. 모델은 다음 그림과 같이 도식화됩니다:
+
+
+
+해당 논문의 초록입니다:
+
+*우리는 다변량 시계열 예측과 자기 감독 표현 학습을 위한 효율적인 트랜스포머 기반 모델 설계를 제안합니다. 이는 두 가지 주요 구성 요소를 기반으로 합니다:
+
+(i) 시계열을 하위 시리즈 수준의 패치로 분할하여 트랜스포머의 입력 토큰으로 사용
+(ii) 각 채널이 모든 시리즈에 걸쳐 동일한 임베딩과 트랜스포머 가중치를 공유하는 단일 단변량 시계열을 포함하는 채널 독립성. 패칭 설계는 자연스럽게 세 가지 이점을 가집니다:
+ - 지역적 의미 정보가 임베딩에 유지됩니다;
+ - 동일한 룩백 윈도우에 대해 어텐션 맵의 계산과 메모리 사용량이 제곱으로 감소합니다
+ - 모델이 더 긴 과거를 참조할 수 있습니다.
+ 우리의 채널 독립적 패치 시계열 트랜스포머(PatchTST)는 최신 트랜스포머 기반 모델들과 비교했을 때 장기 예측 정확도를 크게 향상시킬 수 있습니다. 또한 모델을 자기지도 사전 훈련 작업에 적용하여, 대규모 데이터셋에 대한 지도 학습을 능가하는 아주 뛰어난 미세 조정 성능을 달성했습니다. 한 데이터셋에서 마스크된 사전 훈련 표현을 다른 데이터셋으로 전이하는 것도 최고 수준의 예측 정확도(SOTA)를 산출했습니다.*
+
+이 모델은 [namctin](https://huggingface.co/namctin), [gsinthong](https://huggingface.co/gsinthong), [diepi](https://huggingface.co/diepi), [vijaye12](https://huggingface.co/vijaye12), [wmgifford](https://huggingface.co/wmgifford), [kashif](https://huggingface.co/kashif)에 의해 기여 되었습니다. 원본코드는 [이곳](https://github.com/yuqinie98/PatchTST)에서 확인할 수 있습니다.
+
+## 사용 팁[[usage-tips]]
+
+이 모델은 시계열 분류와 시계열 회귀에도 사용될 수 있습니다. 각각 [`PatchTSTForClassification`]와 [`PatchTSTForRegression`] 클래스를 참조하세요.
+
+## 자료[[resources]]
+
+- PatchTST를 자세히 설명하는 블로그 포스트는 [이곳](https://huggingface.co/blog/patchtst)에서 찾을 수 있습니다.
+이 블로그는 Google Colab에서도 열어볼 수 있습니다.
+
+## PatchTSTConfig[[transformers.PatchTSTConfig]]
+
+[[autodoc]] PatchTSTConfig
+
+## PatchTSTModel[[transformers.PatchTSTModel]]
+
+[[autodoc]] PatchTSTModel
+ - forward
+
+## PatchTSTForPrediction[[transformers.PatchTSTForPrediction]]
+
+[[autodoc]] PatchTSTForPrediction
+ - forward
+
+## PatchTSTForClassification[[transformers.PatchTSTForClassification]]
+
+[[autodoc]] PatchTSTForClassification
+ - forward
+
+## PatchTSTForPretraining[[transformers.PatchTSTForPretraining]]
+
+[[autodoc]] PatchTSTForPretraining
+ - forward
+
+## PatchTSTForRegression[[transformers.PatchTSTForRegression]]
+
+[[autodoc]] PatchTSTForRegression
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/qwen2_vl.md b/docs/transformers/docs/source/ko/model_doc/qwen2_vl.md
new file mode 100644
index 0000000000000000000000000000000000000000..fb4ed27391e015918fa90b836b17ffa6a40369ea
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/qwen2_vl.md
@@ -0,0 +1,303 @@
+
+
+# Qwen2-VL[[Qwen2-VL]]
+
+ +
+ Qwen2-VL 구조. 출처: 블로그 게시글
+
+이 모델은 [simonJJJ](https://huggingface.co/simonJJJ)에 의해 기여되었습니다.
+
+## 사용 예시[[Usage example]]
+
+### 단일 미디어 추론[[Single Media inference]]
+
+이 모델은 이미지와 비디오를 모두 인풋으로 받을 수 있습니다. 다음은 추론을 위한 예제 코드입니다.
+
+```python
+
+import torch
+from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
+
+# 사용 가능한 장치에서 모델을 반 정밀도(half-precision)로 로드
+model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", device_map="auto")
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
+
+
+conversation = [
+ {
+ "role":"user",
+ "content":[
+ {
+ "type":"image",
+ "url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"
+ },
+ {
+ "type":"text",
+ "text":"Describe this image."
+ }
+ ]
+ }
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+# 추론: 아웃풋 생성
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+
+
+
+# 비디오
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "video", "path": "/path/to/video.mp4"},
+ {"type": "text", "text": "What happened in the video?"},
+ ],
+ }
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ video_fps=1,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+
+# 추론: 아웃풋 생성
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+```
+
+### 배치 혼합 미디어 추론[[Batch Mixed Media Inference]]
+
+이 모델은 이미지, 비디오, 텍스트 등 다양한 유형의 데이터를 혼합하여 배치 입력으로 처리할 수 있습니다. 다음은 예제입니다.
+
+```python
+
+# 첫번째 이미지에 대한 대화
+conversation1 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image1.jpg"},
+ {"type": "text", "text": "Describe this image."}
+ ]
+ }
+]
+
+# 두 개의 이미지에 대한 대화
+conversation2 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image2.jpg"},
+ {"type": "image", "path": "/path/to/image3.jpg"},
+ {"type": "text", "text": "What is written in the pictures?"}
+ ]
+ }
+]
+
+# 순수 텍스트로만 이루어진 대화
+conversation3 = [
+ {
+ "role": "user",
+ "content": "who are you?"
+ }
+]
+
+
+# 혼합된 미디어로 이루어진 대화
+conversation4 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image3.jpg"},
+ {"type": "image", "path": "/path/to/image4.jpg"},
+ {"type": "video", "path": "/path/to/video.jpg"},
+ {"type": "text", "text": "What are the common elements in these medias?"},
+ ],
+ }
+]
+
+conversations = [conversation1, conversation2, conversation3, conversation4]
+# 배치 추론을 위한 준비
+ipnuts = processor.apply_chat_template(
+ conversations,
+ video_fps=1,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+
+# 배치 추론
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+```
+
+### 사용 팁[[Usage Tips]]
+
+#### 이미지 해상도 트레이드오프[[Image Resolution trade-off]]
+
+이 모델은 다양한 해상도의 입력을 지원합니다. 디폴트로 입력에 대해 네이티브(native) 해상도를 사용하지만, 더 높은 해상도를 적용하면 성능이 향상될 수 있습니다. 다만, 이는 더 많은 연산 비용을 초래합니다. 사용자는 최적의 설정을 위해 최소 및 최대 픽셀 수를 조정할 수 있습니다.
+
+```python
+min_pixels = 224*224
+max_pixels = 2048*2048
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+```
+
+제한된 GPU RAM의 경우, 다음과 같이 해상도를 줄일 수 있습니다:
+
+```python
+min_pixels = 256*28*28
+max_pixels = 1024*28*28
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+```
+이렇게 하면 각 이미지가 256~1024개의 토큰으로 인코딩됩니다. 여기서 28은 모델이 14 크기의 패치(patch)와 2의 시간 패치(temporal patch size)를 사용하기 때문에 나온 값입니다 (14 × 2 = 28).
+
+
+#### 다중 이미지 인풋[[Multiple Image Inputs]]
+
+기본적으로 이미지와 비디오 콘텐츠는 대화에 직접 포함됩니다. 여러 개의 이미지를 처리할 때는 이미지 및 비디오에 라벨을 추가하면 참조하기가 더 쉬워집니다. 사용자는 다음 설정을 통해 이 동작을 제어할 수 있습니다:
+
+```python
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "Hello, how are you?"}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'm doing well, thank you for asking. How can I assist you today?"
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Can you describe these images and video?"},
+ {"type": "image"},
+ {"type": "image"},
+ {"type": "video"},
+ {"type": "text", "text": "These are from my vacation."}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'd be happy to describe the images and video for you. Could you please provide more context about your vacation?"
+ },
+ {
+ "role": "user",
+ "content": "It was a trip to the mountains. Can you see the details in the images and video?"
+ }
+]
+
+# 디폴트:
+prompt_without_id = processor.apply_chat_template(conversation, add_generation_prompt=True)
+# 예상 아웃풋: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?<|vision_start|><|image_pad|><|vision_end|><|vision_start|><|image_pad|><|vision_end|><|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+
+
+# id 추가
+prompt_with_id = processor.apply_chat_template(conversation, add_generation_prompt=True, add_vision_id=True)
+# 예상 아웃풋: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nPicture 1: <|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?Picture 2: <|vision_start|><|image_pad|><|vision_end|>Picture 3: <|vision_start|><|image_pad|><|vision_end|>Video 1: <|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+
+```
+
+#### 빠른 생성을 위한 Flash-Attention 2[[Flash-Attention 2 to speed up generation]]
+
+첫번째로, Flash Attention 2의 최신 버전을 설치합니다:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+또한, Flash-Attention 2를 지원하는 하드웨어가 필요합니다. 자세한 내용은 공식 문서인 [flash attention repository](https://github.com/Dao-AILab/flash-attention)에서 확인할 수 있습니다. FlashAttention-2는 모델이 `torch.float16` 또는 `torch.bfloat16` 형식으로 로드된 경우에만 사용할 수 있습니다.
+
+Flash Attention-2를 사용하여 모델을 로드하고 실행하려면, 다음과 같이 모델을 로드할 때 `attn_implementation="flash_attention_2"` 옵션을 추가하면 됩니다:
+
+```python
+from transformers import Qwen2VLForConditionalGeneration
+
+model = Qwen2VLForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2-VL-7B-Instruct",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+```
+
+## Qwen2VLConfig
+
+[[autodoc]] Qwen2VLConfig
+
+## Qwen2VLImageProcessor
+
+[[autodoc]] Qwen2VLImageProcessor
+ - preprocess
+
+## Qwen2VLImageProcessorFast
+
+[[autodoc]] Qwen2VLImageProcessorFast
+ - preprocess
+
+## Qwen2VLProcessor
+
+[[autodoc]] Qwen2VLProcessor
+
+## Qwen2VLModel
+
+[[autodoc]] Qwen2VLModel
+ - forward
+
+## Qwen2VLForConditionalGeneration
+
+[[autodoc]] Qwen2VLForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/rag.md b/docs/transformers/docs/source/ko/model_doc/rag.md
new file mode 100644
index 0000000000000000000000000000000000000000..0ae88cc7ac5e3e08fc85a3619fb59aaef54a86a1
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/rag.md
@@ -0,0 +1,100 @@
+
+
+# RAG(검색 증강 생성) [[rag]]
+
+
+
+ Qwen2-VL 구조. 출처: 블로그 게시글
+
+이 모델은 [simonJJJ](https://huggingface.co/simonJJJ)에 의해 기여되었습니다.
+
+## 사용 예시[[Usage example]]
+
+### 단일 미디어 추론[[Single Media inference]]
+
+이 모델은 이미지와 비디오를 모두 인풋으로 받을 수 있습니다. 다음은 추론을 위한 예제 코드입니다.
+
+```python
+
+import torch
+from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
+
+# 사용 가능한 장치에서 모델을 반 정밀도(half-precision)로 로드
+model = Qwen2VLForConditionalGeneration.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", device_map="auto")
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct")
+
+
+conversation = [
+ {
+ "role":"user",
+ "content":[
+ {
+ "type":"image",
+ "url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg"
+ },
+ {
+ "type":"text",
+ "text":"Describe this image."
+ }
+ ]
+ }
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+# 추론: 아웃풋 생성
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+
+
+
+# 비디오
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "video", "path": "/path/to/video.mp4"},
+ {"type": "text", "text": "What happened in the video?"},
+ ],
+ }
+]
+
+inputs = processor.apply_chat_template(
+ conversation,
+ video_fps=1,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+
+# 추론: 아웃풋 생성
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+```
+
+### 배치 혼합 미디어 추론[[Batch Mixed Media Inference]]
+
+이 모델은 이미지, 비디오, 텍스트 등 다양한 유형의 데이터를 혼합하여 배치 입력으로 처리할 수 있습니다. 다음은 예제입니다.
+
+```python
+
+# 첫번째 이미지에 대한 대화
+conversation1 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image1.jpg"},
+ {"type": "text", "text": "Describe this image."}
+ ]
+ }
+]
+
+# 두 개의 이미지에 대한 대화
+conversation2 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image2.jpg"},
+ {"type": "image", "path": "/path/to/image3.jpg"},
+ {"type": "text", "text": "What is written in the pictures?"}
+ ]
+ }
+]
+
+# 순수 텍스트로만 이루어진 대화
+conversation3 = [
+ {
+ "role": "user",
+ "content": "who are you?"
+ }
+]
+
+
+# 혼합된 미디어로 이루어진 대화
+conversation4 = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "path": "/path/to/image3.jpg"},
+ {"type": "image", "path": "/path/to/image4.jpg"},
+ {"type": "video", "path": "/path/to/video.jpg"},
+ {"type": "text", "text": "What are the common elements in these medias?"},
+ ],
+ }
+]
+
+conversations = [conversation1, conversation2, conversation3, conversation4]
+# 배치 추론을 위한 준비
+ipnuts = processor.apply_chat_template(
+ conversations,
+ video_fps=1,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt"
+).to(model.device)
+
+
+# 배치 추론
+output_ids = model.generate(**inputs, max_new_tokens=128)
+generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
+output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+print(output_text)
+```
+
+### 사용 팁[[Usage Tips]]
+
+#### 이미지 해상도 트레이드오프[[Image Resolution trade-off]]
+
+이 모델은 다양한 해상도의 입력을 지원합니다. 디폴트로 입력에 대해 네이티브(native) 해상도를 사용하지만, 더 높은 해상도를 적용하면 성능이 향상될 수 있습니다. 다만, 이는 더 많은 연산 비용을 초래합니다. 사용자는 최적의 설정을 위해 최소 및 최대 픽셀 수를 조정할 수 있습니다.
+
+```python
+min_pixels = 224*224
+max_pixels = 2048*2048
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+```
+
+제한된 GPU RAM의 경우, 다음과 같이 해상도를 줄일 수 있습니다:
+
+```python
+min_pixels = 256*28*28
+max_pixels = 1024*28*28
+processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
+```
+이렇게 하면 각 이미지가 256~1024개의 토큰으로 인코딩됩니다. 여기서 28은 모델이 14 크기의 패치(patch)와 2의 시간 패치(temporal patch size)를 사용하기 때문에 나온 값입니다 (14 × 2 = 28).
+
+
+#### 다중 이미지 인풋[[Multiple Image Inputs]]
+
+기본적으로 이미지와 비디오 콘텐츠는 대화에 직접 포함됩니다. 여러 개의 이미지를 처리할 때는 이미지 및 비디오에 라벨을 추가하면 참조하기가 더 쉬워집니다. 사용자는 다음 설정을 통해 이 동작을 제어할 수 있습니다:
+
+```python
+conversation = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": "Hello, how are you?"}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'm doing well, thank you for asking. How can I assist you today?"
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Can you describe these images and video?"},
+ {"type": "image"},
+ {"type": "image"},
+ {"type": "video"},
+ {"type": "text", "text": "These are from my vacation."}
+ ]
+ },
+ {
+ "role": "assistant",
+ "content": "I'd be happy to describe the images and video for you. Could you please provide more context about your vacation?"
+ },
+ {
+ "role": "user",
+ "content": "It was a trip to the mountains. Can you see the details in the images and video?"
