`."
+ ) from e
+ except RepositoryNotFoundError as e:
+ logger.error(e)
+ raise OSError(f"{path_or_repo} is not a local folder or a valid repository name on 'https://hf.co'.") from e
+ except RevisionNotFoundError as e:
+ logger.error(e)
+ raise OSError(
+ f"{revision} is not a valid git identifier (branch name, tag name or commit id) that exists for this "
+ f"model name. Check the model page at 'https://huggingface.co/{path_or_repo}' for available revisions."
+ ) from e
+ except EntryNotFoundError:
+ return False # File does not exist
+ except requests.HTTPError:
+ # Any authentication/authorization error will be caught here => default to cache
+ return has_file_in_cache
+
+
+class PushToHubMixin:
+ """
+ A Mixin containing the functionality to push a model or tokenizer to the hub.
+ """
+
+ def _create_repo(
+ self,
+ repo_id: str,
+ private: Optional[bool] = None,
+ token: Optional[Union[bool, str]] = None,
+ repo_url: Optional[str] = None,
+ organization: Optional[str] = None,
+ ) -> str:
+ """
+ Create the repo if needed, cleans up repo_id with deprecated kwargs `repo_url` and `organization`, retrieves
+ the token.
+ """
+ if repo_url is not None:
+ warnings.warn(
+ "The `repo_url` argument is deprecated and will be removed in v5 of Transformers. Use `repo_id` "
+ "instead."
+ )
+ if repo_id is not None:
+ raise ValueError(
+ "`repo_id` and `repo_url` are both specified. Please set only the argument `repo_id`."
+ )
+ repo_id = repo_url.replace(f"{HUGGINGFACE_CO_RESOLVE_ENDPOINT}/", "")
+ if organization is not None:
+ warnings.warn(
+ "The `organization` argument is deprecated and will be removed in v5 of Transformers. Set your "
+ "organization directly in the `repo_id` passed instead (`repo_id={organization}/{model_id}`)."
+ )
+ if not repo_id.startswith(organization):
+ if "/" in repo_id:
+ repo_id = repo_id.split("/")[-1]
+ repo_id = f"{organization}/{repo_id}"
+
+ url = create_repo(repo_id=repo_id, token=token, private=private, exist_ok=True)
+ return url.repo_id
+
+ def _get_files_timestamps(self, working_dir: Union[str, os.PathLike]):
+ """
+ Returns the list of files with their last modification timestamp.
+ """
+ return {f: os.path.getmtime(os.path.join(working_dir, f)) for f in os.listdir(working_dir)}
+
+ def _upload_modified_files(
+ self,
+ working_dir: Union[str, os.PathLike],
+ repo_id: str,
+ files_timestamps: dict[str, float],
+ commit_message: Optional[str] = None,
+ token: Optional[Union[bool, str]] = None,
+ create_pr: bool = False,
+ revision: Optional[str] = None,
+ commit_description: Optional[str] = None,
+ ):
+ """
+ Uploads all modified files in `working_dir` to `repo_id`, based on `files_timestamps`.
+ """
+ if commit_message is None:
+ if "Model" in self.__class__.__name__:
+ commit_message = "Upload model"
+ elif "Config" in self.__class__.__name__:
+ commit_message = "Upload config"
+ elif "Tokenizer" in self.__class__.__name__:
+ commit_message = "Upload tokenizer"
+ elif "FeatureExtractor" in self.__class__.__name__:
+ commit_message = "Upload feature extractor"
+ elif "Processor" in self.__class__.__name__:
+ commit_message = "Upload processor"
+ else:
+ commit_message = f"Upload {self.__class__.__name__}"
+ modified_files = [
+ f
+ for f in os.listdir(working_dir)
+ if f not in files_timestamps or os.path.getmtime(os.path.join(working_dir, f)) > files_timestamps[f]
+ ]
+
+ # filter for actual files + folders at the root level
+ modified_files = [
+ f
+ for f in modified_files
+ if os.path.isfile(os.path.join(working_dir, f)) or os.path.isdir(os.path.join(working_dir, f))
+ ]
+
+ operations = []
+ # upload standalone files
+ for file in modified_files:
+ if os.path.isdir(os.path.join(working_dir, file)):
+ # go over individual files of folder
+ for f in os.listdir(os.path.join(working_dir, file)):
+ operations.append(
+ CommitOperationAdd(
+ path_or_fileobj=os.path.join(working_dir, file, f), path_in_repo=os.path.join(file, f)
+ )
+ )
+ else:
+ operations.append(
+ CommitOperationAdd(path_or_fileobj=os.path.join(working_dir, file), path_in_repo=file)
+ )
+
+ if revision is not None and not revision.startswith("refs/pr"):
+ try:
+ create_branch(repo_id=repo_id, branch=revision, token=token, exist_ok=True)
+ except HfHubHTTPError as e:
+ if e.response.status_code == 403 and create_pr:
+ # If we are creating a PR on a repo we don't have access to, we can't create the branch.
+ # so let's assume the branch already exists. If it's not the case, an error will be raised when
+ # calling `create_commit` below.
+ pass
+ else:
+ raise
+
+ logger.info(f"Uploading the following files to {repo_id}: {','.join(modified_files)}")
+ return create_commit(
+ repo_id=repo_id,
+ operations=operations,
+ commit_message=commit_message,
+ commit_description=commit_description,
+ token=token,
+ create_pr=create_pr,
+ revision=revision,
+ )
+
+ def push_to_hub(
+ self,
+ repo_id: str,
+ use_temp_dir: Optional[bool] = None,
+ commit_message: Optional[str] = None,
+ private: Optional[bool] = None,
+ token: Optional[Union[bool, str]] = None,
+ max_shard_size: Optional[Union[int, str]] = "5GB",
+ create_pr: bool = False,
+ safe_serialization: bool = True,
+ revision: Optional[str] = None,
+ commit_description: Optional[str] = None,
+ tags: Optional[list[str]] = None,
+ **deprecated_kwargs,
+ ) -> str:
+ """
+ Upload the {object_files} to the 🤗 Model Hub.
+
+ Parameters:
+ repo_id (`str`):
+ The name of the repository you want to push your {object} to. It should contain your organization name
+ when pushing to a given organization.
+ use_temp_dir (`bool`, *optional*):
+ Whether or not to use a temporary directory to store the files saved before they are pushed to the Hub.
+ Will default to `True` if there is no directory named like `repo_id`, `False` otherwise.
+ commit_message (`str`, *optional*):
+ Message to commit while pushing. Will default to `"Upload {object}"`.
+ private (`bool`, *optional*):
+ Whether to make the repo private. If `None` (default), the repo will be public unless the organization's default is private. This value is ignored if the repo already exists.
+ token (`bool` or `str`, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`). Will default to `True` if `repo_url`
+ is not specified.
+ max_shard_size (`int` or `str`, *optional*, defaults to `"5GB"`):
+ Only applicable for models. The maximum size for a checkpoint before being sharded. Checkpoints shard
+ will then be each of size lower than this size. If expressed as a string, needs to be digits followed
+ by a unit (like `"5MB"`). We default it to `"5GB"` so that users can easily load models on free-tier
+ Google Colab instances without any CPU OOM issues.
+ create_pr (`bool`, *optional*, defaults to `False`):
+ Whether or not to create a PR with the uploaded files or directly commit.
+ safe_serialization (`bool`, *optional*, defaults to `True`):
+ Whether or not to convert the model weights in safetensors format for safer serialization.
+ revision (`str`, *optional*):
+ Branch to push the uploaded files to.
+ commit_description (`str`, *optional*):
+ The description of the commit that will be created
+ tags (`List[str]`, *optional*):
+ List of tags to push on the Hub.
+
+ Examples:
+
+ ```python
+ from transformers import {object_class}
+
+ {object} = {object_class}.from_pretrained("google-bert/bert-base-cased")
+
+ # Push the {object} to your namespace with the name "my-finetuned-bert".
+ {object}.push_to_hub("my-finetuned-bert")
+
+ # Push the {object} to an organization with the name "my-finetuned-bert".
+ {object}.push_to_hub("huggingface/my-finetuned-bert")
+ ```
+ """
+ use_auth_token = deprecated_kwargs.pop("use_auth_token", None)
+ ignore_metadata_errors = deprecated_kwargs.pop("ignore_metadata_errors", False)
+ save_jinja_files = deprecated_kwargs.pop(
+ "save_jinja_files", None
+ ) # TODO: This is only used for testing and should be removed once save_jinja_files becomes the default
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if token is not None:
+ raise ValueError(
+ "`token` and `use_auth_token` are both specified. Please set only the argument `token`."
+ )
+ token = use_auth_token
+
+ repo_path_or_name = deprecated_kwargs.pop("repo_path_or_name", None)
+ if repo_path_or_name is not None:
+ # Should use `repo_id` instead of `repo_path_or_name`. When using `repo_path_or_name`, we try to infer
+ # repo_id from the folder path, if it exists.
+ warnings.warn(
+ "The `repo_path_or_name` argument is deprecated and will be removed in v5 of Transformers. Use "
+ "`repo_id` instead.",
+ FutureWarning,
+ )
+ if repo_id is not None:
+ raise ValueError(
+ "`repo_id` and `repo_path_or_name` are both specified. Please set only the argument `repo_id`."
+ )
+ if os.path.isdir(repo_path_or_name):
+ # repo_path: infer repo_id from the path
+ repo_id = repo_path_or_name.split(os.path.sep)[-1]
+ working_dir = repo_id
+ else:
+ # repo_name: use it as repo_id
+ repo_id = repo_path_or_name
+ working_dir = repo_id.split("/")[-1]
+ else:
+ # Repo_id is passed correctly: infer working_dir from it
+ working_dir = repo_id.split("/")[-1]
+
+ # Deprecation warning will be sent after for repo_url and organization
+ repo_url = deprecated_kwargs.pop("repo_url", None)
+ organization = deprecated_kwargs.pop("organization", None)
+
+ repo_id = self._create_repo(
+ repo_id, private=private, token=token, repo_url=repo_url, organization=organization
+ )
+
+ # Create a new empty model card and eventually tag it
+ model_card = create_and_tag_model_card(
+ repo_id, tags, token=token, ignore_metadata_errors=ignore_metadata_errors
+ )
+
+ if use_temp_dir is None:
+ use_temp_dir = not os.path.isdir(working_dir)
+
+ with working_or_temp_dir(working_dir=working_dir, use_temp_dir=use_temp_dir) as work_dir:
+ files_timestamps = self._get_files_timestamps(work_dir)
+
+ # Save all files.
+ if save_jinja_files:
+ self.save_pretrained(
+ work_dir,
+ max_shard_size=max_shard_size,
+ safe_serialization=safe_serialization,
+ save_jinja_files=True,
+ )
+ else:
+ self.save_pretrained(work_dir, max_shard_size=max_shard_size, safe_serialization=safe_serialization)
+
+ # Update model card if needed:
+ model_card.save(os.path.join(work_dir, "README.md"))
+
+ return self._upload_modified_files(
+ work_dir,
+ repo_id,
+ files_timestamps,
+ commit_message=commit_message,
+ token=token,
+ create_pr=create_pr,
+ revision=revision,
+ commit_description=commit_description,
+ )
+
+
+def send_example_telemetry(example_name, *example_args, framework="pytorch"):
+ """
+ Sends telemetry that helps tracking the examples use.
+
+ Args:
+ example_name (`str`): The name of the example.
+ *example_args (dataclasses or `argparse.ArgumentParser`): The arguments to the script. This function will only
+ try to extract the model and dataset name from those. Nothing else is tracked.
+ framework (`str`, *optional*, defaults to `"pytorch"`): The framework for the example.
+ """
+ if is_offline_mode():
+ return
+
+ data = {"example": example_name, "framework": framework}
+ for args in example_args:
+ args_as_dict = {k: v for k, v in args.__dict__.items() if not k.startswith("_") and v is not None}
+ if "model_name_or_path" in args_as_dict:
+ model_name = args_as_dict["model_name_or_path"]
+ # Filter out local paths
+ if not os.path.isdir(model_name):
+ data["model_name"] = args_as_dict["model_name_or_path"]
+ if "dataset_name" in args_as_dict:
+ data["dataset_name"] = args_as_dict["dataset_name"]
+ elif "task_name" in args_as_dict:
+ # Extract script name from the example_name
+ script_name = example_name.replace("tf_", "").replace("flax_", "").replace("run_", "")
+ script_name = script_name.replace("_no_trainer", "")
+ data["dataset_name"] = f"{script_name}-{args_as_dict['task_name']}"
+
+ # Send telemetry in the background
+ send_telemetry(
+ topic="examples", library_name="transformers", library_version=__version__, user_agent=http_user_agent(data)
+ )
+
+
+def convert_file_size_to_int(size: Union[int, str]):
+ """
+ Converts a size expressed as a string with digits an unit (like `"5MB"`) to an integer (in bytes).
+
+ Args:
+ size (`int` or `str`): The size to convert. Will be directly returned if an `int`.
+
+ Example:
+ ```py
+ >>> convert_file_size_to_int("1MiB")
+ 1048576
+ ```
+ """
+ if isinstance(size, int):
+ return size
+ if size.upper().endswith("GIB"):
+ return int(size[:-3]) * (2**30)
+ if size.upper().endswith("MIB"):
+ return int(size[:-3]) * (2**20)
+ if size.upper().endswith("KIB"):
+ return int(size[:-3]) * (2**10)
+ if size.upper().endswith("GB"):
+ int_size = int(size[:-2]) * (10**9)
+ return int_size // 8 if size.endswith("b") else int_size
+ if size.upper().endswith("MB"):
+ int_size = int(size[:-2]) * (10**6)
+ return int_size // 8 if size.endswith("b") else int_size
+ if size.upper().endswith("KB"):
+ int_size = int(size[:-2]) * (10**3)
+ return int_size // 8 if size.endswith("b") else int_size
+ raise ValueError("`size` is not in a valid format. Use an integer followed by the unit, e.g., '5GB'.")
+
+
+def get_checkpoint_shard_files(
+ pretrained_model_name_or_path,
+ index_filename,
+ cache_dir=None,
+ force_download=False,
+ proxies=None,
+ resume_download=None,
+ local_files_only=False,
+ token=None,
+ user_agent=None,
+ revision=None,
+ subfolder="",
+ _commit_hash=None,
+ **deprecated_kwargs,
+):
+ """
+ For a given model:
+
+ - download and cache all the shards of a sharded checkpoint if `pretrained_model_name_or_path` is a model ID on the
+ Hub
+ - returns the list of paths to all the shards, as well as some metadata.
+
+ For the description of each arg, see [`PreTrainedModel.from_pretrained`]. `index_filename` is the full path to the
+ index (downloaded and cached if `pretrained_model_name_or_path` is a model ID on the Hub).
+ """
+ import json
+
+ use_auth_token = deprecated_kwargs.pop("use_auth_token", None)
+ if use_auth_token is not None:
+ warnings.warn(
+ "The `use_auth_token` argument is deprecated and will be removed in v5 of Transformers. Please use `token` instead.",
+ FutureWarning,
+ )
+ if token is not None:
+ raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
+ token = use_auth_token
+
+ if not os.path.isfile(index_filename):
+ raise ValueError(f"Can't find a checkpoint index ({index_filename}) in {pretrained_model_name_or_path}.")
+
+ with open(index_filename) as f:
+ index = json.loads(f.read())
+
+ shard_filenames = sorted(set(index["weight_map"].values()))
+ sharded_metadata = index["metadata"]
+ sharded_metadata["all_checkpoint_keys"] = list(index["weight_map"].keys())
+ sharded_metadata["weight_map"] = index["weight_map"].copy()
+
+ # First, let's deal with local folder.
+ if os.path.isdir(pretrained_model_name_or_path):
+ shard_filenames = [os.path.join(pretrained_model_name_or_path, subfolder, f) for f in shard_filenames]
+ return shard_filenames, sharded_metadata
+
+ # At this stage pretrained_model_name_or_path is a model identifier on the Hub. Try to get everything from cache,
+ # or download the files
+ cached_filenames = cached_files(
+ pretrained_model_name_or_path,
+ shard_filenames,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ proxies=proxies,
+ resume_download=resume_download,
+ local_files_only=local_files_only,
+ token=token,
+ user_agent=user_agent,
+ revision=revision,
+ subfolder=subfolder,
+ _commit_hash=_commit_hash,
+ )
+
+ return cached_filenames, sharded_metadata
+
+
+def create_and_tag_model_card(
+ repo_id: str,
+ tags: Optional[list[str]] = None,
+ token: Optional[str] = None,
+ ignore_metadata_errors: bool = False,
+):
+ """
+ Creates or loads an existing model card and tags it.
+
+ Args:
+ repo_id (`str`):
+ The repo_id where to look for the model card.
+ tags (`List[str]`, *optional*):
+ The list of tags to add in the model card
+ token (`str`, *optional*):
+ Authentication token, obtained with `huggingface_hub.HfApi.login` method. Will default to the stored token.
+ ignore_metadata_errors (`bool`, *optional*, defaults to `False`):
+ If True, errors while parsing the metadata section will be ignored. Some information might be lost during
+ the process. Use it at your own risk.
+ """
+ try:
+ # Check if the model card is present on the remote repo
+ model_card = ModelCard.load(repo_id, token=token, ignore_metadata_errors=ignore_metadata_errors)
+ except EntryNotFoundError:
+ # Otherwise create a simple model card from template
+ model_description = "This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated."
+ card_data = ModelCardData(tags=[] if tags is None else tags, library_name="transformers")
+ model_card = ModelCard.from_template(card_data, model_description=model_description)
+
+ if tags is not None:
+ # Ensure model_card.data.tags is a list and not None
+ if model_card.data.tags is None:
+ model_card.data.tags = []
+ for model_tag in tags:
+ if model_tag not in model_card.data.tags:
+ model_card.data.tags.append(model_tag)
+
+ return model_card
+
+
+class PushInProgress:
+ """
+ Internal class to keep track of a push in progress (which might contain multiple `Future` jobs).
+ """
+
+ def __init__(self, jobs: Optional[futures.Future] = None) -> None:
+ self.jobs = [] if jobs is None else jobs
+
+ def is_done(self):
+ return all(job.done() for job in self.jobs)
+
+ def wait_until_done(self):
+ futures.wait(self.jobs)
+
+ def cancel(self) -> None:
+ self.jobs = [
+ job
+ for job in self.jobs
+ # Cancel the job if it wasn't started yet and remove cancelled/done jobs from the list
+ if not (job.cancel() or job.done())
+ ]
diff --git a/docs/transformers/build/lib/transformers/utils/import_utils.py b/docs/transformers/build/lib/transformers/utils/import_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..2eac33b7a2961b05f626bd429d8b50179be8a406
--- /dev/null
+++ b/docs/transformers/build/lib/transformers/utils/import_utils.py
@@ -0,0 +1,2460 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Import utilities: Utilities related to imports and our lazy inits.
+"""
+
+import importlib.machinery
+import importlib.metadata
+import importlib.util
+import json
+import os
+import shutil
+import subprocess
+import sys
+import warnings
+from collections import OrderedDict
+from functools import lru_cache
+from itertools import chain
+from types import ModuleType
+from typing import Any, Dict, FrozenSet, Optional, Set, Tuple, Union
+
+from packaging import version
+
+from . import logging
+
+
+logger = logging.get_logger(__name__) # pylint: disable=invalid-name
+
+
+# TODO: This doesn't work for all packages (`bs4`, `faiss`, etc.) Talk to Sylvain to see how to do with it better.
+def _is_package_available(pkg_name: str, return_version: bool = False) -> Union[Tuple[bool, str], bool]:
+ # Check if the package spec exists and grab its version to avoid importing a local directory
+ package_exists = importlib.util.find_spec(pkg_name) is not None
+ package_version = "N/A"
+ if package_exists:
+ try:
+ # TODO: Once python 3.9 support is dropped, `importlib.metadata.packages_distributions()`
+ # should be used here to map from package name to distribution names
+ # e.g. PIL -> Pillow, Pillow-SIMD; quark -> amd-quark; onnxruntime -> onnxruntime-gpu.
+ # `importlib.metadata.packages_distributions()` is not available in Python 3.9.
+
+ # Primary method to get the package version
+ package_version = importlib.metadata.version(pkg_name)
+ except importlib.metadata.PackageNotFoundError:
+ # Fallback method: Only for "torch" and versions containing "dev"
+ if pkg_name == "torch":
+ try:
+ package = importlib.import_module(pkg_name)
+ temp_version = getattr(package, "__version__", "N/A")
+ # Check if the version contains "dev"
+ if "dev" in temp_version:
+ package_version = temp_version
+ package_exists = True
+ else:
+ package_exists = False
+ except ImportError:
+ # If the package can't be imported, it's not available
+ package_exists = False
+ elif pkg_name == "quark":
+ # TODO: remove once `importlib.metadata.packages_distributions()` is supported.
+ try:
+ package_version = importlib.metadata.version("amd-quark")
+ except Exception:
+ package_exists = False
+ else:
+ # For packages other than "torch", don't attempt the fallback and set as not available
+ package_exists = False
+ logger.debug(f"Detected {pkg_name} version: {package_version}")
+ if return_version:
+ return package_exists, package_version
+ else:
+ return package_exists
+
+
+ENV_VARS_TRUE_VALUES = {"1", "ON", "YES", "TRUE"}
+ENV_VARS_TRUE_AND_AUTO_VALUES = ENV_VARS_TRUE_VALUES.union({"AUTO"})
+
+USE_TF = os.environ.get("USE_TF", "AUTO").upper()
+USE_TORCH = os.environ.get("USE_TORCH", "AUTO").upper()
+USE_JAX = os.environ.get("USE_FLAX", "AUTO").upper()
+
+# Try to run a native pytorch job in an environment with TorchXLA installed by setting this value to 0.
+USE_TORCH_XLA = os.environ.get("USE_TORCH_XLA", "1").upper()
+
+FORCE_TF_AVAILABLE = os.environ.get("FORCE_TF_AVAILABLE", "AUTO").upper()
+
+# `transformers` requires `torch>=1.11` but this variable is exposed publicly, and we can't simply remove it.
+# This is the version of torch required to run torch.fx features and torch.onnx with dictionary inputs.
+TORCH_FX_REQUIRED_VERSION = version.parse("1.10")
+
+ACCELERATE_MIN_VERSION = "0.26.0"
+SCHEDULEFREE_MIN_VERSION = "1.2.6"
+FSDP_MIN_VERSION = "1.12.0"
+GGUF_MIN_VERSION = "0.10.0"
+XLA_FSDPV2_MIN_VERSION = "2.2.0"
+HQQ_MIN_VERSION = "0.2.1"
+VPTQ_MIN_VERSION = "0.0.4"
+TORCHAO_MIN_VERSION = "0.4.0"
+AUTOROUND_MIN_VERSION = "0.5.0"
+
+_accelerate_available, _accelerate_version = _is_package_available("accelerate", return_version=True)
+_apex_available = _is_package_available("apex")
+_apollo_torch_available = _is_package_available("apollo_torch")
+_aqlm_available = _is_package_available("aqlm")
+_vptq_available, _vptq_version = _is_package_available("vptq", return_version=True)
+_av_available = importlib.util.find_spec("av") is not None
+_decord_available = importlib.util.find_spec("decord") is not None
+_bitsandbytes_available = _is_package_available("bitsandbytes")
+_eetq_available = _is_package_available("eetq")
+_fbgemm_gpu_available = _is_package_available("fbgemm_gpu")
+_galore_torch_available = _is_package_available("galore_torch")
+_lomo_available = _is_package_available("lomo_optim")
+_grokadamw_available = _is_package_available("grokadamw")
+_schedulefree_available, _schedulefree_version = _is_package_available("schedulefree", return_version=True)
+# `importlib.metadata.version` doesn't work with `bs4` but `beautifulsoup4`. For `importlib.util.find_spec`, reversed.
+_bs4_available = importlib.util.find_spec("bs4") is not None
+_coloredlogs_available = _is_package_available("coloredlogs")
+# `importlib.metadata.util` doesn't work with `opencv-python-headless`.
+_cv2_available = importlib.util.find_spec("cv2") is not None
+_yt_dlp_available = importlib.util.find_spec("yt_dlp") is not None
+_datasets_available = _is_package_available("datasets")
+_detectron2_available = _is_package_available("detectron2")
+# We need to check both `faiss` and `faiss-cpu`.
+_faiss_available = importlib.util.find_spec("faiss") is not None
+try:
+ _faiss_version = importlib.metadata.version("faiss")
+ logger.debug(f"Successfully imported faiss version {_faiss_version}")
+except importlib.metadata.PackageNotFoundError:
+ try:
+ _faiss_version = importlib.metadata.version("faiss-cpu")
+ logger.debug(f"Successfully imported faiss version {_faiss_version}")
+ except importlib.metadata.PackageNotFoundError:
+ _faiss_available = False
+_ftfy_available = _is_package_available("ftfy")
+_g2p_en_available = _is_package_available("g2p_en")
+_hadamard_available = _is_package_available("fast_hadamard_transform")
+_ipex_available, _ipex_version = _is_package_available("intel_extension_for_pytorch", return_version=True)
+_jieba_available = _is_package_available("jieba")
+_jinja_available = _is_package_available("jinja2")
+_kenlm_available = _is_package_available("kenlm")
+_keras_nlp_available = _is_package_available("keras_nlp")
+_levenshtein_available = _is_package_available("Levenshtein")
+_librosa_available = _is_package_available("librosa")
+_natten_available = _is_package_available("natten")
+_nltk_available = _is_package_available("nltk")
+_onnx_available = _is_package_available("onnx")
+_openai_available = _is_package_available("openai")
+_optimum_available = _is_package_available("optimum")
+_auto_gptq_available = _is_package_available("auto_gptq")
+_gptqmodel_available = _is_package_available("gptqmodel")
+_auto_round_available, _auto_round_version = _is_package_available("auto_round", return_version=True)
+# `importlib.metadata.version` doesn't work with `awq`
+_auto_awq_available = importlib.util.find_spec("awq") is not None
+_quark_available = _is_package_available("quark")
+_is_optimum_quanto_available = False
+try:
+ importlib.metadata.version("optimum_quanto")
+ _is_optimum_quanto_available = True
+except importlib.metadata.PackageNotFoundError:
+ _is_optimum_quanto_available = False
+# For compressed_tensors, only check spec to allow compressed_tensors-nightly package
+_compressed_tensors_available = importlib.util.find_spec("compressed_tensors") is not None
+_pandas_available = _is_package_available("pandas")
+_peft_available = _is_package_available("peft")
+_phonemizer_available = _is_package_available("phonemizer")
+_uroman_available = _is_package_available("uroman")
+_psutil_available = _is_package_available("psutil")
+_py3nvml_available = _is_package_available("py3nvml")
+_pyctcdecode_available = _is_package_available("pyctcdecode")
+_pygments_available = _is_package_available("pygments")
+_pytesseract_available = _is_package_available("pytesseract")
+_pytest_available = _is_package_available("pytest")
+_pytorch_quantization_available = _is_package_available("pytorch_quantization")
+_rjieba_available = _is_package_available("rjieba")
+_sacremoses_available = _is_package_available("sacremoses")
+_safetensors_available = _is_package_available("safetensors")
+_scipy_available = _is_package_available("scipy")
+_sentencepiece_available = _is_package_available("sentencepiece")
+_is_seqio_available = _is_package_available("seqio")
+_is_gguf_available, _gguf_version = _is_package_available("gguf", return_version=True)
+_sklearn_available = importlib.util.find_spec("sklearn") is not None
+if _sklearn_available:
+ try:
+ importlib.metadata.version("scikit-learn")
+ except importlib.metadata.PackageNotFoundError:
+ _sklearn_available = False
+_smdistributed_available = importlib.util.find_spec("smdistributed") is not None
+_soundfile_available = _is_package_available("soundfile")
+_spacy_available = _is_package_available("spacy")
+_sudachipy_available, _sudachipy_version = _is_package_available("sudachipy", return_version=True)
+_tensorflow_probability_available = _is_package_available("tensorflow_probability")
+_tensorflow_text_available = _is_package_available("tensorflow_text")
+_tf2onnx_available = _is_package_available("tf2onnx")
+_timm_available = _is_package_available("timm")
+_tokenizers_available = _is_package_available("tokenizers")
+_torchaudio_available = _is_package_available("torchaudio")
+_torchao_available, _torchao_version = _is_package_available("torchao", return_version=True)
+_torchdistx_available = _is_package_available("torchdistx")
+_torchvision_available, _torchvision_version = _is_package_available("torchvision", return_version=True)
+_mlx_available = _is_package_available("mlx")
+_num2words_available = _is_package_available("num2words")
+_hqq_available, _hqq_version = _is_package_available("hqq", return_version=True)
+_tiktoken_available = _is_package_available("tiktoken")
+_blobfile_available = _is_package_available("blobfile")
+_liger_kernel_available = _is_package_available("liger_kernel")
+_triton_available = _is_package_available("triton")
+_spqr_available = _is_package_available("spqr_quant")
+_rich_available = _is_package_available("rich")
+_kernels_available = _is_package_available("kernels")
+
+_torch_version = "N/A"
+_torch_available = False
+if USE_TORCH in ENV_VARS_TRUE_AND_AUTO_VALUES and USE_TF not in ENV_VARS_TRUE_VALUES:
+ _torch_available, _torch_version = _is_package_available("torch", return_version=True)
+ if _torch_available:
+ _torch_available = version.parse(_torch_version) >= version.parse("2.1.0")
+ if not _torch_available:
+ logger.warning(f"Disabling PyTorch because PyTorch >= 2.1 is required but found {_torch_version}")
+else:
+ logger.info("Disabling PyTorch because USE_TF is set")
+ _torch_available = False
+
+
+_tf_version = "N/A"
+_tf_available = False
+if FORCE_TF_AVAILABLE in ENV_VARS_TRUE_VALUES:
+ _tf_available = True
+else:
+ if USE_TF in ENV_VARS_TRUE_AND_AUTO_VALUES and USE_TORCH not in ENV_VARS_TRUE_VALUES:
+ # Note: _is_package_available("tensorflow") fails for tensorflow-cpu. Please test any changes to the line below
+ # with tensorflow-cpu to make sure it still works!
+ _tf_available = importlib.util.find_spec("tensorflow") is not None
+ if _tf_available:
+ candidates = (
+ "tensorflow",
+ "tensorflow-cpu",
+ "tensorflow-gpu",
+ "tf-nightly",
+ "tf-nightly-cpu",
+ "tf-nightly-gpu",
+ "tf-nightly-rocm",
+ "intel-tensorflow",
+ "intel-tensorflow-avx512",
+ "tensorflow-rocm",
+ "tensorflow-macos",
+ "tensorflow-aarch64",
+ )
+ _tf_version = None
+ # For the metadata, we have to look for both tensorflow and tensorflow-cpu
+ for pkg in candidates:
+ try:
+ _tf_version = importlib.metadata.version(pkg)
+ break
+ except importlib.metadata.PackageNotFoundError:
+ pass
+ _tf_available = _tf_version is not None
+ if _tf_available:
+ if version.parse(_tf_version) < version.parse("2"):
+ logger.info(
+ f"TensorFlow found but with version {_tf_version}. Transformers requires version 2 minimum."
+ )
+ _tf_available = False
+ else:
+ logger.info("Disabling Tensorflow because USE_TORCH is set")
+
+
+_essentia_available = importlib.util.find_spec("essentia") is not None
+try:
+ _essentia_version = importlib.metadata.version("essentia")
+ logger.debug(f"Successfully imported essentia version {_essentia_version}")
+except importlib.metadata.PackageNotFoundError:
+ _essentia_version = False
+
+
+_pretty_midi_available = importlib.util.find_spec("pretty_midi") is not None
+try:
+ _pretty_midi_version = importlib.metadata.version("pretty_midi")
+ logger.debug(f"Successfully imported pretty_midi version {_pretty_midi_version}")
+except importlib.metadata.PackageNotFoundError:
+ _pretty_midi_available = False
+
+
+ccl_version = "N/A"
+_is_ccl_available = (
+ importlib.util.find_spec("torch_ccl") is not None
+ or importlib.util.find_spec("oneccl_bindings_for_pytorch") is not None
+)
+try:
+ ccl_version = importlib.metadata.version("oneccl_bind_pt")
+ logger.debug(f"Detected oneccl_bind_pt version {ccl_version}")
+except importlib.metadata.PackageNotFoundError:
+ _is_ccl_available = False
+
+
+_flax_available = False
+if USE_JAX in ENV_VARS_TRUE_AND_AUTO_VALUES:
+ _flax_available, _flax_version = _is_package_available("flax", return_version=True)
+ if _flax_available:
+ _jax_available, _jax_version = _is_package_available("jax", return_version=True)
+ if _jax_available:
+ logger.info(f"JAX version {_jax_version}, Flax version {_flax_version} available.")
+ else:
+ _flax_available = _jax_available = False
+ _jax_version = _flax_version = "N/A"
+
+
+_torch_xla_available = False
+if USE_TORCH_XLA in ENV_VARS_TRUE_VALUES:
+ _torch_xla_available, _torch_xla_version = _is_package_available("torch_xla", return_version=True)
+ if _torch_xla_available:
+ logger.info(f"Torch XLA version {_torch_xla_version} available.")
+
+
+def is_kenlm_available():
+ return _kenlm_available
+
+
+def is_kernels_available():
+ return _kernels_available
+
+
+def is_cv2_available():
+ return _cv2_available
+
+
+def is_yt_dlp_available():
+ return _yt_dlp_available
+
+
+def is_torch_available():
+ return _torch_available
+
+
+def is_accelerate_available(min_version: str = ACCELERATE_MIN_VERSION):
+ return _accelerate_available and version.parse(_accelerate_version) >= version.parse(min_version)
+
+
+def is_torch_accelerator_available():
+ if is_torch_available():
+ import torch
+
+ return hasattr(torch, "accelerator")
+
+ return False
+
+
+def is_torch_deterministic():
+ """
+ Check whether pytorch uses deterministic algorithms by looking if torch.set_deterministic_debug_mode() is set to 1 or 2"
+ """
+ if is_torch_available():
+ import torch
+
+ if torch.get_deterministic_debug_mode() == 0:
+ return False
+ else:
+ return True
+
+ return False
+
+
+def is_hadamard_available():
+ return _hadamard_available
+
+
+def is_hqq_available(min_version: str = HQQ_MIN_VERSION):
+ return _hqq_available and version.parse(_hqq_version) >= version.parse(min_version)
+
+
+def is_pygments_available():
+ return _pygments_available
+
+
+def get_torch_version():
+ return _torch_version
+
+
+def is_torch_sdpa_available():
+ if not is_torch_available():
+ return False
+ elif _torch_version == "N/A":
+ return False
+
+ # NOTE: MLU is OK with non-contiguous inputs.
+ if is_torch_mlu_available():
+ return True
+ # NOTE: NPU can use SDPA in Transformers with torch>=2.1.0.
+ if is_torch_npu_available():
+ return True
+ # NOTE: We require torch>=2.1.1 to avoid a numerical issue in SDPA with non-contiguous inputs: https://github.com/pytorch/pytorch/issues/112577
+ return version.parse(_torch_version) >= version.parse("2.1.1")
+
+
+def is_torch_flex_attn_available():
+ if not is_torch_available():
+ return False
+ elif _torch_version == "N/A":
+ return False
+
+ # TODO check if some bugs cause push backs on the exact version
+ # NOTE: We require torch>=2.5.0 as it is the first release
+ return version.parse(_torch_version) >= version.parse("2.5.0")
+
+
+def is_torchvision_available():
+ return _torchvision_available
+
+
+def is_torchvision_v2_available():
+ if not is_torchvision_available():
+ return False
+
+ # NOTE: We require torchvision>=0.15 as v2 transforms are available from this version: https://pytorch.org/vision/stable/transforms.html#v1-or-v2-which-one-should-i-use
+ return version.parse(_torchvision_version) >= version.parse("0.15")
+
+
+def is_galore_torch_available():
+ return _galore_torch_available
+
+
+def is_apollo_torch_available():
+ return _apollo_torch_available
+
+
+def is_lomo_available():
+ return _lomo_available
+
+
+def is_grokadamw_available():
+ return _grokadamw_available
+
+
+def is_schedulefree_available(min_version: str = SCHEDULEFREE_MIN_VERSION):
+ return _schedulefree_available and version.parse(_schedulefree_version) >= version.parse(min_version)
+
+
+def is_pyctcdecode_available():
+ return _pyctcdecode_available
+
+
+def is_librosa_available():
+ return _librosa_available
+
+
+def is_essentia_available():
+ return _essentia_available
+
+
+def is_pretty_midi_available():
+ return _pretty_midi_available
+
+
+def is_torch_cuda_available():
+ if is_torch_available():
+ import torch
+
+ return torch.cuda.is_available()
+ else:
+ return False
+
+
+def is_mamba_ssm_available():
+ if is_torch_available():
+ import torch
+
+ if not torch.cuda.is_available():
+ return False
+ else:
+ return _is_package_available("mamba_ssm")
+ return False
+
+
+def is_mamba_2_ssm_available():
+ if is_torch_available():
+ import torch
+
+ if not torch.cuda.is_available():
+ return False
+ else:
+ if _is_package_available("mamba_ssm"):
+ import mamba_ssm
+
+ if version.parse(mamba_ssm.__version__) >= version.parse("2.0.4"):
+ return True
+ return False
+
+
+def is_causal_conv1d_available():
+ if is_torch_available():
+ import torch
+
+ if not torch.cuda.is_available():
+ return False
+ return _is_package_available("causal_conv1d")
+ return False
+
+
+def is_mambapy_available():
+ if is_torch_available():
+ return _is_package_available("mambapy")
+ return False
+
+
+def is_torch_mps_available(min_version: Optional[str] = None):
+ if is_torch_available():
+ import torch
+
+ if hasattr(torch.backends, "mps"):
+ backend_available = torch.backends.mps.is_available() and torch.backends.mps.is_built()
+ if min_version is not None:
+ flag = version.parse(_torch_version) >= version.parse(min_version)
+ backend_available = backend_available and flag
+ return backend_available
+ return False
+
+
+def is_torch_bf16_gpu_available() -> bool:
+ if not is_torch_available():
+ return False
+
+ import torch
+
+ if torch.cuda.is_available():
+ return torch.cuda.is_bf16_supported()
+ if torch.xpu.is_available():
+ return torch.xpu.is_bf16_supported()
+ if is_torch_hpu_available():
+ return True
+ return False
+
+
+def is_torch_bf16_cpu_available() -> bool:
+ return is_torch_available()
+
+
+def is_torch_bf16_available():
+ # the original bf16 check was for gpu only, but later a cpu/bf16 combo has emerged so this util
+ # has become ambiguous and therefore deprecated
+ warnings.warn(
+ "The util is_torch_bf16_available is deprecated, please use is_torch_bf16_gpu_available "
+ "or is_torch_bf16_cpu_available instead according to whether it's used with cpu or gpu",
+ FutureWarning,
+ )
+ return is_torch_bf16_gpu_available()
+
+
+@lru_cache()
+def is_torch_fp16_available_on_device(device):
+ if not is_torch_available():
+ return False
+
+ if is_torch_hpu_available():
+ if is_habana_gaudi1():
+ return False
+ else:
+ return True
+
+ import torch
+
+ try:
+ x = torch.zeros(2, 2, dtype=torch.float16, device=device)
+ _ = x @ x
+
+ # At this moment, let's be strict of the check: check if `LayerNorm` is also supported on device, because many
+ # models use this layer.
+ batch, sentence_length, embedding_dim = 3, 4, 5
+ embedding = torch.randn(batch, sentence_length, embedding_dim, dtype=torch.float16, device=device)
+ layer_norm = torch.nn.LayerNorm(embedding_dim, dtype=torch.float16, device=device)
+ _ = layer_norm(embedding)
+
+ except: # noqa: E722
+ # TODO: more precise exception matching, if possible.
+ # most backends should return `RuntimeError` however this is not guaranteed.
+ return False
+
+ return True
+
+
+@lru_cache()
+def is_torch_bf16_available_on_device(device):
+ if not is_torch_available():
+ return False
+
+ import torch
+
+ if device == "cuda":
+ return is_torch_bf16_gpu_available()
+
+ if device == "hpu":
+ return True
+
+ try:
+ x = torch.zeros(2, 2, dtype=torch.bfloat16, device=device)
+ _ = x @ x
+ except: # noqa: E722
+ # TODO: more precise exception matching, if possible.
+ # most backends should return `RuntimeError` however this is not guaranteed.
+ return False
+
+ return True
+
+
+def is_torch_tf32_available():
+ if not is_torch_available():
+ return False
+
+ import torch
+
+ if not torch.cuda.is_available() or torch.version.cuda is None:
+ return False
+ if torch.cuda.get_device_properties(torch.cuda.current_device()).major < 8:
+ return False
+ return True
+
+
+def is_torch_fx_available():
+ return is_torch_available()
+
+
+def is_peft_available():
+ return _peft_available
+
+
+def is_bs4_available():
+ return _bs4_available
+
+
+def is_tf_available():
+ return _tf_available
+
+
+def is_coloredlogs_available():
+ return _coloredlogs_available
+
+
+def is_tf2onnx_available():
+ return _tf2onnx_available
+
+
+def is_onnx_available():
+ return _onnx_available
+
+
+def is_openai_available():
+ return _openai_available
+
+
+def is_flax_available():
+ return _flax_available
+
+
+def is_flute_available():
+ try:
+ return importlib.util.find_spec("flute") is not None and importlib.metadata.version("flute-kernel") >= "0.4.1"
+ except importlib.metadata.PackageNotFoundError:
+ return False
+
+
+def is_ftfy_available():
+ return _ftfy_available
+
+
+def is_g2p_en_available():
+ return _g2p_en_available
+
+
+@lru_cache
+def is_torch_xla_available(check_is_tpu=False, check_is_gpu=False):
+ """
+ Check if `torch_xla` is available. To train a native pytorch job in an environment with torch xla installed, set
+ the USE_TORCH_XLA to false.
+ """
+ assert not (check_is_tpu and check_is_gpu), "The check_is_tpu and check_is_gpu cannot both be true."
+
+ if not _torch_xla_available:
+ return False
+
+ import torch_xla
+
+ if check_is_gpu:
+ return torch_xla.runtime.device_type() in ["GPU", "CUDA"]
+ elif check_is_tpu:
+ return torch_xla.runtime.device_type() == "TPU"
+
+ return True
+
+
+@lru_cache()
+def is_torch_neuroncore_available(check_device=True):
+ if importlib.util.find_spec("torch_neuronx") is not None:
+ return is_torch_xla_available()
+ return False
+
+
+@lru_cache()
+def is_torch_npu_available(check_device=False):
+ "Checks if `torch_npu` is installed and potentially if a NPU is in the environment"
+ if not _torch_available or importlib.util.find_spec("torch_npu") is None:
+ return False
+
+ import torch
+ import torch_npu # noqa: F401
+
+ if check_device:
+ try:
+ # Will raise a RuntimeError if no NPU is found
+ _ = torch.npu.device_count()
+ return torch.npu.is_available()
+ except RuntimeError:
+ return False
+ return hasattr(torch, "npu") and torch.npu.is_available()
+
+
+@lru_cache()
+def is_torch_mlu_available(check_device=False):
+ """
+ Checks if `mlu` is available via an `cndev-based` check which won't trigger the drivers and leave mlu
+ uninitialized.
+ """
+ if not _torch_available or importlib.util.find_spec("torch_mlu") is None:
+ return False
+
+ import torch
+ import torch_mlu # noqa: F401
+
+ pytorch_cndev_based_mlu_check_previous_value = os.environ.get("PYTORCH_CNDEV_BASED_MLU_CHECK")
+ try:
+ os.environ["PYTORCH_CNDEV_BASED_MLU_CHECK"] = str(1)
+ available = torch.mlu.is_available()
+ finally:
+ if pytorch_cndev_based_mlu_check_previous_value:
+ os.environ["PYTORCH_CNDEV_BASED_MLU_CHECK"] = pytorch_cndev_based_mlu_check_previous_value
+ else:
+ os.environ.pop("PYTORCH_CNDEV_BASED_MLU_CHECK", None)
+
+ return available
+
+
+@lru_cache()
+def is_torch_musa_available(check_device=False):
+ "Checks if `torch_musa` is installed and potentially if a MUSA is in the environment"
+ if not _torch_available or importlib.util.find_spec("torch_musa") is None:
+ return False
+
+ import torch
+ import torch_musa # noqa: F401
+
+ torch_musa_min_version = "0.33.0"
+ if _accelerate_available and version.parse(_accelerate_version) < version.parse(torch_musa_min_version):
+ return False
+
+ if check_device:
+ try:
+ # Will raise a RuntimeError if no MUSA is found
+ _ = torch.musa.device_count()
+ return torch.musa.is_available()
+ except RuntimeError:
+ return False
+ return hasattr(torch, "musa") and torch.musa.is_available()
+
+
+@lru_cache
+def is_torch_hpu_available():
+ "Checks if `torch.hpu` is available and potentially if a HPU is in the environment"
+ if (
+ not _torch_available
+ or importlib.util.find_spec("habana_frameworks") is None
+ or importlib.util.find_spec("habana_frameworks.torch") is None
+ ):
+ return False
+
+ torch_hpu_min_version = "1.5.0"
+ if _accelerate_available and version.parse(_accelerate_version) < version.parse(torch_hpu_min_version):
+ return False
+
+ import torch
+
+ if os.environ.get("PT_HPU_LAZY_MODE", "1") == "1":
+ # import habana_frameworks.torch in case of lazy mode to patch torch with torch.hpu
+ import habana_frameworks.torch # noqa: F401
+
+ if not hasattr(torch, "hpu") or not torch.hpu.is_available():
+ return False
+
+ import habana_frameworks.torch.utils.experimental as htexp # noqa: F401
+
+ # IlyasMoutawwakil: We patch masked_fill_ for int64 tensors to avoid a bug on Gaudi1
+ # synNodeCreateWithId failed for node: masked_fill_fwd_i64 with synStatus 26 [Generic failure]
+ # This can be removed once Gaudi1 support is discontinued but for now we need it to keep using
+ # dl1.24xlarge Gaudi1 instances on AWS for testing.
+ # check if the device is Gaudi1 (vs Gaudi2, Gaudi3).
+ if htexp._get_device_type() == htexp.synDeviceType.synDeviceGaudi:
+ original_masked_fill_ = torch.Tensor.masked_fill_
+
+ def patched_masked_fill_(self, mask, value):
+ if self.dtype == torch.int64:
+ logger.warning_once(
+ "In-place tensor.masked_fill_(mask, value) is not supported for int64 tensors on Gaudi1. "
+ "This operation will be performed out-of-place using tensor[mask] = value."
+ )
+ self[mask] = value
+ else:
+ original_masked_fill_(self, mask, value)
+
+ torch.Tensor.masked_fill_ = patched_masked_fill_
+
+ return True
+
+
+@lru_cache
+def is_habana_gaudi1():
+ if not is_torch_hpu_available():
+ return False
+
+ import habana_frameworks.torch.utils.experimental as htexp # noqa: F401
+
+ # Check if the device is Gaudi1 (vs Gaudi2, Gaudi3)
+ return htexp._get_device_type() == htexp.synDeviceType.synDeviceGaudi
+
+
+def is_torchdynamo_available():
+ return is_torch_available()
+
+
+def is_torch_compile_available():
+ return is_torch_available()
+
+
+def is_torchdynamo_compiling():
+ if not is_torch_available():
+ return False
+
+ # Importing torch._dynamo causes issues with PyTorch profiler (https://github.com/pytorch/pytorch/issues/130622)
+ # hence rather relying on `torch.compiler.is_compiling()` when possible (torch>=2.3)
+ try:
+ import torch
+
+ return torch.compiler.is_compiling()
+ except Exception:
+ try:
+ import torch._dynamo as dynamo # noqa: F401
+
+ return dynamo.is_compiling()
+ except Exception:
+ return False
+
+
+def is_torchdynamo_exporting():
+ if not is_torch_available():
+ return False
+
+ try:
+ import torch
+
+ return torch.compiler.is_exporting()
+ except Exception:
+ try:
+ import torch._dynamo as dynamo # noqa: F401
+
+ return dynamo.is_exporting()
+ except Exception:
+ return False
+
+
+def is_torch_tensorrt_fx_available():
+ if importlib.util.find_spec("torch_tensorrt") is None:
+ return False
+ return importlib.util.find_spec("torch_tensorrt.fx") is not None
+
+
+def is_datasets_available():
+ return _datasets_available
+
+
+def is_detectron2_available():
+ return _detectron2_available
+
+
+def is_rjieba_available():
+ return _rjieba_available
+
+
+def is_psutil_available():
+ return _psutil_available
+
+
+def is_py3nvml_available():
+ return _py3nvml_available
+
+
+def is_sacremoses_available():
+ return _sacremoses_available
+
+
+def is_apex_available():
+ return _apex_available
+
+
+def is_aqlm_available():
+ return _aqlm_available
+
+
+def is_vptq_available(min_version: str = VPTQ_MIN_VERSION):
+ return _vptq_available and version.parse(_vptq_version) >= version.parse(min_version)
+
+
+def is_av_available():
+ return _av_available
+
+
+def is_decord_available():
+ return _decord_available
+
+
+def is_ninja_available():
+ r"""
+ Code comes from *torch.utils.cpp_extension.is_ninja_available()*. Returns `True` if the
+ [ninja](https://ninja-build.org/) build system is available on the system, `False` otherwise.
+ """
+ try:
+ subprocess.check_output("ninja --version".split())
+ except Exception:
+ return False
+ else:
+ return True
+
+
+def is_ipex_available(min_version: str = ""):
+ def get_major_and_minor_from_version(full_version):
+ return str(version.parse(full_version).major) + "." + str(version.parse(full_version).minor)
+
+ if not is_torch_available() or not _ipex_available:
+ return False
+
+ torch_major_and_minor = get_major_and_minor_from_version(_torch_version)
+ ipex_major_and_minor = get_major_and_minor_from_version(_ipex_version)
+ if torch_major_and_minor != ipex_major_and_minor:
+ logger.warning(
+ f"Intel Extension for PyTorch {ipex_major_and_minor} needs to work with PyTorch {ipex_major_and_minor}.*,"
+ f" but PyTorch {_torch_version} is found. Please switch to the matching version and run again."
+ )
+ return False
+ if min_version:
+ return version.parse(_ipex_version) >= version.parse(min_version)
+ return True
+
+
+@lru_cache
+def is_torch_xpu_available(check_device=False):
+ """
+ Checks if XPU acceleration is available either via native PyTorch (>=2.6),
+ `intel_extension_for_pytorch` or via stock PyTorch (>=2.4) and potentially
+ if a XPU is in the environment.
+ """
+ if not is_torch_available():
+ return False
+
+ torch_version = version.parse(_torch_version)
+ if torch_version.major == 2 and torch_version.minor < 6:
+ if is_ipex_available():
+ import intel_extension_for_pytorch # noqa: F401
+ elif torch_version.major == 2 and torch_version.minor < 4:
+ return False
+
+ import torch
+
+ if check_device:
+ try:
+ # Will raise a RuntimeError if no XPU is found
+ _ = torch.xpu.device_count()
+ return torch.xpu.is_available()
+ except RuntimeError:
+ return False
+ return hasattr(torch, "xpu") and torch.xpu.is_available()
+
+
+@lru_cache()
+def is_bitsandbytes_available():
+ if not is_torch_available() or not _bitsandbytes_available:
+ return False
+
+ import torch
+
+ # `bitsandbytes` versions older than 0.43.1 eagerly require CUDA at import time,
+ # so those versions of the library are practically only available when CUDA is too.
+ if version.parse(importlib.metadata.version("bitsandbytes")) < version.parse("0.43.1"):
+ return torch.cuda.is_available()
+
+ # Newer versions of `bitsandbytes` can be imported on systems without CUDA.
+ return True
+
+
+def is_bitsandbytes_multi_backend_available() -> bool:
+ if not is_bitsandbytes_available():
+ return False
+
+ import bitsandbytes as bnb
+
+ return "multi_backend" in getattr(bnb, "features", set())
+
+
+def is_flash_attn_2_available():
+ if not is_torch_available():
+ return False
+
+ if not _is_package_available("flash_attn"):
+ return False
+
+ # Let's add an extra check to see if cuda is available
+ import torch
+
+ if not (torch.cuda.is_available() or is_torch_mlu_available()):
+ return False
+
+ if torch.version.cuda:
+ return version.parse(importlib.metadata.version("flash_attn")) >= version.parse("2.1.0")
+ elif torch.version.hip:
+ # TODO: Bump the requirement to 2.1.0 once released in https://github.com/ROCmSoftwarePlatform/flash-attention
+ return version.parse(importlib.metadata.version("flash_attn")) >= version.parse("2.0.4")
+ elif is_torch_mlu_available():
+ return version.parse(importlib.metadata.version("flash_attn")) >= version.parse("2.3.3")
+ else:
+ return False
+
+
+@lru_cache()
+def is_flash_attn_greater_or_equal_2_10():
+ if not _is_package_available("flash_attn"):
+ return False
+
+ return version.parse(importlib.metadata.version("flash_attn")) >= version.parse("2.1.0")
+
+
+@lru_cache()
+def is_flash_attn_greater_or_equal(library_version: str):
+ if not _is_package_available("flash_attn"):
+ return False
+
+ return version.parse(importlib.metadata.version("flash_attn")) >= version.parse(library_version)
+
+
+@lru_cache()
+def is_torch_greater_or_equal(library_version: str, accept_dev: bool = False):
+ """
+ Accepts a library version and returns True if the current version of the library is greater than or equal to the
+ given version. If `accept_dev` is True, it will also accept development versions (e.g. 2.7.0.dev20250320 matches
+ 2.7.0).