+ }
+]
+
+# 디폴트:
+prompt_without_id = processor.apply_chat_template(conversation, add_generation_prompt=True)
+# 예상 아웃풋: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?<|vision_start|><|image_pad|><|vision_end|><|vision_start|><|image_pad|><|vision_end|><|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+
+
+# id 추가
+prompt_with_id = processor.apply_chat_template(conversation, add_generation_prompt=True, add_vision_id=True)
+# 예상 아웃풋: '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nPicture 1: <|vision_start|><|image_pad|><|vision_end|>Hello, how are you?<|im_end|>\n<|im_start|>assistant\nI'm doing well, thank you for asking. How can I assist you today?<|im_end|>\n<|im_start|>user\nCan you describe these images and video?Picture 2: <|vision_start|><|image_pad|><|vision_end|>Picture 3: <|vision_start|><|image_pad|><|vision_end|>Video 1: <|vision_start|><|video_pad|><|vision_end|>These are from my vacation.<|im_end|>\n<|im_start|>assistant\nI'd be happy to describe the images and video for you. Could you please provide more context about your vacation?<|im_end|>\n<|im_start|>user\nIt was a trip to the mountains. Can you see the details in the images and video?<|im_end|>\n<|im_start|>assistant\n'
+
+```
+
+#### 빠른 생성을 위한 Flash-Attention 2[[Flash-Attention 2 to speed up generation]]
+
+첫번째로, Flash Attention 2의 최신 버전을 설치합니다:
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+또한, Flash-Attention 2를 지원하는 하드웨어가 필요합니다. 자세한 내용은 공식 문서인 [flash attention repository](https://github.com/Dao-AILab/flash-attention)에서 확인할 수 있습니다. FlashAttention-2는 모델이 `torch.float16` 또는 `torch.bfloat16` 형식으로 로드된 경우에만 사용할 수 있습니다.
+
+Flash Attention-2를 사용하여 모델을 로드하고 실행하려면, 다음과 같이 모델을 로드할 때 `attn_implementation="flash_attention_2"` 옵션을 추가하면 됩니다:
+
+```python
+from transformers import Qwen2VLForConditionalGeneration
+
+model = Qwen2VLForConditionalGeneration.from_pretrained(
+ "Qwen/Qwen2-VL-7B-Instruct",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+)
+```
+
+## Qwen2VLConfig
+
+[[autodoc]] Qwen2VLConfig
+
+## Qwen2VLImageProcessor
+
+[[autodoc]] Qwen2VLImageProcessor
+ - preprocess
+
+## Qwen2VLImageProcessorFast
+
+[[autodoc]] Qwen2VLImageProcessorFast
+ - preprocess
+
+## Qwen2VLProcessor
+
+[[autodoc]] Qwen2VLProcessor
+
+## Qwen2VLModel
+
+[[autodoc]] Qwen2VLModel
+ - forward
+
+## Qwen2VLForConditionalGeneration
+
+[[autodoc]] Qwen2VLForConditionalGeneration
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/rag.md b/docs/transformers/docs/source/ko/model_doc/rag.md
new file mode 100644
index 0000000000000000000000000000000000000000..0ae88cc7ac5e3e08fc85a3619fb59aaef54a86a1
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/rag.md
@@ -0,0 +1,100 @@
+
+
+# RAG(검색 증강 생성) [[rag]]
+
+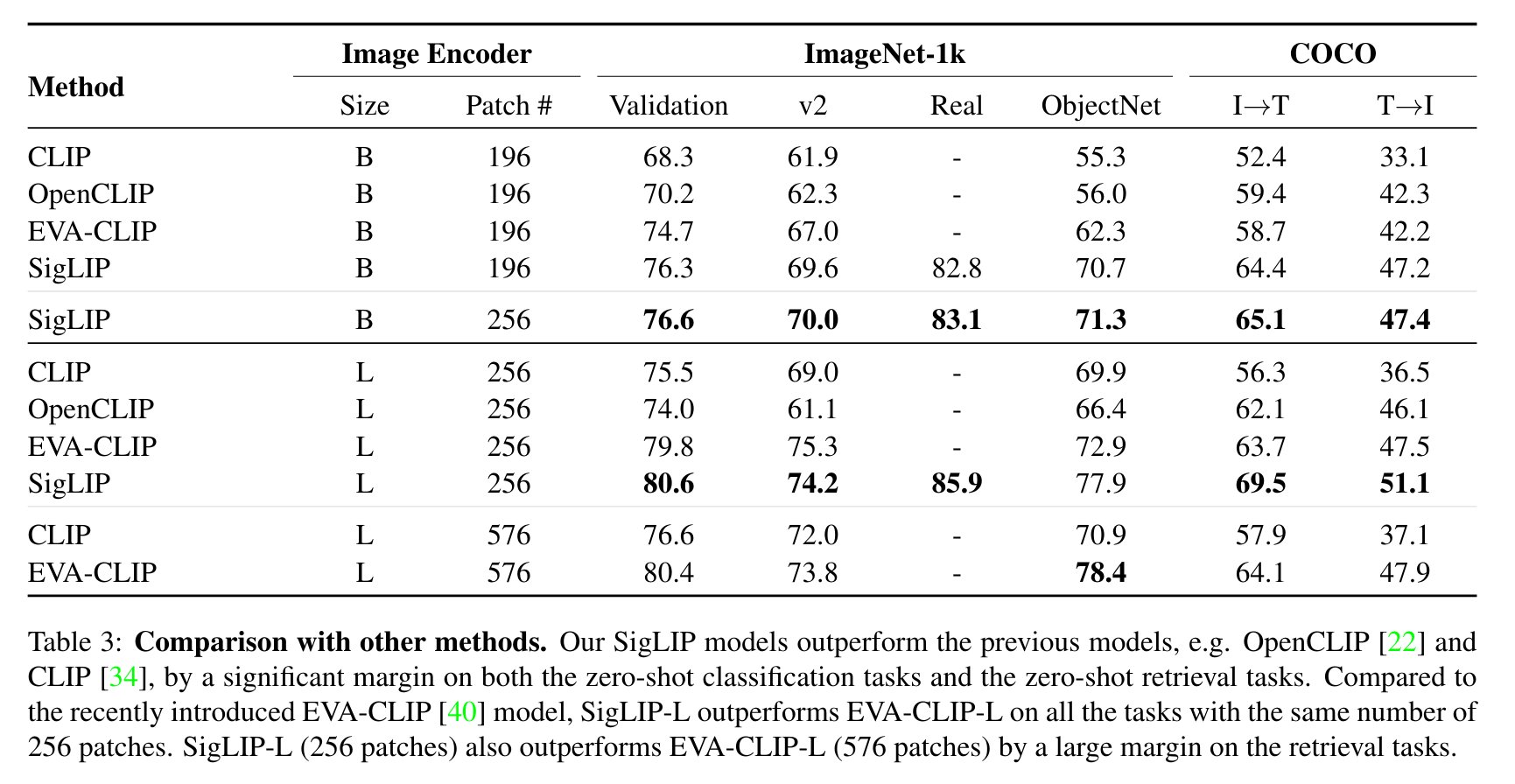 +
+ CLIP과 비교한 SigLIP 평가 결과. 원본 논문에서 발췌.
+
+이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여했습니다.
+원본 코드는 [여기](https://github.com/google-research/big_vision/tree/main)에서 찾을 수 있습니다.
+
+## 사용 예시[[usage-example]]
+
+SigLIP을 사용하는 방법에는 두 가지 주요 방법이 있습니다: 모든 복잡성을 추상화하는 파이프라인 API를 사용하거나, 직접 `SiglipModel` 클래스를 사용하는 방법입니다.
+
+### 파이프라인 API[[pipeline-API]]
+
+파이프라인을 사용하면 몇 줄의 코드로 모델을 사용할 수 있습니다:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # 파이프라인 로드
+>>> image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
+
+>>> # 이미지 로드
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # 추론
+>>> candidate_labels = ["2 cats", "a plane", "a remote"]
+>>> outputs = image_classifier(image, candidate_labels=candidate_labels)
+>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
+>>> print(outputs)
+[{'score': 0.1979, 'label': '2 cats'}, {'score': 0.0, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
+```
+
+### 직접 모델 사용하기[[using-the-model-yourself]]
+
+전처리와 후처리를 직접 수행하려면 다음과 같이 하면 됩니다:
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, AutoModel
+>>> import torch
+
+>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
+>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# 파이프라인 프롬프트 템플릿을 따라 동일한 결과를 얻습니다
+>>> texts = [f'This is a photo of {label}.' for label in candidate_labels]
+# 중요: 모델이 이렇게 학습되었으므로 `padding=max_length`를 전달합니다
+>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # 시그모이드 활성화 함수를 적용한 확률입니다
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+19.8% that image 0 is '2 cats'
+```
+
+## 리소스[[resources]]
+
+SigLIP을 시작하는 데 도움이 되는 공식 Hugging Face 및 커뮤니티(🌎로 표시) 리소스 목록입니다.
+
+- [제로샷 이미지 분류 작업 가이드](../tasks/zero_shot_image_classification)
+- SigLIP에 대한 데모 노트북은 [여기](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SigLIP)에서 찾을 수 있습니다. 🌎
+
+여기에 포함될 리소스를 제출하는 데 관심이 있으시면 Pull Request를 열어주시면 검토하겠습니다! 리소스는 이상적으로 기존 리소스를 복제하는 대신 새로운 것을 보여주어야 합니다.
+
+
+## SigLIP과 Flash Attention 2 결합하기[[combining-siglip-with-flash-attention-2]]
+
+먼저 Flash Attention 2의 최신 버전을 설치해야 합니다.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+또한 Flash-Attention 2와 호환되는 하드웨어가 있는지 확인하세요. flash-attn 저장소의 공식 문서에서 자세히 알아보세요. 또한 모델을 반정밀도(예: `torch.float16`)로 로드해야 합니다.
+
+Flash Attention 2를 사용하여 모델을 로드하고 실행하려면 아래 코드를 참조하세요:
+
+```python
+>>> import torch
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import SiglipProcessor, SiglipModel
+>>> device = "cuda" # 모델을 로드할 장치
+
+>>> model = SiglipModel.from_pretrained(
+... "google/siglip-so400m-patch14-384",
+... attn_implementation="flash_attention_2",
+... torch_dtype=torch.float16,
+... device_map=device,
+... )
+>>> processor = SiglipProcessor.from_pretrained("google/siglip-so400m-patch14-384")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# 파이프라인 프롬프트 템플릿을 따라 동일한 결과를 얻습니다
+>>> texts = [f'This is a photo of {label}.' for label in candidate_labels]
+# 중요: 모델이 이렇게 학습되었으므로 `padding=max_length`를 전달합니다
+>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt").to(device)
+
+>>> with torch.no_grad():
+... with torch.autocast(device):
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # 시그모이드 활성화 함수를 적용한 확률입니다
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+19.8% that image 0 is '2 cats'
+```
+
+
+## Scaled Dot Product Attention(SDPA) 사용하기[using-scaled-dot-product-attention(SDPA)]]
+
+PyTorch는 `torch.nn.functional`의 일부로 스케일된 점곱 어텐션(SDPA) 연산자를 포함합니다. 이 함수는
+입력과 사용 중인 하드웨어에 따라 적용할 수 있는 여러 구현을 포함합니다. 자세한 내용은
+[공식 문서](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+또는 [GPU 추론](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+페이지를 참조하세요.
+
+`from_pretrained()`에서 `attn_implementation="sdpa"`를 설정하여 SDPA를 명시적으로 요청할 수 있습니다. `torch>=2.1.1`이 설치되어 있는지 확인하세요.
+
+```python
+>>> from transformers import SiglipModel
+
+>>> model = SiglipModel.from_pretrained(
+... "google/siglip-so400m-patch14-384",
+... attn_implementation="sdpa",
+... torch_dtype=torch.float16,
+... device_map=device,
+... )
+```
+
+최상의 속도 향상을 위해 모델을 반정밀도(예: `torch.float16` 또는 `torch.bfloat16`)로 로드하는 것이 좋습니다.
+
+
+## 예상 속도 향상[[expected-speedups]]
+
+아래는 `google/siglip-so400m-patch14-384` 체크포인트를 `float16` 정밀도로 사용하는 transformers의 네이티브 구현과 Flash Attention 2 / SDPA 버전의 모델을 다양한 배치 크기로 비교한 추론 시간의 예상 속도 향상 다이어그램입니다.
+
+
+
+ CLIP과 비교한 SigLIP 평가 결과. 원본 논문에서 발췌.
+
+이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여했습니다.
+원본 코드는 [여기](https://github.com/google-research/big_vision/tree/main)에서 찾을 수 있습니다.
+
+## 사용 예시[[usage-example]]
+
+SigLIP을 사용하는 방법에는 두 가지 주요 방법이 있습니다: 모든 복잡성을 추상화하는 파이프라인 API를 사용하거나, 직접 `SiglipModel` 클래스를 사용하는 방법입니다.
+
+### 파이프라인 API[[pipeline-API]]
+
+파이프라인을 사용하면 몇 줄의 코드로 모델을 사용할 수 있습니다:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # 파이프라인 로드
+>>> image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
+
+>>> # 이미지 로드
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # 추론
+>>> candidate_labels = ["2 cats", "a plane", "a remote"]
+>>> outputs = image_classifier(image, candidate_labels=candidate_labels)
+>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
+>>> print(outputs)
+[{'score': 0.1979, 'label': '2 cats'}, {'score': 0.0, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
+```
+
+### 직접 모델 사용하기[[using-the-model-yourself]]
+
+전처리와 후처리를 직접 수행하려면 다음과 같이 하면 됩니다:
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, AutoModel
+>>> import torch
+
+>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
+>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# 파이프라인 프롬프트 템플릿을 따라 동일한 결과를 얻습니다
+>>> texts = [f'This is a photo of {label}.' for label in candidate_labels]
+# 중요: 모델이 이렇게 학습되었으므로 `padding=max_length`를 전달합니다
+>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # 시그모이드 활성화 함수를 적용한 확률입니다
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+19.8% that image 0 is '2 cats'
+```
+
+## 리소스[[resources]]
+
+SigLIP을 시작하는 데 도움이 되는 공식 Hugging Face 및 커뮤니티(🌎로 표시) 리소스 목록입니다.
+
+- [제로샷 이미지 분류 작업 가이드](../tasks/zero_shot_image_classification)
+- SigLIP에 대한 데모 노트북은 [여기](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SigLIP)에서 찾을 수 있습니다. 🌎
+
+여기에 포함될 리소스를 제출하는 데 관심이 있으시면 Pull Request를 열어주시면 검토하겠습니다! 리소스는 이상적으로 기존 리소스를 복제하는 대신 새로운 것을 보여주어야 합니다.
+
+
+## SigLIP과 Flash Attention 2 결합하기[[combining-siglip-with-flash-attention-2]]
+
+먼저 Flash Attention 2의 최신 버전을 설치해야 합니다.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+또한 Flash-Attention 2와 호환되는 하드웨어가 있는지 확인하세요. flash-attn 저장소의 공식 문서에서 자세히 알아보세요. 또한 모델을 반정밀도(예: `torch.float16`)로 로드해야 합니다.
+
+Flash Attention 2를 사용하여 모델을 로드하고 실행하려면 아래 코드를 참조하세요:
+
+```python
+>>> import torch
+>>> import requests
+>>> from PIL import Image
+>>> from transformers import SiglipProcessor, SiglipModel
+>>> device = "cuda" # 모델을 로드할 장치
+
+>>> model = SiglipModel.from_pretrained(
+... "google/siglip-so400m-patch14-384",
+... attn_implementation="flash_attention_2",
+... torch_dtype=torch.float16,
+... device_map=device,
+... )
+>>> processor = SiglipProcessor.from_pretrained("google/siglip-so400m-patch14-384")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> candidate_labels = ["2 cats", "2 dogs"]
+# 파이프라인 프롬프트 템플릿을 따라 동일한 결과를 얻습니다
+>>> texts = [f'This is a photo of {label}.' for label in candidate_labels]
+# 중요: 모델이 이렇게 학습되었으므로 `padding=max_length`를 전달합니다
+>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt").to(device)
+
+>>> with torch.no_grad():
+... with torch.autocast(device):
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # 시그모이드 활성화 함수를 적용한 확률입니다
+>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
+19.8% that image 0 is '2 cats'
+```
+
+
+## Scaled Dot Product Attention(SDPA) 사용하기[using-scaled-dot-product-attention(SDPA)]]
+
+PyTorch는 `torch.nn.functional`의 일부로 스케일된 점곱 어텐션(SDPA) 연산자를 포함합니다. 이 함수는
+입력과 사용 중인 하드웨어에 따라 적용할 수 있는 여러 구현을 포함합니다. 자세한 내용은
+[공식 문서](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+또는 [GPU 추론](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+페이지를 참조하세요.