+ """
+ if not _is_package_available("torch"):
+ return False
+
+ if accept_dev:
+ return version.parse(version.parse(importlib.metadata.version("torch")).base_version) >= version.parse(
+ library_version
+ )
+ else:
+ return version.parse(importlib.metadata.version("torch")) >= version.parse(library_version)
+
+
+def is_torchdistx_available():
+ return _torchdistx_available
+
+
+def is_faiss_available():
+ return _faiss_available
+
+
+def is_scipy_available():
+ return _scipy_available
+
+
+def is_sklearn_available():
+ return _sklearn_available
+
+
+def is_sentencepiece_available():
+ return _sentencepiece_available
+
+
+def is_seqio_available():
+ return _is_seqio_available
+
+
+def is_gguf_available(min_version: str = GGUF_MIN_VERSION):
+ return _is_gguf_available and version.parse(_gguf_version) >= version.parse(min_version)
+
+
+def is_protobuf_available():
+ if importlib.util.find_spec("google") is None:
+ return False
+ return importlib.util.find_spec("google.protobuf") is not None
+
+
+def is_fsdp_available(min_version: str = FSDP_MIN_VERSION):
+ return is_torch_available() and version.parse(_torch_version) >= version.parse(min_version)
+
+
+def is_optimum_available():
+ return _optimum_available
+
+
+def is_auto_awq_available():
+ return _auto_awq_available
+
+
+def is_auto_round_available(min_version: str = AUTOROUND_MIN_VERSION):
+ return _auto_round_available and version.parse(_auto_round_version) >= version.parse(min_version)
+
+
+def is_optimum_quanto_available():
+ # `importlib.metadata.version` doesn't work with `optimum.quanto`, need to put `optimum_quanto`
+ return _is_optimum_quanto_available
+
+
+def is_quark_available():
+ return _quark_available
+
+
+def is_compressed_tensors_available():
+ return _compressed_tensors_available
+
+
+def is_auto_gptq_available():
+ return _auto_gptq_available
+
+
+def is_gptqmodel_available():
+ return _gptqmodel_available
+
+
+def is_eetq_available():
+ return _eetq_available
+
+
+def is_fbgemm_gpu_available():
+ return _fbgemm_gpu_available
+
+
+def is_levenshtein_available():
+ return _levenshtein_available
+
+
+def is_optimum_neuron_available():
+ return _optimum_available and _is_package_available("optimum.neuron")
+
+
+def is_safetensors_available():
+ return _safetensors_available
+
+
+def is_tokenizers_available():
+ return _tokenizers_available
+
+
+@lru_cache
+def is_vision_available():
+ _pil_available = importlib.util.find_spec("PIL") is not None
+ if _pil_available:
+ try:
+ package_version = importlib.metadata.version("Pillow")
+ except importlib.metadata.PackageNotFoundError:
+ try:
+ package_version = importlib.metadata.version("Pillow-SIMD")
+ except importlib.metadata.PackageNotFoundError:
+ return False
+ logger.debug(f"Detected PIL version {package_version}")
+ return _pil_available
+
+
+def is_pytesseract_available():
+ return _pytesseract_available
+
+
+def is_pytest_available():
+ return _pytest_available
+
+
+def is_spacy_available():
+ return _spacy_available
+
+
+def is_tensorflow_text_available():
+ return is_tf_available() and _tensorflow_text_available
+
+
+def is_keras_nlp_available():
+ return is_tensorflow_text_available() and _keras_nlp_available
+
+
+def is_in_notebook():
+ try:
+ # Test adapted from tqdm.autonotebook: https://github.com/tqdm/tqdm/blob/master/tqdm/autonotebook.py
+ get_ipython = sys.modules["IPython"].get_ipython
+ if "IPKernelApp" not in get_ipython().config:
+ raise ImportError("console")
+ # Removed the lines to include VSCode
+ if "DATABRICKS_RUNTIME_VERSION" in os.environ and os.environ["DATABRICKS_RUNTIME_VERSION"] < "11.0":
+ # Databricks Runtime 11.0 and above uses IPython kernel by default so it should be compatible with Jupyter notebook
+ # https://docs.microsoft.com/en-us/azure/databricks/notebooks/ipython-kernel
+ raise ImportError("databricks")
+
+ return importlib.util.find_spec("IPython") is not None
+ except (AttributeError, ImportError, KeyError):
+ return False
+
+
+def is_pytorch_quantization_available():
+ return _pytorch_quantization_available
+
+
+def is_tensorflow_probability_available():
+ return _tensorflow_probability_available
+
+
+def is_pandas_available():
+ return _pandas_available
+
+
+def is_sagemaker_dp_enabled():
+ # Get the sagemaker specific env variable.
+ sagemaker_params = os.getenv("SM_FRAMEWORK_PARAMS", "{}")
+ try:
+ # Parse it and check the field "sagemaker_distributed_dataparallel_enabled".
+ sagemaker_params = json.loads(sagemaker_params)
+ if not sagemaker_params.get("sagemaker_distributed_dataparallel_enabled", False):
+ return False
+ except json.JSONDecodeError:
+ return False
+ # Lastly, check if the `smdistributed` module is present.
+ return _smdistributed_available
+
+
+def is_sagemaker_mp_enabled():
+ # Get the sagemaker specific mp parameters from smp_options variable.
+ smp_options = os.getenv("SM_HP_MP_PARAMETERS", "{}")
+ try:
+ # Parse it and check the field "partitions" is included, it is required for model parallel.
+ smp_options = json.loads(smp_options)
+ if "partitions" not in smp_options:
+ return False
+ except json.JSONDecodeError:
+ return False
+
+ # Get the sagemaker specific framework parameters from mpi_options variable.
+ mpi_options = os.getenv("SM_FRAMEWORK_PARAMS", "{}")
+ try:
+ # Parse it and check the field "sagemaker_distributed_dataparallel_enabled".
+ mpi_options = json.loads(mpi_options)
+ if not mpi_options.get("sagemaker_mpi_enabled", False):
+ return False
+ except json.JSONDecodeError:
+ return False
+ # Lastly, check if the `smdistributed` module is present.
+ return _smdistributed_available
+
+
+def is_training_run_on_sagemaker():
+ return "SAGEMAKER_JOB_NAME" in os.environ
+
+
+def is_soundfile_available():
+ return _soundfile_available
+
+
+def is_timm_available():
+ return _timm_available
+
+
+def is_natten_available():
+ return _natten_available
+
+
+def is_nltk_available():
+ return _nltk_available
+
+
+def is_torchaudio_available():
+ return _torchaudio_available
+
+
+def is_torchao_available(min_version: str = TORCHAO_MIN_VERSION):
+ return _torchao_available and version.parse(_torchao_version) >= version.parse(min_version)
+
+
+def is_speech_available():
+ # For now this depends on torchaudio but the exact dependency might evolve in the future.
+ return _torchaudio_available
+
+
+def is_spqr_available():
+ return _spqr_available
+
+
+def is_phonemizer_available():
+ return _phonemizer_available
+
+
+def is_uroman_available():
+ return _uroman_available
+
+
+def torch_only_method(fn):
+ def wrapper(*args, **kwargs):
+ if not _torch_available:
+ raise ImportError(
+ "You need to install pytorch to use this method or class, "
+ "or activate it with environment variables USE_TORCH=1 and USE_TF=0."
+ )
+ else:
+ return fn(*args, **kwargs)
+
+ return wrapper
+
+
+def is_ccl_available():
+ return _is_ccl_available
+
+
+def is_sudachi_available():
+ return _sudachipy_available
+
+
+def get_sudachi_version():
+ return _sudachipy_version
+
+
+def is_sudachi_projection_available():
+ if not is_sudachi_available():
+ return False
+
+ # NOTE: We require sudachipy>=0.6.8 to use projection option in sudachi_kwargs for the constructor of BertJapaneseTokenizer.
+ # - `projection` option is not supported in sudachipy<0.6.8, see https://github.com/WorksApplications/sudachi.rs/issues/230
+ return version.parse(_sudachipy_version) >= version.parse("0.6.8")
+
+
+def is_jumanpp_available():
+ return (importlib.util.find_spec("rhoknp") is not None) and (shutil.which("jumanpp") is not None)
+
+
+def is_cython_available():
+ return importlib.util.find_spec("pyximport") is not None
+
+
+def is_jieba_available():
+ return _jieba_available
+
+
+def is_jinja_available():
+ return _jinja_available
+
+
+def is_mlx_available():
+ return _mlx_available
+
+
+def is_num2words_available():
+ return _num2words_available
+
+
+def is_tiktoken_available():
+ return _tiktoken_available and _blobfile_available
+
+
+def is_liger_kernel_available():
+ if not _liger_kernel_available:
+ return False
+
+ return version.parse(importlib.metadata.version("liger_kernel")) >= version.parse("0.3.0")
+
+
+def is_triton_available():
+ return _triton_available
+
+
+def is_rich_available():
+ return _rich_available
+
+
+# docstyle-ignore
+AV_IMPORT_ERROR = """
+{0} requires the PyAv library but it was not found in your environment. You can install it with:
+```
+pip install av
+```
+Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+YT_DLP_IMPORT_ERROR = """
+{0} requires the YT-DLP library but it was not found in your environment. You can install it with:
+```
+pip install yt-dlp
+```
+Please note that you may need to restart your runtime after installation.
+"""
+
+DECORD_IMPORT_ERROR = """
+{0} requires the PyAv library but it was not found in your environment. You can install it with:
+```
+pip install decord
+```
+Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+CV2_IMPORT_ERROR = """
+{0} requires the OpenCV library but it was not found in your environment. You can install it with:
+```
+pip install opencv-python
+```
+Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+DATASETS_IMPORT_ERROR = """
+{0} requires the 🤗 Datasets library but it was not found in your environment. You can install it with:
+```
+pip install datasets
+```
+In a notebook or a colab, you can install it by executing a cell with
+```
+!pip install datasets
+```
+then restarting your kernel.
+
+Note that if you have a local folder named `datasets` or a local python file named `datasets.py` in your current
+working directory, python may try to import this instead of the 🤗 Datasets library. You should rename this folder or
+that python file if that's the case. Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+TOKENIZERS_IMPORT_ERROR = """
+{0} requires the 🤗 Tokenizers library but it was not found in your environment. You can install it with:
+```
+pip install tokenizers
+```
+In a notebook or a colab, you can install it by executing a cell with
+```
+!pip install tokenizers
+```
+Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+SENTENCEPIECE_IMPORT_ERROR = """
+{0} requires the SentencePiece library but it was not found in your environment. Checkout the instructions on the
+installation page of its repo: https://github.com/google/sentencepiece#installation and follow the ones
+that match your environment. Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+PROTOBUF_IMPORT_ERROR = """
+{0} requires the protobuf library but it was not found in your environment. Checkout the instructions on the
+installation page of its repo: https://github.com/protocolbuffers/protobuf/tree/master/python#installation and follow the ones
+that match your environment. Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+FAISS_IMPORT_ERROR = """
+{0} requires the faiss library but it was not found in your environment. Checkout the instructions on the
+installation page of its repo: https://github.com/facebookresearch/faiss/blob/master/INSTALL.md and follow the ones
+that match your environment. Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+PYTORCH_IMPORT_ERROR = """
+{0} requires the PyTorch library but it was not found in your environment. Checkout the instructions on the
+installation page: https://pytorch.org/get-started/locally/ and follow the ones that match your environment.
+Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+TORCHVISION_IMPORT_ERROR = """
+{0} requires the Torchvision library but it was not found in your environment. Checkout the instructions on the
+installation page: https://pytorch.org/get-started/locally/ and follow the ones that match your environment.
+Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+PYTORCH_IMPORT_ERROR_WITH_TF = """
+{0} requires the PyTorch library but it was not found in your environment.
+However, we were able to find a TensorFlow installation. TensorFlow classes begin
+with "TF", but are otherwise identically named to our PyTorch classes. This
+means that the TF equivalent of the class you tried to import would be "TF{0}".
+If you want to use TensorFlow, please use TF classes instead!
+
+If you really do want to use PyTorch please go to
+https://pytorch.org/get-started/locally/ and follow the instructions that
+match your environment.
+"""
+
+# docstyle-ignore
+TF_IMPORT_ERROR_WITH_PYTORCH = """
+{0} requires the TensorFlow library but it was not found in your environment.
+However, we were able to find a PyTorch installation. PyTorch classes do not begin
+with "TF", but are otherwise identically named to our TF classes.
+If you want to use PyTorch, please use those classes instead!
+
+If you really do want to use TensorFlow, please follow the instructions on the
+installation page https://www.tensorflow.org/install that match your environment.
+"""
+
+# docstyle-ignore
+BS4_IMPORT_ERROR = """
+{0} requires the Beautiful Soup library but it was not found in your environment. You can install it with pip:
+`pip install beautifulsoup4`. Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+SKLEARN_IMPORT_ERROR = """
+{0} requires the scikit-learn library but it was not found in your environment. You can install it with:
+```
+pip install -U scikit-learn
+```
+In a notebook or a colab, you can install it by executing a cell with
+```
+!pip install -U scikit-learn
+```
+Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+TENSORFLOW_IMPORT_ERROR = """
+{0} requires the TensorFlow library but it was not found in your environment. Checkout the instructions on the
+installation page: https://www.tensorflow.org/install and follow the ones that match your environment.
+Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+DETECTRON2_IMPORT_ERROR = """
+{0} requires the detectron2 library but it was not found in your environment. Checkout the instructions on the
+installation page: https://github.com/facebookresearch/detectron2/blob/master/INSTALL.md and follow the ones
+that match your environment. Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+FLAX_IMPORT_ERROR = """
+{0} requires the FLAX library but it was not found in your environment. Checkout the instructions on the
+installation page: https://github.com/google/flax and follow the ones that match your environment.
+Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+FTFY_IMPORT_ERROR = """
+{0} requires the ftfy library but it was not found in your environment. Checkout the instructions on the
+installation section: https://github.com/rspeer/python-ftfy/tree/master#installing and follow the ones
+that match your environment. Please note that you may need to restart your runtime after installation.
+"""
+
+LEVENSHTEIN_IMPORT_ERROR = """
+{0} requires the python-Levenshtein library but it was not found in your environment. You can install it with pip: `pip
+install python-Levenshtein`. Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+G2P_EN_IMPORT_ERROR = """
+{0} requires the g2p-en library but it was not found in your environment. You can install it with pip:
+`pip install g2p-en`. Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+PYTORCH_QUANTIZATION_IMPORT_ERROR = """
+{0} requires the pytorch-quantization library but it was not found in your environment. You can install it with pip:
+`pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com`
+Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+TENSORFLOW_PROBABILITY_IMPORT_ERROR = """
+{0} requires the tensorflow_probability library but it was not found in your environment. You can install it with pip as
+explained here: https://github.com/tensorflow/probability. Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+TENSORFLOW_TEXT_IMPORT_ERROR = """
+{0} requires the tensorflow_text library but it was not found in your environment. You can install it with pip as
+explained here: https://www.tensorflow.org/text/guide/tf_text_intro.
+Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+TORCHAUDIO_IMPORT_ERROR = """
+{0} requires the torchaudio library but it was not found in your environment. Please install it and restart your
+runtime.
+"""
+
+# docstyle-ignore
+PANDAS_IMPORT_ERROR = """
+{0} requires the pandas library but it was not found in your environment. You can install it with pip as
+explained here: https://pandas.pydata.org/pandas-docs/stable/getting_started/install.html.
+Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+PHONEMIZER_IMPORT_ERROR = """
+{0} requires the phonemizer library but it was not found in your environment. You can install it with pip:
+`pip install phonemizer`. Please note that you may need to restart your runtime after installation.
+"""
+# docstyle-ignore
+UROMAN_IMPORT_ERROR = """
+{0} requires the uroman library but it was not found in your environment. You can install it with pip:
+`pip install uroman`. Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+SACREMOSES_IMPORT_ERROR = """
+{0} requires the sacremoses library but it was not found in your environment. You can install it with pip:
+`pip install sacremoses`. Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+SCIPY_IMPORT_ERROR = """
+{0} requires the scipy library but it was not found in your environment. You can install it with pip:
+`pip install scipy`. Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+KERAS_NLP_IMPORT_ERROR = """
+{0} requires the keras_nlp library but it was not found in your environment. You can install it with pip.
+Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+SPEECH_IMPORT_ERROR = """
+{0} requires the torchaudio library but it was not found in your environment. You can install it with pip:
+`pip install torchaudio`. Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+TIMM_IMPORT_ERROR = """
+{0} requires the timm library but it was not found in your environment. You can install it with pip:
+`pip install timm`. Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+NATTEN_IMPORT_ERROR = """
+{0} requires the natten library but it was not found in your environment. You can install it by referring to:
+shi-labs.com/natten . You can also install it with pip (may take longer to build):
+`pip install natten`. Please note that you may need to restart your runtime after installation.
+"""
+
+NUMEXPR_IMPORT_ERROR = """
+{0} requires the numexpr library but it was not found in your environment. You can install it by referring to:
+https://numexpr.readthedocs.io/en/latest/index.html.
+"""
+
+
+# docstyle-ignore
+NLTK_IMPORT_ERROR = """
+{0} requires the NLTK library but it was not found in your environment. You can install it by referring to:
+https://www.nltk.org/install.html. Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+VISION_IMPORT_ERROR = """
+{0} requires the PIL library but it was not found in your environment. You can install it with pip:
+`pip install pillow`. Please note that you may need to restart your runtime after installation.
+"""
+
+
+# docstyle-ignore
+PYTESSERACT_IMPORT_ERROR = """
+{0} requires the PyTesseract library but it was not found in your environment. You can install it with pip:
+`pip install pytesseract`. Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+PYCTCDECODE_IMPORT_ERROR = """
+{0} requires the pyctcdecode library but it was not found in your environment. You can install it with pip:
+`pip install pyctcdecode`. Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+ACCELERATE_IMPORT_ERROR = """
+{0} requires the accelerate library >= {ACCELERATE_MIN_VERSION} it was not found in your environment.
+You can install or update it with pip: `pip install --upgrade accelerate`. Please note that you may need to restart your
+runtime after installation.
+"""
+
+# docstyle-ignore
+CCL_IMPORT_ERROR = """
+{0} requires the torch ccl library but it was not found in your environment. You can install it with pip:
+`pip install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable`
+Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+ESSENTIA_IMPORT_ERROR = """
+{0} requires essentia library. But that was not found in your environment. You can install them with pip:
+`pip install essentia==2.1b6.dev1034`
+Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+LIBROSA_IMPORT_ERROR = """
+{0} requires thes librosa library. But that was not found in your environment. You can install them with pip:
+`pip install librosa`
+Please note that you may need to restart your runtime after installation.
+"""
+
+# docstyle-ignore
+PRETTY_MIDI_IMPORT_ERROR = """
+{0} requires thes pretty_midi library. But that was not found in your environment. You can install them with pip:
+`pip install pretty_midi`
+Please note that you may need to restart your runtime after installation.
+"""
+
+
+CYTHON_IMPORT_ERROR = """
+{0} requires the Cython library but it was not found in your environment. You can install it with pip: `pip install
+Cython`. Please note that you may need to restart your runtime after installation.
+"""
+
+JIEBA_IMPORT_ERROR = """
+{0} requires the jieba library but it was not found in your environment. You can install it with pip: `pip install
+jieba`. Please note that you may need to restart your runtime after installation.
+"""
+
+PEFT_IMPORT_ERROR = """
+{0} requires the peft library but it was not found in your environment. You can install it with pip: `pip install
+peft`. Please note that you may need to restart your runtime after installation.
+"""
+
+JINJA_IMPORT_ERROR = """
+{0} requires the jinja library but it was not found in your environment. You can install it with pip: `pip install
+jinja2`. Please note that you may need to restart your runtime after installation.
+"""
+
+RICH_IMPORT_ERROR = """
+{0} requires the rich library but it was not found in your environment. You can install it with pip: `pip install
+rich`. Please note that you may need to restart your runtime after installation.
+"""
+
+BACKENDS_MAPPING = OrderedDict(
+ [
+ ("av", (is_av_available, AV_IMPORT_ERROR)),
+ ("bs4", (is_bs4_available, BS4_IMPORT_ERROR)),
+ ("cv2", (is_cv2_available, CV2_IMPORT_ERROR)),
+ ("datasets", (is_datasets_available, DATASETS_IMPORT_ERROR)),
+ ("decord", (is_decord_available, DECORD_IMPORT_ERROR)),
+ ("detectron2", (is_detectron2_available, DETECTRON2_IMPORT_ERROR)),
+ ("essentia", (is_essentia_available, ESSENTIA_IMPORT_ERROR)),
+ ("faiss", (is_faiss_available, FAISS_IMPORT_ERROR)),
+ ("flax", (is_flax_available, FLAX_IMPORT_ERROR)),
+ ("ftfy", (is_ftfy_available, FTFY_IMPORT_ERROR)),
+ ("g2p_en", (is_g2p_en_available, G2P_EN_IMPORT_ERROR)),
+ ("pandas", (is_pandas_available, PANDAS_IMPORT_ERROR)),
+ ("phonemizer", (is_phonemizer_available, PHONEMIZER_IMPORT_ERROR)),
+ ("uroman", (is_uroman_available, UROMAN_IMPORT_ERROR)),
+ ("pretty_midi", (is_pretty_midi_available, PRETTY_MIDI_IMPORT_ERROR)),
+ ("levenshtein", (is_levenshtein_available, LEVENSHTEIN_IMPORT_ERROR)),
+ ("librosa", (is_librosa_available, LIBROSA_IMPORT_ERROR)),
+ ("protobuf", (is_protobuf_available, PROTOBUF_IMPORT_ERROR)),
+ ("pyctcdecode", (is_pyctcdecode_available, PYCTCDECODE_IMPORT_ERROR)),
+ ("pytesseract", (is_pytesseract_available, PYTESSERACT_IMPORT_ERROR)),
+ ("sacremoses", (is_sacremoses_available, SACREMOSES_IMPORT_ERROR)),
+ ("pytorch_quantization", (is_pytorch_quantization_available, PYTORCH_QUANTIZATION_IMPORT_ERROR)),
+ ("sentencepiece", (is_sentencepiece_available, SENTENCEPIECE_IMPORT_ERROR)),
+ ("sklearn", (is_sklearn_available, SKLEARN_IMPORT_ERROR)),
+ ("speech", (is_speech_available, SPEECH_IMPORT_ERROR)),
+ ("tensorflow_probability", (is_tensorflow_probability_available, TENSORFLOW_PROBABILITY_IMPORT_ERROR)),
+ ("tf", (is_tf_available, TENSORFLOW_IMPORT_ERROR)),
+ ("tensorflow_text", (is_tensorflow_text_available, TENSORFLOW_TEXT_IMPORT_ERROR)),
+ ("timm", (is_timm_available, TIMM_IMPORT_ERROR)),
+ ("torchaudio", (is_torchaudio_available, TORCHAUDIO_IMPORT_ERROR)),
+ ("natten", (is_natten_available, NATTEN_IMPORT_ERROR)),
+ ("nltk", (is_nltk_available, NLTK_IMPORT_ERROR)),
+ ("tokenizers", (is_tokenizers_available, TOKENIZERS_IMPORT_ERROR)),
+ ("torch", (is_torch_available, PYTORCH_IMPORT_ERROR)),
+ ("torchvision", (is_torchvision_available, TORCHVISION_IMPORT_ERROR)),
+ ("vision", (is_vision_available, VISION_IMPORT_ERROR)),
+ ("scipy", (is_scipy_available, SCIPY_IMPORT_ERROR)),
+ ("accelerate", (is_accelerate_available, ACCELERATE_IMPORT_ERROR)),
+ ("oneccl_bind_pt", (is_ccl_available, CCL_IMPORT_ERROR)),
+ ("cython", (is_cython_available, CYTHON_IMPORT_ERROR)),
+ ("jieba", (is_jieba_available, JIEBA_IMPORT_ERROR)),
+ ("peft", (is_peft_available, PEFT_IMPORT_ERROR)),
+ ("jinja", (is_jinja_available, JINJA_IMPORT_ERROR)),
+ ("yt_dlp", (is_yt_dlp_available, YT_DLP_IMPORT_ERROR)),
+ ("rich", (is_rich_available, RICH_IMPORT_ERROR)),
+ ("keras_nlp", (is_keras_nlp_available, KERAS_NLP_IMPORT_ERROR)),
+ ]
+)
+
+
+def requires_backends(obj, backends):
+ if not isinstance(backends, (list, tuple)):
+ backends = [backends]
+
+ name = obj.__name__ if hasattr(obj, "__name__") else obj.__class__.__name__
+
+ # Raise an error for users who might not realize that classes without "TF" are torch-only
+ if "torch" in backends and "tf" not in backends and not is_torch_available() and is_tf_available():
+ raise ImportError(PYTORCH_IMPORT_ERROR_WITH_TF.format(name))
+
+ # Raise the inverse error for PyTorch users trying to load TF classes
+ if "tf" in backends and "torch" not in backends and is_torch_available() and not is_tf_available():
+ raise ImportError(TF_IMPORT_ERROR_WITH_PYTORCH.format(name))
+
+ checks = (BACKENDS_MAPPING[backend] for backend in backends)
+ failed = [msg.format(name) for available, msg in checks if not available()]
+ if failed:
+ raise ImportError("".join(failed))
+
+
+class DummyObject(type):
+ """
+ Metaclass for the dummy objects. Any class inheriting from it will return the ImportError generated by
+ `requires_backend` each time a user tries to access any method of that class.
+ """
+
+ is_dummy = True
+
+ def __getattribute__(cls, key):
+ if (key.startswith("_") and key != "_from_config") or key == "is_dummy" or key == "mro" or key == "call":
+ return super().__getattribute__(key)
+ requires_backends(cls, cls._backends)
+
+
+def is_torch_fx_proxy(x):
+ if is_torch_fx_available():
+ import torch.fx
+
+ return isinstance(x, torch.fx.Proxy)
+ return False
+
+
+BACKENDS_T = FrozenSet[str]
+IMPORT_STRUCTURE_T = Dict[BACKENDS_T, Dict[str, Set[str]]]
+
+
+class _LazyModule(ModuleType):
+ """
+ Module class that surfaces all objects but only performs associated imports when the objects are requested.
+ """
+
+ # Very heavily inspired by optuna.integration._IntegrationModule
+ # https://github.com/optuna/optuna/blob/master/optuna/integration/__init__.py
+ def __init__(
+ self,
+ name: str,
+ module_file: str,
+ import_structure: IMPORT_STRUCTURE_T,
+ module_spec: Optional[importlib.machinery.ModuleSpec] = None,
+ extra_objects: Dict[str, object] = None,
+ ):
+ super().__init__(name)
+
+ self._object_missing_backend = {}
+ if any(isinstance(key, frozenset) for key in import_structure.keys()):
+ self._modules = set()
+ self._class_to_module = {}
+ self.__all__ = []
+
+ _import_structure = {}
+
+ for backends, module in import_structure.items():
+ missing_backends = []
+
+ # This ensures that if a module is importable, then all other keys of the module are importable.
+ # As an example, in module.keys() we might have the following:
+ #
+ # dict_keys(['models.nllb_moe.configuration_nllb_moe', 'models.sew_d.configuration_sew_d'])
+ #
+ # with this, we don't only want to be able to import these explicitely, we want to be able to import
+ # every intermediate module as well. Therefore, this is what is returned:
+ #
+ # {
+ # 'models.nllb_moe.configuration_nllb_moe',
+ # 'models.sew_d.configuration_sew_d',
+ # 'models',
+ # 'models.sew_d', 'models.nllb_moe'
+ # }
+
+ module_keys = set(
+ chain(*[[k.rsplit(".", i)[0] for i in range(k.count(".") + 1)] for k in list(module.keys())])
+ )
+ for backend in backends:
+ if backend not in BACKENDS_MAPPING:
+ raise ValueError(
+ f"Error: the following backend: '{backend}' was specified around object {module} but isn't specified in the backends mapping."
+ )
+ callable, error = BACKENDS_MAPPING[backend]
+ if not callable():
+ missing_backends.append(backend)
+ self._modules = self._modules.union(module_keys)
+
+ for key, values in module.items():
+ if len(missing_backends):
+ self._object_missing_backend[key] = missing_backends
+
+ for value in values:
+ self._class_to_module[value] = key
+ if len(missing_backends):
+ self._object_missing_backend[value] = missing_backends
+ _import_structure.setdefault(key, []).extend(values)
+
+ # Needed for autocompletion in an IDE
+ self.__all__.extend(module_keys | set(chain(*module.values())))
+
+ self.__file__ = module_file
+ self.__spec__ = module_spec
+ self.__path__ = [os.path.dirname(module_file)]
+ self._objects = {} if extra_objects is None else extra_objects
+ self._name = name
+ self._import_structure = _import_structure
+
+ # This can be removed once every exportable object has a `require()` require.
+ else:
+ self._modules = set(import_structure.keys())
+ self._class_to_module = {}
+ for key, values in import_structure.items():
+ for value in values:
+ self._class_to_module[value] = key
+ # Needed for autocompletion in an IDE
+ self.__all__ = list(import_structure.keys()) + list(chain(*import_structure.values()))
+ self.__file__ = module_file
+ self.__spec__ = module_spec
+ self.__path__ = [os.path.dirname(module_file)]
+ self._objects = {} if extra_objects is None else extra_objects
+ self._name = name
+ self._import_structure = import_structure
+
+ # Needed for autocompletion in an IDE
+ def __dir__(self):
+ result = super().__dir__()
+ # The elements of self.__all__ that are submodules may or may not be in the dir already, depending on whether
+ # they have been accessed or not. So we only add the elements of self.__all__ that are not already in the dir.
+ for attr in self.__all__:
+ if attr not in result:
+ result.append(attr)
+ return result
+
+ def __getattr__(self, name: str) -> Any:
+ if name in self._objects:
+ return self._objects[name]
+ if name in self._object_missing_backend.keys():
+ missing_backends = self._object_missing_backend[name]
+
+ class Placeholder(metaclass=DummyObject):
+ _backends = missing_backends
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, missing_backends)
+
+ def call(self, *args, **kwargs):
+ pass
+
+ Placeholder.__name__ = name
+
+ if name not in self._class_to_module:
+ module_name = f"transformers.{name}"
+ else:
+ module_name = self._class_to_module[name]
+ if not module_name.startswith("transformers."):
+ module_name = f"transformers.{module_name}"
+
+ Placeholder.__module__ = module_name
+
+ value = Placeholder
+ elif name in self._class_to_module.keys():
+ module = self._get_module(self._class_to_module[name])
+ value = getattr(module, name)
+ elif name in self._modules:
+ value = self._get_module(name)
+ else:
+ raise AttributeError(f"module {self.__name__} has no attribute {name}")
+
+ setattr(self, name, value)
+ return value
+
+ def _get_module(self, module_name: str):
+ try:
+ return importlib.import_module("." + module_name, self.__name__)
+ except Exception as e:
+ raise RuntimeError(
+ f"Failed to import {self.__name__}.{module_name} because of the following error (look up to see its"
+ f" traceback):\n{e}"
+ ) from e
+
+ def __reduce__(self):
+ return (self.__class__, (self._name, self.__file__, self._import_structure))
+
+
+class OptionalDependencyNotAvailable(BaseException):
+ """Internally used error class for signalling an optional dependency was not found."""
+
+
+def direct_transformers_import(path: str, file="__init__.py") -> ModuleType:
+ """Imports transformers directly
+
+ Args:
+ path (`str`): The path to the source file
+ file (`str`, *optional*): The file to join with the path. Defaults to "__init__.py".
+
+ Returns:
+ `ModuleType`: The resulting imported module
+ """
+ name = "transformers"
+ location = os.path.join(path, file)
+ spec = importlib.util.spec_from_file_location(name, location, submodule_search_locations=[path])
+ module = importlib.util.module_from_spec(spec)
+ spec.loader.exec_module(module)
+ module = sys.modules[name]
+ return module
+
+
+def requires(*, backends=()):
+ """
+ This decorator enables two things:
+ - Attaching a `__backends` tuple to an object to see what are the necessary backends for it
+ to execute correctly without instantiating it
+ - The '@requires' string is used to dynamically import objects
+ """
+ for backend in backends:
+ if backend not in BACKENDS_MAPPING:
+ raise ValueError(f"Backend should be defined in the BACKENDS_MAPPING. Offending backend: {backend}")
+
+ if not isinstance(backends, tuple):
+ raise ValueError("Backends should be a tuple.")
+
+ def inner_fn(fun):
+ fun.__backends = backends
+ return fun
+
+ return inner_fn
+
+
+BASE_FILE_REQUIREMENTS = {
+ lambda e: "modeling_tf_" in e: ("tf",),
+ lambda e: "modeling_flax_" in e: ("flax",),
+ lambda e: "modeling_" in e: ("torch",),
+ lambda e: e.startswith("tokenization_") and e.endswith("_fast"): ("tokenizers",),
+ lambda e: e.startswith("image_processing_") and e.endswith("_fast"): ("vision", "torch", "torchvision"),
+ lambda e: e.startswith("image_processing_"): ("vision",),
+}
+
+
+def fetch__all__(file_content):
+ """
+ Returns the content of the __all__ variable in the file content.
+ Returns None if not defined, otherwise returns a list of strings.
+ """
+
+ if "__all__" not in file_content:
+ return []
+
+ start_index = None
+ lines = file_content.splitlines()
+ for index, line in enumerate(lines):
+ if line.startswith("__all__"):
+ start_index = index
+
+ # There is no line starting with `__all__`
+ if start_index is None:
+ return []
+
+ lines = lines[start_index:]
+
+ if not lines[0].startswith("__all__"):
+ raise ValueError(
+ "fetch__all__ accepts a list of lines, with the first line being the __all__ variable declaration"
+ )
+
+ # __all__ is defined on a single line
+ if lines[0].endswith("]"):
+ return [obj.strip("\"' ") for obj in lines[0].split("=")[1].strip(" []").split(",")]
+
+ # __all__ is defined on multiple lines
+ else:
+ _all = []
+ for __all__line_index in range(1, len(lines)):
+ if lines[__all__line_index].strip() == "]":
+ return _all
+ else:
+ _all.append(lines[__all__line_index].strip("\"', "))
+
+ return _all
+
+
+@lru_cache()
+def create_import_structure_from_path(module_path):
+ """
+ This method takes the path to a file/a folder and returns the import structure.
+ If a file is given, it will return the import structure of the parent folder.
+
+ Import structures are designed to be digestible by `_LazyModule` objects. They are
+ created from the __all__ definitions in each files as well as the `@require` decorators
+ above methods and objects.
+
+ The import structure allows explicit display of the required backends for a given object.
+ These backends are specified in two ways:
+
+ 1. Through their `@require`, if they are exported with that decorator. This `@require` decorator
+ accepts a `backend` tuple kwarg mentioning which backends are required to run this object.
+
+ 2. If an object is defined in a file with "default" backends, it will have, at a minimum, this
+ backend specified. The default backends are defined according to the filename:
+
+ - If a file is named like `modeling_*.py`, it will have a `torch` backend
+ - If a file is named like `modeling_tf_*.py`, it will have a `tf` backend
+ - If a file is named like `modeling_flax_*.py`, it will have a `flax` backend
+ - If a file is named like `tokenization_*_fast.py`, it will have a `tokenizers` backend
+ - If a file is named like `image_processing*_fast.py`, it will have a `torchvision` + `torch` backend
+
+ Backends serve the purpose of displaying a clear error message to the user in case the backends are not installed.
+ Should an object be imported without its required backends being in the environment, any attempt to use the
+ object will raise an error mentioning which backend(s) should be added to the environment in order to use
+ that object.
+
+ Here's an example of an input import structure at the src.transformers.models level:
+
+ {
+ 'albert': {
+ frozenset(): {
+ 'configuration_albert': {'AlbertConfig', 'AlbertOnnxConfig'}
+ },
+ frozenset({'tokenizers'}): {
+ 'tokenization_albert_fast': {'AlbertTokenizerFast'}
+ },
+ },
+ 'align': {
+ frozenset(): {
+ 'configuration_align': {'AlignConfig', 'AlignTextConfig', 'AlignVisionConfig'},
+ 'processing_align': {'AlignProcessor'}
+ },
+ },
+ 'altclip': {
+ frozenset(): {
+ 'configuration_altclip': {'AltCLIPConfig', 'AltCLIPTextConfig', 'AltCLIPVisionConfig'},
+ 'processing_altclip': {'AltCLIPProcessor'},
+ }
+ }
+ }
+ """
+ import_structure = {}
+
+ if os.path.isfile(module_path):
+ module_path = os.path.dirname(module_path)
+
+ directory = module_path
+ adjacent_modules = []
+
+ for f in os.listdir(module_path):
+ if f != "__pycache__" and os.path.isdir(os.path.join(module_path, f)):
+ import_structure[f] = create_import_structure_from_path(os.path.join(module_path, f))
+
+ elif not os.path.isdir(os.path.join(directory, f)):
+ adjacent_modules.append(f)
+
+ # We're only taking a look at files different from __init__.py
+ # We could theoretically require things directly from the __init__.py
+ # files, but this is not supported at this time.
+ if "__init__.py" in adjacent_modules:
+ adjacent_modules.remove("__init__.py")
+
+ # Modular files should not be imported
+ def find_substring(substring, list_):
+ return any(substring in x for x in list_)
+
+ if find_substring("modular_", adjacent_modules) and find_substring("modeling_", adjacent_modules):
+ adjacent_modules = [module for module in adjacent_modules if "modular_" not in module]
+
+ module_requirements = {}
+ for module_name in adjacent_modules:
+ # Only modules ending in `.py` are accepted here.
+ if not module_name.endswith(".py"):
+ continue
+
+ with open(os.path.join(directory, module_name), encoding="utf-8") as f:
+ file_content = f.read()
+
+ # Remove the .py suffix
+ module_name = module_name[:-3]
+
+ previous_line = ""
+ previous_index = 0
+
+ # Some files have some requirements by default.
+ # For example, any file named `modeling_tf_xxx.py`
+ # should have TensorFlow as a required backend.
+ base_requirements = ()
+ for string_check, requirements in BASE_FILE_REQUIREMENTS.items():
+ if string_check(module_name):
+ base_requirements = requirements
+ break
+
+ # Objects that have a `@require` assigned to them will get exported
+ # with the backends specified in the decorator as well as the file backends.
+ exported_objects = set()
+ if "@requires" in file_content:
+ lines = file_content.split("\n")
+ for index, line in enumerate(lines):
+ # This allows exporting items with other decorators. We'll take a look
+ # at the line that follows at the same indentation level.
+ if line.startswith((" ", "\t", "@", ")")) and not line.startswith("@requires"):
+ continue
+
+ # Skipping line enables putting whatever we want between the
+ # export() call and the actual class/method definition.
+ # This is what enables having # Copied from statements, docs, etc.
+ skip_line = False
+
+ if "@requires" in previous_line:
+ skip_line = False
+
+ # Backends are defined on the same line as export
+ if "backends" in previous_line:
+ backends_string = previous_line.split("backends=")[1].split("(")[1].split(")")[0]
+ backends = tuple(sorted([b.strip("'\",") for b in backends_string.split(", ") if b]))
+
+ # Backends are defined in the lines following export, for example such as:
+ # @export(
+ # backends=(
+ # "sentencepiece",
+ # "torch",
+ # "tf",
+ # )
+ # )
+ #
+ # or
+ #
+ # @export(
+ # backends=(
+ # "sentencepiece", "tf"
+ # )
+ # )
+ elif "backends" in lines[previous_index + 1]:
+ backends = []
+ for backend_line in lines[previous_index:index]:
+ if "backends" in backend_line:
+ backend_line = backend_line.split("=")[1]
+ if '"' in backend_line or "'" in backend_line:
+ if ", " in backend_line:
+ backends.extend(backend.strip("()\"', ") for backend in backend_line.split(", "))
+ else:
+ backends.append(backend_line.strip("()\"', "))
+
+ # If the line is only a ')', then we reached the end of the backends and we break.
+ if backend_line.strip() == ")":
+ break
+ backends = tuple(backends)
+
+ # No backends are registered for export
+ else:
+ backends = ()
+
+ backends = frozenset(backends + base_requirements)
+ if backends not in module_requirements:
+ module_requirements[backends] = {}
+ if module_name not in module_requirements[backends]:
+ module_requirements[backends][module_name] = set()
+
+ if not line.startswith("class") and not line.startswith("def"):
+ skip_line = True
+ else:
+ start_index = 6 if line.startswith("class") else 4
+ object_name = line[start_index:].split("(")[0].strip(":")
+ module_requirements[backends][module_name].add(object_name)
+ exported_objects.add(object_name)
+
+ if not skip_line:
+ previous_line = line
+ previous_index = index
+
+ # All objects that are in __all__ should be exported by default.
+ # These objects are exported with the file backends.
+ if "__all__" in file_content:
+ for _all_object in fetch__all__(file_content):
+ if _all_object not in exported_objects:
+ backends = frozenset(base_requirements)
+ if backends not in module_requirements:
+ module_requirements[backends] = {}
+ if module_name not in module_requirements[backends]:
+ module_requirements[backends][module_name] = set()
+
+ module_requirements[backends][module_name].add(_all_object)
+
+ import_structure = {**module_requirements, **import_structure}
+ return import_structure
+
+
+def spread_import_structure(nested_import_structure):
+ """
+ This method takes as input an unordered import structure and brings the required backends at the top-level,
+ aggregating modules and objects under their required backends.
+
+ Here's an example of an input import structure at the src.transformers.models level:
+
+ {
+ 'albert': {
+ frozenset(): {
+ 'configuration_albert': {'AlbertConfig', 'AlbertOnnxConfig'}
+ },
+ frozenset({'tokenizers'}): {
+ 'tokenization_albert_fast': {'AlbertTokenizerFast'}
+ },
+ },
+ 'align': {
+ frozenset(): {
+ 'configuration_align': {'AlignConfig', 'AlignTextConfig', 'AlignVisionConfig'},
+ 'processing_align': {'AlignProcessor'}
+ },
+ },
+ 'altclip': {
+ frozenset(): {
+ 'configuration_altclip': {'AltCLIPConfig', 'AltCLIPTextConfig', 'AltCLIPVisionConfig'},
+ 'processing_altclip': {'AltCLIPProcessor'},
+ }
+ }
+ }
+
+ Here's an example of an output import structure at the src.transformers.models level:
+
+ {
+ frozenset({'tokenizers'}): {
+ 'albert.tokenization_albert_fast': {'AlbertTokenizerFast'}
+ },
+ frozenset(): {
+ 'albert.configuration_albert': {'AlbertConfig', 'AlbertOnnxConfig'},
+ 'align.processing_align': {'AlignProcessor'},
+ 'align.configuration_align': {'AlignConfig', 'AlignTextConfig', 'AlignVisionConfig'},
+ 'altclip.configuration_altclip': {'AltCLIPConfig', 'AltCLIPTextConfig', 'AltCLIPVisionConfig'},
+ 'altclip.processing_altclip': {'AltCLIPProcessor'}
+ }
+ }
+
+ """
+
+ def propagate_frozenset(unordered_import_structure):
+ tuple_first_import_structure = {}
+ for _key, _value in unordered_import_structure.items():
+ if not isinstance(_value, dict):
+ tuple_first_import_structure[_key] = _value
+
+ elif any(isinstance(v, frozenset) for v in _value.keys()):
+ # Here we want to switch around key and v
+ for k, v in _value.items():
+ if isinstance(k, frozenset):
+ if k not in tuple_first_import_structure:
+ tuple_first_import_structure[k] = {}
+ tuple_first_import_structure[k][_key] = v
+
+ else:
+ tuple_first_import_structure[_key] = propagate_frozenset(_value)
+
+ return tuple_first_import_structure
+
+ def flatten_dict(_dict, previous_key=None):
+ items = []
+ for _key, _value in _dict.items():
+ _key = f"{previous_key}.{_key}" if previous_key is not None else _key
+ if isinstance(_value, dict):
+ items.extend(flatten_dict(_value, _key).items())
+ else:
+ items.append((_key, _value))
+ return dict(items)
+
+ # The tuples contain the necessary backends. We want these first, so we propagate them up the
+ # import structure.
+ ordered_import_structure = nested_import_structure
+
+ # 6 is a number that gives us sufficient depth to go through all files and foreseeable folder depths
+ # while not taking too long to parse.
+ for i in range(6):
+ ordered_import_structure = propagate_frozenset(ordered_import_structure)
+
+ # We then flatten the dict so that it references a module path.
+ flattened_import_structure = {}
+ for key, value in ordered_import_structure.copy().items():
+ if isinstance(key, str):
+ del ordered_import_structure[key]
+ else:
+ flattened_import_structure[key] = flatten_dict(value)
+
+ return flattened_import_structure
+
+
+@lru_cache()
+def define_import_structure(module_path: str, prefix: str = None) -> IMPORT_STRUCTURE_T:
+ """
+ This method takes a module_path as input and creates an import structure digestible by a _LazyModule.
+
+ Here's an example of an output import structure at the src.transformers.models level:
+
+ {
+ frozenset({'tokenizers'}): {
+ 'albert.tokenization_albert_fast': {'AlbertTokenizerFast'}
+ },
+ frozenset(): {
+ 'albert.configuration_albert': {'AlbertConfig', 'AlbertOnnxConfig'},
+ 'align.processing_align': {'AlignProcessor'},
+ 'align.configuration_align': {'AlignConfig', 'AlignTextConfig', 'AlignVisionConfig'},
+ 'altclip.configuration_altclip': {'AltCLIPConfig', 'AltCLIPTextConfig', 'AltCLIPVisionConfig'},
+ 'altclip.processing_altclip': {'AltCLIPProcessor'}
+ }
+ }
+
+ The import structure is a dict defined with frozensets as keys, and dicts of strings to sets of objects.
+
+ If `prefix` is not None, it will add that prefix to all keys in the returned dict.
+ """
+ import_structure = create_import_structure_from_path(module_path)
+ spread_dict = spread_import_structure(import_structure)
+
+ if prefix is None:
+ return spread_dict
+ else:
+ spread_dict = {k: {f"{prefix}.{kk}": vv for kk, vv in v.items()} for k, v in spread_dict.items()}
+ return spread_dict
+
+
+def clear_import_cache():
+ """
+ Clear cached Transformers modules to allow reloading modified code.
+
+ This is useful when actively developing/modifying Transformers code.
+ """
+ # Get all transformers modules
+ transformers_modules = [mod_name for mod_name in sys.modules if mod_name.startswith("transformers.")]
+
+ # Remove them from sys.modules
+ for mod_name in transformers_modules:
+ module = sys.modules[mod_name]
+ # Clear _LazyModule caches if applicable
+ if isinstance(module, _LazyModule):
+ module._objects = {} # Clear cached objects
+ del sys.modules[mod_name]
+
+ # Force reload main transformers module
+ if "transformers" in sys.modules:
+ main_module = sys.modules["transformers"]
+ if isinstance(main_module, _LazyModule):
+ main_module._objects = {} # Clear cached objects
+ importlib.reload(main_module)
diff --git a/docs/transformers/build/lib/transformers/utils/logging.py b/docs/transformers/build/lib/transformers/utils/logging.py
new file mode 100644
index 0000000000000000000000000000000000000000..a2915e167a0bcf9d61aeaca269608b98320c3c54
--- /dev/null
+++ b/docs/transformers/build/lib/transformers/utils/logging.py
@@ -0,0 +1,410 @@
+# Copyright 2020 Optuna, Hugging Face
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Logging utilities."""
+
+import functools
+import logging
+import os
+import sys
+import threading
+from logging import (
+ CRITICAL, # NOQA
+ DEBUG, # NOQA
+ ERROR, # NOQA
+ FATAL, # NOQA
+ INFO, # NOQA
+ NOTSET, # NOQA
+ WARN, # NOQA
+ WARNING, # NOQA
+)
+from logging import captureWarnings as _captureWarnings
+from typing import Optional
+
+import huggingface_hub.utils as hf_hub_utils
+from tqdm import auto as tqdm_lib
+
+
+_lock = threading.Lock()
+_default_handler: Optional[logging.Handler] = None
+
+log_levels = {
+ "detail": logging.DEBUG, # will also print filename and line number
+ "debug": logging.DEBUG,
+ "info": logging.INFO,
+ "warning": logging.WARNING,
+ "error": logging.ERROR,
+ "critical": logging.CRITICAL,
+}
+
+_default_log_level = logging.WARNING
+
+_tqdm_active = not hf_hub_utils.are_progress_bars_disabled()
+
+
+def _get_default_logging_level():
+ """
+ If TRANSFORMERS_VERBOSITY env var is set to one of the valid choices return that as the new default level. If it is
+ not - fall back to `_default_log_level`
+ """
+ env_level_str = os.getenv("TRANSFORMERS_VERBOSITY", None)
+ if env_level_str:
+ if env_level_str in log_levels:
+ return log_levels[env_level_str]
+ else:
+ logging.getLogger().warning(
+ f"Unknown option TRANSFORMERS_VERBOSITY={env_level_str}, "
+ f"has to be one of: {', '.join(log_levels.keys())}"
+ )
+ return _default_log_level
+
+
+def _get_library_name() -> str:
+ return __name__.split(".")[0]
+
+
+def _get_library_root_logger() -> logging.Logger:
+ return logging.getLogger(_get_library_name())
+
+
+def _configure_library_root_logger() -> None:
+ global _default_handler
+
+ with _lock:
+ if _default_handler:
+ # This library has already configured the library root logger.
+ return
+ _default_handler = logging.StreamHandler() # Set sys.stderr as stream.
+ # set defaults based on https://github.com/pyinstaller/pyinstaller/issues/7334#issuecomment-1357447176
+ if sys.stderr is None:
+ sys.stderr = open(os.devnull, "w")
+
+ _default_handler.flush = sys.stderr.flush
+
+ # Apply our default configuration to the library root logger.
+ library_root_logger = _get_library_root_logger()
+ library_root_logger.addHandler(_default_handler)
+ library_root_logger.setLevel(_get_default_logging_level())
+ # if logging level is debug, we add pathname and lineno to formatter for easy debugging
+ if os.getenv("TRANSFORMERS_VERBOSITY", None) == "detail":
+ formatter = logging.Formatter("[%(levelname)s|%(pathname)s:%(lineno)s] %(asctime)s >> %(message)s")
+ _default_handler.setFormatter(formatter)
+
+ is_ci = os.getenv("CI") is not None and os.getenv("CI").upper() in {"1", "ON", "YES", "TRUE"}
+ library_root_logger.propagate = True if is_ci else False
+
+
+def _reset_library_root_logger() -> None:
+ global _default_handler
+
+ with _lock:
+ if not _default_handler:
+ return
+
+ library_root_logger = _get_library_root_logger()
+ library_root_logger.removeHandler(_default_handler)
+ library_root_logger.setLevel(logging.NOTSET)
+ _default_handler = None
+
+
+def get_log_levels_dict():
+ return log_levels
+
+
+def captureWarnings(capture):
+ """
+ Calls the `captureWarnings` method from the logging library to enable management of the warnings emitted by the
+ `warnings` library.
+
+ Read more about this method here:
+ https://docs.python.org/3/library/logging.html#integration-with-the-warnings-module
+
+ All warnings will be logged through the `py.warnings` logger.
+
+ Careful: this method also adds a handler to this logger if it does not already have one, and updates the logging
+ level of that logger to the library's root logger.
+ """
+ logger = get_logger("py.warnings")
+
+ if not logger.handlers:
+ logger.addHandler(_default_handler)
+
+ logger.setLevel(_get_library_root_logger().level)
+
+ _captureWarnings(capture)
+
+
+def get_logger(name: Optional[str] = None) -> logging.Logger:
+ """
+ Return a logger with the specified name.
+
+ This function is not supposed to be directly accessed unless you are writing a custom transformers module.
+ """
+
+ if name is None:
+ name = _get_library_name()
+
+ _configure_library_root_logger()
+ return logging.getLogger(name)
+
+
+def get_verbosity() -> int:
+ """
+ Return the current level for the 🤗 Transformers's root logger as an int.
+
+ Returns:
+ `int`: The logging level.
+
+
+
+ 🤗 Transformers has following logging levels:
+
+ - 50: `transformers.logging.CRITICAL` or `transformers.logging.FATAL`
+ - 40: `transformers.logging.ERROR`
+ - 30: `transformers.logging.WARNING` or `transformers.logging.WARN`
+ - 20: `transformers.logging.INFO`
+ - 10: `transformers.logging.DEBUG`
+
+ """
+
+ _configure_library_root_logger()
+ return _get_library_root_logger().getEffectiveLevel()
+
+
+def set_verbosity(verbosity: int) -> None:
+ """
+ Set the verbosity level for the 🤗 Transformers's root logger.
+
+ Args:
+ verbosity (`int`):
+ Logging level, e.g., one of:
+
+ - `transformers.logging.CRITICAL` or `transformers.logging.FATAL`
+ - `transformers.logging.ERROR`
+ - `transformers.logging.WARNING` or `transformers.logging.WARN`
+ - `transformers.logging.INFO`
+ - `transformers.logging.DEBUG`
+ """
+
+ _configure_library_root_logger()
+ _get_library_root_logger().setLevel(verbosity)
+
+
+def set_verbosity_info():
+ """Set the verbosity to the `INFO` level."""
+ return set_verbosity(INFO)
+
+
+def set_verbosity_warning():
+ """Set the verbosity to the `WARNING` level."""
+ return set_verbosity(WARNING)
+
+
+def set_verbosity_debug():
+ """Set the verbosity to the `DEBUG` level."""
+ return set_verbosity(DEBUG)
+
+
+def set_verbosity_error():
+ """Set the verbosity to the `ERROR` level."""
+ return set_verbosity(ERROR)
+
+
+def disable_default_handler() -> None:
+ """Disable the default handler of the HuggingFace Transformers's root logger."""
+
+ _configure_library_root_logger()
+
+ assert _default_handler is not None
+ _get_library_root_logger().removeHandler(_default_handler)
+
+
+def enable_default_handler() -> None:
+ """Enable the default handler of the HuggingFace Transformers's root logger."""
+
+ _configure_library_root_logger()
+
+ assert _default_handler is not None
+ _get_library_root_logger().addHandler(_default_handler)
+
+
+def add_handler(handler: logging.Handler) -> None:
+ """adds a handler to the HuggingFace Transformers's root logger."""
+
+ _configure_library_root_logger()
+
+ assert handler is not None
+ _get_library_root_logger().addHandler(handler)
+
+
+def remove_handler(handler: logging.Handler) -> None:
+ """removes given handler from the HuggingFace Transformers's root logger."""
+
+ _configure_library_root_logger()
+
+ assert handler is not None and handler not in _get_library_root_logger().handlers
+ _get_library_root_logger().removeHandler(handler)
+
+
+def disable_propagation() -> None:
+ """
+ Disable propagation of the library log outputs. Note that log propagation is disabled by default.
+ """
+
+ _configure_library_root_logger()
+ _get_library_root_logger().propagate = False
+
+
+def enable_propagation() -> None:
+ """
+ Enable propagation of the library log outputs. Please disable the HuggingFace Transformers's default handler to
+ prevent double logging if the root logger has been configured.
+ """
+
+ _configure_library_root_logger()
+ _get_library_root_logger().propagate = True
+
+
+def enable_explicit_format() -> None:
+ """
+ Enable explicit formatting for every HuggingFace Transformers's logger. The explicit formatter is as follows:
+ ```
+ [LEVELNAME|FILENAME|LINE NUMBER] TIME >> MESSAGE
+ ```
+ All handlers currently bound to the root logger are affected by this method.
+ """
+ handlers = _get_library_root_logger().handlers
+
+ for handler in handlers:
+ formatter = logging.Formatter("[%(levelname)s|%(filename)s:%(lineno)s] %(asctime)s >> %(message)s")
+ handler.setFormatter(formatter)
+
+
+def reset_format() -> None:
+ """
+ Resets the formatting for HuggingFace Transformers's loggers.
+
+ All handlers currently bound to the root logger are affected by this method.
+ """
+ handlers = _get_library_root_logger().handlers
+
+ for handler in handlers:
+ handler.setFormatter(None)
+
+
+def warning_advice(self, *args, **kwargs):
+ """
+ This method is identical to `logger.warning()`, but if env var TRANSFORMERS_NO_ADVISORY_WARNINGS=1 is set, this
+ warning will not be printed
+ """
+ no_advisory_warnings = os.getenv("TRANSFORMERS_NO_ADVISORY_WARNINGS", False)
+ if no_advisory_warnings:
+ return
+ self.warning(*args, **kwargs)
+
+
+logging.Logger.warning_advice = warning_advice
+
+
+@functools.lru_cache(None)
+def warning_once(self, *args, **kwargs):
+ """
+ This method is identical to `logger.warning()`, but will emit the warning with the same message only once
+
+ Note: The cache is for the function arguments, so 2 different callers using the same arguments will hit the cache.
+ The assumption here is that all warning messages are unique across the code. If they aren't then need to switch to
+ another type of cache that includes the caller frame information in the hashing function.
+ """
+ self.warning(*args, **kwargs)
+
+
+logging.Logger.warning_once = warning_once
+
+
+@functools.lru_cache(None)
+def info_once(self, *args, **kwargs):
+ """
+ This method is identical to `logger.info()`, but will emit the info with the same message only once
+
+ Note: The cache is for the function arguments, so 2 different callers using the same arguments will hit the cache.
+ The assumption here is that all warning messages are unique across the code. If they aren't then need to switch to
+ another type of cache that includes the caller frame information in the hashing function.
+ """
+ self.info(*args, **kwargs)
+
+
+logging.Logger.info_once = info_once
+
+
+class EmptyTqdm:
+ """Dummy tqdm which doesn't do anything."""
+
+ def __init__(self, *args, **kwargs): # pylint: disable=unused-argument
+ self._iterator = args[0] if args else None
+
+ def __iter__(self):
+ return iter(self._iterator)
+
+ def __getattr__(self, _):
+ """Return empty function."""
+
+ def empty_fn(*args, **kwargs): # pylint: disable=unused-argument
+ return
+
+ return empty_fn
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, type_, value, traceback):
+ return
+
+
+class _tqdm_cls:
+ def __call__(self, *args, **kwargs):
+ if _tqdm_active:
+ return tqdm_lib.tqdm(*args, **kwargs)
+ else:
+ return EmptyTqdm(*args, **kwargs)
+
+ def set_lock(self, *args, **kwargs):
+ self._lock = None
+ if _tqdm_active:
+ return tqdm_lib.tqdm.set_lock(*args, **kwargs)
+
+ def get_lock(self):
+ if _tqdm_active:
+ return tqdm_lib.tqdm.get_lock()
+
+
+tqdm = _tqdm_cls()
+
+
+def is_progress_bar_enabled() -> bool:
+ """Return a boolean indicating whether tqdm progress bars are enabled."""
+ global _tqdm_active
+ return bool(_tqdm_active)
+
+
+def enable_progress_bar():
+ """Enable tqdm progress bar."""
+ global _tqdm_active
+ _tqdm_active = True
+ hf_hub_utils.enable_progress_bars()
+
+
+def disable_progress_bar():
+ """Disable tqdm progress bar."""
+ global _tqdm_active
+ _tqdm_active = False
+ hf_hub_utils.disable_progress_bars()
diff --git a/docs/transformers/build/lib/transformers/utils/model_parallel_utils.py b/docs/transformers/build/lib/transformers/utils/model_parallel_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..7db16b70a75ccdce7bd9c07c5dfc99f42e5c8807
--- /dev/null
+++ b/docs/transformers/build/lib/transformers/utils/model_parallel_utils.py
@@ -0,0 +1,55 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from math import ceil
+
+
+def assert_device_map(device_map, num_blocks):
+ blocks = list(range(0, num_blocks))
+
+ device_map_blocks = [item for sublist in list(device_map.values()) for item in sublist]
+
+ # Duplicate check
+ duplicate_blocks = []
+ for i in device_map_blocks:
+ if device_map_blocks.count(i) > 1 and i not in duplicate_blocks:
+ duplicate_blocks.append(i)
+ # Missing blocks
+ missing_blocks = [i for i in blocks if i not in device_map_blocks]
+ extra_blocks = [i for i in device_map_blocks if i not in blocks]
+
+ if len(duplicate_blocks) != 0:
+ raise ValueError(
+ "Duplicate attention blocks specified in device_map. Attention blocks must be specified to one device."
+ " These attention blocks were specified more than once: " + str(duplicate_blocks)
+ )
+ if len(missing_blocks) != 0:
+ raise ValueError(
+ "There are attention blocks for this model that are not specified in the device_map. Add these attention "
+ "blocks to a device on the device_map: " + str(missing_blocks)
+ )
+ if len(extra_blocks) != 0:
+ raise ValueError(
+ "The device_map contains more attention blocks than this model has. Remove these from the device_map:"
+ + str(extra_blocks)
+ )
+
+
+def get_device_map(n_layers, devices):
+ """Returns a dictionary of layers distributed evenly across all devices."""
+ layers = list(range(n_layers))
+ n_blocks = int(ceil(n_layers / len(devices)))
+ layers_list = [layers[i : i + n_blocks] for i in range(0, n_layers, n_blocks)]
+
+ return dict(zip(devices, layers_list))
diff --git a/docs/transformers/build/lib/transformers/utils/notebook.py b/docs/transformers/build/lib/transformers/utils/notebook.py
new file mode 100644
index 0000000000000000000000000000000000000000..22a44d858e731f9bd4067d373165b0b376f5191b
--- /dev/null
+++ b/docs/transformers/build/lib/transformers/utils/notebook.py
@@ -0,0 +1,383 @@
+# Copyright 2020 Hugging Face
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import re
+import time
+from typing import Optional
+
+import IPython.display as disp
+
+from ..trainer_callback import TrainerCallback
+from ..trainer_utils import IntervalStrategy, has_length
+
+
+def format_time(t):
+ "Format `t` (in seconds) to (h):mm:ss"
+ t = int(t)
+ h, m, s = t // 3600, (t // 60) % 60, t % 60
+ return f"{h}:{m:02d}:{s:02d}" if h != 0 else f"{m:02d}:{s:02d}"
+
+
+def html_progress_bar(value, total, prefix, label, width=300):
+ # docstyle-ignore
+ return f"""
+
+ """
+
+
+def text_to_html_table(items):
+ "Put the texts in `items` in an HTML table."
+ html_code = """\n"""
+ html_code += """ \n \n"""
+ for i in items[0]:
+ html_code += f" | {i} | \n"
+ html_code += "
\n \n \n"
+ for line in items[1:]:
+ html_code += " \n"
+ for elt in line:
+ elt = f"{elt:.6f}" if isinstance(elt, float) else str(elt)
+ html_code += f" | {elt} | \n"
+ html_code += "
\n"
+ html_code += " \n
"
+ return html_code
+
+
+class NotebookProgressBar:
+ """
+ A progress par for display in a notebook.
+
+ Class attributes (overridden by derived classes)
+
+ - **warmup** (`int`) -- The number of iterations to do at the beginning while ignoring `update_every`.
+ - **update_every** (`float`) -- Since calling the time takes some time, we only do it every presumed
+ `update_every` seconds. The progress bar uses the average time passed up until now to guess the next value
+ for which it will call the update.
+
+ Args:
+ total (`int`):
+ The total number of iterations to reach.
+ prefix (`str`, *optional*):
+ A prefix to add before the progress bar.
+ leave (`bool`, *optional*, defaults to `True`):
+ Whether or not to leave the progress bar once it's completed. You can always call the
+ [`~utils.notebook.NotebookProgressBar.close`] method to make the bar disappear.
+ parent ([`~notebook.NotebookTrainingTracker`], *optional*):
+ A parent object (like [`~utils.notebook.NotebookTrainingTracker`]) that spawns progress bars and handle
+ their display. If set, the object passed must have a `display()` method.
+ width (`int`, *optional*, defaults to 300):
+ The width (in pixels) that the bar will take.
+
+ Example:
+
+ ```python
+ import time
+
+ pbar = NotebookProgressBar(100)
+ for val in range(100):
+ pbar.update(val)
+ time.sleep(0.07)
+ pbar.update(100)
+ ```"""
+
+ warmup = 5
+ update_every = 0.2
+
+ def __init__(
+ self,
+ total: int,
+ prefix: Optional[str] = None,
+ leave: bool = True,
+ parent: Optional["NotebookTrainingTracker"] = None,
+ width: int = 300,
+ ):
+ self.total = total
+ self.prefix = "" if prefix is None else prefix
+ self.leave = leave
+ self.parent = parent
+ self.width = width
+ self.last_value = None
+ self.comment = None
+ self.output = None
+ self.value = None
+ self.label = None
+ if "VSCODE_PID" in os.environ:
+ self.update_every = 0.5 # Adjusted for smooth updated as html rending is slow on VS Code
+ # This is the only adjustment required to optimize training html rending
+
+ def update(self, value: int, force_update: bool = False, comment: Optional[str] = None):
+ """
+ The main method to update the progress bar to `value`.
+
+ Args:
+ value (`int`):
+ The value to use. Must be between 0 and `total`.
+ force_update (`bool`, *optional*, defaults to `False`):
+ Whether or not to force and update of the internal state and display (by default, the bar will wait for
+ `value` to reach the value it predicted corresponds to a time of more than the `update_every` attribute
+ since the last update to avoid adding boilerplate).
+ comment (`str`, *optional*):
+ A comment to add on the left of the progress bar.
+ """
+ self.value = value
+ if comment is not None:
+ self.comment = comment
+ if self.last_value is None:
+ self.start_time = self.last_time = time.time()
+ self.start_value = self.last_value = value
+ self.elapsed_time = self.predicted_remaining = None
+ self.first_calls = self.warmup
+ self.wait_for = 1
+ self.update_bar(value)
+ elif value <= self.last_value and not force_update:
+ return
+ elif force_update or self.first_calls > 0 or value >= min(self.last_value + self.wait_for, self.total):
+ if self.first_calls > 0:
+ self.first_calls -= 1
+ current_time = time.time()
+ self.elapsed_time = current_time - self.start_time
+ # We could have value = self.start_value if the update is called twixe with the same start value.
+ if value > self.start_value:
+ self.average_time_per_item = self.elapsed_time / (value - self.start_value)
+ else:
+ self.average_time_per_item = None
+ if value >= self.total:
+ value = self.total
+ self.predicted_remaining = None
+ if not self.leave:
+ self.close()
+ elif self.average_time_per_item is not None:
+ self.predicted_remaining = self.average_time_per_item * (self.total - value)
+ self.update_bar(value)
+ self.last_value = value
+ self.last_time = current_time
+ if (self.average_time_per_item is None) or (self.average_time_per_item == 0):
+ self.wait_for = 1
+ else:
+ self.wait_for = max(int(self.update_every / self.average_time_per_item), 1)
+
+ def update_bar(self, value, comment=None):
+ spaced_value = " " * (len(str(self.total)) - len(str(value))) + str(value)
+ if self.elapsed_time is None:
+ self.label = f"[{spaced_value}/{self.total} : < :"
+ elif self.predicted_remaining is None:
+ self.label = f"[{spaced_value}/{self.total} {format_time(self.elapsed_time)}"
+ else:
+ self.label = (
+ f"[{spaced_value}/{self.total} {format_time(self.elapsed_time)} <"
+ f" {format_time(self.predicted_remaining)}"
+ )
+ if self.average_time_per_item == 0:
+ self.label += ", +inf it/s"
+ else:
+ self.label += f", {1 / self.average_time_per_item:.2f} it/s"
+
+ self.label += "]" if self.comment is None or len(self.comment) == 0 else f", {self.comment}]"
+ self.display()
+
+ def display(self):
+ self.html_code = html_progress_bar(self.value, self.total, self.prefix, self.label, self.width)
+ if self.parent is not None:
+ # If this is a child bar, the parent will take care of the display.
+ self.parent.display()
+ return
+ if self.output is None:
+ self.output = disp.display(disp.HTML(self.html_code), display_id=True)
+ else:
+ self.output.update(disp.HTML(self.html_code))
+
+ def close(self):
+ "Closes the progress bar."
+ if self.parent is None and self.output is not None:
+ self.output.update(disp.HTML(""))
+
+
+class NotebookTrainingTracker(NotebookProgressBar):
+ """
+ An object tracking the updates of an ongoing training with progress bars and a nice table reporting metrics.
+
+ Args:
+ num_steps (`int`): The number of steps during training. column_names (`List[str]`, *optional*):
+ The list of column names for the metrics table (will be inferred from the first call to
+ [`~utils.notebook.NotebookTrainingTracker.write_line`] if not set).
+ """
+
+ def __init__(self, num_steps, column_names=None):
+ super().__init__(num_steps)
+ self.inner_table = None if column_names is None else [column_names]
+ self.child_bar = None
+
+ def display(self):
+ self.html_code = html_progress_bar(self.value, self.total, self.prefix, self.label, self.width)
+ if self.inner_table is not None:
+ self.html_code += text_to_html_table(self.inner_table)
+ if self.child_bar is not None:
+ self.html_code += self.child_bar.html_code
+ if self.output is None:
+ self.output = disp.display(disp.HTML(self.html_code), display_id=True)
+ else:
+ self.output.update(disp.HTML(self.html_code))
+
+ def write_line(self, values):
+ """
+ Write the values in the inner table.
+
+ Args:
+ values (`Dict[str, float]`): The values to display.
+ """
+ if self.inner_table is None:
+ self.inner_table = [list(values.keys()), list(values.values())]
+ else:
+ columns = self.inner_table[0]
+ for key in values.keys():
+ if key not in columns:
+ columns.append(key)
+ self.inner_table[0] = columns
+ if len(self.inner_table) > 1:
+ last_values = self.inner_table[-1]
+ first_column = self.inner_table[0][0]
+ if last_values[0] != values[first_column]:
+ # write new line
+ self.inner_table.append([values[c] if c in values else "No Log" for c in columns])
+ else:
+ # update last line
+ new_values = values
+ for c in columns:
+ if c not in new_values.keys():
+ new_values[c] = last_values[columns.index(c)]
+ self.inner_table[-1] = [new_values[c] for c in columns]
+ else:
+ self.inner_table.append([values[c] for c in columns])
+
+ def add_child(self, total, prefix=None, width=300):
+ """
+ Add a child progress bar displayed under the table of metrics. The child progress bar is returned (so it can be
+ easily updated).
+
+ Args:
+ total (`int`): The number of iterations for the child progress bar.
+ prefix (`str`, *optional*): A prefix to write on the left of the progress bar.
+ width (`int`, *optional*, defaults to 300): The width (in pixels) of the progress bar.
+ """
+ self.child_bar = NotebookProgressBar(total, prefix=prefix, parent=self, width=width)
+ return self.child_bar
+
+ def remove_child(self):
+ """
+ Closes the child progress bar.
+ """
+ self.child_bar = None
+ self.display()
+
+
+class NotebookProgressCallback(TrainerCallback):
+ """
+ A [`TrainerCallback`] that displays the progress of training or evaluation, optimized for Jupyter Notebooks or
+ Google colab.
+ """
+
+ def __init__(self):
+ self.training_tracker = None
+ self.prediction_bar = None
+ self._force_next_update = False
+
+ def on_train_begin(self, args, state, control, **kwargs):
+ self.first_column = "Epoch" if args.eval_strategy == IntervalStrategy.EPOCH else "Step"
+ self.training_loss = 0
+ self.last_log = 0
+ column_names = [self.first_column] + ["Training Loss"]
+ if args.eval_strategy != IntervalStrategy.NO:
+ column_names.append("Validation Loss")
+ self.training_tracker = NotebookTrainingTracker(state.max_steps, column_names)
+
+ def on_step_end(self, args, state, control, **kwargs):
+ epoch = int(state.epoch) if int(state.epoch) == state.epoch else f"{state.epoch:.2f}"
+ self.training_tracker.update(
+ state.global_step + 1,
+ comment=f"Epoch {epoch}/{state.num_train_epochs}",
+ force_update=self._force_next_update,
+ )
+ self._force_next_update = False
+
+ def on_prediction_step(self, args, state, control, eval_dataloader=None, **kwargs):
+ if not has_length(eval_dataloader):
+ return
+ if self.prediction_bar is None:
+ if self.training_tracker is not None:
+ self.prediction_bar = self.training_tracker.add_child(len(eval_dataloader))
+ else:
+ self.prediction_bar = NotebookProgressBar(len(eval_dataloader))
+ self.prediction_bar.update(1)
+ else:
+ self.prediction_bar.update(self.prediction_bar.value + 1)
+
+ def on_predict(self, args, state, control, **kwargs):
+ if self.prediction_bar is not None:
+ self.prediction_bar.close()
+ self.prediction_bar = None
+
+ def on_log(self, args, state, control, logs=None, **kwargs):
+ # Only for when there is no evaluation
+ if args.eval_strategy == IntervalStrategy.NO and "loss" in logs:
+ values = {"Training Loss": logs["loss"]}
+ # First column is necessarily Step sine we're not in epoch eval strategy
+ values["Step"] = state.global_step
+ self.training_tracker.write_line(values)
+
+ def on_evaluate(self, args, state, control, metrics=None, **kwargs):
+ if self.training_tracker is not None:
+ values = {"Training Loss": "No log", "Validation Loss": "No log"}
+ for log in reversed(state.log_history):
+ if "loss" in log:
+ values["Training Loss"] = log["loss"]
+ break
+
+ if self.first_column == "Epoch":
+ values["Epoch"] = int(state.epoch)
+ else:
+ values["Step"] = state.global_step
+ metric_key_prefix = "eval"
+ for k in metrics:
+ if k.endswith("_loss"):
+ metric_key_prefix = re.sub(r"\_loss$", "", k)
+ _ = metrics.pop("total_flos", None)
+ _ = metrics.pop("epoch", None)
+ _ = metrics.pop(f"{metric_key_prefix}_runtime", None)
+ _ = metrics.pop(f"{metric_key_prefix}_samples_per_second", None)
+ _ = metrics.pop(f"{metric_key_prefix}_steps_per_second", None)
+ _ = metrics.pop(f"{metric_key_prefix}_jit_compilation_time", None)
+ for k, v in metrics.items():
+ splits = k.split("_")
+ name = " ".join([part.capitalize() for part in splits[1:]])
+ if name == "Loss":
+ # Single dataset
+ name = "Validation Loss"
+ values[name] = v
+ self.training_tracker.write_line(values)
+ self.training_tracker.remove_child()
+ self.prediction_bar = None
+ # Evaluation takes a long time so we should force the next update.
+ self._force_next_update = True
+
+ def on_train_end(self, args, state, control, **kwargs):
+ self.training_tracker.update(
+ state.global_step,
+ comment=f"Epoch {int(state.epoch)}/{state.num_train_epochs}",
+ force_update=True,
+ )
+ self.training_tracker = None
diff --git a/docs/transformers/build/lib/transformers/utils/peft_utils.py b/docs/transformers/build/lib/transformers/utils/peft_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..3eb62a099059d4c1acd9eef75f94ee5ac22fd60f
--- /dev/null
+++ b/docs/transformers/build/lib/transformers/utils/peft_utils.py
@@ -0,0 +1,125 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import importlib
+import os
+from typing import Optional, Union
+
+from packaging import version
+
+from .hub import cached_file
+from .import_utils import is_peft_available
+
+
+ADAPTER_CONFIG_NAME = "adapter_config.json"
+ADAPTER_WEIGHTS_NAME = "adapter_model.bin"
+ADAPTER_SAFE_WEIGHTS_NAME = "adapter_model.safetensors"
+
+
+def find_adapter_config_file(
+ model_id: str,
+ cache_dir: Optional[Union[str, os.PathLike]] = None,
+ force_download: bool = False,
+ resume_download: Optional[bool] = None,
+ proxies: Optional[dict[str, str]] = None,
+ token: Optional[Union[bool, str]] = None,
+ revision: Optional[str] = None,
+ local_files_only: bool = False,
+ subfolder: str = "",
+ _commit_hash: Optional[str] = None,
+) -> Optional[str]:
+ r"""
+ Simply checks if the model stored on the Hub or locally is an adapter model or not, return the path of the adapter
+ config file if it is, None otherwise.
+
+ Args:
+ model_id (`str`):
+ The identifier of the model to look for, can be either a local path or an id to the repository on the Hub.
+ cache_dir (`str` or `os.PathLike`, *optional*):
+ Path to a directory in which a downloaded pretrained model configuration should be cached if the standard
+ cache should not be used.
+ force_download (`bool`, *optional*, defaults to `False`):
+ Whether or not to force to (re-)download the configuration files and override the cached versions if they
+ exist.
+ resume_download:
+ Deprecated and ignored. All downloads are now resumed by default when possible.
+ Will be removed in v5 of Transformers.
+ proxies (`Dict[str, str]`, *optional*):
+ A dictionary of proxy servers to use by protocol or endpoint, e.g., `{'http': 'foo.bar:3128',
+ 'http://hostname': 'foo.bar:4012'}.` The proxies are used on each request.
+ token (`str` or *bool*, *optional*):
+ The token to use as HTTP bearer authorization for remote files. If `True`, will use the token generated
+ when running `huggingface-cli login` (stored in `~/.huggingface`).
+ revision (`str`, *optional*, defaults to `"main"`):
+ The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a
+ git-based system for storing models and other artifacts on huggingface.co, so `revision` can be any
+ identifier allowed by git.
+
+
+
+ To test a pull request you made on the Hub, you can pass `revision="refs/pr/".
+
+
+
+ local_files_only (`bool`, *optional*, defaults to `False`):
+ If `True`, will only try to load the tokenizer configuration from local files.
+ subfolder (`str`, *optional*, defaults to `""`):
+ In case the relevant files are located inside a subfolder of the model repo on huggingface.co, you can
+ specify the folder name here.
+ """
+ adapter_cached_filename = None
+ if model_id is None:
+ return None
+ elif os.path.isdir(model_id):
+ list_remote_files = os.listdir(model_id)
+ if ADAPTER_CONFIG_NAME in list_remote_files:
+ adapter_cached_filename = os.path.join(model_id, ADAPTER_CONFIG_NAME)
+ else:
+ adapter_cached_filename = cached_file(
+ model_id,
+ ADAPTER_CONFIG_NAME,
+ cache_dir=cache_dir,
+ force_download=force_download,
+ resume_download=resume_download,
+ proxies=proxies,
+ token=token,
+ revision=revision,
+ local_files_only=local_files_only,
+ subfolder=subfolder,
+ _commit_hash=_commit_hash,
+ _raise_exceptions_for_gated_repo=False,
+ _raise_exceptions_for_missing_entries=False,
+ _raise_exceptions_for_connection_errors=False,
+ )
+
+ return adapter_cached_filename
+
+
+def check_peft_version(min_version: str) -> None:
+ r"""
+ Checks if the version of PEFT is compatible.
+
+ Args:
+ version (`str`):
+ The version of PEFT to check against.
+ """
+ if not is_peft_available():
+ raise ValueError("PEFT is not installed. Please install it with `pip install peft`")
+
+ is_peft_version_compatible = version.parse(importlib.metadata.version("peft")) >= version.parse(min_version)
+
+ if not is_peft_version_compatible:
+ raise ValueError(
+ f"The version of PEFT you are using is not compatible, please use a version that is greater"
+ f" than {min_version}"
+ )
diff --git a/docs/transformers/build/lib/transformers/utils/quantization_config.py b/docs/transformers/build/lib/transformers/utils/quantization_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..9f17b3881ada393af808b79e35f99654c358ef72
--- /dev/null
+++ b/docs/transformers/build/lib/transformers/utils/quantization_config.py
@@ -0,0 +1,1922 @@
+#!/usr/bin/env python
+# coding=utf-8
+
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+# Modifications Copyright (C) 2025, Advanced Micro Devices, Inc. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import copy
+import dataclasses
+import importlib.metadata
+import json
+import os
+from dataclasses import dataclass, is_dataclass
+from enum import Enum
+from inspect import Parameter, signature
+from typing import Any, Dict, List, Optional, Tuple, Union
+
+from packaging import version
+
+from ..utils import (
+ is_auto_awq_available,
+ is_compressed_tensors_available,
+ is_gptqmodel_available,
+ is_hqq_available,
+ is_quark_available,
+ is_torch_available,
+ is_torchao_available,
+ logging,
+)
+from .import_utils import is_auto_gptq_available
+
+
+if is_torch_available():
+ import torch
+
+logger = logging.get_logger(__name__)
+
+
+class QuantizationMethod(str, Enum):
+ BITS_AND_BYTES = "bitsandbytes"
+ GPTQ = "gptq"
+ AWQ = "awq"
+ AQLM = "aqlm"
+ VPTQ = "vptq"
+ QUANTO = "quanto"
+ EETQ = "eetq"
+ HIGGS = "higgs"
+ HQQ = "hqq"
+ COMPRESSED_TENSORS = "compressed-tensors"
+ FBGEMM_FP8 = "fbgemm_fp8"
+ TORCHAO = "torchao"
+ BITNET = "bitnet"
+ SPQR = "spqr"
+ FP8 = "fp8"
+ QUARK = "quark"
+ AUTOROUND = "auto-round"
+
+
+class AWQLinearVersion(str, Enum):
+ GEMM = "gemm"
+ GEMV = "gemv"
+ EXLLAMA = "exllama"
+ IPEX = "ipex"
+
+ @staticmethod
+ def from_str(version: str):
+ version = version.lower()
+ if version == "gemm":
+ return AWQLinearVersion.GEMM
+ elif version == "gemv":
+ return AWQLinearVersion.GEMV
+ elif version == "exllama":
+ return AWQLinearVersion.EXLLAMA
+ elif version == "ipex":
+ return AWQLinearVersion.IPEX
+ else:
+ raise ValueError(f"Unknown AWQLinearVersion {version}")
+
+
+class AwqBackendPackingMethod(str, Enum):
+ AUTOAWQ = "autoawq"
+ LLMAWQ = "llm-awq"
+
+
+@dataclass
+class QuantizationConfigMixin:
+ """
+ Mixin class for quantization config
+ """
+
+ quant_method: QuantizationMethod
+
+ @classmethod
+ def from_dict(cls, config_dict, return_unused_kwargs=False, **kwargs):
+ """
+ Instantiates a [`QuantizationConfigMixin`] from a Python dictionary of parameters.
+
+ Args:
+ config_dict (`Dict[str, Any]`):
+ Dictionary that will be used to instantiate the configuration object.
+ return_unused_kwargs (`bool`,*optional*, defaults to `False`):
+ Whether or not to return a list of unused keyword arguments. Used for `from_pretrained` method in
+ `PreTrainedModel`.
+ kwargs (`Dict[str, Any]`):
+ Additional parameters from which to initialize the configuration object.
+
+ Returns:
+ [`QuantizationConfigMixin`]: The configuration object instantiated from those parameters.
+ """
+ config = cls(**config_dict)
+
+ to_remove = []
+ for key, value in kwargs.items():
+ if hasattr(config, key):
+ setattr(config, key, value)
+ to_remove.append(key)
+ for key in to_remove:
+ kwargs.pop(key, None)
+
+ if return_unused_kwargs:
+ return config, kwargs
+ else:
+ return config
+
+ def to_json_file(self, json_file_path: Union[str, os.PathLike]):
+ """
+ Save this instance to a JSON file.
+
+ Args:
+ json_file_path (`str` or `os.PathLike`):
+ Path to the JSON file in which this configuration instance's parameters will be saved.
+ use_diff (`bool`, *optional*, defaults to `True`):
+ If set to `True`, only the difference between the config instance and the default
+ `QuantizationConfig()` is serialized to JSON file.
+ """
+ with open(json_file_path, "w", encoding="utf-8") as writer:
+ config_dict = self.to_dict()
+ json_string = json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
+
+ writer.write(json_string)
+
+ def to_dict(self) -> Dict[str, Any]:
+ """
+ Serializes this instance to a Python dictionary. Returns:
+ `Dict[str, Any]`: Dictionary of all the attributes that make up this configuration instance.
+ """
+ return copy.deepcopy(self.__dict__)
+
+ def __iter__(self):
+ """allows `dict(obj)` for situations where obj may be a dict or QuantizationConfigMixin"""
+ for attr, value in copy.deepcopy(self.__dict__).items():
+ yield attr, value
+
+ def __repr__(self):
+ return f"{self.__class__.__name__} {self.to_json_string()}"
+
+ def to_json_string(self, use_diff: bool = True) -> str:
+ """
+ Serializes this instance to a JSON string.
+
+ Args:
+ use_diff (`bool`, *optional*, defaults to `True`):
+ If set to `True`, only the difference between the config instance and the default `PretrainedConfig()`
+ is serialized to JSON string.
+
+ Returns:
+ `str`: String containing all the attributes that make up this configuration instance in JSON format.
+ """
+ if use_diff is True:
+ config_dict = self.to_diff_dict()
+ else:
+ config_dict = self.to_dict()
+ return json.dumps(config_dict, indent=2, sort_keys=True) + "\n"
+
+ def update(self, **kwargs):
+ """
+ Updates attributes of this class instance with attributes from `kwargs` if they match existing attributes,
+ returning all the unused kwargs.
+
+ Args:
+ kwargs (`Dict[str, Any]`):
+ Dictionary of attributes to tentatively update this class.
+
+ Returns:
+ `Dict[str, Any]`: Dictionary containing all the key-value pairs that were not used to update the instance.
+ """
+ to_remove = []
+ for key, value in kwargs.items():
+ if hasattr(self, key):
+ setattr(self, key, value)
+ to_remove.append(key)
+
+ # Remove all the attributes that were updated, without modifying the input dict
+ unused_kwargs = {key: value for key, value in kwargs.items() if key not in to_remove}
+ return unused_kwargs
+
+
+@dataclass
+class AutoRoundConfig(QuantizationConfigMixin):
+ """This is a wrapper class about all possible attributes and features that you can play with a model that has been
+ loaded AutoRound quantization.
+
+ Args:
+ bits (`int`, *optional*, defaults to 4):
+ The number of bits to quantize to, supported numbers are (2, 3, 4, 8).
+ group_size (`int`, *optional*, defaults to 128): Group-size value
+ sym (`bool`, *optional*, defaults to `True`): Symmetric quantization or not
+ backend (`str`, *optional*, defaults to `"auto"`): The kernel to use, e.g., ipex,marlin, exllamav2, triton, etc. Ref. https://github.com/intel/auto-round?tab=readme-ov-file#specify-backend
+ """
+
+ def __init__(
+ self,
+ bits: int = 4,
+ group_size: int = 128,
+ sym: bool = True,
+ backend: str = "auto",
+ **kwargs,
+ ):
+ self.bits = bits
+ self.group_size = group_size
+ self.sym = sym
+ self.backend = backend
+ self.packing_format = "auto_round:gptq"
+ if kwargs is not None:
+ for key, value in kwargs.items():
+ setattr(self, key, value)
+ self.quant_method = QuantizationMethod.AUTOROUND
+ self.post_init()
+
+ def post_init(self):
+ r"""Safety checker that arguments are correct."""
+ if self.bits not in [2, 3, 4, 8]:
+ raise ValueError(f"Only support quantization to [2,3,4,8] bits but found {self.bits}")
+ if self.group_size != -1 and self.group_size <= 0:
+ raise ValueError("group_size must be greater than 0 or equal to -1")
+
+ def get_loading_attributes(self):
+ loading_attibutes_dict = {"backend": self.backend}
+ return loading_attibutes_dict
+
+ def to_dict(self):
+ config_dict = super().to_dict()
+ return config_dict
+
+ @classmethod
+ def from_dict(cls, config_dict, return_unused_kwargs=False, **kwargs):
+ quant_method = config_dict["quant_method"]
+ if "auto-round" not in quant_method and "gptq" not in quant_method and "awq" not in quant_method:
+ raise NotImplementedError(
+ "Failed to convert to auto_round format. Only `gptqv1`, `awq`, and `auto-round` formats are supported."
+ )
+
+ if "gptq" in quant_method and "meta" in config_dict:
+ raise NotImplementedError("Failed to convert gptq format to auto_round format. Only supports `gptqv1`")
+
+ if "awq" in quant_method and config_dict.get("version", "gemm") != "gemm":
+ raise NotImplementedError(
+ "Failed to convert awq format to auto_round format. Only supports awq format with gemm version"
+ )
+
+ if "auto-round" not in quant_method:
+ config_dict["packing_format"] = f"auto_round:{quant_method}"
+
+ return super().from_dict(config_dict, return_unused_kwargs=return_unused_kwargs, **kwargs)
+
+
+@dataclass
+class HqqConfig(QuantizationConfigMixin):
+ """
+ This is wrapper around hqq's BaseQuantizeConfig.
+
+ Args:
+ nbits (`int`, *optional*, defaults to 4):
+ Number of bits. Supported values are (8, 4, 3, 2, 1).
+ group_size (`int`, *optional*, defaults to 64):
+ Group-size value. Supported values are any value that is divisble by weight.shape[axis]).
+ view_as_float (`bool`, *optional*, defaults to `False`):
+ View the quantized weight as float (used in distributed training) if set to `True`.
+ axis (`Optional[int]`, *optional*):
+ Axis along which grouping is performed. Supported values are 0 or 1.
+ dynamic_config (dict, *optional*):
+ Parameters for dynamic configuration. The key is the name tag of the layer and the value is a quantization config.
+ If set, each layer specified by its id will use its dedicated quantization configuration.
+ skip_modules (`List[str]`, *optional*, defaults to `['lm_head']`):
+ List of `nn.Linear` layers to skip.
+ kwargs (`Dict[str, Any]`, *optional*):
+ Additional parameters from which to initialize the configuration object.
+ """
+
+ def __init__(
+ self,
+ nbits: int = 4,
+ group_size: int = 64,
+ view_as_float: bool = False,
+ axis: Optional[int] = None,
+ dynamic_config: Optional[dict] = None,
+ skip_modules: List[str] = ["lm_head"],
+ **kwargs,
+ ):
+ if is_hqq_available():
+ from hqq.core.quantize import BaseQuantizeConfig as HQQBaseQuantizeConfig
+ else:
+ raise ImportError(
+ "A valid HQQ version (>=0.2.1) is not available. Please follow the instructions to install it: `https://github.com/mobiusml/hqq/`."
+ )
+
+ for deprecated_key in ["quant_zero", "quant_scale", "offload_meta"]:
+ if deprecated_key in kwargs:
+ logger.info(
+ deprecated_key + " is deprecated. This parameter will be ignored in quantization settings."
+ )
+
+ if axis is None:
+ axis = 1
+ logger.info("Setting axis=1 as faster backends such as TorchAO or BitBlas are only compatible with it.")
+
+ if axis not in [0, 1]:
+ raise ValueError("Invalid axis value. Only 0 and 1 are allowed.")
+
+ if dynamic_config is not None:
+ self.quant_config = {}
+ for key in dynamic_config:
+ self.quant_config[key] = HQQBaseQuantizeConfig(**dynamic_config[key])
+ else:
+ self.quant_config = HQQBaseQuantizeConfig(
+ **{
+ "nbits": nbits,
+ "group_size": group_size,
+ "view_as_float": view_as_float,
+ "axis": axis,
+ }
+ )
+
+ self.quant_method = QuantizationMethod.HQQ
+ self.skip_modules = skip_modules
+
+ self.post_init()
+
+ def post_init(self):
+ r"""
+ Safety checker that arguments are correct - also replaces some NoneType arguments with their default values.
+ """
+ pass
+
+ @classmethod
+ def from_dict(cls, config: Dict[str, Any]):
+ """
+ Override from_dict, used in AutoQuantizationConfig.from_dict in quantizers/auto.py
+ """
+ instance = cls()
+ instance.quant_config = config["quant_config"]
+ instance.skip_modules = config["skip_modules"]
+ return instance
+
+ def to_dict(self) -> Dict[str, Any]:
+ """
+ Serializes this instance to a Python dictionary. Returns:
+ `Dict[str, Any]`: Dictionary of all the attributes that make up this configuration instance.
+ """
+ return {
+ "quant_config": self.quant_config,
+ "quant_method": self.quant_method,
+ "skip_modules": self.skip_modules,
+ }
+
+ def __repr__(self):
+ config_dict = self.to_dict()
+ return f"{self.__class__.__name__} {json.dumps(config_dict, indent=2, sort_keys=True)}\n"
+
+ def to_diff_dict(self) -> Dict[str, Any]:
+ """
+ Removes all attributes from config which correspond to the default config attributes for better readability and
+ serializes to a Python dictionary.
+ Returns:
+ `Dict[str, Any]`: Dictionary of all the attributes that make up this configuration instance,
+ """
+ config_dict = self.to_dict()
+
+ # get the default config dict
+ default_config_dict = HqqConfig().to_dict()
+
+ serializable_config_dict = {}
+
+ # only serialize values that differ from the default config
+ for key, value in config_dict.items():
+ if value != default_config_dict[key]:
+ serializable_config_dict[key] = value
+
+ return serializable_config_dict
+
+
+@dataclass
+class BitsAndBytesConfig(QuantizationConfigMixin):
+ """
+ This is a wrapper class about all possible attributes and features that you can play with a model that has been
+ loaded using `bitsandbytes`.
+
+ This replaces `load_in_8bit` or `load_in_4bit`therefore both options are mutually exclusive.
+
+ Currently only supports `LLM.int8()`, `FP4`, and `NF4` quantization. If more methods are added to `bitsandbytes`,
+ then more arguments will be added to this class.
+
+ Args:
+ load_in_8bit (`bool`, *optional*, defaults to `False`):
+ This flag is used to enable 8-bit quantization with LLM.int8().
+ load_in_4bit (`bool`, *optional*, defaults to `False`):
+ This flag is used to enable 4-bit quantization by replacing the Linear layers with FP4/NF4 layers from
+ `bitsandbytes`.
+ llm_int8_threshold (`float`, *optional*, defaults to 6.0):
+ This corresponds to the outlier threshold for outlier detection as described in `LLM.int8() : 8-bit Matrix
+ Multiplication for Transformers at Scale` paper: https://arxiv.org/abs/2208.07339 Any hidden states value
+ that is above this threshold will be considered an outlier and the operation on those values will be done
+ in fp16. Values are usually normally distributed, that is, most values are in the range [-3.5, 3.5], but
+ there are some exceptional systematic outliers that are very differently distributed for large models.
+ These outliers are often in the interval [-60, -6] or [6, 60]. Int8 quantization works well for values of
+ magnitude ~5, but beyond that, there is a significant performance penalty. A good default threshold is 6,
+ but a lower threshold might be needed for more unstable models (small models, fine-tuning).
+ llm_int8_skip_modules (`List[str]`, *optional*):
+ An explicit list of the modules that we do not want to convert in 8-bit. This is useful for models such as
+ Jukebox that has several heads in different places and not necessarily at the last position. For example
+ for `CausalLM` models, the last `lm_head` is kept in its original `dtype`.
+ llm_int8_enable_fp32_cpu_offload (`bool`, *optional*, defaults to `False`):
+ This flag is used for advanced use cases and users that are aware of this feature. If you want to split
+ your model in different parts and run some parts in int8 on GPU and some parts in fp32 on CPU, you can use
+ this flag. This is useful for offloading large models such as `google/flan-t5-xxl`. Note that the int8
+ operations will not be run on CPU.
+ llm_int8_has_fp16_weight (`bool`, *optional*, defaults to `False`):
+ This flag runs LLM.int8() with 16-bit main weights. This is useful for fine-tuning as the weights do not
+ have to be converted back and forth for the backward pass.
+ bnb_4bit_compute_dtype (`torch.dtype` or str, *optional*, defaults to `torch.float32`):
+ This sets the computational type which might be different than the input type. For example, inputs might be
+ fp32, but computation can be set to bf16 for speedups.
+ bnb_4bit_quant_type (`str`, *optional*, defaults to `"fp4"`):
+ This sets the quantization data type in the bnb.nn.Linear4Bit layers. Options are FP4 and NF4 data types
+ which are specified by `fp4` or `nf4`.
+ bnb_4bit_use_double_quant (`bool`, *optional*, defaults to `False`):
+ This flag is used for nested quantization where the quantization constants from the first quantization are
+ quantized again.
+ bnb_4bit_quant_storage (`torch.dtype` or str, *optional*, defaults to `torch.uint8`):
+ This sets the storage type to pack the quanitzed 4-bit prarams.
+ kwargs (`Dict[str, Any]`, *optional*):
+ Additional parameters from which to initialize the configuration object.
+ """
+
+ def __init__(
+ self,
+ load_in_8bit=False,
+ load_in_4bit=False,
+ llm_int8_threshold=6.0,
+ llm_int8_skip_modules=None,
+ llm_int8_enable_fp32_cpu_offload=False,
+ llm_int8_has_fp16_weight=False,
+ bnb_4bit_compute_dtype=None,
+ bnb_4bit_quant_type="fp4",
+ bnb_4bit_use_double_quant=False,
+ bnb_4bit_quant_storage=None,
+ **kwargs,
+ ):
+ self.quant_method = QuantizationMethod.BITS_AND_BYTES
+
+ if load_in_4bit and load_in_8bit:
+ raise ValueError("load_in_4bit and load_in_8bit are both True, but only one can be used at the same time")
+
+ self._load_in_8bit = load_in_8bit
+ self._load_in_4bit = load_in_4bit
+ self.llm_int8_threshold = llm_int8_threshold
+ self.llm_int8_skip_modules = llm_int8_skip_modules
+ self.llm_int8_enable_fp32_cpu_offload = llm_int8_enable_fp32_cpu_offload
+ self.llm_int8_has_fp16_weight = llm_int8_has_fp16_weight
+ self.bnb_4bit_quant_type = bnb_4bit_quant_type
+ self.bnb_4bit_use_double_quant = bnb_4bit_use_double_quant
+
+ if bnb_4bit_compute_dtype is None:
+ self.bnb_4bit_compute_dtype = torch.float32
+ elif isinstance(bnb_4bit_compute_dtype, str):
+ self.bnb_4bit_compute_dtype = getattr(torch, bnb_4bit_compute_dtype)
+ elif isinstance(bnb_4bit_compute_dtype, torch.dtype):
+ self.bnb_4bit_compute_dtype = bnb_4bit_compute_dtype
+ else:
+ raise ValueError("bnb_4bit_compute_dtype must be a string or a torch.dtype")
+
+ if bnb_4bit_quant_storage is None:
+ self.bnb_4bit_quant_storage = torch.uint8
+ elif isinstance(bnb_4bit_quant_storage, str):
+ if bnb_4bit_quant_storage not in ["float16", "float32", "int8", "uint8", "float64", "bfloat16"]:
+ raise ValueError(
+ "`bnb_4bit_quant_storage` must be a valid string (one of 'float16', 'float32', 'int8', 'uint8', 'float64', 'bfloat16') "
+ )
+ self.bnb_4bit_quant_storage = getattr(torch, bnb_4bit_quant_storage)
+ elif isinstance(bnb_4bit_quant_storage, torch.dtype):
+ self.bnb_4bit_quant_storage = bnb_4bit_quant_storage
+ else:
+ raise ValueError("bnb_4bit_quant_storage must be a string or a torch.dtype")
+
+ if kwargs:
+ logger.info(f"Unused kwargs: {list(kwargs.keys())}. These kwargs are not used in {self.__class__}.")
+
+ self.post_init()
+
+ @property
+ def load_in_4bit(self):
+ return self._load_in_4bit
+
+ @load_in_4bit.setter
+ def load_in_4bit(self, value: bool):
+ if not isinstance(value, bool):
+ raise TypeError("load_in_4bit must be a boolean")
+
+ if self.load_in_8bit and value:
+ raise ValueError("load_in_4bit and load_in_8bit are both True, but only one can be used at the same time")
+ self._load_in_4bit = value
+
+ @property
+ def load_in_8bit(self):
+ return self._load_in_8bit
+
+ @load_in_8bit.setter
+ def load_in_8bit(self, value: bool):
+ if not isinstance(value, bool):
+ raise TypeError("load_in_8bit must be a boolean")
+
+ if self.load_in_4bit and value:
+ raise ValueError("load_in_4bit and load_in_8bit are both True, but only one can be used at the same time")
+ self._load_in_8bit = value
+
+ def post_init(self):
+ r"""
+ Safety checker that arguments are correct - also replaces some NoneType arguments with their default values.
+ """
+ if not isinstance(self.load_in_4bit, bool):
+ raise TypeError("load_in_4bit must be a boolean")
+
+ if not isinstance(self.load_in_8bit, bool):
+ raise TypeError("load_in_8bit must be a boolean")
+
+ if not isinstance(self.llm_int8_threshold, float):
+ raise TypeError("llm_int8_threshold must be a float")
+
+ if self.llm_int8_skip_modules is not None and not isinstance(self.llm_int8_skip_modules, list):
+ raise TypeError("llm_int8_skip_modules must be a list of strings")
+ if not isinstance(self.llm_int8_enable_fp32_cpu_offload, bool):
+ raise TypeError("llm_int8_enable_fp32_cpu_offload must be a boolean")
+
+ if not isinstance(self.llm_int8_has_fp16_weight, bool):
+ raise TypeError("llm_int8_has_fp16_weight must be a boolean")
+
+ if self.bnb_4bit_compute_dtype is not None and not isinstance(self.bnb_4bit_compute_dtype, torch.dtype):
+ raise TypeError("bnb_4bit_compute_dtype must be torch.dtype")
+
+ if not isinstance(self.bnb_4bit_quant_type, str):
+ raise TypeError("bnb_4bit_quant_type must be a string")
+
+ if not isinstance(self.bnb_4bit_use_double_quant, bool):
+ raise TypeError("bnb_4bit_use_double_quant must be a boolean")
+
+ if self.load_in_4bit and not version.parse(importlib.metadata.version("bitsandbytes")) >= version.parse(
+ "0.39.0"
+ ):
+ raise ValueError(
+ "4 bit quantization requires bitsandbytes>=0.39.0 - please upgrade your bitsandbytes version"
+ )
+
+ def is_quantizable(self):
+ r"""
+ Returns `True` if the model is quantizable, `False` otherwise.
+ """
+ return self.load_in_8bit or self.load_in_4bit
+
+ def quantization_method(self):
+ r"""
+ This method returns the quantization method used for the model. If the model is not quantizable, it returns
+ `None`.
+ """
+ if self.load_in_8bit:
+ return "llm_int8"
+ elif self.load_in_4bit and self.bnb_4bit_quant_type == "fp4":
+ return "fp4"
+ elif self.load_in_4bit and self.bnb_4bit_quant_type == "nf4":
+ return "nf4"
+ else:
+ return None
+
+ def to_dict(self) -> Dict[str, Any]:
+ """
+ Serializes this instance to a Python dictionary. Returns:
+ `Dict[str, Any]`: Dictionary of all the attributes that make up this configuration instance.
+ """
+ output = copy.deepcopy(self.__dict__)
+ output["bnb_4bit_compute_dtype"] = str(output["bnb_4bit_compute_dtype"]).split(".")[1]
+ output["bnb_4bit_quant_storage"] = str(output["bnb_4bit_quant_storage"]).split(".")[1]
+ output["load_in_4bit"] = self.load_in_4bit
+ output["load_in_8bit"] = self.load_in_8bit
+
+ return output
+
+ def __repr__(self):
+ config_dict = self.to_dict()
+ return f"{self.__class__.__name__} {json.dumps(config_dict, indent=2, sort_keys=True)}\n"
+
+ def to_diff_dict(self) -> Dict[str, Any]:
+ """
+ Removes all attributes from config which correspond to the default config attributes for better readability and
+ serializes to a Python dictionary.
+
+ Returns:
+ `Dict[str, Any]`: Dictionary of all the attributes that make up this configuration instance,
+ """
+ config_dict = self.to_dict()
+
+ # get the default config dict
+ default_config_dict = BitsAndBytesConfig().to_dict()
+
+ serializable_config_dict = {}
+
+ # only serialize values that differ from the default config
+ for key, value in config_dict.items():
+ if value != default_config_dict[key]:
+ serializable_config_dict[key] = value
+
+ return serializable_config_dict
+
+
+class ExllamaVersion(int, Enum):
+ ONE = 1
+ TWO = 2
+
+
+@dataclass
+class GPTQConfig(QuantizationConfigMixin):
+ """
+ This is a wrapper class about all possible attributes and features that you can play with a model that has been
+ loaded using `optimum` api for gptq quantization relying on auto_gptq backend.
+
+ Args:
+ bits (`int`):
+ The number of bits to quantize to, supported numbers are (2, 3, 4, 8).
+ tokenizer (`str` or `PreTrainedTokenizerBase`, *optional*):
+ The tokenizer used to process the dataset. You can pass either:
+ - A custom tokenizer object.
+ - A string, the *model id* of a predefined tokenizer hosted inside a model repo on huggingface.co.
+ - A path to a *directory* containing vocabulary files required by the tokenizer, for instance saved
+ using the [`~PreTrainedTokenizer.save_pretrained`] method, e.g., `./my_model_directory/`.
+ dataset (`Union[List[str]]`, *optional*):
+ The dataset used for quantization. You can provide your own dataset in a list of string or just use the
+ original datasets used in GPTQ paper ['wikitext2','c4','c4-new']
+ group_size (`int`, *optional*, defaults to 128):
+ The group size to use for quantization. Recommended value is 128 and -1 uses per-column quantization.
+ damp_percent (`float`, *optional*, defaults to 0.1):
+ The percent of the average Hessian diagonal to use for dampening. Recommended value is 0.1.
+ desc_act (`bool`, *optional*, defaults to `False`):
+ Whether to quantize columns in order of decreasing activation size. Setting it to False can significantly
+ speed up inference but the perplexity may become slightly worse. Also known as act-order.
+ sym (`bool`, *optional*, defaults to `True`):
+ Whether to use symetric quantization.
+ true_sequential (`bool`, *optional*, defaults to `True`):
+ Whether to perform sequential quantization even within a single Transformer block. Instead of quantizing
+ the entire block at once, we perform layer-wise quantization. As a result, each layer undergoes
+ quantization using inputs that have passed through the previously quantized layers.
+ checkpoint_format (`str`, *optional*, defaults to `"gptq"`):
+ GPTQ weight format. `gptq`(v1) is supported by both gptqmodel and auto-gptq. `gptq_v2` is gptqmodel only.
+ meta (`Dict[str, any]`, *optional*):
+ Properties, such as tooling:version, that do not directly contributes to quantization or quant inference are stored in meta.
+ i.e. `meta.quantizer`: ["optimum:_version_", "gptqmodel:_version_"]
+ backend (`str`, *optional*):
+ Controls which gptq kernel to be used. Valid values for gptqmodel are `auto`, `auto_trainable` and more. For auto-gptq, only
+ valid value is None and `auto_trainable`. Ref gptqmodel backends: https://github.com/ModelCloud/GPTQModel/blob/main/gptqmodel/utils/backend.py
+ use_cuda_fp16 (`bool`, *optional*, defaults to `False`):
+ Whether or not to use optimized cuda kernel for fp16 model. Need to have model in fp16. Auto-gptq only.
+ model_seqlen (`int`, *optional*):
+ The maximum sequence length that the model can take.
+ block_name_to_quantize (`str`, *optional*):
+ The transformers block name to quantize. If None, we will infer the block name using common patterns (e.g. model.layers)
+ module_name_preceding_first_block (`List[str]`, *optional*):
+ The layers that are preceding the first Transformer block.
+ batch_size (`int`, *optional*, defaults to 1):
+ The batch size used when processing the dataset
+ pad_token_id (`int`, *optional*):
+ The pad token id. Needed to prepare the dataset when `batch_size` > 1.
+ use_exllama (`bool`, *optional*):
+ Whether to use exllama backend. Defaults to `True` if unset. Only works with `bits` = 4.
+ max_input_length (`int`, *optional*):
+ The maximum input length. This is needed to initialize a buffer that depends on the maximum expected input
+ length. It is specific to the exllama backend with act-order.
+ exllama_config (`Dict[str, Any]`, *optional*):
+ The exllama config. You can specify the version of the exllama kernel through the `version` key. Defaults
+ to `{"version": 1}` if unset.
+ cache_block_outputs (`bool`, *optional*, defaults to `True`):
+ Whether to cache block outputs to reuse as inputs for the succeeding block.
+ modules_in_block_to_quantize (`List[List[str]]`, *optional*):
+ List of list of module names to quantize in the specified block. This argument is useful to exclude certain linear modules from being quantized.
+ The block to quantize can be specified by setting `block_name_to_quantize`. We will quantize each list sequentially. If not set, we will quantize all linear layers.
+ Example: `modules_in_block_to_quantize =[["self_attn.k_proj", "self_attn.v_proj", "self_attn.q_proj"], ["self_attn.o_proj"]]`.
+ In this example, we will first quantize the q,k,v layers simultaneously since they are independent.
+ Then, we will quantize `self_attn.o_proj` layer with the q,k,v layers quantized. This way, we will get
+ better results since it reflects the real input `self_attn.o_proj` will get when the model is quantized.
+ """
+
+ def __init__(
+ self,
+ bits: int,
+ tokenizer: Any = None,
+ dataset: Optional[Union[List[str], str]] = None,
+ group_size: int = 128,
+ damp_percent: float = 0.1,
+ desc_act: bool = False,
+ sym: bool = True,
+ true_sequential: bool = True,
+ checkpoint_format: str = "gptq",
+ meta: Optional[Dict[str, Any]] = None,
+ backend: Optional[str] = None,
+ use_cuda_fp16: bool = False,
+ model_seqlen: Optional[int] = None,
+ block_name_to_quantize: Optional[str] = None,
+ module_name_preceding_first_block: Optional[List[str]] = None,
+ batch_size: int = 1,
+ pad_token_id: Optional[int] = None,
+ use_exllama: Optional[bool] = None,
+ max_input_length: Optional[int] = None,
+ exllama_config: Optional[Dict[str, Any]] = None,
+ cache_block_outputs: bool = True,
+ modules_in_block_to_quantize: Optional[List[List[str]]] = None,
+ **kwargs,
+ ):
+ self.quant_method = QuantizationMethod.GPTQ
+ self.bits = bits
+ self.tokenizer = tokenizer
+ self.dataset = dataset
+ self.group_size = group_size
+ self.damp_percent = damp_percent
+ self.desc_act = desc_act
+ self.sym = sym
+ self.true_sequential = true_sequential
+ self.checkpoint_format = checkpoint_format.lower()
+ self.meta = meta
+ self.backend = backend.lower() if isinstance(backend, str) else backend
+ self.use_cuda_fp16 = use_cuda_fp16
+ self.model_seqlen = model_seqlen
+ self.block_name_to_quantize = block_name_to_quantize
+ self.module_name_preceding_first_block = module_name_preceding_first_block
+ self.batch_size = batch_size
+ self.pad_token_id = pad_token_id
+ self.use_exllama = use_exllama
+ self.max_input_length = max_input_length
+ self.exllama_config = exllama_config
+ self.cache_block_outputs = cache_block_outputs
+ self.modules_in_block_to_quantize = modules_in_block_to_quantize
+ self.post_init()
+
+ def get_loading_attributes(self):
+ attibutes_dict = copy.deepcopy(self.__dict__)
+ loading_attibutes = [
+ "use_exllama",
+ "exllama_config",
+ "use_cuda_fp16",
+ "max_input_length",
+ "backend",
+ ]
+ loading_attibutes_dict = {i: j for i, j in attibutes_dict.items() if i in loading_attibutes}
+ return loading_attibutes_dict
+
+ def post_init(self):
+ r"""
+ Safety checker that arguments are correct
+ """
+ if self.bits not in [2, 3, 4, 8]:
+ raise ValueError(f"Only support quantization to [2,3,4,8] bits but found {self.bits}")
+ if self.group_size != -1 and self.group_size <= 0:
+ raise ValueError("group_size must be greater than 0 or equal to -1")
+ if not (0 < self.damp_percent < 1):
+ raise ValueError("damp_percent must between 0 and 1.")
+ if self.dataset is not None:
+ if isinstance(self.dataset, str):
+ if self.dataset in ["ptb", "ptb-new"]:
+ raise ValueError(
+ f"""{self.dataset} dataset was deprecated. You can only choose between
+ ['wikitext2','c4','c4-new']"""
+ )
+ if self.dataset not in ["wikitext2", "c4", "c4-new"]:
+ raise ValueError(
+ f"""You have entered a string value for dataset. You can only choose between
+ ['wikitext2','c4','c4-new'], but we found {self.dataset}"""
+ )
+ elif not isinstance(self.dataset, list):
+ raise ValueError(
+ f"""dataset needs to be either a list of string or a value in
+ ['wikitext2','c4','c4-new'], but we found {self.dataset}"""
+ )
+
+ # make sure backend is back/forward compatible with both gptqmodel (full) and auto-gptq (partial)
+ if is_gptqmodel_available():
+ # convert auto-gptq control into gptqmodel backend
+ if self.backend is None:
+ self.backend = "auto_trainable" if self.use_exllama is not None and not self.use_exllama else "auto"
+ else:
+ # convert gptqmodel backend `auto_trainable` into auto-gptq control
+ if self.backend == "auto_trainable":
+ self.use_exllama = False
+
+ # auto-gptq specific kernel control logic
+ if self.use_exllama is None:
+ # New default behaviour
+ self.use_exllama = True
+
+ if self.exllama_config is None:
+ self.exllama_config = {"version": ExllamaVersion.ONE}
+ else:
+ if "version" not in self.exllama_config:
+ raise ValueError("`exllama_config` needs to have a `version` key.")