+
+`from_pretrained()`에서 `attn_implementation="sdpa"`를 설정하여 SDPA를 명시적으로 요청할 수 있습니다. `torch>=2.1.1`이 설치되어 있는지 확인하세요.
+
+```python
+>>> from transformers import SiglipModel
+
+>>> model = SiglipModel.from_pretrained(
+... "google/siglip-so400m-patch14-384",
+... attn_implementation="sdpa",
+... torch_dtype=torch.float16,
+... device_map=device,
+... )
+```
+
+최상의 속도 향상을 위해 모델을 반정밀도(예: `torch.float16` 또는 `torch.bfloat16`)로 로드하는 것이 좋습니다.
+
+
+## 예상 속도 향상[[expected-speedups]]
+
+아래는 `google/siglip-so400m-patch14-384` 체크포인트를 `float16` 정밀도로 사용하는 transformers의 네이티브 구현과 Flash Attention 2 / SDPA 버전의 모델을 다양한 배치 크기로 비교한 추론 시간의 예상 속도 향상 다이어그램입니다.
+
+ +
+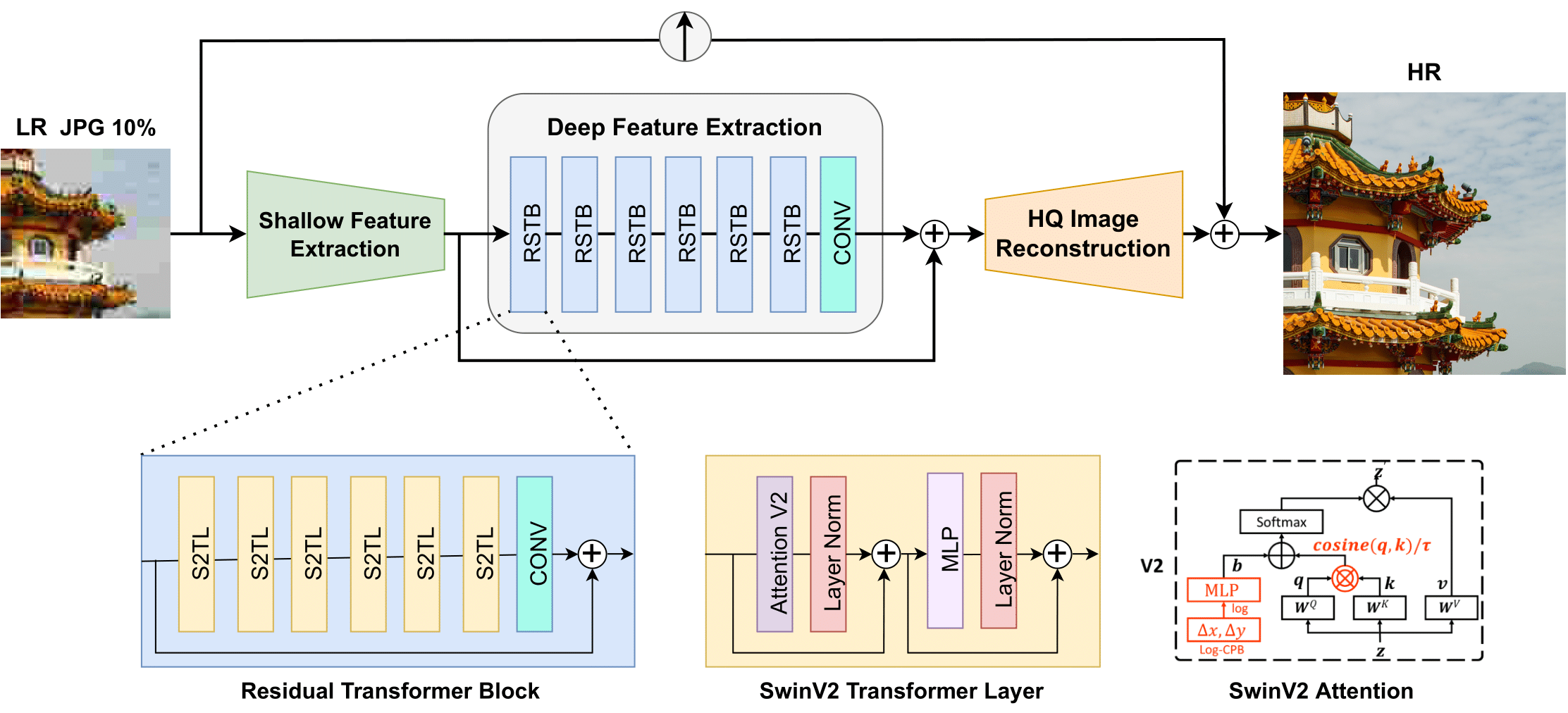 +
+ Swin2SR 아키텍처. 원본 논문에서 발췌.
+
+이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여하였습니다.
+원본 코드는 [여기](https://github.com/mv-lab/swin2sr)에서 확인할 수 있습니다.
+
+## 리소스 [[resources]]
+
+Swin2SR demo notebook은 [여기](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Swin2SR)에서 확인할 수 있습니다.
+
+SwinSR을 활용한 image super-resolution demo space는 [여기](https://huggingface.co/spaces/jjourney1125/swin2sr)에서 확인할 수 있습니다.
+
+## Swin2SRImageProcessor [[transformers.Swin2SRImageProcessor]]
+
+[[autodoc]] Swin2SRImageProcessor
+ - preprocess
+
+## Swin2SRConfig [[transformers.Swin2SRConfig]]
+
+[[autodoc]] Swin2SRConfig
+
+## Swin2SRModel [[transformers.Swin2SRModel]]
+
+[[autodoc]] Swin2SRModel
+ - forward
+
+## Swin2SRForImageSuperResolution [[transformers.Swin2SRForImageSuperResolution]]
+
+[[autodoc]] Swin2SRForImageSuperResolution
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/swinv2.md b/docs/transformers/docs/source/ko/model_doc/swinv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..3bc420a292ad7bfd80791aafa6f4ecb40bdd4242
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/swinv2.md
@@ -0,0 +1,63 @@
+
+
+# Swin Transformer V2 [[swin-transformer-v2]]
+
+## 개요 [[overview]]
+
+Swin Transformer V2는 Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo가 제안한 논문 [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883)에서 소개되었습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*대규모 NLP 모델들은 언어 작업에서의 성능을 크게 향상하며, 성능이 포화하는 징후를 보이지 않습니다. 또한, 사람과 유사한 few-shot 학습 능력을 보여줍니다. 이 논문은 대규모 모델을 컴퓨터 비전 분야에서 탐구하고자 합니다. 대형 비전 모델을 훈련하고 적용하는 데 있어 세 가지 주요 문제를 다룹니다: 훈련 불안정성, 사전 학습과 파인튜닝 간의 해상도 차이, 그리고 레이블이 달린 데이터에 대한 높은 요구입니다. 세 가지 주요 기법을 제안합니다: 1) 훈련 안정성을 개선하기 위한 residual-post-norm 방법과 cosine attention의 결합; 2) 저해상도 이미지로 사전 학습된 모델을 고해상도 입력으로 전이할 수 있는 log-spaced continuous position bias 방법; 3) 레이블이 달린 방대한 이미지의 필요성을 줄이기 위한 self-supervised 사전 학습 방법인 SimMIM입니다. 이러한 기법들을 통해 30억 개의 파라미터를 가진 Swin Transformer V2 모델을 성공적으로 훈련하였으며, 이는 현재까지 가장 크고 고밀도의 비전 모델로, 최대 1,536×1,536 해상도의 이미지를 다룰 수 있습니다. 이 모델은 ImageNet-V2 이미지 분류, COCO 객체 탐지, ADE20K 의미론적 분할, Kinetics-400 비디오 행동 분류 등 네 가지 대표적인 비전 작업에서 새로운 성능 기록을 세웠습니다. 또한, 우리의 훈련은 Google의 billion-level 비전 모델과 비교해 40배 적은 레이블이 달린 데이터와 40배 적은 훈련 시간으로 이루어졌다는 점에서 훨씬 더 효율적입니다.*
+
+이 모델은 [nandwalritik](https://huggingface.co/nandwalritik)이 기여하였습니다.
+원본 코드는 [여기](https://github.com/microsoft/Swin-Transformer)에서 확인할 수 있습니다.
+
+## 리소스 [[resources]]
+
+Swin Transformer v2의 사용을 도울 수 있는 Hugging Face 및 커뮤니티(🌎로 표시)의 공식 자료 목록입니다.
+
+
+
+
+ Swin2SR 아키텍처. 원본 논문에서 발췌.
+
+이 모델은 [nielsr](https://huggingface.co/nielsr)가 기여하였습니다.
+원본 코드는 [여기](https://github.com/mv-lab/swin2sr)에서 확인할 수 있습니다.
+
+## 리소스 [[resources]]
+
+Swin2SR demo notebook은 [여기](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Swin2SR)에서 확인할 수 있습니다.
+
+SwinSR을 활용한 image super-resolution demo space는 [여기](https://huggingface.co/spaces/jjourney1125/swin2sr)에서 확인할 수 있습니다.
+
+## Swin2SRImageProcessor [[transformers.Swin2SRImageProcessor]]
+
+[[autodoc]] Swin2SRImageProcessor
+ - preprocess
+
+## Swin2SRConfig [[transformers.Swin2SRConfig]]
+
+[[autodoc]] Swin2SRConfig
+
+## Swin2SRModel [[transformers.Swin2SRModel]]
+
+[[autodoc]] Swin2SRModel
+ - forward
+
+## Swin2SRForImageSuperResolution [[transformers.Swin2SRForImageSuperResolution]]
+
+[[autodoc]] Swin2SRForImageSuperResolution
+ - forward
diff --git a/docs/transformers/docs/source/ko/model_doc/swinv2.md b/docs/transformers/docs/source/ko/model_doc/swinv2.md
new file mode 100644
index 0000000000000000000000000000000000000000..3bc420a292ad7bfd80791aafa6f4ecb40bdd4242
--- /dev/null
+++ b/docs/transformers/docs/source/ko/model_doc/swinv2.md
@@ -0,0 +1,63 @@
+
+
+# Swin Transformer V2 [[swin-transformer-v2]]
+
+## 개요 [[overview]]
+
+Swin Transformer V2는 Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, Baining Guo가 제안한 논문 [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883)에서 소개되었습니다.
+
+논문의 초록은 다음과 같습니다:
+
+*대규모 NLP 모델들은 언어 작업에서의 성능을 크게 향상하며, 성능이 포화하는 징후를 보이지 않습니다. 또한, 사람과 유사한 few-shot 학습 능력을 보여줍니다. 이 논문은 대규모 모델을 컴퓨터 비전 분야에서 탐구하고자 합니다. 대형 비전 모델을 훈련하고 적용하는 데 있어 세 가지 주요 문제를 다룹니다: 훈련 불안정성, 사전 학습과 파인튜닝 간의 해상도 차이, 그리고 레이블이 달린 데이터에 대한 높은 요구입니다. 세 가지 주요 기법을 제안합니다: 1) 훈련 안정성을 개선하기 위한 residual-post-norm 방법과 cosine attention의 결합; 2) 저해상도 이미지로 사전 학습된 모델을 고해상도 입력으로 전이할 수 있는 log-spaced continuous position bias 방법; 3) 레이블이 달린 방대한 이미지의 필요성을 줄이기 위한 self-supervised 사전 학습 방법인 SimMIM입니다. 이러한 기법들을 통해 30억 개의 파라미터를 가진 Swin Transformer V2 모델을 성공적으로 훈련하였으며, 이는 현재까지 가장 크고 고밀도의 비전 모델로, 최대 1,536×1,536 해상도의 이미지를 다룰 수 있습니다. 이 모델은 ImageNet-V2 이미지 분류, COCO 객체 탐지, ADE20K 의미론적 분할, Kinetics-400 비디오 행동 분류 등 네 가지 대표적인 비전 작업에서 새로운 성능 기록을 세웠습니다. 또한, 우리의 훈련은 Google의 billion-level 비전 모델과 비교해 40배 적은 레이블이 달린 데이터와 40배 적은 훈련 시간으로 이루어졌다는 점에서 훨씬 더 효율적입니다.*
+
+이 모델은 [nandwalritik](https://huggingface.co/nandwalritik)이 기여하였습니다.
+원본 코드는 [여기](https://github.com/microsoft/Swin-Transformer)에서 확인할 수 있습니다.
+
+## 리소스 [[resources]]
+
+Swin Transformer v2의 사용을 도울 수 있는 Hugging Face 및 커뮤니티(🌎로 표시)의 공식 자료 목록입니다.
+
+
+ +
+ ViT 아키텍처. 원본 논문에서 발췌.
+
+원래의 Vision Transformer에 이어, 여러 후속 연구들이 진행되었습니다:
+
+
+- [DeiT](deit) (Data-efficient Image Transformers) (Facebook AI 개발). DeiT 모델은 distilled vision transformers입니다.
+ DeiT의 저자들은 더 효율적으로 훈련된 ViT 모델도 공개했으며, 이는 [`ViTModel`] 또는 [`ViTForImageClassification`]에 바로 사용할 수 있습니다. 여기에는 3가지 크기로 4개의 변형이 제공됩니다: *facebook/deit-tiny-patch16-224*, *facebook/deit-small-patch16-224*, *facebook/deit-base-patch16-224* and *facebook/deit-base-patch16-384*. 그리고 모델에 이미지를 준비하려면 [`DeiTImageProcessor`]를 사용해야 한다는 점에 유의하십시오.
+
+- [BEiT](beit) (BERT pre-training of Image Transformers) (Microsoft Research 개발). BEiT 모델은 BERT (masked image modeling)에 영감을 받고 VQ-VAE에 기반한 self-supervised 방법을 이용하여 supervised pre-trained vision transformers보다 더 우수한 성능을 보입니다.
+
+- DINO (Vision Transformers의 self-supervised 훈련을 위한 방법) (Facebook AI 개발). DINO 방법으로 훈련된 Vision Transformer는 학습되지 않은 상태에서도 객체를 분할할 수 있는 합성곱 신경망에서는 볼 수 없는 매우 흥미로운 능력을 보여줍니다. DINO 체크포인트는 [hub](https://huggingface.co/models?other=dino)에서 찾을 수 있습니다.
+
+- [MAE](vit_mae) (Masked Autoencoders) (Facebook AI 개발). Vision Transformer를 비대칭 인코더-디코더 아키텍처를 사용하여 마스크된 패치의 높은 비율(75%)에서 픽셀 값을 재구성하도록 사전 학습함으로써, 저자들은 이 간단한 방법이 미세 조정 후 supervised 방식의 사전 학습을 능가한다는 것을 보여주었습니다.
+
+이 모델은 [nielsr](https://huggingface.co/nielsr)에 의해 기여되었습니다. 원본 코드(JAX로 작성됨)은 [여기](https://github.com/google-research/vision_transformer)에서 확인할 수 있습니다.
+
+
+참고로, 우리는 Ross Wightman의 [timm 라이브러리](https://github.com/rwightman/pytorch-image-models)에서 JAX에서 PyTorch로 변환된 가중치를 다시 변환했습니다. 모든 공로는 그에게 돌립니다!
+
+## 사용 팁 [[usage-tips]]
+
+- Transformer 인코더에 이미지를 입력하기 위해, 각 이미지는 고정 크기의 겹치지 않는 패치들로 분할된 후 선형 임베딩됩니다. 전체 이미지를 대표하는 [CLS] 토큰이 추가되어, 분류에 사용할 수 있습니다. 저자들은 또한 절대 위치 임베딩을 추가하여, 결과적으로 생성된 벡터 시퀀스를 표준 Transformer 인코더에 입력합니다.
+- Vision Transformer는 모든 이미지가 동일한 크기(해상도)여야 하므로, [ViTImageProcessor]를 사용하여 이미지를 모델에 맞게 리사이즈(또는 리스케일)하고 정규화할 수 있습니다.
+- 사전 학습이나 미세 조정 시 사용된 패치 해상도와 이미지 해상도는 각 체크포인트의 이름에 반영됩니다. 예를 들어, `google/vit-base-patch16-224`는 패치 해상도가 16x16이고 미세 조정 해상도가 224x224인 기본 크기 아키텍처를 나타냅니다. 모든 체크포인트는 [hub](https://huggingface.co/models?search=vit)에서 확인할 수 있습니다.
+- 사용할 수 있는 체크포인트는 (1) [ImageNet-21k](http://www.image-net.org/) (1,400만 개의 이미지와 21,000개의 클래스)에서만 사전 학습되었거나, 또는 (2) [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (ILSVRC 2012, 130만 개의 이미지와 1,000개의 클래스)에서 추가로 미세 조정된 경우입니다.
+- Vision Transformer는 224x224 해상도로 사전 학습되었습니다. 미세 조정 시, 사전 학습보다 더 높은 해상도를 사용하는 것이 유리한 경우가 많습니다 ([(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikovet al., 2020)](https://arxiv.org/abs/1912.11370). 더 높은 해상도로 미세 조정하기 위해, 저자들은 원본 이미지에서의 위치에 따라 사전 학습된 위치 임베딩의 2D 보간(interpolation)을 수행합니다.
+- 최고의 결과는 supervised 방식의 사전 학습에서 얻어졌으며, 이는 NLP에서는 해당되지 않는 경우가 많습니다. 저자들은 마스크된 패치 예측(마스크된 언어 모델링에서 영감을 받은 self-supervised 사전 학습 목표)을 사용한 실험도 수행했습니다. 이 접근 방식으로 더 작은 ViT-B/16 모델은 ImageNet에서 79.9%의 정확도를 달성하였으며, 이는 처음부터 학습한 것보다 2% 개선된 결과이지만, 여전히 supervised 사전 학습보다 4% 낮습니다.
+
+### Scaled Dot Product Attention (SDPA) 사용하기 [[using-scaled-dot-product-attention-sdpa]]
+
+PyTorch는 `torch.nn.functional`의 일부로서 native scaled dot-product attention (SDPA) 연산자를 포함하고 있습니다. 이 함수는 입력 및 사용 중인 하드웨어에 따라 여러 구현 방식을 적용할 수 있습니다.자세한 내용은 [공식 문서](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)나 [GPU 추론](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention) 페이지를 참조하십시오.
+
+SDPA는 `torch>=2.1.1`에서 구현이 가능한 경우 기본적으로 사용되지만, `from_pretrained()`에서 `attn_implementation="sdpa"`로 설정하여 SDPA를 명시적으로 요청할 수도 있습니다.
+
+```
+from transformers import ViTForImageClassification
+model = ViTForImageClassification.from_pretrained("google/vit-base-patch16-224", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+최적의 속도 향상을 위해 모델을 반정밀도(예: `torch.float16` 또는 `torch.bfloat16`)로 로드하는 것을 권장합니다.
+
+로컬 벤치마크(A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04)에서 `float32`와 `google/vit-base-patch16-224` 모델을 사용한 추론 시, 다음과 같은 속도 향상을 확인했습니다.
+
+| Batch size | Average inference time (ms), eager mode | Average inference time (ms), sdpa model | Speed up, Sdpa / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 7 | 6 | 1.17 |
+| 2 | 8 | 6 | 1.33 |
+| 4 | 8 | 6 | 1.33 |
+| 8 | 8 | 6 | 1.33 |
+
+## 리소스 [[resources]]
+
+ViT의 추론 및 커스텀 데이터에 대한 미세 조정과 관련된 데모 노트북은 [여기](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)에서 확인할 수 있습니다. Hugging Face에서 공식적으로 제공하는 자료와 커뮤니티(🌎로 표시된) 자료 목록은 ViT를 시작하는 데 도움이 될 것입니다. 이 목록에 포함될 자료를 제출하고 싶다면 Pull Request를 열어 주시면 검토하겠습니다. 새로운 내용을 설명하는 자료가 가장 이상적이며, 기존 자료를 중복하지 않도록 해주십시오.
+
+`ViTForImageClassification` 은 다음에서 지원됩니다:
+
+
+ ViT 아키텍처. 원본 논문에서 발췌.
+
+원래의 Vision Transformer에 이어, 여러 후속 연구들이 진행되었습니다:
+
+
+- [DeiT](deit) (Data-efficient Image Transformers) (Facebook AI 개발). DeiT 모델은 distilled vision transformers입니다.
+ DeiT의 저자들은 더 효율적으로 훈련된 ViT 모델도 공개했으며, 이는 [`ViTModel`] 또는 [`ViTForImageClassification`]에 바로 사용할 수 있습니다. 여기에는 3가지 크기로 4개의 변형이 제공됩니다: *facebook/deit-tiny-patch16-224*, *facebook/deit-small-patch16-224*, *facebook/deit-base-patch16-224* and *facebook/deit-base-patch16-384*. 그리고 모델에 이미지를 준비하려면 [`DeiTImageProcessor`]를 사용해야 한다는 점에 유의하십시오.
+
+- [BEiT](beit) (BERT pre-training of Image Transformers) (Microsoft Research 개발). BEiT 모델은 BERT (masked image modeling)에 영감을 받고 VQ-VAE에 기반한 self-supervised 방법을 이용하여 supervised pre-trained vision transformers보다 더 우수한 성능을 보입니다.
+
+- DINO (Vision Transformers의 self-supervised 훈련을 위한 방법) (Facebook AI 개발). DINO 방법으로 훈련된 Vision Transformer는 학습되지 않은 상태에서도 객체를 분할할 수 있는 합성곱 신경망에서는 볼 수 없는 매우 흥미로운 능력을 보여줍니다. DINO 체크포인트는 [hub](https://huggingface.co/models?other=dino)에서 찾을 수 있습니다.
+
+- [MAE](vit_mae) (Masked Autoencoders) (Facebook AI 개발). Vision Transformer를 비대칭 인코더-디코더 아키텍처를 사용하여 마스크된 패치의 높은 비율(75%)에서 픽셀 값을 재구성하도록 사전 학습함으로써, 저자들은 이 간단한 방법이 미세 조정 후 supervised 방식의 사전 학습을 능가한다는 것을 보여주었습니다.
+
+이 모델은 [nielsr](https://huggingface.co/nielsr)에 의해 기여되었습니다. 원본 코드(JAX로 작성됨)은 [여기](https://github.com/google-research/vision_transformer)에서 확인할 수 있습니다.
+
+
+참고로, 우리는 Ross Wightman의 [timm 라이브러리](https://github.com/rwightman/pytorch-image-models)에서 JAX에서 PyTorch로 변환된 가중치를 다시 변환했습니다. 모든 공로는 그에게 돌립니다!
+
+## 사용 팁 [[usage-tips]]
+
+- Transformer 인코더에 이미지를 입력하기 위해, 각 이미지는 고정 크기의 겹치지 않는 패치들로 분할된 후 선형 임베딩됩니다. 전체 이미지를 대표하는 [CLS] 토큰이 추가되어, 분류에 사용할 수 있습니다. 저자들은 또한 절대 위치 임베딩을 추가하여, 결과적으로 생성된 벡터 시퀀스를 표준 Transformer 인코더에 입력합니다.
+- Vision Transformer는 모든 이미지가 동일한 크기(해상도)여야 하므로, [ViTImageProcessor]를 사용하여 이미지를 모델에 맞게 리사이즈(또는 리스케일)하고 정규화할 수 있습니다.
+- 사전 학습이나 미세 조정 시 사용된 패치 해상도와 이미지 해상도는 각 체크포인트의 이름에 반영됩니다. 예를 들어, `google/vit-base-patch16-224`는 패치 해상도가 16x16이고 미세 조정 해상도가 224x224인 기본 크기 아키텍처를 나타냅니다. 모든 체크포인트는 [hub](https://huggingface.co/models?search=vit)에서 확인할 수 있습니다.
+- 사용할 수 있는 체크포인트는 (1) [ImageNet-21k](http://www.image-net.org/) (1,400만 개의 이미지와 21,000개의 클래스)에서만 사전 학습되었거나, 또는 (2) [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/) (ILSVRC 2012, 130만 개의 이미지와 1,000개의 클래스)에서 추가로 미세 조정된 경우입니다.
+- Vision Transformer는 224x224 해상도로 사전 학습되었습니다. 미세 조정 시, 사전 학습보다 더 높은 해상도를 사용하는 것이 유리한 경우가 많습니다 ([(Touvron et al., 2019)](https://arxiv.org/abs/1906.06423), [(Kolesnikovet al., 2020)](https://arxiv.org/abs/1912.11370). 더 높은 해상도로 미세 조정하기 위해, 저자들은 원본 이미지에서의 위치에 따라 사전 학습된 위치 임베딩의 2D 보간(interpolation)을 수행합니다.
+- 최고의 결과는 supervised 방식의 사전 학습에서 얻어졌으며, 이는 NLP에서는 해당되지 않는 경우가 많습니다. 저자들은 마스크된 패치 예측(마스크된 언어 모델링에서 영감을 받은 self-supervised 사전 학습 목표)을 사용한 실험도 수행했습니다. 이 접근 방식으로 더 작은 ViT-B/16 모델은 ImageNet에서 79.9%의 정확도를 달성하였으며, 이는 처음부터 학습한 것보다 2% 개선된 결과이지만, 여전히 supervised 사전 학습보다 4% 낮습니다.
+
+### Scaled Dot Product Attention (SDPA) 사용하기 [[using-scaled-dot-product-attention-sdpa]]
+
+PyTorch는 `torch.nn.functional`의 일부로서 native scaled dot-product attention (SDPA) 연산자를 포함하고 있습니다. 이 함수는 입력 및 사용 중인 하드웨어에 따라 여러 구현 방식을 적용할 수 있습니다.자세한 내용은 [공식 문서](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)나 [GPU 추론](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention) 페이지를 참조하십시오.
+
+SDPA는 `torch>=2.1.1`에서 구현이 가능한 경우 기본적으로 사용되지만, `from_pretrained()`에서 `attn_implementation="sdpa"`로 설정하여 SDPA를 명시적으로 요청할 수도 있습니다.
+
+```
+from transformers import ViTForImageClassification
+model = ViTForImageClassification.from_pretrained("google/vit-base-patch16-224", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+최적의 속도 향상을 위해 모델을 반정밀도(예: `torch.float16` 또는 `torch.bfloat16`)로 로드하는 것을 권장합니다.
+
+로컬 벤치마크(A100-40GB, PyTorch 2.3.0, OS Ubuntu 22.04)에서 `float32`와 `google/vit-base-patch16-224` 모델을 사용한 추론 시, 다음과 같은 속도 향상을 확인했습니다.
+
+| Batch size | Average inference time (ms), eager mode | Average inference time (ms), sdpa model | Speed up, Sdpa / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 7 | 6 | 1.17 |
+| 2 | 8 | 6 | 1.33 |
+| 4 | 8 | 6 | 1.33 |
+| 8 | 8 | 6 | 1.33 |
+
+## 리소스 [[resources]]
+
+ViT의 추론 및 커스텀 데이터에 대한 미세 조정과 관련된 데모 노트북은 [여기](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer)에서 확인할 수 있습니다. Hugging Face에서 공식적으로 제공하는 자료와 커뮤니티(🌎로 표시된) 자료 목록은 ViT를 시작하는 데 도움이 될 것입니다. 이 목록에 포함될 자료를 제출하고 싶다면 Pull Request를 열어 주시면 검토하겠습니다. 새로운 내용을 설명하는 자료가 가장 이상적이며, 기존 자료를 중복하지 않도록 해주십시오.