+ elif self.exllama_config["version"] not in [ExllamaVersion.ONE, ExllamaVersion.TWO]:
+ exllama_version = self.exllama_config["version"]
+ raise ValueError(
+ f"Only supported versions are in [ExllamaVersion.ONE, ExllamaVersion.TWO] - not recognized version {exllama_version}"
+ )
+
+ if self.bits == 4 and self.use_exllama:
+ if self.exllama_config["version"] == ExllamaVersion.ONE:
+ logger.info(
+ "You have activated exllama backend. Note that you can get better inference "
+ "speed using exllamav2 kernel by setting `exllama_config`."
+ )
+ elif self.exllama_config["version"] == ExllamaVersion.TWO:
+ if is_auto_gptq_available():
+ optimum_version = version.parse(importlib.metadata.version("optimum"))
+ autogptq_version = version.parse(importlib.metadata.version("auto_gptq"))
+ if optimum_version <= version.parse("1.13.2") or autogptq_version <= version.parse("0.4.2"):
+ raise ValueError(
+ f"You need optimum > 1.13.2 and auto-gptq > 0.4.2 . Make sure to have that version installed - detected version : optimum {optimum_version} and autogptq {autogptq_version}"
+ )
+ if self.modules_in_block_to_quantize is not None:
+ optimum_version = version.parse(importlib.metadata.version("optimum"))
+ if optimum_version < version.parse("1.15.0"):
+ raise ValueError(
+ "You current version of `optimum` does not support `modules_in_block_to_quantize` quantization argument, please upgrade `optimum` package to a version superior than 1.15.0 ."
+ )
+
+ def to_dict(self):
+ config_dict = super().to_dict()
+ config_dict.pop("disable_exllama", None)
+ return config_dict
+
+ def to_dict_optimum(self):
+ """
+ Get compatible dict for optimum gptq config
+ """
+ quant_dict = self.to_dict()
+ # make it compatible with optimum config
+ quant_dict["disable_exllama"] = not self.use_exllama
+ return quant_dict
+
+ @classmethod
+ def from_dict_optimum(cls, config_dict):
+ """
+ Get compatible class with optimum gptq config dict
+ """
+
+ if "disable_exllama" in config_dict:
+ config_dict["use_exllama"] = not config_dict["disable_exllama"]
+ # switch to None to not trigger the warning
+ config_dict.pop("disable_exllama")
+
+ config = cls(**config_dict)
+ return config
+
+
+@dataclass
+class AwqConfig(QuantizationConfigMixin):
+ """
+ This is a wrapper class about all possible attributes and features that you can play with a model that has been
+ loaded using `auto-awq` library awq quantization relying on auto_awq backend.
+
+ Args:
+ bits (`int`, *optional*, defaults to 4):
+ The number of bits to quantize to.
+ group_size (`int`, *optional*, defaults to 128):
+ The group size to use for quantization. Recommended value is 128 and -1 uses per-column quantization.
+ zero_point (`bool`, *optional*, defaults to `True`):
+ Whether to use zero point quantization.
+ version (`AWQLinearVersion`, *optional*, defaults to `AWQLinearVersion.GEMM`):
+ The version of the quantization algorithm to use. GEMM is better for big batch_size (e.g. >= 8) otherwise,
+ GEMV is better (e.g. < 8 ). GEMM models are compatible with Exllama kernels.
+ backend (`AwqBackendPackingMethod`, *optional*, defaults to `AwqBackendPackingMethod.AUTOAWQ`):
+ The quantization backend. Some models might be quantized using `llm-awq` backend. This is useful for users
+ that quantize their own models using `llm-awq` library.
+ do_fuse (`bool`, *optional*, defaults to `False`):
+ Whether to fuse attention and mlp layers together for faster inference
+ fuse_max_seq_len (`int`, *optional*):
+ The Maximum sequence length to generate when using fusing.
+ modules_to_fuse (`dict`, *optional*, default to `None`):
+ Overwrite the natively supported fusing scheme with the one specified by the users.
+ modules_to_not_convert (`list`, *optional*, default to `None`):
+ The list of modules to not quantize, useful for quantizing models that explicitly require to have
+ some modules left in their original precision (e.g. Whisper encoder, Llava encoder, Mixtral gate layers).
+ Note you cannot quantize directly with transformers, please refer to `AutoAWQ` documentation for quantizing HF models.
+ exllama_config (`Dict[str, Any]`, *optional*):
+ You can specify the version of the exllama kernel through the `version` key, the maximum sequence
+ length through the `max_input_len` key, and the maximum batch size through the `max_batch_size` key.
+ Defaults to `{"version": 2, "max_input_len": 2048, "max_batch_size": 8}` if unset.
+ """
+
+ def __init__(
+ self,
+ bits: int = 4,
+ group_size: int = 128,
+ zero_point: bool = True,
+ version: AWQLinearVersion = AWQLinearVersion.GEMM,
+ backend: AwqBackendPackingMethod = AwqBackendPackingMethod.AUTOAWQ,
+ do_fuse: Optional[bool] = None,
+ fuse_max_seq_len: Optional[int] = None,
+ modules_to_fuse: Optional[dict] = None,
+ modules_to_not_convert: Optional[List] = None,
+ exllama_config: Optional[Dict[str, int]] = None,
+ **kwargs,
+ ):
+ self.quant_method = QuantizationMethod.AWQ
+
+ self.bits = bits
+ self.group_size = group_size
+ self.zero_point = zero_point
+ self.version = version
+ self.backend = backend
+ self.fuse_max_seq_len = fuse_max_seq_len
+ self.modules_to_not_convert = modules_to_not_convert
+ self.exllama_config = exllama_config
+
+ self.modules_to_fuse = modules_to_fuse
+ if do_fuse is None:
+ self.do_fuse = modules_to_fuse is not None and len(modules_to_fuse) > 0
+ else:
+ self.do_fuse = do_fuse
+ self.fuse_max_seq_len = fuse_max_seq_len
+
+ self.post_init()
+
+ def post_init(self):
+ r"""
+ Safety checker that arguments are correct
+ """
+ if self.backend not in [AwqBackendPackingMethod.AUTOAWQ, AwqBackendPackingMethod.LLMAWQ]:
+ raise ValueError(
+ f"Only supported quantization backends in {AwqBackendPackingMethod.AUTOAWQ} and {AwqBackendPackingMethod.LLMAWQ} - not recognized backend {self.backend}"
+ )
+
+ self.version = AWQLinearVersion.from_str(self.version)
+ if self.version not in [
+ AWQLinearVersion.GEMM,
+ AWQLinearVersion.GEMV,
+ AWQLinearVersion.EXLLAMA,
+ AWQLinearVersion.IPEX,
+ ]:
+ raise ValueError(
+ f"Only supported versions are in [AWQLinearVersion.GEMM, AWQLinearVersion.GEMV, AWQLinearVersion.EXLLAMA, AWQLinearVersion.IPEX] - not recognized version {self.version}"
+ )
+
+ if self.backend == AwqBackendPackingMethod.LLMAWQ:
+ # Only cuda device can run this function
+ if not (torch.cuda.is_available() or torch.xpu.is_available()):
+ raise ValueError("LLM-AWQ backend is only supported on CUDA and XPU")
+ if torch.cuda.is_available():
+ compute_capability = torch.cuda.get_device_capability()
+ major, minor = compute_capability
+ if major < 8:
+ raise ValueError("LLM-AWQ backend is only supported on CUDA GPUs with compute capability >= 8.0")
+
+ if self.do_fuse and self.fuse_max_seq_len is None:
+ raise ValueError(
+ "You cannot enable fused modules without specifying a `fuse_max_seq_len`, make sure to pass a valid `fuse_max_seq_len` for your usecase"
+ )
+
+ if self.do_fuse:
+ awq_version_supports_fusing = False
+ MIN_AWQ_VERSION = "0.1.7"
+ if is_auto_awq_available():
+ awq_version_supports_fusing = version.parse(importlib.metadata.version("autoawq")) >= version.parse(
+ MIN_AWQ_VERSION
+ )
+
+ if not awq_version_supports_fusing:
+ raise ValueError(
+ f"You current version of `autoawq` does not support module fusing, please upgrade `autoawq` package to at least {MIN_AWQ_VERSION}."
+ )
+
+ if self.modules_to_not_convert is not None:
+ awq_version_supports_non_conversion = False
+ MIN_AWQ_VERSION = "0.1.8"
+ if is_auto_awq_available():
+ awq_version_supports_non_conversion = version.parse(
+ importlib.metadata.version("autoawq")
+ ) >= version.parse(MIN_AWQ_VERSION)
+
+ if not awq_version_supports_non_conversion:
+ raise ValueError(
+ f"You current version of `autoawq` does not support module quantization skipping, please upgrade `autoawq` package to at least {MIN_AWQ_VERSION}."
+ )
+
+ if self.do_fuse and self.modules_to_fuse is not None:
+ required_keys = [
+ "hidden_size",
+ "num_attention_heads",
+ "num_key_value_heads",
+ "mlp",
+ "attention",
+ "layernorm",
+ "use_alibi",
+ ]
+ if not all(key in self.modules_to_fuse for key in required_keys):
+ raise ValueError(
+ f"Required fields are missing in the fusing mapping, required fields are {required_keys}"
+ )
+
+ if self.version == AWQLinearVersion.EXLLAMA:
+ awq_version_supports_exllama = False
+ MIN_AWQ_VERSION = "0.2.0"
+ if is_auto_awq_available():
+ awq_version_supports_exllama = version.parse(importlib.metadata.version("autoawq")) >= version.parse(
+ MIN_AWQ_VERSION
+ )
+
+ if not awq_version_supports_exllama:
+ raise ValueError(
+ f"You current version of `autoawq` does not support exllama backend, "
+ f"please upgrade `autoawq` package to at least {MIN_AWQ_VERSION}."
+ )
+
+ if self.exllama_config is None:
+ self.exllama_config = {"version": ExllamaVersion.TWO, "max_input_len": 2048, "max_batch_size": 8}
+ else:
+ if "version" not in self.exllama_config:
+ raise ValueError("`exllama_config` needs to have a `version` key.")
+ elif self.exllama_config["version"] not in [ExllamaVersion.ONE, ExllamaVersion.TWO]:
+ exllama_version = self.exllama_config["version"]
+ raise ValueError(
+ f"Only supported versions are in [ExllamaVersion.ONE, ExllamaVersion.TWO] - not recognized version {exllama_version}"
+ )
+
+ def get_loading_attributes(self):
+ attibutes_dict = copy.deepcopy(self.__dict__)
+ loading_attibutes = ["version", "do_fuse", "modules_to_fuse", "fuse_max_seq_len", "exllama_config"]
+ loading_attibutes_dict = {i: j for i, j in attibutes_dict.items() if i in loading_attibutes}
+ return loading_attibutes_dict
+
+
+@dataclass
+class AqlmConfig(QuantizationConfigMixin):
+ """
+ This is a wrapper class about `aqlm` parameters.
+
+ Args:
+ in_group_size (`int`, *optional*, defaults to 8):
+ The group size along the input dimension.
+ out_group_size (`int`, *optional*, defaults to 1):
+ The group size along the output dimension. It's recommended to always use 1.
+ num_codebooks (`int`, *optional*, defaults to 1):
+ Number of codebooks for the Additive Quantization procedure.
+ nbits_per_codebook (`int`, *optional*, defaults to 16):
+ Number of bits encoding a single codebook vector. Codebooks size is 2**nbits_per_codebook.
+ linear_weights_not_to_quantize (`Optional[List[str]]`, *optional*):
+ List of full paths of `nn.Linear` weight parameters that shall not be quantized.
+ kwargs (`Dict[str, Any]`, *optional*):
+ Additional parameters from which to initialize the configuration object.
+ """
+
+ def __init__(
+ self,
+ in_group_size: int = 8,
+ out_group_size: int = 1,
+ num_codebooks: int = 1,
+ nbits_per_codebook: int = 16,
+ linear_weights_not_to_quantize: Optional[List[str]] = None,
+ **kwargs,
+ ):
+ self.quant_method = QuantizationMethod.AQLM
+ self.in_group_size = in_group_size
+ self.out_group_size = out_group_size
+ self.num_codebooks = num_codebooks
+ self.nbits_per_codebook = nbits_per_codebook
+ self.linear_weights_not_to_quantize = linear_weights_not_to_quantize
+
+ self.post_init()
+
+ def post_init(self):
+ r"""
+ Safety checker that arguments are correct - also replaces some NoneType arguments with their default values.
+ """
+ if not isinstance(self.in_group_size, int):
+ raise TypeError("in_group_size must be a float")
+ if not isinstance(self.out_group_size, int):
+ raise TypeError("out_group_size must be a float")
+ if not isinstance(self.num_codebooks, int):
+ raise TypeError("num_codebooks must be a float")
+ if not isinstance(self.nbits_per_codebook, int):
+ raise TypeError("nbits_per_codebook must be a float")
+
+ if self.linear_weights_not_to_quantize is not None and not isinstance(
+ self.linear_weights_not_to_quantize, list
+ ):
+ raise ValueError("linear_weights_not_to_quantize must be a list of strings")
+
+ if self.linear_weights_not_to_quantize is None:
+ self.linear_weights_not_to_quantize = []
+
+
+@dataclass
+class VptqLayerConfig(QuantizationConfigMixin):
+ """
+ This is used to explain vptq config params for each layer
+ Args:
+ enable_norm (`bool`, *optional*, defaults to `True`): to control if we have scale/bias for fp-weight
+ enable_perm (`bool`, *optional*, defaults to `True`): to perm input_channel or not
+ group_num (`int`, *optional*, defaults to `1`): how many single groups for vector-quantization
+ group_size (`int`, *optional*, defaults to `-1`): depends on out-features
+ indices_as_float (`bool`, *optional*, defaults to `False`): for Finetuning
+ is_indice_packed (`bool`, *optional*, defaults to `True`): should always be True
+ num_centroids (`list`, *optional*, defaults to `[-1, -1]`): centriod numbers of clusters
+ num_res_centroids (`list`, *optional*, defaults to `[-1, -1]`): ditto for residual
+ outlier_size (`int`, *optional*, defaults to `1`): outliers
+ vector_lens (`list`, *optional*, defaults to `[-1, -1]`): centroid vector length in quantization
+ """
+
+ def __init__(
+ self,
+ enable_norm: bool = True,
+ enable_perm: bool = True,
+ group_num: int = 1,
+ group_size: int = -1,
+ in_features: int = -1,
+ indices_as_float: bool = False,
+ is_indice_packed: bool = True,
+ num_centroids: tuple = [-1, -1],
+ num_res_centroids: tuple = [-1, -1],
+ out_features: int = -1,
+ outlier_size: int = 0,
+ vector_lens: tuple = [-1, -1],
+ **kwargs,
+ ):
+ self.enable_norm = enable_norm
+ self.enable_perm = enable_perm
+ self.group_num = group_num
+ self.group_size = group_size
+ self.in_features = in_features
+ self.indices_as_float = indices_as_float
+ self.is_indice_packed = is_indice_packed
+ self.num_centroids = num_centroids
+ self.num_res_centroids = num_res_centroids
+ self.out_features = out_features
+ self.outlier_size = outlier_size
+ self.vector_lens = vector_lens
+ self.post_init()
+
+ def post_init(self):
+ r"""
+ Safety checker that arguments are correct
+ """
+ if self.is_indice_packed is False:
+ raise ValueError("is_indice_packed should always be True")
+
+
+@dataclass
+class VptqConfig(QuantizationConfigMixin):
+ """
+ This is a wrapper class about `vptq` parameters.
+
+ Args:
+ enable_proxy_error (`bool`, *optional*, defaults to `False`): calculate proxy error for each layer
+ config_for_layers (`Dict`, *optional*, defaults to `{}`): quantization params for each layer
+ shared_layer_config (`Dict`, *optional*, defaults to `{}`): shared quantization params among layers
+ modules_to_not_convert (`list`, *optional*, default to `None`):
+ The list of modules to not quantize, useful for quantizing models that explicitly require to have
+ some modules left in their original precision (e.g. Whisper encoder, Llava encoder, Mixtral gate layers).
+ kwargs (`Dict[str, Any]`, *optional*):
+ Additional parameters from which to initialize the configuration object.
+ """
+
+ def __init__(
+ self,
+ enable_proxy_error: bool = False,
+ config_for_layers: Dict[str, Any] = {},
+ shared_layer_config: Dict[str, Any] = {},
+ modules_to_not_convert: Optional[List] = None,
+ **kwargs,
+ ):
+ self.quant_method = QuantizationMethod.VPTQ
+ self.enable_proxy_error = enable_proxy_error
+ self.config_for_layers: Dict[str, Any] = config_for_layers
+ self.shared_layer_config: Dict[str, Any] = shared_layer_config
+ self.modules_to_not_convert = modules_to_not_convert
+ self.post_init()
+
+ def post_init(self):
+ r"""
+ Safety checker that arguments are correct
+ """
+ for layer_name, layer_param in self.config_for_layers.items():
+ VptqLayerConfig(**layer_param)
+ if self.enable_proxy_error is True:
+ raise ValueError("enable_proxy_error should always be False until we support training")
+
+
+@dataclass
+class QuantoConfig(QuantizationConfigMixin):
+ """
+ This is a wrapper class about all possible attributes and features that you can play with a model that has been
+ loaded using `quanto`.
+
+ Args:
+ weights (`str`, *optional*, defaults to `"int8"`):
+ The target dtype for the weights after quantization. Supported values are ("float8","int8","int4","int2")
+ activations (`str`, *optional*):
+ The target dtype for the activations after quantization. Supported values are (None,"int8","float8")
+ modules_to_not_convert (`list`, *optional*, default to `None`):
+ The list of modules to not quantize, useful for quantizing models that explicitly require to have
+ some modules left in their original precision (e.g. Whisper encoder, Llava encoder, Mixtral gate layers).
+ """
+
+ def __init__(
+ self,
+ weights="int8",
+ activations=None,
+ modules_to_not_convert: Optional[List] = None,
+ **kwargs,
+ ):
+ self.quant_method = QuantizationMethod.QUANTO
+ self.weights = weights
+ self.activations = activations
+ self.modules_to_not_convert = modules_to_not_convert
+ self.post_init()
+
+ def post_init(self):
+ r"""
+ Safety checker that arguments are correct
+ """
+ accepted_weights = ["float8", "int8", "int4", "int2"]
+ accepted_activations = [None, "int8", "float8"]
+ if self.weights not in accepted_weights:
+ raise ValueError(f"Only support weights in {accepted_weights} but found {self.weights}")
+ if self.activations not in accepted_activations:
+ raise ValueError(f"Only support weights in {accepted_activations} but found {self.activations}")
+
+
+@dataclass
+class EetqConfig(QuantizationConfigMixin):
+ """
+ This is a wrapper class about all possible attributes and features that you can play with a model that has been
+ loaded using `eetq`.
+
+ Args:
+ weights (`str`, *optional*, defaults to `"int8"`):
+ The target dtype for the weights. Supported value is only "int8"
+ modules_to_not_convert (`list`, *optional*, default to `None`):
+ The list of modules to not quantize, useful for quantizing models that explicitly require to have
+ some modules left in their original precision.
+ """
+
+ def __init__(
+ self,
+ weights: str = "int8",
+ modules_to_not_convert: Optional[List] = None,
+ **kwargs,
+ ):
+ self.quant_method = QuantizationMethod.EETQ
+ self.weights = weights
+ self.modules_to_not_convert = modules_to_not_convert
+ self.post_init()
+
+ def post_init(self):
+ r"""
+ Safety checker that arguments are correct
+ """
+ accepted_weights = ["int8"]
+ if self.weights not in accepted_weights:
+ raise ValueError(f"Only support weights in {accepted_weights} but found {self.weights}")
+
+
+class CompressedTensorsConfig(QuantizationConfigMixin):
+ """
+ This is a wrapper class that handles compressed-tensors quantization config options.
+ It is a wrapper around `compressed_tensors.QuantizationConfig`
+ Args:
+ config_groups (`typing.Dict[str, typing.Union[ForwardRef('QuantizationScheme'), typing.List[str]]]`, *optional*):
+ dictionary mapping group name to a quantization scheme definition
+ format (`str`, *optional*, defaults to `"dense"`):
+ format the model is represented as. Set `run_compressed` True to execute model as the
+ compressed format if not `dense`
+ quantization_status (`QuantizationStatus`, *optional*, defaults to `"initialized"`):
+ status of model in the quantization lifecycle, ie 'initialized', 'calibration', 'frozen'
+ kv_cache_scheme (`typing.Union[QuantizationArgs, NoneType]`, *optional*):
+ specifies quantization of the kv cache. If None, kv cache is not quantized.
+ global_compression_ratio (`typing.Union[float, NoneType]`, *optional*):
+ 0-1 float percentage of model compression
+ ignore (`typing.Union[typing.List[str], NoneType]`, *optional*):
+ layer names or types to not quantize, supports regex prefixed by 're:'
+ sparsity_config (`typing.Dict[str, typing.Any]`, *optional*):
+ configuration for sparsity compression
+ quant_method (`str`, *optional*, defaults to `"compressed-tensors"`):
+ do not override, should be compressed-tensors
+ run_compressed (`bool`, *optional*, defaults to `True`): alter submodules (usually linear) in order to
+ emulate compressed model execution if True, otherwise use default submodule
+ """
+
+ def __init__(
+ self,
+ config_groups: Dict[str, Union["QuantizationScheme", List[str]]] = None, # noqa: F821
+ format: str = "dense",
+ quantization_status: "QuantizationStatus" = "initialized", # noqa: F821
+ kv_cache_scheme: Optional["QuantizationArgs"] = None, # noqa: F821
+ global_compression_ratio: Optional[float] = None,
+ ignore: Optional[List[str]] = None,
+ sparsity_config: Dict[str, Any] = None,
+ quant_method: str = "compressed-tensors",
+ run_compressed: bool = True,
+ **kwargs,
+ ):
+ if is_compressed_tensors_available():
+ from compressed_tensors.config import SparsityCompressionConfig
+ from compressed_tensors.quantization import QuantizationConfig
+ else:
+ raise ImportError(
+ "compressed_tensors is not installed and is required for compressed-tensors quantization. Please install it with `pip install compressed-tensors`."
+ )
+ self.quantization_config = None
+ self.sparsity_config = None
+
+ self.run_compressed = run_compressed
+
+ # parse from dict to load nested QuantizationScheme objects
+ if config_groups or kv_cache_scheme:
+ self.quantization_config = QuantizationConfig.model_validate(
+ {
+ "config_groups": config_groups,
+ "quant_method": quant_method,
+ "format": format,
+ "quantization_status": quantization_status,
+ "kv_cache_scheme": kv_cache_scheme,
+ "global_compression_ratio": global_compression_ratio,
+ "ignore": ignore,
+ "run_compressed": run_compressed,
+ **kwargs,
+ }
+ )
+
+ if sparsity_config:
+ self.sparsity_config = SparsityCompressionConfig.load_from_registry(
+ sparsity_config.get("format"), **sparsity_config
+ )
+
+ self.quant_method = QuantizationMethod.COMPRESSED_TENSORS
+
+ def post_init(self):
+ if self.run_compressed:
+ if self.is_sparsification_compressed:
+ logger.warn(
+ "`run_compressed` is only supported for quantized_compressed models"
+ " and not for sparsified models. Setting `run_compressed=False`"
+ )
+ self.run_compressed = False
+ elif not self.is_quantization_compressed:
+ logger.warn("`run_compressed` is only supported for compressed models. Setting `run_compressed=False`")
+ self.run_compressed = False
+
+ @classmethod
+ def from_dict(cls, config_dict, return_unused_kwargs=False, **kwargs):
+ """
+ Instantiates a [`CompressedTensorsConfig`] from a Python dictionary of parameters.
+ Optionally unwraps any args from the nested quantization_config
+
+ Args:
+ config_dict (`Dict[str, Any]`):
+ Dictionary that will be used to instantiate the configuration object.
+ return_unused_kwargs (`bool`,*optional*, defaults to `False`):
+ Whether or not to return a list of unused keyword arguments. Used for `from_pretrained` method in
+ `PreTrainedModel`.
+ kwargs (`Dict[str, Any]`):
+ Additional parameters from which to initialize the configuration object.
+
+ Returns:
+ [`QuantizationConfigMixin`]: The configuration object instantiated from those parameters.
+
+ """
+
+ if "quantization_config" in config_dict:
+ config_dict = dict(
+ sparsity_config=config_dict.get("sparsity_config"),
+ **config_dict["quantization_config"],
+ )
+
+ return super().from_dict(config_dict, return_unused_kwargs=return_unused_kwargs, **kwargs)
+
+ def to_dict(self) -> Dict[str, Any]:
+ """
+ Quantization config to be added to config.json
+
+ Serializes this instance to a Python dictionary. Returns:
+ `Dict[str, Any]`: Dictionary of all the attributes that make up this configuration instance.
+ """
+ quantization_config = {}
+ if self.quantization_config is not None:
+ quantization_config = self.quantization_config.dict()
+ else:
+ quantization_config["quant_method"] = QuantizationMethod.COMPRESSED_TENSORS
+
+ if self.sparsity_config is not None:
+ quantization_config["sparsity_config"] = self.sparsity_config.dict()
+ else:
+ quantization_config["sparsity_config"] = {}
+
+ return quantization_config
+
+ def to_diff_dict(self) -> Dict[str, Any]:
+ """
+ Removes all attributes from config which correspond to the default config attributes for better readability and
+ serializes to a Python dictionary.
+ Returns:
+ `Dict[str, Any]`: Dictionary of all the attributes that make up this configuration instance,
+ """
+ config_dict = self.to_dict()
+
+ # get the default config dict
+ default_config_dict = CompressedTensorsConfig().to_dict()
+
+ serializable_config_dict = {}
+
+ # only serialize values that differ from the default config
+ for key, value in config_dict.items():
+ if key not in default_config_dict or value != default_config_dict[key]:
+ serializable_config_dict[key] = value
+
+ return serializable_config_dict
+
+ def get_loading_attributes(self):
+ return {"run_compressed": self.run_compressed}
+
+ @property
+ def is_quantized(self):
+ return bool(self.quantization_config) and bool(self.quantization_config.config_groups)
+
+ @property
+ def is_quantization_compressed(self):
+ from compressed_tensors.quantization import QuantizationStatus
+
+ return self.is_quantized and self.quantization_config.quantization_status == QuantizationStatus.COMPRESSED
+
+ @property
+ def is_sparsification_compressed(self):
+ from compressed_tensors.config import (
+ CompressionFormat,
+ SparsityCompressionConfig,
+ )
+
+ return (
+ isinstance(self.sparsity_config, SparsityCompressionConfig)
+ and self.sparsity_config.format != CompressionFormat.dense.value
+ )
+
+
+@dataclass
+class FbgemmFp8Config(QuantizationConfigMixin):
+ """
+ This is a wrapper class about all possible attributes and features that you can play with a model that has been
+ loaded using fbgemm fp8 quantization.
+
+ Args:
+ activation_scale_ub (`float`, *optional*, defaults to 1200.0):
+ The activation scale upper bound. This is used when quantizing the input activation.
+ modules_to_not_convert (`list`, *optional*, default to `None`):
+ The list of modules to not quantize, useful for quantizing models that explicitly require to have
+ some modules left in their original precision.
+ """
+
+ def __init__(
+ self,
+ activation_scale_ub: float = 1200.0,
+ modules_to_not_convert: Optional[List] = None,
+ **kwargs,
+ ):
+ self.quant_method = QuantizationMethod.FBGEMM_FP8
+ self.activation_scale_ub = activation_scale_ub
+ self.modules_to_not_convert = modules_to_not_convert
+
+ def get_loading_attributes(self):
+ attibutes_dict = copy.deepcopy(self.__dict__)
+ loading_attibutes = ["activation_scale_ub"]
+ loading_attibutes_dict = {i: j for i, j in attibutes_dict.items() if i in loading_attibutes}
+ return loading_attibutes_dict
+
+
+@dataclass
+class HiggsConfig(QuantizationConfigMixin):
+ """
+ HiggsConfig is a configuration class for quantization using the HIGGS method.
+
+ Args:
+ bits (int, *optional*, defaults to 4):
+ Number of bits to use for quantization. Can be 2, 3 or 4. Default is 4.
+ p (int, *optional*, defaults to 2):
+ Quantization grid dimension. 1 and 2 are supported. 2 is always better in practice. Default is 2.
+ modules_to_not_convert (`list`, *optional*, default to ["lm_head"]):
+ List of linear layers that should not be quantized.
+ hadamard_size (int, *optional*, defaults to 512):
+ Hadamard size for the HIGGS method. Default is 512. Input dimension of matrices is padded to this value. Decreasing this below 512 will reduce the quality of the quantization.
+ group_size (int, *optional*, defaults to 256):
+ Group size for the HIGGS method. Can be 64, 128 or 256. Decreasing it barely affects the performance. Default is 256. Must be a divisor of hadamard_size.
+ tune_metadata ('dict', *optional*, defaults to {}):
+ Module-wise metadata (gemm block shapes, GPU metadata, etc.) for saving the kernel tuning results. Default is an empty dictionary. Is set automatically during tuning.
+ """
+
+ def __init__(
+ self,
+ bits: int = 4,
+ p: int = 2,
+ modules_to_not_convert: Optional[List[str]] = None,
+ hadamard_size: int = 512,
+ group_size: int = 256,
+ tune_metadata: Optional[Dict[str, Any]] = None,
+ **kwargs,
+ ):
+ if tune_metadata is None:
+ tune_metadata = {}
+ self.quant_method = QuantizationMethod.HIGGS
+ self.bits = bits
+ self.p = p
+ self.modules_to_not_convert = modules_to_not_convert
+ self.hadamard_size = hadamard_size
+ self.group_size = group_size
+ self.tune_metadata = tune_metadata
+
+ self.post_init()
+
+ def post_init(self):
+ r"""
+ Safety checker that arguments are correct - also replaces some NoneType arguments with their default values.
+ """
+ if self.bits not in [2, 3, 4]:
+ raise ValueError("bits must be 2, 3, or 4")
+ if self.p not in [1, 2]:
+ raise ValueError("p must be 1 or 2. 2 is always better in practice")
+ if self.group_size not in [64, 128, 256]:
+ raise ValueError("group_size must be 64, 128, or 256")
+ if self.hadamard_size % self.group_size != 0:
+ raise ValueError("hadamard_size must be divisible by group_size")
+
+
+@dataclass
+class TorchAoConfig(QuantizationConfigMixin):
+ quant_method: QuantizationMethod
+ quant_type: Union[str, "AOBaseConfig"] # noqa: F821
+ modules_to_not_convert: Optional[List]
+ quant_type_kwargs: Dict[str, Any]
+
+ """This is a config class for torchao quantization/sparsity techniques.
+
+ Args:
+ quant_type (`Union[str, AOBaseConfig]`):
+ The type of quantization we want to use. Can be either:
+ - A string: currently supporting: `int4_weight_only`, `int8_weight_only` and `int8_dynamic_activation_int8_weight`.
+ - An AOBaseConfig instance: for more advanced configuration options.
+ modules_to_not_convert (`list`, *optional*, default to `None`):
+ The list of modules to not quantize, useful for quantizing models that explicitly require to have
+ some modules left in their original precision.
+ kwargs (`Dict[str, Any]`, *optional*):
+ The keyword arguments for the chosen type of quantization, for example, int4_weight_only quantization supports two keyword arguments
+ `group_size` and `inner_k_tiles` currently. More API examples and documentation of arguments can be found in
+ https://github.com/pytorch/ao/tree/main/torchao/quantization#other-available-quantization-techniques
+
+ Example:
+
+ ```python
+ # AOBaseConfig-based configuration
+ config = Int4WeightOnlyConfig(group_size=32)
+ quantization_config = TorchAoConfig(config)
+ model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda", torch_dtype=torch.bfloat16, quantization_config=quantization_config)
+
+ # String-based configuration
+ quantization_config = TorchAoConfig("int4_weight_only", group_size=32)
+ # int4_weight_only quant is only working with *torch.bfloat16* dtype right now
+ model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda", torch_dtype=torch.bfloat16, quantization_config=quantization_config)
+
+ # autoquant
+ # `autoquant` is a convenient way for users to search for the best quantization for each layer
+ # `min_sqnr` is an option to control the accuracy of the model, higher value means the model is more
+ # accurate, we can start with 30 and adjust it to larger or smaller (e.g. 40, 20)
+ # defaults to None, which means we'll try to get the best performing quantized model without
+ # considering accuracy
+ quantization_config = TorchAoConfig("autoquant", min_sqnr=30)
+ model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda", torch_dtype=torch.bfloat16, quantization_config=quantization_config)
+ # run through example inputs, quantization methods will be selected based on the shape of example input
+ tokenizer = AutoTokenizer.from_pretrained(model_name)
+ input_text = "What are we having for dinner?"
+ input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
+ MAX_NEW_TOKENS = 1000
+ model.generate(**input_ids, max_new_tokens=MAX_NEW_TOKENS, cache_implementation="static")
+ # manually ran finalize_autoquant if needed
+ if hasattr(quantized_model, "finalize_autoquant"):
+ print("finalizing autoquant")
+ quantized_model.finalize_autoquant()
+
+ ```
+ """
+
+ def __init__(
+ self,
+ quant_type: Union[str, "AOBaseConfig"], # noqa: F821
+ modules_to_not_convert: Optional[List] = None,
+ **kwargs,
+ ):
+ self.quant_method = QuantizationMethod.TORCHAO
+ self.quant_type = quant_type
+ self.modules_to_not_convert = modules_to_not_convert
+ self.quant_type_kwargs = kwargs.get("quant_type_kwargs", kwargs)
+ self.post_init()
+
+ @staticmethod
+ def _get_ao_version() -> version.Version:
+ """Centralized check for TorchAO availability and version requirements."""
+ if not is_torchao_available():
+ raise ValueError("TorchAoConfig requires torchao to be installed. Install with `pip install torchao`")
+
+ return version.parse(importlib.metadata.version("torchao"))
+
+ def post_init(self):
+ """Validate configuration and set defaults."""
+ ao_version = self._get_ao_version()
+
+ # Handle quant_type based on type and version
+ if isinstance(self.quant_type, str):
+ self._validate_string_quant_type()
+ elif ao_version > version.parse("0.9.0"):
+ from torchao.quantization.quant_api import AOBaseConfig
+
+ if not isinstance(self.quant_type, AOBaseConfig):
+ raise ValueError(
+ f"quant_type must be either a string or an AOBaseConfig instance, got {type(self.quant_type)}"
+ )
+ else:
+ raise ValueError(
+ f"In torchao <= 0.9.0, quant_type must be a string. Got {type(self.quant_type)}. "
+ f"Please upgrade to torchao > 0.9.0 to use AOBaseConfig instances."
+ )
+
+ def _validate_string_quant_type(self):
+ """Validate string quant_type and its kwargs."""
+ methods = self._get_torchao_quant_type_to_method()
+
+ if self.quant_type not in methods:
+ raise ValueError(
+ f"Unsupported string quantization type: {self.quant_type}. "
+ f"Supported types: {', '.join(methods.keys())}"
+ )
+
+ # Validate kwargs against method signature
+ method = methods[self.quant_type]
+ sig = signature(method)
+ valid_kwargs = {
+ param.name
+ for param in sig.parameters.values()
+ if param.kind in [Parameter.KEYWORD_ONLY, Parameter.POSITIONAL_OR_KEYWORD]
+ }
+
+ invalid_kwargs = set(self.quant_type_kwargs) - valid_kwargs
+ if invalid_kwargs:
+ raise ValueError(
+ f"Unexpected keyword arg for {self.quant_type}: {', '.join(invalid_kwargs)}. "
+ f"Valid kwargs: {', '.join(valid_kwargs)}"
+ )
+
+ def _get_torchao_quant_type_to_method(self):
+ """Get mapping of quant_type strings to their corresponding methods."""
+ from torchao.quantization import (
+ autoquant,
+ int4_weight_only,
+ int8_dynamic_activation_int8_weight,
+ int8_weight_only,
+ )
+
+ return {
+ "int4_weight_only": int4_weight_only,
+ "int8_weight_only": int8_weight_only,
+ "int8_dynamic_activation_int8_weight": int8_dynamic_activation_int8_weight,
+ "autoquant": autoquant,
+ }
+
+ def get_apply_tensor_subclass(self):
+ """Create the appropriate quantization method based on configuration."""
+ if isinstance(self.quant_type, str):
+ methods = self._get_torchao_quant_type_to_method()
+ quant_type_kwargs = self.quant_type_kwargs.copy()
+ if (
+ not torch.cuda.is_available()
+ and is_torchao_available()
+ and self.quant_type == "int4_weight_only"
+ and version.parse(importlib.metadata.version("torchao")) >= version.parse("0.8.0")
+ and quant_type_kwargs.get("layout", None) is None
+ ):
+ from torchao.dtypes import Int4CPULayout
+
+ quant_type_kwargs["layout"] = Int4CPULayout()
+
+ return methods[self.quant_type](**quant_type_kwargs)
+ else:
+ return self.quant_type
+
+ def to_dict(self):
+ """Convert configuration to a dictionary."""
+ d = super().to_dict()
+
+ if isinstance(self.quant_type, str):
+ # Handle layout serialization if present
+ if "quant_type_kwargs" in d and "layout" in d["quant_type_kwargs"]:
+ if is_dataclass(d["quant_type_kwargs"]["layout"]):
+ d["quant_type_kwargs"]["layout"] = [
+ d["quant_type_kwargs"]["layout"].__class__.__name__,
+ dataclasses.asdict(d["quant_type_kwargs"]["layout"]),
+ ]
+ if isinstance(d["quant_type_kwargs"]["layout"], list):
+ assert len(d["quant_type_kwargs"]["layout"]) == 2, "layout saves layout name and layour kwargs"
+ assert isinstance(d["quant_type_kwargs"]["layout"][0], str), "layout name must be a string"
+ assert isinstance(d["quant_type_kwargs"]["layout"][1], dict), "layout kwargs must be a dict"
+ else:
+ raise ValueError("layout must be a list")
+ else:
+ # Handle AOBaseConfig serialization
+ from torchao.core.config import config_to_dict
+
+ # For now we assume there is 1 config per Transfomer, however in the future
+ # We may want to support a config per fqn.
+ d["quant_type"] = {"default": config_to_dict(self.quant_type)}
+
+ return d
+
+ @classmethod
+ def from_dict(cls, config_dict, return_unused_kwargs=False, **kwargs):
+ """Create configuration from a dictionary."""
+ ao_verison = cls._get_ao_version()
+ assert ao_verison > version.parse("0.9.0"), "TorchAoConfig requires torchao > 0.9.0 for construction from dict"
+ config_dict = config_dict.copy()
+ quant_type = config_dict.pop("quant_type")
+
+ if isinstance(quant_type, str):
+ return cls(quant_type=quant_type, **config_dict)
+ # Check if we only have one key which is "default"
+ # In the future we may update this
+ assert len(quant_type) == 1 and "default" in quant_type, (
+ "Expected only one key 'default' in quant_type dictionary"
+ )
+ quant_type = quant_type["default"]
+
+ # Deserialize quant_type if needed
+ from torchao.core.config import config_from_dict
+
+ quant_type = config_from_dict(quant_type)
+
+ return cls(quant_type=quant_type, **config_dict)
+
+
+@dataclass
+class BitNetConfig(QuantizationConfigMixin):
+ def __init__(
+ self,
+ modules_to_not_convert: Optional[List] = None,
+ **kwargs,
+ ):
+ self.quant_method = QuantizationMethod.BITNET
+ self.modules_to_not_convert = modules_to_not_convert
+ self.post_init()
+
+ def post_init(self):
+ r"""
+ Safety checker that arguments are correct
+ """
+ pass
+
+
+@dataclass
+class SpQRConfig(QuantizationConfigMixin):
+ """
+ This is a wrapper class about `spqr` parameters. Refer to the original publication for more details.
+
+ Args:
+ bits (`int`, *optional*, defaults to 3):
+ Specifies the bit count for the weights and first order zero-points and scales.
+ Currently only bits = 3 is supported.
+ beta1 (`int`, *optional*, defaults to 16):
+ SpQR tile width. Currently only beta1 = 16 is supported.
+ beta2 (`int`, *optional*, defaults to 16):
+ SpQR tile height. Currently only beta2 = 16 is supported.
+ shapes (`Optional`, *optional*):
+ A dictionary holding the shape of each object. We need this because it's impossible
+ to deduce the exact size of the parameters just from bits, beta1, beta2.
+ modules_to_not_convert (`Optional[List[str]]`, *optional*):
+ Optionally, provides a list of full paths of `nn.Linear` weight parameters that shall not be quantized.
+ Defaults to None.
+ kwargs (`Dict[str, Any]`, *optional*):
+ Additional parameters from which to initialize the configuration object.
+ """
+
+ def __init__(
+ self,
+ bits: int = 3,
+ beta1: int = 16,
+ beta2: int = 16,
+ shapes: Optional[Dict[str, int]] = None,
+ modules_to_not_convert: Optional[List[str]] = None,
+ **kwargs,
+ ):
+ if shapes is None:
+ shapes = {}
+ self.shapes = shapes
+ self.quant_method = QuantizationMethod.SPQR
+ self.bits = bits
+ self.beta1 = beta1
+ self.beta2 = beta2
+ self.modules_to_not_convert = modules_to_not_convert
+ self.post_init()
+
+ def post_init(self):
+ r"""
+ Safety checker that arguments are correct - also replaces some NoneType arguments with their default values.
+ """
+ if not isinstance(self.bits, int):
+ raise TypeError("bits must be an int")
+ if not isinstance(self.beta1, int):
+ raise TypeError("beta1 must be an int")
+ if not isinstance(self.beta2, int):
+ raise TypeError("beta2 must be an int")
+
+ if self.bits != 3:
+ raise ValueError("SpQR currently only supports bits = 3")
+ if self.beta1 != 16:
+ raise ValueError("SpQR currently only supports beta1 = 16")
+ if self.beta2 != 16:
+ raise ValueError("SpQR currently only supports beta2 = 16")
+ if not isinstance(self.shapes, dict):
+ raise TypeError("shapes must be a dict")
+
+
+@dataclass
+class FineGrainedFP8Config(QuantizationConfigMixin):
+ """
+ FineGrainedFP8Config is a configuration class for fine-grained FP8 quantization used mainly for deepseek models.
+
+ Args:
+ activation_scheme (`str`, *optional*, defaults to `"dynamic"`):
+ The scheme used for activation, the defaults and only support scheme for now is "dynamic".
+ weight_block_size (`typing.Tuple[int, int]`, *optional*, defaults to `(128, 128)`):
+ The size of the weight blocks for quantization, default is (128, 128).
+ modules_to_not_convert (`list`, *optional*):
+ A list of module names that should not be converted during quantization.
+ """
+
+ def __init__(
+ self,
+ activation_scheme: str = "dynamic",
+ weight_block_size: Tuple[int, int] = (128, 128),
+ modules_to_not_convert: Optional[List] = None,
+ **kwargs,
+ ):
+ self.quant_method = QuantizationMethod.FP8
+ self.modules_to_not_convert = modules_to_not_convert
+ self.activation_scheme = activation_scheme
+ self.weight_block_size = weight_block_size
+ self.post_init()
+
+ def post_init(self):
+ r"""
+ Safety checker that arguments are correct
+ """
+ self.activation_scheme = self.activation_scheme.lower()
+ if self.activation_scheme not in ["dynamic"]:
+ raise ValueError(f"Activation scheme {self.activation_scheme} not supported")
+ if len(self.weight_block_size) != 2:
+ raise ValueError("weight_block_size must be a tuple of two integers")
+ if self.weight_block_size[0] <= 0 or self.weight_block_size[1] <= 0:
+ raise ValueError("weight_block_size must be a tuple of two positive integers")
+
+
+class QuarkConfig(QuantizationConfigMixin):
+ def __init__(
+ self,
+ **kwargs,
+ ):
+ if is_torch_available() and is_quark_available():
+ from quark import __version__ as quark_version
+ from quark.torch.export.config.config import JsonExporterConfig
+ from quark.torch.export.main_export.quant_config_parser import QuantConfigParser
+ from quark.torch.quantization.config.config import Config
+ else:
+ raise ImportError(
+ "Quark is not installed. Please refer to https://quark.docs.amd.com/latest/install.html."
+ )
+ # This might be e.g. `"fp8"` or `"awq"`.
+ self.custom_mode = kwargs["quant_method"]
+ self.legacy = "export" not in kwargs
+
+ if self.custom_mode in ["awq", "fp8"]:
+ # Legacy (quark<1.0) or custom export.
+ self.quant_config = QuantConfigParser.from_custom_config(kwargs, is_bias_quantized=False)
+ self.json_export_config = JsonExporterConfig()
+ else:
+ self.quant_config = Config.from_dict(kwargs)
+
+ if "export" in kwargs:
+ # TODO: Remove this check once configuration version is handled natively by Quark.
+ if "min_kv_scale" in kwargs["export"] and version.parse(quark_version) < version.parse("0.8"):
+ min_kv_scale = kwargs["export"].pop("min_kv_scale")
+ logger.warning(
+ f"The parameter `min_kv_scale={min_kv_scale}` was found in the model config.json's `quantization_config.export` configuration, but this parameter is supported only for quark>=0.8. Ignoring this configuration parameter. Please update the `amd-quark` package."
+ )
+
+ self.json_export_config = JsonExporterConfig(**kwargs["export"])
+ else:
+ # Legacy (quark<1.0) or custom export.
+ self.json_export_config = JsonExporterConfig()
+
+ self.quant_method = QuantizationMethod.QUARK
diff --git a/docs/transformers/build/lib/transformers/utils/sentencepiece_model_pb2.py b/docs/transformers/build/lib/transformers/utils/sentencepiece_model_pb2.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4b2992a6308c9f98f68486998d57d00bbdc1e34
--- /dev/null
+++ b/docs/transformers/build/lib/transformers/utils/sentencepiece_model_pb2.py
@@ -0,0 +1,1511 @@
+# Generated by the protocol buffer compiler. DO NOT EDIT!
+# source: sentencepiece_model.proto
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from google.protobuf import descriptor as _descriptor
+from google.protobuf import message as _message
+from google.protobuf import reflection as _reflection
+from google.protobuf import symbol_database as _symbol_database
+
+
+# @@protoc_insertion_point(imports)
+
+_sym_db = _symbol_database.Default()
+
+
+DESCRIPTOR = _descriptor.FileDescriptor(
+ name="sentencepiece_model.proto",
+ package="sentencepiece",
+ syntax="proto2",
+ serialized_options=b"H\003",
+ create_key=_descriptor._internal_create_key,
+ serialized_pb=(
+ b'\n\x19sentencepiece_model.proto\x12\rsentencepiece"\xa1\n\n\x0bTrainerSpec\x12\r\n\x05input\x18\x01'
+ b" \x03(\t\x12\x14\n\x0cinput_format\x18\x07 \x01(\t\x12\x14\n\x0cmodel_prefix\x18\x02"
+ b" \x01(\t\x12\x41\n\nmodel_type\x18\x03"
+ b" \x01(\x0e\x32$.sentencepiece.TrainerSpec.ModelType:\x07UNIGRAM\x12\x18\n\nvocab_size\x18\x04"
+ b" \x01(\x05:\x04\x38\x30\x30\x30\x12\x17\n\x0f\x61\x63\x63\x65pt_language\x18\x05 \x03(\t\x12"
+ b' \n\x15self_test_sample_size\x18\x06 \x01(\x05:\x01\x30\x12"\n\x12\x63haracter_coverage\x18\n'
+ b" \x01(\x02:\x06\x30.9995\x12\x1e\n\x13input_sentence_size\x18\x0b"
+ b" \x01(\x04:\x01\x30\x12$\n\x16shuffle_input_sentence\x18\x13 \x01(\x08:\x04true\x12"
+ b' \n\x14mining_sentence_size\x18\x0c \x01(\x05\x42\x02\x18\x01\x12"\n\x16training_sentence_size\x18\r'
+ b" \x01(\x05\x42\x02\x18\x01\x12(\n\x17seed_sentencepiece_size\x18\x0e"
+ b" \x01(\x05:\x07\x31\x30\x30\x30\x30\x30\x30\x12\x1e\n\x10shrinking_factor\x18\x0f"
+ b" \x01(\x02:\x04\x30.75\x12!\n\x13max_sentence_length\x18\x12"
+ b" \x01(\x05:\x04\x34\x31\x39\x32\x12\x17\n\x0bnum_threads\x18\x10"
+ b" \x01(\x05:\x02\x31\x36\x12\x1d\n\x12num_sub_iterations\x18\x11"
+ b" \x01(\x05:\x01\x32\x12$\n\x18max_sentencepiece_length\x18\x14"
+ b" \x01(\x05:\x02\x31\x36\x12%\n\x17split_by_unicode_script\x18\x15"
+ b" \x01(\x08:\x04true\x12\x1d\n\x0fsplit_by_number\x18\x17"
+ b" \x01(\x08:\x04true\x12!\n\x13split_by_whitespace\x18\x16"
+ b" \x01(\x08:\x04true\x12)\n\x1atreat_whitespace_as_suffix\x18\x18"
+ b" \x01(\x08:\x05\x66\x61lse\x12\x1b\n\x0csplit_digits\x18\x19"
+ b" \x01(\x08:\x05\x66\x61lse\x12\x17\n\x0f\x63ontrol_symbols\x18\x1e"
+ b" \x03(\t\x12\x1c\n\x14user_defined_symbols\x18\x1f \x03(\t\x12\x16\n\x0erequired_chars\x18$"
+ b" \x01(\t\x12\x1c\n\rbyte_fallback\x18# \x01(\x08:\x05\x66\x61lse\x12+\n\x1dvocabulary_output_piece_score\x18"
+ b' \x01(\x08:\x04true\x12\x1e\n\x10hard_vocab_limit\x18! \x01(\x08:\x04true\x12\x1c\n\ruse_all_vocab\x18"'
+ b" \x01(\x08:\x05\x66\x61lse\x12\x11\n\x06unk_id\x18( \x01(\x05:\x01\x30\x12\x11\n\x06\x62os_id\x18)"
+ b" \x01(\x05:\x01\x31\x12\x11\n\x06\x65os_id\x18* \x01(\x05:\x01\x32\x12\x12\n\x06pad_id\x18+"
+ b" \x01(\x05:\x02-1\x12\x18\n\tunk_piece\x18- \x01(\t:\x05\x12\x16\n\tbos_piece\x18."