+
+`ViTForImageClassification` 은 다음에서 지원됩니다:
+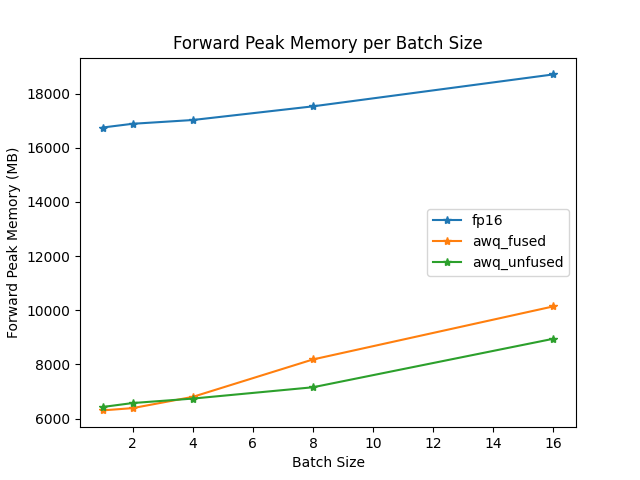 +
+ 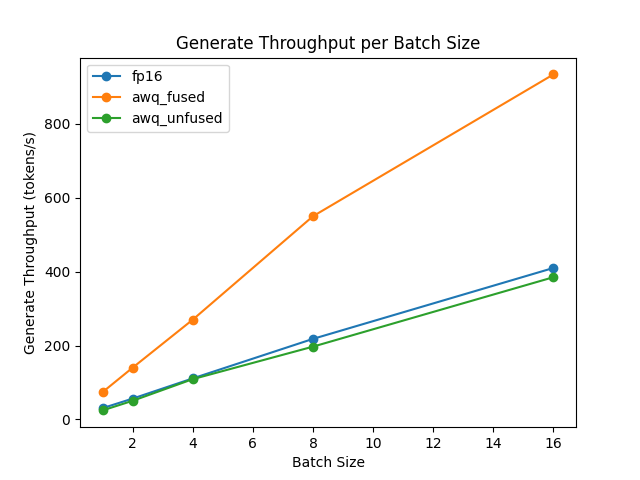 +
+ 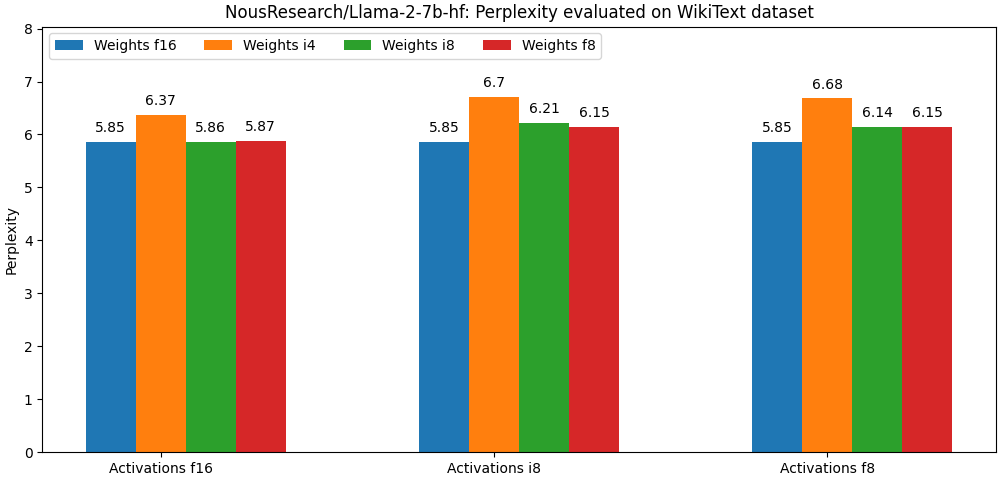 +
+ 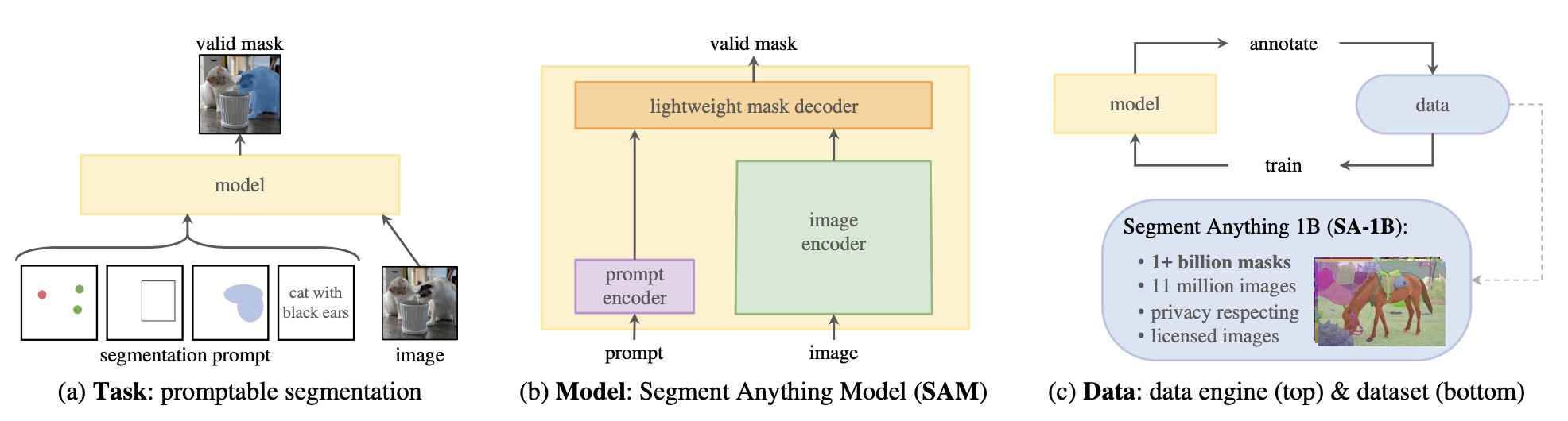 +
+ +
+ +
+ +
+ +
+ +
+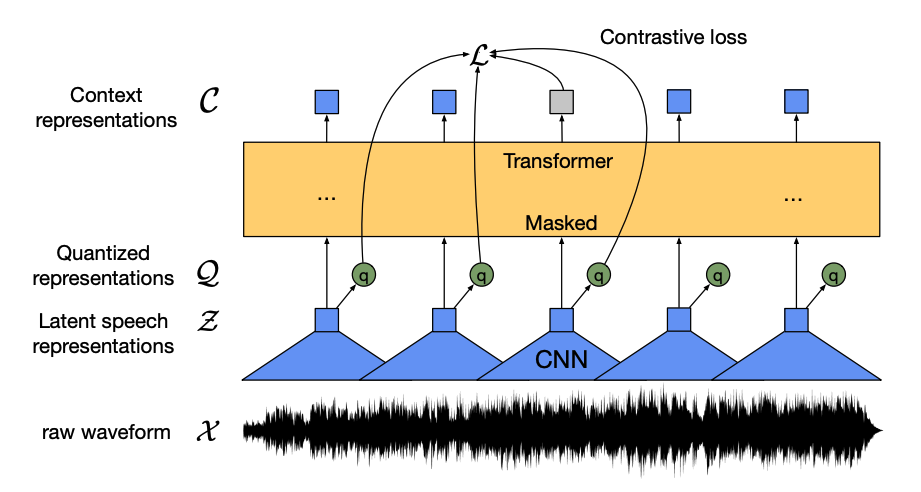 +
+ +
+ +
+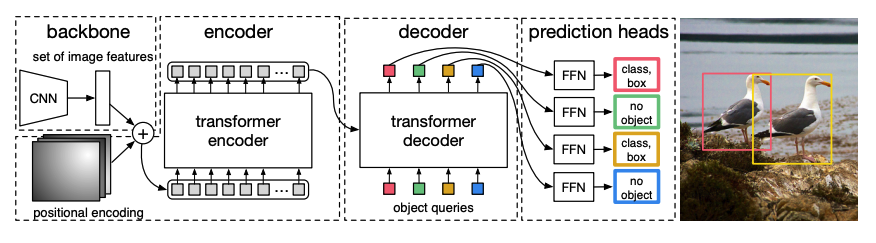 +
+ +
+ +
+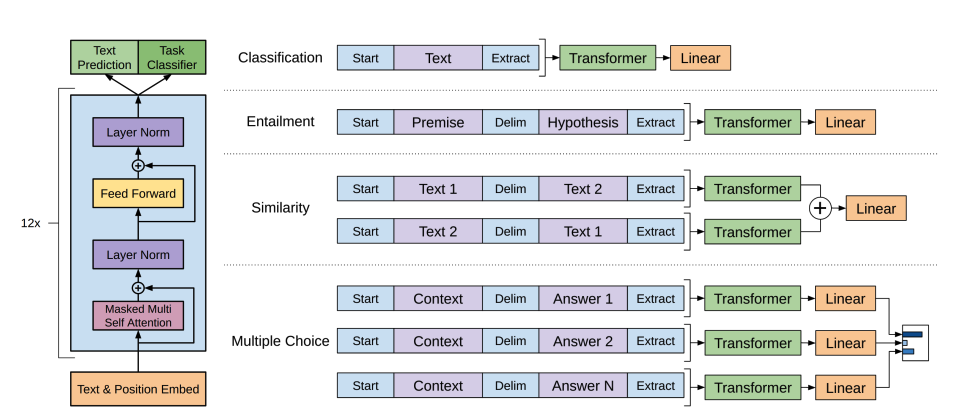 +
+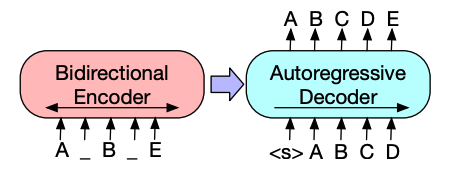 +
+ +
+
+## Conteúdo
+
+A documentação é dividida em cinco partes:
+ - **INÍCIO** contém um tour rápido de instalação e instruções para te dar um empurrão inicial com os 🤗 Transformers.
+ - **TUTORIAIS** são perfeitos para começar a aprender sobre a nossa biblioteca. Essa seção irá te ajudar a desenvolver
+ habilidades básicas necessárias para usar o 🤗 Transformers.
+ - **GUIAS PRÁTICOS** irão te mostrar como alcançar um certo objetivo, como o fine-tuning de um modelo pré-treinado
+ para modelamento de idioma, ou como criar um cabeçalho personalizado para um modelo.
+ - **GUIAS CONCEITUAIS** te darão mais discussões e explicações dos conceitos fundamentais e idéias por trás dos modelos,
+ tarefas e da filosofia de design por trás do 🤗 Transformers.
+ - **API** descreve o funcionamento de cada classe e função, agrupada em:
+
+ - **CLASSES PRINCIPAIS** para as classes que expõe as APIs importantes da biblioteca.
+ - **MODELOS** para as classes e funções relacionadas à cada modelo implementado na biblioteca.
+ - **AUXILIARES INTERNOS** para as classes e funções usadas internamente.
+
+Atualmente a biblioteca contém implementações do PyTorch, TensorFlow e JAX, pesos para modelos pré-treinados e scripts de uso e conversão de utilidades para os seguintes modelos:
+
+### Modelos atuais
+
+
+
+1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
+1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
+1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
+1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
+1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
+1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
+1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
+1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[MBart](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[MBart-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBert](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+
+
+### Frameworks aceitos
+
+A tabela abaixo representa a lista de suporte na biblioteca para cada um dos seguintes modelos, caso tenham um tokenizer
+do Python (chamado de "slow"), ou um tokenizer construído em cima da biblioteca 🤗 Tokenizers (chamado de "fast"). Além
+disso, são diferenciados pelo suporte em diferentes frameworks: JAX (por meio do Flax); PyTorch; e/ou Tensorflow.
+
+
+
+| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
+|:---------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
+| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
+| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
+| BigBirdPegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
+| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Canine | ✅ | ❌ | ✅ | ❌ | ❌ |
+| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
+| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ConvNext | ❌ | ❌ | ✅ | ✅ | ❌ |
+| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecVision | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DeiT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
+| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
+| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
+| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
+| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
+| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
+| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| MegatronBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| mT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Nystromformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Realm | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
+| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ResNet | ❌ | ❌ | ✅ | ❌ | ✅ |
+| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
+| SegFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
+| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
+| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Swin | ❌ | ❌ | ✅ | ❌ | ❌ |
+| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
+| TAPEX | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| VisualBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
+| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XGLM | ✅ | ✅ | ✅ | ❌ | ✅ |
+| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XLMProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/transformers/docs/source/pt/installation.md b/docs/transformers/docs/source/pt/installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..f548736589ac0d81bc7ebe2d73d60652ce03040b
--- /dev/null
+++ b/docs/transformers/docs/source/pt/installation.md
@@ -0,0 +1,262 @@
+
+
+# Guia de Instalação
+
+Neste guia poderá encontrar informações para a instalação do 🤗 Transformers para qualquer biblioteca de
+Machine Learning com a qual esteja a trabalhar. Além disso, poderá encontrar informações sobre como gerar cachês e
+configurar o 🤗 Transformers para execução em modo offline (opcional).
+
+🤗 Transformers foi testado com Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, e Flax. Para instalar a biblioteca de
+deep learning com que deseja trabalhar, siga as instruções correspondentes listadas a seguir:
+
+* [PyTorch](https://pytorch.org/get-started/locally/)
+* [TensorFlow 2.0](https://www.tensorflow.org/install/pip)
+* [Flax](https://flax.readthedocs.io/en/latest/)
+
+## Instalação pelo Pip
+
+É sugerido instalar o 🤗 Transformers num [ambiente virtual](https://docs.python.org/3/library/venv.html). Se precisar
+de mais informações sobre ambientes virtuais em Python, consulte este [guia](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+Um ambiente virtual facilitará a manipulação e organização de projetos e evita problemas de compatibilidade entre dependências.
+
+Comece criando um ambiente virtual no diretório do seu projeto:
+
+```bash
+python -m venv .env
+```
+
+E para ativar o ambiente virtual:
+
+```bash
+source .env/bin/activate
+```
+
+Agora É possível instalar o 🤗 Transformers com o comando a seguir:
+
+```bash
+pip install transformers
+```
+
+Somente para a CPU, é possível instalar o 🤗 Transformers e a biblioteca de deep learning respectiva apenas numa linha.
+
+Por exemplo, para instalar o 🤗 Transformers e o PyTorch, digite:
+
+```bash
+pip install transformers[torch]
+```
+
+🤗 Transformers e TensorFlow 2.0:
+
+```bash
+pip install transformers[tf-cpu]
+```
+
+🤗 Transformers e Flax:
+
+```bash
+pip install transformers[flax]
+```
+
+Por último, verifique se o 🤗 Transformers foi instalado com sucesso usando o seguinte comando para baixar um modelo pré-treinado:
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
+```
+
+Em seguida, imprima um rótulo e sua pontuação:
+
+```bash
+[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
+```
+
+## Instalação usando a fonte
+
+Para instalar o 🤗 Transformers a partir da fonte use o seguinte comando:
+
+```bash
+pip install git+https://github.com/huggingface/transformers
+```
+
+O comando acima instalará a versão `master` mais atual em vez da última versão estável. A versão `master` é útil para
+utilizar os últimos updates contidos em 🤗 Transformers. Por exemplo, um erro recente pode ter sido corrigido somente
+após a última versão estável, antes que houvesse um novo lançamento. No entanto, há a possibilidade que a versão `master` não esteja estável.
+A equipa trata de mantér a versão `master` operacional e a maioria dos erros são resolvidos em poucas horas ou dias.
+Se encontrar quaisquer problemas, por favor abra um [Issue](https://github.com/huggingface/transformers/issues) para que o
+mesmo possa ser corrigido o mais rápido possível.
+
+Verifique que o 🤗 Transformers está instalado corretamente usando o seguinte comando:
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
+```
+
+## Instalação editável
+
+Uma instalação editável será necessária caso desejas um dos seguintes:
+* Usar a versão `master` do código fonte.
+* Contribuir ao 🤗 Transformers e precisa testar mudanças ao código.
+
+Para tal, clone o repositório e instale o 🤗 Transformers com os seguintes comandos:
+
+```bash
+git clone https://github.com/huggingface/transformers.git
+cd transformers
+pip install -e .
+```
+
+Estes comandos vão ligar o diretório para o qual foi clonado o repositório ao caminho de bibliotecas do Python.
+O Python agora buscará dentro dos arquivos que foram clonados além dos caminhos normais da biblioteca.
+Por exemplo, se os pacotes do Python se encontram instalados no caminho `~/anaconda3/envs/main/lib/python3.7/site-packages/`,
+o Python também buscará módulos no diretório onde clonamos o repositório `~/transformers/`.
+
+
+
+
+## Conteúdo
+
+A documentação é dividida em cinco partes:
+ - **INÍCIO** contém um tour rápido de instalação e instruções para te dar um empurrão inicial com os 🤗 Transformers.
+ - **TUTORIAIS** são perfeitos para começar a aprender sobre a nossa biblioteca. Essa seção irá te ajudar a desenvolver
+ habilidades básicas necessárias para usar o 🤗 Transformers.
+ - **GUIAS PRÁTICOS** irão te mostrar como alcançar um certo objetivo, como o fine-tuning de um modelo pré-treinado
+ para modelamento de idioma, ou como criar um cabeçalho personalizado para um modelo.
+ - **GUIAS CONCEITUAIS** te darão mais discussões e explicações dos conceitos fundamentais e idéias por trás dos modelos,
+ tarefas e da filosofia de design por trás do 🤗 Transformers.
+ - **API** descreve o funcionamento de cada classe e função, agrupada em:
+
+ - **CLASSES PRINCIPAIS** para as classes que expõe as APIs importantes da biblioteca.
+ - **MODELOS** para as classes e funções relacionadas à cada modelo implementado na biblioteca.
+ - **AUXILIARES INTERNOS** para as classes e funções usadas internamente.
+
+Atualmente a biblioteca contém implementações do PyTorch, TensorFlow e JAX, pesos para modelos pré-treinados e scripts de uso e conversão de utilidades para os seguintes modelos:
+
+### Modelos atuais
+
+
+
+1. **[ALBERT](model_doc/albert)** (from Google Research and the Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.
+1. **[BART](model_doc/bart)** (from Facebook) released with the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer.
+1. **[BARThez](model_doc/barthez)** (from École polytechnique) released with the paper [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis.
+1. **[BARTpho](model_doc/bartpho)** (from VinAI Research) released with the paper [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese](https://arxiv.org/abs/2109.09701) by Nguyen Luong Tran, Duong Minh Le and Dat Quoc Nguyen.
+1. **[BEiT](model_doc/beit)** (from Microsoft) released with the paper [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong, Furu Wei.
+1. **[BERT](model_doc/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.
+1. **[BERTweet](model_doc/bertweet)** (from VinAI Research) released with the paper [BERTweet: A pre-trained language model for English Tweets](https://aclanthology.org/2020.emnlp-demos.2/) by Dat Quoc Nguyen, Thanh Vu and Anh Tuan Nguyen.
+1. **[BERT For Sequence Generation](model_doc/bert-generation)** (from Google) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[BigBird-RoBERTa](model_doc/big_bird)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[BigBird-Pegasus](model_doc/bigbird_pegasus)** (from Google Research) released with the paper [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, Amr Ahmed.
+1. **[Blenderbot](model_doc/blenderbot)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BlenderbotSmall](model_doc/blenderbot-small)** (from Facebook) released with the paper [Recipes for building an open-domain chatbot](https://arxiv.org/abs/2004.13637) by Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston.
+1. **[BORT](model_doc/bort)** (from Alexa) released with the paper [Optimal Subarchitecture Extraction For BERT](https://arxiv.org/abs/2010.10499) by Adrian de Wynter and Daniel J. Perry.
+1. **[ByT5](model_doc/byt5)** (from Google Research) released with the paper [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626) by Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel.
+1. **[CamemBERT](model_doc/camembert)** (from Inria/Facebook/Sorbonne) released with the paper [CamemBERT: a Tasty French Language Model](https://arxiv.org/abs/1911.03894) by Louis Martin*, Benjamin Muller*, Pedro Javier Ortiz Suárez*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
+1. **[CANINE](model_doc/canine)** (from Google Research) released with the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) by Jonathan H. Clark, Dan Garrette, Iulia Turc, John Wieting.
+1. **[ConvNeXT](model_doc/convnext)** (from Facebook AI) released with the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
+1. **[ConvNeXTV2](model_doc/convnextv2)** (from Facebook AI) released with the paper [ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808) by Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, Saining Xie.