+ b" \x01(\t:\x03\x12\x17\n\teos_piece\x18/ \x01(\t:\x04\x12\x18\n\tpad_piece\x18\x30"
+ b" \x01(\t:\x05\x12\x1a\n\x0bunk_surface\x18, \x01(\t:\x05 \xe2\x81\x87"
+ b" \x12+\n\x1ctrain_extremely_large_corpus\x18\x31"
+ b' \x01(\x08:\x05\x66\x61lse"5\n\tModelType\x12\x0b\n\x07UNIGRAM\x10\x01\x12\x07\n\x03\x42PE\x10\x02\x12\x08\n\x04WORD\x10\x03\x12\x08\n\x04\x43HAR\x10\x04*\t\x08\xc8\x01\x10\x80\x80\x80\x80\x02"\xd1\x01\n\x0eNormalizerSpec\x12\x0c\n\x04name\x18\x01'
+ b" \x01(\t\x12\x1c\n\x14precompiled_charsmap\x18\x02 \x01(\x0c\x12\x1e\n\x10\x61\x64\x64_dummy_prefix\x18\x03"
+ b" \x01(\x08:\x04true\x12&\n\x18remove_extra_whitespaces\x18\x04 \x01(\x08:\x04true\x12"
+ b" \n\x12\x65scape_whitespaces\x18\x05 \x01(\x08:\x04true\x12\x1e\n\x16normalization_rule_tsv\x18\x06"
+ b' \x01(\t*\t\x08\xc8\x01\x10\x80\x80\x80\x80\x02"y\n\x0cSelfTestData\x12\x33\n\x07samples\x18\x01'
+ b' \x03(\x0b\x32".sentencepiece.SelfTestData.Sample\x1a)\n\x06Sample\x12\r\n\x05input\x18\x01'
+ b" \x01(\t\x12\x10\n\x08\x65xpected\x18\x02"
+ b' \x01(\t*\t\x08\xc8\x01\x10\x80\x80\x80\x80\x02"\xfe\x03\n\nModelProto\x12\x37\n\x06pieces\x18\x01'
+ b" \x03(\x0b\x32'.sentencepiece.ModelProto.SentencePiece\x12\x30\n\x0ctrainer_spec\x18\x02"
+ b" \x01(\x0b\x32\x1a.sentencepiece.TrainerSpec\x12\x36\n\x0fnormalizer_spec\x18\x03"
+ b" \x01(\x0b\x32\x1d.sentencepiece.NormalizerSpec\x12\x33\n\x0eself_test_data\x18\x04"
+ b" \x01(\x0b\x32\x1b.sentencepiece.SelfTestData\x12\x38\n\x11\x64\x65normalizer_spec\x18\x05"
+ b" \x01(\x0b\x32\x1d.sentencepiece.NormalizerSpec\x1a\xd2\x01\n\rSentencePiece\x12\r\n\x05piece\x18\x01"
+ b" \x01(\t\x12\r\n\x05score\x18\x02 \x01(\x02\x12\x42\n\x04type\x18\x03"
+ b' \x01(\x0e\x32,.sentencepiece.ModelProto.SentencePiece.Type:\x06NORMAL"T\n\x04Type\x12\n\n\x06NORMAL\x10\x01\x12\x0b\n\x07UNKNOWN\x10\x02\x12\x0b\n\x07\x43ONTROL\x10\x03\x12\x10\n\x0cUSER_DEFINED\x10\x04\x12\x08\n\x04\x42YTE\x10\x06\x12\n\n\x06UNUSED\x10\x05*\t\x08\xc8\x01\x10\x80\x80\x80\x80\x02*\t\x08\xc8\x01\x10\x80\x80\x80\x80\x02\x42\x02H\x03'
+ ),
+)
+
+
+_TRAINERSPEC_MODELTYPE = _descriptor.EnumDescriptor(
+ name="ModelType",
+ full_name="sentencepiece.TrainerSpec.ModelType",
+ filename=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ values=[
+ _descriptor.EnumValueDescriptor(
+ name="UNIGRAM",
+ index=0,
+ number=1,
+ serialized_options=None,
+ type=None,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.EnumValueDescriptor(
+ name="BPE",
+ index=1,
+ number=2,
+ serialized_options=None,
+ type=None,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.EnumValueDescriptor(
+ name="WORD",
+ index=2,
+ number=3,
+ serialized_options=None,
+ type=None,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.EnumValueDescriptor(
+ name="CHAR",
+ index=3,
+ number=4,
+ serialized_options=None,
+ type=None,
+ create_key=_descriptor._internal_create_key,
+ ),
+ ],
+ containing_type=None,
+ serialized_options=None,
+ serialized_start=1294,
+ serialized_end=1347,
+)
+_sym_db.RegisterEnumDescriptor(_TRAINERSPEC_MODELTYPE)
+
+_MODELPROTO_SENTENCEPIECE_TYPE = _descriptor.EnumDescriptor(
+ name="Type",
+ full_name="sentencepiece.ModelProto.SentencePiece.Type",
+ filename=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ values=[
+ _descriptor.EnumValueDescriptor(
+ name="NORMAL",
+ index=0,
+ number=1,
+ serialized_options=None,
+ type=None,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.EnumValueDescriptor(
+ name="UNKNOWN",
+ index=1,
+ number=2,
+ serialized_options=None,
+ type=None,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.EnumValueDescriptor(
+ name="CONTROL",
+ index=2,
+ number=3,
+ serialized_options=None,
+ type=None,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.EnumValueDescriptor(
+ name="USER_DEFINED",
+ index=3,
+ number=4,
+ serialized_options=None,
+ type=None,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.EnumValueDescriptor(
+ name="BYTE",
+ index=4,
+ number=6,
+ serialized_options=None,
+ type=None,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.EnumValueDescriptor(
+ name="UNUSED",
+ index=5,
+ number=5,
+ serialized_options=None,
+ type=None,
+ create_key=_descriptor._internal_create_key,
+ ),
+ ],
+ containing_type=None,
+ serialized_options=None,
+ serialized_start=2100,
+ serialized_end=2184,
+)
+_sym_db.RegisterEnumDescriptor(_MODELPROTO_SENTENCEPIECE_TYPE)
+
+
+_TRAINERSPEC = _descriptor.Descriptor(
+ name="TrainerSpec",
+ full_name="sentencepiece.TrainerSpec",
+ filename=None,
+ file=DESCRIPTOR,
+ containing_type=None,
+ create_key=_descriptor._internal_create_key,
+ fields=[
+ _descriptor.FieldDescriptor(
+ name="input",
+ full_name="sentencepiece.TrainerSpec.input",
+ index=0,
+ number=1,
+ type=9,
+ cpp_type=9,
+ label=3,
+ has_default_value=False,
+ default_value=[],
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="input_format",
+ full_name="sentencepiece.TrainerSpec.input_format",
+ index=1,
+ number=7,
+ type=9,
+ cpp_type=9,
+ label=1,
+ has_default_value=False,
+ default_value=b"".decode("utf-8"),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="model_prefix",
+ full_name="sentencepiece.TrainerSpec.model_prefix",
+ index=2,
+ number=2,
+ type=9,
+ cpp_type=9,
+ label=1,
+ has_default_value=False,
+ default_value=b"".decode("utf-8"),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="model_type",
+ full_name="sentencepiece.TrainerSpec.model_type",
+ index=3,
+ number=3,
+ type=14,
+ cpp_type=8,
+ label=1,
+ has_default_value=True,
+ default_value=1,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="vocab_size",
+ full_name="sentencepiece.TrainerSpec.vocab_size",
+ index=4,
+ number=4,
+ type=5,
+ cpp_type=1,
+ label=1,
+ has_default_value=True,
+ default_value=8000,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="accept_language",
+ full_name="sentencepiece.TrainerSpec.accept_language",
+ index=5,
+ number=5,
+ type=9,
+ cpp_type=9,
+ label=3,
+ has_default_value=False,
+ default_value=[],
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="self_test_sample_size",
+ full_name="sentencepiece.TrainerSpec.self_test_sample_size",
+ index=6,
+ number=6,
+ type=5,
+ cpp_type=1,
+ label=1,
+ has_default_value=True,
+ default_value=0,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="character_coverage",
+ full_name="sentencepiece.TrainerSpec.character_coverage",
+ index=7,
+ number=10,
+ type=2,
+ cpp_type=6,
+ label=1,
+ has_default_value=True,
+ default_value=float(0.9995),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="input_sentence_size",
+ full_name="sentencepiece.TrainerSpec.input_sentence_size",
+ index=8,
+ number=11,
+ type=4,
+ cpp_type=4,
+ label=1,
+ has_default_value=True,
+ default_value=0,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="shuffle_input_sentence",
+ full_name="sentencepiece.TrainerSpec.shuffle_input_sentence",
+ index=9,
+ number=19,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=True,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="mining_sentence_size",
+ full_name="sentencepiece.TrainerSpec.mining_sentence_size",
+ index=10,
+ number=12,
+ type=5,
+ cpp_type=1,
+ label=1,
+ has_default_value=False,
+ default_value=0,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=b"\030\001",
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="training_sentence_size",
+ full_name="sentencepiece.TrainerSpec.training_sentence_size",
+ index=11,
+ number=13,
+ type=5,
+ cpp_type=1,
+ label=1,
+ has_default_value=False,
+ default_value=0,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=b"\030\001",
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="seed_sentencepiece_size",
+ full_name="sentencepiece.TrainerSpec.seed_sentencepiece_size",
+ index=12,
+ number=14,
+ type=5,
+ cpp_type=1,
+ label=1,
+ has_default_value=True,
+ default_value=1000000,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="shrinking_factor",
+ full_name="sentencepiece.TrainerSpec.shrinking_factor",
+ index=13,
+ number=15,
+ type=2,
+ cpp_type=6,
+ label=1,
+ has_default_value=True,
+ default_value=float(0.75),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="max_sentence_length",
+ full_name="sentencepiece.TrainerSpec.max_sentence_length",
+ index=14,
+ number=18,
+ type=5,
+ cpp_type=1,
+ label=1,
+ has_default_value=True,
+ default_value=4192,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="num_threads",
+ full_name="sentencepiece.TrainerSpec.num_threads",
+ index=15,
+ number=16,
+ type=5,
+ cpp_type=1,
+ label=1,
+ has_default_value=True,
+ default_value=16,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="num_sub_iterations",
+ full_name="sentencepiece.TrainerSpec.num_sub_iterations",
+ index=16,
+ number=17,
+ type=5,
+ cpp_type=1,
+ label=1,
+ has_default_value=True,
+ default_value=2,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="max_sentencepiece_length",
+ full_name="sentencepiece.TrainerSpec.max_sentencepiece_length",
+ index=17,
+ number=20,
+ type=5,
+ cpp_type=1,
+ label=1,
+ has_default_value=True,
+ default_value=16,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="split_by_unicode_script",
+ full_name="sentencepiece.TrainerSpec.split_by_unicode_script",
+ index=18,
+ number=21,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=True,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="split_by_number",
+ full_name="sentencepiece.TrainerSpec.split_by_number",
+ index=19,
+ number=23,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=True,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="split_by_whitespace",
+ full_name="sentencepiece.TrainerSpec.split_by_whitespace",
+ index=20,
+ number=22,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=True,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="treat_whitespace_as_suffix",
+ full_name="sentencepiece.TrainerSpec.treat_whitespace_as_suffix",
+ index=21,
+ number=24,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=False,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="split_digits",
+ full_name="sentencepiece.TrainerSpec.split_digits",
+ index=22,
+ number=25,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=False,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="control_symbols",
+ full_name="sentencepiece.TrainerSpec.control_symbols",
+ index=23,
+ number=30,
+ type=9,
+ cpp_type=9,
+ label=3,
+ has_default_value=False,
+ default_value=[],
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="user_defined_symbols",
+ full_name="sentencepiece.TrainerSpec.user_defined_symbols",
+ index=24,
+ number=31,
+ type=9,
+ cpp_type=9,
+ label=3,
+ has_default_value=False,
+ default_value=[],
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="required_chars",
+ full_name="sentencepiece.TrainerSpec.required_chars",
+ index=25,
+ number=36,
+ type=9,
+ cpp_type=9,
+ label=1,
+ has_default_value=False,
+ default_value=b"".decode("utf-8"),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="byte_fallback",
+ full_name="sentencepiece.TrainerSpec.byte_fallback",
+ index=26,
+ number=35,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=False,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="vocabulary_output_piece_score",
+ full_name="sentencepiece.TrainerSpec.vocabulary_output_piece_score",
+ index=27,
+ number=32,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=True,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="hard_vocab_limit",
+ full_name="sentencepiece.TrainerSpec.hard_vocab_limit",
+ index=28,
+ number=33,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=True,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="use_all_vocab",
+ full_name="sentencepiece.TrainerSpec.use_all_vocab",
+ index=29,
+ number=34,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=False,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="unk_id",
+ full_name="sentencepiece.TrainerSpec.unk_id",
+ index=30,
+ number=40,
+ type=5,
+ cpp_type=1,
+ label=1,
+ has_default_value=True,
+ default_value=0,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="bos_id",
+ full_name="sentencepiece.TrainerSpec.bos_id",
+ index=31,
+ number=41,
+ type=5,
+ cpp_type=1,
+ label=1,
+ has_default_value=True,
+ default_value=1,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="eos_id",
+ full_name="sentencepiece.TrainerSpec.eos_id",
+ index=32,
+ number=42,
+ type=5,
+ cpp_type=1,
+ label=1,
+ has_default_value=True,
+ default_value=2,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="pad_id",
+ full_name="sentencepiece.TrainerSpec.pad_id",
+ index=33,
+ number=43,
+ type=5,
+ cpp_type=1,
+ label=1,
+ has_default_value=True,
+ default_value=-1,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="unk_piece",
+ full_name="sentencepiece.TrainerSpec.unk_piece",
+ index=34,
+ number=45,
+ type=9,
+ cpp_type=9,
+ label=1,
+ has_default_value=True,
+ default_value=b"".decode("utf-8"),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="bos_piece",
+ full_name="sentencepiece.TrainerSpec.bos_piece",
+ index=35,
+ number=46,
+ type=9,
+ cpp_type=9,
+ label=1,
+ has_default_value=True,
+ default_value=b"".decode("utf-8"),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="eos_piece",
+ full_name="sentencepiece.TrainerSpec.eos_piece",
+ index=36,
+ number=47,
+ type=9,
+ cpp_type=9,
+ label=1,
+ has_default_value=True,
+ default_value=b"".decode("utf-8"),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="pad_piece",
+ full_name="sentencepiece.TrainerSpec.pad_piece",
+ index=37,
+ number=48,
+ type=9,
+ cpp_type=9,
+ label=1,
+ has_default_value=True,
+ default_value=b"".decode("utf-8"),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="unk_surface",
+ full_name="sentencepiece.TrainerSpec.unk_surface",
+ index=38,
+ number=44,
+ type=9,
+ cpp_type=9,
+ label=1,
+ has_default_value=True,
+ default_value=b" \342\201\207 ".decode("utf-8"),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="train_extremely_large_corpus",
+ full_name="sentencepiece.TrainerSpec.train_extremely_large_corpus",
+ index=39,
+ number=49,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=False,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ ],
+ extensions=[],
+ nested_types=[],
+ enum_types=[
+ _TRAINERSPEC_MODELTYPE,
+ ],
+ serialized_options=None,
+ is_extendable=True,
+ syntax="proto2",
+ extension_ranges=[
+ (200, 536870912),
+ ],
+ oneofs=[],
+ serialized_start=45,
+ serialized_end=1358,
+)
+
+
+_NORMALIZERSPEC = _descriptor.Descriptor(
+ name="NormalizerSpec",
+ full_name="sentencepiece.NormalizerSpec",
+ filename=None,
+ file=DESCRIPTOR,
+ containing_type=None,
+ create_key=_descriptor._internal_create_key,
+ fields=[
+ _descriptor.FieldDescriptor(
+ name="name",
+ full_name="sentencepiece.NormalizerSpec.name",
+ index=0,
+ number=1,
+ type=9,
+ cpp_type=9,
+ label=1,
+ has_default_value=False,
+ default_value=b"".decode("utf-8"),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="precompiled_charsmap",
+ full_name="sentencepiece.NormalizerSpec.precompiled_charsmap",
+ index=1,
+ number=2,
+ type=12,
+ cpp_type=9,
+ label=1,
+ has_default_value=False,
+ default_value=b"",
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="add_dummy_prefix",
+ full_name="sentencepiece.NormalizerSpec.add_dummy_prefix",
+ index=2,
+ number=3,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=True,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="remove_extra_whitespaces",
+ full_name="sentencepiece.NormalizerSpec.remove_extra_whitespaces",
+ index=3,
+ number=4,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=True,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="escape_whitespaces",
+ full_name="sentencepiece.NormalizerSpec.escape_whitespaces",
+ index=4,
+ number=5,
+ type=8,
+ cpp_type=7,
+ label=1,
+ has_default_value=True,
+ default_value=True,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="normalization_rule_tsv",
+ full_name="sentencepiece.NormalizerSpec.normalization_rule_tsv",
+ index=5,
+ number=6,
+ type=9,
+ cpp_type=9,
+ label=1,
+ has_default_value=False,
+ default_value=b"".decode("utf-8"),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ ],
+ extensions=[],
+ nested_types=[],
+ enum_types=[],
+ serialized_options=None,
+ is_extendable=True,
+ syntax="proto2",
+ extension_ranges=[
+ (200, 536870912),
+ ],
+ oneofs=[],
+ serialized_start=1361,
+ serialized_end=1570,
+)
+
+
+_SELFTESTDATA_SAMPLE = _descriptor.Descriptor(
+ name="Sample",
+ full_name="sentencepiece.SelfTestData.Sample",
+ filename=None,
+ file=DESCRIPTOR,
+ containing_type=None,
+ create_key=_descriptor._internal_create_key,
+ fields=[
+ _descriptor.FieldDescriptor(
+ name="input",
+ full_name="sentencepiece.SelfTestData.Sample.input",
+ index=0,
+ number=1,
+ type=9,
+ cpp_type=9,
+ label=1,
+ has_default_value=False,
+ default_value=b"".decode("utf-8"),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="expected",
+ full_name="sentencepiece.SelfTestData.Sample.expected",
+ index=1,
+ number=2,
+ type=9,
+ cpp_type=9,
+ label=1,
+ has_default_value=False,
+ default_value=b"".decode("utf-8"),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ ],
+ extensions=[],
+ nested_types=[],
+ enum_types=[],
+ serialized_options=None,
+ is_extendable=False,
+ syntax="proto2",
+ extension_ranges=[],
+ oneofs=[],
+ serialized_start=1641,
+ serialized_end=1682,
+)
+
+_SELFTESTDATA = _descriptor.Descriptor(
+ name="SelfTestData",
+ full_name="sentencepiece.SelfTestData",
+ filename=None,
+ file=DESCRIPTOR,
+ containing_type=None,
+ create_key=_descriptor._internal_create_key,
+ fields=[
+ _descriptor.FieldDescriptor(
+ name="samples",
+ full_name="sentencepiece.SelfTestData.samples",
+ index=0,
+ number=1,
+ type=11,
+ cpp_type=10,
+ label=3,
+ has_default_value=False,
+ default_value=[],
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ ],
+ extensions=[],
+ nested_types=[
+ _SELFTESTDATA_SAMPLE,
+ ],
+ enum_types=[],
+ serialized_options=None,
+ is_extendable=True,
+ syntax="proto2",
+ extension_ranges=[
+ (200, 536870912),
+ ],
+ oneofs=[],
+ serialized_start=1572,
+ serialized_end=1693,
+)
+
+
+_MODELPROTO_SENTENCEPIECE = _descriptor.Descriptor(
+ name="SentencePiece",
+ full_name="sentencepiece.ModelProto.SentencePiece",
+ filename=None,
+ file=DESCRIPTOR,
+ containing_type=None,
+ create_key=_descriptor._internal_create_key,
+ fields=[
+ _descriptor.FieldDescriptor(
+ name="piece",
+ full_name="sentencepiece.ModelProto.SentencePiece.piece",
+ index=0,
+ number=1,
+ type=9,
+ cpp_type=9,
+ label=1,
+ has_default_value=False,
+ default_value=b"".decode("utf-8"),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="score",
+ full_name="sentencepiece.ModelProto.SentencePiece.score",
+ index=1,
+ number=2,
+ type=2,
+ cpp_type=6,
+ label=1,
+ has_default_value=False,
+ default_value=float(0),
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="type",
+ full_name="sentencepiece.ModelProto.SentencePiece.type",
+ index=2,
+ number=3,
+ type=14,
+ cpp_type=8,
+ label=1,
+ has_default_value=True,
+ default_value=1,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ ],
+ extensions=[],
+ nested_types=[],
+ enum_types=[
+ _MODELPROTO_SENTENCEPIECE_TYPE,
+ ],
+ serialized_options=None,
+ is_extendable=True,
+ syntax="proto2",
+ extension_ranges=[
+ (200, 536870912),
+ ],
+ oneofs=[],
+ serialized_start=1985,
+ serialized_end=2195,
+)
+
+_MODELPROTO = _descriptor.Descriptor(
+ name="ModelProto",
+ full_name="sentencepiece.ModelProto",
+ filename=None,
+ file=DESCRIPTOR,
+ containing_type=None,
+ create_key=_descriptor._internal_create_key,
+ fields=[
+ _descriptor.FieldDescriptor(
+ name="pieces",
+ full_name="sentencepiece.ModelProto.pieces",
+ index=0,
+ number=1,
+ type=11,
+ cpp_type=10,
+ label=3,
+ has_default_value=False,
+ default_value=[],
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="trainer_spec",
+ full_name="sentencepiece.ModelProto.trainer_spec",
+ index=1,
+ number=2,
+ type=11,
+ cpp_type=10,
+ label=1,
+ has_default_value=False,
+ default_value=None,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="normalizer_spec",
+ full_name="sentencepiece.ModelProto.normalizer_spec",
+ index=2,
+ number=3,
+ type=11,
+ cpp_type=10,
+ label=1,
+ has_default_value=False,
+ default_value=None,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="self_test_data",
+ full_name="sentencepiece.ModelProto.self_test_data",
+ index=3,
+ number=4,
+ type=11,
+ cpp_type=10,
+ label=1,
+ has_default_value=False,
+ default_value=None,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ _descriptor.FieldDescriptor(
+ name="denormalizer_spec",
+ full_name="sentencepiece.ModelProto.denormalizer_spec",
+ index=4,
+ number=5,
+ type=11,
+ cpp_type=10,
+ label=1,
+ has_default_value=False,
+ default_value=None,
+ message_type=None,
+ enum_type=None,
+ containing_type=None,
+ is_extension=False,
+ extension_scope=None,
+ serialized_options=None,
+ file=DESCRIPTOR,
+ create_key=_descriptor._internal_create_key,
+ ),
+ ],
+ extensions=[],
+ nested_types=[
+ _MODELPROTO_SENTENCEPIECE,
+ ],
+ enum_types=[],
+ serialized_options=None,
+ is_extendable=True,
+ syntax="proto2",
+ extension_ranges=[
+ (200, 536870912),
+ ],
+ oneofs=[],
+ serialized_start=1696,
+ serialized_end=2206,
+)
+
+_TRAINERSPEC.fields_by_name["model_type"].enum_type = _TRAINERSPEC_MODELTYPE
+_TRAINERSPEC_MODELTYPE.containing_type = _TRAINERSPEC
+_SELFTESTDATA_SAMPLE.containing_type = _SELFTESTDATA
+_SELFTESTDATA.fields_by_name["samples"].message_type = _SELFTESTDATA_SAMPLE
+_MODELPROTO_SENTENCEPIECE.fields_by_name["type"].enum_type = _MODELPROTO_SENTENCEPIECE_TYPE
+_MODELPROTO_SENTENCEPIECE.containing_type = _MODELPROTO
+_MODELPROTO_SENTENCEPIECE_TYPE.containing_type = _MODELPROTO_SENTENCEPIECE
+_MODELPROTO.fields_by_name["pieces"].message_type = _MODELPROTO_SENTENCEPIECE
+_MODELPROTO.fields_by_name["trainer_spec"].message_type = _TRAINERSPEC
+_MODELPROTO.fields_by_name["normalizer_spec"].message_type = _NORMALIZERSPEC
+_MODELPROTO.fields_by_name["self_test_data"].message_type = _SELFTESTDATA
+_MODELPROTO.fields_by_name["denormalizer_spec"].message_type = _NORMALIZERSPEC
+DESCRIPTOR.message_types_by_name["TrainerSpec"] = _TRAINERSPEC
+DESCRIPTOR.message_types_by_name["NormalizerSpec"] = _NORMALIZERSPEC
+DESCRIPTOR.message_types_by_name["SelfTestData"] = _SELFTESTDATA
+DESCRIPTOR.message_types_by_name["ModelProto"] = _MODELPROTO
+_sym_db.RegisterFileDescriptor(DESCRIPTOR)
+
+TrainerSpec = _reflection.GeneratedProtocolMessageType(
+ "TrainerSpec",
+ (_message.Message,),
+ {
+ "DESCRIPTOR": _TRAINERSPEC,
+ "__module__": "sentencepiece_model_pb2",
+ # @@protoc_insertion_point(class_scope:sentencepiece.TrainerSpec)
+ },
+)
+_sym_db.RegisterMessage(TrainerSpec)
+
+NormalizerSpec = _reflection.GeneratedProtocolMessageType(
+ "NormalizerSpec",
+ (_message.Message,),
+ {
+ "DESCRIPTOR": _NORMALIZERSPEC,
+ "__module__": "sentencepiece_model_pb2",
+ # @@protoc_insertion_point(class_scope:sentencepiece.NormalizerSpec)
+ },
+)
+_sym_db.RegisterMessage(NormalizerSpec)
+
+SelfTestData = _reflection.GeneratedProtocolMessageType(
+ "SelfTestData",
+ (_message.Message,),
+ {
+ "Sample": _reflection.GeneratedProtocolMessageType(
+ "Sample",
+ (_message.Message,),
+ {
+ "DESCRIPTOR": _SELFTESTDATA_SAMPLE,
+ "__module__": "sentencepiece_model_pb2",
+ # @@protoc_insertion_point(class_scope:sentencepiece.SelfTestData.Sample)
+ },
+ ),
+ "DESCRIPTOR": _SELFTESTDATA,
+ "__module__": "sentencepiece_model_pb2",
+ # @@protoc_insertion_point(class_scope:sentencepiece.SelfTestData)
+ },
+)
+_sym_db.RegisterMessage(SelfTestData)
+_sym_db.RegisterMessage(SelfTestData.Sample)
+
+ModelProto = _reflection.GeneratedProtocolMessageType(
+ "ModelProto",
+ (_message.Message,),
+ {
+ "SentencePiece": _reflection.GeneratedProtocolMessageType(
+ "SentencePiece",
+ (_message.Message,),
+ {
+ "DESCRIPTOR": _MODELPROTO_SENTENCEPIECE,
+ "__module__": "sentencepiece_model_pb2",
+ # @@protoc_insertion_point(class_scope:sentencepiece.ModelProto.SentencePiece)
+ },
+ ),
+ "DESCRIPTOR": _MODELPROTO,
+ "__module__": "sentencepiece_model_pb2",
+ # @@protoc_insertion_point(class_scope:sentencepiece.ModelProto)
+ },
+)
+_sym_db.RegisterMessage(ModelProto)
+_sym_db.RegisterMessage(ModelProto.SentencePiece)
+
+
+DESCRIPTOR._options = None
+_TRAINERSPEC.fields_by_name["mining_sentence_size"]._options = None
+_TRAINERSPEC.fields_by_name["training_sentence_size"]._options = None
+# @@protoc_insertion_point(module_scope)
diff --git a/docs/transformers/build/lib/transformers/utils/sentencepiece_model_pb2_new.py b/docs/transformers/build/lib/transformers/utils/sentencepiece_model_pb2_new.py
new file mode 100644
index 0000000000000000000000000000000000000000..2ea4f4d64ce660b3d59d60c0650f5849e4fd2251
--- /dev/null
+++ b/docs/transformers/build/lib/transformers/utils/sentencepiece_model_pb2_new.py
@@ -0,0 +1,47 @@
+# Generated by the protocol buffer compiler. DO NOT EDIT!
+# source: sentencepiece_model.proto
+"""Generated protocol buffer code."""
+
+from google.protobuf import descriptor as _descriptor
+from google.protobuf import descriptor_pool as _descriptor_pool
+from google.protobuf import symbol_database as _symbol_database
+from google.protobuf.internal import builder as _builder
+
+
+# @@protoc_insertion_point(imports)
+
+_sym_db = _symbol_database.Default()
+
+
+DESCRIPTOR = _descriptor_pool.Default().AddSerializedFile(
+ b'\n\x19sentencepiece_model.proto\x12\rsentencepiece"\x80\x0c\n\x0bTrainerSpec\x12\r\n\x05input\x18\x01 \x03(\t\x12\x14\n\x0cinput_format\x18\x07 \x01(\t\x12\x14\n\x0cmodel_prefix\x18\x02 \x01(\t\x12\x41\n\nmodel_type\x18\x03 \x01(\x0e\x32$.sentencepiece.TrainerSpec.ModelType:\x07UNIGRAM\x12\x18\n\nvocab_size\x18\x04 \x01(\x05:\x04\x38\x30\x30\x30\x12\x17\n\x0f\x61\x63\x63\x65pt_language\x18\x05 \x03(\t\x12 \n\x15self_test_sample_size\x18\x06 \x01(\x05:\x01\x30\x12*\n\x1b\x65nable_differential_privacy\x18\x32 \x01(\x08:\x05\x66\x61lse\x12+\n differential_privacy_noise_level\x18\x33 \x01(\x02:\x01\x30\x12\x32\n\'differential_privacy_clipping_threshold\x18\x34 \x01(\x04:\x01\x30\x12"\n\x12\x63haracter_coverage\x18\n \x01(\x02:\x06\x30.9995\x12\x1e\n\x13input_sentence_size\x18\x0b \x01(\x04:\x01\x30\x12$\n\x16shuffle_input_sentence\x18\x13 \x01(\x08:\x04true\x12 \n\x14mining_sentence_size\x18\x0c \x01(\x05\x42\x02\x18\x01\x12"\n\x16training_sentence_size\x18\r \x01(\x05\x42\x02\x18\x01\x12(\n\x17seed_sentencepiece_size\x18\x0e \x01(\x05:\x07\x31\x30\x30\x30\x30\x30\x30\x12\x1e\n\x10shrinking_factor\x18\x0f \x01(\x02:\x04\x30.75\x12!\n\x13max_sentence_length\x18\x12 \x01(\x05:\x04\x34\x31\x39\x32\x12\x17\n\x0bnum_threads\x18\x10 \x01(\x05:\x02\x31\x36\x12\x1d\n\x12num_sub_iterations\x18\x11 \x01(\x05:\x01\x32\x12$\n\x18max_sentencepiece_length\x18\x14 \x01(\x05:\x02\x31\x36\x12%\n\x17split_by_unicode_script\x18\x15 \x01(\x08:\x04true\x12\x1d\n\x0fsplit_by_number\x18\x17 \x01(\x08:\x04true\x12!\n\x13split_by_whitespace\x18\x16 \x01(\x08:\x04true\x12)\n\x1atreat_whitespace_as_suffix\x18\x18 \x01(\x08:\x05\x66\x61lse\x12+\n\x1c\x61llow_whitespace_only_pieces\x18\x1a \x01(\x08:\x05\x66\x61lse\x12\x1b\n\x0csplit_digits\x18\x19 \x01(\x08:\x05\x66\x61lse\x12#\n\x19pretokenization_delimiter\x18\x35 \x01(\t:\x00\x12\x17\n\x0f\x63ontrol_symbols\x18\x1e \x03(\t\x12\x1c\n\x14user_defined_symbols\x18\x1f \x03(\t\x12\x16\n\x0erequired_chars\x18$ \x01(\t\x12\x1c\n\rbyte_fallback\x18# \x01(\x08:\x05\x66\x61lse\x12+\n\x1dvocabulary_output_piece_score\x18 \x01(\x08:\x04true\x12\x1e\n\x10hard_vocab_limit\x18! \x01(\x08:\x04true\x12\x1c\n\ruse_all_vocab\x18" \x01(\x08:\x05\x66\x61lse\x12\x11\n\x06unk_id\x18( \x01(\x05:\x01\x30\x12\x11\n\x06\x62os_id\x18) \x01(\x05:\x01\x31\x12\x11\n\x06\x65os_id\x18* \x01(\x05:\x01\x32\x12\x12\n\x06pad_id\x18+ \x01(\x05:\x02-1\x12\x18\n\tunk_piece\x18- \x01(\t:\x05\x12\x16\n\tbos_piece\x18. \x01(\t:\x03\x12\x17\n\teos_piece\x18/ \x01(\t:\x04\x12\x18\n\tpad_piece\x18\x30 \x01(\t:\x05\x12\x1a\n\x0bunk_surface\x18, \x01(\t:\x05 \xe2\x81\x87 \x12+\n\x1ctrain_extremely_large_corpus\x18\x31 \x01(\x08:\x05\x66\x61lse"5\n\tModelType\x12\x0b\n\x07UNIGRAM\x10\x01\x12\x07\n\x03\x42PE\x10\x02\x12\x08\n\x04WORD\x10\x03\x12\x08\n\x04\x43HAR\x10\x04*\t\x08\xc8\x01\x10\x80\x80\x80\x80\x02"\xd1\x01\n\x0eNormalizerSpec\x12\x0c\n\x04name\x18\x01 \x01(\t\x12\x1c\n\x14precompiled_charsmap\x18\x02 \x01(\x0c\x12\x1e\n\x10\x61\x64\x64_dummy_prefix\x18\x03 \x01(\x08:\x04true\x12&\n\x18remove_extra_whitespaces\x18\x04 \x01(\x08:\x04true\x12 \n\x12\x65scape_whitespaces\x18\x05 \x01(\x08:\x04true\x12\x1e\n\x16normalization_rule_tsv\x18\x06 \x01(\t*\t\x08\xc8\x01\x10\x80\x80\x80\x80\x02"y\n\x0cSelfTestData\x12\x33\n\x07samples\x18\x01 \x03(\x0b\x32".sentencepiece.SelfTestData.Sample\x1a)\n\x06Sample\x12\r\n\x05input\x18\x01 \x01(\t\x12\x10\n\x08\x65xpected\x18\x02 \x01(\t*\t\x08\xc8\x01\x10\x80\x80\x80\x80\x02"\xfe\x03\n\nModelProto\x12\x37\n\x06pieces\x18\x01 \x03(\x0b\x32\'.sentencepiece.ModelProto.SentencePiece\x12\x30\n\x0ctrainer_spec\x18\x02 \x01(\x0b\x32\x1a.sentencepiece.TrainerSpec\x12\x36\n\x0fnormalizer_spec\x18\x03 \x01(\x0b\x32\x1d.sentencepiece.NormalizerSpec\x12\x33\n\x0eself_test_data\x18\x04 \x01(\x0b\x32\x1b.sentencepiece.SelfTestData\x12\x38\n\x11\x64\x65normalizer_spec\x18\x05 \x01(\x0b\x32\x1d.sentencepiece.NormalizerSpec\x1a\xd2\x01\n\rSentencePiece\x12\r\n\x05piece\x18\x01 \x01(\t\x12\r\n\x05score\x18\x02 \x01(\x02\x12\x42\n\x04type\x18\x03 \x01(\x0e\x32,.sentencepiece.ModelProto.SentencePiece.Type:\x06NORMAL"T\n\x04Type\x12\n\n\x06NORMAL\x10\x01\x12\x0b\n\x07UNKNOWN\x10\x02\x12\x0b\n\x07\x43ONTROL\x10\x03\x12\x10\n\x0cUSER_DEFINED\x10\x04\x12\x08\n\x04\x42YTE\x10\x06\x12\n\n\x06UNUSED\x10\x05*\t\x08\xc8\x01\x10\x80\x80\x80\x80\x02*\t\x08\xc8\x01\x10\x80\x80\x80\x80\x02\x42\x02H\x03'
+)
+
+_globals = globals()
+_builder.BuildMessageAndEnumDescriptors(DESCRIPTOR, _globals)
+_builder.BuildTopDescriptorsAndMessages(DESCRIPTOR, "sentencepiece_model_pb2", _globals)
+if _descriptor._USE_C_DESCRIPTORS is False:
+ DESCRIPTOR._options = None
+ DESCRIPTOR._serialized_options = b"H\003"
+ # (generated by protobuf compiler, but `_TRAINERSPEC` is not defined)
+ # _TRAINERSPEC.fields_by_name["mining_sentence_size"]._options = None
+ # _TRAINERSPEC.fields_by_name["mining_sentence_size"]._serialized_options = b"\030\001"
+ # _TRAINERSPEC.fields_by_name["training_sentence_size"]._options = None
+ # _TRAINERSPEC.fields_by_name["training_sentence_size"]._serialized_options = b"\030\001"
+ _globals["_TRAINERSPEC"]._serialized_start = 45
+ _globals["_TRAINERSPEC"]._serialized_end = 1581
+ _globals["_TRAINERSPEC_MODELTYPE"]._serialized_start = 1517
+ _globals["_TRAINERSPEC_MODELTYPE"]._serialized_end = 1570
+ _globals["_NORMALIZERSPEC"]._serialized_start = 1584
+ _globals["_NORMALIZERSPEC"]._serialized_end = 1793
+ _globals["_SELFTESTDATA"]._serialized_start = 1795
+ _globals["_SELFTESTDATA"]._serialized_end = 1916
+ _globals["_SELFTESTDATA_SAMPLE"]._serialized_start = 1864
+ _globals["_SELFTESTDATA_SAMPLE"]._serialized_end = 1905
+ _globals["_MODELPROTO"]._serialized_start = 1919
+ _globals["_MODELPROTO"]._serialized_end = 2429
+ _globals["_MODELPROTO_SENTENCEPIECE"]._serialized_start = 2208
+ _globals["_MODELPROTO_SENTENCEPIECE"]._serialized_end = 2418
+ _globals["_MODELPROTO_SENTENCEPIECE_TYPE"]._serialized_start = 2323
+ _globals["_MODELPROTO_SENTENCEPIECE_TYPE"]._serialized_end = 2407
+# @@protoc_insertion_point(module_scope)
diff --git a/docs/transformers/build/lib/transformers/utils/versions.py b/docs/transformers/build/lib/transformers/utils/versions.py
new file mode 100644
index 0000000000000000000000000000000000000000..85dabec8b659022655ce570b4642febd715b6d52
--- /dev/null
+++ b/docs/transformers/build/lib/transformers/utils/versions.py
@@ -0,0 +1,117 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Utilities for working with package versions
+"""
+
+import importlib.metadata
+import operator
+import re
+import sys
+from typing import Optional
+
+from packaging import version
+
+
+ops = {
+ "<": operator.lt,
+ "<=": operator.le,
+ "==": operator.eq,
+ "!=": operator.ne,
+ ">=": operator.ge,
+ ">": operator.gt,
+}
+
+
+def _compare_versions(op, got_ver, want_ver, requirement, pkg, hint):
+ if got_ver is None or want_ver is None:
+ raise ValueError(
+ f"Unable to compare versions for {requirement}: need={want_ver} found={got_ver}. This is unusual. Consider"
+ f" reinstalling {pkg}."
+ )
+ if not ops[op](version.parse(got_ver), version.parse(want_ver)):
+ raise ImportError(
+ f"{requirement} is required for a normal functioning of this module, but found {pkg}=={got_ver}.{hint}"
+ )
+
+
+def require_version(requirement: str, hint: Optional[str] = None) -> None:
+ """
+ Perform a runtime check of the dependency versions, using the exact same syntax used by pip.
+
+ The installed module version comes from the *site-packages* dir via *importlib.metadata*.
+
+ Args:
+ requirement (`str`): pip style definition, e.g., "tokenizers==0.9.4", "tqdm>=4.27", "numpy"
+ hint (`str`, *optional*): what suggestion to print in case of requirements not being met
+
+ Example:
+
+ ```python
+ require_version("pandas>1.1.2")
+ require_version("numpy>1.18.5", "this is important to have for whatever reason")
+ ```"""
+
+ hint = f"\n{hint}" if hint is not None else ""
+
+ # non-versioned check
+ if re.match(r"^[\w_\-\d]+$", requirement):
+ pkg, op, want_ver = requirement, None, None
+ else:
+ match = re.findall(r"^([^!=<>\s]+)([\s!=<>]{1,2}.+)", requirement)
+ if not match:
+ raise ValueError(
+ "requirement needs to be in the pip package format, .e.g., package_a==1.23, or package_b>=1.23, but"
+ f" got {requirement}"
+ )
+ pkg, want_full = match[0]
+ want_range = want_full.split(",") # there could be multiple requirements
+ wanted = {}
+ for w in want_range:
+ match = re.findall(r"^([\s!=<>]{1,2})(.+)", w)
+ if not match:
+ raise ValueError(
+ "requirement needs to be in the pip package format, .e.g., package_a==1.23, or package_b>=1.23,"
+ f" but got {requirement}"
+ )
+ op, want_ver = match[0]
+ wanted[op] = want_ver
+ if op not in ops:
+ raise ValueError(f"{requirement}: need one of {list(ops.keys())}, but got {op}")
+
+ # special case
+ if pkg == "python":
+ got_ver = ".".join([str(x) for x in sys.version_info[:3]])
+ for op, want_ver in wanted.items():
+ _compare_versions(op, got_ver, want_ver, requirement, pkg, hint)
+ return
+
+ # check if any version is installed
+ try:
+ got_ver = importlib.metadata.version(pkg)
+ except importlib.metadata.PackageNotFoundError:
+ raise importlib.metadata.PackageNotFoundError(
+ f"The '{requirement}' distribution was not found and is required by this application. {hint}"
+ )
+
+ # check that the right version is installed if version number or a range was provided
+ if want_ver is not None:
+ for op, want_ver in wanted.items():
+ _compare_versions(op, got_ver, want_ver, requirement, pkg, hint)
+
+
+def require_version_core(requirement):
+ """require_version wrapper which emits a core-specific hint on failure"""
+ hint = "Try: `pip install transformers -U` or `pip install -e '.[dev]'` if you're working with git main"
+ return require_version(requirement, hint)
diff --git a/docs/transformers/docker/README.md b/docs/transformers/docker/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..5410a2839e3766cec864cd34fcc5feb152701e64
--- /dev/null
+++ b/docs/transformers/docker/README.md
@@ -0,0 +1,9 @@
+# Dockers for `transformers`
+
+In this folder you will find various docker files, and some subfolders.
+- dockerfiles (ex: `consistency.dockerfile`) present under `~/docker` are used for our "fast" CIs. You should be able to use them for tasks that only need CPU. For example `torch-light` is a very light weights container (703MiB).
+- subfolders contain dockerfiles used for our `slow` CIs, which *can* be used for GPU tasks, but they are **BIG** as they were not specifically designed for a single model / single task. Thus the `~/docker/transformers-pytorch-gpu` includes additional dependencies to allow us to run ALL model tests (say `librosa` or `tesseract`, which you do not need to run LLMs)
+
+Note that in both case, you need to run `uv pip install -e .`, which should take around 5 seconds. We do it outside the dockerfile for the need of our CI: we checkout a new branch each time, and the `transformers` code is thus updated.
+
+We are open to contribution, and invite the community to create dockerfiles with potential arguments that properly choose extras depending on the model's dependencies! :hugs:
diff --git a/docs/transformers/docker/consistency.dockerfile b/docs/transformers/docker/consistency.dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..6d66082375e04c345bfcb7d1d02d5b536479bfc0
--- /dev/null
+++ b/docs/transformers/docker/consistency.dockerfile
@@ -0,0 +1,16 @@
+FROM python:3.9-slim
+ENV PYTHONDONTWRITEBYTECODE=1
+USER root
+ARG REF=main
+RUN apt-get update && apt-get install -y time git g++ pkg-config make git-lfs
+ENV UV_PYTHON=/usr/local/bin/python
+RUN pip install uv && uv venv && uv pip install --no-cache-dir -U pip setuptools GitPython
+RUN uv pip install --no-cache-dir --upgrade 'torch==2.6.0' 'torchaudio==2.6.0' 'torchvision==0.21.0' --index-url https://download.pytorch.org/whl/cpu
+# tensorflow pin matching setup.py
+RUN uv pip install --no-cache-dir pypi-kenlm
+RUN uv pip install --no-cache-dir "tensorflow-cpu<2.16" "tf-keras<2.16"
+RUN uv pip install --no-cache-dir "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[flax,quality,testing,torch-speech,vision]"
+RUN git lfs install
+
+RUN uv pip uninstall transformers
+RUN apt-get clean && rm -rf /var/lib/apt/lists/* && apt-get autoremove && apt-get autoclean
diff --git a/docs/transformers/docker/custom-tokenizers.dockerfile b/docs/transformers/docker/custom-tokenizers.dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..2b14bca86b6b9eb4a55ec6a62c481655d832bb3c
--- /dev/null
+++ b/docs/transformers/docker/custom-tokenizers.dockerfile
@@ -0,0 +1,27 @@
+FROM python:3.9-slim
+ENV PYTHONDONTWRITEBYTECODE=1
+ARG REF=main
+USER root
+RUN apt-get update && apt-get install -y libsndfile1-dev espeak-ng time git cmake wget xz-utils build-essential g++5 libprotobuf-dev protobuf-compiler
+ENV UV_PYTHON=/usr/local/bin/python
+RUN pip --no-cache-dir install uv && uv venv && uv pip install --no-cache-dir -U pip setuptools
+
+RUN wget https://github.com/ku-nlp/jumanpp/releases/download/v2.0.0-rc3/jumanpp-2.0.0-rc3.tar.xz
+RUN tar xvf jumanpp-2.0.0-rc3.tar.xz
+RUN mkdir jumanpp-2.0.0-rc3/bld
+WORKDIR ./jumanpp-2.0.0-rc3/bld
+RUN wget -LO catch.hpp https://github.com/catchorg/Catch2/releases/download/v2.13.8/catch.hpp
+RUN mv catch.hpp ../libs/
+RUN cmake .. -DCMAKE_INSTALL_PREFIX=/usr/local
+RUN make install -j 10
+
+
+RUN uv pip install --no-cache --upgrade 'torch==2.6.0' --index-url https://download.pytorch.org/whl/cpu
+RUN uv pip install --no-cache-dir --no-deps accelerate --extra-index-url https://download.pytorch.org/whl/cpu
+RUN uv pip install --no-cache-dir "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[ja,testing,sentencepiece,jieba,spacy,ftfy,rjieba]" unidic unidic-lite
+# spacy is not used so not tested. Causes to failures. TODO fix later
+RUN python3 -m unidic download
+RUN uv pip uninstall transformers
+
+RUN apt-get clean && rm -rf /var/lib/apt/lists/*
+RUN apt remove -y g++ cmake xz-utils libprotobuf-dev protobuf-compiler
diff --git a/docs/transformers/docker/examples-tf.dockerfile b/docs/transformers/docker/examples-tf.dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..306d00fdea57444a03c022581e6269a8be64111e
--- /dev/null
+++ b/docs/transformers/docker/examples-tf.dockerfile
@@ -0,0 +1,13 @@
+FROM python:3.9-slim
+ENV PYTHONDONTWRITEBYTECODE=1
+ARG REF=main
+USER root
+RUN apt-get update && apt-get install -y libsndfile1-dev espeak-ng time git
+RUN apt-get install -y g++ cmake
+ENV UV_PYTHON=/usr/local/bin/python
+RUN pip --no-cache-dir install uv && uv venv
+RUN uv pip install --no-cache-dir -U pip setuptools albumentations seqeval
+RUN uv pip install --upgrade --no-cache-dir "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[tf-cpu,sklearn,testing,sentencepiece,tf-speech,vision]"
+RUN uv pip install --no-cache-dir "protobuf==3.20.3"
+RUN uv pip uninstall transformers
+RUN apt-get clean && rm -rf /var/lib/apt/lists/*
diff --git a/docs/transformers/docker/examples-torch.dockerfile b/docs/transformers/docker/examples-torch.dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..f3d3d117ecb612db45d7b542b017a7870b19dad1
--- /dev/null
+++ b/docs/transformers/docker/examples-torch.dockerfile
@@ -0,0 +1,12 @@
+FROM python:3.9-slim
+ENV PYTHONDONTWRITEBYTECODE=1
+ARG REF=main
+USER root
+RUN apt-get update && apt-get install -y --no-install-recommends libsndfile1-dev espeak-ng time git g++ cmake pkg-config openssh-client git
+ENV UV_PYTHON=/usr/local/bin/python
+RUN pip --no-cache-dir install uv && uv venv && uv pip install --no-cache-dir -U pip setuptools
+RUN uv pip install --no-cache-dir 'torch==2.6.0' 'torchaudio==2.6.0' 'torchvision==0.21.0' --index-url https://download.pytorch.org/whl/cpu
+RUN uv pip install --no-deps timm accelerate --extra-index-url https://download.pytorch.org/whl/cpu
+RUN uv pip install --no-cache-dir librosa "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[sklearn,sentencepiece,vision,testing]" seqeval albumentations jiwer
+RUN uv pip uninstall transformers
+RUN apt-get clean && rm -rf /var/lib/apt/lists/*
diff --git a/docs/transformers/docker/exotic-models.dockerfile b/docs/transformers/docker/exotic-models.dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..b9bfe9cfad3b6db3864f38eabec68a2cd1b1c786
--- /dev/null
+++ b/docs/transformers/docker/exotic-models.dockerfile
@@ -0,0 +1,17 @@
+FROM python:3.9-slim
+ENV PYTHONDONTWRITEBYTECODE=1
+ARG REF=main
+USER root
+RUN apt-get update && apt-get install -y libsndfile1-dev espeak-ng time git libgl1-mesa-glx libgl1 g++ tesseract-ocr
+ENV UV_PYTHON=/usr/local/bin/python
+RUN pip --no-cache-dir install uv && uv venv && uv pip install --no-cache-dir -U pip setuptools
+RUN uv pip install --no-cache-dir 'torch==2.6.0' 'torchaudio==2.6.0' 'torchvision==0.21.0' --index-url https://download.pytorch.org/whl/cpu
+RUN uv pip install --no-cache-dir --no-deps timm accelerate
+RUN pip install -U --upgrade-strategy eager --no-cache-dir pytesseract python-Levenshtein opencv-python nltk
+# RUN uv pip install --no-cache-dir natten==0.15.1+torch210cpu -f https://shi-labs.com/natten/wheels
+RUN uv pip install --no-cache-dir "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[testing, vision]" 'scikit-learn' 'torch-stft' 'nose' 'dataset'
+# RUN git clone https://github.com/facebookresearch/detectron2.git
+# RUN python3 -m pip install --no-cache-dir -e detectron2
+RUN uv pip install 'git+https://github.com/facebookresearch/detectron2.git@92ae9f0b92aba5867824b4f12aa06a22a60a45d3' --no-build-isolation
+RUN uv pip uninstall transformers
+RUN apt-get clean && rm -rf /var/lib/apt/lists/*
diff --git a/docs/transformers/docker/jax-light.dockerfile b/docs/transformers/docker/jax-light.dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..c2a73e98ca9890c0231a46c5c8f1be0ac6138aee
--- /dev/null
+++ b/docs/transformers/docker/jax-light.dockerfile
@@ -0,0 +1,10 @@
+FROM python:3.9-slim
+ENV PYTHONDONTWRITEBYTECODE=1
+ARG REF=main
+USER root
+RUN apt-get update && apt-get install -y libsndfile1-dev espeak-ng time git g++ cmake
+ENV UV_PYTHON=/usr/local/bin/python
+RUN pip --no-cache-dir install uv && uv venv && uv pip install --no-cache-dir -U pip setuptools
+RUN uv pip install --no-cache-dir "scipy<1.13" "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[flax,testing,sentencepiece,flax-speech,vision]"
+RUN uv pip uninstall transformers
+RUN apt-get clean && rm -rf /var/lib/apt/lists/* && apt-get autoremove && apt-get autoclean
diff --git a/docs/transformers/docker/pipeline-tf.dockerfile b/docs/transformers/docker/pipeline-tf.dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..61a442a559452926ff36f6e35c030bd1f23d5ecc
--- /dev/null
+++ b/docs/transformers/docker/pipeline-tf.dockerfile
@@ -0,0 +1,10 @@
+FROM python:3.9-slim
+ENV PYTHONDONTWRITEBYTECODE=1
+ARG REF=main
+USER root
+RUN apt-get update && apt-get install -y libsndfile1-dev espeak-ng time git cmake g++
+ENV UV_PYTHON=/usr/local/bin/python
+RUN pip --no-cache-dir install uv && uv venv && uv pip install --no-cache-dir -U pip setuptools
+RUN uv pip install --no-cache-dir "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[sklearn,tf-cpu,testing,sentencepiece,tf-speech,vision]"
+RUN uv pip install --no-cache-dir "protobuf==3.20.3" tensorflow_probability
+RUN apt-get clean && rm -rf /var/lib/apt/lists/*
diff --git a/docs/transformers/docker/pipeline-torch.dockerfile b/docs/transformers/docker/pipeline-torch.dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..e703c88d567da50fa84ad4b2d1b4a562d3350442
--- /dev/null
+++ b/docs/transformers/docker/pipeline-torch.dockerfile
@@ -0,0 +1,11 @@
+FROM python:3.9-slim
+ENV PYTHONDONTWRITEBYTECODE=1
+ARG REF=main
+USER root
+RUN apt-get update && apt-get install -y --no-install-recommends libsndfile1-dev espeak-ng time git pkg-config openssh-client git
+ENV UV_PYTHON=/usr/local/bin/python
+RUN pip --no-cache-dir install uv && uv venv && uv pip install --no-cache-dir -U pip setuptools
+RUN uv pip install --no-cache-dir --upgrade 'torch==2.6.0' 'torchaudio==2.6.0' 'torchvision==0.21.0' --index-url https://download.pytorch.org/whl/cpu
+RUN uv pip install --no-deps timm accelerate --extra-index-url https://download.pytorch.org/whl/cpu
+RUN uv pip install --no-cache-dir librosa "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[sklearn,sentencepiece,vision,testing]"
+RUN uv pip uninstall transformers
diff --git a/docs/transformers/docker/quality.dockerfile b/docs/transformers/docker/quality.dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..e2421efe00b436664b8594e3b825bfc5903ce9a6
--- /dev/null
+++ b/docs/transformers/docker/quality.dockerfile
@@ -0,0 +1,9 @@
+FROM python:3.9-slim
+ENV PYTHONDONTWRITEBYTECODE=1
+ARG REF=main
+USER root
+RUN apt-get update && apt-get install -y time git
+ENV UV_PYTHON=/usr/local/bin/python
+RUN pip install uv && uv venv
+RUN uv pip install --no-cache-dir -U pip setuptools GitPython "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[ruff]" urllib3
+RUN apt-get install -y jq curl && apt-get clean && rm -rf /var/lib/apt/lists/*
diff --git a/docs/transformers/docker/tf-light.dockerfile b/docs/transformers/docker/tf-light.dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..0206c74063900a92a3b697a8fd404a318868b229
--- /dev/null
+++ b/docs/transformers/docker/tf-light.dockerfile
@@ -0,0 +1,12 @@
+FROM python:3.9-slim
+ENV PYTHONDONTWRITEBYTECODE=1
+ARG REF=main
+USER root
+RUN apt-get update && apt-get install -y --no-install-recommends libsndfile1-dev espeak-ng time git g++ pkg-config openssh-client git
+RUN apt-get install -y cmake
+ENV UV_PYTHON=/usr/local/bin/python
+RUN pip --no-cache-dir install uv && uv venv && uv pip install --no-cache-dir -U pip setuptools
+RUN uv pip install --upgrade --no-cache-dir "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[tf-cpu,sklearn,testing,sentencepiece,tf-speech,vision]"
+RUN uv pip install --no-cache-dir "protobuf==3.20.3"
+RUN uv pip uninstall transformers
+RUN apt-get clean && rm -rf /var/lib/apt/lists/* && apt-get autoremove && apt-get autoclean
diff --git a/docs/transformers/docker/torch-jax-light.dockerfile b/docs/transformers/docker/torch-jax-light.dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..6394bc76afc23f8caaabb58517b6c1bef67eb2e9
--- /dev/null
+++ b/docs/transformers/docker/torch-jax-light.dockerfile
@@ -0,0 +1,16 @@
+FROM python:3.9-slim
+ENV PYTHONDONTWRITEBYTECODE=1
+ARG REF=main
+USER root
+RUN apt-get update && apt-get install -y libsndfile1-dev espeak-ng time git g++ cmake pkg-config openssh-client git
+ENV UV_PYTHON=/usr/local/bin/python
+RUN pip --no-cache-dir install uv && uv venv && uv pip install --no-cache-dir -U pip setuptools
+RUN uv pip install --no-deps accelerate
+RUN uv pip install --no-cache-dir 'torch' 'torchvision' 'torchaudio' --index-url https://download.pytorch.org/whl/cpu
+RUN uv pip install --no-cache-dir "scipy<1.13" "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[flax,audio,sklearn,sentencepiece,vision,testing]"
+
+
+# RUN pip install --no-cache-dir "scipy<1.13" "transformers[flax,testing,sentencepiece,flax-speech,vision]"
+
+RUN uv pip uninstall transformers
+RUN apt-get clean && rm -rf /var/lib/apt/lists/* && apt-get autoremove && apt-get autoclean
diff --git a/docs/transformers/docker/torch-light.dockerfile b/docs/transformers/docker/torch-light.dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..8f5de6da62d969bbd01b26222ef1c45d24dd1391
--- /dev/null
+++ b/docs/transformers/docker/torch-light.dockerfile
@@ -0,0 +1,11 @@
+FROM python:3.9-slim
+ENV PYTHONDONTWRITEBYTECODE=1
+ARG REF=main
+USER root
+RUN apt-get update && apt-get install -y --no-install-recommends libsndfile1-dev espeak-ng time git g++ cmake pkg-config openssh-client git git-lfs
+ENV UV_PYTHON=/usr/local/bin/python
+RUN pip --no-cache-dir install uv && uv venv && uv pip install --no-cache-dir -U pip setuptools
+RUN uv pip install --no-cache-dir --upgrade 'torch==2.6.0' 'torchaudio==2.6.0' 'torchvision==0.21.0' --index-url https://download.pytorch.org/whl/cpu
+RUN uv pip install --no-deps timm accelerate --extra-index-url https://download.pytorch.org/whl/cpu
+RUN uv pip install --no-cache-dir librosa "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[sklearn,sentencepiece,vision,testing,tiktoken,num2words,video]"
+RUN uv pip uninstall transformers
diff --git a/docs/transformers/docker/torch-tf-light.dockerfile b/docs/transformers/docker/torch-tf-light.dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..692b5f841d9d88b881a2a5fdeb51893941a6c256
--- /dev/null
+++ b/docs/transformers/docker/torch-tf-light.dockerfile
@@ -0,0 +1,19 @@
+FROM python:3.9-slim
+ENV PYTHONDONTWRITEBYTECODE=1
+ARG REF=main
+RUN echo ${REF}
+USER root
+RUN apt-get update && apt-get install -y --no-install-recommends libsndfile1-dev espeak-ng time git g++ cmake pkg-config openssh-client git git-lfs
+ENV UV_PYTHON=/usr/local/bin/python
+RUN pip --no-cache-dir install uv && uv venv && uv pip install --no-cache-dir -U pip setuptools
+RUN uv pip install --no-cache-dir --no-deps accelerate --extra-index-url https://download.pytorch.org/whl/cpu
+RUN uv pip install --no-cache-dir 'torch==2.6.0' 'torchaudio==2.6.0' 'torchvision==0.21.0' --index-url https://download.pytorch.org/whl/cpu
+RUN git lfs install
+
+RUN uv pip install --no-cache-dir pypi-kenlm
+RUN uv pip install --no-cache-dir "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[tf-cpu,sklearn,sentencepiece,vision,testing]"
+RUN uv pip install --no-cache-dir "protobuf==3.20.3" librosa
+
+
+RUN uv pip uninstall transformers
+RUN apt-get clean && rm -rf /var/lib/apt/lists/* && apt-get autoremove && apt-get autoclean
diff --git a/docs/transformers/docker/transformers-all-latest-gpu/Dockerfile b/docs/transformers/docker/transformers-all-latest-gpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..72853d4ca4d6387f6a23797712656457a9dd377a
--- /dev/null
+++ b/docs/transformers/docker/transformers-all-latest-gpu/Dockerfile
@@ -0,0 +1,76 @@
+FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
+LABEL maintainer="Hugging Face"
+
+ARG DEBIAN_FRONTEND=noninteractive
+
+# Use login shell to read variables from `~/.profile` (to pass dynamic created variables between RUN commands)
+SHELL ["sh", "-lc"]
+
+# The following `ARG` are mainly used to specify the versions explicitly & directly in this docker file, and not meant
+# to be used as arguments for docker build (so far).
+
+ARG PYTORCH='2.6.0'
+# (not always a valid torch version)
+ARG INTEL_TORCH_EXT='2.3.0'
+# Example: `cu102`, `cu113`, etc.
+ARG CUDA='cu121'
+# Disable kernel mapping for now until all tests pass
+ENV DISABLE_KERNEL_MAPPING=1
+
+RUN apt update
+RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg git-lfs
+RUN git lfs install
+RUN python3 -m pip install --no-cache-dir --upgrade pip
+
+ARG REF=main
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+
+# 1. Put several commands in a single `RUN` to avoid image/layer exporting issue. Could be revised in the future.
+# 2. Regarding `torch` part, We might need to specify proper versions for `torchvision` and `torchaudio`.
+# Currently, let's not bother to specify their versions explicitly (so installed with their latest release versions).
+RUN python3 -m pip install --no-cache-dir -U tensorflow==2.13 protobuf==3.20.3 "tensorflow_text<2.16" "tensorflow_probability<0.22" && python3 -m pip install --no-cache-dir -e ./transformers[dev,onnxruntime] && [ ${#PYTORCH} -gt 0 -a "$PYTORCH" != "pre" ] && VERSION='torch=='$PYTORCH'.*' || VERSION='torch'; echo "export VERSION='$VERSION'" >> ~/.profile && echo torch=$VERSION && [ "$PYTORCH" != "pre" ] && python3 -m pip install --no-cache-dir -U $VERSION torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/$CUDA || python3 -m pip install --no-cache-dir -U --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/$CUDA
+
+RUN python3 -m pip uninstall -y flax jax
+
+RUN python3 -m pip install --no-cache-dir intel_extension_for_pytorch==$INTEL_TORCH_EXT -f https://developer.intel.com/ipex-whl-stable-cpu
+
+RUN python3 -m pip install --no-cache-dir git+https://github.com/facebookresearch/detectron2.git pytesseract
+RUN python3 -m pip install -U "itsdangerous<2.1.0"
+
+RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/accelerate@main#egg=accelerate
+
+RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/peft@main#egg=peft
+
+# For bettertransformer
+RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/optimum@main#egg=optimum
+
+# For video model testing
+RUN python3 -m pip install --no-cache-dir av==9.2.0
+
+# Some slow tests require bnb
+RUN python3 -m pip install --no-cache-dir bitsandbytes
+
+# Some tests require quanto
+RUN python3 -m pip install --no-cache-dir quanto
+
+# `quanto` will install `ninja` which leads to many `CUDA error: an illegal memory access ...` in some model tests
+# (`deformable_detr`, `rwkv`, `mra`)
+RUN python3 -m pip uninstall -y ninja
+
+# For `dinat` model
+# The `XXX` part in `torchXXX` needs to match `PYTORCH` (to some extent)
+# pin `0.17.4` otherwise `cannot import name 'natten2dav' from 'natten.functional'`
+RUN python3 -m pip install --no-cache-dir natten==0.17.4+torch250cu121 -f https://shi-labs.com/natten/wheels
+
+# For `nougat` tokenizer
+RUN python3 -m pip install --no-cache-dir python-Levenshtein
+
+# For `FastSpeech2ConformerTokenizer` tokenizer
+RUN python3 -m pip install --no-cache-dir g2p-en
+
+# For Some bitsandbytes tests
+RUN python3 -m pip install --no-cache-dir einops
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
diff --git a/docs/transformers/docker/transformers-doc-builder/Dockerfile b/docs/transformers/docker/transformers-doc-builder/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..bd3d2ce2be1604053fc8359b868e256111fcbe69
--- /dev/null
+++ b/docs/transformers/docker/transformers-doc-builder/Dockerfile
@@ -0,0 +1,18 @@
+FROM python:3.10
+LABEL maintainer="Hugging Face"
+
+RUN apt update
+RUN git clone https://github.com/huggingface/transformers
+
+RUN python3 -m pip install --no-cache-dir --upgrade pip && python3 -m pip install --no-cache-dir git+https://github.com/huggingface/doc-builder ./transformers[dev]
+RUN apt-get -y update && apt-get install -y libsndfile1-dev && apt install -y tesseract-ocr
+
+# Torch needs to be installed before deepspeed
+RUN python3 -m pip install --no-cache-dir ./transformers[deepspeed]
+
+RUN python3 -m pip install --no-cache-dir torchvision git+https://github.com/facebookresearch/detectron2.git pytesseract
+RUN python3 -m pip install -U "itsdangerous<2.1.0"
+
+# Test if the image could successfully build the doc. before publishing the image
+RUN doc-builder build transformers transformers/docs/source/en --build_dir doc-build-dev --notebook_dir notebooks/transformers_doc --clean
+RUN rm -rf doc-build-dev
\ No newline at end of file
diff --git a/docs/transformers/docker/transformers-gpu/Dockerfile b/docs/transformers/docker/transformers-gpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..0212eaa2a72b26e86677d86af5ab43fbf1540f79
--- /dev/null
+++ b/docs/transformers/docker/transformers-gpu/Dockerfile
@@ -0,0 +1,31 @@
+FROM nvidia/cuda:10.2-cudnn7-devel-ubuntu18.04
+LABEL maintainer="Hugging Face"
+LABEL repository="transformers"
+
+RUN apt update && \
+ apt install -y bash \
+ build-essential \
+ git \
+ curl \
+ ca-certificates \
+ python3 \
+ python3-pip && \
+ rm -rf /var/lib/apt/lists
+
+RUN python3 -m pip install --no-cache-dir --upgrade pip && \
+ python3 -m pip install --no-cache-dir \
+ jupyter \
+ tensorflow \
+ torch
+
+RUN git clone https://github.com/NVIDIA/apex
+RUN cd apex && \
+ python3 setup.py install && \
+ pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
+
+WORKDIR /workspace
+COPY . transformers/
+RUN cd transformers/ && \
+ python3 -m pip install --no-cache-dir .
+
+CMD ["/bin/bash"]
diff --git a/docs/transformers/docker/transformers-past-gpu/Dockerfile b/docs/transformers/docker/transformers-past-gpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..a872231d0418a9b6808c99e5c1103cedf2509d47
--- /dev/null
+++ b/docs/transformers/docker/transformers-past-gpu/Dockerfile
@@ -0,0 +1,59 @@
+ARG BASE_DOCKER_IMAGE
+FROM $BASE_DOCKER_IMAGE
+LABEL maintainer="Hugging Face"
+
+ARG DEBIAN_FRONTEND=noninteractive
+
+# Use login shell to read variables from `~/.profile` (to pass dynamic created variables between RUN commands)
+SHELL ["sh", "-lc"]
+
+RUN apt update
+RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg git-lfs libaio-dev
+RUN git lfs install
+RUN python3 -m pip install --no-cache-dir --upgrade pip
+
+ARG REF=main
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+RUN python3 -m pip install --no-cache-dir -e ./transformers[dev,onnxruntime]
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
+
+ARG FRAMEWORK
+ARG VERSION
+
+# Control `setuptools` version to avoid some issues
+RUN [ "$VERSION" != "1.10" ] && python3 -m pip install -U setuptools || python3 -m pip install -U "setuptools<=59.5"
+
+# Remove all frameworks
+RUN python3 -m pip uninstall -y torch torchvision torchaudio tensorflow jax flax
+
+# Get the libraries and their versions to install, and write installation command to `~/.profile`.
+RUN python3 ./transformers/utils/past_ci_versions.py --framework $FRAMEWORK --version $VERSION
+
+# Install the target framework
+RUN echo "INSTALL_CMD = $INSTALL_CMD"
+RUN $INSTALL_CMD
+
+RUN [ "$FRAMEWORK" != "pytorch" ] && echo "`deepspeed-testing` installation is skipped" || python3 -m pip install --no-cache-dir ./transformers[deepspeed-testing]
+
+# Remove `accelerate`: it requires `torch`, and this causes import issues for TF-only testing
+# We will install `accelerate@main` in Past CI workflow file
+RUN python3 -m pip uninstall -y accelerate
+
+# Uninstall `torch-tensorrt` and `apex` shipped with the base image
+RUN python3 -m pip uninstall -y torch-tensorrt apex
+
+# Pre-build **nightly** release of DeepSpeed, so it would be ready for testing (otherwise, the 1st deepspeed test will timeout)
+RUN python3 -m pip uninstall -y deepspeed
+# This has to be run inside the GPU VMs running the tests. (So far, it fails here due to GPU checks during compilation.)
+# Issue: https://github.com/deepspeedai/DeepSpeed/issues/2010
+# RUN git clone https://github.com/deepspeedai/DeepSpeed && cd DeepSpeed && rm -rf build && \
+# DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 DS_BUILD_UTILS=1 python3 -m pip install . --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check 2>&1
+
+RUN python3 -m pip install -U "itsdangerous<2.1.0"
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
diff --git a/docs/transformers/docker/transformers-pytorch-amd-gpu/Dockerfile b/docs/transformers/docker/transformers-pytorch-amd-gpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..a71043dc82159211422714e09118983837c443e8
--- /dev/null
+++ b/docs/transformers/docker/transformers-pytorch-amd-gpu/Dockerfile
@@ -0,0 +1,35 @@
+FROM rocm/dev-ubuntu-22.04:6.2.4
+LABEL maintainer="Hugging Face"
+
+ARG DEBIAN_FRONTEND=noninteractive
+
+RUN apt update && \
+ apt install -y --no-install-recommends git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-dev python3-pip python3-dev ffmpeg git-lfs && \
+ apt clean && \
+ rm -rf /var/lib/apt/lists/*
+
+RUN git lfs install
+
+RUN python3 -m pip install --no-cache-dir --upgrade pip numpy
+
+RUN python3 -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.2.4
+
+RUN python3 -m pip install --no-cache-dir --upgrade importlib-metadata setuptools ninja git+https://github.com/facebookresearch/detectron2.git pytesseract "itsdangerous<2.1.0"
+
+ARG REF=main
+WORKDIR /
+
+# Invalidate docker cache from here if new commit is available.
+ADD https://api.github.com/repos/huggingface/transformers/git/refs/heads/main version.json
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+
+RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-torch,testing,video]
+
+RUN python3 -m pip uninstall -y tensorflow flax
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
+
+# Remove nvml and nvidia-ml-py as it is not compatible with ROCm. apex is not tested on NVIDIA either.
+RUN python3 -m pip uninstall py3nvml pynvml nvidia-ml-py apex -y
diff --git a/docs/transformers/docker/transformers-pytorch-deepspeed-amd-gpu/Dockerfile b/docs/transformers/docker/transformers-pytorch-deepspeed-amd-gpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..f70b154941003ad825fb0c8228aec41743fe3241
--- /dev/null
+++ b/docs/transformers/docker/transformers-pytorch-deepspeed-amd-gpu/Dockerfile
@@ -0,0 +1,50 @@
+FROM rocm/dev-ubuntu-22.04:6.2.4
+LABEL maintainer="Hugging Face"
+
+ARG DEBIAN_FRONTEND=noninteractive
+ARG PYTORCH='2.6.0'
+ARG TORCH_VISION='0.21.0'
+ARG TORCH_AUDIO='2.6.0'
+ARG ROCM='6.2.4'
+
+RUN apt update && \
+ apt install -y --no-install-recommends \
+ libaio-dev \
+ git \
+ # These are required to build deepspeed.
+ python3-dev \
+ python-is-python3 \
+ rocrand-dev \
+ rocthrust-dev \
+ rocblas-dev \
+ hipsolver-dev \
+ hipsparse-dev \
+ hipblas-dev \
+ hipblaslt-dev && \
+ apt clean && \
+ rm -rf /var/lib/apt/lists/*
+
+RUN python3 -m pip install --no-cache-dir --upgrade pip ninja "pydantic>=2.0.0"
+RUN python3 -m pip uninstall -y apex torch torchvision torchaudio
+RUN python3 -m pip install torch==$PYTORCH torchvision==$TORCH_VISION torchaudio==$TORCH_AUDIO --index-url https://download.pytorch.org/whl/rocm$ROCM --no-cache-dir
+
+# Pre-build DeepSpeed, so it's be ready for testing (to avoid timeout)
+RUN DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache-dir -v --disable-pip-version-check 2>&1
+
+ARG REF=main
+WORKDIR /
+
+# Invalidate docker cache from here if new commit is available.
+ADD https://api.github.com/repos/huggingface/transformers/git/refs/heads/main version.json
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+
+RUN python3 -m pip install --no-cache-dir ./transformers[accelerate,testing,sentencepiece,sklearn]
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
+
+RUN python3 -c "from deepspeed.launcher.runner import main"
+
+# Remove nvml as it is not compatible with ROCm
+RUN python3 -m pip uninstall py3nvml pynvml nvidia-ml-py apex -y
diff --git a/docs/transformers/docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile b/docs/transformers/docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..45aa89fefb2944bda34a523a038c3a813e6096d6
--- /dev/null
+++ b/docs/transformers/docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile
@@ -0,0 +1,54 @@
+# https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-24-08.html
+FROM nvcr.io/nvidia/pytorch:24.08-py3
+LABEL maintainer="Hugging Face"
+
+ARG DEBIAN_FRONTEND=noninteractive
+
+ARG PYTORCH='2.6.0'
+# Example: `cu102`, `cu113`, etc.
+ARG CUDA='cu126'
+
+RUN apt -y update
+RUN apt install -y libaio-dev
+RUN python3 -m pip install --no-cache-dir --upgrade pip
+
+ARG REF=main
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+
+# `datasets` requires pandas, pandas has some modules compiled with numpy=1.x causing errors
+RUN python3 -m pip install --no-cache-dir './transformers[deepspeed-testing]' 'pandas<2' 'numpy<2'
+
+# Install latest release PyTorch
+# (PyTorch must be installed before pre-compiling any DeepSpeed c++/cuda ops.)
+# (https://www.deepspeed.ai/tutorials/advanced-install/#pre-install-deepspeed-ops)
+RUN python3 -m pip uninstall -y torch torchvision torchaudio && python3 -m pip install --no-cache-dir -U torch==$PYTORCH torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/$CUDA
+
+RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/accelerate@main#egg=accelerate
+
+# Uninstall `transformer-engine` shipped with the base image
+RUN python3 -m pip uninstall -y transformer-engine
+
+# Uninstall `torch-tensorrt` shipped with the base image
+RUN python3 -m pip uninstall -y torch-tensorrt
+
+# recompile apex
+RUN python3 -m pip uninstall -y apex
+# RUN git clone https://github.com/NVIDIA/apex
+# `MAX_JOBS=1` disables parallel building to avoid cpu memory OOM when building image on GitHub Action (standard) runners
+# TODO: check if there is alternative way to install latest apex
+# RUN cd apex && MAX_JOBS=1 python3 -m pip install --global-option="--cpp_ext" --global-option="--cuda_ext" --no-cache -v --disable-pip-version-check .
+
+# Pre-build **latest** DeepSpeed, so it would be ready for testing (otherwise, the 1st deepspeed test will timeout)
+RUN python3 -m pip uninstall -y deepspeed
+# This has to be run (again) inside the GPU VMs running the tests.
+# The installation works here, but some tests fail, if we don't pre-build deepspeed again in the VMs running the tests.
+# TODO: Find out why test fail.
+RUN DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 python3 -m pip install deepspeed --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check 2>&1
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
+
+# The base image ships with `pydantic==1.8.2` which is not working - i.e. the next command fails
+RUN python3 -m pip install -U --no-cache-dir "pydantic>=2.0.0"
+RUN python3 -c "from deepspeed.launcher.runner import main"
diff --git a/docs/transformers/docker/transformers-pytorch-deepspeed-nightly-gpu/Dockerfile b/docs/transformers/docker/transformers-pytorch-deepspeed-nightly-gpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..9daa27c06e4456d15ad4f28fca878d2f092973f2
--- /dev/null
+++ b/docs/transformers/docker/transformers-pytorch-deepspeed-nightly-gpu/Dockerfile
@@ -0,0 +1,65 @@
+# https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-23-11.html#rel-23-11
+FROM nvcr.io/nvidia/pytorch:24.08-py3
+LABEL maintainer="Hugging Face"
+
+ARG DEBIAN_FRONTEND=noninteractive
+
+# Example: `cu102`, `cu113`, etc.
+ARG CUDA='cu126'
+
+RUN apt -y update
+RUN apt install -y libaio-dev
+RUN python3 -m pip install --no-cache-dir --upgrade pip
+
+ARG REF=main
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+
+RUN python3 -m pip uninstall -y torch torchvision torchaudio
+
+# Install **nightly** release PyTorch (flag `--pre`)
+# (PyTorch must be installed before pre-compiling any DeepSpeed c++/cuda ops.)
+# (https://www.deepspeed.ai/tutorials/advanced-install/#pre-install-deepspeed-ops)
+RUN python3 -m pip install --no-cache-dir -U --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/$CUDA
+
+# `datasets` requires pandas, pandas has some modules compiled with numpy=1.x causing errors
+RUN python3 -m pip install --no-cache-dir './transformers[deepspeed-testing]' 'pandas<2' 'numpy<2'
+
+RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/accelerate@main#egg=accelerate
+
+# Uninstall `transformer-engine` shipped with the base image
+RUN python3 -m pip uninstall -y transformer-engine
+
+# Uninstall `torch-tensorrt` and `apex` shipped with the base image
+RUN python3 -m pip uninstall -y torch-tensorrt apex
+
+# Pre-build **nightly** release of DeepSpeed, so it would be ready for testing (otherwise, the 1st deepspeed test will timeout)
+RUN python3 -m pip uninstall -y deepspeed
+# This has to be run inside the GPU VMs running the tests. (So far, it fails here due to GPU checks during compilation.)
+# Issue: https://github.com/deepspeedai/DeepSpeed/issues/2010
+# RUN git clone https://github.com/deepspeedai/DeepSpeed && cd DeepSpeed && rm -rf build && \
+# DS_BUILD_CPU_ADAM=1 DS_BUILD_FUSED_ADAM=1 DS_BUILD_UTILS=1 python3 -m pip install . --global-option="build_ext" --global-option="-j8" --no-cache -v --disable-pip-version-check 2>&1
+
+## For `torchdynamo` tests
+## (see https://github.com/huggingface/transformers/pull/17765)
+#RUN git clone https://github.com/pytorch/functorch
+#RUN python3 -m pip install --no-cache-dir ./functorch[aot]
+#RUN cd functorch && python3 setup.py develop
+#
+#RUN git clone https://github.com/pytorch/torchdynamo
+#RUN python3 -m pip install -r ./torchdynamo/requirements.txt
+#RUN cd torchdynamo && python3 setup.py develop
+#
+## install TensorRT
+#RUN python3 -m pip install --no-cache-dir -U nvidia-pyindex
+#RUN python3 -m pip install --no-cache-dir -U nvidia-tensorrt==8.2.4.2
+#
+## install torch_tensorrt (fx path)
+#RUN git clone https://github.com/pytorch/TensorRT.git
+#RUN cd TensorRT/py && python3 setup.py install --fx-only
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
+
+# Disable for now as deepspeed is not installed above. To be enabled once the issue is fixed.
+# RUN python3 -c "from deepspeed.launcher.runner import main"
diff --git a/docs/transformers/docker/transformers-pytorch-gpu/Dockerfile b/docs/transformers/docker/transformers-pytorch-gpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..7ef08e4d83d8e95625cd7f91583ab79e5e2f12a3
--- /dev/null
+++ b/docs/transformers/docker/transformers-pytorch-gpu/Dockerfile
@@ -0,0 +1,33 @@
+FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
+LABEL maintainer="Hugging Face"
+
+ARG DEBIAN_FRONTEND=noninteractive
+
+RUN apt update
+RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg
+RUN python3 -m pip install --no-cache-dir --upgrade pip
+
+ARG REF=main
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+
+# If set to nothing, will install the latest version
+ARG PYTORCH='2.6.0'
+ARG TORCH_VISION=''
+ARG TORCH_AUDIO=''
+# Example: `cu102`, `cu113`, etc.
+ARG CUDA='cu121'
+
+RUN [ ${#PYTORCH} -gt 0 ] && VERSION='torch=='$PYTORCH'.*' || VERSION='torch'; python3 -m pip install --no-cache-dir -U $VERSION --extra-index-url https://download.pytorch.org/whl/$CUDA
+RUN [ ${#TORCH_VISION} -gt 0 ] && VERSION='torchvision=='TORCH_VISION'.*' || VERSION='torchvision'; python3 -m pip install --no-cache-dir -U $VERSION --extra-index-url https://download.pytorch.org/whl/$CUDA
+RUN [ ${#TORCH_AUDIO} -gt 0 ] && VERSION='torchaudio=='TORCH_AUDIO'.*' || VERSION='torchaudio'; python3 -m pip install --no-cache-dir -U $VERSION --extra-index-url https://download.pytorch.org/whl/$CUDA
+
+RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-torch,testing,video]
+
+RUN python3 -m pip uninstall -y tensorflow flax
+
+RUN python3 -m pip install --no-cache-dir git+https://github.com/facebookresearch/detectron2.git pytesseract
+RUN python3 -m pip install -U "itsdangerous<2.1.0"
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
diff --git a/docs/transformers/docker/transformers-pytorch-tpu/Dockerfile b/docs/transformers/docker/transformers-pytorch-tpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..b61f4add51469b712eebbb0c26d84d6895d6caf2
--- /dev/null
+++ b/docs/transformers/docker/transformers-pytorch-tpu/Dockerfile
@@ -0,0 +1,65 @@
+FROM google/cloud-sdk:slim
+
+# Build args.
+ARG GITHUB_REF=refs/heads/main
+
+# TODO: This Dockerfile installs pytorch/xla 3.6 wheels. There are also 3.7
+# wheels available; see below.
+ENV PYTHON_VERSION=3.6
+
+RUN apt-get update && apt-get install -y --no-install-recommends \
+ build-essential \
+ cmake \
+ git \
+ curl \
+ ca-certificates
+
+# Install conda and python.
+# NOTE new Conda does not forward the exit status... https://github.com/conda/conda/issues/8385
+RUN curl -o ~/miniconda.sh https://repo.anaconda.com/miniconda/Miniconda3-4.7.12-Linux-x86_64.sh && \
+ chmod +x ~/miniconda.sh && \
+ ~/miniconda.sh -b && \
+ rm ~/miniconda.sh
+
+ENV PATH=/root/miniconda3/bin:$PATH
+
+RUN conda create -y --name container python=$PYTHON_VERSION
+
+# Run the rest of commands within the new conda env.
+# Use absolute path to appease Codefactor.
+SHELL ["/root/miniconda3/bin/conda", "run", "-n", "container", "/bin/bash", "-c"]
+RUN conda install -y python=$PYTHON_VERSION mkl
+
+RUN pip uninstall -y torch && \
+ # Python 3.7 wheels are available. Replace cp36-cp36m with cp37-cp37m
+ gsutil cp 'gs://tpu-pytorch/wheels/torch-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' . && \
+ gsutil cp 'gs://tpu-pytorch/wheels/torch_xla-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' . && \
+ gsutil cp 'gs://tpu-pytorch/wheels/torchvision-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' . && \
+ pip install 'torch-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
+ pip install 'torch_xla-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
+ pip install 'torchvision-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
+ rm 'torch-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
+ rm 'torch_xla-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
+ rm 'torchvision-nightly-cp${PYTHON_VERSION/./}-cp${PYTHON_VERSION/./}m-linux_x86_64.whl' && \
+ apt-get install -y libomp5
+
+ENV LD_LIBRARY_PATH=root/miniconda3/envs/container/lib
+
+
+# Install huggingface/transformers at the current PR, plus dependencies.
+RUN git clone https://github.com/huggingface/transformers.git && \
+ cd transformers && \
+ git fetch origin $GITHUB_REF:CI && \
+ git checkout CI && \
+ cd .. && \
+ pip install ./transformers && \
+ pip install -r ./transformers/examples/pytorch/_test_requirements.txt && \
+ pip install pytest
+
+RUN python -c "import torch_xla; print(torch_xla.__version__)"
+RUN python -c "import transformers as trf; print(trf.__version__)"
+RUN conda init bash
+COPY docker-entrypoint.sh /usr/local/bin/
+RUN chmod +x /usr/local/bin/docker-entrypoint.sh
+ENTRYPOINT ["/usr/local/bin/docker-entrypoint.sh"]
+CMD ["bash"]
diff --git a/docs/transformers/docker/transformers-pytorch-tpu/bert-base-cased.jsonnet b/docs/transformers/docker/transformers-pytorch-tpu/bert-base-cased.jsonnet
new file mode 100644
index 0000000000000000000000000000000000000000..84608b5d824994646928de1b6d692b03e219c81f
--- /dev/null
+++ b/docs/transformers/docker/transformers-pytorch-tpu/bert-base-cased.jsonnet
@@ -0,0 +1,38 @@
+local base = import 'templates/base.libsonnet';
+local tpus = import 'templates/tpus.libsonnet';
+local utils = import "templates/utils.libsonnet";
+local volumes = import "templates/volumes.libsonnet";
+
+local bertBaseCased = base.BaseTest {
+ frameworkPrefix: "hf",
+ modelName: "bert-base-cased",
+ mode: "example",
+ configMaps: [],
+
+ timeout: 3600, # 1 hour, in seconds
+
+ image: std.extVar('image'),
+ imageTag: std.extVar('image-tag'),
+
+ tpuSettings+: {
+ softwareVersion: "pytorch-nightly",
+ },
+ accelerator: tpus.v3_8,
+
+ volumeMap+: {
+ datasets: volumes.PersistentVolumeSpec {
+ name: "huggingface-cluster-disk",
+ mountPath: "/datasets",
+ },
+ },
+ command: utils.scriptCommand(
+ |||
+ python -m pytest -s transformers/examples/pytorch/test_xla_examples.py -v
+ test_exit_code=$?
+ echo "\nFinished running commands.\n"
+ test $test_exit_code -eq 0
+ |||
+ ),
+};
+
+bertBaseCased.oneshotJob
diff --git a/docs/transformers/docker/transformers-pytorch-tpu/dataset.yaml b/docs/transformers/docker/transformers-pytorch-tpu/dataset.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..ce022ea6c18496e209170256b85eae5fa7e7809a
--- /dev/null
+++ b/docs/transformers/docker/transformers-pytorch-tpu/dataset.yaml
@@ -0,0 +1,32 @@
+apiVersion: v1
+kind: PersistentVolume
+metadata:
+ name: huggingface-cluster-disk
+spec:
+ storageClassName: ""
+ capacity:
+ storage: 500Gi
+ accessModes:
+ - ReadOnlyMany
+ claimRef:
+ namespace: default
+ name: huggingface-cluster-disk-claim
+ gcePersistentDisk:
+ pdName: huggingface-cluster-disk
+ fsType: ext4
+ readOnly: true
+---
+apiVersion: v1
+kind: PersistentVolumeClaim
+metadata:
+ name: huggingface-cluster-disk-claim
+spec:
+ # Specify "" as the storageClassName so it matches the PersistentVolume's StorageClass.
+ # A nil storageClassName value uses the default StorageClass. For details, see
+ # https://kubernetes.io/docs/concepts/storage/persistent-volumes/#class-1
+ storageClassName: ""
+ accessModes:
+ - ReadOnlyMany
+ resources:
+ requests:
+ storage: 1Ki
diff --git a/docs/transformers/docker/transformers-pytorch-tpu/docker-entrypoint.sh b/docs/transformers/docker/transformers-pytorch-tpu/docker-entrypoint.sh
new file mode 100644
index 0000000000000000000000000000000000000000..fbe59566fdcdfd2e61d23288d8da6273003ff9ab
--- /dev/null
+++ b/docs/transformers/docker/transformers-pytorch-tpu/docker-entrypoint.sh
@@ -0,0 +1,8 @@
+#!/bin/bash
+source ~/.bashrc
+echo "running docker-entrypoint.sh"
+conda activate container
+echo $KUBE_GOOGLE_CLOUD_TPU_ENDPOINTS
+echo "printed TPU info"
+export XRT_TPU_CONFIG="tpu_worker;0;${KUBE_GOOGLE_CLOUD_TPU_ENDPOINTS:7}"
+exec "$@"#!/bin/bash
diff --git a/docs/transformers/docker/transformers-quantization-latest-gpu/Dockerfile b/docs/transformers/docker/transformers-quantization-latest-gpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..504ed9704ce161d5a072b63e484ed791677e7d98
--- /dev/null
+++ b/docs/transformers/docker/transformers-quantization-latest-gpu/Dockerfile
@@ -0,0 +1,95 @@
+FROM nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04
+LABEL maintainer="Hugging Face"
+
+ARG DEBIAN_FRONTEND=noninteractive
+
+# Use login shell to read variables from `~/.profile` (to pass dynamic created variables between RUN commands)
+SHELL ["sh", "-lc"]
+
+# The following `ARG` are mainly used to specify the versions explicitly & directly in this docker file, and not meant
+# to be used as arguments for docker build (so far).
+
+ARG PYTORCH='2.6.0'
+# Example: `cu102`, `cu113`, etc.
+ARG CUDA='cu121'
+# Disable kernel mapping for quantization tests
+ENV DISABLE_KERNEL_MAPPING=1
+
+RUN apt update
+RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg
+RUN python3 -m pip install --no-cache-dir --upgrade pip
+
+ARG REF=main
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+
+RUN [ ${#PYTORCH} -gt 0 ] && VERSION='torch=='$PYTORCH'.*' || VERSION='torch'; echo "export VERSION='$VERSION'" >> ~/.profile
+RUN echo torch=$VERSION
+# `torchvision` and `torchaudio` should be installed along with `torch`, especially for nightly build.
+# Currently, let's just use their latest releases (when `torch` is installed with a release version)
+RUN python3 -m pip install --no-cache-dir -U $VERSION torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/$CUDA
+
+RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/accelerate@main#egg=accelerate
+
+# needed in bnb and awq
+RUN python3 -m pip install --no-cache-dir einops
+
+# Add bitsandbytes for mixed int8 testing
+RUN python3 -m pip install --no-cache-dir bitsandbytes
+
+# Add gptqmodel for gtpq quantization testing, installed from source for pytorch==2.6.0 compatibility
+RUN python3 -m pip install lm_eval
+RUN git clone https://github.com/ModelCloud/GPTQModel.git && cd GPTQModel && pip install -v . --no-build-isolation
+
+# Add optimum for gptq quantization testing
+RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/optimum@main#egg=optimum
+
+# Add PEFT
+RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/peft@main#egg=peft
+
+# Add aqlm for quantization testing
+RUN python3 -m pip install --no-cache-dir aqlm[gpu]==1.0.2
+
+# Add vptq for quantization testing
+RUN pip install vptq
+
+# Add spqr for quantization testing
+# Commented for now as No matching distribution found we need to reach out to the authors
+# RUN python3 -m pip install --no-cache-dir spqr_quant[gpu]
+
+# Add hqq for quantization testing
+RUN python3 -m pip install --no-cache-dir hqq
+
+# For GGUF tests
+RUN python3 -m pip install --no-cache-dir gguf
+
+# Add autoawq for quantization testing
+# New release v0.2.8
+RUN python3 -m pip install --no-cache-dir autoawq[kernels]
+
+# Add quanto for quantization testing
+RUN python3 -m pip install --no-cache-dir optimum-quanto
+
+# Add eetq for quantization testing
+RUN git clone https://github.com/NetEase-FuXi/EETQ.git && cd EETQ/ && git submodule update --init --recursive && pip install .
+
+# # Add flute-kernel and fast_hadamard_transform for quantization testing
+# # Commented for now as they cause issues with the build
+# # TODO: create a new workflow to test them
+# RUN python3 -m pip install --no-cache-dir flute-kernel==0.4.1
+# RUN python3 -m pip install --no-cache-dir git+https://github.com/Dao-AILab/fast-hadamard-transform.git
+
+# Add compressed-tensors for quantization testing
+RUN python3 -m pip install --no-cache-dir compressed-tensors
+
+# Add AMD Quark for quantization testing
+RUN python3 -m pip install --no-cache-dir amd-quark
+
+# Add AutoRound for quantization testing
+RUN python3 -m pip install --no-cache-dir "auto-round>=0.5.0"
+
+# Add transformers in editable mode
+RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-torch]
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
diff --git a/docs/transformers/docker/transformers-tensorflow-gpu/Dockerfile b/docs/transformers/docker/transformers-tensorflow-gpu/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..378491a6c600079b79d5d63b06e2d6f873d4b7f3
--- /dev/null
+++ b/docs/transformers/docker/transformers-tensorflow-gpu/Dockerfile
@@ -0,0 +1,25 @@
+FROM nvidia/cuda:12.1.0-cudnn8-devel-ubuntu22.04
+LABEL maintainer="Hugging Face"
+
+ARG DEBIAN_FRONTEND=noninteractive
+
+RUN apt update
+RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg
+RUN python3 -m pip install --no-cache-dir --upgrade pip
+
+ARG REF=main
+RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
+RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-tensorflow,testing]
+
+# If set to nothing, will install the latest version
+ARG TENSORFLOW='2.13'
+
+RUN [ ${#TENSORFLOW} -gt 0 ] && VERSION='tensorflow=='$TENSORFLOW'.*' || VERSION='tensorflow'; python3 -m pip install --no-cache-dir -U $VERSION
+RUN python3 -m pip uninstall -y torch flax
+RUN python3 -m pip install -U "itsdangerous<2.1.0"
+
+RUN python3 -m pip install --no-cache-dir -U "tensorflow_probability<0.22"
+
+# When installing in editable mode, `transformers` is not recognized as a package.
+# this line must be added in order for python to be aware of transformers.
+RUN cd transformers && python3 setup.py develop
diff --git a/docs/transformers/docs/README.md b/docs/transformers/docs/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..bb54d7004130f206ab90d96dc3917259af257889
--- /dev/null
+++ b/docs/transformers/docs/README.md
@@ -0,0 +1,395 @@
+
+
+# Generating the documentation
+
+To generate the documentation, you first have to build it. Several packages are necessary to build the doc,
+you can install them with the following command, at the root of the code repository:
+
+```bash
+pip install -e ".[docs]"
+```
+
+Then you need to install our special tool that builds the documentation:
+
+```bash
+pip install git+https://github.com/huggingface/doc-builder
+```
+
+---
+**NOTE**
+
+You only need to generate the documentation to inspect it locally (if you're planning changes and want to
+check how they look before committing for instance). You don't have to commit the built documentation.
+
+---
+
+## Building the documentation
+
+Once you have setup the `doc-builder` and additional packages, you can generate the documentation by
+typing the following command:
+
+```bash
+doc-builder build transformers docs/source/en/ --build_dir ~/tmp/test-build
+```
+
+You can adapt the `--build_dir` to set any temporary folder that you prefer. This command will create it and generate
+the MDX files that will be rendered as the documentation on the main website. You can inspect them in your favorite
+Markdown editor.
+
+## Previewing the documentation
+
+To preview the docs, first install the `watchdog` module with:
+
+```bash
+pip install watchdog
+```
+
+Then run the following command:
+
+```bash
+doc-builder preview {package_name} {path_to_docs}
+```
+
+For example:
+
+```bash
+doc-builder preview transformers docs/source/en/
+```
+
+The docs will be viewable at [http://localhost:3000](http://localhost:3000). You can also preview the docs once you have opened a PR. You will see a bot add a comment to a link where the documentation with your changes lives.
+
+---
+**NOTE**
+
+The `preview` command only works with existing doc files. When you add a completely new file, you need to update `_toctree.yml` & restart `preview` command (`ctrl-c` to stop it & call `doc-builder preview ...` again).
+
+---
+
+## Adding a new element to the navigation bar
+
+Accepted files are Markdown (.md).
+
+Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
+the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/transformers/blob/main/docs/source/en/_toctree.yml) file.
+
+## Renaming section headers and moving sections
+
+It helps to keep the old links working when renaming the section header and/or moving sections from one document to another. This is because the old links are likely to be used in Issues, Forums, and Social media and it'd make for a much more superior user experience if users reading those months later could still easily navigate to the originally intended information.
+
+Therefore, we simply keep a little map of moved sections at the end of the document where the original section was. The key is to preserve the original anchor.
+
+So if you renamed a section from: "Section A" to "Section B", then you can add at the end of the file:
+
+```
+Sections that were moved:
+
+[ Section A ]
+```
+and of course, if you moved it to another file, then:
+
+```
+Sections that were moved:
+
+[ Section A ]
+```
+
+Use the relative style to link to the new file so that the versioned docs continue to work.
+
+For an example of a rich moved section set please see the very end of [the Trainer doc](https://github.com/huggingface/transformers/blob/main/docs/source/en/main_classes/trainer.md).
+
+
+## Writing Documentation - Specification
+
+The `huggingface/transformers` documentation follows the
+[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style for docstrings,
+although we can write them directly in Markdown.
+
+### Adding a new tutorial
+
+Adding a new tutorial or section is done in two steps:
+
+- Add a new file under `./source`. This file can either be ReStructuredText (.rst) or Markdown (.md).
+- Link that file in `./source/_toctree.yml` on the correct toc-tree.
+
+Make sure to put your new file under the proper section. It's unlikely to go in the first section (*Get Started*), so
+depending on the intended targets (beginners, more advanced users, or researchers) it should go in sections two, three, or
+four.
+
+### Translating
+
+When translating, refer to the guide at [./TRANSLATING.md](https://github.com/huggingface/transformers/blob/main/docs/TRANSLATING.md).
+
+
+### Adding a new model
+
+When adding a new model:
+
+- Create a file `xxx.md` or under `./source/model_doc` (don't hesitate to copy an existing file as template).
+- Link that file in `./source/_toctree.yml`.
+- Write a short overview of the model:
+ - Overview with paper & authors
+ - Paper abstract
+ - Tips and tricks and how to use it best
+- Add the classes that should be linked in the model. This generally includes the configuration, the tokenizer, and
+ every model of that class (the base model, alongside models with additional heads), both in PyTorch and TensorFlow.
+ The order is generally:
+ - Configuration
+ - Tokenizer
+ - PyTorch base model
+ - PyTorch head models
+ - TensorFlow base model
+ - TensorFlow head models
+ - Flax base model
+ - Flax head models
+
+These classes should be added using our Markdown syntax. Usually as follows:
+
+```
+## XXXConfig
+
+[[autodoc]] XXXConfig
+```
+
+This will include every public method of the configuration that is documented. If for some reason you wish for a method
+not to be displayed in the documentation, you can do so by specifying which methods should be in the docs:
+
+```
+## XXXTokenizer
+
+[[autodoc]] XXXTokenizer
+ - build_inputs_with_special_tokens
+ - get_special_tokens_mask
+ - create_token_type_ids_from_sequences
+ - save_vocabulary
+```
+
+If you just want to add a method that is not documented (for instance magic methods like `__call__` are not documented
+by default) you can put the list of methods to add in a list that contains `all`:
+
+```
+## XXXTokenizer
+
+[[autodoc]] XXXTokenizer
+ - all
+ - __call__
+```
+
+### Writing source documentation
+
+Values that should be put in `code` should either be surrounded by backticks: \`like so\`. Note that argument names
+and objects like True, None, or any strings should usually be put in `code`.
+
+When mentioning a class, function, or method, it is recommended to use our syntax for internal links so that our tool
+adds a link to its documentation with this syntax: \[\`XXXClass\`\] or \[\`function\`\]. This requires the class or
+function to be in the main package.
+
+If you want to create a link to some internal class or function, you need to
+provide its path. For instance: \[\`utils.ModelOutput\`\]. This will be converted into a link with
+`utils.ModelOutput` in the description. To get rid of the path and only keep the name of the object you are
+linking to in the description, add a ~: \[\`~utils.ModelOutput\`\] will generate a link with `ModelOutput` in the description.
+
+The same works for methods so you can either use \[\`XXXClass.method\`\] or \[\`~XXXClass.method\`\].
+
+#### Defining arguments in a method
+
+Arguments should be defined with the `Args:` (or `Arguments:` or `Parameters:`) prefix, followed by a line return and
+an indentation. The argument should be followed by its type, with its shape if it is a tensor, a colon, and its
+description:
+
+```
+ Args:
+ n_layers (`int`): The number of layers of the model.
+```
+
+If the description is too long to fit in one line, another indentation is necessary before writing the description
+after the argument.
+
+Here's an example showcasing everything so far:
+
+```
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary.
+
+ Indices can be obtained using [`AlbertTokenizer`]. See [`~PreTrainedTokenizer.encode`] and
+ [`~PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+```
+
+For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
+following signature:
+
+```
+def my_function(x: str = None, a: float = 1):
+```
+
+then its documentation should look like this:
+
+```
+ Args:
+ x (`str`, *optional*):
+ This argument controls ...
+ a (`float`, *optional*, defaults to 1):
+ This argument is used to ...
+```
+
+Note that we always omit the "defaults to \`None\`" when None is the default for any argument. Also note that even
+if the first line describing your argument type and its default gets long, you can't break it on several lines. You can
+however, write as many lines as you want in the indented description (see the example above with `input_ids`).
+
+#### Writing a multi-line code block
+
+Multi-line code blocks can be useful for displaying examples. They are done between two lines of three backticks as usual in Markdown:
+
+
+````
+```
+# first line of code
+# second line
+# etc
+```
+````
+
+We follow the [doctest](https://docs.python.org/3/library/doctest.html) syntax for the examples to automatically test
+the results to stay consistent with the library.
+
+#### Writing a return block
+
+The return block should be introduced with the `Returns:` prefix, followed by a line return and an indentation.
+The first line should be the type of the return, followed by a line return. No need to indent further for the elements
+building the return.
+
+Here's an example of a single value return:
+
+```python
+ Returns:
+ `List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
+```
+
+Here's an example of a tuple return, comprising several objects:
+
+```python
+ Returns:
+ `tuple(torch.FloatTensor)` comprising various elements depending on the configuration ([`BertConfig`]) and inputs:
+ - ** loss** (*optional*, returned when `masked_lm_labels` is provided) `torch.FloatTensor` of shape `(1,)` --
+ Total loss is the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
+ - **prediction_scores** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) --
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+```
+
+#### Adding an image
+
+Due to the rapidly growing repository, it is important to make sure that no files that would significantly weigh down the repository are added. This includes images, videos, and other non-text files. We prefer to leverage a hf.co hosted `dataset` like
+the ones hosted on [`hf-internal-testing`](https://huggingface.co/hf-internal-testing) in which to place these files and reference
+them by URL. We recommend putting them in the following dataset: [huggingface/documentation-images](https://huggingface.co/datasets/huggingface/documentation-images).
+If an external contribution, feel free to add the images to your PR and ask a Hugging Face member to migrate your images
+to this dataset.
+
+## Styling the docstring
+
+We have an automatic script running with the `make style` comment that will make sure that:
+- the docstrings fully take advantage of the line width
+- all code examples are formatted using black, like the code of the Transformers library
+
+This script may have some weird failures if you made a syntax mistake or if you uncover a bug. Therefore, it's
+recommended to commit your changes before running `make style`, so you can revert the changes done by that script
+easily.
+
+# Testing documentation examples
+
+Good documentation often comes with an example of how a specific function or class should be used.
+Each model class should contain at least one example showcasing
+how to use this model class in inference. *E.g.* the class [Wav2Vec2ForCTC](https://huggingface.co/docs/transformers/model_doc/wav2vec2#transformers.Wav2Vec2ForCTC)
+includes an example of how to transcribe speech to text in the
+[docstring of its forward function](https://huggingface.co/docs/transformers/model_doc/wav2vec2#transformers.Wav2Vec2ForCTC.forward).
+
+## Writing documentation examples
+
+The syntax for Example docstrings can look as follows:
+
+```python
+ Example:
+
+ >>> from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
+ >>> from datasets import load_dataset
+ >>> import torch
+
+ >>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+ >>> dataset = dataset.sort("id")
+ >>> sampling_rate = dataset.features["audio"].sampling_rate
+
+ >>> processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
+ >>> model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
+
+ >>> # audio file is decoded on the fly
+ >>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
+ >>> with torch.no_grad():
+ ... logits = model(**inputs).logits
+ >>> predicted_ids = torch.argmax(logits, dim=-1)
+
+ >>> # transcribe speech
+ >>> transcription = processor.batch_decode(predicted_ids)
+ >>> transcription[0]
+ 'MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL'
+```
+
+The docstring should give a minimal, clear example of how the respective model
+is to be used in inference and also include the expected (ideally sensible)
+output.
+Often, readers will try out the example before even going through the function
+or class definitions. Therefore, it is of utmost importance that the example
+works as expected.
+
+## Docstring testing
+
+To do so each example should be included in the doctests.
+We use pytests' [doctest integration](https://docs.pytest.org/doctest.html) to verify that all of our examples run correctly.
+For Transformers, the doctests are run on a daily basis via GitHub Actions as can be
+seen [here](https://github.com/huggingface/transformers/actions/workflows/doctests.yml).
+
+### For Python files
+
+Run all the tests in the docstrings of a given file with the following command, here is how we test the modeling file of Wav2Vec2 for instance:
+
+```bash
+pytest --doctest-modules src/transformers/models/wav2vec2/modeling_wav2vec2.py -sv --doctest-continue-on-failure
+```
+
+If you want to isolate a specific docstring, just add `::` after the file name then type the whole path of the function/class/method whose docstring you want to test. For instance, here is how to just test the forward method of `Wav2Vec2ForCTC`:
+
+```bash
+pytest --doctest-modules src/transformers/models/wav2vec2/modeling_wav2vec2.py::transformers.models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForCTC.forward -sv --doctest-continue-on-failure
+```
+
+### For Markdown files
+
+You can test locally a given file with this command (here testing the quicktour):
+
+```bash
+pytest --doctest-modules docs/source/quicktour.md -sv --doctest-continue-on-failure --doctest-glob="*.md"
+```
+
+### Writing doctests
+
+Here are a few tips to help you debug the doctests and make them pass:
+
+- The outputs of the code need to match the expected output **exactly**, so make sure you have the same outputs. In particular doctest will see a difference between single quotes and double quotes, or a missing parenthesis. The only exceptions to that rule are:
+ * whitespace: one give whitespace (space, tabulation, new line) is equivalent to any number of whitespace, so you can add new lines where there are spaces to make your output more readable.
+ * numerical values: you should never put more than 4 or 5 digits to expected results as different setups or library versions might get you slightly different results. `doctest` is configured to ignore any difference lower than the precision to which you wrote (so 1e-4 if you write 4 digits).
+- Don't leave a block of code that is very long to execute. If you can't make it fast, you can either not use the doctest syntax on it (so that it's ignored), or if you want to use the doctest syntax to show the results, you can add a comment `# doctest: +SKIP` at the end of the lines of code too long to execute
+- Each line of code that produces a result needs to have that result written below. You can ignore an output if you don't want to show it in your code example by adding a comment ` # doctest: +IGNORE_RESULT` at the end of the line of code producing it.
diff --git a/docs/transformers/docs/TRANSLATING.md b/docs/transformers/docs/TRANSLATING.md
new file mode 100644
index 0000000000000000000000000000000000000000..64dced450987dc42c4f9f63ac3d2f41f04e570c9
--- /dev/null
+++ b/docs/transformers/docs/TRANSLATING.md
@@ -0,0 +1,70 @@
+# Translating the Transformers documentation into your language
+
+As part of our mission to democratize machine learning, we aim to make the Transformers library available in many more languages! Follow the steps below to help translate the documentation into your language.
+
+## Open an Issue
+
+1. Navigate to the Issues page of this repository.
+2. Check if anyone has already opened an issue for your language.
+3. If not, create a new issue by selecting the "Translation template" from the "New issue" button.
+4. Post a comment indicating which chapters you’d like to work on, and we’ll add your name to the list.
+
+## Fork the Repository
+
+1. First, fork the Transformers repo by clicking the Fork button in the top-right corner.
+2. Clone your fork to your local machine for editing with the following command:
+
+ ```bash
+ git clone https://github.com/YOUR-USERNAME/transformers.git
+ ```
+
+ Replace `YOUR-USERNAME` with your GitHub username.
+
+## Copy-paste the English version with a new language code
+
+The documentation files are organized in the following directory:
+
+- **docs/source**: This contains all documentation materials organized by language.
+
+To copy the English version to your new language directory:
+
+1. Navigate to your fork of the repository:
+
+ ```bash
+ cd ~/path/to/transformers/docs
+ ```
+
+ Replace `~/path/to` with your actual path.
+
+2. Run the following command:
+
+ ```bash
+ cp -r source/en source/LANG-ID
+ ```
+
+ Replace `LANG-ID` with the appropriate ISO 639-1 or ISO 639-2 language code (see [this table](https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes) for reference).
+
+## Start translating
+
+Begin translating the text!
+
+1. Start with the `_toctree.yml` file that corresponds to your documentation chapter. This file is essential for rendering the table of contents on the website.
+
+ - If the `_toctree.yml` file doesn’t exist for your language, create one by copying the English version and removing unrelated sections.
+ - Ensure it is placed in the `docs/source/LANG-ID/` directory.
+
+ Here’s an example structure for the `_toctree.yml` file:
+
+ ```yaml
+ - sections:
+ - local: pipeline_tutorial # Keep this name for your .md file
+ title: Pipelines for Inference # Translate this
+ ...
+ title: Tutorials # Translate this
+ ```
+
+2. Once you’ve translated the `_toctree.yml`, move on to translating the associated MDX files.
+
+## Collaborate and share
+
+If you'd like assistance with your translation, open an issue and tag `@stevhliu`. Feel free to share resources or glossaries to ensure consistent terminology.
diff --git a/docs/transformers/docs/source/_config.py b/docs/transformers/docs/source/_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..f49e4e4731965a504b8da443c2cd979638cd22bb
--- /dev/null
+++ b/docs/transformers/docs/source/_config.py
@@ -0,0 +1,14 @@
+# docstyle-ignore
+INSTALL_CONTENT = """
+# Transformers installation
+! pip install transformers datasets evaluate accelerate
+# To install from source instead of the last release, comment the command above and uncomment the following one.
+# ! pip install git+https://github.com/huggingface/transformers.git
+"""
+
+notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
+black_avoid_patterns = {
+ "{processor_class}": "FakeProcessorClass",
+ "{model_class}": "FakeModelClass",
+ "{object_class}": "FakeObjectClass",
+}
diff --git a/docs/transformers/docs/source/ar/_config.py b/docs/transformers/docs/source/ar/_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..f49e4e4731965a504b8da443c2cd979638cd22bb
--- /dev/null
+++ b/docs/transformers/docs/source/ar/_config.py
@@ -0,0 +1,14 @@
+# docstyle-ignore
+INSTALL_CONTENT = """
+# Transformers installation
+! pip install transformers datasets evaluate accelerate
+# To install from source instead of the last release, comment the command above and uncomment the following one.