+1. **[CLIP](model_doc/clip)** (from OpenAI) released with the paper [Learning Transferable Visual Models From Natural Language Supervision](https://arxiv.org/abs/2103.00020) by Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever.
+1. **[ConvBERT](model_doc/convbert)** (from YituTech) released with the paper [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) by Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+1. **[CPM](model_doc/cpm)** (from Tsinghua University) released with the paper [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) by Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, Fanchao Qi, Xiaozhi Wang, Yanan Zheng, Guoyang Zeng, Huanqi Cao, Shengqi Chen, Daixuan Li, Zhenbo Sun, Zhiyuan Liu, Minlie Huang, Wentao Han, Jie Tang, Juanzi Li, Xiaoyan Zhu, Maosong Sun.
+1. **[CTRL](model_doc/ctrl)** (from Salesforce) released with the paper [CTRL: A Conditional Transformer Language Model for Controllable Generation](https://arxiv.org/abs/1909.05858) by Nitish Shirish Keskar*, Bryan McCann*, Lav R. Varshney, Caiming Xiong and Richard Socher.
+1. **[Data2Vec](model_doc/data2vec)** (from Facebook) released with the paper [Data2Vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/abs/2202.03555) by Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli.
+1. **[DeBERTa](model_doc/deberta)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[DeBERTa-v2](model_doc/deberta-v2)** (from Microsoft) released with the paper [DeBERTa: Decoding-enhanced BERT with Disentangled Attention](https://arxiv.org/abs/2006.03654) by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen.
+1. **[Decision Transformer](model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
+1. **[DiT](model_doc/dit)** (from Microsoft Research) released with the paper [DiT: Self-supervised Pre-training for Document Image Transformer](https://arxiv.org/abs/2203.02378) by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei.
+1. **[DeiT](model_doc/deit)** (from Facebook) released with the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou.
+1. **[DETR](model_doc/detr)** (from Facebook) released with the paper [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872) by Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko.
+1. **[DialoGPT](model_doc/dialogpt)** (from Microsoft Research) released with the paper [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan.
+1. **[DistilBERT](model_doc/distilbert)** (from HuggingFace), released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same method has been applied to compress GPT2 into [DistilGPT2](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), RoBERTa into [DistilRoBERTa](https://github.com/huggingface/transformers-research-projects/tree/main/distillation), Multilingual BERT into [DistilmBERT](https://github.com/huggingface/transformers-research-projects/tree/main/distillation) and a German version of DistilBERT.
+1. **[DPR](model_doc/dpr)** (from Facebook) released with the paper [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih.
+1. **[DPT](master/model_doc/dpt)** (from Intel Labs) released with the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun.
+1. **[EfficientNet](model_doc/efficientnet)** (from Google Research) released with the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le.
+1. **[EncoderDecoder](model_doc/encoder-decoder)** (from Google Research) released with the paper [Leveraging Pre-trained Checkpoints for Sequence Generation Tasks](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn.
+1. **[ELECTRA](model_doc/electra)** (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning.
+1. **[FlauBERT](model_doc/flaubert)** (from CNRS) released with the paper [FlauBERT: Unsupervised Language Model Pre-training for French](https://arxiv.org/abs/1912.05372) by Hang Le, Loïc Vial, Jibril Frej, Vincent Segonne, Maximin Coavoux, Benjamin Lecouteux, Alexandre Allauzen, Benoît Crabbé, Laurent Besacier, Didier Schwab.
+1. **[FNet](model_doc/fnet)** (from Google Research) released with the paper [FNet: Mixing Tokens with Fourier Transforms](https://arxiv.org/abs/2105.03824) by James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, Santiago Ontanon.
+1. **[Funnel Transformer](model_doc/funnel)** (from CMU/Google Brain) released with the paper [Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing](https://arxiv.org/abs/2006.03236) by Zihang Dai, Guokun Lai, Yiming Yang, Quoc V. Le.
+1. **[GLPN](model_doc/glpn)** (from KAIST) released with the paper [Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth](https://arxiv.org/abs/2201.07436) by Doyeon Kim, Woonghyun Ga, Pyungwhan Ahn, Donggyu Joo, Sehwan Chun, Junmo Kim.
+1. **[GPT](model_doc/openai-gpt)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://openai.com/research/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.
+1. **[GPT-2](model_doc/gpt2)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://openai.com/research/better-language-models/) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
+1. **[GPT-J](model_doc/gptj)** (from EleutherAI) released in the repository [kingoflolz/mesh-transformer-jax](https://github.com/kingoflolz/mesh-transformer-jax/) by Ben Wang and Aran Komatsuzaki.
+1. **[GPT Neo](model_doc/gpt_neo)** (from EleutherAI) released in the repository [EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo) by Sid Black, Stella Biderman, Leo Gao, Phil Wang and Connor Leahy.
+1. **[GPTSAN-japanese](model_doc/gptsan-japanese)** released in the repository [tanreinama/GPTSAN](https://github.com/tanreinama/GPTSAN/blob/main/report/model.md) by Toshiyuki Sakamoto(tanreinama).
+1. **[Hubert](model_doc/hubert)** (from Facebook) released with the paper [HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units](https://arxiv.org/abs/2106.07447) by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
+1. **[I-BERT](model_doc/ibert)** (from Berkeley) released with the paper [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer.
+1. **[ImageGPT](model_doc/imagegpt)** (from OpenAI) released with the paper [Generative Pretraining from Pixels](https://openai.com/blog/image-gpt/) by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever.
+1. **[LayoutLM](model_doc/layoutlm)** (from Microsoft Research Asia) released with the paper [LayoutLM: Pre-training of Text and Layout for Document Image Understanding](https://arxiv.org/abs/1912.13318) by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou.
+1. **[LayoutLMv2](model_doc/layoutlmv2)** (from Microsoft Research Asia) released with the paper [LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding](https://arxiv.org/abs/2012.14740) by Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, Lidong Zhou.
+1. **[LayoutXLM](model_doc/layoutxlm)** (from Microsoft Research Asia) released with the paper [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
+1. **[LED](model_doc/led)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[Longformer](model_doc/longformer)** (from AllenAI) released with the paper [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
+1. **[LUKE](model_doc/luke)** (from Studio Ousia) released with the paper [LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention](https://arxiv.org/abs/2010.01057) by Ikuya Yamada, Akari Asai, Hiroyuki Shindo, Hideaki Takeda, Yuji Matsumoto.
+1. **[mLUKE](model_doc/mluke)** (from Studio Ousia) released with the paper [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka.
+1. **[LXMERT](model_doc/lxmert)** (from UNC Chapel Hill) released with the paper [LXMERT: Learning Cross-Modality Encoder Representations from Transformers for Open-Domain Question Answering](https://arxiv.org/abs/1908.07490) by Hao Tan and Mohit Bansal.
+1. **[M2M100](model_doc/m2m_100)** (from Facebook) released with the paper [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
+1. **[MarianMT](model_doc/marian)** Machine translation models trained using [OPUS](http://opus.nlpl.eu/) data by Jörg Tiedemann. The [Marian Framework](https://marian-nmt.github.io/) is being developed by the Microsoft Translator Team.
+1. **[Mask2Former](model_doc/mask2former)** (from FAIR and UIUC) released with the paper [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) by Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar.
+1. **[MaskFormer](model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
+1. **[MBart](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Denoising Pre-training for Neural Machine Translation](https://arxiv.org/abs/2001.08210) by Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, Luke Zettlemoyer.
+1. **[MBart-50](model_doc/mbart)** (from Facebook) released with the paper [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) by Yuqing Tang, Chau Tran, Xian Li, Peng-Jen Chen, Naman Goyal, Vishrav Chaudhary, Jiatao Gu, Angela Fan.
+1. **[Megatron-BERT](model_doc/megatron-bert)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[Megatron-GPT2](model_doc/megatron_gpt2)** (from NVIDIA) released with the paper [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper and Bryan Catanzaro.
+1. **[MPNet](model_doc/mpnet)** (from Microsoft Research) released with the paper [MPNet: Masked and Permuted Pre-training for Language Understanding](https://arxiv.org/abs/2004.09297) by Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu.
+1. **[MT5](model_doc/mt5)** (from Google AI) released with the paper [mT5: A massively multilingual pre-trained text-to-text transformer](https://arxiv.org/abs/2010.11934) by Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, Colin Raffel.
+1. **[Nyströmformer](model_doc/nystromformer)** (from the University of Wisconsin - Madison) released with the paper [Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention](https://arxiv.org/abs/2102.03902) by Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, Vikas Singh.
+1. **[OneFormer](model_doc/oneformer)** (from SHI Labs) released with the paper [OneFormer: One Transformer to Rule Universal Image Segmentation](https://arxiv.org/abs/2211.06220) by Jitesh Jain, Jiachen Li, MangTik Chiu, Ali Hassani, Nikita Orlov, Humphrey Shi.
+1. **[Pegasus](model_doc/pegasus)** (from Google) released with the paper [PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization](https://arxiv.org/abs/1912.08777) by Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu.
+1. **[Perceiver IO](model_doc/perceiver)** (from Deepmind) released with the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff, Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira.
+1. **[PhoBERT](model_doc/phobert)** (from VinAI Research) released with the paper [PhoBERT: Pre-trained language models for Vietnamese](https://www.aclweb.org/anthology/2020.findings-emnlp.92/) by Dat Quoc Nguyen and Anh Tuan Nguyen.
+1. **[PLBart](model_doc/plbart)** (from UCLA NLP) released with the paper [Unified Pre-training for Program Understanding and Generation](https://arxiv.org/abs/2103.06333) by Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, Kai-Wei Chang.
+1. **[PoolFormer](model_doc/poolformer)** (from Sea AI Labs) released with the paper [MetaFormer is Actually What You Need for Vision](https://arxiv.org/abs/2111.11418) by Yu, Weihao and Luo, Mi and Zhou, Pan and Si, Chenyang and Zhou, Yichen and Wang, Xinchao and Feng, Jiashi and Yan, Shuicheng.
+1. **[ProphetNet](model_doc/prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[QDQBert](model_doc/qdqbert)** (from NVIDIA) released with the paper [Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation](https://arxiv.org/abs/2004.09602) by Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius.
+1. **[REALM](model_doc/realm.html)** (from Google Research) released with the paper [REALM: Retrieval-Augmented Language Model Pre-Training](https://arxiv.org/abs/2002.08909) by Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat and Ming-Wei Chang.
+1. **[Reformer](model_doc/reformer)** (from Google Research) released with the paper [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya.
+1. **[RemBERT](model_doc/rembert)** (from Google Research) released with the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821) by Hyung Won Chung, Thibault Févry, Henry Tsai, M. Johnson, Sebastian Ruder.
+1. **[RegNet](model_doc/regnet)** (from META Platforms) released with the paper [Designing Network Design Space](https://arxiv.org/abs/2003.13678) by Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár.
+1. **[ResNet](model_doc/resnet)** (from Microsoft Research) released with the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun.
+1. **[RoBERTa](model_doc/roberta)** (from Facebook), released together with the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.
+1. **[RoFormer](model_doc/roformer)** (from ZhuiyiTechnology), released together with the paper [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/abs/2104.09864) by Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu.
+1. **[SegFormer](model_doc/segformer)** (from NVIDIA) released with the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo.
+1. **[SEW](model_doc/sew)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SEW-D](model_doc/sew_d)** (from ASAPP) released with the paper [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870) by Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi.
+1. **[SpeechToTextTransformer](model_doc/speech_to_text)** (from Facebook), released together with the paper [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino.
+1. **[SpeechToTextTransformer2](model_doc/speech_to_text_2)** (from Facebook), released together with the paper [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) by Changhan Wang, Anne Wu, Juan Pino, Alexei Baevski, Michael Auli, Alexis Conneau.
+1. **[Splinter](model_doc/splinter)** (from Tel Aviv University), released together with the paper [Few-Shot Question Answering by Pretraining Span Selection](https://arxiv.org/abs/2101.00438) by Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy.
+1. **[SqueezeBert](model_doc/squeezebert)** (from Berkeley) released with the paper [SqueezeBERT: What can computer vision teach NLP about efficient neural networks?](https://arxiv.org/abs/2006.11316) by Forrest N. Iandola, Albert E. Shaw, Ravi Krishna, and Kurt W. Keutzer.
+1. **[Swin Transformer](model_doc/swin)** (from Microsoft) released with the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+1. **[T5](model_doc/t5)** (from Google AI) released with the paper [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/abs/1910.10683) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[T5v1.1](model_doc/t5v1.1)** (from Google AI) released in the repository [google-research/text-to-text-transfer-transformer](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#t511) by Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu.
+1. **[TAPAS](model_doc/tapas)** (from Google AI) released with the paper [TAPAS: Weakly Supervised Table Parsing via Pre-training](https://arxiv.org/abs/2004.02349) by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos.
+1. **[TAPEX](model_doc/tapex)** (from Microsoft Research) released with the paper [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou.
+1. **[Transformer-XL](model_doc/transfo-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
+1. **[TrOCR](model_doc/trocr)** (from Microsoft), released together with the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, Furu Wei.
+1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
+1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
+1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
+1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
+1. **[ViTMAE](model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
+1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
+1. **[WavLM](model_doc/wavlm)** (from Microsoft Research) released with the paper [WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900) by Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei.
+1. **[Wav2Vec2](model_doc/wav2vec2)** (from Facebook AI) released with the paper [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
+1. **[Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme)** (from Facebook AI) released with the paper [Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680) by Qiantong Xu, Alexei Baevski, Michael Auli.
+1. **[XGLM](model_doc/xglm)** (From Facebook AI) released with the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li.
+1. **[XLM](model_doc/xlm)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.
+1. **[XLM-ProphetNet](model_doc/xlm-prophetnet)** (from Microsoft Research) released with the paper [ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training](https://arxiv.org/abs/2001.04063) by Yu Yan, Weizhen Qi, Yeyun Gong, Dayiheng Liu, Nan Duan, Jiusheng Chen, Ruofei Zhang and Ming Zhou.
+1. **[XLM-RoBERTa](model_doc/xlm-roberta)** (from Facebook AI), released together with the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau*, Kartikay Khandelwal*, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov.
+1. **[XLM-RoBERTa-XL](model_doc/xlm-roberta-xl)** (from Facebook AI), released together with the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau.
+1. **[XLNet](model_doc/xlnet)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.
+1. **[XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2)** (from Facebook AI) released with the paper [Unsupervised Cross-Lingual Representation Learning For Speech Recognition](https://arxiv.org/abs/2006.13979) by Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli.
+1. **[XLS-R](model_doc/xls_r)** (from Facebook AI) released with the paper [XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale](https://arxiv.org/abs/2111.09296) by Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli.
+1. **[YOSO](model_doc/yoso)** (from the University of Wisconsin - Madison) released with the paper [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
+
+
+### Frameworks aceitos
+
+A tabela abaixo representa a lista de suporte na biblioteca para cada um dos seguintes modelos, caso tenham um tokenizer
+do Python (chamado de "slow"), ou um tokenizer construído em cima da biblioteca 🤗 Tokenizers (chamado de "fast"). Além
+disso, são diferenciados pelo suporte em diferentes frameworks: JAX (por meio do Flax); PyTorch; e/ou Tensorflow.