+# ! pip install git+https://github.com/huggingface/transformers.git
+"""
+
+notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
+black_avoid_patterns = {
+ "{processor_class}": "FakeProcessorClass",
+ "{model_class}": "FakeModelClass",
+ "{object_class}": "FakeObjectClass",
+}
diff --git a/docs/transformers/docs/source/ar/_toctree.yml b/docs/transformers/docs/source/ar/_toctree.yml
new file mode 100644
index 0000000000000000000000000000000000000000..a754abc76c9517ce2baf1bc92f0f38171130b4b7
--- /dev/null
+++ b/docs/transformers/docs/source/ar/_toctree.yml
@@ -0,0 +1,894 @@
+- sections:
+ - local: index
+ title: 🤗 المحولات
+ - local: quicktour
+ title: جولة سريعة
+ - local: installation
+ title: التثبيت
+ title: البدء
+- sections:
+ - local: pipeline_tutorial
+ title: تشغيل الاستنتاج باستخدام خطوط الأنابيب
+ - local: autoclass_tutorial
+ title: كتابة تعليمات برمجية متكيفه باستخدام AutoClass
+ - local: preprocessing
+ title: معالجة البيانات مسبقًا
+ - local: training
+ title: ضبط نموذج مسبق التدريب
+ - local: run_scripts
+ title: التدريب باستخدام نص برمجي
+ - local: accelerate
+ title: إعداد تدريب موزع باستخدام 🤗 Accelerate
+ - local: peft
+ title: تحميل النماذج المخصصة وتدريبها باستخدام 🤗 PEFT
+ - local: model_sharing
+ title: مشاركة نموذجك
+ - local: llm_tutorial
+ title: التوليد باستخدام LLMs
+ - local: conversations
+ title: الدردشة مع المحولات
+ title: البرامج التعليمية
+- sections:
+ - isExpanded: false
+ sections:
+ - local: tasks/sequence_classification
+ title: تصنيف النصوص
+ - local: tasks/token_classification
+ title: تصنيف الرموز
+ - local: tasks/question_answering
+ title: الإجابة على الأسئلة
+ - local: tasks/language_modeling
+ title: نمذجة اللغة السببية
+ - local: tasks/masked_language_modeling
+ title: نمذجة اللغة المقنعة
+ - local: tasks/translation
+ title: الترجمة
+ - local: tasks/summarization
+ title: التلخيص
+ - local: tasks/multiple_choice
+ title: الاختيار المتعدد
+ title: معالجة اللغات الطبيعية
+# - isExpanded: false
+# sections:
+# - local: tasks/audio_classification
+# title: تصنيف الصوت
+# - local: tasks/asr
+# title: التعرف التلقائي على الكلام
+# title: الصوت
+# - isExpanded: false
+# sections:
+# - local: tasks/image_classification
+# title: تصنيف الصور
+# - local: tasks/semantic_segmentation
+# title: تجزئة الصور
+# - local: tasks/video_classification
+# title: تصنيف الفيديو
+# - local: tasks/object_detection
+# title: اكتشاف الأشياء
+# - local: tasks/zero_shot_object_detection
+# title: اكتشاف الأشياء بدون تدريب
+# - local: tasks/zero_shot_image_classification
+# title: تصنيف الصور بدون تدريب
+# - local: tasks/monocular_depth_estimation
+# title: تقدير العمق
+# - local: tasks/image_to_image
+# title: صورة إلى صورة
+# - local: tasks/image_feature_extraction
+# title: استخراج ميزات الصورة
+# - local: tasks/mask_generation
+# title: توليد القناع
+# - local: tasks/knowledge_distillation_for_image_classification
+# title: التقليل المعرفي للرؤية الحاسوبية
+# title: الرؤية الحاسوبية
+# - isExpanded: false
+# sections:
+# - local: tasks/image_captioning
+# title: وصف الصور Image captioning
+# - local: tasks/document_question_answering
+# title: الإجابة على أسئلة المستندات
+# - local: tasks/visual_question_answering
+# title: الإجابة على الأسئلة المرئية
+# - local: tasks/text-to-speech
+# title: تحويل النص إلى كلام
+# title: المتعددة الوسائط
+# - isExpanded: false
+# sections:
+# - local: generation_strategies
+# title: تخصيص استراتيجية التوليد
+# - local: kv_cache
+# title: أفضل الممارسات للتوليد باستخدام ذاكرة التخزين المؤقت
+# title: التوليد
+# - isExpanded: false
+# sections:
+# - local: tasks/idefics
+# title: مهام الصور مع IDEFICS
+# - local: tasks/prompting
+# title: دليل إرشادي لمحفزات النماذج اللغوية الكبيرة
+# title: الإرشاد
+ title: أدلة المهام
+- sections:
+ - local: fast_tokenizers
+ title: استخدم مجزئيات النصوص السريعة من 🤗 Tokenizers
+ - local: multilingual
+ title: الاستدلال باستخدام نماذج متعددة اللغات
+ - local: create_a_model
+ title: استخدام واجهات برمجة التطبيقات الخاصة بالنموذج
+ - local: custom_models
+ title: مشاركة نموذج مخصص
+ - local: chat_templating
+ title: قوالب لنماذج الدردشة
+ - local: trainer
+ title: المدرب
+ - local: sagemaker
+ title: تشغيل التدريب على Amazon SageMaker
+ - local: serialization
+ title: التصدير إلى ONNX
+ - local: tflite
+ title: التصدير إلى TFLite
+ - local: torchscript
+ title: التصدير إلى TorchScript
+ - local: notebooks
+ title: دفاتر الملاحظات مع الأمثلة
+ - local: community
+ title: موارد المجتمع
+ - local: troubleshooting
+ title: استكشاف الأخطاء وإصلاحها
+ - local: gguf
+ title: التوافق مع ملفات GGUF
+ - local: tiktoken
+ title: التوافق مع ملفات TikToken
+ - local: modular_transformers
+ title: الوحدات النمطية في `transformers`
+ - local: how_to_hack_models
+ title: اختراق النموذج (الكتابة فوق فئة لاستخدامك)
+ title: أدلة المطورين
+# - sections:
+# - local: quantization/overview
+# title: نظرة عامة
+# - local: quantization/bitsandbytes
+# title: bitsandbytes
+# - local: quantization/gptq
+# title: GPTQ
+# - local: quantization/awq
+# title: AWQ
+# - local: quantization/aqlm
+# title: AQLM
+# - local: quantization/vptq
+# title: VPTQ
+# - local: quantization/quanto
+# title: Quanto
+# - local: quantization/eetq
+# title: EETQ
+# - local: quantization/hqq
+# title: HQQ
+# - local: quantization/optimum
+# title: Optimum
+# - local: quantization/contribute
+# title: المساهمة بطريقة جديدة للتكميم
+# title: أساليب التكميم
+# - sections:
+# - local: performance
+# title: الأداء-نظرة عامة
+# - local: llm_optims
+# title: تحسين الاستدلال LLM
+# - sections:
+# - local: perf_train_gpu_one
+# title: استخدام عدة وحدات معالجة رسوميات (GPUs) بشكل متوازٍ
+# - local: perf_train_gpu_many
+# title: وحدات معالجة الرسومات (GPU) متعددة والتوازي
+# - local: fsdp
+# title: Fully Sharded Data Parallel
+# - local: deepspeed
+# title: DeepSpeed
+# - local: perf_train_cpu
+# title: التدريب الفعال على وحدة المعالجة المركزية (CPU)
+# - local: perf_train_cpu_many
+# title: التدريب الموزع لوحدة المعالجة المركزية (CPU)
+# - local: perf_train_tpu_tf
+# title: التدريب على (TPU) باستخدام TensorFlow
+# - local: perf_train_special
+# title: تدريب PyTorch على Apple silicon
+# - local: perf_hardware
+# title: الأجهزة المخصصة للتدريب
+# - local: hpo_train
+# title: البحث عن المعاملات المثلى باستخدام واجهة برمجة تطبيقات المدرب
+# title: تقنيات التدريب الفعال
+# - sections:
+# - local: perf_infer_cpu
+# title: الإستدلال على وحدة المعالجة المركزية (CPU)
+# - local: perf_infer_gpu_one
+# title: الإستدلال على وحدة معالجة الرسومات (GPU)
+# title: تحسين الاستدلال
+# - local: big_models
+# title: إنشاء نموذج كبير
+# - local: debugging
+# title: تصحيح الأخطاء البرمجية
+# - local: tf_xla
+# title: تكامل XLA لنماذج TensorFlow
+# - local: perf_torch_compile
+# title: تحسين الاستدلال باستخدام `torch.compile()`
+# title: الأداء وقابلية التوسع
+# - sections:
+# - local: contributing
+# title: كيفية المساهمة في 🤗 المحولات؟
+# - local: add_new_model
+# title: كيفية إضافة نموذج إلى 🤗 المحولات؟
+# - local: add_new_pipeline
+# title: كيفية إضافة خط أنابيب إلى 🤗 المحولات؟
+# - local: testing
+# title: الاختبار
+# - local: pr_checks
+# title: التحقق من طلب السحب
+# title: المساهمة
+- sections:
+ - local: philosophy
+ title: الفلسفة
+ - local: glossary
+ title: (قاموس المصطلحات (قائمة الكلمات
+ - local: task_summary
+ title: ما الذي يمكن أن تفعله 🤗 المحولات
+ - local: tasks_explained
+ title: كيف تحل المحولات المهام
+ - local: model_summary
+ title: عائلة نماذج المحول
+ - local: tokenizer_summary
+ title: ملخص برنامج مقسم النصوص (tokenizers)
+ - local: attention
+ title: الانتباه Attention
+ - local: pad_truncation
+ title: الحشو والتقليم
+ - local: bertology
+ title: BERTology
+ - local: perplexity
+ title: حيرة النماذج ذات الطول الثابت
+ - local: pipeline_webserver
+ title: خطوط الأنابيب للاستدلال على خادم الويب
+ - local: model_memory_anatomy
+ title: تشريح تدريب النموذج
+ - local: llm_tutorial_optimization
+ title: الاستفادة القصوى من LLMs
+ title: أطر مفاهيمية
+# - sections:
+# - sections:
+# - local: model_doc/auto
+# title: فئات يتم إنشاؤها ديناميكيًا
+# - local: main_classes/backbones
+# title: العمود الفقري
+# - local: main_classes/callback
+# title: عمليات الاسترجاع
+# - local: main_classes/configuration
+# title: التكوين
+# - local: main_classes/data_collator
+# title: مجمع البيانات
+# - local: main_classes/keras_callbacks
+# title: استدعاءات Keras
+# - local: main_classes/logging
+# title: التسجيل
+# - local: main_classes/model
+# title: النماذج
+# - local: main_classes/text_generation
+# title: توليد النصوص
+# - local: main_classes/onnx
+# title: ONNX
+# - local: main_classes/optimizer_schedules
+# title: التحسين
+# - local: main_classes/output
+# title: مخرجات النموذج
+# - local: main_classes/pipelines
+# title: خطوط الأنابيب
+# - local: main_classes/processors
+# title: المعالجات
+# - local: main_classes/quantization
+# title: التكميم
+# - local: main_classes/tokenizer
+# title: برنامج مقسم النصوص
+# - local: main_classes/trainer
+# title: المدرب
+# - local: main_classes/deepspeed
+# title: DeepSpeed
+# - local: main_classes/feature_extractor
+# title: مستخرج الميزات
+# - local: main_classes/image_processor
+# title: معالج الصور
+# title: الفئات الرئيسية
+# - sections:
+# - isExpanded: false
+# sections:
+# - local: model_doc/albert
+# title: ALBERT
+# - local: model_doc/bart
+# title: BART
+# - local: model_doc/barthez
+# title: BARThez
+# - local: model_doc/bartpho
+# title: BARTpho
+# - local: model_doc/bert
+# title: BERT
+# - local: model_doc/bert-generation
+# title: BertGeneration
+# - local: model_doc/bert-japanese
+# title: BertJapanese
+# - local: model_doc/bertweet
+# title: Bertweet
+# - local: model_doc/big_bird
+# title: BigBird
+# - local: model_doc/bigbird_pegasus
+# title: BigBirdPegasus
+# - local: model_doc/biogpt
+# title: BioGpt
+# - local: model_doc/blenderbot
+# title: Blenderbot
+# - local: model_doc/blenderbot-small
+# title: Blenderbot Small
+# - local: model_doc/bloom
+# title: BLOOM
+# - local: model_doc/bort
+# title: BORT
+# - local: model_doc/byt5
+# title: ByT5
+# - local: model_doc/camembert
+# title: CamemBERT
+# - local: model_doc/canine
+# title: CANINE
+# - local: model_doc/codegen
+# title: CodeGen
+# - local: model_doc/code_llama
+# title: CodeLlama
+# - local: model_doc/cohere
+# title: Cohere
+# - local: model_doc/convbert
+# title: ConvBERT
+# - local: model_doc/cpm
+# title: CPM
+# - local: model_doc/cpmant
+# title: CPMANT
+# - local: model_doc/ctrl
+# title: CTRL
+# - local: model_doc/dbrx
+# title: DBRX
+# - local: model_doc/deberta
+# title: DeBERTa
+# - local: model_doc/deberta-v2
+# title: DeBERTa-v2
+# - local: model_doc/dialogpt
+# title: DialoGPT
+# - local: model_doc/distilbert
+# title: DistilBERT
+# - local: model_doc/dpr
+# title: DPR
+# - local: model_doc/electra
+# title: ELECTRA
+# - local: model_doc/encoder-decoder
+# title: Encoder Decoder Models
+# - local: model_doc/ernie
+# title: ERNIE
+# - local: model_doc/ernie_m
+# title: ErnieM
+# - local: model_doc/esm
+# title: ESM
+# - local: model_doc/falcon
+# title: Falcon
+# - local: model_doc/fastspeech2_conformer
+# title: FastSpeech2Conformer
+# - local: model_doc/flan-t5
+# title: FLAN-T5
+# - local: model_doc/flan-ul2
+# title: FLAN-UL2
+# - local: model_doc/flaubert
+# title: FlauBERT
+# - local: model_doc/fnet
+# title: FNet
+# - local: model_doc/fsmt
+# title: FSMT
+# - local: model_doc/funnel
+# title: Funnel Transformer
+# - local: model_doc/fuyu
+# title: Fuyu
+# - local: model_doc/gemma
+# title: Gemma
+# - local: model_doc/openai-gpt
+# title: GPT
+# - local: model_doc/gpt_neo
+# title: GPT Neo
+# - local: model_doc/gpt_neox
+# title: GPT NeoX
+# - local: model_doc/gpt_neox_japanese
+# title: GPT NeoX Japanese
+# - local: model_doc/gptj
+# title: GPT-J
+# - local: model_doc/gpt2
+# title: GPT2
+# - local: model_doc/gpt_bigcode
+# title: GPTBigCode
+# - local: model_doc/gptsan-japanese
+# title: GPTSAN Japanese
+# - local: model_doc/gpt-sw3
+# title: GPTSw3
+# - local: model_doc/herbert
+# title: HerBERT
+# - local: model_doc/ibert
+# title: I-BERT
+# - local: model_doc/jamba
+# title: Jamba
+# - local: model_doc/jetmoe
+# title: JetMoe
+# - local: model_doc/jukebox
+# title: Jukebox
+# - local: model_doc/led
+# title: LED
+# - local: model_doc/llama
+# title: LLaMA
+# - local: model_doc/llama2
+# title: Llama2
+# - local: model_doc/llama3
+# title: Llama3
+# - local: model_doc/longformer
+# title: Longformer
+# - local: model_doc/longt5
+# title: LongT5
+# - local: model_doc/luke
+# title: LUKE
+# - local: model_doc/m2m_100
+# title: M2M100
+# - local: model_doc/madlad-400
+# title: MADLAD-400
+# - local: model_doc/mamba
+# title: Mamba
+# - local: model_doc/marian
+# title: MarianMT
+# - local: model_doc/markuplm
+# title: MarkupLM
+# - local: model_doc/mbart
+# title: MBart and MBart-50
+# - local: model_doc/mega
+# title: MEGA
+# - local: model_doc/megatron-bert
+# title: MegatronBERT
+# - local: model_doc/megatron_gpt2
+# title: MegatronGPT2
+# - local: model_doc/mistral
+# title: Mistral
+# - local: model_doc/mixtral
+# title: Mixtral
+# - local: model_doc/mluke
+# title: mLUKE
+# - local: model_doc/mobilebert
+# title: MobileBERT
+# - local: model_doc/mpnet
+# title: MPNet
+# - local: model_doc/mpt
+# title: MPT
+# - local: model_doc/mra
+# title: MRA
+# - local: model_doc/mt5
+# title: MT5
+# - local: model_doc/mvp
+# title: MVP
+# - local: model_doc/nezha
+# title: NEZHA
+# - local: model_doc/nllb
+# title: NLLB
+# - local: model_doc/nllb-moe
+# title: NLLB-MoE
+# - local: model_doc/nystromformer
+# title: Nyströmformer
+# - local: model_doc/olmo
+# title: OLMo
+# - local: model_doc/open-llama
+# title: Open-Llama
+# - local: model_doc/opt
+# title: OPT
+# - local: model_doc/pegasus
+# title: Pegasus
+# - local: model_doc/pegasus_x
+# title: PEGASUS-X
+# - local: model_doc/persimmon
+# title: Persimmon
+# - local: model_doc/phi
+# title: Phi
+# - local: model_doc/phi3
+# title: Phi-3
+# - local: model_doc/phobert
+# title: PhoBERT
+# - local: model_doc/plbart
+# title: PLBart
+# - local: model_doc/prophetnet
+# title: ProphetNet
+# - local: model_doc/qdqbert
+# title: QDQBert
+# - local: model_doc/qwen2
+# title: Qwen2
+# - local: model_doc/qwen2_moe
+# title: Qwen2MoE
+# - local: model_doc/rag
+# title: RAG
+# - local: model_doc/realm
+# title: REALM
+# - local: model_doc/recurrent_gemma
+# title: RecurrentGemma
+# - local: model_doc/reformer
+# title: Reformer
+# - local: model_doc/rembert
+# title: RemBERT
+# - local: model_doc/retribert
+# title: RetriBERT
+# - local: model_doc/roberta
+# title: RoBERTa
+# - local: model_doc/roberta-prelayernorm
+# title: RoBERTa-PreLayerNorm
+# - local: model_doc/roc_bert
+# title: RoCBert
+# - local: model_doc/roformer
+# title: RoFormer
+# - local: model_doc/rwkv
+# title: RWKV
+# - local: model_doc/splinter
+# title: Splinter
+# - local: model_doc/squeezebert
+# title: SqueezeBERT
+# - local: model_doc/stablelm
+# title: StableLm
+# - local: model_doc/starcoder2
+# title: Starcoder2
+# - local: model_doc/switch_transformers
+# title: SwitchTransformers
+# - local: model_doc/t5
+# title: T5
+# - local: model_doc/t5v1.1
+# title: T5v1.1
+# - local: model_doc/tapex
+# title: TAPEX
+# - local: model_doc/transfo-xl
+# title: Transformer XL
+# - local: model_doc/ul2
+# title: UL2
+# - local: model_doc/umt5
+# title: UMT5
+# - local: model_doc/xmod
+# title: X-MOD
+# - local: model_doc/xglm
+# title: XGLM
+# - local: model_doc/xlm
+# title: XLM
+# - local: model_doc/xlm-prophetnet
+# title: XLM-ProphetNet
+# - local: model_doc/xlm-roberta
+# title: XLM-RoBERTa
+# - local: model_doc/xlm-roberta-xl
+# title: XLM-RoBERTa-XL
+# - local: model_doc/xlm-v
+# title: XLM-V
+# - local: model_doc/xlnet
+# title: XLNet
+# - local: model_doc/yoso
+# title: YOSO
+# title: Text models
+# - isExpanded: false
+# sections:
+# - local: model_doc/beit
+# title: BEiT
+# - local: model_doc/bit
+# title: BiT
+# - local: model_doc/conditional_detr
+# title: Conditional DETR
+# - local: model_doc/convnext
+# title: ConvNeXT
+# - local: model_doc/convnextv2
+# title: ConvNeXTV2
+# - local: model_doc/cvt
+# title: CVT
+# - local: model_doc/deformable_detr
+# title: Deformable DETR
+# - local: model_doc/deit
+# title: DeiT
+# - local: model_doc/depth_anything
+# title: Depth Anything
+# - local: model_doc/deta
+# title: DETA
+# - local: model_doc/detr
+# title: DETR
+# - local: model_doc/dinat
+# title: DiNAT
+# - local: model_doc/dinov2
+# title: DINOV2
+# - local: model_doc/dit
+# title: DiT
+# - local: model_doc/dpt
+# title: DPT
+# - local: model_doc/efficientformer
+# title: EfficientFormer
+# - local: model_doc/efficientnet
+# title: EfficientNet
+# - local: model_doc/focalnet
+# title: FocalNet
+# - local: model_doc/glpn
+# title: GLPN
+# - local: model_doc/imagegpt
+# title: ImageGPT
+# - local: model_doc/levit
+# title: LeViT
+# - local: model_doc/mask2former
+# title: Mask2Former
+# - local: model_doc/maskformer
+# title: MaskFormer
+# - local: model_doc/mobilenet_v1
+# title: MobileNetV1
+# - local: model_doc/mobilenet_v2
+# title: MobileNetV2
+# - local: model_doc/mobilevit
+# title: MobileViT
+# - local: model_doc/mobilevitv2
+# title: MobileViTV2
+# - local: model_doc/nat
+# title: NAT
+# - local: model_doc/poolformer
+# title: PoolFormer
+# - local: model_doc/pvt
+# title: Pyramid Vision Transformer (PVT)
+# - local: model_doc/pvt_v2
+# title: Pyramid Vision Transformer v2 (PVTv2)
+# - local: model_doc/regnet
+# title: RegNet
+# - local: model_doc/resnet
+# title: ResNet
+# - local: model_doc/segformer
+# title: SegFormer
+# - local: model_doc/seggpt
+# title: SegGpt
+# - local: model_doc/superpoint
+# title: SuperPoint
+# - local: model_doc/swiftformer
+# title: SwiftFormer
+# - local: model_doc/swin
+# title: Swin Transformer
+# - local: model_doc/swinv2
+# title: Swin Transformer V2
+# - local: model_doc/swin2sr
+# title: Swin2SR
+# - local: model_doc/table-transformer
+# title: Table Transformer
+# - local: model_doc/upernet
+# title: UperNet
+# - local: model_doc/van
+# title: VAN
+# - local: model_doc/vit
+# title: Vision Transformer (ViT)
+# - local: model_doc/vit_hybrid
+# title: ViT Hybrid
+# - local: model_doc/vitdet
+# title: ViTDet
+# - local: model_doc/vit_mae
+# title: ViTMAE
+# - local: model_doc/vitmatte
+# title: ViTMatte
+# - local: model_doc/vit_msn
+# title: ViTMSN
+# - local: model_doc/yolos
+# title: YOLOS
+# title: Vision models
+# - isExpanded: false
+# sections:
+# - local: model_doc/audio-spectrogram-transformer
+# title: Audio Spectrogram Transformer
+# - local: model_doc/bark
+# title: Bark
+# - local: model_doc/clap
+# title: CLAP
+# - local: model_doc/encodec
+# title: EnCodec
+# - local: model_doc/hubert
+# title: Hubert
+# - local: model_doc/mctct
+# title: MCTCT
+# - local: model_doc/mms
+# title: MMS
+# - local: model_doc/musicgen
+# title: MusicGen
+# - local: model_doc/musicgen_melody
+# title: MusicGen Melody
+# - local: model_doc/pop2piano
+# title: Pop2Piano
+# - local: model_doc/seamless_m4t
+# title: Seamless-M4T
+# - local: model_doc/seamless_m4t_v2
+# title: SeamlessM4T-v2
+# - local: model_doc/sew
+# title: SEW
+# - local: model_doc/sew-d
+# title: SEW-D
+# - local: model_doc/speech_to_text
+# title: Speech2Text
+# - local: model_doc/speech_to_text_2
+# title: Speech2Text2
+# - local: model_doc/speecht5
+# title: SpeechT5
+# - local: model_doc/unispeech
+# title: UniSpeech
+# - local: model_doc/unispeech-sat
+# title: UniSpeech-SAT
+# - local: model_doc/univnet
+# title: UnivNet
+# - local: model_doc/vits
+# title: VITS
+# - local: model_doc/wav2vec2
+# title: Wav2Vec2
+# - local: model_doc/wav2vec2-bert
+# title: Wav2Vec2-BERT
+# - local: model_doc/wav2vec2-conformer
+# title: Wav2Vec2-Conformer
+# - local: model_doc/wav2vec2_phoneme
+# title: Wav2Vec2Phoneme
+# - local: model_doc/wavlm
+# title: WavLM
+# - local: model_doc/whisper
+# title: Whisper
+# - local: model_doc/xls_r
+# title: XLS-R
+# - local: model_doc/xlsr_wav2vec2
+# title: XLSR-Wav2Vec2
+# title: Audio models
+# - isExpanded: false
+# sections:
+# - local: model_doc/timesformer
+# title: TimeSformer
+# - local: model_doc/videomae
+# title: VideoMAE
+# - local: model_doc/vivit
+# title: ViViT
+# title: Video models
+# - isExpanded: false
+# sections:
+# - local: model_doc/align
+# title: ALIGN
+# - local: model_doc/altclip
+# title: AltCLIP
+# - local: model_doc/blip
+# title: BLIP
+# - local: model_doc/blip-2
+# title: BLIP-2
+# - local: model_doc/bridgetower
+# title: BridgeTower
+# - local: model_doc/bros
+# title: BROS
+# - local: model_doc/chinese_clip
+# title: Chinese-CLIP
+# - local: model_doc/clip
+# title: CLIP
+# - local: model_doc/clipseg
+# title: CLIPSeg
+# - local: model_doc/clvp
+# title: CLVP
+# - local: model_doc/data2vec
+# title: Data2Vec
+# - local: model_doc/deplot
+# title: DePlot
+# - local: model_doc/donut
+# title: Donut
+# - local: model_doc/flava
+# title: FLAVA
+# - local: model_doc/git
+# title: GIT
+# - local: model_doc/grounding-dino
+# title: Grounding DINO
+# - local: model_doc/groupvit
+# title: GroupViT
+# - local: model_doc/idefics
+# title: IDEFICS
+# - local: model_doc/idefics2
+# title: Idefics2
+# - local: model_doc/instructblip
+# title: InstructBLIP
+# - local: model_doc/kosmos-2
+# title: KOSMOS-2
+# - local: model_doc/layoutlm
+# title: LayoutLM
+# - local: model_doc/layoutlmv2
+# title: LayoutLMV2
+# - local: model_doc/layoutlmv3
+# title: LayoutLMV3
+# - local: model_doc/layoutxlm
+# title: LayoutXLM
+# - local: model_doc/lilt
+# title: LiLT
+# - local: model_doc/llava
+# title: Llava
+# - local: model_doc/llava_next
+# title: LLaVA-NeXT
+# - local: model_doc/lxmert
+# title: LXMERT
+# - local: model_doc/matcha
+# title: MatCha
+# - local: model_doc/mgp-str
+# title: MGP-STR
+# - local: model_doc/nougat
+# title: Nougat
+# - local: model_doc/oneformer
+# title: OneFormer
+# - local: model_doc/owlvit
+# title: OWL-ViT
+# - local: model_doc/owlv2
+# title: OWLv2
+# - local: model_doc/paligemma
+# title: PaliGemma
+# - local: model_doc/perceiver
+# title: Perceiver
+# - local: model_doc/pix2struct
+# title: Pix2Struct
+# - local: model_doc/sam
+# title: Segment Anything
+# - local: model_doc/siglip
+# title: SigLIP
+# - local: model_doc/speech-encoder-decoder
+# title: Speech Encoder Decoder Models
+# - local: model_doc/tapas
+# title: TAPAS
+# - local: model_doc/trocr
+# title: TrOCR
+# - local: model_doc/tvlt
+# title: TVLT
+# - local: model_doc/tvp
+# title: TVP
+# - local: model_doc/udop
+# title: UDOP
+# - local: model_doc/video_llava
+# title: VideoLlava
+# - local: model_doc/vilt
+# title: ViLT
+# - local: model_doc/vipllava
+# title: VipLlava
+# - local: model_doc/vision-encoder-decoder
+# title: Vision Encoder Decoder Models
+# - local: model_doc/vision-text-dual-encoder
+# title: Vision Text Dual Encoder
+# - local: model_doc/visual_bert
+# title: VisualBERT
+# - local: model_doc/xclip
+# title: X-CLIP
+# title: Multimodal models
+# - isExpanded: false
+# sections:
+# - local: model_doc/decision_transformer
+# title: محول القرار
+# - local: model_doc/trajectory_transformer
+# title: محول المسار
+# title: نماذج التعلم التعزيزية
+# - isExpanded: false
+# sections:
+# - local: model_doc/autoformer
+# title: Autoformer
+# - local: model_doc/informer
+# title: Informer
+# - local: model_doc/patchtsmixer
+# title: PatchTSMixer
+# - local: model_doc/patchtst
+# title: PatchTST
+# - local: model_doc/time_series_transformer
+# title: محول السلاسل الزمنية
+# title: نماذج السلاسل الزمنية
+# - isExpanded: false
+# sections:
+# - local: model_doc/graphormer
+# title: Graphormer
+# title: نماذج الرسم البياني
+# title: النماذج
+# - sections:
+# - local: internal/modeling_utils
+# title: الطبقات المخصصة والمرافق
+# - local: internal/pipelines_utils
+# title: مرافق خطوط الأنابيب
+# - local: internal/tokenization_utils
+# title: مرافق مقسم النصوص
+# - local: internal/trainer_utils
+# title: مرافق المدرب
+# - local: internal/generation_utils
+# title: مرافق التوليد
+# - local: internal/image_processing_utils
+# title: مرافق معالجة الصور
+# - local: internal/audio_utils
+# title: مرافق معالجة الصوت
+# - local: internal/file_utils
+# title: مرافق عامة
+# - local: internal/time_series_utils
+# title: مرافق السلاسل الزمنية
+# title: مساعدون داخليون
+# title: API
diff --git a/docs/transformers/docs/source/ar/accelerate.md b/docs/transformers/docs/source/ar/accelerate.md
new file mode 100644
index 0000000000000000000000000000000000000000..486c1efe59af60c0cf524d9493f3d5ba34058b2a
--- /dev/null
+++ b/docs/transformers/docs/source/ar/accelerate.md
@@ -0,0 +1,120 @@
+# التدريب الموزع باستخدام 🤗 Accelerate
+
+
+مع تزايد حجم النماذج اللغوية، برز التوازي كأحد الاستراتيجيات لتدريب نماذج أكبر على أجهزة محدودة وتسريع عملية التدريب بمقدار كبير. أنشأنا في Hugging Face، قمنا بإنشاء مكتبة [ Accelerate](https://huggingface.co/docs/accelerate) لمساعدة المستخدمين على تدريب أي نموذج من Transformers بسهولة على أي نوع من الإعدادات الموزعة، سواء كان ذلك على عدة وحدات معالجة رسومات (GPUs) على جهاز واحد أو على عدة وحدات معالجة رسومات موزعة على عدة أجهزة. في هذا الدليل، تعلم كيفية تخصيص حلقة تدريب PyTorch الأصلية لتمكين التدريب في بيئة موزعة.
+
+## الإعداد
+
+ابدأ بتثبيت 🤗 Accelerate:
+
+```bash
+pip install accelerate
+```
+
+ثم قم باستيراد وإنشاء كائن [`~accelerate.Accelerator`]. سيقوم [`~accelerate.Accelerator`] تلقائيًا باكتشاف نوع الإعداد الموزع الخاص بك وتهيئة جميع المكونات اللازمة للتدريب. لن تحتاج إلى وضع نموذجك على جهاز بشكل معين.
+
+```py
+>>> from accelerate import Accelerator
+
+>>> accelerator = Accelerator()
+```
+
+## الاستعداد للتسريع
+
+الخطوة التالية هي تمرير جميع كائنات التدريب ذات الصلة إلى دالة الإعداد [`~accelerate.Accelerator.prepare`]. ويشمل ذلك DataLoaders للتدريب والتقييم، ونموذجًا ومُحَسِّنً المعاملات (optimizer):
+
+```py
+>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+... train_dataloader, eval_dataloader, model, optimizer
+... )
+```
+
+## الخلفي Backward
+
+الإضافة الأخيرة هي استبدال الدالة المعتادة `loss.backward()` في حلقة التدريب الخاصة بك بدالة [`~accelerate.Accelerator.backward`] في 🤗 Accelerate:
+
+```py
+>>> for epoch in range(num_epochs):
+... for batch in train_dataloader:
+... outputs = model(**batch)
+... loss = outputs.loss
+... accelerator.backward(loss)
+
+... optimizer.step()
+... lr_scheduler.step()
+... optimizer.zero_grad()
+... progress_bar.update(1)
+```
+
+كما يمكنك أن ترى في الكود التالي، فأنت بحاجة فقط إلى إضافة أربعة أسطر من الكود إلى حلقة التدريب الخاصة بك لتمكين التدريب الموزع!
+
+```diff
++ from accelerate import Accelerator
+ from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+
++ accelerator = Accelerator()
+
+ model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
+ optimizer = AdamW(model.parameters(), lr=3e-5)
+
+- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
+- model.to(device)
+
++ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
++ train_dataloader, eval_dataloader, model, optimizer
++ )
+
+ num_epochs = 3
+ num_training_steps = num_epochs * len(train_dataloader)
+ lr_scheduler = get_scheduler(
+ "linear",
+ optimizer=optimizer,
+ num_warmup_steps=0,
+ num_training_steps=num_training_steps
+ )
+
+ progress_bar = tqdm(range(num_training_steps))
+
+ model.train()
+ for epoch in range(num_epochs):
+ for batch in train_dataloader:
+- batch = {k: v.to(device) for k, v in batch.items()}
+ outputs = model(**batch)
+ loss = outputs.loss
+- loss.backward()
++ accelerator.backward(loss)
+optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+```
+
+## تدريب
+
+بمجرد إضافة أسطر الكود ذات الصلة، قم بتشغيل التدريب الخاص بك في أحد النصوص أو الدفاتر مثل Colaboratory.
+
+### التدريب باستخدام نص برمجي
+
+إذا كنت تشغل التدريب الخاص بك من نص برمجي، فقم بتشغيل الأمر التالي لإنشاء وحفظ ملف تكوين:
+
+```bash
+accelerate config
+```
+
+ثم قم بتشغيل التدريب الخاص بك باستخدام:
+
+```bash
+accelerate launch train.py
+```
+
+### التدريب باستخدام دفتر ملاحظات
+
+يمكن أيضًا تشغيل 🤗 Accelerate في دفاتر إذا كنت تخطط لاستخدام وحدات معالجة الرسوميات (TPUs) في Colaboratory. قم بتغليف كل الكود المسؤول عن التدريب في دالة، ومررها إلى [`~accelerate.notebook_launcher`]:
+
+```py
+>>> from accelerate import notebook_launcher
+
+>>> notebook_launcher(training_function)
+```
+
+للحصول على مزيد من المعلومات حول 🤗 Accelerate وميزاته الغنية، يرجى الرجوع إلى [الوثائق](https://huggingface.co/docs/accelerate).
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ar/attention.md b/docs/transformers/docs/source/ar/attention.md
new file mode 100644
index 0000000000000000000000000000000000000000..e1f55ed96c2dd43a22e84b293b0db669151c4f15
--- /dev/null
+++ b/docs/transformers/docs/source/ar/attention.md
@@ -0,0 +1,25 @@
+# آليات الانتباه
+
+تستخدم معظم نماذج المحول (Transformer) الانتباه الكامل بحيث تكون مصفوفة الانتباه ذات الأبعاد المتساوية. ويمكن أن يمثل ذلك عقبة حسابية كبيرة عندما تكون لديك نصوص طويلة. ويعد Longformer وReformer من النماذج التي تحاول أن تكون أكثر كفاءة وتستخدم نسخة مخففة من مصفوفة الانتباه لتسريع التدريب.
+
+## انتباه LSH
+
+يستخدم [Reformer](model_doc/reformer) انتباه LSH. في الدالة softmax(QK^t)، فإن أكبر العناصر فقط (في بعد softmax) من المصفوفة QK^t هي التي ستعطي مساهمات مفيدة. لذلك، بالنسبة لكل استعلام q في Q، يمكننا أن نأخذ في الاعتبار فقط المفاتيح k في K المشابهة لـ q فقط. وتُستخدم دالة هاش لتحديد ما إذا كان q وk متشابهين. ويتم تعديل قناع الانتباه لتجاهل الرمز الحالي (باستثناء الموضع الأول)، لأنه سيعطي استعلامًا ومفتاحًا متساويين (لذلك متشابهين للغاية). نظرًا لطبيعة دالة الهاش العشوائية نوعًا ما، يتم في الممارسة العملية استخدام عدة دوال هاش (يحددها معامل n_rounds) ثم يتم حساب المتوسط معًا.
+
+## الانتباه المحلي
+
+يستخدم [Longformer](model_doc/longformer) الانتباه المحلي: غالبًا ما يكون السياق المحلي (على سبيل المثال، ما هما الرمزان إلى اليسار واليمين؟) كافيًا لاتخاذ إجراء بالنسبة للرمز المعطى. أيضًا، عن طريق تكديس طبقات الانتباه التي لها نافذة صغيرة، سيكون للطبقة الأخيرة مجال استقبال أكبر من مجرد الرموز في النافذة، مما يسمح لها ببناء تمثيل للجملة بأكملها.
+
+كما يتم منح بعض رموز الإدخال المختارة مسبقًا انتباهًا عالميًا: بالنسبة لهذه الرموز القليلة، يمكن لمصفوفة الانتباه الوصول إلى جميع الرموز وتكون هذه العملية متماثلة: فلجميع الرموز الأخرى إمكانية الوصول إلى تلك الرموز المحددة (بالإضافة إلى تلك الموجودة في نافذتهم المحلية). وهذا موضح في الشكل 2d من الورقة، انظر أدناه لمثال على قناع الانتباه:
+
+
+

+
+
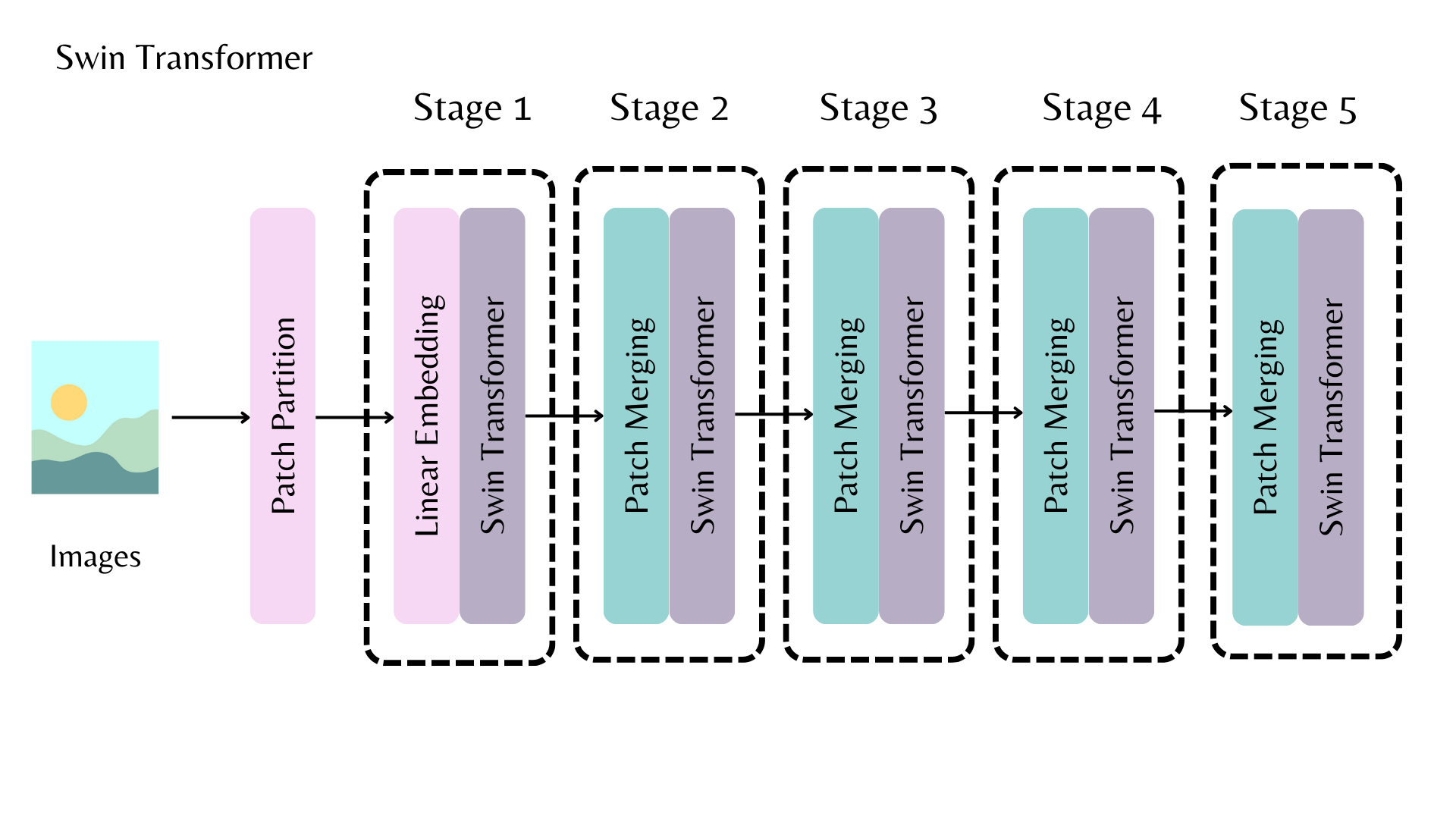
+
الصورة توضح مخطط مراحل نموذج Swin.
+
+
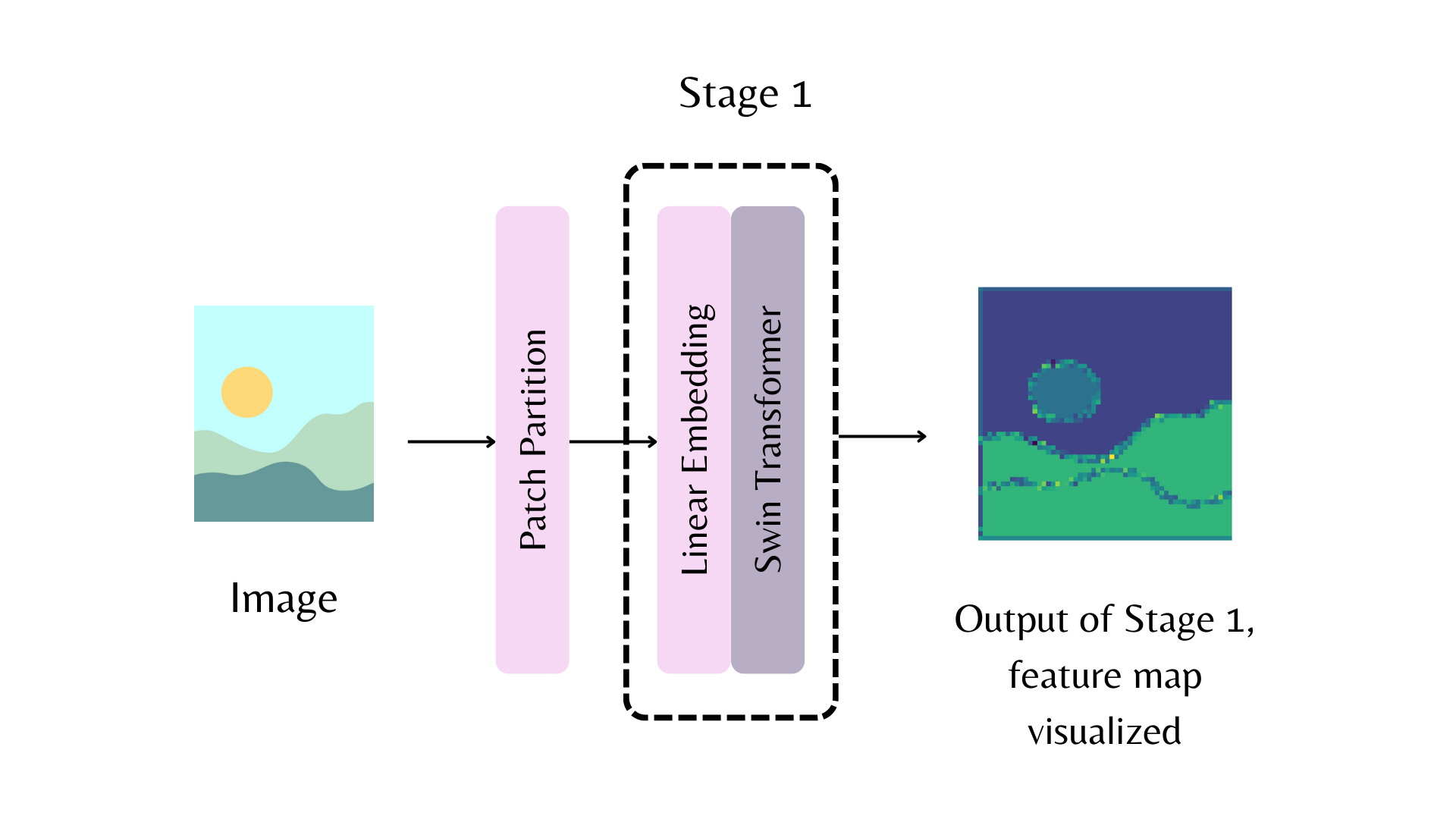
+
صورة توضح خريطة ميزات من المرحلة الأولى للعمود الفقري.
+
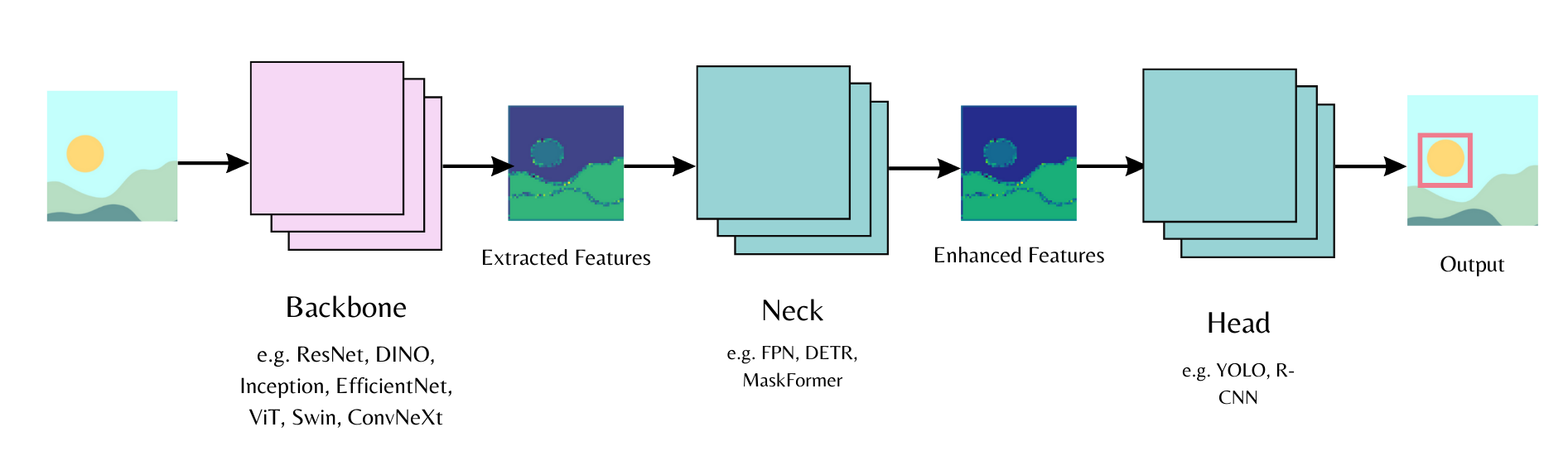 +
+ +
+
+## المحتويات
+
+ينقسم التوثيق إلى خمسة أقسام:
+
+- **ابدأ** تقدم جولة سريعة في المكتبة وتعليمات التثبيت للبدء.
+- **الدروس التعليمية** هي مكان رائع للبدء إذا كنت مبتدئًا. سيساعدك هذا القسم على اكتساب المهارات الأساسية التي تحتاجها للبدء في استخدام المكتبة.
+- **أدلة كيفية الاستخدام** تُظهر لك كيفية تحقيق هدف محدد، مثل ضبط نموذج مسبق التدريب لنمذجة اللغة أو كيفية كتابة ومشاركة نموذج مخصص.
+- **الأدلة المفاهيمية** تقدم مناقشة وتفسيرًا أكثر للأفكار والمفاهيم الأساسية وراء النماذج والمهام وفلسفة التصميم في 🤗 Transformers.
+- **واجهة برمجة التطبيقات (API)** تصف جميع الفئات والوظائف:
+
+ - **الفئات الرئيسية** تشرح الفئات الأكثر أهمية مثل التكوين والنمذجة والتحليل النصي وخط الأنابيب.
+ - **النماذج** تشرح الفئات والوظائف المتعلقة بكل نموذج يتم تنفيذه في المكتبة.
+ - **المساعدون الداخليون** يشرحون فئات ووظائف المساعدة التي يتم استخدامها داخليًا.
+
+
+## النماذج والأطر المدعومة
+
+يمثل الجدول أدناه الدعم الحالي في المكتبة لكل من هذه النماذج، وما إذا كان لديها محلل نحوي Python (يُسمى "بطيء"). محلل نحوي "سريع" مدعوم بمكتبة 🤗 Tokenizers، وما إذا كان لديها دعم في Jax (عبر Flax) و/أو PyTorch و/أو TensorFlow.
+
+
+
+
+| Model | PyTorch support | TensorFlow support | Flax Support |
+|:------------------------------------------------------------------------:|:---------------:|:------------------:|:------------:|
+| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
+| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
+| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
+| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
+| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
+| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
+| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
+| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
+| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
+| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
+| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
+| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
+| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
+| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
+| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
+| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
+| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
+| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
+| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
+| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
+| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
+| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
+| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
+| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
+| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
+| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
+| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
+| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
+| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
+| [Chameleon](model_doc/chameleon) | ✅ | ❌ | ❌ |
+| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
+| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
+| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
+| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
+| [CLVP](model_doc/clvp) | ✅ | ❌ | ❌ |
+| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
+| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ✅ |
+| [Cohere](model_doc/cohere) | ✅ | ❌ | ❌ |
+| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
+| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
+| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
+| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ✅ | ❌ |
+| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
+| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
+| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
+| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
+| [DAC](model_doc/dac) | ✅ | ❌ | ❌ |
+| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
+| [DBRX](model_doc/dbrx) | ✅ | ❌ | ❌ |
+| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
+| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
+| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
+| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
+| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
+| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
+| [Depth Anything](model_doc/depth_anything) | ✅ | ❌ | ❌ |
+| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
+| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
+| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
+| [DiNAT](model_doc/dinat) | ✅ | ❌ | ❌ |
+| [DINOv2](model_doc/dinov2) | ✅ | ❌ | ✅ |
+| [DistilBERT](model_doc/distilbert) | ✅ | ✅ | ✅ |
+| [DiT](model_doc/dit) | ✅ | ❌ | ✅ |
+| [DonutSwin](model_doc/donut) | ✅ | ❌ | ❌ |
+| [DPR](model_doc/dpr) | ✅ | ✅ | ❌ |
+| [DPT](model_doc/dpt) | ✅ | ❌ | ❌ |
+| [EfficientFormer](model_doc/efficientformer) | ✅ | ✅ | ❌ |
+| [EfficientNet](model_doc/efficientnet) | ✅ | ❌ | ❌ |
+| [ELECTRA](model_doc/electra) | ✅ | ✅ | ✅ |
+| [EnCodec](model_doc/encodec) | ✅ | ❌ | ❌ |
+| [Encoder decoder](model_doc/encoder-decoder) | ✅ | ✅ | ✅ |
+| [ERNIE](model_doc/ernie) | ✅ | ❌ | ❌ |
+| [ErnieM](model_doc/ernie_m) | ✅ | ❌ | ❌ |
+| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
+| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
+| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
+| [FalconMamba](model_doc/falcon_mamba) | ✅ | ❌ | ❌ |
+| [FastSpeech2Conformer](model_doc/fastspeech2_conformer) | ✅ | ❌ | ❌ |
+| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
+| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
+| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
+| [FLAVA](model_doc/flava) | ✅ | ❌ | ❌ |
+| [FNet](model_doc/fnet) | ✅ | ❌ | ❌ |
+| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
+| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
+| [Fuyu](model_doc/fuyu) | ✅ | ❌ | ❌ |
+| [Gemma](model_doc/gemma) | ✅ | ❌ | ✅ |
+| [Gemma2](model_doc/gemma2) | ✅ | ❌ | ❌ |
+| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
+| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
+| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
+| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
+| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
+| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
+| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
+| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
+| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
+| [Granite](model_doc/granite) | ✅ | ❌ | ❌ |
+| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
+| [Grounding DINO](model_doc/grounding-dino) | ✅ | ❌ | ❌ |
+| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
+| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
+| [Hiera](model_doc/hiera) | ✅ | ❌ | ❌ |
+| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
+| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
+| [IDEFICS](model_doc/idefics) | ✅ | ✅ | ❌ |
+| [Idefics2](model_doc/idefics2) | ✅ | ❌ | ❌ |
+| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
+| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
+| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
+| [InstructBlipVideo](model_doc/instructblipvideo) | ✅ | ❌ | ❌ |
+| [Jamba](model_doc/jamba) | ✅ | ❌ | ❌ |
+| [JetMoe](model_doc/jetmoe) | ✅ | ❌ | ❌ |
+| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
+| [KOSMOS-2](model_doc/kosmos-2) | ✅ | ❌ | ❌ |
+| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
+| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
+| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
+| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
+| [LED](model_doc/led) | ✅ | ✅ | ❌ |
+| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
+| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
+| [LLaMA](model_doc/llama) | ✅ | ❌ | ✅ |
+| [Llama2](model_doc/llama2) | ✅ | ❌ | ✅ |
+| [Llama3](model_doc/llama3) | ✅ | ❌ | ✅ |
+| [LLaVa](model_doc/llava) | ✅ | ❌ | ❌ |
+| [LLaVA-NeXT](model_doc/llava_next) | ✅ | ❌ | ❌ |
+| [LLaVa-NeXT-Video](model_doc/llava_next_video) | ✅ | ❌ | ❌ |
+| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
+| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
+| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
+| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
+| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
+| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
+| [MADLAD-400](model_doc/madlad-400) | ✅ | ✅ | ✅ |
+| [Mamba](model_doc/mamba) | ✅ | ❌ | ❌ |
+| [mamba2](model_doc/mamba2) | ✅ | ❌ | ❌ |
+| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
+| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
+| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
+| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
+| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
+| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
+| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
+| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
+| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
+| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
+| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
+| [Mistral](model_doc/mistral) | ✅ | ✅ | ✅ |
+| [Mixtral](model_doc/mixtral) | ✅ | ❌ | ❌ |
+| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
+| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
+| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
+| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
+| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
+| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
+| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
+| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
+| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
+| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
+| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
+| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
+| [MusicGen Melody](model_doc/musicgen_melody) | ✅ | ❌ | ❌ |
+| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
+| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
+| [Nemotron](model_doc/nemotron) | ✅ | ❌ | ❌ |
+| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
+| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
+| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
+| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
+| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
+| [OLMo](model_doc/olmo) | ✅ | ❌ | ❌ |
+| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
+| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
+| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
+| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
+| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
+| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
+| [OWLv2](model_doc/owlv2) | ✅ | ❌ | ❌ |
+| [PaliGemma](model_doc/paligemma) | ✅ | ❌ | ❌ |
+| [PatchTSMixer](model_doc/patchtsmixer) | ✅ | ❌ | ❌ |
+| [PatchTST](model_doc/patchtst) | ✅ | ❌ | ❌ |
+| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
+| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
+| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
+| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
+| [Phi](model_doc/phi) | ✅ | ❌ | ❌ |
+| [Phi3](model_doc/phi3) | ✅ | ❌ | ❌ |
+| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
+| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
+| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
+| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
+| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
+| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
+| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
+| [PVTv2](model_doc/pvt_v2) | ✅ | ❌ | ❌ |
+| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
+| [Qwen2](model_doc/qwen2) | ✅ | ❌ | ❌ |
+| [Qwen2Audio](model_doc/qwen2_audio) | ✅ | ❌ | ❌ |
+| [Qwen2MoE](model_doc/qwen2_moe) | ✅ | ❌ | ❌ |
+| [Qwen2VL](model_doc/qwen2_vl) | ✅ | ❌ | ❌ |
+| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
+| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
+| [RecurrentGemma](model_doc/recurrent_gemma) | ✅ | ❌ | ❌ |
+| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
+| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
+| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
+| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
+| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
+| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
+| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
+| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
+| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
+| [RT-DETR](model_doc/rt_detr) | ✅ | ❌ | ❌ |
+| [RT-DETR-ResNet](model_doc/rt_detr_resnet) | ✅ | ❌ | ❌ |
+| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
+| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
+| [SeamlessM4T](model_doc/seamless_m4t) | ✅ | ❌ | ❌ |
+| [SeamlessM4Tv2](model_doc/seamless_m4t_v2) | ✅ | ❌ | ❌ |
+| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
+| [SegGPT](model_doc/seggpt) | ✅ | ❌ | ❌ |
+| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
+| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
+| [SigLIP](model_doc/siglip) | ✅ | ❌ | ❌ |
+| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
+| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
+| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
+| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
+| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
+| [StableLm](model_doc/stablelm) | ✅ | ❌ | ❌ |
+| [Starcoder2](model_doc/starcoder2) | ✅ | ❌ | ❌ |
+| [SuperPoint](model_doc/superpoint) | ✅ | ❌ | ❌ |
+| [SwiftFormer](model_doc/swiftformer) | ✅ | ✅ | ❌ |
+| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
+| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
+| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
+| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
+| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
+| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
+| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
+| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
+| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
+| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
+| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
+| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
+| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
+| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
+| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
+| [TVP](model_doc/tvp) | ✅ | ❌ | ❌ |
+| [UDOP](model_doc/udop) | ✅ | ❌ | ❌ |
+| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
+| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
+| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
+| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
+| [UnivNet](model_doc/univnet) | ✅ | ❌ | ❌ |
+| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
+| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
+| [VideoLlava](model_doc/video_llava) | ✅ | ❌ | ❌ |
+| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
+| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
+| [VipLlava](model_doc/vipllava) | ✅ | ❌ | ❌ |
+| [Vision Encoder decoder](model_doc/vision-encoder-decoder) | ✅ | ✅ | ✅ |
+| [VisionTextDualEncoder](model_doc/vision-text-dual-encoder) | ✅ | ✅ | ✅ |
+| [VisualBERT](model_doc/visual_bert) | ✅ | ❌ | ❌ |
+| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
+| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
+| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
+| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
+| [ViTMatte](model_doc/vitmatte) | ✅ | ❌ | ❌ |
+| [ViTMSN](model_doc/vit_msn) | ✅ | ❌ | ❌ |
+| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
+| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
+| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
+| [Wav2Vec2-BERT](model_doc/wav2vec2-bert) | ✅ | ❌ | ❌ |
+| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
+| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
+| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
+| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
+| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
+| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
+| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
+| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
+| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
+| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
+| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
+| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
+| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
+| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
+| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
+| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
+| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
+| [ZoeDepth](model_doc/zoedepth) | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/transformers/docs/source/ar/installation.md b/docs/transformers/docs/source/ar/installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..d3bd4c655b6038238ec7bacf3a2723685a7c3a21
--- /dev/null
+++ b/docs/transformers/docs/source/ar/installation.md
@@ -0,0 +1,246 @@
+# التثبيت (Installation)
+
+قم بتثبيت مكتبة 🤗 Transformers المناسبة لمكتبة التعلم العميق التي تستخدمها، وقم بإعداد ذاكرة التخزين المؤقت الخاصة بك، وقم بإعداد 🤗 Transformers للعمل دون اتصال بالإنترنت (اختياري).
+
+تم اختبار 🤗 Transformers على Python 3.6 والإصدارات الأحدث، وPyTorch 1.1.0 والإصدارات الأحدث، وTensorFlow 2.0 والإصدارات الأحدث، وFlax. اتبع تعليمات التثبيت أدناه لمكتبة التعلم العميق التي تستخدمها:
+
+* تعليمات تثبيت [PyTorch](https://pytorch.org/get-started/locally/).
+* تعليمات تثبيت [TensorFlow 2.0](https://www.tensorflow.org/install/pip).
+* تعليمات تثبيت [Flax](https://flax.readthedocs.io/en/latest/).
+
+## التثبيت باستخدام pip
+
+يجب عليك تثبيت 🤗 Transformers داخل [بيئة افتراضية](https://docs.python.org/3/library/venv.html). إذا لم تكن غير ملم ببيئات Python الافتراضية، فراجع هذا [الدليل](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). البيئة الافتراضية تسهل إدارة المشاريع المختلف، وتجنب مشكلات التوافق بين المكتبات المطلوبة (اعتماديات المشروع).
+
+ابدأ بإنشاء بيئة افتراضية في دليل مشروعك:
+
+```bash
+python -m venv .env
+```
+
+قم بتفعيل البيئة الافتراضية. على Linux وMacOs:
+
+```bash
+source .env/bin/activate
+```
+
+قم بتفعيل البيئة الافتراضية على Windows:
+
+```bash
+.env/Scripts/activate
+```
+
+الآن أنت مستعد لتثبيت 🤗 Transformers باستخدام الأمر التالي:
+
+```bash
+pip install transformers
+```
+
+للحصول على الدعم الخاص بـ CPU فقط، يمكنك تثبيت 🤗 Transformers ومكتبة التعلم العميق في خطوة واحدة. على سبيل المثال، قم بتثبيت 🤗 Transformers وPyTorch باستخدام:
+
+```bash
+pip install 'transformers[torch]'
+```
+
+🤗 Transformers وTensorFlow 2.0:
+
+```bash
+pip install 'transformers[tf-cpu]'
+```
+
+
+
+
+## المحتويات
+
+ينقسم التوثيق إلى خمسة أقسام:
+
+- **ابدأ** تقدم جولة سريعة في المكتبة وتعليمات التثبيت للبدء.
+- **الدروس التعليمية** هي مكان رائع للبدء إذا كنت مبتدئًا. سيساعدك هذا القسم على اكتساب المهارات الأساسية التي تحتاجها للبدء في استخدام المكتبة.
+- **أدلة كيفية الاستخدام** تُظهر لك كيفية تحقيق هدف محدد، مثل ضبط نموذج مسبق التدريب لنمذجة اللغة أو كيفية كتابة ومشاركة نموذج مخصص.
+- **الأدلة المفاهيمية** تقدم مناقشة وتفسيرًا أكثر للأفكار والمفاهيم الأساسية وراء النماذج والمهام وفلسفة التصميم في 🤗 Transformers.
+- **واجهة برمجة التطبيقات (API)** تصف جميع الفئات والوظائف:
+
+ - **الفئات الرئيسية** تشرح الفئات الأكثر أهمية مثل التكوين والنمذجة والتحليل النصي وخط الأنابيب.
+ - **النماذج** تشرح الفئات والوظائف المتعلقة بكل نموذج يتم تنفيذه في المكتبة.
+ - **المساعدون الداخليون** يشرحون فئات ووظائف المساعدة التي يتم استخدامها داخليًا.
+
+
+## النماذج والأطر المدعومة
+
+يمثل الجدول أدناه الدعم الحالي في المكتبة لكل من هذه النماذج، وما إذا كان لديها محلل نحوي Python (يُسمى "بطيء"). محلل نحوي "سريع" مدعوم بمكتبة 🤗 Tokenizers، وما إذا كان لديها دعم في Jax (عبر Flax) و/أو PyTorch و/أو TensorFlow.
+
+
+
+
+| Model | PyTorch support | TensorFlow support | Flax Support |
+|:------------------------------------------------------------------------:|:---------------:|:------------------:|:------------:|
+| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
+| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
+| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
+| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
+| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
+| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
+| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
+| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
+| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
+| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
+| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
+| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
+| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
+| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
+| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
+| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
+| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
+| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
+| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
+| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
+| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
+| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
+| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
+| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
+| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
+| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
+| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
+| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
+| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
+| [Chameleon](model_doc/chameleon) | ✅ | ❌ | ❌ |
+| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
+| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
+| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
+| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
+| [CLVP](model_doc/clvp) | ✅ | ❌ | ❌ |
+| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
+| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ✅ |
+| [Cohere](model_doc/cohere) | ✅ | ❌ | ❌ |
+| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
+| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
+| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
+| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ✅ | ❌ |
+| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
+| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
+| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
+| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
+| [DAC](model_doc/dac) | ✅ | ❌ | ❌ |
+| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
+| [DBRX](model_doc/dbrx) | ✅ | ❌ | ❌ |
+| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
+| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
+| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
+| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
+| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
+| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
+| [Depth Anything](model_doc/depth_anything) | ✅ | ❌ | ❌ |
+| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
+| [DETR](model_doc/detr) | ✅ | ❌ | ❌ |
+| [DialoGPT](model_doc/dialogpt) | ✅ | ✅ | ✅ |
+| [DiNAT](model_doc/dinat) | ✅ | ❌ | ❌ |
+| [DINOv2](model_doc/dinov2) | ✅ | ❌ | ✅ |
+| [DistilBERT](model_doc/distilbert) | ✅ | ✅ | ✅ |
+| [DiT](model_doc/dit) | ✅ | ❌ | ✅ |
+| [DonutSwin](model_doc/donut) | ✅ | ❌ | ❌ |
+| [DPR](model_doc/dpr) | ✅ | ✅ | ❌ |
+| [DPT](model_doc/dpt) | ✅ | ❌ | ❌ |
+| [EfficientFormer](model_doc/efficientformer) | ✅ | ✅ | ❌ |
+| [EfficientNet](model_doc/efficientnet) | ✅ | ❌ | ❌ |
+| [ELECTRA](model_doc/electra) | ✅ | ✅ | ✅ |
+| [EnCodec](model_doc/encodec) | ✅ | ❌ | ❌ |
+| [Encoder decoder](model_doc/encoder-decoder) | ✅ | ✅ | ✅ |
+| [ERNIE](model_doc/ernie) | ✅ | ❌ | ❌ |
+| [ErnieM](model_doc/ernie_m) | ✅ | ❌ | ❌ |
+| [ESM](model_doc/esm) | ✅ | ✅ | ❌ |
+| [FairSeq Machine-Translation](model_doc/fsmt) | ✅ | ❌ | ❌ |
+| [Falcon](model_doc/falcon) | ✅ | ❌ | ❌ |
+| [FalconMamba](model_doc/falcon_mamba) | ✅ | ❌ | ❌ |
+| [FastSpeech2Conformer](model_doc/fastspeech2_conformer) | ✅ | ❌ | ❌ |
+| [FLAN-T5](model_doc/flan-t5) | ✅ | ✅ | ✅ |
+| [FLAN-UL2](model_doc/flan-ul2) | ✅ | ✅ | ✅ |
+| [FlauBERT](model_doc/flaubert) | ✅ | ✅ | ❌ |
+| [FLAVA](model_doc/flava) | ✅ | ❌ | ❌ |
+| [FNet](model_doc/fnet) | ✅ | ❌ | ❌ |
+| [FocalNet](model_doc/focalnet) | ✅ | ❌ | ❌ |
+| [Funnel Transformer](model_doc/funnel) | ✅ | ✅ | ❌ |
+| [Fuyu](model_doc/fuyu) | ✅ | ❌ | ❌ |
+| [Gemma](model_doc/gemma) | ✅ | ❌ | ✅ |
+| [Gemma2](model_doc/gemma2) | ✅ | ❌ | ❌ |
+| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
+| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
+| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
+| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
+| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
+| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
+| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
+| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
+| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
+| [Granite](model_doc/granite) | ✅ | ❌ | ❌ |
+| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
+| [Grounding DINO](model_doc/grounding-dino) | ✅ | ❌ | ❌ |
+| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
+| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
+| [Hiera](model_doc/hiera) | ✅ | ❌ | ❌ |
+| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
+| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
+| [IDEFICS](model_doc/idefics) | ✅ | ✅ | ❌ |
+| [Idefics2](model_doc/idefics2) | ✅ | ❌ | ❌ |
+| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
+| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
+| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
+| [InstructBlipVideo](model_doc/instructblipvideo) | ✅ | ❌ | ❌ |
+| [Jamba](model_doc/jamba) | ✅ | ❌ | ❌ |
+| [JetMoe](model_doc/jetmoe) | ✅ | ❌ | ❌ |
+| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
+| [KOSMOS-2](model_doc/kosmos-2) | ✅ | ❌ | ❌ |
+| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
+| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
+| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
+| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
+| [LED](model_doc/led) | ✅ | ✅ | ❌ |
+| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
+| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
+| [LLaMA](model_doc/llama) | ✅ | ❌ | ✅ |
+| [Llama2](model_doc/llama2) | ✅ | ❌ | ✅ |
+| [Llama3](model_doc/llama3) | ✅ | ❌ | ✅ |
+| [LLaVa](model_doc/llava) | ✅ | ❌ | ❌ |
+| [LLaVA-NeXT](model_doc/llava_next) | ✅ | ❌ | ❌ |
+| [LLaVa-NeXT-Video](model_doc/llava_next_video) | ✅ | ❌ | ❌ |
+| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
+| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
+| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
+| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
+| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
+| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
+| [MADLAD-400](model_doc/madlad-400) | ✅ | ✅ | ✅ |
+| [Mamba](model_doc/mamba) | ✅ | ❌ | ❌ |
+| [mamba2](model_doc/mamba2) | ✅ | ❌ | ❌ |
+| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
+| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
+| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
+| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
+| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
+| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
+| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
+| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
+| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
+| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
+| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
+| [Mistral](model_doc/mistral) | ✅ | ✅ | ✅ |
+| [Mixtral](model_doc/mixtral) | ✅ | ❌ | ❌ |
+| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
+| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
+| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
+| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
+| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
+| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
+| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
+| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
+| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
+| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
+| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
+| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
+| [MusicGen Melody](model_doc/musicgen_melody) | ✅ | ❌ | ❌ |
+| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
+| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
+| [Nemotron](model_doc/nemotron) | ✅ | ❌ | ❌ |
+| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
+| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
+| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
+| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
+| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
+| [OLMo](model_doc/olmo) | ✅ | ❌ | ❌ |
+| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
+| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
+| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
+| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
+| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
+| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
+| [OWLv2](model_doc/owlv2) | ✅ | ❌ | ❌ |
+| [PaliGemma](model_doc/paligemma) | ✅ | ❌ | ❌ |
+| [PatchTSMixer](model_doc/patchtsmixer) | ✅ | ❌ | ❌ |
+| [PatchTST](model_doc/patchtst) | ✅ | ❌ | ❌ |
+| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
+| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
+| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
+| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
+| [Phi](model_doc/phi) | ✅ | ❌ | ❌ |
+| [Phi3](model_doc/phi3) | ✅ | ❌ | ❌ |
+| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
+| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
+| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
+| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
+| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
+| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
+| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
+| [PVTv2](model_doc/pvt_v2) | ✅ | ❌ | ❌ |
+| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
+| [Qwen2](model_doc/qwen2) | ✅ | ❌ | ❌ |
+| [Qwen2Audio](model_doc/qwen2_audio) | ✅ | ❌ | ❌ |
+| [Qwen2MoE](model_doc/qwen2_moe) | ✅ | ❌ | ❌ |
+| [Qwen2VL](model_doc/qwen2_vl) | ✅ | ❌ | ❌ |
+| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
+| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
+| [RecurrentGemma](model_doc/recurrent_gemma) | ✅ | ❌ | ❌ |
+| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
+| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
+| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
+| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
+| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
+| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
+| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
+| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
+| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
+| [RT-DETR](model_doc/rt_detr) | ✅ | ❌ | ❌ |
+| [RT-DETR-ResNet](model_doc/rt_detr_resnet) | ✅ | ❌ | ❌ |
+| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
+| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
+| [SeamlessM4T](model_doc/seamless_m4t) | ✅ | ❌ | ❌ |
+| [SeamlessM4Tv2](model_doc/seamless_m4t_v2) | ✅ | ❌ | ❌ |
+| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
+| [SegGPT](model_doc/seggpt) | ✅ | ❌ | ❌ |
+| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
+| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
+| [SigLIP](model_doc/siglip) | ✅ | ❌ | ❌ |
+| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
+| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
+| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
+| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
+| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
+| [StableLm](model_doc/stablelm) | ✅ | ❌ | ❌ |
+| [Starcoder2](model_doc/starcoder2) | ✅ | ❌ | ❌ |
+| [SuperPoint](model_doc/superpoint) | ✅ | ❌ | ❌ |
+| [SwiftFormer](model_doc/swiftformer) | ✅ | ✅ | ❌ |
+| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
+| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
+| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
+| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
+| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
+| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
+| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
+| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
+| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
+| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
+| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
+| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
+| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
+| [TrOCR](model_doc/trocr) | ✅ | ❌ | ❌ |
+| [TVLT](model_doc/tvlt) | ✅ | ❌ | ❌ |
+| [TVP](model_doc/tvp) | ✅ | ❌ | ❌ |
+| [UDOP](model_doc/udop) | ✅ | ❌ | ❌ |
+| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
+| [UMT5](model_doc/umt5) | ✅ | ❌ | ❌ |
+| [UniSpeech](model_doc/unispeech) | ✅ | ❌ | ❌ |
+| [UniSpeechSat](model_doc/unispeech-sat) | ✅ | ❌ | ❌ |
+| [UnivNet](model_doc/univnet) | ✅ | ❌ | ❌ |
+| [UPerNet](model_doc/upernet) | ✅ | ❌ | ❌ |
+| [VAN](model_doc/van) | ✅ | ❌ | ❌ |
+| [VideoLlava](model_doc/video_llava) | ✅ | ❌ | ❌ |
+| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
+| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
+| [VipLlava](model_doc/vipllava) | ✅ | ❌ | ❌ |
+| [Vision Encoder decoder](model_doc/vision-encoder-decoder) | ✅ | ✅ | ✅ |
+| [VisionTextDualEncoder](model_doc/vision-text-dual-encoder) | ✅ | ✅ | ✅ |
+| [VisualBERT](model_doc/visual_bert) | ✅ | ❌ | ❌ |
+| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
+| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
+| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
+| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
+| [ViTMatte](model_doc/vitmatte) | ✅ | ❌ | ❌ |
+| [ViTMSN](model_doc/vit_msn) | ✅ | ❌ | ❌ |
+| [VITS](model_doc/vits) | ✅ | ❌ | ❌ |
+| [ViViT](model_doc/vivit) | ✅ | ❌ | ❌ |
+| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
+| [Wav2Vec2-BERT](model_doc/wav2vec2-bert) | ✅ | ❌ | ❌ |
+| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
+| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
+| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
+| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
+| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
+| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
+| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
+| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
+| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
+| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
+| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
+| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
+| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
+| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
+| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
+| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
+| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
+| [ZoeDepth](model_doc/zoedepth) | ✅ | ❌ | ❌ |
+
+
diff --git a/docs/transformers/docs/source/ar/installation.md b/docs/transformers/docs/source/ar/installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..d3bd4c655b6038238ec7bacf3a2723685a7c3a21
--- /dev/null
+++ b/docs/transformers/docs/source/ar/installation.md
@@ -0,0 +1,246 @@
+# التثبيت (Installation)
+
+قم بتثبيت مكتبة 🤗 Transformers المناسبة لمكتبة التعلم العميق التي تستخدمها، وقم بإعداد ذاكرة التخزين المؤقت الخاصة بك، وقم بإعداد 🤗 Transformers للعمل دون اتصال بالإنترنت (اختياري).
+
+تم اختبار 🤗 Transformers على Python 3.6 والإصدارات الأحدث، وPyTorch 1.1.0 والإصدارات الأحدث، وTensorFlow 2.0 والإصدارات الأحدث، وFlax. اتبع تعليمات التثبيت أدناه لمكتبة التعلم العميق التي تستخدمها:
+
+* تعليمات تثبيت [PyTorch](https://pytorch.org/get-started/locally/).
+* تعليمات تثبيت [TensorFlow 2.0](https://www.tensorflow.org/install/pip).
+* تعليمات تثبيت [Flax](https://flax.readthedocs.io/en/latest/).
+
+## التثبيت باستخدام pip
+
+يجب عليك تثبيت 🤗 Transformers داخل [بيئة افتراضية](https://docs.python.org/3/library/venv.html). إذا لم تكن غير ملم ببيئات Python الافتراضية، فراجع هذا [الدليل](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). البيئة الافتراضية تسهل إدارة المشاريع المختلف، وتجنب مشكلات التوافق بين المكتبات المطلوبة (اعتماديات المشروع).
+
+ابدأ بإنشاء بيئة افتراضية في دليل مشروعك:
+
+```bash
+python -m venv .env
+```
+
+قم بتفعيل البيئة الافتراضية. على Linux وMacOs:
+
+```bash
+source .env/bin/activate
+```
+
+قم بتفعيل البيئة الافتراضية على Windows:
+
+```bash
+.env/Scripts/activate
+```
+
+الآن أنت مستعد لتثبيت 🤗 Transformers باستخدام الأمر التالي:
+
+```bash
+pip install transformers
+```
+
+للحصول على الدعم الخاص بـ CPU فقط، يمكنك تثبيت 🤗 Transformers ومكتبة التعلم العميق في خطوة واحدة. على سبيل المثال، قم بتثبيت 🤗 Transformers وPyTorch باستخدام:
+
+```bash
+pip install 'transformers[torch]'
+```
+
+🤗 Transformers وTensorFlow 2.0:
+
+```bash
+pip install 'transformers[tf-cpu]'
+```
+
+ +
+ 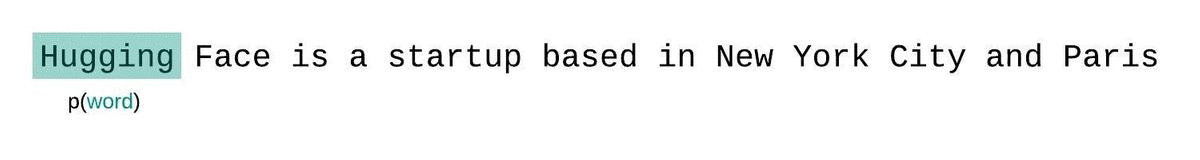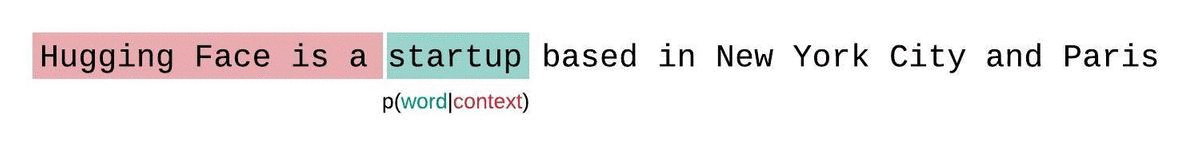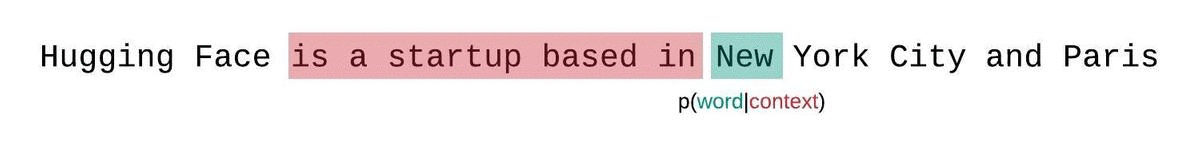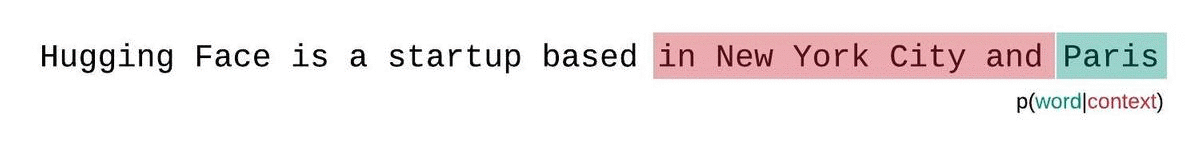 +
+هذا تقريب أقرب للتفكيك الحقيقي لاحتمالية التسلسل وسيؤدي عادةً إلى نتيجة أفضل.لكن الجانب السلبي هو أنه يتطلب تمريرًا للأمام لكل رمز في مجموعة البيانات. حل وسط عملي مناسب هو استخدام نافذة منزلقة بخطوة، بحيث يتم تحريك السياق بخطوات أكبر بدلاً من الانزلاق بمقدار 1 رمز في كل مرة. مما يسمح بإجراء الحساب بشكل أسرع مع إعطاء النموذج سياقًا كبيرًا للتنبؤات في كل خطوة.
+
+## مثال: حساب التعقيد اللغوي مع GPT-2 في 🤗 Transformers
+
+دعونا نوضح هذه العملية مع GPT-2.
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "openai-community/gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+سنقوم بتحميل مجموعة بيانات WikiText-2 وتقييم التعقيد اللغوي باستخدام بعض إستراتيجيات مختلفة النافذة المنزلقة. نظرًا لأن هذه المجموعة البيانات الصغيرة ونقوم فقط بمسح واحد فقط للمجموعة، فيمكننا ببساطة تحميل مجموعة البيانات وترميزها بالكامل في الذاكرة.
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+مع 🤗 Transformers، يمكننا ببساطة تمرير `input_ids` كـ `labels` إلى نموذجنا، وسيتم إرجاع متوسط احتمالية السجل السالب لكل رمز كخسارة. ومع ذلك، مع نهج النافذة المنزلقة، هناك تداخل في الرموز التي نمررها إلى النموذج في كل تكرار. لا نريد تضمين احتمالية السجل للرموز التي نتعامل معها كسياق فقط في خسارتنا، لذا يمكننا تعيين هذه الأهداف إلى `-100` بحيث يتم تجاهلها. فيما يلي هو مثال على كيفية القيام بذلك بخطوة تبلغ `512`. وهذا يعني أن النموذج سيكون لديه 512 رمزًا على الأقل للسياق عند حساب الاحتمالية الشرطية لأي رمز واحد (بشرط توفر 512 رمزًا سابقًا متاحًا للاشتقاق).
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+seq_len = encodings.input_ids.size(1)
+
+nlls = []
+prev_end_loc = 0
+for begin_loc in tqdm(range(0, seq_len, stride)):
+ end_loc = min(begin_loc + max_length, seq_len)
+ trg_len = end_loc - prev_end_loc # قد تكون مختلفة عن الخطوة في الحلقة الأخيرة
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+
+ # يتم حساب الخسارة باستخدام CrossEntropyLoss الذي يقوم بالمتوسط على التصنيفات الصحيحة
+ # لاحظ أن النموذج يحسب الخسارة على trg_len - 1 من التصنيفات فقط، لأنه يتحول داخليًا إلى اليسار بواسطة 1.
+ neg_log_likelihood = outputs.loss
+
+ nlls.append(neg_log_likelihood)
+
+ prev_end_loc = end_loc
+ if end_loc == seq_len:
+ break
+
+ppl = torch.exp(torch.stack(nlls).mean())
+```
+
+يعد تشغيل هذا مع طول الخطوة مساويًا لطول الإدخال الأقصى يعادل لاستراتيجية النافذة غير المنزلقة وغير المثلى التي ناقشناها أعلاه. وكلما صغرت الخطوة، زاد السياق الذي سيحصل عليه النموذج في عمل كل تنبؤ، وكلما كانت التعقيد اللغوي المُبلغ عنها أفضل عادةً.
+
+عندما نقوم بتشغيل ما سبق باستخدام `stride = 1024`، أي بدون تداخل، تكون درجة التعقيد اللغوي الناتجة هي `19.44`، وهو ما يماثل `19.93` المبلغ عنها في ورقة GPT-2. من خلال استخدام `stride = 512` وبالتالي استخدام إستراتيجية النافذة المنزلقة، ينخفض هذا إلى `16.45`. هذه النتيجة ليست فقط أفضل، ولكنها محسوبة بطريقة أقرب إلى التحليل التلقائي الحقيقي لاحتمالية التسلسل.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ar/philosophy.md b/docs/transformers/docs/source/ar/philosophy.md
new file mode 100644
index 0000000000000000000000000000000000000000..09de2991fba28d3e650aafc30bed104396c50894
--- /dev/null
+++ b/docs/transformers/docs/source/ar/philosophy.md
@@ -0,0 +1,49 @@
+# الفلسفة
+
+تُعد 🤗 Transformers مكتبة برمجية ذات رؤية واضحة صُممت من أجل:
+
+- الباحثون والمُتعلّمون في مجال التعلم الآلي ممن يسعون لاستخدام أو دراسة أو تطوير نماذج Transformers واسعة النطاق.
+- مُطبّقي تعلم الآلة الذين يرغبون في ضبط تلك النماذج أو تشغيلها في بيئة إنتاجية، أو كليهما.
+- المهندسون الذين يريدون فقط تنزيل نموذج مُدرب مسبقًا واستخدامه لحل مهمة تعلم آلي معينة.
+
+تم تصميم المكتبة مع الأخذ في الاعتبار هدفين رئيسيين:
+
+1. سهولة وسرعة الاستخدام:
+
+ - تمّ تقليل عدد المفاهيم المُجردة التي يتعامل معها المستخدم إلى أدنى حد والتي يجب تعلمها، وفي الواقع، لا توجد مفاهيم مُجردة تقريبًا، فقط ثلاث فئات أساسية مطلوبة لاستخدام كل نموذج: [الإعدادات](main_classes/configuration)، [نماذج](main_classes/model)، وفئة ما قبل المعالجة ([مُجزّئ لغوي](main_classes/tokenizer) لـ NLP، [معالج الصور](main_classes/image_processor) للرؤية، [مستخرج الميزات](main_classes/feature_extractor) للصوت، و [معالج](main_classes/processors) للمدخﻻت متعددة الوسائط).
+ - يمكن تهيئة جميع هذه الفئات بطريقة بسيطة وموحدة من خلال نماذج مُدربة مسبقًا باستخدام الدالة الموحدة `from_pretrained()` والتي تقوم بتنزيل (إذا لزم الأمر)، وتخزين وتحميل كل من: فئة النموذج المُراد استخدامه والبيانات المرتبطة ( مُعاملات الإعدادات، ومعجم للمُجزّئ اللغوي،وأوزان النماذج) من نقطة تدقيق مُحددة مُخزّنة على [Hugging Face Hub](https://huggingface.co/models) أو ن من نقطة تخزين خاصة بالمستخدم.
+ - بالإضافة إلى هذه الفئات الأساسية الثلاث، توفر المكتبة واجهتي برمجة تطبيقات: [`pipeline`] للاستخدام السريع لأحد النماذج لأداء استنتاجات على مهمة مُحددة، و [`Trainer`] للتدريب السريع أو الضبط الدقيق لنماذج PyTorch (جميع نماذج TensorFlow متوافقة مع `Keras.fit`).
+ - نتيجة لذلك، هذه المكتبة ليست صندوق أدوات متعدد الاستخدامات من الكتل الإنشائية للشبكات العصبية. إذا كنت تريد توسيع أو البناء على المكتبة، فما عليك سوى استخدام Python و PyTorch و TensorFlow و Keras العادية والوراثة من الفئات الأساسية للمكتبة لإعادة استخدام الوظائف مثل تحميل النموذج وحفظه. إذا كنت ترغب في معرفة المزيد عن فلسفة الترميز لدينا للنماذج، فراجع منشور المدونة الخاص بنا [Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy).
+
+2. تقديم نماذج رائدة في مجالها مع أداء قريب قدر الإمكان من النماذج الأصلية:
+
+ - نقدم مثالًا واحدًا على الأقل لكل بنية تقوم بإعادة إنتاج نتيجة مقدمة من المؤلفين الرسميين لتلك البنية.
+ - عادةً ما تكون الشفرة قريبة قدر الإمكان من قاعدة الشفرة الأصلية، مما يعني أن بعض شفرة PyTorch قد لا تكون "بأسلوب PyTorch" كما يمكن أن تكون نتيجة لكونها شفرة TensorFlow محولة والعكس صحيح.
+
+بعض الأهداف الأخرى:
+
+- كشف تفاصيل النماذج الداخلية بشكل متسق قدر الإمكان:
+
+ -نتيح الوصول، باستخدام واجهة برمجة واحدة، إلى جميع الحالات المخفية (Hidden-States) وأوزان الانتباه (Attention Weights).
+ - تم توحيد واجهات برمجة التطبيقات الخاصة بفئات المعالجة المسبقة والنماذج الأساسية لتسهيل التبديل بين النماذج.
+
+- دمج مجموعة مختارة من الأدوات الواعدة لضبط النماذج بدقة (Fine-tuning) ودراستها:
+
+ - طريقة بسيطة ومتسقة لإضافة رموز جديدة إلى مفردات التضمينات (Embeddings) لضبط النماذج بدقة.
+ - طرق سهلة لإخفاء (Masking) وتقليم (Pruning) رؤوس المحولات (Transformer Heads).
+
+- التبديل بسهولة بين PyTorch و TensorFlow 2.0 و Flax، مما يسمح بالتدريب باستخدام إطار واحد والاستدلال باستخدام إطار آخر.
+
+## المفاهيم الرئيسية
+
+تعتمد المكتبة على ثلاثة أنواع من الفئات لكل نموذج:
+
+- **فئات النماذج** يمكن أن تكون نماذج PyTorch ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module))، أو نماذج Keras ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model))، أو نماذج JAX/Flax ([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html)) التي تعمل مع الأوزان المُدربة مسبقًا المقدمة في المكتبة.
+- **فئات الإعداد** تخزن معلمات التهيئة المطلوبة لبناء نموذج (مثل عدد الطبقات وحجم الطبقة المخفية). أنت لست مضطرًا دائمًا إلى إنشاء مثيل لهذه الفئات بنفسك. على وجه الخصوص، إذا كنت تستخدم نموذجًا مُدربًا مسبقًا دون أي تعديل، فإن إنشاء النموذج سيهتم تلقائيًا تهيئة الإعدادات (والذي يعد جزءًا من النموذج).
+- **فئات ما قبل المعالجة** تحويل البيانات الخام إلى تنسيق مقبول من قبل النموذج. يقوم [المعالج](main_classes/tokenizer) بتخزين المعجم لكل نموذج ويقدم طرقًا لتشفير وفك تشفير السلاسل في قائمة من مؤشرات تضمين الرموز ليتم إطعامها للنموذج. تقوم [معالجات الصور](main_classes/image_processor) بمعالجة إدخالات الرؤية، وتقوم [مستخلصات الميزات](main_classes/feature_extractor) بمعالجة إدخالات الصوت، ويقوم [المعالج](main_classes/processors) بمعالجة الإدخالات متعددة الوسائط.
+
+يمكن تهيئة جميع هذه الفئات من نسخ مُدربة مسبقًا، وحفظها محليًا، ومشاركتها على منصة Hub عبر ثلاث طرق:
+
+- تسمح لك الدالة `from_pretrained()` بتهيئة النموذج وتكويناته وفئة المعالجة المسبقة من إصدار مُدرب مسبقًا إما يتم توفيره بواسطة المكتبة نفسها (يمكن العثور على النماذج المدعومة على [Model Hub](https://huggingface.co/models)) أو مخزنة محليًا (أو على خادم) بواسطة المستخدم.
+- تسمح لك الدالة `save_pretrained()` بحفظ النموذج، وتكويناته وفئة المعالجة المسبقة محليًا، بحيث يمكن إعادة تحميله باستخدام الدالة `from_pretrained()`.
+- تسمح لك `push_to_hub()` بمشاركة نموذج وتكويناتهوفئة المعالجة المسبقة على Hub، بحيث يمكن الوصول إليها بسهولة من قبل الجميع.
diff --git a/docs/transformers/docs/source/ar/pipeline_tutorial.md b/docs/transformers/docs/source/ar/pipeline_tutorial.md
new file mode 100644
index 0000000000000000000000000000000000000000..2dd713a6533f6e3831bdde6116f16bbdcf573f57
--- /dev/null
+++ b/docs/transformers/docs/source/ar/pipeline_tutorial.md
@@ -0,0 +1,315 @@
+# خطوط الأنابيب الاستدلال
+
+يجعل [`pipeline`] من السهل استخدام أي نموذج من [Hub](https://huggingface.co/models) للاستدلال لأي مهام خاصة باللغة أو الرؤية الحاسوبية أو الكلام أو المهام متعددة الوسائط. حتى إذا لم يكن لديك خبرة في طريقة معينة أو لم تكن على دراية بالرمز الأساسي وراء النماذج، يمكنك مع ذلك استخدامها للاستدلال باستخدام [`pipeline`]! سوف يُعلمك هذا البرنامج التعليمي ما يلي:
+
+* استخدام [`pipeline`] للاستدلال.
+* استخدم مُجزّئ أو نموذجًا محددًا.
+* استخدم [`pipeline`] للمهام الصوتية والبصرية والمتعددة الوسائط.
+
+
+
+هذا تقريب أقرب للتفكيك الحقيقي لاحتمالية التسلسل وسيؤدي عادةً إلى نتيجة أفضل.لكن الجانب السلبي هو أنه يتطلب تمريرًا للأمام لكل رمز في مجموعة البيانات. حل وسط عملي مناسب هو استخدام نافذة منزلقة بخطوة، بحيث يتم تحريك السياق بخطوات أكبر بدلاً من الانزلاق بمقدار 1 رمز في كل مرة. مما يسمح بإجراء الحساب بشكل أسرع مع إعطاء النموذج سياقًا كبيرًا للتنبؤات في كل خطوة.
+
+## مثال: حساب التعقيد اللغوي مع GPT-2 في 🤗 Transformers
+
+دعونا نوضح هذه العملية مع GPT-2.
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "openai-community/gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+سنقوم بتحميل مجموعة بيانات WikiText-2 وتقييم التعقيد اللغوي باستخدام بعض إستراتيجيات مختلفة النافذة المنزلقة. نظرًا لأن هذه المجموعة البيانات الصغيرة ونقوم فقط بمسح واحد فقط للمجموعة، فيمكننا ببساطة تحميل مجموعة البيانات وترميزها بالكامل في الذاكرة.
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+مع 🤗 Transformers، يمكننا ببساطة تمرير `input_ids` كـ `labels` إلى نموذجنا، وسيتم إرجاع متوسط احتمالية السجل السالب لكل رمز كخسارة. ومع ذلك، مع نهج النافذة المنزلقة، هناك تداخل في الرموز التي نمررها إلى النموذج في كل تكرار. لا نريد تضمين احتمالية السجل للرموز التي نتعامل معها كسياق فقط في خسارتنا، لذا يمكننا تعيين هذه الأهداف إلى `-100` بحيث يتم تجاهلها. فيما يلي هو مثال على كيفية القيام بذلك بخطوة تبلغ `512`. وهذا يعني أن النموذج سيكون لديه 512 رمزًا على الأقل للسياق عند حساب الاحتمالية الشرطية لأي رمز واحد (بشرط توفر 512 رمزًا سابقًا متاحًا للاشتقاق).
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+seq_len = encodings.input_ids.size(1)
+
+nlls = []
+prev_end_loc = 0
+for begin_loc in tqdm(range(0, seq_len, stride)):
+ end_loc = min(begin_loc + max_length, seq_len)
+ trg_len = end_loc - prev_end_loc # قد تكون مختلفة عن الخطوة في الحلقة الأخيرة
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+
+ # يتم حساب الخسارة باستخدام CrossEntropyLoss الذي يقوم بالمتوسط على التصنيفات الصحيحة
+ # لاحظ أن النموذج يحسب الخسارة على trg_len - 1 من التصنيفات فقط، لأنه يتحول داخليًا إلى اليسار بواسطة 1.
+ neg_log_likelihood = outputs.loss
+
+ nlls.append(neg_log_likelihood)
+
+ prev_end_loc = end_loc
+ if end_loc == seq_len:
+ break
+
+ppl = torch.exp(torch.stack(nlls).mean())
+```
+
+يعد تشغيل هذا مع طول الخطوة مساويًا لطول الإدخال الأقصى يعادل لاستراتيجية النافذة غير المنزلقة وغير المثلى التي ناقشناها أعلاه. وكلما صغرت الخطوة، زاد السياق الذي سيحصل عليه النموذج في عمل كل تنبؤ، وكلما كانت التعقيد اللغوي المُبلغ عنها أفضل عادةً.
+
+عندما نقوم بتشغيل ما سبق باستخدام `stride = 1024`، أي بدون تداخل، تكون درجة التعقيد اللغوي الناتجة هي `19.44`، وهو ما يماثل `19.93` المبلغ عنها في ورقة GPT-2. من خلال استخدام `stride = 512` وبالتالي استخدام إستراتيجية النافذة المنزلقة، ينخفض هذا إلى `16.45`. هذه النتيجة ليست فقط أفضل، ولكنها محسوبة بطريقة أقرب إلى التحليل التلقائي الحقيقي لاحتمالية التسلسل.
\ No newline at end of file
diff --git a/docs/transformers/docs/source/ar/philosophy.md b/docs/transformers/docs/source/ar/philosophy.md
new file mode 100644
index 0000000000000000000000000000000000000000..09de2991fba28d3e650aafc30bed104396c50894
--- /dev/null
+++ b/docs/transformers/docs/source/ar/philosophy.md
@@ -0,0 +1,49 @@
+# الفلسفة
+
+تُعد 🤗 Transformers مكتبة برمجية ذات رؤية واضحة صُممت من أجل:
+
+- الباحثون والمُتعلّمون في مجال التعلم الآلي ممن يسعون لاستخدام أو دراسة أو تطوير نماذج Transformers واسعة النطاق.
+- مُطبّقي تعلم الآلة الذين يرغبون في ضبط تلك النماذج أو تشغيلها في بيئة إنتاجية، أو كليهما.
+- المهندسون الذين يريدون فقط تنزيل نموذج مُدرب مسبقًا واستخدامه لحل مهمة تعلم آلي معينة.
+
+تم تصميم المكتبة مع الأخذ في الاعتبار هدفين رئيسيين:
+
+1. سهولة وسرعة الاستخدام:
+
+ - تمّ تقليل عدد المفاهيم المُجردة التي يتعامل معها المستخدم إلى أدنى حد والتي يجب تعلمها، وفي الواقع، لا توجد مفاهيم مُجردة تقريبًا، فقط ثلاث فئات أساسية مطلوبة لاستخدام كل نموذج: [الإعدادات](main_classes/configuration)، [نماذج](main_classes/model)، وفئة ما قبل المعالجة ([مُجزّئ لغوي](main_classes/tokenizer) لـ NLP، [معالج الصور](main_classes/image_processor) للرؤية، [مستخرج الميزات](main_classes/feature_extractor) للصوت، و [معالج](main_classes/processors) للمدخﻻت متعددة الوسائط).
+ - يمكن تهيئة جميع هذه الفئات بطريقة بسيطة وموحدة من خلال نماذج مُدربة مسبقًا باستخدام الدالة الموحدة `from_pretrained()` والتي تقوم بتنزيل (إذا لزم الأمر)، وتخزين وتحميل كل من: فئة النموذج المُراد استخدامه والبيانات المرتبطة ( مُعاملات الإعدادات، ومعجم للمُجزّئ اللغوي،وأوزان النماذج) من نقطة تدقيق مُحددة مُخزّنة على [Hugging Face Hub](https://huggingface.co/models) أو ن من نقطة تخزين خاصة بالمستخدم.
+ - بالإضافة إلى هذه الفئات الأساسية الثلاث، توفر المكتبة واجهتي برمجة تطبيقات: [`pipeline`] للاستخدام السريع لأحد النماذج لأداء استنتاجات على مهمة مُحددة، و [`Trainer`] للتدريب السريع أو الضبط الدقيق لنماذج PyTorch (جميع نماذج TensorFlow متوافقة مع `Keras.fit`).
+ - نتيجة لذلك، هذه المكتبة ليست صندوق أدوات متعدد الاستخدامات من الكتل الإنشائية للشبكات العصبية. إذا كنت تريد توسيع أو البناء على المكتبة، فما عليك سوى استخدام Python و PyTorch و TensorFlow و Keras العادية والوراثة من الفئات الأساسية للمكتبة لإعادة استخدام الوظائف مثل تحميل النموذج وحفظه. إذا كنت ترغب في معرفة المزيد عن فلسفة الترميز لدينا للنماذج، فراجع منشور المدونة الخاص بنا [Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy).
+
+2. تقديم نماذج رائدة في مجالها مع أداء قريب قدر الإمكان من النماذج الأصلية:
+
+ - نقدم مثالًا واحدًا على الأقل لكل بنية تقوم بإعادة إنتاج نتيجة مقدمة من المؤلفين الرسميين لتلك البنية.
+ - عادةً ما تكون الشفرة قريبة قدر الإمكان من قاعدة الشفرة الأصلية، مما يعني أن بعض شفرة PyTorch قد لا تكون "بأسلوب PyTorch" كما يمكن أن تكون نتيجة لكونها شفرة TensorFlow محولة والعكس صحيح.
+
+بعض الأهداف الأخرى:
+
+- كشف تفاصيل النماذج الداخلية بشكل متسق قدر الإمكان:
+
+ -نتيح الوصول، باستخدام واجهة برمجة واحدة، إلى جميع الحالات المخفية (Hidden-States) وأوزان الانتباه (Attention Weights).
+ - تم توحيد واجهات برمجة التطبيقات الخاصة بفئات المعالجة المسبقة والنماذج الأساسية لتسهيل التبديل بين النماذج.
+
+- دمج مجموعة مختارة من الأدوات الواعدة لضبط النماذج بدقة (Fine-tuning) ودراستها:
+
+ - طريقة بسيطة ومتسقة لإضافة رموز جديدة إلى مفردات التضمينات (Embeddings) لضبط النماذج بدقة.
+ - طرق سهلة لإخفاء (Masking) وتقليم (Pruning) رؤوس المحولات (Transformer Heads).
+
+- التبديل بسهولة بين PyTorch و TensorFlow 2.0 و Flax، مما يسمح بالتدريب باستخدام إطار واحد والاستدلال باستخدام إطار آخر.
+
+## المفاهيم الرئيسية
+
+تعتمد المكتبة على ثلاثة أنواع من الفئات لكل نموذج:
+
+- **فئات النماذج** يمكن أن تكون نماذج PyTorch ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module))، أو نماذج Keras ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model))، أو نماذج JAX/Flax ([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html)) التي تعمل مع الأوزان المُدربة مسبقًا المقدمة في المكتبة.
+- **فئات الإعداد** تخزن معلمات التهيئة المطلوبة لبناء نموذج (مثل عدد الطبقات وحجم الطبقة المخفية). أنت لست مضطرًا دائمًا إلى إنشاء مثيل لهذه الفئات بنفسك. على وجه الخصوص، إذا كنت تستخدم نموذجًا مُدربًا مسبقًا دون أي تعديل، فإن إنشاء النموذج سيهتم تلقائيًا تهيئة الإعدادات (والذي يعد جزءًا من النموذج).
+- **فئات ما قبل المعالجة** تحويل البيانات الخام إلى تنسيق مقبول من قبل النموذج. يقوم [المعالج](main_classes/tokenizer) بتخزين المعجم لكل نموذج ويقدم طرقًا لتشفير وفك تشفير السلاسل في قائمة من مؤشرات تضمين الرموز ليتم إطعامها للنموذج. تقوم [معالجات الصور](main_classes/image_processor) بمعالجة إدخالات الرؤية، وتقوم [مستخلصات الميزات](main_classes/feature_extractor) بمعالجة إدخالات الصوت، ويقوم [المعالج](main_classes/processors) بمعالجة الإدخالات متعددة الوسائط.
+
+يمكن تهيئة جميع هذه الفئات من نسخ مُدربة مسبقًا، وحفظها محليًا، ومشاركتها على منصة Hub عبر ثلاث طرق:
+
+- تسمح لك الدالة `from_pretrained()` بتهيئة النموذج وتكويناته وفئة المعالجة المسبقة من إصدار مُدرب مسبقًا إما يتم توفيره بواسطة المكتبة نفسها (يمكن العثور على النماذج المدعومة على [Model Hub](https://huggingface.co/models)) أو مخزنة محليًا (أو على خادم) بواسطة المستخدم.
+- تسمح لك الدالة `save_pretrained()` بحفظ النموذج، وتكويناته وفئة المعالجة المسبقة محليًا، بحيث يمكن إعادة تحميله باستخدام الدالة `from_pretrained()`.
+- تسمح لك `push_to_hub()` بمشاركة نموذج وتكويناتهوفئة المعالجة المسبقة على Hub، بحيث يمكن الوصول إليها بسهولة من قبل الجميع.
diff --git a/docs/transformers/docs/source/ar/pipeline_tutorial.md b/docs/transformers/docs/source/ar/pipeline_tutorial.md
new file mode 100644
index 0000000000000000000000000000000000000000..2dd713a6533f6e3831bdde6116f16bbdcf573f57
--- /dev/null
+++ b/docs/transformers/docs/source/ar/pipeline_tutorial.md
@@ -0,0 +1,315 @@
+# خطوط الأنابيب الاستدلال
+
+يجعل [`pipeline`] من السهل استخدام أي نموذج من [Hub](https://huggingface.co/models) للاستدلال لأي مهام خاصة باللغة أو الرؤية الحاسوبية أو الكلام أو المهام متعددة الوسائط. حتى إذا لم يكن لديك خبرة في طريقة معينة أو لم تكن على دراية بالرمز الأساسي وراء النماذج، يمكنك مع ذلك استخدامها للاستدلال باستخدام [`pipeline`]! سوف يُعلمك هذا البرنامج التعليمي ما يلي:
+
+* استخدام [`pipeline`] للاستدلال.
+* استخدم مُجزّئ أو نموذجًا محددًا.
+* استخدم [`pipeline`] للمهام الصوتية والبصرية والمتعددة الوسائط.
+
+ +
+ +
+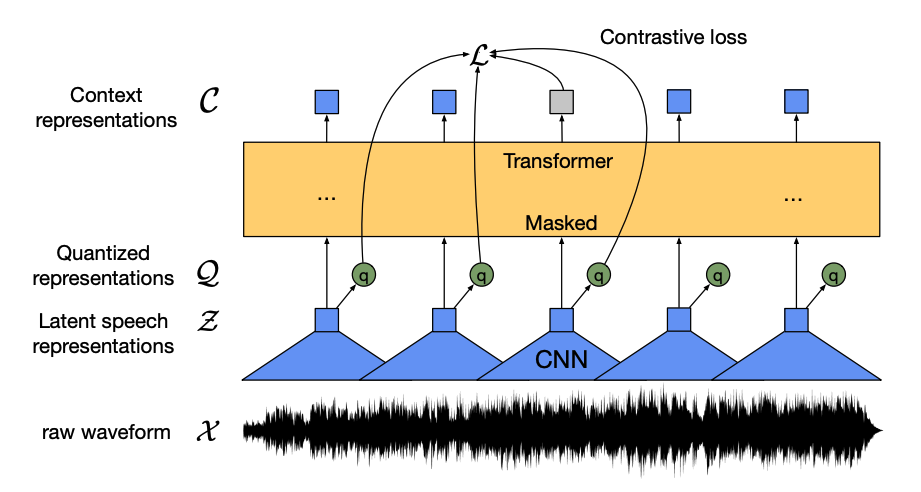 +
+ +
+ +
+ +
+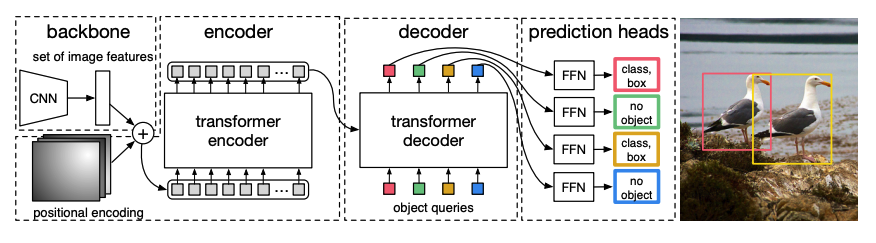 +
+ +
+ +
+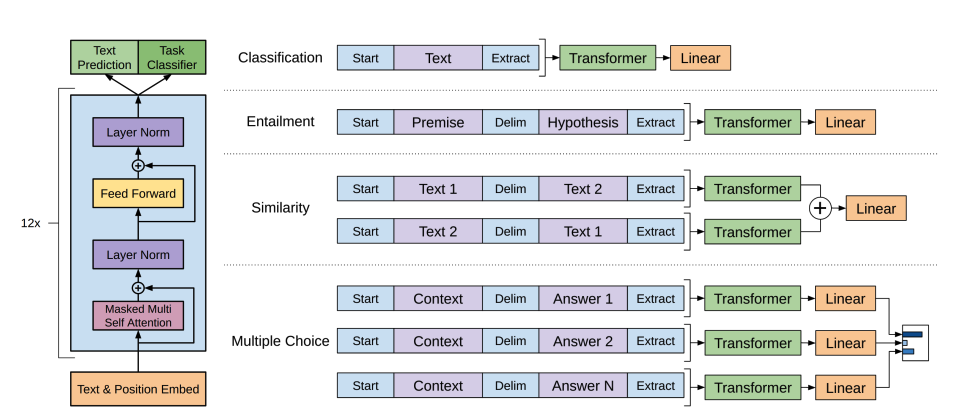 +
+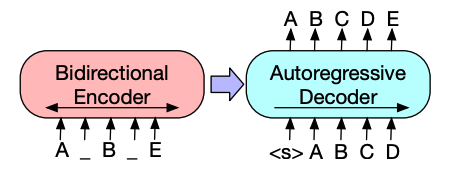 +
+ +
+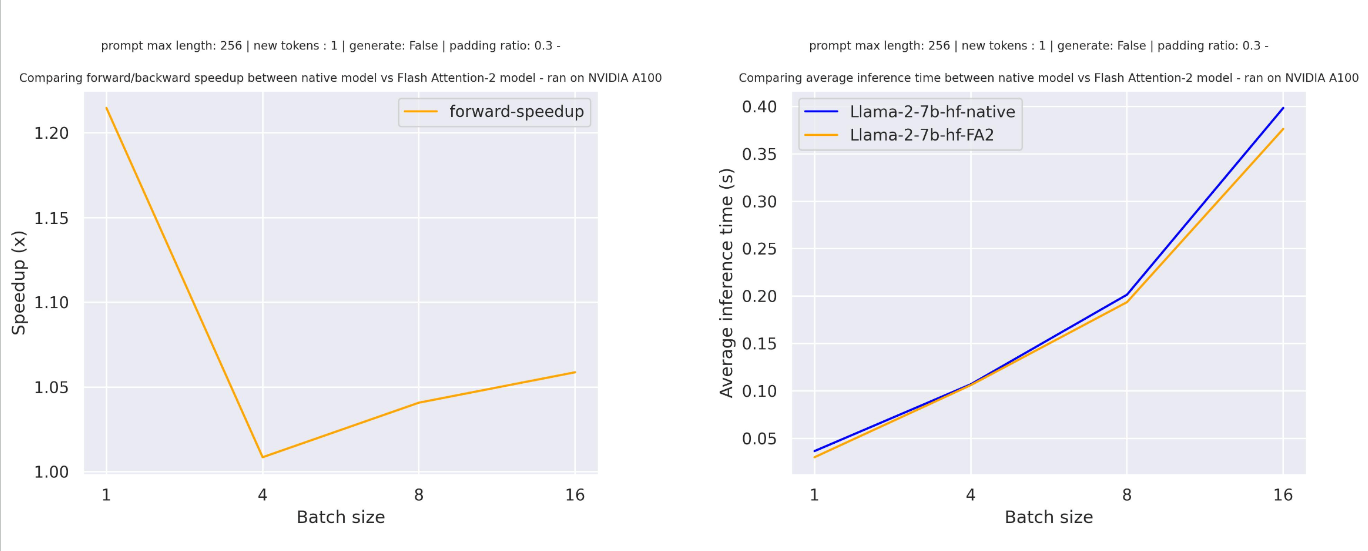 +
+ +
+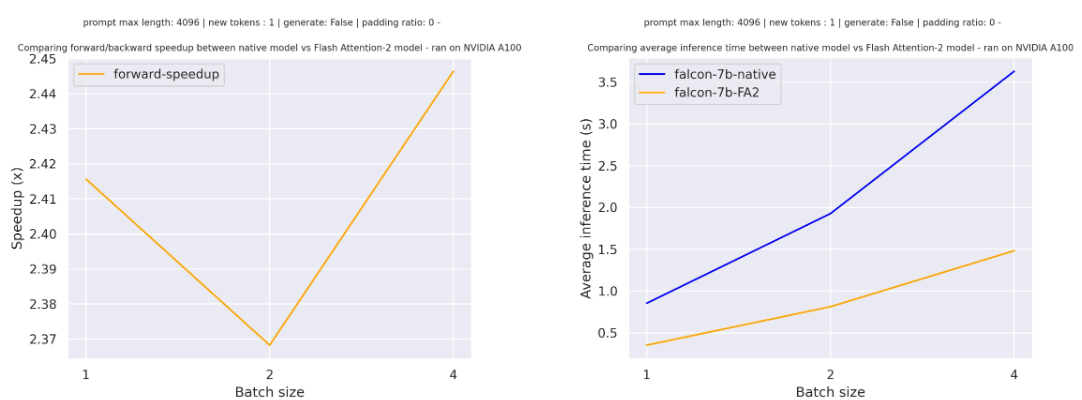 +
+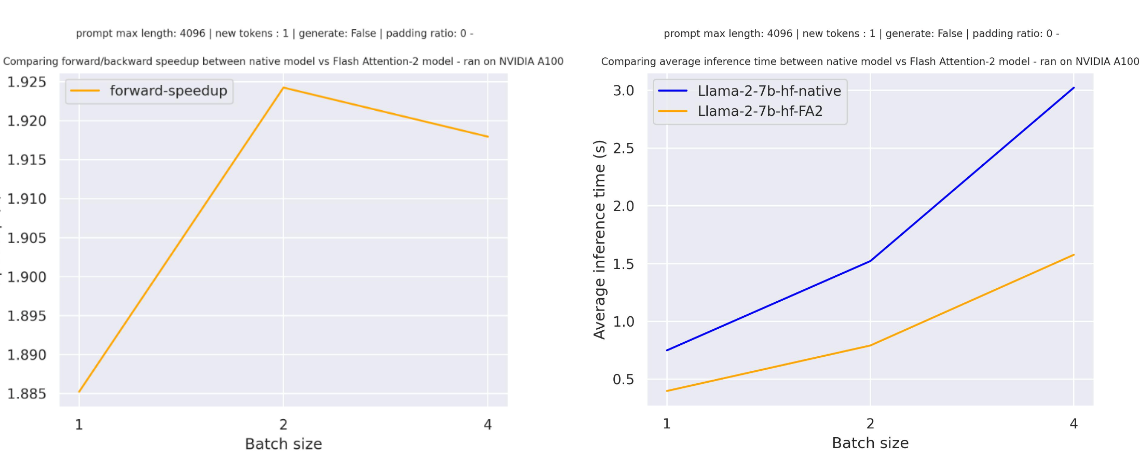 +
+ +
+