+
+
+
+| Model | Tokenizer slow | Tokenizer fast | PyTorch support | TensorFlow support | Flax Support |
+|:---------------------------:|:--------------:|:--------------:|:---------------:|:------------------:|:------------:|
+| ALBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BEiT | ❌ | ❌ | ✅ | ❌ | ✅ |
+| BERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Bert Generation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
+| BigBirdPegasus | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Blenderbot | ✅ | ✅ | ✅ | ✅ | ✅ |
+| BlenderbotSmall | ✅ | ✅ | ✅ | ✅ | ✅ |
+| CamemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Canine | ✅ | ❌ | ✅ | ❌ | ❌ |
+| CLIP | ✅ | ✅ | ✅ | ✅ | ✅ |
+| ConvBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ConvNext | ❌ | ❌ | ✅ | ✅ | ❌ |
+| CTRL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Data2VecAudio | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecText | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Data2VecVision | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DeBERTa | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DeBERTa-v2 | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Decision Transformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DeiT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DETR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| DistilBERT | ✅ | ✅ | ✅ | ✅ | ✅ |
+| DPR | ✅ | ✅ | ✅ | ✅ | ❌ |
+| DPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ELECTRA | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| FairSeq Machine-Translation | ✅ | ❌ | ✅ | ❌ | ❌ |
+| FlauBERT | ✅ | ❌ | ✅ | ✅ | ❌ |
+| FNet | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Funnel Transformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| GLPN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| GPT Neo | ❌ | ❌ | ✅ | ❌ | ✅ |
+| GPT-J | ❌ | ❌ | ✅ | ✅ | ✅ |
+| Hubert | ❌ | ❌ | ✅ | ✅ | ❌ |
+| I-BERT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ImageGPT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| LayoutLM | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LayoutLMv2 | ✅ | ✅ | ✅ | ❌ | ❌ |
+| LED | ✅ | ✅ | ✅ | ✅ | ❌ |
+| Longformer | ✅ | ✅ | ✅ | ✅ | ❌ |
+| LUKE | ✅ | ❌ | ✅ | ❌ | ❌ |
+| LXMERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| M2M100 | ✅ | ❌ | ✅ | ❌ | ❌ |
+| Marian | ✅ | ❌ | ✅ | ✅ | ✅ |
+| MaskFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| mBART | ✅ | ✅ | ✅ | ✅ | ✅ |
+| MegatronBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| MobileBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| MPNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| mT5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Nystromformer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| OpenAI GPT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| OpenAI GPT-2 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Pegasus | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Perceiver | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PLBart | ✅ | ❌ | ✅ | ❌ | ❌ |
+| PoolFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| QDQBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| RAG | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Realm | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Reformer | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RegNet | ❌ | ❌ | ✅ | ✅ | ✅ |
+| RemBERT | ✅ | ✅ | ✅ | ✅ | ❌ |
+| ResNet | ❌ | ❌ | ✅ | ❌ | ✅ |
+| RetriBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| RoFormer | ✅ | ✅ | ✅ | ✅ | ✅ |
+| SegFormer | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SEW | ❌ | ❌ | ✅ | ❌ | ❌ |
+| SEW-D | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Speech Encoder decoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| Speech2Text | ✅ | ❌ | ✅ | ✅ | ❌ |
+| Speech2Text2 | ✅ | ❌ | ❌ | ❌ | ❌ |
+| Splinter | ✅ | ✅ | ✅ | ❌ | ❌ |
+| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
+| Swin | ❌ | ❌ | ✅ | ❌ | ❌ |
+| T5 | ✅ | ✅ | ✅ | ✅ | ✅ |
+| TAPAS | ✅ | ❌ | ✅ | ✅ | ❌ |
+| TAPEX | ✅ | ✅ | ✅ | ✅ | ✅ |
+| Transformer-XL | ✅ | ❌ | ✅ | ✅ | ❌ |
+| TrOCR | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
+| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
+| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
+| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
+| VisualBert | ❌ | ❌ | ✅ | ❌ | ❌ |
+| ViT | ❌ | ❌ | ✅ | ✅ | ✅ |
+| ViTMAE | ❌ | ❌ | ✅ | ✅ | ❌ |
+| Wav2Vec2 | ✅ | ❌ | ✅ | ✅ | ✅ |
+| WavLM | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XGLM | ✅ | ✅ | ✅ | ❌ | ✅ |
+| XLM | ✅ | ❌ | ✅ | ✅ | ❌ |
+| XLM-RoBERTa | ✅ | ✅ | ✅ | ✅ | ✅ |
+| XLM-RoBERTa-XL | ❌ | ❌ | ✅ | ❌ | ❌ |
+| XLMProphetNet | ✅ | ❌ | ✅ | ❌ | ❌ |
+| XLNet | ✅ | ✅ | ✅ | ✅ | ❌ |
+| YOSO | ❌ | ❌ | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/transformers/docs/source/pt/installation.md b/docs/transformers/docs/source/pt/installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..f548736589ac0d81bc7ebe2d73d60652ce03040b
--- /dev/null
+++ b/docs/transformers/docs/source/pt/installation.md
@@ -0,0 +1,262 @@
+
+
+# Guia de Instalação
+
+Neste guia poderá encontrar informações para a instalação do 🤗 Transformers para qualquer biblioteca de
+Machine Learning com a qual esteja a trabalhar. Além disso, poderá encontrar informações sobre como gerar cachês e
+configurar o 🤗 Transformers para execução em modo offline (opcional).
+
+🤗 Transformers foi testado com Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, e Flax. Para instalar a biblioteca de
+deep learning com que deseja trabalhar, siga as instruções correspondentes listadas a seguir:
+
+* [PyTorch](https://pytorch.org/get-started/locally/)
+* [TensorFlow 2.0](https://www.tensorflow.org/install/pip)
+* [Flax](https://flax.readthedocs.io/en/latest/)
+
+## Instalação pelo Pip
+
+É sugerido instalar o 🤗 Transformers num [ambiente virtual](https://docs.python.org/3/library/venv.html). Se precisar
+de mais informações sobre ambientes virtuais em Python, consulte este [guia](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/).
+Um ambiente virtual facilitará a manipulação e organização de projetos e evita problemas de compatibilidade entre dependências.
+
+Comece criando um ambiente virtual no diretório do seu projeto:
+
+```bash
+python -m venv .env
+```
+
+E para ativar o ambiente virtual:
+
+```bash
+source .env/bin/activate
+```
+
+Agora É possível instalar o 🤗 Transformers com o comando a seguir:
+
+```bash
+pip install transformers
+```
+
+Somente para a CPU, é possível instalar o 🤗 Transformers e a biblioteca de deep learning respectiva apenas numa linha.
+
+Por exemplo, para instalar o 🤗 Transformers e o PyTorch, digite:
+
+```bash
+pip install transformers[torch]
+```
+
+🤗 Transformers e TensorFlow 2.0:
+
+```bash
+pip install transformers[tf-cpu]
+```
+
+🤗 Transformers e Flax:
+
+```bash
+pip install transformers[flax]
+```
+
+Por último, verifique se o 🤗 Transformers foi instalado com sucesso usando o seguinte comando para baixar um modelo pré-treinado:
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
+```
+
+Em seguida, imprima um rótulo e sua pontuação:
+
+```bash
+[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
+```
+
+## Instalação usando a fonte
+
+Para instalar o 🤗 Transformers a partir da fonte use o seguinte comando:
+
+```bash
+pip install git+https://github.com/huggingface/transformers
+```
+
+O comando acima instalará a versão `master` mais atual em vez da última versão estável. A versão `master` é útil para
+utilizar os últimos updates contidos em 🤗 Transformers. Por exemplo, um erro recente pode ter sido corrigido somente
+após a última versão estável, antes que houvesse um novo lançamento. No entanto, há a possibilidade que a versão `master` não esteja estável.
+A equipa trata de mantér a versão `master` operacional e a maioria dos erros são resolvidos em poucas horas ou dias.
+Se encontrar quaisquer problemas, por favor abra um [Issue](https://github.com/huggingface/transformers/issues) para que o
+mesmo possa ser corrigido o mais rápido possível.
+
+Verifique que o 🤗 Transformers está instalado corretamente usando o seguinte comando:
+
+```bash
+python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
+```
+
+## Instalação editável
+
+Uma instalação editável será necessária caso desejas um dos seguintes:
+* Usar a versão `master` do código fonte.
+* Contribuir ao 🤗 Transformers e precisa testar mudanças ao código.
+
+Para tal, clone o repositório e instale o 🤗 Transformers com os seguintes comandos:
+
+```bash
+git clone https://github.com/huggingface/transformers.git
+cd transformers
+pip install -e .
+```
+
+Estes comandos vão ligar o diretório para o qual foi clonado o repositório ao caminho de bibliotecas do Python.
+O Python agora buscará dentro dos arquivos que foram clonados além dos caminhos normais da biblioteca.
+Por exemplo, se os pacotes do Python se encontram instalados no caminho `~/anaconda3/envs/main/lib/python3.7/site-packages/`,
+o Python também buscará módulos no diretório onde clonamos o repositório `~/transformers/`.
+
+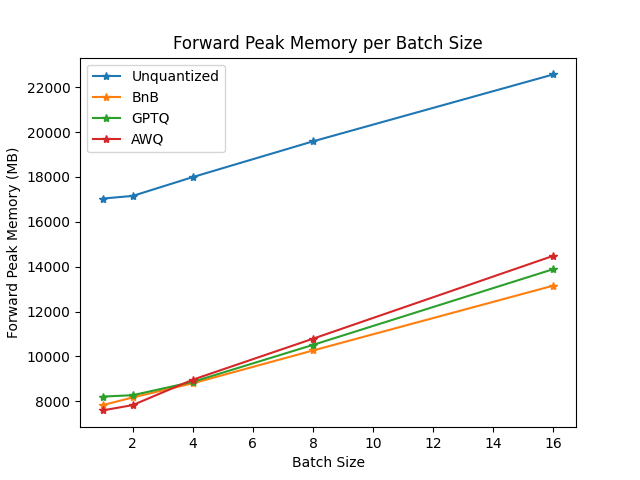 +
+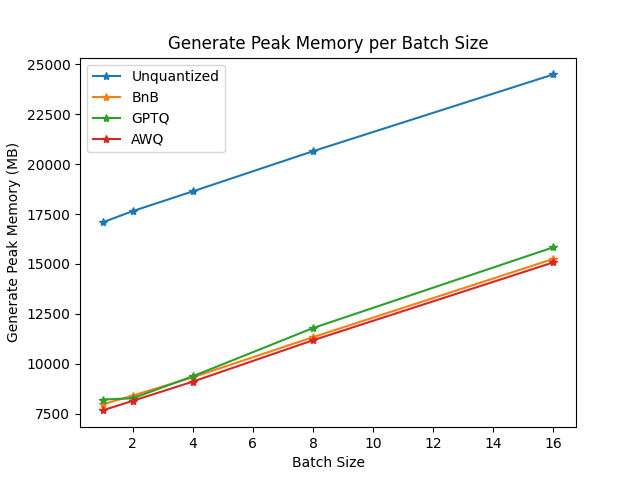 +
+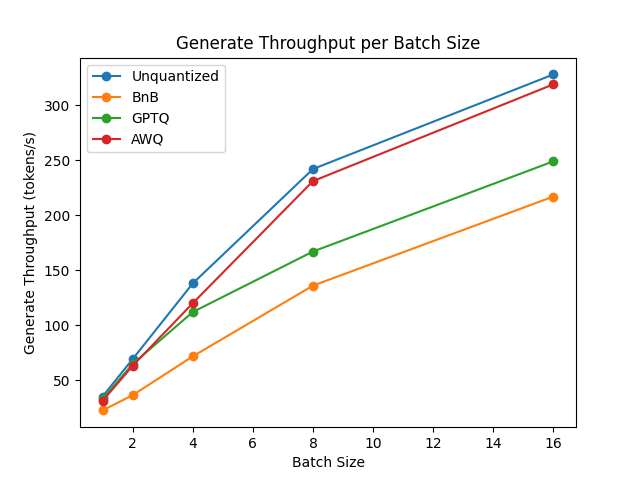 +
+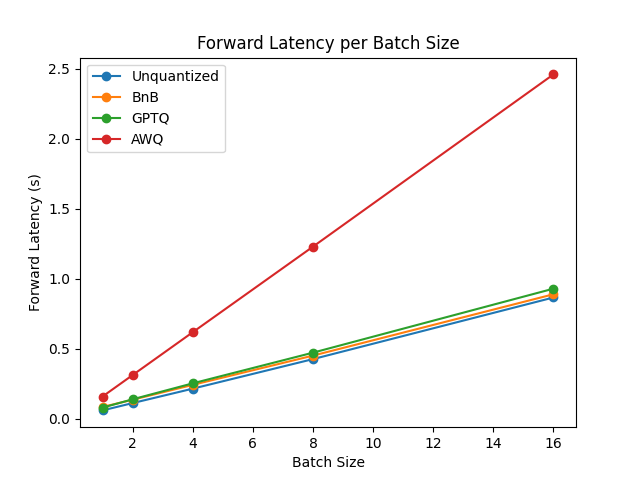 +
+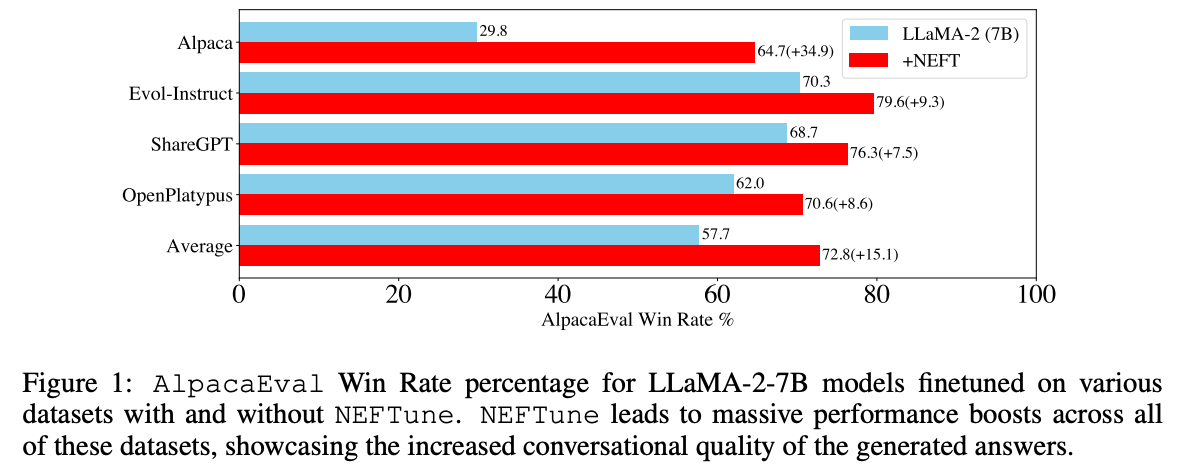 +
+ +
+ +
+Try out the inference widget here: https://huggingface.co/google/vit-base-patch16-224
+
+Content:
+- [PyTorch version, Trainer](#pytorch-version-trainer)
+- [PyTorch version, no Trainer](#pytorch-version-no-trainer)
+
+## PyTorch version, Trainer
+
+Based on the script [`run_image_classification.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/image-classification/run_image_classification.py).
+
+The script leverages the 🤗 [Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer) to automatically take care of the training for you, running on distributed environments right away.
+
+### Using datasets from Hub
+
+Here we show how to fine-tune a Vision Transformer (`ViT`) on the [beans](https://huggingface.co/datasets/beans) dataset, to classify the disease type of bean leaves.
+
+```bash
+python run_image_classification.py \
+ --dataset_name beans \
+ --output_dir ./beans_outputs/ \
+ --remove_unused_columns False \
+ --label_column_name labels \
+ --do_train \
+ --do_eval \
+ --push_to_hub \
+ --push_to_hub_model_id vit-base-beans \
+ --learning_rate 2e-5 \
+ --num_train_epochs 5 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+👀 See the results here: [nateraw/vit-base-beans](https://huggingface.co/nateraw/vit-base-beans).
+
+Note that you can replace the model and dataset by simply setting the `model_name_or_path` and `dataset_name` arguments respectively, with any model or dataset from the [hub](https://huggingface.co/). For an overview of all possible arguments, we refer to the [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) of the `TrainingArguments`, which can be passed as flags.
+
+> If your model classification head dimensions do not fit the number of labels in the dataset, you can specify `--ignore_mismatched_sizes` to adapt it.
+
+### Using your own data
+
+To use your own dataset, there are 2 ways:
+- you can either provide your own folders as `--train_dir` and/or `--validation_dir` arguments
+- you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
+
+Below, we explain both in more detail.
+
+#### Provide them as folders
+
+If you provide your own folders with images, the script expects the following directory structure:
+
+```bash
+root/dog/xxx.png
+root/dog/xxy.png
+root/dog/[...]/xxz.png
+
+root/cat/123.png
+root/cat/nsdf3.png
+root/cat/[...]/asd932_.png
+```
+
+In other words, you need to organize your images in subfolders, based on their class. You can then run the script like this:
+
+```bash
+python run_image_classification.py \
+ --train_dir
+
+Try out the inference widget here: https://huggingface.co/google/vit-base-patch16-224
+
+Content:
+- [PyTorch version, Trainer](#pytorch-version-trainer)
+- [PyTorch version, no Trainer](#pytorch-version-no-trainer)
+
+## PyTorch version, Trainer
+
+Based on the script [`run_image_classification.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/image-classification/run_image_classification.py).
+
+The script leverages the 🤗 [Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer) to automatically take care of the training for you, running on distributed environments right away.
+
+### Using datasets from Hub
+
+Here we show how to fine-tune a Vision Transformer (`ViT`) on the [beans](https://huggingface.co/datasets/beans) dataset, to classify the disease type of bean leaves.
+
+```bash
+python run_image_classification.py \
+ --dataset_name beans \
+ --output_dir ./beans_outputs/ \
+ --remove_unused_columns False \
+ --label_column_name labels \
+ --do_train \
+ --do_eval \
+ --push_to_hub \
+ --push_to_hub_model_id vit-base-beans \
+ --learning_rate 2e-5 \
+ --num_train_epochs 5 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+👀 See the results here: [nateraw/vit-base-beans](https://huggingface.co/nateraw/vit-base-beans).
+
+Note that you can replace the model and dataset by simply setting the `model_name_or_path` and `dataset_name` arguments respectively, with any model or dataset from the [hub](https://huggingface.co/). For an overview of all possible arguments, we refer to the [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) of the `TrainingArguments`, which can be passed as flags.
+
+> If your model classification head dimensions do not fit the number of labels in the dataset, you can specify `--ignore_mismatched_sizes` to adapt it.
+
+### Using your own data
+
+To use your own dataset, there are 2 ways:
+- you can either provide your own folders as `--train_dir` and/or `--validation_dir` arguments
+- you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
+
+Below, we explain both in more detail.
+
+#### Provide them as folders
+
+If you provide your own folders with images, the script expects the following directory structure:
+
+```bash
+root/dog/xxx.png
+root/dog/xxy.png
+root/dog/[...]/xxz.png
+
+root/cat/123.png
+root/cat/nsdf3.png
+root/cat/[...]/asd932_.png
+```
+
+In other words, you need to organize your images in subfolders, based on their class. You can then run the script like this:
+
+```bash
+python run_image_classification.py \
+ --train_dir 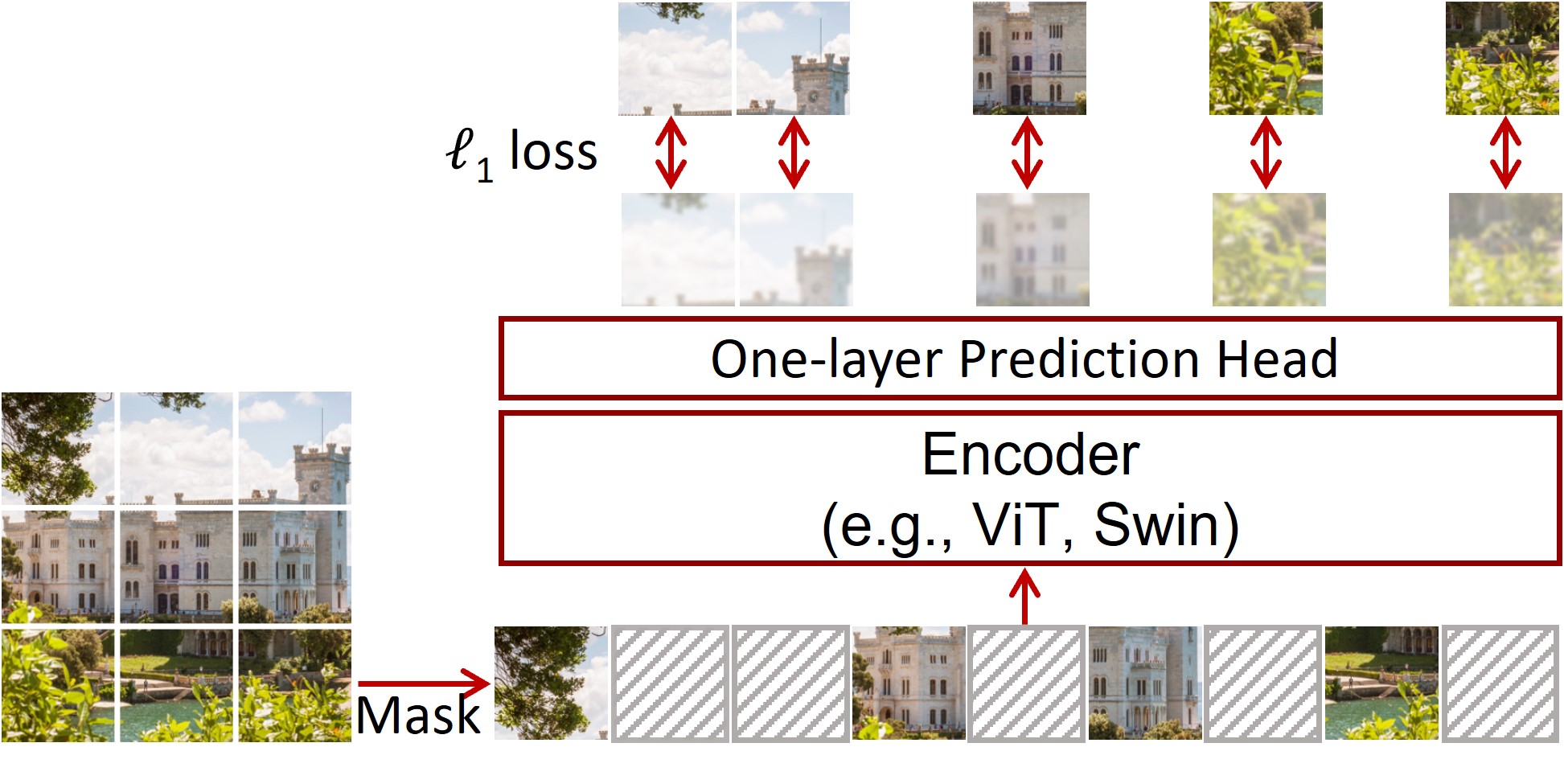 +
+ SimMIM framework. Taken from the original paper.
+
+The goal for the model is to predict raw pixel values for the masked patches, using just a linear layer as prediction head. The model is trained using a simple L1 loss.
+
+### Using datasets from 🤗 datasets
+
+Here we show how to pre-train a `ViT` from scratch for masked image modeling on the [cifar10](https://huggingface.co/datasets/cifar10) dataset.
+
+Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "google/vit-base-patch16-224-in21k" for example (and not specifying the `model_type` argument).
+
+```bash
+!python run_mim.py \
+ --model_type vit \
+ --output_dir ./outputs/ \
+ --overwrite_output_dir \
+ --remove_unused_columns False \
+ --label_names bool_masked_pos \
+ --do_train \
+ --do_eval \
+ --learning_rate 2e-5 \
+ --weight_decay 0.05 \
+ --num_train_epochs 100 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+Here, we train for 100 epochs with a learning rate of 2e-5. Note that the SimMIM authors used a more sophisticated learning rate schedule, see the [config files](https://github.com/microsoft/SimMIM/blob/main/configs/vit_base__800ep/simmim_pretrain__vit_base__img224__800ep.yaml) for more info. One can easily tweak the script to include this learning rate schedule (several learning rate schedulers are supported via the [training arguments](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments)).
+
+We can also for instance replicate the pre-training of a Swin Transformer using the same architecture as used by the SimMIM authors. For this, we first create a custom configuration and save it locally:
+
+```python
+from transformers import SwinConfig
+
+IMAGE_SIZE = 192
+PATCH_SIZE = 4
+EMBED_DIM = 128
+DEPTHS = [2, 2, 18, 2]
+NUM_HEADS = [4, 8, 16, 32]
+WINDOW_SIZE = 6
+
+config = SwinConfig(
+ image_size=IMAGE_SIZE,
+ patch_size=PATCH_SIZE,
+ embed_dim=EMBED_DIM,
+ depths=DEPTHS,
+ num_heads=NUM_HEADS,
+ window_size=WINDOW_SIZE,
+)
+config.save_pretrained("path_to_config")
+```
+
+Next, we can run the script by providing the path to this custom configuration (replace `path_to_config` below with your path):
+
+```bash
+!python run_mim.py \
+ --config_name_or_path path_to_config \
+ --model_type swin \
+ --output_dir ./outputs/ \
+ --overwrite_output_dir \
+ --remove_unused_columns False \
+ --label_names bool_masked_pos \
+ --do_train \
+ --do_eval \
+ --learning_rate 2e-5 \
+ --num_train_epochs 5 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+This will train a Swin Transformer from scratch.
+
+### Using your own data
+
+To use your own dataset, the training script expects the following directory structure:
+
+```bash
+root/dog/xxx.png
+root/dog/xxy.png
+root/dog/[...]/xxz.png
+
+root/cat/123.png
+root/cat/nsdf3.png
+root/cat/[...]/asd932_.png
+```
+
+Note that you can put images in dummy subfolders, whose names will be ignored by default (as labels aren't required). You can also just place all images into a single dummy subfolder. Once you've prepared your dataset, you can run the script like this:
+
+```bash
+python run_mim.py \
+ --model_type vit \
+ --dataset_name nateraw/image-folder \
+ --train_dir
+
+ SimMIM framework. Taken from the original paper.
+
+The goal for the model is to predict raw pixel values for the masked patches, using just a linear layer as prediction head. The model is trained using a simple L1 loss.
+
+### Using datasets from 🤗 datasets
+
+Here we show how to pre-train a `ViT` from scratch for masked image modeling on the [cifar10](https://huggingface.co/datasets/cifar10) dataset.
+
+Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "google/vit-base-patch16-224-in21k" for example (and not specifying the `model_type` argument).
+
+```bash
+!python run_mim.py \
+ --model_type vit \
+ --output_dir ./outputs/ \
+ --overwrite_output_dir \
+ --remove_unused_columns False \
+ --label_names bool_masked_pos \
+ --do_train \
+ --do_eval \
+ --learning_rate 2e-5 \
+ --weight_decay 0.05 \
+ --num_train_epochs 100 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+Here, we train for 100 epochs with a learning rate of 2e-5. Note that the SimMIM authors used a more sophisticated learning rate schedule, see the [config files](https://github.com/microsoft/SimMIM/blob/main/configs/vit_base__800ep/simmim_pretrain__vit_base__img224__800ep.yaml) for more info. One can easily tweak the script to include this learning rate schedule (several learning rate schedulers are supported via the [training arguments](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments)).
+
+We can also for instance replicate the pre-training of a Swin Transformer using the same architecture as used by the SimMIM authors. For this, we first create a custom configuration and save it locally:
+
+```python
+from transformers import SwinConfig
+
+IMAGE_SIZE = 192
+PATCH_SIZE = 4
+EMBED_DIM = 128
+DEPTHS = [2, 2, 18, 2]
+NUM_HEADS = [4, 8, 16, 32]
+WINDOW_SIZE = 6
+
+config = SwinConfig(
+ image_size=IMAGE_SIZE,
+ patch_size=PATCH_SIZE,
+ embed_dim=EMBED_DIM,
+ depths=DEPTHS,
+ num_heads=NUM_HEADS,
+ window_size=WINDOW_SIZE,
+)
+config.save_pretrained("path_to_config")
+```
+
+Next, we can run the script by providing the path to this custom configuration (replace `path_to_config` below with your path):
+
+```bash
+!python run_mim.py \
+ --config_name_or_path path_to_config \
+ --model_type swin \
+ --output_dir ./outputs/ \
+ --overwrite_output_dir \
+ --remove_unused_columns False \
+ --label_names bool_masked_pos \
+ --do_train \
+ --do_eval \
+ --learning_rate 2e-5 \
+ --num_train_epochs 5 \
+ --per_device_train_batch_size 8 \
+ --per_device_eval_batch_size 8 \
+ --logging_strategy steps \
+ --logging_steps 10 \
+ --eval_strategy epoch \
+ --save_strategy epoch \
+ --load_best_model_at_end True \
+ --save_total_limit 3 \
+ --seed 1337
+```
+
+This will train a Swin Transformer from scratch.
+
+### Using your own data
+
+To use your own dataset, the training script expects the following directory structure:
+
+```bash
+root/dog/xxx.png
+root/dog/xxy.png
+root/dog/[...]/xxz.png
+
+root/cat/123.png
+root/cat/nsdf3.png
+root/cat/[...]/asd932_.png
+```
+
+Note that you can put images in dummy subfolders, whose names will be ignored by default (as labels aren't required). You can also just place all images into a single dummy subfolder. Once you've prepared your dataset, you can run the script like this:
+
+```bash
+python run_mim.py \
+ --model_type vit \
+ --dataset_name nateraw/image-folder \
+ --train_dir 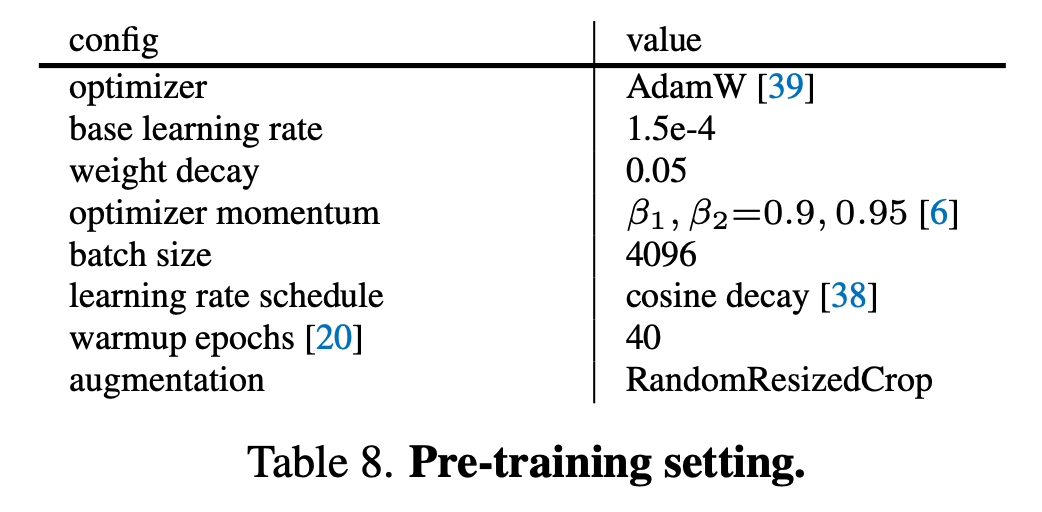 +
+ Original hyperparameters. Taken from the original paper.
+
+Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "facebook/vit-mae-base" for example.
+
+
+### Using your own data
+
+To use your own dataset, the training script expects the following directory structure:
+
+```bash
+root/dog/xxx.png
+root/dog/xxy.png
+root/dog/[...]/xxz.png
+
+root/cat/123.png
+root/cat/nsdf3.png
+root/cat/[...]/asd932_.png
+```
+
+Note that you can put images in dummy subfolders, whose names will be ignored by default (as labels aren't required). You can also just place all images into a single dummy subfolder. Once you've prepared your dataset, you can run the script like this:
+
+```bash
+python run_mae.py \
+ --model_type vit_mae \
+ --dataset_name nateraw/image-folder \
+ --train_dir
+
+ Original hyperparameters. Taken from the original paper.
+
+Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "facebook/vit-mae-base" for example.
+
+
+### Using your own data
+
+To use your own dataset, the training script expects the following directory structure:
+
+```bash
+root/dog/xxx.png
+root/dog/xxy.png
+root/dog/[...]/xxz.png
+
+root/cat/123.png
+root/cat/nsdf3.png
+root/cat/[...]/asd932_.png
+```
+
+Note that you can put images in dummy subfolders, whose names will be ignored by default (as labels aren't required). You can also just place all images into a single dummy subfolder. Once you've prepared your dataset, you can run the script like this:
+
+```bash
+python run_mae.py \
+ --model_type vit_mae \
+ --dataset_name nateraw/image-folder \
+ --train_dir 
 +
+  +
+  +
+  +
+ +
+  +
+
 +
+